diff --git a/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/CONTRIBUTORS.txt b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/CONTRIBUTORS.txt
new file mode 100644
index 000000000..2de71f2df
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/CONTRIBUTORS.txt
@@ -0,0 +1,218 @@
+# This file is autocompleted by 'contributors-txt',
+# using the configuration in 'script/.contributors_aliases.json'.
+# Do not add new persons manually and only add information without
+# using '-' as the line first character.
+# Please verify that your change are stable if you modify manually.
+
+Ex-maintainers
+--------------
+- Claudiu Popa <pcmanticore@gmail.com>
+- Sylvain Thénault <thenault@gmail.com>
+- Torsten Marek <shlomme@gmail.com>
+
+
+Maintainers
+-----------
+- Pierre Sassoulas <pierre.sassoulas@gmail.com>
+- Daniël van Noord <13665637+DanielNoord@users.noreply.github.com>
+- Jacob Walls <jacobtylerwalls@gmail.com>
+- Marc Mueller <30130371+cdce8p@users.noreply.github.com>
+- Hippo91 <guillaume.peillex@gmail.com>
+- Bryce Guinta <bryce.paul.guinta@gmail.com>
+- Ceridwen <ceridwenv@gmail.com>
+- Mark Byrne <31762852+mbyrnepr2@users.noreply.github.com>
+- Łukasz Rogalski <rogalski.91@gmail.com>
+- Florian Bruhin <me@the-compiler.org>
+- Ashley Whetter <ashley@awhetter.co.uk>
+- Dimitri Prybysh <dmand@yandex.ru>
+- Areveny <areveny@protonmail.com>
+
+
+Contributors
+------------
+- Emile Anclin <emile.anclin@logilab.fr>
+- Nick Drozd <nicholasdrozd@gmail.com>
+- Andrew Haigh <hello@nelf.in>
+- Julien Cristau <julien.cristau@logilab.fr>
+- David Liu <david@cs.toronto.edu>
+- Alexandre Fayolle <alexandre.fayolle@logilab.fr>
+- Eevee (Alex Munroe) <amunroe@yelp.com>
+- David Gilman <davidgilman1@gmail.com>
+- Tushar Sadhwani <tushar.sadhwani000@gmail.com>
+- Julien Jehannet <julien.jehannet@logilab.fr>
+- Calen Pennington <calen.pennington@gmail.com>
+- Antonio <antonio@zoftko.com>
+- Hugo van Kemenade <hugovk@users.noreply.github.com>
+- Tim Martin <tim@asymptotic.co.uk>
+- Phil Schaf <flying-sheep@web.de>
+- Alex Hall <alex.mojaki@gmail.com>
+- Raphael Gaschignard <raphael@makeleaps.com>
+- Radosław Ganczarek <radoslaw@ganczarek.in>
+- Paligot Gérard <androwiiid@gmail.com>
+- Ioana Tagirta <ioana.tagirta@gmail.com>
+- Derek Gustafson <degustaf@gmail.com>
+- David Shea <dshea@redhat.com>
+- Daniel Harding <dharding@gmail.com>
+- Christian Clauss <cclauss@me.com>
+- correctmost <134317971+correctmost@users.noreply.github.com>
+- Ville Skyttä <ville.skytta@iki.fi>
+- Rene Zhang <rz99@cornell.edu>
+- Philip Lorenz <philip@bithub.de>
+- Nicolas Chauvat <nicolas.chauvat@logilab.fr>
+- Michael K <michael-k@users.noreply.github.com>
+- Mario Corchero <mariocj89@gmail.com>
+- Marien Zwart <marienz@gentoo.org>
+- Laura Médioni <laura.medioni@logilab.fr>
+- James Addison <55152140+jayaddison@users.noreply.github.com>
+- FELD Boris <lothiraldan@gmail.com>
+- Enji Cooper <yaneurabeya@gmail.com>
+- Dani Alcala <112832187+clavedeluna@users.noreply.github.com>
+- Adrien Di Mascio <Adrien.DiMascio@logilab.fr>
+- tristanlatr <19967168+tristanlatr@users.noreply.github.com>
+- emile@crater.logilab.fr <emile@crater.logilab.fr>
+- doranid <ddandd@gmail.com>
+- brendanator <brendan.maginnis@gmail.com>
+- Tomas Gavenciak <gavento@ucw.cz>
+- Tim Paine <t.paine154@gmail.com>
+- Thomas Hisch <t.hisch@gmail.com>
+- Stefan Scherfke <stefan@sofa-rockers.org>
+- Sergei Lebedev <185856+superbobry@users.noreply.github.com>
+- Saugat Pachhai (सौगात) <suagatchhetri@outlook.com>
+- Ram Rachum <ram@rachum.com>
+- Pierre-Yves David <pierre-yves.david@logilab.fr>
+- Peter Pentchev <roam@ringlet.net>
+- Peter Kolbus <peter.kolbus@gmail.com>
+- Omer Katz <omer.drow@gmail.com>
+- Moises Lopez <moylop260@vauxoo.com>
+- Michal Vasilek <michal@vasilek.cz>
+- Keichi Takahashi <keichi.t@me.com>
+- Kavins Singh <kavinsingh@hotmail.com>
+- Karthikeyan Singaravelan <tir.karthi@gmail.com>
+- Joshua Cannon <joshdcannon@gmail.com>
+- John Vandenberg <jayvdb@gmail.com>
+- Jacob Bogdanov <jacob@bogdanov.dev>
+- Google, Inc. <no-reply@google.com>
+- David Euresti <github@euresti.com>
+- David Douard <david.douard@logilab.fr>
+- David Cain <davidjosephcain@gmail.com>
+- Anthony Truchet <anthony.truchet@logilab.fr>
+- Anthony Sottile <asottile@umich.edu>
+- Alexander Shadchin <alexandr.shadchin@gmail.com>
+- wgehalo <wgehalo@gmail.com>
+- rr- <rr-@sakuya.pl>
+- raylu <lurayl@gmail.com>
+- plucury <plucury@gmail.com>
+- ostr00000 <ostr00000@gmail.com>
+- noah-weingarden <33741795+noah-weingarden@users.noreply.github.com>
+- nathannaveen <42319948+nathannaveen@users.noreply.github.com>
+- mathieui <mathieui@users.noreply.github.com>
+- markmcclain <markmcclain@users.noreply.github.com>
+- ioanatia <ioanatia@users.noreply.github.com>
+- grayjk <grayjk@gmail.com>
+- alm <alonme@users.noreply.github.com>
+- adam-grant-hendry <59346180+adam-grant-hendry@users.noreply.github.com>
+- Zbigniew Jędrzejewski-Szmek <zbyszek@in.waw.pl>
+- Zac Hatfield-Dodds <Zac-HD@users.noreply.github.com>
+- Vilnis Termanis <vilnis.termanis@iotics.com>
+- Valentin Valls <valentin.valls@esrf.fr>
+- Uilian Ries <uilianries@gmail.com>
+- Tomas Novak <ext.Tomas.Novak@skoda-auto.cz>
+- Thirumal Venkat <me@thirumal.in>
+- SupImDos <62866982+SupImDos@users.noreply.github.com>
+- Stanislav Levin <slev@altlinux.org>
+- Simon Hewitt <si@sjhewitt.co.uk>
+- Serhiy Storchaka <storchaka@gmail.com>
+- Roy Wright <roy@wright.org>
+- Robin Jarry <robin.jarry@6wind.com>
+- René Fritze <47802+renefritze@users.noreply.github.com>
+- Redoubts <Redoubts@users.noreply.github.com>
+- Philipp Hörist <philipp@hoerist.com>
+- Peter de Blanc <peter@standard.ai>
+- Peter Talley <peterctalley@gmail.com>
+- Ovidiu Sabou <ovidiu@sabou.org>
+- Oleh Prypin <oleh@pryp.in>
+- Nicolas Noirbent <nicolas@noirbent.fr>
+- Neil Girdhar <mistersheik@gmail.com>
+- Miro Hrončok <miro@hroncok.cz>
+- Michał Masłowski <m.maslowski@clearcode.cc>
+- Mateusz Bysiek <mb@mbdev.pl>
+- Marcelo Trylesinski <marcelotryle@gmail.com>
+- Leandro T. C. Melo <ltcmelo@gmail.com>
+- Konrad Weihmann <kweihmann@outlook.com>
+- Kian Meng, Ang <kianmeng.ang@gmail.com>
+- Kai Mueller <15907922+kasium@users.noreply.github.com>
+- Jörg Thalheim <Mic92@users.noreply.github.com>
+- Jérome Perrin <perrinjerome@gmail.com>
+- JulianJvn <128477611+JulianJvn@users.noreply.github.com>
+- Josef Kemetmüller <josef.kemetmueller@gmail.com>
+- Jonathan Striebel <jstriebel@users.noreply.github.com>
+- John Belmonte <john@neggie.net>
+- Jeff Widman <jeff@jeffwidman.com>
+- Jeff Quast <contact@jeffquast.com>
+- Jarrad Hope <me@jarradhope.com>
+- Jared Garst <jgarst@users.noreply.github.com>
+- Jamie Scott <jamie@jami.org.uk>
+- Jakub Wilk <jwilk@jwilk.net>
+- Iva Miholic <ivamiho@gmail.com>
+- Ionel Maries Cristian <contact@ionelmc.ro>
+- HoverHell <hoverhell@gmail.com>
+- Hashem Nasarat <Hnasar@users.noreply.github.com>
+- HQupgradeHQ <18361586+HQupgradeHQ@users.noreply.github.com>
+- Gwyn Ciesla <gwync@protonmail.com>
+- Grygorii Iermolenko <gyermolenko@gmail.com>
+- Gregory P. Smith <greg@krypto.org>
+- Giuseppe Scrivano <gscrivan@redhat.com>
+- Frédéric Chapoton <fchapoton2@gmail.com>
+- Francis Charette Migneault <francis.charette.migneault@gmail.com>
+- Felix Mölder <felix.moelder@uni-due.de>
+- Federico Bond <federicobond@gmail.com>
+- Eric Vergnaud <eric.vergnaud@wanadoo.fr>
+- DudeNr33 <3929834+DudeNr33@users.noreply.github.com>
+- Dmitry Shachnev <mitya57@users.noreply.github.com>
+- Denis Laxalde <denis.laxalde@logilab.fr>
+- Deepyaman Datta <deepyaman.datta@utexas.edu>
+- David Poirier <david-poirier-csn@users.noreply.github.com>
+- Dave Hirschfeld <dave.hirschfeld@gmail.com>
+- Dave Baum <dbaum@google.com>
+- Daniel Martin <daniel.martin@crowdstrike.com>
+- Daniel Colascione <dancol@dancol.org>
+- Damien Baty <damien@damienbaty.com>
+- Craig Franklin <craigjfranklin@gmail.com>
+- Colin Kennedy <colinvfx@gmail.com>
+- Cole Robinson <crobinso@redhat.com>
+- Christoph Reiter <reiter.christoph@gmail.com>
+- Chris Philip <chrisp533@gmail.com>
+- BioGeek <jeroen.vangoey@gmail.com>
+- Bianca Power <30207144+biancapower@users.noreply.github.com>
+- Benjamin Elven <25181435+S3ntinelX@users.noreply.github.com>
+- Ben Elliston <bje@air.net.au>
+- Becker Awqatty <bawqatty@mide.com>
+- Batuhan Taskaya <isidentical@gmail.com>
+- BasPH <BasPH@users.noreply.github.com>
+- Azeem Bande-Ali <A.BandeAli@gmail.com>
+- Avram Lubkin <aviso@rockhopper.net>
+- Aru Sahni <arusahni@gmail.com>
+- Artsiom Kaval <lezeroq@gmail.com>
+- Anubhav <35621759+anubh-v@users.noreply.github.com>
+- Antoine Boellinger <aboellinger@hotmail.com>
+- Alphadelta14 <alpha@alphaservcomputing.solutions>
+- Alexander Scheel <alexander.m.scheel@gmail.com>
+- Alexander Presnyakov <flagist0@gmail.com>
+- Ahmed Azzaoui <ahmed.azzaoui@engie.com>
+
+Co-Author
+---------
+The following persons were credited manually but did not commit themselves
+under this name, or we did not manage to find their commits in the history.
+
+- François Mockers
+- platings
+- carl
+- alain lefroy
+- Mark Gius
+- Jérome Perrin <perrinjerome@gmail.com>
+- Jamie Scott <jamie@jami.org.uk>
+- correctmost <134317971+correctmost@users.noreply.github.com>
+- Oleh Prypin <oleh@pryp.in>
+- Eric Vergnaud <eric.vergnaud@wanadoo.fr>
+- Hashem Nasarat <Hnasar@users.noreply.github.com>
diff --git a/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/LICENSE b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/LICENSE
new file mode 100644
index 000000000..182e0fbee
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/LICENSE
@@ -0,0 +1,508 @@
+
+ GNU LESSER GENERAL PUBLIC LICENSE
+ Version 2.1, February 1999
+
+ Copyright (C) 1991, 1999 Free Software Foundation, Inc.
+ 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
+ Everyone is permitted to copy and distribute verbatim copies
+ of this license document, but changing it is not allowed.
+
+[This is the first released version of the Lesser GPL. It also counts
+ as the successor of the GNU Library Public License, version 2, hence
+ the version number 2.1.]
+
+ Preamble
+
+ The licenses for most software are designed to take away your
+freedom to share and change it. By contrast, the GNU General Public
+Licenses are intended to guarantee your freedom to share and change
+free software--to make sure the software is free for all its users.
+
+ This license, the Lesser General Public License, applies to some
+specially designated software packages--typically libraries--of the
+Free Software Foundation and other authors who decide to use it. You
+can use it too, but we suggest you first think carefully about whether
+this license or the ordinary General Public License is the better
+strategy to use in any particular case, based on the explanations
+below.
+
+ When we speak of free software, we are referring to freedom of use,
+not price. Our General Public Licenses are designed to make sure that
+you have the freedom to distribute copies of free software (and charge
+for this service if you wish); that you receive source code or can get
+it if you want it; that you can change the software and use pieces of
+it in new free programs; and that you are informed that you can do
+these things.
+
+ To protect your rights, we need to make restrictions that forbid
+distributors to deny you these rights or to ask you to surrender these
+rights. These restrictions translate to certain responsibilities for
+you if you distribute copies of the library or if you modify it.
+
+ For example, if you distribute copies of the library, whether gratis
+or for a fee, you must give the recipients all the rights that we gave
+you. You must make sure that they, too, receive or can get the source
+code. If you link other code with the library, you must provide
+complete object files to the recipients, so that they can relink them
+with the library after making changes to the library and recompiling
+it. And you must show them these terms so they know their rights.
+
+ We protect your rights with a two-step method: (1) we copyright the
+library, and (2) we offer you this license, which gives you legal
+permission to copy, distribute and/or modify the library.
+
+ To protect each distributor, we want to make it very clear that
+there is no warranty for the free library. Also, if the library is
+modified by someone else and passed on, the recipients should know
+that what they have is not the original version, so that the original
+author's reputation will not be affected by problems that might be
+introduced by others.
+
+ Finally, software patents pose a constant threat to the existence of
+any free program. We wish to make sure that a company cannot
+effectively restrict the users of a free program by obtaining a
+restrictive license from a patent holder. Therefore, we insist that
+any patent license obtained for a version of the library must be
+consistent with the full freedom of use specified in this license.
+
+ Most GNU software, including some libraries, is covered by the
+ordinary GNU General Public License. This license, the GNU Lesser
+General Public License, applies to certain designated libraries, and
+is quite different from the ordinary General Public License. We use
+this license for certain libraries in order to permit linking those
+libraries into non-free programs.
+
+ When a program is linked with a library, whether statically or using
+a shared library, the combination of the two is legally speaking a
+combined work, a derivative of the original library. The ordinary
+General Public License therefore permits such linking only if the
+entire combination fits its criteria of freedom. The Lesser General
+Public License permits more lax criteria for linking other code with
+the library.
+
+ We call this license the "Lesser" General Public License because it
+does Less to protect the user's freedom than the ordinary General
+Public License. It also provides other free software developers Less
+of an advantage over competing non-free programs. These disadvantages
+are the reason we use the ordinary General Public License for many
+libraries. However, the Lesser license provides advantages in certain
+special circumstances.
+
+ For example, on rare occasions, there may be a special need to
+encourage the widest possible use of a certain library, so that it
+becomes a de-facto standard. To achieve this, non-free programs must
+be allowed to use the library. A more frequent case is that a free
+library does the same job as widely used non-free libraries. In this
+case, there is little to gain by limiting the free library to free
+software only, so we use the Lesser General Public License.
+
+ In other cases, permission to use a particular library in non-free
+programs enables a greater number of people to use a large body of
+free software. For example, permission to use the GNU C Library in
+non-free programs enables many more people to use the whole GNU
+operating system, as well as its variant, the GNU/Linux operating
+system.
+
+ Although the Lesser General Public License is Less protective of the
+users' freedom, it does ensure that the user of a program that is
+linked with the Library has the freedom and the wherewithal to run
+that program using a modified version of the Library.
+
+ The precise terms and conditions for copying, distribution and
+modification follow. Pay close attention to the difference between a
+"work based on the library" and a "work that uses the library". The
+former contains code derived from the library, whereas the latter must
+be combined with the library in order to run.
+
+ GNU LESSER GENERAL PUBLIC LICENSE
+ TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
+
+ 0. This License Agreement applies to any software library or other
+program which contains a notice placed by the copyright holder or
+other authorized party saying it may be distributed under the terms of
+this Lesser General Public License (also called "this License").
+Each licensee is addressed as "you".
+
+ A "library" means a collection of software functions and/or data
+prepared so as to be conveniently linked with application programs
+(which use some of those functions and data) to form executables.
+
+ The "Library", below, refers to any such software library or work
+which has been distributed under these terms. A "work based on the
+Library" means either the Library or any derivative work under
+copyright law: that is to say, a work containing the Library or a
+portion of it, either verbatim or with modifications and/or translated
+straightforwardly into another language. (Hereinafter, translation is
+included without limitation in the term "modification".)
+
+ "Source code" for a work means the preferred form of the work for
+making modifications to it. For a library, complete source code means
+all the source code for all modules it contains, plus any associated
+interface definition files, plus the scripts used to control
+compilation and installation of the library.
+
+ Activities other than copying, distribution and modification are not
+covered by this License; they are outside its scope. The act of
+running a program using the Library is not restricted, and output from
+such a program is covered only if its contents constitute a work based
+on the Library (independent of the use of the Library in a tool for
+writing it). Whether that is true depends on what the Library does
+and what the program that uses the Library does.
+
+ 1. You may copy and distribute verbatim copies of the Library's
+complete source code as you receive it, in any medium, provided that
+you conspicuously and appropriately publish on each copy an
+appropriate copyright notice and disclaimer of warranty; keep intact
+all the notices that refer to this License and to the absence of any
+warranty; and distribute a copy of this License along with the
+Library.
+
+ You may charge a fee for the physical act of transferring a copy,
+and you may at your option offer warranty protection in exchange for a
+fee.
+
+ 2. You may modify your copy or copies of the Library or any portion
+of it, thus forming a work based on the Library, and copy and
+distribute such modifications or work under the terms of Section 1
+above, provided that you also meet all of these conditions:
+
+ a) The modified work must itself be a software library.
+
+ b) You must cause the files modified to carry prominent notices
+ stating that you changed the files and the date of any change.
+
+ c) You must cause the whole of the work to be licensed at no
+ charge to all third parties under the terms of this License.
+
+ d) If a facility in the modified Library refers to a function or a
+ table of data to be supplied by an application program that uses
+ the facility, other than as an argument passed when the facility
+ is invoked, then you must make a good faith effort to ensure that,
+ in the event an application does not supply such function or
+ table, the facility still operates, and performs whatever part of
+ its purpose remains meaningful.
+
+ (For example, a function in a library to compute square roots has
+ a purpose that is entirely well-defined independent of the
+ application. Therefore, Subsection 2d requires that any
+ application-supplied function or table used by this function must
+ be optional: if the application does not supply it, the square
+ root function must still compute square roots.)
+
+These requirements apply to the modified work as a whole. If
+identifiable sections of that work are not derived from the Library,
+and can be reasonably considered independent and separate works in
+themselves, then this License, and its terms, do not apply to those
+sections when you distribute them as separate works. But when you
+distribute the same sections as part of a whole which is a work based
+on the Library, the distribution of the whole must be on the terms of
+this License, whose permissions for other licensees extend to the
+entire whole, and thus to each and every part regardless of who wrote
+it.
+
+Thus, it is not the intent of this section to claim rights or contest
+your rights to work written entirely by you; rather, the intent is to
+exercise the right to control the distribution of derivative or
+collective works based on the Library.
+
+In addition, mere aggregation of another work not based on the Library
+with the Library (or with a work based on the Library) on a volume of
+a storage or distribution medium does not bring the other work under
+the scope of this License.
+
+ 3. You may opt to apply the terms of the ordinary GNU General Public
+License instead of this License to a given copy of the Library. To do
+this, you must alter all the notices that refer to this License, so
+that they refer to the ordinary GNU General Public License, version 2,
+instead of to this License. (If a newer version than version 2 of the
+ordinary GNU General Public License has appeared, then you can specify
+that version instead if you wish.) Do not make any other change in
+these notices.
+
+ Once this change is made in a given copy, it is irreversible for
+that copy, so the ordinary GNU General Public License applies to all
+subsequent copies and derivative works made from that copy.
+
+ This option is useful when you wish to copy part of the code of
+the Library into a program that is not a library.
+
+ 4. You may copy and distribute the Library (or a portion or
+derivative of it, under Section 2) in object code or executable form
+under the terms of Sections 1 and 2 above provided that you accompany
+it with the complete corresponding machine-readable source code, which
+must be distributed under the terms of Sections 1 and 2 above on a
+medium customarily used for software interchange.
+
+ If distribution of object code is made by offering access to copy
+from a designated place, then offering equivalent access to copy the
+source code from the same place satisfies the requirement to
+distribute the source code, even though third parties are not
+compelled to copy the source along with the object code.
+
+ 5. A program that contains no derivative of any portion of the
+Library, but is designed to work with the Library by being compiled or
+linked with it, is called a "work that uses the Library". Such a
+work, in isolation, is not a derivative work of the Library, and
+therefore falls outside the scope of this License.
+
+ However, linking a "work that uses the Library" with the Library
+creates an executable that is a derivative of the Library (because it
+contains portions of the Library), rather than a "work that uses the
+library". The executable is therefore covered by this License.
+Section 6 states terms for distribution of such executables.
+
+ When a "work that uses the Library" uses material from a header file
+that is part of the Library, the object code for the work may be a
+derivative work of the Library even though the source code is not.
+Whether this is true is especially significant if the work can be
+linked without the Library, or if the work is itself a library. The
+threshold for this to be true is not precisely defined by law.
+
+ If such an object file uses only numerical parameters, data
+structure layouts and accessors, and small macros and small inline
+functions (ten lines or less in length), then the use of the object
+file is unrestricted, regardless of whether it is legally a derivative
+work. (Executables containing this object code plus portions of the
+Library will still fall under Section 6.)
+
+ Otherwise, if the work is a derivative of the Library, you may
+distribute the object code for the work under the terms of Section 6.
+Any executables containing that work also fall under Section 6,
+whether or not they are linked directly with the Library itself.
+
+ 6. As an exception to the Sections above, you may also combine or
+link a "work that uses the Library" with the Library to produce a
+work containing portions of the Library, and distribute that work
+under terms of your choice, provided that the terms permit
+modification of the work for the customer's own use and reverse
+engineering for debugging such modifications.
+
+ You must give prominent notice with each copy of the work that the
+Library is used in it and that the Library and its use are covered by
+this License. You must supply a copy of this License. If the work
+during execution displays copyright notices, you must include the
+copyright notice for the Library among them, as well as a reference
+directing the user to the copy of this License. Also, you must do one
+of these things:
+
+ a) Accompany the work with the complete corresponding
+ machine-readable source code for the Library including whatever
+ changes were used in the work (which must be distributed under
+ Sections 1 and 2 above); and, if the work is an executable linked
+ with the Library, with the complete machine-readable "work that
+ uses the Library", as object code and/or source code, so that the
+ user can modify the Library and then relink to produce a modified
+ executable containing the modified Library. (It is understood
+ that the user who changes the contents of definitions files in the
+ Library will not necessarily be able to recompile the application
+ to use the modified definitions.)
+
+ b) Use a suitable shared library mechanism for linking with the
+ Library. A suitable mechanism is one that (1) uses at run time a
+ copy of the library already present on the user's computer system,
+ rather than copying library functions into the executable, and (2)
+ will operate properly with a modified version of the library, if
+ the user installs one, as long as the modified version is
+ interface-compatible with the version that the work was made with.
+
+ c) Accompany the work with a written offer, valid for at least
+ three years, to give the same user the materials specified in
+ Subsection 6a, above, for a charge no more than the cost of
+ performing this distribution.
+
+ d) If distribution of the work is made by offering access to copy
+ from a designated place, offer equivalent access to copy the above
+ specified materials from the same place.
+
+ e) Verify that the user has already received a copy of these
+ materials or that you have already sent this user a copy.
+
+ For an executable, the required form of the "work that uses the
+Library" must include any data and utility programs needed for
+reproducing the executable from it. However, as a special exception,
+the materials to be distributed need not include anything that is
+normally distributed (in either source or binary form) with the major
+components (compiler, kernel, and so on) of the operating system on
+which the executable runs, unless that component itself accompanies
+the executable.
+
+ It may happen that this requirement contradicts the license
+restrictions of other proprietary libraries that do not normally
+accompany the operating system. Such a contradiction means you cannot
+use both them and the Library together in an executable that you
+distribute.
+
+ 7. You may place library facilities that are a work based on the
+Library side-by-side in a single library together with other library
+facilities not covered by this License, and distribute such a combined
+library, provided that the separate distribution of the work based on
+the Library and of the other library facilities is otherwise
+permitted, and provided that you do these two things:
+
+ a) Accompany the combined library with a copy of the same work
+ based on the Library, uncombined with any other library
+ facilities. This must be distributed under the terms of the
+ Sections above.
+
+ b) Give prominent notice with the combined library of the fact
+ that part of it is a work based on the Library, and explaining
+ where to find the accompanying uncombined form of the same work.
+
+ 8. You may not copy, modify, sublicense, link with, or distribute
+the Library except as expressly provided under this License. Any
+attempt otherwise to copy, modify, sublicense, link with, or
+distribute the Library is void, and will automatically terminate your
+rights under this License. However, parties who have received copies,
+or rights, from you under this License will not have their licenses
+terminated so long as such parties remain in full compliance.
+
+ 9. You are not required to accept this License, since you have not
+signed it. However, nothing else grants you permission to modify or
+distribute the Library or its derivative works. These actions are
+prohibited by law if you do not accept this License. Therefore, by
+modifying or distributing the Library (or any work based on the
+Library), you indicate your acceptance of this License to do so, and
+all its terms and conditions for copying, distributing or modifying
+the Library or works based on it.
+
+ 10. Each time you redistribute the Library (or any work based on the
+Library), the recipient automatically receives a license from the
+original licensor to copy, distribute, link with or modify the Library
+subject to these terms and conditions. You may not impose any further
+restrictions on the recipients' exercise of the rights granted herein.
+You are not responsible for enforcing compliance by third parties with
+this License.
+
+ 11. If, as a consequence of a court judgment or allegation of patent
+infringement or for any other reason (not limited to patent issues),
+conditions are imposed on you (whether by court order, agreement or
+otherwise) that contradict the conditions of this License, they do not
+excuse you from the conditions of this License. If you cannot
+distribute so as to satisfy simultaneously your obligations under this
+License and any other pertinent obligations, then as a consequence you
+may not distribute the Library at all. For example, if a patent
+license would not permit royalty-free redistribution of the Library by
+all those who receive copies directly or indirectly through you, then
+the only way you could satisfy both it and this License would be to
+refrain entirely from distribution of the Library.
+
+If any portion of this section is held invalid or unenforceable under
+any particular circumstance, the balance of the section is intended to
+apply, and the section as a whole is intended to apply in other
+circumstances.
+
+It is not the purpose of this section to induce you to infringe any
+patents or other property right claims or to contest validity of any
+such claims; this section has the sole purpose of protecting the
+integrity of the free software distribution system which is
+implemented by public license practices. Many people have made
+generous contributions to the wide range of software distributed
+through that system in reliance on consistent application of that
+system; it is up to the author/donor to decide if he or she is willing
+to distribute software through any other system and a licensee cannot
+impose that choice.
+
+This section is intended to make thoroughly clear what is believed to
+be a consequence of the rest of this License.
+
+ 12. If the distribution and/or use of the Library is restricted in
+certain countries either by patents or by copyrighted interfaces, the
+original copyright holder who places the Library under this License
+may add an explicit geographical distribution limitation excluding those
+countries, so that distribution is permitted only in or among
+countries not thus excluded. In such case, this License incorporates
+the limitation as if written in the body of this License.
+
+ 13. The Free Software Foundation may publish revised and/or new
+versions of the Lesser General Public License from time to time.
+Such new versions will be similar in spirit to the present version,
+but may differ in detail to address new problems or concerns.
+
+Each version is given a distinguishing version number. If the Library
+specifies a version number of this License which applies to it and
+"any later version", you have the option of following the terms and
+conditions either of that version or of any later version published by
+the Free Software Foundation. If the Library does not specify a
+license version number, you may choose any version ever published by
+the Free Software Foundation.
+
+ 14. If you wish to incorporate parts of the Library into other free
+programs whose distribution conditions are incompatible with these,
+write to the author to ask for permission. For software which is
+copyrighted by the Free Software Foundation, write to the Free
+Software Foundation; we sometimes make exceptions for this. Our
+decision will be guided by the two goals of preserving the free status
+of all derivatives of our free software and of promoting the sharing
+and reuse of software generally.
+
+ NO WARRANTY
+
+ 15. BECAUSE THE LIBRARY IS LICENSED FREE OF CHARGE, THERE IS NO
+WARRANTY FOR THE LIBRARY, TO THE EXTENT PERMITTED BY APPLICABLE LAW.
+EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR
+OTHER PARTIES PROVIDE THE LIBRARY "AS IS" WITHOUT WARRANTY OF ANY
+KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE
+IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
+PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE
+LIBRARY IS WITH YOU. SHOULD THE LIBRARY PROVE DEFECTIVE, YOU ASSUME
+THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
+
+ 16. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN
+WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY
+AND/OR REDISTRIBUTE THE LIBRARY AS PERMITTED ABOVE, BE LIABLE TO YOU
+FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR
+CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE
+LIBRARY (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING
+RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A
+FAILURE OF THE LIBRARY TO OPERATE WITH ANY OTHER SOFTWARE), EVEN IF
+SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH
+DAMAGES.
+
+ END OF TERMS AND CONDITIONS
+
+ How to Apply These Terms to Your New Libraries
+
+ If you develop a new library, and you want it to be of the greatest
+possible use to the public, we recommend making it free software that
+everyone can redistribute and change. You can do so by permitting
+redistribution under these terms (or, alternatively, under the terms
+of the ordinary General Public License).
+
+ To apply these terms, attach the following notices to the library.
+It is safest to attach them to the start of each source file to most
+effectively convey the exclusion of warranty; and each file should
+have at least the "copyright" line and a pointer to where the full
+notice is found.
+
+
+ <one line to give the library's name and a brief idea of what it does.>
+ Copyright (C) <year> <name of author>
+
+ This library is free software; you can redistribute it and/or
+ modify it under the terms of the GNU Lesser General Public
+ License as published by the Free Software Foundation; either
+ version 2.1 of the License, or (at your option) any later version.
+
+ This library is distributed in the hope that it will be useful,
+ but WITHOUT ANY WARRANTY; without even the implied warranty of
+ MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
+ Lesser General Public License for more details.
+
+ You should have received a copy of the GNU Lesser General Public
+ License along with this library; if not, write to the Free Software
+ Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
+
+Also add information on how to contact you by electronic and paper mail.
+
+You should also get your employer (if you work as a programmer) or
+your school, if any, to sign a "copyright disclaimer" for the library,
+if necessary. Here is a sample; alter the names:
+
+ Yoyodyne, Inc., hereby disclaims all copyright interest in the
+ library `Frob' (a library for tweaking knobs) written by James
+ Random Hacker.
+
+ <signature of Ty Coon>, 1 April 1990
+ Ty Coon, President of Vice
+
+That's all there is to it!
diff --git a/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/METADATA b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/METADATA
new file mode 100644
index 000000000..82c08c0a5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/METADATA
@@ -0,0 +1,123 @@
+Metadata-Version: 2.1
+Name: astroid
+Version: 3.3.8
+Summary: An abstract syntax tree for Python with inference support.
+License: LGPL-2.1-or-later
+Project-URL: Docs, https://pylint.readthedocs.io/projects/astroid/en/latest/
+Project-URL: Source Code, https://github.com/pylint-dev/astroid
+Project-URL: Bug tracker, https://github.com/pylint-dev/astroid/issues
+Project-URL: Discord server, https://discord.gg/Egy6P8AMB5
+Keywords: static code analysis,python,abstract syntax tree
+Classifier: Development Status :: 6 - Mature
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: GNU Lesser General Public License v2 (LGPLv2)
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Classifier: Programming Language :: Python :: 3.13
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Software Development :: Libraries :: Python Modules
+Classifier: Topic :: Software Development :: Quality Assurance
+Classifier: Topic :: Software Development :: Testing
+Requires-Python: >=3.9.0
+Description-Content-Type: text/x-rst
+License-File: LICENSE
+License-File: CONTRIBUTORS.txt
+Requires-Dist: typing-extensions>=4.0.0; python_version < "3.11"
+
+Astroid
+=======
+
+.. image:: https://codecov.io/gh/pylint-dev/astroid/branch/main/graph/badge.svg?token=Buxy4WptLb
+ :target: https://codecov.io/gh/pylint-dev/astroid
+ :alt: Coverage badge from codecov
+
+.. image:: https://readthedocs.org/projects/astroid/badge/?version=latest
+ :target: http://astroid.readthedocs.io/en/latest/?badge=latest
+ :alt: Documentation Status
+
+.. image:: https://img.shields.io/badge/code%20style-black-000000.svg
+ :target: https://github.com/ambv/black
+
+.. image:: https://results.pre-commit.ci/badge/github/pylint-dev/astroid/main.svg
+ :target: https://results.pre-commit.ci/latest/github/pylint-dev/astroid/main
+ :alt: pre-commit.ci status
+
+.. |tidelift_logo| image:: https://raw.githubusercontent.com/pylint-dev/astroid/main/doc/media/Tidelift_Logos_RGB_Tidelift_Shorthand_On-White.png
+ :width: 200
+ :alt: Tidelift
+
+.. list-table::
+ :widths: 10 100
+
+ * - |tidelift_logo|
+ - Professional support for astroid is available as part of the
+ `Tidelift Subscription`_. Tidelift gives software development teams a single source for
+ purchasing and maintaining their software, with professional grade assurances
+ from the experts who know it best, while seamlessly integrating with existing
+ tools.
+
+.. _Tidelift Subscription: https://tidelift.com/subscription/pkg/pypi-astroid?utm_source=pypi-astroid&utm_medium=referral&utm_campaign=readme
+
+
+
+What's this?
+------------
+
+The aim of this module is to provide a common base representation of
+python source code. It is currently the library powering pylint's capabilities.
+
+It provides a compatible representation which comes from the `_ast`
+module. It rebuilds the tree generated by the builtin _ast module by
+recursively walking down the AST and building an extended ast. The new
+node classes have additional methods and attributes for different
+usages. They include some support for static inference and local name
+scopes. Furthermore, astroid can also build partial trees by inspecting living
+objects.
+
+
+Installation
+------------
+
+Extract the tarball, jump into the created directory and run::
+
+ pip install .
+
+
+If you want to do an editable installation, you can run::
+
+ pip install -e .
+
+
+If you have any questions, please mail the code-quality@python.org
+mailing list for support. See
+http://mail.python.org/mailman/listinfo/code-quality for subscription
+information and archives.
+
+Documentation
+-------------
+http://astroid.readthedocs.io/en/latest/
+
+
+Python Versions
+---------------
+
+astroid 2.0 is currently available for Python 3 only. If you want Python 2
+support, use an older version of astroid (though note that these versions
+are no longer supported).
+
+Test
+----
+
+Tests are in the 'test' subdirectory. To launch the whole tests suite, you can use
+either `tox` or `pytest`::
+
+ tox
+ pytest
diff --git a/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/RECORD b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/RECORD
new file mode 100644
index 000000000..3218824c7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/RECORD
@@ -0,0 +1,199 @@
+astroid-3.3.8.dist-info/CONTRIBUTORS.txt,sha256=yDGxkao8VsELjevVDxCu5URTI7Fke1h5UBnt3p28b6E,8839
+astroid-3.3.8.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+astroid-3.3.8.dist-info/LICENSE,sha256=_qFr2p5zTeoNnI2fW5CYeO9BcWJjVDKWCf_889tCyyQ,26516
+astroid-3.3.8.dist-info/METADATA,sha256=iNjjc_W3rULBhj9G91VA0t9ntSP0cKAPyghDx3p-aZo,4484
+astroid-3.3.8.dist-info/RECORD,,
+astroid-3.3.8.dist-info/WHEEL,sha256=PZUExdf71Ui_so67QXpySuHtCi3-J3wvF4ORK6k_S8U,91
+astroid-3.3.8.dist-info/top_level.txt,sha256=HsdW4O2x7ZXRj6k-agi3RaQybGLobI3VSE-jt4vQUXM,8
+astroid/__init__.py,sha256=s-gC1t4dI_ZehnQpTVmd6n_NWzR8bLXELA2rDagvBd8,4546
+astroid/__pkginfo__.py,sha256=LXNsdSf05Zuvgc6bfoIb42IA25rOll2M-gx2UayVOXk,283
+astroid/__pycache__/__init__.cpython-312.pyc,,
+astroid/__pycache__/__pkginfo__.cpython-312.pyc,,
+astroid/__pycache__/_ast.cpython-312.pyc,,
+astroid/__pycache__/_backport_stdlib_names.cpython-312.pyc,,
+astroid/__pycache__/arguments.cpython-312.pyc,,
+astroid/__pycache__/astroid_manager.cpython-312.pyc,,
+astroid/__pycache__/bases.cpython-312.pyc,,
+astroid/__pycache__/builder.cpython-312.pyc,,
+astroid/__pycache__/const.cpython-312.pyc,,
+astroid/__pycache__/constraint.cpython-312.pyc,,
+astroid/__pycache__/context.cpython-312.pyc,,
+astroid/__pycache__/decorators.cpython-312.pyc,,
+astroid/__pycache__/exceptions.cpython-312.pyc,,
+astroid/__pycache__/filter_statements.cpython-312.pyc,,
+astroid/__pycache__/helpers.cpython-312.pyc,,
+astroid/__pycache__/inference_tip.cpython-312.pyc,,
+astroid/__pycache__/manager.cpython-312.pyc,,
+astroid/__pycache__/modutils.cpython-312.pyc,,
+astroid/__pycache__/objects.cpython-312.pyc,,
+astroid/__pycache__/protocols.cpython-312.pyc,,
+astroid/__pycache__/raw_building.cpython-312.pyc,,
+astroid/__pycache__/rebuilder.cpython-312.pyc,,
+astroid/__pycache__/test_utils.cpython-312.pyc,,
+astroid/__pycache__/transforms.cpython-312.pyc,,
+astroid/__pycache__/typing.cpython-312.pyc,,
+astroid/__pycache__/util.cpython-312.pyc,,
+astroid/_ast.py,sha256=X88DQBpbexlbkz8sg_SMjGYSDoqAjFsMf0_qaw08Pd8,3033
+astroid/_backport_stdlib_names.py,sha256=NSOKmr7uJW5kI9m3L8WO7vpKYhO-ae7dnL7XQIKQEM8,6886
+astroid/arguments.py,sha256=rvhDH_Hu-5Qw4CihLn8hm0BYxtjKjDixoKdhgxAPbvY,12990
+astroid/astroid_manager.py,sha256=uGIFUKDTjCdy757OF60r3apRqVybugBZh1rudtOSGMA,729
+astroid/bases.py,sha256=HzOQvomzLyi59XZfJBqK1xfs5I6XEipJg0BqFYCEyZ4,27298
+astroid/brain/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+astroid/brain/__pycache__/__init__.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_argparse.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_attrs.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_boto3.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_builtin_inference.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_collections.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_crypt.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_ctypes.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_curses.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_dataclasses.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_datetime.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_dateutil.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_functools.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_gi.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_hashlib.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_http.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_hypothesis.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_io.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_mechanize.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_multiprocessing.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_namedtuple_enum.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_nose.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_core_einsumfunc.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_core_fromnumeric.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_core_function_base.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_core_multiarray.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_core_numeric.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_core_numerictypes.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_core_umath.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_ma.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_ndarray.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_random_mtrand.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_numpy_utils.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_pathlib.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_pkg_resources.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_pytest.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_qt.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_random.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_re.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_regex.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_responses.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_scipy_signal.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_signal.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_six.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_sqlalchemy.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_ssl.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_subprocess.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_threading.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_type.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_typing.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_unittest.cpython-312.pyc,,
+astroid/brain/__pycache__/brain_uuid.cpython-312.pyc,,
+astroid/brain/__pycache__/helpers.cpython-312.pyc,,
+astroid/brain/brain_argparse.py,sha256=2oJSnX1UsMCI0t7iGVvZ5xaCqkq2MQFaxPcKrXP2nKg,1813
+astroid/brain/brain_attrs.py,sha256=zlm6c3dahmbo_inncWD8rhn7YqZN1ObAXEnNBkAVnHI,3352
+astroid/brain/brain_boto3.py,sha256=-kVqdGfXrUDNq5FZhk3Lfrlo7exKfIG9v1uMp4jpmdM,1072
+astroid/brain/brain_builtin_inference.py,sha256=Wz8BoWvocfSHlFMNhbt_0m63MjgL-zzSC5eEmAzus2s,37433
+astroid/brain/brain_collections.py,sha256=VetyHBQO9nWQmaDeujEOfZ92JANUpgIAWLH5-jT6uZ4,4787
+astroid/brain/brain_crypt.py,sha256=ArelObKC8tWzt9lQW36d34YBNmRSKuxgz6ZjgQeq1WI,915
+astroid/brain/brain_ctypes.py,sha256=JbaHdlANVsqmDTLd9D71FOv_aET8xwZFIuZ6p2lI-_8,2720
+astroid/brain/brain_curses.py,sha256=TtZ7F997yRWo7VbCeG9Q3gj-HM4OkI5A76_02gTcuaw,3529
+astroid/brain/brain_dataclasses.py,sha256=lD0CZNgCzdk1z-Sq-xBnWWobUcV7iWGeCYX1Y7pmzEk,22363
+astroid/brain/brain_datetime.py,sha256=yuqQEm_tX9DMmOd5ifezdICCu2amdulJ89oA4NJFsI4,771
+astroid/brain/brain_dateutil.py,sha256=mewM4qHnqVSlOtJIWXAV_zCt1NslOIBonzqM7sxWw94,819
+astroid/brain/brain_functools.py,sha256=OpQOrUuSeYZz-hRQUtCDd4ppCfCpvZb5TRT4ua4E6j0,6390
+astroid/brain/brain_gi.py,sha256=9_7K7cnZxUt0_vu9Pta8kGG7kibEhkQv5AzF9sWu7mQ,7598
+astroid/brain/brain_hashlib.py,sha256=HocoANOtIFPKPo6AI_4g2CC6opSZXPTdX42DTgnLqlU,2757
+astroid/brain/brain_http.py,sha256=ZXNNt_P_qIgOIueaNqIAcQ7BeKD7sPFGvd7wIGCGuBM,10687
+astroid/brain/brain_hypothesis.py,sha256=2Wuesux6myY8xZDQzo1pi2j35d3fQAgsVW01DmJwPCE,1800
+astroid/brain/brain_io.py,sha256=YV_hxg1EGjV3Wprvp5M_YF8pWoC2MK1oyyH3io6hZpk,1589
+astroid/brain/brain_mechanize.py,sha256=lIAvlGm-DWdOSGO5YhGFocYrVPq5IAvj9fAwHyKNKtQ,2698
+astroid/brain/brain_multiprocessing.py,sha256=ATm2DwP-SXt4LH6hhwN-7ova5Bt483efnuKzKkulmfQ,3260
+astroid/brain/brain_namedtuple_enum.py,sha256=9f4wqr4_m_7N3_b6qhCwVKMfgOtSQ4-Jaey2pntYVs0,23912
+astroid/brain/brain_nose.py,sha256=wT4V4Z5aR1Y8iI4mW1A9IMntnFdG0DM7ggj7dKOrhoY,2402
+astroid/brain/brain_numpy_core_einsumfunc.py,sha256=YfPheziU5UKb80hXS0VZcWVHmw_lQ1t0-Q-w13dwQyM,885
+astroid/brain/brain_numpy_core_fromnumeric.py,sha256=WWHy2vj9Oii5O2A1qtR1xZYzlKC_4Dz46m87jC9budI,792
+astroid/brain/brain_numpy_core_function_base.py,sha256=DIcLsQE2DxK8tmqNVs3zp56CqVIuMDHdiEnnzmanI5U,1408
+astroid/brain/brain_numpy_core_multiarray.py,sha256=7JUDxfI5kMSqVr3CQ2zecPEE7Z-_BQ-RNwqJt1vhNzo,4400
+astroid/brain/brain_numpy_core_numeric.py,sha256=c4JT5DFcU5C0ri8buuIOE50lMp47aF8fcnki65AHqaM,1740
+astroid/brain/brain_numpy_core_numerictypes.py,sha256=jG6btkdUpG8fs4q6wQZ5bV1ZbCJ_GmeMfLHbVactsmM,8606
+astroid/brain/brain_numpy_core_umath.py,sha256=IiY0AQ7NqaLwfp8o5Cty-zxTxPnFT9CfUiDkZopLBl8,4939
+astroid/brain/brain_numpy_ma.py,sha256=lQHborbeqfe7pho8O4vLObx2BpXo3GBOACqT62eWl-4,948
+astroid/brain/brain_numpy_ndarray.py,sha256=IoQnvyCFKd3Rwa4AsaRyfmCYD9DjJimIf75HESuIM9Q,9066
+astroid/brain/brain_numpy_random_mtrand.py,sha256=oXDMx-rjy2VuMQWQNiFF048AlXeczGBuqNrm3XrLKi0,3496
+astroid/brain/brain_numpy_utils.py,sha256=hqqCe8pG20rXe4yj9jF2YFe2J3n0ciYkms4OlMNvhJU,2553
+astroid/brain/brain_pathlib.py,sha256=fd19ihpjXFtg9qfpQ6uAGM_CYJ2rPybv5VkB3nwsfwE,1705
+astroid/brain/brain_pkg_resources.py,sha256=XXwO4IPDkOsx8EflB4udGb3Oh-zEpArlAxalBE2YQG4,2252
+astroid/brain/brain_pytest.py,sha256=_thZjYaAr4gm4TS-DVT7V31Afibkx2Js3JRK1L6j23w,2270
+astroid/brain/brain_qt.py,sha256=VA5BSNJLP9KFsmVBxrKtAtEiw7Q-bOsjuwpA9svCgsI,2874
+astroid/brain/brain_random.py,sha256=IO6SnrbLuKpiM0pMtLAW634qa9kmVqDfB2LYv7D94OA,3170
+astroid/brain/brain_re.py,sha256=iG4ufNmkTBAl6Djs1EGsni7RIq59Yw5o6mKK2NcxGbQ,2966
+astroid/brain/brain_regex.py,sha256=GumexoJA0hJ_CVZ4hA5rGPU4J84rhFfctKfte4gFFBE,3433
+astroid/brain/brain_responses.py,sha256=fD21AvxFQINNe636reXCUgA9DVfIaDyLf_Gbf5PIkcQ,1920
+astroid/brain/brain_scipy_signal.py,sha256=SBSOndS7W213XQ17ahKVRxd6GMSHLBhoqfMkgUMF3k4,2328
+astroid/brain/brain_signal.py,sha256=Qt8cFsEwYmwaI_PU5aBBfYV4TLkF0lBPdME-oeGWMYk,3932
+astroid/brain/brain_six.py,sha256=qE9SDxOfC496H-Hd2nhgwtJmvukdA8u-2U09-TwZTXM,7666
+astroid/brain/brain_sqlalchemy.py,sha256=6Lxdfyo4FOjKy6ZuaSD3-GW3YiMhcjwLNCIbHAfJmfs,1061
+astroid/brain/brain_ssl.py,sha256=IOGu2xjcu3uxwfV3sw2rMUmVYxAFRThW2ueN56bmrEE,6716
+astroid/brain/brain_subprocess.py,sha256=10p24yCfwTnX6XOaNM8KYKzIsWqYGrehTnWrTUM2QWc,2971
+astroid/brain/brain_threading.py,sha256=xeSOqbPWCeFCynUEMK787KsrOTR4ZZKgdV7vO880Leo,922
+astroid/brain/brain_type.py,sha256=qW2NH4GtujRjjw5vcX2IEjqqJD6DLX49gqdooLcuFfA,2481
+astroid/brain/brain_typing.py,sha256=H4oEoKYoNr91GVXgWDDz2Imr3F1COr7i5pPmNSSRHmA,16717
+astroid/brain/brain_unittest.py,sha256=MpCSlfCCzLwbEmUTjN3_11cCsF0S6yXOT2v0KDgcxSA,1136
+astroid/brain/brain_uuid.py,sha256=xAxEsoeh3L301R_6kii5g2E8dTrB5eA4gFb4oRKIeM0,727
+astroid/brain/helpers.py,sha256=KEuo67734fSTrgGcCffRlh6tfP0NCFe1RvWrstgd_CI,4303
+astroid/builder.py,sha256=nN0wvqNlNGCJ00hzBFYcATkZKGqDCKoNWjvkT3nIsEs,18715
+astroid/const.py,sha256=uANbZ0pYOAs9QMcQTS5Opou8xX2q04kj99xhdt4mzrw,654
+astroid/constraint.py,sha256=neW7okv9njOB0NT9QVlYm_lH455P7kx-3YOVikq_dco,5086
+astroid/context.py,sha256=BL_yXS7mFGzNB4VZwntkNFC7tKJ_aoexRIBbuLHcQiQ,6311
+astroid/decorators.py,sha256=laTR-B5v_danZdUkiBCCokwhpInqaDx8eZE7koRIxh4,8490
+astroid/exceptions.py,sha256=dHR5xggNKd2DoT7sP12YgjtXPh-Si6sS2G5tflus4ks,12817
+astroid/filter_statements.py,sha256=W92OQCtBIt7uir9fnq8L8oxjA8bazf5X46Md2TraajI,9387
+astroid/helpers.py,sha256=4KpGyyLqO2rj4eeFtb-trQDsAJ5KceTtPUjv4UgUZdE,11906
+astroid/inference_tip.py,sha256=5Dsfn-9qie1Wuzc2XaWzhlPQQxD3fGt64RR3nyptvHc,4586
+astroid/interpreter/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+astroid/interpreter/__pycache__/__init__.cpython-312.pyc,,
+astroid/interpreter/__pycache__/dunder_lookup.cpython-312.pyc,,
+astroid/interpreter/__pycache__/objectmodel.cpython-312.pyc,,
+astroid/interpreter/_import/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+astroid/interpreter/_import/__pycache__/__init__.cpython-312.pyc,,
+astroid/interpreter/_import/__pycache__/spec.cpython-312.pyc,,
+astroid/interpreter/_import/__pycache__/util.cpython-312.pyc,,
+astroid/interpreter/_import/spec.py,sha256=uD-gAzzjWGglbz-vVoIdRQ-40jjZMPdsxYRPLxhhpvw,18956
+astroid/interpreter/_import/util.py,sha256=D31dW6a7PT_Kb5jb_1zbIJkqRmQNaYU6madwynbXmpQ,4702
+astroid/interpreter/dunder_lookup.py,sha256=3-OvzVqHkwndSgZwdfF0wkpN9DomFaTZZdSXnSkLK1U,2515
+astroid/interpreter/objectmodel.py,sha256=fYltBNdVUK3tWxjBjSumVZWNfZiPadiPmGZBur5-zds,34705
+astroid/manager.py,sha256=gzDYWfJT5yXh9kCAkbGXG11hIjIRDcISvbCcms2fVvE,18745
+astroid/modutils.py,sha256=-LFeh9afFccvZOuppab8hx7_jfgqUZ6TAZDhtuQnRxw,22931
+astroid/nodes/__init__.py,sha256=Vk9J5ucY1rwXMivXElZ02YcaFNKInZGKTFoSa1wNbgo,4744
+astroid/nodes/__pycache__/__init__.cpython-312.pyc,,
+astroid/nodes/__pycache__/_base_nodes.cpython-312.pyc,,
+astroid/nodes/__pycache__/as_string.cpython-312.pyc,,
+astroid/nodes/__pycache__/const.cpython-312.pyc,,
+astroid/nodes/__pycache__/node_classes.cpython-312.pyc,,
+astroid/nodes/__pycache__/node_ng.cpython-312.pyc,,
+astroid/nodes/__pycache__/utils.cpython-312.pyc,,
+astroid/nodes/_base_nodes.py,sha256=Lq5SjJneilKMDoa7U8Fqmmn7lCsg4HKpssRob8h32Mg,23991
+astroid/nodes/as_string.py,sha256=TH2w9J6O3-Hgn8MW4j22nayeVhEf_yJ6EzHph3bGVGA,26317
+astroid/nodes/const.py,sha256=aD7rKF5kPM2UFJAR5pzZDAM-Zm7p9LG57E-9FjB1gTc,807
+astroid/nodes/node_classes.py,sha256=GLrgVK2gcFUrS1dX6AGRlAqpDjAJL25CO-38_yvyUZ8,171953
+astroid/nodes/node_ng.py,sha256=z8qqq3SsPvMZdVWaohrOjF3fMQen5doVoj2mmgG-aNc,27012
+astroid/nodes/scoped_nodes/__init__.py,sha256=PM4o8zD1yE0bNAral91_aE7KoCjocM5M21FH1TwOEz0,1229
+astroid/nodes/scoped_nodes/__pycache__/__init__.cpython-312.pyc,,
+astroid/nodes/scoped_nodes/__pycache__/mixin.cpython-312.pyc,,
+astroid/nodes/scoped_nodes/__pycache__/scoped_nodes.cpython-312.pyc,,
+astroid/nodes/scoped_nodes/__pycache__/utils.cpython-312.pyc,,
+astroid/nodes/scoped_nodes/mixin.py,sha256=kDdvUEZRSPmQ88sLD2edjalmU88-UZbUIaBERzCy2Ew,7151
+astroid/nodes/scoped_nodes/scoped_nodes.py,sha256=M3E-lu9BVM4ssoUOGnr2JC_TdkmZ621gnFZGwPeEqrg,104889
+astroid/nodes/scoped_nodes/utils.py,sha256=rBKL_c6byvOWq7yzRSMNWsZQIe5smST8Dnpz40Nni7Q,1181
+astroid/nodes/utils.py,sha256=5strAqVk0zh9cOD4nH8EZiIsaDn5-gLIT2U1hAoY9wU,433
+astroid/objects.py,sha256=u5zjoHkDlfR2TH6u1CgbXnGFrIBOYoBsOJOq2k1TRoI,13013
+astroid/protocols.py,sha256=RItcpSQjksgtTE9zTb_ACVkqH_HrJ1fzxj4eX5IMXPo,31626
+astroid/raw_building.py,sha256=yEmmfYLzbUGzQN3qATMfk1s6--ehvRSqxepKJs1n6aY,25337
+astroid/rebuilder.py,sha256=6chbMTN7U0v8Q1VtefppeUhdFCDtvA9r8UW-lVsGxOw,68224
+astroid/test_utils.py,sha256=gyLSvyMM7QfsfqZhmVW6nM1whn1ArMWTsiHi8_Jy060,2474
+astroid/transforms.py,sha256=lTxhZN5alNxM4fn9Zgma5tqa7XCDYpEdMGqI6auH6Sw,5836
+astroid/typing.py,sha256=RW0e-JFbi7CsgW1j4FP-Af5rG9UNBn4KQ5HLZokq0Kc,2755
+astroid/util.py,sha256=H0hAr2TTxsK97137v9gp59-JmuCMWABmmI_0UOOM9N0,4846
diff --git a/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/WHEEL
new file mode 100644
index 000000000..ae527e7d6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/WHEEL
@@ -0,0 +1,5 @@
+Wheel-Version: 1.0
+Generator: setuptools (75.6.0)
+Root-Is-Purelib: true
+Tag: py3-none-any
+
diff --git a/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/top_level.txt b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/top_level.txt
new file mode 100644
index 000000000..450d4fe9e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid-3.3.8.dist-info/top_level.txt
@@ -0,0 +1 @@
+astroid
diff --git a/solutions/.venv/Lib/site-packages/astroid/__init__.py b/solutions/.venv/Lib/site-packages/astroid/__init__.py
new file mode 100644
index 000000000..f04b4dfdc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/__init__.py
@@ -0,0 +1,186 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Python Abstract Syntax Tree New Generation.
+
+The aim of this module is to provide a common base representation of
+python source code for projects such as pychecker, pyreverse,
+pylint... Well, actually the development of this library is essentially
+governed by pylint's needs.
+
+It mimics the class defined in the python's _ast module with some
+additional methods and attributes. New nodes instances are not fully
+compatible with python's _ast.
+
+Instance attributes are added by a
+builder object, which can either generate extended ast (let's call
+them astroid ;) by visiting an existent ast tree or by inspecting living
+object.
+
+Main modules are:
+
+* nodes and scoped_nodes for more information about methods and
+ attributes added to different node classes
+
+* the manager contains a high level object to get astroid trees from
+ source files and living objects. It maintains a cache of previously
+ constructed tree for quick access
+
+* builder contains the class responsible to build astroid trees
+"""
+
+import functools
+import tokenize
+
+# isort: off
+# We have an isort: off on 'astroid.nodes' because of a circular import.
+from astroid.nodes import node_classes, scoped_nodes
+
+# isort: on
+
+from astroid import raw_building
+from astroid.__pkginfo__ import __version__, version
+from astroid.bases import BaseInstance, BoundMethod, Instance, UnboundMethod
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import extract_node, parse
+from astroid.const import PY310_PLUS, Context
+from astroid.exceptions import (
+ AstroidBuildingError,
+ AstroidError,
+ AstroidImportError,
+ AstroidIndexError,
+ AstroidSyntaxError,
+ AstroidTypeError,
+ AstroidValueError,
+ AttributeInferenceError,
+ DuplicateBasesError,
+ InconsistentMroError,
+ InferenceError,
+ InferenceOverwriteError,
+ MroError,
+ NameInferenceError,
+ NoDefault,
+ NotFoundError,
+ ParentMissingError,
+ ResolveError,
+ StatementMissing,
+ SuperArgumentTypeError,
+ SuperError,
+ TooManyLevelsError,
+ UnresolvableName,
+ UseInferenceDefault,
+)
+from astroid.inference_tip import _inference_tip_cached, inference_tip
+from astroid.objects import ExceptionInstance
+
+# isort: off
+# It's impossible to import from astroid.nodes with a wildcard, because
+# there is a cyclic import that prevent creating an __all__ in astroid/nodes
+# and we need astroid/scoped_nodes and astroid/node_classes to work. So
+# importing with a wildcard would clash with astroid/nodes/scoped_nodes
+# and astroid/nodes/node_classes.
+from astroid.astroid_manager import MANAGER
+from astroid.nodes import (
+ CONST_CLS,
+ AnnAssign,
+ Arguments,
+ Assert,
+ Assign,
+ AssignAttr,
+ AssignName,
+ AsyncFor,
+ AsyncFunctionDef,
+ AsyncWith,
+ Attribute,
+ AugAssign,
+ Await,
+ BinOp,
+ BoolOp,
+ Break,
+ Call,
+ ClassDef,
+ Compare,
+ Comprehension,
+ ComprehensionScope,
+ Const,
+ Continue,
+ Decorators,
+ DelAttr,
+ Delete,
+ DelName,
+ Dict,
+ DictComp,
+ DictUnpack,
+ EmptyNode,
+ EvaluatedObject,
+ ExceptHandler,
+ Expr,
+ For,
+ FormattedValue,
+ FunctionDef,
+ GeneratorExp,
+ Global,
+ If,
+ IfExp,
+ Import,
+ ImportFrom,
+ JoinedStr,
+ Keyword,
+ Lambda,
+ List,
+ ListComp,
+ Match,
+ MatchAs,
+ MatchCase,
+ MatchClass,
+ MatchMapping,
+ MatchOr,
+ MatchSequence,
+ MatchSingleton,
+ MatchStar,
+ MatchValue,
+ Module,
+ Name,
+ NamedExpr,
+ NodeNG,
+ Nonlocal,
+ ParamSpec,
+ Pass,
+ Raise,
+ Return,
+ Set,
+ SetComp,
+ Slice,
+ Starred,
+ Subscript,
+ Try,
+ TryStar,
+ Tuple,
+ TypeAlias,
+ TypeVar,
+ TypeVarTuple,
+ UnaryOp,
+ Unknown,
+ While,
+ With,
+ Yield,
+ YieldFrom,
+ are_exclusive,
+ builtin_lookup,
+ unpack_infer,
+ function_to_method,
+)
+
+# isort: on
+
+from astroid.util import Uninferable
+
+# Performance hack for tokenize. See https://bugs.python.org/issue43014
+# Adapted from https://github.com/PyCQA/pycodestyle/pull/993
+if (
+ not PY310_PLUS
+ and callable(getattr(tokenize, "_compile", None))
+ and getattr(tokenize._compile, "__wrapped__", None) is None # type: ignore[attr-defined]
+):
+ tokenize._compile = functools.lru_cache(tokenize._compile) # type: ignore[attr-defined]
diff --git a/solutions/.venv/Lib/site-packages/astroid/__pkginfo__.py b/solutions/.venv/Lib/site-packages/astroid/__pkginfo__.py
new file mode 100644
index 000000000..bad119adf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/__pkginfo__.py
@@ -0,0 +1,6 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+__version__ = "3.3.8"
+version = __version__
diff --git a/solutions/.venv/Lib/site-packages/astroid/_ast.py b/solutions/.venv/Lib/site-packages/astroid/_ast.py
new file mode 100644
index 000000000..44800e382
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/_ast.py
@@ -0,0 +1,102 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import ast
+from typing import NamedTuple
+
+from astroid.const import Context
+
+
+class FunctionType(NamedTuple):
+ argtypes: list[ast.expr]
+ returns: ast.expr
+
+
+class ParserModule(NamedTuple):
+ unary_op_classes: dict[type[ast.unaryop], str]
+ cmp_op_classes: dict[type[ast.cmpop], str]
+ bool_op_classes: dict[type[ast.boolop], str]
+ bin_op_classes: dict[type[ast.operator], str]
+ context_classes: dict[type[ast.expr_context], Context]
+
+ def parse(
+ self, string: str, type_comments: bool = True, filename: str | None = None
+ ) -> ast.Module:
+ if filename:
+ return ast.parse(string, filename=filename, type_comments=type_comments)
+ return ast.parse(string, type_comments=type_comments)
+
+
+def parse_function_type_comment(type_comment: str) -> FunctionType | None:
+ """Given a correct type comment, obtain a FunctionType object."""
+ func_type = ast.parse(type_comment, "<type_comment>", "func_type") # type: ignore[attr-defined]
+ return FunctionType(argtypes=func_type.argtypes, returns=func_type.returns)
+
+
+def get_parser_module(type_comments: bool = True) -> ParserModule:
+ unary_op_classes = _unary_operators_from_module()
+ cmp_op_classes = _compare_operators_from_module()
+ bool_op_classes = _bool_operators_from_module()
+ bin_op_classes = _binary_operators_from_module()
+ context_classes = _contexts_from_module()
+
+ return ParserModule(
+ unary_op_classes,
+ cmp_op_classes,
+ bool_op_classes,
+ bin_op_classes,
+ context_classes,
+ )
+
+
+def _unary_operators_from_module() -> dict[type[ast.unaryop], str]:
+ return {ast.UAdd: "+", ast.USub: "-", ast.Not: "not", ast.Invert: "~"}
+
+
+def _binary_operators_from_module() -> dict[type[ast.operator], str]:
+ return {
+ ast.Add: "+",
+ ast.BitAnd: "&",
+ ast.BitOr: "|",
+ ast.BitXor: "^",
+ ast.Div: "/",
+ ast.FloorDiv: "//",
+ ast.MatMult: "@",
+ ast.Mod: "%",
+ ast.Mult: "*",
+ ast.Pow: "**",
+ ast.Sub: "-",
+ ast.LShift: "<<",
+ ast.RShift: ">>",
+ }
+
+
+def _bool_operators_from_module() -> dict[type[ast.boolop], str]:
+ return {ast.And: "and", ast.Or: "or"}
+
+
+def _compare_operators_from_module() -> dict[type[ast.cmpop], str]:
+ return {
+ ast.Eq: "==",
+ ast.Gt: ">",
+ ast.GtE: ">=",
+ ast.In: "in",
+ ast.Is: "is",
+ ast.IsNot: "is not",
+ ast.Lt: "<",
+ ast.LtE: "<=",
+ ast.NotEq: "!=",
+ ast.NotIn: "not in",
+ }
+
+
+def _contexts_from_module() -> dict[type[ast.expr_context], Context]:
+ return {
+ ast.Load: Context.Load,
+ ast.Store: Context.Store,
+ ast.Del: Context.Del,
+ ast.Param: Context.Store,
+ }
diff --git a/solutions/.venv/Lib/site-packages/astroid/_backport_stdlib_names.py b/solutions/.venv/Lib/site-packages/astroid/_backport_stdlib_names.py
new file mode 100644
index 000000000..901f90b90
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/_backport_stdlib_names.py
@@ -0,0 +1,352 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Shim to support Python versions < 3.10 that don't have sys.stdlib_module_names
+
+These values were created by cherry-picking the commits from
+https://bugs.python.org/issue42955 into each version, but may be updated
+manually if changes are needed.
+"""
+
+import sys
+
+# TODO: Remove this file when Python 3.9 is no longer supported
+
+PY_3_7 = frozenset(
+ {
+ "__future__",
+ "_abc",
+ "_ast",
+ "_asyncio",
+ "_bisect",
+ "_blake2",
+ "_bootlocale",
+ "_bz2",
+ "_codecs",
+ "_codecs_cn",
+ "_codecs_hk",
+ "_codecs_iso2022",
+ "_codecs_jp",
+ "_codecs_kr",
+ "_codecs_tw",
+ "_collections",
+ "_collections_abc",
+ "_compat_pickle",
+ "_compression",
+ "_contextvars",
+ "_crypt",
+ "_csv",
+ "_ctypes",
+ "_curses",
+ "_curses_panel",
+ "_datetime",
+ "_dbm",
+ "_decimal",
+ "_dummy_thread",
+ "_elementtree",
+ "_functools",
+ "_gdbm",
+ "_hashlib",
+ "_heapq",
+ "_imp",
+ "_io",
+ "_json",
+ "_locale",
+ "_lsprof",
+ "_lzma",
+ "_markupbase",
+ "_md5",
+ "_msi",
+ "_multibytecodec",
+ "_multiprocessing",
+ "_opcode",
+ "_operator",
+ "_osx_support",
+ "_pickle",
+ "_posixsubprocess",
+ "_py_abc",
+ "_pydecimal",
+ "_pyio",
+ "_queue",
+ "_random",
+ "_sha1",
+ "_sha256",
+ "_sha3",
+ "_sha512",
+ "_signal",
+ "_sitebuiltins",
+ "_socket",
+ "_sqlite3",
+ "_sre",
+ "_ssl",
+ "_stat",
+ "_string",
+ "_strptime",
+ "_struct",
+ "_symtable",
+ "_thread",
+ "_threading_local",
+ "_tkinter",
+ "_tracemalloc",
+ "_uuid",
+ "_warnings",
+ "_weakref",
+ "_weakrefset",
+ "_winapi",
+ "abc",
+ "aifc",
+ "antigravity",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "genericpath",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "idlelib",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "nt",
+ "ntpath",
+ "nturl2path",
+ "numbers",
+ "opcode",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "pydoc_data",
+ "pyexpat",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "textwrap",
+ "this",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+ }
+)
+
+PY_3_8 = frozenset(
+ PY_3_7
+ - {
+ "macpath",
+ }
+ | {
+ "_posixshmem",
+ "_statistics",
+ "_xxsubinterpreters",
+ }
+)
+
+PY_3_9 = frozenset(
+ PY_3_8
+ - {
+ "_dummy_thread",
+ "dummy_threading",
+ }
+ | {
+ "_aix_support",
+ "_bootsubprocess",
+ "_peg_parser",
+ "_zoneinfo",
+ "graphlib",
+ "zoneinfo",
+ }
+)
+
+if sys.version_info[:2] == (3, 9):
+ stdlib_module_names = PY_3_9
+else:
+ raise AssertionError("This module is only intended as a backport for Python <= 3.9")
diff --git a/solutions/.venv/Lib/site-packages/astroid/arguments.py b/solutions/.venv/Lib/site-packages/astroid/arguments.py
new file mode 100644
index 000000000..d2dca776d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/arguments.py
@@ -0,0 +1,307 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from astroid import nodes
+from astroid.bases import Instance
+from astroid.context import CallContext, InferenceContext
+from astroid.exceptions import InferenceError, NoDefault
+from astroid.typing import InferenceResult
+from astroid.util import Uninferable, UninferableBase, safe_infer
+
+
+class CallSite:
+ """Class for understanding arguments passed into a call site.
+
+ It needs a call context, which contains the arguments and the
+ keyword arguments that were passed into a given call site.
+ In order to infer what an argument represents, call :meth:`infer_argument`
+ with the corresponding function node and the argument name.
+
+ :param callcontext:
+ An instance of :class:`astroid.context.CallContext`, that holds
+ the arguments for the call site.
+ :param argument_context_map:
+ Additional contexts per node, passed in from :attr:`astroid.context.Context.extra_context`
+ :param context:
+ An instance of :class:`astroid.context.Context`.
+ """
+
+ def __init__(
+ self,
+ callcontext: CallContext,
+ argument_context_map=None,
+ context: InferenceContext | None = None,
+ ):
+ if argument_context_map is None:
+ argument_context_map = {}
+ self.argument_context_map = argument_context_map
+ args = callcontext.args
+ keywords = callcontext.keywords
+ self.duplicated_keywords: set[str] = set()
+ self._unpacked_args = self._unpack_args(args, context=context)
+ self._unpacked_kwargs = self._unpack_keywords(keywords, context=context)
+
+ self.positional_arguments = [
+ arg for arg in self._unpacked_args if not isinstance(arg, UninferableBase)
+ ]
+ self.keyword_arguments = {
+ key: value
+ for key, value in self._unpacked_kwargs.items()
+ if not isinstance(value, UninferableBase)
+ }
+
+ @classmethod
+ def from_call(cls, call_node, context: InferenceContext | None = None):
+ """Get a CallSite object from the given Call node.
+
+ context will be used to force a single inference path.
+ """
+
+ # Determine the callcontext from the given `context` object if any.
+ context = context or InferenceContext()
+ callcontext = CallContext(call_node.args, call_node.keywords)
+ return cls(callcontext, context=context)
+
+ def has_invalid_arguments(self):
+ """Check if in the current CallSite were passed *invalid* arguments.
+
+ This can mean multiple things. For instance, if an unpacking
+ of an invalid object was passed, then this method will return True.
+ Other cases can be when the arguments can't be inferred by astroid,
+ for example, by passing objects which aren't known statically.
+ """
+ return len(self.positional_arguments) != len(self._unpacked_args)
+
+ def has_invalid_keywords(self) -> bool:
+ """Check if in the current CallSite were passed *invalid* keyword arguments.
+
+ For instance, unpacking a dictionary with integer keys is invalid
+ (**{1:2}), because the keys must be strings, which will make this
+ method to return True. Other cases where this might return True if
+ objects which can't be inferred were passed.
+ """
+ return len(self.keyword_arguments) != len(self._unpacked_kwargs)
+
+ def _unpack_keywords(
+ self,
+ keywords: list[tuple[str | None, nodes.NodeNG]],
+ context: InferenceContext | None = None,
+ ):
+ values: dict[str | None, InferenceResult] = {}
+ context = context or InferenceContext()
+ context.extra_context = self.argument_context_map
+ for name, value in keywords:
+ if name is None:
+ # Then it's an unpacking operation (**)
+ inferred = safe_infer(value, context=context)
+ if not isinstance(inferred, nodes.Dict):
+ # Not something we can work with.
+ values[name] = Uninferable
+ continue
+
+ for dict_key, dict_value in inferred.items:
+ dict_key = safe_infer(dict_key, context=context)
+ if not isinstance(dict_key, nodes.Const):
+ values[name] = Uninferable
+ continue
+ if not isinstance(dict_key.value, str):
+ values[name] = Uninferable
+ continue
+ if dict_key.value in values:
+ # The name is already in the dictionary
+ values[dict_key.value] = Uninferable
+ self.duplicated_keywords.add(dict_key.value)
+ continue
+ values[dict_key.value] = dict_value
+ else:
+ values[name] = value
+ return values
+
+ def _unpack_args(self, args, context: InferenceContext | None = None):
+ values = []
+ context = context or InferenceContext()
+ context.extra_context = self.argument_context_map
+ for arg in args:
+ if isinstance(arg, nodes.Starred):
+ inferred = safe_infer(arg.value, context=context)
+ if isinstance(inferred, UninferableBase):
+ values.append(Uninferable)
+ continue
+ if not hasattr(inferred, "elts"):
+ values.append(Uninferable)
+ continue
+ values.extend(inferred.elts)
+ else:
+ values.append(arg)
+ return values
+
+ def infer_argument(
+ self, funcnode: InferenceResult, name: str, context: InferenceContext
+ ): # noqa: C901
+ """Infer a function argument value according to the call context."""
+ if not isinstance(funcnode, (nodes.FunctionDef, nodes.Lambda)):
+ raise InferenceError(
+ f"Can not infer function argument value for non-function node {funcnode!r}.",
+ call_site=self,
+ func=funcnode,
+ arg=name,
+ context=context,
+ )
+
+ if name in self.duplicated_keywords:
+ raise InferenceError(
+ "The arguments passed to {func!r} have duplicate keywords.",
+ call_site=self,
+ func=funcnode,
+ arg=name,
+ context=context,
+ )
+
+ # Look into the keywords first, maybe it's already there.
+ try:
+ return self.keyword_arguments[name].infer(context)
+ except KeyError:
+ pass
+
+ # Too many arguments given and no variable arguments.
+ if len(self.positional_arguments) > len(funcnode.args.args):
+ if not funcnode.args.vararg and not funcnode.args.posonlyargs:
+ raise InferenceError(
+ "Too many positional arguments "
+ "passed to {func!r} that does "
+ "not have *args.",
+ call_site=self,
+ func=funcnode,
+ arg=name,
+ context=context,
+ )
+
+ positional = self.positional_arguments[: len(funcnode.args.args)]
+ vararg = self.positional_arguments[len(funcnode.args.args) :]
+
+ # preserving previous behavior, when vararg and kwarg were not included in find_argname results
+ if name in [funcnode.args.vararg, funcnode.args.kwarg]:
+ argindex = None
+ else:
+ argindex = funcnode.args.find_argname(name)[0]
+
+ kwonlyargs = {arg.name for arg in funcnode.args.kwonlyargs}
+ kwargs = {
+ key: value
+ for key, value in self.keyword_arguments.items()
+ if key not in kwonlyargs
+ }
+ # If there are too few positionals compared to
+ # what the function expects to receive, check to see
+ # if the missing positional arguments were passed
+ # as keyword arguments and if so, place them into the
+ # positional args list.
+ if len(positional) < len(funcnode.args.args):
+ for func_arg in funcnode.args.args:
+ if func_arg.name in kwargs:
+ arg = kwargs.pop(func_arg.name)
+ positional.append(arg)
+
+ if argindex is not None:
+ boundnode = context.boundnode
+ # 2. first argument of instance/class method
+ if argindex == 0 and funcnode.type in {"method", "classmethod"}:
+ # context.boundnode is None when an instance method is called with
+ # the class, e.g. MyClass.method(obj, ...). In this case, self
+ # is the first argument.
+ if boundnode is None and funcnode.type == "method" and positional:
+ return positional[0].infer(context=context)
+ if boundnode is None:
+ # XXX can do better ?
+ boundnode = funcnode.parent.frame()
+
+ if isinstance(boundnode, nodes.ClassDef):
+ # Verify that we're accessing a method
+ # of the metaclass through a class, as in
+ # `cls.metaclass_method`. In this case, the
+ # first argument is always the class.
+ method_scope = funcnode.parent.scope()
+ if method_scope is boundnode.metaclass(context=context):
+ return iter((boundnode,))
+
+ if funcnode.type == "method":
+ if not isinstance(boundnode, Instance):
+ boundnode = boundnode.instantiate_class()
+ return iter((boundnode,))
+ if funcnode.type == "classmethod":
+ return iter((boundnode,))
+ # if we have a method, extract one position
+ # from the index, so we'll take in account
+ # the extra parameter represented by `self` or `cls`
+ if funcnode.type in {"method", "classmethod"} and boundnode:
+ argindex -= 1
+ # 2. search arg index
+ try:
+ return self.positional_arguments[argindex].infer(context)
+ except IndexError:
+ pass
+
+ if funcnode.args.kwarg == name:
+ # It wants all the keywords that were passed into
+ # the call site.
+ if self.has_invalid_keywords():
+ raise InferenceError(
+ "Inference failed to find values for all keyword arguments "
+ "to {func!r}: {unpacked_kwargs!r} doesn't correspond to "
+ "{keyword_arguments!r}.",
+ keyword_arguments=self.keyword_arguments,
+ unpacked_kwargs=self._unpacked_kwargs,
+ call_site=self,
+ func=funcnode,
+ arg=name,
+ context=context,
+ )
+ kwarg = nodes.Dict(
+ lineno=funcnode.args.lineno,
+ col_offset=funcnode.args.col_offset,
+ parent=funcnode.args,
+ end_lineno=funcnode.args.end_lineno,
+ end_col_offset=funcnode.args.end_col_offset,
+ )
+ kwarg.postinit(
+ [(nodes.const_factory(key), value) for key, value in kwargs.items()]
+ )
+ return iter((kwarg,))
+ if funcnode.args.vararg == name:
+ # It wants all the args that were passed into
+ # the call site.
+ if self.has_invalid_arguments():
+ raise InferenceError(
+ "Inference failed to find values for all positional "
+ "arguments to {func!r}: {unpacked_args!r} doesn't "
+ "correspond to {positional_arguments!r}.",
+ positional_arguments=self.positional_arguments,
+ unpacked_args=self._unpacked_args,
+ call_site=self,
+ func=funcnode,
+ arg=name,
+ context=context,
+ )
+ args = nodes.Tuple(
+ lineno=funcnode.args.lineno,
+ col_offset=funcnode.args.col_offset,
+ parent=funcnode.args,
+ )
+ args.postinit(vararg)
+ return iter((args,))
+
+ # Check if it's a default parameter.
+ try:
+ return funcnode.args.default_value(name).infer(context)
+ except NoDefault:
+ pass
+ raise InferenceError(
+ "No value found for argument {arg} to {func!r}",
+ call_site=self,
+ func=funcnode,
+ arg=name,
+ context=context,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/astroid_manager.py b/solutions/.venv/Lib/site-packages/astroid/astroid_manager.py
new file mode 100644
index 000000000..3031057e1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/astroid_manager.py
@@ -0,0 +1,20 @@
+"""
+This file contain the global astroid MANAGER.
+
+It prevents a circular import that happened
+when the only possibility to import it was from astroid.__init__.py.
+
+This AstroidManager is a singleton/borg so it's possible to instantiate an
+AstroidManager() directly.
+"""
+
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_all_brains
+from astroid.manager import AstroidManager
+
+MANAGER = AstroidManager()
+# Register all brains after instantiating the singleton Manager
+register_all_brains(MANAGER)
diff --git a/solutions/.venv/Lib/site-packages/astroid/bases.py b/solutions/.venv/Lib/site-packages/astroid/bases.py
new file mode 100644
index 000000000..4a0d15265
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/bases.py
@@ -0,0 +1,767 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains base classes and functions for the nodes and some
+inference utils.
+"""
+from __future__ import annotations
+
+import collections
+import collections.abc
+from collections.abc import Iterable, Iterator
+from typing import TYPE_CHECKING, Any, Literal
+
+from astroid import decorators, nodes
+from astroid.const import PY310_PLUS
+from astroid.context import (
+ CallContext,
+ InferenceContext,
+ bind_context_to_node,
+ copy_context,
+)
+from astroid.exceptions import (
+ AstroidTypeError,
+ AttributeInferenceError,
+ InferenceError,
+ NameInferenceError,
+)
+from astroid.interpreter import objectmodel
+from astroid.typing import (
+ InferenceErrorInfo,
+ InferenceResult,
+ SuccessfulInferenceResult,
+)
+from astroid.util import Uninferable, UninferableBase, safe_infer
+
+if TYPE_CHECKING:
+ from astroid.constraint import Constraint
+
+
+PROPERTIES = {"builtins.property", "abc.abstractproperty"}
+if PY310_PLUS:
+ PROPERTIES.add("enum.property")
+
+# List of possible property names. We use this list in order
+# to see if a method is a property or not. This should be
+# pretty reliable and fast, the alternative being to check each
+# decorator to see if its a real property-like descriptor, which
+# can be too complicated.
+# Also, these aren't qualified, because each project can
+# define them, we shouldn't expect to know every possible
+# property-like decorator!
+POSSIBLE_PROPERTIES = {
+ "cached_property",
+ "cachedproperty",
+ "lazyproperty",
+ "lazy_property",
+ "reify",
+ "lazyattribute",
+ "lazy_attribute",
+ "LazyProperty",
+ "lazy",
+ "cache_readonly",
+ "DynamicClassAttribute",
+}
+
+
+def _is_property(
+ meth: nodes.FunctionDef | UnboundMethod, context: InferenceContext | None = None
+) -> bool:
+ decoratornames = meth.decoratornames(context=context)
+ if PROPERTIES.intersection(decoratornames):
+ return True
+ stripped = {
+ name.split(".")[-1]
+ for name in decoratornames
+ if not isinstance(name, UninferableBase)
+ }
+ if any(name in stripped for name in POSSIBLE_PROPERTIES):
+ return True
+
+ # Lookup for subclasses of *property*
+ if not meth.decorators:
+ return False
+ for decorator in meth.decorators.nodes or ():
+ inferred = safe_infer(decorator, context=context)
+ if inferred is None or isinstance(inferred, UninferableBase):
+ continue
+ if isinstance(inferred, nodes.ClassDef):
+ for base_class in inferred.bases:
+ if not isinstance(base_class, nodes.Name):
+ continue
+ module, _ = base_class.lookup(base_class.name)
+ if (
+ isinstance(module, nodes.Module)
+ and module.name == "builtins"
+ and base_class.name == "property"
+ ):
+ return True
+
+ return False
+
+
+class Proxy:
+ """A simple proxy object.
+
+ Note:
+
+ Subclasses of this object will need a custom __getattr__
+ if new instance attributes are created. See the Const class
+ """
+
+ _proxied: nodes.ClassDef | nodes.FunctionDef | nodes.Lambda | UnboundMethod
+
+ def __init__(
+ self,
+ proxied: (
+ nodes.ClassDef | nodes.FunctionDef | nodes.Lambda | UnboundMethod | None
+ ) = None,
+ ) -> None:
+ if proxied is None:
+ # This is a hack to allow calling this __init__ during bootstrapping of
+ # builtin classes and their docstrings.
+ # For Const, Generator, and UnionType nodes the _proxied attribute
+ # is set during bootstrapping
+ # as we first need to build the ClassDef that they can proxy.
+ # Thus, if proxied is None self should be a Const or Generator
+ # as that is the only way _proxied will be correctly set as a ClassDef.
+ assert isinstance(self, (nodes.Const, Generator, UnionType))
+ else:
+ self._proxied = proxied
+
+ def __getattr__(self, name: str) -> Any:
+ if name == "_proxied":
+ return self.__class__._proxied
+ if name in self.__dict__:
+ return self.__dict__[name]
+ return getattr(self._proxied, name)
+
+ def infer( # type: ignore[return]
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> collections.abc.Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ yield self
+
+
+def _infer_stmts(
+ stmts: Iterable[InferenceResult],
+ context: InferenceContext | None,
+ frame: nodes.NodeNG | BaseInstance | None = None,
+) -> collections.abc.Generator[InferenceResult]:
+ """Return an iterator on statements inferred by each statement in *stmts*."""
+ inferred = False
+ constraint_failed = False
+ if context is not None:
+ name = context.lookupname
+ context = context.clone()
+ if name is not None:
+ constraints = context.constraints.get(name, {})
+ else:
+ constraints = {}
+ else:
+ name = None
+ constraints = {}
+ context = InferenceContext()
+
+ for stmt in stmts:
+ if isinstance(stmt, UninferableBase):
+ yield stmt
+ inferred = True
+ continue
+ context.lookupname = stmt._infer_name(frame, name)
+ try:
+ stmt_constraints: set[Constraint] = set()
+ for constraint_stmt, potential_constraints in constraints.items():
+ if not constraint_stmt.parent_of(stmt):
+ stmt_constraints.update(potential_constraints)
+ for inf in stmt.infer(context=context):
+ if all(constraint.satisfied_by(inf) for constraint in stmt_constraints):
+ yield inf
+ inferred = True
+ else:
+ constraint_failed = True
+ except NameInferenceError:
+ continue
+ except InferenceError:
+ yield Uninferable
+ inferred = True
+
+ if not inferred and constraint_failed:
+ yield Uninferable
+ elif not inferred:
+ raise InferenceError(
+ "Inference failed for all members of {stmts!r}.",
+ stmts=stmts,
+ frame=frame,
+ context=context,
+ )
+
+
+def _infer_method_result_truth(
+ instance: Instance, method_name: str, context: InferenceContext
+) -> bool | UninferableBase:
+ # Get the method from the instance and try to infer
+ # its return's truth value.
+ meth = next(instance.igetattr(method_name, context=context), None)
+ if meth and hasattr(meth, "infer_call_result"):
+ if not meth.callable():
+ return Uninferable
+ try:
+ context.callcontext = CallContext(args=[], callee=meth)
+ for value in meth.infer_call_result(instance, context=context):
+ if isinstance(value, UninferableBase):
+ return value
+ try:
+ inferred = next(value.infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ return inferred.bool_value()
+ except InferenceError:
+ pass
+ return Uninferable
+
+
+class BaseInstance(Proxy):
+ """An instance base class, which provides lookup methods for potential
+ instances.
+ """
+
+ _proxied: nodes.ClassDef
+
+ special_attributes: objectmodel.ObjectModel
+
+ def display_type(self) -> str:
+ return "Instance of"
+
+ def getattr(
+ self,
+ name: str,
+ context: InferenceContext | None = None,
+ lookupclass: bool = True,
+ ) -> list[InferenceResult]:
+ try:
+ values = self._proxied.instance_attr(name, context)
+ except AttributeInferenceError as exc:
+ if self.special_attributes and name in self.special_attributes:
+ return [self.special_attributes.lookup(name)]
+
+ if lookupclass:
+ # Class attributes not available through the instance
+ # unless they are explicitly defined.
+ return self._proxied.getattr(name, context, class_context=False)
+
+ raise AttributeInferenceError(
+ target=self, attribute=name, context=context
+ ) from exc
+ # since we've no context information, return matching class members as
+ # well
+ if lookupclass:
+ try:
+ return values + self._proxied.getattr(
+ name, context, class_context=False
+ )
+ except AttributeInferenceError:
+ pass
+ return values
+
+ def igetattr(
+ self, name: str, context: InferenceContext | None = None
+ ) -> Iterator[InferenceResult]:
+ """Inferred getattr."""
+ if not context:
+ context = InferenceContext()
+ try:
+ context.lookupname = name
+ # XXX frame should be self._proxied, or not ?
+ get_attr = self.getattr(name, context, lookupclass=False)
+ yield from _infer_stmts(
+ self._wrap_attr(get_attr, context), context, frame=self
+ )
+ except AttributeInferenceError:
+ try:
+ # fallback to class.igetattr since it has some logic to handle
+ # descriptors
+ # But only if the _proxied is the Class.
+ if self._proxied.__class__.__name__ != "ClassDef":
+ raise
+ attrs = self._proxied.igetattr(name, context, class_context=False)
+ yield from self._wrap_attr(attrs, context)
+ except AttributeInferenceError as error:
+ raise InferenceError(**vars(error)) from error
+
+ def _wrap_attr(
+ self, attrs: Iterable[InferenceResult], context: InferenceContext | None = None
+ ) -> Iterator[InferenceResult]:
+ """Wrap bound methods of attrs in a InstanceMethod proxies."""
+ for attr in attrs:
+ if isinstance(attr, UnboundMethod):
+ if _is_property(attr):
+ yield from attr.infer_call_result(self, context)
+ else:
+ yield BoundMethod(attr, self)
+ elif isinstance(attr, nodes.Lambda):
+ if attr.args.arguments and attr.args.arguments[0].name == "self":
+ yield BoundMethod(attr, self)
+ continue
+ yield attr
+ else:
+ yield attr
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ """Infer what a class instance is returning when called."""
+ context = bind_context_to_node(context, self)
+ inferred = False
+
+ # If the call is an attribute on the instance, we infer the attribute itself
+ if isinstance(caller, nodes.Call) and isinstance(caller.func, nodes.Attribute):
+ for res in self.igetattr(caller.func.attrname, context):
+ inferred = True
+ yield res
+
+ # Otherwise we infer the call to the __call__ dunder normally
+ for node in self._proxied.igetattr("__call__", context):
+ if isinstance(node, UninferableBase) or not node.callable():
+ continue
+ if isinstance(node, BaseInstance) and node._proxied is self._proxied:
+ inferred = True
+ yield node
+ # Prevent recursion.
+ continue
+ for res in node.infer_call_result(caller, context):
+ inferred = True
+ yield res
+ if not inferred:
+ raise InferenceError(node=self, caller=caller, context=context)
+
+
+class Instance(BaseInstance):
+ """A special node representing a class instance."""
+
+ special_attributes = objectmodel.InstanceModel()
+
+ def __init__(self, proxied: nodes.ClassDef | None) -> None:
+ super().__init__(proxied)
+
+ @decorators.yes_if_nothing_inferred
+ def infer_binary_op(
+ self,
+ opnode: nodes.AugAssign | nodes.BinOp,
+ operator: str,
+ other: InferenceResult,
+ context: InferenceContext,
+ method: SuccessfulInferenceResult,
+ ) -> Generator[InferenceResult]:
+ return method.infer_call_result(self, context)
+
+ def __repr__(self) -> str:
+ return "<Instance of {}.{} at 0x{}>".format(
+ self._proxied.root().name, self._proxied.name, id(self)
+ )
+
+ def __str__(self) -> str:
+ return f"Instance of {self._proxied.root().name}.{self._proxied.name}"
+
+ def callable(self) -> bool:
+ try:
+ self._proxied.getattr("__call__", class_context=False)
+ return True
+ except AttributeInferenceError:
+ return False
+
+ def pytype(self) -> str:
+ return self._proxied.qname()
+
+ def display_type(self) -> str:
+ return "Instance of"
+
+ def bool_value(
+ self, context: InferenceContext | None = None
+ ) -> bool | UninferableBase:
+ """Infer the truth value for an Instance.
+
+ The truth value of an instance is determined by these conditions:
+
+ * if it implements __bool__ on Python 3 or __nonzero__
+ on Python 2, then its bool value will be determined by
+ calling this special method and checking its result.
+ * when this method is not defined, __len__() is called, if it
+ is defined, and the object is considered true if its result is
+ nonzero. If a class defines neither __len__() nor __bool__(),
+ all its instances are considered true.
+ """
+ context = context or InferenceContext()
+ context.boundnode = self
+
+ try:
+ result = _infer_method_result_truth(self, "__bool__", context)
+ except (InferenceError, AttributeInferenceError):
+ # Fallback to __len__.
+ try:
+ result = _infer_method_result_truth(self, "__len__", context)
+ except (AttributeInferenceError, InferenceError):
+ return True
+ return result
+
+ def getitem(
+ self, index: nodes.Const, context: InferenceContext | None = None
+ ) -> InferenceResult | None:
+ new_context = bind_context_to_node(context, self)
+ if not context:
+ context = new_context
+ method = next(self.igetattr("__getitem__", context=context), None)
+ # Create a new CallContext for providing index as an argument.
+ new_context.callcontext = CallContext(args=[index], callee=method)
+ if not isinstance(method, BoundMethod):
+ raise InferenceError(
+ "Could not find __getitem__ for {node!r}.", node=self, context=context
+ )
+ if len(method.args.arguments) != 2: # (self, index)
+ raise AstroidTypeError(
+ "__getitem__ for {node!r} does not have correct signature",
+ node=self,
+ context=context,
+ )
+ return next(method.infer_call_result(self, new_context), None)
+
+
+class UnboundMethod(Proxy):
+ """A special node representing a method not bound to an instance."""
+
+ _proxied: nodes.FunctionDef | UnboundMethod
+
+ special_attributes: (
+ objectmodel.BoundMethodModel | objectmodel.UnboundMethodModel
+ ) = objectmodel.UnboundMethodModel()
+
+ def __repr__(self) -> str:
+ assert self._proxied.parent, "Expected a parent node"
+ frame = self._proxied.parent.frame()
+ return "<{} {} of {} at 0x{}".format(
+ self.__class__.__name__, self._proxied.name, frame.qname(), id(self)
+ )
+
+ def implicit_parameters(self) -> Literal[0, 1]:
+ return 0
+
+ def is_bound(self) -> bool:
+ return False
+
+ def getattr(self, name: str, context: InferenceContext | None = None):
+ if name in self.special_attributes:
+ return [self.special_attributes.lookup(name)]
+ return self._proxied.getattr(name, context)
+
+ def igetattr(
+ self, name: str, context: InferenceContext | None = None
+ ) -> Iterator[InferenceResult]:
+ if name in self.special_attributes:
+ return iter((self.special_attributes.lookup(name),))
+ return self._proxied.igetattr(name, context)
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ """
+ The boundnode of the regular context with a function called
+ on ``object.__new__`` will be of type ``object``,
+ which is incorrect for the argument in general.
+ If no context is given the ``object.__new__`` call argument will
+ be correctly inferred except when inside a call that requires
+ the additional context (such as a classmethod) of the boundnode
+ to determine which class the method was called from
+ """
+
+ # If we're unbound method __new__ of a builtin, the result is an
+ # instance of the class given as first argument.
+ if self._proxied.name == "__new__":
+ assert self._proxied.parent, "Expected a parent node"
+ qname = self._proxied.parent.frame().qname()
+ # Avoid checking builtins.type: _infer_type_new_call() does more validation
+ if qname.startswith("builtins.") and qname != "builtins.type":
+ return self._infer_builtin_new(caller, context or InferenceContext())
+ return self._proxied.infer_call_result(caller, context)
+
+ def _infer_builtin_new(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext,
+ ) -> collections.abc.Generator[nodes.Const | Instance | UninferableBase]:
+ if not isinstance(caller, nodes.Call):
+ return
+ if not caller.args:
+ return
+ # Attempt to create a constant
+ if len(caller.args) > 1:
+ value = None
+ if isinstance(caller.args[1], nodes.Const):
+ value = caller.args[1].value
+ else:
+ inferred_arg = next(caller.args[1].infer(), None)
+ if isinstance(inferred_arg, nodes.Const):
+ value = inferred_arg.value
+ if value is not None:
+ const = nodes.const_factory(value)
+ assert not isinstance(const, nodes.EmptyNode)
+ yield const
+ return
+
+ node_context = context.extra_context.get(caller.args[0])
+ for inferred in caller.args[0].infer(context=node_context):
+ if isinstance(inferred, UninferableBase):
+ yield inferred
+ if isinstance(inferred, nodes.ClassDef):
+ yield Instance(inferred)
+ raise InferenceError
+
+ def bool_value(self, context: InferenceContext | None = None) -> Literal[True]:
+ return True
+
+
+class BoundMethod(UnboundMethod):
+ """A special node representing a method bound to an instance."""
+
+ special_attributes = objectmodel.BoundMethodModel()
+
+ def __init__(
+ self,
+ proxy: nodes.FunctionDef | nodes.Lambda | UnboundMethod,
+ bound: SuccessfulInferenceResult,
+ ) -> None:
+ super().__init__(proxy)
+ self.bound = bound
+
+ def implicit_parameters(self) -> Literal[0, 1]:
+ if self.name == "__new__":
+ # __new__ acts as a classmethod but the class argument is not implicit.
+ return 0
+ return 1
+
+ def is_bound(self) -> Literal[True]:
+ return True
+
+ def _infer_type_new_call(
+ self, caller: nodes.Call, context: InferenceContext
+ ) -> nodes.ClassDef | None: # noqa: C901
+ """Try to infer what type.__new__(mcs, name, bases, attrs) returns.
+
+ In order for such call to be valid, the metaclass needs to be
+ a subtype of ``type``, the name needs to be a string, the bases
+ needs to be a tuple of classes
+ """
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.nodes import Pass
+
+ # Verify the metaclass
+ try:
+ mcs = next(caller.args[0].infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ if not isinstance(mcs, nodes.ClassDef):
+ # Not a valid first argument.
+ return None
+ if not mcs.is_subtype_of("builtins.type"):
+ # Not a valid metaclass.
+ return None
+
+ # Verify the name
+ try:
+ name = next(caller.args[1].infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ if not isinstance(name, nodes.Const):
+ # Not a valid name, needs to be a const.
+ return None
+ if not isinstance(name.value, str):
+ # Needs to be a string.
+ return None
+
+ # Verify the bases
+ try:
+ bases = next(caller.args[2].infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ if not isinstance(bases, nodes.Tuple):
+ # Needs to be a tuple.
+ return None
+ try:
+ inferred_bases = [next(elt.infer(context=context)) for elt in bases.elts]
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ if any(not isinstance(base, nodes.ClassDef) for base in inferred_bases):
+ # All the bases needs to be Classes
+ return None
+
+ # Verify the attributes.
+ try:
+ attrs = next(caller.args[3].infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ if not isinstance(attrs, nodes.Dict):
+ # Needs to be a dictionary.
+ return None
+ cls_locals: dict[str, list[InferenceResult]] = collections.defaultdict(list)
+ for key, value in attrs.items:
+ try:
+ key = next(key.infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ try:
+ value = next(value.infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context) from e
+ # Ignore non string keys
+ if isinstance(key, nodes.Const) and isinstance(key.value, str):
+ cls_locals[key.value].append(value)
+
+ # Build the class from now.
+ cls = mcs.__class__(
+ name=name.value,
+ lineno=caller.lineno or 0,
+ col_offset=caller.col_offset or 0,
+ parent=caller,
+ end_lineno=caller.end_lineno,
+ end_col_offset=caller.end_col_offset,
+ )
+ empty = Pass(
+ parent=cls,
+ lineno=caller.lineno,
+ col_offset=caller.col_offset,
+ end_lineno=caller.end_lineno,
+ end_col_offset=caller.end_col_offset,
+ )
+ cls.postinit(
+ bases=bases.elts,
+ body=[empty],
+ decorators=None,
+ newstyle=True,
+ metaclass=mcs,
+ keywords=[],
+ )
+ cls.locals = cls_locals
+ return cls
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ context = bind_context_to_node(context, self.bound)
+ if (
+ isinstance(self.bound, nodes.ClassDef)
+ and self.bound.name == "type"
+ and self.name == "__new__"
+ and isinstance(caller, nodes.Call)
+ and len(caller.args) == 4
+ ):
+ # Check if we have a ``type.__new__(mcs, name, bases, attrs)`` call.
+ new_cls = self._infer_type_new_call(caller, context)
+ if new_cls:
+ return iter((new_cls,))
+
+ return super().infer_call_result(caller, context)
+
+ def bool_value(self, context: InferenceContext | None = None) -> Literal[True]:
+ return True
+
+
+class Generator(BaseInstance):
+ """A special node representing a generator.
+
+ Proxied class is set once for all in raw_building.
+ """
+
+ # We defer initialization of special_attributes to the __init__ method since the constructor
+ # of GeneratorModel requires the raw_building to be complete
+ # TODO: This should probably be refactored.
+ special_attributes: objectmodel.GeneratorModel
+
+ def __init__(
+ self,
+ parent: nodes.FunctionDef,
+ generator_initial_context: InferenceContext | None = None,
+ ) -> None:
+ super().__init__()
+ self.parent = parent
+ self._call_context = copy_context(generator_initial_context)
+
+ # See comment above: this is a deferred initialization.
+ Generator.special_attributes = objectmodel.GeneratorModel()
+
+ def infer_yield_types(self) -> Iterator[InferenceResult]:
+ yield from self.parent.infer_yield_result(self._call_context)
+
+ def callable(self) -> Literal[False]:
+ return False
+
+ def pytype(self) -> str:
+ return "builtins.generator"
+
+ def display_type(self) -> str:
+ return "Generator"
+
+ def bool_value(self, context: InferenceContext | None = None) -> Literal[True]:
+ return True
+
+ def __repr__(self) -> str:
+ return f"<Generator({self._proxied.name}) l.{self.lineno} at 0x{id(self)}>"
+
+ def __str__(self) -> str:
+ return f"Generator({self._proxied.name})"
+
+
+class AsyncGenerator(Generator):
+ """Special node representing an async generator."""
+
+ def pytype(self) -> Literal["builtins.async_generator"]:
+ return "builtins.async_generator"
+
+ def display_type(self) -> str:
+ return "AsyncGenerator"
+
+ def __repr__(self) -> str:
+ return f"<AsyncGenerator({self._proxied.name}) l.{self.lineno} at 0x{id(self)}>"
+
+ def __str__(self) -> str:
+ return f"AsyncGenerator({self._proxied.name})"
+
+
+class UnionType(BaseInstance):
+ """Special node representing new style typing unions.
+
+ Proxied class is set once for all in raw_building.
+ """
+
+ def __init__(
+ self,
+ left: UnionType | nodes.ClassDef | nodes.Const,
+ right: UnionType | nodes.ClassDef | nodes.Const,
+ parent: nodes.NodeNG | None = None,
+ ) -> None:
+ super().__init__()
+ self.parent = parent
+ self.left = left
+ self.right = right
+
+ def callable(self) -> Literal[False]:
+ return False
+
+ def bool_value(self, context: InferenceContext | None = None) -> Literal[True]:
+ return True
+
+ def pytype(self) -> Literal["types.UnionType"]:
+ return "types.UnionType"
+
+ def display_type(self) -> str:
+ return "UnionType"
+
+ def __repr__(self) -> str:
+ return f"<UnionType({self._proxied.name}) l.{self.lineno} at 0x{id(self)}>"
+
+ def __str__(self) -> str:
+ return f"UnionType({self._proxied.name})"
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/__init__.py b/solutions/.venv/Lib/site-packages/astroid/brain/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_argparse.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_argparse.py
new file mode 100644
index 000000000..d0da4080a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_argparse.py
@@ -0,0 +1,52 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from astroid import arguments, inference_tip, nodes
+from astroid.context import InferenceContext
+from astroid.exceptions import UseInferenceDefault
+from astroid.manager import AstroidManager
+
+
+def infer_namespace(node, context: InferenceContext | None = None):
+ callsite = arguments.CallSite.from_call(node, context=context)
+ if not callsite.keyword_arguments:
+ # Cannot make sense of it.
+ raise UseInferenceDefault()
+
+ class_node = nodes.ClassDef(
+ "Namespace",
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=nodes.Unknown(),
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ # Set parent manually until ClassDef constructor fixed:
+ # https://github.com/pylint-dev/astroid/issues/1490
+ class_node.parent = node.parent
+ for attr in set(callsite.keyword_arguments):
+ fake_node = nodes.EmptyNode()
+ fake_node.parent = class_node
+ fake_node.attrname = attr
+ class_node.instance_attrs[attr] = [fake_node]
+ return iter((class_node.instantiate_class(),))
+
+
+def _looks_like_namespace(node) -> bool:
+ func = node.func
+ if isinstance(func, nodes.Attribute):
+ return (
+ func.attrname == "Namespace"
+ and isinstance(func.expr, nodes.Name)
+ and func.expr.name == "argparse"
+ )
+ return False
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ nodes.Call, inference_tip(infer_namespace), _looks_like_namespace
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_attrs.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_attrs.py
new file mode 100644
index 000000000..23ec9f66a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_attrs.py
@@ -0,0 +1,103 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Astroid hook for the attrs library
+
+Without this hook pylint reports unsupported-assignment-operation
+for attrs classes
+"""
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import AnnAssign, Assign, AssignName, Call, Unknown
+from astroid.nodes.scoped_nodes import ClassDef
+from astroid.util import safe_infer
+
+ATTRIB_NAMES = frozenset(
+ (
+ "attr.Factory",
+ "attr.ib",
+ "attrib",
+ "attr.attrib",
+ "attr.field",
+ "attrs.field",
+ "field",
+ )
+)
+NEW_ATTRS_NAMES = frozenset(
+ (
+ "attrs.define",
+ "attrs.mutable",
+ "attrs.frozen",
+ )
+)
+ATTRS_NAMES = frozenset(
+ (
+ "attr.s",
+ "attrs",
+ "attr.attrs",
+ "attr.attributes",
+ "attr.define",
+ "attr.mutable",
+ "attr.frozen",
+ *NEW_ATTRS_NAMES,
+ )
+)
+
+
+def is_decorated_with_attrs(node, decorator_names=ATTRS_NAMES) -> bool:
+ """Return whether a decorated node has an attr decorator applied."""
+ if not node.decorators:
+ return False
+ for decorator_attribute in node.decorators.nodes:
+ if isinstance(decorator_attribute, Call): # decorator with arguments
+ decorator_attribute = decorator_attribute.func
+ if decorator_attribute.as_string() in decorator_names:
+ return True
+
+ inferred = safe_infer(decorator_attribute)
+ if inferred and inferred.root().name == "attr._next_gen":
+ return True
+ return False
+
+
+def attr_attributes_transform(node: ClassDef) -> None:
+ """Given that the ClassNode has an attr decorator,
+ rewrite class attributes as instance attributes
+ """
+ # Astroid can't infer this attribute properly
+ # Prevents https://github.com/pylint-dev/pylint/issues/1884
+ node.locals["__attrs_attrs__"] = [Unknown(parent=node)]
+
+ use_bare_annotations = is_decorated_with_attrs(node, NEW_ATTRS_NAMES)
+ for cdef_body_node in node.body:
+ if not isinstance(cdef_body_node, (Assign, AnnAssign)):
+ continue
+ if isinstance(cdef_body_node.value, Call):
+ if cdef_body_node.value.func.as_string() not in ATTRIB_NAMES:
+ continue
+ elif not use_bare_annotations:
+ continue
+ targets = (
+ cdef_body_node.targets
+ if hasattr(cdef_body_node, "targets")
+ else [cdef_body_node.target]
+ )
+ for target in targets:
+ rhs_node = Unknown(
+ lineno=cdef_body_node.lineno,
+ col_offset=cdef_body_node.col_offset,
+ parent=cdef_body_node,
+ )
+ if isinstance(target, AssignName):
+ # Could be a subscript if the code analysed is
+ # i = Optional[str] = ""
+ # See https://github.com/pylint-dev/pylint/issues/4439
+ node.locals[target.name] = [rhs_node]
+ node.instance_attrs[target.name] = [rhs_node]
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ ClassDef, attr_attributes_transform, is_decorated_with_attrs
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_boto3.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_boto3.py
new file mode 100644
index 000000000..55bca14fc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_boto3.py
@@ -0,0 +1,32 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for understanding ``boto3.ServiceRequest()``."""
+
+from astroid import extract_node
+from astroid.manager import AstroidManager
+from astroid.nodes.scoped_nodes import ClassDef
+
+BOTO_SERVICE_FACTORY_QUALIFIED_NAME = "boto3.resources.base.ServiceResource"
+
+
+def service_request_transform(node):
+ """Transform ServiceResource to look like dynamic classes."""
+ code = """
+ def __getattr__(self, attr):
+ return 0
+ """
+ func_getattr = extract_node(code)
+ node.locals["__getattr__"] = [func_getattr]
+ return node
+
+
+def _looks_like_boto3_service_request(node) -> bool:
+ return node.qname() == BOTO_SERVICE_FACTORY_QUALIFIED_NAME
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ ClassDef, service_request_transform, _looks_like_boto3_service_request
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_builtin_inference.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_builtin_inference.py
new file mode 100644
index 000000000..e9d00e2e1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_builtin_inference.py
@@ -0,0 +1,1111 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for various builtins."""
+
+from __future__ import annotations
+
+import itertools
+from collections.abc import Callable, Iterable, Iterator
+from functools import partial
+from typing import TYPE_CHECKING, Any, NoReturn, Union, cast
+
+from astroid import arguments, helpers, inference_tip, nodes, objects, util
+from astroid.builder import AstroidBuilder
+from astroid.context import InferenceContext
+from astroid.exceptions import (
+ AstroidTypeError,
+ AttributeInferenceError,
+ InferenceError,
+ MroError,
+ UseInferenceDefault,
+)
+from astroid.manager import AstroidManager
+from astroid.nodes import scoped_nodes
+from astroid.typing import (
+ ConstFactoryResult,
+ InferenceResult,
+ SuccessfulInferenceResult,
+)
+
+if TYPE_CHECKING:
+ from astroid.bases import Instance
+
+ContainerObjects = Union[
+ objects.FrozenSet,
+ objects.DictItems,
+ objects.DictKeys,
+ objects.DictValues,
+]
+
+BuiltContainers = Union[
+ type[tuple],
+ type[list],
+ type[set],
+ type[frozenset],
+]
+
+CopyResult = Union[
+ nodes.Dict,
+ nodes.List,
+ nodes.Set,
+ objects.FrozenSet,
+]
+
+OBJECT_DUNDER_NEW = "object.__new__"
+
+STR_CLASS = """
+class whatever(object):
+ def join(self, iterable):
+ return {rvalue}
+ def replace(self, old, new, count=None):
+ return {rvalue}
+ def format(self, *args, **kwargs):
+ return {rvalue}
+ def encode(self, encoding='ascii', errors=None):
+ return b''
+ def decode(self, encoding='ascii', errors=None):
+ return u''
+ def capitalize(self):
+ return {rvalue}
+ def title(self):
+ return {rvalue}
+ def lower(self):
+ return {rvalue}
+ def upper(self):
+ return {rvalue}
+ def swapcase(self):
+ return {rvalue}
+ def index(self, sub, start=None, end=None):
+ return 0
+ def find(self, sub, start=None, end=None):
+ return 0
+ def count(self, sub, start=None, end=None):
+ return 0
+ def strip(self, chars=None):
+ return {rvalue}
+ def lstrip(self, chars=None):
+ return {rvalue}
+ def rstrip(self, chars=None):
+ return {rvalue}
+ def rjust(self, width, fillchar=None):
+ return {rvalue}
+ def center(self, width, fillchar=None):
+ return {rvalue}
+ def ljust(self, width, fillchar=None):
+ return {rvalue}
+"""
+
+
+BYTES_CLASS = """
+class whatever(object):
+ def join(self, iterable):
+ return {rvalue}
+ def replace(self, old, new, count=None):
+ return {rvalue}
+ def decode(self, encoding='ascii', errors=None):
+ return u''
+ def capitalize(self):
+ return {rvalue}
+ def title(self):
+ return {rvalue}
+ def lower(self):
+ return {rvalue}
+ def upper(self):
+ return {rvalue}
+ def swapcase(self):
+ return {rvalue}
+ def index(self, sub, start=None, end=None):
+ return 0
+ def find(self, sub, start=None, end=None):
+ return 0
+ def count(self, sub, start=None, end=None):
+ return 0
+ def strip(self, chars=None):
+ return {rvalue}
+ def lstrip(self, chars=None):
+ return {rvalue}
+ def rstrip(self, chars=None):
+ return {rvalue}
+ def rjust(self, width, fillchar=None):
+ return {rvalue}
+ def center(self, width, fillchar=None):
+ return {rvalue}
+ def ljust(self, width, fillchar=None):
+ return {rvalue}
+"""
+
+
+def _use_default() -> NoReturn: # pragma: no cover
+ raise UseInferenceDefault()
+
+
+def _extend_string_class(class_node, code, rvalue):
+ """Function to extend builtin str/unicode class."""
+ code = code.format(rvalue=rvalue)
+ fake = AstroidBuilder(AstroidManager()).string_build(code)["whatever"]
+ for method in fake.mymethods():
+ method.parent = class_node
+ method.lineno = None
+ method.col_offset = None
+ if "__class__" in method.locals:
+ method.locals["__class__"] = [class_node]
+ class_node.locals[method.name] = [method]
+ method.parent = class_node
+
+
+def _extend_builtins(class_transforms):
+ builtin_ast = AstroidManager().builtins_module
+ for class_name, transform in class_transforms.items():
+ transform(builtin_ast[class_name])
+
+
+def on_bootstrap():
+ """Called by astroid_bootstrapping()."""
+ _extend_builtins(
+ {
+ "bytes": partial(_extend_string_class, code=BYTES_CLASS, rvalue="b''"),
+ "str": partial(_extend_string_class, code=STR_CLASS, rvalue="''"),
+ }
+ )
+
+
+def _builtin_filter_predicate(node, builtin_name) -> bool:
+ if (
+ builtin_name == "type"
+ and node.root().name == "re"
+ and isinstance(node.func, nodes.Name)
+ and node.func.name == "type"
+ and isinstance(node.parent, nodes.Assign)
+ and len(node.parent.targets) == 1
+ and isinstance(node.parent.targets[0], nodes.AssignName)
+ and node.parent.targets[0].name in {"Pattern", "Match"}
+ ):
+ # Handle re.Pattern and re.Match in brain_re
+ # Match these patterns from stdlib/re.py
+ # ```py
+ # Pattern = type(...)
+ # Match = type(...)
+ # ```
+ return False
+ if isinstance(node.func, nodes.Name) and node.func.name == builtin_name:
+ return True
+ if isinstance(node.func, nodes.Attribute):
+ return (
+ node.func.attrname == "fromkeys"
+ and isinstance(node.func.expr, nodes.Name)
+ and node.func.expr.name == "dict"
+ )
+ return False
+
+
+def register_builtin_transform(
+ manager: AstroidManager, transform, builtin_name
+) -> None:
+ """Register a new transform function for the given *builtin_name*.
+
+ The transform function must accept two parameters, a node and
+ an optional context.
+ """
+
+ def _transform_wrapper(
+ node: nodes.Call, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator:
+ result = transform(node, context=context)
+ if result:
+ if not result.parent:
+ # Let the transformation function determine
+ # the parent for its result. Otherwise,
+ # we set it to be the node we transformed from.
+ result.parent = node
+
+ if result.lineno is None:
+ result.lineno = node.lineno
+ # Can be a 'Module' see https://github.com/pylint-dev/pylint/issues/4671
+ # We don't have a regression test on this one: tread carefully
+ if hasattr(result, "col_offset") and result.col_offset is None:
+ result.col_offset = node.col_offset
+ return iter([result])
+
+ manager.register_transform(
+ nodes.Call,
+ inference_tip(_transform_wrapper),
+ partial(_builtin_filter_predicate, builtin_name=builtin_name),
+ )
+
+
+def _container_generic_inference(
+ node: nodes.Call,
+ context: InferenceContext | None,
+ node_type: type[nodes.BaseContainer],
+ transform: Callable[[SuccessfulInferenceResult], nodes.BaseContainer | None],
+) -> nodes.BaseContainer:
+ args = node.args
+ if not args:
+ return node_type(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ if len(node.args) > 1:
+ raise UseInferenceDefault()
+
+ (arg,) = args
+ transformed = transform(arg)
+ if not transformed:
+ try:
+ inferred = next(arg.infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ if isinstance(inferred, util.UninferableBase):
+ raise UseInferenceDefault
+ transformed = transform(inferred)
+ if not transformed or isinstance(transformed, util.UninferableBase):
+ raise UseInferenceDefault
+ return transformed
+
+
+def _container_generic_transform(
+ arg: SuccessfulInferenceResult,
+ context: InferenceContext | None,
+ klass: type[nodes.BaseContainer],
+ iterables: tuple[type[nodes.BaseContainer] | type[ContainerObjects], ...],
+ build_elts: BuiltContainers,
+) -> nodes.BaseContainer | None:
+ elts: Iterable | str | bytes
+
+ if isinstance(arg, klass):
+ return arg
+ if isinstance(arg, iterables):
+ arg = cast(Union[nodes.BaseContainer, ContainerObjects], arg)
+ if all(isinstance(elt, nodes.Const) for elt in arg.elts):
+ elts = [cast(nodes.Const, elt).value for elt in arg.elts]
+ else:
+ # TODO: Does not handle deduplication for sets.
+ elts = []
+ for element in arg.elts:
+ if not element:
+ continue
+ inferred = util.safe_infer(element, context=context)
+ if inferred:
+ evaluated_object = nodes.EvaluatedObject(
+ original=element, value=inferred
+ )
+ elts.append(evaluated_object)
+ elif isinstance(arg, nodes.Dict):
+ # Dicts need to have consts as strings already.
+ elts = [
+ item[0].value if isinstance(item[0], nodes.Const) else _use_default()
+ for item in arg.items
+ ]
+ elif isinstance(arg, nodes.Const) and isinstance(arg.value, (str, bytes)):
+ elts = arg.value
+ else:
+ return None
+ return klass.from_elements(elts=build_elts(elts))
+
+
+def _infer_builtin_container(
+ node: nodes.Call,
+ context: InferenceContext | None,
+ klass: type[nodes.BaseContainer],
+ iterables: tuple[type[nodes.NodeNG] | type[ContainerObjects], ...],
+ build_elts: BuiltContainers,
+) -> nodes.BaseContainer:
+ transform_func = partial(
+ _container_generic_transform,
+ context=context,
+ klass=klass,
+ iterables=iterables,
+ build_elts=build_elts,
+ )
+
+ return _container_generic_inference(node, context, klass, transform_func)
+
+
+# pylint: disable=invalid-name
+infer_tuple = partial(
+ _infer_builtin_container,
+ klass=nodes.Tuple,
+ iterables=(
+ nodes.List,
+ nodes.Set,
+ objects.FrozenSet,
+ objects.DictItems,
+ objects.DictKeys,
+ objects.DictValues,
+ ),
+ build_elts=tuple,
+)
+
+infer_list = partial(
+ _infer_builtin_container,
+ klass=nodes.List,
+ iterables=(
+ nodes.Tuple,
+ nodes.Set,
+ objects.FrozenSet,
+ objects.DictItems,
+ objects.DictKeys,
+ objects.DictValues,
+ ),
+ build_elts=list,
+)
+
+infer_set = partial(
+ _infer_builtin_container,
+ klass=nodes.Set,
+ iterables=(nodes.List, nodes.Tuple, objects.FrozenSet, objects.DictKeys),
+ build_elts=set,
+)
+
+infer_frozenset = partial(
+ _infer_builtin_container,
+ klass=objects.FrozenSet,
+ iterables=(nodes.List, nodes.Tuple, nodes.Set, objects.FrozenSet, objects.DictKeys),
+ build_elts=frozenset,
+)
+
+
+def _get_elts(arg, context):
+ def is_iterable(n):
+ return isinstance(n, (nodes.List, nodes.Tuple, nodes.Set))
+
+ try:
+ inferred = next(arg.infer(context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ if isinstance(inferred, nodes.Dict):
+ items = inferred.items
+ elif is_iterable(inferred):
+ items = []
+ for elt in inferred.elts:
+ # If an item is not a pair of two items,
+ # then fallback to the default inference.
+ # Also, take in consideration only hashable items,
+ # tuples and consts. We are choosing Names as well.
+ if not is_iterable(elt):
+ raise UseInferenceDefault()
+ if len(elt.elts) != 2:
+ raise UseInferenceDefault()
+ if not isinstance(elt.elts[0], (nodes.Tuple, nodes.Const, nodes.Name)):
+ raise UseInferenceDefault()
+ items.append(tuple(elt.elts))
+ else:
+ raise UseInferenceDefault()
+ return items
+
+
+def infer_dict(node: nodes.Call, context: InferenceContext | None = None) -> nodes.Dict:
+ """Try to infer a dict call to a Dict node.
+
+ The function treats the following cases:
+
+ * dict()
+ * dict(mapping)
+ * dict(iterable)
+ * dict(iterable, **kwargs)
+ * dict(mapping, **kwargs)
+ * dict(**kwargs)
+
+ If a case can't be inferred, we'll fallback to default inference.
+ """
+ call = arguments.CallSite.from_call(node, context=context)
+ if call.has_invalid_arguments() or call.has_invalid_keywords():
+ raise UseInferenceDefault
+
+ args = call.positional_arguments
+ kwargs = list(call.keyword_arguments.items())
+
+ items: list[tuple[InferenceResult, InferenceResult]]
+ if not args and not kwargs:
+ # dict()
+ return nodes.Dict(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ if kwargs and not args:
+ # dict(a=1, b=2, c=4)
+ items = [(nodes.Const(key), value) for key, value in kwargs]
+ elif len(args) == 1 and kwargs:
+ # dict(some_iterable, b=2, c=4)
+ elts = _get_elts(args[0], context)
+ keys = [(nodes.Const(key), value) for key, value in kwargs]
+ items = elts + keys
+ elif len(args) == 1:
+ items = _get_elts(args[0], context)
+ else:
+ raise UseInferenceDefault()
+ value = nodes.Dict(
+ col_offset=node.col_offset,
+ lineno=node.lineno,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ value.postinit(items)
+ return value
+
+
+def infer_super(
+ node: nodes.Call, context: InferenceContext | None = None
+) -> objects.Super:
+ """Understand super calls.
+
+ There are some restrictions for what can be understood:
+
+ * unbounded super (one argument form) is not understood.
+
+ * if the super call is not inside a function (classmethod or method),
+ then the default inference will be used.
+
+ * if the super arguments can't be inferred, the default inference
+ will be used.
+ """
+ if len(node.args) == 1:
+ # Ignore unbounded super.
+ raise UseInferenceDefault
+
+ scope = node.scope()
+ if not isinstance(scope, nodes.FunctionDef):
+ # Ignore non-method uses of super.
+ raise UseInferenceDefault
+ if scope.type not in ("classmethod", "method"):
+ # Not interested in staticmethods.
+ raise UseInferenceDefault
+
+ cls = scoped_nodes.get_wrapping_class(scope)
+ assert cls is not None
+ if not node.args:
+ mro_pointer = cls
+ # In we are in a classmethod, the interpreter will fill
+ # automatically the class as the second argument, not an instance.
+ if scope.type == "classmethod":
+ mro_type = cls
+ else:
+ mro_type = cls.instantiate_class()
+ else:
+ try:
+ mro_pointer = next(node.args[0].infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ try:
+ mro_type = next(node.args[1].infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+
+ if isinstance(mro_pointer, util.UninferableBase) or isinstance(
+ mro_type, util.UninferableBase
+ ):
+ # No way we could understand this.
+ raise UseInferenceDefault
+
+ super_obj = objects.Super(
+ mro_pointer=mro_pointer,
+ mro_type=mro_type,
+ self_class=cls,
+ scope=scope,
+ call=node,
+ )
+ super_obj.parent = node
+ return super_obj
+
+
+def _infer_getattr_args(node, context):
+ if len(node.args) not in (2, 3):
+ # Not a valid getattr call.
+ raise UseInferenceDefault
+
+ try:
+ obj = next(node.args[0].infer(context=context))
+ attr = next(node.args[1].infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+
+ if isinstance(obj, util.UninferableBase) or isinstance(attr, util.UninferableBase):
+ # If one of the arguments is something we can't infer,
+ # then also make the result of the getattr call something
+ # which is unknown.
+ return util.Uninferable, util.Uninferable
+
+ is_string = isinstance(attr, nodes.Const) and isinstance(attr.value, str)
+ if not is_string:
+ raise UseInferenceDefault
+
+ return obj, attr.value
+
+
+def infer_getattr(node, context: InferenceContext | None = None):
+ """Understand getattr calls.
+
+ If one of the arguments is an Uninferable object, then the
+ result will be an Uninferable object. Otherwise, the normal attribute
+ lookup will be done.
+ """
+ obj, attr = _infer_getattr_args(node, context)
+ if (
+ isinstance(obj, util.UninferableBase)
+ or isinstance(attr, util.UninferableBase)
+ or not hasattr(obj, "igetattr")
+ ):
+ return util.Uninferable
+
+ try:
+ return next(obj.igetattr(attr, context=context))
+ except (StopIteration, InferenceError, AttributeInferenceError):
+ if len(node.args) == 3:
+ # Try to infer the default and return it instead.
+ try:
+ return next(node.args[2].infer(context=context))
+ except (StopIteration, InferenceError) as exc:
+ raise UseInferenceDefault from exc
+
+ raise UseInferenceDefault
+
+
+def infer_hasattr(node, context: InferenceContext | None = None):
+ """Understand hasattr calls.
+
+ This always guarantees three possible outcomes for calling
+ hasattr: Const(False) when we are sure that the object
+ doesn't have the intended attribute, Const(True) when
+ we know that the object has the attribute and Uninferable
+ when we are unsure of the outcome of the function call.
+ """
+ try:
+ obj, attr = _infer_getattr_args(node, context)
+ if (
+ isinstance(obj, util.UninferableBase)
+ or isinstance(attr, util.UninferableBase)
+ or not hasattr(obj, "getattr")
+ ):
+ return util.Uninferable
+ obj.getattr(attr, context=context)
+ except UseInferenceDefault:
+ # Can't infer something from this function call.
+ return util.Uninferable
+ except AttributeInferenceError:
+ # Doesn't have it.
+ return nodes.Const(False)
+ return nodes.Const(True)
+
+
+def infer_callable(node, context: InferenceContext | None = None):
+ """Understand callable calls.
+
+ This follows Python's semantics, where an object
+ is callable if it provides an attribute __call__,
+ even though that attribute is something which can't be
+ called.
+ """
+ if len(node.args) != 1:
+ # Invalid callable call.
+ raise UseInferenceDefault
+
+ argument = node.args[0]
+ try:
+ inferred = next(argument.infer(context=context))
+ except (InferenceError, StopIteration):
+ return util.Uninferable
+ if isinstance(inferred, util.UninferableBase):
+ return util.Uninferable
+ return nodes.Const(inferred.callable())
+
+
+def infer_property(
+ node: nodes.Call, context: InferenceContext | None = None
+) -> objects.Property:
+ """Understand `property` class.
+
+ This only infers the output of `property`
+ call, not the arguments themselves.
+ """
+ if len(node.args) < 1:
+ # Invalid property call.
+ raise UseInferenceDefault
+
+ getter = node.args[0]
+ try:
+ inferred = next(getter.infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+
+ if not isinstance(inferred, (nodes.FunctionDef, nodes.Lambda)):
+ raise UseInferenceDefault
+
+ prop_func = objects.Property(
+ function=inferred,
+ name=inferred.name,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ )
+ # Set parent outside __init__: https://github.com/pylint-dev/astroid/issues/1490
+ prop_func.parent = node
+ prop_func.postinit(
+ body=[],
+ args=inferred.args,
+ doc_node=getattr(inferred, "doc_node", None),
+ )
+ return prop_func
+
+
+def infer_bool(node, context: InferenceContext | None = None):
+ """Understand bool calls."""
+ if len(node.args) > 1:
+ # Invalid bool call.
+ raise UseInferenceDefault
+
+ if not node.args:
+ return nodes.Const(False)
+
+ argument = node.args[0]
+ try:
+ inferred = next(argument.infer(context=context))
+ except (InferenceError, StopIteration):
+ return util.Uninferable
+ if isinstance(inferred, util.UninferableBase):
+ return util.Uninferable
+
+ bool_value = inferred.bool_value(context=context)
+ if isinstance(bool_value, util.UninferableBase):
+ return util.Uninferable
+ return nodes.Const(bool_value)
+
+
+def infer_type(node, context: InferenceContext | None = None):
+ """Understand the one-argument form of *type*."""
+ if len(node.args) != 1:
+ raise UseInferenceDefault
+
+ return helpers.object_type(node.args[0], context)
+
+
+def infer_slice(node, context: InferenceContext | None = None):
+ """Understand `slice` calls."""
+ args = node.args
+ if not 0 < len(args) <= 3:
+ raise UseInferenceDefault
+
+ infer_func = partial(util.safe_infer, context=context)
+ args = [infer_func(arg) for arg in args]
+ for arg in args:
+ if not arg or isinstance(arg, util.UninferableBase):
+ raise UseInferenceDefault
+ if not isinstance(arg, nodes.Const):
+ raise UseInferenceDefault
+ if not isinstance(arg.value, (type(None), int)):
+ raise UseInferenceDefault
+
+ if len(args) < 3:
+ # Make sure we have 3 arguments.
+ args.extend([None] * (3 - len(args)))
+
+ slice_node = nodes.Slice(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ slice_node.postinit(*args)
+ return slice_node
+
+
+def _infer_object__new__decorator(
+ node: nodes.ClassDef, context: InferenceContext | None = None, **kwargs: Any
+) -> Iterator[Instance]:
+ # Instantiate class immediately
+ # since that's what @object.__new__ does
+ return iter((node.instantiate_class(),))
+
+
+def _infer_object__new__decorator_check(node) -> bool:
+ """Predicate before inference_tip.
+
+ Check if the given ClassDef has an @object.__new__ decorator
+ """
+ if not node.decorators:
+ return False
+
+ for decorator in node.decorators.nodes:
+ if isinstance(decorator, nodes.Attribute):
+ if decorator.as_string() == OBJECT_DUNDER_NEW:
+ return True
+ return False
+
+
+def infer_issubclass(callnode, context: InferenceContext | None = None):
+ """Infer issubclass() calls.
+
+ :param nodes.Call callnode: an `issubclass` call
+ :param InferenceContext context: the context for the inference
+ :rtype nodes.Const: Boolean Const value of the `issubclass` call
+ :raises UseInferenceDefault: If the node cannot be inferred
+ """
+ call = arguments.CallSite.from_call(callnode, context=context)
+ if call.keyword_arguments:
+ # issubclass doesn't support keyword arguments
+ raise UseInferenceDefault("TypeError: issubclass() takes no keyword arguments")
+ if len(call.positional_arguments) != 2:
+ raise UseInferenceDefault(
+ f"Expected two arguments, got {len(call.positional_arguments)}"
+ )
+ # The left hand argument is the obj to be checked
+ obj_node, class_or_tuple_node = call.positional_arguments
+
+ try:
+ obj_type = next(obj_node.infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ if not isinstance(obj_type, nodes.ClassDef):
+ raise UseInferenceDefault("TypeError: arg 1 must be class")
+
+ # The right hand argument is the class(es) that the given
+ # object is to be checked against.
+ try:
+ class_container = _class_or_tuple_to_container(
+ class_or_tuple_node, context=context
+ )
+ except InferenceError as exc:
+ raise UseInferenceDefault from exc
+ try:
+ issubclass_bool = helpers.object_issubclass(obj_type, class_container, context)
+ except AstroidTypeError as exc:
+ raise UseInferenceDefault("TypeError: " + str(exc)) from exc
+ except MroError as exc:
+ raise UseInferenceDefault from exc
+ return nodes.Const(issubclass_bool)
+
+
+def infer_isinstance(
+ callnode: nodes.Call, context: InferenceContext | None = None
+) -> nodes.Const:
+ """Infer isinstance calls.
+
+ :param nodes.Call callnode: an isinstance call
+ :raises UseInferenceDefault: If the node cannot be inferred
+ """
+ call = arguments.CallSite.from_call(callnode, context=context)
+ if call.keyword_arguments:
+ # isinstance doesn't support keyword arguments
+ raise UseInferenceDefault("TypeError: isinstance() takes no keyword arguments")
+ if len(call.positional_arguments) != 2:
+ raise UseInferenceDefault(
+ f"Expected two arguments, got {len(call.positional_arguments)}"
+ )
+ # The left hand argument is the obj to be checked
+ obj_node, class_or_tuple_node = call.positional_arguments
+ # The right hand argument is the class(es) that the given
+ # obj is to be check is an instance of
+ try:
+ class_container = _class_or_tuple_to_container(
+ class_or_tuple_node, context=context
+ )
+ except InferenceError as exc:
+ raise UseInferenceDefault from exc
+ try:
+ isinstance_bool = helpers.object_isinstance(obj_node, class_container, context)
+ except AstroidTypeError as exc:
+ raise UseInferenceDefault("TypeError: " + str(exc)) from exc
+ except MroError as exc:
+ raise UseInferenceDefault from exc
+ if isinstance(isinstance_bool, util.UninferableBase):
+ raise UseInferenceDefault
+ return nodes.Const(isinstance_bool)
+
+
+def _class_or_tuple_to_container(
+ node: InferenceResult, context: InferenceContext | None = None
+) -> list[InferenceResult]:
+ # Move inferences results into container
+ # to simplify later logic
+ # raises InferenceError if any of the inferences fall through
+ try:
+ node_infer = next(node.infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(node=node, context=context) from e
+ # arg2 MUST be a type or a TUPLE of types
+ # for isinstance
+ if isinstance(node_infer, nodes.Tuple):
+ try:
+ class_container = [
+ next(node.infer(context=context)) for node in node_infer.elts
+ ]
+ except StopIteration as e:
+ raise InferenceError(node=node, context=context) from e
+ else:
+ class_container = [node_infer]
+ return class_container
+
+
+def infer_len(node, context: InferenceContext | None = None):
+ """Infer length calls.
+
+ :param nodes.Call node: len call to infer
+ :param context.InferenceContext: node context
+ :rtype nodes.Const: a Const node with the inferred length, if possible
+ """
+ call = arguments.CallSite.from_call(node, context=context)
+ if call.keyword_arguments:
+ raise UseInferenceDefault("TypeError: len() must take no keyword arguments")
+ if len(call.positional_arguments) != 1:
+ raise UseInferenceDefault(
+ "TypeError: len() must take exactly one argument "
+ "({len}) given".format(len=len(call.positional_arguments))
+ )
+ [argument_node] = call.positional_arguments
+
+ try:
+ return nodes.Const(helpers.object_len(argument_node, context=context))
+ except (AstroidTypeError, InferenceError) as exc:
+ raise UseInferenceDefault(str(exc)) from exc
+
+
+def infer_str(node, context: InferenceContext | None = None):
+ """Infer str() calls.
+
+ :param nodes.Call node: str() call to infer
+ :param context.InferenceContext: node context
+ :rtype nodes.Const: a Const containing an empty string
+ """
+ call = arguments.CallSite.from_call(node, context=context)
+ if call.keyword_arguments:
+ raise UseInferenceDefault("TypeError: str() must take no keyword arguments")
+ try:
+ return nodes.Const("")
+ except (AstroidTypeError, InferenceError) as exc:
+ raise UseInferenceDefault(str(exc)) from exc
+
+
+def infer_int(node, context: InferenceContext | None = None):
+ """Infer int() calls.
+
+ :param nodes.Call node: int() call to infer
+ :param context.InferenceContext: node context
+ :rtype nodes.Const: a Const containing the integer value of the int() call
+ """
+ call = arguments.CallSite.from_call(node, context=context)
+ if call.keyword_arguments:
+ raise UseInferenceDefault("TypeError: int() must take no keyword arguments")
+
+ if call.positional_arguments:
+ try:
+ first_value = next(call.positional_arguments[0].infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault(str(exc)) from exc
+
+ if isinstance(first_value, util.UninferableBase):
+ raise UseInferenceDefault
+
+ if isinstance(first_value, nodes.Const) and isinstance(
+ first_value.value, (int, str)
+ ):
+ try:
+ actual_value = int(first_value.value)
+ except ValueError:
+ return nodes.Const(0)
+ return nodes.Const(actual_value)
+
+ return nodes.Const(0)
+
+
+def infer_dict_fromkeys(node, context: InferenceContext | None = None):
+ """Infer dict.fromkeys.
+
+ :param nodes.Call node: dict.fromkeys() call to infer
+ :param context.InferenceContext context: node context
+ :rtype nodes.Dict:
+ a Dictionary containing the values that astroid was able to infer.
+ In case the inference failed for any reason, an empty dictionary
+ will be inferred instead.
+ """
+
+ def _build_dict_with_elements(elements):
+ new_node = nodes.Dict(
+ col_offset=node.col_offset,
+ lineno=node.lineno,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ new_node.postinit(elements)
+ return new_node
+
+ call = arguments.CallSite.from_call(node, context=context)
+ if call.keyword_arguments:
+ raise UseInferenceDefault("TypeError: int() must take no keyword arguments")
+ if len(call.positional_arguments) not in {1, 2}:
+ raise UseInferenceDefault(
+ "TypeError: Needs between 1 and 2 positional arguments"
+ )
+
+ default = nodes.Const(None)
+ values = call.positional_arguments[0]
+ try:
+ inferred_values = next(values.infer(context=context))
+ except (InferenceError, StopIteration):
+ return _build_dict_with_elements([])
+ if inferred_values is util.Uninferable:
+ return _build_dict_with_elements([])
+
+ # Limit to a couple of potential values, as this can become pretty complicated
+ accepted_iterable_elements = (nodes.Const,)
+ if isinstance(inferred_values, (nodes.List, nodes.Set, nodes.Tuple)):
+ elements = inferred_values.elts
+ for element in elements:
+ if not isinstance(element, accepted_iterable_elements):
+ # Fallback to an empty dict
+ return _build_dict_with_elements([])
+
+ elements_with_value = [(element, default) for element in elements]
+ return _build_dict_with_elements(elements_with_value)
+ if isinstance(inferred_values, nodes.Const) and isinstance(
+ inferred_values.value, (str, bytes)
+ ):
+ elements_with_value = [
+ (nodes.Const(element), default) for element in inferred_values.value
+ ]
+ return _build_dict_with_elements(elements_with_value)
+ if isinstance(inferred_values, nodes.Dict):
+ keys = inferred_values.itered()
+ for key in keys:
+ if not isinstance(key, accepted_iterable_elements):
+ # Fallback to an empty dict
+ return _build_dict_with_elements([])
+
+ elements_with_value = [(element, default) for element in keys]
+ return _build_dict_with_elements(elements_with_value)
+
+ # Fallback to an empty dictionary
+ return _build_dict_with_elements([])
+
+
+def _infer_copy_method(
+ node: nodes.Call, context: InferenceContext | None = None, **kwargs: Any
+) -> Iterator[CopyResult]:
+ assert isinstance(node.func, nodes.Attribute)
+ inferred_orig, inferred_copy = itertools.tee(node.func.expr.infer(context=context))
+ if all(
+ isinstance(
+ inferred_node, (nodes.Dict, nodes.List, nodes.Set, objects.FrozenSet)
+ )
+ for inferred_node in inferred_orig
+ ):
+ return cast(Iterator[CopyResult], inferred_copy)
+
+ raise UseInferenceDefault
+
+
+def _is_str_format_call(node: nodes.Call) -> bool:
+ """Catch calls to str.format()."""
+ if not isinstance(node.func, nodes.Attribute) or not node.func.attrname == "format":
+ return False
+
+ if isinstance(node.func.expr, nodes.Name):
+ value = util.safe_infer(node.func.expr)
+ else:
+ value = node.func.expr
+
+ return isinstance(value, nodes.Const) and isinstance(value.value, str)
+
+
+def _infer_str_format_call(
+ node: nodes.Call, context: InferenceContext | None = None, **kwargs: Any
+) -> Iterator[ConstFactoryResult | util.UninferableBase]:
+ """Return a Const node based on the template and passed arguments."""
+ call = arguments.CallSite.from_call(node, context=context)
+ assert isinstance(node.func, (nodes.Attribute, nodes.AssignAttr, nodes.DelAttr))
+
+ value: nodes.Const
+ if isinstance(node.func.expr, nodes.Name):
+ if not (inferred := util.safe_infer(node.func.expr)) or not isinstance(
+ inferred, nodes.Const
+ ):
+ return iter([util.Uninferable])
+ value = inferred
+ elif isinstance(node.func.expr, nodes.Const):
+ value = node.func.expr
+ else: # pragma: no cover
+ return iter([util.Uninferable])
+
+ format_template = value.value
+
+ # Get the positional arguments passed
+ inferred_positional: list[nodes.Const] = []
+ for i in call.positional_arguments:
+ one_inferred = util.safe_infer(i, context)
+ if not isinstance(one_inferred, nodes.Const):
+ return iter([util.Uninferable])
+ inferred_positional.append(one_inferred)
+
+ pos_values: list[str] = [i.value for i in inferred_positional]
+
+ # Get the keyword arguments passed
+ inferred_keyword: dict[str, nodes.Const] = {}
+ for k, v in call.keyword_arguments.items():
+ one_inferred = util.safe_infer(v, context)
+ if not isinstance(one_inferred, nodes.Const):
+ return iter([util.Uninferable])
+ inferred_keyword[k] = one_inferred
+
+ keyword_values: dict[str, str] = {k: v.value for k, v in inferred_keyword.items()}
+
+ try:
+ formatted_string = format_template.format(*pos_values, **keyword_values)
+ except (AttributeError, IndexError, KeyError, TypeError, ValueError):
+ # AttributeError: named field in format string was not found in the arguments
+ # IndexError: there are too few arguments to interpolate
+ # TypeError: Unsupported format string
+ # ValueError: Unknown format code
+ return iter([util.Uninferable])
+
+ return iter([nodes.const_factory(formatted_string)])
+
+
+def register(manager: AstroidManager) -> None:
+ # Builtins inference
+ register_builtin_transform(manager, infer_bool, "bool")
+ register_builtin_transform(manager, infer_super, "super")
+ register_builtin_transform(manager, infer_callable, "callable")
+ register_builtin_transform(manager, infer_property, "property")
+ register_builtin_transform(manager, infer_getattr, "getattr")
+ register_builtin_transform(manager, infer_hasattr, "hasattr")
+ register_builtin_transform(manager, infer_tuple, "tuple")
+ register_builtin_transform(manager, infer_set, "set")
+ register_builtin_transform(manager, infer_list, "list")
+ register_builtin_transform(manager, infer_dict, "dict")
+ register_builtin_transform(manager, infer_frozenset, "frozenset")
+ register_builtin_transform(manager, infer_type, "type")
+ register_builtin_transform(manager, infer_slice, "slice")
+ register_builtin_transform(manager, infer_isinstance, "isinstance")
+ register_builtin_transform(manager, infer_issubclass, "issubclass")
+ register_builtin_transform(manager, infer_len, "len")
+ register_builtin_transform(manager, infer_str, "str")
+ register_builtin_transform(manager, infer_int, "int")
+ register_builtin_transform(manager, infer_dict_fromkeys, "dict.fromkeys")
+
+ # Infer object.__new__ calls
+ manager.register_transform(
+ nodes.ClassDef,
+ inference_tip(_infer_object__new__decorator),
+ _infer_object__new__decorator_check,
+ )
+
+ manager.register_transform(
+ nodes.Call,
+ inference_tip(_infer_copy_method),
+ lambda node: isinstance(node.func, nodes.Attribute)
+ and node.func.attrname == "copy",
+ )
+
+ manager.register_transform(
+ nodes.Call,
+ inference_tip(_infer_str_format_call),
+ _is_str_format_call,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_collections.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_collections.py
new file mode 100644
index 000000000..94944e67a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_collections.py
@@ -0,0 +1,138 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder, extract_node, parse
+from astroid.const import PY313_PLUS
+from astroid.context import InferenceContext
+from astroid.exceptions import AttributeInferenceError
+from astroid.manager import AstroidManager
+from astroid.nodes.scoped_nodes import ClassDef
+
+if TYPE_CHECKING:
+ from astroid import nodes
+
+
+def _collections_transform():
+ return parse(
+ """
+ class defaultdict(dict):
+ default_factory = None
+ def __missing__(self, key): pass
+ def __getitem__(self, key): return default_factory
+
+ """
+ + _deque_mock()
+ + _ordered_dict_mock()
+ )
+
+
+def _collections_abc_313_transform() -> nodes.Module:
+ """See https://github.com/python/cpython/pull/124735"""
+ return AstroidBuilder(AstroidManager()).string_build(
+ "from _collections_abc import *"
+ )
+
+
+def _deque_mock():
+ base_deque_class = """
+ class deque(object):
+ maxlen = 0
+ def __init__(self, iterable=None, maxlen=None):
+ self.iterable = iterable or []
+ def append(self, x): pass
+ def appendleft(self, x): pass
+ def clear(self): pass
+ def count(self, x): return 0
+ def extend(self, iterable): pass
+ def extendleft(self, iterable): pass
+ def pop(self): return self.iterable[0]
+ def popleft(self): return self.iterable[0]
+ def remove(self, value): pass
+ def reverse(self): return reversed(self.iterable)
+ def rotate(self, n=1): return self
+ def __iter__(self): return self
+ def __reversed__(self): return self.iterable[::-1]
+ def __getitem__(self, index): return self.iterable[index]
+ def __setitem__(self, index, value): pass
+ def __delitem__(self, index): pass
+ def __bool__(self): return bool(self.iterable)
+ def __nonzero__(self): return bool(self.iterable)
+ def __contains__(self, o): return o in self.iterable
+ def __len__(self): return len(self.iterable)
+ def __copy__(self): return deque(self.iterable)
+ def copy(self): return deque(self.iterable)
+ def index(self, x, start=0, end=0): return 0
+ def insert(self, i, x): pass
+ def __add__(self, other): pass
+ def __iadd__(self, other): pass
+ def __mul__(self, other): pass
+ def __imul__(self, other): pass
+ def __rmul__(self, other): pass
+ @classmethod
+ def __class_getitem__(self, item): return cls"""
+ return base_deque_class
+
+
+def _ordered_dict_mock():
+ base_ordered_dict_class = """
+ class OrderedDict(dict):
+ def __reversed__(self): return self[::-1]
+ def move_to_end(self, key, last=False): pass
+ @classmethod
+ def __class_getitem__(cls, item): return cls"""
+ return base_ordered_dict_class
+
+
+def _looks_like_subscriptable(node: ClassDef) -> bool:
+ """
+ Returns True if the node corresponds to a ClassDef of the Collections.abc module
+ that supports subscripting.
+
+ :param node: ClassDef node
+ """
+ if node.qname().startswith("_collections") or node.qname().startswith(
+ "collections"
+ ):
+ try:
+ node.getattr("__class_getitem__")
+ return True
+ except AttributeInferenceError:
+ pass
+ return False
+
+
+CLASS_GET_ITEM_TEMPLATE = """
+@classmethod
+def __class_getitem__(cls, item):
+ return cls
+"""
+
+
+def easy_class_getitem_inference(node, context: InferenceContext | None = None):
+ # Here __class_getitem__ exists but is quite a mess to infer thus
+ # put an easy inference tip
+ func_to_add = extract_node(CLASS_GET_ITEM_TEMPLATE)
+ node.locals["__class_getitem__"] = [func_to_add]
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "collections", _collections_transform)
+
+ # Starting with Python39 some objects of the collection module are subscriptable
+ # thanks to the __class_getitem__ method but the way it is implemented in
+ # _collection_abc makes it difficult to infer. (We would have to handle AssignName inference in the
+ # getitem method of the ClassDef class) Instead we put here a mock of the __class_getitem__ method
+ manager.register_transform(
+ ClassDef, easy_class_getitem_inference, _looks_like_subscriptable
+ )
+
+ if PY313_PLUS:
+ register_module_extender(
+ manager, "collections.abc", _collections_abc_313_transform
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_crypt.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_crypt.py
new file mode 100644
index 000000000..2a6abbd7c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_crypt.py
@@ -0,0 +1,26 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def _re_transform():
+ return parse(
+ """
+ from collections import namedtuple
+ _Method = namedtuple('_Method', 'name ident salt_chars total_size')
+
+ METHOD_SHA512 = _Method('SHA512', '6', 16, 106)
+ METHOD_SHA256 = _Method('SHA256', '5', 16, 63)
+ METHOD_BLOWFISH = _Method('BLOWFISH', 2, 'b', 22)
+ METHOD_MD5 = _Method('MD5', '1', 8, 34)
+ METHOD_CRYPT = _Method('CRYPT', None, 2, 13)
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "crypt", _re_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_ctypes.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_ctypes.py
new file mode 100644
index 000000000..863ea1874
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_ctypes.py
@@ -0,0 +1,85 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Astroid hooks for ctypes module.
+
+Inside the ctypes module, the value class is defined inside
+the C coded module _ctypes.
+Thus astroid doesn't know that the value member is a builtin type
+among float, int, bytes or str.
+"""
+import sys
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def enrich_ctypes_redefined_types():
+ """
+ For each ctypes redefined types, overload 'value' and '_type_' members
+ definition.
+
+ Overloading 'value' is mandatory otherwise astroid cannot infer the correct type for it.
+ Overloading '_type_' is necessary because the class definition made here replaces the original
+ one, in which '_type_' member is defined. Luckily those original class definitions are very short
+ and contain only the '_type_' member definition.
+ """
+ c_class_to_type = (
+ ("c_byte", "int", "b"),
+ ("c_char", "bytes", "c"),
+ ("c_double", "float", "d"),
+ ("c_float", "float", "f"),
+ ("c_int", "int", "i"),
+ ("c_int16", "int", "h"),
+ ("c_int32", "int", "i"),
+ ("c_int64", "int", "l"),
+ ("c_int8", "int", "b"),
+ ("c_long", "int", "l"),
+ ("c_longdouble", "float", "g"),
+ ("c_longlong", "int", "l"),
+ ("c_short", "int", "h"),
+ ("c_size_t", "int", "L"),
+ ("c_ssize_t", "int", "l"),
+ ("c_ubyte", "int", "B"),
+ ("c_uint", "int", "I"),
+ ("c_uint16", "int", "H"),
+ ("c_uint32", "int", "I"),
+ ("c_uint64", "int", "L"),
+ ("c_uint8", "int", "B"),
+ ("c_ulong", "int", "L"),
+ ("c_ulonglong", "int", "L"),
+ ("c_ushort", "int", "H"),
+ ("c_wchar", "str", "u"),
+ )
+
+ src = [
+ """
+from _ctypes import _SimpleCData
+
+class c_bool(_SimpleCData):
+ def __init__(self, value):
+ self.value = True
+ self._type_ = '?'
+ """
+ ]
+
+ for c_type, builtin_type, type_code in c_class_to_type:
+ src.append(
+ f"""
+class {c_type}(_SimpleCData):
+ def __init__(self, value):
+ self.value = {builtin_type}(value)
+ self._type_ = '{type_code}'
+ """
+ )
+
+ return parse("\n".join(src))
+
+
+def register(manager: AstroidManager) -> None:
+ if not hasattr(sys, "pypy_version_info"):
+ # No need of this module in pypy where everything is written in python
+ register_module_extender(manager, "ctypes", enrich_ctypes_redefined_types)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_curses.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_curses.py
new file mode 100644
index 000000000..f06c52f97
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_curses.py
@@ -0,0 +1,184 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def _curses_transform():
+ return parse(
+ """
+ A_ALTCHARSET = 1
+ A_BLINK = 1
+ A_BOLD = 1
+ A_DIM = 1
+ A_INVIS = 1
+ A_ITALIC = 1
+ A_NORMAL = 1
+ A_PROTECT = 1
+ A_REVERSE = 1
+ A_STANDOUT = 1
+ A_UNDERLINE = 1
+ A_HORIZONTAL = 1
+ A_LEFT = 1
+ A_LOW = 1
+ A_RIGHT = 1
+ A_TOP = 1
+ A_VERTICAL = 1
+ A_CHARTEXT = 1
+ A_ATTRIBUTES = 1
+ A_CHARTEXT = 1
+ A_COLOR = 1
+ KEY_MIN = 1
+ KEY_BREAK = 1
+ KEY_DOWN = 1
+ KEY_UP = 1
+ KEY_LEFT = 1
+ KEY_RIGHT = 1
+ KEY_HOME = 1
+ KEY_BACKSPACE = 1
+ KEY_F0 = 1
+ KEY_Fn = 1
+ KEY_DL = 1
+ KEY_IL = 1
+ KEY_DC = 1
+ KEY_IC = 1
+ KEY_EIC = 1
+ KEY_CLEAR = 1
+ KEY_EOS = 1
+ KEY_EOL = 1
+ KEY_SF = 1
+ KEY_SR = 1
+ KEY_NPAGE = 1
+ KEY_PPAGE = 1
+ KEY_STAB = 1
+ KEY_CTAB = 1
+ KEY_CATAB = 1
+ KEY_ENTER = 1
+ KEY_SRESET = 1
+ KEY_RESET = 1
+ KEY_PRINT = 1
+ KEY_LL = 1
+ KEY_A1 = 1
+ KEY_A3 = 1
+ KEY_B2 = 1
+ KEY_C1 = 1
+ KEY_C3 = 1
+ KEY_BTAB = 1
+ KEY_BEG = 1
+ KEY_CANCEL = 1
+ KEY_CLOSE = 1
+ KEY_COMMAND = 1
+ KEY_COPY = 1
+ KEY_CREATE = 1
+ KEY_END = 1
+ KEY_EXIT = 1
+ KEY_FIND = 1
+ KEY_HELP = 1
+ KEY_MARK = 1
+ KEY_MESSAGE = 1
+ KEY_MOVE = 1
+ KEY_NEXT = 1
+ KEY_OPEN = 1
+ KEY_OPTIONS = 1
+ KEY_PREVIOUS = 1
+ KEY_REDO = 1
+ KEY_REFERENCE = 1
+ KEY_REFRESH = 1
+ KEY_REPLACE = 1
+ KEY_RESTART = 1
+ KEY_RESUME = 1
+ KEY_SAVE = 1
+ KEY_SBEG = 1
+ KEY_SCANCEL = 1
+ KEY_SCOMMAND = 1
+ KEY_SCOPY = 1
+ KEY_SCREATE = 1
+ KEY_SDC = 1
+ KEY_SDL = 1
+ KEY_SELECT = 1
+ KEY_SEND = 1
+ KEY_SEOL = 1
+ KEY_SEXIT = 1
+ KEY_SFIND = 1
+ KEY_SHELP = 1
+ KEY_SHOME = 1
+ KEY_SIC = 1
+ KEY_SLEFT = 1
+ KEY_SMESSAGE = 1
+ KEY_SMOVE = 1
+ KEY_SNEXT = 1
+ KEY_SOPTIONS = 1
+ KEY_SPREVIOUS = 1
+ KEY_SPRINT = 1
+ KEY_SREDO = 1
+ KEY_SREPLACE = 1
+ KEY_SRIGHT = 1
+ KEY_SRSUME = 1
+ KEY_SSAVE = 1
+ KEY_SSUSPEND = 1
+ KEY_SUNDO = 1
+ KEY_SUSPEND = 1
+ KEY_UNDO = 1
+ KEY_MOUSE = 1
+ KEY_RESIZE = 1
+ KEY_MAX = 1
+ ACS_BBSS = 1
+ ACS_BLOCK = 1
+ ACS_BOARD = 1
+ ACS_BSBS = 1
+ ACS_BSSB = 1
+ ACS_BSSS = 1
+ ACS_BTEE = 1
+ ACS_BULLET = 1
+ ACS_CKBOARD = 1
+ ACS_DARROW = 1
+ ACS_DEGREE = 1
+ ACS_DIAMOND = 1
+ ACS_GEQUAL = 1
+ ACS_HLINE = 1
+ ACS_LANTERN = 1
+ ACS_LARROW = 1
+ ACS_LEQUAL = 1
+ ACS_LLCORNER = 1
+ ACS_LRCORNER = 1
+ ACS_LTEE = 1
+ ACS_NEQUAL = 1
+ ACS_PI = 1
+ ACS_PLMINUS = 1
+ ACS_PLUS = 1
+ ACS_RARROW = 1
+ ACS_RTEE = 1
+ ACS_S1 = 1
+ ACS_S3 = 1
+ ACS_S7 = 1
+ ACS_S9 = 1
+ ACS_SBBS = 1
+ ACS_SBSB = 1
+ ACS_SBSS = 1
+ ACS_SSBB = 1
+ ACS_SSBS = 1
+ ACS_SSSB = 1
+ ACS_SSSS = 1
+ ACS_STERLING = 1
+ ACS_TTEE = 1
+ ACS_UARROW = 1
+ ACS_ULCORNER = 1
+ ACS_URCORNER = 1
+ ACS_VLINE = 1
+ COLOR_BLACK = 1
+ COLOR_BLUE = 1
+ COLOR_CYAN = 1
+ COLOR_GREEN = 1
+ COLOR_MAGENTA = 1
+ COLOR_RED = 1
+ COLOR_WHITE = 1
+ COLOR_YELLOW = 1
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "curses", _curses_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_dataclasses.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_dataclasses.py
new file mode 100644
index 000000000..845295bf9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_dataclasses.py
@@ -0,0 +1,643 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Astroid hook for the dataclasses library.
+
+Support built-in dataclasses, pydantic.dataclasses, and marshmallow_dataclass-annotated
+dataclasses. References:
+- https://docs.python.org/3/library/dataclasses.html
+- https://pydantic-docs.helpmanual.io/usage/dataclasses/
+- https://lovasoa.github.io/marshmallow_dataclass/
+"""
+
+from __future__ import annotations
+
+from collections.abc import Iterator
+from typing import Literal, Union
+
+from astroid import bases, context, nodes
+from astroid.builder import parse
+from astroid.const import PY310_PLUS, PY313_PLUS
+from astroid.exceptions import AstroidSyntaxError, InferenceError, UseInferenceDefault
+from astroid.inference_tip import inference_tip
+from astroid.manager import AstroidManager
+from astroid.typing import InferenceResult
+from astroid.util import Uninferable, UninferableBase, safe_infer
+
+_FieldDefaultReturn = Union[
+ None,
+ tuple[Literal["default"], nodes.NodeNG],
+ tuple[Literal["default_factory"], nodes.Call],
+]
+
+DATACLASSES_DECORATORS = frozenset(("dataclass",))
+FIELD_NAME = "field"
+DATACLASS_MODULES = frozenset(
+ ("dataclasses", "marshmallow_dataclass", "pydantic.dataclasses")
+)
+DEFAULT_FACTORY = "_HAS_DEFAULT_FACTORY" # based on typing.py
+
+
+def is_decorated_with_dataclass(
+ node: nodes.ClassDef, decorator_names: frozenset[str] = DATACLASSES_DECORATORS
+) -> bool:
+ """Return True if a decorated node has a `dataclass` decorator applied."""
+ if not isinstance(node, nodes.ClassDef) or not node.decorators:
+ return False
+
+ return any(
+ _looks_like_dataclass_decorator(decorator_attribute, decorator_names)
+ for decorator_attribute in node.decorators.nodes
+ )
+
+
+def dataclass_transform(node: nodes.ClassDef) -> None:
+ """Rewrite a dataclass to be easily understood by pylint."""
+ node.is_dataclass = True
+
+ for assign_node in _get_dataclass_attributes(node):
+ name = assign_node.target.name
+
+ rhs_node = nodes.Unknown(
+ lineno=assign_node.lineno,
+ col_offset=assign_node.col_offset,
+ parent=assign_node,
+ )
+ rhs_node = AstroidManager().visit_transforms(rhs_node)
+ node.instance_attrs[name] = [rhs_node]
+
+ if not _check_generate_dataclass_init(node):
+ return
+
+ kw_only_decorated = False
+ if PY310_PLUS and node.decorators.nodes:
+ for decorator in node.decorators.nodes:
+ if not isinstance(decorator, nodes.Call):
+ kw_only_decorated = False
+ break
+ for keyword in decorator.keywords:
+ if keyword.arg == "kw_only":
+ kw_only_decorated = keyword.value.bool_value()
+
+ init_str = _generate_dataclass_init(
+ node,
+ list(_get_dataclass_attributes(node, init=True)),
+ kw_only_decorated,
+ )
+
+ try:
+ init_node = parse(init_str)["__init__"]
+ except AstroidSyntaxError:
+ pass
+ else:
+ init_node.parent = node
+ init_node.lineno, init_node.col_offset = None, None
+ node.locals["__init__"] = [init_node]
+
+ root = node.root()
+ if DEFAULT_FACTORY not in root.locals:
+ new_assign = parse(f"{DEFAULT_FACTORY} = object()").body[0]
+ new_assign.parent = root
+ root.locals[DEFAULT_FACTORY] = [new_assign.targets[0]]
+
+
+def _get_dataclass_attributes(
+ node: nodes.ClassDef, init: bool = False
+) -> Iterator[nodes.AnnAssign]:
+ """Yield the AnnAssign nodes of dataclass attributes for the node.
+
+ If init is True, also include InitVars.
+ """
+ for assign_node in node.body:
+ if not isinstance(assign_node, nodes.AnnAssign) or not isinstance(
+ assign_node.target, nodes.AssignName
+ ):
+ continue
+
+ # Annotation is never None
+ if _is_class_var(assign_node.annotation): # type: ignore[arg-type]
+ continue
+
+ if _is_keyword_only_sentinel(assign_node.annotation):
+ continue
+
+ # Annotation is never None
+ if not init and _is_init_var(assign_node.annotation): # type: ignore[arg-type]
+ continue
+
+ yield assign_node
+
+
+def _check_generate_dataclass_init(node: nodes.ClassDef) -> bool:
+ """Return True if we should generate an __init__ method for node.
+
+ This is True when:
+ - node doesn't define its own __init__ method
+ - the dataclass decorator was called *without* the keyword argument init=False
+ """
+ if "__init__" in node.locals:
+ return False
+
+ found = None
+
+ for decorator_attribute in node.decorators.nodes:
+ if not isinstance(decorator_attribute, nodes.Call):
+ continue
+
+ if _looks_like_dataclass_decorator(decorator_attribute):
+ found = decorator_attribute
+
+ if found is None:
+ return True
+
+ # Check for keyword arguments of the form init=False
+ return not any(
+ keyword.arg == "init"
+ and not keyword.value.bool_value() # type: ignore[union-attr] # value is never None
+ for keyword in found.keywords
+ )
+
+
+def _find_arguments_from_base_classes(
+ node: nodes.ClassDef,
+) -> tuple[
+ dict[str, tuple[str | None, str | None]], dict[str, tuple[str | None, str | None]]
+]:
+ """Iterate through all bases and get their typing and defaults."""
+ pos_only_store: dict[str, tuple[str | None, str | None]] = {}
+ kw_only_store: dict[str, tuple[str | None, str | None]] = {}
+ # See TODO down below
+ # all_have_defaults = True
+
+ for base in reversed(node.mro()):
+ if not base.is_dataclass:
+ continue
+ try:
+ base_init: nodes.FunctionDef = base.locals["__init__"][0]
+ except KeyError:
+ continue
+
+ pos_only, kw_only = base_init.args._get_arguments_data()
+ for posarg, data in pos_only.items():
+ # if data[1] is None:
+ # if all_have_defaults and pos_only_store:
+ # # TODO: This should return an Uninferable as this would raise
+ # # a TypeError at runtime. However, transforms can't return
+ # # Uninferables currently.
+ # pass
+ # all_have_defaults = False
+ pos_only_store[posarg] = data
+
+ for kwarg, data in kw_only.items():
+ kw_only_store[kwarg] = data
+ return pos_only_store, kw_only_store
+
+
+def _parse_arguments_into_strings(
+ pos_only_store: dict[str, tuple[str | None, str | None]],
+ kw_only_store: dict[str, tuple[str | None, str | None]],
+) -> tuple[str, str]:
+ """Parse positional and keyword arguments into strings for an __init__ method."""
+ pos_only, kw_only = "", ""
+ for pos_arg, data in pos_only_store.items():
+ pos_only += pos_arg
+ if data[0]:
+ pos_only += ": " + data[0]
+ if data[1]:
+ pos_only += " = " + data[1]
+ pos_only += ", "
+ for kw_arg, data in kw_only_store.items():
+ kw_only += kw_arg
+ if data[0]:
+ kw_only += ": " + data[0]
+ if data[1]:
+ kw_only += " = " + data[1]
+ kw_only += ", "
+
+ return pos_only, kw_only
+
+
+def _get_previous_field_default(node: nodes.ClassDef, name: str) -> nodes.NodeNG | None:
+ """Get the default value of a previously defined field."""
+ for base in reversed(node.mro()):
+ if not base.is_dataclass:
+ continue
+ if name in base.locals:
+ for assign in base.locals[name]:
+ if (
+ isinstance(assign.parent, nodes.AnnAssign)
+ and assign.parent.value
+ and isinstance(assign.parent.value, nodes.Call)
+ and _looks_like_dataclass_field_call(assign.parent.value)
+ ):
+ default = _get_field_default(assign.parent.value)
+ if default:
+ return default[1]
+ return None
+
+
+def _generate_dataclass_init( # pylint: disable=too-many-locals
+ node: nodes.ClassDef, assigns: list[nodes.AnnAssign], kw_only_decorated: bool
+) -> str:
+ """Return an init method for a dataclass given the targets."""
+ params: list[str] = []
+ kw_only_params: list[str] = []
+ assignments: list[str] = []
+
+ prev_pos_only_store, prev_kw_only_store = _find_arguments_from_base_classes(node)
+
+ for assign in assigns:
+ name, annotation, value = assign.target.name, assign.annotation, assign.value
+
+ # Check whether this assign is overriden by a property assignment
+ property_node: nodes.FunctionDef | None = None
+ for additional_assign in node.locals[name]:
+ if not isinstance(additional_assign, nodes.FunctionDef):
+ continue
+ if not additional_assign.decorators:
+ continue
+ if "builtins.property" in additional_assign.decoratornames():
+ property_node = additional_assign
+ break
+
+ is_field = isinstance(value, nodes.Call) and _looks_like_dataclass_field_call(
+ value, check_scope=False
+ )
+
+ if is_field:
+ # Skip any fields that have `init=False`
+ if any(
+ keyword.arg == "init" and not keyword.value.bool_value()
+ for keyword in value.keywords # type: ignore[union-attr] # value is never None
+ ):
+ # Also remove the name from the previous arguments to be inserted later
+ prev_pos_only_store.pop(name, None)
+ prev_kw_only_store.pop(name, None)
+ continue
+
+ if _is_init_var(annotation): # type: ignore[arg-type] # annotation is never None
+ init_var = True
+ if isinstance(annotation, nodes.Subscript):
+ annotation = annotation.slice
+ else:
+ # Cannot determine type annotation for parameter from InitVar
+ annotation = None
+ assignment_str = ""
+ else:
+ init_var = False
+ assignment_str = f"self.{name} = {name}"
+
+ ann_str, default_str = None, None
+ if annotation is not None:
+ ann_str = annotation.as_string()
+
+ if value:
+ if is_field:
+ result = _get_field_default(value) # type: ignore[arg-type]
+ if result:
+ default_type, default_node = result
+ if default_type == "default":
+ default_str = default_node.as_string()
+ elif default_type == "default_factory":
+ default_str = DEFAULT_FACTORY
+ assignment_str = (
+ f"self.{name} = {default_node.as_string()} "
+ f"if {name} is {DEFAULT_FACTORY} else {name}"
+ )
+ else:
+ default_str = value.as_string()
+ elif property_node:
+ # We set the result of the property call as default
+ # This hides the fact that this would normally be a 'property object'
+ # But we can't represent those as string
+ try:
+ # Call str to make sure also Uninferable gets stringified
+ default_str = str(
+ next(property_node.infer_call_result(None)).as_string()
+ )
+ except (InferenceError, StopIteration):
+ pass
+ else:
+ # Even with `init=False` the default value still can be propogated to
+ # later assignments. Creating weird signatures like:
+ # (self, a: str = 1) -> None
+ previous_default = _get_previous_field_default(node, name)
+ if previous_default:
+ default_str = previous_default.as_string()
+
+ # Construct the param string to add to the init if necessary
+ param_str = name
+ if ann_str is not None:
+ param_str += f": {ann_str}"
+ if default_str is not None:
+ param_str += f" = {default_str}"
+
+ # If the field is a kw_only field, we need to add it to the kw_only_params
+ # This overwrites whether or not the class is kw_only decorated
+ if is_field:
+ kw_only = [k for k in value.keywords if k.arg == "kw_only"] # type: ignore[union-attr]
+ if kw_only:
+ if kw_only[0].value.bool_value():
+ kw_only_params.append(param_str)
+ else:
+ params.append(param_str)
+ continue
+ # If kw_only decorated, we need to add all parameters to the kw_only_params
+ if kw_only_decorated:
+ if name in prev_kw_only_store:
+ prev_kw_only_store[name] = (ann_str, default_str)
+ else:
+ kw_only_params.append(param_str)
+ else:
+ # If the name was previously seen, overwrite that data
+ # pylint: disable-next=else-if-used
+ if name in prev_pos_only_store:
+ prev_pos_only_store[name] = (ann_str, default_str)
+ elif name in prev_kw_only_store:
+ params = [name, *params]
+ prev_kw_only_store.pop(name)
+ else:
+ params.append(param_str)
+
+ if not init_var:
+ assignments.append(assignment_str)
+
+ prev_pos_only, prev_kw_only = _parse_arguments_into_strings(
+ prev_pos_only_store, prev_kw_only_store
+ )
+
+ # Construct the new init method paramter string
+ # First we do the positional only parameters, making sure to add the
+ # the self parameter and the comma to allow adding keyword only parameters
+ params_string = "" if "self" in prev_pos_only else "self, "
+ params_string += prev_pos_only + ", ".join(params)
+ if not params_string.endswith(", "):
+ params_string += ", "
+
+ # Then we add the keyword only parameters
+ if prev_kw_only or kw_only_params:
+ params_string += "*, "
+ params_string += f"{prev_kw_only}{', '.join(kw_only_params)}"
+
+ assignments_string = "\n ".join(assignments) if assignments else "pass"
+ return f"def __init__({params_string}) -> None:\n {assignments_string}"
+
+
+def infer_dataclass_attribute(
+ node: nodes.Unknown, ctx: context.InferenceContext | None = None
+) -> Iterator[InferenceResult]:
+ """Inference tip for an Unknown node that was dynamically generated to
+ represent a dataclass attribute.
+
+ In the case that a default value is provided, that is inferred first.
+ Then, an Instance of the annotated class is yielded.
+ """
+ assign = node.parent
+ if not isinstance(assign, nodes.AnnAssign):
+ yield Uninferable
+ return
+
+ annotation, value = assign.annotation, assign.value
+ if value is not None:
+ yield from value.infer(context=ctx)
+ if annotation is not None:
+ yield from _infer_instance_from_annotation(annotation, ctx=ctx)
+ else:
+ yield Uninferable
+
+
+def infer_dataclass_field_call(
+ node: nodes.Call, ctx: context.InferenceContext | None = None
+) -> Iterator[InferenceResult]:
+ """Inference tip for dataclass field calls."""
+ if not isinstance(node.parent, (nodes.AnnAssign, nodes.Assign)):
+ raise UseInferenceDefault
+ result = _get_field_default(node)
+ if not result:
+ yield Uninferable
+ else:
+ default_type, default = result
+ if default_type == "default":
+ yield from default.infer(context=ctx)
+ else:
+ new_call = parse(default.as_string()).body[0].value
+ new_call.parent = node.parent
+ yield from new_call.infer(context=ctx)
+
+
+def _looks_like_dataclass_decorator(
+ node: nodes.NodeNG, decorator_names: frozenset[str] = DATACLASSES_DECORATORS
+) -> bool:
+ """Return True if node looks like a dataclass decorator.
+
+ Uses inference to lookup the value of the node, and if that fails,
+ matches against specific names.
+ """
+ if isinstance(node, nodes.Call): # decorator with arguments
+ node = node.func
+ try:
+ inferred = next(node.infer())
+ except (InferenceError, StopIteration):
+ inferred = Uninferable
+
+ if isinstance(inferred, UninferableBase):
+ if isinstance(node, nodes.Name):
+ return node.name in decorator_names
+ if isinstance(node, nodes.Attribute):
+ return node.attrname in decorator_names
+
+ return False
+
+ return (
+ isinstance(inferred, nodes.FunctionDef)
+ and inferred.name in decorator_names
+ and inferred.root().name in DATACLASS_MODULES
+ )
+
+
+def _looks_like_dataclass_attribute(node: nodes.Unknown) -> bool:
+ """Return True if node was dynamically generated as the child of an AnnAssign
+ statement.
+ """
+ parent = node.parent
+ if not parent:
+ return False
+
+ scope = parent.scope()
+ return (
+ isinstance(parent, nodes.AnnAssign)
+ and isinstance(scope, nodes.ClassDef)
+ and is_decorated_with_dataclass(scope)
+ )
+
+
+def _looks_like_dataclass_field_call(
+ node: nodes.Call, check_scope: bool = True
+) -> bool:
+ """Return True if node is calling dataclasses field or Field
+ from an AnnAssign statement directly in the body of a ClassDef.
+
+ If check_scope is False, skips checking the statement and body.
+ """
+ if check_scope:
+ stmt = node.statement()
+ scope = stmt.scope()
+ if not (
+ isinstance(stmt, nodes.AnnAssign)
+ and stmt.value is not None
+ and isinstance(scope, nodes.ClassDef)
+ and is_decorated_with_dataclass(scope)
+ ):
+ return False
+
+ try:
+ inferred = next(node.func.infer())
+ except (InferenceError, StopIteration):
+ return False
+
+ if not isinstance(inferred, nodes.FunctionDef):
+ return False
+
+ return inferred.name == FIELD_NAME and inferred.root().name in DATACLASS_MODULES
+
+
+def _looks_like_dataclasses(node: nodes.Module) -> bool:
+ return node.qname() == "dataclasses"
+
+
+def _resolve_private_replace_to_public(node: nodes.Module) -> None:
+ """In python/cpython@6f3c138, a _replace() method was extracted from
+ replace(), and this indirection made replace() uninferable."""
+ if "_replace" in node.locals:
+ node.locals["replace"] = node.locals["_replace"]
+
+
+def _get_field_default(field_call: nodes.Call) -> _FieldDefaultReturn:
+ """Return a the default value of a field call, and the corresponding keyword
+ argument name.
+
+ field(default=...) results in the ... node
+ field(default_factory=...) results in a Call node with func ... and no arguments
+
+ If neither or both arguments are present, return ("", None) instead,
+ indicating that there is not a valid default value.
+ """
+ default, default_factory = None, None
+ for keyword in field_call.keywords:
+ if keyword.arg == "default":
+ default = keyword.value
+ elif keyword.arg == "default_factory":
+ default_factory = keyword.value
+
+ if default is not None and default_factory is None:
+ return "default", default
+
+ if default is None and default_factory is not None:
+ new_call = nodes.Call(
+ lineno=field_call.lineno,
+ col_offset=field_call.col_offset,
+ parent=field_call.parent,
+ end_lineno=field_call.end_lineno,
+ end_col_offset=field_call.end_col_offset,
+ )
+ new_call.postinit(func=default_factory, args=[], keywords=[])
+ return "default_factory", new_call
+
+ return None
+
+
+def _is_class_var(node: nodes.NodeNG) -> bool:
+ """Return True if node is a ClassVar, with or without subscripting."""
+ try:
+ inferred = next(node.infer())
+ except (InferenceError, StopIteration):
+ return False
+
+ return getattr(inferred, "name", "") == "ClassVar"
+
+
+def _is_keyword_only_sentinel(node: nodes.NodeNG) -> bool:
+ """Return True if node is the KW_ONLY sentinel."""
+ if not PY310_PLUS:
+ return False
+ inferred = safe_infer(node)
+ return (
+ isinstance(inferred, bases.Instance)
+ and inferred.qname() == "dataclasses._KW_ONLY_TYPE"
+ )
+
+
+def _is_init_var(node: nodes.NodeNG) -> bool:
+ """Return True if node is an InitVar, with or without subscripting."""
+ try:
+ inferred = next(node.infer())
+ except (InferenceError, StopIteration):
+ return False
+
+ return getattr(inferred, "name", "") == "InitVar"
+
+
+# Allowed typing classes for which we support inferring instances
+_INFERABLE_TYPING_TYPES = frozenset(
+ (
+ "Dict",
+ "FrozenSet",
+ "List",
+ "Set",
+ "Tuple",
+ )
+)
+
+
+def _infer_instance_from_annotation(
+ node: nodes.NodeNG, ctx: context.InferenceContext | None = None
+) -> Iterator[UninferableBase | bases.Instance]:
+ """Infer an instance corresponding to the type annotation represented by node.
+
+ Currently has limited support for the typing module.
+ """
+ klass = None
+ try:
+ klass = next(node.infer(context=ctx))
+ except (InferenceError, StopIteration):
+ yield Uninferable
+ if not isinstance(klass, nodes.ClassDef):
+ yield Uninferable
+ elif klass.root().name in {
+ "typing",
+ "_collections_abc",
+ "",
+ }: # "" because of synthetic nodes in brain_typing.py
+ if klass.name in _INFERABLE_TYPING_TYPES:
+ yield klass.instantiate_class()
+ else:
+ yield Uninferable
+ else:
+ yield klass.instantiate_class()
+
+
+def register(manager: AstroidManager) -> None:
+ if PY313_PLUS:
+ manager.register_transform(
+ nodes.Module,
+ _resolve_private_replace_to_public,
+ _looks_like_dataclasses,
+ )
+
+ manager.register_transform(
+ nodes.ClassDef, dataclass_transform, is_decorated_with_dataclass
+ )
+
+ manager.register_transform(
+ nodes.Call,
+ inference_tip(infer_dataclass_field_call, raise_on_overwrite=True),
+ _looks_like_dataclass_field_call,
+ )
+
+ manager.register_transform(
+ nodes.Unknown,
+ inference_tip(infer_dataclass_attribute, raise_on_overwrite=True),
+ _looks_like_dataclass_attribute,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_datetime.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_datetime.py
new file mode 100644
index 000000000..06b011ce4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_datetime.py
@@ -0,0 +1,19 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.const import PY312_PLUS
+from astroid.manager import AstroidManager
+
+
+def datetime_transform():
+ """The datetime module was C-accelerated in Python 3.12, so use the
+ Python source."""
+ return AstroidBuilder(AstroidManager()).string_build("from _pydatetime import *")
+
+
+def register(manager: AstroidManager) -> None:
+ if PY312_PLUS:
+ register_module_extender(manager, "datetime", datetime_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_dateutil.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_dateutil.py
new file mode 100644
index 000000000..3630639b0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_dateutil.py
@@ -0,0 +1,27 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for dateutil."""
+
+import textwrap
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.manager import AstroidManager
+
+
+def dateutil_transform():
+ return AstroidBuilder(AstroidManager()).string_build(
+ textwrap.dedent(
+ """
+ import datetime
+ def parse(timestr, parserinfo=None, **kwargs):
+ return datetime.datetime()
+ """
+ )
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "dateutil.parser", dateutil_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_functools.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_functools.py
new file mode 100644
index 000000000..2adf2b604
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_functools.py
@@ -0,0 +1,169 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for understanding functools library module."""
+
+from __future__ import annotations
+
+from collections.abc import Iterator
+from functools import partial
+from itertools import chain
+
+from astroid import BoundMethod, arguments, extract_node, nodes, objects
+from astroid.context import InferenceContext
+from astroid.exceptions import InferenceError, UseInferenceDefault
+from astroid.inference_tip import inference_tip
+from astroid.interpreter import objectmodel
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import AssignName, Attribute, Call, Name
+from astroid.nodes.scoped_nodes import FunctionDef
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+from astroid.util import UninferableBase, safe_infer
+
+LRU_CACHE = "functools.lru_cache"
+
+
+class LruWrappedModel(objectmodel.FunctionModel):
+ """Special attribute model for functions decorated with functools.lru_cache.
+
+ The said decorators patches at decoration time some functions onto
+ the decorated function.
+ """
+
+ @property
+ def attr___wrapped__(self):
+ return self._instance
+
+ @property
+ def attr_cache_info(self):
+ cache_info = extract_node(
+ """
+ from functools import _CacheInfo
+ _CacheInfo(0, 0, 0, 0)
+ """
+ )
+
+ class CacheInfoBoundMethod(BoundMethod):
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ res = safe_infer(cache_info)
+ assert res is not None
+ yield res
+
+ return CacheInfoBoundMethod(proxy=self._instance, bound=self._instance)
+
+ @property
+ def attr_cache_clear(self):
+ node = extract_node("""def cache_clear(self): pass""")
+ return BoundMethod(proxy=node, bound=self._instance.parent.scope())
+
+
+def _transform_lru_cache(node, context: InferenceContext | None = None) -> None:
+ # TODO: this is not ideal, since the node should be immutable,
+ # but due to https://github.com/pylint-dev/astroid/issues/354,
+ # there's not much we can do now.
+ # Replacing the node would work partially, because,
+ # in pylint, the old node would still be available, leading
+ # to spurious false positives.
+ node.special_attributes = LruWrappedModel()(node)
+
+
+def _functools_partial_inference(
+ node: nodes.Call, context: InferenceContext | None = None
+) -> Iterator[objects.PartialFunction]:
+ call = arguments.CallSite.from_call(node, context=context)
+ number_of_positional = len(call.positional_arguments)
+ if number_of_positional < 1:
+ raise UseInferenceDefault("functools.partial takes at least one argument")
+ if number_of_positional == 1 and not call.keyword_arguments:
+ raise UseInferenceDefault(
+ "functools.partial needs at least to have some filled arguments"
+ )
+
+ partial_function = call.positional_arguments[0]
+ try:
+ inferred_wrapped_function = next(partial_function.infer(context=context))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ if isinstance(inferred_wrapped_function, UninferableBase):
+ raise UseInferenceDefault("Cannot infer the wrapped function")
+ if not isinstance(inferred_wrapped_function, FunctionDef):
+ raise UseInferenceDefault("The wrapped function is not a function")
+
+ # Determine if the passed keywords into the callsite are supported
+ # by the wrapped function.
+ if not inferred_wrapped_function.args:
+ function_parameters = []
+ else:
+ function_parameters = chain(
+ inferred_wrapped_function.args.args or (),
+ inferred_wrapped_function.args.posonlyargs or (),
+ inferred_wrapped_function.args.kwonlyargs or (),
+ )
+ parameter_names = {
+ param.name for param in function_parameters if isinstance(param, AssignName)
+ }
+ if set(call.keyword_arguments) - parameter_names:
+ raise UseInferenceDefault("wrapped function received unknown parameters")
+
+ partial_function = objects.PartialFunction(
+ call,
+ name=inferred_wrapped_function.name,
+ lineno=inferred_wrapped_function.lineno,
+ col_offset=inferred_wrapped_function.col_offset,
+ parent=node.parent,
+ )
+ partial_function.postinit(
+ args=inferred_wrapped_function.args,
+ body=inferred_wrapped_function.body,
+ decorators=inferred_wrapped_function.decorators,
+ returns=inferred_wrapped_function.returns,
+ type_comment_returns=inferred_wrapped_function.type_comment_returns,
+ type_comment_args=inferred_wrapped_function.type_comment_args,
+ doc_node=inferred_wrapped_function.doc_node,
+ )
+ return iter((partial_function,))
+
+
+def _looks_like_lru_cache(node) -> bool:
+ """Check if the given function node is decorated with lru_cache."""
+ if not node.decorators:
+ return False
+ for decorator in node.decorators.nodes:
+ if not isinstance(decorator, (Attribute, Call)):
+ continue
+ if _looks_like_functools_member(decorator, "lru_cache"):
+ return True
+ return False
+
+
+def _looks_like_functools_member(node: Attribute | Call, member: str) -> bool:
+ """Check if the given Call node is the wanted member of functools."""
+ if isinstance(node, Attribute):
+ return node.attrname == member
+ if isinstance(node.func, Name):
+ return node.func.name == member
+ if isinstance(node.func, Attribute):
+ return (
+ node.func.attrname == member
+ and isinstance(node.func.expr, Name)
+ and node.func.expr.name == "functools"
+ )
+ return False
+
+
+_looks_like_partial = partial(_looks_like_functools_member, member="partial")
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(FunctionDef, _transform_lru_cache, _looks_like_lru_cache)
+
+ manager.register_transform(
+ Call,
+ inference_tip(_functools_partial_inference),
+ _looks_like_partial,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_gi.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_gi.py
new file mode 100644
index 000000000..4ebbdde2a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_gi.py
@@ -0,0 +1,250 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for the Python 2 GObject introspection bindings.
+
+Helps with understanding everything imported from 'gi.repository'
+"""
+
+# pylint:disable=import-error,import-outside-toplevel
+
+import inspect
+import itertools
+import re
+import sys
+import warnings
+
+from astroid import nodes
+from astroid.builder import AstroidBuilder
+from astroid.exceptions import AstroidBuildingError
+from astroid.manager import AstroidManager
+
+_inspected_modules = {}
+
+_identifier_re = r"^[A-Za-z_]\w*$"
+
+_special_methods = frozenset(
+ {
+ "__lt__",
+ "__le__",
+ "__eq__",
+ "__ne__",
+ "__ge__",
+ "__gt__",
+ "__iter__",
+ "__getitem__",
+ "__setitem__",
+ "__delitem__",
+ "__len__",
+ "__bool__",
+ "__nonzero__",
+ "__next__",
+ "__str__",
+ "__contains__",
+ "__enter__",
+ "__exit__",
+ "__repr__",
+ "__getattr__",
+ "__setattr__",
+ "__delattr__",
+ "__del__",
+ "__hash__",
+ }
+)
+
+
+def _gi_build_stub(parent): # noqa: C901
+ """
+ Inspect the passed module recursively and build stubs for functions,
+ classes, etc.
+ """
+ classes = {}
+ functions = {}
+ constants = {}
+ methods = {}
+ for name in dir(parent):
+ if name.startswith("__") and name not in _special_methods:
+ continue
+
+ # Check if this is a valid name in python
+ if not re.match(_identifier_re, name):
+ continue
+
+ try:
+ obj = getattr(parent, name)
+ except Exception: # pylint: disable=broad-except
+ # gi.module.IntrospectionModule.__getattr__() can raise all kinds of things
+ # like ValueError, TypeError, NotImplementedError, RepositoryError, etc
+ continue
+
+ if inspect.isclass(obj):
+ classes[name] = obj
+ elif inspect.isfunction(obj) or inspect.isbuiltin(obj):
+ functions[name] = obj
+ elif inspect.ismethod(obj) or inspect.ismethoddescriptor(obj):
+ methods[name] = obj
+ elif (
+ str(obj).startswith("<flags")
+ or str(obj).startswith("<enum ")
+ or str(obj).startswith("<GType ")
+ or inspect.isdatadescriptor(obj)
+ ):
+ constants[name] = 0
+ elif isinstance(obj, (int, str)):
+ constants[name] = obj
+ elif callable(obj):
+ # Fall back to a function for anything callable
+ functions[name] = obj
+ else:
+ # Assume everything else is some manner of constant
+ constants[name] = 0
+
+ ret = ""
+
+ if constants:
+ ret += f"# {parent.__name__} constants\n\n"
+ for name in sorted(constants):
+ if name[0].isdigit():
+ # GDK has some busted constant names like
+ # Gdk.EventType.2BUTTON_PRESS
+ continue
+
+ val = constants[name]
+
+ strval = str(val)
+ if isinstance(val, str):
+ strval = '"%s"' % str(val).replace("\\", "\\\\")
+ ret += f"{name} = {strval}\n"
+
+ if ret:
+ ret += "\n\n"
+ if functions:
+ ret += f"# {parent.__name__} functions\n\n"
+ for name in sorted(functions):
+ ret += f"def {name}(*args, **kwargs):\n"
+ ret += " pass\n"
+
+ if ret:
+ ret += "\n\n"
+ if methods:
+ ret += f"# {parent.__name__} methods\n\n"
+ for name in sorted(methods):
+ ret += f"def {name}(self, *args, **kwargs):\n"
+ ret += " pass\n"
+
+ if ret:
+ ret += "\n\n"
+ if classes:
+ ret += f"# {parent.__name__} classes\n\n"
+ for name, obj in sorted(classes.items()):
+ base = "object"
+ if issubclass(obj, Exception):
+ base = "Exception"
+ ret += f"class {name}({base}):\n"
+
+ classret = _gi_build_stub(obj)
+ if not classret:
+ classret = "pass\n"
+
+ for line in classret.splitlines():
+ ret += " " + line + "\n"
+ ret += "\n"
+
+ return ret
+
+
+def _import_gi_module(modname):
+ # we only consider gi.repository submodules
+ if not modname.startswith("gi.repository."):
+ raise AstroidBuildingError(modname=modname)
+ # build astroid representation unless we already tried so
+ if modname not in _inspected_modules:
+ modnames = [modname]
+ optional_modnames = []
+
+ # GLib and GObject may have some special case handling
+ # in pygobject that we need to cope with. However at
+ # least as of pygobject3-3.13.91 the _glib module doesn't
+ # exist anymore, so if treat these modules as optional.
+ if modname == "gi.repository.GLib":
+ optional_modnames.append("gi._glib")
+ elif modname == "gi.repository.GObject":
+ optional_modnames.append("gi._gobject")
+
+ try:
+ modcode = ""
+ for m in itertools.chain(modnames, optional_modnames):
+ try:
+ with warnings.catch_warnings():
+ # Just inspecting the code can raise gi deprecation
+ # warnings, so ignore them.
+ try:
+ from gi import ( # pylint:disable=import-error
+ PyGIDeprecationWarning,
+ PyGIWarning,
+ )
+
+ warnings.simplefilter("ignore", PyGIDeprecationWarning)
+ warnings.simplefilter("ignore", PyGIWarning)
+ except Exception: # pylint:disable=broad-except
+ pass
+
+ __import__(m)
+ modcode += _gi_build_stub(sys.modules[m])
+ except ImportError:
+ if m not in optional_modnames:
+ raise
+ except ImportError:
+ astng = _inspected_modules[modname] = None
+ else:
+ astng = AstroidBuilder(AstroidManager()).string_build(modcode, modname)
+ _inspected_modules[modname] = astng
+ else:
+ astng = _inspected_modules[modname]
+ if astng is None:
+ raise AstroidBuildingError(modname=modname)
+ return astng
+
+
+def _looks_like_require_version(node) -> bool:
+ # Return whether this looks like a call to gi.require_version(<name>, <version>)
+ # Only accept function calls with two constant arguments
+ if len(node.args) != 2:
+ return False
+
+ if not all(isinstance(arg, nodes.Const) for arg in node.args):
+ return False
+
+ func = node.func
+ if isinstance(func, nodes.Attribute):
+ if func.attrname != "require_version":
+ return False
+ if isinstance(func.expr, nodes.Name) and func.expr.name == "gi":
+ return True
+
+ return False
+
+ if isinstance(func, nodes.Name):
+ return func.name == "require_version"
+
+ return False
+
+
+def _register_require_version(node):
+ # Load the gi.require_version locally
+ try:
+ import gi
+
+ gi.require_version(node.args[0].value, node.args[1].value)
+ except Exception: # pylint:disable=broad-except
+ pass
+
+ return node
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_failed_import_hook(_import_gi_module)
+ manager.register_transform(
+ nodes.Call, _register_require_version, _looks_like_require_version
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_hashlib.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_hashlib.py
new file mode 100644
index 000000000..91aa4c427
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_hashlib.py
@@ -0,0 +1,95 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def _hashlib_transform():
+ init_signature = "value='', usedforsecurity=True"
+ digest_signature = "self"
+ shake_digest_signature = "self, length"
+
+ template = """
+ class %(name)s:
+ def __init__(self, %(init_signature)s): pass
+ def digest(%(digest_signature)s):
+ return %(digest)s
+ def copy(self):
+ return self
+ def update(self, value): pass
+ def hexdigest(%(digest_signature)s):
+ return ''
+ @property
+ def name(self):
+ return %(name)r
+ @property
+ def block_size(self):
+ return 1
+ @property
+ def digest_size(self):
+ return 1
+ """
+
+ algorithms_with_signature = dict.fromkeys(
+ [
+ "md5",
+ "sha1",
+ "sha224",
+ "sha256",
+ "sha384",
+ "sha512",
+ "sha3_224",
+ "sha3_256",
+ "sha3_384",
+ "sha3_512",
+ ],
+ (init_signature, digest_signature),
+ )
+
+ blake2b_signature = (
+ "data=b'', *, digest_size=64, key=b'', salt=b'', "
+ "person=b'', fanout=1, depth=1, leaf_size=0, node_offset=0, "
+ "node_depth=0, inner_size=0, last_node=False, usedforsecurity=True"
+ )
+
+ blake2s_signature = (
+ "data=b'', *, digest_size=32, key=b'', salt=b'', "
+ "person=b'', fanout=1, depth=1, leaf_size=0, node_offset=0, "
+ "node_depth=0, inner_size=0, last_node=False, usedforsecurity=True"
+ )
+
+ shake_algorithms = dict.fromkeys(
+ ["shake_128", "shake_256"],
+ (init_signature, shake_digest_signature),
+ )
+ algorithms_with_signature.update(shake_algorithms)
+
+ algorithms_with_signature.update(
+ {
+ "blake2b": (blake2b_signature, digest_signature),
+ "blake2s": (blake2s_signature, digest_signature),
+ }
+ )
+
+ classes = "".join(
+ template
+ % {
+ "name": hashfunc,
+ "digest": 'b""',
+ "init_signature": init_signature,
+ "digest_signature": digest_signature,
+ }
+ for hashfunc, (
+ init_signature,
+ digest_signature,
+ ) in algorithms_with_signature.items()
+ )
+
+ return parse(classes)
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "hashlib", _hashlib_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_http.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_http.py
new file mode 100644
index 000000000..f34f381df
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_http.py
@@ -0,0 +1,213 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid brain hints for some of the `http` module."""
+import textwrap
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.manager import AstroidManager
+
+
+def _http_transform():
+ code = textwrap.dedent(
+ """
+ from enum import IntEnum
+ from collections import namedtuple
+ _HTTPStatus = namedtuple('_HTTPStatus', 'value phrase description')
+
+ class HTTPStatus(IntEnum):
+
+ @property
+ def phrase(self):
+ return ""
+ @property
+ def value(self):
+ return 0
+ @property
+ def description(self):
+ return ""
+
+ # informational
+ CONTINUE = _HTTPStatus(100, 'Continue', 'Request received, please continue')
+ SWITCHING_PROTOCOLS = _HTTPStatus(101, 'Switching Protocols',
+ 'Switching to new protocol; obey Upgrade header')
+ PROCESSING = _HTTPStatus(102, 'Processing', '')
+ OK = _HTTPStatus(200, 'OK', 'Request fulfilled, document follows')
+ CREATED = _HTTPStatus(201, 'Created', 'Document created, URL follows')
+ ACCEPTED = _HTTPStatus(202, 'Accepted',
+ 'Request accepted, processing continues off-line')
+ NON_AUTHORITATIVE_INFORMATION = _HTTPStatus(203,
+ 'Non-Authoritative Information', 'Request fulfilled from cache')
+ NO_CONTENT = _HTTPStatus(204, 'No Content', 'Request fulfilled, nothing follows')
+ RESET_CONTENT =_HTTPStatus(205, 'Reset Content', 'Clear input form for further input')
+ PARTIAL_CONTENT = _HTTPStatus(206, 'Partial Content', 'Partial content follows')
+ MULTI_STATUS = _HTTPStatus(207, 'Multi-Status', '')
+ ALREADY_REPORTED = _HTTPStatus(208, 'Already Reported', '')
+ IM_USED = _HTTPStatus(226, 'IM Used', '')
+ MULTIPLE_CHOICES = _HTTPStatus(300, 'Multiple Choices',
+ 'Object has several resources -- see URI list')
+ MOVED_PERMANENTLY = _HTTPStatus(301, 'Moved Permanently',
+ 'Object moved permanently -- see URI list')
+ FOUND = _HTTPStatus(302, 'Found', 'Object moved temporarily -- see URI list')
+ SEE_OTHER = _HTTPStatus(303, 'See Other', 'Object moved -- see Method and URL list')
+ NOT_MODIFIED = _HTTPStatus(304, 'Not Modified',
+ 'Document has not changed since given time')
+ USE_PROXY = _HTTPStatus(305, 'Use Proxy',
+ 'You must use proxy specified in Location to access this resource')
+ TEMPORARY_REDIRECT = _HTTPStatus(307, 'Temporary Redirect',
+ 'Object moved temporarily -- see URI list')
+ PERMANENT_REDIRECT = _HTTPStatus(308, 'Permanent Redirect',
+ 'Object moved permanently -- see URI list')
+ BAD_REQUEST = _HTTPStatus(400, 'Bad Request',
+ 'Bad request syntax or unsupported method')
+ UNAUTHORIZED = _HTTPStatus(401, 'Unauthorized',
+ 'No permission -- see authorization schemes')
+ PAYMENT_REQUIRED = _HTTPStatus(402, 'Payment Required',
+ 'No payment -- see charging schemes')
+ FORBIDDEN = _HTTPStatus(403, 'Forbidden',
+ 'Request forbidden -- authorization will not help')
+ NOT_FOUND = _HTTPStatus(404, 'Not Found',
+ 'Nothing matches the given URI')
+ METHOD_NOT_ALLOWED = _HTTPStatus(405, 'Method Not Allowed',
+ 'Specified method is invalid for this resource')
+ NOT_ACCEPTABLE = _HTTPStatus(406, 'Not Acceptable',
+ 'URI not available in preferred format')
+ PROXY_AUTHENTICATION_REQUIRED = _HTTPStatus(407,
+ 'Proxy Authentication Required',
+ 'You must authenticate with this proxy before proceeding')
+ REQUEST_TIMEOUT = _HTTPStatus(408, 'Request Timeout',
+ 'Request timed out; try again later')
+ CONFLICT = _HTTPStatus(409, 'Conflict', 'Request conflict')
+ GONE = _HTTPStatus(410, 'Gone',
+ 'URI no longer exists and has been permanently removed')
+ LENGTH_REQUIRED = _HTTPStatus(411, 'Length Required',
+ 'Client must specify Content-Length')
+ PRECONDITION_FAILED = _HTTPStatus(412, 'Precondition Failed',
+ 'Precondition in headers is false')
+ REQUEST_ENTITY_TOO_LARGE = _HTTPStatus(413, 'Request Entity Too Large',
+ 'Entity is too large')
+ REQUEST_URI_TOO_LONG = _HTTPStatus(414, 'Request-URI Too Long',
+ 'URI is too long')
+ UNSUPPORTED_MEDIA_TYPE = _HTTPStatus(415, 'Unsupported Media Type',
+ 'Entity body in unsupported format')
+ REQUESTED_RANGE_NOT_SATISFIABLE = _HTTPStatus(416,
+ 'Requested Range Not Satisfiable',
+ 'Cannot satisfy request range')
+ EXPECTATION_FAILED = _HTTPStatus(417, 'Expectation Failed',
+ 'Expect condition could not be satisfied')
+ MISDIRECTED_REQUEST = _HTTPStatus(421, 'Misdirected Request',
+ 'Server is not able to produce a response')
+ UNPROCESSABLE_ENTITY = _HTTPStatus(422, 'Unprocessable Entity')
+ LOCKED = _HTTPStatus(423, 'Locked')
+ FAILED_DEPENDENCY = _HTTPStatus(424, 'Failed Dependency')
+ UPGRADE_REQUIRED = _HTTPStatus(426, 'Upgrade Required')
+ PRECONDITION_REQUIRED = _HTTPStatus(428, 'Precondition Required',
+ 'The origin server requires the request to be conditional')
+ TOO_MANY_REQUESTS = _HTTPStatus(429, 'Too Many Requests',
+ 'The user has sent too many requests in '
+ 'a given amount of time ("rate limiting")')
+ REQUEST_HEADER_FIELDS_TOO_LARGE = _HTTPStatus(431,
+ 'Request Header Fields Too Large',
+ 'The server is unwilling to process the request because its header '
+ 'fields are too large')
+ UNAVAILABLE_FOR_LEGAL_REASONS = _HTTPStatus(451,
+ 'Unavailable For Legal Reasons',
+ 'The server is denying access to the '
+ 'resource as a consequence of a legal demand')
+ INTERNAL_SERVER_ERROR = _HTTPStatus(500, 'Internal Server Error',
+ 'Server got itself in trouble')
+ NOT_IMPLEMENTED = _HTTPStatus(501, 'Not Implemented',
+ 'Server does not support this operation')
+ BAD_GATEWAY = _HTTPStatus(502, 'Bad Gateway',
+ 'Invalid responses from another server/proxy')
+ SERVICE_UNAVAILABLE = _HTTPStatus(503, 'Service Unavailable',
+ 'The server cannot process the request due to a high load')
+ GATEWAY_TIMEOUT = _HTTPStatus(504, 'Gateway Timeout',
+ 'The gateway server did not receive a timely response')
+ HTTP_VERSION_NOT_SUPPORTED = _HTTPStatus(505, 'HTTP Version Not Supported',
+ 'Cannot fulfill request')
+ VARIANT_ALSO_NEGOTIATES = _HTTPStatus(506, 'Variant Also Negotiates')
+ INSUFFICIENT_STORAGE = _HTTPStatus(507, 'Insufficient Storage')
+ LOOP_DETECTED = _HTTPStatus(508, 'Loop Detected')
+ NOT_EXTENDED = _HTTPStatus(510, 'Not Extended')
+ NETWORK_AUTHENTICATION_REQUIRED = _HTTPStatus(511,
+ 'Network Authentication Required',
+ 'The client needs to authenticate to gain network access')
+ """
+ )
+ return AstroidBuilder(AstroidManager()).string_build(code)
+
+
+def _http_client_transform():
+ return AstroidBuilder(AstroidManager()).string_build(
+ textwrap.dedent(
+ """
+ from http import HTTPStatus
+
+ CONTINUE = HTTPStatus.CONTINUE
+ SWITCHING_PROTOCOLS = HTTPStatus.SWITCHING_PROTOCOLS
+ PROCESSING = HTTPStatus.PROCESSING
+ OK = HTTPStatus.OK
+ CREATED = HTTPStatus.CREATED
+ ACCEPTED = HTTPStatus.ACCEPTED
+ NON_AUTHORITATIVE_INFORMATION = HTTPStatus.NON_AUTHORITATIVE_INFORMATION
+ NO_CONTENT = HTTPStatus.NO_CONTENT
+ RESET_CONTENT = HTTPStatus.RESET_CONTENT
+ PARTIAL_CONTENT = HTTPStatus.PARTIAL_CONTENT
+ MULTI_STATUS = HTTPStatus.MULTI_STATUS
+ ALREADY_REPORTED = HTTPStatus.ALREADY_REPORTED
+ IM_USED = HTTPStatus.IM_USED
+ MULTIPLE_CHOICES = HTTPStatus.MULTIPLE_CHOICES
+ MOVED_PERMANENTLY = HTTPStatus.MOVED_PERMANENTLY
+ FOUND = HTTPStatus.FOUND
+ SEE_OTHER = HTTPStatus.SEE_OTHER
+ NOT_MODIFIED = HTTPStatus.NOT_MODIFIED
+ USE_PROXY = HTTPStatus.USE_PROXY
+ TEMPORARY_REDIRECT = HTTPStatus.TEMPORARY_REDIRECT
+ PERMANENT_REDIRECT = HTTPStatus.PERMANENT_REDIRECT
+ BAD_REQUEST = HTTPStatus.BAD_REQUEST
+ UNAUTHORIZED = HTTPStatus.UNAUTHORIZED
+ PAYMENT_REQUIRED = HTTPStatus.PAYMENT_REQUIRED
+ FORBIDDEN = HTTPStatus.FORBIDDEN
+ NOT_FOUND = HTTPStatus.NOT_FOUND
+ METHOD_NOT_ALLOWED = HTTPStatus.METHOD_NOT_ALLOWED
+ NOT_ACCEPTABLE = HTTPStatus.NOT_ACCEPTABLE
+ PROXY_AUTHENTICATION_REQUIRED = HTTPStatus.PROXY_AUTHENTICATION_REQUIRED
+ REQUEST_TIMEOUT = HTTPStatus.REQUEST_TIMEOUT
+ CONFLICT = HTTPStatus.CONFLICT
+ GONE = HTTPStatus.GONE
+ LENGTH_REQUIRED = HTTPStatus.LENGTH_REQUIRED
+ PRECONDITION_FAILED = HTTPStatus.PRECONDITION_FAILED
+ REQUEST_ENTITY_TOO_LARGE = HTTPStatus.REQUEST_ENTITY_TOO_LARGE
+ REQUEST_URI_TOO_LONG = HTTPStatus.REQUEST_URI_TOO_LONG
+ UNSUPPORTED_MEDIA_TYPE = HTTPStatus.UNSUPPORTED_MEDIA_TYPE
+ REQUESTED_RANGE_NOT_SATISFIABLE = HTTPStatus.REQUESTED_RANGE_NOT_SATISFIABLE
+ EXPECTATION_FAILED = HTTPStatus.EXPECTATION_FAILED
+ UNPROCESSABLE_ENTITY = HTTPStatus.UNPROCESSABLE_ENTITY
+ LOCKED = HTTPStatus.LOCKED
+ FAILED_DEPENDENCY = HTTPStatus.FAILED_DEPENDENCY
+ UPGRADE_REQUIRED = HTTPStatus.UPGRADE_REQUIRED
+ PRECONDITION_REQUIRED = HTTPStatus.PRECONDITION_REQUIRED
+ TOO_MANY_REQUESTS = HTTPStatus.TOO_MANY_REQUESTS
+ REQUEST_HEADER_FIELDS_TOO_LARGE = HTTPStatus.REQUEST_HEADER_FIELDS_TOO_LARGE
+ INTERNAL_SERVER_ERROR = HTTPStatus.INTERNAL_SERVER_ERROR
+ NOT_IMPLEMENTED = HTTPStatus.NOT_IMPLEMENTED
+ BAD_GATEWAY = HTTPStatus.BAD_GATEWAY
+ SERVICE_UNAVAILABLE = HTTPStatus.SERVICE_UNAVAILABLE
+ GATEWAY_TIMEOUT = HTTPStatus.GATEWAY_TIMEOUT
+ HTTP_VERSION_NOT_SUPPORTED = HTTPStatus.HTTP_VERSION_NOT_SUPPORTED
+ VARIANT_ALSO_NEGOTIATES = HTTPStatus.VARIANT_ALSO_NEGOTIATES
+ INSUFFICIENT_STORAGE = HTTPStatus.INSUFFICIENT_STORAGE
+ LOOP_DETECTED = HTTPStatus.LOOP_DETECTED
+ NOT_EXTENDED = HTTPStatus.NOT_EXTENDED
+ NETWORK_AUTHENTICATION_REQUIRED = HTTPStatus.NETWORK_AUTHENTICATION_REQUIRED
+ """
+ )
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "http", _http_transform)
+ register_module_extender(manager, "http.client", _http_client_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_hypothesis.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_hypothesis.py
new file mode 100644
index 000000000..6180520f3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_hypothesis.py
@@ -0,0 +1,55 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Astroid hook for the Hypothesis library.
+
+Without this hook pylint reports no-value-for-parameter for use of strategies
+defined using the `@hypothesis.strategies.composite` decorator. For example:
+
+ from hypothesis import strategies as st
+
+ @st.composite
+ def a_strategy(draw):
+ return draw(st.integers())
+
+ a_strategy()
+"""
+from astroid.manager import AstroidManager
+from astroid.nodes.scoped_nodes import FunctionDef
+
+COMPOSITE_NAMES = (
+ "composite",
+ "st.composite",
+ "strategies.composite",
+ "hypothesis.strategies.composite",
+)
+
+
+def is_decorated_with_st_composite(node) -> bool:
+ """Return whether a decorated node has @st.composite applied."""
+ if node.decorators and node.args.args and node.args.args[0].name == "draw":
+ for decorator_attribute in node.decorators.nodes:
+ if decorator_attribute.as_string() in COMPOSITE_NAMES:
+ return True
+ return False
+
+
+def remove_draw_parameter_from_composite_strategy(node):
+ """Given that the FunctionDef is decorated with @st.composite, remove the
+ first argument (`draw`) - it's always supplied by Hypothesis so we don't
+ need to emit the no-value-for-parameter lint.
+ """
+ del node.args.args[0]
+ del node.args.annotations[0]
+ del node.args.type_comment_args[0]
+ return node
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ node_class=FunctionDef,
+ transform=remove_draw_parameter_from_composite_strategy,
+ predicate=is_decorated_with_st_composite,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_io.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_io.py
new file mode 100644
index 000000000..ab6e60737
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_io.py
@@ -0,0 +1,44 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid brain hints for some of the _io C objects."""
+from astroid.manager import AstroidManager
+from astroid.nodes import ClassDef
+
+BUFFERED = {"BufferedWriter", "BufferedReader"}
+TextIOWrapper = "TextIOWrapper"
+FileIO = "FileIO"
+BufferedWriter = "BufferedWriter"
+
+
+def _generic_io_transform(node, name, cls):
+ """Transform the given name, by adding the given *class* as a member of the
+ node.
+ """
+
+ io_module = AstroidManager().ast_from_module_name("_io")
+ attribute_object = io_module[cls]
+ instance = attribute_object.instantiate_class()
+ node.locals[name] = [instance]
+
+
+def _transform_text_io_wrapper(node):
+ # This is not always correct, since it can vary with the type of the descriptor,
+ # being stdout, stderr or stdin. But we cannot get access to the name of the
+ # stream, which is why we are using the BufferedWriter class as a default
+ # value
+ return _generic_io_transform(node, name="buffer", cls=BufferedWriter)
+
+
+def _transform_buffered(node):
+ return _generic_io_transform(node, name="raw", cls=FileIO)
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ ClassDef, _transform_buffered, lambda node: node.name in BUFFERED
+ )
+ manager.register_transform(
+ ClassDef, _transform_text_io_wrapper, lambda node: node.name == TextIOWrapper
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_mechanize.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_mechanize.py
new file mode 100644
index 000000000..0f0d0193b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_mechanize.py
@@ -0,0 +1,124 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.manager import AstroidManager
+
+
+def mechanize_transform():
+ return AstroidBuilder(AstroidManager()).string_build(
+ """class Browser(object):
+ def __getattr__(self, name):
+ return None
+
+ def __getitem__(self, name):
+ return None
+
+ def __setitem__(self, name, val):
+ return None
+
+ def back(self, n=1):
+ return None
+
+ def clear_history(self):
+ return None
+
+ def click(self, *args, **kwds):
+ return None
+
+ def click_link(self, link=None, **kwds):
+ return None
+
+ def close(self):
+ return None
+
+ def encoding(self):
+ return None
+
+ def find_link(
+ self,
+ text=None,
+ text_regex=None,
+ name=None,
+ name_regex=None,
+ url=None,
+ url_regex=None,
+ tag=None,
+ predicate=None,
+ nr=0,
+ ):
+ return None
+
+ def follow_link(self, link=None, **kwds):
+ return None
+
+ def forms(self):
+ return None
+
+ def geturl(self):
+ return None
+
+ def global_form(self):
+ return None
+
+ def links(self, **kwds):
+ return None
+
+ def open_local_file(self, filename):
+ return None
+
+ def open(self, url, data=None, timeout=None):
+ return None
+
+ def open_novisit(self, url, data=None, timeout=None):
+ return None
+
+ def open_local_file(self, filename):
+ return None
+
+ def reload(self):
+ return None
+
+ def response(self):
+ return None
+
+ def select_form(self, name=None, predicate=None, nr=None, **attrs):
+ return None
+
+ def set_cookie(self, cookie_string):
+ return None
+
+ def set_handle_referer(self, handle):
+ return None
+
+ def set_header(self, header, value=None):
+ return None
+
+ def set_html(self, html, url="http://example.com/"):
+ return None
+
+ def set_response(self, response):
+ return None
+
+ def set_simple_cookie(self, name, value, domain, path="/"):
+ return None
+
+ def submit(self, *args, **kwds):
+ return None
+
+ def title(self):
+ return None
+
+ def viewing_html(self):
+ return None
+
+ def visit_response(self, response, request=None):
+ return None
+"""
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "mechanize", mechanize_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_multiprocessing.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_multiprocessing.py
new file mode 100644
index 000000000..e6413b07c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_multiprocessing.py
@@ -0,0 +1,106 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.bases import BoundMethod
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.exceptions import InferenceError
+from astroid.manager import AstroidManager
+from astroid.nodes.scoped_nodes import FunctionDef
+
+
+def _multiprocessing_transform():
+ module = parse(
+ """
+ from multiprocessing.managers import SyncManager
+ def Manager():
+ return SyncManager()
+ """
+ )
+ # Multiprocessing uses a getattr lookup inside contexts,
+ # in order to get the attributes they need. Since it's extremely
+ # dynamic, we use this approach to fake it.
+ node = parse(
+ """
+ from multiprocessing.context import DefaultContext, BaseContext
+ default = DefaultContext()
+ base = BaseContext()
+ """
+ )
+ try:
+ context = next(node["default"].infer())
+ base = next(node["base"].infer())
+ except (InferenceError, StopIteration):
+ return module
+
+ for node in (context, base):
+ for key, value in node.locals.items():
+ if key.startswith("_"):
+ continue
+
+ value = value[0]
+ if isinstance(value, FunctionDef):
+ # We need to rebound this, since otherwise
+ # it will have an extra argument (self).
+ value = BoundMethod(value, node)
+ module[key] = value
+ return module
+
+
+def _multiprocessing_managers_transform():
+ return parse(
+ """
+ import array
+ import threading
+ import multiprocessing.pool as pool
+ import queue
+
+ class Namespace(object):
+ pass
+
+ class Value(object):
+ def __init__(self, typecode, value, lock=True):
+ self._typecode = typecode
+ self._value = value
+ def get(self):
+ return self._value
+ def set(self, value):
+ self._value = value
+ def __repr__(self):
+ return '%s(%r, %r)'%(type(self).__name__, self._typecode, self._value)
+ value = property(get, set)
+
+ def Array(typecode, sequence, lock=True):
+ return array.array(typecode, sequence)
+
+ class SyncManager(object):
+ Queue = JoinableQueue = queue.Queue
+ Event = threading.Event
+ RLock = threading.RLock
+ Lock = threading.Lock
+ BoundedSemaphore = threading.BoundedSemaphore
+ Condition = threading.Condition
+ Barrier = threading.Barrier
+ Pool = pool.Pool
+ list = list
+ dict = dict
+ Value = Value
+ Array = Array
+ Namespace = Namespace
+ __enter__ = lambda self: self
+ __exit__ = lambda *args: args
+
+ def start(self, initializer=None, initargs=None):
+ pass
+ def shutdown(self):
+ pass
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "multiprocessing.managers", _multiprocessing_managers_transform
+ )
+ register_module_extender(manager, "multiprocessing", _multiprocessing_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_namedtuple_enum.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_namedtuple_enum.py
new file mode 100644
index 000000000..71091d887
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_namedtuple_enum.py
@@ -0,0 +1,673 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for the Python standard library."""
+
+from __future__ import annotations
+
+import functools
+import keyword
+from collections.abc import Iterator
+from textwrap import dedent
+from typing import Final
+
+import astroid
+from astroid import arguments, bases, inference_tip, nodes, util
+from astroid.builder import AstroidBuilder, _extract_single_node, extract_node
+from astroid.context import InferenceContext
+from astroid.exceptions import (
+ AstroidTypeError,
+ AstroidValueError,
+ InferenceError,
+ UseInferenceDefault,
+)
+from astroid.manager import AstroidManager
+
+ENUM_QNAME: Final[str] = "enum.Enum"
+TYPING_NAMEDTUPLE_QUALIFIED: Final = {
+ "typing.NamedTuple",
+ "typing_extensions.NamedTuple",
+}
+TYPING_NAMEDTUPLE_BASENAMES: Final = {
+ "NamedTuple",
+ "typing.NamedTuple",
+ "typing_extensions.NamedTuple",
+}
+
+
+def _infer_first(node, context):
+ if isinstance(node, util.UninferableBase):
+ raise UseInferenceDefault
+ try:
+ value = next(node.infer(context=context))
+ except StopIteration as exc:
+ raise InferenceError from exc
+ if isinstance(value, util.UninferableBase):
+ raise UseInferenceDefault()
+ return value
+
+
+def _find_func_form_arguments(node, context):
+ def _extract_namedtuple_arg_or_keyword( # pylint: disable=inconsistent-return-statements
+ position, key_name=None
+ ):
+ if len(args) > position:
+ return _infer_first(args[position], context)
+ if key_name and key_name in found_keywords:
+ return _infer_first(found_keywords[key_name], context)
+
+ args = node.args
+ keywords = node.keywords
+ found_keywords = (
+ {keyword.arg: keyword.value for keyword in keywords} if keywords else {}
+ )
+
+ name = _extract_namedtuple_arg_or_keyword(position=0, key_name="typename")
+ names = _extract_namedtuple_arg_or_keyword(position=1, key_name="field_names")
+ if name and names:
+ return name.value, names
+
+ raise UseInferenceDefault()
+
+
+def infer_func_form(
+ node: nodes.Call,
+ base_type: list[nodes.NodeNG],
+ context: InferenceContext | None = None,
+ enum: bool = False,
+) -> tuple[nodes.ClassDef, str, list[str]]:
+ """Specific inference function for namedtuple or Python 3 enum."""
+ # node is a Call node, class name as first argument and generated class
+ # attributes as second argument
+
+ # namedtuple or enums list of attributes can be a list of strings or a
+ # whitespace-separate string
+ try:
+ name, names = _find_func_form_arguments(node, context)
+ try:
+ attributes: list[str] = names.value.replace(",", " ").split()
+ except AttributeError as exc:
+ # Handle attributes of NamedTuples
+ if not enum:
+ attributes = []
+ fields = _get_namedtuple_fields(node)
+ if fields:
+ fields_node = extract_node(fields)
+ attributes = [
+ _infer_first(const, context).value for const in fields_node.elts
+ ]
+
+ # Handle attributes of Enums
+ else:
+ # Enums supports either iterator of (name, value) pairs
+ # or mappings.
+ if hasattr(names, "items") and isinstance(names.items, list):
+ attributes = [
+ _infer_first(const[0], context).value
+ for const in names.items
+ if isinstance(const[0], nodes.Const)
+ ]
+ elif hasattr(names, "elts"):
+ # Enums can support either ["a", "b", "c"]
+ # or [("a", 1), ("b", 2), ...], but they can't
+ # be mixed.
+ if all(isinstance(const, nodes.Tuple) for const in names.elts):
+ attributes = [
+ _infer_first(const.elts[0], context).value
+ for const in names.elts
+ if isinstance(const, nodes.Tuple)
+ ]
+ else:
+ attributes = [
+ _infer_first(const, context).value for const in names.elts
+ ]
+ else:
+ raise AttributeError from exc
+ if not attributes:
+ raise AttributeError from exc
+ except (AttributeError, InferenceError) as exc:
+ raise UseInferenceDefault from exc
+
+ if not enum:
+ # namedtuple maps sys.intern(str()) over over field_names
+ attributes = [str(attr) for attr in attributes]
+ # XXX this should succeed *unless* __str__/__repr__ is incorrect or throws
+ # in which case we should not have inferred these values and raised earlier
+ attributes = [attr for attr in attributes if " " not in attr]
+
+ # If we can't infer the name of the class, don't crash, up to this point
+ # we know it is a namedtuple anyway.
+ name = name or "Uninferable"
+ # we want to return a Class node instance with proper attributes set
+ class_node = nodes.ClassDef(
+ name,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=nodes.Unknown(),
+ )
+ # A typical ClassDef automatically adds its name to the parent scope,
+ # but doing so causes problems, so defer setting parent until after init
+ # see: https://github.com/pylint-dev/pylint/issues/5982
+ class_node.parent = node.parent
+ class_node.postinit(
+ # set base class=tuple
+ bases=base_type,
+ body=[],
+ decorators=None,
+ )
+ # XXX add __init__(*attributes) method
+ for attr in attributes:
+ fake_node = nodes.EmptyNode()
+ fake_node.parent = class_node
+ fake_node.attrname = attr
+ class_node.instance_attrs[attr] = [fake_node]
+ return class_node, name, attributes
+
+
+def _has_namedtuple_base(node):
+ """Predicate for class inference tip.
+
+ :type node: ClassDef
+ :rtype: bool
+ """
+ return set(node.basenames) & TYPING_NAMEDTUPLE_BASENAMES
+
+
+def _looks_like(node, name) -> bool:
+ func = node.func
+ if isinstance(func, nodes.Attribute):
+ return func.attrname == name
+ if isinstance(func, nodes.Name):
+ return func.name == name
+ return False
+
+
+_looks_like_namedtuple = functools.partial(_looks_like, name="namedtuple")
+_looks_like_enum = functools.partial(_looks_like, name="Enum")
+_looks_like_typing_namedtuple = functools.partial(_looks_like, name="NamedTuple")
+
+
+def infer_named_tuple(
+ node: nodes.Call, context: InferenceContext | None = None
+) -> Iterator[nodes.ClassDef]:
+ """Specific inference function for namedtuple Call node."""
+ tuple_base_name: list[nodes.NodeNG] = [
+ nodes.Name(
+ name="tuple",
+ parent=node.root(),
+ lineno=0,
+ col_offset=0,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ ]
+ class_node, name, attributes = infer_func_form(
+ node, tuple_base_name, context=context
+ )
+ call_site = arguments.CallSite.from_call(node, context=context)
+ node = extract_node("import collections; collections.namedtuple")
+ try:
+ func = next(node.infer())
+ except StopIteration as e:
+ raise InferenceError(node=node) from e
+ try:
+ rename = next(
+ call_site.infer_argument(func, "rename", context or InferenceContext())
+ ).bool_value()
+ except (InferenceError, StopIteration):
+ rename = False
+
+ try:
+ attributes = _check_namedtuple_attributes(name, attributes, rename)
+ except AstroidTypeError as exc:
+ raise UseInferenceDefault("TypeError: " + str(exc)) from exc
+ except AstroidValueError as exc:
+ raise UseInferenceDefault("ValueError: " + str(exc)) from exc
+
+ replace_args = ", ".join(f"{arg}=None" for arg in attributes)
+ field_def = (
+ " {name} = property(lambda self: self[{index:d}], "
+ "doc='Alias for field number {index:d}')"
+ )
+ field_defs = "\n".join(
+ field_def.format(name=name, index=index)
+ for index, name in enumerate(attributes)
+ )
+ fake = AstroidBuilder(AstroidManager()).string_build(
+ f"""
+class {name}(tuple):
+ __slots__ = ()
+ _fields = {attributes!r}
+ def _asdict(self):
+ return self.__dict__
+ @classmethod
+ def _make(cls, iterable, new=tuple.__new__, len=len):
+ return new(cls, iterable)
+ def _replace(self, {replace_args}):
+ return self
+ def __getnewargs__(self):
+ return tuple(self)
+{field_defs}
+ """
+ )
+ class_node.locals["_asdict"] = fake.body[0].locals["_asdict"]
+ class_node.locals["_make"] = fake.body[0].locals["_make"]
+ class_node.locals["_replace"] = fake.body[0].locals["_replace"]
+ class_node.locals["_fields"] = fake.body[0].locals["_fields"]
+ for attr in attributes:
+ class_node.locals[attr] = fake.body[0].locals[attr]
+ # we use UseInferenceDefault, we can't be a generator so return an iterator
+ return iter([class_node])
+
+
+def _get_renamed_namedtuple_attributes(field_names):
+ names = list(field_names)
+ seen = set()
+ for i, name in enumerate(field_names):
+ if (
+ not all(c.isalnum() or c == "_" for c in name)
+ or keyword.iskeyword(name)
+ or not name
+ or name[0].isdigit()
+ or name.startswith("_")
+ or name in seen
+ ):
+ names[i] = "_%d" % i
+ seen.add(name)
+ return tuple(names)
+
+
+def _check_namedtuple_attributes(typename, attributes, rename=False):
+ attributes = tuple(attributes)
+ if rename:
+ attributes = _get_renamed_namedtuple_attributes(attributes)
+
+ # The following snippet is derived from the CPython Lib/collections/__init__.py sources
+ # <snippet>
+ for name in (typename, *attributes):
+ if not isinstance(name, str):
+ raise AstroidTypeError("Type names and field names must be strings")
+ if not name.isidentifier():
+ raise AstroidValueError(
+ "Type names and field names must be valid" + f"identifiers: {name!r}"
+ )
+ if keyword.iskeyword(name):
+ raise AstroidValueError(
+ f"Type names and field names cannot be a keyword: {name!r}"
+ )
+
+ seen = set()
+ for name in attributes:
+ if name.startswith("_") and not rename:
+ raise AstroidValueError(
+ f"Field names cannot start with an underscore: {name!r}"
+ )
+ if name in seen:
+ raise AstroidValueError(f"Encountered duplicate field name: {name!r}")
+ seen.add(name)
+ # </snippet>
+
+ return attributes
+
+
+def infer_enum(
+ node: nodes.Call, context: InferenceContext | None = None
+) -> Iterator[bases.Instance]:
+ """Specific inference function for enum Call node."""
+ # Raise `UseInferenceDefault` if `node` is a call to a a user-defined Enum.
+ try:
+ inferred = node.func.infer(context)
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+
+ if not any(
+ isinstance(item, nodes.ClassDef) and item.qname() == ENUM_QNAME
+ for item in inferred
+ ):
+ raise UseInferenceDefault
+
+ enum_meta = _extract_single_node(
+ """
+ class EnumMeta(object):
+ 'docstring'
+ def __call__(self, node):
+ class EnumAttribute(object):
+ name = ''
+ value = 0
+ return EnumAttribute()
+ def __iter__(self):
+ class EnumAttribute(object):
+ name = ''
+ value = 0
+ return [EnumAttribute()]
+ def __reversed__(self):
+ class EnumAttribute(object):
+ name = ''
+ value = 0
+ return (EnumAttribute, )
+ def __next__(self):
+ return next(iter(self))
+ def __getitem__(self, attr):
+ class Value(object):
+ @property
+ def name(self):
+ return ''
+ @property
+ def value(self):
+ return attr
+
+ return Value()
+ __members__ = ['']
+ """
+ )
+ class_node = infer_func_form(node, [enum_meta], context=context, enum=True)[0]
+ return iter([class_node.instantiate_class()])
+
+
+INT_FLAG_ADDITION_METHODS = """
+ def __or__(self, other):
+ return {name}(self.value | other.value)
+ def __and__(self, other):
+ return {name}(self.value & other.value)
+ def __xor__(self, other):
+ return {name}(self.value ^ other.value)
+ def __add__(self, other):
+ return {name}(self.value + other.value)
+ def __div__(self, other):
+ return {name}(self.value / other.value)
+ def __invert__(self):
+ return {name}(~self.value)
+ def __mul__(self, other):
+ return {name}(self.value * other.value)
+"""
+
+
+def infer_enum_class(node: nodes.ClassDef) -> nodes.ClassDef:
+ """Specific inference for enums."""
+ for basename in (b for cls in node.mro() for b in cls.basenames):
+ if node.root().name == "enum":
+ # Skip if the class is directly from enum module.
+ break
+ dunder_members = {}
+ target_names = set()
+ for local, values in node.locals.items():
+ if (
+ any(not isinstance(value, nodes.AssignName) for value in values)
+ or local == "_ignore_"
+ ):
+ continue
+
+ stmt = values[0].statement()
+ if isinstance(stmt, nodes.Assign):
+ if isinstance(stmt.targets[0], nodes.Tuple):
+ targets = stmt.targets[0].itered()
+ else:
+ targets = stmt.targets
+ elif isinstance(stmt, nodes.AnnAssign):
+ targets = [stmt.target]
+ else:
+ continue
+
+ inferred_return_value = None
+ if stmt.value is not None:
+ if isinstance(stmt.value, nodes.Const):
+ if isinstance(stmt.value.value, str):
+ inferred_return_value = repr(stmt.value.value)
+ else:
+ inferred_return_value = stmt.value.value
+ else:
+ inferred_return_value = stmt.value.as_string()
+
+ new_targets = []
+ for target in targets:
+ if isinstance(target, nodes.Starred):
+ continue
+ target_names.add(target.name)
+ # Replace all the assignments with our mocked class.
+ classdef = dedent(
+ """
+ class {name}({types}):
+ @property
+ def value(self):
+ return {return_value}
+ @property
+ def _value_(self):
+ return {return_value}
+ @property
+ def name(self):
+ return "{name}"
+ @property
+ def _name_(self):
+ return "{name}"
+ """.format(
+ name=target.name,
+ types=", ".join(node.basenames),
+ return_value=inferred_return_value,
+ )
+ )
+ if "IntFlag" in basename:
+ # Alright, we need to add some additional methods.
+ # Unfortunately we still can't infer the resulting objects as
+ # Enum members, but once we'll be able to do that, the following
+ # should result in some nice symbolic execution
+ classdef += INT_FLAG_ADDITION_METHODS.format(name=target.name)
+
+ fake = AstroidBuilder(
+ AstroidManager(), apply_transforms=False
+ ).string_build(classdef)[target.name]
+ fake.parent = target.parent
+ for method in node.mymethods():
+ fake.locals[method.name] = [method]
+ new_targets.append(fake.instantiate_class())
+ if stmt.value is None:
+ continue
+ dunder_members[local] = fake
+ node.locals[local] = new_targets
+
+ # The undocumented `_value2member_map_` member:
+ node.locals["_value2member_map_"] = [
+ nodes.Dict(
+ parent=node,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ ]
+
+ members = nodes.Dict(
+ parent=node,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ members.postinit(
+ [
+ (
+ nodes.Const(k, parent=members),
+ nodes.Name(
+ v.name,
+ parent=members,
+ lineno=v.lineno,
+ col_offset=v.col_offset,
+ end_lineno=v.end_lineno,
+ end_col_offset=v.end_col_offset,
+ ),
+ )
+ for k, v in dunder_members.items()
+ ]
+ )
+ node.locals["__members__"] = [members]
+ # The enum.Enum class itself defines two @DynamicClassAttribute data-descriptors
+ # "name" and "value" (which we override in the mocked class for each enum member
+ # above). When dealing with inference of an arbitrary instance of the enum
+ # class, e.g. in a method defined in the class body like:
+ # class SomeEnum(enum.Enum):
+ # def method(self):
+ # self.name # <- here
+ # In the absence of an enum member called "name" or "value", these attributes
+ # should resolve to the descriptor on that particular instance, i.e. enum member.
+ # For "value", we have no idea what that should be, but for "name", we at least
+ # know that it should be a string, so infer that as a guess.
+ if "name" not in target_names:
+ code = dedent(
+ """
+ @property
+ def name(self):
+ return ''
+ """
+ )
+ name_dynamicclassattr = AstroidBuilder(AstroidManager()).string_build(code)[
+ "name"
+ ]
+ node.locals["name"] = [name_dynamicclassattr]
+ break
+ return node
+
+
+def infer_typing_namedtuple_class(class_node, context: InferenceContext | None = None):
+ """Infer a subclass of typing.NamedTuple."""
+ # Check if it has the corresponding bases
+ annassigns_fields = [
+ annassign.target.name
+ for annassign in class_node.body
+ if isinstance(annassign, nodes.AnnAssign)
+ ]
+ code = dedent(
+ """
+ from collections import namedtuple
+ namedtuple({typename!r}, {fields!r})
+ """
+ ).format(typename=class_node.name, fields=",".join(annassigns_fields))
+ node = extract_node(code)
+ try:
+ generated_class_node = next(infer_named_tuple(node, context))
+ except StopIteration as e:
+ raise InferenceError(node=node, context=context) from e
+ for method in class_node.mymethods():
+ generated_class_node.locals[method.name] = [method]
+
+ for body_node in class_node.body:
+ if isinstance(body_node, nodes.Assign):
+ for target in body_node.targets:
+ attr = target.name
+ generated_class_node.locals[attr] = class_node.locals[attr]
+ elif isinstance(body_node, nodes.ClassDef):
+ generated_class_node.locals[body_node.name] = [body_node]
+
+ return iter((generated_class_node,))
+
+
+def infer_typing_namedtuple_function(node, context: InferenceContext | None = None):
+ """
+ Starting with python3.9, NamedTuple is a function of the typing module.
+ The class NamedTuple is build dynamically through a call to `type` during
+ initialization of the `_NamedTuple` variable.
+ """
+ klass = extract_node(
+ """
+ from typing import _NamedTuple
+ _NamedTuple
+ """
+ )
+ return klass.infer(context)
+
+
+def infer_typing_namedtuple(
+ node: nodes.Call, context: InferenceContext | None = None
+) -> Iterator[nodes.ClassDef]:
+ """Infer a typing.NamedTuple(...) call."""
+ # This is essentially a namedtuple with different arguments
+ # so we extract the args and infer a named tuple.
+ try:
+ func = next(node.func.infer())
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+
+ if func.qname() not in TYPING_NAMEDTUPLE_QUALIFIED:
+ raise UseInferenceDefault
+
+ if len(node.args) != 2:
+ raise UseInferenceDefault
+
+ if not isinstance(node.args[1], (nodes.List, nodes.Tuple)):
+ raise UseInferenceDefault
+
+ return infer_named_tuple(node, context)
+
+
+def _get_namedtuple_fields(node: nodes.Call) -> str:
+ """Get and return fields of a NamedTuple in code-as-a-string.
+
+ Because the fields are represented in their code form we can
+ extract a node from them later on.
+ """
+ names = []
+ container = None
+ try:
+ container = next(node.args[1].infer())
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ # We pass on IndexError as we'll try to infer 'field_names' from the keywords
+ except IndexError:
+ pass
+ if not container:
+ for keyword_node in node.keywords:
+ if keyword_node.arg == "field_names":
+ try:
+ container = next(keyword_node.value.infer())
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ break
+ if not isinstance(container, nodes.BaseContainer):
+ raise UseInferenceDefault
+ for elt in container.elts:
+ if isinstance(elt, nodes.Const):
+ names.append(elt.as_string())
+ continue
+ if not isinstance(elt, (nodes.List, nodes.Tuple)):
+ raise UseInferenceDefault
+ if len(elt.elts) != 2:
+ raise UseInferenceDefault
+ names.append(elt.elts[0].as_string())
+
+ if names:
+ field_names = f"({','.join(names)},)"
+ else:
+ field_names = ""
+ return field_names
+
+
+def _is_enum_subclass(cls: astroid.ClassDef) -> bool:
+ """Return whether cls is a subclass of an Enum."""
+ return cls.is_subtype_of("enum.Enum")
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ nodes.Call, inference_tip(infer_named_tuple), _looks_like_namedtuple
+ )
+ manager.register_transform(nodes.Call, inference_tip(infer_enum), _looks_like_enum)
+ manager.register_transform(
+ nodes.ClassDef, infer_enum_class, predicate=_is_enum_subclass
+ )
+ manager.register_transform(
+ nodes.ClassDef,
+ inference_tip(infer_typing_namedtuple_class),
+ _has_namedtuple_base,
+ )
+ manager.register_transform(
+ nodes.FunctionDef,
+ inference_tip(infer_typing_namedtuple_function),
+ lambda node: node.name == "NamedTuple"
+ and getattr(node.root(), "name", None) == "typing",
+ )
+ manager.register_transform(
+ nodes.Call,
+ inference_tip(infer_typing_namedtuple),
+ _looks_like_typing_namedtuple,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_nose.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_nose.py
new file mode 100644
index 000000000..742418f2d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_nose.py
@@ -0,0 +1,79 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Hooks for nose library."""
+
+import re
+import textwrap
+
+from astroid.bases import BoundMethod
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.exceptions import InferenceError
+from astroid.manager import AstroidManager
+from astroid.nodes import List, Module
+
+CAPITALS = re.compile("([A-Z])")
+
+
+def _pep8(name, caps=CAPITALS):
+ return caps.sub(lambda m: "_" + m.groups()[0].lower(), name)
+
+
+def _nose_tools_functions():
+ """Get an iterator of names and bound methods."""
+ module = AstroidBuilder().string_build(
+ textwrap.dedent(
+ """
+ import unittest
+
+ class Test(unittest.TestCase):
+ pass
+ a = Test()
+ """
+ )
+ )
+ try:
+ case = next(module["a"].infer())
+ except (InferenceError, StopIteration):
+ return
+ for method in case.methods():
+ if method.name.startswith("assert") and "_" not in method.name:
+ pep8_name = _pep8(method.name)
+ yield pep8_name, BoundMethod(method, case)
+ if method.name == "assertEqual":
+ # nose also exports assert_equals.
+ yield "assert_equals", BoundMethod(method, case)
+
+
+def _nose_tools_transform(node):
+ for method_name, method in _nose_tools_functions():
+ node.locals[method_name] = [method]
+
+
+def _nose_tools_trivial_transform():
+ """Custom transform for the nose.tools module."""
+ stub = AstroidBuilder().string_build("""__all__ = []""")
+ all_entries = ["ok_", "eq_"]
+
+ for pep8_name, method in _nose_tools_functions():
+ all_entries.append(pep8_name)
+ stub[pep8_name] = method
+
+ # Update the __all__ variable, since nose.tools
+ # does this manually with .append.
+ all_assign = stub["__all__"].parent
+ all_object = List(all_entries)
+ all_object.parent = all_assign
+ all_assign.value = all_object
+ return stub
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "nose.tools.trivial", _nose_tools_trivial_transform
+ )
+ manager.register_transform(
+ Module, _nose_tools_transform, lambda n: n.name == "nose.tools"
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_einsumfunc.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_einsumfunc.py
new file mode 100644
index 000000000..b72369cb8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_einsumfunc.py
@@ -0,0 +1,28 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Astroid hooks for numpy.core.einsumfunc module:
+https://github.com/numpy/numpy/blob/main/numpy/core/einsumfunc.py.
+"""
+
+from astroid import nodes
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def numpy_core_einsumfunc_transform() -> nodes.Module:
+ return parse(
+ """
+ def einsum(*operands, out=None, optimize=False, **kwargs):
+ return numpy.ndarray([0, 0])
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "numpy.core.einsumfunc", numpy_core_einsumfunc_transform
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_fromnumeric.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_fromnumeric.py
new file mode 100644
index 000000000..c6be20b6e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_fromnumeric.py
@@ -0,0 +1,23 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for numpy.core.fromnumeric module."""
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def numpy_core_fromnumeric_transform():
+ return parse(
+ """
+ def sum(a, axis=None, dtype=None, out=None, keepdims=None, initial=None):
+ return numpy.ndarray([0, 0])
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "numpy.core.fromnumeric", numpy_core_fromnumeric_transform
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_function_base.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_function_base.py
new file mode 100644
index 000000000..17e1ad11d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_function_base.py
@@ -0,0 +1,34 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for numpy.core.function_base module."""
+
+import functools
+
+from astroid.brain.brain_numpy_utils import (
+ attribute_looks_like_numpy_member,
+ infer_numpy_member,
+)
+from astroid.inference_tip import inference_tip
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import Attribute
+
+METHODS_TO_BE_INFERRED = {
+ "linspace": """def linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0):
+ return numpy.ndarray([0, 0])""",
+ "logspace": """def logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None, axis=0):
+ return numpy.ndarray([0, 0])""",
+ "geomspace": """def geomspace(start, stop, num=50, endpoint=True, dtype=None, axis=0):
+ return numpy.ndarray([0, 0])""",
+}
+
+
+def register(manager: AstroidManager) -> None:
+ for func_name, func_src in METHODS_TO_BE_INFERRED.items():
+ inference_function = functools.partial(infer_numpy_member, func_src)
+ manager.register_transform(
+ Attribute,
+ inference_tip(inference_function),
+ functools.partial(attribute_looks_like_numpy_member, func_name),
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_multiarray.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_multiarray.py
new file mode 100644
index 000000000..404e21cf1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_multiarray.py
@@ -0,0 +1,105 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for numpy.core.multiarray module."""
+
+import functools
+
+from astroid.brain.brain_numpy_utils import (
+ attribute_looks_like_numpy_member,
+ infer_numpy_member,
+ name_looks_like_numpy_member,
+)
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.inference_tip import inference_tip
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import Attribute, Name
+
+
+def numpy_core_multiarray_transform():
+ return parse(
+ """
+ # different functions defined in multiarray.py
+ def inner(a, b):
+ return numpy.ndarray([0, 0])
+
+ def vdot(a, b):
+ return numpy.ndarray([0, 0])
+ """
+ )
+
+
+METHODS_TO_BE_INFERRED = {
+ "array": """def array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0):
+ return numpy.ndarray([0, 0])""",
+ "dot": """def dot(a, b, out=None):
+ return numpy.ndarray([0, 0])""",
+ "empty_like": """def empty_like(a, dtype=None, order='K', subok=True):
+ return numpy.ndarray((0, 0))""",
+ "concatenate": """def concatenate(arrays, axis=None, out=None):
+ return numpy.ndarray((0, 0))""",
+ "where": """def where(condition, x=None, y=None):
+ return numpy.ndarray([0, 0])""",
+ "empty": """def empty(shape, dtype=float, order='C'):
+ return numpy.ndarray([0, 0])""",
+ "bincount": """def bincount(x, weights=None, minlength=0):
+ return numpy.ndarray([0, 0])""",
+ "busday_count": """def busday_count(
+ begindates, enddates, weekmask='1111100', holidays=[], busdaycal=None, out=None
+ ):
+ return numpy.ndarray([0, 0])""",
+ "busday_offset": """def busday_offset(
+ dates, offsets, roll='raise', weekmask='1111100', holidays=None,
+ busdaycal=None, out=None
+ ):
+ return numpy.ndarray([0, 0])""",
+ "can_cast": """def can_cast(from_, to, casting='safe'):
+ return True""",
+ "copyto": """def copyto(dst, src, casting='same_kind', where=True):
+ return None""",
+ "datetime_as_string": """def datetime_as_string(arr, unit=None, timezone='naive', casting='same_kind'):
+ return numpy.ndarray([0, 0])""",
+ "is_busday": """def is_busday(dates, weekmask='1111100', holidays=None, busdaycal=None, out=None):
+ return numpy.ndarray([0, 0])""",
+ "lexsort": """def lexsort(keys, axis=-1):
+ return numpy.ndarray([0, 0])""",
+ "may_share_memory": """def may_share_memory(a, b, max_work=None):
+ return True""",
+ # Not yet available because dtype is not yet present in those brains
+ # "min_scalar_type": """def min_scalar_type(a):
+ # return numpy.dtype('int16')""",
+ "packbits": """def packbits(a, axis=None, bitorder='big'):
+ return numpy.ndarray([0, 0])""",
+ # Not yet available because dtype is not yet present in those brains
+ # "result_type": """def result_type(*arrays_and_dtypes):
+ # return numpy.dtype('int16')""",
+ "shares_memory": """def shares_memory(a, b, max_work=None):
+ return True""",
+ "unpackbits": """def unpackbits(a, axis=None, count=None, bitorder='big'):
+ return numpy.ndarray([0, 0])""",
+ "unravel_index": """def unravel_index(indices, shape, order='C'):
+ return (numpy.ndarray([0, 0]),)""",
+ "zeros": """def zeros(shape, dtype=float, order='C'):
+ return numpy.ndarray([0, 0])""",
+}
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "numpy.core.multiarray", numpy_core_multiarray_transform
+ )
+
+ for method_name, function_src in METHODS_TO_BE_INFERRED.items():
+ inference_function = functools.partial(infer_numpy_member, function_src)
+ manager.register_transform(
+ Attribute,
+ inference_tip(inference_function),
+ functools.partial(attribute_looks_like_numpy_member, method_name),
+ )
+ manager.register_transform(
+ Name,
+ inference_tip(inference_function),
+ functools.partial(name_looks_like_numpy_member, method_name),
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_numeric.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_numeric.py
new file mode 100644
index 000000000..7149c85da
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_numeric.py
@@ -0,0 +1,49 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for numpy.core.numeric module."""
+
+import functools
+
+from astroid.brain.brain_numpy_utils import (
+ attribute_looks_like_numpy_member,
+ infer_numpy_member,
+)
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.inference_tip import inference_tip
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import Attribute
+
+
+def numpy_core_numeric_transform():
+ return parse(
+ """
+ # different functions defined in numeric.py
+ import numpy
+ def zeros_like(a, dtype=None, order='K', subok=True, shape=None): return numpy.ndarray((0, 0))
+ def ones_like(a, dtype=None, order='K', subok=True, shape=None): return numpy.ndarray((0, 0))
+ def full_like(a, fill_value, dtype=None, order='K', subok=True, shape=None): return numpy.ndarray((0, 0))
+ """
+ )
+
+
+METHODS_TO_BE_INFERRED = {
+ "ones": """def ones(shape, dtype=None, order='C'):
+ return numpy.ndarray([0, 0])"""
+}
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "numpy.core.numeric", numpy_core_numeric_transform
+ )
+
+ for method_name, function_src in METHODS_TO_BE_INFERRED.items():
+ inference_function = functools.partial(infer_numpy_member, function_src)
+ manager.register_transform(
+ Attribute,
+ inference_tip(inference_function),
+ functools.partial(attribute_looks_like_numpy_member, method_name),
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_numerictypes.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_numerictypes.py
new file mode 100644
index 000000000..6de299d72
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_numerictypes.py
@@ -0,0 +1,264 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+# TODO(hippo91) : correct the methods signature.
+
+"""Astroid hooks for numpy.core.numerictypes module."""
+from astroid.brain.brain_numpy_utils import numpy_supports_type_hints
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def numpy_core_numerictypes_transform():
+ # TODO: Uniformize the generic API with the ndarray one.
+ # According to numpy doc the generic object should expose
+ # the same API than ndarray. This has been done here partially
+ # through the astype method.
+ generic_src = """
+ class generic(object):
+ def __init__(self, value):
+ self.T = np.ndarray([0, 0])
+ self.base = None
+ self.data = None
+ self.dtype = None
+ self.flags = None
+ # Should be a numpy.flatiter instance but not available for now
+ # Putting an array instead so that iteration and indexing are authorized
+ self.flat = np.ndarray([0, 0])
+ self.imag = None
+ self.itemsize = None
+ self.nbytes = None
+ self.ndim = None
+ self.real = None
+ self.size = None
+ self.strides = None
+
+ def all(self): return uninferable
+ def any(self): return uninferable
+ def argmax(self): return uninferable
+ def argmin(self): return uninferable
+ def argsort(self): return uninferable
+ def astype(self, dtype, order='K', casting='unsafe', subok=True, copy=True): return np.ndarray([0, 0])
+ def base(self): return uninferable
+ def byteswap(self): return uninferable
+ def choose(self): return uninferable
+ def clip(self): return uninferable
+ def compress(self): return uninferable
+ def conj(self): return uninferable
+ def conjugate(self): return uninferable
+ def copy(self): return uninferable
+ def cumprod(self): return uninferable
+ def cumsum(self): return uninferable
+ def data(self): return uninferable
+ def diagonal(self): return uninferable
+ def dtype(self): return uninferable
+ def dump(self): return uninferable
+ def dumps(self): return uninferable
+ def fill(self): return uninferable
+ def flags(self): return uninferable
+ def flat(self): return uninferable
+ def flatten(self): return uninferable
+ def getfield(self): return uninferable
+ def imag(self): return uninferable
+ def item(self): return uninferable
+ def itemset(self): return uninferable
+ def itemsize(self): return uninferable
+ def max(self): return uninferable
+ def mean(self): return uninferable
+ def min(self): return uninferable
+ def nbytes(self): return uninferable
+ def ndim(self): return uninferable
+ def newbyteorder(self): return uninferable
+ def nonzero(self): return uninferable
+ def prod(self): return uninferable
+ def ptp(self): return uninferable
+ def put(self): return uninferable
+ def ravel(self): return uninferable
+ def real(self): return uninferable
+ def repeat(self): return uninferable
+ def reshape(self): return uninferable
+ def resize(self): return uninferable
+ def round(self): return uninferable
+ def searchsorted(self): return uninferable
+ def setfield(self): return uninferable
+ def setflags(self): return uninferable
+ def shape(self): return uninferable
+ def size(self): return uninferable
+ def sort(self): return uninferable
+ def squeeze(self): return uninferable
+ def std(self): return uninferable
+ def strides(self): return uninferable
+ def sum(self): return uninferable
+ def swapaxes(self): return uninferable
+ def take(self): return uninferable
+ def tobytes(self): return uninferable
+ def tofile(self): return uninferable
+ def tolist(self): return uninferable
+ def tostring(self): return uninferable
+ def trace(self): return uninferable
+ def transpose(self): return uninferable
+ def var(self): return uninferable
+ def view(self): return uninferable
+ """
+ if numpy_supports_type_hints():
+ generic_src += """
+ @classmethod
+ def __class_getitem__(cls, value):
+ return cls
+ """
+ return parse(
+ generic_src
+ + """
+ class dtype(object):
+ def __init__(self, obj, align=False, copy=False):
+ self.alignment = None
+ self.base = None
+ self.byteorder = None
+ self.char = None
+ self.descr = None
+ self.fields = None
+ self.flags = None
+ self.hasobject = None
+ self.isalignedstruct = None
+ self.isbuiltin = None
+ self.isnative = None
+ self.itemsize = None
+ self.kind = None
+ self.metadata = None
+ self.name = None
+ self.names = None
+ self.num = None
+ self.shape = None
+ self.str = None
+ self.subdtype = None
+ self.type = None
+
+ def newbyteorder(self, new_order='S'): return uninferable
+ def __neg__(self): return uninferable
+
+ class busdaycalendar(object):
+ def __init__(self, weekmask='1111100', holidays=None):
+ self.holidays = None
+ self.weekmask = None
+
+ class flexible(generic): pass
+ class bool_(generic): pass
+ class number(generic):
+ def __neg__(self): return uninferable
+ class datetime64(generic):
+ def __init__(self, nb, unit=None): pass
+
+
+ class void(flexible):
+ def __init__(self, *args, **kwargs):
+ self.base = None
+ self.dtype = None
+ self.flags = None
+ def getfield(self): return uninferable
+ def setfield(self): return uninferable
+
+
+ class character(flexible): pass
+
+
+ class integer(number):
+ def __init__(self, value):
+ self.denominator = None
+ self.numerator = None
+
+
+ class inexact(number): pass
+
+
+ class str_(str, character):
+ def maketrans(self, x, y=None, z=None): return uninferable
+
+
+ class bytes_(bytes, character):
+ def fromhex(self, string): return uninferable
+ def maketrans(self, frm, to): return uninferable
+
+
+ class signedinteger(integer): pass
+
+
+ class unsignedinteger(integer): pass
+
+
+ class complexfloating(inexact): pass
+
+
+ class floating(inexact): pass
+
+
+ class float64(floating, float):
+ def fromhex(self, string): return uninferable
+
+
+ class uint64(unsignedinteger): pass
+ class complex64(complexfloating): pass
+ class int16(signedinteger): pass
+ class float96(floating): pass
+ class int8(signedinteger): pass
+ class uint32(unsignedinteger): pass
+ class uint8(unsignedinteger): pass
+ class _typedict(dict): pass
+ class complex192(complexfloating): pass
+ class timedelta64(signedinteger):
+ def __init__(self, nb, unit=None): pass
+ class int32(signedinteger): pass
+ class uint16(unsignedinteger): pass
+ class float32(floating): pass
+ class complex128(complexfloating, complex): pass
+ class float16(floating): pass
+ class int64(signedinteger): pass
+
+ buffer_type = memoryview
+ bool8 = bool_
+ byte = int8
+ bytes0 = bytes_
+ cdouble = complex128
+ cfloat = complex128
+ clongdouble = complex192
+ clongfloat = complex192
+ complex_ = complex128
+ csingle = complex64
+ double = float64
+ float_ = float64
+ half = float16
+ int0 = int32
+ int_ = int32
+ intc = int32
+ intp = int32
+ long = int32
+ longcomplex = complex192
+ longdouble = float96
+ longfloat = float96
+ longlong = int64
+ object0 = object_
+ object_ = object_
+ short = int16
+ single = float32
+ singlecomplex = complex64
+ str0 = str_
+ string_ = bytes_
+ ubyte = uint8
+ uint = uint32
+ uint0 = uint32
+ uintc = uint32
+ uintp = uint32
+ ulonglong = uint64
+ unicode = str_
+ unicode_ = str_
+ ushort = uint16
+ void0 = void
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "numpy.core.numerictypes", numpy_core_numerictypes_transform
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_umath.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_umath.py
new file mode 100644
index 000000000..61f335440
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_core_umath.py
@@ -0,0 +1,153 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+# Note: starting with version 1.18 numpy module has `__getattr__` method which prevent
+# `pylint` to emit `no-member` message for all numpy's attributes. (see pylint's module
+# typecheck in `_emit_no_member` function)
+
+"""Astroid hooks for numpy.core.umath module."""
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def numpy_core_umath_transform():
+ ufunc_optional_keyword_arguments = (
+ """out=None, where=True, casting='same_kind', order='K', """
+ """dtype=None, subok=True"""
+ )
+ return parse(
+ """
+ class FakeUfunc:
+ def __init__(self):
+ self.__doc__ = str()
+ self.__name__ = str()
+ self.nin = 0
+ self.nout = 0
+ self.nargs = 0
+ self.ntypes = 0
+ self.types = None
+ self.identity = None
+ self.signature = None
+
+ @classmethod
+ def reduce(cls, a, axis=None, dtype=None, out=None):
+ return numpy.ndarray([0, 0])
+
+ @classmethod
+ def accumulate(cls, array, axis=None, dtype=None, out=None):
+ return numpy.ndarray([0, 0])
+
+ @classmethod
+ def reduceat(cls, a, indices, axis=None, dtype=None, out=None):
+ return numpy.ndarray([0, 0])
+
+ @classmethod
+ def outer(cls, A, B, **kwargs):
+ return numpy.ndarray([0, 0])
+
+ @classmethod
+ def at(cls, a, indices, b=None):
+ return numpy.ndarray([0, 0])
+
+ class FakeUfuncOneArg(FakeUfunc):
+ def __call__(self, x, {opt_args:s}):
+ return numpy.ndarray([0, 0])
+
+ class FakeUfuncOneArgBis(FakeUfunc):
+ def __call__(self, x, {opt_args:s}):
+ return numpy.ndarray([0, 0]), numpy.ndarray([0, 0])
+
+ class FakeUfuncTwoArgs(FakeUfunc):
+ def __call__(self, x1, x2, {opt_args:s}):
+ return numpy.ndarray([0, 0])
+
+ # Constants
+ e = 2.718281828459045
+ euler_gamma = 0.5772156649015329
+
+ # One arg functions with optional kwargs
+ arccos = FakeUfuncOneArg()
+ arccosh = FakeUfuncOneArg()
+ arcsin = FakeUfuncOneArg()
+ arcsinh = FakeUfuncOneArg()
+ arctan = FakeUfuncOneArg()
+ arctanh = FakeUfuncOneArg()
+ cbrt = FakeUfuncOneArg()
+ conj = FakeUfuncOneArg()
+ conjugate = FakeUfuncOneArg()
+ cosh = FakeUfuncOneArg()
+ deg2rad = FakeUfuncOneArg()
+ degrees = FakeUfuncOneArg()
+ exp2 = FakeUfuncOneArg()
+ expm1 = FakeUfuncOneArg()
+ fabs = FakeUfuncOneArg()
+ frexp = FakeUfuncOneArgBis()
+ isfinite = FakeUfuncOneArg()
+ isinf = FakeUfuncOneArg()
+ log = FakeUfuncOneArg()
+ log1p = FakeUfuncOneArg()
+ log2 = FakeUfuncOneArg()
+ logical_not = FakeUfuncOneArg()
+ modf = FakeUfuncOneArgBis()
+ negative = FakeUfuncOneArg()
+ positive = FakeUfuncOneArg()
+ rad2deg = FakeUfuncOneArg()
+ radians = FakeUfuncOneArg()
+ reciprocal = FakeUfuncOneArg()
+ rint = FakeUfuncOneArg()
+ sign = FakeUfuncOneArg()
+ signbit = FakeUfuncOneArg()
+ sinh = FakeUfuncOneArg()
+ spacing = FakeUfuncOneArg()
+ square = FakeUfuncOneArg()
+ tan = FakeUfuncOneArg()
+ tanh = FakeUfuncOneArg()
+ trunc = FakeUfuncOneArg()
+
+ # Two args functions with optional kwargs
+ add = FakeUfuncTwoArgs()
+ bitwise_and = FakeUfuncTwoArgs()
+ bitwise_or = FakeUfuncTwoArgs()
+ bitwise_xor = FakeUfuncTwoArgs()
+ copysign = FakeUfuncTwoArgs()
+ divide = FakeUfuncTwoArgs()
+ divmod = FakeUfuncTwoArgs()
+ equal = FakeUfuncTwoArgs()
+ float_power = FakeUfuncTwoArgs()
+ floor_divide = FakeUfuncTwoArgs()
+ fmax = FakeUfuncTwoArgs()
+ fmin = FakeUfuncTwoArgs()
+ fmod = FakeUfuncTwoArgs()
+ greater = FakeUfuncTwoArgs()
+ gcd = FakeUfuncTwoArgs()
+ hypot = FakeUfuncTwoArgs()
+ heaviside = FakeUfuncTwoArgs()
+ lcm = FakeUfuncTwoArgs()
+ ldexp = FakeUfuncTwoArgs()
+ left_shift = FakeUfuncTwoArgs()
+ less = FakeUfuncTwoArgs()
+ logaddexp = FakeUfuncTwoArgs()
+ logaddexp2 = FakeUfuncTwoArgs()
+ logical_and = FakeUfuncTwoArgs()
+ logical_or = FakeUfuncTwoArgs()
+ logical_xor = FakeUfuncTwoArgs()
+ maximum = FakeUfuncTwoArgs()
+ minimum = FakeUfuncTwoArgs()
+ multiply = FakeUfuncTwoArgs()
+ nextafter = FakeUfuncTwoArgs()
+ not_equal = FakeUfuncTwoArgs()
+ power = FakeUfuncTwoArgs()
+ remainder = FakeUfuncTwoArgs()
+ right_shift = FakeUfuncTwoArgs()
+ subtract = FakeUfuncTwoArgs()
+ true_divide = FakeUfuncTwoArgs()
+ """.format(
+ opt_args=ufunc_optional_keyword_arguments
+ )
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "numpy.core.umath", numpy_core_umath_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_ma.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_ma.py
new file mode 100644
index 000000000..743e462d2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_ma.py
@@ -0,0 +1,32 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for numpy ma module."""
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def numpy_ma_transform():
+ """
+ Infer the call of various numpy.ma functions.
+
+ :param node: node to infer
+ :param context: inference context
+ """
+ return parse(
+ """
+ import numpy.ma
+ def masked_where(condition, a, copy=True):
+ return numpy.ma.masked_array(a, mask=[])
+
+ def masked_invalid(a, copy=True):
+ return numpy.ma.masked_array(a, mask=[])
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "numpy.ma", numpy_ma_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_ndarray.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_ndarray.py
new file mode 100644
index 000000000..5748421fb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_ndarray.py
@@ -0,0 +1,163 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for numpy ndarray class."""
+from __future__ import annotations
+
+from astroid.brain.brain_numpy_utils import numpy_supports_type_hints
+from astroid.builder import extract_node
+from astroid.context import InferenceContext
+from astroid.inference_tip import inference_tip
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import Attribute
+
+
+def infer_numpy_ndarray(node, context: InferenceContext | None = None):
+ ndarray = """
+ class ndarray(object):
+ def __init__(self, shape, dtype=float, buffer=None, offset=0,
+ strides=None, order=None):
+ self.T = numpy.ndarray([0, 0])
+ self.base = None
+ self.ctypes = None
+ self.data = None
+ self.dtype = None
+ self.flags = None
+ # Should be a numpy.flatiter instance but not available for now
+ # Putting an array instead so that iteration and indexing are authorized
+ self.flat = np.ndarray([0, 0])
+ self.imag = np.ndarray([0, 0])
+ self.itemsize = None
+ self.nbytes = None
+ self.ndim = None
+ self.real = np.ndarray([0, 0])
+ self.shape = numpy.ndarray([0, 0])
+ self.size = None
+ self.strides = None
+
+ def __abs__(self): return numpy.ndarray([0, 0])
+ def __add__(self, value): return numpy.ndarray([0, 0])
+ def __and__(self, value): return numpy.ndarray([0, 0])
+ def __array__(self, dtype=None): return numpy.ndarray([0, 0])
+ def __array_wrap__(self, obj): return numpy.ndarray([0, 0])
+ def __contains__(self, key): return True
+ def __copy__(self): return numpy.ndarray([0, 0])
+ def __deepcopy__(self, memo): return numpy.ndarray([0, 0])
+ def __divmod__(self, value): return (numpy.ndarray([0, 0]), numpy.ndarray([0, 0]))
+ def __eq__(self, value): return numpy.ndarray([0, 0])
+ def __float__(self): return 0.
+ def __floordiv__(self): return numpy.ndarray([0, 0])
+ def __ge__(self, value): return numpy.ndarray([0, 0])
+ def __getitem__(self, key): return uninferable
+ def __gt__(self, value): return numpy.ndarray([0, 0])
+ def __iadd__(self, value): return numpy.ndarray([0, 0])
+ def __iand__(self, value): return numpy.ndarray([0, 0])
+ def __ifloordiv__(self, value): return numpy.ndarray([0, 0])
+ def __ilshift__(self, value): return numpy.ndarray([0, 0])
+ def __imod__(self, value): return numpy.ndarray([0, 0])
+ def __imul__(self, value): return numpy.ndarray([0, 0])
+ def __int__(self): return 0
+ def __invert__(self): return numpy.ndarray([0, 0])
+ def __ior__(self, value): return numpy.ndarray([0, 0])
+ def __ipow__(self, value): return numpy.ndarray([0, 0])
+ def __irshift__(self, value): return numpy.ndarray([0, 0])
+ def __isub__(self, value): return numpy.ndarray([0, 0])
+ def __itruediv__(self, value): return numpy.ndarray([0, 0])
+ def __ixor__(self, value): return numpy.ndarray([0, 0])
+ def __le__(self, value): return numpy.ndarray([0, 0])
+ def __len__(self): return 1
+ def __lshift__(self, value): return numpy.ndarray([0, 0])
+ def __lt__(self, value): return numpy.ndarray([0, 0])
+ def __matmul__(self, value): return numpy.ndarray([0, 0])
+ def __mod__(self, value): return numpy.ndarray([0, 0])
+ def __mul__(self, value): return numpy.ndarray([0, 0])
+ def __ne__(self, value): return numpy.ndarray([0, 0])
+ def __neg__(self): return numpy.ndarray([0, 0])
+ def __or__(self, value): return numpy.ndarray([0, 0])
+ def __pos__(self): return numpy.ndarray([0, 0])
+ def __pow__(self): return numpy.ndarray([0, 0])
+ def __repr__(self): return str()
+ def __rshift__(self): return numpy.ndarray([0, 0])
+ def __setitem__(self, key, value): return uninferable
+ def __str__(self): return str()
+ def __sub__(self, value): return numpy.ndarray([0, 0])
+ def __truediv__(self, value): return numpy.ndarray([0, 0])
+ def __xor__(self, value): return numpy.ndarray([0, 0])
+ def all(self, axis=None, out=None, keepdims=False): return np.ndarray([0, 0])
+ def any(self, axis=None, out=None, keepdims=False): return np.ndarray([0, 0])
+ def argmax(self, axis=None, out=None): return np.ndarray([0, 0])
+ def argmin(self, axis=None, out=None): return np.ndarray([0, 0])
+ def argpartition(self, kth, axis=-1, kind='introselect', order=None): return np.ndarray([0, 0])
+ def argsort(self, axis=-1, kind='quicksort', order=None): return np.ndarray([0, 0])
+ def astype(self, dtype, order='K', casting='unsafe', subok=True, copy=True): return np.ndarray([0, 0])
+ def byteswap(self, inplace=False): return np.ndarray([0, 0])
+ def choose(self, choices, out=None, mode='raise'): return np.ndarray([0, 0])
+ def clip(self, min=None, max=None, out=None): return np.ndarray([0, 0])
+ def compress(self, condition, axis=None, out=None): return np.ndarray([0, 0])
+ def conj(self): return np.ndarray([0, 0])
+ def conjugate(self): return np.ndarray([0, 0])
+ def copy(self, order='C'): return np.ndarray([0, 0])
+ def cumprod(self, axis=None, dtype=None, out=None): return np.ndarray([0, 0])
+ def cumsum(self, axis=None, dtype=None, out=None): return np.ndarray([0, 0])
+ def diagonal(self, offset=0, axis1=0, axis2=1): return np.ndarray([0, 0])
+ def dot(self, b, out=None): return np.ndarray([0, 0])
+ def dump(self, file): return None
+ def dumps(self): return str()
+ def fill(self, value): return None
+ def flatten(self, order='C'): return np.ndarray([0, 0])
+ def getfield(self, dtype, offset=0): return np.ndarray([0, 0])
+ def item(self, *args): return uninferable
+ def itemset(self, *args): return None
+ def max(self, axis=None, out=None): return np.ndarray([0, 0])
+ def mean(self, axis=None, dtype=None, out=None, keepdims=False): return np.ndarray([0, 0])
+ def min(self, axis=None, out=None, keepdims=False): return np.ndarray([0, 0])
+ def newbyteorder(self, new_order='S'): return np.ndarray([0, 0])
+ def nonzero(self): return (1,)
+ def partition(self, kth, axis=-1, kind='introselect', order=None): return None
+ def prod(self, axis=None, dtype=None, out=None, keepdims=False): return np.ndarray([0, 0])
+ def ptp(self, axis=None, out=None): return np.ndarray([0, 0])
+ def put(self, indices, values, mode='raise'): return None
+ def ravel(self, order='C'): return np.ndarray([0, 0])
+ def repeat(self, repeats, axis=None): return np.ndarray([0, 0])
+ def reshape(self, shape, order='C'): return np.ndarray([0, 0])
+ def resize(self, new_shape, refcheck=True): return None
+ def round(self, decimals=0, out=None): return np.ndarray([0, 0])
+ def searchsorted(self, v, side='left', sorter=None): return np.ndarray([0, 0])
+ def setfield(self, val, dtype, offset=0): return None
+ def setflags(self, write=None, align=None, uic=None): return None
+ def sort(self, axis=-1, kind='quicksort', order=None): return None
+ def squeeze(self, axis=None): return np.ndarray([0, 0])
+ def std(self, axis=None, dtype=None, out=None, ddof=0, keepdims=False): return np.ndarray([0, 0])
+ def sum(self, axis=None, dtype=None, out=None, keepdims=False): return np.ndarray([0, 0])
+ def swapaxes(self, axis1, axis2): return np.ndarray([0, 0])
+ def take(self, indices, axis=None, out=None, mode='raise'): return np.ndarray([0, 0])
+ def tobytes(self, order='C'): return b''
+ def tofile(self, fid, sep="", format="%s"): return None
+ def tolist(self, ): return []
+ def tostring(self, order='C'): return b''
+ def trace(self, offset=0, axis1=0, axis2=1, dtype=None, out=None): return np.ndarray([0, 0])
+ def transpose(self, *axes): return np.ndarray([0, 0])
+ def var(self, axis=None, dtype=None, out=None, ddof=0, keepdims=False): return np.ndarray([0, 0])
+ def view(self, dtype=None, type=None): return np.ndarray([0, 0])
+ """
+ if numpy_supports_type_hints():
+ ndarray += """
+ @classmethod
+ def __class_getitem__(cls, value):
+ return cls
+ """
+ node = extract_node(ndarray)
+ return node.infer(context=context)
+
+
+def _looks_like_numpy_ndarray(node) -> bool:
+ return isinstance(node, Attribute) and node.attrname == "ndarray"
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ Attribute,
+ inference_tip(infer_numpy_ndarray),
+ _looks_like_numpy_ndarray,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_random_mtrand.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_random_mtrand.py
new file mode 100644
index 000000000..83b1ab06a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_random_mtrand.py
@@ -0,0 +1,72 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+# TODO(hippo91) : correct the functions return types
+"""Astroid hooks for numpy.random.mtrand module."""
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def numpy_random_mtrand_transform():
+ return parse(
+ """
+ def beta(a, b, size=None): return uninferable
+ def binomial(n, p, size=None): return uninferable
+ def bytes(length): return uninferable
+ def chisquare(df, size=None): return uninferable
+ def choice(a, size=None, replace=True, p=None): return uninferable
+ def dirichlet(alpha, size=None): return uninferable
+ def exponential(scale=1.0, size=None): return uninferable
+ def f(dfnum, dfden, size=None): return uninferable
+ def gamma(shape, scale=1.0, size=None): return uninferable
+ def geometric(p, size=None): return uninferable
+ def get_state(): return uninferable
+ def gumbel(loc=0.0, scale=1.0, size=None): return uninferable
+ def hypergeometric(ngood, nbad, nsample, size=None): return uninferable
+ def laplace(loc=0.0, scale=1.0, size=None): return uninferable
+ def logistic(loc=0.0, scale=1.0, size=None): return uninferable
+ def lognormal(mean=0.0, sigma=1.0, size=None): return uninferable
+ def logseries(p, size=None): return uninferable
+ def multinomial(n, pvals, size=None): return uninferable
+ def multivariate_normal(mean, cov, size=None): return uninferable
+ def negative_binomial(n, p, size=None): return uninferable
+ def noncentral_chisquare(df, nonc, size=None): return uninferable
+ def noncentral_f(dfnum, dfden, nonc, size=None): return uninferable
+ def normal(loc=0.0, scale=1.0, size=None): return uninferable
+ def pareto(a, size=None): return uninferable
+ def permutation(x): return uninferable
+ def poisson(lam=1.0, size=None): return uninferable
+ def power(a, size=None): return uninferable
+ def rand(*args): return uninferable
+ def randint(low, high=None, size=None, dtype='l'):
+ import numpy
+ return numpy.ndarray((1,1))
+ def randn(*args): return uninferable
+ def random(size=None): return uninferable
+ def random_integers(low, high=None, size=None): return uninferable
+ def random_sample(size=None): return uninferable
+ def rayleigh(scale=1.0, size=None): return uninferable
+ def seed(seed=None): return uninferable
+ def set_state(state): return uninferable
+ def shuffle(x): return uninferable
+ def standard_cauchy(size=None): return uninferable
+ def standard_exponential(size=None): return uninferable
+ def standard_gamma(shape, size=None): return uninferable
+ def standard_normal(size=None): return uninferable
+ def standard_t(df, size=None): return uninferable
+ def triangular(left, mode, right, size=None): return uninferable
+ def uniform(low=0.0, high=1.0, size=None): return uninferable
+ def vonmises(mu, kappa, size=None): return uninferable
+ def wald(mean, scale, size=None): return uninferable
+ def weibull(a, size=None): return uninferable
+ def zipf(a, size=None): return uninferable
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(
+ manager, "numpy.random.mtrand", numpy_random_mtrand_transform
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_utils.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_utils.py
new file mode 100644
index 000000000..47f24433b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_numpy_utils.py
@@ -0,0 +1,81 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Different utilities for the numpy brains."""
+
+from __future__ import annotations
+
+from astroid.builder import extract_node
+from astroid.context import InferenceContext
+from astroid.nodes.node_classes import Attribute, Import, Name
+
+# Class subscript is available in numpy starting with version 1.20.0
+NUMPY_VERSION_TYPE_HINTS_SUPPORT = ("1", "20", "0")
+
+
+def numpy_supports_type_hints() -> bool:
+ """Returns True if numpy supports type hints."""
+ np_ver = _get_numpy_version()
+ return np_ver and np_ver > NUMPY_VERSION_TYPE_HINTS_SUPPORT
+
+
+def _get_numpy_version() -> tuple[str, str, str]:
+ """
+ Return the numpy version number if numpy can be imported.
+
+ Otherwise returns ('0', '0', '0')
+ """
+ try:
+ import numpy # pylint: disable=import-outside-toplevel
+
+ return tuple(numpy.version.version.split("."))
+ except (ImportError, AttributeError):
+ return ("0", "0", "0")
+
+
+def infer_numpy_member(src, node, context: InferenceContext | None = None):
+ node = extract_node(src)
+ return node.infer(context=context)
+
+
+def _is_a_numpy_module(node: Name) -> bool:
+ """
+ Returns True if the node is a representation of a numpy module.
+
+ For example in :
+ import numpy as np
+ x = np.linspace(1, 2)
+ The node <Name.np> is a representation of the numpy module.
+
+ :param node: node to test
+ :return: True if the node is a representation of the numpy module.
+ """
+ module_nickname = node.name
+ potential_import_target = [
+ x for x in node.lookup(module_nickname)[1] if isinstance(x, Import)
+ ]
+ return any(
+ ("numpy", module_nickname) in target.names or ("numpy", None) in target.names
+ for target in potential_import_target
+ )
+
+
+def name_looks_like_numpy_member(member_name: str, node: Name) -> bool:
+ """
+ Returns True if the Name is a member of numpy whose
+ name is member_name.
+ """
+ return node.name == member_name and node.root().name.startswith("numpy")
+
+
+def attribute_looks_like_numpy_member(member_name: str, node: Attribute) -> bool:
+ """
+ Returns True if the Attribute is a member of numpy whose
+ name is member_name.
+ """
+ return (
+ node.attrname == member_name
+ and isinstance(node.expr, Name)
+ and _is_a_numpy_module(node.expr)
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_pathlib.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_pathlib.py
new file mode 100644
index 000000000..d0f531324
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_pathlib.py
@@ -0,0 +1,54 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from collections.abc import Iterator
+
+from astroid import bases, context, inference_tip, nodes
+from astroid.builder import _extract_single_node
+from astroid.const import PY313_PLUS
+from astroid.exceptions import InferenceError, UseInferenceDefault
+from astroid.manager import AstroidManager
+
+PATH_TEMPLATE = """
+from pathlib import Path
+Path
+"""
+
+
+def _looks_like_parents_subscript(node: nodes.Subscript) -> bool:
+ if not (
+ isinstance(node.value, nodes.Attribute) and node.value.attrname == "parents"
+ ):
+ return False
+
+ try:
+ value = next(node.value.infer())
+ except (InferenceError, StopIteration):
+ return False
+ parents = "builtins.tuple" if PY313_PLUS else "pathlib._PathParents"
+ return (
+ isinstance(value, bases.Instance)
+ and isinstance(value._proxied, nodes.ClassDef)
+ and value.qname() == parents
+ )
+
+
+def infer_parents_subscript(
+ subscript_node: nodes.Subscript, ctx: context.InferenceContext | None = None
+) -> Iterator[bases.Instance]:
+ if isinstance(subscript_node.slice, nodes.Const):
+ path_cls = next(_extract_single_node(PATH_TEMPLATE).infer())
+ return iter([path_cls.instantiate_class()])
+
+ raise UseInferenceDefault
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ nodes.Subscript,
+ inference_tip(infer_parents_subscript),
+ _looks_like_parents_subscript,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_pkg_resources.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_pkg_resources.py
new file mode 100644
index 000000000..a844d15b3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_pkg_resources.py
@@ -0,0 +1,71 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid import parse
+from astroid.brain.helpers import register_module_extender
+from astroid.manager import AstroidManager
+
+
+def pkg_resources_transform():
+ return parse(
+ """
+def require(*requirements):
+ return pkg_resources.working_set.require(*requirements)
+
+def run_script(requires, script_name):
+ return pkg_resources.working_set.run_script(requires, script_name)
+
+def iter_entry_points(group, name=None):
+ return pkg_resources.working_set.iter_entry_points(group, name)
+
+def resource_exists(package_or_requirement, resource_name):
+ return get_provider(package_or_requirement).has_resource(resource_name)
+
+def resource_isdir(package_or_requirement, resource_name):
+ return get_provider(package_or_requirement).resource_isdir(
+ resource_name)
+
+def resource_filename(package_or_requirement, resource_name):
+ return get_provider(package_or_requirement).get_resource_filename(
+ self, resource_name)
+
+def resource_stream(package_or_requirement, resource_name):
+ return get_provider(package_or_requirement).get_resource_stream(
+ self, resource_name)
+
+def resource_string(package_or_requirement, resource_name):
+ return get_provider(package_or_requirement).get_resource_string(
+ self, resource_name)
+
+def resource_listdir(package_or_requirement, resource_name):
+ return get_provider(package_or_requirement).resource_listdir(
+ resource_name)
+
+def extraction_error():
+ pass
+
+def get_cache_path(archive_name, names=()):
+ extract_path = self.extraction_path or get_default_cache()
+ target_path = os.path.join(extract_path, archive_name+'-tmp', *names)
+ return target_path
+
+def postprocess(tempname, filename):
+ pass
+
+def set_extraction_path(path):
+ pass
+
+def cleanup_resources(force=False):
+ pass
+
+def get_distribution(dist):
+ return Distribution(dist)
+
+_namespace_packages = {}
+"""
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "pkg_resources", pkg_resources_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_pytest.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_pytest.py
new file mode 100644
index 000000000..0e0db3904
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_pytest.py
@@ -0,0 +1,84 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for pytest."""
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.manager import AstroidManager
+
+
+def pytest_transform():
+ return AstroidBuilder(AstroidManager()).string_build(
+ """
+
+try:
+ import _pytest.mark
+ import _pytest.recwarn
+ import _pytest.runner
+ import _pytest.python
+ import _pytest.skipping
+ import _pytest.assertion
+except ImportError:
+ pass
+else:
+ deprecated_call = _pytest.recwarn.deprecated_call
+ warns = _pytest.recwarn.warns
+
+ exit = _pytest.runner.exit
+ fail = _pytest.runner.fail
+ skip = _pytest.runner.skip
+ importorskip = _pytest.runner.importorskip
+
+ xfail = _pytest.skipping.xfail
+ mark = _pytest.mark.MarkGenerator()
+ raises = _pytest.python.raises
+
+ # New in pytest 3.0
+ try:
+ approx = _pytest.python.approx
+ register_assert_rewrite = _pytest.assertion.register_assert_rewrite
+ except AttributeError:
+ pass
+
+
+# Moved in pytest 3.0
+
+try:
+ import _pytest.freeze_support
+ freeze_includes = _pytest.freeze_support.freeze_includes
+except ImportError:
+ try:
+ import _pytest.genscript
+ freeze_includes = _pytest.genscript.freeze_includes
+ except ImportError:
+ pass
+
+try:
+ import _pytest.debugging
+ set_trace = _pytest.debugging.pytestPDB().set_trace
+except ImportError:
+ try:
+ import _pytest.pdb
+ set_trace = _pytest.pdb.pytestPDB().set_trace
+ except ImportError:
+ pass
+
+try:
+ import _pytest.fixtures
+ fixture = _pytest.fixtures.fixture
+ yield_fixture = _pytest.fixtures.yield_fixture
+except ImportError:
+ try:
+ import _pytest.python
+ fixture = _pytest.python.fixture
+ yield_fixture = _pytest.python.yield_fixture
+ except ImportError:
+ pass
+"""
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "pytest", pytest_transform)
+ register_module_extender(manager, "py.test", pytest_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_qt.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_qt.py
new file mode 100644
index 000000000..4badfce84
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_qt.py
@@ -0,0 +1,89 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for the PyQT library."""
+
+from astroid import nodes, parse
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.manager import AstroidManager
+
+
+def _looks_like_signal(
+ node: nodes.FunctionDef, signal_name: str = "pyqtSignal"
+) -> bool:
+ """Detect a Signal node."""
+ klasses = node.instance_attrs.get("__class__", [])
+ # On PySide2 or PySide6 (since Qt 5.15.2) the Signal class changed locations
+ if node.qname().partition(".")[0] in {"PySide2", "PySide6"}:
+ return any(cls.qname() == "Signal" for cls in klasses) # pragma: no cover
+ if klasses:
+ try:
+ return klasses[0].name == signal_name
+ except AttributeError: # pragma: no cover
+ # return False if the cls does not have a name attribute
+ pass
+ return False
+
+
+def transform_pyqt_signal(node: nodes.FunctionDef) -> None:
+ module = parse(
+ """
+ _UNSET = object()
+
+ class pyqtSignal(object):
+ def connect(self, slot, type=None, no_receiver_check=False):
+ pass
+ def disconnect(self, slot=_UNSET):
+ pass
+ def emit(self, *args):
+ pass
+ """
+ )
+ signal_cls: nodes.ClassDef = module["pyqtSignal"]
+ node.instance_attrs["emit"] = [signal_cls["emit"]]
+ node.instance_attrs["disconnect"] = [signal_cls["disconnect"]]
+ node.instance_attrs["connect"] = [signal_cls["connect"]]
+
+
+def transform_pyside_signal(node: nodes.FunctionDef) -> None:
+ module = parse(
+ """
+ class NotPySideSignal(object):
+ def connect(self, receiver, type=None):
+ pass
+ def disconnect(self, receiver):
+ pass
+ def emit(self, *args):
+ pass
+ """
+ )
+ signal_cls: nodes.ClassDef = module["NotPySideSignal"]
+ node.instance_attrs["connect"] = [signal_cls["connect"]]
+ node.instance_attrs["disconnect"] = [signal_cls["disconnect"]]
+ node.instance_attrs["emit"] = [signal_cls["emit"]]
+
+
+def pyqt4_qtcore_transform():
+ return AstroidBuilder(AstroidManager()).string_build(
+ """
+
+def SIGNAL(signal_name): pass
+
+class QObject(object):
+ def emit(self, signal): pass
+"""
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "PyQt4.QtCore", pyqt4_qtcore_transform)
+ manager.register_transform(
+ nodes.FunctionDef, transform_pyqt_signal, _looks_like_signal
+ )
+ manager.register_transform(
+ nodes.ClassDef,
+ transform_pyside_signal,
+ lambda node: node.qname() in {"PySide.QtCore.Signal", "PySide2.QtCore.Signal"},
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_random.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_random.py
new file mode 100644
index 000000000..48cc12146
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_random.py
@@ -0,0 +1,103 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import random
+
+from astroid.context import InferenceContext
+from astroid.exceptions import UseInferenceDefault
+from astroid.inference_tip import inference_tip
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import (
+ Attribute,
+ Call,
+ Const,
+ EvaluatedObject,
+ List,
+ Name,
+ Set,
+ Tuple,
+)
+from astroid.util import safe_infer
+
+ACCEPTED_ITERABLES_FOR_SAMPLE = (List, Set, Tuple)
+
+
+def _clone_node_with_lineno(node, parent, lineno):
+ if isinstance(node, EvaluatedObject):
+ node = node.original
+ cls = node.__class__
+ other_fields = node._other_fields
+ _astroid_fields = node._astroid_fields
+ init_params = {
+ "lineno": lineno,
+ "col_offset": node.col_offset,
+ "parent": parent,
+ "end_lineno": node.end_lineno,
+ "end_col_offset": node.end_col_offset,
+ }
+ postinit_params = {param: getattr(node, param) for param in _astroid_fields}
+ if other_fields:
+ init_params.update({param: getattr(node, param) for param in other_fields})
+ new_node = cls(**init_params)
+ if hasattr(node, "postinit") and _astroid_fields:
+ new_node.postinit(**postinit_params)
+ return new_node
+
+
+def infer_random_sample(node, context: InferenceContext | None = None):
+ if len(node.args) != 2:
+ raise UseInferenceDefault
+
+ inferred_length = safe_infer(node.args[1], context=context)
+ if not isinstance(inferred_length, Const):
+ raise UseInferenceDefault
+ if not isinstance(inferred_length.value, int):
+ raise UseInferenceDefault
+
+ inferred_sequence = safe_infer(node.args[0], context=context)
+ if not inferred_sequence:
+ raise UseInferenceDefault
+
+ if not isinstance(inferred_sequence, ACCEPTED_ITERABLES_FOR_SAMPLE):
+ raise UseInferenceDefault
+
+ if inferred_length.value > len(inferred_sequence.elts):
+ # In this case, this will raise a ValueError
+ raise UseInferenceDefault
+
+ try:
+ elts = random.sample(inferred_sequence.elts, inferred_length.value)
+ except ValueError as exc:
+ raise UseInferenceDefault from exc
+
+ new_node = List(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=node.scope(),
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ new_elts = [
+ _clone_node_with_lineno(elt, parent=new_node, lineno=new_node.lineno)
+ for elt in elts
+ ]
+ new_node.postinit(new_elts)
+ return iter((new_node,))
+
+
+def _looks_like_random_sample(node) -> bool:
+ func = node.func
+ if isinstance(func, Attribute):
+ return func.attrname == "sample"
+ if isinstance(func, Name):
+ return func.name == "sample"
+ return False
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ Call, inference_tip(infer_random_sample), _looks_like_random_sample
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_re.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_re.py
new file mode 100644
index 000000000..19f2a5b39
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_re.py
@@ -0,0 +1,96 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from astroid import context, inference_tip, nodes
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import _extract_single_node, parse
+from astroid.const import PY311_PLUS
+from astroid.manager import AstroidManager
+
+
+def _re_transform() -> nodes.Module:
+ # The RegexFlag enum exposes all its entries by updating globals()
+ # In 3.6-3.10 all flags come from sre_compile
+ # On 3.11+ all flags come from re._compiler
+ if PY311_PLUS:
+ import_compiler = "import re._compiler as _compiler"
+ else:
+ import_compiler = "import sre_compile as _compiler"
+ return parse(
+ f"""
+ {import_compiler}
+ NOFLAG = 0
+ ASCII = _compiler.SRE_FLAG_ASCII
+ IGNORECASE = _compiler.SRE_FLAG_IGNORECASE
+ LOCALE = _compiler.SRE_FLAG_LOCALE
+ UNICODE = _compiler.SRE_FLAG_UNICODE
+ MULTILINE = _compiler.SRE_FLAG_MULTILINE
+ DOTALL = _compiler.SRE_FLAG_DOTALL
+ VERBOSE = _compiler.SRE_FLAG_VERBOSE
+ TEMPLATE = _compiler.SRE_FLAG_TEMPLATE
+ DEBUG = _compiler.SRE_FLAG_DEBUG
+ A = ASCII
+ I = IGNORECASE
+ L = LOCALE
+ U = UNICODE
+ M = MULTILINE
+ S = DOTALL
+ X = VERBOSE
+ T = TEMPLATE
+ """
+ )
+
+
+CLASS_GETITEM_TEMPLATE = """
+@classmethod
+def __class_getitem__(cls, item):
+ return cls
+"""
+
+
+def _looks_like_pattern_or_match(node: nodes.Call) -> bool:
+ """Check for re.Pattern or re.Match call in stdlib.
+
+ Match these patterns from stdlib/re.py
+ ```py
+ Pattern = type(...)
+ Match = type(...)
+ ```
+ """
+ return (
+ node.root().name == "re"
+ and isinstance(node.func, nodes.Name)
+ and node.func.name == "type"
+ and isinstance(node.parent, nodes.Assign)
+ and len(node.parent.targets) == 1
+ and isinstance(node.parent.targets[0], nodes.AssignName)
+ and node.parent.targets[0].name in {"Pattern", "Match"}
+ )
+
+
+def infer_pattern_match(node: nodes.Call, ctx: context.InferenceContext | None = None):
+ """Infer re.Pattern and re.Match as classes.
+
+ For PY39+ add `__class_getitem__`.
+ """
+ class_def = nodes.ClassDef(
+ name=node.parent.targets[0].name,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ func_to_add = _extract_single_node(CLASS_GETITEM_TEMPLATE)
+ class_def.locals["__class_getitem__"] = [func_to_add]
+ return iter([class_def])
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "re", _re_transform)
+ manager.register_transform(
+ nodes.Call, inference_tip(infer_pattern_match), _looks_like_pattern_or_match
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_regex.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_regex.py
new file mode 100644
index 000000000..5a2d81e80
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_regex.py
@@ -0,0 +1,94 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from astroid import context, inference_tip, nodes
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import _extract_single_node, parse
+from astroid.manager import AstroidManager
+
+
+def _regex_transform() -> nodes.Module:
+ """The RegexFlag enum exposes all its entries by updating globals().
+
+ We hard-code the flags for now.
+ # pylint: disable-next=line-too-long
+ See https://github.com/mrabarnett/mrab-regex/blob/2022.10.31/regex_3/regex.py#L200
+ """
+ return parse(
+ """
+ A = ASCII = 0x80 # Assume ASCII locale.
+ B = BESTMATCH = 0x1000 # Best fuzzy match.
+ D = DEBUG = 0x200 # Print parsed pattern.
+ E = ENHANCEMATCH = 0x8000 # Attempt to improve the fit after finding the first
+ # fuzzy match.
+ F = FULLCASE = 0x4000 # Unicode full case-folding.
+ I = IGNORECASE = 0x2 # Ignore case.
+ L = LOCALE = 0x4 # Assume current 8-bit locale.
+ M = MULTILINE = 0x8 # Make anchors look for newline.
+ P = POSIX = 0x10000 # POSIX-style matching (leftmost longest).
+ R = REVERSE = 0x400 # Search backwards.
+ S = DOTALL = 0x10 # Make dot match newline.
+ U = UNICODE = 0x20 # Assume Unicode locale.
+ V0 = VERSION0 = 0x2000 # Old legacy behaviour.
+ DEFAULT_VERSION = V0
+ V1 = VERSION1 = 0x100 # New enhanced behaviour.
+ W = WORD = 0x800 # Default Unicode word breaks.
+ X = VERBOSE = 0x40 # Ignore whitespace and comments.
+ T = TEMPLATE = 0x1 # Template (present because re module has it).
+ """
+ )
+
+
+CLASS_GETITEM_TEMPLATE = """
+@classmethod
+def __class_getitem__(cls, item):
+ return cls
+"""
+
+
+def _looks_like_pattern_or_match(node: nodes.Call) -> bool:
+ """Check for regex.Pattern or regex.Match call in stdlib.
+
+ Match these patterns from stdlib/re.py
+ ```py
+ Pattern = type(...)
+ Match = type(...)
+ ```
+ """
+ return (
+ node.root().name == "regex.regex"
+ and isinstance(node.func, nodes.Name)
+ and node.func.name == "type"
+ and isinstance(node.parent, nodes.Assign)
+ and len(node.parent.targets) == 1
+ and isinstance(node.parent.targets[0], nodes.AssignName)
+ and node.parent.targets[0].name in {"Pattern", "Match"}
+ )
+
+
+def infer_pattern_match(node: nodes.Call, ctx: context.InferenceContext | None = None):
+ """Infer regex.Pattern and regex.Match as classes.
+
+ For PY39+ add `__class_getitem__`.
+ """
+ class_def = nodes.ClassDef(
+ name=node.parent.targets[0].name,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ func_to_add = _extract_single_node(CLASS_GETITEM_TEMPLATE)
+ class_def.locals["__class_getitem__"] = [func_to_add]
+ return iter([class_def])
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "regex", _regex_transform)
+ manager.register_transform(
+ nodes.Call, inference_tip(infer_pattern_match), _looks_like_pattern_or_match
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_responses.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_responses.py
new file mode 100644
index 000000000..0a0de8b55
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_responses.py
@@ -0,0 +1,79 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Astroid hooks for responses.
+
+It might need to be manually updated from the public methods of
+:class:`responses.RequestsMock`.
+
+See: https://github.com/getsentry/responses/blob/master/responses.py
+"""
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def responses_funcs():
+ return parse(
+ """
+ DELETE = "DELETE"
+ GET = "GET"
+ HEAD = "HEAD"
+ OPTIONS = "OPTIONS"
+ PATCH = "PATCH"
+ POST = "POST"
+ PUT = "PUT"
+ response_callback = None
+
+ def reset():
+ return
+
+ def add(
+ method=None, # method or ``Response``
+ url=None,
+ body="",
+ adding_headers=None,
+ *args,
+ **kwargs
+ ):
+ return
+
+ def add_passthru(prefix):
+ return
+
+ def remove(method_or_response=None, url=None):
+ return
+
+ def replace(method_or_response=None, url=None, body="", *args, **kwargs):
+ return
+
+ def add_callback(
+ method, url, callback, match_querystring=False, content_type="text/plain"
+ ):
+ return
+
+ calls = []
+
+ def __enter__():
+ return
+
+ def __exit__(type, value, traceback):
+ success = type is None
+ return success
+
+ def activate(func):
+ return func
+
+ def start():
+ return
+
+ def stop(allow_assert=True):
+ return
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "responses", responses_funcs)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_scipy_signal.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_scipy_signal.py
new file mode 100644
index 000000000..7d17a1e95
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_scipy_signal.py
@@ -0,0 +1,89 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for scipy.signal module."""
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def scipy_signal():
+ return parse(
+ """
+ # different functions defined in scipy.signals
+
+ def barthann(M, sym=True):
+ return numpy.ndarray([0])
+
+ def bartlett(M, sym=True):
+ return numpy.ndarray([0])
+
+ def blackman(M, sym=True):
+ return numpy.ndarray([0])
+
+ def blackmanharris(M, sym=True):
+ return numpy.ndarray([0])
+
+ def bohman(M, sym=True):
+ return numpy.ndarray([0])
+
+ def boxcar(M, sym=True):
+ return numpy.ndarray([0])
+
+ def chebwin(M, at, sym=True):
+ return numpy.ndarray([0])
+
+ def cosine(M, sym=True):
+ return numpy.ndarray([0])
+
+ def exponential(M, center=None, tau=1.0, sym=True):
+ return numpy.ndarray([0])
+
+ def flattop(M, sym=True):
+ return numpy.ndarray([0])
+
+ def gaussian(M, std, sym=True):
+ return numpy.ndarray([0])
+
+ def general_gaussian(M, p, sig, sym=True):
+ return numpy.ndarray([0])
+
+ def hamming(M, sym=True):
+ return numpy.ndarray([0])
+
+ def hann(M, sym=True):
+ return numpy.ndarray([0])
+
+ def hanning(M, sym=True):
+ return numpy.ndarray([0])
+
+ def impulse2(system, X0=None, T=None, N=None, **kwargs):
+ return numpy.ndarray([0]), numpy.ndarray([0])
+
+ def kaiser(M, beta, sym=True):
+ return numpy.ndarray([0])
+
+ def nuttall(M, sym=True):
+ return numpy.ndarray([0])
+
+ def parzen(M, sym=True):
+ return numpy.ndarray([0])
+
+ def slepian(M, width, sym=True):
+ return numpy.ndarray([0])
+
+ def step2(system, X0=None, T=None, N=None, **kwargs):
+ return numpy.ndarray([0]), numpy.ndarray([0])
+
+ def triang(M, sym=True):
+ return numpy.ndarray([0])
+
+ def tukey(M, alpha=0.5, sym=True):
+ return numpy.ndarray([0])
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "scipy.signal", scipy_signal)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_signal.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_signal.py
new file mode 100644
index 000000000..649e9749a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_signal.py
@@ -0,0 +1,120 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for the signal library.
+
+The signal module generates the 'Signals', 'Handlers' and 'Sigmasks' IntEnums
+dynamically using the IntEnum._convert() classmethod, which modifies the module
+globals. Astroid is unable to handle this type of code.
+
+Without these hooks, the following are erroneously triggered by Pylint:
+ * E1101: Module 'signal' has no 'Signals' member (no-member)
+ * E1101: Module 'signal' has no 'Handlers' member (no-member)
+ * E1101: Module 'signal' has no 'Sigmasks' member (no-member)
+
+These enums are defined slightly differently depending on the user's operating
+system and platform. These platform differences should follow the current
+Python typeshed stdlib `signal.pyi` stub file, available at:
+
+* https://github.com/python/typeshed/blob/master/stdlib/signal.pyi
+
+Note that the enum.auto() values defined here for the Signals, Handlers and
+Sigmasks IntEnums are just dummy integer values, and do not correspond to the
+actual standard signal numbers - which may vary depending on the system.
+"""
+
+
+import sys
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def _signals_enums_transform():
+ """Generates the AST for 'Signals', 'Handlers' and 'Sigmasks' IntEnums."""
+ return parse(_signals_enum() + _handlers_enum() + _sigmasks_enum())
+
+
+def _signals_enum() -> str:
+ """Generates the source code for the Signals int enum."""
+ signals_enum = """
+ import enum
+ class Signals(enum.IntEnum):
+ SIGABRT = enum.auto()
+ SIGEMT = enum.auto()
+ SIGFPE = enum.auto()
+ SIGILL = enum.auto()
+ SIGINFO = enum.auto()
+ SIGINT = enum.auto()
+ SIGSEGV = enum.auto()
+ SIGTERM = enum.auto()
+ """
+ if sys.platform != "win32":
+ signals_enum += """
+ SIGALRM = enum.auto()
+ SIGBUS = enum.auto()
+ SIGCHLD = enum.auto()
+ SIGCONT = enum.auto()
+ SIGHUP = enum.auto()
+ SIGIO = enum.auto()
+ SIGIOT = enum.auto()
+ SIGKILL = enum.auto()
+ SIGPIPE = enum.auto()
+ SIGPROF = enum.auto()
+ SIGQUIT = enum.auto()
+ SIGSTOP = enum.auto()
+ SIGSYS = enum.auto()
+ SIGTRAP = enum.auto()
+ SIGTSTP = enum.auto()
+ SIGTTIN = enum.auto()
+ SIGTTOU = enum.auto()
+ SIGURG = enum.auto()
+ SIGUSR1 = enum.auto()
+ SIGUSR2 = enum.auto()
+ SIGVTALRM = enum.auto()
+ SIGWINCH = enum.auto()
+ SIGXCPU = enum.auto()
+ SIGXFSZ = enum.auto()
+ """
+ if sys.platform == "win32":
+ signals_enum += """
+ SIGBREAK = enum.auto()
+ """
+ if sys.platform not in ("darwin", "win32"):
+ signals_enum += """
+ SIGCLD = enum.auto()
+ SIGPOLL = enum.auto()
+ SIGPWR = enum.auto()
+ SIGRTMAX = enum.auto()
+ SIGRTMIN = enum.auto()
+ """
+ return signals_enum
+
+
+def _handlers_enum() -> str:
+ """Generates the source code for the Handlers int enum."""
+ return """
+ import enum
+ class Handlers(enum.IntEnum):
+ SIG_DFL = enum.auto()
+ SIG_IGN = eunm.auto()
+ """
+
+
+def _sigmasks_enum() -> str:
+ """Generates the source code for the Sigmasks int enum."""
+ if sys.platform != "win32":
+ return """
+ import enum
+ class Sigmasks(enum.IntEnum):
+ SIG_BLOCK = enum.auto()
+ SIG_UNBLOCK = enum.auto()
+ SIG_SETMASK = enum.auto()
+ """
+ return ""
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "signal", _signals_enums_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_six.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_six.py
new file mode 100644
index 000000000..c222a4220
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_six.py
@@ -0,0 +1,240 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for six module."""
+
+from textwrap import dedent
+
+from astroid import nodes
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder
+from astroid.exceptions import (
+ AstroidBuildingError,
+ AttributeInferenceError,
+ InferenceError,
+)
+from astroid.manager import AstroidManager
+
+SIX_ADD_METACLASS = "six.add_metaclass"
+SIX_WITH_METACLASS = "six.with_metaclass"
+
+
+def default_predicate(line):
+ return line.strip()
+
+
+def _indent(text, prefix, predicate=default_predicate) -> str:
+ """Adds 'prefix' to the beginning of selected lines in 'text'.
+
+ If 'predicate' is provided, 'prefix' will only be added to the lines
+ where 'predicate(line)' is True. If 'predicate' is not provided,
+ it will default to adding 'prefix' to all non-empty lines that do not
+ consist solely of whitespace characters.
+ """
+
+ def prefixed_lines():
+ for line in text.splitlines(True):
+ yield prefix + line if predicate(line) else line
+
+ return "".join(prefixed_lines())
+
+
+_IMPORTS = """
+import _io
+cStringIO = _io.StringIO
+filter = filter
+from itertools import filterfalse
+input = input
+from sys import intern
+map = map
+range = range
+from importlib import reload
+reload_module = lambda module: reload(module)
+from functools import reduce
+from shlex import quote as shlex_quote
+from io import StringIO
+from collections import UserDict, UserList, UserString
+xrange = range
+zip = zip
+from itertools import zip_longest
+import builtins
+import configparser
+import copyreg
+import _dummy_thread
+import http.cookiejar as http_cookiejar
+import http.cookies as http_cookies
+import html.entities as html_entities
+import html.parser as html_parser
+import http.client as http_client
+import http.server as http_server
+BaseHTTPServer = CGIHTTPServer = SimpleHTTPServer = http.server
+import pickle as cPickle
+import queue
+import reprlib
+import socketserver
+import _thread
+import winreg
+import xmlrpc.server as xmlrpc_server
+import xmlrpc.client as xmlrpc_client
+import urllib.robotparser as urllib_robotparser
+import email.mime.multipart as email_mime_multipart
+import email.mime.nonmultipart as email_mime_nonmultipart
+import email.mime.text as email_mime_text
+import email.mime.base as email_mime_base
+import urllib.parse as urllib_parse
+import urllib.error as urllib_error
+import tkinter
+import tkinter.dialog as tkinter_dialog
+import tkinter.filedialog as tkinter_filedialog
+import tkinter.scrolledtext as tkinter_scrolledtext
+import tkinter.simpledialog as tkinder_simpledialog
+import tkinter.tix as tkinter_tix
+import tkinter.ttk as tkinter_ttk
+import tkinter.constants as tkinter_constants
+import tkinter.dnd as tkinter_dnd
+import tkinter.colorchooser as tkinter_colorchooser
+import tkinter.commondialog as tkinter_commondialog
+import tkinter.filedialog as tkinter_tkfiledialog
+import tkinter.font as tkinter_font
+import tkinter.messagebox as tkinter_messagebox
+import urllib
+import urllib.request as urllib_request
+import urllib.robotparser as urllib_robotparser
+import urllib.parse as urllib_parse
+import urllib.error as urllib_error
+"""
+
+
+def six_moves_transform():
+ code = dedent(
+ """
+ class Moves(object):
+ {}
+ moves = Moves()
+ """
+ ).format(_indent(_IMPORTS, " "))
+ module = AstroidBuilder(AstroidManager()).string_build(code)
+ module.name = "six.moves"
+ return module
+
+
+def _six_fail_hook(modname):
+ """Fix six.moves imports due to the dynamic nature of this
+ class.
+
+ Construct a pseudo-module which contains all the necessary imports
+ for six
+
+ :param modname: Name of failed module
+ :type modname: str
+
+ :return: An astroid module
+ :rtype: nodes.Module
+ """
+
+ attribute_of = modname != "six.moves" and modname.startswith("six.moves")
+ if modname != "six.moves" and not attribute_of:
+ raise AstroidBuildingError(modname=modname)
+ module = AstroidBuilder(AstroidManager()).string_build(_IMPORTS)
+ module.name = "six.moves"
+ if attribute_of:
+ # Facilitate import of submodules in Moves
+ start_index = len(module.name)
+ attribute = modname[start_index:].lstrip(".").replace(".", "_")
+ try:
+ import_attr = module.getattr(attribute)[0]
+ except AttributeInferenceError as exc:
+ raise AstroidBuildingError(modname=modname) from exc
+ if isinstance(import_attr, nodes.Import):
+ submodule = AstroidManager().ast_from_module_name(import_attr.names[0][0])
+ return submodule
+ # Let dummy submodule imports pass through
+ # This will cause an Uninferable result, which is okay
+ return module
+
+
+def _looks_like_decorated_with_six_add_metaclass(node) -> bool:
+ if not node.decorators:
+ return False
+
+ for decorator in node.decorators.nodes:
+ if not isinstance(decorator, nodes.Call):
+ continue
+ if decorator.func.as_string() == SIX_ADD_METACLASS:
+ return True
+ return False
+
+
+def transform_six_add_metaclass(node): # pylint: disable=inconsistent-return-statements
+ """Check if the given class node is decorated with *six.add_metaclass*.
+
+ If so, inject its argument as the metaclass of the underlying class.
+ """
+ if not node.decorators:
+ return
+
+ for decorator in node.decorators.nodes:
+ if not isinstance(decorator, nodes.Call):
+ continue
+
+ try:
+ func = next(decorator.func.infer())
+ except (InferenceError, StopIteration):
+ continue
+ if func.qname() == SIX_ADD_METACLASS and decorator.args:
+ metaclass = decorator.args[0]
+ node._metaclass = metaclass
+ return node
+ return
+
+
+def _looks_like_nested_from_six_with_metaclass(node) -> bool:
+ if len(node.bases) != 1:
+ return False
+ base = node.bases[0]
+ if not isinstance(base, nodes.Call):
+ return False
+ try:
+ if hasattr(base.func, "expr"):
+ # format when explicit 'six.with_metaclass' is used
+ mod = base.func.expr.name
+ func = base.func.attrname
+ func = f"{mod}.{func}"
+ else:
+ # format when 'with_metaclass' is used directly (local import from six)
+ # check reference module to avoid 'with_metaclass' name clashes
+ mod = base.parent.parent
+ import_from = mod.locals["with_metaclass"][0]
+ func = f"{import_from.modname}.{base.func.name}"
+ except (AttributeError, KeyError, IndexError):
+ return False
+ return func == SIX_WITH_METACLASS
+
+
+def transform_six_with_metaclass(node):
+ """Check if the given class node is defined with *six.with_metaclass*.
+
+ If so, inject its argument as the metaclass of the underlying class.
+ """
+ call = node.bases[0]
+ node._metaclass = call.args[0]
+ return node
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "six", six_moves_transform)
+ register_module_extender(
+ manager, "requests.packages.urllib3.packages.six", six_moves_transform
+ )
+ manager.register_failed_import_hook(_six_fail_hook)
+ manager.register_transform(
+ nodes.ClassDef,
+ transform_six_add_metaclass,
+ _looks_like_decorated_with_six_add_metaclass,
+ )
+ manager.register_transform(
+ nodes.ClassDef,
+ transform_six_with_metaclass,
+ _looks_like_nested_from_six_with_metaclass,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_sqlalchemy.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_sqlalchemy.py
new file mode 100644
index 000000000..d37b505bf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_sqlalchemy.py
@@ -0,0 +1,40 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def _session_transform():
+ return parse(
+ """
+ from sqlalchemy.orm.session import Session
+
+ class sessionmaker:
+ def __init__(
+ self,
+ bind=None,
+ class_=Session,
+ autoflush=True,
+ autocommit=False,
+ expire_on_commit=True,
+ info=None,
+ **kw
+ ):
+ return
+
+ def __call__(self, **local_kw):
+ return Session()
+
+ def configure(self, **new_kw):
+ return
+
+ return Session()
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "sqlalchemy.orm.session", _session_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_ssl.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_ssl.py
new file mode 100644
index 000000000..23d7ee4f7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_ssl.py
@@ -0,0 +1,164 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for the ssl library."""
+
+from astroid import parse
+from astroid.brain.helpers import register_module_extender
+from astroid.const import PY310_PLUS, PY312_PLUS
+from astroid.manager import AstroidManager
+
+
+def _verifyflags_enum() -> str:
+ enum = """
+ class VerifyFlags(_IntFlag):
+ VERIFY_DEFAULT = 0
+ VERIFY_CRL_CHECK_LEAF = 1
+ VERIFY_CRL_CHECK_CHAIN = 2
+ VERIFY_X509_STRICT = 3
+ VERIFY_X509_TRUSTED_FIRST = 4"""
+ if PY310_PLUS:
+ enum += """
+ VERIFY_ALLOW_PROXY_CERTS = 5
+ VERIFY_X509_PARTIAL_CHAIN = 6
+ """
+ return enum
+
+
+def _options_enum() -> str:
+ enum = """
+ class Options(_IntFlag):
+ OP_ALL = 1
+ OP_NO_SSLv2 = 2
+ OP_NO_SSLv3 = 3
+ OP_NO_TLSv1 = 4
+ OP_NO_TLSv1_1 = 5
+ OP_NO_TLSv1_2 = 6
+ OP_NO_TLSv1_3 = 7
+ OP_CIPHER_SERVER_PREFERENCE = 8
+ OP_SINGLE_DH_USE = 9
+ OP_SINGLE_ECDH_USE = 10
+ OP_NO_COMPRESSION = 11
+ OP_NO_TICKET = 12
+ OP_NO_RENEGOTIATION = 13
+ OP_ENABLE_MIDDLEBOX_COMPAT = 14
+ """
+ if PY312_PLUS:
+ enum += "OP_LEGACY_SERVER_CONNECT = 15"
+ return enum
+
+
+def ssl_transform():
+ return parse(
+ f"""
+ # Import necessary for conversion of objects defined in C into enums
+ from enum import IntEnum as _IntEnum, IntFlag as _IntFlag
+
+ from _ssl import OPENSSL_VERSION_NUMBER, OPENSSL_VERSION_INFO, OPENSSL_VERSION
+ from _ssl import _SSLContext, MemoryBIO
+ from _ssl import (
+ SSLError, SSLZeroReturnError, SSLWantReadError, SSLWantWriteError,
+ SSLSyscallError, SSLEOFError,
+ )
+ from _ssl import CERT_NONE, CERT_OPTIONAL, CERT_REQUIRED
+ from _ssl import txt2obj as _txt2obj, nid2obj as _nid2obj
+ from _ssl import RAND_status, RAND_add, RAND_bytes, RAND_pseudo_bytes
+ try:
+ from _ssl import RAND_egd
+ except ImportError:
+ # LibreSSL does not provide RAND_egd
+ pass
+ from _ssl import (OP_ALL, OP_CIPHER_SERVER_PREFERENCE,
+ OP_NO_COMPRESSION, OP_NO_SSLv2, OP_NO_SSLv3,
+ OP_NO_TLSv1, OP_NO_TLSv1_1, OP_NO_TLSv1_2,
+ OP_SINGLE_DH_USE, OP_SINGLE_ECDH_USE)
+
+ {"from _ssl import OP_LEGACY_SERVER_CONNECT" if PY312_PLUS else ""}
+
+ from _ssl import (ALERT_DESCRIPTION_ACCESS_DENIED, ALERT_DESCRIPTION_BAD_CERTIFICATE,
+ ALERT_DESCRIPTION_BAD_CERTIFICATE_HASH_VALUE,
+ ALERT_DESCRIPTION_BAD_CERTIFICATE_STATUS_RESPONSE,
+ ALERT_DESCRIPTION_BAD_RECORD_MAC,
+ ALERT_DESCRIPTION_CERTIFICATE_EXPIRED,
+ ALERT_DESCRIPTION_CERTIFICATE_REVOKED,
+ ALERT_DESCRIPTION_CERTIFICATE_UNKNOWN,
+ ALERT_DESCRIPTION_CERTIFICATE_UNOBTAINABLE,
+ ALERT_DESCRIPTION_CLOSE_NOTIFY, ALERT_DESCRIPTION_DECODE_ERROR,
+ ALERT_DESCRIPTION_DECOMPRESSION_FAILURE,
+ ALERT_DESCRIPTION_DECRYPT_ERROR,
+ ALERT_DESCRIPTION_HANDSHAKE_FAILURE,
+ ALERT_DESCRIPTION_ILLEGAL_PARAMETER,
+ ALERT_DESCRIPTION_INSUFFICIENT_SECURITY,
+ ALERT_DESCRIPTION_INTERNAL_ERROR,
+ ALERT_DESCRIPTION_NO_RENEGOTIATION,
+ ALERT_DESCRIPTION_PROTOCOL_VERSION,
+ ALERT_DESCRIPTION_RECORD_OVERFLOW,
+ ALERT_DESCRIPTION_UNEXPECTED_MESSAGE,
+ ALERT_DESCRIPTION_UNKNOWN_CA,
+ ALERT_DESCRIPTION_UNKNOWN_PSK_IDENTITY,
+ ALERT_DESCRIPTION_UNRECOGNIZED_NAME,
+ ALERT_DESCRIPTION_UNSUPPORTED_CERTIFICATE,
+ ALERT_DESCRIPTION_UNSUPPORTED_EXTENSION,
+ ALERT_DESCRIPTION_USER_CANCELLED)
+ from _ssl import (SSL_ERROR_EOF, SSL_ERROR_INVALID_ERROR_CODE, SSL_ERROR_SSL,
+ SSL_ERROR_SYSCALL, SSL_ERROR_WANT_CONNECT, SSL_ERROR_WANT_READ,
+ SSL_ERROR_WANT_WRITE, SSL_ERROR_WANT_X509_LOOKUP, SSL_ERROR_ZERO_RETURN)
+ from _ssl import VERIFY_CRL_CHECK_CHAIN, VERIFY_CRL_CHECK_LEAF, VERIFY_DEFAULT, VERIFY_X509_STRICT
+ from _ssl import HAS_SNI, HAS_ECDH, HAS_NPN, HAS_ALPN
+ from _ssl import _OPENSSL_API_VERSION
+ from _ssl import PROTOCOL_SSLv23, PROTOCOL_TLSv1, PROTOCOL_TLSv1_1, PROTOCOL_TLSv1_2
+ from _ssl import PROTOCOL_TLS, PROTOCOL_TLS_CLIENT, PROTOCOL_TLS_SERVER
+
+ class AlertDescription(_IntEnum):
+ ALERT_DESCRIPTION_ACCESS_DENIED = 0
+ ALERT_DESCRIPTION_BAD_CERTIFICATE = 1
+ ALERT_DESCRIPTION_BAD_CERTIFICATE_HASH_VALUE = 2
+ ALERT_DESCRIPTION_BAD_CERTIFICATE_STATUS_RESPONSE = 3
+ ALERT_DESCRIPTION_BAD_RECORD_MAC = 4
+ ALERT_DESCRIPTION_CERTIFICATE_EXPIRED = 5
+ ALERT_DESCRIPTION_CERTIFICATE_REVOKED = 6
+ ALERT_DESCRIPTION_CERTIFICATE_UNKNOWN = 7
+ ALERT_DESCRIPTION_CERTIFICATE_UNOBTAINABLE = 8
+ ALERT_DESCRIPTION_CLOSE_NOTIFY = 9
+ ALERT_DESCRIPTION_DECODE_ERROR = 10
+ ALERT_DESCRIPTION_DECOMPRESSION_FAILURE = 11
+ ALERT_DESCRIPTION_DECRYPT_ERROR = 12
+ ALERT_DESCRIPTION_HANDSHAKE_FAILURE = 13
+ ALERT_DESCRIPTION_ILLEGAL_PARAMETER = 14
+ ALERT_DESCRIPTION_INSUFFICIENT_SECURITY = 15
+ ALERT_DESCRIPTION_INTERNAL_ERROR = 16
+ ALERT_DESCRIPTION_NO_RENEGOTIATION = 17
+ ALERT_DESCRIPTION_PROTOCOL_VERSION = 18
+ ALERT_DESCRIPTION_RECORD_OVERFLOW = 19
+ ALERT_DESCRIPTION_UNEXPECTED_MESSAGE = 20
+ ALERT_DESCRIPTION_UNKNOWN_CA = 21
+ ALERT_DESCRIPTION_UNKNOWN_PSK_IDENTITY = 22
+ ALERT_DESCRIPTION_UNRECOGNIZED_NAME = 23
+ ALERT_DESCRIPTION_UNSUPPORTED_CERTIFICATE = 24
+ ALERT_DESCRIPTION_UNSUPPORTED_EXTENSION = 25
+ ALERT_DESCRIPTION_USER_CANCELLED = 26
+
+ class SSLErrorNumber(_IntEnum):
+ SSL_ERROR_EOF = 0
+ SSL_ERROR_INVALID_ERROR_CODE = 1
+ SSL_ERROR_SSL = 2
+ SSL_ERROR_SYSCALL = 3
+ SSL_ERROR_WANT_CONNECT = 4
+ SSL_ERROR_WANT_READ = 5
+ SSL_ERROR_WANT_WRITE = 6
+ SSL_ERROR_WANT_X509_LOOKUP = 7
+ SSL_ERROR_ZERO_RETURN = 8
+
+ class VerifyMode(_IntEnum):
+ CERT_NONE = 0
+ CERT_OPTIONAL = 1
+ CERT_REQUIRED = 2
+ """
+ + _verifyflags_enum()
+ + _options_enum()
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "ssl", ssl_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_subprocess.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_subprocess.py
new file mode 100644
index 000000000..fbc088a68
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_subprocess.py
@@ -0,0 +1,102 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+import textwrap
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.const import PY310_PLUS, PY311_PLUS
+from astroid.manager import AstroidManager
+
+
+def _subprocess_transform():
+ communicate = (bytes("string", "ascii"), bytes("string", "ascii"))
+ communicate_signature = "def communicate(self, input=None, timeout=None)"
+ args = """\
+ self, args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None,
+ preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None,
+ universal_newlines=None, startupinfo=None, creationflags=0, restore_signals=True,
+ start_new_session=False, pass_fds=(), *, encoding=None, errors=None, text=None,
+ user=None, group=None, extra_groups=None, umask=-1"""
+
+ if PY310_PLUS:
+ args += ", pipesize=-1"
+ if PY311_PLUS:
+ args += ", process_group=None"
+
+ init = f"""
+ def __init__({args}):
+ pass"""
+ wait_signature = "def wait(self, timeout=None)"
+ ctx_manager = """
+ def __enter__(self): return self
+ def __exit__(self, *args): pass
+ """
+ py3_args = "args = []"
+
+ check_output_signature = """
+ check_output(
+ args, *,
+ stdin=None,
+ stderr=None,
+ shell=False,
+ cwd=None,
+ encoding=None,
+ errors=None,
+ universal_newlines=False,
+ timeout=None,
+ env=None,
+ text=None,
+ restore_signals=True,
+ preexec_fn=None,
+ pass_fds=(),
+ input=None,
+ bufsize=0,
+ executable=None,
+ close_fds=False,
+ startupinfo=None,
+ creationflags=0,
+ start_new_session=False
+ ):
+ """.strip()
+
+ code = textwrap.dedent(
+ f"""
+ def {check_output_signature}
+ if universal_newlines:
+ return ""
+ return b""
+
+ class Popen(object):
+ returncode = pid = 0
+ stdin = stdout = stderr = file()
+ {py3_args}
+
+ {communicate_signature}:
+ return {communicate!r}
+ {wait_signature}:
+ return self.returncode
+ def poll(self):
+ return self.returncode
+ def send_signal(self, signal):
+ pass
+ def terminate(self):
+ pass
+ def kill(self):
+ pass
+ {ctx_manager}
+ @classmethod
+ def __class_getitem__(cls, item):
+ pass
+ """
+ )
+
+ init_lines = textwrap.dedent(init).splitlines()
+ indented_init = "\n".join(" " * 4 + line for line in init_lines)
+ code += indented_init
+ return parse(code)
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "subprocess", _subprocess_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_threading.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_threading.py
new file mode 100644
index 000000000..6c6f29bf0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_threading.py
@@ -0,0 +1,32 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def _thread_transform():
+ return parse(
+ """
+ class lock(object):
+ def acquire(self, blocking=True, timeout=-1):
+ return False
+ def release(self):
+ pass
+ def __enter__(self):
+ return True
+ def __exit__(self, *args):
+ pass
+ def locked(self):
+ return False
+
+ def Lock(*args, **kwargs):
+ return lock()
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "threading", _thread_transform)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_type.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_type.py
new file mode 100644
index 000000000..d3461e68d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_type.py
@@ -0,0 +1,68 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Astroid hooks for type support.
+
+Starting from python3.9, type object behaves as it had __class_getitem__ method.
+However it was not possible to simply add this method inside type's body, otherwise
+all types would also have this method. In this case it would have been possible
+to write str[int].
+Guido Van Rossum proposed a hack to handle this in the interpreter:
+https://github.com/python/cpython/blob/67e394562d67cbcd0ac8114e5439494e7645b8f5/Objects/abstract.c#L181-L184
+
+This brain follows the same logic. It is no wise to add permanently the __class_getitem__ method
+to the type object. Instead we choose to add it only in the case of a subscript node
+which inside name node is type.
+Doing this type[int] is allowed whereas str[int] is not.
+
+Thanks to Lukasz Langa for fruitful discussion.
+"""
+
+from __future__ import annotations
+
+from astroid import extract_node, inference_tip, nodes
+from astroid.context import InferenceContext
+from astroid.exceptions import UseInferenceDefault
+from astroid.manager import AstroidManager
+
+
+def _looks_like_type_subscript(node) -> bool:
+ """
+ Try to figure out if a Name node is used inside a type related subscript.
+
+ :param node: node to check
+ :type node: astroid.nodes.node_classes.NodeNG
+ :return: whether the node is a Name node inside a type related subscript
+ """
+ if isinstance(node, nodes.Name) and isinstance(node.parent, nodes.Subscript):
+ return node.name == "type"
+ return False
+
+
+def infer_type_sub(node, context: InferenceContext | None = None):
+ """
+ Infer a type[...] subscript.
+
+ :param node: node to infer
+ :type node: astroid.nodes.node_classes.NodeNG
+ :return: the inferred node
+ :rtype: nodes.NodeNG
+ """
+ node_scope, _ = node.scope().lookup("type")
+ if not isinstance(node_scope, nodes.Module) or node_scope.qname() != "builtins":
+ raise UseInferenceDefault()
+ class_src = """
+ class type:
+ def __class_getitem__(cls, key):
+ return cls
+ """
+ node = extract_node(class_src)
+ return node.infer(context=context)
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ nodes.Name, inference_tip(infer_type_sub), _looks_like_type_subscript
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_typing.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_typing.py
new file mode 100644
index 000000000..5e3a0c90d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_typing.py
@@ -0,0 +1,502 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for typing.py support."""
+
+from __future__ import annotations
+
+import textwrap
+import typing
+from collections.abc import Iterator
+from functools import partial
+from typing import Final
+
+from astroid import context, extract_node, inference_tip
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import AstroidBuilder, _extract_single_node
+from astroid.const import PY312_PLUS, PY313_PLUS
+from astroid.exceptions import (
+ AstroidSyntaxError,
+ AttributeInferenceError,
+ InferenceError,
+ UseInferenceDefault,
+)
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import (
+ Assign,
+ AssignName,
+ Attribute,
+ Call,
+ Const,
+ JoinedStr,
+ Name,
+ NodeNG,
+ Subscript,
+)
+from astroid.nodes.scoped_nodes import ClassDef, FunctionDef
+
+TYPING_TYPEVARS = {"TypeVar", "NewType"}
+TYPING_TYPEVARS_QUALIFIED: Final = {
+ "typing.TypeVar",
+ "typing.NewType",
+ "typing_extensions.TypeVar",
+}
+TYPING_TYPEDDICT_QUALIFIED: Final = {"typing.TypedDict", "typing_extensions.TypedDict"}
+TYPING_TYPE_TEMPLATE = """
+class Meta(type):
+ def __getitem__(self, item):
+ return self
+
+ @property
+ def __args__(self):
+ return ()
+
+class {0}(metaclass=Meta):
+ pass
+"""
+TYPING_MEMBERS = set(getattr(typing, "__all__", []))
+
+TYPING_ALIAS = frozenset(
+ (
+ "typing.Hashable",
+ "typing.Awaitable",
+ "typing.Coroutine",
+ "typing.AsyncIterable",
+ "typing.AsyncIterator",
+ "typing.Iterable",
+ "typing.Iterator",
+ "typing.Reversible",
+ "typing.Sized",
+ "typing.Container",
+ "typing.Collection",
+ "typing.Callable",
+ "typing.AbstractSet",
+ "typing.MutableSet",
+ "typing.Mapping",
+ "typing.MutableMapping",
+ "typing.Sequence",
+ "typing.MutableSequence",
+ "typing.ByteString",
+ "typing.Tuple",
+ "typing.List",
+ "typing.Deque",
+ "typing.Set",
+ "typing.FrozenSet",
+ "typing.MappingView",
+ "typing.KeysView",
+ "typing.ItemsView",
+ "typing.ValuesView",
+ "typing.ContextManager",
+ "typing.AsyncContextManager",
+ "typing.Dict",
+ "typing.DefaultDict",
+ "typing.OrderedDict",
+ "typing.Counter",
+ "typing.ChainMap",
+ "typing.Generator",
+ "typing.AsyncGenerator",
+ "typing.Type",
+ "typing.Pattern",
+ "typing.Match",
+ )
+)
+
+CLASS_GETITEM_TEMPLATE = """
+@classmethod
+def __class_getitem__(cls, item):
+ return cls
+"""
+
+
+def looks_like_typing_typevar_or_newtype(node) -> bool:
+ func = node.func
+ if isinstance(func, Attribute):
+ return func.attrname in TYPING_TYPEVARS
+ if isinstance(func, Name):
+ return func.name in TYPING_TYPEVARS
+ return False
+
+
+def infer_typing_typevar_or_newtype(
+ node: Call, context_itton: context.InferenceContext | None = None
+) -> Iterator[ClassDef]:
+ """Infer a typing.TypeVar(...) or typing.NewType(...) call."""
+ try:
+ func = next(node.func.infer(context=context_itton))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+
+ if func.qname() not in TYPING_TYPEVARS_QUALIFIED:
+ raise UseInferenceDefault
+ if not node.args:
+ raise UseInferenceDefault
+ # Cannot infer from a dynamic class name (f-string)
+ if isinstance(node.args[0], JoinedStr):
+ raise UseInferenceDefault
+
+ typename = node.args[0].as_string().strip("'")
+ try:
+ node = extract_node(TYPING_TYPE_TEMPLATE.format(typename))
+ except AstroidSyntaxError as exc:
+ raise InferenceError from exc
+ return node.infer(context=context_itton)
+
+
+def _looks_like_typing_subscript(node) -> bool:
+ """Try to figure out if a Subscript node *might* be a typing-related subscript."""
+ if isinstance(node, Name):
+ return node.name in TYPING_MEMBERS
+ if isinstance(node, Attribute):
+ return node.attrname in TYPING_MEMBERS
+ if isinstance(node, Subscript):
+ return _looks_like_typing_subscript(node.value)
+ return False
+
+
+def infer_typing_attr(
+ node: Subscript, ctx: context.InferenceContext | None = None
+) -> Iterator[ClassDef]:
+ """Infer a typing.X[...] subscript."""
+ try:
+ value = next(node.value.infer()) # type: ignore[union-attr] # value shouldn't be None for Subscript.
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+
+ if not value.qname().startswith("typing.") or value.qname() in TYPING_ALIAS:
+ # If typing subscript belongs to an alias handle it separately.
+ raise UseInferenceDefault
+
+ if (
+ PY313_PLUS
+ and isinstance(value, FunctionDef)
+ and value.qname() == "typing.Annotated"
+ ):
+ # typing.Annotated is a FunctionDef on 3.13+
+ node._explicit_inference = lambda node, context: iter([value])
+ return iter([value])
+
+ if isinstance(value, ClassDef) and value.qname() in {
+ "typing.Generic",
+ "typing.Annotated",
+ "typing_extensions.Annotated",
+ }:
+ # typing.Generic and typing.Annotated (PY39) are subscriptable
+ # through __class_getitem__. Since astroid can't easily
+ # infer the native methods, replace them for an easy inference tip
+ func_to_add = _extract_single_node(CLASS_GETITEM_TEMPLATE)
+ value.locals["__class_getitem__"] = [func_to_add]
+ if (
+ isinstance(node.parent, ClassDef)
+ and node in node.parent.bases
+ and getattr(node.parent, "__cache", None)
+ ):
+ # node.parent.slots is evaluated and cached before the inference tip
+ # is first applied. Remove the last result to allow a recalculation of slots
+ cache = node.parent.__cache # type: ignore[attr-defined] # Unrecognized getattr
+ if cache.get(node.parent.slots) is not None:
+ del cache[node.parent.slots]
+ # Avoid re-instantiating this class every time it's seen
+ node._explicit_inference = lambda node, context: iter([value])
+ return iter([value])
+
+ node = extract_node(TYPING_TYPE_TEMPLATE.format(value.qname().split(".")[-1]))
+ return node.infer(context=ctx)
+
+
+def _looks_like_generic_class_pep695(node: ClassDef) -> bool:
+ """Check if class is using type parameter. Python 3.12+."""
+ return len(node.type_params) > 0
+
+
+def infer_typing_generic_class_pep695(
+ node: ClassDef, ctx: context.InferenceContext | None = None
+) -> Iterator[ClassDef]:
+ """Add __class_getitem__ for generic classes. Python 3.12+."""
+ func_to_add = _extract_single_node(CLASS_GETITEM_TEMPLATE)
+ node.locals["__class_getitem__"] = [func_to_add]
+ return iter([node])
+
+
+def _looks_like_typedDict( # pylint: disable=invalid-name
+ node: FunctionDef | ClassDef,
+) -> bool:
+ """Check if node is TypedDict FunctionDef."""
+ return node.qname() in TYPING_TYPEDDICT_QUALIFIED
+
+
+def infer_typedDict( # pylint: disable=invalid-name
+ node: FunctionDef, ctx: context.InferenceContext | None = None
+) -> Iterator[ClassDef]:
+ """Replace TypedDict FunctionDef with ClassDef."""
+ class_def = ClassDef(
+ name="TypedDict",
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ parent=node.parent,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ )
+ class_def.postinit(bases=[extract_node("dict")], body=[], decorators=None)
+ func_to_add = _extract_single_node("dict")
+ class_def.locals["__call__"] = [func_to_add]
+ return iter([class_def])
+
+
+def _looks_like_typing_alias(node: Call) -> bool:
+ """
+ Returns True if the node corresponds to a call to _alias function.
+
+ For example :
+
+ MutableSet = _alias(collections.abc.MutableSet, T)
+
+ :param node: call node
+ """
+ return (
+ isinstance(node.func, Name)
+ # TODO: remove _DeprecatedGenericAlias when Py3.14 min
+ and node.func.name in {"_alias", "_DeprecatedGenericAlias"}
+ and len(node.args) == 2
+ and (
+ # _alias function works also for builtins object such as list and dict
+ isinstance(node.args[0], (Attribute, Name))
+ )
+ )
+
+
+def _forbid_class_getitem_access(node: ClassDef) -> None:
+ """Disable the access to __class_getitem__ method for the node in parameters."""
+
+ def full_raiser(origin_func, attr, *args, **kwargs):
+ """
+ Raises an AttributeInferenceError in case of access to __class_getitem__ method.
+ Otherwise, just call origin_func.
+ """
+ if attr == "__class_getitem__":
+ raise AttributeInferenceError("__class_getitem__ access is not allowed")
+ return origin_func(attr, *args, **kwargs)
+
+ try:
+ node.getattr("__class_getitem__")
+ # If we are here, then we are sure to modify an object that does have
+ # __class_getitem__ method (which origin is the protocol defined in
+ # collections module) whereas the typing module considers it should not.
+ # We do not want __class_getitem__ to be found in the classdef
+ partial_raiser = partial(full_raiser, node.getattr)
+ node.getattr = partial_raiser
+ except AttributeInferenceError:
+ pass
+
+
+def infer_typing_alias(
+ node: Call, ctx: context.InferenceContext | None = None
+) -> Iterator[ClassDef]:
+ """
+ Infers the call to _alias function
+ Insert ClassDef, with same name as aliased class,
+ in mro to simulate _GenericAlias.
+
+ :param node: call node
+ :param context: inference context
+
+ # TODO: evaluate if still necessary when Py3.12 is minimum
+ """
+ if (
+ not isinstance(node.parent, Assign)
+ or not len(node.parent.targets) == 1
+ or not isinstance(node.parent.targets[0], AssignName)
+ ):
+ raise UseInferenceDefault
+ try:
+ res = next(node.args[0].infer(context=ctx))
+ except StopIteration as e:
+ raise InferenceError(node=node.args[0], context=ctx) from e
+
+ assign_name = node.parent.targets[0]
+
+ class_def = ClassDef(
+ name=assign_name.name,
+ lineno=assign_name.lineno,
+ col_offset=assign_name.col_offset,
+ parent=node.parent,
+ end_lineno=assign_name.end_lineno,
+ end_col_offset=assign_name.end_col_offset,
+ )
+ if isinstance(res, ClassDef):
+ # Only add `res` as base if it's a `ClassDef`
+ # This isn't the case for `typing.Pattern` and `typing.Match`
+ class_def.postinit(bases=[res], body=[], decorators=None)
+
+ maybe_type_var = node.args[1]
+ if isinstance(maybe_type_var, Const) and maybe_type_var.value > 0:
+ # If typing alias is subscriptable, add `__class_getitem__` to ClassDef
+ func_to_add = _extract_single_node(CLASS_GETITEM_TEMPLATE)
+ class_def.locals["__class_getitem__"] = [func_to_add]
+ else:
+ # If not, make sure that `__class_getitem__` access is forbidden.
+ # This is an issue in cases where the aliased class implements it,
+ # but the typing alias isn't subscriptable. E.g., `typing.ByteString` for PY39+
+ _forbid_class_getitem_access(class_def)
+
+ # Avoid re-instantiating this class every time it's seen
+ node._explicit_inference = lambda node, context: iter([class_def])
+ return iter([class_def])
+
+
+def _looks_like_special_alias(node: Call) -> bool:
+ """Return True if call is for Tuple or Callable alias.
+
+ In PY37 and PY38 the call is to '_VariadicGenericAlias' with 'tuple' as
+ first argument. In PY39+ it is replaced by a call to '_TupleType'.
+
+ PY37: Tuple = _VariadicGenericAlias(tuple, (), inst=False, special=True)
+ PY39: Tuple = _TupleType(tuple, -1, inst=False, name='Tuple')
+
+ PY37: Callable = _VariadicGenericAlias(collections.abc.Callable, (), special=True)
+ PY39: Callable = _CallableType(collections.abc.Callable, 2)
+ """
+ return isinstance(node.func, Name) and (
+ node.func.name == "_TupleType"
+ and isinstance(node.args[0], Name)
+ and node.args[0].name == "tuple"
+ or node.func.name == "_CallableType"
+ and isinstance(node.args[0], Attribute)
+ and node.args[0].as_string() == "collections.abc.Callable"
+ )
+
+
+def infer_special_alias(
+ node: Call, ctx: context.InferenceContext | None = None
+) -> Iterator[ClassDef]:
+ """Infer call to tuple alias as new subscriptable class typing.Tuple."""
+ if not (
+ isinstance(node.parent, Assign)
+ and len(node.parent.targets) == 1
+ and isinstance(node.parent.targets[0], AssignName)
+ ):
+ raise UseInferenceDefault
+ try:
+ res = next(node.args[0].infer(context=ctx))
+ except StopIteration as e:
+ raise InferenceError(node=node.args[0], context=ctx) from e
+
+ assign_name = node.parent.targets[0]
+ class_def = ClassDef(
+ name=assign_name.name,
+ parent=node.parent,
+ lineno=assign_name.lineno,
+ col_offset=assign_name.col_offset,
+ end_lineno=assign_name.end_lineno,
+ end_col_offset=assign_name.end_col_offset,
+ )
+ class_def.postinit(bases=[res], body=[], decorators=None)
+ func_to_add = _extract_single_node(CLASS_GETITEM_TEMPLATE)
+ class_def.locals["__class_getitem__"] = [func_to_add]
+ # Avoid re-instantiating this class every time it's seen
+ node._explicit_inference = lambda node, context: iter([class_def])
+ return iter([class_def])
+
+
+def _looks_like_typing_cast(node: Call) -> bool:
+ return isinstance(node, Call) and (
+ isinstance(node.func, Name)
+ and node.func.name == "cast"
+ or isinstance(node.func, Attribute)
+ and node.func.attrname == "cast"
+ )
+
+
+def infer_typing_cast(
+ node: Call, ctx: context.InferenceContext | None = None
+) -> Iterator[NodeNG]:
+ """Infer call to cast() returning same type as casted-from var."""
+ if not isinstance(node.func, (Name, Attribute)):
+ raise UseInferenceDefault
+
+ try:
+ func = next(node.func.infer(context=ctx))
+ except (InferenceError, StopIteration) as exc:
+ raise UseInferenceDefault from exc
+ if (
+ not isinstance(func, FunctionDef)
+ or func.qname() != "typing.cast"
+ or len(node.args) != 2
+ ):
+ raise UseInferenceDefault
+
+ return node.args[1].infer(context=ctx)
+
+
+def _typing_transform():
+ return AstroidBuilder(AstroidManager()).string_build(
+ textwrap.dedent(
+ """
+ class Generic:
+ @classmethod
+ def __class_getitem__(cls, item): return cls
+ class ParamSpec:
+ @property
+ def args(self):
+ return ParamSpecArgs(self)
+ @property
+ def kwargs(self):
+ return ParamSpecKwargs(self)
+ class ParamSpecArgs: ...
+ class ParamSpecKwargs: ...
+ class TypeAlias: ...
+ class Type:
+ @classmethod
+ def __class_getitem__(cls, item): return cls
+ class TypeVar:
+ @classmethod
+ def __class_getitem__(cls, item): return cls
+ class TypeVarTuple: ...
+ class ContextManager:
+ @classmethod
+ def __class_getitem__(cls, item): return cls
+ class AsyncContextManager:
+ @classmethod
+ def __class_getitem__(cls, item): return cls
+ class Pattern:
+ @classmethod
+ def __class_getitem__(cls, item): return cls
+ class Match:
+ @classmethod
+ def __class_getitem__(cls, item): return cls
+ """
+ )
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ Call,
+ inference_tip(infer_typing_typevar_or_newtype),
+ looks_like_typing_typevar_or_newtype,
+ )
+ manager.register_transform(
+ Subscript, inference_tip(infer_typing_attr), _looks_like_typing_subscript
+ )
+ manager.register_transform(
+ Call, inference_tip(infer_typing_cast), _looks_like_typing_cast
+ )
+
+ manager.register_transform(
+ FunctionDef, inference_tip(infer_typedDict), _looks_like_typedDict
+ )
+
+ manager.register_transform(
+ Call, inference_tip(infer_typing_alias), _looks_like_typing_alias
+ )
+ manager.register_transform(
+ Call, inference_tip(infer_special_alias), _looks_like_special_alias
+ )
+
+ if PY312_PLUS:
+ register_module_extender(manager, "typing", _typing_transform)
+ manager.register_transform(
+ ClassDef,
+ inference_tip(infer_typing_generic_class_pep695),
+ _looks_like_generic_class_pep695,
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_unittest.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_unittest.py
new file mode 100644
index 000000000..a94df0a68
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_unittest.py
@@ -0,0 +1,30 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for unittest module."""
+from astroid.brain.helpers import register_module_extender
+from astroid.builder import parse
+from astroid.manager import AstroidManager
+
+
+def IsolatedAsyncioTestCaseImport():
+ """
+ In the unittest package, the IsolatedAsyncioTestCase class is imported lazily.
+
+ I.E. only when the ``__getattr__`` method of the unittest module is called with
+ 'IsolatedAsyncioTestCase' as argument. Thus the IsolatedAsyncioTestCase
+ is not imported statically (during import time).
+ This function mocks a classical static import of the IsolatedAsyncioTestCase.
+
+ (see https://github.com/pylint-dev/pylint/issues/4060)
+ """
+ return parse(
+ """
+ from .async_case import IsolatedAsyncioTestCase
+ """
+ )
+
+
+def register(manager: AstroidManager) -> None:
+ register_module_extender(manager, "unittest", IsolatedAsyncioTestCaseImport)
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/brain_uuid.py b/solutions/.venv/Lib/site-packages/astroid/brain/brain_uuid.py
new file mode 100644
index 000000000..37800b8e0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/brain_uuid.py
@@ -0,0 +1,19 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Astroid hooks for the UUID module."""
+from astroid.manager import AstroidManager
+from astroid.nodes.node_classes import Const
+from astroid.nodes.scoped_nodes import ClassDef
+
+
+def _patch_uuid_class(node: ClassDef) -> None:
+ # The .int member is patched using __dict__
+ node.locals["int"] = [Const(0, parent=node)]
+
+
+def register(manager: AstroidManager) -> None:
+ manager.register_transform(
+ ClassDef, _patch_uuid_class, lambda node: node.qname() == "uuid.UUID"
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/brain/helpers.py b/solutions/.venv/Lib/site-packages/astroid/brain/helpers.py
new file mode 100644
index 000000000..79d778b5a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/brain/helpers.py
@@ -0,0 +1,131 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from collections.abc import Callable
+
+from astroid.manager import AstroidManager
+from astroid.nodes.scoped_nodes import Module
+
+
+def register_module_extender(
+ manager: AstroidManager, module_name: str, get_extension_mod: Callable[[], Module]
+) -> None:
+ def transform(node: Module) -> None:
+ extension_module = get_extension_mod()
+ for name, objs in extension_module.locals.items():
+ node.locals[name] = objs
+ for obj in objs:
+ if obj.parent is extension_module:
+ obj.parent = node
+
+ manager.register_transform(Module, transform, lambda n: n.name == module_name)
+
+
+# pylint: disable-next=too-many-locals
+def register_all_brains(manager: AstroidManager) -> None:
+ from astroid.brain import ( # pylint: disable=import-outside-toplevel
+ brain_argparse,
+ brain_attrs,
+ brain_boto3,
+ brain_builtin_inference,
+ brain_collections,
+ brain_crypt,
+ brain_ctypes,
+ brain_curses,
+ brain_dataclasses,
+ brain_datetime,
+ brain_dateutil,
+ brain_functools,
+ brain_gi,
+ brain_hashlib,
+ brain_http,
+ brain_hypothesis,
+ brain_io,
+ brain_mechanize,
+ brain_multiprocessing,
+ brain_namedtuple_enum,
+ brain_nose,
+ brain_numpy_core_einsumfunc,
+ brain_numpy_core_fromnumeric,
+ brain_numpy_core_function_base,
+ brain_numpy_core_multiarray,
+ brain_numpy_core_numeric,
+ brain_numpy_core_numerictypes,
+ brain_numpy_core_umath,
+ brain_numpy_ma,
+ brain_numpy_ndarray,
+ brain_numpy_random_mtrand,
+ brain_pathlib,
+ brain_pkg_resources,
+ brain_pytest,
+ brain_qt,
+ brain_random,
+ brain_re,
+ brain_regex,
+ brain_responses,
+ brain_scipy_signal,
+ brain_signal,
+ brain_six,
+ brain_sqlalchemy,
+ brain_ssl,
+ brain_subprocess,
+ brain_threading,
+ brain_type,
+ brain_typing,
+ brain_unittest,
+ brain_uuid,
+ )
+
+ brain_argparse.register(manager)
+ brain_attrs.register(manager)
+ brain_boto3.register(manager)
+ brain_builtin_inference.register(manager)
+ brain_collections.register(manager)
+ brain_crypt.register(manager)
+ brain_ctypes.register(manager)
+ brain_curses.register(manager)
+ brain_dataclasses.register(manager)
+ brain_datetime.register(manager)
+ brain_dateutil.register(manager)
+ brain_functools.register(manager)
+ brain_gi.register(manager)
+ brain_hashlib.register(manager)
+ brain_http.register(manager)
+ brain_hypothesis.register(manager)
+ brain_io.register(manager)
+ brain_mechanize.register(manager)
+ brain_multiprocessing.register(manager)
+ brain_namedtuple_enum.register(manager)
+ brain_nose.register(manager)
+ brain_numpy_core_einsumfunc.register(manager)
+ brain_numpy_core_fromnumeric.register(manager)
+ brain_numpy_core_function_base.register(manager)
+ brain_numpy_core_multiarray.register(manager)
+ brain_numpy_core_numerictypes.register(manager)
+ brain_numpy_core_umath.register(manager)
+ brain_numpy_random_mtrand.register(manager)
+ brain_numpy_ma.register(manager)
+ brain_numpy_ndarray.register(manager)
+ brain_numpy_core_numeric.register(manager)
+ brain_pathlib.register(manager)
+ brain_pkg_resources.register(manager)
+ brain_pytest.register(manager)
+ brain_qt.register(manager)
+ brain_random.register(manager)
+ brain_re.register(manager)
+ brain_regex.register(manager)
+ brain_responses.register(manager)
+ brain_scipy_signal.register(manager)
+ brain_signal.register(manager)
+ brain_six.register(manager)
+ brain_sqlalchemy.register(manager)
+ brain_ssl.register(manager)
+ brain_subprocess.register(manager)
+ brain_threading.register(manager)
+ brain_type.register(manager)
+ brain_typing.register(manager)
+ brain_unittest.register(manager)
+ brain_uuid.register(manager)
diff --git a/solutions/.venv/Lib/site-packages/astroid/builder.py b/solutions/.venv/Lib/site-packages/astroid/builder.py
new file mode 100644
index 000000000..f4be6972b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/builder.py
@@ -0,0 +1,491 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""The AstroidBuilder makes astroid from living object and / or from _ast.
+
+The builder is not thread safe and can't be used to parse different sources
+at the same time.
+"""
+
+from __future__ import annotations
+
+import ast
+import os
+import re
+import textwrap
+import types
+import warnings
+from collections.abc import Iterator, Sequence
+from io import TextIOWrapper
+from tokenize import detect_encoding
+
+from astroid import bases, modutils, nodes, raw_building, rebuilder, util
+from astroid._ast import ParserModule, get_parser_module
+from astroid.const import PY312_PLUS
+from astroid.exceptions import AstroidBuildingError, AstroidSyntaxError, InferenceError
+from astroid.manager import AstroidManager
+
+# The name of the transient function that is used to
+# wrap expressions to be extracted when calling
+# extract_node.
+_TRANSIENT_FUNCTION = "__"
+
+# The comment used to select a statement to be extracted
+# when calling extract_node.
+_STATEMENT_SELECTOR = "#@"
+
+if PY312_PLUS:
+ warnings.filterwarnings("ignore", "invalid escape sequence", SyntaxWarning)
+
+
+def open_source_file(filename: str) -> tuple[TextIOWrapper, str, str]:
+ # pylint: disable=consider-using-with
+ with open(filename, "rb") as byte_stream:
+ encoding = detect_encoding(byte_stream.readline)[0]
+ stream = open(filename, newline=None, encoding=encoding)
+ data = stream.read()
+ return stream, encoding, data
+
+
+def _can_assign_attr(node: nodes.ClassDef, attrname: str | None) -> bool:
+ try:
+ slots = node.slots()
+ except NotImplementedError:
+ pass
+ else:
+ if slots and attrname not in {slot.value for slot in slots}:
+ return False
+ return node.qname() != "builtins.object"
+
+
+class AstroidBuilder(raw_building.InspectBuilder):
+ """Class for building an astroid tree from source code or from a live module.
+
+ The param *manager* specifies the manager class which should be used.
+ If no manager is given, then the default one will be used. The
+ param *apply_transforms* determines if the transforms should be
+ applied after the tree was built from source or from a live object,
+ by default being True.
+ """
+
+ def __init__(
+ self, manager: AstroidManager | None = None, apply_transforms: bool = True
+ ) -> None:
+ super().__init__(manager)
+ self._apply_transforms = apply_transforms
+ if not raw_building.InspectBuilder.bootstrapped:
+ raw_building._astroid_bootstrapping()
+
+ def module_build(
+ self, module: types.ModuleType, modname: str | None = None
+ ) -> nodes.Module:
+ """Build an astroid from a living module instance."""
+ node = None
+ path = getattr(module, "__file__", None)
+ loader = getattr(module, "__loader__", None)
+ # Prefer the loader to get the source rather than assuming we have a
+ # filesystem to read the source file from ourselves.
+ if loader:
+ modname = modname or module.__name__
+ source = loader.get_source(modname)
+ if source:
+ node = self.string_build(source, modname, path=path)
+ if node is None and path is not None:
+ path_, ext = os.path.splitext(modutils._path_from_filename(path))
+ if ext in {".py", ".pyc", ".pyo"} and os.path.exists(path_ + ".py"):
+ node = self.file_build(path_ + ".py", modname)
+ if node is None:
+ # this is a built-in module
+ # get a partial representation by introspection
+ node = self.inspect_build(module, modname=modname, path=path)
+ if self._apply_transforms:
+ # We have to handle transformation by ourselves since the
+ # rebuilder isn't called for builtin nodes
+ node = self._manager.visit_transforms(node)
+ assert isinstance(node, nodes.Module)
+ return node
+
+ def file_build(self, path: str, modname: str | None = None) -> nodes.Module:
+ """Build astroid from a source code file (i.e. from an ast).
+
+ *path* is expected to be a python source file
+ """
+ try:
+ stream, encoding, data = open_source_file(path)
+ except OSError as exc:
+ raise AstroidBuildingError(
+ "Unable to load file {path}:\n{error}",
+ modname=modname,
+ path=path,
+ error=exc,
+ ) from exc
+ except (SyntaxError, LookupError) as exc:
+ raise AstroidSyntaxError(
+ "Python 3 encoding specification error or unknown encoding:\n"
+ "{error}",
+ modname=modname,
+ path=path,
+ error=exc,
+ ) from exc
+ except UnicodeError as exc: # wrong encoding
+ # detect_encoding returns utf-8 if no encoding specified
+ raise AstroidBuildingError(
+ "Wrong or no encoding specified for {filename}.", filename=path
+ ) from exc
+ with stream:
+ # get module name if necessary
+ if modname is None:
+ try:
+ modname = ".".join(modutils.modpath_from_file(path))
+ except ImportError:
+ modname = os.path.splitext(os.path.basename(path))[0]
+ # build astroid representation
+ module, builder = self._data_build(data, modname, path)
+ return self._post_build(module, builder, encoding)
+
+ def string_build(
+ self, data: str, modname: str = "", path: str | None = None
+ ) -> nodes.Module:
+ """Build astroid from source code string."""
+ module, builder = self._data_build(data, modname, path)
+ module.file_bytes = data.encode("utf-8")
+ return self._post_build(module, builder, "utf-8")
+
+ def _post_build(
+ self, module: nodes.Module, builder: rebuilder.TreeRebuilder, encoding: str
+ ) -> nodes.Module:
+ """Handles encoding and delayed nodes after a module has been built."""
+ module.file_encoding = encoding
+ self._manager.cache_module(module)
+ # post tree building steps after we stored the module in the cache:
+ for from_node in builder._import_from_nodes:
+ if from_node.modname == "__future__":
+ for symbol, _ in from_node.names:
+ module.future_imports.add(symbol)
+ self.add_from_names_to_locals(from_node)
+ # handle delayed assattr nodes
+ for delayed in builder._delayed_assattr:
+ self.delayed_assattr(delayed)
+
+ # Visit the transforms
+ if self._apply_transforms:
+ module = self._manager.visit_transforms(module)
+ return module
+
+ def _data_build(
+ self, data: str, modname: str, path: str | None
+ ) -> tuple[nodes.Module, rebuilder.TreeRebuilder]:
+ """Build tree node from data and add some informations."""
+ try:
+ node, parser_module = _parse_string(
+ data, type_comments=True, modname=modname
+ )
+ except (TypeError, ValueError, SyntaxError) as exc:
+ raise AstroidSyntaxError(
+ "Parsing Python code failed:\n{error}",
+ source=data,
+ modname=modname,
+ path=path,
+ error=exc,
+ ) from exc
+
+ if path is not None:
+ node_file = os.path.abspath(path)
+ else:
+ node_file = "<?>"
+ if modname.endswith(".__init__"):
+ modname = modname[:-9]
+ package = True
+ else:
+ package = (
+ path is not None
+ and os.path.splitext(os.path.basename(path))[0] == "__init__"
+ )
+ builder = rebuilder.TreeRebuilder(self._manager, parser_module, data)
+ module = builder.visit_module(node, modname, node_file, package)
+ return module, builder
+
+ def add_from_names_to_locals(self, node: nodes.ImportFrom) -> None:
+ """Store imported names to the locals.
+
+ Resort the locals if coming from a delayed node
+ """
+
+ def _key_func(node: nodes.NodeNG) -> int:
+ return node.fromlineno or 0
+
+ def sort_locals(my_list: list[nodes.NodeNG]) -> None:
+ my_list.sort(key=_key_func)
+
+ assert node.parent # It should always default to the module
+ for name, asname in node.names:
+ if name == "*":
+ try:
+ imported = node.do_import_module()
+ except AstroidBuildingError:
+ continue
+ for name in imported.public_names():
+ node.parent.set_local(name, node)
+ sort_locals(node.parent.scope().locals[name]) # type: ignore[arg-type]
+ else:
+ node.parent.set_local(asname or name, node)
+ sort_locals(node.parent.scope().locals[asname or name]) # type: ignore[arg-type]
+
+ def delayed_assattr(self, node: nodes.AssignAttr) -> None:
+ """Visit a AssAttr node.
+
+ This adds name to locals and handle members definition.
+ """
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ try:
+ for inferred in node.expr.infer():
+ if isinstance(inferred, util.UninferableBase):
+ continue
+ try:
+ # pylint: disable=unidiomatic-typecheck # We want a narrow check on the
+ # parent type, not all of its subclasses
+ if type(inferred) in {bases.Instance, objects.ExceptionInstance}:
+ inferred = inferred._proxied
+ iattrs = inferred.instance_attrs
+ if not _can_assign_attr(inferred, node.attrname):
+ continue
+ elif isinstance(inferred, bases.Instance):
+ # Const, Tuple or other containers that inherit from
+ # `Instance`
+ continue
+ elif isinstance(inferred, (bases.Proxy, util.UninferableBase)):
+ continue
+ elif inferred.is_function:
+ iattrs = inferred.instance_attrs
+ else:
+ iattrs = inferred.locals
+ except AttributeError:
+ # XXX log error
+ continue
+ values = iattrs.setdefault(node.attrname, [])
+ if node in values:
+ continue
+ values.append(node)
+ except InferenceError:
+ pass
+
+
+def build_namespace_package_module(name: str, path: Sequence[str]) -> nodes.Module:
+ module = nodes.Module(name, path=path, package=True)
+ module.postinit(body=[], doc_node=None)
+ return module
+
+
+def parse(
+ code: str,
+ module_name: str = "",
+ path: str | None = None,
+ apply_transforms: bool = True,
+) -> nodes.Module:
+ """Parses a source string in order to obtain an astroid AST from it.
+
+ :param str code: The code for the module.
+ :param str module_name: The name for the module, if any
+ :param str path: The path for the module
+ :param bool apply_transforms:
+ Apply the transforms for the give code. Use it if you
+ don't want the default transforms to be applied.
+ """
+ code = textwrap.dedent(code)
+ builder = AstroidBuilder(
+ manager=AstroidManager(), apply_transforms=apply_transforms
+ )
+ return builder.string_build(code, modname=module_name, path=path)
+
+
+def _extract_expressions(node: nodes.NodeNG) -> Iterator[nodes.NodeNG]:
+ """Find expressions in a call to _TRANSIENT_FUNCTION and extract them.
+
+ The function walks the AST recursively to search for expressions that
+ are wrapped into a call to _TRANSIENT_FUNCTION. If it finds such an
+ expression, it completely removes the function call node from the tree,
+ replacing it by the wrapped expression inside the parent.
+
+ :param node: An astroid node.
+ :type node: astroid.bases.NodeNG
+ :yields: The sequence of wrapped expressions on the modified tree
+ expression can be found.
+ """
+ if (
+ isinstance(node, nodes.Call)
+ and isinstance(node.func, nodes.Name)
+ and node.func.name == _TRANSIENT_FUNCTION
+ ):
+ real_expr = node.args[0]
+ assert node.parent
+ real_expr.parent = node.parent
+ # Search for node in all _astng_fields (the fields checked when
+ # get_children is called) of its parent. Some of those fields may
+ # be lists or tuples, in which case the elements need to be checked.
+ # When we find it, replace it by real_expr, so that the AST looks
+ # like no call to _TRANSIENT_FUNCTION ever took place.
+ for name in node.parent._astroid_fields:
+ child = getattr(node.parent, name)
+ if isinstance(child, list):
+ for idx, compound_child in enumerate(child):
+ if compound_child is node:
+ child[idx] = real_expr
+ elif child is node:
+ setattr(node.parent, name, real_expr)
+ yield real_expr
+ else:
+ for child in node.get_children():
+ yield from _extract_expressions(child)
+
+
+def _find_statement_by_line(node: nodes.NodeNG, line: int) -> nodes.NodeNG | None:
+ """Extracts the statement on a specific line from an AST.
+
+ If the line number of node matches line, it will be returned;
+ otherwise its children are iterated and the function is called
+ recursively.
+
+ :param node: An astroid node.
+ :type node: astroid.bases.NodeNG
+ :param line: The line number of the statement to extract.
+ :type line: int
+ :returns: The statement on the line, or None if no statement for the line
+ can be found.
+ :rtype: astroid.bases.NodeNG or None
+ """
+ if isinstance(node, (nodes.ClassDef, nodes.FunctionDef, nodes.MatchCase)):
+ # This is an inaccuracy in the AST: the nodes that can be
+ # decorated do not carry explicit information on which line
+ # the actual definition (class/def), but .fromline seems to
+ # be close enough.
+ node_line = node.fromlineno
+ else:
+ node_line = node.lineno
+
+ if node_line == line:
+ return node
+
+ for child in node.get_children():
+ result = _find_statement_by_line(child, line)
+ if result:
+ return result
+
+ return None
+
+
+def extract_node(code: str, module_name: str = "") -> nodes.NodeNG | list[nodes.NodeNG]:
+ """Parses some Python code as a module and extracts a designated AST node.
+
+ Statements:
+ To extract one or more statement nodes, append #@ to the end of the line
+
+ Examples:
+ >>> def x():
+ >>> def y():
+ >>> return 1 #@
+
+ The return statement will be extracted.
+
+ >>> class X(object):
+ >>> def meth(self): #@
+ >>> pass
+
+ The function object 'meth' will be extracted.
+
+ Expressions:
+ To extract arbitrary expressions, surround them with the fake
+ function call __(...). After parsing, the surrounded expression
+ will be returned and the whole AST (accessible via the returned
+ node's parent attribute) will look like the function call was
+ never there in the first place.
+
+ Examples:
+ >>> a = __(1)
+
+ The const node will be extracted.
+
+ >>> def x(d=__(foo.bar)): pass
+
+ The node containing the default argument will be extracted.
+
+ >>> def foo(a, b):
+ >>> return 0 < __(len(a)) < b
+
+ The node containing the function call 'len' will be extracted.
+
+ If no statements or expressions are selected, the last toplevel
+ statement will be returned.
+
+ If the selected statement is a discard statement, (i.e. an expression
+ turned into a statement), the wrapped expression is returned instead.
+
+ For convenience, singleton lists are unpacked.
+
+ :param str code: A piece of Python code that is parsed as
+ a module. Will be passed through textwrap.dedent first.
+ :param str module_name: The name of the module.
+ :returns: The designated node from the parse tree, or a list of nodes.
+ """
+
+ def _extract(node: nodes.NodeNG | None) -> nodes.NodeNG | None:
+ if isinstance(node, nodes.Expr):
+ return node.value
+
+ return node
+
+ requested_lines: list[int] = []
+ for idx, line in enumerate(code.splitlines()):
+ if line.strip().endswith(_STATEMENT_SELECTOR):
+ requested_lines.append(idx + 1)
+
+ tree = parse(code, module_name=module_name)
+ if not tree.body:
+ raise ValueError("Empty tree, cannot extract from it")
+
+ extracted: list[nodes.NodeNG | None] = []
+ if requested_lines:
+ extracted = [_find_statement_by_line(tree, line) for line in requested_lines]
+
+ # Modifies the tree.
+ extracted.extend(_extract_expressions(tree))
+
+ if not extracted:
+ extracted.append(tree.body[-1])
+
+ extracted = [_extract(node) for node in extracted]
+ extracted_without_none = [node for node in extracted if node is not None]
+ if len(extracted_without_none) == 1:
+ return extracted_without_none[0]
+ return extracted_without_none
+
+
+def _extract_single_node(code: str, module_name: str = "") -> nodes.NodeNG:
+ """Call extract_node while making sure that only one value is returned."""
+ ret = extract_node(code, module_name)
+ if isinstance(ret, list):
+ return ret[0]
+ return ret
+
+
+def _parse_string(
+ data: str, type_comments: bool = True, modname: str | None = None
+) -> tuple[ast.Module, ParserModule]:
+ parser_module = get_parser_module(type_comments=type_comments)
+ try:
+ parsed = parser_module.parse(
+ data + "\n", type_comments=type_comments, filename=modname
+ )
+ except SyntaxError as exc:
+ # If the type annotations are misplaced for some reason, we do not want
+ # to fail the entire parsing of the file, so we need to retry the
+ # parsing without type comment support. We use a heuristic for
+ # determining if the error is due to type annotations.
+ type_annot_related = re.search(r"#\s+type:", exc.text or "")
+ if not (type_annot_related and type_comments):
+ raise
+
+ parser_module = get_parser_module(type_comments=False)
+ parsed = parser_module.parse(data + "\n", type_comments=False)
+ return parsed, parser_module
diff --git a/solutions/.venv/Lib/site-packages/astroid/const.py b/solutions/.venv/Lib/site-packages/astroid/const.py
new file mode 100644
index 000000000..c01081806
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/const.py
@@ -0,0 +1,25 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+import enum
+import sys
+
+PY310_PLUS = sys.version_info >= (3, 10)
+PY311_PLUS = sys.version_info >= (3, 11)
+PY312_PLUS = sys.version_info >= (3, 12)
+PY313_PLUS = sys.version_info >= (3, 13)
+
+WIN32 = sys.platform == "win32"
+
+IS_PYPY = sys.implementation.name == "pypy"
+IS_JYTHON = sys.implementation.name == "jython"
+
+
+class Context(enum.Enum):
+ Load = 1
+ Store = 2
+ Del = 3
+
+
+_EMPTY_OBJECT_MARKER = object()
diff --git a/solutions/.venv/Lib/site-packages/astroid/constraint.py b/solutions/.venv/Lib/site-packages/astroid/constraint.py
new file mode 100644
index 000000000..08bb80e3c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/constraint.py
@@ -0,0 +1,140 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Classes representing different types of constraints on inference values."""
+from __future__ import annotations
+
+import sys
+from abc import ABC, abstractmethod
+from collections.abc import Iterator
+from typing import TYPE_CHECKING, Union
+
+from astroid import nodes, util
+from astroid.typing import InferenceResult
+
+if sys.version_info >= (3, 11):
+ from typing import Self
+else:
+ from typing_extensions import Self
+
+if TYPE_CHECKING:
+ from astroid import bases
+
+_NameNodes = Union[nodes.AssignAttr, nodes.Attribute, nodes.AssignName, nodes.Name]
+
+
+class Constraint(ABC):
+ """Represents a single constraint on a variable."""
+
+ def __init__(self, node: nodes.NodeNG, negate: bool) -> None:
+ self.node = node
+ """The node that this constraint applies to."""
+ self.negate = negate
+ """True if this constraint is negated. E.g., "is not" instead of "is"."""
+
+ @classmethod
+ @abstractmethod
+ def match(
+ cls, node: _NameNodes, expr: nodes.NodeNG, negate: bool = False
+ ) -> Self | None:
+ """Return a new constraint for node matched from expr, if expr matches
+ the constraint pattern.
+
+ If negate is True, negate the constraint.
+ """
+
+ @abstractmethod
+ def satisfied_by(self, inferred: InferenceResult) -> bool:
+ """Return True if this constraint is satisfied by the given inferred value."""
+
+
+class NoneConstraint(Constraint):
+ """Represents an "is None" or "is not None" constraint."""
+
+ CONST_NONE: nodes.Const = nodes.Const(None)
+
+ @classmethod
+ def match(
+ cls, node: _NameNodes, expr: nodes.NodeNG, negate: bool = False
+ ) -> Self | None:
+ """Return a new constraint for node matched from expr, if expr matches
+ the constraint pattern.
+
+ Negate the constraint based on the value of negate.
+ """
+ if isinstance(expr, nodes.Compare) and len(expr.ops) == 1:
+ left = expr.left
+ op, right = expr.ops[0]
+ if op in {"is", "is not"} and (
+ _matches(left, node) and _matches(right, cls.CONST_NONE)
+ ):
+ negate = (op == "is" and negate) or (op == "is not" and not negate)
+ return cls(node=node, negate=negate)
+
+ return None
+
+ def satisfied_by(self, inferred: InferenceResult) -> bool:
+ """Return True if this constraint is satisfied by the given inferred value."""
+ # Assume true if uninferable
+ if isinstance(inferred, util.UninferableBase):
+ return True
+
+ # Return the XOR of self.negate and matches(inferred, self.CONST_NONE)
+ return self.negate ^ _matches(inferred, self.CONST_NONE)
+
+
+def get_constraints(
+ expr: _NameNodes, frame: nodes.LocalsDictNodeNG
+) -> dict[nodes.If, set[Constraint]]:
+ """Returns the constraints for the given expression.
+
+ The returned dictionary maps the node where the constraint was generated to the
+ corresponding constraint(s).
+
+ Constraints are computed statically by analysing the code surrounding expr.
+ Currently this only supports constraints generated from if conditions.
+ """
+ current_node: nodes.NodeNG | None = expr
+ constraints_mapping: dict[nodes.If, set[Constraint]] = {}
+ while current_node is not None and current_node is not frame:
+ parent = current_node.parent
+ if isinstance(parent, nodes.If):
+ branch, _ = parent.locate_child(current_node)
+ constraints: set[Constraint] | None = None
+ if branch == "body":
+ constraints = set(_match_constraint(expr, parent.test))
+ elif branch == "orelse":
+ constraints = set(_match_constraint(expr, parent.test, invert=True))
+
+ if constraints:
+ constraints_mapping[parent] = constraints
+ current_node = parent
+
+ return constraints_mapping
+
+
+ALL_CONSTRAINT_CLASSES = frozenset((NoneConstraint,))
+"""All supported constraint types."""
+
+
+def _matches(node1: nodes.NodeNG | bases.Proxy, node2: nodes.NodeNG) -> bool:
+ """Returns True if the two nodes match."""
+ if isinstance(node1, nodes.Name) and isinstance(node2, nodes.Name):
+ return node1.name == node2.name
+ if isinstance(node1, nodes.Attribute) and isinstance(node2, nodes.Attribute):
+ return node1.attrname == node2.attrname and _matches(node1.expr, node2.expr)
+ if isinstance(node1, nodes.Const) and isinstance(node2, nodes.Const):
+ return node1.value == node2.value
+
+ return False
+
+
+def _match_constraint(
+ node: _NameNodes, expr: nodes.NodeNG, invert: bool = False
+) -> Iterator[Constraint]:
+ """Yields all constraint patterns for node that match."""
+ for constraint_cls in ALL_CONSTRAINT_CLASSES:
+ constraint = constraint_cls.match(node, expr, invert)
+ if constraint:
+ yield constraint
diff --git a/solutions/.venv/Lib/site-packages/astroid/context.py b/solutions/.venv/Lib/site-packages/astroid/context.py
new file mode 100644
index 000000000..0b8c259fc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/context.py
@@ -0,0 +1,203 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Various context related utilities, including inference and call contexts."""
+
+from __future__ import annotations
+
+import contextlib
+import pprint
+from collections.abc import Iterator, Sequence
+from typing import TYPE_CHECKING, Optional
+
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+if TYPE_CHECKING:
+ from astroid import constraint, nodes
+ from astroid.nodes.node_classes import Keyword, NodeNG
+
+_InferenceCache = dict[
+ tuple["NodeNG", Optional[str], Optional[str], Optional[str]], Sequence["NodeNG"]
+]
+
+_INFERENCE_CACHE: _InferenceCache = {}
+
+
+def _invalidate_cache() -> None:
+ _INFERENCE_CACHE.clear()
+
+
+class InferenceContext:
+ """Provide context for inference.
+
+ Store already inferred nodes to save time
+ Account for already visited nodes to stop infinite recursion
+ """
+
+ __slots__ = (
+ "path",
+ "lookupname",
+ "callcontext",
+ "boundnode",
+ "extra_context",
+ "constraints",
+ "_nodes_inferred",
+ )
+
+ max_inferred = 100
+
+ def __init__(
+ self,
+ path: set[tuple[nodes.NodeNG, str | None]] | None = None,
+ nodes_inferred: list[int] | None = None,
+ ) -> None:
+ if nodes_inferred is None:
+ self._nodes_inferred = [0]
+ else:
+ self._nodes_inferred = nodes_inferred
+
+ self.path = path or set()
+ """Path of visited nodes and their lookupname.
+
+ Currently this key is ``(node, context.lookupname)``
+ """
+ self.lookupname: str | None = None
+ """The original name of the node.
+
+ e.g.
+ foo = 1
+ The inference of 'foo' is nodes.Const(1) but the lookup name is 'foo'
+ """
+ self.callcontext: CallContext | None = None
+ """The call arguments and keywords for the given context."""
+ self.boundnode: SuccessfulInferenceResult | None = None
+ """The bound node of the given context.
+
+ e.g. the bound node of object.__new__(cls) is the object node
+ """
+ self.extra_context: dict[SuccessfulInferenceResult, InferenceContext] = {}
+ """Context that needs to be passed down through call stacks for call arguments."""
+
+ self.constraints: dict[str, dict[nodes.If, set[constraint.Constraint]]] = {}
+ """The constraints on nodes."""
+
+ @property
+ def nodes_inferred(self) -> int:
+ """
+ Number of nodes inferred in this context and all its clones/descendents.
+
+ Wrap inner value in a mutable cell to allow for mutating a class
+ variable in the presence of __slots__
+ """
+ return self._nodes_inferred[0]
+
+ @nodes_inferred.setter
+ def nodes_inferred(self, value: int) -> None:
+ self._nodes_inferred[0] = value
+
+ @property
+ def inferred(self) -> _InferenceCache:
+ """
+ Inferred node contexts to their mapped results.
+
+ Currently the key is ``(node, lookupname, callcontext, boundnode)``
+ and the value is tuple of the inferred results
+ """
+ return _INFERENCE_CACHE
+
+ def push(self, node: nodes.NodeNG) -> bool:
+ """Push node into inference path.
+
+ Allows one to see if the given node has already
+ been looked at for this inference context
+ """
+ name = self.lookupname
+ if (node, name) in self.path:
+ return True
+
+ self.path.add((node, name))
+ return False
+
+ def clone(self) -> InferenceContext:
+ """Clone inference path.
+
+ For example, each side of a binary operation (BinOp)
+ starts with the same context but diverge as each side is inferred
+ so the InferenceContext will need be cloned
+ """
+ # XXX copy lookupname/callcontext ?
+ clone = InferenceContext(self.path.copy(), nodes_inferred=self._nodes_inferred)
+ clone.callcontext = self.callcontext
+ clone.boundnode = self.boundnode
+ clone.extra_context = self.extra_context
+ clone.constraints = self.constraints.copy()
+ return clone
+
+ @contextlib.contextmanager
+ def restore_path(self) -> Iterator[None]:
+ path = set(self.path)
+ yield
+ self.path = path
+
+ def is_empty(self) -> bool:
+ return (
+ not self.path
+ and not self.nodes_inferred
+ and not self.callcontext
+ and not self.boundnode
+ and not self.lookupname
+ and not self.callcontext
+ and not self.extra_context
+ and not self.constraints
+ )
+
+ def __str__(self) -> str:
+ state = (
+ f"{field}={pprint.pformat(getattr(self, field), width=80 - len(field))}"
+ for field in self.__slots__
+ )
+ return "{}({})".format(type(self).__name__, ",\n ".join(state))
+
+
+class CallContext:
+ """Holds information for a call site."""
+
+ __slots__ = ("args", "keywords", "callee")
+
+ def __init__(
+ self,
+ args: list[NodeNG],
+ keywords: list[Keyword] | None = None,
+ callee: InferenceResult | None = None,
+ ):
+ self.args = args # Call positional arguments
+ if keywords:
+ arg_value_pairs = [(arg.arg, arg.value) for arg in keywords]
+ else:
+ arg_value_pairs = []
+ self.keywords = arg_value_pairs # Call keyword arguments
+ self.callee = callee # Function being called
+
+
+def copy_context(context: InferenceContext | None) -> InferenceContext:
+ """Clone a context if given, or return a fresh context."""
+ if context is not None:
+ return context.clone()
+
+ return InferenceContext()
+
+
+def bind_context_to_node(
+ context: InferenceContext | None, node: SuccessfulInferenceResult
+) -> InferenceContext:
+ """Give a context a boundnode
+ to retrieve the correct function name or attribute value
+ with from further inference.
+
+ Do not use an existing context since the boundnode could then
+ be incorrectly propagated higher up in the call stack.
+ """
+ context = copy_context(context)
+ context.boundnode = node
+ return context
diff --git a/solutions/.venv/Lib/site-packages/astroid/decorators.py b/solutions/.venv/Lib/site-packages/astroid/decorators.py
new file mode 100644
index 000000000..6c8b1bac3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/decorators.py
@@ -0,0 +1,234 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""A few useful function/method decorators."""
+
+from __future__ import annotations
+
+import functools
+import inspect
+import sys
+import warnings
+from collections.abc import Callable, Generator
+from typing import TypeVar
+
+from astroid import util
+from astroid.context import InferenceContext
+from astroid.exceptions import InferenceError
+from astroid.typing import InferenceResult
+
+if sys.version_info >= (3, 10):
+ from typing import ParamSpec
+else:
+ from typing_extensions import ParamSpec
+
+_R = TypeVar("_R")
+_P = ParamSpec("_P")
+
+
+def path_wrapper(func):
+ """Return the given infer function wrapped to handle the path.
+
+ Used to stop inference if the node has already been looked
+ at for a given `InferenceContext` to prevent infinite recursion
+ """
+
+ @functools.wraps(func)
+ def wrapped(
+ node, context: InferenceContext | None = None, _func=func, **kwargs
+ ) -> Generator:
+ """Wrapper function handling context."""
+ if context is None:
+ context = InferenceContext()
+ if context.push(node):
+ return
+
+ yielded = set()
+
+ for res in _func(node, context, **kwargs):
+ # unproxy only true instance, not const, tuple, dict...
+ if res.__class__.__name__ == "Instance":
+ ares = res._proxied
+ else:
+ ares = res
+ if ares not in yielded:
+ yield res
+ yielded.add(ares)
+
+ return wrapped
+
+
+def yes_if_nothing_inferred(
+ func: Callable[_P, Generator[InferenceResult]]
+) -> Callable[_P, Generator[InferenceResult]]:
+ def inner(*args: _P.args, **kwargs: _P.kwargs) -> Generator[InferenceResult]:
+ generator = func(*args, **kwargs)
+
+ try:
+ yield next(generator)
+ except StopIteration:
+ # generator is empty
+ yield util.Uninferable
+ return
+
+ yield from generator
+
+ return inner
+
+
+def raise_if_nothing_inferred(
+ func: Callable[_P, Generator[InferenceResult]],
+) -> Callable[_P, Generator[InferenceResult]]:
+ def inner(*args: _P.args, **kwargs: _P.kwargs) -> Generator[InferenceResult]:
+ generator = func(*args, **kwargs)
+ try:
+ yield next(generator)
+ except StopIteration as error:
+ # generator is empty
+ if error.args:
+ raise InferenceError(**error.args[0]) from error
+ raise InferenceError(
+ "StopIteration raised without any error information."
+ ) from error
+ except RecursionError as error:
+ raise InferenceError(
+ f"RecursionError raised with limit {sys.getrecursionlimit()}."
+ ) from error
+
+ yield from generator
+
+ return inner
+
+
+# Expensive decorators only used to emit Deprecation warnings.
+# If no other than the default DeprecationWarning are enabled,
+# fall back to passthrough implementations.
+if util.check_warnings_filter(): # noqa: C901
+
+ def deprecate_default_argument_values(
+ astroid_version: str = "3.0", **arguments: str
+ ) -> Callable[[Callable[_P, _R]], Callable[_P, _R]]:
+ """Decorator which emits a DeprecationWarning if any arguments specified
+ are None or not passed at all.
+
+ Arguments should be a key-value mapping, with the key being the argument to check
+ and the value being a type annotation as string for the value of the argument.
+
+ To improve performance, only used when DeprecationWarnings other than
+ the default one are enabled.
+ """
+ # Helpful links
+ # Decorator for DeprecationWarning: https://stackoverflow.com/a/49802489
+ # Typing of stacked decorators: https://stackoverflow.com/a/68290080
+
+ def deco(func: Callable[_P, _R]) -> Callable[_P, _R]:
+ """Decorator function."""
+
+ @functools.wraps(func)
+ def wrapper(*args: _P.args, **kwargs: _P.kwargs) -> _R:
+ """Emit DeprecationWarnings if conditions are met."""
+
+ keys = list(inspect.signature(func).parameters.keys())
+ for arg, type_annotation in arguments.items():
+ try:
+ index = keys.index(arg)
+ except ValueError:
+ raise ValueError(
+ f"Can't find argument '{arg}' for '{args[0].__class__.__qualname__}'"
+ ) from None
+ if (
+ # Check kwargs
+ # - if found, check it's not None
+ (arg in kwargs and kwargs[arg] is None)
+ # Check args
+ # - make sure not in kwargs
+ # - len(args) needs to be long enough, if too short
+ # arg can't be in args either
+ # - args[index] should not be None
+ or arg not in kwargs
+ and (
+ index == -1
+ or len(args) <= index
+ or (len(args) > index and args[index] is None)
+ )
+ ):
+ warnings.warn(
+ f"'{arg}' will be a required argument for "
+ f"'{args[0].__class__.__qualname__}.{func.__name__}'"
+ f" in astroid {astroid_version} "
+ f"('{arg}' should be of type: '{type_annotation}')",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ return func(*args, **kwargs)
+
+ return wrapper
+
+ return deco
+
+ def deprecate_arguments(
+ astroid_version: str = "3.0", **arguments: str
+ ) -> Callable[[Callable[_P, _R]], Callable[_P, _R]]:
+ """Decorator which emits a DeprecationWarning if any arguments specified
+ are passed.
+
+ Arguments should be a key-value mapping, with the key being the argument to check
+ and the value being a string that explains what to do instead of passing the argument.
+
+ To improve performance, only used when DeprecationWarnings other than
+ the default one are enabled.
+ """
+
+ def deco(func: Callable[_P, _R]) -> Callable[_P, _R]:
+ @functools.wraps(func)
+ def wrapper(*args: _P.args, **kwargs: _P.kwargs) -> _R:
+ keys = list(inspect.signature(func).parameters.keys())
+ for arg, note in arguments.items():
+ try:
+ index = keys.index(arg)
+ except ValueError:
+ raise ValueError(
+ f"Can't find argument '{arg}' for '{args[0].__class__.__qualname__}'"
+ ) from None
+ if arg in kwargs or len(args) > index:
+ warnings.warn(
+ f"The argument '{arg}' for "
+ f"'{args[0].__class__.__qualname__}.{func.__name__}' is deprecated "
+ f"and will be removed in astroid {astroid_version} ({note})",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ return func(*args, **kwargs)
+
+ return wrapper
+
+ return deco
+
+else:
+
+ def deprecate_default_argument_values(
+ astroid_version: str = "3.0", **arguments: str
+ ) -> Callable[[Callable[_P, _R]], Callable[_P, _R]]:
+ """Passthrough decorator to improve performance if DeprecationWarnings are
+ disabled.
+ """
+
+ def deco(func: Callable[_P, _R]) -> Callable[_P, _R]:
+ """Decorator function."""
+ return func
+
+ return deco
+
+ def deprecate_arguments(
+ astroid_version: str = "3.0", **arguments: str
+ ) -> Callable[[Callable[_P, _R]], Callable[_P, _R]]:
+ """Passthrough decorator to improve performance if DeprecationWarnings are
+ disabled.
+ """
+
+ def deco(func: Callable[_P, _R]) -> Callable[_P, _R]:
+ """Decorator function."""
+ return func
+
+ return deco
diff --git a/solutions/.venv/Lib/site-packages/astroid/exceptions.py b/solutions/.venv/Lib/site-packages/astroid/exceptions.py
new file mode 100644
index 000000000..126acb954
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/exceptions.py
@@ -0,0 +1,416 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains exceptions used in the astroid library."""
+
+from __future__ import annotations
+
+from collections.abc import Iterable, Iterator
+from typing import TYPE_CHECKING, Any
+
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+if TYPE_CHECKING:
+ from astroid import arguments, bases, nodes, objects
+ from astroid.context import InferenceContext
+
+__all__ = (
+ "AstroidBuildingError",
+ "AstroidError",
+ "AstroidImportError",
+ "AstroidIndexError",
+ "AstroidSyntaxError",
+ "AstroidTypeError",
+ "AstroidValueError",
+ "AttributeInferenceError",
+ "DuplicateBasesError",
+ "InconsistentMroError",
+ "InferenceError",
+ "InferenceOverwriteError",
+ "MroError",
+ "NameInferenceError",
+ "NoDefault",
+ "NotFoundError",
+ "ParentMissingError",
+ "ResolveError",
+ "StatementMissing",
+ "SuperArgumentTypeError",
+ "SuperError",
+ "TooManyLevelsError",
+ "UnresolvableName",
+ "UseInferenceDefault",
+)
+
+
+class AstroidError(Exception):
+ """Base exception class for all astroid related exceptions.
+
+ AstroidError and its subclasses are structured, intended to hold
+ objects representing state when the exception is thrown. Field
+ values are passed to the constructor as keyword-only arguments.
+ Each subclass has its own set of standard fields, but use your
+ best judgment to decide whether a specific exception instance
+ needs more or fewer fields for debugging. Field values may be
+ used to lazily generate the error message: self.message.format()
+ will be called with the field names and values supplied as keyword
+ arguments.
+ """
+
+ def __init__(self, message: str = "", **kws: Any) -> None:
+ super().__init__(message)
+ self.message = message
+ for key, value in kws.items():
+ setattr(self, key, value)
+
+ def __str__(self) -> str:
+ return self.message.format(**vars(self))
+
+
+class AstroidBuildingError(AstroidError):
+ """Exception class when we are unable to build an astroid representation.
+
+ Standard attributes:
+ modname: Name of the module that AST construction failed for.
+ error: Exception raised during construction.
+ """
+
+ def __init__(
+ self,
+ message: str = "Failed to import module {modname}.",
+ modname: str | None = None,
+ error: Exception | None = None,
+ source: str | None = None,
+ path: str | None = None,
+ cls: type | None = None,
+ class_repr: str | None = None,
+ **kws: Any,
+ ) -> None:
+ self.modname = modname
+ self.error = error
+ self.source = source
+ self.path = path
+ self.cls = cls
+ self.class_repr = class_repr
+ super().__init__(message, **kws)
+
+
+class AstroidImportError(AstroidBuildingError):
+ """Exception class used when a module can't be imported by astroid."""
+
+
+class TooManyLevelsError(AstroidImportError):
+ """Exception class which is raised when a relative import was beyond the top-level.
+
+ Standard attributes:
+ level: The level which was attempted.
+ name: the name of the module on which the relative import was attempted.
+ """
+
+ def __init__(
+ self,
+ message: str = "Relative import with too many levels "
+ "({level}) for module {name!r}",
+ level: int | None = None,
+ name: str | None = None,
+ **kws: Any,
+ ) -> None:
+ self.level = level
+ self.name = name
+ super().__init__(message, **kws)
+
+
+class AstroidSyntaxError(AstroidBuildingError):
+ """Exception class used when a module can't be parsed."""
+
+ def __init__(
+ self,
+ message: str,
+ modname: str | None,
+ error: Exception,
+ path: str | None,
+ source: str | None = None,
+ ) -> None:
+ super().__init__(message, modname, error, source, path)
+
+
+class NoDefault(AstroidError):
+ """Raised by function's `default_value` method when an argument has
+ no default value.
+
+ Standard attributes:
+ func: Function node.
+ name: Name of argument without a default.
+ """
+
+ def __init__(
+ self,
+ message: str = "{func!r} has no default for {name!r}.",
+ func: nodes.FunctionDef | None = None,
+ name: str | None = None,
+ **kws: Any,
+ ) -> None:
+ self.func = func
+ self.name = name
+ super().__init__(message, **kws)
+
+
+class ResolveError(AstroidError):
+ """Base class of astroid resolution/inference error.
+
+ ResolveError is not intended to be raised.
+
+ Standard attributes:
+ context: InferenceContext object.
+ """
+
+ def __init__(
+ self, message: str = "", context: InferenceContext | None = None, **kws: Any
+ ) -> None:
+ self.context = context
+ super().__init__(message, **kws)
+
+
+class MroError(ResolveError):
+ """Error raised when there is a problem with method resolution of a class.
+
+ Standard attributes:
+ mros: A sequence of sequences containing ClassDef nodes.
+ cls: ClassDef node whose MRO resolution failed.
+ context: InferenceContext object.
+ """
+
+ def __init__(
+ self,
+ message: str,
+ mros: Iterable[Iterable[nodes.ClassDef]],
+ cls: nodes.ClassDef,
+ context: InferenceContext | None = None,
+ **kws: Any,
+ ) -> None:
+ self.mros = mros
+ self.cls = cls
+ self.context = context
+ super().__init__(message, **kws)
+
+ def __str__(self) -> str:
+ mro_names = ", ".join(f"({', '.join(b.name for b in m)})" for m in self.mros)
+ return self.message.format(mros=mro_names, cls=self.cls)
+
+
+class DuplicateBasesError(MroError):
+ """Error raised when there are duplicate bases in the same class bases."""
+
+
+class InconsistentMroError(MroError):
+ """Error raised when a class's MRO is inconsistent."""
+
+
+class SuperError(ResolveError):
+ """Error raised when there is a problem with a *super* call.
+
+ Standard attributes:
+ *super_*: The Super instance that raised the exception.
+ context: InferenceContext object.
+ """
+
+ def __init__(self, message: str, super_: objects.Super, **kws: Any) -> None:
+ self.super_ = super_
+ super().__init__(message, **kws)
+
+ def __str__(self) -> str:
+ return self.message.format(**vars(self.super_))
+
+
+class InferenceError(ResolveError): # pylint: disable=too-many-instance-attributes
+ """Raised when we are unable to infer a node.
+
+ Standard attributes:
+ node: The node inference was called on.
+ context: InferenceContext object.
+ """
+
+ def __init__( # pylint: disable=too-many-arguments, too-many-positional-arguments
+ self,
+ message: str = "Inference failed for {node!r}.",
+ node: InferenceResult | None = None,
+ context: InferenceContext | None = None,
+ target: InferenceResult | None = None,
+ targets: InferenceResult | None = None,
+ attribute: str | None = None,
+ unknown: InferenceResult | None = None,
+ assign_path: list[int] | None = None,
+ caller: SuccessfulInferenceResult | None = None,
+ stmts: Iterator[InferenceResult] | None = None,
+ frame: InferenceResult | None = None,
+ call_site: arguments.CallSite | None = None,
+ func: InferenceResult | None = None,
+ arg: str | None = None,
+ positional_arguments: list | None = None,
+ unpacked_args: list | None = None,
+ keyword_arguments: dict | None = None,
+ unpacked_kwargs: dict | None = None,
+ **kws: Any,
+ ) -> None:
+ self.node = node
+ self.context = context
+ self.target = target
+ self.targets = targets
+ self.attribute = attribute
+ self.unknown = unknown
+ self.assign_path = assign_path
+ self.caller = caller
+ self.stmts = stmts
+ self.frame = frame
+ self.call_site = call_site
+ self.func = func
+ self.arg = arg
+ self.positional_arguments = positional_arguments
+ self.unpacked_args = unpacked_args
+ self.keyword_arguments = keyword_arguments
+ self.unpacked_kwargs = unpacked_kwargs
+ super().__init__(message, **kws)
+
+
+# Why does this inherit from InferenceError rather than ResolveError?
+# Changing it causes some inference tests to fail.
+class NameInferenceError(InferenceError):
+ """Raised when a name lookup fails, corresponds to NameError.
+
+ Standard attributes:
+ name: The name for which lookup failed, as a string.
+ scope: The node representing the scope in which the lookup occurred.
+ context: InferenceContext object.
+ """
+
+ def __init__(
+ self,
+ message: str = "{name!r} not found in {scope!r}.",
+ name: str | None = None,
+ scope: nodes.LocalsDictNodeNG | None = None,
+ context: InferenceContext | None = None,
+ **kws: Any,
+ ) -> None:
+ self.name = name
+ self.scope = scope
+ self.context = context
+ super().__init__(message, **kws)
+
+
+class AttributeInferenceError(ResolveError):
+ """Raised when an attribute lookup fails, corresponds to AttributeError.
+
+ Standard attributes:
+ target: The node for which lookup failed.
+ attribute: The attribute for which lookup failed, as a string.
+ context: InferenceContext object.
+ """
+
+ def __init__(
+ self,
+ message: str = "{attribute!r} not found on {target!r}.",
+ attribute: str = "",
+ target: nodes.NodeNG | bases.BaseInstance | None = None,
+ context: InferenceContext | None = None,
+ mros: list[nodes.ClassDef] | None = None,
+ super_: nodes.ClassDef | None = None,
+ cls: nodes.ClassDef | None = None,
+ **kws: Any,
+ ) -> None:
+ self.attribute = attribute
+ self.target = target
+ self.context = context
+ self.mros = mros
+ self.super_ = super_
+ self.cls = cls
+ super().__init__(message, **kws)
+
+
+class UseInferenceDefault(Exception):
+ """Exception to be raised in custom inference function to indicate that it
+ should go back to the default behaviour.
+ """
+
+
+class _NonDeducibleTypeHierarchy(Exception):
+ """Raised when is_subtype / is_supertype can't deduce the relation between two
+ types.
+ """
+
+
+class AstroidIndexError(AstroidError):
+ """Raised when an Indexable / Mapping does not have an index / key."""
+
+ def __init__(
+ self,
+ message: str = "",
+ node: nodes.NodeNG | bases.Instance | None = None,
+ index: nodes.Subscript | None = None,
+ context: InferenceContext | None = None,
+ **kws: Any,
+ ) -> None:
+ self.node = node
+ self.index = index
+ self.context = context
+ super().__init__(message, **kws)
+
+
+class AstroidTypeError(AstroidError):
+ """Raised when a TypeError would be expected in Python code."""
+
+ def __init__(
+ self,
+ message: str = "",
+ node: nodes.NodeNG | bases.Instance | None = None,
+ index: nodes.Subscript | None = None,
+ context: InferenceContext | None = None,
+ **kws: Any,
+ ) -> None:
+ self.node = node
+ self.index = index
+ self.context = context
+ super().__init__(message, **kws)
+
+
+class AstroidValueError(AstroidError):
+ """Raised when a ValueError would be expected in Python code."""
+
+
+class InferenceOverwriteError(AstroidError):
+ """Raised when an inference tip is overwritten.
+
+ Currently only used for debugging.
+ """
+
+
+class ParentMissingError(AstroidError):
+ """Raised when a node which is expected to have a parent attribute is missing one.
+
+ Standard attributes:
+ target: The node for which the parent lookup failed.
+ """
+
+ def __init__(self, target: nodes.NodeNG) -> None:
+ self.target = target
+ super().__init__(message=f"Parent not found on {target!r}.")
+
+
+class StatementMissing(ParentMissingError):
+ """Raised when a call to node.statement() does not return a node.
+
+ This is because a node in the chain does not have a parent attribute
+ and therefore does not return a node for statement().
+
+ Standard attributes:
+ target: The node for which the parent lookup failed.
+ """
+
+ def __init__(self, target: nodes.NodeNG) -> None:
+ super(ParentMissingError, self).__init__(
+ message=f"Statement not found on {target!r}"
+ )
+
+
+SuperArgumentTypeError = SuperError
+UnresolvableName = NameInferenceError
+NotFoundError = AttributeInferenceError
diff --git a/solutions/.venv/Lib/site-packages/astroid/filter_statements.py b/solutions/.venv/Lib/site-packages/astroid/filter_statements.py
new file mode 100644
index 000000000..627e68edc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/filter_statements.py
@@ -0,0 +1,238 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""_filter_stmts and helper functions.
+
+This method gets used in LocalsDictnodes.NodeNG._scope_lookup.
+It is not considered public.
+"""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+from astroid.typing import SuccessfulInferenceResult
+
+if TYPE_CHECKING:
+ from astroid.nodes import _base_nodes
+
+
+def _get_filtered_node_statements(
+ base_node: nodes.NodeNG, stmt_nodes: list[nodes.NodeNG]
+) -> list[tuple[nodes.NodeNG, _base_nodes.Statement]]:
+ statements = [(node, node.statement()) for node in stmt_nodes]
+ # Next we check if we have ExceptHandlers that are parent
+ # of the underlying variable, in which case the last one survives
+ if len(statements) > 1 and all(
+ isinstance(stmt, nodes.ExceptHandler) for _, stmt in statements
+ ):
+ statements = [
+ (node, stmt) for node, stmt in statements if stmt.parent_of(base_node)
+ ]
+ return statements
+
+
+def _is_from_decorator(node) -> bool:
+ """Return whether the given node is the child of a decorator."""
+ return any(isinstance(parent, nodes.Decorators) for parent in node.node_ancestors())
+
+
+def _get_if_statement_ancestor(node: nodes.NodeNG) -> nodes.If | None:
+ """Return the first parent node that is an If node (or None)."""
+ for parent in node.node_ancestors():
+ if isinstance(parent, nodes.If):
+ return parent
+ return None
+
+
+def _filter_stmts(
+ base_node: _base_nodes.LookupMixIn,
+ stmts: list[SuccessfulInferenceResult],
+ frame: nodes.LocalsDictNodeNG,
+ offset: int,
+) -> list[nodes.NodeNG]:
+ """Filter the given list of statements to remove ignorable statements.
+
+ If base_node is not a frame itself and the name is found in the inner
+ frame locals, statements will be filtered to remove ignorable
+ statements according to base_node's location.
+
+ :param stmts: The statements to filter.
+
+ :param frame: The frame that all of the given statements belong to.
+
+ :param offset: The line offset to filter statements up to.
+
+ :returns: The filtered statements.
+ """
+ # if offset == -1, my actual frame is not the inner frame but its parent
+ #
+ # class A(B): pass
+ #
+ # we need this to resolve B correctly
+ if offset == -1:
+ myframe = base_node.frame().parent.frame()
+ else:
+ myframe = base_node.frame()
+ # If the frame of this node is the same as the statement
+ # of this node, then the node is part of a class or
+ # a function definition and the frame of this node should be the
+ # the upper frame, not the frame of the definition.
+ # For more information why this is important,
+ # see Pylint issue #295.
+ # For example, for 'b', the statement is the same
+ # as the frame / scope:
+ #
+ # def test(b=1):
+ # ...
+ if base_node.parent and base_node.statement() is myframe and myframe.parent:
+ myframe = myframe.parent.frame()
+
+ mystmt: _base_nodes.Statement | None = None
+ if base_node.parent:
+ mystmt = base_node.statement()
+
+ # line filtering if we are in the same frame
+ #
+ # take care node may be missing lineno information (this is the case for
+ # nodes inserted for living objects)
+ if myframe is frame and mystmt and mystmt.fromlineno is not None:
+ assert mystmt.fromlineno is not None, mystmt
+ mylineno = mystmt.fromlineno + offset
+ else:
+ # disabling lineno filtering
+ mylineno = 0
+
+ _stmts: list[nodes.NodeNG] = []
+ _stmt_parents = []
+ statements = _get_filtered_node_statements(base_node, stmts)
+ for node, stmt in statements:
+ # line filtering is on and we have reached our location, break
+ if stmt.fromlineno and stmt.fromlineno > mylineno > 0:
+ break
+ # Ignore decorators with the same name as the
+ # decorated function
+ # Fixes issue #375
+ if mystmt is stmt and _is_from_decorator(base_node):
+ continue
+ if node.has_base(base_node):
+ break
+
+ if isinstance(node, nodes.EmptyNode):
+ # EmptyNode does not have assign_type(), so just add it and move on
+ _stmts.append(node)
+ continue
+
+ assign_type = node.assign_type()
+ _stmts, done = assign_type._get_filtered_stmts(base_node, node, _stmts, mystmt)
+ if done:
+ break
+
+ optional_assign = assign_type.optional_assign
+ if optional_assign and assign_type.parent_of(base_node):
+ # we are inside a loop, loop var assignment is hiding previous
+ # assignment
+ _stmts = [node]
+ _stmt_parents = [stmt.parent]
+ continue
+
+ if isinstance(assign_type, nodes.NamedExpr):
+ # If the NamedExpr is in an if statement we do some basic control flow inference
+ if_parent = _get_if_statement_ancestor(assign_type)
+ if if_parent:
+ # If the if statement is within another if statement we append the node
+ # to possible statements
+ if _get_if_statement_ancestor(if_parent):
+ optional_assign = False
+ _stmts.append(node)
+ _stmt_parents.append(stmt.parent)
+ # Else we assume that it will be evaluated
+ else:
+ _stmts = [node]
+ _stmt_parents = [stmt.parent]
+ else:
+ _stmts = [node]
+ _stmt_parents = [stmt.parent]
+
+ # XXX comment various branches below!!!
+ try:
+ pindex = _stmt_parents.index(stmt.parent)
+ except ValueError:
+ pass
+ else:
+ # we got a parent index, this means the currently visited node
+ # is at the same block level as a previously visited node
+ if _stmts[pindex].assign_type().parent_of(assign_type):
+ # both statements are not at the same block level
+ continue
+ # if currently visited node is following previously considered
+ # assignment and both are not exclusive, we can drop the
+ # previous one. For instance in the following code ::
+ #
+ # if a:
+ # x = 1
+ # else:
+ # x = 2
+ # print x
+ #
+ # we can't remove neither x = 1 nor x = 2 when looking for 'x'
+ # of 'print x'; while in the following ::
+ #
+ # x = 1
+ # x = 2
+ # print x
+ #
+ # we can remove x = 1 when we see x = 2
+ #
+ # moreover, on loop assignment types, assignment won't
+ # necessarily be done if the loop has no iteration, so we don't
+ # want to clear previous assignments if any (hence the test on
+ # optional_assign)
+ if not (optional_assign or nodes.are_exclusive(_stmts[pindex], node)):
+ del _stmt_parents[pindex]
+ del _stmts[pindex]
+
+ # If base_node and node are exclusive, then we can ignore node
+ if nodes.are_exclusive(base_node, node):
+ continue
+
+ # An AssignName node overrides previous assignments if:
+ # 1. node's statement always assigns
+ # 2. node and base_node are in the same block (i.e., has the same parent as base_node)
+ if isinstance(node, (nodes.NamedExpr, nodes.AssignName)):
+ if isinstance(stmt, nodes.ExceptHandler):
+ # If node's statement is an ExceptHandler, then it is the variable
+ # bound to the caught exception. If base_node is not contained within
+ # the exception handler block, node should override previous assignments;
+ # otherwise, node should be ignored, as an exception variable
+ # is local to the handler block.
+ if stmt.parent_of(base_node):
+ _stmts = []
+ _stmt_parents = []
+ else:
+ continue
+ elif not optional_assign and mystmt and stmt.parent is mystmt.parent:
+ _stmts = []
+ _stmt_parents = []
+ elif isinstance(node, nodes.DelName):
+ # Remove all previously stored assignments
+ _stmts = []
+ _stmt_parents = []
+ continue
+ # Add the new assignment
+ _stmts.append(node)
+ if isinstance(node, nodes.Arguments) or isinstance(
+ node.parent, nodes.Arguments
+ ):
+ # Special case for _stmt_parents when node is a function parameter;
+ # in this case, stmt is the enclosing FunctionDef, which is what we
+ # want to add to _stmt_parents, not stmt.parent. This case occurs when
+ # node is an Arguments node (representing varargs or kwargs parameter),
+ # and when node.parent is an Arguments node (other parameters).
+ # See issue #180.
+ _stmt_parents.append(stmt)
+ else:
+ _stmt_parents.append(stmt.parent)
+ return _stmts
diff --git a/solutions/.venv/Lib/site-packages/astroid/helpers.py b/solutions/.venv/Lib/site-packages/astroid/helpers.py
new file mode 100644
index 000000000..fe57b16bb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/helpers.py
@@ -0,0 +1,338 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Various helper utilities."""
+
+from __future__ import annotations
+
+import warnings
+from collections.abc import Generator
+
+from astroid import bases, manager, nodes, objects, raw_building, util
+from astroid.context import CallContext, InferenceContext
+from astroid.exceptions import (
+ AstroidTypeError,
+ AttributeInferenceError,
+ InferenceError,
+ MroError,
+ _NonDeducibleTypeHierarchy,
+)
+from astroid.nodes import scoped_nodes
+from astroid.typing import InferenceResult
+from astroid.util import safe_infer as real_safe_infer
+
+
+def safe_infer(
+ node: nodes.NodeNG | bases.Proxy | util.UninferableBase,
+ context: InferenceContext | None = None,
+) -> InferenceResult | None:
+ # When removing, also remove the real_safe_infer alias
+ warnings.warn(
+ "Import safe_infer from astroid.util; this shim in astroid.helpers will be removed.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ return real_safe_infer(node, context=context)
+
+
+def _build_proxy_class(cls_name: str, builtins: nodes.Module) -> nodes.ClassDef:
+ proxy = raw_building.build_class(cls_name)
+ proxy.parent = builtins
+ return proxy
+
+
+def _function_type(
+ function: nodes.Lambda | nodes.FunctionDef | bases.UnboundMethod,
+ builtins: nodes.Module,
+) -> nodes.ClassDef:
+ if isinstance(function, (scoped_nodes.Lambda, scoped_nodes.FunctionDef)):
+ if function.root().name == "builtins":
+ cls_name = "builtin_function_or_method"
+ else:
+ cls_name = "function"
+ elif isinstance(function, bases.BoundMethod):
+ cls_name = "method"
+ else:
+ cls_name = "function"
+ return _build_proxy_class(cls_name, builtins)
+
+
+def _object_type(
+ node: InferenceResult, context: InferenceContext | None = None
+) -> Generator[InferenceResult | None]:
+ astroid_manager = manager.AstroidManager()
+ builtins = astroid_manager.builtins_module
+ context = context or InferenceContext()
+
+ for inferred in node.infer(context=context):
+ if isinstance(inferred, scoped_nodes.ClassDef):
+ if inferred.newstyle:
+ metaclass = inferred.metaclass(context=context)
+ if metaclass:
+ yield metaclass
+ continue
+ yield builtins.getattr("type")[0]
+ elif isinstance(
+ inferred,
+ (scoped_nodes.Lambda, bases.UnboundMethod, scoped_nodes.FunctionDef),
+ ):
+ yield _function_type(inferred, builtins)
+ elif isinstance(inferred, scoped_nodes.Module):
+ yield _build_proxy_class("module", builtins)
+ elif isinstance(inferred, nodes.Unknown):
+ raise InferenceError
+ elif isinstance(inferred, util.UninferableBase):
+ yield inferred
+ elif isinstance(inferred, (bases.Proxy, nodes.Slice, objects.Super)):
+ yield inferred._proxied
+ else: # pragma: no cover
+ raise AssertionError(f"We don't handle {type(inferred)} currently")
+
+
+def object_type(
+ node: InferenceResult, context: InferenceContext | None = None
+) -> InferenceResult | None:
+ """Obtain the type of the given node.
+
+ This is used to implement the ``type`` builtin, which means that it's
+ used for inferring type calls, as well as used in a couple of other places
+ in the inference.
+ The node will be inferred first, so this function can support all
+ sorts of objects, as long as they support inference.
+ """
+
+ try:
+ types = set(_object_type(node, context))
+ except InferenceError:
+ return util.Uninferable
+ if len(types) > 1 or not types:
+ return util.Uninferable
+ return next(iter(types))
+
+
+def _object_type_is_subclass(
+ obj_type: InferenceResult | None,
+ class_or_seq: list[InferenceResult],
+ context: InferenceContext | None = None,
+) -> util.UninferableBase | bool:
+ if isinstance(obj_type, util.UninferableBase) or not isinstance(
+ obj_type, nodes.ClassDef
+ ):
+ return util.Uninferable
+
+ # Instances are not types
+ class_seq = [
+ item if not isinstance(item, bases.Instance) else util.Uninferable
+ for item in class_or_seq
+ ]
+ # strict compatibility with issubclass
+ # issubclass(type, (object, 1)) evaluates to true
+ # issubclass(object, (1, type)) raises TypeError
+ for klass in class_seq:
+ if isinstance(klass, util.UninferableBase):
+ raise AstroidTypeError("arg 2 must be a type or tuple of types")
+
+ for obj_subclass in obj_type.mro():
+ if obj_subclass == klass:
+ return True
+ return False
+
+
+def object_isinstance(
+ node: InferenceResult,
+ class_or_seq: list[InferenceResult],
+ context: InferenceContext | None = None,
+) -> util.UninferableBase | bool:
+ """Check if a node 'isinstance' any node in class_or_seq.
+
+ :raises AstroidTypeError: if the given ``classes_or_seq`` are not types
+ """
+ obj_type = object_type(node, context)
+ if isinstance(obj_type, util.UninferableBase):
+ return util.Uninferable
+ return _object_type_is_subclass(obj_type, class_or_seq, context=context)
+
+
+def object_issubclass(
+ node: nodes.NodeNG,
+ class_or_seq: list[InferenceResult],
+ context: InferenceContext | None = None,
+) -> util.UninferableBase | bool:
+ """Check if a type is a subclass of any node in class_or_seq.
+
+ :raises AstroidTypeError: if the given ``classes_or_seq`` are not types
+ :raises AstroidError: if the type of the given node cannot be inferred
+ or its type's mro doesn't work
+ """
+ if not isinstance(node, nodes.ClassDef):
+ raise TypeError(f"{node} needs to be a ClassDef node")
+ return _object_type_is_subclass(node, class_or_seq, context=context)
+
+
+def has_known_bases(klass, context: InferenceContext | None = None) -> bool:
+ """Return whether all base classes of a class could be inferred."""
+ try:
+ return klass._all_bases_known
+ except AttributeError:
+ pass
+ for base in klass.bases:
+ result = real_safe_infer(base, context=context)
+ # TODO: check for A->B->A->B pattern in class structure too?
+ if (
+ not isinstance(result, scoped_nodes.ClassDef)
+ or result is klass
+ or not has_known_bases(result, context=context)
+ ):
+ klass._all_bases_known = False
+ return False
+ klass._all_bases_known = True
+ return True
+
+
+def _type_check(type1, type2) -> bool:
+ if not all(map(has_known_bases, (type1, type2))):
+ raise _NonDeducibleTypeHierarchy
+
+ if not all([type1.newstyle, type2.newstyle]):
+ return False
+ try:
+ return type1 in type2.mro()[:-1]
+ except MroError as e:
+ # The MRO is invalid.
+ raise _NonDeducibleTypeHierarchy from e
+
+
+def is_subtype(type1, type2) -> bool:
+ """Check if *type1* is a subtype of *type2*."""
+ return _type_check(type1=type2, type2=type1)
+
+
+def is_supertype(type1, type2) -> bool:
+ """Check if *type2* is a supertype of *type1*."""
+ return _type_check(type1, type2)
+
+
+def class_instance_as_index(node: bases.Instance) -> nodes.Const | None:
+ """Get the value as an index for the given instance.
+
+ If an instance provides an __index__ method, then it can
+ be used in some scenarios where an integer is expected,
+ for instance when multiplying or subscripting a list.
+ """
+ context = InferenceContext()
+ try:
+ for inferred in node.igetattr("__index__", context=context):
+ if not isinstance(inferred, bases.BoundMethod):
+ continue
+
+ context.boundnode = node
+ context.callcontext = CallContext(args=[], callee=inferred)
+ for result in inferred.infer_call_result(node, context=context):
+ if isinstance(result, nodes.Const) and isinstance(result.value, int):
+ return result
+ except InferenceError:
+ pass
+ return None
+
+
+def object_len(node, context: InferenceContext | None = None):
+ """Infer length of given node object.
+
+ :param Union[nodes.ClassDef, nodes.Instance] node:
+ :param node: Node to infer length of
+
+ :raises AstroidTypeError: If an invalid node is returned
+ from __len__ method or no __len__ method exists
+ :raises InferenceError: If the given node cannot be inferred
+ or if multiple nodes are inferred or if the code executed in python
+ would result in a infinite recursive check for length
+ :rtype int: Integer length of node
+ """
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.objects import FrozenSet
+
+ inferred_node = real_safe_infer(node, context=context)
+
+ # prevent self referential length calls from causing a recursion error
+ # see https://github.com/pylint-dev/astroid/issues/777
+ node_frame = node.frame()
+ if (
+ isinstance(node_frame, scoped_nodes.FunctionDef)
+ and node_frame.name == "__len__"
+ and isinstance(inferred_node, bases.Proxy)
+ and inferred_node._proxied == node_frame.parent
+ ):
+ message = (
+ "Self referential __len__ function will "
+ "cause a RecursionError on line {} of {}".format(
+ node.lineno, node.root().file
+ )
+ )
+ raise InferenceError(message)
+
+ if inferred_node is None or isinstance(inferred_node, util.UninferableBase):
+ raise InferenceError(node=node)
+ if isinstance(inferred_node, nodes.Const) and isinstance(
+ inferred_node.value, (bytes, str)
+ ):
+ return len(inferred_node.value)
+ if isinstance(inferred_node, (nodes.List, nodes.Set, nodes.Tuple, FrozenSet)):
+ return len(inferred_node.elts)
+ if isinstance(inferred_node, nodes.Dict):
+ return len(inferred_node.items)
+
+ node_type = object_type(inferred_node, context=context)
+ if not node_type:
+ raise InferenceError(node=node)
+
+ try:
+ len_call = next(node_type.igetattr("__len__", context=context))
+ except StopIteration as e:
+ raise AstroidTypeError(str(e)) from e
+ except AttributeInferenceError as e:
+ raise AstroidTypeError(
+ f"object of type '{node_type.pytype()}' has no len()"
+ ) from e
+
+ inferred = len_call.infer_call_result(node, context)
+ if isinstance(inferred, util.UninferableBase):
+ raise InferenceError(node=node, context=context)
+ result_of_len = next(inferred, None)
+ if (
+ isinstance(result_of_len, nodes.Const)
+ and result_of_len.pytype() == "builtins.int"
+ ):
+ return result_of_len.value
+ if (
+ result_of_len is None
+ or isinstance(result_of_len, bases.Instance)
+ and result_of_len.is_subtype_of("builtins.int")
+ ):
+ # Fake a result as we don't know the arguments of the instance call.
+ return 0
+ raise AstroidTypeError(
+ f"'{result_of_len}' object cannot be interpreted as an integer"
+ )
+
+
+def _higher_function_scope(node: nodes.NodeNG) -> nodes.FunctionDef | None:
+ """Search for the first function which encloses the given
+ scope.
+
+ This can be used for looking up in that function's
+ scope, in case looking up in a lower scope for a particular
+ name fails.
+
+ :param node: A scope node.
+ :returns:
+ ``None``, if no parent function scope was found,
+ otherwise an instance of :class:`astroid.nodes.scoped_nodes.Function`,
+ which encloses the given node.
+ """
+ current = node
+ while current.parent and not isinstance(current.parent, nodes.FunctionDef):
+ current = current.parent
+ if current and current.parent:
+ return current.parent
+ return None
diff --git a/solutions/.venv/Lib/site-packages/astroid/inference_tip.py b/solutions/.venv/Lib/site-packages/astroid/inference_tip.py
new file mode 100644
index 000000000..c3187c067
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/inference_tip.py
@@ -0,0 +1,130 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Transform utilities (filters and decorator)."""
+
+from __future__ import annotations
+
+from collections import OrderedDict
+from collections.abc import Generator
+from typing import Any, TypeVar
+
+from astroid.context import InferenceContext
+from astroid.exceptions import InferenceOverwriteError, UseInferenceDefault
+from astroid.nodes import NodeNG
+from astroid.typing import (
+ InferenceResult,
+ InferFn,
+ TransformFn,
+)
+
+_cache: OrderedDict[
+ tuple[InferFn[Any], NodeNG, InferenceContext | None], list[InferenceResult]
+] = OrderedDict()
+
+_CURRENTLY_INFERRING: set[tuple[InferFn[Any], NodeNG]] = set()
+
+_NodesT = TypeVar("_NodesT", bound=NodeNG)
+
+
+def clear_inference_tip_cache() -> None:
+ """Clear the inference tips cache."""
+ _cache.clear()
+
+
+def _inference_tip_cached(func: InferFn[_NodesT]) -> InferFn[_NodesT]:
+ """Cache decorator used for inference tips."""
+
+ def inner(
+ node: _NodesT,
+ context: InferenceContext | None = None,
+ **kwargs: Any,
+ ) -> Generator[InferenceResult]:
+ partial_cache_key = (func, node)
+ if partial_cache_key in _CURRENTLY_INFERRING:
+ # If through recursion we end up trying to infer the same
+ # func + node we raise here.
+ _CURRENTLY_INFERRING.remove(partial_cache_key)
+ raise UseInferenceDefault
+ if context is not None and context.is_empty():
+ # Fresh, empty contexts will defeat the cache.
+ context = None
+ try:
+ yield from _cache[func, node, context]
+ return
+ except KeyError:
+ # Recursion guard with a partial cache key.
+ # Using the full key causes a recursion error on PyPy.
+ # It's a pragmatic compromise to avoid so much recursive inference
+ # with slightly different contexts while still passing the simple
+ # test cases included with this commit.
+ _CURRENTLY_INFERRING.add(partial_cache_key)
+ try:
+ # May raise UseInferenceDefault
+ result = _cache[func, node, context] = list(
+ func(node, context, **kwargs)
+ )
+ except Exception as e:
+ # Suppress the KeyError from the cache miss.
+ raise e from None
+ finally:
+ # Remove recursion guard.
+ try:
+ _CURRENTLY_INFERRING.remove(partial_cache_key)
+ except KeyError:
+ pass # Recursion may beat us to the punch.
+
+ if len(_cache) > 64:
+ _cache.popitem(last=False)
+
+ # https://github.com/pylint-dev/pylint/issues/8686
+ yield from result # pylint: disable=used-before-assignment
+
+ return inner
+
+
+def inference_tip(
+ infer_function: InferFn[_NodesT], raise_on_overwrite: bool = False
+) -> TransformFn[_NodesT]:
+ """Given an instance specific inference function, return a function to be
+ given to AstroidManager().register_transform to set this inference function.
+
+ :param bool raise_on_overwrite: Raise an `InferenceOverwriteError`
+ if the inference tip will overwrite another. Used for debugging
+
+ Typical usage
+
+ .. sourcecode:: python
+
+ AstroidManager().register_transform(Call, inference_tip(infer_named_tuple),
+ predicate)
+
+ .. Note::
+
+ Using an inference tip will override
+ any previously set inference tip for the given
+ node. Use a predicate in the transform to prevent
+ excess overwrites.
+ """
+
+ def transform(
+ node: _NodesT, infer_function: InferFn[_NodesT] = infer_function
+ ) -> _NodesT:
+ if (
+ raise_on_overwrite
+ and node._explicit_inference is not None
+ and node._explicit_inference is not infer_function
+ ):
+ raise InferenceOverwriteError(
+ "Inference already set to {existing_inference}. "
+ "Trying to overwrite with {new_inference} for {node}".format(
+ existing_inference=infer_function,
+ new_inference=node._explicit_inference,
+ node=node,
+ )
+ )
+ node._explicit_inference = _inference_tip_cached(infer_function)
+ return node
+
+ return transform
diff --git a/solutions/.venv/Lib/site-packages/astroid/interpreter/__init__.py b/solutions/.venv/Lib/site-packages/astroid/interpreter/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/__init__.py b/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/spec.py b/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/spec.py
new file mode 100644
index 000000000..fd53da56e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/spec.py
@@ -0,0 +1,516 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import abc
+import enum
+import importlib
+import importlib.machinery
+import importlib.util
+import os
+import pathlib
+import sys
+import types
+import warnings
+import zipimport
+from collections.abc import Iterable, Iterator, Sequence
+from functools import lru_cache
+from pathlib import Path
+from typing import Any, Literal, NamedTuple, Protocol
+
+from astroid.const import PY310_PLUS
+from astroid.modutils import EXT_LIB_DIRS
+
+from . import util
+
+
+# The MetaPathFinder protocol comes from typeshed, which says:
+# Intentionally omits one deprecated and one optional method of `importlib.abc.MetaPathFinder`
+class _MetaPathFinder(Protocol):
+ def find_spec(
+ self,
+ fullname: str,
+ path: Sequence[str] | None,
+ target: types.ModuleType | None = ...,
+ ) -> importlib.machinery.ModuleSpec | None: ... # pragma: no cover
+
+
+class ModuleType(enum.Enum):
+ """Python module types used for ModuleSpec."""
+
+ C_BUILTIN = enum.auto()
+ C_EXTENSION = enum.auto()
+ PKG_DIRECTORY = enum.auto()
+ PY_CODERESOURCE = enum.auto()
+ PY_COMPILED = enum.auto()
+ PY_FROZEN = enum.auto()
+ PY_RESOURCE = enum.auto()
+ PY_SOURCE = enum.auto()
+ PY_ZIPMODULE = enum.auto()
+ PY_NAMESPACE = enum.auto()
+
+
+_MetaPathFinderModuleTypes: dict[str, ModuleType] = {
+ # Finders created by setuptools editable installs
+ "_EditableFinder": ModuleType.PY_SOURCE,
+ "_EditableNamespaceFinder": ModuleType.PY_NAMESPACE,
+ # Finders create by six
+ "_SixMetaPathImporter": ModuleType.PY_SOURCE,
+}
+
+_EditableFinderClasses: set[str] = {
+ "_EditableFinder",
+ "_EditableNamespaceFinder",
+}
+
+
+class ModuleSpec(NamedTuple):
+ """Defines a class similar to PEP 420's ModuleSpec.
+
+ A module spec defines a name of a module, its type, location
+ and where submodules can be found, if the module is a package.
+ """
+
+ name: str
+ type: ModuleType | None
+ location: str | None = None
+ origin: str | None = None
+ submodule_search_locations: Sequence[str] | None = None
+
+
+class Finder:
+ """A finder is a class which knows how to find a particular module."""
+
+ def __init__(self, path: Sequence[str] | None = None) -> None:
+ self._path = path or sys.path
+
+ @abc.abstractmethod
+ def find_module(
+ self,
+ modname: str,
+ module_parts: Sequence[str],
+ processed: list[str],
+ submodule_path: Sequence[str] | None,
+ ) -> ModuleSpec | None:
+ """Find the given module.
+
+ Each finder is responsible for each protocol of finding, as long as
+ they all return a ModuleSpec.
+
+ :param modname: The module which needs to be searched.
+ :param module_parts: It should be a list of strings,
+ where each part contributes to the module's
+ namespace.
+ :param processed: What parts from the module parts were processed
+ so far.
+ :param submodule_path: A list of paths where the module
+ can be looked into.
+ :returns: A ModuleSpec, describing how and where the module was found,
+ None, otherwise.
+ """
+
+ def contribute_to_path(
+ self, spec: ModuleSpec, processed: list[str]
+ ) -> Sequence[str] | None:
+ """Get a list of extra paths where this finder can search."""
+
+
+class ImportlibFinder(Finder):
+ """A finder based on the importlib module."""
+
+ _SUFFIXES: Sequence[tuple[str, ModuleType]] = (
+ [(s, ModuleType.C_EXTENSION) for s in importlib.machinery.EXTENSION_SUFFIXES]
+ + [(s, ModuleType.PY_SOURCE) for s in importlib.machinery.SOURCE_SUFFIXES]
+ + [(s, ModuleType.PY_COMPILED) for s in importlib.machinery.BYTECODE_SUFFIXES]
+ )
+
+ def find_module(
+ self,
+ modname: str,
+ module_parts: Sequence[str],
+ processed: list[str],
+ submodule_path: Sequence[str] | None,
+ ) -> ModuleSpec | None:
+ # Although we should be able to use `find_spec` this doesn't work on PyPy for builtins.
+ # Therefore, we use the `builtin_module_nams` heuristic for these.
+ if submodule_path is None and modname in sys.builtin_module_names:
+ return ModuleSpec(
+ name=modname,
+ location=None,
+ type=ModuleType.C_BUILTIN,
+ )
+
+ if submodule_path is not None:
+ search_paths = list(submodule_path)
+ else:
+ search_paths = sys.path
+
+ suffixes = (".py", ".pyi", importlib.machinery.BYTECODE_SUFFIXES[0])
+ for entry in search_paths:
+ package_directory = os.path.join(entry, modname)
+ for suffix in suffixes:
+ package_file_name = "__init__" + suffix
+ file_path = os.path.join(package_directory, package_file_name)
+ if os.path.isfile(file_path):
+ return ModuleSpec(
+ name=modname,
+ location=package_directory,
+ type=ModuleType.PKG_DIRECTORY,
+ )
+ for suffix, type_ in ImportlibFinder._SUFFIXES:
+ file_name = modname + suffix
+ file_path = os.path.join(entry, file_name)
+ if os.path.isfile(file_path):
+ return ModuleSpec(name=modname, location=file_path, type=type_)
+
+ # sys.stdlib_module_names was added in Python 3.10
+ if PY310_PLUS:
+ # If the module name matches a stdlib module name, check whether this is a frozen
+ # module. Note that `find_spec` actually imports parent modules, so we want to make
+ # sure we only run this code for stuff that can be expected to be frozen. For now
+ # this is only stdlib.
+ if modname in sys.stdlib_module_names or (
+ processed and processed[0] in sys.stdlib_module_names
+ ):
+ try:
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=Warning)
+ spec = importlib.util.find_spec(".".join((*processed, modname)))
+ except ValueError:
+ spec = None
+
+ if (
+ spec
+ and spec.loader # type: ignore[comparison-overlap] # noqa: E501
+ is importlib.machinery.FrozenImporter
+ ):
+ return ModuleSpec(
+ name=modname,
+ location=getattr(spec.loader_state, "filename", None),
+ type=ModuleType.PY_FROZEN,
+ )
+ else:
+ # NOTE: This is broken code. It doesn't work on Python 3.13+ where submodules can also
+ # be frozen. However, we don't want to worry about this and we don't want to break
+ # support for older versions of Python. This is just copy-pasted from the old non
+ # working version to at least have no functional behaviour change on <=3.10.
+ # It can be removed after 3.10 is no longer supported in favour of the logic above.
+ if submodule_path is None: # pylint: disable=else-if-used
+ try:
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=UserWarning)
+ spec = importlib.util.find_spec(modname)
+ if (
+ spec
+ and spec.loader # type: ignore[comparison-overlap] # noqa: E501
+ is importlib.machinery.FrozenImporter
+ ):
+ # No need for BuiltinImporter; builtins handled above
+ return ModuleSpec(
+ name=modname,
+ location=getattr(spec.loader_state, "filename", None),
+ type=ModuleType.PY_FROZEN,
+ )
+ except ValueError:
+ pass
+
+ return None
+
+ def contribute_to_path(
+ self, spec: ModuleSpec, processed: list[str]
+ ) -> Sequence[str] | None:
+ if spec.location is None:
+ # Builtin.
+ return None
+
+ if _is_setuptools_namespace(Path(spec.location)):
+ # extend_path is called, search sys.path for module/packages
+ # of this name see pkgutil.extend_path documentation
+ path = [
+ os.path.join(p, *processed)
+ for p in sys.path
+ if os.path.isdir(os.path.join(p, *processed))
+ ]
+ elif spec.name == "distutils" and not any(
+ spec.location.lower().startswith(ext_lib_dir.lower())
+ for ext_lib_dir in EXT_LIB_DIRS
+ ):
+ # virtualenv below 20.0 patches distutils in an unexpected way
+ # so we just find the location of distutils that will be
+ # imported to avoid spurious import-error messages
+ # https://github.com/pylint-dev/pylint/issues/5645
+ # A regression test to create this scenario exists in release-tests.yml
+ # and can be triggered manually from GitHub Actions
+ distutils_spec = importlib.util.find_spec("distutils")
+ if distutils_spec and distutils_spec.origin:
+ origin_path = Path(
+ distutils_spec.origin
+ ) # e.g. .../distutils/__init__.py
+ path = [str(origin_path.parent)] # e.g. .../distutils
+ else:
+ path = [spec.location]
+ else:
+ path = [spec.location]
+ return path
+
+
+class ExplicitNamespacePackageFinder(ImportlibFinder):
+ """A finder for the explicit namespace packages."""
+
+ def find_module(
+ self,
+ modname: str,
+ module_parts: Sequence[str],
+ processed: list[str],
+ submodule_path: Sequence[str] | None,
+ ) -> ModuleSpec | None:
+ if processed:
+ modname = ".".join([*processed, modname])
+ if util.is_namespace(modname) and modname in sys.modules:
+ return ModuleSpec(
+ name=modname,
+ location="",
+ origin="namespace",
+ type=ModuleType.PY_NAMESPACE,
+ submodule_search_locations=sys.modules[modname].__path__,
+ )
+ return None
+
+ def contribute_to_path(
+ self, spec: ModuleSpec, processed: list[str]
+ ) -> Sequence[str] | None:
+ return spec.submodule_search_locations
+
+
+class ZipFinder(Finder):
+ """Finder that knows how to find a module inside zip files."""
+
+ def __init__(self, path: Sequence[str]) -> None:
+ super().__init__(path)
+ for entry_path in path:
+ if entry_path not in sys.path_importer_cache:
+ try:
+ sys.path_importer_cache[entry_path] = zipimport.zipimporter( # type: ignore[assignment]
+ entry_path
+ )
+ except zipimport.ZipImportError:
+ continue
+
+ def find_module(
+ self,
+ modname: str,
+ module_parts: Sequence[str],
+ processed: list[str],
+ submodule_path: Sequence[str] | None,
+ ) -> ModuleSpec | None:
+ try:
+ file_type, filename, path = _search_zip(module_parts)
+ except ImportError:
+ return None
+
+ return ModuleSpec(
+ name=modname,
+ location=filename,
+ origin="egg",
+ type=file_type,
+ submodule_search_locations=path,
+ )
+
+
+class PathSpecFinder(Finder):
+ """Finder based on importlib.machinery.PathFinder."""
+
+ def find_module(
+ self,
+ modname: str,
+ module_parts: Sequence[str],
+ processed: list[str],
+ submodule_path: Sequence[str] | None,
+ ) -> ModuleSpec | None:
+ spec = importlib.machinery.PathFinder.find_spec(modname, path=submodule_path)
+ if spec is not None:
+ is_namespace_pkg = spec.origin is None
+ location = spec.origin if not is_namespace_pkg else None
+ module_type = ModuleType.PY_NAMESPACE if is_namespace_pkg else None
+ return ModuleSpec(
+ name=spec.name,
+ location=location,
+ origin=spec.origin,
+ type=module_type,
+ submodule_search_locations=list(spec.submodule_search_locations or []),
+ )
+ return spec
+
+ def contribute_to_path(
+ self, spec: ModuleSpec, processed: list[str]
+ ) -> Sequence[str] | None:
+ if spec.type == ModuleType.PY_NAMESPACE:
+ return spec.submodule_search_locations
+ return None
+
+
+_SPEC_FINDERS = (
+ ImportlibFinder,
+ ZipFinder,
+ PathSpecFinder,
+ ExplicitNamespacePackageFinder,
+)
+
+
+def _is_setuptools_namespace(location: pathlib.Path) -> bool:
+ try:
+ with open(location / "__init__.py", "rb") as stream:
+ data = stream.read(4096)
+ except OSError:
+ return False
+ extend_path = b"pkgutil" in data and b"extend_path" in data
+ declare_namespace = (
+ b"pkg_resources" in data and b"declare_namespace(__name__)" in data
+ )
+ return extend_path or declare_namespace
+
+
+def _get_zipimporters() -> Iterator[tuple[str, zipimport.zipimporter]]:
+ for filepath, importer in sys.path_importer_cache.items():
+ if importer is not None and isinstance(importer, zipimport.zipimporter):
+ yield filepath, importer
+
+
+def _search_zip(
+ modpath: Sequence[str],
+) -> tuple[Literal[ModuleType.PY_ZIPMODULE], str, str]:
+ for filepath, importer in _get_zipimporters():
+ if PY310_PLUS:
+ found: Any = importer.find_spec(modpath[0])
+ else:
+ found = importer.find_module(modpath[0])
+ if found:
+ if PY310_PLUS:
+ if not importer.find_spec(os.path.sep.join(modpath)):
+ raise ImportError(
+ "No module named {} in {}/{}".format(
+ ".".join(modpath[1:]), filepath, modpath
+ )
+ )
+ elif not importer.find_module(os.path.sep.join(modpath)):
+ raise ImportError(
+ "No module named {} in {}/{}".format(
+ ".".join(modpath[1:]), filepath, modpath
+ )
+ )
+ return (
+ ModuleType.PY_ZIPMODULE,
+ os.path.abspath(filepath) + os.path.sep + os.path.sep.join(modpath),
+ filepath,
+ )
+ raise ImportError(f"No module named {'.'.join(modpath)}")
+
+
+def _find_spec_with_path(
+ search_path: Sequence[str],
+ modname: str,
+ module_parts: list[str],
+ processed: list[str],
+ submodule_path: Sequence[str] | None,
+) -> tuple[Finder | _MetaPathFinder, ModuleSpec]:
+ for finder in _SPEC_FINDERS:
+ finder_instance = finder(search_path)
+ spec = finder_instance.find_module(
+ modname, module_parts, processed, submodule_path
+ )
+ if spec is None:
+ continue
+ return finder_instance, spec
+
+ # Support for custom finders
+ for meta_finder in sys.meta_path:
+ # See if we support the customer import hook of the meta_finder
+ meta_finder_name = meta_finder.__class__.__name__
+ if meta_finder_name not in _MetaPathFinderModuleTypes:
+ # Setuptools>62 creates its EditableFinders dynamically and have
+ # "type" as their __class__.__name__. We check __name__ as well
+ # to see if we can support the finder.
+ try:
+ meta_finder_name = meta_finder.__name__ # type: ignore[attr-defined]
+ except AttributeError:
+ continue
+ if meta_finder_name not in _MetaPathFinderModuleTypes:
+ continue
+
+ module_type = _MetaPathFinderModuleTypes[meta_finder_name]
+
+ # Meta path finders are supposed to have a find_spec method since
+ # Python 3.4. However, some third-party finders do not implement it.
+ # PEP302 does not refer to find_spec as well.
+ # See: https://github.com/pylint-dev/astroid/pull/1752/
+ if not hasattr(meta_finder, "find_spec"):
+ continue
+
+ spec = meta_finder.find_spec(modname, submodule_path)
+ if spec:
+ return (
+ meta_finder,
+ ModuleSpec(
+ spec.name,
+ module_type,
+ spec.origin,
+ spec.origin,
+ spec.submodule_search_locations,
+ ),
+ )
+
+ raise ImportError(f"No module named {'.'.join(module_parts)}")
+
+
+def find_spec(modpath: Iterable[str], path: Iterable[str] | None = None) -> ModuleSpec:
+ """Find a spec for the given module.
+
+ :type modpath: list or tuple
+ :param modpath:
+ split module's name (i.e name of a module or package split
+ on '.'), with leading empty strings for explicit relative import
+
+ :type path: list or None
+ :param path:
+ optional list of path where the module or package should be
+ searched (use sys.path if nothing or None is given)
+
+ :rtype: ModuleSpec
+ :return: A module spec, which describes how the module was
+ found and where.
+ """
+ return _find_spec(tuple(modpath), tuple(path) if path else None)
+
+
+@lru_cache(maxsize=1024)
+def _find_spec(module_path: tuple, path: tuple) -> ModuleSpec:
+ _path = path or sys.path
+
+ # Need a copy for not mutating the argument.
+ modpath = list(module_path)
+
+ submodule_path = None
+ module_parts = modpath[:]
+ processed: list[str] = []
+
+ while modpath:
+ modname = modpath.pop(0)
+ finder, spec = _find_spec_with_path(
+ _path, modname, module_parts, processed, submodule_path or path
+ )
+ processed.append(modname)
+ if modpath:
+ if isinstance(finder, Finder):
+ submodule_path = finder.contribute_to_path(spec, processed)
+ # If modname is a package from an editable install, update submodule_path
+ # so that the next module in the path will be found inside of it using importlib.
+ # Existence of __name__ is guaranteed by _find_spec_with_path.
+ elif finder.__name__ in _EditableFinderClasses: # type: ignore[attr-defined]
+ submodule_path = spec.submodule_search_locations
+
+ if spec.type == ModuleType.PKG_DIRECTORY:
+ spec = spec._replace(submodule_search_locations=submodule_path)
+
+ return spec
diff --git a/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/util.py b/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/util.py
new file mode 100644
index 000000000..511ec4f97
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/interpreter/_import/util.py
@@ -0,0 +1,112 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import pathlib
+import sys
+from functools import lru_cache
+from importlib._bootstrap_external import _NamespacePath
+from importlib.util import _find_spec_from_path # type: ignore[attr-defined]
+
+from astroid.const import IS_PYPY
+
+if sys.version_info >= (3, 11):
+ from importlib.machinery import NamespaceLoader
+else:
+ from importlib._bootstrap_external import _NamespaceLoader as NamespaceLoader
+
+
+@lru_cache(maxsize=4096)
+def is_namespace(modname: str) -> bool:
+ from astroid.modutils import ( # pylint: disable=import-outside-toplevel
+ EXT_LIB_DIRS,
+ STD_LIB_DIRS,
+ )
+
+ STD_AND_EXT_LIB_DIRS = STD_LIB_DIRS.union(EXT_LIB_DIRS)
+
+ if modname in sys.builtin_module_names:
+ return False
+
+ found_spec = None
+
+ # find_spec() attempts to import parent packages when given dotted paths.
+ # That's unacceptable here, so we fallback to _find_spec_from_path(), which does
+ # not, but requires instead that each single parent ('astroid', 'nodes', etc.)
+ # be specced from left to right.
+ processed_components = []
+ last_submodule_search_locations: _NamespacePath | None = None
+ for component in modname.split("."):
+ processed_components.append(component)
+ working_modname = ".".join(processed_components)
+ try:
+ # Both the modname and the path are built iteratively, with the
+ # path (e.g. ['a', 'a/b', 'a/b/c']) lagging the modname by one
+ found_spec = _find_spec_from_path(
+ working_modname, path=last_submodule_search_locations
+ )
+ except AttributeError:
+ return False
+ except ValueError:
+ if modname == "__main__":
+ return False
+ try:
+ # .pth files will be on sys.modules
+ # __spec__ is set inconsistently on PyPy so we can't really on the heuristic here
+ # See: https://foss.heptapod.net/pypy/pypy/-/issues/3736
+ # Check first fragment of modname, e.g. "astroid", not "astroid.interpreter"
+ # because of cffi's behavior
+ # See: https://github.com/pylint-dev/astroid/issues/1776
+ mod = sys.modules[processed_components[0]]
+ return (
+ mod.__spec__ is None
+ and getattr(mod, "__file__", None) is None
+ and hasattr(mod, "__path__")
+ and not IS_PYPY
+ )
+ except KeyError:
+ return False
+ except AttributeError:
+ # Workaround for "py" module
+ # https://github.com/pytest-dev/apipkg/issues/13
+ return False
+ except KeyError:
+ # Intermediate steps might raise KeyErrors
+ # https://github.com/python/cpython/issues/93334
+ # TODO: update if fixed in importlib
+ # For tree a > b > c.py
+ # >>> from importlib.machinery import PathFinder
+ # >>> PathFinder.find_spec('a.b', ['a'])
+ # KeyError: 'a'
+
+ # Repair last_submodule_search_locations
+ if last_submodule_search_locations:
+ # pylint: disable=unsubscriptable-object
+ last_item = last_submodule_search_locations[-1]
+ # e.g. for failure example above, add 'a/b' and keep going
+ # so that find_spec('a.b.c', path=['a', 'a/b']) succeeds
+ assumed_location = pathlib.Path(last_item) / component
+ last_submodule_search_locations.append(str(assumed_location))
+ continue
+
+ # Update last_submodule_search_locations for next iteration
+ if found_spec and found_spec.submodule_search_locations:
+ # But immediately return False if we can detect we are in stdlib
+ # or external lib (e.g site-packages)
+ if any(
+ any(location.startswith(lib_dir) for lib_dir in STD_AND_EXT_LIB_DIRS)
+ for location in found_spec.submodule_search_locations
+ ):
+ return False
+ last_submodule_search_locations = found_spec.submodule_search_locations
+
+ return (
+ found_spec is not None
+ and found_spec.submodule_search_locations is not None
+ and found_spec.origin is None
+ and (
+ found_spec.loader is None or isinstance(found_spec.loader, NamespaceLoader)
+ )
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/interpreter/dunder_lookup.py b/solutions/.venv/Lib/site-packages/astroid/interpreter/dunder_lookup.py
new file mode 100644
index 000000000..727c1ad46
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/interpreter/dunder_lookup.py
@@ -0,0 +1,77 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Contains logic for retrieving special methods.
+
+This implementation does not rely on the dot attribute access
+logic, found in ``.getattr()``. The difference between these two
+is that the dunder methods are looked with the type slots
+(you can find more about these here
+http://lucumr.pocoo.org/2014/8/16/the-python-i-would-like-to-see/)
+As such, the lookup for the special methods is actually simpler than
+the dot attribute access.
+"""
+from __future__ import annotations
+
+import itertools
+from typing import TYPE_CHECKING
+
+import astroid
+from astroid.exceptions import AttributeInferenceError
+
+if TYPE_CHECKING:
+ from astroid import nodes
+ from astroid.context import InferenceContext
+
+
+def _lookup_in_mro(node, name) -> list:
+ attrs = node.locals.get(name, [])
+
+ nodes = itertools.chain.from_iterable(
+ ancestor.locals.get(name, []) for ancestor in node.ancestors(recurs=True)
+ )
+ values = list(itertools.chain(attrs, nodes))
+ if not values:
+ raise AttributeInferenceError(attribute=name, target=node)
+
+ return values
+
+
+def lookup(
+ node: nodes.NodeNG, name: str, context: InferenceContext | None = None
+) -> list:
+ """Lookup the given special method name in the given *node*.
+
+ If the special method was found, then a list of attributes
+ will be returned. Otherwise, `astroid.AttributeInferenceError`
+ is going to be raised.
+ """
+ if isinstance(
+ node, (astroid.List, astroid.Tuple, astroid.Const, astroid.Dict, astroid.Set)
+ ):
+ return _builtin_lookup(node, name)
+ if isinstance(node, astroid.Instance):
+ return _lookup_in_mro(node, name)
+ if isinstance(node, astroid.ClassDef):
+ return _class_lookup(node, name, context=context)
+
+ raise AttributeInferenceError(attribute=name, target=node)
+
+
+def _class_lookup(
+ node: nodes.ClassDef, name: str, context: InferenceContext | None = None
+) -> list:
+ metaclass = node.metaclass(context=context)
+ if metaclass is None:
+ raise AttributeInferenceError(attribute=name, target=node)
+
+ return _lookup_in_mro(metaclass, name)
+
+
+def _builtin_lookup(node, name) -> list:
+ values = node.locals.get(name, [])
+ if not values:
+ raise AttributeInferenceError(attribute=name, target=node)
+
+ return values
diff --git a/solutions/.venv/Lib/site-packages/astroid/interpreter/objectmodel.py b/solutions/.venv/Lib/site-packages/astroid/interpreter/objectmodel.py
new file mode 100644
index 000000000..0f553ab08
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/interpreter/objectmodel.py
@@ -0,0 +1,1029 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Data object model, as per https://docs.python.org/3/reference/datamodel.html.
+
+This module describes, at least partially, a data object model for some
+of astroid's nodes. The model contains special attributes that nodes such
+as functions, classes, modules etc have, such as __doc__, __class__,
+__module__ etc, being used when doing attribute lookups over nodes.
+
+For instance, inferring `obj.__class__` will first trigger an inference
+of the `obj` variable. If it was successfully inferred, then an attribute
+`__class__ will be looked for in the inferred object. This is the part
+where the data model occurs. The model is attached to those nodes
+and the lookup mechanism will try to see if attributes such as
+`__class__` are defined by the model or not. If they are defined,
+the model will be requested to return the corresponding value of that
+attribute. Thus the model can be viewed as a special part of the lookup
+mechanism.
+"""
+
+from __future__ import annotations
+
+import itertools
+import os
+import pprint
+import types
+from collections.abc import Iterator
+from functools import lru_cache
+from typing import TYPE_CHECKING, Any, Literal
+
+import astroid
+from astroid import bases, nodes, util
+from astroid.context import InferenceContext, copy_context
+from astroid.exceptions import AttributeInferenceError, InferenceError, NoDefault
+from astroid.manager import AstroidManager
+from astroid.nodes import node_classes
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+if TYPE_CHECKING:
+ from astroid.objects import Property
+
+IMPL_PREFIX = "attr_"
+LEN_OF_IMPL_PREFIX = len(IMPL_PREFIX)
+
+
+def _dunder_dict(instance, attributes):
+ obj = node_classes.Dict(
+ parent=instance,
+ lineno=instance.lineno,
+ col_offset=instance.col_offset,
+ end_lineno=instance.end_lineno,
+ end_col_offset=instance.end_col_offset,
+ )
+
+ # Convert the keys to node strings
+ keys = [
+ node_classes.Const(value=value, parent=obj) for value in list(attributes.keys())
+ ]
+
+ # The original attribute has a list of elements for each key,
+ # but that is not useful for retrieving the special attribute's value.
+ # In this case, we're picking the last value from each list.
+ values = [elem[-1] for elem in attributes.values()]
+
+ obj.postinit(list(zip(keys, values)))
+ return obj
+
+
+def _get_bound_node(model: ObjectModel) -> Any:
+ # TODO: Use isinstance instead of try ... except after _instance has typing
+ try:
+ return model._instance._proxied
+ except AttributeError:
+ return model._instance
+
+
+class ObjectModel:
+ def __init__(self):
+ self._instance = None
+
+ def __repr__(self):
+ result = []
+ cname = type(self).__name__
+ string = "%(cname)s(%(fields)s)"
+ alignment = len(cname) + 1
+ for field in sorted(self.attributes()):
+ width = 80 - len(field) - alignment
+ lines = pprint.pformat(field, indent=2, width=width).splitlines(True)
+
+ inner = [lines[0]]
+ for line in lines[1:]:
+ inner.append(" " * alignment + line)
+ result.append(field)
+
+ return string % {
+ "cname": cname,
+ "fields": (",\n" + " " * alignment).join(result),
+ }
+
+ def __call__(self, instance):
+ self._instance = instance
+ return self
+
+ def __get__(self, instance, cls=None):
+ # ObjectModel needs to be a descriptor so that just doing
+ # `special_attributes = SomeObjectModel` should be enough in the body of a node.
+ # But at the same time, node.special_attributes should return an object
+ # which can be used for manipulating the special attributes. That's the reason
+ # we pass the instance through which it got accessed to ObjectModel.__call__,
+ # returning itself afterwards, so we can still have access to the
+ # underlying data model and to the instance for which it got accessed.
+ return self(instance)
+
+ def __contains__(self, name) -> bool:
+ return name in self.attributes()
+
+ @lru_cache # noqa
+ def attributes(self) -> list[str]:
+ """Get the attributes which are exported by this object model."""
+ return [o[LEN_OF_IMPL_PREFIX:] for o in dir(self) if o.startswith(IMPL_PREFIX)]
+
+ def lookup(self, name):
+ """Look up the given *name* in the current model.
+
+ It should return an AST or an interpreter object,
+ but if the name is not found, then an AttributeInferenceError will be raised.
+ """
+ if name in self.attributes():
+ return getattr(self, IMPL_PREFIX + name)
+ raise AttributeInferenceError(target=self._instance, attribute=name)
+
+ @property
+ def attr___new__(self) -> bases.BoundMethod:
+ """Calling cls.__new__(type) on an object returns an instance of 'type'."""
+ from astroid import builder # pylint: disable=import-outside-toplevel
+
+ node: nodes.FunctionDef = builder.extract_node(
+ """def __new__(self, cls): return cls()"""
+ )
+ # We set the parent as being the ClassDef of 'object' as that
+ # triggers correct inference as a call to __new__ in bases.py
+ node.parent = AstroidManager().builtins_module["object"]
+
+ return bases.BoundMethod(proxy=node, bound=_get_bound_node(self))
+
+ @property
+ def attr___init__(self) -> bases.BoundMethod:
+ """Calling cls.__init__() normally returns None."""
+ from astroid import builder # pylint: disable=import-outside-toplevel
+
+ # The *args and **kwargs are necessary not to trigger warnings about missing
+ # or extra parameters for '__init__' methods we don't infer correctly.
+ # This BoundMethod is the fallback value for those.
+ node: nodes.FunctionDef = builder.extract_node(
+ """def __init__(self, *args, **kwargs): return None"""
+ )
+ # We set the parent as being the ClassDef of 'object' as that
+ # is where this method originally comes from
+ node.parent = AstroidManager().builtins_module["object"]
+
+ return bases.BoundMethod(proxy=node, bound=_get_bound_node(self))
+
+
+class ModuleModel(ObjectModel):
+ def _builtins(self):
+ builtins_ast_module = AstroidManager().builtins_module
+ return builtins_ast_module.special_attributes.lookup("__dict__")
+
+ @property
+ def attr_builtins(self):
+ return self._builtins()
+
+ @property
+ def attr___path__(self):
+ if not self._instance.package:
+ raise AttributeInferenceError(target=self._instance, attribute="__path__")
+
+ path_objs = [
+ node_classes.Const(
+ value=(
+ path if not path.endswith("__init__.py") else os.path.dirname(path)
+ ),
+ parent=self._instance,
+ )
+ for path in self._instance.path
+ ]
+
+ container = node_classes.List(parent=self._instance)
+ container.postinit(path_objs)
+
+ return container
+
+ @property
+ def attr___name__(self):
+ return node_classes.Const(value=self._instance.name, parent=self._instance)
+
+ @property
+ def attr___doc__(self):
+ return node_classes.Const(
+ value=getattr(self._instance.doc_node, "value", None),
+ parent=self._instance,
+ )
+
+ @property
+ def attr___file__(self):
+ return node_classes.Const(value=self._instance.file, parent=self._instance)
+
+ @property
+ def attr___dict__(self):
+ return _dunder_dict(self._instance, self._instance.globals)
+
+ @property
+ def attr___package__(self):
+ if not self._instance.package:
+ value = ""
+ else:
+ value = self._instance.name
+
+ return node_classes.Const(value=value, parent=self._instance)
+
+ # These are related to the Python 3 implementation of the
+ # import system,
+ # https://docs.python.org/3/reference/import.html#import-related-module-attributes
+
+ @property
+ def attr___spec__(self):
+ # No handling for now.
+ return node_classes.Unknown()
+
+ @property
+ def attr___loader__(self):
+ # No handling for now.
+ return node_classes.Unknown()
+
+ @property
+ def attr___cached__(self):
+ # No handling for now.
+ return node_classes.Unknown()
+
+
+class FunctionModel(ObjectModel):
+ @property
+ def attr___name__(self):
+ return node_classes.Const(value=self._instance.name, parent=self._instance)
+
+ @property
+ def attr___doc__(self):
+ return node_classes.Const(
+ value=getattr(self._instance.doc_node, "value", None),
+ parent=self._instance,
+ )
+
+ @property
+ def attr___qualname__(self):
+ return node_classes.Const(value=self._instance.qname(), parent=self._instance)
+
+ @property
+ def attr___defaults__(self):
+ func = self._instance
+ if not func.args.defaults:
+ return node_classes.Const(value=None, parent=func)
+
+ defaults_obj = node_classes.Tuple(parent=func)
+ defaults_obj.postinit(func.args.defaults)
+ return defaults_obj
+
+ @property
+ def attr___annotations__(self):
+ obj = node_classes.Dict(
+ parent=self._instance,
+ lineno=self._instance.lineno,
+ col_offset=self._instance.col_offset,
+ end_lineno=self._instance.end_lineno,
+ end_col_offset=self._instance.end_col_offset,
+ )
+
+ if not self._instance.returns:
+ returns = None
+ else:
+ returns = self._instance.returns
+
+ args = self._instance.args
+ pair_annotations = itertools.chain(
+ zip(args.args or [], args.annotations),
+ zip(args.kwonlyargs, args.kwonlyargs_annotations),
+ zip(args.posonlyargs or [], args.posonlyargs_annotations),
+ )
+
+ annotations = {
+ arg.name: annotation for (arg, annotation) in pair_annotations if annotation
+ }
+ if args.varargannotation:
+ annotations[args.vararg] = args.varargannotation
+ if args.kwargannotation:
+ annotations[args.kwarg] = args.kwargannotation
+ if returns:
+ annotations["return"] = returns
+
+ items = [
+ (node_classes.Const(key, parent=obj), value)
+ for (key, value) in annotations.items()
+ ]
+
+ obj.postinit(items)
+ return obj
+
+ @property
+ def attr___dict__(self):
+ return node_classes.Dict(
+ parent=self._instance,
+ lineno=self._instance.lineno,
+ col_offset=self._instance.col_offset,
+ end_lineno=self._instance.end_lineno,
+ end_col_offset=self._instance.end_col_offset,
+ )
+
+ attr___globals__ = attr___dict__
+
+ @property
+ def attr___kwdefaults__(self):
+ def _default_args(args, parent):
+ for arg in args.kwonlyargs:
+ try:
+ default = args.default_value(arg.name)
+ except NoDefault:
+ continue
+
+ name = node_classes.Const(arg.name, parent=parent)
+ yield name, default
+
+ args = self._instance.args
+ obj = node_classes.Dict(
+ parent=self._instance,
+ lineno=self._instance.lineno,
+ col_offset=self._instance.col_offset,
+ end_lineno=self._instance.end_lineno,
+ end_col_offset=self._instance.end_col_offset,
+ )
+ defaults = dict(_default_args(args, obj))
+
+ obj.postinit(list(defaults.items()))
+ return obj
+
+ @property
+ def attr___module__(self):
+ return node_classes.Const(self._instance.root().qname())
+
+ @property
+ def attr___get__(self):
+ func = self._instance
+
+ class DescriptorBoundMethod(bases.BoundMethod):
+ """Bound method which knows how to understand calling descriptor
+ binding.
+ """
+
+ def implicit_parameters(self) -> Literal[0]:
+ # Different than BoundMethod since the signature
+ # is different.
+ return 0
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[bases.BoundMethod]:
+ if len(caller.args) > 2 or len(caller.args) < 1:
+ raise InferenceError(
+ "Invalid arguments for descriptor binding",
+ target=self,
+ context=context,
+ )
+
+ context = copy_context(context)
+ try:
+ cls = next(caller.args[0].infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(context=context, node=caller.args[0]) from e
+
+ if isinstance(cls, util.UninferableBase):
+ raise InferenceError(
+ "Invalid class inferred", target=self, context=context
+ )
+
+ # For some reason func is a Node that the below
+ # code is not expecting
+ if isinstance(func, bases.BoundMethod):
+ yield func
+ return
+
+ # Rebuild the original value, but with the parent set as the
+ # class where it will be bound.
+ new_func = func.__class__(
+ name=func.name,
+ lineno=func.lineno,
+ col_offset=func.col_offset,
+ parent=func.parent,
+ end_lineno=func.end_lineno,
+ end_col_offset=func.end_col_offset,
+ )
+ # pylint: disable=no-member
+ new_func.postinit(
+ func.args,
+ func.body,
+ func.decorators,
+ func.returns,
+ doc_node=func.doc_node,
+ )
+
+ # Build a proper bound method that points to our newly built function.
+ proxy = bases.UnboundMethod(new_func)
+ yield bases.BoundMethod(proxy=proxy, bound=cls)
+
+ @property
+ def args(self):
+ """Overwrite the underlying args to match those of the underlying func.
+
+ Usually the underlying *func* is a function/method, as in:
+
+ def test(self):
+ pass
+
+ This has only the *self* parameter but when we access test.__get__
+ we get a new object which has two parameters, *self* and *type*.
+ """
+ nonlocal func
+ arguments = astroid.Arguments(
+ parent=func.args.parent, vararg=None, kwarg=None
+ )
+
+ positional_or_keyword_params = func.args.args.copy()
+ positional_or_keyword_params.append(
+ astroid.AssignName(
+ name="type",
+ lineno=0,
+ col_offset=0,
+ parent=arguments,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ )
+
+ positional_only_params = func.args.posonlyargs.copy()
+
+ arguments.postinit(
+ args=positional_or_keyword_params,
+ posonlyargs=positional_only_params,
+ defaults=[],
+ kwonlyargs=[],
+ kw_defaults=[],
+ annotations=[],
+ kwonlyargs_annotations=[],
+ posonlyargs_annotations=[],
+ )
+ return arguments
+
+ return DescriptorBoundMethod(proxy=self._instance, bound=self._instance)
+
+ # These are here just for completion.
+ @property
+ def attr___ne__(self):
+ return node_classes.Unknown()
+
+ attr___subclasshook__ = attr___ne__
+ attr___str__ = attr___ne__
+ attr___sizeof__ = attr___ne__
+ attr___setattr___ = attr___ne__
+ attr___repr__ = attr___ne__
+ attr___reduce__ = attr___ne__
+ attr___reduce_ex__ = attr___ne__
+ attr___lt__ = attr___ne__
+ attr___eq__ = attr___ne__
+ attr___gt__ = attr___ne__
+ attr___format__ = attr___ne__
+ attr___delattr___ = attr___ne__
+ attr___getattribute__ = attr___ne__
+ attr___hash__ = attr___ne__
+ attr___dir__ = attr___ne__
+ attr___call__ = attr___ne__
+ attr___class__ = attr___ne__
+ attr___closure__ = attr___ne__
+ attr___code__ = attr___ne__
+
+
+class ClassModel(ObjectModel):
+ def __init__(self):
+ # Add a context so that inferences called from an instance don't recurse endlessly
+ self.context = InferenceContext()
+
+ super().__init__()
+
+ @property
+ def attr___annotations__(self) -> node_classes.Unkown:
+ return node_classes.Unknown()
+
+ @property
+ def attr___module__(self):
+ return node_classes.Const(self._instance.root().qname())
+
+ @property
+ def attr___name__(self):
+ return node_classes.Const(self._instance.name)
+
+ @property
+ def attr___qualname__(self):
+ return node_classes.Const(self._instance.qname())
+
+ @property
+ def attr___doc__(self):
+ return node_classes.Const(getattr(self._instance.doc_node, "value", None))
+
+ @property
+ def attr___mro__(self):
+ if not self._instance.newstyle:
+ raise AttributeInferenceError(target=self._instance, attribute="__mro__")
+
+ mro = self._instance.mro()
+ obj = node_classes.Tuple(parent=self._instance)
+ obj.postinit(mro)
+ return obj
+
+ @property
+ def attr_mro(self):
+ if not self._instance.newstyle:
+ raise AttributeInferenceError(target=self._instance, attribute="mro")
+
+ other_self = self
+
+ # Cls.mro is a method and we need to return one in order to have a proper inference.
+ # The method we're returning is capable of inferring the underlying MRO though.
+ class MroBoundMethod(bases.BoundMethod):
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[node_classes.Tuple]:
+ yield other_self.attr___mro__
+
+ implicit_metaclass = self._instance.implicit_metaclass()
+ mro_method = implicit_metaclass.locals["mro"][0]
+ return MroBoundMethod(proxy=mro_method, bound=implicit_metaclass)
+
+ @property
+ def attr___bases__(self):
+ obj = node_classes.Tuple()
+ context = InferenceContext()
+ elts = list(self._instance._inferred_bases(context))
+ obj.postinit(elts=elts)
+ return obj
+
+ @property
+ def attr___class__(self):
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid import helpers
+
+ return helpers.object_type(self._instance)
+
+ @property
+ def attr___subclasses__(self):
+ """Get the subclasses of the underlying class.
+
+ This looks only in the current module for retrieving the subclasses,
+ thus it might miss a couple of them.
+ """
+ if not self._instance.newstyle:
+ raise AttributeInferenceError(
+ target=self._instance, attribute="__subclasses__"
+ )
+
+ qname = self._instance.qname()
+ root = self._instance.root()
+ classes = [
+ cls
+ for cls in root.nodes_of_class(nodes.ClassDef)
+ if cls != self._instance and cls.is_subtype_of(qname, context=self.context)
+ ]
+
+ obj = node_classes.List(parent=self._instance)
+ obj.postinit(classes)
+
+ class SubclassesBoundMethod(bases.BoundMethod):
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[node_classes.List]:
+ yield obj
+
+ implicit_metaclass = self._instance.implicit_metaclass()
+ subclasses_method = implicit_metaclass.locals["__subclasses__"][0]
+ return SubclassesBoundMethod(proxy=subclasses_method, bound=implicit_metaclass)
+
+ @property
+ def attr___dict__(self):
+ return node_classes.Dict(
+ parent=self._instance,
+ lineno=self._instance.lineno,
+ col_offset=self._instance.col_offset,
+ end_lineno=self._instance.end_lineno,
+ end_col_offset=self._instance.end_col_offset,
+ )
+
+ @property
+ def attr___call__(self):
+ """Calling a class A() returns an instance of A."""
+ return self._instance.instantiate_class()
+
+
+class SuperModel(ObjectModel):
+ @property
+ def attr___thisclass__(self):
+ return self._instance.mro_pointer
+
+ @property
+ def attr___self_class__(self):
+ return self._instance._self_class
+
+ @property
+ def attr___self__(self):
+ return self._instance.type
+
+ @property
+ def attr___class__(self):
+ return self._instance._proxied
+
+
+class UnboundMethodModel(ObjectModel):
+ @property
+ def attr___class__(self):
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid import helpers
+
+ return helpers.object_type(self._instance)
+
+ @property
+ def attr___func__(self):
+ return self._instance._proxied
+
+ @property
+ def attr___self__(self):
+ return node_classes.Const(value=None, parent=self._instance)
+
+ attr_im_func = attr___func__
+ attr_im_class = attr___class__
+ attr_im_self = attr___self__
+
+
+class ContextManagerModel(ObjectModel):
+ """Model for context managers.
+
+ Based on 3.3.9 of the Data Model documentation:
+ https://docs.python.org/3/reference/datamodel.html#with-statement-context-managers
+ """
+
+ @property
+ def attr___enter__(self) -> bases.BoundMethod:
+ """Representation of the base implementation of __enter__.
+
+ As per Python documentation:
+ Enter the runtime context related to this object. The with statement
+ will bind this method's return value to the target(s) specified in the
+ as clause of the statement, if any.
+ """
+ from astroid import builder # pylint: disable=import-outside-toplevel
+
+ node: nodes.FunctionDef = builder.extract_node("""def __enter__(self): ...""")
+ # We set the parent as being the ClassDef of 'object' as that
+ # is where this method originally comes from
+ node.parent = AstroidManager().builtins_module["object"]
+
+ return bases.BoundMethod(proxy=node, bound=_get_bound_node(self))
+
+ @property
+ def attr___exit__(self) -> bases.BoundMethod:
+ """Representation of the base implementation of __exit__.
+
+ As per Python documentation:
+ Exit the runtime context related to this object. The parameters describe the
+ exception that caused the context to be exited. If the context was exited
+ without an exception, all three arguments will be None.
+ """
+ from astroid import builder # pylint: disable=import-outside-toplevel
+
+ node: nodes.FunctionDef = builder.extract_node(
+ """def __exit__(self, exc_type, exc_value, traceback): ..."""
+ )
+ # We set the parent as being the ClassDef of 'object' as that
+ # is where this method originally comes from
+ node.parent = AstroidManager().builtins_module["object"]
+
+ return bases.BoundMethod(proxy=node, bound=_get_bound_node(self))
+
+
+class BoundMethodModel(FunctionModel):
+ @property
+ def attr___func__(self):
+ return self._instance._proxied._proxied
+
+ @property
+ def attr___self__(self):
+ return self._instance.bound
+
+
+class GeneratorModel(FunctionModel, ContextManagerModel):
+ def __new__(cls, *args, **kwargs):
+ # Append the values from the GeneratorType unto this object.
+ ret = super().__new__(cls, *args, **kwargs)
+ generator = AstroidManager().builtins_module["generator"]
+ for name, values in generator.locals.items():
+ method = values[0]
+
+ def patched(cls, meth=method):
+ return meth
+
+ setattr(type(ret), IMPL_PREFIX + name, property(patched))
+
+ return ret
+
+ @property
+ def attr___name__(self):
+ return node_classes.Const(
+ value=self._instance.parent.name, parent=self._instance
+ )
+
+ @property
+ def attr___doc__(self):
+ return node_classes.Const(
+ value=getattr(self._instance.parent.doc_node, "value", None),
+ parent=self._instance,
+ )
+
+
+class AsyncGeneratorModel(GeneratorModel):
+ def __new__(cls, *args, **kwargs):
+ # Append the values from the AGeneratorType unto this object.
+ ret = super().__new__(cls, *args, **kwargs)
+ astroid_builtins = AstroidManager().builtins_module
+ generator = astroid_builtins.get("async_generator")
+ if generator is None:
+ # Make it backward compatible.
+ generator = astroid_builtins.get("generator")
+
+ for name, values in generator.locals.items():
+ method = values[0]
+
+ def patched(cls, meth=method):
+ return meth
+
+ setattr(type(ret), IMPL_PREFIX + name, property(patched))
+
+ return ret
+
+
+class InstanceModel(ObjectModel):
+ @property
+ def attr___class__(self):
+ return self._instance._proxied
+
+ @property
+ def attr___module__(self):
+ return node_classes.Const(self._instance.root().qname())
+
+ @property
+ def attr___doc__(self):
+ return node_classes.Const(getattr(self._instance.doc_node, "value", None))
+
+ @property
+ def attr___dict__(self):
+ return _dunder_dict(self._instance, self._instance.instance_attrs)
+
+
+# Exception instances
+
+
+class ExceptionInstanceModel(InstanceModel):
+ @property
+ def attr_args(self) -> nodes.Tuple:
+ return nodes.Tuple(parent=self._instance)
+
+ @property
+ def attr___traceback__(self):
+ builtins_ast_module = AstroidManager().builtins_module
+ traceback_type = builtins_ast_module[types.TracebackType.__name__]
+ return traceback_type.instantiate_class()
+
+
+class SyntaxErrorInstanceModel(ExceptionInstanceModel):
+ @property
+ def attr_text(self):
+ return node_classes.Const("")
+
+
+class OSErrorInstanceModel(ExceptionInstanceModel):
+ @property
+ def attr_filename(self):
+ return node_classes.Const("")
+
+ @property
+ def attr_errno(self):
+ return node_classes.Const(0)
+
+ @property
+ def attr_strerror(self):
+ return node_classes.Const("")
+
+ attr_filename2 = attr_filename
+
+
+class ImportErrorInstanceModel(ExceptionInstanceModel):
+ @property
+ def attr_name(self):
+ return node_classes.Const("")
+
+ @property
+ def attr_path(self):
+ return node_classes.Const("")
+
+
+class UnicodeDecodeErrorInstanceModel(ExceptionInstanceModel):
+ @property
+ def attr_object(self):
+ return node_classes.Const(b"")
+
+
+BUILTIN_EXCEPTIONS = {
+ "builtins.SyntaxError": SyntaxErrorInstanceModel,
+ "builtins.ImportError": ImportErrorInstanceModel,
+ "builtins.UnicodeDecodeError": UnicodeDecodeErrorInstanceModel,
+ # These are all similar to OSError in terms of attributes
+ "builtins.OSError": OSErrorInstanceModel,
+ "builtins.BlockingIOError": OSErrorInstanceModel,
+ "builtins.BrokenPipeError": OSErrorInstanceModel,
+ "builtins.ChildProcessError": OSErrorInstanceModel,
+ "builtins.ConnectionAbortedError": OSErrorInstanceModel,
+ "builtins.ConnectionError": OSErrorInstanceModel,
+ "builtins.ConnectionRefusedError": OSErrorInstanceModel,
+ "builtins.ConnectionResetError": OSErrorInstanceModel,
+ "builtins.FileExistsError": OSErrorInstanceModel,
+ "builtins.FileNotFoundError": OSErrorInstanceModel,
+ "builtins.InterruptedError": OSErrorInstanceModel,
+ "builtins.IsADirectoryError": OSErrorInstanceModel,
+ "builtins.NotADirectoryError": OSErrorInstanceModel,
+ "builtins.PermissionError": OSErrorInstanceModel,
+ "builtins.ProcessLookupError": OSErrorInstanceModel,
+ "builtins.TimeoutError": OSErrorInstanceModel,
+}
+
+
+class DictModel(ObjectModel):
+ @property
+ def attr___class__(self):
+ return self._instance._proxied
+
+ def _generic_dict_attribute(self, obj, name):
+ """Generate a bound method that can infer the given *obj*."""
+
+ class DictMethodBoundMethod(astroid.BoundMethod):
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ yield obj
+
+ meth = next(self._instance._proxied.igetattr(name), None)
+ return DictMethodBoundMethod(proxy=meth, bound=self._instance)
+
+ @property
+ def attr_items(self):
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ elems = []
+ obj = node_classes.List(parent=self._instance)
+ for key, value in self._instance.items:
+ elem = node_classes.Tuple(parent=obj)
+ elem.postinit((key, value))
+ elems.append(elem)
+ obj.postinit(elts=elems)
+
+ items_obj = objects.DictItems(obj)
+ return self._generic_dict_attribute(items_obj, "items")
+
+ @property
+ def attr_keys(self):
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ keys = [key for (key, _) in self._instance.items]
+ obj = node_classes.List(parent=self._instance)
+ obj.postinit(elts=keys)
+
+ keys_obj = objects.DictKeys(obj)
+ return self._generic_dict_attribute(keys_obj, "keys")
+
+ @property
+ def attr_values(self):
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ values = [value for (_, value) in self._instance.items]
+ obj = node_classes.List(parent=self._instance)
+ obj.postinit(values)
+
+ values_obj = objects.DictValues(obj)
+ return self._generic_dict_attribute(values_obj, "values")
+
+
+class PropertyModel(ObjectModel):
+ """Model for a builtin property."""
+
+ def _init_function(self, name):
+ function = nodes.FunctionDef(
+ name=name,
+ parent=self._instance,
+ lineno=self._instance.lineno,
+ col_offset=self._instance.col_offset,
+ end_lineno=self._instance.end_lineno,
+ end_col_offset=self._instance.end_col_offset,
+ )
+
+ args = nodes.Arguments(parent=function, vararg=None, kwarg=None)
+ args.postinit(
+ args=[],
+ defaults=[],
+ kwonlyargs=[],
+ kw_defaults=[],
+ annotations=[],
+ posonlyargs=[],
+ posonlyargs_annotations=[],
+ kwonlyargs_annotations=[],
+ )
+
+ function.postinit(args=args, body=[])
+ return function
+
+ @property
+ def attr_fget(self):
+ func = self._instance
+
+ class PropertyFuncAccessor(nodes.FunctionDef):
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ nonlocal func
+ if caller and len(caller.args) != 1:
+ raise InferenceError(
+ "fget() needs a single argument", target=self, context=context
+ )
+
+ yield from func.function.infer_call_result(
+ caller=caller, context=context
+ )
+
+ property_accessor = PropertyFuncAccessor(
+ name="fget",
+ parent=self._instance,
+ lineno=self._instance.lineno,
+ col_offset=self._instance.col_offset,
+ end_lineno=self._instance.end_lineno,
+ end_col_offset=self._instance.end_col_offset,
+ )
+ property_accessor.postinit(args=func.args, body=func.body)
+ return property_accessor
+
+ @property
+ def attr_fset(self):
+ func = self._instance
+
+ def find_setter(func: Property) -> astroid.FunctionDef | None:
+ """
+ Given a property, find the corresponding setter function and returns it.
+
+ :param func: property for which the setter has to be found
+ :return: the setter function or None
+ """
+ for target in [
+ t for t in func.parent.get_children() if t.name == func.function.name
+ ]:
+ for dec_name in target.decoratornames():
+ if dec_name.endswith(func.function.name + ".setter"):
+ return target
+ return None
+
+ func_setter = find_setter(func)
+ if not func_setter:
+ raise InferenceError(
+ f"Unable to find the setter of property {func.function.name}"
+ )
+
+ class PropertyFuncAccessor(nodes.FunctionDef):
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ nonlocal func_setter
+ if caller and len(caller.args) != 2:
+ raise InferenceError(
+ "fset() needs two arguments", target=self, context=context
+ )
+ yield from func_setter.infer_call_result(caller=caller, context=context)
+
+ property_accessor = PropertyFuncAccessor(
+ name="fset",
+ parent=self._instance,
+ lineno=self._instance.lineno,
+ col_offset=self._instance.col_offset,
+ end_lineno=self._instance.end_lineno,
+ end_col_offset=self._instance.end_col_offset,
+ )
+ property_accessor.postinit(args=func_setter.args, body=func_setter.body)
+ return property_accessor
+
+ @property
+ def attr_setter(self):
+ return self._init_function("setter")
+
+ @property
+ def attr_deleter(self):
+ return self._init_function("deleter")
+
+ @property
+ def attr_getter(self):
+ return self._init_function("getter")
+
+ # pylint: enable=import-outside-toplevel
diff --git a/solutions/.venv/Lib/site-packages/astroid/manager.py b/solutions/.venv/Lib/site-packages/astroid/manager.py
new file mode 100644
index 000000000..e5398c45a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/manager.py
@@ -0,0 +1,486 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""astroid manager: avoid multiple astroid build of a same module when
+possible by providing a class responsible to get astroid representation
+from various source and using a cache of built modules)
+"""
+
+from __future__ import annotations
+
+import collections
+import os
+import types
+import zipimport
+from collections.abc import Callable, Iterator, Sequence
+from typing import Any, ClassVar
+
+from astroid import nodes
+from astroid.context import InferenceContext, _invalidate_cache
+from astroid.exceptions import AstroidBuildingError, AstroidImportError
+from astroid.interpreter._import import spec, util
+from astroid.modutils import (
+ NoSourceFile,
+ _cache_normalize_path_,
+ _has_init,
+ file_info_from_modpath,
+ get_source_file,
+ is_module_name_part_of_extension_package_whitelist,
+ is_python_source,
+ is_stdlib_module,
+ load_module_from_name,
+ modpath_from_file,
+)
+from astroid.transforms import TransformVisitor
+from astroid.typing import AstroidManagerBrain, InferenceResult
+
+ZIP_IMPORT_EXTS = (".zip", ".egg", ".whl", ".pyz", ".pyzw")
+
+
+def safe_repr(obj: Any) -> str:
+ try:
+ return repr(obj)
+ except Exception: # pylint: disable=broad-except
+ return "???"
+
+
+class AstroidManager:
+ """Responsible to build astroid from files or modules.
+
+ Use the Borg (singleton) pattern.
+ """
+
+ name = "astroid loader"
+ brain: ClassVar[AstroidManagerBrain] = {
+ "astroid_cache": {},
+ "_mod_file_cache": {},
+ "_failed_import_hooks": [],
+ "always_load_extensions": False,
+ "optimize_ast": False,
+ "max_inferable_values": 100,
+ "extension_package_whitelist": set(),
+ "module_denylist": set(),
+ "_transform": TransformVisitor(),
+ "prefer_stubs": False,
+ }
+
+ def __init__(self) -> None:
+ # NOTE: cache entries are added by the [re]builder
+ self.astroid_cache = AstroidManager.brain["astroid_cache"]
+ self._mod_file_cache = AstroidManager.brain["_mod_file_cache"]
+ self._failed_import_hooks = AstroidManager.brain["_failed_import_hooks"]
+ self.extension_package_whitelist = AstroidManager.brain[
+ "extension_package_whitelist"
+ ]
+ self.module_denylist = AstroidManager.brain["module_denylist"]
+ self._transform = AstroidManager.brain["_transform"]
+ self.prefer_stubs = AstroidManager.brain["prefer_stubs"]
+
+ @property
+ def always_load_extensions(self) -> bool:
+ return AstroidManager.brain["always_load_extensions"]
+
+ @always_load_extensions.setter
+ def always_load_extensions(self, value: bool) -> None:
+ AstroidManager.brain["always_load_extensions"] = value
+
+ @property
+ def optimize_ast(self) -> bool:
+ return AstroidManager.brain["optimize_ast"]
+
+ @optimize_ast.setter
+ def optimize_ast(self, value: bool) -> None:
+ AstroidManager.brain["optimize_ast"] = value
+
+ @property
+ def max_inferable_values(self) -> int:
+ return AstroidManager.brain["max_inferable_values"]
+
+ @max_inferable_values.setter
+ def max_inferable_values(self, value: int) -> None:
+ AstroidManager.brain["max_inferable_values"] = value
+
+ @property
+ def register_transform(self):
+ # This and unregister_transform below are exported for convenience
+ return self._transform.register_transform
+
+ @property
+ def unregister_transform(self):
+ return self._transform.unregister_transform
+
+ @property
+ def builtins_module(self) -> nodes.Module:
+ return self.astroid_cache["builtins"]
+
+ @property
+ def prefer_stubs(self) -> bool:
+ return AstroidManager.brain["prefer_stubs"]
+
+ @prefer_stubs.setter
+ def prefer_stubs(self, value: bool) -> None:
+ AstroidManager.brain["prefer_stubs"] = value
+
+ def visit_transforms(self, node: nodes.NodeNG) -> InferenceResult:
+ """Visit the transforms and apply them to the given *node*."""
+ return self._transform.visit(node)
+
+ def ast_from_file(
+ self,
+ filepath: str,
+ modname: str | None = None,
+ fallback: bool = True,
+ source: bool = False,
+ ) -> nodes.Module:
+ """Given a module name, return the astroid object."""
+ if modname is None:
+ try:
+ modname = ".".join(modpath_from_file(filepath))
+ except ImportError:
+ modname = filepath
+ if (
+ modname in self.astroid_cache
+ and self.astroid_cache[modname].file == filepath
+ ):
+ return self.astroid_cache[modname]
+ # Call get_source_file() only after a cache miss,
+ # since it calls os.path.exists().
+ try:
+ filepath = get_source_file(
+ filepath, include_no_ext=True, prefer_stubs=self.prefer_stubs
+ )
+ source = True
+ except NoSourceFile:
+ pass
+ # Second attempt on the cache after get_source_file().
+ if (
+ modname in self.astroid_cache
+ and self.astroid_cache[modname].file == filepath
+ ):
+ return self.astroid_cache[modname]
+ if source:
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.builder import AstroidBuilder
+
+ return AstroidBuilder(self).file_build(filepath, modname)
+ if fallback and modname:
+ return self.ast_from_module_name(modname)
+ raise AstroidBuildingError("Unable to build an AST for {path}.", path=filepath)
+
+ def ast_from_string(
+ self, data: str, modname: str = "", filepath: str | None = None
+ ) -> nodes.Module:
+ """Given some source code as a string, return its corresponding astroid
+ object.
+ """
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.builder import AstroidBuilder
+
+ return AstroidBuilder(self).string_build(data, modname, filepath)
+
+ def _build_stub_module(self, modname: str) -> nodes.Module:
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.builder import AstroidBuilder
+
+ return AstroidBuilder(self).string_build("", modname)
+
+ def _build_namespace_module(
+ self, modname: str, path: Sequence[str]
+ ) -> nodes.Module:
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.builder import build_namespace_package_module
+
+ return build_namespace_package_module(modname, path)
+
+ def _can_load_extension(self, modname: str) -> bool:
+ if self.always_load_extensions:
+ return True
+ if is_stdlib_module(modname):
+ return True
+ return is_module_name_part_of_extension_package_whitelist(
+ modname, self.extension_package_whitelist
+ )
+
+ def ast_from_module_name( # noqa: C901
+ self,
+ modname: str | None,
+ context_file: str | None = None,
+ use_cache: bool = True,
+ ) -> nodes.Module:
+ """Given a module name, return the astroid object."""
+ if modname is None:
+ raise AstroidBuildingError("No module name given.")
+ # Sometimes we don't want to use the cache. For example, when we're
+ # importing a module with the same name as the file that is importing
+ # we want to fallback on the import system to make sure we get the correct
+ # module.
+ if modname in self.module_denylist:
+ raise AstroidImportError(f"Skipping ignored module {modname!r}")
+ if modname in self.astroid_cache and use_cache:
+ return self.astroid_cache[modname]
+ if modname == "__main__":
+ return self._build_stub_module(modname)
+ if context_file:
+ old_cwd = os.getcwd()
+ os.chdir(os.path.dirname(context_file))
+ try:
+ found_spec = self.file_from_module_name(modname, context_file)
+ if found_spec.type == spec.ModuleType.PY_ZIPMODULE:
+ module = self.zip_import_data(found_spec.location)
+ if module is not None:
+ return module
+
+ elif found_spec.type in (
+ spec.ModuleType.C_BUILTIN,
+ spec.ModuleType.C_EXTENSION,
+ ):
+ if (
+ found_spec.type == spec.ModuleType.C_EXTENSION
+ and not self._can_load_extension(modname)
+ ):
+ return self._build_stub_module(modname)
+ try:
+ named_module = load_module_from_name(modname)
+ except Exception as e:
+ raise AstroidImportError(
+ "Loading {modname} failed with:\n{error}",
+ modname=modname,
+ path=found_spec.location,
+ ) from e
+ return self.ast_from_module(named_module, modname)
+
+ elif found_spec.type == spec.ModuleType.PY_COMPILED:
+ raise AstroidImportError(
+ "Unable to load compiled module {modname}.",
+ modname=modname,
+ path=found_spec.location,
+ )
+
+ elif found_spec.type == spec.ModuleType.PY_NAMESPACE:
+ return self._build_namespace_module(
+ modname, found_spec.submodule_search_locations or []
+ )
+ elif found_spec.type == spec.ModuleType.PY_FROZEN:
+ if found_spec.location is None:
+ return self._build_stub_module(modname)
+ # For stdlib frozen modules we can determine the location and
+ # can therefore create a module from the source file
+ return self.ast_from_file(found_spec.location, modname, fallback=False)
+
+ if found_spec.location is None:
+ raise AstroidImportError(
+ "Can't find a file for module {modname}.", modname=modname
+ )
+
+ return self.ast_from_file(found_spec.location, modname, fallback=False)
+ except AstroidBuildingError as e:
+ for hook in self._failed_import_hooks:
+ try:
+ return hook(modname)
+ except AstroidBuildingError:
+ pass
+ raise e
+ finally:
+ if context_file:
+ os.chdir(old_cwd)
+
+ def zip_import_data(self, filepath: str) -> nodes.Module | None:
+ if zipimport is None:
+ return None
+
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.builder import AstroidBuilder
+
+ builder = AstroidBuilder(self)
+ for ext in ZIP_IMPORT_EXTS:
+ try:
+ eggpath, resource = filepath.rsplit(ext + os.path.sep, 1)
+ except ValueError:
+ continue
+ try:
+ importer = zipimport.zipimporter(eggpath + ext)
+ zmodname = resource.replace(os.path.sep, ".")
+ if importer.is_package(resource):
+ zmodname = zmodname + ".__init__"
+ module = builder.string_build(
+ importer.get_source(resource), zmodname, filepath
+ )
+ return module
+ except Exception: # pylint: disable=broad-except
+ continue
+ return None
+
+ def file_from_module_name(
+ self, modname: str, contextfile: str | None
+ ) -> spec.ModuleSpec:
+ try:
+ value = self._mod_file_cache[(modname, contextfile)]
+ except KeyError:
+ try:
+ value = file_info_from_modpath(
+ modname.split("."), context_file=contextfile
+ )
+ except ImportError as e:
+ value = AstroidImportError(
+ "Failed to import module {modname} with error:\n{error}.",
+ modname=modname,
+ # we remove the traceback here to save on memory usage (since these exceptions are cached)
+ error=e.with_traceback(None),
+ )
+ self._mod_file_cache[(modname, contextfile)] = value
+ if isinstance(value, AstroidBuildingError):
+ # we remove the traceback here to save on memory usage (since these exceptions are cached)
+ raise value.with_traceback(None) # pylint: disable=no-member
+ return value
+
+ def ast_from_module(
+ self, module: types.ModuleType, modname: str | None = None
+ ) -> nodes.Module:
+ """Given an imported module, return the astroid object."""
+ modname = modname or module.__name__
+ if modname in self.astroid_cache:
+ return self.astroid_cache[modname]
+ try:
+ # some builtin modules don't have __file__ attribute
+ filepath = module.__file__
+ if is_python_source(filepath):
+ # Type is checked in is_python_source
+ return self.ast_from_file(filepath, modname) # type: ignore[arg-type]
+ except AttributeError:
+ pass
+
+ # pylint: disable=import-outside-toplevel; circular import
+ from astroid.builder import AstroidBuilder
+
+ return AstroidBuilder(self).module_build(module, modname)
+
+ def ast_from_class(self, klass: type, modname: str | None = None) -> nodes.ClassDef:
+ """Get astroid for the given class."""
+ if modname is None:
+ try:
+ modname = klass.__module__
+ except AttributeError as exc:
+ raise AstroidBuildingError(
+ "Unable to get module for class {class_name}.",
+ cls=klass,
+ class_repr=safe_repr(klass),
+ modname=modname,
+ ) from exc
+ modastroid = self.ast_from_module_name(modname)
+ ret = modastroid.getattr(klass.__name__)[0]
+ assert isinstance(ret, nodes.ClassDef)
+ return ret
+
+ def infer_ast_from_something(
+ self, obj: object, context: InferenceContext | None = None
+ ) -> Iterator[InferenceResult]:
+ """Infer astroid for the given class."""
+ if hasattr(obj, "__class__") and not isinstance(obj, type):
+ klass = obj.__class__
+ elif isinstance(obj, type):
+ klass = obj
+ else:
+ raise AstroidBuildingError( # pragma: no cover
+ "Unable to get type for {class_repr}.",
+ cls=None,
+ class_repr=safe_repr(obj),
+ )
+ try:
+ modname = klass.__module__
+ except AttributeError as exc:
+ raise AstroidBuildingError(
+ "Unable to get module for {class_repr}.",
+ cls=klass,
+ class_repr=safe_repr(klass),
+ ) from exc
+ except Exception as exc:
+ raise AstroidImportError(
+ "Unexpected error while retrieving module for {class_repr}:\n"
+ "{error}",
+ cls=klass,
+ class_repr=safe_repr(klass),
+ ) from exc
+ try:
+ name = klass.__name__
+ except AttributeError as exc:
+ raise AstroidBuildingError(
+ "Unable to get name for {class_repr}:\n",
+ cls=klass,
+ class_repr=safe_repr(klass),
+ ) from exc
+ except Exception as exc:
+ raise AstroidImportError(
+ "Unexpected error while retrieving name for {class_repr}:\n{error}",
+ cls=klass,
+ class_repr=safe_repr(klass),
+ ) from exc
+ # take care, on living object __module__ is regularly wrong :(
+ modastroid = self.ast_from_module_name(modname)
+ if klass is obj:
+ yield from modastroid.igetattr(name, context)
+ else:
+ for inferred in modastroid.igetattr(name, context):
+ yield inferred.instantiate_class()
+
+ def register_failed_import_hook(self, hook: Callable[[str], nodes.Module]) -> None:
+ """Registers a hook to resolve imports that cannot be found otherwise.
+
+ `hook` must be a function that accepts a single argument `modname` which
+ contains the name of the module or package that could not be imported.
+ If `hook` can resolve the import, must return a node of type `astroid.Module`,
+ otherwise, it must raise `AstroidBuildingError`.
+ """
+ self._failed_import_hooks.append(hook)
+
+ def cache_module(self, module: nodes.Module) -> None:
+ """Cache a module if no module with the same name is known yet."""
+ self.astroid_cache.setdefault(module.name, module)
+
+ def bootstrap(self) -> None:
+ """Bootstrap the required AST modules needed for the manager to work.
+
+ The bootstrap usually involves building the AST for the builtins
+ module, which is required by the rest of astroid to work correctly.
+ """
+ from astroid import raw_building # pylint: disable=import-outside-toplevel
+
+ raw_building._astroid_bootstrapping()
+
+ def clear_cache(self) -> None:
+ """Clear the underlying caches, bootstrap the builtins module and
+ re-register transforms.
+ """
+ # import here because of cyclic imports
+ # pylint: disable=import-outside-toplevel
+ from astroid.brain.helpers import register_all_brains
+ from astroid.inference_tip import clear_inference_tip_cache
+ from astroid.interpreter._import.spec import _find_spec
+ from astroid.interpreter.objectmodel import ObjectModel
+ from astroid.nodes._base_nodes import LookupMixIn
+ from astroid.nodes.scoped_nodes import ClassDef
+
+ clear_inference_tip_cache()
+ _invalidate_cache() # inference context cache
+
+ self.astroid_cache.clear()
+ self._mod_file_cache.clear()
+
+ # NB: not a new TransformVisitor()
+ AstroidManager.brain["_transform"].transforms = collections.defaultdict(list)
+
+ for lru_cache in (
+ LookupMixIn.lookup,
+ _cache_normalize_path_,
+ _has_init,
+ util.is_namespace,
+ ObjectModel.attributes,
+ ClassDef._metaclass_lookup_attribute,
+ _find_spec,
+ ):
+ lru_cache.cache_clear() # type: ignore[attr-defined]
+
+ self.bootstrap()
+
+ # Reload brain plugins. During initialisation this is done in astroid.manager.py
+ register_all_brains(self)
diff --git a/solutions/.venv/Lib/site-packages/astroid/modutils.py b/solutions/.venv/Lib/site-packages/astroid/modutils.py
new file mode 100644
index 000000000..8f7d0d3fe
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/modutils.py
@@ -0,0 +1,691 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Python modules manipulation utility functions.
+
+:type PY_SOURCE_EXTS: tuple(str)
+:var PY_SOURCE_EXTS: list of possible python source file extension
+
+:type STD_LIB_DIRS: set of str
+:var STD_LIB_DIRS: directories where standard modules are located
+
+:type BUILTIN_MODULES: dict
+:var BUILTIN_MODULES: dictionary with builtin module names has key
+"""
+
+from __future__ import annotations
+
+import importlib
+import importlib.machinery
+import importlib.util
+import io
+import itertools
+import logging
+import os
+import sys
+import sysconfig
+import types
+import warnings
+from collections.abc import Callable, Iterable, Sequence
+from contextlib import redirect_stderr, redirect_stdout
+from functools import lru_cache
+
+from astroid.const import IS_JYTHON, PY310_PLUS
+from astroid.interpreter._import import spec, util
+
+if PY310_PLUS:
+ from sys import stdlib_module_names
+else:
+ from astroid._backport_stdlib_names import stdlib_module_names
+
+logger = logging.getLogger(__name__)
+
+
+if sys.platform.startswith("win"):
+ PY_SOURCE_EXTS = ("py", "pyw", "pyi")
+ PY_SOURCE_EXTS_STUBS_FIRST = ("pyi", "pyw", "py")
+ PY_COMPILED_EXTS = ("dll", "pyd")
+else:
+ PY_SOURCE_EXTS = ("py", "pyi")
+ PY_SOURCE_EXTS_STUBS_FIRST = ("pyi", "py")
+ PY_COMPILED_EXTS = ("so",)
+
+
+# TODO: Adding `platstdlib` is a fix for a workaround in virtualenv. At some point we should
+# revisit whether this is still necessary. See https://github.com/pylint-dev/astroid/pull/1323.
+STD_LIB_DIRS = {sysconfig.get_path("stdlib"), sysconfig.get_path("platstdlib")}
+
+if os.name == "nt":
+ STD_LIB_DIRS.add(os.path.join(sys.prefix, "dlls"))
+ try:
+ # real_prefix is defined when running inside virtual environments,
+ # created with the **virtualenv** library.
+ # Deprecated in virtualenv==16.7.9
+ # See: https://github.com/pypa/virtualenv/issues/1622
+ STD_LIB_DIRS.add(os.path.join(sys.real_prefix, "dlls")) # type: ignore[attr-defined]
+ except AttributeError:
+ # sys.base_exec_prefix is always defined, but in a virtual environment
+ # created with the stdlib **venv** module, it points to the original
+ # installation, if the virtual env is activated.
+ try:
+ STD_LIB_DIRS.add(os.path.join(sys.base_exec_prefix, "dlls"))
+ except AttributeError:
+ pass
+
+if os.name == "posix":
+ # Need the real prefix if we're in a virtualenv, otherwise
+ # the usual one will do.
+ # Deprecated in virtualenv==16.7.9
+ # See: https://github.com/pypa/virtualenv/issues/1622
+ try:
+ prefix: str = sys.real_prefix # type: ignore[attr-defined]
+ except AttributeError:
+ prefix = sys.prefix
+
+ def _posix_path(path: str) -> str:
+ base_python = "python%d.%d" % sys.version_info[:2]
+ return os.path.join(prefix, path, base_python)
+
+ STD_LIB_DIRS.add(_posix_path("lib"))
+ if sys.maxsize > 2**32:
+ # This tries to fix a problem with /usr/lib64 builds,
+ # where systems are running both 32-bit and 64-bit code
+ # on the same machine, which reflects into the places where
+ # standard library could be found. More details can be found
+ # here http://bugs.python.org/issue1294959.
+ # An easy reproducing case would be
+ # https://github.com/pylint-dev/pylint/issues/712#issuecomment-163178753
+ STD_LIB_DIRS.add(_posix_path("lib64"))
+
+EXT_LIB_DIRS = {sysconfig.get_path("purelib"), sysconfig.get_path("platlib")}
+BUILTIN_MODULES = dict.fromkeys(sys.builtin_module_names, True)
+
+
+class NoSourceFile(Exception):
+ """Exception raised when we are not able to get a python
+ source file for a precompiled file.
+ """
+
+
+def _normalize_path(path: str) -> str:
+ """Resolve symlinks in path and convert to absolute path.
+
+ Note that environment variables and ~ in the path need to be expanded in
+ advance.
+
+ This can be cached by using _cache_normalize_path.
+ """
+ return os.path.normcase(os.path.realpath(path))
+
+
+def _path_from_filename(filename: str, is_jython: bool = IS_JYTHON) -> str:
+ if not is_jython:
+ return filename
+ head, has_pyclass, _ = filename.partition("$py.class")
+ if has_pyclass:
+ return head + ".py"
+ return filename
+
+
+def _handle_blacklist(
+ blacklist: Sequence[str], dirnames: list[str], filenames: list[str]
+) -> None:
+ """Remove files/directories in the black list.
+
+ dirnames/filenames are usually from os.walk
+ """
+ for norecurs in blacklist:
+ if norecurs in dirnames:
+ dirnames.remove(norecurs)
+ elif norecurs in filenames:
+ filenames.remove(norecurs)
+
+
+@lru_cache
+def _cache_normalize_path_(path: str) -> str:
+ return _normalize_path(path)
+
+
+def _cache_normalize_path(path: str) -> str:
+ """Normalize path with caching."""
+ # _module_file calls abspath on every path in sys.path every time it's
+ # called; on a larger codebase this easily adds up to half a second just
+ # assembling path components. This cache alleviates that.
+ if not path: # don't cache result for ''
+ return _normalize_path(path)
+ return _cache_normalize_path_(path)
+
+
+def load_module_from_name(dotted_name: str) -> types.ModuleType:
+ """Load a Python module from its name.
+
+ :type dotted_name: str
+ :param dotted_name: python name of a module or package
+
+ :raise ImportError: if the module or package is not found
+
+ :rtype: module
+ :return: the loaded module
+ """
+ try:
+ return sys.modules[dotted_name]
+ except KeyError:
+ pass
+
+ # Capture and log anything emitted during import to avoid
+ # contaminating JSON reports in pylint
+ with (
+ redirect_stderr(io.StringIO()) as stderr,
+ redirect_stdout(io.StringIO()) as stdout,
+ ):
+ module = importlib.import_module(dotted_name)
+
+ stderr_value = stderr.getvalue()
+ if stderr_value:
+ logger.error(
+ "Captured stderr while importing %s:\n%s", dotted_name, stderr_value
+ )
+ stdout_value = stdout.getvalue()
+ if stdout_value:
+ logger.info(
+ "Captured stdout while importing %s:\n%s", dotted_name, stdout_value
+ )
+
+ return module
+
+
+def load_module_from_modpath(parts: Sequence[str]) -> types.ModuleType:
+ """Load a python module from its split name.
+
+ :param parts:
+ python name of a module or package split on '.'
+
+ :raise ImportError: if the module or package is not found
+
+ :return: the loaded module
+ """
+ return load_module_from_name(".".join(parts))
+
+
+def load_module_from_file(filepath: str) -> types.ModuleType:
+ """Load a Python module from it's path.
+
+ :type filepath: str
+ :param filepath: path to the python module or package
+
+ :raise ImportError: if the module or package is not found
+
+ :rtype: module
+ :return: the loaded module
+ """
+ modpath = modpath_from_file(filepath)
+ return load_module_from_modpath(modpath)
+
+
+def check_modpath_has_init(path: str, mod_path: list[str]) -> bool:
+ """Check there are some __init__.py all along the way."""
+ modpath: list[str] = []
+ for part in mod_path:
+ modpath.append(part)
+ path = os.path.join(path, part)
+ if not _has_init(path):
+ old_namespace = util.is_namespace(".".join(modpath))
+ if not old_namespace:
+ return False
+ return True
+
+
+def _get_relative_base_path(filename: str, path_to_check: str) -> list[str] | None:
+ """Extracts the relative mod path of the file to import from.
+
+ Check if a file is within the passed in path and if so, returns the
+ relative mod path from the one passed in.
+
+ If the filename is no in path_to_check, returns None
+
+ Note this function will look for both abs and realpath of the file,
+ this allows to find the relative base path even if the file is a
+ symlink of a file in the passed in path
+
+ Examples:
+ _get_relative_base_path("/a/b/c/d.py", "/a/b") -> ["c","d"]
+ _get_relative_base_path("/a/b/c/d.py", "/dev") -> None
+ """
+ importable_path = None
+ path_to_check = os.path.normcase(path_to_check)
+ abs_filename = os.path.abspath(filename)
+ if os.path.normcase(abs_filename).startswith(path_to_check):
+ importable_path = abs_filename
+
+ real_filename = os.path.realpath(filename)
+ if os.path.normcase(real_filename).startswith(path_to_check):
+ importable_path = real_filename
+
+ if importable_path:
+ base_path = os.path.splitext(importable_path)[0]
+ relative_base_path = base_path[len(path_to_check) :]
+ return [pkg for pkg in relative_base_path.split(os.sep) if pkg]
+
+ return None
+
+
+def modpath_from_file_with_callback(
+ filename: str,
+ path: Sequence[str] | None = None,
+ is_package_cb: Callable[[str, list[str]], bool] | None = None,
+) -> list[str]:
+ filename = os.path.expanduser(_path_from_filename(filename))
+ paths_to_check = sys.path.copy()
+ if path:
+ paths_to_check += path
+ for pathname in itertools.chain(
+ paths_to_check, map(_cache_normalize_path, paths_to_check)
+ ):
+ if not pathname:
+ continue
+ modpath = _get_relative_base_path(filename, pathname)
+ if not modpath:
+ continue
+ assert is_package_cb is not None
+ if is_package_cb(pathname, modpath[:-1]):
+ return modpath
+
+ raise ImportError(
+ "Unable to find module for {} in {}".format(filename, ", \n".join(sys.path))
+ )
+
+
+def modpath_from_file(filename: str, path: Sequence[str] | None = None) -> list[str]:
+ """Get the corresponding split module's name from a filename.
+
+ This function will return the name of a module or package split on `.`.
+
+ :type filename: str
+ :param filename: file's path for which we want the module's name
+
+ :type Optional[List[str]] path:
+ Optional list of path where the module or package should be
+ searched (use sys.path if nothing or None is given)
+
+ :raise ImportError:
+ if the corresponding module's name has not been found
+
+ :rtype: list(str)
+ :return: the corresponding split module's name
+ """
+ return modpath_from_file_with_callback(filename, path, check_modpath_has_init)
+
+
+def file_from_modpath(
+ modpath: list[str],
+ path: Sequence[str] | None = None,
+ context_file: str | None = None,
+) -> str | None:
+ return file_info_from_modpath(modpath, path, context_file).location
+
+
+def file_info_from_modpath(
+ modpath: list[str],
+ path: Sequence[str] | None = None,
+ context_file: str | None = None,
+) -> spec.ModuleSpec:
+ """Given a mod path (i.e. split module / package name), return the
+ corresponding file.
+
+ Giving priority to source file over precompiled file if it exists.
+
+ :param modpath:
+ split module's name (i.e name of a module or package split
+ on '.')
+ (this means explicit relative imports that start with dots have
+ empty strings in this list!)
+
+ :param path:
+ optional list of path where the module or package should be
+ searched (use sys.path if nothing or None is given)
+
+ :param context_file:
+ context file to consider, necessary if the identifier has been
+ introduced using a relative import unresolvable in the actual
+ context (i.e. modutils)
+
+ :raise ImportError: if there is no such module in the directory
+
+ :return:
+ the path to the module's file or None if it's an integrated
+ builtin module such as 'sys'
+ """
+ if context_file is not None:
+ context: str | None = os.path.dirname(context_file)
+ else:
+ context = context_file
+ if modpath[0] == "xml":
+ # handle _xmlplus
+ try:
+ return _spec_from_modpath(["_xmlplus"] + modpath[1:], path, context)
+ except ImportError:
+ return _spec_from_modpath(modpath, path, context)
+ elif modpath == ["os", "path"]:
+ # FIXME: currently ignoring search_path...
+ return spec.ModuleSpec(
+ name="os.path",
+ location=os.path.__file__,
+ type=spec.ModuleType.PY_SOURCE,
+ )
+ return _spec_from_modpath(modpath, path, context)
+
+
+def get_module_part(dotted_name: str, context_file: str | None = None) -> str:
+ """Given a dotted name return the module part of the name :
+
+ >>> get_module_part('astroid.as_string.dump')
+ 'astroid.as_string'
+
+ :param dotted_name: full name of the identifier we are interested in
+
+ :param context_file:
+ context file to consider, necessary if the identifier has been
+ introduced using a relative import unresolvable in the actual
+ context (i.e. modutils)
+
+ :raise ImportError: if there is no such module in the directory
+
+ :return:
+ the module part of the name or None if we have not been able at
+ all to import the given name
+
+ XXX: deprecated, since it doesn't handle package precedence over module
+ (see #10066)
+ """
+ # os.path trick
+ if dotted_name.startswith("os.path"):
+ return "os.path"
+ parts = dotted_name.split(".")
+ if context_file is not None:
+ # first check for builtin module which won't be considered latter
+ # in that case (path != None)
+ if parts[0] in BUILTIN_MODULES:
+ if len(parts) > 2:
+ raise ImportError(dotted_name)
+ return parts[0]
+ # don't use += or insert, we want a new list to be created !
+ path: list[str] | None = None
+ starti = 0
+ if parts[0] == "":
+ assert (
+ context_file is not None
+ ), "explicit relative import, but no context_file?"
+ path = [] # prevent resolving the import non-relatively
+ starti = 1
+ # for all further dots: change context
+ while starti < len(parts) and parts[starti] == "":
+ starti += 1
+ assert (
+ context_file is not None
+ ), "explicit relative import, but no context_file?"
+ context_file = os.path.dirname(context_file)
+ for i in range(starti, len(parts)):
+ try:
+ file_from_modpath(
+ parts[starti : i + 1], path=path, context_file=context_file
+ )
+ except ImportError:
+ if i < max(1, len(parts) - 2):
+ raise
+ return ".".join(parts[:i])
+ return dotted_name
+
+
+def get_module_files(
+ src_directory: str, blacklist: Sequence[str], list_all: bool = False
+) -> list[str]:
+ """Given a package directory return a list of all available python
+ module's files in the package and its subpackages.
+
+ :param src_directory:
+ path of the directory corresponding to the package
+
+ :param blacklist: iterable
+ list of files or directories to ignore.
+
+ :param list_all:
+ get files from all paths, including ones without __init__.py
+
+ :return:
+ the list of all available python module's files in the package and
+ its subpackages
+ """
+ files: list[str] = []
+ for directory, dirnames, filenames in os.walk(src_directory):
+ if directory in blacklist:
+ continue
+ _handle_blacklist(blacklist, dirnames, filenames)
+ # check for __init__.py
+ if not list_all and {"__init__.py", "__init__.pyi"}.isdisjoint(filenames):
+ dirnames[:] = ()
+ continue
+ for filename in filenames:
+ if _is_python_file(filename):
+ src = os.path.join(directory, filename)
+ files.append(src)
+ return files
+
+
+def get_source_file(
+ filename: str, include_no_ext: bool = False, prefer_stubs: bool = False
+) -> str:
+ """Given a python module's file name return the matching source file
+ name (the filename will be returned identically if it's already an
+ absolute path to a python source file).
+
+ :param filename: python module's file name
+
+ :raise NoSourceFile: if no source file exists on the file system
+
+ :return: the absolute path of the source file if it exists
+ """
+ filename = os.path.abspath(_path_from_filename(filename))
+ base, orig_ext = os.path.splitext(filename)
+ if orig_ext == ".pyi" and os.path.exists(f"{base}{orig_ext}"):
+ return f"{base}{orig_ext}"
+ for ext in PY_SOURCE_EXTS_STUBS_FIRST if prefer_stubs else PY_SOURCE_EXTS:
+ source_path = f"{base}.{ext}"
+ if os.path.exists(source_path):
+ return source_path
+ if include_no_ext and not orig_ext and os.path.exists(base):
+ return base
+ raise NoSourceFile(filename)
+
+
+def is_python_source(filename: str | None) -> bool:
+ """Return: True if the filename is a python source file."""
+ if not filename:
+ return False
+ return os.path.splitext(filename)[1][1:] in PY_SOURCE_EXTS
+
+
+def is_stdlib_module(modname: str) -> bool:
+ """Return: True if the modname is in the standard library"""
+ return modname.split(".")[0] in stdlib_module_names
+
+
+def module_in_path(modname: str, path: str | Iterable[str]) -> bool:
+ """Try to determine if a module is imported from one of the specified paths
+
+ :param modname: name of the module
+
+ :param path: paths to consider
+
+ :return:
+ true if the module:
+ - is located on the path listed in one of the directory in `paths`
+ """
+
+ modname = modname.split(".")[0]
+ try:
+ filename = file_from_modpath([modname])
+ except ImportError:
+ # Import failed, we can't check path if we don't know it
+ return False
+
+ if filename is None:
+ # No filename likely means it's compiled in, or potentially a namespace
+ return False
+ filename = _normalize_path(filename)
+
+ if isinstance(path, str):
+ return filename.startswith(_cache_normalize_path(path))
+
+ return any(filename.startswith(_cache_normalize_path(entry)) for entry in path)
+
+
+def is_standard_module(modname: str, std_path: Iterable[str] | None = None) -> bool:
+ """Try to guess if a module is a standard python module (by default,
+ see `std_path` parameter's description).
+
+ :param modname: name of the module we are interested in
+
+ :param std_path: list of path considered has standard
+
+ :return:
+ true if the module:
+ - is located on the path listed in one of the directory in `std_path`
+ - is a built-in module
+ """
+ warnings.warn(
+ "is_standard_module() is deprecated. Use, is_stdlib_module() or module_in_path() instead",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+
+ modname = modname.split(".")[0]
+ try:
+ filename = file_from_modpath([modname])
+ except ImportError:
+ # import failed, i'm probably not so wrong by supposing it's
+ # not standard...
+ return False
+ # modules which are not living in a file are considered standard
+ # (sys and __builtin__ for instance)
+ if filename is None:
+ # we assume there are no namespaces in stdlib
+ return not util.is_namespace(modname)
+ filename = _normalize_path(filename)
+ for path in EXT_LIB_DIRS:
+ if filename.startswith(_cache_normalize_path(path)):
+ return False
+ if std_path is None:
+ std_path = STD_LIB_DIRS
+
+ return any(filename.startswith(_cache_normalize_path(path)) for path in std_path)
+
+
+def is_relative(modname: str, from_file: str) -> bool:
+ """Return true if the given module name is relative to the given
+ file name.
+
+ :param modname: name of the module we are interested in
+
+ :param from_file:
+ path of the module from which modname has been imported
+
+ :return:
+ true if the module has been imported relatively to `from_file`
+ """
+ if not os.path.isdir(from_file):
+ from_file = os.path.dirname(from_file)
+ if from_file in sys.path:
+ return False
+ return bool(
+ importlib.machinery.PathFinder.find_spec(
+ modname.split(".", maxsplit=1)[0], [from_file]
+ )
+ )
+
+
+# internal only functions #####################################################
+
+
+def _spec_from_modpath(
+ modpath: list[str],
+ path: Sequence[str] | None = None,
+ context: str | None = None,
+) -> spec.ModuleSpec:
+ """Given a mod path (i.e. split module / package name), return the
+ corresponding spec.
+
+ this function is used internally, see `file_from_modpath`'s
+ documentation for more information
+ """
+ assert modpath
+ location = None
+ if context is not None:
+ try:
+ found_spec = spec.find_spec(modpath, [context])
+ location = found_spec.location
+ except ImportError:
+ found_spec = spec.find_spec(modpath, path)
+ location = found_spec.location
+ else:
+ found_spec = spec.find_spec(modpath, path)
+ if found_spec.type == spec.ModuleType.PY_COMPILED:
+ try:
+ assert found_spec.location is not None
+ location = get_source_file(found_spec.location)
+ return found_spec._replace(
+ location=location, type=spec.ModuleType.PY_SOURCE
+ )
+ except NoSourceFile:
+ return found_spec._replace(location=location)
+ elif found_spec.type == spec.ModuleType.C_BUILTIN:
+ # integrated builtin module
+ return found_spec._replace(location=None)
+ elif found_spec.type == spec.ModuleType.PKG_DIRECTORY:
+ assert found_spec.location is not None
+ location = _has_init(found_spec.location)
+ return found_spec._replace(location=location, type=spec.ModuleType.PY_SOURCE)
+ return found_spec
+
+
+def _is_python_file(filename: str) -> bool:
+ """Return true if the given filename should be considered as a python file.
+
+ .pyc and .pyo are ignored
+ """
+ return filename.endswith((".py", ".pyi", ".so", ".pyd", ".pyw"))
+
+
+@lru_cache(maxsize=1024)
+def _has_init(directory: str) -> str | None:
+ """If the given directory has a valid __init__ file, return its path,
+ else return None.
+ """
+ mod_or_pack = os.path.join(directory, "__init__")
+ for ext in (*PY_SOURCE_EXTS, "pyc", "pyo"):
+ if os.path.exists(mod_or_pack + "." + ext):
+ return mod_or_pack + "." + ext
+ return None
+
+
+def is_namespace(specobj: spec.ModuleSpec) -> bool:
+ return specobj.type == spec.ModuleType.PY_NAMESPACE
+
+
+def is_directory(specobj: spec.ModuleSpec) -> bool:
+ return specobj.type == spec.ModuleType.PKG_DIRECTORY
+
+
+def is_module_name_part_of_extension_package_whitelist(
+ module_name: str, package_whitelist: set[str]
+) -> bool:
+ """
+ Returns True if one part of the module name is in the package whitelist.
+
+ >>> is_module_name_part_of_extension_package_whitelist('numpy.core.umath', {'numpy'})
+ True
+ """
+ parts = module_name.split(".")
+ return any(
+ ".".join(parts[:x]) in package_whitelist for x in range(1, len(parts) + 1)
+ )
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/__init__.py b/solutions/.venv/Lib/site-packages/astroid/nodes/__init__.py
new file mode 100644
index 000000000..769cf278e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/__init__.py
@@ -0,0 +1,297 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Every available node class.
+
+.. seealso::
+ :doc:`ast documentation <green_tree_snakes:nodes>`
+
+All nodes inherit from :class:`~astroid.nodes.node_classes.NodeNG`.
+"""
+
+# Nodes not present in the builtin ast module: DictUnpack, Unknown, and EvaluatedObject.
+from astroid.nodes.node_classes import (
+ CONST_CLS,
+ AnnAssign,
+ Arguments,
+ Assert,
+ Assign,
+ AssignAttr,
+ AssignName,
+ AsyncFor,
+ AsyncWith,
+ Attribute,
+ AugAssign,
+ Await,
+ BaseContainer,
+ BinOp,
+ BoolOp,
+ Break,
+ Call,
+ Compare,
+ Comprehension,
+ Const,
+ Continue,
+ Decorators,
+ DelAttr,
+ Delete,
+ DelName,
+ Dict,
+ DictUnpack,
+ EmptyNode,
+ EvaluatedObject,
+ ExceptHandler,
+ Expr,
+ For,
+ FormattedValue,
+ Global,
+ If,
+ IfExp,
+ Import,
+ ImportFrom,
+ JoinedStr,
+ Keyword,
+ List,
+ Match,
+ MatchAs,
+ MatchCase,
+ MatchClass,
+ MatchMapping,
+ MatchOr,
+ MatchSequence,
+ MatchSingleton,
+ MatchStar,
+ MatchValue,
+ Name,
+ NamedExpr,
+ NodeNG,
+ Nonlocal,
+ ParamSpec,
+ Pass,
+ Pattern,
+ Raise,
+ Return,
+ Set,
+ Slice,
+ Starred,
+ Subscript,
+ Try,
+ TryStar,
+ Tuple,
+ TypeAlias,
+ TypeVar,
+ TypeVarTuple,
+ UnaryOp,
+ Unknown,
+ While,
+ With,
+ Yield,
+ YieldFrom,
+ are_exclusive,
+ const_factory,
+ unpack_infer,
+)
+from astroid.nodes.scoped_nodes import (
+ AsyncFunctionDef,
+ ClassDef,
+ ComprehensionScope,
+ DictComp,
+ FunctionDef,
+ GeneratorExp,
+ Lambda,
+ ListComp,
+ LocalsDictNodeNG,
+ Module,
+ SetComp,
+ builtin_lookup,
+ function_to_method,
+ get_wrapping_class,
+)
+from astroid.nodes.utils import Position
+
+ALL_NODE_CLASSES = (
+ BaseContainer,
+ AnnAssign,
+ Arguments,
+ Assert,
+ Assign,
+ AssignAttr,
+ AssignName,
+ AsyncFor,
+ AsyncFunctionDef,
+ AsyncWith,
+ Attribute,
+ AugAssign,
+ Await,
+ BinOp,
+ BoolOp,
+ Break,
+ Call,
+ ClassDef,
+ Compare,
+ Comprehension,
+ ComprehensionScope,
+ Const,
+ const_factory,
+ Continue,
+ Decorators,
+ DelAttr,
+ Delete,
+ DelName,
+ Dict,
+ DictComp,
+ DictUnpack,
+ EmptyNode,
+ EvaluatedObject,
+ ExceptHandler,
+ Expr,
+ For,
+ FormattedValue,
+ FunctionDef,
+ GeneratorExp,
+ Global,
+ If,
+ IfExp,
+ Import,
+ ImportFrom,
+ JoinedStr,
+ Keyword,
+ Lambda,
+ List,
+ ListComp,
+ LocalsDictNodeNG,
+ Match,
+ MatchAs,
+ MatchCase,
+ MatchClass,
+ MatchMapping,
+ MatchOr,
+ MatchSequence,
+ MatchSingleton,
+ MatchStar,
+ MatchValue,
+ Module,
+ Name,
+ NamedExpr,
+ NodeNG,
+ Nonlocal,
+ ParamSpec,
+ Pass,
+ Pattern,
+ Raise,
+ Return,
+ Set,
+ SetComp,
+ Slice,
+ Starred,
+ Subscript,
+ Try,
+ TryStar,
+ Tuple,
+ TypeAlias,
+ TypeVar,
+ TypeVarTuple,
+ UnaryOp,
+ Unknown,
+ While,
+ With,
+ Yield,
+ YieldFrom,
+)
+
+__all__ = (
+ "AnnAssign",
+ "are_exclusive",
+ "Arguments",
+ "Assert",
+ "Assign",
+ "AssignAttr",
+ "AssignName",
+ "AsyncFor",
+ "AsyncFunctionDef",
+ "AsyncWith",
+ "Attribute",
+ "AugAssign",
+ "Await",
+ "BaseContainer",
+ "BinOp",
+ "BoolOp",
+ "Break",
+ "builtin_lookup",
+ "Call",
+ "ClassDef",
+ "CONST_CLS",
+ "Compare",
+ "Comprehension",
+ "ComprehensionScope",
+ "Const",
+ "const_factory",
+ "Continue",
+ "Decorators",
+ "DelAttr",
+ "Delete",
+ "DelName",
+ "Dict",
+ "DictComp",
+ "DictUnpack",
+ "EmptyNode",
+ "EvaluatedObject",
+ "ExceptHandler",
+ "Expr",
+ "For",
+ "FormattedValue",
+ "FunctionDef",
+ "function_to_method",
+ "GeneratorExp",
+ "get_wrapping_class",
+ "Global",
+ "If",
+ "IfExp",
+ "Import",
+ "ImportFrom",
+ "JoinedStr",
+ "Keyword",
+ "Lambda",
+ "List",
+ "ListComp",
+ "LocalsDictNodeNG",
+ "Match",
+ "MatchAs",
+ "MatchCase",
+ "MatchClass",
+ "MatchMapping",
+ "MatchOr",
+ "MatchSequence",
+ "MatchSingleton",
+ "MatchStar",
+ "MatchValue",
+ "Module",
+ "Name",
+ "NamedExpr",
+ "NodeNG",
+ "Nonlocal",
+ "ParamSpec",
+ "Pass",
+ "Position",
+ "Raise",
+ "Return",
+ "Set",
+ "SetComp",
+ "Slice",
+ "Starred",
+ "Subscript",
+ "Try",
+ "TryStar",
+ "Tuple",
+ "TypeAlias",
+ "TypeVar",
+ "TypeVarTuple",
+ "UnaryOp",
+ "Unknown",
+ "unpack_infer",
+ "While",
+ "With",
+ "Yield",
+ "YieldFrom",
+)
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/_base_nodes.py b/solutions/.venv/Lib/site-packages/astroid/nodes/_base_nodes.py
new file mode 100644
index 000000000..2d210f17a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/_base_nodes.py
@@ -0,0 +1,675 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains some base nodes that can be inherited for the different nodes.
+
+Previously these were called Mixin nodes.
+"""
+
+from __future__ import annotations
+
+import itertools
+from collections.abc import Callable, Generator, Iterator
+from functools import cached_property, lru_cache, partial
+from typing import TYPE_CHECKING, Any, ClassVar, Optional, Union
+
+from astroid import bases, nodes, util
+from astroid.const import PY310_PLUS
+from astroid.context import (
+ CallContext,
+ InferenceContext,
+ bind_context_to_node,
+)
+from astroid.exceptions import (
+ AttributeInferenceError,
+ InferenceError,
+)
+from astroid.interpreter import dunder_lookup
+from astroid.nodes.node_ng import NodeNG
+from astroid.typing import InferenceResult
+
+if TYPE_CHECKING:
+ from astroid.nodes.node_classes import LocalsDictNodeNG
+
+ GetFlowFactory = Callable[
+ [
+ InferenceResult,
+ Optional[InferenceResult],
+ Union[nodes.AugAssign, nodes.BinOp],
+ InferenceResult,
+ Optional[InferenceResult],
+ InferenceContext,
+ InferenceContext,
+ ],
+ list[partial[Generator[InferenceResult]]],
+ ]
+
+
+class Statement(NodeNG):
+ """Statement node adding a few attributes.
+
+ NOTE: This class is part of the public API of 'astroid.nodes'.
+ """
+
+ is_statement = True
+ """Whether this node indicates a statement."""
+
+ def next_sibling(self):
+ """The next sibling statement node.
+
+ :returns: The next sibling statement node.
+ :rtype: NodeNG or None
+ """
+ stmts = self.parent.child_sequence(self)
+ index = stmts.index(self)
+ try:
+ return stmts[index + 1]
+ except IndexError:
+ return None
+
+ def previous_sibling(self):
+ """The previous sibling statement.
+
+ :returns: The previous sibling statement node.
+ :rtype: NodeNG or None
+ """
+ stmts = self.parent.child_sequence(self)
+ index = stmts.index(self)
+ if index >= 1:
+ return stmts[index - 1]
+ return None
+
+
+class NoChildrenNode(NodeNG):
+ """Base nodes for nodes with no children, e.g. Pass."""
+
+ def get_children(self) -> Iterator[NodeNG]:
+ yield from ()
+
+
+class FilterStmtsBaseNode(NodeNG):
+ """Base node for statement filtering and assignment type."""
+
+ def _get_filtered_stmts(self, _, node, _stmts, mystmt: Statement | None):
+ """Method used in _filter_stmts to get statements and trigger break."""
+ if self.statement() is mystmt:
+ # original node's statement is the assignment, only keep
+ # current node (gen exp, list comp)
+ return [node], True
+ return _stmts, False
+
+ def assign_type(self):
+ return self
+
+
+class AssignTypeNode(NodeNG):
+ """Base node for nodes that can 'assign' such as AnnAssign."""
+
+ def assign_type(self):
+ return self
+
+ def _get_filtered_stmts(self, lookup_node, node, _stmts, mystmt: Statement | None):
+ """Method used in filter_stmts."""
+ if self is mystmt:
+ return _stmts, True
+ if self.statement() is mystmt:
+ # original node's statement is the assignment, only keep
+ # current node (gen exp, list comp)
+ return [node], True
+ return _stmts, False
+
+
+class ParentAssignNode(AssignTypeNode):
+ """Base node for nodes whose assign_type is determined by the parent node."""
+
+ def assign_type(self):
+ return self.parent.assign_type()
+
+
+class ImportNode(FilterStmtsBaseNode, NoChildrenNode, Statement):
+ """Base node for From and Import Nodes."""
+
+ modname: str | None
+ """The module that is being imported from.
+
+ This is ``None`` for relative imports.
+ """
+
+ names: list[tuple[str, str | None]]
+ """What is being imported from the module.
+
+ Each entry is a :class:`tuple` of the name being imported,
+ and the alias that the name is assigned to (if any).
+ """
+
+ def _infer_name(self, frame, name):
+ return name
+
+ def do_import_module(self, modname: str | None = None) -> nodes.Module:
+ """Return the ast for a module whose name is <modname> imported by <self>."""
+ mymodule = self.root()
+ level: int | None = getattr(self, "level", None) # Import has no level
+ if modname is None:
+ modname = self.modname
+ # If the module ImportNode is importing is a module with the same name
+ # as the file that contains the ImportNode we don't want to use the cache
+ # to make sure we use the import system to get the correct module.
+ if (
+ modname
+ # pylint: disable-next=no-member # pylint doesn't recognize type of mymodule
+ and mymodule.relative_to_absolute_name(modname, level) == mymodule.name
+ ):
+ use_cache = False
+ else:
+ use_cache = True
+
+ # pylint: disable-next=no-member # pylint doesn't recognize type of mymodule
+ return mymodule.import_module(
+ modname,
+ level=level,
+ relative_only=bool(level and level >= 1),
+ use_cache=use_cache,
+ )
+
+ def real_name(self, asname: str) -> str:
+ """Get name from 'as' name."""
+ for name, _asname in self.names:
+ if name == "*":
+ return asname
+ if not _asname:
+ name = name.split(".", 1)[0]
+ _asname = name
+ if asname == _asname:
+ return name
+ raise AttributeInferenceError(
+ "Could not find original name for {attribute} in {target!r}",
+ target=self,
+ attribute=asname,
+ )
+
+
+class MultiLineBlockNode(NodeNG):
+ """Base node for multi-line blocks, e.g. For and FunctionDef.
+
+ Note that this does not apply to every node with a `body` field.
+ For instance, an If node has a multi-line body, but the body of an
+ IfExpr is not multi-line, and hence cannot contain Return nodes,
+ Assign nodes, etc.
+ """
+
+ _multi_line_block_fields: ClassVar[tuple[str, ...]] = ()
+
+ @cached_property
+ def _multi_line_blocks(self):
+ return tuple(getattr(self, field) for field in self._multi_line_block_fields)
+
+ def _get_return_nodes_skip_functions(self):
+ for block in self._multi_line_blocks:
+ for child_node in block:
+ if child_node.is_function:
+ continue
+ yield from child_node._get_return_nodes_skip_functions()
+
+ def _get_yield_nodes_skip_functions(self):
+ for block in self._multi_line_blocks:
+ for child_node in block:
+ if child_node.is_function:
+ continue
+ yield from child_node._get_yield_nodes_skip_functions()
+
+ def _get_yield_nodes_skip_lambdas(self):
+ for block in self._multi_line_blocks:
+ for child_node in block:
+ if child_node.is_lambda:
+ continue
+ yield from child_node._get_yield_nodes_skip_lambdas()
+
+ @cached_property
+ def _assign_nodes_in_scope(self) -> list[nodes.Assign]:
+ children_assign_nodes = (
+ child_node._assign_nodes_in_scope
+ for block in self._multi_line_blocks
+ for child_node in block
+ )
+ return list(itertools.chain.from_iterable(children_assign_nodes))
+
+
+class MultiLineWithElseBlockNode(MultiLineBlockNode):
+ """Base node for multi-line blocks that can have else statements."""
+
+ @cached_property
+ def blockstart_tolineno(self):
+ return self.lineno
+
+ def _elsed_block_range(
+ self, lineno: int, orelse: list[nodes.NodeNG], last: int | None = None
+ ) -> tuple[int, int]:
+ """Handle block line numbers range for try/finally, for, if and while
+ statements.
+ """
+ if lineno == self.fromlineno:
+ return lineno, lineno
+ if orelse:
+ if lineno >= orelse[0].fromlineno:
+ return lineno, orelse[-1].tolineno
+ return lineno, orelse[0].fromlineno - 1
+ return lineno, last or self.tolineno
+
+
+class LookupMixIn(NodeNG):
+ """Mixin to look up a name in the right scope."""
+
+ @lru_cache # noqa
+ def lookup(self, name: str) -> tuple[LocalsDictNodeNG, list[NodeNG]]:
+ """Lookup where the given variable is assigned.
+
+ The lookup starts from self's scope. If self is not a frame itself
+ and the name is found in the inner frame locals, statements will be
+ filtered to remove ignorable statements according to self's location.
+
+ :param name: The name of the variable to find assignments for.
+
+ :returns: The scope node and the list of assignments associated to the
+ given name according to the scope where it has been found (locals,
+ globals or builtin).
+ """
+ return self.scope().scope_lookup(self, name)
+
+ def ilookup(self, name):
+ """Lookup the inferred values of the given variable.
+
+ :param name: The variable name to find values for.
+ :type name: str
+
+ :returns: The inferred values of the statements returned from
+ :meth:`lookup`.
+ :rtype: iterable
+ """
+ frame, stmts = self.lookup(name)
+ context = InferenceContext()
+ return bases._infer_stmts(stmts, context, frame)
+
+
+def _reflected_name(name) -> str:
+ return "__r" + name[2:]
+
+
+def _augmented_name(name) -> str:
+ return "__i" + name[2:]
+
+
+BIN_OP_METHOD = {
+ "+": "__add__",
+ "-": "__sub__",
+ "/": "__truediv__",
+ "//": "__floordiv__",
+ "*": "__mul__",
+ "**": "__pow__",
+ "%": "__mod__",
+ "&": "__and__",
+ "|": "__or__",
+ "^": "__xor__",
+ "<<": "__lshift__",
+ ">>": "__rshift__",
+ "@": "__matmul__",
+}
+
+REFLECTED_BIN_OP_METHOD = {
+ key: _reflected_name(value) for (key, value) in BIN_OP_METHOD.items()
+}
+AUGMENTED_OP_METHOD = {
+ key + "=": _augmented_name(value) for (key, value) in BIN_OP_METHOD.items()
+}
+
+
+class OperatorNode(NodeNG):
+ @staticmethod
+ def _filter_operation_errors(
+ infer_callable: Callable[
+ [InferenceContext | None],
+ Generator[InferenceResult | util.BadOperationMessage],
+ ],
+ context: InferenceContext | None,
+ error: type[util.BadOperationMessage],
+ ) -> Generator[InferenceResult]:
+ for result in infer_callable(context):
+ if isinstance(result, error):
+ # For the sake of .infer(), we don't care about operation
+ # errors, which is the job of a linter. So return something
+ # which shows that we can't infer the result.
+ yield util.Uninferable
+ else:
+ yield result
+
+ @staticmethod
+ def _is_not_implemented(const) -> bool:
+ """Check if the given const node is NotImplemented."""
+ return isinstance(const, nodes.Const) and const.value is NotImplemented
+
+ @staticmethod
+ def _infer_old_style_string_formatting(
+ instance: nodes.Const, other: nodes.NodeNG, context: InferenceContext
+ ) -> tuple[util.UninferableBase | nodes.Const]:
+ """Infer the result of '"string" % ...'.
+
+ TODO: Instead of returning Uninferable we should rely
+ on the call to '%' to see if the result is actually uninferable.
+ """
+ if isinstance(other, nodes.Tuple):
+ if util.Uninferable in other.elts:
+ return (util.Uninferable,)
+ inferred_positional = [util.safe_infer(i, context) for i in other.elts]
+ if all(isinstance(i, nodes.Const) for i in inferred_positional):
+ values = tuple(i.value for i in inferred_positional)
+ else:
+ values = None
+ elif isinstance(other, nodes.Dict):
+ values: dict[Any, Any] = {}
+ for pair in other.items:
+ key = util.safe_infer(pair[0], context)
+ if not isinstance(key, nodes.Const):
+ return (util.Uninferable,)
+ value = util.safe_infer(pair[1], context)
+ if not isinstance(value, nodes.Const):
+ return (util.Uninferable,)
+ values[key.value] = value.value
+ elif isinstance(other, nodes.Const):
+ values = other.value
+ else:
+ return (util.Uninferable,)
+
+ try:
+ return (nodes.const_factory(instance.value % values),)
+ except (TypeError, KeyError, ValueError):
+ return (util.Uninferable,)
+
+ @staticmethod
+ def _invoke_binop_inference(
+ instance: InferenceResult,
+ opnode: nodes.AugAssign | nodes.BinOp,
+ op: str,
+ other: InferenceResult,
+ context: InferenceContext,
+ method_name: str,
+ ) -> Generator[InferenceResult]:
+ """Invoke binary operation inference on the given instance."""
+ methods = dunder_lookup.lookup(instance, method_name)
+ context = bind_context_to_node(context, instance)
+ method = methods[0]
+ context.callcontext.callee = method
+
+ if (
+ isinstance(instance, nodes.Const)
+ and isinstance(instance.value, str)
+ and op == "%"
+ ):
+ return iter(
+ OperatorNode._infer_old_style_string_formatting(
+ instance, other, context
+ )
+ )
+
+ try:
+ inferred = next(method.infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(node=method, context=context) from e
+ if isinstance(inferred, util.UninferableBase):
+ raise InferenceError
+ if not isinstance(
+ instance,
+ (nodes.Const, nodes.Tuple, nodes.List, nodes.ClassDef, bases.Instance),
+ ):
+ raise InferenceError # pragma: no cover # Used as a failsafe
+ return instance.infer_binary_op(opnode, op, other, context, inferred)
+
+ @staticmethod
+ def _aug_op(
+ instance: InferenceResult,
+ opnode: nodes.AugAssign,
+ op: str,
+ other: InferenceResult,
+ context: InferenceContext,
+ reverse: bool = False,
+ ) -> partial[Generator[InferenceResult]]:
+ """Get an inference callable for an augmented binary operation."""
+ method_name = AUGMENTED_OP_METHOD[op]
+ return partial(
+ OperatorNode._invoke_binop_inference,
+ instance=instance,
+ op=op,
+ opnode=opnode,
+ other=other,
+ context=context,
+ method_name=method_name,
+ )
+
+ @staticmethod
+ def _bin_op(
+ instance: InferenceResult,
+ opnode: nodes.AugAssign | nodes.BinOp,
+ op: str,
+ other: InferenceResult,
+ context: InferenceContext,
+ reverse: bool = False,
+ ) -> partial[Generator[InferenceResult]]:
+ """Get an inference callable for a normal binary operation.
+
+ If *reverse* is True, then the reflected method will be used instead.
+ """
+ if reverse:
+ method_name = REFLECTED_BIN_OP_METHOD[op]
+ else:
+ method_name = BIN_OP_METHOD[op]
+ return partial(
+ OperatorNode._invoke_binop_inference,
+ instance=instance,
+ op=op,
+ opnode=opnode,
+ other=other,
+ context=context,
+ method_name=method_name,
+ )
+
+ @staticmethod
+ def _bin_op_or_union_type(
+ left: bases.UnionType | nodes.ClassDef | nodes.Const,
+ right: bases.UnionType | nodes.ClassDef | nodes.Const,
+ ) -> Generator[InferenceResult]:
+ """Create a new UnionType instance for binary or, e.g. int | str."""
+ yield bases.UnionType(left, right)
+
+ @staticmethod
+ def _get_binop_contexts(context, left, right):
+ """Get contexts for binary operations.
+
+ This will return two inference contexts, the first one
+ for x.__op__(y), the other one for y.__rop__(x), where
+ only the arguments are inversed.
+ """
+ # The order is important, since the first one should be
+ # left.__op__(right).
+ for arg in (right, left):
+ new_context = context.clone()
+ new_context.callcontext = CallContext(args=[arg])
+ new_context.boundnode = None
+ yield new_context
+
+ @staticmethod
+ def _same_type(type1, type2) -> bool:
+ """Check if type1 is the same as type2."""
+ return type1.qname() == type2.qname()
+
+ @staticmethod
+ def _get_aug_flow(
+ left: InferenceResult,
+ left_type: InferenceResult | None,
+ aug_opnode: nodes.AugAssign,
+ right: InferenceResult,
+ right_type: InferenceResult | None,
+ context: InferenceContext,
+ reverse_context: InferenceContext,
+ ) -> list[partial[Generator[InferenceResult]]]:
+ """Get the flow for augmented binary operations.
+
+ The rules are a bit messy:
+
+ * if left and right have the same type, then left.__augop__(right)
+ is first tried and then left.__op__(right).
+ * if left and right are unrelated typewise, then
+ left.__augop__(right) is tried, then left.__op__(right)
+ is tried and then right.__rop__(left) is tried.
+ * if left is a subtype of right, then left.__augop__(right)
+ is tried and then left.__op__(right).
+ * if left is a supertype of right, then left.__augop__(right)
+ is tried, then right.__rop__(left) and then
+ left.__op__(right)
+ """
+ from astroid import helpers # pylint: disable=import-outside-toplevel
+
+ bin_op = aug_opnode.op.strip("=")
+ aug_op = aug_opnode.op
+ if OperatorNode._same_type(left_type, right_type):
+ methods = [
+ OperatorNode._aug_op(left, aug_opnode, aug_op, right, context),
+ OperatorNode._bin_op(left, aug_opnode, bin_op, right, context),
+ ]
+ elif helpers.is_subtype(left_type, right_type):
+ methods = [
+ OperatorNode._aug_op(left, aug_opnode, aug_op, right, context),
+ OperatorNode._bin_op(left, aug_opnode, bin_op, right, context),
+ ]
+ elif helpers.is_supertype(left_type, right_type):
+ methods = [
+ OperatorNode._aug_op(left, aug_opnode, aug_op, right, context),
+ OperatorNode._bin_op(
+ right, aug_opnode, bin_op, left, reverse_context, reverse=True
+ ),
+ OperatorNode._bin_op(left, aug_opnode, bin_op, right, context),
+ ]
+ else:
+ methods = [
+ OperatorNode._aug_op(left, aug_opnode, aug_op, right, context),
+ OperatorNode._bin_op(left, aug_opnode, bin_op, right, context),
+ OperatorNode._bin_op(
+ right, aug_opnode, bin_op, left, reverse_context, reverse=True
+ ),
+ ]
+ return methods
+
+ @staticmethod
+ def _get_binop_flow(
+ left: InferenceResult,
+ left_type: InferenceResult | None,
+ binary_opnode: nodes.AugAssign | nodes.BinOp,
+ right: InferenceResult,
+ right_type: InferenceResult | None,
+ context: InferenceContext,
+ reverse_context: InferenceContext,
+ ) -> list[partial[Generator[InferenceResult]]]:
+ """Get the flow for binary operations.
+
+ The rules are a bit messy:
+
+ * if left and right have the same type, then only one
+ method will be called, left.__op__(right)
+ * if left and right are unrelated typewise, then first
+ left.__op__(right) is tried and if this does not exist
+ or returns NotImplemented, then right.__rop__(left) is tried.
+ * if left is a subtype of right, then only left.__op__(right)
+ is tried.
+ * if left is a supertype of right, then right.__rop__(left)
+ is first tried and then left.__op__(right)
+ """
+ from astroid import helpers # pylint: disable=import-outside-toplevel
+
+ op = binary_opnode.op
+ if OperatorNode._same_type(left_type, right_type):
+ methods = [OperatorNode._bin_op(left, binary_opnode, op, right, context)]
+ elif helpers.is_subtype(left_type, right_type):
+ methods = [OperatorNode._bin_op(left, binary_opnode, op, right, context)]
+ elif helpers.is_supertype(left_type, right_type):
+ methods = [
+ OperatorNode._bin_op(
+ right, binary_opnode, op, left, reverse_context, reverse=True
+ ),
+ OperatorNode._bin_op(left, binary_opnode, op, right, context),
+ ]
+ else:
+ methods = [
+ OperatorNode._bin_op(left, binary_opnode, op, right, context),
+ OperatorNode._bin_op(
+ right, binary_opnode, op, left, reverse_context, reverse=True
+ ),
+ ]
+
+ if (
+ PY310_PLUS
+ and op == "|"
+ and (
+ isinstance(left, (bases.UnionType, nodes.ClassDef))
+ or isinstance(left, nodes.Const)
+ and left.value is None
+ )
+ and (
+ isinstance(right, (bases.UnionType, nodes.ClassDef))
+ or isinstance(right, nodes.Const)
+ and right.value is None
+ )
+ ):
+ methods.extend([partial(OperatorNode._bin_op_or_union_type, left, right)])
+ return methods
+
+ @staticmethod
+ def _infer_binary_operation(
+ left: InferenceResult,
+ right: InferenceResult,
+ binary_opnode: nodes.AugAssign | nodes.BinOp,
+ context: InferenceContext,
+ flow_factory: GetFlowFactory,
+ ) -> Generator[InferenceResult | util.BadBinaryOperationMessage]:
+ """Infer a binary operation between a left operand and a right operand.
+
+ This is used by both normal binary operations and augmented binary
+ operations, the only difference is the flow factory used.
+ """
+ from astroid import helpers # pylint: disable=import-outside-toplevel
+
+ context, reverse_context = OperatorNode._get_binop_contexts(
+ context, left, right
+ )
+ left_type = helpers.object_type(left)
+ right_type = helpers.object_type(right)
+ methods = flow_factory(
+ left, left_type, binary_opnode, right, right_type, context, reverse_context
+ )
+ for method in methods:
+ try:
+ results = list(method())
+ except AttributeError:
+ continue
+ except AttributeInferenceError:
+ continue
+ except InferenceError:
+ yield util.Uninferable
+ return
+ else:
+ if any(isinstance(result, util.UninferableBase) for result in results):
+ yield util.Uninferable
+ return
+
+ if all(map(OperatorNode._is_not_implemented, results)):
+ continue
+ not_implemented = sum(
+ 1 for result in results if OperatorNode._is_not_implemented(result)
+ )
+ if not_implemented and not_implemented != len(results):
+ # Can't infer yet what this is.
+ yield util.Uninferable
+ return
+
+ yield from results
+ return
+
+ # The operation doesn't seem to be supported so let the caller know about it
+ yield util.BadBinaryOperationMessage(left_type, binary_opnode.op, right_type)
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/as_string.py b/solutions/.venv/Lib/site-packages/astroid/nodes/as_string.py
new file mode 100644
index 000000000..f36115ff6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/as_string.py
@@ -0,0 +1,703 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module renders Astroid nodes as string"""
+
+from __future__ import annotations
+
+import warnings
+from collections.abc import Iterator
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+if TYPE_CHECKING:
+ from astroid import objects
+ from astroid.nodes import Const
+ from astroid.nodes.node_classes import (
+ Match,
+ MatchAs,
+ MatchCase,
+ MatchClass,
+ MatchMapping,
+ MatchOr,
+ MatchSequence,
+ MatchSingleton,
+ MatchStar,
+ MatchValue,
+ Unknown,
+ )
+
+# pylint: disable=unused-argument
+
+DOC_NEWLINE = "\0"
+
+
+# Visitor pattern require argument all the time and is not better with staticmethod
+# noinspection PyUnusedLocal,PyMethodMayBeStatic
+class AsStringVisitor:
+ """Visitor to render an Astroid node as a valid python code string"""
+
+ def __init__(self, indent: str = " "):
+ self.indent: str = indent
+
+ def __call__(self, node) -> str:
+ """Makes this visitor behave as a simple function"""
+ return node.accept(self).replace(DOC_NEWLINE, "\n")
+
+ def _docs_dedent(self, doc_node: Const | None) -> str:
+ """Stop newlines in docs being indented by self._stmt_list"""
+ if not doc_node:
+ return ""
+
+ return '\n{}"""{}"""'.format(
+ self.indent, doc_node.value.replace("\n", DOC_NEWLINE)
+ )
+
+ def _stmt_list(self, stmts: list, indent: bool = True) -> str:
+ """return a list of nodes to string"""
+ stmts_str: str = "\n".join(
+ nstr for nstr in [n.accept(self) for n in stmts] if nstr
+ )
+ if not indent:
+ return stmts_str
+
+ return self.indent + stmts_str.replace("\n", "\n" + self.indent)
+
+ def _precedence_parens(self, node, child, is_left: bool = True) -> str:
+ """Wrap child in parens only if required to keep same semantics"""
+ if self._should_wrap(node, child, is_left):
+ return f"({child.accept(self)})"
+
+ return child.accept(self)
+
+ def _should_wrap(self, node, child, is_left: bool) -> bool:
+ """Wrap child if:
+ - it has lower precedence
+ - same precedence with position opposite to associativity direction
+ """
+ node_precedence = node.op_precedence()
+ child_precedence = child.op_precedence()
+
+ if node_precedence > child_precedence:
+ # 3 * (4 + 5)
+ return True
+
+ if (
+ node_precedence == child_precedence
+ and is_left != node.op_left_associative()
+ ):
+ # 3 - (4 - 5)
+ # (2**3)**4
+ return True
+
+ return False
+
+ # visit_<node> methods ###########################################
+
+ def visit_await(self, node) -> str:
+ return f"await {node.value.accept(self)}"
+
+ def visit_asyncwith(self, node) -> str:
+ return f"async {self.visit_with(node)}"
+
+ def visit_asyncfor(self, node) -> str:
+ return f"async {self.visit_for(node)}"
+
+ def visit_arguments(self, node) -> str:
+ """return an astroid.Function node as string"""
+ return node.format_args()
+
+ def visit_assignattr(self, node) -> str:
+ """return an astroid.AssAttr node as string"""
+ return self.visit_attribute(node)
+
+ def visit_assert(self, node) -> str:
+ """return an astroid.Assert node as string"""
+ if node.fail:
+ return f"assert {node.test.accept(self)}, {node.fail.accept(self)}"
+ return f"assert {node.test.accept(self)}"
+
+ def visit_assignname(self, node) -> str:
+ """return an astroid.AssName node as string"""
+ return node.name
+
+ def visit_assign(self, node) -> str:
+ """return an astroid.Assign node as string"""
+ lhs = " = ".join(n.accept(self) for n in node.targets)
+ return f"{lhs} = {node.value.accept(self)}"
+
+ def visit_augassign(self, node) -> str:
+ """return an astroid.AugAssign node as string"""
+ return f"{node.target.accept(self)} {node.op} {node.value.accept(self)}"
+
+ def visit_annassign(self, node) -> str:
+ """Return an astroid.AugAssign node as string"""
+
+ target = node.target.accept(self)
+ annotation = node.annotation.accept(self)
+ if node.value is None:
+ return f"{target}: {annotation}"
+ return f"{target}: {annotation} = {node.value.accept(self)}"
+
+ def visit_binop(self, node) -> str:
+ """return an astroid.BinOp node as string"""
+ left = self._precedence_parens(node, node.left)
+ right = self._precedence_parens(node, node.right, is_left=False)
+ if node.op == "**":
+ return f"{left}{node.op}{right}"
+
+ return f"{left} {node.op} {right}"
+
+ def visit_boolop(self, node) -> str:
+ """return an astroid.BoolOp node as string"""
+ values = [f"{self._precedence_parens(node, n)}" for n in node.values]
+ return (f" {node.op} ").join(values)
+
+ def visit_break(self, node) -> str:
+ """return an astroid.Break node as string"""
+ return "break"
+
+ def visit_call(self, node) -> str:
+ """return an astroid.Call node as string"""
+ expr_str = self._precedence_parens(node, node.func)
+ args = [arg.accept(self) for arg in node.args]
+ if node.keywords:
+ keywords = [kwarg.accept(self) for kwarg in node.keywords]
+ else:
+ keywords = []
+
+ args.extend(keywords)
+ return f"{expr_str}({', '.join(args)})"
+
+ def visit_classdef(self, node) -> str:
+ """return an astroid.ClassDef node as string"""
+ decorate = node.decorators.accept(self) if node.decorators else ""
+ args = [n.accept(self) for n in node.bases]
+ if node._metaclass and not node.has_metaclass_hack():
+ args.append("metaclass=" + node._metaclass.accept(self))
+ args += [n.accept(self) for n in node.keywords]
+ args_str = f"({', '.join(args)})" if args else ""
+ docs = self._docs_dedent(node.doc_node)
+ # TODO: handle type_params
+ return "\n\n{}class {}{}:{}\n{}\n".format(
+ decorate, node.name, args_str, docs, self._stmt_list(node.body)
+ )
+
+ def visit_compare(self, node) -> str:
+ """return an astroid.Compare node as string"""
+ rhs_str = " ".join(
+ f"{op} {self._precedence_parens(node, expr, is_left=False)}"
+ for op, expr in node.ops
+ )
+ return f"{self._precedence_parens(node, node.left)} {rhs_str}"
+
+ def visit_comprehension(self, node) -> str:
+ """return an astroid.Comprehension node as string"""
+ ifs = "".join(f" if {n.accept(self)}" for n in node.ifs)
+ generated = f"for {node.target.accept(self)} in {node.iter.accept(self)}{ifs}"
+ return f"{'async ' if node.is_async else ''}{generated}"
+
+ def visit_const(self, node) -> str:
+ """return an astroid.Const node as string"""
+ if node.value is Ellipsis:
+ return "..."
+ return repr(node.value)
+
+ def visit_continue(self, node) -> str:
+ """return an astroid.Continue node as string"""
+ return "continue"
+
+ def visit_delete(self, node) -> str: # XXX check if correct
+ """return an astroid.Delete node as string"""
+ return f"del {', '.join(child.accept(self) for child in node.targets)}"
+
+ def visit_delattr(self, node) -> str:
+ """return an astroid.DelAttr node as string"""
+ return self.visit_attribute(node)
+
+ def visit_delname(self, node) -> str:
+ """return an astroid.DelName node as string"""
+ return node.name
+
+ def visit_decorators(self, node) -> str:
+ """return an astroid.Decorators node as string"""
+ return "@%s\n" % "\n@".join(item.accept(self) for item in node.nodes)
+
+ def visit_dict(self, node) -> str:
+ """return an astroid.Dict node as string"""
+ return "{%s}" % ", ".join(self._visit_dict(node))
+
+ def _visit_dict(self, node) -> Iterator[str]:
+ for key, value in node.items:
+ key = key.accept(self)
+ value = value.accept(self)
+ if key == "**":
+ # It can only be a DictUnpack node.
+ yield key + value
+ else:
+ yield f"{key}: {value}"
+
+ def visit_dictunpack(self, node) -> str:
+ return "**"
+
+ def visit_dictcomp(self, node) -> str:
+ """return an astroid.DictComp node as string"""
+ return "{{{}: {} {}}}".format(
+ node.key.accept(self),
+ node.value.accept(self),
+ " ".join(n.accept(self) for n in node.generators),
+ )
+
+ def visit_expr(self, node) -> str:
+ """return an astroid.Discard node as string"""
+ return node.value.accept(self)
+
+ def visit_emptynode(self, node) -> str:
+ """dummy method for visiting an Empty node"""
+ return ""
+
+ def visit_excepthandler(self, node) -> str:
+ n = "except"
+ if isinstance(getattr(node, "parent", None), nodes.TryStar):
+ n = "except*"
+ if node.type:
+ if node.name:
+ excs = f"{n} {node.type.accept(self)} as {node.name.accept(self)}"
+ else:
+ excs = f"{n} {node.type.accept(self)}"
+ else:
+ excs = f"{n}"
+ return f"{excs}:\n{self._stmt_list(node.body)}"
+
+ def visit_empty(self, node) -> str:
+ """return an Empty node as string"""
+ return ""
+
+ def visit_for(self, node) -> str:
+ """return an astroid.For node as string"""
+ fors = "for {} in {}:\n{}".format(
+ node.target.accept(self), node.iter.accept(self), self._stmt_list(node.body)
+ )
+ if node.orelse:
+ fors = f"{fors}\nelse:\n{self._stmt_list(node.orelse)}"
+ return fors
+
+ def visit_importfrom(self, node) -> str:
+ """return an astroid.ImportFrom node as string"""
+ return "from {} import {}".format(
+ "." * (node.level or 0) + node.modname, _import_string(node.names)
+ )
+
+ def visit_joinedstr(self, node) -> str:
+ string = "".join(
+ # Use repr on the string literal parts
+ # to get proper escapes, e.g. \n, \\, \"
+ # But strip the quotes off the ends
+ # (they will always be one character: ' or ")
+ (
+ repr(value.value)[1:-1]
+ # Literal braces must be doubled to escape them
+ .replace("{", "{{").replace("}", "}}")
+ # Each value in values is either a string literal (Const)
+ # or a FormattedValue
+ if type(value).__name__ == "Const"
+ else value.accept(self)
+ )
+ for value in node.values
+ )
+
+ # Try to find surrounding quotes that don't appear at all in the string.
+ # Because the formatted values inside {} can't contain backslash (\)
+ # using a triple quote is sometimes necessary
+ for quote in ("'", '"', '"""', "'''"):
+ if quote not in string:
+ break
+
+ return "f" + quote + string + quote
+
+ def visit_formattedvalue(self, node) -> str:
+ result = node.value.accept(self)
+ if node.conversion and node.conversion >= 0:
+ # e.g. if node.conversion == 114: result += "!r"
+ result += "!" + chr(node.conversion)
+ if node.format_spec:
+ # The format spec is itself a JoinedString, i.e. an f-string
+ # We strip the f and quotes of the ends
+ result += ":" + node.format_spec.accept(self)[2:-1]
+ return "{%s}" % result
+
+ def handle_functiondef(self, node: nodes.FunctionDef, keyword: str) -> str:
+ """return a (possibly async) function definition node as string"""
+ decorate = node.decorators.accept(self) if node.decorators else ""
+ docs = self._docs_dedent(node.doc_node)
+ trailer = ":"
+ if node.returns:
+ return_annotation = " -> " + node.returns.as_string()
+ trailer = return_annotation + ":"
+ # TODO: handle type_params
+ def_format = "\n%s%s %s(%s)%s%s\n%s"
+ return def_format % (
+ decorate,
+ keyword,
+ node.name,
+ node.args.accept(self),
+ trailer,
+ docs,
+ self._stmt_list(node.body),
+ )
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> str:
+ """return an astroid.FunctionDef node as string"""
+ return self.handle_functiondef(node, "def")
+
+ def visit_asyncfunctiondef(self, node: nodes.AsyncFunctionDef) -> str:
+ """return an astroid.AsyncFunction node as string"""
+ return self.handle_functiondef(node, "async def")
+
+ def visit_generatorexp(self, node) -> str:
+ """return an astroid.GeneratorExp node as string"""
+ return "({} {})".format(
+ node.elt.accept(self), " ".join(n.accept(self) for n in node.generators)
+ )
+
+ def visit_attribute(self, node) -> str:
+ """return an astroid.Getattr node as string"""
+ try:
+ left = self._precedence_parens(node, node.expr)
+ except RecursionError:
+ warnings.warn(
+ "Recursion limit exhausted; defaulting to adding parentheses.",
+ UserWarning,
+ stacklevel=2,
+ )
+ left = f"({node.expr.accept(self)})"
+ if left.isdigit():
+ left = f"({left})"
+ return f"{left}.{node.attrname}"
+
+ def visit_global(self, node) -> str:
+ """return an astroid.Global node as string"""
+ return f"global {', '.join(node.names)}"
+
+ def visit_if(self, node) -> str:
+ """return an astroid.If node as string"""
+ ifs = [f"if {node.test.accept(self)}:\n{self._stmt_list(node.body)}"]
+ if node.has_elif_block():
+ ifs.append(f"el{self._stmt_list(node.orelse, indent=False)}")
+ elif node.orelse:
+ ifs.append(f"else:\n{self._stmt_list(node.orelse)}")
+ return "\n".join(ifs)
+
+ def visit_ifexp(self, node) -> str:
+ """return an astroid.IfExp node as string"""
+ return "{} if {} else {}".format(
+ self._precedence_parens(node, node.body, is_left=True),
+ self._precedence_parens(node, node.test, is_left=True),
+ self._precedence_parens(node, node.orelse, is_left=False),
+ )
+
+ def visit_import(self, node) -> str:
+ """return an astroid.Import node as string"""
+ return f"import {_import_string(node.names)}"
+
+ def visit_keyword(self, node) -> str:
+ """return an astroid.Keyword node as string"""
+ if node.arg is None:
+ return f"**{node.value.accept(self)}"
+ return f"{node.arg}={node.value.accept(self)}"
+
+ def visit_lambda(self, node) -> str:
+ """return an astroid.Lambda node as string"""
+ args = node.args.accept(self)
+ body = node.body.accept(self)
+ if args:
+ return f"lambda {args}: {body}"
+
+ return f"lambda: {body}"
+
+ def visit_list(self, node) -> str:
+ """return an astroid.List node as string"""
+ return f"[{', '.join(child.accept(self) for child in node.elts)}]"
+
+ def visit_listcomp(self, node) -> str:
+ """return an astroid.ListComp node as string"""
+ return "[{} {}]".format(
+ node.elt.accept(self), " ".join(n.accept(self) for n in node.generators)
+ )
+
+ def visit_module(self, node) -> str:
+ """return an astroid.Module node as string"""
+ docs = f'"""{node.doc_node.value}"""\n\n' if node.doc_node else ""
+ return docs + "\n".join(n.accept(self) for n in node.body) + "\n\n"
+
+ def visit_name(self, node) -> str:
+ """return an astroid.Name node as string"""
+ return node.name
+
+ def visit_namedexpr(self, node) -> str:
+ """Return an assignment expression node as string"""
+ target = node.target.accept(self)
+ value = node.value.accept(self)
+ return f"{target} := {value}"
+
+ def visit_nonlocal(self, node) -> str:
+ """return an astroid.Nonlocal node as string"""
+ return f"nonlocal {', '.join(node.names)}"
+
+ def visit_paramspec(self, node: nodes.ParamSpec) -> str:
+ """return an astroid.ParamSpec node as string"""
+ return node.name.accept(self)
+
+ def visit_pass(self, node) -> str:
+ """return an astroid.Pass node as string"""
+ return "pass"
+
+ def visit_partialfunction(self, node: objects.PartialFunction) -> str:
+ """Return an objects.PartialFunction as string."""
+ return self.visit_functiondef(node)
+
+ def visit_raise(self, node) -> str:
+ """return an astroid.Raise node as string"""
+ if node.exc:
+ if node.cause:
+ return f"raise {node.exc.accept(self)} from {node.cause.accept(self)}"
+ return f"raise {node.exc.accept(self)}"
+ return "raise"
+
+ def visit_return(self, node) -> str:
+ """return an astroid.Return node as string"""
+ if node.is_tuple_return() and len(node.value.elts) > 1:
+ elts = [child.accept(self) for child in node.value.elts]
+ return f"return {', '.join(elts)}"
+
+ if node.value:
+ return f"return {node.value.accept(self)}"
+
+ return "return"
+
+ def visit_set(self, node) -> str:
+ """return an astroid.Set node as string"""
+ return "{%s}" % ", ".join(child.accept(self) for child in node.elts)
+
+ def visit_setcomp(self, node) -> str:
+ """return an astroid.SetComp node as string"""
+ return "{{{} {}}}".format(
+ node.elt.accept(self), " ".join(n.accept(self) for n in node.generators)
+ )
+
+ def visit_slice(self, node) -> str:
+ """return an astroid.Slice node as string"""
+ lower = node.lower.accept(self) if node.lower else ""
+ upper = node.upper.accept(self) if node.upper else ""
+ step = node.step.accept(self) if node.step else ""
+ if step:
+ return f"{lower}:{upper}:{step}"
+ return f"{lower}:{upper}"
+
+ def visit_subscript(self, node) -> str:
+ """return an astroid.Subscript node as string"""
+ idx = node.slice
+ if idx.__class__.__name__.lower() == "index":
+ idx = idx.value
+ idxstr = idx.accept(self)
+ if idx.__class__.__name__.lower() == "tuple" and idx.elts:
+ # Remove parenthesis in tuple and extended slice.
+ # a[(::1, 1:)] is not valid syntax.
+ idxstr = idxstr[1:-1]
+ return f"{self._precedence_parens(node, node.value)}[{idxstr}]"
+
+ def visit_try(self, node) -> str:
+ """return an astroid.Try node as string"""
+ trys = [f"try:\n{self._stmt_list(node.body)}"]
+ for handler in node.handlers:
+ trys.append(handler.accept(self))
+ if node.orelse:
+ trys.append(f"else:\n{self._stmt_list(node.orelse)}")
+ if node.finalbody:
+ trys.append(f"finally:\n{self._stmt_list(node.finalbody)}")
+ return "\n".join(trys)
+
+ def visit_trystar(self, node) -> str:
+ """return an astroid.TryStar node as string"""
+ trys = [f"try:\n{self._stmt_list(node.body)}"]
+ for handler in node.handlers:
+ trys.append(handler.accept(self))
+ if node.orelse:
+ trys.append(f"else:\n{self._stmt_list(node.orelse)}")
+ if node.finalbody:
+ trys.append(f"finally:\n{self._stmt_list(node.finalbody)}")
+ return "\n".join(trys)
+
+ def visit_tuple(self, node) -> str:
+ """return an astroid.Tuple node as string"""
+ if len(node.elts) == 1:
+ return f"({node.elts[0].accept(self)}, )"
+ return f"({', '.join(child.accept(self) for child in node.elts)})"
+
+ def visit_typealias(self, node: nodes.TypeAlias) -> str:
+ """return an astroid.TypeAlias node as string"""
+ return node.name.accept(self) if node.name else "_"
+
+ def visit_typevar(self, node: nodes.TypeVar) -> str:
+ """return an astroid.TypeVar node as string"""
+ return node.name.accept(self) if node.name else "_"
+
+ def visit_typevartuple(self, node: nodes.TypeVarTuple) -> str:
+ """return an astroid.TypeVarTuple node as string"""
+ return "*" + node.name.accept(self) if node.name else ""
+
+ def visit_unaryop(self, node) -> str:
+ """return an astroid.UnaryOp node as string"""
+ if node.op == "not":
+ operator = "not "
+ else:
+ operator = node.op
+ return f"{operator}{self._precedence_parens(node, node.operand)}"
+
+ def visit_while(self, node) -> str:
+ """return an astroid.While node as string"""
+ whiles = f"while {node.test.accept(self)}:\n{self._stmt_list(node.body)}"
+ if node.orelse:
+ whiles = f"{whiles}\nelse:\n{self._stmt_list(node.orelse)}"
+ return whiles
+
+ def visit_with(self, node) -> str: # 'with' without 'as' is possible
+ """return an astroid.With node as string"""
+ items = ", ".join(
+ f"{expr.accept(self)}" + (v and f" as {v.accept(self)}" or "")
+ for expr, v in node.items
+ )
+ return f"with {items}:\n{self._stmt_list(node.body)}"
+
+ def visit_yield(self, node) -> str:
+ """yield an ast.Yield node as string"""
+ yi_val = (" " + node.value.accept(self)) if node.value else ""
+ expr = "yield" + yi_val
+ if node.parent.is_statement:
+ return expr
+
+ return f"({expr})"
+
+ def visit_yieldfrom(self, node) -> str:
+ """Return an astroid.YieldFrom node as string."""
+ yi_val = (" " + node.value.accept(self)) if node.value else ""
+ expr = "yield from" + yi_val
+ if node.parent.is_statement:
+ return expr
+
+ return f"({expr})"
+
+ def visit_starred(self, node) -> str:
+ """return Starred node as string"""
+ return "*" + node.value.accept(self)
+
+ def visit_match(self, node: Match) -> str:
+ """Return an astroid.Match node as string."""
+ return f"match {node.subject.accept(self)}:\n{self._stmt_list(node.cases)}"
+
+ def visit_matchcase(self, node: MatchCase) -> str:
+ """Return an astroid.MatchCase node as string."""
+ guard_str = f" if {node.guard.accept(self)}" if node.guard else ""
+ return (
+ f"case {node.pattern.accept(self)}{guard_str}:\n"
+ f"{self._stmt_list(node.body)}"
+ )
+
+ def visit_matchvalue(self, node: MatchValue) -> str:
+ """Return an astroid.MatchValue node as string."""
+ return node.value.accept(self)
+
+ @staticmethod
+ def visit_matchsingleton(node: MatchSingleton) -> str:
+ """Return an astroid.MatchSingleton node as string."""
+ return str(node.value)
+
+ def visit_matchsequence(self, node: MatchSequence) -> str:
+ """Return an astroid.MatchSequence node as string."""
+ if node.patterns is None:
+ return "[]"
+ return f"[{', '.join(p.accept(self) for p in node.patterns)}]"
+
+ def visit_matchmapping(self, node: MatchMapping) -> str:
+ """Return an astroid.MatchMapping node as string."""
+ mapping_strings: list[str] = []
+ if node.keys and node.patterns:
+ mapping_strings.extend(
+ f"{key.accept(self)}: {p.accept(self)}"
+ for key, p in zip(node.keys, node.patterns)
+ )
+ if node.rest:
+ mapping_strings.append(f"**{node.rest.accept(self)}")
+ return f"{'{'}{', '.join(mapping_strings)}{'}'}"
+
+ def visit_matchclass(self, node: MatchClass) -> str:
+ """Return an astroid.MatchClass node as string."""
+ if node.cls is None:
+ raise AssertionError(f"{node} does not have a 'cls' node")
+ class_strings: list[str] = []
+ if node.patterns:
+ class_strings.extend(p.accept(self) for p in node.patterns)
+ if node.kwd_attrs and node.kwd_patterns:
+ for attr, pattern in zip(node.kwd_attrs, node.kwd_patterns):
+ class_strings.append(f"{attr}={pattern.accept(self)}")
+ return f"{node.cls.accept(self)}({', '.join(class_strings)})"
+
+ def visit_matchstar(self, node: MatchStar) -> str:
+ """Return an astroid.MatchStar node as string."""
+ return f"*{node.name.accept(self) if node.name else '_'}"
+
+ def visit_matchas(self, node: MatchAs) -> str:
+ """Return an astroid.MatchAs node as string."""
+ # pylint: disable=import-outside-toplevel
+ # Prevent circular dependency
+ from astroid.nodes.node_classes import MatchClass, MatchMapping, MatchSequence
+
+ if isinstance(node.parent, (MatchSequence, MatchMapping, MatchClass)):
+ return node.name.accept(self) if node.name else "_"
+ return (
+ f"{node.pattern.accept(self) if node.pattern else '_'}"
+ f"{f' as {node.name.accept(self)}' if node.name else ''}"
+ )
+
+ def visit_matchor(self, node: MatchOr) -> str:
+ """Return an astroid.MatchOr node as string."""
+ if node.patterns is None:
+ raise AssertionError(f"{node} does not have pattern nodes")
+ return " | ".join(p.accept(self) for p in node.patterns)
+
+ # These aren't for real AST nodes, but for inference objects.
+
+ def visit_frozenset(self, node):
+ return node.parent.accept(self)
+
+ def visit_super(self, node):
+ return node.parent.accept(self)
+
+ def visit_uninferable(self, node):
+ return str(node)
+
+ def visit_property(self, node):
+ return node.function.accept(self)
+
+ def visit_evaluatedobject(self, node):
+ return node.original.accept(self)
+
+ def visit_unknown(self, node: Unknown) -> str:
+ return str(node)
+
+
+def _import_string(names) -> str:
+ """return a list of (name, asname) formatted as a string"""
+ _names = []
+ for name, asname in names:
+ if asname is not None:
+ _names.append(f"{name} as {asname}")
+ else:
+ _names.append(name)
+ return ", ".join(_names)
+
+
+# This sets the default indent to 4 spaces.
+to_code = AsStringVisitor(" ")
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/const.py b/solutions/.venv/Lib/site-packages/astroid/nodes/const.py
new file mode 100644
index 000000000..f66b633f7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/const.py
@@ -0,0 +1,27 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+OP_PRECEDENCE = {
+ op: precedence
+ for precedence, ops in enumerate(
+ [
+ ["Lambda"], # lambda x: x + 1
+ ["IfExp"], # 1 if True else 2
+ ["or"],
+ ["and"],
+ ["not"],
+ ["Compare"], # in, not in, is, is not, <, <=, >, >=, !=, ==
+ ["|"],
+ ["^"],
+ ["&"],
+ ["<<", ">>"],
+ ["+", "-"],
+ ["*", "@", "/", "//", "%"],
+ ["UnaryOp"], # +, -, ~
+ ["**"],
+ ["Await"],
+ ]
+ )
+ for op in ops
+}
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/node_classes.py b/solutions/.venv/Lib/site-packages/astroid/nodes/node_classes.py
new file mode 100644
index 000000000..6845ca99c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/node_classes.py
@@ -0,0 +1,5545 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Module for some node classes. More nodes in scoped_nodes.py"""
+
+from __future__ import annotations
+
+import abc
+import ast
+import itertools
+import operator
+import sys
+import typing
+import warnings
+from collections.abc import Callable, Generator, Iterable, Iterator, Mapping
+from functools import cached_property
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ ClassVar,
+ Literal,
+ Optional,
+ Union,
+)
+
+from astroid import decorators, protocols, util
+from astroid.bases import Instance, _infer_stmts
+from astroid.const import _EMPTY_OBJECT_MARKER, Context
+from astroid.context import CallContext, InferenceContext, copy_context
+from astroid.exceptions import (
+ AstroidBuildingError,
+ AstroidError,
+ AstroidIndexError,
+ AstroidTypeError,
+ AstroidValueError,
+ AttributeInferenceError,
+ InferenceError,
+ NameInferenceError,
+ NoDefault,
+ ParentMissingError,
+ _NonDeducibleTypeHierarchy,
+)
+from astroid.interpreter import dunder_lookup
+from astroid.manager import AstroidManager
+from astroid.nodes import _base_nodes
+from astroid.nodes.const import OP_PRECEDENCE
+from astroid.nodes.node_ng import NodeNG
+from astroid.typing import (
+ ConstFactoryResult,
+ InferenceErrorInfo,
+ InferenceResult,
+ SuccessfulInferenceResult,
+)
+
+if sys.version_info >= (3, 11):
+ from typing import Self
+else:
+ from typing_extensions import Self
+
+if TYPE_CHECKING:
+ from astroid import nodes
+ from astroid.nodes import LocalsDictNodeNG
+
+
+def _is_const(value) -> bool:
+ return isinstance(value, tuple(CONST_CLS))
+
+
+_NodesT = typing.TypeVar("_NodesT", bound=NodeNG)
+_BadOpMessageT = typing.TypeVar("_BadOpMessageT", bound=util.BadOperationMessage)
+
+AssignedStmtsPossibleNode = Union["List", "Tuple", "AssignName", "AssignAttr", None]
+AssignedStmtsCall = Callable[
+ [
+ _NodesT,
+ AssignedStmtsPossibleNode,
+ Optional[InferenceContext],
+ Optional[list[int]],
+ ],
+ Any,
+]
+InferBinaryOperation = Callable[
+ [_NodesT, Optional[InferenceContext]],
+ Generator[Union[InferenceResult, _BadOpMessageT]],
+]
+InferLHS = Callable[
+ [_NodesT, Optional[InferenceContext]],
+ Generator[InferenceResult, None, Optional[InferenceErrorInfo]],
+]
+InferUnaryOp = Callable[[_NodesT, str], ConstFactoryResult]
+
+
+@decorators.raise_if_nothing_inferred
+def unpack_infer(stmt, context: InferenceContext | None = None):
+ """recursively generate nodes inferred by the given statement.
+ If the inferred value is a list or a tuple, recurse on the elements
+ """
+ if isinstance(stmt, (List, Tuple)):
+ for elt in stmt.elts:
+ if elt is util.Uninferable:
+ yield elt
+ continue
+ yield from unpack_infer(elt, context)
+ return {"node": stmt, "context": context}
+ # if inferred is a final node, return it and stop
+ inferred = next(stmt.infer(context), util.Uninferable)
+ if inferred is stmt:
+ yield inferred
+ return {"node": stmt, "context": context}
+ # else, infer recursively, except Uninferable object that should be returned as is
+ for inferred in stmt.infer(context):
+ if isinstance(inferred, util.UninferableBase):
+ yield inferred
+ else:
+ yield from unpack_infer(inferred, context)
+
+ return {"node": stmt, "context": context}
+
+
+def are_exclusive(stmt1, stmt2, exceptions: list[str] | None = None) -> bool:
+ """return true if the two given statements are mutually exclusive
+
+ `exceptions` may be a list of exception names. If specified, discard If
+ branches and check one of the statement is in an exception handler catching
+ one of the given exceptions.
+
+ algorithm :
+ 1) index stmt1's parents
+ 2) climb among stmt2's parents until we find a common parent
+ 3) if the common parent is a If or Try statement, look if nodes are
+ in exclusive branches
+ """
+ # index stmt1's parents
+ stmt1_parents = {}
+ children = {}
+ previous = stmt1
+ for node in stmt1.node_ancestors():
+ stmt1_parents[node] = 1
+ children[node] = previous
+ previous = node
+ # climb among stmt2's parents until we find a common parent
+ previous = stmt2
+ for node in stmt2.node_ancestors():
+ if node in stmt1_parents:
+ # if the common parent is a If or Try statement, look if
+ # nodes are in exclusive branches
+ if isinstance(node, If) and exceptions is None:
+ c2attr, c2node = node.locate_child(previous)
+ c1attr, c1node = node.locate_child(children[node])
+ if "test" in (c1attr, c2attr):
+ # If any node is `If.test`, then it must be inclusive with
+ # the other node (`If.body` and `If.orelse`)
+ return False
+ if c1attr != c2attr:
+ # different `If` branches (`If.body` and `If.orelse`)
+ return True
+ elif isinstance(node, Try):
+ c2attr, c2node = node.locate_child(previous)
+ c1attr, c1node = node.locate_child(children[node])
+ if c1node is not c2node:
+ first_in_body_caught_by_handlers = (
+ c2attr == "handlers"
+ and c1attr == "body"
+ and previous.catch(exceptions)
+ )
+ second_in_body_caught_by_handlers = (
+ c2attr == "body"
+ and c1attr == "handlers"
+ and children[node].catch(exceptions)
+ )
+ first_in_else_other_in_handlers = (
+ c2attr == "handlers" and c1attr == "orelse"
+ )
+ second_in_else_other_in_handlers = (
+ c2attr == "orelse" and c1attr == "handlers"
+ )
+ if any(
+ (
+ first_in_body_caught_by_handlers,
+ second_in_body_caught_by_handlers,
+ first_in_else_other_in_handlers,
+ second_in_else_other_in_handlers,
+ )
+ ):
+ return True
+ elif c2attr == "handlers" and c1attr == "handlers":
+ return previous is not children[node]
+ return False
+ previous = node
+ return False
+
+
+# getitem() helpers.
+
+_SLICE_SENTINEL = object()
+
+
+def _slice_value(index, context: InferenceContext | None = None):
+ """Get the value of the given slice index."""
+
+ if isinstance(index, Const):
+ if isinstance(index.value, (int, type(None))):
+ return index.value
+ elif index is None:
+ return None
+ else:
+ # Try to infer what the index actually is.
+ # Since we can't return all the possible values,
+ # we'll stop at the first possible value.
+ try:
+ inferred = next(index.infer(context=context))
+ except (InferenceError, StopIteration):
+ pass
+ else:
+ if isinstance(inferred, Const):
+ if isinstance(inferred.value, (int, type(None))):
+ return inferred.value
+
+ # Use a sentinel, because None can be a valid
+ # value that this function can return,
+ # as it is the case for unspecified bounds.
+ return _SLICE_SENTINEL
+
+
+def _infer_slice(node, context: InferenceContext | None = None):
+ lower = _slice_value(node.lower, context)
+ upper = _slice_value(node.upper, context)
+ step = _slice_value(node.step, context)
+ if all(elem is not _SLICE_SENTINEL for elem in (lower, upper, step)):
+ return slice(lower, upper, step)
+
+ raise AstroidTypeError(
+ message="Could not infer slice used in subscript",
+ node=node,
+ index=node.parent,
+ context=context,
+ )
+
+
+def _container_getitem(instance, elts, index, context: InferenceContext | None = None):
+ """Get a slice or an item, using the given *index*, for the given sequence."""
+ try:
+ if isinstance(index, Slice):
+ index_slice = _infer_slice(index, context=context)
+ new_cls = instance.__class__()
+ new_cls.elts = elts[index_slice]
+ new_cls.parent = instance.parent
+ return new_cls
+ if isinstance(index, Const):
+ return elts[index.value]
+ except ValueError as exc:
+ raise AstroidValueError(
+ message="Slice {index!r} cannot index container",
+ node=instance,
+ index=index,
+ context=context,
+ ) from exc
+ except IndexError as exc:
+ raise AstroidIndexError(
+ message="Index {index!s} out of range",
+ node=instance,
+ index=index,
+ context=context,
+ ) from exc
+ except TypeError as exc:
+ raise AstroidTypeError(
+ message="Type error {error!r}", node=instance, index=index, context=context
+ ) from exc
+
+ raise AstroidTypeError(f"Could not use {index} as subscript index")
+
+
+class BaseContainer(_base_nodes.ParentAssignNode, Instance, metaclass=abc.ABCMeta):
+ """Base class for Set, FrozenSet, Tuple and List."""
+
+ _astroid_fields = ("elts",)
+
+ def __init__(
+ self,
+ lineno: int | None,
+ col_offset: int | None,
+ parent: NodeNG | None,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.elts: list[SuccessfulInferenceResult] = []
+ """The elements in the node."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, elts: list[SuccessfulInferenceResult]) -> None:
+ self.elts = elts
+
+ @classmethod
+ def from_elements(cls, elts: Iterable[Any]) -> Self:
+ """Create a node of this type from the given list of elements.
+
+ :param elts: The list of elements that the node should contain.
+
+ :returns: A new node containing the given elements.
+ """
+ node = cls(
+ lineno=None,
+ col_offset=None,
+ parent=None,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ node.elts = [const_factory(e) if _is_const(e) else e for e in elts]
+ return node
+
+ def itered(self):
+ """An iterator over the elements this node contains.
+
+ :returns: The contents of this node.
+ :rtype: iterable(NodeNG)
+ """
+ return self.elts
+
+ def bool_value(self, context: InferenceContext | None = None) -> bool:
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ """
+ return bool(self.elts)
+
+ @abc.abstractmethod
+ def pytype(self) -> str:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+
+ def get_children(self):
+ yield from self.elts
+
+ @decorators.raise_if_nothing_inferred
+ def _infer(
+ self,
+ context: InferenceContext | None = None,
+ **kwargs: Any,
+ ) -> Iterator[Self]:
+ has_starred_named_expr = any(
+ isinstance(e, (Starred, NamedExpr)) for e in self.elts
+ )
+ if has_starred_named_expr:
+ values = self._infer_sequence_helper(context)
+ new_seq = type(self)(
+ lineno=self.lineno,
+ col_offset=self.col_offset,
+ parent=self.parent,
+ end_lineno=self.end_lineno,
+ end_col_offset=self.end_col_offset,
+ )
+ new_seq.postinit(values)
+
+ yield new_seq
+ else:
+ yield self
+
+ def _infer_sequence_helper(
+ self, context: InferenceContext | None = None
+ ) -> list[SuccessfulInferenceResult]:
+ """Infer all values based on BaseContainer.elts."""
+ values = []
+
+ for elt in self.elts:
+ if isinstance(elt, Starred):
+ starred = util.safe_infer(elt.value, context)
+ if not starred:
+ raise InferenceError(node=self, context=context)
+ if not hasattr(starred, "elts"):
+ raise InferenceError(node=self, context=context)
+ # TODO: fresh context?
+ values.extend(starred._infer_sequence_helper(context))
+ elif isinstance(elt, NamedExpr):
+ value = util.safe_infer(elt.value, context)
+ if not value:
+ raise InferenceError(node=self, context=context)
+ values.append(value)
+ else:
+ values.append(elt)
+ return values
+
+
+# Name classes
+
+
+class AssignName(
+ _base_nodes.NoChildrenNode,
+ _base_nodes.LookupMixIn,
+ _base_nodes.ParentAssignNode,
+):
+ """Variation of :class:`ast.Assign` representing assignment to a name.
+
+ An :class:`AssignName` is the name of something that is assigned to.
+ This includes variables defined in a function signature or in a loop.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('variable = range(10)')
+ >>> node
+ <Assign l.1 at 0x7effe1db8550>
+ >>> list(node.get_children())
+ [<AssignName.variable l.1 at 0x7effe1db8748>, <Call l.1 at 0x7effe1db8630>]
+ >>> list(node.get_children())[0].as_string()
+ 'variable'
+ """
+
+ _other_fields = ("name",)
+
+ def __init__(
+ self,
+ name: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.name = name
+ """The name that is assigned to."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ assigned_stmts = protocols.assend_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ """Infer an AssignName: need to inspect the RHS part of the
+ assign node.
+ """
+ if isinstance(self.parent, AugAssign):
+ return self.parent.infer(context)
+
+ stmts = list(self.assigned_stmts(context=context))
+ return _infer_stmts(stmts, context)
+
+ @decorators.raise_if_nothing_inferred
+ def infer_lhs(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ """Infer a Name: use name lookup rules.
+
+ Same implementation as Name._infer."""
+ # pylint: disable=import-outside-toplevel
+ from astroid.constraint import get_constraints
+ from astroid.helpers import _higher_function_scope
+
+ frame, stmts = self.lookup(self.name)
+ if not stmts:
+ # Try to see if the name is enclosed in a nested function
+ # and use the higher (first function) scope for searching.
+ parent_function = _higher_function_scope(self.scope())
+ if parent_function:
+ _, stmts = parent_function.lookup(self.name)
+
+ if not stmts:
+ raise NameInferenceError(
+ name=self.name, scope=self.scope(), context=context
+ )
+ context = copy_context(context)
+ context.lookupname = self.name
+ context.constraints[self.name] = get_constraints(self, frame)
+
+ return _infer_stmts(stmts, context, frame)
+
+
+class DelName(
+ _base_nodes.NoChildrenNode, _base_nodes.LookupMixIn, _base_nodes.ParentAssignNode
+):
+ """Variation of :class:`ast.Delete` representing deletion of a name.
+
+ A :class:`DelName` is the name of something that is deleted.
+
+ >>> import astroid
+ >>> node = astroid.extract_node("del variable #@")
+ >>> list(node.get_children())
+ [<DelName.variable l.1 at 0x7effe1da4d30>]
+ >>> list(node.get_children())[0].as_string()
+ 'variable'
+ """
+
+ _other_fields = ("name",)
+
+ def __init__(
+ self,
+ name: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.name = name
+ """The name that is being deleted."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+
+class Name(_base_nodes.LookupMixIn, _base_nodes.NoChildrenNode):
+ """Class representing an :class:`ast.Name` node.
+
+ A :class:`Name` node is something that is named, but not covered by
+ :class:`AssignName` or :class:`DelName`.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('range(10)')
+ >>> node
+ <Call l.1 at 0x7effe1db8710>
+ >>> list(node.get_children())
+ [<Name.range l.1 at 0x7effe1db86a0>, <Const.int l.1 at 0x7effe1db8518>]
+ >>> list(node.get_children())[0].as_string()
+ 'range'
+ """
+
+ _other_fields = ("name",)
+
+ def __init__(
+ self,
+ name: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.name = name
+ """The name that this node refers to."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def _get_name_nodes(self):
+ yield self
+
+ for child_node in self.get_children():
+ yield from child_node._get_name_nodes()
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ """Infer a Name: use name lookup rules
+
+ Same implementation as AssignName._infer_lhs."""
+ # pylint: disable=import-outside-toplevel
+ from astroid.constraint import get_constraints
+ from astroid.helpers import _higher_function_scope
+
+ frame, stmts = self.lookup(self.name)
+ if not stmts:
+ # Try to see if the name is enclosed in a nested function
+ # and use the higher (first function) scope for searching.
+ parent_function = _higher_function_scope(self.scope())
+ if parent_function:
+ _, stmts = parent_function.lookup(self.name)
+
+ if not stmts:
+ raise NameInferenceError(
+ name=self.name, scope=self.scope(), context=context
+ )
+ context = copy_context(context)
+ context.lookupname = self.name
+ context.constraints[self.name] = get_constraints(self, frame)
+
+ return _infer_stmts(stmts, context, frame)
+
+
+DEPRECATED_ARGUMENT_DEFAULT = "DEPRECATED_ARGUMENT_DEFAULT"
+
+
+class Arguments(
+ _base_nodes.AssignTypeNode
+): # pylint: disable=too-many-instance-attributes
+ """Class representing an :class:`ast.arguments` node.
+
+ An :class:`Arguments` node represents that arguments in a
+ function definition.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('def foo(bar): pass')
+ >>> node
+ <FunctionDef.foo l.1 at 0x7effe1db8198>
+ >>> node.args
+ <Arguments l.1 at 0x7effe1db82e8>
+ """
+
+ # Python 3.4+ uses a different approach regarding annotations,
+ # each argument is a new class, _ast.arg, which exposes an
+ # 'annotation' attribute. In astroid though, arguments are exposed
+ # as is in the Arguments node and the only way to expose annotations
+ # is by using something similar with Python 3.3:
+ # - we expose 'varargannotation' and 'kwargannotation' of annotations
+ # of varargs and kwargs.
+ # - we expose 'annotation', a list with annotations for
+ # for each normal argument. If an argument doesn't have an
+ # annotation, its value will be None.
+ _astroid_fields = (
+ "args",
+ "defaults",
+ "kwonlyargs",
+ "posonlyargs",
+ "posonlyargs_annotations",
+ "kw_defaults",
+ "annotations",
+ "varargannotation",
+ "kwargannotation",
+ "kwonlyargs_annotations",
+ "type_comment_args",
+ "type_comment_kwonlyargs",
+ "type_comment_posonlyargs",
+ )
+
+ _other_fields = ("vararg", "kwarg")
+
+ args: list[AssignName] | None
+ """The names of the required arguments.
+
+ Can be None if the associated function does not have a retrievable
+ signature and the arguments are therefore unknown.
+ This can happen with (builtin) functions implemented in C that have
+ incomplete signature information.
+ """
+
+ defaults: list[NodeNG] | None
+ """The default values for arguments that can be passed positionally."""
+
+ kwonlyargs: list[AssignName]
+ """The keyword arguments that cannot be passed positionally."""
+
+ posonlyargs: list[AssignName]
+ """The arguments that can only be passed positionally."""
+
+ kw_defaults: list[NodeNG | None] | None
+ """The default values for keyword arguments that cannot be passed positionally."""
+
+ annotations: list[NodeNG | None]
+ """The type annotations of arguments that can be passed positionally."""
+
+ posonlyargs_annotations: list[NodeNG | None]
+ """The type annotations of arguments that can only be passed positionally."""
+
+ kwonlyargs_annotations: list[NodeNG | None]
+ """The type annotations of arguments that cannot be passed positionally."""
+
+ type_comment_args: list[NodeNG | None]
+ """The type annotation, passed by a type comment, of each argument.
+
+ If an argument does not have a type comment,
+ the value for that argument will be None.
+ """
+
+ type_comment_kwonlyargs: list[NodeNG | None]
+ """The type annotation, passed by a type comment, of each keyword only argument.
+
+ If an argument does not have a type comment,
+ the value for that argument will be None.
+ """
+
+ type_comment_posonlyargs: list[NodeNG | None]
+ """The type annotation, passed by a type comment, of each positional argument.
+
+ If an argument does not have a type comment,
+ the value for that argument will be None.
+ """
+
+ varargannotation: NodeNG | None
+ """The type annotation for the variable length arguments."""
+
+ kwargannotation: NodeNG | None
+ """The type annotation for the variable length keyword arguments."""
+
+ vararg_node: AssignName | None
+ """The node for variable length arguments"""
+
+ kwarg_node: AssignName | None
+ """The node for variable keyword arguments"""
+
+ def __init__(
+ self,
+ vararg: str | None,
+ kwarg: str | None,
+ parent: NodeNG,
+ vararg_node: AssignName | None = None,
+ kwarg_node: AssignName | None = None,
+ ) -> None:
+ """Almost all attributes can be None for living objects where introspection failed."""
+ super().__init__(
+ parent=parent,
+ lineno=None,
+ col_offset=None,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+
+ self.vararg = vararg
+ """The name of the variable length arguments."""
+
+ self.kwarg = kwarg
+ """The name of the variable length keyword arguments."""
+
+ self.vararg_node = vararg_node
+ self.kwarg_node = kwarg_node
+
+ # pylint: disable=too-many-arguments, too-many-positional-arguments
+ def postinit(
+ self,
+ args: list[AssignName] | None,
+ defaults: list[NodeNG] | None,
+ kwonlyargs: list[AssignName],
+ kw_defaults: list[NodeNG | None] | None,
+ annotations: list[NodeNG | None],
+ posonlyargs: list[AssignName],
+ kwonlyargs_annotations: list[NodeNG | None],
+ posonlyargs_annotations: list[NodeNG | None],
+ varargannotation: NodeNG | None = None,
+ kwargannotation: NodeNG | None = None,
+ type_comment_args: list[NodeNG | None] | None = None,
+ type_comment_kwonlyargs: list[NodeNG | None] | None = None,
+ type_comment_posonlyargs: list[NodeNG | None] | None = None,
+ ) -> None:
+ self.args = args
+ self.defaults = defaults
+ self.kwonlyargs = kwonlyargs
+ self.posonlyargs = posonlyargs
+ self.kw_defaults = kw_defaults
+ self.annotations = annotations
+ self.kwonlyargs_annotations = kwonlyargs_annotations
+ self.posonlyargs_annotations = posonlyargs_annotations
+
+ # Parameters that got added later and need a default
+ self.varargannotation = varargannotation
+ self.kwargannotation = kwargannotation
+ if type_comment_args is None:
+ type_comment_args = []
+ self.type_comment_args = type_comment_args
+ if type_comment_kwonlyargs is None:
+ type_comment_kwonlyargs = []
+ self.type_comment_kwonlyargs = type_comment_kwonlyargs
+ if type_comment_posonlyargs is None:
+ type_comment_posonlyargs = []
+ self.type_comment_posonlyargs = type_comment_posonlyargs
+
+ assigned_stmts = protocols.arguments_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def _infer_name(self, frame, name):
+ if self.parent is frame:
+ return name
+ return None
+
+ @cached_property
+ def fromlineno(self) -> int:
+ """The first line that this node appears on in the source code.
+
+ Can also return 0 if the line can not be determined.
+ """
+ lineno = super().fromlineno
+ return max(lineno, self.parent.fromlineno or 0)
+
+ @cached_property
+ def arguments(self):
+ """Get all the arguments for this node. This includes:
+ * Positional only arguments
+ * Positional arguments
+ * Keyword arguments
+ * Variable arguments (.e.g *args)
+ * Variable keyword arguments (e.g **kwargs)
+ """
+ retval = list(itertools.chain((self.posonlyargs or ()), (self.args or ())))
+ if self.vararg_node:
+ retval.append(self.vararg_node)
+ retval += self.kwonlyargs or ()
+ if self.kwarg_node:
+ retval.append(self.kwarg_node)
+
+ return retval
+
+ def format_args(self, *, skippable_names: set[str] | None = None) -> str:
+ """Get the arguments formatted as string.
+
+ :returns: The formatted arguments.
+ :rtype: str
+ """
+ result = []
+ positional_only_defaults = []
+ positional_or_keyword_defaults = self.defaults
+ if self.defaults:
+ args = self.args or []
+ positional_or_keyword_defaults = self.defaults[-len(args) :]
+ positional_only_defaults = self.defaults[: len(self.defaults) - len(args)]
+
+ if self.posonlyargs:
+ result.append(
+ _format_args(
+ self.posonlyargs,
+ positional_only_defaults,
+ self.posonlyargs_annotations,
+ skippable_names=skippable_names,
+ )
+ )
+ result.append("/")
+ if self.args:
+ result.append(
+ _format_args(
+ self.args,
+ positional_or_keyword_defaults,
+ getattr(self, "annotations", None),
+ skippable_names=skippable_names,
+ )
+ )
+ if self.vararg:
+ result.append(f"*{self.vararg}")
+ if self.kwonlyargs:
+ if not self.vararg:
+ result.append("*")
+ result.append(
+ _format_args(
+ self.kwonlyargs,
+ self.kw_defaults,
+ self.kwonlyargs_annotations,
+ skippable_names=skippable_names,
+ )
+ )
+ if self.kwarg:
+ result.append(f"**{self.kwarg}")
+ return ", ".join(result)
+
+ def _get_arguments_data(
+ self,
+ ) -> tuple[
+ dict[str, tuple[str | None, str | None]],
+ dict[str, tuple[str | None, str | None]],
+ ]:
+ """Get the arguments as dictionary with information about typing and defaults.
+
+ The return tuple contains a dictionary for positional and keyword arguments with their typing
+ and their default value, if any.
+ The method follows a similar order as format_args but instead of formatting into a string it
+ returns the data that is used to do so.
+ """
+ pos_only: dict[str, tuple[str | None, str | None]] = {}
+ kw_only: dict[str, tuple[str | None, str | None]] = {}
+
+ # Setup and match defaults with arguments
+ positional_only_defaults = []
+ positional_or_keyword_defaults = self.defaults
+ if self.defaults:
+ args = self.args or []
+ positional_or_keyword_defaults = self.defaults[-len(args) :]
+ positional_only_defaults = self.defaults[: len(self.defaults) - len(args)]
+
+ for index, posonly in enumerate(self.posonlyargs):
+ annotation, default = self.posonlyargs_annotations[index], None
+ if annotation is not None:
+ annotation = annotation.as_string()
+ if positional_only_defaults:
+ default = positional_only_defaults[index].as_string()
+ pos_only[posonly.name] = (annotation, default)
+
+ for index, arg in enumerate(self.args):
+ annotation, default = self.annotations[index], None
+ if annotation is not None:
+ annotation = annotation.as_string()
+ if positional_or_keyword_defaults:
+ defaults_offset = len(self.args) - len(positional_or_keyword_defaults)
+ default_index = index - defaults_offset
+ if (
+ default_index > -1
+ and positional_or_keyword_defaults[default_index] is not None
+ ):
+ default = positional_or_keyword_defaults[default_index].as_string()
+ pos_only[arg.name] = (annotation, default)
+
+ if self.vararg:
+ annotation = self.varargannotation
+ if annotation is not None:
+ annotation = annotation.as_string()
+ pos_only[self.vararg] = (annotation, None)
+
+ for index, kwarg in enumerate(self.kwonlyargs):
+ annotation = self.kwonlyargs_annotations[index]
+ if annotation is not None:
+ annotation = annotation.as_string()
+ default = self.kw_defaults[index]
+ if default is not None:
+ default = default.as_string()
+ kw_only[kwarg.name] = (annotation, default)
+
+ if self.kwarg:
+ annotation = self.kwargannotation
+ if annotation is not None:
+ annotation = annotation.as_string()
+ kw_only[self.kwarg] = (annotation, None)
+
+ return pos_only, kw_only
+
+ def default_value(self, argname):
+ """Get the default value for an argument.
+
+ :param argname: The name of the argument to get the default value for.
+ :type argname: str
+
+ :raises NoDefault: If there is no default value defined for the
+ given argument.
+ """
+ args = [
+ arg for arg in self.arguments if arg.name not in [self.vararg, self.kwarg]
+ ]
+
+ index = _find_arg(argname, self.kwonlyargs)[0]
+ if (index is not None) and (len(self.kw_defaults) > index):
+ if self.kw_defaults[index] is not None:
+ return self.kw_defaults[index]
+ raise NoDefault(func=self.parent, name=argname)
+
+ index = _find_arg(argname, args)[0]
+ if index is not None:
+ idx = index - (len(args) - len(self.defaults) - len(self.kw_defaults))
+ if idx >= 0:
+ return self.defaults[idx]
+
+ raise NoDefault(func=self.parent, name=argname)
+
+ def is_argument(self, name) -> bool:
+ """Check if the given name is defined in the arguments.
+
+ :param name: The name to check for.
+ :type name: str
+
+ :returns: Whether the given name is defined in the arguments,
+ """
+ if name == self.vararg:
+ return True
+ if name == self.kwarg:
+ return True
+ return self.find_argname(name)[1] is not None
+
+ def find_argname(self, argname, rec=DEPRECATED_ARGUMENT_DEFAULT):
+ """Get the index and :class:`AssignName` node for given name.
+
+ :param argname: The name of the argument to search for.
+ :type argname: str
+
+ :returns: The index and node for the argument.
+ :rtype: tuple(str or None, AssignName or None)
+ """
+ if rec != DEPRECATED_ARGUMENT_DEFAULT: # pragma: no cover
+ warnings.warn(
+ "The rec argument will be removed in astroid 3.1.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ if self.arguments:
+ index, argument = _find_arg(argname, self.arguments)
+ if argument:
+ return index, argument
+ return None, None
+
+ def get_children(self):
+ yield from self.posonlyargs or ()
+
+ for elt in self.posonlyargs_annotations:
+ if elt is not None:
+ yield elt
+
+ yield from self.args or ()
+
+ if self.defaults is not None:
+ yield from self.defaults
+ yield from self.kwonlyargs
+
+ for elt in self.kw_defaults or ():
+ if elt is not None:
+ yield elt
+
+ for elt in self.annotations:
+ if elt is not None:
+ yield elt
+
+ if self.varargannotation is not None:
+ yield self.varargannotation
+
+ if self.kwargannotation is not None:
+ yield self.kwargannotation
+
+ for elt in self.kwonlyargs_annotations:
+ if elt is not None:
+ yield elt
+
+ @decorators.raise_if_nothing_inferred
+ def _infer(
+ self: nodes.Arguments, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ # pylint: disable-next=import-outside-toplevel
+ from astroid.protocols import _arguments_infer_argname
+
+ if context is None or context.lookupname is None:
+ raise InferenceError(node=self, context=context)
+ return _arguments_infer_argname(self, context.lookupname, context)
+
+
+def _find_arg(argname, args):
+ for i, arg in enumerate(args):
+ if arg.name == argname:
+ return i, arg
+ return None, None
+
+
+def _format_args(
+ args, defaults=None, annotations=None, skippable_names: set[str] | None = None
+) -> str:
+ if skippable_names is None:
+ skippable_names = set()
+ values = []
+ if args is None:
+ return ""
+ if annotations is None:
+ annotations = []
+ if defaults is not None:
+ default_offset = len(args) - len(defaults)
+ else:
+ default_offset = None
+ packed = itertools.zip_longest(args, annotations)
+ for i, (arg, annotation) in enumerate(packed):
+ if arg.name in skippable_names:
+ continue
+ if isinstance(arg, Tuple):
+ values.append(f"({_format_args(arg.elts)})")
+ else:
+ argname = arg.name
+ default_sep = "="
+ if annotation is not None:
+ argname += ": " + annotation.as_string()
+ default_sep = " = "
+ values.append(argname)
+
+ if default_offset is not None and i >= default_offset:
+ if defaults[i - default_offset] is not None:
+ values[-1] += default_sep + defaults[i - default_offset].as_string()
+ return ", ".join(values)
+
+
+def _infer_attribute(
+ node: nodes.AssignAttr | nodes.Attribute,
+ context: InferenceContext | None = None,
+ **kwargs: Any,
+) -> Generator[InferenceResult, None, InferenceErrorInfo]:
+ """Infer an AssignAttr/Attribute node by using getattr on the associated object."""
+ # pylint: disable=import-outside-toplevel
+ from astroid.constraint import get_constraints
+ from astroid.nodes import ClassDef
+
+ for owner in node.expr.infer(context):
+ if isinstance(owner, util.UninferableBase):
+ yield owner
+ continue
+
+ context = copy_context(context)
+ old_boundnode = context.boundnode
+ try:
+ context.boundnode = owner
+ if isinstance(owner, (ClassDef, Instance)):
+ frame = owner if isinstance(owner, ClassDef) else owner._proxied
+ context.constraints[node.attrname] = get_constraints(node, frame=frame)
+ if node.attrname == "argv" and owner.name == "sys":
+ # sys.argv will never be inferable during static analysis
+ # It's value would be the args passed to the linter itself
+ yield util.Uninferable
+ else:
+ yield from owner.igetattr(node.attrname, context)
+ except (
+ AttributeInferenceError,
+ InferenceError,
+ AttributeError,
+ ):
+ pass
+ finally:
+ context.boundnode = old_boundnode
+ return InferenceErrorInfo(node=node, context=context)
+
+
+class AssignAttr(_base_nodes.LookupMixIn, _base_nodes.ParentAssignNode):
+ """Variation of :class:`ast.Assign` representing assignment to an attribute.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('self.attribute = range(10)')
+ >>> node
+ <Assign l.1 at 0x7effe1d521d0>
+ >>> list(node.get_children())
+ [<AssignAttr.attribute l.1 at 0x7effe1d52320>, <Call l.1 at 0x7effe1d522e8>]
+ >>> list(node.get_children())[0].as_string()
+ 'self.attribute'
+ """
+
+ expr: NodeNG
+
+ _astroid_fields = ("expr",)
+ _other_fields = ("attrname",)
+
+ def __init__(
+ self,
+ attrname: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.attrname = attrname
+ """The name of the attribute being assigned to."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, expr: NodeNG) -> None:
+ self.expr = expr
+
+ assigned_stmts = protocols.assend_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def get_children(self):
+ yield self.expr
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ """Infer an AssignAttr: need to inspect the RHS part of the
+ assign node.
+ """
+ if isinstance(self.parent, AugAssign):
+ return self.parent.infer(context)
+
+ stmts = list(self.assigned_stmts(context=context))
+ return _infer_stmts(stmts, context)
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def infer_lhs(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ return _infer_attribute(self, context, **kwargs)
+
+
+class Assert(_base_nodes.Statement):
+ """Class representing an :class:`ast.Assert` node.
+
+ An :class:`Assert` node represents an assert statement.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('assert len(things) == 10, "Not enough things"')
+ >>> node
+ <Assert l.1 at 0x7effe1d527b8>
+ """
+
+ _astroid_fields = ("test", "fail")
+
+ test: NodeNG
+ """The test that passes or fails the assertion."""
+
+ fail: NodeNG | None
+ """The message shown when the assertion fails."""
+
+ def postinit(self, test: NodeNG, fail: NodeNG | None) -> None:
+ self.fail = fail
+ self.test = test
+
+ def get_children(self):
+ yield self.test
+
+ if self.fail is not None:
+ yield self.fail
+
+
+class Assign(_base_nodes.AssignTypeNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.Assign` node.
+
+ An :class:`Assign` is a statement where something is explicitly
+ asssigned to.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('variable = range(10)')
+ >>> node
+ <Assign l.1 at 0x7effe1db8550>
+ """
+
+ targets: list[NodeNG]
+ """What is being assigned to."""
+
+ value: NodeNG
+ """The value being assigned to the variables."""
+
+ type_annotation: NodeNG | None
+ """If present, this will contain the type annotation passed by a type comment"""
+
+ _astroid_fields = ("targets", "value")
+ _other_other_fields = ("type_annotation",)
+
+ def postinit(
+ self,
+ targets: list[NodeNG],
+ value: NodeNG,
+ type_annotation: NodeNG | None,
+ ) -> None:
+ self.targets = targets
+ self.value = value
+ self.type_annotation = type_annotation
+
+ assigned_stmts = protocols.assign_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def get_children(self):
+ yield from self.targets
+
+ yield self.value
+
+ @cached_property
+ def _assign_nodes_in_scope(self) -> list[nodes.Assign]:
+ return [self, *self.value._assign_nodes_in_scope]
+
+ def _get_yield_nodes_skip_functions(self):
+ yield from self.value._get_yield_nodes_skip_functions()
+
+ def _get_yield_nodes_skip_lambdas(self):
+ yield from self.value._get_yield_nodes_skip_lambdas()
+
+
+class AnnAssign(_base_nodes.AssignTypeNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.AnnAssign` node.
+
+ An :class:`AnnAssign` is an assignment with a type annotation.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('variable: List[int] = range(10)')
+ >>> node
+ <AnnAssign l.1 at 0x7effe1d4c630>
+ """
+
+ _astroid_fields = ("target", "annotation", "value")
+ _other_fields = ("simple",)
+
+ target: Name | Attribute | Subscript
+ """What is being assigned to."""
+
+ annotation: NodeNG
+ """The type annotation of what is being assigned to."""
+
+ value: NodeNG | None
+ """The value being assigned to the variables."""
+
+ simple: int
+ """Whether :attr:`target` is a pure name or a complex statement."""
+
+ def postinit(
+ self,
+ target: Name | Attribute | Subscript,
+ annotation: NodeNG,
+ simple: int,
+ value: NodeNG | None,
+ ) -> None:
+ self.target = target
+ self.annotation = annotation
+ self.value = value
+ self.simple = simple
+
+ assigned_stmts = protocols.assign_annassigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def get_children(self):
+ yield self.target
+ yield self.annotation
+
+ if self.value is not None:
+ yield self.value
+
+
+class AugAssign(
+ _base_nodes.AssignTypeNode, _base_nodes.OperatorNode, _base_nodes.Statement
+):
+ """Class representing an :class:`ast.AugAssign` node.
+
+ An :class:`AugAssign` is an assignment paired with an operator.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('variable += 1')
+ >>> node
+ <AugAssign l.1 at 0x7effe1db4d68>
+ """
+
+ _astroid_fields = ("target", "value")
+ _other_fields = ("op",)
+
+ target: Name | Attribute | Subscript
+ """What is being assigned to."""
+
+ value: NodeNG
+ """The value being assigned to the variable."""
+
+ def __init__(
+ self,
+ op: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.op = op
+ """The operator that is being combined with the assignment.
+
+ This includes the equals sign.
+ """
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, target: Name | Attribute | Subscript, value: NodeNG) -> None:
+ self.target = target
+ self.value = value
+
+ assigned_stmts = protocols.assign_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def type_errors(
+ self, context: InferenceContext | None = None
+ ) -> list[util.BadBinaryOperationMessage]:
+ """Get a list of type errors which can occur during inference.
+
+ Each TypeError is represented by a :class:`BadBinaryOperationMessage` ,
+ which holds the original exception.
+
+ If any inferred result is uninferable, an empty list is returned.
+ """
+ bad = []
+ try:
+ for result in self._infer_augassign(context=context):
+ if result is util.Uninferable:
+ raise InferenceError
+ if isinstance(result, util.BadBinaryOperationMessage):
+ bad.append(result)
+ except InferenceError:
+ return []
+ return bad
+
+ def get_children(self):
+ yield self.target
+ yield self.value
+
+ def _get_yield_nodes_skip_functions(self):
+ """An AugAssign node can contain a Yield node in the value"""
+ yield from self.value._get_yield_nodes_skip_functions()
+ yield from super()._get_yield_nodes_skip_functions()
+
+ def _get_yield_nodes_skip_lambdas(self):
+ """An AugAssign node can contain a Yield node in the value"""
+ yield from self.value._get_yield_nodes_skip_lambdas()
+ yield from super()._get_yield_nodes_skip_lambdas()
+
+ def _infer_augassign(
+ self, context: InferenceContext | None = None
+ ) -> Generator[InferenceResult | util.BadBinaryOperationMessage]:
+ """Inference logic for augmented binary operations."""
+ context = context or InferenceContext()
+
+ rhs_context = context.clone()
+
+ lhs_iter = self.target.infer_lhs(context=context)
+ rhs_iter = self.value.infer(context=rhs_context)
+
+ for lhs, rhs in itertools.product(lhs_iter, rhs_iter):
+ if any(isinstance(value, util.UninferableBase) for value in (rhs, lhs)):
+ # Don't know how to process this.
+ yield util.Uninferable
+ return
+
+ try:
+ yield from self._infer_binary_operation(
+ left=lhs,
+ right=rhs,
+ binary_opnode=self,
+ context=context,
+ flow_factory=self._get_aug_flow,
+ )
+ except _NonDeducibleTypeHierarchy:
+ yield util.Uninferable
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self: nodes.AugAssign, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ return self._filter_operation_errors(
+ self._infer_augassign, context, util.BadBinaryOperationMessage
+ )
+
+
+class BinOp(_base_nodes.OperatorNode):
+ """Class representing an :class:`ast.BinOp` node.
+
+ A :class:`BinOp` node is an application of a binary operator.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('a + b')
+ >>> node
+ <BinOp l.1 at 0x7f23b2e8cfd0>
+ """
+
+ _astroid_fields = ("left", "right")
+ _other_fields = ("op",)
+
+ left: NodeNG
+ """What is being applied to the operator on the left side."""
+
+ right: NodeNG
+ """What is being applied to the operator on the right side."""
+
+ def __init__(
+ self,
+ op: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.op = op
+ """The operator."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, left: NodeNG, right: NodeNG) -> None:
+ self.left = left
+ self.right = right
+
+ def type_errors(
+ self, context: InferenceContext | None = None
+ ) -> list[util.BadBinaryOperationMessage]:
+ """Get a list of type errors which can occur during inference.
+
+ Each TypeError is represented by a :class:`BadBinaryOperationMessage`,
+ which holds the original exception.
+
+ If any inferred result is uninferable, an empty list is returned.
+ """
+ bad = []
+ try:
+ for result in self._infer_binop(context=context):
+ if result is util.Uninferable:
+ raise InferenceError
+ if isinstance(result, util.BadBinaryOperationMessage):
+ bad.append(result)
+ except InferenceError:
+ return []
+ return bad
+
+ def get_children(self):
+ yield self.left
+ yield self.right
+
+ def op_precedence(self):
+ return OP_PRECEDENCE[self.op]
+
+ def op_left_associative(self) -> bool:
+ # 2**3**4 == 2**(3**4)
+ return self.op != "**"
+
+ def _infer_binop(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ """Binary operation inference logic."""
+ left = self.left
+ right = self.right
+
+ # we use two separate contexts for evaluating lhs and rhs because
+ # 1. evaluating lhs may leave some undesired entries in context.path
+ # which may not let us infer right value of rhs
+ context = context or InferenceContext()
+ lhs_context = copy_context(context)
+ rhs_context = copy_context(context)
+ lhs_iter = left.infer(context=lhs_context)
+ rhs_iter = right.infer(context=rhs_context)
+ for lhs, rhs in itertools.product(lhs_iter, rhs_iter):
+ if any(isinstance(value, util.UninferableBase) for value in (rhs, lhs)):
+ # Don't know how to process this.
+ yield util.Uninferable
+ return
+
+ try:
+ yield from self._infer_binary_operation(
+ lhs, rhs, self, context, self._get_binop_flow
+ )
+ except _NonDeducibleTypeHierarchy:
+ yield util.Uninferable
+
+ @decorators.yes_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self: nodes.BinOp, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ return self._filter_operation_errors(
+ self._infer_binop, context, util.BadBinaryOperationMessage
+ )
+
+
+class BoolOp(NodeNG):
+ """Class representing an :class:`ast.BoolOp` node.
+
+ A :class:`BoolOp` is an application of a boolean operator.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('a and b')
+ >>> node
+ <BinOp l.1 at 0x7f23b2e71c50>
+ """
+
+ _astroid_fields = ("values",)
+ _other_fields = ("op",)
+
+ def __init__(
+ self,
+ op: str,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param op: The operator.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.op: str = op
+ """The operator."""
+
+ self.values: list[NodeNG] = []
+ """The values being applied to the operator."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, values: list[NodeNG] | None = None) -> None:
+ """Do some setup after initialisation.
+
+ :param values: The values being applied to the operator.
+ """
+ if values is not None:
+ self.values = values
+
+ def get_children(self):
+ yield from self.values
+
+ def op_precedence(self):
+ return OP_PRECEDENCE[self.op]
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self: nodes.BoolOp, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ """Infer a boolean operation (and / or / not).
+
+ The function will calculate the boolean operation
+ for all pairs generated through inference for each component
+ node.
+ """
+ values = self.values
+ if self.op == "or":
+ predicate = operator.truth
+ else:
+ predicate = operator.not_
+
+ try:
+ inferred_values = [value.infer(context=context) for value in values]
+ except InferenceError:
+ yield util.Uninferable
+ return None
+
+ for pair in itertools.product(*inferred_values):
+ if any(isinstance(item, util.UninferableBase) for item in pair):
+ # Can't infer the final result, just yield Uninferable.
+ yield util.Uninferable
+ continue
+
+ bool_values = [item.bool_value() for item in pair]
+ if any(isinstance(item, util.UninferableBase) for item in bool_values):
+ # Can't infer the final result, just yield Uninferable.
+ yield util.Uninferable
+ continue
+
+ # Since the boolean operations are short circuited operations,
+ # this code yields the first value for which the predicate is True
+ # and if no value respected the predicate, then the last value will
+ # be returned (or Uninferable if there was no last value).
+ # This is conforming to the semantics of `and` and `or`:
+ # 1 and 0 -> 1
+ # 0 and 1 -> 0
+ # 1 or 0 -> 1
+ # 0 or 1 -> 1
+ value = util.Uninferable
+ for value, bool_value in zip(pair, bool_values):
+ if predicate(bool_value):
+ yield value
+ break
+ else:
+ yield value
+
+ return InferenceErrorInfo(node=self, context=context)
+
+
+class Break(_base_nodes.NoChildrenNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.Break` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('break')
+ >>> node
+ <Break l.1 at 0x7f23b2e9e5c0>
+ """
+
+
+class Call(NodeNG):
+ """Class representing an :class:`ast.Call` node.
+
+ A :class:`Call` node is a call to a function, method, etc.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('function()')
+ >>> node
+ <Call l.1 at 0x7f23b2e71eb8>
+ """
+
+ _astroid_fields = ("func", "args", "keywords")
+
+ func: NodeNG
+ """What is being called."""
+
+ args: list[NodeNG]
+ """The positional arguments being given to the call."""
+
+ keywords: list[Keyword]
+ """The keyword arguments being given to the call."""
+
+ def postinit(
+ self, func: NodeNG, args: list[NodeNG], keywords: list[Keyword]
+ ) -> None:
+ self.func = func
+ self.args = args
+ self.keywords = keywords
+
+ @property
+ def starargs(self) -> list[Starred]:
+ """The positional arguments that unpack something."""
+ return [arg for arg in self.args if isinstance(arg, Starred)]
+
+ @property
+ def kwargs(self) -> list[Keyword]:
+ """The keyword arguments that unpack something."""
+ return [keyword for keyword in self.keywords if keyword.arg is None]
+
+ def get_children(self):
+ yield self.func
+
+ yield from self.args
+
+ yield from self.keywords
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo]:
+ """Infer a Call node by trying to guess what the function returns."""
+ callcontext = copy_context(context)
+ callcontext.boundnode = None
+ if context is not None:
+ callcontext.extra_context = self._populate_context_lookup(context.clone())
+
+ for callee in self.func.infer(context):
+ if isinstance(callee, util.UninferableBase):
+ yield callee
+ continue
+ try:
+ if hasattr(callee, "infer_call_result"):
+ callcontext.callcontext = CallContext(
+ args=self.args, keywords=self.keywords, callee=callee
+ )
+ yield from callee.infer_call_result(
+ caller=self, context=callcontext
+ )
+ except InferenceError:
+ continue
+ return InferenceErrorInfo(node=self, context=context)
+
+ def _populate_context_lookup(self, context: InferenceContext | None):
+ """Allows context to be saved for later for inference inside a function."""
+ context_lookup: dict[InferenceResult, InferenceContext] = {}
+ if context is None:
+ return context_lookup
+ for arg in self.args:
+ if isinstance(arg, Starred):
+ context_lookup[arg.value] = context
+ else:
+ context_lookup[arg] = context
+ keywords = self.keywords if self.keywords is not None else []
+ for keyword in keywords:
+ context_lookup[keyword.value] = context
+ return context_lookup
+
+
+COMPARE_OPS: dict[str, Callable[[Any, Any], bool]] = {
+ "==": operator.eq,
+ "!=": operator.ne,
+ "<": operator.lt,
+ "<=": operator.le,
+ ">": operator.gt,
+ ">=": operator.ge,
+ "in": lambda a, b: a in b,
+ "not in": lambda a, b: a not in b,
+}
+UNINFERABLE_OPS = {
+ "is",
+ "is not",
+}
+
+
+class Compare(NodeNG):
+ """Class representing an :class:`ast.Compare` node.
+
+ A :class:`Compare` node indicates a comparison.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('a <= b <= c')
+ >>> node
+ <Compare l.1 at 0x7f23b2e9e6d8>
+ >>> node.ops
+ [('<=', <Name.b l.1 at 0x7f23b2e9e2b0>), ('<=', <Name.c l.1 at 0x7f23b2e9e390>)]
+ """
+
+ _astroid_fields = ("left", "ops")
+
+ left: NodeNG
+ """The value at the left being applied to a comparison operator."""
+
+ ops: list[tuple[str, NodeNG]]
+ """The remainder of the operators and their relevant right hand value."""
+
+ def postinit(self, left: NodeNG, ops: list[tuple[str, NodeNG]]) -> None:
+ self.left = left
+ self.ops = ops
+
+ def get_children(self):
+ """Get the child nodes below this node.
+
+ Overridden to handle the tuple fields and skip returning the operator
+ strings.
+
+ :returns: The children.
+ :rtype: iterable(NodeNG)
+ """
+ yield self.left
+ for _, comparator in self.ops:
+ yield comparator # we don't want the 'op'
+
+ def last_child(self):
+ """An optimized version of list(get_children())[-1]
+
+ :returns: The last child.
+ :rtype: NodeNG
+ """
+ # XXX maybe if self.ops:
+ return self.ops[-1][1]
+ # return self.left
+
+ # TODO: move to util?
+ @staticmethod
+ def _to_literal(node: SuccessfulInferenceResult) -> Any:
+ # Can raise SyntaxError or ValueError from ast.literal_eval
+ # Can raise AttributeError from node.as_string() as not all nodes have a visitor
+ # Is this the stupidest idea or the simplest idea?
+ return ast.literal_eval(node.as_string())
+
+ def _do_compare(
+ self,
+ left_iter: Iterable[InferenceResult],
+ op: str,
+ right_iter: Iterable[InferenceResult],
+ ) -> bool | util.UninferableBase:
+ """
+ If all possible combinations are either True or False, return that:
+ >>> _do_compare([1, 2], '<=', [3, 4])
+ True
+ >>> _do_compare([1, 2], '==', [3, 4])
+ False
+
+ If any item is uninferable, or if some combinations are True and some
+ are False, return Uninferable:
+ >>> _do_compare([1, 3], '<=', [2, 4])
+ util.Uninferable
+ """
+ retval: bool | None = None
+ if op in UNINFERABLE_OPS:
+ return util.Uninferable
+ op_func = COMPARE_OPS[op]
+
+ for left, right in itertools.product(left_iter, right_iter):
+ if isinstance(left, util.UninferableBase) or isinstance(
+ right, util.UninferableBase
+ ):
+ return util.Uninferable
+
+ try:
+ left, right = self._to_literal(left), self._to_literal(right)
+ except (SyntaxError, ValueError, AttributeError):
+ return util.Uninferable
+
+ try:
+ expr = op_func(left, right)
+ except TypeError as exc:
+ raise AstroidTypeError from exc
+
+ if retval is None:
+ retval = expr
+ elif retval != expr:
+ return util.Uninferable
+ # (or both, but "True | False" is basically the same)
+
+ assert retval is not None
+ return retval # it was all the same value
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[nodes.Const | util.UninferableBase]:
+ """Chained comparison inference logic."""
+ retval: bool | util.UninferableBase = True
+
+ ops = self.ops
+ left_node = self.left
+ lhs = list(left_node.infer(context=context))
+ # should we break early if first element is uninferable?
+ for op, right_node in ops:
+ # eagerly evaluate rhs so that values can be re-used as lhs
+ rhs = list(right_node.infer(context=context))
+ try:
+ retval = self._do_compare(lhs, op, rhs)
+ except AstroidTypeError:
+ retval = util.Uninferable
+ break
+ if retval is not True:
+ break # short-circuit
+ lhs = rhs # continue
+ if retval is util.Uninferable:
+ yield retval # type: ignore[misc]
+ else:
+ yield Const(retval)
+
+
+class Comprehension(NodeNG):
+ """Class representing an :class:`ast.comprehension` node.
+
+ A :class:`Comprehension` indicates the loop inside any type of
+ comprehension including generator expressions.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('[x for x in some_values]')
+ >>> list(node.get_children())
+ [<Name.x l.1 at 0x7f23b2e352b0>, <Comprehension l.1 at 0x7f23b2e35320>]
+ >>> list(node.get_children())[1].as_string()
+ 'for x in some_values'
+ """
+
+ _astroid_fields = ("target", "iter", "ifs")
+ _other_fields = ("is_async",)
+
+ optional_assign = True
+ """Whether this node optionally assigns a variable."""
+
+ target: NodeNG
+ """What is assigned to by the comprehension."""
+
+ iter: NodeNG
+ """What is iterated over by the comprehension."""
+
+ ifs: list[NodeNG]
+ """The contents of any if statements that filter the comprehension."""
+
+ is_async: bool
+ """Whether this is an asynchronous comprehension or not."""
+
+ def postinit(
+ self,
+ target: NodeNG,
+ iter: NodeNG, # pylint: disable = redefined-builtin
+ ifs: list[NodeNG],
+ is_async: bool,
+ ) -> None:
+ self.target = target
+ self.iter = iter
+ self.ifs = ifs
+ self.is_async = is_async
+
+ assigned_stmts = protocols.for_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def assign_type(self):
+ """The type of assignment that this node performs.
+
+ :returns: The assignment type.
+ :rtype: NodeNG
+ """
+ return self
+
+ def _get_filtered_stmts(
+ self, lookup_node, node, stmts, mystmt: _base_nodes.Statement | None
+ ):
+ """method used in filter_stmts"""
+ if self is mystmt:
+ if isinstance(lookup_node, (Const, Name)):
+ return [lookup_node], True
+
+ elif self.statement() is mystmt:
+ # original node's statement is the assignment, only keeps
+ # current node (gen exp, list comp)
+
+ return [node], True
+
+ return stmts, False
+
+ def get_children(self):
+ yield self.target
+ yield self.iter
+
+ yield from self.ifs
+
+
+class Const(_base_nodes.NoChildrenNode, Instance):
+ """Class representing any constant including num, str, bool, None, bytes.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('(5, "This is a string.", True, None, b"bytes")')
+ >>> node
+ <Tuple.tuple l.1 at 0x7f23b2e358d0>
+ >>> list(node.get_children())
+ [<Const.int l.1 at 0x7f23b2e35940>,
+ <Const.str l.1 at 0x7f23b2e35978>,
+ <Const.bool l.1 at 0x7f23b2e359b0>,
+ <Const.NoneType l.1 at 0x7f23b2e359e8>,
+ <Const.bytes l.1 at 0x7f23b2e35a20>]
+ """
+
+ _other_fields = ("value", "kind")
+
+ def __init__(
+ self,
+ value: Any,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ kind: str | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param value: The value that the constant represents.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param kind: The string prefix. "u" for u-prefixed strings and ``None`` otherwise. Python 3.8+ only.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.value: Any = value
+ """The value that the constant represents."""
+
+ self.kind: str | None = kind # can be None
+ """"The string prefix. "u" for u-prefixed strings and ``None`` otherwise. Python 3.8+ only."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ Instance.__init__(self, None)
+
+ infer_unary_op = protocols.const_infer_unary_op
+ infer_binary_op = protocols.const_infer_binary_op
+
+ def __getattr__(self, name):
+ # This is needed because of Proxy's __getattr__ method.
+ # Calling object.__new__ on this class without calling
+ # __init__ would result in an infinite loop otherwise
+ # since __getattr__ is called when an attribute doesn't
+ # exist and self._proxied indirectly calls self.value
+ # and Proxy __getattr__ calls self.value
+ if name == "value":
+ raise AttributeError
+ return super().__getattr__(name)
+
+ def getitem(self, index, context: InferenceContext | None = None):
+ """Get an item from this node if subscriptable.
+
+ :param index: The node to use as a subscript index.
+ :type index: Const or Slice
+
+ :raises AstroidTypeError: When the given index cannot be used as a
+ subscript index, or if this node is not subscriptable.
+ """
+ if isinstance(index, Const):
+ index_value = index.value
+ elif isinstance(index, Slice):
+ index_value = _infer_slice(index, context=context)
+
+ else:
+ raise AstroidTypeError(
+ f"Could not use type {type(index)} as subscript index"
+ )
+
+ try:
+ if isinstance(self.value, (str, bytes)):
+ return Const(self.value[index_value])
+ except ValueError as exc:
+ raise AstroidValueError(
+ f"Could not index {self.value!r} with {index_value!r}"
+ ) from exc
+ except IndexError as exc:
+ raise AstroidIndexError(
+ message="Index {index!r} out of range",
+ node=self,
+ index=index,
+ context=context,
+ ) from exc
+ except TypeError as exc:
+ raise AstroidTypeError(
+ message="Type error {error!r}", node=self, index=index, context=context
+ ) from exc
+
+ raise AstroidTypeError(f"{self!r} (value={self.value})")
+
+ def has_dynamic_getattr(self) -> bool:
+ """Check if the node has a custom __getattr__ or __getattribute__.
+
+ :returns: Whether the class has a custom __getattr__ or __getattribute__.
+ For a :class:`Const` this is always ``False``.
+ """
+ return False
+
+ def itered(self):
+ """An iterator over the elements this node contains.
+
+ :returns: The contents of this node.
+ :rtype: iterable(Const)
+
+ :raises TypeError: If this node does not represent something that is iterable.
+ """
+ if isinstance(self.value, str):
+ return [const_factory(elem) for elem in self.value]
+ raise TypeError(f"Cannot iterate over type {type(self.value)!r}")
+
+ def pytype(self) -> str:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ return self._proxied.qname()
+
+ def bool_value(self, context: InferenceContext | None = None):
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ :rtype: bool
+ """
+ return bool(self.value)
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator[Const]:
+ yield self
+
+
+class Continue(_base_nodes.NoChildrenNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.Continue` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('continue')
+ >>> node
+ <Continue l.1 at 0x7f23b2e35588>
+ """
+
+
+class Decorators(NodeNG):
+ """A node representing a list of decorators.
+
+ A :class:`Decorators` is the decorators that are applied to
+ a method or function.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ @property
+ def my_property(self):
+ return 3
+ ''')
+ >>> node
+ <FunctionDef.my_property l.2 at 0x7f23b2e35d30>
+ >>> list(node.get_children())[0]
+ <Decorators l.1 at 0x7f23b2e35d68>
+ """
+
+ _astroid_fields = ("nodes",)
+
+ nodes: list[NodeNG]
+ """The decorators that this node contains."""
+
+ def postinit(self, nodes: list[NodeNG]) -> None:
+ self.nodes = nodes
+
+ def scope(self) -> LocalsDictNodeNG:
+ """The first parent node defining a new scope.
+ These can be Module, FunctionDef, ClassDef, Lambda, or GeneratorExp nodes.
+
+ :returns: The first parent scope node.
+ """
+ # skip the function node to go directly to the upper level scope
+ if not self.parent:
+ raise ParentMissingError(target=self)
+ if not self.parent.parent:
+ raise ParentMissingError(target=self.parent)
+ return self.parent.parent.scope()
+
+ def get_children(self):
+ yield from self.nodes
+
+
+class DelAttr(_base_nodes.ParentAssignNode):
+ """Variation of :class:`ast.Delete` representing deletion of an attribute.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('del self.attr')
+ >>> node
+ <Delete l.1 at 0x7f23b2e35f60>
+ >>> list(node.get_children())[0]
+ <DelAttr.attr l.1 at 0x7f23b2e411d0>
+ """
+
+ _astroid_fields = ("expr",)
+ _other_fields = ("attrname",)
+
+ expr: NodeNG
+ """The name that this node represents."""
+
+ def __init__(
+ self,
+ attrname: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.attrname = attrname
+ """The name of the attribute that is being deleted."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, expr: NodeNG) -> None:
+ self.expr = expr
+
+ def get_children(self):
+ yield self.expr
+
+
+class Delete(_base_nodes.AssignTypeNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.Delete` node.
+
+ A :class:`Delete` is a ``del`` statement this is deleting something.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('del self.attr')
+ >>> node
+ <Delete l.1 at 0x7f23b2e35f60>
+ """
+
+ _astroid_fields = ("targets",)
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.targets: list[NodeNG] = []
+ """What is being deleted."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, targets: list[NodeNG]) -> None:
+ self.targets = targets
+
+ def get_children(self):
+ yield from self.targets
+
+
+class Dict(NodeNG, Instance):
+ """Class representing an :class:`ast.Dict` node.
+
+ A :class:`Dict` is a dictionary that is created with ``{}`` syntax.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('{1: "1"}')
+ >>> node
+ <Dict.dict l.1 at 0x7f23b2e35cc0>
+ """
+
+ _astroid_fields = ("items",)
+
+ def __init__(
+ self,
+ lineno: int | None,
+ col_offset: int | None,
+ parent: NodeNG | None,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.items: list[tuple[InferenceResult, InferenceResult]] = []
+ """The key-value pairs contained in the dictionary."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, items: list[tuple[InferenceResult, InferenceResult]]) -> None:
+ """Do some setup after initialisation.
+
+ :param items: The key-value pairs contained in the dictionary.
+ """
+ self.items = items
+
+ infer_unary_op = protocols.dict_infer_unary_op
+
+ def pytype(self) -> Literal["builtins.dict"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ return "builtins.dict"
+
+ def get_children(self):
+ """Get the key and value nodes below this node.
+
+ Children are returned in the order that they are defined in the source
+ code, key first then the value.
+
+ :returns: The children.
+ :rtype: iterable(NodeNG)
+ """
+ for key, value in self.items:
+ yield key
+ yield value
+
+ def last_child(self):
+ """An optimized version of list(get_children())[-1]
+
+ :returns: The last child, or None if no children exist.
+ :rtype: NodeNG or None
+ """
+ if self.items:
+ return self.items[-1][1]
+ return None
+
+ def itered(self):
+ """An iterator over the keys this node contains.
+
+ :returns: The keys of this node.
+ :rtype: iterable(NodeNG)
+ """
+ return [key for (key, _) in self.items]
+
+ def getitem(
+ self, index: Const | Slice, context: InferenceContext | None = None
+ ) -> NodeNG:
+ """Get an item from this node.
+
+ :param index: The node to use as a subscript index.
+
+ :raises AstroidTypeError: When the given index cannot be used as a
+ subscript index, or if this node is not subscriptable.
+ :raises AstroidIndexError: If the given index does not exist in the
+ dictionary.
+ """
+ for key, value in self.items:
+ # TODO(cpopa): no support for overriding yet, {1:2, **{1: 3}}.
+ if isinstance(key, DictUnpack):
+ inferred_value = util.safe_infer(value, context)
+ if not isinstance(inferred_value, Dict):
+ continue
+
+ try:
+ return inferred_value.getitem(index, context)
+ except (AstroidTypeError, AstroidIndexError):
+ continue
+
+ for inferredkey in key.infer(context):
+ if isinstance(inferredkey, util.UninferableBase):
+ continue
+ if isinstance(inferredkey, Const) and isinstance(index, Const):
+ if inferredkey.value == index.value:
+ return value
+
+ raise AstroidIndexError(index)
+
+ def bool_value(self, context: InferenceContext | None = None):
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ :rtype: bool
+ """
+ return bool(self.items)
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator[nodes.Dict]:
+ if not any(isinstance(k, DictUnpack) for k, _ in self.items):
+ yield self
+ else:
+ items = self._infer_map(context)
+ new_seq = type(self)(
+ lineno=self.lineno,
+ col_offset=self.col_offset,
+ parent=self.parent,
+ end_lineno=self.end_lineno,
+ end_col_offset=self.end_col_offset,
+ )
+ new_seq.postinit(list(items.items()))
+ yield new_seq
+
+ @staticmethod
+ def _update_with_replacement(
+ lhs_dict: dict[SuccessfulInferenceResult, SuccessfulInferenceResult],
+ rhs_dict: dict[SuccessfulInferenceResult, SuccessfulInferenceResult],
+ ) -> dict[SuccessfulInferenceResult, SuccessfulInferenceResult]:
+ """Delete nodes that equate to duplicate keys.
+
+ Since an astroid node doesn't 'equal' another node with the same value,
+ this function uses the as_string method to make sure duplicate keys
+ don't get through
+
+ Note that both the key and the value are astroid nodes
+
+ Fixes issue with DictUnpack causing duplicate keys
+ in inferred Dict items
+
+ :param lhs_dict: Dictionary to 'merge' nodes into
+ :param rhs_dict: Dictionary with nodes to pull from
+ :return : merged dictionary of nodes
+ """
+ combined_dict = itertools.chain(lhs_dict.items(), rhs_dict.items())
+ # Overwrite keys which have the same string values
+ string_map = {key.as_string(): (key, value) for key, value in combined_dict}
+ # Return to dictionary
+ return dict(string_map.values())
+
+ def _infer_map(
+ self, context: InferenceContext | None
+ ) -> dict[SuccessfulInferenceResult, SuccessfulInferenceResult]:
+ """Infer all values based on Dict.items."""
+ values: dict[SuccessfulInferenceResult, SuccessfulInferenceResult] = {}
+ for name, value in self.items:
+ if isinstance(name, DictUnpack):
+ double_starred = util.safe_infer(value, context)
+ if not double_starred:
+ raise InferenceError
+ if not isinstance(double_starred, Dict):
+ raise InferenceError(node=self, context=context)
+ unpack_items = double_starred._infer_map(context)
+ values = self._update_with_replacement(values, unpack_items)
+ else:
+ key = util.safe_infer(name, context=context)
+ safe_value = util.safe_infer(value, context=context)
+ if any(not elem for elem in (key, safe_value)):
+ raise InferenceError(node=self, context=context)
+ # safe_value is SuccessfulInferenceResult as bool(Uninferable) == False
+ values = self._update_with_replacement(values, {key: safe_value})
+ return values
+
+
+class Expr(_base_nodes.Statement):
+ """Class representing an :class:`ast.Expr` node.
+
+ An :class:`Expr` is any expression that does not have its value used or
+ stored.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('method()')
+ >>> node
+ <Call l.1 at 0x7f23b2e352b0>
+ >>> node.parent
+ <Expr l.1 at 0x7f23b2e35278>
+ """
+
+ _astroid_fields = ("value",)
+
+ value: NodeNG
+ """What the expression does."""
+
+ def postinit(self, value: NodeNG) -> None:
+ self.value = value
+
+ def get_children(self):
+ yield self.value
+
+ def _get_yield_nodes_skip_functions(self):
+ if not self.value.is_function:
+ yield from self.value._get_yield_nodes_skip_functions()
+
+ def _get_yield_nodes_skip_lambdas(self):
+ if not self.value.is_lambda:
+ yield from self.value._get_yield_nodes_skip_lambdas()
+
+
+class EmptyNode(_base_nodes.NoChildrenNode):
+ """Holds an arbitrary object in the :attr:`LocalsDictNodeNG.locals`."""
+
+ object = None
+
+ def __init__(
+ self,
+ lineno: None = None,
+ col_offset: None = None,
+ parent: None = None,
+ *,
+ end_lineno: None = None,
+ end_col_offset: None = None,
+ ) -> None:
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def has_underlying_object(self) -> bool:
+ return self.object is not None and self.object is not _EMPTY_OBJECT_MARKER
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ if not self.has_underlying_object():
+ yield util.Uninferable
+ else:
+ try:
+ yield from AstroidManager().infer_ast_from_something(
+ self.object, context=context
+ )
+ except AstroidError:
+ yield util.Uninferable
+
+
+class ExceptHandler(
+ _base_nodes.MultiLineBlockNode, _base_nodes.AssignTypeNode, _base_nodes.Statement
+):
+ """Class representing an :class:`ast.ExceptHandler`. node.
+
+ An :class:`ExceptHandler` is an ``except`` block on a try-except.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ try:
+ do_something()
+ except Exception as error:
+ print("Error!")
+ ''')
+ >>> node
+ <Try l.2 at 0x7f23b2e9d908>
+ >>> node.handlers
+ [<ExceptHandler l.4 at 0x7f23b2e9e860>]
+ """
+
+ _astroid_fields = ("type", "name", "body")
+ _multi_line_block_fields = ("body",)
+
+ type: NodeNG | None
+ """The types that the block handles."""
+
+ name: AssignName | None
+ """The name that the caught exception is assigned to."""
+
+ body: list[NodeNG]
+ """The contents of the block."""
+
+ assigned_stmts = protocols.excepthandler_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def postinit(
+ self,
+ type: NodeNG | None, # pylint: disable = redefined-builtin
+ name: AssignName | None,
+ body: list[NodeNG],
+ ) -> None:
+ self.type = type
+ self.name = name
+ self.body = body
+
+ def get_children(self):
+ if self.type is not None:
+ yield self.type
+
+ if self.name is not None:
+ yield self.name
+
+ yield from self.body
+
+ @cached_property
+ def blockstart_tolineno(self):
+ """The line on which the beginning of this block ends.
+
+ :type: int
+ """
+ if self.name:
+ return self.name.tolineno
+ if self.type:
+ return self.type.tolineno
+ return self.lineno
+
+ def catch(self, exceptions: list[str] | None) -> bool:
+ """Check if this node handles any of the given
+
+ :param exceptions: The names of the exceptions to check for.
+ """
+ if self.type is None or exceptions is None:
+ return True
+ return any(node.name in exceptions for node in self.type._get_name_nodes())
+
+
+class For(
+ _base_nodes.MultiLineWithElseBlockNode,
+ _base_nodes.AssignTypeNode,
+ _base_nodes.Statement,
+):
+ """Class representing an :class:`ast.For` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('for thing in things: print(thing)')
+ >>> node
+ <For l.1 at 0x7f23b2e8cf28>
+ """
+
+ _astroid_fields = ("target", "iter", "body", "orelse")
+ _other_other_fields = ("type_annotation",)
+ _multi_line_block_fields = ("body", "orelse")
+
+ optional_assign = True
+ """Whether this node optionally assigns a variable.
+
+ This is always ``True`` for :class:`For` nodes.
+ """
+
+ target: NodeNG
+ """What the loop assigns to."""
+
+ iter: NodeNG
+ """What the loop iterates over."""
+
+ body: list[NodeNG]
+ """The contents of the body of the loop."""
+
+ orelse: list[NodeNG]
+ """The contents of the ``else`` block of the loop."""
+
+ type_annotation: NodeNG | None
+ """If present, this will contain the type annotation passed by a type comment"""
+
+ def postinit(
+ self,
+ target: NodeNG,
+ iter: NodeNG, # pylint: disable = redefined-builtin
+ body: list[NodeNG],
+ orelse: list[NodeNG],
+ type_annotation: NodeNG | None,
+ ) -> None:
+ self.target = target
+ self.iter = iter
+ self.body = body
+ self.orelse = orelse
+ self.type_annotation = type_annotation
+
+ assigned_stmts = protocols.for_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ @cached_property
+ def blockstart_tolineno(self):
+ """The line on which the beginning of this block ends.
+
+ :type: int
+ """
+ return self.iter.tolineno
+
+ def get_children(self):
+ yield self.target
+ yield self.iter
+
+ yield from self.body
+ yield from self.orelse
+
+
+class AsyncFor(For):
+ """Class representing an :class:`ast.AsyncFor` node.
+
+ An :class:`AsyncFor` is an asynchronous :class:`For` built with
+ the ``async`` keyword.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ async def func(things):
+ async for thing in things:
+ print(thing)
+ ''')
+ >>> node
+ <AsyncFunctionDef.func l.2 at 0x7f23b2e416d8>
+ >>> node.body[0]
+ <AsyncFor l.3 at 0x7f23b2e417b8>
+ """
+
+
+class Await(NodeNG):
+ """Class representing an :class:`ast.Await` node.
+
+ An :class:`Await` is the ``await`` keyword.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ async def func(things):
+ await other_func()
+ ''')
+ >>> node
+ <AsyncFunctionDef.func l.2 at 0x7f23b2e41748>
+ >>> node.body[0]
+ <Expr l.3 at 0x7f23b2e419e8>
+ >>> list(node.body[0].get_children())[0]
+ <Await l.3 at 0x7f23b2e41a20>
+ """
+
+ _astroid_fields = ("value",)
+
+ value: NodeNG
+ """What to wait for."""
+
+ def postinit(self, value: NodeNG) -> None:
+ self.value = value
+
+ def get_children(self):
+ yield self.value
+
+
+class ImportFrom(_base_nodes.ImportNode):
+ """Class representing an :class:`ast.ImportFrom` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('from my_package import my_module')
+ >>> node
+ <ImportFrom l.1 at 0x7f23b2e415c0>
+ """
+
+ _other_fields = ("modname", "names", "level")
+
+ def __init__(
+ self,
+ fromname: str | None,
+ names: list[tuple[str, str | None]],
+ level: int | None = 0,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param fromname: The module that is being imported from.
+
+ :param names: What is being imported from the module.
+
+ :param level: The level of relative import.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.modname: str | None = fromname # can be None
+ """The module that is being imported from.
+
+ This is ``None`` for relative imports.
+ """
+
+ self.names: list[tuple[str, str | None]] = names
+ """What is being imported from the module.
+
+ Each entry is a :class:`tuple` of the name being imported,
+ and the alias that the name is assigned to (if any).
+ """
+
+ # TODO When is 'level' None?
+ self.level: int | None = level # can be None
+ """The level of relative import.
+
+ Essentially this is the number of dots in the import.
+ This is always 0 for absolute imports.
+ """
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self,
+ context: InferenceContext | None = None,
+ asname: bool = True,
+ **kwargs: Any,
+ ) -> Generator[InferenceResult]:
+ """Infer a ImportFrom node: return the imported module/object."""
+ context = context or InferenceContext()
+ name = context.lookupname
+ if name is None:
+ raise InferenceError(node=self, context=context)
+ if asname:
+ try:
+ name = self.real_name(name)
+ except AttributeInferenceError as exc:
+ # See https://github.com/pylint-dev/pylint/issues/4692
+ raise InferenceError(node=self, context=context) from exc
+ try:
+ module = self.do_import_module()
+ except AstroidBuildingError as exc:
+ raise InferenceError(node=self, context=context) from exc
+
+ try:
+ context = copy_context(context)
+ context.lookupname = name
+ stmts = module.getattr(name, ignore_locals=module is self.root())
+ return _infer_stmts(stmts, context)
+ except AttributeInferenceError as error:
+ raise InferenceError(
+ str(error), target=self, attribute=name, context=context
+ ) from error
+
+
+class Attribute(NodeNG):
+ """Class representing an :class:`ast.Attribute` node."""
+
+ expr: NodeNG
+
+ _astroid_fields = ("expr",)
+ _other_fields = ("attrname",)
+
+ def __init__(
+ self,
+ attrname: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.attrname = attrname
+ """The name of the attribute."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, expr: NodeNG) -> None:
+ self.expr = expr
+
+ def get_children(self):
+ yield self.expr
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo]:
+ return _infer_attribute(self, context, **kwargs)
+
+
+class Global(_base_nodes.NoChildrenNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.Global` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('global a_global')
+ >>> node
+ <Global l.1 at 0x7f23b2e9de10>
+ """
+
+ _other_fields = ("names",)
+
+ def __init__(
+ self,
+ names: list[str],
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param names: The names being declared as global.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.names: list[str] = names
+ """The names being declared as global."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def _infer_name(self, frame, name):
+ return name
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ if context is None or context.lookupname is None:
+ raise InferenceError(node=self, context=context)
+ try:
+ # pylint: disable-next=no-member
+ return _infer_stmts(self.root().getattr(context.lookupname), context)
+ except AttributeInferenceError as error:
+ raise InferenceError(
+ str(error), target=self, attribute=context.lookupname, context=context
+ ) from error
+
+
+class If(_base_nodes.MultiLineWithElseBlockNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.If` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('if condition: print(True)')
+ >>> node
+ <If l.1 at 0x7f23b2e9dd30>
+ """
+
+ _astroid_fields = ("test", "body", "orelse")
+ _multi_line_block_fields = ("body", "orelse")
+
+ test: NodeNG
+ """The condition that the statement tests."""
+
+ body: list[NodeNG]
+ """The contents of the block."""
+
+ orelse: list[NodeNG]
+ """The contents of the ``else`` block."""
+
+ def postinit(self, test: NodeNG, body: list[NodeNG], orelse: list[NodeNG]) -> None:
+ self.test = test
+ self.body = body
+ self.orelse = orelse
+
+ @cached_property
+ def blockstart_tolineno(self):
+ """The line on which the beginning of this block ends.
+
+ :type: int
+ """
+ return self.test.tolineno
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from the given line number to where this node ends.
+
+ :param lineno: The line number to start the range at.
+
+ :returns: The range of line numbers that this node belongs to,
+ starting at the given line number.
+ """
+ if lineno == self.body[0].fromlineno:
+ return lineno, lineno
+ if lineno <= self.body[-1].tolineno:
+ return lineno, self.body[-1].tolineno
+ return self._elsed_block_range(lineno, self.orelse, self.body[0].fromlineno - 1)
+
+ def get_children(self):
+ yield self.test
+
+ yield from self.body
+ yield from self.orelse
+
+ def has_elif_block(self):
+ return len(self.orelse) == 1 and isinstance(self.orelse[0], If)
+
+ def _get_yield_nodes_skip_functions(self):
+ """An If node can contain a Yield node in the test"""
+ yield from self.test._get_yield_nodes_skip_functions()
+ yield from super()._get_yield_nodes_skip_functions()
+
+ def _get_yield_nodes_skip_lambdas(self):
+ """An If node can contain a Yield node in the test"""
+ yield from self.test._get_yield_nodes_skip_lambdas()
+ yield from super()._get_yield_nodes_skip_lambdas()
+
+
+class IfExp(NodeNG):
+ """Class representing an :class:`ast.IfExp` node.
+ >>> import astroid
+ >>> node = astroid.extract_node('value if condition else other')
+ >>> node
+ <IfExp l.1 at 0x7f23b2e9dbe0>
+ """
+
+ _astroid_fields = ("test", "body", "orelse")
+
+ test: NodeNG
+ """The condition that the statement tests."""
+
+ body: NodeNG
+ """The contents of the block."""
+
+ orelse: NodeNG
+ """The contents of the ``else`` block."""
+
+ def postinit(self, test: NodeNG, body: NodeNG, orelse: NodeNG) -> None:
+ self.test = test
+ self.body = body
+ self.orelse = orelse
+
+ def get_children(self):
+ yield self.test
+ yield self.body
+ yield self.orelse
+
+ def op_left_associative(self) -> Literal[False]:
+ # `1 if True else 2 if False else 3` is parsed as
+ # `1 if True else (2 if False else 3)`
+ return False
+
+ @decorators.raise_if_nothing_inferred
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ """Support IfExp inference.
+
+ If we can't infer the truthiness of the condition, we default
+ to inferring both branches. Otherwise, we infer either branch
+ depending on the condition.
+ """
+ both_branches = False
+ # We use two separate contexts for evaluating lhs and rhs because
+ # evaluating lhs may leave some undesired entries in context.path
+ # which may not let us infer right value of rhs.
+
+ context = context or InferenceContext()
+ lhs_context = copy_context(context)
+ rhs_context = copy_context(context)
+ try:
+ test = next(self.test.infer(context=context.clone()))
+ except (InferenceError, StopIteration):
+ both_branches = True
+ else:
+ if not isinstance(test, util.UninferableBase):
+ if test.bool_value():
+ yield from self.body.infer(context=lhs_context)
+ else:
+ yield from self.orelse.infer(context=rhs_context)
+ else:
+ both_branches = True
+ if both_branches:
+ yield from self.body.infer(context=lhs_context)
+ yield from self.orelse.infer(context=rhs_context)
+
+
+class Import(_base_nodes.ImportNode):
+ """Class representing an :class:`ast.Import` node.
+ >>> import astroid
+ >>> node = astroid.extract_node('import astroid')
+ >>> node
+ <Import l.1 at 0x7f23b2e4e5c0>
+ """
+
+ _other_fields = ("names",)
+
+ def __init__(
+ self,
+ names: list[tuple[str, str | None]],
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param names: The names being imported.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.names: list[tuple[str, str | None]] = names
+ """The names being imported.
+
+ Each entry is a :class:`tuple` of the name being imported,
+ and the alias that the name is assigned to (if any).
+ """
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self,
+ context: InferenceContext | None = None,
+ asname: bool = True,
+ **kwargs: Any,
+ ) -> Generator[nodes.Module]:
+ """Infer an Import node: return the imported module/object."""
+ context = context or InferenceContext()
+ name = context.lookupname
+ if name is None:
+ raise InferenceError(node=self, context=context)
+
+ try:
+ if asname:
+ yield self.do_import_module(self.real_name(name))
+ else:
+ yield self.do_import_module(name)
+ except AstroidBuildingError as exc:
+ raise InferenceError(node=self, context=context) from exc
+
+
+class Keyword(NodeNG):
+ """Class representing an :class:`ast.keyword` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('function(a_kwarg=True)')
+ >>> node
+ <Call l.1 at 0x7f23b2e9e320>
+ >>> node.keywords
+ [<Keyword l.1 at 0x7f23b2e9e9b0>]
+ """
+
+ _astroid_fields = ("value",)
+ _other_fields = ("arg",)
+
+ value: NodeNG
+ """The value being assigned to the keyword argument."""
+
+ def __init__(
+ self,
+ arg: str | None,
+ lineno: int | None,
+ col_offset: int | None,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.arg = arg
+ """The argument being assigned to."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, value: NodeNG) -> None:
+ self.value = value
+
+ def get_children(self):
+ yield self.value
+
+
+class List(BaseContainer):
+ """Class representing an :class:`ast.List` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('[1, 2, 3]')
+ >>> node
+ <List.list l.1 at 0x7f23b2e9e128>
+ """
+
+ _other_fields = ("ctx",)
+
+ def __init__(
+ self,
+ ctx: Context | None = None,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param ctx: Whether the list is assigned to or loaded from.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.ctx: Context | None = ctx
+ """Whether the list is assigned to or loaded from."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ assigned_stmts = protocols.sequence_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ infer_unary_op = protocols.list_infer_unary_op
+ infer_binary_op = protocols.tl_infer_binary_op
+
+ def pytype(self) -> Literal["builtins.list"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ return "builtins.list"
+
+ def getitem(self, index, context: InferenceContext | None = None):
+ """Get an item from this node.
+
+ :param index: The node to use as a subscript index.
+ :type index: Const or Slice
+ """
+ return _container_getitem(self, self.elts, index, context=context)
+
+
+class Nonlocal(_base_nodes.NoChildrenNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.Nonlocal` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ def function():
+ nonlocal var
+ ''')
+ >>> node
+ <FunctionDef.function l.2 at 0x7f23b2e9e208>
+ >>> node.body[0]
+ <Nonlocal l.3 at 0x7f23b2e9e908>
+ """
+
+ _other_fields = ("names",)
+
+ def __init__(
+ self,
+ names: list[str],
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param names: The names being declared as not local.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.names: list[str] = names
+ """The names being declared as not local."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def _infer_name(self, frame, name):
+ return name
+
+
+class ParamSpec(_base_nodes.AssignTypeNode):
+ """Class representing a :class:`ast.ParamSpec` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('type Alias[**P] = Callable[P, int]')
+ >>> node.type_params[0]
+ <ParamSpec l.1 at 0x7f23b2e4e198>
+ """
+
+ _astroid_fields = ("name",)
+
+ name: AssignName
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int,
+ end_col_offset: int,
+ ) -> None:
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, *, name: AssignName) -> None:
+ self.name = name
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator[ParamSpec]:
+ yield self
+
+ assigned_stmts = protocols.generic_type_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+
+class Pass(_base_nodes.NoChildrenNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.Pass` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('pass')
+ >>> node
+ <Pass l.1 at 0x7f23b2e9e748>
+ """
+
+
+class Raise(_base_nodes.Statement):
+ """Class representing an :class:`ast.Raise` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('raise RuntimeError("Something bad happened!")')
+ >>> node
+ <Raise l.1 at 0x7f23b2e9e828>
+ """
+
+ _astroid_fields = ("exc", "cause")
+
+ exc: NodeNG | None
+ """What is being raised."""
+
+ cause: NodeNG | None
+ """The exception being used to raise this one."""
+
+ def postinit(
+ self,
+ exc: NodeNG | None,
+ cause: NodeNG | None,
+ ) -> None:
+ self.exc = exc
+ self.cause = cause
+
+ def raises_not_implemented(self) -> bool:
+ """Check if this node raises a :class:`NotImplementedError`.
+
+ :returns: Whether this node raises a :class:`NotImplementedError`.
+ """
+ if not self.exc:
+ return False
+ return any(
+ name.name == "NotImplementedError" for name in self.exc._get_name_nodes()
+ )
+
+ def get_children(self):
+ if self.exc is not None:
+ yield self.exc
+
+ if self.cause is not None:
+ yield self.cause
+
+
+class Return(_base_nodes.Statement):
+ """Class representing an :class:`ast.Return` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('return True')
+ >>> node
+ <Return l.1 at 0x7f23b8211908>
+ """
+
+ _astroid_fields = ("value",)
+
+ value: NodeNG | None
+ """The value being returned."""
+
+ def postinit(self, value: NodeNG | None) -> None:
+ self.value = value
+
+ def get_children(self):
+ if self.value is not None:
+ yield self.value
+
+ def is_tuple_return(self):
+ return isinstance(self.value, Tuple)
+
+ def _get_return_nodes_skip_functions(self):
+ yield self
+
+
+class Set(BaseContainer):
+ """Class representing an :class:`ast.Set` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('{1, 2, 3}')
+ >>> node
+ <Set.set l.1 at 0x7f23b2e71d68>
+ """
+
+ infer_unary_op = protocols.set_infer_unary_op
+
+ def pytype(self) -> Literal["builtins.set"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ return "builtins.set"
+
+
+class Slice(NodeNG):
+ """Class representing an :class:`ast.Slice` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('things[1:3]')
+ >>> node
+ <Subscript l.1 at 0x7f23b2e71f60>
+ >>> node.slice
+ <Slice l.1 at 0x7f23b2e71e80>
+ """
+
+ _astroid_fields = ("lower", "upper", "step")
+
+ lower: NodeNG | None
+ """The lower index in the slice."""
+
+ upper: NodeNG | None
+ """The upper index in the slice."""
+
+ step: NodeNG | None
+ """The step to take between indexes."""
+
+ def postinit(
+ self,
+ lower: NodeNG | None,
+ upper: NodeNG | None,
+ step: NodeNG | None,
+ ) -> None:
+ self.lower = lower
+ self.upper = upper
+ self.step = step
+
+ def _wrap_attribute(self, attr):
+ """Wrap the empty attributes of the Slice in a Const node."""
+ if not attr:
+ const = const_factory(attr)
+ const.parent = self
+ return const
+ return attr
+
+ @cached_property
+ def _proxied(self) -> nodes.ClassDef:
+ builtins = AstroidManager().builtins_module
+ return builtins.getattr("slice")[0]
+
+ def pytype(self) -> Literal["builtins.slice"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ return "builtins.slice"
+
+ def display_type(self) -> Literal["Slice"]:
+ """A human readable type of this node.
+
+ :returns: The type of this node.
+ """
+ return "Slice"
+
+ def igetattr(
+ self, attrname: str, context: InferenceContext | None = None
+ ) -> Iterator[SuccessfulInferenceResult]:
+ """Infer the possible values of the given attribute on the slice.
+
+ :param attrname: The name of the attribute to infer.
+
+ :returns: The inferred possible values.
+ """
+ if attrname == "start":
+ yield self._wrap_attribute(self.lower)
+ elif attrname == "stop":
+ yield self._wrap_attribute(self.upper)
+ elif attrname == "step":
+ yield self._wrap_attribute(self.step)
+ else:
+ yield from self.getattr(attrname, context=context)
+
+ def getattr(self, attrname, context: InferenceContext | None = None):
+ return self._proxied.getattr(attrname, context)
+
+ def get_children(self):
+ if self.lower is not None:
+ yield self.lower
+
+ if self.upper is not None:
+ yield self.upper
+
+ if self.step is not None:
+ yield self.step
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator[Slice]:
+ yield self
+
+
+class Starred(_base_nodes.ParentAssignNode):
+ """Class representing an :class:`ast.Starred` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('*args')
+ >>> node
+ <Starred l.1 at 0x7f23b2e41978>
+ """
+
+ _astroid_fields = ("value",)
+ _other_fields = ("ctx",)
+
+ value: NodeNG
+ """What is being unpacked."""
+
+ def __init__(
+ self,
+ ctx: Context,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.ctx = ctx
+ """Whether the starred item is assigned to or loaded from."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, value: NodeNG) -> None:
+ self.value = value
+
+ assigned_stmts = protocols.starred_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def get_children(self):
+ yield self.value
+
+
+class Subscript(NodeNG):
+ """Class representing an :class:`ast.Subscript` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('things[1:3]')
+ >>> node
+ <Subscript l.1 at 0x7f23b2e71f60>
+ """
+
+ _SUBSCRIPT_SENTINEL = object()
+ _astroid_fields = ("value", "slice")
+ _other_fields = ("ctx",)
+
+ value: NodeNG
+ """What is being indexed."""
+
+ slice: NodeNG
+ """The slice being used to lookup."""
+
+ def __init__(
+ self,
+ ctx: Context,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.ctx = ctx
+ """Whether the subscripted item is assigned to or loaded from."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ # pylint: disable=redefined-builtin; had to use the same name as builtin ast module.
+ def postinit(self, value: NodeNG, slice: NodeNG) -> None:
+ self.value = value
+ self.slice = slice
+
+ def get_children(self):
+ yield self.value
+ yield self.slice
+
+ def _infer_subscript(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ """Inference for subscripts.
+
+ We're understanding if the index is a Const
+ or a slice, passing the result of inference
+ to the value's `getitem` method, which should
+ handle each supported index type accordingly.
+ """
+ from astroid import helpers # pylint: disable=import-outside-toplevel
+
+ found_one = False
+ for value in self.value.infer(context):
+ if isinstance(value, util.UninferableBase):
+ yield util.Uninferable
+ return None
+ for index in self.slice.infer(context):
+ if isinstance(index, util.UninferableBase):
+ yield util.Uninferable
+ return None
+
+ # Try to deduce the index value.
+ index_value = self._SUBSCRIPT_SENTINEL
+ if value.__class__ == Instance:
+ index_value = index
+ elif index.__class__ == Instance:
+ instance_as_index = helpers.class_instance_as_index(index)
+ if instance_as_index:
+ index_value = instance_as_index
+ else:
+ index_value = index
+
+ if index_value is self._SUBSCRIPT_SENTINEL:
+ raise InferenceError(node=self, context=context)
+
+ try:
+ assigned = value.getitem(index_value, context)
+ except (
+ AstroidTypeError,
+ AstroidIndexError,
+ AstroidValueError,
+ AttributeInferenceError,
+ AttributeError,
+ ) as exc:
+ raise InferenceError(node=self, context=context) from exc
+
+ # Prevent inferring if the inferred subscript
+ # is the same as the original subscripted object.
+ if self is assigned or isinstance(assigned, util.UninferableBase):
+ yield util.Uninferable
+ return None
+ yield from assigned.infer(context)
+ found_one = True
+
+ if found_one:
+ return InferenceErrorInfo(node=self, context=context)
+ return None
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(self, context: InferenceContext | None = None, **kwargs: Any):
+ return self._infer_subscript(context, **kwargs)
+
+ @decorators.raise_if_nothing_inferred
+ def infer_lhs(self, context: InferenceContext | None = None, **kwargs: Any):
+ return self._infer_subscript(context, **kwargs)
+
+
+class Try(_base_nodes.MultiLineWithElseBlockNode, _base_nodes.Statement):
+ """Class representing a :class:`ast.Try` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ try:
+ do_something()
+ except Exception as error:
+ print("Error!")
+ finally:
+ print("Cleanup!")
+ ''')
+ >>> node
+ <Try l.2 at 0x7f23b2e41d68>
+ """
+
+ _astroid_fields = ("body", "handlers", "orelse", "finalbody")
+ _multi_line_block_fields = ("body", "handlers", "orelse", "finalbody")
+
+ def __init__(
+ self,
+ *,
+ lineno: int,
+ col_offset: int,
+ end_lineno: int,
+ end_col_offset: int,
+ parent: NodeNG,
+ ) -> None:
+ """
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.body: list[NodeNG] = []
+ """The contents of the block to catch exceptions from."""
+
+ self.handlers: list[ExceptHandler] = []
+ """The exception handlers."""
+
+ self.orelse: list[NodeNG] = []
+ """The contents of the ``else`` block."""
+
+ self.finalbody: list[NodeNG] = []
+ """The contents of the ``finally`` block."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ body: list[NodeNG],
+ handlers: list[ExceptHandler],
+ orelse: list[NodeNG],
+ finalbody: list[NodeNG],
+ ) -> None:
+ """Do some setup after initialisation.
+
+ :param body: The contents of the block to catch exceptions from.
+
+ :param handlers: The exception handlers.
+
+ :param orelse: The contents of the ``else`` block.
+
+ :param finalbody: The contents of the ``finally`` block.
+ """
+ self.body = body
+ self.handlers = handlers
+ self.orelse = orelse
+ self.finalbody = finalbody
+
+ def _infer_name(self, frame, name):
+ return name
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from a given line number to where this node ends."""
+ if lineno == self.fromlineno:
+ return lineno, lineno
+ if self.body and self.body[0].fromlineno <= lineno <= self.body[-1].tolineno:
+ # Inside try body - return from lineno till end of try body
+ return lineno, self.body[-1].tolineno
+ for exhandler in self.handlers:
+ if exhandler.type and lineno == exhandler.type.fromlineno:
+ return lineno, lineno
+ if exhandler.body[0].fromlineno <= lineno <= exhandler.body[-1].tolineno:
+ return lineno, exhandler.body[-1].tolineno
+ if self.orelse:
+ if self.orelse[0].fromlineno - 1 == lineno:
+ return lineno, lineno
+ if self.orelse[0].fromlineno <= lineno <= self.orelse[-1].tolineno:
+ return lineno, self.orelse[-1].tolineno
+ if self.finalbody:
+ if self.finalbody[0].fromlineno - 1 == lineno:
+ return lineno, lineno
+ if self.finalbody[0].fromlineno <= lineno <= self.finalbody[-1].tolineno:
+ return lineno, self.finalbody[-1].tolineno
+ return lineno, self.tolineno
+
+ def get_children(self):
+ yield from self.body
+ yield from self.handlers
+ yield from self.orelse
+ yield from self.finalbody
+
+
+class TryStar(_base_nodes.MultiLineWithElseBlockNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.TryStar` node."""
+
+ _astroid_fields = ("body", "handlers", "orelse", "finalbody")
+ _multi_line_block_fields = ("body", "handlers", "orelse", "finalbody")
+
+ def __init__(
+ self,
+ *,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ ) -> None:
+ """
+ :param lineno: The line that this node appears on in the source code.
+ :param col_offset: The column that this node appears on in the
+ source code.
+ :param parent: The parent node in the syntax tree.
+ :param end_lineno: The last line this node appears on in the source code.
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.body: list[NodeNG] = []
+ """The contents of the block to catch exceptions from."""
+
+ self.handlers: list[ExceptHandler] = []
+ """The exception handlers."""
+
+ self.orelse: list[NodeNG] = []
+ """The contents of the ``else`` block."""
+
+ self.finalbody: list[NodeNG] = []
+ """The contents of the ``finally`` block."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ body: list[NodeNG] | None = None,
+ handlers: list[ExceptHandler] | None = None,
+ orelse: list[NodeNG] | None = None,
+ finalbody: list[NodeNG] | None = None,
+ ) -> None:
+ """Do some setup after initialisation.
+ :param body: The contents of the block to catch exceptions from.
+ :param handlers: The exception handlers.
+ :param orelse: The contents of the ``else`` block.
+ :param finalbody: The contents of the ``finally`` block.
+ """
+ if body:
+ self.body = body
+ if handlers:
+ self.handlers = handlers
+ if orelse:
+ self.orelse = orelse
+ if finalbody:
+ self.finalbody = finalbody
+
+ def _infer_name(self, frame, name):
+ return name
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from a given line number to where this node ends."""
+ if lineno == self.fromlineno:
+ return lineno, lineno
+ if self.body and self.body[0].fromlineno <= lineno <= self.body[-1].tolineno:
+ # Inside try body - return from lineno till end of try body
+ return lineno, self.body[-1].tolineno
+ for exhandler in self.handlers:
+ if exhandler.type and lineno == exhandler.type.fromlineno:
+ return lineno, lineno
+ if exhandler.body[0].fromlineno <= lineno <= exhandler.body[-1].tolineno:
+ return lineno, exhandler.body[-1].tolineno
+ if self.orelse:
+ if self.orelse[0].fromlineno - 1 == lineno:
+ return lineno, lineno
+ if self.orelse[0].fromlineno <= lineno <= self.orelse[-1].tolineno:
+ return lineno, self.orelse[-1].tolineno
+ if self.finalbody:
+ if self.finalbody[0].fromlineno - 1 == lineno:
+ return lineno, lineno
+ if self.finalbody[0].fromlineno <= lineno <= self.finalbody[-1].tolineno:
+ return lineno, self.finalbody[-1].tolineno
+ return lineno, self.tolineno
+
+ def get_children(self):
+ yield from self.body
+ yield from self.handlers
+ yield from self.orelse
+ yield from self.finalbody
+
+
+class Tuple(BaseContainer):
+ """Class representing an :class:`ast.Tuple` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('(1, 2, 3)')
+ >>> node
+ <Tuple.tuple l.1 at 0x7f23b2e41780>
+ """
+
+ _other_fields = ("ctx",)
+
+ def __init__(
+ self,
+ ctx: Context | None = None,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param ctx: Whether the tuple is assigned to or loaded from.
+
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.ctx: Context | None = ctx
+ """Whether the tuple is assigned to or loaded from."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ assigned_stmts = protocols.sequence_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ infer_unary_op = protocols.tuple_infer_unary_op
+ infer_binary_op = protocols.tl_infer_binary_op
+
+ def pytype(self) -> Literal["builtins.tuple"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ return "builtins.tuple"
+
+ def getitem(self, index, context: InferenceContext | None = None):
+ """Get an item from this node.
+
+ :param index: The node to use as a subscript index.
+ :type index: Const or Slice
+ """
+ return _container_getitem(self, self.elts, index, context=context)
+
+
+class TypeAlias(_base_nodes.AssignTypeNode, _base_nodes.Statement):
+ """Class representing a :class:`ast.TypeAlias` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('type Point = tuple[float, float]')
+ >>> node
+ <TypeAlias l.1 at 0x7f23b2e4e198>
+ """
+
+ _astroid_fields = ("name", "type_params", "value")
+
+ name: AssignName
+ type_params: list[TypeVar | ParamSpec | TypeVarTuple]
+ value: NodeNG
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int,
+ end_col_offset: int,
+ ) -> None:
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ name: AssignName,
+ type_params: list[TypeVar | ParamSpec | TypeVarTuple],
+ value: NodeNG,
+ ) -> None:
+ self.name = name
+ self.type_params = type_params
+ self.value = value
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator[TypeAlias]:
+ yield self
+
+ assigned_stmts: ClassVar[
+ Callable[
+ [
+ TypeAlias,
+ AssignName,
+ InferenceContext | None,
+ None,
+ ],
+ Generator[NodeNG],
+ ]
+ ] = protocols.assign_assigned_stmts
+
+
+class TypeVar(_base_nodes.AssignTypeNode):
+ """Class representing a :class:`ast.TypeVar` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('type Point[T] = tuple[float, float]')
+ >>> node.type_params[0]
+ <TypeVar l.1 at 0x7f23b2e4e198>
+ """
+
+ _astroid_fields = ("name", "bound")
+
+ name: AssignName
+ bound: NodeNG | None
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int,
+ end_col_offset: int,
+ ) -> None:
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, *, name: AssignName, bound: NodeNG | None) -> None:
+ self.name = name
+ self.bound = bound
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator[TypeVar]:
+ yield self
+
+ assigned_stmts = protocols.generic_type_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+
+class TypeVarTuple(_base_nodes.AssignTypeNode):
+ """Class representing a :class:`ast.TypeVarTuple` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('type Alias[*Ts] = tuple[*Ts]')
+ >>> node.type_params[0]
+ <TypeVarTuple l.1 at 0x7f23b2e4e198>
+ """
+
+ _astroid_fields = ("name",)
+
+ name: AssignName
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int,
+ end_col_offset: int,
+ ) -> None:
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, *, name: AssignName) -> None:
+ self.name = name
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Iterator[TypeVarTuple]:
+ yield self
+
+ assigned_stmts = protocols.generic_type_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+
+UNARY_OP_METHOD = {
+ "+": "__pos__",
+ "-": "__neg__",
+ "~": "__invert__",
+ "not": None, # XXX not '__nonzero__'
+}
+
+
+class UnaryOp(_base_nodes.OperatorNode):
+ """Class representing an :class:`ast.UnaryOp` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('-5')
+ >>> node
+ <UnaryOp l.1 at 0x7f23b2e4e198>
+ """
+
+ _astroid_fields = ("operand",)
+ _other_fields = ("op",)
+
+ operand: NodeNG
+ """What the unary operator is applied to."""
+
+ def __init__(
+ self,
+ op: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.op = op
+ """The operator."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, operand: NodeNG) -> None:
+ self.operand = operand
+
+ def type_errors(
+ self, context: InferenceContext | None = None
+ ) -> list[util.BadUnaryOperationMessage]:
+ """Get a list of type errors which can occur during inference.
+
+ Each TypeError is represented by a :class:`BadUnaryOperationMessage`,
+ which holds the original exception.
+
+ If any inferred result is uninferable, an empty list is returned.
+ """
+ bad = []
+ try:
+ for result in self._infer_unaryop(context=context):
+ if result is util.Uninferable:
+ raise InferenceError
+ if isinstance(result, util.BadUnaryOperationMessage):
+ bad.append(result)
+ except InferenceError:
+ return []
+ return bad
+
+ def get_children(self):
+ yield self.operand
+
+ def op_precedence(self):
+ if self.op == "not":
+ return OP_PRECEDENCE[self.op]
+
+ return super().op_precedence()
+
+ def _infer_unaryop(
+ self: nodes.UnaryOp, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[
+ InferenceResult | util.BadUnaryOperationMessage, None, InferenceErrorInfo
+ ]:
+ """Infer what an UnaryOp should return when evaluated."""
+ from astroid.nodes import ClassDef # pylint: disable=import-outside-toplevel
+
+ for operand in self.operand.infer(context):
+ try:
+ yield operand.infer_unary_op(self.op)
+ except TypeError as exc:
+ # The operand doesn't support this operation.
+ yield util.BadUnaryOperationMessage(operand, self.op, exc)
+ except AttributeError as exc:
+ meth = UNARY_OP_METHOD[self.op]
+ if meth is None:
+ # `not node`. Determine node's boolean
+ # value and negate its result, unless it is
+ # Uninferable, which will be returned as is.
+ bool_value = operand.bool_value()
+ if not isinstance(bool_value, util.UninferableBase):
+ yield const_factory(not bool_value)
+ else:
+ yield util.Uninferable
+ else:
+ if not isinstance(operand, (Instance, ClassDef)):
+ # The operation was used on something which
+ # doesn't support it.
+ yield util.BadUnaryOperationMessage(operand, self.op, exc)
+ continue
+
+ try:
+ try:
+ methods = dunder_lookup.lookup(operand, meth)
+ except AttributeInferenceError:
+ yield util.BadUnaryOperationMessage(operand, self.op, exc)
+ continue
+
+ meth = methods[0]
+ inferred = next(meth.infer(context=context), None)
+ if (
+ isinstance(inferred, util.UninferableBase)
+ or not inferred.callable()
+ ):
+ continue
+
+ context = copy_context(context)
+ context.boundnode = operand
+ context.callcontext = CallContext(args=[], callee=inferred)
+
+ call_results = inferred.infer_call_result(self, context=context)
+ result = next(call_results, None)
+ if result is None:
+ # Failed to infer, return the same type.
+ yield operand
+ else:
+ yield result
+ except AttributeInferenceError as inner_exc:
+ # The unary operation special method was not found.
+ yield util.BadUnaryOperationMessage(operand, self.op, inner_exc)
+ except InferenceError:
+ yield util.Uninferable
+
+ @decorators.raise_if_nothing_inferred
+ @decorators.path_wrapper
+ def _infer(
+ self: nodes.UnaryOp, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo]:
+ """Infer what an UnaryOp should return when evaluated."""
+ yield from self._filter_operation_errors(
+ self._infer_unaryop, context, util.BadUnaryOperationMessage
+ )
+ return InferenceErrorInfo(node=self, context=context)
+
+
+class While(_base_nodes.MultiLineWithElseBlockNode, _base_nodes.Statement):
+ """Class representing an :class:`ast.While` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ while condition():
+ print("True")
+ ''')
+ >>> node
+ <While l.2 at 0x7f23b2e4e390>
+ """
+
+ _astroid_fields = ("test", "body", "orelse")
+ _multi_line_block_fields = ("body", "orelse")
+
+ test: NodeNG
+ """The condition that the loop tests."""
+
+ body: list[NodeNG]
+ """The contents of the loop."""
+
+ orelse: list[NodeNG]
+ """The contents of the ``else`` block."""
+
+ def postinit(
+ self,
+ test: NodeNG,
+ body: list[NodeNG],
+ orelse: list[NodeNG],
+ ) -> None:
+ self.test = test
+ self.body = body
+ self.orelse = orelse
+
+ @cached_property
+ def blockstart_tolineno(self):
+ """The line on which the beginning of this block ends.
+
+ :type: int
+ """
+ return self.test.tolineno
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from the given line number to where this node ends.
+
+ :param lineno: The line number to start the range at.
+
+ :returns: The range of line numbers that this node belongs to,
+ starting at the given line number.
+ """
+ return self._elsed_block_range(lineno, self.orelse)
+
+ def get_children(self):
+ yield self.test
+
+ yield from self.body
+ yield from self.orelse
+
+ def _get_yield_nodes_skip_functions(self):
+ """A While node can contain a Yield node in the test"""
+ yield from self.test._get_yield_nodes_skip_functions()
+ yield from super()._get_yield_nodes_skip_functions()
+
+ def _get_yield_nodes_skip_lambdas(self):
+ """A While node can contain a Yield node in the test"""
+ yield from self.test._get_yield_nodes_skip_lambdas()
+ yield from super()._get_yield_nodes_skip_lambdas()
+
+
+class With(
+ _base_nodes.MultiLineWithElseBlockNode,
+ _base_nodes.AssignTypeNode,
+ _base_nodes.Statement,
+):
+ """Class representing an :class:`ast.With` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ with open(file_path) as file_:
+ print(file_.read())
+ ''')
+ >>> node
+ <With l.2 at 0x7f23b2e4e710>
+ """
+
+ _astroid_fields = ("items", "body")
+ _other_other_fields = ("type_annotation",)
+ _multi_line_block_fields = ("body",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.items: list[tuple[NodeNG, NodeNG | None]] = []
+ """The pairs of context managers and the names they are assigned to."""
+
+ self.body: list[NodeNG] = []
+ """The contents of the ``with`` block."""
+
+ self.type_annotation: NodeNG | None = None # can be None
+ """If present, this will contain the type annotation passed by a type comment"""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ items: list[tuple[NodeNG, NodeNG | None]] | None = None,
+ body: list[NodeNG] | None = None,
+ type_annotation: NodeNG | None = None,
+ ) -> None:
+ """Do some setup after initialisation.
+
+ :param items: The pairs of context managers and the names
+ they are assigned to.
+
+ :param body: The contents of the ``with`` block.
+ """
+ if items is not None:
+ self.items = items
+ if body is not None:
+ self.body = body
+ self.type_annotation = type_annotation
+
+ assigned_stmts = protocols.with_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ @cached_property
+ def blockstart_tolineno(self):
+ """The line on which the beginning of this block ends.
+
+ :type: int
+ """
+ return self.items[-1][0].tolineno
+
+ def get_children(self):
+ """Get the child nodes below this node.
+
+ :returns: The children.
+ :rtype: iterable(NodeNG)
+ """
+ for expr, var in self.items:
+ yield expr
+ if var:
+ yield var
+ yield from self.body
+
+
+class AsyncWith(With):
+ """Asynchronous ``with`` built with the ``async`` keyword."""
+
+
+class Yield(NodeNG):
+ """Class representing an :class:`ast.Yield` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('yield True')
+ >>> node
+ <Yield l.1 at 0x7f23b2e4e5f8>
+ """
+
+ _astroid_fields = ("value",)
+
+ value: NodeNG | None
+ """The value to yield."""
+
+ def postinit(self, value: NodeNG | None) -> None:
+ self.value = value
+
+ def get_children(self):
+ if self.value is not None:
+ yield self.value
+
+ def _get_yield_nodes_skip_functions(self):
+ yield self
+
+ def _get_yield_nodes_skip_lambdas(self):
+ yield self
+
+
+class YieldFrom(Yield): # TODO value is required, not optional
+ """Class representing an :class:`ast.YieldFrom` node."""
+
+
+class DictUnpack(_base_nodes.NoChildrenNode):
+ """Represents the unpacking of dicts into dicts using :pep:`448`."""
+
+
+class FormattedValue(NodeNG):
+ """Class representing an :class:`ast.FormattedValue` node.
+
+ Represents a :pep:`498` format string.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('f"Format {type_}"')
+ >>> node
+ <JoinedStr l.1 at 0x7f23b2e4ed30>
+ >>> node.values
+ [<Const.str l.1 at 0x7f23b2e4eda0>, <FormattedValue l.1 at 0x7f23b2e4edd8>]
+ """
+
+ _astroid_fields = ("value", "format_spec")
+ _other_fields = ("conversion",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.value: NodeNG
+ """The value to be formatted into the string."""
+
+ self.conversion: int
+ """The type of formatting to be applied to the value.
+
+ .. seealso::
+ :class:`ast.FormattedValue`
+ """
+
+ self.format_spec: JoinedStr | None = None
+ """The formatting to be applied to the value.
+
+ .. seealso::
+ :class:`ast.FormattedValue`
+ """
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ value: NodeNG,
+ conversion: int,
+ format_spec: JoinedStr | None = None,
+ ) -> None:
+ """Do some setup after initialisation.
+
+ :param value: The value to be formatted into the string.
+
+ :param conversion: The type of formatting to be applied to the value.
+
+ :param format_spec: The formatting to be applied to the value.
+ :type format_spec: JoinedStr or None
+ """
+ self.value = value
+ self.conversion = conversion
+ self.format_spec = format_spec
+
+ def get_children(self):
+ yield self.value
+
+ if self.format_spec is not None:
+ yield self.format_spec
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ format_specs = Const("") if self.format_spec is None else self.format_spec
+ uninferable_already_generated = False
+ for format_spec in format_specs.infer(context, **kwargs):
+ if not isinstance(format_spec, Const):
+ if not uninferable_already_generated:
+ yield util.Uninferable
+ uninferable_already_generated = True
+ continue
+ for value in self.value.infer(context, **kwargs):
+ value_to_format = value
+ if isinstance(value, Const):
+ value_to_format = value.value
+ try:
+ formatted = format(value_to_format, format_spec.value)
+ yield Const(
+ formatted,
+ lineno=self.lineno,
+ col_offset=self.col_offset,
+ end_lineno=self.end_lineno,
+ end_col_offset=self.end_col_offset,
+ )
+ continue
+ except (ValueError, TypeError):
+ # happens when format_spec.value is invalid
+ yield util.Uninferable
+ uninferable_already_generated = True
+ continue
+
+
+MISSING_VALUE = "{MISSING_VALUE}"
+
+
+class JoinedStr(NodeNG):
+ """Represents a list of string expressions to be joined.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('f"Format {type_}"')
+ >>> node
+ <JoinedStr l.1 at 0x7f23b2e4ed30>
+ """
+
+ _astroid_fields = ("values",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.values: list[NodeNG] = []
+ """The string expressions to be joined.
+
+ :type: list(FormattedValue or Const)
+ """
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, values: list[NodeNG] | None = None) -> None:
+ """Do some setup after initialisation.
+
+ :param value: The string expressions to be joined.
+
+ :type: list(FormattedValue or Const)
+ """
+ if values is not None:
+ self.values = values
+
+ def get_children(self):
+ yield from self.values
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ yield from self._infer_from_values(self.values, context)
+
+ @classmethod
+ def _infer_from_values(
+ cls, nodes: list[NodeNG], context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ if not nodes:
+ yield
+ return
+ if len(nodes) == 1:
+ yield from nodes[0]._infer(context, **kwargs)
+ return
+ uninferable_already_generated = False
+ for prefix in nodes[0]._infer(context, **kwargs):
+ for suffix in cls._infer_from_values(nodes[1:], context, **kwargs):
+ result = ""
+ for node in (prefix, suffix):
+ if isinstance(node, Const):
+ result += str(node.value)
+ continue
+ result += MISSING_VALUE
+ if MISSING_VALUE in result:
+ if not uninferable_already_generated:
+ uninferable_already_generated = True
+ yield util.Uninferable
+ else:
+ yield Const(result)
+
+
+class NamedExpr(_base_nodes.AssignTypeNode):
+ """Represents the assignment from the assignment expression
+
+ >>> import astroid
+ >>> module = astroid.parse('if a := 1: pass')
+ >>> module.body[0].test
+ <NamedExpr l.1 at 0x7f23b2e4ed30>
+ """
+
+ _astroid_fields = ("target", "value")
+
+ optional_assign = True
+ """Whether this node optionally assigns a variable.
+
+ Since NamedExpr are not always called they do not always assign."""
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """
+ :param lineno: The line that this node appears on in the source code.
+
+ :param col_offset: The column that this node appears on in the
+ source code.
+
+ :param parent: The parent node in the syntax tree.
+
+ :param end_lineno: The last line this node appears on in the source code.
+
+ :param end_col_offset: The end column this node appears on in the
+ source code. Note: This is after the last symbol.
+ """
+ self.target: NodeNG
+ """The assignment target
+
+ :type: Name
+ """
+
+ self.value: NodeNG
+ """The value that gets assigned in the expression"""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, target: NodeNG, value: NodeNG) -> None:
+ self.target = target
+ self.value = value
+
+ assigned_stmts = protocols.named_expr_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+ def frame(
+ self, *, future: Literal[None, True] = None
+ ) -> nodes.FunctionDef | nodes.Module | nodes.ClassDef | nodes.Lambda:
+ """The first parent frame node.
+
+ A frame node is a :class:`Module`, :class:`FunctionDef`,
+ or :class:`ClassDef`.
+
+ :returns: The first parent frame node.
+ """
+ if future is not None:
+ warnings.warn(
+ "The future arg will be removed in astroid 4.0.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ if not self.parent:
+ raise ParentMissingError(target=self)
+
+ # For certain parents NamedExpr evaluate to the scope of the parent
+ if isinstance(self.parent, (Arguments, Keyword, Comprehension)):
+ if not self.parent.parent:
+ raise ParentMissingError(target=self.parent)
+ if not self.parent.parent.parent:
+ raise ParentMissingError(target=self.parent.parent)
+ return self.parent.parent.parent.frame()
+
+ return self.parent.frame()
+
+ def scope(self) -> LocalsDictNodeNG:
+ """The first parent node defining a new scope.
+ These can be Module, FunctionDef, ClassDef, Lambda, or GeneratorExp nodes.
+
+ :returns: The first parent scope node.
+ """
+ if not self.parent:
+ raise ParentMissingError(target=self)
+
+ # For certain parents NamedExpr evaluate to the scope of the parent
+ if isinstance(self.parent, (Arguments, Keyword, Comprehension)):
+ if not self.parent.parent:
+ raise ParentMissingError(target=self.parent)
+ if not self.parent.parent.parent:
+ raise ParentMissingError(target=self.parent.parent)
+ return self.parent.parent.parent.scope()
+
+ return self.parent.scope()
+
+ def set_local(self, name: str, stmt: NodeNG) -> None:
+ """Define that the given name is declared in the given statement node.
+ NamedExpr's in Arguments, Keyword or Comprehension are evaluated in their
+ parent's parent scope. So we add to their frame's locals.
+
+ .. seealso:: :meth:`scope`
+
+ :param name: The name that is being defined.
+
+ :param stmt: The statement that defines the given name.
+ """
+ self.frame().set_local(name, stmt)
+
+
+class Unknown(_base_nodes.AssignTypeNode):
+ """This node represents a node in a constructed AST where
+ introspection is not possible. At the moment, it's only used in
+ the args attribute of FunctionDef nodes where function signature
+ introspection failed.
+ """
+
+ name = "Unknown"
+
+ def __init__(
+ self,
+ lineno: None = None,
+ col_offset: None = None,
+ parent: None = None,
+ *,
+ end_lineno: None = None,
+ end_col_offset: None = None,
+ ) -> None:
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def qname(self) -> Literal["Unknown"]:
+ return "Unknown"
+
+ def _infer(self, context: InferenceContext | None = None, **kwargs):
+ """Inference on an Unknown node immediately terminates."""
+ yield util.Uninferable
+
+
+class EvaluatedObject(NodeNG):
+ """Contains an object that has already been inferred
+
+ This class is useful to pre-evaluate a particular node,
+ with the resulting class acting as the non-evaluated node.
+ """
+
+ name = "EvaluatedObject"
+ _astroid_fields = ("original",)
+ _other_fields = ("value",)
+
+ def __init__(
+ self, original: SuccessfulInferenceResult, value: InferenceResult
+ ) -> None:
+ self.original: SuccessfulInferenceResult = original
+ """The original node that has already been evaluated"""
+
+ self.value: InferenceResult = value
+ """The inferred value"""
+
+ super().__init__(
+ lineno=self.original.lineno,
+ col_offset=self.original.col_offset,
+ parent=self.original.parent,
+ end_lineno=self.original.end_lineno,
+ end_col_offset=self.original.end_col_offset,
+ )
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[NodeNG | util.UninferableBase]:
+ yield self.value
+
+
+# Pattern matching #######################################################
+
+
+class Match(_base_nodes.Statement, _base_nodes.MultiLineBlockNode):
+ """Class representing a :class:`ast.Match` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case 200:
+ ...
+ case _:
+ ...
+ ''')
+ >>> node
+ <Match l.2 at 0x10c24e170>
+ """
+
+ _astroid_fields = ("subject", "cases")
+ _multi_line_block_fields = ("cases",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.subject: NodeNG
+ self.cases: list[MatchCase]
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ subject: NodeNG,
+ cases: list[MatchCase],
+ ) -> None:
+ self.subject = subject
+ self.cases = cases
+
+
+class Pattern(NodeNG):
+ """Base class for all Pattern nodes."""
+
+
+class MatchCase(_base_nodes.MultiLineBlockNode):
+ """Class representing a :class:`ast.match_case` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case 200:
+ ...
+ ''')
+ >>> node.cases[0]
+ <MatchCase l.3 at 0x10c24e590>
+ """
+
+ _astroid_fields = ("pattern", "guard", "body")
+ _multi_line_block_fields = ("body",)
+
+ lineno: None
+ col_offset: None
+ end_lineno: None
+ end_col_offset: None
+
+ def __init__(self, *, parent: NodeNG | None = None) -> None:
+ self.pattern: Pattern
+ self.guard: NodeNG | None
+ self.body: list[NodeNG]
+ super().__init__(
+ parent=parent,
+ lineno=None,
+ col_offset=None,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+
+ def postinit(
+ self,
+ *,
+ pattern: Pattern,
+ guard: NodeNG | None,
+ body: list[NodeNG],
+ ) -> None:
+ self.pattern = pattern
+ self.guard = guard
+ self.body = body
+
+
+class MatchValue(Pattern):
+ """Class representing a :class:`ast.MatchValue` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case 200:
+ ...
+ ''')
+ >>> node.cases[0].pattern
+ <MatchValue l.3 at 0x10c24e200>
+ """
+
+ _astroid_fields = ("value",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.value: NodeNG
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, *, value: NodeNG) -> None:
+ self.value = value
+
+
+class MatchSingleton(Pattern):
+ """Class representing a :class:`ast.MatchSingleton` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case True:
+ ...
+ case False:
+ ...
+ case None:
+ ...
+ ''')
+ >>> node.cases[0].pattern
+ <MatchSingleton l.3 at 0x10c2282e0>
+ >>> node.cases[1].pattern
+ <MatchSingleton l.5 at 0x10c228af0>
+ >>> node.cases[2].pattern
+ <MatchSingleton l.7 at 0x10c229f90>
+ """
+
+ _other_fields = ("value",)
+
+ def __init__(
+ self,
+ *,
+ value: Literal[True, False, None],
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ ) -> None:
+ self.value = value
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+
+class MatchSequence(Pattern):
+ """Class representing a :class:`ast.MatchSequence` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case [1, 2]:
+ ...
+ case (1, 2, *_):
+ ...
+ ''')
+ >>> node.cases[0].pattern
+ <MatchSequence l.3 at 0x10ca80d00>
+ >>> node.cases[1].pattern
+ <MatchSequence l.5 at 0x10ca80b20>
+ """
+
+ _astroid_fields = ("patterns",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.patterns: list[Pattern]
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, *, patterns: list[Pattern]) -> None:
+ self.patterns = patterns
+
+
+class MatchMapping(_base_nodes.AssignTypeNode, Pattern):
+ """Class representing a :class:`ast.MatchMapping` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case {1: "Hello", 2: "World", 3: _, **rest}:
+ ...
+ ''')
+ >>> node.cases[0].pattern
+ <MatchMapping l.3 at 0x10c8a8850>
+ """
+
+ _astroid_fields = ("keys", "patterns", "rest")
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.keys: list[NodeNG]
+ self.patterns: list[Pattern]
+ self.rest: AssignName | None
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ keys: list[NodeNG],
+ patterns: list[Pattern],
+ rest: AssignName | None,
+ ) -> None:
+ self.keys = keys
+ self.patterns = patterns
+ self.rest = rest
+
+ assigned_stmts = protocols.match_mapping_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+
+class MatchClass(Pattern):
+ """Class representing a :class:`ast.MatchClass` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case Point2D(0, 0):
+ ...
+ case Point3D(x=0, y=0, z=0):
+ ...
+ ''')
+ >>> node.cases[0].pattern
+ <MatchClass l.3 at 0x10ca83940>
+ >>> node.cases[1].pattern
+ <MatchClass l.5 at 0x10ca80880>
+ """
+
+ _astroid_fields = ("cls", "patterns", "kwd_patterns")
+ _other_fields = ("kwd_attrs",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.cls: NodeNG
+ self.patterns: list[Pattern]
+ self.kwd_attrs: list[str]
+ self.kwd_patterns: list[Pattern]
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ cls: NodeNG,
+ patterns: list[Pattern],
+ kwd_attrs: list[str],
+ kwd_patterns: list[Pattern],
+ ) -> None:
+ self.cls = cls
+ self.patterns = patterns
+ self.kwd_attrs = kwd_attrs
+ self.kwd_patterns = kwd_patterns
+
+
+class MatchStar(_base_nodes.AssignTypeNode, Pattern):
+ """Class representing a :class:`ast.MatchStar` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case [1, *_]:
+ ...
+ ''')
+ >>> node.cases[0].pattern.patterns[1]
+ <MatchStar l.3 at 0x10ca809a0>
+ """
+
+ _astroid_fields = ("name",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.name: AssignName | None
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, *, name: AssignName | None) -> None:
+ self.name = name
+
+ assigned_stmts = protocols.match_star_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+
+class MatchAs(_base_nodes.AssignTypeNode, Pattern):
+ """Class representing a :class:`ast.MatchAs` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case [1, a]:
+ ...
+ case {'key': b}:
+ ...
+ case Point2D(0, 0) as c:
+ ...
+ case d:
+ ...
+ ''')
+ >>> node.cases[0].pattern.patterns[1]
+ <MatchAs l.3 at 0x10d0b2da0>
+ >>> node.cases[1].pattern.patterns[0]
+ <MatchAs l.5 at 0x10d0b2920>
+ >>> node.cases[2].pattern
+ <MatchAs l.7 at 0x10d0b06a0>
+ >>> node.cases[3].pattern
+ <MatchAs l.9 at 0x10d09b880>
+ """
+
+ _astroid_fields = ("pattern", "name")
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.pattern: Pattern | None
+ self.name: AssignName | None
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self,
+ *,
+ pattern: Pattern | None,
+ name: AssignName | None,
+ ) -> None:
+ self.pattern = pattern
+ self.name = name
+
+ assigned_stmts = protocols.match_as_assigned_stmts
+ """Returns the assigned statement (non inferred) according to the assignment type.
+ See astroid/protocols.py for actual implementation.
+ """
+
+
+class MatchOr(Pattern):
+ """Class representing a :class:`ast.MatchOr` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ match x:
+ case 400 | 401 | 402:
+ ...
+ ''')
+ >>> node.cases[0].pattern
+ <MatchOr l.3 at 0x10d0b0b50>
+ """
+
+ _astroid_fields = ("patterns",)
+
+ def __init__(
+ self,
+ lineno: int | None = None,
+ col_offset: int | None = None,
+ parent: NodeNG | None = None,
+ *,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.patterns: list[Pattern]
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, *, patterns: list[Pattern]) -> None:
+ self.patterns = patterns
+
+
+# constants ##############################################################
+
+# The _proxied attribute of all container types (List, Tuple, etc.)
+# are set during bootstrapping by _astroid_bootstrapping().
+CONST_CLS: dict[type, type[NodeNG]] = {
+ list: List,
+ tuple: Tuple,
+ dict: Dict,
+ set: Set,
+ type(None): Const,
+ type(NotImplemented): Const,
+ type(...): Const,
+ bool: Const,
+ int: Const,
+ float: Const,
+ complex: Const,
+ str: Const,
+ bytes: Const,
+}
+
+
+def _create_basic_elements(
+ value: Iterable[Any], node: List | Set | Tuple
+) -> list[NodeNG]:
+ """Create a list of nodes to function as the elements of a new node."""
+ elements: list[NodeNG] = []
+ for element in value:
+ element_node = const_factory(element)
+ element_node.parent = node
+ elements.append(element_node)
+ return elements
+
+
+def _create_dict_items(
+ values: Mapping[Any, Any], node: Dict
+) -> list[tuple[SuccessfulInferenceResult, SuccessfulInferenceResult]]:
+ """Create a list of node pairs to function as the items of a new dict node."""
+ elements: list[tuple[SuccessfulInferenceResult, SuccessfulInferenceResult]] = []
+ for key, value in values.items():
+ key_node = const_factory(key)
+ key_node.parent = node
+ value_node = const_factory(value)
+ value_node.parent = node
+ elements.append((key_node, value_node))
+ return elements
+
+
+def const_factory(value: Any) -> ConstFactoryResult:
+ """Return an astroid node for a python value."""
+ assert not isinstance(value, NodeNG)
+
+ # This only handles instances of the CONST types. Any
+ # subclasses get inferred as EmptyNode.
+ # TODO: See if we should revisit these with the normal builder.
+ if value.__class__ not in CONST_CLS:
+ node = EmptyNode()
+ node.object = value
+ return node
+
+ instance: List | Set | Tuple | Dict
+ initializer_cls = CONST_CLS[value.__class__]
+ if issubclass(initializer_cls, (List, Set, Tuple)):
+ instance = initializer_cls(
+ lineno=None,
+ col_offset=None,
+ parent=None,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ instance.postinit(_create_basic_elements(value, instance))
+ return instance
+ if issubclass(initializer_cls, Dict):
+ instance = initializer_cls(
+ lineno=None,
+ col_offset=None,
+ parent=None,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ instance.postinit(_create_dict_items(value, instance))
+ return instance
+ return Const(value)
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/node_ng.py b/solutions/.venv/Lib/site-packages/astroid/nodes/node_ng.py
new file mode 100644
index 000000000..3a482f3cc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/node_ng.py
@@ -0,0 +1,785 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import pprint
+import sys
+import warnings
+from collections.abc import Generator, Iterator
+from functools import cached_property
+from functools import singledispatch as _singledispatch
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ ClassVar,
+ Literal,
+ TypeVar,
+ Union,
+ cast,
+ overload,
+)
+
+from astroid import util
+from astroid.context import InferenceContext
+from astroid.exceptions import (
+ AstroidError,
+ InferenceError,
+ ParentMissingError,
+ StatementMissing,
+ UseInferenceDefault,
+)
+from astroid.manager import AstroidManager
+from astroid.nodes.as_string import AsStringVisitor
+from astroid.nodes.const import OP_PRECEDENCE
+from astroid.nodes.utils import Position
+from astroid.typing import InferenceErrorInfo, InferenceResult, InferFn
+
+if sys.version_info >= (3, 11):
+ from typing import Self
+else:
+ from typing_extensions import Self
+
+
+if TYPE_CHECKING:
+ from astroid import nodes
+ from astroid.nodes import _base_nodes
+
+
+# Types for 'NodeNG.nodes_of_class()'
+_NodesT = TypeVar("_NodesT", bound="NodeNG")
+_NodesT2 = TypeVar("_NodesT2", bound="NodeNG")
+_NodesT3 = TypeVar("_NodesT3", bound="NodeNG")
+SkipKlassT = Union[None, type["NodeNG"], tuple[type["NodeNG"], ...]]
+
+
+class NodeNG:
+ """A node of the new Abstract Syntax Tree (AST).
+
+ This is the base class for all Astroid node classes.
+ """
+
+ is_statement: ClassVar[bool] = False
+ """Whether this node indicates a statement."""
+ optional_assign: ClassVar[bool] = (
+ False # True for For (and for Comprehension if py <3.0)
+ )
+ """Whether this node optionally assigns a variable.
+
+ This is for loop assignments because loop won't necessarily perform an
+ assignment if the loop has no iterations.
+ This is also the case from comprehensions in Python 2.
+ """
+ is_function: ClassVar[bool] = False # True for FunctionDef nodes
+ """Whether this node indicates a function."""
+ is_lambda: ClassVar[bool] = False
+
+ # Attributes below are set by the builder module or by raw factories
+ _astroid_fields: ClassVar[tuple[str, ...]] = ()
+ """Node attributes that contain child nodes.
+
+ This is redefined in most concrete classes.
+ """
+ _other_fields: ClassVar[tuple[str, ...]] = ()
+ """Node attributes that do not contain child nodes."""
+ _other_other_fields: ClassVar[tuple[str, ...]] = ()
+ """Attributes that contain AST-dependent fields."""
+ # instance specific inference function infer(node, context)
+ _explicit_inference: InferFn[Self] | None = None
+
+ def __init__(
+ self,
+ lineno: int | None,
+ col_offset: int | None,
+ parent: NodeNG | None,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.lineno = lineno
+ """The line that this node appears on in the source code."""
+
+ self.col_offset = col_offset
+ """The column that this node appears on in the source code."""
+
+ self.parent = parent
+ """The parent node in the syntax tree."""
+
+ self.end_lineno = end_lineno
+ """The last line this node appears on in the source code."""
+
+ self.end_col_offset = end_col_offset
+ """The end column this node appears on in the source code.
+
+ Note: This is after the last symbol.
+ """
+
+ self.position: Position | None = None
+ """Position of keyword(s) and name.
+
+ Used as fallback for block nodes which might not provide good
+ enough positional information. E.g. ClassDef, FunctionDef.
+ """
+
+ def infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult]:
+ """Get a generator of the inferred values.
+
+ This is the main entry point to the inference system.
+
+ .. seealso:: :ref:`inference`
+
+ If the instance has some explicit inference function set, it will be
+ called instead of the default interface.
+
+ :returns: The inferred values.
+ :rtype: iterable
+ """
+ if context is None:
+ context = InferenceContext()
+ else:
+ context = context.extra_context.get(self, context)
+ if self._explicit_inference is not None:
+ # explicit_inference is not bound, give it self explicitly
+ try:
+ for result in self._explicit_inference(
+ self, # type: ignore[arg-type]
+ context,
+ **kwargs,
+ ):
+ context.nodes_inferred += 1
+ yield result
+ return
+ except UseInferenceDefault:
+ pass
+
+ key = (self, context.lookupname, context.callcontext, context.boundnode)
+ if key in context.inferred:
+ yield from context.inferred[key]
+ return
+
+ results = []
+
+ # Limit inference amount to help with performance issues with
+ # exponentially exploding possible results.
+ limit = AstroidManager().max_inferable_values
+ for i, result in enumerate(self._infer(context=context, **kwargs)):
+ if i >= limit or (context.nodes_inferred > context.max_inferred):
+ results.append(util.Uninferable)
+ yield util.Uninferable
+ break
+ results.append(result)
+ yield result
+ context.nodes_inferred += 1
+
+ # Cache generated results for subsequent inferences of the
+ # same node using the same context
+ context.inferred[key] = tuple(results)
+ return
+
+ def repr_name(self) -> str:
+ """Get a name for nice representation.
+
+ This is either :attr:`name`, :attr:`attrname`, or the empty string.
+ """
+ if all(name not in self._astroid_fields for name in ("name", "attrname")):
+ return getattr(self, "name", "") or getattr(self, "attrname", "")
+ return ""
+
+ def __str__(self) -> str:
+ rname = self.repr_name()
+ cname = type(self).__name__
+ if rname:
+ string = "%(cname)s.%(rname)s(%(fields)s)"
+ alignment = len(cname) + len(rname) + 2
+ else:
+ string = "%(cname)s(%(fields)s)"
+ alignment = len(cname) + 1
+ result = []
+ for field in self._other_fields + self._astroid_fields:
+ value = getattr(self, field, "Unknown")
+ width = 80 - len(field) - alignment
+ lines = pprint.pformat(value, indent=2, width=width).splitlines(True)
+
+ inner = [lines[0]]
+ for line in lines[1:]:
+ inner.append(" " * alignment + line)
+ result.append(f"{field}={''.join(inner)}")
+
+ return string % {
+ "cname": cname,
+ "rname": rname,
+ "fields": (",\n" + " " * alignment).join(result),
+ }
+
+ def __repr__(self) -> str:
+ rname = self.repr_name()
+ # The dependencies used to calculate fromlineno (if not cached) may not exist at the time
+ try:
+ lineno = self.fromlineno
+ except AttributeError:
+ lineno = 0
+ if rname:
+ string = "<%(cname)s.%(rname)s l.%(lineno)s at 0x%(id)x>"
+ else:
+ string = "<%(cname)s l.%(lineno)s at 0x%(id)x>"
+ return string % {
+ "cname": type(self).__name__,
+ "rname": rname,
+ "lineno": lineno,
+ "id": id(self),
+ }
+
+ def accept(self, visitor: AsStringVisitor) -> str:
+ """Visit this node using the given visitor."""
+ func = getattr(visitor, "visit_" + self.__class__.__name__.lower())
+ return func(self)
+
+ def get_children(self) -> Iterator[NodeNG]:
+ """Get the child nodes below this node."""
+ for field in self._astroid_fields:
+ attr = getattr(self, field)
+ if attr is None:
+ continue
+ if isinstance(attr, (list, tuple)):
+ yield from attr
+ else:
+ yield attr
+ yield from ()
+
+ def last_child(self) -> NodeNG | None:
+ """An optimized version of list(get_children())[-1]."""
+ for field in self._astroid_fields[::-1]:
+ attr = getattr(self, field)
+ if not attr: # None or empty list / tuple
+ continue
+ if isinstance(attr, (list, tuple)):
+ return attr[-1]
+ return attr
+ return None
+
+ def node_ancestors(self) -> Iterator[NodeNG]:
+ """Yield parent, grandparent, etc until there are no more."""
+ parent = self.parent
+ while parent is not None:
+ yield parent
+ parent = parent.parent
+
+ def parent_of(self, node) -> bool:
+ """Check if this node is the parent of the given node.
+
+ :param node: The node to check if it is the child.
+ :type node: NodeNG
+
+ :returns: Whether this node is the parent of the given node.
+ """
+ return any(self is parent for parent in node.node_ancestors())
+
+ def statement(self, *, future: Literal[None, True] = None) -> _base_nodes.Statement:
+ """The first parent node, including self, marked as statement node.
+
+ :raises StatementMissing: If self has no parent attribute.
+ """
+ if future is not None:
+ warnings.warn(
+ "The future arg will be removed in astroid 4.0.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ if self.is_statement:
+ return cast("_base_nodes.Statement", self)
+ if not self.parent:
+ raise StatementMissing(target=self)
+ return self.parent.statement()
+
+ def frame(
+ self, *, future: Literal[None, True] = None
+ ) -> nodes.FunctionDef | nodes.Module | nodes.ClassDef | nodes.Lambda:
+ """The first parent frame node.
+
+ A frame node is a :class:`Module`, :class:`FunctionDef`,
+ :class:`ClassDef` or :class:`Lambda`.
+
+ :returns: The first parent frame node.
+ :raises ParentMissingError: If self has no parent attribute.
+ """
+ if future is not None:
+ warnings.warn(
+ "The future arg will be removed in astroid 4.0.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ if self.parent is None:
+ raise ParentMissingError(target=self)
+ return self.parent.frame(future=future)
+
+ def scope(self) -> nodes.LocalsDictNodeNG:
+ """The first parent node defining a new scope.
+
+ These can be Module, FunctionDef, ClassDef, Lambda, or GeneratorExp nodes.
+
+ :returns: The first parent scope node.
+ """
+ if not self.parent:
+ raise ParentMissingError(target=self)
+ return self.parent.scope()
+
+ def root(self) -> nodes.Module:
+ """Return the root node of the syntax tree.
+
+ :returns: The root node.
+ """
+ if not (parent := self.parent):
+ return self # type: ignore[return-value] # Only 'Module' does not have a parent node.
+
+ while parent.parent:
+ parent = parent.parent
+ return parent # type: ignore[return-value] # Only 'Module' does not have a parent node.
+
+ def child_sequence(self, child):
+ """Search for the sequence that contains this child.
+
+ :param child: The child node to search sequences for.
+ :type child: NodeNG
+
+ :returns: The sequence containing the given child node.
+ :rtype: iterable(NodeNG)
+
+ :raises AstroidError: If no sequence could be found that contains
+ the given child.
+ """
+ for field in self._astroid_fields:
+ node_or_sequence = getattr(self, field)
+ if node_or_sequence is child:
+ return [node_or_sequence]
+ # /!\ compiler.ast Nodes have an __iter__ walking over child nodes
+ if (
+ isinstance(node_or_sequence, (tuple, list))
+ and child in node_or_sequence
+ ):
+ return node_or_sequence
+
+ msg = "Could not find %s in %s's children"
+ raise AstroidError(msg % (repr(child), repr(self)))
+
+ def locate_child(self, child):
+ """Find the field of this node that contains the given child.
+
+ :param child: The child node to search fields for.
+ :type child: NodeNG
+
+ :returns: A tuple of the name of the field that contains the child,
+ and the sequence or node that contains the child node.
+ :rtype: tuple(str, iterable(NodeNG) or NodeNG)
+
+ :raises AstroidError: If no field could be found that contains
+ the given child.
+ """
+ for field in self._astroid_fields:
+ node_or_sequence = getattr(self, field)
+ # /!\ compiler.ast Nodes have an __iter__ walking over child nodes
+ if child is node_or_sequence:
+ return field, child
+ if (
+ isinstance(node_or_sequence, (tuple, list))
+ and child in node_or_sequence
+ ):
+ return field, node_or_sequence
+ msg = "Could not find %s in %s's children"
+ raise AstroidError(msg % (repr(child), repr(self)))
+
+ # FIXME : should we merge child_sequence and locate_child ? locate_child
+ # is only used in are_exclusive, child_sequence one time in pylint.
+
+ def next_sibling(self):
+ """The next sibling statement node.
+
+ :returns: The next sibling statement node.
+ :rtype: NodeNG or None
+ """
+ return self.parent.next_sibling()
+
+ def previous_sibling(self):
+ """The previous sibling statement.
+
+ :returns: The previous sibling statement node.
+ :rtype: NodeNG or None
+ """
+ return self.parent.previous_sibling()
+
+ # these are lazy because they're relatively expensive to compute for every
+ # single node, and they rarely get looked at
+
+ @cached_property
+ def fromlineno(self) -> int:
+ """The first line that this node appears on in the source code.
+
+ Can also return 0 if the line can not be determined.
+ """
+ if self.lineno is None:
+ return self._fixed_source_line()
+ return self.lineno
+
+ @cached_property
+ def tolineno(self) -> int:
+ """The last line that this node appears on in the source code.
+
+ Can also return 0 if the line can not be determined.
+ """
+ if self.end_lineno is not None:
+ return self.end_lineno
+ if not self._astroid_fields:
+ # can't have children
+ last_child = None
+ else:
+ last_child = self.last_child()
+ if last_child is None:
+ return self.fromlineno
+ return last_child.tolineno
+
+ def _fixed_source_line(self) -> int:
+ """Attempt to find the line that this node appears on.
+
+ We need this method since not all nodes have :attr:`lineno` set.
+ Will return 0 if the line number can not be determined.
+ """
+ line = self.lineno
+ _node = self
+ try:
+ while line is None:
+ _node = next(_node.get_children())
+ line = _node.lineno
+ except StopIteration:
+ parent = self.parent
+ while parent and line is None:
+ line = parent.lineno
+ parent = parent.parent
+ return line or 0
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from the given line number to where this node ends.
+
+ :param lineno: The line number to start the range at.
+
+ :returns: The range of line numbers that this node belongs to,
+ starting at the given line number.
+ """
+ return lineno, self.tolineno
+
+ def set_local(self, name: str, stmt: NodeNG) -> None:
+ """Define that the given name is declared in the given statement node.
+
+ This definition is stored on the parent scope node.
+
+ .. seealso:: :meth:`scope`
+
+ :param name: The name that is being defined.
+
+ :param stmt: The statement that defines the given name.
+ """
+ assert self.parent
+ self.parent.set_local(name, stmt)
+
+ @overload
+ def nodes_of_class(
+ self,
+ klass: type[_NodesT],
+ skip_klass: SkipKlassT = ...,
+ ) -> Iterator[_NodesT]: ...
+
+ @overload
+ def nodes_of_class(
+ self,
+ klass: tuple[type[_NodesT], type[_NodesT2]],
+ skip_klass: SkipKlassT = ...,
+ ) -> Iterator[_NodesT] | Iterator[_NodesT2]: ...
+
+ @overload
+ def nodes_of_class(
+ self,
+ klass: tuple[type[_NodesT], type[_NodesT2], type[_NodesT3]],
+ skip_klass: SkipKlassT = ...,
+ ) -> Iterator[_NodesT] | Iterator[_NodesT2] | Iterator[_NodesT3]: ...
+
+ @overload
+ def nodes_of_class(
+ self,
+ klass: tuple[type[_NodesT], ...],
+ skip_klass: SkipKlassT = ...,
+ ) -> Iterator[_NodesT]: ...
+
+ def nodes_of_class( # type: ignore[misc] # mypy doesn't correctly recognize the overloads
+ self,
+ klass: (
+ type[_NodesT]
+ | tuple[type[_NodesT], type[_NodesT2]]
+ | tuple[type[_NodesT], type[_NodesT2], type[_NodesT3]]
+ | tuple[type[_NodesT], ...]
+ ),
+ skip_klass: SkipKlassT = None,
+ ) -> Iterator[_NodesT] | Iterator[_NodesT2] | Iterator[_NodesT3]:
+ """Get the nodes (including this one or below) of the given types.
+
+ :param klass: The types of node to search for.
+
+ :param skip_klass: The types of node to ignore. This is useful to ignore
+ subclasses of :attr:`klass`.
+
+ :returns: The node of the given types.
+ """
+ if isinstance(self, klass):
+ yield self
+
+ if skip_klass is None:
+ for child_node in self.get_children():
+ yield from child_node.nodes_of_class(klass, skip_klass)
+
+ return
+
+ for child_node in self.get_children():
+ if isinstance(child_node, skip_klass):
+ continue
+ yield from child_node.nodes_of_class(klass, skip_klass)
+
+ @cached_property
+ def _assign_nodes_in_scope(self) -> list[nodes.Assign]:
+ return []
+
+ def _get_name_nodes(self):
+ for child_node in self.get_children():
+ yield from child_node._get_name_nodes()
+
+ def _get_return_nodes_skip_functions(self):
+ yield from ()
+
+ def _get_yield_nodes_skip_functions(self):
+ yield from ()
+
+ def _get_yield_nodes_skip_lambdas(self):
+ yield from ()
+
+ def _infer_name(self, frame, name):
+ # overridden for ImportFrom, Import, Global, Try, TryStar and Arguments
+ pass
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[InferenceResult, None, InferenceErrorInfo | None]:
+ """We don't know how to resolve a statement by default."""
+ # this method is overridden by most concrete classes
+ raise InferenceError(
+ "No inference function for {node!r}.", node=self, context=context
+ )
+
+ def inferred(self):
+ """Get a list of the inferred values.
+
+ .. seealso:: :ref:`inference`
+
+ :returns: The inferred values.
+ :rtype: list
+ """
+ return list(self.infer())
+
+ def instantiate_class(self):
+ """Instantiate an instance of the defined class.
+
+ .. note::
+
+ On anything other than a :class:`ClassDef` this will return self.
+
+ :returns: An instance of the defined class.
+ :rtype: object
+ """
+ return self
+
+ def has_base(self, node) -> bool:
+ """Check if this node inherits from the given type.
+
+ :param node: The node defining the base to look for.
+ Usually this is a :class:`Name` node.
+ :type node: NodeNG
+ """
+ return False
+
+ def callable(self) -> bool:
+ """Whether this node defines something that is callable.
+
+ :returns: Whether this defines something that is callable.
+ """
+ return False
+
+ def eq(self, value) -> bool:
+ return False
+
+ def as_string(self) -> str:
+ """Get the source code that this node represents."""
+ return AsStringVisitor()(self)
+
+ def repr_tree(
+ self,
+ ids=False,
+ include_linenos=False,
+ ast_state=False,
+ indent=" ",
+ max_depth=0,
+ max_width=80,
+ ) -> str:
+ """Get a string representation of the AST from this node.
+
+ :param ids: If true, includes the ids with the node type names.
+ :type ids: bool
+
+ :param include_linenos: If true, includes the line numbers and
+ column offsets.
+ :type include_linenos: bool
+
+ :param ast_state: If true, includes information derived from
+ the whole AST like local and global variables.
+ :type ast_state: bool
+
+ :param indent: A string to use to indent the output string.
+ :type indent: str
+
+ :param max_depth: If set to a positive integer, won't return
+ nodes deeper than max_depth in the string.
+ :type max_depth: int
+
+ :param max_width: Attempt to format the output string to stay
+ within this number of characters, but can exceed it under some
+ circumstances. Only positive integer values are valid, the default is 80.
+ :type max_width: int
+
+ :returns: The string representation of the AST.
+ :rtype: str
+ """
+
+ @_singledispatch
+ def _repr_tree(node, result, done, cur_indent="", depth=1):
+ """Outputs a representation of a non-tuple/list, non-node that's
+ contained within an AST, including strings.
+ """
+ lines = pprint.pformat(
+ node, width=max(max_width - len(cur_indent), 1)
+ ).splitlines(True)
+ result.append(lines[0])
+ result.extend([cur_indent + line for line in lines[1:]])
+ return len(lines) != 1
+
+ # pylint: disable=unused-variable,useless-suppression; doesn't understand singledispatch
+ @_repr_tree.register(tuple)
+ @_repr_tree.register(list)
+ def _repr_seq(node, result, done, cur_indent="", depth=1):
+ """Outputs a representation of a sequence that's contained within an
+ AST.
+ """
+ cur_indent += indent
+ result.append("[")
+ if not node:
+ broken = False
+ elif len(node) == 1:
+ broken = _repr_tree(node[0], result, done, cur_indent, depth)
+ elif len(node) == 2:
+ broken = _repr_tree(node[0], result, done, cur_indent, depth)
+ if not broken:
+ result.append(", ")
+ else:
+ result.append(",\n")
+ result.append(cur_indent)
+ broken = _repr_tree(node[1], result, done, cur_indent, depth) or broken
+ else:
+ result.append("\n")
+ result.append(cur_indent)
+ for child in node[:-1]:
+ _repr_tree(child, result, done, cur_indent, depth)
+ result.append(",\n")
+ result.append(cur_indent)
+ _repr_tree(node[-1], result, done, cur_indent, depth)
+ broken = True
+ result.append("]")
+ return broken
+
+ # pylint: disable=unused-variable,useless-suppression; doesn't understand singledispatch
+ @_repr_tree.register(NodeNG)
+ def _repr_node(node, result, done, cur_indent="", depth=1):
+ """Outputs a strings representation of an astroid node."""
+ if node in done:
+ result.append(
+ indent + f"<Recursion on {type(node).__name__} with id={id(node)}"
+ )
+ return False
+ done.add(node)
+
+ if max_depth and depth > max_depth:
+ result.append("...")
+ return False
+ depth += 1
+ cur_indent += indent
+ if ids:
+ result.append(f"{type(node).__name__}<0x{id(node):x}>(\n")
+ else:
+ result.append(f"{type(node).__name__}(")
+ fields = []
+ if include_linenos:
+ fields.extend(("lineno", "col_offset"))
+ fields.extend(node._other_fields)
+ fields.extend(node._astroid_fields)
+ if ast_state:
+ fields.extend(node._other_other_fields)
+ if not fields:
+ broken = False
+ elif len(fields) == 1:
+ result.append(f"{fields[0]}=")
+ broken = _repr_tree(
+ getattr(node, fields[0]), result, done, cur_indent, depth
+ )
+ else:
+ result.append("\n")
+ result.append(cur_indent)
+ for field in fields[:-1]:
+ # TODO: Remove this after removal of the 'doc' attribute
+ if field == "doc":
+ continue
+ result.append(f"{field}=")
+ _repr_tree(getattr(node, field), result, done, cur_indent, depth)
+ result.append(",\n")
+ result.append(cur_indent)
+ result.append(f"{fields[-1]}=")
+ _repr_tree(getattr(node, fields[-1]), result, done, cur_indent, depth)
+ broken = True
+ result.append(")")
+ return broken
+
+ result: list[str] = []
+ _repr_tree(self, result, set())
+ return "".join(result)
+
+ def bool_value(self, context: InferenceContext | None = None):
+ """Determine the boolean value of this node.
+
+ The boolean value of a node can have three
+ possible values:
+
+ * False: For instance, empty data structures,
+ False, empty strings, instances which return
+ explicitly False from the __nonzero__ / __bool__
+ method.
+ * True: Most of constructs are True by default:
+ classes, functions, modules etc
+ * Uninferable: The inference engine is uncertain of the
+ node's value.
+
+ :returns: The boolean value of this node.
+ :rtype: bool or Uninferable
+ """
+ return util.Uninferable
+
+ def op_precedence(self):
+ # Look up by class name or default to highest precedence
+ return OP_PRECEDENCE.get(self.__class__.__name__, len(OP_PRECEDENCE))
+
+ def op_left_associative(self) -> bool:
+ # Everything is left associative except `**` and IfExp
+ return True
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/__init__.py b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/__init__.py
new file mode 100644
index 000000000..f00dc3093
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/__init__.py
@@ -0,0 +1,45 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains all classes that are considered a "scoped" node and anything
+related.
+
+A scope node is a node that opens a new local scope in the language definition:
+Module, ClassDef, FunctionDef (and Lambda, GeneratorExp, DictComp and SetComp to some extent).
+"""
+
+from astroid.nodes.scoped_nodes.mixin import ComprehensionScope, LocalsDictNodeNG
+from astroid.nodes.scoped_nodes.scoped_nodes import (
+ AsyncFunctionDef,
+ ClassDef,
+ DictComp,
+ FunctionDef,
+ GeneratorExp,
+ Lambda,
+ ListComp,
+ Module,
+ SetComp,
+ _is_metaclass,
+ function_to_method,
+ get_wrapping_class,
+)
+from astroid.nodes.scoped_nodes.utils import builtin_lookup
+
+__all__ = (
+ "AsyncFunctionDef",
+ "ClassDef",
+ "ComprehensionScope",
+ "DictComp",
+ "FunctionDef",
+ "GeneratorExp",
+ "Lambda",
+ "ListComp",
+ "LocalsDictNodeNG",
+ "Module",
+ "SetComp",
+ "builtin_lookup",
+ "function_to_method",
+ "get_wrapping_class",
+ "_is_metaclass",
+)
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/mixin.py b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/mixin.py
new file mode 100644
index 000000000..8874c0691
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/mixin.py
@@ -0,0 +1,202 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains mixin classes for scoped nodes."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING, TypeVar, overload
+
+from astroid.exceptions import ParentMissingError
+from astroid.filter_statements import _filter_stmts
+from astroid.nodes import _base_nodes, scoped_nodes
+from astroid.nodes.scoped_nodes.utils import builtin_lookup
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+if TYPE_CHECKING:
+ from astroid import nodes
+
+_T = TypeVar("_T")
+
+
+class LocalsDictNodeNG(_base_nodes.LookupMixIn):
+ """this class provides locals handling common to Module, FunctionDef
+ and ClassDef nodes, including a dict like interface for direct access
+ to locals information
+ """
+
+ # attributes below are set by the builder module or by raw factories
+ locals: dict[str, list[InferenceResult]]
+ """A map of the name of a local variable to the node defining the local."""
+
+ def qname(self) -> str:
+ """Get the 'qualified' name of the node.
+
+ For example: module.name, module.class.name ...
+
+ :returns: The qualified name.
+ :rtype: str
+ """
+ # pylint: disable=no-member; github.com/pylint-dev/astroid/issues/278
+ if self.parent is None:
+ return self.name
+ try:
+ return f"{self.parent.frame().qname()}.{self.name}"
+ except ParentMissingError:
+ return self.name
+
+ def scope(self: _T) -> _T:
+ """The first parent node defining a new scope.
+
+ :returns: The first parent scope node.
+ :rtype: Module or FunctionDef or ClassDef or Lambda or GenExpr
+ """
+ return self
+
+ def scope_lookup(
+ self, node: _base_nodes.LookupMixIn, name: str, offset: int = 0
+ ) -> tuple[LocalsDictNodeNG, list[nodes.NodeNG]]:
+ """Lookup where the given variable is assigned.
+
+ :param node: The node to look for assignments up to.
+ Any assignments after the given node are ignored.
+
+ :param name: The name of the variable to find assignments for.
+
+ :param offset: The line offset to filter statements up to.
+
+ :returns: This scope node and the list of assignments associated to the
+ given name according to the scope where it has been found (locals,
+ globals or builtin).
+ """
+ raise NotImplementedError
+
+ def _scope_lookup(
+ self, node: _base_nodes.LookupMixIn, name: str, offset: int = 0
+ ) -> tuple[LocalsDictNodeNG, list[nodes.NodeNG]]:
+ """XXX method for interfacing the scope lookup"""
+ try:
+ stmts = _filter_stmts(node, self.locals[name], self, offset)
+ except KeyError:
+ stmts = ()
+ if stmts:
+ return self, stmts
+
+ # Handle nested scopes: since class names do not extend to nested
+ # scopes (e.g., methods), we find the next enclosing non-class scope
+ pscope = self.parent and self.parent.scope()
+ while pscope is not None:
+ if not isinstance(pscope, scoped_nodes.ClassDef):
+ return pscope.scope_lookup(node, name)
+ pscope = pscope.parent and pscope.parent.scope()
+
+ # self is at the top level of a module, or is enclosed only by ClassDefs
+ return builtin_lookup(name)
+
+ def set_local(self, name: str, stmt: nodes.NodeNG) -> None:
+ """Define that the given name is declared in the given statement node.
+
+ .. seealso:: :meth:`scope`
+
+ :param name: The name that is being defined.
+
+ :param stmt: The statement that defines the given name.
+ """
+ # assert not stmt in self.locals.get(name, ()), (self, stmt)
+ self.locals.setdefault(name, []).append(stmt)
+
+ __setitem__ = set_local
+
+ def _append_node(self, child: nodes.NodeNG) -> None:
+ """append a child, linking it in the tree"""
+ # pylint: disable=no-member; depending by the class
+ # which uses the current class as a mixin or base class.
+ # It's rewritten in 2.0, so it makes no sense for now
+ # to spend development time on it.
+ self.body.append(child) # type: ignore[attr-defined]
+ child.parent = self
+
+ @overload
+ def add_local_node(
+ self, child_node: nodes.ClassDef, name: str | None = ...
+ ) -> None: ...
+
+ @overload
+ def add_local_node(self, child_node: nodes.NodeNG, name: str) -> None: ...
+
+ def add_local_node(self, child_node: nodes.NodeNG, name: str | None = None) -> None:
+ """Append a child that should alter the locals of this scope node.
+
+ :param child_node: The child node that will alter locals.
+
+ :param name: The name of the local that will be altered by
+ the given child node.
+ """
+ if name != "__class__":
+ # add __class__ node as a child will cause infinite recursion later!
+ self._append_node(child_node)
+ self.set_local(name or child_node.name, child_node) # type: ignore[attr-defined]
+
+ def __getitem__(self, item: str) -> SuccessfulInferenceResult:
+ """The first node the defines the given local.
+
+ :param item: The name of the locally defined object.
+
+ :raises KeyError: If the name is not defined.
+ """
+ return self.locals[item][0]
+
+ def __iter__(self):
+ """Iterate over the names of locals defined in this scoped node.
+
+ :returns: The names of the defined locals.
+ :rtype: iterable(str)
+ """
+ return iter(self.keys())
+
+ def keys(self):
+ """The names of locals defined in this scoped node.
+
+ :returns: The names of the defined locals.
+ :rtype: list(str)
+ """
+ return list(self.locals.keys())
+
+ def values(self):
+ """The nodes that define the locals in this scoped node.
+
+ :returns: The nodes that define locals.
+ :rtype: list(NodeNG)
+ """
+ # pylint: disable=consider-using-dict-items
+ # It look like this class override items/keys/values,
+ # probably not worth the headache
+ return [self[key] for key in self.keys()]
+
+ def items(self):
+ """Get the names of the locals and the node that defines the local.
+
+ :returns: The names of locals and their associated node.
+ :rtype: list(tuple(str, NodeNG))
+ """
+ return list(zip(self.keys(), self.values()))
+
+ def __contains__(self, name) -> bool:
+ """Check if a local is defined in this scope.
+
+ :param name: The name of the local to check for.
+ :type name: str
+
+ :returns: Whether this node has a local of the given name,
+ """
+ return name in self.locals
+
+
+class ComprehensionScope(LocalsDictNodeNG):
+ """Scoping for different types of comprehensions."""
+
+ scope_lookup = LocalsDictNodeNG._scope_lookup
+
+ generators: list[nodes.Comprehension]
+ """The generators that are looped through."""
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/scoped_nodes.py b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/scoped_nodes.py
new file mode 100644
index 000000000..d733a6ae2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/scoped_nodes.py
@@ -0,0 +1,2989 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+This module contains the classes for "scoped" node, i.e. which are opening a
+new local scope in the language definition : Module, ClassDef, FunctionDef (and
+Lambda, GeneratorExp, DictComp and SetComp to some extent).
+"""
+
+from __future__ import annotations
+
+import io
+import itertools
+import os
+import warnings
+from collections.abc import Generator, Iterable, Iterator, Sequence
+from functools import cached_property, lru_cache
+from typing import TYPE_CHECKING, Any, ClassVar, Literal, NoReturn, TypeVar
+
+from astroid import bases, protocols, util
+from astroid.context import (
+ CallContext,
+ InferenceContext,
+ bind_context_to_node,
+ copy_context,
+)
+from astroid.exceptions import (
+ AstroidBuildingError,
+ AstroidTypeError,
+ AttributeInferenceError,
+ DuplicateBasesError,
+ InconsistentMroError,
+ InferenceError,
+ MroError,
+ ParentMissingError,
+ StatementMissing,
+ TooManyLevelsError,
+)
+from astroid.interpreter.dunder_lookup import lookup
+from astroid.interpreter.objectmodel import ClassModel, FunctionModel, ModuleModel
+from astroid.manager import AstroidManager
+from astroid.nodes import (
+ Arguments,
+ Const,
+ NodeNG,
+ Unknown,
+ _base_nodes,
+ const_factory,
+ node_classes,
+)
+from astroid.nodes.scoped_nodes.mixin import ComprehensionScope, LocalsDictNodeNG
+from astroid.nodes.scoped_nodes.utils import builtin_lookup
+from astroid.nodes.utils import Position
+from astroid.typing import (
+ InferBinaryOp,
+ InferenceErrorInfo,
+ InferenceResult,
+ SuccessfulInferenceResult,
+)
+
+if TYPE_CHECKING:
+ from astroid import nodes, objects
+ from astroid.nodes._base_nodes import LookupMixIn
+
+
+ITER_METHODS = ("__iter__", "__getitem__")
+EXCEPTION_BASE_CLASSES = frozenset({"Exception", "BaseException"})
+BUILTIN_DESCRIPTORS = frozenset(
+ {"classmethod", "staticmethod", "builtins.classmethod", "builtins.staticmethod"}
+)
+
+_T = TypeVar("_T")
+
+
+def _c3_merge(sequences, cls, context):
+ """Merges MROs in *sequences* to a single MRO using the C3 algorithm.
+
+ Adapted from http://www.python.org/download/releases/2.3/mro/.
+
+ """
+ result = []
+ while True:
+ sequences = [s for s in sequences if s] # purge empty sequences
+ if not sequences:
+ return result
+ for s1 in sequences: # find merge candidates among seq heads
+ candidate = s1[0]
+ for s2 in sequences:
+ if candidate in s2[1:]:
+ candidate = None
+ break # reject the current head, it appears later
+ else:
+ break
+ if not candidate:
+ # Show all the remaining bases, which were considered as
+ # candidates for the next mro sequence.
+ raise InconsistentMroError(
+ message="Cannot create a consistent method resolution order "
+ "for MROs {mros} of class {cls!r}.",
+ mros=sequences,
+ cls=cls,
+ context=context,
+ )
+
+ result.append(candidate)
+ # remove the chosen candidate
+ for seq in sequences:
+ if seq[0] == candidate:
+ del seq[0]
+ return None
+
+
+def clean_typing_generic_mro(sequences: list[list[ClassDef]]) -> None:
+ """A class can inherit from typing.Generic directly, as base,
+ and as base of bases. The merged MRO must however only contain the last entry.
+ To prepare for _c3_merge, remove some typing.Generic entries from
+ sequences if multiple are present.
+
+ This method will check if Generic is in inferred_bases and also
+ part of bases_mro. If true, remove it from inferred_bases
+ as well as its entry the bases_mro.
+
+ Format sequences: [[self]] + bases_mro + [inferred_bases]
+ """
+ bases_mro = sequences[1:-1]
+ inferred_bases = sequences[-1]
+ # Check if Generic is part of inferred_bases
+ for i, base in enumerate(inferred_bases):
+ if base.qname() == "typing.Generic":
+ position_in_inferred_bases = i
+ break
+ else:
+ return
+ # Check if also part of bases_mro
+ # Ignore entry for typing.Generic
+ for i, seq in enumerate(bases_mro):
+ if i == position_in_inferred_bases:
+ continue
+ if any(base.qname() == "typing.Generic" for base in seq):
+ break
+ else:
+ return
+ # Found multiple Generics in mro, remove entry from inferred_bases
+ # and the corresponding one from bases_mro
+ inferred_bases.pop(position_in_inferred_bases)
+ bases_mro.pop(position_in_inferred_bases)
+
+
+def clean_duplicates_mro(
+ sequences: list[list[ClassDef]],
+ cls: ClassDef,
+ context: InferenceContext | None,
+) -> list[list[ClassDef]]:
+ for sequence in sequences:
+ seen = set()
+ for node in sequence:
+ lineno_and_qname = (node.lineno, node.qname())
+ if lineno_and_qname in seen:
+ raise DuplicateBasesError(
+ message="Duplicates found in MROs {mros} for {cls!r}.",
+ mros=sequences,
+ cls=cls,
+ context=context,
+ )
+ seen.add(lineno_and_qname)
+ return sequences
+
+
+def function_to_method(n, klass):
+ if isinstance(n, FunctionDef):
+ if n.type == "classmethod":
+ return bases.BoundMethod(n, klass)
+ if n.type == "property":
+ return n
+ if n.type != "staticmethod":
+ return bases.UnboundMethod(n)
+ return n
+
+
+class Module(LocalsDictNodeNG):
+ """Class representing an :class:`ast.Module` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('import astroid')
+ >>> node
+ <Import l.1 at 0x7f23b2e4e5c0>
+ >>> node.parent
+ <Module l.0 at 0x7f23b2e4eda0>
+ """
+
+ _astroid_fields = ("doc_node", "body")
+
+ doc_node: Const | None
+ """The doc node associated with this node."""
+
+ # attributes below are set by the builder module or by raw factories
+
+ file_bytes: str | bytes | None = None
+ """The string/bytes that this ast was built from."""
+
+ file_encoding: str | None = None
+ """The encoding of the source file.
+
+ This is used to get unicode out of a source file.
+ Python 2 only.
+ """
+
+ special_attributes = ModuleModel()
+ """The names of special attributes that this module has."""
+
+ # names of module attributes available through the global scope
+ scope_attrs: ClassVar[set[str]] = {
+ "__name__",
+ "__doc__",
+ "__file__",
+ "__path__",
+ "__package__",
+ }
+ """The names of module attributes available through the global scope."""
+
+ _other_fields = (
+ "name",
+ "file",
+ "path",
+ "package",
+ "pure_python",
+ "future_imports",
+ )
+ _other_other_fields = ("locals", "globals")
+
+ def __init__(
+ self,
+ name: str,
+ file: str | None = None,
+ path: Sequence[str] | None = None,
+ package: bool = False,
+ pure_python: bool = True,
+ ) -> None:
+ self.name = name
+ """The name of the module."""
+
+ self.file = file
+ """The path to the file that this ast has been extracted from.
+
+ This will be ``None`` when the representation has been built from a
+ built-in module.
+ """
+
+ self.path = path
+
+ self.package = package
+ """Whether the node represents a package or a module."""
+
+ self.pure_python = pure_python
+ """Whether the ast was built from source."""
+
+ self.globals: dict[str, list[InferenceResult]]
+ """A map of the name of a global variable to the node defining the global."""
+
+ self.locals = self.globals = {}
+ """A map of the name of a local variable to the node defining the local."""
+
+ self.body: list[node_classes.NodeNG] = []
+ """The contents of the module."""
+
+ self.future_imports: set[str] = set()
+ """The imports from ``__future__``."""
+
+ super().__init__(
+ lineno=0, parent=None, col_offset=0, end_lineno=None, end_col_offset=None
+ )
+
+ # pylint: enable=redefined-builtin
+
+ def postinit(
+ self, body: list[node_classes.NodeNG], *, doc_node: Const | None = None
+ ):
+ self.body = body
+ self.doc_node = doc_node
+
+ def _get_stream(self):
+ if self.file_bytes is not None:
+ return io.BytesIO(self.file_bytes)
+ if self.file is not None:
+ # pylint: disable=consider-using-with
+ stream = open(self.file, "rb")
+ return stream
+ return None
+
+ def stream(self):
+ """Get a stream to the underlying file or bytes.
+
+ :type: file or io.BytesIO or None
+ """
+ return self._get_stream()
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from where this node starts to where this node ends.
+
+ :param lineno: Unused.
+
+ :returns: The range of line numbers that this node belongs to.
+ """
+ return self.fromlineno, self.tolineno
+
+ def scope_lookup(
+ self, node: LookupMixIn, name: str, offset: int = 0
+ ) -> tuple[LocalsDictNodeNG, list[node_classes.NodeNG]]:
+ """Lookup where the given variable is assigned.
+
+ :param node: The node to look for assignments up to.
+ Any assignments after the given node are ignored.
+
+ :param name: The name of the variable to find assignments for.
+
+ :param offset: The line offset to filter statements up to.
+
+ :returns: This scope node and the list of assignments associated to the
+ given name according to the scope where it has been found (locals,
+ globals or builtin).
+ """
+ if name in self.scope_attrs and name not in self.locals:
+ try:
+ return self, self.getattr(name)
+ except AttributeInferenceError:
+ return self, []
+ return self._scope_lookup(node, name, offset)
+
+ def pytype(self) -> Literal["builtins.module"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ return "builtins.module"
+
+ def display_type(self) -> str:
+ """A human readable type of this node.
+
+ :returns: The type of this node.
+ :rtype: str
+ """
+ return "Module"
+
+ def getattr(
+ self, name, context: InferenceContext | None = None, ignore_locals=False
+ ):
+ if not name:
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ result = []
+ name_in_locals = name in self.locals
+
+ if name in self.special_attributes and not ignore_locals and not name_in_locals:
+ result = [self.special_attributes.lookup(name)]
+ if name == "__name__":
+ result.append(const_factory("__main__"))
+ elif not ignore_locals and name_in_locals:
+ result = self.locals[name]
+ elif self.package:
+ try:
+ result = [self.import_module(name, relative_only=True)]
+ except (AstroidBuildingError, SyntaxError) as exc:
+ raise AttributeInferenceError(
+ target=self, attribute=name, context=context
+ ) from exc
+ result = [n for n in result if not isinstance(n, node_classes.DelName)]
+ if result:
+ return result
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ def igetattr(
+ self, name: str, context: InferenceContext | None = None
+ ) -> Iterator[InferenceResult]:
+ """Infer the possible values of the given variable.
+
+ :param name: The name of the variable to infer.
+
+ :returns: The inferred possible values.
+ """
+ # set lookup name since this is necessary to infer on import nodes for
+ # instance
+ context = copy_context(context)
+ context.lookupname = name
+ try:
+ return bases._infer_stmts(self.getattr(name, context), context, frame=self)
+ except AttributeInferenceError as error:
+ raise InferenceError(
+ str(error), target=self, attribute=name, context=context
+ ) from error
+
+ def fully_defined(self) -> bool:
+ """Check if this module has been build from a .py file.
+
+ If so, the module contains a complete representation,
+ including the code.
+
+ :returns: Whether the module has been built from a .py file.
+ """
+ return self.file is not None and self.file.endswith(".py")
+
+ def statement(self, *, future: Literal[None, True] = None) -> NoReturn:
+ """The first parent node, including self, marked as statement node.
+
+ When called on a :class:`Module` this raises a StatementMissing.
+ """
+ if future is not None:
+ warnings.warn(
+ "The future arg will be removed in astroid 4.0.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ raise StatementMissing(target=self)
+
+ def previous_sibling(self):
+ """The previous sibling statement.
+
+ :returns: The previous sibling statement node.
+ :rtype: NodeNG or None
+ """
+
+ def next_sibling(self):
+ """The next sibling statement node.
+
+ :returns: The next sibling statement node.
+ :rtype: NodeNG or None
+ """
+
+ _absolute_import_activated = True
+
+ def absolute_import_activated(self) -> bool:
+ """Whether :pep:`328` absolute import behaviour has been enabled.
+
+ :returns: Whether :pep:`328` has been enabled.
+ """
+ return self._absolute_import_activated
+
+ def import_module(
+ self,
+ modname: str,
+ relative_only: bool = False,
+ level: int | None = None,
+ use_cache: bool = True,
+ ) -> Module:
+ """Get the ast for a given module as if imported from this module.
+
+ :param modname: The name of the module to "import".
+
+ :param relative_only: Whether to only consider relative imports.
+
+ :param level: The level of relative import.
+
+ :param use_cache: Whether to use the astroid_cache of modules.
+
+ :returns: The imported module ast.
+ """
+ if relative_only and level is None:
+ level = 0
+ absmodname = self.relative_to_absolute_name(modname, level)
+
+ try:
+ return AstroidManager().ast_from_module_name(
+ absmodname, use_cache=use_cache
+ )
+ except AstroidBuildingError:
+ # we only want to import a sub module or package of this module,
+ # skip here
+ if relative_only:
+ raise
+ # Don't repeat the same operation, e.g. for missing modules
+ # like "_winapi" or "nt" on POSIX systems.
+ if modname == absmodname:
+ raise
+ return AstroidManager().ast_from_module_name(modname, use_cache=use_cache)
+
+ def relative_to_absolute_name(self, modname: str, level: int | None) -> str:
+ """Get the absolute module name for a relative import.
+
+ The relative import can be implicit or explicit.
+
+ :param modname: The module name to convert.
+
+ :param level: The level of relative import.
+
+ :returns: The absolute module name.
+
+ :raises TooManyLevelsError: When the relative import refers to a
+ module too far above this one.
+ """
+ # XXX this returns non sens when called on an absolute import
+ # like 'pylint.checkers.astroid.utils'
+ # XXX doesn't return absolute name if self.name isn't absolute name
+ if self.absolute_import_activated() and level is None:
+ return modname
+ if level:
+ if self.package:
+ level = level - 1
+ package_name = self.name.rsplit(".", level)[0]
+ elif (
+ self.path
+ and not os.path.exists(os.path.dirname(self.path[0]) + "/__init__.py")
+ and os.path.exists(
+ os.path.dirname(self.path[0]) + "/" + modname.split(".")[0]
+ )
+ ):
+ level = level - 1
+ package_name = ""
+ else:
+ package_name = self.name.rsplit(".", level)[0]
+ if level and self.name.count(".") < level:
+ raise TooManyLevelsError(level=level, name=self.name)
+
+ elif self.package:
+ package_name = self.name
+ else:
+ package_name = self.name.rsplit(".", 1)[0]
+
+ if package_name:
+ if not modname:
+ return package_name
+ return f"{package_name}.{modname}"
+ return modname
+
+ def wildcard_import_names(self):
+ """The list of imported names when this module is 'wildcard imported'.
+
+ It doesn't include the '__builtins__' name which is added by the
+ current CPython implementation of wildcard imports.
+
+ :returns: The list of imported names.
+ :rtype: list(str)
+ """
+ # We separate the different steps of lookup in try/excepts
+ # to avoid catching too many Exceptions
+ default = [name for name in self.keys() if not name.startswith("_")]
+ try:
+ all_values = self["__all__"]
+ except KeyError:
+ return default
+
+ try:
+ explicit = next(all_values.assigned_stmts())
+ except (InferenceError, StopIteration):
+ return default
+ except AttributeError:
+ # not an assignment node
+ # XXX infer?
+ return default
+
+ # Try our best to detect the exported name.
+ inferred = []
+ try:
+ explicit = next(explicit.infer())
+ except (InferenceError, StopIteration):
+ return default
+ if not isinstance(explicit, (node_classes.Tuple, node_classes.List)):
+ return default
+
+ def str_const(node) -> bool:
+ return isinstance(node, node_classes.Const) and isinstance(node.value, str)
+
+ for node in explicit.elts:
+ if str_const(node):
+ inferred.append(node.value)
+ else:
+ try:
+ inferred_node = next(node.infer())
+ except (InferenceError, StopIteration):
+ continue
+ if str_const(inferred_node):
+ inferred.append(inferred_node.value)
+ return inferred
+
+ def public_names(self):
+ """The list of the names that are publicly available in this module.
+
+ :returns: The list of public names.
+ :rtype: list(str)
+ """
+ return [name for name in self.keys() if not name.startswith("_")]
+
+ def bool_value(self, context: InferenceContext | None = None) -> bool:
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`Module` this is always ``True``.
+ """
+ return True
+
+ def get_children(self):
+ yield from self.body
+
+ def frame(self: _T, *, future: Literal[None, True] = None) -> _T:
+ """The node's frame node.
+
+ A frame node is a :class:`Module`, :class:`FunctionDef`,
+ :class:`ClassDef` or :class:`Lambda`.
+
+ :returns: The node itself.
+ """
+ return self
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[Module]:
+ yield self
+
+
+class GeneratorExp(ComprehensionScope):
+ """Class representing an :class:`ast.GeneratorExp` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('(thing for thing in things if thing)')
+ >>> node
+ <GeneratorExp l.1 at 0x7f23b2e4e400>
+ """
+
+ _astroid_fields = ("elt", "generators")
+ _other_other_fields = ("locals",)
+ elt: NodeNG
+ """The element that forms the output of the expression."""
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.locals = {}
+ """A map of the name of a local variable to the node defining the local."""
+
+ self.generators: list[nodes.Comprehension] = []
+ """The generators that are looped through."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, elt: NodeNG, generators: list[nodes.Comprehension]) -> None:
+ self.elt = elt
+ self.generators = generators
+
+ def bool_value(self, context: InferenceContext | None = None) -> Literal[True]:
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`GeneratorExp` this is always ``True``.
+ """
+ return True
+
+ def get_children(self):
+ yield self.elt
+
+ yield from self.generators
+
+
+class DictComp(ComprehensionScope):
+ """Class representing an :class:`ast.DictComp` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('{k:v for k, v in things if k > v}')
+ >>> node
+ <DictComp l.1 at 0x7f23b2e41d68>
+ """
+
+ _astroid_fields = ("key", "value", "generators")
+ _other_other_fields = ("locals",)
+ key: NodeNG
+ """What produces the keys."""
+
+ value: NodeNG
+ """What produces the values."""
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.locals = {}
+ """A map of the name of a local variable to the node defining the local."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(
+ self, key: NodeNG, value: NodeNG, generators: list[nodes.Comprehension]
+ ) -> None:
+ self.key = key
+ self.value = value
+ self.generators = generators
+
+ def bool_value(self, context: InferenceContext | None = None):
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`DictComp` this is always :class:`Uninferable`.
+ :rtype: Uninferable
+ """
+ return util.Uninferable
+
+ def get_children(self):
+ yield self.key
+ yield self.value
+
+ yield from self.generators
+
+
+class SetComp(ComprehensionScope):
+ """Class representing an :class:`ast.SetComp` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('{thing for thing in things if thing}')
+ >>> node
+ <SetComp l.1 at 0x7f23b2e41898>
+ """
+
+ _astroid_fields = ("elt", "generators")
+ _other_other_fields = ("locals",)
+ elt: NodeNG
+ """The element that forms the output of the expression."""
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.locals = {}
+ """A map of the name of a local variable to the node defining the local."""
+
+ self.generators: list[nodes.Comprehension] = []
+ """The generators that are looped through."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, elt: NodeNG, generators: list[nodes.Comprehension]) -> None:
+ self.elt = elt
+ self.generators = generators
+
+ def bool_value(self, context: InferenceContext | None = None):
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`SetComp` this is always :class:`Uninferable`.
+ :rtype: Uninferable
+ """
+ return util.Uninferable
+
+ def get_children(self):
+ yield self.elt
+
+ yield from self.generators
+
+
+class ListComp(ComprehensionScope):
+ """Class representing an :class:`ast.ListComp` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('[thing for thing in things if thing]')
+ >>> node
+ <ListComp l.1 at 0x7f23b2e418d0>
+ """
+
+ _astroid_fields = ("elt", "generators")
+ _other_other_fields = ("locals",)
+
+ elt: NodeNG
+ """The element that forms the output of the expression."""
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.locals = {}
+ """A map of the name of a local variable to the node defining it."""
+
+ self.generators: list[nodes.Comprehension] = []
+ """The generators that are looped through."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, elt: NodeNG, generators: list[nodes.Comprehension]):
+ self.elt = elt
+ self.generators = generators
+
+ def bool_value(self, context: InferenceContext | None = None):
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`ListComp` this is always :class:`Uninferable`.
+ :rtype: Uninferable
+ """
+ return util.Uninferable
+
+ def get_children(self):
+ yield self.elt
+
+ yield from self.generators
+
+
+def _infer_decorator_callchain(node):
+ """Detect decorator call chaining and see if the end result is a
+ static or a classmethod.
+ """
+ if not isinstance(node, FunctionDef):
+ return None
+ if not node.parent:
+ return None
+ try:
+ result = next(node.infer_call_result(node.parent), None)
+ except InferenceError:
+ return None
+ if isinstance(result, bases.Instance):
+ result = result._proxied
+ if isinstance(result, ClassDef):
+ if result.is_subtype_of("builtins.classmethod"):
+ return "classmethod"
+ if result.is_subtype_of("builtins.staticmethod"):
+ return "staticmethod"
+ if isinstance(result, FunctionDef):
+ if not result.decorators:
+ return None
+ # Determine if this function is decorated with one of the builtin descriptors we want.
+ for decorator in result.decorators.nodes:
+ if isinstance(decorator, node_classes.Name):
+ if decorator.name in BUILTIN_DESCRIPTORS:
+ return decorator.name
+ if (
+ isinstance(decorator, node_classes.Attribute)
+ and isinstance(decorator.expr, node_classes.Name)
+ and decorator.expr.name == "builtins"
+ and decorator.attrname in BUILTIN_DESCRIPTORS
+ ):
+ return decorator.attrname
+ return None
+
+
+class Lambda(_base_nodes.FilterStmtsBaseNode, LocalsDictNodeNG):
+ """Class representing an :class:`ast.Lambda` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('lambda arg: arg + 1')
+ >>> node
+ <Lambda.<lambda> l.1 at 0x7f23b2e41518>
+ """
+
+ _astroid_fields: ClassVar[tuple[str, ...]] = ("args", "body")
+ _other_other_fields: ClassVar[tuple[str, ...]] = ("locals",)
+ name = "<lambda>"
+ is_lambda = True
+ special_attributes = FunctionModel()
+ """The names of special attributes that this function has."""
+
+ args: Arguments
+ """The arguments that the function takes."""
+
+ body: NodeNG
+ """The contents of the function body."""
+
+ def implicit_parameters(self) -> Literal[0]:
+ return 0
+
+ @property
+ def type(self) -> Literal["method", "function"]:
+ """Whether this is a method or function.
+
+ :returns: 'method' if this is a method, 'function' otherwise.
+ """
+ if self.args.arguments and self.args.arguments[0].name == "self":
+ if self.parent and isinstance(self.parent.scope(), ClassDef):
+ return "method"
+ return "function"
+
+ def __init__(
+ self,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ):
+ self.locals = {}
+ """A map of the name of a local variable to the node defining it."""
+
+ self.instance_attrs: dict[str, list[NodeNG]] = {}
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+
+ def postinit(self, args: Arguments, body: NodeNG) -> None:
+ self.args = args
+ self.body = body
+
+ def pytype(self) -> Literal["builtins.instancemethod", "builtins.function"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ if "method" in self.type:
+ return "builtins.instancemethod"
+ return "builtins.function"
+
+ def display_type(self) -> str:
+ """A human readable type of this node.
+
+ :returns: The type of this node.
+ :rtype: str
+ """
+ if "method" in self.type:
+ return "Method"
+ return "Function"
+
+ def callable(self) -> Literal[True]:
+ """Whether this node defines something that is callable.
+
+ :returns: Whether this defines something that is callable
+ For a :class:`Lambda` this is always ``True``.
+ """
+ return True
+
+ def argnames(self) -> list[str]:
+ """Get the names of each of the arguments, including that
+ of the collections of variable-length arguments ("args", "kwargs",
+ etc.), as well as positional-only and keyword-only arguments.
+
+ :returns: The names of the arguments.
+ :rtype: list(str)
+ """
+ if self.args.arguments: # maybe None with builtin functions
+ names = [elt.name for elt in self.args.arguments]
+ else:
+ names = []
+
+ return names
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ """Infer what the function returns when called."""
+ return self.body.infer(context)
+
+ def scope_lookup(
+ self, node: LookupMixIn, name: str, offset: int = 0
+ ) -> tuple[LocalsDictNodeNG, list[NodeNG]]:
+ """Lookup where the given names is assigned.
+
+ :param node: The node to look for assignments up to.
+ Any assignments after the given node are ignored.
+
+ :param name: The name to find assignments for.
+
+ :param offset: The line offset to filter statements up to.
+
+ :returns: This scope node and the list of assignments associated to the
+ given name according to the scope where it has been found (locals,
+ globals or builtin).
+ """
+ if (self.args.defaults and node in self.args.defaults) or (
+ self.args.kw_defaults and node in self.args.kw_defaults
+ ):
+ if not self.parent:
+ raise ParentMissingError(target=self)
+ frame = self.parent.frame()
+ # line offset to avoid that def func(f=func) resolve the default
+ # value to the defined function
+ offset = -1
+ else:
+ # check this is not used in function decorators
+ frame = self
+ return frame._scope_lookup(node, name, offset)
+
+ def bool_value(self, context: InferenceContext | None = None) -> Literal[True]:
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`Lambda` this is always ``True``.
+ """
+ return True
+
+ def get_children(self):
+ yield self.args
+ yield self.body
+
+ def frame(self: _T, *, future: Literal[None, True] = None) -> _T:
+ """The node's frame node.
+
+ A frame node is a :class:`Module`, :class:`FunctionDef`,
+ :class:`ClassDef` or :class:`Lambda`.
+
+ :returns: The node itself.
+ """
+ return self
+
+ def getattr(
+ self, name: str, context: InferenceContext | None = None
+ ) -> list[NodeNG]:
+ if not name:
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ found_attrs = []
+ if name in self.instance_attrs:
+ found_attrs = self.instance_attrs[name]
+ if name in self.special_attributes:
+ found_attrs.append(self.special_attributes.lookup(name))
+ if found_attrs:
+ return found_attrs
+ raise AttributeInferenceError(target=self, attribute=name)
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[Lambda]:
+ yield self
+
+ def _get_yield_nodes_skip_functions(self):
+ """A Lambda node can contain a Yield node in the body."""
+ yield from self.body._get_yield_nodes_skip_functions()
+
+
+class FunctionDef(
+ _base_nodes.MultiLineBlockNode,
+ _base_nodes.FilterStmtsBaseNode,
+ _base_nodes.Statement,
+ LocalsDictNodeNG,
+):
+ """Class representing an :class:`ast.FunctionDef`.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ ... def my_func(arg):
+ ... return arg + 1
+ ... ''')
+ >>> node
+ <FunctionDef.my_func l.2 at 0x7f23b2e71e10>
+ """
+
+ _astroid_fields = (
+ "decorators",
+ "args",
+ "returns",
+ "type_params",
+ "doc_node",
+ "body",
+ )
+ _multi_line_block_fields = ("body",)
+ returns = None
+
+ decorators: node_classes.Decorators | None
+ """The decorators that are applied to this method or function."""
+
+ doc_node: Const | None
+ """The doc node associated with this node."""
+
+ args: Arguments
+ """The arguments that the function takes."""
+
+ is_function = True
+ """Whether this node indicates a function.
+
+ For a :class:`FunctionDef` this is always ``True``.
+
+ :type: bool
+ """
+ type_annotation = None
+ """If present, this will contain the type annotation passed by a type comment
+
+ :type: NodeNG or None
+ """
+ type_comment_args = None
+ """
+ If present, this will contain the type annotation for arguments
+ passed by a type comment
+ """
+ type_comment_returns = None
+ """If present, this will contain the return type annotation, passed by a type comment"""
+ # attributes below are set by the builder module or by raw factories
+ _other_fields = ("name", "position")
+ _other_other_fields = (
+ "locals",
+ "_type",
+ "type_comment_returns",
+ "type_comment_args",
+ )
+ _type = None
+
+ name = "<functiondef>"
+
+ special_attributes = FunctionModel()
+ """The names of special attributes that this function has."""
+
+ def __init__(
+ self,
+ name: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.name = name
+ """The name of the function."""
+
+ self.locals = {}
+ """A map of the name of a local variable to the node defining it."""
+
+ self.body: list[NodeNG] = []
+ """The contents of the function body."""
+
+ self.type_params: list[nodes.TypeVar | nodes.ParamSpec | nodes.TypeVarTuple] = (
+ []
+ )
+ """PEP 695 (Python 3.12+) type params, e.g. first 'T' in def func[T]() -> T: ..."""
+
+ self.instance_attrs: dict[str, list[NodeNG]] = {}
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+ if parent and not isinstance(parent, Unknown):
+ frame = parent.frame()
+ frame.set_local(name, self)
+
+ def postinit(
+ self,
+ args: Arguments,
+ body: list[NodeNG],
+ decorators: node_classes.Decorators | None = None,
+ returns=None,
+ type_comment_returns=None,
+ type_comment_args=None,
+ *,
+ position: Position | None = None,
+ doc_node: Const | None = None,
+ type_params: (
+ list[nodes.TypeVar | nodes.ParamSpec | nodes.TypeVarTuple] | None
+ ) = None,
+ ):
+ """Do some setup after initialisation.
+
+ :param args: The arguments that the function takes.
+
+ :param body: The contents of the function body.
+
+ :param decorators: The decorators that are applied to this
+ method or function.
+ :params type_comment_returns:
+ The return type annotation passed via a type comment.
+ :params type_comment_args:
+ The args type annotation passed via a type comment.
+ :params position:
+ Position of function keyword(s) and name.
+ :param doc_node:
+ The doc node associated with this node.
+ :param type_params:
+ The type_params associated with this node.
+ """
+ self.args = args
+ self.body = body
+ self.decorators = decorators
+ self.returns = returns
+ self.type_comment_returns = type_comment_returns
+ self.type_comment_args = type_comment_args
+ self.position = position
+ self.doc_node = doc_node
+ self.type_params = type_params or []
+
+ @cached_property
+ def extra_decorators(self) -> list[node_classes.Call]:
+ """The extra decorators that this function can have.
+
+ Additional decorators are considered when they are used as
+ assignments, as in ``method = staticmethod(method)``.
+ The property will return all the callables that are used for
+ decoration.
+ """
+ if not self.parent or not isinstance(frame := self.parent.frame(), ClassDef):
+ return []
+
+ decorators: list[node_classes.Call] = []
+ for assign in frame._assign_nodes_in_scope:
+ if isinstance(assign.value, node_classes.Call) and isinstance(
+ assign.value.func, node_classes.Name
+ ):
+ for assign_node in assign.targets:
+ if not isinstance(assign_node, node_classes.AssignName):
+ # Support only `name = callable(name)`
+ continue
+
+ if assign_node.name != self.name:
+ # Interested only in the assignment nodes that
+ # decorates the current method.
+ continue
+ try:
+ meth = frame[self.name]
+ except KeyError:
+ continue
+ else:
+ # Must be a function and in the same frame as the
+ # original method.
+ if (
+ isinstance(meth, FunctionDef)
+ and assign_node.frame() == frame
+ ):
+ decorators.append(assign.value)
+ return decorators
+
+ def pytype(self) -> Literal["builtins.instancemethod", "builtins.function"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ if "method" in self.type:
+ return "builtins.instancemethod"
+ return "builtins.function"
+
+ def display_type(self) -> str:
+ """A human readable type of this node.
+
+ :returns: The type of this node.
+ :rtype: str
+ """
+ if "method" in self.type:
+ return "Method"
+ return "Function"
+
+ def callable(self) -> Literal[True]:
+ return True
+
+ def argnames(self) -> list[str]:
+ """Get the names of each of the arguments, including that
+ of the collections of variable-length arguments ("args", "kwargs",
+ etc.), as well as positional-only and keyword-only arguments.
+
+ :returns: The names of the arguments.
+ :rtype: list(str)
+ """
+ if self.args.arguments: # maybe None with builtin functions
+ names = [elt.name for elt in self.args.arguments]
+ else:
+ names = []
+
+ return names
+
+ def getattr(
+ self, name: str, context: InferenceContext | None = None
+ ) -> list[NodeNG]:
+ if not name:
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ found_attrs = []
+ if name in self.instance_attrs:
+ found_attrs = self.instance_attrs[name]
+ if name in self.special_attributes:
+ found_attrs.append(self.special_attributes.lookup(name))
+ if found_attrs:
+ return found_attrs
+ raise AttributeInferenceError(target=self, attribute=name)
+
+ @cached_property
+ def type(self) -> str: # pylint: disable=too-many-return-statements # noqa: C901
+ """The function type for this node.
+
+ Possible values are: method, function, staticmethod, classmethod.
+ """
+ for decorator in self.extra_decorators:
+ if decorator.func.name in BUILTIN_DESCRIPTORS:
+ return decorator.func.name
+
+ if not self.parent:
+ raise ParentMissingError(target=self)
+
+ frame = self.parent.frame()
+ type_name = "function"
+ if isinstance(frame, ClassDef):
+ if self.name == "__new__":
+ return "classmethod"
+ if self.name == "__init_subclass__":
+ return "classmethod"
+ if self.name == "__class_getitem__":
+ return "classmethod"
+
+ type_name = "method"
+
+ if not self.decorators:
+ return type_name
+
+ for node in self.decorators.nodes:
+ if isinstance(node, node_classes.Name):
+ if node.name in BUILTIN_DESCRIPTORS:
+ return node.name
+ if (
+ isinstance(node, node_classes.Attribute)
+ and isinstance(node.expr, node_classes.Name)
+ and node.expr.name == "builtins"
+ and node.attrname in BUILTIN_DESCRIPTORS
+ ):
+ return node.attrname
+
+ if isinstance(node, node_classes.Call):
+ # Handle the following case:
+ # @some_decorator(arg1, arg2)
+ # def func(...)
+ #
+ try:
+ current = next(node.func.infer())
+ except (InferenceError, StopIteration):
+ continue
+ _type = _infer_decorator_callchain(current)
+ if _type is not None:
+ return _type
+
+ try:
+ for inferred in node.infer():
+ # Check to see if this returns a static or a class method.
+ _type = _infer_decorator_callchain(inferred)
+ if _type is not None:
+ return _type
+
+ if not isinstance(inferred, ClassDef):
+ continue
+ for ancestor in inferred.ancestors():
+ if not isinstance(ancestor, ClassDef):
+ continue
+ if ancestor.is_subtype_of("builtins.classmethod"):
+ return "classmethod"
+ if ancestor.is_subtype_of("builtins.staticmethod"):
+ return "staticmethod"
+ except InferenceError:
+ pass
+ return type_name
+
+ @cached_property
+ def fromlineno(self) -> int:
+ """The first line that this node appears on in the source code.
+
+ Can also return 0 if the line can not be determined.
+ """
+ # lineno is the line number of the first decorator, we want the def
+ # statement lineno. Similar to 'ClassDef.fromlineno'
+ lineno = self.lineno or 0
+ if self.decorators is not None:
+ lineno += sum(
+ node.tolineno - (node.lineno or 0) + 1 for node in self.decorators.nodes
+ )
+
+ return lineno or 0
+
+ @cached_property
+ def blockstart_tolineno(self):
+ """The line on which the beginning of this block ends.
+
+ :type: int
+ """
+ return self.args.tolineno
+
+ def implicit_parameters(self) -> Literal[0, 1]:
+ return 1 if self.is_bound() else 0
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from the given line number to where this node ends.
+
+ :param lineno: Unused.
+
+ :returns: The range of line numbers that this node belongs to,
+ """
+ return self.fromlineno, self.tolineno
+
+ def igetattr(
+ self, name: str, context: InferenceContext | None = None
+ ) -> Iterator[InferenceResult]:
+ """Inferred getattr, which returns an iterator of inferred statements."""
+ try:
+ return bases._infer_stmts(self.getattr(name, context), context, frame=self)
+ except AttributeInferenceError as error:
+ raise InferenceError(
+ str(error), target=self, attribute=name, context=context
+ ) from error
+
+ def is_method(self) -> bool:
+ """Check if this function node represents a method.
+
+ :returns: Whether this is a method.
+ """
+ # check we are defined in a ClassDef, because this is usually expected
+ # (e.g. pylint...) when is_method() return True
+ return (
+ self.type != "function"
+ and self.parent is not None
+ and isinstance(self.parent.frame(), ClassDef)
+ )
+
+ def decoratornames(self, context: InferenceContext | None = None) -> set[str]:
+ """Get the qualified names of each of the decorators on this function.
+
+ :param context:
+ An inference context that can be passed to inference functions
+ :returns: The names of the decorators.
+ """
+ result = set()
+ decoratornodes = []
+ if self.decorators is not None:
+ decoratornodes += self.decorators.nodes
+ decoratornodes += self.extra_decorators
+ for decnode in decoratornodes:
+ try:
+ for infnode in decnode.infer(context=context):
+ result.add(infnode.qname())
+ except InferenceError:
+ continue
+ return result
+
+ def is_bound(self) -> bool:
+ """Check if the function is bound to an instance or class.
+
+ :returns: Whether the function is bound to an instance or class.
+ """
+ return self.type in {"method", "classmethod"}
+
+ def is_abstract(self, pass_is_abstract=True, any_raise_is_abstract=False) -> bool:
+ """Check if the method is abstract.
+
+ A method is considered abstract if any of the following is true:
+ * The only statement is 'raise NotImplementedError'
+ * The only statement is 'raise <SomeException>' and any_raise_is_abstract is True
+ * The only statement is 'pass' and pass_is_abstract is True
+ * The method is annotated with abc.astractproperty/abc.abstractmethod
+
+ :returns: Whether the method is abstract.
+ """
+ if self.decorators:
+ for node in self.decorators.nodes:
+ try:
+ inferred = next(node.infer())
+ except (InferenceError, StopIteration):
+ continue
+ if inferred and inferred.qname() in {
+ "abc.abstractproperty",
+ "abc.abstractmethod",
+ }:
+ return True
+
+ for child_node in self.body:
+ if isinstance(child_node, node_classes.Raise):
+ if any_raise_is_abstract:
+ return True
+ if child_node.raises_not_implemented():
+ return True
+ return pass_is_abstract and isinstance(child_node, node_classes.Pass)
+ # empty function is the same as function with a single "pass" statement
+ if pass_is_abstract:
+ return True
+
+ return False
+
+ def is_generator(self) -> bool:
+ """Check if this is a generator function.
+
+ :returns: Whether this is a generator function.
+ """
+ yields_without_lambdas = set(self._get_yield_nodes_skip_lambdas())
+ yields_without_functions = set(self._get_yield_nodes_skip_functions())
+ # Want an intersecting member that is neither in a lambda nor a function
+ return bool(yields_without_lambdas & yields_without_functions)
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[objects.Property | FunctionDef, None, InferenceErrorInfo]:
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ if not self.decorators or not bases._is_property(self):
+ yield self
+ return InferenceErrorInfo(node=self, context=context)
+
+ # When inferring a property, we instantiate a new `objects.Property` object,
+ # which in turn, because it inherits from `FunctionDef`, sets itself in the locals
+ # of the wrapping frame. This means that every time we infer a property, the locals
+ # are mutated with a new instance of the property. To avoid this, we detect this
+ # scenario and avoid passing the `parent` argument to the constructor.
+ if not self.parent:
+ raise ParentMissingError(target=self)
+ parent_frame = self.parent.frame()
+ property_already_in_parent_locals = self.name in parent_frame.locals and any(
+ isinstance(val, objects.Property) for val in parent_frame.locals[self.name]
+ )
+ # We also don't want to pass parent if the definition is within a Try node
+ if isinstance(
+ self.parent,
+ (node_classes.Try, node_classes.If),
+ ):
+ property_already_in_parent_locals = True
+
+ prop_func = objects.Property(
+ function=self,
+ name=self.name,
+ lineno=self.lineno,
+ parent=self.parent if not property_already_in_parent_locals else None,
+ col_offset=self.col_offset,
+ )
+ if property_already_in_parent_locals:
+ prop_func.parent = self.parent
+ prop_func.postinit(body=[], args=self.args, doc_node=self.doc_node)
+ yield prop_func
+ return InferenceErrorInfo(node=self, context=context)
+
+ def infer_yield_result(self, context: InferenceContext | None = None):
+ """Infer what the function yields when called
+
+ :returns: What the function yields
+ :rtype: iterable(NodeNG or Uninferable) or None
+ """
+ for yield_ in self.nodes_of_class(node_classes.Yield):
+ if yield_.value is None:
+ const = node_classes.Const(None)
+ const.parent = yield_
+ const.lineno = yield_.lineno
+ yield const
+ elif yield_.scope() == self:
+ yield from yield_.value.infer(context=context)
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ """Infer what the function returns when called."""
+ if self.is_generator():
+ if isinstance(self, AsyncFunctionDef):
+ generator_cls: type[bases.Generator] = bases.AsyncGenerator
+ else:
+ generator_cls = bases.Generator
+ result = generator_cls(self, generator_initial_context=context)
+ yield result
+ return
+ # This is really a gigantic hack to work around metaclass generators
+ # that return transient class-generating functions. Pylint's AST structure
+ # cannot handle a base class object that is only used for calling __new__,
+ # but does not contribute to the inheritance structure itself. We inject
+ # a fake class into the hierarchy here for several well-known metaclass
+ # generators, and filter it out later.
+ if (
+ self.name == "with_metaclass"
+ and caller is not None
+ and self.args.args
+ and len(self.args.args) == 1
+ and self.args.vararg is not None
+ ):
+ if isinstance(caller.args, Arguments):
+ assert caller.args.args is not None
+ metaclass = next(caller.args.args[0].infer(context), None)
+ elif isinstance(caller.args, list):
+ metaclass = next(caller.args[0].infer(context), None)
+ else:
+ raise TypeError( # pragma: no cover
+ f"caller.args was neither Arguments nor list; got {type(caller.args)}"
+ )
+ if isinstance(metaclass, ClassDef):
+ try:
+ class_bases = [
+ # Find the first non-None inferred base value
+ next(
+ b
+ for b in arg.infer(
+ context=context.clone() if context else context
+ )
+ if not (isinstance(b, Const) and b.value is None)
+ )
+ for arg in caller.args[1:]
+ ]
+ except StopIteration as e:
+ raise InferenceError(node=caller.args[1:], context=context) from e
+ new_class = ClassDef(
+ name="temporary_class",
+ lineno=0,
+ col_offset=0,
+ end_lineno=0,
+ end_col_offset=0,
+ parent=self,
+ )
+ new_class.hide = True
+ new_class.postinit(
+ bases=[
+ base
+ for base in class_bases
+ if not isinstance(base, util.UninferableBase)
+ ],
+ body=[],
+ decorators=None,
+ metaclass=metaclass,
+ )
+ yield new_class
+ return
+ returns = self._get_return_nodes_skip_functions()
+
+ first_return = next(returns, None)
+ if not first_return:
+ if self.body:
+ if self.is_abstract(pass_is_abstract=True, any_raise_is_abstract=True):
+ yield util.Uninferable
+ else:
+ yield node_classes.Const(None)
+ return
+
+ raise InferenceError("The function does not have any return statements")
+
+ for returnnode in itertools.chain((first_return,), returns):
+ if returnnode.value is None:
+ yield node_classes.Const(None)
+ else:
+ try:
+ yield from returnnode.value.infer(context)
+ except InferenceError:
+ yield util.Uninferable
+
+ def bool_value(self, context: InferenceContext | None = None) -> bool:
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`FunctionDef` this is always ``True``.
+ """
+ return True
+
+ def get_children(self):
+ if self.decorators is not None:
+ yield self.decorators
+
+ yield self.args
+
+ if self.returns is not None:
+ yield self.returns
+ yield from self.type_params
+
+ yield from self.body
+
+ def scope_lookup(
+ self, node: LookupMixIn, name: str, offset: int = 0
+ ) -> tuple[LocalsDictNodeNG, list[nodes.NodeNG]]:
+ """Lookup where the given name is assigned."""
+ if name == "__class__":
+ # __class__ is an implicit closure reference created by the compiler
+ # if any methods in a class body refer to either __class__ or super.
+ # In our case, we want to be able to look it up in the current scope
+ # when `__class__` is being used.
+ if self.parent and isinstance(frame := self.parent.frame(), ClassDef):
+ return self, [frame]
+
+ if (self.args.defaults and node in self.args.defaults) or (
+ self.args.kw_defaults and node in self.args.kw_defaults
+ ):
+ if not self.parent:
+ raise ParentMissingError(target=self)
+ frame = self.parent.frame()
+ # line offset to avoid that def func(f=func) resolve the default
+ # value to the defined function
+ offset = -1
+ else:
+ # check this is not used in function decorators
+ frame = self
+ return frame._scope_lookup(node, name, offset)
+
+ def frame(self: _T, *, future: Literal[None, True] = None) -> _T:
+ """The node's frame node.
+
+ A frame node is a :class:`Module`, :class:`FunctionDef`,
+ :class:`ClassDef` or :class:`Lambda`.
+
+ :returns: The node itself.
+ """
+ return self
+
+
+class AsyncFunctionDef(FunctionDef):
+ """Class representing an :class:`ast.FunctionDef` node.
+
+ A :class:`AsyncFunctionDef` is an asynchronous function
+ created with the `async` keyword.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ async def func(things):
+ async for thing in things:
+ print(thing)
+ ''')
+ >>> node
+ <AsyncFunctionDef.func l.2 at 0x7f23b2e416d8>
+ >>> node.body[0]
+ <AsyncFor l.3 at 0x7f23b2e417b8>
+ """
+
+
+def _is_metaclass(
+ klass: ClassDef,
+ seen: set[str] | None = None,
+ context: InferenceContext | None = None,
+) -> bool:
+ """Return if the given class can be
+ used as a metaclass.
+ """
+ if klass.name == "type":
+ return True
+ if seen is None:
+ seen = set()
+ for base in klass.bases:
+ try:
+ for baseobj in base.infer(context=context):
+ baseobj_name = baseobj.qname()
+ if baseobj_name in seen:
+ continue
+
+ seen.add(baseobj_name)
+ if isinstance(baseobj, bases.Instance):
+ # not abstract
+ return False
+ if baseobj is klass:
+ continue
+ if not isinstance(baseobj, ClassDef):
+ continue
+ if baseobj._type == "metaclass":
+ return True
+ if _is_metaclass(baseobj, seen, context=context):
+ return True
+ except InferenceError:
+ continue
+ return False
+
+
+def _class_type(
+ klass: ClassDef,
+ ancestors: set[str] | None = None,
+ context: InferenceContext | None = None,
+) -> Literal["class", "exception", "metaclass"]:
+ """return a ClassDef node type to differ metaclass and exception
+ from 'regular' classes
+ """
+ # XXX we have to store ancestors in case we have an ancestor loop
+ if klass._type is not None:
+ return klass._type
+ if _is_metaclass(klass, context=context):
+ klass._type = "metaclass"
+ elif klass.name.endswith("Exception"):
+ klass._type = "exception"
+ else:
+ if ancestors is None:
+ ancestors = set()
+ klass_name = klass.qname()
+ if klass_name in ancestors:
+ # XXX we are in loop ancestors, and have found no type
+ klass._type = "class"
+ return "class"
+ ancestors.add(klass_name)
+ for base in klass.ancestors(recurs=False):
+ name = _class_type(base, ancestors)
+ if name != "class":
+ if name == "metaclass" and klass._type != "metaclass":
+ # don't propagate it if the current class
+ # can't be a metaclass
+ continue
+ klass._type = base.type
+ break
+ if klass._type is None:
+ klass._type = "class"
+ return klass._type
+
+
+def get_wrapping_class(node):
+ """Get the class that wraps the given node.
+
+ We consider that a class wraps a node if the class
+ is a parent for the said node.
+
+ :returns: The class that wraps the given node
+ :rtype: ClassDef or None
+ """
+
+ klass = node.frame()
+ while klass is not None and not isinstance(klass, ClassDef):
+ if klass.parent is None:
+ klass = None
+ else:
+ klass = klass.parent.frame()
+ return klass
+
+
+class ClassDef( # pylint: disable=too-many-instance-attributes
+ _base_nodes.FilterStmtsBaseNode, LocalsDictNodeNG, _base_nodes.Statement
+):
+ """Class representing an :class:`ast.ClassDef` node.
+
+ >>> import astroid
+ >>> node = astroid.extract_node('''
+ class Thing:
+ def my_meth(self, arg):
+ return arg + self.offset
+ ''')
+ >>> node
+ <ClassDef.Thing l.2 at 0x7f23b2e9e748>
+ """
+
+ # some of the attributes below are set by the builder module or
+ # by a raw factories
+
+ # a dictionary of class instances attributes
+ _astroid_fields = (
+ "decorators",
+ "bases",
+ "keywords",
+ "doc_node",
+ "body",
+ "type_params",
+ ) # name
+
+ decorators = None
+ """The decorators that are applied to this class.
+
+ :type: Decorators or None
+ """
+ special_attributes = ClassModel()
+ """The names of special attributes that this class has.
+
+ :type: objectmodel.ClassModel
+ """
+
+ _type: Literal["class", "exception", "metaclass"] | None = None
+ _metaclass: NodeNG | None = None
+ _metaclass_hack = False
+ hide = False
+ type = property(
+ _class_type,
+ doc=(
+ "The class type for this node.\n\n"
+ "Possible values are: class, metaclass, exception.\n\n"
+ ":type: str"
+ ),
+ )
+ _other_fields = ("name", "is_dataclass", "position")
+ _other_other_fields = ("locals", "_newstyle")
+ _newstyle: bool | None = None
+
+ def __init__(
+ self,
+ name: str,
+ lineno: int,
+ col_offset: int,
+ parent: NodeNG,
+ *,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ self.instance_attrs: dict[str, NodeNG] = {}
+ self.locals = {}
+ """A map of the name of a local variable to the node defining it."""
+
+ self.keywords: list[node_classes.Keyword] = []
+ """The keywords given to the class definition.
+
+ This is usually for :pep:`3115` style metaclass declaration.
+ """
+
+ self.bases: list[SuccessfulInferenceResult] = []
+ """What the class inherits from."""
+
+ self.body: list[NodeNG] = []
+ """The contents of the class body."""
+
+ self.name = name
+ """The name of the class."""
+
+ self.decorators = None
+ """The decorators that are applied to this class."""
+
+ self.doc_node: Const | None = None
+ """The doc node associated with this node."""
+
+ self.is_dataclass: bool = False
+ """Whether this class is a dataclass."""
+
+ self.type_params: list[nodes.TypeVar | nodes.ParamSpec | nodes.TypeVarTuple] = (
+ []
+ )
+ """PEP 695 (Python 3.12+) type params, e.g. class MyClass[T]: ..."""
+
+ super().__init__(
+ lineno=lineno,
+ col_offset=col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+ if parent and not isinstance(parent, Unknown):
+ parent.frame().set_local(name, self)
+
+ for local_name, node in self.implicit_locals():
+ self.add_local_node(node, local_name)
+
+ infer_binary_op: ClassVar[InferBinaryOp[ClassDef]] = (
+ protocols.instance_class_infer_binary_op
+ )
+
+ def implicit_parameters(self) -> Literal[1]:
+ return 1
+
+ def implicit_locals(self):
+ """Get implicitly defined class definition locals.
+
+ :returns: the the name and Const pair for each local
+ :rtype: tuple(tuple(str, node_classes.Const), ...)
+ """
+ locals_ = (("__module__", self.special_attributes.attr___module__),)
+ # __qualname__ is defined in PEP3155
+ locals_ += (
+ ("__qualname__", self.special_attributes.attr___qualname__),
+ ("__annotations__", self.special_attributes.attr___annotations__),
+ )
+ return locals_
+
+ # pylint: disable=redefined-outer-name
+ def postinit(
+ self,
+ bases: list[SuccessfulInferenceResult],
+ body: list[NodeNG],
+ decorators: node_classes.Decorators | None,
+ newstyle: bool | None = None,
+ metaclass: NodeNG | None = None,
+ keywords: list[node_classes.Keyword] | None = None,
+ *,
+ position: Position | None = None,
+ doc_node: Const | None = None,
+ type_params: (
+ list[nodes.TypeVar | nodes.ParamSpec | nodes.TypeVarTuple] | None
+ ) = None,
+ ) -> None:
+ if keywords is not None:
+ self.keywords = keywords
+ self.bases = bases
+ self.body = body
+ self.decorators = decorators
+ self._newstyle = newstyle
+ self._metaclass = metaclass
+ self.position = position
+ self.doc_node = doc_node
+ self.type_params = type_params or []
+
+ def _newstyle_impl(self, context: InferenceContext | None = None):
+ if context is None:
+ context = InferenceContext()
+ if self._newstyle is not None:
+ return self._newstyle
+ for base in self.ancestors(recurs=False, context=context):
+ if base._newstyle_impl(context):
+ self._newstyle = True
+ break
+ klass = self.declared_metaclass()
+ # could be any callable, we'd need to infer the result of klass(name,
+ # bases, dict). punt if it's not a class node.
+ if klass is not None and isinstance(klass, ClassDef):
+ self._newstyle = klass._newstyle_impl(context)
+ if self._newstyle is None:
+ self._newstyle = False
+ return self._newstyle
+
+ _newstyle = None
+ newstyle = property(
+ _newstyle_impl,
+ doc=("Whether this is a new style class or not\n\n" ":type: bool or None"),
+ )
+
+ @cached_property
+ def blockstart_tolineno(self):
+ """The line on which the beginning of this block ends.
+
+ :type: int
+ """
+ if self.bases:
+ return self.bases[-1].tolineno
+
+ return self.fromlineno
+
+ def block_range(self, lineno: int) -> tuple[int, int]:
+ """Get a range from the given line number to where this node ends.
+
+ :param lineno: Unused.
+
+ :returns: The range of line numbers that this node belongs to,
+ """
+ return self.fromlineno, self.tolineno
+
+ def pytype(self) -> Literal["builtins.type", "builtins.classobj"]:
+ """Get the name of the type that this node represents.
+
+ :returns: The name of the type.
+ """
+ if self.newstyle:
+ return "builtins.type"
+ return "builtins.classobj"
+
+ def display_type(self) -> str:
+ """A human readable type of this node.
+
+ :returns: The type of this node.
+ :rtype: str
+ """
+ return "Class"
+
+ def callable(self) -> bool:
+ """Whether this node defines something that is callable.
+
+ :returns: Whether this defines something that is callable.
+ For a :class:`ClassDef` this is always ``True``.
+ """
+ return True
+
+ def is_subtype_of(self, type_name, context: InferenceContext | None = None) -> bool:
+ """Whether this class is a subtype of the given type.
+
+ :param type_name: The name of the type of check against.
+ :type type_name: str
+
+ :returns: Whether this class is a subtype of the given type.
+ """
+ if self.qname() == type_name:
+ return True
+
+ return any(anc.qname() == type_name for anc in self.ancestors(context=context))
+
+ def _infer_type_call(self, caller, context):
+ try:
+ name_node = next(caller.args[0].infer(context))
+ except StopIteration as e:
+ raise InferenceError(node=caller.args[0], context=context) from e
+ if isinstance(name_node, node_classes.Const) and isinstance(
+ name_node.value, str
+ ):
+ name = name_node.value
+ else:
+ return util.Uninferable
+
+ result = ClassDef(
+ name,
+ lineno=0,
+ col_offset=0,
+ end_lineno=0,
+ end_col_offset=0,
+ parent=Unknown(),
+ )
+
+ # Get the bases of the class.
+ try:
+ class_bases = next(caller.args[1].infer(context))
+ except StopIteration as e:
+ raise InferenceError(node=caller.args[1], context=context) from e
+ if isinstance(class_bases, (node_classes.Tuple, node_classes.List)):
+ bases = []
+ for base in class_bases.itered():
+ inferred = next(base.infer(context=context), None)
+ if inferred:
+ bases.append(
+ node_classes.EvaluatedObject(original=base, value=inferred)
+ )
+ result.bases = bases
+ else:
+ # There is currently no AST node that can represent an 'unknown'
+ # node (Uninferable is not an AST node), therefore we simply return Uninferable here
+ # although we know at least the name of the class.
+ return util.Uninferable
+
+ # Get the members of the class
+ try:
+ members = next(caller.args[2].infer(context))
+ except (InferenceError, StopIteration):
+ members = None
+
+ if members and isinstance(members, node_classes.Dict):
+ for attr, value in members.items:
+ if isinstance(attr, node_classes.Const) and isinstance(attr.value, str):
+ result.locals[attr.value] = [value]
+
+ result.parent = caller.parent
+ return result
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ """infer what a class is returning when called"""
+ if self.is_subtype_of("builtins.type", context) and len(caller.args) == 3:
+ result = self._infer_type_call(caller, context)
+ yield result
+ return
+
+ dunder_call = None
+ try:
+ metaclass = self.metaclass(context=context)
+ if metaclass is not None:
+ # Only get __call__ if it's defined locally for the metaclass.
+ # Otherwise we will find ObjectModel.__call__ which will
+ # return an instance of the metaclass. Instantiating the class is
+ # handled later.
+ if "__call__" in metaclass.locals:
+ dunder_call = next(metaclass.igetattr("__call__", context))
+ except (AttributeInferenceError, StopIteration):
+ pass
+
+ if dunder_call and dunder_call.qname() != "builtins.type.__call__":
+ # Call type.__call__ if not set metaclass
+ # (since type is the default metaclass)
+ context = bind_context_to_node(context, self)
+ context.callcontext.callee = dunder_call
+ yield from dunder_call.infer_call_result(caller, context)
+ else:
+ yield self.instantiate_class()
+
+ def scope_lookup(
+ self, node: LookupMixIn, name: str, offset: int = 0
+ ) -> tuple[LocalsDictNodeNG, list[nodes.NodeNG]]:
+ """Lookup where the given name is assigned.
+
+ :param node: The node to look for assignments up to.
+ Any assignments after the given node are ignored.
+
+ :param name: The name to find assignments for.
+
+ :param offset: The line offset to filter statements up to.
+
+ :returns: This scope node and the list of assignments associated to the
+ given name according to the scope where it has been found (locals,
+ globals or builtin).
+ """
+ # If the name looks like a builtin name, just try to look
+ # into the upper scope of this class. We might have a
+ # decorator that it's poorly named after a builtin object
+ # inside this class.
+ lookup_upper_frame = (
+ isinstance(node.parent, node_classes.Decorators)
+ and name in AstroidManager().builtins_module
+ )
+ if (
+ any(
+ node == base or base.parent_of(node) and not self.type_params
+ for base in self.bases
+ )
+ or lookup_upper_frame
+ ):
+ # Handle the case where we have either a name
+ # in the bases of a class, which exists before
+ # the actual definition or the case where we have
+ # a Getattr node, with that name.
+ #
+ # name = ...
+ # class A(name):
+ # def name(self): ...
+ #
+ # import name
+ # class A(name.Name):
+ # def name(self): ...
+ if not self.parent:
+ raise ParentMissingError(target=self)
+ frame = self.parent.frame()
+ # line offset to avoid that class A(A) resolve the ancestor to
+ # the defined class
+ offset = -1
+ else:
+ frame = self
+ return frame._scope_lookup(node, name, offset)
+
+ @property
+ def basenames(self):
+ """The names of the parent classes
+
+ Names are given in the order they appear in the class definition.
+
+ :type: list(str)
+ """
+ return [bnode.as_string() for bnode in self.bases]
+
+ def ancestors(
+ self, recurs: bool = True, context: InferenceContext | None = None
+ ) -> Generator[ClassDef]:
+ """Iterate over the base classes in prefixed depth first order.
+
+ :param recurs: Whether to recurse or return direct ancestors only.
+
+ :returns: The base classes
+ """
+ # FIXME: should be possible to choose the resolution order
+ # FIXME: inference make infinite loops possible here
+ yielded = {self}
+ if context is None:
+ context = InferenceContext()
+ if not self.bases and self.qname() != "builtins.object":
+ # This should always be a ClassDef (which we don't assert for)
+ yield builtin_lookup("object")[1][0] # type: ignore[misc]
+ return
+
+ for stmt in self.bases:
+ with context.restore_path():
+ try:
+ for baseobj in stmt.infer(context):
+ if not isinstance(baseobj, ClassDef):
+ if isinstance(baseobj, bases.Instance):
+ baseobj = baseobj._proxied
+ else:
+ continue
+ if not baseobj.hide:
+ if baseobj in yielded:
+ continue
+ yielded.add(baseobj)
+ yield baseobj
+ if not recurs:
+ continue
+ for grandpa in baseobj.ancestors(recurs=True, context=context):
+ if grandpa is self:
+ # This class is the ancestor of itself.
+ break
+ if grandpa in yielded:
+ continue
+ yielded.add(grandpa)
+ yield grandpa
+ except InferenceError:
+ continue
+
+ def local_attr_ancestors(self, name, context: InferenceContext | None = None):
+ """Iterate over the parents that define the given name.
+
+ :param name: The name to find definitions for.
+ :type name: str
+
+ :returns: The parents that define the given name.
+ :rtype: iterable(NodeNG)
+ """
+ # Look up in the mro if we can. This will result in the
+ # attribute being looked up just as Python does it.
+ try:
+ ancestors: Iterable[ClassDef] = self.mro(context)[1:]
+ except MroError:
+ # Fallback to use ancestors, we can't determine
+ # a sane MRO.
+ ancestors = self.ancestors(context=context)
+ for astroid in ancestors:
+ if name in astroid:
+ yield astroid
+
+ def instance_attr_ancestors(self, name, context: InferenceContext | None = None):
+ """Iterate over the parents that define the given name as an attribute.
+
+ :param name: The name to find definitions for.
+ :type name: str
+
+ :returns: The parents that define the given name as
+ an instance attribute.
+ :rtype: iterable(NodeNG)
+ """
+ for astroid in self.ancestors(context=context):
+ if name in astroid.instance_attrs:
+ yield astroid
+
+ def has_base(self, node) -> bool:
+ """Whether this class directly inherits from the given node.
+
+ :param node: The node to check for.
+ :type node: NodeNG
+
+ :returns: Whether this class directly inherits from the given node.
+ """
+ return node in self.bases
+
+ def local_attr(self, name, context: InferenceContext | None = None):
+ """Get the list of assign nodes associated to the given name.
+
+ Assignments are looked for in both this class and in parents.
+
+ :returns: The list of assignments to the given name.
+ :rtype: list(NodeNG)
+
+ :raises AttributeInferenceError: If no attribute with this name
+ can be found in this class or parent classes.
+ """
+ result = []
+ if name in self.locals:
+ result = self.locals[name]
+ else:
+ class_node = next(self.local_attr_ancestors(name, context), None)
+ if class_node:
+ result = class_node.locals[name]
+ result = [n for n in result if not isinstance(n, node_classes.DelAttr)]
+ if result:
+ return result
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ def instance_attr(self, name, context: InferenceContext | None = None):
+ """Get the list of nodes associated to the given attribute name.
+
+ Assignments are looked for in both this class and in parents.
+
+ :returns: The list of assignments to the given name.
+ :rtype: list(NodeNG)
+
+ :raises AttributeInferenceError: If no attribute with this name
+ can be found in this class or parent classes.
+ """
+ # Return a copy, so we don't modify self.instance_attrs,
+ # which could lead to infinite loop.
+ values = list(self.instance_attrs.get(name, []))
+ # get all values from parents
+ for class_node in self.instance_attr_ancestors(name, context):
+ values += class_node.instance_attrs[name]
+ values = [n for n in values if not isinstance(n, node_classes.DelAttr)]
+ if values:
+ return values
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ def instantiate_class(self) -> bases.Instance:
+ """Get an :class:`Instance` of the :class:`ClassDef` node.
+
+ :returns: An :class:`Instance` of the :class:`ClassDef` node
+ """
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ try:
+ if any(cls.name in EXCEPTION_BASE_CLASSES for cls in self.mro()):
+ # Subclasses of exceptions can be exception instances
+ return objects.ExceptionInstance(self)
+ except MroError:
+ pass
+ return bases.Instance(self)
+
+ def getattr(
+ self,
+ name: str,
+ context: InferenceContext | None = None,
+ class_context: bool = True,
+ ) -> list[InferenceResult]:
+ """Get an attribute from this class, using Python's attribute semantic.
+
+ This method doesn't look in the :attr:`instance_attrs` dictionary
+ since it is done by an :class:`Instance` proxy at inference time.
+ It may return an :class:`Uninferable` object if
+ the attribute has not been
+ found, but a ``__getattr__`` or ``__getattribute__`` method is defined.
+ If ``class_context`` is given, then it is considered that the
+ attribute is accessed from a class context,
+ e.g. ClassDef.attribute, otherwise it might have been accessed
+ from an instance as well. If ``class_context`` is used in that
+ case, then a lookup in the implicit metaclass and the explicit
+ metaclass will be done.
+
+ :param name: The attribute to look for.
+
+ :param class_context: Whether the attribute can be accessed statically.
+
+ :returns: The attribute.
+
+ :raises AttributeInferenceError: If the attribute cannot be inferred.
+ """
+ if not name:
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ # don't modify the list in self.locals!
+ values: list[InferenceResult] = list(self.locals.get(name, []))
+ for classnode in self.ancestors(recurs=True, context=context):
+ values += classnode.locals.get(name, [])
+
+ if name in self.special_attributes and class_context and not values:
+ result = [self.special_attributes.lookup(name)]
+ if name == "__bases__":
+ # Need special treatment, since they are mutable
+ # and we need to return all the values.
+ result += values
+ return result
+
+ if class_context:
+ values += self._metaclass_lookup_attribute(name, context)
+
+ # Remove AnnAssigns without value, which are not attributes in the purest sense.
+ for value in values.copy():
+ if isinstance(value, node_classes.AssignName):
+ stmt = value.statement()
+ if isinstance(stmt, node_classes.AnnAssign) and stmt.value is None:
+ values.pop(values.index(value))
+
+ if not values:
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ return values
+
+ @lru_cache(maxsize=1024) # noqa
+ def _metaclass_lookup_attribute(self, name, context):
+ """Search the given name in the implicit and the explicit metaclass."""
+ attrs = set()
+ implicit_meta = self.implicit_metaclass()
+ context = copy_context(context)
+ metaclass = self.metaclass(context=context)
+ for cls in (implicit_meta, metaclass):
+ if cls and cls != self and isinstance(cls, ClassDef):
+ cls_attributes = self._get_attribute_from_metaclass(cls, name, context)
+ attrs.update(set(cls_attributes))
+ return attrs
+
+ def _get_attribute_from_metaclass(self, cls, name, context):
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ try:
+ attrs = cls.getattr(name, context=context, class_context=True)
+ except AttributeInferenceError:
+ return
+
+ for attr in bases._infer_stmts(attrs, context, frame=cls):
+ if not isinstance(attr, FunctionDef):
+ yield attr
+ continue
+
+ if isinstance(attr, objects.Property):
+ yield attr
+ continue
+ if attr.type == "classmethod":
+ # If the method is a classmethod, then it will
+ # be bound to the metaclass, not to the class
+ # from where the attribute is retrieved.
+ # get_wrapping_class could return None, so just
+ # default to the current class.
+ frame = get_wrapping_class(attr) or self
+ yield bases.BoundMethod(attr, frame)
+ elif attr.type == "staticmethod":
+ yield attr
+ else:
+ yield bases.BoundMethod(attr, self)
+
+ def igetattr(
+ self,
+ name: str,
+ context: InferenceContext | None = None,
+ class_context: bool = True,
+ ) -> Iterator[InferenceResult]:
+ """Infer the possible values of the given variable.
+
+ :param name: The name of the variable to infer.
+
+ :returns: The inferred possible values.
+ """
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ # set lookup name since this is necessary to infer on import nodes for
+ # instance
+ context = copy_context(context)
+ context.lookupname = name
+
+ metaclass = self.metaclass(context=context)
+ try:
+ attributes = self.getattr(name, context, class_context=class_context)
+ # If we have more than one attribute, make sure that those starting from
+ # the second one are from the same scope. This is to account for modifications
+ # to the attribute happening *after* the attribute's definition (e.g. AugAssigns on lists)
+ if len(attributes) > 1:
+ first_attr, attributes = attributes[0], attributes[1:]
+ first_scope = first_attr.parent.scope()
+ attributes = [first_attr] + [
+ attr
+ for attr in attributes
+ if attr.parent and attr.parent.scope() == first_scope
+ ]
+ functions = [attr for attr in attributes if isinstance(attr, FunctionDef)]
+ setter = None
+ for function in functions:
+ dec_names = function.decoratornames(context=context)
+ for dec_name in dec_names:
+ if dec_name is util.Uninferable:
+ continue
+ if dec_name.split(".")[-1] == "setter":
+ setter = function
+ if setter:
+ break
+ if functions:
+ # Prefer only the last function, unless a property is involved.
+ last_function = functions[-1]
+ attributes = [
+ a
+ for a in attributes
+ if a not in functions or a is last_function or bases._is_property(a)
+ ]
+
+ for inferred in bases._infer_stmts(attributes, context, frame=self):
+ # yield Uninferable object instead of descriptors when necessary
+ if not isinstance(inferred, node_classes.Const) and isinstance(
+ inferred, bases.Instance
+ ):
+ try:
+ inferred._proxied.getattr("__get__", context)
+ except AttributeInferenceError:
+ yield inferred
+ else:
+ yield util.Uninferable
+ elif isinstance(inferred, objects.Property):
+ function = inferred.function
+ if not class_context:
+ if not context.callcontext and not setter:
+ context.callcontext = CallContext(
+ args=function.args.arguments, callee=function
+ )
+ # Through an instance so we can solve the property
+ yield from function.infer_call_result(
+ caller=self, context=context
+ )
+ # If we're in a class context, we need to determine if the property
+ # was defined in the metaclass (a derived class must be a subclass of
+ # the metaclass of all its bases), in which case we can resolve the
+ # property. If not, i.e. the property is defined in some base class
+ # instead, then we return the property object
+ elif metaclass and function.parent.scope() is metaclass:
+ # Resolve a property as long as it is not accessed through
+ # the class itself.
+ yield from function.infer_call_result(
+ caller=self, context=context
+ )
+ else:
+ yield inferred
+ else:
+ yield function_to_method(inferred, self)
+ except AttributeInferenceError as error:
+ if not name.startswith("__") and self.has_dynamic_getattr(context):
+ # class handle some dynamic attributes, return a Uninferable object
+ yield util.Uninferable
+ else:
+ raise InferenceError(
+ str(error), target=self, attribute=name, context=context
+ ) from error
+
+ def has_dynamic_getattr(self, context: InferenceContext | None = None) -> bool:
+ """Check if the class has a custom __getattr__ or __getattribute__.
+
+ If any such method is found and it is not from
+ builtins, nor from an extension module, then the function
+ will return True.
+
+ :returns: Whether the class has a custom __getattr__ or __getattribute__.
+ """
+
+ def _valid_getattr(node):
+ root = node.root()
+ return root.name != "builtins" and getattr(root, "pure_python", None)
+
+ try:
+ return _valid_getattr(self.getattr("__getattr__", context)[0])
+ except AttributeInferenceError:
+ # if self.newstyle: XXX cause an infinite recursion error
+ try:
+ getattribute = self.getattr("__getattribute__", context)[0]
+ return _valid_getattr(getattribute)
+ except AttributeInferenceError:
+ pass
+ return False
+
+ def getitem(self, index, context: InferenceContext | None = None):
+ """Return the inference of a subscript.
+
+ This is basically looking up the method in the metaclass and calling it.
+
+ :returns: The inferred value of a subscript to this class.
+ :rtype: NodeNG
+
+ :raises AstroidTypeError: If this class does not define a
+ ``__getitem__`` method.
+ """
+ try:
+ methods = lookup(self, "__getitem__", context=context)
+ except AttributeInferenceError as exc:
+ if isinstance(self, ClassDef):
+ # subscripting a class definition may be
+ # achieved thanks to __class_getitem__ method
+ # which is a classmethod defined in the class
+ # that supports subscript and not in the metaclass
+ try:
+ methods = self.getattr("__class_getitem__")
+ # Here it is assumed that the __class_getitem__ node is
+ # a FunctionDef. One possible improvement would be to deal
+ # with more generic inference.
+ except AttributeInferenceError:
+ raise AstroidTypeError(node=self, context=context) from exc
+ else:
+ raise AstroidTypeError(node=self, context=context) from exc
+
+ method = methods[0]
+
+ # Create a new callcontext for providing index as an argument.
+ new_context = bind_context_to_node(context, self)
+ new_context.callcontext = CallContext(args=[index], callee=method)
+
+ try:
+ return next(method.infer_call_result(self, new_context), util.Uninferable)
+ except AttributeError:
+ # Starting with python3.9, builtin types list, dict etc...
+ # are subscriptable thanks to __class_getitem___ classmethod.
+ # However in such case the method is bound to an EmptyNode and
+ # EmptyNode doesn't have infer_call_result method yielding to
+ # AttributeError
+ if (
+ isinstance(method, node_classes.EmptyNode)
+ and self.pytype() == "builtins.type"
+ ):
+ return self
+ raise
+ except InferenceError:
+ return util.Uninferable
+
+ def methods(self):
+ """Iterate over all of the method defined in this class and its parents.
+
+ :returns: The methods defined on the class.
+ :rtype: iterable(FunctionDef)
+ """
+ done = {}
+ for astroid in itertools.chain(iter((self,)), self.ancestors()):
+ for meth in astroid.mymethods():
+ if meth.name in done:
+ continue
+ done[meth.name] = None
+ yield meth
+
+ def mymethods(self):
+ """Iterate over all of the method defined in this class only.
+
+ :returns: The methods defined on the class.
+ :rtype: iterable(FunctionDef)
+ """
+ for member in self.values():
+ if isinstance(member, FunctionDef):
+ yield member
+
+ def implicit_metaclass(self):
+ """Get the implicit metaclass of the current class.
+
+ For newstyle classes, this will return an instance of builtins.type.
+ For oldstyle classes, it will simply return None, since there's
+ no implicit metaclass there.
+
+ :returns: The metaclass.
+ :rtype: builtins.type or None
+ """
+ if self.newstyle:
+ return builtin_lookup("type")[1][0]
+ return None
+
+ def declared_metaclass(
+ self, context: InferenceContext | None = None
+ ) -> SuccessfulInferenceResult | None:
+ """Return the explicit declared metaclass for the current class.
+
+ An explicit declared metaclass is defined
+ either by passing the ``metaclass`` keyword argument
+ in the class definition line (Python 3) or (Python 2) by
+ having a ``__metaclass__`` class attribute, or if there are
+ no explicit bases but there is a global ``__metaclass__`` variable.
+
+ :returns: The metaclass of this class,
+ or None if one could not be found.
+ """
+ for base in self.bases:
+ try:
+ for baseobj in base.infer(context=context):
+ if isinstance(baseobj, ClassDef) and baseobj.hide:
+ self._metaclass = baseobj._metaclass
+ self._metaclass_hack = True
+ break
+ except InferenceError:
+ pass
+
+ if self._metaclass:
+ # Expects this from Py3k TreeRebuilder
+ try:
+ return next(
+ node
+ for node in self._metaclass.infer(context=context)
+ if not isinstance(node, util.UninferableBase)
+ )
+ except (InferenceError, StopIteration):
+ return None
+
+ return None
+
+ def _find_metaclass(
+ self, seen: set[ClassDef] | None = None, context: InferenceContext | None = None
+ ) -> SuccessfulInferenceResult | None:
+ if seen is None:
+ seen = set()
+ seen.add(self)
+
+ klass = self.declared_metaclass(context=context)
+ if klass is None:
+ for parent in self.ancestors(context=context):
+ if parent not in seen:
+ klass = parent._find_metaclass(seen)
+ if klass is not None:
+ break
+ return klass
+
+ def metaclass(
+ self, context: InferenceContext | None = None
+ ) -> SuccessfulInferenceResult | None:
+ """Get the metaclass of this class.
+
+ If this class does not define explicitly a metaclass,
+ then the first defined metaclass in ancestors will be used
+ instead.
+
+ :returns: The metaclass of this class.
+ """
+ return self._find_metaclass(context=context)
+
+ def has_metaclass_hack(self):
+ return self._metaclass_hack
+
+ def _islots(self):
+ """Return an iterator with the inferred slots."""
+ if "__slots__" not in self.locals:
+ return None
+ for slots in self.igetattr("__slots__"):
+ # check if __slots__ is a valid type
+ for meth in ITER_METHODS:
+ try:
+ slots.getattr(meth)
+ break
+ except AttributeInferenceError:
+ continue
+ else:
+ continue
+
+ if isinstance(slots, node_classes.Const):
+ # a string. Ignore the following checks,
+ # but yield the node, only if it has a value
+ if slots.value:
+ yield slots
+ continue
+ if not hasattr(slots, "itered"):
+ # we can't obtain the values, maybe a .deque?
+ continue
+
+ if isinstance(slots, node_classes.Dict):
+ values = [item[0] for item in slots.items]
+ else:
+ values = slots.itered()
+ if isinstance(values, util.UninferableBase):
+ continue
+ if not values:
+ # Stop the iteration, because the class
+ # has an empty list of slots.
+ return values
+
+ for elt in values:
+ try:
+ for inferred in elt.infer():
+ if not isinstance(
+ inferred, node_classes.Const
+ ) or not isinstance(inferred.value, str):
+ continue
+ if not inferred.value:
+ continue
+ yield inferred
+ except InferenceError:
+ continue
+
+ return None
+
+ def _slots(self):
+ if not self.newstyle:
+ raise NotImplementedError(
+ "The concept of slots is undefined for old-style classes."
+ )
+
+ slots = self._islots()
+ try:
+ first = next(slots)
+ except StopIteration as exc:
+ # The class doesn't have a __slots__ definition or empty slots.
+ if exc.args and exc.args[0] not in ("", None):
+ return exc.args[0]
+ return None
+ return [first, *slots]
+
+ # Cached, because inferring them all the time is expensive
+ @cached_property
+ def _all_slots(self):
+ """Get all the slots for this node.
+
+ :returns: The names of slots for this class.
+ If the class doesn't define any slot, through the ``__slots__``
+ variable, then this function will return a None.
+ Also, it will return None in the case the slots were not inferred.
+ :rtype: list(str) or None
+ """
+
+ def grouped_slots(
+ mro: list[ClassDef],
+ ) -> Iterator[node_classes.NodeNG | None]:
+ for cls in mro:
+ # Not interested in object, since it can't have slots.
+ if cls.qname() == "builtins.object":
+ continue
+ try:
+ cls_slots = cls._slots()
+ except NotImplementedError:
+ continue
+ if cls_slots is not None:
+ yield from cls_slots
+ else:
+ yield None
+
+ if not self.newstyle:
+ raise NotImplementedError(
+ "The concept of slots is undefined for old-style classes."
+ )
+
+ try:
+ mro = self.mro()
+ except MroError as e:
+ raise NotImplementedError(
+ "Cannot get slots while parsing mro fails."
+ ) from e
+
+ slots = list(grouped_slots(mro))
+ if not all(slot is not None for slot in slots):
+ return None
+
+ return sorted(set(slots), key=lambda item: item.value)
+
+ def slots(self):
+ return self._all_slots
+
+ def _inferred_bases(self, context: InferenceContext | None = None):
+ # Similar with .ancestors, but the difference is when one base is inferred,
+ # only the first object is wanted. That's because
+ # we aren't interested in superclasses, as in the following
+ # example:
+ #
+ # class SomeSuperClass(object): pass
+ # class SomeClass(SomeSuperClass): pass
+ # class Test(SomeClass): pass
+ #
+ # Inferring SomeClass from the Test's bases will give
+ # us both SomeClass and SomeSuperClass, but we are interested
+ # only in SomeClass.
+
+ if context is None:
+ context = InferenceContext()
+ if not self.bases and self.qname() != "builtins.object":
+ yield builtin_lookup("object")[1][0]
+ return
+
+ for stmt in self.bases:
+ try:
+ # Find the first non-None inferred base value
+ baseobj = next(
+ b
+ for b in stmt.infer(context=context.clone())
+ if not (isinstance(b, Const) and b.value is None)
+ )
+ except (InferenceError, StopIteration):
+ continue
+ if isinstance(baseobj, bases.Instance):
+ baseobj = baseobj._proxied
+ if not isinstance(baseobj, ClassDef):
+ continue
+ if not baseobj.hide:
+ yield baseobj
+ else:
+ yield from baseobj.bases
+
+ def _compute_mro(self, context: InferenceContext | None = None):
+ if self.qname() == "builtins.object":
+ return [self]
+
+ inferred_bases = list(self._inferred_bases(context=context))
+ bases_mro = []
+ for base in inferred_bases:
+ if base is self:
+ continue
+
+ try:
+ mro = base._compute_mro(context=context)
+ bases_mro.append(mro)
+ except NotImplementedError:
+ # Some classes have in their ancestors both newstyle and
+ # old style classes. For these we can't retrieve the .mro,
+ # although in Python it's possible, since the class we are
+ # currently working is in fact new style.
+ # So, we fallback to ancestors here.
+ ancestors = list(base.ancestors(context=context))
+ bases_mro.append(ancestors)
+
+ unmerged_mro: list[list[ClassDef]] = [[self], *bases_mro, inferred_bases]
+ unmerged_mro = clean_duplicates_mro(unmerged_mro, self, context)
+ clean_typing_generic_mro(unmerged_mro)
+ return _c3_merge(unmerged_mro, self, context)
+
+ def mro(self, context: InferenceContext | None = None) -> list[ClassDef]:
+ """Get the method resolution order, using C3 linearization.
+
+ :returns: The list of ancestors, sorted by the mro.
+ :rtype: list(NodeNG)
+ :raises DuplicateBasesError: Duplicate bases in the same class base
+ :raises InconsistentMroError: A class' MRO is inconsistent
+ """
+ return self._compute_mro(context=context)
+
+ def bool_value(self, context: InferenceContext | None = None) -> Literal[True]:
+ """Determine the boolean value of this node.
+
+ :returns: The boolean value of this node.
+ For a :class:`ClassDef` this is always ``True``.
+ """
+ return True
+
+ def get_children(self):
+ if self.decorators is not None:
+ yield self.decorators
+
+ yield from self.bases
+ if self.keywords is not None:
+ yield from self.keywords
+ yield from self.type_params
+
+ yield from self.body
+
+ @cached_property
+ def _assign_nodes_in_scope(self):
+ children_assign_nodes = (
+ child_node._assign_nodes_in_scope for child_node in self.body
+ )
+ return list(itertools.chain.from_iterable(children_assign_nodes))
+
+ def frame(self: _T, *, future: Literal[None, True] = None) -> _T:
+ """The node's frame node.
+
+ A frame node is a :class:`Module`, :class:`FunctionDef`,
+ :class:`ClassDef` or :class:`Lambda`.
+
+ :returns: The node itself.
+ """
+ return self
+
+ def _infer(
+ self, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[ClassDef]:
+ yield self
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/utils.py b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/utils.py
new file mode 100644
index 000000000..8892008d8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/scoped_nodes/utils.py
@@ -0,0 +1,35 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains utility functions for scoped nodes."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid.manager import AstroidManager
+
+if TYPE_CHECKING:
+ from astroid import nodes
+
+
+def builtin_lookup(name: str) -> tuple[nodes.Module, list[nodes.NodeNG]]:
+ """Lookup a name in the builtin module.
+
+ Return the list of matching statements and the ast for the builtin module
+ """
+ manager = AstroidManager()
+ try:
+ _builtin_astroid = manager.builtins_module
+ except KeyError:
+ # User manipulated the astroid cache directly! Rebuild everything.
+ manager.clear_cache()
+ _builtin_astroid = manager.builtins_module
+ if name == "__dict__":
+ return _builtin_astroid, ()
+ try:
+ stmts: list[nodes.NodeNG] = _builtin_astroid.locals[name] # type: ignore[assignment]
+ except KeyError:
+ stmts = []
+ return _builtin_astroid, stmts
diff --git a/solutions/.venv/Lib/site-packages/astroid/nodes/utils.py b/solutions/.venv/Lib/site-packages/astroid/nodes/utils.py
new file mode 100644
index 000000000..6dc482898
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/nodes/utils.py
@@ -0,0 +1,14 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from typing import NamedTuple
+
+
+class Position(NamedTuple):
+ """Position with line and column information."""
+
+ lineno: int
+ col_offset: int
+ end_lineno: int
+ end_col_offset: int
diff --git a/solutions/.venv/Lib/site-packages/astroid/objects.py b/solutions/.venv/Lib/site-packages/astroid/objects.py
new file mode 100644
index 000000000..2d12f5980
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/objects.py
@@ -0,0 +1,366 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""
+Inference objects are a way to represent composite AST nodes,
+which are used only as inference results, so they can't be found in the
+original AST tree. For instance, inferring the following frozenset use,
+leads to an inferred FrozenSet:
+
+ Call(func=Name('frozenset'), args=Tuple(...))
+"""
+
+from __future__ import annotations
+
+from collections.abc import Generator, Iterator
+from functools import cached_property
+from typing import Any, Literal, NoReturn, TypeVar
+
+from astroid import bases, util
+from astroid.context import InferenceContext
+from astroid.exceptions import (
+ AttributeInferenceError,
+ InferenceError,
+ MroError,
+ SuperError,
+)
+from astroid.interpreter import objectmodel
+from astroid.manager import AstroidManager
+from astroid.nodes import node_classes, scoped_nodes
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+_T = TypeVar("_T")
+
+
+class FrozenSet(node_classes.BaseContainer):
+ """Class representing a FrozenSet composite node."""
+
+ def pytype(self) -> Literal["builtins.frozenset"]:
+ return "builtins.frozenset"
+
+ def _infer(self, context: InferenceContext | None = None, **kwargs: Any):
+ yield self
+
+ @cached_property
+ def _proxied(self): # pylint: disable=method-hidden
+ ast_builtins = AstroidManager().builtins_module
+ return ast_builtins.getattr("frozenset")[0]
+
+
+class Super(node_classes.NodeNG):
+ """Proxy class over a super call.
+
+ This class offers almost the same behaviour as Python's super,
+ which is MRO lookups for retrieving attributes from the parents.
+
+ The *mro_pointer* is the place in the MRO from where we should
+ start looking, not counting it. *mro_type* is the object which
+ provides the MRO, it can be both a type or an instance.
+ *self_class* is the class where the super call is, while
+ *scope* is the function where the super call is.
+ """
+
+ special_attributes = objectmodel.SuperModel()
+
+ def __init__(
+ self,
+ mro_pointer: SuccessfulInferenceResult,
+ mro_type: SuccessfulInferenceResult,
+ self_class: scoped_nodes.ClassDef,
+ scope: scoped_nodes.FunctionDef,
+ call: node_classes.Call,
+ ) -> None:
+ self.type = mro_type
+ self.mro_pointer = mro_pointer
+ self._class_based = False
+ self._self_class = self_class
+ self._scope = scope
+ super().__init__(
+ parent=scope,
+ lineno=scope.lineno,
+ col_offset=scope.col_offset,
+ end_lineno=scope.end_lineno,
+ end_col_offset=scope.end_col_offset,
+ )
+
+ def _infer(self, context: InferenceContext | None = None, **kwargs: Any):
+ yield self
+
+ def super_mro(self):
+ """Get the MRO which will be used to lookup attributes in this super."""
+ if not isinstance(self.mro_pointer, scoped_nodes.ClassDef):
+ raise SuperError(
+ "The first argument to super must be a subtype of "
+ "type, not {mro_pointer}.",
+ super_=self,
+ )
+
+ if isinstance(self.type, scoped_nodes.ClassDef):
+ # `super(type, type)`, most likely in a class method.
+ self._class_based = True
+ mro_type = self.type
+ else:
+ mro_type = getattr(self.type, "_proxied", None)
+ if not isinstance(mro_type, (bases.Instance, scoped_nodes.ClassDef)):
+ raise SuperError(
+ "The second argument to super must be an "
+ "instance or subtype of type, not {type}.",
+ super_=self,
+ )
+
+ if not mro_type.newstyle:
+ raise SuperError("Unable to call super on old-style classes.", super_=self)
+
+ mro = mro_type.mro()
+ if self.mro_pointer not in mro:
+ raise SuperError(
+ "The second argument to super must be an "
+ "instance or subtype of type, not {type}.",
+ super_=self,
+ )
+
+ index = mro.index(self.mro_pointer)
+ return mro[index + 1 :]
+
+ @cached_property
+ def _proxied(self):
+ ast_builtins = AstroidManager().builtins_module
+ return ast_builtins.getattr("super")[0]
+
+ def pytype(self) -> Literal["builtins.super"]:
+ return "builtins.super"
+
+ def display_type(self) -> str:
+ return "Super of"
+
+ @property
+ def name(self):
+ """Get the name of the MRO pointer."""
+ return self.mro_pointer.name
+
+ def qname(self) -> Literal["super"]:
+ return "super"
+
+ def igetattr( # noqa: C901
+ self, name: str, context: InferenceContext | None = None
+ ) -> Iterator[InferenceResult]:
+ """Retrieve the inferred values of the given attribute name."""
+ # '__class__' is a special attribute that should be taken directly
+ # from the special attributes dict
+ if name == "__class__":
+ yield self.special_attributes.lookup(name)
+ return
+
+ try:
+ mro = self.super_mro()
+ # Don't let invalid MROs or invalid super calls
+ # leak out as is from this function.
+ except SuperError as exc:
+ raise AttributeInferenceError(
+ (
+ "Lookup for {name} on {target!r} because super call {super!r} "
+ "is invalid."
+ ),
+ target=self,
+ attribute=name,
+ context=context,
+ super_=exc.super_,
+ ) from exc
+ except MroError as exc:
+ raise AttributeInferenceError(
+ (
+ "Lookup for {name} on {target!r} failed because {cls!r} has an "
+ "invalid MRO."
+ ),
+ target=self,
+ attribute=name,
+ context=context,
+ mros=exc.mros,
+ cls=exc.cls,
+ ) from exc
+ found = False
+ for cls in mro:
+ if name not in cls.locals:
+ continue
+
+ found = True
+ for inferred in bases._infer_stmts([cls[name]], context, frame=self):
+ if not isinstance(inferred, scoped_nodes.FunctionDef):
+ yield inferred
+ continue
+
+ # We can obtain different descriptors from a super depending
+ # on what we are accessing and where the super call is.
+ if inferred.type == "classmethod":
+ yield bases.BoundMethod(inferred, cls)
+ elif self._scope.type == "classmethod" and inferred.type == "method":
+ yield inferred
+ elif self._class_based or inferred.type == "staticmethod":
+ yield inferred
+ elif isinstance(inferred, Property):
+ function = inferred.function
+ try:
+ yield from function.infer_call_result(
+ caller=self, context=context
+ )
+ except InferenceError:
+ yield util.Uninferable
+ elif bases._is_property(inferred):
+ # TODO: support other descriptors as well.
+ try:
+ yield from inferred.infer_call_result(self, context)
+ except InferenceError:
+ yield util.Uninferable
+ else:
+ yield bases.BoundMethod(inferred, cls)
+
+ # Only if we haven't found any explicit overwrites for the
+ # attribute we look it up in the special attributes
+ if not found and name in self.special_attributes:
+ yield self.special_attributes.lookup(name)
+ return
+
+ if not found:
+ raise AttributeInferenceError(target=self, attribute=name, context=context)
+
+ def getattr(self, name, context: InferenceContext | None = None):
+ return list(self.igetattr(name, context=context))
+
+
+class ExceptionInstance(bases.Instance):
+ """Class for instances of exceptions.
+
+ It has special treatment for some of the exceptions's attributes,
+ which are transformed at runtime into certain concrete objects, such as
+ the case of .args.
+ """
+
+ @cached_property
+ def special_attributes(self):
+ qname = self.qname()
+ instance = objectmodel.BUILTIN_EXCEPTIONS.get(
+ qname, objectmodel.ExceptionInstanceModel
+ )
+ return instance()(self)
+
+
+class DictInstance(bases.Instance):
+ """Special kind of instances for dictionaries.
+
+ This instance knows the underlying object model of the dictionaries, which means
+ that methods such as .values or .items can be properly inferred.
+ """
+
+ special_attributes = objectmodel.DictModel()
+
+
+# Custom objects tailored for dictionaries, which are used to
+# disambiguate between the types of Python 2 dict's method returns
+# and Python 3 (where they return set like objects).
+class DictItems(bases.Proxy):
+ __str__ = node_classes.NodeNG.__str__
+ __repr__ = node_classes.NodeNG.__repr__
+
+
+class DictKeys(bases.Proxy):
+ __str__ = node_classes.NodeNG.__str__
+ __repr__ = node_classes.NodeNG.__repr__
+
+
+class DictValues(bases.Proxy):
+ __str__ = node_classes.NodeNG.__str__
+ __repr__ = node_classes.NodeNG.__repr__
+
+
+class PartialFunction(scoped_nodes.FunctionDef):
+ """A class representing partial function obtained via functools.partial."""
+
+ def __init__(self, call, name=None, lineno=None, col_offset=None, parent=None):
+ # TODO: Pass end_lineno, end_col_offset and parent as well
+ super().__init__(
+ name,
+ lineno=lineno,
+ col_offset=col_offset,
+ parent=node_classes.Unknown(),
+ end_col_offset=0,
+ end_lineno=0,
+ )
+ # A typical FunctionDef automatically adds its name to the parent scope,
+ # but a partial should not, so defer setting parent until after init
+ self.parent = parent
+ self.filled_args = call.positional_arguments[1:]
+ self.filled_keywords = call.keyword_arguments
+
+ wrapped_function = call.positional_arguments[0]
+ inferred_wrapped_function = next(wrapped_function.infer())
+ if isinstance(inferred_wrapped_function, PartialFunction):
+ self.filled_args = inferred_wrapped_function.filled_args + self.filled_args
+ self.filled_keywords = {
+ **inferred_wrapped_function.filled_keywords,
+ **self.filled_keywords,
+ }
+
+ self.filled_positionals = len(self.filled_args)
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> Iterator[InferenceResult]:
+ if context:
+ assert (
+ context.callcontext
+ ), "CallContext should be set before inferring call result"
+ current_passed_keywords = {
+ keyword for (keyword, _) in context.callcontext.keywords
+ }
+ for keyword, value in self.filled_keywords.items():
+ if keyword not in current_passed_keywords:
+ context.callcontext.keywords.append((keyword, value))
+
+ call_context_args = context.callcontext.args or []
+ context.callcontext.args = self.filled_args + call_context_args
+
+ return super().infer_call_result(caller=caller, context=context)
+
+ def qname(self) -> str:
+ return self.__class__.__name__
+
+
+# TODO: Hack to solve the circular import problem between node_classes and objects
+# This is not needed in 2.0, which has a cleaner design overall
+node_classes.Dict.__bases__ = (node_classes.NodeNG, DictInstance)
+
+
+class Property(scoped_nodes.FunctionDef):
+ """Class representing a Python property."""
+
+ def __init__(self, function, name=None, lineno=None, col_offset=None, parent=None):
+ self.function = function
+ super().__init__(
+ name,
+ lineno=lineno,
+ col_offset=col_offset,
+ parent=parent,
+ end_col_offset=function.end_col_offset,
+ end_lineno=function.end_lineno,
+ )
+
+ special_attributes = objectmodel.PropertyModel()
+ type = "property"
+
+ def pytype(self) -> Literal["builtins.property"]:
+ return "builtins.property"
+
+ def infer_call_result(
+ self,
+ caller: SuccessfulInferenceResult | None,
+ context: InferenceContext | None = None,
+ ) -> NoReturn:
+ raise InferenceError("Properties are not callable")
+
+ def _infer(
+ self: _T, context: InferenceContext | None = None, **kwargs: Any
+ ) -> Generator[_T]:
+ yield self
diff --git a/solutions/.venv/Lib/site-packages/astroid/protocols.py b/solutions/.venv/Lib/site-packages/astroid/protocols.py
new file mode 100644
index 000000000..bacb786a9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/protocols.py
@@ -0,0 +1,930 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains a set of functions to handle python protocols for nodes
+where it makes sense.
+"""
+
+from __future__ import annotations
+
+import collections
+import itertools
+import operator as operator_mod
+from collections.abc import Callable, Generator, Iterator, Sequence
+from typing import TYPE_CHECKING, Any, TypeVar
+
+from astroid import bases, decorators, nodes, util
+from astroid.const import Context
+from astroid.context import InferenceContext, copy_context
+from astroid.exceptions import (
+ AstroidIndexError,
+ AstroidTypeError,
+ AttributeInferenceError,
+ InferenceError,
+ NoDefault,
+)
+from astroid.nodes import node_classes
+from astroid.typing import (
+ ConstFactoryResult,
+ InferenceResult,
+ SuccessfulInferenceResult,
+)
+
+if TYPE_CHECKING:
+ _TupleListNodeT = TypeVar("_TupleListNodeT", nodes.Tuple, nodes.List)
+
+_CONTEXTLIB_MGR = "contextlib.contextmanager"
+
+_UNARY_OPERATORS: dict[str, Callable[[Any], Any]] = {
+ "+": operator_mod.pos,
+ "-": operator_mod.neg,
+ "~": operator_mod.invert,
+ "not": operator_mod.not_,
+}
+
+
+def _infer_unary_op(obj: Any, op: str) -> ConstFactoryResult:
+ """Perform unary operation on `obj`, unless it is `NotImplemented`.
+
+ Can raise TypeError if operation is unsupported.
+ """
+ if obj is NotImplemented:
+ value = obj
+ else:
+ func = _UNARY_OPERATORS[op]
+ value = func(obj)
+ return nodes.const_factory(value)
+
+
+def tuple_infer_unary_op(self, op):
+ return _infer_unary_op(tuple(self.elts), op)
+
+
+def list_infer_unary_op(self, op):
+ return _infer_unary_op(self.elts, op)
+
+
+def set_infer_unary_op(self, op):
+ return _infer_unary_op(set(self.elts), op)
+
+
+def const_infer_unary_op(self, op):
+ return _infer_unary_op(self.value, op)
+
+
+def dict_infer_unary_op(self, op):
+ return _infer_unary_op(dict(self.items), op)
+
+
+# Binary operations
+
+BIN_OP_IMPL = {
+ "+": lambda a, b: a + b,
+ "-": lambda a, b: a - b,
+ "/": lambda a, b: a / b,
+ "//": lambda a, b: a // b,
+ "*": lambda a, b: a * b,
+ "**": lambda a, b: a**b,
+ "%": lambda a, b: a % b,
+ "&": lambda a, b: a & b,
+ "|": lambda a, b: a | b,
+ "^": lambda a, b: a ^ b,
+ "<<": lambda a, b: a << b,
+ ">>": lambda a, b: a >> b,
+ "@": operator_mod.matmul,
+}
+for _KEY, _IMPL in list(BIN_OP_IMPL.items()):
+ BIN_OP_IMPL[_KEY + "="] = _IMPL
+
+
+@decorators.yes_if_nothing_inferred
+def const_infer_binary_op(
+ self: nodes.Const,
+ opnode: nodes.AugAssign | nodes.BinOp,
+ operator: str,
+ other: InferenceResult,
+ context: InferenceContext,
+ _: SuccessfulInferenceResult,
+) -> Generator[ConstFactoryResult | util.UninferableBase]:
+ not_implemented = nodes.Const(NotImplemented)
+ if isinstance(other, nodes.Const):
+ if (
+ operator == "**"
+ and isinstance(self.value, (int, float))
+ and isinstance(other.value, (int, float))
+ and (self.value > 1e5 or other.value > 1e5)
+ ):
+ yield not_implemented
+ return
+ try:
+ impl = BIN_OP_IMPL[operator]
+ try:
+ yield nodes.const_factory(impl(self.value, other.value))
+ except TypeError:
+ # ArithmeticError is not enough: float >> float is a TypeError
+ yield not_implemented
+ except Exception: # pylint: disable=broad-except
+ yield util.Uninferable
+ except TypeError:
+ yield not_implemented
+ elif isinstance(self.value, str) and operator == "%":
+ # TODO(cpopa): implement string interpolation later on.
+ yield util.Uninferable
+ else:
+ yield not_implemented
+
+
+def _multiply_seq_by_int(
+ self: _TupleListNodeT,
+ opnode: nodes.AugAssign | nodes.BinOp,
+ value: int,
+ context: InferenceContext,
+) -> _TupleListNodeT:
+ node = self.__class__(parent=opnode)
+ if value > 1e8:
+ node.elts = [util.Uninferable]
+ return node
+ filtered_elts = (
+ util.safe_infer(elt, context) or util.Uninferable
+ for elt in self.elts
+ if not isinstance(elt, util.UninferableBase)
+ )
+ node.elts = list(filtered_elts) * value
+ return node
+
+
+def _filter_uninferable_nodes(
+ elts: Sequence[InferenceResult], context: InferenceContext
+) -> Iterator[SuccessfulInferenceResult]:
+ for elt in elts:
+ if isinstance(elt, util.UninferableBase):
+ yield nodes.Unknown()
+ else:
+ for inferred in elt.infer(context):
+ if not isinstance(inferred, util.UninferableBase):
+ yield inferred
+ else:
+ yield nodes.Unknown()
+
+
+@decorators.yes_if_nothing_inferred
+def tl_infer_binary_op(
+ self: _TupleListNodeT,
+ opnode: nodes.AugAssign | nodes.BinOp,
+ operator: str,
+ other: InferenceResult,
+ context: InferenceContext,
+ method: SuccessfulInferenceResult,
+) -> Generator[_TupleListNodeT | nodes.Const | util.UninferableBase]:
+ """Infer a binary operation on a tuple or list.
+
+ The instance on which the binary operation is performed is a tuple
+ or list. This refers to the left-hand side of the operation, so:
+ 'tuple() + 1' or '[] + A()'
+ """
+ from astroid import helpers # pylint: disable=import-outside-toplevel
+
+ # For tuples and list the boundnode is no longer the tuple or list instance
+ context.boundnode = None
+ not_implemented = nodes.Const(NotImplemented)
+ if isinstance(other, self.__class__) and operator == "+":
+ node = self.__class__(parent=opnode)
+ node.elts = list(
+ itertools.chain(
+ _filter_uninferable_nodes(self.elts, context),
+ _filter_uninferable_nodes(other.elts, context),
+ )
+ )
+ yield node
+ elif isinstance(other, nodes.Const) and operator == "*":
+ if not isinstance(other.value, int):
+ yield not_implemented
+ return
+ yield _multiply_seq_by_int(self, opnode, other.value, context)
+ elif isinstance(other, bases.Instance) and operator == "*":
+ # Verify if the instance supports __index__.
+ as_index = helpers.class_instance_as_index(other)
+ if not as_index:
+ yield util.Uninferable
+ elif not isinstance(as_index.value, int): # pragma: no cover
+ # already checked by class_instance_as_index() but faster than casting
+ raise AssertionError("Please open a bug report.")
+ else:
+ yield _multiply_seq_by_int(self, opnode, as_index.value, context)
+ else:
+ yield not_implemented
+
+
+@decorators.yes_if_nothing_inferred
+def instance_class_infer_binary_op(
+ self: nodes.ClassDef,
+ opnode: nodes.AugAssign | nodes.BinOp,
+ operator: str,
+ other: InferenceResult,
+ context: InferenceContext,
+ method: SuccessfulInferenceResult,
+) -> Generator[InferenceResult]:
+ return method.infer_call_result(self, context)
+
+
+# assignment ##################################################################
+# pylint: disable-next=pointless-string-statement
+"""The assigned_stmts method is responsible to return the assigned statement
+(e.g. not inferred) according to the assignment type.
+
+The `assign_path` argument is used to record the lhs path of the original node.
+For instance if we want assigned statements for 'c' in 'a, (b,c)', assign_path
+will be [1, 1] once arrived to the Assign node.
+
+The `context` argument is the current inference context which should be given
+to any intermediary inference necessary.
+"""
+
+
+def _resolve_looppart(parts, assign_path, context):
+ """Recursive function to resolve multiple assignments on loops."""
+ assign_path = assign_path[:]
+ index = assign_path.pop(0)
+ for part in parts:
+ if isinstance(part, util.UninferableBase):
+ continue
+ if not hasattr(part, "itered"):
+ continue
+ try:
+ itered = part.itered()
+ except TypeError:
+ continue
+ try:
+ if isinstance(itered[index], (nodes.Const, nodes.Name)):
+ itered = [part]
+ except IndexError:
+ pass
+ for stmt in itered:
+ index_node = nodes.Const(index)
+ try:
+ assigned = stmt.getitem(index_node, context)
+ except (AttributeError, AstroidTypeError, AstroidIndexError):
+ continue
+ if not assign_path:
+ # we achieved to resolved the assignment path,
+ # don't infer the last part
+ yield assigned
+ elif isinstance(assigned, util.UninferableBase):
+ break
+ else:
+ # we are not yet on the last part of the path
+ # search on each possibly inferred value
+ try:
+ yield from _resolve_looppart(
+ assigned.infer(context), assign_path, context
+ )
+ except InferenceError:
+ break
+
+
+@decorators.raise_if_nothing_inferred
+def for_assigned_stmts(
+ self: nodes.For | nodes.Comprehension,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ if isinstance(self, nodes.AsyncFor) or getattr(self, "is_async", False):
+ # Skip inferring of async code for now
+ return {
+ "node": self,
+ "unknown": node,
+ "assign_path": assign_path,
+ "context": context,
+ }
+ if assign_path is None:
+ for lst in self.iter.infer(context):
+ if isinstance(lst, (nodes.Tuple, nodes.List)):
+ yield from lst.elts
+ else:
+ yield from _resolve_looppart(self.iter.infer(context), assign_path, context)
+ return {
+ "node": self,
+ "unknown": node,
+ "assign_path": assign_path,
+ "context": context,
+ }
+
+
+def sequence_assigned_stmts(
+ self: nodes.Tuple | nodes.List,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ if assign_path is None:
+ assign_path = []
+ try:
+ index = self.elts.index(node) # type: ignore[arg-type]
+ except ValueError as exc:
+ raise InferenceError(
+ "Tried to retrieve a node {node!r} which does not exist",
+ node=self,
+ assign_path=assign_path,
+ context=context,
+ ) from exc
+
+ assign_path.insert(0, index)
+ return self.parent.assigned_stmts(
+ node=self, context=context, assign_path=assign_path
+ )
+
+
+def assend_assigned_stmts(
+ self: nodes.AssignName | nodes.AssignAttr,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ return self.parent.assigned_stmts(node=self, context=context)
+
+
+def _arguments_infer_argname(
+ self, name: str | None, context: InferenceContext
+) -> Generator[InferenceResult]:
+ # arguments information may be missing, in which case we can't do anything
+ # more
+ from astroid import arguments # pylint: disable=import-outside-toplevel
+
+ if not self.arguments:
+ yield util.Uninferable
+ return
+
+ args = [arg for arg in self.arguments if arg.name not in [self.vararg, self.kwarg]]
+ functype = self.parent.type
+ # first argument of instance/class method
+ if (
+ args
+ and getattr(self.arguments[0], "name", None) == name
+ and functype != "staticmethod"
+ ):
+ cls = self.parent.parent.scope()
+ is_metaclass = isinstance(cls, nodes.ClassDef) and cls.type == "metaclass"
+ # If this is a metaclass, then the first argument will always
+ # be the class, not an instance.
+ if context.boundnode and isinstance(context.boundnode, bases.Instance):
+ cls = context.boundnode._proxied
+ if is_metaclass or functype == "classmethod":
+ yield cls
+ return
+ if functype == "method":
+ yield cls.instantiate_class()
+ return
+
+ if context and context.callcontext:
+ callee = context.callcontext.callee
+ while hasattr(callee, "_proxied"):
+ callee = callee._proxied
+ if getattr(callee, "name", None) == self.parent.name:
+ call_site = arguments.CallSite(context.callcontext, context.extra_context)
+ yield from call_site.infer_argument(self.parent, name, context)
+ return
+
+ if name == self.vararg:
+ vararg = nodes.const_factory(())
+ vararg.parent = self
+ if not args and self.parent.name == "__init__":
+ cls = self.parent.parent.scope()
+ vararg.elts = [cls.instantiate_class()]
+ yield vararg
+ return
+ if name == self.kwarg:
+ kwarg = nodes.const_factory({})
+ kwarg.parent = self
+ yield kwarg
+ return
+ # if there is a default value, yield it. And then yield Uninferable to reflect
+ # we can't guess given argument value
+ try:
+ context = copy_context(context)
+ yield from self.default_value(name).infer(context)
+ yield util.Uninferable
+ except NoDefault:
+ yield util.Uninferable
+
+
+def arguments_assigned_stmts(
+ self: nodes.Arguments,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ from astroid import arguments # pylint: disable=import-outside-toplevel
+
+ try:
+ node_name = node.name # type: ignore[union-attr]
+ except AttributeError:
+ # Added to handle edge cases where node.name is not defined.
+ # https://github.com/pylint-dev/astroid/pull/1644#discussion_r901545816
+ node_name = None # pragma: no cover
+
+ if context and context.callcontext:
+ callee = context.callcontext.callee
+ while hasattr(callee, "_proxied"):
+ callee = callee._proxied
+ else:
+ return _arguments_infer_argname(self, node_name, context)
+ if node and getattr(callee, "name", None) == node.frame().name:
+ # reset call context/name
+ callcontext = context.callcontext
+ context = copy_context(context)
+ context.callcontext = None
+ args = arguments.CallSite(callcontext, context=context)
+ return args.infer_argument(self.parent, node_name, context)
+ return _arguments_infer_argname(self, node_name, context)
+
+
+@decorators.raise_if_nothing_inferred
+def assign_assigned_stmts(
+ self: nodes.AugAssign | nodes.Assign | nodes.AnnAssign | nodes.TypeAlias,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ if not assign_path:
+ yield self.value
+ return None
+ yield from _resolve_assignment_parts(
+ self.value.infer(context), assign_path, context
+ )
+
+ return {
+ "node": self,
+ "unknown": node,
+ "assign_path": assign_path,
+ "context": context,
+ }
+
+
+def assign_annassigned_stmts(
+ self: nodes.AnnAssign,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ for inferred in assign_assigned_stmts(self, node, context, assign_path):
+ if inferred is None:
+ yield util.Uninferable
+ else:
+ yield inferred
+
+
+def _resolve_assignment_parts(parts, assign_path, context):
+ """Recursive function to resolve multiple assignments."""
+ assign_path = assign_path[:]
+ index = assign_path.pop(0)
+ for part in parts:
+ assigned = None
+ if isinstance(part, nodes.Dict):
+ # A dictionary in an iterating context
+ try:
+ assigned, _ = part.items[index]
+ except IndexError:
+ return
+
+ elif hasattr(part, "getitem"):
+ index_node = nodes.Const(index)
+ try:
+ assigned = part.getitem(index_node, context)
+ except (AstroidTypeError, AstroidIndexError):
+ return
+
+ if not assigned:
+ return
+
+ if not assign_path:
+ # we achieved to resolved the assignment path, don't infer the
+ # last part
+ yield assigned
+ elif isinstance(assigned, util.UninferableBase):
+ return
+ else:
+ # we are not yet on the last part of the path search on each
+ # possibly inferred value
+ try:
+ yield from _resolve_assignment_parts(
+ assigned.infer(context), assign_path, context
+ )
+ except InferenceError:
+ return
+
+
+@decorators.raise_if_nothing_inferred
+def excepthandler_assigned_stmts(
+ self: nodes.ExceptHandler,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ from astroid import objects # pylint: disable=import-outside-toplevel
+
+ for assigned in node_classes.unpack_infer(self.type):
+ if isinstance(assigned, nodes.ClassDef):
+ assigned = objects.ExceptionInstance(assigned)
+
+ yield assigned
+ return {
+ "node": self,
+ "unknown": node,
+ "assign_path": assign_path,
+ "context": context,
+ }
+
+
+def _infer_context_manager(self, mgr, context):
+ try:
+ inferred = next(mgr.infer(context=context))
+ except StopIteration as e:
+ raise InferenceError(node=mgr) from e
+ if isinstance(inferred, bases.Generator):
+ # Check if it is decorated with contextlib.contextmanager.
+ func = inferred.parent
+ if not func.decorators:
+ raise InferenceError(
+ "No decorators found on inferred generator %s", node=func
+ )
+
+ for decorator_node in func.decorators.nodes:
+ decorator = next(decorator_node.infer(context=context), None)
+ if isinstance(decorator, nodes.FunctionDef):
+ if decorator.qname() == _CONTEXTLIB_MGR:
+ break
+ else:
+ # It doesn't interest us.
+ raise InferenceError(node=func)
+ try:
+ yield next(inferred.infer_yield_types())
+ except StopIteration as e:
+ raise InferenceError(node=func) from e
+
+ elif isinstance(inferred, bases.Instance):
+ try:
+ enter = next(inferred.igetattr("__enter__", context=context))
+ except (InferenceError, AttributeInferenceError, StopIteration) as exc:
+ raise InferenceError(node=inferred) from exc
+ if not isinstance(enter, bases.BoundMethod):
+ raise InferenceError(node=enter)
+ yield from enter.infer_call_result(self, context)
+ else:
+ raise InferenceError(node=mgr)
+
+
+@decorators.raise_if_nothing_inferred
+def with_assigned_stmts(
+ self: nodes.With,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ """Infer names and other nodes from a *with* statement.
+
+ This enables only inference for name binding in a *with* statement.
+ For instance, in the following code, inferring `func` will return
+ the `ContextManager` class, not whatever ``__enter__`` returns.
+ We are doing this intentionally, because we consider that the context
+ manager result is whatever __enter__ returns and what it is binded
+ using the ``as`` keyword.
+
+ class ContextManager(object):
+ def __enter__(self):
+ return 42
+ with ContextManager() as f:
+ pass
+
+ # ContextManager().infer() will return ContextManager
+ # f.infer() will return 42.
+
+ Arguments:
+ self: nodes.With
+ node: The target of the assignment, `as (a, b)` in `with foo as (a, b)`.
+ context: Inference context used for caching already inferred objects
+ assign_path:
+ A list of indices, where each index specifies what item to fetch from
+ the inference results.
+ """
+ try:
+ mgr = next(mgr for (mgr, vars) in self.items if vars == node)
+ except StopIteration:
+ return None
+ if assign_path is None:
+ yield from _infer_context_manager(self, mgr, context)
+ else:
+ for result in _infer_context_manager(self, mgr, context):
+ # Walk the assign_path and get the item at the final index.
+ obj = result
+ for index in assign_path:
+ if not hasattr(obj, "elts"):
+ raise InferenceError(
+ "Wrong type ({targets!r}) for {node!r} assignment",
+ node=self,
+ targets=node,
+ assign_path=assign_path,
+ context=context,
+ )
+ try:
+ obj = obj.elts[index]
+ except IndexError as exc:
+ raise InferenceError(
+ "Tried to infer a nonexistent target with index {index} "
+ "in {node!r}.",
+ node=self,
+ targets=node,
+ assign_path=assign_path,
+ context=context,
+ ) from exc
+ except TypeError as exc:
+ raise InferenceError(
+ "Tried to unpack a non-iterable value in {node!r}.",
+ node=self,
+ targets=node,
+ assign_path=assign_path,
+ context=context,
+ ) from exc
+ yield obj
+ return {
+ "node": self,
+ "unknown": node,
+ "assign_path": assign_path,
+ "context": context,
+ }
+
+
+@decorators.raise_if_nothing_inferred
+def named_expr_assigned_stmts(
+ self: nodes.NamedExpr,
+ node: node_classes.AssignedStmtsPossibleNode,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ """Infer names and other nodes from an assignment expression."""
+ if self.target == node:
+ yield from self.value.infer(context=context)
+ else:
+ raise InferenceError(
+ "Cannot infer NamedExpr node {node!r}",
+ node=self,
+ assign_path=assign_path,
+ context=context,
+ )
+
+
+@decorators.yes_if_nothing_inferred
+def starred_assigned_stmts( # noqa: C901
+ self: nodes.Starred,
+ node: node_classes.AssignedStmtsPossibleNode = None,
+ context: InferenceContext | None = None,
+ assign_path: list[int] | None = None,
+) -> Any:
+ """
+ Arguments:
+ self: nodes.Starred
+ node: a node related to the current underlying Node.
+ context: Inference context used for caching already inferred objects
+ assign_path:
+ A list of indices, where each index specifies what item to fetch from
+ the inference results.
+ """
+
+ # pylint: disable=too-many-locals,too-many-statements
+ def _determine_starred_iteration_lookups(
+ starred: nodes.Starred, target: nodes.Tuple, lookups: list[tuple[int, int]]
+ ) -> None:
+ # Determine the lookups for the rhs of the iteration
+ itered = target.itered()
+ for index, element in enumerate(itered):
+ if (
+ isinstance(element, nodes.Starred)
+ and element.value.name == starred.value.name
+ ):
+ lookups.append((index, len(itered)))
+ break
+ if isinstance(element, nodes.Tuple):
+ lookups.append((index, len(element.itered())))
+ _determine_starred_iteration_lookups(starred, element, lookups)
+
+ stmt = self.statement()
+ if not isinstance(stmt, (nodes.Assign, nodes.For)):
+ raise InferenceError(
+ "Statement {stmt!r} enclosing {node!r} must be an Assign or For node.",
+ node=self,
+ stmt=stmt,
+ unknown=node,
+ context=context,
+ )
+
+ if context is None:
+ context = InferenceContext()
+
+ if isinstance(stmt, nodes.Assign):
+ value = stmt.value
+ lhs = stmt.targets[0]
+ if not isinstance(lhs, nodes.BaseContainer):
+ yield util.Uninferable
+ return
+
+ if sum(1 for _ in lhs.nodes_of_class(nodes.Starred)) > 1:
+ raise InferenceError(
+ "Too many starred arguments in the assignment targets {lhs!r}.",
+ node=self,
+ targets=lhs,
+ unknown=node,
+ context=context,
+ )
+
+ try:
+ rhs = next(value.infer(context))
+ except (InferenceError, StopIteration):
+ yield util.Uninferable
+ return
+ if isinstance(rhs, util.UninferableBase) or not hasattr(rhs, "itered"):
+ yield util.Uninferable
+ return
+
+ try:
+ elts = collections.deque(rhs.itered()) # type: ignore[union-attr]
+ except TypeError:
+ yield util.Uninferable
+ return
+
+ # Unpack iteratively the values from the rhs of the assignment,
+ # until the find the starred node. What will remain will
+ # be the list of values which the Starred node will represent
+ # This is done in two steps, from left to right to remove
+ # anything before the starred node and from right to left
+ # to remove anything after the starred node.
+
+ for index, left_node in enumerate(lhs.elts):
+ if not isinstance(left_node, nodes.Starred):
+ if not elts:
+ break
+ elts.popleft()
+ continue
+ lhs_elts = collections.deque(reversed(lhs.elts[index:]))
+ for right_node in lhs_elts:
+ if not isinstance(right_node, nodes.Starred):
+ if not elts:
+ break
+ elts.pop()
+ continue
+
+ # We're done unpacking.
+ packed = nodes.List(
+ ctx=Context.Store,
+ parent=self,
+ lineno=lhs.lineno,
+ col_offset=lhs.col_offset,
+ )
+ packed.postinit(elts=list(elts))
+ yield packed
+ break
+
+ if isinstance(stmt, nodes.For):
+ try:
+ inferred_iterable = next(stmt.iter.infer(context=context))
+ except (InferenceError, StopIteration):
+ yield util.Uninferable
+ return
+ if isinstance(inferred_iterable, util.UninferableBase) or not hasattr(
+ inferred_iterable, "itered"
+ ):
+ yield util.Uninferable
+ return
+ try:
+ itered = inferred_iterable.itered() # type: ignore[union-attr]
+ except TypeError:
+ yield util.Uninferable
+ return
+
+ target = stmt.target
+
+ if not isinstance(target, nodes.Tuple):
+ raise InferenceError(
+ "Could not make sense of this, the target must be a tuple",
+ context=context,
+ )
+
+ lookups: list[tuple[int, int]] = []
+ _determine_starred_iteration_lookups(self, target, lookups)
+ if not lookups:
+ raise InferenceError(
+ "Could not make sense of this, needs at least a lookup", context=context
+ )
+
+ # Make the last lookup a slice, since that what we want for a Starred node
+ last_element_index, last_element_length = lookups[-1]
+ is_starred_last = last_element_index == (last_element_length - 1)
+
+ lookup_slice = slice(
+ last_element_index,
+ None if is_starred_last else (last_element_length - last_element_index),
+ )
+ last_lookup = lookup_slice
+
+ for element in itered:
+ # We probably want to infer the potential values *for each* element in an
+ # iterable, but we can't infer a list of all values, when only a list of
+ # step values are expected:
+ #
+ # for a, *b in [...]:
+ # b
+ #
+ # *b* should now point to just the elements at that particular iteration step,
+ # which astroid can't know about.
+
+ found_element = None
+ for index, lookup in enumerate(lookups):
+ if not hasattr(element, "itered"):
+ break
+ if index + 1 is len(lookups):
+ cur_lookup: slice | int = last_lookup
+ else:
+ # Grab just the index, not the whole length
+ cur_lookup = lookup[0]
+ try:
+ itered_inner_element = element.itered()
+ element = itered_inner_element[cur_lookup]
+ except IndexError:
+ break
+ except TypeError:
+ # Most likely the itered() call failed, cannot make sense of this
+ yield util.Uninferable
+ return
+ else:
+ found_element = element
+
+ unpacked = nodes.List(
+ ctx=Context.Store,
+ parent=self,
+ lineno=self.lineno,
+ col_offset=self.col_offset,
+ )
+ unpacked.postinit(elts=found_element or [])
+ yield unpacked
+ return
+
+ yield util.Uninferable
+
+
+@decorators.yes_if_nothing_inferred
+def match_mapping_assigned_stmts(
+ self: nodes.MatchMapping,
+ node: nodes.AssignName,
+ context: InferenceContext | None = None,
+ assign_path: None = None,
+) -> Generator[nodes.NodeNG]:
+ """Return empty generator (return -> raises StopIteration) so inferred value
+ is Uninferable.
+ """
+ return
+ yield
+
+
+@decorators.yes_if_nothing_inferred
+def match_star_assigned_stmts(
+ self: nodes.MatchStar,
+ node: nodes.AssignName,
+ context: InferenceContext | None = None,
+ assign_path: None = None,
+) -> Generator[nodes.NodeNG]:
+ """Return empty generator (return -> raises StopIteration) so inferred value
+ is Uninferable.
+ """
+ return
+ yield
+
+
+@decorators.yes_if_nothing_inferred
+def match_as_assigned_stmts(
+ self: nodes.MatchAs,
+ node: nodes.AssignName,
+ context: InferenceContext | None = None,
+ assign_path: None = None,
+) -> Generator[nodes.NodeNG]:
+ """Infer MatchAs as the Match subject if it's the only MatchCase pattern
+ else raise StopIteration to yield Uninferable.
+ """
+ if (
+ isinstance(self.parent, nodes.MatchCase)
+ and isinstance(self.parent.parent, nodes.Match)
+ and self.pattern is None
+ ):
+ yield self.parent.parent.subject
+
+
+@decorators.yes_if_nothing_inferred
+def generic_type_assigned_stmts(
+ self: nodes.TypeVar | nodes.TypeVarTuple | nodes.ParamSpec,
+ node: nodes.AssignName,
+ context: InferenceContext | None = None,
+ assign_path: None = None,
+) -> Generator[nodes.NodeNG]:
+ """Hack. Return any Node so inference doesn't fail
+ when evaluating __class_getitem__. Revert if it's causing issues.
+ """
+ yield nodes.Const(None)
diff --git a/solutions/.venv/Lib/site-packages/astroid/raw_building.py b/solutions/.venv/Lib/site-packages/astroid/raw_building.py
new file mode 100644
index 000000000..a89a87b57
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/raw_building.py
@@ -0,0 +1,737 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""this module contains a set of functions to create astroid trees from scratch
+(build_* functions) or from living object (object_build_* functions)
+"""
+
+from __future__ import annotations
+
+import builtins
+import inspect
+import io
+import logging
+import os
+import sys
+import types
+import warnings
+from collections.abc import Iterable
+from contextlib import redirect_stderr, redirect_stdout
+from typing import Any, Union
+
+from astroid import bases, nodes
+from astroid.const import _EMPTY_OBJECT_MARKER, IS_PYPY
+from astroid.manager import AstroidManager
+from astroid.nodes import node_classes
+
+logger = logging.getLogger(__name__)
+
+
+_FunctionTypes = Union[
+ types.FunctionType,
+ types.MethodType,
+ types.BuiltinFunctionType,
+ types.WrapperDescriptorType,
+ types.MethodDescriptorType,
+ types.ClassMethodDescriptorType,
+]
+
+# the keys of CONST_CLS eg python builtin types
+_CONSTANTS = tuple(node_classes.CONST_CLS)
+TYPE_NONE = type(None)
+TYPE_NOTIMPLEMENTED = type(NotImplemented)
+TYPE_ELLIPSIS = type(...)
+
+
+def _attach_local_node(parent, node, name: str) -> None:
+ node.name = name # needed by add_local_node
+ parent.add_local_node(node)
+
+
+def _add_dunder_class(func, member) -> None:
+ """Add a __class__ member to the given func node, if we can determine it."""
+ python_cls = member.__class__
+ cls_name = getattr(python_cls, "__name__", None)
+ if not cls_name:
+ return
+ cls_bases = [ancestor.__name__ for ancestor in python_cls.__bases__]
+ ast_klass = build_class(cls_name, cls_bases, python_cls.__doc__)
+ func.instance_attrs["__class__"] = [ast_klass]
+
+
+def attach_dummy_node(node, name: str, runtime_object=_EMPTY_OBJECT_MARKER) -> None:
+ """create a dummy node and register it in the locals of the given
+ node with the specified name
+ """
+ enode = nodes.EmptyNode()
+ enode.object = runtime_object
+ _attach_local_node(node, enode, name)
+
+
+def attach_const_node(node, name: str, value) -> None:
+ """create a Const node and register it in the locals of the given
+ node with the specified name
+ """
+ if name not in node.special_attributes:
+ _attach_local_node(node, nodes.const_factory(value), name)
+
+
+def attach_import_node(node, modname: str, membername: str) -> None:
+ """create a ImportFrom node and register it in the locals of the given
+ node with the specified name
+ """
+ from_node = nodes.ImportFrom(modname, [(membername, None)])
+ _attach_local_node(node, from_node, membername)
+
+
+def build_module(name: str, doc: str | None = None) -> nodes.Module:
+ """create and initialize an astroid Module node"""
+ node = nodes.Module(name, pure_python=False, package=False)
+ node.postinit(
+ body=[],
+ doc_node=nodes.Const(value=doc) if doc else None,
+ )
+ return node
+
+
+def build_class(
+ name: str, basenames: Iterable[str] = (), doc: str | None = None
+) -> nodes.ClassDef:
+ """Create and initialize an astroid ClassDef node."""
+ node = nodes.ClassDef(
+ name,
+ lineno=0,
+ col_offset=0,
+ end_lineno=0,
+ end_col_offset=0,
+ parent=nodes.Unknown(),
+ )
+ node.postinit(
+ bases=[
+ nodes.Name(
+ name=base,
+ lineno=0,
+ col_offset=0,
+ parent=node,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ for base in basenames
+ ],
+ body=[],
+ decorators=None,
+ doc_node=nodes.Const(value=doc) if doc else None,
+ )
+ return node
+
+
+def build_function(
+ name: str,
+ args: list[str] | None = None,
+ posonlyargs: list[str] | None = None,
+ defaults: list[Any] | None = None,
+ doc: str | None = None,
+ kwonlyargs: list[str] | None = None,
+ kwonlydefaults: list[Any] | None = None,
+) -> nodes.FunctionDef:
+ """create and initialize an astroid FunctionDef node"""
+ # first argument is now a list of decorators
+ func = nodes.FunctionDef(
+ name,
+ lineno=0,
+ col_offset=0,
+ parent=node_classes.Unknown(),
+ end_col_offset=0,
+ end_lineno=0,
+ )
+ argsnode = nodes.Arguments(parent=func, vararg=None, kwarg=None)
+
+ # If args is None we don't have any information about the signature
+ # (in contrast to when there are no arguments and args == []). We pass
+ # this to the builder to indicate this.
+ if args is not None:
+ # We set the lineno and col_offset to 0 because we don't have any
+ # information about the location of the function definition.
+ arguments = [
+ nodes.AssignName(
+ name=arg,
+ parent=argsnode,
+ lineno=0,
+ col_offset=0,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ for arg in args
+ ]
+ else:
+ arguments = None
+
+ default_nodes: list[nodes.NodeNG] | None
+ if defaults is None:
+ default_nodes = None
+ else:
+ default_nodes = []
+ for default in defaults:
+ default_node = nodes.const_factory(default)
+ default_node.parent = argsnode
+ default_nodes.append(default_node)
+
+ kwonlydefault_nodes: list[nodes.NodeNG | None] | None
+ if kwonlydefaults is None:
+ kwonlydefault_nodes = None
+ else:
+ kwonlydefault_nodes = []
+ for kwonlydefault in kwonlydefaults:
+ kwonlydefault_node = nodes.const_factory(kwonlydefault)
+ kwonlydefault_node.parent = argsnode
+ kwonlydefault_nodes.append(kwonlydefault_node)
+
+ # We set the lineno and col_offset to 0 because we don't have any
+ # information about the location of the kwonly and posonlyargs.
+ argsnode.postinit(
+ args=arguments,
+ defaults=default_nodes,
+ kwonlyargs=[
+ nodes.AssignName(
+ name=arg,
+ parent=argsnode,
+ lineno=0,
+ col_offset=0,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ for arg in kwonlyargs or ()
+ ],
+ kw_defaults=kwonlydefault_nodes,
+ annotations=[],
+ posonlyargs=[
+ nodes.AssignName(
+ name=arg,
+ parent=argsnode,
+ lineno=0,
+ col_offset=0,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ for arg in posonlyargs or ()
+ ],
+ kwonlyargs_annotations=[],
+ posonlyargs_annotations=[],
+ )
+ func.postinit(
+ args=argsnode,
+ body=[],
+ doc_node=nodes.Const(value=doc) if doc else None,
+ )
+ if args:
+ register_arguments(func)
+ return func
+
+
+def build_from_import(fromname: str, names: list[str]) -> nodes.ImportFrom:
+ """create and initialize an astroid ImportFrom import statement"""
+ return nodes.ImportFrom(fromname, [(name, None) for name in names])
+
+
+def register_arguments(func: nodes.FunctionDef, args: list | None = None) -> None:
+ """add given arguments to local
+
+ args is a list that may contains nested lists
+ (i.e. def func(a, (b, c, d)): ...)
+ """
+ # If no args are passed in, get the args from the function.
+ if args is None:
+ if func.args.vararg:
+ func.set_local(func.args.vararg, func.args)
+ if func.args.kwarg:
+ func.set_local(func.args.kwarg, func.args)
+ args = func.args.args
+ # If the function has no args, there is nothing left to do.
+ if args is None:
+ return
+ for arg in args:
+ if isinstance(arg, nodes.AssignName):
+ func.set_local(arg.name, arg)
+ else:
+ register_arguments(func, arg.elts)
+
+
+def object_build_class(
+ node: nodes.Module | nodes.ClassDef, member: type, localname: str
+) -> nodes.ClassDef:
+ """create astroid for a living class object"""
+ basenames = [base.__name__ for base in member.__bases__]
+ return _base_class_object_build(node, member, basenames, localname=localname)
+
+
+def _get_args_info_from_callable(
+ member: _FunctionTypes,
+) -> tuple[list[str], list[str], list[Any], list[str], list[Any]]:
+ """Returns args, posonlyargs, defaults, kwonlyargs.
+
+ :note: currently ignores the return annotation.
+ """
+ signature = inspect.signature(member)
+ args: list[str] = []
+ defaults: list[Any] = []
+ posonlyargs: list[str] = []
+ kwonlyargs: list[str] = []
+ kwonlydefaults: list[Any] = []
+
+ for param_name, param in signature.parameters.items():
+ if param.kind == inspect.Parameter.POSITIONAL_ONLY:
+ posonlyargs.append(param_name)
+ elif param.kind == inspect.Parameter.POSITIONAL_OR_KEYWORD:
+ args.append(param_name)
+ elif param.kind == inspect.Parameter.VAR_POSITIONAL:
+ args.append(param_name)
+ elif param.kind == inspect.Parameter.VAR_KEYWORD:
+ args.append(param_name)
+ elif param.kind == inspect.Parameter.KEYWORD_ONLY:
+ kwonlyargs.append(param_name)
+ if param.default is not inspect.Parameter.empty:
+ kwonlydefaults.append(param.default)
+ continue
+ if param.default is not inspect.Parameter.empty:
+ defaults.append(param.default)
+
+ return args, posonlyargs, defaults, kwonlyargs, kwonlydefaults
+
+
+def object_build_function(
+ node: nodes.Module | nodes.ClassDef, member: _FunctionTypes, localname: str
+) -> None:
+ """create astroid for a living function object"""
+ (
+ args,
+ posonlyargs,
+ defaults,
+ kwonlyargs,
+ kwonly_defaults,
+ ) = _get_args_info_from_callable(member)
+
+ func = build_function(
+ getattr(member, "__name__", None) or localname,
+ args,
+ posonlyargs,
+ defaults,
+ member.__doc__,
+ kwonlyargs=kwonlyargs,
+ kwonlydefaults=kwonly_defaults,
+ )
+
+ node.add_local_node(func, localname)
+
+
+def object_build_datadescriptor(
+ node: nodes.Module | nodes.ClassDef, member: type, name: str
+) -> nodes.ClassDef:
+ """create astroid for a living data descriptor object"""
+ return _base_class_object_build(node, member, [], name)
+
+
+def object_build_methoddescriptor(
+ node: nodes.Module | nodes.ClassDef,
+ member: _FunctionTypes,
+ localname: str,
+) -> None:
+ """create astroid for a living method descriptor object"""
+ # FIXME get arguments ?
+ func = build_function(
+ getattr(member, "__name__", None) or localname, doc=member.__doc__
+ )
+ node.add_local_node(func, localname)
+ _add_dunder_class(func, member)
+
+
+def _base_class_object_build(
+ node: nodes.Module | nodes.ClassDef,
+ member: type,
+ basenames: list[str],
+ name: str | None = None,
+ localname: str | None = None,
+) -> nodes.ClassDef:
+ """create astroid for a living class object, with a given set of base names
+ (e.g. ancestors)
+ """
+ class_name = name or getattr(member, "__name__", None) or localname
+ assert isinstance(class_name, str)
+ klass = build_class(
+ class_name,
+ basenames,
+ member.__doc__,
+ )
+ klass._newstyle = isinstance(member, type)
+ node.add_local_node(klass, localname)
+ try:
+ # limit the instantiation trick since it's too dangerous
+ # (such as infinite test execution...)
+ # this at least resolves common case such as Exception.args,
+ # OSError.errno
+ if issubclass(member, Exception):
+ instdict = member().__dict__
+ else:
+ raise TypeError
+ except TypeError:
+ pass
+ else:
+ for item_name, obj in instdict.items():
+ valnode = nodes.EmptyNode()
+ valnode.object = obj
+ valnode.parent = klass
+ valnode.lineno = 1
+ klass.instance_attrs[item_name] = [valnode]
+ return klass
+
+
+def _build_from_function(
+ node: nodes.Module | nodes.ClassDef,
+ name: str,
+ member: _FunctionTypes,
+ module: types.ModuleType,
+) -> None:
+ # verify this is not an imported function
+ try:
+ code = member.__code__ # type: ignore[union-attr]
+ except AttributeError:
+ # Some implementations don't provide the code object,
+ # such as Jython.
+ code = None
+ filename = getattr(code, "co_filename", None)
+ if filename is None:
+ assert isinstance(member, object)
+ object_build_methoddescriptor(node, member, name)
+ elif filename != getattr(module, "__file__", None):
+ attach_dummy_node(node, name, member)
+ else:
+ object_build_function(node, member, name)
+
+
+def _safe_has_attribute(obj, member: str) -> bool:
+ """Required because unexpected RunTimeError can be raised.
+
+ See https://github.com/pylint-dev/astroid/issues/1958
+ """
+ try:
+ return hasattr(obj, member)
+ except Exception: # pylint: disable=broad-except
+ return False
+
+
+class InspectBuilder:
+ """class for building nodes from living object
+
+ this is actually a really minimal representation, including only Module,
+ FunctionDef and ClassDef nodes and some others as guessed.
+ """
+
+ bootstrapped: bool = False
+
+ def __init__(self, manager_instance: AstroidManager | None = None) -> None:
+ self._manager = manager_instance or AstroidManager()
+ self._done: dict[types.ModuleType | type, nodes.Module | nodes.ClassDef] = {}
+ self._module: types.ModuleType
+
+ def inspect_build(
+ self,
+ module: types.ModuleType,
+ modname: str | None = None,
+ path: str | None = None,
+ ) -> nodes.Module:
+ """build astroid from a living module (i.e. using inspect)
+ this is used when there is no python source code available (either
+ because it's a built-in module or because the .py is not available)
+ """
+ self._module = module
+ if modname is None:
+ modname = module.__name__
+ try:
+ node = build_module(modname, module.__doc__)
+ except AttributeError:
+ # in jython, java modules have no __doc__ (see #109562)
+ node = build_module(modname)
+ if path is None:
+ node.path = node.file = path
+ else:
+ node.path = [os.path.abspath(path)]
+ node.file = node.path[0]
+ node.name = modname
+ self._manager.cache_module(node)
+ node.package = hasattr(module, "__path__")
+ self._done = {}
+ self.object_build(node, module)
+ return node
+
+ def object_build(
+ self, node: nodes.Module | nodes.ClassDef, obj: types.ModuleType | type
+ ) -> None:
+ """recursive method which create a partial ast from real objects
+ (only function, class, and method are handled)
+ """
+ if obj in self._done:
+ return None
+ self._done[obj] = node
+ for name in dir(obj):
+ # inspect.ismethod() and inspect.isbuiltin() in PyPy return
+ # the opposite of what they do in CPython for __class_getitem__.
+ pypy__class_getitem__ = IS_PYPY and name == "__class_getitem__"
+ try:
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ member = getattr(obj, name)
+ except AttributeError:
+ # damned ExtensionClass.Base, I know you're there !
+ attach_dummy_node(node, name)
+ continue
+ if inspect.ismethod(member) and not pypy__class_getitem__:
+ member = member.__func__
+ if inspect.isfunction(member):
+ _build_from_function(node, name, member, self._module)
+ elif inspect.isbuiltin(member) or pypy__class_getitem__:
+ if self.imported_member(node, member, name):
+ continue
+ object_build_methoddescriptor(node, member, name)
+ elif inspect.isclass(member):
+ if self.imported_member(node, member, name):
+ continue
+ if member in self._done:
+ class_node = self._done[member]
+ assert isinstance(class_node, nodes.ClassDef)
+ if class_node not in node.locals.get(name, ()):
+ node.add_local_node(class_node, name)
+ else:
+ class_node = object_build_class(node, member, name)
+ # recursion
+ self.object_build(class_node, member)
+ if name == "__class__" and class_node.parent is None:
+ class_node.parent = self._done[self._module]
+ elif inspect.ismethoddescriptor(member):
+ object_build_methoddescriptor(node, member, name)
+ elif inspect.isdatadescriptor(member):
+ object_build_datadescriptor(node, member, name)
+ elif isinstance(member, _CONSTANTS):
+ attach_const_node(node, name, member)
+ elif inspect.isroutine(member):
+ # This should be called for Jython, where some builtin
+ # methods aren't caught by isbuiltin branch.
+ _build_from_function(node, name, member, self._module)
+ elif _safe_has_attribute(member, "__all__"):
+ module = build_module(name)
+ _attach_local_node(node, module, name)
+ # recursion
+ self.object_build(module, member)
+ else:
+ # create an empty node so that the name is actually defined
+ attach_dummy_node(node, name, member)
+ return None
+
+ def imported_member(self, node, member, name: str) -> bool:
+ """verify this is not an imported class or handle it"""
+ # /!\ some classes like ExtensionClass doesn't have a __module__
+ # attribute ! Also, this may trigger an exception on badly built module
+ # (see http://www.logilab.org/ticket/57299 for instance)
+ try:
+ modname = getattr(member, "__module__", None)
+ except TypeError:
+ modname = None
+ if modname is None:
+ if name in {"__new__", "__subclasshook__"}:
+ # Python 2.5.1 (r251:54863, Sep 1 2010, 22:03:14)
+ # >>> print object.__new__.__module__
+ # None
+ modname = builtins.__name__
+ else:
+ attach_dummy_node(node, name, member)
+ return True
+
+ # On PyPy during bootstrapping we infer _io while _module is
+ # builtins. In CPython _io names itself io, see http://bugs.python.org/issue18602
+ # Therefore, this basically checks whether we are not in PyPy.
+ if modname == "_io" and not self._module.__name__ == "builtins":
+ return False
+
+ real_name = {"gtk": "gtk_gtk"}.get(modname, modname)
+
+ if real_name != self._module.__name__:
+ # check if it sounds valid and then add an import node, else use a
+ # dummy node
+ try:
+ with (
+ redirect_stderr(io.StringIO()) as stderr,
+ redirect_stdout(io.StringIO()) as stdout,
+ ):
+ getattr(sys.modules[modname], name)
+ stderr_value = stderr.getvalue()
+ if stderr_value:
+ logger.error(
+ "Captured stderr while getting %s from %s:\n%s",
+ name,
+ sys.modules[modname],
+ stderr_value,
+ )
+ stdout_value = stdout.getvalue()
+ if stdout_value:
+ logger.info(
+ "Captured stdout while getting %s from %s:\n%s",
+ name,
+ sys.modules[modname],
+ stdout_value,
+ )
+ except (KeyError, AttributeError):
+ attach_dummy_node(node, name, member)
+ else:
+ attach_import_node(node, modname, name)
+ return True
+ return False
+
+
+# astroid bootstrapping ######################################################
+
+_CONST_PROXY: dict[type, nodes.ClassDef] = {}
+
+
+def _set_proxied(const) -> nodes.ClassDef:
+ # TODO : find a nicer way to handle this situation;
+ return _CONST_PROXY[const.value.__class__]
+
+
+def _astroid_bootstrapping() -> None:
+ """astroid bootstrapping the builtins module"""
+ # this boot strapping is necessary since we need the Const nodes to
+ # inspect_build builtins, and then we can proxy Const
+ builder = InspectBuilder()
+ astroid_builtin = builder.inspect_build(builtins)
+
+ for cls, node_cls in node_classes.CONST_CLS.items():
+ if cls is TYPE_NONE:
+ proxy = build_class("NoneType")
+ proxy.parent = astroid_builtin
+ elif cls is TYPE_NOTIMPLEMENTED:
+ proxy = build_class("NotImplementedType")
+ proxy.parent = astroid_builtin
+ elif cls is TYPE_ELLIPSIS:
+ proxy = build_class("Ellipsis")
+ proxy.parent = astroid_builtin
+ else:
+ proxy = astroid_builtin.getattr(cls.__name__)[0]
+ assert isinstance(proxy, nodes.ClassDef)
+ if cls in (dict, list, set, tuple):
+ node_cls._proxied = proxy
+ else:
+ _CONST_PROXY[cls] = proxy
+
+ # Set the builtin module as parent for some builtins.
+ nodes.Const._proxied = property(_set_proxied)
+
+ _GeneratorType = nodes.ClassDef(
+ types.GeneratorType.__name__,
+ lineno=0,
+ col_offset=0,
+ end_lineno=0,
+ end_col_offset=0,
+ parent=nodes.Unknown(),
+ )
+ _GeneratorType.parent = astroid_builtin
+ generator_doc_node = (
+ nodes.Const(value=types.GeneratorType.__doc__)
+ if types.GeneratorType.__doc__
+ else None
+ )
+ _GeneratorType.postinit(
+ bases=[],
+ body=[],
+ decorators=None,
+ doc_node=generator_doc_node,
+ )
+ bases.Generator._proxied = _GeneratorType
+ builder.object_build(bases.Generator._proxied, types.GeneratorType)
+
+ if hasattr(types, "AsyncGeneratorType"):
+ _AsyncGeneratorType = nodes.ClassDef(
+ types.AsyncGeneratorType.__name__,
+ lineno=0,
+ col_offset=0,
+ end_lineno=0,
+ end_col_offset=0,
+ parent=nodes.Unknown(),
+ )
+ _AsyncGeneratorType.parent = astroid_builtin
+ async_generator_doc_node = (
+ nodes.Const(value=types.AsyncGeneratorType.__doc__)
+ if types.AsyncGeneratorType.__doc__
+ else None
+ )
+ _AsyncGeneratorType.postinit(
+ bases=[],
+ body=[],
+ decorators=None,
+ doc_node=async_generator_doc_node,
+ )
+ bases.AsyncGenerator._proxied = _AsyncGeneratorType
+ builder.object_build(bases.AsyncGenerator._proxied, types.AsyncGeneratorType)
+
+ if hasattr(types, "UnionType"):
+ _UnionTypeType = nodes.ClassDef(
+ types.UnionType.__name__,
+ lineno=0,
+ col_offset=0,
+ end_lineno=0,
+ end_col_offset=0,
+ parent=nodes.Unknown(),
+ )
+ _UnionTypeType.parent = astroid_builtin
+ union_type_doc_node = (
+ nodes.Const(value=types.UnionType.__doc__)
+ if types.UnionType.__doc__
+ else None
+ )
+ _UnionTypeType.postinit(
+ bases=[],
+ body=[],
+ decorators=None,
+ doc_node=union_type_doc_node,
+ )
+ bases.UnionType._proxied = _UnionTypeType
+ builder.object_build(bases.UnionType._proxied, types.UnionType)
+
+ builtin_types = (
+ types.GetSetDescriptorType,
+ types.GeneratorType,
+ types.MemberDescriptorType,
+ TYPE_NONE,
+ TYPE_NOTIMPLEMENTED,
+ types.FunctionType,
+ types.MethodType,
+ types.BuiltinFunctionType,
+ types.ModuleType,
+ types.TracebackType,
+ )
+ for _type in builtin_types:
+ if _type.__name__ not in astroid_builtin:
+ klass = nodes.ClassDef(
+ _type.__name__,
+ lineno=0,
+ col_offset=0,
+ end_lineno=0,
+ end_col_offset=0,
+ parent=nodes.Unknown(),
+ )
+ klass.parent = astroid_builtin
+ klass.postinit(
+ bases=[],
+ body=[],
+ decorators=None,
+ doc_node=nodes.Const(value=_type.__doc__) if _type.__doc__ else None,
+ )
+ builder.object_build(klass, _type)
+ astroid_builtin[_type.__name__] = klass
+
+ InspectBuilder.bootstrapped = True
+
+ # pylint: disable-next=import-outside-toplevel
+ from astroid.brain.brain_builtin_inference import on_bootstrap
+
+ # Instantiates an AstroidBuilder(), which is where
+ # InspectBuilder.bootstrapped is checked, so place after bootstrapped=True.
+ on_bootstrap()
diff --git a/solutions/.venv/Lib/site-packages/astroid/rebuilder.py b/solutions/.venv/Lib/site-packages/astroid/rebuilder.py
new file mode 100644
index 000000000..b78388501
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/rebuilder.py
@@ -0,0 +1,1867 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""This module contains utilities for rebuilding an _ast tree in
+order to get a single Astroid representation.
+"""
+
+from __future__ import annotations
+
+import ast
+import sys
+import token
+from collections.abc import Callable, Generator
+from io import StringIO
+from tokenize import TokenInfo, generate_tokens
+from typing import TYPE_CHECKING, Final, TypeVar, Union, cast, overload
+
+from astroid import nodes
+from astroid._ast import ParserModule, get_parser_module, parse_function_type_comment
+from astroid.const import PY312_PLUS, Context
+from astroid.manager import AstroidManager
+from astroid.nodes import NodeNG
+from astroid.nodes.node_classes import AssignName
+from astroid.nodes.utils import Position
+from astroid.typing import InferenceResult
+
+REDIRECT: Final[dict[str, str]] = {
+ "arguments": "Arguments",
+ "comprehension": "Comprehension",
+ "ListCompFor": "Comprehension",
+ "GenExprFor": "Comprehension",
+ "excepthandler": "ExceptHandler",
+ "keyword": "Keyword",
+ "match_case": "MatchCase",
+}
+
+
+T_Doc = TypeVar(
+ "T_Doc",
+ "ast.Module",
+ "ast.ClassDef",
+ Union["ast.FunctionDef", "ast.AsyncFunctionDef"],
+)
+_FunctionT = TypeVar("_FunctionT", nodes.FunctionDef, nodes.AsyncFunctionDef)
+_ForT = TypeVar("_ForT", nodes.For, nodes.AsyncFor)
+_WithT = TypeVar("_WithT", nodes.With, nodes.AsyncWith)
+NodesWithDocsType = Union[nodes.Module, nodes.ClassDef, nodes.FunctionDef]
+
+
+# noinspection PyMethodMayBeStatic
+class TreeRebuilder:
+ """Rebuilds the _ast tree to become an Astroid tree."""
+
+ def __init__(
+ self,
+ manager: AstroidManager,
+ parser_module: ParserModule | None = None,
+ data: str | None = None,
+ ) -> None:
+ self._manager = manager
+ self._data = data.split("\n") if data else None
+ self._global_names: list[dict[str, list[nodes.Global]]] = []
+ self._import_from_nodes: list[nodes.ImportFrom] = []
+ self._delayed_assattr: list[nodes.AssignAttr] = []
+ self._visit_meths: dict[type[ast.AST], Callable[[ast.AST, NodeNG], NodeNG]] = {}
+
+ if parser_module is None:
+ self._parser_module = get_parser_module()
+ else:
+ self._parser_module = parser_module
+
+ def _get_doc(self, node: T_Doc) -> tuple[T_Doc, ast.Constant | ast.Str | None]:
+ """Return the doc ast node."""
+ try:
+ if node.body and isinstance(node.body[0], ast.Expr):
+ first_value = node.body[0].value
+ if isinstance(first_value, ast.Constant) and isinstance(
+ first_value.value, str
+ ):
+ doc_ast_node = first_value
+ node.body = node.body[1:]
+ return node, doc_ast_node
+ except IndexError:
+ pass # ast built from scratch
+ return node, None
+
+ def _get_context(
+ self,
+ node: (
+ ast.Attribute
+ | ast.List
+ | ast.Name
+ | ast.Subscript
+ | ast.Starred
+ | ast.Tuple
+ ),
+ ) -> Context:
+ return self._parser_module.context_classes.get(type(node.ctx), Context.Load)
+
+ def _get_position_info(
+ self,
+ node: ast.ClassDef | ast.FunctionDef | ast.AsyncFunctionDef,
+ parent: nodes.ClassDef | nodes.FunctionDef | nodes.AsyncFunctionDef,
+ ) -> Position | None:
+ """Return position information for ClassDef and FunctionDef nodes.
+
+ In contrast to AST positions, these only include the actual keyword(s)
+ and the class / function name.
+
+ >>> @decorator
+ >>> async def some_func(var: int) -> None:
+ >>> ^^^^^^^^^^^^^^^^^^^
+ """
+ if not self._data:
+ return None
+ end_lineno = node.end_lineno
+ if node.body:
+ end_lineno = node.body[0].lineno
+ # pylint: disable-next=unsubscriptable-object
+ data = "\n".join(self._data[node.lineno - 1 : end_lineno])
+
+ start_token: TokenInfo | None = None
+ keyword_tokens: tuple[int, ...] = (token.NAME,)
+ if isinstance(parent, nodes.AsyncFunctionDef):
+ search_token = "async"
+ elif isinstance(parent, nodes.FunctionDef):
+ search_token = "def"
+ else:
+ search_token = "class"
+
+ for t in generate_tokens(StringIO(data).readline):
+ if (
+ start_token is not None
+ and t.type == token.NAME
+ and t.string == node.name
+ ):
+ break
+ if t.type in keyword_tokens:
+ if t.string == search_token:
+ start_token = t
+ continue
+ if t.string in {"def"}:
+ continue
+ start_token = None
+ else:
+ return None
+
+ return Position(
+ lineno=node.lineno + start_token.start[0] - 1,
+ col_offset=start_token.start[1],
+ end_lineno=node.lineno + t.end[0] - 1,
+ end_col_offset=t.end[1],
+ )
+
+ def visit_module(
+ self, node: ast.Module, modname: str, modpath: str, package: bool
+ ) -> nodes.Module:
+ """Visit a Module node by returning a fresh instance of it.
+
+ Note: Method not called by 'visit'
+ """
+ node, doc_ast_node = self._get_doc(node)
+ newnode = nodes.Module(
+ name=modname,
+ file=modpath,
+ path=[modpath],
+ package=package,
+ )
+ newnode.postinit(
+ [self.visit(child, newnode) for child in node.body],
+ doc_node=self.visit(doc_ast_node, newnode),
+ )
+ return newnode
+
+ if TYPE_CHECKING: # noqa: C901
+
+ @overload
+ def visit(self, node: ast.arg, parent: NodeNG) -> nodes.AssignName: ...
+
+ @overload
+ def visit(self, node: ast.arguments, parent: NodeNG) -> nodes.Arguments: ...
+
+ @overload
+ def visit(self, node: ast.Assert, parent: NodeNG) -> nodes.Assert: ...
+
+ @overload
+ def visit(
+ self, node: ast.AsyncFunctionDef, parent: NodeNG
+ ) -> nodes.AsyncFunctionDef: ...
+
+ @overload
+ def visit(self, node: ast.AsyncFor, parent: NodeNG) -> nodes.AsyncFor: ...
+
+ @overload
+ def visit(self, node: ast.Await, parent: NodeNG) -> nodes.Await: ...
+
+ @overload
+ def visit(self, node: ast.AsyncWith, parent: NodeNG) -> nodes.AsyncWith: ...
+
+ @overload
+ def visit(self, node: ast.Assign, parent: NodeNG) -> nodes.Assign: ...
+
+ @overload
+ def visit(self, node: ast.AnnAssign, parent: NodeNG) -> nodes.AnnAssign: ...
+
+ @overload
+ def visit(self, node: ast.AugAssign, parent: NodeNG) -> nodes.AugAssign: ...
+
+ @overload
+ def visit(self, node: ast.BinOp, parent: NodeNG) -> nodes.BinOp: ...
+
+ @overload
+ def visit(self, node: ast.BoolOp, parent: NodeNG) -> nodes.BoolOp: ...
+
+ @overload
+ def visit(self, node: ast.Break, parent: NodeNG) -> nodes.Break: ...
+
+ @overload
+ def visit(self, node: ast.Call, parent: NodeNG) -> nodes.Call: ...
+
+ @overload
+ def visit(self, node: ast.ClassDef, parent: NodeNG) -> nodes.ClassDef: ...
+
+ @overload
+ def visit(self, node: ast.Continue, parent: NodeNG) -> nodes.Continue: ...
+
+ @overload
+ def visit(self, node: ast.Compare, parent: NodeNG) -> nodes.Compare: ...
+
+ @overload
+ def visit(
+ self, node: ast.comprehension, parent: NodeNG
+ ) -> nodes.Comprehension: ...
+
+ @overload
+ def visit(self, node: ast.Delete, parent: NodeNG) -> nodes.Delete: ...
+
+ @overload
+ def visit(self, node: ast.Dict, parent: NodeNG) -> nodes.Dict: ...
+
+ @overload
+ def visit(self, node: ast.DictComp, parent: NodeNG) -> nodes.DictComp: ...
+
+ @overload
+ def visit(self, node: ast.Expr, parent: NodeNG) -> nodes.Expr: ...
+
+ @overload
+ def visit(
+ self, node: ast.ExceptHandler, parent: NodeNG
+ ) -> nodes.ExceptHandler: ...
+
+ @overload
+ def visit(self, node: ast.For, parent: NodeNG) -> nodes.For: ...
+
+ @overload
+ def visit(self, node: ast.ImportFrom, parent: NodeNG) -> nodes.ImportFrom: ...
+
+ @overload
+ def visit(self, node: ast.FunctionDef, parent: NodeNG) -> nodes.FunctionDef: ...
+
+ @overload
+ def visit(
+ self, node: ast.GeneratorExp, parent: NodeNG
+ ) -> nodes.GeneratorExp: ...
+
+ @overload
+ def visit(self, node: ast.Attribute, parent: NodeNG) -> nodes.Attribute: ...
+
+ @overload
+ def visit(self, node: ast.Global, parent: NodeNG) -> nodes.Global: ...
+
+ @overload
+ def visit(self, node: ast.If, parent: NodeNG) -> nodes.If: ...
+
+ @overload
+ def visit(self, node: ast.IfExp, parent: NodeNG) -> nodes.IfExp: ...
+
+ @overload
+ def visit(self, node: ast.Import, parent: NodeNG) -> nodes.Import: ...
+
+ @overload
+ def visit(self, node: ast.JoinedStr, parent: NodeNG) -> nodes.JoinedStr: ...
+
+ @overload
+ def visit(
+ self, node: ast.FormattedValue, parent: NodeNG
+ ) -> nodes.FormattedValue: ...
+
+ @overload
+ def visit(self, node: ast.NamedExpr, parent: NodeNG) -> nodes.NamedExpr: ...
+
+ @overload
+ def visit(self, node: ast.keyword, parent: NodeNG) -> nodes.Keyword: ...
+
+ @overload
+ def visit(self, node: ast.Lambda, parent: NodeNG) -> nodes.Lambda: ...
+
+ @overload
+ def visit(self, node: ast.List, parent: NodeNG) -> nodes.List: ...
+
+ @overload
+ def visit(self, node: ast.ListComp, parent: NodeNG) -> nodes.ListComp: ...
+
+ @overload
+ def visit(
+ self, node: ast.Name, parent: NodeNG
+ ) -> nodes.Name | nodes.Const | nodes.AssignName | nodes.DelName: ...
+
+ @overload
+ def visit(self, node: ast.Nonlocal, parent: NodeNG) -> nodes.Nonlocal: ...
+
+ @overload
+ def visit(self, node: ast.Constant, parent: NodeNG) -> nodes.Const: ...
+
+ if sys.version_info >= (3, 12):
+
+ @overload
+ def visit(self, node: ast.ParamSpec, parent: NodeNG) -> nodes.ParamSpec: ...
+
+ @overload
+ def visit(self, node: ast.Pass, parent: NodeNG) -> nodes.Pass: ...
+
+ @overload
+ def visit(self, node: ast.Raise, parent: NodeNG) -> nodes.Raise: ...
+
+ @overload
+ def visit(self, node: ast.Return, parent: NodeNG) -> nodes.Return: ...
+
+ @overload
+ def visit(self, node: ast.Set, parent: NodeNG) -> nodes.Set: ...
+
+ @overload
+ def visit(self, node: ast.SetComp, parent: NodeNG) -> nodes.SetComp: ...
+
+ @overload
+ def visit(self, node: ast.Slice, parent: nodes.Subscript) -> nodes.Slice: ...
+
+ @overload
+ def visit(self, node: ast.Subscript, parent: NodeNG) -> nodes.Subscript: ...
+
+ @overload
+ def visit(self, node: ast.Starred, parent: NodeNG) -> nodes.Starred: ...
+
+ @overload
+ def visit(self, node: ast.Try, parent: NodeNG) -> nodes.Try: ...
+
+ if sys.version_info >= (3, 11):
+
+ @overload
+ def visit(self, node: ast.TryStar, parent: NodeNG) -> nodes.TryStar: ...
+
+ @overload
+ def visit(self, node: ast.Tuple, parent: NodeNG) -> nodes.Tuple: ...
+
+ if sys.version_info >= (3, 12):
+
+ @overload
+ def visit(self, node: ast.TypeAlias, parent: NodeNG) -> nodes.TypeAlias: ...
+
+ @overload
+ def visit(self, node: ast.TypeVar, parent: NodeNG) -> nodes.TypeVar: ...
+
+ @overload
+ def visit(
+ self, node: ast.TypeVarTuple, parent: NodeNG
+ ) -> nodes.TypeVarTuple: ...
+
+ @overload
+ def visit(self, node: ast.UnaryOp, parent: NodeNG) -> nodes.UnaryOp: ...
+
+ @overload
+ def visit(self, node: ast.While, parent: NodeNG) -> nodes.While: ...
+
+ @overload
+ def visit(self, node: ast.With, parent: NodeNG) -> nodes.With: ...
+
+ @overload
+ def visit(self, node: ast.Yield, parent: NodeNG) -> nodes.Yield: ...
+
+ @overload
+ def visit(self, node: ast.YieldFrom, parent: NodeNG) -> nodes.YieldFrom: ...
+
+ if sys.version_info >= (3, 10):
+
+ @overload
+ def visit(self, node: ast.Match, parent: NodeNG) -> nodes.Match: ...
+
+ @overload
+ def visit(
+ self, node: ast.match_case, parent: NodeNG
+ ) -> nodes.MatchCase: ...
+
+ @overload
+ def visit(
+ self, node: ast.MatchValue, parent: NodeNG
+ ) -> nodes.MatchValue: ...
+
+ @overload
+ def visit(
+ self, node: ast.MatchSingleton, parent: NodeNG
+ ) -> nodes.MatchSingleton: ...
+
+ @overload
+ def visit(
+ self, node: ast.MatchSequence, parent: NodeNG
+ ) -> nodes.MatchSequence: ...
+
+ @overload
+ def visit(
+ self, node: ast.MatchMapping, parent: NodeNG
+ ) -> nodes.MatchMapping: ...
+
+ @overload
+ def visit(
+ self, node: ast.MatchClass, parent: NodeNG
+ ) -> nodes.MatchClass: ...
+
+ @overload
+ def visit(self, node: ast.MatchStar, parent: NodeNG) -> nodes.MatchStar: ...
+
+ @overload
+ def visit(self, node: ast.MatchAs, parent: NodeNG) -> nodes.MatchAs: ...
+
+ @overload
+ def visit(self, node: ast.MatchOr, parent: NodeNG) -> nodes.MatchOr: ...
+
+ @overload
+ def visit(self, node: ast.pattern, parent: NodeNG) -> nodes.Pattern: ...
+
+ @overload
+ def visit(self, node: ast.AST, parent: NodeNG) -> NodeNG: ...
+
+ @overload
+ def visit(self, node: None, parent: NodeNG) -> None: ...
+
+ def visit(self, node: ast.AST | None, parent: NodeNG) -> NodeNG | None:
+ if node is None:
+ return None
+ cls = node.__class__
+ if cls in self._visit_meths:
+ visit_method = self._visit_meths[cls]
+ else:
+ cls_name = cls.__name__
+ visit_name = "visit_" + REDIRECT.get(cls_name, cls_name).lower()
+ visit_method = getattr(self, visit_name)
+ self._visit_meths[cls] = visit_method
+ return visit_method(node, parent)
+
+ def _save_assignment(self, node: nodes.AssignName | nodes.DelName) -> None:
+ """Save assignment situation since node.parent is not available yet."""
+ if self._global_names and node.name in self._global_names[-1]:
+ node.root().set_local(node.name, node)
+ else:
+ assert node.parent
+ assert node.name
+ node.parent.set_local(node.name, node)
+
+ def visit_arg(self, node: ast.arg, parent: NodeNG) -> nodes.AssignName:
+ """Visit an arg node by returning a fresh AssName instance."""
+ return self.visit_assignname(node, parent, node.arg)
+
+ def visit_arguments(self, node: ast.arguments, parent: NodeNG) -> nodes.Arguments:
+ """Visit an Arguments node by returning a fresh instance of it."""
+ vararg: str | None = None
+ kwarg: str | None = None
+ vararg_node = node.vararg
+ kwarg_node = node.kwarg
+
+ newnode = nodes.Arguments(
+ node.vararg.arg if node.vararg else None,
+ node.kwarg.arg if node.kwarg else None,
+ parent,
+ (
+ AssignName(
+ vararg_node.arg,
+ vararg_node.lineno,
+ vararg_node.col_offset,
+ parent,
+ end_lineno=vararg_node.end_lineno,
+ end_col_offset=vararg_node.end_col_offset,
+ )
+ if vararg_node
+ else None
+ ),
+ (
+ AssignName(
+ kwarg_node.arg,
+ kwarg_node.lineno,
+ kwarg_node.col_offset,
+ parent,
+ end_lineno=kwarg_node.end_lineno,
+ end_col_offset=kwarg_node.end_col_offset,
+ )
+ if kwarg_node
+ else None
+ ),
+ )
+ args = [self.visit(child, newnode) for child in node.args]
+ defaults = [self.visit(child, newnode) for child in node.defaults]
+ varargannotation: NodeNG | None = None
+ kwargannotation: NodeNG | None = None
+ if node.vararg:
+ vararg = node.vararg.arg
+ varargannotation = self.visit(node.vararg.annotation, newnode)
+ if node.kwarg:
+ kwarg = node.kwarg.arg
+ kwargannotation = self.visit(node.kwarg.annotation, newnode)
+
+ kwonlyargs = [self.visit(child, newnode) for child in node.kwonlyargs]
+ kw_defaults = [self.visit(child, newnode) for child in node.kw_defaults]
+ annotations = [self.visit(arg.annotation, newnode) for arg in node.args]
+ kwonlyargs_annotations = [
+ self.visit(arg.annotation, newnode) for arg in node.kwonlyargs
+ ]
+
+ posonlyargs = [self.visit(child, newnode) for child in node.posonlyargs]
+ posonlyargs_annotations = [
+ self.visit(arg.annotation, newnode) for arg in node.posonlyargs
+ ]
+ type_comment_args = [
+ self.check_type_comment(child, parent=newnode) for child in node.args
+ ]
+ type_comment_kwonlyargs = [
+ self.check_type_comment(child, parent=newnode) for child in node.kwonlyargs
+ ]
+ type_comment_posonlyargs = [
+ self.check_type_comment(child, parent=newnode) for child in node.posonlyargs
+ ]
+
+ newnode.postinit(
+ args=args,
+ defaults=defaults,
+ kwonlyargs=kwonlyargs,
+ posonlyargs=posonlyargs,
+ kw_defaults=kw_defaults,
+ annotations=annotations,
+ kwonlyargs_annotations=kwonlyargs_annotations,
+ posonlyargs_annotations=posonlyargs_annotations,
+ varargannotation=varargannotation,
+ kwargannotation=kwargannotation,
+ type_comment_args=type_comment_args,
+ type_comment_kwonlyargs=type_comment_kwonlyargs,
+ type_comment_posonlyargs=type_comment_posonlyargs,
+ )
+ # save argument names in locals:
+ assert newnode.parent
+ if vararg:
+ newnode.parent.set_local(vararg, newnode)
+ if kwarg:
+ newnode.parent.set_local(kwarg, newnode)
+ return newnode
+
+ def visit_assert(self, node: ast.Assert, parent: NodeNG) -> nodes.Assert:
+ """Visit a Assert node by returning a fresh instance of it."""
+ newnode = nodes.Assert(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ msg: NodeNG | None = None
+ if node.msg:
+ msg = self.visit(node.msg, newnode)
+ newnode.postinit(self.visit(node.test, newnode), msg)
+ return newnode
+
+ def check_type_comment(
+ self,
+ node: ast.Assign | ast.arg | ast.For | ast.AsyncFor | ast.With | ast.AsyncWith,
+ parent: (
+ nodes.Assign
+ | nodes.Arguments
+ | nodes.For
+ | nodes.AsyncFor
+ | nodes.With
+ | nodes.AsyncWith
+ ),
+ ) -> NodeNG | None:
+ if not node.type_comment:
+ return None
+
+ try:
+ type_comment_ast = self._parser_module.parse(node.type_comment)
+ except SyntaxError:
+ # Invalid type comment, just skip it.
+ return None
+
+ # For '# type: # any comment' ast.parse returns a Module node,
+ # without any nodes in the body.
+ if not type_comment_ast.body:
+ return None
+
+ type_object = self.visit(type_comment_ast.body[0], parent=parent)
+ if not isinstance(type_object, nodes.Expr):
+ return None
+
+ return type_object.value
+
+ def check_function_type_comment(
+ self, node: ast.FunctionDef | ast.AsyncFunctionDef, parent: NodeNG
+ ) -> tuple[NodeNG | None, list[NodeNG]] | None:
+ if not node.type_comment:
+ return None
+
+ try:
+ type_comment_ast = parse_function_type_comment(node.type_comment)
+ except SyntaxError:
+ # Invalid type comment, just skip it.
+ return None
+
+ if not type_comment_ast:
+ return None
+
+ returns: NodeNG | None = None
+ argtypes: list[NodeNG] = [
+ self.visit(elem, parent) for elem in (type_comment_ast.argtypes or [])
+ ]
+ if type_comment_ast.returns:
+ returns = self.visit(type_comment_ast.returns, parent)
+
+ return returns, argtypes
+
+ def visit_asyncfunctiondef(
+ self, node: ast.AsyncFunctionDef, parent: NodeNG
+ ) -> nodes.AsyncFunctionDef:
+ return self._visit_functiondef(nodes.AsyncFunctionDef, node, parent)
+
+ def visit_asyncfor(self, node: ast.AsyncFor, parent: NodeNG) -> nodes.AsyncFor:
+ return self._visit_for(nodes.AsyncFor, node, parent)
+
+ def visit_await(self, node: ast.Await, parent: NodeNG) -> nodes.Await:
+ newnode = nodes.Await(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(value=self.visit(node.value, newnode))
+ return newnode
+
+ def visit_asyncwith(self, node: ast.AsyncWith, parent: NodeNG) -> nodes.AsyncWith:
+ return self._visit_with(nodes.AsyncWith, node, parent)
+
+ def visit_assign(self, node: ast.Assign, parent: NodeNG) -> nodes.Assign:
+ """Visit a Assign node by returning a fresh instance of it."""
+ newnode = nodes.Assign(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ type_annotation = self.check_type_comment(node, parent=newnode)
+ newnode.postinit(
+ targets=[self.visit(child, newnode) for child in node.targets],
+ value=self.visit(node.value, newnode),
+ type_annotation=type_annotation,
+ )
+ return newnode
+
+ def visit_annassign(self, node: ast.AnnAssign, parent: NodeNG) -> nodes.AnnAssign:
+ """Visit an AnnAssign node by returning a fresh instance of it."""
+ newnode = nodes.AnnAssign(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ target=self.visit(node.target, newnode),
+ annotation=self.visit(node.annotation, newnode),
+ simple=node.simple,
+ value=self.visit(node.value, newnode),
+ )
+ return newnode
+
+ @overload
+ def visit_assignname(
+ self, node: ast.AST, parent: NodeNG, node_name: str
+ ) -> nodes.AssignName: ...
+
+ @overload
+ def visit_assignname(
+ self, node: ast.AST, parent: NodeNG, node_name: None
+ ) -> None: ...
+
+ def visit_assignname(
+ self, node: ast.AST, parent: NodeNG, node_name: str | None
+ ) -> nodes.AssignName | None:
+ """Visit a node and return a AssignName node.
+
+ Note: Method not called by 'visit'
+ """
+ if node_name is None:
+ return None
+ newnode = nodes.AssignName(
+ name=node_name,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ self._save_assignment(newnode)
+ return newnode
+
+ def visit_augassign(self, node: ast.AugAssign, parent: NodeNG) -> nodes.AugAssign:
+ """Visit a AugAssign node by returning a fresh instance of it."""
+ newnode = nodes.AugAssign(
+ op=self._parser_module.bin_op_classes[type(node.op)] + "=",
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.target, newnode), self.visit(node.value, newnode)
+ )
+ return newnode
+
+ def visit_binop(self, node: ast.BinOp, parent: NodeNG) -> nodes.BinOp:
+ """Visit a BinOp node by returning a fresh instance of it."""
+ newnode = nodes.BinOp(
+ op=self._parser_module.bin_op_classes[type(node.op)],
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.left, newnode), self.visit(node.right, newnode)
+ )
+ return newnode
+
+ def visit_boolop(self, node: ast.BoolOp, parent: NodeNG) -> nodes.BoolOp:
+ """Visit a BoolOp node by returning a fresh instance of it."""
+ newnode = nodes.BoolOp(
+ op=self._parser_module.bool_op_classes[type(node.op)],
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit([self.visit(child, newnode) for child in node.values])
+ return newnode
+
+ def visit_break(self, node: ast.Break, parent: NodeNG) -> nodes.Break:
+ """Visit a Break node by returning a fresh instance of it."""
+ return nodes.Break(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+
+ def visit_call(self, node: ast.Call, parent: NodeNG) -> nodes.Call:
+ """Visit a CallFunc node by returning a fresh instance of it."""
+ newnode = nodes.Call(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ func=self.visit(node.func, newnode),
+ args=[self.visit(child, newnode) for child in node.args],
+ keywords=[self.visit(child, newnode) for child in node.keywords],
+ )
+ return newnode
+
+ def visit_classdef(
+ self, node: ast.ClassDef, parent: NodeNG, newstyle: bool = True
+ ) -> nodes.ClassDef:
+ """Visit a ClassDef node to become astroid."""
+ node, doc_ast_node = self._get_doc(node)
+ newnode = nodes.ClassDef(
+ name=node.name,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ metaclass = None
+ for keyword in node.keywords:
+ if keyword.arg == "metaclass":
+ metaclass = self.visit(keyword, newnode).value
+ break
+ decorators = self.visit_decorators(node, newnode)
+ newnode.postinit(
+ [self.visit(child, newnode) for child in node.bases],
+ [self.visit(child, newnode) for child in node.body],
+ decorators,
+ newstyle,
+ metaclass,
+ [
+ self.visit(kwd, newnode)
+ for kwd in node.keywords
+ if kwd.arg != "metaclass"
+ ],
+ position=self._get_position_info(node, newnode),
+ doc_node=self.visit(doc_ast_node, newnode),
+ type_params=(
+ [self.visit(param, newnode) for param in node.type_params]
+ if PY312_PLUS
+ else []
+ ),
+ )
+ return newnode
+
+ def visit_continue(self, node: ast.Continue, parent: NodeNG) -> nodes.Continue:
+ """Visit a Continue node by returning a fresh instance of it."""
+ return nodes.Continue(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+
+ def visit_compare(self, node: ast.Compare, parent: NodeNG) -> nodes.Compare:
+ """Visit a Compare node by returning a fresh instance of it."""
+ newnode = nodes.Compare(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.left, newnode),
+ [
+ (
+ self._parser_module.cmp_op_classes[op.__class__],
+ self.visit(expr, newnode),
+ )
+ for (op, expr) in zip(node.ops, node.comparators)
+ ],
+ )
+ return newnode
+
+ def visit_comprehension(
+ self, node: ast.comprehension, parent: NodeNG
+ ) -> nodes.Comprehension:
+ """Visit a Comprehension node by returning a fresh instance of it."""
+ newnode = nodes.Comprehension(
+ parent=parent,
+ # Comprehension nodes don't have these attributes
+ # see https://docs.python.org/3/library/ast.html#abstract-grammar
+ lineno=None,
+ col_offset=None,
+ end_lineno=None,
+ end_col_offset=None,
+ )
+ newnode.postinit(
+ self.visit(node.target, newnode),
+ self.visit(node.iter, newnode),
+ [self.visit(child, newnode) for child in node.ifs],
+ bool(node.is_async),
+ )
+ return newnode
+
+ def visit_decorators(
+ self,
+ node: ast.ClassDef | ast.FunctionDef | ast.AsyncFunctionDef,
+ parent: NodeNG,
+ ) -> nodes.Decorators | None:
+ """Visit a Decorators node by returning a fresh instance of it.
+
+ Note: Method not called by 'visit'
+ """
+ if not node.decorator_list:
+ return None
+ # /!\ node is actually an _ast.FunctionDef node while
+ # parent is an astroid.nodes.FunctionDef node
+
+ # Set the line number of the first decorator for Python 3.8+.
+ lineno = node.decorator_list[0].lineno
+ end_lineno = node.decorator_list[-1].end_lineno
+ end_col_offset = node.decorator_list[-1].end_col_offset
+
+ newnode = nodes.Decorators(
+ lineno=lineno,
+ col_offset=node.col_offset,
+ end_lineno=end_lineno,
+ end_col_offset=end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit([self.visit(child, newnode) for child in node.decorator_list])
+ return newnode
+
+ def visit_delete(self, node: ast.Delete, parent: NodeNG) -> nodes.Delete:
+ """Visit a Delete node by returning a fresh instance of it."""
+ newnode = nodes.Delete(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit([self.visit(child, newnode) for child in node.targets])
+ return newnode
+
+ def _visit_dict_items(
+ self, node: ast.Dict, parent: NodeNG, newnode: nodes.Dict
+ ) -> Generator[tuple[NodeNG, NodeNG]]:
+ for key, value in zip(node.keys, node.values):
+ rebuilt_key: NodeNG
+ rebuilt_value = self.visit(value, newnode)
+ if not key:
+ # Extended unpacking
+ rebuilt_key = nodes.DictUnpack(
+ lineno=rebuilt_value.lineno,
+ col_offset=rebuilt_value.col_offset,
+ end_lineno=rebuilt_value.end_lineno,
+ end_col_offset=rebuilt_value.end_col_offset,
+ parent=parent,
+ )
+ else:
+ rebuilt_key = self.visit(key, newnode)
+ yield rebuilt_key, rebuilt_value
+
+ def visit_dict(self, node: ast.Dict, parent: NodeNG) -> nodes.Dict:
+ """Visit a Dict node by returning a fresh instance of it."""
+ newnode = nodes.Dict(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ items: list[tuple[InferenceResult, InferenceResult]] = list(
+ self._visit_dict_items(node, parent, newnode)
+ )
+ newnode.postinit(items)
+ return newnode
+
+ def visit_dictcomp(self, node: ast.DictComp, parent: NodeNG) -> nodes.DictComp:
+ """Visit a DictComp node by returning a fresh instance of it."""
+ newnode = nodes.DictComp(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.key, newnode),
+ self.visit(node.value, newnode),
+ [self.visit(child, newnode) for child in node.generators],
+ )
+ return newnode
+
+ def visit_expr(self, node: ast.Expr, parent: NodeNG) -> nodes.Expr:
+ """Visit a Expr node by returning a fresh instance of it."""
+ newnode = nodes.Expr(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.value, newnode))
+ return newnode
+
+ def visit_excepthandler(
+ self, node: ast.ExceptHandler, parent: NodeNG
+ ) -> nodes.ExceptHandler:
+ """Visit an ExceptHandler node by returning a fresh instance of it."""
+ newnode = nodes.ExceptHandler(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.type, newnode),
+ self.visit_assignname(node, newnode, node.name),
+ [self.visit(child, newnode) for child in node.body],
+ )
+ return newnode
+
+ @overload
+ def _visit_for(
+ self, cls: type[nodes.For], node: ast.For, parent: NodeNG
+ ) -> nodes.For: ...
+
+ @overload
+ def _visit_for(
+ self, cls: type[nodes.AsyncFor], node: ast.AsyncFor, parent: NodeNG
+ ) -> nodes.AsyncFor: ...
+
+ def _visit_for(
+ self, cls: type[_ForT], node: ast.For | ast.AsyncFor, parent: NodeNG
+ ) -> _ForT:
+ """Visit a For node by returning a fresh instance of it."""
+ newnode = cls(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ type_annotation = self.check_type_comment(node, parent=newnode)
+ newnode.postinit(
+ target=self.visit(node.target, newnode),
+ iter=self.visit(node.iter, newnode),
+ body=[self.visit(child, newnode) for child in node.body],
+ orelse=[self.visit(child, newnode) for child in node.orelse],
+ type_annotation=type_annotation,
+ )
+ return newnode
+
+ def visit_for(self, node: ast.For, parent: NodeNG) -> nodes.For:
+ return self._visit_for(nodes.For, node, parent)
+
+ def visit_importfrom(
+ self, node: ast.ImportFrom, parent: NodeNG
+ ) -> nodes.ImportFrom:
+ """Visit an ImportFrom node by returning a fresh instance of it."""
+ names = [(alias.name, alias.asname) for alias in node.names]
+ newnode = nodes.ImportFrom(
+ fromname=node.module or "",
+ names=names,
+ level=node.level or None,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # store From names to add them to locals after building
+ self._import_from_nodes.append(newnode)
+ return newnode
+
+ @overload
+ def _visit_functiondef(
+ self, cls: type[nodes.FunctionDef], node: ast.FunctionDef, parent: NodeNG
+ ) -> nodes.FunctionDef: ...
+
+ @overload
+ def _visit_functiondef(
+ self,
+ cls: type[nodes.AsyncFunctionDef],
+ node: ast.AsyncFunctionDef,
+ parent: NodeNG,
+ ) -> nodes.AsyncFunctionDef: ...
+
+ def _visit_functiondef(
+ self,
+ cls: type[_FunctionT],
+ node: ast.FunctionDef | ast.AsyncFunctionDef,
+ parent: NodeNG,
+ ) -> _FunctionT:
+ """Visit an FunctionDef node to become astroid."""
+ self._global_names.append({})
+ node, doc_ast_node = self._get_doc(node)
+
+ lineno = node.lineno
+ if node.decorator_list:
+ # Python 3.8 sets the line number of a decorated function
+ # to be the actual line number of the function, but the
+ # previous versions expected the decorator's line number instead.
+ # We reset the function's line number to that of the
+ # first decorator to maintain backward compatibility.
+ # It's not ideal but this discrepancy was baked into
+ # the framework for *years*.
+ lineno = node.decorator_list[0].lineno
+
+ newnode = cls(
+ name=node.name,
+ lineno=lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ decorators = self.visit_decorators(node, newnode)
+ returns: NodeNG | None
+ if node.returns:
+ returns = self.visit(node.returns, newnode)
+ else:
+ returns = None
+
+ type_comment_args = type_comment_returns = None
+ type_comment_annotation = self.check_function_type_comment(node, newnode)
+ if type_comment_annotation:
+ type_comment_returns, type_comment_args = type_comment_annotation
+ newnode.postinit(
+ args=self.visit(node.args, newnode),
+ body=[self.visit(child, newnode) for child in node.body],
+ decorators=decorators,
+ returns=returns,
+ type_comment_returns=type_comment_returns,
+ type_comment_args=type_comment_args,
+ position=self._get_position_info(node, newnode),
+ doc_node=self.visit(doc_ast_node, newnode),
+ type_params=(
+ [self.visit(param, newnode) for param in node.type_params]
+ if PY312_PLUS
+ else []
+ ),
+ )
+ self._global_names.pop()
+ return newnode
+
+ def visit_functiondef(
+ self, node: ast.FunctionDef, parent: NodeNG
+ ) -> nodes.FunctionDef:
+ return self._visit_functiondef(nodes.FunctionDef, node, parent)
+
+ def visit_generatorexp(
+ self, node: ast.GeneratorExp, parent: NodeNG
+ ) -> nodes.GeneratorExp:
+ """Visit a GeneratorExp node by returning a fresh instance of it."""
+ newnode = nodes.GeneratorExp(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.elt, newnode),
+ [self.visit(child, newnode) for child in node.generators],
+ )
+ return newnode
+
+ def visit_attribute(
+ self, node: ast.Attribute, parent: NodeNG
+ ) -> nodes.Attribute | nodes.AssignAttr | nodes.DelAttr:
+ """Visit an Attribute node by returning a fresh instance of it."""
+ context = self._get_context(node)
+ newnode: nodes.Attribute | nodes.AssignAttr | nodes.DelAttr
+ if context == Context.Del:
+ # FIXME : maybe we should reintroduce and visit_delattr ?
+ # for instance, deactivating assign_ctx
+ newnode = nodes.DelAttr(
+ attrname=node.attr,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ elif context == Context.Store:
+ newnode = nodes.AssignAttr(
+ attrname=node.attr,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # Prohibit a local save if we are in an ExceptHandler.
+ if not isinstance(parent, nodes.ExceptHandler):
+ # mypy doesn't recognize that newnode has to be AssignAttr because it
+ # doesn't support ParamSpec
+ # See https://github.com/python/mypy/issues/8645
+ self._delayed_assattr.append(newnode) # type: ignore[arg-type]
+ else:
+ newnode = nodes.Attribute(
+ attrname=node.attr,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.value, newnode))
+ return newnode
+
+ def visit_global(self, node: ast.Global, parent: NodeNG) -> nodes.Global:
+ """Visit a Global node to become astroid."""
+ newnode = nodes.Global(
+ names=node.names,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ if self._global_names: # global at the module level, no effect
+ for name in node.names:
+ self._global_names[-1].setdefault(name, []).append(newnode)
+ return newnode
+
+ def visit_if(self, node: ast.If, parent: NodeNG) -> nodes.If:
+ """Visit an If node by returning a fresh instance of it."""
+ newnode = nodes.If(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.test, newnode),
+ [self.visit(child, newnode) for child in node.body],
+ [self.visit(child, newnode) for child in node.orelse],
+ )
+ return newnode
+
+ def visit_ifexp(self, node: ast.IfExp, parent: NodeNG) -> nodes.IfExp:
+ """Visit a IfExp node by returning a fresh instance of it."""
+ newnode = nodes.IfExp(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.test, newnode),
+ self.visit(node.body, newnode),
+ self.visit(node.orelse, newnode),
+ )
+ return newnode
+
+ def visit_import(self, node: ast.Import, parent: NodeNG) -> nodes.Import:
+ """Visit a Import node by returning a fresh instance of it."""
+ names = [(alias.name, alias.asname) for alias in node.names]
+ newnode = nodes.Import(
+ names=names,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # save import names in parent's locals:
+ for name, asname in newnode.names:
+ name = asname or name
+ parent.set_local(name.split(".")[0], newnode)
+ return newnode
+
+ def visit_joinedstr(self, node: ast.JoinedStr, parent: NodeNG) -> nodes.JoinedStr:
+ newnode = nodes.JoinedStr(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit([self.visit(child, newnode) for child in node.values])
+ return newnode
+
+ def visit_formattedvalue(
+ self, node: ast.FormattedValue, parent: NodeNG
+ ) -> nodes.FormattedValue:
+ newnode = nodes.FormattedValue(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ value=self.visit(node.value, newnode),
+ conversion=node.conversion,
+ format_spec=self.visit(node.format_spec, newnode),
+ )
+ return newnode
+
+ def visit_namedexpr(self, node: ast.NamedExpr, parent: NodeNG) -> nodes.NamedExpr:
+ newnode = nodes.NamedExpr(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.target, newnode), self.visit(node.value, newnode)
+ )
+ return newnode
+
+ def visit_keyword(self, node: ast.keyword, parent: NodeNG) -> nodes.Keyword:
+ """Visit a Keyword node by returning a fresh instance of it."""
+ newnode = nodes.Keyword(
+ arg=node.arg,
+ # position attributes added in 3.9
+ lineno=getattr(node, "lineno", None),
+ col_offset=getattr(node, "col_offset", None),
+ end_lineno=getattr(node, "end_lineno", None),
+ end_col_offset=getattr(node, "end_col_offset", None),
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.value, newnode))
+ return newnode
+
+ def visit_lambda(self, node: ast.Lambda, parent: NodeNG) -> nodes.Lambda:
+ """Visit a Lambda node by returning a fresh instance of it."""
+ newnode = nodes.Lambda(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.args, newnode), self.visit(node.body, newnode))
+ return newnode
+
+ def visit_list(self, node: ast.List, parent: NodeNG) -> nodes.List:
+ """Visit a List node by returning a fresh instance of it."""
+ context = self._get_context(node)
+ newnode = nodes.List(
+ ctx=context,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit([self.visit(child, newnode) for child in node.elts])
+ return newnode
+
+ def visit_listcomp(self, node: ast.ListComp, parent: NodeNG) -> nodes.ListComp:
+ """Visit a ListComp node by returning a fresh instance of it."""
+ newnode = nodes.ListComp(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.elt, newnode),
+ [self.visit(child, newnode) for child in node.generators],
+ )
+ return newnode
+
+ def visit_name(
+ self, node: ast.Name, parent: NodeNG
+ ) -> nodes.Name | nodes.AssignName | nodes.DelName:
+ """Visit a Name node by returning a fresh instance of it."""
+ context = self._get_context(node)
+ newnode: nodes.Name | nodes.AssignName | nodes.DelName
+ if context == Context.Del:
+ newnode = nodes.DelName(
+ name=node.id,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ elif context == Context.Store:
+ newnode = nodes.AssignName(
+ name=node.id,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ else:
+ newnode = nodes.Name(
+ name=node.id,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # XXX REMOVE me :
+ if context in (Context.Del, Context.Store): # 'Aug' ??
+ newnode = cast(Union[nodes.AssignName, nodes.DelName], newnode)
+ self._save_assignment(newnode)
+ return newnode
+
+ def visit_nonlocal(self, node: ast.Nonlocal, parent: NodeNG) -> nodes.Nonlocal:
+ """Visit a Nonlocal node and return a new instance of it."""
+ return nodes.Nonlocal(
+ names=node.names,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+
+ def visit_constant(self, node: ast.Constant, parent: NodeNG) -> nodes.Const:
+ """Visit a Constant node by returning a fresh instance of Const."""
+ return nodes.Const(
+ value=node.value,
+ kind=node.kind,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+
+ def visit_paramspec(self, node: ast.ParamSpec, parent: NodeNG) -> nodes.ParamSpec:
+ """Visit a ParamSpec node by returning a fresh instance of it."""
+ newnode = nodes.ParamSpec(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # Add AssignName node for 'node.name'
+ # https://bugs.python.org/issue43994
+ newnode.postinit(name=self.visit_assignname(node, newnode, node.name))
+ return newnode
+
+ def visit_pass(self, node: ast.Pass, parent: NodeNG) -> nodes.Pass:
+ """Visit a Pass node by returning a fresh instance of it."""
+ return nodes.Pass(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+
+ def visit_raise(self, node: ast.Raise, parent: NodeNG) -> nodes.Raise:
+ """Visit a Raise node by returning a fresh instance of it."""
+ newnode = nodes.Raise(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # no traceback; anyway it is not used in Pylint
+ newnode.postinit(
+ exc=self.visit(node.exc, newnode),
+ cause=self.visit(node.cause, newnode),
+ )
+ return newnode
+
+ def visit_return(self, node: ast.Return, parent: NodeNG) -> nodes.Return:
+ """Visit a Return node by returning a fresh instance of it."""
+ newnode = nodes.Return(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.value, newnode))
+ return newnode
+
+ def visit_set(self, node: ast.Set, parent: NodeNG) -> nodes.Set:
+ """Visit a Set node by returning a fresh instance of it."""
+ newnode = nodes.Set(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit([self.visit(child, newnode) for child in node.elts])
+ return newnode
+
+ def visit_setcomp(self, node: ast.SetComp, parent: NodeNG) -> nodes.SetComp:
+ """Visit a SetComp node by returning a fresh instance of it."""
+ newnode = nodes.SetComp(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.elt, newnode),
+ [self.visit(child, newnode) for child in node.generators],
+ )
+ return newnode
+
+ def visit_slice(self, node: ast.Slice, parent: nodes.Subscript) -> nodes.Slice:
+ """Visit a Slice node by returning a fresh instance of it."""
+ newnode = nodes.Slice(
+ # position attributes added in 3.9
+ lineno=getattr(node, "lineno", None),
+ col_offset=getattr(node, "col_offset", None),
+ end_lineno=getattr(node, "end_lineno", None),
+ end_col_offset=getattr(node, "end_col_offset", None),
+ parent=parent,
+ )
+ newnode.postinit(
+ lower=self.visit(node.lower, newnode),
+ upper=self.visit(node.upper, newnode),
+ step=self.visit(node.step, newnode),
+ )
+ return newnode
+
+ def visit_subscript(self, node: ast.Subscript, parent: NodeNG) -> nodes.Subscript:
+ """Visit a Subscript node by returning a fresh instance of it."""
+ context = self._get_context(node)
+ newnode = nodes.Subscript(
+ ctx=context,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.value, newnode), self.visit(node.slice, newnode)
+ )
+ return newnode
+
+ def visit_starred(self, node: ast.Starred, parent: NodeNG) -> nodes.Starred:
+ """Visit a Starred node and return a new instance of it."""
+ context = self._get_context(node)
+ newnode = nodes.Starred(
+ ctx=context,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.value, newnode))
+ return newnode
+
+ def visit_try(self, node: ast.Try, parent: NodeNG) -> nodes.Try:
+ """Visit a Try node by returning a fresh instance of it"""
+ newnode = nodes.Try(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ body=[self.visit(child, newnode) for child in node.body],
+ handlers=[self.visit(child, newnode) for child in node.handlers],
+ orelse=[self.visit(child, newnode) for child in node.orelse],
+ finalbody=[self.visit(child, newnode) for child in node.finalbody],
+ )
+ return newnode
+
+ def visit_trystar(self, node: ast.TryStar, parent: NodeNG) -> nodes.TryStar:
+ newnode = nodes.TryStar(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ body=[self.visit(n, newnode) for n in node.body],
+ handlers=[self.visit(n, newnode) for n in node.handlers],
+ orelse=[self.visit(n, newnode) for n in node.orelse],
+ finalbody=[self.visit(n, newnode) for n in node.finalbody],
+ )
+ return newnode
+
+ def visit_tuple(self, node: ast.Tuple, parent: NodeNG) -> nodes.Tuple:
+ """Visit a Tuple node by returning a fresh instance of it."""
+ context = self._get_context(node)
+ newnode = nodes.Tuple(
+ ctx=context,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit([self.visit(child, newnode) for child in node.elts])
+ return newnode
+
+ def visit_typealias(self, node: ast.TypeAlias, parent: NodeNG) -> nodes.TypeAlias:
+ """Visit a TypeAlias node by returning a fresh instance of it."""
+ newnode = nodes.TypeAlias(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ name=self.visit(node.name, newnode),
+ type_params=[self.visit(p, newnode) for p in node.type_params],
+ value=self.visit(node.value, newnode),
+ )
+ return newnode
+
+ def visit_typevar(self, node: ast.TypeVar, parent: NodeNG) -> nodes.TypeVar:
+ """Visit a TypeVar node by returning a fresh instance of it."""
+ newnode = nodes.TypeVar(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # Add AssignName node for 'node.name'
+ # https://bugs.python.org/issue43994
+ newnode.postinit(
+ name=self.visit_assignname(node, newnode, node.name),
+ bound=self.visit(node.bound, newnode),
+ )
+ return newnode
+
+ def visit_typevartuple(
+ self, node: ast.TypeVarTuple, parent: NodeNG
+ ) -> nodes.TypeVarTuple:
+ """Visit a TypeVarTuple node by returning a fresh instance of it."""
+ newnode = nodes.TypeVarTuple(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # Add AssignName node for 'node.name'
+ # https://bugs.python.org/issue43994
+ newnode.postinit(name=self.visit_assignname(node, newnode, node.name))
+ return newnode
+
+ def visit_unaryop(self, node: ast.UnaryOp, parent: NodeNG) -> nodes.UnaryOp:
+ """Visit a UnaryOp node by returning a fresh instance of it."""
+ newnode = nodes.UnaryOp(
+ op=self._parser_module.unary_op_classes[node.op.__class__],
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.operand, newnode))
+ return newnode
+
+ def visit_while(self, node: ast.While, parent: NodeNG) -> nodes.While:
+ """Visit a While node by returning a fresh instance of it."""
+ newnode = nodes.While(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ self.visit(node.test, newnode),
+ [self.visit(child, newnode) for child in node.body],
+ [self.visit(child, newnode) for child in node.orelse],
+ )
+ return newnode
+
+ @overload
+ def _visit_with(
+ self, cls: type[nodes.With], node: ast.With, parent: NodeNG
+ ) -> nodes.With: ...
+
+ @overload
+ def _visit_with(
+ self, cls: type[nodes.AsyncWith], node: ast.AsyncWith, parent: NodeNG
+ ) -> nodes.AsyncWith: ...
+
+ def _visit_with(
+ self,
+ cls: type[_WithT],
+ node: ast.With | ast.AsyncWith,
+ parent: NodeNG,
+ ) -> _WithT:
+ newnode = cls(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+
+ def visit_child(child: ast.withitem) -> tuple[NodeNG, NodeNG | None]:
+ expr = self.visit(child.context_expr, newnode)
+ var = self.visit(child.optional_vars, newnode)
+ return expr, var
+
+ type_annotation = self.check_type_comment(node, parent=newnode)
+ newnode.postinit(
+ items=[visit_child(child) for child in node.items],
+ body=[self.visit(child, newnode) for child in node.body],
+ type_annotation=type_annotation,
+ )
+ return newnode
+
+ def visit_with(self, node: ast.With, parent: NodeNG) -> NodeNG:
+ return self._visit_with(nodes.With, node, parent)
+
+ def visit_yield(self, node: ast.Yield, parent: NodeNG) -> NodeNG:
+ """Visit a Yield node by returning a fresh instance of it."""
+ newnode = nodes.Yield(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.value, newnode))
+ return newnode
+
+ def visit_yieldfrom(self, node: ast.YieldFrom, parent: NodeNG) -> NodeNG:
+ newnode = nodes.YieldFrom(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(self.visit(node.value, newnode))
+ return newnode
+
+ if sys.version_info >= (3, 10):
+
+ def visit_match(self, node: ast.Match, parent: NodeNG) -> nodes.Match:
+ newnode = nodes.Match(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ subject=self.visit(node.subject, newnode),
+ cases=[self.visit(case, newnode) for case in node.cases],
+ )
+ return newnode
+
+ def visit_matchcase(
+ self, node: ast.match_case, parent: NodeNG
+ ) -> nodes.MatchCase:
+ newnode = nodes.MatchCase(parent=parent)
+ newnode.postinit(
+ pattern=self.visit(node.pattern, newnode),
+ guard=self.visit(node.guard, newnode),
+ body=[self.visit(child, newnode) for child in node.body],
+ )
+ return newnode
+
+ def visit_matchvalue(
+ self, node: ast.MatchValue, parent: NodeNG
+ ) -> nodes.MatchValue:
+ newnode = nodes.MatchValue(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(value=self.visit(node.value, newnode))
+ return newnode
+
+ def visit_matchsingleton(
+ self, node: ast.MatchSingleton, parent: NodeNG
+ ) -> nodes.MatchSingleton:
+ return nodes.MatchSingleton(
+ value=node.value,
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+
+ def visit_matchsequence(
+ self, node: ast.MatchSequence, parent: NodeNG
+ ) -> nodes.MatchSequence:
+ newnode = nodes.MatchSequence(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ patterns=[self.visit(pattern, newnode) for pattern in node.patterns]
+ )
+ return newnode
+
+ def visit_matchmapping(
+ self, node: ast.MatchMapping, parent: NodeNG
+ ) -> nodes.MatchMapping:
+ newnode = nodes.MatchMapping(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # Add AssignName node for 'node.name'
+ # https://bugs.python.org/issue43994
+ newnode.postinit(
+ keys=[self.visit(child, newnode) for child in node.keys],
+ patterns=[self.visit(pattern, newnode) for pattern in node.patterns],
+ rest=self.visit_assignname(node, newnode, node.rest),
+ )
+ return newnode
+
+ def visit_matchclass(
+ self, node: ast.MatchClass, parent: NodeNG
+ ) -> nodes.MatchClass:
+ newnode = nodes.MatchClass(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ cls=self.visit(node.cls, newnode),
+ patterns=[self.visit(pattern, newnode) for pattern in node.patterns],
+ kwd_attrs=node.kwd_attrs,
+ kwd_patterns=[
+ self.visit(pattern, newnode) for pattern in node.kwd_patterns
+ ],
+ )
+ return newnode
+
+ def visit_matchstar(
+ self, node: ast.MatchStar, parent: NodeNG
+ ) -> nodes.MatchStar:
+ newnode = nodes.MatchStar(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # Add AssignName node for 'node.name'
+ # https://bugs.python.org/issue43994
+ newnode.postinit(name=self.visit_assignname(node, newnode, node.name))
+ return newnode
+
+ def visit_matchas(self, node: ast.MatchAs, parent: NodeNG) -> nodes.MatchAs:
+ newnode = nodes.MatchAs(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ # Add AssignName node for 'node.name'
+ # https://bugs.python.org/issue43994
+ newnode.postinit(
+ pattern=self.visit(node.pattern, newnode),
+ name=self.visit_assignname(node, newnode, node.name),
+ )
+ return newnode
+
+ def visit_matchor(self, node: ast.MatchOr, parent: NodeNG) -> nodes.MatchOr:
+ newnode = nodes.MatchOr(
+ lineno=node.lineno,
+ col_offset=node.col_offset,
+ end_lineno=node.end_lineno,
+ end_col_offset=node.end_col_offset,
+ parent=parent,
+ )
+ newnode.postinit(
+ patterns=[self.visit(pattern, newnode) for pattern in node.patterns]
+ )
+ return newnode
diff --git a/solutions/.venv/Lib/site-packages/astroid/test_utils.py b/solutions/.venv/Lib/site-packages/astroid/test_utils.py
new file mode 100644
index 000000000..afddb1a4f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/test_utils.py
@@ -0,0 +1,78 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+"""Utility functions for test code that uses astroid ASTs as input."""
+
+from __future__ import annotations
+
+import contextlib
+import functools
+import sys
+import warnings
+from collections.abc import Callable
+
+import pytest
+
+from astroid import manager, nodes, transforms
+
+
+def require_version(minver: str = "0.0.0", maxver: str = "4.0.0") -> Callable:
+ """Compare version of python interpreter to the given one and skips the test if older."""
+
+ def parse(python_version: str) -> tuple[int, ...]:
+ try:
+ return tuple(int(v) for v in python_version.split("."))
+ except ValueError as e:
+ msg = f"{python_version} is not a correct version : should be X.Y[.Z]."
+ raise ValueError(msg) from e
+
+ min_version = parse(minver)
+ max_version = parse(maxver)
+
+ def check_require_version(f):
+ current: tuple[int, int, int] = sys.version_info[:3]
+ if min_version < current <= max_version:
+ return f
+
+ version: str = ".".join(str(v) for v in sys.version_info)
+
+ @functools.wraps(f)
+ def new_f(*args, **kwargs):
+ if current <= min_version:
+ pytest.skip(f"Needs Python > {minver}. Current version is {version}.")
+ elif current > max_version:
+ pytest.skip(f"Needs Python <= {maxver}. Current version is {version}.")
+
+ return new_f
+
+ return check_require_version
+
+
+def get_name_node(start_from, name, index=0):
+ return [n for n in start_from.nodes_of_class(nodes.Name) if n.name == name][index]
+
+
+@contextlib.contextmanager
+def enable_warning(warning):
+ warnings.simplefilter("always", warning)
+ try:
+ yield
+ finally:
+ # Reset it to default value, so it will take
+ # into account the values from the -W flag.
+ warnings.simplefilter("default", warning)
+
+
+def brainless_manager():
+ m = manager.AstroidManager()
+ # avoid caching into the AstroidManager borg since we get problems
+ # with other tests :
+ m.__dict__ = {}
+ m._failed_import_hooks = []
+ m.astroid_cache = {}
+ m._mod_file_cache = {}
+ m._transform = transforms.TransformVisitor()
+ m.extension_package_whitelist = set()
+ m.module_denylist = set()
+ return m
diff --git a/solutions/.venv/Lib/site-packages/astroid/transforms.py b/solutions/.venv/Lib/site-packages/astroid/transforms.py
new file mode 100644
index 000000000..5f0e53313
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/transforms.py
@@ -0,0 +1,158 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import warnings
+from collections import defaultdict
+from collections.abc import Callable
+from typing import TYPE_CHECKING, Optional, TypeVar, Union, cast, overload
+
+from astroid.context import _invalidate_cache
+from astroid.typing import SuccessfulInferenceResult, TransformFn
+
+if TYPE_CHECKING:
+ from astroid import nodes
+
+ _SuccessfulInferenceResultT = TypeVar(
+ "_SuccessfulInferenceResultT", bound=SuccessfulInferenceResult
+ )
+ _Predicate = Optional[Callable[[_SuccessfulInferenceResultT], bool]]
+
+_Vistables = Union[
+ "nodes.NodeNG", list["nodes.NodeNG"], tuple["nodes.NodeNG", ...], str, None
+]
+_VisitReturns = Union[
+ SuccessfulInferenceResult,
+ list[SuccessfulInferenceResult],
+ tuple[SuccessfulInferenceResult, ...],
+ str,
+ None,
+]
+
+
+class TransformVisitor:
+ """A visitor for handling transforms.
+
+ The standard approach of using it is to call
+ :meth:`~visit` with an *astroid* module and the class
+ will take care of the rest, walking the tree and running the
+ transforms for each encountered node.
+
+ Based on its usage in AstroidManager.brain, it should not be reinstantiated.
+ """
+
+ def __init__(self) -> None:
+ # The typing here is incorrect, but it's the best we can do
+ # Refer to register_transform and unregister_transform for the correct types
+ self.transforms: defaultdict[
+ type[SuccessfulInferenceResult],
+ list[
+ tuple[
+ TransformFn[SuccessfulInferenceResult],
+ _Predicate[SuccessfulInferenceResult],
+ ]
+ ],
+ ] = defaultdict(list)
+
+ def _transform(self, node: SuccessfulInferenceResult) -> SuccessfulInferenceResult:
+ """Call matching transforms for the given node if any and return the
+ transformed node.
+ """
+ cls = node.__class__
+
+ for transform_func, predicate in self.transforms[cls]:
+ if predicate is None or predicate(node):
+ ret = transform_func(node)
+ # if the transformation function returns something, it's
+ # expected to be a replacement for the node
+ if ret is not None:
+ _invalidate_cache()
+ node = ret
+ if ret.__class__ != cls:
+ # Can no longer apply the rest of the transforms.
+ break
+ return node
+
+ def _visit(self, node: nodes.NodeNG) -> SuccessfulInferenceResult:
+ for name in node._astroid_fields:
+ value = getattr(node, name)
+ value = cast(_Vistables, value)
+ visited = self._visit_generic(value)
+ if visited != value:
+ setattr(node, name, visited)
+ return self._transform(node)
+
+ @overload
+ def _visit_generic(self, node: None) -> None: ...
+
+ @overload
+ def _visit_generic(self, node: str) -> str: ...
+
+ @overload
+ def _visit_generic(
+ self, node: list[nodes.NodeNG]
+ ) -> list[SuccessfulInferenceResult]: ...
+
+ @overload
+ def _visit_generic(
+ self, node: tuple[nodes.NodeNG, ...]
+ ) -> tuple[SuccessfulInferenceResult, ...]: ...
+
+ @overload
+ def _visit_generic(self, node: nodes.NodeNG) -> SuccessfulInferenceResult: ...
+
+ def _visit_generic(self, node: _Vistables) -> _VisitReturns:
+ if isinstance(node, list):
+ return [self._visit_generic(child) for child in node]
+ if isinstance(node, tuple):
+ return tuple(self._visit_generic(child) for child in node)
+ if not node or isinstance(node, str):
+ return node
+
+ try:
+ return self._visit(node)
+ except RecursionError:
+ # Returning the node untransformed is better than giving up.
+ warnings.warn(
+ f"Astroid was unable to transform {node}.\n"
+ "Some functionality will be missing unless the system recursion limit is lifted.\n"
+ "From pylint, try: --init-hook='import sys; sys.setrecursionlimit(2000)' or higher.",
+ UserWarning,
+ stacklevel=0,
+ )
+ return node
+
+ def register_transform(
+ self,
+ node_class: type[_SuccessfulInferenceResultT],
+ transform: TransformFn[_SuccessfulInferenceResultT],
+ predicate: _Predicate[_SuccessfulInferenceResultT] | None = None,
+ ) -> None:
+ """Register `transform(node)` function to be applied on the given node.
+
+ The transform will only be applied if `predicate` is None or returns true
+ when called with the node as argument.
+
+ The transform function may return a value which is then used to
+ substitute the original node in the tree.
+ """
+ self.transforms[node_class].append((transform, predicate)) # type: ignore[index, arg-type]
+
+ def unregister_transform(
+ self,
+ node_class: type[_SuccessfulInferenceResultT],
+ transform: TransformFn[_SuccessfulInferenceResultT],
+ predicate: _Predicate[_SuccessfulInferenceResultT] | None = None,
+ ) -> None:
+ """Unregister the given transform."""
+ self.transforms[node_class].remove((transform, predicate)) # type: ignore[index, arg-type]
+
+ def visit(self, node: nodes.NodeNG) -> SuccessfulInferenceResult:
+ """Walk the given astroid *tree* and transform each encountered node.
+
+ Only the nodes which have transforms registered will actually
+ be replaced or changed.
+ """
+ return self._visit(node)
diff --git a/solutions/.venv/Lib/site-packages/astroid/typing.py b/solutions/.venv/Lib/site-packages/astroid/typing.py
new file mode 100644
index 000000000..77cc12030
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/typing.py
@@ -0,0 +1,97 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from collections.abc import Callable, Generator
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Generic,
+ Protocol,
+ TypedDict,
+ TypeVar,
+ Union,
+)
+
+if TYPE_CHECKING:
+ from collections.abc import Iterator
+
+ from astroid import bases, exceptions, nodes, transforms, util
+ from astroid.context import InferenceContext
+ from astroid.interpreter._import import spec
+
+
+class InferenceErrorInfo(TypedDict):
+ """Store additional Inference error information
+ raised with StopIteration exception.
+ """
+
+ node: nodes.NodeNG
+ context: InferenceContext | None
+
+
+class AstroidManagerBrain(TypedDict):
+ """Dictionary to store relevant information for a AstroidManager class."""
+
+ astroid_cache: dict[str, nodes.Module]
+ _mod_file_cache: dict[
+ tuple[str, str | None], spec.ModuleSpec | exceptions.AstroidImportError
+ ]
+ _failed_import_hooks: list[Callable[[str], nodes.Module]]
+ always_load_extensions: bool
+ optimize_ast: bool
+ max_inferable_values: int
+ extension_package_whitelist: set[str]
+ _transform: transforms.TransformVisitor
+
+
+InferenceResult = Union["nodes.NodeNG", "util.UninferableBase", "bases.Proxy"]
+SuccessfulInferenceResult = Union["nodes.NodeNG", "bases.Proxy"]
+_SuccessfulInferenceResultT = TypeVar(
+ "_SuccessfulInferenceResultT", bound=SuccessfulInferenceResult
+)
+_SuccessfulInferenceResultT_contra = TypeVar(
+ "_SuccessfulInferenceResultT_contra",
+ bound=SuccessfulInferenceResult,
+ contravariant=True,
+)
+
+ConstFactoryResult = Union[
+ "nodes.List",
+ "nodes.Set",
+ "nodes.Tuple",
+ "nodes.Dict",
+ "nodes.Const",
+ "nodes.EmptyNode",
+]
+
+InferBinaryOp = Callable[
+ [
+ _SuccessfulInferenceResultT,
+ Union["nodes.AugAssign", "nodes.BinOp"],
+ str,
+ InferenceResult,
+ "InferenceContext",
+ SuccessfulInferenceResult,
+ ],
+ Generator[InferenceResult],
+]
+
+
+class InferFn(Protocol, Generic[_SuccessfulInferenceResultT_contra]):
+ def __call__(
+ self,
+ node: _SuccessfulInferenceResultT_contra,
+ context: InferenceContext | None = None,
+ **kwargs: Any,
+ ) -> Iterator[InferenceResult]: ... # pragma: no cover
+
+
+class TransformFn(Protocol, Generic[_SuccessfulInferenceResultT]):
+ def __call__(
+ self,
+ node: _SuccessfulInferenceResultT,
+ infer_function: InferFn[_SuccessfulInferenceResultT] = ...,
+ ) -> _SuccessfulInferenceResultT | None: ... # pragma: no cover
diff --git a/solutions/.venv/Lib/site-packages/astroid/util.py b/solutions/.venv/Lib/site-packages/astroid/util.py
new file mode 100644
index 000000000..510b81cc1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/astroid/util.py
@@ -0,0 +1,159 @@
+# Licensed under the LGPL: https://www.gnu.org/licenses/old-licenses/lgpl-2.1.en.html
+# For details: https://github.com/pylint-dev/astroid/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/astroid/blob/main/CONTRIBUTORS.txt
+
+
+from __future__ import annotations
+
+import warnings
+from typing import TYPE_CHECKING, Any, Final, Literal
+
+from astroid.exceptions import InferenceError
+
+if TYPE_CHECKING:
+ from astroid import bases, nodes
+ from astroid.context import InferenceContext
+ from astroid.typing import InferenceResult
+
+
+class UninferableBase:
+ """Special inference object, which is returned when inference fails.
+
+ This is meant to be used as a singleton. Use astroid.util.Uninferable to access it.
+ """
+
+ def __repr__(self) -> Literal["Uninferable"]:
+ return "Uninferable"
+
+ __str__ = __repr__
+
+ def __getattribute__(self, name: str) -> Any:
+ if name == "next":
+ raise AttributeError("next method should not be called")
+ if name.startswith("__") and name.endswith("__"):
+ return object.__getattribute__(self, name)
+ if name == "accept":
+ return object.__getattribute__(self, name)
+ return self
+
+ def __call__(self, *args: Any, **kwargs: Any) -> UninferableBase:
+ return self
+
+ def __bool__(self) -> Literal[False]:
+ return False
+
+ __nonzero__ = __bool__
+
+ def accept(self, visitor):
+ return visitor.visit_uninferable(self)
+
+
+Uninferable: Final = UninferableBase()
+
+
+class BadOperationMessage:
+ """Object which describes a TypeError occurred somewhere in the inference chain.
+
+ This is not an exception, but a container object which holds the types and
+ the error which occurred.
+ """
+
+
+class BadUnaryOperationMessage(BadOperationMessage):
+ """Object which describes operational failures on UnaryOps."""
+
+ def __init__(self, operand, op, error):
+ self.operand = operand
+ self.op = op
+ self.error = error
+
+ @property
+ def _object_type_helper(self):
+ from astroid import helpers # pylint: disable=import-outside-toplevel
+
+ return helpers.object_type
+
+ def _object_type(self, obj):
+ objtype = self._object_type_helper(obj)
+ if isinstance(objtype, UninferableBase):
+ return None
+
+ return objtype
+
+ def __str__(self) -> str:
+ if hasattr(self.operand, "name"):
+ operand_type = self.operand.name
+ else:
+ object_type = self._object_type(self.operand)
+ if hasattr(object_type, "name"):
+ operand_type = object_type.name
+ else:
+ # Just fallback to as_string
+ operand_type = object_type.as_string()
+
+ msg = "bad operand type for unary {}: {}"
+ return msg.format(self.op, operand_type)
+
+
+class BadBinaryOperationMessage(BadOperationMessage):
+ """Object which describes type errors for BinOps."""
+
+ def __init__(self, left_type, op, right_type):
+ self.left_type = left_type
+ self.right_type = right_type
+ self.op = op
+
+ def __str__(self) -> str:
+ msg = "unsupported operand type(s) for {}: {!r} and {!r}"
+ return msg.format(self.op, self.left_type.name, self.right_type.name)
+
+
+def _instancecheck(cls, other) -> bool:
+ wrapped = cls.__wrapped__
+ other_cls = other.__class__
+ is_instance_of = wrapped is other_cls or issubclass(other_cls, wrapped)
+ warnings.warn(
+ "%r is deprecated and slated for removal in astroid "
+ "2.0, use %r instead" % (cls.__class__.__name__, wrapped.__name__),
+ PendingDeprecationWarning,
+ stacklevel=2,
+ )
+ return is_instance_of
+
+
+def check_warnings_filter() -> bool:
+ """Return True if any other than the default DeprecationWarning filter is enabled.
+
+ https://docs.python.org/3/library/warnings.html#default-warning-filter
+ """
+ return any(
+ issubclass(DeprecationWarning, filter[2])
+ and filter[0] != "ignore"
+ and filter[3] != "__main__"
+ for filter in warnings.filters
+ )
+
+
+def safe_infer(
+ node: nodes.NodeNG | bases.Proxy | UninferableBase,
+ context: InferenceContext | None = None,
+) -> InferenceResult | None:
+ """Return the inferred value for the given node.
+
+ Return None if inference failed or if there is some ambiguity (more than
+ one node has been inferred).
+ """
+ if isinstance(node, UninferableBase):
+ return node
+ try:
+ inferit = node.infer(context=context)
+ value = next(inferit)
+ except (InferenceError, StopIteration):
+ return None
+ try:
+ next(inferit)
+ return None # None if there is ambiguity on the inferred node
+ except InferenceError:
+ return None # there is some kind of ambiguity
+ except StopIteration:
+ return value
diff --git a/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/METADATA b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/METADATA
new file mode 100644
index 000000000..a1b5c5754
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/METADATA
@@ -0,0 +1,441 @@
+Metadata-Version: 2.1
+Name: colorama
+Version: 0.4.6
+Summary: Cross-platform colored terminal text.
+Project-URL: Homepage, https://github.com/tartley/colorama
+Author-email: Jonathan Hartley <tartley@tartley.com>
+License-File: LICENSE.txt
+Keywords: ansi,color,colour,crossplatform,terminal,text,windows,xplatform
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: BSD License
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 2
+Classifier: Programming Language :: Python :: 2.7
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Terminals
+Requires-Python: !=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*,!=3.6.*,>=2.7
+Description-Content-Type: text/x-rst
+
+.. image:: https://img.shields.io/pypi/v/colorama.svg
+ :target: https://pypi.org/project/colorama/
+ :alt: Latest Version
+
+.. image:: https://img.shields.io/pypi/pyversions/colorama.svg
+ :target: https://pypi.org/project/colorama/
+ :alt: Supported Python versions
+
+.. image:: https://github.com/tartley/colorama/actions/workflows/test.yml/badge.svg
+ :target: https://github.com/tartley/colorama/actions/workflows/test.yml
+ :alt: Build Status
+
+Colorama
+========
+
+Makes ANSI escape character sequences (for producing colored terminal text and
+cursor positioning) work under MS Windows.
+
+.. |donate| image:: https://www.paypalobjects.com/en_US/i/btn/btn_donate_SM.gif
+ :target: https://www.paypal.com/cgi-bin/webscr?cmd=_donations&business=2MZ9D2GMLYCUJ&item_name=Colorama¤cy_code=USD
+ :alt: Donate with Paypal
+
+`PyPI for releases <https://pypi.org/project/colorama/>`_ |
+`Github for source <https://github.com/tartley/colorama>`_ |
+`Colorama for enterprise on Tidelift <https://github.com/tartley/colorama/blob/master/ENTERPRISE.md>`_
+
+If you find Colorama useful, please |donate| to the authors. Thank you!
+
+Installation
+------------
+
+Tested on CPython 2.7, 3.7, 3.8, 3.9 and 3.10 and Pypy 2.7 and 3.8.
+
+No requirements other than the standard library.
+
+.. code-block:: bash
+
+ pip install colorama
+ # or
+ conda install -c anaconda colorama
+
+Description
+-----------
+
+ANSI escape character sequences have long been used to produce colored terminal
+text and cursor positioning on Unix and Macs. Colorama makes this work on
+Windows, too, by wrapping ``stdout``, stripping ANSI sequences it finds (which
+would appear as gobbledygook in the output), and converting them into the
+appropriate win32 calls to modify the state of the terminal. On other platforms,
+Colorama does nothing.
+
+This has the upshot of providing a simple cross-platform API for printing
+colored terminal text from Python, and has the happy side-effect that existing
+applications or libraries which use ANSI sequences to produce colored output on
+Linux or Macs can now also work on Windows, simply by calling
+``colorama.just_fix_windows_console()`` (since v0.4.6) or ``colorama.init()``
+(all versions, but may have other side-effects – see below).
+
+An alternative approach is to install ``ansi.sys`` on Windows machines, which
+provides the same behaviour for all applications running in terminals. Colorama
+is intended for situations where that isn't easy (e.g., maybe your app doesn't
+have an installer.)
+
+Demo scripts in the source code repository print some colored text using
+ANSI sequences. Compare their output under Gnome-terminal's built in ANSI
+handling, versus on Windows Command-Prompt using Colorama:
+
+.. image:: https://github.com/tartley/colorama/raw/master/screenshots/ubuntu-demo.png
+ :width: 661
+ :height: 357
+ :alt: ANSI sequences on Ubuntu under gnome-terminal.
+
+.. image:: https://github.com/tartley/colorama/raw/master/screenshots/windows-demo.png
+ :width: 668
+ :height: 325
+ :alt: Same ANSI sequences on Windows, using Colorama.
+
+These screenshots show that, on Windows, Colorama does not support ANSI 'dim
+text'; it looks the same as 'normal text'.
+
+Usage
+-----
+
+Initialisation
+..............
+
+If the only thing you want from Colorama is to get ANSI escapes to work on
+Windows, then run:
+
+.. code-block:: python
+
+ from colorama import just_fix_windows_console
+ just_fix_windows_console()
+
+If you're on a recent version of Windows 10 or better, and your stdout/stderr
+are pointing to a Windows console, then this will flip the magic configuration
+switch to enable Windows' built-in ANSI support.
+
+If you're on an older version of Windows, and your stdout/stderr are pointing to
+a Windows console, then this will wrap ``sys.stdout`` and/or ``sys.stderr`` in a
+magic file object that intercepts ANSI escape sequences and issues the
+appropriate Win32 calls to emulate them.
+
+In all other circumstances, it does nothing whatsoever. Basically the idea is
+that this makes Windows act like Unix with respect to ANSI escape handling.
+
+It's safe to call this function multiple times. It's safe to call this function
+on non-Windows platforms, but it won't do anything. It's safe to call this
+function when one or both of your stdout/stderr are redirected to a file – it
+won't do anything to those streams.
+
+Alternatively, you can use the older interface with more features (but also more
+potential footguns):
+
+.. code-block:: python
+
+ from colorama import init
+ init()
+
+This does the same thing as ``just_fix_windows_console``, except for the
+following differences:
+
+- It's not safe to call ``init`` multiple times; you can end up with multiple
+ layers of wrapping and broken ANSI support.
+
+- Colorama will apply a heuristic to guess whether stdout/stderr support ANSI,
+ and if it thinks they don't, then it will wrap ``sys.stdout`` and
+ ``sys.stderr`` in a magic file object that strips out ANSI escape sequences
+ before printing them. This happens on all platforms, and can be convenient if
+ you want to write your code to emit ANSI escape sequences unconditionally, and
+ let Colorama decide whether they should actually be output. But note that
+ Colorama's heuristic is not particularly clever.
+
+- ``init`` also accepts explicit keyword args to enable/disable various
+ functionality – see below.
+
+To stop using Colorama before your program exits, simply call ``deinit()``.
+This will restore ``stdout`` and ``stderr`` to their original values, so that
+Colorama is disabled. To resume using Colorama again, call ``reinit()``; it is
+cheaper than calling ``init()`` again (but does the same thing).
+
+Most users should depend on ``colorama >= 0.4.6``, and use
+``just_fix_windows_console``. The old ``init`` interface will be supported
+indefinitely for backwards compatibility, but we don't plan to fix any issues
+with it, also for backwards compatibility.
+
+Colored Output
+..............
+
+Cross-platform printing of colored text can then be done using Colorama's
+constant shorthand for ANSI escape sequences. These are deliberately
+rudimentary, see below.
+
+.. code-block:: python
+
+ from colorama import Fore, Back, Style
+ print(Fore.RED + 'some red text')
+ print(Back.GREEN + 'and with a green background')
+ print(Style.DIM + 'and in dim text')
+ print(Style.RESET_ALL)
+ print('back to normal now')
+
+...or simply by manually printing ANSI sequences from your own code:
+
+.. code-block:: python
+
+ print('\033[31m' + 'some red text')
+ print('\033[39m') # and reset to default color
+
+...or, Colorama can be used in conjunction with existing ANSI libraries
+such as the venerable `Termcolor <https://pypi.org/project/termcolor/>`_
+the fabulous `Blessings <https://pypi.org/project/blessings/>`_,
+or the incredible `_Rich <https://pypi.org/project/rich/>`_.
+
+If you wish Colorama's Fore, Back and Style constants were more capable,
+then consider using one of the above highly capable libraries to generate
+colors, etc, and use Colorama just for its primary purpose: to convert
+those ANSI sequences to also work on Windows:
+
+SIMILARLY, do not send PRs adding the generation of new ANSI types to Colorama.
+We are only interested in converting ANSI codes to win32 API calls, not
+shortcuts like the above to generate ANSI characters.
+
+.. code-block:: python
+
+ from colorama import just_fix_windows_console
+ from termcolor import colored
+
+ # use Colorama to make Termcolor work on Windows too
+ just_fix_windows_console()
+
+ # then use Termcolor for all colored text output
+ print(colored('Hello, World!', 'green', 'on_red'))
+
+Available formatting constants are::
+
+ Fore: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
+ Back: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
+ Style: DIM, NORMAL, BRIGHT, RESET_ALL
+
+``Style.RESET_ALL`` resets foreground, background, and brightness. Colorama will
+perform this reset automatically on program exit.
+
+These are fairly well supported, but not part of the standard::
+
+ Fore: LIGHTBLACK_EX, LIGHTRED_EX, LIGHTGREEN_EX, LIGHTYELLOW_EX, LIGHTBLUE_EX, LIGHTMAGENTA_EX, LIGHTCYAN_EX, LIGHTWHITE_EX
+ Back: LIGHTBLACK_EX, LIGHTRED_EX, LIGHTGREEN_EX, LIGHTYELLOW_EX, LIGHTBLUE_EX, LIGHTMAGENTA_EX, LIGHTCYAN_EX, LIGHTWHITE_EX
+
+Cursor Positioning
+..................
+
+ANSI codes to reposition the cursor are supported. See ``demos/demo06.py`` for
+an example of how to generate them.
+
+Init Keyword Args
+.................
+
+``init()`` accepts some ``**kwargs`` to override default behaviour.
+
+init(autoreset=False):
+ If you find yourself repeatedly sending reset sequences to turn off color
+ changes at the end of every print, then ``init(autoreset=True)`` will
+ automate that:
+
+ .. code-block:: python
+
+ from colorama import init
+ init(autoreset=True)
+ print(Fore.RED + 'some red text')
+ print('automatically back to default color again')
+
+init(strip=None):
+ Pass ``True`` or ``False`` to override whether ANSI codes should be
+ stripped from the output. The default behaviour is to strip if on Windows
+ or if output is redirected (not a tty).
+
+init(convert=None):
+ Pass ``True`` or ``False`` to override whether to convert ANSI codes in the
+ output into win32 calls. The default behaviour is to convert if on Windows
+ and output is to a tty (terminal).
+
+init(wrap=True):
+ On Windows, Colorama works by replacing ``sys.stdout`` and ``sys.stderr``
+ with proxy objects, which override the ``.write()`` method to do their work.
+ If this wrapping causes you problems, then this can be disabled by passing
+ ``init(wrap=False)``. The default behaviour is to wrap if ``autoreset`` or
+ ``strip`` or ``convert`` are True.
+
+ When wrapping is disabled, colored printing on non-Windows platforms will
+ continue to work as normal. To do cross-platform colored output, you can
+ use Colorama's ``AnsiToWin32`` proxy directly:
+
+ .. code-block:: python
+
+ import sys
+ from colorama import init, AnsiToWin32
+ init(wrap=False)
+ stream = AnsiToWin32(sys.stderr).stream
+
+ # Python 2
+ print >>stream, Fore.BLUE + 'blue text on stderr'
+
+ # Python 3
+ print(Fore.BLUE + 'blue text on stderr', file=stream)
+
+Recognised ANSI Sequences
+.........................
+
+ANSI sequences generally take the form::
+
+ ESC [ <param> ; <param> ... <command>
+
+Where ``<param>`` is an integer, and ``<command>`` is a single letter. Zero or
+more params are passed to a ``<command>``. If no params are passed, it is
+generally synonymous with passing a single zero. No spaces exist in the
+sequence; they have been inserted here simply to read more easily.
+
+The only ANSI sequences that Colorama converts into win32 calls are::
+
+ ESC [ 0 m # reset all (colors and brightness)
+ ESC [ 1 m # bright
+ ESC [ 2 m # dim (looks same as normal brightness)
+ ESC [ 22 m # normal brightness
+
+ # FOREGROUND:
+ ESC [ 30 m # black
+ ESC [ 31 m # red
+ ESC [ 32 m # green
+ ESC [ 33 m # yellow
+ ESC [ 34 m # blue
+ ESC [ 35 m # magenta
+ ESC [ 36 m # cyan
+ ESC [ 37 m # white
+ ESC [ 39 m # reset
+
+ # BACKGROUND
+ ESC [ 40 m # black
+ ESC [ 41 m # red
+ ESC [ 42 m # green
+ ESC [ 43 m # yellow
+ ESC [ 44 m # blue
+ ESC [ 45 m # magenta
+ ESC [ 46 m # cyan
+ ESC [ 47 m # white
+ ESC [ 49 m # reset
+
+ # cursor positioning
+ ESC [ y;x H # position cursor at x across, y down
+ ESC [ y;x f # position cursor at x across, y down
+ ESC [ n A # move cursor n lines up
+ ESC [ n B # move cursor n lines down
+ ESC [ n C # move cursor n characters forward
+ ESC [ n D # move cursor n characters backward
+
+ # clear the screen
+ ESC [ mode J # clear the screen
+
+ # clear the line
+ ESC [ mode K # clear the line
+
+Multiple numeric params to the ``'m'`` command can be combined into a single
+sequence::
+
+ ESC [ 36 ; 45 ; 1 m # bright cyan text on magenta background
+
+All other ANSI sequences of the form ``ESC [ <param> ; <param> ... <command>``
+are silently stripped from the output on Windows.
+
+Any other form of ANSI sequence, such as single-character codes or alternative
+initial characters, are not recognised or stripped. It would be cool to add
+them though. Let me know if it would be useful for you, via the Issues on
+GitHub.
+
+Status & Known Problems
+-----------------------
+
+I've personally only tested it on Windows XP (CMD, Console2), Ubuntu
+(gnome-terminal, xterm), and OS X.
+
+Some valid ANSI sequences aren't recognised.
+
+If you're hacking on the code, see `README-hacking.md`_. ESPECIALLY, see the
+explanation there of why we do not want PRs that allow Colorama to generate new
+types of ANSI codes.
+
+See outstanding issues and wish-list:
+https://github.com/tartley/colorama/issues
+
+If anything doesn't work for you, or doesn't do what you expected or hoped for,
+I'd love to hear about it on that issues list, would be delighted by patches,
+and would be happy to grant commit access to anyone who submits a working patch
+or two.
+
+.. _README-hacking.md: README-hacking.md
+
+License
+-------
+
+Copyright Jonathan Hartley & Arnon Yaari, 2013-2020. BSD 3-Clause license; see
+LICENSE file.
+
+Professional support
+--------------------
+
+.. |tideliftlogo| image:: https://cdn2.hubspot.net/hubfs/4008838/website/logos/logos_for_download/Tidelift_primary-shorthand-logo.png
+ :alt: Tidelift
+ :target: https://tidelift.com/subscription/pkg/pypi-colorama?utm_source=pypi-colorama&utm_medium=referral&utm_campaign=readme
+
+.. list-table::
+ :widths: 10 100
+
+ * - |tideliftlogo|
+ - Professional support for colorama is available as part of the
+ `Tidelift Subscription`_.
+ Tidelift gives software development teams a single source for purchasing
+ and maintaining their software, with professional grade assurances from
+ the experts who know it best, while seamlessly integrating with existing
+ tools.
+
+.. _Tidelift Subscription: https://tidelift.com/subscription/pkg/pypi-colorama?utm_source=pypi-colorama&utm_medium=referral&utm_campaign=readme
+
+Thanks
+------
+
+See the CHANGELOG for more thanks!
+
+* Marc Schlaich (schlamar) for a ``setup.py`` fix for Python2.5.
+* Marc Abramowitz, reported & fixed a crash on exit with closed ``stdout``,
+ providing a solution to issue #7's setuptools/distutils debate,
+ and other fixes.
+* User 'eryksun', for guidance on correctly instantiating ``ctypes.windll``.
+* Matthew McCormick for politely pointing out a longstanding crash on non-Win.
+* Ben Hoyt, for a magnificent fix under 64-bit Windows.
+* Jesse at Empty Square for submitting a fix for examples in the README.
+* User 'jamessp', an observant documentation fix for cursor positioning.
+* User 'vaal1239', Dave Mckee & Lackner Kristof for a tiny but much-needed Win7
+ fix.
+* Julien Stuyck, for wisely suggesting Python3 compatible updates to README.
+* Daniel Griffith for multiple fabulous patches.
+* Oscar Lesta for a valuable fix to stop ANSI chars being sent to non-tty
+ output.
+* Roger Binns, for many suggestions, valuable feedback, & bug reports.
+* Tim Golden for thought and much appreciated feedback on the initial idea.
+* User 'Zearin' for updates to the README file.
+* John Szakmeister for adding support for light colors
+* Charles Merriam for adding documentation to demos
+* Jurko for a fix on 64-bit Windows CPython2.5 w/o ctypes
+* Florian Bruhin for a fix when stdout or stderr are None
+* Thomas Weininger for fixing ValueError on Windows
+* Remi Rampin for better Github integration and fixes to the README file
+* Simeon Visser for closing a file handle using 'with' and updating classifiers
+ to include Python 3.3 and 3.4
+* Andy Neff for fixing RESET of LIGHT_EX colors.
+* Jonathan Hartley for the initial idea and implementation.
diff --git a/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/RECORD b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/RECORD
new file mode 100644
index 000000000..cd6b130d4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/RECORD
@@ -0,0 +1,31 @@
+colorama-0.4.6.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+colorama-0.4.6.dist-info/METADATA,sha256=e67SnrUMOym9sz_4TjF3vxvAV4T3aF7NyqRHHH3YEMw,17158
+colorama-0.4.6.dist-info/RECORD,,
+colorama-0.4.6.dist-info/WHEEL,sha256=cdcF4Fbd0FPtw2EMIOwH-3rSOTUdTCeOSXRMD1iLUb8,105
+colorama-0.4.6.dist-info/licenses/LICENSE.txt,sha256=ysNcAmhuXQSlpxQL-zs25zrtSWZW6JEQLkKIhteTAxg,1491
+colorama/__init__.py,sha256=wePQA4U20tKgYARySLEC047ucNX-g8pRLpYBuiHlLb8,266
+colorama/__pycache__/__init__.cpython-312.pyc,,
+colorama/__pycache__/ansi.cpython-312.pyc,,
+colorama/__pycache__/ansitowin32.cpython-312.pyc,,
+colorama/__pycache__/initialise.cpython-312.pyc,,
+colorama/__pycache__/win32.cpython-312.pyc,,
+colorama/__pycache__/winterm.cpython-312.pyc,,
+colorama/ansi.py,sha256=Top4EeEuaQdBWdteKMEcGOTeKeF19Q-Wo_6_Cj5kOzQ,2522
+colorama/ansitowin32.py,sha256=vPNYa3OZbxjbuFyaVo0Tmhmy1FZ1lKMWCnT7odXpItk,11128
+colorama/initialise.py,sha256=-hIny86ClXo39ixh5iSCfUIa2f_h_bgKRDW7gqs-KLU,3325
+colorama/tests/__init__.py,sha256=MkgPAEzGQd-Rq0w0PZXSX2LadRWhUECcisJY8lSrm4Q,75
+colorama/tests/__pycache__/__init__.cpython-312.pyc,,
+colorama/tests/__pycache__/ansi_test.cpython-312.pyc,,
+colorama/tests/__pycache__/ansitowin32_test.cpython-312.pyc,,
+colorama/tests/__pycache__/initialise_test.cpython-312.pyc,,
+colorama/tests/__pycache__/isatty_test.cpython-312.pyc,,
+colorama/tests/__pycache__/utils.cpython-312.pyc,,
+colorama/tests/__pycache__/winterm_test.cpython-312.pyc,,
+colorama/tests/ansi_test.py,sha256=FeViDrUINIZcr505PAxvU4AjXz1asEiALs9GXMhwRaE,2839
+colorama/tests/ansitowin32_test.py,sha256=RN7AIhMJ5EqDsYaCjVo-o4u8JzDD4ukJbmevWKS70rY,10678
+colorama/tests/initialise_test.py,sha256=BbPy-XfyHwJ6zKozuQOvNvQZzsx9vdb_0bYXn7hsBTc,6741
+colorama/tests/isatty_test.py,sha256=Pg26LRpv0yQDB5Ac-sxgVXG7hsA1NYvapFgApZfYzZg,1866
+colorama/tests/utils.py,sha256=1IIRylG39z5-dzq09R_ngufxyPZxgldNbrxKxUGwGKE,1079
+colorama/tests/winterm_test.py,sha256=qoWFPEjym5gm2RuMwpf3pOis3a5r_PJZFCzK254JL8A,3709
+colorama/win32.py,sha256=YQOKwMTwtGBbsY4dL5HYTvwTeP9wIQra5MvPNddpxZs,6181
+colorama/winterm.py,sha256=XCQFDHjPi6AHYNdZwy0tA02H-Jh48Jp-HvCjeLeLp3U,7134
diff --git a/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/WHEEL
new file mode 100644
index 000000000..d79189fda
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/WHEEL
@@ -0,0 +1,5 @@
+Wheel-Version: 1.0
+Generator: hatchling 1.11.1
+Root-Is-Purelib: true
+Tag: py2-none-any
+Tag: py3-none-any
diff --git a/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/licenses/LICENSE.txt b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/licenses/LICENSE.txt
new file mode 100644
index 000000000..3105888ec
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama-0.4.6.dist-info/licenses/LICENSE.txt
@@ -0,0 +1,27 @@
+Copyright (c) 2010 Jonathan Hartley
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are met:
+
+* Redistributions of source code must retain the above copyright notice, this
+ list of conditions and the following disclaimer.
+
+* Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+* Neither the name of the copyright holders, nor those of its contributors
+ may be used to endorse or promote products derived from this software without
+ specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
+ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
+WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
diff --git a/solutions/.venv/Lib/site-packages/colorama/__init__.py b/solutions/.venv/Lib/site-packages/colorama/__init__.py
new file mode 100644
index 000000000..383101cdb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/__init__.py
@@ -0,0 +1,7 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+from .initialise import init, deinit, reinit, colorama_text, just_fix_windows_console
+from .ansi import Fore, Back, Style, Cursor
+from .ansitowin32 import AnsiToWin32
+
+__version__ = '0.4.6'
+
diff --git a/solutions/.venv/Lib/site-packages/colorama/ansi.py b/solutions/.venv/Lib/site-packages/colorama/ansi.py
new file mode 100644
index 000000000..11ec695ff
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/ansi.py
@@ -0,0 +1,102 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+'''
+This module generates ANSI character codes to printing colors to terminals.
+See: http://en.wikipedia.org/wiki/ANSI_escape_code
+'''
+
+CSI = '\033['
+OSC = '\033]'
+BEL = '\a'
+
+
+def code_to_chars(code):
+ return CSI + str(code) + 'm'
+
+def set_title(title):
+ return OSC + '2;' + title + BEL
+
+def clear_screen(mode=2):
+ return CSI + str(mode) + 'J'
+
+def clear_line(mode=2):
+ return CSI + str(mode) + 'K'
+
+
+class AnsiCodes(object):
+ def __init__(self):
+ # the subclasses declare class attributes which are numbers.
+ # Upon instantiation we define instance attributes, which are the same
+ # as the class attributes but wrapped with the ANSI escape sequence
+ for name in dir(self):
+ if not name.startswith('_'):
+ value = getattr(self, name)
+ setattr(self, name, code_to_chars(value))
+
+
+class AnsiCursor(object):
+ def UP(self, n=1):
+ return CSI + str(n) + 'A'
+ def DOWN(self, n=1):
+ return CSI + str(n) + 'B'
+ def FORWARD(self, n=1):
+ return CSI + str(n) + 'C'
+ def BACK(self, n=1):
+ return CSI + str(n) + 'D'
+ def POS(self, x=1, y=1):
+ return CSI + str(y) + ';' + str(x) + 'H'
+
+
+class AnsiFore(AnsiCodes):
+ BLACK = 30
+ RED = 31
+ GREEN = 32
+ YELLOW = 33
+ BLUE = 34
+ MAGENTA = 35
+ CYAN = 36
+ WHITE = 37
+ RESET = 39
+
+ # These are fairly well supported, but not part of the standard.
+ LIGHTBLACK_EX = 90
+ LIGHTRED_EX = 91
+ LIGHTGREEN_EX = 92
+ LIGHTYELLOW_EX = 93
+ LIGHTBLUE_EX = 94
+ LIGHTMAGENTA_EX = 95
+ LIGHTCYAN_EX = 96
+ LIGHTWHITE_EX = 97
+
+
+class AnsiBack(AnsiCodes):
+ BLACK = 40
+ RED = 41
+ GREEN = 42
+ YELLOW = 43
+ BLUE = 44
+ MAGENTA = 45
+ CYAN = 46
+ WHITE = 47
+ RESET = 49
+
+ # These are fairly well supported, but not part of the standard.
+ LIGHTBLACK_EX = 100
+ LIGHTRED_EX = 101
+ LIGHTGREEN_EX = 102
+ LIGHTYELLOW_EX = 103
+ LIGHTBLUE_EX = 104
+ LIGHTMAGENTA_EX = 105
+ LIGHTCYAN_EX = 106
+ LIGHTWHITE_EX = 107
+
+
+class AnsiStyle(AnsiCodes):
+ BRIGHT = 1
+ DIM = 2
+ NORMAL = 22
+ RESET_ALL = 0
+
+Fore = AnsiFore()
+Back = AnsiBack()
+Style = AnsiStyle()
+Cursor = AnsiCursor()
diff --git a/solutions/.venv/Lib/site-packages/colorama/ansitowin32.py b/solutions/.venv/Lib/site-packages/colorama/ansitowin32.py
new file mode 100644
index 000000000..abf209e60
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/ansitowin32.py
@@ -0,0 +1,277 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+import re
+import sys
+import os
+
+from .ansi import AnsiFore, AnsiBack, AnsiStyle, Style, BEL
+from .winterm import enable_vt_processing, WinTerm, WinColor, WinStyle
+from .win32 import windll, winapi_test
+
+
+winterm = None
+if windll is not None:
+ winterm = WinTerm()
+
+
+class StreamWrapper(object):
+ '''
+ Wraps a stream (such as stdout), acting as a transparent proxy for all
+ attribute access apart from method 'write()', which is delegated to our
+ Converter instance.
+ '''
+ def __init__(self, wrapped, converter):
+ # double-underscore everything to prevent clashes with names of
+ # attributes on the wrapped stream object.
+ self.__wrapped = wrapped
+ self.__convertor = converter
+
+ def __getattr__(self, name):
+ return getattr(self.__wrapped, name)
+
+ def __enter__(self, *args, **kwargs):
+ # special method lookup bypasses __getattr__/__getattribute__, see
+ # https://stackoverflow.com/questions/12632894/why-doesnt-getattr-work-with-exit
+ # thus, contextlib magic methods are not proxied via __getattr__
+ return self.__wrapped.__enter__(*args, **kwargs)
+
+ def __exit__(self, *args, **kwargs):
+ return self.__wrapped.__exit__(*args, **kwargs)
+
+ def __setstate__(self, state):
+ self.__dict__ = state
+
+ def __getstate__(self):
+ return self.__dict__
+
+ def write(self, text):
+ self.__convertor.write(text)
+
+ def isatty(self):
+ stream = self.__wrapped
+ if 'PYCHARM_HOSTED' in os.environ:
+ if stream is not None and (stream is sys.__stdout__ or stream is sys.__stderr__):
+ return True
+ try:
+ stream_isatty = stream.isatty
+ except AttributeError:
+ return False
+ else:
+ return stream_isatty()
+
+ @property
+ def closed(self):
+ stream = self.__wrapped
+ try:
+ return stream.closed
+ # AttributeError in the case that the stream doesn't support being closed
+ # ValueError for the case that the stream has already been detached when atexit runs
+ except (AttributeError, ValueError):
+ return True
+
+
+class AnsiToWin32(object):
+ '''
+ Implements a 'write()' method which, on Windows, will strip ANSI character
+ sequences from the text, and if outputting to a tty, will convert them into
+ win32 function calls.
+ '''
+ ANSI_CSI_RE = re.compile('\001?\033\\[((?:\\d|;)*)([a-zA-Z])\002?') # Control Sequence Introducer
+ ANSI_OSC_RE = re.compile('\001?\033\\]([^\a]*)(\a)\002?') # Operating System Command
+
+ def __init__(self, wrapped, convert=None, strip=None, autoreset=False):
+ # The wrapped stream (normally sys.stdout or sys.stderr)
+ self.wrapped = wrapped
+
+ # should we reset colors to defaults after every .write()
+ self.autoreset = autoreset
+
+ # create the proxy wrapping our output stream
+ self.stream = StreamWrapper(wrapped, self)
+
+ on_windows = os.name == 'nt'
+ # We test if the WinAPI works, because even if we are on Windows
+ # we may be using a terminal that doesn't support the WinAPI
+ # (e.g. Cygwin Terminal). In this case it's up to the terminal
+ # to support the ANSI codes.
+ conversion_supported = on_windows and winapi_test()
+ try:
+ fd = wrapped.fileno()
+ except Exception:
+ fd = -1
+ system_has_native_ansi = not on_windows or enable_vt_processing(fd)
+ have_tty = not self.stream.closed and self.stream.isatty()
+ need_conversion = conversion_supported and not system_has_native_ansi
+
+ # should we strip ANSI sequences from our output?
+ if strip is None:
+ strip = need_conversion or not have_tty
+ self.strip = strip
+
+ # should we should convert ANSI sequences into win32 calls?
+ if convert is None:
+ convert = need_conversion and have_tty
+ self.convert = convert
+
+ # dict of ansi codes to win32 functions and parameters
+ self.win32_calls = self.get_win32_calls()
+
+ # are we wrapping stderr?
+ self.on_stderr = self.wrapped is sys.stderr
+
+ def should_wrap(self):
+ '''
+ True if this class is actually needed. If false, then the output
+ stream will not be affected, nor will win32 calls be issued, so
+ wrapping stdout is not actually required. This will generally be
+ False on non-Windows platforms, unless optional functionality like
+ autoreset has been requested using kwargs to init()
+ '''
+ return self.convert or self.strip or self.autoreset
+
+ def get_win32_calls(self):
+ if self.convert and winterm:
+ return {
+ AnsiStyle.RESET_ALL: (winterm.reset_all, ),
+ AnsiStyle.BRIGHT: (winterm.style, WinStyle.BRIGHT),
+ AnsiStyle.DIM: (winterm.style, WinStyle.NORMAL),
+ AnsiStyle.NORMAL: (winterm.style, WinStyle.NORMAL),
+ AnsiFore.BLACK: (winterm.fore, WinColor.BLACK),
+ AnsiFore.RED: (winterm.fore, WinColor.RED),
+ AnsiFore.GREEN: (winterm.fore, WinColor.GREEN),
+ AnsiFore.YELLOW: (winterm.fore, WinColor.YELLOW),
+ AnsiFore.BLUE: (winterm.fore, WinColor.BLUE),
+ AnsiFore.MAGENTA: (winterm.fore, WinColor.MAGENTA),
+ AnsiFore.CYAN: (winterm.fore, WinColor.CYAN),
+ AnsiFore.WHITE: (winterm.fore, WinColor.GREY),
+ AnsiFore.RESET: (winterm.fore, ),
+ AnsiFore.LIGHTBLACK_EX: (winterm.fore, WinColor.BLACK, True),
+ AnsiFore.LIGHTRED_EX: (winterm.fore, WinColor.RED, True),
+ AnsiFore.LIGHTGREEN_EX: (winterm.fore, WinColor.GREEN, True),
+ AnsiFore.LIGHTYELLOW_EX: (winterm.fore, WinColor.YELLOW, True),
+ AnsiFore.LIGHTBLUE_EX: (winterm.fore, WinColor.BLUE, True),
+ AnsiFore.LIGHTMAGENTA_EX: (winterm.fore, WinColor.MAGENTA, True),
+ AnsiFore.LIGHTCYAN_EX: (winterm.fore, WinColor.CYAN, True),
+ AnsiFore.LIGHTWHITE_EX: (winterm.fore, WinColor.GREY, True),
+ AnsiBack.BLACK: (winterm.back, WinColor.BLACK),
+ AnsiBack.RED: (winterm.back, WinColor.RED),
+ AnsiBack.GREEN: (winterm.back, WinColor.GREEN),
+ AnsiBack.YELLOW: (winterm.back, WinColor.YELLOW),
+ AnsiBack.BLUE: (winterm.back, WinColor.BLUE),
+ AnsiBack.MAGENTA: (winterm.back, WinColor.MAGENTA),
+ AnsiBack.CYAN: (winterm.back, WinColor.CYAN),
+ AnsiBack.WHITE: (winterm.back, WinColor.GREY),
+ AnsiBack.RESET: (winterm.back, ),
+ AnsiBack.LIGHTBLACK_EX: (winterm.back, WinColor.BLACK, True),
+ AnsiBack.LIGHTRED_EX: (winterm.back, WinColor.RED, True),
+ AnsiBack.LIGHTGREEN_EX: (winterm.back, WinColor.GREEN, True),
+ AnsiBack.LIGHTYELLOW_EX: (winterm.back, WinColor.YELLOW, True),
+ AnsiBack.LIGHTBLUE_EX: (winterm.back, WinColor.BLUE, True),
+ AnsiBack.LIGHTMAGENTA_EX: (winterm.back, WinColor.MAGENTA, True),
+ AnsiBack.LIGHTCYAN_EX: (winterm.back, WinColor.CYAN, True),
+ AnsiBack.LIGHTWHITE_EX: (winterm.back, WinColor.GREY, True),
+ }
+ return dict()
+
+ def write(self, text):
+ if self.strip or self.convert:
+ self.write_and_convert(text)
+ else:
+ self.wrapped.write(text)
+ self.wrapped.flush()
+ if self.autoreset:
+ self.reset_all()
+
+
+ def reset_all(self):
+ if self.convert:
+ self.call_win32('m', (0,))
+ elif not self.strip and not self.stream.closed:
+ self.wrapped.write(Style.RESET_ALL)
+
+
+ def write_and_convert(self, text):
+ '''
+ Write the given text to our wrapped stream, stripping any ANSI
+ sequences from the text, and optionally converting them into win32
+ calls.
+ '''
+ cursor = 0
+ text = self.convert_osc(text)
+ for match in self.ANSI_CSI_RE.finditer(text):
+ start, end = match.span()
+ self.write_plain_text(text, cursor, start)
+ self.convert_ansi(*match.groups())
+ cursor = end
+ self.write_plain_text(text, cursor, len(text))
+
+
+ def write_plain_text(self, text, start, end):
+ if start < end:
+ self.wrapped.write(text[start:end])
+ self.wrapped.flush()
+
+
+ def convert_ansi(self, paramstring, command):
+ if self.convert:
+ params = self.extract_params(command, paramstring)
+ self.call_win32(command, params)
+
+
+ def extract_params(self, command, paramstring):
+ if command in 'Hf':
+ params = tuple(int(p) if len(p) != 0 else 1 for p in paramstring.split(';'))
+ while len(params) < 2:
+ # defaults:
+ params = params + (1,)
+ else:
+ params = tuple(int(p) for p in paramstring.split(';') if len(p) != 0)
+ if len(params) == 0:
+ # defaults:
+ if command in 'JKm':
+ params = (0,)
+ elif command in 'ABCD':
+ params = (1,)
+
+ return params
+
+
+ def call_win32(self, command, params):
+ if command == 'm':
+ for param in params:
+ if param in self.win32_calls:
+ func_args = self.win32_calls[param]
+ func = func_args[0]
+ args = func_args[1:]
+ kwargs = dict(on_stderr=self.on_stderr)
+ func(*args, **kwargs)
+ elif command in 'J':
+ winterm.erase_screen(params[0], on_stderr=self.on_stderr)
+ elif command in 'K':
+ winterm.erase_line(params[0], on_stderr=self.on_stderr)
+ elif command in 'Hf': # cursor position - absolute
+ winterm.set_cursor_position(params, on_stderr=self.on_stderr)
+ elif command in 'ABCD': # cursor position - relative
+ n = params[0]
+ # A - up, B - down, C - forward, D - back
+ x, y = {'A': (0, -n), 'B': (0, n), 'C': (n, 0), 'D': (-n, 0)}[command]
+ winterm.cursor_adjust(x, y, on_stderr=self.on_stderr)
+
+
+ def convert_osc(self, text):
+ for match in self.ANSI_OSC_RE.finditer(text):
+ start, end = match.span()
+ text = text[:start] + text[end:]
+ paramstring, command = match.groups()
+ if command == BEL:
+ if paramstring.count(";") == 1:
+ params = paramstring.split(";")
+ # 0 - change title and icon (we will only change title)
+ # 1 - change icon (we don't support this)
+ # 2 - change title
+ if params[0] in '02':
+ winterm.set_title(params[1])
+ return text
+
+
+ def flush(self):
+ self.wrapped.flush()
diff --git a/solutions/.venv/Lib/site-packages/colorama/initialise.py b/solutions/.venv/Lib/site-packages/colorama/initialise.py
new file mode 100644
index 000000000..d5fd4b71f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/initialise.py
@@ -0,0 +1,121 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+import atexit
+import contextlib
+import sys
+
+from .ansitowin32 import AnsiToWin32
+
+
+def _wipe_internal_state_for_tests():
+ global orig_stdout, orig_stderr
+ orig_stdout = None
+ orig_stderr = None
+
+ global wrapped_stdout, wrapped_stderr
+ wrapped_stdout = None
+ wrapped_stderr = None
+
+ global atexit_done
+ atexit_done = False
+
+ global fixed_windows_console
+ fixed_windows_console = False
+
+ try:
+ # no-op if it wasn't registered
+ atexit.unregister(reset_all)
+ except AttributeError:
+ # python 2: no atexit.unregister. Oh well, we did our best.
+ pass
+
+
+def reset_all():
+ if AnsiToWin32 is not None: # Issue #74: objects might become None at exit
+ AnsiToWin32(orig_stdout).reset_all()
+
+
+def init(autoreset=False, convert=None, strip=None, wrap=True):
+
+ if not wrap and any([autoreset, convert, strip]):
+ raise ValueError('wrap=False conflicts with any other arg=True')
+
+ global wrapped_stdout, wrapped_stderr
+ global orig_stdout, orig_stderr
+
+ orig_stdout = sys.stdout
+ orig_stderr = sys.stderr
+
+ if sys.stdout is None:
+ wrapped_stdout = None
+ else:
+ sys.stdout = wrapped_stdout = \
+ wrap_stream(orig_stdout, convert, strip, autoreset, wrap)
+ if sys.stderr is None:
+ wrapped_stderr = None
+ else:
+ sys.stderr = wrapped_stderr = \
+ wrap_stream(orig_stderr, convert, strip, autoreset, wrap)
+
+ global atexit_done
+ if not atexit_done:
+ atexit.register(reset_all)
+ atexit_done = True
+
+
+def deinit():
+ if orig_stdout is not None:
+ sys.stdout = orig_stdout
+ if orig_stderr is not None:
+ sys.stderr = orig_stderr
+
+
+def just_fix_windows_console():
+ global fixed_windows_console
+
+ if sys.platform != "win32":
+ return
+ if fixed_windows_console:
+ return
+ if wrapped_stdout is not None or wrapped_stderr is not None:
+ # Someone already ran init() and it did stuff, so we won't second-guess them
+ return
+
+ # On newer versions of Windows, AnsiToWin32.__init__ will implicitly enable the
+ # native ANSI support in the console as a side-effect. We only need to actually
+ # replace sys.stdout/stderr if we're in the old-style conversion mode.
+ new_stdout = AnsiToWin32(sys.stdout, convert=None, strip=None, autoreset=False)
+ if new_stdout.convert:
+ sys.stdout = new_stdout
+ new_stderr = AnsiToWin32(sys.stderr, convert=None, strip=None, autoreset=False)
+ if new_stderr.convert:
+ sys.stderr = new_stderr
+
+ fixed_windows_console = True
+
+@contextlib.contextmanager
+def colorama_text(*args, **kwargs):
+ init(*args, **kwargs)
+ try:
+ yield
+ finally:
+ deinit()
+
+
+def reinit():
+ if wrapped_stdout is not None:
+ sys.stdout = wrapped_stdout
+ if wrapped_stderr is not None:
+ sys.stderr = wrapped_stderr
+
+
+def wrap_stream(stream, convert, strip, autoreset, wrap):
+ if wrap:
+ wrapper = AnsiToWin32(stream,
+ convert=convert, strip=strip, autoreset=autoreset)
+ if wrapper.should_wrap():
+ stream = wrapper.stream
+ return stream
+
+
+# Use this for initial setup as well, to reduce code duplication
+_wipe_internal_state_for_tests()
diff --git a/solutions/.venv/Lib/site-packages/colorama/tests/__init__.py b/solutions/.venv/Lib/site-packages/colorama/tests/__init__.py
new file mode 100644
index 000000000..8c5661e93
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/tests/__init__.py
@@ -0,0 +1 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
diff --git a/solutions/.venv/Lib/site-packages/colorama/tests/ansi_test.py b/solutions/.venv/Lib/site-packages/colorama/tests/ansi_test.py
new file mode 100644
index 000000000..0a20c80f8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/tests/ansi_test.py
@@ -0,0 +1,76 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+import sys
+from unittest import TestCase, main
+
+from ..ansi import Back, Fore, Style
+from ..ansitowin32 import AnsiToWin32
+
+stdout_orig = sys.stdout
+stderr_orig = sys.stderr
+
+
+class AnsiTest(TestCase):
+
+ def setUp(self):
+ # sanity check: stdout should be a file or StringIO object.
+ # It will only be AnsiToWin32 if init() has previously wrapped it
+ self.assertNotEqual(type(sys.stdout), AnsiToWin32)
+ self.assertNotEqual(type(sys.stderr), AnsiToWin32)
+
+ def tearDown(self):
+ sys.stdout = stdout_orig
+ sys.stderr = stderr_orig
+
+
+ def testForeAttributes(self):
+ self.assertEqual(Fore.BLACK, '\033[30m')
+ self.assertEqual(Fore.RED, '\033[31m')
+ self.assertEqual(Fore.GREEN, '\033[32m')
+ self.assertEqual(Fore.YELLOW, '\033[33m')
+ self.assertEqual(Fore.BLUE, '\033[34m')
+ self.assertEqual(Fore.MAGENTA, '\033[35m')
+ self.assertEqual(Fore.CYAN, '\033[36m')
+ self.assertEqual(Fore.WHITE, '\033[37m')
+ self.assertEqual(Fore.RESET, '\033[39m')
+
+ # Check the light, extended versions.
+ self.assertEqual(Fore.LIGHTBLACK_EX, '\033[90m')
+ self.assertEqual(Fore.LIGHTRED_EX, '\033[91m')
+ self.assertEqual(Fore.LIGHTGREEN_EX, '\033[92m')
+ self.assertEqual(Fore.LIGHTYELLOW_EX, '\033[93m')
+ self.assertEqual(Fore.LIGHTBLUE_EX, '\033[94m')
+ self.assertEqual(Fore.LIGHTMAGENTA_EX, '\033[95m')
+ self.assertEqual(Fore.LIGHTCYAN_EX, '\033[96m')
+ self.assertEqual(Fore.LIGHTWHITE_EX, '\033[97m')
+
+
+ def testBackAttributes(self):
+ self.assertEqual(Back.BLACK, '\033[40m')
+ self.assertEqual(Back.RED, '\033[41m')
+ self.assertEqual(Back.GREEN, '\033[42m')
+ self.assertEqual(Back.YELLOW, '\033[43m')
+ self.assertEqual(Back.BLUE, '\033[44m')
+ self.assertEqual(Back.MAGENTA, '\033[45m')
+ self.assertEqual(Back.CYAN, '\033[46m')
+ self.assertEqual(Back.WHITE, '\033[47m')
+ self.assertEqual(Back.RESET, '\033[49m')
+
+ # Check the light, extended versions.
+ self.assertEqual(Back.LIGHTBLACK_EX, '\033[100m')
+ self.assertEqual(Back.LIGHTRED_EX, '\033[101m')
+ self.assertEqual(Back.LIGHTGREEN_EX, '\033[102m')
+ self.assertEqual(Back.LIGHTYELLOW_EX, '\033[103m')
+ self.assertEqual(Back.LIGHTBLUE_EX, '\033[104m')
+ self.assertEqual(Back.LIGHTMAGENTA_EX, '\033[105m')
+ self.assertEqual(Back.LIGHTCYAN_EX, '\033[106m')
+ self.assertEqual(Back.LIGHTWHITE_EX, '\033[107m')
+
+
+ def testStyleAttributes(self):
+ self.assertEqual(Style.DIM, '\033[2m')
+ self.assertEqual(Style.NORMAL, '\033[22m')
+ self.assertEqual(Style.BRIGHT, '\033[1m')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/solutions/.venv/Lib/site-packages/colorama/tests/ansitowin32_test.py b/solutions/.venv/Lib/site-packages/colorama/tests/ansitowin32_test.py
new file mode 100644
index 000000000..91ca551f9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/tests/ansitowin32_test.py
@@ -0,0 +1,294 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+from io import StringIO, TextIOWrapper
+from unittest import TestCase, main
+try:
+ from contextlib import ExitStack
+except ImportError:
+ # python 2
+ from contextlib2 import ExitStack
+
+try:
+ from unittest.mock import MagicMock, Mock, patch
+except ImportError:
+ from mock import MagicMock, Mock, patch
+
+from ..ansitowin32 import AnsiToWin32, StreamWrapper
+from ..win32 import ENABLE_VIRTUAL_TERMINAL_PROCESSING
+from .utils import osname
+
+
+class StreamWrapperTest(TestCase):
+
+ def testIsAProxy(self):
+ mockStream = Mock()
+ wrapper = StreamWrapper(mockStream, None)
+ self.assertTrue( wrapper.random_attr is mockStream.random_attr )
+
+ def testDelegatesWrite(self):
+ mockStream = Mock()
+ mockConverter = Mock()
+ wrapper = StreamWrapper(mockStream, mockConverter)
+ wrapper.write('hello')
+ self.assertTrue(mockConverter.write.call_args, (('hello',), {}))
+
+ def testDelegatesContext(self):
+ mockConverter = Mock()
+ s = StringIO()
+ with StreamWrapper(s, mockConverter) as fp:
+ fp.write(u'hello')
+ self.assertTrue(s.closed)
+
+ def testProxyNoContextManager(self):
+ mockStream = MagicMock()
+ mockStream.__enter__.side_effect = AttributeError()
+ mockConverter = Mock()
+ with self.assertRaises(AttributeError) as excinfo:
+ with StreamWrapper(mockStream, mockConverter) as wrapper:
+ wrapper.write('hello')
+
+ def test_closed_shouldnt_raise_on_closed_stream(self):
+ stream = StringIO()
+ stream.close()
+ wrapper = StreamWrapper(stream, None)
+ self.assertEqual(wrapper.closed, True)
+
+ def test_closed_shouldnt_raise_on_detached_stream(self):
+ stream = TextIOWrapper(StringIO())
+ stream.detach()
+ wrapper = StreamWrapper(stream, None)
+ self.assertEqual(wrapper.closed, True)
+
+class AnsiToWin32Test(TestCase):
+
+ def testInit(self):
+ mockStdout = Mock()
+ auto = Mock()
+ stream = AnsiToWin32(mockStdout, autoreset=auto)
+ self.assertEqual(stream.wrapped, mockStdout)
+ self.assertEqual(stream.autoreset, auto)
+
+ @patch('colorama.ansitowin32.winterm', None)
+ @patch('colorama.ansitowin32.winapi_test', lambda *_: True)
+ def testStripIsTrueOnWindows(self):
+ with osname('nt'):
+ mockStdout = Mock()
+ stream = AnsiToWin32(mockStdout)
+ self.assertTrue(stream.strip)
+
+ def testStripIsFalseOffWindows(self):
+ with osname('posix'):
+ mockStdout = Mock(closed=False)
+ stream = AnsiToWin32(mockStdout)
+ self.assertFalse(stream.strip)
+
+ def testWriteStripsAnsi(self):
+ mockStdout = Mock()
+ stream = AnsiToWin32(mockStdout)
+ stream.wrapped = Mock()
+ stream.write_and_convert = Mock()
+ stream.strip = True
+
+ stream.write('abc')
+
+ self.assertFalse(stream.wrapped.write.called)
+ self.assertEqual(stream.write_and_convert.call_args, (('abc',), {}))
+
+ def testWriteDoesNotStripAnsi(self):
+ mockStdout = Mock()
+ stream = AnsiToWin32(mockStdout)
+ stream.wrapped = Mock()
+ stream.write_and_convert = Mock()
+ stream.strip = False
+ stream.convert = False
+
+ stream.write('abc')
+
+ self.assertFalse(stream.write_and_convert.called)
+ self.assertEqual(stream.wrapped.write.call_args, (('abc',), {}))
+
+ def assert_autoresets(self, convert, autoreset=True):
+ stream = AnsiToWin32(Mock())
+ stream.convert = convert
+ stream.reset_all = Mock()
+ stream.autoreset = autoreset
+ stream.winterm = Mock()
+
+ stream.write('abc')
+
+ self.assertEqual(stream.reset_all.called, autoreset)
+
+ def testWriteAutoresets(self):
+ self.assert_autoresets(convert=True)
+ self.assert_autoresets(convert=False)
+ self.assert_autoresets(convert=True, autoreset=False)
+ self.assert_autoresets(convert=False, autoreset=False)
+
+ def testWriteAndConvertWritesPlainText(self):
+ stream = AnsiToWin32(Mock())
+ stream.write_and_convert( 'abc' )
+ self.assertEqual( stream.wrapped.write.call_args, (('abc',), {}) )
+
+ def testWriteAndConvertStripsAllValidAnsi(self):
+ stream = AnsiToWin32(Mock())
+ stream.call_win32 = Mock()
+ data = [
+ 'abc\033[mdef',
+ 'abc\033[0mdef',
+ 'abc\033[2mdef',
+ 'abc\033[02mdef',
+ 'abc\033[002mdef',
+ 'abc\033[40mdef',
+ 'abc\033[040mdef',
+ 'abc\033[0;1mdef',
+ 'abc\033[40;50mdef',
+ 'abc\033[50;30;40mdef',
+ 'abc\033[Adef',
+ 'abc\033[0Gdef',
+ 'abc\033[1;20;128Hdef',
+ ]
+ for datum in data:
+ stream.wrapped.write.reset_mock()
+ stream.write_and_convert( datum )
+ self.assertEqual(
+ [args[0] for args in stream.wrapped.write.call_args_list],
+ [ ('abc',), ('def',) ]
+ )
+
+ def testWriteAndConvertSkipsEmptySnippets(self):
+ stream = AnsiToWin32(Mock())
+ stream.call_win32 = Mock()
+ stream.write_and_convert( '\033[40m\033[41m' )
+ self.assertFalse( stream.wrapped.write.called )
+
+ def testWriteAndConvertCallsWin32WithParamsAndCommand(self):
+ stream = AnsiToWin32(Mock())
+ stream.convert = True
+ stream.call_win32 = Mock()
+ stream.extract_params = Mock(return_value='params')
+ data = {
+ 'abc\033[adef': ('a', 'params'),
+ 'abc\033[;;bdef': ('b', 'params'),
+ 'abc\033[0cdef': ('c', 'params'),
+ 'abc\033[;;0;;Gdef': ('G', 'params'),
+ 'abc\033[1;20;128Hdef': ('H', 'params'),
+ }
+ for datum, expected in data.items():
+ stream.call_win32.reset_mock()
+ stream.write_and_convert( datum )
+ self.assertEqual( stream.call_win32.call_args[0], expected )
+
+ def test_reset_all_shouldnt_raise_on_closed_orig_stdout(self):
+ stream = StringIO()
+ converter = AnsiToWin32(stream)
+ stream.close()
+
+ converter.reset_all()
+
+ def test_wrap_shouldnt_raise_on_closed_orig_stdout(self):
+ stream = StringIO()
+ stream.close()
+ with \
+ patch("colorama.ansitowin32.os.name", "nt"), \
+ patch("colorama.ansitowin32.winapi_test", lambda: True):
+ converter = AnsiToWin32(stream)
+ self.assertTrue(converter.strip)
+ self.assertFalse(converter.convert)
+
+ def test_wrap_shouldnt_raise_on_missing_closed_attr(self):
+ with \
+ patch("colorama.ansitowin32.os.name", "nt"), \
+ patch("colorama.ansitowin32.winapi_test", lambda: True):
+ converter = AnsiToWin32(object())
+ self.assertTrue(converter.strip)
+ self.assertFalse(converter.convert)
+
+ def testExtractParams(self):
+ stream = AnsiToWin32(Mock())
+ data = {
+ '': (0,),
+ ';;': (0,),
+ '2': (2,),
+ ';;002;;': (2,),
+ '0;1': (0, 1),
+ ';;003;;456;;': (3, 456),
+ '11;22;33;44;55': (11, 22, 33, 44, 55),
+ }
+ for datum, expected in data.items():
+ self.assertEqual(stream.extract_params('m', datum), expected)
+
+ def testCallWin32UsesLookup(self):
+ listener = Mock()
+ stream = AnsiToWin32(listener)
+ stream.win32_calls = {
+ 1: (lambda *_, **__: listener(11),),
+ 2: (lambda *_, **__: listener(22),),
+ 3: (lambda *_, **__: listener(33),),
+ }
+ stream.call_win32('m', (3, 1, 99, 2))
+ self.assertEqual(
+ [a[0][0] for a in listener.call_args_list],
+ [33, 11, 22] )
+
+ def test_osc_codes(self):
+ mockStdout = Mock()
+ stream = AnsiToWin32(mockStdout, convert=True)
+ with patch('colorama.ansitowin32.winterm') as winterm:
+ data = [
+ '\033]0\x07', # missing arguments
+ '\033]0;foo\x08', # wrong OSC command
+ '\033]0;colorama_test_title\x07', # should work
+ '\033]1;colorama_test_title\x07', # wrong set command
+ '\033]2;colorama_test_title\x07', # should work
+ '\033]' + ';' * 64 + '\x08', # see issue #247
+ ]
+ for code in data:
+ stream.write(code)
+ self.assertEqual(winterm.set_title.call_count, 2)
+
+ def test_native_windows_ansi(self):
+ with ExitStack() as stack:
+ def p(a, b):
+ stack.enter_context(patch(a, b, create=True))
+ # Pretend to be on Windows
+ p("colorama.ansitowin32.os.name", "nt")
+ p("colorama.ansitowin32.winapi_test", lambda: True)
+ p("colorama.win32.winapi_test", lambda: True)
+ p("colorama.winterm.win32.windll", "non-None")
+ p("colorama.winterm.get_osfhandle", lambda _: 1234)
+
+ # Pretend that our mock stream has native ANSI support
+ p(
+ "colorama.winterm.win32.GetConsoleMode",
+ lambda _: ENABLE_VIRTUAL_TERMINAL_PROCESSING,
+ )
+ SetConsoleMode = Mock()
+ p("colorama.winterm.win32.SetConsoleMode", SetConsoleMode)
+
+ stdout = Mock()
+ stdout.closed = False
+ stdout.isatty.return_value = True
+ stdout.fileno.return_value = 1
+
+ # Our fake console says it has native vt support, so AnsiToWin32 should
+ # enable that support and do nothing else.
+ stream = AnsiToWin32(stdout)
+ SetConsoleMode.assert_called_with(1234, ENABLE_VIRTUAL_TERMINAL_PROCESSING)
+ self.assertFalse(stream.strip)
+ self.assertFalse(stream.convert)
+ self.assertFalse(stream.should_wrap())
+
+ # Now let's pretend we're on an old Windows console, that doesn't have
+ # native ANSI support.
+ p("colorama.winterm.win32.GetConsoleMode", lambda _: 0)
+ SetConsoleMode = Mock()
+ p("colorama.winterm.win32.SetConsoleMode", SetConsoleMode)
+
+ stream = AnsiToWin32(stdout)
+ SetConsoleMode.assert_called_with(1234, ENABLE_VIRTUAL_TERMINAL_PROCESSING)
+ self.assertTrue(stream.strip)
+ self.assertTrue(stream.convert)
+ self.assertTrue(stream.should_wrap())
+
+
+if __name__ == '__main__':
+ main()
diff --git a/solutions/.venv/Lib/site-packages/colorama/tests/initialise_test.py b/solutions/.venv/Lib/site-packages/colorama/tests/initialise_test.py
new file mode 100644
index 000000000..89f9b0751
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/tests/initialise_test.py
@@ -0,0 +1,189 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+import sys
+from unittest import TestCase, main, skipUnless
+
+try:
+ from unittest.mock import patch, Mock
+except ImportError:
+ from mock import patch, Mock
+
+from ..ansitowin32 import StreamWrapper
+from ..initialise import init, just_fix_windows_console, _wipe_internal_state_for_tests
+from .utils import osname, replace_by
+
+orig_stdout = sys.stdout
+orig_stderr = sys.stderr
+
+
+class InitTest(TestCase):
+
+ @skipUnless(sys.stdout.isatty(), "sys.stdout is not a tty")
+ def setUp(self):
+ # sanity check
+ self.assertNotWrapped()
+
+ def tearDown(self):
+ _wipe_internal_state_for_tests()
+ sys.stdout = orig_stdout
+ sys.stderr = orig_stderr
+
+ def assertWrapped(self):
+ self.assertIsNot(sys.stdout, orig_stdout, 'stdout should be wrapped')
+ self.assertIsNot(sys.stderr, orig_stderr, 'stderr should be wrapped')
+ self.assertTrue(isinstance(sys.stdout, StreamWrapper),
+ 'bad stdout wrapper')
+ self.assertTrue(isinstance(sys.stderr, StreamWrapper),
+ 'bad stderr wrapper')
+
+ def assertNotWrapped(self):
+ self.assertIs(sys.stdout, orig_stdout, 'stdout should not be wrapped')
+ self.assertIs(sys.stderr, orig_stderr, 'stderr should not be wrapped')
+
+ @patch('colorama.initialise.reset_all')
+ @patch('colorama.ansitowin32.winapi_test', lambda *_: True)
+ @patch('colorama.ansitowin32.enable_vt_processing', lambda *_: False)
+ def testInitWrapsOnWindows(self, _):
+ with osname("nt"):
+ init()
+ self.assertWrapped()
+
+ @patch('colorama.initialise.reset_all')
+ @patch('colorama.ansitowin32.winapi_test', lambda *_: False)
+ def testInitDoesntWrapOnEmulatedWindows(self, _):
+ with osname("nt"):
+ init()
+ self.assertNotWrapped()
+
+ def testInitDoesntWrapOnNonWindows(self):
+ with osname("posix"):
+ init()
+ self.assertNotWrapped()
+
+ def testInitDoesntWrapIfNone(self):
+ with replace_by(None):
+ init()
+ # We can't use assertNotWrapped here because replace_by(None)
+ # changes stdout/stderr already.
+ self.assertIsNone(sys.stdout)
+ self.assertIsNone(sys.stderr)
+
+ def testInitAutoresetOnWrapsOnAllPlatforms(self):
+ with osname("posix"):
+ init(autoreset=True)
+ self.assertWrapped()
+
+ def testInitWrapOffDoesntWrapOnWindows(self):
+ with osname("nt"):
+ init(wrap=False)
+ self.assertNotWrapped()
+
+ def testInitWrapOffIncompatibleWithAutoresetOn(self):
+ self.assertRaises(ValueError, lambda: init(autoreset=True, wrap=False))
+
+ @patch('colorama.win32.SetConsoleTextAttribute')
+ @patch('colorama.initialise.AnsiToWin32')
+ def testAutoResetPassedOn(self, mockATW32, _):
+ with osname("nt"):
+ init(autoreset=True)
+ self.assertEqual(len(mockATW32.call_args_list), 2)
+ self.assertEqual(mockATW32.call_args_list[1][1]['autoreset'], True)
+ self.assertEqual(mockATW32.call_args_list[0][1]['autoreset'], True)
+
+ @patch('colorama.initialise.AnsiToWin32')
+ def testAutoResetChangeable(self, mockATW32):
+ with osname("nt"):
+ init()
+
+ init(autoreset=True)
+ self.assertEqual(len(mockATW32.call_args_list), 4)
+ self.assertEqual(mockATW32.call_args_list[2][1]['autoreset'], True)
+ self.assertEqual(mockATW32.call_args_list[3][1]['autoreset'], True)
+
+ init()
+ self.assertEqual(len(mockATW32.call_args_list), 6)
+ self.assertEqual(
+ mockATW32.call_args_list[4][1]['autoreset'], False)
+ self.assertEqual(
+ mockATW32.call_args_list[5][1]['autoreset'], False)
+
+
+ @patch('colorama.initialise.atexit.register')
+ def testAtexitRegisteredOnlyOnce(self, mockRegister):
+ init()
+ self.assertTrue(mockRegister.called)
+ mockRegister.reset_mock()
+ init()
+ self.assertFalse(mockRegister.called)
+
+
+class JustFixWindowsConsoleTest(TestCase):
+ def _reset(self):
+ _wipe_internal_state_for_tests()
+ sys.stdout = orig_stdout
+ sys.stderr = orig_stderr
+
+ def tearDown(self):
+ self._reset()
+
+ @patch("colorama.ansitowin32.winapi_test", lambda: True)
+ def testJustFixWindowsConsole(self):
+ if sys.platform != "win32":
+ # just_fix_windows_console should be a no-op
+ just_fix_windows_console()
+ self.assertIs(sys.stdout, orig_stdout)
+ self.assertIs(sys.stderr, orig_stderr)
+ else:
+ def fake_std():
+ # Emulate stdout=not a tty, stderr=tty
+ # to check that we handle both cases correctly
+ stdout = Mock()
+ stdout.closed = False
+ stdout.isatty.return_value = False
+ stdout.fileno.return_value = 1
+ sys.stdout = stdout
+
+ stderr = Mock()
+ stderr.closed = False
+ stderr.isatty.return_value = True
+ stderr.fileno.return_value = 2
+ sys.stderr = stderr
+
+ for native_ansi in [False, True]:
+ with patch(
+ 'colorama.ansitowin32.enable_vt_processing',
+ lambda *_: native_ansi
+ ):
+ self._reset()
+ fake_std()
+
+ # Regular single-call test
+ prev_stdout = sys.stdout
+ prev_stderr = sys.stderr
+ just_fix_windows_console()
+ self.assertIs(sys.stdout, prev_stdout)
+ if native_ansi:
+ self.assertIs(sys.stderr, prev_stderr)
+ else:
+ self.assertIsNot(sys.stderr, prev_stderr)
+
+ # second call without resetting is always a no-op
+ prev_stdout = sys.stdout
+ prev_stderr = sys.stderr
+ just_fix_windows_console()
+ self.assertIs(sys.stdout, prev_stdout)
+ self.assertIs(sys.stderr, prev_stderr)
+
+ self._reset()
+ fake_std()
+
+ # If init() runs first, just_fix_windows_console should be a no-op
+ init()
+ prev_stdout = sys.stdout
+ prev_stderr = sys.stderr
+ just_fix_windows_console()
+ self.assertIs(prev_stdout, sys.stdout)
+ self.assertIs(prev_stderr, sys.stderr)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/solutions/.venv/Lib/site-packages/colorama/tests/isatty_test.py b/solutions/.venv/Lib/site-packages/colorama/tests/isatty_test.py
new file mode 100644
index 000000000..0f84e4bef
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/tests/isatty_test.py
@@ -0,0 +1,57 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+import sys
+from unittest import TestCase, main
+
+from ..ansitowin32 import StreamWrapper, AnsiToWin32
+from .utils import pycharm, replace_by, replace_original_by, StreamTTY, StreamNonTTY
+
+
+def is_a_tty(stream):
+ return StreamWrapper(stream, None).isatty()
+
+class IsattyTest(TestCase):
+
+ def test_TTY(self):
+ tty = StreamTTY()
+ self.assertTrue(is_a_tty(tty))
+ with pycharm():
+ self.assertTrue(is_a_tty(tty))
+
+ def test_nonTTY(self):
+ non_tty = StreamNonTTY()
+ self.assertFalse(is_a_tty(non_tty))
+ with pycharm():
+ self.assertFalse(is_a_tty(non_tty))
+
+ def test_withPycharm(self):
+ with pycharm():
+ self.assertTrue(is_a_tty(sys.stderr))
+ self.assertTrue(is_a_tty(sys.stdout))
+
+ def test_withPycharmTTYOverride(self):
+ tty = StreamTTY()
+ with pycharm(), replace_by(tty):
+ self.assertTrue(is_a_tty(tty))
+
+ def test_withPycharmNonTTYOverride(self):
+ non_tty = StreamNonTTY()
+ with pycharm(), replace_by(non_tty):
+ self.assertFalse(is_a_tty(non_tty))
+
+ def test_withPycharmNoneOverride(self):
+ with pycharm():
+ with replace_by(None), replace_original_by(None):
+ self.assertFalse(is_a_tty(None))
+ self.assertFalse(is_a_tty(StreamNonTTY()))
+ self.assertTrue(is_a_tty(StreamTTY()))
+
+ def test_withPycharmStreamWrapped(self):
+ with pycharm():
+ self.assertTrue(AnsiToWin32(StreamTTY()).stream.isatty())
+ self.assertFalse(AnsiToWin32(StreamNonTTY()).stream.isatty())
+ self.assertTrue(AnsiToWin32(sys.stdout).stream.isatty())
+ self.assertTrue(AnsiToWin32(sys.stderr).stream.isatty())
+
+
+if __name__ == '__main__':
+ main()
diff --git a/solutions/.venv/Lib/site-packages/colorama/tests/utils.py b/solutions/.venv/Lib/site-packages/colorama/tests/utils.py
new file mode 100644
index 000000000..472fafb44
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/tests/utils.py
@@ -0,0 +1,49 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+from contextlib import contextmanager
+from io import StringIO
+import sys
+import os
+
+
+class StreamTTY(StringIO):
+ def isatty(self):
+ return True
+
+class StreamNonTTY(StringIO):
+ def isatty(self):
+ return False
+
+@contextmanager
+def osname(name):
+ orig = os.name
+ os.name = name
+ yield
+ os.name = orig
+
+@contextmanager
+def replace_by(stream):
+ orig_stdout = sys.stdout
+ orig_stderr = sys.stderr
+ sys.stdout = stream
+ sys.stderr = stream
+ yield
+ sys.stdout = orig_stdout
+ sys.stderr = orig_stderr
+
+@contextmanager
+def replace_original_by(stream):
+ orig_stdout = sys.__stdout__
+ orig_stderr = sys.__stderr__
+ sys.__stdout__ = stream
+ sys.__stderr__ = stream
+ yield
+ sys.__stdout__ = orig_stdout
+ sys.__stderr__ = orig_stderr
+
+@contextmanager
+def pycharm():
+ os.environ["PYCHARM_HOSTED"] = "1"
+ non_tty = StreamNonTTY()
+ with replace_by(non_tty), replace_original_by(non_tty):
+ yield
+ del os.environ["PYCHARM_HOSTED"]
diff --git a/solutions/.venv/Lib/site-packages/colorama/tests/winterm_test.py b/solutions/.venv/Lib/site-packages/colorama/tests/winterm_test.py
new file mode 100644
index 000000000..d0955f9e6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/tests/winterm_test.py
@@ -0,0 +1,131 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+import sys
+from unittest import TestCase, main, skipUnless
+
+try:
+ from unittest.mock import Mock, patch
+except ImportError:
+ from mock import Mock, patch
+
+from ..winterm import WinColor, WinStyle, WinTerm
+
+
+class WinTermTest(TestCase):
+
+ @patch('colorama.winterm.win32')
+ def testInit(self, mockWin32):
+ mockAttr = Mock()
+ mockAttr.wAttributes = 7 + 6 * 16 + 8
+ mockWin32.GetConsoleScreenBufferInfo.return_value = mockAttr
+ term = WinTerm()
+ self.assertEqual(term._fore, 7)
+ self.assertEqual(term._back, 6)
+ self.assertEqual(term._style, 8)
+
+ @skipUnless(sys.platform.startswith("win"), "requires Windows")
+ def testGetAttrs(self):
+ term = WinTerm()
+
+ term._fore = 0
+ term._back = 0
+ term._style = 0
+ self.assertEqual(term.get_attrs(), 0)
+
+ term._fore = WinColor.YELLOW
+ self.assertEqual(term.get_attrs(), WinColor.YELLOW)
+
+ term._back = WinColor.MAGENTA
+ self.assertEqual(
+ term.get_attrs(),
+ WinColor.YELLOW + WinColor.MAGENTA * 16)
+
+ term._style = WinStyle.BRIGHT
+ self.assertEqual(
+ term.get_attrs(),
+ WinColor.YELLOW + WinColor.MAGENTA * 16 + WinStyle.BRIGHT)
+
+ @patch('colorama.winterm.win32')
+ def testResetAll(self, mockWin32):
+ mockAttr = Mock()
+ mockAttr.wAttributes = 1 + 2 * 16 + 8
+ mockWin32.GetConsoleScreenBufferInfo.return_value = mockAttr
+ term = WinTerm()
+
+ term.set_console = Mock()
+ term._fore = -1
+ term._back = -1
+ term._style = -1
+
+ term.reset_all()
+
+ self.assertEqual(term._fore, 1)
+ self.assertEqual(term._back, 2)
+ self.assertEqual(term._style, 8)
+ self.assertEqual(term.set_console.called, True)
+
+ @skipUnless(sys.platform.startswith("win"), "requires Windows")
+ def testFore(self):
+ term = WinTerm()
+ term.set_console = Mock()
+ term._fore = 0
+
+ term.fore(5)
+
+ self.assertEqual(term._fore, 5)
+ self.assertEqual(term.set_console.called, True)
+
+ @skipUnless(sys.platform.startswith("win"), "requires Windows")
+ def testBack(self):
+ term = WinTerm()
+ term.set_console = Mock()
+ term._back = 0
+
+ term.back(5)
+
+ self.assertEqual(term._back, 5)
+ self.assertEqual(term.set_console.called, True)
+
+ @skipUnless(sys.platform.startswith("win"), "requires Windows")
+ def testStyle(self):
+ term = WinTerm()
+ term.set_console = Mock()
+ term._style = 0
+
+ term.style(22)
+
+ self.assertEqual(term._style, 22)
+ self.assertEqual(term.set_console.called, True)
+
+ @patch('colorama.winterm.win32')
+ def testSetConsole(self, mockWin32):
+ mockAttr = Mock()
+ mockAttr.wAttributes = 0
+ mockWin32.GetConsoleScreenBufferInfo.return_value = mockAttr
+ term = WinTerm()
+ term.windll = Mock()
+
+ term.set_console()
+
+ self.assertEqual(
+ mockWin32.SetConsoleTextAttribute.call_args,
+ ((mockWin32.STDOUT, term.get_attrs()), {})
+ )
+
+ @patch('colorama.winterm.win32')
+ def testSetConsoleOnStderr(self, mockWin32):
+ mockAttr = Mock()
+ mockAttr.wAttributes = 0
+ mockWin32.GetConsoleScreenBufferInfo.return_value = mockAttr
+ term = WinTerm()
+ term.windll = Mock()
+
+ term.set_console(on_stderr=True)
+
+ self.assertEqual(
+ mockWin32.SetConsoleTextAttribute.call_args,
+ ((mockWin32.STDERR, term.get_attrs()), {})
+ )
+
+
+if __name__ == '__main__':
+ main()
diff --git a/solutions/.venv/Lib/site-packages/colorama/win32.py b/solutions/.venv/Lib/site-packages/colorama/win32.py
new file mode 100644
index 000000000..841b0e270
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/win32.py
@@ -0,0 +1,180 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+
+# from winbase.h
+STDOUT = -11
+STDERR = -12
+
+ENABLE_VIRTUAL_TERMINAL_PROCESSING = 0x0004
+
+try:
+ import ctypes
+ from ctypes import LibraryLoader
+ windll = LibraryLoader(ctypes.WinDLL)
+ from ctypes import wintypes
+except (AttributeError, ImportError):
+ windll = None
+ SetConsoleTextAttribute = lambda *_: None
+ winapi_test = lambda *_: None
+else:
+ from ctypes import byref, Structure, c_char, POINTER
+
+ COORD = wintypes._COORD
+
+ class CONSOLE_SCREEN_BUFFER_INFO(Structure):
+ """struct in wincon.h."""
+ _fields_ = [
+ ("dwSize", COORD),
+ ("dwCursorPosition", COORD),
+ ("wAttributes", wintypes.WORD),
+ ("srWindow", wintypes.SMALL_RECT),
+ ("dwMaximumWindowSize", COORD),
+ ]
+ def __str__(self):
+ return '(%d,%d,%d,%d,%d,%d,%d,%d,%d,%d,%d)' % (
+ self.dwSize.Y, self.dwSize.X
+ , self.dwCursorPosition.Y, self.dwCursorPosition.X
+ , self.wAttributes
+ , self.srWindow.Top, self.srWindow.Left, self.srWindow.Bottom, self.srWindow.Right
+ , self.dwMaximumWindowSize.Y, self.dwMaximumWindowSize.X
+ )
+
+ _GetStdHandle = windll.kernel32.GetStdHandle
+ _GetStdHandle.argtypes = [
+ wintypes.DWORD,
+ ]
+ _GetStdHandle.restype = wintypes.HANDLE
+
+ _GetConsoleScreenBufferInfo = windll.kernel32.GetConsoleScreenBufferInfo
+ _GetConsoleScreenBufferInfo.argtypes = [
+ wintypes.HANDLE,
+ POINTER(CONSOLE_SCREEN_BUFFER_INFO),
+ ]
+ _GetConsoleScreenBufferInfo.restype = wintypes.BOOL
+
+ _SetConsoleTextAttribute = windll.kernel32.SetConsoleTextAttribute
+ _SetConsoleTextAttribute.argtypes = [
+ wintypes.HANDLE,
+ wintypes.WORD,
+ ]
+ _SetConsoleTextAttribute.restype = wintypes.BOOL
+
+ _SetConsoleCursorPosition = windll.kernel32.SetConsoleCursorPosition
+ _SetConsoleCursorPosition.argtypes = [
+ wintypes.HANDLE,
+ COORD,
+ ]
+ _SetConsoleCursorPosition.restype = wintypes.BOOL
+
+ _FillConsoleOutputCharacterA = windll.kernel32.FillConsoleOutputCharacterA
+ _FillConsoleOutputCharacterA.argtypes = [
+ wintypes.HANDLE,
+ c_char,
+ wintypes.DWORD,
+ COORD,
+ POINTER(wintypes.DWORD),
+ ]
+ _FillConsoleOutputCharacterA.restype = wintypes.BOOL
+
+ _FillConsoleOutputAttribute = windll.kernel32.FillConsoleOutputAttribute
+ _FillConsoleOutputAttribute.argtypes = [
+ wintypes.HANDLE,
+ wintypes.WORD,
+ wintypes.DWORD,
+ COORD,
+ POINTER(wintypes.DWORD),
+ ]
+ _FillConsoleOutputAttribute.restype = wintypes.BOOL
+
+ _SetConsoleTitleW = windll.kernel32.SetConsoleTitleW
+ _SetConsoleTitleW.argtypes = [
+ wintypes.LPCWSTR
+ ]
+ _SetConsoleTitleW.restype = wintypes.BOOL
+
+ _GetConsoleMode = windll.kernel32.GetConsoleMode
+ _GetConsoleMode.argtypes = [
+ wintypes.HANDLE,
+ POINTER(wintypes.DWORD)
+ ]
+ _GetConsoleMode.restype = wintypes.BOOL
+
+ _SetConsoleMode = windll.kernel32.SetConsoleMode
+ _SetConsoleMode.argtypes = [
+ wintypes.HANDLE,
+ wintypes.DWORD
+ ]
+ _SetConsoleMode.restype = wintypes.BOOL
+
+ def _winapi_test(handle):
+ csbi = CONSOLE_SCREEN_BUFFER_INFO()
+ success = _GetConsoleScreenBufferInfo(
+ handle, byref(csbi))
+ return bool(success)
+
+ def winapi_test():
+ return any(_winapi_test(h) for h in
+ (_GetStdHandle(STDOUT), _GetStdHandle(STDERR)))
+
+ def GetConsoleScreenBufferInfo(stream_id=STDOUT):
+ handle = _GetStdHandle(stream_id)
+ csbi = CONSOLE_SCREEN_BUFFER_INFO()
+ success = _GetConsoleScreenBufferInfo(
+ handle, byref(csbi))
+ return csbi
+
+ def SetConsoleTextAttribute(stream_id, attrs):
+ handle = _GetStdHandle(stream_id)
+ return _SetConsoleTextAttribute(handle, attrs)
+
+ def SetConsoleCursorPosition(stream_id, position, adjust=True):
+ position = COORD(*position)
+ # If the position is out of range, do nothing.
+ if position.Y <= 0 or position.X <= 0:
+ return
+ # Adjust for Windows' SetConsoleCursorPosition:
+ # 1. being 0-based, while ANSI is 1-based.
+ # 2. expecting (x,y), while ANSI uses (y,x).
+ adjusted_position = COORD(position.Y - 1, position.X - 1)
+ if adjust:
+ # Adjust for viewport's scroll position
+ sr = GetConsoleScreenBufferInfo(STDOUT).srWindow
+ adjusted_position.Y += sr.Top
+ adjusted_position.X += sr.Left
+ # Resume normal processing
+ handle = _GetStdHandle(stream_id)
+ return _SetConsoleCursorPosition(handle, adjusted_position)
+
+ def FillConsoleOutputCharacter(stream_id, char, length, start):
+ handle = _GetStdHandle(stream_id)
+ char = c_char(char.encode())
+ length = wintypes.DWORD(length)
+ num_written = wintypes.DWORD(0)
+ # Note that this is hard-coded for ANSI (vs wide) bytes.
+ success = _FillConsoleOutputCharacterA(
+ handle, char, length, start, byref(num_written))
+ return num_written.value
+
+ def FillConsoleOutputAttribute(stream_id, attr, length, start):
+ ''' FillConsoleOutputAttribute( hConsole, csbi.wAttributes, dwConSize, coordScreen, &cCharsWritten )'''
+ handle = _GetStdHandle(stream_id)
+ attribute = wintypes.WORD(attr)
+ length = wintypes.DWORD(length)
+ num_written = wintypes.DWORD(0)
+ # Note that this is hard-coded for ANSI (vs wide) bytes.
+ return _FillConsoleOutputAttribute(
+ handle, attribute, length, start, byref(num_written))
+
+ def SetConsoleTitle(title):
+ return _SetConsoleTitleW(title)
+
+ def GetConsoleMode(handle):
+ mode = wintypes.DWORD()
+ success = _GetConsoleMode(handle, byref(mode))
+ if not success:
+ raise ctypes.WinError()
+ return mode.value
+
+ def SetConsoleMode(handle, mode):
+ success = _SetConsoleMode(handle, mode)
+ if not success:
+ raise ctypes.WinError()
diff --git a/solutions/.venv/Lib/site-packages/colorama/winterm.py b/solutions/.venv/Lib/site-packages/colorama/winterm.py
new file mode 100644
index 000000000..aad867e8c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/colorama/winterm.py
@@ -0,0 +1,195 @@
+# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file.
+try:
+ from msvcrt import get_osfhandle
+except ImportError:
+ def get_osfhandle(_):
+ raise OSError("This isn't windows!")
+
+
+from . import win32
+
+# from wincon.h
+class WinColor(object):
+ BLACK = 0
+ BLUE = 1
+ GREEN = 2
+ CYAN = 3
+ RED = 4
+ MAGENTA = 5
+ YELLOW = 6
+ GREY = 7
+
+# from wincon.h
+class WinStyle(object):
+ NORMAL = 0x00 # dim text, dim background
+ BRIGHT = 0x08 # bright text, dim background
+ BRIGHT_BACKGROUND = 0x80 # dim text, bright background
+
+class WinTerm(object):
+
+ def __init__(self):
+ self._default = win32.GetConsoleScreenBufferInfo(win32.STDOUT).wAttributes
+ self.set_attrs(self._default)
+ self._default_fore = self._fore
+ self._default_back = self._back
+ self._default_style = self._style
+ # In order to emulate LIGHT_EX in windows, we borrow the BRIGHT style.
+ # So that LIGHT_EX colors and BRIGHT style do not clobber each other,
+ # we track them separately, since LIGHT_EX is overwritten by Fore/Back
+ # and BRIGHT is overwritten by Style codes.
+ self._light = 0
+
+ def get_attrs(self):
+ return self._fore + self._back * 16 + (self._style | self._light)
+
+ def set_attrs(self, value):
+ self._fore = value & 7
+ self._back = (value >> 4) & 7
+ self._style = value & (WinStyle.BRIGHT | WinStyle.BRIGHT_BACKGROUND)
+
+ def reset_all(self, on_stderr=None):
+ self.set_attrs(self._default)
+ self.set_console(attrs=self._default)
+ self._light = 0
+
+ def fore(self, fore=None, light=False, on_stderr=False):
+ if fore is None:
+ fore = self._default_fore
+ self._fore = fore
+ # Emulate LIGHT_EX with BRIGHT Style
+ if light:
+ self._light |= WinStyle.BRIGHT
+ else:
+ self._light &= ~WinStyle.BRIGHT
+ self.set_console(on_stderr=on_stderr)
+
+ def back(self, back=None, light=False, on_stderr=False):
+ if back is None:
+ back = self._default_back
+ self._back = back
+ # Emulate LIGHT_EX with BRIGHT_BACKGROUND Style
+ if light:
+ self._light |= WinStyle.BRIGHT_BACKGROUND
+ else:
+ self._light &= ~WinStyle.BRIGHT_BACKGROUND
+ self.set_console(on_stderr=on_stderr)
+
+ def style(self, style=None, on_stderr=False):
+ if style is None:
+ style = self._default_style
+ self._style = style
+ self.set_console(on_stderr=on_stderr)
+
+ def set_console(self, attrs=None, on_stderr=False):
+ if attrs is None:
+ attrs = self.get_attrs()
+ handle = win32.STDOUT
+ if on_stderr:
+ handle = win32.STDERR
+ win32.SetConsoleTextAttribute(handle, attrs)
+
+ def get_position(self, handle):
+ position = win32.GetConsoleScreenBufferInfo(handle).dwCursorPosition
+ # Because Windows coordinates are 0-based,
+ # and win32.SetConsoleCursorPosition expects 1-based.
+ position.X += 1
+ position.Y += 1
+ return position
+
+ def set_cursor_position(self, position=None, on_stderr=False):
+ if position is None:
+ # I'm not currently tracking the position, so there is no default.
+ # position = self.get_position()
+ return
+ handle = win32.STDOUT
+ if on_stderr:
+ handle = win32.STDERR
+ win32.SetConsoleCursorPosition(handle, position)
+
+ def cursor_adjust(self, x, y, on_stderr=False):
+ handle = win32.STDOUT
+ if on_stderr:
+ handle = win32.STDERR
+ position = self.get_position(handle)
+ adjusted_position = (position.Y + y, position.X + x)
+ win32.SetConsoleCursorPosition(handle, adjusted_position, adjust=False)
+
+ def erase_screen(self, mode=0, on_stderr=False):
+ # 0 should clear from the cursor to the end of the screen.
+ # 1 should clear from the cursor to the beginning of the screen.
+ # 2 should clear the entire screen, and move cursor to (1,1)
+ handle = win32.STDOUT
+ if on_stderr:
+ handle = win32.STDERR
+ csbi = win32.GetConsoleScreenBufferInfo(handle)
+ # get the number of character cells in the current buffer
+ cells_in_screen = csbi.dwSize.X * csbi.dwSize.Y
+ # get number of character cells before current cursor position
+ cells_before_cursor = csbi.dwSize.X * csbi.dwCursorPosition.Y + csbi.dwCursorPosition.X
+ if mode == 0:
+ from_coord = csbi.dwCursorPosition
+ cells_to_erase = cells_in_screen - cells_before_cursor
+ elif mode == 1:
+ from_coord = win32.COORD(0, 0)
+ cells_to_erase = cells_before_cursor
+ elif mode == 2:
+ from_coord = win32.COORD(0, 0)
+ cells_to_erase = cells_in_screen
+ else:
+ # invalid mode
+ return
+ # fill the entire screen with blanks
+ win32.FillConsoleOutputCharacter(handle, ' ', cells_to_erase, from_coord)
+ # now set the buffer's attributes accordingly
+ win32.FillConsoleOutputAttribute(handle, self.get_attrs(), cells_to_erase, from_coord)
+ if mode == 2:
+ # put the cursor where needed
+ win32.SetConsoleCursorPosition(handle, (1, 1))
+
+ def erase_line(self, mode=0, on_stderr=False):
+ # 0 should clear from the cursor to the end of the line.
+ # 1 should clear from the cursor to the beginning of the line.
+ # 2 should clear the entire line.
+ handle = win32.STDOUT
+ if on_stderr:
+ handle = win32.STDERR
+ csbi = win32.GetConsoleScreenBufferInfo(handle)
+ if mode == 0:
+ from_coord = csbi.dwCursorPosition
+ cells_to_erase = csbi.dwSize.X - csbi.dwCursorPosition.X
+ elif mode == 1:
+ from_coord = win32.COORD(0, csbi.dwCursorPosition.Y)
+ cells_to_erase = csbi.dwCursorPosition.X
+ elif mode == 2:
+ from_coord = win32.COORD(0, csbi.dwCursorPosition.Y)
+ cells_to_erase = csbi.dwSize.X
+ else:
+ # invalid mode
+ return
+ # fill the entire screen with blanks
+ win32.FillConsoleOutputCharacter(handle, ' ', cells_to_erase, from_coord)
+ # now set the buffer's attributes accordingly
+ win32.FillConsoleOutputAttribute(handle, self.get_attrs(), cells_to_erase, from_coord)
+
+ def set_title(self, title):
+ win32.SetConsoleTitle(title)
+
+
+def enable_vt_processing(fd):
+ if win32.windll is None or not win32.winapi_test():
+ return False
+
+ try:
+ handle = get_osfhandle(fd)
+ mode = win32.GetConsoleMode(handle)
+ win32.SetConsoleMode(
+ handle,
+ mode | win32.ENABLE_VIRTUAL_TERMINAL_PROCESSING,
+ )
+
+ mode = win32.GetConsoleMode(handle)
+ if mode & win32.ENABLE_VIRTUAL_TERMINAL_PROCESSING:
+ return True
+ # Can get TypeError in testsuite where 'fd' is a Mock()
+ except (OSError, TypeError):
+ return False
diff --git a/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/LICENSE b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/LICENSE
new file mode 100644
index 000000000..1eb999e0b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/LICENSE
@@ -0,0 +1,35 @@
+Copyright (c) 2004-2016 California Institute of Technology.
+Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+All rights reserved.
+
+This software is available subject to the conditions and terms laid
+out below. By downloading and using this software you are agreeing
+to the following conditions.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions
+are met:
+
+ - Redistributions of source code must retain the above copyright
+ notice, this list of conditions and the following disclaimer.
+
+ - Redistributions in binary form must reproduce the above copyright
+ notice, this list of conditions and the following disclaimer in the
+ documentation and/or other materials provided with the distribution.
+
+ - Neither the names of the copyright holders nor the names of any of
+ the contributors may be used to endorse or promote products derived
+ from this software without specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
+"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED
+TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
+PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
+CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
+EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
+PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS;
+OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY,
+WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR
+OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF
+ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+
diff --git a/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/METADATA b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/METADATA
new file mode 100644
index 000000000..3397cd0a0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/METADATA
@@ -0,0 +1,281 @@
+Metadata-Version: 2.1
+Name: dill
+Version: 0.3.9
+Summary: serialize all of Python
+Home-page: https://github.com/uqfoundation/dill
+Download-URL: https://pypi.org/project/dill/#files
+Author: Mike McKerns
+Author-email: mmckerns@uqfoundation.org
+Maintainer: Mike McKerns
+Maintainer-email: mmckerns@uqfoundation.org
+License: BSD-3-Clause
+Project-URL: Documentation, http://dill.rtfd.io
+Project-URL: Source Code, https://github.com/uqfoundation/dill
+Project-URL: Bug Tracker, https://github.com/uqfoundation/dill/issues
+Platform: Linux
+Platform: Windows
+Platform: Mac
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Intended Audience :: Developers
+Classifier: Intended Audience :: Science/Research
+Classifier: License :: OSI Approved :: BSD License
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Classifier: Programming Language :: Python :: 3.13
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Scientific/Engineering
+Classifier: Topic :: Software Development
+Requires-Python: >=3.8
+License-File: LICENSE
+Provides-Extra: graph
+Requires-Dist: objgraph >=1.7.2 ; extra == 'graph'
+Provides-Extra: profile
+Requires-Dist: gprof2dot >=2022.7.29 ; extra == 'profile'
+Provides-Extra: readline
+
+-----------------------------
+dill: serialize all of Python
+-----------------------------
+
+About Dill
+==========
+
+``dill`` extends Python's ``pickle`` module for serializing and de-serializing
+Python objects to the majority of the built-in Python types. Serialization
+is the process of converting an object to a byte stream, and the inverse
+of which is converting a byte stream back to a Python object hierarchy.
+
+``dill`` provides the user the same interface as the ``pickle`` module, and
+also includes some additional features. In addition to pickling Python
+objects, ``dill`` provides the ability to save the state of an interpreter
+session in a single command. Hence, it would be feasible to save an
+interpreter session, close the interpreter, ship the pickled file to
+another computer, open a new interpreter, unpickle the session and
+thus continue from the 'saved' state of the original interpreter
+session.
+
+``dill`` can be used to store Python objects to a file, but the primary
+usage is to send Python objects across the network as a byte stream.
+``dill`` is quite flexible, and allows arbitrary user defined classes
+and functions to be serialized. Thus ``dill`` is not intended to be
+secure against erroneously or maliciously constructed data. It is
+left to the user to decide whether the data they unpickle is from
+a trustworthy source.
+
+``dill`` is part of ``pathos``, a Python framework for heterogeneous computing.
+``dill`` is in active development, so any user feedback, bug reports, comments,
+or suggestions are highly appreciated. A list of issues is located at
+https://github.com/uqfoundation/dill/issues, with a legacy list maintained at
+https://uqfoundation.github.io/project/pathos/query.
+
+
+Major Features
+==============
+
+``dill`` can pickle the following standard types:
+
+ - none, type, bool, int, float, complex, bytes, str,
+ - tuple, list, dict, file, buffer, builtin,
+ - Python classes, namedtuples, dataclasses, metaclasses,
+ - instances of classes,
+ - set, frozenset, array, functions, exceptions
+
+``dill`` can also pickle more 'exotic' standard types:
+
+ - functions with yields, nested functions, lambdas,
+ - cell, method, unboundmethod, module, code, methodwrapper,
+ - methoddescriptor, getsetdescriptor, memberdescriptor, wrapperdescriptor,
+ - dictproxy, slice, notimplemented, ellipsis, quit
+
+``dill`` cannot yet pickle these standard types:
+
+ - frame, generator, traceback
+
+``dill`` also provides the capability to:
+
+ - save and load Python interpreter sessions
+ - save and extract the source code from functions and classes
+ - interactively diagnose pickling errors
+
+
+Current Release
+===============
+
+The latest released version of ``dill`` is available from:
+
+ https://pypi.org/project/dill
+
+``dill`` is distributed under a 3-clause BSD license.
+
+
+Development Version
+===================
+
+You can get the latest development version with all the shiny new features at:
+
+ https://github.com/uqfoundation
+
+If you have a new contribution, please submit a pull request.
+
+
+Installation
+============
+
+``dill`` can be installed with ``pip``::
+
+ $ pip install dill
+
+To optionally include the ``objgraph`` diagnostic tool in the install::
+
+ $ pip install dill[graph]
+
+To optionally include the ``gprof2dot`` diagnostic tool in the install::
+
+ $ pip install dill[profile]
+
+For windows users, to optionally install session history tools::
+
+ $ pip install dill[readline]
+
+
+Requirements
+============
+
+``dill`` requires:
+
+ - ``python`` (or ``pypy``), **>=3.8**
+ - ``setuptools``, **>=42**
+
+Optional requirements:
+
+ - ``objgraph``, **>=1.7.2**
+ - ``gprof2dot``, **>=2022.7.29**
+ - ``pyreadline``, **>=1.7.1** (on windows)
+
+
+Basic Usage
+===========
+
+``dill`` is a drop-in replacement for ``pickle``. Existing code can be
+updated to allow complete pickling using::
+
+ >>> import dill as pickle
+
+or::
+
+ >>> from dill import dumps, loads
+
+``dumps`` converts the object to a unique byte string, and ``loads`` performs
+the inverse operation::
+
+ >>> squared = lambda x: x**2
+ >>> loads(dumps(squared))(3)
+ 9
+
+There are a number of options to control serialization which are provided
+as keyword arguments to several ``dill`` functions:
+
+* with *protocol*, the pickle protocol level can be set. This uses the
+ same value as the ``pickle`` module, *DEFAULT_PROTOCOL*.
+* with *byref=True*, ``dill`` to behave a lot more like pickle with
+ certain objects (like modules) pickled by reference as opposed to
+ attempting to pickle the object itself.
+* with *recurse=True*, objects referred to in the global dictionary are
+ recursively traced and pickled, instead of the default behavior of
+ attempting to store the entire global dictionary.
+* with *fmode*, the contents of the file can be pickled along with the file
+ handle, which is useful if the object is being sent over the wire to a
+ remote system which does not have the original file on disk. Options are
+ *HANDLE_FMODE* for just the handle, *CONTENTS_FMODE* for the file content
+ and *FILE_FMODE* for content and handle.
+* with *ignore=False*, objects reconstructed with types defined in the
+ top-level script environment use the existing type in the environment
+ rather than a possibly different reconstructed type.
+
+The default serialization can also be set globally in *dill.settings*.
+Thus, we can modify how ``dill`` handles references to the global dictionary
+locally or globally::
+
+ >>> import dill.settings
+ >>> dumps(absolute) == dumps(absolute, recurse=True)
+ False
+ >>> dill.settings['recurse'] = True
+ >>> dumps(absolute) == dumps(absolute, recurse=True)
+ True
+
+``dill`` also includes source code inspection, as an alternate to pickling::
+
+ >>> import dill.source
+ >>> print(dill.source.getsource(squared))
+ squared = lambda x:x**2
+
+To aid in debugging pickling issues, use *dill.detect* which provides
+tools like pickle tracing::
+
+ >>> import dill.detect
+ >>> with dill.detect.trace():
+ >>> dumps(squared)
+ ┬ F1: <function <lambda> at 0x7fe074f8c280>
+ ├┬ F2: <function _create_function at 0x7fe074c49c10>
+ │└ # F2 [34 B]
+ ├┬ Co: <code object <lambda> at 0x7fe07501eb30, file "<stdin>", line 1>
+ │├┬ F2: <function _create_code at 0x7fe074c49ca0>
+ ││└ # F2 [19 B]
+ │└ # Co [87 B]
+ ├┬ D1: <dict object at 0x7fe0750d4680>
+ │└ # D1 [22 B]
+ ├┬ D2: <dict object at 0x7fe074c5a1c0>
+ │└ # D2 [2 B]
+ ├┬ D2: <dict object at 0x7fe074f903c0>
+ │├┬ D2: <dict object at 0x7fe074f8ebc0>
+ ││└ # D2 [2 B]
+ │└ # D2 [23 B]
+ └ # F1 [180 B]
+
+With trace, we see how ``dill`` stored the lambda (``F1``) by first storing
+``_create_function``, the underlying code object (``Co``) and ``_create_code``
+(which is used to handle code objects), then we handle the reference to
+the global dict (``D2``) plus other dictionaries (``D1`` and ``D2``) that
+save the lambda object's state. A ``#`` marks when the object is actually stored.
+
+
+More Information
+================
+
+Probably the best way to get started is to look at the documentation at
+http://dill.rtfd.io. Also see ``dill.tests`` for a set of scripts that
+demonstrate how ``dill`` can serialize different Python objects. You can
+run the test suite with ``python -m dill.tests``. The contents of any
+pickle file can be examined with ``undill``. As ``dill`` conforms to
+the ``pickle`` interface, the examples and documentation found at
+http://docs.python.org/library/pickle.html also apply to ``dill``
+if one will ``import dill as pickle``. The source code is also generally
+well documented, so further questions may be resolved by inspecting the
+code itself. Please feel free to submit a ticket on github, or ask a
+question on stackoverflow (**@Mike McKerns**).
+If you would like to share how you use ``dill`` in your work, please send
+an email (to **mmckerns at uqfoundation dot org**).
+
+
+Citation
+========
+
+If you use ``dill`` to do research that leads to publication, we ask that you
+acknowledge use of ``dill`` by citing the following in your publication::
+
+ M.M. McKerns, L. Strand, T. Sullivan, A. Fang, M.A.G. Aivazis,
+ "Building a framework for predictive science", Proceedings of
+ the 10th Python in Science Conference, 2011;
+ http://arxiv.org/pdf/1202.1056
+
+ Michael McKerns and Michael Aivazis,
+ "pathos: a framework for heterogeneous computing", 2010- ;
+ https://uqfoundation.github.io/project/pathos
+
+Please see https://uqfoundation.github.io/project/pathos or
+http://arxiv.org/pdf/1202.1056 for further information.
diff --git a/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/RECORD b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/RECORD
new file mode 100644
index 000000000..d1cf52c97
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/RECORD
@@ -0,0 +1,101 @@
+../../Scripts/get_gprof,sha256=xJj-MYWFXx6ma1sVVXhZW_NyiNo_q_xcImJhnRlcEeI,2538
+../../Scripts/get_objgraph,sha256=LqV--CgJDLVIXK-wV-EmoB2IFXAp5JXfBmXrn5BGp5A,1732
+../../Scripts/undill,sha256=Paq34K1XIgB4OalXMMk9DYtW_aKR33zeCxQuZuFtuAc,668
+dill-0.3.9.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+dill-0.3.9.dist-info/LICENSE,sha256=UeiKI-eId86r1yfCGcel4z9l2pugOsT9KFupBKoc4is,1790
+dill-0.3.9.dist-info/METADATA,sha256=_FFzic5yJVTlvzEQffApWsBq905JF3St0SGXAjlIulo,10174
+dill-0.3.9.dist-info/RECORD,,
+dill-0.3.9.dist-info/WHEEL,sha256=GJ7t_kWBFywbagK5eo9IoUwLW6oyOeTKmQ-9iHFVNxQ,92
+dill-0.3.9.dist-info/top_level.txt,sha256=HLSIyYIjQzJiBvs3_-16ntezE3j6mWGTW0DT1xDd7X0,5
+dill/__diff.py,sha256=d0X0PkF-MN2XI8vQXth0S2yp338z7sQ_DVUMxzYa7ew,7146
+dill/__info__.py,sha256=2c-q6__qU-eAto8Hr4UCv8ykw1QzdfWEnZtOyWeevOs,10756
+dill/__init__.py,sha256=j-Jxl3H6bxatS0h2f8ywWs7DChwk7B9ozuZQBVcjYGU,3798
+dill/__pycache__/__diff.cpython-312.pyc,,
+dill/__pycache__/__info__.cpython-312.pyc,,
+dill/__pycache__/__init__.cpython-312.pyc,,
+dill/__pycache__/_dill.cpython-312.pyc,,
+dill/__pycache__/_objects.cpython-312.pyc,,
+dill/__pycache__/_shims.cpython-312.pyc,,
+dill/__pycache__/detect.cpython-312.pyc,,
+dill/__pycache__/logger.cpython-312.pyc,,
+dill/__pycache__/objtypes.cpython-312.pyc,,
+dill/__pycache__/pointers.cpython-312.pyc,,
+dill/__pycache__/session.cpython-312.pyc,,
+dill/__pycache__/settings.cpython-312.pyc,,
+dill/__pycache__/source.cpython-312.pyc,,
+dill/__pycache__/temp.cpython-312.pyc,,
+dill/_dill.py,sha256=MY3QRoToKg-bAh_WAlb5YRH3HuC0_sHabc-snh7b80o,89603
+dill/_objects.py,sha256=Nc0GKdQpwe1mALjg6UIqeXm-FQkgpJ8v3pkxS_C5O8s,19716
+dill/_shims.py,sha256=IuzQcyPET5VWmWMoSGStieoedvNXlb5suDpa4bykTbQ,6635
+dill/detect.py,sha256=Mb-PfCxn1mg0l3TmHXyPNVEc4n3fuxc_nue6eL3-q_o,11114
+dill/logger.py,sha256=D2mTGFLfnKrDnLRFJAFIwWkHUQasWqAgE5GniK7pjDM,11143
+dill/objtypes.py,sha256=BamGH3BEM6lLlxisuvXcGjsCRLNeoLs4_rFZrM5r2yM,736
+dill/pointers.py,sha256=vnQzjwGtKMGnmbdYRXRWNLMyceNPSw4f7UpvwCXLYbE,4467
+dill/session.py,sha256=9L3QF-inmkKoJ0D7mXyFCTcZsVeReHoRPVDcByt-Mdc,23541
+dill/settings.py,sha256=7I3yvSpPKstOqpoW2gv3X77kXK-hZlqCnF7nJUGhxTY,630
+dill/source.py,sha256=6TaPbKFWuqE23v0NABXXYnqokNRN8pYqmNUPvKTw47Q,45507
+dill/temp.py,sha256=KJUry4t0UjQCh5t4LXcxNyMF_uOGHwcjTuNYTJD9qdA,8027
+dill/tests/__init__.py,sha256=Gx-chVB-l-e7ncsGp2zF4BimTjbUyO7BY7RkrO835vY,479
+dill/tests/__main__.py,sha256=fHhioQwcOvTPlf1RM_wVQ0Y3ndETWJOuXJQ2rVtqliA,899
+dill/tests/__pycache__/__init__.cpython-312.pyc,,
+dill/tests/__pycache__/__main__.cpython-312.pyc,,
+dill/tests/__pycache__/test_abc.cpython-312.pyc,,
+dill/tests/__pycache__/test_check.cpython-312.pyc,,
+dill/tests/__pycache__/test_classdef.cpython-312.pyc,,
+dill/tests/__pycache__/test_dataclasses.cpython-312.pyc,,
+dill/tests/__pycache__/test_detect.cpython-312.pyc,,
+dill/tests/__pycache__/test_dictviews.cpython-312.pyc,,
+dill/tests/__pycache__/test_diff.cpython-312.pyc,,
+dill/tests/__pycache__/test_extendpickle.cpython-312.pyc,,
+dill/tests/__pycache__/test_fglobals.cpython-312.pyc,,
+dill/tests/__pycache__/test_file.cpython-312.pyc,,
+dill/tests/__pycache__/test_functions.cpython-312.pyc,,
+dill/tests/__pycache__/test_functors.cpython-312.pyc,,
+dill/tests/__pycache__/test_logger.cpython-312.pyc,,
+dill/tests/__pycache__/test_mixins.cpython-312.pyc,,
+dill/tests/__pycache__/test_module.cpython-312.pyc,,
+dill/tests/__pycache__/test_moduledict.cpython-312.pyc,,
+dill/tests/__pycache__/test_nested.cpython-312.pyc,,
+dill/tests/__pycache__/test_objects.cpython-312.pyc,,
+dill/tests/__pycache__/test_properties.cpython-312.pyc,,
+dill/tests/__pycache__/test_pycapsule.cpython-312.pyc,,
+dill/tests/__pycache__/test_recursive.cpython-312.pyc,,
+dill/tests/__pycache__/test_registered.cpython-312.pyc,,
+dill/tests/__pycache__/test_restricted.cpython-312.pyc,,
+dill/tests/__pycache__/test_selected.cpython-312.pyc,,
+dill/tests/__pycache__/test_session.cpython-312.pyc,,
+dill/tests/__pycache__/test_source.cpython-312.pyc,,
+dill/tests/__pycache__/test_sources.cpython-312.pyc,,
+dill/tests/__pycache__/test_temp.cpython-312.pyc,,
+dill/tests/__pycache__/test_threads.cpython-312.pyc,,
+dill/tests/__pycache__/test_weakref.cpython-312.pyc,,
+dill/tests/test_abc.py,sha256=BSjSKKCQ5_iPfFxAd0yBq4KSAJxelrlC3IzoAhjd1C4,4227
+dill/tests/test_check.py,sha256=4F5gkX6zxY7C5sD2_0Tkqf3T3jmQl0K15FOxYUTZQl0,1396
+dill/tests/test_classdef.py,sha256=fI3fVk4SlsjNMMs5RfU6DUCaxpP7YYRjvLZ2nhXMHuc,8600
+dill/tests/test_dataclasses.py,sha256=yKjFuG24ymLtjk-sZZdhvNY7aDqerTDpMcfi_eV4ft0,890
+dill/tests/test_detect.py,sha256=DFIrE-JetKlPCmPev9vJbF95i9lxHQZDUi_qAz5q3sk,4144
+dill/tests/test_dictviews.py,sha256=Jhol0cQWPwoQrp7OPxGhU8FNRX2GgfFp9fTahCvQEPA,1337
+dill/tests/test_diff.py,sha256=5VIWf2fpV6auLHNfzkHLTrgx6AJBlE2xe5Wanfmq8TM,2667
+dill/tests/test_extendpickle.py,sha256=gONrMBHO94Edhnqm1wo49hgzwmaxHs7L-86Hs-7albY,1315
+dill/tests/test_fglobals.py,sha256=DCvdojmKcLN_X9vX4Qe1FbsqjeoJK-wsY2uJwBfNFro,1676
+dill/tests/test_file.py,sha256=jUU2h8qaDOIe1mn_Ng7wqCZcd7Ucx3TAaI-K_90_Tbk,13578
+dill/tests/test_functions.py,sha256=-mqTpUbzRu8GynjBGD25dRDm8qInIe07sRZmCcA_iXY,4267
+dill/tests/test_functors.py,sha256=7rx9wLmrgFwF0gUm_-SGOISPYSok0XjmrQ-jFMRt6gs,930
+dill/tests/test_logger.py,sha256=D9zGRaA-CEadG13orPS_D4gPVZlkqXf9Zu8wn2oMiYc,2385
+dill/tests/test_mixins.py,sha256=YtB24BjodooLj85ijFbAxiM7LlFQZAUL8RQVx9vIAwY,4007
+dill/tests/test_module.py,sha256=KLl_gZJJqDY7S_bD5wCqKL8JQCS0MDMoipVQSDfASlo,1943
+dill/tests/test_moduledict.py,sha256=faXG6-5AcmCfP3xe2FYGOUdSosU-9TWnKU_ZVqPDaxY,1182
+dill/tests/test_nested.py,sha256=ViWiOrChLZktS0z6qyKqMxDdTuy9kAX4qMgH_OreMcc,3146
+dill/tests/test_objects.py,sha256=pPAth0toC_UWztuKHC7NZlsRBb0g_gSAt70UbUtXEXo,1931
+dill/tests/test_properties.py,sha256=h35c-lYir1JG6oLPtrA0eYE0xoSohIimsA3yIfRw6yA,1346
+dill/tests/test_pycapsule.py,sha256=EXFyB6g1Wx9O9LM6StIeUKhrhln4_hou1xrtGwkt4Cw,1417
+dill/tests/test_recursive.py,sha256=bfr-BsK1Xu0PU7l2srHsDXdY2l1LeM3L3w7NraXO0cc,4182
+dill/tests/test_registered.py,sha256=J3oku053VfdJgYh4Z5_kyFRf-C52JglIzjcyxEaYOhk,1573
+dill/tests/test_restricted.py,sha256=xLMIae8sYJksAj9hKKyHFHIL8vtbGpFeOULz59snYM4,783
+dill/tests/test_selected.py,sha256=wPKFTnXThwUm2Ycypt08yv6Wh39SmGeyrUxeENN2gRc,3258
+dill/tests/test_session.py,sha256=KoSPvs4c4VJ8mFMF7EUlD_3GwcOhhipt9fqHr--Go-4,10161
+dill/tests/test_source.py,sha256=vuJV0Y9xLiq5wJUD1yNbjTTxeaxYIUiJsL6PVPs25R8,7059
+dill/tests/test_sources.py,sha256=8FWkpEL3zTHn4_5RjwoNEJvKBy4RriUB3O6ARDyXqUg,8667
+dill/tests/test_temp.py,sha256=F_7nJkSetLIBSAYMw1-hYh03iVrEYwGs-4GIUzoBOfY,2619
+dill/tests/test_threads.py,sha256=knJA-lRvAAnYyePaAQTKGqu0OG9BIXdbgZhW47ZXY9s,1252
+dill/tests/test_weakref.py,sha256=mrjZP5aPtUP1wBD6ibPsDsfI9ffmq_Ykt7ltoodi5Lg,1602
diff --git a/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/WHEEL
new file mode 100644
index 000000000..bab98d675
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/WHEEL
@@ -0,0 +1,5 @@
+Wheel-Version: 1.0
+Generator: bdist_wheel (0.43.0)
+Root-Is-Purelib: true
+Tag: py3-none-any
+
diff --git a/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/top_level.txt b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/top_level.txt
new file mode 100644
index 000000000..85eea7018
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill-0.3.9.dist-info/top_level.txt
@@ -0,0 +1 @@
+dill
diff --git a/solutions/.venv/Lib/site-packages/dill/__diff.py b/solutions/.venv/Lib/site-packages/dill/__diff.py
new file mode 100644
index 000000000..f42711002
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/__diff.py
@@ -0,0 +1,234 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+"""
+Module to show if an object has changed since it was memorised
+"""
+
+import builtins
+import os
+import sys
+import types
+try:
+ import numpy.ma
+ HAS_NUMPY = True
+except ImportError:
+ HAS_NUMPY = False
+
+# pypy doesn't use reference counting
+getrefcount = getattr(sys, 'getrefcount', lambda x:0)
+
+# memo of objects indexed by id to a tuple (attributes, sequence items)
+# attributes is a dict indexed by attribute name to attribute id
+# sequence items is either a list of ids, of a dictionary of keys to ids
+memo = {}
+id_to_obj = {}
+# types that cannot have changing attributes
+builtins_types = set((str, list, dict, set, frozenset, int))
+dont_memo = set(id(i) for i in (memo, sys.modules, sys.path_importer_cache,
+ os.environ, id_to_obj))
+
+
+def get_attrs(obj):
+ """
+ Gets all the attributes of an object though its __dict__ or return None
+ """
+ if type(obj) in builtins_types \
+ or type(obj) is type and obj in builtins_types:
+ return
+ return getattr(obj, '__dict__', None)
+
+
+def get_seq(obj, cache={str: False, frozenset: False, list: True, set: True,
+ dict: True, tuple: True, type: False,
+ types.ModuleType: False, types.FunctionType: False,
+ types.BuiltinFunctionType: False}):
+ """
+ Gets all the items in a sequence or return None
+ """
+ try:
+ o_type = obj.__class__
+ except AttributeError:
+ o_type = type(obj)
+ hsattr = hasattr
+ if o_type in cache:
+ if cache[o_type]:
+ if hsattr(obj, "copy"):
+ return obj.copy()
+ return obj
+ elif HAS_NUMPY and o_type in (numpy.ndarray, numpy.ma.core.MaskedConstant):
+ if obj.shape and obj.size:
+ return obj
+ else:
+ return []
+ elif hsattr(obj, "__contains__") and hsattr(obj, "__iter__") \
+ and hsattr(obj, "__len__") and hsattr(o_type, "__contains__") \
+ and hsattr(o_type, "__iter__") and hsattr(o_type, "__len__"):
+ cache[o_type] = True
+ if hsattr(obj, "copy"):
+ return obj.copy()
+ return obj
+ else:
+ cache[o_type] = False
+ return None
+
+
+def memorise(obj, force=False):
+ """
+ Adds an object to the memo, and recursively adds all the objects
+ attributes, and if it is a container, its items. Use force=True to update
+ an object already in the memo. Updating is not recursively done.
+ """
+ obj_id = id(obj)
+ if obj_id in memo and not force or obj_id in dont_memo:
+ return
+ id_ = id
+ g = get_attrs(obj)
+ if g is None:
+ attrs_id = None
+ else:
+ attrs_id = dict((key,id_(value)) for key, value in g.items())
+
+ s = get_seq(obj)
+ if s is None:
+ seq_id = None
+ elif hasattr(s, "items"):
+ seq_id = dict((id_(key),id_(value)) for key, value in s.items())
+ elif not hasattr(s, "__len__"): #XXX: avoid TypeError from unexpected case
+ seq_id = None
+ else:
+ seq_id = [id_(i) for i in s]
+
+ memo[obj_id] = attrs_id, seq_id
+ id_to_obj[obj_id] = obj
+ mem = memorise
+ if g is not None:
+ [mem(value) for key, value in g.items()]
+
+ if s is not None:
+ if hasattr(s, "items"):
+ [(mem(key), mem(item))
+ for key, item in s.items()]
+ else:
+ if hasattr(s, '__len__'):
+ [mem(item) for item in s]
+ else: mem(s)
+
+
+def release_gone():
+ itop, mp, src = id_to_obj.pop, memo.pop, getrefcount
+ [(itop(id_), mp(id_)) for id_, obj in list(id_to_obj.items())
+ if src(obj) < 4] #XXX: correct for pypy?
+
+
+def whats_changed(obj, seen=None, simple=False, first=True):
+ """
+ Check an object against the memo. Returns a list in the form
+ (attribute changes, container changed). Attribute changes is a dict of
+ attribute name to attribute value. container changed is a boolean.
+ If simple is true, just returns a boolean. None for either item means
+ that it has not been checked yet
+ """
+ # Special cases
+ if first:
+ # ignore the _ variable, which only appears in interactive sessions
+ if "_" in builtins.__dict__:
+ del builtins._
+ if seen is None:
+ seen = {}
+
+ obj_id = id(obj)
+
+ if obj_id in seen:
+ if simple:
+ return any(seen[obj_id])
+ return seen[obj_id]
+
+ # Safety checks
+ if obj_id in dont_memo:
+ seen[obj_id] = [{}, False]
+ if simple:
+ return False
+ return seen[obj_id]
+ elif obj_id not in memo:
+ if simple:
+ return True
+ else:
+ raise RuntimeError("Object not memorised " + str(obj))
+
+ seen[obj_id] = ({}, False)
+
+ chngd = whats_changed
+ id_ = id
+
+ # compare attributes
+ attrs = get_attrs(obj)
+ if attrs is None:
+ changed = {}
+ else:
+ obj_attrs = memo[obj_id][0]
+ obj_get = obj_attrs.get
+ changed = dict((key,None) for key in obj_attrs if key not in attrs)
+ for key, o in attrs.items():
+ if id_(o) != obj_get(key, None) or chngd(o, seen, True, False):
+ changed[key] = o
+
+ # compare sequence
+ items = get_seq(obj)
+ seq_diff = False
+ if (items is not None) and (hasattr(items, '__len__')):
+ obj_seq = memo[obj_id][1]
+ if (len(items) != len(obj_seq)):
+ seq_diff = True
+ elif hasattr(obj, "items"): # dict type obj
+ obj_get = obj_seq.get
+ for key, item in items.items():
+ if id_(item) != obj_get(id_(key)) \
+ or chngd(key, seen, True, False) \
+ or chngd(item, seen, True, False):
+ seq_diff = True
+ break
+ else:
+ for i, j in zip(items, obj_seq): # list type obj
+ if id_(i) != j or chngd(i, seen, True, False):
+ seq_diff = True
+ break
+ seen[obj_id] = changed, seq_diff
+ if simple:
+ return changed or seq_diff
+ return changed, seq_diff
+
+
+def has_changed(*args, **kwds):
+ kwds['simple'] = True # ignore simple if passed in
+ return whats_changed(*args, **kwds)
+
+__import__ = __import__
+
+
+def _imp(*args, **kwds):
+ """
+ Replaces the default __import__, to allow a module to be memorised
+ before the user can change it
+ """
+ before = set(sys.modules.keys())
+ mod = __import__(*args, **kwds)
+ after = set(sys.modules.keys()).difference(before)
+ for m in after:
+ memorise(sys.modules[m])
+ return mod
+
+builtins.__import__ = _imp
+if hasattr(builtins, "_"):
+ del builtins._
+
+# memorise all already imported modules. This implies that this must be
+# imported first for any changes to be recorded
+for mod in list(sys.modules.values()):
+ memorise(mod)
+release_gone()
diff --git a/solutions/.venv/Lib/site-packages/dill/__info__.py b/solutions/.venv/Lib/site-packages/dill/__info__.py
new file mode 100644
index 000000000..0bcefb82d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/__info__.py
@@ -0,0 +1,291 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+'''
+-----------------------------
+dill: serialize all of Python
+-----------------------------
+
+About Dill
+==========
+
+``dill`` extends Python's ``pickle`` module for serializing and de-serializing
+Python objects to the majority of the built-in Python types. Serialization
+is the process of converting an object to a byte stream, and the inverse
+of which is converting a byte stream back to a Python object hierarchy.
+
+``dill`` provides the user the same interface as the ``pickle`` module, and
+also includes some additional features. In addition to pickling Python
+objects, ``dill`` provides the ability to save the state of an interpreter
+session in a single command. Hence, it would be feasible to save an
+interpreter session, close the interpreter, ship the pickled file to
+another computer, open a new interpreter, unpickle the session and
+thus continue from the 'saved' state of the original interpreter
+session.
+
+``dill`` can be used to store Python objects to a file, but the primary
+usage is to send Python objects across the network as a byte stream.
+``dill`` is quite flexible, and allows arbitrary user defined classes
+and functions to be serialized. Thus ``dill`` is not intended to be
+secure against erroneously or maliciously constructed data. It is
+left to the user to decide whether the data they unpickle is from
+a trustworthy source.
+
+``dill`` is part of ``pathos``, a Python framework for heterogeneous computing.
+``dill`` is in active development, so any user feedback, bug reports, comments,
+or suggestions are highly appreciated. A list of issues is located at
+https://github.com/uqfoundation/dill/issues, with a legacy list maintained at
+https://uqfoundation.github.io/project/pathos/query.
+
+
+Major Features
+==============
+
+``dill`` can pickle the following standard types:
+
+ - none, type, bool, int, float, complex, bytes, str,
+ - tuple, list, dict, file, buffer, builtin,
+ - Python classes, namedtuples, dataclasses, metaclasses,
+ - instances of classes,
+ - set, frozenset, array, functions, exceptions
+
+``dill`` can also pickle more 'exotic' standard types:
+
+ - functions with yields, nested functions, lambdas,
+ - cell, method, unboundmethod, module, code, methodwrapper,
+ - methoddescriptor, getsetdescriptor, memberdescriptor, wrapperdescriptor,
+ - dictproxy, slice, notimplemented, ellipsis, quit
+
+``dill`` cannot yet pickle these standard types:
+
+ - frame, generator, traceback
+
+``dill`` also provides the capability to:
+
+ - save and load Python interpreter sessions
+ - save and extract the source code from functions and classes
+ - interactively diagnose pickling errors
+
+
+Current Release
+===============
+
+The latest released version of ``dill`` is available from:
+
+ https://pypi.org/project/dill
+
+``dill`` is distributed under a 3-clause BSD license.
+
+
+Development Version
+===================
+
+You can get the latest development version with all the shiny new features at:
+
+ https://github.com/uqfoundation
+
+If you have a new contribution, please submit a pull request.
+
+
+Installation
+============
+
+``dill`` can be installed with ``pip``::
+
+ $ pip install dill
+
+To optionally include the ``objgraph`` diagnostic tool in the install::
+
+ $ pip install dill[graph]
+
+To optionally include the ``gprof2dot`` diagnostic tool in the install::
+
+ $ pip install dill[profile]
+
+For windows users, to optionally install session history tools::
+
+ $ pip install dill[readline]
+
+
+Requirements
+============
+
+``dill`` requires:
+
+ - ``python`` (or ``pypy``), **>=3.8**
+ - ``setuptools``, **>=42**
+
+Optional requirements:
+
+ - ``objgraph``, **>=1.7.2**
+ - ``gprof2dot``, **>=2022.7.29**
+ - ``pyreadline``, **>=1.7.1** (on windows)
+
+
+Basic Usage
+===========
+
+``dill`` is a drop-in replacement for ``pickle``. Existing code can be
+updated to allow complete pickling using::
+
+ >>> import dill as pickle
+
+or::
+
+ >>> from dill import dumps, loads
+
+``dumps`` converts the object to a unique byte string, and ``loads`` performs
+the inverse operation::
+
+ >>> squared = lambda x: x**2
+ >>> loads(dumps(squared))(3)
+ 9
+
+There are a number of options to control serialization which are provided
+as keyword arguments to several ``dill`` functions:
+
+* with *protocol*, the pickle protocol level can be set. This uses the
+ same value as the ``pickle`` module, *DEFAULT_PROTOCOL*.
+* with *byref=True*, ``dill`` to behave a lot more like pickle with
+ certain objects (like modules) pickled by reference as opposed to
+ attempting to pickle the object itself.
+* with *recurse=True*, objects referred to in the global dictionary are
+ recursively traced and pickled, instead of the default behavior of
+ attempting to store the entire global dictionary.
+* with *fmode*, the contents of the file can be pickled along with the file
+ handle, which is useful if the object is being sent over the wire to a
+ remote system which does not have the original file on disk. Options are
+ *HANDLE_FMODE* for just the handle, *CONTENTS_FMODE* for the file content
+ and *FILE_FMODE* for content and handle.
+* with *ignore=False*, objects reconstructed with types defined in the
+ top-level script environment use the existing type in the environment
+ rather than a possibly different reconstructed type.
+
+The default serialization can also be set globally in *dill.settings*.
+Thus, we can modify how ``dill`` handles references to the global dictionary
+locally or globally::
+
+ >>> import dill.settings
+ >>> dumps(absolute) == dumps(absolute, recurse=True)
+ False
+ >>> dill.settings['recurse'] = True
+ >>> dumps(absolute) == dumps(absolute, recurse=True)
+ True
+
+``dill`` also includes source code inspection, as an alternate to pickling::
+
+ >>> import dill.source
+ >>> print(dill.source.getsource(squared))
+ squared = lambda x:x**2
+
+To aid in debugging pickling issues, use *dill.detect* which provides
+tools like pickle tracing::
+
+ >>> import dill.detect
+ >>> with dill.detect.trace():
+ >>> dumps(squared)
+ ┬ F1: <function <lambda> at 0x7fe074f8c280>
+ ├┬ F2: <function _create_function at 0x7fe074c49c10>
+ │└ # F2 [34 B]
+ ├┬ Co: <code object <lambda> at 0x7fe07501eb30, file "<stdin>", line 1>
+ │├┬ F2: <function _create_code at 0x7fe074c49ca0>
+ ││└ # F2 [19 B]
+ │└ # Co [87 B]
+ ├┬ D1: <dict object at 0x7fe0750d4680>
+ │└ # D1 [22 B]
+ ├┬ D2: <dict object at 0x7fe074c5a1c0>
+ │└ # D2 [2 B]
+ ├┬ D2: <dict object at 0x7fe074f903c0>
+ │├┬ D2: <dict object at 0x7fe074f8ebc0>
+ ││└ # D2 [2 B]
+ │└ # D2 [23 B]
+ └ # F1 [180 B]
+
+With trace, we see how ``dill`` stored the lambda (``F1``) by first storing
+``_create_function``, the underlying code object (``Co``) and ``_create_code``
+(which is used to handle code objects), then we handle the reference to
+the global dict (``D2``) plus other dictionaries (``D1`` and ``D2``) that
+save the lambda object's state. A ``#`` marks when the object is actually stored.
+
+
+More Information
+================
+
+Probably the best way to get started is to look at the documentation at
+http://dill.rtfd.io. Also see ``dill.tests`` for a set of scripts that
+demonstrate how ``dill`` can serialize different Python objects. You can
+run the test suite with ``python -m dill.tests``. The contents of any
+pickle file can be examined with ``undill``. As ``dill`` conforms to
+the ``pickle`` interface, the examples and documentation found at
+http://docs.python.org/library/pickle.html also apply to ``dill``
+if one will ``import dill as pickle``. The source code is also generally
+well documented, so further questions may be resolved by inspecting the
+code itself. Please feel free to submit a ticket on github, or ask a
+question on stackoverflow (**@Mike McKerns**).
+If you would like to share how you use ``dill`` in your work, please send
+an email (to **mmckerns at uqfoundation dot org**).
+
+
+Citation
+========
+
+If you use ``dill`` to do research that leads to publication, we ask that you
+acknowledge use of ``dill`` by citing the following in your publication::
+
+ M.M. McKerns, L. Strand, T. Sullivan, A. Fang, M.A.G. Aivazis,
+ "Building a framework for predictive science", Proceedings of
+ the 10th Python in Science Conference, 2011;
+ http://arxiv.org/pdf/1202.1056
+
+ Michael McKerns and Michael Aivazis,
+ "pathos: a framework for heterogeneous computing", 2010- ;
+ https://uqfoundation.github.io/project/pathos
+
+Please see https://uqfoundation.github.io/project/pathos or
+http://arxiv.org/pdf/1202.1056 for further information.
+
+'''
+
+__version__ = '0.3.9'
+__author__ = 'Mike McKerns'
+
+__license__ = '''
+Copyright (c) 2004-2016 California Institute of Technology.
+Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+All rights reserved.
+
+This software is available subject to the conditions and terms laid
+out below. By downloading and using this software you are agreeing
+to the following conditions.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions
+are met:
+
+ - Redistributions of source code must retain the above copyright
+ notice, this list of conditions and the following disclaimer.
+
+ - Redistributions in binary form must reproduce the above copyright
+ notice, this list of conditions and the following disclaimer in the
+ documentation and/or other materials provided with the distribution.
+
+ - Neither the names of the copyright holders nor the names of any of
+ the contributors may be used to endorse or promote products derived
+ from this software without specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
+"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED
+TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
+PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
+CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
+EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
+PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS;
+OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY,
+WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR
+OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF
+ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+
+'''
diff --git a/solutions/.venv/Lib/site-packages/dill/__init__.py b/solutions/.venv/Lib/site-packages/dill/__init__.py
new file mode 100644
index 000000000..549048a43
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/__init__.py
@@ -0,0 +1,119 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+# author, version, license, and long description
+try: # the package is installed
+ from .__info__ import __version__, __author__, __doc__, __license__
+except: # pragma: no cover
+ import os
+ import sys
+ parent = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))
+ sys.path.append(parent)
+ # get distribution meta info
+ from version import (__version__, __author__,
+ get_license_text, get_readme_as_rst)
+ __license__ = get_license_text(os.path.join(parent, 'LICENSE'))
+ __license__ = "\n%s" % __license__
+ __doc__ = get_readme_as_rst(os.path.join(parent, 'README.md'))
+ del os, sys, parent, get_license_text, get_readme_as_rst
+
+
+from ._dill import (
+ dump, dumps, load, loads, copy,
+ Pickler, Unpickler, register, pickle, pickles, check,
+ DEFAULT_PROTOCOL, HIGHEST_PROTOCOL, HANDLE_FMODE, CONTENTS_FMODE, FILE_FMODE,
+ PickleError, PickleWarning, PicklingError, PicklingWarning, UnpicklingError,
+ UnpicklingWarning,
+)
+from .session import (
+ dump_module, load_module, load_module_asdict,
+ dump_session, load_session # backward compatibility
+)
+from . import detect, logger, session, source, temp
+
+# get global settings
+from .settings import settings
+
+# make sure "trace" is turned off
+logger.trace(False)
+
+objects = {}
+# local import of dill._objects
+#from . import _objects
+#objects.update(_objects.succeeds)
+#del _objects
+
+# local import of dill.objtypes
+from . import objtypes as types
+
+def load_types(pickleable=True, unpickleable=True):
+ """load pickleable and/or unpickleable types to ``dill.types``
+
+ ``dill.types`` is meant to mimic the ``types`` module, providing a
+ registry of object types. By default, the module is empty (for import
+ speed purposes). Use the ``load_types`` function to load selected object
+ types to the ``dill.types`` module.
+
+ Args:
+ pickleable (bool, default=True): if True, load pickleable types.
+ unpickleable (bool, default=True): if True, load unpickleable types.
+
+ Returns:
+ None
+ """
+ from importlib import reload
+ # local import of dill.objects
+ from . import _objects
+ if pickleable:
+ objects.update(_objects.succeeds)
+ else:
+ [objects.pop(obj,None) for obj in _objects.succeeds]
+ if unpickleable:
+ objects.update(_objects.failures)
+ else:
+ [objects.pop(obj,None) for obj in _objects.failures]
+ objects.update(_objects.registered)
+ del _objects
+ # reset contents of types to 'empty'
+ [types.__dict__.pop(obj) for obj in list(types.__dict__.keys()) \
+ if obj.find('Type') != -1]
+ # add corresponding types from objects to types
+ reload(types)
+
+def extend(use_dill=True):
+ '''add (or remove) dill types to/from the pickle registry
+
+ by default, ``dill`` populates its types to ``pickle.Pickler.dispatch``.
+ Thus, all ``dill`` types are available upon calling ``'import pickle'``.
+ To drop all ``dill`` types from the ``pickle`` dispatch, *use_dill=False*.
+
+ Args:
+ use_dill (bool, default=True): if True, extend the dispatch table.
+
+ Returns:
+ None
+ '''
+ from ._dill import _revert_extension, _extend
+ if use_dill: _extend()
+ else: _revert_extension()
+ return
+
+extend()
+
+
+def license():
+ """print license"""
+ print (__license__)
+ return
+
+def citation():
+ """print citation"""
+ print (__doc__[-491:-118])
+ return
+
+# end of file
diff --git a/solutions/.venv/Lib/site-packages/dill/_dill.py b/solutions/.venv/Lib/site-packages/dill/_dill.py
new file mode 100644
index 000000000..53738dfb4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/_dill.py
@@ -0,0 +1,2226 @@
+# -*- coding: utf-8 -*-
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2015 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+dill: a utility for serialization of python objects
+
+The primary functions in `dill` are :func:`dump` and
+:func:`dumps` for serialization ("pickling") to a
+file or to a string, respectively, and :func:`load`
+and :func:`loads` for deserialization ("unpickling"),
+similarly, from a file or from a string. Other notable
+functions are :func:`~dill.dump_module` and
+:func:`~dill.load_module`, which are used to save and
+restore module objects, including an intepreter session.
+
+Based on code written by Oren Tirosh and Armin Ronacher.
+Extended to a (near) full set of the builtin types (in types module),
+and coded to the pickle interface, by <mmckerns@caltech.edu>.
+Initial port to python3 by Jonathan Dobson, continued by mmckerns.
+Tested against "all" python types (Std. Lib. CH 1-15 @ 2.7) by mmckerns.
+Tested against CH16+ Std. Lib. ... TBD.
+"""
+
+from __future__ import annotations
+
+__all__ = [
+ 'dump','dumps','load','loads','copy',
+ 'Pickler','Unpickler','register','pickle','pickles','check',
+ 'DEFAULT_PROTOCOL','HIGHEST_PROTOCOL','HANDLE_FMODE','CONTENTS_FMODE','FILE_FMODE',
+ 'PickleError','PickleWarning','PicklingError','PicklingWarning','UnpicklingError',
+ 'UnpicklingWarning',
+]
+
+__module__ = 'dill'
+
+import warnings
+from .logger import adapter as logger
+from .logger import trace as _trace
+log = logger # backward compatibility (see issue #582)
+
+import os
+import sys
+diff = None
+_use_diff = False
+OLD38 = (sys.hexversion < 0x3080000)
+OLD39 = (sys.hexversion < 0x3090000)
+OLD310 = (sys.hexversion < 0x30a0000)
+OLD312a7 = (sys.hexversion < 0x30c00a7)
+#XXX: get types from .objtypes ?
+import builtins as __builtin__
+from pickle import _Pickler as StockPickler, Unpickler as StockUnpickler
+from pickle import GLOBAL, POP
+from _thread import LockType
+from _thread import RLock as RLockType
+try:
+ from _thread import _ExceptHookArgs as ExceptHookArgsType
+except ImportError:
+ ExceptHookArgsType = None
+try:
+ from _thread import _ThreadHandle as ThreadHandleType
+except ImportError:
+ ThreadHandleType = None
+#from io import IOBase
+from types import CodeType, FunctionType, MethodType, GeneratorType, \
+ TracebackType, FrameType, ModuleType, BuiltinMethodType
+BufferType = memoryview #XXX: unregistered
+ClassType = type # no 'old-style' classes
+EllipsisType = type(Ellipsis)
+#FileType = IOBase
+NotImplementedType = type(NotImplemented)
+SliceType = slice
+TypeType = type # 'new-style' classes #XXX: unregistered
+XRangeType = range
+from types import MappingProxyType as DictProxyType, new_class
+from pickle import DEFAULT_PROTOCOL, HIGHEST_PROTOCOL, PickleError, PicklingError, UnpicklingError
+import __main__ as _main_module
+import marshal
+import gc
+# import zlib
+import abc
+import dataclasses
+from weakref import ReferenceType, ProxyType, CallableProxyType
+from collections import OrderedDict
+from enum import Enum, EnumMeta
+from functools import partial
+from operator import itemgetter, attrgetter
+GENERATOR_FAIL = False
+import importlib.machinery
+EXTENSION_SUFFIXES = tuple(importlib.machinery.EXTENSION_SUFFIXES)
+try:
+ import ctypes
+ HAS_CTYPES = True
+ # if using `pypy`, pythonapi is not found
+ IS_PYPY = not hasattr(ctypes, 'pythonapi')
+except ImportError:
+ HAS_CTYPES = False
+ IS_PYPY = False
+NumpyUfuncType = None
+NumpyDType = None
+NumpyArrayType = None
+try:
+ if not importlib.machinery.PathFinder().find_spec('numpy'):
+ raise ImportError("No module named 'numpy'")
+ NumpyUfuncType = True
+ NumpyDType = True
+ NumpyArrayType = True
+except ImportError:
+ pass
+def __hook__():
+ global NumpyArrayType, NumpyDType, NumpyUfuncType
+ from numpy import ufunc as NumpyUfuncType
+ from numpy import ndarray as NumpyArrayType
+ from numpy import dtype as NumpyDType
+ return True
+if NumpyArrayType: # then has numpy
+ def ndarraysubclassinstance(obj_type):
+ if all((c.__module__, c.__name__) != ('numpy', 'ndarray') for c in obj_type.__mro__):
+ return False
+ # anything below here is a numpy array (or subclass) instance
+ __hook__() # import numpy (so the following works!!!)
+ # verify that __reduce__ has not been overridden
+ if obj_type.__reduce_ex__ is not NumpyArrayType.__reduce_ex__ \
+ or obj_type.__reduce__ is not NumpyArrayType.__reduce__:
+ return False
+ return True
+ def numpyufunc(obj_type):
+ return any((c.__module__, c.__name__) == ('numpy', 'ufunc') for c in obj_type.__mro__)
+ def numpydtype(obj_type):
+ if all((c.__module__, c.__name__) != ('numpy', 'dtype') for c in obj_type.__mro__):
+ return False
+ # anything below here is a numpy dtype
+ __hook__() # import numpy (so the following works!!!)
+ return obj_type is type(NumpyDType) # handles subclasses
+else:
+ def ndarraysubclassinstance(obj): return False
+ def numpyufunc(obj): return False
+ def numpydtype(obj): return False
+
+from types import GetSetDescriptorType, ClassMethodDescriptorType, \
+ WrapperDescriptorType, MethodDescriptorType, MemberDescriptorType, \
+ MethodWrapperType #XXX: unused
+
+# make sure to add these 'hand-built' types to _typemap
+CellType = type((lambda x: lambda y: x)(0).__closure__[0])
+PartialType = type(partial(int, base=2))
+SuperType = type(super(Exception, TypeError()))
+ItemGetterType = type(itemgetter(0))
+AttrGetterType = type(attrgetter('__repr__'))
+
+try:
+ from functools import _lru_cache_wrapper as LRUCacheType
+except ImportError:
+ LRUCacheType = None
+
+if not isinstance(LRUCacheType, type):
+ LRUCacheType = None
+
+def get_file_type(*args, **kwargs):
+ open = kwargs.pop("open", __builtin__.open)
+ f = open(os.devnull, *args, **kwargs)
+ t = type(f)
+ f.close()
+ return t
+
+IS_PYODIDE = sys.platform == 'emscripten'
+
+FileType = get_file_type('rb', buffering=0)
+TextWrapperType = get_file_type('r', buffering=-1)
+BufferedRandomType = None if IS_PYODIDE else get_file_type('r+b', buffering=-1)
+BufferedReaderType = get_file_type('rb', buffering=-1)
+BufferedWriterType = get_file_type('wb', buffering=-1)
+try:
+ from _pyio import open as _open
+ PyTextWrapperType = get_file_type('r', buffering=-1, open=_open)
+ PyBufferedRandomType = None if IS_PYODIDE else get_file_type('r+b', buffering=-1, open=_open)
+ PyBufferedReaderType = get_file_type('rb', buffering=-1, open=_open)
+ PyBufferedWriterType = get_file_type('wb', buffering=-1, open=_open)
+except ImportError:
+ PyTextWrapperType = PyBufferedRandomType = PyBufferedReaderType = PyBufferedWriterType = None
+from io import BytesIO as StringIO
+InputType = OutputType = None
+from socket import socket as SocketType
+#FIXME: additionally calls ForkingPickler.register several times
+from multiprocessing.reduction import _reduce_socket as reduce_socket
+try: #pragma: no cover
+ IS_IPYTHON = __IPYTHON__ # is True
+ ExitType = None # IPython.core.autocall.ExitAutocall
+ IPYTHON_SINGLETONS = ('exit', 'quit', 'get_ipython')
+except NameError:
+ IS_IPYTHON = False
+ try: ExitType = type(exit) # apparently 'exit' can be removed
+ except NameError: ExitType = None
+ IPYTHON_SINGLETONS = ()
+
+import inspect
+import typing
+
+
+### Shims for different versions of Python and dill
+class Sentinel(object):
+ """
+ Create a unique sentinel object that is pickled as a constant.
+ """
+ def __init__(self, name, module_name=None):
+ self.name = name
+ if module_name is None:
+ # Use the calling frame's module
+ self.__module__ = inspect.currentframe().f_back.f_globals['__name__']
+ else:
+ self.__module__ = module_name # pragma: no cover
+ def __repr__(self):
+ return self.__module__ + '.' + self.name # pragma: no cover
+ def __copy__(self):
+ return self # pragma: no cover
+ def __deepcopy__(self, memo):
+ return self # pragma: no cover
+ def __reduce__(self):
+ return self.name
+ def __reduce_ex__(self, protocol):
+ return self.name
+
+from . import _shims
+from ._shims import Reduce, Getattr
+
+### File modes
+#: Pickles the file handle, preserving mode. The position of the unpickled
+#: object is as for a new file handle.
+HANDLE_FMODE = 0
+#: Pickles the file contents, creating a new file if on load the file does
+#: not exist. The position = min(pickled position, EOF) and mode is chosen
+#: as such that "best" preserves behavior of the original file.
+CONTENTS_FMODE = 1
+#: Pickles the entire file (handle and contents), preserving mode and position.
+FILE_FMODE = 2
+
+### Shorthands (modified from python2.5/lib/pickle.py)
+def copy(obj, *args, **kwds):
+ """
+ Use pickling to 'copy' an object (i.e. `loads(dumps(obj))`).
+
+ See :func:`dumps` and :func:`loads` for keyword arguments.
+ """
+ ignore = kwds.pop('ignore', Unpickler.settings['ignore'])
+ return loads(dumps(obj, *args, **kwds), ignore=ignore)
+
+def dump(obj, file, protocol=None, byref=None, fmode=None, recurse=None, **kwds):#, strictio=None):
+ """
+ Pickle an object to a file.
+
+ See :func:`dumps` for keyword arguments.
+ """
+ from .settings import settings
+ protocol = settings['protocol'] if protocol is None else int(protocol)
+ _kwds = kwds.copy()
+ _kwds.update(dict(byref=byref, fmode=fmode, recurse=recurse))
+ Pickler(file, protocol, **_kwds).dump(obj)
+ return
+
+def dumps(obj, protocol=None, byref=None, fmode=None, recurse=None, **kwds):#, strictio=None):
+ """
+ Pickle an object to a string.
+
+ *protocol* is the pickler protocol, as defined for Python *pickle*.
+
+ If *byref=True*, then dill behaves a lot more like pickle as certain
+ objects (like modules) are pickled by reference as opposed to attempting
+ to pickle the object itself.
+
+ If *recurse=True*, then objects referred to in the global dictionary
+ are recursively traced and pickled, instead of the default behavior
+ of attempting to store the entire global dictionary. This is needed for
+ functions defined via *exec()*.
+
+ *fmode* (:const:`HANDLE_FMODE`, :const:`CONTENTS_FMODE`,
+ or :const:`FILE_FMODE`) indicates how file handles will be pickled.
+ For example, when pickling a data file handle for transfer to a remote
+ compute service, *FILE_FMODE* will include the file contents in the
+ pickle and cursor position so that a remote method can operate
+ transparently on an object with an open file handle.
+
+ Default values for keyword arguments can be set in :mod:`dill.settings`.
+ """
+ file = StringIO()
+ dump(obj, file, protocol, byref, fmode, recurse, **kwds)#, strictio)
+ return file.getvalue()
+
+def load(file, ignore=None, **kwds):
+ """
+ Unpickle an object from a file.
+
+ See :func:`loads` for keyword arguments.
+ """
+ return Unpickler(file, ignore=ignore, **kwds).load()
+
+def loads(str, ignore=None, **kwds):
+ """
+ Unpickle an object from a string.
+
+ If *ignore=False* then objects whose class is defined in the module
+ *__main__* are updated to reference the existing class in *__main__*,
+ otherwise they are left to refer to the reconstructed type, which may
+ be different.
+
+ Default values for keyword arguments can be set in :mod:`dill.settings`.
+ """
+ file = StringIO(str)
+ return load(file, ignore, **kwds)
+
+# def dumpzs(obj, protocol=None):
+# """pickle an object to a compressed string"""
+# return zlib.compress(dumps(obj, protocol))
+
+# def loadzs(str):
+# """unpickle an object from a compressed string"""
+# return loads(zlib.decompress(str))
+
+### End: Shorthands ###
+
+class MetaCatchingDict(dict):
+ def get(self, key, default=None):
+ try:
+ return self[key]
+ except KeyError:
+ return default
+
+ def __missing__(self, key):
+ if issubclass(key, type):
+ return save_type
+ else:
+ raise KeyError()
+
+class PickleWarning(Warning, PickleError):
+ pass
+
+class PicklingWarning(PickleWarning, PicklingError):
+ pass
+
+class UnpicklingWarning(PickleWarning, UnpicklingError):
+ pass
+
+### Extend the Picklers
+class Pickler(StockPickler):
+ """python's Pickler extended to interpreter sessions"""
+ dispatch: typing.Dict[type, typing.Callable[[Pickler, typing.Any], None]] \
+ = MetaCatchingDict(StockPickler.dispatch.copy())
+ """The dispatch table, a dictionary of serializing functions used
+ by Pickler to save objects of specific types. Use :func:`pickle`
+ or :func:`register` to associate types to custom functions.
+
+ :meta hide-value:
+ """
+ _session = False
+ from .settings import settings
+
+ def __init__(self, file, *args, **kwds):
+ settings = Pickler.settings
+ _byref = kwds.pop('byref', None)
+ #_strictio = kwds.pop('strictio', None)
+ _fmode = kwds.pop('fmode', None)
+ _recurse = kwds.pop('recurse', None)
+ StockPickler.__init__(self, file, *args, **kwds)
+ self._main = _main_module
+ self._diff_cache = {}
+ self._byref = settings['byref'] if _byref is None else _byref
+ self._strictio = False #_strictio
+ self._fmode = settings['fmode'] if _fmode is None else _fmode
+ self._recurse = settings['recurse'] if _recurse is None else _recurse
+ self._postproc = OrderedDict()
+ self._file = file
+
+ def save(self, obj, save_persistent_id=True):
+ # numpy hack
+ obj_type = type(obj)
+ if NumpyArrayType and not (obj_type is type or obj_type in Pickler.dispatch):
+ # register if the object is a numpy ufunc
+ # thanks to Paul Kienzle for pointing out ufuncs didn't pickle
+ if numpyufunc(obj_type):
+ @register(obj_type)
+ def save_numpy_ufunc(pickler, obj):
+ logger.trace(pickler, "Nu: %s", obj)
+ name = getattr(obj, '__qualname__', getattr(obj, '__name__', None))
+ StockPickler.save_global(pickler, obj, name=name)
+ logger.trace(pickler, "# Nu")
+ return
+ # NOTE: the above 'save' performs like:
+ # import copy_reg
+ # def udump(f): return f.__name__
+ # def uload(name): return getattr(numpy, name)
+ # copy_reg.pickle(NumpyUfuncType, udump, uload)
+ # register if the object is a numpy dtype
+ if numpydtype(obj_type):
+ @register(obj_type)
+ def save_numpy_dtype(pickler, obj):
+ logger.trace(pickler, "Dt: %s", obj)
+ pickler.save_reduce(_create_dtypemeta, (obj.type,), obj=obj)
+ logger.trace(pickler, "# Dt")
+ return
+ # NOTE: the above 'save' performs like:
+ # import copy_reg
+ # def uload(name): return type(NumpyDType(name))
+ # def udump(f): return uload, (f.type,)
+ # copy_reg.pickle(NumpyDTypeType, udump, uload)
+ # register if the object is a subclassed numpy array instance
+ if ndarraysubclassinstance(obj_type):
+ @register(obj_type)
+ def save_numpy_array(pickler, obj):
+ logger.trace(pickler, "Nu: (%s, %s)", obj.shape, obj.dtype)
+ npdict = getattr(obj, '__dict__', None)
+ f, args, state = obj.__reduce__()
+ pickler.save_reduce(_create_array, (f,args,state,npdict), obj=obj)
+ logger.trace(pickler, "# Nu")
+ return
+ # end numpy hack
+
+ if GENERATOR_FAIL and obj_type is GeneratorType:
+ msg = "Can't pickle %s: attribute lookup builtins.generator failed" % GeneratorType
+ raise PicklingError(msg)
+ StockPickler.save(self, obj, save_persistent_id)
+
+ save.__doc__ = StockPickler.save.__doc__
+
+ def dump(self, obj): #NOTE: if settings change, need to update attributes
+ logger.trace_setup(self)
+ StockPickler.dump(self, obj)
+ dump.__doc__ = StockPickler.dump.__doc__
+
+class Unpickler(StockUnpickler):
+ """python's Unpickler extended to interpreter sessions and more types"""
+ from .settings import settings
+ _session = False
+
+ def find_class(self, module, name):
+ if (module, name) == ('__builtin__', '__main__'):
+ return self._main.__dict__ #XXX: above set w/save_module_dict
+ elif (module, name) == ('__builtin__', 'NoneType'):
+ return type(None) #XXX: special case: NoneType missing
+ if module == 'dill.dill': module = 'dill._dill'
+ return StockUnpickler.find_class(self, module, name)
+
+ def __init__(self, *args, **kwds):
+ settings = Pickler.settings
+ _ignore = kwds.pop('ignore', None)
+ StockUnpickler.__init__(self, *args, **kwds)
+ self._main = _main_module
+ self._ignore = settings['ignore'] if _ignore is None else _ignore
+
+ def load(self): #NOTE: if settings change, need to update attributes
+ obj = StockUnpickler.load(self)
+ if type(obj).__module__ == getattr(_main_module, '__name__', '__main__'):
+ if not self._ignore:
+ # point obj class to main
+ try: obj.__class__ = getattr(self._main, type(obj).__name__)
+ except (AttributeError,TypeError): pass # defined in a file
+ #_main_module.__dict__.update(obj.__dict__) #XXX: should update globals ?
+ return obj
+ load.__doc__ = StockUnpickler.load.__doc__
+ pass
+
+'''
+def dispatch_table():
+ """get the dispatch table of registered types"""
+ return Pickler.dispatch
+'''
+
+pickle_dispatch_copy = StockPickler.dispatch.copy()
+
+def pickle(t, func):
+ """expose :attr:`~Pickler.dispatch` table for user-created extensions"""
+ Pickler.dispatch[t] = func
+ return
+
+def register(t):
+ """decorator to register types to Pickler's :attr:`~Pickler.dispatch` table"""
+ def proxy(func):
+ Pickler.dispatch[t] = func
+ return func
+ return proxy
+
+def _revert_extension():
+ """drop dill-registered types from pickle's dispatch table"""
+ for type, func in list(StockPickler.dispatch.items()):
+ if func.__module__ == __name__:
+ del StockPickler.dispatch[type]
+ if type in pickle_dispatch_copy:
+ StockPickler.dispatch[type] = pickle_dispatch_copy[type]
+
+def use_diff(on=True):
+ """
+ Reduces size of pickles by only including object which have changed.
+
+ Decreases pickle size but increases CPU time needed.
+ Also helps avoid some unpickleable objects.
+ MUST be called at start of script, otherwise changes will not be recorded.
+ """
+ global _use_diff, diff
+ _use_diff = on
+ if _use_diff and diff is None:
+ try:
+ from . import diff as d
+ except ImportError:
+ import diff as d
+ diff = d
+
+def _create_typemap():
+ import types
+ d = dict(list(__builtin__.__dict__.items()) + \
+ list(types.__dict__.items())).items()
+ for key, value in d:
+ if getattr(value, '__module__', None) == 'builtins' \
+ and type(value) is type:
+ yield key, value
+ return
+_reverse_typemap = dict(_create_typemap())
+_reverse_typemap.update({
+ 'PartialType': PartialType,
+ 'SuperType': SuperType,
+ 'ItemGetterType': ItemGetterType,
+ 'AttrGetterType': AttrGetterType,
+})
+if sys.hexversion < 0x30800a2:
+ _reverse_typemap.update({
+ 'CellType': CellType,
+ })
+
+# "Incidental" implementation specific types. Unpickling these types in another
+# implementation of Python (PyPy -> CPython) is not guaranteed to work
+
+# This dictionary should contain all types that appear in Python implementations
+# but are not defined in https://docs.python.org/3/library/types.html#standard-interpreter-types
+x=OrderedDict()
+_incedental_reverse_typemap = {
+ 'FileType': FileType,
+ 'BufferedRandomType': BufferedRandomType,
+ 'BufferedReaderType': BufferedReaderType,
+ 'BufferedWriterType': BufferedWriterType,
+ 'TextWrapperType': TextWrapperType,
+ 'PyBufferedRandomType': PyBufferedRandomType,
+ 'PyBufferedReaderType': PyBufferedReaderType,
+ 'PyBufferedWriterType': PyBufferedWriterType,
+ 'PyTextWrapperType': PyTextWrapperType,
+}
+
+_incedental_reverse_typemap.update({
+ "DictKeysType": type({}.keys()),
+ "DictValuesType": type({}.values()),
+ "DictItemsType": type({}.items()),
+
+ "OdictKeysType": type(x.keys()),
+ "OdictValuesType": type(x.values()),
+ "OdictItemsType": type(x.items()),
+})
+
+if ExitType:
+ _incedental_reverse_typemap['ExitType'] = ExitType
+if InputType:
+ _incedental_reverse_typemap['InputType'] = InputType
+ _incedental_reverse_typemap['OutputType'] = OutputType
+
+'''
+try:
+ import symtable
+ _incedental_reverse_typemap["SymtableEntryType"] = type(symtable.symtable("", "string", "exec")._table)
+except: #FIXME: fails to pickle
+ pass
+
+if sys.hexversion >= 0x30a00a0:
+ _incedental_reverse_typemap['LineIteratorType'] = type(compile('3', '', 'eval').co_lines())
+'''
+
+if sys.hexversion >= 0x30b00b0:
+ from types import GenericAlias
+ _incedental_reverse_typemap["GenericAliasIteratorType"] = type(iter(GenericAlias(list, (int,))))
+ '''
+ _incedental_reverse_typemap['PositionsIteratorType'] = type(compile('3', '', 'eval').co_positions())
+ '''
+
+try:
+ import winreg
+ _incedental_reverse_typemap["HKEYType"] = winreg.HKEYType
+except ImportError:
+ pass
+
+_reverse_typemap.update(_incedental_reverse_typemap)
+_incedental_types = set(_incedental_reverse_typemap.values())
+
+del x
+
+_typemap = dict((v, k) for k, v in _reverse_typemap.items())
+
+def _unmarshal(string):
+ return marshal.loads(string)
+
+def _load_type(name):
+ return _reverse_typemap[name]
+
+def _create_type(typeobj, *args):
+ return typeobj(*args)
+
+def _create_function(fcode, fglobals, fname=None, fdefaults=None,
+ fclosure=None, fdict=None, fkwdefaults=None):
+ # same as FunctionType, but enable passing __dict__ to new function,
+ # __dict__ is the storehouse for attributes added after function creation
+ func = FunctionType(fcode, fglobals or dict(), fname, fdefaults, fclosure)
+ if fdict is not None:
+ func.__dict__.update(fdict) #XXX: better copy? option to copy?
+ if fkwdefaults is not None:
+ func.__kwdefaults__ = fkwdefaults
+ # 'recurse' only stores referenced modules/objects in fglobals,
+ # thus we need to make sure that we have __builtins__ as well
+ if "__builtins__" not in func.__globals__:
+ func.__globals__["__builtins__"] = globals()["__builtins__"]
+ # assert id(fglobals) == id(func.__globals__)
+ return func
+
+class match:
+ """
+ Make avaialable a limited structural pattern matching-like syntax for Python < 3.10
+
+ Patterns can be only tuples (without types) currently.
+ Inspired by the package pattern-matching-PEP634.
+
+ Usage:
+ >>> with match(args) as m:
+ >>> if m.case(('x', 'y')):
+ >>> # use m.x and m.y
+ >>> elif m.case(('x', 'y', 'z')):
+ >>> # use m.x, m.y and m.z
+
+ Equivalent native code for Python >= 3.10:
+ >>> match args:
+ >>> case (x, y):
+ >>> # use x and y
+ >>> case (x, y, z):
+ >>> # use x, y and z
+ """
+ def __init__(self, value):
+ self.value = value
+ self._fields = None
+ def __enter__(self):
+ return self
+ def __exit__(self, *exc_info):
+ return False
+ def case(self, args): # *args, **kwargs):
+ """just handles tuple patterns"""
+ if len(self.value) != len(args): # + len(kwargs):
+ return False
+ #if not all(isinstance(arg, pat) for arg, pat in zip(self.value[len(args):], kwargs.values())):
+ # return False
+ self.args = args # (*args, *kwargs)
+ return True
+ @property
+ def fields(self):
+ # Only bind names to values if necessary.
+ if self._fields is None:
+ self._fields = dict(zip(self.args, self.value))
+ return self._fields
+ def __getattr__(self, item):
+ return self.fields[item]
+
+ALL_CODE_PARAMS = [
+ # Version New attribute CodeType parameters
+ ((3,11,'a'), 'co_endlinetable', 'argcount posonlyargcount kwonlyargcount nlocals stacksize flags code consts names varnames filename name qualname firstlineno linetable endlinetable columntable exceptiontable freevars cellvars'),
+ ((3,11), 'co_exceptiontable', 'argcount posonlyargcount kwonlyargcount nlocals stacksize flags code consts names varnames filename name qualname firstlineno linetable exceptiontable freevars cellvars'),
+ ((3,10), 'co_linetable', 'argcount posonlyargcount kwonlyargcount nlocals stacksize flags code consts names varnames filename name firstlineno linetable freevars cellvars'),
+ ((3,8), 'co_posonlyargcount', 'argcount posonlyargcount kwonlyargcount nlocals stacksize flags code consts names varnames filename name firstlineno lnotab freevars cellvars'),
+ ((3,7), 'co_kwonlyargcount', 'argcount kwonlyargcount nlocals stacksize flags code consts names varnames filename name firstlineno lnotab freevars cellvars'),
+ ]
+for version, new_attr, params in ALL_CODE_PARAMS:
+ if hasattr(CodeType, new_attr):
+ CODE_VERSION = version
+ CODE_PARAMS = params.split()
+ break
+ENCODE_PARAMS = set(CODE_PARAMS).intersection(
+ ['code', 'lnotab', 'linetable', 'endlinetable', 'columntable', 'exceptiontable'])
+
+def _create_code(*args):
+ if not isinstance(args[0], int): # co_lnotab stored from >= 3.10
+ LNOTAB, *args = args
+ else: # from < 3.10 (or pre-LNOTAB storage)
+ LNOTAB = b''
+
+ with match(args) as m:
+ # Python 3.11/3.12a (18 members)
+ if m.case((
+ 'argcount', 'posonlyargcount', 'kwonlyargcount', 'nlocals', 'stacksize', 'flags', # args[0:6]
+ 'code', 'consts', 'names', 'varnames', 'filename', 'name', 'qualname', 'firstlineno', # args[6:14]
+ 'linetable', 'exceptiontable', 'freevars', 'cellvars' # args[14:]
+ )):
+ if CODE_VERSION == (3,11):
+ return CodeType(
+ *args[:6],
+ args[6].encode() if hasattr(args[6], 'encode') else args[6], # code
+ *args[7:14],
+ args[14].encode() if hasattr(args[14], 'encode') else args[14], # linetable
+ args[15].encode() if hasattr(args[15], 'encode') else args[15], # exceptiontable
+ args[16],
+ args[17],
+ )
+ fields = m.fields
+ # Python 3.10 or 3.8/3.9 (16 members)
+ elif m.case((
+ 'argcount', 'posonlyargcount', 'kwonlyargcount', 'nlocals', 'stacksize', 'flags', # args[0:6]
+ 'code', 'consts', 'names', 'varnames', 'filename', 'name', 'firstlineno', # args[6:13]
+ 'LNOTAB_OR_LINETABLE', 'freevars', 'cellvars' # args[13:]
+ )):
+ if CODE_VERSION == (3,10) or CODE_VERSION == (3,8):
+ return CodeType(
+ *args[:6],
+ args[6].encode() if hasattr(args[6], 'encode') else args[6], # code
+ *args[7:13],
+ args[13].encode() if hasattr(args[13], 'encode') else args[13], # lnotab/linetable
+ args[14],
+ args[15],
+ )
+ fields = m.fields
+ if CODE_VERSION >= (3,10):
+ fields['linetable'] = m.LNOTAB_OR_LINETABLE
+ else:
+ fields['lnotab'] = LNOTAB if LNOTAB else m.LNOTAB_OR_LINETABLE
+ # Python 3.7 (15 args)
+ elif m.case((
+ 'argcount', 'kwonlyargcount', 'nlocals', 'stacksize', 'flags', # args[0:5]
+ 'code', 'consts', 'names', 'varnames', 'filename', 'name', 'firstlineno', # args[5:12]
+ 'lnotab', 'freevars', 'cellvars' # args[12:]
+ )):
+ if CODE_VERSION == (3,7):
+ return CodeType(
+ *args[:5],
+ args[5].encode() if hasattr(args[5], 'encode') else args[5], # code
+ *args[6:12],
+ args[12].encode() if hasattr(args[12], 'encode') else args[12], # lnotab
+ args[13],
+ args[14],
+ )
+ fields = m.fields
+ # Python 3.11a (20 members)
+ elif m.case((
+ 'argcount', 'posonlyargcount', 'kwonlyargcount', 'nlocals', 'stacksize', 'flags', # args[0:6]
+ 'code', 'consts', 'names', 'varnames', 'filename', 'name', 'qualname', 'firstlineno', # args[6:14]
+ 'linetable', 'endlinetable', 'columntable', 'exceptiontable', 'freevars', 'cellvars' # args[14:]
+ )):
+ if CODE_VERSION == (3,11,'a'):
+ return CodeType(
+ *args[:6],
+ args[6].encode() if hasattr(args[6], 'encode') else args[6], # code
+ *args[7:14],
+ *(a.encode() if hasattr(a, 'encode') else a for a in args[14:18]), # linetable-exceptiontable
+ args[18],
+ args[19],
+ )
+ fields = m.fields
+ else:
+ raise UnpicklingError("pattern match for code object failed")
+
+ # The args format doesn't match this version.
+ fields.setdefault('posonlyargcount', 0) # from python <= 3.7
+ fields.setdefault('lnotab', LNOTAB) # from python >= 3.10
+ fields.setdefault('linetable', b'') # from python <= 3.9
+ fields.setdefault('qualname', fields['name']) # from python <= 3.10
+ fields.setdefault('exceptiontable', b'') # from python <= 3.10
+ fields.setdefault('endlinetable', None) # from python != 3.11a
+ fields.setdefault('columntable', None) # from python != 3.11a
+
+ args = (fields[k].encode() if k in ENCODE_PARAMS and hasattr(fields[k], 'encode') else fields[k]
+ for k in CODE_PARAMS)
+ return CodeType(*args)
+
+def _create_ftype(ftypeobj, func, args, kwds):
+ if kwds is None:
+ kwds = {}
+ if args is None:
+ args = ()
+ return ftypeobj(func, *args, **kwds)
+
+def _create_typing_tuple(argz, *args): #NOTE: workaround python/cpython#94245
+ if not argz:
+ return typing.Tuple[()].copy_with(())
+ if argz == ((),):
+ return typing.Tuple[()]
+ return typing.Tuple[argz]
+
+if ThreadHandleType:
+ def _create_thread_handle(ident, done, *args): #XXX: ignores 'blocking'
+ from threading import _make_thread_handle
+ handle = _make_thread_handle(ident)
+ if done:
+ handle._set_done()
+ return handle
+
+def _create_lock(locked, *args): #XXX: ignores 'blocking'
+ from threading import Lock
+ lock = Lock()
+ if locked:
+ if not lock.acquire(False):
+ raise UnpicklingError("Cannot acquire lock")
+ return lock
+
+def _create_rlock(count, owner, *args): #XXX: ignores 'blocking'
+ lock = RLockType()
+ if owner is not None:
+ lock._acquire_restore((count, owner))
+ if owner and not lock._is_owned():
+ raise UnpicklingError("Cannot acquire lock")
+ return lock
+
+# thanks to matsjoyce for adding all the different file modes
+def _create_filehandle(name, mode, position, closed, open, strictio, fmode, fdata): # buffering=0
+ # only pickles the handle, not the file contents... good? or StringIO(data)?
+ # (for file contents see: http://effbot.org/librarybook/copy-reg.htm)
+ # NOTE: handle special cases first (are there more special cases?)
+ names = {'<stdin>':sys.__stdin__, '<stdout>':sys.__stdout__,
+ '<stderr>':sys.__stderr__} #XXX: better fileno=(0,1,2) ?
+ if name in list(names.keys()):
+ f = names[name] #XXX: safer "f=sys.stdin"
+ elif name == '<tmpfile>':
+ f = os.tmpfile()
+ elif name == '<fdopen>':
+ import tempfile
+ f = tempfile.TemporaryFile(mode)
+ else:
+ try:
+ exists = os.path.exists(name)
+ except Exception:
+ exists = False
+ if not exists:
+ if strictio:
+ raise FileNotFoundError("[Errno 2] No such file or directory: '%s'" % name)
+ elif "r" in mode and fmode != FILE_FMODE:
+ name = '<fdopen>' # or os.devnull?
+ current_size = 0 # or maintain position?
+ else:
+ current_size = os.path.getsize(name)
+
+ if position > current_size:
+ if strictio:
+ raise ValueError("invalid buffer size")
+ elif fmode == CONTENTS_FMODE:
+ position = current_size
+ # try to open the file by name
+ # NOTE: has different fileno
+ try:
+ #FIXME: missing: *buffering*, encoding, softspace
+ if fmode == FILE_FMODE:
+ f = open(name, mode if "w" in mode else "w")
+ f.write(fdata)
+ if "w" not in mode:
+ f.close()
+ f = open(name, mode)
+ elif name == '<fdopen>': # file did not exist
+ import tempfile
+ f = tempfile.TemporaryFile(mode)
+ # treat x mode as w mode
+ elif fmode == CONTENTS_FMODE \
+ and ("w" in mode or "x" in mode):
+ # stop truncation when opening
+ flags = os.O_CREAT
+ if "+" in mode:
+ flags |= os.O_RDWR
+ else:
+ flags |= os.O_WRONLY
+ f = os.fdopen(os.open(name, flags), mode)
+ # set name to the correct value
+ r = getattr(f, "buffer", f)
+ r = getattr(r, "raw", r)
+ r.name = name
+ assert f.name == name
+ else:
+ f = open(name, mode)
+ except (IOError, FileNotFoundError):
+ err = sys.exc_info()[1]
+ raise UnpicklingError(err)
+ if closed:
+ f.close()
+ elif position >= 0 and fmode != HANDLE_FMODE:
+ f.seek(position)
+ return f
+
+def _create_stringi(value, position, closed):
+ f = StringIO(value)
+ if closed: f.close()
+ else: f.seek(position)
+ return f
+
+def _create_stringo(value, position, closed):
+ f = StringIO()
+ if closed: f.close()
+ else:
+ f.write(value)
+ f.seek(position)
+ return f
+
+class _itemgetter_helper(object):
+ def __init__(self):
+ self.items = []
+ def __getitem__(self, item):
+ self.items.append(item)
+ return
+
+class _attrgetter_helper(object):
+ def __init__(self, attrs, index=None):
+ self.attrs = attrs
+ self.index = index
+ def __getattribute__(self, attr):
+ attrs = object.__getattribute__(self, "attrs")
+ index = object.__getattribute__(self, "index")
+ if index is None:
+ index = len(attrs)
+ attrs.append(attr)
+ else:
+ attrs[index] = ".".join([attrs[index], attr])
+ return type(self)(attrs, index)
+
+class _dictproxy_helper(dict):
+ def __ror__(self, a):
+ return a
+
+_dictproxy_helper_instance = _dictproxy_helper()
+
+__d = {}
+try:
+ # In CPython 3.9 and later, this trick can be used to exploit the
+ # implementation of the __or__ function of MappingProxyType to get the true
+ # mapping referenced by the proxy. It may work for other implementations,
+ # but is not guaranteed.
+ MAPPING_PROXY_TRICK = __d is (DictProxyType(__d) | _dictproxy_helper_instance)
+except Exception:
+ MAPPING_PROXY_TRICK = False
+del __d
+
+# _CELL_REF and _CELL_EMPTY are used to stay compatible with versions of dill
+# whose _create_cell functions do not have a default value.
+# _CELL_REF can be safely removed entirely (replaced by empty tuples for calls
+# to _create_cell) once breaking changes are allowed.
+_CELL_REF = None
+_CELL_EMPTY = Sentinel('_CELL_EMPTY')
+
+def _create_cell(contents=None):
+ if contents is not _CELL_EMPTY:
+ value = contents
+ return (lambda: value).__closure__[0]
+
+def _create_weakref(obj, *args):
+ from weakref import ref
+ if obj is None: # it's dead
+ from collections import UserDict
+ return ref(UserDict(), *args)
+ return ref(obj, *args)
+
+def _create_weakproxy(obj, callable=False, *args):
+ from weakref import proxy
+ if obj is None: # it's dead
+ if callable: return proxy(lambda x:x, *args)
+ from collections import UserDict
+ return proxy(UserDict(), *args)
+ return proxy(obj, *args)
+
+def _eval_repr(repr_str):
+ return eval(repr_str)
+
+def _create_array(f, args, state, npdict=None):
+ #array = numpy.core.multiarray._reconstruct(*args)
+ array = f(*args)
+ array.__setstate__(state)
+ if npdict is not None: # we also have saved state in __dict__
+ array.__dict__.update(npdict)
+ return array
+
+def _create_dtypemeta(scalar_type):
+ if NumpyDType is True: __hook__() # a bit hacky I think
+ if scalar_type is None:
+ return NumpyDType
+ return type(NumpyDType(scalar_type))
+
+def _create_namedtuple(name, fieldnames, modulename, defaults=None):
+ class_ = _import_module(modulename + '.' + name, safe=True)
+ if class_ is not None:
+ return class_
+ import collections
+ t = collections.namedtuple(name, fieldnames, defaults=defaults, module=modulename)
+ return t
+
+def _create_capsule(pointer, name, context, destructor):
+ attr_found = False
+ try:
+ # based on https://github.com/python/cpython/blob/f4095e53ab708d95e019c909d5928502775ba68f/Objects/capsule.c#L209-L231
+ uname = name.decode('utf8')
+ for i in range(1, uname.count('.')+1):
+ names = uname.rsplit('.', i)
+ try:
+ module = __import__(names[0])
+ except ImportError:
+ pass
+ obj = module
+ for attr in names[1:]:
+ obj = getattr(obj, attr)
+ capsule = obj
+ attr_found = True
+ break
+ except Exception:
+ pass
+
+ if attr_found:
+ if _PyCapsule_IsValid(capsule, name):
+ return capsule
+ raise UnpicklingError("%s object exists at %s but a PyCapsule object was expected." % (type(capsule), name))
+ else:
+ #warnings.warn('Creating a new PyCapsule %s for a C data structure that may not be present in memory. Segmentation faults or other memory errors are possible.' % (name,), UnpicklingWarning)
+ capsule = _PyCapsule_New(pointer, name, destructor)
+ _PyCapsule_SetContext(capsule, context)
+ return capsule
+
+def _getattr(objclass, name, repr_str):
+ # hack to grab the reference directly
+ try: #XXX: works only for __builtin__ ?
+ attr = repr_str.split("'")[3]
+ return eval(attr+'.__dict__["'+name+'"]')
+ except Exception:
+ try:
+ attr = objclass.__dict__
+ if type(attr) is DictProxyType:
+ attr = attr[name]
+ else:
+ attr = getattr(objclass,name)
+ except (AttributeError, KeyError):
+ attr = getattr(objclass,name)
+ return attr
+
+def _get_attr(self, name):
+ # stop recursive pickling
+ return getattr(self, name, None) or getattr(__builtin__, name)
+
+def _import_module(import_name, safe=False):
+ try:
+ if import_name.startswith('__runtime__.'):
+ return sys.modules[import_name]
+ elif '.' in import_name:
+ items = import_name.split('.')
+ module = '.'.join(items[:-1])
+ obj = items[-1]
+ submodule = getattr(__import__(module, None, None, [obj]), obj)
+ if isinstance(submodule, (ModuleType, type)):
+ return submodule
+ return __import__(import_name, None, None, [obj])
+ else:
+ return __import__(import_name)
+ except (ImportError, AttributeError, KeyError):
+ if safe:
+ return None
+ raise
+
+# https://github.com/python/cpython/blob/a8912a0f8d9eba6d502c37d522221f9933e976db/Lib/pickle.py#L322-L333
+def _getattribute(obj, name):
+ for subpath in name.split('.'):
+ if subpath == '<locals>':
+ raise AttributeError("Can't get local attribute {!r} on {!r}"
+ .format(name, obj))
+ try:
+ parent = obj
+ obj = getattr(obj, subpath)
+ except AttributeError:
+ raise AttributeError("Can't get attribute {!r} on {!r}"
+ .format(name, obj))
+ return obj, parent
+
+def _locate_function(obj, pickler=None):
+ module_name = getattr(obj, '__module__', None)
+ if module_name in ['__main__', None] or \
+ pickler and is_dill(pickler, child=False) and pickler._session and module_name == pickler._main.__name__:
+ return False
+ if hasattr(obj, '__qualname__'):
+ module = _import_module(module_name, safe=True)
+ try:
+ found, _ = _getattribute(module, obj.__qualname__)
+ return found is obj
+ except AttributeError:
+ return False
+ else:
+ found = _import_module(module_name + '.' + obj.__name__, safe=True)
+ return found is obj
+
+
+def _setitems(dest, source):
+ for k, v in source.items():
+ dest[k] = v
+
+
+def _save_with_postproc(pickler, reduction, is_pickler_dill=None, obj=Getattr.NO_DEFAULT, postproc_list=None):
+ if obj is Getattr.NO_DEFAULT:
+ obj = Reduce(reduction) # pragma: no cover
+
+ if is_pickler_dill is None:
+ is_pickler_dill = is_dill(pickler, child=True)
+ if is_pickler_dill:
+ # assert id(obj) not in pickler._postproc, str(obj) + ' already pushed on stack!'
+ # if not hasattr(pickler, 'x'): pickler.x = 0
+ # print(pickler.x*' ', 'push', obj, id(obj), pickler._recurse)
+ # pickler.x += 1
+ if postproc_list is None:
+ postproc_list = []
+
+ # Recursive object not supported. Default to a global instead.
+ if id(obj) in pickler._postproc:
+ name = '%s.%s ' % (obj.__module__, getattr(obj, '__qualname__', obj.__name__)) if hasattr(obj, '__module__') else ''
+ warnings.warn('Cannot pickle %r: %shas recursive self-references that trigger a RecursionError.' % (obj, name), PicklingWarning)
+ pickler.save_global(obj)
+ return
+ pickler._postproc[id(obj)] = postproc_list
+
+ # TODO: Use state_setter in Python 3.8 to allow for faster cPickle implementations
+ pickler.save_reduce(*reduction, obj=obj)
+
+ if is_pickler_dill:
+ # pickler.x -= 1
+ # print(pickler.x*' ', 'pop', obj, id(obj))
+ postproc = pickler._postproc.pop(id(obj))
+ # assert postproc_list == postproc, 'Stack tampered!'
+ for reduction in reversed(postproc):
+ if reduction[0] is _setitems:
+ # use the internal machinery of pickle.py to speedup when
+ # updating a dictionary in postproc
+ dest, source = reduction[1]
+ if source:
+ pickler.write(pickler.get(pickler.memo[id(dest)][0]))
+ pickler._batch_setitems(iter(source.items()))
+ else:
+ # Updating with an empty dictionary. Same as doing nothing.
+ continue
+ else:
+ pickler.save_reduce(*reduction)
+ # pop None created by calling preprocessing step off stack
+ pickler.write(POP)
+
+#@register(CodeType)
+#def save_code(pickler, obj):
+# logger.trace(pickler, "Co: %s", obj)
+# pickler.save_reduce(_unmarshal, (marshal.dumps(obj),), obj=obj)
+# logger.trace(pickler, "# Co")
+# return
+
+# The following function is based on 'save_codeobject' from 'cloudpickle'
+# Copyright (c) 2012, Regents of the University of California.
+# Copyright (c) 2009 `PiCloud, Inc. <http://www.picloud.com>`_.
+# License: https://github.com/cloudpipe/cloudpickle/blob/master/LICENSE
+@register(CodeType)
+def save_code(pickler, obj):
+ logger.trace(pickler, "Co: %s", obj)
+ if hasattr(obj, "co_endlinetable"): # python 3.11a (20 args)
+ args = (
+ obj.co_lnotab, # for < python 3.10 [not counted in args]
+ obj.co_argcount, obj.co_posonlyargcount,
+ obj.co_kwonlyargcount, obj.co_nlocals, obj.co_stacksize,
+ obj.co_flags, obj.co_code, obj.co_consts, obj.co_names,
+ obj.co_varnames, obj.co_filename, obj.co_name, obj.co_qualname,
+ obj.co_firstlineno, obj.co_linetable, obj.co_endlinetable,
+ obj.co_columntable, obj.co_exceptiontable, obj.co_freevars,
+ obj.co_cellvars
+ )
+ elif hasattr(obj, "co_exceptiontable"): # python 3.11 (18 args)
+ with warnings.catch_warnings():
+ if not OLD312a7: # issue 597
+ warnings.filterwarnings('ignore', category=DeprecationWarning)
+ args = (
+ obj.co_lnotab, # for < python 3.10 [not counted in args]
+ obj.co_argcount, obj.co_posonlyargcount,
+ obj.co_kwonlyargcount, obj.co_nlocals, obj.co_stacksize,
+ obj.co_flags, obj.co_code, obj.co_consts, obj.co_names,
+ obj.co_varnames, obj.co_filename, obj.co_name, obj.co_qualname,
+ obj.co_firstlineno, obj.co_linetable, obj.co_exceptiontable,
+ obj.co_freevars, obj.co_cellvars
+ )
+ elif hasattr(obj, "co_linetable"): # python 3.10 (16 args)
+ args = (
+ obj.co_lnotab, # for < python 3.10 [not counted in args]
+ obj.co_argcount, obj.co_posonlyargcount,
+ obj.co_kwonlyargcount, obj.co_nlocals, obj.co_stacksize,
+ obj.co_flags, obj.co_code, obj.co_consts, obj.co_names,
+ obj.co_varnames, obj.co_filename, obj.co_name,
+ obj.co_firstlineno, obj.co_linetable, obj.co_freevars,
+ obj.co_cellvars
+ )
+ elif hasattr(obj, "co_posonlyargcount"): # python 3.8 (16 args)
+ args = (
+ obj.co_argcount, obj.co_posonlyargcount,
+ obj.co_kwonlyargcount, obj.co_nlocals, obj.co_stacksize,
+ obj.co_flags, obj.co_code, obj.co_consts, obj.co_names,
+ obj.co_varnames, obj.co_filename, obj.co_name,
+ obj.co_firstlineno, obj.co_lnotab, obj.co_freevars,
+ obj.co_cellvars
+ )
+ else: # python 3.7 (15 args)
+ args = (
+ obj.co_argcount, obj.co_kwonlyargcount, obj.co_nlocals,
+ obj.co_stacksize, obj.co_flags, obj.co_code, obj.co_consts,
+ obj.co_names, obj.co_varnames, obj.co_filename,
+ obj.co_name, obj.co_firstlineno, obj.co_lnotab,
+ obj.co_freevars, obj.co_cellvars
+ )
+
+ pickler.save_reduce(_create_code, args, obj=obj)
+ logger.trace(pickler, "# Co")
+ return
+
+def _repr_dict(obj):
+ """Make a short string representation of a dictionary."""
+ return "<%s object at %#012x>" % (type(obj).__name__, id(obj))
+
+@register(dict)
+def save_module_dict(pickler, obj):
+ if is_dill(pickler, child=False) and obj == pickler._main.__dict__ and \
+ not (pickler._session and pickler._first_pass):
+ logger.trace(pickler, "D1: %s", _repr_dict(obj)) # obj
+ pickler.write(bytes('c__builtin__\n__main__\n', 'UTF-8'))
+ logger.trace(pickler, "# D1")
+ elif (not is_dill(pickler, child=False)) and (obj == _main_module.__dict__):
+ logger.trace(pickler, "D3: %s", _repr_dict(obj)) # obj
+ pickler.write(bytes('c__main__\n__dict__\n', 'UTF-8')) #XXX: works in general?
+ logger.trace(pickler, "# D3")
+ elif '__name__' in obj and obj != _main_module.__dict__ \
+ and type(obj['__name__']) is str \
+ and obj is getattr(_import_module(obj['__name__'],True), '__dict__', None):
+ logger.trace(pickler, "D4: %s", _repr_dict(obj)) # obj
+ pickler.write(bytes('c%s\n__dict__\n' % obj['__name__'], 'UTF-8'))
+ logger.trace(pickler, "# D4")
+ else:
+ logger.trace(pickler, "D2: %s", _repr_dict(obj)) # obj
+ if is_dill(pickler, child=False) and pickler._session:
+ # we only care about session the first pass thru
+ pickler._first_pass = False
+ StockPickler.save_dict(pickler, obj)
+ logger.trace(pickler, "# D2")
+ return
+
+
+if not OLD310 and MAPPING_PROXY_TRICK:
+ def save_dict_view(dicttype):
+ def save_dict_view_for_function(func):
+ def _save_dict_view(pickler, obj):
+ logger.trace(pickler, "Dkvi: <%s>", obj)
+ mapping = obj.mapping | _dictproxy_helper_instance
+ pickler.save_reduce(func, (mapping,), obj=obj)
+ logger.trace(pickler, "# Dkvi")
+ return _save_dict_view
+ return [
+ (funcname, save_dict_view_for_function(getattr(dicttype, funcname)))
+ for funcname in ('keys', 'values', 'items')
+ ]
+else:
+ # The following functions are based on 'cloudpickle'
+ # https://github.com/cloudpipe/cloudpickle/blob/5d89947288a18029672596a4d719093cc6d5a412/cloudpickle/cloudpickle.py#L922-L940
+ # Copyright (c) 2012, Regents of the University of California.
+ # Copyright (c) 2009 `PiCloud, Inc. <http://www.picloud.com>`_.
+ # License: https://github.com/cloudpipe/cloudpickle/blob/master/LICENSE
+ def save_dict_view(dicttype):
+ def save_dict_keys(pickler, obj):
+ logger.trace(pickler, "Dk: <%s>", obj)
+ dict_constructor = _shims.Reduce(dicttype.fromkeys, (list(obj),))
+ pickler.save_reduce(dicttype.keys, (dict_constructor,), obj=obj)
+ logger.trace(pickler, "# Dk")
+
+ def save_dict_values(pickler, obj):
+ logger.trace(pickler, "Dv: <%s>", obj)
+ dict_constructor = _shims.Reduce(dicttype, (enumerate(obj),))
+ pickler.save_reduce(dicttype.values, (dict_constructor,), obj=obj)
+ logger.trace(pickler, "# Dv")
+
+ def save_dict_items(pickler, obj):
+ logger.trace(pickler, "Di: <%s>", obj)
+ pickler.save_reduce(dicttype.items, (dicttype(obj),), obj=obj)
+ logger.trace(pickler, "# Di")
+
+ return (
+ ('keys', save_dict_keys),
+ ('values', save_dict_values),
+ ('items', save_dict_items)
+ )
+
+for __dicttype in (
+ dict,
+ OrderedDict
+):
+ __obj = __dicttype()
+ for __funcname, __savefunc in save_dict_view(__dicttype):
+ __tview = type(getattr(__obj, __funcname)())
+ if __tview not in Pickler.dispatch:
+ Pickler.dispatch[__tview] = __savefunc
+del __dicttype, __obj, __funcname, __tview, __savefunc
+
+
+@register(ClassType)
+def save_classobj(pickler, obj): #FIXME: enable pickler._byref
+ if not _locate_function(obj, pickler):
+ logger.trace(pickler, "C1: %s", obj)
+ pickler.save_reduce(ClassType, (obj.__name__, obj.__bases__,
+ obj.__dict__), obj=obj)
+ #XXX: or obj.__dict__.copy()), obj=obj) ?
+ logger.trace(pickler, "# C1")
+ else:
+ logger.trace(pickler, "C2: %s", obj)
+ name = getattr(obj, '__qualname__', getattr(obj, '__name__', None))
+ StockPickler.save_global(pickler, obj, name=name)
+ logger.trace(pickler, "# C2")
+ return
+
+@register(typing._GenericAlias)
+def save_generic_alias(pickler, obj):
+ args = obj.__args__
+ if type(obj.__reduce__()) is str:
+ logger.trace(pickler, "Ga0: %s", obj)
+ StockPickler.save_global(pickler, obj, name=obj.__reduce__())
+ logger.trace(pickler, "# Ga0")
+ elif obj.__origin__ is tuple and (not args or args == ((),)):
+ logger.trace(pickler, "Ga1: %s", obj)
+ pickler.save_reduce(_create_typing_tuple, (args,), obj=obj)
+ logger.trace(pickler, "# Ga1")
+ else:
+ logger.trace(pickler, "Ga2: %s", obj)
+ StockPickler.save_reduce(pickler, *obj.__reduce__(), obj=obj)
+ logger.trace(pickler, "# Ga2")
+ return
+
+if ThreadHandleType:
+ @register(ThreadHandleType)
+ def save_thread_handle(pickler, obj):
+ logger.trace(pickler, "Th: %s", obj)
+ pickler.save_reduce(_create_thread_handle, (obj.ident, obj.is_done()), obj=obj)
+ logger.trace(pickler, "# Th")
+ return
+
+@register(LockType) #XXX: copied Thread will have new Event (due to new Lock)
+def save_lock(pickler, obj):
+ logger.trace(pickler, "Lo: %s", obj)
+ pickler.save_reduce(_create_lock, (obj.locked(),), obj=obj)
+ logger.trace(pickler, "# Lo")
+ return
+
+@register(RLockType)
+def save_rlock(pickler, obj):
+ logger.trace(pickler, "RL: %s", obj)
+ r = obj.__repr__() # don't use _release_save as it unlocks the lock
+ count = int(r.split('count=')[1].split()[0].rstrip('>'))
+ owner = int(r.split('owner=')[1].split()[0])
+ pickler.save_reduce(_create_rlock, (count,owner,), obj=obj)
+ logger.trace(pickler, "# RL")
+ return
+
+#@register(SocketType) #FIXME: causes multiprocess test_pickling FAIL
+def save_socket(pickler, obj):
+ logger.trace(pickler, "So: %s", obj)
+ pickler.save_reduce(*reduce_socket(obj))
+ logger.trace(pickler, "# So")
+ return
+
+def _save_file(pickler, obj, open_):
+ if obj.closed:
+ position = 0
+ else:
+ obj.flush()
+ if obj in (sys.__stdout__, sys.__stderr__, sys.__stdin__):
+ position = -1
+ else:
+ position = obj.tell()
+ if is_dill(pickler, child=True) and pickler._fmode == FILE_FMODE:
+ f = open_(obj.name, "r")
+ fdata = f.read()
+ f.close()
+ else:
+ fdata = ""
+ if is_dill(pickler, child=True):
+ strictio = pickler._strictio
+ fmode = pickler._fmode
+ else:
+ strictio = False
+ fmode = 0 # HANDLE_FMODE
+ pickler.save_reduce(_create_filehandle, (obj.name, obj.mode, position,
+ obj.closed, open_, strictio,
+ fmode, fdata), obj=obj)
+ return
+
+
+@register(FileType) #XXX: in 3.x has buffer=0, needs different _create?
+@register(BufferedReaderType)
+@register(BufferedWriterType)
+@register(TextWrapperType)
+def save_file(pickler, obj):
+ logger.trace(pickler, "Fi: %s", obj)
+ f = _save_file(pickler, obj, open)
+ logger.trace(pickler, "# Fi")
+ return f
+
+if BufferedRandomType:
+ @register(BufferedRandomType)
+ def save_file(pickler, obj):
+ logger.trace(pickler, "Fi: %s", obj)
+ f = _save_file(pickler, obj, open)
+ logger.trace(pickler, "# Fi")
+ return f
+
+if PyTextWrapperType:
+ @register(PyBufferedReaderType)
+ @register(PyBufferedWriterType)
+ @register(PyTextWrapperType)
+ def save_file(pickler, obj):
+ logger.trace(pickler, "Fi: %s", obj)
+ f = _save_file(pickler, obj, _open)
+ logger.trace(pickler, "# Fi")
+ return f
+
+ if PyBufferedRandomType:
+ @register(PyBufferedRandomType)
+ def save_file(pickler, obj):
+ logger.trace(pickler, "Fi: %s", obj)
+ f = _save_file(pickler, obj, _open)
+ logger.trace(pickler, "# Fi")
+ return f
+
+
+# The following two functions are based on 'saveCStringIoInput'
+# and 'saveCStringIoOutput' from spickle
+# Copyright (c) 2011 by science+computing ag
+# License: http://www.apache.org/licenses/LICENSE-2.0
+if InputType:
+ @register(InputType)
+ def save_stringi(pickler, obj):
+ logger.trace(pickler, "Io: %s", obj)
+ if obj.closed:
+ value = ''; position = 0
+ else:
+ value = obj.getvalue(); position = obj.tell()
+ pickler.save_reduce(_create_stringi, (value, position, \
+ obj.closed), obj=obj)
+ logger.trace(pickler, "# Io")
+ return
+
+ @register(OutputType)
+ def save_stringo(pickler, obj):
+ logger.trace(pickler, "Io: %s", obj)
+ if obj.closed:
+ value = ''; position = 0
+ else:
+ value = obj.getvalue(); position = obj.tell()
+ pickler.save_reduce(_create_stringo, (value, position, \
+ obj.closed), obj=obj)
+ logger.trace(pickler, "# Io")
+ return
+
+if LRUCacheType is not None:
+ from functools import lru_cache
+ @register(LRUCacheType)
+ def save_lru_cache(pickler, obj):
+ logger.trace(pickler, "LRU: %s", obj)
+ if OLD39:
+ kwargs = obj.cache_info()
+ args = (kwargs.maxsize,)
+ else:
+ kwargs = obj.cache_parameters()
+ args = (kwargs['maxsize'], kwargs['typed'])
+ if args != lru_cache.__defaults__:
+ wrapper = Reduce(lru_cache, args, is_callable=True)
+ else:
+ wrapper = lru_cache
+ pickler.save_reduce(wrapper, (obj.__wrapped__,), obj=obj)
+ logger.trace(pickler, "# LRU")
+ return
+
+@register(SuperType)
+def save_super(pickler, obj):
+ logger.trace(pickler, "Su: %s", obj)
+ pickler.save_reduce(super, (obj.__thisclass__, obj.__self__), obj=obj)
+ logger.trace(pickler, "# Su")
+ return
+
+if IS_PYPY:
+ @register(MethodType)
+ def save_instancemethod0(pickler, obj):
+ code = getattr(obj.__func__, '__code__', None)
+ if code is not None and type(code) is not CodeType \
+ and getattr(obj.__self__, obj.__name__) == obj:
+ # Some PyPy builtin functions have no module name
+ logger.trace(pickler, "Me2: %s", obj)
+ # TODO: verify that this works for all PyPy builtin methods
+ pickler.save_reduce(getattr, (obj.__self__, obj.__name__), obj=obj)
+ logger.trace(pickler, "# Me2")
+ return
+
+ logger.trace(pickler, "Me1: %s", obj)
+ pickler.save_reduce(MethodType, (obj.__func__, obj.__self__), obj=obj)
+ logger.trace(pickler, "# Me1")
+ return
+else:
+ @register(MethodType)
+ def save_instancemethod0(pickler, obj):
+ logger.trace(pickler, "Me1: %s", obj)
+ pickler.save_reduce(MethodType, (obj.__func__, obj.__self__), obj=obj)
+ logger.trace(pickler, "# Me1")
+ return
+
+if not IS_PYPY:
+ @register(MemberDescriptorType)
+ @register(GetSetDescriptorType)
+ @register(MethodDescriptorType)
+ @register(WrapperDescriptorType)
+ @register(ClassMethodDescriptorType)
+ def save_wrapper_descriptor(pickler, obj):
+ logger.trace(pickler, "Wr: %s", obj)
+ pickler.save_reduce(_getattr, (obj.__objclass__, obj.__name__,
+ obj.__repr__()), obj=obj)
+ logger.trace(pickler, "# Wr")
+ return
+else:
+ @register(MemberDescriptorType)
+ @register(GetSetDescriptorType)
+ def save_wrapper_descriptor(pickler, obj):
+ logger.trace(pickler, "Wr: %s", obj)
+ pickler.save_reduce(_getattr, (obj.__objclass__, obj.__name__,
+ obj.__repr__()), obj=obj)
+ logger.trace(pickler, "# Wr")
+ return
+
+@register(CellType)
+def save_cell(pickler, obj):
+ try:
+ f = obj.cell_contents
+ except ValueError: # cell is empty
+ logger.trace(pickler, "Ce3: %s", obj)
+ # _shims._CELL_EMPTY is defined in _shims.py to support PyPy 2.7.
+ # It unpickles to a sentinel object _dill._CELL_EMPTY, also created in
+ # _shims.py. This object is not present in Python 3 because the cell's
+ # contents can be deleted in newer versions of Python. The reduce object
+ # will instead unpickle to None if unpickled in Python 3.
+
+ # When breaking changes are made to dill, (_shims._CELL_EMPTY,) can
+ # be replaced by () OR the delattr function can be removed repending on
+ # whichever is more convienient.
+ pickler.save_reduce(_create_cell, (_shims._CELL_EMPTY,), obj=obj)
+ # Call the function _delattr on the cell's cell_contents attribute
+ # The result of this function call will be None
+ pickler.save_reduce(_shims._delattr, (obj, 'cell_contents'))
+ # pop None created by calling _delattr off stack
+ pickler.write(POP)
+ logger.trace(pickler, "# Ce3")
+ return
+ if is_dill(pickler, child=True):
+ if id(f) in pickler._postproc:
+ # Already seen. Add to its postprocessing.
+ postproc = pickler._postproc[id(f)]
+ else:
+ # Haven't seen it. Add to the highest possible object and set its
+ # value as late as possible to prevent cycle.
+ postproc = next(iter(pickler._postproc.values()), None)
+ if postproc is not None:
+ logger.trace(pickler, "Ce2: %s", obj)
+ # _CELL_REF is defined in _shims.py to support older versions of
+ # dill. When breaking changes are made to dill, (_CELL_REF,) can
+ # be replaced by ()
+ pickler.save_reduce(_create_cell, (_CELL_REF,), obj=obj)
+ postproc.append((_shims._setattr, (obj, 'cell_contents', f)))
+ logger.trace(pickler, "# Ce2")
+ return
+ logger.trace(pickler, "Ce1: %s", obj)
+ pickler.save_reduce(_create_cell, (f,), obj=obj)
+ logger.trace(pickler, "# Ce1")
+ return
+
+if MAPPING_PROXY_TRICK:
+ @register(DictProxyType)
+ def save_dictproxy(pickler, obj):
+ logger.trace(pickler, "Mp: %s", _repr_dict(obj)) # obj
+ mapping = obj | _dictproxy_helper_instance
+ pickler.save_reduce(DictProxyType, (mapping,), obj=obj)
+ logger.trace(pickler, "# Mp")
+ return
+else:
+ @register(DictProxyType)
+ def save_dictproxy(pickler, obj):
+ logger.trace(pickler, "Mp: %s", _repr_dict(obj)) # obj
+ pickler.save_reduce(DictProxyType, (obj.copy(),), obj=obj)
+ logger.trace(pickler, "# Mp")
+ return
+
+@register(SliceType)
+def save_slice(pickler, obj):
+ logger.trace(pickler, "Sl: %s", obj)
+ pickler.save_reduce(slice, (obj.start, obj.stop, obj.step), obj=obj)
+ logger.trace(pickler, "# Sl")
+ return
+
+@register(XRangeType)
+@register(EllipsisType)
+@register(NotImplementedType)
+def save_singleton(pickler, obj):
+ logger.trace(pickler, "Si: %s", obj)
+ pickler.save_reduce(_eval_repr, (obj.__repr__(),), obj=obj)
+ logger.trace(pickler, "# Si")
+ return
+
+def _proxy_helper(obj): # a dead proxy returns a reference to None
+ """get memory address of proxy's reference object"""
+ _repr = repr(obj)
+ try: _str = str(obj)
+ except ReferenceError: # it's a dead proxy
+ return id(None)
+ if _str == _repr: return id(obj) # it's a repr
+ try: # either way, it's a proxy from here
+ address = int(_str.rstrip('>').split(' at ')[-1], base=16)
+ except ValueError: # special case: proxy of a 'type'
+ if not IS_PYPY:
+ address = int(_repr.rstrip('>').split(' at ')[-1], base=16)
+ else:
+ objects = iter(gc.get_objects())
+ for _obj in objects:
+ if repr(_obj) == _str: return id(_obj)
+ # all bad below... nothing found so throw ReferenceError
+ msg = "Cannot reference object for proxy at '%s'" % id(obj)
+ raise ReferenceError(msg)
+ return address
+
+def _locate_object(address, module=None):
+ """get object located at the given memory address (inverse of id(obj))"""
+ special = [None, True, False] #XXX: more...?
+ for obj in special:
+ if address == id(obj): return obj
+ if module:
+ objects = iter(module.__dict__.values())
+ else: objects = iter(gc.get_objects())
+ for obj in objects:
+ if address == id(obj): return obj
+ # all bad below... nothing found so throw ReferenceError or TypeError
+ try: address = hex(address)
+ except TypeError:
+ raise TypeError("'%s' is not a valid memory address" % str(address))
+ raise ReferenceError("Cannot reference object at '%s'" % address)
+
+@register(ReferenceType)
+def save_weakref(pickler, obj):
+ refobj = obj()
+ logger.trace(pickler, "R1: %s", obj)
+ #refobj = ctypes.pythonapi.PyWeakref_GetObject(obj) # dead returns "None"
+ pickler.save_reduce(_create_weakref, (refobj,), obj=obj)
+ logger.trace(pickler, "# R1")
+ return
+
+@register(ProxyType)
+@register(CallableProxyType)
+def save_weakproxy(pickler, obj):
+ # Must do string substitution here and use %r to avoid ReferenceError.
+ logger.trace(pickler, "R2: %r" % obj)
+ refobj = _locate_object(_proxy_helper(obj))
+ pickler.save_reduce(_create_weakproxy, (refobj, callable(obj)), obj=obj)
+ logger.trace(pickler, "# R2")
+ return
+
+def _is_builtin_module(module):
+ if not hasattr(module, "__file__"): return True
+ if module.__file__ is None: return False
+ # If a module file name starts with prefix, it should be a builtin
+ # module, so should always be pickled as a reference.
+ names = ["base_prefix", "base_exec_prefix", "exec_prefix", "prefix", "real_prefix"]
+ rp = os.path.realpath
+ # See https://github.com/uqfoundation/dill/issues/566
+ return (
+ any(
+ module.__file__.startswith(getattr(sys, name))
+ or rp(module.__file__).startswith(rp(getattr(sys, name)))
+ for name in names
+ if hasattr(sys, name)
+ )
+ or module.__file__.endswith(EXTENSION_SUFFIXES)
+ or 'site-packages' in module.__file__
+ )
+
+def _is_imported_module(module):
+ return getattr(module, '__loader__', None) is not None or module in sys.modules.values()
+
+@register(ModuleType)
+def save_module(pickler, obj):
+ if False: #_use_diff:
+ if obj.__name__.split('.', 1)[0] != "dill":
+ try:
+ changed = diff.whats_changed(obj, seen=pickler._diff_cache)[0]
+ except RuntimeError: # not memorised module, probably part of dill
+ pass
+ else:
+ logger.trace(pickler, "M2: %s with diff", obj)
+ logger.info("Diff: %s", changed.keys())
+ pickler.save_reduce(_import_module, (obj.__name__,), obj=obj,
+ state=changed)
+ logger.trace(pickler, "# M2")
+ return
+
+ logger.trace(pickler, "M1: %s", obj)
+ pickler.save_reduce(_import_module, (obj.__name__,), obj=obj)
+ logger.trace(pickler, "# M1")
+ else:
+ builtin_mod = _is_builtin_module(obj)
+ is_session_main = is_dill(pickler, child=True) and obj is pickler._main
+ if (obj.__name__ not in ("builtins", "dill", "dill._dill") and not builtin_mod
+ or is_session_main):
+ logger.trace(pickler, "M1: %s", obj)
+ # Hack for handling module-type objects in load_module().
+ mod_name = obj.__name__ if _is_imported_module(obj) else '__runtime__.%s' % obj.__name__
+ # Second references are saved as __builtin__.__main__ in save_module_dict().
+ main_dict = obj.__dict__.copy()
+ for item in ('__builtins__', '__loader__'):
+ main_dict.pop(item, None)
+ for item in IPYTHON_SINGLETONS: #pragma: no cover
+ if getattr(main_dict.get(item), '__module__', '').startswith('IPython'):
+ del main_dict[item]
+ pickler.save_reduce(_import_module, (mod_name,), obj=obj, state=main_dict)
+ logger.trace(pickler, "# M1")
+ elif obj.__name__ == "dill._dill":
+ logger.trace(pickler, "M2: %s", obj)
+ pickler.save_global(obj, name="_dill")
+ logger.trace(pickler, "# M2")
+ else:
+ logger.trace(pickler, "M2: %s", obj)
+ pickler.save_reduce(_import_module, (obj.__name__,), obj=obj)
+ logger.trace(pickler, "# M2")
+ return
+
+# The following function is based on '_extract_class_dict' from 'cloudpickle'
+# Copyright (c) 2012, Regents of the University of California.
+# Copyright (c) 2009 `PiCloud, Inc. <http://www.picloud.com>`_.
+# License: https://github.com/cloudpipe/cloudpickle/blob/master/LICENSE
+def _get_typedict_type(cls, clsdict, attrs, postproc_list):
+ """Retrieve a copy of the dict of a class without the inherited methods"""
+ if len(cls.__bases__) == 1:
+ inherited_dict = cls.__bases__[0].__dict__
+ else:
+ inherited_dict = {}
+ for base in reversed(cls.__bases__):
+ inherited_dict.update(base.__dict__)
+ to_remove = []
+ for name, value in dict.items(clsdict):
+ try:
+ base_value = inherited_dict[name]
+ if value is base_value and hasattr(value, '__qualname__'):
+ to_remove.append(name)
+ except KeyError:
+ pass
+ for name in to_remove:
+ dict.pop(clsdict, name)
+
+ if issubclass(type(cls), type):
+ clsdict.pop('__dict__', None)
+ clsdict.pop('__weakref__', None)
+ # clsdict.pop('__prepare__', None)
+ return clsdict, attrs
+
+def _get_typedict_abc(obj, _dict, attrs, postproc_list):
+ if hasattr(abc, '_get_dump'):
+ (registry, _, _, _) = abc._get_dump(obj)
+ register = obj.register
+ postproc_list.extend((register, (reg(),)) for reg in registry)
+ elif hasattr(obj, '_abc_registry'):
+ registry = obj._abc_registry
+ register = obj.register
+ postproc_list.extend((register, (reg,)) for reg in registry)
+ else:
+ raise PicklingError("Cannot find registry of ABC %s", obj)
+
+ if '_abc_registry' in _dict:
+ _dict.pop('_abc_registry', None)
+ _dict.pop('_abc_cache', None)
+ _dict.pop('_abc_negative_cache', None)
+ # _dict.pop('_abc_negative_cache_version', None)
+ else:
+ _dict.pop('_abc_impl', None)
+ return _dict, attrs
+
+@register(TypeType)
+def save_type(pickler, obj, postproc_list=None):
+ if obj in _typemap:
+ logger.trace(pickler, "T1: %s", obj)
+ # if obj in _incedental_types:
+ # warnings.warn('Type %r may only exist on this implementation of Python and cannot be unpickled in other implementations.' % (obj,), PicklingWarning)
+ pickler.save_reduce(_load_type, (_typemap[obj],), obj=obj)
+ logger.trace(pickler, "# T1")
+ elif obj.__bases__ == (tuple,) and all([hasattr(obj, attr) for attr in ('_fields','_asdict','_make','_replace')]):
+ # special case: namedtuples
+ logger.trace(pickler, "T6: %s", obj)
+
+ obj_name = getattr(obj, '__qualname__', getattr(obj, '__name__', None))
+ if obj.__name__ != obj_name:
+ if postproc_list is None:
+ postproc_list = []
+ postproc_list.append((setattr, (obj, '__qualname__', obj_name)))
+
+ if not obj._field_defaults:
+ _save_with_postproc(pickler, (_create_namedtuple, (obj.__name__, obj._fields, obj.__module__)), obj=obj, postproc_list=postproc_list)
+ else:
+ defaults = [obj._field_defaults[field] for field in obj._fields if field in obj._field_defaults]
+ _save_with_postproc(pickler, (_create_namedtuple, (obj.__name__, obj._fields, obj.__module__, defaults)), obj=obj, postproc_list=postproc_list)
+ logger.trace(pickler, "# T6")
+ return
+
+ # special caes: NoneType, NotImplementedType, EllipsisType, EnumMeta, etc
+ elif obj is type(None):
+ logger.trace(pickler, "T7: %s", obj)
+ #XXX: pickler.save_reduce(type, (None,), obj=obj)
+ pickler.write(GLOBAL + b'__builtin__\nNoneType\n')
+ logger.trace(pickler, "# T7")
+ elif obj is NotImplementedType:
+ logger.trace(pickler, "T7: %s", obj)
+ pickler.save_reduce(type, (NotImplemented,), obj=obj)
+ logger.trace(pickler, "# T7")
+ elif obj is EllipsisType:
+ logger.trace(pickler, "T7: %s", obj)
+ pickler.save_reduce(type, (Ellipsis,), obj=obj)
+ logger.trace(pickler, "# T7")
+ elif obj is EnumMeta:
+ logger.trace(pickler, "T7: %s", obj)
+ pickler.write(GLOBAL + b'enum\nEnumMeta\n')
+ logger.trace(pickler, "# T7")
+ elif obj is ExceptHookArgsType: #NOTE: must be after NoneType for pypy
+ logger.trace(pickler, "T7: %s", obj)
+ pickler.write(GLOBAL + b'threading\nExceptHookArgs\n')
+ logger.trace(pickler, "# T7")
+
+ else:
+ _byref = getattr(pickler, '_byref', None)
+ obj_recursive = id(obj) in getattr(pickler, '_postproc', ())
+ incorrectly_named = not _locate_function(obj, pickler)
+ if not _byref and not obj_recursive and incorrectly_named: # not a function, but the name was held over
+ if postproc_list is None:
+ postproc_list = []
+
+ # thanks to Tom Stepleton pointing out pickler._session unneeded
+ logger.trace(pickler, "T2: %s", obj)
+ _dict, attrs = _get_typedict_type(obj, obj.__dict__.copy(), None, postproc_list) # copy dict proxy to a dict
+
+ #print (_dict)
+ #print ("%s\n%s" % (type(obj), obj.__name__))
+ #print ("%s\n%s" % (obj.__bases__, obj.__dict__))
+ slots = _dict.get('__slots__', ())
+ if type(slots) == str:
+ # __slots__ accepts a single string
+ slots = (slots,)
+
+ for name in slots:
+ _dict.pop(name, None)
+
+ if isinstance(obj, abc.ABCMeta):
+ logger.trace(pickler, "ABC: %s", obj)
+ _dict, attrs = _get_typedict_abc(obj, _dict, attrs, postproc_list)
+ logger.trace(pickler, "# ABC")
+
+ qualname = getattr(obj, '__qualname__', None)
+ if attrs is not None:
+ for k, v in attrs.items():
+ postproc_list.append((setattr, (obj, k, v)))
+ # TODO: Consider using the state argument to save_reduce?
+ if qualname is not None:
+ postproc_list.append((setattr, (obj, '__qualname__', qualname)))
+
+ if not hasattr(obj, '__orig_bases__'):
+ _save_with_postproc(pickler, (_create_type, (
+ type(obj), obj.__name__, obj.__bases__, _dict
+ )), obj=obj, postproc_list=postproc_list)
+ else:
+ # This case will always work, but might be overkill.
+ _metadict = {
+ 'metaclass': type(obj)
+ }
+
+ if _dict:
+ _dict_update = PartialType(_setitems, source=_dict)
+ else:
+ _dict_update = None
+
+ _save_with_postproc(pickler, (new_class, (
+ obj.__name__, obj.__orig_bases__, _metadict, _dict_update
+ )), obj=obj, postproc_list=postproc_list)
+ logger.trace(pickler, "# T2")
+ else:
+ obj_name = getattr(obj, '__qualname__', getattr(obj, '__name__', None))
+ logger.trace(pickler, "T4: %s", obj)
+ if incorrectly_named:
+ warnings.warn(
+ "Cannot locate reference to %r." % (obj,),
+ PicklingWarning,
+ stacklevel=3,
+ )
+ if obj_recursive:
+ warnings.warn(
+ "Cannot pickle %r: %s.%s has recursive self-references that "
+ "trigger a RecursionError." % (obj, obj.__module__, obj_name),
+ PicklingWarning,
+ stacklevel=3,
+ )
+ #print (obj.__dict__)
+ #print ("%s\n%s" % (type(obj), obj.__name__))
+ #print ("%s\n%s" % (obj.__bases__, obj.__dict__))
+ StockPickler.save_global(pickler, obj, name=obj_name)
+ logger.trace(pickler, "# T4")
+ return
+
+@register(property)
+@register(abc.abstractproperty)
+def save_property(pickler, obj):
+ logger.trace(pickler, "Pr: %s", obj)
+ pickler.save_reduce(type(obj), (obj.fget, obj.fset, obj.fdel, obj.__doc__),
+ obj=obj)
+ logger.trace(pickler, "# Pr")
+
+@register(staticmethod)
+@register(classmethod)
+@register(abc.abstractstaticmethod)
+@register(abc.abstractclassmethod)
+def save_classmethod(pickler, obj):
+ logger.trace(pickler, "Cm: %s", obj)
+ orig_func = obj.__func__
+
+ # if type(obj.__dict__) is dict:
+ # if obj.__dict__:
+ # state = obj.__dict__
+ # else:
+ # state = None
+ # else:
+ # state = (None, {'__dict__', obj.__dict__})
+
+ pickler.save_reduce(type(obj), (orig_func,), obj=obj)
+ logger.trace(pickler, "# Cm")
+
+@register(FunctionType)
+def save_function(pickler, obj):
+ if not _locate_function(obj, pickler):
+ if type(obj.__code__) is not CodeType:
+ # Some PyPy builtin functions have no module name, and thus are not
+ # able to be located
+ module_name = getattr(obj, '__module__', None)
+ if module_name is None:
+ module_name = __builtin__.__name__
+ module = _import_module(module_name, safe=True)
+ _pypy_builtin = False
+ try:
+ found, _ = _getattribute(module, obj.__qualname__)
+ if getattr(found, '__func__', None) is obj:
+ _pypy_builtin = True
+ except AttributeError:
+ pass
+
+ if _pypy_builtin:
+ logger.trace(pickler, "F3: %s", obj)
+ pickler.save_reduce(getattr, (found, '__func__'), obj=obj)
+ logger.trace(pickler, "# F3")
+ return
+
+ logger.trace(pickler, "F1: %s", obj)
+ _recurse = getattr(pickler, '_recurse', None)
+ _postproc = getattr(pickler, '_postproc', None)
+ _main_modified = getattr(pickler, '_main_modified', None)
+ _original_main = getattr(pickler, '_original_main', __builtin__)#'None'
+ postproc_list = []
+ if _recurse:
+ # recurse to get all globals referred to by obj
+ from .detect import globalvars
+ globs_copy = globalvars(obj, recurse=True, builtin=True)
+
+ # Add the name of the module to the globs dictionary to prevent
+ # the duplication of the dictionary. Pickle the unpopulated
+ # globals dictionary and set the remaining items after the function
+ # is created to correctly handle recursion.
+ globs = {'__name__': obj.__module__}
+ else:
+ globs_copy = obj.__globals__
+
+ # If the globals is the __dict__ from the module being saved as a
+ # session, substitute it by the dictionary being actually saved.
+ if _main_modified and globs_copy is _original_main.__dict__:
+ globs_copy = getattr(pickler, '_main', _original_main).__dict__
+ globs = globs_copy
+ # If the globals is a module __dict__, do not save it in the pickle.
+ elif globs_copy is not None and obj.__module__ is not None and \
+ getattr(_import_module(obj.__module__, True), '__dict__', None) is globs_copy:
+ globs = globs_copy
+ else:
+ globs = {'__name__': obj.__module__}
+
+ if globs_copy is not None and globs is not globs_copy:
+ # In the case that the globals are copied, we need to ensure that
+ # the globals dictionary is updated when all objects in the
+ # dictionary are already created.
+ glob_ids = {id(g) for g in globs_copy.values()}
+ for stack_element in _postproc:
+ if stack_element in glob_ids:
+ _postproc[stack_element].append((_setitems, (globs, globs_copy)))
+ break
+ else:
+ postproc_list.append((_setitems, (globs, globs_copy)))
+
+ closure = obj.__closure__
+ state_dict = {}
+ for fattrname in ('__doc__', '__kwdefaults__', '__annotations__'):
+ fattr = getattr(obj, fattrname, None)
+ if fattr is not None:
+ state_dict[fattrname] = fattr
+ if obj.__qualname__ != obj.__name__:
+ state_dict['__qualname__'] = obj.__qualname__
+ if '__name__' not in globs or obj.__module__ != globs['__name__']:
+ state_dict['__module__'] = obj.__module__
+
+ state = obj.__dict__
+ if type(state) is not dict:
+ state_dict['__dict__'] = state
+ state = None
+ if state_dict:
+ state = state, state_dict
+
+ _save_with_postproc(pickler, (_create_function, (
+ obj.__code__, globs, obj.__name__, obj.__defaults__,
+ closure
+ ), state), obj=obj, postproc_list=postproc_list)
+
+ # Lift closure cell update to earliest function (#458)
+ if _postproc:
+ topmost_postproc = next(iter(_postproc.values()), None)
+ if closure and topmost_postproc:
+ for cell in closure:
+ possible_postproc = (setattr, (cell, 'cell_contents', obj))
+ try:
+ topmost_postproc.remove(possible_postproc)
+ except ValueError:
+ continue
+
+ # Change the value of the cell
+ pickler.save_reduce(*possible_postproc)
+ # pop None created by calling preprocessing step off stack
+ pickler.write(POP)
+
+ logger.trace(pickler, "# F1")
+ else:
+ logger.trace(pickler, "F2: %s", obj)
+ name = getattr(obj, '__qualname__', getattr(obj, '__name__', None))
+ StockPickler.save_global(pickler, obj, name=name)
+ logger.trace(pickler, "# F2")
+ return
+
+if HAS_CTYPES and hasattr(ctypes, 'pythonapi'):
+ _PyCapsule_New = ctypes.pythonapi.PyCapsule_New
+ _PyCapsule_New.argtypes = (ctypes.c_void_p, ctypes.c_char_p, ctypes.c_void_p)
+ _PyCapsule_New.restype = ctypes.py_object
+ _PyCapsule_GetPointer = ctypes.pythonapi.PyCapsule_GetPointer
+ _PyCapsule_GetPointer.argtypes = (ctypes.py_object, ctypes.c_char_p)
+ _PyCapsule_GetPointer.restype = ctypes.c_void_p
+ _PyCapsule_GetDestructor = ctypes.pythonapi.PyCapsule_GetDestructor
+ _PyCapsule_GetDestructor.argtypes = (ctypes.py_object,)
+ _PyCapsule_GetDestructor.restype = ctypes.c_void_p
+ _PyCapsule_GetContext = ctypes.pythonapi.PyCapsule_GetContext
+ _PyCapsule_GetContext.argtypes = (ctypes.py_object,)
+ _PyCapsule_GetContext.restype = ctypes.c_void_p
+ _PyCapsule_GetName = ctypes.pythonapi.PyCapsule_GetName
+ _PyCapsule_GetName.argtypes = (ctypes.py_object,)
+ _PyCapsule_GetName.restype = ctypes.c_char_p
+ _PyCapsule_IsValid = ctypes.pythonapi.PyCapsule_IsValid
+ _PyCapsule_IsValid.argtypes = (ctypes.py_object, ctypes.c_char_p)
+ _PyCapsule_IsValid.restype = ctypes.c_bool
+ _PyCapsule_SetContext = ctypes.pythonapi.PyCapsule_SetContext
+ _PyCapsule_SetContext.argtypes = (ctypes.py_object, ctypes.c_void_p)
+ _PyCapsule_SetDestructor = ctypes.pythonapi.PyCapsule_SetDestructor
+ _PyCapsule_SetDestructor.argtypes = (ctypes.py_object, ctypes.c_void_p)
+ _PyCapsule_SetName = ctypes.pythonapi.PyCapsule_SetName
+ _PyCapsule_SetName.argtypes = (ctypes.py_object, ctypes.c_char_p)
+ _PyCapsule_SetPointer = ctypes.pythonapi.PyCapsule_SetPointer
+ _PyCapsule_SetPointer.argtypes = (ctypes.py_object, ctypes.c_void_p)
+ #from _socket import CAPI as _testcapsule
+ _testcapsule_name = b'dill._dill._testcapsule'
+ _testcapsule = _PyCapsule_New(
+ ctypes.cast(_PyCapsule_New, ctypes.c_void_p),
+ ctypes.c_char_p(_testcapsule_name),
+ None
+ )
+ PyCapsuleType = type(_testcapsule)
+ @register(PyCapsuleType)
+ def save_capsule(pickler, obj):
+ logger.trace(pickler, "Cap: %s", obj)
+ name = _PyCapsule_GetName(obj)
+ #warnings.warn('Pickling a PyCapsule (%s) does not pickle any C data structures and could cause segmentation faults or other memory errors when unpickling.' % (name,), PicklingWarning)
+ pointer = _PyCapsule_GetPointer(obj, name)
+ context = _PyCapsule_GetContext(obj)
+ destructor = _PyCapsule_GetDestructor(obj)
+ pickler.save_reduce(_create_capsule, (pointer, name, context, destructor), obj=obj)
+ logger.trace(pickler, "# Cap")
+ _incedental_reverse_typemap['PyCapsuleType'] = PyCapsuleType
+ _reverse_typemap['PyCapsuleType'] = PyCapsuleType
+ _incedental_types.add(PyCapsuleType)
+else:
+ _testcapsule = None
+
+
+#############################
+# A quick fix for issue #500
+# This should be removed when a better solution is found.
+
+if hasattr(dataclasses, "_HAS_DEFAULT_FACTORY_CLASS"):
+ @register(dataclasses._HAS_DEFAULT_FACTORY_CLASS)
+ def save_dataclasses_HAS_DEFAULT_FACTORY_CLASS(pickler, obj):
+ logger.trace(pickler, "DcHDF: %s", obj)
+ pickler.write(GLOBAL + b"dataclasses\n_HAS_DEFAULT_FACTORY\n")
+ logger.trace(pickler, "# DcHDF")
+
+if hasattr(dataclasses, "MISSING"):
+ @register(type(dataclasses.MISSING))
+ def save_dataclasses_MISSING_TYPE(pickler, obj):
+ logger.trace(pickler, "DcM: %s", obj)
+ pickler.write(GLOBAL + b"dataclasses\nMISSING\n")
+ logger.trace(pickler, "# DcM")
+
+if hasattr(dataclasses, "KW_ONLY"):
+ @register(type(dataclasses.KW_ONLY))
+ def save_dataclasses_KW_ONLY_TYPE(pickler, obj):
+ logger.trace(pickler, "DcKWO: %s", obj)
+ pickler.write(GLOBAL + b"dataclasses\nKW_ONLY\n")
+ logger.trace(pickler, "# DcKWO")
+
+if hasattr(dataclasses, "_FIELD_BASE"):
+ @register(dataclasses._FIELD_BASE)
+ def save_dataclasses_FIELD_BASE(pickler, obj):
+ logger.trace(pickler, "DcFB: %s", obj)
+ pickler.write(GLOBAL + b"dataclasses\n" + obj.name.encode() + b"\n")
+ logger.trace(pickler, "# DcFB")
+
+#############################
+
+# quick sanity checking
+def pickles(obj,exact=False,safe=False,**kwds):
+ """
+ Quick check if object pickles with dill.
+
+ If *exact=True* then an equality test is done to check if the reconstructed
+ object matches the original object.
+
+ If *safe=True* then any exception will raised in copy signal that the
+ object is not picklable, otherwise only pickling errors will be trapped.
+
+ Additional keyword arguments are as :func:`dumps` and :func:`loads`.
+ """
+ if safe: exceptions = (Exception,) # RuntimeError, ValueError
+ else:
+ exceptions = (TypeError, AssertionError, NotImplementedError, PicklingError, UnpicklingError)
+ try:
+ pik = copy(obj, **kwds)
+ #FIXME: should check types match first, then check content if "exact"
+ try:
+ #FIXME: should be "(pik == obj).all()" for numpy comparison, though that'll fail if shapes differ
+ result = bool(pik.all() == obj.all())
+ except (AttributeError, TypeError):
+ warnings.filterwarnings('ignore') #FIXME: be specific
+ result = pik == obj
+ if warnings.filters: del warnings.filters[0]
+ if hasattr(result, 'toarray'): # for unusual types like sparse matrix
+ result = result.toarray().all()
+ if result: return True
+ if not exact:
+ result = type(pik) == type(obj)
+ if result: return result
+ # class instances might have been dumped with byref=False
+ return repr(type(pik)) == repr(type(obj)) #XXX: InstanceType?
+ return False
+ except exceptions:
+ return False
+
+def check(obj, *args, **kwds):
+ """
+ Check pickling of an object across another process.
+
+ *python* is the path to the python interpreter (defaults to sys.executable)
+
+ Set *verbose=True* to print the unpickled object in the other process.
+
+ Additional keyword arguments are as :func:`dumps` and :func:`loads`.
+ """
+ # == undocumented ==
+ # python -- the string path or executable name of the selected python
+ # verbose -- if True, be verbose about printing warning messages
+ # all other args and kwds are passed to dill.dumps #FIXME: ignore on load
+ verbose = kwds.pop('verbose', False)
+ python = kwds.pop('python', None)
+ if python is None:
+ import sys
+ python = sys.executable
+ # type check
+ isinstance(python, str)
+ import subprocess
+ fail = True
+ try:
+ _obj = dumps(obj, *args, **kwds)
+ fail = False
+ finally:
+ if fail and verbose:
+ print("DUMP FAILED")
+ #FIXME: fails if python interpreter path contains spaces
+ # Use the following instead (which also processes the 'ignore' keyword):
+ # ignore = kwds.pop('ignore', None)
+ # unpickle = "dill.loads(%s, ignore=%s)"%(repr(_obj), repr(ignore))
+ # cmd = [python, "-c", "import dill; print(%s)"%unpickle]
+ # msg = "SUCCESS" if not subprocess.call(cmd) else "LOAD FAILED"
+ msg = "%s -c import dill; print(dill.loads(%s))" % (python, repr(_obj))
+ msg = "SUCCESS" if not subprocess.call(msg.split(None,2)) else "LOAD FAILED"
+ if verbose:
+ print(msg)
+ return
+
+# use to protect against missing attributes
+def is_dill(pickler, child=None):
+ "check the dill-ness of your pickler"
+ if child is False or not hasattr(pickler.__class__, 'mro'):
+ return 'dill' in pickler.__module__
+ return Pickler in pickler.__class__.mro()
+
+def _extend():
+ """extend pickle with all of dill's registered types"""
+ # need to have pickle not choke on _main_module? use is_dill(pickler)
+ for t,func in Pickler.dispatch.items():
+ try:
+ StockPickler.dispatch[t] = func
+ except Exception: #TypeError, PicklingError, UnpicklingError
+ logger.trace(pickler, "skip: %s", t)
+ return
+
+del diff, _use_diff, use_diff
+
+# EOF
diff --git a/solutions/.venv/Lib/site-packages/dill/_objects.py b/solutions/.venv/Lib/site-packages/dill/_objects.py
new file mode 100644
index 000000000..7723c13ca
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/_objects.py
@@ -0,0 +1,541 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+all Python Standard Library objects (currently: CH 1-15 @ 2.7)
+and some other common objects (i.e. numpy.ndarray)
+"""
+
+__all__ = ['registered','failures','succeeds']
+
+# helper imports
+import warnings; warnings.filterwarnings("ignore", category=DeprecationWarning)
+import sys
+import queue as Queue
+#import dbm as anydbm #XXX: delete foo
+from io import BytesIO as StringIO
+import re
+import array
+import collections
+import codecs
+import struct
+import dataclasses
+import datetime
+import calendar
+import weakref
+import pprint
+import decimal
+import numbers
+import functools
+import itertools
+import operator
+import tempfile
+import shelve
+import zlib
+import gzip
+import zipfile
+import tarfile
+import csv
+import hashlib
+import hmac
+import os
+import logging
+import logging.handlers
+import optparse
+#import __hello__
+import threading
+import socket
+import contextlib
+try:
+ import bz2
+ import sqlite3
+ import dbm.ndbm as dbm
+ HAS_ALL = True
+except ImportError: # Ubuntu
+ HAS_ALL = False
+try:
+ #import curses
+ #from curses import textpad, panel
+ HAS_CURSES = True
+except ImportError: # Windows
+ HAS_CURSES = False
+try:
+ import ctypes
+ HAS_CTYPES = True
+ # if using `pypy`, pythonapi is not found
+ IS_PYPY = not hasattr(ctypes, 'pythonapi')
+except ImportError: # MacPorts
+ HAS_CTYPES = False
+ IS_PYPY = False
+
+IS_PYODIDE = sys.platform == 'emscripten'
+
+# helper objects
+class _class:
+ def _method(self):
+ pass
+# @classmethod
+# def _clsmethod(cls): #XXX: test me
+# pass
+# @staticmethod
+# def _static(self): #XXX: test me
+# pass
+class _class2:
+ def __call__(self):
+ pass
+_instance2 = _class2()
+class _newclass(object):
+ def _method(self):
+ pass
+# @classmethod
+# def _clsmethod(cls): #XXX: test me
+# pass
+# @staticmethod
+# def _static(self): #XXX: test me
+# pass
+class _newclass2(object):
+ __slots__ = ['descriptor']
+def _function(x): yield x
+def _function2():
+ try: raise
+ except Exception:
+ from sys import exc_info
+ e, er, tb = exc_info()
+ return er, tb
+if HAS_CTYPES:
+ class _Struct(ctypes.Structure):
+ pass
+ _Struct._fields_ = [("_field", ctypes.c_int),("next", ctypes.POINTER(_Struct))]
+_filedescrip, _tempfile = tempfile.mkstemp('r') # deleted in cleanup
+if sys.hexversion < 0x30d00a1:
+ _tmpf = tempfile.TemporaryFile('w') # emits OSError 9 in python 3.13
+else:
+ _tmpf = tempfile.NamedTemporaryFile('w').file # for > python 3.9
+
+# objects used by dill for type declaration
+registered = d = {}
+# objects dill fails to pickle
+failures = x = {}
+# all other type objects
+succeeds = a = {}
+
+# types module (part of CH 8)
+a['BooleanType'] = bool(1)
+a['BuiltinFunctionType'] = len
+a['BuiltinMethodType'] = a['BuiltinFunctionType']
+a['BytesType'] = _bytes = codecs.latin_1_encode('\x00')[0] # bytes(1)
+a['ClassType'] = _class
+a['ComplexType'] = complex(1)
+a['DictType'] = _dict = {}
+a['DictionaryType'] = a['DictType']
+a['FloatType'] = float(1)
+a['FunctionType'] = _function
+a['InstanceType'] = _instance = _class()
+a['IntType'] = _int = int(1)
+a['ListType'] = _list = []
+a['NoneType'] = None
+a['ObjectType'] = object()
+a['StringType'] = _str = str(1)
+a['TupleType'] = _tuple = ()
+a['TypeType'] = type
+a['LongType'] = _int
+a['UnicodeType'] = _str
+# built-in constants (CH 4)
+a['CopyrightType'] = copyright
+# built-in types (CH 5)
+a['ClassObjectType'] = _newclass # <type 'type'>
+a['ClassInstanceType'] = _newclass() # <type 'class'>
+a['SetType'] = _set = set()
+a['FrozenSetType'] = frozenset()
+# built-in exceptions (CH 6)
+a['ExceptionType'] = _exception = _function2()[0]
+# string services (CH 7)
+a['SREPatternType'] = _srepattern = re.compile('')
+# data types (CH 8)
+a['ArrayType'] = array.array("f")
+a['DequeType'] = collections.deque([0])
+a['DefaultDictType'] = collections.defaultdict(_function, _dict)
+a['TZInfoType'] = datetime.tzinfo()
+a['DateTimeType'] = datetime.datetime.today()
+a['CalendarType'] = calendar.Calendar()
+# numeric and mathematical types (CH 9)
+a['DecimalType'] = decimal.Decimal(1)
+a['CountType'] = itertools.count(0)
+# data compression and archiving (CH 12)
+a['TarInfoType'] = tarfile.TarInfo()
+# generic operating system services (CH 15)
+a['LoggerType'] = _logger = logging.getLogger()
+a['FormatterType'] = logging.Formatter() # pickle ok
+a['FilterType'] = logging.Filter() # pickle ok
+a['LogRecordType'] = logging.makeLogRecord(_dict) # pickle ok
+a['OptionParserType'] = _oparser = optparse.OptionParser() # pickle ok
+a['OptionGroupType'] = optparse.OptionGroup(_oparser,"foo") # pickle ok
+a['OptionType'] = optparse.Option('--foo') # pickle ok
+if HAS_CTYPES:
+ z = x if IS_PYPY else a
+ z['CCharType'] = _cchar = ctypes.c_char()
+ z['CWCharType'] = ctypes.c_wchar() # fail == 2.6
+ z['CByteType'] = ctypes.c_byte()
+ z['CUByteType'] = ctypes.c_ubyte()
+ z['CShortType'] = ctypes.c_short()
+ z['CUShortType'] = ctypes.c_ushort()
+ z['CIntType'] = ctypes.c_int()
+ z['CUIntType'] = ctypes.c_uint()
+ z['CLongType'] = ctypes.c_long()
+ z['CULongType'] = ctypes.c_ulong()
+ z['CLongLongType'] = ctypes.c_longlong()
+ z['CULongLongType'] = ctypes.c_ulonglong()
+ z['CFloatType'] = ctypes.c_float()
+ z['CDoubleType'] = ctypes.c_double()
+ z['CSizeTType'] = ctypes.c_size_t()
+ del z
+ a['CLibraryLoaderType'] = ctypes.cdll
+ a['StructureType'] = _Struct
+ # if not IS_PYPY:
+ # a['BigEndianStructureType'] = ctypes.BigEndianStructure()
+#NOTE: also LittleEndianStructureType and UnionType... abstract classes
+#NOTE: remember for ctypesobj.contents creates a new python object
+#NOTE: ctypes.c_int._objects is memberdescriptor for object's __dict__
+#NOTE: base class of all ctypes data types is non-public _CData
+
+import fractions
+import io
+from io import StringIO as TextIO
+# built-in functions (CH 2)
+a['ByteArrayType'] = bytearray([1])
+# numeric and mathematical types (CH 9)
+a['FractionType'] = fractions.Fraction()
+a['NumberType'] = numbers.Number()
+# generic operating system services (CH 15)
+a['IOBaseType'] = io.IOBase()
+a['RawIOBaseType'] = io.RawIOBase()
+a['TextIOBaseType'] = io.TextIOBase()
+a['BufferedIOBaseType'] = io.BufferedIOBase()
+a['UnicodeIOType'] = TextIO() # the new StringIO
+a['LoggerAdapterType'] = logging.LoggerAdapter(_logger,_dict) # pickle ok
+if HAS_CTYPES:
+ z = x if IS_PYPY else a
+ z['CBoolType'] = ctypes.c_bool(1)
+ z['CLongDoubleType'] = ctypes.c_longdouble()
+ del z
+import argparse
+# data types (CH 8)
+a['OrderedDictType'] = collections.OrderedDict(_dict)
+a['CounterType'] = collections.Counter(_dict)
+if HAS_CTYPES:
+ z = x if IS_PYPY else a
+ z['CSSizeTType'] = ctypes.c_ssize_t()
+ del z
+# generic operating system services (CH 15)
+a['NullHandlerType'] = logging.NullHandler() # pickle ok # new 2.7
+a['ArgParseFileType'] = argparse.FileType() # pickle ok
+
+# -- pickle fails on all below here -----------------------------------------
+# types module (part of CH 8)
+a['CodeType'] = compile('','','exec')
+a['DictProxyType'] = type.__dict__
+a['DictProxyType2'] = _newclass.__dict__
+a['EllipsisType'] = Ellipsis
+a['ClosedFileType'] = open(os.devnull, 'wb', buffering=0).close()
+a['GetSetDescriptorType'] = array.array.typecode
+a['LambdaType'] = _lambda = lambda x: lambda y: x #XXX: works when not imported!
+a['MemberDescriptorType'] = _newclass2.descriptor
+if not IS_PYPY:
+ a['MemberDescriptorType2'] = datetime.timedelta.days
+a['MethodType'] = _method = _class()._method #XXX: works when not imported!
+a['ModuleType'] = datetime
+a['NotImplementedType'] = NotImplemented
+a['SliceType'] = slice(1)
+a['UnboundMethodType'] = _class._method #XXX: works when not imported!
+d['TextWrapperType'] = open(os.devnull, 'r') # same as mode='w','w+','r+'
+if not IS_PYODIDE:
+ d['BufferedRandomType'] = open(os.devnull, 'r+b') # same as mode='w+b'
+d['BufferedReaderType'] = open(os.devnull, 'rb') # (default: buffering=-1)
+d['BufferedWriterType'] = open(os.devnull, 'wb')
+try: # oddities: deprecated
+ from _pyio import open as _open
+ d['PyTextWrapperType'] = _open(os.devnull, 'r', buffering=-1)
+ if not IS_PYODIDE:
+ d['PyBufferedRandomType'] = _open(os.devnull, 'r+b', buffering=-1)
+ d['PyBufferedReaderType'] = _open(os.devnull, 'rb', buffering=-1)
+ d['PyBufferedWriterType'] = _open(os.devnull, 'wb', buffering=-1)
+except ImportError:
+ pass
+# other (concrete) object types
+z = d if sys.hexversion < 0x30800a2 else a
+z['CellType'] = (_lambda)(0).__closure__[0]
+del z
+a['XRangeType'] = _xrange = range(1)
+a['MethodDescriptorType'] = type.__dict__['mro']
+a['WrapperDescriptorType'] = type.__repr__
+#a['WrapperDescriptorType2'] = type.__dict__['__module__']#XXX: GetSetDescriptor
+a['ClassMethodDescriptorType'] = type.__dict__['__prepare__']
+# built-in functions (CH 2)
+_methodwrap = (1).__lt__
+a['MethodWrapperType'] = _methodwrap
+a['StaticMethodType'] = staticmethod(_method)
+a['ClassMethodType'] = classmethod(_method)
+a['PropertyType'] = property()
+d['SuperType'] = super(Exception, _exception)
+# string services (CH 7)
+_in = _bytes
+a['InputType'] = _cstrI = StringIO(_in)
+a['OutputType'] = _cstrO = StringIO()
+# data types (CH 8)
+a['WeakKeyDictionaryType'] = weakref.WeakKeyDictionary()
+a['WeakValueDictionaryType'] = weakref.WeakValueDictionary()
+a['ReferenceType'] = weakref.ref(_instance)
+a['DeadReferenceType'] = weakref.ref(_class())
+a['ProxyType'] = weakref.proxy(_instance)
+a['DeadProxyType'] = weakref.proxy(_class())
+a['CallableProxyType'] = weakref.proxy(_instance2)
+a['DeadCallableProxyType'] = weakref.proxy(_class2())
+a['QueueType'] = Queue.Queue()
+# numeric and mathematical types (CH 9)
+d['PartialType'] = functools.partial(int,base=2)
+a['IzipType'] = zip('0','1')
+a['ChainType'] = itertools.chain('0','1')
+d['ItemGetterType'] = operator.itemgetter(0)
+d['AttrGetterType'] = operator.attrgetter('__repr__')
+# file and directory access (CH 10)
+_fileW = _cstrO
+# data persistence (CH 11)
+if HAS_ALL:
+ x['ConnectionType'] = _conn = sqlite3.connect(':memory:')
+ x['CursorType'] = _conn.cursor()
+a['ShelveType'] = shelve.Shelf({})
+# data compression and archiving (CH 12)
+if HAS_ALL:
+ x['BZ2FileType'] = bz2.BZ2File(os.devnull)
+ x['BZ2CompressorType'] = bz2.BZ2Compressor()
+ x['BZ2DecompressorType'] = bz2.BZ2Decompressor()
+#x['ZipFileType'] = _zip = zipfile.ZipFile(os.devnull,'w')
+#_zip.write(_tempfile,'x') [causes annoying warning/error printed on import]
+#a['ZipInfoType'] = _zip.getinfo('x')
+a['TarFileType'] = tarfile.open(fileobj=_fileW,mode='w')
+# file formats (CH 13)
+x['DialectType'] = csv.get_dialect('excel')
+if sys.hexversion < 0x30d00a1:
+ import xdrlib
+ a['PackerType'] = xdrlib.Packer()
+# optional operating system services (CH 16)
+a['LockType'] = threading.Lock()
+a['RLockType'] = threading.RLock()
+# generic operating system services (CH 15) # also closed/open and r/w/etc...
+a['NamedLoggerType'] = _logger = logging.getLogger(__name__)
+#a['FrozenModuleType'] = __hello__ #FIXME: prints "Hello world..."
+# interprocess communication (CH 17)
+x['SocketType'] = _socket = socket.socket()
+x['SocketPairType'] = socket.socketpair()[0]
+# python runtime services (CH 27)
+a['GeneratorContextManagerType'] = contextlib.contextmanager(max)([1])
+
+try: # ipython
+ __IPYTHON__ is True # is ipython
+except NameError:
+ # built-in constants (CH 4)
+ a['QuitterType'] = quit
+ d['ExitType'] = a['QuitterType']
+try: # numpy #FIXME: slow... 0.05 to 0.1 sec to import numpy
+ from numpy import ufunc as _numpy_ufunc
+ from numpy import array as _numpy_array
+ from numpy import int32 as _numpy_int32
+ a['NumpyUfuncType'] = _numpy_ufunc
+ a['NumpyArrayType'] = _numpy_array
+ a['NumpyInt32Type'] = _numpy_int32
+except ImportError:
+ pass
+# numeric and mathematical types (CH 9)
+a['ProductType'] = itertools.product('0','1')
+# generic operating system services (CH 15)
+a['FileHandlerType'] = logging.FileHandler(os.devnull)
+a['RotatingFileHandlerType'] = logging.handlers.RotatingFileHandler(os.devnull)
+a['SocketHandlerType'] = logging.handlers.SocketHandler('localhost',514)
+a['MemoryHandlerType'] = logging.handlers.MemoryHandler(1)
+# data types (CH 8)
+a['WeakSetType'] = weakref.WeakSet() # 2.7
+# generic operating system services (CH 15) [errors when dill is imported]
+#a['ArgumentParserType'] = _parser = argparse.ArgumentParser('PROG')
+#a['NamespaceType'] = _parser.parse_args() # pickle ok
+#a['SubParsersActionType'] = _parser.add_subparsers()
+#a['MutuallyExclusiveGroupType'] = _parser.add_mutually_exclusive_group()
+#a['ArgumentGroupType'] = _parser.add_argument_group()
+
+# -- dill fails in some versions below here ---------------------------------
+# types module (part of CH 8)
+d['FileType'] = open(os.devnull, 'rb', buffering=0) # same 'wb','wb+','rb+'
+# built-in functions (CH 2)
+# Iterators:
+a['ListIteratorType'] = iter(_list) # empty vs non-empty
+a['SetIteratorType'] = iter(_set) #XXX: empty vs non-empty #FIXME: list_iterator
+a['TupleIteratorType']= iter(_tuple) # empty vs non-empty
+a['XRangeIteratorType'] = iter(_xrange) # empty vs non-empty
+a["BytesIteratorType"] = iter(b'')
+a["BytearrayIteratorType"] = iter(bytearray(b''))
+z = x if IS_PYPY else a
+z["CallableIteratorType"] = iter(iter, None)
+del z
+x["MemoryIteratorType"] = iter(memoryview(b''))
+a["ListReverseiteratorType"] = reversed([])
+X = a['OrderedDictType']
+d["OdictKeysType"] = X.keys()
+d["OdictValuesType"] = X.values()
+d["OdictItemsType"] = X.items()
+a["OdictIteratorType"] = iter(X.keys()) #FIXME: list_iterator
+del X
+#FIXME: list_iterator
+a['DictionaryItemIteratorType'] = iter(type.__dict__.items())
+a['DictionaryKeyIteratorType'] = iter(type.__dict__.keys())
+a['DictionaryValueIteratorType'] = iter(type.__dict__.values())
+if sys.hexversion >= 0x30800a0:
+ a["DictReversekeyiteratorType"] = reversed({}.keys())
+ a["DictReversevalueiteratorType"] = reversed({}.values())
+ a["DictReverseitemiteratorType"] = reversed({}.items())
+
+try:
+ import symtable
+ #FIXME: fails to pickle
+ x["SymtableEntryType"] = symtable.symtable("", "string", "exec")._table
+except ImportError:
+ pass
+
+if sys.hexversion >= 0x30a00a0 and not IS_PYPY:
+ x['LineIteratorType'] = compile('3', '', 'eval').co_lines()
+
+if sys.hexversion >= 0x30b00b0:
+ from types import GenericAlias
+ d["GenericAliasIteratorType"] = iter(GenericAlias(list, (int,)))
+ x['PositionsIteratorType'] = compile('3', '', 'eval').co_positions()
+
+# data types (CH 8)
+a['PrettyPrinterType'] = pprint.PrettyPrinter()
+# numeric and mathematical types (CH 9)
+a['CycleType'] = itertools.cycle('0')
+# file and directory access (CH 10)
+a['TemporaryFileType'] = _tmpf
+# data compression and archiving (CH 12)
+x['GzipFileType'] = gzip.GzipFile(fileobj=_fileW)
+# generic operating system services (CH 15)
+a['StreamHandlerType'] = logging.StreamHandler()
+# numeric and mathematical types (CH 9)
+a['PermutationsType'] = itertools.permutations('0')
+a['CombinationsType'] = itertools.combinations('0',1)
+a['RepeatType'] = itertools.repeat(0)
+a['CompressType'] = itertools.compress('0',[1])
+#XXX: ...and etc
+
+# -- dill fails on all below here -------------------------------------------
+# types module (part of CH 8)
+x['GeneratorType'] = _generator = _function(1) #XXX: priority
+x['FrameType'] = _generator.gi_frame #XXX: inspect.currentframe()
+x['TracebackType'] = _function2()[1] #(see: inspect.getouterframes,getframeinfo)
+# other (concrete) object types
+# (also: Capsule / CObject ?)
+# built-in functions (CH 2)
+# built-in types (CH 5)
+# string services (CH 7)
+x['StructType'] = struct.Struct('c')
+x['CallableIteratorType'] = _srepattern.finditer('')
+x['SREMatchType'] = _srepattern.match('')
+x['SREScannerType'] = _srepattern.scanner('')
+x['StreamReader'] = codecs.StreamReader(_cstrI) #XXX: ... and etc
+# python object persistence (CH 11)
+# x['DbShelveType'] = shelve.open('foo','n')#,protocol=2) #XXX: delete foo
+if HAS_ALL:
+ z = a if IS_PYPY else x
+ z['DbmType'] = dbm.open(_tempfile,'n')
+ del z
+# x['DbCursorType'] = _dbcursor = anydbm.open('foo','n') #XXX: delete foo
+# x['DbType'] = _dbcursor.db
+# data compression and archiving (CH 12)
+x['ZlibCompressType'] = zlib.compressobj()
+x['ZlibDecompressType'] = zlib.decompressobj()
+# file formats (CH 13)
+x['CSVReaderType'] = csv.reader(_cstrI)
+x['CSVWriterType'] = csv.writer(_cstrO)
+x['CSVDictReaderType'] = csv.DictReader(_cstrI)
+x['CSVDictWriterType'] = csv.DictWriter(_cstrO,{})
+# cryptographic services (CH 14)
+x['HashType'] = hashlib.md5()
+if (sys.hexversion < 0x30800a1):
+ x['HMACType'] = hmac.new(_in)
+else:
+ x['HMACType'] = hmac.new(_in, digestmod='md5')
+# generic operating system services (CH 15)
+if HAS_CURSES: pass
+ #x['CursesWindowType'] = _curwin = curses.initscr() #FIXME: messes up tty
+ #x['CursesTextPadType'] = textpad.Textbox(_curwin)
+ #x['CursesPanelType'] = panel.new_panel(_curwin)
+if HAS_CTYPES:
+ x['CCharPType'] = ctypes.c_char_p()
+ x['CWCharPType'] = ctypes.c_wchar_p()
+ x['CVoidPType'] = ctypes.c_void_p()
+ if sys.platform[:3] == 'win':
+ x['CDLLType'] = _cdll = ctypes.cdll.msvcrt
+ else:
+ x['CDLLType'] = _cdll = ctypes.CDLL(None)
+ if not IS_PYPY:
+ x['PyDLLType'] = _pydll = ctypes.pythonapi
+ x['FuncPtrType'] = _cdll._FuncPtr()
+ x['CCharArrayType'] = ctypes.create_string_buffer(1)
+ x['CWCharArrayType'] = ctypes.create_unicode_buffer(1)
+ x['CParamType'] = ctypes.byref(_cchar)
+ x['LPCCharType'] = ctypes.pointer(_cchar)
+ x['LPCCharObjType'] = _lpchar = ctypes.POINTER(ctypes.c_char)
+ x['NullPtrType'] = _lpchar()
+ x['NullPyObjectType'] = ctypes.py_object()
+ x['PyObjectType'] = ctypes.py_object(lambda :None)
+ z = a if IS_PYPY else x
+ z['FieldType'] = _field = _Struct._field
+ z['CFUNCTYPEType'] = _cfunc = ctypes.CFUNCTYPE(ctypes.c_char)
+ if sys.hexversion < 0x30c00b3:
+ x['CFunctionType'] = _cfunc(str)
+ del z
+# numeric and mathematical types (CH 9)
+a['MethodCallerType'] = operator.methodcaller('mro') # 2.6
+# built-in types (CH 5)
+x['MemoryType'] = memoryview(_in) # 2.7
+x['MemoryType2'] = memoryview(bytearray(_in)) # 2.7
+d['DictItemsType'] = _dict.items() # 2.7
+d['DictKeysType'] = _dict.keys() # 2.7
+d['DictValuesType'] = _dict.values() # 2.7
+# generic operating system services (CH 15)
+a['RawTextHelpFormatterType'] = argparse.RawTextHelpFormatter('PROG')
+a['RawDescriptionHelpFormatterType'] = argparse.RawDescriptionHelpFormatter('PROG')
+a['ArgDefaultsHelpFormatterType'] = argparse.ArgumentDefaultsHelpFormatter('PROG')
+z = a if IS_PYPY else x
+z['CmpKeyType'] = _cmpkey = functools.cmp_to_key(_methodwrap) # 2.7, >=3.2
+z['CmpKeyObjType'] = _cmpkey('0') #2.7, >=3.2
+del z
+# oddities: removed, etc
+x['BufferType'] = x['MemoryType']
+
+from dill._dill import _testcapsule
+if _testcapsule is not None:
+ d['PyCapsuleType'] = _testcapsule
+del _testcapsule
+
+if hasattr(dataclasses, '_HAS_DEFAULT_FACTORY'):
+ a['DataclassesHasDefaultFactoryType'] = dataclasses._HAS_DEFAULT_FACTORY
+
+if hasattr(dataclasses, 'MISSING'):
+ a['DataclassesMissingType'] = dataclasses.MISSING
+
+if hasattr(dataclasses, 'KW_ONLY'):
+ a['DataclassesKWOnlyType'] = dataclasses.KW_ONLY
+
+if hasattr(dataclasses, '_FIELD_BASE'):
+ a['DataclassesFieldBaseType'] = dataclasses._FIELD
+
+# -- cleanup ----------------------------------------------------------------
+a.update(d) # registered also succeed
+if sys.platform[:3] == 'win':
+ os.close(_filedescrip) # required on win32
+os.remove(_tempfile)
+
+
+# EOF
diff --git a/solutions/.venv/Lib/site-packages/dill/_shims.py b/solutions/.venv/Lib/site-packages/dill/_shims.py
new file mode 100644
index 000000000..da1abbecc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/_shims.py
@@ -0,0 +1,193 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Author: Anirudh Vegesana (avegesan@cs.stanford.edu)
+# Copyright (c) 2021-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+Provides shims for compatibility between versions of dill and Python.
+
+Compatibility shims should be provided in this file. Here are two simple example
+use cases.
+
+Deprecation of constructor function:
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+Assume that we were transitioning _import_module in _dill.py to
+the builtin function importlib.import_module when present.
+
+@move_to(_dill)
+def _import_module(import_name):
+ ... # code already in _dill.py
+
+_import_module = Getattr(importlib, 'import_module', Getattr(_dill, '_import_module', None))
+
+The code will attempt to find import_module in the importlib module. If not
+present, it will use the _import_module function in _dill.
+
+Emulate new Python behavior in older Python versions:
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+CellType.cell_contents behaves differently in Python 3.6 and 3.7. It is
+read-only in Python 3.6 and writable and deletable in 3.7.
+
+if _dill.OLD37 and _dill.HAS_CTYPES and ...:
+ @move_to(_dill)
+ def _setattr(object, name, value):
+ if type(object) is _dill.CellType and name == 'cell_contents':
+ _PyCell_Set.argtypes = (ctypes.py_object, ctypes.py_object)
+ _PyCell_Set(object, value)
+ else:
+ setattr(object, name, value)
+... # more cases below
+
+_setattr = Getattr(_dill, '_setattr', setattr)
+
+_dill._setattr will be used when present to emulate Python 3.7 functionality in
+older versions of Python while defaulting to the standard setattr in 3.7+.
+
+See this PR for the discussion that lead to this system:
+https://github.com/uqfoundation/dill/pull/443
+"""
+
+import inspect
+import sys
+
+_dill = sys.modules['dill._dill']
+
+
+class Reduce(object):
+ """
+ Reduce objects are wrappers used for compatibility enforcement during
+ unpickle-time. They should only be used in calls to pickler.save and
+ other Reduce objects. They are only evaluated within unpickler.load.
+
+ Pickling a Reduce object makes the two implementations equivalent:
+
+ pickler.save(Reduce(*reduction))
+
+ pickler.save_reduce(*reduction, obj=reduction)
+ """
+ __slots__ = ['reduction']
+ def __new__(cls, *reduction, **kwargs):
+ """
+ Args:
+ *reduction: a tuple that matches the format given here:
+ https://docs.python.org/3/library/pickle.html#object.__reduce__
+ is_callable: a bool to indicate that the object created by
+ unpickling `reduction` is callable. If true, the current Reduce
+ is allowed to be used as the function in further save_reduce calls
+ or Reduce objects.
+ """
+ is_callable = kwargs.get('is_callable', False) # Pleases Py2. Can be removed later
+ if is_callable:
+ self = object.__new__(_CallableReduce)
+ else:
+ self = object.__new__(Reduce)
+ self.reduction = reduction
+ return self
+ def __repr__(self):
+ return 'Reduce%s' % (self.reduction,)
+ def __copy__(self):
+ return self # pragma: no cover
+ def __deepcopy__(self, memo):
+ return self # pragma: no cover
+ def __reduce__(self):
+ return self.reduction
+ def __reduce_ex__(self, protocol):
+ return self.__reduce__()
+
+class _CallableReduce(Reduce):
+ # A version of Reduce for functions. Used to trick pickler.save_reduce into
+ # thinking that Reduce objects of functions are themselves meaningful functions.
+ def __call__(self, *args, **kwargs):
+ reduction = self.__reduce__()
+ func = reduction[0]
+ f_args = reduction[1]
+ obj = func(*f_args)
+ return obj(*args, **kwargs)
+
+__NO_DEFAULT = _dill.Sentinel('Getattr.NO_DEFAULT')
+
+def Getattr(object, name, default=__NO_DEFAULT):
+ """
+ A Reduce object that represents the getattr operation. When unpickled, the
+ Getattr will access an attribute 'name' of 'object' and return the value
+ stored there. If the attribute doesn't exist, the default value will be
+ returned if present.
+
+ The following statements are equivalent:
+
+ Getattr(collections, 'OrderedDict')
+ Getattr(collections, 'spam', None)
+ Getattr(*args)
+
+ Reduce(getattr, (collections, 'OrderedDict'))
+ Reduce(getattr, (collections, 'spam', None))
+ Reduce(getattr, args)
+
+ During unpickling, the first two will result in collections.OrderedDict and
+ None respectively because the first attribute exists and the second one does
+ not, forcing it to use the default value given in the third argument.
+ """
+
+ if default is Getattr.NO_DEFAULT:
+ reduction = (getattr, (object, name))
+ else:
+ reduction = (getattr, (object, name, default))
+
+ return Reduce(*reduction, is_callable=callable(default))
+
+Getattr.NO_DEFAULT = __NO_DEFAULT
+del __NO_DEFAULT
+
+def move_to(module, name=None):
+ def decorator(func):
+ if name is None:
+ fname = func.__name__
+ else:
+ fname = name
+ module.__dict__[fname] = func
+ func.__module__ = module.__name__
+ return func
+ return decorator
+
+def register_shim(name, default):
+ """
+ A easier to understand and more compact way of "softly" defining a function.
+ These two pieces of code are equivalent:
+
+ if _dill.OLD3X:
+ def _create_class():
+ ...
+ _create_class = register_shim('_create_class', types.new_class)
+
+ if _dill.OLD3X:
+ @move_to(_dill)
+ def _create_class():
+ ...
+ _create_class = Getattr(_dill, '_create_class', types.new_class)
+
+ Intuitively, it creates a function or object in the versions of dill/python
+ that require special reimplementations, and use a core library or default
+ implementation if that function or object does not exist.
+ """
+ func = globals().get(name)
+ if func is not None:
+ _dill.__dict__[name] = func
+ func.__module__ = _dill.__name__
+
+ if default is Getattr.NO_DEFAULT:
+ reduction = (getattr, (_dill, name))
+ else:
+ reduction = (getattr, (_dill, name, default))
+
+ return Reduce(*reduction, is_callable=callable(default))
+
+######################
+## Compatibility Shims are defined below
+######################
+
+_CELL_EMPTY = register_shim('_CELL_EMPTY', None)
+
+_setattr = register_shim('_setattr', setattr)
+_delattr = register_shim('_delattr', delattr)
diff --git a/solutions/.venv/Lib/site-packages/dill/detect.py b/solutions/.venv/Lib/site-packages/dill/detect.py
new file mode 100644
index 000000000..6f76e729d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/detect.py
@@ -0,0 +1,284 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+Methods for detecting objects leading to pickling failures.
+"""
+
+import dis
+from inspect import ismethod, isfunction, istraceback, isframe, iscode
+
+from .pointers import parent, reference, at, parents, children
+from .logger import trace
+
+__all__ = ['baditems','badobjects','badtypes','code','errors','freevars',
+ 'getmodule','globalvars','nestedcode','nestedglobals','outermost',
+ 'referredglobals','referrednested','trace','varnames']
+
+def getmodule(object, _filename=None, force=False):
+ """get the module of the object"""
+ from inspect import getmodule as getmod
+ module = getmod(object, _filename)
+ if module or not force: return module
+ import builtins
+ from .source import getname
+ name = getname(object, force=True)
+ return builtins if name in vars(builtins).keys() else None
+
+def outermost(func): # is analogous to getsource(func,enclosing=True)
+ """get outermost enclosing object (i.e. the outer function in a closure)
+
+ NOTE: this is the object-equivalent of getsource(func, enclosing=True)
+ """
+ if ismethod(func):
+ _globals = func.__func__.__globals__ or {}
+ elif isfunction(func):
+ _globals = func.__globals__ or {}
+ else:
+ return #XXX: or raise? no matches
+ _globals = _globals.items()
+ # get the enclosing source
+ from .source import getsourcelines
+ try: lines,lnum = getsourcelines(func, enclosing=True)
+ except Exception: #TypeError, IOError
+ lines,lnum = [],None
+ code = ''.join(lines)
+ # get all possible names,objects that are named in the enclosing source
+ _locals = ((name,obj) for (name,obj) in _globals if name in code)
+ # now only save the objects that generate the enclosing block
+ for name,obj in _locals: #XXX: don't really need 'name'
+ try:
+ if getsourcelines(obj) == (lines,lnum): return obj
+ except Exception: #TypeError, IOError
+ pass
+ return #XXX: or raise? no matches
+
+def nestedcode(func, recurse=True): #XXX: or return dict of {co_name: co} ?
+ """get the code objects for any nested functions (e.g. in a closure)"""
+ func = code(func)
+ if not iscode(func): return [] #XXX: or raise? no matches
+ nested = set()
+ for co in func.co_consts:
+ if co is None: continue
+ co = code(co)
+ if co:
+ nested.add(co)
+ if recurse: nested |= set(nestedcode(co, recurse=True))
+ return list(nested)
+
+def code(func):
+ """get the code object for the given function or method
+
+ NOTE: use dill.source.getsource(CODEOBJ) to get the source code
+ """
+ if ismethod(func): func = func.__func__
+ if isfunction(func): func = func.__code__
+ if istraceback(func): func = func.tb_frame
+ if isframe(func): func = func.f_code
+ if iscode(func): return func
+ return
+
+#XXX: ugly: parse dis.dis for name after "<code object" in line and in globals?
+def referrednested(func, recurse=True): #XXX: return dict of {__name__: obj} ?
+ """get functions defined inside of func (e.g. inner functions in a closure)
+
+ NOTE: results may differ if the function has been executed or not.
+ If len(nestedcode(func)) > len(referrednested(func)), try calling func().
+ If possible, python builds code objects, but delays building functions
+ until func() is called.
+ """
+ import gc
+ funcs = set()
+ # get the code objects, and try to track down by referrence
+ for co in nestedcode(func, recurse):
+ # look for function objects that refer to the code object
+ for obj in gc.get_referrers(co):
+ # get methods
+ _ = getattr(obj, '__func__', None) # ismethod
+ if getattr(_, '__code__', None) is co: funcs.add(obj)
+ # get functions
+ elif getattr(obj, '__code__', None) is co: funcs.add(obj)
+ # get frame objects
+ elif getattr(obj, 'f_code', None) is co: funcs.add(obj)
+ # get code objects
+ elif hasattr(obj, 'co_code') and obj is co: funcs.add(obj)
+# frameobjs => func.__code__.co_varnames not in func.__code__.co_cellvars
+# funcobjs => func.__code__.co_cellvars not in func.__code__.co_varnames
+# frameobjs are not found, however funcobjs are...
+# (see: test_mixins.quad ... and test_mixins.wtf)
+# after execution, code objects get compiled, and then may be found by gc
+ return list(funcs)
+
+
+def freevars(func):
+ """get objects defined in enclosing code that are referred to by func
+
+ returns a dict of {name:object}"""
+ if ismethod(func): func = func.__func__
+ if isfunction(func):
+ closures = func.__closure__ or ()
+ func = func.__code__.co_freevars # get freevars
+ else:
+ return {}
+
+ def get_cell_contents():
+ for name, c in zip(func, closures):
+ try:
+ cell_contents = c.cell_contents
+ except ValueError: # cell is empty
+ continue
+ yield name, c.cell_contents
+
+ return dict(get_cell_contents())
+
+# thanks to Davies Liu for recursion of globals
+def nestedglobals(func, recurse=True):
+ """get the names of any globals found within func"""
+ func = code(func)
+ if func is None: return list()
+ import sys
+ from .temp import capture
+ CAN_NULL = sys.hexversion >= 0x30b00a7 # NULL may be prepended >= 3.11a7
+ names = set()
+ with capture('stdout') as out:
+ dis.dis(func) #XXX: dis.dis(None) disassembles last traceback
+ for line in out.getvalue().splitlines():
+ if '_GLOBAL' in line:
+ name = line.split('(')[-1].split(')')[0]
+ if CAN_NULL:
+ names.add(name.replace('NULL + ', '').replace(' + NULL', ''))
+ else:
+ names.add(name)
+ for co in getattr(func, 'co_consts', tuple()):
+ if co and recurse and iscode(co):
+ names.update(nestedglobals(co, recurse=True))
+ return list(names)
+
+def referredglobals(func, recurse=True, builtin=False):
+ """get the names of objects in the global scope referred to by func"""
+ return globalvars(func, recurse, builtin).keys()
+
+def globalvars(func, recurse=True, builtin=False):
+ """get objects defined in global scope that are referred to by func
+
+ return a dict of {name:object}"""
+ if ismethod(func): func = func.__func__
+ if isfunction(func):
+ globs = vars(getmodule(sum)).copy() if builtin else {}
+ # get references from within closure
+ orig_func, func = func, set()
+ for obj in orig_func.__closure__ or {}:
+ try:
+ cell_contents = obj.cell_contents
+ except ValueError: # cell is empty
+ pass
+ else:
+ _vars = globalvars(cell_contents, recurse, builtin) or {}
+ func.update(_vars) #XXX: (above) be wary of infinte recursion?
+ globs.update(_vars)
+ # get globals
+ globs.update(orig_func.__globals__ or {})
+ # get names of references
+ if not recurse:
+ func.update(orig_func.__code__.co_names)
+ else:
+ func.update(nestedglobals(orig_func.__code__))
+ # find globals for all entries of func
+ for key in func.copy(): #XXX: unnecessary...?
+ nested_func = globs.get(key)
+ if nested_func is orig_func:
+ #func.remove(key) if key in func else None
+ continue #XXX: globalvars(func, False)?
+ func.update(globalvars(nested_func, True, builtin))
+ elif iscode(func):
+ globs = vars(getmodule(sum)).copy() if builtin else {}
+ #globs.update(globals())
+ if not recurse:
+ func = func.co_names # get names
+ else:
+ orig_func = func.co_name # to stop infinite recursion
+ func = set(nestedglobals(func))
+ # find globals for all entries of func
+ for key in func.copy(): #XXX: unnecessary...?
+ if key is orig_func:
+ #func.remove(key) if key in func else None
+ continue #XXX: globalvars(func, False)?
+ nested_func = globs.get(key)
+ func.update(globalvars(nested_func, True, builtin))
+ else:
+ return {}
+ #NOTE: if name not in __globals__, then we skip it...
+ return dict((name,globs[name]) for name in func if name in globs)
+
+
+def varnames(func):
+ """get names of variables defined by func
+
+ returns a tuple (local vars, local vars referrenced by nested functions)"""
+ func = code(func)
+ if not iscode(func):
+ return () #XXX: better ((),())? or None?
+ return func.co_varnames, func.co_cellvars
+
+
+def baditems(obj, exact=False, safe=False): #XXX: obj=globals() ?
+ """get items in object that fail to pickle"""
+ if not hasattr(obj,'__iter__'): # is not iterable
+ return [j for j in (badobjects(obj,0,exact,safe),) if j is not None]
+ obj = obj.values() if getattr(obj,'values',None) else obj
+ _obj = [] # can't use a set, as items may be unhashable
+ [_obj.append(badobjects(i,0,exact,safe)) for i in obj if i not in _obj]
+ return [j for j in _obj if j is not None]
+
+
+def badobjects(obj, depth=0, exact=False, safe=False):
+ """get objects that fail to pickle"""
+ from dill import pickles
+ if not depth:
+ if pickles(obj,exact,safe): return None
+ return obj
+ return dict(((attr, badobjects(getattr(obj,attr),depth-1,exact,safe)) \
+ for attr in dir(obj) if not pickles(getattr(obj,attr),exact,safe)))
+
+def badtypes(obj, depth=0, exact=False, safe=False):
+ """get types for objects that fail to pickle"""
+ from dill import pickles
+ if not depth:
+ if pickles(obj,exact,safe): return None
+ return type(obj)
+ return dict(((attr, badtypes(getattr(obj,attr),depth-1,exact,safe)) \
+ for attr in dir(obj) if not pickles(getattr(obj,attr),exact,safe)))
+
+def errors(obj, depth=0, exact=False, safe=False):
+ """get errors for objects that fail to pickle"""
+ from dill import pickles, copy
+ if not depth:
+ try:
+ pik = copy(obj)
+ if exact:
+ assert pik == obj, \
+ "Unpickling produces %s instead of %s" % (pik,obj)
+ assert type(pik) == type(obj), \
+ "Unpickling produces %s instead of %s" % (type(pik),type(obj))
+ return None
+ except Exception:
+ import sys
+ return sys.exc_info()[1]
+ _dict = {}
+ for attr in dir(obj):
+ try:
+ _attr = getattr(obj,attr)
+ except Exception:
+ import sys
+ _dict[attr] = sys.exc_info()[1]
+ continue
+ if not pickles(_attr,exact,safe):
+ _dict[attr] = errors(_attr,depth-1,exact,safe)
+ return _dict
+
+
+# EOF
diff --git a/solutions/.venv/Lib/site-packages/dill/logger.py b/solutions/.venv/Lib/site-packages/dill/logger.py
new file mode 100644
index 000000000..6d444c966
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/logger.py
@@ -0,0 +1,285 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+#
+# Author: Leonardo Gama (@leogama)
+# Copyright (c) 2022-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+Logging utilities for dill.
+
+The 'logger' object is dill's top-level logger.
+
+The 'adapter' object wraps the logger and implements a 'trace()' method that
+generates a detailed tree-style trace for the pickling call at log level INFO.
+
+The 'trace()' function sets and resets dill's logger log level, enabling and
+disabling the pickling trace.
+
+The trace shows a tree structure depicting the depth of each object serialized
+*with dill save functions*, but not the ones that use save functions from
+'pickle._Pickler.dispatch'. If the information is available, it also displays
+the size in bytes that the object contributed to the pickle stream (including
+its child objects). Sample trace output:
+
+ >>> import dill, dill.tests
+ >>> dill.detect.trace(True)
+ >>> dill.dump_session(main=dill.tests)
+ ┬ M1: <module 'dill.tests' from '.../dill/tests/__init__.py'>
+ ├┬ F2: <function _import_module at 0x7f0d2dce1b80>
+ │└ # F2 [32 B]
+ ├┬ D2: <dict object at 0x7f0d2e98a540>
+ │├┬ T4: <class '_frozen_importlib.ModuleSpec'>
+ ││└ # T4 [35 B]
+ │├┬ D2: <dict object at 0x7f0d2ef0e8c0>
+ ││├┬ T4: <class '_frozen_importlib_external.SourceFileLoader'>
+ │││└ # T4 [50 B]
+ ││├┬ D2: <dict object at 0x7f0d2e988a40>
+ │││└ # D2 [84 B]
+ ││└ # D2 [413 B]
+ │└ # D2 [763 B]
+ └ # M1 [813 B]
+"""
+
+__all__ = ['adapter', 'logger', 'trace']
+
+import codecs
+import contextlib
+import locale
+import logging
+import math
+import os
+from functools import partial
+from typing import TextIO, Union
+
+import dill
+
+# Tree drawing characters: Unicode to ASCII map.
+ASCII_MAP = str.maketrans({"│": "|", "├": "|", "┬": "+", "└": "`"})
+
+## Notes about the design choices ##
+
+# Here is some domumentation of the Standard Library's logging internals that
+# can't be found completely in the official documentation. dill's logger is
+# obtained by calling logging.getLogger('dill') and therefore is an instance of
+# logging.getLoggerClass() at the call time. As this is controlled by the user,
+# in order to add some functionality to it it's necessary to use a LoggerAdapter
+# to wrap it, overriding some of the adapter's methods and creating new ones.
+#
+# Basic calling sequence
+# ======================
+#
+# Python's logging functionality can be conceptually divided into five steps:
+# 0. Check logging level -> abort if call level is greater than logger level
+# 1. Gather information -> construct a LogRecord from passed arguments and context
+# 2. Filter (optional) -> discard message if the record matches a filter
+# 3. Format -> format message with args, then format output string with message plus record
+# 4. Handle -> write the formatted string to output as defined in the handler
+#
+# dill.logging.logger.log -> # or logger.info, etc.
+# Logger.log -> \
+# Logger._log -> }- accept 'extra' parameter for custom record entries
+# Logger.makeRecord -> /
+# LogRecord.__init__
+# Logger.handle ->
+# Logger.callHandlers ->
+# Handler.handle ->
+# Filterer.filter ->
+# Filter.filter
+# StreamHandler.emit ->
+# Handler.format ->
+# Formatter.format ->
+# LogRecord.getMessage # does: record.message = msg % args
+# Formatter.formatMessage ->
+# PercentStyle.format # does: self._fmt % vars(record)
+#
+# NOTE: All methods from the second line on are from logging.__init__.py
+
+class TraceAdapter(logging.LoggerAdapter):
+ """
+ Tracks object tree depth and calculates pickled object size.
+
+ A single instance of this wraps the module's logger, as the logging API
+ doesn't allow setting it directly with a custom Logger subclass. The added
+ 'trace()' method receives a pickle instance as the first argument and
+ creates extra values to be added in the LogRecord from it, then calls
+ 'info()'.
+
+ Usage of logger with 'trace()' method:
+
+ >>> from dill.logger import adapter as logger #NOTE: not dill.logger.logger
+ >>> ...
+ >>> def save_atype(pickler, obj):
+ >>> logger.trace(pickler, "Message with %s and %r etc. placeholders", 'text', obj)
+ >>> ...
+ """
+ def __init__(self, logger):
+ self.logger = logger
+ def addHandler(self, handler):
+ formatter = TraceFormatter("%(prefix)s%(message)s%(suffix)s", handler=handler)
+ handler.setFormatter(formatter)
+ self.logger.addHandler(handler)
+ def removeHandler(self, handler):
+ self.logger.removeHandler(handler)
+ def process(self, msg, kwargs):
+ # A no-op override, as we don't have self.extra.
+ return msg, kwargs
+ def trace_setup(self, pickler):
+ # Called by Pickler.dump().
+ if not dill._dill.is_dill(pickler, child=False):
+ return
+ if self.isEnabledFor(logging.INFO):
+ pickler._trace_depth = 1
+ pickler._size_stack = []
+ else:
+ pickler._trace_depth = None
+ def trace(self, pickler, msg, *args, **kwargs):
+ if not hasattr(pickler, '_trace_depth'):
+ logger.info(msg, *args, **kwargs)
+ return
+ if pickler._trace_depth is None:
+ return
+ extra = kwargs.get('extra', {})
+ pushed_obj = msg.startswith('#')
+ size = None
+ try:
+ # Streams are not required to be tellable.
+ size = pickler._file.tell()
+ frame = pickler.framer.current_frame
+ try:
+ size += frame.tell()
+ except AttributeError:
+ # PyPy may use a BytesBuilder as frame
+ size += len(frame)
+ except (AttributeError, TypeError):
+ pass
+ if size is not None:
+ if not pushed_obj:
+ pickler._size_stack.append(size)
+ else:
+ size -= pickler._size_stack.pop()
+ extra['size'] = size
+ if pushed_obj:
+ pickler._trace_depth -= 1
+ extra['depth'] = pickler._trace_depth
+ kwargs['extra'] = extra
+ self.info(msg, *args, **kwargs)
+ if not pushed_obj:
+ pickler._trace_depth += 1
+
+class TraceFormatter(logging.Formatter):
+ """
+ Generates message prefix and suffix from record.
+
+ This Formatter adds prefix and suffix strings to the log message in trace
+ mode (an also provides empty string defaults for normal logs).
+ """
+ def __init__(self, *args, handler=None, **kwargs):
+ super().__init__(*args, **kwargs)
+ try:
+ encoding = handler.stream.encoding
+ if encoding is None:
+ raise AttributeError
+ except AttributeError:
+ encoding = locale.getpreferredencoding()
+ try:
+ encoding = codecs.lookup(encoding).name
+ except LookupError:
+ self.is_utf8 = False
+ else:
+ self.is_utf8 = (encoding == codecs.lookup('utf-8').name)
+ def format(self, record):
+ fields = {'prefix': "", 'suffix': ""}
+ if getattr(record, 'depth', 0) > 0:
+ if record.msg.startswith("#"):
+ prefix = (record.depth - 1)*"│" + "└"
+ elif record.depth == 1:
+ prefix = "┬"
+ else:
+ prefix = (record.depth - 2)*"│" + "├┬"
+ if not self.is_utf8:
+ prefix = prefix.translate(ASCII_MAP) + "-"
+ fields['prefix'] = prefix + " "
+ if hasattr(record, 'size') and record.size is not None and record.size >= 1:
+ # Show object size in human-readable form.
+ power = int(math.log(record.size, 2)) // 10
+ size = record.size >> power*10
+ fields['suffix'] = " [%d %sB]" % (size, "KMGTP"[power] + "i" if power else "")
+ vars(record).update(fields)
+ return super().format(record)
+
+logger = logging.getLogger('dill')
+logger.propagate = False
+adapter = TraceAdapter(logger)
+stderr_handler = logging._StderrHandler()
+adapter.addHandler(stderr_handler)
+
+def trace(arg: Union[bool, TextIO, str, os.PathLike] = None, *, mode: str = 'a') -> None:
+ """print a trace through the stack when pickling; useful for debugging
+
+ With a single boolean argument, enable or disable the tracing.
+
+ Example usage:
+
+ >>> import dill
+ >>> dill.detect.trace(True)
+ >>> dill.dump_session()
+
+ Alternatively, ``trace()`` can be used as a context manager. With no
+ arguments, it just takes care of restoring the tracing state on exit.
+ Either a file handle, or a file name and (optionally) a file mode may be
+ specitfied to redirect the tracing output in the ``with`` block context. A
+ log function is yielded by the manager so the user can write extra
+ information to the file.
+
+ Example usage:
+
+ >>> from dill import detect
+ >>> D = {'a': 42, 'b': {'x': None}}
+ >>> with detect.trace():
+ >>> dumps(D)
+ ┬ D2: <dict object at 0x7f2721804800>
+ ├┬ D2: <dict object at 0x7f27217f5c40>
+ │└ # D2 [8 B]
+ └ # D2 [22 B]
+ >>> squared = lambda x: x**2
+ >>> with detect.trace('output.txt', mode='w') as log:
+ >>> log("> D = %r", D)
+ >>> dumps(D)
+ >>> log("> squared = %r", squared)
+ >>> dumps(squared)
+
+ Arguments:
+ arg: a boolean value, or an optional file-like or path-like object for the context manager
+ mode: mode string for ``open()`` if a file name is passed as the first argument
+ """
+ if repr(arg) not in ('False', 'True'):
+ return TraceManager(file=arg, mode=mode)
+ logger.setLevel(logging.INFO if arg else logging.WARNING)
+
+class TraceManager(contextlib.AbstractContextManager):
+ """context manager version of trace(); can redirect the trace to a file"""
+ def __init__(self, file, mode):
+ self.file = file
+ self.mode = mode
+ self.redirect = file is not None
+ self.file_is_stream = hasattr(file, 'write')
+ def __enter__(self):
+ if self.redirect:
+ stderr_handler.flush()
+ if self.file_is_stream:
+ self.handler = logging.StreamHandler(self.file)
+ else:
+ self.handler = logging.FileHandler(self.file, self.mode)
+ adapter.removeHandler(stderr_handler)
+ adapter.addHandler(self.handler)
+ self.old_level = adapter.getEffectiveLevel()
+ adapter.setLevel(logging.INFO)
+ return adapter.info
+ def __exit__(self, *exc_info):
+ adapter.setLevel(self.old_level)
+ if self.redirect:
+ adapter.removeHandler(self.handler)
+ adapter.addHandler(stderr_handler)
+ if not self.file_is_stream:
+ self.handler.close()
diff --git a/solutions/.venv/Lib/site-packages/dill/objtypes.py b/solutions/.venv/Lib/site-packages/dill/objtypes.py
new file mode 100644
index 000000000..526b5835e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/objtypes.py
@@ -0,0 +1,24 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+all Python Standard Library object types (currently: CH 1-15 @ 2.7)
+and some other common object types (i.e. numpy.ndarray)
+
+to load more objects and types, use dill.load_types()
+"""
+
+# non-local import of dill.objects
+from dill import objects
+for _type in objects.keys():
+ exec("%s = type(objects['%s'])" % (_type,_type))
+
+del objects
+try:
+ del _type
+except NameError:
+ pass
diff --git a/solutions/.venv/Lib/site-packages/dill/pointers.py b/solutions/.venv/Lib/site-packages/dill/pointers.py
new file mode 100644
index 000000000..c3b48cae0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/pointers.py
@@ -0,0 +1,122 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+__all__ = ['parent', 'reference', 'at', 'parents', 'children']
+
+import gc
+import sys
+
+from ._dill import _proxy_helper as reference
+from ._dill import _locate_object as at
+
+def parent(obj, objtype, ignore=()):
+ """
+>>> listiter = iter([4,5,6,7])
+>>> obj = parent(listiter, list)
+>>> obj == [4,5,6,7] # actually 'is', but don't have handle any longer
+True
+
+NOTE: objtype can be a single type (e.g. int or list) or a tuple of types.
+
+WARNING: if obj is a sequence (e.g. list), may produce unexpected results.
+Parent finds *one* parent (e.g. the last member of the sequence).
+ """
+ depth = 1 #XXX: always looking for the parent (only, right?)
+ chain = parents(obj, objtype, depth, ignore)
+ parent = chain.pop()
+ if parent is obj:
+ return None
+ return parent
+
+
+def parents(obj, objtype, depth=1, ignore=()): #XXX: objtype=object ?
+ """Find the chain of referents for obj. Chain will end with obj.
+
+ objtype: an object type or tuple of types to search for
+ depth: search depth (e.g. depth=2 is 'grandparents')
+ ignore: an object or tuple of objects to ignore in the search
+ """
+ edge_func = gc.get_referents # looking for refs, not back_refs
+ predicate = lambda x: isinstance(x, objtype) # looking for parent type
+ #if objtype is None: predicate = lambda x: True #XXX: in obj.mro() ?
+ ignore = (ignore,) if not hasattr(ignore, '__len__') else ignore
+ ignore = (id(obj) for obj in ignore)
+ chain = find_chain(obj, predicate, edge_func, depth)[::-1]
+ #XXX: should pop off obj... ?
+ return chain
+
+
+def children(obj, objtype, depth=1, ignore=()): #XXX: objtype=object ?
+ """Find the chain of referrers for obj. Chain will start with obj.
+
+ objtype: an object type or tuple of types to search for
+ depth: search depth (e.g. depth=2 is 'grandchildren')
+ ignore: an object or tuple of objects to ignore in the search
+
+ NOTE: a common thing to ignore is all globals, 'ignore=(globals(),)'
+
+ NOTE: repeated calls may yield different results, as python stores
+ the last value in the special variable '_'; thus, it is often good
+ to execute something to replace '_' (e.g. >>> 1+1).
+ """
+ edge_func = gc.get_referrers # looking for back_refs, not refs
+ predicate = lambda x: isinstance(x, objtype) # looking for child type
+ #if objtype is None: predicate = lambda x: True #XXX: in obj.mro() ?
+ ignore = (ignore,) if not hasattr(ignore, '__len__') else ignore
+ ignore = (id(obj) for obj in ignore)
+ chain = find_chain(obj, predicate, edge_func, depth, ignore)
+ #XXX: should pop off obj... ?
+ return chain
+
+
+# more generic helper function (cut-n-paste from objgraph)
+# Source at http://mg.pov.lt/objgraph/
+# Copyright (c) 2008-2010 Marius Gedminas <marius@pov.lt>
+# Copyright (c) 2010 Stefano Rivera <stefano@rivera.za.net>
+# Released under the MIT licence (see objgraph/objgrah.py)
+
+def find_chain(obj, predicate, edge_func, max_depth=20, extra_ignore=()):
+ queue = [obj]
+ depth = {id(obj): 0}
+ parent = {id(obj): None}
+ ignore = set(extra_ignore)
+ ignore.add(id(extra_ignore))
+ ignore.add(id(queue))
+ ignore.add(id(depth))
+ ignore.add(id(parent))
+ ignore.add(id(ignore))
+ ignore.add(id(sys._getframe())) # this function
+ ignore.add(id(sys._getframe(1))) # find_chain/find_backref_chain, likely
+ gc.collect()
+ while queue:
+ target = queue.pop(0)
+ if predicate(target):
+ chain = [target]
+ while parent[id(target)] is not None:
+ target = parent[id(target)]
+ chain.append(target)
+ return chain
+ tdepth = depth[id(target)]
+ if tdepth < max_depth:
+ referrers = edge_func(target)
+ ignore.add(id(referrers))
+ for source in referrers:
+ if id(source) in ignore:
+ continue
+ if id(source) not in depth:
+ depth[id(source)] = tdepth + 1
+ parent[id(source)] = target
+ queue.append(source)
+ return [obj] # not found
+
+
+# backward compatibility
+refobject = at
+
+
+# EOF
diff --git a/solutions/.venv/Lib/site-packages/dill/session.py b/solutions/.venv/Lib/site-packages/dill/session.py
new file mode 100644
index 000000000..b99c8ad3b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/session.py
@@ -0,0 +1,612 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Author: Leonardo Gama (@leogama)
+# Copyright (c) 2008-2015 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+Pickle and restore the intepreter session.
+"""
+
+__all__ = [
+ 'dump_module', 'load_module', 'load_module_asdict',
+ 'dump_session', 'load_session' # backward compatibility
+]
+
+import re
+import os
+import sys
+import warnings
+import pathlib
+import tempfile
+
+TEMPDIR = pathlib.PurePath(tempfile.gettempdir())
+
+# Type hints.
+from typing import Optional, Union
+
+from dill import _dill, Pickler, Unpickler
+from ._dill import (
+ BuiltinMethodType, FunctionType, MethodType, ModuleType, TypeType,
+ _import_module, _is_builtin_module, _is_imported_module, _main_module,
+ _reverse_typemap, __builtin__, UnpicklingError,
+)
+
+def _module_map():
+ """get map of imported modules"""
+ from collections import defaultdict
+ from types import SimpleNamespace
+ modmap = SimpleNamespace(
+ by_name=defaultdict(list),
+ by_id=defaultdict(list),
+ top_level={},
+ )
+ for modname, module in sys.modules.items():
+ if modname in ('__main__', '__mp_main__') or not isinstance(module, ModuleType):
+ continue
+ if '.' not in modname:
+ modmap.top_level[id(module)] = modname
+ for objname, modobj in module.__dict__.items():
+ modmap.by_name[objname].append((modobj, modname))
+ modmap.by_id[id(modobj)].append((modobj, objname, modname))
+ return modmap
+
+IMPORTED_AS_TYPES = (ModuleType, TypeType, FunctionType, MethodType, BuiltinMethodType)
+if 'PyCapsuleType' in _reverse_typemap:
+ IMPORTED_AS_TYPES += (_reverse_typemap['PyCapsuleType'],)
+IMPORTED_AS_MODULES = ('ctypes', 'typing', 'subprocess', 'threading',
+ r'concurrent\.futures(\.\w+)?', r'multiprocessing(\.\w+)?')
+IMPORTED_AS_MODULES = tuple(re.compile(x) for x in IMPORTED_AS_MODULES)
+
+def _lookup_module(modmap, name, obj, main_module):
+ """lookup name or id of obj if module is imported"""
+ for modobj, modname in modmap.by_name[name]:
+ if modobj is obj and sys.modules[modname] is not main_module:
+ return modname, name
+ __module__ = getattr(obj, '__module__', None)
+ if isinstance(obj, IMPORTED_AS_TYPES) or (__module__ is not None
+ and any(regex.fullmatch(__module__) for regex in IMPORTED_AS_MODULES)):
+ for modobj, objname, modname in modmap.by_id[id(obj)]:
+ if sys.modules[modname] is not main_module:
+ return modname, objname
+ return None, None
+
+def _stash_modules(main_module):
+ modmap = _module_map()
+ newmod = ModuleType(main_module.__name__)
+
+ imported = []
+ imported_as = []
+ imported_top_level = [] # keep separated for backward compatibility
+ original = {}
+ for name, obj in main_module.__dict__.items():
+ if obj is main_module:
+ original[name] = newmod # self-reference
+ elif obj is main_module.__dict__:
+ original[name] = newmod.__dict__
+ # Avoid incorrectly matching a singleton value in another package (ex.: __doc__).
+ elif any(obj is singleton for singleton in (None, False, True)) \
+ or isinstance(obj, ModuleType) and _is_builtin_module(obj): # always saved by ref
+ original[name] = obj
+ else:
+ source_module, objname = _lookup_module(modmap, name, obj, main_module)
+ if source_module is not None:
+ if objname == name:
+ imported.append((source_module, name))
+ else:
+ imported_as.append((source_module, objname, name))
+ else:
+ try:
+ imported_top_level.append((modmap.top_level[id(obj)], name))
+ except KeyError:
+ original[name] = obj
+
+ if len(original) < len(main_module.__dict__):
+ newmod.__dict__.update(original)
+ newmod.__dill_imported = imported
+ newmod.__dill_imported_as = imported_as
+ newmod.__dill_imported_top_level = imported_top_level
+ if getattr(newmod, '__loader__', None) is None and _is_imported_module(main_module):
+ # Trick _is_imported_module() to force saving as an imported module.
+ newmod.__loader__ = True # will be discarded by save_module()
+ return newmod
+ else:
+ return main_module
+
+def _restore_modules(unpickler, main_module):
+ try:
+ for modname, name in main_module.__dict__.pop('__dill_imported'):
+ main_module.__dict__[name] = unpickler.find_class(modname, name)
+ for modname, objname, name in main_module.__dict__.pop('__dill_imported_as'):
+ main_module.__dict__[name] = unpickler.find_class(modname, objname)
+ for modname, name in main_module.__dict__.pop('__dill_imported_top_level'):
+ main_module.__dict__[name] = __import__(modname)
+ except KeyError:
+ pass
+
+#NOTE: 06/03/15 renamed main_module to main
+def dump_module(
+ filename: Union[str, os.PathLike] = None,
+ module: Optional[Union[ModuleType, str]] = None,
+ refimported: bool = False,
+ **kwds
+) -> None:
+ """Pickle the current state of :py:mod:`__main__` or another module to a file.
+
+ Save the contents of :py:mod:`__main__` (e.g. from an interactive
+ interpreter session), an imported module, or a module-type object (e.g.
+ built with :py:class:`~types.ModuleType`), to a file. The pickled
+ module can then be restored with the function :py:func:`load_module`.
+
+ Args:
+ filename: a path-like object or a writable stream. If `None`
+ (the default), write to a named file in a temporary directory.
+ module: a module object or the name of an importable module. If `None`
+ (the default), :py:mod:`__main__` is saved.
+ refimported: if `True`, all objects identified as having been imported
+ into the module's namespace are saved by reference. *Note:* this is
+ similar but independent from ``dill.settings[`byref`]``, as
+ ``refimported`` refers to virtually all imported objects, while
+ ``byref`` only affects select objects.
+ **kwds: extra keyword arguments passed to :py:class:`Pickler()`.
+
+ Raises:
+ :py:exc:`PicklingError`: if pickling fails.
+
+ Examples:
+
+ - Save current interpreter session state:
+
+ >>> import dill
+ >>> squared = lambda x: x*x
+ >>> dill.dump_module() # save state of __main__ to /tmp/session.pkl
+
+ - Save the state of an imported/importable module:
+
+ >>> import dill
+ >>> import pox
+ >>> pox.plus_one = lambda x: x+1
+ >>> dill.dump_module('pox_session.pkl', module=pox)
+
+ - Save the state of a non-importable, module-type object:
+
+ >>> import dill
+ >>> from types import ModuleType
+ >>> foo = ModuleType('foo')
+ >>> foo.values = [1,2,3]
+ >>> import math
+ >>> foo.sin = math.sin
+ >>> dill.dump_module('foo_session.pkl', module=foo, refimported=True)
+
+ - Restore the state of the saved modules:
+
+ >>> import dill
+ >>> dill.load_module()
+ >>> squared(2)
+ 4
+ >>> pox = dill.load_module('pox_session.pkl')
+ >>> pox.plus_one(1)
+ 2
+ >>> foo = dill.load_module('foo_session.pkl')
+ >>> [foo.sin(x) for x in foo.values]
+ [0.8414709848078965, 0.9092974268256817, 0.1411200080598672]
+
+ - Use `refimported` to save imported objects by reference:
+
+ >>> import dill
+ >>> from html.entities import html5
+ >>> type(html5), len(html5)
+ (dict, 2231)
+ >>> import io
+ >>> buf = io.BytesIO()
+ >>> dill.dump_module(buf) # saves __main__, with html5 saved by value
+ >>> len(buf.getvalue()) # pickle size in bytes
+ 71665
+ >>> buf = io.BytesIO()
+ >>> dill.dump_module(buf, refimported=True) # html5 saved by reference
+ >>> len(buf.getvalue())
+ 438
+
+ *Changed in version 0.3.6:* Function ``dump_session()`` was renamed to
+ ``dump_module()``. Parameters ``main`` and ``byref`` were renamed to
+ ``module`` and ``refimported``, respectively.
+
+ Note:
+ Currently, ``dill.settings['byref']`` and ``dill.settings['recurse']``
+ don't apply to this function.
+ """
+ for old_par, par in [('main', 'module'), ('byref', 'refimported')]:
+ if old_par in kwds:
+ message = "The argument %r has been renamed %r" % (old_par, par)
+ if old_par == 'byref':
+ message += " to distinguish it from dill.settings['byref']"
+ warnings.warn(message + ".", PendingDeprecationWarning)
+ if locals()[par]: # the defaults are None and False
+ raise TypeError("both %r and %r arguments were used" % (par, old_par))
+ refimported = kwds.pop('byref', refimported)
+ module = kwds.pop('main', module)
+
+ from .settings import settings
+ protocol = settings['protocol']
+ main = module
+ if main is None:
+ main = _main_module
+ elif isinstance(main, str):
+ main = _import_module(main)
+ if not isinstance(main, ModuleType):
+ raise TypeError("%r is not a module" % main)
+ if hasattr(filename, 'write'):
+ file = filename
+ else:
+ if filename is None:
+ filename = str(TEMPDIR/'session.pkl')
+ file = open(filename, 'wb')
+ try:
+ pickler = Pickler(file, protocol, **kwds)
+ pickler._original_main = main
+ if refimported:
+ main = _stash_modules(main)
+ pickler._main = main #FIXME: dill.settings are disabled
+ pickler._byref = False # disable pickling by name reference
+ pickler._recurse = False # disable pickling recursion for globals
+ pickler._session = True # is best indicator of when pickling a session
+ pickler._first_pass = True
+ pickler._main_modified = main is not pickler._original_main
+ pickler.dump(main)
+ finally:
+ if file is not filename: # if newly opened file
+ file.close()
+ return
+
+# Backward compatibility.
+def dump_session(filename=None, main=None, byref=False, **kwds):
+ warnings.warn("dump_session() has been renamed dump_module()", PendingDeprecationWarning)
+ dump_module(filename, module=main, refimported=byref, **kwds)
+dump_session.__doc__ = dump_module.__doc__
+
+class _PeekableReader:
+ """lightweight stream wrapper that implements peek()"""
+ def __init__(self, stream):
+ self.stream = stream
+ def read(self, n):
+ return self.stream.read(n)
+ def readline(self):
+ return self.stream.readline()
+ def tell(self):
+ return self.stream.tell()
+ def close(self):
+ return self.stream.close()
+ def peek(self, n):
+ stream = self.stream
+ try:
+ if hasattr(stream, 'flush'): stream.flush()
+ position = stream.tell()
+ stream.seek(position) # assert seek() works before reading
+ chunk = stream.read(n)
+ stream.seek(position)
+ return chunk
+ except (AttributeError, OSError):
+ raise NotImplementedError("stream is not peekable: %r", stream) from None
+
+def _make_peekable(stream):
+ """return stream as an object with a peek() method"""
+ import io
+ if hasattr(stream, 'peek'):
+ return stream
+ if not (hasattr(stream, 'tell') and hasattr(stream, 'seek')):
+ try:
+ return io.BufferedReader(stream)
+ except Exception:
+ pass
+ return _PeekableReader(stream)
+
+def _identify_module(file, main=None):
+ """identify the name of the module stored in the given file-type object"""
+ from pickletools import genops
+ UNICODE = {'UNICODE', 'BINUNICODE', 'SHORT_BINUNICODE'}
+ found_import = False
+ try:
+ for opcode, arg, pos in genops(file.peek(256)):
+ if not found_import:
+ if opcode.name in ('GLOBAL', 'SHORT_BINUNICODE') and \
+ arg.endswith('_import_module'):
+ found_import = True
+ else:
+ if opcode.name in UNICODE:
+ return arg
+ else:
+ raise UnpicklingError("reached STOP without finding main module")
+ except (NotImplementedError, ValueError) as error:
+ # ValueError occours when the end of the chunk is reached (without a STOP).
+ if isinstance(error, NotImplementedError) and main is not None:
+ # file is not peekable, but we have main.
+ return None
+ raise UnpicklingError("unable to identify main module") from error
+
+def load_module(
+ filename: Union[str, os.PathLike] = None,
+ module: Optional[Union[ModuleType, str]] = None,
+ **kwds
+) -> Optional[ModuleType]:
+ """Update the selected module (default is :py:mod:`__main__`) with
+ the state saved at ``filename``.
+
+ Restore a module to the state saved with :py:func:`dump_module`. The
+ saved module can be :py:mod:`__main__` (e.g. an interpreter session),
+ an imported module, or a module-type object (e.g. created with
+ :py:class:`~types.ModuleType`).
+
+ When restoring the state of a non-importable module-type object, the
+ current instance of this module may be passed as the argument ``main``.
+ Otherwise, a new instance is created with :py:class:`~types.ModuleType`
+ and returned.
+
+ Args:
+ filename: a path-like object or a readable stream. If `None`
+ (the default), read from a named file in a temporary directory.
+ module: a module object or the name of an importable module;
+ the module name and kind (i.e. imported or non-imported) must
+ match the name and kind of the module stored at ``filename``.
+ **kwds: extra keyword arguments passed to :py:class:`Unpickler()`.
+
+ Raises:
+ :py:exc:`UnpicklingError`: if unpickling fails.
+ :py:exc:`ValueError`: if the argument ``main`` and module saved
+ at ``filename`` are incompatible.
+
+ Returns:
+ A module object, if the saved module is not :py:mod:`__main__` or
+ a module instance wasn't provided with the argument ``main``.
+
+ Examples:
+
+ - Save the state of some modules:
+
+ >>> import dill
+ >>> squared = lambda x: x*x
+ >>> dill.dump_module() # save state of __main__ to /tmp/session.pkl
+ >>>
+ >>> import pox # an imported module
+ >>> pox.plus_one = lambda x: x+1
+ >>> dill.dump_module('pox_session.pkl', module=pox)
+ >>>
+ >>> from types import ModuleType
+ >>> foo = ModuleType('foo') # a module-type object
+ >>> foo.values = [1,2,3]
+ >>> import math
+ >>> foo.sin = math.sin
+ >>> dill.dump_module('foo_session.pkl', module=foo, refimported=True)
+
+ - Restore the state of the interpreter:
+
+ >>> import dill
+ >>> dill.load_module() # updates __main__ from /tmp/session.pkl
+ >>> squared(2)
+ 4
+
+ - Load the saved state of an importable module:
+
+ >>> import dill
+ >>> pox = dill.load_module('pox_session.pkl')
+ >>> pox.plus_one(1)
+ 2
+ >>> import sys
+ >>> pox in sys.modules.values()
+ True
+
+ - Load the saved state of a non-importable module-type object:
+
+ >>> import dill
+ >>> foo = dill.load_module('foo_session.pkl')
+ >>> [foo.sin(x) for x in foo.values]
+ [0.8414709848078965, 0.9092974268256817, 0.1411200080598672]
+ >>> import math
+ >>> foo.sin is math.sin # foo.sin was saved by reference
+ True
+ >>> import sys
+ >>> foo in sys.modules.values()
+ False
+
+ - Update the state of a non-importable module-type object:
+
+ >>> import dill
+ >>> from types import ModuleType
+ >>> foo = ModuleType('foo')
+ >>> foo.values = ['a','b']
+ >>> foo.sin = lambda x: x*x
+ >>> dill.load_module('foo_session.pkl', module=foo)
+ >>> [foo.sin(x) for x in foo.values]
+ [0.8414709848078965, 0.9092974268256817, 0.1411200080598672]
+
+ *Changed in version 0.3.6:* Function ``load_session()`` was renamed to
+ ``load_module()``. Parameter ``main`` was renamed to ``module``.
+
+ See also:
+ :py:func:`load_module_asdict` to load the contents of module saved
+ with :py:func:`dump_module` into a dictionary.
+ """
+ if 'main' in kwds:
+ warnings.warn(
+ "The argument 'main' has been renamed 'module'.",
+ PendingDeprecationWarning
+ )
+ if module is not None:
+ raise TypeError("both 'module' and 'main' arguments were used")
+ module = kwds.pop('main')
+ main = module
+ if hasattr(filename, 'read'):
+ file = filename
+ else:
+ if filename is None:
+ filename = str(TEMPDIR/'session.pkl')
+ file = open(filename, 'rb')
+ try:
+ file = _make_peekable(file)
+ #FIXME: dill.settings are disabled
+ unpickler = Unpickler(file, **kwds)
+ unpickler._session = True
+
+ # Resolve unpickler._main
+ pickle_main = _identify_module(file, main)
+ if main is None and pickle_main is not None:
+ main = pickle_main
+ if isinstance(main, str):
+ if main.startswith('__runtime__.'):
+ # Create runtime module to load the session into.
+ main = ModuleType(main.partition('.')[-1])
+ else:
+ main = _import_module(main)
+ if main is not None:
+ if not isinstance(main, ModuleType):
+ raise TypeError("%r is not a module" % main)
+ unpickler._main = main
+ else:
+ main = unpickler._main
+
+ # Check against the pickle's main.
+ is_main_imported = _is_imported_module(main)
+ if pickle_main is not None:
+ is_runtime_mod = pickle_main.startswith('__runtime__.')
+ if is_runtime_mod:
+ pickle_main = pickle_main.partition('.')[-1]
+ error_msg = "can't update{} module{} %r with the saved state of{} module{} %r"
+ if is_runtime_mod and is_main_imported:
+ raise ValueError(
+ error_msg.format(" imported", "", "", "-type object")
+ % (main.__name__, pickle_main)
+ )
+ if not is_runtime_mod and not is_main_imported:
+ raise ValueError(
+ error_msg.format("", "-type object", " imported", "")
+ % (pickle_main, main.__name__)
+ )
+ if main.__name__ != pickle_main:
+ raise ValueError(error_msg.format("", "", "", "") % (main.__name__, pickle_main))
+
+ # This is for find_class() to be able to locate it.
+ if not is_main_imported:
+ runtime_main = '__runtime__.%s' % main.__name__
+ sys.modules[runtime_main] = main
+
+ loaded = unpickler.load()
+ finally:
+ if not hasattr(filename, 'read'): # if newly opened file
+ file.close()
+ try:
+ del sys.modules[runtime_main]
+ except (KeyError, NameError):
+ pass
+ assert loaded is main
+ _restore_modules(unpickler, main)
+ if main is _main_module or main is module:
+ return None
+ else:
+ return main
+
+# Backward compatibility.
+def load_session(filename=None, main=None, **kwds):
+ warnings.warn("load_session() has been renamed load_module().", PendingDeprecationWarning)
+ load_module(filename, module=main, **kwds)
+load_session.__doc__ = load_module.__doc__
+
+def load_module_asdict(
+ filename: Union[str, os.PathLike] = None,
+ update: bool = False,
+ **kwds
+) -> dict:
+ """
+ Load the contents of a saved module into a dictionary.
+
+ ``load_module_asdict()`` is the near-equivalent of::
+
+ lambda filename: vars(dill.load_module(filename)).copy()
+
+ however, does not alter the original module. Also, the path of
+ the loaded module is stored in the ``__session__`` attribute.
+
+ Args:
+ filename: a path-like object or a readable stream. If `None`
+ (the default), read from a named file in a temporary directory.
+ update: if `True`, initialize the dictionary with the current state
+ of the module prior to loading the state stored at filename.
+ **kwds: extra keyword arguments passed to :py:class:`Unpickler()`
+
+ Raises:
+ :py:exc:`UnpicklingError`: if unpickling fails
+
+ Returns:
+ A copy of the restored module's dictionary.
+
+ Note:
+ If ``update`` is True, the corresponding module may first be imported
+ into the current namespace before the saved state is loaded from
+ filename to the dictionary. Note that any module that is imported into
+ the current namespace as a side-effect of using ``update`` will not be
+ modified by loading the saved module in filename to a dictionary.
+
+ Example:
+ >>> import dill
+ >>> alist = [1, 2, 3]
+ >>> anum = 42
+ >>> dill.dump_module()
+ >>> anum = 0
+ >>> new_var = 'spam'
+ >>> main = dill.load_module_asdict()
+ >>> main['__name__'], main['__session__']
+ ('__main__', '/tmp/session.pkl')
+ >>> main is globals() # loaded objects don't reference globals
+ False
+ >>> main['alist'] == alist
+ True
+ >>> main['alist'] is alist # was saved by value
+ False
+ >>> main['anum'] == anum # changed after the session was saved
+ False
+ >>> new_var in main # would be True if the option 'update' was set
+ False
+ """
+ if 'module' in kwds:
+ raise TypeError("'module' is an invalid keyword argument for load_module_asdict()")
+ if hasattr(filename, 'read'):
+ file = filename
+ else:
+ if filename is None:
+ filename = str(TEMPDIR/'session.pkl')
+ file = open(filename, 'rb')
+ try:
+ file = _make_peekable(file)
+ main_name = _identify_module(file)
+ old_main = sys.modules.get(main_name)
+ main = ModuleType(main_name)
+ if update:
+ if old_main is None:
+ old_main = _import_module(main_name)
+ main.__dict__.update(old_main.__dict__)
+ else:
+ main.__builtins__ = __builtin__
+ sys.modules[main_name] = main
+ load_module(file, **kwds)
+ finally:
+ if not hasattr(filename, 'read'): # if newly opened file
+ file.close()
+ try:
+ if old_main is None:
+ del sys.modules[main_name]
+ else:
+ sys.modules[main_name] = old_main
+ except NameError: # failed before setting old_main
+ pass
+ main.__session__ = str(filename)
+ return main.__dict__
+
+
+# Internal exports for backward compatibility with dill v0.3.5.1
+# Can't be placed in dill._dill because of circular import problems.
+for name in (
+ '_lookup_module', '_module_map', '_restore_modules', '_stash_modules',
+ 'dump_session', 'load_session' # backward compatibility functions
+):
+ setattr(_dill, name, globals()[name])
+del name
diff --git a/solutions/.venv/Lib/site-packages/dill/settings.py b/solutions/.venv/Lib/site-packages/dill/settings.py
new file mode 100644
index 000000000..19c18fc5f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/settings.py
@@ -0,0 +1,25 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+global settings for Pickler
+"""
+
+from pickle import DEFAULT_PROTOCOL
+
+settings = {
+ #'main' : None,
+ 'protocol' : DEFAULT_PROTOCOL,
+ 'byref' : False,
+ #'strictio' : False,
+ 'fmode' : 0, #HANDLE_FMODE
+ 'recurse' : False,
+ 'ignore' : False,
+}
+
+del DEFAULT_PROTOCOL
+
diff --git a/solutions/.venv/Lib/site-packages/dill/source.py b/solutions/.venv/Lib/site-packages/dill/source.py
new file mode 100644
index 000000000..18bd875c9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/source.py
@@ -0,0 +1,1023 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+#
+# inspired by inspect.py from Python-2.7.6
+# inspect.py author: 'Ka-Ping Yee <ping@lfw.org>'
+# inspect.py merged into original dill.source by Mike McKerns 4/13/14
+"""
+Extensions to python's 'inspect' module, which can be used
+to retrieve information from live python objects. The methods
+defined in this module are augmented to facilitate access to
+source code of interactively defined functions and classes,
+as well as provide access to source code for objects defined
+in a file.
+"""
+
+__all__ = ['findsource', 'getsourcelines', 'getsource', 'indent', 'outdent', \
+ '_wrap', 'dumpsource', 'getname', '_namespace', 'getimport', \
+ '_importable', 'importable','isdynamic', 'isfrommain']
+
+import linecache
+import re
+from inspect import (getblock, getfile, getmodule, getsourcefile, indentsize,
+ isbuiltin, isclass, iscode, isframe, isfunction, ismethod,
+ ismodule, istraceback)
+from tokenize import TokenError
+
+from ._dill import IS_IPYTHON
+
+
+def isfrommain(obj):
+ "check if object was built in __main__"
+ module = getmodule(obj)
+ if module and module.__name__ == '__main__':
+ return True
+ return False
+
+
+def isdynamic(obj):
+ "check if object was built in the interpreter"
+ try: file = getfile(obj)
+ except TypeError: file = None
+ if file == '<stdin>' and isfrommain(obj):
+ return True
+ return False
+
+
+def _matchlambda(func, line):
+ """check if lambda object 'func' matches raw line of code 'line'"""
+ from .detect import code as getcode
+ from .detect import freevars, globalvars, varnames
+ dummy = lambda : '__this_is_a_big_dummy_function__'
+ # process the line (removing leading whitespace, etc)
+ lhs,rhs = line.split('lambda ',1)[-1].split(":", 1) #FIXME: if !1 inputs
+ try: #FIXME: unsafe
+ _ = eval("lambda %s : %s" % (lhs,rhs), globals(),locals())
+ except Exception: _ = dummy
+ # get code objects, for comparison
+ _, code = getcode(_).co_code, getcode(func).co_code
+ # check if func is in closure
+ _f = [line.count(i) for i in freevars(func).keys()]
+ if not _f: # not in closure
+ # check if code matches
+ if _ == code: return True
+ return False
+ # weak check on freevars
+ if not all(_f): return False #XXX: VERY WEAK
+ # weak check on varnames and globalvars
+ _f = varnames(func)
+ _f = [line.count(i) for i in _f[0]+_f[1]]
+ if _f and not all(_f): return False #XXX: VERY WEAK
+ _f = [line.count(i) for i in globalvars(func).keys()]
+ if _f and not all(_f): return False #XXX: VERY WEAK
+ # check if func is a double lambda
+ if (line.count('lambda ') > 1) and (lhs in freevars(func).keys()):
+ _lhs,_rhs = rhs.split('lambda ',1)[-1].split(":",1) #FIXME: if !1 inputs
+ try: #FIXME: unsafe
+ _f = eval("lambda %s : %s" % (_lhs,_rhs), globals(),locals())
+ except Exception: _f = dummy
+ # get code objects, for comparison
+ _, code = getcode(_f).co_code, getcode(func).co_code
+ if len(_) != len(code): return False
+ #NOTE: should be same code same order, but except for 't' and '\x88'
+ _ = set((i,j) for (i,j) in zip(_,code) if i != j)
+ if len(_) != 1: return False #('t','\x88')
+ return True
+ # check indentsize
+ if not indentsize(line): return False #FIXME: is this a good check???
+ # check if code 'pattern' matches
+ #XXX: or pattern match against dis.dis(code)? (or use uncompyle2?)
+ _ = _.split(_[0]) # 't' #XXX: remove matching values if starts the same?
+ _f = code.split(code[0]) # '\x88'
+ #NOTE: should be same code different order, with different first element
+ _ = dict(re.match(r'([\W\D\S])(.*)', _[i]).groups() for i in range(1,len(_)))
+ _f = dict(re.match(r'([\W\D\S])(.*)', _f[i]).groups() for i in range(1,len(_f)))
+ if (_.keys() == _f.keys()) and (sorted(_.values()) == sorted(_f.values())):
+ return True
+ return False
+
+
+def findsource(object):
+ """Return the entire source file and starting line number for an object.
+ For interactively-defined objects, the 'file' is the interpreter's history.
+
+ The argument may be a module, class, method, function, traceback, frame,
+ or code object. The source code is returned as a list of all the lines
+ in the file and the line number indexes a line in that list. An IOError
+ is raised if the source code cannot be retrieved, while a TypeError is
+ raised for objects where the source code is unavailable (e.g. builtins)."""
+
+ module = getmodule(object)
+ try: file = getfile(module)
+ except TypeError: file = None
+ is_module_main = (module and module.__name__ == '__main__' and not file)
+ if IS_IPYTHON and is_module_main:
+ #FIXME: quick fix for functions and classes in IPython interpreter
+ try:
+ file = getfile(object)
+ sourcefile = getsourcefile(object)
+ except TypeError:
+ if isclass(object):
+ for object_method in filter(isfunction, object.__dict__.values()):
+ # look for a method of the class
+ file_candidate = getfile(object_method)
+ if not file_candidate.startswith('<ipython-input-'):
+ continue
+ file = file_candidate
+ sourcefile = getsourcefile(object_method)
+ break
+ if file:
+ lines = linecache.getlines(file)
+ else:
+ # fallback to use history
+ history = '\n'.join(get_ipython().history_manager.input_hist_parsed)
+ lines = [line + '\n' for line in history.splitlines()]
+ # use readline when working in interpreter (i.e. __main__ and not file)
+ elif is_module_main:
+ try:
+ import readline
+ err = ''
+ except ImportError:
+ import sys
+ err = sys.exc_info()[1].args[0]
+ if sys.platform[:3] == 'win':
+ err += ", please install 'pyreadline'"
+ if err:
+ raise IOError(err)
+ lbuf = readline.get_current_history_length()
+ lines = [readline.get_history_item(i)+'\n' for i in range(1,lbuf+1)]
+ else:
+ try: # special handling for class instances
+ if not isclass(object) and isclass(type(object)): # __class__
+ file = getfile(module)
+ sourcefile = getsourcefile(module)
+ else: # builtins fail with a TypeError
+ file = getfile(object)
+ sourcefile = getsourcefile(object)
+ except (TypeError, AttributeError): # fail with better error
+ file = getfile(object)
+ sourcefile = getsourcefile(object)
+ if not sourcefile and file[:1] + file[-1:] != '<>':
+ raise IOError('source code not available')
+ file = sourcefile if sourcefile else file
+
+ module = getmodule(object, file)
+ if module:
+ lines = linecache.getlines(file, module.__dict__)
+ else:
+ lines = linecache.getlines(file)
+
+ if not lines:
+ raise IOError('could not extract source code')
+
+ #FIXME: all below may fail if exec used (i.e. exec('f = lambda x:x') )
+ if ismodule(object):
+ return lines, 0
+
+ #NOTE: beneficial if search goes from end to start of buffer history
+ name = pat1 = obj = ''
+ pat2 = r'^(\s*@)'
+# pat1b = r'^(\s*%s\W*=)' % name #FIXME: finds 'f = decorate(f)', not exec
+ if ismethod(object):
+ name = object.__name__
+ if name == '<lambda>': pat1 = r'(.*(?<!\w)lambda(:|\s))'
+ else: pat1 = r'^(\s*def\s)'
+ object = object.__func__
+ if isfunction(object):
+ name = object.__name__
+ if name == '<lambda>':
+ pat1 = r'(.*(?<!\w)lambda(:|\s))'
+ obj = object #XXX: better a copy?
+ else: pat1 = r'^(\s*def\s)'
+ object = object.__code__
+ if istraceback(object):
+ object = object.tb_frame
+ if isframe(object):
+ object = object.f_code
+ if iscode(object):
+ if not hasattr(object, 'co_firstlineno'):
+ raise IOError('could not find function definition')
+ stdin = object.co_filename == '<stdin>'
+ if stdin:
+ lnum = len(lines) - 1 # can't get lnum easily, so leverage pat
+ if not pat1: pat1 = r'^(\s*def\s)|(.*(?<!\w)lambda(:|\s))|^(\s*@)'
+ else:
+ lnum = object.co_firstlineno - 1
+ pat1 = r'^(\s*def\s)|(.*(?<!\w)lambda(:|\s))|^(\s*@)'
+ pat1 = re.compile(pat1); pat2 = re.compile(pat2)
+ #XXX: candidate_lnum = [n for n in range(lnum) if pat1.match(lines[n])]
+ while lnum > 0: #XXX: won't find decorators in <stdin> ?
+ line = lines[lnum]
+ if pat1.match(line):
+ if not stdin: break # co_firstlineno does the job
+ if name == '<lambda>': # hackery needed to confirm a match
+ if _matchlambda(obj, line): break
+ else: # not a lambda, just look for the name
+ if name in line: # need to check for decorator...
+ hats = 0
+ for _lnum in range(lnum-1,-1,-1):
+ if pat2.match(lines[_lnum]): hats += 1
+ else: break
+ lnum = lnum - hats
+ break
+ lnum = lnum - 1
+ return lines, lnum
+
+ try: # turn instances into classes
+ if not isclass(object) and isclass(type(object)): # __class__
+ object = object.__class__ #XXX: sometimes type(class) is better?
+ #XXX: we don't find how the instance was built
+ except AttributeError: pass
+ if isclass(object):
+ name = object.__name__
+ pat = re.compile(r'^(\s*)class\s*' + name + r'\b')
+ # make some effort to find the best matching class definition:
+ # use the one with the least indentation, which is the one
+ # that's most probably not inside a function definition.
+ candidates = []
+ for i in range(len(lines)-1,-1,-1):
+ match = pat.match(lines[i])
+ if match:
+ # if it's at toplevel, it's already the best one
+ if lines[i][0] == 'c':
+ return lines, i
+ # else add whitespace to candidate list
+ candidates.append((match.group(1), i))
+ if candidates:
+ # this will sort by whitespace, and by line number,
+ # less whitespace first #XXX: should sort high lnum before low
+ candidates.sort()
+ return lines, candidates[0][1]
+ else:
+ raise IOError('could not find class definition')
+ raise IOError('could not find code object')
+
+
+def getblocks(object, lstrip=False, enclosing=False, locate=False):
+ """Return a list of source lines and starting line number for an object.
+ Interactively-defined objects refer to lines in the interpreter's history.
+
+ If enclosing=True, then also return any enclosing code.
+ If lstrip=True, ensure there is no indentation in the first line of code.
+ If locate=True, then also return the line number for the block of code.
+
+ DEPRECATED: use 'getsourcelines' instead
+ """
+ lines, lnum = findsource(object)
+
+ if ismodule(object):
+ if lstrip: lines = _outdent(lines)
+ return ([lines], [0]) if locate is True else [lines]
+
+ #XXX: 'enclosing' means: closures only? or classes and files?
+ indent = indentsize(lines[lnum])
+ block = getblock(lines[lnum:]) #XXX: catch any TokenError here?
+
+ if not enclosing or not indent:
+ if lstrip: block = _outdent(block)
+ return ([block], [lnum]) if locate is True else [block]
+
+ pat1 = r'^(\s*def\s)|(.*(?<!\w)lambda(:|\s))'; pat1 = re.compile(pat1)
+ pat2 = r'^(\s*@)'; pat2 = re.compile(pat2)
+ #pat3 = r'^(\s*class\s)'; pat3 = re.compile(pat3) #XXX: enclosing class?
+ #FIXME: bound methods need enclosing class (and then instantiation)
+ # *or* somehow apply a partial using the instance
+
+ skip = 0
+ line = 0
+ blocks = []; _lnum = []
+ target = ''.join(block)
+ while line <= lnum: #XXX: repeat lnum? or until line < lnum?
+ # see if starts with ('def','lambda') and contains our target block
+ if pat1.match(lines[line]):
+ if not skip:
+ try: code = getblock(lines[line:])
+ except TokenError: code = [lines[line]]
+ if indentsize(lines[line]) > indent: #XXX: should be >= ?
+ line += len(code) - skip
+ elif target in ''.join(code):
+ blocks.append(code) # save code block as the potential winner
+ _lnum.append(line - skip) # save the line number for the match
+ line += len(code) - skip
+ else:
+ line += 1
+ skip = 0
+ # find skip: the number of consecutive decorators
+ elif pat2.match(lines[line]):
+ try: code = getblock(lines[line:])
+ except TokenError: code = [lines[line]]
+ skip = 1
+ for _line in code[1:]: # skip lines that are decorators
+ if not pat2.match(_line): break
+ skip += 1
+ line += skip
+ # no match: reset skip and go to the next line
+ else:
+ line +=1
+ skip = 0
+
+ if not blocks:
+ blocks = [block]
+ _lnum = [lnum]
+ if lstrip: blocks = [_outdent(block) for block in blocks]
+ # return last match
+ return (blocks, _lnum) if locate is True else blocks
+
+
+def getsourcelines(object, lstrip=False, enclosing=False):
+ """Return a list of source lines and starting line number for an object.
+ Interactively-defined objects refer to lines in the interpreter's history.
+
+ The argument may be a module, class, method, function, traceback, frame,
+ or code object. The source code is returned as a list of the lines
+ corresponding to the object and the line number indicates where in the
+ original source file the first line of code was found. An IOError is
+ raised if the source code cannot be retrieved, while a TypeError is
+ raised for objects where the source code is unavailable (e.g. builtins).
+
+ If lstrip=True, ensure there is no indentation in the first line of code.
+ If enclosing=True, then also return any enclosing code."""
+ code, n = getblocks(object, lstrip=lstrip, enclosing=enclosing, locate=True)
+ return code[-1], n[-1]
+
+
+#NOTE: broke backward compatibility 4/16/14 (was lstrip=True, force=True)
+def getsource(object, alias='', lstrip=False, enclosing=False, \
+ force=False, builtin=False):
+ """Return the text of the source code for an object. The source code for
+ interactively-defined objects are extracted from the interpreter's history.
+
+ The argument may be a module, class, method, function, traceback, frame,
+ or code object. The source code is returned as a single string. An
+ IOError is raised if the source code cannot be retrieved, while a
+ TypeError is raised for objects where the source code is unavailable
+ (e.g. builtins).
+
+ If alias is provided, then add a line of code that renames the object.
+ If lstrip=True, ensure there is no indentation in the first line of code.
+ If enclosing=True, then also return any enclosing code.
+ If force=True, catch (TypeError,IOError) and try to use import hooks.
+ If builtin=True, force an import for any builtins
+ """
+ # hascode denotes a callable
+ hascode = _hascode(object)
+ # is a class instance type (and not in builtins)
+ instance = _isinstance(object)
+
+ # get source lines; if fail, try to 'force' an import
+ try: # fails for builtins, and other assorted object types
+ lines, lnum = getsourcelines(object, enclosing=enclosing)
+ except (TypeError, IOError): # failed to get source, resort to import hooks
+ if not force: # don't try to get types that findsource can't get
+ raise
+ if not getmodule(object): # get things like 'None' and '1'
+ if not instance: return getimport(object, alias, builtin=builtin)
+ # special handling (numpy arrays, ...)
+ _import = getimport(object, builtin=builtin)
+ name = getname(object, force=True)
+ _alias = "%s = " % alias if alias else ""
+ if alias == name: _alias = ""
+ return _import+_alias+"%s\n" % name
+ else: #FIXME: could use a good bit of cleanup, since using getimport...
+ if not instance: return getimport(object, alias, builtin=builtin)
+ # now we are dealing with an instance...
+ name = object.__class__.__name__
+ module = object.__module__
+ if module in ['builtins','__builtin__']:
+ return getimport(object, alias, builtin=builtin)
+ else: #FIXME: leverage getimport? use 'from module import name'?
+ lines, lnum = ["%s = __import__('%s', fromlist=['%s']).%s\n" % (name,module,name,name)], 0
+ obj = eval(lines[0].lstrip(name + ' = '))
+ lines, lnum = getsourcelines(obj, enclosing=enclosing)
+
+ # strip leading indent (helps ensure can be imported)
+ if lstrip or alias:
+ lines = _outdent(lines)
+
+ # instantiate, if there's a nice repr #XXX: BAD IDEA???
+ if instance: #and force: #XXX: move into findsource or getsourcelines ?
+ if '(' in repr(object): lines.append('%r\n' % object)
+ #else: #XXX: better to somehow to leverage __reduce__ ?
+ # reconstructor,args = object.__reduce__()
+ # _ = reconstructor(*args)
+ else: # fall back to serialization #XXX: bad idea?
+ #XXX: better not duplicate work? #XXX: better new/enclose=True?
+ lines = dumpsource(object, alias='', new=force, enclose=False)
+ lines, lnum = [line+'\n' for line in lines.split('\n')][:-1], 0
+ #else: object.__code__ # raise AttributeError
+
+ # add an alias to the source code
+ if alias:
+ if hascode:
+ skip = 0
+ for line in lines: # skip lines that are decorators
+ if not line.startswith('@'): break
+ skip += 1
+ #XXX: use regex from findsource / getsourcelines ?
+ if lines[skip].lstrip().startswith('def '): # we have a function
+ if alias != object.__name__:
+ lines.append('\n%s = %s\n' % (alias, object.__name__))
+ elif 'lambda ' in lines[skip]: # we have a lambda
+ if alias != lines[skip].split('=')[0].strip():
+ lines[skip] = '%s = %s' % (alias, lines[skip])
+ else: # ...try to use the object's name
+ if alias != object.__name__:
+ lines.append('\n%s = %s\n' % (alias, object.__name__))
+ else: # class or class instance
+ if instance:
+ if alias != lines[-1].split('=')[0].strip():
+ lines[-1] = ('%s = ' % alias) + lines[-1]
+ else:
+ name = getname(object, force=True) or object.__name__
+ if alias != name:
+ lines.append('\n%s = %s\n' % (alias, name))
+ return ''.join(lines)
+
+
+def _hascode(object):
+ '''True if object has an attribute that stores it's __code__'''
+ return getattr(object,'__code__',None) or getattr(object,'func_code',None)
+
+def _isinstance(object):
+ '''True if object is a class instance type (and is not a builtin)'''
+ if _hascode(object) or isclass(object) or ismodule(object):
+ return False
+ if istraceback(object) or isframe(object) or iscode(object):
+ return False
+ # special handling (numpy arrays, ...)
+ if not getmodule(object) and getmodule(type(object)).__name__ in ['numpy']:
+ return True
+# # check if is instance of a builtin
+# if not getmodule(object) and getmodule(type(object)).__name__ in ['__builtin__','builtins']:
+# return False
+ _types = ('<class ',"<type 'instance'>")
+ if not repr(type(object)).startswith(_types): #FIXME: weak hack
+ return False
+ if not getmodule(object) or object.__module__ in ['builtins','__builtin__'] or getname(object, force=True) in ['array']:
+ return False
+ return True # by process of elimination... it's what we want
+
+
+def _intypes(object):
+ '''check if object is in the 'types' module'''
+ import types
+ # allow user to pass in object or object.__name__
+ if type(object) is not type(''):
+ object = getname(object, force=True)
+ if object == 'ellipsis': object = 'EllipsisType'
+ return True if hasattr(types, object) else False
+
+
+def _isstring(object): #XXX: isstringlike better?
+ '''check if object is a string-like type'''
+ return isinstance(object, (str, bytes))
+
+
+def indent(code, spaces=4):
+ '''indent a block of code with whitespace (default is 4 spaces)'''
+ indent = indentsize(code)
+ from numbers import Integral
+ if isinstance(spaces, Integral): spaces = ' '*spaces
+ # if '\t' is provided, will indent with a tab
+ nspaces = indentsize(spaces)
+ # blank lines (etc) need to be ignored
+ lines = code.split('\n')
+## stq = "'''"; dtq = '"""'
+## in_stq = in_dtq = False
+ for i in range(len(lines)):
+ #FIXME: works... but shouldn't indent 2nd+ lines of multiline doc
+ _indent = indentsize(lines[i])
+ if indent > _indent: continue
+ lines[i] = spaces+lines[i]
+## #FIXME: may fail when stq and dtq in same line (depends on ordering)
+## nstq, ndtq = lines[i].count(stq), lines[i].count(dtq)
+## if not in_dtq and not in_stq:
+## lines[i] = spaces+lines[i] # we indent
+## # entering a comment block
+## if nstq%2: in_stq = not in_stq
+## if ndtq%2: in_dtq = not in_dtq
+## # leaving a comment block
+## elif in_dtq and ndtq%2: in_dtq = not in_dtq
+## elif in_stq and nstq%2: in_stq = not in_stq
+## else: pass
+ if lines[-1].strip() == '': lines[-1] = ''
+ return '\n'.join(lines)
+
+
+def _outdent(lines, spaces=None, all=True):
+ '''outdent lines of code, accounting for docs and line continuations'''
+ indent = indentsize(lines[0])
+ if spaces is None or spaces > indent or spaces < 0: spaces = indent
+ for i in range(len(lines) if all else 1):
+ #FIXME: works... but shouldn't outdent 2nd+ lines of multiline doc
+ _indent = indentsize(lines[i])
+ if spaces > _indent: _spaces = _indent
+ else: _spaces = spaces
+ lines[i] = lines[i][_spaces:]
+ return lines
+
+def outdent(code, spaces=None, all=True):
+ '''outdent a block of code (default is to strip all leading whitespace)'''
+ indent = indentsize(code)
+ if spaces is None or spaces > indent or spaces < 0: spaces = indent
+ #XXX: will this delete '\n' in some cases?
+ if not all: return code[spaces:]
+ return '\n'.join(_outdent(code.split('\n'), spaces=spaces, all=all))
+
+
+# _wrap provides an wrapper to correctly exec and load into locals
+__globals__ = globals()
+__locals__ = locals()
+def _wrap(f):
+ """ encapsulate a function and it's __import__ """
+ def func(*args, **kwds):
+ try:
+ # _ = eval(getsource(f, force=True)) #XXX: safer but less robust
+ exec(getimportable(f, alias='_'), __globals__, __locals__)
+ except Exception:
+ raise ImportError('cannot import name ' + f.__name__)
+ return _(*args, **kwds)
+ func.__name__ = f.__name__
+ func.__doc__ = f.__doc__
+ return func
+
+
+def _enclose(object, alias=''): #FIXME: needs alias to hold returned object
+ """create a function enclosure around the source of some object"""
+ #XXX: dummy and stub should append a random string
+ dummy = '__this_is_a_big_dummy_enclosing_function__'
+ stub = '__this_is_a_stub_variable__'
+ code = 'def %s():\n' % dummy
+ code += indent(getsource(object, alias=stub, lstrip=True, force=True))
+ code += indent('return %s\n' % stub)
+ if alias: code += '%s = ' % alias
+ code += '%s(); del %s\n' % (dummy, dummy)
+ #code += "globals().pop('%s',lambda :None)()\n" % dummy
+ return code
+
+
+def dumpsource(object, alias='', new=False, enclose=True):
+ """'dump to source', where the code includes a pickled object.
+
+ If new=True and object is a class instance, then create a new
+ instance using the unpacked class source code. If enclose, then
+ create the object inside a function enclosure (thus minimizing
+ any global namespace pollution).
+ """
+ from dill import dumps
+ pik = repr(dumps(object))
+ code = 'import dill\n'
+ if enclose:
+ stub = '__this_is_a_stub_variable__' #XXX: *must* be same _enclose.stub
+ pre = '%s = ' % stub
+ new = False #FIXME: new=True doesn't work with enclose=True
+ else:
+ stub = alias
+ pre = '%s = ' % stub if alias else alias
+
+ # if a 'new' instance is not needed, then just dump and load
+ if not new or not _isinstance(object):
+ code += pre + 'dill.loads(%s)\n' % pik
+ else: #XXX: other cases where source code is needed???
+ code += getsource(object.__class__, alias='', lstrip=True, force=True)
+ mod = repr(object.__module__) # should have a module (no builtins here)
+ code += pre + 'dill.loads(%s.replace(b%s,bytes(__name__,"UTF-8")))\n' % (pik,mod)
+ #code += 'del %s' % object.__class__.__name__ #NOTE: kills any existing!
+
+ if enclose:
+ # generation of the 'enclosure'
+ dummy = '__this_is_a_big_dummy_object__'
+ dummy = _enclose(dummy, alias=alias)
+ # hack to replace the 'dummy' with the 'real' code
+ dummy = dummy.split('\n')
+ code = dummy[0]+'\n' + indent(code) + '\n'.join(dummy[-3:])
+
+ return code #XXX: better 'dumpsourcelines', returning list of lines?
+
+
+def getname(obj, force=False, fqn=False): #XXX: throw(?) to raise error on fail?
+ """get the name of the object. for lambdas, get the name of the pointer """
+ if fqn: return '.'.join(_namespace(obj)) #NOTE: returns 'type'
+ module = getmodule(obj)
+ if not module: # things like "None" and "1"
+ if not force: return None #NOTE: returns 'instance' NOT 'type' #FIXME?
+ # handle some special cases
+ if hasattr(obj, 'dtype') and not obj.shape:
+ return getname(obj.__class__) + "(" + repr(obj.tolist()) + ")"
+ return repr(obj)
+ try:
+ #XXX: 'wrong' for decorators and curried functions ?
+ # if obj.func_closure: ...use logic from getimportable, etc ?
+ name = obj.__name__
+ if name == '<lambda>':
+ return getsource(obj).split('=',1)[0].strip()
+ # handle some special cases
+ if module.__name__ in ['builtins','__builtin__']:
+ if name == 'ellipsis': name = 'EllipsisType'
+ return name
+ except AttributeError: #XXX: better to just throw AttributeError ?
+ if not force: return None
+ name = repr(obj)
+ if name.startswith('<'): # or name.split('('):
+ return None
+ return name
+
+
+def _namespace(obj):
+ """_namespace(obj); return namespace hierarchy (as a list of names)
+ for the given object. For an instance, find the class hierarchy.
+
+ For example:
+
+ >>> from functools import partial
+ >>> p = partial(int, base=2)
+ >>> _namespace(p)
+ [\'functools\', \'partial\']
+ """
+ # mostly for functions and modules and such
+ #FIXME: 'wrong' for decorators and curried functions
+ try: #XXX: needs some work and testing on different types
+ module = qual = str(getmodule(obj)).split()[1].strip('>').strip('"').strip("'")
+ qual = qual.split('.')
+ if ismodule(obj):
+ return qual
+ # get name of a lambda, function, etc
+ name = getname(obj) or obj.__name__ # failing, raise AttributeError
+ # check special cases (NoneType, ...)
+ if module in ['builtins','__builtin__']: # BuiltinFunctionType
+ if _intypes(name): return ['types'] + [name]
+ return qual + [name] #XXX: can be wrong for some aliased objects
+ except Exception: pass
+ # special case: numpy.inf and numpy.nan (we don't want them as floats)
+ if str(obj) in ['inf','nan','Inf','NaN']: # is more, but are they needed?
+ return ['numpy'] + [str(obj)]
+ # mostly for classes and class instances and such
+ module = getattr(obj.__class__, '__module__', None)
+ qual = str(obj.__class__)
+ try: qual = qual[qual.index("'")+1:-2]
+ except ValueError: pass # str(obj.__class__) made the 'try' unnecessary
+ qual = qual.split(".")
+ if module in ['builtins','__builtin__']:
+ # check special cases (NoneType, Ellipsis, ...)
+ if qual[-1] == 'ellipsis': qual[-1] = 'EllipsisType'
+ if _intypes(qual[-1]): module = 'types' #XXX: BuiltinFunctionType
+ qual = [module] + qual
+ return qual
+
+
+#NOTE: 05/25/14 broke backward compatibility: added 'alias' as 3rd argument
+def _getimport(head, tail, alias='', verify=True, builtin=False):
+ """helper to build a likely import string from head and tail of namespace.
+ ('head','tail') are used in the following context: "from head import tail"
+
+ If verify=True, then test the import string before returning it.
+ If builtin=True, then force an import for builtins where possible.
+ If alias is provided, then rename the object on import.
+ """
+ # special handling for a few common types
+ if tail in ['Ellipsis', 'NotImplemented'] and head in ['types']:
+ head = len.__module__
+ elif tail in ['None'] and head in ['types']:
+ _alias = '%s = ' % alias if alias else ''
+ if alias == tail: _alias = ''
+ return _alias+'%s\n' % tail
+ # we don't need to import from builtins, so return ''
+# elif tail in ['NoneType','int','float','long','complex']: return '' #XXX: ?
+ if head in ['builtins','__builtin__']:
+ # special cases (NoneType, Ellipsis, ...) #XXX: BuiltinFunctionType
+ if tail == 'ellipsis': tail = 'EllipsisType'
+ if _intypes(tail): head = 'types'
+ elif not builtin:
+ _alias = '%s = ' % alias if alias else ''
+ if alias == tail: _alias = ''
+ return _alias+'%s\n' % tail
+ else: pass # handle builtins below
+ # get likely import string
+ if not head: _str = "import %s" % tail
+ else: _str = "from %s import %s" % (head, tail)
+ _alias = " as %s\n" % alias if alias else "\n"
+ if alias == tail: _alias = "\n"
+ _str += _alias
+ # FIXME: fails on most decorators, currying, and such...
+ # (could look for magic __wrapped__ or __func__ attr)
+ # (could fix in 'namespace' to check obj for closure)
+ if verify and not head.startswith('dill.'):# weird behavior for dill
+ #print(_str)
+ try: exec(_str) #XXX: check if == obj? (name collision)
+ except ImportError: #XXX: better top-down or bottom-up recursion?
+ _head = head.rsplit(".",1)[0] #(or get all, then compare == obj?)
+ if not _head: raise
+ if _head != head:
+ _str = _getimport(_head, tail, alias, verify)
+ return _str
+
+
+#XXX: rename builtin to force? vice versa? verify to force? (as in getsource)
+#NOTE: 05/25/14 broke backward compatibility: added 'alias' as 2nd argument
+def getimport(obj, alias='', verify=True, builtin=False, enclosing=False):
+ """get the likely import string for the given object
+
+ obj is the object to inspect
+ If verify=True, then test the import string before returning it.
+ If builtin=True, then force an import for builtins where possible.
+ If enclosing=True, get the import for the outermost enclosing callable.
+ If alias is provided, then rename the object on import.
+ """
+ if enclosing:
+ from .detect import outermost
+ _obj = outermost(obj)
+ obj = _obj if _obj else obj
+ # get the namespace
+ qual = _namespace(obj)
+ head = '.'.join(qual[:-1])
+ tail = qual[-1]
+ # for named things... with a nice repr #XXX: move into _namespace?
+ try: # look for '<...>' and be mindful it might be in lists, dicts, etc...
+ name = repr(obj).split('<',1)[1].split('>',1)[1]
+ name = None # we have a 'object'-style repr
+ except Exception: # it's probably something 'importable'
+ if head in ['builtins','__builtin__']:
+ name = repr(obj) #XXX: catch [1,2], (1,2), set([1,2])... others?
+ elif _isinstance(obj):
+ name = getname(obj, force=True).split('(')[0]
+ else:
+ name = repr(obj).split('(')[0]
+ #if not repr(obj).startswith('<'): name = repr(obj).split('(')[0]
+ #else: name = None
+ if name: # try using name instead of tail
+ try: return _getimport(head, name, alias, verify, builtin)
+ except ImportError: pass
+ except SyntaxError:
+ if head in ['builtins','__builtin__']:
+ _alias = '%s = ' % alias if alias else ''
+ if alias == name: _alias = ''
+ return _alias+'%s\n' % name
+ else: pass
+ try:
+ #if type(obj) is type(abs): _builtin = builtin # BuiltinFunctionType
+ #else: _builtin = False
+ return _getimport(head, tail, alias, verify, builtin)
+ except ImportError:
+ raise # could do some checking against obj
+ except SyntaxError:
+ if head in ['builtins','__builtin__']:
+ _alias = '%s = ' % alias if alias else ''
+ if alias == tail: _alias = ''
+ return _alias+'%s\n' % tail
+ raise # could do some checking against obj
+
+
+def _importable(obj, alias='', source=None, enclosing=False, force=True, \
+ builtin=True, lstrip=True):
+ """get an import string (or the source code) for the given object
+
+ This function will attempt to discover the name of the object, or the repr
+ of the object, or the source code for the object. To attempt to force
+ discovery of the source code, use source=True, to attempt to force the
+ use of an import, use source=False; otherwise an import will be sought
+ for objects not defined in __main__. The intent is to build a string
+ that can be imported from a python file. obj is the object to inspect.
+ If alias is provided, then rename the object with the given alias.
+
+ If source=True, use these options:
+ If enclosing=True, then also return any enclosing code.
+ If force=True, catch (TypeError,IOError) and try to use import hooks.
+ If lstrip=True, ensure there is no indentation in the first line of code.
+
+ If source=False, use these options:
+ If enclosing=True, get the import for the outermost enclosing callable.
+ If force=True, then don't test the import string before returning it.
+ If builtin=True, then force an import for builtins where possible.
+ """
+ if source is None:
+ source = True if isfrommain(obj) else False
+ if source: # first try to get the source
+ try:
+ return getsource(obj, alias, enclosing=enclosing, \
+ force=force, lstrip=lstrip, builtin=builtin)
+ except Exception: pass
+ try:
+ if not _isinstance(obj):
+ return getimport(obj, alias, enclosing=enclosing, \
+ verify=(not force), builtin=builtin)
+ # first 'get the import', then 'get the instance'
+ _import = getimport(obj, enclosing=enclosing, \
+ verify=(not force), builtin=builtin)
+ name = getname(obj, force=True)
+ if not name:
+ raise AttributeError("object has no atribute '__name__'")
+ _alias = "%s = " % alias if alias else ""
+ if alias == name: _alias = ""
+ return _import+_alias+"%s\n" % name
+
+ except Exception: pass
+ if not source: # try getsource, only if it hasn't been tried yet
+ try:
+ return getsource(obj, alias, enclosing=enclosing, \
+ force=force, lstrip=lstrip, builtin=builtin)
+ except Exception: pass
+ # get the name (of functions, lambdas, and classes)
+ # or hope that obj can be built from the __repr__
+ #XXX: what to do about class instances and such?
+ obj = getname(obj, force=force)
+ # we either have __repr__ or __name__ (or None)
+ if not obj or obj.startswith('<'):
+ raise AttributeError("object has no atribute '__name__'")
+ _alias = '%s = ' % alias if alias else ''
+ if alias == obj: _alias = ''
+ return _alias+'%s\n' % obj
+ #XXX: possible failsafe... (for example, for instances when source=False)
+ # "import dill; result = dill.loads(<pickled_object>); # repr(<object>)"
+
+def _closuredimport(func, alias='', builtin=False):
+ """get import for closured objects; return a dict of 'name' and 'import'"""
+ import re
+ from .detect import freevars, outermost
+ free_vars = freevars(func)
+ func_vars = {}
+ # split into 'funcs' and 'non-funcs'
+ for name,obj in list(free_vars.items()):
+ if not isfunction(obj): continue
+ # get import for 'funcs'
+ fobj = free_vars.pop(name)
+ src = getsource(fobj)
+ if src.lstrip().startswith('@'): # we have a decorator
+ src = getimport(fobj, alias=alias, builtin=builtin)
+ else: # we have to "hack" a bit... and maybe be lucky
+ encl = outermost(func)
+ # pattern: 'func = enclosing(fobj'
+ pat = r'.*[\w\s]=\s*'+getname(encl)+r'\('+getname(fobj)
+ mod = getname(getmodule(encl))
+ #HACK: get file containing 'outer' function; is func there?
+ lines,_ = findsource(encl)
+ candidate = [line for line in lines if getname(encl) in line and \
+ re.match(pat, line)]
+ if not candidate:
+ mod = getname(getmodule(fobj))
+ #HACK: get file containing 'inner' function; is func there?
+ lines,_ = findsource(fobj)
+ candidate = [line for line in lines \
+ if getname(fobj) in line and re.match(pat, line)]
+ if not len(candidate): raise TypeError('import could not be found')
+ candidate = candidate[-1]
+ name = candidate.split('=',1)[0].split()[-1].strip()
+ src = _getimport(mod, name, alias=alias, builtin=builtin)
+ func_vars[name] = src
+ if not func_vars:
+ name = outermost(func)
+ mod = getname(getmodule(name))
+ if not mod or name is func: # then it can be handled by getimport
+ name = getname(func, force=True) #XXX: better key?
+ src = getimport(func, alias=alias, builtin=builtin)
+ else:
+ lines,_ = findsource(name)
+ # pattern: 'func = enclosing('
+ candidate = [line for line in lines if getname(name) in line and \
+ re.match(r'.*[\w\s]=\s*'+getname(name)+r'\(', line)]
+ if not len(candidate): raise TypeError('import could not be found')
+ candidate = candidate[-1]
+ name = candidate.split('=',1)[0].split()[-1].strip()
+ src = _getimport(mod, name, alias=alias, builtin=builtin)
+ func_vars[name] = src
+ return func_vars
+
+#XXX: should be able to use __qualname__
+def _closuredsource(func, alias=''):
+ """get source code for closured objects; return a dict of 'name'
+ and 'code blocks'"""
+ #FIXME: this entire function is a messy messy HACK
+ # - pollutes global namespace
+ # - fails if name of freevars are reused
+ # - can unnecessarily duplicate function code
+ from .detect import freevars
+ free_vars = freevars(func)
+ func_vars = {}
+ # split into 'funcs' and 'non-funcs'
+ for name,obj in list(free_vars.items()):
+ if not isfunction(obj):
+ # get source for 'non-funcs'
+ free_vars[name] = getsource(obj, force=True, alias=name)
+ continue
+ # get source for 'funcs'
+ fobj = free_vars.pop(name)
+ src = getsource(fobj, alias) # DO NOT include dependencies
+ # if source doesn't start with '@', use name as the alias
+ if not src.lstrip().startswith('@'): #FIXME: 'enclose' in dummy;
+ src = importable(fobj,alias=name)# wrong ref 'name'
+ org = getsource(func, alias, enclosing=False, lstrip=True)
+ src = (src, org) # undecorated first, then target
+ else: #NOTE: reproduces the code!
+ org = getsource(func, enclosing=True, lstrip=False)
+ src = importable(fobj, alias, source=True) # include dependencies
+ src = (org, src) # target first, then decorated
+ func_vars[name] = src
+ src = ''.join(free_vars.values())
+ if not func_vars: #FIXME: 'enclose' in dummy; wrong ref 'name'
+ org = getsource(func, alias, force=True, enclosing=False, lstrip=True)
+ src = (src, org) # variables first, then target
+ else:
+ src = (src, None) # just variables (better '' instead of None?)
+ func_vars[None] = src
+ # FIXME: remove duplicates (however, order is important...)
+ return func_vars
+
+def importable(obj, alias='', source=None, builtin=True):
+ """get an importable string (i.e. source code or the import string)
+ for the given object, including any required objects from the enclosing
+ and global scope
+
+ This function will attempt to discover the name of the object, or the repr
+ of the object, or the source code for the object. To attempt to force
+ discovery of the source code, use source=True, to attempt to force the
+ use of an import, use source=False; otherwise an import will be sought
+ for objects not defined in __main__. The intent is to build a string
+ that can be imported from a python file.
+
+ obj is the object to inspect. If alias is provided, then rename the
+ object with the given alias. If builtin=True, then force an import for
+ builtins where possible.
+ """
+ #NOTE: we always 'force', and 'lstrip' as necessary
+ #NOTE: for 'enclosing', use importable(outermost(obj))
+ if source is None:
+ source = True if isfrommain(obj) else False
+ elif builtin and isbuiltin(obj):
+ source = False
+ tried_source = tried_import = False
+ while True:
+ if not source: # we want an import
+ try:
+ if _isinstance(obj): # for instances, punt to _importable
+ return _importable(obj, alias, source=False, builtin=builtin)
+ src = _closuredimport(obj, alias=alias, builtin=builtin)
+ if len(src) == 0:
+ raise NotImplementedError('not implemented')
+ if len(src) > 1:
+ raise NotImplementedError('not implemented')
+ return list(src.values())[0]
+ except Exception:
+ if tried_source: raise
+ tried_import = True
+ # we want the source
+ try:
+ src = _closuredsource(obj, alias=alias)
+ if len(src) == 0:
+ raise NotImplementedError('not implemented')
+ # groan... an inline code stitcher
+ def _code_stitcher(block):
+ "stitch together the strings in tuple 'block'"
+ if block[0] and block[-1]: block = '\n'.join(block)
+ elif block[0]: block = block[0]
+ elif block[-1]: block = block[-1]
+ else: block = ''
+ return block
+ # get free_vars first
+ _src = _code_stitcher(src.pop(None))
+ _src = [_src] if _src else []
+ # get func_vars
+ for xxx in src.values():
+ xxx = _code_stitcher(xxx)
+ if xxx: _src.append(xxx)
+ # make a single source string
+ if not len(_src):
+ src = ''
+ elif len(_src) == 1:
+ src = _src[0]
+ else:
+ src = '\n'.join(_src)
+ # get source code of objects referred to by obj in global scope
+ from .detect import globalvars
+ obj = globalvars(obj) #XXX: don't worry about alias? recurse? etc?
+ obj = list(getsource(_obj,name,force=True) for (name,_obj) in obj.items() if not isbuiltin(_obj))
+ obj = '\n'.join(obj) if obj else ''
+ # combine all referred-to source (global then enclosing)
+ if not obj: return src
+ if not src: return obj
+ return obj + src
+ except Exception:
+ if tried_import: raise
+ tried_source = True
+ source = not source
+ # should never get here
+ return
+
+
+# backward compatibility
+def getimportable(obj, alias='', byname=True, explicit=False):
+ return importable(obj,alias,source=(not byname),builtin=explicit)
+ #return outdent(_importable(obj,alias,source=(not byname),builtin=explicit))
+def likely_import(obj, passive=False, explicit=False):
+ return getimport(obj, verify=(not passive), builtin=explicit)
+def _likely_import(first, last, passive=False, explicit=True):
+ return _getimport(first, last, verify=(not passive), builtin=explicit)
+_get_name = getname
+getblocks_from_history = getblocks
+
+
+
+# EOF
diff --git a/solutions/.venv/Lib/site-packages/dill/temp.py b/solutions/.venv/Lib/site-packages/dill/temp.py
new file mode 100644
index 000000000..c4d7165e1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/temp.py
@@ -0,0 +1,252 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+Methods for serialized objects (or source code) stored in temporary files
+and file-like objects.
+"""
+#XXX: better instead to have functions write to any given file-like object ?
+#XXX: currently, all file-like objects are created by the function...
+
+__all__ = ['dump_source', 'dump', 'dumpIO_source', 'dumpIO',\
+ 'load_source', 'load', 'loadIO_source', 'loadIO',\
+ 'capture']
+
+import contextlib
+
+
+@contextlib.contextmanager
+def capture(stream='stdout'):
+ """builds a context that temporarily replaces the given stream name
+
+ >>> with capture('stdout') as out:
+ ... print ("foo!")
+ ...
+ >>> print (out.getvalue())
+ foo!
+
+ """
+ import sys
+ from io import StringIO
+ orig = getattr(sys, stream)
+ setattr(sys, stream, StringIO())
+ try:
+ yield getattr(sys, stream)
+ finally:
+ setattr(sys, stream, orig)
+
+
+def b(x): # deal with b'foo' versus 'foo'
+ import codecs
+ return codecs.latin_1_encode(x)[0]
+
+def load_source(file, **kwds):
+ """load an object that was stored with dill.temp.dump_source
+
+ file: filehandle
+ alias: string name of stored object
+ mode: mode to open the file, one of: {'r', 'rb'}
+
+ >>> f = lambda x: x**2
+ >>> pyfile = dill.temp.dump_source(f, alias='_f')
+ >>> _f = dill.temp.load_source(pyfile)
+ >>> _f(4)
+ 16
+ """
+ alias = kwds.pop('alias', None)
+ mode = kwds.pop('mode', 'r')
+ fname = getattr(file, 'name', file) # fname=file.name or fname=file (if str)
+ source = open(fname, mode=mode, **kwds).read()
+ if not alias:
+ tag = source.strip().splitlines()[-1].split()
+ if tag[0] != '#NAME:':
+ stub = source.splitlines()[0]
+ raise IOError("unknown name for code: %s" % stub)
+ alias = tag[-1]
+ local = {}
+ exec(source, local)
+ _ = eval("%s" % alias, local)
+ return _
+
+def dump_source(object, **kwds):
+ """write object source to a NamedTemporaryFile (instead of dill.dump)
+Loads with "import" or "dill.temp.load_source". Returns the filehandle.
+
+ >>> f = lambda x: x**2
+ >>> pyfile = dill.temp.dump_source(f, alias='_f')
+ >>> _f = dill.temp.load_source(pyfile)
+ >>> _f(4)
+ 16
+
+ >>> f = lambda x: x**2
+ >>> pyfile = dill.temp.dump_source(f, dir='.')
+ >>> modulename = os.path.basename(pyfile.name).split('.py')[0]
+ >>> exec('from %s import f as _f' % modulename)
+ >>> _f(4)
+ 16
+
+Optional kwds:
+ If 'alias' is specified, the object will be renamed to the given string.
+
+ If 'prefix' is specified, the file name will begin with that prefix,
+ otherwise a default prefix is used.
+
+ If 'dir' is specified, the file will be created in that directory,
+ otherwise a default directory is used.
+
+ If 'text' is specified and true, the file is opened in text
+ mode. Else (the default) the file is opened in binary mode. On
+ some operating systems, this makes no difference.
+
+NOTE: Keep the return value for as long as you want your file to exist !
+ """ #XXX: write a "load_source"?
+ from .source import importable, getname
+ import tempfile
+ kwds.setdefault('delete', True)
+ kwds.pop('suffix', '') # this is *always* '.py'
+ alias = kwds.pop('alias', '') #XXX: include an alias so a name is known
+ name = str(alias) or getname(object)
+ name = "\n#NAME: %s\n" % name
+ #XXX: assumes kwds['dir'] is writable and on $PYTHONPATH
+ file = tempfile.NamedTemporaryFile(suffix='.py', **kwds)
+ file.write(b(''.join([importable(object, alias=alias),name])))
+ file.flush()
+ return file
+
+def load(file, **kwds):
+ """load an object that was stored with dill.temp.dump
+
+ file: filehandle
+ mode: mode to open the file, one of: {'r', 'rb'}
+
+ >>> dumpfile = dill.temp.dump([1, 2, 3, 4, 5])
+ >>> dill.temp.load(dumpfile)
+ [1, 2, 3, 4, 5]
+ """
+ import dill as pickle
+ mode = kwds.pop('mode', 'rb')
+ name = getattr(file, 'name', file) # name=file.name or name=file (if str)
+ return pickle.load(open(name, mode=mode, **kwds))
+
+def dump(object, **kwds):
+ """dill.dump of object to a NamedTemporaryFile.
+Loads with "dill.temp.load". Returns the filehandle.
+
+ >>> dumpfile = dill.temp.dump([1, 2, 3, 4, 5])
+ >>> dill.temp.load(dumpfile)
+ [1, 2, 3, 4, 5]
+
+Optional kwds:
+ If 'suffix' is specified, the file name will end with that suffix,
+ otherwise there will be no suffix.
+
+ If 'prefix' is specified, the file name will begin with that prefix,
+ otherwise a default prefix is used.
+
+ If 'dir' is specified, the file will be created in that directory,
+ otherwise a default directory is used.
+
+ If 'text' is specified and true, the file is opened in text
+ mode. Else (the default) the file is opened in binary mode. On
+ some operating systems, this makes no difference.
+
+NOTE: Keep the return value for as long as you want your file to exist !
+ """
+ import dill as pickle
+ import tempfile
+ kwds.setdefault('delete', True)
+ file = tempfile.NamedTemporaryFile(**kwds)
+ pickle.dump(object, file)
+ file.flush()
+ return file
+
+def loadIO(buffer, **kwds):
+ """load an object that was stored with dill.temp.dumpIO
+
+ buffer: buffer object
+
+ >>> dumpfile = dill.temp.dumpIO([1, 2, 3, 4, 5])
+ >>> dill.temp.loadIO(dumpfile)
+ [1, 2, 3, 4, 5]
+ """
+ import dill as pickle
+ from io import BytesIO as StringIO
+ value = getattr(buffer, 'getvalue', buffer) # value or buffer.getvalue
+ if value != buffer: value = value() # buffer.getvalue()
+ return pickle.load(StringIO(value))
+
+def dumpIO(object, **kwds):
+ """dill.dump of object to a buffer.
+Loads with "dill.temp.loadIO". Returns the buffer object.
+
+ >>> dumpfile = dill.temp.dumpIO([1, 2, 3, 4, 5])
+ >>> dill.temp.loadIO(dumpfile)
+ [1, 2, 3, 4, 5]
+ """
+ import dill as pickle
+ from io import BytesIO as StringIO
+ file = StringIO()
+ pickle.dump(object, file)
+ file.flush()
+ return file
+
+def loadIO_source(buffer, **kwds):
+ """load an object that was stored with dill.temp.dumpIO_source
+
+ buffer: buffer object
+ alias: string name of stored object
+
+ >>> f = lambda x:x**2
+ >>> pyfile = dill.temp.dumpIO_source(f, alias='_f')
+ >>> _f = dill.temp.loadIO_source(pyfile)
+ >>> _f(4)
+ 16
+ """
+ alias = kwds.pop('alias', None)
+ source = getattr(buffer, 'getvalue', buffer) # source or buffer.getvalue
+ if source != buffer: source = source() # buffer.getvalue()
+ source = source.decode() # buffer to string
+ if not alias:
+ tag = source.strip().splitlines()[-1].split()
+ if tag[0] != '#NAME:':
+ stub = source.splitlines()[0]
+ raise IOError("unknown name for code: %s" % stub)
+ alias = tag[-1]
+ local = {}
+ exec(source, local)
+ _ = eval("%s" % alias, local)
+ return _
+
+def dumpIO_source(object, **kwds):
+ """write object source to a buffer (instead of dill.dump)
+Loads by with dill.temp.loadIO_source. Returns the buffer object.
+
+ >>> f = lambda x:x**2
+ >>> pyfile = dill.temp.dumpIO_source(f, alias='_f')
+ >>> _f = dill.temp.loadIO_source(pyfile)
+ >>> _f(4)
+ 16
+
+Optional kwds:
+ If 'alias' is specified, the object will be renamed to the given string.
+ """
+ from .source import importable, getname
+ from io import BytesIO as StringIO
+ alias = kwds.pop('alias', '') #XXX: include an alias so a name is known
+ name = str(alias) or getname(object)
+ name = "\n#NAME: %s\n" % name
+ #XXX: assumes kwds['dir'] is writable and on $PYTHONPATH
+ file = StringIO()
+ file.write(b(''.join([importable(object, alias=alias),name])))
+ file.flush()
+ return file
+
+
+del contextlib
+
+
+# EOF
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/__init__.py b/solutions/.venv/Lib/site-packages/dill/tests/__init__.py
new file mode 100644
index 000000000..3fbec382c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/__init__.py
@@ -0,0 +1,22 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2018-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+to run this test suite, first build and install `dill`.
+
+ $ python -m pip install ../..
+
+
+then run the tests with:
+
+ $ python -m dill.tests
+
+
+or, if `nose` is installed:
+
+ $ nosetests
+
+"""
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/__main__.py b/solutions/.venv/Lib/site-packages/dill/tests/__main__.py
new file mode 100644
index 000000000..b84d24cb8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/__main__.py
@@ -0,0 +1,35 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2018-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import glob
+import os
+import sys
+import subprocess as sp
+python = sys.executable
+try:
+ import pox
+ python = pox.which_python(version=True) or python
+except ImportError:
+ pass
+shell = sys.platform[:3] == 'win'
+
+suite = os.path.dirname(__file__) or os.path.curdir
+tests = glob.glob(suite + os.path.sep + 'test_*.py')
+
+
+if __name__ == '__main__':
+
+ failed = 0
+ for test in tests:
+ p = sp.Popen([python, test], shell=shell).wait()
+ if p:
+ print('F', end='', flush=True)
+ failed = 1
+ else:
+ print('.', end='', flush=True)
+ print('')
+ exit(failed)
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_abc.py b/solutions/.venv/Lib/site-packages/dill/tests/test_abc.py
new file mode 100644
index 000000000..b16d30920
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_abc.py
@@ -0,0 +1,169 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2023-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+test dill's ability to pickle abstract base class objects
+"""
+import dill
+import abc
+from abc import ABC
+import warnings
+
+from types import FunctionType
+
+dill.settings['recurse'] = True
+
+class OneTwoThree(ABC):
+ @abc.abstractmethod
+ def foo(self):
+ """A method"""
+ pass
+
+ @property
+ @abc.abstractmethod
+ def bar(self):
+ """Property getter"""
+ pass
+
+ @bar.setter
+ @abc.abstractmethod
+ def bar(self, value):
+ """Property setter"""
+ pass
+
+ @classmethod
+ @abc.abstractmethod
+ def cfoo(cls):
+ """Class method"""
+ pass
+
+ @staticmethod
+ @abc.abstractmethod
+ def sfoo():
+ """Static method"""
+ pass
+
+class EasyAsAbc(OneTwoThree):
+ def __init__(self):
+ self._bar = None
+
+ def foo(self):
+ return "Instance Method FOO"
+
+ @property
+ def bar(self):
+ return self._bar
+
+ @bar.setter
+ def bar(self, value):
+ self._bar = value
+
+ @classmethod
+ def cfoo(cls):
+ return "Class Method CFOO"
+
+ @staticmethod
+ def sfoo():
+ return "Static Method SFOO"
+
+def test_abc_non_local():
+ assert dill.copy(OneTwoThree) is not OneTwoThree
+ assert dill.copy(EasyAsAbc) is not EasyAsAbc
+
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore", dill.PicklingWarning)
+ assert dill.copy(OneTwoThree, byref=True) is OneTwoThree
+ assert dill.copy(EasyAsAbc, byref=True) is EasyAsAbc
+
+ instance = EasyAsAbc()
+ # Set a property that StockPickle can't preserve
+ instance.bar = lambda x: x**2
+ depickled = dill.copy(instance)
+ assert type(depickled) is type(instance) #NOTE: issue #612, test_abc_local
+ #NOTE: dill.copy of local (or non-local) classes should (not) be the same?
+ assert type(depickled.bar) is FunctionType
+ assert depickled.bar(3) == 9
+ assert depickled.sfoo() == "Static Method SFOO"
+ assert depickled.cfoo() == "Class Method CFOO"
+ assert depickled.foo() == "Instance Method FOO"
+
+def test_abc_local():
+ """
+ Test using locally scoped ABC class
+ """
+ class LocalABC(ABC):
+ @abc.abstractmethod
+ def foo(self):
+ pass
+
+ def baz(self):
+ return repr(self)
+
+ labc = dill.copy(LocalABC)
+ assert labc is not LocalABC
+ assert type(labc) is type(LocalABC)
+ #NOTE: dill.copy of local (or non-local) classes should (not) be the same?
+ # <class '__main__.LocalABC'>
+ # <class '__main__.test_abc_local.<locals>.LocalABC'>
+
+ class Real(labc):
+ def foo(self):
+ return "True!"
+
+ def baz(self):
+ return "My " + super(Real, self).baz()
+
+ real = Real()
+ assert real.foo() == "True!"
+
+ try:
+ labc()
+ except TypeError as e:
+ # Expected error
+ pass
+ else:
+ print('Failed to raise type error')
+ assert False
+
+ labc2, pik = dill.copy((labc, Real()))
+ assert 'Real' == type(pik).__name__
+ assert '.Real' in type(pik).__qualname__
+ assert type(pik) is not Real
+ assert labc2 is not LocalABC
+ assert labc2 is not labc
+ assert isinstance(pik, labc2)
+ assert not isinstance(pik, labc)
+ assert not isinstance(pik, LocalABC)
+ assert pik.baz() == "My " + repr(pik)
+
+def test_meta_local_no_cache():
+ """
+ Test calling metaclass and cache registration
+ """
+ LocalMetaABC = abc.ABCMeta('LocalMetaABC', (), {})
+
+ class ClassyClass:
+ pass
+
+ class KlassyClass:
+ pass
+
+ LocalMetaABC.register(ClassyClass)
+
+ assert not issubclass(KlassyClass, LocalMetaABC)
+ assert issubclass(ClassyClass, LocalMetaABC)
+
+ res = dill.dumps((LocalMetaABC, ClassyClass, KlassyClass))
+
+ lmabc, cc, kc = dill.loads(res)
+ assert type(lmabc) == type(LocalMetaABC)
+ assert not issubclass(kc, lmabc)
+ assert issubclass(cc, lmabc)
+
+if __name__ == '__main__':
+ test_abc_non_local()
+ test_abc_local()
+ test_meta_local_no_cache()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_check.py b/solutions/.venv/Lib/site-packages/dill/tests/test_check.py
new file mode 100644
index 000000000..c0ab757a3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_check.py
@@ -0,0 +1,62 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+from dill import check
+import sys
+
+from dill.temp import capture
+
+
+#FIXME: this doesn't catch output... it's from the internal call
+def raise_check(func, **kwds):
+ try:
+ with capture('stdout') as out:
+ check(func, **kwds)
+ except Exception:
+ e = sys.exc_info()[1]
+ raise AssertionError(str(e))
+ else:
+ assert 'Traceback' not in out.getvalue()
+ finally:
+ out.close()
+
+
+f = lambda x:x**2
+
+
+def test_simple(verbose=None):
+ raise_check(f, verbose=verbose)
+
+
+def test_recurse(verbose=None):
+ raise_check(f, recurse=True, verbose=verbose)
+
+
+def test_byref(verbose=None):
+ raise_check(f, byref=True, verbose=verbose)
+
+
+def test_protocol(verbose=None):
+ raise_check(f, protocol=True, verbose=verbose)
+
+
+def test_python(verbose=None):
+ raise_check(f, python=None, verbose=verbose)
+
+
+#TODO: test incompatible versions
+#TODO: test dump failure
+#TODO: test load failure
+
+
+if __name__ == '__main__':
+ test_simple()
+ test_recurse()
+ test_byref()
+ test_protocol()
+ test_python()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_classdef.py b/solutions/.venv/Lib/site-packages/dill/tests/test_classdef.py
new file mode 100644
index 000000000..b09df50ca
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_classdef.py
@@ -0,0 +1,340 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+from enum import EnumMeta
+import sys
+dill.settings['recurse'] = True
+
+# test classdefs
+class _class:
+ def _method(self):
+ pass
+ def ok(self):
+ return True
+
+class _class2:
+ def __call__(self):
+ pass
+ def ok(self):
+ return True
+
+class _newclass(object):
+ def _method(self):
+ pass
+ def ok(self):
+ return True
+
+class _newclass2(object):
+ def __call__(self):
+ pass
+ def ok(self):
+ return True
+
+class _meta(type):
+ pass
+
+def __call__(self):
+ pass
+def ok(self):
+ return True
+
+_mclass = _meta("_mclass", (object,), {"__call__": __call__, "ok": ok})
+
+del __call__
+del ok
+
+o = _class()
+oc = _class2()
+n = _newclass()
+nc = _newclass2()
+m = _mclass()
+
+if sys.hexversion < 0x03090000:
+ import typing
+ class customIntList(typing.List[int]):
+ pass
+else:
+ class customIntList(list[int]):
+ pass
+
+# test pickles for class instances
+def test_class_instances():
+ assert dill.pickles(o)
+ assert dill.pickles(oc)
+ assert dill.pickles(n)
+ assert dill.pickles(nc)
+ assert dill.pickles(m)
+
+def test_class_objects():
+ clslist = [_class,_class2,_newclass,_newclass2,_mclass]
+ objlist = [o,oc,n,nc,m]
+ _clslist = [dill.dumps(obj) for obj in clslist]
+ _objlist = [dill.dumps(obj) for obj in objlist]
+
+ for obj in clslist:
+ globals().pop(obj.__name__)
+ del clslist
+ for obj in ['o','oc','n','nc']:
+ globals().pop(obj)
+ del objlist
+ del obj
+
+ for obj,cls in zip(_objlist,_clslist):
+ _cls = dill.loads(cls)
+ _obj = dill.loads(obj)
+ assert _obj.ok()
+ assert _cls.ok(_cls())
+ if _cls.__name__ == "_mclass":
+ assert type(_cls).__name__ == "_meta"
+
+# test NoneType
+def test_specialtypes():
+ assert dill.pickles(type(None))
+ assert dill.pickles(type(NotImplemented))
+ assert dill.pickles(type(Ellipsis))
+ assert dill.pickles(type(EnumMeta))
+
+from collections import namedtuple
+Z = namedtuple("Z", ['a','b'])
+Zi = Z(0,1)
+X = namedtuple("Y", ['a','b'])
+X.__name__ = "X"
+X.__qualname__ = "X" #XXX: name must 'match' or fails to pickle
+Xi = X(0,1)
+Bad = namedtuple("FakeName", ['a','b'])
+Badi = Bad(0,1)
+Defaults = namedtuple('Defaults', ['x', 'y'], defaults=[1])
+Defaultsi = Defaults(2)
+
+# test namedtuple
+def test_namedtuple():
+ assert Z is dill.loads(dill.dumps(Z))
+ assert Zi == dill.loads(dill.dumps(Zi))
+ assert X is dill.loads(dill.dumps(X))
+ assert Xi == dill.loads(dill.dumps(Xi))
+ assert Defaults is dill.loads(dill.dumps(Defaults))
+ assert Defaultsi == dill.loads(dill.dumps(Defaultsi))
+ assert Bad is not dill.loads(dill.dumps(Bad))
+ assert Bad._fields == dill.loads(dill.dumps(Bad))._fields
+ assert tuple(Badi) == tuple(dill.loads(dill.dumps(Badi)))
+
+ class A:
+ class B(namedtuple("C", ["one", "two"])):
+ '''docstring'''
+ B.__module__ = 'testing'
+
+ a = A()
+ assert dill.copy(a)
+
+ assert dill.copy(A.B).__name__ == 'B'
+ assert dill.copy(A.B).__qualname__.endswith('.<locals>.A.B')
+ assert dill.copy(A.B).__doc__ == 'docstring'
+ assert dill.copy(A.B).__module__ == 'testing'
+
+ from typing import NamedTuple
+
+ def A():
+ class B(NamedTuple):
+ x: int
+ return B
+
+ assert type(dill.copy(A()(8))).__qualname__ == type(A()(8)).__qualname__
+
+def test_dtype():
+ try:
+ import numpy as np
+
+ dti = np.dtype('int')
+ assert np.dtype == dill.copy(np.dtype)
+ assert dti == dill.copy(dti)
+ except ImportError: pass
+
+
+def test_array_nested():
+ try:
+ import numpy as np
+
+ x = np.array([1])
+ y = (x,)
+ assert y == dill.copy(y)
+
+ except ImportError: pass
+
+
+def test_array_subclass():
+ try:
+ import numpy as np
+
+ class TestArray(np.ndarray):
+ def __new__(cls, input_array, color):
+ obj = np.asarray(input_array).view(cls)
+ obj.color = color
+ return obj
+ def __array_finalize__(self, obj):
+ if obj is None:
+ return
+ if isinstance(obj, type(self)):
+ self.color = obj.color
+ def __getnewargs__(self):
+ return np.asarray(self), self.color
+
+ a1 = TestArray(np.zeros(100), color='green')
+ if not dill._dill.IS_PYPY:
+ assert dill.pickles(a1)
+ assert a1.__dict__ == dill.copy(a1).__dict__
+
+ a2 = a1[0:9]
+ if not dill._dill.IS_PYPY:
+ assert dill.pickles(a2)
+ assert a2.__dict__ == dill.copy(a2).__dict__
+
+ class TestArray2(np.ndarray):
+ color = 'blue'
+
+ a3 = TestArray2([1,2,3,4,5])
+ a3.color = 'green'
+ if not dill._dill.IS_PYPY:
+ assert dill.pickles(a3)
+ assert a3.__dict__ == dill.copy(a3).__dict__
+
+ except ImportError: pass
+
+
+def test_method_decorator():
+ class A(object):
+ @classmethod
+ def test(cls):
+ pass
+
+ a = A()
+
+ res = dill.dumps(a)
+ new_obj = dill.loads(res)
+ new_obj.__class__.test()
+
+# test slots
+class Y(object):
+ __slots__ = ('y', '__weakref__')
+ def __init__(self, y):
+ self.y = y
+
+value = 123
+y = Y(value)
+
+class Y2(object):
+ __slots__ = 'y'
+ def __init__(self, y):
+ self.y = y
+
+def test_slots():
+ assert dill.pickles(Y)
+ assert dill.pickles(y)
+ assert dill.pickles(Y.y)
+ assert dill.copy(y).y == value
+ assert dill.copy(Y2(value)).y == value
+
+def test_origbases():
+ assert dill.copy(customIntList).__orig_bases__ == customIntList.__orig_bases__
+
+def test_attr():
+ import attr
+ @attr.s
+ class A:
+ a = attr.ib()
+
+ v = A(1)
+ assert dill.copy(v) == v
+
+def test_metaclass():
+ class metaclass_with_new(type):
+ def __new__(mcls, name, bases, ns, **kwds):
+ cls = super().__new__(mcls, name, bases, ns, **kwds)
+ assert mcls is not None
+ assert cls.method(mcls)
+ return cls
+ def method(cls, mcls):
+ return isinstance(cls, mcls)
+
+ l = locals()
+ exec("""class subclass_with_new(metaclass=metaclass_with_new):
+ def __new__(cls):
+ self = super().__new__(cls)
+ return self""", None, l)
+ subclass_with_new = l['subclass_with_new']
+
+ assert dill.copy(subclass_with_new())
+
+def test_enummeta():
+ from http import HTTPStatus
+ import enum
+ assert dill.copy(HTTPStatus.OK) is HTTPStatus.OK
+ assert dill.copy(enum.EnumMeta) is enum.EnumMeta
+
+def test_inherit(): #NOTE: see issue #612
+ class Foo:
+ w = 0
+ x = 1
+ y = 1.1
+ a = ()
+ b = (1,)
+ n = None
+
+ class Bar(Foo):
+ w = 2
+ x = 1
+ y = 1.1
+ z = 0.2
+ a = ()
+ b = (1,)
+ c = (2,)
+ n = None
+
+ Baz = dill.copy(Bar)
+
+ import platform
+ is_pypy = platform.python_implementation() == 'PyPy'
+ assert Bar.__dict__ == Baz.__dict__
+ # ints
+ assert 'w' in Bar.__dict__ and 'w' in Baz.__dict__
+ assert Bar.__dict__['w'] is Baz.__dict__['w']
+ assert 'x' in Bar.__dict__ and 'x' in Baz.__dict__
+ assert Bar.__dict__['x'] is Baz.__dict__['x']
+ # floats
+ assert 'y' in Bar.__dict__ and 'y' in Baz.__dict__
+ same = Bar.__dict__['y'] is Baz.__dict__['y']
+ assert same if is_pypy else not same
+ assert 'z' in Bar.__dict__ and 'z' in Baz.__dict__
+ same = Bar.__dict__['z'] is Baz.__dict__['z']
+ assert same if is_pypy else not same
+ # tuples
+ assert 'a' in Bar.__dict__ and 'a' in Baz.__dict__
+ assert Bar.__dict__['a'] is Baz.__dict__['a']
+ assert 'b' in Bar.__dict__ and 'b' in Baz.__dict__
+ assert Bar.__dict__['b'] is not Baz.__dict__['b']
+ assert 'c' in Bar.__dict__ and 'c' in Baz.__dict__
+ assert Bar.__dict__['c'] is not Baz.__dict__['c']
+ # None
+ assert 'n' in Bar.__dict__ and 'n' in Baz.__dict__
+ assert Bar.__dict__['n'] is Baz.__dict__['n']
+
+
+if __name__ == '__main__':
+ test_class_instances()
+ test_class_objects()
+ test_specialtypes()
+ test_namedtuple()
+ test_dtype()
+ test_array_nested()
+ test_array_subclass()
+ test_method_decorator()
+ test_slots()
+ test_origbases()
+ test_metaclass()
+ test_enummeta()
+ test_inherit()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_dataclasses.py b/solutions/.venv/Lib/site-packages/dill/tests/test_dataclasses.py
new file mode 100644
index 000000000..10dc51c50
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_dataclasses.py
@@ -0,0 +1,35 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Author: Anirudh Vegesana (avegesan@cs.stanford.edu)
+# Copyright (c) 2022-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+test pickling a dataclass
+"""
+
+import dill
+import dataclasses
+
+def test_dataclasses():
+ # Issue #500
+ @dataclasses.dataclass
+ class A:
+ x: int
+ y: str
+
+ @dataclasses.dataclass
+ class B:
+ a: A
+
+ a = A(1, "test")
+ before = B(a)
+ save = dill.dumps(before)
+ after = dill.loads(save)
+ assert before != after # classes don't match
+ assert before == B(A(**dataclasses.asdict(after.a)))
+ assert dataclasses.asdict(before) == dataclasses.asdict(after)
+
+if __name__ == '__main__':
+ test_dataclasses()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_detect.py b/solutions/.venv/Lib/site-packages/dill/tests/test_detect.py
new file mode 100644
index 000000000..5ab16bb45
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_detect.py
@@ -0,0 +1,160 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+from dill.detect import baditems, badobjects, badtypes, errors, parent, at, globalvars
+from dill import settings
+from dill._dill import IS_PYPY
+from pickle import PicklingError
+
+import inspect
+import sys
+import os
+
+def test_bad_things():
+ f = inspect.currentframe()
+ assert baditems(f) == [f]
+ #assert baditems(globals()) == [f] #XXX
+ assert badobjects(f) is f
+ assert badtypes(f) == type(f)
+ assert type(errors(f)) is TypeError
+ d = badtypes(f, 1)
+ assert isinstance(d, dict)
+ assert list(badobjects(f, 1).keys()) == list(d.keys())
+ assert list(errors(f, 1).keys()) == list(d.keys())
+ s = set([(err.__class__.__name__,err.args[0]) for err in list(errors(f, 1).values())])
+ a = dict(s)
+ if not os.environ.get('COVERAGE'): #XXX: travis-ci
+ proxy = 0 if type(f.f_locals) is dict else 1
+ assert len(s) == len(a) + proxy # TypeError (and possibly PicklingError)
+ n = 2
+ assert len(a) is n if 'PicklingError' in a.keys() else n-1
+
+def test_parent():
+ x = [4,5,6,7]
+ listiter = iter(x)
+ obj = parent(listiter, list)
+ assert obj is x
+
+ if IS_PYPY: assert parent(obj, int) is None
+ else: assert parent(obj, int) is x[-1] # python oddly? finds last int
+ assert at(id(at)) is at
+
+a, b, c = 1, 2, 3
+
+def squared(x):
+ return a+x**2
+
+def foo(x):
+ def bar(y):
+ return squared(x)+y
+ return bar
+
+class _class:
+ def _method(self):
+ pass
+ def ok(self):
+ return True
+
+def test_globals():
+ def f():
+ a
+ def g():
+ b
+ def h():
+ c
+ assert globalvars(f) == dict(a=1, b=2, c=3)
+
+ res = globalvars(foo, recurse=True)
+ assert set(res) == set(['squared', 'a'])
+ res = globalvars(foo, recurse=False)
+ assert res == {}
+ zap = foo(2)
+ res = globalvars(zap, recurse=True)
+ assert set(res) == set(['squared', 'a'])
+ res = globalvars(zap, recurse=False)
+ assert set(res) == set(['squared'])
+ del zap
+ res = globalvars(squared)
+ assert set(res) == set(['a'])
+ # FIXME: should find referenced __builtins__
+ #res = globalvars(_class, recurse=True)
+ #assert set(res) == set(['True'])
+ #res = globalvars(_class, recurse=False)
+ #assert res == {}
+ #res = globalvars(_class.ok, recurse=True)
+ #assert set(res) == set(['True'])
+ #res = globalvars(_class.ok, recurse=False)
+ #assert set(res) == set(['True'])
+
+
+#98 dill ignores __getstate__ in interactive lambdas
+bar = [0]
+
+class Foo(object):
+ def __init__(self):
+ pass
+ def __getstate__(self):
+ bar[0] = bar[0]+1
+ return {}
+ def __setstate__(self, data):
+ pass
+
+f = Foo()
+
+def test_getstate():
+ from dill import dumps, loads
+ dumps(f)
+ b = bar[0]
+ dumps(lambda: f, recurse=False) # doesn't call __getstate__
+ assert bar[0] == b
+ dumps(lambda: f, recurse=True) # calls __getstate__
+ assert bar[0] == b + 1
+
+#97 serialize lambdas in test files
+def test_deleted():
+ global sin
+ from dill import dumps, loads
+ from math import sin, pi
+
+ def sinc(x):
+ return sin(x)/x
+
+ settings['recurse'] = True
+ _sinc = dumps(sinc)
+ sin = globals().pop('sin')
+ sin = 1
+ del sin
+ sinc_ = loads(_sinc) # no NameError... pickling preserves 'sin'
+ res = sinc_(1)
+ from math import sin
+ assert sinc(1) == res
+
+
+def test_lambdify():
+ try:
+ from sympy import symbols, lambdify
+ except ImportError:
+ return
+ settings['recurse'] = True
+ x = symbols("x")
+ y = x**2
+ f = lambdify([x], y)
+ z = min
+ d = globals()
+ globalvars(f, recurse=True, builtin=True)
+ assert z is min
+ assert d is globals()
+
+
+if __name__ == '__main__':
+ test_bad_things()
+ test_parent()
+ test_globals()
+ test_getstate()
+ test_deleted()
+ test_lambdify()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_dictviews.py b/solutions/.venv/Lib/site-packages/dill/tests/test_dictviews.py
new file mode 100644
index 000000000..4e94ce32c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_dictviews.py
@@ -0,0 +1,39 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Author: Anirudh Vegesana (avegesan@cs.stanford.edu)
+# Copyright (c) 2021-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+from dill._dill import OLD310, MAPPING_PROXY_TRICK, DictProxyType
+
+def test_dictproxy():
+ assert dill.copy(DictProxyType({'a': 2}))
+
+def test_dictviews():
+ x = {'a': 1}
+ assert dill.copy(x.keys())
+ assert dill.copy(x.values())
+ assert dill.copy(x.items())
+
+def test_dictproxy_trick():
+ if not OLD310 and MAPPING_PROXY_TRICK:
+ x = {'a': 1}
+ all_views = (x.values(), x.items(), x.keys(), x)
+ seperate_views = dill.copy(all_views)
+ new_x = seperate_views[-1]
+ new_x['b'] = 2
+ new_x['c'] = 1
+ assert len(new_x) == 3 and len(x) == 1
+ assert len(seperate_views[0]) == 3 and len(all_views[0]) == 1
+ assert len(seperate_views[1]) == 3 and len(all_views[1]) == 1
+ assert len(seperate_views[2]) == 3 and len(all_views[2]) == 1
+ assert dict(all_views[1]) == x
+ assert dict(seperate_views[1]) == new_x
+
+if __name__ == '__main__':
+ test_dictproxy()
+ test_dictviews()
+ test_dictproxy_trick()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_diff.py b/solutions/.venv/Lib/site-packages/dill/tests/test_diff.py
new file mode 100644
index 000000000..a17530534
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_diff.py
@@ -0,0 +1,107 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+from dill import __diff as diff
+
+import sys
+IS_PYPY = not hasattr(sys, 'getrefcount')
+
+class A:
+ pass
+
+def test_diff():
+ a = A()
+ b = A()
+ c = A()
+ a.a = b
+ b.a = c
+ diff.memorise(a)
+ assert not diff.has_changed(a)
+ c.a = 1
+ assert diff.has_changed(a)
+ diff.memorise(c, force=True)
+ assert not diff.has_changed(a)
+ c.a = 2
+ assert diff.has_changed(a)
+ changed = diff.whats_changed(a)
+ assert list(changed[0].keys()) == ["a"]
+ assert not changed[1]
+
+ a2 = []
+ b2 = [a2]
+ c2 = [b2]
+ diff.memorise(c2)
+ assert not diff.has_changed(c2)
+ a2.append(1)
+ assert diff.has_changed(c2)
+ changed = diff.whats_changed(c2)
+ assert changed[0] == {}
+ assert changed[1]
+
+ a3 = {}
+ b3 = {1: a3}
+ c3 = {1: b3}
+ diff.memorise(c3)
+ assert not diff.has_changed(c3)
+ a3[1] = 1
+ assert diff.has_changed(c3)
+ changed = diff.whats_changed(c3)
+ assert changed[0] == {}
+ assert changed[1]
+
+ if not IS_PYPY:
+ import abc
+ # make sure the "_abc_invaldation_counter" doesn't make test fail
+ diff.memorise(abc.ABCMeta, force=True)
+ assert not diff.has_changed(abc)
+ abc.ABCMeta.zzz = 1
+ assert diff.has_changed(abc)
+ changed = diff.whats_changed(abc)
+ assert list(changed[0].keys()) == ["ABCMeta"]
+ assert not changed[1]
+
+ '''
+ import Queue
+ diff.memorise(Queue, force=True)
+ assert not diff.has_changed(Queue)
+ Queue.Queue.zzz = 1
+ assert diff.has_changed(Queue)
+ changed = diff.whats_changed(Queue)
+ assert list(changed[0].keys()) == ["Queue"]
+ assert not changed[1]
+
+ import math
+ diff.memorise(math, force=True)
+ assert not diff.has_changed(math)
+ math.zzz = 1
+ assert diff.has_changed(math)
+ changed = diff.whats_changed(math)
+ assert list(changed[0].keys()) == ["zzz"]
+ assert not changed[1]
+ '''
+
+ a = A()
+ b = A()
+ c = A()
+ a.a = b
+ b.a = c
+ diff.memorise(a)
+ assert not diff.has_changed(a)
+ c.a = 1
+ assert diff.has_changed(a)
+ diff.memorise(c, force=True)
+ assert not diff.has_changed(a)
+ del c.a
+ assert diff.has_changed(a)
+ changed = diff.whats_changed(a)
+ assert list(changed[0].keys()) == ["a"]
+ assert not changed[1]
+
+
+if __name__ == '__main__':
+ test_diff()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_extendpickle.py b/solutions/.venv/Lib/site-packages/dill/tests/test_extendpickle.py
new file mode 100644
index 000000000..3b274d4bf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_extendpickle.py
@@ -0,0 +1,53 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill as pickle
+from io import BytesIO as StringIO
+
+
+def my_fn(x):
+ return x * 17
+
+
+def test_extend():
+ obj = lambda : my_fn(34)
+ assert obj() == 578
+
+ obj_io = StringIO()
+ pickler = pickle.Pickler(obj_io)
+ pickler.dump(obj)
+
+ obj_str = obj_io.getvalue()
+
+ obj2_io = StringIO(obj_str)
+ unpickler = pickle.Unpickler(obj2_io)
+ obj2 = unpickler.load()
+
+ assert obj2() == 578
+
+
+def test_isdill():
+ obj_io = StringIO()
+ pickler = pickle.Pickler(obj_io)
+ assert pickle._dill.is_dill(pickler) is True
+
+ pickler = pickle._dill.StockPickler(obj_io)
+ assert pickle._dill.is_dill(pickler) is False
+
+ try:
+ import multiprocess as mp
+ pickler = mp.reduction.ForkingPickler(obj_io)
+ assert pickle._dill.is_dill(pickler, child=True) is True
+ assert pickle._dill.is_dill(pickler, child=False) is False
+ except Exception:
+ pass
+
+
+if __name__ == '__main__':
+ test_extend()
+ test_isdill()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_fglobals.py b/solutions/.venv/Lib/site-packages/dill/tests/test_fglobals.py
new file mode 100644
index 000000000..80b356545
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_fglobals.py
@@ -0,0 +1,55 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2021-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+dill.settings['recurse'] = True
+
+def get_fun_with_strftime():
+ def fun_with_strftime():
+ import datetime
+ return datetime.datetime.strptime("04-01-1943", "%d-%m-%Y").strftime(
+ "%Y-%m-%d %H:%M:%S"
+ )
+ return fun_with_strftime
+
+
+def get_fun_with_strftime2():
+ import datetime
+ return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
+
+
+def test_doc_dill_issue_219():
+ back_fn = dill.loads(dill.dumps(get_fun_with_strftime()))
+ assert back_fn() == "1943-01-04 00:00:00"
+ dupl = dill.loads(dill.dumps(get_fun_with_strftime2))
+ assert dupl() == get_fun_with_strftime2()
+
+
+def get_fun_with_internal_import():
+ def fun_with_import():
+ import re
+ return re.compile("$")
+ return fun_with_import
+
+
+def test_method_with_internal_import_should_work():
+ import re
+ back_fn = dill.loads(dill.dumps(get_fun_with_internal_import()))
+ import inspect
+ if hasattr(inspect, 'getclosurevars'):
+ vars = inspect.getclosurevars(back_fn)
+ assert vars.globals == {}
+ assert vars.nonlocals == {}
+ assert back_fn() == re.compile("$")
+ assert "__builtins__" in back_fn.__globals__
+
+
+if __name__ == "__main__":
+ import sys
+ if (sys.version_info[:3] != (3,10,0) or sys.version_info[3] != 'alpha'):
+ test_doc_dill_issue_219()
+ test_method_with_internal_import_should_work()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_file.py b/solutions/.venv/Lib/site-packages/dill/tests/test_file.py
new file mode 100644
index 000000000..ad949f367
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_file.py
@@ -0,0 +1,500 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import os
+import sys
+import string
+import random
+
+import dill
+
+
+dill.settings['recurse'] = True
+
+fname = "_test_file.txt"
+rand_chars = list(string.ascii_letters) + ["\n"] * 40 # bias newline
+
+buffer_error = ValueError("invalid buffer size")
+dne_error = FileNotFoundError("[Errno 2] No such file or directory: '%s'" % fname)
+
+
+def write_randomness(number=200):
+ f = open(fname, "w")
+ for i in range(number):
+ f.write(random.choice(rand_chars))
+ f.close()
+ f = open(fname, "r")
+ contents = f.read()
+ f.close()
+ return contents
+
+
+def trunc_file():
+ open(fname, "w").close()
+
+
+def throws(op, args, exc):
+ try:
+ op(*args)
+ except type(exc):
+ return sys.exc_info()[1].args == exc.args
+ else:
+ return False
+
+
+def teardown_module():
+ if os.path.exists(fname):
+ os.remove(fname)
+
+
+def bench(strictio, fmode, skippypy):
+ import platform
+ if skippypy and platform.python_implementation() == 'PyPy':
+ # Skip for PyPy...
+ return
+
+ # file exists, with same contents
+ # read
+
+ write_randomness()
+
+ f = open(fname, "r")
+ _f = dill.loads(dill.dumps(f, fmode=fmode))#, strictio=strictio))
+ assert _f.mode == f.mode
+ assert _f.tell() == f.tell()
+ assert _f.read() == f.read()
+ f.close()
+ _f.close()
+
+ # write
+
+ f = open(fname, "w")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ f.close()
+ f2 = dill.loads(f_dumped) #FIXME: fails due to pypy/issues/1233
+ # TypeError: expected py_object instance instead of str
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2name = f2.name
+ f2.write(" world!")
+ f2.close()
+
+ if fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == " world!"
+ assert f2mode == f1mode
+ assert f2tell == 0
+ elif fmode == dill.CONTENTS_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2mode == f1mode
+ assert f2tell == ftell
+ assert f2name == fname
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2mode == f1mode
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+
+ # append
+
+ trunc_file()
+
+ f = open(fname, "a")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ f.close()
+ f2 = dill.loads(f_dumped)
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2.write(" world!")
+ f2.close()
+
+ assert f2mode == f1mode
+ if fmode == dill.CONTENTS_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2tell == ftell
+ elif fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2tell == ftell
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+
+ # file exists, with different contents (smaller size)
+ # read
+
+ write_randomness()
+
+ f = open(fname, "r")
+ fstr = f.read()
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ f.close()
+ _flen = 150
+ _fstr = write_randomness(number=_flen)
+
+ if strictio: # throw error if ftell > EOF
+ assert throws(dill.loads, (f_dumped,), buffer_error)
+ else:
+ f2 = dill.loads(f_dumped)
+ assert f2.mode == f1mode
+ if fmode == dill.CONTENTS_FMODE:
+ assert f2.tell() == _flen
+ assert f2.read() == ""
+ f2.seek(0)
+ assert f2.read() == _fstr
+ assert f2.tell() == _flen # 150
+ elif fmode == dill.HANDLE_FMODE:
+ assert f2.tell() == 0
+ assert f2.read() == _fstr
+ assert f2.tell() == _flen # 150
+ elif fmode == dill.FILE_FMODE:
+ assert f2.tell() == ftell # 200
+ assert f2.read() == ""
+ f2.seek(0)
+ assert f2.read() == fstr
+ assert f2.tell() == ftell # 200
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+ f2.close()
+
+ # write
+
+ write_randomness()
+
+ f = open(fname, "w")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ f.close()
+ fstr = open(fname).read()
+
+ f = open(fname, "w")
+ f.write("h")
+ _ftell = f.tell()
+ f.close()
+
+ if strictio: # throw error if ftell > EOF
+ assert throws(dill.loads, (f_dumped,), buffer_error)
+ else:
+ f2 = dill.loads(f_dumped)
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2.write(" world!")
+ f2.close()
+ if fmode == dill.CONTENTS_FMODE:
+ assert open(fname).read() == "h world!"
+ assert f2mode == f1mode
+ assert f2tell == _ftell
+ elif fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == " world!"
+ assert f2mode == f1mode
+ assert f2tell == 0
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2mode == f1mode
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+ f2.close()
+
+ # append
+
+ trunc_file()
+
+ f = open(fname, "a")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ f.close()
+ fstr = open(fname).read()
+
+ f = open(fname, "w")
+ f.write("h")
+ _ftell = f.tell()
+ f.close()
+
+ if strictio: # throw error if ftell > EOF
+ assert throws(dill.loads, (f_dumped,), buffer_error)
+ else:
+ f2 = dill.loads(f_dumped)
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2.write(" world!")
+ f2.close()
+ assert f2mode == f1mode
+ if fmode == dill.CONTENTS_FMODE:
+ # position of writes cannot be changed on some OSs
+ assert open(fname).read() == "h world!"
+ assert f2tell == _ftell
+ elif fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == "h world!"
+ assert f2tell == _ftell
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+ f2.close()
+
+ # file does not exist
+ # read
+
+ write_randomness()
+
+ f = open(fname, "r")
+ fstr = f.read()
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ f.close()
+
+ os.remove(fname)
+
+ if strictio: # throw error if file DNE
+ assert throws(dill.loads, (f_dumped,), dne_error)
+ else:
+ f2 = dill.loads(f_dumped)
+ assert f2.mode == f1mode
+ if fmode == dill.CONTENTS_FMODE:
+ # FIXME: this fails on systems where f2.tell() always returns 0
+ # assert f2.tell() == ftell # 200
+ assert f2.read() == ""
+ f2.seek(0)
+ assert f2.read() == ""
+ assert f2.tell() == 0
+ elif fmode == dill.FILE_FMODE:
+ assert f2.tell() == ftell # 200
+ assert f2.read() == ""
+ f2.seek(0)
+ assert f2.read() == fstr
+ assert f2.tell() == ftell # 200
+ elif fmode == dill.HANDLE_FMODE:
+ assert f2.tell() == 0
+ assert f2.read() == ""
+ assert f2.tell() == 0
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+ f2.close()
+
+ # write
+
+ write_randomness()
+
+ f = open(fname, "w+")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ ftell = f.tell()
+ f1mode = f.mode
+ f.close()
+
+ os.remove(fname)
+
+ if strictio: # throw error if file DNE
+ assert throws(dill.loads, (f_dumped,), dne_error)
+ else:
+ f2 = dill.loads(f_dumped)
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2.write(" world!")
+ f2.close()
+ if fmode == dill.CONTENTS_FMODE:
+ assert open(fname).read() == " world!"
+ assert f2mode == 'w+'
+ assert f2tell == 0
+ elif fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == " world!"
+ assert f2mode == f1mode
+ assert f2tell == 0
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2mode == f1mode
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+
+ # append
+
+ trunc_file()
+
+ f = open(fname, "a")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ ftell = f.tell()
+ f1mode = f.mode
+ f.close()
+
+ os.remove(fname)
+
+ if strictio: # throw error if file DNE
+ assert throws(dill.loads, (f_dumped,), dne_error)
+ else:
+ f2 = dill.loads(f_dumped)
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2.write(" world!")
+ f2.close()
+ assert f2mode == f1mode
+ if fmode == dill.CONTENTS_FMODE:
+ assert open(fname).read() == " world!"
+ assert f2tell == 0
+ elif fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == " world!"
+ assert f2tell == 0
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+
+ # file exists, with different contents (larger size)
+ # read
+
+ write_randomness()
+
+ f = open(fname, "r")
+ fstr = f.read()
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ f.close()
+ _flen = 250
+ _fstr = write_randomness(number=_flen)
+
+ # XXX: no safe_file: no way to be 'safe'?
+
+ f2 = dill.loads(f_dumped)
+ assert f2.mode == f1mode
+ if fmode == dill.CONTENTS_FMODE:
+ assert f2.tell() == ftell # 200
+ assert f2.read() == _fstr[ftell:]
+ f2.seek(0)
+ assert f2.read() == _fstr
+ assert f2.tell() == _flen # 250
+ elif fmode == dill.HANDLE_FMODE:
+ assert f2.tell() == 0
+ assert f2.read() == _fstr
+ assert f2.tell() == _flen # 250
+ elif fmode == dill.FILE_FMODE:
+ assert f2.tell() == ftell # 200
+ assert f2.read() == ""
+ f2.seek(0)
+ assert f2.read() == fstr
+ assert f2.tell() == ftell # 200
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+ f2.close() # XXX: other alternatives?
+
+ # write
+
+ f = open(fname, "w")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+
+ fstr = open(fname).read()
+
+ f.write(" and goodbye!")
+ _ftell = f.tell()
+ f.close()
+
+ # XXX: no safe_file: no way to be 'safe'?
+
+ f2 = dill.loads(f_dumped)
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2.write(" world!")
+ f2.close()
+ if fmode == dill.CONTENTS_FMODE:
+ assert open(fname).read() == "hello world!odbye!"
+ assert f2mode == f1mode
+ assert f2tell == ftell
+ elif fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == " world!"
+ assert f2mode == f1mode
+ assert f2tell == 0
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2mode == f1mode
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+ f2.close()
+
+ # append
+
+ trunc_file()
+
+ f = open(fname, "a")
+ f.write("hello")
+ f_dumped = dill.dumps(f, fmode=fmode)#, strictio=strictio)
+ f1mode = f.mode
+ ftell = f.tell()
+ fstr = open(fname).read()
+
+ f.write(" and goodbye!")
+ _ftell = f.tell()
+ f.close()
+
+ # XXX: no safe_file: no way to be 'safe'?
+
+ f2 = dill.loads(f_dumped)
+ f2mode = f2.mode
+ f2tell = f2.tell()
+ f2.write(" world!")
+ f2.close()
+ assert f2mode == f1mode
+ if fmode == dill.CONTENTS_FMODE:
+ assert open(fname).read() == "hello and goodbye! world!"
+ assert f2tell == ftell
+ elif fmode == dill.HANDLE_FMODE:
+ assert open(fname).read() == "hello and goodbye! world!"
+ assert f2tell == _ftell
+ elif fmode == dill.FILE_FMODE:
+ assert open(fname).read() == "hello world!"
+ assert f2tell == ftell
+ else:
+ raise RuntimeError("Unknown file mode '%s'" % fmode)
+ f2.close()
+
+
+def test_nostrictio_handlefmode():
+ bench(False, dill.HANDLE_FMODE, False)
+ teardown_module()
+
+
+def test_nostrictio_filefmode():
+ bench(False, dill.FILE_FMODE, False)
+ teardown_module()
+
+
+def test_nostrictio_contentsfmode():
+ bench(False, dill.CONTENTS_FMODE, True)
+ teardown_module()
+
+
+#bench(True, dill.HANDLE_FMODE, False)
+#bench(True, dill.FILE_FMODE, False)
+#bench(True, dill.CONTENTS_FMODE, True)
+
+
+if __name__ == '__main__':
+ test_nostrictio_handlefmode()
+ test_nostrictio_filefmode()
+ test_nostrictio_contentsfmode()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_functions.py b/solutions/.venv/Lib/site-packages/dill/tests/test_functions.py
new file mode 100644
index 000000000..305acc657
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_functions.py
@@ -0,0 +1,141 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2019-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import functools
+import dill
+import sys
+dill.settings['recurse'] = True
+
+
+def function_a(a):
+ return a
+
+
+def function_b(b, b1):
+ return b + b1
+
+
+def function_c(c, c1=1):
+ return c + c1
+
+
+def function_d(d, d1, d2=1):
+ """doc string"""
+ return d + d1 + d2
+
+function_d.__module__ = 'a module'
+
+
+exec('''
+def function_e(e, *e1, e2=1, e3=2):
+ return e + sum(e1) + e2 + e3''')
+
+globalvar = 0
+
+@functools.lru_cache(None)
+def function_with_cache(x):
+ global globalvar
+ globalvar += x
+ return globalvar
+
+
+def function_with_unassigned_variable():
+ if False:
+ value = None
+ return (lambda: value)
+
+
+def test_issue_510():
+ # A very bizzare use of functions and methods that pickle doesn't get
+ # correctly for odd reasons.
+ class Foo:
+ def __init__(self):
+ def f2(self):
+ return self
+ self.f2 = f2.__get__(self)
+
+ import dill, pickletools
+ f = Foo()
+ f1 = dill.copy(f)
+ assert f1.f2() is f1
+
+
+def test_functions():
+ dumped_func_a = dill.dumps(function_a)
+ assert dill.loads(dumped_func_a)(0) == 0
+
+ dumped_func_b = dill.dumps(function_b)
+ assert dill.loads(dumped_func_b)(1,2) == 3
+
+ dumped_func_c = dill.dumps(function_c)
+ assert dill.loads(dumped_func_c)(1) == 2
+ assert dill.loads(dumped_func_c)(1, 2) == 3
+
+ dumped_func_d = dill.dumps(function_d)
+ assert dill.loads(dumped_func_d).__doc__ == function_d.__doc__
+ assert dill.loads(dumped_func_d).__module__ == function_d.__module__
+ assert dill.loads(dumped_func_d)(1, 2) == 4
+ assert dill.loads(dumped_func_d)(1, 2, 3) == 6
+ assert dill.loads(dumped_func_d)(1, 2, d2=3) == 6
+
+ function_with_cache(1)
+ globalvar = 0
+ dumped_func_cache = dill.dumps(function_with_cache)
+ assert function_with_cache(2) == 3
+ assert function_with_cache(1) == 1
+ assert function_with_cache(3) == 6
+ assert function_with_cache(2) == 3
+
+ empty_cell = function_with_unassigned_variable()
+ cell_copy = dill.loads(dill.dumps(empty_cell))
+ assert 'empty' in str(cell_copy.__closure__[0])
+ try:
+ cell_copy()
+ except Exception:
+ # this is good
+ pass
+ else:
+ raise AssertionError('cell_copy() did not read an empty cell')
+
+ exec('''
+dumped_func_e = dill.dumps(function_e)
+assert dill.loads(dumped_func_e)(1, 2) == 6
+assert dill.loads(dumped_func_e)(1, 2, 3) == 9
+assert dill.loads(dumped_func_e)(1, 2, e2=3) == 8
+assert dill.loads(dumped_func_e)(1, 2, e2=3, e3=4) == 10
+assert dill.loads(dumped_func_e)(1, 2, 3, e2=4) == 12
+assert dill.loads(dumped_func_e)(1, 2, 3, e2=4, e3=5) == 15''')
+
+def test_code_object():
+ import warnings
+ from dill._dill import ALL_CODE_PARAMS, CODE_PARAMS, CODE_VERSION, _create_code
+ code = function_c.__code__
+ warnings.filterwarnings('ignore', category=DeprecationWarning) # issue 597
+ LNOTAB = getattr(code, 'co_lnotab', b'')
+ if warnings.filters: del warnings.filters[0]
+ fields = {f: getattr(code, 'co_'+f) for f in CODE_PARAMS}
+ fields.setdefault('posonlyargcount', 0) # python >= 3.8
+ fields.setdefault('lnotab', LNOTAB) # python <= 3.9
+ fields.setdefault('linetable', b'') # python >= 3.10
+ fields.setdefault('qualname', fields['name']) # python >= 3.11
+ fields.setdefault('exceptiontable', b'') # python >= 3.11
+ fields.setdefault('endlinetable', None) # python == 3.11a
+ fields.setdefault('columntable', None) # python == 3.11a
+
+ for version, _, params in ALL_CODE_PARAMS:
+ args = tuple(fields[p] for p in params.split())
+ try:
+ _create_code(*args)
+ if version >= (3,10):
+ _create_code(fields['lnotab'], *args)
+ except Exception as error:
+ raise Exception("failed to construct code object with format version {}".format(version)) from error
+
+if __name__ == '__main__':
+ test_functions()
+ test_issue_510()
+ test_code_object()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_functors.py b/solutions/.venv/Lib/site-packages/dill/tests/test_functors.py
new file mode 100644
index 000000000..1008be691
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_functors.py
@@ -0,0 +1,39 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import functools
+import dill
+dill.settings['recurse'] = True
+
+
+def f(a, b, c): # without keywords
+ pass
+
+
+def g(a, b, c=2): # with keywords
+ pass
+
+
+def h(a=1, b=2, c=3): # without args
+ pass
+
+
+def test_functools():
+ fp = functools.partial(f, 1, 2)
+ gp = functools.partial(g, 1, c=2)
+ hp = functools.partial(h, 1, c=2)
+ bp = functools.partial(int, base=2)
+
+ assert dill.pickles(fp, safe=True)
+ assert dill.pickles(gp, safe=True)
+ assert dill.pickles(hp, safe=True)
+ assert dill.pickles(bp, safe=True)
+
+
+if __name__ == '__main__':
+ test_functools()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_logger.py b/solutions/.venv/Lib/site-packages/dill/tests/test_logger.py
new file mode 100644
index 000000000..b878a1054
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_logger.py
@@ -0,0 +1,70 @@
+#!/usr/bin/env python
+
+# Author: Leonardo Gama (@leogama)
+# Copyright (c) 2022-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import logging
+import re
+import tempfile
+
+import dill
+from dill import detect
+from dill.logger import stderr_handler, adapter as logger
+
+try:
+ from StringIO import StringIO
+except ImportError:
+ from io import StringIO
+
+test_obj = {'a': (1, 2), 'b': object(), 'f': lambda x: x**2, 'big': list(range(10))}
+
+def test_logging(should_trace):
+ buffer = StringIO()
+ handler = logging.StreamHandler(buffer)
+ logger.addHandler(handler)
+ try:
+ dill.dumps(test_obj)
+ if should_trace:
+ regex = re.compile(r'(\S*┬ \w.*[^)]' # begin pickling object
+ r'|│*└ # \w.* \[\d+ (\wi)?B])' # object written (with size)
+ )
+ for line in buffer.getvalue().splitlines():
+ assert regex.fullmatch(line)
+ return buffer.getvalue()
+ else:
+ assert buffer.getvalue() == ""
+ finally:
+ logger.removeHandler(handler)
+ buffer.close()
+
+def test_trace_to_file(stream_trace):
+ file = tempfile.NamedTemporaryFile(mode='r')
+ with detect.trace(file.name, mode='w'):
+ dill.dumps(test_obj)
+ file_trace = file.read()
+ file.close()
+ # Apparently, objects can change location in memory...
+ reghex = re.compile(r'0x[0-9A-Za-z]+')
+ file_trace, stream_trace = reghex.sub('0x', file_trace), reghex.sub('0x', stream_trace)
+ # PyPy prints dictionary contents with repr(dict)...
+ regdict = re.compile(r'(dict\.__repr__ of ).*')
+ file_trace, stream_trace = regdict.sub(r'\1{}>', file_trace), regdict.sub(r'\1{}>', stream_trace)
+ assert file_trace == stream_trace
+
+if __name__ == '__main__':
+ logger.removeHandler(stderr_handler)
+ test_logging(should_trace=False)
+ detect.trace(True)
+ test_logging(should_trace=True)
+ detect.trace(False)
+ test_logging(should_trace=False)
+
+ loglevel = logging.ERROR
+ logger.setLevel(loglevel)
+ with detect.trace():
+ stream_trace = test_logging(should_trace=True)
+ test_logging(should_trace=False)
+ assert logger.getEffectiveLevel() == loglevel
+ test_trace_to_file(stream_trace)
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_mixins.py b/solutions/.venv/Lib/site-packages/dill/tests/test_mixins.py
new file mode 100644
index 000000000..6d67daded
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_mixins.py
@@ -0,0 +1,121 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+dill.settings['recurse'] = True
+
+
+def wtf(x,y,z):
+ def zzz():
+ return x
+ def yyy():
+ return y
+ def xxx():
+ return z
+ return zzz,yyy
+
+
+def quad(a=1, b=1, c=0):
+ inverted = [False]
+ def invert():
+ inverted[0] = not inverted[0]
+ def dec(f):
+ def func(*args, **kwds):
+ x = f(*args, **kwds)
+ if inverted[0]: x = -x
+ return a*x**2 + b*x + c
+ func.__wrapped__ = f
+ func.invert = invert
+ func.inverted = inverted
+ return func
+ return dec
+
+
+@quad(a=0,b=2)
+def double_add(*args):
+ return sum(args)
+
+
+fx = sum([1,2,3])
+
+
+### to make it interesting...
+def quad_factory(a=1,b=1,c=0):
+ def dec(f):
+ def func(*args,**kwds):
+ fx = f(*args,**kwds)
+ return a*fx**2 + b*fx + c
+ return func
+ return dec
+
+
+@quad_factory(a=0,b=4,c=0)
+def quadish(x):
+ return x+1
+
+
+quadratic = quad_factory()
+
+
+def doubler(f):
+ def inner(*args, **kwds):
+ fx = f(*args, **kwds)
+ return 2*fx
+ return inner
+
+
+@doubler
+def quadruple(x):
+ return 2*x
+
+
+def test_mixins():
+ # test mixins
+ assert double_add(1,2,3) == 2*fx
+ double_add.invert()
+ assert double_add(1,2,3) == -2*fx
+
+ _d = dill.copy(double_add)
+ assert _d(1,2,3) == -2*fx
+ #_d.invert() #FIXME: fails seemingly randomly
+ #assert _d(1,2,3) == 2*fx
+
+ assert _d.__wrapped__(1,2,3) == fx
+
+ # XXX: issue or feature? in python3.4, inverted is linked through copy
+ if not double_add.inverted[0]:
+ double_add.invert()
+
+ # test some stuff from source and pointers
+ ds = dill.source
+ dd = dill.detect
+ assert ds.getsource(dd.freevars(quadish)['f']) == '@quad_factory(a=0,b=4,c=0)\ndef quadish(x):\n return x+1\n'
+ assert ds.getsource(dd.freevars(quadruple)['f']) == '@doubler\ndef quadruple(x):\n return 2*x\n'
+ assert ds.importable(quadish, source=False) == 'from %s import quadish\n' % __name__
+ assert ds.importable(quadruple, source=False) == 'from %s import quadruple\n' % __name__
+ assert ds.importable(quadratic, source=False) == 'from %s import quadratic\n' % __name__
+ assert ds.importable(double_add, source=False) == 'from %s import double_add\n' % __name__
+ assert ds.importable(quadruple, source=True) == 'def doubler(f):\n def inner(*args, **kwds):\n fx = f(*args, **kwds)\n return 2*fx\n return inner\n\n@doubler\ndef quadruple(x):\n return 2*x\n'
+ #***** #FIXME: this needs work
+ result = ds.importable(quadish, source=True)
+ a,b,c,_,result = result.split('\n',4)
+ assert result == 'def quad_factory(a=1,b=1,c=0):\n def dec(f):\n def func(*args,**kwds):\n fx = f(*args,**kwds)\n return a*fx**2 + b*fx + c\n return func\n return dec\n\n@quad_factory(a=0,b=4,c=0)\ndef quadish(x):\n return x+1\n'
+ assert set([a,b,c]) == set(['a = 0', 'c = 0', 'b = 4'])
+ result = ds.importable(quadratic, source=True)
+ a,b,c,result = result.split('\n',3)
+ assert result == '\ndef dec(f):\n def func(*args,**kwds):\n fx = f(*args,**kwds)\n return a*fx**2 + b*fx + c\n return func\n'
+ assert set([a,b,c]) == set(['a = 1', 'c = 0', 'b = 1'])
+ result = ds.importable(double_add, source=True)
+ a,b,c,d,_,result = result.split('\n',5)
+ assert result == 'def quad(a=1, b=1, c=0):\n inverted = [False]\n def invert():\n inverted[0] = not inverted[0]\n def dec(f):\n def func(*args, **kwds):\n x = f(*args, **kwds)\n if inverted[0]: x = -x\n return a*x**2 + b*x + c\n func.__wrapped__ = f\n func.invert = invert\n func.inverted = inverted\n return func\n return dec\n\n@quad(a=0,b=2)\ndef double_add(*args):\n return sum(args)\n'
+ assert set([a,b,c,d]) == set(['a = 0', 'c = 0', 'b = 2', 'inverted = [True]'])
+ #*****
+
+
+if __name__ == '__main__':
+ test_mixins()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_module.py b/solutions/.venv/Lib/site-packages/dill/tests/test_module.py
new file mode 100644
index 000000000..b696d728e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_module.py
@@ -0,0 +1,84 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import sys
+import dill
+import test_mixins as module
+from importlib import reload
+dill.settings['recurse'] = True
+
+cached = (module.__cached__ if hasattr(module, "__cached__")
+ else module.__file__.split(".", 1)[0] + ".pyc")
+
+module.a = 1234
+
+pik_mod = dill.dumps(module)
+
+module.a = 0
+
+# remove module
+del sys.modules[module.__name__]
+del module
+
+module = dill.loads(pik_mod)
+def test_attributes():
+ #assert hasattr(module, "a") and module.a == 1234 #FIXME: -m dill.tests
+ assert module.double_add(1, 2, 3) == 2 * module.fx
+
+# Restart, and test use_diff
+
+reload(module)
+
+try:
+ dill.use_diff()
+
+ module.a = 1234
+
+ pik_mod = dill.dumps(module)
+
+ module.a = 0
+
+ # remove module
+ del sys.modules[module.__name__]
+ del module
+
+ module = dill.loads(pik_mod)
+ def test_diff_attributes():
+ assert hasattr(module, "a") and module.a == 1234
+ assert module.double_add(1, 2, 3) == 2 * module.fx
+
+except AttributeError:
+ def test_diff_attributes():
+ pass
+
+# clean up
+import os
+if os.path.exists(cached):
+ os.remove(cached)
+pycache = os.path.join(os.path.dirname(module.__file__), "__pycache__")
+if os.path.exists(pycache) and not os.listdir(pycache):
+ os.removedirs(pycache)
+
+
+# test when module is None
+import math
+
+def get_lambda(str, **kwarg):
+ return eval(str, kwarg, None)
+
+obj = get_lambda('lambda x: math.exp(x)', math=math)
+
+def test_module_is_none():
+ assert obj.__module__ is None
+ assert dill.copy(obj)(3) == obj(3)
+
+
+if __name__ == '__main__':
+ test_attributes()
+ test_diff_attributes()
+ test_module_is_none()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_moduledict.py b/solutions/.venv/Lib/site-packages/dill/tests/test_moduledict.py
new file mode 100644
index 000000000..5e6e87b36
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_moduledict.py
@@ -0,0 +1,54 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+dill.settings['recurse'] = True
+
+def f(func):
+ def w(*args):
+ return f(*args)
+ return w
+
+@f
+def f2(): pass
+
+# check when __main__ and on import
+def test_decorated():
+ assert dill.pickles(f2)
+
+
+import doctest
+import logging
+logging.basicConfig(level=logging.DEBUG)
+
+class SomeUnreferencedUnpicklableClass(object):
+ def __reduce__(self):
+ raise Exception
+
+unpicklable = SomeUnreferencedUnpicklableClass()
+
+# This works fine outside of Doctest:
+def test_normal():
+ serialized = dill.dumps(lambda x: x)
+
+# should not try to pickle unpicklable object in __globals__
+def tests():
+ """
+ >>> serialized = dill.dumps(lambda x: x)
+ """
+ return
+
+#print("\n\nRunning Doctest:")
+def test_doctest():
+ doctest.testmod()
+
+
+if __name__ == '__main__':
+ test_decorated()
+ test_normal()
+ test_doctest()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_nested.py b/solutions/.venv/Lib/site-packages/dill/tests/test_nested.py
new file mode 100644
index 000000000..9109f55c8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_nested.py
@@ -0,0 +1,135 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+test dill's ability to handle nested functions
+"""
+
+import os
+import math
+
+import dill as pickle
+pickle.settings['recurse'] = True
+
+
+# the nested function: pickle should fail here, but dill is ok.
+def adder(augend):
+ zero = [0]
+
+ def inner(addend):
+ return addend + augend + zero[0]
+ return inner
+
+
+# rewrite the nested function using a class: standard pickle should work here.
+class cadder(object):
+ def __init__(self, augend):
+ self.augend = augend
+ self.zero = [0]
+
+ def __call__(self, addend):
+ return addend + self.augend + self.zero[0]
+
+
+# rewrite again, but as an old-style class
+class c2adder:
+ def __init__(self, augend):
+ self.augend = augend
+ self.zero = [0]
+
+ def __call__(self, addend):
+ return addend + self.augend + self.zero[0]
+
+
+# some basic class stuff
+class basic(object):
+ pass
+
+
+class basic2:
+ pass
+
+
+x = 5
+y = 1
+
+
+def test_basic():
+ a = [0, 1, 2]
+ pa = pickle.dumps(a)
+ pmath = pickle.dumps(math) #XXX: FAILS in pickle
+ pmap = pickle.dumps(map)
+ # ...
+ la = pickle.loads(pa)
+ lmath = pickle.loads(pmath)
+ lmap = pickle.loads(pmap)
+ assert list(map(math.sin, a)) == list(lmap(lmath.sin, la))
+
+
+def test_basic_class():
+ pbasic2 = pickle.dumps(basic2)
+ _pbasic2 = pickle.loads(pbasic2)()
+ pbasic = pickle.dumps(basic)
+ _pbasic = pickle.loads(pbasic)()
+
+
+def test_c2adder():
+ pc2adder = pickle.dumps(c2adder)
+ pc2add5 = pickle.loads(pc2adder)(x)
+ assert pc2add5(y) == x+y
+
+
+def test_pickled_cadder():
+ pcadder = pickle.dumps(cadder)
+ pcadd5 = pickle.loads(pcadder)(x)
+ assert pcadd5(y) == x+y
+
+
+def test_raw_adder_and_inner():
+ add5 = adder(x)
+ assert add5(y) == x+y
+
+
+def test_pickled_adder():
+ padder = pickle.dumps(adder)
+ padd5 = pickle.loads(padder)(x)
+ assert padd5(y) == x+y
+
+
+def test_pickled_inner():
+ add5 = adder(x)
+ pinner = pickle.dumps(add5) #XXX: FAILS in pickle
+ p5add = pickle.loads(pinner)
+ assert p5add(y) == x+y
+
+
+def test_moduledict_where_not_main():
+ try:
+ from . import test_moduledict
+ except ImportError:
+ import test_moduledict
+ name = 'test_moduledict.py'
+ if os.path.exists(name) and os.path.exists(name+'c'):
+ os.remove(name+'c')
+
+ if os.path.exists(name) and hasattr(test_moduledict, "__cached__") \
+ and os.path.exists(test_moduledict.__cached__):
+ os.remove(getattr(test_moduledict, "__cached__"))
+
+ if os.path.exists("__pycache__") and not os.listdir("__pycache__"):
+ os.removedirs("__pycache__")
+
+
+if __name__ == '__main__':
+ test_basic()
+ test_basic_class()
+ test_c2adder()
+ test_pickled_cadder()
+ test_raw_adder_and_inner()
+ test_pickled_adder()
+ test_pickled_inner()
+ test_moduledict_where_not_main()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_objects.py b/solutions/.venv/Lib/site-packages/dill/tests/test_objects.py
new file mode 100644
index 000000000..7db288de0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_objects.py
@@ -0,0 +1,63 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+demonstrate dill's ability to pickle different python types
+test pickling of all Python Standard Library objects (currently: CH 1-14 @ 2.7)
+"""
+
+import dill as pickle
+pickle.settings['recurse'] = True
+#pickle.detect.trace(True)
+#import pickle
+
+# get all objects for testing
+from dill import load_types, objects, extend
+load_types(pickleable=True,unpickleable=False)
+
+# uncomment the next two lines to test cloudpickle
+#extend(False)
+#import cloudpickle as pickle
+
+# helper objects
+class _class:
+ def _method(self):
+ pass
+
+# objects that *fail* if imported
+special = {}
+special['LambdaType'] = _lambda = lambda x: lambda y: x
+special['MethodType'] = _method = _class()._method
+special['UnboundMethodType'] = _class._method
+objects.update(special)
+
+def pickles(name, exact=False, verbose=True):
+ """quick check if object pickles with dill"""
+ obj = objects[name]
+ try:
+ pik = pickle.loads(pickle.dumps(obj))
+ if exact:
+ try:
+ assert pik == obj
+ except AssertionError:
+ assert type(obj) == type(pik)
+ if verbose: print ("weak: %s %s" % (name, type(obj)))
+ else:
+ assert type(obj) == type(pik)
+ except Exception:
+ if verbose: print ("fails: %s %s" % (name, type(obj)))
+
+
+def test_objects(verbose=True):
+ for member in objects.keys():
+ #pickles(member, exact=True, verbose=verbose)
+ pickles(member, exact=False, verbose=verbose)
+
+if __name__ == '__main__':
+ import warnings
+ warnings.simplefilter('ignore')
+ test_objects(verbose=False)
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_properties.py b/solutions/.venv/Lib/site-packages/dill/tests/test_properties.py
new file mode 100644
index 000000000..df3f5b58f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_properties.py
@@ -0,0 +1,62 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import sys
+
+import dill
+dill.settings['recurse'] = True
+
+
+class Foo(object):
+ def __init__(self):
+ self._data = 1
+
+ def _get_data(self):
+ return self._data
+
+ def _set_data(self, x):
+ self._data = x
+
+ data = property(_get_data, _set_data)
+
+
+def test_data_not_none():
+ FooS = dill.copy(Foo)
+ assert FooS.data.fget is not None
+ assert FooS.data.fset is not None
+ assert FooS.data.fdel is None
+
+
+def test_data_unchanged():
+ FooS = dill.copy(Foo)
+ try:
+ res = FooS().data
+ except Exception:
+ e = sys.exc_info()[1]
+ raise AssertionError(str(e))
+ else:
+ assert res == 1
+
+
+def test_data_changed():
+ FooS = dill.copy(Foo)
+ try:
+ f = FooS()
+ f.data = 1024
+ res = f.data
+ except Exception:
+ e = sys.exc_info()[1]
+ raise AssertionError(str(e))
+ else:
+ assert res == 1024
+
+
+if __name__ == '__main__':
+ test_data_not_none()
+ test_data_unchanged()
+ test_data_changed()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_pycapsule.py b/solutions/.venv/Lib/site-packages/dill/tests/test_pycapsule.py
new file mode 100644
index 000000000..34ca00c33
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_pycapsule.py
@@ -0,0 +1,45 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Author: Anirudh Vegesana (avegesan@cs.stanford.edu)
+# Copyright (c) 2022-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+test pickling a PyCapsule object
+"""
+
+import dill
+import warnings
+
+test_pycapsule = None
+
+if dill._dill._testcapsule is not None:
+ import ctypes
+ def test_pycapsule():
+ name = ctypes.create_string_buffer(b'dill._testcapsule')
+ capsule = dill._dill._PyCapsule_New(
+ ctypes.cast(dill._dill._PyCapsule_New, ctypes.c_void_p),
+ name,
+ None
+ )
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ dill.copy(capsule)
+ dill._testcapsule = capsule
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ dill.copy(capsule)
+ dill._testcapsule = None
+ try:
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore", dill.PicklingWarning)
+ dill.copy(capsule)
+ except dill.UnpicklingError:
+ pass
+ else:
+ raise AssertionError("Expected a different error")
+
+if __name__ == '__main__':
+ if test_pycapsule is not None:
+ test_pycapsule()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_recursive.py b/solutions/.venv/Lib/site-packages/dill/tests/test_recursive.py
new file mode 100644
index 000000000..b84f19e4b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_recursive.py
@@ -0,0 +1,177 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2019-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+from functools import partial
+import warnings
+
+
+def copy(obj, byref=False, recurse=False):
+ if byref:
+ try:
+ return dill.copy(obj, byref=byref, recurse=recurse)
+ except Exception:
+ pass
+ else:
+ raise AssertionError('Copy of %s with byref=True should have given a warning!' % (obj,))
+
+ warnings.simplefilter('ignore')
+ val = dill.copy(obj, byref=byref, recurse=recurse)
+ warnings.simplefilter('error')
+ return val
+ else:
+ return dill.copy(obj, byref=byref, recurse=recurse)
+
+
+class obj1(object):
+ def __init__(self):
+ super(obj1, self).__init__()
+
+class obj2(object):
+ def __init__(self):
+ super(obj2, self).__init__()
+
+class obj3(object):
+ super_ = super
+ def __init__(self):
+ obj3.super_(obj3, self).__init__()
+
+
+def test_super():
+ assert copy(obj1(), byref=True)
+ assert copy(obj1(), byref=True, recurse=True)
+ assert copy(obj1(), recurse=True)
+ assert copy(obj1())
+
+ assert copy(obj2(), byref=True)
+ assert copy(obj2(), byref=True, recurse=True)
+ assert copy(obj2(), recurse=True)
+ assert copy(obj2())
+
+ assert copy(obj3(), byref=True)
+ assert copy(obj3(), byref=True, recurse=True)
+ assert copy(obj3(), recurse=True)
+ assert copy(obj3())
+
+
+def get_trigger(model):
+ pass
+
+class Machine(object):
+ def __init__(self):
+ self.child = Model()
+ self.trigger = partial(get_trigger, self)
+ self.child.trigger = partial(get_trigger, self.child)
+
+class Model(object):
+ pass
+
+
+
+def test_partial():
+ assert copy(Machine(), byref=True)
+ assert copy(Machine(), byref=True, recurse=True)
+ assert copy(Machine(), recurse=True)
+ assert copy(Machine())
+
+
+class Machine2(object):
+ def __init__(self):
+ self.go = partial(self.member, self)
+ def member(self, model):
+ pass
+
+
+class SubMachine(Machine2):
+ def __init__(self):
+ super(SubMachine, self).__init__()
+
+
+def test_partials():
+ assert copy(SubMachine(), byref=True)
+ assert copy(SubMachine(), byref=True, recurse=True)
+ assert copy(SubMachine(), recurse=True)
+ assert copy(SubMachine())
+
+
+class obj4(object):
+ def __init__(self):
+ super(obj4, self).__init__()
+ a = self
+ class obj5(object):
+ def __init__(self):
+ super(obj5, self).__init__()
+ self.a = a
+ self.b = obj5()
+
+
+def test_circular_reference():
+ assert copy(obj4())
+ obj4_copy = dill.loads(dill.dumps(obj4()))
+ assert type(obj4_copy) is type(obj4_copy).__init__.__closure__[0].cell_contents
+ assert type(obj4_copy.b) is type(obj4_copy.b).__init__.__closure__[0].cell_contents
+
+
+def f():
+ def g():
+ return g
+ return g
+
+
+def test_function_cells():
+ assert copy(f())
+
+
+def fib(n):
+ assert n >= 0
+ if n <= 1:
+ return n
+ else:
+ return fib(n-1) + fib(n-2)
+
+
+def test_recursive_function():
+ global fib
+ fib2 = copy(fib, recurse=True)
+ fib3 = copy(fib)
+ fib4 = fib
+ del fib
+ assert fib2(5) == 5
+ for _fib in (fib3, fib4):
+ try:
+ _fib(5)
+ except Exception:
+ # This is expected to fail because fib no longer exists
+ pass
+ else:
+ raise AssertionError("Function fib shouldn't have been found")
+ fib = fib4
+
+
+def collection_function_recursion():
+ d = {}
+ def g():
+ return d
+ d['g'] = g
+ return g
+
+
+def test_collection_function_recursion():
+ g = copy(collection_function_recursion())
+ assert g()['g'] is g
+
+
+if __name__ == '__main__':
+ with warnings.catch_warnings():
+ warnings.simplefilter('error')
+ test_super()
+ test_partial()
+ test_partials()
+ test_circular_reference()
+ test_function_cells()
+ test_recursive_function()
+ test_collection_function_recursion()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_registered.py b/solutions/.venv/Lib/site-packages/dill/tests/test_registered.py
new file mode 100644
index 000000000..393e2f3ea
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_registered.py
@@ -0,0 +1,64 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2022-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+test pickling registered objects
+"""
+
+import dill
+from dill._objects import failures, registered, succeeds
+import warnings
+warnings.filterwarnings('ignore')
+
+def check(d, ok=True):
+ res = []
+ for k,v in d.items():
+ try:
+ z = dill.copy(v)
+ if ok: res.append(k)
+ except:
+ if not ok: res.append(k)
+ return res
+
+fails = check(failures)
+try:
+ assert not bool(fails)
+except AssertionError as e:
+ print("FAILS: %s" % fails)
+ raise e from None
+
+register = check(registered, ok=False)
+try:
+ assert not bool(register)
+except AssertionError as e:
+ print("REGISTER: %s" % register)
+ raise e from None
+
+success = check(succeeds, ok=False)
+try:
+ assert not bool(success)
+except AssertionError as e:
+ print("SUCCESS: %s" % success)
+ raise e from None
+
+import builtins
+import types
+q = dill._dill._reverse_typemap
+p = {k:v for k,v in q.items() if k not in vars(builtins) and k not in vars(types)}
+
+diff = set(p.keys()).difference(registered.keys())
+try:
+ assert not bool(diff)
+except AssertionError as e:
+ print("DIFF: %s" % diff)
+ raise e from None
+
+miss = set(registered.keys()).difference(p.keys())
+try:
+ assert not bool(miss)
+except AssertionError as e:
+ print("MISS: %s" % miss)
+ raise e from None
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_restricted.py b/solutions/.venv/Lib/site-packages/dill/tests/test_restricted.py
new file mode 100644
index 000000000..cdb773e36
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_restricted.py
@@ -0,0 +1,27 @@
+#!/usr/bin/env python
+#
+# Author: Kirill Makhonin (@kirillmakhonin)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+
+class RestrictedType:
+ def __bool__(*args, **kwargs):
+ raise Exception('Restricted function')
+
+ __eq__ = __lt__ = __le__ = __ne__ = __gt__ = __ge__ = __hash__ = __bool__
+
+glob_obj = RestrictedType()
+
+def restricted_func():
+ a = glob_obj
+
+def test_function_with_restricted_object():
+ deserialized = dill.loads(dill.dumps(restricted_func, recurse=True))
+
+
+if __name__ == '__main__':
+ test_function_with_restricted_object()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_selected.py b/solutions/.venv/Lib/site-packages/dill/tests/test_selected.py
new file mode 100644
index 000000000..bcc640afc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_selected.py
@@ -0,0 +1,126 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+testing some selected object types
+"""
+
+import dill
+dill.settings['recurse'] = True
+
+verbose = False
+
+def test_dict_contents():
+ c = type.__dict__
+ for i,j in c.items():
+ #try:
+ ok = dill.pickles(j)
+ #except Exception:
+ # print ("FAIL: %s with %s" % (i, dill.detect.errors(j)))
+ if verbose: print ("%s: %s, %s" % (ok, type(j), j))
+ assert ok
+ if verbose: print ("")
+
+def _g(x): yield x;
+
+def _f():
+ try: raise
+ except Exception:
+ from sys import exc_info
+ e, er, tb = exc_info()
+ return er, tb
+
+class _d(object):
+ def _method(self):
+ pass
+
+from dill import objects
+from dill import load_types
+load_types(pickleable=True,unpickleable=False)
+_newclass = objects['ClassObjectType']
+# some clean-up #FIXME: should happen internal to dill
+objects['TemporaryFileType'].close()
+objects['TextWrapperType'].close()
+if 'BufferedRandomType' in objects:
+ objects['BufferedRandomType'].close()
+objects['BufferedReaderType'].close()
+objects['BufferedWriterType'].close()
+objects['FileType'].close()
+del objects
+
+# getset_descriptor for new-style classes (fails on '_method', if not __main__)
+def test_class_descriptors():
+ d = _d.__dict__
+ for i in d.values():
+ ok = dill.pickles(i)
+ if verbose: print ("%s: %s, %s" % (ok, type(i), i))
+ assert ok
+ if verbose: print ("")
+ od = _newclass.__dict__
+ for i in od.values():
+ ok = dill.pickles(i)
+ if verbose: print ("%s: %s, %s" % (ok, type(i), i))
+ assert ok
+ if verbose: print ("")
+
+# (__main__) class instance for new-style classes
+def test_class():
+ o = _d()
+ oo = _newclass()
+ ok = dill.pickles(o)
+ if verbose: print ("%s: %s, %s" % (ok, type(o), o))
+ assert ok
+ ok = dill.pickles(oo)
+ if verbose: print ("%s: %s, %s" % (ok, type(oo), oo))
+ assert ok
+ if verbose: print ("")
+
+# frames, generators, and tracebacks (all depend on frame)
+def test_frame_related():
+ g = _g(1)
+ f = g.gi_frame
+ e,t = _f()
+ _is = lambda ok: ok
+ ok = dill.pickles(f)
+ if verbose: print ("%s: %s, %s" % (ok, type(f), f))
+ assert not ok
+ ok = dill.pickles(g)
+ if verbose: print ("%s: %s, %s" % (ok, type(g), g))
+ assert _is(not ok) #XXX: dill fails
+ ok = dill.pickles(t)
+ if verbose: print ("%s: %s, %s" % (ok, type(t), t))
+ assert not ok #XXX: dill fails
+ ok = dill.pickles(e)
+ if verbose: print ("%s: %s, %s" % (ok, type(e), e))
+ assert ok
+ if verbose: print ("")
+
+def test_typing():
+ import typing
+ x = typing.Any
+ assert x == dill.copy(x)
+ x = typing.Dict[int, str]
+ assert x == dill.copy(x)
+ x = typing.List[int]
+ assert x == dill.copy(x)
+ x = typing.Tuple[int, str]
+ assert x == dill.copy(x)
+ x = typing.Tuple[int]
+ assert x == dill.copy(x)
+ x = typing.Tuple[()]
+ assert x == dill.copy(x)
+ x = typing.Tuple[()].copy_with(())
+ assert x == dill.copy(x)
+ return
+
+
+if __name__ == '__main__':
+ test_frame_related()
+ test_dict_contents()
+ test_class()
+ test_class_descriptors()
+ test_typing()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_session.py b/solutions/.venv/Lib/site-packages/dill/tests/test_session.py
new file mode 100644
index 000000000..200642def
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_session.py
@@ -0,0 +1,280 @@
+#!/usr/bin/env python
+
+# Author: Leonardo Gama (@leogama)
+# Copyright (c) 2022-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import atexit
+import os
+import sys
+import __main__
+from contextlib import suppress
+from io import BytesIO
+
+import dill
+
+session_file = os.path.join(os.path.dirname(__file__), 'session-refimported-%s.pkl')
+
+###################
+# Child process #
+###################
+
+def _error_line(error, obj, refimported):
+ import traceback
+ line = traceback.format_exc().splitlines()[-2].replace('[obj]', '['+repr(obj)+']')
+ return "while testing (with refimported=%s): %s" % (refimported, line.lstrip())
+
+if __name__ == '__main__' and len(sys.argv) >= 3 and sys.argv[1] == '--child':
+ # Test session loading in a fresh interpreter session.
+ refimported = (sys.argv[2] == 'True')
+ dill.load_module(session_file % refimported, module='__main__')
+
+ def test_modules(refimported):
+ # FIXME: In this test setting with CPython 3.7, 'calendar' is not included
+ # in sys.modules, independent of the value of refimported. Tried to
+ # run garbage collection just before loading the session with no luck. It
+ # fails even when preceding them with 'import calendar'. Needed to run
+ # these kinds of tests in a supbrocess. Failing test sample:
+ # assert globals()['day_name'] is sys.modules['calendar'].__dict__['day_name']
+ try:
+ for obj in ('json', 'url', 'local_mod', 'sax', 'dom'):
+ assert globals()[obj].__name__ in sys.modules
+ assert 'calendar' in sys.modules and 'cmath' in sys.modules
+ import calendar, cmath
+
+ for obj in ('Calendar', 'isleap'):
+ assert globals()[obj] is sys.modules['calendar'].__dict__[obj]
+ assert __main__.day_name.__module__ == 'calendar'
+ if refimported:
+ assert __main__.day_name is calendar.day_name
+
+ assert __main__.complex_log is cmath.log
+
+ except AssertionError as error:
+ error.args = (_error_line(error, obj, refimported),)
+ raise
+
+ test_modules(refimported)
+ sys.exit()
+
+####################
+# Parent process #
+####################
+
+# Create various kinds of objects to test different internal logics.
+
+## Modules.
+import json # top-level module
+import urllib as url # top-level module under alias
+from xml import sax # submodule
+import xml.dom.minidom as dom # submodule under alias
+import test_dictviews as local_mod # non-builtin top-level module
+
+## Imported objects.
+from calendar import Calendar, isleap, day_name # class, function, other object
+from cmath import log as complex_log # imported with alias
+
+## Local objects.
+x = 17
+empty = None
+names = ['Alice', 'Bob', 'Carol']
+def squared(x): return x**2
+cubed = lambda x: x**3
+class Person:
+ def __init__(self, name, age):
+ self.name = name
+ self.age = age
+person = Person(names[0], x)
+class CalendarSubclass(Calendar):
+ def weekdays(self):
+ return [day_name[i] for i in self.iterweekdays()]
+cal = CalendarSubclass()
+selfref = __main__
+
+# Setup global namespace for session saving tests.
+class TestNamespace:
+ test_globals = globals().copy()
+ def __init__(self, **extra):
+ self.extra = extra
+ def __enter__(self):
+ self.backup = globals().copy()
+ globals().clear()
+ globals().update(self.test_globals)
+ globals().update(self.extra)
+ return self
+ def __exit__(self, *exc_info):
+ globals().clear()
+ globals().update(self.backup)
+
+def _clean_up_cache(module):
+ cached = module.__file__.split('.', 1)[0] + '.pyc'
+ cached = module.__cached__ if hasattr(module, '__cached__') else cached
+ pycache = os.path.join(os.path.dirname(module.__file__), '__pycache__')
+ for remove, file in [(os.remove, cached), (os.removedirs, pycache)]:
+ with suppress(OSError):
+ remove(file)
+
+atexit.register(_clean_up_cache, local_mod)
+
+def _test_objects(main, globals_copy, refimported):
+ try:
+ main_dict = __main__.__dict__
+ global Person, person, Calendar, CalendarSubclass, cal, selfref
+
+ for obj in ('json', 'url', 'local_mod', 'sax', 'dom'):
+ assert globals()[obj].__name__ == globals_copy[obj].__name__
+
+ for obj in ('x', 'empty', 'names'):
+ assert main_dict[obj] == globals_copy[obj]
+
+ for obj in ['squared', 'cubed']:
+ assert main_dict[obj].__globals__ is main_dict
+ assert main_dict[obj](3) == globals_copy[obj](3)
+
+ assert Person.__module__ == __main__.__name__
+ assert isinstance(person, Person)
+ assert person.age == globals_copy['person'].age
+
+ assert issubclass(CalendarSubclass, Calendar)
+ assert isinstance(cal, CalendarSubclass)
+ assert cal.weekdays() == globals_copy['cal'].weekdays()
+
+ assert selfref is __main__
+
+ except AssertionError as error:
+ error.args = (_error_line(error, obj, refimported),)
+ raise
+
+def test_session_main(refimported):
+ """test dump/load_module() for __main__, both in this process and in a subprocess"""
+ extra_objects = {}
+ if refimported:
+ # Test unpickleable imported object in main.
+ from sys import flags
+ extra_objects['flags'] = flags
+
+ with TestNamespace(**extra_objects) as ns:
+ try:
+ # Test session loading in a new session.
+ dill.dump_module(session_file % refimported, refimported=refimported)
+ from dill.tests.__main__ import python, shell, sp
+ error = sp.call([python, __file__, '--child', str(refimported)], shell=shell)
+ if error: sys.exit(error)
+ finally:
+ with suppress(OSError):
+ os.remove(session_file % refimported)
+
+ # Test session loading in the same session.
+ session_buffer = BytesIO()
+ dill.dump_module(session_buffer, refimported=refimported)
+ session_buffer.seek(0)
+ dill.load_module(session_buffer, module='__main__')
+ ns.backup['_test_objects'](__main__, ns.backup, refimported)
+
+def test_session_other():
+ """test dump/load_module() for a module other than __main__"""
+ import test_classdef as module
+ atexit.register(_clean_up_cache, module)
+ module.selfref = module
+ dict_objects = [obj for obj in module.__dict__.keys() if not obj.startswith('__')]
+
+ session_buffer = BytesIO()
+ dill.dump_module(session_buffer, module)
+
+ for obj in dict_objects:
+ del module.__dict__[obj]
+
+ session_buffer.seek(0)
+ dill.load_module(session_buffer, module)
+
+ assert all(obj in module.__dict__ for obj in dict_objects)
+ assert module.selfref is module
+
+def test_runtime_module():
+ from types import ModuleType
+ modname = '__runtime__'
+ runtime = ModuleType(modname)
+ runtime.x = 42
+
+ mod = dill.session._stash_modules(runtime)
+ if mod is not runtime:
+ print("There are objects to save by referenece that shouldn't be:",
+ mod.__dill_imported, mod.__dill_imported_as, mod.__dill_imported_top_level,
+ file=sys.stderr)
+
+ # This is also for code coverage, tests the use case of dump_module(refimported=True)
+ # without imported objects in the namespace. It's a contrived example because
+ # even dill can't be in it. This should work after fixing #462.
+ session_buffer = BytesIO()
+ dill.dump_module(session_buffer, module=runtime, refimported=True)
+ session_dump = session_buffer.getvalue()
+
+ # Pass a new runtime created module with the same name.
+ runtime = ModuleType(modname) # empty
+ return_val = dill.load_module(BytesIO(session_dump), module=runtime)
+ assert return_val is None
+ assert runtime.__name__ == modname
+ assert runtime.x == 42
+ assert runtime not in sys.modules.values()
+
+ # Pass nothing as main. load_module() must create it.
+ session_buffer.seek(0)
+ runtime = dill.load_module(BytesIO(session_dump))
+ assert runtime.__name__ == modname
+ assert runtime.x == 42
+ assert runtime not in sys.modules.values()
+
+def test_refimported_imported_as():
+ import collections
+ import concurrent.futures
+ import types
+ import typing
+ mod = sys.modules['__test__'] = types.ModuleType('__test__')
+ dill.executor = concurrent.futures.ThreadPoolExecutor(max_workers=1)
+ mod.Dict = collections.UserDict # select by type
+ mod.AsyncCM = typing.AsyncContextManager # select by __module__
+ mod.thread_exec = dill.executor # select by __module__ with regex
+
+ session_buffer = BytesIO()
+ dill.dump_module(session_buffer, mod, refimported=True)
+ session_buffer.seek(0)
+ mod = dill.load(session_buffer)
+ del sys.modules['__test__']
+
+ assert set(mod.__dill_imported_as) == {
+ ('collections', 'UserDict', 'Dict'),
+ ('typing', 'AsyncContextManager', 'AsyncCM'),
+ ('dill', 'executor', 'thread_exec'),
+ }
+
+def test_load_module_asdict():
+ with TestNamespace():
+ session_buffer = BytesIO()
+ dill.dump_module(session_buffer)
+
+ global empty, names, x, y
+ x = y = 0 # change x and create y
+ del empty
+ globals_state = globals().copy()
+
+ session_buffer.seek(0)
+ main_vars = dill.load_module_asdict(session_buffer)
+
+ assert main_vars is not globals()
+ assert globals() == globals_state
+
+ assert main_vars['__name__'] == '__main__'
+ assert main_vars['names'] == names
+ assert main_vars['names'] is not names
+ assert main_vars['x'] != x
+ assert 'y' not in main_vars
+ assert 'empty' in main_vars
+
+if __name__ == '__main__':
+ test_session_main(refimported=False)
+ test_session_main(refimported=True)
+ test_session_other()
+ test_runtime_module()
+ test_refimported_imported_as()
+ test_load_module_asdict()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_source.py b/solutions/.venv/Lib/site-packages/dill/tests/test_source.py
new file mode 100644
index 000000000..51dc85276
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_source.py
@@ -0,0 +1,173 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+from dill.source import getsource, getname, _wrap, getimport
+from dill.source import importable
+from dill._dill import IS_PYPY
+
+import sys
+PY310b = 0x30a00b1
+
+f = lambda x: x**2
+def g(x): return f(x) - x
+
+def h(x):
+ def g(x): return x
+ return g(x) - x
+
+class Foo(object):
+ def bar(self, x):
+ return x*x+x
+_foo = Foo()
+
+def add(x,y):
+ return x+y
+
+# yes, same as 'f', but things are tricky when it comes to pointers
+squared = lambda x:x**2
+
+class Bar:
+ pass
+_bar = Bar()
+
+ # inspect.getsourcelines # dill.source.getblocks
+def test_getsource():
+ assert getsource(f) == 'f = lambda x: x**2\n'
+ assert getsource(g) == 'def g(x): return f(x) - x\n'
+ assert getsource(h) == 'def h(x):\n def g(x): return x\n return g(x) - x\n'
+ assert getname(f) == 'f'
+ assert getname(g) == 'g'
+ assert getname(h) == 'h'
+ assert _wrap(f)(4) == 16
+ assert _wrap(g)(4) == 12
+ assert _wrap(h)(4) == 0
+
+ assert getname(Foo) == 'Foo'
+ assert getname(Bar) == 'Bar'
+ assert getsource(Bar) == 'class Bar:\n pass\n'
+ assert getsource(Foo) == 'class Foo(object):\n def bar(self, x):\n return x*x+x\n'
+ #XXX: add getsource for _foo, _bar
+
+# test itself
+def test_itself():
+ assert getimport(getimport)=='from dill.source import getimport\n'
+
+# builtin functions and objects
+def test_builtin():
+ assert getimport(pow) == 'pow\n'
+ assert getimport(100) == '100\n'
+ assert getimport(True) == 'True\n'
+ assert getimport(pow, builtin=True) == 'from builtins import pow\n'
+ assert getimport(100, builtin=True) == '100\n'
+ assert getimport(True, builtin=True) == 'True\n'
+ # this is kinda BS... you can't import a None
+ assert getimport(None) == 'None\n'
+ assert getimport(None, builtin=True) == 'None\n'
+
+
+# other imported functions
+def test_imported():
+ from math import sin
+ assert getimport(sin) == 'from math import sin\n'
+
+# interactively defined functions
+def test_dynamic():
+ assert getimport(add) == 'from %s import add\n' % __name__
+ # interactive lambdas
+ assert getimport(squared) == 'from %s import squared\n' % __name__
+
+# classes and class instances
+def test_classes():
+ from io import BytesIO as StringIO
+ y = "from _io import BytesIO\n"
+ x = y if (IS_PYPY or sys.hexversion >= PY310b) else "from io import BytesIO\n"
+ s = StringIO()
+
+ assert getimport(StringIO) == x
+ assert getimport(s) == y
+ # interactively defined classes and class instances
+ assert getimport(Foo) == 'from %s import Foo\n' % __name__
+ assert getimport(_foo) == 'from %s import Foo\n' % __name__
+
+
+# test importable
+def test_importable():
+ assert importable(add, source=False) == 'from %s import add\n' % __name__
+ assert importable(squared, source=False) == 'from %s import squared\n' % __name__
+ assert importable(Foo, source=False) == 'from %s import Foo\n' % __name__
+ assert importable(Foo.bar, source=False) == 'from %s import bar\n' % __name__
+ assert importable(_foo.bar, source=False) == 'from %s import bar\n' % __name__
+ assert importable(None, source=False) == 'None\n'
+ assert importable(100, source=False) == '100\n'
+
+ assert importable(add, source=True) == 'def add(x,y):\n return x+y\n'
+ assert importable(squared, source=True) == 'squared = lambda x:x**2\n'
+ assert importable(None, source=True) == 'None\n'
+ assert importable(Bar, source=True) == 'class Bar:\n pass\n'
+ assert importable(Foo, source=True) == 'class Foo(object):\n def bar(self, x):\n return x*x+x\n'
+ assert importable(Foo.bar, source=True) == 'def bar(self, x):\n return x*x+x\n'
+ assert importable(Foo.bar, source=False) == 'from %s import bar\n' % __name__
+ assert importable(Foo.bar, alias='memo', source=False) == 'from %s import bar as memo\n' % __name__
+ assert importable(Foo, alias='memo', source=False) == 'from %s import Foo as memo\n' % __name__
+ assert importable(squared, alias='memo', source=False) == 'from %s import squared as memo\n' % __name__
+ assert importable(squared, alias='memo', source=True) == 'memo = squared = lambda x:x**2\n'
+ assert importable(add, alias='memo', source=True) == 'def add(x,y):\n return x+y\n\nmemo = add\n'
+ assert importable(None, alias='memo', source=True) == 'memo = None\n'
+ assert importable(100, alias='memo', source=True) == 'memo = 100\n'
+ assert importable(add, builtin=True, source=False) == 'from %s import add\n' % __name__
+ assert importable(squared, builtin=True, source=False) == 'from %s import squared\n' % __name__
+ assert importable(Foo, builtin=True, source=False) == 'from %s import Foo\n' % __name__
+ assert importable(Foo.bar, builtin=True, source=False) == 'from %s import bar\n' % __name__
+ assert importable(_foo.bar, builtin=True, source=False) == 'from %s import bar\n' % __name__
+ assert importable(None, builtin=True, source=False) == 'None\n'
+ assert importable(100, builtin=True, source=False) == '100\n'
+
+
+def test_numpy():
+ try:
+ import numpy as np
+ y = np.array
+ x = y([1,2,3])
+ assert importable(x, source=False) == 'from numpy import array\narray([1, 2, 3])\n'
+ assert importable(y, source=False) == 'from %s import array\n' % y.__module__
+ assert importable(x, source=True) == 'from numpy import array\narray([1, 2, 3])\n'
+ assert importable(y, source=True) == 'from %s import array\n' % y.__module__
+ y = np.int64
+ x = y(0)
+ assert importable(x, source=False) == 'from numpy import int64\nint64(0)\n'
+ assert importable(y, source=False) == 'from %s import int64\n' % y.__module__
+ assert importable(x, source=True) == 'from numpy import int64\nint64(0)\n'
+ assert importable(y, source=True) == 'from %s import int64\n' % y.__module__
+ y = np.bool_
+ x = y(0)
+ import warnings
+ with warnings.catch_warnings():
+ warnings.filterwarnings('ignore', category=FutureWarning)
+ warnings.filterwarnings('ignore', category=DeprecationWarning)
+ if hasattr(np, 'bool'): b = 'bool_' if np.bool is bool else 'bool'
+ else: b = 'bool_'
+ assert importable(x, source=False) == 'from numpy import %s\n%s(False)\n' % (b,b)
+ assert importable(y, source=False) == 'from %s import %s\n' % (y.__module__,b)
+ assert importable(x, source=True) == 'from numpy import %s\n%s(False)\n' % (b,b)
+ assert importable(y, source=True) == 'from %s import %s\n' % (y.__module__,b)
+ except ImportError: pass
+
+#NOTE: if before getimport(pow), will cause pow to throw AssertionError
+def test_foo():
+ assert importable(_foo, source=True).startswith("import dill\nclass Foo(object):\n def bar(self, x):\n return x*x+x\ndill.loads(")
+
+if __name__ == '__main__':
+ test_getsource()
+ test_itself()
+ test_builtin()
+ test_imported()
+ test_dynamic()
+ test_classes()
+ test_importable()
+ test_numpy()
+ test_foo()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_sources.py b/solutions/.venv/Lib/site-packages/dill/tests/test_sources.py
new file mode 100644
index 000000000..9deb24227
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_sources.py
@@ -0,0 +1,190 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @uqfoundation)
+# Copyright (c) 2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+check that dill.source performs as expected with changes to locals in 3.13.0b1
+see: https://github.com/python/cpython/issues/118888
+"""
+# repeat functions from test_source.py
+f = lambda x: x**2
+def g(x): return f(x) - x
+
+def h(x):
+ def g(x): return x
+ return g(x) - x
+
+class Foo(object):
+ def bar(self, x):
+ return x*x+x
+_foo = Foo()
+
+def add(x,y):
+ return x+y
+
+squared = lambda x:x**2
+
+class Bar:
+ pass
+_bar = Bar()
+
+# repeat, but from test_source.py
+import test_source as ts
+
+# test objects created in other test modules
+import test_mixins as tm
+
+import dill.source as ds
+
+
+def test_isfrommain():
+ assert ds.isfrommain(add) == True
+ assert ds.isfrommain(squared) == True
+ assert ds.isfrommain(Bar) == True
+ assert ds.isfrommain(_bar) == True
+ assert ds.isfrommain(ts.add) == False
+ assert ds.isfrommain(ts.squared) == False
+ assert ds.isfrommain(ts.Bar) == False
+ assert ds.isfrommain(ts._bar) == False
+ assert ds.isfrommain(tm.quad) == False
+ assert ds.isfrommain(tm.double_add) == False
+ assert ds.isfrommain(tm.quadratic) == False
+ assert ds.isdynamic(add) == False
+ assert ds.isdynamic(squared) == False
+ assert ds.isdynamic(ts.add) == False
+ assert ds.isdynamic(ts.squared) == False
+ assert ds.isdynamic(tm.double_add) == False
+ assert ds.isdynamic(tm.quadratic) == False
+
+
+def test_matchlambda():
+ assert ds._matchlambda(f, 'f = lambda x: x**2\n')
+ assert ds._matchlambda(squared, 'squared = lambda x:x**2\n')
+ assert ds._matchlambda(ts.f, 'f = lambda x: x**2\n')
+ assert ds._matchlambda(ts.squared, 'squared = lambda x:x**2\n')
+
+
+def test_findsource():
+ lines, lineno = ds.findsource(add)
+ assert lines[lineno] == 'def add(x,y):\n'
+ lines, lineno = ds.findsource(ts.add)
+ assert lines[lineno] == 'def add(x,y):\n'
+ lines, lineno = ds.findsource(squared)
+ assert lines[lineno] == 'squared = lambda x:x**2\n'
+ lines, lineno = ds.findsource(ts.squared)
+ assert lines[lineno] == 'squared = lambda x:x**2\n'
+ lines, lineno = ds.findsource(Bar)
+ assert lines[lineno] == 'class Bar:\n'
+ lines, lineno = ds.findsource(ts.Bar)
+ assert lines[lineno] == 'class Bar:\n'
+ lines, lineno = ds.findsource(_bar)
+ assert lines[lineno] == 'class Bar:\n'
+ lines, lineno = ds.findsource(ts._bar)
+ assert lines[lineno] == 'class Bar:\n'
+ lines, lineno = ds.findsource(tm.quad)
+ assert lines[lineno] == 'def quad(a=1, b=1, c=0):\n'
+ lines, lineno = ds.findsource(tm.double_add)
+ assert lines[lineno] == ' def func(*args, **kwds):\n'
+ lines, lineno = ds.findsource(tm.quadratic)
+ assert lines[lineno] == ' def dec(f):\n'
+
+
+def test_getsourcelines():
+ assert ''.join(ds.getsourcelines(add)[0]) == 'def add(x,y):\n return x+y\n'
+ assert ''.join(ds.getsourcelines(ts.add)[0]) == 'def add(x,y):\n return x+y\n'
+ assert ''.join(ds.getsourcelines(squared)[0]) == 'squared = lambda x:x**2\n'
+ assert ''.join(ds.getsourcelines(ts.squared)[0]) == 'squared = lambda x:x**2\n'
+ assert ''.join(ds.getsourcelines(Bar)[0]) == 'class Bar:\n pass\n'
+ assert ''.join(ds.getsourcelines(ts.Bar)[0]) == 'class Bar:\n pass\n'
+ assert ''.join(ds.getsourcelines(_bar)[0]) == 'class Bar:\n pass\n' #XXX: ?
+ assert ''.join(ds.getsourcelines(ts._bar)[0]) == 'class Bar:\n pass\n' #XXX: ?
+ assert ''.join(ds.getsourcelines(tm.quad)[0]) == 'def quad(a=1, b=1, c=0):\n inverted = [False]\n def invert():\n inverted[0] = not inverted[0]\n def dec(f):\n def func(*args, **kwds):\n x = f(*args, **kwds)\n if inverted[0]: x = -x\n return a*x**2 + b*x + c\n func.__wrapped__ = f\n func.invert = invert\n func.inverted = inverted\n return func\n return dec\n'
+ assert ''.join(ds.getsourcelines(tm.quadratic)[0]) == ' def dec(f):\n def func(*args,**kwds):\n fx = f(*args,**kwds)\n return a*fx**2 + b*fx + c\n return func\n'
+ assert ''.join(ds.getsourcelines(tm.quadratic, lstrip=True)[0]) == 'def dec(f):\n def func(*args,**kwds):\n fx = f(*args,**kwds)\n return a*fx**2 + b*fx + c\n return func\n'
+ assert ''.join(ds.getsourcelines(tm.quadratic, enclosing=True)[0]) == 'def quad_factory(a=1,b=1,c=0):\n def dec(f):\n def func(*args,**kwds):\n fx = f(*args,**kwds)\n return a*fx**2 + b*fx + c\n return func\n return dec\n'
+ assert ''.join(ds.getsourcelines(tm.double_add)[0]) == ' def func(*args, **kwds):\n x = f(*args, **kwds)\n if inverted[0]: x = -x\n return a*x**2 + b*x + c\n'
+ assert ''.join(ds.getsourcelines(tm.double_add, enclosing=True)[0]) == 'def quad(a=1, b=1, c=0):\n inverted = [False]\n def invert():\n inverted[0] = not inverted[0]\n def dec(f):\n def func(*args, **kwds):\n x = f(*args, **kwds)\n if inverted[0]: x = -x\n return a*x**2 + b*x + c\n func.__wrapped__ = f\n func.invert = invert\n func.inverted = inverted\n return func\n return dec\n'
+
+
+def test_indent():
+ assert ds.outdent(''.join(ds.getsourcelines(tm.quadratic)[0])) == ''.join(ds.getsourcelines(tm.quadratic, lstrip=True)[0])
+ assert ds.indent(''.join(ds.getsourcelines(tm.quadratic, lstrip=True)[0]), 2) == ''.join(ds.getsourcelines(tm.quadratic)[0])
+
+
+def test_dumpsource():
+ local = {}
+ exec(ds.dumpsource(add, alias='raw'), {}, local)
+ exec(ds.dumpsource(ts.add, alias='mod'), {}, local)
+ assert local['raw'](1,2) == local['mod'](1,2)
+ exec(ds.dumpsource(squared, alias='raw'), {}, local)
+ exec(ds.dumpsource(ts.squared, alias='mod'), {}, local)
+ assert local['raw'](3) == local['mod'](3)
+ assert ds._wrap(add)(1,2) == ds._wrap(ts.add)(1,2)
+ assert ds._wrap(squared)(3) == ds._wrap(ts.squared)(3)
+
+
+def test_name():
+ assert ds._namespace(add) == ds.getname(add, fqn=True).split('.')
+ assert ds._namespace(ts.add) == ds.getname(ts.add, fqn=True).split('.')
+ assert ds._namespace(squared) == ds.getname(squared, fqn=True).split('.')
+ assert ds._namespace(ts.squared) == ds.getname(ts.squared, fqn=True).split('.')
+ assert ds._namespace(Bar) == ds.getname(Bar, fqn=True).split('.')
+ assert ds._namespace(ts.Bar) == ds.getname(ts.Bar, fqn=True).split('.')
+ assert ds._namespace(tm.quad) == ds.getname(tm.quad, fqn=True).split('.')
+ #XXX: the following also works, however behavior may be wrong for nested functions
+ #assert ds._namespace(tm.double_add) == ds.getname(tm.double_add, fqn=True).split('.')
+ #assert ds._namespace(tm.quadratic) == ds.getname(tm.quadratic, fqn=True).split('.')
+ assert ds.getname(add) == 'add'
+ assert ds.getname(ts.add) == 'add'
+ assert ds.getname(squared) == 'squared'
+ assert ds.getname(ts.squared) == 'squared'
+ assert ds.getname(Bar) == 'Bar'
+ assert ds.getname(ts.Bar) == 'Bar'
+ assert ds.getname(tm.quad) == 'quad'
+ assert ds.getname(tm.double_add) == 'func' #XXX: ?
+ assert ds.getname(tm.quadratic) == 'dec' #XXX: ?
+
+
+def test_getimport():
+ local = {}
+ exec(ds.getimport(add, alias='raw'), {}, local)
+ exec(ds.getimport(ts.add, alias='mod'), {}, local)
+ assert local['raw'](1,2) == local['mod'](1,2)
+ exec(ds.getimport(squared, alias='raw'), {}, local)
+ exec(ds.getimport(ts.squared, alias='mod'), {}, local)
+ assert local['raw'](3) == local['mod'](3)
+ exec(ds.getimport(Bar, alias='raw'), {}, local)
+ exec(ds.getimport(ts.Bar, alias='mod'), {}, local)
+ assert ds.getname(local['raw']) == ds.getname(local['mod'])
+ exec(ds.getimport(tm.quad, alias='mod'), {}, local)
+ assert local['mod']()(sum)([1,2,3]) == tm.quad()(sum)([1,2,3])
+ #FIXME: wrong results for nested functions (e.g. tm.double_add, tm.quadratic)
+
+
+def test_importable():
+ assert ds.importable(add, source=False) == ds.getimport(add)
+ assert ds.importable(add) == ds.getsource(add)
+ assert ds.importable(squared, source=False) == ds.getimport(squared)
+ assert ds.importable(squared) == ds.getsource(squared)
+ assert ds.importable(Bar, source=False) == ds.getimport(Bar)
+ assert ds.importable(Bar) == ds.getsource(Bar)
+ assert ds.importable(ts.add) == ds.getimport(ts.add)
+ assert ds.importable(ts.add, source=True) == ds.getsource(ts.add)
+ assert ds.importable(ts.squared) == ds.getimport(ts.squared)
+ assert ds.importable(ts.squared, source=True) == ds.getsource(ts.squared)
+ assert ds.importable(ts.Bar) == ds.getimport(ts.Bar)
+ assert ds.importable(ts.Bar, source=True) == ds.getsource(ts.Bar)
+
+
+if __name__ == '__main__':
+ test_isfrommain()
+ test_matchlambda()
+ test_findsource()
+ test_getsourcelines()
+ test_indent()
+ test_dumpsource()
+ test_name()
+ test_getimport()
+ test_importable()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_temp.py b/solutions/.venv/Lib/site-packages/dill/tests/test_temp.py
new file mode 100644
index 000000000..30ae35a31
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_temp.py
@@ -0,0 +1,103 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import sys
+from dill.temp import dump, dump_source, dumpIO, dumpIO_source
+from dill.temp import load, load_source, loadIO, loadIO_source
+WINDOWS = sys.platform[:3] == 'win'
+
+
+f = lambda x: x**2
+x = [1,2,3,4,5]
+
+# source code to tempfile
+def test_code_to_tempfile():
+ if not WINDOWS: #see: https://bugs.python.org/issue14243
+ pyfile = dump_source(f, alias='_f')
+ _f = load_source(pyfile)
+ assert _f(4) == f(4)
+
+# source code to stream
+def test_code_to_stream():
+ pyfile = dumpIO_source(f, alias='_f')
+ _f = loadIO_source(pyfile)
+ assert _f(4) == f(4)
+
+# pickle to tempfile
+def test_pickle_to_tempfile():
+ if not WINDOWS: #see: https://bugs.python.org/issue14243
+ dumpfile = dump(x)
+ _x = load(dumpfile)
+ assert _x == x
+
+# pickle to stream
+def test_pickle_to_stream():
+ dumpfile = dumpIO(x)
+ _x = loadIO(dumpfile)
+ assert _x == x
+
+### now testing the objects ###
+f = lambda x: x**2
+def g(x): return f(x) - x
+
+def h(x):
+ def g(x): return x
+ return g(x) - x
+
+class Foo(object):
+ def bar(self, x):
+ return x*x+x
+_foo = Foo()
+
+def add(x,y):
+ return x+y
+
+# yes, same as 'f', but things are tricky when it comes to pointers
+squared = lambda x:x**2
+
+class Bar:
+ pass
+_bar = Bar()
+
+
+# test function-type objects that take 2 args
+def test_two_arg_functions():
+ for obj in [add]:
+ pyfile = dumpIO_source(obj, alias='_obj')
+ _obj = loadIO_source(pyfile)
+ assert _obj(4,2) == obj(4,2)
+
+# test function-type objects that take 1 arg
+def test_one_arg_functions():
+ for obj in [g, h, squared]:
+ pyfile = dumpIO_source(obj, alias='_obj')
+ _obj = loadIO_source(pyfile)
+ assert _obj(4) == obj(4)
+
+# test instance-type objects
+#for obj in [_bar, _foo]:
+# pyfile = dumpIO_source(obj, alias='_obj')
+# _obj = loadIO_source(pyfile)
+# assert type(_obj) == type(obj)
+
+# test the rest of the objects
+def test_the_rest():
+ for obj in [Bar, Foo, Foo.bar, _foo.bar]:
+ pyfile = dumpIO_source(obj, alias='_obj')
+ _obj = loadIO_source(pyfile)
+ assert _obj.__name__ == obj.__name__
+
+
+if __name__ == '__main__':
+ test_code_to_tempfile()
+ test_code_to_stream()
+ test_pickle_to_tempfile()
+ test_pickle_to_stream()
+ test_two_arg_functions()
+ test_one_arg_functions()
+ test_the_rest()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_threads.py b/solutions/.venv/Lib/site-packages/dill/tests/test_threads.py
new file mode 100644
index 000000000..45f1f58c5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_threads.py
@@ -0,0 +1,46 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+dill.settings['recurse'] = True
+
+
+def test_new_thread():
+ import threading
+ t = threading.Thread()
+ t_ = dill.copy(t)
+ assert t.is_alive() == t_.is_alive()
+ for i in ['daemon','name','ident','native_id']:
+ if hasattr(t, i):
+ assert getattr(t, i) == getattr(t_, i)
+
+def test_run_thread():
+ import threading
+ t = threading.Thread()
+ t.start()
+ t_ = dill.copy(t)
+ assert t.is_alive() == t_.is_alive()
+ for i in ['daemon','name','ident','native_id']:
+ if hasattr(t, i):
+ assert getattr(t, i) == getattr(t_, i)
+
+def test_join_thread():
+ import threading
+ t = threading.Thread()
+ t.start()
+ t.join()
+ t_ = dill.copy(t)
+ assert t.is_alive() == t_.is_alive()
+ for i in ['daemon','name','ident','native_id']:
+ if hasattr(t, i):
+ assert getattr(t, i) == getattr(t_, i)
+
+
+if __name__ == '__main__':
+ test_new_thread()
+ test_run_thread()
+ test_join_thread()
diff --git a/solutions/.venv/Lib/site-packages/dill/tests/test_weakref.py b/solutions/.venv/Lib/site-packages/dill/tests/test_weakref.py
new file mode 100644
index 000000000..df5cbce93
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/dill/tests/test_weakref.py
@@ -0,0 +1,72 @@
+#!/usr/bin/env python
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+
+import dill
+dill.settings['recurse'] = True
+import weakref
+
+class _class:
+ def _method(self):
+ pass
+
+class _callable_class:
+ def __call__(self):
+ pass
+
+def _function():
+ pass
+
+
+def test_weakref():
+ o = _class()
+ oc = _callable_class()
+ f = _function
+ x = _class
+
+ # ReferenceType
+ r = weakref.ref(o)
+ d_r = weakref.ref(_class())
+ fr = weakref.ref(f)
+ xr = weakref.ref(x)
+
+ # ProxyType
+ p = weakref.proxy(o)
+ d_p = weakref.proxy(_class())
+
+ # CallableProxyType
+ cp = weakref.proxy(oc)
+ d_cp = weakref.proxy(_callable_class())
+ fp = weakref.proxy(f)
+ xp = weakref.proxy(x)
+
+ objlist = [r,d_r,fr,xr, p,d_p, cp,d_cp,fp,xp]
+ #dill.detect.trace(True)
+
+ for obj in objlist:
+ res = dill.detect.errors(obj)
+ if res:
+ print ("%r:\n %s" % (obj, res))
+ # else:
+ # print ("PASS: %s" % obj)
+ assert not res
+
+def test_dictproxy():
+ from dill._dill import DictProxyType
+ try:
+ m = DictProxyType({"foo": "bar"})
+ except Exception:
+ m = type.__dict__
+ mp = dill.copy(m)
+ assert mp.items() == m.items()
+
+
+if __name__ == '__main__':
+ test_weakref()
+ from dill._dill import IS_PYPY
+ if not IS_PYPY:
+ test_dictproxy()
diff --git a/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/LICENSE b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/LICENSE
new file mode 100644
index 000000000..b5083a50d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/LICENSE
@@ -0,0 +1,21 @@
+The MIT License (MIT)
+
+Copyright (c) 2013 Timothy Edmund Crosley
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/METADATA b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/METADATA
new file mode 100644
index 000000000..fdce4a7fb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/METADATA
@@ -0,0 +1,378 @@
+Metadata-Version: 2.1
+Name: isort
+Version: 5.13.2
+Summary: A Python utility / library to sort Python imports.
+Home-page: https://pycqa.github.io/isort/
+License: MIT
+Keywords: Refactor,Lint,Imports,Sort,Clean
+Author: Timothy Crosley
+Author-email: timothy.crosley@gmail.com
+Requires-Python: >=3.8.0
+Classifier: Development Status :: 6 - Mature
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Natural Language :: English
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Software Development :: Libraries
+Classifier: Topic :: Utilities
+Provides-Extra: colors
+Provides-Extra: plugins
+Requires-Dist: colorama (>=0.4.6) ; extra == "colors"
+Project-URL: Changelog, https://github.com/pycqa/isort/blob/main/CHANGELOG.md
+Project-URL: Documentation, https://pycqa.github.io/isort/
+Project-URL: Repository, https://github.com/pycqa/isort
+Description-Content-Type: text/markdown
+
+[](https://pycqa.github.io/isort/)
+
+------------------------------------------------------------------------
+
+[](https://badge.fury.io/py/isort)
+[](https://github.com/pycqa/isort/actions?query=workflow%3ATest)
+[](https://github.com/pycqa/isort/actions?query=workflow%3ALint)
+[](https://codecov.io/gh/pycqa/isort)
+[](https://pypi.org/project/isort/)
+[](https://gitter.im/timothycrosley/isort?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
+[](https://pepy.tech/project/isort)
+[](https://github.com/psf/black)
+[](https://pycqa.github.io/isort/)
+[](https://deepsource.io/gh/pycqa/isort/?ref=repository-badge)
+_________________
+
+[Read Latest Documentation](https://pycqa.github.io/isort/) - [Browse GitHub Code Repository](https://github.com/pycqa/isort/)
+_________________
+
+isort your imports, so you don't have to.
+
+isort is a Python utility / library to sort imports alphabetically and
+automatically separate into sections and by type. It provides a command line
+utility, Python library and [plugins for various
+editors](https://github.com/pycqa/isort/wiki/isort-Plugins) to
+quickly sort all your imports. It requires Python 3.8+ to run but
+supports formatting Python 2 code too.
+
+- [Try isort now from your browser!](https://pycqa.github.io/isort/docs/quick_start/0.-try.html)
+- [Using black? See the isort and black compatibility guide.](https://pycqa.github.io/isort/docs/configuration/black_compatibility.html)
+- [isort has official support for pre-commit!](https://pycqa.github.io/isort/docs/configuration/pre-commit.html)
+
+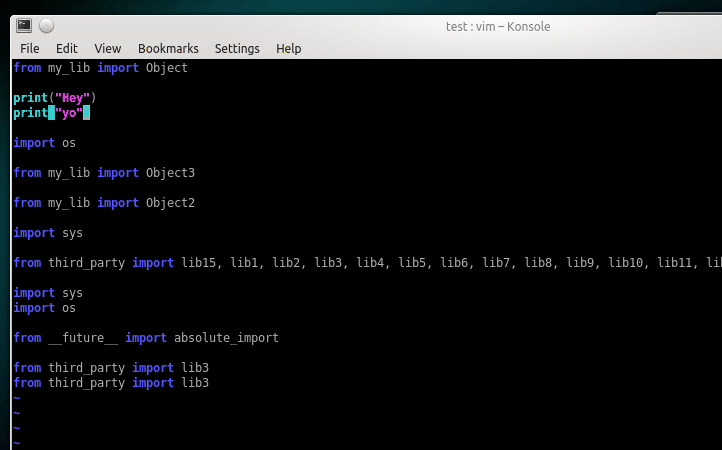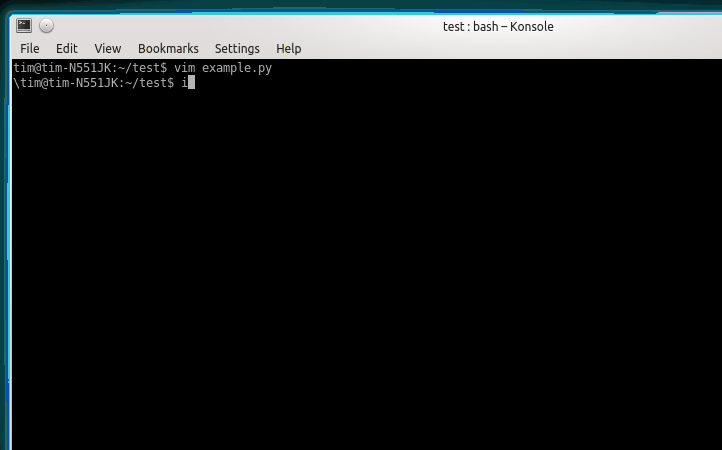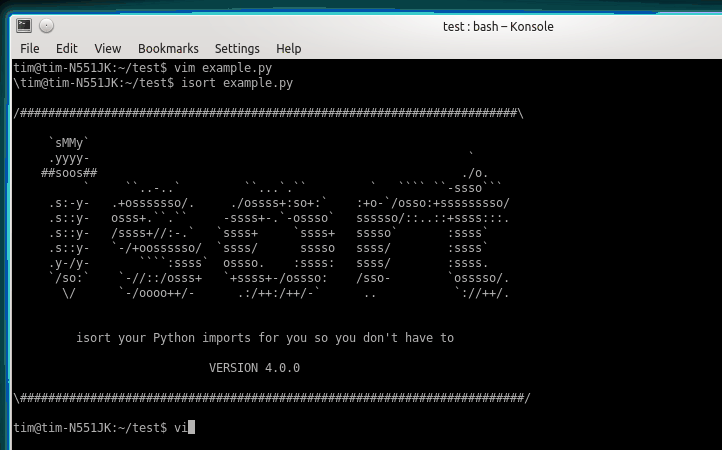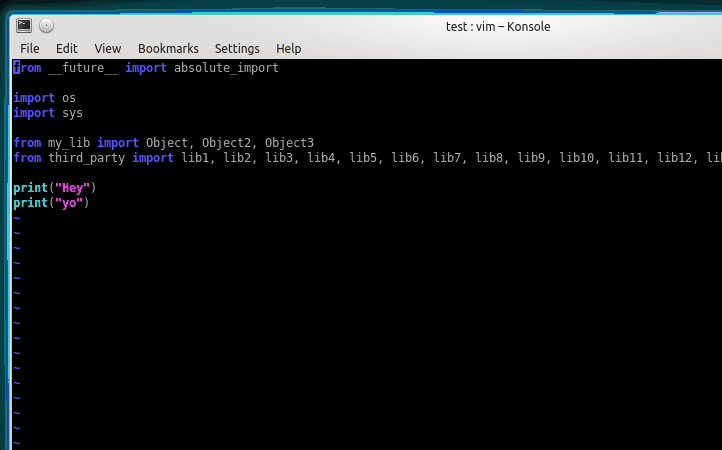
+
+Before isort:
+
+```python
+from my_lib import Object
+
+import os
+
+from my_lib import Object3
+
+from my_lib import Object2
+
+import sys
+
+from third_party import lib15, lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8, lib9, lib10, lib11, lib12, lib13, lib14
+
+import sys
+
+from __future__ import absolute_import
+
+from third_party import lib3
+
+print("Hey")
+print("yo")
+```
+
+After isort:
+
+```python
+from __future__ import absolute_import
+
+import os
+import sys
+
+from third_party import (lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8,
+ lib9, lib10, lib11, lib12, lib13, lib14, lib15)
+
+from my_lib import Object, Object2, Object3
+
+print("Hey")
+print("yo")
+```
+
+## Installing isort
+
+Installing isort is as simple as:
+
+```bash
+pip install isort
+```
+
+## Using isort
+
+**From the command line**:
+
+To run on specific files:
+
+```bash
+isort mypythonfile.py mypythonfile2.py
+```
+
+To apply recursively:
+
+```bash
+isort .
+```
+
+If [globstar](https://www.gnu.org/software/bash/manual/html_node/The-Shopt-Builtin.html)
+is enabled, `isort .` is equivalent to:
+
+```bash
+isort **/*.py
+```
+
+To view proposed changes without applying them:
+
+```bash
+isort mypythonfile.py --diff
+```
+
+Finally, to atomically run isort against a project, only applying
+changes if they don't introduce syntax errors:
+
+```bash
+isort --atomic .
+```
+
+(Note: this is disabled by default, as it prevents isort from
+running against code written using a different version of Python.)
+
+**From within Python**:
+
+```python
+import isort
+
+isort.file("pythonfile.py")
+```
+
+or:
+
+```python
+import isort
+
+sorted_code = isort.code("import b\nimport a\n")
+```
+
+## Installing isort's for your preferred text editor
+
+Several plugins have been written that enable to use isort from within a
+variety of text-editors. You can find a full list of them [on the isort
+wiki](https://github.com/pycqa/isort/wiki/isort-Plugins).
+Additionally, I will enthusiastically accept pull requests that include
+plugins for other text editors and add documentation for them as I am
+notified.
+
+## Multi line output modes
+
+You will notice above the \"multi\_line\_output\" setting. This setting
+defines how from imports wrap when they extend past the line\_length
+limit and has [12 possible settings](https://pycqa.github.io/isort/docs/configuration/multi_line_output_modes.html).
+
+## Indentation
+
+To change the how constant indents appear - simply change the
+indent property with the following accepted formats:
+
+- Number of spaces you would like. For example: 4 would cause standard
+ 4 space indentation.
+- Tab
+- A verbatim string with quotes around it.
+
+For example:
+
+```python
+" "
+```
+
+is equivalent to 4.
+
+For the import styles that use parentheses, you can control whether or
+not to include a trailing comma after the last import with the
+`include_trailing_comma` option (defaults to `False`).
+
+## Intelligently Balanced Multi-line Imports
+
+As of isort 3.1.0 support for balanced multi-line imports has been
+added. With this enabled isort will dynamically change the import length
+to the one that produces the most balanced grid, while staying below the
+maximum import length defined.
+
+Example:
+
+```python
+from __future__ import (absolute_import, division,
+ print_function, unicode_literals)
+```
+
+Will be produced instead of:
+
+```python
+from __future__ import (absolute_import, division, print_function,
+ unicode_literals)
+```
+
+To enable this set `balanced_wrapping` to `True` in your config or pass
+the `-e` option into the command line utility.
+
+## Custom Sections and Ordering
+
+isort provides configuration options to change almost every aspect of how
+imports are organized, ordered, or grouped together in sections.
+
+[Click here](https://pycqa.github.io/isort/docs/configuration/custom_sections_and_ordering.html) for an overview of all these options.
+
+## Skip processing of imports (outside of configuration)
+
+To make isort ignore a single import simply add a comment at the end of
+the import line containing the text `isort:skip`:
+
+```python
+import module # isort:skip
+```
+
+or:
+
+```python
+from xyz import (abc, # isort:skip
+ yo,
+ hey)
+```
+
+To make isort skip an entire file simply add `isort:skip_file` to the
+module's doc string:
+
+```python
+""" my_module.py
+ Best module ever
+
+ isort:skip_file
+"""
+
+import b
+import a
+```
+
+## Adding or removing an import from multiple files
+
+isort can be ran or configured to add / remove imports automatically.
+
+[See a complete guide here.](https://pycqa.github.io/isort/docs/configuration/add_or_remove_imports.html)
+
+## Using isort to verify code
+
+The `--check-only` option
+-------------------------
+
+isort can also be used to verify that code is correctly formatted
+by running it with `-c`. Any files that contain incorrectly sorted
+and/or formatted imports will be outputted to `stderr`.
+
+```bash
+isort **/*.py -c -v
+
+SUCCESS: /home/timothy/Projects/Open_Source/isort/isort_kate_plugin.py Everything Looks Good!
+ERROR: /home/timothy/Projects/Open_Source/isort/isort/isort.py Imports are incorrectly sorted.
+```
+
+One great place this can be used is with a pre-commit git hook, such as
+this one by \@acdha:
+
+<https://gist.github.com/acdha/8717683>
+
+This can help to ensure a certain level of code quality throughout a
+project.
+
+## Git hook
+
+isort provides a hook function that can be integrated into your Git
+pre-commit script to check Python code before committing.
+
+[More info here.](https://pycqa.github.io/isort/docs/configuration/git_hook.html)
+
+## Setuptools integration
+
+Upon installation, isort enables a `setuptools` command that checks
+Python files declared by your project.
+
+[More info here.](https://pycqa.github.io/isort/docs/configuration/setuptools_integration.html)
+
+## Spread the word
+
+[](https://pycqa.github.io/isort/)
+
+Place this badge at the top of your repository to let others know your project uses isort.
+
+For README.md:
+
+```markdown
+[](https://pycqa.github.io/isort/)
+```
+
+Or README.rst:
+
+```rst
+.. image:: https://img.shields.io/badge/%20imports-isort-%231674b1?style=flat&labelColor=ef8336
+ :target: https://pycqa.github.io/isort/
+```
+
+## Security contact information
+
+To report a security vulnerability, please use the [Tidelift security
+contact](https://tidelift.com/security). Tidelift will coordinate the
+fix and disclosure.
+
+## Why isort?
+
+isort simply stands for import sort. It was originally called
+"sortImports" however I got tired of typing the extra characters and
+came to the realization camelCase is not pythonic.
+
+I wrote isort because in an organization I used to work in the manager
+came in one day and decided all code must have alphabetically sorted
+imports. The code base was huge - and he meant for us to do it by hand.
+However, being a programmer - I\'m too lazy to spend 8 hours mindlessly
+performing a function, but not too lazy to spend 16 hours automating it.
+I was given permission to open source sortImports and here we are :)
+
+------------------------------------------------------------------------
+
+[Get professionally supported isort with the Tidelift
+Subscription](https://tidelift.com/subscription/pkg/pypi-isort?utm_source=pypi-isort&utm_medium=referral&utm_campaign=readme)
+
+Professional support for isort is available as part of the [Tidelift
+Subscription](https://tidelift.com/subscription/pkg/pypi-isort?utm_source=pypi-isort&utm_medium=referral&utm_campaign=readme).
+Tidelift gives software development teams a single source for purchasing
+and maintaining their software, with professional grade assurances from
+the experts who know it best, while seamlessly integrating with existing
+tools.
+
+------------------------------------------------------------------------
+
+Thanks and I hope you find isort useful!
+
+~Timothy Crosley
+
diff --git a/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/RECORD b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/RECORD
new file mode 100644
index 000000000..09a04e027
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/RECORD
@@ -0,0 +1,99 @@
+../../Scripts/isort-identify-imports.exe,sha256=H3UPvy233WovTPbtSoOQmkthuvD8RUo0vi1Pc7i5f0U,108477
+../../Scripts/isort.exe,sha256=ha4bh2IkJBe5vvmdpimtcVoAEXMt9oyojBnhr-JmdyM,108443
+isort-5.13.2.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+isort-5.13.2.dist-info/LICENSE,sha256=BjKUABw9Uj26y6ud1UrCKZgnVsyvWSylMkCysM3YIGU,1089
+isort-5.13.2.dist-info/METADATA,sha256=Dqdc14Z_Bj6uRr-d_06cWhzSc3a2h2x2TLvCkA-16jo,12230
+isort-5.13.2.dist-info/RECORD,,
+isort-5.13.2.dist-info/WHEEL,sha256=vVCvjcmxuUltf8cYhJ0sJMRDLr1XsPuxEId8YDzbyCY,88
+isort-5.13.2.dist-info/entry_points.txt,sha256=stP-G7UtFo06wllIxS1jKbEJpc4u_3WPiLh_r13BGcc,213
+isort/__init__.py,sha256=5S6lmnFHXlZbzl7ni97ZANzkXePqKPkRUaMJyul3dIo,871
+isort/__main__.py,sha256=iK0trzN9CCXpQX-XPZDZ9JVkm2Lc0q0oiAgsa6FkJb4,36
+isort/__pycache__/__init__.cpython-312.pyc,,
+isort/__pycache__/__main__.cpython-312.pyc,,
+isort/__pycache__/_version.cpython-312.pyc,,
+isort/__pycache__/api.cpython-312.pyc,,
+isort/__pycache__/comments.cpython-312.pyc,,
+isort/__pycache__/core.cpython-312.pyc,,
+isort/__pycache__/exceptions.cpython-312.pyc,,
+isort/__pycache__/files.cpython-312.pyc,,
+isort/__pycache__/format.cpython-312.pyc,,
+isort/__pycache__/hooks.cpython-312.pyc,,
+isort/__pycache__/identify.cpython-312.pyc,,
+isort/__pycache__/io.cpython-312.pyc,,
+isort/__pycache__/literal.cpython-312.pyc,,
+isort/__pycache__/logo.cpython-312.pyc,,
+isort/__pycache__/main.cpython-312.pyc,,
+isort/__pycache__/output.cpython-312.pyc,,
+isort/__pycache__/parse.cpython-312.pyc,,
+isort/__pycache__/place.cpython-312.pyc,,
+isort/__pycache__/profiles.cpython-312.pyc,,
+isort/__pycache__/pylama_isort.cpython-312.pyc,,
+isort/__pycache__/sections.cpython-312.pyc,,
+isort/__pycache__/settings.cpython-312.pyc,,
+isort/__pycache__/setuptools_commands.cpython-312.pyc,,
+isort/__pycache__/sorting.cpython-312.pyc,,
+isort/__pycache__/utils.cpython-312.pyc,,
+isort/__pycache__/wrap.cpython-312.pyc,,
+isort/__pycache__/wrap_modes.cpython-312.pyc,,
+isort/_vendored/tomli/LICENSE,sha256=uAgWsNUwuKzLTCIReDeQmEpuO2GSLCte6S8zcqsnQv4,1072
+isort/_vendored/tomli/__init__.py,sha256=Y3N65pvphV_EF4k2qKiq_vYcohIUHhT05GzdRc0TOy8,213
+isort/_vendored/tomli/__pycache__/__init__.cpython-312.pyc,,
+isort/_vendored/tomli/__pycache__/_parser.cpython-312.pyc,,
+isort/_vendored/tomli/__pycache__/_re.cpython-312.pyc,,
+isort/_vendored/tomli/_parser.py,sha256=fhOEEYZATanBBAn-hyy0Au_aZbdqXfdKB8mGTvI1W3k,21397
+isort/_vendored/tomli/_re.py,sha256=3r6TD3gNGFjgOsfpy8aLpxgvasL__pvaN2m1R5DTxeQ,2833
+isort/_vendored/tomli/py.typed,sha256=8PjyZ1aVoQpRVvt71muvuq5qE-jTFZkK-GLHkhdebmc,26
+isort/_version.py,sha256=pXTtYi-S-p8e00o2Ad-PNREL9wAQaPgQzk_c_jndLOw,72
+isort/api.py,sha256=kzuy8vxvy99ri4YoOFCbjkzRJOr2VsG8OXHjGq7VSts,26120
+isort/comments.py,sha256=6tLt0QRuSQvo-tpgTTM4oJKk-oqaE8MOTA95l89LtQQ,933
+isort/core.py,sha256=uwoIfw-j-Pc4IYFGB_gC5JjjowuC3H6CdZI_a2PzDMk,22524
+isort/deprecated/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+isort/deprecated/__pycache__/__init__.cpython-312.pyc,,
+isort/deprecated/__pycache__/finders.cpython-312.pyc,,
+isort/deprecated/finders.py,sha256=M70Hzr88DaVy-WTqyfgTYh7MJ45skf3p-usYlQBVILA,14309
+isort/exceptions.py,sha256=xmUyF5uS1K_rtlMDWoaAmtD_PA0B82u6rqgxgEjUjcw,7060
+isort/files.py,sha256=3wRqIAAquCCTF5aPzpzoDsWBvrTy49vqG11hAFseJD8,1589
+isort/format.py,sha256=E9Og4mc7ajxyMAFmUlAK2ZmW7N75uexfY0c9q-zmyzA,5483
+isort/hooks.py,sha256=Ye-vm0Q4mLFxm1rNCLxdNxbEa7D-lO2UyL2vLnvje78,3338
+isort/identify.py,sha256=sp2xQDb42ubf8DVIoDajwxBtwuiFygLrLeejKdmJYio,8369
+isort/io.py,sha256=ElUxFk-SBeMKVQ2nSVs4L1liDHHtf6umsTpNyjaGk1g,2216
+isort/literal.py,sha256=1fXUljG4ol2eKEikoLzorD_ir2v7Q3-3oKlxaitNfZ4,3713
+isort/logo.py,sha256=cL3al79O7O0G2viqRMRfBPp0qtRZmJw2nHSCZw8XWdQ,388
+isort/main.py,sha256=ZtHrhaiGHBXPLcaLbsRFNPHMJV7JJkqH8QYiWpXC7x8,46907
+isort/output.py,sha256=yVWZ9W8HCiXJVLFlYl4mp9h4peN7a_cNK4-QDdpzsdE,27804
+isort/parse.py,sha256=gP5aF7n12j3QEfH-XApkUAfreVUtkkxh_eCEGV640Xg,25487
+isort/place.py,sha256=u3qN5rt_A2IcVZ5ndcGMohLZvsRWzVrJe3nikIf7S_4,5171
+isort/profiles.py,sha256=Z_UlADUI865Ft42Cp3v_d_rfqo1bKEuiSfKUlpby5tU,2144
+isort/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+isort/pylama_isort.py,sha256=vNP7jAxZy7ryZR4hotynA4JCzAxLtbasT9AYpZiiClk,1308
+isort/sections.py,sha256=xG5bwU4tOIKUmeBBhZ45EIfjP8HgDOx796bPvD5zWCw,297
+isort/settings.py,sha256=OsmqlmM6VZJp5I-RnSPI4IW5J1bifdW6G6HUXhRsD9o,35623
+isort/setuptools_commands.py,sha256=uzeBcGerTKtoy9tHo7O-jVeYzq3nQAWfluODpmR86jw,2297
+isort/sorting.py,sha256=m4Mbe1wq5RtUZIp6guuh6dCBRVD4igCGLXkaTO3l1iU,4515
+isort/stdlibs/__init__.py,sha256=JMQzqkCXFp_jyrAsFTeju-GvsmnsnLKd0yHTOQK7kYQ,100
+isort/stdlibs/__pycache__/__init__.cpython-312.pyc,,
+isort/stdlibs/__pycache__/all.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py2.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py27.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py3.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py310.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py311.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py312.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py36.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py37.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py38.cpython-312.pyc,,
+isort/stdlibs/__pycache__/py39.cpython-312.pyc,,
+isort/stdlibs/all.py,sha256=n8Es1WK6UlupYyVvf1PDjGbionqix-afC3LkY8nzTcw,57
+isort/stdlibs/py2.py,sha256=dTgWTa7ggz1cwN8fuI9eIs9-5nTmkRxG_uO61CGwfXI,41
+isort/stdlibs/py27.py,sha256=QriKfttNSHsjaRtDfR5WXytjzf7Xi7p9lxiOOcmA2JM,4504
+isort/stdlibs/py3.py,sha256=uYFvQcqzO01T5I9SJDcylSEcOtxK7qZZjxeivH6KCI0,199
+isort/stdlibs/py310.py,sha256=d9wONMDYRrmhB90Dk-9NOUeYZqDn242pC3fbhZNMvXY,3278
+isort/stdlibs/py311.py,sha256=K92xqlugDD-9YGdHYEPxVhQMm6_NyF7Nprla81ZTZaE,3337
+isort/stdlibs/py312.py,sha256=FZKkx5XsH0moKJjZlmWsYVtcczXOwK3Xt8sb4MoyN_A,3264
+isort/stdlibs/py36.py,sha256=iuXIDLcFrSviMMSOP4PoKWCG5BveMnZbFravpduSUss,3310
+isort/stdlibs/py37.py,sha256=dLxxRerCvb4O9vrifTg5KWgO0L3a6AQB13haK_tSBRw,3334
+isort/stdlibs/py38.py,sha256=xsUSUZD5XUYX0PIuf9A3bSMD4ZcbfPyzqJqCudSfhaU,3319
+isort/stdlibs/py39.py,sha256=tlVRkhoDpoNJxJd803NdTt_hgzzuukJMkUQMgpE-vlA,3307
+isort/utils.py,sha256=5EEZUfZyyWcJLk2qnNF8ObDib_qPU4zwEQvWjpKRgb0,2413
+isort/wrap.py,sha256=6l2K2M5vivj0wXG-K4heR3rqvMQ-9BxAmRfpxH-FHU8,6389
+isort/wrap_modes.py,sha256=AkmL_oaQFslTTgWIYN2WlCb2NeQLqM0yVLCUJTstKxQ,13446
diff --git a/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/WHEEL
new file mode 100644
index 000000000..4ba767148
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/WHEEL
@@ -0,0 +1,4 @@
+Wheel-Version: 1.0
+Generator: poetry-core 1.4.0
+Root-Is-Purelib: true
+Tag: py3-none-any
diff --git a/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/entry_points.txt b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/entry_points.txt
new file mode 100644
index 000000000..21bc432bd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort-5.13.2.dist-info/entry_points.txt
@@ -0,0 +1,10 @@
+[console_scripts]
+isort=isort.main:main
+isort-identify-imports=isort.main:identify_imports_main
+
+[distutils.commands]
+isort=isort.setuptools_commands:ISortCommand
+
+[pylama.linter]
+isort=isort.pylama_isort:Linter
+
diff --git a/solutions/.venv/Lib/site-packages/isort/__init__.py b/solutions/.venv/Lib/site-packages/isort/__init__.py
new file mode 100644
index 000000000..e0754da42
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/__init__.py
@@ -0,0 +1,38 @@
+"""Defines the public isort interface"""
+__all__ = (
+ "Config",
+ "ImportKey",
+ "__version__",
+ "check_code",
+ "check_file",
+ "check_stream",
+ "code",
+ "file",
+ "find_imports_in_code",
+ "find_imports_in_file",
+ "find_imports_in_paths",
+ "find_imports_in_stream",
+ "place_module",
+ "place_module_with_reason",
+ "settings",
+ "stream",
+)
+
+from . import settings
+from ._version import __version__
+from .api import ImportKey
+from .api import check_code_string as check_code
+from .api import (
+ check_file,
+ check_stream,
+ find_imports_in_code,
+ find_imports_in_file,
+ find_imports_in_paths,
+ find_imports_in_stream,
+ place_module,
+ place_module_with_reason,
+)
+from .api import sort_code_string as code
+from .api import sort_file as file
+from .api import sort_stream as stream
+from .settings import Config
diff --git a/solutions/.venv/Lib/site-packages/isort/__main__.py b/solutions/.venv/Lib/site-packages/isort/__main__.py
new file mode 100644
index 000000000..94b1d057b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/__main__.py
@@ -0,0 +1,3 @@
+from isort.main import main
+
+main()
diff --git a/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/LICENSE b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/LICENSE
new file mode 100644
index 000000000..e859590f8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2021 Taneli Hukkinen
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/__init__.py b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/__init__.py
new file mode 100644
index 000000000..5b9f2478d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/__init__.py
@@ -0,0 +1,6 @@
+"""A lil' TOML parser."""
+
+__all__ = ("loads", "load", "TOMLDecodeError")
+__version__ = "1.2.0" # DO NOT EDIT THIS LINE MANUALLY. LET bump2version UTILITY DO IT
+
+from ._parser import TOMLDecodeError, load, loads
diff --git a/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/_parser.py b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/_parser.py
new file mode 100644
index 000000000..156848fc4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/_parser.py
@@ -0,0 +1,650 @@
+import string
+import warnings
+from types import MappingProxyType
+from typing import IO, Any, Callable, Dict, FrozenSet, Iterable, NamedTuple, Optional, Tuple
+
+from ._re import (
+ RE_DATETIME,
+ RE_LOCALTIME,
+ RE_NUMBER,
+ match_to_datetime,
+ match_to_localtime,
+ match_to_number,
+)
+
+ASCII_CTRL = frozenset(chr(i) for i in range(32)) | frozenset(chr(127))
+
+# Neither of these sets include quotation mark or backslash. They are
+# currently handled as separate cases in the parser functions.
+ILLEGAL_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t")
+ILLEGAL_MULTILINE_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t\n\r")
+
+ILLEGAL_LITERAL_STR_CHARS = ILLEGAL_BASIC_STR_CHARS
+ILLEGAL_MULTILINE_LITERAL_STR_CHARS = ASCII_CTRL - frozenset("\t\n")
+
+ILLEGAL_COMMENT_CHARS = ILLEGAL_BASIC_STR_CHARS
+
+TOML_WS = frozenset(" \t")
+TOML_WS_AND_NEWLINE = TOML_WS | frozenset("\n")
+BARE_KEY_CHARS = frozenset(string.ascii_letters + string.digits + "-_")
+KEY_INITIAL_CHARS = BARE_KEY_CHARS | frozenset("\"'")
+HEXDIGIT_CHARS = frozenset(string.hexdigits)
+
+BASIC_STR_ESCAPE_REPLACEMENTS = MappingProxyType(
+ {
+ "\\b": "\u0008", # backspace
+ "\\t": "\u0009", # tab
+ "\\n": "\u000A", # linefeed
+ "\\f": "\u000C", # form feed
+ "\\r": "\u000D", # carriage return
+ '\\"': "\u0022", # quote
+ "\\\\": "\u005C", # backslash
+ }
+)
+
+# Type annotations
+ParseFloat = Callable[[str], Any]
+Key = Tuple[str, ...]
+Pos = int
+
+
+class TOMLDecodeError(ValueError):
+ """An error raised if a document is not valid TOML."""
+
+
+def load(fp: IO, *, parse_float: ParseFloat = float) -> Dict[str, Any]:
+ """Parse TOML from a file object."""
+ s = fp.read()
+ if isinstance(s, bytes):
+ s = s.decode()
+ else:
+ warnings.warn(
+ "Text file object support is deprecated in favor of binary file objects."
+ ' Use `open("foo.toml", "rb")` to open the file in binary mode.',
+ DeprecationWarning,
+ )
+ return loads(s, parse_float=parse_float)
+
+
+def loads(s: str, *, parse_float: ParseFloat = float) -> Dict[str, Any]: # noqa: C901
+ """Parse TOML from a string."""
+
+ # The spec allows converting "\r\n" to "\n", even in string
+ # literals. Let's do so to simplify parsing.
+ src = s.replace("\r\n", "\n")
+ pos = 0
+ out = Output(NestedDict(), Flags())
+ header: Key = ()
+
+ # Parse one statement at a time
+ # (typically means one line in TOML source)
+ while True:
+ # 1. Skip line leading whitespace
+ pos = skip_chars(src, pos, TOML_WS)
+
+ # 2. Parse rules. Expect one of the following:
+ # - end of file
+ # - end of line
+ # - comment
+ # - key/value pair
+ # - append dict to list (and move to its namespace)
+ # - create dict (and move to its namespace)
+ # Skip trailing whitespace when applicable.
+ try:
+ char = src[pos]
+ except IndexError:
+ break
+ if char == "\n":
+ pos += 1
+ continue
+ if char in KEY_INITIAL_CHARS:
+ pos = key_value_rule(src, pos, out, header, parse_float)
+ pos = skip_chars(src, pos, TOML_WS)
+ elif char == "[":
+ try:
+ second_char: Optional[str] = src[pos + 1]
+ except IndexError:
+ second_char = None
+ if second_char == "[":
+ pos, header = create_list_rule(src, pos, out)
+ else:
+ pos, header = create_dict_rule(src, pos, out)
+ pos = skip_chars(src, pos, TOML_WS)
+ elif char != "#":
+ raise suffixed_err(src, pos, "Invalid statement")
+
+ # 3. Skip comment
+ pos = skip_comment(src, pos)
+
+ # 4. Expect end of line or end of file
+ try:
+ char = src[pos]
+ except IndexError:
+ break
+ if char != "\n":
+ raise suffixed_err(src, pos, "Expected newline or end of document after a statement")
+ pos += 1
+
+ return out.data.dict
+
+
+class Flags:
+ """Flags that map to parsed keys/namespaces."""
+
+ # Marks an immutable namespace (inline array or inline table).
+ FROZEN = 0
+ # Marks a nest that has been explicitly created and can no longer
+ # be opened using the "[table]" syntax.
+ EXPLICIT_NEST = 1
+
+ def __init__(self) -> None:
+ self._flags: Dict[str, dict] = {}
+
+ def unset_all(self, key: Key) -> None:
+ cont = self._flags
+ for k in key[:-1]:
+ if k not in cont:
+ return
+ cont = cont[k]["nested"]
+ cont.pop(key[-1], None)
+
+ def set_for_relative_key(self, head_key: Key, rel_key: Key, flag: int) -> None:
+ cont = self._flags
+ for k in head_key:
+ if k not in cont:
+ cont[k] = {"flags": set(), "recursive_flags": set(), "nested": {}}
+ cont = cont[k]["nested"]
+ for k in rel_key:
+ if k in cont:
+ cont[k]["flags"].add(flag)
+ else:
+ cont[k] = {"flags": {flag}, "recursive_flags": set(), "nested": {}}
+ cont = cont[k]["nested"]
+
+ def set(self, key: Key, flag: int, *, recursive: bool) -> None: # noqa: A003
+ cont = self._flags
+ key_parent, key_stem = key[:-1], key[-1]
+ for k in key_parent:
+ if k not in cont:
+ cont[k] = {"flags": set(), "recursive_flags": set(), "nested": {}}
+ cont = cont[k]["nested"]
+ if key_stem not in cont:
+ cont[key_stem] = {"flags": set(), "recursive_flags": set(), "nested": {}}
+ cont[key_stem]["recursive_flags" if recursive else "flags"].add(flag)
+
+ def is_(self, key: Key, flag: int) -> bool:
+ if not key:
+ return False # document root has no flags
+ cont = self._flags
+ for k in key[:-1]:
+ if k not in cont:
+ return False
+ inner_cont = cont[k]
+ if flag in inner_cont["recursive_flags"]:
+ return True
+ cont = inner_cont["nested"]
+ key_stem = key[-1]
+ if key_stem in cont:
+ cont = cont[key_stem]
+ return flag in cont["flags"] or flag in cont["recursive_flags"]
+ return False
+
+
+class NestedDict:
+ def __init__(self) -> None:
+ # The parsed content of the TOML document
+ self.dict: Dict[str, Any] = {}
+
+ def get_or_create_nest(
+ self,
+ key: Key,
+ *,
+ access_lists: bool = True,
+ ) -> dict:
+ cont: Any = self.dict
+ for k in key:
+ if k not in cont:
+ cont[k] = {}
+ cont = cont[k]
+ if access_lists and isinstance(cont, list):
+ cont = cont[-1]
+ if not isinstance(cont, dict):
+ raise KeyError("There is no nest behind this key")
+ return cont
+
+ def append_nest_to_list(self, key: Key) -> None:
+ cont = self.get_or_create_nest(key[:-1])
+ last_key = key[-1]
+ if last_key in cont:
+ list_ = cont[last_key]
+ if not isinstance(list_, list):
+ raise KeyError("An object other than list found behind this key")
+ list_.append({})
+ else:
+ cont[last_key] = [{}]
+
+
+class Output(NamedTuple):
+ data: NestedDict
+ flags: Flags
+
+
+def skip_chars(src: str, pos: Pos, chars: Iterable[str]) -> Pos:
+ try:
+ while src[pos] in chars:
+ pos += 1
+ except IndexError:
+ pass
+ return pos
+
+
+def skip_until(
+ src: str,
+ pos: Pos,
+ expect: str,
+ *,
+ error_on: FrozenSet[str],
+ error_on_eof: bool,
+) -> Pos:
+ try:
+ new_pos = src.index(expect, pos)
+ except ValueError:
+ new_pos = len(src)
+ if error_on_eof:
+ raise suffixed_err(src, new_pos, f'Expected "{expect!r}"')
+
+ if not error_on.isdisjoint(src[pos:new_pos]):
+ while src[pos] not in error_on:
+ pos += 1
+ raise suffixed_err(src, pos, f'Found invalid character "{src[pos]!r}"')
+ return new_pos
+
+
+def skip_comment(src: str, pos: Pos) -> Pos:
+ try:
+ char: Optional[str] = src[pos]
+ except IndexError:
+ char = None
+ if char == "#":
+ return skip_until(src, pos + 1, "\n", error_on=ILLEGAL_COMMENT_CHARS, error_on_eof=False)
+ return pos
+
+
+def skip_comments_and_array_ws(src: str, pos: Pos) -> Pos:
+ while True:
+ pos_before_skip = pos
+ pos = skip_chars(src, pos, TOML_WS_AND_NEWLINE)
+ pos = skip_comment(src, pos)
+ if pos == pos_before_skip:
+ return pos
+
+
+def create_dict_rule(src: str, pos: Pos, out: Output) -> Tuple[Pos, Key]:
+ pos += 1 # Skip "["
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, key = parse_key(src, pos)
+
+ if out.flags.is_(key, Flags.EXPLICIT_NEST) or out.flags.is_(key, Flags.FROZEN):
+ raise suffixed_err(src, pos, f"Can not declare {key} twice")
+ out.flags.set(key, Flags.EXPLICIT_NEST, recursive=False)
+ try:
+ out.data.get_or_create_nest(key)
+ except KeyError:
+ raise suffixed_err(src, pos, "Can not overwrite a value")
+
+ if not src.startswith("]", pos):
+ raise suffixed_err(src, pos, 'Expected "]" at the end of a table declaration')
+ return pos + 1, key
+
+
+def create_list_rule(src: str, pos: Pos, out: Output) -> Tuple[Pos, Key]:
+ pos += 2 # Skip "[["
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, key = parse_key(src, pos)
+
+ if out.flags.is_(key, Flags.FROZEN):
+ raise suffixed_err(src, pos, f"Can not mutate immutable namespace {key}")
+ # Free the namespace now that it points to another empty list item...
+ out.flags.unset_all(key)
+ # ...but this key precisely is still prohibited from table declaration
+ out.flags.set(key, Flags.EXPLICIT_NEST, recursive=False)
+ try:
+ out.data.append_nest_to_list(key)
+ except KeyError:
+ raise suffixed_err(src, pos, "Can not overwrite a value")
+
+ if not src.startswith("]]", pos):
+ raise suffixed_err(src, pos, 'Expected "]]" at the end of an array declaration')
+ return pos + 2, key
+
+
+def key_value_rule(src: str, pos: Pos, out: Output, header: Key, parse_float: ParseFloat) -> Pos:
+ pos, key, value = parse_key_value_pair(src, pos, parse_float)
+ key_parent, key_stem = key[:-1], key[-1]
+ abs_key_parent = header + key_parent
+
+ if out.flags.is_(abs_key_parent, Flags.FROZEN):
+ raise suffixed_err(src, pos, f"Can not mutate immutable namespace {abs_key_parent}")
+ # Containers in the relative path can't be opened with the table syntax after this
+ out.flags.set_for_relative_key(header, key, Flags.EXPLICIT_NEST)
+ try:
+ nest = out.data.get_or_create_nest(abs_key_parent)
+ except KeyError:
+ raise suffixed_err(src, pos, "Can not overwrite a value")
+ if key_stem in nest:
+ raise suffixed_err(src, pos, "Can not overwrite a value")
+ # Mark inline table and array namespaces recursively immutable
+ if isinstance(value, (dict, list)):
+ out.flags.set(header + key, Flags.FROZEN, recursive=True)
+ nest[key_stem] = value
+ return pos
+
+
+def parse_key_value_pair(src: str, pos: Pos, parse_float: ParseFloat) -> Tuple[Pos, Key, Any]:
+ pos, key = parse_key(src, pos)
+ try:
+ char: Optional[str] = src[pos]
+ except IndexError:
+ char = None
+ if char != "=":
+ raise suffixed_err(src, pos, 'Expected "=" after a key in a key/value pair')
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, value = parse_value(src, pos, parse_float)
+ return pos, key, value
+
+
+def parse_key(src: str, pos: Pos) -> Tuple[Pos, Key]:
+ pos, key_part = parse_key_part(src, pos)
+ key: Key = (key_part,)
+ pos = skip_chars(src, pos, TOML_WS)
+ while True:
+ try:
+ char: Optional[str] = src[pos]
+ except IndexError:
+ char = None
+ if char != ".":
+ return pos, key
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, key_part = parse_key_part(src, pos)
+ key += (key_part,)
+ pos = skip_chars(src, pos, TOML_WS)
+
+
+def parse_key_part(src: str, pos: Pos) -> Tuple[Pos, str]:
+ try:
+ char: Optional[str] = src[pos]
+ except IndexError:
+ char = None
+ if char in BARE_KEY_CHARS:
+ start_pos = pos
+ pos = skip_chars(src, pos, BARE_KEY_CHARS)
+ return pos, src[start_pos:pos]
+ if char == "'":
+ return parse_literal_str(src, pos)
+ if char == '"':
+ return parse_one_line_basic_str(src, pos)
+ raise suffixed_err(src, pos, "Invalid initial character for a key part")
+
+
+def parse_one_line_basic_str(src: str, pos: Pos) -> Tuple[Pos, str]:
+ pos += 1
+ return parse_basic_str(src, pos, multiline=False)
+
+
+def parse_array(src: str, pos: Pos, parse_float: ParseFloat) -> Tuple[Pos, list]:
+ pos += 1
+ array: list = []
+
+ pos = skip_comments_and_array_ws(src, pos)
+ if src.startswith("]", pos):
+ return pos + 1, array
+ while True:
+ pos, val = parse_value(src, pos, parse_float)
+ array.append(val)
+ pos = skip_comments_and_array_ws(src, pos)
+
+ c = src[pos : pos + 1]
+ if c == "]":
+ return pos + 1, array
+ if c != ",":
+ raise suffixed_err(src, pos, "Unclosed array")
+ pos += 1
+
+ pos = skip_comments_and_array_ws(src, pos)
+ if src.startswith("]", pos):
+ return pos + 1, array
+
+
+def parse_inline_table(src: str, pos: Pos, parse_float: ParseFloat) -> Tuple[Pos, dict]:
+ pos += 1
+ nested_dict = NestedDict()
+ flags = Flags()
+
+ pos = skip_chars(src, pos, TOML_WS)
+ if src.startswith("}", pos):
+ return pos + 1, nested_dict.dict
+ while True:
+ pos, key, value = parse_key_value_pair(src, pos, parse_float)
+ key_parent, key_stem = key[:-1], key[-1]
+ if flags.is_(key, Flags.FROZEN):
+ raise suffixed_err(src, pos, f"Can not mutate immutable namespace {key}")
+ try:
+ nest = nested_dict.get_or_create_nest(key_parent, access_lists=False)
+ except KeyError:
+ raise suffixed_err(src, pos, "Can not overwrite a value")
+ if key_stem in nest:
+ raise suffixed_err(src, pos, f'Duplicate inline table key "{key_stem}"')
+ nest[key_stem] = value
+ pos = skip_chars(src, pos, TOML_WS)
+ c = src[pos : pos + 1]
+ if c == "}":
+ return pos + 1, nested_dict.dict
+ if c != ",":
+ raise suffixed_err(src, pos, "Unclosed inline table")
+ if isinstance(value, (dict, list)):
+ flags.set(key, Flags.FROZEN, recursive=True)
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS)
+
+
+def parse_basic_str_escape( # noqa: C901
+ src: str, pos: Pos, *, multiline: bool = False
+) -> Tuple[Pos, str]:
+ escape_id = src[pos : pos + 2]
+ pos += 2
+ if multiline and escape_id in {"\\ ", "\\\t", "\\\n"}:
+ # Skip whitespace until next non-whitespace character or end of
+ # the doc. Error if non-whitespace is found before newline.
+ if escape_id != "\\\n":
+ pos = skip_chars(src, pos, TOML_WS)
+ try:
+ char = src[pos]
+ except IndexError:
+ return pos, ""
+ if char != "\n":
+ raise suffixed_err(src, pos, 'Unescaped "\\" in a string')
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS_AND_NEWLINE)
+ return pos, ""
+ if escape_id == "\\u":
+ return parse_hex_char(src, pos, 4)
+ if escape_id == "\\U":
+ return parse_hex_char(src, pos, 8)
+ try:
+ return pos, BASIC_STR_ESCAPE_REPLACEMENTS[escape_id]
+ except KeyError:
+ if len(escape_id) != 2:
+ raise suffixed_err(src, pos, "Unterminated string")
+ raise suffixed_err(src, pos, 'Unescaped "\\" in a string')
+
+
+def parse_basic_str_escape_multiline(src: str, pos: Pos) -> Tuple[Pos, str]:
+ return parse_basic_str_escape(src, pos, multiline=True)
+
+
+def parse_hex_char(src: str, pos: Pos, hex_len: int) -> Tuple[Pos, str]:
+ hex_str = src[pos : pos + hex_len]
+ if len(hex_str) != hex_len or not HEXDIGIT_CHARS.issuperset(hex_str):
+ raise suffixed_err(src, pos, "Invalid hex value")
+ pos += hex_len
+ hex_int = int(hex_str, 16)
+ if not is_unicode_scalar_value(hex_int):
+ raise suffixed_err(src, pos, "Escaped character is not a Unicode scalar value")
+ return pos, chr(hex_int)
+
+
+def parse_literal_str(src: str, pos: Pos) -> Tuple[Pos, str]:
+ pos += 1 # Skip starting apostrophe
+ start_pos = pos
+ pos = skip_until(src, pos, "'", error_on=ILLEGAL_LITERAL_STR_CHARS, error_on_eof=True)
+ return pos + 1, src[start_pos:pos] # Skip ending apostrophe
+
+
+def parse_multiline_str(src: str, pos: Pos, *, literal: bool) -> Tuple[Pos, str]:
+ pos += 3
+ if src.startswith("\n", pos):
+ pos += 1
+
+ if literal:
+ delim = "'"
+ end_pos = skip_until(
+ src,
+ pos,
+ "'''",
+ error_on=ILLEGAL_MULTILINE_LITERAL_STR_CHARS,
+ error_on_eof=True,
+ )
+ result = src[pos:end_pos]
+ pos = end_pos + 3
+ else:
+ delim = '"'
+ pos, result = parse_basic_str(src, pos, multiline=True)
+
+ # Add at maximum two extra apostrophes/quotes if the end sequence
+ # is 4 or 5 chars long instead of just 3.
+ if not src.startswith(delim, pos):
+ return pos, result
+ pos += 1
+ if not src.startswith(delim, pos):
+ return pos, result + delim
+ pos += 1
+ return pos, result + (delim * 2)
+
+
+def parse_basic_str(src: str, pos: Pos, *, multiline: bool) -> Tuple[Pos, str]:
+ if multiline:
+ error_on = ILLEGAL_MULTILINE_BASIC_STR_CHARS
+ parse_escapes = parse_basic_str_escape_multiline
+ else:
+ error_on = ILLEGAL_BASIC_STR_CHARS
+ parse_escapes = parse_basic_str_escape
+ result = ""
+ start_pos = pos
+ while True:
+ try:
+ char = src[pos]
+ except IndexError:
+ raise suffixed_err(src, pos, "Unterminated string")
+ if char == '"':
+ if not multiline:
+ return pos + 1, result + src[start_pos:pos]
+ if src.startswith('"""', pos):
+ return pos + 3, result + src[start_pos:pos]
+ pos += 1
+ continue
+ if char == "\\":
+ result += src[start_pos:pos]
+ pos, parsed_escape = parse_escapes(src, pos)
+ result += parsed_escape
+ start_pos = pos
+ continue
+ if char in error_on:
+ raise suffixed_err(src, pos, f'Illegal character "{char!r}"')
+ pos += 1
+
+
+def parse_value(src: str, pos: Pos, parse_float: ParseFloat) -> Tuple[Pos, Any]: # noqa: C901
+ try:
+ char: Optional[str] = src[pos]
+ except IndexError:
+ char = None
+
+ # Basic strings
+ if char == '"':
+ if src.startswith('"""', pos):
+ return parse_multiline_str(src, pos, literal=False)
+ return parse_one_line_basic_str(src, pos)
+
+ # Literal strings
+ if char == "'":
+ if src.startswith("'''", pos):
+ return parse_multiline_str(src, pos, literal=True)
+ return parse_literal_str(src, pos)
+
+ # Booleans
+ if char == "t":
+ if src.startswith("true", pos):
+ return pos + 4, True
+ if char == "f":
+ if src.startswith("false", pos):
+ return pos + 5, False
+
+ # Dates and times
+ datetime_match = RE_DATETIME.match(src, pos)
+ if datetime_match:
+ try:
+ datetime_obj = match_to_datetime(datetime_match)
+ except ValueError:
+ raise suffixed_err(src, pos, "Invalid date or datetime")
+ return datetime_match.end(), datetime_obj
+ localtime_match = RE_LOCALTIME.match(src, pos)
+ if localtime_match:
+ return localtime_match.end(), match_to_localtime(localtime_match)
+
+ # Integers and "normal" floats.
+ # The regex will greedily match any type starting with a decimal
+ # char, so needs to be located after handling of dates and times.
+ number_match = RE_NUMBER.match(src, pos)
+ if number_match:
+ return number_match.end(), match_to_number(number_match, parse_float)
+
+ # Arrays
+ if char == "[":
+ return parse_array(src, pos, parse_float)
+
+ # Inline tables
+ if char == "{":
+ return parse_inline_table(src, pos, parse_float)
+
+ # Special floats
+ first_three = src[pos : pos + 3]
+ if first_three in {"inf", "nan"}:
+ return pos + 3, parse_float(first_three)
+ first_four = src[pos : pos + 4]
+ if first_four in {"-inf", "+inf", "-nan", "+nan"}:
+ return pos + 4, parse_float(first_four)
+
+ raise suffixed_err(src, pos, "Invalid value")
+
+
+def suffixed_err(src: str, pos: Pos, msg: str) -> TOMLDecodeError:
+ """Return a `TOMLDecodeError` where error message is suffixed with
+ coordinates in source."""
+
+ def coord_repr(src: str, pos: Pos) -> str:
+ if pos >= len(src):
+ return "end of document"
+ line = src.count("\n", 0, pos) + 1
+ if line == 1:
+ column = pos + 1
+ else:
+ column = pos - src.rindex("\n", 0, pos)
+ return f"line {line}, column {column}"
+
+ return TOMLDecodeError(f"{msg} (at {coord_repr(src, pos)})")
+
+
+def is_unicode_scalar_value(codepoint: int) -> bool:
+ return (0 <= codepoint <= 55295) or (57344 <= codepoint <= 1114111)
diff --git a/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/_re.py b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/_re.py
new file mode 100644
index 000000000..8238aa171
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/_re.py
@@ -0,0 +1,100 @@
+import re
+from datetime import date, datetime, time, timedelta, timezone, tzinfo
+from functools import lru_cache
+from typing import TYPE_CHECKING, Any, Optional, Union
+
+if TYPE_CHECKING:
+ from tomli._parser import ParseFloat
+
+# E.g.
+# - 00:32:00.999999
+# - 00:32:00
+_TIME_RE_STR = r"([01][0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9])(?:\.([0-9]{1,6})[0-9]*)?"
+
+RE_NUMBER = re.compile(
+ r"""
+0
+(?:
+ x[0-9A-Fa-f](?:_?[0-9A-Fa-f])* # hex
+ |
+ b[01](?:_?[01])* # bin
+ |
+ o[0-7](?:_?[0-7])* # oct
+)
+|
+[+-]?(?:0|[1-9](?:_?[0-9])*) # dec, integer part
+(?P<floatpart>
+ (?:\.[0-9](?:_?[0-9])*)? # optional fractional part
+ (?:[eE][+-]?[0-9](?:_?[0-9])*)? # optional exponent part
+)
+""",
+ flags=re.VERBOSE,
+)
+RE_LOCALTIME = re.compile(_TIME_RE_STR)
+RE_DATETIME = re.compile(
+ rf"""
+([0-9]{{4}})-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01]) # date, e.g. 1988-10-27
+(?:
+ [T ]
+ {_TIME_RE_STR}
+ (?:(Z)|([+-])([01][0-9]|2[0-3]):([0-5][0-9]))? # optional time offset
+)?
+""",
+ flags=re.VERBOSE,
+)
+
+
+def match_to_datetime(match: "re.Match") -> Union[datetime, date]:
+ """Convert a `RE_DATETIME` match to `datetime.datetime` or `datetime.date`.
+
+ Raises ValueError if the match does not correspond to a valid date
+ or datetime.
+ """
+ (
+ year_str,
+ month_str,
+ day_str,
+ hour_str,
+ minute_str,
+ sec_str,
+ micros_str,
+ zulu_time,
+ offset_sign_str,
+ offset_hour_str,
+ offset_minute_str,
+ ) = match.groups()
+ year, month, day = int(year_str), int(month_str), int(day_str)
+ if hour_str is None:
+ return date(year, month, day)
+ hour, minute, sec = int(hour_str), int(minute_str), int(sec_str)
+ micros = int(micros_str.ljust(6, "0")) if micros_str else 0
+ if offset_sign_str:
+ tz: Optional[tzinfo] = cached_tz(offset_hour_str, offset_minute_str, offset_sign_str)
+ elif zulu_time:
+ tz = timezone.utc
+ else: # local date-time
+ tz = None
+ return datetime(year, month, day, hour, minute, sec, micros, tzinfo=tz)
+
+
+@lru_cache(maxsize=None)
+def cached_tz(hour_str: str, minute_str: str, sign_str: str) -> timezone:
+ sign = 1 if sign_str == "+" else -1
+ return timezone(
+ timedelta(
+ hours=sign * int(hour_str),
+ minutes=sign * int(minute_str),
+ )
+ )
+
+
+def match_to_localtime(match: "re.Match") -> time:
+ hour_str, minute_str, sec_str, micros_str = match.groups()
+ micros = int(micros_str.ljust(6, "0")) if micros_str else 0
+ return time(int(hour_str), int(minute_str), int(sec_str), micros)
+
+
+def match_to_number(match: "re.Match", parse_float: "ParseFloat") -> Any:
+ if match.group("floatpart"):
+ return parse_float(match.group())
+ return int(match.group(), 0)
diff --git a/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/py.typed b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/py.typed
new file mode 100644
index 000000000..7632ecf77
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/_vendored/tomli/py.typed
@@ -0,0 +1 @@
+# Marker file for PEP 561
diff --git a/solutions/.venv/Lib/site-packages/isort/_version.py b/solutions/.venv/Lib/site-packages/isort/_version.py
new file mode 100644
index 000000000..4a8ec67f6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/_version.py
@@ -0,0 +1,3 @@
+from importlib import metadata
+
+__version__ = metadata.version("isort")
diff --git a/solutions/.venv/Lib/site-packages/isort/api.py b/solutions/.venv/Lib/site-packages/isort/api.py
new file mode 100644
index 000000000..2c89d3739
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/api.py
@@ -0,0 +1,651 @@
+__all__ = (
+ "ImportKey",
+ "check_code_string",
+ "check_file",
+ "check_stream",
+ "find_imports_in_code",
+ "find_imports_in_file",
+ "find_imports_in_paths",
+ "find_imports_in_stream",
+ "place_module",
+ "place_module_with_reason",
+ "sort_code_string",
+ "sort_file",
+ "sort_stream",
+)
+
+import contextlib
+import shutil
+import sys
+from enum import Enum
+from io import StringIO
+from itertools import chain
+from pathlib import Path
+from typing import Any, Iterator, Optional, Set, TextIO, Union, cast
+from warnings import warn
+
+from isort import core
+
+from . import files, identify, io
+from .exceptions import (
+ ExistingSyntaxErrors,
+ FileSkipComment,
+ FileSkipSetting,
+ IntroducedSyntaxErrors,
+)
+from .format import ask_whether_to_apply_changes_to_file, create_terminal_printer, show_unified_diff
+from .io import Empty, File
+from .place import module as place_module # noqa: F401
+from .place import module_with_reason as place_module_with_reason # noqa: F401
+from .settings import CYTHON_EXTENSIONS, DEFAULT_CONFIG, Config
+
+
+class ImportKey(Enum):
+ """Defines how to key an individual import, generally for deduping.
+
+ Import keys are defined from less to more specific:
+
+ from x.y import z as a
+ ______| | | |
+ | | | |
+ PACKAGE | | |
+ ________| | |
+ | | |
+ MODULE | |
+ _________________| |
+ | |
+ ATTRIBUTE |
+ ______________________|
+ |
+ ALIAS
+ """
+
+ PACKAGE = 1
+ MODULE = 2
+ ATTRIBUTE = 3
+ ALIAS = 4
+
+
+def sort_code_string(
+ code: str,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ **config_kwargs: Any,
+) -> str:
+ """Sorts any imports within the provided code string, returning a new string with them sorted.
+
+ - **code**: The string of code with imports that need to be sorted.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - ****config_kwargs**: Any config modifications.
+ """
+ input_stream = StringIO(code)
+ output_stream = StringIO()
+ config = _config(path=file_path, config=config, **config_kwargs)
+ sort_stream(
+ input_stream,
+ output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ show_diff=show_diff,
+ )
+ output_stream.seek(0)
+ return output_stream.read()
+
+
+def check_code_string(
+ code: str,
+ show_diff: Union[bool, TextIO] = False,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ **config_kwargs: Any,
+) -> bool:
+ """Checks the order, format, and categorization of imports within the provided code string.
+ Returns `True` if everything is correct, otherwise `False`.
+
+ - **code**: The string of code with imports that need to be sorted.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(path=file_path, config=config, **config_kwargs)
+ return check_stream(
+ StringIO(code),
+ show_diff=show_diff,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+
+
+def sort_stream(
+ input_stream: TextIO,
+ output_stream: TextIO,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ raise_on_skip: bool = True,
+ **config_kwargs: Any,
+) -> bool:
+ """Sorts any imports within the provided code stream, outputs to the provided output stream.
+ Returns `True` if anything is modified from the original input stream, otherwise `False`.
+
+ - **input_stream**: The stream of code with imports that need to be sorted.
+ - **output_stream**: The stream where sorted imports should be written to.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - ****config_kwargs**: Any config modifications.
+ """
+ extension = extension or (file_path and file_path.suffix.lstrip(".")) or "py"
+ if show_diff:
+ _output_stream = StringIO()
+ _input_stream = StringIO(input_stream.read())
+ changed = sort_stream(
+ input_stream=_input_stream,
+ output_stream=_output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ raise_on_skip=raise_on_skip,
+ **config_kwargs,
+ )
+ _output_stream.seek(0)
+ _input_stream.seek(0)
+ show_unified_diff(
+ file_input=_input_stream.read(),
+ file_output=_output_stream.read(),
+ file_path=file_path,
+ output=output_stream if show_diff is True else show_diff,
+ color_output=config.color_output,
+ )
+ return changed
+
+ config = _config(path=file_path, config=config, **config_kwargs)
+ content_source = str(file_path or "Passed in content")
+ if not disregard_skip and file_path and config.is_skipped(file_path):
+ raise FileSkipSetting(content_source)
+
+ _internal_output = output_stream
+
+ if config.atomic:
+ try:
+ file_content = input_stream.read()
+ compile(file_content, content_source, "exec", 0, 1)
+ except SyntaxError:
+ if extension not in CYTHON_EXTENSIONS:
+ raise ExistingSyntaxErrors(content_source)
+ if config.verbose:
+ warn(
+ f"{content_source} Python AST errors found but ignored due to Cython extension"
+ )
+ input_stream = StringIO(file_content)
+
+ if not output_stream.readable():
+ _internal_output = StringIO()
+
+ try:
+ changed = core.process(
+ input_stream,
+ _internal_output,
+ extension=extension,
+ config=config,
+ raise_on_skip=raise_on_skip,
+ )
+ except FileSkipComment:
+ raise FileSkipComment(content_source)
+
+ if config.atomic:
+ _internal_output.seek(0)
+ try:
+ compile(_internal_output.read(), content_source, "exec", 0, 1)
+ _internal_output.seek(0)
+ except SyntaxError: # pragma: no cover
+ if extension not in CYTHON_EXTENSIONS:
+ raise IntroducedSyntaxErrors(content_source)
+ if config.verbose:
+ warn(
+ f"{content_source} Python AST errors found but ignored due to Cython extension"
+ )
+ if _internal_output != output_stream:
+ output_stream.write(_internal_output.read())
+
+ return changed
+
+
+def check_stream(
+ input_stream: TextIO,
+ show_diff: Union[bool, TextIO] = False,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ **config_kwargs: Any,
+) -> bool:
+ """Checks any imports within the provided code stream, returning `False` if any unsorted or
+ incorrectly imports are found or `True` if no problems are identified.
+
+ - **input_stream**: The stream of code with imports that need to be sorted.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(path=file_path, config=config, **config_kwargs)
+
+ if show_diff:
+ input_stream = StringIO(input_stream.read())
+
+ changed: bool = sort_stream(
+ input_stream=input_stream,
+ output_stream=Empty,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+ printer = create_terminal_printer(
+ color=config.color_output, error=config.format_error, success=config.format_success
+ )
+ if not changed:
+ if config.verbose and not config.only_modified:
+ printer.success(f"{file_path or ''} Everything Looks Good!")
+ return True
+
+ printer.error(f"{file_path or ''} Imports are incorrectly sorted and/or formatted.")
+ if show_diff:
+ output_stream = StringIO()
+ input_stream.seek(0)
+ file_contents = input_stream.read()
+ sort_stream(
+ input_stream=StringIO(file_contents),
+ output_stream=output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+ output_stream.seek(0)
+
+ show_unified_diff(
+ file_input=file_contents,
+ file_output=output_stream.read(),
+ file_path=file_path,
+ output=None if show_diff is True else show_diff,
+ color_output=config.color_output,
+ )
+ return False
+
+
+def check_file(
+ filename: Union[str, Path],
+ show_diff: Union[bool, TextIO] = False,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = True,
+ extension: Optional[str] = None,
+ **config_kwargs: Any,
+) -> bool:
+ """Checks any imports within the provided file, returning `False` if any unsorted or
+ incorrectly imports are found or `True` if no problems are identified.
+
+ - **filename**: The name or Path of the file to check.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - ****config_kwargs**: Any config modifications.
+ """
+ file_config: Config = config
+
+ if "config_trie" in config_kwargs:
+ config_trie = config_kwargs.pop("config_trie", None)
+ if config_trie:
+ config_info = config_trie.search(filename)
+ if config.verbose:
+ print(f"{config_info[0]} used for file {filename}")
+
+ file_config = Config(**config_info[1])
+
+ with io.File.read(filename) as source_file:
+ return check_stream(
+ source_file.stream,
+ show_diff=show_diff,
+ extension=extension,
+ config=file_config,
+ file_path=file_path or source_file.path,
+ disregard_skip=disregard_skip,
+ **config_kwargs,
+ )
+
+
+def _tmp_file(source_file: File) -> Path:
+ return source_file.path.with_suffix(source_file.path.suffix + ".isorted")
+
+
+@contextlib.contextmanager
+def _in_memory_output_stream_context() -> Iterator[TextIO]:
+ yield StringIO(newline=None)
+
+
+@contextlib.contextmanager
+def _file_output_stream_context(filename: Union[str, Path], source_file: File) -> Iterator[TextIO]:
+ tmp_file = _tmp_file(source_file)
+ with tmp_file.open("w+", encoding=source_file.encoding, newline="") as output_stream:
+ shutil.copymode(filename, tmp_file)
+ yield output_stream
+
+
+def sort_file(
+ filename: Union[str, Path],
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = True,
+ ask_to_apply: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ write_to_stdout: bool = False,
+ output: Optional[TextIO] = None,
+ **config_kwargs: Any,
+) -> bool:
+ """Sorts and formats any groups of imports imports within the provided file or Path.
+ Returns `True` if the file has been changed, otherwise `False`.
+
+ - **filename**: The name or Path of the file to format.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **ask_to_apply**: If `True`, prompt before applying any changes.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **write_to_stdout**: If `True`, write to stdout instead of the input file.
+ - **output**: If a TextIO is provided, results will be written there rather than replacing
+ the original file content.
+ - ****config_kwargs**: Any config modifications.
+ """
+ file_config: Config = config
+
+ if "config_trie" in config_kwargs:
+ config_trie = config_kwargs.pop("config_trie", None)
+ if config_trie:
+ config_info = config_trie.search(filename)
+ if config.verbose:
+ print(f"{config_info[0]} used for file {filename}")
+
+ file_config = Config(**config_info[1])
+
+ with io.File.read(filename) as source_file:
+ actual_file_path = file_path or source_file.path
+ config = _config(path=actual_file_path, config=file_config, **config_kwargs)
+ changed: bool = False
+ try:
+ if write_to_stdout:
+ changed = sort_stream(
+ input_stream=source_file.stream,
+ output_stream=sys.stdout,
+ config=config,
+ file_path=actual_file_path,
+ disregard_skip=disregard_skip,
+ extension=extension,
+ )
+ else:
+ if output is None:
+ try:
+ if config.overwrite_in_place:
+ output_stream_context = _in_memory_output_stream_context()
+ else:
+ output_stream_context = _file_output_stream_context(
+ filename, source_file
+ )
+ with output_stream_context as output_stream:
+ changed = sort_stream(
+ input_stream=source_file.stream,
+ output_stream=output_stream,
+ config=config,
+ file_path=actual_file_path,
+ disregard_skip=disregard_skip,
+ extension=extension,
+ )
+ output_stream.seek(0)
+ if changed:
+ if show_diff or ask_to_apply:
+ source_file.stream.seek(0)
+ show_unified_diff(
+ file_input=source_file.stream.read(),
+ file_output=output_stream.read(),
+ file_path=actual_file_path,
+ output=None
+ if show_diff is True
+ else cast(TextIO, show_diff),
+ color_output=config.color_output,
+ )
+ if show_diff or (
+ ask_to_apply
+ and not ask_whether_to_apply_changes_to_file(
+ str(source_file.path)
+ )
+ ):
+ return False
+ source_file.stream.close()
+ if config.overwrite_in_place:
+ output_stream.seek(0)
+ with source_file.path.open("w") as fs:
+ shutil.copyfileobj(output_stream, fs)
+ if changed:
+ if not config.overwrite_in_place:
+ tmp_file = _tmp_file(source_file)
+ tmp_file.replace(source_file.path)
+ if not config.quiet:
+ print(f"Fixing {source_file.path}")
+ finally:
+ try: # Python 3.8+: use `missing_ok=True` instead of try except.
+ if not config.overwrite_in_place: # pragma: no branch
+ tmp_file = _tmp_file(source_file)
+ tmp_file.unlink()
+ except FileNotFoundError:
+ pass # pragma: no cover
+ else:
+ changed = sort_stream(
+ input_stream=source_file.stream,
+ output_stream=output,
+ config=config,
+ file_path=actual_file_path,
+ disregard_skip=disregard_skip,
+ extension=extension,
+ )
+ if changed and show_diff:
+ source_file.stream.seek(0)
+ output.seek(0)
+ show_unified_diff(
+ file_input=source_file.stream.read(),
+ file_output=output.read(),
+ file_path=actual_file_path,
+ output=None if show_diff is True else show_diff,
+ color_output=config.color_output,
+ )
+ source_file.stream.close()
+
+ except ExistingSyntaxErrors:
+ warn(f"{actual_file_path} unable to sort due to existing syntax errors")
+ except IntroducedSyntaxErrors: # pragma: no cover
+ warn(f"{actual_file_path} unable to sort as isort introduces new syntax errors")
+
+ return changed
+
+
+def find_imports_in_code(
+ code: str,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ unique: Union[bool, ImportKey] = False,
+ top_only: bool = False,
+ **config_kwargs: Any,
+) -> Iterator[identify.Import]:
+ """Finds and returns all imports within the provided code string.
+
+ - **code**: The string of code with imports that need to be sorted.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **unique**: If True, only the first instance of an import is returned.
+ - **top_only**: If True, only return imports that occur before the first function or class.
+ - ****config_kwargs**: Any config modifications.
+ """
+ yield from find_imports_in_stream(
+ input_stream=StringIO(code),
+ config=config,
+ file_path=file_path,
+ unique=unique,
+ top_only=top_only,
+ **config_kwargs,
+ )
+
+
+def find_imports_in_stream(
+ input_stream: TextIO,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ unique: Union[bool, ImportKey] = False,
+ top_only: bool = False,
+ _seen: Optional[Set[str]] = None,
+ **config_kwargs: Any,
+) -> Iterator[identify.Import]:
+ """Finds and returns all imports within the provided code stream.
+
+ - **input_stream**: The stream of code with imports that need to be sorted.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **unique**: If True, only the first instance of an import is returned.
+ - **top_only**: If True, only return imports that occur before the first function or class.
+ - **_seen**: An optional set of imports already seen. Generally meant only for internal use.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(config=config, **config_kwargs)
+ identified_imports = identify.imports(
+ input_stream, config=config, file_path=file_path, top_only=top_only
+ )
+ if not unique:
+ yield from identified_imports
+
+ seen: Set[str] = set() if _seen is None else _seen
+ for identified_import in identified_imports:
+ if unique in (True, ImportKey.ALIAS):
+ key = identified_import.statement()
+ elif unique == ImportKey.ATTRIBUTE:
+ key = f"{identified_import.module}.{identified_import.attribute}"
+ elif unique == ImportKey.MODULE:
+ key = identified_import.module
+ elif unique == ImportKey.PACKAGE: # pragma: no branch # type checking ensures this
+ key = identified_import.module.split(".")[0]
+
+ if key and key not in seen:
+ seen.add(key)
+ yield identified_import
+
+
+def find_imports_in_file(
+ filename: Union[str, Path],
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ unique: Union[bool, ImportKey] = False,
+ top_only: bool = False,
+ **config_kwargs: Any,
+) -> Iterator[identify.Import]:
+ """Finds and returns all imports within the provided source file.
+
+ - **filename**: The name or Path of the file to look for imports in.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **unique**: If True, only the first instance of an import is returned.
+ - **top_only**: If True, only return imports that occur before the first function or class.
+ - ****config_kwargs**: Any config modifications.
+ """
+ with io.File.read(filename) as source_file:
+ yield from find_imports_in_stream(
+ input_stream=source_file.stream,
+ config=config,
+ file_path=file_path or source_file.path,
+ unique=unique,
+ top_only=top_only,
+ **config_kwargs,
+ )
+
+
+def find_imports_in_paths(
+ paths: Iterator[Union[str, Path]],
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ unique: Union[bool, ImportKey] = False,
+ top_only: bool = False,
+ **config_kwargs: Any,
+) -> Iterator[identify.Import]:
+ """Finds and returns all imports within the provided source paths.
+
+ - **paths**: A collection of paths to recursively look for imports within.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **unique**: If True, only the first instance of an import is returned.
+ - **top_only**: If True, only return imports that occur before the first function or class.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(config=config, **config_kwargs)
+ seen: Optional[Set[str]] = set() if unique else None
+ yield from chain(
+ *(
+ find_imports_in_file(
+ file_name, unique=unique, config=config, top_only=top_only, _seen=seen
+ )
+ for file_name in files.find(map(str, paths), config, [], [])
+ )
+ )
+
+
+def _config(
+ path: Optional[Path] = None, config: Config = DEFAULT_CONFIG, **config_kwargs: Any
+) -> Config:
+ if path and (
+ config is DEFAULT_CONFIG
+ and "settings_path" not in config_kwargs
+ and "settings_file" not in config_kwargs
+ ):
+ config_kwargs["settings_path"] = path
+
+ if config_kwargs:
+ if config is not DEFAULT_CONFIG:
+ raise ValueError(
+ "You can either specify custom configuration options using kwargs or "
+ "passing in a Config object. Not Both!"
+ )
+
+ config = Config(**config_kwargs)
+
+ return config
diff --git a/solutions/.venv/Lib/site-packages/isort/comments.py b/solutions/.venv/Lib/site-packages/isort/comments.py
new file mode 100644
index 000000000..55c3da674
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/comments.py
@@ -0,0 +1,32 @@
+from typing import List, Optional, Tuple
+
+
+def parse(line: str) -> Tuple[str, str]:
+ """Parses import lines for comments and returns back the
+ import statement and the associated comment.
+ """
+ comment_start = line.find("#")
+ if comment_start != -1:
+ return (line[:comment_start], line[comment_start + 1 :].strip())
+
+ return (line, "")
+
+
+def add_to_line(
+ comments: Optional[List[str]],
+ original_string: str = "",
+ removed: bool = False,
+ comment_prefix: str = "",
+) -> str:
+ """Returns a string with comments added if removed is not set."""
+ if removed:
+ return parse(original_string)[0]
+
+ if not comments:
+ return original_string
+
+ unique_comments: List[str] = []
+ for comment in comments:
+ if comment not in unique_comments:
+ unique_comments.append(comment)
+ return f"{parse(original_string)[0]}{comment_prefix} {'; '.join(unique_comments)}"
diff --git a/solutions/.venv/Lib/site-packages/isort/core.py b/solutions/.venv/Lib/site-packages/isort/core.py
new file mode 100644
index 000000000..101038548
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/core.py
@@ -0,0 +1,510 @@
+import textwrap
+from io import StringIO
+from itertools import chain
+from typing import List, TextIO, Union
+
+import isort.literal
+from isort.settings import DEFAULT_CONFIG, Config
+
+from . import output, parse
+from .exceptions import ExistingSyntaxErrors, FileSkipComment
+from .format import format_natural, remove_whitespace
+from .settings import FILE_SKIP_COMMENTS
+
+CIMPORT_IDENTIFIERS = ("cimport ", "cimport*", "from.cimport")
+IMPORT_START_IDENTIFIERS = ("from ", "from.import", "import ", "import*") + CIMPORT_IDENTIFIERS
+DOCSTRING_INDICATORS = ('"""', "'''")
+COMMENT_INDICATORS = DOCSTRING_INDICATORS + ("'", '"', "#")
+CODE_SORT_COMMENTS = (
+ "# isort: list",
+ "# isort: dict",
+ "# isort: set",
+ "# isort: unique-list",
+ "# isort: tuple",
+ "# isort: unique-tuple",
+ "# isort: assignments",
+)
+LITERAL_TYPE_MAPPING = {"(": "tuple", "[": "list", "{": "set"}
+
+
+def process(
+ input_stream: TextIO,
+ output_stream: TextIO,
+ extension: str = "py",
+ raise_on_skip: bool = True,
+ config: Config = DEFAULT_CONFIG,
+) -> bool:
+ """Parses stream identifying sections of contiguous imports and sorting them
+
+ Code with unsorted imports is read from the provided `input_stream`, sorted and then
+ outputted to the specified `output_stream`.
+
+ - `input_stream`: Text stream with unsorted import sections.
+ - `output_stream`: Text stream to output sorted inputs into.
+ - `config`: Config settings to use when sorting imports. Defaults settings.
+ - *Default*: `isort.settings.DEFAULT_CONFIG`.
+ - `extension`: The file extension or file extension rules that should be used.
+ - *Default*: `"py"`.
+ - *Choices*: `["py", "pyi", "pyx"]`.
+
+ Returns `True` if there were changes that needed to be made (errors present) from what
+ was provided in the input_stream, otherwise `False`.
+ """
+ line_separator: str = config.line_ending
+ add_imports: List[str] = [format_natural(addition) for addition in config.add_imports]
+ import_section: str = ""
+ next_import_section: str = ""
+ next_cimports: bool = False
+ in_quote: str = ""
+ was_in_quote: bool = False
+ first_comment_index_start: int = -1
+ first_comment_index_end: int = -1
+ contains_imports: bool = False
+ in_top_comment: bool = False
+ first_import_section: bool = True
+ indent: str = ""
+ isort_off: bool = False
+ skip_file: bool = False
+ code_sorting: Union[bool, str] = False
+ code_sorting_section: str = ""
+ code_sorting_indent: str = ""
+ cimports: bool = False
+ made_changes: bool = False
+ stripped_line: str = ""
+ end_of_file: bool = False
+ verbose_output: List[str] = []
+ lines_before: List[str] = []
+ is_reexport: bool = False
+ sort_section_pointer: int = 0
+
+ if config.float_to_top:
+ new_input = ""
+ current = ""
+ isort_off = False
+ for line in chain(input_stream, (None,)):
+ if isort_off and line is not None:
+ if line == "# isort: on\n":
+ isort_off = False
+ new_input += line
+ elif line in ("# isort: split\n", "# isort: off\n", None) or str(line).endswith(
+ "# isort: split\n"
+ ):
+ if line == "# isort: off\n":
+ isort_off = True
+ if current:
+ if add_imports:
+ add_line_separator = line_separator or "\n"
+ current += add_line_separator + add_line_separator.join(add_imports)
+ add_imports = []
+ parsed = parse.file_contents(current, config=config)
+ verbose_output += parsed.verbose_output
+ extra_space = ""
+ while current and current[-1] == "\n":
+ extra_space += "\n"
+ current = current[:-1]
+ extra_space = extra_space.replace("\n", "", 1)
+ sorted_output = output.sorted_imports(
+ parsed, config, extension, import_type="import"
+ )
+ made_changes = made_changes or _has_changed(
+ before=current,
+ after=sorted_output,
+ line_separator=parsed.line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+ new_input += sorted_output
+ new_input += extra_space
+ current = ""
+ new_input += line or ""
+ else:
+ current += line or ""
+
+ input_stream = StringIO(new_input)
+
+ for index, line in enumerate(chain(input_stream, (None,))):
+ if line is None:
+ if index == 0 and not config.force_adds:
+ return False
+
+ not_imports = True
+ end_of_file = True
+ line = ""
+ if not line_separator:
+ line_separator = "\n"
+
+ if code_sorting and code_sorting_section:
+ if is_reexport:
+ output_stream.seek(sort_section_pointer, 0)
+ sorted_code = textwrap.indent(
+ isort.literal.assignment(
+ code_sorting_section,
+ str(code_sorting),
+ extension,
+ config=_indented_config(config, indent),
+ ),
+ code_sorting_indent,
+ )
+ made_changes = made_changes or _has_changed(
+ before=code_sorting_section,
+ after=sorted_code,
+ line_separator=line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+ sort_section_pointer += output_stream.write(sorted_code)
+ else:
+ stripped_line = line.strip()
+ if stripped_line and not line_separator:
+ line_separator = line[len(line.rstrip()) :].replace(" ", "").replace("\t", "")
+
+ for file_skip_comment in FILE_SKIP_COMMENTS:
+ if file_skip_comment in line:
+ if raise_on_skip:
+ raise FileSkipComment("Passed in content")
+ isort_off = True
+ skip_file = True
+
+ if not in_quote:
+ if stripped_line == "# isort: off":
+ isort_off = True
+ elif stripped_line.startswith("# isort: dont-add-imports"):
+ add_imports = []
+ elif stripped_line.startswith("# isort: dont-add-import:"):
+ import_not_to_add = stripped_line.split("# isort: dont-add-import:", 1)[
+ 1
+ ].strip()
+ add_imports = [
+ import_to_add
+ for import_to_add in add_imports
+ if not import_to_add == import_not_to_add
+ ]
+
+ if (
+ (index == 0 or (index in (1, 2) and not contains_imports))
+ and stripped_line.startswith("#")
+ and stripped_line not in config.section_comments
+ and stripped_line not in CODE_SORT_COMMENTS
+ ):
+ in_top_comment = True
+ elif in_top_comment and (
+ not line.startswith("#")
+ or stripped_line in config.section_comments
+ or stripped_line in CODE_SORT_COMMENTS
+ ):
+ in_top_comment = False
+ first_comment_index_end = index - 1
+
+ was_in_quote = bool(in_quote)
+ if (not stripped_line.startswith("#") or in_quote) and '"' in line or "'" in line:
+ char_index = 0
+ if first_comment_index_start == -1 and (
+ line.startswith('"') or line.startswith("'")
+ ):
+ first_comment_index_start = index
+ while char_index < len(line):
+ if line[char_index] == "\\":
+ char_index += 1
+ elif in_quote:
+ if line[char_index : char_index + len(in_quote)] == in_quote:
+ in_quote = ""
+ if first_comment_index_end < first_comment_index_start:
+ first_comment_index_end = index
+ elif line[char_index] in ("'", '"'):
+ long_quote = line[char_index : char_index + 3]
+ if long_quote in ('"""', "'''"):
+ in_quote = long_quote
+ char_index += 2
+ else:
+ in_quote = line[char_index]
+ elif line[char_index] == "#":
+ break
+ char_index += 1
+
+ not_imports = bool(in_quote) or was_in_quote or in_top_comment or isort_off
+ if not (in_quote or was_in_quote or in_top_comment):
+ if isort_off:
+ if not skip_file and stripped_line == "# isort: on":
+ isort_off = False
+ elif stripped_line.endswith("# isort: split"):
+ not_imports = True
+ elif stripped_line in CODE_SORT_COMMENTS:
+ code_sorting = stripped_line.split("isort: ")[1].strip()
+ code_sorting_indent = line[: -len(line.lstrip())]
+ not_imports = True
+ elif config.sort_reexports and stripped_line.startswith("__all__"):
+ _, rhs = stripped_line.split("=")
+ code_sorting = LITERAL_TYPE_MAPPING.get(rhs.lstrip()[0], "tuple")
+ code_sorting_indent = line[: -len(line.lstrip())]
+ not_imports = True
+ code_sorting_section += line
+ is_reexport = True
+ sort_section_pointer -= len(line)
+ elif code_sorting:
+ if not stripped_line:
+ sorted_code = textwrap.indent(
+ isort.literal.assignment(
+ code_sorting_section,
+ str(code_sorting),
+ extension,
+ config=_indented_config(config, indent),
+ ),
+ code_sorting_indent,
+ )
+ made_changes = made_changes or _has_changed(
+ before=code_sorting_section,
+ after=sorted_code,
+ line_separator=line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+ if is_reexport:
+ output_stream.seek(sort_section_pointer, 0)
+ sort_section_pointer += output_stream.write(sorted_code)
+ not_imports = True
+ code_sorting = False
+ code_sorting_section = ""
+ code_sorting_indent = ""
+ is_reexport = False
+ else:
+ code_sorting_section += line
+ line = ""
+ elif (
+ stripped_line in config.section_comments
+ or stripped_line in config.section_comments_end
+ ):
+ if import_section and not contains_imports:
+ output_stream.write(import_section)
+ import_section = line
+ not_imports = False
+ else:
+ import_section += line
+ indent = line[: -len(line.lstrip())]
+ elif not (stripped_line or contains_imports):
+ not_imports = True
+ elif (
+ not stripped_line
+ or stripped_line.startswith("#")
+ and (not indent or indent + line.lstrip() == line)
+ and not config.treat_all_comments_as_code
+ and stripped_line not in config.treat_comments_as_code
+ ):
+ import_section += line
+ elif stripped_line.startswith(IMPORT_START_IDENTIFIERS):
+ new_indent = line[: -len(line.lstrip())]
+ import_statement = line
+ stripped_line = line.strip().split("#")[0]
+ while stripped_line.endswith("\\") or (
+ "(" in stripped_line and ")" not in stripped_line
+ ):
+ if stripped_line.endswith("\\"):
+ while stripped_line and stripped_line.endswith("\\"):
+ line = input_stream.readline()
+ stripped_line = line.strip().split("#")[0]
+ import_statement += line
+ else:
+ while ")" not in stripped_line:
+ line = input_stream.readline()
+
+ if not line: # end of file without closing parenthesis
+ raise ExistingSyntaxErrors("Parenthesis is not closed")
+
+ stripped_line = line.strip().split("#")[0]
+ import_statement += line
+
+ if (
+ import_statement.lstrip().startswith("from")
+ and "import" not in import_statement
+ ):
+ line = import_statement
+ not_imports = True
+ else:
+ did_contain_imports = contains_imports
+ contains_imports = True
+
+ cimport_statement: bool = False
+ if (
+ import_statement.lstrip().startswith(CIMPORT_IDENTIFIERS)
+ or " cimport " in import_statement
+ or " cimport*" in import_statement
+ or " cimport(" in import_statement
+ or (
+ ".cimport" in import_statement
+ and "cython.cimports" not in import_statement
+ ) # Allow pure python imports. See #2062
+ ):
+ cimport_statement = True
+
+ if cimport_statement != cimports or (
+ new_indent != indent
+ and import_section
+ and (not did_contain_imports or len(new_indent) < len(indent))
+ ):
+ indent = new_indent
+ if import_section:
+ next_cimports = cimport_statement
+ next_import_section = import_statement
+ import_statement = ""
+ not_imports = True
+ line = ""
+ else:
+ cimports = cimport_statement
+ else:
+ if new_indent != indent:
+ if import_section and did_contain_imports:
+ import_statement = indent + import_statement.lstrip()
+ else:
+ indent = new_indent
+ import_section += import_statement
+ else:
+ not_imports = True
+
+ sort_section_pointer += len(line)
+
+ if not_imports:
+ if not was_in_quote and config.lines_before_imports > -1:
+ if line.strip() == "":
+ lines_before += line
+ continue
+ if not import_section:
+ output_stream.write("".join(lines_before))
+ lines_before = []
+
+ raw_import_section: str = import_section
+ if (
+ add_imports
+ and (stripped_line or end_of_file)
+ and not config.append_only
+ and not in_top_comment
+ and not was_in_quote
+ and not import_section
+ and not line.lstrip().startswith(COMMENT_INDICATORS)
+ and not (line.rstrip().endswith(DOCSTRING_INDICATORS) and "=" not in line)
+ ):
+ add_line_separator = line_separator or "\n"
+ import_section = add_line_separator.join(add_imports) + add_line_separator
+ if end_of_file and index != 0:
+ output_stream.write(add_line_separator)
+ contains_imports = True
+ add_imports = []
+
+ if next_import_section and not import_section: # pragma: no cover
+ raw_import_section = import_section = next_import_section
+ next_import_section = ""
+
+ if import_section:
+ if add_imports and (contains_imports or not config.append_only) and not indent:
+ import_section = (
+ line_separator.join(add_imports) + line_separator + import_section
+ )
+ contains_imports = True
+ add_imports = []
+
+ if not indent:
+ import_section += line
+ raw_import_section += line
+ if not contains_imports:
+ output_stream.write(import_section)
+
+ else:
+ leading_whitespace = import_section[: -len(import_section.lstrip())]
+ trailing_whitespace = import_section[len(import_section.rstrip()) :]
+ if first_import_section and not import_section.lstrip(
+ line_separator
+ ).startswith(COMMENT_INDICATORS):
+ import_section = import_section.lstrip(line_separator)
+ raw_import_section = raw_import_section.lstrip(line_separator)
+ first_import_section = False
+
+ if indent:
+ import_section = "".join(
+ line[len(indent) :] for line in import_section.splitlines(keepends=True)
+ )
+
+ parsed_content = parse.file_contents(import_section, config=config)
+ verbose_output += parsed_content.verbose_output
+
+ sorted_import_section = output.sorted_imports(
+ parsed_content,
+ _indented_config(config, indent),
+ extension,
+ import_type="cimport" if cimports else "import",
+ )
+ if not (import_section.strip() and not sorted_import_section):
+ if indent:
+ sorted_import_section = (
+ leading_whitespace
+ + textwrap.indent(sorted_import_section, indent).strip()
+ + trailing_whitespace
+ )
+
+ made_changes = made_changes or _has_changed(
+ before=raw_import_section,
+ after=sorted_import_section,
+ line_separator=line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+ output_stream.write(sorted_import_section)
+ if not line and not indent and next_import_section:
+ output_stream.write(line_separator)
+
+ if indent:
+ output_stream.write(line)
+ if not next_import_section:
+ indent = ""
+
+ if next_import_section:
+ cimports = next_cimports
+ contains_imports = True
+ else:
+ contains_imports = False
+ import_section = next_import_section
+ next_import_section = ""
+ else:
+ output_stream.write(line)
+ not_imports = False
+
+ if stripped_line and not in_quote and not import_section and not next_import_section:
+ if stripped_line == "yield":
+ while not stripped_line or stripped_line == "yield":
+ new_line = input_stream.readline()
+ if not new_line:
+ break
+
+ output_stream.write(new_line)
+ stripped_line = new_line.strip().split("#")[0]
+
+ if stripped_line.startswith("raise") or stripped_line.startswith("yield"):
+ while stripped_line.endswith("\\"):
+ new_line = input_stream.readline()
+ if not new_line:
+ break
+
+ output_stream.write(new_line)
+ stripped_line = new_line.strip().split("#")[0]
+
+ if made_changes and config.only_modified:
+ for output_str in verbose_output:
+ print(output_str)
+
+ return made_changes
+
+
+def _indented_config(config: Config, indent: str) -> Config:
+ if not indent:
+ return config
+
+ return Config(
+ config=config,
+ line_length=max(config.line_length - len(indent), 0),
+ wrap_length=max(config.wrap_length - len(indent), 0),
+ lines_after_imports=1,
+ import_headings=config.import_headings if config.indented_import_headings else {},
+ import_footers=config.import_footers if config.indented_import_headings else {},
+ )
+
+
+def _has_changed(before: str, after: str, line_separator: str, ignore_whitespace: bool) -> bool:
+ if ignore_whitespace:
+ return (
+ remove_whitespace(before, line_separator=line_separator).strip()
+ != remove_whitespace(after, line_separator=line_separator).strip()
+ )
+ return before.strip() != after.strip()
diff --git a/solutions/.venv/Lib/site-packages/isort/deprecated/__init__.py b/solutions/.venv/Lib/site-packages/isort/deprecated/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/isort/deprecated/finders.py b/solutions/.venv/Lib/site-packages/isort/deprecated/finders.py
new file mode 100644
index 000000000..eac650e25
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/deprecated/finders.py
@@ -0,0 +1,394 @@
+"""Finders try to find right section for passed module name"""
+import importlib.machinery
+import inspect
+import os
+import os.path
+import re
+import sys
+import sysconfig
+from abc import ABCMeta, abstractmethod
+from contextlib import contextmanager
+from fnmatch import fnmatch
+from functools import lru_cache
+from glob import glob
+from pathlib import Path
+from typing import Dict, Iterable, Iterator, List, Optional, Pattern, Sequence, Tuple, Type
+
+from isort import sections
+from isort.settings import KNOWN_SECTION_MAPPING, Config
+from isort.utils import exists_case_sensitive
+
+try:
+ from pipreqs import pipreqs # type: ignore
+
+except ImportError:
+ pipreqs = None
+
+try:
+ from pip_api import parse_requirements # type: ignore
+
+except ImportError:
+ parse_requirements = None
+
+
+@contextmanager
+def chdir(path: str) -> Iterator[None]:
+ """Context manager for changing dir and restoring previous workdir after exit."""
+ curdir = os.getcwd()
+ os.chdir(path)
+ try:
+ yield
+ finally:
+ os.chdir(curdir)
+
+
+class BaseFinder(metaclass=ABCMeta):
+ def __init__(self, config: Config) -> None:
+ self.config = config
+
+ @abstractmethod
+ def find(self, module_name: str) -> Optional[str]:
+ raise NotImplementedError
+
+
+class ForcedSeparateFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ for forced_separate in self.config.forced_separate:
+ # Ensure all forced_separate patterns will match to end of string
+ path_glob = forced_separate
+ if not forced_separate.endswith("*"):
+ path_glob = f"{forced_separate}*"
+
+ if fnmatch(module_name, path_glob) or fnmatch(module_name, "." + path_glob):
+ return forced_separate
+ return None
+
+
+class LocalFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ if module_name.startswith("."):
+ return "LOCALFOLDER"
+ return None
+
+
+class KnownPatternFinder(BaseFinder):
+ def __init__(self, config: Config) -> None:
+ super().__init__(config)
+
+ self.known_patterns: List[Tuple[Pattern[str], str]] = []
+ for placement in reversed(config.sections):
+ known_placement = KNOWN_SECTION_MAPPING.get(placement, placement).lower()
+ config_key = f"known_{known_placement}"
+ known_patterns = list(
+ getattr(self.config, config_key, self.config.known_other.get(known_placement, []))
+ )
+ known_patterns = [
+ pattern
+ for known_pattern in known_patterns
+ for pattern in self._parse_known_pattern(known_pattern)
+ ]
+ for known_pattern in known_patterns:
+ regexp = "^" + known_pattern.replace("*", ".*").replace("?", ".?") + "$"
+ self.known_patterns.append((re.compile(regexp), placement))
+
+ def _parse_known_pattern(self, pattern: str) -> List[str]:
+ """Expand pattern if identified as a directory and return found sub packages"""
+ if pattern.endswith(os.path.sep):
+ patterns = [
+ filename
+ for filename in os.listdir(os.path.join(self.config.directory, pattern))
+ if os.path.isdir(os.path.join(self.config.directory, pattern, filename))
+ ]
+ else:
+ patterns = [pattern]
+
+ return patterns
+
+ def find(self, module_name: str) -> Optional[str]:
+ # Try to find most specific placement instruction match (if any)
+ parts = module_name.split(".")
+ module_names_to_check = (".".join(parts[:first_k]) for first_k in range(len(parts), 0, -1))
+ for module_name_to_check in module_names_to_check:
+ for pattern, placement in self.known_patterns:
+ if pattern.match(module_name_to_check):
+ return placement
+ return None
+
+
+class PathFinder(BaseFinder):
+ def __init__(self, config: Config, path: str = ".") -> None:
+ super().__init__(config)
+
+ # restore the original import path (i.e. not the path to bin/isort)
+ root_dir = os.path.abspath(path)
+ src_dir = f"{root_dir}/src"
+ self.paths = [root_dir, src_dir]
+
+ # virtual env
+ self.virtual_env = self.config.virtual_env or os.environ.get("VIRTUAL_ENV")
+ if self.virtual_env:
+ self.virtual_env = os.path.realpath(self.virtual_env)
+ self.virtual_env_src = ""
+ if self.virtual_env:
+ self.virtual_env_src = f"{self.virtual_env}/src/"
+ for venv_path in glob(f"{self.virtual_env}/lib/python*/site-packages"):
+ if venv_path not in self.paths:
+ self.paths.append(venv_path)
+ for nested_venv_path in glob(f"{self.virtual_env}/lib/python*/*/site-packages"):
+ if nested_venv_path not in self.paths:
+ self.paths.append(nested_venv_path)
+ for venv_src_path in glob(f"{self.virtual_env}/src/*"):
+ if os.path.isdir(venv_src_path):
+ self.paths.append(venv_src_path)
+
+ # conda
+ self.conda_env = self.config.conda_env or os.environ.get("CONDA_PREFIX") or ""
+ if self.conda_env:
+ self.conda_env = os.path.realpath(self.conda_env)
+ for conda_path in glob(f"{self.conda_env}/lib/python*/site-packages"):
+ if conda_path not in self.paths:
+ self.paths.append(conda_path)
+ for nested_conda_path in glob(f"{self.conda_env}/lib/python*/*/site-packages"):
+ if nested_conda_path not in self.paths:
+ self.paths.append(nested_conda_path)
+
+ # handle case-insensitive paths on windows
+ self.stdlib_lib_prefix = os.path.normcase(sysconfig.get_paths()["stdlib"])
+ if self.stdlib_lib_prefix not in self.paths:
+ self.paths.append(self.stdlib_lib_prefix)
+
+ # add system paths
+ for system_path in sys.path[1:]:
+ if system_path not in self.paths:
+ self.paths.append(system_path)
+
+ def find(self, module_name: str) -> Optional[str]:
+ for prefix in self.paths:
+ package_path = "/".join((prefix, module_name.split(".")[0]))
+ path_obj = Path(package_path).resolve()
+ is_module = (
+ exists_case_sensitive(package_path + ".py")
+ or any(
+ exists_case_sensitive(package_path + ext_suffix)
+ for ext_suffix in importlib.machinery.EXTENSION_SUFFIXES
+ )
+ or exists_case_sensitive(package_path + "/__init__.py")
+ )
+ is_package = exists_case_sensitive(package_path) and os.path.isdir(package_path)
+ if is_module or is_package:
+ if (
+ "site-packages" in prefix
+ or "dist-packages" in prefix
+ or (self.virtual_env and self.virtual_env_src in prefix)
+ ):
+ return sections.THIRDPARTY
+ if os.path.normcase(prefix) == self.stdlib_lib_prefix:
+ return sections.STDLIB
+ if self.conda_env and self.conda_env in prefix:
+ return sections.THIRDPARTY
+ for src_path in self.config.src_paths:
+ if src_path in path_obj.parents and not self.config.is_skipped(path_obj):
+ return sections.FIRSTPARTY
+
+ if os.path.normcase(prefix).startswith(self.stdlib_lib_prefix):
+ return sections.STDLIB # pragma: no cover - edge case for one OS. Hard to test.
+
+ return self.config.default_section
+ return None
+
+
+class ReqsBaseFinder(BaseFinder):
+ enabled = False
+
+ def __init__(self, config: Config, path: str = ".") -> None:
+ super().__init__(config)
+ self.path = path
+ if self.enabled:
+ self.mapping = self._load_mapping()
+ self.names = self._load_names()
+
+ @abstractmethod
+ def _get_names(self, path: str) -> Iterator[str]:
+ raise NotImplementedError
+
+ @abstractmethod
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ raise NotImplementedError
+
+ @staticmethod
+ def _load_mapping() -> Optional[Dict[str, str]]:
+ """Return list of mappings `package_name -> module_name`
+
+ Example:
+ django-haystack -> haystack
+ """
+ if not pipreqs:
+ return None
+ path = os.path.dirname(inspect.getfile(pipreqs))
+ path = os.path.join(path, "mapping")
+ with open(path) as f:
+ mappings: Dict[str, str] = {} # pypi_name: import_name
+ for line in f:
+ import_name, _, pypi_name = line.strip().partition(":")
+ mappings[pypi_name] = import_name
+ return mappings
+ # return dict(tuple(line.strip().split(":")[::-1]) for line in f)
+
+ def _load_names(self) -> List[str]:
+ """Return list of thirdparty modules from requirements"""
+ names = []
+ for path in self._get_files():
+ for name in self._get_names(path):
+ names.append(self._normalize_name(name))
+ return names
+
+ @staticmethod
+ def _get_parents(path: str) -> Iterator[str]:
+ prev = ""
+ while path != prev:
+ prev = path
+ yield path
+ path = os.path.dirname(path)
+
+ def _get_files(self) -> Iterator[str]:
+ """Return paths to all requirements files"""
+ path = os.path.abspath(self.path)
+ if os.path.isfile(path):
+ path = os.path.dirname(path)
+
+ for path in self._get_parents(path): # noqa
+ yield from self._get_files_from_dir(path)
+
+ def _normalize_name(self, name: str) -> str:
+ """Convert package name to module name
+
+ Examples:
+ Django -> django
+ django-haystack -> django_haystack
+ Flask-RESTFul -> flask_restful
+ """
+ if self.mapping:
+ name = self.mapping.get(name.replace("-", "_"), name)
+ return name.lower().replace("-", "_")
+
+ def find(self, module_name: str) -> Optional[str]:
+ # required lib not installed yet
+ if not self.enabled:
+ return None
+
+ module_name, _sep, _submodules = module_name.partition(".")
+ module_name = module_name.lower()
+ if not module_name:
+ return None
+
+ for name in self.names:
+ if module_name == name:
+ return sections.THIRDPARTY
+ return None
+
+
+class RequirementsFinder(ReqsBaseFinder):
+ exts = (".txt", ".in")
+ enabled = bool(parse_requirements)
+
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ """Return paths to requirements files from passed dir."""
+ yield from self._get_files_from_dir_cached(path)
+
+ @classmethod
+ @lru_cache(maxsize=16)
+ def _get_files_from_dir_cached(cls, path: str) -> List[str]:
+ results = []
+
+ for fname in os.listdir(path):
+ if "requirements" not in fname:
+ continue
+ full_path = os.path.join(path, fname)
+
+ # *requirements*/*.{txt,in}
+ if os.path.isdir(full_path):
+ for subfile_name in os.listdir(full_path):
+ for ext in cls.exts:
+ if subfile_name.endswith(ext):
+ results.append(os.path.join(full_path, subfile_name))
+ continue
+
+ # *requirements*.{txt,in}
+ if os.path.isfile(full_path):
+ for ext in cls.exts:
+ if fname.endswith(ext):
+ results.append(full_path)
+ break
+
+ return results
+
+ def _get_names(self, path: str) -> Iterator[str]:
+ """Load required packages from path to requirements file"""
+ yield from self._get_names_cached(path)
+
+ @classmethod
+ @lru_cache(maxsize=16)
+ def _get_names_cached(cls, path: str) -> List[str]:
+ result = []
+
+ with chdir(os.path.dirname(path)):
+ requirements = parse_requirements(Path(path))
+ for req in requirements.values():
+ if req.name:
+ result.append(req.name)
+
+ return result
+
+
+class DefaultFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ return self.config.default_section
+
+
+class FindersManager:
+ _default_finders_classes: Sequence[Type[BaseFinder]] = (
+ ForcedSeparateFinder,
+ LocalFinder,
+ KnownPatternFinder,
+ PathFinder,
+ RequirementsFinder,
+ DefaultFinder,
+ )
+
+ def __init__(
+ self, config: Config, finder_classes: Optional[Iterable[Type[BaseFinder]]] = None
+ ) -> None:
+ self.verbose: bool = config.verbose
+
+ if finder_classes is None:
+ finder_classes = self._default_finders_classes
+ finders: List[BaseFinder] = []
+ for finder_cls in finder_classes:
+ try:
+ finders.append(finder_cls(config))
+ except Exception as exception:
+ # if one finder fails to instantiate isort can continue using the rest
+ if self.verbose:
+ print(
+ (
+ f"{finder_cls.__name__} encountered an error ({exception}) during "
+ "instantiation and cannot be used"
+ )
+ )
+ self.finders: Tuple[BaseFinder, ...] = tuple(finders)
+
+ def find(self, module_name: str) -> Optional[str]:
+ for finder in self.finders:
+ try:
+ section = finder.find(module_name)
+ if section is not None:
+ return section
+ except Exception as exception:
+ # isort has to be able to keep trying to identify the correct
+ # import section even if one approach fails
+ if self.verbose:
+ print(
+ f"{finder.__class__.__name__} encountered an error ({exception}) while "
+ f"trying to identify the {module_name} module"
+ )
+ return None
diff --git a/solutions/.venv/Lib/site-packages/isort/exceptions.py b/solutions/.venv/Lib/site-packages/isort/exceptions.py
new file mode 100644
index 000000000..6be82406a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/exceptions.py
@@ -0,0 +1,197 @@
+"""All isort specific exception classes should be defined here"""
+from functools import partial
+from pathlib import Path
+from typing import Any, Dict, List, Type, Union
+
+from .profiles import profiles
+
+
+class ISortError(Exception):
+ """Base isort exception object from which all isort sourced exceptions should inherit"""
+
+ def __reduce__(self): # type: ignore
+ return (partial(type(self), **self.__dict__), ())
+
+
+class InvalidSettingsPath(ISortError):
+ """Raised when a settings path is provided that is neither a valid file or directory"""
+
+ def __init__(self, settings_path: str):
+ super().__init__(
+ f"isort was told to use the settings_path: {settings_path} as the base directory or "
+ "file that represents the starting point of config file discovery, but it does not "
+ "exist."
+ )
+ self.settings_path = settings_path
+
+
+class ExistingSyntaxErrors(ISortError):
+ """Raised when isort is told to sort imports within code that has existing syntax errors"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"isort was told to sort imports within code that contains syntax errors: "
+ f"{file_path}."
+ )
+ self.file_path = file_path
+
+
+class IntroducedSyntaxErrors(ISortError):
+ """Raised when isort has introduced a syntax error in the process of sorting imports"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"isort introduced syntax errors when attempting to sort the imports contained within "
+ f"{file_path}."
+ )
+ self.file_path = file_path
+
+
+class FileSkipped(ISortError):
+ """Should be raised when a file is skipped for any reason"""
+
+ def __init__(self, message: str, file_path: str):
+ super().__init__(message)
+ self.message = message
+ self.file_path = file_path
+
+
+class FileSkipComment(FileSkipped):
+ """Raised when an entire file is skipped due to a isort skip file comment"""
+
+ def __init__(self, file_path: str, **kwargs: str):
+ super().__init__(
+ f"{file_path} contains a file skip comment and was skipped.", file_path=file_path
+ )
+
+
+class FileSkipSetting(FileSkipped):
+ """Raised when an entire file is skipped due to provided isort settings"""
+
+ def __init__(self, file_path: str, **kwargs: str):
+ super().__init__(
+ f"{file_path} was skipped as it's listed in 'skip' setting"
+ " or matches a glob in 'skip_glob' setting",
+ file_path=file_path,
+ )
+
+
+class ProfileDoesNotExist(ISortError):
+ """Raised when a profile is set by the user that doesn't exist"""
+
+ def __init__(self, profile: str):
+ super().__init__(
+ f"Specified profile of {profile} does not exist. "
+ f"Available profiles: {','.join(profiles)}."
+ )
+ self.profile = profile
+
+
+class SortingFunctionDoesNotExist(ISortError):
+ """Raised when the specified sorting function isn't available"""
+
+ def __init__(self, sort_order: str, available_sort_orders: List[str]):
+ super().__init__(
+ f"Specified sort_order of {sort_order} does not exist. "
+ f"Available sort_orders: {','.join(available_sort_orders)}."
+ )
+ self.sort_order = sort_order
+ self.available_sort_orders = available_sort_orders
+
+
+class FormattingPluginDoesNotExist(ISortError):
+ """Raised when a formatting plugin is set by the user that doesn't exist"""
+
+ def __init__(self, formatter: str):
+ super().__init__(f"Specified formatting plugin of {formatter} does not exist. ")
+ self.formatter = formatter
+
+
+class LiteralParsingFailure(ISortError):
+ """Raised when one of isorts literal sorting comments is used but isort can't parse the
+ the given data structure.
+ """
+
+ def __init__(self, code: str, original_error: Union[Exception, Type[Exception]]):
+ super().__init__(
+ f"isort failed to parse the given literal {code}. It's important to note "
+ "that isort literal sorting only supports simple literals parsable by "
+ f"ast.literal_eval which gave the exception of {original_error}."
+ )
+ self.code = code
+ self.original_error = original_error
+
+
+class LiteralSortTypeMismatch(ISortError):
+ """Raised when an isort literal sorting comment is used, with a type that doesn't match the
+ supplied data structure's type.
+ """
+
+ def __init__(self, kind: type, expected_kind: type):
+ super().__init__(
+ f"isort was told to sort a literal of type {expected_kind} but was given "
+ f"a literal of type {kind}."
+ )
+ self.kind = kind
+ self.expected_kind = expected_kind
+
+
+class AssignmentsFormatMismatch(ISortError):
+ """Raised when isort is told to sort assignments but the format of the assignment section
+ doesn't match isort's expectation.
+ """
+
+ def __init__(self, code: str):
+ super().__init__(
+ "isort was told to sort a section of assignments, however the given code:\n\n"
+ f"{code}\n\n"
+ "Does not match isort's strict single line formatting requirement for assignment "
+ "sorting:\n\n"
+ "{variable_name} = {value}\n"
+ "{variable_name2} = {value2}\n"
+ "...\n\n"
+ )
+ self.code = code
+
+
+class UnsupportedSettings(ISortError):
+ """Raised when settings are passed into isort (either from config, CLI, or runtime)
+ that it doesn't support.
+ """
+
+ @staticmethod
+ def _format_option(name: str, value: Any, source: str) -> str:
+ return f"\t- {name} = {value} (source: '{source}')"
+
+ def __init__(self, unsupported_settings: Dict[str, Dict[str, str]]):
+ errors = "\n".join(
+ self._format_option(name, **option) for name, option in unsupported_settings.items()
+ )
+
+ super().__init__(
+ "isort was provided settings that it doesn't support:\n\n"
+ f"{errors}\n\n"
+ "For a complete and up-to-date listing of supported settings see: "
+ "https://pycqa.github.io/isort/docs/configuration/options.\n"
+ )
+ self.unsupported_settings = unsupported_settings
+
+
+class UnsupportedEncoding(ISortError):
+ """Raised when isort encounters an encoding error while trying to read a file"""
+
+ def __init__(self, filename: Union[str, Path]):
+ super().__init__(f"Unknown or unsupported encoding in {filename}")
+ self.filename = filename
+
+
+class MissingSection(ISortError):
+ """Raised when isort encounters an import that matches a section that is not defined"""
+
+ def __init__(self, import_module: str, section: str):
+ super().__init__(
+ f"Found {import_module} import while parsing, but {section} was not included "
+ "in the `sections` setting of your config. Please add it before continuing\n"
+ "See https://pycqa.github.io/isort/#custom-sections-and-ordering "
+ "for more info."
+ )
diff --git a/solutions/.venv/Lib/site-packages/isort/files.py b/solutions/.venv/Lib/site-packages/isort/files.py
new file mode 100644
index 000000000..28a916cbb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/files.py
@@ -0,0 +1,41 @@
+import os
+from pathlib import Path
+from typing import Iterable, Iterator, List, Set
+
+from isort.settings import Config
+
+
+def find(
+ paths: Iterable[str], config: Config, skipped: List[str], broken: List[str]
+) -> Iterator[str]:
+ """Fines and provides an iterator for all Python source files defined in paths."""
+ visited_dirs: Set[Path] = set()
+
+ for path in paths:
+ if os.path.isdir(path):
+ for dirpath, dirnames, filenames in os.walk(
+ path, topdown=True, followlinks=config.follow_links
+ ):
+ base_path = Path(dirpath)
+ for dirname in list(dirnames):
+ full_path = base_path / dirname
+ resolved_path = full_path.resolve()
+ if config.is_skipped(full_path):
+ skipped.append(dirname)
+ dirnames.remove(dirname)
+ else:
+ if resolved_path in visited_dirs: # pragma: no cover
+ dirnames.remove(dirname)
+ visited_dirs.add(resolved_path)
+
+ for filename in filenames:
+ filepath = os.path.join(dirpath, filename)
+ if config.is_supported_filetype(filepath):
+ if config.is_skipped(Path(os.path.abspath(filepath))):
+ skipped.append(filename)
+ else:
+ yield filepath
+ elif not os.path.exists(path):
+ broken.append(path)
+ else:
+ yield path
diff --git a/solutions/.venv/Lib/site-packages/isort/format.py b/solutions/.venv/Lib/site-packages/isort/format.py
new file mode 100644
index 000000000..71ae8ced0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/format.py
@@ -0,0 +1,157 @@
+import re
+import sys
+from datetime import datetime
+from difflib import unified_diff
+from pathlib import Path
+from typing import Optional, TextIO
+
+try:
+ import colorama
+except ImportError:
+ colorama_unavailable = True
+else:
+ colorama_unavailable = False
+
+
+ADDED_LINE_PATTERN = re.compile(r"\+[^+]")
+REMOVED_LINE_PATTERN = re.compile(r"-[^-]")
+
+
+def format_simplified(import_line: str) -> str:
+ import_line = import_line.strip()
+ if import_line.startswith("from "):
+ import_line = import_line.replace("from ", "")
+ import_line = import_line.replace(" import ", ".")
+ elif import_line.startswith("import "):
+ import_line = import_line.replace("import ", "")
+
+ return import_line
+
+
+def format_natural(import_line: str) -> str:
+ import_line = import_line.strip()
+ if not import_line.startswith("from ") and not import_line.startswith("import "):
+ if "." not in import_line:
+ return f"import {import_line}"
+ parts = import_line.split(".")
+ end = parts.pop(-1)
+ return f"from {'.'.join(parts)} import {end}"
+
+ return import_line
+
+
+def show_unified_diff(
+ *,
+ file_input: str,
+ file_output: str,
+ file_path: Optional[Path],
+ output: Optional[TextIO] = None,
+ color_output: bool = False,
+) -> None:
+ """Shows a unified_diff for the provided input and output against the provided file path.
+
+ - **file_input**: A string that represents the contents of a file before changes.
+ - **file_output**: A string that represents the contents of a file after changes.
+ - **file_path**: A Path object that represents the file path of the file being changed.
+ - **output**: A stream to output the diff to. If non is provided uses sys.stdout.
+ - **color_output**: Use color in output if True.
+ """
+ printer = create_terminal_printer(color_output, output)
+ file_name = "" if file_path is None else str(file_path)
+ file_mtime = str(
+ datetime.now() if file_path is None else datetime.fromtimestamp(file_path.stat().st_mtime)
+ )
+ unified_diff_lines = unified_diff(
+ file_input.splitlines(keepends=True),
+ file_output.splitlines(keepends=True),
+ fromfile=file_name + ":before",
+ tofile=file_name + ":after",
+ fromfiledate=file_mtime,
+ tofiledate=str(datetime.now()),
+ )
+ for line in unified_diff_lines:
+ printer.diff_line(line)
+
+
+def ask_whether_to_apply_changes_to_file(file_path: str) -> bool:
+ answer = None
+ while answer not in ("yes", "y", "no", "n", "quit", "q"):
+ answer = input(f"Apply suggested changes to '{file_path}' [y/n/q]? ") # nosec
+ answer = answer.lower()
+ if answer in ("no", "n"):
+ return False
+ if answer in ("quit", "q"):
+ sys.exit(1)
+ return True
+
+
+def remove_whitespace(content: str, line_separator: str = "\n") -> str:
+ content = content.replace(line_separator, "").replace(" ", "").replace("\x0c", "")
+ return content
+
+
+class BasicPrinter:
+ ERROR = "ERROR"
+ SUCCESS = "SUCCESS"
+
+ def __init__(self, error: str, success: str, output: Optional[TextIO] = None):
+ self.output = output or sys.stdout
+ self.success_message = success
+ self.error_message = error
+
+ def success(self, message: str) -> None:
+ print(self.success_message.format(success=self.SUCCESS, message=message), file=self.output)
+
+ def error(self, message: str) -> None:
+ print(self.error_message.format(error=self.ERROR, message=message), file=sys.stderr)
+
+ def diff_line(self, line: str) -> None:
+ self.output.write(line)
+
+
+class ColoramaPrinter(BasicPrinter):
+ def __init__(self, error: str, success: str, output: Optional[TextIO]):
+ super().__init__(error, success, output=output)
+
+ # Note: this constants are instance variables instead ofs class variables
+ # because they refer to colorama which might not be installed.
+ self.ERROR = self.style_text("ERROR", colorama.Fore.RED)
+ self.SUCCESS = self.style_text("SUCCESS", colorama.Fore.GREEN)
+ self.ADDED_LINE = colorama.Fore.GREEN
+ self.REMOVED_LINE = colorama.Fore.RED
+
+ @staticmethod
+ def style_text(text: str, style: Optional[str] = None) -> str:
+ if style is None:
+ return text
+ return style + text + str(colorama.Style.RESET_ALL)
+
+ def diff_line(self, line: str) -> None:
+ style = None
+ if re.match(ADDED_LINE_PATTERN, line):
+ style = self.ADDED_LINE
+ elif re.match(REMOVED_LINE_PATTERN, line):
+ style = self.REMOVED_LINE
+ self.output.write(self.style_text(line, style))
+
+
+def create_terminal_printer(
+ color: bool, output: Optional[TextIO] = None, error: str = "", success: str = ""
+) -> BasicPrinter:
+ if color and colorama_unavailable:
+ no_colorama_message = (
+ "\n"
+ "Sorry, but to use --color (color_output) the colorama python package is required.\n\n"
+ "Reference: https://pypi.org/project/colorama/\n\n"
+ "You can either install it separately on your system or as the colors extra "
+ "for isort. Ex: \n\n"
+ "$ pip install isort[colors]\n"
+ )
+ print(no_colorama_message, file=sys.stderr)
+ sys.exit(1)
+
+ if not colorama_unavailable:
+ colorama.init(strip=False)
+ return (
+ ColoramaPrinter(error, success, output) if color else BasicPrinter(error, success, output)
+ )
diff --git a/solutions/.venv/Lib/site-packages/isort/hooks.py b/solutions/.venv/Lib/site-packages/isort/hooks.py
new file mode 100644
index 000000000..bb566108a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/hooks.py
@@ -0,0 +1,93 @@
+"""Defines a git hook to allow pre-commit warnings and errors about import order.
+
+usage:
+ exit_code = git_hook(strict=True|False, modify=True|False)
+"""
+import os
+import subprocess # nosec - Needed for hook
+from pathlib import Path
+from typing import List, Optional
+
+from isort import Config, api, exceptions
+
+
+def get_output(command: List[str]) -> str:
+ """Run a command and return raw output
+
+ :param str command: the command to run
+ :returns: the stdout output of the command
+ """
+ result = subprocess.run(command, stdout=subprocess.PIPE, check=True) # nosec - trusted input
+ return result.stdout.decode()
+
+
+def get_lines(command: List[str]) -> List[str]:
+ """Run a command and return lines of output
+
+ :param str command: the command to run
+ :returns: list of whitespace-stripped lines output by command
+ """
+ stdout = get_output(command)
+ return [line.strip() for line in stdout.splitlines()]
+
+
+def git_hook(
+ strict: bool = False,
+ modify: bool = False,
+ lazy: bool = False,
+ settings_file: str = "",
+ directories: Optional[List[str]] = None,
+) -> int:
+ """Git pre-commit hook to check staged files for isort errors
+
+ :param bool strict - if True, return number of errors on exit,
+ causing the hook to fail. If False, return zero so it will
+ just act as a warning.
+ :param bool modify - if True, fix the sources if they are not
+ sorted properly. If False, only report result without
+ modifying anything.
+ :param bool lazy - if True, also check/fix unstaged files.
+ This is useful if you frequently use ``git commit -a`` for example.
+ If False, only check/fix the staged files for isort errors.
+ :param str settings_file - A path to a file to be used as
+ the configuration file for this run.
+ When settings_file is the empty string, the configuration file
+ will be searched starting at the directory containing the first
+ staged file, if any, and going upward in the directory structure.
+ :param list[str] directories - A list of directories to restrict the hook to.
+
+ :return number of errors if in strict mode, 0 otherwise.
+ """
+ # Get list of files modified and staged
+ diff_cmd = ["git", "diff-index", "--cached", "--name-only", "--diff-filter=ACMRTUXB", "HEAD"]
+ if lazy:
+ diff_cmd.remove("--cached")
+ if directories:
+ diff_cmd.extend(directories)
+
+ files_modified = get_lines(diff_cmd)
+ if not files_modified:
+ return 0
+
+ errors = 0
+ config = Config(
+ settings_file=settings_file,
+ settings_path=os.path.dirname(os.path.abspath(files_modified[0])),
+ )
+ for filename in files_modified:
+ if filename.endswith(".py"):
+ # Get the staged contents of the file
+ staged_cmd = ["git", "show", f":{filename}"]
+ staged_contents = get_output(staged_cmd)
+
+ try:
+ if not api.check_code_string(
+ staged_contents, file_path=Path(filename), config=config
+ ):
+ errors += 1
+ if modify:
+ api.sort_file(filename, config=config)
+ except exceptions.FileSkipped: # pragma: no cover
+ pass
+
+ return errors if strict else 0
diff --git a/solutions/.venv/Lib/site-packages/isort/identify.py b/solutions/.venv/Lib/site-packages/isort/identify.py
new file mode 100644
index 000000000..8223e256d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/identify.py
@@ -0,0 +1,206 @@
+"""Fast stream based import identification.
+Eventually this will likely replace parse.py
+"""
+from functools import partial
+from pathlib import Path
+from typing import Iterator, NamedTuple, Optional, TextIO, Tuple
+
+from isort.parse import normalize_line, skip_line, strip_syntax
+
+from .comments import parse as parse_comments
+from .settings import DEFAULT_CONFIG, Config
+
+STATEMENT_DECLARATIONS: Tuple[str, ...] = ("def ", "cdef ", "cpdef ", "class ", "@", "async def")
+
+
+class Import(NamedTuple):
+ line_number: int
+ indented: bool
+ module: str
+ attribute: Optional[str] = None
+ alias: Optional[str] = None
+ cimport: bool = False
+ file_path: Optional[Path] = None
+
+ def statement(self) -> str:
+ import_cmd = "cimport" if self.cimport else "import"
+ if self.attribute:
+ import_string = f"from {self.module} {import_cmd} {self.attribute}"
+ else:
+ import_string = f"{import_cmd} {self.module}"
+ if self.alias:
+ import_string += f" as {self.alias}"
+ return import_string
+
+ def __str__(self) -> str:
+ return (
+ f"{self.file_path or ''}:{self.line_number} "
+ f"{'indented ' if self.indented else ''}{self.statement()}"
+ )
+
+
+def imports(
+ input_stream: TextIO,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ top_only: bool = False,
+) -> Iterator[Import]:
+ """Parses a python file taking out and categorizing imports."""
+ in_quote = ""
+
+ indexed_input = enumerate(input_stream)
+ for index, raw_line in indexed_input:
+ (skipping_line, in_quote) = skip_line(
+ raw_line, in_quote=in_quote, index=index, section_comments=config.section_comments
+ )
+
+ if top_only and not in_quote and raw_line.startswith(STATEMENT_DECLARATIONS):
+ break
+ if skipping_line:
+ continue
+
+ stripped_line = raw_line.strip().split("#")[0]
+ if stripped_line.startswith("raise") or stripped_line.startswith("yield"):
+ if stripped_line == "yield":
+ while not stripped_line or stripped_line == "yield":
+ try:
+ index, next_line = next(indexed_input)
+ except StopIteration:
+ break
+
+ stripped_line = next_line.strip().split("#")[0]
+ while stripped_line.endswith("\\"):
+ try:
+ index, next_line = next(indexed_input)
+ except StopIteration:
+ break
+
+ stripped_line = next_line.strip().split("#")[0]
+ continue # pragma: no cover
+
+ line, *end_of_line_comment = raw_line.split("#", 1)
+ statements = [line.strip() for line in line.split(";")]
+ if end_of_line_comment:
+ statements[-1] = f"{statements[-1]}#{end_of_line_comment[0]}"
+
+ for statement in statements:
+ line, _raw_line = normalize_line(statement)
+ if line.startswith(("import ", "cimport ")):
+ type_of_import = "straight"
+ elif line.startswith("from "):
+ type_of_import = "from"
+ else:
+ continue # pragma: no cover
+
+ import_string, _ = parse_comments(line)
+ normalized_import_string = (
+ import_string.replace("import(", "import (").replace("\\", " ").replace("\n", " ")
+ )
+ cimports: bool = (
+ " cimport " in normalized_import_string
+ or normalized_import_string.startswith("cimport")
+ )
+ identified_import = partial(
+ Import,
+ index + 1, # line numbers use 1 based indexing
+ raw_line.startswith((" ", "\t")),
+ cimport=cimports,
+ file_path=file_path,
+ )
+
+ if "(" in line.split("#", 1)[0]:
+ while not line.split("#")[0].strip().endswith(")"):
+ try:
+ index, next_line = next(indexed_input)
+ except StopIteration:
+ break
+
+ line, _ = parse_comments(next_line)
+ import_string += "\n" + line
+ else:
+ while line.strip().endswith("\\"):
+ try:
+ index, next_line = next(indexed_input)
+ except StopIteration:
+ break
+
+ line, _ = parse_comments(next_line)
+
+ # Still need to check for parentheses after an escaped line
+ if "(" in line.split("#")[0] and ")" not in line.split("#")[0]:
+ import_string += "\n" + line
+
+ while not line.split("#")[0].strip().endswith(")"):
+ try:
+ index, next_line = next(indexed_input)
+ except StopIteration:
+ break
+ line, _ = parse_comments(next_line)
+ import_string += "\n" + line
+ else:
+ if import_string.strip().endswith(
+ (" import", " cimport")
+ ) or line.strip().startswith(("import ", "cimport ")):
+ import_string += "\n" + line
+ else:
+ import_string = (
+ import_string.rstrip().rstrip("\\") + " " + line.lstrip()
+ )
+
+ if type_of_import == "from":
+ import_string = (
+ import_string.replace("import(", "import (")
+ .replace("\\", " ")
+ .replace("\n", " ")
+ )
+ parts = import_string.split(" cimport " if cimports else " import ")
+
+ from_import = parts[0].split(" ")
+ import_string = (" cimport " if cimports else " import ").join(
+ [from_import[0] + " " + "".join(from_import[1:])] + parts[1:]
+ )
+
+ just_imports = [
+ item.replace("{|", "{ ").replace("|}", " }")
+ for item in strip_syntax(import_string).split()
+ ]
+
+ direct_imports = just_imports[1:]
+ top_level_module = ""
+ if "as" in just_imports and (just_imports.index("as") + 1) < len(just_imports):
+ while "as" in just_imports:
+ attribute = None
+ as_index = just_imports.index("as")
+ if type_of_import == "from":
+ attribute = just_imports[as_index - 1]
+ top_level_module = just_imports[0]
+ module = top_level_module + "." + attribute
+ alias = just_imports[as_index + 1]
+ direct_imports.remove(attribute)
+ direct_imports.remove(alias)
+ direct_imports.remove("as")
+ just_imports[1:] = direct_imports
+ if attribute == alias and config.remove_redundant_aliases:
+ yield identified_import(top_level_module, attribute)
+ else:
+ yield identified_import(top_level_module, attribute, alias=alias)
+
+ else:
+ module = just_imports[as_index - 1]
+ alias = just_imports[as_index + 1]
+ just_imports.remove(alias)
+ just_imports.remove("as")
+ just_imports.remove(module)
+ if module == alias and config.remove_redundant_aliases:
+ yield identified_import(module)
+ else:
+ yield identified_import(module, alias=alias)
+
+ if just_imports:
+ if type_of_import == "from":
+ module = just_imports.pop(0)
+ for attribute in just_imports:
+ yield identified_import(module, attribute)
+ else:
+ for module in just_imports:
+ yield identified_import(module)
diff --git a/solutions/.venv/Lib/site-packages/isort/io.py b/solutions/.venv/Lib/site-packages/isort/io.py
new file mode 100644
index 000000000..946989171
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/io.py
@@ -0,0 +1,71 @@
+"""Defines any IO utilities used by isort"""
+import dataclasses
+import re
+import tokenize
+from contextlib import contextmanager
+from io import BytesIO, StringIO, TextIOWrapper
+from pathlib import Path
+from typing import Any, Callable, Iterator, TextIO, Union
+
+from isort.exceptions import UnsupportedEncoding
+
+_ENCODING_PATTERN = re.compile(rb"^[ \t\f]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)")
+
+
+@dataclasses.dataclass(frozen=True)
+class File:
+ stream: TextIO
+ path: Path
+ encoding: str
+
+ @staticmethod
+ def detect_encoding(filename: Union[str, Path], readline: Callable[[], bytes]) -> str:
+ try:
+ return tokenize.detect_encoding(readline)[0]
+ except Exception:
+ raise UnsupportedEncoding(filename)
+
+ @staticmethod
+ def from_contents(contents: str, filename: str) -> "File":
+ encoding = File.detect_encoding(filename, BytesIO(contents.encode("utf-8")).readline)
+ return File(stream=StringIO(contents), path=Path(filename).resolve(), encoding=encoding)
+
+ @property
+ def extension(self) -> str:
+ return self.path.suffix.lstrip(".")
+
+ @staticmethod
+ def _open(filename: Union[str, Path]) -> TextIOWrapper:
+ """Open a file in read only mode using the encoding detected by
+ detect_encoding().
+ """
+ buffer = open(filename, "rb")
+ try:
+ encoding = File.detect_encoding(filename, buffer.readline)
+ buffer.seek(0)
+ text = TextIOWrapper(buffer, encoding, line_buffering=True, newline="")
+ text.mode = "r" # type: ignore
+ return text
+ except Exception:
+ buffer.close()
+ raise
+
+ @staticmethod
+ @contextmanager
+ def read(filename: Union[str, Path]) -> Iterator["File"]:
+ file_path = Path(filename).resolve()
+ stream = None
+ try:
+ stream = File._open(file_path)
+ yield File(stream=stream, path=file_path, encoding=stream.encoding)
+ finally:
+ if stream is not None:
+ stream.close()
+
+
+class _EmptyIO(StringIO):
+ def write(self, *args: Any, **kwargs: Any) -> None: # type: ignore # skipcq: PTC-W0049
+ pass
+
+
+Empty = _EmptyIO()
diff --git a/solutions/.venv/Lib/site-packages/isort/literal.py b/solutions/.venv/Lib/site-packages/isort/literal.py
new file mode 100644
index 000000000..d21006993
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/literal.py
@@ -0,0 +1,114 @@
+import ast
+from pprint import PrettyPrinter
+from typing import Any, Callable, Dict, List, Set, Tuple
+
+from isort.exceptions import (
+ AssignmentsFormatMismatch,
+ LiteralParsingFailure,
+ LiteralSortTypeMismatch,
+)
+from isort.settings import DEFAULT_CONFIG, Config
+
+
+class ISortPrettyPrinter(PrettyPrinter):
+ """an isort customized pretty printer for sorted literals"""
+
+ def __init__(self, config: Config):
+ super().__init__(width=config.line_length, compact=True)
+
+
+type_mapping: Dict[str, Tuple[type, Callable[[Any, ISortPrettyPrinter], str]]] = {}
+
+
+def assignments(code: str) -> str:
+ values = {}
+ for line in code.splitlines(keepends=True):
+ if not line.strip():
+ continue
+ if " = " not in line:
+ raise AssignmentsFormatMismatch(code)
+ variable_name, value = line.split(" = ", 1)
+ values[variable_name] = value
+
+ return "".join(
+ f"{variable_name} = {values[variable_name]}" for variable_name in sorted(values.keys())
+ )
+
+
+def assignment(code: str, sort_type: str, extension: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Sorts the literal present within the provided code against the provided sort type,
+ returning the sorted representation of the source code.
+ """
+ if sort_type == "assignments":
+ return assignments(code)
+ if sort_type not in type_mapping:
+ raise ValueError(
+ "Trying to sort using an undefined sort_type. "
+ f"Defined sort types are {', '.join(type_mapping.keys())}."
+ )
+
+ variable_name, literal = code.split("=")
+ variable_name = variable_name.strip()
+ literal = literal.lstrip()
+ try:
+ value = ast.literal_eval(literal)
+ except Exception as error:
+ raise LiteralParsingFailure(code, error)
+
+ expected_type, sort_function = type_mapping[sort_type]
+ if type(value) != expected_type:
+ raise LiteralSortTypeMismatch(type(value), expected_type)
+
+ printer = ISortPrettyPrinter(config)
+ sorted_value_code = f"{variable_name} = {sort_function(value, printer)}"
+ if config.formatting_function:
+ sorted_value_code = config.formatting_function(
+ sorted_value_code, extension, config
+ ).rstrip()
+
+ sorted_value_code += code[len(code.rstrip()) :]
+ return sorted_value_code
+
+
+def register_type(
+ name: str, kind: type
+) -> Callable[[Callable[[Any, ISortPrettyPrinter], str]], Callable[[Any, ISortPrettyPrinter], str]]:
+ """Registers a new literal sort type."""
+
+ def wrap(
+ function: Callable[[Any, ISortPrettyPrinter], str]
+ ) -> Callable[[Any, ISortPrettyPrinter], str]:
+ type_mapping[name] = (kind, function)
+ return function
+
+ return wrap
+
+
+@register_type("dict", dict)
+def _dict(value: Dict[Any, Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(dict(sorted(value.items(), key=lambda item: item[1]))) # type: ignore
+
+
+@register_type("list", list)
+def _list(value: List[Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(sorted(value))
+
+
+@register_type("unique-list", list)
+def _unique_list(value: List[Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(list(sorted(set(value))))
+
+
+@register_type("set", set)
+def _set(value: Set[Any], printer: ISortPrettyPrinter) -> str:
+ return "{" + printer.pformat(tuple(sorted(value)))[1:-1] + "}"
+
+
+@register_type("tuple", tuple)
+def _tuple(value: Tuple[Any, ...], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(tuple(sorted(value)))
+
+
+@register_type("unique-tuple", tuple)
+def _unique_tuple(value: Tuple[Any, ...], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(tuple(sorted(set(value))))
diff --git a/solutions/.venv/Lib/site-packages/isort/logo.py b/solutions/.venv/Lib/site-packages/isort/logo.py
new file mode 100644
index 000000000..6377d8686
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/logo.py
@@ -0,0 +1,19 @@
+from ._version import __version__
+
+ASCII_ART = rf"""
+ _ _
+ (_) ___ ___ _ __| |_
+ | |/ _/ / _ \/ '__ _/
+ | |\__ \/\_\/| | | |_
+ |_|\___/\___/\_/ \_/
+
+ isort your imports, so you don't have to.
+
+ VERSION {__version__}
+"""
+
+__doc__ = f"""
+```python
+{ASCII_ART}
+```
+"""
diff --git a/solutions/.venv/Lib/site-packages/isort/main.py b/solutions/.venv/Lib/site-packages/isort/main.py
new file mode 100644
index 000000000..7dd85e05c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/main.py
@@ -0,0 +1,1300 @@
+"""Tool for sorting imports alphabetically, and automatically separated into sections."""
+import argparse
+import functools
+import json
+import os
+import sys
+from gettext import gettext as _
+from io import TextIOWrapper
+from pathlib import Path
+from typing import Any, Dict, List, Optional, Sequence, Union
+from warnings import warn
+
+from . import __version__, api, files, sections
+from .exceptions import FileSkipped, ISortError, UnsupportedEncoding
+from .format import create_terminal_printer
+from .logo import ASCII_ART
+from .profiles import profiles
+from .settings import VALID_PY_TARGETS, Config, find_all_configs
+from .utils import Trie
+from .wrap_modes import WrapModes
+
+DEPRECATED_SINGLE_DASH_ARGS = {
+ "-ac",
+ "-af",
+ "-ca",
+ "-cs",
+ "-df",
+ "-ds",
+ "-dt",
+ "-fas",
+ "-fass",
+ "-ff",
+ "-fgw",
+ "-fss",
+ "-lai",
+ "-lbt",
+ "-le",
+ "-ls",
+ "-nis",
+ "-nlb",
+ "-ot",
+ "-rr",
+ "-sd",
+ "-sg",
+ "-sl",
+ "-sp",
+ "-tc",
+ "-wl",
+ "-ws",
+}
+QUICK_GUIDE = f"""
+{ASCII_ART}
+
+Nothing to do: no files or paths have have been passed in!
+
+Try one of the following:
+
+ `isort .` - sort all Python files, starting from the current directory, recursively.
+ `isort . --interactive` - Do the same, but ask before making any changes.
+ `isort . --check --diff` - Check to see if imports are correctly sorted within this project.
+ `isort --help` - In-depth information about isort's available command-line options.
+
+Visit https://pycqa.github.io/isort/ for complete information about how to use isort.
+"""
+
+
+class SortAttempt:
+ def __init__(self, incorrectly_sorted: bool, skipped: bool, supported_encoding: bool) -> None:
+ self.incorrectly_sorted = incorrectly_sorted
+ self.skipped = skipped
+ self.supported_encoding = supported_encoding
+
+
+def sort_imports(
+ file_name: str,
+ config: Config,
+ check: bool = False,
+ ask_to_apply: bool = False,
+ write_to_stdout: bool = False,
+ **kwargs: Any,
+) -> Optional[SortAttempt]:
+ incorrectly_sorted: bool = False
+ skipped: bool = False
+ try:
+ if check:
+ try:
+ incorrectly_sorted = not api.check_file(file_name, config=config, **kwargs)
+ except FileSkipped:
+ skipped = True
+ return SortAttempt(incorrectly_sorted, skipped, True)
+
+ try:
+ incorrectly_sorted = not api.sort_file(
+ file_name,
+ config=config,
+ ask_to_apply=ask_to_apply,
+ write_to_stdout=write_to_stdout,
+ **kwargs,
+ )
+ except FileSkipped:
+ skipped = True
+ return SortAttempt(incorrectly_sorted, skipped, True)
+ except (OSError, ValueError) as error:
+ warn(f"Unable to parse file {file_name} due to {error}")
+ return None
+ except UnsupportedEncoding:
+ if config.verbose:
+ warn(f"Encoding not supported for {file_name}")
+ return SortAttempt(incorrectly_sorted, skipped, False)
+ except ISortError as error:
+ _print_hard_fail(config, message=str(error))
+ sys.exit(1)
+ except Exception:
+ _print_hard_fail(config, offending_file=file_name)
+ raise
+
+
+def _print_hard_fail(
+ config: Config, offending_file: Optional[str] = None, message: Optional[str] = None
+) -> None:
+ """Fail on unrecoverable exception with custom message."""
+ message = message or (
+ f"Unrecoverable exception thrown when parsing {offending_file or ''}! "
+ "This should NEVER happen.\n"
+ "If encountered, please open an issue: https://github.com/PyCQA/isort/issues/new"
+ )
+ printer = create_terminal_printer(
+ color=config.color_output, error=config.format_error, success=config.format_success
+ )
+ printer.error(message)
+
+
+def _build_arg_parser() -> argparse.ArgumentParser:
+ parser = argparse.ArgumentParser(
+ description="Sort Python import definitions alphabetically "
+ "within logical sections. Run with no arguments to see a quick "
+ "start guide, otherwise, one or more files/directories/stdin must be provided. "
+ "Use `-` as the first argument to represent stdin. Use --interactive to use the pre 5.0.0 "
+ "interactive behavior."
+ " "
+ "If you've used isort 4 but are new to isort 5, see the upgrading guide: "
+ "https://pycqa.github.io/isort/docs/upgrade_guides/5.0.0.html",
+ add_help=False, # prevent help option from appearing in "optional arguments" group
+ )
+
+ general_group = parser.add_argument_group("general options")
+ target_group = parser.add_argument_group("target options")
+ output_group = parser.add_argument_group("general output options")
+ inline_args_group = output_group.add_mutually_exclusive_group()
+ section_group = parser.add_argument_group("section output options")
+ deprecated_group = parser.add_argument_group("deprecated options")
+
+ general_group.add_argument(
+ "-h",
+ "--help",
+ action="help",
+ default=argparse.SUPPRESS,
+ help=_("show this help message and exit"),
+ )
+ general_group.add_argument(
+ "-V",
+ "--version",
+ action="store_true",
+ dest="show_version",
+ help="Displays the currently installed version of isort.",
+ )
+ general_group.add_argument(
+ "--vn",
+ "--version-number",
+ action="version",
+ version=__version__,
+ help="Returns just the current version number without the logo",
+ )
+ general_group.add_argument(
+ "-v",
+ "--verbose",
+ action="store_true",
+ dest="verbose",
+ help="Shows verbose output, such as when files are skipped or when a check is successful.",
+ )
+ general_group.add_argument(
+ "--only-modified",
+ "--om",
+ dest="only_modified",
+ action="store_true",
+ help="Suppresses verbose output for non-modified files.",
+ )
+ general_group.add_argument(
+ "--dedup-headings",
+ dest="dedup_headings",
+ action="store_true",
+ help="Tells isort to only show an identical custom import heading comment once, even if"
+ " there are multiple sections with the comment set.",
+ )
+ general_group.add_argument(
+ "-q",
+ "--quiet",
+ action="store_true",
+ dest="quiet",
+ help="Shows extra quiet output, only errors are outputted.",
+ )
+ general_group.add_argument(
+ "-d",
+ "--stdout",
+ help="Force resulting output to stdout, instead of in-place.",
+ dest="write_to_stdout",
+ action="store_true",
+ )
+ general_group.add_argument(
+ "--overwrite-in-place",
+ help="Tells isort to overwrite in place using the same file handle. "
+ "Comes at a performance and memory usage penalty over its standard "
+ "approach but ensures all file flags and modes stay unchanged.",
+ dest="overwrite_in_place",
+ action="store_true",
+ )
+ general_group.add_argument(
+ "--show-config",
+ dest="show_config",
+ action="store_true",
+ help="See isort's determined config, as well as sources of config options.",
+ )
+ general_group.add_argument(
+ "--show-files",
+ dest="show_files",
+ action="store_true",
+ help="See the files isort will be run against with the current config options.",
+ )
+ general_group.add_argument(
+ "--df",
+ "--diff",
+ dest="show_diff",
+ action="store_true",
+ help="Prints a diff of all the changes isort would make to a file, instead of "
+ "changing it in place",
+ )
+ general_group.add_argument(
+ "-c",
+ "--check-only",
+ "--check",
+ action="store_true",
+ dest="check",
+ help="Checks the file for unsorted / unformatted imports and prints them to the "
+ "command line without modifying the file. Returns 0 when nothing would change and "
+ "returns 1 when the file would be reformatted.",
+ )
+ general_group.add_argument(
+ "--ws",
+ "--ignore-whitespace",
+ action="store_true",
+ dest="ignore_whitespace",
+ help="Tells isort to ignore whitespace differences when --check-only is being used.",
+ )
+ general_group.add_argument(
+ "--sp",
+ "--settings-path",
+ "--settings-file",
+ "--settings",
+ dest="settings_path",
+ help="Explicitly set the settings path or file instead of auto determining "
+ "based on file location.",
+ )
+ general_group.add_argument(
+ "--cr",
+ "--config-root",
+ dest="config_root",
+ help="Explicitly set the config root for resolving all configs. When used "
+ "with the --resolve-all-configs flag, isort will look at all sub-folders "
+ "in this config root to resolve config files and sort files based on the "
+ "closest available config(if any)",
+ )
+ general_group.add_argument(
+ "--resolve-all-configs",
+ dest="resolve_all_configs",
+ action="store_true",
+ help="Tells isort to resolve the configs for all sub-directories "
+ "and sort files in terms of its closest config files.",
+ )
+ general_group.add_argument(
+ "--profile",
+ dest="profile",
+ type=str,
+ help="Base profile type to use for configuration. "
+ f"Profiles include: {', '.join(profiles.keys())}. As well as any shared profiles.",
+ )
+ general_group.add_argument(
+ "--old-finders",
+ "--magic-placement",
+ dest="old_finders",
+ action="store_true",
+ help="Use the old deprecated finder logic that relies on environment introspection magic.",
+ )
+ general_group.add_argument(
+ "-j",
+ "--jobs",
+ help="Number of files to process in parallel. Negative value means use number of CPUs.",
+ dest="jobs",
+ type=int,
+ nargs="?",
+ const=-1,
+ )
+ general_group.add_argument(
+ "--ac",
+ "--atomic",
+ dest="atomic",
+ action="store_true",
+ help="Ensures the output doesn't save if the resulting file contains syntax errors.",
+ )
+ general_group.add_argument(
+ "--interactive",
+ dest="ask_to_apply",
+ action="store_true",
+ help="Tells isort to apply changes interactively.",
+ )
+ general_group.add_argument(
+ "--format-error",
+ dest="format_error",
+ help="Override the format used to print errors.",
+ )
+ general_group.add_argument(
+ "--format-success",
+ dest="format_success",
+ help="Override the format used to print success.",
+ )
+ general_group.add_argument(
+ "--srx",
+ "--sort-reexports",
+ dest="sort_reexports",
+ action="store_true",
+ help="Automatically sort all re-exports (module level __all__ collections)",
+ )
+
+ target_group.add_argument(
+ "files", nargs="*", help="One or more Python source files that need their imports sorted."
+ )
+ target_group.add_argument(
+ "--filter-files",
+ dest="filter_files",
+ action="store_true",
+ help="Tells isort to filter files even when they are explicitly passed in as "
+ "part of the CLI command.",
+ )
+ target_group.add_argument(
+ "-s",
+ "--skip",
+ help="Files that isort should skip over. If you want to skip multiple "
+ "files you should specify twice: --skip file1 --skip file2. Values can be "
+ "file names, directory names or file paths. To skip all files in a nested path "
+ "use --skip-glob.",
+ dest="skip",
+ action="append",
+ )
+ target_group.add_argument(
+ "--extend-skip",
+ help="Extends --skip to add additional files that isort should skip over. "
+ "If you want to skip multiple "
+ "files you should specify twice: --skip file1 --skip file2. Values can be "
+ "file names, directory names or file paths. To skip all files in a nested path "
+ "use --skip-glob.",
+ dest="extend_skip",
+ action="append",
+ )
+ target_group.add_argument(
+ "--sg",
+ "--skip-glob",
+ help="Files that isort should skip over.",
+ dest="skip_glob",
+ action="append",
+ )
+ target_group.add_argument(
+ "--extend-skip-glob",
+ help="Additional files that isort should skip over (extending --skip-glob).",
+ dest="extend_skip_glob",
+ action="append",
+ )
+ target_group.add_argument(
+ "--gitignore",
+ "--skip-gitignore",
+ action="store_true",
+ dest="skip_gitignore",
+ help="Treat project as a git repository and ignore files listed in .gitignore."
+ "\nNOTE: This requires git to be installed and accessible from the same shell as isort.",
+ )
+ target_group.add_argument(
+ "--ext",
+ "--extension",
+ "--supported-extension",
+ dest="supported_extensions",
+ action="append",
+ help="Specifies what extensions isort can be run against.",
+ )
+ target_group.add_argument(
+ "--blocked-extension",
+ dest="blocked_extensions",
+ action="append",
+ help="Specifies what extensions isort can never be run against.",
+ )
+ target_group.add_argument(
+ "--dont-follow-links",
+ dest="dont_follow_links",
+ action="store_true",
+ help="Tells isort not to follow symlinks that are encountered when running recursively.",
+ )
+ target_group.add_argument(
+ "--filename",
+ dest="filename",
+ help="Provide the filename associated with a stream.",
+ )
+ target_group.add_argument(
+ "--allow-root",
+ action="store_true",
+ default=False,
+ help="Tells isort not to treat / specially, allowing it to be run against the root dir.",
+ )
+
+ output_group.add_argument(
+ "-a",
+ "--add-import",
+ dest="add_imports",
+ action="append",
+ help="Adds the specified import line to all files, "
+ "automatically determining correct placement.",
+ )
+ output_group.add_argument(
+ "--append",
+ "--append-only",
+ dest="append_only",
+ action="store_true",
+ help="Only adds the imports specified in --add-import if the file"
+ " contains existing imports.",
+ )
+ output_group.add_argument(
+ "--af",
+ "--force-adds",
+ dest="force_adds",
+ action="store_true",
+ help="Forces import adds even if the original file is empty.",
+ )
+ output_group.add_argument(
+ "--rm",
+ "--remove-import",
+ dest="remove_imports",
+ action="append",
+ help="Removes the specified import from all files.",
+ )
+ output_group.add_argument(
+ "--float-to-top",
+ dest="float_to_top",
+ action="store_true",
+ help="Causes all non-indented imports to float to the top of the file having its imports "
+ "sorted (immediately below the top of file comment).\n"
+ "This can be an excellent shortcut for collecting imports every once in a while "
+ "when you place them in the middle of a file to avoid context switching.\n\n"
+ "*NOTE*: It currently doesn't work with cimports and introduces some extra over-head "
+ "and a performance penalty.",
+ )
+ output_group.add_argument(
+ "--dont-float-to-top",
+ dest="dont_float_to_top",
+ action="store_true",
+ help="Forces --float-to-top setting off. See --float-to-top for more information.",
+ )
+ output_group.add_argument(
+ "--ca",
+ "--combine-as",
+ dest="combine_as_imports",
+ action="store_true",
+ help="Combines as imports on the same line.",
+ )
+ output_group.add_argument(
+ "--cs",
+ "--combine-star",
+ dest="combine_star",
+ action="store_true",
+ help="Ensures that if a star import is present, "
+ "nothing else is imported from that namespace.",
+ )
+ output_group.add_argument(
+ "-e",
+ "--balanced",
+ dest="balanced_wrapping",
+ action="store_true",
+ help="Balances wrapping to produce the most consistent line length possible",
+ )
+ output_group.add_argument(
+ "--ff",
+ "--from-first",
+ dest="from_first",
+ action="store_true",
+ help="Switches the typical ordering preference, "
+ "showing from imports first then straight ones.",
+ )
+ output_group.add_argument(
+ "--fgw",
+ "--force-grid-wrap",
+ nargs="?",
+ const=2,
+ type=int,
+ dest="force_grid_wrap",
+ help="Force number of from imports (defaults to 2 when passed as CLI flag without value) "
+ "to be grid wrapped regardless of line "
+ "length. If 0 is passed in (the global default) only line length is considered.",
+ )
+ output_group.add_argument(
+ "-i",
+ "--indent",
+ help='String to place for indents defaults to " " (4 spaces).',
+ dest="indent",
+ type=str,
+ )
+ output_group.add_argument(
+ "--lbi", "--lines-before-imports", dest="lines_before_imports", type=int
+ )
+ output_group.add_argument(
+ "--lai", "--lines-after-imports", dest="lines_after_imports", type=int
+ )
+ output_group.add_argument(
+ "--lbt", "--lines-between-types", dest="lines_between_types", type=int
+ )
+ output_group.add_argument(
+ "--le",
+ "--line-ending",
+ dest="line_ending",
+ help="Forces line endings to the specified value. "
+ "If not set, values will be guessed per-file.",
+ )
+ output_group.add_argument(
+ "--ls",
+ "--length-sort",
+ help="Sort imports by their string length.",
+ dest="length_sort",
+ action="store_true",
+ )
+ output_group.add_argument(
+ "--lss",
+ "--length-sort-straight",
+ help="Sort straight imports by their string length. Similar to `length_sort` "
+ "but applies only to straight imports and doesn't affect from imports.",
+ dest="length_sort_straight",
+ action="store_true",
+ )
+ output_group.add_argument(
+ "-m",
+ "--multi-line",
+ dest="multi_line_output",
+ choices=list(WrapModes.__members__.keys())
+ + [str(mode.value) for mode in WrapModes.__members__.values()],
+ type=str,
+ help="Multi line output (0-grid, 1-vertical, 2-hanging, 3-vert-hanging, 4-vert-grid, "
+ "5-vert-grid-grouped, 6-deprecated-alias-for-5, 7-noqa, "
+ "8-vertical-hanging-indent-bracket, 9-vertical-prefix-from-module-import, "
+ "10-hanging-indent-with-parentheses).",
+ )
+ output_group.add_argument(
+ "-n",
+ "--ensure-newline-before-comments",
+ dest="ensure_newline_before_comments",
+ action="store_true",
+ help="Inserts a blank line before a comment following an import.",
+ )
+ inline_args_group.add_argument(
+ "--nis",
+ "--no-inline-sort",
+ dest="no_inline_sort",
+ action="store_true",
+ help="Leaves `from` imports with multiple imports 'as-is' "
+ "(e.g. `from foo import a, c ,b`).",
+ )
+ output_group.add_argument(
+ "--ot",
+ "--order-by-type",
+ dest="order_by_type",
+ action="store_true",
+ help="Order imports by type, which is determined by case, in addition to alphabetically.\n"
+ "\n**NOTE**: type here refers to the implied type from the import name capitalization.\n"
+ ' isort does not do type introspection for the imports. These "types" are simply: '
+ "CONSTANT_VARIABLE, CamelCaseClass, variable_or_function. If your project follows PEP8"
+ " or a related coding standard and has many imports this is a good default, otherwise you "
+ "likely will want to turn it off. From the CLI the `--dont-order-by-type` option will turn "
+ "this off.",
+ )
+ output_group.add_argument(
+ "--dt",
+ "--dont-order-by-type",
+ dest="dont_order_by_type",
+ action="store_true",
+ help="Don't order imports by type, which is determined by case, in addition to "
+ "alphabetically.\n\n"
+ "**NOTE**: type here refers to the implied type from the import name capitalization.\n"
+ ' isort does not do type introspection for the imports. These "types" are simply: '
+ "CONSTANT_VARIABLE, CamelCaseClass, variable_or_function. If your project follows PEP8"
+ " or a related coding standard and has many imports this is a good default. You can turn "
+ "this on from the CLI using `--order-by-type`.",
+ )
+ output_group.add_argument(
+ "--rr",
+ "--reverse-relative",
+ dest="reverse_relative",
+ action="store_true",
+ help="Reverse order of relative imports.",
+ )
+ output_group.add_argument(
+ "--reverse-sort",
+ dest="reverse_sort",
+ action="store_true",
+ help="Reverses the ordering of imports.",
+ )
+ output_group.add_argument(
+ "--sort-order",
+ dest="sort_order",
+ help="Specify sorting function. Can be built in (natural[default] = force numbers "
+ "to be sequential, native = Python's built-in sorted function) or an installable plugin.",
+ )
+ inline_args_group.add_argument(
+ "--sl",
+ "--force-single-line-imports",
+ dest="force_single_line",
+ action="store_true",
+ help="Forces all from imports to appear on their own line",
+ )
+ output_group.add_argument(
+ "--nsl",
+ "--single-line-exclusions",
+ help="One or more modules to exclude from the single line rule.",
+ dest="single_line_exclusions",
+ action="append",
+ )
+ output_group.add_argument(
+ "--tc",
+ "--trailing-comma",
+ dest="include_trailing_comma",
+ action="store_true",
+ help="Includes a trailing comma on multi line imports that include parentheses.",
+ )
+ output_group.add_argument(
+ "--up",
+ "--use-parentheses",
+ dest="use_parentheses",
+ action="store_true",
+ help="Use parentheses for line continuation on length limit instead of slashes."
+ " **NOTE**: This is separate from wrap modes, and only affects how individual lines that "
+ " are too long get continued, not sections of multiple imports.",
+ )
+ output_group.add_argument(
+ "-l",
+ "-w",
+ "--line-length",
+ "--line-width",
+ help="The max length of an import line (used for wrapping long imports).",
+ dest="line_length",
+ type=int,
+ )
+ output_group.add_argument(
+ "--wl",
+ "--wrap-length",
+ dest="wrap_length",
+ type=int,
+ help="Specifies how long lines that are wrapped should be, if not set line_length is used."
+ "\nNOTE: wrap_length must be LOWER than or equal to line_length.",
+ )
+ output_group.add_argument(
+ "--case-sensitive",
+ dest="case_sensitive",
+ action="store_true",
+ help="Tells isort to include casing when sorting module names",
+ )
+ output_group.add_argument(
+ "--remove-redundant-aliases",
+ dest="remove_redundant_aliases",
+ action="store_true",
+ help=(
+ "Tells isort to remove redundant aliases from imports, such as `import os as os`."
+ " This defaults to `False` simply because some projects use these seemingly useless "
+ " aliases to signify intent and change behaviour."
+ ),
+ )
+ output_group.add_argument(
+ "--honor-noqa",
+ dest="honor_noqa",
+ action="store_true",
+ help="Tells isort to honor noqa comments to enforce skipping those comments.",
+ )
+ output_group.add_argument(
+ "--treat-comment-as-code",
+ dest="treat_comments_as_code",
+ action="append",
+ help="Tells isort to treat the specified single line comment(s) as if they are code.",
+ )
+ output_group.add_argument(
+ "--treat-all-comment-as-code",
+ dest="treat_all_comments_as_code",
+ action="store_true",
+ help="Tells isort to treat all single line comments as if they are code.",
+ )
+ output_group.add_argument(
+ "--formatter",
+ dest="formatter",
+ type=str,
+ help="Specifies the name of a formatting plugin to use when producing output.",
+ )
+ output_group.add_argument(
+ "--color",
+ dest="color_output",
+ action="store_true",
+ help="Tells isort to use color in terminal output.",
+ )
+ output_group.add_argument(
+ "--ext-format",
+ dest="ext_format",
+ help="Tells isort to format the given files according to an extensions formatting rules.",
+ )
+ output_group.add_argument(
+ "--star-first",
+ help="Forces star imports above others to avoid overriding directly imported variables.",
+ dest="star_first",
+ action="store_true",
+ )
+ output_group.add_argument(
+ "--split-on-trailing-comma",
+ help="Split imports list followed by a trailing comma into VERTICAL_HANGING_INDENT mode",
+ dest="split_on_trailing_comma",
+ action="store_true",
+ )
+
+ section_group.add_argument(
+ "--sd",
+ "--section-default",
+ dest="default_section",
+ help="Sets the default section for import options: " + str(sections.DEFAULT),
+ )
+ section_group.add_argument(
+ "--only-sections",
+ "--os",
+ dest="only_sections",
+ action="store_true",
+ help="Causes imports to be sorted based on their sections like STDLIB, THIRDPARTY, etc. "
+ "Within sections, the imports are ordered by their import style and the imports with "
+ "the same style maintain their relative positions.",
+ )
+ section_group.add_argument(
+ "--ds",
+ "--no-sections",
+ help="Put all imports into the same section bucket",
+ dest="no_sections",
+ action="store_true",
+ )
+ section_group.add_argument(
+ "--fas",
+ "--force-alphabetical-sort",
+ action="store_true",
+ dest="force_alphabetical_sort",
+ help="Force all imports to be sorted as a single section",
+ )
+ section_group.add_argument(
+ "--fss",
+ "--force-sort-within-sections",
+ action="store_true",
+ dest="force_sort_within_sections",
+ help="Don't sort straight-style imports (like import sys) before from-style imports "
+ "(like from itertools import groupby). Instead, sort the imports by module, "
+ "independent of import style.",
+ )
+ section_group.add_argument(
+ "--hcss",
+ "--honor-case-in-force-sorted-sections",
+ action="store_true",
+ dest="honor_case_in_force_sorted_sections",
+ help="Honor `--case-sensitive` when `--force-sort-within-sections` is being used. "
+ "Without this option set, `--order-by-type` decides module name ordering too.",
+ )
+ section_group.add_argument(
+ "--srss",
+ "--sort-relative-in-force-sorted-sections",
+ action="store_true",
+ dest="sort_relative_in_force_sorted_sections",
+ help="When using `--force-sort-within-sections`, sort relative imports the same "
+ "way as they are sorted when not using that setting.",
+ )
+ section_group.add_argument(
+ "--fass",
+ "--force-alphabetical-sort-within-sections",
+ action="store_true",
+ dest="force_alphabetical_sort_within_sections",
+ help="Force all imports to be sorted alphabetically within a section",
+ )
+ section_group.add_argument(
+ "-t",
+ "--top",
+ help="Force specific imports to the top of their appropriate section.",
+ dest="force_to_top",
+ action="append",
+ )
+ section_group.add_argument(
+ "--combine-straight-imports",
+ "--csi",
+ dest="combine_straight_imports",
+ action="store_true",
+ help="Combines all the bare straight imports of the same section in a single line. "
+ "Won't work with sections which have 'as' imports",
+ )
+ section_group.add_argument(
+ "--nlb",
+ "--no-lines-before",
+ help="Sections which should not be split with previous by empty lines",
+ dest="no_lines_before",
+ action="append",
+ )
+ section_group.add_argument(
+ "--src",
+ "--src-path",
+ dest="src_paths",
+ action="append",
+ help="Add an explicitly defined source path "
+ "(modules within src paths have their imports automatically categorized as first_party)."
+ " Glob expansion (`*` and `**`) is supported for this option.",
+ )
+ section_group.add_argument(
+ "-b",
+ "--builtin",
+ dest="known_standard_library",
+ action="append",
+ help="Force isort to recognize a module as part of Python's standard library.",
+ )
+ section_group.add_argument(
+ "--extra-builtin",
+ dest="extra_standard_library",
+ action="append",
+ help="Extra modules to be included in the list of ones in Python's standard library.",
+ )
+ section_group.add_argument(
+ "-f",
+ "--future",
+ dest="known_future_library",
+ action="append",
+ help="Force isort to recognize a module as part of Python's internal future compatibility "
+ "libraries. WARNING: this overrides the behavior of __future__ handling and therefore"
+ " can result in code that can't execute. If you're looking to add dependencies such "
+ "as six, a better option is to create another section below --future using custom "
+ "sections. See: https://github.com/PyCQA/isort#custom-sections-and-ordering and the "
+ "discussion here: https://github.com/PyCQA/isort/issues/1463.",
+ )
+ section_group.add_argument(
+ "-o",
+ "--thirdparty",
+ dest="known_third_party",
+ action="append",
+ help="Force isort to recognize a module as being part of a third party library.",
+ )
+ section_group.add_argument(
+ "-p",
+ "--project",
+ dest="known_first_party",
+ action="append",
+ help="Force isort to recognize a module as being part of the current python project.",
+ )
+ section_group.add_argument(
+ "--known-local-folder",
+ dest="known_local_folder",
+ action="append",
+ help="Force isort to recognize a module as being a local folder. "
+ "Generally, this is reserved for relative imports (from . import module).",
+ )
+ section_group.add_argument(
+ "--virtual-env",
+ dest="virtual_env",
+ help="Virtual environment to use for determining whether a package is third-party",
+ )
+ section_group.add_argument(
+ "--conda-env",
+ dest="conda_env",
+ help="Conda environment to use for determining whether a package is third-party",
+ )
+ section_group.add_argument(
+ "--py",
+ "--python-version",
+ action="store",
+ dest="py_version",
+ choices=tuple(VALID_PY_TARGETS) + ("auto",),
+ help="Tells isort to set the known standard library based on the specified Python "
+ "version. Default is to assume any Python 3 version could be the target, and use a union "
+ "of all stdlib modules across versions. If auto is specified, the version of the "
+ "interpreter used to run isort "
+ f"(currently: {sys.version_info.major}{sys.version_info.minor}) will be used.",
+ )
+
+ # deprecated options
+ deprecated_group.add_argument(
+ "--recursive",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--recursive",
+ help=argparse.SUPPRESS,
+ )
+ deprecated_group.add_argument(
+ "-rc", dest="deprecated_flags", action="append_const", const="-rc", help=argparse.SUPPRESS
+ )
+ deprecated_group.add_argument(
+ "--dont-skip",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--dont-skip",
+ help=argparse.SUPPRESS,
+ )
+ deprecated_group.add_argument(
+ "-ns", dest="deprecated_flags", action="append_const", const="-ns", help=argparse.SUPPRESS
+ )
+ deprecated_group.add_argument(
+ "--apply",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--apply",
+ help=argparse.SUPPRESS,
+ )
+ deprecated_group.add_argument(
+ "-k",
+ "--keep-direct-and-as",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--keep-direct-and-as",
+ help=argparse.SUPPRESS,
+ )
+
+ return parser
+
+
+def parse_args(argv: Optional[Sequence[str]] = None) -> Dict[str, Any]:
+ argv = sys.argv[1:] if argv is None else list(argv)
+ remapped_deprecated_args = []
+ for index, arg in enumerate(argv):
+ if arg in DEPRECATED_SINGLE_DASH_ARGS:
+ remapped_deprecated_args.append(arg)
+ argv[index] = f"-{arg}"
+
+ parser = _build_arg_parser()
+ arguments = {key: value for key, value in vars(parser.parse_args(argv)).items() if value}
+ if remapped_deprecated_args:
+ arguments["remapped_deprecated_args"] = remapped_deprecated_args
+ if "dont_order_by_type" in arguments:
+ arguments["order_by_type"] = False
+ del arguments["dont_order_by_type"]
+ if "dont_follow_links" in arguments:
+ arguments["follow_links"] = False
+ del arguments["dont_follow_links"]
+ if "dont_float_to_top" in arguments:
+ del arguments["dont_float_to_top"]
+ if arguments.get("float_to_top", False):
+ sys.exit("Can't set both --float-to-top and --dont-float-to-top.")
+ else:
+ arguments["float_to_top"] = False
+ multi_line_output = arguments.get("multi_line_output", None)
+ if multi_line_output:
+ if multi_line_output.isdigit():
+ arguments["multi_line_output"] = WrapModes(int(multi_line_output))
+ else:
+ arguments["multi_line_output"] = WrapModes[multi_line_output]
+
+ return arguments
+
+
+def _preconvert(item: Any) -> Union[str, List[Any]]:
+ """Preconverts objects from native types into JSONifyiable types"""
+ if isinstance(item, (set, frozenset)):
+ return list(item)
+ if isinstance(item, WrapModes):
+ return str(item.name)
+ if isinstance(item, Path):
+ return str(item)
+ if callable(item) and hasattr(item, "__name__"):
+ return str(item.__name__)
+ raise TypeError(f"Unserializable object {item} of type {type(item)}")
+
+
+def identify_imports_main(
+ argv: Optional[Sequence[str]] = None, stdin: Optional[TextIOWrapper] = None
+) -> None:
+ parser = argparse.ArgumentParser(
+ description="Get all import definitions from a given file."
+ "Use `-` as the first argument to represent stdin."
+ )
+ parser.add_argument(
+ "files", nargs="+", help="One or more Python source files that need their imports sorted."
+ )
+ parser.add_argument(
+ "--top-only",
+ action="store_true",
+ default=False,
+ help="Only identify imports that occur in before functions or classes.",
+ )
+
+ target_group = parser.add_argument_group("target options")
+ target_group.add_argument(
+ "--follow-links",
+ action="store_true",
+ default=False,
+ help="Tells isort to follow symlinks that are encountered when running recursively.",
+ )
+
+ uniqueness = parser.add_mutually_exclusive_group()
+ uniqueness.add_argument(
+ "--unique",
+ action="store_true",
+ default=False,
+ help="If true, isort will only identify unique imports.",
+ )
+ uniqueness.add_argument(
+ "--packages",
+ dest="unique",
+ action="store_const",
+ const=api.ImportKey.PACKAGE,
+ default=False,
+ help="If true, isort will only identify the unique top level modules imported.",
+ )
+ uniqueness.add_argument(
+ "--modules",
+ dest="unique",
+ action="store_const",
+ const=api.ImportKey.MODULE,
+ default=False,
+ help="If true, isort will only identify the unique modules imported.",
+ )
+ uniqueness.add_argument(
+ "--attributes",
+ dest="unique",
+ action="store_const",
+ const=api.ImportKey.ATTRIBUTE,
+ default=False,
+ help="If true, isort will only identify the unique attributes imported.",
+ )
+
+ arguments = parser.parse_args(argv)
+
+ file_names = arguments.files
+ if file_names == ["-"]:
+ identified_imports = api.find_imports_in_stream(
+ sys.stdin if stdin is None else stdin,
+ unique=arguments.unique,
+ top_only=arguments.top_only,
+ follow_links=arguments.follow_links,
+ )
+ else:
+ identified_imports = api.find_imports_in_paths(
+ file_names,
+ unique=arguments.unique,
+ top_only=arguments.top_only,
+ follow_links=arguments.follow_links,
+ )
+
+ for identified_import in identified_imports:
+ if arguments.unique == api.ImportKey.PACKAGE:
+ print(identified_import.module.split(".")[0])
+ elif arguments.unique == api.ImportKey.MODULE:
+ print(identified_import.module)
+ elif arguments.unique == api.ImportKey.ATTRIBUTE:
+ print(f"{identified_import.module}.{identified_import.attribute}")
+ else:
+ print(str(identified_import))
+
+
+def main(argv: Optional[Sequence[str]] = None, stdin: Optional[TextIOWrapper] = None) -> None:
+ arguments = parse_args(argv)
+ if arguments.get("show_version"):
+ print(ASCII_ART)
+ return
+
+ show_config: bool = arguments.pop("show_config", False)
+ show_files: bool = arguments.pop("show_files", False)
+ if show_config and show_files:
+ sys.exit("Error: either specify show-config or show-files not both.")
+
+ if "settings_path" in arguments:
+ if os.path.isfile(arguments["settings_path"]):
+ arguments["settings_file"] = os.path.abspath(arguments["settings_path"])
+ arguments["settings_path"] = os.path.dirname(arguments["settings_file"])
+ else:
+ arguments["settings_path"] = os.path.abspath(arguments["settings_path"])
+
+ if "virtual_env" in arguments:
+ venv = arguments["virtual_env"]
+ arguments["virtual_env"] = os.path.abspath(venv)
+ if not os.path.isdir(arguments["virtual_env"]):
+ warn(f"virtual_env dir does not exist: {arguments['virtual_env']}")
+
+ file_names = arguments.pop("files", [])
+ if not file_names and not show_config:
+ print(QUICK_GUIDE)
+ if arguments:
+ sys.exit("Error: arguments passed in without any paths or content.")
+ return
+ if "settings_path" not in arguments:
+ arguments["settings_path"] = (
+ arguments.get("filename", None) or os.getcwd()
+ if file_names == ["-"]
+ else os.path.abspath(file_names[0] if file_names else ".")
+ )
+ if not os.path.isdir(arguments["settings_path"]):
+ arguments["settings_path"] = os.path.dirname(arguments["settings_path"])
+
+ config_dict = arguments.copy()
+ ask_to_apply = config_dict.pop("ask_to_apply", False)
+ jobs = config_dict.pop("jobs", None)
+ check = config_dict.pop("check", False)
+ show_diff = config_dict.pop("show_diff", False)
+ write_to_stdout = config_dict.pop("write_to_stdout", False)
+ deprecated_flags = config_dict.pop("deprecated_flags", False)
+ remapped_deprecated_args = config_dict.pop("remapped_deprecated_args", False)
+ stream_filename = config_dict.pop("filename", None)
+ ext_format = config_dict.pop("ext_format", None)
+ allow_root = config_dict.pop("allow_root", None)
+ resolve_all_configs = config_dict.pop("resolve_all_configs", False)
+ wrong_sorted_files = False
+ all_attempt_broken = False
+ no_valid_encodings = False
+
+ config_trie: Optional[Trie] = None
+ if resolve_all_configs:
+ config_trie = find_all_configs(config_dict.pop("config_root", "."))
+
+ if "src_paths" in config_dict:
+ config_dict["src_paths"] = {
+ Path(src_path).resolve() for src_path in config_dict.get("src_paths", ())
+ }
+
+ config = Config(**config_dict)
+ if show_config:
+ print(json.dumps(config.__dict__, indent=4, separators=(",", ": "), default=_preconvert))
+ return
+ if file_names == ["-"]:
+ file_path = Path(stream_filename) if stream_filename else None
+ if show_files:
+ sys.exit("Error: can't show files for streaming input.")
+
+ input_stream = sys.stdin if stdin is None else stdin
+ if check:
+ incorrectly_sorted = not api.check_stream(
+ input_stream=input_stream,
+ config=config,
+ show_diff=show_diff,
+ file_path=file_path,
+ extension=ext_format,
+ )
+
+ wrong_sorted_files = incorrectly_sorted
+ else:
+ try:
+ api.sort_stream(
+ input_stream=input_stream,
+ output_stream=sys.stdout,
+ config=config,
+ show_diff=show_diff,
+ file_path=file_path,
+ extension=ext_format,
+ raise_on_skip=False,
+ )
+ except FileSkipped:
+ sys.stdout.write(input_stream.read())
+ elif "/" in file_names and not allow_root:
+ printer = create_terminal_printer(
+ color=config.color_output, error=config.format_error, success=config.format_success
+ )
+ printer.error("it is dangerous to operate recursively on '/'")
+ printer.error("use --allow-root to override this failsafe")
+ sys.exit(1)
+ else:
+ if stream_filename:
+ printer = create_terminal_printer(
+ color=config.color_output, error=config.format_error, success=config.format_success
+ )
+ printer.error("Filename override is intended only for stream (-) sorting.")
+ sys.exit(1)
+ skipped: List[str] = []
+ broken: List[str] = []
+
+ if config.filter_files:
+ filtered_files = []
+ for file_name in file_names:
+ if config.is_skipped(Path(file_name)):
+ skipped.append(file_name)
+ else:
+ filtered_files.append(file_name)
+ file_names = filtered_files
+
+ file_names = files.find(file_names, config, skipped, broken)
+ if show_files:
+ for file_name in file_names:
+ print(file_name)
+ return
+ num_skipped = 0
+ num_broken = 0
+ num_invalid_encoding = 0
+ if config.verbose:
+ print(ASCII_ART)
+
+ if jobs:
+ import multiprocessing
+
+ executor = multiprocessing.Pool(jobs if jobs > 0 else multiprocessing.cpu_count())
+ attempt_iterator = executor.imap(
+ functools.partial(
+ sort_imports,
+ config=config,
+ check=check,
+ ask_to_apply=ask_to_apply,
+ write_to_stdout=write_to_stdout,
+ extension=ext_format,
+ config_trie=config_trie,
+ ),
+ file_names,
+ )
+ else:
+ # https://github.com/python/typeshed/pull/2814
+ attempt_iterator = (
+ sort_imports( # type: ignore
+ file_name,
+ config=config,
+ check=check,
+ ask_to_apply=ask_to_apply,
+ show_diff=show_diff,
+ write_to_stdout=write_to_stdout,
+ extension=ext_format,
+ config_trie=config_trie,
+ )
+ for file_name in file_names
+ )
+
+ # If any files passed in are missing considered as error, should be removed
+ is_no_attempt = True
+ any_encoding_valid = False
+ for sort_attempt in attempt_iterator:
+ if not sort_attempt:
+ continue # pragma: no cover - shouldn't happen, satisfies type constraint
+ incorrectly_sorted = sort_attempt.incorrectly_sorted
+ if arguments.get("check", False) and incorrectly_sorted:
+ wrong_sorted_files = True
+ if sort_attempt.skipped:
+ num_skipped += (
+ 1 # pragma: no cover - shouldn't happen, due to skip in iter_source_code
+ )
+
+ if not sort_attempt.supported_encoding:
+ num_invalid_encoding += 1
+ else:
+ any_encoding_valid = True
+
+ is_no_attempt = False
+
+ num_skipped += len(skipped)
+ if num_skipped and not config.quiet:
+ if config.verbose:
+ for was_skipped in skipped:
+ print(
+ f"{was_skipped} was skipped as it's listed in 'skip' setting, "
+ "matches a glob in 'skip_glob' setting, or is in a .gitignore file with "
+ "--skip-gitignore enabled."
+ )
+ print(f"Skipped {num_skipped} files")
+
+ num_broken += len(broken)
+ if num_broken and not config.quiet:
+ if config.verbose:
+ for was_broken in broken:
+ warn(f"{was_broken} was broken path, make sure it exists correctly")
+ print(f"Broken {num_broken} paths")
+
+ if num_broken > 0 and is_no_attempt:
+ all_attempt_broken = True
+ if num_invalid_encoding > 0 and not any_encoding_valid:
+ no_valid_encodings = True
+
+ if not config.quiet and (remapped_deprecated_args or deprecated_flags):
+ if remapped_deprecated_args:
+ warn(
+ "W0502: The following deprecated single dash CLI flags were used and translated: "
+ f"{', '.join(remapped_deprecated_args)}!"
+ )
+ if deprecated_flags:
+ warn(
+ "W0501: The following deprecated CLI flags were used and ignored: "
+ f"{', '.join(deprecated_flags)}!"
+ )
+ warn(
+ "W0500: Please see the 5.0.0 Upgrade guide: "
+ "https://pycqa.github.io/isort/docs/upgrade_guides/5.0.0.html"
+ )
+
+ if wrong_sorted_files:
+ sys.exit(1)
+
+ if all_attempt_broken:
+ sys.exit(1)
+
+ if no_valid_encodings:
+ printer = create_terminal_printer(
+ color=config.color_output, error=config.format_error, success=config.format_success
+ )
+ printer.error("No valid encodings.")
+ sys.exit(1)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/solutions/.venv/Lib/site-packages/isort/output.py b/solutions/.venv/Lib/site-packages/isort/output.py
new file mode 100644
index 000000000..3cb3c08b0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/output.py
@@ -0,0 +1,669 @@
+import copy
+import itertools
+from functools import partial
+from typing import Any, Iterable, List, Optional, Set, Tuple, Type
+
+from isort.format import format_simplified
+
+from . import parse, sorting, wrap
+from .comments import add_to_line as with_comments
+from .identify import STATEMENT_DECLARATIONS
+from .settings import DEFAULT_CONFIG, Config
+
+
+def sorted_imports(
+ parsed: parse.ParsedContent,
+ config: Config = DEFAULT_CONFIG,
+ extension: str = "py",
+ import_type: str = "import",
+) -> str:
+ """Adds the imports back to the file.
+
+ (at the index of the first import) sorted alphabetically and split between groups
+
+ """
+ if parsed.import_index == -1:
+ return _output_as_string(parsed.lines_without_imports, parsed.line_separator)
+
+ formatted_output: List[str] = parsed.lines_without_imports.copy()
+ remove_imports = [format_simplified(removal) for removal in config.remove_imports]
+
+ sections: Iterable[str] = itertools.chain(parsed.sections, config.forced_separate)
+
+ if config.no_sections:
+ parsed.imports["no_sections"] = {"straight": {}, "from": {}}
+ base_sections: Tuple[str, ...] = ()
+ for section in sections:
+ if section == "FUTURE":
+ base_sections = ("FUTURE",)
+ continue
+ parsed.imports["no_sections"]["straight"].update(
+ parsed.imports[section].get("straight", {})
+ )
+ parsed.imports["no_sections"]["from"].update(parsed.imports[section].get("from", {}))
+ sections = base_sections + ("no_sections",)
+
+ output: List[str] = []
+ seen_headings: Set[str] = set()
+ pending_lines_before = False
+ for section in sections:
+ straight_modules = parsed.imports[section]["straight"]
+ if not config.only_sections:
+ straight_modules = sorting.sort(
+ config,
+ straight_modules,
+ key=lambda key: sorting.module_key(
+ key, config, section_name=section, straight_import=True
+ ),
+ reverse=config.reverse_sort,
+ )
+
+ from_modules = parsed.imports[section]["from"]
+ if not config.only_sections:
+ from_modules = sorting.sort(
+ config,
+ from_modules,
+ key=lambda key: sorting.module_key(key, config, section_name=section),
+ reverse=config.reverse_sort,
+ )
+
+ if config.star_first:
+ star_modules = []
+ other_modules = []
+ for module in from_modules:
+ if "*" in parsed.imports[section]["from"][module]:
+ star_modules.append(module)
+ else:
+ other_modules.append(module)
+ from_modules = star_modules + other_modules
+
+ straight_imports = _with_straight_imports(
+ parsed, config, straight_modules, section, remove_imports, import_type
+ )
+ from_imports = _with_from_imports(
+ parsed, config, from_modules, section, remove_imports, import_type
+ )
+
+ lines_between = [""] * (
+ config.lines_between_types if from_modules and straight_modules else 0
+ )
+ if config.from_first:
+ section_output = from_imports + lines_between + straight_imports
+ else:
+ section_output = straight_imports + lines_between + from_imports
+
+ if config.force_sort_within_sections:
+ # collapse comments
+ comments_above = []
+ new_section_output: List[str] = []
+ for line in section_output:
+ if not line:
+ continue
+ if line.startswith("#"):
+ comments_above.append(line)
+ elif comments_above:
+ new_section_output.append(_LineWithComments(line, comments_above))
+ comments_above = []
+ else:
+ new_section_output.append(line)
+ # only_sections options is not imposed if force_sort_within_sections is True
+ new_section_output = sorting.sort(
+ config,
+ new_section_output,
+ key=partial(sorting.section_key, config=config),
+ reverse=config.reverse_sort,
+ )
+
+ # uncollapse comments
+ section_output = []
+ for line in new_section_output:
+ comments = getattr(line, "comments", ())
+ if comments:
+ section_output.extend(comments)
+ section_output.append(str(line))
+
+ section_name = section
+ no_lines_before = section_name in config.no_lines_before
+
+ if section_output:
+ if section_name in parsed.place_imports:
+ parsed.place_imports[section_name] = section_output
+ continue
+
+ section_title = config.import_headings.get(section_name.lower(), "")
+ if section_title and section_title not in seen_headings:
+ if config.dedup_headings:
+ seen_headings.add(section_title)
+ section_comment = f"# {section_title}"
+ if section_comment not in parsed.lines_without_imports[0:1]: # pragma: no branch
+ section_output.insert(0, section_comment)
+
+ section_footer = config.import_footers.get(section_name.lower(), "")
+ if section_footer and section_footer not in seen_headings:
+ if config.dedup_headings:
+ seen_headings.add(section_footer)
+ section_comment_end = f"# {section_footer}"
+ if (
+ section_comment_end not in parsed.lines_without_imports[-1:]
+ ): # pragma: no branch
+ section_output.append("") # Empty line for black compatibility
+ section_output.append(section_comment_end)
+
+ if pending_lines_before or not no_lines_before:
+ output += [""] * config.lines_between_sections
+
+ output += section_output
+
+ pending_lines_before = False
+ else:
+ pending_lines_before = pending_lines_before or not no_lines_before
+
+ if config.ensure_newline_before_comments:
+ output = _ensure_newline_before_comment(output)
+
+ while output and output[-1].strip() == "":
+ output.pop() # pragma: no cover
+ while output and output[0].strip() == "":
+ output.pop(0)
+
+ if config.formatting_function:
+ output = config.formatting_function(
+ parsed.line_separator.join(output), extension, config
+ ).splitlines()
+
+ output_at = 0
+ if parsed.import_index < parsed.original_line_count:
+ output_at = parsed.import_index
+ formatted_output[output_at:0] = output
+
+ if output:
+ imports_tail = output_at + len(output)
+ while [
+ character.strip() for character in formatted_output[imports_tail : imports_tail + 1]
+ ] == [""]:
+ formatted_output.pop(imports_tail)
+
+ if len(formatted_output) > imports_tail:
+ next_construct = ""
+ tail = formatted_output[imports_tail:]
+
+ for index, line in enumerate(tail): # pragma: no branch
+ should_skip, in_quote, *_ = parse.skip_line(
+ line,
+ in_quote="",
+ index=len(formatted_output),
+ section_comments=config.section_comments,
+ needs_import=False,
+ )
+ if not should_skip and line.strip():
+ if (
+ line.strip().startswith("#")
+ and len(tail) > (index + 1)
+ and tail[index + 1].strip()
+ ):
+ continue
+ next_construct = line
+ break
+ if in_quote: # pragma: no branch
+ next_construct = line
+ break
+
+ if config.lines_after_imports != -1:
+ lines_after_imports = config.lines_after_imports
+ if config.profile == "black" and extension == "pyi": # special case for black
+ lines_after_imports = 1
+ formatted_output[imports_tail:0] = ["" for line in range(lines_after_imports)]
+ elif extension != "pyi" and next_construct.startswith(STATEMENT_DECLARATIONS):
+ formatted_output[imports_tail:0] = ["", ""]
+ else:
+ formatted_output[imports_tail:0] = [""]
+
+ if config.lines_before_imports != -1:
+ lines_before_imports = config.lines_before_imports
+ if config.profile == "black" and extension == "pyi": # special case for black
+ lines_before_imports = 1
+ formatted_output[:0] = ["" for line in range(lines_before_imports)]
+
+ if parsed.place_imports:
+ new_out_lines = []
+ for index, line in enumerate(formatted_output):
+ new_out_lines.append(line)
+ if line in parsed.import_placements:
+ new_out_lines.extend(parsed.place_imports[parsed.import_placements[line]])
+ if (
+ len(formatted_output) <= (index + 1)
+ or formatted_output[index + 1].strip() != ""
+ ):
+ new_out_lines.append("")
+ formatted_output = new_out_lines
+
+ return _output_as_string(formatted_output, parsed.line_separator)
+
+
+def _with_from_imports(
+ parsed: parse.ParsedContent,
+ config: Config,
+ from_modules: Iterable[str],
+ section: str,
+ remove_imports: List[str],
+ import_type: str,
+) -> List[str]:
+ output: List[str] = []
+ for module in from_modules:
+ if module in remove_imports:
+ continue
+
+ import_start = f"from {module} {import_type} "
+ from_imports = list(parsed.imports[section]["from"][module])
+ if (
+ not config.no_inline_sort
+ or (config.force_single_line and module not in config.single_line_exclusions)
+ ) and not config.only_sections:
+ from_imports = sorting.sort(
+ config,
+ from_imports,
+ key=lambda key: sorting.module_key(
+ key,
+ config,
+ True,
+ config.force_alphabetical_sort_within_sections,
+ section_name=section,
+ ),
+ reverse=config.reverse_sort,
+ )
+ if remove_imports:
+ from_imports = [
+ line for line in from_imports if f"{module}.{line}" not in remove_imports
+ ]
+
+ sub_modules = [f"{module}.{from_import}" for from_import in from_imports]
+ as_imports = {
+ from_import: [
+ f"{from_import} as {as_module}" for as_module in parsed.as_map["from"][sub_module]
+ ]
+ for from_import, sub_module in zip(from_imports, sub_modules)
+ if sub_module in parsed.as_map["from"]
+ }
+ if config.combine_as_imports and not ("*" in from_imports and config.combine_star):
+ if not config.no_inline_sort:
+ for as_import in as_imports:
+ if not config.only_sections:
+ as_imports[as_import] = sorting.sort(config, as_imports[as_import])
+ for from_import in copy.copy(from_imports):
+ if from_import in as_imports:
+ idx = from_imports.index(from_import)
+ if parsed.imports[section]["from"][module][from_import]:
+ from_imports[(idx + 1) : (idx + 1)] = as_imports.pop(from_import)
+ else:
+ from_imports[idx : (idx + 1)] = as_imports.pop(from_import)
+
+ only_show_as_imports = False
+ comments = parsed.categorized_comments["from"].pop(module, ())
+ above_comments = parsed.categorized_comments["above"]["from"].pop(module, None)
+ while from_imports:
+ if above_comments:
+ output.extend(above_comments)
+ above_comments = None
+
+ if "*" in from_imports and config.combine_star:
+ import_statement = wrap.line(
+ with_comments(
+ _with_star_comments(parsed, module, list(comments or ())),
+ f"{import_start}*",
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ from_imports = [
+ from_import for from_import in from_imports if from_import in as_imports
+ ]
+ only_show_as_imports = True
+ elif config.force_single_line and module not in config.single_line_exclusions:
+ import_statement = ""
+ while from_imports:
+ from_import = from_imports.pop(0)
+ single_import_line = with_comments(
+ comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ comment = (
+ parsed.categorized_comments["nested"].get(module, {}).pop(from_import, None)
+ )
+ if comment:
+ single_import_line += (
+ f"{comments and ';' or config.comment_prefix} " f"{comment}"
+ )
+ if from_import in as_imports:
+ if (
+ parsed.imports[section]["from"][module][from_import]
+ and not only_show_as_imports
+ ):
+ output.append(
+ wrap.line(single_import_line, parsed.line_separator, config)
+ )
+ from_comments = parsed.categorized_comments["straight"].get(
+ f"{module}.{from_import}"
+ )
+
+ if not config.only_sections:
+ output.extend(
+ with_comments(
+ from_comments,
+ wrap.line(
+ import_start + as_import, parsed.line_separator, config
+ ),
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ for as_import in sorting.sort(config, as_imports[from_import])
+ )
+
+ else:
+ output.extend(
+ with_comments(
+ from_comments,
+ wrap.line(
+ import_start + as_import, parsed.line_separator, config
+ ),
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ for as_import in as_imports[from_import]
+ )
+ else:
+ output.append(wrap.line(single_import_line, parsed.line_separator, config))
+ comments = None
+ else:
+ while from_imports and from_imports[0] in as_imports:
+ from_import = from_imports.pop(0)
+
+ if not config.only_sections:
+ as_imports[from_import] = sorting.sort(config, as_imports[from_import])
+ from_comments = (
+ parsed.categorized_comments["straight"].get(f"{module}.{from_import}") or []
+ )
+ if (
+ parsed.imports[section]["from"][module][from_import]
+ and not only_show_as_imports
+ ):
+ specific_comment = (
+ parsed.categorized_comments["nested"]
+ .get(module, {})
+ .pop(from_import, None)
+ )
+ if specific_comment:
+ from_comments.append(specific_comment)
+ output.append(
+ wrap.line(
+ with_comments(
+ from_comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ )
+ from_comments = []
+
+ for as_import in as_imports[from_import]:
+ specific_comment = (
+ parsed.categorized_comments["nested"]
+ .get(module, {})
+ .pop(as_import, None)
+ )
+ if specific_comment:
+ from_comments.append(specific_comment)
+
+ output.append(
+ wrap.line(
+ with_comments(
+ from_comments,
+ import_start + as_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ )
+
+ from_comments = []
+
+ if "*" in from_imports:
+ output.append(
+ with_comments(
+ _with_star_comments(parsed, module, []),
+ f"{import_start}*",
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ )
+ from_imports.remove("*")
+
+ for from_import in copy.copy(from_imports):
+ comment = (
+ parsed.categorized_comments["nested"].get(module, {}).pop(from_import, None)
+ )
+ if comment:
+ from_imports.remove(from_import)
+ if from_imports:
+ use_comments = []
+ else:
+ use_comments = comments
+ comments = None
+ single_import_line = with_comments(
+ use_comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ single_import_line += (
+ f"{use_comments and ';' or config.comment_prefix} " f"{comment}"
+ )
+ output.append(wrap.line(single_import_line, parsed.line_separator, config))
+
+ from_import_section = []
+ while from_imports and (
+ from_imports[0] not in as_imports
+ or (
+ config.combine_as_imports
+ and parsed.imports[section]["from"][module][from_import]
+ )
+ ):
+ from_import_section.append(from_imports.pop(0))
+ if config.combine_as_imports:
+ comments = (comments or []) + list(
+ parsed.categorized_comments["from"].pop(f"{module}.__combined_as__", ())
+ )
+ import_statement = with_comments(
+ comments,
+ import_start + (", ").join(from_import_section),
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ if not from_import_section:
+ import_statement = ""
+
+ do_multiline_reformat = False
+
+ force_grid_wrap = config.force_grid_wrap
+ if force_grid_wrap and len(from_import_section) >= force_grid_wrap:
+ do_multiline_reformat = True
+
+ if len(import_statement) > config.line_length and len(from_import_section) > 1:
+ do_multiline_reformat = True
+
+ # If line too long AND have imports AND we are
+ # NOT using GRID or VERTICAL wrap modes
+ if (
+ len(import_statement) > config.line_length
+ and len(from_import_section) > 0
+ and config.multi_line_output
+ not in (wrap.Modes.GRID, wrap.Modes.VERTICAL) # type: ignore
+ ):
+ do_multiline_reformat = True
+
+ if config.split_on_trailing_comma and module in parsed.trailing_commas:
+ import_statement = wrap.import_statement(
+ import_start=import_start,
+ from_imports=from_import_section,
+ comments=comments,
+ line_separator=parsed.line_separator,
+ config=config,
+ explode=True,
+ )
+
+ elif do_multiline_reformat:
+ import_statement = wrap.import_statement(
+ import_start=import_start,
+ from_imports=from_import_section,
+ comments=comments,
+ line_separator=parsed.line_separator,
+ config=config,
+ )
+ if config.multi_line_output == wrap.Modes.GRID: # type: ignore
+ other_import_statement = wrap.import_statement(
+ import_start=import_start,
+ from_imports=from_import_section,
+ comments=comments,
+ line_separator=parsed.line_separator,
+ config=config,
+ multi_line_output=wrap.Modes.VERTICAL_GRID, # type: ignore
+ )
+ if (
+ max(
+ len(import_line)
+ for import_line in import_statement.split(parsed.line_separator)
+ )
+ > config.line_length
+ ):
+ import_statement = other_import_statement
+ elif len(import_statement) > config.line_length:
+ import_statement = wrap.line(import_statement, parsed.line_separator, config)
+
+ if import_statement:
+ output.append(import_statement)
+ return output
+
+
+def _with_straight_imports(
+ parsed: parse.ParsedContent,
+ config: Config,
+ straight_modules: Iterable[str],
+ section: str,
+ remove_imports: List[str],
+ import_type: str,
+) -> List[str]:
+ output: List[str] = []
+
+ as_imports = any((module in parsed.as_map["straight"] for module in straight_modules))
+
+ # combine_straight_imports only works for bare imports, 'as' imports not included
+ if config.combine_straight_imports and not as_imports:
+ if not straight_modules:
+ return []
+
+ above_comments: List[str] = []
+ inline_comments: List[str] = []
+
+ for module in straight_modules:
+ if module in parsed.categorized_comments["above"]["straight"]:
+ above_comments.extend(parsed.categorized_comments["above"]["straight"].pop(module))
+ if module in parsed.categorized_comments["straight"]:
+ inline_comments.extend(parsed.categorized_comments["straight"][module])
+
+ combined_straight_imports = ", ".join(straight_modules)
+ if inline_comments:
+ combined_inline_comments = " ".join(inline_comments)
+ else:
+ combined_inline_comments = ""
+
+ output.extend(above_comments)
+
+ if combined_inline_comments:
+ output.append(
+ f"{import_type} {combined_straight_imports} # {combined_inline_comments}"
+ )
+ else:
+ output.append(f"{import_type} {combined_straight_imports}")
+
+ return output
+
+ for module in straight_modules:
+ if module in remove_imports:
+ continue
+
+ import_definition = []
+ if module in parsed.as_map["straight"]:
+ if parsed.imports[section]["straight"][module]:
+ import_definition.append((f"{import_type} {module}", module))
+ import_definition.extend(
+ (f"{import_type} {module} as {as_import}", f"{module} as {as_import}")
+ for as_import in parsed.as_map["straight"][module]
+ )
+ else:
+ import_definition.append((f"{import_type} {module}", module))
+
+ comments_above = parsed.categorized_comments["above"]["straight"].pop(module, None)
+ if comments_above:
+ output.extend(comments_above)
+ output.extend(
+ with_comments(
+ parsed.categorized_comments["straight"].get(imodule),
+ idef,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ for idef, imodule in import_definition
+ )
+
+ return output
+
+
+def _output_as_string(lines: List[str], line_separator: str) -> str:
+ return line_separator.join(_normalize_empty_lines(lines))
+
+
+def _normalize_empty_lines(lines: List[str]) -> List[str]:
+ while lines and lines[-1].strip() == "":
+ lines.pop(-1)
+
+ lines.append("")
+ return lines
+
+
+class _LineWithComments(str):
+ comments: List[str]
+
+ def __new__(
+ cls: Type["_LineWithComments"], value: Any, comments: List[str]
+ ) -> "_LineWithComments":
+ instance = super().__new__(cls, value)
+ instance.comments = comments
+ return instance
+
+
+def _ensure_newline_before_comment(output: List[str]) -> List[str]:
+ new_output: List[str] = []
+
+ def is_comment(line: Optional[str]) -> bool:
+ return line.startswith("#") if line else False
+
+ for line, prev_line in zip(output, [None] + output): # type: ignore
+ if is_comment(line) and prev_line != "" and not is_comment(prev_line):
+ new_output.append("")
+ new_output.append(line)
+ return new_output
+
+
+def _with_star_comments(parsed: parse.ParsedContent, module: str, comments: List[str]) -> List[str]:
+ star_comment = parsed.categorized_comments["nested"].get(module, {}).pop("*", None)
+ if star_comment:
+ return comments + [star_comment]
+ return comments
diff --git a/solutions/.venv/Lib/site-packages/isort/parse.py b/solutions/.venv/Lib/site-packages/isort/parse.py
new file mode 100644
index 000000000..2c3c41ef1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/parse.py
@@ -0,0 +1,600 @@
+"""Defines parsing functions used by isort for parsing import definitions"""
+import re
+from collections import OrderedDict, defaultdict
+from functools import partial
+from itertools import chain
+from typing import TYPE_CHECKING, Any, Dict, List, NamedTuple, Optional, Set, Tuple
+from warnings import warn
+
+from . import place
+from .comments import parse as parse_comments
+from .exceptions import MissingSection
+from .settings import DEFAULT_CONFIG, Config
+
+if TYPE_CHECKING:
+ from mypy_extensions import TypedDict
+
+ CommentsAboveDict = TypedDict(
+ "CommentsAboveDict", {"straight": Dict[str, Any], "from": Dict[str, Any]}
+ )
+
+ CommentsDict = TypedDict(
+ "CommentsDict",
+ {
+ "from": Dict[str, Any],
+ "straight": Dict[str, Any],
+ "nested": Dict[str, Any],
+ "above": CommentsAboveDict,
+ },
+ )
+
+
+def _infer_line_separator(contents: str) -> str:
+ if "\r\n" in contents:
+ return "\r\n"
+ if "\r" in contents:
+ return "\r"
+ return "\n"
+
+
+def normalize_line(raw_line: str) -> Tuple[str, str]:
+ """Normalizes import related statements in the provided line.
+
+ Returns (normalized_line: str, raw_line: str)
+ """
+ line = re.sub(r"from(\.+)cimport ", r"from \g<1> cimport ", raw_line)
+ line = re.sub(r"from(\.+)import ", r"from \g<1> import ", line)
+ line = line.replace("import*", "import *")
+ line = re.sub(r" (\.+)import ", r" \g<1> import ", line)
+ line = re.sub(r" (\.+)cimport ", r" \g<1> cimport ", line)
+ line = line.replace("\t", " ")
+ return line, raw_line
+
+
+def import_type(line: str, config: Config = DEFAULT_CONFIG) -> Optional[str]:
+ """If the current line is an import line it will return its type (from or straight)"""
+ if config.honor_noqa and line.lower().rstrip().endswith("noqa"):
+ return None
+ if "isort:skip" in line or "isort: skip" in line or "isort: split" in line:
+ return None
+ if line.startswith(("import ", "cimport ")):
+ return "straight"
+ if line.startswith("from "):
+ return "from"
+ return None
+
+
+def strip_syntax(import_string: str) -> str:
+ import_string = import_string.replace("_import", "[[i]]")
+ import_string = import_string.replace("_cimport", "[[ci]]")
+ for remove_syntax in ["\\", "(", ")", ","]:
+ import_string = import_string.replace(remove_syntax, " ")
+ import_list = import_string.split()
+ for key in ("from", "import", "cimport"):
+ if key in import_list:
+ import_list.remove(key)
+ import_string = " ".join(import_list)
+ import_string = import_string.replace("[[i]]", "_import")
+ import_string = import_string.replace("[[ci]]", "_cimport")
+ return import_string.replace("{ ", "{|").replace(" }", "|}")
+
+
+def skip_line(
+ line: str,
+ in_quote: str,
+ index: int,
+ section_comments: Tuple[str, ...],
+ needs_import: bool = True,
+) -> Tuple[bool, str]:
+ """Determine if a given line should be skipped.
+
+ Returns back a tuple containing:
+
+ (skip_line: bool,
+ in_quote: str,)
+ """
+ should_skip = bool(in_quote)
+ if '"' in line or "'" in line:
+ char_index = 0
+ while char_index < len(line):
+ if line[char_index] == "\\":
+ char_index += 1
+ elif in_quote:
+ if line[char_index : char_index + len(in_quote)] == in_quote:
+ in_quote = ""
+ elif line[char_index] in ("'", '"'):
+ long_quote = line[char_index : char_index + 3]
+ if long_quote in ('"""', "'''"):
+ in_quote = long_quote
+ char_index += 2
+ else:
+ in_quote = line[char_index]
+ elif line[char_index] == "#":
+ break
+ char_index += 1
+
+ if ";" in line.split("#")[0] and needs_import:
+ for part in (part.strip() for part in line.split(";")):
+ if (
+ part
+ and not part.startswith("from ")
+ and not part.startswith(("import ", "cimport "))
+ ):
+ should_skip = True
+
+ return (bool(should_skip or in_quote), in_quote)
+
+
+class ParsedContent(NamedTuple):
+ in_lines: List[str]
+ lines_without_imports: List[str]
+ import_index: int
+ place_imports: Dict[str, List[str]]
+ import_placements: Dict[str, str]
+ as_map: Dict[str, Dict[str, List[str]]]
+ imports: Dict[str, Dict[str, Any]]
+ categorized_comments: "CommentsDict"
+ change_count: int
+ original_line_count: int
+ line_separator: str
+ sections: Any
+ verbose_output: List[str]
+ trailing_commas: Set[str]
+
+
+def file_contents(contents: str, config: Config = DEFAULT_CONFIG) -> ParsedContent:
+ """Parses a python file taking out and categorizing imports."""
+ line_separator: str = config.line_ending or _infer_line_separator(contents)
+ in_lines = contents.splitlines()
+ if contents and contents[-1] in ("\n", "\r"):
+ in_lines.append("")
+
+ out_lines = []
+ original_line_count = len(in_lines)
+ if config.old_finders:
+ from .deprecated.finders import FindersManager
+
+ finder = FindersManager(config=config).find
+ else:
+ finder = partial(place.module, config=config)
+
+ line_count = len(in_lines)
+
+ place_imports: Dict[str, List[str]] = {}
+ import_placements: Dict[str, str] = {}
+ as_map: Dict[str, Dict[str, List[str]]] = {
+ "straight": defaultdict(list),
+ "from": defaultdict(list),
+ }
+ imports: OrderedDict[str, Dict[str, Any]] = OrderedDict()
+ verbose_output: List[str] = []
+
+ for section in chain(config.sections, config.forced_separate):
+ imports[section] = {"straight": OrderedDict(), "from": OrderedDict()}
+ categorized_comments: CommentsDict = {
+ "from": {},
+ "straight": {},
+ "nested": {},
+ "above": {"straight": {}, "from": {}},
+ }
+
+ trailing_commas: Set[str] = set()
+
+ index = 0
+ import_index = -1
+ in_quote = ""
+ while index < line_count:
+ line = in_lines[index]
+ index += 1
+ statement_index = index
+ (skipping_line, in_quote) = skip_line(
+ line, in_quote=in_quote, index=index, section_comments=config.section_comments
+ )
+
+ if (
+ line in config.section_comments or line in config.section_comments_end
+ ) and not skipping_line:
+ if import_index == -1: # pragma: no branch
+ import_index = index - 1
+ continue
+
+ if "isort:imports-" in line and line.startswith("#"):
+ section = line.split("isort:imports-")[-1].split()[0].upper()
+ place_imports[section] = []
+ import_placements[line] = section
+ elif "isort: imports-" in line and line.startswith("#"):
+ section = line.split("isort: imports-")[-1].split()[0].upper()
+ place_imports[section] = []
+ import_placements[line] = section
+
+ if skipping_line:
+ out_lines.append(line)
+ continue
+
+ lstripped_line = line.lstrip()
+ if (
+ config.float_to_top
+ and import_index == -1
+ and line
+ and not in_quote
+ and not lstripped_line.startswith("#")
+ and not lstripped_line.startswith("'''")
+ and not lstripped_line.startswith('"""')
+ ):
+ if not lstripped_line.startswith("import") and not lstripped_line.startswith("from"):
+ import_index = index - 1
+ while import_index and not in_lines[import_index - 1]:
+ import_index -= 1
+ else:
+ commentless = line.split("#", 1)[0].strip()
+ if (
+ ("isort:skip" in line or "isort: skip" in line)
+ and "(" in commentless
+ and ")" not in commentless
+ ):
+ import_index = index
+
+ starting_line = line
+ while "isort:skip" in starting_line or "isort: skip" in starting_line:
+ commentless = starting_line.split("#", 1)[0]
+ if (
+ "(" in commentless
+ and not commentless.rstrip().endswith(")")
+ and import_index < line_count
+ ):
+ while import_index < line_count and not commentless.rstrip().endswith(
+ ")"
+ ):
+ commentless = in_lines[import_index].split("#", 1)[0]
+ import_index += 1
+ else:
+ import_index += 1
+
+ if import_index >= line_count:
+ break
+
+ starting_line = in_lines[import_index]
+
+ line, *end_of_line_comment = line.split("#", 1)
+ if ";" in line:
+ statements = [line.strip() for line in line.split(";")]
+ else:
+ statements = [line]
+ if end_of_line_comment:
+ statements[-1] = f"{statements[-1]}#{end_of_line_comment[0]}"
+
+ for statement in statements:
+ line, raw_line = normalize_line(statement)
+ type_of_import = import_type(line, config) or ""
+ raw_lines = [raw_line]
+ if not type_of_import:
+ out_lines.append(raw_line)
+ continue
+
+ if import_index == -1:
+ import_index = index - 1
+ nested_comments = {}
+ import_string, comment = parse_comments(line)
+ comments = [comment] if comment else []
+ line_parts = [part for part in strip_syntax(import_string).strip().split(" ") if part]
+ if type_of_import == "from" and len(line_parts) == 2 and comments:
+ nested_comments[line_parts[-1]] = comments[0]
+
+ if "(" in line.split("#", 1)[0] and index < line_count:
+ while not line.split("#")[0].strip().endswith(")") and index < line_count:
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+ stripped_line = strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line.replace(" as ", "")
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+ raw_lines.append(line)
+ else:
+ while line.strip().endswith("\\"):
+ line, new_comment = parse_comments(in_lines[index])
+ line = line.lstrip()
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+
+ # Still need to check for parentheses after an escaped line
+ if (
+ "(" in line.split("#")[0]
+ and ")" not in line.split("#")[0]
+ and index < line_count
+ ):
+ stripped_line = strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line.replace(" as ", "")
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+ raw_lines.append(line)
+
+ while not line.split("#")[0].strip().endswith(")") and index < line_count:
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+ stripped_line = strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line.replace(" as ", "")
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+ raw_lines.append(line)
+
+ stripped_line = strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line.replace(" as ", "")
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ if import_string.strip().endswith(
+ (" import", " cimport")
+ ) or line.strip().startswith(("import ", "cimport ")):
+ import_string += line_separator + line
+ else:
+ import_string = import_string.rstrip().rstrip("\\") + " " + line.lstrip()
+
+ if type_of_import == "from":
+ cimports: bool
+ import_string = (
+ import_string.replace("import(", "import (")
+ .replace("\\", " ")
+ .replace("\n", " ")
+ )
+ if "import " not in import_string:
+ out_lines.extend(raw_lines)
+ continue
+
+ if " cimport " in import_string:
+ parts = import_string.split(" cimport ")
+ cimports = True
+
+ else:
+ parts = import_string.split(" import ")
+ cimports = False
+
+ from_import = parts[0].split(" ")
+ import_string = (" cimport " if cimports else " import ").join(
+ [from_import[0] + " " + "".join(from_import[1:])] + parts[1:]
+ )
+
+ just_imports = [
+ item.replace("{|", "{ ").replace("|}", " }")
+ for item in strip_syntax(import_string).split()
+ ]
+
+ attach_comments_to: Optional[List[Any]] = None
+ direct_imports = just_imports[1:]
+ straight_import = True
+ top_level_module = ""
+ if "as" in just_imports and (just_imports.index("as") + 1) < len(just_imports):
+ straight_import = False
+ while "as" in just_imports:
+ nested_module = None
+ as_index = just_imports.index("as")
+ if type_of_import == "from":
+ nested_module = just_imports[as_index - 1]
+ top_level_module = just_imports[0]
+ module = top_level_module + "." + nested_module
+ as_name = just_imports[as_index + 1]
+ direct_imports.remove(nested_module)
+ direct_imports.remove(as_name)
+ direct_imports.remove("as")
+ if nested_module == as_name and config.remove_redundant_aliases:
+ pass
+ elif as_name not in as_map["from"][module]: # pragma: no branch
+ as_map["from"][module].append(as_name)
+
+ full_name = f"{nested_module} as {as_name}"
+ associated_comment = nested_comments.get(full_name)
+ if associated_comment:
+ categorized_comments["nested"].setdefault(top_level_module, {})[
+ full_name
+ ] = associated_comment
+ if associated_comment in comments: # pragma: no branch
+ comments.pop(comments.index(associated_comment))
+ else:
+ module = just_imports[as_index - 1]
+ as_name = just_imports[as_index + 1]
+ if module == as_name and config.remove_redundant_aliases:
+ pass
+ elif as_name not in as_map["straight"][module]:
+ as_map["straight"][module].append(as_name)
+
+ if comments and attach_comments_to is None:
+ if nested_module and config.combine_as_imports:
+ attach_comments_to = categorized_comments["from"].setdefault(
+ f"{top_level_module}.__combined_as__", []
+ )
+ else:
+ if type_of_import == "from" or (
+ config.remove_redundant_aliases and as_name == module.split(".")[-1]
+ ):
+ attach_comments_to = categorized_comments["straight"].setdefault(
+ module, []
+ )
+ else:
+ attach_comments_to = categorized_comments["straight"].setdefault(
+ f"{module} as {as_name}", []
+ )
+ del just_imports[as_index : as_index + 2]
+
+ if type_of_import == "from":
+ import_from = just_imports.pop(0)
+ placed_module = finder(import_from)
+ if config.verbose and not config.only_modified:
+ print(f"from-type place_module for {import_from} returned {placed_module}")
+
+ elif config.verbose:
+ verbose_output.append(
+ f"from-type place_module for {import_from} returned {placed_module}"
+ )
+ if placed_module == "":
+ warn(
+ f"could not place module {import_from} of line {line} --"
+ " Do you need to define a default section?"
+ )
+
+ if placed_module and placed_module not in imports:
+ raise MissingSection(import_module=import_from, section=placed_module)
+
+ root = imports[placed_module][type_of_import] # type: ignore
+ for import_name in just_imports:
+ associated_comment = nested_comments.get(import_name)
+ if associated_comment:
+ categorized_comments["nested"].setdefault(import_from, {})[
+ import_name
+ ] = associated_comment
+ if associated_comment in comments: # pragma: no branch
+ comments.pop(comments.index(associated_comment))
+ if (
+ config.force_single_line
+ and comments
+ and attach_comments_to is None
+ and len(just_imports) == 1
+ ):
+ nested_from_comments = categorized_comments["nested"].setdefault(
+ import_from, {}
+ )
+ existing_comment = nested_from_comments.get(just_imports[0], "")
+ nested_from_comments[
+ just_imports[0]
+ ] = f"{existing_comment}{'; ' if existing_comment else ''}{'; '.join(comments)}"
+ comments = []
+
+ if comments and attach_comments_to is None:
+ attach_comments_to = categorized_comments["from"].setdefault(import_from, [])
+
+ if len(out_lines) > max(import_index, 1) - 1:
+ last = out_lines[-1].rstrip() if out_lines else ""
+ while (
+ last.startswith("#")
+ and not last.endswith('"""')
+ and not last.endswith("'''")
+ and "isort:imports-" not in last
+ and "isort: imports-" not in last
+ and not config.treat_all_comments_as_code
+ and not last.strip() in config.treat_comments_as_code
+ ):
+ categorized_comments["above"]["from"].setdefault(import_from, []).insert(
+ 0, out_lines.pop(-1)
+ )
+ if out_lines:
+ last = out_lines[-1].rstrip()
+ else:
+ last = ""
+ if statement_index - 1 == import_index: # pragma: no cover
+ import_index -= len(
+ categorized_comments["above"]["from"].get(import_from, [])
+ )
+
+ if import_from not in root:
+ root[import_from] = OrderedDict(
+ (module, module in direct_imports) for module in just_imports
+ )
+ else:
+ root[import_from].update(
+ (module, root[import_from].get(module, False) or module in direct_imports)
+ for module in just_imports
+ )
+
+ if comments and attach_comments_to is not None:
+ attach_comments_to.extend(comments)
+
+ if (
+ just_imports
+ and just_imports[-1]
+ and "," in import_string.split(just_imports[-1])[-1]
+ ):
+ trailing_commas.add(import_from)
+ else:
+ if comments and attach_comments_to is not None:
+ attach_comments_to.extend(comments)
+ comments = []
+
+ for module in just_imports:
+ if comments:
+ categorized_comments["straight"][module] = comments
+ comments = []
+
+ if len(out_lines) > max(import_index, +1, 1) - 1:
+ last = out_lines[-1].rstrip() if out_lines else ""
+ while (
+ last.startswith("#")
+ and not last.endswith('"""')
+ and not last.endswith("'''")
+ and "isort:imports-" not in last
+ and "isort: imports-" not in last
+ and not config.treat_all_comments_as_code
+ and not last.strip() in config.treat_comments_as_code
+ ):
+ categorized_comments["above"]["straight"].setdefault(module, []).insert(
+ 0, out_lines.pop(-1)
+ )
+ if out_lines:
+ last = out_lines[-1].rstrip()
+ else:
+ last = ""
+ if index - 1 == import_index:
+ import_index -= len(
+ categorized_comments["above"]["straight"].get(module, [])
+ )
+ placed_module = finder(module)
+ if config.verbose and not config.only_modified:
+ print(f"else-type place_module for {module} returned {placed_module}")
+
+ elif config.verbose:
+ verbose_output.append(
+ f"else-type place_module for {module} returned {placed_module}"
+ )
+ if placed_module == "":
+ warn(
+ f"could not place module {module} of line {line} --"
+ " Do you need to define a default section?"
+ )
+ imports.setdefault("", {"straight": OrderedDict(), "from": OrderedDict()})
+
+ if placed_module and placed_module not in imports:
+ raise MissingSection(import_module=module, section=placed_module)
+
+ straight_import |= imports[placed_module][type_of_import].get( # type: ignore
+ module, False
+ )
+ imports[placed_module][type_of_import][module] = straight_import # type: ignore
+
+ change_count = len(out_lines) - original_line_count
+
+ return ParsedContent(
+ in_lines=in_lines,
+ lines_without_imports=out_lines,
+ import_index=import_index,
+ place_imports=place_imports,
+ import_placements=import_placements,
+ as_map=as_map,
+ imports=imports,
+ categorized_comments=categorized_comments,
+ change_count=change_count,
+ original_line_count=original_line_count,
+ line_separator=line_separator,
+ sections=config.sections,
+ verbose_output=verbose_output,
+ trailing_commas=trailing_commas,
+ )
diff --git a/solutions/.venv/Lib/site-packages/isort/place.py b/solutions/.venv/Lib/site-packages/isort/place.py
new file mode 100644
index 000000000..8a972f504
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/place.py
@@ -0,0 +1,145 @@
+"""Contains all logic related to placing an import within a certain section."""
+import importlib
+from fnmatch import fnmatch
+from functools import lru_cache
+from pathlib import Path
+from typing import FrozenSet, Iterable, Optional, Tuple
+
+from isort import sections
+from isort.settings import DEFAULT_CONFIG, Config
+from isort.utils import exists_case_sensitive
+
+LOCAL = "LOCALFOLDER"
+
+
+def module(name: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Returns the section placement for the given module name."""
+ return module_with_reason(name, config)[0]
+
+
+@lru_cache(maxsize=1000)
+def module_with_reason(name: str, config: Config = DEFAULT_CONFIG) -> Tuple[str, str]:
+ """Returns the section placement for the given module name alongside the reasoning."""
+ return (
+ _forced_separate(name, config)
+ or _local(name, config)
+ or _known_pattern(name, config)
+ or _src_path(name, config)
+ or (config.default_section, "Default option in Config or universal default.")
+ )
+
+
+def _forced_separate(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ for forced_separate in config.forced_separate:
+ # Ensure all forced_separate patterns will match to end of string
+ path_glob = forced_separate
+ if not forced_separate.endswith("*"):
+ path_glob = f"{forced_separate}*"
+
+ if fnmatch(name, path_glob) or fnmatch(name, "." + path_glob):
+ return (forced_separate, f"Matched forced_separate ({forced_separate}) config value.")
+
+ return None
+
+
+def _local(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ if name.startswith("."):
+ return (LOCAL, "Module name started with a dot.")
+
+ return None
+
+
+def _known_pattern(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ parts = name.split(".")
+ module_names_to_check = (".".join(parts[:first_k]) for first_k in range(len(parts), 0, -1))
+ for module_name_to_check in module_names_to_check:
+ for pattern, placement in config.known_patterns:
+ if placement in config.sections and pattern.match(module_name_to_check):
+ return (placement, f"Matched configured known pattern {pattern}")
+
+ return None
+
+
+def _src_path(
+ name: str,
+ config: Config,
+ src_paths: Optional[Iterable[Path]] = None,
+ prefix: Tuple[str, ...] = (),
+) -> Optional[Tuple[str, str]]:
+ if src_paths is None:
+ src_paths = config.src_paths
+
+ root_module_name, *nested_module = name.split(".", 1)
+ new_prefix = prefix + (root_module_name,)
+ namespace = ".".join(new_prefix)
+
+ for src_path in src_paths:
+ module_path = (src_path / root_module_name).resolve()
+ if not prefix and not module_path.is_dir() and src_path.name == root_module_name:
+ module_path = src_path.resolve()
+ if nested_module and (
+ namespace in config.namespace_packages
+ or (
+ config.auto_identify_namespace_packages
+ and _is_namespace_package(module_path, config.supported_extensions)
+ )
+ ):
+ return _src_path(nested_module[0], config, (module_path,), new_prefix)
+ if (
+ _is_module(module_path)
+ or _is_package(module_path)
+ or _src_path_is_module(src_path, root_module_name)
+ ):
+ return (sections.FIRSTPARTY, f"Found in one of the configured src_paths: {src_path}.")
+
+ return None
+
+
+def _is_module(path: Path) -> bool:
+ return (
+ exists_case_sensitive(str(path.with_suffix(".py")))
+ or any(
+ exists_case_sensitive(str(path.with_suffix(ext_suffix)))
+ for ext_suffix in importlib.machinery.EXTENSION_SUFFIXES
+ )
+ or exists_case_sensitive(str(path / "__init__.py"))
+ )
+
+
+def _is_package(path: Path) -> bool:
+ return exists_case_sensitive(str(path)) and path.is_dir()
+
+
+def _is_namespace_package(path: Path, src_extensions: FrozenSet[str]) -> bool:
+ if not _is_package(path):
+ return False
+
+ init_file = path / "__init__.py"
+ if not init_file.exists():
+ filenames = [
+ filepath
+ for filepath in path.iterdir()
+ if filepath.suffix.lstrip(".") in src_extensions
+ or filepath.name.lower() in ("setup.cfg", "pyproject.toml")
+ ]
+ if filenames:
+ return False
+ else:
+ with init_file.open("rb") as open_init_file:
+ file_start = open_init_file.read(4096)
+ if (
+ b"__import__('pkg_resources').declare_namespace(__name__)" not in file_start
+ and b'__import__("pkg_resources").declare_namespace(__name__)' not in file_start
+ and b"__path__ = __import__('pkgutil').extend_path(__path__, __name__)"
+ not in file_start
+ and b'__path__ = __import__("pkgutil").extend_path(__path__, __name__)'
+ not in file_start
+ ):
+ return False
+ return True
+
+
+def _src_path_is_module(src_path: Path, module_name: str) -> bool:
+ return (
+ module_name == src_path.name and src_path.is_dir() and exists_case_sensitive(str(src_path))
+ )
diff --git a/solutions/.venv/Lib/site-packages/isort/profiles.py b/solutions/.venv/Lib/site-packages/isort/profiles.py
new file mode 100644
index 000000000..fe2aac492
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/profiles.py
@@ -0,0 +1,88 @@
+"""Common profiles are defined here to be easily used within a project using --profile {name}"""
+from typing import Any, Dict
+
+black = {
+ "multi_line_output": 3,
+ "include_trailing_comma": True,
+ "force_grid_wrap": 0,
+ "use_parentheses": True,
+ "ensure_newline_before_comments": True,
+ "line_length": 88,
+}
+django = {
+ "combine_as_imports": True,
+ "include_trailing_comma": True,
+ "multi_line_output": 5,
+ "line_length": 79,
+}
+pycharm = {
+ "multi_line_output": 3,
+ "force_grid_wrap": 2,
+ "lines_after_imports": 2,
+}
+google = {
+ "force_single_line": True,
+ "force_sort_within_sections": True,
+ "lexicographical": True,
+ "single_line_exclusions": ("typing",),
+ "order_by_type": False,
+ "group_by_package": True,
+}
+open_stack = {
+ "force_single_line": True,
+ "force_sort_within_sections": True,
+ "lexicographical": True,
+}
+plone = black.copy()
+plone.update(
+ {
+ "force_alphabetical_sort": True,
+ "force_single_line": True,
+ "lines_after_imports": 2,
+ }
+)
+attrs = {
+ "atomic": True,
+ "force_grid_wrap": 0,
+ "include_trailing_comma": True,
+ "lines_after_imports": 2,
+ "lines_between_types": 1,
+ "multi_line_output": 3,
+ "use_parentheses": True,
+}
+hug = {
+ "multi_line_output": 3,
+ "include_trailing_comma": True,
+ "force_grid_wrap": 0,
+ "use_parentheses": True,
+ "line_length": 100,
+}
+wemake = {
+ "multi_line_output": 3,
+ "include_trailing_comma": True,
+ "use_parentheses": True,
+ "line_length": 79,
+}
+appnexus = {
+ **black,
+ "force_sort_within_sections": True,
+ "order_by_type": False,
+ "case_sensitive": False,
+ "reverse_relative": True,
+ "sort_relative_in_force_sorted_sections": True,
+ "sections": ["FUTURE", "STDLIB", "THIRDPARTY", "FIRSTPARTY", "APPLICATION", "LOCALFOLDER"],
+ "no_lines_before": "LOCALFOLDER",
+}
+
+profiles: Dict[str, Dict[str, Any]] = {
+ "black": black,
+ "django": django,
+ "pycharm": pycharm,
+ "google": google,
+ "open_stack": open_stack,
+ "plone": plone,
+ "attrs": attrs,
+ "hug": hug,
+ "wemake": wemake,
+ "appnexus": appnexus,
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/py.typed b/solutions/.venv/Lib/site-packages/isort/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/isort/pylama_isort.py b/solutions/.venv/Lib/site-packages/isort/pylama_isort.py
new file mode 100644
index 000000000..52da5356a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/pylama_isort.py
@@ -0,0 +1,45 @@
+import os
+import sys
+from contextlib import contextmanager
+from typing import Any, Dict, Iterator, List, Optional
+
+from pylama.lint import Linter as BaseLinter # type: ignore
+
+from isort.exceptions import FileSkipped
+
+from . import api
+
+
+@contextmanager
+def suppress_stdout() -> Iterator[None]:
+ stdout = sys.stdout
+ with open(os.devnull, "w") as devnull:
+ sys.stdout = devnull
+ yield
+ sys.stdout = stdout
+
+
+class Linter(BaseLinter): # type: ignore
+ def allow(self, path: str) -> bool:
+ """Determine if this path should be linted."""
+ return path.endswith(".py")
+
+ def run(
+ self, path: str, params: Optional[Dict[str, Any]] = None, **meta: Any
+ ) -> List[Dict[str, Any]]:
+ """Lint the file. Return an array of error dicts if appropriate."""
+ with suppress_stdout():
+ try:
+ if not api.check_file(path, disregard_skip=False, **params or {}):
+ return [
+ {
+ "lnum": 0,
+ "col": 0,
+ "text": "Incorrectly sorted imports.",
+ "type": "ISORT",
+ }
+ ]
+ except FileSkipped:
+ pass
+
+ return []
diff --git a/solutions/.venv/Lib/site-packages/isort/sections.py b/solutions/.venv/Lib/site-packages/isort/sections.py
new file mode 100644
index 000000000..f59db6926
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/sections.py
@@ -0,0 +1,9 @@
+"""Defines all sections isort uses by default"""
+from typing import Tuple
+
+FUTURE: str = "FUTURE"
+STDLIB: str = "STDLIB"
+THIRDPARTY: str = "THIRDPARTY"
+FIRSTPARTY: str = "FIRSTPARTY"
+LOCALFOLDER: str = "LOCALFOLDER"
+DEFAULT: Tuple[str, ...] = (FUTURE, STDLIB, THIRDPARTY, FIRSTPARTY, LOCALFOLDER)
diff --git a/solutions/.venv/Lib/site-packages/isort/settings.py b/solutions/.venv/Lib/site-packages/isort/settings.py
new file mode 100644
index 000000000..a3658ffff
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/settings.py
@@ -0,0 +1,937 @@
+"""isort/settings.py.
+
+Defines how the default settings for isort should be loaded
+"""
+import configparser
+import fnmatch
+import os
+import posixpath
+import re
+import stat
+import subprocess # nosec: Needed for gitignore support.
+import sys
+from dataclasses import dataclass, field
+from pathlib import Path
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Callable,
+ Dict,
+ FrozenSet,
+ Iterable,
+ List,
+ Optional,
+ Pattern,
+ Set,
+ Tuple,
+ Type,
+ Union,
+)
+from warnings import warn
+
+from . import sorting, stdlibs
+from .exceptions import (
+ FormattingPluginDoesNotExist,
+ InvalidSettingsPath,
+ ProfileDoesNotExist,
+ SortingFunctionDoesNotExist,
+ UnsupportedSettings,
+)
+from .profiles import profiles as profiles
+from .sections import DEFAULT as SECTION_DEFAULTS
+from .sections import FIRSTPARTY, FUTURE, LOCALFOLDER, STDLIB, THIRDPARTY
+from .utils import Trie
+from .wrap_modes import WrapModes
+from .wrap_modes import from_string as wrap_mode_from_string
+
+if TYPE_CHECKING:
+ tomllib: Any
+else:
+ if sys.version_info >= (3, 11):
+ import tomllib
+ else:
+ from ._vendored import tomli as tomllib
+
+_SHEBANG_RE = re.compile(rb"^#!.*\bpython[23w]?\b")
+CYTHON_EXTENSIONS = frozenset({"pyx", "pxd"})
+SUPPORTED_EXTENSIONS = frozenset({"py", "pyi", *CYTHON_EXTENSIONS})
+BLOCKED_EXTENSIONS = frozenset({"pex"})
+FILE_SKIP_COMMENTS: Tuple[str, ...] = (
+ "isort:" + "skip_file",
+ "isort: " + "skip_file",
+) # Concatenated to avoid this file being skipped
+MAX_CONFIG_SEARCH_DEPTH: int = 25 # The number of parent directories to for a config file within
+STOP_CONFIG_SEARCH_ON_DIRS: Tuple[str, ...] = (".git", ".hg")
+VALID_PY_TARGETS: Tuple[str, ...] = tuple(
+ target.replace("py", "") for target in dir(stdlibs) if not target.startswith("_")
+)
+CONFIG_SOURCES: Tuple[str, ...] = (
+ ".isort.cfg",
+ "pyproject.toml",
+ "setup.cfg",
+ "tox.ini",
+ ".editorconfig",
+)
+DEFAULT_SKIP: FrozenSet[str] = frozenset(
+ {
+ ".venv",
+ "venv",
+ ".tox",
+ ".eggs",
+ ".git",
+ ".hg",
+ ".mypy_cache",
+ ".nox",
+ ".svn",
+ ".bzr",
+ "_build",
+ "buck-out",
+ "build",
+ "dist",
+ ".pants.d",
+ ".direnv",
+ "node_modules",
+ "__pypackages__",
+ ".pytype",
+ }
+)
+
+CONFIG_SECTIONS: Dict[str, Tuple[str, ...]] = {
+ ".isort.cfg": ("settings", "isort"),
+ "pyproject.toml": ("tool.isort",),
+ "setup.cfg": ("isort", "tool:isort"),
+ "tox.ini": ("isort", "tool:isort"),
+ ".editorconfig": ("*", "*.py", "**.py", "*.{py}"),
+}
+FALLBACK_CONFIG_SECTIONS: Tuple[str, ...] = ("isort", "tool:isort", "tool.isort")
+
+IMPORT_HEADING_PREFIX = "import_heading_"
+IMPORT_FOOTER_PREFIX = "import_footer_"
+KNOWN_PREFIX = "known_"
+KNOWN_SECTION_MAPPING: Dict[str, str] = {
+ STDLIB: "STANDARD_LIBRARY",
+ FUTURE: "FUTURE_LIBRARY",
+ FIRSTPARTY: "FIRST_PARTY",
+ THIRDPARTY: "THIRD_PARTY",
+ LOCALFOLDER: "LOCAL_FOLDER",
+}
+
+RUNTIME_SOURCE = "runtime"
+
+DEPRECATED_SETTINGS = ("not_skip", "keep_direct_and_as_imports")
+
+_STR_BOOLEAN_MAPPING = {
+ "y": True,
+ "yes": True,
+ "t": True,
+ "on": True,
+ "1": True,
+ "true": True,
+ "n": False,
+ "no": False,
+ "f": False,
+ "off": False,
+ "0": False,
+ "false": False,
+}
+
+
+@dataclass(frozen=True)
+class _Config:
+ """Defines the data schema and defaults used for isort configuration.
+
+ NOTE: known lists, such as known_standard_library, are intentionally not complete as they are
+ dynamically determined later on.
+ """
+
+ py_version: str = "3"
+ force_to_top: FrozenSet[str] = frozenset()
+ skip: FrozenSet[str] = DEFAULT_SKIP
+ extend_skip: FrozenSet[str] = frozenset()
+ skip_glob: FrozenSet[str] = frozenset()
+ extend_skip_glob: FrozenSet[str] = frozenset()
+ skip_gitignore: bool = False
+ line_length: int = 79
+ wrap_length: int = 0
+ line_ending: str = ""
+ sections: Tuple[str, ...] = SECTION_DEFAULTS
+ no_sections: bool = False
+ known_future_library: FrozenSet[str] = frozenset(("__future__",))
+ known_third_party: FrozenSet[str] = frozenset()
+ known_first_party: FrozenSet[str] = frozenset()
+ known_local_folder: FrozenSet[str] = frozenset()
+ known_standard_library: FrozenSet[str] = frozenset()
+ extra_standard_library: FrozenSet[str] = frozenset()
+ known_other: Dict[str, FrozenSet[str]] = field(default_factory=dict)
+ multi_line_output: WrapModes = WrapModes.GRID # type: ignore
+ forced_separate: Tuple[str, ...] = ()
+ indent: str = " " * 4
+ comment_prefix: str = " #"
+ length_sort: bool = False
+ length_sort_straight: bool = False
+ length_sort_sections: FrozenSet[str] = frozenset()
+ add_imports: FrozenSet[str] = frozenset()
+ remove_imports: FrozenSet[str] = frozenset()
+ append_only: bool = False
+ reverse_relative: bool = False
+ force_single_line: bool = False
+ single_line_exclusions: Tuple[str, ...] = ()
+ default_section: str = THIRDPARTY
+ import_headings: Dict[str, str] = field(default_factory=dict)
+ import_footers: Dict[str, str] = field(default_factory=dict)
+ balanced_wrapping: bool = False
+ use_parentheses: bool = False
+ order_by_type: bool = True
+ atomic: bool = False
+ lines_before_imports: int = -1
+ lines_after_imports: int = -1
+ lines_between_sections: int = 1
+ lines_between_types: int = 0
+ combine_as_imports: bool = False
+ combine_star: bool = False
+ include_trailing_comma: bool = False
+ from_first: bool = False
+ verbose: bool = False
+ quiet: bool = False
+ force_adds: bool = False
+ force_alphabetical_sort_within_sections: bool = False
+ force_alphabetical_sort: bool = False
+ force_grid_wrap: int = 0
+ force_sort_within_sections: bool = False
+ lexicographical: bool = False
+ group_by_package: bool = False
+ ignore_whitespace: bool = False
+ no_lines_before: FrozenSet[str] = frozenset()
+ no_inline_sort: bool = False
+ ignore_comments: bool = False
+ case_sensitive: bool = False
+ sources: Tuple[Dict[str, Any], ...] = ()
+ virtual_env: str = ""
+ conda_env: str = ""
+ ensure_newline_before_comments: bool = False
+ directory: str = ""
+ profile: str = ""
+ honor_noqa: bool = False
+ src_paths: Tuple[Path, ...] = ()
+ old_finders: bool = False
+ remove_redundant_aliases: bool = False
+ float_to_top: bool = False
+ filter_files: bool = False
+ formatter: str = ""
+ formatting_function: Optional[Callable[[str, str, object], str]] = None
+ color_output: bool = False
+ treat_comments_as_code: FrozenSet[str] = frozenset()
+ treat_all_comments_as_code: bool = False
+ supported_extensions: FrozenSet[str] = SUPPORTED_EXTENSIONS
+ blocked_extensions: FrozenSet[str] = BLOCKED_EXTENSIONS
+ constants: FrozenSet[str] = frozenset()
+ classes: FrozenSet[str] = frozenset()
+ variables: FrozenSet[str] = frozenset()
+ dedup_headings: bool = False
+ only_sections: bool = False
+ only_modified: bool = False
+ combine_straight_imports: bool = False
+ auto_identify_namespace_packages: bool = True
+ namespace_packages: FrozenSet[str] = frozenset()
+ follow_links: bool = True
+ indented_import_headings: bool = True
+ honor_case_in_force_sorted_sections: bool = False
+ sort_relative_in_force_sorted_sections: bool = False
+ overwrite_in_place: bool = False
+ reverse_sort: bool = False
+ star_first: bool = False
+ import_dependencies = Dict[str, str]
+ git_ls_files: Dict[Path, Set[str]] = field(default_factory=dict)
+ format_error: str = "{error}: {message}"
+ format_success: str = "{success}: {message}"
+ sort_order: str = "natural"
+ sort_reexports: bool = False
+ split_on_trailing_comma: bool = False
+
+ def __post_init__(self) -> None:
+ py_version = self.py_version
+ if py_version == "auto": # pragma: no cover
+ if sys.version_info.major == 2 and sys.version_info.minor <= 6:
+ py_version = "2"
+ elif sys.version_info.major == 3 and (
+ sys.version_info.minor <= 5 or sys.version_info.minor >= 12
+ ):
+ py_version = "3"
+ else:
+ py_version = f"{sys.version_info.major}{sys.version_info.minor}"
+
+ if py_version not in VALID_PY_TARGETS:
+ raise ValueError(
+ f"The python version {py_version} is not supported. "
+ "You can set a python version with the -py or --python-version flag. "
+ f"The following versions are supported: {VALID_PY_TARGETS}"
+ )
+
+ if py_version != "all":
+ object.__setattr__(self, "py_version", f"py{py_version}")
+
+ if not self.known_standard_library:
+ object.__setattr__(
+ self, "known_standard_library", frozenset(getattr(stdlibs, self.py_version).stdlib)
+ )
+
+ if self.multi_line_output == WrapModes.VERTICAL_GRID_GROUPED_NO_COMMA: # type: ignore
+ vertical_grid_grouped = WrapModes.VERTICAL_GRID_GROUPED # type: ignore
+ object.__setattr__(self, "multi_line_output", vertical_grid_grouped)
+ if self.force_alphabetical_sort:
+ object.__setattr__(self, "force_alphabetical_sort_within_sections", True)
+ object.__setattr__(self, "no_sections", True)
+ object.__setattr__(self, "lines_between_types", 1)
+ object.__setattr__(self, "from_first", True)
+ if self.wrap_length > self.line_length:
+ raise ValueError(
+ "wrap_length must be set lower than or equal to line_length: "
+ f"{self.wrap_length} > {self.line_length}."
+ )
+
+ def __hash__(self) -> int:
+ return id(self)
+
+
+_DEFAULT_SETTINGS = {**vars(_Config()), "source": "defaults"}
+
+
+class Config(_Config):
+ def __init__(
+ self,
+ settings_file: str = "",
+ settings_path: str = "",
+ config: Optional[_Config] = None,
+ **config_overrides: Any,
+ ):
+ self._known_patterns: Optional[List[Tuple[Pattern[str], str]]] = None
+ self._section_comments: Optional[Tuple[str, ...]] = None
+ self._section_comments_end: Optional[Tuple[str, ...]] = None
+ self._skips: Optional[FrozenSet[str]] = None
+ self._skip_globs: Optional[FrozenSet[str]] = None
+ self._sorting_function: Optional[Callable[..., List[str]]] = None
+
+ if config:
+ config_vars = vars(config).copy()
+ config_vars.update(config_overrides)
+ config_vars["py_version"] = config_vars["py_version"].replace("py", "")
+ config_vars.pop("_known_patterns")
+ config_vars.pop("_section_comments")
+ config_vars.pop("_section_comments_end")
+ config_vars.pop("_skips")
+ config_vars.pop("_skip_globs")
+ config_vars.pop("_sorting_function")
+ super().__init__(**config_vars)
+ return
+
+ # We can't use self.quiet to conditionally show warnings before super.__init__() is called
+ # at the end of this method. _Config is also frozen so setting self.quiet isn't possible.
+ # Therefore we extract quiet early here in a variable and use that in warning conditions.
+ quiet = config_overrides.get("quiet", False)
+
+ sources: List[Dict[str, Any]] = [_DEFAULT_SETTINGS]
+
+ config_settings: Dict[str, Any]
+ project_root: str
+ if settings_file:
+ config_settings = _get_config_data(
+ settings_file,
+ CONFIG_SECTIONS.get(os.path.basename(settings_file), FALLBACK_CONFIG_SECTIONS),
+ )
+ project_root = os.path.dirname(settings_file)
+ if not config_settings and not quiet:
+ warn(
+ f"A custom settings file was specified: {settings_file} but no configuration "
+ "was found inside. This can happen when [settings] is used as the config "
+ "header instead of [isort]. "
+ "See: https://pycqa.github.io/isort/docs/configuration/config_files"
+ "/#custom_config_files for more information."
+ )
+ elif settings_path:
+ if not os.path.exists(settings_path):
+ raise InvalidSettingsPath(settings_path)
+
+ settings_path = os.path.abspath(settings_path)
+ project_root, config_settings = _find_config(settings_path)
+ else:
+ config_settings = {}
+ project_root = os.getcwd()
+
+ profile_name = config_overrides.get("profile", config_settings.get("profile", ""))
+ profile: Dict[str, Any] = {}
+ if profile_name:
+ if profile_name not in profiles:
+ import pkg_resources
+
+ for plugin in pkg_resources.iter_entry_points("isort.profiles"):
+ profiles.setdefault(plugin.name, plugin.load())
+
+ if profile_name not in profiles:
+ raise ProfileDoesNotExist(profile_name)
+
+ profile = profiles[profile_name].copy()
+ profile["source"] = f"{profile_name} profile"
+ sources.append(profile)
+
+ if config_settings:
+ sources.append(config_settings)
+ if config_overrides:
+ config_overrides["source"] = RUNTIME_SOURCE
+ sources.append(config_overrides)
+
+ combined_config = {**profile, **config_settings, **config_overrides}
+ if "indent" in combined_config:
+ indent = str(combined_config["indent"])
+ if indent.isdigit():
+ indent = " " * int(indent)
+ else:
+ indent = indent.strip("'").strip('"')
+ if indent.lower() == "tab":
+ indent = "\t"
+ combined_config["indent"] = indent
+
+ known_other = {}
+ import_headings = {}
+ import_footers = {}
+ for key, value in tuple(combined_config.items()):
+ # Collect all known sections beyond those that have direct entries
+ if key.startswith(KNOWN_PREFIX) and key not in (
+ "known_standard_library",
+ "known_future_library",
+ "known_third_party",
+ "known_first_party",
+ "known_local_folder",
+ ):
+ import_heading = key[len(KNOWN_PREFIX) :].lower()
+ maps_to_section = import_heading.upper()
+ combined_config.pop(key)
+ if maps_to_section in KNOWN_SECTION_MAPPING:
+ section_name = f"known_{KNOWN_SECTION_MAPPING[maps_to_section].lower()}"
+ if section_name in combined_config and not quiet:
+ warn(
+ f"Can't set both {key} and {section_name} in the same config file.\n"
+ f"Default to {section_name} if unsure."
+ "\n\n"
+ "See: https://pycqa.github.io/isort/"
+ "#custom-sections-and-ordering."
+ )
+ else:
+ combined_config[section_name] = frozenset(value)
+ else:
+ known_other[import_heading] = frozenset(value)
+ if maps_to_section not in combined_config.get("sections", ()) and not quiet:
+ warn(
+ f"`{key}` setting is defined, but {maps_to_section} is not"
+ " included in `sections` config option:"
+ f" {combined_config.get('sections', SECTION_DEFAULTS)}.\n\n"
+ "See: https://pycqa.github.io/isort/"
+ "#custom-sections-and-ordering."
+ )
+ if key.startswith(IMPORT_HEADING_PREFIX):
+ import_headings[key[len(IMPORT_HEADING_PREFIX) :].lower()] = str(value)
+ if key.startswith(IMPORT_FOOTER_PREFIX):
+ import_footers[key[len(IMPORT_FOOTER_PREFIX) :].lower()] = str(value)
+
+ # Coerce all provided config values into their correct type
+ default_value = _DEFAULT_SETTINGS.get(key, None)
+ if default_value is None:
+ continue
+
+ combined_config[key] = type(default_value)(value)
+
+ for section in combined_config.get("sections", ()):
+ if section in SECTION_DEFAULTS:
+ continue
+
+ if not section.lower() in known_other:
+ config_keys = ", ".join(known_other.keys())
+ warn(
+ f"`sections` setting includes {section}, but no known_{section.lower()} "
+ "is defined. "
+ f"The following known_SECTION config options are defined: {config_keys}."
+ )
+
+ if "directory" not in combined_config:
+ combined_config["directory"] = (
+ os.path.dirname(config_settings["source"])
+ if config_settings.get("source", None)
+ else os.getcwd()
+ )
+
+ path_root = Path(combined_config.get("directory", project_root)).resolve()
+ path_root = path_root if path_root.is_dir() else path_root.parent
+ if "src_paths" not in combined_config:
+ combined_config["src_paths"] = (path_root / "src", path_root)
+ else:
+ src_paths: List[Path] = []
+ for src_path in combined_config.get("src_paths", ()):
+ full_paths = (
+ path_root.glob(src_path) if "*" in str(src_path) else [path_root / src_path]
+ )
+ for path in full_paths:
+ if path not in src_paths:
+ src_paths.append(path)
+
+ combined_config["src_paths"] = tuple(src_paths)
+
+ if "formatter" in combined_config:
+ import pkg_resources
+
+ for plugin in pkg_resources.iter_entry_points("isort.formatters"):
+ if plugin.name == combined_config["formatter"]:
+ combined_config["formatting_function"] = plugin.load()
+ break
+ else:
+ raise FormattingPluginDoesNotExist(combined_config["formatter"])
+
+ # Remove any config values that are used for creating config object but
+ # aren't defined in dataclass
+ combined_config.pop("source", None)
+ combined_config.pop("sources", None)
+ combined_config.pop("runtime_src_paths", None)
+
+ deprecated_options_used = [
+ option for option in combined_config if option in DEPRECATED_SETTINGS
+ ]
+ if deprecated_options_used:
+ for deprecated_option in deprecated_options_used:
+ combined_config.pop(deprecated_option)
+ if not quiet:
+ warn(
+ "W0503: Deprecated config options were used: "
+ f"{', '.join(deprecated_options_used)}."
+ "Please see the 5.0.0 upgrade guide: "
+ "https://pycqa.github.io/isort/docs/upgrade_guides/5.0.0.html"
+ )
+
+ if known_other:
+ combined_config["known_other"] = known_other
+ if import_headings:
+ for import_heading_key in import_headings:
+ combined_config.pop(f"{IMPORT_HEADING_PREFIX}{import_heading_key}")
+ combined_config["import_headings"] = import_headings
+ if import_footers:
+ for import_footer_key in import_footers:
+ combined_config.pop(f"{IMPORT_FOOTER_PREFIX}{import_footer_key}")
+ combined_config["import_footers"] = import_footers
+
+ unsupported_config_errors = {}
+ for option in set(combined_config.keys()).difference(
+ getattr(_Config, "__dataclass_fields__", {}).keys()
+ ):
+ for source in reversed(sources):
+ if option in source:
+ unsupported_config_errors[option] = {
+ "value": source[option],
+ "source": source["source"],
+ }
+ if unsupported_config_errors:
+ raise UnsupportedSettings(unsupported_config_errors)
+
+ super().__init__(sources=tuple(sources), **combined_config)
+
+ def is_supported_filetype(self, file_name: str) -> bool:
+ _root, ext = os.path.splitext(file_name)
+ ext = ext.lstrip(".")
+ if ext in self.supported_extensions:
+ return True
+ if ext in self.blocked_extensions:
+ return False
+
+ # Skip editor backup files.
+ if file_name.endswith("~"):
+ return False
+
+ try:
+ if stat.S_ISFIFO(os.stat(file_name).st_mode):
+ return False
+ except OSError:
+ pass
+
+ try:
+ with open(file_name, "rb") as fp:
+ line = fp.readline(100)
+ except OSError:
+ return False
+ else:
+ return bool(_SHEBANG_RE.match(line))
+
+ def _check_folder_git_ls_files(self, folder: str) -> Optional[Path]:
+ env = {**os.environ, "LANG": "C.UTF-8"}
+ try:
+ topfolder_result = subprocess.check_output( # nosec # skipcq: PYL-W1510
+ ["git", "-C", folder, "rev-parse", "--show-toplevel"], encoding="utf-8", env=env
+ )
+ except subprocess.CalledProcessError:
+ return None
+
+ git_folder = Path(topfolder_result.rstrip()).resolve()
+
+ # files committed to git
+ tracked_files = (
+ subprocess.check_output( # nosec # skipcq: PYL-W1510
+ ["git", "-C", str(git_folder), "ls-files", "-z"],
+ encoding="utf-8",
+ env=env,
+ )
+ .rstrip("\0")
+ .split("\0")
+ )
+ # files that haven't been committed yet, but aren't ignored
+ tracked_files_others = (
+ subprocess.check_output( # nosec # skipcq: PYL-W1510
+ ["git", "-C", str(git_folder), "ls-files", "-z", "--others", "--exclude-standard"],
+ encoding="utf-8",
+ env=env,
+ )
+ .rstrip("\0")
+ .split("\0")
+ )
+
+ self.git_ls_files[git_folder] = {
+ str(git_folder / Path(f)) for f in tracked_files + tracked_files_others
+ }
+ return git_folder
+
+ def is_skipped(self, file_path: Path) -> bool:
+ """Returns True if the file and/or folder should be skipped based on current settings."""
+ if self.directory and Path(self.directory) in file_path.resolve().parents:
+ file_name = os.path.relpath(file_path.resolve(), self.directory)
+ else:
+ file_name = str(file_path)
+
+ os_path = str(file_path)
+
+ normalized_path = os_path.replace("\\", "/")
+ if normalized_path[1:2] == ":":
+ normalized_path = normalized_path[2:]
+
+ for skip_path in self.skips:
+ if posixpath.abspath(normalized_path) == posixpath.abspath(
+ skip_path.replace("\\", "/")
+ ):
+ return True
+
+ position = os.path.split(file_name)
+ while position[1]:
+ if position[1] in self.skips:
+ return True
+ position = os.path.split(position[0])
+
+ for sglob in self.skip_globs:
+ if fnmatch.fnmatch(file_name, sglob) or fnmatch.fnmatch("/" + file_name, sglob):
+ return True
+
+ if not (os.path.isfile(os_path) or os.path.isdir(os_path) or os.path.islink(os_path)):
+ return True
+
+ if self.skip_gitignore:
+ if file_path.name == ".git": # pragma: no cover
+ return True
+
+ git_folder = None
+
+ file_paths = [file_path, file_path.resolve()]
+ for folder in self.git_ls_files:
+ if any(folder in path.parents for path in file_paths):
+ git_folder = folder
+ break
+ else:
+ git_folder = self._check_folder_git_ls_files(str(file_path.parent))
+
+ # git_ls_files are good files you should parse. If you're not in the allow list, skip.
+
+ if (
+ git_folder
+ and not file_path.is_dir()
+ and str(file_path.resolve()) not in self.git_ls_files[git_folder]
+ ):
+ return True
+
+ return False
+
+ @property
+ def known_patterns(self) -> List[Tuple[Pattern[str], str]]:
+ if self._known_patterns is not None:
+ return self._known_patterns
+
+ self._known_patterns = []
+ pattern_sections = [STDLIB] + [section for section in self.sections if section != STDLIB]
+ for placement in reversed(pattern_sections):
+ known_placement = KNOWN_SECTION_MAPPING.get(placement, placement).lower()
+ config_key = f"{KNOWN_PREFIX}{known_placement}"
+ known_modules = getattr(self, config_key, self.known_other.get(known_placement, ()))
+ extra_modules = getattr(self, f"extra_{known_placement}", ())
+ all_modules = set(extra_modules).union(known_modules)
+ known_patterns = [
+ pattern
+ for known_pattern in all_modules
+ for pattern in self._parse_known_pattern(known_pattern)
+ ]
+ for known_pattern in known_patterns:
+ regexp = "^" + known_pattern.replace("*", ".*").replace("?", ".?") + "$"
+ self._known_patterns.append((re.compile(regexp), placement))
+
+ return self._known_patterns
+
+ @property
+ def section_comments(self) -> Tuple[str, ...]:
+ if self._section_comments is not None:
+ return self._section_comments
+
+ self._section_comments = tuple(f"# {heading}" for heading in self.import_headings.values())
+ return self._section_comments
+
+ @property
+ def section_comments_end(self) -> Tuple[str, ...]:
+ if self._section_comments_end is not None:
+ return self._section_comments_end
+
+ self._section_comments_end = tuple(f"# {footer}" for footer in self.import_footers.values())
+ return self._section_comments_end
+
+ @property
+ def skips(self) -> FrozenSet[str]:
+ if self._skips is not None:
+ return self._skips
+
+ self._skips = self.skip.union(self.extend_skip)
+ return self._skips
+
+ @property
+ def skip_globs(self) -> FrozenSet[str]:
+ if self._skip_globs is not None:
+ return self._skip_globs
+
+ self._skip_globs = self.skip_glob.union(self.extend_skip_glob)
+ return self._skip_globs
+
+ @property
+ def sorting_function(self) -> Callable[..., List[str]]:
+ if self._sorting_function is not None:
+ return self._sorting_function
+
+ if self.sort_order == "natural":
+ self._sorting_function = sorting.naturally
+ elif self.sort_order == "native":
+ self._sorting_function = sorted
+ else:
+ available_sort_orders = ["natural", "native"]
+ import pkg_resources
+
+ for sort_plugin in pkg_resources.iter_entry_points("isort.sort_function"):
+ available_sort_orders.append(sort_plugin.name)
+ if sort_plugin.name == self.sort_order:
+ self._sorting_function = sort_plugin.load()
+ break
+ else:
+ raise SortingFunctionDoesNotExist(self.sort_order, available_sort_orders)
+
+ return self._sorting_function
+
+ def _parse_known_pattern(self, pattern: str) -> List[str]:
+ """Expand pattern if identified as a directory and return found sub packages"""
+ if pattern.endswith(os.path.sep):
+ patterns = [
+ filename
+ for filename in os.listdir(os.path.join(self.directory, pattern))
+ if os.path.isdir(os.path.join(self.directory, pattern, filename))
+ ]
+ else:
+ patterns = [pattern]
+
+ return patterns
+
+
+def _get_str_to_type_converter(setting_name: str) -> Union[Callable[[str], Any], Type[Any]]:
+ type_converter: Union[Callable[[str], Any], Type[Any]] = type(
+ _DEFAULT_SETTINGS.get(setting_name, "")
+ )
+ if type_converter == WrapModes:
+ type_converter = wrap_mode_from_string
+ return type_converter
+
+
+def _as_list(value: str) -> List[str]:
+ if isinstance(value, list):
+ return [item.strip() for item in value]
+ filtered = [item.strip() for item in value.replace("\n", ",").split(",") if item.strip()]
+ return filtered
+
+
+def _abspaths(cwd: str, values: Iterable[str]) -> Set[str]:
+ paths = {
+ os.path.join(cwd, value)
+ if not value.startswith(os.path.sep) and value.endswith(os.path.sep)
+ else value
+ for value in values
+ }
+ return paths
+
+
+def _find_config(path: str) -> Tuple[str, Dict[str, Any]]:
+ current_directory = path
+ tries = 0
+ while current_directory and tries < MAX_CONFIG_SEARCH_DEPTH:
+ for config_file_name in CONFIG_SOURCES:
+ potential_config_file = os.path.join(current_directory, config_file_name)
+ if os.path.isfile(potential_config_file):
+ config_data: Dict[str, Any]
+ try:
+ config_data = _get_config_data(
+ potential_config_file, CONFIG_SECTIONS[config_file_name]
+ )
+ except Exception:
+ warn(f"Failed to pull configuration information from {potential_config_file}")
+ config_data = {}
+ if config_data:
+ return (current_directory, config_data)
+
+ for stop_dir in STOP_CONFIG_SEARCH_ON_DIRS:
+ if os.path.isdir(os.path.join(current_directory, stop_dir)):
+ return (current_directory, {})
+
+ new_directory = os.path.split(current_directory)[0]
+ if new_directory == current_directory:
+ break
+
+ current_directory = new_directory
+ tries += 1
+
+ return (path, {})
+
+
+def find_all_configs(path: str) -> Trie:
+ """
+ Looks for config files in the path provided and in all of its sub-directories.
+ Parses and stores any config file encountered in a trie and returns the root of
+ the trie
+ """
+ trie_root = Trie("default", {})
+
+ for dirpath, _, _ in os.walk(path):
+ for config_file_name in CONFIG_SOURCES:
+ potential_config_file = os.path.join(dirpath, config_file_name)
+ if os.path.isfile(potential_config_file):
+ config_data: Dict[str, Any]
+ try:
+ config_data = _get_config_data(
+ potential_config_file, CONFIG_SECTIONS[config_file_name]
+ )
+ except Exception:
+ warn(f"Failed to pull configuration information from {potential_config_file}")
+ config_data = {}
+
+ if config_data:
+ trie_root.insert(potential_config_file, config_data)
+ break
+
+ return trie_root
+
+
+def _get_config_data(file_path: str, sections: Tuple[str, ...]) -> Dict[str, Any]:
+ settings: Dict[str, Any] = {}
+
+ if file_path.endswith(".toml"):
+ with open(file_path, "rb") as bin_config_file:
+ config = tomllib.load(bin_config_file)
+ for section in sections:
+ config_section = config
+ for key in section.split("."):
+ config_section = config_section.get(key, {})
+ settings.update(config_section)
+ else:
+ with open(file_path, encoding="utf-8") as config_file:
+ if file_path.endswith(".editorconfig"):
+ line = "\n"
+ last_position = config_file.tell()
+ while line:
+ line = config_file.readline()
+ if "[" in line:
+ config_file.seek(last_position)
+ break
+ last_position = config_file.tell()
+
+ config = configparser.ConfigParser(strict=False)
+ config.read_file(config_file)
+ for section in sections:
+ if section.startswith("*.{") and section.endswith("}"):
+ extension = section[len("*.{") : -1]
+ for config_key in config.keys():
+ if (
+ config_key.startswith("*.{")
+ and config_key.endswith("}")
+ and extension
+ in map(
+ lambda text: text.strip(), config_key[len("*.{") : -1].split(",") # type: ignore # noqa
+ )
+ ):
+ settings.update(config.items(config_key))
+
+ elif config.has_section(section):
+ settings.update(config.items(section))
+
+ if settings:
+ settings["source"] = file_path
+
+ if file_path.endswith(".editorconfig"):
+ indent_style = settings.pop("indent_style", "").strip()
+ indent_size = settings.pop("indent_size", "").strip()
+ if indent_size == "tab":
+ indent_size = settings.pop("tab_width", "").strip()
+
+ if indent_style == "space":
+ settings["indent"] = " " * (indent_size and int(indent_size) or 4)
+
+ elif indent_style == "tab":
+ settings["indent"] = "\t" * (indent_size and int(indent_size) or 1)
+
+ max_line_length = settings.pop("max_line_length", "").strip()
+ if max_line_length and (max_line_length == "off" or max_line_length.isdigit()):
+ settings["line_length"] = (
+ float("inf") if max_line_length == "off" else int(max_line_length)
+ )
+ settings = {
+ key: value
+ for key, value in settings.items()
+ if key in _DEFAULT_SETTINGS.keys() or key.startswith(KNOWN_PREFIX)
+ }
+
+ for key, value in settings.items():
+ existing_value_type = _get_str_to_type_converter(key)
+ if existing_value_type == tuple:
+ settings[key] = tuple(_as_list(value))
+ elif existing_value_type == frozenset:
+ settings[key] = frozenset(_as_list(settings.get(key))) # type: ignore
+ elif existing_value_type == bool:
+ # Only some configuration formats support native boolean values.
+ if not isinstance(value, bool):
+ value = _as_bool(value)
+ settings[key] = value
+ elif key.startswith(KNOWN_PREFIX):
+ settings[key] = _abspaths(os.path.dirname(file_path), _as_list(value))
+ elif key == "force_grid_wrap":
+ try:
+ result = existing_value_type(value)
+ except ValueError: # backwards compatibility for true / false force grid wrap
+ result = 0 if value.lower().strip() == "false" else 2
+ settings[key] = result
+ elif key == "comment_prefix":
+ settings[key] = str(value).strip("'").strip('"')
+ else:
+ settings[key] = existing_value_type(value)
+
+ return settings
+
+
+def _as_bool(value: str) -> bool:
+ """Given a string value that represents True or False, returns the Boolean equivalent.
+ Heavily inspired from distutils strtobool.
+ """
+ try:
+ return _STR_BOOLEAN_MAPPING[value.lower()]
+ except KeyError:
+ raise ValueError(f"invalid truth value {value}")
+
+
+DEFAULT_CONFIG = Config()
diff --git a/solutions/.venv/Lib/site-packages/isort/setuptools_commands.py b/solutions/.venv/Lib/site-packages/isort/setuptools_commands.py
new file mode 100644
index 000000000..e0538ffe1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/setuptools_commands.py
@@ -0,0 +1,61 @@
+import glob
+import os
+import sys
+from typing import Any, Dict, Iterator, List
+from warnings import warn
+
+import setuptools # type: ignore
+
+from . import api
+from .settings import DEFAULT_CONFIG
+
+
+class ISortCommand(setuptools.Command): # type: ignore
+ """The :class:`ISortCommand` class is used by setuptools to perform
+ imports checks on registered modules.
+ """
+
+ description = "Run isort on modules registered in setuptools"
+ user_options: List[Any] = []
+
+ def initialize_options(self) -> None:
+ default_settings = vars(DEFAULT_CONFIG).copy()
+ for key, value in default_settings.items():
+ setattr(self, key, value)
+
+ def finalize_options(self) -> None:
+ """Get options from config files."""
+ self.arguments: Dict[str, Any] = {} # skipcq: PYL-W0201
+ self.arguments["settings_path"] = os.getcwd()
+
+ def distribution_files(self) -> Iterator[str]:
+ """Find distribution packages."""
+ # This is verbatim from flake8
+ if self.distribution.packages: # pragma: no cover
+ package_dirs = self.distribution.package_dir or {}
+ for package in self.distribution.packages:
+ pkg_dir = package
+ if package in package_dirs:
+ pkg_dir = package_dirs[package]
+ elif "" in package_dirs: # pragma: no cover
+ pkg_dir = package_dirs[""] + os.path.sep + pkg_dir
+ yield pkg_dir.replace(".", os.path.sep)
+
+ if self.distribution.py_modules:
+ for filename in self.distribution.py_modules:
+ yield f"{filename}.py"
+ # Don't miss the setup.py file itself
+ yield "setup.py"
+
+ def run(self) -> None:
+ arguments = self.arguments
+ wrong_sorted_files = False
+ for path in self.distribution_files():
+ for python_file in glob.iglob(os.path.join(path, "*.py")):
+ try:
+ if not api.check_file(python_file, **arguments):
+ wrong_sorted_files = True # pragma: no cover
+ except OSError as error: # pragma: no cover
+ warn(f"Unable to parse file {python_file} due to {error}")
+ if wrong_sorted_files:
+ sys.exit(1) # pragma: no cover
diff --git a/solutions/.venv/Lib/site-packages/isort/sorting.py b/solutions/.venv/Lib/site-packages/isort/sorting.py
new file mode 100644
index 000000000..7ad70b221
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/sorting.py
@@ -0,0 +1,130 @@
+import re
+from typing import TYPE_CHECKING, Any, Callable, Iterable, List, Optional
+
+if TYPE_CHECKING:
+ from .settings import Config
+else:
+ Config = Any
+
+_import_line_intro_re = re.compile("^(?:from|import) ")
+_import_line_midline_import_re = re.compile(" import ")
+
+
+def module_key(
+ module_name: str,
+ config: Config,
+ sub_imports: bool = False,
+ ignore_case: bool = False,
+ section_name: Optional[Any] = None,
+ straight_import: Optional[bool] = False,
+) -> str:
+ match = re.match(r"^(\.+)\s*(.*)", module_name)
+ if match:
+ sep = " " if config.reverse_relative else "_"
+ module_name = sep.join(match.groups())
+
+ prefix = ""
+ if ignore_case:
+ module_name = str(module_name).lower()
+ else:
+ module_name = str(module_name)
+
+ if sub_imports and config.order_by_type:
+ if module_name in config.constants:
+ prefix = "A"
+ elif module_name in config.classes:
+ prefix = "B"
+ elif module_name in config.variables:
+ prefix = "C"
+ elif module_name.isupper() and len(module_name) > 1: # see issue #376
+ prefix = "A"
+ elif module_name in config.classes or module_name[0:1].isupper():
+ prefix = "B"
+ else:
+ prefix = "C"
+ if not config.case_sensitive:
+ module_name = module_name.lower()
+
+ length_sort = (
+ config.length_sort
+ or (config.length_sort_straight and straight_import)
+ or str(section_name).lower() in config.length_sort_sections
+ )
+ _length_sort_maybe = (str(len(module_name)) + ":" + module_name) if length_sort else module_name
+ return f"{module_name in config.force_to_top and 'A' or 'B'}{prefix}{_length_sort_maybe}"
+
+
+def section_key(line: str, config: Config) -> str:
+ section = "B"
+
+ if (
+ not config.sort_relative_in_force_sorted_sections
+ and config.reverse_relative
+ and line.startswith("from .")
+ ):
+ match = re.match(r"^from (\.+)\s*(.*)", line)
+ if match: # pragma: no cover - regex always matches if line starts with "from ."
+ line = f"from {' '.join(match.groups())}"
+ if config.group_by_package and line.strip().startswith("from"):
+ line = line.split(" import", 1)[0]
+
+ if config.lexicographical:
+ line = _import_line_intro_re.sub("", _import_line_midline_import_re.sub(".", line))
+ else:
+ line = re.sub("^from ", "", line)
+ line = re.sub("^import ", "", line)
+ if config.sort_relative_in_force_sorted_sections:
+ sep = " " if config.reverse_relative else "_"
+ line = re.sub(r"^(\.+)", rf"\1{sep}", line)
+ if line.split(" ")[0] in config.force_to_top:
+ section = "A"
+ # * If honor_case_in_force_sorted_sections is true, and case_sensitive and
+ # order_by_type are different, only ignore case in part of the line.
+ # * Otherwise, let order_by_type decide the sorting of the whole line. This
+ # is only "correct" if case_sensitive and order_by_type have the same value.
+ if config.honor_case_in_force_sorted_sections and config.case_sensitive != config.order_by_type:
+ split_module = line.split(" import ", 1)
+ if len(split_module) > 1:
+ module_name, names = split_module
+ if not config.case_sensitive:
+ module_name = module_name.lower()
+ if not config.order_by_type:
+ names = names.lower()
+ line = " import ".join([module_name, names])
+ elif not config.case_sensitive:
+ line = line.lower()
+ elif not config.order_by_type:
+ line = line.lower()
+
+ return f"{section}{len(line) if config.length_sort else ''}{line}"
+
+
+def sort(
+ config: Config,
+ to_sort: Iterable[str],
+ key: Optional[Callable[[str], Any]] = None,
+ reverse: bool = False,
+) -> List[str]:
+ return config.sorting_function(to_sort, key=key, reverse=reverse)
+
+
+def naturally(
+ to_sort: Iterable[str], key: Optional[Callable[[str], Any]] = None, reverse: bool = False
+) -> List[str]:
+ """Returns a naturally sorted list"""
+ if key is None:
+ key_callback = _natural_keys
+ else:
+
+ def key_callback(text: str) -> List[Any]:
+ return _natural_keys(key(text)) # type: ignore
+
+ return sorted(to_sort, key=key_callback, reverse=reverse)
+
+
+def _atoi(text: str) -> Any:
+ return int(text) if text.isdigit() else text
+
+
+def _natural_keys(text: str) -> List[Any]:
+ return [_atoi(c) for c in re.split(r"(\d+)", text)]
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/__init__.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/__init__.py
new file mode 100644
index 000000000..fc9dcbb8d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/__init__.py
@@ -0,0 +1,2 @@
+from . import all as _all
+from . import py2, py3, py27, py36, py37, py38, py39, py310, py311, py312
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/all.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/all.py
new file mode 100644
index 000000000..08a365e19
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/all.py
@@ -0,0 +1,3 @@
+from . import py2, py3
+
+stdlib = py2.stdlib | py3.stdlib
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py2.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py2.py
new file mode 100644
index 000000000..74af019e4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py2.py
@@ -0,0 +1,3 @@
+from . import py27
+
+stdlib = py27.stdlib
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py27.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py27.py
new file mode 100644
index 000000000..a9bc99d0c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py27.py
@@ -0,0 +1,301 @@
+"""
+File contains the standard library of Python 2.7.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "AL",
+ "BaseHTTPServer",
+ "Bastion",
+ "CGIHTTPServer",
+ "Carbon",
+ "ColorPicker",
+ "ConfigParser",
+ "Cookie",
+ "DEVICE",
+ "DocXMLRPCServer",
+ "EasyDialogs",
+ "FL",
+ "FrameWork",
+ "GL",
+ "HTMLParser",
+ "MacOS",
+ "MimeWriter",
+ "MiniAEFrame",
+ "Nav",
+ "PixMapWrapper",
+ "Queue",
+ "SUNAUDIODEV",
+ "ScrolledText",
+ "SimpleHTTPServer",
+ "SimpleXMLRPCServer",
+ "SocketServer",
+ "StringIO",
+ "Tix",
+ "Tkinter",
+ "UserDict",
+ "UserList",
+ "UserString",
+ "W",
+ "__builtin__",
+ "_ast",
+ "_winreg",
+ "abc",
+ "aepack",
+ "aetools",
+ "aetypes",
+ "aifc",
+ "al",
+ "anydbm",
+ "applesingle",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "autoGIL",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "bsddb",
+ "buildtools",
+ "bz2",
+ "cPickle",
+ "cProfile",
+ "cStringIO",
+ "calendar",
+ "cd",
+ "cfmfile",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "commands",
+ "compileall",
+ "compiler",
+ "contextlib",
+ "cookielib",
+ "copy",
+ "copy_reg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbhash",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dircache",
+ "dis",
+ "distutils",
+ "dl",
+ "doctest",
+ "dumbdbm",
+ "dummy_thread",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "errno",
+ "exceptions",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "findertools",
+ "fl",
+ "flp",
+ "fm",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fpformat",
+ "fractions",
+ "ftplib",
+ "functools",
+ "future_builtins",
+ "gc",
+ "gdbm",
+ "gensuitemodule",
+ "getopt",
+ "getpass",
+ "gettext",
+ "gl",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "hotshot",
+ "htmlentitydefs",
+ "htmllib",
+ "httplib",
+ "ic",
+ "icopen",
+ "imageop",
+ "imaplib",
+ "imgfile",
+ "imghdr",
+ "imp",
+ "importlib",
+ "imputil",
+ "inspect",
+ "io",
+ "itertools",
+ "jpeg",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "macerrors",
+ "macostools",
+ "macpath",
+ "macresource",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "md5",
+ "mhlib",
+ "mimetools",
+ "mimetypes",
+ "mimify",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multifile",
+ "multiprocessing",
+ "mutex",
+ "netrc",
+ "new",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "popen2",
+ "poplib",
+ "posix",
+ "posixfile",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "resource",
+ "rexec",
+ "rfc822",
+ "rlcompleter",
+ "robotparser",
+ "runpy",
+ "sched",
+ "select",
+ "sets",
+ "sgmllib",
+ "sha",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statvfs",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "sunaudiodev",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "thread",
+ "threading",
+ "time",
+ "timeit",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "ttk",
+ "tty",
+ "turtle",
+ "types",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "urllib2",
+ "urlparse",
+ "user",
+ "uu",
+ "uuid",
+ "videoreader",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "whichdb",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpclib",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py3.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py3.py
new file mode 100644
index 000000000..c94e97972
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py3.py
@@ -0,0 +1,11 @@
+from . import py36, py37, py38, py39, py310, py311, py312
+
+stdlib = (
+ py36.stdlib
+ | py37.stdlib
+ | py38.stdlib
+ | py39.stdlib
+ | py310.stdlib
+ | py311.stdlib
+ | py312.stdlib
+)
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py310.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py310.py
new file mode 100644
index 000000000..f45cf50a3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py310.py
@@ -0,0 +1,222 @@
+"""
+File contains the standard library of Python 3.10.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_ast",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "graphlib",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "idlelib",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+ "zoneinfo",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py311.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py311.py
new file mode 100644
index 000000000..8f1d6e1fa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py311.py
@@ -0,0 +1,225 @@
+"""
+File contains the standard library of Python 3.11.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_ast",
+ "_thread",
+ "_tkinter",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "graphlib",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "idlelib",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "sitecustomize",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "tomllib",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "usercustomize",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+ "zoneinfo",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py312.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py312.py
new file mode 100644
index 000000000..cedf2a2f7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py312.py
@@ -0,0 +1,220 @@
+"""
+File contains the standard library of Python 3.12.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_ast",
+ "_thread",
+ "_tkinter",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asyncio",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "doctest",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "graphlib",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "idlelib",
+ "imaplib",
+ "imghdr",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "sitecustomize",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "tomllib",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "usercustomize",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+ "zoneinfo",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py36.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py36.py
new file mode 100644
index 000000000..59ebd24cb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py36.py
@@ -0,0 +1,224 @@
+"""
+File contains the standard library of Python 3.6.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_ast",
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py37.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py37.py
new file mode 100644
index 000000000..e0ad1228a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py37.py
@@ -0,0 +1,225 @@
+"""
+File contains the standard library of Python 3.7.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_ast",
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py38.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py38.py
new file mode 100644
index 000000000..3d89fd26b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py38.py
@@ -0,0 +1,224 @@
+"""
+File contains the standard library of Python 3.8.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_ast",
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/stdlibs/py39.py b/solutions/.venv/Lib/site-packages/isort/stdlibs/py39.py
new file mode 100644
index 000000000..4b7dd5954
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/stdlibs/py39.py
@@ -0,0 +1,224 @@
+"""
+File contains the standard library of Python 3.9.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_ast",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "graphlib",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+ "zoneinfo",
+}
diff --git a/solutions/.venv/Lib/site-packages/isort/utils.py b/solutions/.venv/Lib/site-packages/isort/utils.py
new file mode 100644
index 000000000..339c86f6a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/utils.py
@@ -0,0 +1,72 @@
+import os
+import sys
+from pathlib import Path
+from typing import Any, Dict, Optional, Tuple
+
+
+class TrieNode:
+ def __init__(self, config_file: str = "", config_data: Optional[Dict[str, Any]] = None) -> None:
+ if not config_data:
+ config_data = {}
+
+ self.nodes: Dict[str, TrieNode] = {}
+ self.config_info: Tuple[str, Dict[str, Any]] = (config_file, config_data)
+
+
+class Trie:
+ """
+ A prefix tree to store the paths of all config files and to search the nearest config
+ associated with each file
+ """
+
+ def __init__(self, config_file: str = "", config_data: Optional[Dict[str, Any]] = None) -> None:
+ self.root: TrieNode = TrieNode(config_file, config_data)
+
+ def insert(self, config_file: str, config_data: Dict[str, Any]) -> None:
+ resolved_config_path_as_tuple = Path(config_file).parent.resolve().parts
+
+ temp = self.root
+
+ for path in resolved_config_path_as_tuple:
+ if path not in temp.nodes:
+ temp.nodes[path] = TrieNode()
+
+ temp = temp.nodes[path]
+
+ temp.config_info = (config_file, config_data)
+
+ def search(self, filename: str) -> Tuple[str, Dict[str, Any]]:
+ """
+ Returns the closest config relative to filename by doing a depth
+ first search on the prefix tree.
+ """
+ resolved_file_path_as_tuple = Path(filename).resolve().parts
+
+ temp = self.root
+
+ last_stored_config: Tuple[str, Dict[str, Any]] = ("", {})
+
+ for path in resolved_file_path_as_tuple:
+ if temp.config_info[0]:
+ last_stored_config = temp.config_info
+
+ if path not in temp.nodes:
+ break
+
+ temp = temp.nodes[path]
+
+ return last_stored_config
+
+
+def exists_case_sensitive(path: str) -> bool:
+ """Returns if the given path exists and also matches the case on Windows.
+
+ When finding files that can be imported, it is important for the cases to match because while
+ file os.path.exists("module.py") and os.path.exists("MODULE.py") both return True on Windows,
+ Python can only import using the case of the real file.
+ """
+ result = os.path.exists(path)
+ if (sys.platform.startswith("win") or sys.platform == "darwin") and result: # pragma: no cover
+ directory, basename = os.path.split(path)
+ result = basename in os.listdir(directory)
+ return result
diff --git a/solutions/.venv/Lib/site-packages/isort/wrap.py b/solutions/.venv/Lib/site-packages/isort/wrap.py
new file mode 100644
index 000000000..119531ad6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/wrap.py
@@ -0,0 +1,147 @@
+import copy
+import re
+from typing import List, Optional, Sequence
+
+from .settings import DEFAULT_CONFIG, Config
+from .wrap_modes import WrapModes as Modes
+from .wrap_modes import formatter_from_string, vertical_hanging_indent
+
+
+def import_statement(
+ import_start: str,
+ from_imports: List[str],
+ comments: Sequence[str] = (),
+ line_separator: str = "\n",
+ config: Config = DEFAULT_CONFIG,
+ multi_line_output: Optional[Modes] = None,
+ explode: bool = False,
+) -> str:
+ """Returns a multi-line wrapped form of the provided from import statement."""
+ if explode:
+ formatter = vertical_hanging_indent
+ line_length = 1
+ include_trailing_comma = True
+ else:
+ formatter = formatter_from_string((multi_line_output or config.multi_line_output).name)
+ line_length = config.wrap_length or config.line_length
+ include_trailing_comma = config.include_trailing_comma
+ dynamic_indent = " " * (len(import_start) + 1)
+ indent = config.indent
+ statement = formatter(
+ statement=import_start,
+ imports=copy.copy(from_imports),
+ white_space=dynamic_indent,
+ indent=indent,
+ line_length=line_length,
+ comments=comments,
+ line_separator=line_separator,
+ comment_prefix=config.comment_prefix,
+ include_trailing_comma=include_trailing_comma,
+ remove_comments=config.ignore_comments,
+ )
+ if config.balanced_wrapping:
+ lines = statement.split(line_separator)
+ line_count = len(lines)
+ if len(lines) > 1:
+ minimum_length = min(len(line) for line in lines[:-1])
+ else:
+ minimum_length = 0
+ new_import_statement = statement
+ while len(lines[-1]) < minimum_length and len(lines) == line_count and line_length > 10:
+ statement = new_import_statement
+ line_length -= 1
+ new_import_statement = formatter(
+ statement=import_start,
+ imports=copy.copy(from_imports),
+ white_space=dynamic_indent,
+ indent=indent,
+ line_length=line_length,
+ comments=comments,
+ line_separator=line_separator,
+ comment_prefix=config.comment_prefix,
+ include_trailing_comma=include_trailing_comma,
+ remove_comments=config.ignore_comments,
+ )
+ lines = new_import_statement.split(line_separator)
+ if statement.count(line_separator) == 0:
+ return _wrap_line(statement, line_separator, config)
+ return statement
+
+
+def line(content: str, line_separator: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Returns a line wrapped to the specified line-length, if possible."""
+ wrap_mode = config.multi_line_output
+ if len(content) > config.line_length and wrap_mode != Modes.NOQA: # type: ignore
+ line_without_comment = content
+ comment = None
+ if "#" in content:
+ line_without_comment, comment = content.split("#", 1)
+ for splitter in ("import ", "cimport ", ".", "as "):
+ exp = r"\b" + re.escape(splitter) + r"\b"
+ if re.search(exp, line_without_comment) and not line_without_comment.strip().startswith(
+ splitter
+ ):
+ line_parts = re.split(exp, line_without_comment)
+ if comment and not (config.use_parentheses and "noqa" in comment):
+ _comma_maybe = (
+ ","
+ if (
+ config.include_trailing_comma
+ and config.use_parentheses
+ and not line_without_comment.rstrip().endswith(",")
+ )
+ else ""
+ )
+ line_parts[
+ -1
+ ] = f"{line_parts[-1].strip()}{_comma_maybe}{config.comment_prefix}{comment}"
+ next_line = []
+ while (len(content) + 2) > (
+ config.wrap_length or config.line_length
+ ) and line_parts:
+ next_line.append(line_parts.pop())
+ content = splitter.join(line_parts)
+ if not content:
+ content = next_line.pop()
+
+ cont_line = _wrap_line(
+ config.indent + splitter.join(next_line).lstrip(),
+ line_separator,
+ config,
+ )
+ if config.use_parentheses:
+ if splitter == "as ":
+ output = f"{content}{splitter}{cont_line.lstrip()}"
+ else:
+ _comma = "," if config.include_trailing_comma and not comment else ""
+
+ if wrap_mode in (
+ Modes.VERTICAL_HANGING_INDENT, # type: ignore
+ Modes.VERTICAL_GRID_GROUPED, # type: ignore
+ ):
+ _separator = line_separator
+ else:
+ _separator = ""
+ noqa_comment = ""
+ if comment and "noqa" in comment:
+ noqa_comment = f"{config.comment_prefix}{comment}"
+ cont_line = cont_line.rstrip()
+ _comma = "," if config.include_trailing_comma else ""
+ output = (
+ f"{content}{splitter}({noqa_comment}"
+ f"{line_separator}{cont_line}{_comma}{_separator})"
+ )
+ lines = output.split(line_separator)
+ if config.comment_prefix in lines[-1] and lines[-1].endswith(")"):
+ content, comment = lines[-1].split(config.comment_prefix, 1)
+ lines[-1] = content + ")" + config.comment_prefix + comment[:-1]
+ output = line_separator.join(lines)
+ return output
+ return f"{content}{splitter}\\{line_separator}{cont_line}"
+ elif len(content) > config.line_length and wrap_mode == Modes.NOQA and "# NOQA" not in content: # type: ignore
+ return f"{content}{config.comment_prefix} NOQA"
+
+ return content
+
+
+_wrap_line = line
diff --git a/solutions/.venv/Lib/site-packages/isort/wrap_modes.py b/solutions/.venv/Lib/site-packages/isort/wrap_modes.py
new file mode 100644
index 000000000..b4ffd0ac7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/isort/wrap_modes.py
@@ -0,0 +1,373 @@
+"""Defines all wrap modes that can be used when outputting formatted imports"""
+import enum
+from inspect import signature
+from typing import Any, Callable, Dict, List
+
+import isort.comments
+
+_wrap_modes: Dict[str, Callable[..., str]] = {}
+
+
+def from_string(value: str) -> "WrapModes":
+ return getattr(WrapModes, str(value), None) or WrapModes(int(value))
+
+
+def formatter_from_string(name: str) -> Callable[..., str]:
+ return _wrap_modes.get(name.upper(), grid)
+
+
+def _wrap_mode_interface(
+ statement: str,
+ imports: List[str],
+ white_space: str,
+ indent: str,
+ line_length: int,
+ comments: List[str],
+ line_separator: str,
+ comment_prefix: str,
+ include_trailing_comma: bool,
+ remove_comments: bool,
+) -> str:
+ """Defines the common interface used by all wrap mode functions"""
+ return ""
+
+
+def _wrap_mode(function: Callable[..., str]) -> Callable[..., str]:
+ """Registers an individual wrap mode. Function name and order are significant and used for
+ creating enum.
+ """
+ _wrap_modes[function.__name__.upper()] = function
+ function.__signature__ = signature(_wrap_mode_interface) # type: ignore
+ function.__annotations__ = _wrap_mode_interface.__annotations__
+ return function
+
+
+@_wrap_mode
+def grid(**interface: Any) -> str:
+ if not interface["imports"]:
+ return ""
+
+ interface["statement"] += "(" + interface["imports"].pop(0)
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ if (
+ len(next_statement.split(interface["line_separator"])[-1]) + 1
+ > interface["line_length"]
+ ):
+ lines = [f"{interface['white_space']}{next_import.split(' ')[0]}"]
+ for part in next_import.split(" ")[1:]:
+ new_line = f"{lines[-1]} {part}"
+ if len(new_line) + 1 > interface["line_length"]:
+ lines.append(f"{interface['white_space']}{part}")
+ else:
+ lines[-1] = new_line
+ next_import = interface["line_separator"].join(lines)
+ interface["statement"] = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ f"{interface['statement']},",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{next_import}"
+ )
+ interface["comments"] = []
+ else:
+ interface["statement"] += ", " + next_import
+ return f"{interface['statement']}{',' if interface['include_trailing_comma'] else ''})"
+
+
+@_wrap_mode
+def vertical(**interface: Any) -> str:
+ if not interface["imports"]:
+ return ""
+
+ first_import = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ interface["imports"].pop(0) + ",",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + interface["line_separator"]
+ + interface["white_space"]
+ )
+
+ _imports = ("," + interface["line_separator"] + interface["white_space"]).join(
+ interface["imports"]
+ )
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ return f"{interface['statement']}({first_import}{_imports}{_comma_maybe})"
+
+
+def _hanging_indent_end_line(line: str) -> str:
+ if not line.endswith(" "):
+ line += " "
+ return line + "\\"
+
+
+@_wrap_mode
+def hanging_indent(**interface: Any) -> str:
+ if not interface["imports"]:
+ return ""
+
+ line_length_limit = interface["line_length"] - 3
+
+ next_import = interface["imports"].pop(0)
+ next_statement = interface["statement"] + next_import
+ # Check for first import
+ if len(next_statement) > line_length_limit:
+ next_statement = (
+ _hanging_indent_end_line(interface["statement"])
+ + interface["line_separator"]
+ + interface["indent"]
+ + next_import
+ )
+
+ interface["statement"] = next_statement
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = interface["statement"] + ", " + next_import
+ if len(next_statement.split(interface["line_separator"])[-1]) > line_length_limit:
+ next_statement = (
+ _hanging_indent_end_line(interface["statement"] + ",")
+ + f"{interface['line_separator']}{interface['indent']}{next_import}"
+ )
+ interface["statement"] = next_statement
+
+ if interface["comments"]:
+ statement_with_comments = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"],
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ if len(statement_with_comments.split(interface["line_separator"])[-1]) <= (
+ line_length_limit + 2
+ ):
+ return statement_with_comments
+ return (
+ _hanging_indent_end_line(interface["statement"])
+ + str(interface["line_separator"])
+ + isort.comments.add_to_line(
+ interface["comments"],
+ interface["indent"],
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"].lstrip(),
+ )
+ )
+ return str(interface["statement"])
+
+
+@_wrap_mode
+def vertical_hanging_indent(**interface: Any) -> str:
+ _line_with_comments = isort.comments.add_to_line(
+ interface["comments"],
+ "",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ _imports = ("," + interface["line_separator"] + interface["indent"]).join(interface["imports"])
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ return (
+ f"{interface['statement']}({_line_with_comments}{interface['line_separator']}"
+ f"{interface['indent']}{_imports}{_comma_maybe}{interface['line_separator']})"
+ )
+
+
+def _vertical_grid_common(need_trailing_char: bool, **interface: Any) -> str:
+ if not interface["imports"]:
+ return ""
+
+ interface["statement"] += (
+ isort.comments.add_to_line(
+ interface["comments"],
+ "(",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + interface["line_separator"]
+ + interface["indent"]
+ + interface["imports"].pop(0)
+ )
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = f"{interface['statement']}, {next_import}"
+ current_line_length = len(next_statement.split(interface["line_separator"])[-1])
+ if interface["imports"] or interface["include_trailing_comma"]:
+ # We need to account for a comma after this import.
+ current_line_length += 1
+ if not interface["imports"] and need_trailing_char:
+ # We need to account for a closing ) we're going to add.
+ current_line_length += 1
+ if current_line_length > interface["line_length"]:
+ next_statement = (
+ f"{interface['statement']},{interface['line_separator']}"
+ f"{interface['indent']}{next_import}"
+ )
+ interface["statement"] = next_statement
+ if interface["include_trailing_comma"]:
+ interface["statement"] += ","
+ return str(interface["statement"])
+
+
+@_wrap_mode
+def vertical_grid(**interface: Any) -> str:
+ return _vertical_grid_common(need_trailing_char=True, **interface) + ")"
+
+
+@_wrap_mode
+def vertical_grid_grouped(**interface: Any) -> str:
+ return (
+ _vertical_grid_common(need_trailing_char=False, **interface)
+ + str(interface["line_separator"])
+ + ")"
+ )
+
+
+@_wrap_mode
+def vertical_grid_grouped_no_comma(**interface: Any) -> str:
+ # This is a deprecated alias for vertical_grid_grouped above. This function
+ # needs to exist for backwards compatibility but should never get called.
+ raise NotImplementedError
+
+
+@_wrap_mode
+def noqa(**interface: Any) -> str:
+ _imports = ", ".join(interface["imports"])
+ retval = f"{interface['statement']}{_imports}"
+ comment_str = " ".join(interface["comments"])
+ if interface["comments"]:
+ if (
+ len(retval) + len(interface["comment_prefix"]) + 1 + len(comment_str)
+ <= interface["line_length"]
+ ):
+ return f"{retval}{interface['comment_prefix']} {comment_str}"
+ if "NOQA" in interface["comments"]:
+ return f"{retval}{interface['comment_prefix']} {comment_str}"
+ return f"{retval}{interface['comment_prefix']} NOQA {comment_str}"
+
+ if len(retval) <= interface["line_length"]:
+ return retval
+ return f"{retval}{interface['comment_prefix']} NOQA"
+
+
+@_wrap_mode
+def vertical_hanging_indent_bracket(**interface: Any) -> str:
+ if not interface["imports"]:
+ return ""
+ statement = vertical_hanging_indent(**interface)
+ return f'{statement[:-1]}{interface["indent"]})'
+
+
+@_wrap_mode
+def vertical_prefix_from_module_import(**interface: Any) -> str:
+ if not interface["imports"]:
+ return ""
+
+ prefix_statement = interface["statement"]
+ output_statement = prefix_statement + interface["imports"].pop(0)
+ comments = interface["comments"]
+
+ statement = output_statement
+ statement_with_comments = ""
+ for next_import in interface["imports"]:
+ statement = statement + ", " + next_import
+ statement_with_comments = isort.comments.add_to_line(
+ comments,
+ statement,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ if (
+ len(statement_with_comments.split(interface["line_separator"])[-1]) + 1
+ > interface["line_length"]
+ ):
+ statement = (
+ isort.comments.add_to_line(
+ comments,
+ output_statement,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{prefix_statement}{next_import}"
+ )
+ comments = []
+ output_statement = statement
+
+ if comments and statement_with_comments:
+ output_statement = statement_with_comments
+ return str(output_statement)
+
+
+@_wrap_mode
+def hanging_indent_with_parentheses(**interface: Any) -> str:
+ if not interface["imports"]:
+ return ""
+
+ line_length_limit = interface["line_length"] - 1
+
+ interface["statement"] += "("
+ next_import = interface["imports"].pop(0)
+ next_statement = interface["statement"] + next_import
+ # Check for first import
+ if len(next_statement) > line_length_limit:
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"],
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{interface['indent']}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ if (
+ not interface["line_separator"] in interface["statement"]
+ and "#" in interface["statement"]
+ ): # pragma: no cover # TODO: fix, this is because of test run inconsistency.
+ line, comments = interface["statement"].split("#", 1)
+ next_statement = (
+ f"{line.rstrip()}, {next_import}{interface['comment_prefix']}{comments}"
+ )
+ else:
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ current_line = next_statement.split(interface["line_separator"])[-1]
+ if len(current_line) > line_length_limit:
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ",",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{interface['indent']}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ return f"{interface['statement']}{',' if interface['include_trailing_comma'] else ''})"
+
+
+@_wrap_mode
+def backslash_grid(**interface: Any) -> str:
+ interface["indent"] = interface["white_space"][:-1]
+ return hanging_indent(**interface)
+
+
+WrapModes = enum.Enum( # type: ignore
+ "WrapModes", {wrap_mode: index for index, wrap_mode in enumerate(_wrap_modes.keys())}
+)
diff --git a/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/LICENSE b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/LICENSE
new file mode 100644
index 000000000..8fd356e83
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/LICENSE
@@ -0,0 +1,25 @@
+Copyright © <year> Ned Batchelder
+Copyright © 2011-2013 Tarek Ziade <tarek@ziade.org>
+Copyright © 2013 Florent Xicluna <florent.xicluna@gmail.com>
+
+Licensed under the terms of the Expat License
+
+Permission is hereby granted, free of charge, to any person
+obtaining a copy of this software and associated documentation files
+(the "Software"), to deal in the Software without restriction,
+including without limitation the rights to use, copy, modify, merge,
+publish, distribute, sublicense, and/or sell copies of the Software,
+and to permit persons to whom the Software is furnished to do so,
+subject to the following conditions:
+
+The above copyright notice and this permission notice shall be
+included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS
+BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN
+ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
+CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/METADATA b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/METADATA
new file mode 100644
index 000000000..e25facd03
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/METADATA
@@ -0,0 +1,199 @@
+Metadata-Version: 2.1
+Name: mccabe
+Version: 0.7.0
+Summary: McCabe checker, plugin for flake8
+Home-page: https://github.com/pycqa/mccabe
+Author: Tarek Ziade
+Author-email: tarek@ziade.org
+Maintainer: Ian Stapleton Cordasco
+Maintainer-email: graffatcolmingov@gmail.com
+License: Expat license
+Keywords: flake8 mccabe
+Platform: UNKNOWN
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3.6
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Topic :: Software Development :: Libraries :: Python Modules
+Classifier: Topic :: Software Development :: Quality Assurance
+Requires-Python: >=3.6
+License-File: LICENSE
+
+McCabe complexity checker
+=========================
+
+Ned's script to check McCabe complexity.
+
+This module provides a plugin for ``flake8``, the Python code checker.
+
+
+Installation
+------------
+
+You can install, upgrade, or uninstall ``mccabe`` with these commands::
+
+ $ pip install mccabe
+ $ pip install --upgrade mccabe
+ $ pip uninstall mccabe
+
+
+Standalone script
+-----------------
+
+The complexity checker can be used directly::
+
+ $ python -m mccabe --min 5 mccabe.py
+ ("185:1: 'PathGraphingAstVisitor.visitIf'", 5)
+ ("71:1: 'PathGraph.to_dot'", 5)
+ ("245:1: 'McCabeChecker.run'", 5)
+ ("283:1: 'main'", 7)
+ ("203:1: 'PathGraphingAstVisitor.visitTryExcept'", 5)
+ ("257:1: 'get_code_complexity'", 5)
+
+
+Plugin for Flake8
+-----------------
+
+When both ``flake8 2+`` and ``mccabe`` are installed, the plugin is
+available in ``flake8``::
+
+ $ flake8 --version
+ 2.0 (pep8: 1.4.2, pyflakes: 0.6.1, mccabe: 0.2)
+
+By default the plugin is disabled. Use the ``--max-complexity`` switch to
+enable it. It will emit a warning if the McCabe complexity of a function is
+higher than the provided value::
+
+ $ flake8 --max-complexity 10 coolproject
+ ...
+ coolproject/mod.py:1204:1: C901 'CoolFactory.prepare' is too complex (14)
+
+This feature is quite useful for detecting over-complex code. According to McCabe,
+anything that goes beyond 10 is too complex.
+
+Flake8 has many features that mccabe does not provide. Flake8 allows users to
+ignore violations reported by plugins with ``# noqa``. Read more about this in
+`their documentation
+<http://flake8.pycqa.org/en/latest/user/violations.html#in-line-ignoring-errors>`__.
+To silence violations reported by ``mccabe``, place your ``# noqa: C901`` on
+the function definition line, where the error is reported for (possibly a
+decorator).
+
+
+Links
+-----
+
+* Feedback and ideas: http://mail.python.org/mailman/listinfo/code-quality
+
+* Cyclomatic complexity: http://en.wikipedia.org/wiki/Cyclomatic_complexity
+
+* Ned Batchelder's script:
+ http://nedbatchelder.com/blog/200803/python_code_complexity_microtool.html
+
+* McCabe complexity: http://en.wikipedia.org/wiki/Cyclomatic_complexity
+
+
+Changes
+-------
+
+0.7.0 - 2021-01-23
+``````````````````
+
+* Drop support for all versions of Python lower than 3.6
+
+* Add support for Python 3.8, 3.9, and 3.10
+
+* Fix option declaration for Flake8
+
+0.6.1 - 2017-01-26
+``````````````````
+
+* Fix signature for ``PathGraphingAstVisitor.default`` to match the signature
+ for ``ASTVisitor``
+
+0.6.0 - 2017-01-23
+``````````````````
+
+* Add support for Python 3.6
+
+* Fix handling for missing statement types
+
+0.5.3 - 2016-12-14
+``````````````````
+
+* Report actual column number of violation instead of the start of the line
+
+0.5.2 - 2016-07-31
+``````````````````
+
+* When opening files ourselves, make sure we always name the file variable
+
+0.5.1 - 2016-07-28
+``````````````````
+
+* Set default maximum complexity to -1 on the class itself
+
+0.5.0 - 2016-05-30
+``````````````````
+
+* PyCon 2016 PDX release
+
+* Add support for Flake8 3.0
+
+0.4.0 - 2016-01-27
+``````````````````
+
+* Stop testing on Python 3.2
+
+* Add support for async/await keywords on Python 3.5 from PEP 0492
+
+0.3.1 - 2015-06-14
+``````````````````
+
+* Include ``test_mccabe.py`` in releases.
+
+* Always coerce the ``max_complexity`` value from Flake8's entry-point to an
+ integer.
+
+0.3 - 2014-12-17
+````````````````
+
+* Computation was wrong: the mccabe complexity starts at 1, not 2.
+
+* The ``max-complexity`` value is now inclusive. E.g.: if the
+ value is 10 and the reported complexity is 10, then it passes.
+
+* Add tests.
+
+
+0.2.1 - 2013-04-03
+``````````````````
+
+* Do not require ``setuptools`` in setup.py. It works around an issue
+ with ``pip`` and Python 3.
+
+
+0.2 - 2013-02-22
+````````````````
+
+* Rename project to ``mccabe``.
+
+* Provide ``flake8.extension`` setuptools entry point.
+
+* Read ``max-complexity`` from the configuration file.
+
+* Rename argument ``min_complexity`` to ``threshold``.
+
+
+0.1 - 2013-02-11
+````````````````
+* First release
+
+
diff --git a/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/RECORD b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/RECORD
new file mode 100644
index 000000000..10d11b24e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/RECORD
@@ -0,0 +1,9 @@
+__pycache__/mccabe.cpython-312.pyc,,
+mccabe-0.7.0.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+mccabe-0.7.0.dist-info/LICENSE,sha256=EPvAA8uvims89xlbgNrJbIba85ADmyq_bntuc1r9fXQ,1221
+mccabe-0.7.0.dist-info/METADATA,sha256=oMxU_cw4ev2Q23YTL3NRg4pebHSqlrbF_DSSs-cpfBE,5035
+mccabe-0.7.0.dist-info/RECORD,,
+mccabe-0.7.0.dist-info/WHEEL,sha256=z9j0xAa_JmUKMpmz72K0ZGALSM_n-wQVmGbleXx2VHg,110
+mccabe-0.7.0.dist-info/entry_points.txt,sha256=N2NH182GXTUyTm8r8XMgadb9C-CRa5dUr1k8OC91uGE,47
+mccabe-0.7.0.dist-info/top_level.txt,sha256=21cXuqZE-lpcfAqqANvX9EjI1ED1p8zcViv064u3RKA,7
+mccabe.py,sha256=g_kB8oPilNLemdOirPaZymQyyjqAH0kowrncUQaaw00,10654
diff --git a/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/WHEEL
new file mode 100644
index 000000000..0b18a2811
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/WHEEL
@@ -0,0 +1,6 @@
+Wheel-Version: 1.0
+Generator: bdist_wheel (0.37.1)
+Root-Is-Purelib: true
+Tag: py2-none-any
+Tag: py3-none-any
+
diff --git a/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/entry_points.txt b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/entry_points.txt
new file mode 100644
index 000000000..cc6645bdc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/entry_points.txt
@@ -0,0 +1,3 @@
+[flake8.extension]
+C90 = mccabe:McCabeChecker
+
diff --git a/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/top_level.txt b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/top_level.txt
new file mode 100644
index 000000000..8831b36b4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe-0.7.0.dist-info/top_level.txt
@@ -0,0 +1 @@
+mccabe
diff --git a/solutions/.venv/Lib/site-packages/mccabe.py b/solutions/.venv/Lib/site-packages/mccabe.py
new file mode 100644
index 000000000..5746504c7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/mccabe.py
@@ -0,0 +1,346 @@
+""" Meager code path measurement tool.
+ Ned Batchelder
+ http://nedbatchelder.com/blog/200803/python_code_complexity_microtool.html
+ MIT License.
+"""
+from __future__ import with_statement
+
+import optparse
+import sys
+import tokenize
+
+from collections import defaultdict
+try:
+ import ast
+ from ast import iter_child_nodes
+except ImportError: # Python 2.5
+ from flake8.util import ast, iter_child_nodes
+
+__version__ = '0.7.0'
+
+
+class ASTVisitor(object):
+ """Performs a depth-first walk of the AST."""
+
+ def __init__(self):
+ self.node = None
+ self._cache = {}
+
+ def default(self, node, *args):
+ for child in iter_child_nodes(node):
+ self.dispatch(child, *args)
+
+ def dispatch(self, node, *args):
+ self.node = node
+ klass = node.__class__
+ meth = self._cache.get(klass)
+ if meth is None:
+ className = klass.__name__
+ meth = getattr(self.visitor, 'visit' + className, self.default)
+ self._cache[klass] = meth
+ return meth(node, *args)
+
+ def preorder(self, tree, visitor, *args):
+ """Do preorder walk of tree using visitor"""
+ self.visitor = visitor
+ visitor.visit = self.dispatch
+ self.dispatch(tree, *args) # XXX *args make sense?
+
+
+class PathNode(object):
+ def __init__(self, name, look="circle"):
+ self.name = name
+ self.look = look
+
+ def to_dot(self):
+ print('node [shape=%s,label="%s"] %d;' % (
+ self.look, self.name, self.dot_id()))
+
+ def dot_id(self):
+ return id(self)
+
+
+class PathGraph(object):
+ def __init__(self, name, entity, lineno, column=0):
+ self.name = name
+ self.entity = entity
+ self.lineno = lineno
+ self.column = column
+ self.nodes = defaultdict(list)
+
+ def connect(self, n1, n2):
+ self.nodes[n1].append(n2)
+ # Ensure that the destination node is always counted.
+ self.nodes[n2] = []
+
+ def to_dot(self):
+ print('subgraph {')
+ for node in self.nodes:
+ node.to_dot()
+ for node, nexts in self.nodes.items():
+ for next in nexts:
+ print('%s -- %s;' % (node.dot_id(), next.dot_id()))
+ print('}')
+
+ def complexity(self):
+ """ Return the McCabe complexity for the graph.
+ V-E+2
+ """
+ num_edges = sum([len(n) for n in self.nodes.values()])
+ num_nodes = len(self.nodes)
+ return num_edges - num_nodes + 2
+
+
+class PathGraphingAstVisitor(ASTVisitor):
+ """ A visitor for a parsed Abstract Syntax Tree which finds executable
+ statements.
+ """
+
+ def __init__(self):
+ super(PathGraphingAstVisitor, self).__init__()
+ self.classname = ""
+ self.graphs = {}
+ self.reset()
+
+ def reset(self):
+ self.graph = None
+ self.tail = None
+
+ def dispatch_list(self, node_list):
+ for node in node_list:
+ self.dispatch(node)
+
+ def visitFunctionDef(self, node):
+
+ if self.classname:
+ entity = '%s%s' % (self.classname, node.name)
+ else:
+ entity = node.name
+
+ name = '%d:%d: %r' % (node.lineno, node.col_offset, entity)
+
+ if self.graph is not None:
+ # closure
+ pathnode = self.appendPathNode(name)
+ self.tail = pathnode
+ self.dispatch_list(node.body)
+ bottom = PathNode("", look='point')
+ self.graph.connect(self.tail, bottom)
+ self.graph.connect(pathnode, bottom)
+ self.tail = bottom
+ else:
+ self.graph = PathGraph(name, entity, node.lineno, node.col_offset)
+ pathnode = PathNode(name)
+ self.tail = pathnode
+ self.dispatch_list(node.body)
+ self.graphs["%s%s" % (self.classname, node.name)] = self.graph
+ self.reset()
+
+ visitAsyncFunctionDef = visitFunctionDef
+
+ def visitClassDef(self, node):
+ old_classname = self.classname
+ self.classname += node.name + "."
+ self.dispatch_list(node.body)
+ self.classname = old_classname
+
+ def appendPathNode(self, name):
+ if not self.tail:
+ return
+ pathnode = PathNode(name)
+ self.graph.connect(self.tail, pathnode)
+ self.tail = pathnode
+ return pathnode
+
+ def visitSimpleStatement(self, node):
+ if node.lineno is None:
+ lineno = 0
+ else:
+ lineno = node.lineno
+ name = "Stmt %d" % lineno
+ self.appendPathNode(name)
+
+ def default(self, node, *args):
+ if isinstance(node, ast.stmt):
+ self.visitSimpleStatement(node)
+ else:
+ super(PathGraphingAstVisitor, self).default(node, *args)
+
+ def visitLoop(self, node):
+ name = "Loop %d" % node.lineno
+ self._subgraph(node, name)
+
+ visitAsyncFor = visitFor = visitWhile = visitLoop
+
+ def visitIf(self, node):
+ name = "If %d" % node.lineno
+ self._subgraph(node, name)
+
+ def _subgraph(self, node, name, extra_blocks=()):
+ """create the subgraphs representing any `if` and `for` statements"""
+ if self.graph is None:
+ # global loop
+ self.graph = PathGraph(name, name, node.lineno, node.col_offset)
+ pathnode = PathNode(name)
+ self._subgraph_parse(node, pathnode, extra_blocks)
+ self.graphs["%s%s" % (self.classname, name)] = self.graph
+ self.reset()
+ else:
+ pathnode = self.appendPathNode(name)
+ self._subgraph_parse(node, pathnode, extra_blocks)
+
+ def _subgraph_parse(self, node, pathnode, extra_blocks):
+ """parse the body and any `else` block of `if` and `for` statements"""
+ loose_ends = []
+ self.tail = pathnode
+ self.dispatch_list(node.body)
+ loose_ends.append(self.tail)
+ for extra in extra_blocks:
+ self.tail = pathnode
+ self.dispatch_list(extra.body)
+ loose_ends.append(self.tail)
+ if node.orelse:
+ self.tail = pathnode
+ self.dispatch_list(node.orelse)
+ loose_ends.append(self.tail)
+ else:
+ loose_ends.append(pathnode)
+ if pathnode:
+ bottom = PathNode("", look='point')
+ for le in loose_ends:
+ self.graph.connect(le, bottom)
+ self.tail = bottom
+
+ def visitTryExcept(self, node):
+ name = "TryExcept %d" % node.lineno
+ self._subgraph(node, name, extra_blocks=node.handlers)
+
+ visitTry = visitTryExcept
+
+ def visitWith(self, node):
+ name = "With %d" % node.lineno
+ self.appendPathNode(name)
+ self.dispatch_list(node.body)
+
+ visitAsyncWith = visitWith
+
+
+class McCabeChecker(object):
+ """McCabe cyclomatic complexity checker."""
+ name = 'mccabe'
+ version = __version__
+ _code = 'C901'
+ _error_tmpl = "C901 %r is too complex (%d)"
+ max_complexity = -1
+
+ def __init__(self, tree, filename):
+ self.tree = tree
+
+ @classmethod
+ def add_options(cls, parser):
+ flag = '--max-complexity'
+ kwargs = {
+ 'default': -1,
+ 'action': 'store',
+ 'type': int,
+ 'help': 'McCabe complexity threshold',
+ 'parse_from_config': 'True',
+ }
+ config_opts = getattr(parser, 'config_options', None)
+ if isinstance(config_opts, list):
+ # Flake8 2.x
+ kwargs.pop('parse_from_config')
+ parser.add_option(flag, **kwargs)
+ parser.config_options.append('max-complexity')
+ else:
+ parser.add_option(flag, **kwargs)
+
+ @classmethod
+ def parse_options(cls, options):
+ cls.max_complexity = int(options.max_complexity)
+
+ def run(self):
+ if self.max_complexity < 0:
+ return
+ visitor = PathGraphingAstVisitor()
+ visitor.preorder(self.tree, visitor)
+ for graph in visitor.graphs.values():
+ if graph.complexity() > self.max_complexity:
+ text = self._error_tmpl % (graph.entity, graph.complexity())
+ yield graph.lineno, graph.column, text, type(self)
+
+
+def get_code_complexity(code, threshold=7, filename='stdin'):
+ try:
+ tree = compile(code, filename, "exec", ast.PyCF_ONLY_AST)
+ except SyntaxError:
+ e = sys.exc_info()[1]
+ sys.stderr.write("Unable to parse %s: %s\n" % (filename, e))
+ return 0
+
+ complx = []
+ McCabeChecker.max_complexity = threshold
+ for lineno, offset, text, check in McCabeChecker(tree, filename).run():
+ complx.append('%s:%d:1: %s' % (filename, lineno, text))
+
+ if len(complx) == 0:
+ return 0
+ print('\n'.join(complx))
+ return len(complx)
+
+
+def get_module_complexity(module_path, threshold=7):
+ """Returns the complexity of a module"""
+ code = _read(module_path)
+ return get_code_complexity(code, threshold, filename=module_path)
+
+
+def _read(filename):
+ if (2, 5) < sys.version_info < (3, 0):
+ with open(filename, 'rU') as f:
+ return f.read()
+ elif (3, 0) <= sys.version_info < (4, 0):
+ """Read the source code."""
+ try:
+ with open(filename, 'rb') as f:
+ (encoding, _) = tokenize.detect_encoding(f.readline)
+ except (LookupError, SyntaxError, UnicodeError):
+ # Fall back if file encoding is improperly declared
+ with open(filename, encoding='latin-1') as f:
+ return f.read()
+ with open(filename, 'r', encoding=encoding) as f:
+ return f.read()
+
+
+def main(argv=None):
+ if argv is None:
+ argv = sys.argv[1:]
+ opar = optparse.OptionParser()
+ opar.add_option("-d", "--dot", dest="dot",
+ help="output a graphviz dot file", action="store_true")
+ opar.add_option("-m", "--min", dest="threshold",
+ help="minimum complexity for output", type="int",
+ default=1)
+
+ options, args = opar.parse_args(argv)
+
+ code = _read(args[0])
+ tree = compile(code, args[0], "exec", ast.PyCF_ONLY_AST)
+ visitor = PathGraphingAstVisitor()
+ visitor.preorder(tree, visitor)
+
+ if options.dot:
+ print('graph {')
+ for graph in visitor.graphs.values():
+ if (not options.threshold or
+ graph.complexity() >= options.threshold):
+ graph.to_dot()
+ print('}')
+ else:
+ for graph in visitor.graphs.values():
+ if graph.complexity() >= options.threshold:
+ print(graph.name, graph.complexity())
+
+
+if __name__ == '__main__':
+ main(sys.argv[1:])
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/AUTHORS.txt b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/AUTHORS.txt
new file mode 100644
index 000000000..8ccefbc6e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/AUTHORS.txt
@@ -0,0 +1,799 @@
+@Switch01
+A_Rog
+Aakanksha Agrawal
+Abhinav Sagar
+ABHYUDAY PRATAP SINGH
+abs51295
+AceGentile
+Adam Chainz
+Adam Tse
+Adam Wentz
+admin
+Adolfo Ochagavía
+Adrien Morison
+Agus
+ahayrapetyan
+Ahilya
+AinsworthK
+Akash Srivastava
+Alan Yee
+Albert Tugushev
+Albert-Guan
+albertg
+Alberto Sottile
+Aleks Bunin
+Ales Erjavec
+Alethea Flowers
+Alex Gaynor
+Alex Grönholm
+Alex Hedges
+Alex Loosley
+Alex Morega
+Alex Stachowiak
+Alexander Shtyrov
+Alexandre Conrad
+Alexey Popravka
+Aleš Erjavec
+Alli
+Ami Fischman
+Ananya Maiti
+Anatoly Techtonik
+Anders Kaseorg
+Andre Aguiar
+Andreas Lutro
+Andrei Geacar
+Andrew Gaul
+Andrew Shymanel
+Andrey Bienkowski
+Andrey Bulgakov
+Andrés Delfino
+Andy Freeland
+Andy Kluger
+Ani Hayrapetyan
+Aniruddha Basak
+Anish Tambe
+Anrs Hu
+Anthony Sottile
+Antoine Musso
+Anton Ovchinnikov
+Anton Patrushev
+Anton Zelenov
+Antonio Alvarado Hernandez
+Antony Lee
+Antti Kaihola
+Anubhav Patel
+Anudit Nagar
+Anuj Godase
+AQNOUCH Mohammed
+AraHaan
+arena
+arenasys
+Arindam Choudhury
+Armin Ronacher
+Arnon Yaari
+Artem
+Arun Babu Neelicattu
+Ashley Manton
+Ashwin Ramaswami
+atse
+Atsushi Odagiri
+Avinash Karhana
+Avner Cohen
+Awit (Ah-Wit) Ghirmai
+Baptiste Mispelon
+Barney Gale
+barneygale
+Bartek Ogryczak
+Bastian Venthur
+Ben Bodenmiller
+Ben Darnell
+Ben Hoyt
+Ben Mares
+Ben Rosser
+Bence Nagy
+Benjamin Peterson
+Benjamin VanEvery
+Benoit Pierre
+Berker Peksag
+Bernard
+Bernard Tyers
+Bernardo B. Marques
+Bernhard M. Wiedemann
+Bertil Hatt
+Bhavam Vidyarthi
+Blazej Michalik
+Bogdan Opanchuk
+BorisZZZ
+Brad Erickson
+Bradley Ayers
+Branch Vincent
+Brandon L. Reiss
+Brandt Bucher
+Brannon Dorsey
+Brett Randall
+Brett Rosen
+Brian Cristante
+Brian Rosner
+briantracy
+BrownTruck
+Bruno Oliveira
+Bruno Renié
+Bruno S
+Bstrdsmkr
+Buck Golemon
+burrows
+Bussonnier Matthias
+bwoodsend
+c22
+Caleb Martinez
+Calvin Smith
+Carl Meyer
+Carlos Liam
+Carol Willing
+Carter Thayer
+Cass
+Chandrasekhar Atina
+Charlie Marsh
+Chih-Hsuan Yen
+Chris Brinker
+Chris Hunt
+Chris Jerdonek
+Chris Kuehl
+Chris Markiewicz
+Chris McDonough
+Chris Pawley
+Chris Pryer
+Chris Wolfe
+Christian Clauss
+Christian Heimes
+Christian Oudard
+Christoph Reiter
+Christopher Hunt
+Christopher Snyder
+chrysle
+cjc7373
+Clark Boylan
+Claudio Jolowicz
+Clay McClure
+Cody
+Cody Soyland
+Colin Watson
+Collin Anderson
+Connor Osborn
+Cooper Lees
+Cooper Ry Lees
+Cory Benfield
+Cory Wright
+Craig Kerstiens
+Cristian Sorinel
+Cristina
+Cristina Muñoz
+ctg123
+Curtis Doty
+cytolentino
+Daan De Meyer
+Dale
+Damian
+Damian Quiroga
+Damian Shaw
+Dan Black
+Dan Savilonis
+Dan Sully
+Dane Hillard
+daniel
+Daniel Collins
+Daniel Hahler
+Daniel Holth
+Daniel Jost
+Daniel Katz
+Daniel Shaulov
+Daniele Esposti
+Daniele Nicolodi
+Daniele Procida
+Daniil Konovalenko
+Danny Hermes
+Danny McClanahan
+Darren Kavanagh
+Dav Clark
+Dave Abrahams
+Dave Jones
+David Aguilar
+David Black
+David Bordeynik
+David Caro
+David D Lowe
+David Evans
+David Hewitt
+David Linke
+David Poggi
+David Poznik
+David Pursehouse
+David Runge
+David Tucker
+David Wales
+Davidovich
+ddelange
+Deepak Sharma
+Deepyaman Datta
+Denise Yu
+dependabot[bot]
+derwolfe
+Desetude
+Devesh Kumar Singh
+devsagul
+Diego Caraballo
+Diego Ramirez
+DiegoCaraballo
+Dimitri Merejkowsky
+Dimitri Papadopoulos
+Dimitri Papadopoulos Orfanos
+Dirk Stolle
+Dmitry Gladkov
+Dmitry Volodin
+Domen Kožar
+Dominic Davis-Foster
+Donald Stufft
+Dongweiming
+doron zarhi
+Dos Moonen
+Douglas Thor
+DrFeathers
+Dustin Ingram
+Dustin Rodrigues
+Dwayne Bailey
+Ed Morley
+Edgar Ramírez
+Edgar Ramírez Mondragón
+Ee Durbin
+Efflam Lemaillet
+efflamlemaillet
+Eitan Adler
+ekristina
+elainechan
+Eli Schwartz
+Elisha Hollander
+Ellen Marie Dash
+Emil Burzo
+Emil Styrke
+Emmanuel Arias
+Endoh Takanao
+enoch
+Erdinc Mutlu
+Eric Cousineau
+Eric Gillingham
+Eric Hanchrow
+Eric Hopper
+Erik M. Bray
+Erik Rose
+Erwin Janssen
+Eugene Vereshchagin
+everdimension
+Federico
+Felipe Peter
+Felix Yan
+fiber-space
+Filip Kokosiński
+Filipe Laíns
+Finn Womack
+finnagin
+Flavio Amurrio
+Florian Briand
+Florian Rathgeber
+Francesco
+Francesco Montesano
+Fredrik Orderud
+Frost Ming
+Gabriel Curio
+Gabriel de Perthuis
+Garry Polley
+gavin
+gdanielson
+Geoffrey Sneddon
+George Song
+Georgi Valkov
+Georgy Pchelkin
+ghost
+Giftlin Rajaiah
+gizmoguy1
+gkdoc
+Godefroid Chapelle
+Gopinath M
+GOTO Hayato
+gousaiyang
+gpiks
+Greg Roodt
+Greg Ward
+Guilherme Espada
+Guillaume Seguin
+gutsytechster
+Guy Rozendorn
+Guy Tuval
+gzpan123
+Hanjun Kim
+Hari Charan
+Harsh Vardhan
+harupy
+Harutaka Kawamura
+hauntsaninja
+Henrich Hartzer
+Henry Schreiner
+Herbert Pfennig
+Holly Stotelmyer
+Honnix
+Hsiaoming Yang
+Hugo Lopes Tavares
+Hugo van Kemenade
+Hugues Bruant
+Hynek Schlawack
+Ian Bicking
+Ian Cordasco
+Ian Lee
+Ian Stapleton Cordasco
+Ian Wienand
+Igor Kuzmitshov
+Igor Sobreira
+Ikko Ashimine
+Ilan Schnell
+Illia Volochii
+Ilya Baryshev
+Inada Naoki
+Ionel Cristian Mărieș
+Ionel Maries Cristian
+Itamar Turner-Trauring
+Ivan Pozdeev
+J. Nick Koston
+Jacob Kim
+Jacob Walls
+Jaime Sanz
+jakirkham
+Jakub Kuczys
+Jakub Stasiak
+Jakub Vysoky
+Jakub Wilk
+James Cleveland
+James Curtin
+James Firth
+James Gerity
+James Polley
+Jan Pokorný
+Jannis Leidel
+Jarek Potiuk
+jarondl
+Jason Curtis
+Jason R. Coombs
+JasonMo
+JasonMo1
+Jay Graves
+Jean Abou Samra
+Jean-Christophe Fillion-Robin
+Jeff Barber
+Jeff Dairiki
+Jeff Widman
+Jelmer Vernooij
+jenix21
+Jeremy Fleischman
+Jeremy Stanley
+Jeremy Zafran
+Jesse Rittner
+Jiashuo Li
+Jim Fisher
+Jim Garrison
+Jinzhe Zeng
+Jiun Bae
+Jivan Amara
+Joe Bylund
+Joe Michelini
+John Paton
+John Sirois
+John T. Wodder II
+John-Scott Atlakson
+johnthagen
+Jon Banafato
+Jon Dufresne
+Jon Parise
+Jonas Nockert
+Jonathan Herbert
+Joonatan Partanen
+Joost Molenaar
+Jorge Niedbalski
+Joseph Bylund
+Joseph Long
+Josh Bronson
+Josh Cannon
+Josh Hansen
+Josh Schneier
+Joshua
+Juan Luis Cano Rodríguez
+Juanjo Bazán
+Judah Rand
+Julian Berman
+Julian Gethmann
+Julien Demoor
+Jussi Kukkonen
+jwg4
+Jyrki Pulliainen
+Kai Chen
+Kai Mueller
+Kamal Bin Mustafa
+kasium
+kaustav haldar
+keanemind
+Keith Maxwell
+Kelsey Hightower
+Kenneth Belitzky
+Kenneth Reitz
+Kevin Burke
+Kevin Carter
+Kevin Frommelt
+Kevin R Patterson
+Kexuan Sun
+Kit Randel
+Klaas van Schelven
+KOLANICH
+konstin
+kpinc
+Krishna Oza
+Kumar McMillan
+Kuntal Majumder
+Kurt McKee
+Kyle Persohn
+lakshmanaram
+Laszlo Kiss-Kollar
+Laurent Bristiel
+Laurent LAPORTE
+Laurie O
+Laurie Opperman
+layday
+Leon Sasson
+Lev Givon
+Lincoln de Sousa
+Lipis
+lorddavidiii
+Loren Carvalho
+Lucas Cimon
+Ludovic Gasc
+Luis Medel
+Lukas Geiger
+Lukas Juhrich
+Luke Macken
+Luo Jiebin
+luojiebin
+luz.paz
+László Kiss Kollár
+M00nL1ght
+Marc Abramowitz
+Marc Tamlyn
+Marcus Smith
+Mariatta
+Mark Kohler
+Mark McLoughlin
+Mark Williams
+Markus Hametner
+Martey Dodoo
+Martin Fischer
+Martin Häcker
+Martin Pavlasek
+Masaki
+Masklinn
+Matej Stuchlik
+Mathew Jennings
+Mathieu Bridon
+Mathieu Kniewallner
+Matt Bacchi
+Matt Good
+Matt Maker
+Matt Robenolt
+Matt Wozniski
+matthew
+Matthew Einhorn
+Matthew Feickert
+Matthew Gilliard
+Matthew Hughes
+Matthew Iversen
+Matthew Treinish
+Matthew Trumbell
+Matthew Willson
+Matthias Bussonnier
+mattip
+Maurits van Rees
+Max W Chase
+Maxim Kurnikov
+Maxime Rouyrre
+mayeut
+mbaluna
+mdebi
+memoselyk
+meowmeowcat
+Michael
+Michael Aquilina
+Michael E. Karpeles
+Michael Klich
+Michael Mintz
+Michael Williamson
+michaelpacer
+Michał Górny
+Mickaël Schoentgen
+Miguel Araujo Perez
+Mihir Singh
+Mike
+Mike Hendricks
+Min RK
+MinRK
+Miro Hrončok
+Monica Baluna
+montefra
+Monty Taylor
+morotti
+mrKazzila
+Muha Ajjan
+Nadav Wexler
+Nahuel Ambrosini
+Nate Coraor
+Nate Prewitt
+Nathan Houghton
+Nathaniel J. Smith
+Nehal J Wani
+Neil Botelho
+Nguyễn Gia Phong
+Nicholas Serra
+Nick Coghlan
+Nick Stenning
+Nick Timkovich
+Nicolas Bock
+Nicole Harris
+Nikhil Benesch
+Nikhil Ladha
+Nikita Chepanov
+Nikolay Korolev
+Nipunn Koorapati
+Nitesh Sharma
+Niyas Sait
+Noah
+Noah Gorny
+Nowell Strite
+NtaleGrey
+nvdv
+OBITORASU
+Ofek Lev
+ofrinevo
+Oliver Freund
+Oliver Jeeves
+Oliver Mannion
+Oliver Tonnhofer
+Olivier Girardot
+Olivier Grisel
+Ollie Rutherfurd
+OMOTO Kenji
+Omry Yadan
+onlinejudge95
+Oren Held
+Oscar Benjamin
+Oz N Tiram
+Pachwenko
+Patrick Dubroy
+Patrick Jenkins
+Patrick Lawson
+patricktokeeffe
+Patrik Kopkan
+Paul Ganssle
+Paul Kehrer
+Paul Moore
+Paul Nasrat
+Paul Oswald
+Paul van der Linden
+Paulus Schoutsen
+Pavel Safronov
+Pavithra Eswaramoorthy
+Pawel Jasinski
+Paweł Szramowski
+Pekka Klärck
+Peter Gessler
+Peter Lisák
+Peter Shen
+Peter Waller
+Petr Viktorin
+petr-tik
+Phaneendra Chiruvella
+Phil Elson
+Phil Freo
+Phil Pennock
+Phil Whelan
+Philip Jägenstedt
+Philip Molloy
+Philippe Ombredanne
+Pi Delport
+Pierre-Yves Rofes
+Pieter Degroote
+pip
+Prabakaran Kumaresshan
+Prabhjyotsing Surjit Singh Sodhi
+Prabhu Marappan
+Pradyun Gedam
+Prashant Sharma
+Pratik Mallya
+pre-commit-ci[bot]
+Preet Thakkar
+Preston Holmes
+Przemek Wrzos
+Pulkit Goyal
+q0w
+Qiangning Hong
+Qiming Xu
+Quentin Lee
+Quentin Pradet
+R. David Murray
+Rafael Caricio
+Ralf Schmitt
+Ran Benita
+Razzi Abuissa
+rdb
+Reece Dunham
+Remi Rampin
+Rene Dudfield
+Riccardo Magliocchetti
+Riccardo Schirone
+Richard Jones
+Richard Si
+Ricky Ng-Adam
+Rishi
+rmorotti
+RobberPhex
+Robert Collins
+Robert McGibbon
+Robert Pollak
+Robert T. McGibbon
+robin elisha robinson
+Roey Berman
+Rohan Jain
+Roman Bogorodskiy
+Roman Donchenko
+Romuald Brunet
+ronaudinho
+Ronny Pfannschmidt
+Rory McCann
+Ross Brattain
+Roy Wellington Ⅳ
+Ruairidh MacLeod
+Russell Keith-Magee
+Ryan Shepherd
+Ryan Wooden
+ryneeverett
+S. Guliaev
+Sachi King
+Salvatore Rinchiera
+sandeepkiran-js
+Sander Van Balen
+Savio Jomton
+schlamar
+Scott Kitterman
+Sean
+seanj
+Sebastian Jordan
+Sebastian Schaetz
+Segev Finer
+SeongSoo Cho
+Sergey Vasilyev
+Seth Michael Larson
+Seth Woodworth
+Shahar Epstein
+Shantanu
+shenxianpeng
+shireenrao
+Shivansh-007
+Shixian Sheng
+Shlomi Fish
+Shovan Maity
+Simeon Visser
+Simon Cross
+Simon Pichugin
+sinoroc
+sinscary
+snook92
+socketubs
+Sorin Sbarnea
+Srinivas Nyayapati
+Srishti Hegde
+Stavros Korokithakis
+Stefan Scherfke
+Stefano Rivera
+Stephan Erb
+Stephen Rosen
+stepshal
+Steve (Gadget) Barnes
+Steve Barnes
+Steve Dower
+Steve Kowalik
+Steven Myint
+Steven Silvester
+stonebig
+studioj
+Stéphane Bidoul
+Stéphane Bidoul (ACSONE)
+Stéphane Klein
+Sumana Harihareswara
+Surbhi Sharma
+Sviatoslav Sydorenko
+Sviatoslav Sydorenko (Святослав Сидоренко)
+Swat009
+Sylvain
+Takayuki SHIMIZUKAWA
+Taneli Hukkinen
+tbeswick
+Thiago
+Thijs Triemstra
+Thomas Fenzl
+Thomas Grainger
+Thomas Guettler
+Thomas Johansson
+Thomas Kluyver
+Thomas Smith
+Thomas VINCENT
+Tim D. Smith
+Tim Gates
+Tim Harder
+Tim Heap
+tim smith
+tinruufu
+Tobias Hermann
+Tom Forbes
+Tom Freudenheim
+Tom V
+Tomas Hrnciar
+Tomas Orsava
+Tomer Chachamu
+Tommi Enenkel | AnB
+Tomáš Hrnčiar
+Tony Beswick
+Tony Narlock
+Tony Zhaocheng Tan
+TonyBeswick
+toonarmycaptain
+Toshio Kuratomi
+toxinu
+Travis Swicegood
+Tushar Sadhwani
+Tzu-ping Chung
+Valentin Haenel
+Victor Stinner
+victorvpaulo
+Vikram - Google
+Viktor Szépe
+Ville Skyttä
+Vinay Sajip
+Vincent Philippon
+Vinicyus Macedo
+Vipul Kumar
+Vitaly Babiy
+Vladimir Fokow
+Vladimir Rutsky
+W. Trevor King
+Wil Tan
+Wilfred Hughes
+William Edwards
+William ML Leslie
+William T Olson
+William Woodruff
+Wilson Mo
+wim glenn
+Winson Luk
+Wolfgang Maier
+Wu Zhenyu
+XAMES3
+Xavier Fernandez
+Xianpeng Shen
+xoviat
+xtreak
+YAMAMOTO Takashi
+Yen Chi Hsuan
+Yeray Diaz Diaz
+Yoval P
+Yu Jian
+Yuan Jing Vincent Yan
+Yusuke Hayashi
+Zearin
+Zhiping Deng
+ziebam
+Zvezdan Petkovic
+Łukasz Langa
+Роман Донченко
+Семён Марьясин
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/LICENSE.txt b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/LICENSE.txt
new file mode 100644
index 000000000..8e7b65eaf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/LICENSE.txt
@@ -0,0 +1,20 @@
+Copyright (c) 2008-present The pip developers (see AUTHORS.txt file)
+
+Permission is hereby granted, free of charge, to any person obtaining
+a copy of this software and associated documentation files (the
+"Software"), to deal in the Software without restriction, including
+without limitation the rights to use, copy, modify, merge, publish,
+distribute, sublicense, and/or sell copies of the Software, and to
+permit persons to whom the Software is furnished to do so, subject to
+the following conditions:
+
+The above copyright notice and this permission notice shall be
+included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
+LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
+WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/METADATA b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/METADATA
new file mode 100644
index 000000000..9e5aa3a48
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/METADATA
@@ -0,0 +1,90 @@
+Metadata-Version: 2.1
+Name: pip
+Version: 24.3.1
+Summary: The PyPA recommended tool for installing Python packages.
+Author-email: The pip developers <distutils-sig@python.org>
+License: MIT
+Project-URL: Homepage, https://pip.pypa.io/
+Project-URL: Documentation, https://pip.pypa.io
+Project-URL: Source, https://github.com/pypa/pip
+Project-URL: Changelog, https://pip.pypa.io/en/stable/news/
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Topic :: Software Development :: Build Tools
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Classifier: Programming Language :: Python :: 3.13
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Requires-Python: >=3.8
+Description-Content-Type: text/x-rst
+License-File: LICENSE.txt
+License-File: AUTHORS.txt
+
+pip - The Python Package Installer
+==================================
+
+.. |pypi-version| image:: https://img.shields.io/pypi/v/pip.svg
+ :target: https://pypi.org/project/pip/
+ :alt: PyPI
+
+.. |python-versions| image:: https://img.shields.io/pypi/pyversions/pip
+ :target: https://pypi.org/project/pip
+ :alt: PyPI - Python Version
+
+.. |docs-badge| image:: https://readthedocs.org/projects/pip/badge/?version=latest
+ :target: https://pip.pypa.io/en/latest
+ :alt: Documentation
+
+|pypi-version| |python-versions| |docs-badge|
+
+pip is the `package installer`_ for Python. You can use pip to install packages from the `Python Package Index`_ and other indexes.
+
+Please take a look at our documentation for how to install and use pip:
+
+* `Installation`_
+* `Usage`_
+
+We release updates regularly, with a new version every 3 months. Find more details in our documentation:
+
+* `Release notes`_
+* `Release process`_
+
+If you find bugs, need help, or want to talk to the developers, please use our mailing lists or chat rooms:
+
+* `Issue tracking`_
+* `Discourse channel`_
+* `User IRC`_
+
+If you want to get involved head over to GitHub to get the source code, look at our development documentation and feel free to jump on the developer mailing lists and chat rooms:
+
+* `GitHub page`_
+* `Development documentation`_
+* `Development IRC`_
+
+Code of Conduct
+---------------
+
+Everyone interacting in the pip project's codebases, issue trackers, chat
+rooms, and mailing lists is expected to follow the `PSF Code of Conduct`_.
+
+.. _package installer: https://packaging.python.org/guides/tool-recommendations/
+.. _Python Package Index: https://pypi.org
+.. _Installation: https://pip.pypa.io/en/stable/installation/
+.. _Usage: https://pip.pypa.io/en/stable/
+.. _Release notes: https://pip.pypa.io/en/stable/news.html
+.. _Release process: https://pip.pypa.io/en/latest/development/release-process/
+.. _GitHub page: https://github.com/pypa/pip
+.. _Development documentation: https://pip.pypa.io/en/latest/development
+.. _Issue tracking: https://github.com/pypa/pip/issues
+.. _Discourse channel: https://discuss.python.org/c/packaging
+.. _User IRC: https://kiwiirc.com/nextclient/#ircs://irc.libera.chat:+6697/pypa
+.. _Development IRC: https://kiwiirc.com/nextclient/#ircs://irc.libera.chat:+6697/pypa-dev
+.. _PSF Code of Conduct: https://github.com/pypa/.github/blob/main/CODE_OF_CONDUCT.md
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/RECORD b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/RECORD
new file mode 100644
index 000000000..9a11b4ffe
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/RECORD
@@ -0,0 +1,853 @@
+../../Scripts/pip.exe,sha256=IE1CfbwYXe0mfbr20MJt6USLIQsvawe0odXWsWBc1vA,108457
+../../Scripts/pip3.12.exe,sha256=IE1CfbwYXe0mfbr20MJt6USLIQsvawe0odXWsWBc1vA,108457
+../../Scripts/pip3.exe,sha256=IE1CfbwYXe0mfbr20MJt6USLIQsvawe0odXWsWBc1vA,108457
+pip-24.3.1.dist-info/AUTHORS.txt,sha256=Cbb630k8EL9FkBzX9Vpi6hpYWrLSlh08eXodL5u0eLI,10925
+pip-24.3.1.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+pip-24.3.1.dist-info/LICENSE.txt,sha256=Y0MApmnUmurmWxLGxIySTFGkzfPR_whtw0VtyLyqIQQ,1093
+pip-24.3.1.dist-info/METADATA,sha256=V8iCNK1GYbC82PWsLMsASDh9AO4veocRlM4Pn9q2KFI,3677
+pip-24.3.1.dist-info/RECORD,,
+pip-24.3.1.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip-24.3.1.dist-info/WHEEL,sha256=OVMc5UfuAQiSplgO0_WdW7vXVGAt9Hdd6qtN4HotdyA,91
+pip-24.3.1.dist-info/entry_points.txt,sha256=eeIjuzfnfR2PrhbjnbzFU6MnSS70kZLxwaHHq6M-bD0,87
+pip-24.3.1.dist-info/top_level.txt,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+pip/__init__.py,sha256=faXY_neeYrA_88plEhkyhwAaYeds7wu5U1iGwP24J0s,357
+pip/__main__.py,sha256=WzbhHXTbSE6gBY19mNN9m4s5o_365LOvTYSgqgbdBhE,854
+pip/__pip-runner__.py,sha256=cPPWuJ6NK_k-GzfvlejLFgwzmYUROmpAR6QC3Q-vkXQ,1450
+pip/__pycache__/__init__.cpython-312.pyc,,
+pip/__pycache__/__main__.cpython-312.pyc,,
+pip/__pycache__/__pip-runner__.cpython-312.pyc,,
+pip/_internal/__init__.py,sha256=MfcoOluDZ8QMCFYal04IqOJ9q6m2V7a0aOsnI-WOxUo,513
+pip/_internal/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/__pycache__/build_env.cpython-312.pyc,,
+pip/_internal/__pycache__/cache.cpython-312.pyc,,
+pip/_internal/__pycache__/configuration.cpython-312.pyc,,
+pip/_internal/__pycache__/exceptions.cpython-312.pyc,,
+pip/_internal/__pycache__/main.cpython-312.pyc,,
+pip/_internal/__pycache__/pyproject.cpython-312.pyc,,
+pip/_internal/__pycache__/self_outdated_check.cpython-312.pyc,,
+pip/_internal/__pycache__/wheel_builder.cpython-312.pyc,,
+pip/_internal/build_env.py,sha256=wsTPOWyPTKvUREUcO585OU01kbQufpdigY8fVHv3WIw,10584
+pip/_internal/cache.py,sha256=Jb698p5PNigRtpW5o26wQNkkUv4MnQ94mc471wL63A0,10369
+pip/_internal/cli/__init__.py,sha256=FkHBgpxxb-_gd6r1FjnNhfMOzAUYyXoXKJ6abijfcFU,132
+pip/_internal/cli/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/autocompletion.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/base_command.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/cmdoptions.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/command_context.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/index_command.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/main.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/main_parser.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/parser.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/progress_bars.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/req_command.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/spinners.cpython-312.pyc,,
+pip/_internal/cli/__pycache__/status_codes.cpython-312.pyc,,
+pip/_internal/cli/autocompletion.py,sha256=Lli3Mr6aDNu7ZkJJFFvwD2-hFxNI6Avz8OwMyS5TVrs,6865
+pip/_internal/cli/base_command.py,sha256=F8nUcSM-Y-MQljJUe724-yxmc5viFXHyM_zH70NmIh4,8289
+pip/_internal/cli/cmdoptions.py,sha256=mDqBr0d0hoztbRJs-PWtcKpqNAc7khU6ZpoesZKocT8,30110
+pip/_internal/cli/command_context.py,sha256=RHgIPwtObh5KhMrd3YZTkl8zbVG-6Okml7YbFX4Ehg0,774
+pip/_internal/cli/index_command.py,sha256=-0oPTruZGkLSMrWDleZ6UtcKP3G-SImRRuhH0RfVE3o,5631
+pip/_internal/cli/main.py,sha256=BDZef-bWe9g9Jpr4OVs4dDf-845HJsKw835T7AqEnAc,2817
+pip/_internal/cli/main_parser.py,sha256=laDpsuBDl6kyfywp9eMMA9s84jfH2TJJn-vmL0GG90w,4338
+pip/_internal/cli/parser.py,sha256=VCMtduzECUV87KaHNu-xJ-wLNL82yT3x16V4XBxOAqI,10825
+pip/_internal/cli/progress_bars.py,sha256=VgydyqjZvfhqpuNcFDn00QNuA9GxRe9CKrRG8jhPuKU,2723
+pip/_internal/cli/req_command.py,sha256=DqeFhmUMs6o6Ev8qawAcOoYNdAZsfyKS0MZI5jsJYwQ,12250
+pip/_internal/cli/spinners.py,sha256=hIJ83GerdFgFCdobIA23Jggetegl_uC4Sp586nzFbPE,5118
+pip/_internal/cli/status_codes.py,sha256=sEFHUaUJbqv8iArL3HAtcztWZmGOFX01hTesSytDEh0,116
+pip/_internal/commands/__init__.py,sha256=5oRO9O3dM2vGuh0bFw4HOVletryrz5HHMmmPWwJrH9U,3882
+pip/_internal/commands/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/cache.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/check.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/completion.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/configuration.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/debug.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/download.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/freeze.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/hash.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/help.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/index.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/inspect.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/install.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/list.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/search.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/show.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/uninstall.cpython-312.pyc,,
+pip/_internal/commands/__pycache__/wheel.cpython-312.pyc,,
+pip/_internal/commands/cache.py,sha256=xg76_ZFEBC6zoQ3gXLRfMZJft4z2a0RwH4GEFZC6nnU,7944
+pip/_internal/commands/check.py,sha256=Hr_4eiMd9cgVDgEvjtIdw915NmL7ROIWW8enkr8slPQ,2268
+pip/_internal/commands/completion.py,sha256=HT4lD0bgsflHq2IDgYfiEdp7IGGtE7s6MgI3xn0VQEw,4287
+pip/_internal/commands/configuration.py,sha256=n98enwp6y0b5G6fiRQjaZo43FlJKYve_daMhN-4BRNc,9766
+pip/_internal/commands/debug.py,sha256=DNDRgE9YsKrbYzU0s3VKi8rHtKF4X13CJ_br_8PUXO0,6797
+pip/_internal/commands/download.py,sha256=0qB0nys6ZEPsog451lDsjL5Bx7Z97t-B80oFZKhpzKM,5273
+pip/_internal/commands/freeze.py,sha256=2Vt72BYTSm9rzue6d8dNzt8idxWK4Db6Hd-anq7GQ80,3203
+pip/_internal/commands/hash.py,sha256=EVVOuvGtoPEdFi8SNnmdqlCQrhCxV-kJsdwtdcCnXGQ,1703
+pip/_internal/commands/help.py,sha256=gcc6QDkcgHMOuAn5UxaZwAStsRBrnGSn_yxjS57JIoM,1132
+pip/_internal/commands/index.py,sha256=RAXxmJwFhVb5S1BYzb5ifX3sn9Na8v2CCVYwSMP8pao,4731
+pip/_internal/commands/inspect.py,sha256=PGrY9TRTRCM3y5Ml8Bdk8DEOXquWRfscr4DRo1LOTPc,3189
+pip/_internal/commands/install.py,sha256=iqesiLIZc6Op9uihMQFYRhAA2DQRZUxbM4z1BwXoFls,29428
+pip/_internal/commands/list.py,sha256=oiIzSjLP6__d7dIS3q0Xb5ywsaOThBWRqMyjjKzkPdM,12769
+pip/_internal/commands/search.py,sha256=fWkUQVx_gm8ebbFAlCgqtxKXT9rNahpJ-BI__3HNZpg,5626
+pip/_internal/commands/show.py,sha256=IG9L5uo8w6UA4tI_IlmaxLCoNKPa5JNJCljj3NWs0OE,7507
+pip/_internal/commands/uninstall.py,sha256=7pOR7enK76gimyxQbzxcG1OsyLXL3DvX939xmM8Fvtg,3892
+pip/_internal/commands/wheel.py,sha256=eJRhr_qoNNxWAkkdJCNiQM7CXd4E1_YyQhsqJnBPGGg,6414
+pip/_internal/configuration.py,sha256=XkAiBS0hpzsM-LF0Qu5hvPWO_Bs67-oQKRYFBuMbESs,14006
+pip/_internal/distributions/__init__.py,sha256=Hq6kt6gXBgjNit5hTTWLAzeCNOKoB-N0pGYSqehrli8,858
+pip/_internal/distributions/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/distributions/__pycache__/base.cpython-312.pyc,,
+pip/_internal/distributions/__pycache__/installed.cpython-312.pyc,,
+pip/_internal/distributions/__pycache__/sdist.cpython-312.pyc,,
+pip/_internal/distributions/__pycache__/wheel.cpython-312.pyc,,
+pip/_internal/distributions/base.py,sha256=QeB9qvKXDIjLdPBDE5fMgpfGqMMCr-govnuoQnGuiF8,1783
+pip/_internal/distributions/installed.py,sha256=QinHFbWAQ8oE0pbD8MFZWkwlnfU1QYTccA1vnhrlYOU,842
+pip/_internal/distributions/sdist.py,sha256=PlcP4a6-R6c98XnOM-b6Lkb3rsvh9iG4ok8shaanrzs,6751
+pip/_internal/distributions/wheel.py,sha256=THBYfnv7VVt8mYhMYUtH13S1E7FDwtDyDfmUcl8ai0E,1317
+pip/_internal/exceptions.py,sha256=2_byISIv3kSnI_9T-Esfxrt0LnTRgcUHyxu0twsHjQY,26481
+pip/_internal/index/__init__.py,sha256=vpt-JeTZefh8a-FC22ZeBSXFVbuBcXSGiILhQZJaNpQ,30
+pip/_internal/index/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/index/__pycache__/collector.cpython-312.pyc,,
+pip/_internal/index/__pycache__/package_finder.cpython-312.pyc,,
+pip/_internal/index/__pycache__/sources.cpython-312.pyc,,
+pip/_internal/index/collector.py,sha256=RdPO0JLAlmyBWPAWYHPyRoGjz3GNAeTngCNkbGey_mE,16265
+pip/_internal/index/package_finder.py,sha256=yRC4xsyudwKnNoU6IXvNoyqYo5ScT7lB6Wa-z2eh7cs,37666
+pip/_internal/index/sources.py,sha256=lPBLK5Xiy8Q6IQMio26Wl7ocfZOKkgGklIBNyUJ23fI,8632
+pip/_internal/locations/__init__.py,sha256=UaAxeZ_f93FyouuFf4p7SXYF-4WstXuEvd3LbmPCAno,14925
+pip/_internal/locations/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/locations/__pycache__/_distutils.cpython-312.pyc,,
+pip/_internal/locations/__pycache__/_sysconfig.cpython-312.pyc,,
+pip/_internal/locations/__pycache__/base.cpython-312.pyc,,
+pip/_internal/locations/_distutils.py,sha256=x6nyVLj7X11Y4khIdf-mFlxMl2FWadtVEgeb8upc_WI,6013
+pip/_internal/locations/_sysconfig.py,sha256=IGzds60qsFneRogC-oeBaY7bEh3lPt_v47kMJChQXsU,7724
+pip/_internal/locations/base.py,sha256=RQiPi1d4FVM2Bxk04dQhXZ2PqkeljEL2fZZ9SYqIQ78,2556
+pip/_internal/main.py,sha256=r-UnUe8HLo5XFJz8inTcOOTiu_sxNhgHb6VwlGUllOI,340
+pip/_internal/metadata/__init__.py,sha256=9pU3W3s-6HtjFuYhWcLTYVmSaziklPv7k2x8p7X1GmA,4339
+pip/_internal/metadata/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/metadata/__pycache__/_json.cpython-312.pyc,,
+pip/_internal/metadata/__pycache__/base.cpython-312.pyc,,
+pip/_internal/metadata/__pycache__/pkg_resources.cpython-312.pyc,,
+pip/_internal/metadata/_json.py,sha256=P0cAJrH_mtmMZvlZ16ZXm_-izA4lpr5wy08laICuiaA,2644
+pip/_internal/metadata/base.py,sha256=ft0K5XNgI4ETqZnRv2-CtvgYiMOMAeGMAzxT-f6VLJA,25298
+pip/_internal/metadata/importlib/__init__.py,sha256=jUUidoxnHcfITHHaAWG1G2i5fdBYklv_uJcjo2x7VYE,135
+pip/_internal/metadata/importlib/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/metadata/importlib/__pycache__/_compat.cpython-312.pyc,,
+pip/_internal/metadata/importlib/__pycache__/_dists.cpython-312.pyc,,
+pip/_internal/metadata/importlib/__pycache__/_envs.cpython-312.pyc,,
+pip/_internal/metadata/importlib/_compat.py,sha256=c6av8sP8BBjAZuFSJow1iWfygUXNM3xRTCn5nqw6B9M,2796
+pip/_internal/metadata/importlib/_dists.py,sha256=anh0mLI-FYRPUhAdipd0Va3YJJc6HelCKQ0bFhY10a0,8017
+pip/_internal/metadata/importlib/_envs.py,sha256=UUB980XSrDWrMpQ1_G45i0r8Hqlg_tg3IPQ63mEqbNc,7431
+pip/_internal/metadata/pkg_resources.py,sha256=U07ETAINSGeSRBfWUG93E4tZZbaW_f7PGzEqZN0hulc,10542
+pip/_internal/models/__init__.py,sha256=3DHUd_qxpPozfzouoqa9g9ts1Czr5qaHfFxbnxriepM,63
+pip/_internal/models/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/models/__pycache__/candidate.cpython-312.pyc,,
+pip/_internal/models/__pycache__/direct_url.cpython-312.pyc,,
+pip/_internal/models/__pycache__/format_control.cpython-312.pyc,,
+pip/_internal/models/__pycache__/index.cpython-312.pyc,,
+pip/_internal/models/__pycache__/installation_report.cpython-312.pyc,,
+pip/_internal/models/__pycache__/link.cpython-312.pyc,,
+pip/_internal/models/__pycache__/scheme.cpython-312.pyc,,
+pip/_internal/models/__pycache__/search_scope.cpython-312.pyc,,
+pip/_internal/models/__pycache__/selection_prefs.cpython-312.pyc,,
+pip/_internal/models/__pycache__/target_python.cpython-312.pyc,,
+pip/_internal/models/__pycache__/wheel.cpython-312.pyc,,
+pip/_internal/models/candidate.py,sha256=zzgFRuw_kWPjKpGw7LC0ZUMD2CQ2EberUIYs8izjdCA,753
+pip/_internal/models/direct_url.py,sha256=uBtY2HHd3TO9cKQJWh0ThvE5FRr-MWRYChRU4IG9HZE,6578
+pip/_internal/models/format_control.py,sha256=wtsQqSK9HaUiNxQEuB-C62eVimw6G4_VQFxV9-_KDBE,2486
+pip/_internal/models/index.py,sha256=tYnL8oxGi4aSNWur0mG8DAP7rC6yuha_MwJO8xw0crI,1030
+pip/_internal/models/installation_report.py,sha256=zRVZoaz-2vsrezj_H3hLOhMZCK9c7TbzWgC-jOalD00,2818
+pip/_internal/models/link.py,sha256=jHax9O-9zlSzEwjBCDkx0OXjKXwBDwOuPwn-PsR8dCs,21034
+pip/_internal/models/scheme.py,sha256=PakmHJM3e8OOWSZFtfz1Az7f1meONJnkGuQxFlt3wBE,575
+pip/_internal/models/search_scope.py,sha256=67NEnsYY84784S-MM7ekQuo9KXLH-7MzFntXjapvAo0,4531
+pip/_internal/models/selection_prefs.py,sha256=qaFfDs3ciqoXPg6xx45N1jPLqccLJw4N0s4P0PyHTQ8,2015
+pip/_internal/models/target_python.py,sha256=2XaH2rZ5ZF-K5wcJbEMGEl7SqrTToDDNkrtQ2v_v_-Q,4271
+pip/_internal/models/wheel.py,sha256=G7dND_s4ebPkEL7RJ1qCY0QhUUWIIK6AnjWgRATF5no,4539
+pip/_internal/network/__init__.py,sha256=jf6Tt5nV_7zkARBrKojIXItgejvoegVJVKUbhAa5Ioc,50
+pip/_internal/network/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/network/__pycache__/auth.cpython-312.pyc,,
+pip/_internal/network/__pycache__/cache.cpython-312.pyc,,
+pip/_internal/network/__pycache__/download.cpython-312.pyc,,
+pip/_internal/network/__pycache__/lazy_wheel.cpython-312.pyc,,
+pip/_internal/network/__pycache__/session.cpython-312.pyc,,
+pip/_internal/network/__pycache__/utils.cpython-312.pyc,,
+pip/_internal/network/__pycache__/xmlrpc.cpython-312.pyc,,
+pip/_internal/network/auth.py,sha256=D4gASjUrqoDFlSt6gQ767KAAjv6PUyJU0puDlhXNVRE,20809
+pip/_internal/network/cache.py,sha256=48A971qCzKNFvkb57uGEk7-0xaqPS0HWj2711QNTxkU,3935
+pip/_internal/network/download.py,sha256=FLOP29dPYECBiAi7eEjvAbNkyzaKNqbyjOT2m8HPW8U,6048
+pip/_internal/network/lazy_wheel.py,sha256=PBdoMoNQQIA84Fhgne38jWF52W4x_KtsHjxgv4dkRKA,7622
+pip/_internal/network/session.py,sha256=XmanBKjVwPFmh1iJ58q6TDh9xabH37gREuQJ_feuZGA,18741
+pip/_internal/network/utils.py,sha256=Inaxel-NxBu4PQWkjyErdnfewsFCcgHph7dzR1-FboY,4088
+pip/_internal/network/xmlrpc.py,sha256=sAxzOacJ-N1NXGPvap9jC3zuYWSnnv3GXtgR2-E2APA,1838
+pip/_internal/operations/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_internal/operations/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/operations/__pycache__/check.cpython-312.pyc,,
+pip/_internal/operations/__pycache__/freeze.cpython-312.pyc,,
+pip/_internal/operations/__pycache__/prepare.cpython-312.pyc,,
+pip/_internal/operations/build/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_internal/operations/build/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/operations/build/__pycache__/build_tracker.cpython-312.pyc,,
+pip/_internal/operations/build/__pycache__/metadata.cpython-312.pyc,,
+pip/_internal/operations/build/__pycache__/metadata_editable.cpython-312.pyc,,
+pip/_internal/operations/build/__pycache__/metadata_legacy.cpython-312.pyc,,
+pip/_internal/operations/build/__pycache__/wheel.cpython-312.pyc,,
+pip/_internal/operations/build/__pycache__/wheel_editable.cpython-312.pyc,,
+pip/_internal/operations/build/__pycache__/wheel_legacy.cpython-312.pyc,,
+pip/_internal/operations/build/build_tracker.py,sha256=-ARW_TcjHCOX7D2NUOGntB4Fgc6b4aolsXkAK6BWL7w,4774
+pip/_internal/operations/build/metadata.py,sha256=9S0CUD8U3QqZeXp-Zyt8HxwU90lE4QrnYDgrqZDzBnc,1422
+pip/_internal/operations/build/metadata_editable.py,sha256=VLL7LvntKE8qxdhUdEJhcotFzUsOSI8NNS043xULKew,1474
+pip/_internal/operations/build/metadata_legacy.py,sha256=8i6i1QZX9m_lKPStEFsHKM0MT4a-CD408JOw99daLmo,2190
+pip/_internal/operations/build/wheel.py,sha256=sT12FBLAxDC6wyrDorh8kvcZ1jG5qInCRWzzP-UkJiQ,1075
+pip/_internal/operations/build/wheel_editable.py,sha256=yOtoH6zpAkoKYEUtr8FhzrYnkNHQaQBjWQ2HYae1MQg,1417
+pip/_internal/operations/build/wheel_legacy.py,sha256=K-6kNhmj-1xDF45ny1yheMerF0ui4EoQCLzEoHh6-tc,3045
+pip/_internal/operations/check.py,sha256=L24vRL8VWbyywdoeAhM89WCd8zLTnjIbULlKelUgIec,5912
+pip/_internal/operations/freeze.py,sha256=V59yEyCSz_YhZuhH09-6aV_zvYBMrS_IxFFNqn2QzlA,9864
+pip/_internal/operations/install/__init__.py,sha256=mX7hyD2GNBO2mFGokDQ30r_GXv7Y_PLdtxcUv144e-s,51
+pip/_internal/operations/install/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/operations/install/__pycache__/editable_legacy.cpython-312.pyc,,
+pip/_internal/operations/install/__pycache__/wheel.cpython-312.pyc,,
+pip/_internal/operations/install/editable_legacy.py,sha256=PoEsNEPGbIZ2yQphPsmYTKLOCMs4gv5OcCdzW124NcA,1283
+pip/_internal/operations/install/wheel.py,sha256=X5Iz9yUg5LlK5VNQ9g2ikc6dcRu8EPi_SUi5iuEDRgo,27615
+pip/_internal/operations/prepare.py,sha256=joWJwPkuqGscQgVNImLK71e9hRapwKvRCM8HclysmvU,28118
+pip/_internal/pyproject.py,sha256=rw4fwlptDp1hZgYoplwbAGwWA32sWQkp7ysf8Ju6iXc,7287
+pip/_internal/req/__init__.py,sha256=HxBFtZy_BbCclLgr26waMtpzYdO5T3vxePvpGAXSt5s,2653
+pip/_internal/req/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/req/__pycache__/constructors.cpython-312.pyc,,
+pip/_internal/req/__pycache__/req_file.cpython-312.pyc,,
+pip/_internal/req/__pycache__/req_install.cpython-312.pyc,,
+pip/_internal/req/__pycache__/req_set.cpython-312.pyc,,
+pip/_internal/req/__pycache__/req_uninstall.cpython-312.pyc,,
+pip/_internal/req/constructors.py,sha256=v1qzCN1mIldwx-nCrPc8JO4lxkm3Fv8M5RWvt8LISjc,18430
+pip/_internal/req/req_file.py,sha256=gOOJTzL-mDRPcQhjwqjDrjn4V-3rK9TnEFnU3v8RA4Q,18752
+pip/_internal/req/req_install.py,sha256=yhT98NGDoAEk03jznTJnYCznzhiMEEA2ocgsUG_dcNU,35788
+pip/_internal/req/req_set.py,sha256=j3esG0s6SzoVReX9rWn4rpYNtyET_fwxbwJPRimvRxo,2858
+pip/_internal/req/req_uninstall.py,sha256=qzDIxJo-OETWqGais7tSMCDcWbATYABT-Tid3ityF0s,23853
+pip/_internal/resolution/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_internal/resolution/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/resolution/__pycache__/base.cpython-312.pyc,,
+pip/_internal/resolution/base.py,sha256=qlmh325SBVfvG6Me9gc5Nsh5sdwHBwzHBq6aEXtKsLA,583
+pip/_internal/resolution/legacy/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_internal/resolution/legacy/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/resolution/legacy/__pycache__/resolver.cpython-312.pyc,,
+pip/_internal/resolution/legacy/resolver.py,sha256=3HZiJBRd1FTN6jQpI4qRO8-TbLYeIbUTS6PFvXnXs2w,24068
+pip/_internal/resolution/resolvelib/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_internal/resolution/resolvelib/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/base.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/candidates.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/factory.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/found_candidates.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/provider.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/reporter.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/requirements.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/__pycache__/resolver.cpython-312.pyc,,
+pip/_internal/resolution/resolvelib/base.py,sha256=DCf669FsqyQY5uqXeePDHQY1e4QO-pBzWH8O0s9-K94,5023
+pip/_internal/resolution/resolvelib/candidates.py,sha256=5UZ1upNnmqsP-nmEZaDYxaBgCoejw_e2WVGmmAvBxXc,20001
+pip/_internal/resolution/resolvelib/factory.py,sha256=511CaUR41LqjALuFafLVfx15WRvMhxYTdjQCoSvp4gw,32661
+pip/_internal/resolution/resolvelib/found_candidates.py,sha256=9hrTyQqFvl9I7Tji79F1AxHv39Qh1rkJ_7deSHSMfQc,6383
+pip/_internal/resolution/resolvelib/provider.py,sha256=bcsFnYvlmtB80cwVdW1fIwgol8ZNr1f1VHyRTkz47SM,9935
+pip/_internal/resolution/resolvelib/reporter.py,sha256=00JtoXEkTlw0-rl_sl54d71avwOsJHt9GGHcrj5Sza0,3168
+pip/_internal/resolution/resolvelib/requirements.py,sha256=7JG4Z72e5Yk4vU0S5ulGvbqTy4FMQGYhY5zQhX9zTtY,8065
+pip/_internal/resolution/resolvelib/resolver.py,sha256=nLJOsVMEVi2gQUVJoUFKMZAeu2f7GRMjGMvNSWyz0Bc,12592
+pip/_internal/self_outdated_check.py,sha256=pkjQixuWyQ1vrVxZAaYD6SSHgXuFUnHZybXEWTkh0S0,8145
+pip/_internal/utils/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_internal/utils/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/_jaraco_text.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/_log.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/appdirs.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/compat.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/compatibility_tags.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/datetime.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/deprecation.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/direct_url_helpers.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/egg_link.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/encoding.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/entrypoints.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/filesystem.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/filetypes.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/glibc.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/hashes.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/logging.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/misc.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/packaging.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/retry.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/setuptools_build.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/subprocess.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/temp_dir.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/unpacking.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/urls.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/virtualenv.cpython-312.pyc,,
+pip/_internal/utils/__pycache__/wheel.cpython-312.pyc,,
+pip/_internal/utils/_jaraco_text.py,sha256=M15uUPIh5NpP1tdUGBxRau6q1ZAEtI8-XyLEETscFfE,3350
+pip/_internal/utils/_log.py,sha256=-jHLOE_THaZz5BFcCnoSL9EYAtJ0nXem49s9of4jvKw,1015
+pip/_internal/utils/appdirs.py,sha256=swgcTKOm3daLeXTW6v5BUS2Ti2RvEnGRQYH_yDXklAo,1665
+pip/_internal/utils/compat.py,sha256=ckkFveBiYQjRWjkNsajt_oWPS57tJvE8XxoC4OIYgCY,2399
+pip/_internal/utils/compatibility_tags.py,sha256=OWq5axHpW-MEEPztGdvgADrgJPAcV9a88Rxm4Z8VBs8,6272
+pip/_internal/utils/datetime.py,sha256=m21Y3wAtQc-ji6Veb6k_M5g6A0ZyFI4egchTdnwh-pQ,242
+pip/_internal/utils/deprecation.py,sha256=k7Qg_UBAaaTdyq82YVARA6D7RmcGTXGv7fnfcgigj4Q,3707
+pip/_internal/utils/direct_url_helpers.py,sha256=r2MRtkVDACv9AGqYODBUC9CjwgtsUU1s68hmgfCJMtA,3196
+pip/_internal/utils/egg_link.py,sha256=0FePZoUYKv4RGQ2t6x7w5Z427wbA_Uo3WZnAkrgsuqo,2463
+pip/_internal/utils/encoding.py,sha256=qqsXDtiwMIjXMEiIVSaOjwH5YmirCaK-dIzb6-XJsL0,1169
+pip/_internal/utils/entrypoints.py,sha256=YlhLTRl2oHBAuqhc-zmL7USS67TPWVHImjeAQHreZTQ,3064
+pip/_internal/utils/filesystem.py,sha256=ajvA-q4ocliW9kPp8Yquh-4vssXbu-UKbo5FV9V4X64,4950
+pip/_internal/utils/filetypes.py,sha256=i8XAQ0eFCog26Fw9yV0Yb1ygAqKYB1w9Cz9n0fj8gZU,716
+pip/_internal/utils/glibc.py,sha256=vUkWq_1pJuzcYNcGKLlQmABoUiisK8noYY1yc8Wq4w4,3734
+pip/_internal/utils/hashes.py,sha256=XGGLL0AG8-RhWnyz87xF6MFZ--BKadHU35D47eApCKI,4972
+pip/_internal/utils/logging.py,sha256=7BFKB1uFjdxD5crM-GtwA5T2qjbQ2LPD-gJDuJeDNTg,11606
+pip/_internal/utils/misc.py,sha256=NRV0_2fFhzy1jhvInSBv4dqCmTwct8PV7Kp0m-BPRGM,23530
+pip/_internal/utils/packaging.py,sha256=iI3LH43lVNR4hWBOqF6lFsZq4aycb2j0UcHlmDmcqUg,2109
+pip/_internal/utils/retry.py,sha256=mhFbykXjhTnZfgzeuy-vl9c8nECnYn_CMtwNJX2tYzQ,1392
+pip/_internal/utils/setuptools_build.py,sha256=ouXpud-jeS8xPyTPsXJ-m34NPvK5os45otAzdSV_IJE,4435
+pip/_internal/utils/subprocess.py,sha256=EsvqSRiSMHF98T8Txmu6NLU3U--MpTTQjtNgKP0P--M,8988
+pip/_internal/utils/temp_dir.py,sha256=5qOXe8M4JeY6vaFQM867d5zkp1bSwMZ-KT5jymmP0Zg,9310
+pip/_internal/utils/unpacking.py,sha256=eyDkSsk4nW8ZfiSjNzJduCznpHyaGHVv3ak_LMGsiEM,11951
+pip/_internal/utils/urls.py,sha256=qceSOZb5lbNDrHNsv7_S4L4Ytszja5NwPKUMnZHbYnM,1599
+pip/_internal/utils/virtualenv.py,sha256=S6f7csYorRpiD6cvn3jISZYc3I8PJC43H5iMFpRAEDU,3456
+pip/_internal/utils/wheel.py,sha256=b442jkydFHjXzDy6cMR7MpzWBJ1Q82hR5F33cmcHV3g,4494
+pip/_internal/vcs/__init__.py,sha256=UAqvzpbi0VbZo3Ub6skEeZAw-ooIZR-zX_WpCbxyCoU,596
+pip/_internal/vcs/__pycache__/__init__.cpython-312.pyc,,
+pip/_internal/vcs/__pycache__/bazaar.cpython-312.pyc,,
+pip/_internal/vcs/__pycache__/git.cpython-312.pyc,,
+pip/_internal/vcs/__pycache__/mercurial.cpython-312.pyc,,
+pip/_internal/vcs/__pycache__/subversion.cpython-312.pyc,,
+pip/_internal/vcs/__pycache__/versioncontrol.cpython-312.pyc,,
+pip/_internal/vcs/bazaar.py,sha256=EKStcQaKpNu0NK4p5Q10Oc4xb3DUxFw024XrJy40bFQ,3528
+pip/_internal/vcs/git.py,sha256=3tpc9LQA_J4IVW5r5NvWaaSeDzcmJOrSFZN0J8vIKfU,18177
+pip/_internal/vcs/mercurial.py,sha256=oULOhzJ2Uie-06d1omkL-_Gc6meGaUkyogvqG9ZCyPs,5249
+pip/_internal/vcs/subversion.py,sha256=ddTugHBqHzV3ebKlU5QXHPN4gUqlyXbOx8q8NgXKvs8,11735
+pip/_internal/vcs/versioncontrol.py,sha256=cvf_-hnTAjQLXJ3d17FMNhQfcO1AcKWUF10tfrYyP-c,22440
+pip/_internal/wheel_builder.py,sha256=DL3A8LKeRj_ACp11WS5wSgASgPFqeyAeXJKdXfmaWXU,11799
+pip/_vendor/__init__.py,sha256=JYuAXvClhInxIrA2FTp5p-uuWVL7WV6-vEpTs46-Qh4,4873
+pip/_vendor/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/__pycache__/typing_extensions.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__init__.py,sha256=GiYoagwPEiJ_xR_lbwWGaoCiPtF_rz4isjfjdDAgHU4,676
+pip/_vendor/cachecontrol/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/_cmd.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/adapter.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/cache.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/controller.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/filewrapper.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/heuristics.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/serialize.cpython-312.pyc,,
+pip/_vendor/cachecontrol/__pycache__/wrapper.cpython-312.pyc,,
+pip/_vendor/cachecontrol/_cmd.py,sha256=iist2EpzJvDVIhMAxXq8iFnTBsiZAd6iplxfmNboNyk,1737
+pip/_vendor/cachecontrol/adapter.py,sha256=fByO_Pd_EOemjWbuocvBWdN85xT0q_TBm2lxS6vD4fk,6355
+pip/_vendor/cachecontrol/cache.py,sha256=OTQj72tUf8C1uEgczdl3Gc8vkldSzsTITKtDGKMx4z8,1952
+pip/_vendor/cachecontrol/caches/__init__.py,sha256=dtrrroK5BnADR1GWjCZ19aZ0tFsMfvFBtLQQU1sp_ag,303
+pip/_vendor/cachecontrol/caches/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/cachecontrol/caches/__pycache__/file_cache.cpython-312.pyc,,
+pip/_vendor/cachecontrol/caches/__pycache__/redis_cache.cpython-312.pyc,,
+pip/_vendor/cachecontrol/caches/file_cache.py,sha256=9AlmmTJc6cslb6k5z_6q0sGPHVrMj8zv-uWy-simmfE,5406
+pip/_vendor/cachecontrol/caches/redis_cache.py,sha256=9rmqwtYu_ljVkW6_oLqbC7EaX_a8YT_yLuna-eS0dgo,1386
+pip/_vendor/cachecontrol/controller.py,sha256=o-ejGJlBmpKK8QQLyTPJj0t7siU8XVHXuV8MCybCxQ8,18575
+pip/_vendor/cachecontrol/filewrapper.py,sha256=STttGmIPBvZzt2b51dUOwoWX5crcMCpKZOisM3f5BNc,4292
+pip/_vendor/cachecontrol/heuristics.py,sha256=IYe4QmHERWsMvtxNrp920WeaIsaTTyqLB14DSheSbtY,4834
+pip/_vendor/cachecontrol/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/cachecontrol/serialize.py,sha256=HQd2IllQ05HzPkVLMXTF2uX5mjEQjDBkxCqUJUODpZk,5163
+pip/_vendor/cachecontrol/wrapper.py,sha256=hsGc7g8QGQTT-4f8tgz3AM5qwScg6FO0BSdLSRdEvpU,1417
+pip/_vendor/certifi/__init__.py,sha256=p_GYZrjUwPBUhpLlCZoGb0miKBKSqDAyZC5DvIuqbHQ,94
+pip/_vendor/certifi/__main__.py,sha256=1k3Cr95vCxxGRGDljrW3wMdpZdL3Nhf0u1n-k2qdsCY,255
+pip/_vendor/certifi/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/certifi/__pycache__/__main__.cpython-312.pyc,,
+pip/_vendor/certifi/__pycache__/core.cpython-312.pyc,,
+pip/_vendor/certifi/cacert.pem,sha256=lO3rZukXdPyuk6BWUJFOKQliWaXH6HGh9l1GGrUgG0c,299427
+pip/_vendor/certifi/core.py,sha256=2SRT5rIcQChFDbe37BQa-kULxAgJ8qN6l1jfqTp4HIs,4486
+pip/_vendor/certifi/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/distlib/__init__.py,sha256=dcwgYGYGQqAEawBXPDtIx80DO_3cOmFv8HTc8JMzknQ,625
+pip/_vendor/distlib/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/compat.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/database.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/index.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/locators.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/manifest.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/markers.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/metadata.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/resources.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/scripts.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/util.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/version.cpython-312.pyc,,
+pip/_vendor/distlib/__pycache__/wheel.cpython-312.pyc,,
+pip/_vendor/distlib/compat.py,sha256=2jRSjRI4o-vlXeTK2BCGIUhkc6e9ZGhSsacRM5oseTw,41467
+pip/_vendor/distlib/database.py,sha256=mHy_LxiXIsIVRb-T0-idBrVLw3Ffij5teHCpbjmJ9YU,51160
+pip/_vendor/distlib/index.py,sha256=lTbw268rRhj8dw1sib3VZ_0EhSGgoJO3FKJzSFMOaeA,20797
+pip/_vendor/distlib/locators.py,sha256=oBeAZpFuPQSY09MgNnLfQGGAXXvVO96BFpZyKMuK4tM,51026
+pip/_vendor/distlib/manifest.py,sha256=3qfmAmVwxRqU1o23AlfXrQGZzh6g_GGzTAP_Hb9C5zQ,14168
+pip/_vendor/distlib/markers.py,sha256=X6sDvkFGcYS8gUW8hfsWuKEKAqhQZAJ7iXOMLxRYjYk,5164
+pip/_vendor/distlib/metadata.py,sha256=zil3sg2EUfLXVigljY2d_03IJt-JSs7nX-73fECMX2s,38724
+pip/_vendor/distlib/resources.py,sha256=LwbPksc0A1JMbi6XnuPdMBUn83X7BPuFNWqPGEKI698,10820
+pip/_vendor/distlib/scripts.py,sha256=BJliaDAZaVB7WAkwokgC3HXwLD2iWiHaVI50H7C6eG8,18608
+pip/_vendor/distlib/t32.exe,sha256=a0GV5kCoWsMutvliiCKmIgV98eRZ33wXoS-XrqvJQVs,97792
+pip/_vendor/distlib/t64-arm.exe,sha256=68TAa32V504xVBnufojh0PcenpR3U4wAqTqf-MZqbPw,182784
+pip/_vendor/distlib/t64.exe,sha256=gaYY8hy4fbkHYTTnA4i26ct8IQZzkBG2pRdy0iyuBrc,108032
+pip/_vendor/distlib/util.py,sha256=vMPGvsS4j9hF6Y9k3Tyom1aaHLb0rFmZAEyzeAdel9w,66682
+pip/_vendor/distlib/version.py,sha256=s5VIs8wBn0fxzGxWM_aA2ZZyx525HcZbMvcTlTyZ3Rg,23727
+pip/_vendor/distlib/w32.exe,sha256=R4csx3-OGM9kL4aPIzQKRo5TfmRSHZo6QWyLhDhNBks,91648
+pip/_vendor/distlib/w64-arm.exe,sha256=xdyYhKj0WDcVUOCb05blQYvzdYIKMbmJn2SZvzkcey4,168448
+pip/_vendor/distlib/w64.exe,sha256=ejGf-rojoBfXseGLpya6bFTFPWRG21X5KvU8J5iU-K0,101888
+pip/_vendor/distlib/wheel.py,sha256=DFIVguEQHCdxnSdAO0dfFsgMcvVZitg7bCOuLwZ7A_s,43979
+pip/_vendor/distro/__init__.py,sha256=2fHjF-SfgPvjyNZ1iHh_wjqWdR_Yo5ODHwZC0jLBPhc,981
+pip/_vendor/distro/__main__.py,sha256=bu9d3TifoKciZFcqRBuygV3GSuThnVD_m2IK4cz96Vs,64
+pip/_vendor/distro/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/distro/__pycache__/__main__.cpython-312.pyc,,
+pip/_vendor/distro/__pycache__/distro.cpython-312.pyc,,
+pip/_vendor/distro/distro.py,sha256=XqbefacAhDT4zr_trnbA15eY8vdK4GTghgmvUGrEM_4,49430
+pip/_vendor/distro/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/idna/__init__.py,sha256=KJQN1eQBr8iIK5SKrJ47lXvxG0BJ7Lm38W4zT0v_8lk,849
+pip/_vendor/idna/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/idna/__pycache__/codec.cpython-312.pyc,,
+pip/_vendor/idna/__pycache__/compat.cpython-312.pyc,,
+pip/_vendor/idna/__pycache__/core.cpython-312.pyc,,
+pip/_vendor/idna/__pycache__/idnadata.cpython-312.pyc,,
+pip/_vendor/idna/__pycache__/intranges.cpython-312.pyc,,
+pip/_vendor/idna/__pycache__/package_data.cpython-312.pyc,,
+pip/_vendor/idna/__pycache__/uts46data.cpython-312.pyc,,
+pip/_vendor/idna/codec.py,sha256=PS6m-XmdST7Wj7J7ulRMakPDt5EBJyYrT3CPtjh-7t4,3426
+pip/_vendor/idna/compat.py,sha256=0_sOEUMT4CVw9doD3vyRhX80X19PwqFoUBs7gWsFME4,321
+pip/_vendor/idna/core.py,sha256=lyhpoe2vulEaB_65xhXmoKgO-xUqFDvcwxu5hpNNO4E,12663
+pip/_vendor/idna/idnadata.py,sha256=dqRwytzkjIHMBa2R1lYvHDwACenZPt8eGVu1Y8UBE-E,78320
+pip/_vendor/idna/intranges.py,sha256=YBr4fRYuWH7kTKS2tXlFjM24ZF1Pdvcir-aywniInqg,1881
+pip/_vendor/idna/package_data.py,sha256=Tkt0KnIeyIlnHddOaz9WSkkislNgokJAuE-p5GorMqo,21
+pip/_vendor/idna/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/idna/uts46data.py,sha256=1KuksWqLuccPXm2uyRVkhfiFLNIhM_H2m4azCcnOqEU,206503
+pip/_vendor/msgpack/__init__.py,sha256=gsMP7JTECZNUSjvOyIbdhNOkpB9Z8BcGwabVGY2UcdQ,1077
+pip/_vendor/msgpack/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/msgpack/__pycache__/exceptions.cpython-312.pyc,,
+pip/_vendor/msgpack/__pycache__/ext.cpython-312.pyc,,
+pip/_vendor/msgpack/__pycache__/fallback.cpython-312.pyc,,
+pip/_vendor/msgpack/exceptions.py,sha256=dCTWei8dpkrMsQDcjQk74ATl9HsIBH0ybt8zOPNqMYc,1081
+pip/_vendor/msgpack/ext.py,sha256=fKp00BqDLjUtZnPd70Llr138zk8JsCuSpJkkZ5S4dt8,5629
+pip/_vendor/msgpack/fallback.py,sha256=wdUWJkWX2gzfRW9BBCTOuIE1Wvrf5PtBtR8ZtY7G_EE,33175
+pip/_vendor/packaging/__init__.py,sha256=dtw2bNmWCQ9WnMoK3bk_elL1svSlikXtLpZhCFIB9SE,496
+pip/_vendor/packaging/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/_elffile.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/_manylinux.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/_musllinux.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/_parser.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/_structures.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/_tokenizer.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/markers.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/metadata.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/requirements.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/specifiers.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/tags.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/utils.cpython-312.pyc,,
+pip/_vendor/packaging/__pycache__/version.cpython-312.pyc,,
+pip/_vendor/packaging/_elffile.py,sha256=_LcJW4YNKywYsl4169B2ukKRqwxjxst_8H0FRVQKlz8,3282
+pip/_vendor/packaging/_manylinux.py,sha256=Xo4V0PZz8sbuVCbTni0t1CR0AHeir_7ib4lTmV8scD4,9586
+pip/_vendor/packaging/_musllinux.py,sha256=p9ZqNYiOItGee8KcZFeHF_YcdhVwGHdK6r-8lgixvGQ,2694
+pip/_vendor/packaging/_parser.py,sha256=s_TvTvDNK0NrM2QB3VKThdWFM4Nc0P6JnkObkl3MjpM,10236
+pip/_vendor/packaging/_structures.py,sha256=q3eVNmbWJGG_S0Dit_S3Ao8qQqz_5PYTXFAKBZe5yr4,1431
+pip/_vendor/packaging/_tokenizer.py,sha256=J6v5H7Jzvb-g81xp_2QACKwO7LxHQA6ikryMU7zXwN8,5273
+pip/_vendor/packaging/markers.py,sha256=dWKSqn5Sp-jDmOG-W3GfLHKjwhf1IsznbT71VlBoB5M,10671
+pip/_vendor/packaging/metadata.py,sha256=KINuSkJ12u-SyoKNTy_pHNGAfMUtxNvZ53qA1zAKcKI,32349
+pip/_vendor/packaging/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/packaging/requirements.py,sha256=gYyRSAdbrIyKDY66ugIDUQjRMvxkH2ALioTmX3tnL6o,2947
+pip/_vendor/packaging/specifiers.py,sha256=HfGgfNJRvrzC759gnnoojHyiWs_DYmcw5PEh5jHH-YE,39738
+pip/_vendor/packaging/tags.py,sha256=Fo6_cit95-7QfcMb16XtI7AUiSMgdwA_hCO_9lV2pz4,21388
+pip/_vendor/packaging/utils.py,sha256=NAdYUwnlAOpkat_RthavX8a07YuVxgGL_vwrx73GSDM,5287
+pip/_vendor/packaging/version.py,sha256=wE4sSVlF-d1H6HFC1vszEe35CwTig_fh4HHIFg95hFE,16210
+pip/_vendor/pkg_resources/__init__.py,sha256=jrhDRbOubP74QuPXxd7U7Po42PH2l-LZ2XfcO7llpZ4,124463
+pip/_vendor/pkg_resources/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/platformdirs/__init__.py,sha256=FTA6LGNm40GwNZt3gG3uLAacWvf2E_2HTmH0rAALGR8,22285
+pip/_vendor/platformdirs/__main__.py,sha256=jBJ8zb7Mpx5ebcqF83xrpO94MaeCpNGHVf9cvDN2JLg,1505
+pip/_vendor/platformdirs/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/platformdirs/__pycache__/__main__.cpython-312.pyc,,
+pip/_vendor/platformdirs/__pycache__/android.cpython-312.pyc,,
+pip/_vendor/platformdirs/__pycache__/api.cpython-312.pyc,,
+pip/_vendor/platformdirs/__pycache__/macos.cpython-312.pyc,,
+pip/_vendor/platformdirs/__pycache__/unix.cpython-312.pyc,,
+pip/_vendor/platformdirs/__pycache__/version.cpython-312.pyc,,
+pip/_vendor/platformdirs/__pycache__/windows.cpython-312.pyc,,
+pip/_vendor/platformdirs/android.py,sha256=xZXY9Jd46WOsxT2U6-5HsNtDZ-IQqxcEUrBLl3hYk4o,9016
+pip/_vendor/platformdirs/api.py,sha256=QBYdUac2eC521ek_y53uD1Dcq-lJX8IgSRVd4InC6uc,8996
+pip/_vendor/platformdirs/macos.py,sha256=wftsbsvq6nZ0WORXSiCrZNkRHz_WKuktl0a6mC7MFkI,5580
+pip/_vendor/platformdirs/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/platformdirs/unix.py,sha256=Cci9Wqt35dAMsg6HT9nRGHSBW5obb0pR3AE1JJnsCXg,10643
+pip/_vendor/platformdirs/version.py,sha256=r7F76tZRjgQKzrpx_I0_ZMQOMU-PS7eGnHD7zEK3KB0,411
+pip/_vendor/platformdirs/windows.py,sha256=IFpiohUBwxPtCzlyKwNtxyW4Jk8haa6W8o59mfrDXVo,10125
+pip/_vendor/pygments/__init__.py,sha256=7N1oiaWulw_nCsTY4EEixYLz15pWY5u4uPAFFi-ielU,2983
+pip/_vendor/pygments/__main__.py,sha256=isIhBxLg65nLlXukG4VkMuPfNdd7gFzTZ_R_z3Q8diY,353
+pip/_vendor/pygments/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/__main__.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/cmdline.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/console.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/filter.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/formatter.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/lexer.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/modeline.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/plugin.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/regexopt.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/scanner.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/sphinxext.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/style.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/token.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/unistring.cpython-312.pyc,,
+pip/_vendor/pygments/__pycache__/util.cpython-312.pyc,,
+pip/_vendor/pygments/cmdline.py,sha256=LIVzmAunlk9sRJJp54O4KRy9GDIN4Wu13v9p9QzfGPM,23656
+pip/_vendor/pygments/console.py,sha256=yhP9UsLAVmWKVQf2446JJewkA7AiXeeTf4Ieg3Oi2fU,1718
+pip/_vendor/pygments/filter.py,sha256=_ADNPCskD8_GmodHi6_LoVgPU3Zh336aBCT5cOeTMs0,1910
+pip/_vendor/pygments/filters/__init__.py,sha256=RdedK2KWKXlKwR7cvkfr3NUj9YiZQgMgilRMFUg2jPA,40392
+pip/_vendor/pygments/filters/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/pygments/formatter.py,sha256=jDWBTndlBH2Z5IYZFVDnP0qn1CaTQjTWt7iAGtCnJEg,4390
+pip/_vendor/pygments/formatters/__init__.py,sha256=8No-NUs8rBTSSBJIv4hSEQt2M0cFB4hwAT0snVc2QGE,5385
+pip/_vendor/pygments/formatters/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/_mapping.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/bbcode.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/groff.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/html.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/img.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/irc.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/latex.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/other.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/pangomarkup.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/rtf.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/svg.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/terminal.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/__pycache__/terminal256.cpython-312.pyc,,
+pip/_vendor/pygments/formatters/_mapping.py,sha256=1Cw37FuQlNacnxRKmtlPX4nyLoX9_ttko5ZwscNUZZ4,4176
+pip/_vendor/pygments/formatters/bbcode.py,sha256=3JQLI45tcrQ_kRUMjuab6C7Hb0XUsbVWqqbSn9cMjkI,3320
+pip/_vendor/pygments/formatters/groff.py,sha256=M39k0PaSSZRnxWjqBSVPkF0mu1-Vr7bm6RsFvs-CNN4,5106
+pip/_vendor/pygments/formatters/html.py,sha256=SE2jc3YCqbMS3rZW9EAmDlAUhdVxJ52gA4dileEvCGU,35669
+pip/_vendor/pygments/formatters/img.py,sha256=MwA4xWPLOwh6j7Yc6oHzjuqSPt0M1fh5r-5BTIIUfsU,23287
+pip/_vendor/pygments/formatters/irc.py,sha256=dp1Z0l_ObJ5NFh9MhqLGg5ptG5hgJqedT2Vkutt9v0M,4981
+pip/_vendor/pygments/formatters/latex.py,sha256=XMmhOCqUKDBQtG5mGJNAFYxApqaC5puo5cMmPfK3944,19306
+pip/_vendor/pygments/formatters/other.py,sha256=56PMJOliin-rAUdnRM0i1wsV1GdUPd_dvQq0_UPfF9c,5034
+pip/_vendor/pygments/formatters/pangomarkup.py,sha256=y16U00aVYYEFpeCfGXlYBSMacG425CbfoG8oKbKegIg,2218
+pip/_vendor/pygments/formatters/rtf.py,sha256=ZT90dmcKyJboIB0mArhL7IhE467GXRN0G7QAUgG03To,11957
+pip/_vendor/pygments/formatters/svg.py,sha256=KKsiophPupHuxm0So-MsbQEWOT54IAiSF7hZPmxtKXE,7174
+pip/_vendor/pygments/formatters/terminal.py,sha256=AojNG4MlKq2L6IsC_VnXHu4AbHCBn9Otog6u45XvxeI,4674
+pip/_vendor/pygments/formatters/terminal256.py,sha256=kGkNUVo3FpwjytIDS0if79EuUoroAprcWt3igrcIqT0,11753
+pip/_vendor/pygments/lexer.py,sha256=TYHDt___gNW4axTl2zvPZff-VQi8fPaIh5OKRcVSjUM,35349
+pip/_vendor/pygments/lexers/__init__.py,sha256=pIlxyQJuu_syh9lE080cq8ceVbEVcKp0osAFU5fawJU,12115
+pip/_vendor/pygments/lexers/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/pygments/lexers/__pycache__/_mapping.cpython-312.pyc,,
+pip/_vendor/pygments/lexers/__pycache__/python.cpython-312.pyc,,
+pip/_vendor/pygments/lexers/_mapping.py,sha256=61-h3zr103m01OS5BUq_AfUiL9YI06Ves9ipQ7k4vr4,76097
+pip/_vendor/pygments/lexers/python.py,sha256=2J_YJrPTr_A6fJY_qKiKv0GpgPwHMrlMSeo59qN3fe4,53687
+pip/_vendor/pygments/modeline.py,sha256=gtRYZBS-CKOCDXHhGZqApboHBaZwGH8gznN3O6nuxj4,1005
+pip/_vendor/pygments/plugin.py,sha256=ioeJ3QeoJ-UQhZpY9JL7vbxsTVuwwM7BCu-Jb8nN0AU,1891
+pip/_vendor/pygments/regexopt.py,sha256=Hky4EB13rIXEHQUNkwmCrYqtIlnXDehNR3MztafZ43w,3072
+pip/_vendor/pygments/scanner.py,sha256=NDy3ofK_fHRFK4hIDvxpamG871aewqcsIb6sgTi7Fhk,3092
+pip/_vendor/pygments/sphinxext.py,sha256=iOptJBcqOGPwMEJ2p70PvwpZPIGdvdZ8dxvq6kzxDgA,7981
+pip/_vendor/pygments/style.py,sha256=rSCZWFpg1_DwFMXDU0nEVmAcBHpuQGf9RxvOPPQvKLQ,6420
+pip/_vendor/pygments/styles/__init__.py,sha256=qUk6_1z5KmT8EdJFZYgESmG6P_HJF_2vVrDD7HSCGYY,2042
+pip/_vendor/pygments/styles/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/pygments/styles/__pycache__/_mapping.cpython-312.pyc,,
+pip/_vendor/pygments/styles/_mapping.py,sha256=6lovFUE29tz6EsV3XYY4hgozJ7q1JL7cfO3UOlgnS8w,3312
+pip/_vendor/pygments/token.py,sha256=qZwT7LSPy5YBY3JgDjut642CCy7JdQzAfmqD9NmT5j0,6226
+pip/_vendor/pygments/unistring.py,sha256=p5c1i-HhoIhWemy9CUsaN9o39oomYHNxXll0Xfw6tEA,63208
+pip/_vendor/pygments/util.py,sha256=2tj2nS1X9_OpcuSjf8dOET2bDVZhs8cEKd_uT6-Fgg8,10031
+pip/_vendor/pyproject_hooks/__init__.py,sha256=kCehmy0UaBa9oVMD7ZIZrnswfnP3LXZ5lvnNJAL5JBM,491
+pip/_vendor/pyproject_hooks/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/pyproject_hooks/__pycache__/_compat.cpython-312.pyc,,
+pip/_vendor/pyproject_hooks/__pycache__/_impl.cpython-312.pyc,,
+pip/_vendor/pyproject_hooks/_compat.py,sha256=by6evrYnqkisiM-MQcvOKs5bgDMzlOSgZqRHNqf04zE,138
+pip/_vendor/pyproject_hooks/_impl.py,sha256=61GJxzQip0IInhuO69ZI5GbNQ82XEDUB_1Gg5_KtUoc,11920
+pip/_vendor/pyproject_hooks/_in_process/__init__.py,sha256=9gQATptbFkelkIy0OfWFEACzqxXJMQDWCH9rBOAZVwQ,546
+pip/_vendor/pyproject_hooks/_in_process/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/pyproject_hooks/_in_process/__pycache__/_in_process.cpython-312.pyc,,
+pip/_vendor/pyproject_hooks/_in_process/_in_process.py,sha256=m2b34c917IW5o-Q_6TYIHlsK9lSUlNiyrITTUH_zwew,10927
+pip/_vendor/requests/__init__.py,sha256=HlB_HzhrzGtfD_aaYUwUh1zWXLZ75_YCLyit75d0Vz8,5057
+pip/_vendor/requests/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/__version__.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/_internal_utils.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/adapters.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/api.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/auth.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/certs.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/compat.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/cookies.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/exceptions.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/help.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/hooks.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/models.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/packages.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/sessions.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/status_codes.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/structures.cpython-312.pyc,,
+pip/_vendor/requests/__pycache__/utils.cpython-312.pyc,,
+pip/_vendor/requests/__version__.py,sha256=FVfglgZmNQnmYPXpOohDU58F5EUb_-VnSTaAesS187g,435
+pip/_vendor/requests/_internal_utils.py,sha256=nMQymr4hs32TqVo5AbCrmcJEhvPUh7xXlluyqwslLiQ,1495
+pip/_vendor/requests/adapters.py,sha256=J7VeVxKBvawbtlX2DERVo05J9BXTcWYLMHNd1Baa-bk,27607
+pip/_vendor/requests/api.py,sha256=_Zb9Oa7tzVIizTKwFrPjDEY9ejtm_OnSRERnADxGsQs,6449
+pip/_vendor/requests/auth.py,sha256=kF75tqnLctZ9Mf_hm9TZIj4cQWnN5uxRz8oWsx5wmR0,10186
+pip/_vendor/requests/certs.py,sha256=PVPooB0jP5hkZEULSCwC074532UFbR2Ptgu0I5zwmCs,575
+pip/_vendor/requests/compat.py,sha256=Mo9f9xZpefod8Zm-n9_StJcVTmwSukXR2p3IQyyVXvU,1485
+pip/_vendor/requests/cookies.py,sha256=bNi-iqEj4NPZ00-ob-rHvzkvObzN3lEpgw3g6paS3Xw,18590
+pip/_vendor/requests/exceptions.py,sha256=D1wqzYWne1mS2rU43tP9CeN1G7QAy7eqL9o1god6Ejw,4272
+pip/_vendor/requests/help.py,sha256=hRKaf9u0G7fdwrqMHtF3oG16RKktRf6KiwtSq2Fo1_0,3813
+pip/_vendor/requests/hooks.py,sha256=CiuysiHA39V5UfcCBXFIx83IrDpuwfN9RcTUgv28ftQ,733
+pip/_vendor/requests/models.py,sha256=x4K4CmH-lC0l2Kb-iPfMN4dRXxHEcbOaEWBL_i09AwI,35483
+pip/_vendor/requests/packages.py,sha256=_ZQDCJTJ8SP3kVWunSqBsRZNPzj2c1WFVqbdr08pz3U,1057
+pip/_vendor/requests/sessions.py,sha256=ykTI8UWGSltOfH07HKollH7kTBGw4WhiBVaQGmckTw4,30495
+pip/_vendor/requests/status_codes.py,sha256=iJUAeA25baTdw-6PfD0eF4qhpINDJRJI-yaMqxs4LEI,4322
+pip/_vendor/requests/structures.py,sha256=-IbmhVz06S-5aPSZuUthZ6-6D9XOjRuTXHOabY041XM,2912
+pip/_vendor/requests/utils.py,sha256=L79vnFbzJ3SFLKtJwpoWe41Tozi3RlZv94pY1TFIyow,33631
+pip/_vendor/resolvelib/__init__.py,sha256=h509TdEcpb5-44JonaU3ex2TM15GVBLjM9CNCPwnTTs,537
+pip/_vendor/resolvelib/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/resolvelib/__pycache__/providers.cpython-312.pyc,,
+pip/_vendor/resolvelib/__pycache__/reporters.cpython-312.pyc,,
+pip/_vendor/resolvelib/__pycache__/resolvers.cpython-312.pyc,,
+pip/_vendor/resolvelib/__pycache__/structs.cpython-312.pyc,,
+pip/_vendor/resolvelib/compat/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/resolvelib/compat/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/resolvelib/compat/__pycache__/collections_abc.cpython-312.pyc,,
+pip/_vendor/resolvelib/compat/collections_abc.py,sha256=uy8xUZ-NDEw916tugUXm8HgwCGiMO0f-RcdnpkfXfOs,156
+pip/_vendor/resolvelib/providers.py,sha256=fuuvVrCetu5gsxPB43ERyjfO8aReS3rFQHpDgiItbs4,5871
+pip/_vendor/resolvelib/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/resolvelib/reporters.py,sha256=TSbRmWzTc26w0ggsV1bxVpeWDB8QNIre6twYl7GIZBE,1601
+pip/_vendor/resolvelib/resolvers.py,sha256=G8rsLZSq64g5VmIq-lB7UcIJ1gjAxIQJmTF4REZleQ0,20511
+pip/_vendor/resolvelib/structs.py,sha256=0_1_XO8z_CLhegP3Vpf9VJ3zJcfLm0NOHRM-i0Ykz3o,4963
+pip/_vendor/rich/__init__.py,sha256=dRxjIL-SbFVY0q3IjSMrfgBTHrm1LZDgLOygVBwiYZc,6090
+pip/_vendor/rich/__main__.py,sha256=eO7Cq8JnrgG8zVoeImiAs92q3hXNMIfp0w5lMsO7Q2Y,8477
+pip/_vendor/rich/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/__main__.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_cell_widths.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_emoji_codes.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_emoji_replace.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_export_format.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_extension.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_fileno.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_inspect.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_log_render.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_loop.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_null_file.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_palettes.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_pick.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_ratio.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_spinners.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_stack.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_timer.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_win32_console.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_windows.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_windows_renderer.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/_wrap.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/abc.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/align.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/ansi.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/bar.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/box.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/cells.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/color.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/color_triplet.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/columns.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/console.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/constrain.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/containers.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/control.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/default_styles.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/diagnose.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/emoji.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/errors.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/file_proxy.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/filesize.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/highlighter.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/json.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/jupyter.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/layout.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/live.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/live_render.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/logging.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/markup.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/measure.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/padding.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/pager.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/palette.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/panel.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/pretty.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/progress.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/progress_bar.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/prompt.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/protocol.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/region.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/repr.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/rule.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/scope.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/screen.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/segment.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/spinner.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/status.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/style.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/styled.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/syntax.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/table.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/terminal_theme.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/text.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/theme.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/themes.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/traceback.cpython-312.pyc,,
+pip/_vendor/rich/__pycache__/tree.cpython-312.pyc,,
+pip/_vendor/rich/_cell_widths.py,sha256=fbmeyetEdHjzE_Vx2l1uK7tnPOhMs2X1lJfO3vsKDpA,10209
+pip/_vendor/rich/_emoji_codes.py,sha256=hu1VL9nbVdppJrVoijVshRlcRRe_v3dju3Mmd2sKZdY,140235
+pip/_vendor/rich/_emoji_replace.py,sha256=n-kcetsEUx2ZUmhQrfeMNc-teeGhpuSQ5F8VPBsyvDo,1064
+pip/_vendor/rich/_export_format.py,sha256=RI08pSrm5tBSzPMvnbTqbD9WIalaOoN5d4M1RTmLq1Y,2128
+pip/_vendor/rich/_extension.py,sha256=Xt47QacCKwYruzjDi-gOBq724JReDj9Cm9xUi5fr-34,265
+pip/_vendor/rich/_fileno.py,sha256=HWZxP5C2ajMbHryvAQZseflVfQoGzsKOHzKGsLD8ynQ,799
+pip/_vendor/rich/_inspect.py,sha256=oZJGw31e64dwXSCmrDnvZbwVb1ZKhWfU8wI3VWohjJk,9695
+pip/_vendor/rich/_log_render.py,sha256=1ByI0PA1ZpxZY3CGJOK54hjlq4X-Bz_boIjIqCd8Kns,3225
+pip/_vendor/rich/_loop.py,sha256=hV_6CLdoPm0va22Wpw4zKqM0RYsz3TZxXj0PoS-9eDQ,1236
+pip/_vendor/rich/_null_file.py,sha256=tGSXk_v-IZmbj1GAzHit8A3kYIQMiCpVsCFfsC-_KJ4,1387
+pip/_vendor/rich/_palettes.py,sha256=cdev1JQKZ0JvlguV9ipHgznTdnvlIzUFDBb0It2PzjI,7063
+pip/_vendor/rich/_pick.py,sha256=evDt8QN4lF5CiwrUIXlOJCntitBCOsI3ZLPEIAVRLJU,423
+pip/_vendor/rich/_ratio.py,sha256=Zt58apszI6hAAcXPpgdWKpu3c31UBWebOeR4mbyptvU,5471
+pip/_vendor/rich/_spinners.py,sha256=U2r1_g_1zSjsjiUdAESc2iAMc3i4ri_S8PYP6kQ5z1I,19919
+pip/_vendor/rich/_stack.py,sha256=-C8OK7rxn3sIUdVwxZBBpeHhIzX0eI-VM3MemYfaXm0,351
+pip/_vendor/rich/_timer.py,sha256=zelxbT6oPFZnNrwWPpc1ktUeAT-Vc4fuFcRZLQGLtMI,417
+pip/_vendor/rich/_win32_console.py,sha256=P0vxI2fcndym1UU1S37XAzQzQnkyY7YqAKmxm24_gug,22820
+pip/_vendor/rich/_windows.py,sha256=aBwaD_S56SbgopIvayVmpk0Y28uwY2C5Bab1wl3Bp-I,1925
+pip/_vendor/rich/_windows_renderer.py,sha256=t74ZL3xuDCP3nmTp9pH1L5LiI2cakJuQRQleHCJerlk,2783
+pip/_vendor/rich/_wrap.py,sha256=FlSsom5EX0LVkA3KWy34yHnCfLtqX-ZIepXKh-70rpc,3404
+pip/_vendor/rich/abc.py,sha256=ON-E-ZqSSheZ88VrKX2M3PXpFbGEUUZPMa_Af0l-4f0,890
+pip/_vendor/rich/align.py,sha256=sCUkisXkQfoq-IQPyBELfJ8l7LihZJX3HbH8K7Cie-M,10368
+pip/_vendor/rich/ansi.py,sha256=iD6532QYqnBm6hADulKjrV8l8kFJ-9fEVooHJHH3hMg,6906
+pip/_vendor/rich/bar.py,sha256=ldbVHOzKJOnflVNuv1xS7g6dLX2E3wMnXkdPbpzJTcs,3263
+pip/_vendor/rich/box.py,sha256=nr5fYIUghB_iUCEq6y0Z3LlCT8gFPDrzN9u2kn7tJl4,10831
+pip/_vendor/rich/cells.py,sha256=aMmGK4BjXhgE6_JF1ZEGmW3O7mKkE8g84vUnj4Et4To,4780
+pip/_vendor/rich/color.py,sha256=bCRATVdRe5IClJ6Hl62de2PKQ_U4i2MZ4ugjUEg7Tao,18223
+pip/_vendor/rich/color_triplet.py,sha256=3lhQkdJbvWPoLDO-AnYImAWmJvV5dlgYNCVZ97ORaN4,1054
+pip/_vendor/rich/columns.py,sha256=HUX0KcMm9dsKNi11fTbiM_h2iDtl8ySCaVcxlalEzq8,7131
+pip/_vendor/rich/console.py,sha256=deFZIubq2M9A2MCsKFAsFQlWDvcOMsGuUA07QkOaHIw,99173
+pip/_vendor/rich/constrain.py,sha256=1VIPuC8AgtKWrcncQrjBdYqA3JVWysu6jZo1rrh7c7Q,1288
+pip/_vendor/rich/containers.py,sha256=c_56TxcedGYqDepHBMTuZdUIijitAQgnox-Qde0Z1qo,5502
+pip/_vendor/rich/control.py,sha256=DSkHTUQLorfSERAKE_oTAEUFefZnZp4bQb4q8rHbKws,6630
+pip/_vendor/rich/default_styles.py,sha256=-Fe318kMVI_IwciK5POpThcO0-9DYJ67TZAN6DlmlmM,8082
+pip/_vendor/rich/diagnose.py,sha256=an6uouwhKPAlvQhYpNNpGq9EJysfMIOvvCbO3oSoR24,972
+pip/_vendor/rich/emoji.py,sha256=omTF9asaAnsM4yLY94eR_9dgRRSm1lHUszX20D1yYCQ,2501
+pip/_vendor/rich/errors.py,sha256=5pP3Kc5d4QJ_c0KFsxrfyhjiPVe7J1zOqSFbFAzcV-Y,642
+pip/_vendor/rich/file_proxy.py,sha256=Tl9THMDZ-Pk5Wm8sI1gGg_U5DhusmxD-FZ0fUbcU0W0,1683
+pip/_vendor/rich/filesize.py,sha256=9fTLAPCAwHmBXdRv7KZU194jSgNrRb6Wx7RIoBgqeKY,2508
+pip/_vendor/rich/highlighter.py,sha256=6ZAjUcNhBRajBCo9umFUclyi2xL0-55JL7S0vYGUJu4,9585
+pip/_vendor/rich/json.py,sha256=vVEoKdawoJRjAFayPwXkMBPLy7RSTs-f44wSQDR2nJ0,5031
+pip/_vendor/rich/jupyter.py,sha256=QyoKoE_8IdCbrtiSHp9TsTSNyTHY0FO5whE7jOTd9UE,3252
+pip/_vendor/rich/layout.py,sha256=ajkSFAtEVv9EFTcFs-w4uZfft7nEXhNzL7ZVdgrT5rI,14004
+pip/_vendor/rich/live.py,sha256=vUcnJV2LMSK3sQNaILbm0-_B8BpAeiHfcQMAMLfpRe0,14271
+pip/_vendor/rich/live_render.py,sha256=zJtB471jGziBtEwxc54x12wEQtH4BuQr1SA8v9kU82w,3666
+pip/_vendor/rich/logging.py,sha256=uB-cB-3Q4bmXDLLpbOWkmFviw-Fde39zyMV6tKJ2WHQ,11903
+pip/_vendor/rich/markup.py,sha256=3euGKP5s41NCQwaSjTnJxus5iZMHjxpIM0W6fCxra38,8451
+pip/_vendor/rich/measure.py,sha256=HmrIJX8sWRTHbgh8MxEay_83VkqNW_70s8aKP5ZcYI8,5305
+pip/_vendor/rich/padding.py,sha256=kTFGsdGe0os7tXLnHKpwTI90CXEvrceeZGCshmJy5zw,4970
+pip/_vendor/rich/pager.py,sha256=SO_ETBFKbg3n_AgOzXm41Sv36YxXAyI3_R-KOY2_uSc,828
+pip/_vendor/rich/palette.py,sha256=lInvR1ODDT2f3UZMfL1grq7dY_pDdKHw4bdUgOGaM4Y,3396
+pip/_vendor/rich/panel.py,sha256=2Fd1V7e1kHxlPFIusoHY5T7-Cs0RpkrihgVG9ZVqJ4g,10705
+pip/_vendor/rich/pretty.py,sha256=5oIHP_CGWnHEnD0zMdW5qfGC5kHqIKn7zH_eC4crULE,35848
+pip/_vendor/rich/progress.py,sha256=P02xi7T2Ua3qq17o83bkshe4c0v_45cg8VyTj6US6Vg,59715
+pip/_vendor/rich/progress_bar.py,sha256=L4jw8E6Qb_x-jhOrLVhkuMaPmiAhFIl8jHQbWFrKuR8,8164
+pip/_vendor/rich/prompt.py,sha256=wdOn2X8XTJKnLnlw6PoMY7xG4iUPp3ezt4O5gqvpV-E,11304
+pip/_vendor/rich/protocol.py,sha256=5hHHDDNHckdk8iWH5zEbi-zuIVSF5hbU2jIo47R7lTE,1391
+pip/_vendor/rich/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/rich/region.py,sha256=rNT9xZrVZTYIXZC0NYn41CJQwYNbR-KecPOxTgQvB8Y,166
+pip/_vendor/rich/repr.py,sha256=5MZJZmONgC6kud-QW-_m1okXwL2aR6u6y-pUcUCJz28,4431
+pip/_vendor/rich/rule.py,sha256=0fNaS_aERa3UMRc3T5WMpN_sumtDxfaor2y3of1ftBk,4602
+pip/_vendor/rich/scope.py,sha256=TMUU8qo17thyqQCPqjDLYpg_UU1k5qVd-WwiJvnJVas,2843
+pip/_vendor/rich/screen.py,sha256=YoeReESUhx74grqb0mSSb9lghhysWmFHYhsbMVQjXO8,1591
+pip/_vendor/rich/segment.py,sha256=hU1ueeXqI6YeFa08K9DAjlF2QLxcJY9pwZx7RsXavlk,24246
+pip/_vendor/rich/spinner.py,sha256=15koCmF0DQeD8-k28Lpt6X_zJQUlzEhgo_6A6uy47lc,4339
+pip/_vendor/rich/status.py,sha256=kkPph3YeAZBo-X-4wPp8gTqZyU466NLwZBA4PZTTewo,4424
+pip/_vendor/rich/style.py,sha256=3hiocH_4N8vwRm3-8yFWzM7tSwjjEven69XqWasSQwM,27073
+pip/_vendor/rich/styled.py,sha256=eZNnzGrI4ki_54pgY3Oj0T-x3lxdXTYh4_ryDB24wBU,1258
+pip/_vendor/rich/syntax.py,sha256=TnZDuOD4DeHFbkaVEAji1gf8qgAlMU9Boe_GksMGCkk,35475
+pip/_vendor/rich/table.py,sha256=nGEvAZHF4dy1vT9h9Gj9O5qhSQO3ODAxJv0RY1vnIB8,39680
+pip/_vendor/rich/terminal_theme.py,sha256=1j5-ufJfnvlAo5Qsi_ACZiXDmwMXzqgmFByObT9-yJY,3370
+pip/_vendor/rich/text.py,sha256=5rQ3zvNrg5UZKNLecbh7fiw9v3HeFulNVtRY_CBDjjE,47312
+pip/_vendor/rich/theme.py,sha256=belFJogzA0W0HysQabKaHOc3RWH2ko3fQAJhoN-AFdo,3777
+pip/_vendor/rich/themes.py,sha256=0xgTLozfabebYtcJtDdC5QkX5IVUEaviqDUJJh4YVFk,102
+pip/_vendor/rich/traceback.py,sha256=CUpxYLjQWIb6vQQ6O72X0hvDV6caryGqU6UweHgOyCY,29601
+pip/_vendor/rich/tree.py,sha256=meAOUU6sYnoBEOX2ILrPLY9k5bWrWNQKkaiEFvHinXM,9167
+pip/_vendor/tomli/__init__.py,sha256=JhUwV66DB1g4Hvt1UQCVMdfCu-IgAV8FXmvDU9onxd4,396
+pip/_vendor/tomli/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/tomli/__pycache__/_parser.cpython-312.pyc,,
+pip/_vendor/tomli/__pycache__/_re.cpython-312.pyc,,
+pip/_vendor/tomli/__pycache__/_types.cpython-312.pyc,,
+pip/_vendor/tomli/_parser.py,sha256=g9-ENaALS-B8dokYpCuzUFalWlog7T-SIYMjLZSWrtM,22633
+pip/_vendor/tomli/_re.py,sha256=dbjg5ChZT23Ka9z9DHOXfdtSpPwUfdgMXnj8NOoly-w,2943
+pip/_vendor/tomli/_types.py,sha256=-GTG2VUqkpxwMqzmVO4F7ybKddIbAnuAHXfmWQcTi3Q,254
+pip/_vendor/tomli/py.typed,sha256=8PjyZ1aVoQpRVvt71muvuq5qE-jTFZkK-GLHkhdebmc,26
+pip/_vendor/truststore/__init__.py,sha256=WIDeyzWm7EVX44g354M25vpRXbeY1lsPH6EmUJUcq4o,1264
+pip/_vendor/truststore/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/truststore/__pycache__/_api.cpython-312.pyc,,
+pip/_vendor/truststore/__pycache__/_macos.cpython-312.pyc,,
+pip/_vendor/truststore/__pycache__/_openssl.cpython-312.pyc,,
+pip/_vendor/truststore/__pycache__/_ssl_constants.cpython-312.pyc,,
+pip/_vendor/truststore/__pycache__/_windows.cpython-312.pyc,,
+pip/_vendor/truststore/_api.py,sha256=GeXRNTlxPZ3kif4kNoh6JY0oE4QRzTGcgXr6l_X_Gk0,10555
+pip/_vendor/truststore/_macos.py,sha256=nZlLkOmszUE0g6ryRwBVGY5COzPyudcsiJtDWarM5LQ,20503
+pip/_vendor/truststore/_openssl.py,sha256=LLUZ7ZGaio-i5dpKKjKCSeSufmn6T8pi9lDcFnvSyq0,2324
+pip/_vendor/truststore/_ssl_constants.py,sha256=NUD4fVKdSD02ri7-db0tnO0VqLP9aHuzmStcW7tAl08,1130
+pip/_vendor/truststore/_windows.py,sha256=rAHyKYD8M7t-bXfG8VgOVa3TpfhVhbt4rZQlO45YuP8,17993
+pip/_vendor/truststore/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/typing_extensions.py,sha256=78hFl0HpDY-ylHUVCnWdU5nTHxUP2-S-3wEZk6CQmLk,134499
+pip/_vendor/urllib3/__init__.py,sha256=iXLcYiJySn0GNbWOOZDDApgBL1JgP44EZ8i1760S8Mc,3333
+pip/_vendor/urllib3/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/_collections.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/_version.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/connection.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/connectionpool.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/exceptions.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/fields.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/filepost.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/poolmanager.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/request.cpython-312.pyc,,
+pip/_vendor/urllib3/__pycache__/response.cpython-312.pyc,,
+pip/_vendor/urllib3/_collections.py,sha256=pyASJJhW7wdOpqJj9QJA8FyGRfr8E8uUUhqUvhF0728,11372
+pip/_vendor/urllib3/_version.py,sha256=t9wGB6ooOTXXgiY66K1m6BZS1CJyXHAU8EoWDTe6Shk,64
+pip/_vendor/urllib3/connection.py,sha256=ttIA909BrbTUzwkqEe_TzZVh4JOOj7g61Ysei2mrwGg,20314
+pip/_vendor/urllib3/connectionpool.py,sha256=e2eiAwNbFNCKxj4bwDKNK-w7HIdSz3OmMxU_TIt-evQ,40408
+pip/_vendor/urllib3/contrib/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/urllib3/contrib/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/__pycache__/_appengine_environ.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/__pycache__/appengine.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/__pycache__/ntlmpool.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/__pycache__/pyopenssl.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/__pycache__/securetransport.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/__pycache__/socks.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/_appengine_environ.py,sha256=bDbyOEhW2CKLJcQqAKAyrEHN-aklsyHFKq6vF8ZFsmk,957
+pip/_vendor/urllib3/contrib/_securetransport/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/urllib3/contrib/_securetransport/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/_securetransport/__pycache__/bindings.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/_securetransport/__pycache__/low_level.cpython-312.pyc,,
+pip/_vendor/urllib3/contrib/_securetransport/bindings.py,sha256=4Xk64qIkPBt09A5q-RIFUuDhNc9mXilVapm7WnYnzRw,17632
+pip/_vendor/urllib3/contrib/_securetransport/low_level.py,sha256=B2JBB2_NRP02xK6DCa1Pa9IuxrPwxzDzZbixQkb7U9M,13922
+pip/_vendor/urllib3/contrib/appengine.py,sha256=VR68eAVE137lxTgjBDwCna5UiBZTOKa01Aj_-5BaCz4,11036
+pip/_vendor/urllib3/contrib/ntlmpool.py,sha256=NlfkW7WMdW8ziqudopjHoW299og1BTWi0IeIibquFwk,4528
+pip/_vendor/urllib3/contrib/pyopenssl.py,sha256=hDJh4MhyY_p-oKlFcYcQaVQRDv6GMmBGuW9yjxyeejM,17081
+pip/_vendor/urllib3/contrib/securetransport.py,sha256=Fef1IIUUFHqpevzXiDPbIGkDKchY2FVKeVeLGR1Qq3g,34446
+pip/_vendor/urllib3/contrib/socks.py,sha256=aRi9eWXo9ZEb95XUxef4Z21CFlnnjbEiAo9HOseoMt4,7097
+pip/_vendor/urllib3/exceptions.py,sha256=0Mnno3KHTNfXRfY7638NufOPkUb6mXOm-Lqj-4x2w8A,8217
+pip/_vendor/urllib3/fields.py,sha256=kvLDCg_JmH1lLjUUEY_FLS8UhY7hBvDPuVETbY8mdrM,8579
+pip/_vendor/urllib3/filepost.py,sha256=5b_qqgRHVlL7uLtdAYBzBh-GHmU5AfJVt_2N0XS3PeY,2440
+pip/_vendor/urllib3/packages/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/urllib3/packages/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/urllib3/packages/__pycache__/six.cpython-312.pyc,,
+pip/_vendor/urllib3/packages/backports/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pip/_vendor/urllib3/packages/backports/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/urllib3/packages/backports/__pycache__/makefile.cpython-312.pyc,,
+pip/_vendor/urllib3/packages/backports/__pycache__/weakref_finalize.cpython-312.pyc,,
+pip/_vendor/urllib3/packages/backports/makefile.py,sha256=nbzt3i0agPVP07jqqgjhaYjMmuAi_W5E0EywZivVO8E,1417
+pip/_vendor/urllib3/packages/backports/weakref_finalize.py,sha256=tRCal5OAhNSRyb0DhHp-38AtIlCsRP8BxF3NX-6rqIA,5343
+pip/_vendor/urllib3/packages/six.py,sha256=b9LM0wBXv7E7SrbCjAm4wwN-hrH-iNxv18LgWNMMKPo,34665
+pip/_vendor/urllib3/poolmanager.py,sha256=aWyhXRtNO4JUnCSVVqKTKQd8EXTvUm1VN9pgs2bcONo,19990
+pip/_vendor/urllib3/request.py,sha256=YTWFNr7QIwh7E1W9dde9LM77v2VWTJ5V78XuTTw7D1A,6691
+pip/_vendor/urllib3/response.py,sha256=fmDJAFkG71uFTn-sVSTh2Iw0WmcXQYqkbRjihvwBjU8,30641
+pip/_vendor/urllib3/util/__init__.py,sha256=JEmSmmqqLyaw8P51gUImZh8Gwg9i1zSe-DoqAitn2nc,1155
+pip/_vendor/urllib3/util/__pycache__/__init__.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/connection.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/proxy.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/queue.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/request.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/response.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/retry.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/ssl_.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/ssl_match_hostname.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/ssltransport.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/timeout.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/url.cpython-312.pyc,,
+pip/_vendor/urllib3/util/__pycache__/wait.cpython-312.pyc,,
+pip/_vendor/urllib3/util/connection.py,sha256=5Lx2B1PW29KxBn2T0xkN1CBgRBa3gGVJBKoQoRogEVk,4901
+pip/_vendor/urllib3/util/proxy.py,sha256=zUvPPCJrp6dOF0N4GAVbOcl6o-4uXKSrGiTkkr5vUS4,1605
+pip/_vendor/urllib3/util/queue.py,sha256=nRgX8_eX-_VkvxoX096QWoz8Ps0QHUAExILCY_7PncM,498
+pip/_vendor/urllib3/util/request.py,sha256=C0OUt2tcU6LRiQJ7YYNP9GvPrSvl7ziIBekQ-5nlBZk,3997
+pip/_vendor/urllib3/util/response.py,sha256=GJpg3Egi9qaJXRwBh5wv-MNuRWan5BIu40oReoxWP28,3510
+pip/_vendor/urllib3/util/retry.py,sha256=6ENvOZ8PBDzh8kgixpql9lIrb2dxH-k7ZmBanJF2Ng4,22050
+pip/_vendor/urllib3/util/ssl_.py,sha256=QDuuTxPSCj1rYtZ4xpD7Ux-r20TD50aHyqKyhQ7Bq4A,17460
+pip/_vendor/urllib3/util/ssl_match_hostname.py,sha256=Ir4cZVEjmAk8gUAIHWSi7wtOO83UCYABY2xFD1Ql_WA,5758
+pip/_vendor/urllib3/util/ssltransport.py,sha256=NA-u5rMTrDFDFC8QzRKUEKMG0561hOD4qBTr3Z4pv6E,6895
+pip/_vendor/urllib3/util/timeout.py,sha256=cwq4dMk87mJHSBktK1miYJ-85G-3T3RmT20v7SFCpno,10168
+pip/_vendor/urllib3/util/url.py,sha256=lCAE7M5myA8EDdW0sJuyyZhVB9K_j38ljWhHAnFaWoE,14296
+pip/_vendor/urllib3/util/wait.py,sha256=fOX0_faozG2P7iVojQoE1mbydweNyTcm-hXEfFrTtLI,5403
+pip/_vendor/vendor.txt,sha256=43152uDtpsunEE29vmLqqKZUosdrbvzIFkzscLB55Cg,332
+pip/py.typed,sha256=EBVvvPRTn_eIpz5e5QztSCdrMX7Qwd7VP93RSoIlZ2I,286
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/REQUESTED b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/REQUESTED
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/WHEEL
new file mode 100644
index 000000000..da25d7b42
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/WHEEL
@@ -0,0 +1,5 @@
+Wheel-Version: 1.0
+Generator: setuptools (75.2.0)
+Root-Is-Purelib: true
+Tag: py3-none-any
+
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/entry_points.txt b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/entry_points.txt
new file mode 100644
index 000000000..25fcf7e2c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/entry_points.txt
@@ -0,0 +1,3 @@
+[console_scripts]
+pip = pip._internal.cli.main:main
+pip3 = pip._internal.cli.main:main
diff --git a/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/top_level.txt b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/top_level.txt
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip-24.3.1.dist-info/top_level.txt
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/pip/__init__.py b/solutions/.venv/Lib/site-packages/pip/__init__.py
new file mode 100644
index 000000000..efefccffc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/__init__.py
@@ -0,0 +1,13 @@
+from typing import List, Optional
+
+__version__ = "24.3.1"
+
+
+def main(args: Optional[List[str]] = None) -> int:
+ """This is an internal API only meant for use by pip's own console scripts.
+
+ For additional details, see https://github.com/pypa/pip/issues/7498.
+ """
+ from pip._internal.utils.entrypoints import _wrapper
+
+ return _wrapper(args)
diff --git a/solutions/.venv/Lib/site-packages/pip/__main__.py b/solutions/.venv/Lib/site-packages/pip/__main__.py
new file mode 100644
index 000000000..599132611
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/__main__.py
@@ -0,0 +1,24 @@
+import os
+import sys
+
+# Remove '' and current working directory from the first entry
+# of sys.path, if present to avoid using current directory
+# in pip commands check, freeze, install, list and show,
+# when invoked as python -m pip <command>
+if sys.path[0] in ("", os.getcwd()):
+ sys.path.pop(0)
+
+# If we are running from a wheel, add the wheel to sys.path
+# This allows the usage python pip-*.whl/pip install pip-*.whl
+if __package__ == "":
+ # __file__ is pip-*.whl/pip/__main__.py
+ # first dirname call strips of '/__main__.py', second strips off '/pip'
+ # Resulting path is the name of the wheel itself
+ # Add that to sys.path so we can import pip
+ path = os.path.dirname(os.path.dirname(__file__))
+ sys.path.insert(0, path)
+
+if __name__ == "__main__":
+ from pip._internal.cli.main import main as _main
+
+ sys.exit(_main())
diff --git a/solutions/.venv/Lib/site-packages/pip/__pip-runner__.py b/solutions/.venv/Lib/site-packages/pip/__pip-runner__.py
new file mode 100644
index 000000000..c633787fc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/__pip-runner__.py
@@ -0,0 +1,50 @@
+"""Execute exactly this copy of pip, within a different environment.
+
+This file is named as it is, to ensure that this module can't be imported via
+an import statement.
+"""
+
+# /!\ This version compatibility check section must be Python 2 compatible. /!\
+
+import sys
+
+# Copied from pyproject.toml
+PYTHON_REQUIRES = (3, 8)
+
+
+def version_str(version): # type: ignore
+ return ".".join(str(v) for v in version)
+
+
+if sys.version_info[:2] < PYTHON_REQUIRES:
+ raise SystemExit(
+ "This version of pip does not support python {} (requires >={}).".format(
+ version_str(sys.version_info[:2]), version_str(PYTHON_REQUIRES)
+ )
+ )
+
+# From here on, we can use Python 3 features, but the syntax must remain
+# Python 2 compatible.
+
+import runpy # noqa: E402
+from importlib.machinery import PathFinder # noqa: E402
+from os.path import dirname # noqa: E402
+
+PIP_SOURCES_ROOT = dirname(dirname(__file__))
+
+
+class PipImportRedirectingFinder:
+ @classmethod
+ def find_spec(self, fullname, path=None, target=None): # type: ignore
+ if fullname != "pip":
+ return None
+
+ spec = PathFinder.find_spec(fullname, [PIP_SOURCES_ROOT], target)
+ assert spec, (PIP_SOURCES_ROOT, fullname)
+ return spec
+
+
+sys.meta_path.insert(0, PipImportRedirectingFinder())
+
+assert __name__ == "__main__", "Cannot run __pip-runner__.py as a non-main module"
+runpy.run_module("pip", run_name="__main__", alter_sys=True)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/__init__.py
new file mode 100644
index 000000000..1a5b7f87f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/__init__.py
@@ -0,0 +1,18 @@
+from typing import List, Optional
+
+from pip._internal.utils import _log
+
+# init_logging() must be called before any call to logging.getLogger()
+# which happens at import of most modules.
+_log.init_logging()
+
+
+def main(args: Optional[List[str]] = None) -> int:
+ """This is preserved for old console scripts that may still be referencing
+ it.
+
+ For additional details, see https://github.com/pypa/pip/issues/7498.
+ """
+ from pip._internal.utils.entrypoints import _wrapper
+
+ return _wrapper(args)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/build_env.py b/solutions/.venv/Lib/site-packages/pip/_internal/build_env.py
new file mode 100644
index 000000000..0f1e2667c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/build_env.py
@@ -0,0 +1,319 @@
+"""Build Environment used for isolation during sdist building
+"""
+
+import logging
+import os
+import pathlib
+import site
+import sys
+import textwrap
+from collections import OrderedDict
+from types import TracebackType
+from typing import TYPE_CHECKING, Iterable, List, Optional, Set, Tuple, Type, Union
+
+from pip._vendor.certifi import where
+from pip._vendor.packaging.version import Version
+
+from pip import __file__ as pip_location
+from pip._internal.cli.spinners import open_spinner
+from pip._internal.locations import get_platlib, get_purelib, get_scheme
+from pip._internal.metadata import get_default_environment, get_environment
+from pip._internal.utils.logging import VERBOSE
+from pip._internal.utils.packaging import get_requirement
+from pip._internal.utils.subprocess import call_subprocess
+from pip._internal.utils.temp_dir import TempDirectory, tempdir_kinds
+
+if TYPE_CHECKING:
+ from pip._internal.index.package_finder import PackageFinder
+
+logger = logging.getLogger(__name__)
+
+
+def _dedup(a: str, b: str) -> Union[Tuple[str], Tuple[str, str]]:
+ return (a, b) if a != b else (a,)
+
+
+class _Prefix:
+ def __init__(self, path: str) -> None:
+ self.path = path
+ self.setup = False
+ scheme = get_scheme("", prefix=path)
+ self.bin_dir = scheme.scripts
+ self.lib_dirs = _dedup(scheme.purelib, scheme.platlib)
+
+
+def get_runnable_pip() -> str:
+ """Get a file to pass to a Python executable, to run the currently-running pip.
+
+ This is used to run a pip subprocess, for installing requirements into the build
+ environment.
+ """
+ source = pathlib.Path(pip_location).resolve().parent
+
+ if not source.is_dir():
+ # This would happen if someone is using pip from inside a zip file. In that
+ # case, we can use that directly.
+ return str(source)
+
+ return os.fsdecode(source / "__pip-runner__.py")
+
+
+def _get_system_sitepackages() -> Set[str]:
+ """Get system site packages
+
+ Usually from site.getsitepackages,
+ but fallback on `get_purelib()/get_platlib()` if unavailable
+ (e.g. in a virtualenv created by virtualenv<20)
+
+ Returns normalized set of strings.
+ """
+ if hasattr(site, "getsitepackages"):
+ system_sites = site.getsitepackages()
+ else:
+ # virtualenv < 20 overwrites site.py without getsitepackages
+ # fallback on get_purelib/get_platlib.
+ # this is known to miss things, but shouldn't in the cases
+ # where getsitepackages() has been removed (inside a virtualenv)
+ system_sites = [get_purelib(), get_platlib()]
+ return {os.path.normcase(path) for path in system_sites}
+
+
+class BuildEnvironment:
+ """Creates and manages an isolated environment to install build deps"""
+
+ def __init__(self) -> None:
+ temp_dir = TempDirectory(kind=tempdir_kinds.BUILD_ENV, globally_managed=True)
+
+ self._prefixes = OrderedDict(
+ (name, _Prefix(os.path.join(temp_dir.path, name)))
+ for name in ("normal", "overlay")
+ )
+
+ self._bin_dirs: List[str] = []
+ self._lib_dirs: List[str] = []
+ for prefix in reversed(list(self._prefixes.values())):
+ self._bin_dirs.append(prefix.bin_dir)
+ self._lib_dirs.extend(prefix.lib_dirs)
+
+ # Customize site to:
+ # - ensure .pth files are honored
+ # - prevent access to system site packages
+ system_sites = _get_system_sitepackages()
+
+ self._site_dir = os.path.join(temp_dir.path, "site")
+ if not os.path.exists(self._site_dir):
+ os.mkdir(self._site_dir)
+ with open(
+ os.path.join(self._site_dir, "sitecustomize.py"), "w", encoding="utf-8"
+ ) as fp:
+ fp.write(
+ textwrap.dedent(
+ """
+ import os, site, sys
+
+ # First, drop system-sites related paths.
+ original_sys_path = sys.path[:]
+ known_paths = set()
+ for path in {system_sites!r}:
+ site.addsitedir(path, known_paths=known_paths)
+ system_paths = set(
+ os.path.normcase(path)
+ for path in sys.path[len(original_sys_path):]
+ )
+ original_sys_path = [
+ path for path in original_sys_path
+ if os.path.normcase(path) not in system_paths
+ ]
+ sys.path = original_sys_path
+
+ # Second, add lib directories.
+ # ensuring .pth file are processed.
+ for path in {lib_dirs!r}:
+ assert not path in sys.path
+ site.addsitedir(path)
+ """
+ ).format(system_sites=system_sites, lib_dirs=self._lib_dirs)
+ )
+
+ def __enter__(self) -> None:
+ self._save_env = {
+ name: os.environ.get(name, None)
+ for name in ("PATH", "PYTHONNOUSERSITE", "PYTHONPATH")
+ }
+
+ path = self._bin_dirs[:]
+ old_path = self._save_env["PATH"]
+ if old_path:
+ path.extend(old_path.split(os.pathsep))
+
+ pythonpath = [self._site_dir]
+
+ os.environ.update(
+ {
+ "PATH": os.pathsep.join(path),
+ "PYTHONNOUSERSITE": "1",
+ "PYTHONPATH": os.pathsep.join(pythonpath),
+ }
+ )
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ for varname, old_value in self._save_env.items():
+ if old_value is None:
+ os.environ.pop(varname, None)
+ else:
+ os.environ[varname] = old_value
+
+ def check_requirements(
+ self, reqs: Iterable[str]
+ ) -> Tuple[Set[Tuple[str, str]], Set[str]]:
+ """Return 2 sets:
+ - conflicting requirements: set of (installed, wanted) reqs tuples
+ - missing requirements: set of reqs
+ """
+ missing = set()
+ conflicting = set()
+ if reqs:
+ env = (
+ get_environment(self._lib_dirs)
+ if hasattr(self, "_lib_dirs")
+ else get_default_environment()
+ )
+ for req_str in reqs:
+ req = get_requirement(req_str)
+ # We're explicitly evaluating with an empty extra value, since build
+ # environments are not provided any mechanism to select specific extras.
+ if req.marker is not None and not req.marker.evaluate({"extra": ""}):
+ continue
+ dist = env.get_distribution(req.name)
+ if not dist:
+ missing.add(req_str)
+ continue
+ if isinstance(dist.version, Version):
+ installed_req_str = f"{req.name}=={dist.version}"
+ else:
+ installed_req_str = f"{req.name}==={dist.version}"
+ if not req.specifier.contains(dist.version, prereleases=True):
+ conflicting.add((installed_req_str, req_str))
+ # FIXME: Consider direct URL?
+ return conflicting, missing
+
+ def install_requirements(
+ self,
+ finder: "PackageFinder",
+ requirements: Iterable[str],
+ prefix_as_string: str,
+ *,
+ kind: str,
+ ) -> None:
+ prefix = self._prefixes[prefix_as_string]
+ assert not prefix.setup
+ prefix.setup = True
+ if not requirements:
+ return
+ self._install_requirements(
+ get_runnable_pip(),
+ finder,
+ requirements,
+ prefix,
+ kind=kind,
+ )
+
+ @staticmethod
+ def _install_requirements(
+ pip_runnable: str,
+ finder: "PackageFinder",
+ requirements: Iterable[str],
+ prefix: _Prefix,
+ *,
+ kind: str,
+ ) -> None:
+ args: List[str] = [
+ sys.executable,
+ pip_runnable,
+ "install",
+ "--ignore-installed",
+ "--no-user",
+ "--prefix",
+ prefix.path,
+ "--no-warn-script-location",
+ "--disable-pip-version-check",
+ # The prefix specified two lines above, thus
+ # target from config file or env var should be ignored
+ "--target",
+ "",
+ ]
+ if logger.getEffectiveLevel() <= logging.DEBUG:
+ args.append("-vv")
+ elif logger.getEffectiveLevel() <= VERBOSE:
+ args.append("-v")
+ for format_control in ("no_binary", "only_binary"):
+ formats = getattr(finder.format_control, format_control)
+ args.extend(
+ (
+ "--" + format_control.replace("_", "-"),
+ ",".join(sorted(formats or {":none:"})),
+ )
+ )
+
+ index_urls = finder.index_urls
+ if index_urls:
+ args.extend(["-i", index_urls[0]])
+ for extra_index in index_urls[1:]:
+ args.extend(["--extra-index-url", extra_index])
+ else:
+ args.append("--no-index")
+ for link in finder.find_links:
+ args.extend(["--find-links", link])
+
+ for host in finder.trusted_hosts:
+ args.extend(["--trusted-host", host])
+ if finder.allow_all_prereleases:
+ args.append("--pre")
+ if finder.prefer_binary:
+ args.append("--prefer-binary")
+ args.append("--")
+ args.extend(requirements)
+ extra_environ = {"_PIP_STANDALONE_CERT": where()}
+ with open_spinner(f"Installing {kind}") as spinner:
+ call_subprocess(
+ args,
+ command_desc=f"pip subprocess to install {kind}",
+ spinner=spinner,
+ extra_environ=extra_environ,
+ )
+
+
+class NoOpBuildEnvironment(BuildEnvironment):
+ """A no-op drop-in replacement for BuildEnvironment"""
+
+ def __init__(self) -> None:
+ pass
+
+ def __enter__(self) -> None:
+ pass
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ pass
+
+ def cleanup(self) -> None:
+ pass
+
+ def install_requirements(
+ self,
+ finder: "PackageFinder",
+ requirements: Iterable[str],
+ prefix_as_string: str,
+ *,
+ kind: str,
+ ) -> None:
+ raise NotImplementedError()
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cache.py b/solutions/.venv/Lib/site-packages/pip/_internal/cache.py
new file mode 100644
index 000000000..6b4512672
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cache.py
@@ -0,0 +1,290 @@
+"""Cache Management
+"""
+
+import hashlib
+import json
+import logging
+import os
+from pathlib import Path
+from typing import Any, Dict, List, Optional
+
+from pip._vendor.packaging.tags import Tag, interpreter_name, interpreter_version
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.exceptions import InvalidWheelFilename
+from pip._internal.models.direct_url import DirectUrl
+from pip._internal.models.link import Link
+from pip._internal.models.wheel import Wheel
+from pip._internal.utils.temp_dir import TempDirectory, tempdir_kinds
+from pip._internal.utils.urls import path_to_url
+
+logger = logging.getLogger(__name__)
+
+ORIGIN_JSON_NAME = "origin.json"
+
+
+def _hash_dict(d: Dict[str, str]) -> str:
+ """Return a stable sha224 of a dictionary."""
+ s = json.dumps(d, sort_keys=True, separators=(",", ":"), ensure_ascii=True)
+ return hashlib.sha224(s.encode("ascii")).hexdigest()
+
+
+class Cache:
+ """An abstract class - provides cache directories for data from links
+
+ :param cache_dir: The root of the cache.
+ """
+
+ def __init__(self, cache_dir: str) -> None:
+ super().__init__()
+ assert not cache_dir or os.path.isabs(cache_dir)
+ self.cache_dir = cache_dir or None
+
+ def _get_cache_path_parts(self, link: Link) -> List[str]:
+ """Get parts of part that must be os.path.joined with cache_dir"""
+
+ # We want to generate an url to use as our cache key, we don't want to
+ # just reuse the URL because it might have other items in the fragment
+ # and we don't care about those.
+ key_parts = {"url": link.url_without_fragment}
+ if link.hash_name is not None and link.hash is not None:
+ key_parts[link.hash_name] = link.hash
+ if link.subdirectory_fragment:
+ key_parts["subdirectory"] = link.subdirectory_fragment
+
+ # Include interpreter name, major and minor version in cache key
+ # to cope with ill-behaved sdists that build a different wheel
+ # depending on the python version their setup.py is being run on,
+ # and don't encode the difference in compatibility tags.
+ # https://github.com/pypa/pip/issues/7296
+ key_parts["interpreter_name"] = interpreter_name()
+ key_parts["interpreter_version"] = interpreter_version()
+
+ # Encode our key url with sha224, we'll use this because it has similar
+ # security properties to sha256, but with a shorter total output (and
+ # thus less secure). However the differences don't make a lot of
+ # difference for our use case here.
+ hashed = _hash_dict(key_parts)
+
+ # We want to nest the directories some to prevent having a ton of top
+ # level directories where we might run out of sub directories on some
+ # FS.
+ parts = [hashed[:2], hashed[2:4], hashed[4:6], hashed[6:]]
+
+ return parts
+
+ def _get_candidates(self, link: Link, canonical_package_name: str) -> List[Any]:
+ can_not_cache = not self.cache_dir or not canonical_package_name or not link
+ if can_not_cache:
+ return []
+
+ path = self.get_path_for_link(link)
+ if os.path.isdir(path):
+ return [(candidate, path) for candidate in os.listdir(path)]
+ return []
+
+ def get_path_for_link(self, link: Link) -> str:
+ """Return a directory to store cached items in for link."""
+ raise NotImplementedError()
+
+ def get(
+ self,
+ link: Link,
+ package_name: Optional[str],
+ supported_tags: List[Tag],
+ ) -> Link:
+ """Returns a link to a cached item if it exists, otherwise returns the
+ passed link.
+ """
+ raise NotImplementedError()
+
+
+class SimpleWheelCache(Cache):
+ """A cache of wheels for future installs."""
+
+ def __init__(self, cache_dir: str) -> None:
+ super().__init__(cache_dir)
+
+ def get_path_for_link(self, link: Link) -> str:
+ """Return a directory to store cached wheels for link
+
+ Because there are M wheels for any one sdist, we provide a directory
+ to cache them in, and then consult that directory when looking up
+ cache hits.
+
+ We only insert things into the cache if they have plausible version
+ numbers, so that we don't contaminate the cache with things that were
+ not unique. E.g. ./package might have dozens of installs done for it
+ and build a version of 0.0...and if we built and cached a wheel, we'd
+ end up using the same wheel even if the source has been edited.
+
+ :param link: The link of the sdist for which this will cache wheels.
+ """
+ parts = self._get_cache_path_parts(link)
+ assert self.cache_dir
+ # Store wheels within the root cache_dir
+ return os.path.join(self.cache_dir, "wheels", *parts)
+
+ def get(
+ self,
+ link: Link,
+ package_name: Optional[str],
+ supported_tags: List[Tag],
+ ) -> Link:
+ candidates = []
+
+ if not package_name:
+ return link
+
+ canonical_package_name = canonicalize_name(package_name)
+ for wheel_name, wheel_dir in self._get_candidates(link, canonical_package_name):
+ try:
+ wheel = Wheel(wheel_name)
+ except InvalidWheelFilename:
+ continue
+ if canonicalize_name(wheel.name) != canonical_package_name:
+ logger.debug(
+ "Ignoring cached wheel %s for %s as it "
+ "does not match the expected distribution name %s.",
+ wheel_name,
+ link,
+ package_name,
+ )
+ continue
+ if not wheel.supported(supported_tags):
+ # Built for a different python/arch/etc
+ continue
+ candidates.append(
+ (
+ wheel.support_index_min(supported_tags),
+ wheel_name,
+ wheel_dir,
+ )
+ )
+
+ if not candidates:
+ return link
+
+ _, wheel_name, wheel_dir = min(candidates)
+ return Link(path_to_url(os.path.join(wheel_dir, wheel_name)))
+
+
+class EphemWheelCache(SimpleWheelCache):
+ """A SimpleWheelCache that creates it's own temporary cache directory"""
+
+ def __init__(self) -> None:
+ self._temp_dir = TempDirectory(
+ kind=tempdir_kinds.EPHEM_WHEEL_CACHE,
+ globally_managed=True,
+ )
+
+ super().__init__(self._temp_dir.path)
+
+
+class CacheEntry:
+ def __init__(
+ self,
+ link: Link,
+ persistent: bool,
+ ):
+ self.link = link
+ self.persistent = persistent
+ self.origin: Optional[DirectUrl] = None
+ origin_direct_url_path = Path(self.link.file_path).parent / ORIGIN_JSON_NAME
+ if origin_direct_url_path.exists():
+ try:
+ self.origin = DirectUrl.from_json(
+ origin_direct_url_path.read_text(encoding="utf-8")
+ )
+ except Exception as e:
+ logger.warning(
+ "Ignoring invalid cache entry origin file %s for %s (%s)",
+ origin_direct_url_path,
+ link.filename,
+ e,
+ )
+
+
+class WheelCache(Cache):
+ """Wraps EphemWheelCache and SimpleWheelCache into a single Cache
+
+ This Cache allows for gracefully degradation, using the ephem wheel cache
+ when a certain link is not found in the simple wheel cache first.
+ """
+
+ def __init__(self, cache_dir: str) -> None:
+ super().__init__(cache_dir)
+ self._wheel_cache = SimpleWheelCache(cache_dir)
+ self._ephem_cache = EphemWheelCache()
+
+ def get_path_for_link(self, link: Link) -> str:
+ return self._wheel_cache.get_path_for_link(link)
+
+ def get_ephem_path_for_link(self, link: Link) -> str:
+ return self._ephem_cache.get_path_for_link(link)
+
+ def get(
+ self,
+ link: Link,
+ package_name: Optional[str],
+ supported_tags: List[Tag],
+ ) -> Link:
+ cache_entry = self.get_cache_entry(link, package_name, supported_tags)
+ if cache_entry is None:
+ return link
+ return cache_entry.link
+
+ def get_cache_entry(
+ self,
+ link: Link,
+ package_name: Optional[str],
+ supported_tags: List[Tag],
+ ) -> Optional[CacheEntry]:
+ """Returns a CacheEntry with a link to a cached item if it exists or
+ None. The cache entry indicates if the item was found in the persistent
+ or ephemeral cache.
+ """
+ retval = self._wheel_cache.get(
+ link=link,
+ package_name=package_name,
+ supported_tags=supported_tags,
+ )
+ if retval is not link:
+ return CacheEntry(retval, persistent=True)
+
+ retval = self._ephem_cache.get(
+ link=link,
+ package_name=package_name,
+ supported_tags=supported_tags,
+ )
+ if retval is not link:
+ return CacheEntry(retval, persistent=False)
+
+ return None
+
+ @staticmethod
+ def record_download_origin(cache_dir: str, download_info: DirectUrl) -> None:
+ origin_path = Path(cache_dir) / ORIGIN_JSON_NAME
+ if origin_path.exists():
+ try:
+ origin = DirectUrl.from_json(origin_path.read_text(encoding="utf-8"))
+ except Exception as e:
+ logger.warning(
+ "Could not read origin file %s in cache entry (%s). "
+ "Will attempt to overwrite it.",
+ origin_path,
+ e,
+ )
+ else:
+ # TODO: use DirectUrl.equivalent when
+ # https://github.com/pypa/pip/pull/10564 is merged.
+ if origin.url != download_info.url:
+ logger.warning(
+ "Origin URL %s in cache entry %s does not match download URL "
+ "%s. This is likely a pip bug or a cache corruption issue. "
+ "Will overwrite it with the new value.",
+ origin.url,
+ cache_dir,
+ download_info.url,
+ )
+ origin_path.write_text(download_info.to_json(), encoding="utf-8")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/__init__.py
new file mode 100644
index 000000000..e589bb917
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/__init__.py
@@ -0,0 +1,4 @@
+"""Subpackage containing all of pip's command line interface related code
+"""
+
+# This file intentionally does not import submodules
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/autocompletion.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/autocompletion.py
new file mode 100644
index 000000000..f3f70ac85
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/autocompletion.py
@@ -0,0 +1,176 @@
+"""Logic that powers autocompletion installed by ``pip completion``.
+"""
+
+import optparse
+import os
+import sys
+from itertools import chain
+from typing import Any, Iterable, List, Optional
+
+from pip._internal.cli.main_parser import create_main_parser
+from pip._internal.commands import commands_dict, create_command
+from pip._internal.metadata import get_default_environment
+
+
+def autocomplete() -> None:
+ """Entry Point for completion of main and subcommand options."""
+ # Don't complete if user hasn't sourced bash_completion file.
+ if "PIP_AUTO_COMPLETE" not in os.environ:
+ return
+ # Don't complete if autocompletion environment variables
+ # are not present
+ if not os.environ.get("COMP_WORDS") or not os.environ.get("COMP_CWORD"):
+ return
+ cwords = os.environ["COMP_WORDS"].split()[1:]
+ cword = int(os.environ["COMP_CWORD"])
+ try:
+ current = cwords[cword - 1]
+ except IndexError:
+ current = ""
+
+ parser = create_main_parser()
+ subcommands = list(commands_dict)
+ options = []
+
+ # subcommand
+ subcommand_name: Optional[str] = None
+ for word in cwords:
+ if word in subcommands:
+ subcommand_name = word
+ break
+ # subcommand options
+ if subcommand_name is not None:
+ # special case: 'help' subcommand has no options
+ if subcommand_name == "help":
+ sys.exit(1)
+ # special case: list locally installed dists for show and uninstall
+ should_list_installed = not current.startswith("-") and subcommand_name in [
+ "show",
+ "uninstall",
+ ]
+ if should_list_installed:
+ env = get_default_environment()
+ lc = current.lower()
+ installed = [
+ dist.canonical_name
+ for dist in env.iter_installed_distributions(local_only=True)
+ if dist.canonical_name.startswith(lc)
+ and dist.canonical_name not in cwords[1:]
+ ]
+ # if there are no dists installed, fall back to option completion
+ if installed:
+ for dist in installed:
+ print(dist)
+ sys.exit(1)
+
+ should_list_installables = (
+ not current.startswith("-") and subcommand_name == "install"
+ )
+ if should_list_installables:
+ for path in auto_complete_paths(current, "path"):
+ print(path)
+ sys.exit(1)
+
+ subcommand = create_command(subcommand_name)
+
+ for opt in subcommand.parser.option_list_all:
+ if opt.help != optparse.SUPPRESS_HELP:
+ options += [
+ (opt_str, opt.nargs) for opt_str in opt._long_opts + opt._short_opts
+ ]
+
+ # filter out previously specified options from available options
+ prev_opts = [x.split("=")[0] for x in cwords[1 : cword - 1]]
+ options = [(x, v) for (x, v) in options if x not in prev_opts]
+ # filter options by current input
+ options = [(k, v) for k, v in options if k.startswith(current)]
+ # get completion type given cwords and available subcommand options
+ completion_type = get_path_completion_type(
+ cwords,
+ cword,
+ subcommand.parser.option_list_all,
+ )
+ # get completion files and directories if ``completion_type`` is
+ # ``<file>``, ``<dir>`` or ``<path>``
+ if completion_type:
+ paths = auto_complete_paths(current, completion_type)
+ options = [(path, 0) for path in paths]
+ for option in options:
+ opt_label = option[0]
+ # append '=' to options which require args
+ if option[1] and option[0][:2] == "--":
+ opt_label += "="
+ print(opt_label)
+ else:
+ # show main parser options only when necessary
+
+ opts = [i.option_list for i in parser.option_groups]
+ opts.append(parser.option_list)
+ flattened_opts = chain.from_iterable(opts)
+ if current.startswith("-"):
+ for opt in flattened_opts:
+ if opt.help != optparse.SUPPRESS_HELP:
+ subcommands += opt._long_opts + opt._short_opts
+ else:
+ # get completion type given cwords and all available options
+ completion_type = get_path_completion_type(cwords, cword, flattened_opts)
+ if completion_type:
+ subcommands = list(auto_complete_paths(current, completion_type))
+
+ print(" ".join([x for x in subcommands if x.startswith(current)]))
+ sys.exit(1)
+
+
+def get_path_completion_type(
+ cwords: List[str], cword: int, opts: Iterable[Any]
+) -> Optional[str]:
+ """Get the type of path completion (``file``, ``dir``, ``path`` or None)
+
+ :param cwords: same as the environmental variable ``COMP_WORDS``
+ :param cword: same as the environmental variable ``COMP_CWORD``
+ :param opts: The available options to check
+ :return: path completion type (``file``, ``dir``, ``path`` or None)
+ """
+ if cword < 2 or not cwords[cword - 2].startswith("-"):
+ return None
+ for opt in opts:
+ if opt.help == optparse.SUPPRESS_HELP:
+ continue
+ for o in str(opt).split("/"):
+ if cwords[cword - 2].split("=")[0] == o:
+ if not opt.metavar or any(
+ x in ("path", "file", "dir") for x in opt.metavar.split("/")
+ ):
+ return opt.metavar
+ return None
+
+
+def auto_complete_paths(current: str, completion_type: str) -> Iterable[str]:
+ """If ``completion_type`` is ``file`` or ``path``, list all regular files
+ and directories starting with ``current``; otherwise only list directories
+ starting with ``current``.
+
+ :param current: The word to be completed
+ :param completion_type: path completion type(``file``, ``path`` or ``dir``)
+ :return: A generator of regular files and/or directories
+ """
+ directory, filename = os.path.split(current)
+ current_path = os.path.abspath(directory)
+ # Don't complete paths if they can't be accessed
+ if not os.access(current_path, os.R_OK):
+ return
+ filename = os.path.normcase(filename)
+ # list all files that start with ``filename``
+ file_list = (
+ x for x in os.listdir(current_path) if os.path.normcase(x).startswith(filename)
+ )
+ for f in file_list:
+ opt = os.path.join(current_path, f)
+ comp_file = os.path.normcase(os.path.join(directory, f))
+ # complete regular files when there is not ``<dir>`` after option
+ # complete directories when there is ``<file>``, ``<path>`` or
+ # ``<dir>``after option
+ if completion_type != "dir" and os.path.isfile(opt):
+ yield comp_file
+ elif os.path.isdir(opt):
+ yield os.path.join(comp_file, "")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/base_command.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/base_command.py
new file mode 100644
index 000000000..bc1ab6594
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/base_command.py
@@ -0,0 +1,231 @@
+"""Base Command class, and related routines"""
+
+import logging
+import logging.config
+import optparse
+import os
+import sys
+import traceback
+from optparse import Values
+from typing import List, Optional, Tuple
+
+from pip._vendor.rich import reconfigure
+from pip._vendor.rich import traceback as rich_traceback
+
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.command_context import CommandContextMixIn
+from pip._internal.cli.parser import ConfigOptionParser, UpdatingDefaultsHelpFormatter
+from pip._internal.cli.status_codes import (
+ ERROR,
+ PREVIOUS_BUILD_DIR_ERROR,
+ UNKNOWN_ERROR,
+ VIRTUALENV_NOT_FOUND,
+)
+from pip._internal.exceptions import (
+ BadCommand,
+ CommandError,
+ DiagnosticPipError,
+ InstallationError,
+ NetworkConnectionError,
+ PreviousBuildDirError,
+)
+from pip._internal.utils.filesystem import check_path_owner
+from pip._internal.utils.logging import BrokenStdoutLoggingError, setup_logging
+from pip._internal.utils.misc import get_prog, normalize_path
+from pip._internal.utils.temp_dir import TempDirectoryTypeRegistry as TempDirRegistry
+from pip._internal.utils.temp_dir import global_tempdir_manager, tempdir_registry
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+__all__ = ["Command"]
+
+logger = logging.getLogger(__name__)
+
+
+class Command(CommandContextMixIn):
+ usage: str = ""
+ ignore_require_venv: bool = False
+
+ def __init__(self, name: str, summary: str, isolated: bool = False) -> None:
+ super().__init__()
+
+ self.name = name
+ self.summary = summary
+ self.parser = ConfigOptionParser(
+ usage=self.usage,
+ prog=f"{get_prog()} {name}",
+ formatter=UpdatingDefaultsHelpFormatter(),
+ add_help_option=False,
+ name=name,
+ description=self.__doc__,
+ isolated=isolated,
+ )
+
+ self.tempdir_registry: Optional[TempDirRegistry] = None
+
+ # Commands should add options to this option group
+ optgroup_name = f"{self.name.capitalize()} Options"
+ self.cmd_opts = optparse.OptionGroup(self.parser, optgroup_name)
+
+ # Add the general options
+ gen_opts = cmdoptions.make_option_group(
+ cmdoptions.general_group,
+ self.parser,
+ )
+ self.parser.add_option_group(gen_opts)
+
+ self.add_options()
+
+ def add_options(self) -> None:
+ pass
+
+ def handle_pip_version_check(self, options: Values) -> None:
+ """
+ This is a no-op so that commands by default do not do the pip version
+ check.
+ """
+ # Make sure we do the pip version check if the index_group options
+ # are present.
+ assert not hasattr(options, "no_index")
+
+ def run(self, options: Values, args: List[str]) -> int:
+ raise NotImplementedError
+
+ def _run_wrapper(self, level_number: int, options: Values, args: List[str]) -> int:
+ def _inner_run() -> int:
+ try:
+ return self.run(options, args)
+ finally:
+ self.handle_pip_version_check(options)
+
+ if options.debug_mode:
+ rich_traceback.install(show_locals=True)
+ return _inner_run()
+
+ try:
+ status = _inner_run()
+ assert isinstance(status, int)
+ return status
+ except DiagnosticPipError as exc:
+ logger.error("%s", exc, extra={"rich": True})
+ logger.debug("Exception information:", exc_info=True)
+
+ return ERROR
+ except PreviousBuildDirError as exc:
+ logger.critical(str(exc))
+ logger.debug("Exception information:", exc_info=True)
+
+ return PREVIOUS_BUILD_DIR_ERROR
+ except (
+ InstallationError,
+ BadCommand,
+ NetworkConnectionError,
+ ) as exc:
+ logger.critical(str(exc))
+ logger.debug("Exception information:", exc_info=True)
+
+ return ERROR
+ except CommandError as exc:
+ logger.critical("%s", exc)
+ logger.debug("Exception information:", exc_info=True)
+
+ return ERROR
+ except BrokenStdoutLoggingError:
+ # Bypass our logger and write any remaining messages to
+ # stderr because stdout no longer works.
+ print("ERROR: Pipe to stdout was broken", file=sys.stderr)
+ if level_number <= logging.DEBUG:
+ traceback.print_exc(file=sys.stderr)
+
+ return ERROR
+ except KeyboardInterrupt:
+ logger.critical("Operation cancelled by user")
+ logger.debug("Exception information:", exc_info=True)
+
+ return ERROR
+ except BaseException:
+ logger.critical("Exception:", exc_info=True)
+
+ return UNKNOWN_ERROR
+
+ def parse_args(self, args: List[str]) -> Tuple[Values, List[str]]:
+ # factored out for testability
+ return self.parser.parse_args(args)
+
+ def main(self, args: List[str]) -> int:
+ try:
+ with self.main_context():
+ return self._main(args)
+ finally:
+ logging.shutdown()
+
+ def _main(self, args: List[str]) -> int:
+ # We must initialize this before the tempdir manager, otherwise the
+ # configuration would not be accessible by the time we clean up the
+ # tempdir manager.
+ self.tempdir_registry = self.enter_context(tempdir_registry())
+ # Intentionally set as early as possible so globally-managed temporary
+ # directories are available to the rest of the code.
+ self.enter_context(global_tempdir_manager())
+
+ options, args = self.parse_args(args)
+
+ # Set verbosity so that it can be used elsewhere.
+ self.verbosity = options.verbose - options.quiet
+
+ reconfigure(no_color=options.no_color)
+ level_number = setup_logging(
+ verbosity=self.verbosity,
+ no_color=options.no_color,
+ user_log_file=options.log,
+ )
+
+ always_enabled_features = set(options.features_enabled) & set(
+ cmdoptions.ALWAYS_ENABLED_FEATURES
+ )
+ if always_enabled_features:
+ logger.warning(
+ "The following features are always enabled: %s. ",
+ ", ".join(sorted(always_enabled_features)),
+ )
+
+ # Make sure that the --python argument isn't specified after the
+ # subcommand. We can tell, because if --python was specified,
+ # we should only reach this point if we're running in the created
+ # subprocess, which has the _PIP_RUNNING_IN_SUBPROCESS environment
+ # variable set.
+ if options.python and "_PIP_RUNNING_IN_SUBPROCESS" not in os.environ:
+ logger.critical(
+ "The --python option must be placed before the pip subcommand name"
+ )
+ sys.exit(ERROR)
+
+ # TODO: Try to get these passing down from the command?
+ # without resorting to os.environ to hold these.
+ # This also affects isolated builds and it should.
+
+ if options.no_input:
+ os.environ["PIP_NO_INPUT"] = "1"
+
+ if options.exists_action:
+ os.environ["PIP_EXISTS_ACTION"] = " ".join(options.exists_action)
+
+ if options.require_venv and not self.ignore_require_venv:
+ # If a venv is required check if it can really be found
+ if not running_under_virtualenv():
+ logger.critical("Could not find an activated virtualenv (required).")
+ sys.exit(VIRTUALENV_NOT_FOUND)
+
+ if options.cache_dir:
+ options.cache_dir = normalize_path(options.cache_dir)
+ if not check_path_owner(options.cache_dir):
+ logger.warning(
+ "The directory '%s' or its parent directory is not owned "
+ "or is not writable by the current user. The cache "
+ "has been disabled. Check the permissions and owner of "
+ "that directory. If executing pip with sudo, you should "
+ "use sudo's -H flag.",
+ options.cache_dir,
+ )
+ options.cache_dir = None
+
+ return self._run_wrapper(level_number, options, args)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/cmdoptions.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/cmdoptions.py
new file mode 100644
index 000000000..0b7cff77b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/cmdoptions.py
@@ -0,0 +1,1075 @@
+"""
+shared options and groups
+
+The principle here is to define options once, but *not* instantiate them
+globally. One reason being that options with action='append' can carry state
+between parses. pip parses general options twice internally, and shouldn't
+pass on state. To be consistent, all options will follow this design.
+"""
+
+# The following comment should be removed at some point in the future.
+# mypy: strict-optional=False
+
+import importlib.util
+import logging
+import os
+import textwrap
+from functools import partial
+from optparse import SUPPRESS_HELP, Option, OptionGroup, OptionParser, Values
+from textwrap import dedent
+from typing import Any, Callable, Dict, Optional, Tuple
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.cli.parser import ConfigOptionParser
+from pip._internal.exceptions import CommandError
+from pip._internal.locations import USER_CACHE_DIR, get_src_prefix
+from pip._internal.models.format_control import FormatControl
+from pip._internal.models.index import PyPI
+from pip._internal.models.target_python import TargetPython
+from pip._internal.utils.hashes import STRONG_HASHES
+from pip._internal.utils.misc import strtobool
+
+logger = logging.getLogger(__name__)
+
+
+def raise_option_error(parser: OptionParser, option: Option, msg: str) -> None:
+ """
+ Raise an option parsing error using parser.error().
+
+ Args:
+ parser: an OptionParser instance.
+ option: an Option instance.
+ msg: the error text.
+ """
+ msg = f"{option} error: {msg}"
+ msg = textwrap.fill(" ".join(msg.split()))
+ parser.error(msg)
+
+
+def make_option_group(group: Dict[str, Any], parser: ConfigOptionParser) -> OptionGroup:
+ """
+ Return an OptionGroup object
+ group -- assumed to be dict with 'name' and 'options' keys
+ parser -- an optparse Parser
+ """
+ option_group = OptionGroup(parser, group["name"])
+ for option in group["options"]:
+ option_group.add_option(option())
+ return option_group
+
+
+def check_dist_restriction(options: Values, check_target: bool = False) -> None:
+ """Function for determining if custom platform options are allowed.
+
+ :param options: The OptionParser options.
+ :param check_target: Whether or not to check if --target is being used.
+ """
+ dist_restriction_set = any(
+ [
+ options.python_version,
+ options.platforms,
+ options.abis,
+ options.implementation,
+ ]
+ )
+
+ binary_only = FormatControl(set(), {":all:"})
+ sdist_dependencies_allowed = (
+ options.format_control != binary_only and not options.ignore_dependencies
+ )
+
+ # Installations or downloads using dist restrictions must not combine
+ # source distributions and dist-specific wheels, as they are not
+ # guaranteed to be locally compatible.
+ if dist_restriction_set and sdist_dependencies_allowed:
+ raise CommandError(
+ "When restricting platform and interpreter constraints using "
+ "--python-version, --platform, --abi, or --implementation, "
+ "either --no-deps must be set, or --only-binary=:all: must be "
+ "set and --no-binary must not be set (or must be set to "
+ ":none:)."
+ )
+
+ if check_target:
+ if not options.dry_run and dist_restriction_set and not options.target_dir:
+ raise CommandError(
+ "Can not use any platform or abi specific options unless "
+ "installing via '--target' or using '--dry-run'"
+ )
+
+
+def _path_option_check(option: Option, opt: str, value: str) -> str:
+ return os.path.expanduser(value)
+
+
+def _package_name_option_check(option: Option, opt: str, value: str) -> str:
+ return canonicalize_name(value)
+
+
+class PipOption(Option):
+ TYPES = Option.TYPES + ("path", "package_name")
+ TYPE_CHECKER = Option.TYPE_CHECKER.copy()
+ TYPE_CHECKER["package_name"] = _package_name_option_check
+ TYPE_CHECKER["path"] = _path_option_check
+
+
+###########
+# options #
+###########
+
+help_: Callable[..., Option] = partial(
+ Option,
+ "-h",
+ "--help",
+ dest="help",
+ action="help",
+ help="Show help.",
+)
+
+debug_mode: Callable[..., Option] = partial(
+ Option,
+ "--debug",
+ dest="debug_mode",
+ action="store_true",
+ default=False,
+ help=(
+ "Let unhandled exceptions propagate outside the main subroutine, "
+ "instead of logging them to stderr."
+ ),
+)
+
+isolated_mode: Callable[..., Option] = partial(
+ Option,
+ "--isolated",
+ dest="isolated_mode",
+ action="store_true",
+ default=False,
+ help=(
+ "Run pip in an isolated mode, ignoring environment variables and user "
+ "configuration."
+ ),
+)
+
+require_virtualenv: Callable[..., Option] = partial(
+ Option,
+ "--require-virtualenv",
+ "--require-venv",
+ dest="require_venv",
+ action="store_true",
+ default=False,
+ help=(
+ "Allow pip to only run in a virtual environment; "
+ "exit with an error otherwise."
+ ),
+)
+
+override_externally_managed: Callable[..., Option] = partial(
+ Option,
+ "--break-system-packages",
+ dest="override_externally_managed",
+ action="store_true",
+ help="Allow pip to modify an EXTERNALLY-MANAGED Python installation",
+)
+
+python: Callable[..., Option] = partial(
+ Option,
+ "--python",
+ dest="python",
+ help="Run pip with the specified Python interpreter.",
+)
+
+verbose: Callable[..., Option] = partial(
+ Option,
+ "-v",
+ "--verbose",
+ dest="verbose",
+ action="count",
+ default=0,
+ help="Give more output. Option is additive, and can be used up to 3 times.",
+)
+
+no_color: Callable[..., Option] = partial(
+ Option,
+ "--no-color",
+ dest="no_color",
+ action="store_true",
+ default=False,
+ help="Suppress colored output.",
+)
+
+version: Callable[..., Option] = partial(
+ Option,
+ "-V",
+ "--version",
+ dest="version",
+ action="store_true",
+ help="Show version and exit.",
+)
+
+quiet: Callable[..., Option] = partial(
+ Option,
+ "-q",
+ "--quiet",
+ dest="quiet",
+ action="count",
+ default=0,
+ help=(
+ "Give less output. Option is additive, and can be used up to 3"
+ " times (corresponding to WARNING, ERROR, and CRITICAL logging"
+ " levels)."
+ ),
+)
+
+progress_bar: Callable[..., Option] = partial(
+ Option,
+ "--progress-bar",
+ dest="progress_bar",
+ type="choice",
+ choices=["on", "off", "raw"],
+ default="on",
+ help="Specify whether the progress bar should be used [on, off, raw] (default: on)",
+)
+
+log: Callable[..., Option] = partial(
+ PipOption,
+ "--log",
+ "--log-file",
+ "--local-log",
+ dest="log",
+ metavar="path",
+ type="path",
+ help="Path to a verbose appending log.",
+)
+
+no_input: Callable[..., Option] = partial(
+ Option,
+ # Don't ask for input
+ "--no-input",
+ dest="no_input",
+ action="store_true",
+ default=False,
+ help="Disable prompting for input.",
+)
+
+keyring_provider: Callable[..., Option] = partial(
+ Option,
+ "--keyring-provider",
+ dest="keyring_provider",
+ choices=["auto", "disabled", "import", "subprocess"],
+ default="auto",
+ help=(
+ "Enable the credential lookup via the keyring library if user input is allowed."
+ " Specify which mechanism to use [disabled, import, subprocess]."
+ " (default: disabled)"
+ ),
+)
+
+proxy: Callable[..., Option] = partial(
+ Option,
+ "--proxy",
+ dest="proxy",
+ type="str",
+ default="",
+ help="Specify a proxy in the form scheme://[user:passwd@]proxy.server:port.",
+)
+
+retries: Callable[..., Option] = partial(
+ Option,
+ "--retries",
+ dest="retries",
+ type="int",
+ default=5,
+ help="Maximum number of retries each connection should attempt "
+ "(default %default times).",
+)
+
+timeout: Callable[..., Option] = partial(
+ Option,
+ "--timeout",
+ "--default-timeout",
+ metavar="sec",
+ dest="timeout",
+ type="float",
+ default=15,
+ help="Set the socket timeout (default %default seconds).",
+)
+
+
+def exists_action() -> Option:
+ return Option(
+ # Option when path already exist
+ "--exists-action",
+ dest="exists_action",
+ type="choice",
+ choices=["s", "i", "w", "b", "a"],
+ default=[],
+ action="append",
+ metavar="action",
+ help="Default action when a path already exists: "
+ "(s)witch, (i)gnore, (w)ipe, (b)ackup, (a)bort.",
+ )
+
+
+cert: Callable[..., Option] = partial(
+ PipOption,
+ "--cert",
+ dest="cert",
+ type="path",
+ metavar="path",
+ help=(
+ "Path to PEM-encoded CA certificate bundle. "
+ "If provided, overrides the default. "
+ "See 'SSL Certificate Verification' in pip documentation "
+ "for more information."
+ ),
+)
+
+client_cert: Callable[..., Option] = partial(
+ PipOption,
+ "--client-cert",
+ dest="client_cert",
+ type="path",
+ default=None,
+ metavar="path",
+ help="Path to SSL client certificate, a single file containing the "
+ "private key and the certificate in PEM format.",
+)
+
+index_url: Callable[..., Option] = partial(
+ Option,
+ "-i",
+ "--index-url",
+ "--pypi-url",
+ dest="index_url",
+ metavar="URL",
+ default=PyPI.simple_url,
+ help="Base URL of the Python Package Index (default %default). "
+ "This should point to a repository compliant with PEP 503 "
+ "(the simple repository API) or a local directory laid out "
+ "in the same format.",
+)
+
+
+def extra_index_url() -> Option:
+ return Option(
+ "--extra-index-url",
+ dest="extra_index_urls",
+ metavar="URL",
+ action="append",
+ default=[],
+ help="Extra URLs of package indexes to use in addition to "
+ "--index-url. Should follow the same rules as "
+ "--index-url.",
+ )
+
+
+no_index: Callable[..., Option] = partial(
+ Option,
+ "--no-index",
+ dest="no_index",
+ action="store_true",
+ default=False,
+ help="Ignore package index (only looking at --find-links URLs instead).",
+)
+
+
+def find_links() -> Option:
+ return Option(
+ "-f",
+ "--find-links",
+ dest="find_links",
+ action="append",
+ default=[],
+ metavar="url",
+ help="If a URL or path to an html file, then parse for links to "
+ "archives such as sdist (.tar.gz) or wheel (.whl) files. "
+ "If a local path or file:// URL that's a directory, "
+ "then look for archives in the directory listing. "
+ "Links to VCS project URLs are not supported.",
+ )
+
+
+def trusted_host() -> Option:
+ return Option(
+ "--trusted-host",
+ dest="trusted_hosts",
+ action="append",
+ metavar="HOSTNAME",
+ default=[],
+ help="Mark this host or host:port pair as trusted, even though it "
+ "does not have valid or any HTTPS.",
+ )
+
+
+def constraints() -> Option:
+ return Option(
+ "-c",
+ "--constraint",
+ dest="constraints",
+ action="append",
+ default=[],
+ metavar="file",
+ help="Constrain versions using the given constraints file. "
+ "This option can be used multiple times.",
+ )
+
+
+def requirements() -> Option:
+ return Option(
+ "-r",
+ "--requirement",
+ dest="requirements",
+ action="append",
+ default=[],
+ metavar="file",
+ help="Install from the given requirements file. "
+ "This option can be used multiple times.",
+ )
+
+
+def editable() -> Option:
+ return Option(
+ "-e",
+ "--editable",
+ dest="editables",
+ action="append",
+ default=[],
+ metavar="path/url",
+ help=(
+ "Install a project in editable mode (i.e. setuptools "
+ '"develop mode") from a local project path or a VCS url.'
+ ),
+ )
+
+
+def _handle_src(option: Option, opt_str: str, value: str, parser: OptionParser) -> None:
+ value = os.path.abspath(value)
+ setattr(parser.values, option.dest, value)
+
+
+src: Callable[..., Option] = partial(
+ PipOption,
+ "--src",
+ "--source",
+ "--source-dir",
+ "--source-directory",
+ dest="src_dir",
+ type="path",
+ metavar="dir",
+ default=get_src_prefix(),
+ action="callback",
+ callback=_handle_src,
+ help="Directory to check out editable projects into. "
+ 'The default in a virtualenv is "<venv path>/src". '
+ 'The default for global installs is "<current dir>/src".',
+)
+
+
+def _get_format_control(values: Values, option: Option) -> Any:
+ """Get a format_control object."""
+ return getattr(values, option.dest)
+
+
+def _handle_no_binary(
+ option: Option, opt_str: str, value: str, parser: OptionParser
+) -> None:
+ existing = _get_format_control(parser.values, option)
+ FormatControl.handle_mutual_excludes(
+ value,
+ existing.no_binary,
+ existing.only_binary,
+ )
+
+
+def _handle_only_binary(
+ option: Option, opt_str: str, value: str, parser: OptionParser
+) -> None:
+ existing = _get_format_control(parser.values, option)
+ FormatControl.handle_mutual_excludes(
+ value,
+ existing.only_binary,
+ existing.no_binary,
+ )
+
+
+def no_binary() -> Option:
+ format_control = FormatControl(set(), set())
+ return Option(
+ "--no-binary",
+ dest="format_control",
+ action="callback",
+ callback=_handle_no_binary,
+ type="str",
+ default=format_control,
+ help="Do not use binary packages. Can be supplied multiple times, and "
+ 'each time adds to the existing value. Accepts either ":all:" to '
+ 'disable all binary packages, ":none:" to empty the set (notice '
+ "the colons), or one or more package names with commas between "
+ "them (no colons). Note that some packages are tricky to compile "
+ "and may fail to install when this option is used on them.",
+ )
+
+
+def only_binary() -> Option:
+ format_control = FormatControl(set(), set())
+ return Option(
+ "--only-binary",
+ dest="format_control",
+ action="callback",
+ callback=_handle_only_binary,
+ type="str",
+ default=format_control,
+ help="Do not use source packages. Can be supplied multiple times, and "
+ 'each time adds to the existing value. Accepts either ":all:" to '
+ 'disable all source packages, ":none:" to empty the set, or one '
+ "or more package names with commas between them. Packages "
+ "without binary distributions will fail to install when this "
+ "option is used on them.",
+ )
+
+
+platforms: Callable[..., Option] = partial(
+ Option,
+ "--platform",
+ dest="platforms",
+ metavar="platform",
+ action="append",
+ default=None,
+ help=(
+ "Only use wheels compatible with <platform>. Defaults to the "
+ "platform of the running system. Use this option multiple times to "
+ "specify multiple platforms supported by the target interpreter."
+ ),
+)
+
+
+# This was made a separate function for unit-testing purposes.
+def _convert_python_version(value: str) -> Tuple[Tuple[int, ...], Optional[str]]:
+ """
+ Convert a version string like "3", "37", or "3.7.3" into a tuple of ints.
+
+ :return: A 2-tuple (version_info, error_msg), where `error_msg` is
+ non-None if and only if there was a parsing error.
+ """
+ if not value:
+ # The empty string is the same as not providing a value.
+ return (None, None)
+
+ parts = value.split(".")
+ if len(parts) > 3:
+ return ((), "at most three version parts are allowed")
+
+ if len(parts) == 1:
+ # Then we are in the case of "3" or "37".
+ value = parts[0]
+ if len(value) > 1:
+ parts = [value[0], value[1:]]
+
+ try:
+ version_info = tuple(int(part) for part in parts)
+ except ValueError:
+ return ((), "each version part must be an integer")
+
+ return (version_info, None)
+
+
+def _handle_python_version(
+ option: Option, opt_str: str, value: str, parser: OptionParser
+) -> None:
+ """
+ Handle a provided --python-version value.
+ """
+ version_info, error_msg = _convert_python_version(value)
+ if error_msg is not None:
+ msg = f"invalid --python-version value: {value!r}: {error_msg}"
+ raise_option_error(parser, option=option, msg=msg)
+
+ parser.values.python_version = version_info
+
+
+python_version: Callable[..., Option] = partial(
+ Option,
+ "--python-version",
+ dest="python_version",
+ metavar="python_version",
+ action="callback",
+ callback=_handle_python_version,
+ type="str",
+ default=None,
+ help=dedent(
+ """\
+ The Python interpreter version to use for wheel and "Requires-Python"
+ compatibility checks. Defaults to a version derived from the running
+ interpreter. The version can be specified using up to three dot-separated
+ integers (e.g. "3" for 3.0.0, "3.7" for 3.7.0, or "3.7.3"). A major-minor
+ version can also be given as a string without dots (e.g. "37" for 3.7.0).
+ """
+ ),
+)
+
+
+implementation: Callable[..., Option] = partial(
+ Option,
+ "--implementation",
+ dest="implementation",
+ metavar="implementation",
+ default=None,
+ help=(
+ "Only use wheels compatible with Python "
+ "implementation <implementation>, e.g. 'pp', 'jy', 'cp', "
+ " or 'ip'. If not specified, then the current "
+ "interpreter implementation is used. Use 'py' to force "
+ "implementation-agnostic wheels."
+ ),
+)
+
+
+abis: Callable[..., Option] = partial(
+ Option,
+ "--abi",
+ dest="abis",
+ metavar="abi",
+ action="append",
+ default=None,
+ help=(
+ "Only use wheels compatible with Python abi <abi>, e.g. 'pypy_41'. "
+ "If not specified, then the current interpreter abi tag is used. "
+ "Use this option multiple times to specify multiple abis supported "
+ "by the target interpreter. Generally you will need to specify "
+ "--implementation, --platform, and --python-version when using this "
+ "option."
+ ),
+)
+
+
+def add_target_python_options(cmd_opts: OptionGroup) -> None:
+ cmd_opts.add_option(platforms())
+ cmd_opts.add_option(python_version())
+ cmd_opts.add_option(implementation())
+ cmd_opts.add_option(abis())
+
+
+def make_target_python(options: Values) -> TargetPython:
+ target_python = TargetPython(
+ platforms=options.platforms,
+ py_version_info=options.python_version,
+ abis=options.abis,
+ implementation=options.implementation,
+ )
+
+ return target_python
+
+
+def prefer_binary() -> Option:
+ return Option(
+ "--prefer-binary",
+ dest="prefer_binary",
+ action="store_true",
+ default=False,
+ help=(
+ "Prefer binary packages over source packages, even if the "
+ "source packages are newer."
+ ),
+ )
+
+
+cache_dir: Callable[..., Option] = partial(
+ PipOption,
+ "--cache-dir",
+ dest="cache_dir",
+ default=USER_CACHE_DIR,
+ metavar="dir",
+ type="path",
+ help="Store the cache data in <dir>.",
+)
+
+
+def _handle_no_cache_dir(
+ option: Option, opt: str, value: str, parser: OptionParser
+) -> None:
+ """
+ Process a value provided for the --no-cache-dir option.
+
+ This is an optparse.Option callback for the --no-cache-dir option.
+ """
+ # The value argument will be None if --no-cache-dir is passed via the
+ # command-line, since the option doesn't accept arguments. However,
+ # the value can be non-None if the option is triggered e.g. by an
+ # environment variable, like PIP_NO_CACHE_DIR=true.
+ if value is not None:
+ # Then parse the string value to get argument error-checking.
+ try:
+ strtobool(value)
+ except ValueError as exc:
+ raise_option_error(parser, option=option, msg=str(exc))
+
+ # Originally, setting PIP_NO_CACHE_DIR to a value that strtobool()
+ # converted to 0 (like "false" or "no") caused cache_dir to be disabled
+ # rather than enabled (logic would say the latter). Thus, we disable
+ # the cache directory not just on values that parse to True, but (for
+ # backwards compatibility reasons) also on values that parse to False.
+ # In other words, always set it to False if the option is provided in
+ # some (valid) form.
+ parser.values.cache_dir = False
+
+
+no_cache: Callable[..., Option] = partial(
+ Option,
+ "--no-cache-dir",
+ dest="cache_dir",
+ action="callback",
+ callback=_handle_no_cache_dir,
+ help="Disable the cache.",
+)
+
+no_deps: Callable[..., Option] = partial(
+ Option,
+ "--no-deps",
+ "--no-dependencies",
+ dest="ignore_dependencies",
+ action="store_true",
+ default=False,
+ help="Don't install package dependencies.",
+)
+
+ignore_requires_python: Callable[..., Option] = partial(
+ Option,
+ "--ignore-requires-python",
+ dest="ignore_requires_python",
+ action="store_true",
+ help="Ignore the Requires-Python information.",
+)
+
+no_build_isolation: Callable[..., Option] = partial(
+ Option,
+ "--no-build-isolation",
+ dest="build_isolation",
+ action="store_false",
+ default=True,
+ help="Disable isolation when building a modern source distribution. "
+ "Build dependencies specified by PEP 518 must be already installed "
+ "if this option is used.",
+)
+
+check_build_deps: Callable[..., Option] = partial(
+ Option,
+ "--check-build-dependencies",
+ dest="check_build_deps",
+ action="store_true",
+ default=False,
+ help="Check the build dependencies when PEP517 is used.",
+)
+
+
+def _handle_no_use_pep517(
+ option: Option, opt: str, value: str, parser: OptionParser
+) -> None:
+ """
+ Process a value provided for the --no-use-pep517 option.
+
+ This is an optparse.Option callback for the no_use_pep517 option.
+ """
+ # Since --no-use-pep517 doesn't accept arguments, the value argument
+ # will be None if --no-use-pep517 is passed via the command-line.
+ # However, the value can be non-None if the option is triggered e.g.
+ # by an environment variable, for example "PIP_NO_USE_PEP517=true".
+ if value is not None:
+ msg = """A value was passed for --no-use-pep517,
+ probably using either the PIP_NO_USE_PEP517 environment variable
+ or the "no-use-pep517" config file option. Use an appropriate value
+ of the PIP_USE_PEP517 environment variable or the "use-pep517"
+ config file option instead.
+ """
+ raise_option_error(parser, option=option, msg=msg)
+
+ # If user doesn't wish to use pep517, we check if setuptools and wheel are installed
+ # and raise error if it is not.
+ packages = ("setuptools", "wheel")
+ if not all(importlib.util.find_spec(package) for package in packages):
+ msg = (
+ f"It is not possible to use --no-use-pep517 "
+ f"without {' and '.join(packages)} installed."
+ )
+ raise_option_error(parser, option=option, msg=msg)
+
+ # Otherwise, --no-use-pep517 was passed via the command-line.
+ parser.values.use_pep517 = False
+
+
+use_pep517: Any = partial(
+ Option,
+ "--use-pep517",
+ dest="use_pep517",
+ action="store_true",
+ default=None,
+ help="Use PEP 517 for building source distributions "
+ "(use --no-use-pep517 to force legacy behaviour).",
+)
+
+no_use_pep517: Any = partial(
+ Option,
+ "--no-use-pep517",
+ dest="use_pep517",
+ action="callback",
+ callback=_handle_no_use_pep517,
+ default=None,
+ help=SUPPRESS_HELP,
+)
+
+
+def _handle_config_settings(
+ option: Option, opt_str: str, value: str, parser: OptionParser
+) -> None:
+ key, sep, val = value.partition("=")
+ if sep != "=":
+ parser.error(f"Arguments to {opt_str} must be of the form KEY=VAL")
+ dest = getattr(parser.values, option.dest)
+ if dest is None:
+ dest = {}
+ setattr(parser.values, option.dest, dest)
+ if key in dest:
+ if isinstance(dest[key], list):
+ dest[key].append(val)
+ else:
+ dest[key] = [dest[key], val]
+ else:
+ dest[key] = val
+
+
+config_settings: Callable[..., Option] = partial(
+ Option,
+ "-C",
+ "--config-settings",
+ dest="config_settings",
+ type=str,
+ action="callback",
+ callback=_handle_config_settings,
+ metavar="settings",
+ help="Configuration settings to be passed to the PEP 517 build backend. "
+ "Settings take the form KEY=VALUE. Use multiple --config-settings options "
+ "to pass multiple keys to the backend.",
+)
+
+build_options: Callable[..., Option] = partial(
+ Option,
+ "--build-option",
+ dest="build_options",
+ metavar="options",
+ action="append",
+ help="Extra arguments to be supplied to 'setup.py bdist_wheel'.",
+)
+
+global_options: Callable[..., Option] = partial(
+ Option,
+ "--global-option",
+ dest="global_options",
+ action="append",
+ metavar="options",
+ help="Extra global options to be supplied to the setup.py "
+ "call before the install or bdist_wheel command.",
+)
+
+no_clean: Callable[..., Option] = partial(
+ Option,
+ "--no-clean",
+ action="store_true",
+ default=False,
+ help="Don't clean up build directories.",
+)
+
+pre: Callable[..., Option] = partial(
+ Option,
+ "--pre",
+ action="store_true",
+ default=False,
+ help="Include pre-release and development versions. By default, "
+ "pip only finds stable versions.",
+)
+
+disable_pip_version_check: Callable[..., Option] = partial(
+ Option,
+ "--disable-pip-version-check",
+ dest="disable_pip_version_check",
+ action="store_true",
+ default=False,
+ help="Don't periodically check PyPI to determine whether a new version "
+ "of pip is available for download. Implied with --no-index.",
+)
+
+root_user_action: Callable[..., Option] = partial(
+ Option,
+ "--root-user-action",
+ dest="root_user_action",
+ default="warn",
+ choices=["warn", "ignore"],
+ help="Action if pip is run as a root user [warn, ignore] (default: warn)",
+)
+
+
+def _handle_merge_hash(
+ option: Option, opt_str: str, value: str, parser: OptionParser
+) -> None:
+ """Given a value spelled "algo:digest", append the digest to a list
+ pointed to in a dict by the algo name."""
+ if not parser.values.hashes:
+ parser.values.hashes = {}
+ try:
+ algo, digest = value.split(":", 1)
+ except ValueError:
+ parser.error(
+ f"Arguments to {opt_str} must be a hash name "
+ "followed by a value, like --hash=sha256:"
+ "abcde..."
+ )
+ if algo not in STRONG_HASHES:
+ parser.error(
+ "Allowed hash algorithms for {} are {}.".format(
+ opt_str, ", ".join(STRONG_HASHES)
+ )
+ )
+ parser.values.hashes.setdefault(algo, []).append(digest)
+
+
+hash: Callable[..., Option] = partial(
+ Option,
+ "--hash",
+ # Hash values eventually end up in InstallRequirement.hashes due to
+ # __dict__ copying in process_line().
+ dest="hashes",
+ action="callback",
+ callback=_handle_merge_hash,
+ type="string",
+ help="Verify that the package's archive matches this "
+ "hash before installing. Example: --hash=sha256:abcdef...",
+)
+
+
+require_hashes: Callable[..., Option] = partial(
+ Option,
+ "--require-hashes",
+ dest="require_hashes",
+ action="store_true",
+ default=False,
+ help="Require a hash to check each requirement against, for "
+ "repeatable installs. This option is implied when any package in a "
+ "requirements file has a --hash option.",
+)
+
+
+list_path: Callable[..., Option] = partial(
+ PipOption,
+ "--path",
+ dest="path",
+ type="path",
+ action="append",
+ help="Restrict to the specified installation path for listing "
+ "packages (can be used multiple times).",
+)
+
+
+def check_list_path_option(options: Values) -> None:
+ if options.path and (options.user or options.local):
+ raise CommandError("Cannot combine '--path' with '--user' or '--local'")
+
+
+list_exclude: Callable[..., Option] = partial(
+ PipOption,
+ "--exclude",
+ dest="excludes",
+ action="append",
+ metavar="package",
+ type="package_name",
+ help="Exclude specified package from the output",
+)
+
+
+no_python_version_warning: Callable[..., Option] = partial(
+ Option,
+ "--no-python-version-warning",
+ dest="no_python_version_warning",
+ action="store_true",
+ default=False,
+ help="Silence deprecation warnings for upcoming unsupported Pythons.",
+)
+
+
+# Features that are now always on. A warning is printed if they are used.
+ALWAYS_ENABLED_FEATURES = [
+ "truststore", # always on since 24.2
+ "no-binary-enable-wheel-cache", # always on since 23.1
+]
+
+use_new_feature: Callable[..., Option] = partial(
+ Option,
+ "--use-feature",
+ dest="features_enabled",
+ metavar="feature",
+ action="append",
+ default=[],
+ choices=[
+ "fast-deps",
+ ]
+ + ALWAYS_ENABLED_FEATURES,
+ help="Enable new functionality, that may be backward incompatible.",
+)
+
+use_deprecated_feature: Callable[..., Option] = partial(
+ Option,
+ "--use-deprecated",
+ dest="deprecated_features_enabled",
+ metavar="feature",
+ action="append",
+ default=[],
+ choices=[
+ "legacy-resolver",
+ "legacy-certs",
+ ],
+ help=("Enable deprecated functionality, that will be removed in the future."),
+)
+
+
+##########
+# groups #
+##########
+
+general_group: Dict[str, Any] = {
+ "name": "General Options",
+ "options": [
+ help_,
+ debug_mode,
+ isolated_mode,
+ require_virtualenv,
+ python,
+ verbose,
+ version,
+ quiet,
+ log,
+ no_input,
+ keyring_provider,
+ proxy,
+ retries,
+ timeout,
+ exists_action,
+ trusted_host,
+ cert,
+ client_cert,
+ cache_dir,
+ no_cache,
+ disable_pip_version_check,
+ no_color,
+ no_python_version_warning,
+ use_new_feature,
+ use_deprecated_feature,
+ ],
+}
+
+index_group: Dict[str, Any] = {
+ "name": "Package Index Options",
+ "options": [
+ index_url,
+ extra_index_url,
+ no_index,
+ find_links,
+ ],
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/command_context.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/command_context.py
new file mode 100644
index 000000000..139995ac3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/command_context.py
@@ -0,0 +1,27 @@
+from contextlib import ExitStack, contextmanager
+from typing import ContextManager, Generator, TypeVar
+
+_T = TypeVar("_T", covariant=True)
+
+
+class CommandContextMixIn:
+ def __init__(self) -> None:
+ super().__init__()
+ self._in_main_context = False
+ self._main_context = ExitStack()
+
+ @contextmanager
+ def main_context(self) -> Generator[None, None, None]:
+ assert not self._in_main_context
+
+ self._in_main_context = True
+ try:
+ with self._main_context:
+ yield
+ finally:
+ self._in_main_context = False
+
+ def enter_context(self, context_provider: ContextManager[_T]) -> _T:
+ assert self._in_main_context
+
+ return self._main_context.enter_context(context_provider)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/index_command.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/index_command.py
new file mode 100644
index 000000000..db105d0fe
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/index_command.py
@@ -0,0 +1,170 @@
+"""
+Contains command classes which may interact with an index / the network.
+
+Unlike its sister module, req_command, this module still uses lazy imports
+so commands which don't always hit the network (e.g. list w/o --outdated or
+--uptodate) don't need waste time importing PipSession and friends.
+"""
+
+import logging
+import os
+import sys
+from optparse import Values
+from typing import TYPE_CHECKING, List, Optional
+
+from pip._vendor import certifi
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.command_context import CommandContextMixIn
+
+if TYPE_CHECKING:
+ from ssl import SSLContext
+
+ from pip._internal.network.session import PipSession
+
+logger = logging.getLogger(__name__)
+
+
+def _create_truststore_ssl_context() -> Optional["SSLContext"]:
+ if sys.version_info < (3, 10):
+ logger.debug("Disabling truststore because Python version isn't 3.10+")
+ return None
+
+ try:
+ import ssl
+ except ImportError:
+ logger.warning("Disabling truststore since ssl support is missing")
+ return None
+
+ try:
+ from pip._vendor import truststore
+ except ImportError:
+ logger.warning("Disabling truststore because platform isn't supported")
+ return None
+
+ ctx = truststore.SSLContext(ssl.PROTOCOL_TLS_CLIENT)
+ ctx.load_verify_locations(certifi.where())
+ return ctx
+
+
+class SessionCommandMixin(CommandContextMixIn):
+ """
+ A class mixin for command classes needing _build_session().
+ """
+
+ def __init__(self) -> None:
+ super().__init__()
+ self._session: Optional[PipSession] = None
+
+ @classmethod
+ def _get_index_urls(cls, options: Values) -> Optional[List[str]]:
+ """Return a list of index urls from user-provided options."""
+ index_urls = []
+ if not getattr(options, "no_index", False):
+ url = getattr(options, "index_url", None)
+ if url:
+ index_urls.append(url)
+ urls = getattr(options, "extra_index_urls", None)
+ if urls:
+ index_urls.extend(urls)
+ # Return None rather than an empty list
+ return index_urls or None
+
+ def get_default_session(self, options: Values) -> "PipSession":
+ """Get a default-managed session."""
+ if self._session is None:
+ self._session = self.enter_context(self._build_session(options))
+ # there's no type annotation on requests.Session, so it's
+ # automatically ContextManager[Any] and self._session becomes Any,
+ # then https://github.com/python/mypy/issues/7696 kicks in
+ assert self._session is not None
+ return self._session
+
+ def _build_session(
+ self,
+ options: Values,
+ retries: Optional[int] = None,
+ timeout: Optional[int] = None,
+ ) -> "PipSession":
+ from pip._internal.network.session import PipSession
+
+ cache_dir = options.cache_dir
+ assert not cache_dir or os.path.isabs(cache_dir)
+
+ if "legacy-certs" not in options.deprecated_features_enabled:
+ ssl_context = _create_truststore_ssl_context()
+ else:
+ ssl_context = None
+
+ session = PipSession(
+ cache=os.path.join(cache_dir, "http-v2") if cache_dir else None,
+ retries=retries if retries is not None else options.retries,
+ trusted_hosts=options.trusted_hosts,
+ index_urls=self._get_index_urls(options),
+ ssl_context=ssl_context,
+ )
+
+ # Handle custom ca-bundles from the user
+ if options.cert:
+ session.verify = options.cert
+
+ # Handle SSL client certificate
+ if options.client_cert:
+ session.cert = options.client_cert
+
+ # Handle timeouts
+ if options.timeout or timeout:
+ session.timeout = timeout if timeout is not None else options.timeout
+
+ # Handle configured proxies
+ if options.proxy:
+ session.proxies = {
+ "http": options.proxy,
+ "https": options.proxy,
+ }
+ session.trust_env = False
+
+ # Determine if we can prompt the user for authentication or not
+ session.auth.prompting = not options.no_input
+ session.auth.keyring_provider = options.keyring_provider
+
+ return session
+
+
+def _pip_self_version_check(session: "PipSession", options: Values) -> None:
+ from pip._internal.self_outdated_check import pip_self_version_check as check
+
+ check(session, options)
+
+
+class IndexGroupCommand(Command, SessionCommandMixin):
+ """
+ Abstract base class for commands with the index_group options.
+
+ This also corresponds to the commands that permit the pip version check.
+ """
+
+ def handle_pip_version_check(self, options: Values) -> None:
+ """
+ Do the pip version check if not disabled.
+
+ This overrides the default behavior of not doing the check.
+ """
+ # Make sure the index_group options are present.
+ assert hasattr(options, "no_index")
+
+ if options.disable_pip_version_check or options.no_index:
+ return
+
+ try:
+ # Otherwise, check if we're using the latest version of pip available.
+ session = self._build_session(
+ options,
+ retries=0,
+ timeout=min(5, options.timeout),
+ )
+ with session:
+ _pip_self_version_check(session, options)
+ except Exception:
+ logger.warning("There was an error checking the latest version of pip.")
+ logger.debug("See below for error", exc_info=True)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/main.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/main.py
new file mode 100644
index 000000000..563ac79c9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/main.py
@@ -0,0 +1,80 @@
+"""Primary application entrypoint.
+"""
+
+import locale
+import logging
+import os
+import sys
+import warnings
+from typing import List, Optional
+
+from pip._internal.cli.autocompletion import autocomplete
+from pip._internal.cli.main_parser import parse_command
+from pip._internal.commands import create_command
+from pip._internal.exceptions import PipError
+from pip._internal.utils import deprecation
+
+logger = logging.getLogger(__name__)
+
+
+# Do not import and use main() directly! Using it directly is actively
+# discouraged by pip's maintainers. The name, location and behavior of
+# this function is subject to change, so calling it directly is not
+# portable across different pip versions.
+
+# In addition, running pip in-process is unsupported and unsafe. This is
+# elaborated in detail at
+# https://pip.pypa.io/en/stable/user_guide/#using-pip-from-your-program.
+# That document also provides suggestions that should work for nearly
+# all users that are considering importing and using main() directly.
+
+# However, we know that certain users will still want to invoke pip
+# in-process. If you understand and accept the implications of using pip
+# in an unsupported manner, the best approach is to use runpy to avoid
+# depending on the exact location of this entry point.
+
+# The following example shows how to use runpy to invoke pip in that
+# case:
+#
+# sys.argv = ["pip", your, args, here]
+# runpy.run_module("pip", run_name="__main__")
+#
+# Note that this will exit the process after running, unlike a direct
+# call to main. As it is not safe to do any processing after calling
+# main, this should not be an issue in practice.
+
+
+def main(args: Optional[List[str]] = None) -> int:
+ if args is None:
+ args = sys.argv[1:]
+
+ # Suppress the pkg_resources deprecation warning
+ # Note - we use a module of .*pkg_resources to cover
+ # the normal case (pip._vendor.pkg_resources) and the
+ # devendored case (a bare pkg_resources)
+ warnings.filterwarnings(
+ action="ignore", category=DeprecationWarning, module=".*pkg_resources"
+ )
+
+ # Configure our deprecation warnings to be sent through loggers
+ deprecation.install_warning_logger()
+
+ autocomplete()
+
+ try:
+ cmd_name, cmd_args = parse_command(args)
+ except PipError as exc:
+ sys.stderr.write(f"ERROR: {exc}")
+ sys.stderr.write(os.linesep)
+ sys.exit(1)
+
+ # Needed for locale.getpreferredencoding(False) to work
+ # in pip._internal.utils.encoding.auto_decode
+ try:
+ locale.setlocale(locale.LC_ALL, "")
+ except locale.Error as e:
+ # setlocale can apparently crash if locale are uninitialized
+ logger.debug("Ignoring error %s when setting locale", e)
+ command = create_command(cmd_name, isolated=("--isolated" in cmd_args))
+
+ return command.main(cmd_args)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/main_parser.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/main_parser.py
new file mode 100644
index 000000000..5ade356b9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/main_parser.py
@@ -0,0 +1,134 @@
+"""A single place for constructing and exposing the main parser
+"""
+
+import os
+import subprocess
+import sys
+from typing import List, Optional, Tuple
+
+from pip._internal.build_env import get_runnable_pip
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.parser import ConfigOptionParser, UpdatingDefaultsHelpFormatter
+from pip._internal.commands import commands_dict, get_similar_commands
+from pip._internal.exceptions import CommandError
+from pip._internal.utils.misc import get_pip_version, get_prog
+
+__all__ = ["create_main_parser", "parse_command"]
+
+
+def create_main_parser() -> ConfigOptionParser:
+ """Creates and returns the main parser for pip's CLI"""
+
+ parser = ConfigOptionParser(
+ usage="\n%prog <command> [options]",
+ add_help_option=False,
+ formatter=UpdatingDefaultsHelpFormatter(),
+ name="global",
+ prog=get_prog(),
+ )
+ parser.disable_interspersed_args()
+
+ parser.version = get_pip_version()
+
+ # add the general options
+ gen_opts = cmdoptions.make_option_group(cmdoptions.general_group, parser)
+ parser.add_option_group(gen_opts)
+
+ # so the help formatter knows
+ parser.main = True # type: ignore
+
+ # create command listing for description
+ description = [""] + [
+ f"{name:27} {command_info.summary}"
+ for name, command_info in commands_dict.items()
+ ]
+ parser.description = "\n".join(description)
+
+ return parser
+
+
+def identify_python_interpreter(python: str) -> Optional[str]:
+ # If the named file exists, use it.
+ # If it's a directory, assume it's a virtual environment and
+ # look for the environment's Python executable.
+ if os.path.exists(python):
+ if os.path.isdir(python):
+ # bin/python for Unix, Scripts/python.exe for Windows
+ # Try both in case of odd cases like cygwin.
+ for exe in ("bin/python", "Scripts/python.exe"):
+ py = os.path.join(python, exe)
+ if os.path.exists(py):
+ return py
+ else:
+ return python
+
+ # Could not find the interpreter specified
+ return None
+
+
+def parse_command(args: List[str]) -> Tuple[str, List[str]]:
+ parser = create_main_parser()
+
+ # Note: parser calls disable_interspersed_args(), so the result of this
+ # call is to split the initial args into the general options before the
+ # subcommand and everything else.
+ # For example:
+ # args: ['--timeout=5', 'install', '--user', 'INITools']
+ # general_options: ['--timeout==5']
+ # args_else: ['install', '--user', 'INITools']
+ general_options, args_else = parser.parse_args(args)
+
+ # --python
+ if general_options.python and "_PIP_RUNNING_IN_SUBPROCESS" not in os.environ:
+ # Re-invoke pip using the specified Python interpreter
+ interpreter = identify_python_interpreter(general_options.python)
+ if interpreter is None:
+ raise CommandError(
+ f"Could not locate Python interpreter {general_options.python}"
+ )
+
+ pip_cmd = [
+ interpreter,
+ get_runnable_pip(),
+ ]
+ pip_cmd.extend(args)
+
+ # Set a flag so the child doesn't re-invoke itself, causing
+ # an infinite loop.
+ os.environ["_PIP_RUNNING_IN_SUBPROCESS"] = "1"
+ returncode = 0
+ try:
+ proc = subprocess.run(pip_cmd)
+ returncode = proc.returncode
+ except (subprocess.SubprocessError, OSError) as exc:
+ raise CommandError(f"Failed to run pip under {interpreter}: {exc}")
+ sys.exit(returncode)
+
+ # --version
+ if general_options.version:
+ sys.stdout.write(parser.version)
+ sys.stdout.write(os.linesep)
+ sys.exit()
+
+ # pip || pip help -> print_help()
+ if not args_else or (args_else[0] == "help" and len(args_else) == 1):
+ parser.print_help()
+ sys.exit()
+
+ # the subcommand name
+ cmd_name = args_else[0]
+
+ if cmd_name not in commands_dict:
+ guess = get_similar_commands(cmd_name)
+
+ msg = [f'unknown command "{cmd_name}"']
+ if guess:
+ msg.append(f'maybe you meant "{guess}"')
+
+ raise CommandError(" - ".join(msg))
+
+ # all the args without the subcommand
+ cmd_args = args[:]
+ cmd_args.remove(cmd_name)
+
+ return cmd_name, cmd_args
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/parser.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/parser.py
new file mode 100644
index 000000000..bc4aca032
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/parser.py
@@ -0,0 +1,294 @@
+"""Base option parser setup"""
+
+import logging
+import optparse
+import shutil
+import sys
+import textwrap
+from contextlib import suppress
+from typing import Any, Dict, Generator, List, NoReturn, Optional, Tuple
+
+from pip._internal.cli.status_codes import UNKNOWN_ERROR
+from pip._internal.configuration import Configuration, ConfigurationError
+from pip._internal.utils.misc import redact_auth_from_url, strtobool
+
+logger = logging.getLogger(__name__)
+
+
+class PrettyHelpFormatter(optparse.IndentedHelpFormatter):
+ """A prettier/less verbose help formatter for optparse."""
+
+ def __init__(self, *args: Any, **kwargs: Any) -> None:
+ # help position must be aligned with __init__.parseopts.description
+ kwargs["max_help_position"] = 30
+ kwargs["indent_increment"] = 1
+ kwargs["width"] = shutil.get_terminal_size()[0] - 2
+ super().__init__(*args, **kwargs)
+
+ def format_option_strings(self, option: optparse.Option) -> str:
+ return self._format_option_strings(option)
+
+ def _format_option_strings(
+ self, option: optparse.Option, mvarfmt: str = " <{}>", optsep: str = ", "
+ ) -> str:
+ """
+ Return a comma-separated list of option strings and metavars.
+
+ :param option: tuple of (short opt, long opt), e.g: ('-f', '--format')
+ :param mvarfmt: metavar format string
+ :param optsep: separator
+ """
+ opts = []
+
+ if option._short_opts:
+ opts.append(option._short_opts[0])
+ if option._long_opts:
+ opts.append(option._long_opts[0])
+ if len(opts) > 1:
+ opts.insert(1, optsep)
+
+ if option.takes_value():
+ assert option.dest is not None
+ metavar = option.metavar or option.dest.lower()
+ opts.append(mvarfmt.format(metavar.lower()))
+
+ return "".join(opts)
+
+ def format_heading(self, heading: str) -> str:
+ if heading == "Options":
+ return ""
+ return heading + ":\n"
+
+ def format_usage(self, usage: str) -> str:
+ """
+ Ensure there is only one newline between usage and the first heading
+ if there is no description.
+ """
+ msg = "\nUsage: {}\n".format(self.indent_lines(textwrap.dedent(usage), " "))
+ return msg
+
+ def format_description(self, description: Optional[str]) -> str:
+ # leave full control over description to us
+ if description:
+ if hasattr(self.parser, "main"):
+ label = "Commands"
+ else:
+ label = "Description"
+ # some doc strings have initial newlines, some don't
+ description = description.lstrip("\n")
+ # some doc strings have final newlines and spaces, some don't
+ description = description.rstrip()
+ # dedent, then reindent
+ description = self.indent_lines(textwrap.dedent(description), " ")
+ description = f"{label}:\n{description}\n"
+ return description
+ else:
+ return ""
+
+ def format_epilog(self, epilog: Optional[str]) -> str:
+ # leave full control over epilog to us
+ if epilog:
+ return epilog
+ else:
+ return ""
+
+ def indent_lines(self, text: str, indent: str) -> str:
+ new_lines = [indent + line for line in text.split("\n")]
+ return "\n".join(new_lines)
+
+
+class UpdatingDefaultsHelpFormatter(PrettyHelpFormatter):
+ """Custom help formatter for use in ConfigOptionParser.
+
+ This is updates the defaults before expanding them, allowing
+ them to show up correctly in the help listing.
+
+ Also redact auth from url type options
+ """
+
+ def expand_default(self, option: optparse.Option) -> str:
+ default_values = None
+ if self.parser is not None:
+ assert isinstance(self.parser, ConfigOptionParser)
+ self.parser._update_defaults(self.parser.defaults)
+ assert option.dest is not None
+ default_values = self.parser.defaults.get(option.dest)
+ help_text = super().expand_default(option)
+
+ if default_values and option.metavar == "URL":
+ if isinstance(default_values, str):
+ default_values = [default_values]
+
+ # If its not a list, we should abort and just return the help text
+ if not isinstance(default_values, list):
+ default_values = []
+
+ for val in default_values:
+ help_text = help_text.replace(val, redact_auth_from_url(val))
+
+ return help_text
+
+
+class CustomOptionParser(optparse.OptionParser):
+ def insert_option_group(
+ self, idx: int, *args: Any, **kwargs: Any
+ ) -> optparse.OptionGroup:
+ """Insert an OptionGroup at a given position."""
+ group = self.add_option_group(*args, **kwargs)
+
+ self.option_groups.pop()
+ self.option_groups.insert(idx, group)
+
+ return group
+
+ @property
+ def option_list_all(self) -> List[optparse.Option]:
+ """Get a list of all options, including those in option groups."""
+ res = self.option_list[:]
+ for i in self.option_groups:
+ res.extend(i.option_list)
+
+ return res
+
+
+class ConfigOptionParser(CustomOptionParser):
+ """Custom option parser which updates its defaults by checking the
+ configuration files and environmental variables"""
+
+ def __init__(
+ self,
+ *args: Any,
+ name: str,
+ isolated: bool = False,
+ **kwargs: Any,
+ ) -> None:
+ self.name = name
+ self.config = Configuration(isolated)
+
+ assert self.name
+ super().__init__(*args, **kwargs)
+
+ def check_default(self, option: optparse.Option, key: str, val: Any) -> Any:
+ try:
+ return option.check_value(key, val)
+ except optparse.OptionValueError as exc:
+ print(f"An error occurred during configuration: {exc}")
+ sys.exit(3)
+
+ def _get_ordered_configuration_items(
+ self,
+ ) -> Generator[Tuple[str, Any], None, None]:
+ # Configuration gives keys in an unordered manner. Order them.
+ override_order = ["global", self.name, ":env:"]
+
+ # Pool the options into different groups
+ section_items: Dict[str, List[Tuple[str, Any]]] = {
+ name: [] for name in override_order
+ }
+ for section_key, val in self.config.items():
+ # ignore empty values
+ if not val:
+ logger.debug(
+ "Ignoring configuration key '%s' as it's value is empty.",
+ section_key,
+ )
+ continue
+
+ section, key = section_key.split(".", 1)
+ if section in override_order:
+ section_items[section].append((key, val))
+
+ # Yield each group in their override order
+ for section in override_order:
+ for key, val in section_items[section]:
+ yield key, val
+
+ def _update_defaults(self, defaults: Dict[str, Any]) -> Dict[str, Any]:
+ """Updates the given defaults with values from the config files and
+ the environ. Does a little special handling for certain types of
+ options (lists)."""
+
+ # Accumulate complex default state.
+ self.values = optparse.Values(self.defaults)
+ late_eval = set()
+ # Then set the options with those values
+ for key, val in self._get_ordered_configuration_items():
+ # '--' because configuration supports only long names
+ option = self.get_option("--" + key)
+
+ # Ignore options not present in this parser. E.g. non-globals put
+ # in [global] by users that want them to apply to all applicable
+ # commands.
+ if option is None:
+ continue
+
+ assert option.dest is not None
+
+ if option.action in ("store_true", "store_false"):
+ try:
+ val = strtobool(val)
+ except ValueError:
+ self.error(
+ f"{val} is not a valid value for {key} option, "
+ "please specify a boolean value like yes/no, "
+ "true/false or 1/0 instead."
+ )
+ elif option.action == "count":
+ with suppress(ValueError):
+ val = strtobool(val)
+ with suppress(ValueError):
+ val = int(val)
+ if not isinstance(val, int) or val < 0:
+ self.error(
+ f"{val} is not a valid value for {key} option, "
+ "please instead specify either a non-negative integer "
+ "or a boolean value like yes/no or false/true "
+ "which is equivalent to 1/0."
+ )
+ elif option.action == "append":
+ val = val.split()
+ val = [self.check_default(option, key, v) for v in val]
+ elif option.action == "callback":
+ assert option.callback is not None
+ late_eval.add(option.dest)
+ opt_str = option.get_opt_string()
+ val = option.convert_value(opt_str, val)
+ # From take_action
+ args = option.callback_args or ()
+ kwargs = option.callback_kwargs or {}
+ option.callback(option, opt_str, val, self, *args, **kwargs)
+ else:
+ val = self.check_default(option, key, val)
+
+ defaults[option.dest] = val
+
+ for key in late_eval:
+ defaults[key] = getattr(self.values, key)
+ self.values = None
+ return defaults
+
+ def get_default_values(self) -> optparse.Values:
+ """Overriding to make updating the defaults after instantiation of
+ the option parser possible, _update_defaults() does the dirty work."""
+ if not self.process_default_values:
+ # Old, pre-Optik 1.5 behaviour.
+ return optparse.Values(self.defaults)
+
+ # Load the configuration, or error out in case of an error
+ try:
+ self.config.load()
+ except ConfigurationError as err:
+ self.exit(UNKNOWN_ERROR, str(err))
+
+ defaults = self._update_defaults(self.defaults.copy()) # ours
+ for option in self._get_all_options():
+ assert option.dest is not None
+ default = defaults.get(option.dest)
+ if isinstance(default, str):
+ opt_str = option.get_opt_string()
+ defaults[option.dest] = option.check_value(opt_str, default)
+ return optparse.Values(defaults)
+
+ def error(self, msg: str) -> NoReturn:
+ self.print_usage(sys.stderr)
+ self.exit(UNKNOWN_ERROR, f"{msg}\n")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/progress_bars.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/progress_bars.py
new file mode 100644
index 000000000..1236180c0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/progress_bars.py
@@ -0,0 +1,94 @@
+import functools
+import sys
+from typing import Callable, Generator, Iterable, Iterator, Optional, Tuple
+
+from pip._vendor.rich.progress import (
+ BarColumn,
+ DownloadColumn,
+ FileSizeColumn,
+ Progress,
+ ProgressColumn,
+ SpinnerColumn,
+ TextColumn,
+ TimeElapsedColumn,
+ TimeRemainingColumn,
+ TransferSpeedColumn,
+)
+
+from pip._internal.cli.spinners import RateLimiter
+from pip._internal.utils.logging import get_indentation
+
+DownloadProgressRenderer = Callable[[Iterable[bytes]], Iterator[bytes]]
+
+
+def _rich_progress_bar(
+ iterable: Iterable[bytes],
+ *,
+ bar_type: str,
+ size: Optional[int],
+) -> Generator[bytes, None, None]:
+ assert bar_type == "on", "This should only be used in the default mode."
+
+ if not size:
+ total = float("inf")
+ columns: Tuple[ProgressColumn, ...] = (
+ TextColumn("[progress.description]{task.description}"),
+ SpinnerColumn("line", speed=1.5),
+ FileSizeColumn(),
+ TransferSpeedColumn(),
+ TimeElapsedColumn(),
+ )
+ else:
+ total = size
+ columns = (
+ TextColumn("[progress.description]{task.description}"),
+ BarColumn(),
+ DownloadColumn(),
+ TransferSpeedColumn(),
+ TextColumn("eta"),
+ TimeRemainingColumn(),
+ )
+
+ progress = Progress(*columns, refresh_per_second=5)
+ task_id = progress.add_task(" " * (get_indentation() + 2), total=total)
+ with progress:
+ for chunk in iterable:
+ yield chunk
+ progress.update(task_id, advance=len(chunk))
+
+
+def _raw_progress_bar(
+ iterable: Iterable[bytes],
+ *,
+ size: Optional[int],
+) -> Generator[bytes, None, None]:
+ def write_progress(current: int, total: int) -> None:
+ sys.stdout.write("Progress %d of %d\n" % (current, total))
+ sys.stdout.flush()
+
+ current = 0
+ total = size or 0
+ rate_limiter = RateLimiter(0.25)
+
+ write_progress(current, total)
+ for chunk in iterable:
+ current += len(chunk)
+ if rate_limiter.ready() or current == total:
+ write_progress(current, total)
+ rate_limiter.reset()
+ yield chunk
+
+
+def get_download_progress_renderer(
+ *, bar_type: str, size: Optional[int] = None
+) -> DownloadProgressRenderer:
+ """Get an object that can be used to render the download progress.
+
+ Returns a callable, that takes an iterable to "wrap".
+ """
+ if bar_type == "on":
+ return functools.partial(_rich_progress_bar, bar_type=bar_type, size=size)
+ elif bar_type == "raw":
+ return functools.partial(_raw_progress_bar, size=size)
+ else:
+ return iter # no-op, when passed an iterator
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/req_command.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/req_command.py
new file mode 100644
index 000000000..92900f94f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/req_command.py
@@ -0,0 +1,329 @@
+"""Contains the RequirementCommand base class.
+
+This class is in a separate module so the commands that do not always
+need PackageFinder capability don't unnecessarily import the
+PackageFinder machinery and all its vendored dependencies, etc.
+"""
+
+import logging
+from functools import partial
+from optparse import Values
+from typing import Any, List, Optional, Tuple
+
+from pip._internal.cache import WheelCache
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.index_command import IndexGroupCommand
+from pip._internal.cli.index_command import SessionCommandMixin as SessionCommandMixin
+from pip._internal.exceptions import CommandError, PreviousBuildDirError
+from pip._internal.index.collector import LinkCollector
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.models.selection_prefs import SelectionPreferences
+from pip._internal.models.target_python import TargetPython
+from pip._internal.network.session import PipSession
+from pip._internal.operations.build.build_tracker import BuildTracker
+from pip._internal.operations.prepare import RequirementPreparer
+from pip._internal.req.constructors import (
+ install_req_from_editable,
+ install_req_from_line,
+ install_req_from_parsed_requirement,
+ install_req_from_req_string,
+)
+from pip._internal.req.req_file import parse_requirements
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.resolution.base import BaseResolver
+from pip._internal.utils.temp_dir import (
+ TempDirectory,
+ TempDirectoryTypeRegistry,
+ tempdir_kinds,
+)
+
+logger = logging.getLogger(__name__)
+
+
+KEEPABLE_TEMPDIR_TYPES = [
+ tempdir_kinds.BUILD_ENV,
+ tempdir_kinds.EPHEM_WHEEL_CACHE,
+ tempdir_kinds.REQ_BUILD,
+]
+
+
+def with_cleanup(func: Any) -> Any:
+ """Decorator for common logic related to managing temporary
+ directories.
+ """
+
+ def configure_tempdir_registry(registry: TempDirectoryTypeRegistry) -> None:
+ for t in KEEPABLE_TEMPDIR_TYPES:
+ registry.set_delete(t, False)
+
+ def wrapper(
+ self: RequirementCommand, options: Values, args: List[Any]
+ ) -> Optional[int]:
+ assert self.tempdir_registry is not None
+ if options.no_clean:
+ configure_tempdir_registry(self.tempdir_registry)
+
+ try:
+ return func(self, options, args)
+ except PreviousBuildDirError:
+ # This kind of conflict can occur when the user passes an explicit
+ # build directory with a pre-existing folder. In that case we do
+ # not want to accidentally remove it.
+ configure_tempdir_registry(self.tempdir_registry)
+ raise
+
+ return wrapper
+
+
+class RequirementCommand(IndexGroupCommand):
+ def __init__(self, *args: Any, **kw: Any) -> None:
+ super().__init__(*args, **kw)
+
+ self.cmd_opts.add_option(cmdoptions.no_clean())
+
+ @staticmethod
+ def determine_resolver_variant(options: Values) -> str:
+ """Determines which resolver should be used, based on the given options."""
+ if "legacy-resolver" in options.deprecated_features_enabled:
+ return "legacy"
+
+ return "resolvelib"
+
+ @classmethod
+ def make_requirement_preparer(
+ cls,
+ temp_build_dir: TempDirectory,
+ options: Values,
+ build_tracker: BuildTracker,
+ session: PipSession,
+ finder: PackageFinder,
+ use_user_site: bool,
+ download_dir: Optional[str] = None,
+ verbosity: int = 0,
+ ) -> RequirementPreparer:
+ """
+ Create a RequirementPreparer instance for the given parameters.
+ """
+ temp_build_dir_path = temp_build_dir.path
+ assert temp_build_dir_path is not None
+ legacy_resolver = False
+
+ resolver_variant = cls.determine_resolver_variant(options)
+ if resolver_variant == "resolvelib":
+ lazy_wheel = "fast-deps" in options.features_enabled
+ if lazy_wheel:
+ logger.warning(
+ "pip is using lazily downloaded wheels using HTTP "
+ "range requests to obtain dependency information. "
+ "This experimental feature is enabled through "
+ "--use-feature=fast-deps and it is not ready for "
+ "production."
+ )
+ else:
+ legacy_resolver = True
+ lazy_wheel = False
+ if "fast-deps" in options.features_enabled:
+ logger.warning(
+ "fast-deps has no effect when used with the legacy resolver."
+ )
+
+ return RequirementPreparer(
+ build_dir=temp_build_dir_path,
+ src_dir=options.src_dir,
+ download_dir=download_dir,
+ build_isolation=options.build_isolation,
+ check_build_deps=options.check_build_deps,
+ build_tracker=build_tracker,
+ session=session,
+ progress_bar=options.progress_bar,
+ finder=finder,
+ require_hashes=options.require_hashes,
+ use_user_site=use_user_site,
+ lazy_wheel=lazy_wheel,
+ verbosity=verbosity,
+ legacy_resolver=legacy_resolver,
+ )
+
+ @classmethod
+ def make_resolver(
+ cls,
+ preparer: RequirementPreparer,
+ finder: PackageFinder,
+ options: Values,
+ wheel_cache: Optional[WheelCache] = None,
+ use_user_site: bool = False,
+ ignore_installed: bool = True,
+ ignore_requires_python: bool = False,
+ force_reinstall: bool = False,
+ upgrade_strategy: str = "to-satisfy-only",
+ use_pep517: Optional[bool] = None,
+ py_version_info: Optional[Tuple[int, ...]] = None,
+ ) -> BaseResolver:
+ """
+ Create a Resolver instance for the given parameters.
+ """
+ make_install_req = partial(
+ install_req_from_req_string,
+ isolated=options.isolated_mode,
+ use_pep517=use_pep517,
+ )
+ resolver_variant = cls.determine_resolver_variant(options)
+ # The long import name and duplicated invocation is needed to convince
+ # Mypy into correctly typechecking. Otherwise it would complain the
+ # "Resolver" class being redefined.
+ if resolver_variant == "resolvelib":
+ import pip._internal.resolution.resolvelib.resolver
+
+ return pip._internal.resolution.resolvelib.resolver.Resolver(
+ preparer=preparer,
+ finder=finder,
+ wheel_cache=wheel_cache,
+ make_install_req=make_install_req,
+ use_user_site=use_user_site,
+ ignore_dependencies=options.ignore_dependencies,
+ ignore_installed=ignore_installed,
+ ignore_requires_python=ignore_requires_python,
+ force_reinstall=force_reinstall,
+ upgrade_strategy=upgrade_strategy,
+ py_version_info=py_version_info,
+ )
+ import pip._internal.resolution.legacy.resolver
+
+ return pip._internal.resolution.legacy.resolver.Resolver(
+ preparer=preparer,
+ finder=finder,
+ wheel_cache=wheel_cache,
+ make_install_req=make_install_req,
+ use_user_site=use_user_site,
+ ignore_dependencies=options.ignore_dependencies,
+ ignore_installed=ignore_installed,
+ ignore_requires_python=ignore_requires_python,
+ force_reinstall=force_reinstall,
+ upgrade_strategy=upgrade_strategy,
+ py_version_info=py_version_info,
+ )
+
+ def get_requirements(
+ self,
+ args: List[str],
+ options: Values,
+ finder: PackageFinder,
+ session: PipSession,
+ ) -> List[InstallRequirement]:
+ """
+ Parse command-line arguments into the corresponding requirements.
+ """
+ requirements: List[InstallRequirement] = []
+ for filename in options.constraints:
+ for parsed_req in parse_requirements(
+ filename,
+ constraint=True,
+ finder=finder,
+ options=options,
+ session=session,
+ ):
+ req_to_add = install_req_from_parsed_requirement(
+ parsed_req,
+ isolated=options.isolated_mode,
+ user_supplied=False,
+ )
+ requirements.append(req_to_add)
+
+ for req in args:
+ req_to_add = install_req_from_line(
+ req,
+ comes_from=None,
+ isolated=options.isolated_mode,
+ use_pep517=options.use_pep517,
+ user_supplied=True,
+ config_settings=getattr(options, "config_settings", None),
+ )
+ requirements.append(req_to_add)
+
+ for req in options.editables:
+ req_to_add = install_req_from_editable(
+ req,
+ user_supplied=True,
+ isolated=options.isolated_mode,
+ use_pep517=options.use_pep517,
+ config_settings=getattr(options, "config_settings", None),
+ )
+ requirements.append(req_to_add)
+
+ # NOTE: options.require_hashes may be set if --require-hashes is True
+ for filename in options.requirements:
+ for parsed_req in parse_requirements(
+ filename, finder=finder, options=options, session=session
+ ):
+ req_to_add = install_req_from_parsed_requirement(
+ parsed_req,
+ isolated=options.isolated_mode,
+ use_pep517=options.use_pep517,
+ user_supplied=True,
+ config_settings=(
+ parsed_req.options.get("config_settings")
+ if parsed_req.options
+ else None
+ ),
+ )
+ requirements.append(req_to_add)
+
+ # If any requirement has hash options, enable hash checking.
+ if any(req.has_hash_options for req in requirements):
+ options.require_hashes = True
+
+ if not (args or options.editables or options.requirements):
+ opts = {"name": self.name}
+ if options.find_links:
+ raise CommandError(
+ "You must give at least one requirement to {name} "
+ '(maybe you meant "pip {name} {links}"?)'.format(
+ **dict(opts, links=" ".join(options.find_links))
+ )
+ )
+ else:
+ raise CommandError(
+ "You must give at least one requirement to {name} "
+ '(see "pip help {name}")'.format(**opts)
+ )
+
+ return requirements
+
+ @staticmethod
+ def trace_basic_info(finder: PackageFinder) -> None:
+ """
+ Trace basic information about the provided objects.
+ """
+ # Display where finder is looking for packages
+ search_scope = finder.search_scope
+ locations = search_scope.get_formatted_locations()
+ if locations:
+ logger.info(locations)
+
+ def _build_package_finder(
+ self,
+ options: Values,
+ session: PipSession,
+ target_python: Optional[TargetPython] = None,
+ ignore_requires_python: Optional[bool] = None,
+ ) -> PackageFinder:
+ """
+ Create a package finder appropriate to this requirement command.
+
+ :param ignore_requires_python: Whether to ignore incompatible
+ "Requires-Python" values in links. Defaults to False.
+ """
+ link_collector = LinkCollector.create(session, options=options)
+ selection_prefs = SelectionPreferences(
+ allow_yanked=True,
+ format_control=options.format_control,
+ allow_all_prereleases=options.pre,
+ prefer_binary=options.prefer_binary,
+ ignore_requires_python=ignore_requires_python,
+ )
+
+ return PackageFinder.create(
+ link_collector=link_collector,
+ selection_prefs=selection_prefs,
+ target_python=target_python,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/spinners.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/spinners.py
new file mode 100644
index 000000000..cf2b976f3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/spinners.py
@@ -0,0 +1,159 @@
+import contextlib
+import itertools
+import logging
+import sys
+import time
+from typing import IO, Generator, Optional
+
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.logging import get_indentation
+
+logger = logging.getLogger(__name__)
+
+
+class SpinnerInterface:
+ def spin(self) -> None:
+ raise NotImplementedError()
+
+ def finish(self, final_status: str) -> None:
+ raise NotImplementedError()
+
+
+class InteractiveSpinner(SpinnerInterface):
+ def __init__(
+ self,
+ message: str,
+ file: Optional[IO[str]] = None,
+ spin_chars: str = "-\\|/",
+ # Empirically, 8 updates/second looks nice
+ min_update_interval_seconds: float = 0.125,
+ ):
+ self._message = message
+ if file is None:
+ file = sys.stdout
+ self._file = file
+ self._rate_limiter = RateLimiter(min_update_interval_seconds)
+ self._finished = False
+
+ self._spin_cycle = itertools.cycle(spin_chars)
+
+ self._file.write(" " * get_indentation() + self._message + " ... ")
+ self._width = 0
+
+ def _write(self, status: str) -> None:
+ assert not self._finished
+ # Erase what we wrote before by backspacing to the beginning, writing
+ # spaces to overwrite the old text, and then backspacing again
+ backup = "\b" * self._width
+ self._file.write(backup + " " * self._width + backup)
+ # Now we have a blank slate to add our status
+ self._file.write(status)
+ self._width = len(status)
+ self._file.flush()
+ self._rate_limiter.reset()
+
+ def spin(self) -> None:
+ if self._finished:
+ return
+ if not self._rate_limiter.ready():
+ return
+ self._write(next(self._spin_cycle))
+
+ def finish(self, final_status: str) -> None:
+ if self._finished:
+ return
+ self._write(final_status)
+ self._file.write("\n")
+ self._file.flush()
+ self._finished = True
+
+
+# Used for dumb terminals, non-interactive installs (no tty), etc.
+# We still print updates occasionally (once every 60 seconds by default) to
+# act as a keep-alive for systems like Travis-CI that take lack-of-output as
+# an indication that a task has frozen.
+class NonInteractiveSpinner(SpinnerInterface):
+ def __init__(self, message: str, min_update_interval_seconds: float = 60.0) -> None:
+ self._message = message
+ self._finished = False
+ self._rate_limiter = RateLimiter(min_update_interval_seconds)
+ self._update("started")
+
+ def _update(self, status: str) -> None:
+ assert not self._finished
+ self._rate_limiter.reset()
+ logger.info("%s: %s", self._message, status)
+
+ def spin(self) -> None:
+ if self._finished:
+ return
+ if not self._rate_limiter.ready():
+ return
+ self._update("still running...")
+
+ def finish(self, final_status: str) -> None:
+ if self._finished:
+ return
+ self._update(f"finished with status '{final_status}'")
+ self._finished = True
+
+
+class RateLimiter:
+ def __init__(self, min_update_interval_seconds: float) -> None:
+ self._min_update_interval_seconds = min_update_interval_seconds
+ self._last_update: float = 0
+
+ def ready(self) -> bool:
+ now = time.time()
+ delta = now - self._last_update
+ return delta >= self._min_update_interval_seconds
+
+ def reset(self) -> None:
+ self._last_update = time.time()
+
+
+@contextlib.contextmanager
+def open_spinner(message: str) -> Generator[SpinnerInterface, None, None]:
+ # Interactive spinner goes directly to sys.stdout rather than being routed
+ # through the logging system, but it acts like it has level INFO,
+ # i.e. it's only displayed if we're at level INFO or better.
+ # Non-interactive spinner goes through the logging system, so it is always
+ # in sync with logging configuration.
+ if sys.stdout.isatty() and logger.getEffectiveLevel() <= logging.INFO:
+ spinner: SpinnerInterface = InteractiveSpinner(message)
+ else:
+ spinner = NonInteractiveSpinner(message)
+ try:
+ with hidden_cursor(sys.stdout):
+ yield spinner
+ except KeyboardInterrupt:
+ spinner.finish("canceled")
+ raise
+ except Exception:
+ spinner.finish("error")
+ raise
+ else:
+ spinner.finish("done")
+
+
+HIDE_CURSOR = "\x1b[?25l"
+SHOW_CURSOR = "\x1b[?25h"
+
+
+@contextlib.contextmanager
+def hidden_cursor(file: IO[str]) -> Generator[None, None, None]:
+ # The Windows terminal does not support the hide/show cursor ANSI codes,
+ # even via colorama. So don't even try.
+ if WINDOWS:
+ yield
+ # We don't want to clutter the output with control characters if we're
+ # writing to a file, or if the user is running with --quiet.
+ # See https://github.com/pypa/pip/issues/3418
+ elif not file.isatty() or logger.getEffectiveLevel() > logging.INFO:
+ yield
+ else:
+ file.write(HIDE_CURSOR)
+ try:
+ yield
+ finally:
+ file.write(SHOW_CURSOR)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/cli/status_codes.py b/solutions/.venv/Lib/site-packages/pip/_internal/cli/status_codes.py
new file mode 100644
index 000000000..5e29502cd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/cli/status_codes.py
@@ -0,0 +1,6 @@
+SUCCESS = 0
+ERROR = 1
+UNKNOWN_ERROR = 2
+VIRTUALENV_NOT_FOUND = 3
+PREVIOUS_BUILD_DIR_ERROR = 4
+NO_MATCHES_FOUND = 23
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/__init__.py
new file mode 100644
index 000000000..858a41014
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/__init__.py
@@ -0,0 +1,132 @@
+"""
+Package containing all pip commands
+"""
+
+import importlib
+from collections import namedtuple
+from typing import Any, Dict, Optional
+
+from pip._internal.cli.base_command import Command
+
+CommandInfo = namedtuple("CommandInfo", "module_path, class_name, summary")
+
+# This dictionary does a bunch of heavy lifting for help output:
+# - Enables avoiding additional (costly) imports for presenting `--help`.
+# - The ordering matters for help display.
+#
+# Even though the module path starts with the same "pip._internal.commands"
+# prefix, the full path makes testing easier (specifically when modifying
+# `commands_dict` in test setup / teardown).
+commands_dict: Dict[str, CommandInfo] = {
+ "install": CommandInfo(
+ "pip._internal.commands.install",
+ "InstallCommand",
+ "Install packages.",
+ ),
+ "download": CommandInfo(
+ "pip._internal.commands.download",
+ "DownloadCommand",
+ "Download packages.",
+ ),
+ "uninstall": CommandInfo(
+ "pip._internal.commands.uninstall",
+ "UninstallCommand",
+ "Uninstall packages.",
+ ),
+ "freeze": CommandInfo(
+ "pip._internal.commands.freeze",
+ "FreezeCommand",
+ "Output installed packages in requirements format.",
+ ),
+ "inspect": CommandInfo(
+ "pip._internal.commands.inspect",
+ "InspectCommand",
+ "Inspect the python environment.",
+ ),
+ "list": CommandInfo(
+ "pip._internal.commands.list",
+ "ListCommand",
+ "List installed packages.",
+ ),
+ "show": CommandInfo(
+ "pip._internal.commands.show",
+ "ShowCommand",
+ "Show information about installed packages.",
+ ),
+ "check": CommandInfo(
+ "pip._internal.commands.check",
+ "CheckCommand",
+ "Verify installed packages have compatible dependencies.",
+ ),
+ "config": CommandInfo(
+ "pip._internal.commands.configuration",
+ "ConfigurationCommand",
+ "Manage local and global configuration.",
+ ),
+ "search": CommandInfo(
+ "pip._internal.commands.search",
+ "SearchCommand",
+ "Search PyPI for packages.",
+ ),
+ "cache": CommandInfo(
+ "pip._internal.commands.cache",
+ "CacheCommand",
+ "Inspect and manage pip's wheel cache.",
+ ),
+ "index": CommandInfo(
+ "pip._internal.commands.index",
+ "IndexCommand",
+ "Inspect information available from package indexes.",
+ ),
+ "wheel": CommandInfo(
+ "pip._internal.commands.wheel",
+ "WheelCommand",
+ "Build wheels from your requirements.",
+ ),
+ "hash": CommandInfo(
+ "pip._internal.commands.hash",
+ "HashCommand",
+ "Compute hashes of package archives.",
+ ),
+ "completion": CommandInfo(
+ "pip._internal.commands.completion",
+ "CompletionCommand",
+ "A helper command used for command completion.",
+ ),
+ "debug": CommandInfo(
+ "pip._internal.commands.debug",
+ "DebugCommand",
+ "Show information useful for debugging.",
+ ),
+ "help": CommandInfo(
+ "pip._internal.commands.help",
+ "HelpCommand",
+ "Show help for commands.",
+ ),
+}
+
+
+def create_command(name: str, **kwargs: Any) -> Command:
+ """
+ Create an instance of the Command class with the given name.
+ """
+ module_path, class_name, summary = commands_dict[name]
+ module = importlib.import_module(module_path)
+ command_class = getattr(module, class_name)
+ command = command_class(name=name, summary=summary, **kwargs)
+
+ return command
+
+
+def get_similar_commands(name: str) -> Optional[str]:
+ """Command name auto-correct."""
+ from difflib import get_close_matches
+
+ name = name.lower()
+
+ close_commands = get_close_matches(name, commands_dict.keys())
+
+ if close_commands:
+ return close_commands[0]
+ else:
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/cache.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/cache.py
new file mode 100644
index 000000000..328336152
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/cache.py
@@ -0,0 +1,225 @@
+import os
+import textwrap
+from optparse import Values
+from typing import Any, List
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import ERROR, SUCCESS
+from pip._internal.exceptions import CommandError, PipError
+from pip._internal.utils import filesystem
+from pip._internal.utils.logging import getLogger
+
+logger = getLogger(__name__)
+
+
+class CacheCommand(Command):
+ """
+ Inspect and manage pip's wheel cache.
+
+ Subcommands:
+
+ - dir: Show the cache directory.
+ - info: Show information about the cache.
+ - list: List filenames of packages stored in the cache.
+ - remove: Remove one or more package from the cache.
+ - purge: Remove all items from the cache.
+
+ ``<pattern>`` can be a glob expression or a package name.
+ """
+
+ ignore_require_venv = True
+ usage = """
+ %prog dir
+ %prog info
+ %prog list [<pattern>] [--format=[human, abspath]]
+ %prog remove <pattern>
+ %prog purge
+ """
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "--format",
+ action="store",
+ dest="list_format",
+ default="human",
+ choices=("human", "abspath"),
+ help="Select the output format among: human (default) or abspath",
+ )
+
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ handlers = {
+ "dir": self.get_cache_dir,
+ "info": self.get_cache_info,
+ "list": self.list_cache_items,
+ "remove": self.remove_cache_items,
+ "purge": self.purge_cache,
+ }
+
+ if not options.cache_dir:
+ logger.error("pip cache commands can not function since cache is disabled.")
+ return ERROR
+
+ # Determine action
+ if not args or args[0] not in handlers:
+ logger.error(
+ "Need an action (%s) to perform.",
+ ", ".join(sorted(handlers)),
+ )
+ return ERROR
+
+ action = args[0]
+
+ # Error handling happens here, not in the action-handlers.
+ try:
+ handlers[action](options, args[1:])
+ except PipError as e:
+ logger.error(e.args[0])
+ return ERROR
+
+ return SUCCESS
+
+ def get_cache_dir(self, options: Values, args: List[Any]) -> None:
+ if args:
+ raise CommandError("Too many arguments")
+
+ logger.info(options.cache_dir)
+
+ def get_cache_info(self, options: Values, args: List[Any]) -> None:
+ if args:
+ raise CommandError("Too many arguments")
+
+ num_http_files = len(self._find_http_files(options))
+ num_packages = len(self._find_wheels(options, "*"))
+
+ http_cache_location = self._cache_dir(options, "http-v2")
+ old_http_cache_location = self._cache_dir(options, "http")
+ wheels_cache_location = self._cache_dir(options, "wheels")
+ http_cache_size = filesystem.format_size(
+ filesystem.directory_size(http_cache_location)
+ + filesystem.directory_size(old_http_cache_location)
+ )
+ wheels_cache_size = filesystem.format_directory_size(wheels_cache_location)
+
+ message = (
+ textwrap.dedent(
+ """
+ Package index page cache location (pip v23.3+): {http_cache_location}
+ Package index page cache location (older pips): {old_http_cache_location}
+ Package index page cache size: {http_cache_size}
+ Number of HTTP files: {num_http_files}
+ Locally built wheels location: {wheels_cache_location}
+ Locally built wheels size: {wheels_cache_size}
+ Number of locally built wheels: {package_count}
+ """ # noqa: E501
+ )
+ .format(
+ http_cache_location=http_cache_location,
+ old_http_cache_location=old_http_cache_location,
+ http_cache_size=http_cache_size,
+ num_http_files=num_http_files,
+ wheels_cache_location=wheels_cache_location,
+ package_count=num_packages,
+ wheels_cache_size=wheels_cache_size,
+ )
+ .strip()
+ )
+
+ logger.info(message)
+
+ def list_cache_items(self, options: Values, args: List[Any]) -> None:
+ if len(args) > 1:
+ raise CommandError("Too many arguments")
+
+ if args:
+ pattern = args[0]
+ else:
+ pattern = "*"
+
+ files = self._find_wheels(options, pattern)
+ if options.list_format == "human":
+ self.format_for_human(files)
+ else:
+ self.format_for_abspath(files)
+
+ def format_for_human(self, files: List[str]) -> None:
+ if not files:
+ logger.info("No locally built wheels cached.")
+ return
+
+ results = []
+ for filename in files:
+ wheel = os.path.basename(filename)
+ size = filesystem.format_file_size(filename)
+ results.append(f" - {wheel} ({size})")
+ logger.info("Cache contents:\n")
+ logger.info("\n".join(sorted(results)))
+
+ def format_for_abspath(self, files: List[str]) -> None:
+ if files:
+ logger.info("\n".join(sorted(files)))
+
+ def remove_cache_items(self, options: Values, args: List[Any]) -> None:
+ if len(args) > 1:
+ raise CommandError("Too many arguments")
+
+ if not args:
+ raise CommandError("Please provide a pattern")
+
+ files = self._find_wheels(options, args[0])
+
+ no_matching_msg = "No matching packages"
+ if args[0] == "*":
+ # Only fetch http files if no specific pattern given
+ files += self._find_http_files(options)
+ else:
+ # Add the pattern to the log message
+ no_matching_msg += f' for pattern "{args[0]}"'
+
+ if not files:
+ logger.warning(no_matching_msg)
+
+ for filename in files:
+ os.unlink(filename)
+ logger.verbose("Removed %s", filename)
+ logger.info("Files removed: %s", len(files))
+
+ def purge_cache(self, options: Values, args: List[Any]) -> None:
+ if args:
+ raise CommandError("Too many arguments")
+
+ return self.remove_cache_items(options, ["*"])
+
+ def _cache_dir(self, options: Values, subdir: str) -> str:
+ return os.path.join(options.cache_dir, subdir)
+
+ def _find_http_files(self, options: Values) -> List[str]:
+ old_http_dir = self._cache_dir(options, "http")
+ new_http_dir = self._cache_dir(options, "http-v2")
+ return filesystem.find_files(old_http_dir, "*") + filesystem.find_files(
+ new_http_dir, "*"
+ )
+
+ def _find_wheels(self, options: Values, pattern: str) -> List[str]:
+ wheel_dir = self._cache_dir(options, "wheels")
+
+ # The wheel filename format, as specified in PEP 427, is:
+ # {distribution}-{version}(-{build})?-{python}-{abi}-{platform}.whl
+ #
+ # Additionally, non-alphanumeric values in the distribution are
+ # normalized to underscores (_), meaning hyphens can never occur
+ # before `-{version}`.
+ #
+ # Given that information:
+ # - If the pattern we're given contains a hyphen (-), the user is
+ # providing at least the version. Thus, we can just append `*.whl`
+ # to match the rest of it.
+ # - If the pattern we're given doesn't contain a hyphen (-), the
+ # user is only providing the name. Thus, we append `-*.whl` to
+ # match the hyphen before the version, followed by anything else.
+ #
+ # PEP 427: https://www.python.org/dev/peps/pep-0427/
+ pattern = pattern + ("*.whl" if "-" in pattern else "-*.whl")
+
+ return filesystem.find_files(wheel_dir, pattern)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/check.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/check.py
new file mode 100644
index 000000000..f54a16dc0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/check.py
@@ -0,0 +1,67 @@
+import logging
+from optparse import Values
+from typing import List
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import ERROR, SUCCESS
+from pip._internal.metadata import get_default_environment
+from pip._internal.operations.check import (
+ check_package_set,
+ check_unsupported,
+ create_package_set_from_installed,
+)
+from pip._internal.utils.compatibility_tags import get_supported
+from pip._internal.utils.misc import write_output
+
+logger = logging.getLogger(__name__)
+
+
+class CheckCommand(Command):
+ """Verify installed packages have compatible dependencies."""
+
+ ignore_require_venv = True
+ usage = """
+ %prog [options]"""
+
+ def run(self, options: Values, args: List[str]) -> int:
+ package_set, parsing_probs = create_package_set_from_installed()
+ missing, conflicting = check_package_set(package_set)
+ unsupported = list(
+ check_unsupported(
+ get_default_environment().iter_installed_distributions(),
+ get_supported(),
+ )
+ )
+
+ for project_name in missing:
+ version = package_set[project_name].version
+ for dependency in missing[project_name]:
+ write_output(
+ "%s %s requires %s, which is not installed.",
+ project_name,
+ version,
+ dependency[0],
+ )
+
+ for project_name in conflicting:
+ version = package_set[project_name].version
+ for dep_name, dep_version, req in conflicting[project_name]:
+ write_output(
+ "%s %s has requirement %s, but you have %s %s.",
+ project_name,
+ version,
+ req,
+ dep_name,
+ dep_version,
+ )
+ for package in unsupported:
+ write_output(
+ "%s %s is not supported on this platform",
+ package.raw_name,
+ package.version,
+ )
+ if missing or conflicting or parsing_probs or unsupported:
+ return ERROR
+ else:
+ write_output("No broken requirements found.")
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/completion.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/completion.py
new file mode 100644
index 000000000..9e89e2798
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/completion.py
@@ -0,0 +1,130 @@
+import sys
+import textwrap
+from optparse import Values
+from typing import List
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.utils.misc import get_prog
+
+BASE_COMPLETION = """
+# pip {shell} completion start{script}# pip {shell} completion end
+"""
+
+COMPLETION_SCRIPTS = {
+ "bash": """
+ _pip_completion()
+ {{
+ COMPREPLY=( $( COMP_WORDS="${{COMP_WORDS[*]}}" \\
+ COMP_CWORD=$COMP_CWORD \\
+ PIP_AUTO_COMPLETE=1 $1 2>/dev/null ) )
+ }}
+ complete -o default -F _pip_completion {prog}
+ """,
+ "zsh": """
+ #compdef -P pip[0-9.]#
+ __pip() {{
+ compadd $( COMP_WORDS="$words[*]" \\
+ COMP_CWORD=$((CURRENT-1)) \\
+ PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )
+ }}
+ if [[ $zsh_eval_context[-1] == loadautofunc ]]; then
+ # autoload from fpath, call function directly
+ __pip "$@"
+ else
+ # eval/source/. command, register function for later
+ compdef __pip -P 'pip[0-9.]#'
+ fi
+ """,
+ "fish": """
+ function __fish_complete_pip
+ set -lx COMP_WORDS (commandline -o) ""
+ set -lx COMP_CWORD ( \\
+ math (contains -i -- (commandline -t) $COMP_WORDS)-1 \\
+ )
+ set -lx PIP_AUTO_COMPLETE 1
+ string split \\ -- (eval $COMP_WORDS[1])
+ end
+ complete -fa "(__fish_complete_pip)" -c {prog}
+ """,
+ "powershell": """
+ if ((Test-Path Function:\\TabExpansion) -and -not `
+ (Test-Path Function:\\_pip_completeBackup)) {{
+ Rename-Item Function:\\TabExpansion _pip_completeBackup
+ }}
+ function TabExpansion($line, $lastWord) {{
+ $lastBlock = [regex]::Split($line, '[|;]')[-1].TrimStart()
+ if ($lastBlock.StartsWith("{prog} ")) {{
+ $Env:COMP_WORDS=$lastBlock
+ $Env:COMP_CWORD=$lastBlock.Split().Length - 1
+ $Env:PIP_AUTO_COMPLETE=1
+ (& {prog}).Split()
+ Remove-Item Env:COMP_WORDS
+ Remove-Item Env:COMP_CWORD
+ Remove-Item Env:PIP_AUTO_COMPLETE
+ }}
+ elseif (Test-Path Function:\\_pip_completeBackup) {{
+ # Fall back on existing tab expansion
+ _pip_completeBackup $line $lastWord
+ }}
+ }}
+ """,
+}
+
+
+class CompletionCommand(Command):
+ """A helper command to be used for command completion."""
+
+ ignore_require_venv = True
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "--bash",
+ "-b",
+ action="store_const",
+ const="bash",
+ dest="shell",
+ help="Emit completion code for bash",
+ )
+ self.cmd_opts.add_option(
+ "--zsh",
+ "-z",
+ action="store_const",
+ const="zsh",
+ dest="shell",
+ help="Emit completion code for zsh",
+ )
+ self.cmd_opts.add_option(
+ "--fish",
+ "-f",
+ action="store_const",
+ const="fish",
+ dest="shell",
+ help="Emit completion code for fish",
+ )
+ self.cmd_opts.add_option(
+ "--powershell",
+ "-p",
+ action="store_const",
+ const="powershell",
+ dest="shell",
+ help="Emit completion code for powershell",
+ )
+
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ """Prints the completion code of the given shell"""
+ shells = COMPLETION_SCRIPTS.keys()
+ shell_options = ["--" + shell for shell in sorted(shells)]
+ if options.shell in shells:
+ script = textwrap.dedent(
+ COMPLETION_SCRIPTS.get(options.shell, "").format(prog=get_prog())
+ )
+ print(BASE_COMPLETION.format(script=script, shell=options.shell))
+ return SUCCESS
+ else:
+ sys.stderr.write(
+ "ERROR: You must pass {}\n".format(" or ".join(shell_options))
+ )
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/configuration.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/configuration.py
new file mode 100644
index 000000000..1a1dc6b6c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/configuration.py
@@ -0,0 +1,280 @@
+import logging
+import os
+import subprocess
+from optparse import Values
+from typing import Any, List, Optional
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import ERROR, SUCCESS
+from pip._internal.configuration import (
+ Configuration,
+ Kind,
+ get_configuration_files,
+ kinds,
+)
+from pip._internal.exceptions import PipError
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.misc import get_prog, write_output
+
+logger = logging.getLogger(__name__)
+
+
+class ConfigurationCommand(Command):
+ """
+ Manage local and global configuration.
+
+ Subcommands:
+
+ - list: List the active configuration (or from the file specified)
+ - edit: Edit the configuration file in an editor
+ - get: Get the value associated with command.option
+ - set: Set the command.option=value
+ - unset: Unset the value associated with command.option
+ - debug: List the configuration files and values defined under them
+
+ Configuration keys should be dot separated command and option name,
+ with the special prefix "global" affecting any command. For example,
+ "pip config set global.index-url https://example.org/" would configure
+ the index url for all commands, but "pip config set download.timeout 10"
+ would configure a 10 second timeout only for "pip download" commands.
+
+ If none of --user, --global and --site are passed, a virtual
+ environment configuration file is used if one is active and the file
+ exists. Otherwise, all modifications happen to the user file by
+ default.
+ """
+
+ ignore_require_venv = True
+ usage = """
+ %prog [<file-option>] list
+ %prog [<file-option>] [--editor <editor-path>] edit
+
+ %prog [<file-option>] get command.option
+ %prog [<file-option>] set command.option value
+ %prog [<file-option>] unset command.option
+ %prog [<file-option>] debug
+ """
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "--editor",
+ dest="editor",
+ action="store",
+ default=None,
+ help=(
+ "Editor to use to edit the file. Uses VISUAL or EDITOR "
+ "environment variables if not provided."
+ ),
+ )
+
+ self.cmd_opts.add_option(
+ "--global",
+ dest="global_file",
+ action="store_true",
+ default=False,
+ help="Use the system-wide configuration file only",
+ )
+
+ self.cmd_opts.add_option(
+ "--user",
+ dest="user_file",
+ action="store_true",
+ default=False,
+ help="Use the user configuration file only",
+ )
+
+ self.cmd_opts.add_option(
+ "--site",
+ dest="site_file",
+ action="store_true",
+ default=False,
+ help="Use the current environment configuration file only",
+ )
+
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ handlers = {
+ "list": self.list_values,
+ "edit": self.open_in_editor,
+ "get": self.get_name,
+ "set": self.set_name_value,
+ "unset": self.unset_name,
+ "debug": self.list_config_values,
+ }
+
+ # Determine action
+ if not args or args[0] not in handlers:
+ logger.error(
+ "Need an action (%s) to perform.",
+ ", ".join(sorted(handlers)),
+ )
+ return ERROR
+
+ action = args[0]
+
+ # Determine which configuration files are to be loaded
+ # Depends on whether the command is modifying.
+ try:
+ load_only = self._determine_file(
+ options, need_value=(action in ["get", "set", "unset", "edit"])
+ )
+ except PipError as e:
+ logger.error(e.args[0])
+ return ERROR
+
+ # Load a new configuration
+ self.configuration = Configuration(
+ isolated=options.isolated_mode, load_only=load_only
+ )
+ self.configuration.load()
+
+ # Error handling happens here, not in the action-handlers.
+ try:
+ handlers[action](options, args[1:])
+ except PipError as e:
+ logger.error(e.args[0])
+ return ERROR
+
+ return SUCCESS
+
+ def _determine_file(self, options: Values, need_value: bool) -> Optional[Kind]:
+ file_options = [
+ key
+ for key, value in (
+ (kinds.USER, options.user_file),
+ (kinds.GLOBAL, options.global_file),
+ (kinds.SITE, options.site_file),
+ )
+ if value
+ ]
+
+ if not file_options:
+ if not need_value:
+ return None
+ # Default to user, unless there's a site file.
+ elif any(
+ os.path.exists(site_config_file)
+ for site_config_file in get_configuration_files()[kinds.SITE]
+ ):
+ return kinds.SITE
+ else:
+ return kinds.USER
+ elif len(file_options) == 1:
+ return file_options[0]
+
+ raise PipError(
+ "Need exactly one file to operate upon "
+ "(--user, --site, --global) to perform."
+ )
+
+ def list_values(self, options: Values, args: List[str]) -> None:
+ self._get_n_args(args, "list", n=0)
+
+ for key, value in sorted(self.configuration.items()):
+ write_output("%s=%r", key, value)
+
+ def get_name(self, options: Values, args: List[str]) -> None:
+ key = self._get_n_args(args, "get [name]", n=1)
+ value = self.configuration.get_value(key)
+
+ write_output("%s", value)
+
+ def set_name_value(self, options: Values, args: List[str]) -> None:
+ key, value = self._get_n_args(args, "set [name] [value]", n=2)
+ self.configuration.set_value(key, value)
+
+ self._save_configuration()
+
+ def unset_name(self, options: Values, args: List[str]) -> None:
+ key = self._get_n_args(args, "unset [name]", n=1)
+ self.configuration.unset_value(key)
+
+ self._save_configuration()
+
+ def list_config_values(self, options: Values, args: List[str]) -> None:
+ """List config key-value pairs across different config files"""
+ self._get_n_args(args, "debug", n=0)
+
+ self.print_env_var_values()
+ # Iterate over config files and print if they exist, and the
+ # key-value pairs present in them if they do
+ for variant, files in sorted(self.configuration.iter_config_files()):
+ write_output("%s:", variant)
+ for fname in files:
+ with indent_log():
+ file_exists = os.path.exists(fname)
+ write_output("%s, exists: %r", fname, file_exists)
+ if file_exists:
+ self.print_config_file_values(variant)
+
+ def print_config_file_values(self, variant: Kind) -> None:
+ """Get key-value pairs from the file of a variant"""
+ for name, value in self.configuration.get_values_in_config(variant).items():
+ with indent_log():
+ write_output("%s: %s", name, value)
+
+ def print_env_var_values(self) -> None:
+ """Get key-values pairs present as environment variables"""
+ write_output("%s:", "env_var")
+ with indent_log():
+ for key, value in sorted(self.configuration.get_environ_vars()):
+ env_var = f"PIP_{key.upper()}"
+ write_output("%s=%r", env_var, value)
+
+ def open_in_editor(self, options: Values, args: List[str]) -> None:
+ editor = self._determine_editor(options)
+
+ fname = self.configuration.get_file_to_edit()
+ if fname is None:
+ raise PipError("Could not determine appropriate file.")
+ elif '"' in fname:
+ # This shouldn't happen, unless we see a username like that.
+ # If that happens, we'd appreciate a pull request fixing this.
+ raise PipError(
+ f'Can not open an editor for a file name containing "\n{fname}'
+ )
+
+ try:
+ subprocess.check_call(f'{editor} "{fname}"', shell=True)
+ except FileNotFoundError as e:
+ if not e.filename:
+ e.filename = editor
+ raise
+ except subprocess.CalledProcessError as e:
+ raise PipError(f"Editor Subprocess exited with exit code {e.returncode}")
+
+ def _get_n_args(self, args: List[str], example: str, n: int) -> Any:
+ """Helper to make sure the command got the right number of arguments"""
+ if len(args) != n:
+ msg = (
+ f"Got unexpected number of arguments, expected {n}. "
+ f'(example: "{get_prog()} config {example}")'
+ )
+ raise PipError(msg)
+
+ if n == 1:
+ return args[0]
+ else:
+ return args
+
+ def _save_configuration(self) -> None:
+ # We successfully ran a modifying command. Need to save the
+ # configuration.
+ try:
+ self.configuration.save()
+ except Exception:
+ logger.exception(
+ "Unable to save configuration. Please report this as a bug."
+ )
+ raise PipError("Internal Error.")
+
+ def _determine_editor(self, options: Values) -> str:
+ if options.editor is not None:
+ return options.editor
+ elif "VISUAL" in os.environ:
+ return os.environ["VISUAL"]
+ elif "EDITOR" in os.environ:
+ return os.environ["EDITOR"]
+ else:
+ raise PipError("Could not determine editor to use.")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/debug.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/debug.py
new file mode 100644
index 000000000..567ca967e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/debug.py
@@ -0,0 +1,201 @@
+import locale
+import logging
+import os
+import sys
+from optparse import Values
+from types import ModuleType
+from typing import Any, Dict, List, Optional
+
+import pip._vendor
+from pip._vendor.certifi import where
+from pip._vendor.packaging.version import parse as parse_version
+
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.cmdoptions import make_target_python
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.configuration import Configuration
+from pip._internal.metadata import get_environment
+from pip._internal.utils.compat import open_text_resource
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.misc import get_pip_version
+
+logger = logging.getLogger(__name__)
+
+
+def show_value(name: str, value: Any) -> None:
+ logger.info("%s: %s", name, value)
+
+
+def show_sys_implementation() -> None:
+ logger.info("sys.implementation:")
+ implementation_name = sys.implementation.name
+ with indent_log():
+ show_value("name", implementation_name)
+
+
+def create_vendor_txt_map() -> Dict[str, str]:
+ with open_text_resource("pip._vendor", "vendor.txt") as f:
+ # Purge non version specifying lines.
+ # Also, remove any space prefix or suffixes (including comments).
+ lines = [
+ line.strip().split(" ", 1)[0] for line in f.readlines() if "==" in line
+ ]
+
+ # Transform into "module" -> version dict.
+ return dict(line.split("==", 1) for line in lines)
+
+
+def get_module_from_module_name(module_name: str) -> Optional[ModuleType]:
+ # Module name can be uppercase in vendor.txt for some reason...
+ module_name = module_name.lower().replace("-", "_")
+ # PATCH: setuptools is actually only pkg_resources.
+ if module_name == "setuptools":
+ module_name = "pkg_resources"
+
+ try:
+ __import__(f"pip._vendor.{module_name}", globals(), locals(), level=0)
+ return getattr(pip._vendor, module_name)
+ except ImportError:
+ # We allow 'truststore' to fail to import due
+ # to being unavailable on Python 3.9 and earlier.
+ if module_name == "truststore" and sys.version_info < (3, 10):
+ return None
+ raise
+
+
+def get_vendor_version_from_module(module_name: str) -> Optional[str]:
+ module = get_module_from_module_name(module_name)
+ version = getattr(module, "__version__", None)
+
+ if module and not version:
+ # Try to find version in debundled module info.
+ assert module.__file__ is not None
+ env = get_environment([os.path.dirname(module.__file__)])
+ dist = env.get_distribution(module_name)
+ if dist:
+ version = str(dist.version)
+
+ return version
+
+
+def show_actual_vendor_versions(vendor_txt_versions: Dict[str, str]) -> None:
+ """Log the actual version and print extra info if there is
+ a conflict or if the actual version could not be imported.
+ """
+ for module_name, expected_version in vendor_txt_versions.items():
+ extra_message = ""
+ actual_version = get_vendor_version_from_module(module_name)
+ if not actual_version:
+ extra_message = (
+ " (Unable to locate actual module version, using"
+ " vendor.txt specified version)"
+ )
+ actual_version = expected_version
+ elif parse_version(actual_version) != parse_version(expected_version):
+ extra_message = (
+ " (CONFLICT: vendor.txt suggests version should"
+ f" be {expected_version})"
+ )
+ logger.info("%s==%s%s", module_name, actual_version, extra_message)
+
+
+def show_vendor_versions() -> None:
+ logger.info("vendored library versions:")
+
+ vendor_txt_versions = create_vendor_txt_map()
+ with indent_log():
+ show_actual_vendor_versions(vendor_txt_versions)
+
+
+def show_tags(options: Values) -> None:
+ tag_limit = 10
+
+ target_python = make_target_python(options)
+ tags = target_python.get_sorted_tags()
+
+ # Display the target options that were explicitly provided.
+ formatted_target = target_python.format_given()
+ suffix = ""
+ if formatted_target:
+ suffix = f" (target: {formatted_target})"
+
+ msg = f"Compatible tags: {len(tags)}{suffix}"
+ logger.info(msg)
+
+ if options.verbose < 1 and len(tags) > tag_limit:
+ tags_limited = True
+ tags = tags[:tag_limit]
+ else:
+ tags_limited = False
+
+ with indent_log():
+ for tag in tags:
+ logger.info(str(tag))
+
+ if tags_limited:
+ msg = f"...\n[First {tag_limit} tags shown. Pass --verbose to show all.]"
+ logger.info(msg)
+
+
+def ca_bundle_info(config: Configuration) -> str:
+ levels = {key.split(".", 1)[0] for key, _ in config.items()}
+ if not levels:
+ return "Not specified"
+
+ levels_that_override_global = ["install", "wheel", "download"]
+ global_overriding_level = [
+ level for level in levels if level in levels_that_override_global
+ ]
+ if not global_overriding_level:
+ return "global"
+
+ if "global" in levels:
+ levels.remove("global")
+ return ", ".join(levels)
+
+
+class DebugCommand(Command):
+ """
+ Display debug information.
+ """
+
+ usage = """
+ %prog <options>"""
+ ignore_require_venv = True
+
+ def add_options(self) -> None:
+ cmdoptions.add_target_python_options(self.cmd_opts)
+ self.parser.insert_option_group(0, self.cmd_opts)
+ self.parser.config.load()
+
+ def run(self, options: Values, args: List[str]) -> int:
+ logger.warning(
+ "This command is only meant for debugging. "
+ "Do not use this with automation for parsing and getting these "
+ "details, since the output and options of this command may "
+ "change without notice."
+ )
+ show_value("pip version", get_pip_version())
+ show_value("sys.version", sys.version)
+ show_value("sys.executable", sys.executable)
+ show_value("sys.getdefaultencoding", sys.getdefaultencoding())
+ show_value("sys.getfilesystemencoding", sys.getfilesystemencoding())
+ show_value(
+ "locale.getpreferredencoding",
+ locale.getpreferredencoding(),
+ )
+ show_value("sys.platform", sys.platform)
+ show_sys_implementation()
+
+ show_value("'cert' config value", ca_bundle_info(self.parser.config))
+ show_value("REQUESTS_CA_BUNDLE", os.environ.get("REQUESTS_CA_BUNDLE"))
+ show_value("CURL_CA_BUNDLE", os.environ.get("CURL_CA_BUNDLE"))
+ show_value("pip._vendor.certifi.where()", where())
+ show_value("pip._vendor.DEBUNDLED", pip._vendor.DEBUNDLED)
+
+ show_vendor_versions()
+
+ show_tags(options)
+
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/download.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/download.py
new file mode 100644
index 000000000..917bbb91d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/download.py
@@ -0,0 +1,146 @@
+import logging
+import os
+from optparse import Values
+from typing import List
+
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.cmdoptions import make_target_python
+from pip._internal.cli.req_command import RequirementCommand, with_cleanup
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.operations.build.build_tracker import get_build_tracker
+from pip._internal.req.req_install import check_legacy_setup_py_options
+from pip._internal.utils.misc import ensure_dir, normalize_path, write_output
+from pip._internal.utils.temp_dir import TempDirectory
+
+logger = logging.getLogger(__name__)
+
+
+class DownloadCommand(RequirementCommand):
+ """
+ Download packages from:
+
+ - PyPI (and other indexes) using requirement specifiers.
+ - VCS project urls.
+ - Local project directories.
+ - Local or remote source archives.
+
+ pip also supports downloading from "requirements files", which provide
+ an easy way to specify a whole environment to be downloaded.
+ """
+
+ usage = """
+ %prog [options] <requirement specifier> [package-index-options] ...
+ %prog [options] -r <requirements file> [package-index-options] ...
+ %prog [options] <vcs project url> ...
+ %prog [options] <local project path> ...
+ %prog [options] <archive url/path> ..."""
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(cmdoptions.constraints())
+ self.cmd_opts.add_option(cmdoptions.requirements())
+ self.cmd_opts.add_option(cmdoptions.no_deps())
+ self.cmd_opts.add_option(cmdoptions.global_options())
+ self.cmd_opts.add_option(cmdoptions.no_binary())
+ self.cmd_opts.add_option(cmdoptions.only_binary())
+ self.cmd_opts.add_option(cmdoptions.prefer_binary())
+ self.cmd_opts.add_option(cmdoptions.src())
+ self.cmd_opts.add_option(cmdoptions.pre())
+ self.cmd_opts.add_option(cmdoptions.require_hashes())
+ self.cmd_opts.add_option(cmdoptions.progress_bar())
+ self.cmd_opts.add_option(cmdoptions.no_build_isolation())
+ self.cmd_opts.add_option(cmdoptions.use_pep517())
+ self.cmd_opts.add_option(cmdoptions.no_use_pep517())
+ self.cmd_opts.add_option(cmdoptions.check_build_deps())
+ self.cmd_opts.add_option(cmdoptions.ignore_requires_python())
+
+ self.cmd_opts.add_option(
+ "-d",
+ "--dest",
+ "--destination-dir",
+ "--destination-directory",
+ dest="download_dir",
+ metavar="dir",
+ default=os.curdir,
+ help="Download packages into <dir>.",
+ )
+
+ cmdoptions.add_target_python_options(self.cmd_opts)
+
+ index_opts = cmdoptions.make_option_group(
+ cmdoptions.index_group,
+ self.parser,
+ )
+
+ self.parser.insert_option_group(0, index_opts)
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ @with_cleanup
+ def run(self, options: Values, args: List[str]) -> int:
+ options.ignore_installed = True
+ # editable doesn't really make sense for `pip download`, but the bowels
+ # of the RequirementSet code require that property.
+ options.editables = []
+
+ cmdoptions.check_dist_restriction(options)
+
+ options.download_dir = normalize_path(options.download_dir)
+ ensure_dir(options.download_dir)
+
+ session = self.get_default_session(options)
+
+ target_python = make_target_python(options)
+ finder = self._build_package_finder(
+ options=options,
+ session=session,
+ target_python=target_python,
+ ignore_requires_python=options.ignore_requires_python,
+ )
+
+ build_tracker = self.enter_context(get_build_tracker())
+
+ directory = TempDirectory(
+ delete=not options.no_clean,
+ kind="download",
+ globally_managed=True,
+ )
+
+ reqs = self.get_requirements(args, options, finder, session)
+ check_legacy_setup_py_options(options, reqs)
+
+ preparer = self.make_requirement_preparer(
+ temp_build_dir=directory,
+ options=options,
+ build_tracker=build_tracker,
+ session=session,
+ finder=finder,
+ download_dir=options.download_dir,
+ use_user_site=False,
+ verbosity=self.verbosity,
+ )
+
+ resolver = self.make_resolver(
+ preparer=preparer,
+ finder=finder,
+ options=options,
+ ignore_requires_python=options.ignore_requires_python,
+ use_pep517=options.use_pep517,
+ py_version_info=options.python_version,
+ )
+
+ self.trace_basic_info(finder)
+
+ requirement_set = resolver.resolve(reqs, check_supported_wheels=True)
+
+ downloaded: List[str] = []
+ for req in requirement_set.requirements.values():
+ if req.satisfied_by is None:
+ assert req.name is not None
+ preparer.save_linked_requirement(req)
+ downloaded.append(req.name)
+
+ preparer.prepare_linked_requirements_more(requirement_set.requirements.values())
+
+ if downloaded:
+ write_output("Successfully downloaded %s", " ".join(downloaded))
+
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/freeze.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/freeze.py
new file mode 100644
index 000000000..885fdfeb8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/freeze.py
@@ -0,0 +1,109 @@
+import sys
+from optparse import Values
+from typing import AbstractSet, List
+
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.operations.freeze import freeze
+from pip._internal.utils.compat import stdlib_pkgs
+
+
+def _should_suppress_build_backends() -> bool:
+ return sys.version_info < (3, 12)
+
+
+def _dev_pkgs() -> AbstractSet[str]:
+ pkgs = {"pip"}
+
+ if _should_suppress_build_backends():
+ pkgs |= {"setuptools", "distribute", "wheel"}
+
+ return pkgs
+
+
+class FreezeCommand(Command):
+ """
+ Output installed packages in requirements format.
+
+ packages are listed in a case-insensitive sorted order.
+ """
+
+ ignore_require_venv = True
+ usage = """
+ %prog [options]"""
+ log_streams = ("ext://sys.stderr", "ext://sys.stderr")
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "-r",
+ "--requirement",
+ dest="requirements",
+ action="append",
+ default=[],
+ metavar="file",
+ help=(
+ "Use the order in the given requirements file and its "
+ "comments when generating output. This option can be "
+ "used multiple times."
+ ),
+ )
+ self.cmd_opts.add_option(
+ "-l",
+ "--local",
+ dest="local",
+ action="store_true",
+ default=False,
+ help=(
+ "If in a virtualenv that has global access, do not output "
+ "globally-installed packages."
+ ),
+ )
+ self.cmd_opts.add_option(
+ "--user",
+ dest="user",
+ action="store_true",
+ default=False,
+ help="Only output packages installed in user-site.",
+ )
+ self.cmd_opts.add_option(cmdoptions.list_path())
+ self.cmd_opts.add_option(
+ "--all",
+ dest="freeze_all",
+ action="store_true",
+ help=(
+ "Do not skip these packages in the output:"
+ " {}".format(", ".join(_dev_pkgs()))
+ ),
+ )
+ self.cmd_opts.add_option(
+ "--exclude-editable",
+ dest="exclude_editable",
+ action="store_true",
+ help="Exclude editable package from output.",
+ )
+ self.cmd_opts.add_option(cmdoptions.list_exclude())
+
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ skip = set(stdlib_pkgs)
+ if not options.freeze_all:
+ skip.update(_dev_pkgs())
+
+ if options.excludes:
+ skip.update(options.excludes)
+
+ cmdoptions.check_list_path_option(options)
+
+ for line in freeze(
+ requirement=options.requirements,
+ local_only=options.local,
+ user_only=options.user,
+ paths=options.path,
+ isolated=options.isolated_mode,
+ skip=skip,
+ exclude_editable=options.exclude_editable,
+ ):
+ sys.stdout.write(line + "\n")
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/hash.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/hash.py
new file mode 100644
index 000000000..042dac813
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/hash.py
@@ -0,0 +1,59 @@
+import hashlib
+import logging
+import sys
+from optparse import Values
+from typing import List
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import ERROR, SUCCESS
+from pip._internal.utils.hashes import FAVORITE_HASH, STRONG_HASHES
+from pip._internal.utils.misc import read_chunks, write_output
+
+logger = logging.getLogger(__name__)
+
+
+class HashCommand(Command):
+ """
+ Compute a hash of a local package archive.
+
+ These can be used with --hash in a requirements file to do repeatable
+ installs.
+ """
+
+ usage = "%prog [options] <file> ..."
+ ignore_require_venv = True
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "-a",
+ "--algorithm",
+ dest="algorithm",
+ choices=STRONG_HASHES,
+ action="store",
+ default=FAVORITE_HASH,
+ help="The hash algorithm to use: one of {}".format(
+ ", ".join(STRONG_HASHES)
+ ),
+ )
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ if not args:
+ self.parser.print_usage(sys.stderr)
+ return ERROR
+
+ algorithm = options.algorithm
+ for path in args:
+ write_output(
+ "%s:\n--hash=%s:%s", path, algorithm, _hash_of_file(path, algorithm)
+ )
+ return SUCCESS
+
+
+def _hash_of_file(path: str, algorithm: str) -> str:
+ """Return the hash digest of a file."""
+ with open(path, "rb") as archive:
+ hash = hashlib.new(algorithm)
+ for chunk in read_chunks(archive):
+ hash.update(chunk)
+ return hash.hexdigest()
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/help.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/help.py
new file mode 100644
index 000000000..62066318b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/help.py
@@ -0,0 +1,41 @@
+from optparse import Values
+from typing import List
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.exceptions import CommandError
+
+
+class HelpCommand(Command):
+ """Show help for commands"""
+
+ usage = """
+ %prog <command>"""
+ ignore_require_venv = True
+
+ def run(self, options: Values, args: List[str]) -> int:
+ from pip._internal.commands import (
+ commands_dict,
+ create_command,
+ get_similar_commands,
+ )
+
+ try:
+ # 'pip help' with no args is handled by pip.__init__.parseopt()
+ cmd_name = args[0] # the command we need help for
+ except IndexError:
+ return SUCCESS
+
+ if cmd_name not in commands_dict:
+ guess = get_similar_commands(cmd_name)
+
+ msg = [f'unknown command "{cmd_name}"']
+ if guess:
+ msg.append(f'maybe you meant "{guess}"')
+
+ raise CommandError(" - ".join(msg))
+
+ command = create_command(cmd_name)
+ command.parser.print_help()
+
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/index.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/index.py
new file mode 100644
index 000000000..2e2661bba
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/index.py
@@ -0,0 +1,139 @@
+import logging
+from optparse import Values
+from typing import Any, Iterable, List, Optional
+
+from pip._vendor.packaging.version import Version
+
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.req_command import IndexGroupCommand
+from pip._internal.cli.status_codes import ERROR, SUCCESS
+from pip._internal.commands.search import print_dist_installation_info
+from pip._internal.exceptions import CommandError, DistributionNotFound, PipError
+from pip._internal.index.collector import LinkCollector
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.models.selection_prefs import SelectionPreferences
+from pip._internal.models.target_python import TargetPython
+from pip._internal.network.session import PipSession
+from pip._internal.utils.misc import write_output
+
+logger = logging.getLogger(__name__)
+
+
+class IndexCommand(IndexGroupCommand):
+ """
+ Inspect information available from package indexes.
+ """
+
+ ignore_require_venv = True
+ usage = """
+ %prog versions <package>
+ """
+
+ def add_options(self) -> None:
+ cmdoptions.add_target_python_options(self.cmd_opts)
+
+ self.cmd_opts.add_option(cmdoptions.ignore_requires_python())
+ self.cmd_opts.add_option(cmdoptions.pre())
+ self.cmd_opts.add_option(cmdoptions.no_binary())
+ self.cmd_opts.add_option(cmdoptions.only_binary())
+
+ index_opts = cmdoptions.make_option_group(
+ cmdoptions.index_group,
+ self.parser,
+ )
+
+ self.parser.insert_option_group(0, index_opts)
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ handlers = {
+ "versions": self.get_available_package_versions,
+ }
+
+ logger.warning(
+ "pip index is currently an experimental command. "
+ "It may be removed/changed in a future release "
+ "without prior warning."
+ )
+
+ # Determine action
+ if not args or args[0] not in handlers:
+ logger.error(
+ "Need an action (%s) to perform.",
+ ", ".join(sorted(handlers)),
+ )
+ return ERROR
+
+ action = args[0]
+
+ # Error handling happens here, not in the action-handlers.
+ try:
+ handlers[action](options, args[1:])
+ except PipError as e:
+ logger.error(e.args[0])
+ return ERROR
+
+ return SUCCESS
+
+ def _build_package_finder(
+ self,
+ options: Values,
+ session: PipSession,
+ target_python: Optional[TargetPython] = None,
+ ignore_requires_python: Optional[bool] = None,
+ ) -> PackageFinder:
+ """
+ Create a package finder appropriate to the index command.
+ """
+ link_collector = LinkCollector.create(session, options=options)
+
+ # Pass allow_yanked=False to ignore yanked versions.
+ selection_prefs = SelectionPreferences(
+ allow_yanked=False,
+ allow_all_prereleases=options.pre,
+ ignore_requires_python=ignore_requires_python,
+ )
+
+ return PackageFinder.create(
+ link_collector=link_collector,
+ selection_prefs=selection_prefs,
+ target_python=target_python,
+ )
+
+ def get_available_package_versions(self, options: Values, args: List[Any]) -> None:
+ if len(args) != 1:
+ raise CommandError("You need to specify exactly one argument")
+
+ target_python = cmdoptions.make_target_python(options)
+ query = args[0]
+
+ with self._build_session(options) as session:
+ finder = self._build_package_finder(
+ options=options,
+ session=session,
+ target_python=target_python,
+ ignore_requires_python=options.ignore_requires_python,
+ )
+
+ versions: Iterable[Version] = (
+ candidate.version for candidate in finder.find_all_candidates(query)
+ )
+
+ if not options.pre:
+ # Remove prereleases
+ versions = (
+ version for version in versions if not version.is_prerelease
+ )
+ versions = set(versions)
+
+ if not versions:
+ raise DistributionNotFound(
+ f"No matching distribution found for {query}"
+ )
+
+ formatted_versions = [str(ver) for ver in sorted(versions, reverse=True)]
+ latest = formatted_versions[0]
+
+ write_output(f"{query} ({latest})")
+ write_output("Available versions: {}".format(", ".join(formatted_versions)))
+ print_dist_installation_info(query, latest)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/inspect.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/inspect.py
new file mode 100644
index 000000000..e810c1316
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/inspect.py
@@ -0,0 +1,92 @@
+import logging
+from optparse import Values
+from typing import Any, Dict, List
+
+from pip._vendor.packaging.markers import default_environment
+from pip._vendor.rich import print_json
+
+from pip import __version__
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.metadata import BaseDistribution, get_environment
+from pip._internal.utils.compat import stdlib_pkgs
+from pip._internal.utils.urls import path_to_url
+
+logger = logging.getLogger(__name__)
+
+
+class InspectCommand(Command):
+ """
+ Inspect the content of a Python environment and produce a report in JSON format.
+ """
+
+ ignore_require_venv = True
+ usage = """
+ %prog [options]"""
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "--local",
+ action="store_true",
+ default=False,
+ help=(
+ "If in a virtualenv that has global access, do not list "
+ "globally-installed packages."
+ ),
+ )
+ self.cmd_opts.add_option(
+ "--user",
+ dest="user",
+ action="store_true",
+ default=False,
+ help="Only output packages installed in user-site.",
+ )
+ self.cmd_opts.add_option(cmdoptions.list_path())
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ cmdoptions.check_list_path_option(options)
+ dists = get_environment(options.path).iter_installed_distributions(
+ local_only=options.local,
+ user_only=options.user,
+ skip=set(stdlib_pkgs),
+ )
+ output = {
+ "version": "1",
+ "pip_version": __version__,
+ "installed": [self._dist_to_dict(dist) for dist in dists],
+ "environment": default_environment(),
+ # TODO tags? scheme?
+ }
+ print_json(data=output)
+ return SUCCESS
+
+ def _dist_to_dict(self, dist: BaseDistribution) -> Dict[str, Any]:
+ res: Dict[str, Any] = {
+ "metadata": dist.metadata_dict,
+ "metadata_location": dist.info_location,
+ }
+ # direct_url. Note that we don't have download_info (as in the installation
+ # report) since it is not recorded in installed metadata.
+ direct_url = dist.direct_url
+ if direct_url is not None:
+ res["direct_url"] = direct_url.to_dict()
+ else:
+ # Emulate direct_url for legacy editable installs.
+ editable_project_location = dist.editable_project_location
+ if editable_project_location is not None:
+ res["direct_url"] = {
+ "url": path_to_url(editable_project_location),
+ "dir_info": {
+ "editable": True,
+ },
+ }
+ # installer
+ installer = dist.installer
+ if dist.installer:
+ res["installer"] = installer
+ # requested
+ if dist.installed_with_dist_info:
+ res["requested"] = dist.requested
+ return res
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/install.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/install.py
new file mode 100644
index 000000000..ad45a2f2a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/install.py
@@ -0,0 +1,783 @@
+import errno
+import json
+import operator
+import os
+import shutil
+import site
+from optparse import SUPPRESS_HELP, Values
+from typing import List, Optional
+
+from pip._vendor.packaging.utils import canonicalize_name
+from pip._vendor.rich import print_json
+
+from pip._internal.cache import WheelCache
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.cmdoptions import make_target_python
+from pip._internal.cli.req_command import (
+ RequirementCommand,
+ with_cleanup,
+)
+from pip._internal.cli.status_codes import ERROR, SUCCESS
+from pip._internal.exceptions import CommandError, InstallationError
+from pip._internal.locations import get_scheme
+from pip._internal.metadata import get_environment
+from pip._internal.models.installation_report import InstallationReport
+from pip._internal.operations.build.build_tracker import get_build_tracker
+from pip._internal.operations.check import ConflictDetails, check_install_conflicts
+from pip._internal.req import install_given_reqs
+from pip._internal.req.req_install import (
+ InstallRequirement,
+ check_legacy_setup_py_options,
+)
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.filesystem import test_writable_dir
+from pip._internal.utils.logging import getLogger
+from pip._internal.utils.misc import (
+ check_externally_managed,
+ ensure_dir,
+ get_pip_version,
+ protect_pip_from_modification_on_windows,
+ warn_if_run_as_root,
+ write_output,
+)
+from pip._internal.utils.temp_dir import TempDirectory
+from pip._internal.utils.virtualenv import (
+ running_under_virtualenv,
+ virtualenv_no_global,
+)
+from pip._internal.wheel_builder import build, should_build_for_install_command
+
+logger = getLogger(__name__)
+
+
+class InstallCommand(RequirementCommand):
+ """
+ Install packages from:
+
+ - PyPI (and other indexes) using requirement specifiers.
+ - VCS project urls.
+ - Local project directories.
+ - Local or remote source archives.
+
+ pip also supports installing from "requirements files", which provide
+ an easy way to specify a whole environment to be installed.
+ """
+
+ usage = """
+ %prog [options] <requirement specifier> [package-index-options] ...
+ %prog [options] -r <requirements file> [package-index-options] ...
+ %prog [options] [-e] <vcs project url> ...
+ %prog [options] [-e] <local project path> ...
+ %prog [options] <archive url/path> ..."""
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(cmdoptions.requirements())
+ self.cmd_opts.add_option(cmdoptions.constraints())
+ self.cmd_opts.add_option(cmdoptions.no_deps())
+ self.cmd_opts.add_option(cmdoptions.pre())
+
+ self.cmd_opts.add_option(cmdoptions.editable())
+ self.cmd_opts.add_option(
+ "--dry-run",
+ action="store_true",
+ dest="dry_run",
+ default=False,
+ help=(
+ "Don't actually install anything, just print what would be. "
+ "Can be used in combination with --ignore-installed "
+ "to 'resolve' the requirements."
+ ),
+ )
+ self.cmd_opts.add_option(
+ "-t",
+ "--target",
+ dest="target_dir",
+ metavar="dir",
+ default=None,
+ help=(
+ "Install packages into <dir>. "
+ "By default this will not replace existing files/folders in "
+ "<dir>. Use --upgrade to replace existing packages in <dir> "
+ "with new versions."
+ ),
+ )
+ cmdoptions.add_target_python_options(self.cmd_opts)
+
+ self.cmd_opts.add_option(
+ "--user",
+ dest="use_user_site",
+ action="store_true",
+ help=(
+ "Install to the Python user install directory for your "
+ "platform. Typically ~/.local/, or %APPDATA%\\Python on "
+ "Windows. (See the Python documentation for site.USER_BASE "
+ "for full details.)"
+ ),
+ )
+ self.cmd_opts.add_option(
+ "--no-user",
+ dest="use_user_site",
+ action="store_false",
+ help=SUPPRESS_HELP,
+ )
+ self.cmd_opts.add_option(
+ "--root",
+ dest="root_path",
+ metavar="dir",
+ default=None,
+ help="Install everything relative to this alternate root directory.",
+ )
+ self.cmd_opts.add_option(
+ "--prefix",
+ dest="prefix_path",
+ metavar="dir",
+ default=None,
+ help=(
+ "Installation prefix where lib, bin and other top-level "
+ "folders are placed. Note that the resulting installation may "
+ "contain scripts and other resources which reference the "
+ "Python interpreter of pip, and not that of ``--prefix``. "
+ "See also the ``--python`` option if the intention is to "
+ "install packages into another (possibly pip-free) "
+ "environment."
+ ),
+ )
+
+ self.cmd_opts.add_option(cmdoptions.src())
+
+ self.cmd_opts.add_option(
+ "-U",
+ "--upgrade",
+ dest="upgrade",
+ action="store_true",
+ help=(
+ "Upgrade all specified packages to the newest available "
+ "version. The handling of dependencies depends on the "
+ "upgrade-strategy used."
+ ),
+ )
+
+ self.cmd_opts.add_option(
+ "--upgrade-strategy",
+ dest="upgrade_strategy",
+ default="only-if-needed",
+ choices=["only-if-needed", "eager"],
+ help=(
+ "Determines how dependency upgrading should be handled "
+ "[default: %default]. "
+ '"eager" - dependencies are upgraded regardless of '
+ "whether the currently installed version satisfies the "
+ "requirements of the upgraded package(s). "
+ '"only-if-needed" - are upgraded only when they do not '
+ "satisfy the requirements of the upgraded package(s)."
+ ),
+ )
+
+ self.cmd_opts.add_option(
+ "--force-reinstall",
+ dest="force_reinstall",
+ action="store_true",
+ help="Reinstall all packages even if they are already up-to-date.",
+ )
+
+ self.cmd_opts.add_option(
+ "-I",
+ "--ignore-installed",
+ dest="ignore_installed",
+ action="store_true",
+ help=(
+ "Ignore the installed packages, overwriting them. "
+ "This can break your system if the existing package "
+ "is of a different version or was installed "
+ "with a different package manager!"
+ ),
+ )
+
+ self.cmd_opts.add_option(cmdoptions.ignore_requires_python())
+ self.cmd_opts.add_option(cmdoptions.no_build_isolation())
+ self.cmd_opts.add_option(cmdoptions.use_pep517())
+ self.cmd_opts.add_option(cmdoptions.no_use_pep517())
+ self.cmd_opts.add_option(cmdoptions.check_build_deps())
+ self.cmd_opts.add_option(cmdoptions.override_externally_managed())
+
+ self.cmd_opts.add_option(cmdoptions.config_settings())
+ self.cmd_opts.add_option(cmdoptions.global_options())
+
+ self.cmd_opts.add_option(
+ "--compile",
+ action="store_true",
+ dest="compile",
+ default=True,
+ help="Compile Python source files to bytecode",
+ )
+
+ self.cmd_opts.add_option(
+ "--no-compile",
+ action="store_false",
+ dest="compile",
+ help="Do not compile Python source files to bytecode",
+ )
+
+ self.cmd_opts.add_option(
+ "--no-warn-script-location",
+ action="store_false",
+ dest="warn_script_location",
+ default=True,
+ help="Do not warn when installing scripts outside PATH",
+ )
+ self.cmd_opts.add_option(
+ "--no-warn-conflicts",
+ action="store_false",
+ dest="warn_about_conflicts",
+ default=True,
+ help="Do not warn about broken dependencies",
+ )
+ self.cmd_opts.add_option(cmdoptions.no_binary())
+ self.cmd_opts.add_option(cmdoptions.only_binary())
+ self.cmd_opts.add_option(cmdoptions.prefer_binary())
+ self.cmd_opts.add_option(cmdoptions.require_hashes())
+ self.cmd_opts.add_option(cmdoptions.progress_bar())
+ self.cmd_opts.add_option(cmdoptions.root_user_action())
+
+ index_opts = cmdoptions.make_option_group(
+ cmdoptions.index_group,
+ self.parser,
+ )
+
+ self.parser.insert_option_group(0, index_opts)
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ self.cmd_opts.add_option(
+ "--report",
+ dest="json_report_file",
+ metavar="file",
+ default=None,
+ help=(
+ "Generate a JSON file describing what pip did to install "
+ "the provided requirements. "
+ "Can be used in combination with --dry-run and --ignore-installed "
+ "to 'resolve' the requirements. "
+ "When - is used as file name it writes to stdout. "
+ "When writing to stdout, please combine with the --quiet option "
+ "to avoid mixing pip logging output with JSON output."
+ ),
+ )
+
+ @with_cleanup
+ def run(self, options: Values, args: List[str]) -> int:
+ if options.use_user_site and options.target_dir is not None:
+ raise CommandError("Can not combine '--user' and '--target'")
+
+ # Check whether the environment we're installing into is externally
+ # managed, as specified in PEP 668. Specifying --root, --target, or
+ # --prefix disables the check, since there's no reliable way to locate
+ # the EXTERNALLY-MANAGED file for those cases. An exception is also
+ # made specifically for "--dry-run --report" for convenience.
+ installing_into_current_environment = (
+ not (options.dry_run and options.json_report_file)
+ and options.root_path is None
+ and options.target_dir is None
+ and options.prefix_path is None
+ )
+ if (
+ installing_into_current_environment
+ and not options.override_externally_managed
+ ):
+ check_externally_managed()
+
+ upgrade_strategy = "to-satisfy-only"
+ if options.upgrade:
+ upgrade_strategy = options.upgrade_strategy
+
+ cmdoptions.check_dist_restriction(options, check_target=True)
+
+ logger.verbose("Using %s", get_pip_version())
+ options.use_user_site = decide_user_install(
+ options.use_user_site,
+ prefix_path=options.prefix_path,
+ target_dir=options.target_dir,
+ root_path=options.root_path,
+ isolated_mode=options.isolated_mode,
+ )
+
+ target_temp_dir: Optional[TempDirectory] = None
+ target_temp_dir_path: Optional[str] = None
+ if options.target_dir:
+ options.ignore_installed = True
+ options.target_dir = os.path.abspath(options.target_dir)
+ if (
+ # fmt: off
+ os.path.exists(options.target_dir) and
+ not os.path.isdir(options.target_dir)
+ # fmt: on
+ ):
+ raise CommandError(
+ "Target path exists but is not a directory, will not continue."
+ )
+
+ # Create a target directory for using with the target option
+ target_temp_dir = TempDirectory(kind="target")
+ target_temp_dir_path = target_temp_dir.path
+ self.enter_context(target_temp_dir)
+
+ global_options = options.global_options or []
+
+ session = self.get_default_session(options)
+
+ target_python = make_target_python(options)
+ finder = self._build_package_finder(
+ options=options,
+ session=session,
+ target_python=target_python,
+ ignore_requires_python=options.ignore_requires_python,
+ )
+ build_tracker = self.enter_context(get_build_tracker())
+
+ directory = TempDirectory(
+ delete=not options.no_clean,
+ kind="install",
+ globally_managed=True,
+ )
+
+ try:
+ reqs = self.get_requirements(args, options, finder, session)
+ check_legacy_setup_py_options(options, reqs)
+
+ wheel_cache = WheelCache(options.cache_dir)
+
+ # Only when installing is it permitted to use PEP 660.
+ # In other circumstances (pip wheel, pip download) we generate
+ # regular (i.e. non editable) metadata and wheels.
+ for req in reqs:
+ req.permit_editable_wheels = True
+
+ preparer = self.make_requirement_preparer(
+ temp_build_dir=directory,
+ options=options,
+ build_tracker=build_tracker,
+ session=session,
+ finder=finder,
+ use_user_site=options.use_user_site,
+ verbosity=self.verbosity,
+ )
+ resolver = self.make_resolver(
+ preparer=preparer,
+ finder=finder,
+ options=options,
+ wheel_cache=wheel_cache,
+ use_user_site=options.use_user_site,
+ ignore_installed=options.ignore_installed,
+ ignore_requires_python=options.ignore_requires_python,
+ force_reinstall=options.force_reinstall,
+ upgrade_strategy=upgrade_strategy,
+ use_pep517=options.use_pep517,
+ py_version_info=options.python_version,
+ )
+
+ self.trace_basic_info(finder)
+
+ requirement_set = resolver.resolve(
+ reqs, check_supported_wheels=not options.target_dir
+ )
+
+ if options.json_report_file:
+ report = InstallationReport(requirement_set.requirements_to_install)
+ if options.json_report_file == "-":
+ print_json(data=report.to_dict())
+ else:
+ with open(options.json_report_file, "w", encoding="utf-8") as f:
+ json.dump(report.to_dict(), f, indent=2, ensure_ascii=False)
+
+ if options.dry_run:
+ would_install_items = sorted(
+ (r.metadata["name"], r.metadata["version"])
+ for r in requirement_set.requirements_to_install
+ )
+ if would_install_items:
+ write_output(
+ "Would install %s",
+ " ".join("-".join(item) for item in would_install_items),
+ )
+ return SUCCESS
+
+ try:
+ pip_req = requirement_set.get_requirement("pip")
+ except KeyError:
+ modifying_pip = False
+ else:
+ # If we're not replacing an already installed pip,
+ # we're not modifying it.
+ modifying_pip = pip_req.satisfied_by is None
+ if modifying_pip:
+ # Eagerly import this module to avoid crashes. Otherwise, this
+ # module would be imported *after* pip was replaced, resulting in
+ # crashes if the new self_outdated_check module was incompatible
+ # with the rest of pip that's already imported.
+ import pip._internal.self_outdated_check # noqa: F401
+ protect_pip_from_modification_on_windows(modifying_pip=modifying_pip)
+
+ reqs_to_build = [
+ r
+ for r in requirement_set.requirements.values()
+ if should_build_for_install_command(r)
+ ]
+
+ _, build_failures = build(
+ reqs_to_build,
+ wheel_cache=wheel_cache,
+ verify=True,
+ build_options=[],
+ global_options=global_options,
+ )
+
+ if build_failures:
+ raise InstallationError(
+ "ERROR: Failed to build installable wheels for some "
+ "pyproject.toml based projects ({})".format(
+ ", ".join(r.name for r in build_failures) # type: ignore
+ )
+ )
+
+ to_install = resolver.get_installation_order(requirement_set)
+
+ # Check for conflicts in the package set we're installing.
+ conflicts: Optional[ConflictDetails] = None
+ should_warn_about_conflicts = (
+ not options.ignore_dependencies and options.warn_about_conflicts
+ )
+ if should_warn_about_conflicts:
+ conflicts = self._determine_conflicts(to_install)
+
+ # Don't warn about script install locations if
+ # --target or --prefix has been specified
+ warn_script_location = options.warn_script_location
+ if options.target_dir or options.prefix_path:
+ warn_script_location = False
+
+ installed = install_given_reqs(
+ to_install,
+ global_options,
+ root=options.root_path,
+ home=target_temp_dir_path,
+ prefix=options.prefix_path,
+ warn_script_location=warn_script_location,
+ use_user_site=options.use_user_site,
+ pycompile=options.compile,
+ )
+
+ lib_locations = get_lib_location_guesses(
+ user=options.use_user_site,
+ home=target_temp_dir_path,
+ root=options.root_path,
+ prefix=options.prefix_path,
+ isolated=options.isolated_mode,
+ )
+ env = get_environment(lib_locations)
+
+ # Display a summary of installed packages, with extra care to
+ # display a package name as it was requested by the user.
+ installed.sort(key=operator.attrgetter("name"))
+ summary = []
+ installed_versions = {}
+ for distribution in env.iter_all_distributions():
+ installed_versions[distribution.canonical_name] = distribution.version
+ for package in installed:
+ display_name = package.name
+ version = installed_versions.get(canonicalize_name(display_name), None)
+ if version:
+ text = f"{display_name}-{version}"
+ else:
+ text = display_name
+ summary.append(text)
+
+ if conflicts is not None:
+ self._warn_about_conflicts(
+ conflicts,
+ resolver_variant=self.determine_resolver_variant(options),
+ )
+
+ installed_desc = " ".join(summary)
+ if installed_desc:
+ write_output(
+ "Successfully installed %s",
+ installed_desc,
+ )
+ except OSError as error:
+ show_traceback = self.verbosity >= 1
+
+ message = create_os_error_message(
+ error,
+ show_traceback,
+ options.use_user_site,
+ )
+ logger.error(message, exc_info=show_traceback)
+
+ return ERROR
+
+ if options.target_dir:
+ assert target_temp_dir
+ self._handle_target_dir(
+ options.target_dir, target_temp_dir, options.upgrade
+ )
+ if options.root_user_action == "warn":
+ warn_if_run_as_root()
+ return SUCCESS
+
+ def _handle_target_dir(
+ self, target_dir: str, target_temp_dir: TempDirectory, upgrade: bool
+ ) -> None:
+ ensure_dir(target_dir)
+
+ # Checking both purelib and platlib directories for installed
+ # packages to be moved to target directory
+ lib_dir_list = []
+
+ # Checking both purelib and platlib directories for installed
+ # packages to be moved to target directory
+ scheme = get_scheme("", home=target_temp_dir.path)
+ purelib_dir = scheme.purelib
+ platlib_dir = scheme.platlib
+ data_dir = scheme.data
+
+ if os.path.exists(purelib_dir):
+ lib_dir_list.append(purelib_dir)
+ if os.path.exists(platlib_dir) and platlib_dir != purelib_dir:
+ lib_dir_list.append(platlib_dir)
+ if os.path.exists(data_dir):
+ lib_dir_list.append(data_dir)
+
+ for lib_dir in lib_dir_list:
+ for item in os.listdir(lib_dir):
+ if lib_dir == data_dir:
+ ddir = os.path.join(data_dir, item)
+ if any(s.startswith(ddir) for s in lib_dir_list[:-1]):
+ continue
+ target_item_dir = os.path.join(target_dir, item)
+ if os.path.exists(target_item_dir):
+ if not upgrade:
+ logger.warning(
+ "Target directory %s already exists. Specify "
+ "--upgrade to force replacement.",
+ target_item_dir,
+ )
+ continue
+ if os.path.islink(target_item_dir):
+ logger.warning(
+ "Target directory %s already exists and is "
+ "a link. pip will not automatically replace "
+ "links, please remove if replacement is "
+ "desired.",
+ target_item_dir,
+ )
+ continue
+ if os.path.isdir(target_item_dir):
+ shutil.rmtree(target_item_dir)
+ else:
+ os.remove(target_item_dir)
+
+ shutil.move(os.path.join(lib_dir, item), target_item_dir)
+
+ def _determine_conflicts(
+ self, to_install: List[InstallRequirement]
+ ) -> Optional[ConflictDetails]:
+ try:
+ return check_install_conflicts(to_install)
+ except Exception:
+ logger.exception(
+ "Error while checking for conflicts. Please file an issue on "
+ "pip's issue tracker: https://github.com/pypa/pip/issues/new"
+ )
+ return None
+
+ def _warn_about_conflicts(
+ self, conflict_details: ConflictDetails, resolver_variant: str
+ ) -> None:
+ package_set, (missing, conflicting) = conflict_details
+ if not missing and not conflicting:
+ return
+
+ parts: List[str] = []
+ if resolver_variant == "legacy":
+ parts.append(
+ "pip's legacy dependency resolver does not consider dependency "
+ "conflicts when selecting packages. This behaviour is the "
+ "source of the following dependency conflicts."
+ )
+ else:
+ assert resolver_variant == "resolvelib"
+ parts.append(
+ "pip's dependency resolver does not currently take into account "
+ "all the packages that are installed. This behaviour is the "
+ "source of the following dependency conflicts."
+ )
+
+ # NOTE: There is some duplication here, with commands/check.py
+ for project_name in missing:
+ version = package_set[project_name][0]
+ for dependency in missing[project_name]:
+ message = (
+ f"{project_name} {version} requires {dependency[1]}, "
+ "which is not installed."
+ )
+ parts.append(message)
+
+ for project_name in conflicting:
+ version = package_set[project_name][0]
+ for dep_name, dep_version, req in conflicting[project_name]:
+ message = (
+ "{name} {version} requires {requirement}, but {you} have "
+ "{dep_name} {dep_version} which is incompatible."
+ ).format(
+ name=project_name,
+ version=version,
+ requirement=req,
+ dep_name=dep_name,
+ dep_version=dep_version,
+ you=("you" if resolver_variant == "resolvelib" else "you'll"),
+ )
+ parts.append(message)
+
+ logger.critical("\n".join(parts))
+
+
+def get_lib_location_guesses(
+ user: bool = False,
+ home: Optional[str] = None,
+ root: Optional[str] = None,
+ isolated: bool = False,
+ prefix: Optional[str] = None,
+) -> List[str]:
+ scheme = get_scheme(
+ "",
+ user=user,
+ home=home,
+ root=root,
+ isolated=isolated,
+ prefix=prefix,
+ )
+ return [scheme.purelib, scheme.platlib]
+
+
+def site_packages_writable(root: Optional[str], isolated: bool) -> bool:
+ return all(
+ test_writable_dir(d)
+ for d in set(get_lib_location_guesses(root=root, isolated=isolated))
+ )
+
+
+def decide_user_install(
+ use_user_site: Optional[bool],
+ prefix_path: Optional[str] = None,
+ target_dir: Optional[str] = None,
+ root_path: Optional[str] = None,
+ isolated_mode: bool = False,
+) -> bool:
+ """Determine whether to do a user install based on the input options.
+
+ If use_user_site is False, no additional checks are done.
+ If use_user_site is True, it is checked for compatibility with other
+ options.
+ If use_user_site is None, the default behaviour depends on the environment,
+ which is provided by the other arguments.
+ """
+ # In some cases (config from tox), use_user_site can be set to an integer
+ # rather than a bool, which 'use_user_site is False' wouldn't catch.
+ if (use_user_site is not None) and (not use_user_site):
+ logger.debug("Non-user install by explicit request")
+ return False
+
+ if use_user_site:
+ if prefix_path:
+ raise CommandError(
+ "Can not combine '--user' and '--prefix' as they imply "
+ "different installation locations"
+ )
+ if virtualenv_no_global():
+ raise InstallationError(
+ "Can not perform a '--user' install. User site-packages "
+ "are not visible in this virtualenv."
+ )
+ logger.debug("User install by explicit request")
+ return True
+
+ # If we are here, user installs have not been explicitly requested/avoided
+ assert use_user_site is None
+
+ # user install incompatible with --prefix/--target
+ if prefix_path or target_dir:
+ logger.debug("Non-user install due to --prefix or --target option")
+ return False
+
+ # If user installs are not enabled, choose a non-user install
+ if not site.ENABLE_USER_SITE:
+ logger.debug("Non-user install because user site-packages disabled")
+ return False
+
+ # If we have permission for a non-user install, do that,
+ # otherwise do a user install.
+ if site_packages_writable(root=root_path, isolated=isolated_mode):
+ logger.debug("Non-user install because site-packages writeable")
+ return False
+
+ logger.info(
+ "Defaulting to user installation because normal site-packages "
+ "is not writeable"
+ )
+ return True
+
+
+def create_os_error_message(
+ error: OSError, show_traceback: bool, using_user_site: bool
+) -> str:
+ """Format an error message for an OSError
+
+ It may occur anytime during the execution of the install command.
+ """
+ parts = []
+
+ # Mention the error if we are not going to show a traceback
+ parts.append("Could not install packages due to an OSError")
+ if not show_traceback:
+ parts.append(": ")
+ parts.append(str(error))
+ else:
+ parts.append(".")
+
+ # Spilt the error indication from a helper message (if any)
+ parts[-1] += "\n"
+
+ # Suggest useful actions to the user:
+ # (1) using user site-packages or (2) verifying the permissions
+ if error.errno == errno.EACCES:
+ user_option_part = "Consider using the `--user` option"
+ permissions_part = "Check the permissions"
+
+ if not running_under_virtualenv() and not using_user_site:
+ parts.extend(
+ [
+ user_option_part,
+ " or ",
+ permissions_part.lower(),
+ ]
+ )
+ else:
+ parts.append(permissions_part)
+ parts.append(".\n")
+
+ # Suggest the user to enable Long Paths if path length is
+ # more than 260
+ if (
+ WINDOWS
+ and error.errno == errno.ENOENT
+ and error.filename
+ and len(error.filename) > 260
+ ):
+ parts.append(
+ "HINT: This error might have occurred since "
+ "this system does not have Windows Long Path "
+ "support enabled. You can find information on "
+ "how to enable this at "
+ "https://pip.pypa.io/warnings/enable-long-paths\n"
+ )
+
+ return "".join(parts).strip() + "\n"
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/list.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/list.py
new file mode 100644
index 000000000..849437024
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/list.py
@@ -0,0 +1,375 @@
+import json
+import logging
+from optparse import Values
+from typing import TYPE_CHECKING, Generator, List, Optional, Sequence, Tuple, cast
+
+from pip._vendor.packaging.utils import canonicalize_name
+from pip._vendor.packaging.version import Version
+
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.index_command import IndexGroupCommand
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.exceptions import CommandError
+from pip._internal.metadata import BaseDistribution, get_environment
+from pip._internal.models.selection_prefs import SelectionPreferences
+from pip._internal.utils.compat import stdlib_pkgs
+from pip._internal.utils.misc import tabulate, write_output
+
+if TYPE_CHECKING:
+ from pip._internal.index.package_finder import PackageFinder
+ from pip._internal.network.session import PipSession
+
+ class _DistWithLatestInfo(BaseDistribution):
+ """Give the distribution object a couple of extra fields.
+
+ These will be populated during ``get_outdated()``. This is dirty but
+ makes the rest of the code much cleaner.
+ """
+
+ latest_version: Version
+ latest_filetype: str
+
+ _ProcessedDists = Sequence[_DistWithLatestInfo]
+
+
+logger = logging.getLogger(__name__)
+
+
+class ListCommand(IndexGroupCommand):
+ """
+ List installed packages, including editables.
+
+ Packages are listed in a case-insensitive sorted order.
+ """
+
+ ignore_require_venv = True
+ usage = """
+ %prog [options]"""
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "-o",
+ "--outdated",
+ action="store_true",
+ default=False,
+ help="List outdated packages",
+ )
+ self.cmd_opts.add_option(
+ "-u",
+ "--uptodate",
+ action="store_true",
+ default=False,
+ help="List uptodate packages",
+ )
+ self.cmd_opts.add_option(
+ "-e",
+ "--editable",
+ action="store_true",
+ default=False,
+ help="List editable projects.",
+ )
+ self.cmd_opts.add_option(
+ "-l",
+ "--local",
+ action="store_true",
+ default=False,
+ help=(
+ "If in a virtualenv that has global access, do not list "
+ "globally-installed packages."
+ ),
+ )
+ self.cmd_opts.add_option(
+ "--user",
+ dest="user",
+ action="store_true",
+ default=False,
+ help="Only output packages installed in user-site.",
+ )
+ self.cmd_opts.add_option(cmdoptions.list_path())
+ self.cmd_opts.add_option(
+ "--pre",
+ action="store_true",
+ default=False,
+ help=(
+ "Include pre-release and development versions. By default, "
+ "pip only finds stable versions."
+ ),
+ )
+
+ self.cmd_opts.add_option(
+ "--format",
+ action="store",
+ dest="list_format",
+ default="columns",
+ choices=("columns", "freeze", "json"),
+ help=(
+ "Select the output format among: columns (default), freeze, or json. "
+ "The 'freeze' format cannot be used with the --outdated option."
+ ),
+ )
+
+ self.cmd_opts.add_option(
+ "--not-required",
+ action="store_true",
+ dest="not_required",
+ help="List packages that are not dependencies of installed packages.",
+ )
+
+ self.cmd_opts.add_option(
+ "--exclude-editable",
+ action="store_false",
+ dest="include_editable",
+ help="Exclude editable package from output.",
+ )
+ self.cmd_opts.add_option(
+ "--include-editable",
+ action="store_true",
+ dest="include_editable",
+ help="Include editable package from output.",
+ default=True,
+ )
+ self.cmd_opts.add_option(cmdoptions.list_exclude())
+ index_opts = cmdoptions.make_option_group(cmdoptions.index_group, self.parser)
+
+ self.parser.insert_option_group(0, index_opts)
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def handle_pip_version_check(self, options: Values) -> None:
+ if options.outdated or options.uptodate:
+ super().handle_pip_version_check(options)
+
+ def _build_package_finder(
+ self, options: Values, session: "PipSession"
+ ) -> "PackageFinder":
+ """
+ Create a package finder appropriate to this list command.
+ """
+ # Lazy import the heavy index modules as most list invocations won't need 'em.
+ from pip._internal.index.collector import LinkCollector
+ from pip._internal.index.package_finder import PackageFinder
+
+ link_collector = LinkCollector.create(session, options=options)
+
+ # Pass allow_yanked=False to ignore yanked versions.
+ selection_prefs = SelectionPreferences(
+ allow_yanked=False,
+ allow_all_prereleases=options.pre,
+ )
+
+ return PackageFinder.create(
+ link_collector=link_collector,
+ selection_prefs=selection_prefs,
+ )
+
+ def run(self, options: Values, args: List[str]) -> int:
+ if options.outdated and options.uptodate:
+ raise CommandError("Options --outdated and --uptodate cannot be combined.")
+
+ if options.outdated and options.list_format == "freeze":
+ raise CommandError(
+ "List format 'freeze' cannot be used with the --outdated option."
+ )
+
+ cmdoptions.check_list_path_option(options)
+
+ skip = set(stdlib_pkgs)
+ if options.excludes:
+ skip.update(canonicalize_name(n) for n in options.excludes)
+
+ packages: _ProcessedDists = [
+ cast("_DistWithLatestInfo", d)
+ for d in get_environment(options.path).iter_installed_distributions(
+ local_only=options.local,
+ user_only=options.user,
+ editables_only=options.editable,
+ include_editables=options.include_editable,
+ skip=skip,
+ )
+ ]
+
+ # get_not_required must be called firstly in order to find and
+ # filter out all dependencies correctly. Otherwise a package
+ # can't be identified as requirement because some parent packages
+ # could be filtered out before.
+ if options.not_required:
+ packages = self.get_not_required(packages, options)
+
+ if options.outdated:
+ packages = self.get_outdated(packages, options)
+ elif options.uptodate:
+ packages = self.get_uptodate(packages, options)
+
+ self.output_package_listing(packages, options)
+ return SUCCESS
+
+ def get_outdated(
+ self, packages: "_ProcessedDists", options: Values
+ ) -> "_ProcessedDists":
+ return [
+ dist
+ for dist in self.iter_packages_latest_infos(packages, options)
+ if dist.latest_version > dist.version
+ ]
+
+ def get_uptodate(
+ self, packages: "_ProcessedDists", options: Values
+ ) -> "_ProcessedDists":
+ return [
+ dist
+ for dist in self.iter_packages_latest_infos(packages, options)
+ if dist.latest_version == dist.version
+ ]
+
+ def get_not_required(
+ self, packages: "_ProcessedDists", options: Values
+ ) -> "_ProcessedDists":
+ dep_keys = {
+ canonicalize_name(dep.name)
+ for dist in packages
+ for dep in (dist.iter_dependencies() or ())
+ }
+
+ # Create a set to remove duplicate packages, and cast it to a list
+ # to keep the return type consistent with get_outdated and
+ # get_uptodate
+ return list({pkg for pkg in packages if pkg.canonical_name not in dep_keys})
+
+ def iter_packages_latest_infos(
+ self, packages: "_ProcessedDists", options: Values
+ ) -> Generator["_DistWithLatestInfo", None, None]:
+ with self._build_session(options) as session:
+ finder = self._build_package_finder(options, session)
+
+ def latest_info(
+ dist: "_DistWithLatestInfo",
+ ) -> Optional["_DistWithLatestInfo"]:
+ all_candidates = finder.find_all_candidates(dist.canonical_name)
+ if not options.pre:
+ # Remove prereleases
+ all_candidates = [
+ candidate
+ for candidate in all_candidates
+ if not candidate.version.is_prerelease
+ ]
+
+ evaluator = finder.make_candidate_evaluator(
+ project_name=dist.canonical_name,
+ )
+ best_candidate = evaluator.sort_best_candidate(all_candidates)
+ if best_candidate is None:
+ return None
+
+ remote_version = best_candidate.version
+ if best_candidate.link.is_wheel:
+ typ = "wheel"
+ else:
+ typ = "sdist"
+ dist.latest_version = remote_version
+ dist.latest_filetype = typ
+ return dist
+
+ for dist in map(latest_info, packages):
+ if dist is not None:
+ yield dist
+
+ def output_package_listing(
+ self, packages: "_ProcessedDists", options: Values
+ ) -> None:
+ packages = sorted(
+ packages,
+ key=lambda dist: dist.canonical_name,
+ )
+ if options.list_format == "columns" and packages:
+ data, header = format_for_columns(packages, options)
+ self.output_package_listing_columns(data, header)
+ elif options.list_format == "freeze":
+ for dist in packages:
+ if options.verbose >= 1:
+ write_output(
+ "%s==%s (%s)", dist.raw_name, dist.version, dist.location
+ )
+ else:
+ write_output("%s==%s", dist.raw_name, dist.version)
+ elif options.list_format == "json":
+ write_output(format_for_json(packages, options))
+
+ def output_package_listing_columns(
+ self, data: List[List[str]], header: List[str]
+ ) -> None:
+ # insert the header first: we need to know the size of column names
+ if len(data) > 0:
+ data.insert(0, header)
+
+ pkg_strings, sizes = tabulate(data)
+
+ # Create and add a separator.
+ if len(data) > 0:
+ pkg_strings.insert(1, " ".join("-" * x for x in sizes))
+
+ for val in pkg_strings:
+ write_output(val)
+
+
+def format_for_columns(
+ pkgs: "_ProcessedDists", options: Values
+) -> Tuple[List[List[str]], List[str]]:
+ """
+ Convert the package data into something usable
+ by output_package_listing_columns.
+ """
+ header = ["Package", "Version"]
+
+ running_outdated = options.outdated
+ if running_outdated:
+ header.extend(["Latest", "Type"])
+
+ has_editables = any(x.editable for x in pkgs)
+ if has_editables:
+ header.append("Editable project location")
+
+ if options.verbose >= 1:
+ header.append("Location")
+ if options.verbose >= 1:
+ header.append("Installer")
+
+ data = []
+ for proj in pkgs:
+ # if we're working on the 'outdated' list, separate out the
+ # latest_version and type
+ row = [proj.raw_name, proj.raw_version]
+
+ if running_outdated:
+ row.append(str(proj.latest_version))
+ row.append(proj.latest_filetype)
+
+ if has_editables:
+ row.append(proj.editable_project_location or "")
+
+ if options.verbose >= 1:
+ row.append(proj.location or "")
+ if options.verbose >= 1:
+ row.append(proj.installer)
+
+ data.append(row)
+
+ return data, header
+
+
+def format_for_json(packages: "_ProcessedDists", options: Values) -> str:
+ data = []
+ for dist in packages:
+ info = {
+ "name": dist.raw_name,
+ "version": str(dist.version),
+ }
+ if options.verbose >= 1:
+ info["location"] = dist.location or ""
+ info["installer"] = dist.installer
+ if options.outdated:
+ info["latest_version"] = str(dist.latest_version)
+ info["latest_filetype"] = dist.latest_filetype
+ editable_project_location = dist.editable_project_location
+ if editable_project_location:
+ info["editable_project_location"] = editable_project_location
+ data.append(info)
+ return json.dumps(data)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/search.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/search.py
new file mode 100644
index 000000000..74b8d656b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/search.py
@@ -0,0 +1,172 @@
+import logging
+import shutil
+import sys
+import textwrap
+import xmlrpc.client
+from collections import OrderedDict
+from optparse import Values
+from typing import TYPE_CHECKING, Dict, List, Optional, TypedDict
+
+from pip._vendor.packaging.version import parse as parse_version
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.req_command import SessionCommandMixin
+from pip._internal.cli.status_codes import NO_MATCHES_FOUND, SUCCESS
+from pip._internal.exceptions import CommandError
+from pip._internal.metadata import get_default_environment
+from pip._internal.models.index import PyPI
+from pip._internal.network.xmlrpc import PipXmlrpcTransport
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.misc import write_output
+
+if TYPE_CHECKING:
+
+ class TransformedHit(TypedDict):
+ name: str
+ summary: str
+ versions: List[str]
+
+
+logger = logging.getLogger(__name__)
+
+
+class SearchCommand(Command, SessionCommandMixin):
+ """Search for PyPI packages whose name or summary contains <query>."""
+
+ usage = """
+ %prog [options] <query>"""
+ ignore_require_venv = True
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "-i",
+ "--index",
+ dest="index",
+ metavar="URL",
+ default=PyPI.pypi_url,
+ help="Base URL of Python Package Index (default %default)",
+ )
+
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ if not args:
+ raise CommandError("Missing required argument (search query).")
+ query = args
+ pypi_hits = self.search(query, options)
+ hits = transform_hits(pypi_hits)
+
+ terminal_width = None
+ if sys.stdout.isatty():
+ terminal_width = shutil.get_terminal_size()[0]
+
+ print_results(hits, terminal_width=terminal_width)
+ if pypi_hits:
+ return SUCCESS
+ return NO_MATCHES_FOUND
+
+ def search(self, query: List[str], options: Values) -> List[Dict[str, str]]:
+ index_url = options.index
+
+ session = self.get_default_session(options)
+
+ transport = PipXmlrpcTransport(index_url, session)
+ pypi = xmlrpc.client.ServerProxy(index_url, transport)
+ try:
+ hits = pypi.search({"name": query, "summary": query}, "or")
+ except xmlrpc.client.Fault as fault:
+ message = (
+ f"XMLRPC request failed [code: {fault.faultCode}]\n{fault.faultString}"
+ )
+ raise CommandError(message)
+ assert isinstance(hits, list)
+ return hits
+
+
+def transform_hits(hits: List[Dict[str, str]]) -> List["TransformedHit"]:
+ """
+ The list from pypi is really a list of versions. We want a list of
+ packages with the list of versions stored inline. This converts the
+ list from pypi into one we can use.
+ """
+ packages: Dict[str, TransformedHit] = OrderedDict()
+ for hit in hits:
+ name = hit["name"]
+ summary = hit["summary"]
+ version = hit["version"]
+
+ if name not in packages.keys():
+ packages[name] = {
+ "name": name,
+ "summary": summary,
+ "versions": [version],
+ }
+ else:
+ packages[name]["versions"].append(version)
+
+ # if this is the highest version, replace summary and score
+ if version == highest_version(packages[name]["versions"]):
+ packages[name]["summary"] = summary
+
+ return list(packages.values())
+
+
+def print_dist_installation_info(name: str, latest: str) -> None:
+ env = get_default_environment()
+ dist = env.get_distribution(name)
+ if dist is not None:
+ with indent_log():
+ if dist.version == latest:
+ write_output("INSTALLED: %s (latest)", dist.version)
+ else:
+ write_output("INSTALLED: %s", dist.version)
+ if parse_version(latest).pre:
+ write_output(
+ "LATEST: %s (pre-release; install"
+ " with `pip install --pre`)",
+ latest,
+ )
+ else:
+ write_output("LATEST: %s", latest)
+
+
+def print_results(
+ hits: List["TransformedHit"],
+ name_column_width: Optional[int] = None,
+ terminal_width: Optional[int] = None,
+) -> None:
+ if not hits:
+ return
+ if name_column_width is None:
+ name_column_width = (
+ max(
+ [
+ len(hit["name"]) + len(highest_version(hit.get("versions", ["-"])))
+ for hit in hits
+ ]
+ )
+ + 4
+ )
+
+ for hit in hits:
+ name = hit["name"]
+ summary = hit["summary"] or ""
+ latest = highest_version(hit.get("versions", ["-"]))
+ if terminal_width is not None:
+ target_width = terminal_width - name_column_width - 5
+ if target_width > 10:
+ # wrap and indent summary to fit terminal
+ summary_lines = textwrap.wrap(summary, target_width)
+ summary = ("\n" + " " * (name_column_width + 3)).join(summary_lines)
+
+ name_latest = f"{name} ({latest})"
+ line = f"{name_latest:{name_column_width}} - {summary}"
+ try:
+ write_output(line)
+ print_dist_installation_info(name, latest)
+ except UnicodeEncodeError:
+ pass
+
+
+def highest_version(versions: List[str]) -> str:
+ return max(versions, key=parse_version)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/show.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/show.py
new file mode 100644
index 000000000..c54d548f5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/show.py
@@ -0,0 +1,217 @@
+import logging
+from optparse import Values
+from typing import Generator, Iterable, Iterator, List, NamedTuple, Optional
+
+from pip._vendor.packaging.requirements import InvalidRequirement
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.status_codes import ERROR, SUCCESS
+from pip._internal.metadata import BaseDistribution, get_default_environment
+from pip._internal.utils.misc import write_output
+
+logger = logging.getLogger(__name__)
+
+
+class ShowCommand(Command):
+ """
+ Show information about one or more installed packages.
+
+ The output is in RFC-compliant mail header format.
+ """
+
+ usage = """
+ %prog [options] <package> ..."""
+ ignore_require_venv = True
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "-f",
+ "--files",
+ dest="files",
+ action="store_true",
+ default=False,
+ help="Show the full list of installed files for each package.",
+ )
+
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ if not args:
+ logger.warning("ERROR: Please provide a package name or names.")
+ return ERROR
+ query = args
+
+ results = search_packages_info(query)
+ if not print_results(
+ results, list_files=options.files, verbose=options.verbose
+ ):
+ return ERROR
+ return SUCCESS
+
+
+class _PackageInfo(NamedTuple):
+ name: str
+ version: str
+ location: str
+ editable_project_location: Optional[str]
+ requires: List[str]
+ required_by: List[str]
+ installer: str
+ metadata_version: str
+ classifiers: List[str]
+ summary: str
+ homepage: str
+ project_urls: List[str]
+ author: str
+ author_email: str
+ license: str
+ entry_points: List[str]
+ files: Optional[List[str]]
+
+
+def search_packages_info(query: List[str]) -> Generator[_PackageInfo, None, None]:
+ """
+ Gather details from installed distributions. Print distribution name,
+ version, location, and installed files. Installed files requires a
+ pip generated 'installed-files.txt' in the distributions '.egg-info'
+ directory.
+ """
+ env = get_default_environment()
+
+ installed = {dist.canonical_name: dist for dist in env.iter_all_distributions()}
+ query_names = [canonicalize_name(name) for name in query]
+ missing = sorted(
+ [name for name, pkg in zip(query, query_names) if pkg not in installed]
+ )
+ if missing:
+ logger.warning("Package(s) not found: %s", ", ".join(missing))
+
+ def _get_requiring_packages(current_dist: BaseDistribution) -> Iterator[str]:
+ return (
+ dist.metadata["Name"] or "UNKNOWN"
+ for dist in installed.values()
+ if current_dist.canonical_name
+ in {canonicalize_name(d.name) for d in dist.iter_dependencies()}
+ )
+
+ for query_name in query_names:
+ try:
+ dist = installed[query_name]
+ except KeyError:
+ continue
+
+ try:
+ requires = sorted(
+ # Avoid duplicates in requirements (e.g. due to environment markers).
+ {req.name for req in dist.iter_dependencies()},
+ key=str.lower,
+ )
+ except InvalidRequirement:
+ requires = sorted(dist.iter_raw_dependencies(), key=str.lower)
+
+ try:
+ required_by = sorted(_get_requiring_packages(dist), key=str.lower)
+ except InvalidRequirement:
+ required_by = ["#N/A"]
+
+ try:
+ entry_points_text = dist.read_text("entry_points.txt")
+ entry_points = entry_points_text.splitlines(keepends=False)
+ except FileNotFoundError:
+ entry_points = []
+
+ files_iter = dist.iter_declared_entries()
+ if files_iter is None:
+ files: Optional[List[str]] = None
+ else:
+ files = sorted(files_iter)
+
+ metadata = dist.metadata
+
+ project_urls = metadata.get_all("Project-URL", [])
+ homepage = metadata.get("Home-page", "")
+ if not homepage:
+ # It's common that there is a "homepage" Project-URL, but Home-page
+ # remains unset (especially as PEP 621 doesn't surface the field).
+ #
+ # This logic was taken from PyPI's codebase.
+ for url in project_urls:
+ url_label, url = url.split(",", maxsplit=1)
+ normalized_label = (
+ url_label.casefold().replace("-", "").replace("_", "").strip()
+ )
+ if normalized_label == "homepage":
+ homepage = url.strip()
+ break
+
+ yield _PackageInfo(
+ name=dist.raw_name,
+ version=dist.raw_version,
+ location=dist.location or "",
+ editable_project_location=dist.editable_project_location,
+ requires=requires,
+ required_by=required_by,
+ installer=dist.installer,
+ metadata_version=dist.metadata_version or "",
+ classifiers=metadata.get_all("Classifier", []),
+ summary=metadata.get("Summary", ""),
+ homepage=homepage,
+ project_urls=project_urls,
+ author=metadata.get("Author", ""),
+ author_email=metadata.get("Author-email", ""),
+ license=metadata.get("License", ""),
+ entry_points=entry_points,
+ files=files,
+ )
+
+
+def print_results(
+ distributions: Iterable[_PackageInfo],
+ list_files: bool,
+ verbose: bool,
+) -> bool:
+ """
+ Print the information from installed distributions found.
+ """
+ results_printed = False
+ for i, dist in enumerate(distributions):
+ results_printed = True
+ if i > 0:
+ write_output("---")
+
+ write_output("Name: %s", dist.name)
+ write_output("Version: %s", dist.version)
+ write_output("Summary: %s", dist.summary)
+ write_output("Home-page: %s", dist.homepage)
+ write_output("Author: %s", dist.author)
+ write_output("Author-email: %s", dist.author_email)
+ write_output("License: %s", dist.license)
+ write_output("Location: %s", dist.location)
+ if dist.editable_project_location is not None:
+ write_output(
+ "Editable project location: %s", dist.editable_project_location
+ )
+ write_output("Requires: %s", ", ".join(dist.requires))
+ write_output("Required-by: %s", ", ".join(dist.required_by))
+
+ if verbose:
+ write_output("Metadata-Version: %s", dist.metadata_version)
+ write_output("Installer: %s", dist.installer)
+ write_output("Classifiers:")
+ for classifier in dist.classifiers:
+ write_output(" %s", classifier)
+ write_output("Entry-points:")
+ for entry in dist.entry_points:
+ write_output(" %s", entry.strip())
+ write_output("Project-URLs:")
+ for project_url in dist.project_urls:
+ write_output(" %s", project_url)
+ if list_files:
+ write_output("Files:")
+ if dist.files is None:
+ write_output("Cannot locate RECORD or installed-files.txt")
+ else:
+ for line in dist.files:
+ write_output(" %s", line.strip())
+ return results_printed
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/uninstall.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/uninstall.py
new file mode 100644
index 000000000..bc0edeac9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/uninstall.py
@@ -0,0 +1,114 @@
+import logging
+from optparse import Values
+from typing import List
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.base_command import Command
+from pip._internal.cli.index_command import SessionCommandMixin
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.exceptions import InstallationError
+from pip._internal.req import parse_requirements
+from pip._internal.req.constructors import (
+ install_req_from_line,
+ install_req_from_parsed_requirement,
+)
+from pip._internal.utils.misc import (
+ check_externally_managed,
+ protect_pip_from_modification_on_windows,
+ warn_if_run_as_root,
+)
+
+logger = logging.getLogger(__name__)
+
+
+class UninstallCommand(Command, SessionCommandMixin):
+ """
+ Uninstall packages.
+
+ pip is able to uninstall most installed packages. Known exceptions are:
+
+ - Pure distutils packages installed with ``python setup.py install``, which
+ leave behind no metadata to determine what files were installed.
+ - Script wrappers installed by ``python setup.py develop``.
+ """
+
+ usage = """
+ %prog [options] <package> ...
+ %prog [options] -r <requirements file> ..."""
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "-r",
+ "--requirement",
+ dest="requirements",
+ action="append",
+ default=[],
+ metavar="file",
+ help=(
+ "Uninstall all the packages listed in the given requirements "
+ "file. This option can be used multiple times."
+ ),
+ )
+ self.cmd_opts.add_option(
+ "-y",
+ "--yes",
+ dest="yes",
+ action="store_true",
+ help="Don't ask for confirmation of uninstall deletions.",
+ )
+ self.cmd_opts.add_option(cmdoptions.root_user_action())
+ self.cmd_opts.add_option(cmdoptions.override_externally_managed())
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ def run(self, options: Values, args: List[str]) -> int:
+ session = self.get_default_session(options)
+
+ reqs_to_uninstall = {}
+ for name in args:
+ req = install_req_from_line(
+ name,
+ isolated=options.isolated_mode,
+ )
+ if req.name:
+ reqs_to_uninstall[canonicalize_name(req.name)] = req
+ else:
+ logger.warning(
+ "Invalid requirement: %r ignored -"
+ " the uninstall command expects named"
+ " requirements.",
+ name,
+ )
+ for filename in options.requirements:
+ for parsed_req in parse_requirements(
+ filename, options=options, session=session
+ ):
+ req = install_req_from_parsed_requirement(
+ parsed_req, isolated=options.isolated_mode
+ )
+ if req.name:
+ reqs_to_uninstall[canonicalize_name(req.name)] = req
+ if not reqs_to_uninstall:
+ raise InstallationError(
+ f"You must give at least one requirement to {self.name} (see "
+ f'"pip help {self.name}")'
+ )
+
+ if not options.override_externally_managed:
+ check_externally_managed()
+
+ protect_pip_from_modification_on_windows(
+ modifying_pip="pip" in reqs_to_uninstall
+ )
+
+ for req in reqs_to_uninstall.values():
+ uninstall_pathset = req.uninstall(
+ auto_confirm=options.yes,
+ verbose=self.verbosity > 0,
+ )
+ if uninstall_pathset:
+ uninstall_pathset.commit()
+ if options.root_user_action == "warn":
+ warn_if_run_as_root()
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/commands/wheel.py b/solutions/.venv/Lib/site-packages/pip/_internal/commands/wheel.py
new file mode 100644
index 000000000..278719f4e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/commands/wheel.py
@@ -0,0 +1,182 @@
+import logging
+import os
+import shutil
+from optparse import Values
+from typing import List
+
+from pip._internal.cache import WheelCache
+from pip._internal.cli import cmdoptions
+from pip._internal.cli.req_command import RequirementCommand, with_cleanup
+from pip._internal.cli.status_codes import SUCCESS
+from pip._internal.exceptions import CommandError
+from pip._internal.operations.build.build_tracker import get_build_tracker
+from pip._internal.req.req_install import (
+ InstallRequirement,
+ check_legacy_setup_py_options,
+)
+from pip._internal.utils.misc import ensure_dir, normalize_path
+from pip._internal.utils.temp_dir import TempDirectory
+from pip._internal.wheel_builder import build, should_build_for_wheel_command
+
+logger = logging.getLogger(__name__)
+
+
+class WheelCommand(RequirementCommand):
+ """
+ Build Wheel archives for your requirements and dependencies.
+
+ Wheel is a built-package format, and offers the advantage of not
+ recompiling your software during every install. For more details, see the
+ wheel docs: https://wheel.readthedocs.io/en/latest/
+
+ 'pip wheel' uses the build system interface as described here:
+ https://pip.pypa.io/en/stable/reference/build-system/
+
+ """
+
+ usage = """
+ %prog [options] <requirement specifier> ...
+ %prog [options] -r <requirements file> ...
+ %prog [options] [-e] <vcs project url> ...
+ %prog [options] [-e] <local project path> ...
+ %prog [options] <archive url/path> ..."""
+
+ def add_options(self) -> None:
+ self.cmd_opts.add_option(
+ "-w",
+ "--wheel-dir",
+ dest="wheel_dir",
+ metavar="dir",
+ default=os.curdir,
+ help=(
+ "Build wheels into <dir>, where the default is the "
+ "current working directory."
+ ),
+ )
+ self.cmd_opts.add_option(cmdoptions.no_binary())
+ self.cmd_opts.add_option(cmdoptions.only_binary())
+ self.cmd_opts.add_option(cmdoptions.prefer_binary())
+ self.cmd_opts.add_option(cmdoptions.no_build_isolation())
+ self.cmd_opts.add_option(cmdoptions.use_pep517())
+ self.cmd_opts.add_option(cmdoptions.no_use_pep517())
+ self.cmd_opts.add_option(cmdoptions.check_build_deps())
+ self.cmd_opts.add_option(cmdoptions.constraints())
+ self.cmd_opts.add_option(cmdoptions.editable())
+ self.cmd_opts.add_option(cmdoptions.requirements())
+ self.cmd_opts.add_option(cmdoptions.src())
+ self.cmd_opts.add_option(cmdoptions.ignore_requires_python())
+ self.cmd_opts.add_option(cmdoptions.no_deps())
+ self.cmd_opts.add_option(cmdoptions.progress_bar())
+
+ self.cmd_opts.add_option(
+ "--no-verify",
+ dest="no_verify",
+ action="store_true",
+ default=False,
+ help="Don't verify if built wheel is valid.",
+ )
+
+ self.cmd_opts.add_option(cmdoptions.config_settings())
+ self.cmd_opts.add_option(cmdoptions.build_options())
+ self.cmd_opts.add_option(cmdoptions.global_options())
+
+ self.cmd_opts.add_option(
+ "--pre",
+ action="store_true",
+ default=False,
+ help=(
+ "Include pre-release and development versions. By default, "
+ "pip only finds stable versions."
+ ),
+ )
+
+ self.cmd_opts.add_option(cmdoptions.require_hashes())
+
+ index_opts = cmdoptions.make_option_group(
+ cmdoptions.index_group,
+ self.parser,
+ )
+
+ self.parser.insert_option_group(0, index_opts)
+ self.parser.insert_option_group(0, self.cmd_opts)
+
+ @with_cleanup
+ def run(self, options: Values, args: List[str]) -> int:
+ session = self.get_default_session(options)
+
+ finder = self._build_package_finder(options, session)
+
+ options.wheel_dir = normalize_path(options.wheel_dir)
+ ensure_dir(options.wheel_dir)
+
+ build_tracker = self.enter_context(get_build_tracker())
+
+ directory = TempDirectory(
+ delete=not options.no_clean,
+ kind="wheel",
+ globally_managed=True,
+ )
+
+ reqs = self.get_requirements(args, options, finder, session)
+ check_legacy_setup_py_options(options, reqs)
+
+ wheel_cache = WheelCache(options.cache_dir)
+
+ preparer = self.make_requirement_preparer(
+ temp_build_dir=directory,
+ options=options,
+ build_tracker=build_tracker,
+ session=session,
+ finder=finder,
+ download_dir=options.wheel_dir,
+ use_user_site=False,
+ verbosity=self.verbosity,
+ )
+
+ resolver = self.make_resolver(
+ preparer=preparer,
+ finder=finder,
+ options=options,
+ wheel_cache=wheel_cache,
+ ignore_requires_python=options.ignore_requires_python,
+ use_pep517=options.use_pep517,
+ )
+
+ self.trace_basic_info(finder)
+
+ requirement_set = resolver.resolve(reqs, check_supported_wheels=True)
+
+ reqs_to_build: List[InstallRequirement] = []
+ for req in requirement_set.requirements.values():
+ if req.is_wheel:
+ preparer.save_linked_requirement(req)
+ elif should_build_for_wheel_command(req):
+ reqs_to_build.append(req)
+
+ preparer.prepare_linked_requirements_more(requirement_set.requirements.values())
+
+ # build wheels
+ build_successes, build_failures = build(
+ reqs_to_build,
+ wheel_cache=wheel_cache,
+ verify=(not options.no_verify),
+ build_options=options.build_options or [],
+ global_options=options.global_options or [],
+ )
+ for req in build_successes:
+ assert req.link and req.link.is_wheel
+ assert req.local_file_path
+ # copy from cache to target directory
+ try:
+ shutil.copy(req.local_file_path, options.wheel_dir)
+ except OSError as e:
+ logger.warning(
+ "Building wheel for %s failed: %s",
+ req.name,
+ e,
+ )
+ build_failures.append(req)
+ if len(build_failures) != 0:
+ raise CommandError("Failed to build one or more wheels")
+
+ return SUCCESS
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/configuration.py b/solutions/.venv/Lib/site-packages/pip/_internal/configuration.py
new file mode 100644
index 000000000..c25273d5f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/configuration.py
@@ -0,0 +1,383 @@
+"""Configuration management setup
+
+Some terminology:
+- name
+ As written in config files.
+- value
+ Value associated with a name
+- key
+ Name combined with it's section (section.name)
+- variant
+ A single word describing where the configuration key-value pair came from
+"""
+
+import configparser
+import locale
+import os
+import sys
+from typing import Any, Dict, Iterable, List, NewType, Optional, Tuple
+
+from pip._internal.exceptions import (
+ ConfigurationError,
+ ConfigurationFileCouldNotBeLoaded,
+)
+from pip._internal.utils import appdirs
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.logging import getLogger
+from pip._internal.utils.misc import ensure_dir, enum
+
+RawConfigParser = configparser.RawConfigParser # Shorthand
+Kind = NewType("Kind", str)
+
+CONFIG_BASENAME = "pip.ini" if WINDOWS else "pip.conf"
+ENV_NAMES_IGNORED = "version", "help"
+
+# The kinds of configurations there are.
+kinds = enum(
+ USER="user", # User Specific
+ GLOBAL="global", # System Wide
+ SITE="site", # [Virtual] Environment Specific
+ ENV="env", # from PIP_CONFIG_FILE
+ ENV_VAR="env-var", # from Environment Variables
+)
+OVERRIDE_ORDER = kinds.GLOBAL, kinds.USER, kinds.SITE, kinds.ENV, kinds.ENV_VAR
+VALID_LOAD_ONLY = kinds.USER, kinds.GLOBAL, kinds.SITE
+
+logger = getLogger(__name__)
+
+
+# NOTE: Maybe use the optionx attribute to normalize keynames.
+def _normalize_name(name: str) -> str:
+ """Make a name consistent regardless of source (environment or file)"""
+ name = name.lower().replace("_", "-")
+ if name.startswith("--"):
+ name = name[2:] # only prefer long opts
+ return name
+
+
+def _disassemble_key(name: str) -> List[str]:
+ if "." not in name:
+ error_message = (
+ "Key does not contain dot separated section and key. "
+ f"Perhaps you wanted to use 'global.{name}' instead?"
+ )
+ raise ConfigurationError(error_message)
+ return name.split(".", 1)
+
+
+def get_configuration_files() -> Dict[Kind, List[str]]:
+ global_config_files = [
+ os.path.join(path, CONFIG_BASENAME) for path in appdirs.site_config_dirs("pip")
+ ]
+
+ site_config_file = os.path.join(sys.prefix, CONFIG_BASENAME)
+ legacy_config_file = os.path.join(
+ os.path.expanduser("~"),
+ "pip" if WINDOWS else ".pip",
+ CONFIG_BASENAME,
+ )
+ new_config_file = os.path.join(appdirs.user_config_dir("pip"), CONFIG_BASENAME)
+ return {
+ kinds.GLOBAL: global_config_files,
+ kinds.SITE: [site_config_file],
+ kinds.USER: [legacy_config_file, new_config_file],
+ }
+
+
+class Configuration:
+ """Handles management of configuration.
+
+ Provides an interface to accessing and managing configuration files.
+
+ This class converts provides an API that takes "section.key-name" style
+ keys and stores the value associated with it as "key-name" under the
+ section "section".
+
+ This allows for a clean interface wherein the both the section and the
+ key-name are preserved in an easy to manage form in the configuration files
+ and the data stored is also nice.
+ """
+
+ def __init__(self, isolated: bool, load_only: Optional[Kind] = None) -> None:
+ super().__init__()
+
+ if load_only is not None and load_only not in VALID_LOAD_ONLY:
+ raise ConfigurationError(
+ "Got invalid value for load_only - should be one of {}".format(
+ ", ".join(map(repr, VALID_LOAD_ONLY))
+ )
+ )
+ self.isolated = isolated
+ self.load_only = load_only
+
+ # Because we keep track of where we got the data from
+ self._parsers: Dict[Kind, List[Tuple[str, RawConfigParser]]] = {
+ variant: [] for variant in OVERRIDE_ORDER
+ }
+ self._config: Dict[Kind, Dict[str, Any]] = {
+ variant: {} for variant in OVERRIDE_ORDER
+ }
+ self._modified_parsers: List[Tuple[str, RawConfigParser]] = []
+
+ def load(self) -> None:
+ """Loads configuration from configuration files and environment"""
+ self._load_config_files()
+ if not self.isolated:
+ self._load_environment_vars()
+
+ def get_file_to_edit(self) -> Optional[str]:
+ """Returns the file with highest priority in configuration"""
+ assert self.load_only is not None, "Need to be specified a file to be editing"
+
+ try:
+ return self._get_parser_to_modify()[0]
+ except IndexError:
+ return None
+
+ def items(self) -> Iterable[Tuple[str, Any]]:
+ """Returns key-value pairs like dict.items() representing the loaded
+ configuration
+ """
+ return self._dictionary.items()
+
+ def get_value(self, key: str) -> Any:
+ """Get a value from the configuration."""
+ orig_key = key
+ key = _normalize_name(key)
+ try:
+ return self._dictionary[key]
+ except KeyError:
+ # disassembling triggers a more useful error message than simply
+ # "No such key" in the case that the key isn't in the form command.option
+ _disassemble_key(key)
+ raise ConfigurationError(f"No such key - {orig_key}")
+
+ def set_value(self, key: str, value: Any) -> None:
+ """Modify a value in the configuration."""
+ key = _normalize_name(key)
+ self._ensure_have_load_only()
+
+ assert self.load_only
+ fname, parser = self._get_parser_to_modify()
+
+ if parser is not None:
+ section, name = _disassemble_key(key)
+
+ # Modify the parser and the configuration
+ if not parser.has_section(section):
+ parser.add_section(section)
+ parser.set(section, name, value)
+
+ self._config[self.load_only][key] = value
+ self._mark_as_modified(fname, parser)
+
+ def unset_value(self, key: str) -> None:
+ """Unset a value in the configuration."""
+ orig_key = key
+ key = _normalize_name(key)
+ self._ensure_have_load_only()
+
+ assert self.load_only
+ if key not in self._config[self.load_only]:
+ raise ConfigurationError(f"No such key - {orig_key}")
+
+ fname, parser = self._get_parser_to_modify()
+
+ if parser is not None:
+ section, name = _disassemble_key(key)
+ if not (
+ parser.has_section(section) and parser.remove_option(section, name)
+ ):
+ # The option was not removed.
+ raise ConfigurationError(
+ "Fatal Internal error [id=1]. Please report as a bug."
+ )
+
+ # The section may be empty after the option was removed.
+ if not parser.items(section):
+ parser.remove_section(section)
+ self._mark_as_modified(fname, parser)
+
+ del self._config[self.load_only][key]
+
+ def save(self) -> None:
+ """Save the current in-memory state."""
+ self._ensure_have_load_only()
+
+ for fname, parser in self._modified_parsers:
+ logger.info("Writing to %s", fname)
+
+ # Ensure directory exists.
+ ensure_dir(os.path.dirname(fname))
+
+ # Ensure directory's permission(need to be writeable)
+ try:
+ with open(fname, "w") as f:
+ parser.write(f)
+ except OSError as error:
+ raise ConfigurationError(
+ f"An error occurred while writing to the configuration file "
+ f"{fname}: {error}"
+ )
+
+ #
+ # Private routines
+ #
+
+ def _ensure_have_load_only(self) -> None:
+ if self.load_only is None:
+ raise ConfigurationError("Needed a specific file to be modifying.")
+ logger.debug("Will be working with %s variant only", self.load_only)
+
+ @property
+ def _dictionary(self) -> Dict[str, Any]:
+ """A dictionary representing the loaded configuration."""
+ # NOTE: Dictionaries are not populated if not loaded. So, conditionals
+ # are not needed here.
+ retval = {}
+
+ for variant in OVERRIDE_ORDER:
+ retval.update(self._config[variant])
+
+ return retval
+
+ def _load_config_files(self) -> None:
+ """Loads configuration from configuration files"""
+ config_files = dict(self.iter_config_files())
+ if config_files[kinds.ENV][0:1] == [os.devnull]:
+ logger.debug(
+ "Skipping loading configuration files due to "
+ "environment's PIP_CONFIG_FILE being os.devnull"
+ )
+ return
+
+ for variant, files in config_files.items():
+ for fname in files:
+ # If there's specific variant set in `load_only`, load only
+ # that variant, not the others.
+ if self.load_only is not None and variant != self.load_only:
+ logger.debug("Skipping file '%s' (variant: %s)", fname, variant)
+ continue
+
+ parser = self._load_file(variant, fname)
+
+ # Keeping track of the parsers used
+ self._parsers[variant].append((fname, parser))
+
+ def _load_file(self, variant: Kind, fname: str) -> RawConfigParser:
+ logger.verbose("For variant '%s', will try loading '%s'", variant, fname)
+ parser = self._construct_parser(fname)
+
+ for section in parser.sections():
+ items = parser.items(section)
+ self._config[variant].update(self._normalized_keys(section, items))
+
+ return parser
+
+ def _construct_parser(self, fname: str) -> RawConfigParser:
+ parser = configparser.RawConfigParser()
+ # If there is no such file, don't bother reading it but create the
+ # parser anyway, to hold the data.
+ # Doing this is useful when modifying and saving files, where we don't
+ # need to construct a parser.
+ if os.path.exists(fname):
+ locale_encoding = locale.getpreferredencoding(False)
+ try:
+ parser.read(fname, encoding=locale_encoding)
+ except UnicodeDecodeError:
+ # See https://github.com/pypa/pip/issues/4963
+ raise ConfigurationFileCouldNotBeLoaded(
+ reason=f"contains invalid {locale_encoding} characters",
+ fname=fname,
+ )
+ except configparser.Error as error:
+ # See https://github.com/pypa/pip/issues/4893
+ raise ConfigurationFileCouldNotBeLoaded(error=error)
+ return parser
+
+ def _load_environment_vars(self) -> None:
+ """Loads configuration from environment variables"""
+ self._config[kinds.ENV_VAR].update(
+ self._normalized_keys(":env:", self.get_environ_vars())
+ )
+
+ def _normalized_keys(
+ self, section: str, items: Iterable[Tuple[str, Any]]
+ ) -> Dict[str, Any]:
+ """Normalizes items to construct a dictionary with normalized keys.
+
+ This routine is where the names become keys and are made the same
+ regardless of source - configuration files or environment.
+ """
+ normalized = {}
+ for name, val in items:
+ key = section + "." + _normalize_name(name)
+ normalized[key] = val
+ return normalized
+
+ def get_environ_vars(self) -> Iterable[Tuple[str, str]]:
+ """Returns a generator with all environmental vars with prefix PIP_"""
+ for key, val in os.environ.items():
+ if key.startswith("PIP_"):
+ name = key[4:].lower()
+ if name not in ENV_NAMES_IGNORED:
+ yield name, val
+
+ # XXX: This is patched in the tests.
+ def iter_config_files(self) -> Iterable[Tuple[Kind, List[str]]]:
+ """Yields variant and configuration files associated with it.
+
+ This should be treated like items of a dictionary. The order
+ here doesn't affect what gets overridden. That is controlled
+ by OVERRIDE_ORDER. However this does control the order they are
+ displayed to the user. It's probably most ergononmic to display
+ things in the same order as OVERRIDE_ORDER
+ """
+ # SMELL: Move the conditions out of this function
+
+ env_config_file = os.environ.get("PIP_CONFIG_FILE", None)
+ config_files = get_configuration_files()
+
+ yield kinds.GLOBAL, config_files[kinds.GLOBAL]
+
+ # per-user config is not loaded when env_config_file exists
+ should_load_user_config = not self.isolated and not (
+ env_config_file and os.path.exists(env_config_file)
+ )
+ if should_load_user_config:
+ # The legacy config file is overridden by the new config file
+ yield kinds.USER, config_files[kinds.USER]
+
+ # virtualenv config
+ yield kinds.SITE, config_files[kinds.SITE]
+
+ if env_config_file is not None:
+ yield kinds.ENV, [env_config_file]
+ else:
+ yield kinds.ENV, []
+
+ def get_values_in_config(self, variant: Kind) -> Dict[str, Any]:
+ """Get values present in a config file"""
+ return self._config[variant]
+
+ def _get_parser_to_modify(self) -> Tuple[str, RawConfigParser]:
+ # Determine which parser to modify
+ assert self.load_only
+ parsers = self._parsers[self.load_only]
+ if not parsers:
+ # This should not happen if everything works correctly.
+ raise ConfigurationError(
+ "Fatal Internal error [id=2]. Please report as a bug."
+ )
+
+ # Use the highest priority parser.
+ return parsers[-1]
+
+ # XXX: This is patched in the tests.
+ def _mark_as_modified(self, fname: str, parser: RawConfigParser) -> None:
+ file_parser_tuple = (fname, parser)
+ if file_parser_tuple not in self._modified_parsers:
+ self._modified_parsers.append(file_parser_tuple)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({self._dictionary!r})"
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/distributions/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/__init__.py
new file mode 100644
index 000000000..9a89a838b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/__init__.py
@@ -0,0 +1,21 @@
+from pip._internal.distributions.base import AbstractDistribution
+from pip._internal.distributions.sdist import SourceDistribution
+from pip._internal.distributions.wheel import WheelDistribution
+from pip._internal.req.req_install import InstallRequirement
+
+
+def make_distribution_for_install_requirement(
+ install_req: InstallRequirement,
+) -> AbstractDistribution:
+ """Returns a Distribution for the given InstallRequirement"""
+ # Editable requirements will always be source distributions. They use the
+ # legacy logic until we create a modern standard for them.
+ if install_req.editable:
+ return SourceDistribution(install_req)
+
+ # If it's a wheel, it's a WheelDistribution
+ if install_req.is_wheel:
+ return WheelDistribution(install_req)
+
+ # Otherwise, a SourceDistribution
+ return SourceDistribution(install_req)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/distributions/base.py b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/base.py
new file mode 100644
index 000000000..6e4d0c91a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/base.py
@@ -0,0 +1,53 @@
+import abc
+from typing import TYPE_CHECKING, Optional
+
+from pip._internal.metadata.base import BaseDistribution
+from pip._internal.req import InstallRequirement
+
+if TYPE_CHECKING:
+ from pip._internal.index.package_finder import PackageFinder
+
+
+class AbstractDistribution(metaclass=abc.ABCMeta):
+ """A base class for handling installable artifacts.
+
+ The requirements for anything installable are as follows:
+
+ - we must be able to determine the requirement name
+ (or we can't correctly handle the non-upgrade case).
+
+ - for packages with setup requirements, we must also be able
+ to determine their requirements without installing additional
+ packages (for the same reason as run-time dependencies)
+
+ - we must be able to create a Distribution object exposing the
+ above metadata.
+
+ - if we need to do work in the build tracker, we must be able to generate a unique
+ string to identify the requirement in the build tracker.
+ """
+
+ def __init__(self, req: InstallRequirement) -> None:
+ super().__init__()
+ self.req = req
+
+ @abc.abstractproperty
+ def build_tracker_id(self) -> Optional[str]:
+ """A string that uniquely identifies this requirement to the build tracker.
+
+ If None, then this dist has no work to do in the build tracker, and
+ ``.prepare_distribution_metadata()`` will not be called."""
+ raise NotImplementedError()
+
+ @abc.abstractmethod
+ def get_metadata_distribution(self) -> BaseDistribution:
+ raise NotImplementedError()
+
+ @abc.abstractmethod
+ def prepare_distribution_metadata(
+ self,
+ finder: "PackageFinder",
+ build_isolation: bool,
+ check_build_deps: bool,
+ ) -> None:
+ raise NotImplementedError()
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/distributions/installed.py b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/installed.py
new file mode 100644
index 000000000..ab8d53be7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/installed.py
@@ -0,0 +1,29 @@
+from typing import Optional
+
+from pip._internal.distributions.base import AbstractDistribution
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.metadata import BaseDistribution
+
+
+class InstalledDistribution(AbstractDistribution):
+ """Represents an installed package.
+
+ This does not need any preparation as the required information has already
+ been computed.
+ """
+
+ @property
+ def build_tracker_id(self) -> Optional[str]:
+ return None
+
+ def get_metadata_distribution(self) -> BaseDistribution:
+ assert self.req.satisfied_by is not None, "not actually installed"
+ return self.req.satisfied_by
+
+ def prepare_distribution_metadata(
+ self,
+ finder: PackageFinder,
+ build_isolation: bool,
+ check_build_deps: bool,
+ ) -> None:
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/distributions/sdist.py b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/sdist.py
new file mode 100644
index 000000000..28ea5cea1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/sdist.py
@@ -0,0 +1,158 @@
+import logging
+from typing import TYPE_CHECKING, Iterable, Optional, Set, Tuple
+
+from pip._internal.build_env import BuildEnvironment
+from pip._internal.distributions.base import AbstractDistribution
+from pip._internal.exceptions import InstallationError
+from pip._internal.metadata import BaseDistribution
+from pip._internal.utils.subprocess import runner_with_spinner_message
+
+if TYPE_CHECKING:
+ from pip._internal.index.package_finder import PackageFinder
+
+logger = logging.getLogger(__name__)
+
+
+class SourceDistribution(AbstractDistribution):
+ """Represents a source distribution.
+
+ The preparation step for these needs metadata for the packages to be
+ generated, either using PEP 517 or using the legacy `setup.py egg_info`.
+ """
+
+ @property
+ def build_tracker_id(self) -> Optional[str]:
+ """Identify this requirement uniquely by its link."""
+ assert self.req.link
+ return self.req.link.url_without_fragment
+
+ def get_metadata_distribution(self) -> BaseDistribution:
+ return self.req.get_dist()
+
+ def prepare_distribution_metadata(
+ self,
+ finder: "PackageFinder",
+ build_isolation: bool,
+ check_build_deps: bool,
+ ) -> None:
+ # Load pyproject.toml, to determine whether PEP 517 is to be used
+ self.req.load_pyproject_toml()
+
+ # Set up the build isolation, if this requirement should be isolated
+ should_isolate = self.req.use_pep517 and build_isolation
+ if should_isolate:
+ # Setup an isolated environment and install the build backend static
+ # requirements in it.
+ self._prepare_build_backend(finder)
+ # Check that if the requirement is editable, it either supports PEP 660 or
+ # has a setup.py or a setup.cfg. This cannot be done earlier because we need
+ # to setup the build backend to verify it supports build_editable, nor can
+ # it be done later, because we want to avoid installing build requirements
+ # needlessly. Doing it here also works around setuptools generating
+ # UNKNOWN.egg-info when running get_requires_for_build_wheel on a directory
+ # without setup.py nor setup.cfg.
+ self.req.isolated_editable_sanity_check()
+ # Install the dynamic build requirements.
+ self._install_build_reqs(finder)
+ # Check if the current environment provides build dependencies
+ should_check_deps = self.req.use_pep517 and check_build_deps
+ if should_check_deps:
+ pyproject_requires = self.req.pyproject_requires
+ assert pyproject_requires is not None
+ conflicting, missing = self.req.build_env.check_requirements(
+ pyproject_requires
+ )
+ if conflicting:
+ self._raise_conflicts("the backend dependencies", conflicting)
+ if missing:
+ self._raise_missing_reqs(missing)
+ self.req.prepare_metadata()
+
+ def _prepare_build_backend(self, finder: "PackageFinder") -> None:
+ # Isolate in a BuildEnvironment and install the build-time
+ # requirements.
+ pyproject_requires = self.req.pyproject_requires
+ assert pyproject_requires is not None
+
+ self.req.build_env = BuildEnvironment()
+ self.req.build_env.install_requirements(
+ finder, pyproject_requires, "overlay", kind="build dependencies"
+ )
+ conflicting, missing = self.req.build_env.check_requirements(
+ self.req.requirements_to_check
+ )
+ if conflicting:
+ self._raise_conflicts("PEP 517/518 supported requirements", conflicting)
+ if missing:
+ logger.warning(
+ "Missing build requirements in pyproject.toml for %s.",
+ self.req,
+ )
+ logger.warning(
+ "The project does not specify a build backend, and "
+ "pip cannot fall back to setuptools without %s.",
+ " and ".join(map(repr, sorted(missing))),
+ )
+
+ def _get_build_requires_wheel(self) -> Iterable[str]:
+ with self.req.build_env:
+ runner = runner_with_spinner_message("Getting requirements to build wheel")
+ backend = self.req.pep517_backend
+ assert backend is not None
+ with backend.subprocess_runner(runner):
+ return backend.get_requires_for_build_wheel()
+
+ def _get_build_requires_editable(self) -> Iterable[str]:
+ with self.req.build_env:
+ runner = runner_with_spinner_message(
+ "Getting requirements to build editable"
+ )
+ backend = self.req.pep517_backend
+ assert backend is not None
+ with backend.subprocess_runner(runner):
+ return backend.get_requires_for_build_editable()
+
+ def _install_build_reqs(self, finder: "PackageFinder") -> None:
+ # Install any extra build dependencies that the backend requests.
+ # This must be done in a second pass, as the pyproject.toml
+ # dependencies must be installed before we can call the backend.
+ if (
+ self.req.editable
+ and self.req.permit_editable_wheels
+ and self.req.supports_pyproject_editable
+ ):
+ build_reqs = self._get_build_requires_editable()
+ else:
+ build_reqs = self._get_build_requires_wheel()
+ conflicting, missing = self.req.build_env.check_requirements(build_reqs)
+ if conflicting:
+ self._raise_conflicts("the backend dependencies", conflicting)
+ self.req.build_env.install_requirements(
+ finder, missing, "normal", kind="backend dependencies"
+ )
+
+ def _raise_conflicts(
+ self, conflicting_with: str, conflicting_reqs: Set[Tuple[str, str]]
+ ) -> None:
+ format_string = (
+ "Some build dependencies for {requirement} "
+ "conflict with {conflicting_with}: {description}."
+ )
+ error_message = format_string.format(
+ requirement=self.req,
+ conflicting_with=conflicting_with,
+ description=", ".join(
+ f"{installed} is incompatible with {wanted}"
+ for installed, wanted in sorted(conflicting_reqs)
+ ),
+ )
+ raise InstallationError(error_message)
+
+ def _raise_missing_reqs(self, missing: Set[str]) -> None:
+ format_string = (
+ "Some build dependencies for {requirement} are missing: {missing}."
+ )
+ error_message = format_string.format(
+ requirement=self.req, missing=", ".join(map(repr, sorted(missing)))
+ )
+ raise InstallationError(error_message)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/distributions/wheel.py b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/wheel.py
new file mode 100644
index 000000000..bfadd39dc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/distributions/wheel.py
@@ -0,0 +1,42 @@
+from typing import TYPE_CHECKING, Optional
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.distributions.base import AbstractDistribution
+from pip._internal.metadata import (
+ BaseDistribution,
+ FilesystemWheel,
+ get_wheel_distribution,
+)
+
+if TYPE_CHECKING:
+ from pip._internal.index.package_finder import PackageFinder
+
+
+class WheelDistribution(AbstractDistribution):
+ """Represents a wheel distribution.
+
+ This does not need any preparation as wheels can be directly unpacked.
+ """
+
+ @property
+ def build_tracker_id(self) -> Optional[str]:
+ return None
+
+ def get_metadata_distribution(self) -> BaseDistribution:
+ """Loads the metadata from the wheel file into memory and returns a
+ Distribution that uses it, not relying on the wheel file or
+ requirement.
+ """
+ assert self.req.local_file_path, "Set as part of preparation during download"
+ assert self.req.name, "Wheels are never unnamed"
+ wheel = FilesystemWheel(self.req.local_file_path)
+ return get_wheel_distribution(wheel, canonicalize_name(self.req.name))
+
+ def prepare_distribution_metadata(
+ self,
+ finder: "PackageFinder",
+ build_isolation: bool,
+ check_build_deps: bool,
+ ) -> None:
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/exceptions.py b/solutions/.venv/Lib/site-packages/pip/_internal/exceptions.py
new file mode 100644
index 000000000..45a876a85
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/exceptions.py
@@ -0,0 +1,809 @@
+"""Exceptions used throughout package.
+
+This module MUST NOT try to import from anything within `pip._internal` to
+operate. This is expected to be importable from any/all files within the
+subpackage and, thus, should not depend on them.
+"""
+
+import configparser
+import contextlib
+import locale
+import logging
+import pathlib
+import re
+import sys
+from itertools import chain, groupby, repeat
+from typing import TYPE_CHECKING, Dict, Iterator, List, Literal, Optional, Union
+
+from pip._vendor.packaging.requirements import InvalidRequirement
+from pip._vendor.packaging.version import InvalidVersion
+from pip._vendor.rich.console import Console, ConsoleOptions, RenderResult
+from pip._vendor.rich.markup import escape
+from pip._vendor.rich.text import Text
+
+if TYPE_CHECKING:
+ from hashlib import _Hash
+
+ from pip._vendor.requests.models import Request, Response
+
+ from pip._internal.metadata import BaseDistribution
+ from pip._internal.req.req_install import InstallRequirement
+
+logger = logging.getLogger(__name__)
+
+
+#
+# Scaffolding
+#
+def _is_kebab_case(s: str) -> bool:
+ return re.match(r"^[a-z]+(-[a-z]+)*$", s) is not None
+
+
+def _prefix_with_indent(
+ s: Union[Text, str],
+ console: Console,
+ *,
+ prefix: str,
+ indent: str,
+) -> Text:
+ if isinstance(s, Text):
+ text = s
+ else:
+ text = console.render_str(s)
+
+ return console.render_str(prefix, overflow="ignore") + console.render_str(
+ f"\n{indent}", overflow="ignore"
+ ).join(text.split(allow_blank=True))
+
+
+class PipError(Exception):
+ """The base pip error."""
+
+
+class DiagnosticPipError(PipError):
+ """An error, that presents diagnostic information to the user.
+
+ This contains a bunch of logic, to enable pretty presentation of our error
+ messages. Each error gets a unique reference. Each error can also include
+ additional context, a hint and/or a note -- which are presented with the
+ main error message in a consistent style.
+
+ This is adapted from the error output styling in `sphinx-theme-builder`.
+ """
+
+ reference: str
+
+ def __init__(
+ self,
+ *,
+ kind: 'Literal["error", "warning"]' = "error",
+ reference: Optional[str] = None,
+ message: Union[str, Text],
+ context: Optional[Union[str, Text]],
+ hint_stmt: Optional[Union[str, Text]],
+ note_stmt: Optional[Union[str, Text]] = None,
+ link: Optional[str] = None,
+ ) -> None:
+ # Ensure a proper reference is provided.
+ if reference is None:
+ assert hasattr(self, "reference"), "error reference not provided!"
+ reference = self.reference
+ assert _is_kebab_case(reference), "error reference must be kebab-case!"
+
+ self.kind = kind
+ self.reference = reference
+
+ self.message = message
+ self.context = context
+
+ self.note_stmt = note_stmt
+ self.hint_stmt = hint_stmt
+
+ self.link = link
+
+ super().__init__(f"<{self.__class__.__name__}: {self.reference}>")
+
+ def __repr__(self) -> str:
+ return (
+ f"<{self.__class__.__name__}("
+ f"reference={self.reference!r}, "
+ f"message={self.message!r}, "
+ f"context={self.context!r}, "
+ f"note_stmt={self.note_stmt!r}, "
+ f"hint_stmt={self.hint_stmt!r}"
+ ")>"
+ )
+
+ def __rich_console__(
+ self,
+ console: Console,
+ options: ConsoleOptions,
+ ) -> RenderResult:
+ colour = "red" if self.kind == "error" else "yellow"
+
+ yield f"[{colour} bold]{self.kind}[/]: [bold]{self.reference}[/]"
+ yield ""
+
+ if not options.ascii_only:
+ # Present the main message, with relevant context indented.
+ if self.context is not None:
+ yield _prefix_with_indent(
+ self.message,
+ console,
+ prefix=f"[{colour}]×[/] ",
+ indent=f"[{colour}]│[/] ",
+ )
+ yield _prefix_with_indent(
+ self.context,
+ console,
+ prefix=f"[{colour}]╰─>[/] ",
+ indent=f"[{colour}] [/] ",
+ )
+ else:
+ yield _prefix_with_indent(
+ self.message,
+ console,
+ prefix="[red]×[/] ",
+ indent=" ",
+ )
+ else:
+ yield self.message
+ if self.context is not None:
+ yield ""
+ yield self.context
+
+ if self.note_stmt is not None or self.hint_stmt is not None:
+ yield ""
+
+ if self.note_stmt is not None:
+ yield _prefix_with_indent(
+ self.note_stmt,
+ console,
+ prefix="[magenta bold]note[/]: ",
+ indent=" ",
+ )
+ if self.hint_stmt is not None:
+ yield _prefix_with_indent(
+ self.hint_stmt,
+ console,
+ prefix="[cyan bold]hint[/]: ",
+ indent=" ",
+ )
+
+ if self.link is not None:
+ yield ""
+ yield f"Link: {self.link}"
+
+
+#
+# Actual Errors
+#
+class ConfigurationError(PipError):
+ """General exception in configuration"""
+
+
+class InstallationError(PipError):
+ """General exception during installation"""
+
+
+class MissingPyProjectBuildRequires(DiagnosticPipError):
+ """Raised when pyproject.toml has `build-system`, but no `build-system.requires`."""
+
+ reference = "missing-pyproject-build-system-requires"
+
+ def __init__(self, *, package: str) -> None:
+ super().__init__(
+ message=f"Can not process {escape(package)}",
+ context=Text(
+ "This package has an invalid pyproject.toml file.\n"
+ "The [build-system] table is missing the mandatory `requires` key."
+ ),
+ note_stmt="This is an issue with the package mentioned above, not pip.",
+ hint_stmt=Text("See PEP 518 for the detailed specification."),
+ )
+
+
+class InvalidPyProjectBuildRequires(DiagnosticPipError):
+ """Raised when pyproject.toml an invalid `build-system.requires`."""
+
+ reference = "invalid-pyproject-build-system-requires"
+
+ def __init__(self, *, package: str, reason: str) -> None:
+ super().__init__(
+ message=f"Can not process {escape(package)}",
+ context=Text(
+ "This package has an invalid `build-system.requires` key in "
+ f"pyproject.toml.\n{reason}"
+ ),
+ note_stmt="This is an issue with the package mentioned above, not pip.",
+ hint_stmt=Text("See PEP 518 for the detailed specification."),
+ )
+
+
+class NoneMetadataError(PipError):
+ """Raised when accessing a Distribution's "METADATA" or "PKG-INFO".
+
+ This signifies an inconsistency, when the Distribution claims to have
+ the metadata file (if not, raise ``FileNotFoundError`` instead), but is
+ not actually able to produce its content. This may be due to permission
+ errors.
+ """
+
+ def __init__(
+ self,
+ dist: "BaseDistribution",
+ metadata_name: str,
+ ) -> None:
+ """
+ :param dist: A Distribution object.
+ :param metadata_name: The name of the metadata being accessed
+ (can be "METADATA" or "PKG-INFO").
+ """
+ self.dist = dist
+ self.metadata_name = metadata_name
+
+ def __str__(self) -> str:
+ # Use `dist` in the error message because its stringification
+ # includes more information, like the version and location.
+ return f"None {self.metadata_name} metadata found for distribution: {self.dist}"
+
+
+class UserInstallationInvalid(InstallationError):
+ """A --user install is requested on an environment without user site."""
+
+ def __str__(self) -> str:
+ return "User base directory is not specified"
+
+
+class InvalidSchemeCombination(InstallationError):
+ def __str__(self) -> str:
+ before = ", ".join(str(a) for a in self.args[:-1])
+ return f"Cannot set {before} and {self.args[-1]} together"
+
+
+class DistributionNotFound(InstallationError):
+ """Raised when a distribution cannot be found to satisfy a requirement"""
+
+
+class RequirementsFileParseError(InstallationError):
+ """Raised when a general error occurs parsing a requirements file line."""
+
+
+class BestVersionAlreadyInstalled(PipError):
+ """Raised when the most up-to-date version of a package is already
+ installed."""
+
+
+class BadCommand(PipError):
+ """Raised when virtualenv or a command is not found"""
+
+
+class CommandError(PipError):
+ """Raised when there is an error in command-line arguments"""
+
+
+class PreviousBuildDirError(PipError):
+ """Raised when there's a previous conflicting build directory"""
+
+
+class NetworkConnectionError(PipError):
+ """HTTP connection error"""
+
+ def __init__(
+ self,
+ error_msg: str,
+ response: Optional["Response"] = None,
+ request: Optional["Request"] = None,
+ ) -> None:
+ """
+ Initialize NetworkConnectionError with `request` and `response`
+ objects.
+ """
+ self.response = response
+ self.request = request
+ self.error_msg = error_msg
+ if (
+ self.response is not None
+ and not self.request
+ and hasattr(response, "request")
+ ):
+ self.request = self.response.request
+ super().__init__(error_msg, response, request)
+
+ def __str__(self) -> str:
+ return str(self.error_msg)
+
+
+class InvalidWheelFilename(InstallationError):
+ """Invalid wheel filename."""
+
+
+class UnsupportedWheel(InstallationError):
+ """Unsupported wheel."""
+
+
+class InvalidWheel(InstallationError):
+ """Invalid (e.g. corrupt) wheel."""
+
+ def __init__(self, location: str, name: str):
+ self.location = location
+ self.name = name
+
+ def __str__(self) -> str:
+ return f"Wheel '{self.name}' located at {self.location} is invalid."
+
+
+class MetadataInconsistent(InstallationError):
+ """Built metadata contains inconsistent information.
+
+ This is raised when the metadata contains values (e.g. name and version)
+ that do not match the information previously obtained from sdist filename,
+ user-supplied ``#egg=`` value, or an install requirement name.
+ """
+
+ def __init__(
+ self, ireq: "InstallRequirement", field: str, f_val: str, m_val: str
+ ) -> None:
+ self.ireq = ireq
+ self.field = field
+ self.f_val = f_val
+ self.m_val = m_val
+
+ def __str__(self) -> str:
+ return (
+ f"Requested {self.ireq} has inconsistent {self.field}: "
+ f"expected {self.f_val!r}, but metadata has {self.m_val!r}"
+ )
+
+
+class MetadataInvalid(InstallationError):
+ """Metadata is invalid."""
+
+ def __init__(self, ireq: "InstallRequirement", error: str) -> None:
+ self.ireq = ireq
+ self.error = error
+
+ def __str__(self) -> str:
+ return f"Requested {self.ireq} has invalid metadata: {self.error}"
+
+
+class InstallationSubprocessError(DiagnosticPipError, InstallationError):
+ """A subprocess call failed."""
+
+ reference = "subprocess-exited-with-error"
+
+ def __init__(
+ self,
+ *,
+ command_description: str,
+ exit_code: int,
+ output_lines: Optional[List[str]],
+ ) -> None:
+ if output_lines is None:
+ output_prompt = Text("See above for output.")
+ else:
+ output_prompt = (
+ Text.from_markup(f"[red][{len(output_lines)} lines of output][/]\n")
+ + Text("".join(output_lines))
+ + Text.from_markup(R"[red]\[end of output][/]")
+ )
+
+ super().__init__(
+ message=(
+ f"[green]{escape(command_description)}[/] did not run successfully.\n"
+ f"exit code: {exit_code}"
+ ),
+ context=output_prompt,
+ hint_stmt=None,
+ note_stmt=(
+ "This error originates from a subprocess, and is likely not a "
+ "problem with pip."
+ ),
+ )
+
+ self.command_description = command_description
+ self.exit_code = exit_code
+
+ def __str__(self) -> str:
+ return f"{self.command_description} exited with {self.exit_code}"
+
+
+class MetadataGenerationFailed(InstallationSubprocessError, InstallationError):
+ reference = "metadata-generation-failed"
+
+ def __init__(
+ self,
+ *,
+ package_details: str,
+ ) -> None:
+ super(InstallationSubprocessError, self).__init__(
+ message="Encountered error while generating package metadata.",
+ context=escape(package_details),
+ hint_stmt="See above for details.",
+ note_stmt="This is an issue with the package mentioned above, not pip.",
+ )
+
+ def __str__(self) -> str:
+ return "metadata generation failed"
+
+
+class HashErrors(InstallationError):
+ """Multiple HashError instances rolled into one for reporting"""
+
+ def __init__(self) -> None:
+ self.errors: List[HashError] = []
+
+ def append(self, error: "HashError") -> None:
+ self.errors.append(error)
+
+ def __str__(self) -> str:
+ lines = []
+ self.errors.sort(key=lambda e: e.order)
+ for cls, errors_of_cls in groupby(self.errors, lambda e: e.__class__):
+ lines.append(cls.head)
+ lines.extend(e.body() for e in errors_of_cls)
+ if lines:
+ return "\n".join(lines)
+ return ""
+
+ def __bool__(self) -> bool:
+ return bool(self.errors)
+
+
+class HashError(InstallationError):
+ """
+ A failure to verify a package against known-good hashes
+
+ :cvar order: An int sorting hash exception classes by difficulty of
+ recovery (lower being harder), so the user doesn't bother fretting
+ about unpinned packages when he has deeper issues, like VCS
+ dependencies, to deal with. Also keeps error reports in a
+ deterministic order.
+ :cvar head: A section heading for display above potentially many
+ exceptions of this kind
+ :ivar req: The InstallRequirement that triggered this error. This is
+ pasted on after the exception is instantiated, because it's not
+ typically available earlier.
+
+ """
+
+ req: Optional["InstallRequirement"] = None
+ head = ""
+ order: int = -1
+
+ def body(self) -> str:
+ """Return a summary of me for display under the heading.
+
+ This default implementation simply prints a description of the
+ triggering requirement.
+
+ :param req: The InstallRequirement that provoked this error, with
+ its link already populated by the resolver's _populate_link().
+
+ """
+ return f" {self._requirement_name()}"
+
+ def __str__(self) -> str:
+ return f"{self.head}\n{self.body()}"
+
+ def _requirement_name(self) -> str:
+ """Return a description of the requirement that triggered me.
+
+ This default implementation returns long description of the req, with
+ line numbers
+
+ """
+ return str(self.req) if self.req else "unknown package"
+
+
+class VcsHashUnsupported(HashError):
+ """A hash was provided for a version-control-system-based requirement, but
+ we don't have a method for hashing those."""
+
+ order = 0
+ head = (
+ "Can't verify hashes for these requirements because we don't "
+ "have a way to hash version control repositories:"
+ )
+
+
+class DirectoryUrlHashUnsupported(HashError):
+ """A hash was provided for a version-control-system-based requirement, but
+ we don't have a method for hashing those."""
+
+ order = 1
+ head = (
+ "Can't verify hashes for these file:// requirements because they "
+ "point to directories:"
+ )
+
+
+class HashMissing(HashError):
+ """A hash was needed for a requirement but is absent."""
+
+ order = 2
+ head = (
+ "Hashes are required in --require-hashes mode, but they are "
+ "missing from some requirements. Here is a list of those "
+ "requirements along with the hashes their downloaded archives "
+ "actually had. Add lines like these to your requirements files to "
+ "prevent tampering. (If you did not enable --require-hashes "
+ "manually, note that it turns on automatically when any package "
+ "has a hash.)"
+ )
+
+ def __init__(self, gotten_hash: str) -> None:
+ """
+ :param gotten_hash: The hash of the (possibly malicious) archive we
+ just downloaded
+ """
+ self.gotten_hash = gotten_hash
+
+ def body(self) -> str:
+ # Dodge circular import.
+ from pip._internal.utils.hashes import FAVORITE_HASH
+
+ package = None
+ if self.req:
+ # In the case of URL-based requirements, display the original URL
+ # seen in the requirements file rather than the package name,
+ # so the output can be directly copied into the requirements file.
+ package = (
+ self.req.original_link
+ if self.req.is_direct
+ # In case someone feeds something downright stupid
+ # to InstallRequirement's constructor.
+ else getattr(self.req, "req", None)
+ )
+ return " {} --hash={}:{}".format(
+ package or "unknown package", FAVORITE_HASH, self.gotten_hash
+ )
+
+
+class HashUnpinned(HashError):
+ """A requirement had a hash specified but was not pinned to a specific
+ version."""
+
+ order = 3
+ head = (
+ "In --require-hashes mode, all requirements must have their "
+ "versions pinned with ==. These do not:"
+ )
+
+
+class HashMismatch(HashError):
+ """
+ Distribution file hash values don't match.
+
+ :ivar package_name: The name of the package that triggered the hash
+ mismatch. Feel free to write to this after the exception is raise to
+ improve its error message.
+
+ """
+
+ order = 4
+ head = (
+ "THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS "
+ "FILE. If you have updated the package versions, please update "
+ "the hashes. Otherwise, examine the package contents carefully; "
+ "someone may have tampered with them."
+ )
+
+ def __init__(self, allowed: Dict[str, List[str]], gots: Dict[str, "_Hash"]) -> None:
+ """
+ :param allowed: A dict of algorithm names pointing to lists of allowed
+ hex digests
+ :param gots: A dict of algorithm names pointing to hashes we
+ actually got from the files under suspicion
+ """
+ self.allowed = allowed
+ self.gots = gots
+
+ def body(self) -> str:
+ return f" {self._requirement_name()}:\n{self._hash_comparison()}"
+
+ def _hash_comparison(self) -> str:
+ """
+ Return a comparison of actual and expected hash values.
+
+ Example::
+
+ Expected sha256 abcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcde
+ or 123451234512345123451234512345123451234512345
+ Got bcdefbcdefbcdefbcdefbcdefbcdefbcdefbcdefbcdef
+
+ """
+
+ def hash_then_or(hash_name: str) -> "chain[str]":
+ # For now, all the decent hashes have 6-char names, so we can get
+ # away with hard-coding space literals.
+ return chain([hash_name], repeat(" or"))
+
+ lines: List[str] = []
+ for hash_name, expecteds in self.allowed.items():
+ prefix = hash_then_or(hash_name)
+ lines.extend((f" Expected {next(prefix)} {e}") for e in expecteds)
+ lines.append(
+ f" Got {self.gots[hash_name].hexdigest()}\n"
+ )
+ return "\n".join(lines)
+
+
+class UnsupportedPythonVersion(InstallationError):
+ """Unsupported python version according to Requires-Python package
+ metadata."""
+
+
+class ConfigurationFileCouldNotBeLoaded(ConfigurationError):
+ """When there are errors while loading a configuration file"""
+
+ def __init__(
+ self,
+ reason: str = "could not be loaded",
+ fname: Optional[str] = None,
+ error: Optional[configparser.Error] = None,
+ ) -> None:
+ super().__init__(error)
+ self.reason = reason
+ self.fname = fname
+ self.error = error
+
+ def __str__(self) -> str:
+ if self.fname is not None:
+ message_part = f" in {self.fname}."
+ else:
+ assert self.error is not None
+ message_part = f".\n{self.error}\n"
+ return f"Configuration file {self.reason}{message_part}"
+
+
+_DEFAULT_EXTERNALLY_MANAGED_ERROR = f"""\
+The Python environment under {sys.prefix} is managed externally, and may not be
+manipulated by the user. Please use specific tooling from the distributor of
+the Python installation to interact with this environment instead.
+"""
+
+
+class ExternallyManagedEnvironment(DiagnosticPipError):
+ """The current environment is externally managed.
+
+ This is raised when the current environment is externally managed, as
+ defined by `PEP 668`_. The ``EXTERNALLY-MANAGED`` configuration is checked
+ and displayed when the error is bubbled up to the user.
+
+ :param error: The error message read from ``EXTERNALLY-MANAGED``.
+ """
+
+ reference = "externally-managed-environment"
+
+ def __init__(self, error: Optional[str]) -> None:
+ if error is None:
+ context = Text(_DEFAULT_EXTERNALLY_MANAGED_ERROR)
+ else:
+ context = Text(error)
+ super().__init__(
+ message="This environment is externally managed",
+ context=context,
+ note_stmt=(
+ "If you believe this is a mistake, please contact your "
+ "Python installation or OS distribution provider. "
+ "You can override this, at the risk of breaking your Python "
+ "installation or OS, by passing --break-system-packages."
+ ),
+ hint_stmt=Text("See PEP 668 for the detailed specification."),
+ )
+
+ @staticmethod
+ def _iter_externally_managed_error_keys() -> Iterator[str]:
+ # LC_MESSAGES is in POSIX, but not the C standard. The most common
+ # platform that does not implement this category is Windows, where
+ # using other categories for console message localization is equally
+ # unreliable, so we fall back to the locale-less vendor message. This
+ # can always be re-evaluated when a vendor proposes a new alternative.
+ try:
+ category = locale.LC_MESSAGES
+ except AttributeError:
+ lang: Optional[str] = None
+ else:
+ lang, _ = locale.getlocale(category)
+ if lang is not None:
+ yield f"Error-{lang}"
+ for sep in ("-", "_"):
+ before, found, _ = lang.partition(sep)
+ if not found:
+ continue
+ yield f"Error-{before}"
+ yield "Error"
+
+ @classmethod
+ def from_config(
+ cls,
+ config: Union[pathlib.Path, str],
+ ) -> "ExternallyManagedEnvironment":
+ parser = configparser.ConfigParser(interpolation=None)
+ try:
+ parser.read(config, encoding="utf-8")
+ section = parser["externally-managed"]
+ for key in cls._iter_externally_managed_error_keys():
+ with contextlib.suppress(KeyError):
+ return cls(section[key])
+ except KeyError:
+ pass
+ except (OSError, UnicodeDecodeError, configparser.ParsingError):
+ from pip._internal.utils._log import VERBOSE
+
+ exc_info = logger.isEnabledFor(VERBOSE)
+ logger.warning("Failed to read %s", config, exc_info=exc_info)
+ return cls(None)
+
+
+class UninstallMissingRecord(DiagnosticPipError):
+ reference = "uninstall-no-record-file"
+
+ def __init__(self, *, distribution: "BaseDistribution") -> None:
+ installer = distribution.installer
+ if not installer or installer == "pip":
+ dep = f"{distribution.raw_name}=={distribution.version}"
+ hint = Text.assemble(
+ "You might be able to recover from this via: ",
+ (f"pip install --force-reinstall --no-deps {dep}", "green"),
+ )
+ else:
+ hint = Text(
+ f"The package was installed by {installer}. "
+ "You should check if it can uninstall the package."
+ )
+
+ super().__init__(
+ message=Text(f"Cannot uninstall {distribution}"),
+ context=(
+ "The package's contents are unknown: "
+ f"no RECORD file was found for {distribution.raw_name}."
+ ),
+ hint_stmt=hint,
+ )
+
+
+class LegacyDistutilsInstall(DiagnosticPipError):
+ reference = "uninstall-distutils-installed-package"
+
+ def __init__(self, *, distribution: "BaseDistribution") -> None:
+ super().__init__(
+ message=Text(f"Cannot uninstall {distribution}"),
+ context=(
+ "It is a distutils installed project and thus we cannot accurately "
+ "determine which files belong to it which would lead to only a partial "
+ "uninstall."
+ ),
+ hint_stmt=None,
+ )
+
+
+class InvalidInstalledPackage(DiagnosticPipError):
+ reference = "invalid-installed-package"
+
+ def __init__(
+ self,
+ *,
+ dist: "BaseDistribution",
+ invalid_exc: Union[InvalidRequirement, InvalidVersion],
+ ) -> None:
+ installed_location = dist.installed_location
+
+ if isinstance(invalid_exc, InvalidRequirement):
+ invalid_type = "requirement"
+ else:
+ invalid_type = "version"
+
+ super().__init__(
+ message=Text(
+ f"Cannot process installed package {dist} "
+ + (f"in {installed_location!r} " if installed_location else "")
+ + f"because it has an invalid {invalid_type}:\n{invalid_exc.args[0]}"
+ ),
+ context=(
+ "Starting with pip 24.1, packages with invalid "
+ f"{invalid_type}s can not be processed."
+ ),
+ hint_stmt="To proceed this package must be uninstalled.",
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/index/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/index/__init__.py
new file mode 100644
index 000000000..7a17b7b3b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/index/__init__.py
@@ -0,0 +1,2 @@
+"""Index interaction code
+"""
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/index/collector.py b/solutions/.venv/Lib/site-packages/pip/_internal/index/collector.py
new file mode 100644
index 000000000..5f8fdee3d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/index/collector.py
@@ -0,0 +1,494 @@
+"""
+The main purpose of this module is to expose LinkCollector.collect_sources().
+"""
+
+import collections
+import email.message
+import functools
+import itertools
+import json
+import logging
+import os
+import urllib.parse
+import urllib.request
+from dataclasses import dataclass
+from html.parser import HTMLParser
+from optparse import Values
+from typing import (
+ Callable,
+ Dict,
+ Iterable,
+ List,
+ MutableMapping,
+ NamedTuple,
+ Optional,
+ Protocol,
+ Sequence,
+ Tuple,
+ Union,
+)
+
+from pip._vendor import requests
+from pip._vendor.requests import Response
+from pip._vendor.requests.exceptions import RetryError, SSLError
+
+from pip._internal.exceptions import NetworkConnectionError
+from pip._internal.models.link import Link
+from pip._internal.models.search_scope import SearchScope
+from pip._internal.network.session import PipSession
+from pip._internal.network.utils import raise_for_status
+from pip._internal.utils.filetypes import is_archive_file
+from pip._internal.utils.misc import redact_auth_from_url
+from pip._internal.vcs import vcs
+
+from .sources import CandidatesFromPage, LinkSource, build_source
+
+logger = logging.getLogger(__name__)
+
+ResponseHeaders = MutableMapping[str, str]
+
+
+def _match_vcs_scheme(url: str) -> Optional[str]:
+ """Look for VCS schemes in the URL.
+
+ Returns the matched VCS scheme, or None if there's no match.
+ """
+ for scheme in vcs.schemes:
+ if url.lower().startswith(scheme) and url[len(scheme)] in "+:":
+ return scheme
+ return None
+
+
+class _NotAPIContent(Exception):
+ def __init__(self, content_type: str, request_desc: str) -> None:
+ super().__init__(content_type, request_desc)
+ self.content_type = content_type
+ self.request_desc = request_desc
+
+
+def _ensure_api_header(response: Response) -> None:
+ """
+ Check the Content-Type header to ensure the response contains a Simple
+ API Response.
+
+ Raises `_NotAPIContent` if the content type is not a valid content-type.
+ """
+ content_type = response.headers.get("Content-Type", "Unknown")
+
+ content_type_l = content_type.lower()
+ if content_type_l.startswith(
+ (
+ "text/html",
+ "application/vnd.pypi.simple.v1+html",
+ "application/vnd.pypi.simple.v1+json",
+ )
+ ):
+ return
+
+ raise _NotAPIContent(content_type, response.request.method)
+
+
+class _NotHTTP(Exception):
+ pass
+
+
+def _ensure_api_response(url: str, session: PipSession) -> None:
+ """
+ Send a HEAD request to the URL, and ensure the response contains a simple
+ API Response.
+
+ Raises `_NotHTTP` if the URL is not available for a HEAD request, or
+ `_NotAPIContent` if the content type is not a valid content type.
+ """
+ scheme, netloc, path, query, fragment = urllib.parse.urlsplit(url)
+ if scheme not in {"http", "https"}:
+ raise _NotHTTP()
+
+ resp = session.head(url, allow_redirects=True)
+ raise_for_status(resp)
+
+ _ensure_api_header(resp)
+
+
+def _get_simple_response(url: str, session: PipSession) -> Response:
+ """Access an Simple API response with GET, and return the response.
+
+ This consists of three parts:
+
+ 1. If the URL looks suspiciously like an archive, send a HEAD first to
+ check the Content-Type is HTML or Simple API, to avoid downloading a
+ large file. Raise `_NotHTTP` if the content type cannot be determined, or
+ `_NotAPIContent` if it is not HTML or a Simple API.
+ 2. Actually perform the request. Raise HTTP exceptions on network failures.
+ 3. Check the Content-Type header to make sure we got a Simple API response,
+ and raise `_NotAPIContent` otherwise.
+ """
+ if is_archive_file(Link(url).filename):
+ _ensure_api_response(url, session=session)
+
+ logger.debug("Getting page %s", redact_auth_from_url(url))
+
+ resp = session.get(
+ url,
+ headers={
+ "Accept": ", ".join(
+ [
+ "application/vnd.pypi.simple.v1+json",
+ "application/vnd.pypi.simple.v1+html; q=0.1",
+ "text/html; q=0.01",
+ ]
+ ),
+ # We don't want to blindly returned cached data for
+ # /simple/, because authors generally expecting that
+ # twine upload && pip install will function, but if
+ # they've done a pip install in the last ~10 minutes
+ # it won't. Thus by setting this to zero we will not
+ # blindly use any cached data, however the benefit of
+ # using max-age=0 instead of no-cache, is that we will
+ # still support conditional requests, so we will still
+ # minimize traffic sent in cases where the page hasn't
+ # changed at all, we will just always incur the round
+ # trip for the conditional GET now instead of only
+ # once per 10 minutes.
+ # For more information, please see pypa/pip#5670.
+ "Cache-Control": "max-age=0",
+ },
+ )
+ raise_for_status(resp)
+
+ # The check for archives above only works if the url ends with
+ # something that looks like an archive. However that is not a
+ # requirement of an url. Unless we issue a HEAD request on every
+ # url we cannot know ahead of time for sure if something is a
+ # Simple API response or not. However we can check after we've
+ # downloaded it.
+ _ensure_api_header(resp)
+
+ logger.debug(
+ "Fetched page %s as %s",
+ redact_auth_from_url(url),
+ resp.headers.get("Content-Type", "Unknown"),
+ )
+
+ return resp
+
+
+def _get_encoding_from_headers(headers: ResponseHeaders) -> Optional[str]:
+ """Determine if we have any encoding information in our headers."""
+ if headers and "Content-Type" in headers:
+ m = email.message.Message()
+ m["content-type"] = headers["Content-Type"]
+ charset = m.get_param("charset")
+ if charset:
+ return str(charset)
+ return None
+
+
+class CacheablePageContent:
+ def __init__(self, page: "IndexContent") -> None:
+ assert page.cache_link_parsing
+ self.page = page
+
+ def __eq__(self, other: object) -> bool:
+ return isinstance(other, type(self)) and self.page.url == other.page.url
+
+ def __hash__(self) -> int:
+ return hash(self.page.url)
+
+
+class ParseLinks(Protocol):
+ def __call__(self, page: "IndexContent") -> Iterable[Link]: ...
+
+
+def with_cached_index_content(fn: ParseLinks) -> ParseLinks:
+ """
+ Given a function that parses an Iterable[Link] from an IndexContent, cache the
+ function's result (keyed by CacheablePageContent), unless the IndexContent
+ `page` has `page.cache_link_parsing == False`.
+ """
+
+ @functools.lru_cache(maxsize=None)
+ def wrapper(cacheable_page: CacheablePageContent) -> List[Link]:
+ return list(fn(cacheable_page.page))
+
+ @functools.wraps(fn)
+ def wrapper_wrapper(page: "IndexContent") -> List[Link]:
+ if page.cache_link_parsing:
+ return wrapper(CacheablePageContent(page))
+ return list(fn(page))
+
+ return wrapper_wrapper
+
+
+@with_cached_index_content
+def parse_links(page: "IndexContent") -> Iterable[Link]:
+ """
+ Parse a Simple API's Index Content, and yield its anchor elements as Link objects.
+ """
+
+ content_type_l = page.content_type.lower()
+ if content_type_l.startswith("application/vnd.pypi.simple.v1+json"):
+ data = json.loads(page.content)
+ for file in data.get("files", []):
+ link = Link.from_json(file, page.url)
+ if link is None:
+ continue
+ yield link
+ return
+
+ parser = HTMLLinkParser(page.url)
+ encoding = page.encoding or "utf-8"
+ parser.feed(page.content.decode(encoding))
+
+ url = page.url
+ base_url = parser.base_url or url
+ for anchor in parser.anchors:
+ link = Link.from_element(anchor, page_url=url, base_url=base_url)
+ if link is None:
+ continue
+ yield link
+
+
+@dataclass(frozen=True)
+class IndexContent:
+ """Represents one response (or page), along with its URL.
+
+ :param encoding: the encoding to decode the given content.
+ :param url: the URL from which the HTML was downloaded.
+ :param cache_link_parsing: whether links parsed from this page's url
+ should be cached. PyPI index urls should
+ have this set to False, for example.
+ """
+
+ content: bytes
+ content_type: str
+ encoding: Optional[str]
+ url: str
+ cache_link_parsing: bool = True
+
+ def __str__(self) -> str:
+ return redact_auth_from_url(self.url)
+
+
+class HTMLLinkParser(HTMLParser):
+ """
+ HTMLParser that keeps the first base HREF and a list of all anchor
+ elements' attributes.
+ """
+
+ def __init__(self, url: str) -> None:
+ super().__init__(convert_charrefs=True)
+
+ self.url: str = url
+ self.base_url: Optional[str] = None
+ self.anchors: List[Dict[str, Optional[str]]] = []
+
+ def handle_starttag(self, tag: str, attrs: List[Tuple[str, Optional[str]]]) -> None:
+ if tag == "base" and self.base_url is None:
+ href = self.get_href(attrs)
+ if href is not None:
+ self.base_url = href
+ elif tag == "a":
+ self.anchors.append(dict(attrs))
+
+ def get_href(self, attrs: List[Tuple[str, Optional[str]]]) -> Optional[str]:
+ for name, value in attrs:
+ if name == "href":
+ return value
+ return None
+
+
+def _handle_get_simple_fail(
+ link: Link,
+ reason: Union[str, Exception],
+ meth: Optional[Callable[..., None]] = None,
+) -> None:
+ if meth is None:
+ meth = logger.debug
+ meth("Could not fetch URL %s: %s - skipping", link, reason)
+
+
+def _make_index_content(
+ response: Response, cache_link_parsing: bool = True
+) -> IndexContent:
+ encoding = _get_encoding_from_headers(response.headers)
+ return IndexContent(
+ response.content,
+ response.headers["Content-Type"],
+ encoding=encoding,
+ url=response.url,
+ cache_link_parsing=cache_link_parsing,
+ )
+
+
+def _get_index_content(link: Link, *, session: PipSession) -> Optional["IndexContent"]:
+ url = link.url.split("#", 1)[0]
+
+ # Check for VCS schemes that do not support lookup as web pages.
+ vcs_scheme = _match_vcs_scheme(url)
+ if vcs_scheme:
+ logger.warning(
+ "Cannot look at %s URL %s because it does not support lookup as web pages.",
+ vcs_scheme,
+ link,
+ )
+ return None
+
+ # Tack index.html onto file:// URLs that point to directories
+ scheme, _, path, _, _, _ = urllib.parse.urlparse(url)
+ if scheme == "file" and os.path.isdir(urllib.request.url2pathname(path)):
+ # add trailing slash if not present so urljoin doesn't trim
+ # final segment
+ if not url.endswith("/"):
+ url += "/"
+ # TODO: In the future, it would be nice if pip supported PEP 691
+ # style responses in the file:// URLs, however there's no
+ # standard file extension for application/vnd.pypi.simple.v1+json
+ # so we'll need to come up with something on our own.
+ url = urllib.parse.urljoin(url, "index.html")
+ logger.debug(" file: URL is directory, getting %s", url)
+
+ try:
+ resp = _get_simple_response(url, session=session)
+ except _NotHTTP:
+ logger.warning(
+ "Skipping page %s because it looks like an archive, and cannot "
+ "be checked by a HTTP HEAD request.",
+ link,
+ )
+ except _NotAPIContent as exc:
+ logger.warning(
+ "Skipping page %s because the %s request got Content-Type: %s. "
+ "The only supported Content-Types are application/vnd.pypi.simple.v1+json, "
+ "application/vnd.pypi.simple.v1+html, and text/html",
+ link,
+ exc.request_desc,
+ exc.content_type,
+ )
+ except NetworkConnectionError as exc:
+ _handle_get_simple_fail(link, exc)
+ except RetryError as exc:
+ _handle_get_simple_fail(link, exc)
+ except SSLError as exc:
+ reason = "There was a problem confirming the ssl certificate: "
+ reason += str(exc)
+ _handle_get_simple_fail(link, reason, meth=logger.info)
+ except requests.ConnectionError as exc:
+ _handle_get_simple_fail(link, f"connection error: {exc}")
+ except requests.Timeout:
+ _handle_get_simple_fail(link, "timed out")
+ else:
+ return _make_index_content(resp, cache_link_parsing=link.cache_link_parsing)
+ return None
+
+
+class CollectedSources(NamedTuple):
+ find_links: Sequence[Optional[LinkSource]]
+ index_urls: Sequence[Optional[LinkSource]]
+
+
+class LinkCollector:
+ """
+ Responsible for collecting Link objects from all configured locations,
+ making network requests as needed.
+
+ The class's main method is its collect_sources() method.
+ """
+
+ def __init__(
+ self,
+ session: PipSession,
+ search_scope: SearchScope,
+ ) -> None:
+ self.search_scope = search_scope
+ self.session = session
+
+ @classmethod
+ def create(
+ cls,
+ session: PipSession,
+ options: Values,
+ suppress_no_index: bool = False,
+ ) -> "LinkCollector":
+ """
+ :param session: The Session to use to make requests.
+ :param suppress_no_index: Whether to ignore the --no-index option
+ when constructing the SearchScope object.
+ """
+ index_urls = [options.index_url] + options.extra_index_urls
+ if options.no_index and not suppress_no_index:
+ logger.debug(
+ "Ignoring indexes: %s",
+ ",".join(redact_auth_from_url(url) for url in index_urls),
+ )
+ index_urls = []
+
+ # Make sure find_links is a list before passing to create().
+ find_links = options.find_links or []
+
+ search_scope = SearchScope.create(
+ find_links=find_links,
+ index_urls=index_urls,
+ no_index=options.no_index,
+ )
+ link_collector = LinkCollector(
+ session=session,
+ search_scope=search_scope,
+ )
+ return link_collector
+
+ @property
+ def find_links(self) -> List[str]:
+ return self.search_scope.find_links
+
+ def fetch_response(self, location: Link) -> Optional[IndexContent]:
+ """
+ Fetch an HTML page containing package links.
+ """
+ return _get_index_content(location, session=self.session)
+
+ def collect_sources(
+ self,
+ project_name: str,
+ candidates_from_page: CandidatesFromPage,
+ ) -> CollectedSources:
+ # The OrderedDict calls deduplicate sources by URL.
+ index_url_sources = collections.OrderedDict(
+ build_source(
+ loc,
+ candidates_from_page=candidates_from_page,
+ page_validator=self.session.is_secure_origin,
+ expand_dir=False,
+ cache_link_parsing=False,
+ project_name=project_name,
+ )
+ for loc in self.search_scope.get_index_urls_locations(project_name)
+ ).values()
+ find_links_sources = collections.OrderedDict(
+ build_source(
+ loc,
+ candidates_from_page=candidates_from_page,
+ page_validator=self.session.is_secure_origin,
+ expand_dir=True,
+ cache_link_parsing=True,
+ project_name=project_name,
+ )
+ for loc in self.find_links
+ ).values()
+
+ if logger.isEnabledFor(logging.DEBUG):
+ lines = [
+ f"* {s.link}"
+ for s in itertools.chain(find_links_sources, index_url_sources)
+ if s is not None and s.link is not None
+ ]
+ lines = [
+ f"{len(lines)} location(s) to search "
+ f"for versions of {project_name}:"
+ ] + lines
+ logger.debug("\n".join(lines))
+
+ return CollectedSources(
+ find_links=list(find_links_sources),
+ index_urls=list(index_url_sources),
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/index/package_finder.py b/solutions/.venv/Lib/site-packages/pip/_internal/index/package_finder.py
new file mode 100644
index 000000000..0d65ce35f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/index/package_finder.py
@@ -0,0 +1,1020 @@
+"""Routines related to PyPI, indexes"""
+
+import enum
+import functools
+import itertools
+import logging
+import re
+from dataclasses import dataclass
+from typing import TYPE_CHECKING, FrozenSet, Iterable, List, Optional, Set, Tuple, Union
+
+from pip._vendor.packaging import specifiers
+from pip._vendor.packaging.tags import Tag
+from pip._vendor.packaging.utils import canonicalize_name
+from pip._vendor.packaging.version import InvalidVersion, _BaseVersion
+from pip._vendor.packaging.version import parse as parse_version
+
+from pip._internal.exceptions import (
+ BestVersionAlreadyInstalled,
+ DistributionNotFound,
+ InvalidWheelFilename,
+ UnsupportedWheel,
+)
+from pip._internal.index.collector import LinkCollector, parse_links
+from pip._internal.models.candidate import InstallationCandidate
+from pip._internal.models.format_control import FormatControl
+from pip._internal.models.link import Link
+from pip._internal.models.search_scope import SearchScope
+from pip._internal.models.selection_prefs import SelectionPreferences
+from pip._internal.models.target_python import TargetPython
+from pip._internal.models.wheel import Wheel
+from pip._internal.req import InstallRequirement
+from pip._internal.utils._log import getLogger
+from pip._internal.utils.filetypes import WHEEL_EXTENSION
+from pip._internal.utils.hashes import Hashes
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.misc import build_netloc
+from pip._internal.utils.packaging import check_requires_python
+from pip._internal.utils.unpacking import SUPPORTED_EXTENSIONS
+
+if TYPE_CHECKING:
+ from pip._vendor.typing_extensions import TypeGuard
+
+__all__ = ["FormatControl", "BestCandidateResult", "PackageFinder"]
+
+
+logger = getLogger(__name__)
+
+BuildTag = Union[Tuple[()], Tuple[int, str]]
+CandidateSortingKey = Tuple[int, int, int, _BaseVersion, Optional[int], BuildTag]
+
+
+def _check_link_requires_python(
+ link: Link,
+ version_info: Tuple[int, int, int],
+ ignore_requires_python: bool = False,
+) -> bool:
+ """
+ Return whether the given Python version is compatible with a link's
+ "Requires-Python" value.
+
+ :param version_info: A 3-tuple of ints representing the Python
+ major-minor-micro version to check.
+ :param ignore_requires_python: Whether to ignore the "Requires-Python"
+ value if the given Python version isn't compatible.
+ """
+ try:
+ is_compatible = check_requires_python(
+ link.requires_python,
+ version_info=version_info,
+ )
+ except specifiers.InvalidSpecifier:
+ logger.debug(
+ "Ignoring invalid Requires-Python (%r) for link: %s",
+ link.requires_python,
+ link,
+ )
+ else:
+ if not is_compatible:
+ version = ".".join(map(str, version_info))
+ if not ignore_requires_python:
+ logger.verbose(
+ "Link requires a different Python (%s not in: %r): %s",
+ version,
+ link.requires_python,
+ link,
+ )
+ return False
+
+ logger.debug(
+ "Ignoring failed Requires-Python check (%s not in: %r) for link: %s",
+ version,
+ link.requires_python,
+ link,
+ )
+
+ return True
+
+
+class LinkType(enum.Enum):
+ candidate = enum.auto()
+ different_project = enum.auto()
+ yanked = enum.auto()
+ format_unsupported = enum.auto()
+ format_invalid = enum.auto()
+ platform_mismatch = enum.auto()
+ requires_python_mismatch = enum.auto()
+
+
+class LinkEvaluator:
+ """
+ Responsible for evaluating links for a particular project.
+ """
+
+ _py_version_re = re.compile(r"-py([123]\.?[0-9]?)$")
+
+ # Don't include an allow_yanked default value to make sure each call
+ # site considers whether yanked releases are allowed. This also causes
+ # that decision to be made explicit in the calling code, which helps
+ # people when reading the code.
+ def __init__(
+ self,
+ project_name: str,
+ canonical_name: str,
+ formats: FrozenSet[str],
+ target_python: TargetPython,
+ allow_yanked: bool,
+ ignore_requires_python: Optional[bool] = None,
+ ) -> None:
+ """
+ :param project_name: The user supplied package name.
+ :param canonical_name: The canonical package name.
+ :param formats: The formats allowed for this package. Should be a set
+ with 'binary' or 'source' or both in it.
+ :param target_python: The target Python interpreter to use when
+ evaluating link compatibility. This is used, for example, to
+ check wheel compatibility, as well as when checking the Python
+ version, e.g. the Python version embedded in a link filename
+ (or egg fragment) and against an HTML link's optional PEP 503
+ "data-requires-python" attribute.
+ :param allow_yanked: Whether files marked as yanked (in the sense
+ of PEP 592) are permitted to be candidates for install.
+ :param ignore_requires_python: Whether to ignore incompatible
+ PEP 503 "data-requires-python" values in HTML links. Defaults
+ to False.
+ """
+ if ignore_requires_python is None:
+ ignore_requires_python = False
+
+ self._allow_yanked = allow_yanked
+ self._canonical_name = canonical_name
+ self._ignore_requires_python = ignore_requires_python
+ self._formats = formats
+ self._target_python = target_python
+
+ self.project_name = project_name
+
+ def evaluate_link(self, link: Link) -> Tuple[LinkType, str]:
+ """
+ Determine whether a link is a candidate for installation.
+
+ :return: A tuple (result, detail), where *result* is an enum
+ representing whether the evaluation found a candidate, or the reason
+ why one is not found. If a candidate is found, *detail* will be the
+ candidate's version string; if one is not found, it contains the
+ reason the link fails to qualify.
+ """
+ version = None
+ if link.is_yanked and not self._allow_yanked:
+ reason = link.yanked_reason or "<none given>"
+ return (LinkType.yanked, f"yanked for reason: {reason}")
+
+ if link.egg_fragment:
+ egg_info = link.egg_fragment
+ ext = link.ext
+ else:
+ egg_info, ext = link.splitext()
+ if not ext:
+ return (LinkType.format_unsupported, "not a file")
+ if ext not in SUPPORTED_EXTENSIONS:
+ return (
+ LinkType.format_unsupported,
+ f"unsupported archive format: {ext}",
+ )
+ if "binary" not in self._formats and ext == WHEEL_EXTENSION:
+ reason = f"No binaries permitted for {self.project_name}"
+ return (LinkType.format_unsupported, reason)
+ if "macosx10" in link.path and ext == ".zip":
+ return (LinkType.format_unsupported, "macosx10 one")
+ if ext == WHEEL_EXTENSION:
+ try:
+ wheel = Wheel(link.filename)
+ except InvalidWheelFilename:
+ return (
+ LinkType.format_invalid,
+ "invalid wheel filename",
+ )
+ if canonicalize_name(wheel.name) != self._canonical_name:
+ reason = f"wrong project name (not {self.project_name})"
+ return (LinkType.different_project, reason)
+
+ supported_tags = self._target_python.get_unsorted_tags()
+ if not wheel.supported(supported_tags):
+ # Include the wheel's tags in the reason string to
+ # simplify troubleshooting compatibility issues.
+ file_tags = ", ".join(wheel.get_formatted_file_tags())
+ reason = (
+ f"none of the wheel's tags ({file_tags}) are compatible "
+ f"(run pip debug --verbose to show compatible tags)"
+ )
+ return (LinkType.platform_mismatch, reason)
+
+ version = wheel.version
+
+ # This should be up by the self.ok_binary check, but see issue 2700.
+ if "source" not in self._formats and ext != WHEEL_EXTENSION:
+ reason = f"No sources permitted for {self.project_name}"
+ return (LinkType.format_unsupported, reason)
+
+ if not version:
+ version = _extract_version_from_fragment(
+ egg_info,
+ self._canonical_name,
+ )
+ if not version:
+ reason = f"Missing project version for {self.project_name}"
+ return (LinkType.format_invalid, reason)
+
+ match = self._py_version_re.search(version)
+ if match:
+ version = version[: match.start()]
+ py_version = match.group(1)
+ if py_version != self._target_python.py_version:
+ return (
+ LinkType.platform_mismatch,
+ "Python version is incorrect",
+ )
+
+ supports_python = _check_link_requires_python(
+ link,
+ version_info=self._target_python.py_version_info,
+ ignore_requires_python=self._ignore_requires_python,
+ )
+ if not supports_python:
+ reason = f"{version} Requires-Python {link.requires_python}"
+ return (LinkType.requires_python_mismatch, reason)
+
+ logger.debug("Found link %s, version: %s", link, version)
+
+ return (LinkType.candidate, version)
+
+
+def filter_unallowed_hashes(
+ candidates: List[InstallationCandidate],
+ hashes: Optional[Hashes],
+ project_name: str,
+) -> List[InstallationCandidate]:
+ """
+ Filter out candidates whose hashes aren't allowed, and return a new
+ list of candidates.
+
+ If at least one candidate has an allowed hash, then all candidates with
+ either an allowed hash or no hash specified are returned. Otherwise,
+ the given candidates are returned.
+
+ Including the candidates with no hash specified when there is a match
+ allows a warning to be logged if there is a more preferred candidate
+ with no hash specified. Returning all candidates in the case of no
+ matches lets pip report the hash of the candidate that would otherwise
+ have been installed (e.g. permitting the user to more easily update
+ their requirements file with the desired hash).
+ """
+ if not hashes:
+ logger.debug(
+ "Given no hashes to check %s links for project %r: "
+ "discarding no candidates",
+ len(candidates),
+ project_name,
+ )
+ # Make sure we're not returning back the given value.
+ return list(candidates)
+
+ matches_or_no_digest = []
+ # Collect the non-matches for logging purposes.
+ non_matches = []
+ match_count = 0
+ for candidate in candidates:
+ link = candidate.link
+ if not link.has_hash:
+ pass
+ elif link.is_hash_allowed(hashes=hashes):
+ match_count += 1
+ else:
+ non_matches.append(candidate)
+ continue
+
+ matches_or_no_digest.append(candidate)
+
+ if match_count:
+ filtered = matches_or_no_digest
+ else:
+ # Make sure we're not returning back the given value.
+ filtered = list(candidates)
+
+ if len(filtered) == len(candidates):
+ discard_message = "discarding no candidates"
+ else:
+ discard_message = "discarding {} non-matches:\n {}".format(
+ len(non_matches),
+ "\n ".join(str(candidate.link) for candidate in non_matches),
+ )
+
+ logger.debug(
+ "Checked %s links for project %r against %s hashes "
+ "(%s matches, %s no digest): %s",
+ len(candidates),
+ project_name,
+ hashes.digest_count,
+ match_count,
+ len(matches_or_no_digest) - match_count,
+ discard_message,
+ )
+
+ return filtered
+
+
+@dataclass
+class CandidatePreferences:
+ """
+ Encapsulates some of the preferences for filtering and sorting
+ InstallationCandidate objects.
+ """
+
+ prefer_binary: bool = False
+ allow_all_prereleases: bool = False
+
+
+class BestCandidateResult:
+ """A collection of candidates, returned by `PackageFinder.find_best_candidate`.
+
+ This class is only intended to be instantiated by CandidateEvaluator's
+ `compute_best_candidate()` method.
+ """
+
+ def __init__(
+ self,
+ candidates: List[InstallationCandidate],
+ applicable_candidates: List[InstallationCandidate],
+ best_candidate: Optional[InstallationCandidate],
+ ) -> None:
+ """
+ :param candidates: A sequence of all available candidates found.
+ :param applicable_candidates: The applicable candidates.
+ :param best_candidate: The most preferred candidate found, or None
+ if no applicable candidates were found.
+ """
+ assert set(applicable_candidates) <= set(candidates)
+
+ if best_candidate is None:
+ assert not applicable_candidates
+ else:
+ assert best_candidate in applicable_candidates
+
+ self._applicable_candidates = applicable_candidates
+ self._candidates = candidates
+
+ self.best_candidate = best_candidate
+
+ def iter_all(self) -> Iterable[InstallationCandidate]:
+ """Iterate through all candidates."""
+ return iter(self._candidates)
+
+ def iter_applicable(self) -> Iterable[InstallationCandidate]:
+ """Iterate through the applicable candidates."""
+ return iter(self._applicable_candidates)
+
+
+class CandidateEvaluator:
+ """
+ Responsible for filtering and sorting candidates for installation based
+ on what tags are valid.
+ """
+
+ @classmethod
+ def create(
+ cls,
+ project_name: str,
+ target_python: Optional[TargetPython] = None,
+ prefer_binary: bool = False,
+ allow_all_prereleases: bool = False,
+ specifier: Optional[specifiers.BaseSpecifier] = None,
+ hashes: Optional[Hashes] = None,
+ ) -> "CandidateEvaluator":
+ """Create a CandidateEvaluator object.
+
+ :param target_python: The target Python interpreter to use when
+ checking compatibility. If None (the default), a TargetPython
+ object will be constructed from the running Python.
+ :param specifier: An optional object implementing `filter`
+ (e.g. `packaging.specifiers.SpecifierSet`) to filter applicable
+ versions.
+ :param hashes: An optional collection of allowed hashes.
+ """
+ if target_python is None:
+ target_python = TargetPython()
+ if specifier is None:
+ specifier = specifiers.SpecifierSet()
+
+ supported_tags = target_python.get_sorted_tags()
+
+ return cls(
+ project_name=project_name,
+ supported_tags=supported_tags,
+ specifier=specifier,
+ prefer_binary=prefer_binary,
+ allow_all_prereleases=allow_all_prereleases,
+ hashes=hashes,
+ )
+
+ def __init__(
+ self,
+ project_name: str,
+ supported_tags: List[Tag],
+ specifier: specifiers.BaseSpecifier,
+ prefer_binary: bool = False,
+ allow_all_prereleases: bool = False,
+ hashes: Optional[Hashes] = None,
+ ) -> None:
+ """
+ :param supported_tags: The PEP 425 tags supported by the target
+ Python in order of preference (most preferred first).
+ """
+ self._allow_all_prereleases = allow_all_prereleases
+ self._hashes = hashes
+ self._prefer_binary = prefer_binary
+ self._project_name = project_name
+ self._specifier = specifier
+ self._supported_tags = supported_tags
+ # Since the index of the tag in the _supported_tags list is used
+ # as a priority, precompute a map from tag to index/priority to be
+ # used in wheel.find_most_preferred_tag.
+ self._wheel_tag_preferences = {
+ tag: idx for idx, tag in enumerate(supported_tags)
+ }
+
+ def get_applicable_candidates(
+ self,
+ candidates: List[InstallationCandidate],
+ ) -> List[InstallationCandidate]:
+ """
+ Return the applicable candidates from a list of candidates.
+ """
+ # Using None infers from the specifier instead.
+ allow_prereleases = self._allow_all_prereleases or None
+ specifier = self._specifier
+
+ # We turn the version object into a str here because otherwise
+ # when we're debundled but setuptools isn't, Python will see
+ # packaging.version.Version and
+ # pkg_resources._vendor.packaging.version.Version as different
+ # types. This way we'll use a str as a common data interchange
+ # format. If we stop using the pkg_resources provided specifier
+ # and start using our own, we can drop the cast to str().
+ candidates_and_versions = [(c, str(c.version)) for c in candidates]
+ versions = set(
+ specifier.filter(
+ (v for _, v in candidates_and_versions),
+ prereleases=allow_prereleases,
+ )
+ )
+
+ applicable_candidates = [c for c, v in candidates_and_versions if v in versions]
+ filtered_applicable_candidates = filter_unallowed_hashes(
+ candidates=applicable_candidates,
+ hashes=self._hashes,
+ project_name=self._project_name,
+ )
+
+ return sorted(filtered_applicable_candidates, key=self._sort_key)
+
+ def _sort_key(self, candidate: InstallationCandidate) -> CandidateSortingKey:
+ """
+ Function to pass as the `key` argument to a call to sorted() to sort
+ InstallationCandidates by preference.
+
+ Returns a tuple such that tuples sorting as greater using Python's
+ default comparison operator are more preferred.
+
+ The preference is as follows:
+
+ First and foremost, candidates with allowed (matching) hashes are
+ always preferred over candidates without matching hashes. This is
+ because e.g. if the only candidate with an allowed hash is yanked,
+ we still want to use that candidate.
+
+ Second, excepting hash considerations, candidates that have been
+ yanked (in the sense of PEP 592) are always less preferred than
+ candidates that haven't been yanked. Then:
+
+ If not finding wheels, they are sorted by version only.
+ If finding wheels, then the sort order is by version, then:
+ 1. existing installs
+ 2. wheels ordered via Wheel.support_index_min(self._supported_tags)
+ 3. source archives
+ If prefer_binary was set, then all wheels are sorted above sources.
+
+ Note: it was considered to embed this logic into the Link
+ comparison operators, but then different sdist links
+ with the same version, would have to be considered equal
+ """
+ valid_tags = self._supported_tags
+ support_num = len(valid_tags)
+ build_tag: BuildTag = ()
+ binary_preference = 0
+ link = candidate.link
+ if link.is_wheel:
+ # can raise InvalidWheelFilename
+ wheel = Wheel(link.filename)
+ try:
+ pri = -(
+ wheel.find_most_preferred_tag(
+ valid_tags, self._wheel_tag_preferences
+ )
+ )
+ except ValueError:
+ raise UnsupportedWheel(
+ f"{wheel.filename} is not a supported wheel for this platform. It "
+ "can't be sorted."
+ )
+ if self._prefer_binary:
+ binary_preference = 1
+ if wheel.build_tag is not None:
+ match = re.match(r"^(\d+)(.*)$", wheel.build_tag)
+ assert match is not None, "guaranteed by filename validation"
+ build_tag_groups = match.groups()
+ build_tag = (int(build_tag_groups[0]), build_tag_groups[1])
+ else: # sdist
+ pri = -(support_num)
+ has_allowed_hash = int(link.is_hash_allowed(self._hashes))
+ yank_value = -1 * int(link.is_yanked) # -1 for yanked.
+ return (
+ has_allowed_hash,
+ yank_value,
+ binary_preference,
+ candidate.version,
+ pri,
+ build_tag,
+ )
+
+ def sort_best_candidate(
+ self,
+ candidates: List[InstallationCandidate],
+ ) -> Optional[InstallationCandidate]:
+ """
+ Return the best candidate per the instance's sort order, or None if
+ no candidate is acceptable.
+ """
+ if not candidates:
+ return None
+ best_candidate = max(candidates, key=self._sort_key)
+ return best_candidate
+
+ def compute_best_candidate(
+ self,
+ candidates: List[InstallationCandidate],
+ ) -> BestCandidateResult:
+ """
+ Compute and return a `BestCandidateResult` instance.
+ """
+ applicable_candidates = self.get_applicable_candidates(candidates)
+
+ best_candidate = self.sort_best_candidate(applicable_candidates)
+
+ return BestCandidateResult(
+ candidates,
+ applicable_candidates=applicable_candidates,
+ best_candidate=best_candidate,
+ )
+
+
+class PackageFinder:
+ """This finds packages.
+
+ This is meant to match easy_install's technique for looking for
+ packages, by reading pages and looking for appropriate links.
+ """
+
+ def __init__(
+ self,
+ link_collector: LinkCollector,
+ target_python: TargetPython,
+ allow_yanked: bool,
+ format_control: Optional[FormatControl] = None,
+ candidate_prefs: Optional[CandidatePreferences] = None,
+ ignore_requires_python: Optional[bool] = None,
+ ) -> None:
+ """
+ This constructor is primarily meant to be used by the create() class
+ method and from tests.
+
+ :param format_control: A FormatControl object, used to control
+ the selection of source packages / binary packages when consulting
+ the index and links.
+ :param candidate_prefs: Options to use when creating a
+ CandidateEvaluator object.
+ """
+ if candidate_prefs is None:
+ candidate_prefs = CandidatePreferences()
+
+ format_control = format_control or FormatControl(set(), set())
+
+ self._allow_yanked = allow_yanked
+ self._candidate_prefs = candidate_prefs
+ self._ignore_requires_python = ignore_requires_python
+ self._link_collector = link_collector
+ self._target_python = target_python
+
+ self.format_control = format_control
+
+ # These are boring links that have already been logged somehow.
+ self._logged_links: Set[Tuple[Link, LinkType, str]] = set()
+
+ # Don't include an allow_yanked default value to make sure each call
+ # site considers whether yanked releases are allowed. This also causes
+ # that decision to be made explicit in the calling code, which helps
+ # people when reading the code.
+ @classmethod
+ def create(
+ cls,
+ link_collector: LinkCollector,
+ selection_prefs: SelectionPreferences,
+ target_python: Optional[TargetPython] = None,
+ ) -> "PackageFinder":
+ """Create a PackageFinder.
+
+ :param selection_prefs: The candidate selection preferences, as a
+ SelectionPreferences object.
+ :param target_python: The target Python interpreter to use when
+ checking compatibility. If None (the default), a TargetPython
+ object will be constructed from the running Python.
+ """
+ if target_python is None:
+ target_python = TargetPython()
+
+ candidate_prefs = CandidatePreferences(
+ prefer_binary=selection_prefs.prefer_binary,
+ allow_all_prereleases=selection_prefs.allow_all_prereleases,
+ )
+
+ return cls(
+ candidate_prefs=candidate_prefs,
+ link_collector=link_collector,
+ target_python=target_python,
+ allow_yanked=selection_prefs.allow_yanked,
+ format_control=selection_prefs.format_control,
+ ignore_requires_python=selection_prefs.ignore_requires_python,
+ )
+
+ @property
+ def target_python(self) -> TargetPython:
+ return self._target_python
+
+ @property
+ def search_scope(self) -> SearchScope:
+ return self._link_collector.search_scope
+
+ @search_scope.setter
+ def search_scope(self, search_scope: SearchScope) -> None:
+ self._link_collector.search_scope = search_scope
+
+ @property
+ def find_links(self) -> List[str]:
+ return self._link_collector.find_links
+
+ @property
+ def index_urls(self) -> List[str]:
+ return self.search_scope.index_urls
+
+ @property
+ def trusted_hosts(self) -> Iterable[str]:
+ for host_port in self._link_collector.session.pip_trusted_origins:
+ yield build_netloc(*host_port)
+
+ @property
+ def allow_all_prereleases(self) -> bool:
+ return self._candidate_prefs.allow_all_prereleases
+
+ def set_allow_all_prereleases(self) -> None:
+ self._candidate_prefs.allow_all_prereleases = True
+
+ @property
+ def prefer_binary(self) -> bool:
+ return self._candidate_prefs.prefer_binary
+
+ def set_prefer_binary(self) -> None:
+ self._candidate_prefs.prefer_binary = True
+
+ def requires_python_skipped_reasons(self) -> List[str]:
+ reasons = {
+ detail
+ for _, result, detail in self._logged_links
+ if result == LinkType.requires_python_mismatch
+ }
+ return sorted(reasons)
+
+ def make_link_evaluator(self, project_name: str) -> LinkEvaluator:
+ canonical_name = canonicalize_name(project_name)
+ formats = self.format_control.get_allowed_formats(canonical_name)
+
+ return LinkEvaluator(
+ project_name=project_name,
+ canonical_name=canonical_name,
+ formats=formats,
+ target_python=self._target_python,
+ allow_yanked=self._allow_yanked,
+ ignore_requires_python=self._ignore_requires_python,
+ )
+
+ def _sort_links(self, links: Iterable[Link]) -> List[Link]:
+ """
+ Returns elements of links in order, non-egg links first, egg links
+ second, while eliminating duplicates
+ """
+ eggs, no_eggs = [], []
+ seen: Set[Link] = set()
+ for link in links:
+ if link not in seen:
+ seen.add(link)
+ if link.egg_fragment:
+ eggs.append(link)
+ else:
+ no_eggs.append(link)
+ return no_eggs + eggs
+
+ def _log_skipped_link(self, link: Link, result: LinkType, detail: str) -> None:
+ entry = (link, result, detail)
+ if entry not in self._logged_links:
+ # Put the link at the end so the reason is more visible and because
+ # the link string is usually very long.
+ logger.debug("Skipping link: %s: %s", detail, link)
+ self._logged_links.add(entry)
+
+ def get_install_candidate(
+ self, link_evaluator: LinkEvaluator, link: Link
+ ) -> Optional[InstallationCandidate]:
+ """
+ If the link is a candidate for install, convert it to an
+ InstallationCandidate and return it. Otherwise, return None.
+ """
+ result, detail = link_evaluator.evaluate_link(link)
+ if result != LinkType.candidate:
+ self._log_skipped_link(link, result, detail)
+ return None
+
+ try:
+ return InstallationCandidate(
+ name=link_evaluator.project_name,
+ link=link,
+ version=detail,
+ )
+ except InvalidVersion:
+ return None
+
+ def evaluate_links(
+ self, link_evaluator: LinkEvaluator, links: Iterable[Link]
+ ) -> List[InstallationCandidate]:
+ """
+ Convert links that are candidates to InstallationCandidate objects.
+ """
+ candidates = []
+ for link in self._sort_links(links):
+ candidate = self.get_install_candidate(link_evaluator, link)
+ if candidate is not None:
+ candidates.append(candidate)
+
+ return candidates
+
+ def process_project_url(
+ self, project_url: Link, link_evaluator: LinkEvaluator
+ ) -> List[InstallationCandidate]:
+ logger.debug(
+ "Fetching project page and analyzing links: %s",
+ project_url,
+ )
+ index_response = self._link_collector.fetch_response(project_url)
+ if index_response is None:
+ return []
+
+ page_links = list(parse_links(index_response))
+
+ with indent_log():
+ package_links = self.evaluate_links(
+ link_evaluator,
+ links=page_links,
+ )
+
+ return package_links
+
+ @functools.lru_cache(maxsize=None)
+ def find_all_candidates(self, project_name: str) -> List[InstallationCandidate]:
+ """Find all available InstallationCandidate for project_name
+
+ This checks index_urls and find_links.
+ All versions found are returned as an InstallationCandidate list.
+
+ See LinkEvaluator.evaluate_link() for details on which files
+ are accepted.
+ """
+ link_evaluator = self.make_link_evaluator(project_name)
+
+ collected_sources = self._link_collector.collect_sources(
+ project_name=project_name,
+ candidates_from_page=functools.partial(
+ self.process_project_url,
+ link_evaluator=link_evaluator,
+ ),
+ )
+
+ page_candidates_it = itertools.chain.from_iterable(
+ source.page_candidates()
+ for sources in collected_sources
+ for source in sources
+ if source is not None
+ )
+ page_candidates = list(page_candidates_it)
+
+ file_links_it = itertools.chain.from_iterable(
+ source.file_links()
+ for sources in collected_sources
+ for source in sources
+ if source is not None
+ )
+ file_candidates = self.evaluate_links(
+ link_evaluator,
+ sorted(file_links_it, reverse=True),
+ )
+
+ if logger.isEnabledFor(logging.DEBUG) and file_candidates:
+ paths = []
+ for candidate in file_candidates:
+ assert candidate.link.url # we need to have a URL
+ try:
+ paths.append(candidate.link.file_path)
+ except Exception:
+ paths.append(candidate.link.url) # it's not a local file
+
+ logger.debug("Local files found: %s", ", ".join(paths))
+
+ # This is an intentional priority ordering
+ return file_candidates + page_candidates
+
+ def make_candidate_evaluator(
+ self,
+ project_name: str,
+ specifier: Optional[specifiers.BaseSpecifier] = None,
+ hashes: Optional[Hashes] = None,
+ ) -> CandidateEvaluator:
+ """Create a CandidateEvaluator object to use."""
+ candidate_prefs = self._candidate_prefs
+ return CandidateEvaluator.create(
+ project_name=project_name,
+ target_python=self._target_python,
+ prefer_binary=candidate_prefs.prefer_binary,
+ allow_all_prereleases=candidate_prefs.allow_all_prereleases,
+ specifier=specifier,
+ hashes=hashes,
+ )
+
+ @functools.lru_cache(maxsize=None)
+ def find_best_candidate(
+ self,
+ project_name: str,
+ specifier: Optional[specifiers.BaseSpecifier] = None,
+ hashes: Optional[Hashes] = None,
+ ) -> BestCandidateResult:
+ """Find matches for the given project and specifier.
+
+ :param specifier: An optional object implementing `filter`
+ (e.g. `packaging.specifiers.SpecifierSet`) to filter applicable
+ versions.
+
+ :return: A `BestCandidateResult` instance.
+ """
+ candidates = self.find_all_candidates(project_name)
+ candidate_evaluator = self.make_candidate_evaluator(
+ project_name=project_name,
+ specifier=specifier,
+ hashes=hashes,
+ )
+ return candidate_evaluator.compute_best_candidate(candidates)
+
+ def find_requirement(
+ self, req: InstallRequirement, upgrade: bool
+ ) -> Optional[InstallationCandidate]:
+ """Try to find a Link matching req
+
+ Expects req, an InstallRequirement and upgrade, a boolean
+ Returns a InstallationCandidate if found,
+ Raises DistributionNotFound or BestVersionAlreadyInstalled otherwise
+ """
+ hashes = req.hashes(trust_internet=False)
+ best_candidate_result = self.find_best_candidate(
+ req.name,
+ specifier=req.specifier,
+ hashes=hashes,
+ )
+ best_candidate = best_candidate_result.best_candidate
+
+ installed_version: Optional[_BaseVersion] = None
+ if req.satisfied_by is not None:
+ installed_version = req.satisfied_by.version
+
+ def _format_versions(cand_iter: Iterable[InstallationCandidate]) -> str:
+ # This repeated parse_version and str() conversion is needed to
+ # handle different vendoring sources from pip and pkg_resources.
+ # If we stop using the pkg_resources provided specifier and start
+ # using our own, we can drop the cast to str().
+ return (
+ ", ".join(
+ sorted(
+ {str(c.version) for c in cand_iter},
+ key=parse_version,
+ )
+ )
+ or "none"
+ )
+
+ if installed_version is None and best_candidate is None:
+ logger.critical(
+ "Could not find a version that satisfies the requirement %s "
+ "(from versions: %s)",
+ req,
+ _format_versions(best_candidate_result.iter_all()),
+ )
+
+ raise DistributionNotFound(f"No matching distribution found for {req}")
+
+ def _should_install_candidate(
+ candidate: Optional[InstallationCandidate],
+ ) -> "TypeGuard[InstallationCandidate]":
+ if installed_version is None:
+ return True
+ if best_candidate is None:
+ return False
+ return best_candidate.version > installed_version
+
+ if not upgrade and installed_version is not None:
+ if _should_install_candidate(best_candidate):
+ logger.debug(
+ "Existing installed version (%s) satisfies requirement "
+ "(most up-to-date version is %s)",
+ installed_version,
+ best_candidate.version,
+ )
+ else:
+ logger.debug(
+ "Existing installed version (%s) is most up-to-date and "
+ "satisfies requirement",
+ installed_version,
+ )
+ return None
+
+ if _should_install_candidate(best_candidate):
+ logger.debug(
+ "Using version %s (newest of versions: %s)",
+ best_candidate.version,
+ _format_versions(best_candidate_result.iter_applicable()),
+ )
+ return best_candidate
+
+ # We have an existing version, and its the best version
+ logger.debug(
+ "Installed version (%s) is most up-to-date (past versions: %s)",
+ installed_version,
+ _format_versions(best_candidate_result.iter_applicable()),
+ )
+ raise BestVersionAlreadyInstalled
+
+
+def _find_name_version_sep(fragment: str, canonical_name: str) -> int:
+ """Find the separator's index based on the package's canonical name.
+
+ :param fragment: A <package>+<version> filename "fragment" (stem) or
+ egg fragment.
+ :param canonical_name: The package's canonical name.
+
+ This function is needed since the canonicalized name does not necessarily
+ have the same length as the egg info's name part. An example::
+
+ >>> fragment = 'foo__bar-1.0'
+ >>> canonical_name = 'foo-bar'
+ >>> _find_name_version_sep(fragment, canonical_name)
+ 8
+ """
+ # Project name and version must be separated by one single dash. Find all
+ # occurrences of dashes; if the string in front of it matches the canonical
+ # name, this is the one separating the name and version parts.
+ for i, c in enumerate(fragment):
+ if c != "-":
+ continue
+ if canonicalize_name(fragment[:i]) == canonical_name:
+ return i
+ raise ValueError(f"{fragment} does not match {canonical_name}")
+
+
+def _extract_version_from_fragment(fragment: str, canonical_name: str) -> Optional[str]:
+ """Parse the version string from a <package>+<version> filename
+ "fragment" (stem) or egg fragment.
+
+ :param fragment: The string to parse. E.g. foo-2.1
+ :param canonical_name: The canonicalized name of the package this
+ belongs to.
+ """
+ try:
+ version_start = _find_name_version_sep(fragment, canonical_name) + 1
+ except ValueError:
+ return None
+ version = fragment[version_start:]
+ if not version:
+ return None
+ return version
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/index/sources.py b/solutions/.venv/Lib/site-packages/pip/_internal/index/sources.py
new file mode 100644
index 000000000..3dafb30e6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/index/sources.py
@@ -0,0 +1,284 @@
+import logging
+import mimetypes
+import os
+from collections import defaultdict
+from typing import Callable, Dict, Iterable, List, Optional, Tuple
+
+from pip._vendor.packaging.utils import (
+ InvalidSdistFilename,
+ InvalidWheelFilename,
+ canonicalize_name,
+ parse_sdist_filename,
+ parse_wheel_filename,
+)
+
+from pip._internal.models.candidate import InstallationCandidate
+from pip._internal.models.link import Link
+from pip._internal.utils.urls import path_to_url, url_to_path
+from pip._internal.vcs import is_url
+
+logger = logging.getLogger(__name__)
+
+FoundCandidates = Iterable[InstallationCandidate]
+FoundLinks = Iterable[Link]
+CandidatesFromPage = Callable[[Link], Iterable[InstallationCandidate]]
+PageValidator = Callable[[Link], bool]
+
+
+class LinkSource:
+ @property
+ def link(self) -> Optional[Link]:
+ """Returns the underlying link, if there's one."""
+ raise NotImplementedError()
+
+ def page_candidates(self) -> FoundCandidates:
+ """Candidates found by parsing an archive listing HTML file."""
+ raise NotImplementedError()
+
+ def file_links(self) -> FoundLinks:
+ """Links found by specifying archives directly."""
+ raise NotImplementedError()
+
+
+def _is_html_file(file_url: str) -> bool:
+ return mimetypes.guess_type(file_url, strict=False)[0] == "text/html"
+
+
+class _FlatDirectoryToUrls:
+ """Scans directory and caches results"""
+
+ def __init__(self, path: str) -> None:
+ self._path = path
+ self._page_candidates: List[str] = []
+ self._project_name_to_urls: Dict[str, List[str]] = defaultdict(list)
+ self._scanned_directory = False
+
+ def _scan_directory(self) -> None:
+ """Scans directory once and populates both page_candidates
+ and project_name_to_urls at the same time
+ """
+ for entry in os.scandir(self._path):
+ url = path_to_url(entry.path)
+ if _is_html_file(url):
+ self._page_candidates.append(url)
+ continue
+
+ # File must have a valid wheel or sdist name,
+ # otherwise not worth considering as a package
+ try:
+ project_filename = parse_wheel_filename(entry.name)[0]
+ except InvalidWheelFilename:
+ try:
+ project_filename = parse_sdist_filename(entry.name)[0]
+ except InvalidSdistFilename:
+ continue
+
+ self._project_name_to_urls[project_filename].append(url)
+ self._scanned_directory = True
+
+ @property
+ def page_candidates(self) -> List[str]:
+ if not self._scanned_directory:
+ self._scan_directory()
+
+ return self._page_candidates
+
+ @property
+ def project_name_to_urls(self) -> Dict[str, List[str]]:
+ if not self._scanned_directory:
+ self._scan_directory()
+
+ return self._project_name_to_urls
+
+
+class _FlatDirectorySource(LinkSource):
+ """Link source specified by ``--find-links=<path-to-dir>``.
+
+ This looks the content of the directory, and returns:
+
+ * ``page_candidates``: Links listed on each HTML file in the directory.
+ * ``file_candidates``: Archives in the directory.
+ """
+
+ _paths_to_urls: Dict[str, _FlatDirectoryToUrls] = {}
+
+ def __init__(
+ self,
+ candidates_from_page: CandidatesFromPage,
+ path: str,
+ project_name: str,
+ ) -> None:
+ self._candidates_from_page = candidates_from_page
+ self._project_name = canonicalize_name(project_name)
+
+ # Get existing instance of _FlatDirectoryToUrls if it exists
+ if path in self._paths_to_urls:
+ self._path_to_urls = self._paths_to_urls[path]
+ else:
+ self._path_to_urls = _FlatDirectoryToUrls(path=path)
+ self._paths_to_urls[path] = self._path_to_urls
+
+ @property
+ def link(self) -> Optional[Link]:
+ return None
+
+ def page_candidates(self) -> FoundCandidates:
+ for url in self._path_to_urls.page_candidates:
+ yield from self._candidates_from_page(Link(url))
+
+ def file_links(self) -> FoundLinks:
+ for url in self._path_to_urls.project_name_to_urls[self._project_name]:
+ yield Link(url)
+
+
+class _LocalFileSource(LinkSource):
+ """``--find-links=<path-or-url>`` or ``--[extra-]index-url=<path-or-url>``.
+
+ If a URL is supplied, it must be a ``file:`` URL. If a path is supplied to
+ the option, it is converted to a URL first. This returns:
+
+ * ``page_candidates``: Links listed on an HTML file.
+ * ``file_candidates``: The non-HTML file.
+ """
+
+ def __init__(
+ self,
+ candidates_from_page: CandidatesFromPage,
+ link: Link,
+ ) -> None:
+ self._candidates_from_page = candidates_from_page
+ self._link = link
+
+ @property
+ def link(self) -> Optional[Link]:
+ return self._link
+
+ def page_candidates(self) -> FoundCandidates:
+ if not _is_html_file(self._link.url):
+ return
+ yield from self._candidates_from_page(self._link)
+
+ def file_links(self) -> FoundLinks:
+ if _is_html_file(self._link.url):
+ return
+ yield self._link
+
+
+class _RemoteFileSource(LinkSource):
+ """``--find-links=<url>`` or ``--[extra-]index-url=<url>``.
+
+ This returns:
+
+ * ``page_candidates``: Links listed on an HTML file.
+ * ``file_candidates``: The non-HTML file.
+ """
+
+ def __init__(
+ self,
+ candidates_from_page: CandidatesFromPage,
+ page_validator: PageValidator,
+ link: Link,
+ ) -> None:
+ self._candidates_from_page = candidates_from_page
+ self._page_validator = page_validator
+ self._link = link
+
+ @property
+ def link(self) -> Optional[Link]:
+ return self._link
+
+ def page_candidates(self) -> FoundCandidates:
+ if not self._page_validator(self._link):
+ return
+ yield from self._candidates_from_page(self._link)
+
+ def file_links(self) -> FoundLinks:
+ yield self._link
+
+
+class _IndexDirectorySource(LinkSource):
+ """``--[extra-]index-url=<path-to-directory>``.
+
+ This is treated like a remote URL; ``candidates_from_page`` contains logic
+ for this by appending ``index.html`` to the link.
+ """
+
+ def __init__(
+ self,
+ candidates_from_page: CandidatesFromPage,
+ link: Link,
+ ) -> None:
+ self._candidates_from_page = candidates_from_page
+ self._link = link
+
+ @property
+ def link(self) -> Optional[Link]:
+ return self._link
+
+ def page_candidates(self) -> FoundCandidates:
+ yield from self._candidates_from_page(self._link)
+
+ def file_links(self) -> FoundLinks:
+ return ()
+
+
+def build_source(
+ location: str,
+ *,
+ candidates_from_page: CandidatesFromPage,
+ page_validator: PageValidator,
+ expand_dir: bool,
+ cache_link_parsing: bool,
+ project_name: str,
+) -> Tuple[Optional[str], Optional[LinkSource]]:
+ path: Optional[str] = None
+ url: Optional[str] = None
+ if os.path.exists(location): # Is a local path.
+ url = path_to_url(location)
+ path = location
+ elif location.startswith("file:"): # A file: URL.
+ url = location
+ path = url_to_path(location)
+ elif is_url(location):
+ url = location
+
+ if url is None:
+ msg = (
+ "Location '%s' is ignored: "
+ "it is either a non-existing path or lacks a specific scheme."
+ )
+ logger.warning(msg, location)
+ return (None, None)
+
+ if path is None:
+ source: LinkSource = _RemoteFileSource(
+ candidates_from_page=candidates_from_page,
+ page_validator=page_validator,
+ link=Link(url, cache_link_parsing=cache_link_parsing),
+ )
+ return (url, source)
+
+ if os.path.isdir(path):
+ if expand_dir:
+ source = _FlatDirectorySource(
+ candidates_from_page=candidates_from_page,
+ path=path,
+ project_name=project_name,
+ )
+ else:
+ source = _IndexDirectorySource(
+ candidates_from_page=candidates_from_page,
+ link=Link(url, cache_link_parsing=cache_link_parsing),
+ )
+ return (url, source)
+ elif os.path.isfile(path):
+ source = _LocalFileSource(
+ candidates_from_page=candidates_from_page,
+ link=Link(url, cache_link_parsing=cache_link_parsing),
+ )
+ return (url, source)
+ logger.warning(
+ "Location '%s' is ignored: it is neither a file nor a directory.",
+ location,
+ )
+ return (url, None)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/locations/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/locations/__init__.py
new file mode 100644
index 000000000..32382be7f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/locations/__init__.py
@@ -0,0 +1,456 @@
+import functools
+import logging
+import os
+import pathlib
+import sys
+import sysconfig
+from typing import Any, Dict, Generator, Optional, Tuple
+
+from pip._internal.models.scheme import SCHEME_KEYS, Scheme
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.deprecation import deprecated
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+from . import _sysconfig
+from .base import (
+ USER_CACHE_DIR,
+ get_major_minor_version,
+ get_src_prefix,
+ is_osx_framework,
+ site_packages,
+ user_site,
+)
+
+__all__ = [
+ "USER_CACHE_DIR",
+ "get_bin_prefix",
+ "get_bin_user",
+ "get_major_minor_version",
+ "get_platlib",
+ "get_purelib",
+ "get_scheme",
+ "get_src_prefix",
+ "site_packages",
+ "user_site",
+]
+
+
+logger = logging.getLogger(__name__)
+
+
+_PLATLIBDIR: str = getattr(sys, "platlibdir", "lib")
+
+_USE_SYSCONFIG_DEFAULT = sys.version_info >= (3, 10)
+
+
+def _should_use_sysconfig() -> bool:
+ """This function determines the value of _USE_SYSCONFIG.
+
+ By default, pip uses sysconfig on Python 3.10+.
+ But Python distributors can override this decision by setting:
+ sysconfig._PIP_USE_SYSCONFIG = True / False
+ Rationale in https://github.com/pypa/pip/issues/10647
+
+ This is a function for testability, but should be constant during any one
+ run.
+ """
+ return bool(getattr(sysconfig, "_PIP_USE_SYSCONFIG", _USE_SYSCONFIG_DEFAULT))
+
+
+_USE_SYSCONFIG = _should_use_sysconfig()
+
+if not _USE_SYSCONFIG:
+ # Import distutils lazily to avoid deprecation warnings,
+ # but import it soon enough that it is in memory and available during
+ # a pip reinstall.
+ from . import _distutils
+
+# Be noisy about incompatibilities if this platforms "should" be using
+# sysconfig, but is explicitly opting out and using distutils instead.
+if _USE_SYSCONFIG_DEFAULT and not _USE_SYSCONFIG:
+ _MISMATCH_LEVEL = logging.WARNING
+else:
+ _MISMATCH_LEVEL = logging.DEBUG
+
+
+def _looks_like_bpo_44860() -> bool:
+ """The resolution to bpo-44860 will change this incorrect platlib.
+
+ See <https://bugs.python.org/issue44860>.
+ """
+ from distutils.command.install import INSTALL_SCHEMES
+
+ try:
+ unix_user_platlib = INSTALL_SCHEMES["unix_user"]["platlib"]
+ except KeyError:
+ return False
+ return unix_user_platlib == "$usersite"
+
+
+def _looks_like_red_hat_patched_platlib_purelib(scheme: Dict[str, str]) -> bool:
+ platlib = scheme["platlib"]
+ if "/$platlibdir/" in platlib:
+ platlib = platlib.replace("/$platlibdir/", f"/{_PLATLIBDIR}/")
+ if "/lib64/" not in platlib:
+ return False
+ unpatched = platlib.replace("/lib64/", "/lib/")
+ return unpatched.replace("$platbase/", "$base/") == scheme["purelib"]
+
+
+@functools.lru_cache(maxsize=None)
+def _looks_like_red_hat_lib() -> bool:
+ """Red Hat patches platlib in unix_prefix and unix_home, but not purelib.
+
+ This is the only way I can see to tell a Red Hat-patched Python.
+ """
+ from distutils.command.install import INSTALL_SCHEMES
+
+ return all(
+ k in INSTALL_SCHEMES
+ and _looks_like_red_hat_patched_platlib_purelib(INSTALL_SCHEMES[k])
+ for k in ("unix_prefix", "unix_home")
+ )
+
+
+@functools.lru_cache(maxsize=None)
+def _looks_like_debian_scheme() -> bool:
+ """Debian adds two additional schemes."""
+ from distutils.command.install import INSTALL_SCHEMES
+
+ return "deb_system" in INSTALL_SCHEMES and "unix_local" in INSTALL_SCHEMES
+
+
+@functools.lru_cache(maxsize=None)
+def _looks_like_red_hat_scheme() -> bool:
+ """Red Hat patches ``sys.prefix`` and ``sys.exec_prefix``.
+
+ Red Hat's ``00251-change-user-install-location.patch`` changes the install
+ command's ``prefix`` and ``exec_prefix`` to append ``"/local"``. This is
+ (fortunately?) done quite unconditionally, so we create a default command
+ object without any configuration to detect this.
+ """
+ from distutils.command.install import install
+ from distutils.dist import Distribution
+
+ cmd: Any = install(Distribution())
+ cmd.finalize_options()
+ return (
+ cmd.exec_prefix == f"{os.path.normpath(sys.exec_prefix)}/local"
+ and cmd.prefix == f"{os.path.normpath(sys.prefix)}/local"
+ )
+
+
+@functools.lru_cache(maxsize=None)
+def _looks_like_slackware_scheme() -> bool:
+ """Slackware patches sysconfig but fails to patch distutils and site.
+
+ Slackware changes sysconfig's user scheme to use ``"lib64"`` for the lib
+ path, but does not do the same to the site module.
+ """
+ if user_site is None: # User-site not available.
+ return False
+ try:
+ paths = sysconfig.get_paths(scheme="posix_user", expand=False)
+ except KeyError: # User-site not available.
+ return False
+ return "/lib64/" in paths["purelib"] and "/lib64/" not in user_site
+
+
+@functools.lru_cache(maxsize=None)
+def _looks_like_msys2_mingw_scheme() -> bool:
+ """MSYS2 patches distutils and sysconfig to use a UNIX-like scheme.
+
+ However, MSYS2 incorrectly patches sysconfig ``nt`` scheme. The fix is
+ likely going to be included in their 3.10 release, so we ignore the warning.
+ See msys2/MINGW-packages#9319.
+
+ MSYS2 MINGW's patch uses lowercase ``"lib"`` instead of the usual uppercase,
+ and is missing the final ``"site-packages"``.
+ """
+ paths = sysconfig.get_paths("nt", expand=False)
+ return all(
+ "Lib" not in p and "lib" in p and not p.endswith("site-packages")
+ for p in (paths[key] for key in ("platlib", "purelib"))
+ )
+
+
+def _fix_abiflags(parts: Tuple[str]) -> Generator[str, None, None]:
+ ldversion = sysconfig.get_config_var("LDVERSION")
+ abiflags = getattr(sys, "abiflags", None)
+
+ # LDVERSION does not end with sys.abiflags. Just return the path unchanged.
+ if not ldversion or not abiflags or not ldversion.endswith(abiflags):
+ yield from parts
+ return
+
+ # Strip sys.abiflags from LDVERSION-based path components.
+ for part in parts:
+ if part.endswith(ldversion):
+ part = part[: (0 - len(abiflags))]
+ yield part
+
+
+@functools.lru_cache(maxsize=None)
+def _warn_mismatched(old: pathlib.Path, new: pathlib.Path, *, key: str) -> None:
+ issue_url = "https://github.com/pypa/pip/issues/10151"
+ message = (
+ "Value for %s does not match. Please report this to <%s>"
+ "\ndistutils: %s"
+ "\nsysconfig: %s"
+ )
+ logger.log(_MISMATCH_LEVEL, message, key, issue_url, old, new)
+
+
+def _warn_if_mismatch(old: pathlib.Path, new: pathlib.Path, *, key: str) -> bool:
+ if old == new:
+ return False
+ _warn_mismatched(old, new, key=key)
+ return True
+
+
+@functools.lru_cache(maxsize=None)
+def _log_context(
+ *,
+ user: bool = False,
+ home: Optional[str] = None,
+ root: Optional[str] = None,
+ prefix: Optional[str] = None,
+) -> None:
+ parts = [
+ "Additional context:",
+ "user = %r",
+ "home = %r",
+ "root = %r",
+ "prefix = %r",
+ ]
+
+ logger.log(_MISMATCH_LEVEL, "\n".join(parts), user, home, root, prefix)
+
+
+def get_scheme(
+ dist_name: str,
+ user: bool = False,
+ home: Optional[str] = None,
+ root: Optional[str] = None,
+ isolated: bool = False,
+ prefix: Optional[str] = None,
+) -> Scheme:
+ new = _sysconfig.get_scheme(
+ dist_name,
+ user=user,
+ home=home,
+ root=root,
+ isolated=isolated,
+ prefix=prefix,
+ )
+ if _USE_SYSCONFIG:
+ return new
+
+ old = _distutils.get_scheme(
+ dist_name,
+ user=user,
+ home=home,
+ root=root,
+ isolated=isolated,
+ prefix=prefix,
+ )
+
+ warning_contexts = []
+ for k in SCHEME_KEYS:
+ old_v = pathlib.Path(getattr(old, k))
+ new_v = pathlib.Path(getattr(new, k))
+
+ if old_v == new_v:
+ continue
+
+ # distutils incorrectly put PyPy packages under ``site-packages/python``
+ # in the ``posix_home`` scheme, but PyPy devs said they expect the
+ # directory name to be ``pypy`` instead. So we treat this as a bug fix
+ # and not warn about it. See bpo-43307 and python/cpython#24628.
+ skip_pypy_special_case = (
+ sys.implementation.name == "pypy"
+ and home is not None
+ and k in ("platlib", "purelib")
+ and old_v.parent == new_v.parent
+ and old_v.name.startswith("python")
+ and new_v.name.startswith("pypy")
+ )
+ if skip_pypy_special_case:
+ continue
+
+ # sysconfig's ``osx_framework_user`` does not include ``pythonX.Y`` in
+ # the ``include`` value, but distutils's ``headers`` does. We'll let
+ # CPython decide whether this is a bug or feature. See bpo-43948.
+ skip_osx_framework_user_special_case = (
+ user
+ and is_osx_framework()
+ and k == "headers"
+ and old_v.parent.parent == new_v.parent
+ and old_v.parent.name.startswith("python")
+ )
+ if skip_osx_framework_user_special_case:
+ continue
+
+ # On Red Hat and derived Linux distributions, distutils is patched to
+ # use "lib64" instead of "lib" for platlib.
+ if k == "platlib" and _looks_like_red_hat_lib():
+ continue
+
+ # On Python 3.9+, sysconfig's posix_user scheme sets platlib against
+ # sys.platlibdir, but distutils's unix_user incorrectly coninutes
+ # using the same $usersite for both platlib and purelib. This creates a
+ # mismatch when sys.platlibdir is not "lib".
+ skip_bpo_44860 = (
+ user
+ and k == "platlib"
+ and not WINDOWS
+ and sys.version_info >= (3, 9)
+ and _PLATLIBDIR != "lib"
+ and _looks_like_bpo_44860()
+ )
+ if skip_bpo_44860:
+ continue
+
+ # Slackware incorrectly patches posix_user to use lib64 instead of lib,
+ # but not usersite to match the location.
+ skip_slackware_user_scheme = (
+ user
+ and k in ("platlib", "purelib")
+ and not WINDOWS
+ and _looks_like_slackware_scheme()
+ )
+ if skip_slackware_user_scheme:
+ continue
+
+ # Both Debian and Red Hat patch Python to place the system site under
+ # /usr/local instead of /usr. Debian also places lib in dist-packages
+ # instead of site-packages, but the /usr/local check should cover it.
+ skip_linux_system_special_case = (
+ not (user or home or prefix or running_under_virtualenv())
+ and old_v.parts[1:3] == ("usr", "local")
+ and len(new_v.parts) > 1
+ and new_v.parts[1] == "usr"
+ and (len(new_v.parts) < 3 or new_v.parts[2] != "local")
+ and (_looks_like_red_hat_scheme() or _looks_like_debian_scheme())
+ )
+ if skip_linux_system_special_case:
+ continue
+
+ # MSYS2 MINGW's sysconfig patch does not include the "site-packages"
+ # part of the path. This is incorrect and will be fixed in MSYS.
+ skip_msys2_mingw_bug = (
+ WINDOWS and k in ("platlib", "purelib") and _looks_like_msys2_mingw_scheme()
+ )
+ if skip_msys2_mingw_bug:
+ continue
+
+ # CPython's POSIX install script invokes pip (via ensurepip) against the
+ # interpreter located in the source tree, not the install site. This
+ # triggers special logic in sysconfig that's not present in distutils.
+ # https://github.com/python/cpython/blob/8c21941ddaf/Lib/sysconfig.py#L178-L194
+ skip_cpython_build = (
+ sysconfig.is_python_build(check_home=True)
+ and not WINDOWS
+ and k in ("headers", "include", "platinclude")
+ )
+ if skip_cpython_build:
+ continue
+
+ warning_contexts.append((old_v, new_v, f"scheme.{k}"))
+
+ if not warning_contexts:
+ return old
+
+ # Check if this path mismatch is caused by distutils config files. Those
+ # files will no longer work once we switch to sysconfig, so this raises a
+ # deprecation message for them.
+ default_old = _distutils.distutils_scheme(
+ dist_name,
+ user,
+ home,
+ root,
+ isolated,
+ prefix,
+ ignore_config_files=True,
+ )
+ if any(default_old[k] != getattr(old, k) for k in SCHEME_KEYS):
+ deprecated(
+ reason=(
+ "Configuring installation scheme with distutils config files "
+ "is deprecated and will no longer work in the near future. If you "
+ "are using a Homebrew or Linuxbrew Python, please see discussion "
+ "at https://github.com/Homebrew/homebrew-core/issues/76621"
+ ),
+ replacement=None,
+ gone_in=None,
+ )
+ return old
+
+ # Post warnings about this mismatch so user can report them back.
+ for old_v, new_v, key in warning_contexts:
+ _warn_mismatched(old_v, new_v, key=key)
+ _log_context(user=user, home=home, root=root, prefix=prefix)
+
+ return old
+
+
+def get_bin_prefix() -> str:
+ new = _sysconfig.get_bin_prefix()
+ if _USE_SYSCONFIG:
+ return new
+
+ old = _distutils.get_bin_prefix()
+ if _warn_if_mismatch(pathlib.Path(old), pathlib.Path(new), key="bin_prefix"):
+ _log_context()
+ return old
+
+
+def get_bin_user() -> str:
+ return _sysconfig.get_scheme("", user=True).scripts
+
+
+def _looks_like_deb_system_dist_packages(value: str) -> bool:
+ """Check if the value is Debian's APT-controlled dist-packages.
+
+ Debian's ``distutils.sysconfig.get_python_lib()`` implementation returns the
+ default package path controlled by APT, but does not patch ``sysconfig`` to
+ do the same. This is similar to the bug worked around in ``get_scheme()``,
+ but here the default is ``deb_system`` instead of ``unix_local``. Ultimately
+ we can't do anything about this Debian bug, and this detection allows us to
+ skip the warning when needed.
+ """
+ if not _looks_like_debian_scheme():
+ return False
+ if value == "/usr/lib/python3/dist-packages":
+ return True
+ return False
+
+
+def get_purelib() -> str:
+ """Return the default pure-Python lib location."""
+ new = _sysconfig.get_purelib()
+ if _USE_SYSCONFIG:
+ return new
+
+ old = _distutils.get_purelib()
+ if _looks_like_deb_system_dist_packages(old):
+ return old
+ if _warn_if_mismatch(pathlib.Path(old), pathlib.Path(new), key="purelib"):
+ _log_context()
+ return old
+
+
+def get_platlib() -> str:
+ """Return the default platform-shared lib location."""
+ new = _sysconfig.get_platlib()
+ if _USE_SYSCONFIG:
+ return new
+
+ from . import _distutils
+
+ old = _distutils.get_platlib()
+ if _looks_like_deb_system_dist_packages(old):
+ return old
+ if _warn_if_mismatch(pathlib.Path(old), pathlib.Path(new), key="platlib"):
+ _log_context()
+ return old
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/locations/_distutils.py b/solutions/.venv/Lib/site-packages/pip/_internal/locations/_distutils.py
new file mode 100644
index 000000000..3d8562569
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/locations/_distutils.py
@@ -0,0 +1,172 @@
+"""Locations where we look for configs, install stuff, etc"""
+
+# The following comment should be removed at some point in the future.
+# mypy: strict-optional=False
+
+# If pip's going to use distutils, it should not be using the copy that setuptools
+# might have injected into the environment. This is done by removing the injected
+# shim, if it's injected.
+#
+# See https://github.com/pypa/pip/issues/8761 for the original discussion and
+# rationale for why this is done within pip.
+try:
+ __import__("_distutils_hack").remove_shim()
+except (ImportError, AttributeError):
+ pass
+
+import logging
+import os
+import sys
+from distutils.cmd import Command as DistutilsCommand
+from distutils.command.install import SCHEME_KEYS
+from distutils.command.install import install as distutils_install_command
+from distutils.sysconfig import get_python_lib
+from typing import Dict, List, Optional, Union
+
+from pip._internal.models.scheme import Scheme
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+from .base import get_major_minor_version
+
+logger = logging.getLogger(__name__)
+
+
+def distutils_scheme(
+ dist_name: str,
+ user: bool = False,
+ home: Optional[str] = None,
+ root: Optional[str] = None,
+ isolated: bool = False,
+ prefix: Optional[str] = None,
+ *,
+ ignore_config_files: bool = False,
+) -> Dict[str, str]:
+ """
+ Return a distutils install scheme
+ """
+ from distutils.dist import Distribution
+
+ dist_args: Dict[str, Union[str, List[str]]] = {"name": dist_name}
+ if isolated:
+ dist_args["script_args"] = ["--no-user-cfg"]
+
+ d = Distribution(dist_args)
+ if not ignore_config_files:
+ try:
+ d.parse_config_files()
+ except UnicodeDecodeError:
+ paths = d.find_config_files()
+ logger.warning(
+ "Ignore distutils configs in %s due to encoding errors.",
+ ", ".join(os.path.basename(p) for p in paths),
+ )
+ obj: Optional[DistutilsCommand] = None
+ obj = d.get_command_obj("install", create=True)
+ assert obj is not None
+ i: distutils_install_command = obj
+ # NOTE: setting user or home has the side-effect of creating the home dir
+ # or user base for installations during finalize_options()
+ # ideally, we'd prefer a scheme class that has no side-effects.
+ assert not (user and prefix), f"user={user} prefix={prefix}"
+ assert not (home and prefix), f"home={home} prefix={prefix}"
+ i.user = user or i.user
+ if user or home:
+ i.prefix = ""
+ i.prefix = prefix or i.prefix
+ i.home = home or i.home
+ i.root = root or i.root
+ i.finalize_options()
+
+ scheme: Dict[str, str] = {}
+ for key in SCHEME_KEYS:
+ scheme[key] = getattr(i, "install_" + key)
+
+ # install_lib specified in setup.cfg should install *everything*
+ # into there (i.e. it takes precedence over both purelib and
+ # platlib). Note, i.install_lib is *always* set after
+ # finalize_options(); we only want to override here if the user
+ # has explicitly requested it hence going back to the config
+ if "install_lib" in d.get_option_dict("install"):
+ scheme.update({"purelib": i.install_lib, "platlib": i.install_lib})
+
+ if running_under_virtualenv():
+ if home:
+ prefix = home
+ elif user:
+ prefix = i.install_userbase
+ else:
+ prefix = i.prefix
+ scheme["headers"] = os.path.join(
+ prefix,
+ "include",
+ "site",
+ f"python{get_major_minor_version()}",
+ dist_name,
+ )
+
+ if root is not None:
+ path_no_drive = os.path.splitdrive(os.path.abspath(scheme["headers"]))[1]
+ scheme["headers"] = os.path.join(root, path_no_drive[1:])
+
+ return scheme
+
+
+def get_scheme(
+ dist_name: str,
+ user: bool = False,
+ home: Optional[str] = None,
+ root: Optional[str] = None,
+ isolated: bool = False,
+ prefix: Optional[str] = None,
+) -> Scheme:
+ """
+ Get the "scheme" corresponding to the input parameters. The distutils
+ documentation provides the context for the available schemes:
+ https://docs.python.org/3/install/index.html#alternate-installation
+
+ :param dist_name: the name of the package to retrieve the scheme for, used
+ in the headers scheme path
+ :param user: indicates to use the "user" scheme
+ :param home: indicates to use the "home" scheme and provides the base
+ directory for the same
+ :param root: root under which other directories are re-based
+ :param isolated: equivalent to --no-user-cfg, i.e. do not consider
+ ~/.pydistutils.cfg (posix) or ~/pydistutils.cfg (non-posix) for
+ scheme paths
+ :param prefix: indicates to use the "prefix" scheme and provides the
+ base directory for the same
+ """
+ scheme = distutils_scheme(dist_name, user, home, root, isolated, prefix)
+ return Scheme(
+ platlib=scheme["platlib"],
+ purelib=scheme["purelib"],
+ headers=scheme["headers"],
+ scripts=scheme["scripts"],
+ data=scheme["data"],
+ )
+
+
+def get_bin_prefix() -> str:
+ # XXX: In old virtualenv versions, sys.prefix can contain '..' components,
+ # so we need to call normpath to eliminate them.
+ prefix = os.path.normpath(sys.prefix)
+ if WINDOWS:
+ bin_py = os.path.join(prefix, "Scripts")
+ # buildout uses 'bin' on Windows too?
+ if not os.path.exists(bin_py):
+ bin_py = os.path.join(prefix, "bin")
+ return bin_py
+ # Forcing to use /usr/local/bin for standard macOS framework installs
+ # Also log to ~/Library/Logs/ for use with the Console.app log viewer
+ if sys.platform[:6] == "darwin" and prefix[:16] == "/System/Library/":
+ return "/usr/local/bin"
+ return os.path.join(prefix, "bin")
+
+
+def get_purelib() -> str:
+ return get_python_lib(plat_specific=False)
+
+
+def get_platlib() -> str:
+ return get_python_lib(plat_specific=True)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/locations/_sysconfig.py b/solutions/.venv/Lib/site-packages/pip/_internal/locations/_sysconfig.py
new file mode 100644
index 000000000..ca860ea56
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/locations/_sysconfig.py
@@ -0,0 +1,214 @@
+import logging
+import os
+import sys
+import sysconfig
+import typing
+
+from pip._internal.exceptions import InvalidSchemeCombination, UserInstallationInvalid
+from pip._internal.models.scheme import SCHEME_KEYS, Scheme
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+from .base import change_root, get_major_minor_version, is_osx_framework
+
+logger = logging.getLogger(__name__)
+
+
+# Notes on _infer_* functions.
+# Unfortunately ``get_default_scheme()`` didn't exist before 3.10, so there's no
+# way to ask things like "what is the '_prefix' scheme on this platform". These
+# functions try to answer that with some heuristics while accounting for ad-hoc
+# platforms not covered by CPython's default sysconfig implementation. If the
+# ad-hoc implementation does not fully implement sysconfig, we'll fall back to
+# a POSIX scheme.
+
+_AVAILABLE_SCHEMES = set(sysconfig.get_scheme_names())
+
+_PREFERRED_SCHEME_API = getattr(sysconfig, "get_preferred_scheme", None)
+
+
+def _should_use_osx_framework_prefix() -> bool:
+ """Check for Apple's ``osx_framework_library`` scheme.
+
+ Python distributed by Apple's Command Line Tools has this special scheme
+ that's used when:
+
+ * This is a framework build.
+ * We are installing into the system prefix.
+
+ This does not account for ``pip install --prefix`` (also means we're not
+ installing to the system prefix), which should use ``posix_prefix``, but
+ logic here means ``_infer_prefix()`` outputs ``osx_framework_library``. But
+ since ``prefix`` is not available for ``sysconfig.get_default_scheme()``,
+ which is the stdlib replacement for ``_infer_prefix()``, presumably Apple
+ wouldn't be able to magically switch between ``osx_framework_library`` and
+ ``posix_prefix``. ``_infer_prefix()`` returning ``osx_framework_library``
+ means its behavior is consistent whether we use the stdlib implementation
+ or our own, and we deal with this special case in ``get_scheme()`` instead.
+ """
+ return (
+ "osx_framework_library" in _AVAILABLE_SCHEMES
+ and not running_under_virtualenv()
+ and is_osx_framework()
+ )
+
+
+def _infer_prefix() -> str:
+ """Try to find a prefix scheme for the current platform.
+
+ This tries:
+
+ * A special ``osx_framework_library`` for Python distributed by Apple's
+ Command Line Tools, when not running in a virtual environment.
+ * Implementation + OS, used by PyPy on Windows (``pypy_nt``).
+ * Implementation without OS, used by PyPy on POSIX (``pypy``).
+ * OS + "prefix", used by CPython on POSIX (``posix_prefix``).
+ * Just the OS name, used by CPython on Windows (``nt``).
+
+ If none of the above works, fall back to ``posix_prefix``.
+ """
+ if _PREFERRED_SCHEME_API:
+ return _PREFERRED_SCHEME_API("prefix")
+ if _should_use_osx_framework_prefix():
+ return "osx_framework_library"
+ implementation_suffixed = f"{sys.implementation.name}_{os.name}"
+ if implementation_suffixed in _AVAILABLE_SCHEMES:
+ return implementation_suffixed
+ if sys.implementation.name in _AVAILABLE_SCHEMES:
+ return sys.implementation.name
+ suffixed = f"{os.name}_prefix"
+ if suffixed in _AVAILABLE_SCHEMES:
+ return suffixed
+ if os.name in _AVAILABLE_SCHEMES: # On Windows, prefx is just called "nt".
+ return os.name
+ return "posix_prefix"
+
+
+def _infer_user() -> str:
+ """Try to find a user scheme for the current platform."""
+ if _PREFERRED_SCHEME_API:
+ return _PREFERRED_SCHEME_API("user")
+ if is_osx_framework() and not running_under_virtualenv():
+ suffixed = "osx_framework_user"
+ else:
+ suffixed = f"{os.name}_user"
+ if suffixed in _AVAILABLE_SCHEMES:
+ return suffixed
+ if "posix_user" not in _AVAILABLE_SCHEMES: # User scheme unavailable.
+ raise UserInstallationInvalid()
+ return "posix_user"
+
+
+def _infer_home() -> str:
+ """Try to find a home for the current platform."""
+ if _PREFERRED_SCHEME_API:
+ return _PREFERRED_SCHEME_API("home")
+ suffixed = f"{os.name}_home"
+ if suffixed in _AVAILABLE_SCHEMES:
+ return suffixed
+ return "posix_home"
+
+
+# Update these keys if the user sets a custom home.
+_HOME_KEYS = [
+ "installed_base",
+ "base",
+ "installed_platbase",
+ "platbase",
+ "prefix",
+ "exec_prefix",
+]
+if sysconfig.get_config_var("userbase") is not None:
+ _HOME_KEYS.append("userbase")
+
+
+def get_scheme(
+ dist_name: str,
+ user: bool = False,
+ home: typing.Optional[str] = None,
+ root: typing.Optional[str] = None,
+ isolated: bool = False,
+ prefix: typing.Optional[str] = None,
+) -> Scheme:
+ """
+ Get the "scheme" corresponding to the input parameters.
+
+ :param dist_name: the name of the package to retrieve the scheme for, used
+ in the headers scheme path
+ :param user: indicates to use the "user" scheme
+ :param home: indicates to use the "home" scheme
+ :param root: root under which other directories are re-based
+ :param isolated: ignored, but kept for distutils compatibility (where
+ this controls whether the user-site pydistutils.cfg is honored)
+ :param prefix: indicates to use the "prefix" scheme and provides the
+ base directory for the same
+ """
+ if user and prefix:
+ raise InvalidSchemeCombination("--user", "--prefix")
+ if home and prefix:
+ raise InvalidSchemeCombination("--home", "--prefix")
+
+ if home is not None:
+ scheme_name = _infer_home()
+ elif user:
+ scheme_name = _infer_user()
+ else:
+ scheme_name = _infer_prefix()
+
+ # Special case: When installing into a custom prefix, use posix_prefix
+ # instead of osx_framework_library. See _should_use_osx_framework_prefix()
+ # docstring for details.
+ if prefix is not None and scheme_name == "osx_framework_library":
+ scheme_name = "posix_prefix"
+
+ if home is not None:
+ variables = {k: home for k in _HOME_KEYS}
+ elif prefix is not None:
+ variables = {k: prefix for k in _HOME_KEYS}
+ else:
+ variables = {}
+
+ paths = sysconfig.get_paths(scheme=scheme_name, vars=variables)
+
+ # Logic here is very arbitrary, we're doing it for compatibility, don't ask.
+ # 1. Pip historically uses a special header path in virtual environments.
+ # 2. If the distribution name is not known, distutils uses 'UNKNOWN'. We
+ # only do the same when not running in a virtual environment because
+ # pip's historical header path logic (see point 1) did not do this.
+ if running_under_virtualenv():
+ if user:
+ base = variables.get("userbase", sys.prefix)
+ else:
+ base = variables.get("base", sys.prefix)
+ python_xy = f"python{get_major_minor_version()}"
+ paths["include"] = os.path.join(base, "include", "site", python_xy)
+ elif not dist_name:
+ dist_name = "UNKNOWN"
+
+ scheme = Scheme(
+ platlib=paths["platlib"],
+ purelib=paths["purelib"],
+ headers=os.path.join(paths["include"], dist_name),
+ scripts=paths["scripts"],
+ data=paths["data"],
+ )
+ if root is not None:
+ converted_keys = {}
+ for key in SCHEME_KEYS:
+ converted_keys[key] = change_root(root, getattr(scheme, key))
+ scheme = Scheme(**converted_keys)
+ return scheme
+
+
+def get_bin_prefix() -> str:
+ # Forcing to use /usr/local/bin for standard macOS framework installs.
+ if sys.platform[:6] == "darwin" and sys.prefix[:16] == "/System/Library/":
+ return "/usr/local/bin"
+ return sysconfig.get_paths()["scripts"]
+
+
+def get_purelib() -> str:
+ return sysconfig.get_paths()["purelib"]
+
+
+def get_platlib() -> str:
+ return sysconfig.get_paths()["platlib"]
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/locations/base.py b/solutions/.venv/Lib/site-packages/pip/_internal/locations/base.py
new file mode 100644
index 000000000..3f9f896e6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/locations/base.py
@@ -0,0 +1,81 @@
+import functools
+import os
+import site
+import sys
+import sysconfig
+import typing
+
+from pip._internal.exceptions import InstallationError
+from pip._internal.utils import appdirs
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+# Application Directories
+USER_CACHE_DIR = appdirs.user_cache_dir("pip")
+
+# FIXME doesn't account for venv linked to global site-packages
+site_packages: str = sysconfig.get_path("purelib")
+
+
+def get_major_minor_version() -> str:
+ """
+ Return the major-minor version of the current Python as a string, e.g.
+ "3.7" or "3.10".
+ """
+ return "{}.{}".format(*sys.version_info)
+
+
+def change_root(new_root: str, pathname: str) -> str:
+ """Return 'pathname' with 'new_root' prepended.
+
+ If 'pathname' is relative, this is equivalent to os.path.join(new_root, pathname).
+ Otherwise, it requires making 'pathname' relative and then joining the
+ two, which is tricky on DOS/Windows and Mac OS.
+
+ This is borrowed from Python's standard library's distutils module.
+ """
+ if os.name == "posix":
+ if not os.path.isabs(pathname):
+ return os.path.join(new_root, pathname)
+ else:
+ return os.path.join(new_root, pathname[1:])
+
+ elif os.name == "nt":
+ (drive, path) = os.path.splitdrive(pathname)
+ if path[0] == "\\":
+ path = path[1:]
+ return os.path.join(new_root, path)
+
+ else:
+ raise InstallationError(
+ f"Unknown platform: {os.name}\n"
+ "Can not change root path prefix on unknown platform."
+ )
+
+
+def get_src_prefix() -> str:
+ if running_under_virtualenv():
+ src_prefix = os.path.join(sys.prefix, "src")
+ else:
+ # FIXME: keep src in cwd for now (it is not a temporary folder)
+ try:
+ src_prefix = os.path.join(os.getcwd(), "src")
+ except OSError:
+ # In case the current working directory has been renamed or deleted
+ sys.exit("The folder you are executing pip from can no longer be found.")
+
+ # under macOS + virtualenv sys.prefix is not properly resolved
+ # it is something like /path/to/python/bin/..
+ return os.path.abspath(src_prefix)
+
+
+try:
+ # Use getusersitepackages if this is present, as it ensures that the
+ # value is initialised properly.
+ user_site: typing.Optional[str] = site.getusersitepackages()
+except AttributeError:
+ user_site = site.USER_SITE
+
+
+@functools.lru_cache(maxsize=None)
+def is_osx_framework() -> bool:
+ return bool(sysconfig.get_config_var("PYTHONFRAMEWORK"))
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/main.py b/solutions/.venv/Lib/site-packages/pip/_internal/main.py
new file mode 100644
index 000000000..33c6d24cd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/main.py
@@ -0,0 +1,12 @@
+from typing import List, Optional
+
+
+def main(args: Optional[List[str]] = None) -> int:
+ """This is preserved for old console scripts that may still be referencing
+ it.
+
+ For additional details, see https://github.com/pypa/pip/issues/7498.
+ """
+ from pip._internal.utils.entrypoints import _wrapper
+
+ return _wrapper(args)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/__init__.py
new file mode 100644
index 000000000..aa232b6ca
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/__init__.py
@@ -0,0 +1,128 @@
+import contextlib
+import functools
+import os
+import sys
+from typing import TYPE_CHECKING, List, Optional, Type, cast
+
+from pip._internal.utils.misc import strtobool
+
+from .base import BaseDistribution, BaseEnvironment, FilesystemWheel, MemoryWheel, Wheel
+
+if TYPE_CHECKING:
+ from typing import Literal, Protocol
+else:
+ Protocol = object
+
+__all__ = [
+ "BaseDistribution",
+ "BaseEnvironment",
+ "FilesystemWheel",
+ "MemoryWheel",
+ "Wheel",
+ "get_default_environment",
+ "get_environment",
+ "get_wheel_distribution",
+ "select_backend",
+]
+
+
+def _should_use_importlib_metadata() -> bool:
+ """Whether to use the ``importlib.metadata`` or ``pkg_resources`` backend.
+
+ By default, pip uses ``importlib.metadata`` on Python 3.11+, and
+ ``pkg_resourcess`` otherwise. This can be overridden by a couple of ways:
+
+ * If environment variable ``_PIP_USE_IMPORTLIB_METADATA`` is set, it
+ dictates whether ``importlib.metadata`` is used, regardless of Python
+ version.
+ * On Python 3.11+, Python distributors can patch ``importlib.metadata``
+ to add a global constant ``_PIP_USE_IMPORTLIB_METADATA = False``. This
+ makes pip use ``pkg_resources`` (unless the user set the aforementioned
+ environment variable to *True*).
+ """
+ with contextlib.suppress(KeyError, ValueError):
+ return bool(strtobool(os.environ["_PIP_USE_IMPORTLIB_METADATA"]))
+ if sys.version_info < (3, 11):
+ return False
+ import importlib.metadata
+
+ return bool(getattr(importlib.metadata, "_PIP_USE_IMPORTLIB_METADATA", True))
+
+
+class Backend(Protocol):
+ NAME: 'Literal["importlib", "pkg_resources"]'
+ Distribution: Type[BaseDistribution]
+ Environment: Type[BaseEnvironment]
+
+
+@functools.lru_cache(maxsize=None)
+def select_backend() -> Backend:
+ if _should_use_importlib_metadata():
+ from . import importlib
+
+ return cast(Backend, importlib)
+ from . import pkg_resources
+
+ return cast(Backend, pkg_resources)
+
+
+def get_default_environment() -> BaseEnvironment:
+ """Get the default representation for the current environment.
+
+ This returns an Environment instance from the chosen backend. The default
+ Environment instance should be built from ``sys.path`` and may use caching
+ to share instance state accorss calls.
+ """
+ return select_backend().Environment.default()
+
+
+def get_environment(paths: Optional[List[str]]) -> BaseEnvironment:
+ """Get a representation of the environment specified by ``paths``.
+
+ This returns an Environment instance from the chosen backend based on the
+ given import paths. The backend must build a fresh instance representing
+ the state of installed distributions when this function is called.
+ """
+ return select_backend().Environment.from_paths(paths)
+
+
+def get_directory_distribution(directory: str) -> BaseDistribution:
+ """Get the distribution metadata representation in the specified directory.
+
+ This returns a Distribution instance from the chosen backend based on
+ the given on-disk ``.dist-info`` directory.
+ """
+ return select_backend().Distribution.from_directory(directory)
+
+
+def get_wheel_distribution(wheel: Wheel, canonical_name: str) -> BaseDistribution:
+ """Get the representation of the specified wheel's distribution metadata.
+
+ This returns a Distribution instance from the chosen backend based on
+ the given wheel's ``.dist-info`` directory.
+
+ :param canonical_name: Normalized project name of the given wheel.
+ """
+ return select_backend().Distribution.from_wheel(wheel, canonical_name)
+
+
+def get_metadata_distribution(
+ metadata_contents: bytes,
+ filename: str,
+ canonical_name: str,
+) -> BaseDistribution:
+ """Get the dist representation of the specified METADATA file contents.
+
+ This returns a Distribution instance from the chosen backend sourced from the data
+ in `metadata_contents`.
+
+ :param metadata_contents: Contents of a METADATA file within a dist, or one served
+ via PEP 658.
+ :param filename: Filename for the dist this metadata represents.
+ :param canonical_name: Normalized project name of the given dist.
+ """
+ return select_backend().Distribution.from_metadata_file_contents(
+ metadata_contents,
+ filename,
+ canonical_name,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/_json.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/_json.py
new file mode 100644
index 000000000..9097dd585
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/_json.py
@@ -0,0 +1,84 @@
+# Extracted from https://github.com/pfmoore/pkg_metadata
+
+from email.header import Header, decode_header, make_header
+from email.message import Message
+from typing import Any, Dict, List, Union, cast
+
+METADATA_FIELDS = [
+ # Name, Multiple-Use
+ ("Metadata-Version", False),
+ ("Name", False),
+ ("Version", False),
+ ("Dynamic", True),
+ ("Platform", True),
+ ("Supported-Platform", True),
+ ("Summary", False),
+ ("Description", False),
+ ("Description-Content-Type", False),
+ ("Keywords", False),
+ ("Home-page", False),
+ ("Download-URL", False),
+ ("Author", False),
+ ("Author-email", False),
+ ("Maintainer", False),
+ ("Maintainer-email", False),
+ ("License", False),
+ ("Classifier", True),
+ ("Requires-Dist", True),
+ ("Requires-Python", False),
+ ("Requires-External", True),
+ ("Project-URL", True),
+ ("Provides-Extra", True),
+ ("Provides-Dist", True),
+ ("Obsoletes-Dist", True),
+]
+
+
+def json_name(field: str) -> str:
+ return field.lower().replace("-", "_")
+
+
+def msg_to_json(msg: Message) -> Dict[str, Any]:
+ """Convert a Message object into a JSON-compatible dictionary."""
+
+ def sanitise_header(h: Union[Header, str]) -> str:
+ if isinstance(h, Header):
+ chunks = []
+ for bytes, encoding in decode_header(h):
+ if encoding == "unknown-8bit":
+ try:
+ # See if UTF-8 works
+ bytes.decode("utf-8")
+ encoding = "utf-8"
+ except UnicodeDecodeError:
+ # If not, latin1 at least won't fail
+ encoding = "latin1"
+ chunks.append((bytes, encoding))
+ return str(make_header(chunks))
+ return str(h)
+
+ result = {}
+ for field, multi in METADATA_FIELDS:
+ if field not in msg:
+ continue
+ key = json_name(field)
+ if multi:
+ value: Union[str, List[str]] = [
+ sanitise_header(v) for v in msg.get_all(field) # type: ignore
+ ]
+ else:
+ value = sanitise_header(msg.get(field)) # type: ignore
+ if key == "keywords":
+ # Accept both comma-separated and space-separated
+ # forms, for better compatibility with old data.
+ if "," in value:
+ value = [v.strip() for v in value.split(",")]
+ else:
+ value = value.split()
+ result[key] = value
+
+ payload = cast(str, msg.get_payload())
+ if payload:
+ result["description"] = payload
+
+ return result
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/base.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/base.py
new file mode 100644
index 000000000..9eabcdb27
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/base.py
@@ -0,0 +1,688 @@
+import csv
+import email.message
+import functools
+import json
+import logging
+import pathlib
+import re
+import zipfile
+from typing import (
+ IO,
+ Any,
+ Collection,
+ Container,
+ Dict,
+ Iterable,
+ Iterator,
+ List,
+ NamedTuple,
+ Optional,
+ Protocol,
+ Tuple,
+ Union,
+)
+
+from pip._vendor.packaging.requirements import Requirement
+from pip._vendor.packaging.specifiers import InvalidSpecifier, SpecifierSet
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+from pip._vendor.packaging.version import Version
+
+from pip._internal.exceptions import NoneMetadataError
+from pip._internal.locations import site_packages, user_site
+from pip._internal.models.direct_url import (
+ DIRECT_URL_METADATA_NAME,
+ DirectUrl,
+ DirectUrlValidationError,
+)
+from pip._internal.utils.compat import stdlib_pkgs # TODO: Move definition here.
+from pip._internal.utils.egg_link import egg_link_path_from_sys_path
+from pip._internal.utils.misc import is_local, normalize_path
+from pip._internal.utils.urls import url_to_path
+
+from ._json import msg_to_json
+
+InfoPath = Union[str, pathlib.PurePath]
+
+logger = logging.getLogger(__name__)
+
+
+class BaseEntryPoint(Protocol):
+ @property
+ def name(self) -> str:
+ raise NotImplementedError()
+
+ @property
+ def value(self) -> str:
+ raise NotImplementedError()
+
+ @property
+ def group(self) -> str:
+ raise NotImplementedError()
+
+
+def _convert_installed_files_path(
+ entry: Tuple[str, ...],
+ info: Tuple[str, ...],
+) -> str:
+ """Convert a legacy installed-files.txt path into modern RECORD path.
+
+ The legacy format stores paths relative to the info directory, while the
+ modern format stores paths relative to the package root, e.g. the
+ site-packages directory.
+
+ :param entry: Path parts of the installed-files.txt entry.
+ :param info: Path parts of the egg-info directory relative to package root.
+ :returns: The converted entry.
+
+ For best compatibility with symlinks, this does not use ``abspath()`` or
+ ``Path.resolve()``, but tries to work with path parts:
+
+ 1. While ``entry`` starts with ``..``, remove the equal amounts of parts
+ from ``info``; if ``info`` is empty, start appending ``..`` instead.
+ 2. Join the two directly.
+ """
+ while entry and entry[0] == "..":
+ if not info or info[-1] == "..":
+ info += ("..",)
+ else:
+ info = info[:-1]
+ entry = entry[1:]
+ return str(pathlib.Path(*info, *entry))
+
+
+class RequiresEntry(NamedTuple):
+ requirement: str
+ extra: str
+ marker: str
+
+
+class BaseDistribution(Protocol):
+ @classmethod
+ def from_directory(cls, directory: str) -> "BaseDistribution":
+ """Load the distribution from a metadata directory.
+
+ :param directory: Path to a metadata directory, e.g. ``.dist-info``.
+ """
+ raise NotImplementedError()
+
+ @classmethod
+ def from_metadata_file_contents(
+ cls,
+ metadata_contents: bytes,
+ filename: str,
+ project_name: str,
+ ) -> "BaseDistribution":
+ """Load the distribution from the contents of a METADATA file.
+
+ This is used to implement PEP 658 by generating a "shallow" dist object that can
+ be used for resolution without downloading or building the actual dist yet.
+
+ :param metadata_contents: The contents of a METADATA file.
+ :param filename: File name for the dist with this metadata.
+ :param project_name: Name of the project this dist represents.
+ """
+ raise NotImplementedError()
+
+ @classmethod
+ def from_wheel(cls, wheel: "Wheel", name: str) -> "BaseDistribution":
+ """Load the distribution from a given wheel.
+
+ :param wheel: A concrete wheel definition.
+ :param name: File name of the wheel.
+
+ :raises InvalidWheel: Whenever loading of the wheel causes a
+ :py:exc:`zipfile.BadZipFile` exception to be thrown.
+ :raises UnsupportedWheel: If the wheel is a valid zip, but malformed
+ internally.
+ """
+ raise NotImplementedError()
+
+ def __repr__(self) -> str:
+ return f"{self.raw_name} {self.raw_version} ({self.location})"
+
+ def __str__(self) -> str:
+ return f"{self.raw_name} {self.raw_version}"
+
+ @property
+ def location(self) -> Optional[str]:
+ """Where the distribution is loaded from.
+
+ A string value is not necessarily a filesystem path, since distributions
+ can be loaded from other sources, e.g. arbitrary zip archives. ``None``
+ means the distribution is created in-memory.
+
+ Do not canonicalize this value with e.g. ``pathlib.Path.resolve()``. If
+ this is a symbolic link, we want to preserve the relative path between
+ it and files in the distribution.
+ """
+ raise NotImplementedError()
+
+ @property
+ def editable_project_location(self) -> Optional[str]:
+ """The project location for editable distributions.
+
+ This is the directory where pyproject.toml or setup.py is located.
+ None if the distribution is not installed in editable mode.
+ """
+ # TODO: this property is relatively costly to compute, memoize it ?
+ direct_url = self.direct_url
+ if direct_url:
+ if direct_url.is_local_editable():
+ return url_to_path(direct_url.url)
+ else:
+ # Search for an .egg-link file by walking sys.path, as it was
+ # done before by dist_is_editable().
+ egg_link_path = egg_link_path_from_sys_path(self.raw_name)
+ if egg_link_path:
+ # TODO: get project location from second line of egg_link file
+ # (https://github.com/pypa/pip/issues/10243)
+ return self.location
+ return None
+
+ @property
+ def installed_location(self) -> Optional[str]:
+ """The distribution's "installed" location.
+
+ This should generally be a ``site-packages`` directory. This is
+ usually ``dist.location``, except for legacy develop-installed packages,
+ where ``dist.location`` is the source code location, and this is where
+ the ``.egg-link`` file is.
+
+ The returned location is normalized (in particular, with symlinks removed).
+ """
+ raise NotImplementedError()
+
+ @property
+ def info_location(self) -> Optional[str]:
+ """Location of the .[egg|dist]-info directory or file.
+
+ Similarly to ``location``, a string value is not necessarily a
+ filesystem path. ``None`` means the distribution is created in-memory.
+
+ For a modern .dist-info installation on disk, this should be something
+ like ``{location}/{raw_name}-{version}.dist-info``.
+
+ Do not canonicalize this value with e.g. ``pathlib.Path.resolve()``. If
+ this is a symbolic link, we want to preserve the relative path between
+ it and other files in the distribution.
+ """
+ raise NotImplementedError()
+
+ @property
+ def installed_by_distutils(self) -> bool:
+ """Whether this distribution is installed with legacy distutils format.
+
+ A distribution installed with "raw" distutils not patched by setuptools
+ uses one single file at ``info_location`` to store metadata. We need to
+ treat this specially on uninstallation.
+ """
+ info_location = self.info_location
+ if not info_location:
+ return False
+ return pathlib.Path(info_location).is_file()
+
+ @property
+ def installed_as_egg(self) -> bool:
+ """Whether this distribution is installed as an egg.
+
+ This usually indicates the distribution was installed by (older versions
+ of) easy_install.
+ """
+ location = self.location
+ if not location:
+ return False
+ return location.endswith(".egg")
+
+ @property
+ def installed_with_setuptools_egg_info(self) -> bool:
+ """Whether this distribution is installed with the ``.egg-info`` format.
+
+ This usually indicates the distribution was installed with setuptools
+ with an old pip version or with ``single-version-externally-managed``.
+
+ Note that this ensure the metadata store is a directory. distutils can
+ also installs an ``.egg-info``, but as a file, not a directory. This
+ property is *False* for that case. Also see ``installed_by_distutils``.
+ """
+ info_location = self.info_location
+ if not info_location:
+ return False
+ if not info_location.endswith(".egg-info"):
+ return False
+ return pathlib.Path(info_location).is_dir()
+
+ @property
+ def installed_with_dist_info(self) -> bool:
+ """Whether this distribution is installed with the "modern format".
+
+ This indicates a "modern" installation, e.g. storing metadata in the
+ ``.dist-info`` directory. This applies to installations made by
+ setuptools (but through pip, not directly), or anything using the
+ standardized build backend interface (PEP 517).
+ """
+ info_location = self.info_location
+ if not info_location:
+ return False
+ if not info_location.endswith(".dist-info"):
+ return False
+ return pathlib.Path(info_location).is_dir()
+
+ @property
+ def canonical_name(self) -> NormalizedName:
+ raise NotImplementedError()
+
+ @property
+ def version(self) -> Version:
+ raise NotImplementedError()
+
+ @property
+ def raw_version(self) -> str:
+ raise NotImplementedError()
+
+ @property
+ def setuptools_filename(self) -> str:
+ """Convert a project name to its setuptools-compatible filename.
+
+ This is a copy of ``pkg_resources.to_filename()`` for compatibility.
+ """
+ return self.raw_name.replace("-", "_")
+
+ @property
+ def direct_url(self) -> Optional[DirectUrl]:
+ """Obtain a DirectUrl from this distribution.
+
+ Returns None if the distribution has no `direct_url.json` metadata,
+ or if `direct_url.json` is invalid.
+ """
+ try:
+ content = self.read_text(DIRECT_URL_METADATA_NAME)
+ except FileNotFoundError:
+ return None
+ try:
+ return DirectUrl.from_json(content)
+ except (
+ UnicodeDecodeError,
+ json.JSONDecodeError,
+ DirectUrlValidationError,
+ ) as e:
+ logger.warning(
+ "Error parsing %s for %s: %s",
+ DIRECT_URL_METADATA_NAME,
+ self.canonical_name,
+ e,
+ )
+ return None
+
+ @property
+ def installer(self) -> str:
+ try:
+ installer_text = self.read_text("INSTALLER")
+ except (OSError, ValueError, NoneMetadataError):
+ return "" # Fail silently if the installer file cannot be read.
+ for line in installer_text.splitlines():
+ cleaned_line = line.strip()
+ if cleaned_line:
+ return cleaned_line
+ return ""
+
+ @property
+ def requested(self) -> bool:
+ return self.is_file("REQUESTED")
+
+ @property
+ def editable(self) -> bool:
+ return bool(self.editable_project_location)
+
+ @property
+ def local(self) -> bool:
+ """If distribution is installed in the current virtual environment.
+
+ Always True if we're not in a virtualenv.
+ """
+ if self.installed_location is None:
+ return False
+ return is_local(self.installed_location)
+
+ @property
+ def in_usersite(self) -> bool:
+ if self.installed_location is None or user_site is None:
+ return False
+ return self.installed_location.startswith(normalize_path(user_site))
+
+ @property
+ def in_site_packages(self) -> bool:
+ if self.installed_location is None or site_packages is None:
+ return False
+ return self.installed_location.startswith(normalize_path(site_packages))
+
+ def is_file(self, path: InfoPath) -> bool:
+ """Check whether an entry in the info directory is a file."""
+ raise NotImplementedError()
+
+ def iter_distutils_script_names(self) -> Iterator[str]:
+ """Find distutils 'scripts' entries metadata.
+
+ If 'scripts' is supplied in ``setup.py``, distutils records those in the
+ installed distribution's ``scripts`` directory, a file for each script.
+ """
+ raise NotImplementedError()
+
+ def read_text(self, path: InfoPath) -> str:
+ """Read a file in the info directory.
+
+ :raise FileNotFoundError: If ``path`` does not exist in the directory.
+ :raise NoneMetadataError: If ``path`` exists in the info directory, but
+ cannot be read.
+ """
+ raise NotImplementedError()
+
+ def iter_entry_points(self) -> Iterable[BaseEntryPoint]:
+ raise NotImplementedError()
+
+ def _metadata_impl(self) -> email.message.Message:
+ raise NotImplementedError()
+
+ @functools.cached_property
+ def metadata(self) -> email.message.Message:
+ """Metadata of distribution parsed from e.g. METADATA or PKG-INFO.
+
+ This should return an empty message if the metadata file is unavailable.
+
+ :raises NoneMetadataError: If the metadata file is available, but does
+ not contain valid metadata.
+ """
+ metadata = self._metadata_impl()
+ self._add_egg_info_requires(metadata)
+ return metadata
+
+ @property
+ def metadata_dict(self) -> Dict[str, Any]:
+ """PEP 566 compliant JSON-serializable representation of METADATA or PKG-INFO.
+
+ This should return an empty dict if the metadata file is unavailable.
+
+ :raises NoneMetadataError: If the metadata file is available, but does
+ not contain valid metadata.
+ """
+ return msg_to_json(self.metadata)
+
+ @property
+ def metadata_version(self) -> Optional[str]:
+ """Value of "Metadata-Version:" in distribution metadata, if available."""
+ return self.metadata.get("Metadata-Version")
+
+ @property
+ def raw_name(self) -> str:
+ """Value of "Name:" in distribution metadata."""
+ # The metadata should NEVER be missing the Name: key, but if it somehow
+ # does, fall back to the known canonical name.
+ return self.metadata.get("Name", self.canonical_name)
+
+ @property
+ def requires_python(self) -> SpecifierSet:
+ """Value of "Requires-Python:" in distribution metadata.
+
+ If the key does not exist or contains an invalid value, an empty
+ SpecifierSet should be returned.
+ """
+ value = self.metadata.get("Requires-Python")
+ if value is None:
+ return SpecifierSet()
+ try:
+ # Convert to str to satisfy the type checker; this can be a Header object.
+ spec = SpecifierSet(str(value))
+ except InvalidSpecifier as e:
+ message = "Package %r has an invalid Requires-Python: %s"
+ logger.warning(message, self.raw_name, e)
+ return SpecifierSet()
+ return spec
+
+ def iter_dependencies(self, extras: Collection[str] = ()) -> Iterable[Requirement]:
+ """Dependencies of this distribution.
+
+ For modern .dist-info distributions, this is the collection of
+ "Requires-Dist:" entries in distribution metadata.
+ """
+ raise NotImplementedError()
+
+ def iter_raw_dependencies(self) -> Iterable[str]:
+ """Raw Requires-Dist metadata."""
+ return self.metadata.get_all("Requires-Dist", [])
+
+ def iter_provided_extras(self) -> Iterable[NormalizedName]:
+ """Extras provided by this distribution.
+
+ For modern .dist-info distributions, this is the collection of
+ "Provides-Extra:" entries in distribution metadata.
+
+ The return value of this function is expected to be normalised names,
+ per PEP 685, with the returned value being handled appropriately by
+ `iter_dependencies`.
+ """
+ raise NotImplementedError()
+
+ def _iter_declared_entries_from_record(self) -> Optional[Iterator[str]]:
+ try:
+ text = self.read_text("RECORD")
+ except FileNotFoundError:
+ return None
+ # This extra Path-str cast normalizes entries.
+ return (str(pathlib.Path(row[0])) for row in csv.reader(text.splitlines()))
+
+ def _iter_declared_entries_from_legacy(self) -> Optional[Iterator[str]]:
+ try:
+ text = self.read_text("installed-files.txt")
+ except FileNotFoundError:
+ return None
+ paths = (p for p in text.splitlines(keepends=False) if p)
+ root = self.location
+ info = self.info_location
+ if root is None or info is None:
+ return paths
+ try:
+ info_rel = pathlib.Path(info).relative_to(root)
+ except ValueError: # info is not relative to root.
+ return paths
+ if not info_rel.parts: # info *is* root.
+ return paths
+ return (
+ _convert_installed_files_path(pathlib.Path(p).parts, info_rel.parts)
+ for p in paths
+ )
+
+ def iter_declared_entries(self) -> Optional[Iterator[str]]:
+ """Iterate through file entries declared in this distribution.
+
+ For modern .dist-info distributions, this is the files listed in the
+ ``RECORD`` metadata file. For legacy setuptools distributions, this
+ comes from ``installed-files.txt``, with entries normalized to be
+ compatible with the format used by ``RECORD``.
+
+ :return: An iterator for listed entries, or None if the distribution
+ contains neither ``RECORD`` nor ``installed-files.txt``.
+ """
+ return (
+ self._iter_declared_entries_from_record()
+ or self._iter_declared_entries_from_legacy()
+ )
+
+ def _iter_requires_txt_entries(self) -> Iterator[RequiresEntry]:
+ """Parse a ``requires.txt`` in an egg-info directory.
+
+ This is an INI-ish format where an egg-info stores dependencies. A
+ section name describes extra other environment markers, while each entry
+ is an arbitrary string (not a key-value pair) representing a dependency
+ as a requirement string (no markers).
+
+ There is a construct in ``importlib.metadata`` called ``Sectioned`` that
+ does mostly the same, but the format is currently considered private.
+ """
+ try:
+ content = self.read_text("requires.txt")
+ except FileNotFoundError:
+ return
+ extra = marker = "" # Section-less entries don't have markers.
+ for line in content.splitlines():
+ line = line.strip()
+ if not line or line.startswith("#"): # Comment; ignored.
+ continue
+ if line.startswith("[") and line.endswith("]"): # A section header.
+ extra, _, marker = line.strip("[]").partition(":")
+ continue
+ yield RequiresEntry(requirement=line, extra=extra, marker=marker)
+
+ def _iter_egg_info_extras(self) -> Iterable[str]:
+ """Get extras from the egg-info directory."""
+ known_extras = {""}
+ for entry in self._iter_requires_txt_entries():
+ extra = canonicalize_name(entry.extra)
+ if extra in known_extras:
+ continue
+ known_extras.add(extra)
+ yield extra
+
+ def _iter_egg_info_dependencies(self) -> Iterable[str]:
+ """Get distribution dependencies from the egg-info directory.
+
+ To ease parsing, this converts a legacy dependency entry into a PEP 508
+ requirement string. Like ``_iter_requires_txt_entries()``, there is code
+ in ``importlib.metadata`` that does mostly the same, but not do exactly
+ what we need.
+
+ Namely, ``importlib.metadata`` does not normalize the extra name before
+ putting it into the requirement string, which causes marker comparison
+ to fail because the dist-info format do normalize. This is consistent in
+ all currently available PEP 517 backends, although not standardized.
+ """
+ for entry in self._iter_requires_txt_entries():
+ extra = canonicalize_name(entry.extra)
+ if extra and entry.marker:
+ marker = f'({entry.marker}) and extra == "{extra}"'
+ elif extra:
+ marker = f'extra == "{extra}"'
+ elif entry.marker:
+ marker = entry.marker
+ else:
+ marker = ""
+ if marker:
+ yield f"{entry.requirement} ; {marker}"
+ else:
+ yield entry.requirement
+
+ def _add_egg_info_requires(self, metadata: email.message.Message) -> None:
+ """Add egg-info requires.txt information to the metadata."""
+ if not metadata.get_all("Requires-Dist"):
+ for dep in self._iter_egg_info_dependencies():
+ metadata["Requires-Dist"] = dep
+ if not metadata.get_all("Provides-Extra"):
+ for extra in self._iter_egg_info_extras():
+ metadata["Provides-Extra"] = extra
+
+
+class BaseEnvironment:
+ """An environment containing distributions to introspect."""
+
+ @classmethod
+ def default(cls) -> "BaseEnvironment":
+ raise NotImplementedError()
+
+ @classmethod
+ def from_paths(cls, paths: Optional[List[str]]) -> "BaseEnvironment":
+ raise NotImplementedError()
+
+ def get_distribution(self, name: str) -> Optional["BaseDistribution"]:
+ """Given a requirement name, return the installed distributions.
+
+ The name may not be normalized. The implementation must canonicalize
+ it for lookup.
+ """
+ raise NotImplementedError()
+
+ def _iter_distributions(self) -> Iterator["BaseDistribution"]:
+ """Iterate through installed distributions.
+
+ This function should be implemented by subclass, but never called
+ directly. Use the public ``iter_distribution()`` instead, which
+ implements additional logic to make sure the distributions are valid.
+ """
+ raise NotImplementedError()
+
+ def iter_all_distributions(self) -> Iterator[BaseDistribution]:
+ """Iterate through all installed distributions without any filtering."""
+ for dist in self._iter_distributions():
+ # Make sure the distribution actually comes from a valid Python
+ # packaging distribution. Pip's AdjacentTempDirectory leaves folders
+ # e.g. ``~atplotlib.dist-info`` if cleanup was interrupted. The
+ # valid project name pattern is taken from PEP 508.
+ project_name_valid = re.match(
+ r"^([A-Z0-9]|[A-Z0-9][A-Z0-9._-]*[A-Z0-9])$",
+ dist.canonical_name,
+ flags=re.IGNORECASE,
+ )
+ if not project_name_valid:
+ logger.warning(
+ "Ignoring invalid distribution %s (%s)",
+ dist.canonical_name,
+ dist.location,
+ )
+ continue
+ yield dist
+
+ def iter_installed_distributions(
+ self,
+ local_only: bool = True,
+ skip: Container[str] = stdlib_pkgs,
+ include_editables: bool = True,
+ editables_only: bool = False,
+ user_only: bool = False,
+ ) -> Iterator[BaseDistribution]:
+ """Return a list of installed distributions.
+
+ This is based on ``iter_all_distributions()`` with additional filtering
+ options. Note that ``iter_installed_distributions()`` without arguments
+ is *not* equal to ``iter_all_distributions()``, since some of the
+ configurations exclude packages by default.
+
+ :param local_only: If True (default), only return installations
+ local to the current virtualenv, if in a virtualenv.
+ :param skip: An iterable of canonicalized project names to ignore;
+ defaults to ``stdlib_pkgs``.
+ :param include_editables: If False, don't report editables.
+ :param editables_only: If True, only report editables.
+ :param user_only: If True, only report installations in the user
+ site directory.
+ """
+ it = self.iter_all_distributions()
+ if local_only:
+ it = (d for d in it if d.local)
+ if not include_editables:
+ it = (d for d in it if not d.editable)
+ if editables_only:
+ it = (d for d in it if d.editable)
+ if user_only:
+ it = (d for d in it if d.in_usersite)
+ return (d for d in it if d.canonical_name not in skip)
+
+
+class Wheel(Protocol):
+ location: str
+
+ def as_zipfile(self) -> zipfile.ZipFile:
+ raise NotImplementedError()
+
+
+class FilesystemWheel(Wheel):
+ def __init__(self, location: str) -> None:
+ self.location = location
+
+ def as_zipfile(self) -> zipfile.ZipFile:
+ return zipfile.ZipFile(self.location, allowZip64=True)
+
+
+class MemoryWheel(Wheel):
+ def __init__(self, location: str, stream: IO[bytes]) -> None:
+ self.location = location
+ self.stream = stream
+
+ def as_zipfile(self) -> zipfile.ZipFile:
+ return zipfile.ZipFile(self.stream, allowZip64=True)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/__init__.py
new file mode 100644
index 000000000..a779138db
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/__init__.py
@@ -0,0 +1,6 @@
+from ._dists import Distribution
+from ._envs import Environment
+
+__all__ = ["NAME", "Distribution", "Environment"]
+
+NAME = "importlib"
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_compat.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_compat.py
new file mode 100644
index 000000000..ec1e815cd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_compat.py
@@ -0,0 +1,85 @@
+import importlib.metadata
+import os
+from typing import Any, Optional, Protocol, Tuple, cast
+
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+
+
+class BadMetadata(ValueError):
+ def __init__(self, dist: importlib.metadata.Distribution, *, reason: str) -> None:
+ self.dist = dist
+ self.reason = reason
+
+ def __str__(self) -> str:
+ return f"Bad metadata in {self.dist} ({self.reason})"
+
+
+class BasePath(Protocol):
+ """A protocol that various path objects conform.
+
+ This exists because importlib.metadata uses both ``pathlib.Path`` and
+ ``zipfile.Path``, and we need a common base for type hints (Union does not
+ work well since ``zipfile.Path`` is too new for our linter setup).
+
+ This does not mean to be exhaustive, but only contains things that present
+ in both classes *that we need*.
+ """
+
+ @property
+ def name(self) -> str:
+ raise NotImplementedError()
+
+ @property
+ def parent(self) -> "BasePath":
+ raise NotImplementedError()
+
+
+def get_info_location(d: importlib.metadata.Distribution) -> Optional[BasePath]:
+ """Find the path to the distribution's metadata directory.
+
+ HACK: This relies on importlib.metadata's private ``_path`` attribute. Not
+ all distributions exist on disk, so importlib.metadata is correct to not
+ expose the attribute as public. But pip's code base is old and not as clean,
+ so we do this to avoid having to rewrite too many things. Hopefully we can
+ eliminate this some day.
+ """
+ return getattr(d, "_path", None)
+
+
+def parse_name_and_version_from_info_directory(
+ dist: importlib.metadata.Distribution,
+) -> Tuple[Optional[str], Optional[str]]:
+ """Get a name and version from the metadata directory name.
+
+ This is much faster than reading distribution metadata.
+ """
+ info_location = get_info_location(dist)
+ if info_location is None:
+ return None, None
+
+ stem, suffix = os.path.splitext(info_location.name)
+ if suffix == ".dist-info":
+ name, sep, version = stem.partition("-")
+ if sep:
+ return name, version
+
+ if suffix == ".egg-info":
+ name = stem.split("-", 1)[0]
+ return name, None
+
+ return None, None
+
+
+def get_dist_canonical_name(dist: importlib.metadata.Distribution) -> NormalizedName:
+ """Get the distribution's normalized name.
+
+ The ``name`` attribute is only available in Python 3.10 or later. We are
+ targeting exactly that, but Mypy does not know this.
+ """
+ if name := parse_name_and_version_from_info_directory(dist)[0]:
+ return canonicalize_name(name)
+
+ name = cast(Any, dist).name
+ if not isinstance(name, str):
+ raise BadMetadata(dist, reason="invalid metadata entry 'name'")
+ return canonicalize_name(name)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_dists.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_dists.py
new file mode 100644
index 000000000..36cd32623
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_dists.py
@@ -0,0 +1,221 @@
+import email.message
+import importlib.metadata
+import pathlib
+import zipfile
+from typing import (
+ Collection,
+ Dict,
+ Iterable,
+ Iterator,
+ Mapping,
+ Optional,
+ Sequence,
+ cast,
+)
+
+from pip._vendor.packaging.requirements import Requirement
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+from pip._vendor.packaging.version import Version
+from pip._vendor.packaging.version import parse as parse_version
+
+from pip._internal.exceptions import InvalidWheel, UnsupportedWheel
+from pip._internal.metadata.base import (
+ BaseDistribution,
+ BaseEntryPoint,
+ InfoPath,
+ Wheel,
+)
+from pip._internal.utils.misc import normalize_path
+from pip._internal.utils.packaging import get_requirement
+from pip._internal.utils.temp_dir import TempDirectory
+from pip._internal.utils.wheel import parse_wheel, read_wheel_metadata_file
+
+from ._compat import (
+ BasePath,
+ get_dist_canonical_name,
+ parse_name_and_version_from_info_directory,
+)
+
+
+class WheelDistribution(importlib.metadata.Distribution):
+ """An ``importlib.metadata.Distribution`` read from a wheel.
+
+ Although ``importlib.metadata.PathDistribution`` accepts ``zipfile.Path``,
+ its implementation is too "lazy" for pip's needs (we can't keep the ZipFile
+ handle open for the entire lifetime of the distribution object).
+
+ This implementation eagerly reads the entire metadata directory into the
+ memory instead, and operates from that.
+ """
+
+ def __init__(
+ self,
+ files: Mapping[pathlib.PurePosixPath, bytes],
+ info_location: pathlib.PurePosixPath,
+ ) -> None:
+ self._files = files
+ self.info_location = info_location
+
+ @classmethod
+ def from_zipfile(
+ cls,
+ zf: zipfile.ZipFile,
+ name: str,
+ location: str,
+ ) -> "WheelDistribution":
+ info_dir, _ = parse_wheel(zf, name)
+ paths = (
+ (name, pathlib.PurePosixPath(name.split("/", 1)[-1]))
+ for name in zf.namelist()
+ if name.startswith(f"{info_dir}/")
+ )
+ files = {
+ relpath: read_wheel_metadata_file(zf, fullpath)
+ for fullpath, relpath in paths
+ }
+ info_location = pathlib.PurePosixPath(location, info_dir)
+ return cls(files, info_location)
+
+ def iterdir(self, path: InfoPath) -> Iterator[pathlib.PurePosixPath]:
+ # Only allow iterating through the metadata directory.
+ if pathlib.PurePosixPath(str(path)) in self._files:
+ return iter(self._files)
+ raise FileNotFoundError(path)
+
+ def read_text(self, filename: str) -> Optional[str]:
+ try:
+ data = self._files[pathlib.PurePosixPath(filename)]
+ except KeyError:
+ return None
+ try:
+ text = data.decode("utf-8")
+ except UnicodeDecodeError as e:
+ wheel = self.info_location.parent
+ error = f"Error decoding metadata for {wheel}: {e} in {filename} file"
+ raise UnsupportedWheel(error)
+ return text
+
+
+class Distribution(BaseDistribution):
+ def __init__(
+ self,
+ dist: importlib.metadata.Distribution,
+ info_location: Optional[BasePath],
+ installed_location: Optional[BasePath],
+ ) -> None:
+ self._dist = dist
+ self._info_location = info_location
+ self._installed_location = installed_location
+
+ @classmethod
+ def from_directory(cls, directory: str) -> BaseDistribution:
+ info_location = pathlib.Path(directory)
+ dist = importlib.metadata.Distribution.at(info_location)
+ return cls(dist, info_location, info_location.parent)
+
+ @classmethod
+ def from_metadata_file_contents(
+ cls,
+ metadata_contents: bytes,
+ filename: str,
+ project_name: str,
+ ) -> BaseDistribution:
+ # Generate temp dir to contain the metadata file, and write the file contents.
+ temp_dir = pathlib.Path(
+ TempDirectory(kind="metadata", globally_managed=True).path
+ )
+ metadata_path = temp_dir / "METADATA"
+ metadata_path.write_bytes(metadata_contents)
+ # Construct dist pointing to the newly created directory.
+ dist = importlib.metadata.Distribution.at(metadata_path.parent)
+ return cls(dist, metadata_path.parent, None)
+
+ @classmethod
+ def from_wheel(cls, wheel: Wheel, name: str) -> BaseDistribution:
+ try:
+ with wheel.as_zipfile() as zf:
+ dist = WheelDistribution.from_zipfile(zf, name, wheel.location)
+ except zipfile.BadZipFile as e:
+ raise InvalidWheel(wheel.location, name) from e
+ return cls(dist, dist.info_location, pathlib.PurePosixPath(wheel.location))
+
+ @property
+ def location(self) -> Optional[str]:
+ if self._info_location is None:
+ return None
+ return str(self._info_location.parent)
+
+ @property
+ def info_location(self) -> Optional[str]:
+ if self._info_location is None:
+ return None
+ return str(self._info_location)
+
+ @property
+ def installed_location(self) -> Optional[str]:
+ if self._installed_location is None:
+ return None
+ return normalize_path(str(self._installed_location))
+
+ @property
+ def canonical_name(self) -> NormalizedName:
+ return get_dist_canonical_name(self._dist)
+
+ @property
+ def version(self) -> Version:
+ if version := parse_name_and_version_from_info_directory(self._dist)[1]:
+ return parse_version(version)
+ return parse_version(self._dist.version)
+
+ @property
+ def raw_version(self) -> str:
+ return self._dist.version
+
+ def is_file(self, path: InfoPath) -> bool:
+ return self._dist.read_text(str(path)) is not None
+
+ def iter_distutils_script_names(self) -> Iterator[str]:
+ # A distutils installation is always "flat" (not in e.g. egg form), so
+ # if this distribution's info location is NOT a pathlib.Path (but e.g.
+ # zipfile.Path), it can never contain any distutils scripts.
+ if not isinstance(self._info_location, pathlib.Path):
+ return
+ for child in self._info_location.joinpath("scripts").iterdir():
+ yield child.name
+
+ def read_text(self, path: InfoPath) -> str:
+ content = self._dist.read_text(str(path))
+ if content is None:
+ raise FileNotFoundError(path)
+ return content
+
+ def iter_entry_points(self) -> Iterable[BaseEntryPoint]:
+ # importlib.metadata's EntryPoint structure sasitfies BaseEntryPoint.
+ return self._dist.entry_points
+
+ def _metadata_impl(self) -> email.message.Message:
+ # From Python 3.10+, importlib.metadata declares PackageMetadata as the
+ # return type. This protocol is unfortunately a disaster now and misses
+ # a ton of fields that we need, including get() and get_payload(). We
+ # rely on the implementation that the object is actually a Message now,
+ # until upstream can improve the protocol. (python/cpython#94952)
+ return cast(email.message.Message, self._dist.metadata)
+
+ def iter_provided_extras(self) -> Iterable[NormalizedName]:
+ return [
+ canonicalize_name(extra)
+ for extra in self.metadata.get_all("Provides-Extra", [])
+ ]
+
+ def iter_dependencies(self, extras: Collection[str] = ()) -> Iterable[Requirement]:
+ contexts: Sequence[Dict[str, str]] = [{"extra": e} for e in extras]
+ for req_string in self.metadata.get_all("Requires-Dist", []):
+ # strip() because email.message.Message.get_all() may return a leading \n
+ # in case a long header was wrapped.
+ req = get_requirement(req_string.strip())
+ if not req.marker:
+ yield req
+ elif not extras and req.marker.evaluate({"extra": ""}):
+ yield req
+ elif any(req.marker.evaluate(context) for context in contexts):
+ yield req
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_envs.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_envs.py
new file mode 100644
index 000000000..4d906fd31
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/importlib/_envs.py
@@ -0,0 +1,189 @@
+import functools
+import importlib.metadata
+import logging
+import os
+import pathlib
+import sys
+import zipfile
+import zipimport
+from typing import Iterator, List, Optional, Sequence, Set, Tuple
+
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+
+from pip._internal.metadata.base import BaseDistribution, BaseEnvironment
+from pip._internal.models.wheel import Wheel
+from pip._internal.utils.deprecation import deprecated
+from pip._internal.utils.filetypes import WHEEL_EXTENSION
+
+from ._compat import BadMetadata, BasePath, get_dist_canonical_name, get_info_location
+from ._dists import Distribution
+
+logger = logging.getLogger(__name__)
+
+
+def _looks_like_wheel(location: str) -> bool:
+ if not location.endswith(WHEEL_EXTENSION):
+ return False
+ if not os.path.isfile(location):
+ return False
+ if not Wheel.wheel_file_re.match(os.path.basename(location)):
+ return False
+ return zipfile.is_zipfile(location)
+
+
+class _DistributionFinder:
+ """Finder to locate distributions.
+
+ The main purpose of this class is to memoize found distributions' names, so
+ only one distribution is returned for each package name. At lot of pip code
+ assumes this (because it is setuptools's behavior), and not doing the same
+ can potentially cause a distribution in lower precedence path to override a
+ higher precedence one if the caller is not careful.
+
+ Eventually we probably want to make it possible to see lower precedence
+ installations as well. It's useful feature, after all.
+ """
+
+ FoundResult = Tuple[importlib.metadata.Distribution, Optional[BasePath]]
+
+ def __init__(self) -> None:
+ self._found_names: Set[NormalizedName] = set()
+
+ def _find_impl(self, location: str) -> Iterator[FoundResult]:
+ """Find distributions in a location."""
+ # Skip looking inside a wheel. Since a package inside a wheel is not
+ # always valid (due to .data directories etc.), its .dist-info entry
+ # should not be considered an installed distribution.
+ if _looks_like_wheel(location):
+ return
+ # To know exactly where we find a distribution, we have to feed in the
+ # paths one by one, instead of dumping the list to importlib.metadata.
+ for dist in importlib.metadata.distributions(path=[location]):
+ info_location = get_info_location(dist)
+ try:
+ name = get_dist_canonical_name(dist)
+ except BadMetadata as e:
+ logger.warning("Skipping %s due to %s", info_location, e.reason)
+ continue
+ if name in self._found_names:
+ continue
+ self._found_names.add(name)
+ yield dist, info_location
+
+ def find(self, location: str) -> Iterator[BaseDistribution]:
+ """Find distributions in a location.
+
+ The path can be either a directory, or a ZIP archive.
+ """
+ for dist, info_location in self._find_impl(location):
+ if info_location is None:
+ installed_location: Optional[BasePath] = None
+ else:
+ installed_location = info_location.parent
+ yield Distribution(dist, info_location, installed_location)
+
+ def find_linked(self, location: str) -> Iterator[BaseDistribution]:
+ """Read location in egg-link files and return distributions in there.
+
+ The path should be a directory; otherwise this returns nothing. This
+ follows how setuptools does this for compatibility. The first non-empty
+ line in the egg-link is read as a path (resolved against the egg-link's
+ containing directory if relative). Distributions found at that linked
+ location are returned.
+ """
+ path = pathlib.Path(location)
+ if not path.is_dir():
+ return
+ for child in path.iterdir():
+ if child.suffix != ".egg-link":
+ continue
+ with child.open() as f:
+ lines = (line.strip() for line in f)
+ target_rel = next((line for line in lines if line), "")
+ if not target_rel:
+ continue
+ target_location = str(path.joinpath(target_rel))
+ for dist, info_location in self._find_impl(target_location):
+ yield Distribution(dist, info_location, path)
+
+ def _find_eggs_in_dir(self, location: str) -> Iterator[BaseDistribution]:
+ from pip._vendor.pkg_resources import find_distributions
+
+ from pip._internal.metadata import pkg_resources as legacy
+
+ with os.scandir(location) as it:
+ for entry in it:
+ if not entry.name.endswith(".egg"):
+ continue
+ for dist in find_distributions(entry.path):
+ yield legacy.Distribution(dist)
+
+ def _find_eggs_in_zip(self, location: str) -> Iterator[BaseDistribution]:
+ from pip._vendor.pkg_resources import find_eggs_in_zip
+
+ from pip._internal.metadata import pkg_resources as legacy
+
+ try:
+ importer = zipimport.zipimporter(location)
+ except zipimport.ZipImportError:
+ return
+ for dist in find_eggs_in_zip(importer, location):
+ yield legacy.Distribution(dist)
+
+ def find_eggs(self, location: str) -> Iterator[BaseDistribution]:
+ """Find eggs in a location.
+
+ This actually uses the old *pkg_resources* backend. We likely want to
+ deprecate this so we can eventually remove the *pkg_resources*
+ dependency entirely. Before that, this should first emit a deprecation
+ warning for some versions when using the fallback since importing
+ *pkg_resources* is slow for those who don't need it.
+ """
+ if os.path.isdir(location):
+ yield from self._find_eggs_in_dir(location)
+ if zipfile.is_zipfile(location):
+ yield from self._find_eggs_in_zip(location)
+
+
+@functools.lru_cache(maxsize=None) # Warn a distribution exactly once.
+def _emit_egg_deprecation(location: Optional[str]) -> None:
+ deprecated(
+ reason=f"Loading egg at {location} is deprecated.",
+ replacement="to use pip for package installation",
+ gone_in="25.1",
+ issue=12330,
+ )
+
+
+class Environment(BaseEnvironment):
+ def __init__(self, paths: Sequence[str]) -> None:
+ self._paths = paths
+
+ @classmethod
+ def default(cls) -> BaseEnvironment:
+ return cls(sys.path)
+
+ @classmethod
+ def from_paths(cls, paths: Optional[List[str]]) -> BaseEnvironment:
+ if paths is None:
+ return cls(sys.path)
+ return cls(paths)
+
+ def _iter_distributions(self) -> Iterator[BaseDistribution]:
+ finder = _DistributionFinder()
+ for location in self._paths:
+ yield from finder.find(location)
+ for dist in finder.find_eggs(location):
+ _emit_egg_deprecation(dist.location)
+ yield dist
+ # This must go last because that's how pkg_resources tie-breaks.
+ yield from finder.find_linked(location)
+
+ def get_distribution(self, name: str) -> Optional[BaseDistribution]:
+ canonical_name = canonicalize_name(name)
+ matches = (
+ distribution
+ for distribution in self.iter_all_distributions()
+ if distribution.canonical_name == canonical_name
+ )
+ return next(matches, None)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/metadata/pkg_resources.py b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/pkg_resources.py
new file mode 100644
index 000000000..4ea84f93a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/metadata/pkg_resources.py
@@ -0,0 +1,301 @@
+import email.message
+import email.parser
+import logging
+import os
+import zipfile
+from typing import (
+ Collection,
+ Iterable,
+ Iterator,
+ List,
+ Mapping,
+ NamedTuple,
+ Optional,
+)
+
+from pip._vendor import pkg_resources
+from pip._vendor.packaging.requirements import Requirement
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+from pip._vendor.packaging.version import Version
+from pip._vendor.packaging.version import parse as parse_version
+
+from pip._internal.exceptions import InvalidWheel, NoneMetadataError, UnsupportedWheel
+from pip._internal.utils.egg_link import egg_link_path_from_location
+from pip._internal.utils.misc import display_path, normalize_path
+from pip._internal.utils.wheel import parse_wheel, read_wheel_metadata_file
+
+from .base import (
+ BaseDistribution,
+ BaseEntryPoint,
+ BaseEnvironment,
+ InfoPath,
+ Wheel,
+)
+
+__all__ = ["NAME", "Distribution", "Environment"]
+
+logger = logging.getLogger(__name__)
+
+NAME = "pkg_resources"
+
+
+class EntryPoint(NamedTuple):
+ name: str
+ value: str
+ group: str
+
+
+class InMemoryMetadata:
+ """IMetadataProvider that reads metadata files from a dictionary.
+
+ This also maps metadata decoding exceptions to our internal exception type.
+ """
+
+ def __init__(self, metadata: Mapping[str, bytes], wheel_name: str) -> None:
+ self._metadata = metadata
+ self._wheel_name = wheel_name
+
+ def has_metadata(self, name: str) -> bool:
+ return name in self._metadata
+
+ def get_metadata(self, name: str) -> str:
+ try:
+ return self._metadata[name].decode()
+ except UnicodeDecodeError as e:
+ # Augment the default error with the origin of the file.
+ raise UnsupportedWheel(
+ f"Error decoding metadata for {self._wheel_name}: {e} in {name} file"
+ )
+
+ def get_metadata_lines(self, name: str) -> Iterable[str]:
+ return pkg_resources.yield_lines(self.get_metadata(name))
+
+ def metadata_isdir(self, name: str) -> bool:
+ return False
+
+ def metadata_listdir(self, name: str) -> List[str]:
+ return []
+
+ def run_script(self, script_name: str, namespace: str) -> None:
+ pass
+
+
+class Distribution(BaseDistribution):
+ def __init__(self, dist: pkg_resources.Distribution) -> None:
+ self._dist = dist
+ # This is populated lazily, to avoid loading metadata for all possible
+ # distributions eagerly.
+ self.__extra_mapping: Optional[Mapping[NormalizedName, str]] = None
+
+ @property
+ def _extra_mapping(self) -> Mapping[NormalizedName, str]:
+ if self.__extra_mapping is None:
+ self.__extra_mapping = {
+ canonicalize_name(extra): extra for extra in self._dist.extras
+ }
+
+ return self.__extra_mapping
+
+ @classmethod
+ def from_directory(cls, directory: str) -> BaseDistribution:
+ dist_dir = directory.rstrip(os.sep)
+
+ # Build a PathMetadata object, from path to metadata. :wink:
+ base_dir, dist_dir_name = os.path.split(dist_dir)
+ metadata = pkg_resources.PathMetadata(base_dir, dist_dir)
+
+ # Determine the correct Distribution object type.
+ if dist_dir.endswith(".egg-info"):
+ dist_cls = pkg_resources.Distribution
+ dist_name = os.path.splitext(dist_dir_name)[0]
+ else:
+ assert dist_dir.endswith(".dist-info")
+ dist_cls = pkg_resources.DistInfoDistribution
+ dist_name = os.path.splitext(dist_dir_name)[0].split("-")[0]
+
+ dist = dist_cls(base_dir, project_name=dist_name, metadata=metadata)
+ return cls(dist)
+
+ @classmethod
+ def from_metadata_file_contents(
+ cls,
+ metadata_contents: bytes,
+ filename: str,
+ project_name: str,
+ ) -> BaseDistribution:
+ metadata_dict = {
+ "METADATA": metadata_contents,
+ }
+ dist = pkg_resources.DistInfoDistribution(
+ location=filename,
+ metadata=InMemoryMetadata(metadata_dict, filename),
+ project_name=project_name,
+ )
+ return cls(dist)
+
+ @classmethod
+ def from_wheel(cls, wheel: Wheel, name: str) -> BaseDistribution:
+ try:
+ with wheel.as_zipfile() as zf:
+ info_dir, _ = parse_wheel(zf, name)
+ metadata_dict = {
+ path.split("/", 1)[-1]: read_wheel_metadata_file(zf, path)
+ for path in zf.namelist()
+ if path.startswith(f"{info_dir}/")
+ }
+ except zipfile.BadZipFile as e:
+ raise InvalidWheel(wheel.location, name) from e
+ except UnsupportedWheel as e:
+ raise UnsupportedWheel(f"{name} has an invalid wheel, {e}")
+ dist = pkg_resources.DistInfoDistribution(
+ location=wheel.location,
+ metadata=InMemoryMetadata(metadata_dict, wheel.location),
+ project_name=name,
+ )
+ return cls(dist)
+
+ @property
+ def location(self) -> Optional[str]:
+ return self._dist.location
+
+ @property
+ def installed_location(self) -> Optional[str]:
+ egg_link = egg_link_path_from_location(self.raw_name)
+ if egg_link:
+ location = egg_link
+ elif self.location:
+ location = self.location
+ else:
+ return None
+ return normalize_path(location)
+
+ @property
+ def info_location(self) -> Optional[str]:
+ return self._dist.egg_info
+
+ @property
+ def installed_by_distutils(self) -> bool:
+ # A distutils-installed distribution is provided by FileMetadata. This
+ # provider has a "path" attribute not present anywhere else. Not the
+ # best introspection logic, but pip has been doing this for a long time.
+ try:
+ return bool(self._dist._provider.path)
+ except AttributeError:
+ return False
+
+ @property
+ def canonical_name(self) -> NormalizedName:
+ return canonicalize_name(self._dist.project_name)
+
+ @property
+ def version(self) -> Version:
+ return parse_version(self._dist.version)
+
+ @property
+ def raw_version(self) -> str:
+ return self._dist.version
+
+ def is_file(self, path: InfoPath) -> bool:
+ return self._dist.has_metadata(str(path))
+
+ def iter_distutils_script_names(self) -> Iterator[str]:
+ yield from self._dist.metadata_listdir("scripts")
+
+ def read_text(self, path: InfoPath) -> str:
+ name = str(path)
+ if not self._dist.has_metadata(name):
+ raise FileNotFoundError(name)
+ content = self._dist.get_metadata(name)
+ if content is None:
+ raise NoneMetadataError(self, name)
+ return content
+
+ def iter_entry_points(self) -> Iterable[BaseEntryPoint]:
+ for group, entries in self._dist.get_entry_map().items():
+ for name, entry_point in entries.items():
+ name, _, value = str(entry_point).partition("=")
+ yield EntryPoint(name=name.strip(), value=value.strip(), group=group)
+
+ def _metadata_impl(self) -> email.message.Message:
+ """
+ :raises NoneMetadataError: if the distribution reports `has_metadata()`
+ True but `get_metadata()` returns None.
+ """
+ if isinstance(self._dist, pkg_resources.DistInfoDistribution):
+ metadata_name = "METADATA"
+ else:
+ metadata_name = "PKG-INFO"
+ try:
+ metadata = self.read_text(metadata_name)
+ except FileNotFoundError:
+ if self.location:
+ displaying_path = display_path(self.location)
+ else:
+ displaying_path = repr(self.location)
+ logger.warning("No metadata found in %s", displaying_path)
+ metadata = ""
+ feed_parser = email.parser.FeedParser()
+ feed_parser.feed(metadata)
+ return feed_parser.close()
+
+ def iter_dependencies(self, extras: Collection[str] = ()) -> Iterable[Requirement]:
+ if extras:
+ relevant_extras = set(self._extra_mapping) & set(
+ map(canonicalize_name, extras)
+ )
+ extras = [self._extra_mapping[extra] for extra in relevant_extras]
+ return self._dist.requires(extras)
+
+ def iter_provided_extras(self) -> Iterable[NormalizedName]:
+ return self._extra_mapping.keys()
+
+
+class Environment(BaseEnvironment):
+ def __init__(self, ws: pkg_resources.WorkingSet) -> None:
+ self._ws = ws
+
+ @classmethod
+ def default(cls) -> BaseEnvironment:
+ return cls(pkg_resources.working_set)
+
+ @classmethod
+ def from_paths(cls, paths: Optional[List[str]]) -> BaseEnvironment:
+ return cls(pkg_resources.WorkingSet(paths))
+
+ def _iter_distributions(self) -> Iterator[BaseDistribution]:
+ for dist in self._ws:
+ yield Distribution(dist)
+
+ def _search_distribution(self, name: str) -> Optional[BaseDistribution]:
+ """Find a distribution matching the ``name`` in the environment.
+
+ This searches from *all* distributions available in the environment, to
+ match the behavior of ``pkg_resources.get_distribution()``.
+ """
+ canonical_name = canonicalize_name(name)
+ for dist in self.iter_all_distributions():
+ if dist.canonical_name == canonical_name:
+ return dist
+ return None
+
+ def get_distribution(self, name: str) -> Optional[BaseDistribution]:
+ # Search the distribution by looking through the working set.
+ dist = self._search_distribution(name)
+ if dist:
+ return dist
+
+ # If distribution could not be found, call working_set.require to
+ # update the working set, and try to find the distribution again.
+ # This might happen for e.g. when you install a package twice, once
+ # using setup.py develop and again using setup.py install. Now when
+ # running pip uninstall twice, the package gets removed from the
+ # working set in the first uninstall, so we have to populate the
+ # working set again so that pip knows about it and the packages gets
+ # picked up and is successfully uninstalled the second time too.
+ try:
+ # We didn't pass in any version specifiers, so this can never
+ # raise pkg_resources.VersionConflict.
+ self._ws.require(name)
+ except pkg_resources.DistributionNotFound:
+ return None
+ return self._search_distribution(name)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/__init__.py
new file mode 100644
index 000000000..7855226e4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/__init__.py
@@ -0,0 +1,2 @@
+"""A package that contains models that represent entities.
+"""
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/candidate.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/candidate.py
new file mode 100644
index 000000000..f27f28315
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/candidate.py
@@ -0,0 +1,25 @@
+from dataclasses import dataclass
+
+from pip._vendor.packaging.version import Version
+from pip._vendor.packaging.version import parse as parse_version
+
+from pip._internal.models.link import Link
+
+
+@dataclass(frozen=True)
+class InstallationCandidate:
+ """Represents a potential "candidate" for installation."""
+
+ __slots__ = ["name", "version", "link"]
+
+ name: str
+ version: Version
+ link: Link
+
+ def __init__(self, name: str, version: str, link: Link) -> None:
+ object.__setattr__(self, "name", name)
+ object.__setattr__(self, "version", parse_version(version))
+ object.__setattr__(self, "link", link)
+
+ def __str__(self) -> str:
+ return f"{self.name!r} candidate (version {self.version} at {self.link})"
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/direct_url.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/direct_url.py
new file mode 100644
index 000000000..fc5ec8d4a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/direct_url.py
@@ -0,0 +1,224 @@
+""" PEP 610 """
+
+import json
+import re
+import urllib.parse
+from dataclasses import dataclass
+from typing import Any, ClassVar, Dict, Iterable, Optional, Type, TypeVar, Union
+
+__all__ = [
+ "DirectUrl",
+ "DirectUrlValidationError",
+ "DirInfo",
+ "ArchiveInfo",
+ "VcsInfo",
+]
+
+T = TypeVar("T")
+
+DIRECT_URL_METADATA_NAME = "direct_url.json"
+ENV_VAR_RE = re.compile(r"^\$\{[A-Za-z0-9-_]+\}(:\$\{[A-Za-z0-9-_]+\})?$")
+
+
+class DirectUrlValidationError(Exception):
+ pass
+
+
+def _get(
+ d: Dict[str, Any], expected_type: Type[T], key: str, default: Optional[T] = None
+) -> Optional[T]:
+ """Get value from dictionary and verify expected type."""
+ if key not in d:
+ return default
+ value = d[key]
+ if not isinstance(value, expected_type):
+ raise DirectUrlValidationError(
+ f"{value!r} has unexpected type for {key} (expected {expected_type})"
+ )
+ return value
+
+
+def _get_required(
+ d: Dict[str, Any], expected_type: Type[T], key: str, default: Optional[T] = None
+) -> T:
+ value = _get(d, expected_type, key, default)
+ if value is None:
+ raise DirectUrlValidationError(f"{key} must have a value")
+ return value
+
+
+def _exactly_one_of(infos: Iterable[Optional["InfoType"]]) -> "InfoType":
+ infos = [info for info in infos if info is not None]
+ if not infos:
+ raise DirectUrlValidationError(
+ "missing one of archive_info, dir_info, vcs_info"
+ )
+ if len(infos) > 1:
+ raise DirectUrlValidationError(
+ "more than one of archive_info, dir_info, vcs_info"
+ )
+ assert infos[0] is not None
+ return infos[0]
+
+
+def _filter_none(**kwargs: Any) -> Dict[str, Any]:
+ """Make dict excluding None values."""
+ return {k: v for k, v in kwargs.items() if v is not None}
+
+
+@dataclass
+class VcsInfo:
+ name: ClassVar = "vcs_info"
+
+ vcs: str
+ commit_id: str
+ requested_revision: Optional[str] = None
+
+ @classmethod
+ def _from_dict(cls, d: Optional[Dict[str, Any]]) -> Optional["VcsInfo"]:
+ if d is None:
+ return None
+ return cls(
+ vcs=_get_required(d, str, "vcs"),
+ commit_id=_get_required(d, str, "commit_id"),
+ requested_revision=_get(d, str, "requested_revision"),
+ )
+
+ def _to_dict(self) -> Dict[str, Any]:
+ return _filter_none(
+ vcs=self.vcs,
+ requested_revision=self.requested_revision,
+ commit_id=self.commit_id,
+ )
+
+
+class ArchiveInfo:
+ name = "archive_info"
+
+ def __init__(
+ self,
+ hash: Optional[str] = None,
+ hashes: Optional[Dict[str, str]] = None,
+ ) -> None:
+ # set hashes before hash, since the hash setter will further populate hashes
+ self.hashes = hashes
+ self.hash = hash
+
+ @property
+ def hash(self) -> Optional[str]:
+ return self._hash
+
+ @hash.setter
+ def hash(self, value: Optional[str]) -> None:
+ if value is not None:
+ # Auto-populate the hashes key to upgrade to the new format automatically.
+ # We don't back-populate the legacy hash key from hashes.
+ try:
+ hash_name, hash_value = value.split("=", 1)
+ except ValueError:
+ raise DirectUrlValidationError(
+ f"invalid archive_info.hash format: {value!r}"
+ )
+ if self.hashes is None:
+ self.hashes = {hash_name: hash_value}
+ elif hash_name not in self.hashes:
+ self.hashes = self.hashes.copy()
+ self.hashes[hash_name] = hash_value
+ self._hash = value
+
+ @classmethod
+ def _from_dict(cls, d: Optional[Dict[str, Any]]) -> Optional["ArchiveInfo"]:
+ if d is None:
+ return None
+ return cls(hash=_get(d, str, "hash"), hashes=_get(d, dict, "hashes"))
+
+ def _to_dict(self) -> Dict[str, Any]:
+ return _filter_none(hash=self.hash, hashes=self.hashes)
+
+
+@dataclass
+class DirInfo:
+ name: ClassVar = "dir_info"
+
+ editable: bool = False
+
+ @classmethod
+ def _from_dict(cls, d: Optional[Dict[str, Any]]) -> Optional["DirInfo"]:
+ if d is None:
+ return None
+ return cls(editable=_get_required(d, bool, "editable", default=False))
+
+ def _to_dict(self) -> Dict[str, Any]:
+ return _filter_none(editable=self.editable or None)
+
+
+InfoType = Union[ArchiveInfo, DirInfo, VcsInfo]
+
+
+@dataclass
+class DirectUrl:
+ url: str
+ info: InfoType
+ subdirectory: Optional[str] = None
+
+ def _remove_auth_from_netloc(self, netloc: str) -> str:
+ if "@" not in netloc:
+ return netloc
+ user_pass, netloc_no_user_pass = netloc.split("@", 1)
+ if (
+ isinstance(self.info, VcsInfo)
+ and self.info.vcs == "git"
+ and user_pass == "git"
+ ):
+ return netloc
+ if ENV_VAR_RE.match(user_pass):
+ return netloc
+ return netloc_no_user_pass
+
+ @property
+ def redacted_url(self) -> str:
+ """url with user:password part removed unless it is formed with
+ environment variables as specified in PEP 610, or it is ``git``
+ in the case of a git URL.
+ """
+ purl = urllib.parse.urlsplit(self.url)
+ netloc = self._remove_auth_from_netloc(purl.netloc)
+ surl = urllib.parse.urlunsplit(
+ (purl.scheme, netloc, purl.path, purl.query, purl.fragment)
+ )
+ return surl
+
+ def validate(self) -> None:
+ self.from_dict(self.to_dict())
+
+ @classmethod
+ def from_dict(cls, d: Dict[str, Any]) -> "DirectUrl":
+ return DirectUrl(
+ url=_get_required(d, str, "url"),
+ subdirectory=_get(d, str, "subdirectory"),
+ info=_exactly_one_of(
+ [
+ ArchiveInfo._from_dict(_get(d, dict, "archive_info")),
+ DirInfo._from_dict(_get(d, dict, "dir_info")),
+ VcsInfo._from_dict(_get(d, dict, "vcs_info")),
+ ]
+ ),
+ )
+
+ def to_dict(self) -> Dict[str, Any]:
+ res = _filter_none(
+ url=self.redacted_url,
+ subdirectory=self.subdirectory,
+ )
+ res[self.info.name] = self.info._to_dict()
+ return res
+
+ @classmethod
+ def from_json(cls, s: str) -> "DirectUrl":
+ return cls.from_dict(json.loads(s))
+
+ def to_json(self) -> str:
+ return json.dumps(self.to_dict(), sort_keys=True)
+
+ def is_local_editable(self) -> bool:
+ return isinstance(self.info, DirInfo) and self.info.editable
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/format_control.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/format_control.py
new file mode 100644
index 000000000..ccd11272c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/format_control.py
@@ -0,0 +1,78 @@
+from typing import FrozenSet, Optional, Set
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.exceptions import CommandError
+
+
+class FormatControl:
+ """Helper for managing formats from which a package can be installed."""
+
+ __slots__ = ["no_binary", "only_binary"]
+
+ def __init__(
+ self,
+ no_binary: Optional[Set[str]] = None,
+ only_binary: Optional[Set[str]] = None,
+ ) -> None:
+ if no_binary is None:
+ no_binary = set()
+ if only_binary is None:
+ only_binary = set()
+
+ self.no_binary = no_binary
+ self.only_binary = only_binary
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, self.__class__):
+ return NotImplemented
+
+ if self.__slots__ != other.__slots__:
+ return False
+
+ return all(getattr(self, k) == getattr(other, k) for k in self.__slots__)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({self.no_binary}, {self.only_binary})"
+
+ @staticmethod
+ def handle_mutual_excludes(value: str, target: Set[str], other: Set[str]) -> None:
+ if value.startswith("-"):
+ raise CommandError(
+ "--no-binary / --only-binary option requires 1 argument."
+ )
+ new = value.split(",")
+ while ":all:" in new:
+ other.clear()
+ target.clear()
+ target.add(":all:")
+ del new[: new.index(":all:") + 1]
+ # Without a none, we want to discard everything as :all: covers it
+ if ":none:" not in new:
+ return
+ for name in new:
+ if name == ":none:":
+ target.clear()
+ continue
+ name = canonicalize_name(name)
+ other.discard(name)
+ target.add(name)
+
+ def get_allowed_formats(self, canonical_name: str) -> FrozenSet[str]:
+ result = {"binary", "source"}
+ if canonical_name in self.only_binary:
+ result.discard("source")
+ elif canonical_name in self.no_binary:
+ result.discard("binary")
+ elif ":all:" in self.only_binary:
+ result.discard("source")
+ elif ":all:" in self.no_binary:
+ result.discard("binary")
+ return frozenset(result)
+
+ def disallow_binaries(self) -> None:
+ self.handle_mutual_excludes(
+ ":all:",
+ self.no_binary,
+ self.only_binary,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/index.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/index.py
new file mode 100644
index 000000000..b94c32511
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/index.py
@@ -0,0 +1,28 @@
+import urllib.parse
+
+
+class PackageIndex:
+ """Represents a Package Index and provides easier access to endpoints"""
+
+ __slots__ = ["url", "netloc", "simple_url", "pypi_url", "file_storage_domain"]
+
+ def __init__(self, url: str, file_storage_domain: str) -> None:
+ super().__init__()
+ self.url = url
+ self.netloc = urllib.parse.urlsplit(url).netloc
+ self.simple_url = self._url_for_path("simple")
+ self.pypi_url = self._url_for_path("pypi")
+
+ # This is part of a temporary hack used to block installs of PyPI
+ # packages which depend on external urls only necessary until PyPI can
+ # block such packages themselves
+ self.file_storage_domain = file_storage_domain
+
+ def _url_for_path(self, path: str) -> str:
+ return urllib.parse.urljoin(self.url, path)
+
+
+PyPI = PackageIndex("https://pypi.org/", file_storage_domain="files.pythonhosted.org")
+TestPyPI = PackageIndex(
+ "https://test.pypi.org/", file_storage_domain="test-files.pythonhosted.org"
+)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/installation_report.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/installation_report.py
new file mode 100644
index 000000000..b9c6330df
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/installation_report.py
@@ -0,0 +1,56 @@
+from typing import Any, Dict, Sequence
+
+from pip._vendor.packaging.markers import default_environment
+
+from pip import __version__
+from pip._internal.req.req_install import InstallRequirement
+
+
+class InstallationReport:
+ def __init__(self, install_requirements: Sequence[InstallRequirement]):
+ self._install_requirements = install_requirements
+
+ @classmethod
+ def _install_req_to_dict(cls, ireq: InstallRequirement) -> Dict[str, Any]:
+ assert ireq.download_info, f"No download_info for {ireq}"
+ res = {
+ # PEP 610 json for the download URL. download_info.archive_info.hashes may
+ # be absent when the requirement was installed from the wheel cache
+ # and the cache entry was populated by an older pip version that did not
+ # record origin.json.
+ "download_info": ireq.download_info.to_dict(),
+ # is_direct is true if the requirement was a direct URL reference (which
+ # includes editable requirements), and false if the requirement was
+ # downloaded from a PEP 503 index or --find-links.
+ "is_direct": ireq.is_direct,
+ # is_yanked is true if the requirement was yanked from the index, but
+ # was still selected by pip to conform to PEP 592.
+ "is_yanked": ireq.link.is_yanked if ireq.link else False,
+ # requested is true if the requirement was specified by the user (aka
+ # top level requirement), and false if it was installed as a dependency of a
+ # requirement. https://peps.python.org/pep-0376/#requested
+ "requested": ireq.user_supplied,
+ # PEP 566 json encoding for metadata
+ # https://www.python.org/dev/peps/pep-0566/#json-compatible-metadata
+ "metadata": ireq.get_dist().metadata_dict,
+ }
+ if ireq.user_supplied and ireq.extras:
+ # For top level requirements, the list of requested extras, if any.
+ res["requested_extras"] = sorted(ireq.extras)
+ return res
+
+ def to_dict(self) -> Dict[str, Any]:
+ return {
+ "version": "1",
+ "pip_version": __version__,
+ "install": [
+ self._install_req_to_dict(ireq) for ireq in self._install_requirements
+ ],
+ # https://peps.python.org/pep-0508/#environment-markers
+ # TODO: currently, the resolver uses the default environment to evaluate
+ # environment markers, so that is what we report here. In the future, it
+ # should also take into account options such as --python-version or
+ # --platform, perhaps under the form of an environment_override field?
+ # https://github.com/pypa/pip/issues/11198
+ "environment": default_environment(),
+ }
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/link.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/link.py
new file mode 100644
index 000000000..2f41f2f6a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/link.py
@@ -0,0 +1,590 @@
+import functools
+import itertools
+import logging
+import os
+import posixpath
+import re
+import urllib.parse
+from dataclasses import dataclass
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Dict,
+ List,
+ Mapping,
+ NamedTuple,
+ Optional,
+ Tuple,
+ Union,
+)
+
+from pip._internal.utils.deprecation import deprecated
+from pip._internal.utils.filetypes import WHEEL_EXTENSION
+from pip._internal.utils.hashes import Hashes
+from pip._internal.utils.misc import (
+ pairwise,
+ redact_auth_from_url,
+ split_auth_from_netloc,
+ splitext,
+)
+from pip._internal.utils.urls import path_to_url, url_to_path
+
+if TYPE_CHECKING:
+ from pip._internal.index.collector import IndexContent
+
+logger = logging.getLogger(__name__)
+
+
+# Order matters, earlier hashes have a precedence over later hashes for what
+# we will pick to use.
+_SUPPORTED_HASHES = ("sha512", "sha384", "sha256", "sha224", "sha1", "md5")
+
+
+@dataclass(frozen=True)
+class LinkHash:
+ """Links to content may have embedded hash values. This class parses those.
+
+ `name` must be any member of `_SUPPORTED_HASHES`.
+
+ This class can be converted to and from `ArchiveInfo`. While ArchiveInfo intends to
+ be JSON-serializable to conform to PEP 610, this class contains the logic for
+ parsing a hash name and value for correctness, and then checking whether that hash
+ conforms to a schema with `.is_hash_allowed()`."""
+
+ name: str
+ value: str
+
+ _hash_url_fragment_re = re.compile(
+ # NB: we do not validate that the second group (.*) is a valid hex
+ # digest. Instead, we simply keep that string in this class, and then check it
+ # against Hashes when hash-checking is needed. This is easier to debug than
+ # proactively discarding an invalid hex digest, as we handle incorrect hashes
+ # and malformed hashes in the same place.
+ r"[#&]({choices})=([^&]*)".format(
+ choices="|".join(re.escape(hash_name) for hash_name in _SUPPORTED_HASHES)
+ ),
+ )
+
+ def __post_init__(self) -> None:
+ assert self.name in _SUPPORTED_HASHES
+
+ @classmethod
+ @functools.lru_cache(maxsize=None)
+ def find_hash_url_fragment(cls, url: str) -> Optional["LinkHash"]:
+ """Search a string for a checksum algorithm name and encoded output value."""
+ match = cls._hash_url_fragment_re.search(url)
+ if match is None:
+ return None
+ name, value = match.groups()
+ return cls(name=name, value=value)
+
+ def as_dict(self) -> Dict[str, str]:
+ return {self.name: self.value}
+
+ def as_hashes(self) -> Hashes:
+ """Return a Hashes instance which checks only for the current hash."""
+ return Hashes({self.name: [self.value]})
+
+ def is_hash_allowed(self, hashes: Optional[Hashes]) -> bool:
+ """
+ Return True if the current hash is allowed by `hashes`.
+ """
+ if hashes is None:
+ return False
+ return hashes.is_hash_allowed(self.name, hex_digest=self.value)
+
+
+@dataclass(frozen=True)
+class MetadataFile:
+ """Information about a core metadata file associated with a distribution."""
+
+ hashes: Optional[Dict[str, str]]
+
+ def __post_init__(self) -> None:
+ if self.hashes is not None:
+ assert all(name in _SUPPORTED_HASHES for name in self.hashes)
+
+
+def supported_hashes(hashes: Optional[Dict[str, str]]) -> Optional[Dict[str, str]]:
+ # Remove any unsupported hash types from the mapping. If this leaves no
+ # supported hashes, return None
+ if hashes is None:
+ return None
+ hashes = {n: v for n, v in hashes.items() if n in _SUPPORTED_HASHES}
+ if not hashes:
+ return None
+ return hashes
+
+
+def _clean_url_path_part(part: str) -> str:
+ """
+ Clean a "part" of a URL path (i.e. after splitting on "@" characters).
+ """
+ # We unquote prior to quoting to make sure nothing is double quoted.
+ return urllib.parse.quote(urllib.parse.unquote(part))
+
+
+def _clean_file_url_path(part: str) -> str:
+ """
+ Clean the first part of a URL path that corresponds to a local
+ filesystem path (i.e. the first part after splitting on "@" characters).
+ """
+ # We unquote prior to quoting to make sure nothing is double quoted.
+ # Also, on Windows the path part might contain a drive letter which
+ # should not be quoted. On Linux where drive letters do not
+ # exist, the colon should be quoted. We rely on urllib.request
+ # to do the right thing here.
+ return urllib.request.pathname2url(urllib.request.url2pathname(part))
+
+
+# percent-encoded: /
+_reserved_chars_re = re.compile("(@|%2F)", re.IGNORECASE)
+
+
+def _clean_url_path(path: str, is_local_path: bool) -> str:
+ """
+ Clean the path portion of a URL.
+ """
+ if is_local_path:
+ clean_func = _clean_file_url_path
+ else:
+ clean_func = _clean_url_path_part
+
+ # Split on the reserved characters prior to cleaning so that
+ # revision strings in VCS URLs are properly preserved.
+ parts = _reserved_chars_re.split(path)
+
+ cleaned_parts = []
+ for to_clean, reserved in pairwise(itertools.chain(parts, [""])):
+ cleaned_parts.append(clean_func(to_clean))
+ # Normalize %xx escapes (e.g. %2f -> %2F)
+ cleaned_parts.append(reserved.upper())
+
+ return "".join(cleaned_parts)
+
+
+def _ensure_quoted_url(url: str) -> str:
+ """
+ Make sure a link is fully quoted.
+ For example, if ' ' occurs in the URL, it will be replaced with "%20",
+ and without double-quoting other characters.
+ """
+ # Split the URL into parts according to the general structure
+ # `scheme://netloc/path;parameters?query#fragment`.
+ result = urllib.parse.urlparse(url)
+ # If the netloc is empty, then the URL refers to a local filesystem path.
+ is_local_path = not result.netloc
+ path = _clean_url_path(result.path, is_local_path=is_local_path)
+ return urllib.parse.urlunparse(result._replace(path=path))
+
+
+@functools.total_ordering
+class Link:
+ """Represents a parsed link from a Package Index's simple URL"""
+
+ __slots__ = [
+ "_parsed_url",
+ "_url",
+ "_hashes",
+ "comes_from",
+ "requires_python",
+ "yanked_reason",
+ "metadata_file_data",
+ "cache_link_parsing",
+ "egg_fragment",
+ ]
+
+ def __init__(
+ self,
+ url: str,
+ comes_from: Optional[Union[str, "IndexContent"]] = None,
+ requires_python: Optional[str] = None,
+ yanked_reason: Optional[str] = None,
+ metadata_file_data: Optional[MetadataFile] = None,
+ cache_link_parsing: bool = True,
+ hashes: Optional[Mapping[str, str]] = None,
+ ) -> None:
+ """
+ :param url: url of the resource pointed to (href of the link)
+ :param comes_from: instance of IndexContent where the link was found,
+ or string.
+ :param requires_python: String containing the `Requires-Python`
+ metadata field, specified in PEP 345. This may be specified by
+ a data-requires-python attribute in the HTML link tag, as
+ described in PEP 503.
+ :param yanked_reason: the reason the file has been yanked, if the
+ file has been yanked, or None if the file hasn't been yanked.
+ This is the value of the "data-yanked" attribute, if present, in
+ a simple repository HTML link. If the file has been yanked but
+ no reason was provided, this should be the empty string. See
+ PEP 592 for more information and the specification.
+ :param metadata_file_data: the metadata attached to the file, or None if
+ no such metadata is provided. This argument, if not None, indicates
+ that a separate metadata file exists, and also optionally supplies
+ hashes for that file.
+ :param cache_link_parsing: A flag that is used elsewhere to determine
+ whether resources retrieved from this link should be cached. PyPI
+ URLs should generally have this set to False, for example.
+ :param hashes: A mapping of hash names to digests to allow us to
+ determine the validity of a download.
+ """
+
+ # The comes_from, requires_python, and metadata_file_data arguments are
+ # only used by classmethods of this class, and are not used in client
+ # code directly.
+
+ # url can be a UNC windows share
+ if url.startswith("\\\\"):
+ url = path_to_url(url)
+
+ self._parsed_url = urllib.parse.urlsplit(url)
+ # Store the url as a private attribute to prevent accidentally
+ # trying to set a new value.
+ self._url = url
+
+ link_hash = LinkHash.find_hash_url_fragment(url)
+ hashes_from_link = {} if link_hash is None else link_hash.as_dict()
+ if hashes is None:
+ self._hashes = hashes_from_link
+ else:
+ self._hashes = {**hashes, **hashes_from_link}
+
+ self.comes_from = comes_from
+ self.requires_python = requires_python if requires_python else None
+ self.yanked_reason = yanked_reason
+ self.metadata_file_data = metadata_file_data
+
+ self.cache_link_parsing = cache_link_parsing
+ self.egg_fragment = self._egg_fragment()
+
+ @classmethod
+ def from_json(
+ cls,
+ file_data: Dict[str, Any],
+ page_url: str,
+ ) -> Optional["Link"]:
+ """
+ Convert an pypi json document from a simple repository page into a Link.
+ """
+ file_url = file_data.get("url")
+ if file_url is None:
+ return None
+
+ url = _ensure_quoted_url(urllib.parse.urljoin(page_url, file_url))
+ pyrequire = file_data.get("requires-python")
+ yanked_reason = file_data.get("yanked")
+ hashes = file_data.get("hashes", {})
+
+ # PEP 714: Indexes must use the name core-metadata, but
+ # clients should support the old name as a fallback for compatibility.
+ metadata_info = file_data.get("core-metadata")
+ if metadata_info is None:
+ metadata_info = file_data.get("dist-info-metadata")
+
+ # The metadata info value may be a boolean, or a dict of hashes.
+ if isinstance(metadata_info, dict):
+ # The file exists, and hashes have been supplied
+ metadata_file_data = MetadataFile(supported_hashes(metadata_info))
+ elif metadata_info:
+ # The file exists, but there are no hashes
+ metadata_file_data = MetadataFile(None)
+ else:
+ # False or not present: the file does not exist
+ metadata_file_data = None
+
+ # The Link.yanked_reason expects an empty string instead of a boolean.
+ if yanked_reason and not isinstance(yanked_reason, str):
+ yanked_reason = ""
+ # The Link.yanked_reason expects None instead of False.
+ elif not yanked_reason:
+ yanked_reason = None
+
+ return cls(
+ url,
+ comes_from=page_url,
+ requires_python=pyrequire,
+ yanked_reason=yanked_reason,
+ hashes=hashes,
+ metadata_file_data=metadata_file_data,
+ )
+
+ @classmethod
+ def from_element(
+ cls,
+ anchor_attribs: Dict[str, Optional[str]],
+ page_url: str,
+ base_url: str,
+ ) -> Optional["Link"]:
+ """
+ Convert an anchor element's attributes in a simple repository page to a Link.
+ """
+ href = anchor_attribs.get("href")
+ if not href:
+ return None
+
+ url = _ensure_quoted_url(urllib.parse.urljoin(base_url, href))
+ pyrequire = anchor_attribs.get("data-requires-python")
+ yanked_reason = anchor_attribs.get("data-yanked")
+
+ # PEP 714: Indexes must use the name data-core-metadata, but
+ # clients should support the old name as a fallback for compatibility.
+ metadata_info = anchor_attribs.get("data-core-metadata")
+ if metadata_info is None:
+ metadata_info = anchor_attribs.get("data-dist-info-metadata")
+ # The metadata info value may be the string "true", or a string of
+ # the form "hashname=hashval"
+ if metadata_info == "true":
+ # The file exists, but there are no hashes
+ metadata_file_data = MetadataFile(None)
+ elif metadata_info is None:
+ # The file does not exist
+ metadata_file_data = None
+ else:
+ # The file exists, and hashes have been supplied
+ hashname, sep, hashval = metadata_info.partition("=")
+ if sep == "=":
+ metadata_file_data = MetadataFile(supported_hashes({hashname: hashval}))
+ else:
+ # Error - data is wrong. Treat as no hashes supplied.
+ logger.debug(
+ "Index returned invalid data-dist-info-metadata value: %s",
+ metadata_info,
+ )
+ metadata_file_data = MetadataFile(None)
+
+ return cls(
+ url,
+ comes_from=page_url,
+ requires_python=pyrequire,
+ yanked_reason=yanked_reason,
+ metadata_file_data=metadata_file_data,
+ )
+
+ def __str__(self) -> str:
+ if self.requires_python:
+ rp = f" (requires-python:{self.requires_python})"
+ else:
+ rp = ""
+ if self.comes_from:
+ return f"{redact_auth_from_url(self._url)} (from {self.comes_from}){rp}"
+ else:
+ return redact_auth_from_url(str(self._url))
+
+ def __repr__(self) -> str:
+ return f"<Link {self}>"
+
+ def __hash__(self) -> int:
+ return hash(self.url)
+
+ def __eq__(self, other: Any) -> bool:
+ if not isinstance(other, Link):
+ return NotImplemented
+ return self.url == other.url
+
+ def __lt__(self, other: Any) -> bool:
+ if not isinstance(other, Link):
+ return NotImplemented
+ return self.url < other.url
+
+ @property
+ def url(self) -> str:
+ return self._url
+
+ @property
+ def filename(self) -> str:
+ path = self.path.rstrip("/")
+ name = posixpath.basename(path)
+ if not name:
+ # Make sure we don't leak auth information if the netloc
+ # includes a username and password.
+ netloc, user_pass = split_auth_from_netloc(self.netloc)
+ return netloc
+
+ name = urllib.parse.unquote(name)
+ assert name, f"URL {self._url!r} produced no filename"
+ return name
+
+ @property
+ def file_path(self) -> str:
+ return url_to_path(self.url)
+
+ @property
+ def scheme(self) -> str:
+ return self._parsed_url.scheme
+
+ @property
+ def netloc(self) -> str:
+ """
+ This can contain auth information.
+ """
+ return self._parsed_url.netloc
+
+ @property
+ def path(self) -> str:
+ return urllib.parse.unquote(self._parsed_url.path)
+
+ def splitext(self) -> Tuple[str, str]:
+ return splitext(posixpath.basename(self.path.rstrip("/")))
+
+ @property
+ def ext(self) -> str:
+ return self.splitext()[1]
+
+ @property
+ def url_without_fragment(self) -> str:
+ scheme, netloc, path, query, fragment = self._parsed_url
+ return urllib.parse.urlunsplit((scheme, netloc, path, query, ""))
+
+ _egg_fragment_re = re.compile(r"[#&]egg=([^&]*)")
+
+ # Per PEP 508.
+ _project_name_re = re.compile(
+ r"^([A-Z0-9]|[A-Z0-9][A-Z0-9._-]*[A-Z0-9])$", re.IGNORECASE
+ )
+
+ def _egg_fragment(self) -> Optional[str]:
+ match = self._egg_fragment_re.search(self._url)
+ if not match:
+ return None
+
+ # An egg fragment looks like a PEP 508 project name, along with
+ # an optional extras specifier. Anything else is invalid.
+ project_name = match.group(1)
+ if not self._project_name_re.match(project_name):
+ deprecated(
+ reason=f"{self} contains an egg fragment with a non-PEP 508 name",
+ replacement="to use the req @ url syntax, and remove the egg fragment",
+ gone_in="25.0",
+ issue=11617,
+ )
+
+ return project_name
+
+ _subdirectory_fragment_re = re.compile(r"[#&]subdirectory=([^&]*)")
+
+ @property
+ def subdirectory_fragment(self) -> Optional[str]:
+ match = self._subdirectory_fragment_re.search(self._url)
+ if not match:
+ return None
+ return match.group(1)
+
+ def metadata_link(self) -> Optional["Link"]:
+ """Return a link to the associated core metadata file (if any)."""
+ if self.metadata_file_data is None:
+ return None
+ metadata_url = f"{self.url_without_fragment}.metadata"
+ if self.metadata_file_data.hashes is None:
+ return Link(metadata_url)
+ return Link(metadata_url, hashes=self.metadata_file_data.hashes)
+
+ def as_hashes(self) -> Hashes:
+ return Hashes({k: [v] for k, v in self._hashes.items()})
+
+ @property
+ def hash(self) -> Optional[str]:
+ return next(iter(self._hashes.values()), None)
+
+ @property
+ def hash_name(self) -> Optional[str]:
+ return next(iter(self._hashes), None)
+
+ @property
+ def show_url(self) -> str:
+ return posixpath.basename(self._url.split("#", 1)[0].split("?", 1)[0])
+
+ @property
+ def is_file(self) -> bool:
+ return self.scheme == "file"
+
+ def is_existing_dir(self) -> bool:
+ return self.is_file and os.path.isdir(self.file_path)
+
+ @property
+ def is_wheel(self) -> bool:
+ return self.ext == WHEEL_EXTENSION
+
+ @property
+ def is_vcs(self) -> bool:
+ from pip._internal.vcs import vcs
+
+ return self.scheme in vcs.all_schemes
+
+ @property
+ def is_yanked(self) -> bool:
+ return self.yanked_reason is not None
+
+ @property
+ def has_hash(self) -> bool:
+ return bool(self._hashes)
+
+ def is_hash_allowed(self, hashes: Optional[Hashes]) -> bool:
+ """
+ Return True if the link has a hash and it is allowed by `hashes`.
+ """
+ if hashes is None:
+ return False
+ return any(hashes.is_hash_allowed(k, v) for k, v in self._hashes.items())
+
+
+class _CleanResult(NamedTuple):
+ """Convert link for equivalency check.
+
+ This is used in the resolver to check whether two URL-specified requirements
+ likely point to the same distribution and can be considered equivalent. This
+ equivalency logic avoids comparing URLs literally, which can be too strict
+ (e.g. "a=1&b=2" vs "b=2&a=1") and produce conflicts unexpecting to users.
+
+ Currently this does three things:
+
+ 1. Drop the basic auth part. This is technically wrong since a server can
+ serve different content based on auth, but if it does that, it is even
+ impossible to guarantee two URLs without auth are equivalent, since
+ the user can input different auth information when prompted. So the
+ practical solution is to assume the auth doesn't affect the response.
+ 2. Parse the query to avoid the ordering issue. Note that ordering under the
+ same key in the query are NOT cleaned; i.e. "a=1&a=2" and "a=2&a=1" are
+ still considered different.
+ 3. Explicitly drop most of the fragment part, except ``subdirectory=`` and
+ hash values, since it should have no impact the downloaded content. Note
+ that this drops the "egg=" part historically used to denote the requested
+ project (and extras), which is wrong in the strictest sense, but too many
+ people are supplying it inconsistently to cause superfluous resolution
+ conflicts, so we choose to also ignore them.
+ """
+
+ parsed: urllib.parse.SplitResult
+ query: Dict[str, List[str]]
+ subdirectory: str
+ hashes: Dict[str, str]
+
+
+def _clean_link(link: Link) -> _CleanResult:
+ parsed = link._parsed_url
+ netloc = parsed.netloc.rsplit("@", 1)[-1]
+ # According to RFC 8089, an empty host in file: means localhost.
+ if parsed.scheme == "file" and not netloc:
+ netloc = "localhost"
+ fragment = urllib.parse.parse_qs(parsed.fragment)
+ if "egg" in fragment:
+ logger.debug("Ignoring egg= fragment in %s", link)
+ try:
+ # If there are multiple subdirectory values, use the first one.
+ # This matches the behavior of Link.subdirectory_fragment.
+ subdirectory = fragment["subdirectory"][0]
+ except (IndexError, KeyError):
+ subdirectory = ""
+ # If there are multiple hash values under the same algorithm, use the
+ # first one. This matches the behavior of Link.hash_value.
+ hashes = {k: fragment[k][0] for k in _SUPPORTED_HASHES if k in fragment}
+ return _CleanResult(
+ parsed=parsed._replace(netloc=netloc, query="", fragment=""),
+ query=urllib.parse.parse_qs(parsed.query),
+ subdirectory=subdirectory,
+ hashes=hashes,
+ )
+
+
+@functools.lru_cache(maxsize=None)
+def links_equivalent(link1: Link, link2: Link) -> bool:
+ return _clean_link(link1) == _clean_link(link2)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/scheme.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/scheme.py
new file mode 100644
index 000000000..06a9a550e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/scheme.py
@@ -0,0 +1,25 @@
+"""
+For types associated with installation schemes.
+
+For a general overview of available schemes and their context, see
+https://docs.python.org/3/install/index.html#alternate-installation.
+"""
+
+from dataclasses import dataclass
+
+SCHEME_KEYS = ["platlib", "purelib", "headers", "scripts", "data"]
+
+
+@dataclass(frozen=True)
+class Scheme:
+ """A Scheme holds paths which are used as the base directories for
+ artifacts associated with a Python package.
+ """
+
+ __slots__ = SCHEME_KEYS
+
+ platlib: str
+ purelib: str
+ headers: str
+ scripts: str
+ data: str
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/search_scope.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/search_scope.py
new file mode 100644
index 000000000..ee7bc8622
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/search_scope.py
@@ -0,0 +1,127 @@
+import itertools
+import logging
+import os
+import posixpath
+import urllib.parse
+from dataclasses import dataclass
+from typing import List
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.models.index import PyPI
+from pip._internal.utils.compat import has_tls
+from pip._internal.utils.misc import normalize_path, redact_auth_from_url
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass(frozen=True)
+class SearchScope:
+ """
+ Encapsulates the locations that pip is configured to search.
+ """
+
+ __slots__ = ["find_links", "index_urls", "no_index"]
+
+ find_links: List[str]
+ index_urls: List[str]
+ no_index: bool
+
+ @classmethod
+ def create(
+ cls,
+ find_links: List[str],
+ index_urls: List[str],
+ no_index: bool,
+ ) -> "SearchScope":
+ """
+ Create a SearchScope object after normalizing the `find_links`.
+ """
+ # Build find_links. If an argument starts with ~, it may be
+ # a local file relative to a home directory. So try normalizing
+ # it and if it exists, use the normalized version.
+ # This is deliberately conservative - it might be fine just to
+ # blindly normalize anything starting with a ~...
+ built_find_links: List[str] = []
+ for link in find_links:
+ if link.startswith("~"):
+ new_link = normalize_path(link)
+ if os.path.exists(new_link):
+ link = new_link
+ built_find_links.append(link)
+
+ # If we don't have TLS enabled, then WARN if anyplace we're looking
+ # relies on TLS.
+ if not has_tls():
+ for link in itertools.chain(index_urls, built_find_links):
+ parsed = urllib.parse.urlparse(link)
+ if parsed.scheme == "https":
+ logger.warning(
+ "pip is configured with locations that require "
+ "TLS/SSL, however the ssl module in Python is not "
+ "available."
+ )
+ break
+
+ return cls(
+ find_links=built_find_links,
+ index_urls=index_urls,
+ no_index=no_index,
+ )
+
+ def get_formatted_locations(self) -> str:
+ lines = []
+ redacted_index_urls = []
+ if self.index_urls and self.index_urls != [PyPI.simple_url]:
+ for url in self.index_urls:
+ redacted_index_url = redact_auth_from_url(url)
+
+ # Parse the URL
+ purl = urllib.parse.urlsplit(redacted_index_url)
+
+ # URL is generally invalid if scheme and netloc is missing
+ # there are issues with Python and URL parsing, so this test
+ # is a bit crude. See bpo-20271, bpo-23505. Python doesn't
+ # always parse invalid URLs correctly - it should raise
+ # exceptions for malformed URLs
+ if not purl.scheme and not purl.netloc:
+ logger.warning(
+ 'The index url "%s" seems invalid, please provide a scheme.',
+ redacted_index_url,
+ )
+
+ redacted_index_urls.append(redacted_index_url)
+
+ lines.append(
+ "Looking in indexes: {}".format(", ".join(redacted_index_urls))
+ )
+
+ if self.find_links:
+ lines.append(
+ "Looking in links: {}".format(
+ ", ".join(redact_auth_from_url(url) for url in self.find_links)
+ )
+ )
+ return "\n".join(lines)
+
+ def get_index_urls_locations(self, project_name: str) -> List[str]:
+ """Returns the locations found via self.index_urls
+
+ Checks the url_name on the main (first in the list) index and
+ use this url_name to produce all locations
+ """
+
+ def mkurl_pypi_url(url: str) -> str:
+ loc = posixpath.join(
+ url, urllib.parse.quote(canonicalize_name(project_name))
+ )
+ # For maximum compatibility with easy_install, ensure the path
+ # ends in a trailing slash. Although this isn't in the spec
+ # (and PyPI can handle it without the slash) some other index
+ # implementations might break if they relied on easy_install's
+ # behavior.
+ if not loc.endswith("/"):
+ loc = loc + "/"
+ return loc
+
+ return [mkurl_pypi_url(url) for url in self.index_urls]
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/selection_prefs.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/selection_prefs.py
new file mode 100644
index 000000000..e9b50aa51
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/selection_prefs.py
@@ -0,0 +1,53 @@
+from typing import Optional
+
+from pip._internal.models.format_control import FormatControl
+
+
+# TODO: This needs Python 3.10's improved slots support for dataclasses
+# to be converted into a dataclass.
+class SelectionPreferences:
+ """
+ Encapsulates the candidate selection preferences for downloading
+ and installing files.
+ """
+
+ __slots__ = [
+ "allow_yanked",
+ "allow_all_prereleases",
+ "format_control",
+ "prefer_binary",
+ "ignore_requires_python",
+ ]
+
+ # Don't include an allow_yanked default value to make sure each call
+ # site considers whether yanked releases are allowed. This also causes
+ # that decision to be made explicit in the calling code, which helps
+ # people when reading the code.
+ def __init__(
+ self,
+ allow_yanked: bool,
+ allow_all_prereleases: bool = False,
+ format_control: Optional[FormatControl] = None,
+ prefer_binary: bool = False,
+ ignore_requires_python: Optional[bool] = None,
+ ) -> None:
+ """Create a SelectionPreferences object.
+
+ :param allow_yanked: Whether files marked as yanked (in the sense
+ of PEP 592) are permitted to be candidates for install.
+ :param format_control: A FormatControl object or None. Used to control
+ the selection of source packages / binary packages when consulting
+ the index and links.
+ :param prefer_binary: Whether to prefer an old, but valid, binary
+ dist over a new source dist.
+ :param ignore_requires_python: Whether to ignore incompatible
+ "Requires-Python" values in links. Defaults to False.
+ """
+ if ignore_requires_python is None:
+ ignore_requires_python = False
+
+ self.allow_yanked = allow_yanked
+ self.allow_all_prereleases = allow_all_prereleases
+ self.format_control = format_control
+ self.prefer_binary = prefer_binary
+ self.ignore_requires_python = ignore_requires_python
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/target_python.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/target_python.py
new file mode 100644
index 000000000..88925a9fd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/target_python.py
@@ -0,0 +1,121 @@
+import sys
+from typing import List, Optional, Set, Tuple
+
+from pip._vendor.packaging.tags import Tag
+
+from pip._internal.utils.compatibility_tags import get_supported, version_info_to_nodot
+from pip._internal.utils.misc import normalize_version_info
+
+
+class TargetPython:
+ """
+ Encapsulates the properties of a Python interpreter one is targeting
+ for a package install, download, etc.
+ """
+
+ __slots__ = [
+ "_given_py_version_info",
+ "abis",
+ "implementation",
+ "platforms",
+ "py_version",
+ "py_version_info",
+ "_valid_tags",
+ "_valid_tags_set",
+ ]
+
+ def __init__(
+ self,
+ platforms: Optional[List[str]] = None,
+ py_version_info: Optional[Tuple[int, ...]] = None,
+ abis: Optional[List[str]] = None,
+ implementation: Optional[str] = None,
+ ) -> None:
+ """
+ :param platforms: A list of strings or None. If None, searches for
+ packages that are supported by the current system. Otherwise, will
+ find packages that can be built on the platforms passed in. These
+ packages will only be downloaded for distribution: they will
+ not be built locally.
+ :param py_version_info: An optional tuple of ints representing the
+ Python version information to use (e.g. `sys.version_info[:3]`).
+ This can have length 1, 2, or 3 when provided.
+ :param abis: A list of strings or None. This is passed to
+ compatibility_tags.py's get_supported() function as is.
+ :param implementation: A string or None. This is passed to
+ compatibility_tags.py's get_supported() function as is.
+ """
+ # Store the given py_version_info for when we call get_supported().
+ self._given_py_version_info = py_version_info
+
+ if py_version_info is None:
+ py_version_info = sys.version_info[:3]
+ else:
+ py_version_info = normalize_version_info(py_version_info)
+
+ py_version = ".".join(map(str, py_version_info[:2]))
+
+ self.abis = abis
+ self.implementation = implementation
+ self.platforms = platforms
+ self.py_version = py_version
+ self.py_version_info = py_version_info
+
+ # This is used to cache the return value of get_(un)sorted_tags.
+ self._valid_tags: Optional[List[Tag]] = None
+ self._valid_tags_set: Optional[Set[Tag]] = None
+
+ def format_given(self) -> str:
+ """
+ Format the given, non-None attributes for display.
+ """
+ display_version = None
+ if self._given_py_version_info is not None:
+ display_version = ".".join(
+ str(part) for part in self._given_py_version_info
+ )
+
+ key_values = [
+ ("platforms", self.platforms),
+ ("version_info", display_version),
+ ("abis", self.abis),
+ ("implementation", self.implementation),
+ ]
+ return " ".join(
+ f"{key}={value!r}" for key, value in key_values if value is not None
+ )
+
+ def get_sorted_tags(self) -> List[Tag]:
+ """
+ Return the supported PEP 425 tags to check wheel candidates against.
+
+ The tags are returned in order of preference (most preferred first).
+ """
+ if self._valid_tags is None:
+ # Pass versions=None if no py_version_info was given since
+ # versions=None uses special default logic.
+ py_version_info = self._given_py_version_info
+ if py_version_info is None:
+ version = None
+ else:
+ version = version_info_to_nodot(py_version_info)
+
+ tags = get_supported(
+ version=version,
+ platforms=self.platforms,
+ abis=self.abis,
+ impl=self.implementation,
+ )
+ self._valid_tags = tags
+
+ return self._valid_tags
+
+ def get_unsorted_tags(self) -> Set[Tag]:
+ """Exactly the same as get_sorted_tags, but returns a set.
+
+ This is important for performance.
+ """
+ if self._valid_tags_set is None:
+ self._valid_tags_set = set(self.get_sorted_tags())
+
+ return self._valid_tags_set
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/models/wheel.py b/solutions/.venv/Lib/site-packages/pip/_internal/models/wheel.py
new file mode 100644
index 000000000..ea8560089
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/models/wheel.py
@@ -0,0 +1,118 @@
+"""Represents a wheel file and provides access to the various parts of the
+name that have meaning.
+"""
+
+import re
+from typing import Dict, Iterable, List
+
+from pip._vendor.packaging.tags import Tag
+from pip._vendor.packaging.utils import (
+ InvalidWheelFilename as PackagingInvalidWheelName,
+)
+from pip._vendor.packaging.utils import parse_wheel_filename
+
+from pip._internal.exceptions import InvalidWheelFilename
+from pip._internal.utils.deprecation import deprecated
+
+
+class Wheel:
+ """A wheel file"""
+
+ wheel_file_re = re.compile(
+ r"""^(?P<namever>(?P<name>[^\s-]+?)-(?P<ver>[^\s-]*?))
+ ((-(?P<build>\d[^-]*?))?-(?P<pyver>[^\s-]+?)-(?P<abi>[^\s-]+?)-(?P<plat>[^\s-]+?)
+ \.whl|\.dist-info)$""",
+ re.VERBOSE,
+ )
+
+ def __init__(self, filename: str) -> None:
+ """
+ :raises InvalidWheelFilename: when the filename is invalid for a wheel
+ """
+ wheel_info = self.wheel_file_re.match(filename)
+ if not wheel_info:
+ raise InvalidWheelFilename(f"{filename} is not a valid wheel filename.")
+ self.filename = filename
+ self.name = wheel_info.group("name").replace("_", "-")
+ _version = wheel_info.group("ver")
+ if "_" in _version:
+ try:
+ parse_wheel_filename(filename)
+ except PackagingInvalidWheelName as e:
+ deprecated(
+ reason=(
+ f"Wheel filename {filename!r} is not correctly normalised. "
+ "Future versions of pip will raise the following error:\n"
+ f"{e.args[0]}\n\n"
+ ),
+ replacement=(
+ "to rename the wheel to use a correctly normalised "
+ "name (this may require updating the version in "
+ "the project metadata)"
+ ),
+ gone_in="25.1",
+ issue=12938,
+ )
+
+ _version = _version.replace("_", "-")
+
+ self.version = _version
+ self.build_tag = wheel_info.group("build")
+ self.pyversions = wheel_info.group("pyver").split(".")
+ self.abis = wheel_info.group("abi").split(".")
+ self.plats = wheel_info.group("plat").split(".")
+
+ # All the tag combinations from this file
+ self.file_tags = {
+ Tag(x, y, z) for x in self.pyversions for y in self.abis for z in self.plats
+ }
+
+ def get_formatted_file_tags(self) -> List[str]:
+ """Return the wheel's tags as a sorted list of strings."""
+ return sorted(str(tag) for tag in self.file_tags)
+
+ def support_index_min(self, tags: List[Tag]) -> int:
+ """Return the lowest index that one of the wheel's file_tag combinations
+ achieves in the given list of supported tags.
+
+ For example, if there are 8 supported tags and one of the file tags
+ is first in the list, then return 0.
+
+ :param tags: the PEP 425 tags to check the wheel against, in order
+ with most preferred first.
+
+ :raises ValueError: If none of the wheel's file tags match one of
+ the supported tags.
+ """
+ try:
+ return next(i for i, t in enumerate(tags) if t in self.file_tags)
+ except StopIteration:
+ raise ValueError()
+
+ def find_most_preferred_tag(
+ self, tags: List[Tag], tag_to_priority: Dict[Tag, int]
+ ) -> int:
+ """Return the priority of the most preferred tag that one of the wheel's file
+ tag combinations achieves in the given list of supported tags using the given
+ tag_to_priority mapping, where lower priorities are more-preferred.
+
+ This is used in place of support_index_min in some cases in order to avoid
+ an expensive linear scan of a large list of tags.
+
+ :param tags: the PEP 425 tags to check the wheel against.
+ :param tag_to_priority: a mapping from tag to priority of that tag, where
+ lower is more preferred.
+
+ :raises ValueError: If none of the wheel's file tags match one of
+ the supported tags.
+ """
+ return min(
+ tag_to_priority[tag] for tag in self.file_tags if tag in tag_to_priority
+ )
+
+ def supported(self, tags: Iterable[Tag]) -> bool:
+ """Return whether the wheel is compatible with one of the given tags.
+
+ :param tags: the PEP 425 tags to check the wheel against.
+ """
+ return not self.file_tags.isdisjoint(tags)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/__init__.py
new file mode 100644
index 000000000..b51bde91b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/__init__.py
@@ -0,0 +1,2 @@
+"""Contains purely network-related utilities.
+"""
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/auth.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/auth.py
new file mode 100644
index 000000000..1a2606ed0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/auth.py
@@ -0,0 +1,566 @@
+"""Network Authentication Helpers
+
+Contains interface (MultiDomainBasicAuth) and associated glue code for
+providing credentials in the context of network requests.
+"""
+
+import logging
+import os
+import shutil
+import subprocess
+import sysconfig
+import typing
+import urllib.parse
+from abc import ABC, abstractmethod
+from functools import lru_cache
+from os.path import commonprefix
+from pathlib import Path
+from typing import Any, Dict, List, NamedTuple, Optional, Tuple
+
+from pip._vendor.requests.auth import AuthBase, HTTPBasicAuth
+from pip._vendor.requests.models import Request, Response
+from pip._vendor.requests.utils import get_netrc_auth
+
+from pip._internal.utils.logging import getLogger
+from pip._internal.utils.misc import (
+ ask,
+ ask_input,
+ ask_password,
+ remove_auth_from_url,
+ split_auth_netloc_from_url,
+)
+from pip._internal.vcs.versioncontrol import AuthInfo
+
+logger = getLogger(__name__)
+
+KEYRING_DISABLED = False
+
+
+class Credentials(NamedTuple):
+ url: str
+ username: str
+ password: str
+
+
+class KeyRingBaseProvider(ABC):
+ """Keyring base provider interface"""
+
+ has_keyring: bool
+
+ @abstractmethod
+ def get_auth_info(
+ self, url: str, username: Optional[str]
+ ) -> Optional[AuthInfo]: ...
+
+ @abstractmethod
+ def save_auth_info(self, url: str, username: str, password: str) -> None: ...
+
+
+class KeyRingNullProvider(KeyRingBaseProvider):
+ """Keyring null provider"""
+
+ has_keyring = False
+
+ def get_auth_info(self, url: str, username: Optional[str]) -> Optional[AuthInfo]:
+ return None
+
+ def save_auth_info(self, url: str, username: str, password: str) -> None:
+ return None
+
+
+class KeyRingPythonProvider(KeyRingBaseProvider):
+ """Keyring interface which uses locally imported `keyring`"""
+
+ has_keyring = True
+
+ def __init__(self) -> None:
+ import keyring
+
+ self.keyring = keyring
+
+ def get_auth_info(self, url: str, username: Optional[str]) -> Optional[AuthInfo]:
+ # Support keyring's get_credential interface which supports getting
+ # credentials without a username. This is only available for
+ # keyring>=15.2.0.
+ if hasattr(self.keyring, "get_credential"):
+ logger.debug("Getting credentials from keyring for %s", url)
+ cred = self.keyring.get_credential(url, username)
+ if cred is not None:
+ return cred.username, cred.password
+ return None
+
+ if username is not None:
+ logger.debug("Getting password from keyring for %s", url)
+ password = self.keyring.get_password(url, username)
+ if password:
+ return username, password
+ return None
+
+ def save_auth_info(self, url: str, username: str, password: str) -> None:
+ self.keyring.set_password(url, username, password)
+
+
+class KeyRingCliProvider(KeyRingBaseProvider):
+ """Provider which uses `keyring` cli
+
+ Instead of calling the keyring package installed alongside pip
+ we call keyring on the command line which will enable pip to
+ use which ever installation of keyring is available first in
+ PATH.
+ """
+
+ has_keyring = True
+
+ def __init__(self, cmd: str) -> None:
+ self.keyring = cmd
+
+ def get_auth_info(self, url: str, username: Optional[str]) -> Optional[AuthInfo]:
+ # This is the default implementation of keyring.get_credential
+ # https://github.com/jaraco/keyring/blob/97689324abcf01bd1793d49063e7ca01e03d7d07/keyring/backend.py#L134-L139
+ if username is not None:
+ password = self._get_password(url, username)
+ if password is not None:
+ return username, password
+ return None
+
+ def save_auth_info(self, url: str, username: str, password: str) -> None:
+ return self._set_password(url, username, password)
+
+ def _get_password(self, service_name: str, username: str) -> Optional[str]:
+ """Mirror the implementation of keyring.get_password using cli"""
+ if self.keyring is None:
+ return None
+
+ cmd = [self.keyring, "get", service_name, username]
+ env = os.environ.copy()
+ env["PYTHONIOENCODING"] = "utf-8"
+ res = subprocess.run(
+ cmd,
+ stdin=subprocess.DEVNULL,
+ stdout=subprocess.PIPE,
+ env=env,
+ )
+ if res.returncode:
+ return None
+ return res.stdout.decode("utf-8").strip(os.linesep)
+
+ def _set_password(self, service_name: str, username: str, password: str) -> None:
+ """Mirror the implementation of keyring.set_password using cli"""
+ if self.keyring is None:
+ return None
+ env = os.environ.copy()
+ env["PYTHONIOENCODING"] = "utf-8"
+ subprocess.run(
+ [self.keyring, "set", service_name, username],
+ input=f"{password}{os.linesep}".encode(),
+ env=env,
+ check=True,
+ )
+ return None
+
+
+@lru_cache(maxsize=None)
+def get_keyring_provider(provider: str) -> KeyRingBaseProvider:
+ logger.verbose("Keyring provider requested: %s", provider)
+
+ # keyring has previously failed and been disabled
+ if KEYRING_DISABLED:
+ provider = "disabled"
+ if provider in ["import", "auto"]:
+ try:
+ impl = KeyRingPythonProvider()
+ logger.verbose("Keyring provider set: import")
+ return impl
+ except ImportError:
+ pass
+ except Exception as exc:
+ # In the event of an unexpected exception
+ # we should warn the user
+ msg = "Installed copy of keyring fails with exception %s"
+ if provider == "auto":
+ msg = msg + ", trying to find a keyring executable as a fallback"
+ logger.warning(msg, exc, exc_info=logger.isEnabledFor(logging.DEBUG))
+ if provider in ["subprocess", "auto"]:
+ cli = shutil.which("keyring")
+ if cli and cli.startswith(sysconfig.get_path("scripts")):
+ # all code within this function is stolen from shutil.which implementation
+ @typing.no_type_check
+ def PATH_as_shutil_which_determines_it() -> str:
+ path = os.environ.get("PATH", None)
+ if path is None:
+ try:
+ path = os.confstr("CS_PATH")
+ except (AttributeError, ValueError):
+ # os.confstr() or CS_PATH is not available
+ path = os.defpath
+ # bpo-35755: Don't use os.defpath if the PATH environment variable is
+ # set to an empty string
+
+ return path
+
+ scripts = Path(sysconfig.get_path("scripts"))
+
+ paths = []
+ for path in PATH_as_shutil_which_determines_it().split(os.pathsep):
+ p = Path(path)
+ try:
+ if not p.samefile(scripts):
+ paths.append(path)
+ except FileNotFoundError:
+ pass
+
+ path = os.pathsep.join(paths)
+
+ cli = shutil.which("keyring", path=path)
+
+ if cli:
+ logger.verbose("Keyring provider set: subprocess with executable %s", cli)
+ return KeyRingCliProvider(cli)
+
+ logger.verbose("Keyring provider set: disabled")
+ return KeyRingNullProvider()
+
+
+class MultiDomainBasicAuth(AuthBase):
+ def __init__(
+ self,
+ prompting: bool = True,
+ index_urls: Optional[List[str]] = None,
+ keyring_provider: str = "auto",
+ ) -> None:
+ self.prompting = prompting
+ self.index_urls = index_urls
+ self.keyring_provider = keyring_provider # type: ignore[assignment]
+ self.passwords: Dict[str, AuthInfo] = {}
+ # When the user is prompted to enter credentials and keyring is
+ # available, we will offer to save them. If the user accepts,
+ # this value is set to the credentials they entered. After the
+ # request authenticates, the caller should call
+ # ``save_credentials`` to save these.
+ self._credentials_to_save: Optional[Credentials] = None
+
+ @property
+ def keyring_provider(self) -> KeyRingBaseProvider:
+ return get_keyring_provider(self._keyring_provider)
+
+ @keyring_provider.setter
+ def keyring_provider(self, provider: str) -> None:
+ # The free function get_keyring_provider has been decorated with
+ # functools.cache. If an exception occurs in get_keyring_auth that
+ # cache will be cleared and keyring disabled, take that into account
+ # if you want to remove this indirection.
+ self._keyring_provider = provider
+
+ @property
+ def use_keyring(self) -> bool:
+ # We won't use keyring when --no-input is passed unless
+ # a specific provider is requested because it might require
+ # user interaction
+ return self.prompting or self._keyring_provider not in ["auto", "disabled"]
+
+ def _get_keyring_auth(
+ self,
+ url: Optional[str],
+ username: Optional[str],
+ ) -> Optional[AuthInfo]:
+ """Return the tuple auth for a given url from keyring."""
+ # Do nothing if no url was provided
+ if not url:
+ return None
+
+ try:
+ return self.keyring_provider.get_auth_info(url, username)
+ except Exception as exc:
+ # Log the full exception (with stacktrace) at debug, so it'll only
+ # show up when running in verbose mode.
+ logger.debug("Keyring is skipped due to an exception", exc_info=True)
+ # Always log a shortened version of the exception.
+ logger.warning(
+ "Keyring is skipped due to an exception: %s",
+ str(exc),
+ )
+ global KEYRING_DISABLED
+ KEYRING_DISABLED = True
+ get_keyring_provider.cache_clear()
+ return None
+
+ def _get_index_url(self, url: str) -> Optional[str]:
+ """Return the original index URL matching the requested URL.
+
+ Cached or dynamically generated credentials may work against
+ the original index URL rather than just the netloc.
+
+ The provided url should have had its username and password
+ removed already. If the original index url had credentials then
+ they will be included in the return value.
+
+ Returns None if no matching index was found, or if --no-index
+ was specified by the user.
+ """
+ if not url or not self.index_urls:
+ return None
+
+ url = remove_auth_from_url(url).rstrip("/") + "/"
+ parsed_url = urllib.parse.urlsplit(url)
+
+ candidates = []
+
+ for index in self.index_urls:
+ index = index.rstrip("/") + "/"
+ parsed_index = urllib.parse.urlsplit(remove_auth_from_url(index))
+ if parsed_url == parsed_index:
+ return index
+
+ if parsed_url.netloc != parsed_index.netloc:
+ continue
+
+ candidate = urllib.parse.urlsplit(index)
+ candidates.append(candidate)
+
+ if not candidates:
+ return None
+
+ candidates.sort(
+ reverse=True,
+ key=lambda candidate: commonprefix(
+ [
+ parsed_url.path,
+ candidate.path,
+ ]
+ ).rfind("/"),
+ )
+
+ return urllib.parse.urlunsplit(candidates[0])
+
+ def _get_new_credentials(
+ self,
+ original_url: str,
+ *,
+ allow_netrc: bool = True,
+ allow_keyring: bool = False,
+ ) -> AuthInfo:
+ """Find and return credentials for the specified URL."""
+ # Split the credentials and netloc from the url.
+ url, netloc, url_user_password = split_auth_netloc_from_url(
+ original_url,
+ )
+
+ # Start with the credentials embedded in the url
+ username, password = url_user_password
+ if username is not None and password is not None:
+ logger.debug("Found credentials in url for %s", netloc)
+ return url_user_password
+
+ # Find a matching index url for this request
+ index_url = self._get_index_url(url)
+ if index_url:
+ # Split the credentials from the url.
+ index_info = split_auth_netloc_from_url(index_url)
+ if index_info:
+ index_url, _, index_url_user_password = index_info
+ logger.debug("Found index url %s", index_url)
+
+ # If an index URL was found, try its embedded credentials
+ if index_url and index_url_user_password[0] is not None:
+ username, password = index_url_user_password
+ if username is not None and password is not None:
+ logger.debug("Found credentials in index url for %s", netloc)
+ return index_url_user_password
+
+ # Get creds from netrc if we still don't have them
+ if allow_netrc:
+ netrc_auth = get_netrc_auth(original_url)
+ if netrc_auth:
+ logger.debug("Found credentials in netrc for %s", netloc)
+ return netrc_auth
+
+ # If we don't have a password and keyring is available, use it.
+ if allow_keyring:
+ # The index url is more specific than the netloc, so try it first
+ # fmt: off
+ kr_auth = (
+ self._get_keyring_auth(index_url, username) or
+ self._get_keyring_auth(netloc, username)
+ )
+ # fmt: on
+ if kr_auth:
+ logger.debug("Found credentials in keyring for %s", netloc)
+ return kr_auth
+
+ return username, password
+
+ def _get_url_and_credentials(
+ self, original_url: str
+ ) -> Tuple[str, Optional[str], Optional[str]]:
+ """Return the credentials to use for the provided URL.
+
+ If allowed, netrc and keyring may be used to obtain the
+ correct credentials.
+
+ Returns (url_without_credentials, username, password). Note
+ that even if the original URL contains credentials, this
+ function may return a different username and password.
+ """
+ url, netloc, _ = split_auth_netloc_from_url(original_url)
+
+ # Try to get credentials from original url
+ username, password = self._get_new_credentials(original_url)
+
+ # If credentials not found, use any stored credentials for this netloc.
+ # Do this if either the username or the password is missing.
+ # This accounts for the situation in which the user has specified
+ # the username in the index url, but the password comes from keyring.
+ if (username is None or password is None) and netloc in self.passwords:
+ un, pw = self.passwords[netloc]
+ # It is possible that the cached credentials are for a different username,
+ # in which case the cache should be ignored.
+ if username is None or username == un:
+ username, password = un, pw
+
+ if username is not None or password is not None:
+ # Convert the username and password if they're None, so that
+ # this netloc will show up as "cached" in the conditional above.
+ # Further, HTTPBasicAuth doesn't accept None, so it makes sense to
+ # cache the value that is going to be used.
+ username = username or ""
+ password = password or ""
+
+ # Store any acquired credentials.
+ self.passwords[netloc] = (username, password)
+
+ assert (
+ # Credentials were found
+ (username is not None and password is not None)
+ # Credentials were not found
+ or (username is None and password is None)
+ ), f"Could not load credentials from url: {original_url}"
+
+ return url, username, password
+
+ def __call__(self, req: Request) -> Request:
+ # Get credentials for this request
+ url, username, password = self._get_url_and_credentials(req.url)
+
+ # Set the url of the request to the url without any credentials
+ req.url = url
+
+ if username is not None and password is not None:
+ # Send the basic auth with this request
+ req = HTTPBasicAuth(username, password)(req)
+
+ # Attach a hook to handle 401 responses
+ req.register_hook("response", self.handle_401)
+
+ return req
+
+ # Factored out to allow for easy patching in tests
+ def _prompt_for_password(
+ self, netloc: str
+ ) -> Tuple[Optional[str], Optional[str], bool]:
+ username = ask_input(f"User for {netloc}: ") if self.prompting else None
+ if not username:
+ return None, None, False
+ if self.use_keyring:
+ auth = self._get_keyring_auth(netloc, username)
+ if auth and auth[0] is not None and auth[1] is not None:
+ return auth[0], auth[1], False
+ password = ask_password("Password: ")
+ return username, password, True
+
+ # Factored out to allow for easy patching in tests
+ def _should_save_password_to_keyring(self) -> bool:
+ if (
+ not self.prompting
+ or not self.use_keyring
+ or not self.keyring_provider.has_keyring
+ ):
+ return False
+ return ask("Save credentials to keyring [y/N]: ", ["y", "n"]) == "y"
+
+ def handle_401(self, resp: Response, **kwargs: Any) -> Response:
+ # We only care about 401 responses, anything else we want to just
+ # pass through the actual response
+ if resp.status_code != 401:
+ return resp
+
+ username, password = None, None
+
+ # Query the keyring for credentials:
+ if self.use_keyring:
+ username, password = self._get_new_credentials(
+ resp.url,
+ allow_netrc=False,
+ allow_keyring=True,
+ )
+
+ # We are not able to prompt the user so simply return the response
+ if not self.prompting and not username and not password:
+ return resp
+
+ parsed = urllib.parse.urlparse(resp.url)
+
+ # Prompt the user for a new username and password
+ save = False
+ if not username and not password:
+ username, password, save = self._prompt_for_password(parsed.netloc)
+
+ # Store the new username and password to use for future requests
+ self._credentials_to_save = None
+ if username is not None and password is not None:
+ self.passwords[parsed.netloc] = (username, password)
+
+ # Prompt to save the password to keyring
+ if save and self._should_save_password_to_keyring():
+ self._credentials_to_save = Credentials(
+ url=parsed.netloc,
+ username=username,
+ password=password,
+ )
+
+ # Consume content and release the original connection to allow our new
+ # request to reuse the same one.
+ # The result of the assignment isn't used, it's just needed to consume
+ # the content.
+ _ = resp.content
+ resp.raw.release_conn()
+
+ # Add our new username and password to the request
+ req = HTTPBasicAuth(username or "", password or "")(resp.request)
+ req.register_hook("response", self.warn_on_401)
+
+ # On successful request, save the credentials that were used to
+ # keyring. (Note that if the user responded "no" above, this member
+ # is not set and nothing will be saved.)
+ if self._credentials_to_save:
+ req.register_hook("response", self.save_credentials)
+
+ # Send our new request
+ new_resp = resp.connection.send(req, **kwargs)
+ new_resp.history.append(resp)
+
+ return new_resp
+
+ def warn_on_401(self, resp: Response, **kwargs: Any) -> None:
+ """Response callback to warn about incorrect credentials."""
+ if resp.status_code == 401:
+ logger.warning(
+ "401 Error, Credentials not correct for %s",
+ resp.request.url,
+ )
+
+ def save_credentials(self, resp: Response, **kwargs: Any) -> None:
+ """Response callback to save credentials on success."""
+ assert (
+ self.keyring_provider.has_keyring
+ ), "should never reach here without keyring"
+
+ creds = self._credentials_to_save
+ self._credentials_to_save = None
+ if creds and resp.status_code < 400:
+ try:
+ logger.info("Saving credentials to keyring")
+ self.keyring_provider.save_auth_info(
+ creds.url, creds.username, creds.password
+ )
+ except Exception:
+ logger.exception("Failed to save credentials")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/cache.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/cache.py
new file mode 100644
index 000000000..4d0fb545d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/cache.py
@@ -0,0 +1,106 @@
+"""HTTP cache implementation.
+"""
+
+import os
+from contextlib import contextmanager
+from datetime import datetime
+from typing import BinaryIO, Generator, Optional, Union
+
+from pip._vendor.cachecontrol.cache import SeparateBodyBaseCache
+from pip._vendor.cachecontrol.caches import SeparateBodyFileCache
+from pip._vendor.requests.models import Response
+
+from pip._internal.utils.filesystem import adjacent_tmp_file, replace
+from pip._internal.utils.misc import ensure_dir
+
+
+def is_from_cache(response: Response) -> bool:
+ return getattr(response, "from_cache", False)
+
+
+@contextmanager
+def suppressed_cache_errors() -> Generator[None, None, None]:
+ """If we can't access the cache then we can just skip caching and process
+ requests as if caching wasn't enabled.
+ """
+ try:
+ yield
+ except OSError:
+ pass
+
+
+class SafeFileCache(SeparateBodyBaseCache):
+ """
+ A file based cache which is safe to use even when the target directory may
+ not be accessible or writable.
+
+ There is a race condition when two processes try to write and/or read the
+ same entry at the same time, since each entry consists of two separate
+ files (https://github.com/psf/cachecontrol/issues/324). We therefore have
+ additional logic that makes sure that both files to be present before
+ returning an entry; this fixes the read side of the race condition.
+
+ For the write side, we assume that the server will only ever return the
+ same data for the same URL, which ought to be the case for files pip is
+ downloading. PyPI does not have a mechanism to swap out a wheel for
+ another wheel, for example. If this assumption is not true, the
+ CacheControl issue will need to be fixed.
+ """
+
+ def __init__(self, directory: str) -> None:
+ assert directory is not None, "Cache directory must not be None."
+ super().__init__()
+ self.directory = directory
+
+ def _get_cache_path(self, name: str) -> str:
+ # From cachecontrol.caches.file_cache.FileCache._fn, brought into our
+ # class for backwards-compatibility and to avoid using a non-public
+ # method.
+ hashed = SeparateBodyFileCache.encode(name)
+ parts = list(hashed[:5]) + [hashed]
+ return os.path.join(self.directory, *parts)
+
+ def get(self, key: str) -> Optional[bytes]:
+ # The cache entry is only valid if both metadata and body exist.
+ metadata_path = self._get_cache_path(key)
+ body_path = metadata_path + ".body"
+ if not (os.path.exists(metadata_path) and os.path.exists(body_path)):
+ return None
+ with suppressed_cache_errors():
+ with open(metadata_path, "rb") as f:
+ return f.read()
+
+ def _write(self, path: str, data: bytes) -> None:
+ with suppressed_cache_errors():
+ ensure_dir(os.path.dirname(path))
+
+ with adjacent_tmp_file(path) as f:
+ f.write(data)
+
+ replace(f.name, path)
+
+ def set(
+ self, key: str, value: bytes, expires: Union[int, datetime, None] = None
+ ) -> None:
+ path = self._get_cache_path(key)
+ self._write(path, value)
+
+ def delete(self, key: str) -> None:
+ path = self._get_cache_path(key)
+ with suppressed_cache_errors():
+ os.remove(path)
+ with suppressed_cache_errors():
+ os.remove(path + ".body")
+
+ def get_body(self, key: str) -> Optional[BinaryIO]:
+ # The cache entry is only valid if both metadata and body exist.
+ metadata_path = self._get_cache_path(key)
+ body_path = metadata_path + ".body"
+ if not (os.path.exists(metadata_path) and os.path.exists(body_path)):
+ return None
+ with suppressed_cache_errors():
+ return open(body_path, "rb")
+
+ def set_body(self, key: str, body: bytes) -> None:
+ path = self._get_cache_path(key) + ".body"
+ self._write(path, body)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/download.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/download.py
new file mode 100644
index 000000000..5c3bce3d2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/download.py
@@ -0,0 +1,187 @@
+"""Download files with progress indicators.
+"""
+
+import email.message
+import logging
+import mimetypes
+import os
+from typing import Iterable, Optional, Tuple
+
+from pip._vendor.requests.models import Response
+
+from pip._internal.cli.progress_bars import get_download_progress_renderer
+from pip._internal.exceptions import NetworkConnectionError
+from pip._internal.models.index import PyPI
+from pip._internal.models.link import Link
+from pip._internal.network.cache import is_from_cache
+from pip._internal.network.session import PipSession
+from pip._internal.network.utils import HEADERS, raise_for_status, response_chunks
+from pip._internal.utils.misc import format_size, redact_auth_from_url, splitext
+
+logger = logging.getLogger(__name__)
+
+
+def _get_http_response_size(resp: Response) -> Optional[int]:
+ try:
+ return int(resp.headers["content-length"])
+ except (ValueError, KeyError, TypeError):
+ return None
+
+
+def _prepare_download(
+ resp: Response,
+ link: Link,
+ progress_bar: str,
+) -> Iterable[bytes]:
+ total_length = _get_http_response_size(resp)
+
+ if link.netloc == PyPI.file_storage_domain:
+ url = link.show_url
+ else:
+ url = link.url_without_fragment
+
+ logged_url = redact_auth_from_url(url)
+
+ if total_length:
+ logged_url = f"{logged_url} ({format_size(total_length)})"
+
+ if is_from_cache(resp):
+ logger.info("Using cached %s", logged_url)
+ else:
+ logger.info("Downloading %s", logged_url)
+
+ if logger.getEffectiveLevel() > logging.INFO:
+ show_progress = False
+ elif is_from_cache(resp):
+ show_progress = False
+ elif not total_length:
+ show_progress = True
+ elif total_length > (512 * 1024):
+ show_progress = True
+ else:
+ show_progress = False
+
+ chunks = response_chunks(resp)
+
+ if not show_progress:
+ return chunks
+
+ renderer = get_download_progress_renderer(bar_type=progress_bar, size=total_length)
+ return renderer(chunks)
+
+
+def sanitize_content_filename(filename: str) -> str:
+ """
+ Sanitize the "filename" value from a Content-Disposition header.
+ """
+ return os.path.basename(filename)
+
+
+def parse_content_disposition(content_disposition: str, default_filename: str) -> str:
+ """
+ Parse the "filename" value from a Content-Disposition header, and
+ return the default filename if the result is empty.
+ """
+ m = email.message.Message()
+ m["content-type"] = content_disposition
+ filename = m.get_param("filename")
+ if filename:
+ # We need to sanitize the filename to prevent directory traversal
+ # in case the filename contains ".." path parts.
+ filename = sanitize_content_filename(str(filename))
+ return filename or default_filename
+
+
+def _get_http_response_filename(resp: Response, link: Link) -> str:
+ """Get an ideal filename from the given HTTP response, falling back to
+ the link filename if not provided.
+ """
+ filename = link.filename # fallback
+ # Have a look at the Content-Disposition header for a better guess
+ content_disposition = resp.headers.get("content-disposition")
+ if content_disposition:
+ filename = parse_content_disposition(content_disposition, filename)
+ ext: Optional[str] = splitext(filename)[1]
+ if not ext:
+ ext = mimetypes.guess_extension(resp.headers.get("content-type", ""))
+ if ext:
+ filename += ext
+ if not ext and link.url != resp.url:
+ ext = os.path.splitext(resp.url)[1]
+ if ext:
+ filename += ext
+ return filename
+
+
+def _http_get_download(session: PipSession, link: Link) -> Response:
+ target_url = link.url.split("#", 1)[0]
+ resp = session.get(target_url, headers=HEADERS, stream=True)
+ raise_for_status(resp)
+ return resp
+
+
+class Downloader:
+ def __init__(
+ self,
+ session: PipSession,
+ progress_bar: str,
+ ) -> None:
+ self._session = session
+ self._progress_bar = progress_bar
+
+ def __call__(self, link: Link, location: str) -> Tuple[str, str]:
+ """Download the file given by link into location."""
+ try:
+ resp = _http_get_download(self._session, link)
+ except NetworkConnectionError as e:
+ assert e.response is not None
+ logger.critical(
+ "HTTP error %s while getting %s", e.response.status_code, link
+ )
+ raise
+
+ filename = _get_http_response_filename(resp, link)
+ filepath = os.path.join(location, filename)
+
+ chunks = _prepare_download(resp, link, self._progress_bar)
+ with open(filepath, "wb") as content_file:
+ for chunk in chunks:
+ content_file.write(chunk)
+ content_type = resp.headers.get("Content-Type", "")
+ return filepath, content_type
+
+
+class BatchDownloader:
+ def __init__(
+ self,
+ session: PipSession,
+ progress_bar: str,
+ ) -> None:
+ self._session = session
+ self._progress_bar = progress_bar
+
+ def __call__(
+ self, links: Iterable[Link], location: str
+ ) -> Iterable[Tuple[Link, Tuple[str, str]]]:
+ """Download the files given by links into location."""
+ for link in links:
+ try:
+ resp = _http_get_download(self._session, link)
+ except NetworkConnectionError as e:
+ assert e.response is not None
+ logger.critical(
+ "HTTP error %s while getting %s",
+ e.response.status_code,
+ link,
+ )
+ raise
+
+ filename = _get_http_response_filename(resp, link)
+ filepath = os.path.join(location, filename)
+
+ chunks = _prepare_download(resp, link, self._progress_bar)
+ with open(filepath, "wb") as content_file:
+ for chunk in chunks:
+ content_file.write(chunk)
+ content_type = resp.headers.get("Content-Type", "")
+ yield link, (filepath, content_type)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/lazy_wheel.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/lazy_wheel.py
new file mode 100644
index 000000000..03f883c1f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/lazy_wheel.py
@@ -0,0 +1,210 @@
+"""Lazy ZIP over HTTP"""
+
+__all__ = ["HTTPRangeRequestUnsupported", "dist_from_wheel_url"]
+
+from bisect import bisect_left, bisect_right
+from contextlib import contextmanager
+from tempfile import NamedTemporaryFile
+from typing import Any, Dict, Generator, List, Optional, Tuple
+from zipfile import BadZipFile, ZipFile
+
+from pip._vendor.packaging.utils import canonicalize_name
+from pip._vendor.requests.models import CONTENT_CHUNK_SIZE, Response
+
+from pip._internal.metadata import BaseDistribution, MemoryWheel, get_wheel_distribution
+from pip._internal.network.session import PipSession
+from pip._internal.network.utils import HEADERS, raise_for_status, response_chunks
+
+
+class HTTPRangeRequestUnsupported(Exception):
+ pass
+
+
+def dist_from_wheel_url(name: str, url: str, session: PipSession) -> BaseDistribution:
+ """Return a distribution object from the given wheel URL.
+
+ This uses HTTP range requests to only fetch the portion of the wheel
+ containing metadata, just enough for the object to be constructed.
+ If such requests are not supported, HTTPRangeRequestUnsupported
+ is raised.
+ """
+ with LazyZipOverHTTP(url, session) as zf:
+ # For read-only ZIP files, ZipFile only needs methods read,
+ # seek, seekable and tell, not the whole IO protocol.
+ wheel = MemoryWheel(zf.name, zf) # type: ignore
+ # After context manager exit, wheel.name
+ # is an invalid file by intention.
+ return get_wheel_distribution(wheel, canonicalize_name(name))
+
+
+class LazyZipOverHTTP:
+ """File-like object mapped to a ZIP file over HTTP.
+
+ This uses HTTP range requests to lazily fetch the file's content,
+ which is supposed to be fed to ZipFile. If such requests are not
+ supported by the server, raise HTTPRangeRequestUnsupported
+ during initialization.
+ """
+
+ def __init__(
+ self, url: str, session: PipSession, chunk_size: int = CONTENT_CHUNK_SIZE
+ ) -> None:
+ head = session.head(url, headers=HEADERS)
+ raise_for_status(head)
+ assert head.status_code == 200
+ self._session, self._url, self._chunk_size = session, url, chunk_size
+ self._length = int(head.headers["Content-Length"])
+ self._file = NamedTemporaryFile()
+ self.truncate(self._length)
+ self._left: List[int] = []
+ self._right: List[int] = []
+ if "bytes" not in head.headers.get("Accept-Ranges", "none"):
+ raise HTTPRangeRequestUnsupported("range request is not supported")
+ self._check_zip()
+
+ @property
+ def mode(self) -> str:
+ """Opening mode, which is always rb."""
+ return "rb"
+
+ @property
+ def name(self) -> str:
+ """Path to the underlying file."""
+ return self._file.name
+
+ def seekable(self) -> bool:
+ """Return whether random access is supported, which is True."""
+ return True
+
+ def close(self) -> None:
+ """Close the file."""
+ self._file.close()
+
+ @property
+ def closed(self) -> bool:
+ """Whether the file is closed."""
+ return self._file.closed
+
+ def read(self, size: int = -1) -> bytes:
+ """Read up to size bytes from the object and return them.
+
+ As a convenience, if size is unspecified or -1,
+ all bytes until EOF are returned. Fewer than
+ size bytes may be returned if EOF is reached.
+ """
+ download_size = max(size, self._chunk_size)
+ start, length = self.tell(), self._length
+ stop = length if size < 0 else min(start + download_size, length)
+ start = max(0, stop - download_size)
+ self._download(start, stop - 1)
+ return self._file.read(size)
+
+ def readable(self) -> bool:
+ """Return whether the file is readable, which is True."""
+ return True
+
+ def seek(self, offset: int, whence: int = 0) -> int:
+ """Change stream position and return the new absolute position.
+
+ Seek to offset relative position indicated by whence:
+ * 0: Start of stream (the default). pos should be >= 0;
+ * 1: Current position - pos may be negative;
+ * 2: End of stream - pos usually negative.
+ """
+ return self._file.seek(offset, whence)
+
+ def tell(self) -> int:
+ """Return the current position."""
+ return self._file.tell()
+
+ def truncate(self, size: Optional[int] = None) -> int:
+ """Resize the stream to the given size in bytes.
+
+ If size is unspecified resize to the current position.
+ The current stream position isn't changed.
+
+ Return the new file size.
+ """
+ return self._file.truncate(size)
+
+ def writable(self) -> bool:
+ """Return False."""
+ return False
+
+ def __enter__(self) -> "LazyZipOverHTTP":
+ self._file.__enter__()
+ return self
+
+ def __exit__(self, *exc: Any) -> None:
+ self._file.__exit__(*exc)
+
+ @contextmanager
+ def _stay(self) -> Generator[None, None, None]:
+ """Return a context manager keeping the position.
+
+ At the end of the block, seek back to original position.
+ """
+ pos = self.tell()
+ try:
+ yield
+ finally:
+ self.seek(pos)
+
+ def _check_zip(self) -> None:
+ """Check and download until the file is a valid ZIP."""
+ end = self._length - 1
+ for start in reversed(range(0, end, self._chunk_size)):
+ self._download(start, end)
+ with self._stay():
+ try:
+ # For read-only ZIP files, ZipFile only needs
+ # methods read, seek, seekable and tell.
+ ZipFile(self)
+ except BadZipFile:
+ pass
+ else:
+ break
+
+ def _stream_response(
+ self, start: int, end: int, base_headers: Dict[str, str] = HEADERS
+ ) -> Response:
+ """Return HTTP response to a range request from start to end."""
+ headers = base_headers.copy()
+ headers["Range"] = f"bytes={start}-{end}"
+ # TODO: Get range requests to be correctly cached
+ headers["Cache-Control"] = "no-cache"
+ return self._session.get(self._url, headers=headers, stream=True)
+
+ def _merge(
+ self, start: int, end: int, left: int, right: int
+ ) -> Generator[Tuple[int, int], None, None]:
+ """Return a generator of intervals to be fetched.
+
+ Args:
+ start (int): Start of needed interval
+ end (int): End of needed interval
+ left (int): Index of first overlapping downloaded data
+ right (int): Index after last overlapping downloaded data
+ """
+ lslice, rslice = self._left[left:right], self._right[left:right]
+ i = start = min([start] + lslice[:1])
+ end = max([end] + rslice[-1:])
+ for j, k in zip(lslice, rslice):
+ if j > i:
+ yield i, j - 1
+ i = k + 1
+ if i <= end:
+ yield i, end
+ self._left[left:right], self._right[left:right] = [start], [end]
+
+ def _download(self, start: int, end: int) -> None:
+ """Download bytes from start to end inclusively."""
+ with self._stay():
+ left = bisect_left(self._right, start)
+ right = bisect_right(self._left, end)
+ for start, end in self._merge(start, end, left, right):
+ response = self._stream_response(start, end)
+ response.raise_for_status()
+ self.seek(start)
+ for chunk in response_chunks(response, self._chunk_size):
+ self._file.write(chunk)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/session.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/session.py
new file mode 100644
index 000000000..1765b4f6b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/session.py
@@ -0,0 +1,522 @@
+"""PipSession and supporting code, containing all pip-specific
+network request configuration and behavior.
+"""
+
+import email.utils
+import functools
+import io
+import ipaddress
+import json
+import logging
+import mimetypes
+import os
+import platform
+import shutil
+import subprocess
+import sys
+import urllib.parse
+import warnings
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Dict,
+ Generator,
+ List,
+ Mapping,
+ Optional,
+ Sequence,
+ Tuple,
+ Union,
+)
+
+from pip._vendor import requests, urllib3
+from pip._vendor.cachecontrol import CacheControlAdapter as _BaseCacheControlAdapter
+from pip._vendor.requests.adapters import DEFAULT_POOLBLOCK, BaseAdapter
+from pip._vendor.requests.adapters import HTTPAdapter as _BaseHTTPAdapter
+from pip._vendor.requests.models import PreparedRequest, Response
+from pip._vendor.requests.structures import CaseInsensitiveDict
+from pip._vendor.urllib3.connectionpool import ConnectionPool
+from pip._vendor.urllib3.exceptions import InsecureRequestWarning
+
+from pip import __version__
+from pip._internal.metadata import get_default_environment
+from pip._internal.models.link import Link
+from pip._internal.network.auth import MultiDomainBasicAuth
+from pip._internal.network.cache import SafeFileCache
+
+# Import ssl from compat so the initial import occurs in only one place.
+from pip._internal.utils.compat import has_tls
+from pip._internal.utils.glibc import libc_ver
+from pip._internal.utils.misc import build_url_from_netloc, parse_netloc
+from pip._internal.utils.urls import url_to_path
+
+if TYPE_CHECKING:
+ from ssl import SSLContext
+
+ from pip._vendor.urllib3.poolmanager import PoolManager
+
+
+logger = logging.getLogger(__name__)
+
+SecureOrigin = Tuple[str, str, Optional[Union[int, str]]]
+
+
+# Ignore warning raised when using --trusted-host.
+warnings.filterwarnings("ignore", category=InsecureRequestWarning)
+
+
+SECURE_ORIGINS: List[SecureOrigin] = [
+ # protocol, hostname, port
+ # Taken from Chrome's list of secure origins (See: http://bit.ly/1qrySKC)
+ ("https", "*", "*"),
+ ("*", "localhost", "*"),
+ ("*", "127.0.0.0/8", "*"),
+ ("*", "::1/128", "*"),
+ ("file", "*", None),
+ # ssh is always secure.
+ ("ssh", "*", "*"),
+]
+
+
+# These are environment variables present when running under various
+# CI systems. For each variable, some CI systems that use the variable
+# are indicated. The collection was chosen so that for each of a number
+# of popular systems, at least one of the environment variables is used.
+# This list is used to provide some indication of and lower bound for
+# CI traffic to PyPI. Thus, it is okay if the list is not comprehensive.
+# For more background, see: https://github.com/pypa/pip/issues/5499
+CI_ENVIRONMENT_VARIABLES = (
+ # Azure Pipelines
+ "BUILD_BUILDID",
+ # Jenkins
+ "BUILD_ID",
+ # AppVeyor, CircleCI, Codeship, Gitlab CI, Shippable, Travis CI
+ "CI",
+ # Explicit environment variable.
+ "PIP_IS_CI",
+)
+
+
+def looks_like_ci() -> bool:
+ """
+ Return whether it looks like pip is running under CI.
+ """
+ # We don't use the method of checking for a tty (e.g. using isatty())
+ # because some CI systems mimic a tty (e.g. Travis CI). Thus that
+ # method doesn't provide definitive information in either direction.
+ return any(name in os.environ for name in CI_ENVIRONMENT_VARIABLES)
+
+
+@functools.lru_cache(maxsize=1)
+def user_agent() -> str:
+ """
+ Return a string representing the user agent.
+ """
+ data: Dict[str, Any] = {
+ "installer": {"name": "pip", "version": __version__},
+ "python": platform.python_version(),
+ "implementation": {
+ "name": platform.python_implementation(),
+ },
+ }
+
+ if data["implementation"]["name"] == "CPython":
+ data["implementation"]["version"] = platform.python_version()
+ elif data["implementation"]["name"] == "PyPy":
+ pypy_version_info = sys.pypy_version_info # type: ignore
+ if pypy_version_info.releaselevel == "final":
+ pypy_version_info = pypy_version_info[:3]
+ data["implementation"]["version"] = ".".join(
+ [str(x) for x in pypy_version_info]
+ )
+ elif data["implementation"]["name"] == "Jython":
+ # Complete Guess
+ data["implementation"]["version"] = platform.python_version()
+ elif data["implementation"]["name"] == "IronPython":
+ # Complete Guess
+ data["implementation"]["version"] = platform.python_version()
+
+ if sys.platform.startswith("linux"):
+ from pip._vendor import distro
+
+ linux_distribution = distro.name(), distro.version(), distro.codename()
+ distro_infos: Dict[str, Any] = dict(
+ filter(
+ lambda x: x[1],
+ zip(["name", "version", "id"], linux_distribution),
+ )
+ )
+ libc = dict(
+ filter(
+ lambda x: x[1],
+ zip(["lib", "version"], libc_ver()),
+ )
+ )
+ if libc:
+ distro_infos["libc"] = libc
+ if distro_infos:
+ data["distro"] = distro_infos
+
+ if sys.platform.startswith("darwin") and platform.mac_ver()[0]:
+ data["distro"] = {"name": "macOS", "version": platform.mac_ver()[0]}
+
+ if platform.system():
+ data.setdefault("system", {})["name"] = platform.system()
+
+ if platform.release():
+ data.setdefault("system", {})["release"] = platform.release()
+
+ if platform.machine():
+ data["cpu"] = platform.machine()
+
+ if has_tls():
+ import _ssl as ssl
+
+ data["openssl_version"] = ssl.OPENSSL_VERSION
+
+ setuptools_dist = get_default_environment().get_distribution("setuptools")
+ if setuptools_dist is not None:
+ data["setuptools_version"] = str(setuptools_dist.version)
+
+ if shutil.which("rustc") is not None:
+ # If for any reason `rustc --version` fails, silently ignore it
+ try:
+ rustc_output = subprocess.check_output(
+ ["rustc", "--version"], stderr=subprocess.STDOUT, timeout=0.5
+ )
+ except Exception:
+ pass
+ else:
+ if rustc_output.startswith(b"rustc "):
+ # The format of `rustc --version` is:
+ # `b'rustc 1.52.1 (9bc8c42bb 2021-05-09)\n'`
+ # We extract just the middle (1.52.1) part
+ data["rustc_version"] = rustc_output.split(b" ")[1].decode()
+
+ # Use None rather than False so as not to give the impression that
+ # pip knows it is not being run under CI. Rather, it is a null or
+ # inconclusive result. Also, we include some value rather than no
+ # value to make it easier to know that the check has been run.
+ data["ci"] = True if looks_like_ci() else None
+
+ user_data = os.environ.get("PIP_USER_AGENT_USER_DATA")
+ if user_data is not None:
+ data["user_data"] = user_data
+
+ return "{data[installer][name]}/{data[installer][version]} {json}".format(
+ data=data,
+ json=json.dumps(data, separators=(",", ":"), sort_keys=True),
+ )
+
+
+class LocalFSAdapter(BaseAdapter):
+ def send(
+ self,
+ request: PreparedRequest,
+ stream: bool = False,
+ timeout: Optional[Union[float, Tuple[float, float]]] = None,
+ verify: Union[bool, str] = True,
+ cert: Optional[Union[str, Tuple[str, str]]] = None,
+ proxies: Optional[Mapping[str, str]] = None,
+ ) -> Response:
+ pathname = url_to_path(request.url)
+
+ resp = Response()
+ resp.status_code = 200
+ resp.url = request.url
+
+ try:
+ stats = os.stat(pathname)
+ except OSError as exc:
+ # format the exception raised as a io.BytesIO object,
+ # to return a better error message:
+ resp.status_code = 404
+ resp.reason = type(exc).__name__
+ resp.raw = io.BytesIO(f"{resp.reason}: {exc}".encode())
+ else:
+ modified = email.utils.formatdate(stats.st_mtime, usegmt=True)
+ content_type = mimetypes.guess_type(pathname)[0] or "text/plain"
+ resp.headers = CaseInsensitiveDict(
+ {
+ "Content-Type": content_type,
+ "Content-Length": stats.st_size,
+ "Last-Modified": modified,
+ }
+ )
+
+ resp.raw = open(pathname, "rb")
+ resp.close = resp.raw.close
+
+ return resp
+
+ def close(self) -> None:
+ pass
+
+
+class _SSLContextAdapterMixin:
+ """Mixin to add the ``ssl_context`` constructor argument to HTTP adapters.
+
+ The additional argument is forwarded directly to the pool manager. This allows us
+ to dynamically decide what SSL store to use at runtime, which is used to implement
+ the optional ``truststore`` backend.
+ """
+
+ def __init__(
+ self,
+ *,
+ ssl_context: Optional["SSLContext"] = None,
+ **kwargs: Any,
+ ) -> None:
+ self._ssl_context = ssl_context
+ super().__init__(**kwargs)
+
+ def init_poolmanager(
+ self,
+ connections: int,
+ maxsize: int,
+ block: bool = DEFAULT_POOLBLOCK,
+ **pool_kwargs: Any,
+ ) -> "PoolManager":
+ if self._ssl_context is not None:
+ pool_kwargs.setdefault("ssl_context", self._ssl_context)
+ return super().init_poolmanager( # type: ignore[misc]
+ connections=connections,
+ maxsize=maxsize,
+ block=block,
+ **pool_kwargs,
+ )
+
+
+class HTTPAdapter(_SSLContextAdapterMixin, _BaseHTTPAdapter):
+ pass
+
+
+class CacheControlAdapter(_SSLContextAdapterMixin, _BaseCacheControlAdapter):
+ pass
+
+
+class InsecureHTTPAdapter(HTTPAdapter):
+ def cert_verify(
+ self,
+ conn: ConnectionPool,
+ url: str,
+ verify: Union[bool, str],
+ cert: Optional[Union[str, Tuple[str, str]]],
+ ) -> None:
+ super().cert_verify(conn=conn, url=url, verify=False, cert=cert)
+
+
+class InsecureCacheControlAdapter(CacheControlAdapter):
+ def cert_verify(
+ self,
+ conn: ConnectionPool,
+ url: str,
+ verify: Union[bool, str],
+ cert: Optional[Union[str, Tuple[str, str]]],
+ ) -> None:
+ super().cert_verify(conn=conn, url=url, verify=False, cert=cert)
+
+
+class PipSession(requests.Session):
+ timeout: Optional[int] = None
+
+ def __init__(
+ self,
+ *args: Any,
+ retries: int = 0,
+ cache: Optional[str] = None,
+ trusted_hosts: Sequence[str] = (),
+ index_urls: Optional[List[str]] = None,
+ ssl_context: Optional["SSLContext"] = None,
+ **kwargs: Any,
+ ) -> None:
+ """
+ :param trusted_hosts: Domains not to emit warnings for when not using
+ HTTPS.
+ """
+ super().__init__(*args, **kwargs)
+
+ # Namespace the attribute with "pip_" just in case to prevent
+ # possible conflicts with the base class.
+ self.pip_trusted_origins: List[Tuple[str, Optional[int]]] = []
+
+ # Attach our User Agent to the request
+ self.headers["User-Agent"] = user_agent()
+
+ # Attach our Authentication handler to the session
+ self.auth = MultiDomainBasicAuth(index_urls=index_urls)
+
+ # Create our urllib3.Retry instance which will allow us to customize
+ # how we handle retries.
+ retries = urllib3.Retry(
+ # Set the total number of retries that a particular request can
+ # have.
+ total=retries,
+ # A 503 error from PyPI typically means that the Fastly -> Origin
+ # connection got interrupted in some way. A 503 error in general
+ # is typically considered a transient error so we'll go ahead and
+ # retry it.
+ # A 500 may indicate transient error in Amazon S3
+ # A 502 may be a transient error from a CDN like CloudFlare or CloudFront
+ # A 520 or 527 - may indicate transient error in CloudFlare
+ status_forcelist=[500, 502, 503, 520, 527],
+ # Add a small amount of back off between failed requests in
+ # order to prevent hammering the service.
+ backoff_factor=0.25,
+ ) # type: ignore
+
+ # Our Insecure HTTPAdapter disables HTTPS validation. It does not
+ # support caching so we'll use it for all http:// URLs.
+ # If caching is disabled, we will also use it for
+ # https:// hosts that we've marked as ignoring
+ # TLS errors for (trusted-hosts).
+ insecure_adapter = InsecureHTTPAdapter(max_retries=retries)
+
+ # We want to _only_ cache responses on securely fetched origins or when
+ # the host is specified as trusted. We do this because
+ # we can't validate the response of an insecurely/untrusted fetched
+ # origin, and we don't want someone to be able to poison the cache and
+ # require manual eviction from the cache to fix it.
+ if cache:
+ secure_adapter = CacheControlAdapter(
+ cache=SafeFileCache(cache),
+ max_retries=retries,
+ ssl_context=ssl_context,
+ )
+ self._trusted_host_adapter = InsecureCacheControlAdapter(
+ cache=SafeFileCache(cache),
+ max_retries=retries,
+ )
+ else:
+ secure_adapter = HTTPAdapter(max_retries=retries, ssl_context=ssl_context)
+ self._trusted_host_adapter = insecure_adapter
+
+ self.mount("https://", secure_adapter)
+ self.mount("http://", insecure_adapter)
+
+ # Enable file:// urls
+ self.mount("file://", LocalFSAdapter())
+
+ for host in trusted_hosts:
+ self.add_trusted_host(host, suppress_logging=True)
+
+ def update_index_urls(self, new_index_urls: List[str]) -> None:
+ """
+ :param new_index_urls: New index urls to update the authentication
+ handler with.
+ """
+ self.auth.index_urls = new_index_urls
+
+ def add_trusted_host(
+ self, host: str, source: Optional[str] = None, suppress_logging: bool = False
+ ) -> None:
+ """
+ :param host: It is okay to provide a host that has previously been
+ added.
+ :param source: An optional source string, for logging where the host
+ string came from.
+ """
+ if not suppress_logging:
+ msg = f"adding trusted host: {host!r}"
+ if source is not None:
+ msg += f" (from {source})"
+ logger.info(msg)
+
+ parsed_host, parsed_port = parse_netloc(host)
+ if parsed_host is None:
+ raise ValueError(f"Trusted host URL must include a host part: {host!r}")
+ if (parsed_host, parsed_port) not in self.pip_trusted_origins:
+ self.pip_trusted_origins.append((parsed_host, parsed_port))
+
+ self.mount(
+ build_url_from_netloc(host, scheme="http") + "/", self._trusted_host_adapter
+ )
+ self.mount(build_url_from_netloc(host) + "/", self._trusted_host_adapter)
+ if not parsed_port:
+ self.mount(
+ build_url_from_netloc(host, scheme="http") + ":",
+ self._trusted_host_adapter,
+ )
+ # Mount wildcard ports for the same host.
+ self.mount(build_url_from_netloc(host) + ":", self._trusted_host_adapter)
+
+ def iter_secure_origins(self) -> Generator[SecureOrigin, None, None]:
+ yield from SECURE_ORIGINS
+ for host, port in self.pip_trusted_origins:
+ yield ("*", host, "*" if port is None else port)
+
+ def is_secure_origin(self, location: Link) -> bool:
+ # Determine if this url used a secure transport mechanism
+ parsed = urllib.parse.urlparse(str(location))
+ origin_protocol, origin_host, origin_port = (
+ parsed.scheme,
+ parsed.hostname,
+ parsed.port,
+ )
+
+ # The protocol to use to see if the protocol matches.
+ # Don't count the repository type as part of the protocol: in
+ # cases such as "git+ssh", only use "ssh". (I.e., Only verify against
+ # the last scheme.)
+ origin_protocol = origin_protocol.rsplit("+", 1)[-1]
+
+ # Determine if our origin is a secure origin by looking through our
+ # hardcoded list of secure origins, as well as any additional ones
+ # configured on this PackageFinder instance.
+ for secure_origin in self.iter_secure_origins():
+ secure_protocol, secure_host, secure_port = secure_origin
+ if origin_protocol != secure_protocol and secure_protocol != "*":
+ continue
+
+ try:
+ addr = ipaddress.ip_address(origin_host or "")
+ network = ipaddress.ip_network(secure_host)
+ except ValueError:
+ # We don't have both a valid address or a valid network, so
+ # we'll check this origin against hostnames.
+ if (
+ origin_host
+ and origin_host.lower() != secure_host.lower()
+ and secure_host != "*"
+ ):
+ continue
+ else:
+ # We have a valid address and network, so see if the address
+ # is contained within the network.
+ if addr not in network:
+ continue
+
+ # Check to see if the port matches.
+ if (
+ origin_port != secure_port
+ and secure_port != "*"
+ and secure_port is not None
+ ):
+ continue
+
+ # If we've gotten here, then this origin matches the current
+ # secure origin and we should return True
+ return True
+
+ # If we've gotten to this point, then the origin isn't secure and we
+ # will not accept it as a valid location to search. We will however
+ # log a warning that we are ignoring it.
+ logger.warning(
+ "The repository located at %s is not a trusted or secure host and "
+ "is being ignored. If this repository is available via HTTPS we "
+ "recommend you use HTTPS instead, otherwise you may silence "
+ "this warning and allow it anyway with '--trusted-host %s'.",
+ origin_host,
+ origin_host,
+ )
+
+ return False
+
+ def request(self, method: str, url: str, *args: Any, **kwargs: Any) -> Response:
+ # Allow setting a default timeout on a session
+ kwargs.setdefault("timeout", self.timeout)
+ # Allow setting a default proxies on a session
+ kwargs.setdefault("proxies", self.proxies)
+
+ # Dispatch the actual request
+ return super().request(method, url, *args, **kwargs)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/utils.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/utils.py
new file mode 100644
index 000000000..bba4c265e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/utils.py
@@ -0,0 +1,98 @@
+from typing import Dict, Generator
+
+from pip._vendor.requests.models import Response
+
+from pip._internal.exceptions import NetworkConnectionError
+
+# The following comments and HTTP headers were originally added by
+# Donald Stufft in git commit 22c562429a61bb77172039e480873fb239dd8c03.
+#
+# We use Accept-Encoding: identity here because requests defaults to
+# accepting compressed responses. This breaks in a variety of ways
+# depending on how the server is configured.
+# - Some servers will notice that the file isn't a compressible file
+# and will leave the file alone and with an empty Content-Encoding
+# - Some servers will notice that the file is already compressed and
+# will leave the file alone, adding a Content-Encoding: gzip header
+# - Some servers won't notice anything at all and will take a file
+# that's already been compressed and compress it again, and set
+# the Content-Encoding: gzip header
+# By setting this to request only the identity encoding we're hoping
+# to eliminate the third case. Hopefully there does not exist a server
+# which when given a file will notice it is already compressed and that
+# you're not asking for a compressed file and will then decompress it
+# before sending because if that's the case I don't think it'll ever be
+# possible to make this work.
+HEADERS: Dict[str, str] = {"Accept-Encoding": "identity"}
+
+DOWNLOAD_CHUNK_SIZE = 256 * 1024
+
+
+def raise_for_status(resp: Response) -> None:
+ http_error_msg = ""
+ if isinstance(resp.reason, bytes):
+ # We attempt to decode utf-8 first because some servers
+ # choose to localize their reason strings. If the string
+ # isn't utf-8, we fall back to iso-8859-1 for all other
+ # encodings.
+ try:
+ reason = resp.reason.decode("utf-8")
+ except UnicodeDecodeError:
+ reason = resp.reason.decode("iso-8859-1")
+ else:
+ reason = resp.reason
+
+ if 400 <= resp.status_code < 500:
+ http_error_msg = (
+ f"{resp.status_code} Client Error: {reason} for url: {resp.url}"
+ )
+
+ elif 500 <= resp.status_code < 600:
+ http_error_msg = (
+ f"{resp.status_code} Server Error: {reason} for url: {resp.url}"
+ )
+
+ if http_error_msg:
+ raise NetworkConnectionError(http_error_msg, response=resp)
+
+
+def response_chunks(
+ response: Response, chunk_size: int = DOWNLOAD_CHUNK_SIZE
+) -> Generator[bytes, None, None]:
+ """Given a requests Response, provide the data chunks."""
+ try:
+ # Special case for urllib3.
+ for chunk in response.raw.stream(
+ chunk_size,
+ # We use decode_content=False here because we don't
+ # want urllib3 to mess with the raw bytes we get
+ # from the server. If we decompress inside of
+ # urllib3 then we cannot verify the checksum
+ # because the checksum will be of the compressed
+ # file. This breakage will only occur if the
+ # server adds a Content-Encoding header, which
+ # depends on how the server was configured:
+ # - Some servers will notice that the file isn't a
+ # compressible file and will leave the file alone
+ # and with an empty Content-Encoding
+ # - Some servers will notice that the file is
+ # already compressed and will leave the file
+ # alone and will add a Content-Encoding: gzip
+ # header
+ # - Some servers won't notice anything at all and
+ # will take a file that's already been compressed
+ # and compress it again and set the
+ # Content-Encoding: gzip header
+ #
+ # By setting this not to decode automatically we
+ # hope to eliminate problems with the second case.
+ decode_content=False,
+ ):
+ yield chunk
+ except AttributeError:
+ # Standard file-like object.
+ while True:
+ chunk = response.raw.read(chunk_size)
+ if not chunk:
+ break
+ yield chunk
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/network/xmlrpc.py b/solutions/.venv/Lib/site-packages/pip/_internal/network/xmlrpc.py
new file mode 100644
index 000000000..22ec8d2f4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/network/xmlrpc.py
@@ -0,0 +1,62 @@
+"""xmlrpclib.Transport implementation
+"""
+
+import logging
+import urllib.parse
+import xmlrpc.client
+from typing import TYPE_CHECKING, Tuple
+
+from pip._internal.exceptions import NetworkConnectionError
+from pip._internal.network.session import PipSession
+from pip._internal.network.utils import raise_for_status
+
+if TYPE_CHECKING:
+ from xmlrpc.client import _HostType, _Marshallable
+
+ from _typeshed import SizedBuffer
+
+logger = logging.getLogger(__name__)
+
+
+class PipXmlrpcTransport(xmlrpc.client.Transport):
+ """Provide a `xmlrpclib.Transport` implementation via a `PipSession`
+ object.
+ """
+
+ def __init__(
+ self, index_url: str, session: PipSession, use_datetime: bool = False
+ ) -> None:
+ super().__init__(use_datetime)
+ index_parts = urllib.parse.urlparse(index_url)
+ self._scheme = index_parts.scheme
+ self._session = session
+
+ def request(
+ self,
+ host: "_HostType",
+ handler: str,
+ request_body: "SizedBuffer",
+ verbose: bool = False,
+ ) -> Tuple["_Marshallable", ...]:
+ assert isinstance(host, str)
+ parts = (self._scheme, host, handler, None, None, None)
+ url = urllib.parse.urlunparse(parts)
+ try:
+ headers = {"Content-Type": "text/xml"}
+ response = self._session.post(
+ url,
+ data=request_body,
+ headers=headers,
+ stream=True,
+ )
+ raise_for_status(response)
+ self.verbose = verbose
+ return self.parse_response(response.raw)
+ except NetworkConnectionError as exc:
+ assert exc.response
+ logger.critical(
+ "HTTP error %s while getting %s",
+ exc.response.status_code,
+ url,
+ )
+ raise
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/build_tracker.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/build_tracker.py
new file mode 100644
index 000000000..0ed8dd235
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/build_tracker.py
@@ -0,0 +1,138 @@
+import contextlib
+import hashlib
+import logging
+import os
+from types import TracebackType
+from typing import Dict, Generator, Optional, Type, Union
+
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.utils.temp_dir import TempDirectory
+
+logger = logging.getLogger(__name__)
+
+
+@contextlib.contextmanager
+def update_env_context_manager(**changes: str) -> Generator[None, None, None]:
+ target = os.environ
+
+ # Save values from the target and change them.
+ non_existent_marker = object()
+ saved_values: Dict[str, Union[object, str]] = {}
+ for name, new_value in changes.items():
+ try:
+ saved_values[name] = target[name]
+ except KeyError:
+ saved_values[name] = non_existent_marker
+ target[name] = new_value
+
+ try:
+ yield
+ finally:
+ # Restore original values in the target.
+ for name, original_value in saved_values.items():
+ if original_value is non_existent_marker:
+ del target[name]
+ else:
+ assert isinstance(original_value, str) # for mypy
+ target[name] = original_value
+
+
+@contextlib.contextmanager
+def get_build_tracker() -> Generator["BuildTracker", None, None]:
+ root = os.environ.get("PIP_BUILD_TRACKER")
+ with contextlib.ExitStack() as ctx:
+ if root is None:
+ root = ctx.enter_context(TempDirectory(kind="build-tracker")).path
+ ctx.enter_context(update_env_context_manager(PIP_BUILD_TRACKER=root))
+ logger.debug("Initialized build tracking at %s", root)
+
+ with BuildTracker(root) as tracker:
+ yield tracker
+
+
+class TrackerId(str):
+ """Uniquely identifying string provided to the build tracker."""
+
+
+class BuildTracker:
+ """Ensure that an sdist cannot request itself as a setup requirement.
+
+ When an sdist is prepared, it identifies its setup requirements in the
+ context of ``BuildTracker.track()``. If a requirement shows up recursively, this
+ raises an exception.
+
+ This stops fork bombs embedded in malicious packages."""
+
+ def __init__(self, root: str) -> None:
+ self._root = root
+ self._entries: Dict[TrackerId, InstallRequirement] = {}
+ logger.debug("Created build tracker: %s", self._root)
+
+ def __enter__(self) -> "BuildTracker":
+ logger.debug("Entered build tracker: %s", self._root)
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.cleanup()
+
+ def _entry_path(self, key: TrackerId) -> str:
+ hashed = hashlib.sha224(key.encode()).hexdigest()
+ return os.path.join(self._root, hashed)
+
+ def add(self, req: InstallRequirement, key: TrackerId) -> None:
+ """Add an InstallRequirement to build tracking."""
+
+ # Get the file to write information about this requirement.
+ entry_path = self._entry_path(key)
+
+ # Try reading from the file. If it exists and can be read from, a build
+ # is already in progress, so a LookupError is raised.
+ try:
+ with open(entry_path) as fp:
+ contents = fp.read()
+ except FileNotFoundError:
+ pass
+ else:
+ message = f"{req.link} is already being built: {contents}"
+ raise LookupError(message)
+
+ # If we're here, req should really not be building already.
+ assert key not in self._entries
+
+ # Start tracking this requirement.
+ with open(entry_path, "w", encoding="utf-8") as fp:
+ fp.write(str(req))
+ self._entries[key] = req
+
+ logger.debug("Added %s to build tracker %r", req, self._root)
+
+ def remove(self, req: InstallRequirement, key: TrackerId) -> None:
+ """Remove an InstallRequirement from build tracking."""
+
+ # Delete the created file and the corresponding entry.
+ os.unlink(self._entry_path(key))
+ del self._entries[key]
+
+ logger.debug("Removed %s from build tracker %r", req, self._root)
+
+ def cleanup(self) -> None:
+ for key, req in list(self._entries.items()):
+ self.remove(req, key)
+
+ logger.debug("Removed build tracker: %r", self._root)
+
+ @contextlib.contextmanager
+ def track(self, req: InstallRequirement, key: str) -> Generator[None, None, None]:
+ """Ensure that `key` cannot install itself as a setup requirement.
+
+ :raises LookupError: If `key` was already provided in a parent invocation of
+ the context introduced by this method."""
+ tracker_id = TrackerId(key)
+ self.add(req, tracker_id)
+ yield
+ self.remove(req, tracker_id)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata.py
new file mode 100644
index 000000000..c66ac354d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata.py
@@ -0,0 +1,39 @@
+"""Metadata generation logic for source distributions.
+"""
+
+import os
+
+from pip._vendor.pyproject_hooks import BuildBackendHookCaller
+
+from pip._internal.build_env import BuildEnvironment
+from pip._internal.exceptions import (
+ InstallationSubprocessError,
+ MetadataGenerationFailed,
+)
+from pip._internal.utils.subprocess import runner_with_spinner_message
+from pip._internal.utils.temp_dir import TempDirectory
+
+
+def generate_metadata(
+ build_env: BuildEnvironment, backend: BuildBackendHookCaller, details: str
+) -> str:
+ """Generate metadata using mechanisms described in PEP 517.
+
+ Returns the generated metadata directory.
+ """
+ metadata_tmpdir = TempDirectory(kind="modern-metadata", globally_managed=True)
+
+ metadata_dir = metadata_tmpdir.path
+
+ with build_env:
+ # Note that BuildBackendHookCaller implements a fallback for
+ # prepare_metadata_for_build_wheel, so we don't have to
+ # consider the possibility that this hook doesn't exist.
+ runner = runner_with_spinner_message("Preparing metadata (pyproject.toml)")
+ with backend.subprocess_runner(runner):
+ try:
+ distinfo_dir = backend.prepare_metadata_for_build_wheel(metadata_dir)
+ except InstallationSubprocessError as error:
+ raise MetadataGenerationFailed(package_details=details) from error
+
+ return os.path.join(metadata_dir, distinfo_dir)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata_editable.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata_editable.py
new file mode 100644
index 000000000..27c69f0d1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata_editable.py
@@ -0,0 +1,41 @@
+"""Metadata generation logic for source distributions.
+"""
+
+import os
+
+from pip._vendor.pyproject_hooks import BuildBackendHookCaller
+
+from pip._internal.build_env import BuildEnvironment
+from pip._internal.exceptions import (
+ InstallationSubprocessError,
+ MetadataGenerationFailed,
+)
+from pip._internal.utils.subprocess import runner_with_spinner_message
+from pip._internal.utils.temp_dir import TempDirectory
+
+
+def generate_editable_metadata(
+ build_env: BuildEnvironment, backend: BuildBackendHookCaller, details: str
+) -> str:
+ """Generate metadata using mechanisms described in PEP 660.
+
+ Returns the generated metadata directory.
+ """
+ metadata_tmpdir = TempDirectory(kind="modern-metadata", globally_managed=True)
+
+ metadata_dir = metadata_tmpdir.path
+
+ with build_env:
+ # Note that BuildBackendHookCaller implements a fallback for
+ # prepare_metadata_for_build_wheel/editable, so we don't have to
+ # consider the possibility that this hook doesn't exist.
+ runner = runner_with_spinner_message(
+ "Preparing editable metadata (pyproject.toml)"
+ )
+ with backend.subprocess_runner(runner):
+ try:
+ distinfo_dir = backend.prepare_metadata_for_build_editable(metadata_dir)
+ except InstallationSubprocessError as error:
+ raise MetadataGenerationFailed(package_details=details) from error
+
+ return os.path.join(metadata_dir, distinfo_dir)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata_legacy.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata_legacy.py
new file mode 100644
index 000000000..c01dd1c67
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/metadata_legacy.py
@@ -0,0 +1,74 @@
+"""Metadata generation logic for legacy source distributions.
+"""
+
+import logging
+import os
+
+from pip._internal.build_env import BuildEnvironment
+from pip._internal.cli.spinners import open_spinner
+from pip._internal.exceptions import (
+ InstallationError,
+ InstallationSubprocessError,
+ MetadataGenerationFailed,
+)
+from pip._internal.utils.setuptools_build import make_setuptools_egg_info_args
+from pip._internal.utils.subprocess import call_subprocess
+from pip._internal.utils.temp_dir import TempDirectory
+
+logger = logging.getLogger(__name__)
+
+
+def _find_egg_info(directory: str) -> str:
+ """Find an .egg-info subdirectory in `directory`."""
+ filenames = [f for f in os.listdir(directory) if f.endswith(".egg-info")]
+
+ if not filenames:
+ raise InstallationError(f"No .egg-info directory found in {directory}")
+
+ if len(filenames) > 1:
+ raise InstallationError(
+ f"More than one .egg-info directory found in {directory}"
+ )
+
+ return os.path.join(directory, filenames[0])
+
+
+def generate_metadata(
+ build_env: BuildEnvironment,
+ setup_py_path: str,
+ source_dir: str,
+ isolated: bool,
+ details: str,
+) -> str:
+ """Generate metadata using setup.py-based defacto mechanisms.
+
+ Returns the generated metadata directory.
+ """
+ logger.debug(
+ "Running setup.py (path:%s) egg_info for package %s",
+ setup_py_path,
+ details,
+ )
+
+ egg_info_dir = TempDirectory(kind="pip-egg-info", globally_managed=True).path
+
+ args = make_setuptools_egg_info_args(
+ setup_py_path,
+ egg_info_dir=egg_info_dir,
+ no_user_config=isolated,
+ )
+
+ with build_env:
+ with open_spinner("Preparing metadata (setup.py)") as spinner:
+ try:
+ call_subprocess(
+ args,
+ cwd=source_dir,
+ command_desc="python setup.py egg_info",
+ spinner=spinner,
+ )
+ except InstallationSubprocessError as error:
+ raise MetadataGenerationFailed(package_details=details) from error
+
+ # Return the .egg-info directory.
+ return _find_egg_info(egg_info_dir)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel.py
new file mode 100644
index 000000000..064811ad1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel.py
@@ -0,0 +1,37 @@
+import logging
+import os
+from typing import Optional
+
+from pip._vendor.pyproject_hooks import BuildBackendHookCaller
+
+from pip._internal.utils.subprocess import runner_with_spinner_message
+
+logger = logging.getLogger(__name__)
+
+
+def build_wheel_pep517(
+ name: str,
+ backend: BuildBackendHookCaller,
+ metadata_directory: str,
+ tempd: str,
+) -> Optional[str]:
+ """Build one InstallRequirement using the PEP 517 build process.
+
+ Returns path to wheel if successfully built. Otherwise, returns None.
+ """
+ assert metadata_directory is not None
+ try:
+ logger.debug("Destination directory: %s", tempd)
+
+ runner = runner_with_spinner_message(
+ f"Building wheel for {name} (pyproject.toml)"
+ )
+ with backend.subprocess_runner(runner):
+ wheel_name = backend.build_wheel(
+ tempd,
+ metadata_directory=metadata_directory,
+ )
+ except Exception:
+ logger.error("Failed building wheel for %s", name)
+ return None
+ return os.path.join(tempd, wheel_name)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel_editable.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel_editable.py
new file mode 100644
index 000000000..719d69dd8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel_editable.py
@@ -0,0 +1,46 @@
+import logging
+import os
+from typing import Optional
+
+from pip._vendor.pyproject_hooks import BuildBackendHookCaller, HookMissing
+
+from pip._internal.utils.subprocess import runner_with_spinner_message
+
+logger = logging.getLogger(__name__)
+
+
+def build_wheel_editable(
+ name: str,
+ backend: BuildBackendHookCaller,
+ metadata_directory: str,
+ tempd: str,
+) -> Optional[str]:
+ """Build one InstallRequirement using the PEP 660 build process.
+
+ Returns path to wheel if successfully built. Otherwise, returns None.
+ """
+ assert metadata_directory is not None
+ try:
+ logger.debug("Destination directory: %s", tempd)
+
+ runner = runner_with_spinner_message(
+ f"Building editable for {name} (pyproject.toml)"
+ )
+ with backend.subprocess_runner(runner):
+ try:
+ wheel_name = backend.build_editable(
+ tempd,
+ metadata_directory=metadata_directory,
+ )
+ except HookMissing as e:
+ logger.error(
+ "Cannot build editable %s because the build "
+ "backend does not have the %s hook",
+ name,
+ e,
+ )
+ return None
+ except Exception:
+ logger.error("Failed building editable for %s", name)
+ return None
+ return os.path.join(tempd, wheel_name)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel_legacy.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel_legacy.py
new file mode 100644
index 000000000..3ee2a7058
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/build/wheel_legacy.py
@@ -0,0 +1,102 @@
+import logging
+import os.path
+from typing import List, Optional
+
+from pip._internal.cli.spinners import open_spinner
+from pip._internal.utils.setuptools_build import make_setuptools_bdist_wheel_args
+from pip._internal.utils.subprocess import call_subprocess, format_command_args
+
+logger = logging.getLogger(__name__)
+
+
+def format_command_result(
+ command_args: List[str],
+ command_output: str,
+) -> str:
+ """Format command information for logging."""
+ command_desc = format_command_args(command_args)
+ text = f"Command arguments: {command_desc}\n"
+
+ if not command_output:
+ text += "Command output: None"
+ elif logger.getEffectiveLevel() > logging.DEBUG:
+ text += "Command output: [use --verbose to show]"
+ else:
+ if not command_output.endswith("\n"):
+ command_output += "\n"
+ text += f"Command output:\n{command_output}"
+
+ return text
+
+
+def get_legacy_build_wheel_path(
+ names: List[str],
+ temp_dir: str,
+ name: str,
+ command_args: List[str],
+ command_output: str,
+) -> Optional[str]:
+ """Return the path to the wheel in the temporary build directory."""
+ # Sort for determinism.
+ names = sorted(names)
+ if not names:
+ msg = f"Legacy build of wheel for {name!r} created no files.\n"
+ msg += format_command_result(command_args, command_output)
+ logger.warning(msg)
+ return None
+
+ if len(names) > 1:
+ msg = (
+ f"Legacy build of wheel for {name!r} created more than one file.\n"
+ f"Filenames (choosing first): {names}\n"
+ )
+ msg += format_command_result(command_args, command_output)
+ logger.warning(msg)
+
+ return os.path.join(temp_dir, names[0])
+
+
+def build_wheel_legacy(
+ name: str,
+ setup_py_path: str,
+ source_dir: str,
+ global_options: List[str],
+ build_options: List[str],
+ tempd: str,
+) -> Optional[str]:
+ """Build one unpacked package using the "legacy" build process.
+
+ Returns path to wheel if successfully built. Otherwise, returns None.
+ """
+ wheel_args = make_setuptools_bdist_wheel_args(
+ setup_py_path,
+ global_options=global_options,
+ build_options=build_options,
+ destination_dir=tempd,
+ )
+
+ spin_message = f"Building wheel for {name} (setup.py)"
+ with open_spinner(spin_message) as spinner:
+ logger.debug("Destination directory: %s", tempd)
+
+ try:
+ output = call_subprocess(
+ wheel_args,
+ command_desc="python setup.py bdist_wheel",
+ cwd=source_dir,
+ spinner=spinner,
+ )
+ except Exception:
+ spinner.finish("error")
+ logger.error("Failed building wheel for %s", name)
+ return None
+
+ names = os.listdir(tempd)
+ wheel_path = get_legacy_build_wheel_path(
+ names=names,
+ temp_dir=tempd,
+ name=name,
+ command_args=wheel_args,
+ command_output=output,
+ )
+ return wheel_path
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/check.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/check.py
new file mode 100644
index 000000000..4b6fbc4c3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/check.py
@@ -0,0 +1,181 @@
+"""Validation of dependencies of packages
+"""
+
+import logging
+from contextlib import suppress
+from email.parser import Parser
+from functools import reduce
+from typing import (
+ Callable,
+ Dict,
+ FrozenSet,
+ Generator,
+ Iterable,
+ List,
+ NamedTuple,
+ Optional,
+ Set,
+ Tuple,
+)
+
+from pip._vendor.packaging.requirements import Requirement
+from pip._vendor.packaging.tags import Tag, parse_tag
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+from pip._vendor.packaging.version import Version
+
+from pip._internal.distributions import make_distribution_for_install_requirement
+from pip._internal.metadata import get_default_environment
+from pip._internal.metadata.base import BaseDistribution
+from pip._internal.req.req_install import InstallRequirement
+
+logger = logging.getLogger(__name__)
+
+
+class PackageDetails(NamedTuple):
+ version: Version
+ dependencies: List[Requirement]
+
+
+# Shorthands
+PackageSet = Dict[NormalizedName, PackageDetails]
+Missing = Tuple[NormalizedName, Requirement]
+Conflicting = Tuple[NormalizedName, Version, Requirement]
+
+MissingDict = Dict[NormalizedName, List[Missing]]
+ConflictingDict = Dict[NormalizedName, List[Conflicting]]
+CheckResult = Tuple[MissingDict, ConflictingDict]
+ConflictDetails = Tuple[PackageSet, CheckResult]
+
+
+def create_package_set_from_installed() -> Tuple[PackageSet, bool]:
+ """Converts a list of distributions into a PackageSet."""
+ package_set = {}
+ problems = False
+ env = get_default_environment()
+ for dist in env.iter_installed_distributions(local_only=False, skip=()):
+ name = dist.canonical_name
+ try:
+ dependencies = list(dist.iter_dependencies())
+ package_set[name] = PackageDetails(dist.version, dependencies)
+ except (OSError, ValueError) as e:
+ # Don't crash on unreadable or broken metadata.
+ logger.warning("Error parsing dependencies of %s: %s", name, e)
+ problems = True
+ return package_set, problems
+
+
+def check_package_set(
+ package_set: PackageSet, should_ignore: Optional[Callable[[str], bool]] = None
+) -> CheckResult:
+ """Check if a package set is consistent
+
+ If should_ignore is passed, it should be a callable that takes a
+ package name and returns a boolean.
+ """
+
+ missing = {}
+ conflicting = {}
+
+ for package_name, package_detail in package_set.items():
+ # Info about dependencies of package_name
+ missing_deps: Set[Missing] = set()
+ conflicting_deps: Set[Conflicting] = set()
+
+ if should_ignore and should_ignore(package_name):
+ continue
+
+ for req in package_detail.dependencies:
+ name = canonicalize_name(req.name)
+
+ # Check if it's missing
+ if name not in package_set:
+ missed = True
+ if req.marker is not None:
+ missed = req.marker.evaluate({"extra": ""})
+ if missed:
+ missing_deps.add((name, req))
+ continue
+
+ # Check if there's a conflict
+ version = package_set[name].version
+ if not req.specifier.contains(version, prereleases=True):
+ conflicting_deps.add((name, version, req))
+
+ if missing_deps:
+ missing[package_name] = sorted(missing_deps, key=str)
+ if conflicting_deps:
+ conflicting[package_name] = sorted(conflicting_deps, key=str)
+
+ return missing, conflicting
+
+
+def check_install_conflicts(to_install: List[InstallRequirement]) -> ConflictDetails:
+ """For checking if the dependency graph would be consistent after \
+ installing given requirements
+ """
+ # Start from the current state
+ package_set, _ = create_package_set_from_installed()
+ # Install packages
+ would_be_installed = _simulate_installation_of(to_install, package_set)
+
+ # Only warn about directly-dependent packages; create a whitelist of them
+ whitelist = _create_whitelist(would_be_installed, package_set)
+
+ return (
+ package_set,
+ check_package_set(
+ package_set, should_ignore=lambda name: name not in whitelist
+ ),
+ )
+
+
+def check_unsupported(
+ packages: Iterable[BaseDistribution],
+ supported_tags: Iterable[Tag],
+) -> Generator[BaseDistribution, None, None]:
+ for p in packages:
+ with suppress(FileNotFoundError):
+ wheel_file = p.read_text("WHEEL")
+ wheel_tags: FrozenSet[Tag] = reduce(
+ frozenset.union,
+ map(parse_tag, Parser().parsestr(wheel_file).get_all("Tag", [])),
+ frozenset(),
+ )
+ if wheel_tags.isdisjoint(supported_tags):
+ yield p
+
+
+def _simulate_installation_of(
+ to_install: List[InstallRequirement], package_set: PackageSet
+) -> Set[NormalizedName]:
+ """Computes the version of packages after installing to_install."""
+ # Keep track of packages that were installed
+ installed = set()
+
+ # Modify it as installing requirement_set would (assuming no errors)
+ for inst_req in to_install:
+ abstract_dist = make_distribution_for_install_requirement(inst_req)
+ dist = abstract_dist.get_metadata_distribution()
+ name = dist.canonical_name
+ package_set[name] = PackageDetails(dist.version, list(dist.iter_dependencies()))
+
+ installed.add(name)
+
+ return installed
+
+
+def _create_whitelist(
+ would_be_installed: Set[NormalizedName], package_set: PackageSet
+) -> Set[NormalizedName]:
+ packages_affected = set(would_be_installed)
+
+ for package_name in package_set:
+ if package_name in packages_affected:
+ continue
+
+ for req in package_set[package_name].dependencies:
+ if canonicalize_name(req.name) in packages_affected:
+ packages_affected.add(package_name)
+ break
+
+ return packages_affected
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/freeze.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/freeze.py
new file mode 100644
index 000000000..bb1039fb7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/freeze.py
@@ -0,0 +1,258 @@
+import collections
+import logging
+import os
+from typing import Container, Dict, Generator, Iterable, List, NamedTuple, Optional, Set
+
+from pip._vendor.packaging.utils import canonicalize_name
+from pip._vendor.packaging.version import InvalidVersion
+
+from pip._internal.exceptions import BadCommand, InstallationError
+from pip._internal.metadata import BaseDistribution, get_environment
+from pip._internal.req.constructors import (
+ install_req_from_editable,
+ install_req_from_line,
+)
+from pip._internal.req.req_file import COMMENT_RE
+from pip._internal.utils.direct_url_helpers import direct_url_as_pep440_direct_reference
+
+logger = logging.getLogger(__name__)
+
+
+class _EditableInfo(NamedTuple):
+ requirement: str
+ comments: List[str]
+
+
+def freeze(
+ requirement: Optional[List[str]] = None,
+ local_only: bool = False,
+ user_only: bool = False,
+ paths: Optional[List[str]] = None,
+ isolated: bool = False,
+ exclude_editable: bool = False,
+ skip: Container[str] = (),
+) -> Generator[str, None, None]:
+ installations: Dict[str, FrozenRequirement] = {}
+
+ dists = get_environment(paths).iter_installed_distributions(
+ local_only=local_only,
+ skip=(),
+ user_only=user_only,
+ )
+ for dist in dists:
+ req = FrozenRequirement.from_dist(dist)
+ if exclude_editable and req.editable:
+ continue
+ installations[req.canonical_name] = req
+
+ if requirement:
+ # the options that don't get turned into an InstallRequirement
+ # should only be emitted once, even if the same option is in multiple
+ # requirements files, so we need to keep track of what has been emitted
+ # so that we don't emit it again if it's seen again
+ emitted_options: Set[str] = set()
+ # keep track of which files a requirement is in so that we can
+ # give an accurate warning if a requirement appears multiple times.
+ req_files: Dict[str, List[str]] = collections.defaultdict(list)
+ for req_file_path in requirement:
+ with open(req_file_path) as req_file:
+ for line in req_file:
+ if (
+ not line.strip()
+ or line.strip().startswith("#")
+ or line.startswith(
+ (
+ "-r",
+ "--requirement",
+ "-f",
+ "--find-links",
+ "-i",
+ "--index-url",
+ "--pre",
+ "--trusted-host",
+ "--process-dependency-links",
+ "--extra-index-url",
+ "--use-feature",
+ )
+ )
+ ):
+ line = line.rstrip()
+ if line not in emitted_options:
+ emitted_options.add(line)
+ yield line
+ continue
+
+ if line.startswith("-e") or line.startswith("--editable"):
+ if line.startswith("-e"):
+ line = line[2:].strip()
+ else:
+ line = line[len("--editable") :].strip().lstrip("=")
+ line_req = install_req_from_editable(
+ line,
+ isolated=isolated,
+ )
+ else:
+ line_req = install_req_from_line(
+ COMMENT_RE.sub("", line).strip(),
+ isolated=isolated,
+ )
+
+ if not line_req.name:
+ logger.info(
+ "Skipping line in requirement file [%s] because "
+ "it's not clear what it would install: %s",
+ req_file_path,
+ line.strip(),
+ )
+ logger.info(
+ " (add #egg=PackageName to the URL to avoid"
+ " this warning)"
+ )
+ else:
+ line_req_canonical_name = canonicalize_name(line_req.name)
+ if line_req_canonical_name not in installations:
+ # either it's not installed, or it is installed
+ # but has been processed already
+ if not req_files[line_req.name]:
+ logger.warning(
+ "Requirement file [%s] contains %s, but "
+ "package %r is not installed",
+ req_file_path,
+ COMMENT_RE.sub("", line).strip(),
+ line_req.name,
+ )
+ else:
+ req_files[line_req.name].append(req_file_path)
+ else:
+ yield str(installations[line_req_canonical_name]).rstrip()
+ del installations[line_req_canonical_name]
+ req_files[line_req.name].append(req_file_path)
+
+ # Warn about requirements that were included multiple times (in a
+ # single requirements file or in different requirements files).
+ for name, files in req_files.items():
+ if len(files) > 1:
+ logger.warning(
+ "Requirement %s included multiple times [%s]",
+ name,
+ ", ".join(sorted(set(files))),
+ )
+
+ yield ("## The following requirements were added by pip freeze:")
+ for installation in sorted(installations.values(), key=lambda x: x.name.lower()):
+ if installation.canonical_name not in skip:
+ yield str(installation).rstrip()
+
+
+def _format_as_name_version(dist: BaseDistribution) -> str:
+ try:
+ dist_version = dist.version
+ except InvalidVersion:
+ # legacy version
+ return f"{dist.raw_name}==={dist.raw_version}"
+ else:
+ return f"{dist.raw_name}=={dist_version}"
+
+
+def _get_editable_info(dist: BaseDistribution) -> _EditableInfo:
+ """
+ Compute and return values (req, comments) for use in
+ FrozenRequirement.from_dist().
+ """
+ editable_project_location = dist.editable_project_location
+ assert editable_project_location
+ location = os.path.normcase(os.path.abspath(editable_project_location))
+
+ from pip._internal.vcs import RemoteNotFoundError, RemoteNotValidError, vcs
+
+ vcs_backend = vcs.get_backend_for_dir(location)
+
+ if vcs_backend is None:
+ display = _format_as_name_version(dist)
+ logger.debug(
+ 'No VCS found for editable requirement "%s" in: %r',
+ display,
+ location,
+ )
+ return _EditableInfo(
+ requirement=location,
+ comments=[f"# Editable install with no version control ({display})"],
+ )
+
+ vcs_name = type(vcs_backend).__name__
+
+ try:
+ req = vcs_backend.get_src_requirement(location, dist.raw_name)
+ except RemoteNotFoundError:
+ display = _format_as_name_version(dist)
+ return _EditableInfo(
+ requirement=location,
+ comments=[f"# Editable {vcs_name} install with no remote ({display})"],
+ )
+ except RemoteNotValidError as ex:
+ display = _format_as_name_version(dist)
+ return _EditableInfo(
+ requirement=location,
+ comments=[
+ f"# Editable {vcs_name} install ({display}) with either a deleted "
+ f"local remote or invalid URI:",
+ f"# '{ex.url}'",
+ ],
+ )
+ except BadCommand:
+ logger.warning(
+ "cannot determine version of editable source in %s "
+ "(%s command not found in path)",
+ location,
+ vcs_backend.name,
+ )
+ return _EditableInfo(requirement=location, comments=[])
+ except InstallationError as exc:
+ logger.warning("Error when trying to get requirement for VCS system %s", exc)
+ else:
+ return _EditableInfo(requirement=req, comments=[])
+
+ logger.warning("Could not determine repository location of %s", location)
+
+ return _EditableInfo(
+ requirement=location,
+ comments=["## !! Could not determine repository location"],
+ )
+
+
+class FrozenRequirement:
+ def __init__(
+ self,
+ name: str,
+ req: str,
+ editable: bool,
+ comments: Iterable[str] = (),
+ ) -> None:
+ self.name = name
+ self.canonical_name = canonicalize_name(name)
+ self.req = req
+ self.editable = editable
+ self.comments = comments
+
+ @classmethod
+ def from_dist(cls, dist: BaseDistribution) -> "FrozenRequirement":
+ editable = dist.editable
+ if editable:
+ req, comments = _get_editable_info(dist)
+ else:
+ comments = []
+ direct_url = dist.direct_url
+ if direct_url:
+ # if PEP 610 metadata is present, use it
+ req = direct_url_as_pep440_direct_reference(direct_url, dist.raw_name)
+ else:
+ # name==version requirement
+ req = _format_as_name_version(dist)
+
+ return cls(dist.raw_name, req, editable, comments=comments)
+
+ def __str__(self) -> str:
+ req = self.req
+ if self.editable:
+ req = f"-e {req}"
+ return "\n".join(list(self.comments) + [str(req)]) + "\n"
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/__init__.py
new file mode 100644
index 000000000..24d6a5dd3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/__init__.py
@@ -0,0 +1,2 @@
+"""For modules related to installing packages.
+"""
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/editable_legacy.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/editable_legacy.py
new file mode 100644
index 000000000..9aaa699a6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/editable_legacy.py
@@ -0,0 +1,47 @@
+"""Legacy editable installation process, i.e. `setup.py develop`.
+"""
+
+import logging
+from typing import Optional, Sequence
+
+from pip._internal.build_env import BuildEnvironment
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.setuptools_build import make_setuptools_develop_args
+from pip._internal.utils.subprocess import call_subprocess
+
+logger = logging.getLogger(__name__)
+
+
+def install_editable(
+ *,
+ global_options: Sequence[str],
+ prefix: Optional[str],
+ home: Optional[str],
+ use_user_site: bool,
+ name: str,
+ setup_py_path: str,
+ isolated: bool,
+ build_env: BuildEnvironment,
+ unpacked_source_directory: str,
+) -> None:
+ """Install a package in editable mode. Most arguments are pass-through
+ to setuptools.
+ """
+ logger.info("Running setup.py develop for %s", name)
+
+ args = make_setuptools_develop_args(
+ setup_py_path,
+ global_options=global_options,
+ no_user_config=isolated,
+ prefix=prefix,
+ home=home,
+ use_user_site=use_user_site,
+ )
+
+ with indent_log():
+ with build_env:
+ call_subprocess(
+ args,
+ command_desc="python setup.py develop",
+ cwd=unpacked_source_directory,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/wheel.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/wheel.py
new file mode 100644
index 000000000..aef42aa9e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/install/wheel.py
@@ -0,0 +1,741 @@
+"""Support for installing and building the "wheel" binary package format.
+"""
+
+import collections
+import compileall
+import contextlib
+import csv
+import importlib
+import logging
+import os.path
+import re
+import shutil
+import sys
+import warnings
+from base64 import urlsafe_b64encode
+from email.message import Message
+from itertools import chain, filterfalse, starmap
+from typing import (
+ IO,
+ TYPE_CHECKING,
+ Any,
+ BinaryIO,
+ Callable,
+ Dict,
+ Generator,
+ Iterable,
+ Iterator,
+ List,
+ NewType,
+ Optional,
+ Protocol,
+ Sequence,
+ Set,
+ Tuple,
+ Union,
+ cast,
+)
+from zipfile import ZipFile, ZipInfo
+
+from pip._vendor.distlib.scripts import ScriptMaker
+from pip._vendor.distlib.util import get_export_entry
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.exceptions import InstallationError
+from pip._internal.locations import get_major_minor_version
+from pip._internal.metadata import (
+ BaseDistribution,
+ FilesystemWheel,
+ get_wheel_distribution,
+)
+from pip._internal.models.direct_url import DIRECT_URL_METADATA_NAME, DirectUrl
+from pip._internal.models.scheme import SCHEME_KEYS, Scheme
+from pip._internal.utils.filesystem import adjacent_tmp_file, replace
+from pip._internal.utils.misc import StreamWrapper, ensure_dir, hash_file, partition
+from pip._internal.utils.unpacking import (
+ current_umask,
+ is_within_directory,
+ set_extracted_file_to_default_mode_plus_executable,
+ zip_item_is_executable,
+)
+from pip._internal.utils.wheel import parse_wheel
+
+if TYPE_CHECKING:
+
+ class File(Protocol):
+ src_record_path: "RecordPath"
+ dest_path: str
+ changed: bool
+
+ def save(self) -> None:
+ pass
+
+
+logger = logging.getLogger(__name__)
+
+RecordPath = NewType("RecordPath", str)
+InstalledCSVRow = Tuple[RecordPath, str, Union[int, str]]
+
+
+def rehash(path: str, blocksize: int = 1 << 20) -> Tuple[str, str]:
+ """Return (encoded_digest, length) for path using hashlib.sha256()"""
+ h, length = hash_file(path, blocksize)
+ digest = "sha256=" + urlsafe_b64encode(h.digest()).decode("latin1").rstrip("=")
+ return (digest, str(length))
+
+
+def csv_io_kwargs(mode: str) -> Dict[str, Any]:
+ """Return keyword arguments to properly open a CSV file
+ in the given mode.
+ """
+ return {"mode": mode, "newline": "", "encoding": "utf-8"}
+
+
+def fix_script(path: str) -> bool:
+ """Replace #!python with #!/path/to/python
+ Return True if file was changed.
+ """
+ # XXX RECORD hashes will need to be updated
+ assert os.path.isfile(path)
+
+ with open(path, "rb") as script:
+ firstline = script.readline()
+ if not firstline.startswith(b"#!python"):
+ return False
+ exename = sys.executable.encode(sys.getfilesystemencoding())
+ firstline = b"#!" + exename + os.linesep.encode("ascii")
+ rest = script.read()
+ with open(path, "wb") as script:
+ script.write(firstline)
+ script.write(rest)
+ return True
+
+
+def wheel_root_is_purelib(metadata: Message) -> bool:
+ return metadata.get("Root-Is-Purelib", "").lower() == "true"
+
+
+def get_entrypoints(dist: BaseDistribution) -> Tuple[Dict[str, str], Dict[str, str]]:
+ console_scripts = {}
+ gui_scripts = {}
+ for entry_point in dist.iter_entry_points():
+ if entry_point.group == "console_scripts":
+ console_scripts[entry_point.name] = entry_point.value
+ elif entry_point.group == "gui_scripts":
+ gui_scripts[entry_point.name] = entry_point.value
+ return console_scripts, gui_scripts
+
+
+def message_about_scripts_not_on_PATH(scripts: Sequence[str]) -> Optional[str]:
+ """Determine if any scripts are not on PATH and format a warning.
+ Returns a warning message if one or more scripts are not on PATH,
+ otherwise None.
+ """
+ if not scripts:
+ return None
+
+ # Group scripts by the path they were installed in
+ grouped_by_dir: Dict[str, Set[str]] = collections.defaultdict(set)
+ for destfile in scripts:
+ parent_dir = os.path.dirname(destfile)
+ script_name = os.path.basename(destfile)
+ grouped_by_dir[parent_dir].add(script_name)
+
+ # We don't want to warn for directories that are on PATH.
+ not_warn_dirs = [
+ os.path.normcase(os.path.normpath(i)).rstrip(os.sep)
+ for i in os.environ.get("PATH", "").split(os.pathsep)
+ ]
+ # If an executable sits with sys.executable, we don't warn for it.
+ # This covers the case of venv invocations without activating the venv.
+ not_warn_dirs.append(
+ os.path.normcase(os.path.normpath(os.path.dirname(sys.executable)))
+ )
+ warn_for: Dict[str, Set[str]] = {
+ parent_dir: scripts
+ for parent_dir, scripts in grouped_by_dir.items()
+ if os.path.normcase(os.path.normpath(parent_dir)) not in not_warn_dirs
+ }
+ if not warn_for:
+ return None
+
+ # Format a message
+ msg_lines = []
+ for parent_dir, dir_scripts in warn_for.items():
+ sorted_scripts: List[str] = sorted(dir_scripts)
+ if len(sorted_scripts) == 1:
+ start_text = f"script {sorted_scripts[0]} is"
+ else:
+ start_text = "scripts {} are".format(
+ ", ".join(sorted_scripts[:-1]) + " and " + sorted_scripts[-1]
+ )
+
+ msg_lines.append(
+ f"The {start_text} installed in '{parent_dir}' which is not on PATH."
+ )
+
+ last_line_fmt = (
+ "Consider adding {} to PATH or, if you prefer "
+ "to suppress this warning, use --no-warn-script-location."
+ )
+ if len(msg_lines) == 1:
+ msg_lines.append(last_line_fmt.format("this directory"))
+ else:
+ msg_lines.append(last_line_fmt.format("these directories"))
+
+ # Add a note if any directory starts with ~
+ warn_for_tilde = any(
+ i[0] == "~" for i in os.environ.get("PATH", "").split(os.pathsep) if i
+ )
+ if warn_for_tilde:
+ tilde_warning_msg = (
+ "NOTE: The current PATH contains path(s) starting with `~`, "
+ "which may not be expanded by all applications."
+ )
+ msg_lines.append(tilde_warning_msg)
+
+ # Returns the formatted multiline message
+ return "\n".join(msg_lines)
+
+
+def _normalized_outrows(
+ outrows: Iterable[InstalledCSVRow],
+) -> List[Tuple[str, str, str]]:
+ """Normalize the given rows of a RECORD file.
+
+ Items in each row are converted into str. Rows are then sorted to make
+ the value more predictable for tests.
+
+ Each row is a 3-tuple (path, hash, size) and corresponds to a record of
+ a RECORD file (see PEP 376 and PEP 427 for details). For the rows
+ passed to this function, the size can be an integer as an int or string,
+ or the empty string.
+ """
+ # Normally, there should only be one row per path, in which case the
+ # second and third elements don't come into play when sorting.
+ # However, in cases in the wild where a path might happen to occur twice,
+ # we don't want the sort operation to trigger an error (but still want
+ # determinism). Since the third element can be an int or string, we
+ # coerce each element to a string to avoid a TypeError in this case.
+ # For additional background, see--
+ # https://github.com/pypa/pip/issues/5868
+ return sorted(
+ (record_path, hash_, str(size)) for record_path, hash_, size in outrows
+ )
+
+
+def _record_to_fs_path(record_path: RecordPath, lib_dir: str) -> str:
+ return os.path.join(lib_dir, record_path)
+
+
+def _fs_to_record_path(path: str, lib_dir: str) -> RecordPath:
+ # On Windows, do not handle relative paths if they belong to different
+ # logical disks
+ if os.path.splitdrive(path)[0].lower() == os.path.splitdrive(lib_dir)[0].lower():
+ path = os.path.relpath(path, lib_dir)
+
+ path = path.replace(os.path.sep, "/")
+ return cast("RecordPath", path)
+
+
+def get_csv_rows_for_installed(
+ old_csv_rows: List[List[str]],
+ installed: Dict[RecordPath, RecordPath],
+ changed: Set[RecordPath],
+ generated: List[str],
+ lib_dir: str,
+) -> List[InstalledCSVRow]:
+ """
+ :param installed: A map from archive RECORD path to installation RECORD
+ path.
+ """
+ installed_rows: List[InstalledCSVRow] = []
+ for row in old_csv_rows:
+ if len(row) > 3:
+ logger.warning("RECORD line has more than three elements: %s", row)
+ old_record_path = cast("RecordPath", row[0])
+ new_record_path = installed.pop(old_record_path, old_record_path)
+ if new_record_path in changed:
+ digest, length = rehash(_record_to_fs_path(new_record_path, lib_dir))
+ else:
+ digest = row[1] if len(row) > 1 else ""
+ length = row[2] if len(row) > 2 else ""
+ installed_rows.append((new_record_path, digest, length))
+ for f in generated:
+ path = _fs_to_record_path(f, lib_dir)
+ digest, length = rehash(f)
+ installed_rows.append((path, digest, length))
+ return installed_rows + [
+ (installed_record_path, "", "") for installed_record_path in installed.values()
+ ]
+
+
+def get_console_script_specs(console: Dict[str, str]) -> List[str]:
+ """
+ Given the mapping from entrypoint name to callable, return the relevant
+ console script specs.
+ """
+ # Don't mutate caller's version
+ console = console.copy()
+
+ scripts_to_generate = []
+
+ # Special case pip and setuptools to generate versioned wrappers
+ #
+ # The issue is that some projects (specifically, pip and setuptools) use
+ # code in setup.py to create "versioned" entry points - pip2.7 on Python
+ # 2.7, pip3.3 on Python 3.3, etc. But these entry points are baked into
+ # the wheel metadata at build time, and so if the wheel is installed with
+ # a *different* version of Python the entry points will be wrong. The
+ # correct fix for this is to enhance the metadata to be able to describe
+ # such versioned entry points.
+ # Currently, projects using versioned entry points will either have
+ # incorrect versioned entry points, or they will not be able to distribute
+ # "universal" wheels (i.e., they will need a wheel per Python version).
+ #
+ # Because setuptools and pip are bundled with _ensurepip and virtualenv,
+ # we need to use universal wheels. As a workaround, we
+ # override the versioned entry points in the wheel and generate the
+ # correct ones.
+ #
+ # To add the level of hack in this section of code, in order to support
+ # ensurepip this code will look for an ``ENSUREPIP_OPTIONS`` environment
+ # variable which will control which version scripts get installed.
+ #
+ # ENSUREPIP_OPTIONS=altinstall
+ # - Only pipX.Y and easy_install-X.Y will be generated and installed
+ # ENSUREPIP_OPTIONS=install
+ # - pipX.Y, pipX, easy_install-X.Y will be generated and installed. Note
+ # that this option is technically if ENSUREPIP_OPTIONS is set and is
+ # not altinstall
+ # DEFAULT
+ # - The default behavior is to install pip, pipX, pipX.Y, easy_install
+ # and easy_install-X.Y.
+ pip_script = console.pop("pip", None)
+ if pip_script:
+ if "ENSUREPIP_OPTIONS" not in os.environ:
+ scripts_to_generate.append("pip = " + pip_script)
+
+ if os.environ.get("ENSUREPIP_OPTIONS", "") != "altinstall":
+ scripts_to_generate.append(f"pip{sys.version_info[0]} = {pip_script}")
+
+ scripts_to_generate.append(f"pip{get_major_minor_version()} = {pip_script}")
+ # Delete any other versioned pip entry points
+ pip_ep = [k for k in console if re.match(r"pip(\d+(\.\d+)?)?$", k)]
+ for k in pip_ep:
+ del console[k]
+ easy_install_script = console.pop("easy_install", None)
+ if easy_install_script:
+ if "ENSUREPIP_OPTIONS" not in os.environ:
+ scripts_to_generate.append("easy_install = " + easy_install_script)
+
+ scripts_to_generate.append(
+ f"easy_install-{get_major_minor_version()} = {easy_install_script}"
+ )
+ # Delete any other versioned easy_install entry points
+ easy_install_ep = [
+ k for k in console if re.match(r"easy_install(-\d+\.\d+)?$", k)
+ ]
+ for k in easy_install_ep:
+ del console[k]
+
+ # Generate the console entry points specified in the wheel
+ scripts_to_generate.extend(starmap("{} = {}".format, console.items()))
+
+ return scripts_to_generate
+
+
+class ZipBackedFile:
+ def __init__(
+ self, src_record_path: RecordPath, dest_path: str, zip_file: ZipFile
+ ) -> None:
+ self.src_record_path = src_record_path
+ self.dest_path = dest_path
+ self._zip_file = zip_file
+ self.changed = False
+
+ def _getinfo(self) -> ZipInfo:
+ return self._zip_file.getinfo(self.src_record_path)
+
+ def save(self) -> None:
+ # When we open the output file below, any existing file is truncated
+ # before we start writing the new contents. This is fine in most
+ # cases, but can cause a segfault if pip has loaded a shared
+ # object (e.g. from pyopenssl through its vendored urllib3)
+ # Since the shared object is mmap'd an attempt to call a
+ # symbol in it will then cause a segfault. Unlinking the file
+ # allows writing of new contents while allowing the process to
+ # continue to use the old copy.
+ if os.path.exists(self.dest_path):
+ os.unlink(self.dest_path)
+
+ zipinfo = self._getinfo()
+
+ # optimization: the file is created by open(),
+ # skip the decompression when there is 0 bytes to decompress.
+ with open(self.dest_path, "wb") as dest:
+ if zipinfo.file_size > 0:
+ with self._zip_file.open(zipinfo) as f:
+ blocksize = min(zipinfo.file_size, 1024 * 1024)
+ shutil.copyfileobj(f, dest, blocksize)
+
+ if zip_item_is_executable(zipinfo):
+ set_extracted_file_to_default_mode_plus_executable(self.dest_path)
+
+
+class ScriptFile:
+ def __init__(self, file: "File") -> None:
+ self._file = file
+ self.src_record_path = self._file.src_record_path
+ self.dest_path = self._file.dest_path
+ self.changed = False
+
+ def save(self) -> None:
+ self._file.save()
+ self.changed = fix_script(self.dest_path)
+
+
+class MissingCallableSuffix(InstallationError):
+ def __init__(self, entry_point: str) -> None:
+ super().__init__(
+ f"Invalid script entry point: {entry_point} - A callable "
+ "suffix is required. Cf https://packaging.python.org/"
+ "specifications/entry-points/#use-for-scripts for more "
+ "information."
+ )
+
+
+def _raise_for_invalid_entrypoint(specification: str) -> None:
+ entry = get_export_entry(specification)
+ if entry is not None and entry.suffix is None:
+ raise MissingCallableSuffix(str(entry))
+
+
+class PipScriptMaker(ScriptMaker):
+ def make(
+ self, specification: str, options: Optional[Dict[str, Any]] = None
+ ) -> List[str]:
+ _raise_for_invalid_entrypoint(specification)
+ return super().make(specification, options)
+
+
+def _install_wheel( # noqa: C901, PLR0915 function is too long
+ name: str,
+ wheel_zip: ZipFile,
+ wheel_path: str,
+ scheme: Scheme,
+ pycompile: bool = True,
+ warn_script_location: bool = True,
+ direct_url: Optional[DirectUrl] = None,
+ requested: bool = False,
+) -> None:
+ """Install a wheel.
+
+ :param name: Name of the project to install
+ :param wheel_zip: open ZipFile for wheel being installed
+ :param scheme: Distutils scheme dictating the install directories
+ :param req_description: String used in place of the requirement, for
+ logging
+ :param pycompile: Whether to byte-compile installed Python files
+ :param warn_script_location: Whether to check that scripts are installed
+ into a directory on PATH
+ :raises UnsupportedWheel:
+ * when the directory holds an unpacked wheel with incompatible
+ Wheel-Version
+ * when the .dist-info dir does not match the wheel
+ """
+ info_dir, metadata = parse_wheel(wheel_zip, name)
+
+ if wheel_root_is_purelib(metadata):
+ lib_dir = scheme.purelib
+ else:
+ lib_dir = scheme.platlib
+
+ # Record details of the files moved
+ # installed = files copied from the wheel to the destination
+ # changed = files changed while installing (scripts #! line typically)
+ # generated = files newly generated during the install (script wrappers)
+ installed: Dict[RecordPath, RecordPath] = {}
+ changed: Set[RecordPath] = set()
+ generated: List[str] = []
+
+ def record_installed(
+ srcfile: RecordPath, destfile: str, modified: bool = False
+ ) -> None:
+ """Map archive RECORD paths to installation RECORD paths."""
+ newpath = _fs_to_record_path(destfile, lib_dir)
+ installed[srcfile] = newpath
+ if modified:
+ changed.add(newpath)
+
+ def is_dir_path(path: RecordPath) -> bool:
+ return path.endswith("/")
+
+ def assert_no_path_traversal(dest_dir_path: str, target_path: str) -> None:
+ if not is_within_directory(dest_dir_path, target_path):
+ message = (
+ "The wheel {!r} has a file {!r} trying to install"
+ " outside the target directory {!r}"
+ )
+ raise InstallationError(
+ message.format(wheel_path, target_path, dest_dir_path)
+ )
+
+ def root_scheme_file_maker(
+ zip_file: ZipFile, dest: str
+ ) -> Callable[[RecordPath], "File"]:
+ def make_root_scheme_file(record_path: RecordPath) -> "File":
+ normed_path = os.path.normpath(record_path)
+ dest_path = os.path.join(dest, normed_path)
+ assert_no_path_traversal(dest, dest_path)
+ return ZipBackedFile(record_path, dest_path, zip_file)
+
+ return make_root_scheme_file
+
+ def data_scheme_file_maker(
+ zip_file: ZipFile, scheme: Scheme
+ ) -> Callable[[RecordPath], "File"]:
+ scheme_paths = {key: getattr(scheme, key) for key in SCHEME_KEYS}
+
+ def make_data_scheme_file(record_path: RecordPath) -> "File":
+ normed_path = os.path.normpath(record_path)
+ try:
+ _, scheme_key, dest_subpath = normed_path.split(os.path.sep, 2)
+ except ValueError:
+ message = (
+ f"Unexpected file in {wheel_path}: {record_path!r}. .data directory"
+ " contents should be named like: '<scheme key>/<path>'."
+ )
+ raise InstallationError(message)
+
+ try:
+ scheme_path = scheme_paths[scheme_key]
+ except KeyError:
+ valid_scheme_keys = ", ".join(sorted(scheme_paths))
+ message = (
+ f"Unknown scheme key used in {wheel_path}: {scheme_key} "
+ f"(for file {record_path!r}). .data directory contents "
+ f"should be in subdirectories named with a valid scheme "
+ f"key ({valid_scheme_keys})"
+ )
+ raise InstallationError(message)
+
+ dest_path = os.path.join(scheme_path, dest_subpath)
+ assert_no_path_traversal(scheme_path, dest_path)
+ return ZipBackedFile(record_path, dest_path, zip_file)
+
+ return make_data_scheme_file
+
+ def is_data_scheme_path(path: RecordPath) -> bool:
+ return path.split("/", 1)[0].endswith(".data")
+
+ paths = cast(List[RecordPath], wheel_zip.namelist())
+ file_paths = filterfalse(is_dir_path, paths)
+ root_scheme_paths, data_scheme_paths = partition(is_data_scheme_path, file_paths)
+
+ make_root_scheme_file = root_scheme_file_maker(wheel_zip, lib_dir)
+ files: Iterator[File] = map(make_root_scheme_file, root_scheme_paths)
+
+ def is_script_scheme_path(path: RecordPath) -> bool:
+ parts = path.split("/", 2)
+ return len(parts) > 2 and parts[0].endswith(".data") and parts[1] == "scripts"
+
+ other_scheme_paths, script_scheme_paths = partition(
+ is_script_scheme_path, data_scheme_paths
+ )
+
+ make_data_scheme_file = data_scheme_file_maker(wheel_zip, scheme)
+ other_scheme_files = map(make_data_scheme_file, other_scheme_paths)
+ files = chain(files, other_scheme_files)
+
+ # Get the defined entry points
+ distribution = get_wheel_distribution(
+ FilesystemWheel(wheel_path),
+ canonicalize_name(name),
+ )
+ console, gui = get_entrypoints(distribution)
+
+ def is_entrypoint_wrapper(file: "File") -> bool:
+ # EP, EP.exe and EP-script.py are scripts generated for
+ # entry point EP by setuptools
+ path = file.dest_path
+ name = os.path.basename(path)
+ if name.lower().endswith(".exe"):
+ matchname = name[:-4]
+ elif name.lower().endswith("-script.py"):
+ matchname = name[:-10]
+ elif name.lower().endswith(".pya"):
+ matchname = name[:-4]
+ else:
+ matchname = name
+ # Ignore setuptools-generated scripts
+ return matchname in console or matchname in gui
+
+ script_scheme_files: Iterator[File] = map(
+ make_data_scheme_file, script_scheme_paths
+ )
+ script_scheme_files = filterfalse(is_entrypoint_wrapper, script_scheme_files)
+ script_scheme_files = map(ScriptFile, script_scheme_files)
+ files = chain(files, script_scheme_files)
+
+ existing_parents = set()
+ for file in files:
+ # directory creation is lazy and after file filtering
+ # to ensure we don't install empty dirs; empty dirs can't be
+ # uninstalled.
+ parent_dir = os.path.dirname(file.dest_path)
+ if parent_dir not in existing_parents:
+ ensure_dir(parent_dir)
+ existing_parents.add(parent_dir)
+ file.save()
+ record_installed(file.src_record_path, file.dest_path, file.changed)
+
+ def pyc_source_file_paths() -> Generator[str, None, None]:
+ # We de-duplicate installation paths, since there can be overlap (e.g.
+ # file in .data maps to same location as file in wheel root).
+ # Sorting installation paths makes it easier to reproduce and debug
+ # issues related to permissions on existing files.
+ for installed_path in sorted(set(installed.values())):
+ full_installed_path = os.path.join(lib_dir, installed_path)
+ if not os.path.isfile(full_installed_path):
+ continue
+ if not full_installed_path.endswith(".py"):
+ continue
+ yield full_installed_path
+
+ def pyc_output_path(path: str) -> str:
+ """Return the path the pyc file would have been written to."""
+ return importlib.util.cache_from_source(path)
+
+ # Compile all of the pyc files for the installed files
+ if pycompile:
+ with contextlib.redirect_stdout(
+ StreamWrapper.from_stream(sys.stdout)
+ ) as stdout:
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore")
+ for path in pyc_source_file_paths():
+ success = compileall.compile_file(path, force=True, quiet=True)
+ if success:
+ pyc_path = pyc_output_path(path)
+ assert os.path.exists(pyc_path)
+ pyc_record_path = cast(
+ "RecordPath", pyc_path.replace(os.path.sep, "/")
+ )
+ record_installed(pyc_record_path, pyc_path)
+ logger.debug(stdout.getvalue())
+
+ maker = PipScriptMaker(None, scheme.scripts)
+
+ # Ensure old scripts are overwritten.
+ # See https://github.com/pypa/pip/issues/1800
+ maker.clobber = True
+
+ # Ensure we don't generate any variants for scripts because this is almost
+ # never what somebody wants.
+ # See https://bitbucket.org/pypa/distlib/issue/35/
+ maker.variants = {""}
+
+ # This is required because otherwise distlib creates scripts that are not
+ # executable.
+ # See https://bitbucket.org/pypa/distlib/issue/32/
+ maker.set_mode = True
+
+ # Generate the console and GUI entry points specified in the wheel
+ scripts_to_generate = get_console_script_specs(console)
+
+ gui_scripts_to_generate = list(starmap("{} = {}".format, gui.items()))
+
+ generated_console_scripts = maker.make_multiple(scripts_to_generate)
+ generated.extend(generated_console_scripts)
+
+ generated.extend(maker.make_multiple(gui_scripts_to_generate, {"gui": True}))
+
+ if warn_script_location:
+ msg = message_about_scripts_not_on_PATH(generated_console_scripts)
+ if msg is not None:
+ logger.warning(msg)
+
+ generated_file_mode = 0o666 & ~current_umask()
+
+ @contextlib.contextmanager
+ def _generate_file(path: str, **kwargs: Any) -> Generator[BinaryIO, None, None]:
+ with adjacent_tmp_file(path, **kwargs) as f:
+ yield f
+ os.chmod(f.name, generated_file_mode)
+ replace(f.name, path)
+
+ dest_info_dir = os.path.join(lib_dir, info_dir)
+
+ # Record pip as the installer
+ installer_path = os.path.join(dest_info_dir, "INSTALLER")
+ with _generate_file(installer_path) as installer_file:
+ installer_file.write(b"pip\n")
+ generated.append(installer_path)
+
+ # Record the PEP 610 direct URL reference
+ if direct_url is not None:
+ direct_url_path = os.path.join(dest_info_dir, DIRECT_URL_METADATA_NAME)
+ with _generate_file(direct_url_path) as direct_url_file:
+ direct_url_file.write(direct_url.to_json().encode("utf-8"))
+ generated.append(direct_url_path)
+
+ # Record the REQUESTED file
+ if requested:
+ requested_path = os.path.join(dest_info_dir, "REQUESTED")
+ with open(requested_path, "wb"):
+ pass
+ generated.append(requested_path)
+
+ record_text = distribution.read_text("RECORD")
+ record_rows = list(csv.reader(record_text.splitlines()))
+
+ rows = get_csv_rows_for_installed(
+ record_rows,
+ installed=installed,
+ changed=changed,
+ generated=generated,
+ lib_dir=lib_dir,
+ )
+
+ # Record details of all files installed
+ record_path = os.path.join(dest_info_dir, "RECORD")
+
+ with _generate_file(record_path, **csv_io_kwargs("w")) as record_file:
+ # Explicitly cast to typing.IO[str] as a workaround for the mypy error:
+ # "writer" has incompatible type "BinaryIO"; expected "_Writer"
+ writer = csv.writer(cast("IO[str]", record_file))
+ writer.writerows(_normalized_outrows(rows))
+
+
+@contextlib.contextmanager
+def req_error_context(req_description: str) -> Generator[None, None, None]:
+ try:
+ yield
+ except InstallationError as e:
+ message = f"For req: {req_description}. {e.args[0]}"
+ raise InstallationError(message) from e
+
+
+def install_wheel(
+ name: str,
+ wheel_path: str,
+ scheme: Scheme,
+ req_description: str,
+ pycompile: bool = True,
+ warn_script_location: bool = True,
+ direct_url: Optional[DirectUrl] = None,
+ requested: bool = False,
+) -> None:
+ with ZipFile(wheel_path, allowZip64=True) as z:
+ with req_error_context(req_description):
+ _install_wheel(
+ name=name,
+ wheel_zip=z,
+ wheel_path=wheel_path,
+ scheme=scheme,
+ pycompile=pycompile,
+ warn_script_location=warn_script_location,
+ direct_url=direct_url,
+ requested=requested,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/operations/prepare.py b/solutions/.venv/Lib/site-packages/pip/_internal/operations/prepare.py
new file mode 100644
index 000000000..e6aa34472
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/operations/prepare.py
@@ -0,0 +1,732 @@
+"""Prepares a distribution for installation
+"""
+
+# The following comment should be removed at some point in the future.
+# mypy: strict-optional=False
+
+import mimetypes
+import os
+import shutil
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Dict, Iterable, List, Optional
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.distributions import make_distribution_for_install_requirement
+from pip._internal.distributions.installed import InstalledDistribution
+from pip._internal.exceptions import (
+ DirectoryUrlHashUnsupported,
+ HashMismatch,
+ HashUnpinned,
+ InstallationError,
+ MetadataInconsistent,
+ NetworkConnectionError,
+ VcsHashUnsupported,
+)
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.metadata import BaseDistribution, get_metadata_distribution
+from pip._internal.models.direct_url import ArchiveInfo
+from pip._internal.models.link import Link
+from pip._internal.models.wheel import Wheel
+from pip._internal.network.download import BatchDownloader, Downloader
+from pip._internal.network.lazy_wheel import (
+ HTTPRangeRequestUnsupported,
+ dist_from_wheel_url,
+)
+from pip._internal.network.session import PipSession
+from pip._internal.operations.build.build_tracker import BuildTracker
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.utils._log import getLogger
+from pip._internal.utils.direct_url_helpers import (
+ direct_url_for_editable,
+ direct_url_from_link,
+)
+from pip._internal.utils.hashes import Hashes, MissingHashes
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.misc import (
+ display_path,
+ hash_file,
+ hide_url,
+ redact_auth_from_requirement,
+)
+from pip._internal.utils.temp_dir import TempDirectory
+from pip._internal.utils.unpacking import unpack_file
+from pip._internal.vcs import vcs
+
+logger = getLogger(__name__)
+
+
+def _get_prepared_distribution(
+ req: InstallRequirement,
+ build_tracker: BuildTracker,
+ finder: PackageFinder,
+ build_isolation: bool,
+ check_build_deps: bool,
+) -> BaseDistribution:
+ """Prepare a distribution for installation."""
+ abstract_dist = make_distribution_for_install_requirement(req)
+ tracker_id = abstract_dist.build_tracker_id
+ if tracker_id is not None:
+ with build_tracker.track(req, tracker_id):
+ abstract_dist.prepare_distribution_metadata(
+ finder, build_isolation, check_build_deps
+ )
+ return abstract_dist.get_metadata_distribution()
+
+
+def unpack_vcs_link(link: Link, location: str, verbosity: int) -> None:
+ vcs_backend = vcs.get_backend_for_scheme(link.scheme)
+ assert vcs_backend is not None
+ vcs_backend.unpack(location, url=hide_url(link.url), verbosity=verbosity)
+
+
+@dataclass
+class File:
+ path: str
+ content_type: Optional[str] = None
+
+ def __post_init__(self) -> None:
+ if self.content_type is None:
+ self.content_type = mimetypes.guess_type(self.path)[0]
+
+
+def get_http_url(
+ link: Link,
+ download: Downloader,
+ download_dir: Optional[str] = None,
+ hashes: Optional[Hashes] = None,
+) -> File:
+ temp_dir = TempDirectory(kind="unpack", globally_managed=True)
+ # If a download dir is specified, is the file already downloaded there?
+ already_downloaded_path = None
+ if download_dir:
+ already_downloaded_path = _check_download_dir(link, download_dir, hashes)
+
+ if already_downloaded_path:
+ from_path = already_downloaded_path
+ content_type = None
+ else:
+ # let's download to a tmp dir
+ from_path, content_type = download(link, temp_dir.path)
+ if hashes:
+ hashes.check_against_path(from_path)
+
+ return File(from_path, content_type)
+
+
+def get_file_url(
+ link: Link, download_dir: Optional[str] = None, hashes: Optional[Hashes] = None
+) -> File:
+ """Get file and optionally check its hash."""
+ # If a download dir is specified, is the file already there and valid?
+ already_downloaded_path = None
+ if download_dir:
+ already_downloaded_path = _check_download_dir(link, download_dir, hashes)
+
+ if already_downloaded_path:
+ from_path = already_downloaded_path
+ else:
+ from_path = link.file_path
+
+ # If --require-hashes is off, `hashes` is either empty, the
+ # link's embedded hash, or MissingHashes; it is required to
+ # match. If --require-hashes is on, we are satisfied by any
+ # hash in `hashes` matching: a URL-based or an option-based
+ # one; no internet-sourced hash will be in `hashes`.
+ if hashes:
+ hashes.check_against_path(from_path)
+ return File(from_path, None)
+
+
+def unpack_url(
+ link: Link,
+ location: str,
+ download: Downloader,
+ verbosity: int,
+ download_dir: Optional[str] = None,
+ hashes: Optional[Hashes] = None,
+) -> Optional[File]:
+ """Unpack link into location, downloading if required.
+
+ :param hashes: A Hashes object, one of whose embedded hashes must match,
+ or HashMismatch will be raised. If the Hashes is empty, no matches are
+ required, and unhashable types of requirements (like VCS ones, which
+ would ordinarily raise HashUnsupported) are allowed.
+ """
+ # non-editable vcs urls
+ if link.is_vcs:
+ unpack_vcs_link(link, location, verbosity=verbosity)
+ return None
+
+ assert not link.is_existing_dir()
+
+ # file urls
+ if link.is_file:
+ file = get_file_url(link, download_dir, hashes=hashes)
+
+ # http urls
+ else:
+ file = get_http_url(
+ link,
+ download,
+ download_dir,
+ hashes=hashes,
+ )
+
+ # unpack the archive to the build dir location. even when only downloading
+ # archives, they have to be unpacked to parse dependencies, except wheels
+ if not link.is_wheel:
+ unpack_file(file.path, location, file.content_type)
+
+ return file
+
+
+def _check_download_dir(
+ link: Link,
+ download_dir: str,
+ hashes: Optional[Hashes],
+ warn_on_hash_mismatch: bool = True,
+) -> Optional[str]:
+ """Check download_dir for previously downloaded file with correct hash
+ If a correct file is found return its path else None
+ """
+ download_path = os.path.join(download_dir, link.filename)
+
+ if not os.path.exists(download_path):
+ return None
+
+ # If already downloaded, does its hash match?
+ logger.info("File was already downloaded %s", download_path)
+ if hashes:
+ try:
+ hashes.check_against_path(download_path)
+ except HashMismatch:
+ if warn_on_hash_mismatch:
+ logger.warning(
+ "Previously-downloaded file %s has bad hash. Re-downloading.",
+ download_path,
+ )
+ os.unlink(download_path)
+ return None
+ return download_path
+
+
+class RequirementPreparer:
+ """Prepares a Requirement"""
+
+ def __init__(
+ self,
+ build_dir: str,
+ download_dir: Optional[str],
+ src_dir: str,
+ build_isolation: bool,
+ check_build_deps: bool,
+ build_tracker: BuildTracker,
+ session: PipSession,
+ progress_bar: str,
+ finder: PackageFinder,
+ require_hashes: bool,
+ use_user_site: bool,
+ lazy_wheel: bool,
+ verbosity: int,
+ legacy_resolver: bool,
+ ) -> None:
+ super().__init__()
+
+ self.src_dir = src_dir
+ self.build_dir = build_dir
+ self.build_tracker = build_tracker
+ self._session = session
+ self._download = Downloader(session, progress_bar)
+ self._batch_download = BatchDownloader(session, progress_bar)
+ self.finder = finder
+
+ # Where still-packed archives should be written to. If None, they are
+ # not saved, and are deleted immediately after unpacking.
+ self.download_dir = download_dir
+
+ # Is build isolation allowed?
+ self.build_isolation = build_isolation
+
+ # Should check build dependencies?
+ self.check_build_deps = check_build_deps
+
+ # Should hash-checking be required?
+ self.require_hashes = require_hashes
+
+ # Should install in user site-packages?
+ self.use_user_site = use_user_site
+
+ # Should wheels be downloaded lazily?
+ self.use_lazy_wheel = lazy_wheel
+
+ # How verbose should underlying tooling be?
+ self.verbosity = verbosity
+
+ # Are we using the legacy resolver?
+ self.legacy_resolver = legacy_resolver
+
+ # Memoized downloaded files, as mapping of url: path.
+ self._downloaded: Dict[str, str] = {}
+
+ # Previous "header" printed for a link-based InstallRequirement
+ self._previous_requirement_header = ("", "")
+
+ def _log_preparing_link(self, req: InstallRequirement) -> None:
+ """Provide context for the requirement being prepared."""
+ if req.link.is_file and not req.is_wheel_from_cache:
+ message = "Processing %s"
+ information = str(display_path(req.link.file_path))
+ else:
+ message = "Collecting %s"
+ information = redact_auth_from_requirement(req.req) if req.req else str(req)
+
+ # If we used req.req, inject requirement source if available (this
+ # would already be included if we used req directly)
+ if req.req and req.comes_from:
+ if isinstance(req.comes_from, str):
+ comes_from: Optional[str] = req.comes_from
+ else:
+ comes_from = req.comes_from.from_path()
+ if comes_from:
+ information += f" (from {comes_from})"
+
+ if (message, information) != self._previous_requirement_header:
+ self._previous_requirement_header = (message, information)
+ logger.info(message, information)
+
+ if req.is_wheel_from_cache:
+ with indent_log():
+ logger.info("Using cached %s", req.link.filename)
+
+ def _ensure_link_req_src_dir(
+ self, req: InstallRequirement, parallel_builds: bool
+ ) -> None:
+ """Ensure source_dir of a linked InstallRequirement."""
+ # Since source_dir is only set for editable requirements.
+ if req.link.is_wheel:
+ # We don't need to unpack wheels, so no need for a source
+ # directory.
+ return
+ assert req.source_dir is None
+ if req.link.is_existing_dir():
+ # build local directories in-tree
+ req.source_dir = req.link.file_path
+ return
+
+ # We always delete unpacked sdists after pip runs.
+ req.ensure_has_source_dir(
+ self.build_dir,
+ autodelete=True,
+ parallel_builds=parallel_builds,
+ )
+ req.ensure_pristine_source_checkout()
+
+ def _get_linked_req_hashes(self, req: InstallRequirement) -> Hashes:
+ # By the time this is called, the requirement's link should have
+ # been checked so we can tell what kind of requirements req is
+ # and raise some more informative errors than otherwise.
+ # (For example, we can raise VcsHashUnsupported for a VCS URL
+ # rather than HashMissing.)
+ if not self.require_hashes:
+ return req.hashes(trust_internet=True)
+
+ # We could check these first 2 conditions inside unpack_url
+ # and save repetition of conditions, but then we would
+ # report less-useful error messages for unhashable
+ # requirements, complaining that there's no hash provided.
+ if req.link.is_vcs:
+ raise VcsHashUnsupported()
+ if req.link.is_existing_dir():
+ raise DirectoryUrlHashUnsupported()
+
+ # Unpinned packages are asking for trouble when a new version
+ # is uploaded. This isn't a security check, but it saves users
+ # a surprising hash mismatch in the future.
+ # file:/// URLs aren't pinnable, so don't complain about them
+ # not being pinned.
+ if not req.is_direct and not req.is_pinned:
+ raise HashUnpinned()
+
+ # If known-good hashes are missing for this requirement,
+ # shim it with a facade object that will provoke hash
+ # computation and then raise a HashMissing exception
+ # showing the user what the hash should be.
+ return req.hashes(trust_internet=False) or MissingHashes()
+
+ def _fetch_metadata_only(
+ self,
+ req: InstallRequirement,
+ ) -> Optional[BaseDistribution]:
+ if self.legacy_resolver:
+ logger.debug(
+ "Metadata-only fetching is not used in the legacy resolver",
+ )
+ return None
+ if self.require_hashes:
+ logger.debug(
+ "Metadata-only fetching is not used as hash checking is required",
+ )
+ return None
+ # Try PEP 658 metadata first, then fall back to lazy wheel if unavailable.
+ return self._fetch_metadata_using_link_data_attr(
+ req
+ ) or self._fetch_metadata_using_lazy_wheel(req.link)
+
+ def _fetch_metadata_using_link_data_attr(
+ self,
+ req: InstallRequirement,
+ ) -> Optional[BaseDistribution]:
+ """Fetch metadata from the data-dist-info-metadata attribute, if possible."""
+ # (1) Get the link to the metadata file, if provided by the backend.
+ metadata_link = req.link.metadata_link()
+ if metadata_link is None:
+ return None
+ assert req.req is not None
+ logger.verbose(
+ "Obtaining dependency information for %s from %s",
+ req.req,
+ metadata_link,
+ )
+ # (2) Download the contents of the METADATA file, separate from the dist itself.
+ metadata_file = get_http_url(
+ metadata_link,
+ self._download,
+ hashes=metadata_link.as_hashes(),
+ )
+ with open(metadata_file.path, "rb") as f:
+ metadata_contents = f.read()
+ # (3) Generate a dist just from those file contents.
+ metadata_dist = get_metadata_distribution(
+ metadata_contents,
+ req.link.filename,
+ req.req.name,
+ )
+ # (4) Ensure the Name: field from the METADATA file matches the name from the
+ # install requirement.
+ #
+ # NB: raw_name will fall back to the name from the install requirement if
+ # the Name: field is not present, but it's noted in the raw_name docstring
+ # that that should NEVER happen anyway.
+ if canonicalize_name(metadata_dist.raw_name) != canonicalize_name(req.req.name):
+ raise MetadataInconsistent(
+ req, "Name", req.req.name, metadata_dist.raw_name
+ )
+ return metadata_dist
+
+ def _fetch_metadata_using_lazy_wheel(
+ self,
+ link: Link,
+ ) -> Optional[BaseDistribution]:
+ """Fetch metadata using lazy wheel, if possible."""
+ # --use-feature=fast-deps must be provided.
+ if not self.use_lazy_wheel:
+ return None
+ if link.is_file or not link.is_wheel:
+ logger.debug(
+ "Lazy wheel is not used as %r does not point to a remote wheel",
+ link,
+ )
+ return None
+
+ wheel = Wheel(link.filename)
+ name = canonicalize_name(wheel.name)
+ logger.info(
+ "Obtaining dependency information from %s %s",
+ name,
+ wheel.version,
+ )
+ url = link.url.split("#", 1)[0]
+ try:
+ return dist_from_wheel_url(name, url, self._session)
+ except HTTPRangeRequestUnsupported:
+ logger.debug("%s does not support range requests", url)
+ return None
+
+ def _complete_partial_requirements(
+ self,
+ partially_downloaded_reqs: Iterable[InstallRequirement],
+ parallel_builds: bool = False,
+ ) -> None:
+ """Download any requirements which were only fetched by metadata."""
+ # Download to a temporary directory. These will be copied over as
+ # needed for downstream 'download', 'wheel', and 'install' commands.
+ temp_dir = TempDirectory(kind="unpack", globally_managed=True).path
+
+ # Map each link to the requirement that owns it. This allows us to set
+ # `req.local_file_path` on the appropriate requirement after passing
+ # all the links at once into BatchDownloader.
+ links_to_fully_download: Dict[Link, InstallRequirement] = {}
+ for req in partially_downloaded_reqs:
+ assert req.link
+ links_to_fully_download[req.link] = req
+
+ batch_download = self._batch_download(
+ links_to_fully_download.keys(),
+ temp_dir,
+ )
+ for link, (filepath, _) in batch_download:
+ logger.debug("Downloading link %s to %s", link, filepath)
+ req = links_to_fully_download[link]
+ # Record the downloaded file path so wheel reqs can extract a Distribution
+ # in .get_dist().
+ req.local_file_path = filepath
+ # Record that the file is downloaded so we don't do it again in
+ # _prepare_linked_requirement().
+ self._downloaded[req.link.url] = filepath
+
+ # If this is an sdist, we need to unpack it after downloading, but the
+ # .source_dir won't be set up until we are in _prepare_linked_requirement().
+ # Add the downloaded archive to the install requirement to unpack after
+ # preparing the source dir.
+ if not req.is_wheel:
+ req.needs_unpacked_archive(Path(filepath))
+
+ # This step is necessary to ensure all lazy wheels are processed
+ # successfully by the 'download', 'wheel', and 'install' commands.
+ for req in partially_downloaded_reqs:
+ self._prepare_linked_requirement(req, parallel_builds)
+
+ def prepare_linked_requirement(
+ self, req: InstallRequirement, parallel_builds: bool = False
+ ) -> BaseDistribution:
+ """Prepare a requirement to be obtained from req.link."""
+ assert req.link
+ self._log_preparing_link(req)
+ with indent_log():
+ # Check if the relevant file is already available
+ # in the download directory
+ file_path = None
+ if self.download_dir is not None and req.link.is_wheel:
+ hashes = self._get_linked_req_hashes(req)
+ file_path = _check_download_dir(
+ req.link,
+ self.download_dir,
+ hashes,
+ # When a locally built wheel has been found in cache, we don't warn
+ # about re-downloading when the already downloaded wheel hash does
+ # not match. This is because the hash must be checked against the
+ # original link, not the cached link. It that case the already
+ # downloaded file will be removed and re-fetched from cache (which
+ # implies a hash check against the cache entry's origin.json).
+ warn_on_hash_mismatch=not req.is_wheel_from_cache,
+ )
+
+ if file_path is not None:
+ # The file is already available, so mark it as downloaded
+ self._downloaded[req.link.url] = file_path
+ else:
+ # The file is not available, attempt to fetch only metadata
+ metadata_dist = self._fetch_metadata_only(req)
+ if metadata_dist is not None:
+ req.needs_more_preparation = True
+ return metadata_dist
+
+ # None of the optimizations worked, fully prepare the requirement
+ return self._prepare_linked_requirement(req, parallel_builds)
+
+ def prepare_linked_requirements_more(
+ self, reqs: Iterable[InstallRequirement], parallel_builds: bool = False
+ ) -> None:
+ """Prepare linked requirements more, if needed."""
+ reqs = [req for req in reqs if req.needs_more_preparation]
+ for req in reqs:
+ # Determine if any of these requirements were already downloaded.
+ if self.download_dir is not None and req.link.is_wheel:
+ hashes = self._get_linked_req_hashes(req)
+ file_path = _check_download_dir(req.link, self.download_dir, hashes)
+ if file_path is not None:
+ self._downloaded[req.link.url] = file_path
+ req.needs_more_preparation = False
+
+ # Prepare requirements we found were already downloaded for some
+ # reason. The other downloads will be completed separately.
+ partially_downloaded_reqs: List[InstallRequirement] = []
+ for req in reqs:
+ if req.needs_more_preparation:
+ partially_downloaded_reqs.append(req)
+ else:
+ self._prepare_linked_requirement(req, parallel_builds)
+
+ # TODO: separate this part out from RequirementPreparer when the v1
+ # resolver can be removed!
+ self._complete_partial_requirements(
+ partially_downloaded_reqs,
+ parallel_builds=parallel_builds,
+ )
+
+ def _prepare_linked_requirement(
+ self, req: InstallRequirement, parallel_builds: bool
+ ) -> BaseDistribution:
+ assert req.link
+ link = req.link
+
+ hashes = self._get_linked_req_hashes(req)
+
+ if hashes and req.is_wheel_from_cache:
+ assert req.download_info is not None
+ assert link.is_wheel
+ assert link.is_file
+ # We need to verify hashes, and we have found the requirement in the cache
+ # of locally built wheels.
+ if (
+ isinstance(req.download_info.info, ArchiveInfo)
+ and req.download_info.info.hashes
+ and hashes.has_one_of(req.download_info.info.hashes)
+ ):
+ # At this point we know the requirement was built from a hashable source
+ # artifact, and we verified that the cache entry's hash of the original
+ # artifact matches one of the hashes we expect. We don't verify hashes
+ # against the cached wheel, because the wheel is not the original.
+ hashes = None
+ else:
+ logger.warning(
+ "The hashes of the source archive found in cache entry "
+ "don't match, ignoring cached built wheel "
+ "and re-downloading source."
+ )
+ req.link = req.cached_wheel_source_link
+ link = req.link
+
+ self._ensure_link_req_src_dir(req, parallel_builds)
+
+ if link.is_existing_dir():
+ local_file = None
+ elif link.url not in self._downloaded:
+ try:
+ local_file = unpack_url(
+ link,
+ req.source_dir,
+ self._download,
+ self.verbosity,
+ self.download_dir,
+ hashes,
+ )
+ except NetworkConnectionError as exc:
+ raise InstallationError(
+ f"Could not install requirement {req} because of HTTP "
+ f"error {exc} for URL {link}"
+ )
+ else:
+ file_path = self._downloaded[link.url]
+ if hashes:
+ hashes.check_against_path(file_path)
+ local_file = File(file_path, content_type=None)
+
+ # If download_info is set, we got it from the wheel cache.
+ if req.download_info is None:
+ # Editables don't go through this function (see
+ # prepare_editable_requirement).
+ assert not req.editable
+ req.download_info = direct_url_from_link(link, req.source_dir)
+ # Make sure we have a hash in download_info. If we got it as part of the
+ # URL, it will have been verified and we can rely on it. Otherwise we
+ # compute it from the downloaded file.
+ # FIXME: https://github.com/pypa/pip/issues/11943
+ if (
+ isinstance(req.download_info.info, ArchiveInfo)
+ and not req.download_info.info.hashes
+ and local_file
+ ):
+ hash = hash_file(local_file.path)[0].hexdigest()
+ # We populate info.hash for backward compatibility.
+ # This will automatically populate info.hashes.
+ req.download_info.info.hash = f"sha256={hash}"
+
+ # For use in later processing,
+ # preserve the file path on the requirement.
+ if local_file:
+ req.local_file_path = local_file.path
+
+ dist = _get_prepared_distribution(
+ req,
+ self.build_tracker,
+ self.finder,
+ self.build_isolation,
+ self.check_build_deps,
+ )
+ return dist
+
+ def save_linked_requirement(self, req: InstallRequirement) -> None:
+ assert self.download_dir is not None
+ assert req.link is not None
+ link = req.link
+ if link.is_vcs or (link.is_existing_dir() and req.editable):
+ # Make a .zip of the source_dir we already created.
+ req.archive(self.download_dir)
+ return
+
+ if link.is_existing_dir():
+ logger.debug(
+ "Not copying link to destination directory "
+ "since it is a directory: %s",
+ link,
+ )
+ return
+ if req.local_file_path is None:
+ # No distribution was downloaded for this requirement.
+ return
+
+ download_location = os.path.join(self.download_dir, link.filename)
+ if not os.path.exists(download_location):
+ shutil.copy(req.local_file_path, download_location)
+ download_path = display_path(download_location)
+ logger.info("Saved %s", download_path)
+
+ def prepare_editable_requirement(
+ self,
+ req: InstallRequirement,
+ ) -> BaseDistribution:
+ """Prepare an editable requirement."""
+ assert req.editable, "cannot prepare a non-editable req as editable"
+
+ logger.info("Obtaining %s", req)
+
+ with indent_log():
+ if self.require_hashes:
+ raise InstallationError(
+ f"The editable requirement {req} cannot be installed when "
+ "requiring hashes, because there is no single file to "
+ "hash."
+ )
+ req.ensure_has_source_dir(self.src_dir)
+ req.update_editable()
+ assert req.source_dir
+ req.download_info = direct_url_for_editable(req.unpacked_source_directory)
+
+ dist = _get_prepared_distribution(
+ req,
+ self.build_tracker,
+ self.finder,
+ self.build_isolation,
+ self.check_build_deps,
+ )
+
+ req.check_if_exists(self.use_user_site)
+
+ return dist
+
+ def prepare_installed_requirement(
+ self,
+ req: InstallRequirement,
+ skip_reason: str,
+ ) -> BaseDistribution:
+ """Prepare an already-installed requirement."""
+ assert req.satisfied_by, "req should have been satisfied but isn't"
+ assert skip_reason is not None, (
+ "did not get skip reason skipped but req.satisfied_by "
+ f"is set to {req.satisfied_by}"
+ )
+ logger.info(
+ "Requirement %s: %s (%s)", skip_reason, req, req.satisfied_by.version
+ )
+ with indent_log():
+ if self.require_hashes:
+ logger.debug(
+ "Since it is already installed, we are trusting this "
+ "package without checking its hash. To ensure a "
+ "completely repeatable environment, install into an "
+ "empty virtualenv."
+ )
+ return InstalledDistribution(req).get_metadata_distribution()
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/pyproject.py b/solutions/.venv/Lib/site-packages/pip/_internal/pyproject.py
new file mode 100644
index 000000000..2a9cad480
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/pyproject.py
@@ -0,0 +1,185 @@
+import importlib.util
+import os
+import sys
+from collections import namedtuple
+from typing import Any, List, Optional
+
+if sys.version_info >= (3, 11):
+ import tomllib
+else:
+ from pip._vendor import tomli as tomllib
+
+from pip._vendor.packaging.requirements import InvalidRequirement
+
+from pip._internal.exceptions import (
+ InstallationError,
+ InvalidPyProjectBuildRequires,
+ MissingPyProjectBuildRequires,
+)
+from pip._internal.utils.packaging import get_requirement
+
+
+def _is_list_of_str(obj: Any) -> bool:
+ return isinstance(obj, list) and all(isinstance(item, str) for item in obj)
+
+
+def make_pyproject_path(unpacked_source_directory: str) -> str:
+ return os.path.join(unpacked_source_directory, "pyproject.toml")
+
+
+BuildSystemDetails = namedtuple(
+ "BuildSystemDetails", ["requires", "backend", "check", "backend_path"]
+)
+
+
+def load_pyproject_toml(
+ use_pep517: Optional[bool], pyproject_toml: str, setup_py: str, req_name: str
+) -> Optional[BuildSystemDetails]:
+ """Load the pyproject.toml file.
+
+ Parameters:
+ use_pep517 - Has the user requested PEP 517 processing? None
+ means the user hasn't explicitly specified.
+ pyproject_toml - Location of the project's pyproject.toml file
+ setup_py - Location of the project's setup.py file
+ req_name - The name of the requirement we're processing (for
+ error reporting)
+
+ Returns:
+ None if we should use the legacy code path, otherwise a tuple
+ (
+ requirements from pyproject.toml,
+ name of PEP 517 backend,
+ requirements we should check are installed after setting
+ up the build environment
+ directory paths to import the backend from (backend-path),
+ relative to the project root.
+ )
+ """
+ has_pyproject = os.path.isfile(pyproject_toml)
+ has_setup = os.path.isfile(setup_py)
+
+ if not has_pyproject and not has_setup:
+ raise InstallationError(
+ f"{req_name} does not appear to be a Python project: "
+ f"neither 'setup.py' nor 'pyproject.toml' found."
+ )
+
+ if has_pyproject:
+ with open(pyproject_toml, encoding="utf-8") as f:
+ pp_toml = tomllib.loads(f.read())
+ build_system = pp_toml.get("build-system")
+ else:
+ build_system = None
+
+ # The following cases must use PEP 517
+ # We check for use_pep517 being non-None and falsey because that means
+ # the user explicitly requested --no-use-pep517. The value 0 as
+ # opposed to False can occur when the value is provided via an
+ # environment variable or config file option (due to the quirk of
+ # strtobool() returning an integer in pip's configuration code).
+ if has_pyproject and not has_setup:
+ if use_pep517 is not None and not use_pep517:
+ raise InstallationError(
+ "Disabling PEP 517 processing is invalid: "
+ "project does not have a setup.py"
+ )
+ use_pep517 = True
+ elif build_system and "build-backend" in build_system:
+ if use_pep517 is not None and not use_pep517:
+ raise InstallationError(
+ "Disabling PEP 517 processing is invalid: "
+ "project specifies a build backend of {} "
+ "in pyproject.toml".format(build_system["build-backend"])
+ )
+ use_pep517 = True
+
+ # If we haven't worked out whether to use PEP 517 yet,
+ # and the user hasn't explicitly stated a preference,
+ # we do so if the project has a pyproject.toml file
+ # or if we cannot import setuptools or wheels.
+
+ # We fallback to PEP 517 when without setuptools or without the wheel package,
+ # so setuptools can be installed as a default build backend.
+ # For more info see:
+ # https://discuss.python.org/t/pip-without-setuptools-could-the-experience-be-improved/11810/9
+ # https://github.com/pypa/pip/issues/8559
+ elif use_pep517 is None:
+ use_pep517 = (
+ has_pyproject
+ or not importlib.util.find_spec("setuptools")
+ or not importlib.util.find_spec("wheel")
+ )
+
+ # At this point, we know whether we're going to use PEP 517.
+ assert use_pep517 is not None
+
+ # If we're using the legacy code path, there is nothing further
+ # for us to do here.
+ if not use_pep517:
+ return None
+
+ if build_system is None:
+ # Either the user has a pyproject.toml with no build-system
+ # section, or the user has no pyproject.toml, but has opted in
+ # explicitly via --use-pep517.
+ # In the absence of any explicit backend specification, we
+ # assume the setuptools backend that most closely emulates the
+ # traditional direct setup.py execution, and require wheel and
+ # a version of setuptools that supports that backend.
+
+ build_system = {
+ "requires": ["setuptools>=40.8.0"],
+ "build-backend": "setuptools.build_meta:__legacy__",
+ }
+
+ # If we're using PEP 517, we have build system information (either
+ # from pyproject.toml, or defaulted by the code above).
+ # Note that at this point, we do not know if the user has actually
+ # specified a backend, though.
+ assert build_system is not None
+
+ # Ensure that the build-system section in pyproject.toml conforms
+ # to PEP 518.
+
+ # Specifying the build-system table but not the requires key is invalid
+ if "requires" not in build_system:
+ raise MissingPyProjectBuildRequires(package=req_name)
+
+ # Error out if requires is not a list of strings
+ requires = build_system["requires"]
+ if not _is_list_of_str(requires):
+ raise InvalidPyProjectBuildRequires(
+ package=req_name,
+ reason="It is not a list of strings.",
+ )
+
+ # Each requirement must be valid as per PEP 508
+ for requirement in requires:
+ try:
+ get_requirement(requirement)
+ except InvalidRequirement as error:
+ raise InvalidPyProjectBuildRequires(
+ package=req_name,
+ reason=f"It contains an invalid requirement: {requirement!r}",
+ ) from error
+
+ backend = build_system.get("build-backend")
+ backend_path = build_system.get("backend-path", [])
+ check: List[str] = []
+ if backend is None:
+ # If the user didn't specify a backend, we assume they want to use
+ # the setuptools backend. But we can't be sure they have included
+ # a version of setuptools which supplies the backend. So we
+ # make a note to check that this requirement is present once
+ # we have set up the environment.
+ # This is quite a lot of work to check for a very specific case. But
+ # the problem is, that case is potentially quite common - projects that
+ # adopted PEP 518 early for the ability to specify requirements to
+ # execute setup.py, but never considered needing to mention the build
+ # tools themselves. The original PEP 518 code had a similar check (but
+ # implemented in a different way).
+ backend = "setuptools.build_meta:__legacy__"
+ check = ["setuptools>=40.8.0"]
+
+ return BuildSystemDetails(requires, backend, check, backend_path)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/req/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/req/__init__.py
new file mode 100644
index 000000000..422d851d7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/req/__init__.py
@@ -0,0 +1,90 @@
+import collections
+import logging
+from dataclasses import dataclass
+from typing import Generator, List, Optional, Sequence, Tuple
+
+from pip._internal.utils.logging import indent_log
+
+from .req_file import parse_requirements
+from .req_install import InstallRequirement
+from .req_set import RequirementSet
+
+__all__ = [
+ "RequirementSet",
+ "InstallRequirement",
+ "parse_requirements",
+ "install_given_reqs",
+]
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass(frozen=True)
+class InstallationResult:
+ name: str
+
+
+def _validate_requirements(
+ requirements: List[InstallRequirement],
+) -> Generator[Tuple[str, InstallRequirement], None, None]:
+ for req in requirements:
+ assert req.name, f"invalid to-be-installed requirement: {req}"
+ yield req.name, req
+
+
+def install_given_reqs(
+ requirements: List[InstallRequirement],
+ global_options: Sequence[str],
+ root: Optional[str],
+ home: Optional[str],
+ prefix: Optional[str],
+ warn_script_location: bool,
+ use_user_site: bool,
+ pycompile: bool,
+) -> List[InstallationResult]:
+ """
+ Install everything in the given list.
+
+ (to be called after having downloaded and unpacked the packages)
+ """
+ to_install = collections.OrderedDict(_validate_requirements(requirements))
+
+ if to_install:
+ logger.info(
+ "Installing collected packages: %s",
+ ", ".join(to_install.keys()),
+ )
+
+ installed = []
+
+ with indent_log():
+ for req_name, requirement in to_install.items():
+ if requirement.should_reinstall:
+ logger.info("Attempting uninstall: %s", req_name)
+ with indent_log():
+ uninstalled_pathset = requirement.uninstall(auto_confirm=True)
+ else:
+ uninstalled_pathset = None
+
+ try:
+ requirement.install(
+ global_options,
+ root=root,
+ home=home,
+ prefix=prefix,
+ warn_script_location=warn_script_location,
+ use_user_site=use_user_site,
+ pycompile=pycompile,
+ )
+ except Exception:
+ # if install did not succeed, rollback previous uninstall
+ if uninstalled_pathset and not requirement.install_succeeded:
+ uninstalled_pathset.rollback()
+ raise
+ else:
+ if uninstalled_pathset and requirement.install_succeeded:
+ uninstalled_pathset.commit()
+
+ installed.append(InstallationResult(req_name))
+
+ return installed
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/req/constructors.py b/solutions/.venv/Lib/site-packages/pip/_internal/req/constructors.py
new file mode 100644
index 000000000..56a964f31
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/req/constructors.py
@@ -0,0 +1,560 @@
+"""Backing implementation for InstallRequirement's various constructors
+
+The idea here is that these formed a major chunk of InstallRequirement's size
+so, moving them and support code dedicated to them outside of that class
+helps creates for better understandability for the rest of the code.
+
+These are meant to be used elsewhere within pip to create instances of
+InstallRequirement.
+"""
+
+import copy
+import logging
+import os
+import re
+from dataclasses import dataclass
+from typing import Collection, Dict, List, Optional, Set, Tuple, Union
+
+from pip._vendor.packaging.markers import Marker
+from pip._vendor.packaging.requirements import InvalidRequirement, Requirement
+from pip._vendor.packaging.specifiers import Specifier
+
+from pip._internal.exceptions import InstallationError
+from pip._internal.models.index import PyPI, TestPyPI
+from pip._internal.models.link import Link
+from pip._internal.models.wheel import Wheel
+from pip._internal.req.req_file import ParsedRequirement
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.utils.filetypes import is_archive_file
+from pip._internal.utils.misc import is_installable_dir
+from pip._internal.utils.packaging import get_requirement
+from pip._internal.utils.urls import path_to_url
+from pip._internal.vcs import is_url, vcs
+
+__all__ = [
+ "install_req_from_editable",
+ "install_req_from_line",
+ "parse_editable",
+]
+
+logger = logging.getLogger(__name__)
+operators = Specifier._operators.keys()
+
+
+def _strip_extras(path: str) -> Tuple[str, Optional[str]]:
+ m = re.match(r"^(.+)(\[[^\]]+\])$", path)
+ extras = None
+ if m:
+ path_no_extras = m.group(1)
+ extras = m.group(2)
+ else:
+ path_no_extras = path
+
+ return path_no_extras, extras
+
+
+def convert_extras(extras: Optional[str]) -> Set[str]:
+ if not extras:
+ return set()
+ return get_requirement("placeholder" + extras.lower()).extras
+
+
+def _set_requirement_extras(req: Requirement, new_extras: Set[str]) -> Requirement:
+ """
+ Returns a new requirement based on the given one, with the supplied extras. If the
+ given requirement already has extras those are replaced (or dropped if no new extras
+ are given).
+ """
+ match: Optional[re.Match[str]] = re.fullmatch(
+ # see https://peps.python.org/pep-0508/#complete-grammar
+ r"([\w\t .-]+)(\[[^\]]*\])?(.*)",
+ str(req),
+ flags=re.ASCII,
+ )
+ # ireq.req is a valid requirement so the regex should always match
+ assert (
+ match is not None
+ ), f"regex match on requirement {req} failed, this should never happen"
+ pre: Optional[str] = match.group(1)
+ post: Optional[str] = match.group(3)
+ assert (
+ pre is not None and post is not None
+ ), f"regex group selection for requirement {req} failed, this should never happen"
+ extras: str = "[{}]".format(",".join(sorted(new_extras)) if new_extras else "")
+ return get_requirement(f"{pre}{extras}{post}")
+
+
+def parse_editable(editable_req: str) -> Tuple[Optional[str], str, Set[str]]:
+ """Parses an editable requirement into:
+ - a requirement name
+ - an URL
+ - extras
+ - editable options
+ Accepted requirements:
+ svn+http://blahblah@rev#egg=Foobar[baz]&subdirectory=version_subdir
+ .[some_extra]
+ """
+
+ url = editable_req
+
+ # If a file path is specified with extras, strip off the extras.
+ url_no_extras, extras = _strip_extras(url)
+
+ if os.path.isdir(url_no_extras):
+ # Treating it as code that has already been checked out
+ url_no_extras = path_to_url(url_no_extras)
+
+ if url_no_extras.lower().startswith("file:"):
+ package_name = Link(url_no_extras).egg_fragment
+ if extras:
+ return (
+ package_name,
+ url_no_extras,
+ get_requirement("placeholder" + extras.lower()).extras,
+ )
+ else:
+ return package_name, url_no_extras, set()
+
+ for version_control in vcs:
+ if url.lower().startswith(f"{version_control}:"):
+ url = f"{version_control}+{url}"
+ break
+
+ link = Link(url)
+
+ if not link.is_vcs:
+ backends = ", ".join(vcs.all_schemes)
+ raise InstallationError(
+ f"{editable_req} is not a valid editable requirement. "
+ f"It should either be a path to a local project or a VCS URL "
+ f"(beginning with {backends})."
+ )
+
+ package_name = link.egg_fragment
+ if not package_name:
+ raise InstallationError(
+ f"Could not detect requirement name for '{editable_req}', "
+ "please specify one with #egg=your_package_name"
+ )
+ return package_name, url, set()
+
+
+def check_first_requirement_in_file(filename: str) -> None:
+ """Check if file is parsable as a requirements file.
+
+ This is heavily based on ``pkg_resources.parse_requirements``, but
+ simplified to just check the first meaningful line.
+
+ :raises InvalidRequirement: If the first meaningful line cannot be parsed
+ as an requirement.
+ """
+ with open(filename, encoding="utf-8", errors="ignore") as f:
+ # Create a steppable iterator, so we can handle \-continuations.
+ lines = (
+ line
+ for line in (line.strip() for line in f)
+ if line and not line.startswith("#") # Skip blank lines/comments.
+ )
+
+ for line in lines:
+ # Drop comments -- a hash without a space may be in a URL.
+ if " #" in line:
+ line = line[: line.find(" #")]
+ # If there is a line continuation, drop it, and append the next line.
+ if line.endswith("\\"):
+ line = line[:-2].strip() + next(lines, "")
+ get_requirement(line)
+ return
+
+
+def deduce_helpful_msg(req: str) -> str:
+ """Returns helpful msg in case requirements file does not exist,
+ or cannot be parsed.
+
+ :params req: Requirements file path
+ """
+ if not os.path.exists(req):
+ return f" File '{req}' does not exist."
+ msg = " The path does exist. "
+ # Try to parse and check if it is a requirements file.
+ try:
+ check_first_requirement_in_file(req)
+ except InvalidRequirement:
+ logger.debug("Cannot parse '%s' as requirements file", req)
+ else:
+ msg += (
+ f"The argument you provided "
+ f"({req}) appears to be a"
+ f" requirements file. If that is the"
+ f" case, use the '-r' flag to install"
+ f" the packages specified within it."
+ )
+ return msg
+
+
+@dataclass(frozen=True)
+class RequirementParts:
+ requirement: Optional[Requirement]
+ link: Optional[Link]
+ markers: Optional[Marker]
+ extras: Set[str]
+
+
+def parse_req_from_editable(editable_req: str) -> RequirementParts:
+ name, url, extras_override = parse_editable(editable_req)
+
+ if name is not None:
+ try:
+ req: Optional[Requirement] = get_requirement(name)
+ except InvalidRequirement as exc:
+ raise InstallationError(f"Invalid requirement: {name!r}: {exc}")
+ else:
+ req = None
+
+ link = Link(url)
+
+ return RequirementParts(req, link, None, extras_override)
+
+
+# ---- The actual constructors follow ----
+
+
+def install_req_from_editable(
+ editable_req: str,
+ comes_from: Optional[Union[InstallRequirement, str]] = None,
+ *,
+ use_pep517: Optional[bool] = None,
+ isolated: bool = False,
+ global_options: Optional[List[str]] = None,
+ hash_options: Optional[Dict[str, List[str]]] = None,
+ constraint: bool = False,
+ user_supplied: bool = False,
+ permit_editable_wheels: bool = False,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+) -> InstallRequirement:
+ parts = parse_req_from_editable(editable_req)
+
+ return InstallRequirement(
+ parts.requirement,
+ comes_from=comes_from,
+ user_supplied=user_supplied,
+ editable=True,
+ permit_editable_wheels=permit_editable_wheels,
+ link=parts.link,
+ constraint=constraint,
+ use_pep517=use_pep517,
+ isolated=isolated,
+ global_options=global_options,
+ hash_options=hash_options,
+ config_settings=config_settings,
+ extras=parts.extras,
+ )
+
+
+def _looks_like_path(name: str) -> bool:
+ """Checks whether the string "looks like" a path on the filesystem.
+
+ This does not check whether the target actually exists, only judge from the
+ appearance.
+
+ Returns true if any of the following conditions is true:
+ * a path separator is found (either os.path.sep or os.path.altsep);
+ * a dot is found (which represents the current directory).
+ """
+ if os.path.sep in name:
+ return True
+ if os.path.altsep is not None and os.path.altsep in name:
+ return True
+ if name.startswith("."):
+ return True
+ return False
+
+
+def _get_url_from_path(path: str, name: str) -> Optional[str]:
+ """
+ First, it checks whether a provided path is an installable directory. If it
+ is, returns the path.
+
+ If false, check if the path is an archive file (such as a .whl).
+ The function checks if the path is a file. If false, if the path has
+ an @, it will treat it as a PEP 440 URL requirement and return the path.
+ """
+ if _looks_like_path(name) and os.path.isdir(path):
+ if is_installable_dir(path):
+ return path_to_url(path)
+ # TODO: The is_installable_dir test here might not be necessary
+ # now that it is done in load_pyproject_toml too.
+ raise InstallationError(
+ f"Directory {name!r} is not installable. Neither 'setup.py' "
+ "nor 'pyproject.toml' found."
+ )
+ if not is_archive_file(path):
+ return None
+ if os.path.isfile(path):
+ return path_to_url(path)
+ urlreq_parts = name.split("@", 1)
+ if len(urlreq_parts) >= 2 and not _looks_like_path(urlreq_parts[0]):
+ # If the path contains '@' and the part before it does not look
+ # like a path, try to treat it as a PEP 440 URL req instead.
+ return None
+ logger.warning(
+ "Requirement %r looks like a filename, but the file does not exist",
+ name,
+ )
+ return path_to_url(path)
+
+
+def parse_req_from_line(name: str, line_source: Optional[str]) -> RequirementParts:
+ if is_url(name):
+ marker_sep = "; "
+ else:
+ marker_sep = ";"
+ if marker_sep in name:
+ name, markers_as_string = name.split(marker_sep, 1)
+ markers_as_string = markers_as_string.strip()
+ if not markers_as_string:
+ markers = None
+ else:
+ markers = Marker(markers_as_string)
+ else:
+ markers = None
+ name = name.strip()
+ req_as_string = None
+ path = os.path.normpath(os.path.abspath(name))
+ link = None
+ extras_as_string = None
+
+ if is_url(name):
+ link = Link(name)
+ else:
+ p, extras_as_string = _strip_extras(path)
+ url = _get_url_from_path(p, name)
+ if url is not None:
+ link = Link(url)
+
+ # it's a local file, dir, or url
+ if link:
+ # Handle relative file URLs
+ if link.scheme == "file" and re.search(r"\.\./", link.url):
+ link = Link(path_to_url(os.path.normpath(os.path.abspath(link.path))))
+ # wheel file
+ if link.is_wheel:
+ wheel = Wheel(link.filename) # can raise InvalidWheelFilename
+ req_as_string = f"{wheel.name}=={wheel.version}"
+ else:
+ # set the req to the egg fragment. when it's not there, this
+ # will become an 'unnamed' requirement
+ req_as_string = link.egg_fragment
+
+ # a requirement specifier
+ else:
+ req_as_string = name
+
+ extras = convert_extras(extras_as_string)
+
+ def with_source(text: str) -> str:
+ if not line_source:
+ return text
+ return f"{text} (from {line_source})"
+
+ def _parse_req_string(req_as_string: str) -> Requirement:
+ try:
+ return get_requirement(req_as_string)
+ except InvalidRequirement as exc:
+ if os.path.sep in req_as_string:
+ add_msg = "It looks like a path."
+ add_msg += deduce_helpful_msg(req_as_string)
+ elif "=" in req_as_string and not any(
+ op in req_as_string for op in operators
+ ):
+ add_msg = "= is not a valid operator. Did you mean == ?"
+ else:
+ add_msg = ""
+ msg = with_source(f"Invalid requirement: {req_as_string!r}: {exc}")
+ if add_msg:
+ msg += f"\nHint: {add_msg}"
+ raise InstallationError(msg)
+
+ if req_as_string is not None:
+ req: Optional[Requirement] = _parse_req_string(req_as_string)
+ else:
+ req = None
+
+ return RequirementParts(req, link, markers, extras)
+
+
+def install_req_from_line(
+ name: str,
+ comes_from: Optional[Union[str, InstallRequirement]] = None,
+ *,
+ use_pep517: Optional[bool] = None,
+ isolated: bool = False,
+ global_options: Optional[List[str]] = None,
+ hash_options: Optional[Dict[str, List[str]]] = None,
+ constraint: bool = False,
+ line_source: Optional[str] = None,
+ user_supplied: bool = False,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+) -> InstallRequirement:
+ """Creates an InstallRequirement from a name, which might be a
+ requirement, directory containing 'setup.py', filename, or URL.
+
+ :param line_source: An optional string describing where the line is from,
+ for logging purposes in case of an error.
+ """
+ parts = parse_req_from_line(name, line_source)
+
+ return InstallRequirement(
+ parts.requirement,
+ comes_from,
+ link=parts.link,
+ markers=parts.markers,
+ use_pep517=use_pep517,
+ isolated=isolated,
+ global_options=global_options,
+ hash_options=hash_options,
+ config_settings=config_settings,
+ constraint=constraint,
+ extras=parts.extras,
+ user_supplied=user_supplied,
+ )
+
+
+def install_req_from_req_string(
+ req_string: str,
+ comes_from: Optional[InstallRequirement] = None,
+ isolated: bool = False,
+ use_pep517: Optional[bool] = None,
+ user_supplied: bool = False,
+) -> InstallRequirement:
+ try:
+ req = get_requirement(req_string)
+ except InvalidRequirement as exc:
+ raise InstallationError(f"Invalid requirement: {req_string!r}: {exc}")
+
+ domains_not_allowed = [
+ PyPI.file_storage_domain,
+ TestPyPI.file_storage_domain,
+ ]
+ if (
+ req.url
+ and comes_from
+ and comes_from.link
+ and comes_from.link.netloc in domains_not_allowed
+ ):
+ # Explicitly disallow pypi packages that depend on external urls
+ raise InstallationError(
+ "Packages installed from PyPI cannot depend on packages "
+ "which are not also hosted on PyPI.\n"
+ f"{comes_from.name} depends on {req} "
+ )
+
+ return InstallRequirement(
+ req,
+ comes_from,
+ isolated=isolated,
+ use_pep517=use_pep517,
+ user_supplied=user_supplied,
+ )
+
+
+def install_req_from_parsed_requirement(
+ parsed_req: ParsedRequirement,
+ isolated: bool = False,
+ use_pep517: Optional[bool] = None,
+ user_supplied: bool = False,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+) -> InstallRequirement:
+ if parsed_req.is_editable:
+ req = install_req_from_editable(
+ parsed_req.requirement,
+ comes_from=parsed_req.comes_from,
+ use_pep517=use_pep517,
+ constraint=parsed_req.constraint,
+ isolated=isolated,
+ user_supplied=user_supplied,
+ config_settings=config_settings,
+ )
+
+ else:
+ req = install_req_from_line(
+ parsed_req.requirement,
+ comes_from=parsed_req.comes_from,
+ use_pep517=use_pep517,
+ isolated=isolated,
+ global_options=(
+ parsed_req.options.get("global_options", [])
+ if parsed_req.options
+ else []
+ ),
+ hash_options=(
+ parsed_req.options.get("hashes", {}) if parsed_req.options else {}
+ ),
+ constraint=parsed_req.constraint,
+ line_source=parsed_req.line_source,
+ user_supplied=user_supplied,
+ config_settings=config_settings,
+ )
+ return req
+
+
+def install_req_from_link_and_ireq(
+ link: Link, ireq: InstallRequirement
+) -> InstallRequirement:
+ return InstallRequirement(
+ req=ireq.req,
+ comes_from=ireq.comes_from,
+ editable=ireq.editable,
+ link=link,
+ markers=ireq.markers,
+ use_pep517=ireq.use_pep517,
+ isolated=ireq.isolated,
+ global_options=ireq.global_options,
+ hash_options=ireq.hash_options,
+ config_settings=ireq.config_settings,
+ user_supplied=ireq.user_supplied,
+ )
+
+
+def install_req_drop_extras(ireq: InstallRequirement) -> InstallRequirement:
+ """
+ Creates a new InstallationRequirement using the given template but without
+ any extras. Sets the original requirement as the new one's parent
+ (comes_from).
+ """
+ return InstallRequirement(
+ req=(
+ _set_requirement_extras(ireq.req, set()) if ireq.req is not None else None
+ ),
+ comes_from=ireq,
+ editable=ireq.editable,
+ link=ireq.link,
+ markers=ireq.markers,
+ use_pep517=ireq.use_pep517,
+ isolated=ireq.isolated,
+ global_options=ireq.global_options,
+ hash_options=ireq.hash_options,
+ constraint=ireq.constraint,
+ extras=[],
+ config_settings=ireq.config_settings,
+ user_supplied=ireq.user_supplied,
+ permit_editable_wheels=ireq.permit_editable_wheels,
+ )
+
+
+def install_req_extend_extras(
+ ireq: InstallRequirement,
+ extras: Collection[str],
+) -> InstallRequirement:
+ """
+ Returns a copy of an installation requirement with some additional extras.
+ Makes a shallow copy of the ireq object.
+ """
+ result = copy.copy(ireq)
+ result.extras = {*ireq.extras, *extras}
+ result.req = (
+ _set_requirement_extras(ireq.req, result.extras)
+ if ireq.req is not None
+ else None
+ )
+ return result
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/req/req_file.py b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_file.py
new file mode 100644
index 000000000..eb2a1f699
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_file.py
@@ -0,0 +1,574 @@
+"""
+Requirements file parsing
+"""
+
+import logging
+import optparse
+import os
+import re
+import shlex
+import urllib.parse
+from optparse import Values
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Callable,
+ Dict,
+ Generator,
+ Iterable,
+ List,
+ NoReturn,
+ Optional,
+ Tuple,
+)
+
+from pip._internal.cli import cmdoptions
+from pip._internal.exceptions import InstallationError, RequirementsFileParseError
+from pip._internal.models.search_scope import SearchScope
+from pip._internal.utils.encoding import auto_decode
+
+if TYPE_CHECKING:
+ from pip._internal.index.package_finder import PackageFinder
+ from pip._internal.network.session import PipSession
+
+__all__ = ["parse_requirements"]
+
+ReqFileLines = Iterable[Tuple[int, str]]
+
+LineParser = Callable[[str], Tuple[str, Values]]
+
+SCHEME_RE = re.compile(r"^(http|https|file):", re.I)
+COMMENT_RE = re.compile(r"(^|\s+)#.*$")
+
+# Matches environment variable-style values in '${MY_VARIABLE_1}' with the
+# variable name consisting of only uppercase letters, digits or the '_'
+# (underscore). This follows the POSIX standard defined in IEEE Std 1003.1,
+# 2013 Edition.
+ENV_VAR_RE = re.compile(r"(?P<var>\$\{(?P<name>[A-Z0-9_]+)\})")
+
+SUPPORTED_OPTIONS: List[Callable[..., optparse.Option]] = [
+ cmdoptions.index_url,
+ cmdoptions.extra_index_url,
+ cmdoptions.no_index,
+ cmdoptions.constraints,
+ cmdoptions.requirements,
+ cmdoptions.editable,
+ cmdoptions.find_links,
+ cmdoptions.no_binary,
+ cmdoptions.only_binary,
+ cmdoptions.prefer_binary,
+ cmdoptions.require_hashes,
+ cmdoptions.pre,
+ cmdoptions.trusted_host,
+ cmdoptions.use_new_feature,
+]
+
+# options to be passed to requirements
+SUPPORTED_OPTIONS_REQ: List[Callable[..., optparse.Option]] = [
+ cmdoptions.global_options,
+ cmdoptions.hash,
+ cmdoptions.config_settings,
+]
+
+SUPPORTED_OPTIONS_EDITABLE_REQ: List[Callable[..., optparse.Option]] = [
+ cmdoptions.config_settings,
+]
+
+
+# the 'dest' string values
+SUPPORTED_OPTIONS_REQ_DEST = [str(o().dest) for o in SUPPORTED_OPTIONS_REQ]
+SUPPORTED_OPTIONS_EDITABLE_REQ_DEST = [
+ str(o().dest) for o in SUPPORTED_OPTIONS_EDITABLE_REQ
+]
+
+logger = logging.getLogger(__name__)
+
+
+class ParsedRequirement:
+ def __init__(
+ self,
+ requirement: str,
+ is_editable: bool,
+ comes_from: str,
+ constraint: bool,
+ options: Optional[Dict[str, Any]] = None,
+ line_source: Optional[str] = None,
+ ) -> None:
+ self.requirement = requirement
+ self.is_editable = is_editable
+ self.comes_from = comes_from
+ self.options = options
+ self.constraint = constraint
+ self.line_source = line_source
+
+
+class ParsedLine:
+ def __init__(
+ self,
+ filename: str,
+ lineno: int,
+ args: str,
+ opts: Values,
+ constraint: bool,
+ ) -> None:
+ self.filename = filename
+ self.lineno = lineno
+ self.opts = opts
+ self.constraint = constraint
+
+ if args:
+ self.is_requirement = True
+ self.is_editable = False
+ self.requirement = args
+ elif opts.editables:
+ self.is_requirement = True
+ self.is_editable = True
+ # We don't support multiple -e on one line
+ self.requirement = opts.editables[0]
+ else:
+ self.is_requirement = False
+
+
+def parse_requirements(
+ filename: str,
+ session: "PipSession",
+ finder: Optional["PackageFinder"] = None,
+ options: Optional[optparse.Values] = None,
+ constraint: bool = False,
+) -> Generator[ParsedRequirement, None, None]:
+ """Parse a requirements file and yield ParsedRequirement instances.
+
+ :param filename: Path or url of requirements file.
+ :param session: PipSession instance.
+ :param finder: Instance of pip.index.PackageFinder.
+ :param options: cli options.
+ :param constraint: If true, parsing a constraint file rather than
+ requirements file.
+ """
+ line_parser = get_line_parser(finder)
+ parser = RequirementsFileParser(session, line_parser)
+
+ for parsed_line in parser.parse(filename, constraint):
+ parsed_req = handle_line(
+ parsed_line, options=options, finder=finder, session=session
+ )
+ if parsed_req is not None:
+ yield parsed_req
+
+
+def preprocess(content: str) -> ReqFileLines:
+ """Split, filter, and join lines, and return a line iterator
+
+ :param content: the content of the requirements file
+ """
+ lines_enum: ReqFileLines = enumerate(content.splitlines(), start=1)
+ lines_enum = join_lines(lines_enum)
+ lines_enum = ignore_comments(lines_enum)
+ lines_enum = expand_env_variables(lines_enum)
+ return lines_enum
+
+
+def handle_requirement_line(
+ line: ParsedLine,
+ options: Optional[optparse.Values] = None,
+) -> ParsedRequirement:
+ # preserve for the nested code path
+ line_comes_from = "{} {} (line {})".format(
+ "-c" if line.constraint else "-r",
+ line.filename,
+ line.lineno,
+ )
+
+ assert line.is_requirement
+
+ # get the options that apply to requirements
+ if line.is_editable:
+ supported_dest = SUPPORTED_OPTIONS_EDITABLE_REQ_DEST
+ else:
+ supported_dest = SUPPORTED_OPTIONS_REQ_DEST
+ req_options = {}
+ for dest in supported_dest:
+ if dest in line.opts.__dict__ and line.opts.__dict__[dest]:
+ req_options[dest] = line.opts.__dict__[dest]
+
+ line_source = f"line {line.lineno} of {line.filename}"
+ return ParsedRequirement(
+ requirement=line.requirement,
+ is_editable=line.is_editable,
+ comes_from=line_comes_from,
+ constraint=line.constraint,
+ options=req_options,
+ line_source=line_source,
+ )
+
+
+def handle_option_line(
+ opts: Values,
+ filename: str,
+ lineno: int,
+ finder: Optional["PackageFinder"] = None,
+ options: Optional[optparse.Values] = None,
+ session: Optional["PipSession"] = None,
+) -> None:
+ if opts.hashes:
+ logger.warning(
+ "%s line %s has --hash but no requirement, and will be ignored.",
+ filename,
+ lineno,
+ )
+
+ if options:
+ # percolate options upward
+ if opts.require_hashes:
+ options.require_hashes = opts.require_hashes
+ if opts.features_enabled:
+ options.features_enabled.extend(
+ f for f in opts.features_enabled if f not in options.features_enabled
+ )
+
+ # set finder options
+ if finder:
+ find_links = finder.find_links
+ index_urls = finder.index_urls
+ no_index = finder.search_scope.no_index
+ if opts.no_index is True:
+ no_index = True
+ index_urls = []
+ if opts.index_url and not no_index:
+ index_urls = [opts.index_url]
+ if opts.extra_index_urls and not no_index:
+ index_urls.extend(opts.extra_index_urls)
+ if opts.find_links:
+ # FIXME: it would be nice to keep track of the source
+ # of the find_links: support a find-links local path
+ # relative to a requirements file.
+ value = opts.find_links[0]
+ req_dir = os.path.dirname(os.path.abspath(filename))
+ relative_to_reqs_file = os.path.join(req_dir, value)
+ if os.path.exists(relative_to_reqs_file):
+ value = relative_to_reqs_file
+ find_links.append(value)
+
+ if session:
+ # We need to update the auth urls in session
+ session.update_index_urls(index_urls)
+
+ search_scope = SearchScope(
+ find_links=find_links,
+ index_urls=index_urls,
+ no_index=no_index,
+ )
+ finder.search_scope = search_scope
+
+ if opts.pre:
+ finder.set_allow_all_prereleases()
+
+ if opts.prefer_binary:
+ finder.set_prefer_binary()
+
+ if session:
+ for host in opts.trusted_hosts or []:
+ source = f"line {lineno} of {filename}"
+ session.add_trusted_host(host, source=source)
+
+
+def handle_line(
+ line: ParsedLine,
+ options: Optional[optparse.Values] = None,
+ finder: Optional["PackageFinder"] = None,
+ session: Optional["PipSession"] = None,
+) -> Optional[ParsedRequirement]:
+ """Handle a single parsed requirements line; This can result in
+ creating/yielding requirements, or updating the finder.
+
+ :param line: The parsed line to be processed.
+ :param options: CLI options.
+ :param finder: The finder - updated by non-requirement lines.
+ :param session: The session - updated by non-requirement lines.
+
+ Returns a ParsedRequirement object if the line is a requirement line,
+ otherwise returns None.
+
+ For lines that contain requirements, the only options that have an effect
+ are from SUPPORTED_OPTIONS_REQ, and they are scoped to the
+ requirement. Other options from SUPPORTED_OPTIONS may be present, but are
+ ignored.
+
+ For lines that do not contain requirements, the only options that have an
+ effect are from SUPPORTED_OPTIONS. Options from SUPPORTED_OPTIONS_REQ may
+ be present, but are ignored. These lines may contain multiple options
+ (although our docs imply only one is supported), and all our parsed and
+ affect the finder.
+ """
+
+ if line.is_requirement:
+ parsed_req = handle_requirement_line(line, options)
+ return parsed_req
+ else:
+ handle_option_line(
+ line.opts,
+ line.filename,
+ line.lineno,
+ finder,
+ options,
+ session,
+ )
+ return None
+
+
+class RequirementsFileParser:
+ def __init__(
+ self,
+ session: "PipSession",
+ line_parser: LineParser,
+ ) -> None:
+ self._session = session
+ self._line_parser = line_parser
+
+ def parse(
+ self, filename: str, constraint: bool
+ ) -> Generator[ParsedLine, None, None]:
+ """Parse a given file, yielding parsed lines."""
+ yield from self._parse_and_recurse(
+ filename, constraint, [{os.path.abspath(filename): None}]
+ )
+
+ def _parse_and_recurse(
+ self,
+ filename: str,
+ constraint: bool,
+ parsed_files_stack: List[Dict[str, Optional[str]]],
+ ) -> Generator[ParsedLine, None, None]:
+ for line in self._parse_file(filename, constraint):
+ if not line.is_requirement and (
+ line.opts.requirements or line.opts.constraints
+ ):
+ # parse a nested requirements file
+ if line.opts.requirements:
+ req_path = line.opts.requirements[0]
+ nested_constraint = False
+ else:
+ req_path = line.opts.constraints[0]
+ nested_constraint = True
+
+ # original file is over http
+ if SCHEME_RE.search(filename):
+ # do a url join so relative paths work
+ req_path = urllib.parse.urljoin(filename, req_path)
+ # original file and nested file are paths
+ elif not SCHEME_RE.search(req_path):
+ # do a join so relative paths work
+ # and then abspath so that we can identify recursive references
+ req_path = os.path.abspath(
+ os.path.join(
+ os.path.dirname(filename),
+ req_path,
+ )
+ )
+ parsed_files = parsed_files_stack[0]
+ if req_path in parsed_files:
+ initial_file = parsed_files[req_path]
+ tail = (
+ f" and again in {initial_file}"
+ if initial_file is not None
+ else ""
+ )
+ raise RequirementsFileParseError(
+ f"{req_path} recursively references itself in {filename}{tail}"
+ )
+ # Keeping a track where was each file first included in
+ new_parsed_files = parsed_files.copy()
+ new_parsed_files[req_path] = filename
+ yield from self._parse_and_recurse(
+ req_path, nested_constraint, [new_parsed_files, *parsed_files_stack]
+ )
+ else:
+ yield line
+
+ def _parse_file(
+ self, filename: str, constraint: bool
+ ) -> Generator[ParsedLine, None, None]:
+ _, content = get_file_content(filename, self._session)
+
+ lines_enum = preprocess(content)
+
+ for line_number, line in lines_enum:
+ try:
+ args_str, opts = self._line_parser(line)
+ except OptionParsingError as e:
+ # add offending line
+ msg = f"Invalid requirement: {line}\n{e.msg}"
+ raise RequirementsFileParseError(msg)
+
+ yield ParsedLine(
+ filename,
+ line_number,
+ args_str,
+ opts,
+ constraint,
+ )
+
+
+def get_line_parser(finder: Optional["PackageFinder"]) -> LineParser:
+ def parse_line(line: str) -> Tuple[str, Values]:
+ # Build new parser for each line since it accumulates appendable
+ # options.
+ parser = build_parser()
+ defaults = parser.get_default_values()
+ defaults.index_url = None
+ if finder:
+ defaults.format_control = finder.format_control
+
+ args_str, options_str = break_args_options(line)
+
+ try:
+ options = shlex.split(options_str)
+ except ValueError as e:
+ raise OptionParsingError(f"Could not split options: {options_str}") from e
+
+ opts, _ = parser.parse_args(options, defaults)
+
+ return args_str, opts
+
+ return parse_line
+
+
+def break_args_options(line: str) -> Tuple[str, str]:
+ """Break up the line into an args and options string. We only want to shlex
+ (and then optparse) the options, not the args. args can contain markers
+ which are corrupted by shlex.
+ """
+ tokens = line.split(" ")
+ args = []
+ options = tokens[:]
+ for token in tokens:
+ if token.startswith("-") or token.startswith("--"):
+ break
+ else:
+ args.append(token)
+ options.pop(0)
+ return " ".join(args), " ".join(options)
+
+
+class OptionParsingError(Exception):
+ def __init__(self, msg: str) -> None:
+ self.msg = msg
+
+
+def build_parser() -> optparse.OptionParser:
+ """
+ Return a parser for parsing requirement lines
+ """
+ parser = optparse.OptionParser(add_help_option=False)
+
+ option_factories = SUPPORTED_OPTIONS + SUPPORTED_OPTIONS_REQ
+ for option_factory in option_factories:
+ option = option_factory()
+ parser.add_option(option)
+
+ # By default optparse sys.exits on parsing errors. We want to wrap
+ # that in our own exception.
+ def parser_exit(self: Any, msg: str) -> "NoReturn":
+ raise OptionParsingError(msg)
+
+ # NOTE: mypy disallows assigning to a method
+ # https://github.com/python/mypy/issues/2427
+ parser.exit = parser_exit # type: ignore
+
+ return parser
+
+
+def join_lines(lines_enum: ReqFileLines) -> ReqFileLines:
+ """Joins a line ending in '\' with the previous line (except when following
+ comments). The joined line takes on the index of the first line.
+ """
+ primary_line_number = None
+ new_line: List[str] = []
+ for line_number, line in lines_enum:
+ if not line.endswith("\\") or COMMENT_RE.match(line):
+ if COMMENT_RE.match(line):
+ # this ensures comments are always matched later
+ line = " " + line
+ if new_line:
+ new_line.append(line)
+ assert primary_line_number is not None
+ yield primary_line_number, "".join(new_line)
+ new_line = []
+ else:
+ yield line_number, line
+ else:
+ if not new_line:
+ primary_line_number = line_number
+ new_line.append(line.strip("\\"))
+
+ # last line contains \
+ if new_line:
+ assert primary_line_number is not None
+ yield primary_line_number, "".join(new_line)
+
+ # TODO: handle space after '\'.
+
+
+def ignore_comments(lines_enum: ReqFileLines) -> ReqFileLines:
+ """
+ Strips comments and filter empty lines.
+ """
+ for line_number, line in lines_enum:
+ line = COMMENT_RE.sub("", line)
+ line = line.strip()
+ if line:
+ yield line_number, line
+
+
+def expand_env_variables(lines_enum: ReqFileLines) -> ReqFileLines:
+ """Replace all environment variables that can be retrieved via `os.getenv`.
+
+ The only allowed format for environment variables defined in the
+ requirement file is `${MY_VARIABLE_1}` to ensure two things:
+
+ 1. Strings that contain a `$` aren't accidentally (partially) expanded.
+ 2. Ensure consistency across platforms for requirement files.
+
+ These points are the result of a discussion on the `github pull
+ request #3514 <https://github.com/pypa/pip/pull/3514>`_.
+
+ Valid characters in variable names follow the `POSIX standard
+ <http://pubs.opengroup.org/onlinepubs/9699919799/>`_ and are limited
+ to uppercase letter, digits and the `_` (underscore).
+ """
+ for line_number, line in lines_enum:
+ for env_var, var_name in ENV_VAR_RE.findall(line):
+ value = os.getenv(var_name)
+ if not value:
+ continue
+
+ line = line.replace(env_var, value)
+
+ yield line_number, line
+
+
+def get_file_content(url: str, session: "PipSession") -> Tuple[str, str]:
+ """Gets the content of a file; it may be a filename, file: URL, or
+ http: URL. Returns (location, content). Content is unicode.
+ Respects # -*- coding: declarations on the retrieved files.
+
+ :param url: File path or url.
+ :param session: PipSession instance.
+ """
+ scheme = urllib.parse.urlsplit(url).scheme
+ # Pip has special support for file:// URLs (LocalFSAdapter).
+ if scheme in ["http", "https", "file"]:
+ # Delay importing heavy network modules until absolutely necessary.
+ from pip._internal.network.utils import raise_for_status
+
+ resp = session.get(url)
+ raise_for_status(resp)
+ return resp.url, resp.text
+
+ # Assume this is a bare path.
+ try:
+ with open(url, "rb") as f:
+ content = auto_decode(f.read())
+ except OSError as exc:
+ raise InstallationError(f"Could not open requirements file: {exc}")
+ return url, content
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/req/req_install.py b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_install.py
new file mode 100644
index 000000000..834bc5133
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_install.py
@@ -0,0 +1,934 @@
+import functools
+import logging
+import os
+import shutil
+import sys
+import uuid
+import zipfile
+from optparse import Values
+from pathlib import Path
+from typing import Any, Collection, Dict, Iterable, List, Optional, Sequence, Union
+
+from pip._vendor.packaging.markers import Marker
+from pip._vendor.packaging.requirements import Requirement
+from pip._vendor.packaging.specifiers import SpecifierSet
+from pip._vendor.packaging.utils import canonicalize_name
+from pip._vendor.packaging.version import Version
+from pip._vendor.packaging.version import parse as parse_version
+from pip._vendor.pyproject_hooks import BuildBackendHookCaller
+
+from pip._internal.build_env import BuildEnvironment, NoOpBuildEnvironment
+from pip._internal.exceptions import InstallationError, PreviousBuildDirError
+from pip._internal.locations import get_scheme
+from pip._internal.metadata import (
+ BaseDistribution,
+ get_default_environment,
+ get_directory_distribution,
+ get_wheel_distribution,
+)
+from pip._internal.metadata.base import FilesystemWheel
+from pip._internal.models.direct_url import DirectUrl
+from pip._internal.models.link import Link
+from pip._internal.operations.build.metadata import generate_metadata
+from pip._internal.operations.build.metadata_editable import generate_editable_metadata
+from pip._internal.operations.build.metadata_legacy import (
+ generate_metadata as generate_metadata_legacy,
+)
+from pip._internal.operations.install.editable_legacy import (
+ install_editable as install_editable_legacy,
+)
+from pip._internal.operations.install.wheel import install_wheel
+from pip._internal.pyproject import load_pyproject_toml, make_pyproject_path
+from pip._internal.req.req_uninstall import UninstallPathSet
+from pip._internal.utils.deprecation import deprecated
+from pip._internal.utils.hashes import Hashes
+from pip._internal.utils.misc import (
+ ConfiguredBuildBackendHookCaller,
+ ask_path_exists,
+ backup_dir,
+ display_path,
+ hide_url,
+ is_installable_dir,
+ redact_auth_from_requirement,
+ redact_auth_from_url,
+)
+from pip._internal.utils.packaging import get_requirement
+from pip._internal.utils.subprocess import runner_with_spinner_message
+from pip._internal.utils.temp_dir import TempDirectory, tempdir_kinds
+from pip._internal.utils.unpacking import unpack_file
+from pip._internal.utils.virtualenv import running_under_virtualenv
+from pip._internal.vcs import vcs
+
+logger = logging.getLogger(__name__)
+
+
+class InstallRequirement:
+ """
+ Represents something that may be installed later on, may have information
+ about where to fetch the relevant requirement and also contains logic for
+ installing the said requirement.
+ """
+
+ def __init__(
+ self,
+ req: Optional[Requirement],
+ comes_from: Optional[Union[str, "InstallRequirement"]],
+ editable: bool = False,
+ link: Optional[Link] = None,
+ markers: Optional[Marker] = None,
+ use_pep517: Optional[bool] = None,
+ isolated: bool = False,
+ *,
+ global_options: Optional[List[str]] = None,
+ hash_options: Optional[Dict[str, List[str]]] = None,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+ constraint: bool = False,
+ extras: Collection[str] = (),
+ user_supplied: bool = False,
+ permit_editable_wheels: bool = False,
+ ) -> None:
+ assert req is None or isinstance(req, Requirement), req
+ self.req = req
+ self.comes_from = comes_from
+ self.constraint = constraint
+ self.editable = editable
+ self.permit_editable_wheels = permit_editable_wheels
+
+ # source_dir is the local directory where the linked requirement is
+ # located, or unpacked. In case unpacking is needed, creating and
+ # populating source_dir is done by the RequirementPreparer. Note this
+ # is not necessarily the directory where pyproject.toml or setup.py is
+ # located - that one is obtained via unpacked_source_directory.
+ self.source_dir: Optional[str] = None
+ if self.editable:
+ assert link
+ if link.is_file:
+ self.source_dir = os.path.normpath(os.path.abspath(link.file_path))
+
+ # original_link is the direct URL that was provided by the user for the
+ # requirement, either directly or via a constraints file.
+ if link is None and req and req.url:
+ # PEP 508 URL requirement
+ link = Link(req.url)
+ self.link = self.original_link = link
+
+ # When this InstallRequirement is a wheel obtained from the cache of locally
+ # built wheels, this is the source link corresponding to the cache entry, which
+ # was used to download and build the cached wheel.
+ self.cached_wheel_source_link: Optional[Link] = None
+
+ # Information about the location of the artifact that was downloaded . This
+ # property is guaranteed to be set in resolver results.
+ self.download_info: Optional[DirectUrl] = None
+
+ # Path to any downloaded or already-existing package.
+ self.local_file_path: Optional[str] = None
+ if self.link and self.link.is_file:
+ self.local_file_path = self.link.file_path
+
+ if extras:
+ self.extras = extras
+ elif req:
+ self.extras = req.extras
+ else:
+ self.extras = set()
+ if markers is None and req:
+ markers = req.marker
+ self.markers = markers
+
+ # This holds the Distribution object if this requirement is already installed.
+ self.satisfied_by: Optional[BaseDistribution] = None
+ # Whether the installation process should try to uninstall an existing
+ # distribution before installing this requirement.
+ self.should_reinstall = False
+ # Temporary build location
+ self._temp_build_dir: Optional[TempDirectory] = None
+ # Set to True after successful installation
+ self.install_succeeded: Optional[bool] = None
+ # Supplied options
+ self.global_options = global_options if global_options else []
+ self.hash_options = hash_options if hash_options else {}
+ self.config_settings = config_settings
+ # Set to True after successful preparation of this requirement
+ self.prepared = False
+ # User supplied requirement are explicitly requested for installation
+ # by the user via CLI arguments or requirements files, as opposed to,
+ # e.g. dependencies, extras or constraints.
+ self.user_supplied = user_supplied
+
+ self.isolated = isolated
+ self.build_env: BuildEnvironment = NoOpBuildEnvironment()
+
+ # For PEP 517, the directory where we request the project metadata
+ # gets stored. We need this to pass to build_wheel, so the backend
+ # can ensure that the wheel matches the metadata (see the PEP for
+ # details).
+ self.metadata_directory: Optional[str] = None
+
+ # The static build requirements (from pyproject.toml)
+ self.pyproject_requires: Optional[List[str]] = None
+
+ # Build requirements that we will check are available
+ self.requirements_to_check: List[str] = []
+
+ # The PEP 517 backend we should use to build the project
+ self.pep517_backend: Optional[BuildBackendHookCaller] = None
+
+ # Are we using PEP 517 for this requirement?
+ # After pyproject.toml has been loaded, the only valid values are True
+ # and False. Before loading, None is valid (meaning "use the default").
+ # Setting an explicit value before loading pyproject.toml is supported,
+ # but after loading this flag should be treated as read only.
+ self.use_pep517 = use_pep517
+
+ # If config settings are provided, enforce PEP 517.
+ if self.config_settings:
+ if self.use_pep517 is False:
+ logger.warning(
+ "--no-use-pep517 ignored for %s "
+ "because --config-settings are specified.",
+ self,
+ )
+ self.use_pep517 = True
+
+ # This requirement needs more preparation before it can be built
+ self.needs_more_preparation = False
+
+ # This requirement needs to be unpacked before it can be installed.
+ self._archive_source: Optional[Path] = None
+
+ def __str__(self) -> str:
+ if self.req:
+ s = redact_auth_from_requirement(self.req)
+ if self.link:
+ s += f" from {redact_auth_from_url(self.link.url)}"
+ elif self.link:
+ s = redact_auth_from_url(self.link.url)
+ else:
+ s = "<InstallRequirement>"
+ if self.satisfied_by is not None:
+ if self.satisfied_by.location is not None:
+ location = display_path(self.satisfied_by.location)
+ else:
+ location = "<memory>"
+ s += f" in {location}"
+ if self.comes_from:
+ if isinstance(self.comes_from, str):
+ comes_from: Optional[str] = self.comes_from
+ else:
+ comes_from = self.comes_from.from_path()
+ if comes_from:
+ s += f" (from {comes_from})"
+ return s
+
+ def __repr__(self) -> str:
+ return (
+ f"<{self.__class__.__name__} object: "
+ f"{str(self)} editable={self.editable!r}>"
+ )
+
+ def format_debug(self) -> str:
+ """An un-tested helper for getting state, for debugging."""
+ attributes = vars(self)
+ names = sorted(attributes)
+
+ state = (f"{attr}={attributes[attr]!r}" for attr in sorted(names))
+ return "<{name} object: {{{state}}}>".format(
+ name=self.__class__.__name__,
+ state=", ".join(state),
+ )
+
+ # Things that are valid for all kinds of requirements?
+ @property
+ def name(self) -> Optional[str]:
+ if self.req is None:
+ return None
+ return self.req.name
+
+ @functools.cached_property
+ def supports_pyproject_editable(self) -> bool:
+ if not self.use_pep517:
+ return False
+ assert self.pep517_backend
+ with self.build_env:
+ runner = runner_with_spinner_message(
+ "Checking if build backend supports build_editable"
+ )
+ with self.pep517_backend.subprocess_runner(runner):
+ return "build_editable" in self.pep517_backend._supported_features()
+
+ @property
+ def specifier(self) -> SpecifierSet:
+ assert self.req is not None
+ return self.req.specifier
+
+ @property
+ def is_direct(self) -> bool:
+ """Whether this requirement was specified as a direct URL."""
+ return self.original_link is not None
+
+ @property
+ def is_pinned(self) -> bool:
+ """Return whether I am pinned to an exact version.
+
+ For example, some-package==1.2 is pinned; some-package>1.2 is not.
+ """
+ assert self.req is not None
+ specifiers = self.req.specifier
+ return len(specifiers) == 1 and next(iter(specifiers)).operator in {"==", "==="}
+
+ def match_markers(self, extras_requested: Optional[Iterable[str]] = None) -> bool:
+ if not extras_requested:
+ # Provide an extra to safely evaluate the markers
+ # without matching any extra
+ extras_requested = ("",)
+ if self.markers is not None:
+ return any(
+ self.markers.evaluate({"extra": extra}) for extra in extras_requested
+ )
+ else:
+ return True
+
+ @property
+ def has_hash_options(self) -> bool:
+ """Return whether any known-good hashes are specified as options.
+
+ These activate --require-hashes mode; hashes specified as part of a
+ URL do not.
+
+ """
+ return bool(self.hash_options)
+
+ def hashes(self, trust_internet: bool = True) -> Hashes:
+ """Return a hash-comparer that considers my option- and URL-based
+ hashes to be known-good.
+
+ Hashes in URLs--ones embedded in the requirements file, not ones
+ downloaded from an index server--are almost peers with ones from
+ flags. They satisfy --require-hashes (whether it was implicitly or
+ explicitly activated) but do not activate it. md5 and sha224 are not
+ allowed in flags, which should nudge people toward good algos. We
+ always OR all hashes together, even ones from URLs.
+
+ :param trust_internet: Whether to trust URL-based (#md5=...) hashes
+ downloaded from the internet, as by populate_link()
+
+ """
+ good_hashes = self.hash_options.copy()
+ if trust_internet:
+ link = self.link
+ elif self.is_direct and self.user_supplied:
+ link = self.original_link
+ else:
+ link = None
+ if link and link.hash:
+ assert link.hash_name is not None
+ good_hashes.setdefault(link.hash_name, []).append(link.hash)
+ return Hashes(good_hashes)
+
+ def from_path(self) -> Optional[str]:
+ """Format a nice indicator to show where this "comes from" """
+ if self.req is None:
+ return None
+ s = str(self.req)
+ if self.comes_from:
+ comes_from: Optional[str]
+ if isinstance(self.comes_from, str):
+ comes_from = self.comes_from
+ else:
+ comes_from = self.comes_from.from_path()
+ if comes_from:
+ s += "->" + comes_from
+ return s
+
+ def ensure_build_location(
+ self, build_dir: str, autodelete: bool, parallel_builds: bool
+ ) -> str:
+ assert build_dir is not None
+ if self._temp_build_dir is not None:
+ assert self._temp_build_dir.path
+ return self._temp_build_dir.path
+ if self.req is None:
+ # Some systems have /tmp as a symlink which confuses custom
+ # builds (such as numpy). Thus, we ensure that the real path
+ # is returned.
+ self._temp_build_dir = TempDirectory(
+ kind=tempdir_kinds.REQ_BUILD, globally_managed=True
+ )
+
+ return self._temp_build_dir.path
+
+ # This is the only remaining place where we manually determine the path
+ # for the temporary directory. It is only needed for editables where
+ # it is the value of the --src option.
+
+ # When parallel builds are enabled, add a UUID to the build directory
+ # name so multiple builds do not interfere with each other.
+ dir_name: str = canonicalize_name(self.req.name)
+ if parallel_builds:
+ dir_name = f"{dir_name}_{uuid.uuid4().hex}"
+
+ # FIXME: Is there a better place to create the build_dir? (hg and bzr
+ # need this)
+ if not os.path.exists(build_dir):
+ logger.debug("Creating directory %s", build_dir)
+ os.makedirs(build_dir)
+ actual_build_dir = os.path.join(build_dir, dir_name)
+ # `None` indicates that we respect the globally-configured deletion
+ # settings, which is what we actually want when auto-deleting.
+ delete_arg = None if autodelete else False
+ return TempDirectory(
+ path=actual_build_dir,
+ delete=delete_arg,
+ kind=tempdir_kinds.REQ_BUILD,
+ globally_managed=True,
+ ).path
+
+ def _set_requirement(self) -> None:
+ """Set requirement after generating metadata."""
+ assert self.req is None
+ assert self.metadata is not None
+ assert self.source_dir is not None
+
+ # Construct a Requirement object from the generated metadata
+ if isinstance(parse_version(self.metadata["Version"]), Version):
+ op = "=="
+ else:
+ op = "==="
+
+ self.req = get_requirement(
+ "".join(
+ [
+ self.metadata["Name"],
+ op,
+ self.metadata["Version"],
+ ]
+ )
+ )
+
+ def warn_on_mismatching_name(self) -> None:
+ assert self.req is not None
+ metadata_name = canonicalize_name(self.metadata["Name"])
+ if canonicalize_name(self.req.name) == metadata_name:
+ # Everything is fine.
+ return
+
+ # If we're here, there's a mismatch. Log a warning about it.
+ logger.warning(
+ "Generating metadata for package %s "
+ "produced metadata for project name %s. Fix your "
+ "#egg=%s fragments.",
+ self.name,
+ metadata_name,
+ self.name,
+ )
+ self.req = get_requirement(metadata_name)
+
+ def check_if_exists(self, use_user_site: bool) -> None:
+ """Find an installed distribution that satisfies or conflicts
+ with this requirement, and set self.satisfied_by or
+ self.should_reinstall appropriately.
+ """
+ if self.req is None:
+ return
+ existing_dist = get_default_environment().get_distribution(self.req.name)
+ if not existing_dist:
+ return
+
+ version_compatible = self.req.specifier.contains(
+ existing_dist.version,
+ prereleases=True,
+ )
+ if not version_compatible:
+ self.satisfied_by = None
+ if use_user_site:
+ if existing_dist.in_usersite:
+ self.should_reinstall = True
+ elif running_under_virtualenv() and existing_dist.in_site_packages:
+ raise InstallationError(
+ f"Will not install to the user site because it will "
+ f"lack sys.path precedence to {existing_dist.raw_name} "
+ f"in {existing_dist.location}"
+ )
+ else:
+ self.should_reinstall = True
+ else:
+ if self.editable:
+ self.should_reinstall = True
+ # when installing editables, nothing pre-existing should ever
+ # satisfy
+ self.satisfied_by = None
+ else:
+ self.satisfied_by = existing_dist
+
+ # Things valid for wheels
+ @property
+ def is_wheel(self) -> bool:
+ if not self.link:
+ return False
+ return self.link.is_wheel
+
+ @property
+ def is_wheel_from_cache(self) -> bool:
+ # When True, it means that this InstallRequirement is a local wheel file in the
+ # cache of locally built wheels.
+ return self.cached_wheel_source_link is not None
+
+ # Things valid for sdists
+ @property
+ def unpacked_source_directory(self) -> str:
+ assert self.source_dir, f"No source dir for {self}"
+ return os.path.join(
+ self.source_dir, self.link and self.link.subdirectory_fragment or ""
+ )
+
+ @property
+ def setup_py_path(self) -> str:
+ assert self.source_dir, f"No source dir for {self}"
+ setup_py = os.path.join(self.unpacked_source_directory, "setup.py")
+
+ return setup_py
+
+ @property
+ def setup_cfg_path(self) -> str:
+ assert self.source_dir, f"No source dir for {self}"
+ setup_cfg = os.path.join(self.unpacked_source_directory, "setup.cfg")
+
+ return setup_cfg
+
+ @property
+ def pyproject_toml_path(self) -> str:
+ assert self.source_dir, f"No source dir for {self}"
+ return make_pyproject_path(self.unpacked_source_directory)
+
+ def load_pyproject_toml(self) -> None:
+ """Load the pyproject.toml file.
+
+ After calling this routine, all of the attributes related to PEP 517
+ processing for this requirement have been set. In particular, the
+ use_pep517 attribute can be used to determine whether we should
+ follow the PEP 517 or legacy (setup.py) code path.
+ """
+ pyproject_toml_data = load_pyproject_toml(
+ self.use_pep517, self.pyproject_toml_path, self.setup_py_path, str(self)
+ )
+
+ if pyproject_toml_data is None:
+ assert not self.config_settings
+ self.use_pep517 = False
+ return
+
+ self.use_pep517 = True
+ requires, backend, check, backend_path = pyproject_toml_data
+ self.requirements_to_check = check
+ self.pyproject_requires = requires
+ self.pep517_backend = ConfiguredBuildBackendHookCaller(
+ self,
+ self.unpacked_source_directory,
+ backend,
+ backend_path=backend_path,
+ )
+
+ def isolated_editable_sanity_check(self) -> None:
+ """Check that an editable requirement if valid for use with PEP 517/518.
+
+ This verifies that an editable that has a pyproject.toml either supports PEP 660
+ or as a setup.py or a setup.cfg
+ """
+ if (
+ self.editable
+ and self.use_pep517
+ and not self.supports_pyproject_editable
+ and not os.path.isfile(self.setup_py_path)
+ and not os.path.isfile(self.setup_cfg_path)
+ ):
+ raise InstallationError(
+ f"Project {self} has a 'pyproject.toml' and its build "
+ f"backend is missing the 'build_editable' hook. Since it does not "
+ f"have a 'setup.py' nor a 'setup.cfg', "
+ f"it cannot be installed in editable mode. "
+ f"Consider using a build backend that supports PEP 660."
+ )
+
+ def prepare_metadata(self) -> None:
+ """Ensure that project metadata is available.
+
+ Under PEP 517 and PEP 660, call the backend hook to prepare the metadata.
+ Under legacy processing, call setup.py egg-info.
+ """
+ assert self.source_dir, f"No source dir for {self}"
+ details = self.name or f"from {self.link}"
+
+ if self.use_pep517:
+ assert self.pep517_backend is not None
+ if (
+ self.editable
+ and self.permit_editable_wheels
+ and self.supports_pyproject_editable
+ ):
+ self.metadata_directory = generate_editable_metadata(
+ build_env=self.build_env,
+ backend=self.pep517_backend,
+ details=details,
+ )
+ else:
+ self.metadata_directory = generate_metadata(
+ build_env=self.build_env,
+ backend=self.pep517_backend,
+ details=details,
+ )
+ else:
+ self.metadata_directory = generate_metadata_legacy(
+ build_env=self.build_env,
+ setup_py_path=self.setup_py_path,
+ source_dir=self.unpacked_source_directory,
+ isolated=self.isolated,
+ details=details,
+ )
+
+ # Act on the newly generated metadata, based on the name and version.
+ if not self.name:
+ self._set_requirement()
+ else:
+ self.warn_on_mismatching_name()
+
+ self.assert_source_matches_version()
+
+ @property
+ def metadata(self) -> Any:
+ if not hasattr(self, "_metadata"):
+ self._metadata = self.get_dist().metadata
+
+ return self._metadata
+
+ def get_dist(self) -> BaseDistribution:
+ if self.metadata_directory:
+ return get_directory_distribution(self.metadata_directory)
+ elif self.local_file_path and self.is_wheel:
+ assert self.req is not None
+ return get_wheel_distribution(
+ FilesystemWheel(self.local_file_path),
+ canonicalize_name(self.req.name),
+ )
+ raise AssertionError(
+ f"InstallRequirement {self} has no metadata directory and no wheel: "
+ f"can't make a distribution."
+ )
+
+ def assert_source_matches_version(self) -> None:
+ assert self.source_dir, f"No source dir for {self}"
+ version = self.metadata["version"]
+ if self.req and self.req.specifier and version not in self.req.specifier:
+ logger.warning(
+ "Requested %s, but installing version %s",
+ self,
+ version,
+ )
+ else:
+ logger.debug(
+ "Source in %s has version %s, which satisfies requirement %s",
+ display_path(self.source_dir),
+ version,
+ self,
+ )
+
+ # For both source distributions and editables
+ def ensure_has_source_dir(
+ self,
+ parent_dir: str,
+ autodelete: bool = False,
+ parallel_builds: bool = False,
+ ) -> None:
+ """Ensure that a source_dir is set.
+
+ This will create a temporary build dir if the name of the requirement
+ isn't known yet.
+
+ :param parent_dir: The ideal pip parent_dir for the source_dir.
+ Generally src_dir for editables and build_dir for sdists.
+ :return: self.source_dir
+ """
+ if self.source_dir is None:
+ self.source_dir = self.ensure_build_location(
+ parent_dir,
+ autodelete=autodelete,
+ parallel_builds=parallel_builds,
+ )
+
+ def needs_unpacked_archive(self, archive_source: Path) -> None:
+ assert self._archive_source is None
+ self._archive_source = archive_source
+
+ def ensure_pristine_source_checkout(self) -> None:
+ """Ensure the source directory has not yet been built in."""
+ assert self.source_dir is not None
+ if self._archive_source is not None:
+ unpack_file(str(self._archive_source), self.source_dir)
+ elif is_installable_dir(self.source_dir):
+ # If a checkout exists, it's unwise to keep going.
+ # version inconsistencies are logged later, but do not fail
+ # the installation.
+ raise PreviousBuildDirError(
+ f"pip can't proceed with requirements '{self}' due to a "
+ f"pre-existing build directory ({self.source_dir}). This is likely "
+ "due to a previous installation that failed . pip is "
+ "being responsible and not assuming it can delete this. "
+ "Please delete it and try again."
+ )
+
+ # For editable installations
+ def update_editable(self) -> None:
+ if not self.link:
+ logger.debug(
+ "Cannot update repository at %s; repository location is unknown",
+ self.source_dir,
+ )
+ return
+ assert self.editable
+ assert self.source_dir
+ if self.link.scheme == "file":
+ # Static paths don't get updated
+ return
+ vcs_backend = vcs.get_backend_for_scheme(self.link.scheme)
+ # Editable requirements are validated in Requirement constructors.
+ # So here, if it's neither a path nor a valid VCS URL, it's a bug.
+ assert vcs_backend, f"Unsupported VCS URL {self.link.url}"
+ hidden_url = hide_url(self.link.url)
+ vcs_backend.obtain(self.source_dir, url=hidden_url, verbosity=0)
+
+ # Top-level Actions
+ def uninstall(
+ self, auto_confirm: bool = False, verbose: bool = False
+ ) -> Optional[UninstallPathSet]:
+ """
+ Uninstall the distribution currently satisfying this requirement.
+
+ Prompts before removing or modifying files unless
+ ``auto_confirm`` is True.
+
+ Refuses to delete or modify files outside of ``sys.prefix`` -
+ thus uninstallation within a virtual environment can only
+ modify that virtual environment, even if the virtualenv is
+ linked to global site-packages.
+
+ """
+ assert self.req
+ dist = get_default_environment().get_distribution(self.req.name)
+ if not dist:
+ logger.warning("Skipping %s as it is not installed.", self.name)
+ return None
+ logger.info("Found existing installation: %s", dist)
+
+ uninstalled_pathset = UninstallPathSet.from_dist(dist)
+ uninstalled_pathset.remove(auto_confirm, verbose)
+ return uninstalled_pathset
+
+ def _get_archive_name(self, path: str, parentdir: str, rootdir: str) -> str:
+ def _clean_zip_name(name: str, prefix: str) -> str:
+ assert name.startswith(
+ prefix + os.path.sep
+ ), f"name {name!r} doesn't start with prefix {prefix!r}"
+ name = name[len(prefix) + 1 :]
+ name = name.replace(os.path.sep, "/")
+ return name
+
+ assert self.req is not None
+ path = os.path.join(parentdir, path)
+ name = _clean_zip_name(path, rootdir)
+ return self.req.name + "/" + name
+
+ def archive(self, build_dir: Optional[str]) -> None:
+ """Saves archive to provided build_dir.
+
+ Used for saving downloaded VCS requirements as part of `pip download`.
+ """
+ assert self.source_dir
+ if build_dir is None:
+ return
+
+ create_archive = True
+ archive_name = "{}-{}.zip".format(self.name, self.metadata["version"])
+ archive_path = os.path.join(build_dir, archive_name)
+
+ if os.path.exists(archive_path):
+ response = ask_path_exists(
+ f"The file {display_path(archive_path)} exists. (i)gnore, (w)ipe, "
+ "(b)ackup, (a)bort ",
+ ("i", "w", "b", "a"),
+ )
+ if response == "i":
+ create_archive = False
+ elif response == "w":
+ logger.warning("Deleting %s", display_path(archive_path))
+ os.remove(archive_path)
+ elif response == "b":
+ dest_file = backup_dir(archive_path)
+ logger.warning(
+ "Backing up %s to %s",
+ display_path(archive_path),
+ display_path(dest_file),
+ )
+ shutil.move(archive_path, dest_file)
+ elif response == "a":
+ sys.exit(-1)
+
+ if not create_archive:
+ return
+
+ zip_output = zipfile.ZipFile(
+ archive_path,
+ "w",
+ zipfile.ZIP_DEFLATED,
+ allowZip64=True,
+ )
+ with zip_output:
+ dir = os.path.normcase(os.path.abspath(self.unpacked_source_directory))
+ for dirpath, dirnames, filenames in os.walk(dir):
+ for dirname in dirnames:
+ dir_arcname = self._get_archive_name(
+ dirname,
+ parentdir=dirpath,
+ rootdir=dir,
+ )
+ zipdir = zipfile.ZipInfo(dir_arcname + "/")
+ zipdir.external_attr = 0x1ED << 16 # 0o755
+ zip_output.writestr(zipdir, "")
+ for filename in filenames:
+ file_arcname = self._get_archive_name(
+ filename,
+ parentdir=dirpath,
+ rootdir=dir,
+ )
+ filename = os.path.join(dirpath, filename)
+ zip_output.write(filename, file_arcname)
+
+ logger.info("Saved %s", display_path(archive_path))
+
+ def install(
+ self,
+ global_options: Optional[Sequence[str]] = None,
+ root: Optional[str] = None,
+ home: Optional[str] = None,
+ prefix: Optional[str] = None,
+ warn_script_location: bool = True,
+ use_user_site: bool = False,
+ pycompile: bool = True,
+ ) -> None:
+ assert self.req is not None
+ scheme = get_scheme(
+ self.req.name,
+ user=use_user_site,
+ home=home,
+ root=root,
+ isolated=self.isolated,
+ prefix=prefix,
+ )
+
+ if self.editable and not self.is_wheel:
+ deprecated(
+ reason=(
+ f"Legacy editable install of {self} (setup.py develop) "
+ "is deprecated."
+ ),
+ replacement=(
+ "to add a pyproject.toml or enable --use-pep517, "
+ "and use setuptools >= 64. "
+ "If the resulting installation is not behaving as expected, "
+ "try using --config-settings editable_mode=compat. "
+ "Please consult the setuptools documentation for more information"
+ ),
+ gone_in="25.0",
+ issue=11457,
+ )
+ if self.config_settings:
+ logger.warning(
+ "--config-settings ignored for legacy editable install of %s. "
+ "Consider upgrading to a version of setuptools "
+ "that supports PEP 660 (>= 64).",
+ self,
+ )
+ install_editable_legacy(
+ global_options=global_options if global_options is not None else [],
+ prefix=prefix,
+ home=home,
+ use_user_site=use_user_site,
+ name=self.req.name,
+ setup_py_path=self.setup_py_path,
+ isolated=self.isolated,
+ build_env=self.build_env,
+ unpacked_source_directory=self.unpacked_source_directory,
+ )
+ self.install_succeeded = True
+ return
+
+ assert self.is_wheel
+ assert self.local_file_path
+
+ install_wheel(
+ self.req.name,
+ self.local_file_path,
+ scheme=scheme,
+ req_description=str(self.req),
+ pycompile=pycompile,
+ warn_script_location=warn_script_location,
+ direct_url=self.download_info if self.is_direct else None,
+ requested=self.user_supplied,
+ )
+ self.install_succeeded = True
+
+
+def check_invalid_constraint_type(req: InstallRequirement) -> str:
+ # Check for unsupported forms
+ problem = ""
+ if not req.name:
+ problem = "Unnamed requirements are not allowed as constraints"
+ elif req.editable:
+ problem = "Editable requirements are not allowed as constraints"
+ elif req.extras:
+ problem = "Constraints cannot have extras"
+
+ if problem:
+ deprecated(
+ reason=(
+ "Constraints are only allowed to take the form of a package "
+ "name and a version specifier. Other forms were originally "
+ "permitted as an accident of the implementation, but were "
+ "undocumented. The new implementation of the resolver no "
+ "longer supports these forms."
+ ),
+ replacement="replacing the constraint with a requirement",
+ # No plan yet for when the new resolver becomes default
+ gone_in=None,
+ issue=8210,
+ )
+
+ return problem
+
+
+def _has_option(options: Values, reqs: List[InstallRequirement], option: str) -> bool:
+ if getattr(options, option, None):
+ return True
+ for req in reqs:
+ if getattr(req, option, None):
+ return True
+ return False
+
+
+def check_legacy_setup_py_options(
+ options: Values,
+ reqs: List[InstallRequirement],
+) -> None:
+ has_build_options = _has_option(options, reqs, "build_options")
+ has_global_options = _has_option(options, reqs, "global_options")
+ if has_build_options or has_global_options:
+ deprecated(
+ reason="--build-option and --global-option are deprecated.",
+ issue=11859,
+ replacement="to use --config-settings",
+ gone_in="25.0",
+ )
+ logger.warning(
+ "Implying --no-binary=:all: due to the presence of "
+ "--build-option / --global-option. "
+ )
+ options.format_control.disallow_binaries()
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/req/req_set.py b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_set.py
new file mode 100644
index 000000000..ec7a6e07a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_set.py
@@ -0,0 +1,82 @@
+import logging
+from collections import OrderedDict
+from typing import Dict, List
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.req.req_install import InstallRequirement
+
+logger = logging.getLogger(__name__)
+
+
+class RequirementSet:
+ def __init__(self, check_supported_wheels: bool = True) -> None:
+ """Create a RequirementSet."""
+
+ self.requirements: Dict[str, InstallRequirement] = OrderedDict()
+ self.check_supported_wheels = check_supported_wheels
+
+ self.unnamed_requirements: List[InstallRequirement] = []
+
+ def __str__(self) -> str:
+ requirements = sorted(
+ (req for req in self.requirements.values() if not req.comes_from),
+ key=lambda req: canonicalize_name(req.name or ""),
+ )
+ return " ".join(str(req.req) for req in requirements)
+
+ def __repr__(self) -> str:
+ requirements = sorted(
+ self.requirements.values(),
+ key=lambda req: canonicalize_name(req.name or ""),
+ )
+
+ format_string = "<{classname} object; {count} requirement(s): {reqs}>"
+ return format_string.format(
+ classname=self.__class__.__name__,
+ count=len(requirements),
+ reqs=", ".join(str(req.req) for req in requirements),
+ )
+
+ def add_unnamed_requirement(self, install_req: InstallRequirement) -> None:
+ assert not install_req.name
+ self.unnamed_requirements.append(install_req)
+
+ def add_named_requirement(self, install_req: InstallRequirement) -> None:
+ assert install_req.name
+
+ project_name = canonicalize_name(install_req.name)
+ self.requirements[project_name] = install_req
+
+ def has_requirement(self, name: str) -> bool:
+ project_name = canonicalize_name(name)
+
+ return (
+ project_name in self.requirements
+ and not self.requirements[project_name].constraint
+ )
+
+ def get_requirement(self, name: str) -> InstallRequirement:
+ project_name = canonicalize_name(name)
+
+ if project_name in self.requirements:
+ return self.requirements[project_name]
+
+ raise KeyError(f"No project with the name {name!r}")
+
+ @property
+ def all_requirements(self) -> List[InstallRequirement]:
+ return self.unnamed_requirements + list(self.requirements.values())
+
+ @property
+ def requirements_to_install(self) -> List[InstallRequirement]:
+ """Return the list of requirements that need to be installed.
+
+ TODO remove this property together with the legacy resolver, since the new
+ resolver only returns requirements that need to be installed.
+ """
+ return [
+ install_req
+ for install_req in self.all_requirements
+ if not install_req.constraint and not install_req.satisfied_by
+ ]
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/req/req_uninstall.py b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_uninstall.py
new file mode 100644
index 000000000..26df20844
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/req/req_uninstall.py
@@ -0,0 +1,633 @@
+import functools
+import os
+import sys
+import sysconfig
+from importlib.util import cache_from_source
+from typing import Any, Callable, Dict, Generator, Iterable, List, Optional, Set, Tuple
+
+from pip._internal.exceptions import LegacyDistutilsInstall, UninstallMissingRecord
+from pip._internal.locations import get_bin_prefix, get_bin_user
+from pip._internal.metadata import BaseDistribution
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.egg_link import egg_link_path_from_location
+from pip._internal.utils.logging import getLogger, indent_log
+from pip._internal.utils.misc import ask, normalize_path, renames, rmtree
+from pip._internal.utils.temp_dir import AdjacentTempDirectory, TempDirectory
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+logger = getLogger(__name__)
+
+
+def _script_names(
+ bin_dir: str, script_name: str, is_gui: bool
+) -> Generator[str, None, None]:
+ """Create the fully qualified name of the files created by
+ {console,gui}_scripts for the given ``dist``.
+ Returns the list of file names
+ """
+ exe_name = os.path.join(bin_dir, script_name)
+ yield exe_name
+ if not WINDOWS:
+ return
+ yield f"{exe_name}.exe"
+ yield f"{exe_name}.exe.manifest"
+ if is_gui:
+ yield f"{exe_name}-script.pyw"
+ else:
+ yield f"{exe_name}-script.py"
+
+
+def _unique(
+ fn: Callable[..., Generator[Any, None, None]]
+) -> Callable[..., Generator[Any, None, None]]:
+ @functools.wraps(fn)
+ def unique(*args: Any, **kw: Any) -> Generator[Any, None, None]:
+ seen: Set[Any] = set()
+ for item in fn(*args, **kw):
+ if item not in seen:
+ seen.add(item)
+ yield item
+
+ return unique
+
+
+@_unique
+def uninstallation_paths(dist: BaseDistribution) -> Generator[str, None, None]:
+ """
+ Yield all the uninstallation paths for dist based on RECORD-without-.py[co]
+
+ Yield paths to all the files in RECORD. For each .py file in RECORD, add
+ the .pyc and .pyo in the same directory.
+
+ UninstallPathSet.add() takes care of the __pycache__ .py[co].
+
+ If RECORD is not found, raises an error,
+ with possible information from the INSTALLER file.
+
+ https://packaging.python.org/specifications/recording-installed-packages/
+ """
+ location = dist.location
+ assert location is not None, "not installed"
+
+ entries = dist.iter_declared_entries()
+ if entries is None:
+ raise UninstallMissingRecord(distribution=dist)
+
+ for entry in entries:
+ path = os.path.join(location, entry)
+ yield path
+ if path.endswith(".py"):
+ dn, fn = os.path.split(path)
+ base = fn[:-3]
+ path = os.path.join(dn, base + ".pyc")
+ yield path
+ path = os.path.join(dn, base + ".pyo")
+ yield path
+
+
+def compact(paths: Iterable[str]) -> Set[str]:
+ """Compact a path set to contain the minimal number of paths
+ necessary to contain all paths in the set. If /a/path/ and
+ /a/path/to/a/file.txt are both in the set, leave only the
+ shorter path."""
+
+ sep = os.path.sep
+ short_paths: Set[str] = set()
+ for path in sorted(paths, key=len):
+ should_skip = any(
+ path.startswith(shortpath.rstrip("*"))
+ and path[len(shortpath.rstrip("*").rstrip(sep))] == sep
+ for shortpath in short_paths
+ )
+ if not should_skip:
+ short_paths.add(path)
+ return short_paths
+
+
+def compress_for_rename(paths: Iterable[str]) -> Set[str]:
+ """Returns a set containing the paths that need to be renamed.
+
+ This set may include directories when the original sequence of paths
+ included every file on disk.
+ """
+ case_map = {os.path.normcase(p): p for p in paths}
+ remaining = set(case_map)
+ unchecked = sorted({os.path.split(p)[0] for p in case_map.values()}, key=len)
+ wildcards: Set[str] = set()
+
+ def norm_join(*a: str) -> str:
+ return os.path.normcase(os.path.join(*a))
+
+ for root in unchecked:
+ if any(os.path.normcase(root).startswith(w) for w in wildcards):
+ # This directory has already been handled.
+ continue
+
+ all_files: Set[str] = set()
+ all_subdirs: Set[str] = set()
+ for dirname, subdirs, files in os.walk(root):
+ all_subdirs.update(norm_join(root, dirname, d) for d in subdirs)
+ all_files.update(norm_join(root, dirname, f) for f in files)
+ # If all the files we found are in our remaining set of files to
+ # remove, then remove them from the latter set and add a wildcard
+ # for the directory.
+ if not (all_files - remaining):
+ remaining.difference_update(all_files)
+ wildcards.add(root + os.sep)
+
+ return set(map(case_map.__getitem__, remaining)) | wildcards
+
+
+def compress_for_output_listing(paths: Iterable[str]) -> Tuple[Set[str], Set[str]]:
+ """Returns a tuple of 2 sets of which paths to display to user
+
+ The first set contains paths that would be deleted. Files of a package
+ are not added and the top-level directory of the package has a '*' added
+ at the end - to signify that all it's contents are removed.
+
+ The second set contains files that would have been skipped in the above
+ folders.
+ """
+
+ will_remove = set(paths)
+ will_skip = set()
+
+ # Determine folders and files
+ folders = set()
+ files = set()
+ for path in will_remove:
+ if path.endswith(".pyc"):
+ continue
+ if path.endswith("__init__.py") or ".dist-info" in path:
+ folders.add(os.path.dirname(path))
+ files.add(path)
+
+ _normcased_files = set(map(os.path.normcase, files))
+
+ folders = compact(folders)
+
+ # This walks the tree using os.walk to not miss extra folders
+ # that might get added.
+ for folder in folders:
+ for dirpath, _, dirfiles in os.walk(folder):
+ for fname in dirfiles:
+ if fname.endswith(".pyc"):
+ continue
+
+ file_ = os.path.join(dirpath, fname)
+ if (
+ os.path.isfile(file_)
+ and os.path.normcase(file_) not in _normcased_files
+ ):
+ # We are skipping this file. Add it to the set.
+ will_skip.add(file_)
+
+ will_remove = files | {os.path.join(folder, "*") for folder in folders}
+
+ return will_remove, will_skip
+
+
+class StashedUninstallPathSet:
+ """A set of file rename operations to stash files while
+ tentatively uninstalling them."""
+
+ def __init__(self) -> None:
+ # Mapping from source file root to [Adjacent]TempDirectory
+ # for files under that directory.
+ self._save_dirs: Dict[str, TempDirectory] = {}
+ # (old path, new path) tuples for each move that may need
+ # to be undone.
+ self._moves: List[Tuple[str, str]] = []
+
+ def _get_directory_stash(self, path: str) -> str:
+ """Stashes a directory.
+
+ Directories are stashed adjacent to their original location if
+ possible, or else moved/copied into the user's temp dir."""
+
+ try:
+ save_dir: TempDirectory = AdjacentTempDirectory(path)
+ except OSError:
+ save_dir = TempDirectory(kind="uninstall")
+ self._save_dirs[os.path.normcase(path)] = save_dir
+
+ return save_dir.path
+
+ def _get_file_stash(self, path: str) -> str:
+ """Stashes a file.
+
+ If no root has been provided, one will be created for the directory
+ in the user's temp directory."""
+ path = os.path.normcase(path)
+ head, old_head = os.path.dirname(path), None
+ save_dir = None
+
+ while head != old_head:
+ try:
+ save_dir = self._save_dirs[head]
+ break
+ except KeyError:
+ pass
+ head, old_head = os.path.dirname(head), head
+ else:
+ # Did not find any suitable root
+ head = os.path.dirname(path)
+ save_dir = TempDirectory(kind="uninstall")
+ self._save_dirs[head] = save_dir
+
+ relpath = os.path.relpath(path, head)
+ if relpath and relpath != os.path.curdir:
+ return os.path.join(save_dir.path, relpath)
+ return save_dir.path
+
+ def stash(self, path: str) -> str:
+ """Stashes the directory or file and returns its new location.
+ Handle symlinks as files to avoid modifying the symlink targets.
+ """
+ path_is_dir = os.path.isdir(path) and not os.path.islink(path)
+ if path_is_dir:
+ new_path = self._get_directory_stash(path)
+ else:
+ new_path = self._get_file_stash(path)
+
+ self._moves.append((path, new_path))
+ if path_is_dir and os.path.isdir(new_path):
+ # If we're moving a directory, we need to
+ # remove the destination first or else it will be
+ # moved to inside the existing directory.
+ # We just created new_path ourselves, so it will
+ # be removable.
+ os.rmdir(new_path)
+ renames(path, new_path)
+ return new_path
+
+ def commit(self) -> None:
+ """Commits the uninstall by removing stashed files."""
+ for save_dir in self._save_dirs.values():
+ save_dir.cleanup()
+ self._moves = []
+ self._save_dirs = {}
+
+ def rollback(self) -> None:
+ """Undoes the uninstall by moving stashed files back."""
+ for p in self._moves:
+ logger.info("Moving to %s\n from %s", *p)
+
+ for new_path, path in self._moves:
+ try:
+ logger.debug("Replacing %s from %s", new_path, path)
+ if os.path.isfile(new_path) or os.path.islink(new_path):
+ os.unlink(new_path)
+ elif os.path.isdir(new_path):
+ rmtree(new_path)
+ renames(path, new_path)
+ except OSError as ex:
+ logger.error("Failed to restore %s", new_path)
+ logger.debug("Exception: %s", ex)
+
+ self.commit()
+
+ @property
+ def can_rollback(self) -> bool:
+ return bool(self._moves)
+
+
+class UninstallPathSet:
+ """A set of file paths to be removed in the uninstallation of a
+ requirement."""
+
+ def __init__(self, dist: BaseDistribution) -> None:
+ self._paths: Set[str] = set()
+ self._refuse: Set[str] = set()
+ self._pth: Dict[str, UninstallPthEntries] = {}
+ self._dist = dist
+ self._moved_paths = StashedUninstallPathSet()
+ # Create local cache of normalize_path results. Creating an UninstallPathSet
+ # can result in hundreds/thousands of redundant calls to normalize_path with
+ # the same args, which hurts performance.
+ self._normalize_path_cached = functools.lru_cache(normalize_path)
+
+ def _permitted(self, path: str) -> bool:
+ """
+ Return True if the given path is one we are permitted to
+ remove/modify, False otherwise.
+
+ """
+ # aka is_local, but caching normalized sys.prefix
+ if not running_under_virtualenv():
+ return True
+ return path.startswith(self._normalize_path_cached(sys.prefix))
+
+ def add(self, path: str) -> None:
+ head, tail = os.path.split(path)
+
+ # we normalize the head to resolve parent directory symlinks, but not
+ # the tail, since we only want to uninstall symlinks, not their targets
+ path = os.path.join(self._normalize_path_cached(head), os.path.normcase(tail))
+
+ if not os.path.exists(path):
+ return
+ if self._permitted(path):
+ self._paths.add(path)
+ else:
+ self._refuse.add(path)
+
+ # __pycache__ files can show up after 'installed-files.txt' is created,
+ # due to imports
+ if os.path.splitext(path)[1] == ".py":
+ self.add(cache_from_source(path))
+
+ def add_pth(self, pth_file: str, entry: str) -> None:
+ pth_file = self._normalize_path_cached(pth_file)
+ if self._permitted(pth_file):
+ if pth_file not in self._pth:
+ self._pth[pth_file] = UninstallPthEntries(pth_file)
+ self._pth[pth_file].add(entry)
+ else:
+ self._refuse.add(pth_file)
+
+ def remove(self, auto_confirm: bool = False, verbose: bool = False) -> None:
+ """Remove paths in ``self._paths`` with confirmation (unless
+ ``auto_confirm`` is True)."""
+
+ if not self._paths:
+ logger.info(
+ "Can't uninstall '%s'. No files were found to uninstall.",
+ self._dist.raw_name,
+ )
+ return
+
+ dist_name_version = f"{self._dist.raw_name}-{self._dist.raw_version}"
+ logger.info("Uninstalling %s:", dist_name_version)
+
+ with indent_log():
+ if auto_confirm or self._allowed_to_proceed(verbose):
+ moved = self._moved_paths
+
+ for_rename = compress_for_rename(self._paths)
+
+ for path in sorted(compact(for_rename)):
+ moved.stash(path)
+ logger.verbose("Removing file or directory %s", path)
+
+ for pth in self._pth.values():
+ pth.remove()
+
+ logger.info("Successfully uninstalled %s", dist_name_version)
+
+ def _allowed_to_proceed(self, verbose: bool) -> bool:
+ """Display which files would be deleted and prompt for confirmation"""
+
+ def _display(msg: str, paths: Iterable[str]) -> None:
+ if not paths:
+ return
+
+ logger.info(msg)
+ with indent_log():
+ for path in sorted(compact(paths)):
+ logger.info(path)
+
+ if not verbose:
+ will_remove, will_skip = compress_for_output_listing(self._paths)
+ else:
+ # In verbose mode, display all the files that are going to be
+ # deleted.
+ will_remove = set(self._paths)
+ will_skip = set()
+
+ _display("Would remove:", will_remove)
+ _display("Would not remove (might be manually added):", will_skip)
+ _display("Would not remove (outside of prefix):", self._refuse)
+ if verbose:
+ _display("Will actually move:", compress_for_rename(self._paths))
+
+ return ask("Proceed (Y/n)? ", ("y", "n", "")) != "n"
+
+ def rollback(self) -> None:
+ """Rollback the changes previously made by remove()."""
+ if not self._moved_paths.can_rollback:
+ logger.error(
+ "Can't roll back %s; was not uninstalled",
+ self._dist.raw_name,
+ )
+ return
+ logger.info("Rolling back uninstall of %s", self._dist.raw_name)
+ self._moved_paths.rollback()
+ for pth in self._pth.values():
+ pth.rollback()
+
+ def commit(self) -> None:
+ """Remove temporary save dir: rollback will no longer be possible."""
+ self._moved_paths.commit()
+
+ @classmethod
+ def from_dist(cls, dist: BaseDistribution) -> "UninstallPathSet":
+ dist_location = dist.location
+ info_location = dist.info_location
+ if dist_location is None:
+ logger.info(
+ "Not uninstalling %s since it is not installed",
+ dist.canonical_name,
+ )
+ return cls(dist)
+
+ normalized_dist_location = normalize_path(dist_location)
+ if not dist.local:
+ logger.info(
+ "Not uninstalling %s at %s, outside environment %s",
+ dist.canonical_name,
+ normalized_dist_location,
+ sys.prefix,
+ )
+ return cls(dist)
+
+ if normalized_dist_location in {
+ p
+ for p in {sysconfig.get_path("stdlib"), sysconfig.get_path("platstdlib")}
+ if p
+ }:
+ logger.info(
+ "Not uninstalling %s at %s, as it is in the standard library.",
+ dist.canonical_name,
+ normalized_dist_location,
+ )
+ return cls(dist)
+
+ paths_to_remove = cls(dist)
+ develop_egg_link = egg_link_path_from_location(dist.raw_name)
+
+ # Distribution is installed with metadata in a "flat" .egg-info
+ # directory. This means it is not a modern .dist-info installation, an
+ # egg, or legacy editable.
+ setuptools_flat_installation = (
+ dist.installed_with_setuptools_egg_info
+ and info_location is not None
+ and os.path.exists(info_location)
+ # If dist is editable and the location points to a ``.egg-info``,
+ # we are in fact in the legacy editable case.
+ and not info_location.endswith(f"{dist.setuptools_filename}.egg-info")
+ )
+
+ # Uninstall cases order do matter as in the case of 2 installs of the
+ # same package, pip needs to uninstall the currently detected version
+ if setuptools_flat_installation:
+ if info_location is not None:
+ paths_to_remove.add(info_location)
+ installed_files = dist.iter_declared_entries()
+ if installed_files is not None:
+ for installed_file in installed_files:
+ paths_to_remove.add(os.path.join(dist_location, installed_file))
+ # FIXME: need a test for this elif block
+ # occurs with --single-version-externally-managed/--record outside
+ # of pip
+ elif dist.is_file("top_level.txt"):
+ try:
+ namespace_packages = dist.read_text("namespace_packages.txt")
+ except FileNotFoundError:
+ namespaces = []
+ else:
+ namespaces = namespace_packages.splitlines(keepends=False)
+ for top_level_pkg in [
+ p
+ for p in dist.read_text("top_level.txt").splitlines()
+ if p and p not in namespaces
+ ]:
+ path = os.path.join(dist_location, top_level_pkg)
+ paths_to_remove.add(path)
+ paths_to_remove.add(f"{path}.py")
+ paths_to_remove.add(f"{path}.pyc")
+ paths_to_remove.add(f"{path}.pyo")
+
+ elif dist.installed_by_distutils:
+ raise LegacyDistutilsInstall(distribution=dist)
+
+ elif dist.installed_as_egg:
+ # package installed by easy_install
+ # We cannot match on dist.egg_name because it can slightly vary
+ # i.e. setuptools-0.6c11-py2.6.egg vs setuptools-0.6rc11-py2.6.egg
+ paths_to_remove.add(dist_location)
+ easy_install_egg = os.path.split(dist_location)[1]
+ easy_install_pth = os.path.join(
+ os.path.dirname(dist_location),
+ "easy-install.pth",
+ )
+ paths_to_remove.add_pth(easy_install_pth, "./" + easy_install_egg)
+
+ elif dist.installed_with_dist_info:
+ for path in uninstallation_paths(dist):
+ paths_to_remove.add(path)
+
+ elif develop_egg_link:
+ # PEP 660 modern editable is handled in the ``.dist-info`` case
+ # above, so this only covers the setuptools-style editable.
+ with open(develop_egg_link) as fh:
+ link_pointer = os.path.normcase(fh.readline().strip())
+ normalized_link_pointer = paths_to_remove._normalize_path_cached(
+ link_pointer
+ )
+ assert os.path.samefile(
+ normalized_link_pointer, normalized_dist_location
+ ), (
+ f"Egg-link {develop_egg_link} (to {link_pointer}) does not match "
+ f"installed location of {dist.raw_name} (at {dist_location})"
+ )
+ paths_to_remove.add(develop_egg_link)
+ easy_install_pth = os.path.join(
+ os.path.dirname(develop_egg_link), "easy-install.pth"
+ )
+ paths_to_remove.add_pth(easy_install_pth, dist_location)
+
+ else:
+ logger.debug(
+ "Not sure how to uninstall: %s - Check: %s",
+ dist,
+ dist_location,
+ )
+
+ if dist.in_usersite:
+ bin_dir = get_bin_user()
+ else:
+ bin_dir = get_bin_prefix()
+
+ # find distutils scripts= scripts
+ try:
+ for script in dist.iter_distutils_script_names():
+ paths_to_remove.add(os.path.join(bin_dir, script))
+ if WINDOWS:
+ paths_to_remove.add(os.path.join(bin_dir, f"{script}.bat"))
+ except (FileNotFoundError, NotADirectoryError):
+ pass
+
+ # find console_scripts and gui_scripts
+ def iter_scripts_to_remove(
+ dist: BaseDistribution,
+ bin_dir: str,
+ ) -> Generator[str, None, None]:
+ for entry_point in dist.iter_entry_points():
+ if entry_point.group == "console_scripts":
+ yield from _script_names(bin_dir, entry_point.name, False)
+ elif entry_point.group == "gui_scripts":
+ yield from _script_names(bin_dir, entry_point.name, True)
+
+ for s in iter_scripts_to_remove(dist, bin_dir):
+ paths_to_remove.add(s)
+
+ return paths_to_remove
+
+
+class UninstallPthEntries:
+ def __init__(self, pth_file: str) -> None:
+ self.file = pth_file
+ self.entries: Set[str] = set()
+ self._saved_lines: Optional[List[bytes]] = None
+
+ def add(self, entry: str) -> None:
+ entry = os.path.normcase(entry)
+ # On Windows, os.path.normcase converts the entry to use
+ # backslashes. This is correct for entries that describe absolute
+ # paths outside of site-packages, but all the others use forward
+ # slashes.
+ # os.path.splitdrive is used instead of os.path.isabs because isabs
+ # treats non-absolute paths with drive letter markings like c:foo\bar
+ # as absolute paths. It also does not recognize UNC paths if they don't
+ # have more than "\\sever\share". Valid examples: "\\server\share\" or
+ # "\\server\share\folder".
+ if WINDOWS and not os.path.splitdrive(entry)[0]:
+ entry = entry.replace("\\", "/")
+ self.entries.add(entry)
+
+ def remove(self) -> None:
+ logger.verbose("Removing pth entries from %s:", self.file)
+
+ # If the file doesn't exist, log a warning and return
+ if not os.path.isfile(self.file):
+ logger.warning("Cannot remove entries from nonexistent file %s", self.file)
+ return
+ with open(self.file, "rb") as fh:
+ # windows uses '\r\n' with py3k, but uses '\n' with py2.x
+ lines = fh.readlines()
+ self._saved_lines = lines
+ if any(b"\r\n" in line for line in lines):
+ endline = "\r\n"
+ else:
+ endline = "\n"
+ # handle missing trailing newline
+ if lines and not lines[-1].endswith(endline.encode("utf-8")):
+ lines[-1] = lines[-1] + endline.encode("utf-8")
+ for entry in self.entries:
+ try:
+ logger.verbose("Removing entry: %s", entry)
+ lines.remove((entry + endline).encode("utf-8"))
+ except ValueError:
+ pass
+ with open(self.file, "wb") as fh:
+ fh.writelines(lines)
+
+ def rollback(self) -> bool:
+ if self._saved_lines is None:
+ logger.error("Cannot roll back changes to %s, none were made", self.file)
+ return False
+ logger.debug("Rolling %s back to previous state", self.file)
+ with open(self.file, "wb") as fh:
+ fh.writelines(self._saved_lines)
+ return True
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/base.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/base.py
new file mode 100644
index 000000000..42dade18c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/base.py
@@ -0,0 +1,20 @@
+from typing import Callable, List, Optional
+
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.req.req_set import RequirementSet
+
+InstallRequirementProvider = Callable[
+ [str, Optional[InstallRequirement]], InstallRequirement
+]
+
+
+class BaseResolver:
+ def resolve(
+ self, root_reqs: List[InstallRequirement], check_supported_wheels: bool
+ ) -> RequirementSet:
+ raise NotImplementedError()
+
+ def get_installation_order(
+ self, req_set: RequirementSet
+ ) -> List[InstallRequirement]:
+ raise NotImplementedError()
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/legacy/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/legacy/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/legacy/resolver.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/legacy/resolver.py
new file mode 100644
index 000000000..1dd0d7041
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/legacy/resolver.py
@@ -0,0 +1,597 @@
+"""Dependency Resolution
+
+The dependency resolution in pip is performed as follows:
+
+for top-level requirements:
+ a. only one spec allowed per project, regardless of conflicts or not.
+ otherwise a "double requirement" exception is raised
+ b. they override sub-dependency requirements.
+for sub-dependencies
+ a. "first found, wins" (where the order is breadth first)
+"""
+
+import logging
+import sys
+from collections import defaultdict
+from itertools import chain
+from typing import DefaultDict, Iterable, List, Optional, Set, Tuple
+
+from pip._vendor.packaging import specifiers
+from pip._vendor.packaging.requirements import Requirement
+
+from pip._internal.cache import WheelCache
+from pip._internal.exceptions import (
+ BestVersionAlreadyInstalled,
+ DistributionNotFound,
+ HashError,
+ HashErrors,
+ InstallationError,
+ NoneMetadataError,
+ UnsupportedPythonVersion,
+)
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.metadata import BaseDistribution
+from pip._internal.models.link import Link
+from pip._internal.models.wheel import Wheel
+from pip._internal.operations.prepare import RequirementPreparer
+from pip._internal.req.req_install import (
+ InstallRequirement,
+ check_invalid_constraint_type,
+)
+from pip._internal.req.req_set import RequirementSet
+from pip._internal.resolution.base import BaseResolver, InstallRequirementProvider
+from pip._internal.utils import compatibility_tags
+from pip._internal.utils.compatibility_tags import get_supported
+from pip._internal.utils.direct_url_helpers import direct_url_from_link
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.misc import normalize_version_info
+from pip._internal.utils.packaging import check_requires_python
+
+logger = logging.getLogger(__name__)
+
+DiscoveredDependencies = DefaultDict[Optional[str], List[InstallRequirement]]
+
+
+def _check_dist_requires_python(
+ dist: BaseDistribution,
+ version_info: Tuple[int, int, int],
+ ignore_requires_python: bool = False,
+) -> None:
+ """
+ Check whether the given Python version is compatible with a distribution's
+ "Requires-Python" value.
+
+ :param version_info: A 3-tuple of ints representing the Python
+ major-minor-micro version to check.
+ :param ignore_requires_python: Whether to ignore the "Requires-Python"
+ value if the given Python version isn't compatible.
+
+ :raises UnsupportedPythonVersion: When the given Python version isn't
+ compatible.
+ """
+ # This idiosyncratically converts the SpecifierSet to str and let
+ # check_requires_python then parse it again into SpecifierSet. But this
+ # is the legacy resolver so I'm just not going to bother refactoring.
+ try:
+ requires_python = str(dist.requires_python)
+ except FileNotFoundError as e:
+ raise NoneMetadataError(dist, str(e))
+ try:
+ is_compatible = check_requires_python(
+ requires_python,
+ version_info=version_info,
+ )
+ except specifiers.InvalidSpecifier as exc:
+ logger.warning(
+ "Package %r has an invalid Requires-Python: %s", dist.raw_name, exc
+ )
+ return
+
+ if is_compatible:
+ return
+
+ version = ".".join(map(str, version_info))
+ if ignore_requires_python:
+ logger.debug(
+ "Ignoring failed Requires-Python check for package %r: %s not in %r",
+ dist.raw_name,
+ version,
+ requires_python,
+ )
+ return
+
+ raise UnsupportedPythonVersion(
+ f"Package {dist.raw_name!r} requires a different Python: "
+ f"{version} not in {requires_python!r}"
+ )
+
+
+class Resolver(BaseResolver):
+ """Resolves which packages need to be installed/uninstalled to perform \
+ the requested operation without breaking the requirements of any package.
+ """
+
+ _allowed_strategies = {"eager", "only-if-needed", "to-satisfy-only"}
+
+ def __init__(
+ self,
+ preparer: RequirementPreparer,
+ finder: PackageFinder,
+ wheel_cache: Optional[WheelCache],
+ make_install_req: InstallRequirementProvider,
+ use_user_site: bool,
+ ignore_dependencies: bool,
+ ignore_installed: bool,
+ ignore_requires_python: bool,
+ force_reinstall: bool,
+ upgrade_strategy: str,
+ py_version_info: Optional[Tuple[int, ...]] = None,
+ ) -> None:
+ super().__init__()
+ assert upgrade_strategy in self._allowed_strategies
+
+ if py_version_info is None:
+ py_version_info = sys.version_info[:3]
+ else:
+ py_version_info = normalize_version_info(py_version_info)
+
+ self._py_version_info = py_version_info
+
+ self.preparer = preparer
+ self.finder = finder
+ self.wheel_cache = wheel_cache
+
+ self.upgrade_strategy = upgrade_strategy
+ self.force_reinstall = force_reinstall
+ self.ignore_dependencies = ignore_dependencies
+ self.ignore_installed = ignore_installed
+ self.ignore_requires_python = ignore_requires_python
+ self.use_user_site = use_user_site
+ self._make_install_req = make_install_req
+
+ self._discovered_dependencies: DiscoveredDependencies = defaultdict(list)
+
+ def resolve(
+ self, root_reqs: List[InstallRequirement], check_supported_wheels: bool
+ ) -> RequirementSet:
+ """Resolve what operations need to be done
+
+ As a side-effect of this method, the packages (and their dependencies)
+ are downloaded, unpacked and prepared for installation. This
+ preparation is done by ``pip.operations.prepare``.
+
+ Once PyPI has static dependency metadata available, it would be
+ possible to move the preparation to become a step separated from
+ dependency resolution.
+ """
+ requirement_set = RequirementSet(check_supported_wheels=check_supported_wheels)
+ for req in root_reqs:
+ if req.constraint:
+ check_invalid_constraint_type(req)
+ self._add_requirement_to_set(requirement_set, req)
+
+ # Actually prepare the files, and collect any exceptions. Most hash
+ # exceptions cannot be checked ahead of time, because
+ # _populate_link() needs to be called before we can make decisions
+ # based on link type.
+ discovered_reqs: List[InstallRequirement] = []
+ hash_errors = HashErrors()
+ for req in chain(requirement_set.all_requirements, discovered_reqs):
+ try:
+ discovered_reqs.extend(self._resolve_one(requirement_set, req))
+ except HashError as exc:
+ exc.req = req
+ hash_errors.append(exc)
+
+ if hash_errors:
+ raise hash_errors
+
+ return requirement_set
+
+ def _add_requirement_to_set(
+ self,
+ requirement_set: RequirementSet,
+ install_req: InstallRequirement,
+ parent_req_name: Optional[str] = None,
+ extras_requested: Optional[Iterable[str]] = None,
+ ) -> Tuple[List[InstallRequirement], Optional[InstallRequirement]]:
+ """Add install_req as a requirement to install.
+
+ :param parent_req_name: The name of the requirement that needed this
+ added. The name is used because when multiple unnamed requirements
+ resolve to the same name, we could otherwise end up with dependency
+ links that point outside the Requirements set. parent_req must
+ already be added. Note that None implies that this is a user
+ supplied requirement, vs an inferred one.
+ :param extras_requested: an iterable of extras used to evaluate the
+ environment markers.
+ :return: Additional requirements to scan. That is either [] if
+ the requirement is not applicable, or [install_req] if the
+ requirement is applicable and has just been added.
+ """
+ # If the markers do not match, ignore this requirement.
+ if not install_req.match_markers(extras_requested):
+ logger.info(
+ "Ignoring %s: markers '%s' don't match your environment",
+ install_req.name,
+ install_req.markers,
+ )
+ return [], None
+
+ # If the wheel is not supported, raise an error.
+ # Should check this after filtering out based on environment markers to
+ # allow specifying different wheels based on the environment/OS, in a
+ # single requirements file.
+ if install_req.link and install_req.link.is_wheel:
+ wheel = Wheel(install_req.link.filename)
+ tags = compatibility_tags.get_supported()
+ if requirement_set.check_supported_wheels and not wheel.supported(tags):
+ raise InstallationError(
+ f"{wheel.filename} is not a supported wheel on this platform."
+ )
+
+ # This next bit is really a sanity check.
+ assert (
+ not install_req.user_supplied or parent_req_name is None
+ ), "a user supplied req shouldn't have a parent"
+
+ # Unnamed requirements are scanned again and the requirement won't be
+ # added as a dependency until after scanning.
+ if not install_req.name:
+ requirement_set.add_unnamed_requirement(install_req)
+ return [install_req], None
+
+ try:
+ existing_req: Optional[InstallRequirement] = (
+ requirement_set.get_requirement(install_req.name)
+ )
+ except KeyError:
+ existing_req = None
+
+ has_conflicting_requirement = (
+ parent_req_name is None
+ and existing_req
+ and not existing_req.constraint
+ and existing_req.extras == install_req.extras
+ and existing_req.req
+ and install_req.req
+ and existing_req.req.specifier != install_req.req.specifier
+ )
+ if has_conflicting_requirement:
+ raise InstallationError(
+ f"Double requirement given: {install_req} "
+ f"(already in {existing_req}, name={install_req.name!r})"
+ )
+
+ # When no existing requirement exists, add the requirement as a
+ # dependency and it will be scanned again after.
+ if not existing_req:
+ requirement_set.add_named_requirement(install_req)
+ # We'd want to rescan this requirement later
+ return [install_req], install_req
+
+ # Assume there's no need to scan, and that we've already
+ # encountered this for scanning.
+ if install_req.constraint or not existing_req.constraint:
+ return [], existing_req
+
+ does_not_satisfy_constraint = install_req.link and not (
+ existing_req.link and install_req.link.path == existing_req.link.path
+ )
+ if does_not_satisfy_constraint:
+ raise InstallationError(
+ f"Could not satisfy constraints for '{install_req.name}': "
+ "installation from path or url cannot be "
+ "constrained to a version"
+ )
+ # If we're now installing a constraint, mark the existing
+ # object for real installation.
+ existing_req.constraint = False
+ # If we're now installing a user supplied requirement,
+ # mark the existing object as such.
+ if install_req.user_supplied:
+ existing_req.user_supplied = True
+ existing_req.extras = tuple(
+ sorted(set(existing_req.extras) | set(install_req.extras))
+ )
+ logger.debug(
+ "Setting %s extras to: %s",
+ existing_req,
+ existing_req.extras,
+ )
+ # Return the existing requirement for addition to the parent and
+ # scanning again.
+ return [existing_req], existing_req
+
+ def _is_upgrade_allowed(self, req: InstallRequirement) -> bool:
+ if self.upgrade_strategy == "to-satisfy-only":
+ return False
+ elif self.upgrade_strategy == "eager":
+ return True
+ else:
+ assert self.upgrade_strategy == "only-if-needed"
+ return req.user_supplied or req.constraint
+
+ def _set_req_to_reinstall(self, req: InstallRequirement) -> None:
+ """
+ Set a requirement to be installed.
+ """
+ # Don't uninstall the conflict if doing a user install and the
+ # conflict is not a user install.
+ assert req.satisfied_by is not None
+ if not self.use_user_site or req.satisfied_by.in_usersite:
+ req.should_reinstall = True
+ req.satisfied_by = None
+
+ def _check_skip_installed(
+ self, req_to_install: InstallRequirement
+ ) -> Optional[str]:
+ """Check if req_to_install should be skipped.
+
+ This will check if the req is installed, and whether we should upgrade
+ or reinstall it, taking into account all the relevant user options.
+
+ After calling this req_to_install will only have satisfied_by set to
+ None if the req_to_install is to be upgraded/reinstalled etc. Any
+ other value will be a dist recording the current thing installed that
+ satisfies the requirement.
+
+ Note that for vcs urls and the like we can't assess skipping in this
+ routine - we simply identify that we need to pull the thing down,
+ then later on it is pulled down and introspected to assess upgrade/
+ reinstalls etc.
+
+ :return: A text reason for why it was skipped, or None.
+ """
+ if self.ignore_installed:
+ return None
+
+ req_to_install.check_if_exists(self.use_user_site)
+ if not req_to_install.satisfied_by:
+ return None
+
+ if self.force_reinstall:
+ self._set_req_to_reinstall(req_to_install)
+ return None
+
+ if not self._is_upgrade_allowed(req_to_install):
+ if self.upgrade_strategy == "only-if-needed":
+ return "already satisfied, skipping upgrade"
+ return "already satisfied"
+
+ # Check for the possibility of an upgrade. For link-based
+ # requirements we have to pull the tree down and inspect to assess
+ # the version #, so it's handled way down.
+ if not req_to_install.link:
+ try:
+ self.finder.find_requirement(req_to_install, upgrade=True)
+ except BestVersionAlreadyInstalled:
+ # Then the best version is installed.
+ return "already up-to-date"
+ except DistributionNotFound:
+ # No distribution found, so we squash the error. It will
+ # be raised later when we re-try later to do the install.
+ # Why don't we just raise here?
+ pass
+
+ self._set_req_to_reinstall(req_to_install)
+ return None
+
+ def _find_requirement_link(self, req: InstallRequirement) -> Optional[Link]:
+ upgrade = self._is_upgrade_allowed(req)
+ best_candidate = self.finder.find_requirement(req, upgrade)
+ if not best_candidate:
+ return None
+
+ # Log a warning per PEP 592 if necessary before returning.
+ link = best_candidate.link
+ if link.is_yanked:
+ reason = link.yanked_reason or "<none given>"
+ msg = (
+ # Mark this as a unicode string to prevent
+ # "UnicodeEncodeError: 'ascii' codec can't encode character"
+ # in Python 2 when the reason contains non-ascii characters.
+ "The candidate selected for download or install is a "
+ f"yanked version: {best_candidate}\n"
+ f"Reason for being yanked: {reason}"
+ )
+ logger.warning(msg)
+
+ return link
+
+ def _populate_link(self, req: InstallRequirement) -> None:
+ """Ensure that if a link can be found for this, that it is found.
+
+ Note that req.link may still be None - if the requirement is already
+ installed and not needed to be upgraded based on the return value of
+ _is_upgrade_allowed().
+
+ If preparer.require_hashes is True, don't use the wheel cache, because
+ cached wheels, always built locally, have different hashes than the
+ files downloaded from the index server and thus throw false hash
+ mismatches. Furthermore, cached wheels at present have undeterministic
+ contents due to file modification times.
+ """
+ if req.link is None:
+ req.link = self._find_requirement_link(req)
+
+ if self.wheel_cache is None or self.preparer.require_hashes:
+ return
+
+ assert req.link is not None, "_find_requirement_link unexpectedly returned None"
+ cache_entry = self.wheel_cache.get_cache_entry(
+ link=req.link,
+ package_name=req.name,
+ supported_tags=get_supported(),
+ )
+ if cache_entry is not None:
+ logger.debug("Using cached wheel link: %s", cache_entry.link)
+ if req.link is req.original_link and cache_entry.persistent:
+ req.cached_wheel_source_link = req.link
+ if cache_entry.origin is not None:
+ req.download_info = cache_entry.origin
+ else:
+ # Legacy cache entry that does not have origin.json.
+ # download_info may miss the archive_info.hashes field.
+ req.download_info = direct_url_from_link(
+ req.link, link_is_in_wheel_cache=cache_entry.persistent
+ )
+ req.link = cache_entry.link
+
+ def _get_dist_for(self, req: InstallRequirement) -> BaseDistribution:
+ """Takes a InstallRequirement and returns a single AbstractDist \
+ representing a prepared variant of the same.
+ """
+ if req.editable:
+ return self.preparer.prepare_editable_requirement(req)
+
+ # satisfied_by is only evaluated by calling _check_skip_installed,
+ # so it must be None here.
+ assert req.satisfied_by is None
+ skip_reason = self._check_skip_installed(req)
+
+ if req.satisfied_by:
+ return self.preparer.prepare_installed_requirement(req, skip_reason)
+
+ # We eagerly populate the link, since that's our "legacy" behavior.
+ self._populate_link(req)
+ dist = self.preparer.prepare_linked_requirement(req)
+
+ # NOTE
+ # The following portion is for determining if a certain package is
+ # going to be re-installed/upgraded or not and reporting to the user.
+ # This should probably get cleaned up in a future refactor.
+
+ # req.req is only avail after unpack for URL
+ # pkgs repeat check_if_exists to uninstall-on-upgrade
+ # (#14)
+ if not self.ignore_installed:
+ req.check_if_exists(self.use_user_site)
+
+ if req.satisfied_by:
+ should_modify = (
+ self.upgrade_strategy != "to-satisfy-only"
+ or self.force_reinstall
+ or self.ignore_installed
+ or req.link.scheme == "file"
+ )
+ if should_modify:
+ self._set_req_to_reinstall(req)
+ else:
+ logger.info(
+ "Requirement already satisfied (use --upgrade to upgrade): %s",
+ req,
+ )
+ return dist
+
+ def _resolve_one(
+ self,
+ requirement_set: RequirementSet,
+ req_to_install: InstallRequirement,
+ ) -> List[InstallRequirement]:
+ """Prepare a single requirements file.
+
+ :return: A list of additional InstallRequirements to also install.
+ """
+ # Tell user what we are doing for this requirement:
+ # obtain (editable), skipping, processing (local url), collecting
+ # (remote url or package name)
+ if req_to_install.constraint or req_to_install.prepared:
+ return []
+
+ req_to_install.prepared = True
+
+ # Parse and return dependencies
+ dist = self._get_dist_for(req_to_install)
+ # This will raise UnsupportedPythonVersion if the given Python
+ # version isn't compatible with the distribution's Requires-Python.
+ _check_dist_requires_python(
+ dist,
+ version_info=self._py_version_info,
+ ignore_requires_python=self.ignore_requires_python,
+ )
+
+ more_reqs: List[InstallRequirement] = []
+
+ def add_req(subreq: Requirement, extras_requested: Iterable[str]) -> None:
+ # This idiosyncratically converts the Requirement to str and let
+ # make_install_req then parse it again into Requirement. But this is
+ # the legacy resolver so I'm just not going to bother refactoring.
+ sub_install_req = self._make_install_req(str(subreq), req_to_install)
+ parent_req_name = req_to_install.name
+ to_scan_again, add_to_parent = self._add_requirement_to_set(
+ requirement_set,
+ sub_install_req,
+ parent_req_name=parent_req_name,
+ extras_requested=extras_requested,
+ )
+ if parent_req_name and add_to_parent:
+ self._discovered_dependencies[parent_req_name].append(add_to_parent)
+ more_reqs.extend(to_scan_again)
+
+ with indent_log():
+ # We add req_to_install before its dependencies, so that we
+ # can refer to it when adding dependencies.
+ assert req_to_install.name is not None
+ if not requirement_set.has_requirement(req_to_install.name):
+ # 'unnamed' requirements will get added here
+ # 'unnamed' requirements can only come from being directly
+ # provided by the user.
+ assert req_to_install.user_supplied
+ self._add_requirement_to_set(
+ requirement_set, req_to_install, parent_req_name=None
+ )
+
+ if not self.ignore_dependencies:
+ if req_to_install.extras:
+ logger.debug(
+ "Installing extra requirements: %r",
+ ",".join(req_to_install.extras),
+ )
+ missing_requested = sorted(
+ set(req_to_install.extras) - set(dist.iter_provided_extras())
+ )
+ for missing in missing_requested:
+ logger.warning(
+ "%s %s does not provide the extra '%s'",
+ dist.raw_name,
+ dist.version,
+ missing,
+ )
+
+ available_requested = sorted(
+ set(dist.iter_provided_extras()) & set(req_to_install.extras)
+ )
+ for subreq in dist.iter_dependencies(available_requested):
+ add_req(subreq, extras_requested=available_requested)
+
+ return more_reqs
+
+ def get_installation_order(
+ self, req_set: RequirementSet
+ ) -> List[InstallRequirement]:
+ """Create the installation order.
+
+ The installation order is topological - requirements are installed
+ before the requiring thing. We break cycles at an arbitrary point,
+ and make no other guarantees.
+ """
+ # The current implementation, which we may change at any point
+ # installs the user specified things in the order given, except when
+ # dependencies must come earlier to achieve topological order.
+ order = []
+ ordered_reqs: Set[InstallRequirement] = set()
+
+ def schedule(req: InstallRequirement) -> None:
+ if req.satisfied_by or req in ordered_reqs:
+ return
+ if req.constraint:
+ return
+ ordered_reqs.add(req)
+ for dep in self._discovered_dependencies[req.name]:
+ schedule(dep)
+ order.append(req)
+
+ for install_req in req_set.requirements.values():
+ schedule(install_req)
+ return order
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/base.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/base.py
new file mode 100644
index 000000000..0f31dc9b3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/base.py
@@ -0,0 +1,139 @@
+from dataclasses import dataclass
+from typing import FrozenSet, Iterable, Optional, Tuple
+
+from pip._vendor.packaging.specifiers import SpecifierSet
+from pip._vendor.packaging.utils import NormalizedName
+from pip._vendor.packaging.version import Version
+
+from pip._internal.models.link import Link, links_equivalent
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.utils.hashes import Hashes
+
+CandidateLookup = Tuple[Optional["Candidate"], Optional[InstallRequirement]]
+
+
+def format_name(project: NormalizedName, extras: FrozenSet[NormalizedName]) -> str:
+ if not extras:
+ return project
+ extras_expr = ",".join(sorted(extras))
+ return f"{project}[{extras_expr}]"
+
+
+@dataclass(frozen=True)
+class Constraint:
+ specifier: SpecifierSet
+ hashes: Hashes
+ links: FrozenSet[Link]
+
+ @classmethod
+ def empty(cls) -> "Constraint":
+ return Constraint(SpecifierSet(), Hashes(), frozenset())
+
+ @classmethod
+ def from_ireq(cls, ireq: InstallRequirement) -> "Constraint":
+ links = frozenset([ireq.link]) if ireq.link else frozenset()
+ return Constraint(ireq.specifier, ireq.hashes(trust_internet=False), links)
+
+ def __bool__(self) -> bool:
+ return bool(self.specifier) or bool(self.hashes) or bool(self.links)
+
+ def __and__(self, other: InstallRequirement) -> "Constraint":
+ if not isinstance(other, InstallRequirement):
+ return NotImplemented
+ specifier = self.specifier & other.specifier
+ hashes = self.hashes & other.hashes(trust_internet=False)
+ links = self.links
+ if other.link:
+ links = links.union([other.link])
+ return Constraint(specifier, hashes, links)
+
+ def is_satisfied_by(self, candidate: "Candidate") -> bool:
+ # Reject if there are any mismatched URL constraints on this package.
+ if self.links and not all(_match_link(link, candidate) for link in self.links):
+ return False
+ # We can safely always allow prereleases here since PackageFinder
+ # already implements the prerelease logic, and would have filtered out
+ # prerelease candidates if the user does not expect them.
+ return self.specifier.contains(candidate.version, prereleases=True)
+
+
+class Requirement:
+ @property
+ def project_name(self) -> NormalizedName:
+ """The "project name" of a requirement.
+
+ This is different from ``name`` if this requirement contains extras,
+ in which case ``name`` would contain the ``[...]`` part, while this
+ refers to the name of the project.
+ """
+ raise NotImplementedError("Subclass should override")
+
+ @property
+ def name(self) -> str:
+ """The name identifying this requirement in the resolver.
+
+ This is different from ``project_name`` if this requirement contains
+ extras, where ``project_name`` would not contain the ``[...]`` part.
+ """
+ raise NotImplementedError("Subclass should override")
+
+ def is_satisfied_by(self, candidate: "Candidate") -> bool:
+ return False
+
+ def get_candidate_lookup(self) -> CandidateLookup:
+ raise NotImplementedError("Subclass should override")
+
+ def format_for_error(self) -> str:
+ raise NotImplementedError("Subclass should override")
+
+
+def _match_link(link: Link, candidate: "Candidate") -> bool:
+ if candidate.source_link:
+ return links_equivalent(link, candidate.source_link)
+ return False
+
+
+class Candidate:
+ @property
+ def project_name(self) -> NormalizedName:
+ """The "project name" of the candidate.
+
+ This is different from ``name`` if this candidate contains extras,
+ in which case ``name`` would contain the ``[...]`` part, while this
+ refers to the name of the project.
+ """
+ raise NotImplementedError("Override in subclass")
+
+ @property
+ def name(self) -> str:
+ """The name identifying this candidate in the resolver.
+
+ This is different from ``project_name`` if this candidate contains
+ extras, where ``project_name`` would not contain the ``[...]`` part.
+ """
+ raise NotImplementedError("Override in subclass")
+
+ @property
+ def version(self) -> Version:
+ raise NotImplementedError("Override in subclass")
+
+ @property
+ def is_installed(self) -> bool:
+ raise NotImplementedError("Override in subclass")
+
+ @property
+ def is_editable(self) -> bool:
+ raise NotImplementedError("Override in subclass")
+
+ @property
+ def source_link(self) -> Optional[Link]:
+ raise NotImplementedError("Override in subclass")
+
+ def iter_dependencies(self, with_requires: bool) -> Iterable[Optional[Requirement]]:
+ raise NotImplementedError("Override in subclass")
+
+ def get_install_requirement(self) -> Optional[InstallRequirement]:
+ raise NotImplementedError("Override in subclass")
+
+ def format_for_error(self) -> str:
+ raise NotImplementedError("Subclass should override")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/candidates.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/candidates.py
new file mode 100644
index 000000000..6617644fe
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/candidates.py
@@ -0,0 +1,574 @@
+import logging
+import sys
+from typing import TYPE_CHECKING, Any, FrozenSet, Iterable, Optional, Tuple, Union, cast
+
+from pip._vendor.packaging.requirements import InvalidRequirement
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+from pip._vendor.packaging.version import Version
+
+from pip._internal.exceptions import (
+ HashError,
+ InstallationSubprocessError,
+ InvalidInstalledPackage,
+ MetadataInconsistent,
+ MetadataInvalid,
+)
+from pip._internal.metadata import BaseDistribution
+from pip._internal.models.link import Link, links_equivalent
+from pip._internal.models.wheel import Wheel
+from pip._internal.req.constructors import (
+ install_req_from_editable,
+ install_req_from_line,
+)
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.utils.direct_url_helpers import direct_url_from_link
+from pip._internal.utils.misc import normalize_version_info
+
+from .base import Candidate, Requirement, format_name
+
+if TYPE_CHECKING:
+ from .factory import Factory
+
+logger = logging.getLogger(__name__)
+
+BaseCandidate = Union[
+ "AlreadyInstalledCandidate",
+ "EditableCandidate",
+ "LinkCandidate",
+]
+
+# Avoid conflicting with the PyPI package "Python".
+REQUIRES_PYTHON_IDENTIFIER = cast(NormalizedName, "<Python from Requires-Python>")
+
+
+def as_base_candidate(candidate: Candidate) -> Optional[BaseCandidate]:
+ """The runtime version of BaseCandidate."""
+ base_candidate_classes = (
+ AlreadyInstalledCandidate,
+ EditableCandidate,
+ LinkCandidate,
+ )
+ if isinstance(candidate, base_candidate_classes):
+ return candidate
+ return None
+
+
+def make_install_req_from_link(
+ link: Link, template: InstallRequirement
+) -> InstallRequirement:
+ assert not template.editable, "template is editable"
+ if template.req:
+ line = str(template.req)
+ else:
+ line = link.url
+ ireq = install_req_from_line(
+ line,
+ user_supplied=template.user_supplied,
+ comes_from=template.comes_from,
+ use_pep517=template.use_pep517,
+ isolated=template.isolated,
+ constraint=template.constraint,
+ global_options=template.global_options,
+ hash_options=template.hash_options,
+ config_settings=template.config_settings,
+ )
+ ireq.original_link = template.original_link
+ ireq.link = link
+ ireq.extras = template.extras
+ return ireq
+
+
+def make_install_req_from_editable(
+ link: Link, template: InstallRequirement
+) -> InstallRequirement:
+ assert template.editable, "template not editable"
+ ireq = install_req_from_editable(
+ link.url,
+ user_supplied=template.user_supplied,
+ comes_from=template.comes_from,
+ use_pep517=template.use_pep517,
+ isolated=template.isolated,
+ constraint=template.constraint,
+ permit_editable_wheels=template.permit_editable_wheels,
+ global_options=template.global_options,
+ hash_options=template.hash_options,
+ config_settings=template.config_settings,
+ )
+ ireq.extras = template.extras
+ return ireq
+
+
+def _make_install_req_from_dist(
+ dist: BaseDistribution, template: InstallRequirement
+) -> InstallRequirement:
+ if template.req:
+ line = str(template.req)
+ elif template.link:
+ line = f"{dist.canonical_name} @ {template.link.url}"
+ else:
+ line = f"{dist.canonical_name}=={dist.version}"
+ ireq = install_req_from_line(
+ line,
+ user_supplied=template.user_supplied,
+ comes_from=template.comes_from,
+ use_pep517=template.use_pep517,
+ isolated=template.isolated,
+ constraint=template.constraint,
+ global_options=template.global_options,
+ hash_options=template.hash_options,
+ config_settings=template.config_settings,
+ )
+ ireq.satisfied_by = dist
+ return ireq
+
+
+class _InstallRequirementBackedCandidate(Candidate):
+ """A candidate backed by an ``InstallRequirement``.
+
+ This represents a package request with the target not being already
+ in the environment, and needs to be fetched and installed. The backing
+ ``InstallRequirement`` is responsible for most of the leg work; this
+ class exposes appropriate information to the resolver.
+
+ :param link: The link passed to the ``InstallRequirement``. The backing
+ ``InstallRequirement`` will use this link to fetch the distribution.
+ :param source_link: The link this candidate "originates" from. This is
+ different from ``link`` when the link is found in the wheel cache.
+ ``link`` would point to the wheel cache, while this points to the
+ found remote link (e.g. from pypi.org).
+ """
+
+ dist: BaseDistribution
+ is_installed = False
+
+ def __init__(
+ self,
+ link: Link,
+ source_link: Link,
+ ireq: InstallRequirement,
+ factory: "Factory",
+ name: Optional[NormalizedName] = None,
+ version: Optional[Version] = None,
+ ) -> None:
+ self._link = link
+ self._source_link = source_link
+ self._factory = factory
+ self._ireq = ireq
+ self._name = name
+ self._version = version
+ self.dist = self._prepare()
+ self._hash: Optional[int] = None
+
+ def __str__(self) -> str:
+ return f"{self.name} {self.version}"
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({str(self._link)!r})"
+
+ def __hash__(self) -> int:
+ if self._hash is not None:
+ return self._hash
+
+ self._hash = hash((self.__class__, self._link))
+ return self._hash
+
+ def __eq__(self, other: Any) -> bool:
+ if isinstance(other, self.__class__):
+ return links_equivalent(self._link, other._link)
+ return False
+
+ @property
+ def source_link(self) -> Optional[Link]:
+ return self._source_link
+
+ @property
+ def project_name(self) -> NormalizedName:
+ """The normalised name of the project the candidate refers to"""
+ if self._name is None:
+ self._name = self.dist.canonical_name
+ return self._name
+
+ @property
+ def name(self) -> str:
+ return self.project_name
+
+ @property
+ def version(self) -> Version:
+ if self._version is None:
+ self._version = self.dist.version
+ return self._version
+
+ def format_for_error(self) -> str:
+ return (
+ f"{self.name} {self.version} "
+ f"(from {self._link.file_path if self._link.is_file else self._link})"
+ )
+
+ def _prepare_distribution(self) -> BaseDistribution:
+ raise NotImplementedError("Override in subclass")
+
+ def _check_metadata_consistency(self, dist: BaseDistribution) -> None:
+ """Check for consistency of project name and version of dist."""
+ if self._name is not None and self._name != dist.canonical_name:
+ raise MetadataInconsistent(
+ self._ireq,
+ "name",
+ self._name,
+ dist.canonical_name,
+ )
+ if self._version is not None and self._version != dist.version:
+ raise MetadataInconsistent(
+ self._ireq,
+ "version",
+ str(self._version),
+ str(dist.version),
+ )
+ # check dependencies are valid
+ # TODO performance: this means we iterate the dependencies at least twice,
+ # we may want to cache parsed Requires-Dist
+ try:
+ list(dist.iter_dependencies(list(dist.iter_provided_extras())))
+ except InvalidRequirement as e:
+ raise MetadataInvalid(self._ireq, str(e))
+
+ def _prepare(self) -> BaseDistribution:
+ try:
+ dist = self._prepare_distribution()
+ except HashError as e:
+ # Provide HashError the underlying ireq that caused it. This
+ # provides context for the resulting error message to show the
+ # offending line to the user.
+ e.req = self._ireq
+ raise
+ except InstallationSubprocessError as exc:
+ # The output has been presented already, so don't duplicate it.
+ exc.context = "See above for output."
+ raise
+
+ self._check_metadata_consistency(dist)
+ return dist
+
+ def iter_dependencies(self, with_requires: bool) -> Iterable[Optional[Requirement]]:
+ requires = self.dist.iter_dependencies() if with_requires else ()
+ for r in requires:
+ yield from self._factory.make_requirements_from_spec(str(r), self._ireq)
+ yield self._factory.make_requires_python_requirement(self.dist.requires_python)
+
+ def get_install_requirement(self) -> Optional[InstallRequirement]:
+ return self._ireq
+
+
+class LinkCandidate(_InstallRequirementBackedCandidate):
+ is_editable = False
+
+ def __init__(
+ self,
+ link: Link,
+ template: InstallRequirement,
+ factory: "Factory",
+ name: Optional[NormalizedName] = None,
+ version: Optional[Version] = None,
+ ) -> None:
+ source_link = link
+ cache_entry = factory.get_wheel_cache_entry(source_link, name)
+ if cache_entry is not None:
+ logger.debug("Using cached wheel link: %s", cache_entry.link)
+ link = cache_entry.link
+ ireq = make_install_req_from_link(link, template)
+ assert ireq.link == link
+ if ireq.link.is_wheel and not ireq.link.is_file:
+ wheel = Wheel(ireq.link.filename)
+ wheel_name = canonicalize_name(wheel.name)
+ assert name == wheel_name, f"{name!r} != {wheel_name!r} for wheel"
+ # Version may not be present for PEP 508 direct URLs
+ if version is not None:
+ wheel_version = Version(wheel.version)
+ assert (
+ version == wheel_version
+ ), f"{version!r} != {wheel_version!r} for wheel {name}"
+
+ if cache_entry is not None:
+ assert ireq.link.is_wheel
+ assert ireq.link.is_file
+ if cache_entry.persistent and template.link is template.original_link:
+ ireq.cached_wheel_source_link = source_link
+ if cache_entry.origin is not None:
+ ireq.download_info = cache_entry.origin
+ else:
+ # Legacy cache entry that does not have origin.json.
+ # download_info may miss the archive_info.hashes field.
+ ireq.download_info = direct_url_from_link(
+ source_link, link_is_in_wheel_cache=cache_entry.persistent
+ )
+
+ super().__init__(
+ link=link,
+ source_link=source_link,
+ ireq=ireq,
+ factory=factory,
+ name=name,
+ version=version,
+ )
+
+ def _prepare_distribution(self) -> BaseDistribution:
+ preparer = self._factory.preparer
+ return preparer.prepare_linked_requirement(self._ireq, parallel_builds=True)
+
+
+class EditableCandidate(_InstallRequirementBackedCandidate):
+ is_editable = True
+
+ def __init__(
+ self,
+ link: Link,
+ template: InstallRequirement,
+ factory: "Factory",
+ name: Optional[NormalizedName] = None,
+ version: Optional[Version] = None,
+ ) -> None:
+ super().__init__(
+ link=link,
+ source_link=link,
+ ireq=make_install_req_from_editable(link, template),
+ factory=factory,
+ name=name,
+ version=version,
+ )
+
+ def _prepare_distribution(self) -> BaseDistribution:
+ return self._factory.preparer.prepare_editable_requirement(self._ireq)
+
+
+class AlreadyInstalledCandidate(Candidate):
+ is_installed = True
+ source_link = None
+
+ def __init__(
+ self,
+ dist: BaseDistribution,
+ template: InstallRequirement,
+ factory: "Factory",
+ ) -> None:
+ self.dist = dist
+ self._ireq = _make_install_req_from_dist(dist, template)
+ self._factory = factory
+ self._version = None
+
+ # This is just logging some messages, so we can do it eagerly.
+ # The returned dist would be exactly the same as self.dist because we
+ # set satisfied_by in _make_install_req_from_dist.
+ # TODO: Supply reason based on force_reinstall and upgrade_strategy.
+ skip_reason = "already satisfied"
+ factory.preparer.prepare_installed_requirement(self._ireq, skip_reason)
+
+ def __str__(self) -> str:
+ return str(self.dist)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({self.dist!r})"
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, AlreadyInstalledCandidate):
+ return NotImplemented
+ return self.name == other.name and self.version == other.version
+
+ def __hash__(self) -> int:
+ return hash((self.name, self.version))
+
+ @property
+ def project_name(self) -> NormalizedName:
+ return self.dist.canonical_name
+
+ @property
+ def name(self) -> str:
+ return self.project_name
+
+ @property
+ def version(self) -> Version:
+ if self._version is None:
+ self._version = self.dist.version
+ return self._version
+
+ @property
+ def is_editable(self) -> bool:
+ return self.dist.editable
+
+ def format_for_error(self) -> str:
+ return f"{self.name} {self.version} (Installed)"
+
+ def iter_dependencies(self, with_requires: bool) -> Iterable[Optional[Requirement]]:
+ if not with_requires:
+ return
+
+ try:
+ for r in self.dist.iter_dependencies():
+ yield from self._factory.make_requirements_from_spec(str(r), self._ireq)
+ except InvalidRequirement as exc:
+ raise InvalidInstalledPackage(dist=self.dist, invalid_exc=exc) from None
+
+ def get_install_requirement(self) -> Optional[InstallRequirement]:
+ return None
+
+
+class ExtrasCandidate(Candidate):
+ """A candidate that has 'extras', indicating additional dependencies.
+
+ Requirements can be for a project with dependencies, something like
+ foo[extra]. The extras don't affect the project/version being installed
+ directly, but indicate that we need additional dependencies. We model that
+ by having an artificial ExtrasCandidate that wraps the "base" candidate.
+
+ The ExtrasCandidate differs from the base in the following ways:
+
+ 1. It has a unique name, of the form foo[extra]. This causes the resolver
+ to treat it as a separate node in the dependency graph.
+ 2. When we're getting the candidate's dependencies,
+ a) We specify that we want the extra dependencies as well.
+ b) We add a dependency on the base candidate.
+ See below for why this is needed.
+ 3. We return None for the underlying InstallRequirement, as the base
+ candidate will provide it, and we don't want to end up with duplicates.
+
+ The dependency on the base candidate is needed so that the resolver can't
+ decide that it should recommend foo[extra1] version 1.0 and foo[extra2]
+ version 2.0. Having those candidates depend on foo=1.0 and foo=2.0
+ respectively forces the resolver to recognise that this is a conflict.
+ """
+
+ def __init__(
+ self,
+ base: BaseCandidate,
+ extras: FrozenSet[str],
+ *,
+ comes_from: Optional[InstallRequirement] = None,
+ ) -> None:
+ """
+ :param comes_from: the InstallRequirement that led to this candidate if it
+ differs from the base's InstallRequirement. This will often be the
+ case in the sense that this candidate's requirement has the extras
+ while the base's does not. Unlike the InstallRequirement backed
+ candidates, this requirement is used solely for reporting purposes,
+ it does not do any leg work.
+ """
+ self.base = base
+ self.extras = frozenset(canonicalize_name(e) for e in extras)
+ self._comes_from = comes_from if comes_from is not None else self.base._ireq
+
+ def __str__(self) -> str:
+ name, rest = str(self.base).split(" ", 1)
+ return "{}[{}] {}".format(name, ",".join(self.extras), rest)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}(base={self.base!r}, extras={self.extras!r})"
+
+ def __hash__(self) -> int:
+ return hash((self.base, self.extras))
+
+ def __eq__(self, other: Any) -> bool:
+ if isinstance(other, self.__class__):
+ return self.base == other.base and self.extras == other.extras
+ return False
+
+ @property
+ def project_name(self) -> NormalizedName:
+ return self.base.project_name
+
+ @property
+ def name(self) -> str:
+ """The normalised name of the project the candidate refers to"""
+ return format_name(self.base.project_name, self.extras)
+
+ @property
+ def version(self) -> Version:
+ return self.base.version
+
+ def format_for_error(self) -> str:
+ return "{} [{}]".format(
+ self.base.format_for_error(), ", ".join(sorted(self.extras))
+ )
+
+ @property
+ def is_installed(self) -> bool:
+ return self.base.is_installed
+
+ @property
+ def is_editable(self) -> bool:
+ return self.base.is_editable
+
+ @property
+ def source_link(self) -> Optional[Link]:
+ return self.base.source_link
+
+ def iter_dependencies(self, with_requires: bool) -> Iterable[Optional[Requirement]]:
+ factory = self.base._factory
+
+ # Add a dependency on the exact base
+ # (See note 2b in the class docstring)
+ yield factory.make_requirement_from_candidate(self.base)
+ if not with_requires:
+ return
+
+ # The user may have specified extras that the candidate doesn't
+ # support. We ignore any unsupported extras here.
+ valid_extras = self.extras.intersection(self.base.dist.iter_provided_extras())
+ invalid_extras = self.extras.difference(self.base.dist.iter_provided_extras())
+ for extra in sorted(invalid_extras):
+ logger.warning(
+ "%s %s does not provide the extra '%s'",
+ self.base.name,
+ self.version,
+ extra,
+ )
+
+ for r in self.base.dist.iter_dependencies(valid_extras):
+ yield from factory.make_requirements_from_spec(
+ str(r),
+ self._comes_from,
+ valid_extras,
+ )
+
+ def get_install_requirement(self) -> Optional[InstallRequirement]:
+ # We don't return anything here, because we always
+ # depend on the base candidate, and we'll get the
+ # install requirement from that.
+ return None
+
+
+class RequiresPythonCandidate(Candidate):
+ is_installed = False
+ source_link = None
+
+ def __init__(self, py_version_info: Optional[Tuple[int, ...]]) -> None:
+ if py_version_info is not None:
+ version_info = normalize_version_info(py_version_info)
+ else:
+ version_info = sys.version_info[:3]
+ self._version = Version(".".join(str(c) for c in version_info))
+
+ # We don't need to implement __eq__() and __ne__() since there is always
+ # only one RequiresPythonCandidate in a resolution, i.e. the host Python.
+ # The built-in object.__eq__() and object.__ne__() do exactly what we want.
+
+ def __str__(self) -> str:
+ return f"Python {self._version}"
+
+ @property
+ def project_name(self) -> NormalizedName:
+ return REQUIRES_PYTHON_IDENTIFIER
+
+ @property
+ def name(self) -> str:
+ return REQUIRES_PYTHON_IDENTIFIER
+
+ @property
+ def version(self) -> Version:
+ return self._version
+
+ def format_for_error(self) -> str:
+ return f"Python {self.version}"
+
+ def iter_dependencies(self, with_requires: bool) -> Iterable[Optional[Requirement]]:
+ return ()
+
+ def get_install_requirement(self) -> Optional[InstallRequirement]:
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/factory.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/factory.py
new file mode 100644
index 000000000..dc6e2e12e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/factory.py
@@ -0,0 +1,823 @@
+import contextlib
+import functools
+import logging
+from typing import (
+ TYPE_CHECKING,
+ Callable,
+ Dict,
+ FrozenSet,
+ Iterable,
+ Iterator,
+ List,
+ Mapping,
+ NamedTuple,
+ Optional,
+ Protocol,
+ Sequence,
+ Set,
+ Tuple,
+ TypeVar,
+ cast,
+)
+
+from pip._vendor.packaging.requirements import InvalidRequirement
+from pip._vendor.packaging.specifiers import SpecifierSet
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+from pip._vendor.packaging.version import InvalidVersion, Version
+from pip._vendor.resolvelib import ResolutionImpossible
+
+from pip._internal.cache import CacheEntry, WheelCache
+from pip._internal.exceptions import (
+ DistributionNotFound,
+ InstallationError,
+ InvalidInstalledPackage,
+ MetadataInconsistent,
+ MetadataInvalid,
+ UnsupportedPythonVersion,
+ UnsupportedWheel,
+)
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.metadata import BaseDistribution, get_default_environment
+from pip._internal.models.link import Link
+from pip._internal.models.wheel import Wheel
+from pip._internal.operations.prepare import RequirementPreparer
+from pip._internal.req.constructors import (
+ install_req_drop_extras,
+ install_req_from_link_and_ireq,
+)
+from pip._internal.req.req_install import (
+ InstallRequirement,
+ check_invalid_constraint_type,
+)
+from pip._internal.resolution.base import InstallRequirementProvider
+from pip._internal.utils.compatibility_tags import get_supported
+from pip._internal.utils.hashes import Hashes
+from pip._internal.utils.packaging import get_requirement
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+from .base import Candidate, Constraint, Requirement
+from .candidates import (
+ AlreadyInstalledCandidate,
+ BaseCandidate,
+ EditableCandidate,
+ ExtrasCandidate,
+ LinkCandidate,
+ RequiresPythonCandidate,
+ as_base_candidate,
+)
+from .found_candidates import FoundCandidates, IndexCandidateInfo
+from .requirements import (
+ ExplicitRequirement,
+ RequiresPythonRequirement,
+ SpecifierRequirement,
+ SpecifierWithoutExtrasRequirement,
+ UnsatisfiableRequirement,
+)
+
+if TYPE_CHECKING:
+
+ class ConflictCause(Protocol):
+ requirement: RequiresPythonRequirement
+ parent: Candidate
+
+
+logger = logging.getLogger(__name__)
+
+C = TypeVar("C")
+Cache = Dict[Link, C]
+
+
+class CollectedRootRequirements(NamedTuple):
+ requirements: List[Requirement]
+ constraints: Dict[str, Constraint]
+ user_requested: Dict[str, int]
+
+
+class Factory:
+ def __init__(
+ self,
+ finder: PackageFinder,
+ preparer: RequirementPreparer,
+ make_install_req: InstallRequirementProvider,
+ wheel_cache: Optional[WheelCache],
+ use_user_site: bool,
+ force_reinstall: bool,
+ ignore_installed: bool,
+ ignore_requires_python: bool,
+ py_version_info: Optional[Tuple[int, ...]] = None,
+ ) -> None:
+ self._finder = finder
+ self.preparer = preparer
+ self._wheel_cache = wheel_cache
+ self._python_candidate = RequiresPythonCandidate(py_version_info)
+ self._make_install_req_from_spec = make_install_req
+ self._use_user_site = use_user_site
+ self._force_reinstall = force_reinstall
+ self._ignore_requires_python = ignore_requires_python
+
+ self._build_failures: Cache[InstallationError] = {}
+ self._link_candidate_cache: Cache[LinkCandidate] = {}
+ self._editable_candidate_cache: Cache[EditableCandidate] = {}
+ self._installed_candidate_cache: Dict[str, AlreadyInstalledCandidate] = {}
+ self._extras_candidate_cache: Dict[
+ Tuple[int, FrozenSet[NormalizedName]], ExtrasCandidate
+ ] = {}
+ self._supported_tags_cache = get_supported()
+
+ if not ignore_installed:
+ env = get_default_environment()
+ self._installed_dists = {
+ dist.canonical_name: dist
+ for dist in env.iter_installed_distributions(local_only=False)
+ }
+ else:
+ self._installed_dists = {}
+
+ @property
+ def force_reinstall(self) -> bool:
+ return self._force_reinstall
+
+ def _fail_if_link_is_unsupported_wheel(self, link: Link) -> None:
+ if not link.is_wheel:
+ return
+ wheel = Wheel(link.filename)
+ if wheel.supported(self._finder.target_python.get_unsorted_tags()):
+ return
+ msg = f"{link.filename} is not a supported wheel on this platform."
+ raise UnsupportedWheel(msg)
+
+ def _make_extras_candidate(
+ self,
+ base: BaseCandidate,
+ extras: FrozenSet[str],
+ *,
+ comes_from: Optional[InstallRequirement] = None,
+ ) -> ExtrasCandidate:
+ cache_key = (id(base), frozenset(canonicalize_name(e) for e in extras))
+ try:
+ candidate = self._extras_candidate_cache[cache_key]
+ except KeyError:
+ candidate = ExtrasCandidate(base, extras, comes_from=comes_from)
+ self._extras_candidate_cache[cache_key] = candidate
+ return candidate
+
+ def _make_candidate_from_dist(
+ self,
+ dist: BaseDistribution,
+ extras: FrozenSet[str],
+ template: InstallRequirement,
+ ) -> Candidate:
+ try:
+ base = self._installed_candidate_cache[dist.canonical_name]
+ except KeyError:
+ base = AlreadyInstalledCandidate(dist, template, factory=self)
+ self._installed_candidate_cache[dist.canonical_name] = base
+ if not extras:
+ return base
+ return self._make_extras_candidate(base, extras, comes_from=template)
+
+ def _make_candidate_from_link(
+ self,
+ link: Link,
+ extras: FrozenSet[str],
+ template: InstallRequirement,
+ name: Optional[NormalizedName],
+ version: Optional[Version],
+ ) -> Optional[Candidate]:
+ base: Optional[BaseCandidate] = self._make_base_candidate_from_link(
+ link, template, name, version
+ )
+ if not extras or base is None:
+ return base
+ return self._make_extras_candidate(base, extras, comes_from=template)
+
+ def _make_base_candidate_from_link(
+ self,
+ link: Link,
+ template: InstallRequirement,
+ name: Optional[NormalizedName],
+ version: Optional[Version],
+ ) -> Optional[BaseCandidate]:
+ # TODO: Check already installed candidate, and use it if the link and
+ # editable flag match.
+
+ if link in self._build_failures:
+ # We already tried this candidate before, and it does not build.
+ # Don't bother trying again.
+ return None
+
+ if template.editable:
+ if link not in self._editable_candidate_cache:
+ try:
+ self._editable_candidate_cache[link] = EditableCandidate(
+ link,
+ template,
+ factory=self,
+ name=name,
+ version=version,
+ )
+ except (MetadataInconsistent, MetadataInvalid) as e:
+ logger.info(
+ "Discarding [blue underline]%s[/]: [yellow]%s[reset]",
+ link,
+ e,
+ extra={"markup": True},
+ )
+ self._build_failures[link] = e
+ return None
+
+ return self._editable_candidate_cache[link]
+ else:
+ if link not in self._link_candidate_cache:
+ try:
+ self._link_candidate_cache[link] = LinkCandidate(
+ link,
+ template,
+ factory=self,
+ name=name,
+ version=version,
+ )
+ except MetadataInconsistent as e:
+ logger.info(
+ "Discarding [blue underline]%s[/]: [yellow]%s[reset]",
+ link,
+ e,
+ extra={"markup": True},
+ )
+ self._build_failures[link] = e
+ return None
+ return self._link_candidate_cache[link]
+
+ def _iter_found_candidates(
+ self,
+ ireqs: Sequence[InstallRequirement],
+ specifier: SpecifierSet,
+ hashes: Hashes,
+ prefers_installed: bool,
+ incompatible_ids: Set[int],
+ ) -> Iterable[Candidate]:
+ if not ireqs:
+ return ()
+
+ # The InstallRequirement implementation requires us to give it a
+ # "template". Here we just choose the first requirement to represent
+ # all of them.
+ # Hopefully the Project model can correct this mismatch in the future.
+ template = ireqs[0]
+ assert template.req, "Candidates found on index must be PEP 508"
+ name = canonicalize_name(template.req.name)
+
+ extras: FrozenSet[str] = frozenset()
+ for ireq in ireqs:
+ assert ireq.req, "Candidates found on index must be PEP 508"
+ specifier &= ireq.req.specifier
+ hashes &= ireq.hashes(trust_internet=False)
+ extras |= frozenset(ireq.extras)
+
+ def _get_installed_candidate() -> Optional[Candidate]:
+ """Get the candidate for the currently-installed version."""
+ # If --force-reinstall is set, we want the version from the index
+ # instead, so we "pretend" there is nothing installed.
+ if self._force_reinstall:
+ return None
+ try:
+ installed_dist = self._installed_dists[name]
+ except KeyError:
+ return None
+
+ try:
+ # Don't use the installed distribution if its version
+ # does not fit the current dependency graph.
+ if not specifier.contains(installed_dist.version, prereleases=True):
+ return None
+ except InvalidVersion as e:
+ raise InvalidInstalledPackage(dist=installed_dist, invalid_exc=e)
+
+ candidate = self._make_candidate_from_dist(
+ dist=installed_dist,
+ extras=extras,
+ template=template,
+ )
+ # The candidate is a known incompatibility. Don't use it.
+ if id(candidate) in incompatible_ids:
+ return None
+ return candidate
+
+ def iter_index_candidate_infos() -> Iterator[IndexCandidateInfo]:
+ result = self._finder.find_best_candidate(
+ project_name=name,
+ specifier=specifier,
+ hashes=hashes,
+ )
+ icans = list(result.iter_applicable())
+
+ # PEP 592: Yanked releases are ignored unless the specifier
+ # explicitly pins a version (via '==' or '===') that can be
+ # solely satisfied by a yanked release.
+ all_yanked = all(ican.link.is_yanked for ican in icans)
+
+ def is_pinned(specifier: SpecifierSet) -> bool:
+ for sp in specifier:
+ if sp.operator == "===":
+ return True
+ if sp.operator != "==":
+ continue
+ if sp.version.endswith(".*"):
+ continue
+ return True
+ return False
+
+ pinned = is_pinned(specifier)
+
+ # PackageFinder returns earlier versions first, so we reverse.
+ for ican in reversed(icans):
+ if not (all_yanked and pinned) and ican.link.is_yanked:
+ continue
+ func = functools.partial(
+ self._make_candidate_from_link,
+ link=ican.link,
+ extras=extras,
+ template=template,
+ name=name,
+ version=ican.version,
+ )
+ yield ican.version, func
+
+ return FoundCandidates(
+ iter_index_candidate_infos,
+ _get_installed_candidate(),
+ prefers_installed,
+ incompatible_ids,
+ )
+
+ def _iter_explicit_candidates_from_base(
+ self,
+ base_requirements: Iterable[Requirement],
+ extras: FrozenSet[str],
+ ) -> Iterator[Candidate]:
+ """Produce explicit candidates from the base given an extra-ed package.
+
+ :param base_requirements: Requirements known to the resolver. The
+ requirements are guaranteed to not have extras.
+ :param extras: The extras to inject into the explicit requirements'
+ candidates.
+ """
+ for req in base_requirements:
+ lookup_cand, _ = req.get_candidate_lookup()
+ if lookup_cand is None: # Not explicit.
+ continue
+ # We've stripped extras from the identifier, and should always
+ # get a BaseCandidate here, unless there's a bug elsewhere.
+ base_cand = as_base_candidate(lookup_cand)
+ assert base_cand is not None, "no extras here"
+ yield self._make_extras_candidate(base_cand, extras)
+
+ def _iter_candidates_from_constraints(
+ self,
+ identifier: str,
+ constraint: Constraint,
+ template: InstallRequirement,
+ ) -> Iterator[Candidate]:
+ """Produce explicit candidates from constraints.
+
+ This creates "fake" InstallRequirement objects that are basically clones
+ of what "should" be the template, but with original_link set to link.
+ """
+ for link in constraint.links:
+ self._fail_if_link_is_unsupported_wheel(link)
+ candidate = self._make_base_candidate_from_link(
+ link,
+ template=install_req_from_link_and_ireq(link, template),
+ name=canonicalize_name(identifier),
+ version=None,
+ )
+ if candidate:
+ yield candidate
+
+ def find_candidates(
+ self,
+ identifier: str,
+ requirements: Mapping[str, Iterable[Requirement]],
+ incompatibilities: Mapping[str, Iterator[Candidate]],
+ constraint: Constraint,
+ prefers_installed: bool,
+ is_satisfied_by: Callable[[Requirement, Candidate], bool],
+ ) -> Iterable[Candidate]:
+ # Collect basic lookup information from the requirements.
+ explicit_candidates: Set[Candidate] = set()
+ ireqs: List[InstallRequirement] = []
+ for req in requirements[identifier]:
+ cand, ireq = req.get_candidate_lookup()
+ if cand is not None:
+ explicit_candidates.add(cand)
+ if ireq is not None:
+ ireqs.append(ireq)
+
+ # If the current identifier contains extras, add requires and explicit
+ # candidates from entries from extra-less identifier.
+ with contextlib.suppress(InvalidRequirement):
+ parsed_requirement = get_requirement(identifier)
+ if parsed_requirement.name != identifier:
+ explicit_candidates.update(
+ self._iter_explicit_candidates_from_base(
+ requirements.get(parsed_requirement.name, ()),
+ frozenset(parsed_requirement.extras),
+ ),
+ )
+ for req in requirements.get(parsed_requirement.name, []):
+ _, ireq = req.get_candidate_lookup()
+ if ireq is not None:
+ ireqs.append(ireq)
+
+ # Add explicit candidates from constraints. We only do this if there are
+ # known ireqs, which represent requirements not already explicit. If
+ # there are no ireqs, we're constraining already-explicit requirements,
+ # which is handled later when we return the explicit candidates.
+ if ireqs:
+ try:
+ explicit_candidates.update(
+ self._iter_candidates_from_constraints(
+ identifier,
+ constraint,
+ template=ireqs[0],
+ ),
+ )
+ except UnsupportedWheel:
+ # If we're constrained to install a wheel incompatible with the
+ # target architecture, no candidates will ever be valid.
+ return ()
+
+ # Since we cache all the candidates, incompatibility identification
+ # can be made quicker by comparing only the id() values.
+ incompat_ids = {id(c) for c in incompatibilities.get(identifier, ())}
+
+ # If none of the requirements want an explicit candidate, we can ask
+ # the finder for candidates.
+ if not explicit_candidates:
+ return self._iter_found_candidates(
+ ireqs,
+ constraint.specifier,
+ constraint.hashes,
+ prefers_installed,
+ incompat_ids,
+ )
+
+ return (
+ c
+ for c in explicit_candidates
+ if id(c) not in incompat_ids
+ and constraint.is_satisfied_by(c)
+ and all(is_satisfied_by(req, c) for req in requirements[identifier])
+ )
+
+ def _make_requirements_from_install_req(
+ self, ireq: InstallRequirement, requested_extras: Iterable[str]
+ ) -> Iterator[Requirement]:
+ """
+ Returns requirement objects associated with the given InstallRequirement. In
+ most cases this will be a single object but the following special cases exist:
+ - the InstallRequirement has markers that do not apply -> result is empty
+ - the InstallRequirement has both a constraint (or link) and extras
+ -> result is split in two requirement objects: one with the constraint
+ (or link) and one with the extra. This allows centralized constraint
+ handling for the base, resulting in fewer candidate rejections.
+ """
+ if not ireq.match_markers(requested_extras):
+ logger.info(
+ "Ignoring %s: markers '%s' don't match your environment",
+ ireq.name,
+ ireq.markers,
+ )
+ elif not ireq.link:
+ if ireq.extras and ireq.req is not None and ireq.req.specifier:
+ yield SpecifierWithoutExtrasRequirement(ireq)
+ yield SpecifierRequirement(ireq)
+ else:
+ self._fail_if_link_is_unsupported_wheel(ireq.link)
+ # Always make the link candidate for the base requirement to make it
+ # available to `find_candidates` for explicit candidate lookup for any
+ # set of extras.
+ # The extras are required separately via a second requirement.
+ cand = self._make_base_candidate_from_link(
+ ireq.link,
+ template=install_req_drop_extras(ireq) if ireq.extras else ireq,
+ name=canonicalize_name(ireq.name) if ireq.name else None,
+ version=None,
+ )
+ if cand is None:
+ # There's no way we can satisfy a URL requirement if the underlying
+ # candidate fails to build. An unnamed URL must be user-supplied, so
+ # we fail eagerly. If the URL is named, an unsatisfiable requirement
+ # can make the resolver do the right thing, either backtrack (and
+ # maybe find some other requirement that's buildable) or raise a
+ # ResolutionImpossible eventually.
+ if not ireq.name:
+ raise self._build_failures[ireq.link]
+ yield UnsatisfiableRequirement(canonicalize_name(ireq.name))
+ else:
+ # require the base from the link
+ yield self.make_requirement_from_candidate(cand)
+ if ireq.extras:
+ # require the extras on top of the base candidate
+ yield self.make_requirement_from_candidate(
+ self._make_extras_candidate(cand, frozenset(ireq.extras))
+ )
+
+ def collect_root_requirements(
+ self, root_ireqs: List[InstallRequirement]
+ ) -> CollectedRootRequirements:
+ collected = CollectedRootRequirements([], {}, {})
+ for i, ireq in enumerate(root_ireqs):
+ if ireq.constraint:
+ # Ensure we only accept valid constraints
+ problem = check_invalid_constraint_type(ireq)
+ if problem:
+ raise InstallationError(problem)
+ if not ireq.match_markers():
+ continue
+ assert ireq.name, "Constraint must be named"
+ name = canonicalize_name(ireq.name)
+ if name in collected.constraints:
+ collected.constraints[name] &= ireq
+ else:
+ collected.constraints[name] = Constraint.from_ireq(ireq)
+ else:
+ reqs = list(
+ self._make_requirements_from_install_req(
+ ireq,
+ requested_extras=(),
+ )
+ )
+ if not reqs:
+ continue
+ template = reqs[0]
+ if ireq.user_supplied and template.name not in collected.user_requested:
+ collected.user_requested[template.name] = i
+ collected.requirements.extend(reqs)
+ # Put requirements with extras at the end of the root requires. This does not
+ # affect resolvelib's picking preference but it does affect its initial criteria
+ # population: by putting extras at the end we enable the candidate finder to
+ # present resolvelib with a smaller set of candidates to resolvelib, already
+ # taking into account any non-transient constraints on the associated base. This
+ # means resolvelib will have fewer candidates to visit and reject.
+ # Python's list sort is stable, meaning relative order is kept for objects with
+ # the same key.
+ collected.requirements.sort(key=lambda r: r.name != r.project_name)
+ return collected
+
+ def make_requirement_from_candidate(
+ self, candidate: Candidate
+ ) -> ExplicitRequirement:
+ return ExplicitRequirement(candidate)
+
+ def make_requirements_from_spec(
+ self,
+ specifier: str,
+ comes_from: Optional[InstallRequirement],
+ requested_extras: Iterable[str] = (),
+ ) -> Iterator[Requirement]:
+ """
+ Returns requirement objects associated with the given specifier. In most cases
+ this will be a single object but the following special cases exist:
+ - the specifier has markers that do not apply -> result is empty
+ - the specifier has both a constraint and extras -> result is split
+ in two requirement objects: one with the constraint and one with the
+ extra. This allows centralized constraint handling for the base,
+ resulting in fewer candidate rejections.
+ """
+ ireq = self._make_install_req_from_spec(specifier, comes_from)
+ return self._make_requirements_from_install_req(ireq, requested_extras)
+
+ def make_requires_python_requirement(
+ self,
+ specifier: SpecifierSet,
+ ) -> Optional[Requirement]:
+ if self._ignore_requires_python:
+ return None
+ # Don't bother creating a dependency for an empty Requires-Python.
+ if not str(specifier):
+ return None
+ return RequiresPythonRequirement(specifier, self._python_candidate)
+
+ def get_wheel_cache_entry(
+ self, link: Link, name: Optional[str]
+ ) -> Optional[CacheEntry]:
+ """Look up the link in the wheel cache.
+
+ If ``preparer.require_hashes`` is True, don't use the wheel cache,
+ because cached wheels, always built locally, have different hashes
+ than the files downloaded from the index server and thus throw false
+ hash mismatches. Furthermore, cached wheels at present have
+ nondeterministic contents due to file modification times.
+ """
+ if self._wheel_cache is None:
+ return None
+ return self._wheel_cache.get_cache_entry(
+ link=link,
+ package_name=name,
+ supported_tags=self._supported_tags_cache,
+ )
+
+ def get_dist_to_uninstall(self, candidate: Candidate) -> Optional[BaseDistribution]:
+ # TODO: Are there more cases this needs to return True? Editable?
+ dist = self._installed_dists.get(candidate.project_name)
+ if dist is None: # Not installed, no uninstallation required.
+ return None
+
+ # We're installing into global site. The current installation must
+ # be uninstalled, no matter it's in global or user site, because the
+ # user site installation has precedence over global.
+ if not self._use_user_site:
+ return dist
+
+ # We're installing into user site. Remove the user site installation.
+ if dist.in_usersite:
+ return dist
+
+ # We're installing into user site, but the installed incompatible
+ # package is in global site. We can't uninstall that, and would let
+ # the new user installation to "shadow" it. But shadowing won't work
+ # in virtual environments, so we error out.
+ if running_under_virtualenv() and dist.in_site_packages:
+ message = (
+ f"Will not install to the user site because it will lack "
+ f"sys.path precedence to {dist.raw_name} in {dist.location}"
+ )
+ raise InstallationError(message)
+ return None
+
+ def _report_requires_python_error(
+ self, causes: Sequence["ConflictCause"]
+ ) -> UnsupportedPythonVersion:
+ assert causes, "Requires-Python error reported with no cause"
+
+ version = self._python_candidate.version
+
+ if len(causes) == 1:
+ specifier = str(causes[0].requirement.specifier)
+ message = (
+ f"Package {causes[0].parent.name!r} requires a different "
+ f"Python: {version} not in {specifier!r}"
+ )
+ return UnsupportedPythonVersion(message)
+
+ message = f"Packages require a different Python. {version} not in:"
+ for cause in causes:
+ package = cause.parent.format_for_error()
+ specifier = str(cause.requirement.specifier)
+ message += f"\n{specifier!r} (required by {package})"
+ return UnsupportedPythonVersion(message)
+
+ def _report_single_requirement_conflict(
+ self, req: Requirement, parent: Optional[Candidate]
+ ) -> DistributionNotFound:
+ if parent is None:
+ req_disp = str(req)
+ else:
+ req_disp = f"{req} (from {parent.name})"
+
+ cands = self._finder.find_all_candidates(req.project_name)
+ skipped_by_requires_python = self._finder.requires_python_skipped_reasons()
+
+ versions_set: Set[Version] = set()
+ yanked_versions_set: Set[Version] = set()
+ for c in cands:
+ is_yanked = c.link.is_yanked if c.link else False
+ if is_yanked:
+ yanked_versions_set.add(c.version)
+ else:
+ versions_set.add(c.version)
+
+ versions = [str(v) for v in sorted(versions_set)]
+ yanked_versions = [str(v) for v in sorted(yanked_versions_set)]
+
+ if yanked_versions:
+ # Saying "version X is yanked" isn't entirely accurate.
+ # https://github.com/pypa/pip/issues/11745#issuecomment-1402805842
+ logger.critical(
+ "Ignored the following yanked versions: %s",
+ ", ".join(yanked_versions) or "none",
+ )
+ if skipped_by_requires_python:
+ logger.critical(
+ "Ignored the following versions that require a different python "
+ "version: %s",
+ "; ".join(skipped_by_requires_python) or "none",
+ )
+ logger.critical(
+ "Could not find a version that satisfies the requirement %s "
+ "(from versions: %s)",
+ req_disp,
+ ", ".join(versions) or "none",
+ )
+ if str(req) == "requirements.txt":
+ logger.info(
+ "HINT: You are attempting to install a package literally "
+ 'named "requirements.txt" (which cannot exist). Consider '
+ "using the '-r' flag to install the packages listed in "
+ "requirements.txt"
+ )
+
+ return DistributionNotFound(f"No matching distribution found for {req}")
+
+ def get_installation_error(
+ self,
+ e: "ResolutionImpossible[Requirement, Candidate]",
+ constraints: Dict[str, Constraint],
+ ) -> InstallationError:
+ assert e.causes, "Installation error reported with no cause"
+
+ # If one of the things we can't solve is "we need Python X.Y",
+ # that is what we report.
+ requires_python_causes = [
+ cause
+ for cause in e.causes
+ if isinstance(cause.requirement, RequiresPythonRequirement)
+ and not cause.requirement.is_satisfied_by(self._python_candidate)
+ ]
+ if requires_python_causes:
+ # The comprehension above makes sure all Requirement instances are
+ # RequiresPythonRequirement, so let's cast for convenience.
+ return self._report_requires_python_error(
+ cast("Sequence[ConflictCause]", requires_python_causes),
+ )
+
+ # Otherwise, we have a set of causes which can't all be satisfied
+ # at once.
+
+ # The simplest case is when we have *one* cause that can't be
+ # satisfied. We just report that case.
+ if len(e.causes) == 1:
+ req, parent = e.causes[0]
+ if req.name not in constraints:
+ return self._report_single_requirement_conflict(req, parent)
+
+ # OK, we now have a list of requirements that can't all be
+ # satisfied at once.
+
+ # A couple of formatting helpers
+ def text_join(parts: List[str]) -> str:
+ if len(parts) == 1:
+ return parts[0]
+
+ return ", ".join(parts[:-1]) + " and " + parts[-1]
+
+ def describe_trigger(parent: Candidate) -> str:
+ ireq = parent.get_install_requirement()
+ if not ireq or not ireq.comes_from:
+ return f"{parent.name}=={parent.version}"
+ if isinstance(ireq.comes_from, InstallRequirement):
+ return str(ireq.comes_from.name)
+ return str(ireq.comes_from)
+
+ triggers = set()
+ for req, parent in e.causes:
+ if parent is None:
+ # This is a root requirement, so we can report it directly
+ trigger = req.format_for_error()
+ else:
+ trigger = describe_trigger(parent)
+ triggers.add(trigger)
+
+ if triggers:
+ info = text_join(sorted(triggers))
+ else:
+ info = "the requested packages"
+
+ msg = (
+ f"Cannot install {info} because these package versions "
+ "have conflicting dependencies."
+ )
+ logger.critical(msg)
+ msg = "\nThe conflict is caused by:"
+
+ relevant_constraints = set()
+ for req, parent in e.causes:
+ if req.name in constraints:
+ relevant_constraints.add(req.name)
+ msg = msg + "\n "
+ if parent:
+ msg = msg + f"{parent.name} {parent.version} depends on "
+ else:
+ msg = msg + "The user requested "
+ msg = msg + req.format_for_error()
+ for key in relevant_constraints:
+ spec = constraints[key].specifier
+ msg += f"\n The user requested (constraint) {key}{spec}"
+
+ msg = (
+ msg
+ + "\n\n"
+ + "To fix this you could try to:\n"
+ + "1. loosen the range of package versions you've specified\n"
+ + "2. remove package versions to allow pip to attempt to solve "
+ + "the dependency conflict\n"
+ )
+
+ logger.info(msg)
+
+ return DistributionNotFound(
+ "ResolutionImpossible: for help visit "
+ "https://pip.pypa.io/en/latest/topics/dependency-resolution/"
+ "#dealing-with-dependency-conflicts"
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/found_candidates.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/found_candidates.py
new file mode 100644
index 000000000..a1d57e0f4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/found_candidates.py
@@ -0,0 +1,174 @@
+"""Utilities to lazily create and visit candidates found.
+
+Creating and visiting a candidate is a *very* costly operation. It involves
+fetching, extracting, potentially building modules from source, and verifying
+distribution metadata. It is therefore crucial for performance to keep
+everything here lazy all the way down, so we only touch candidates that we
+absolutely need, and not "download the world" when we only need one version of
+something.
+"""
+
+import functools
+import logging
+from collections.abc import Sequence
+from typing import TYPE_CHECKING, Any, Callable, Iterator, Optional, Set, Tuple
+
+from pip._vendor.packaging.version import _BaseVersion
+
+from pip._internal.exceptions import MetadataInvalid
+
+from .base import Candidate
+
+logger = logging.getLogger(__name__)
+
+IndexCandidateInfo = Tuple[_BaseVersion, Callable[[], Optional[Candidate]]]
+
+if TYPE_CHECKING:
+ SequenceCandidate = Sequence[Candidate]
+else:
+ # For compatibility: Python before 3.9 does not support using [] on the
+ # Sequence class.
+ #
+ # >>> from collections.abc import Sequence
+ # >>> Sequence[str]
+ # Traceback (most recent call last):
+ # File "<stdin>", line 1, in <module>
+ # TypeError: 'ABCMeta' object is not subscriptable
+ #
+ # TODO: Remove this block after dropping Python 3.8 support.
+ SequenceCandidate = Sequence
+
+
+def _iter_built(infos: Iterator[IndexCandidateInfo]) -> Iterator[Candidate]:
+ """Iterator for ``FoundCandidates``.
+
+ This iterator is used when the package is not already installed. Candidates
+ from index come later in their normal ordering.
+ """
+ versions_found: Set[_BaseVersion] = set()
+ for version, func in infos:
+ if version in versions_found:
+ continue
+ try:
+ candidate = func()
+ except MetadataInvalid as e:
+ logger.warning(
+ "Ignoring version %s of %s since it has invalid metadata:\n"
+ "%s\n"
+ "Please use pip<24.1 if you need to use this version.",
+ version,
+ e.ireq.name,
+ e,
+ )
+ # Mark version as found to avoid trying other candidates with the same
+ # version, since they most likely have invalid metadata as well.
+ versions_found.add(version)
+ else:
+ if candidate is None:
+ continue
+ yield candidate
+ versions_found.add(version)
+
+
+def _iter_built_with_prepended(
+ installed: Candidate, infos: Iterator[IndexCandidateInfo]
+) -> Iterator[Candidate]:
+ """Iterator for ``FoundCandidates``.
+
+ This iterator is used when the resolver prefers the already-installed
+ candidate and NOT to upgrade. The installed candidate is therefore
+ always yielded first, and candidates from index come later in their
+ normal ordering, except skipped when the version is already installed.
+ """
+ yield installed
+ versions_found: Set[_BaseVersion] = {installed.version}
+ for version, func in infos:
+ if version in versions_found:
+ continue
+ candidate = func()
+ if candidate is None:
+ continue
+ yield candidate
+ versions_found.add(version)
+
+
+def _iter_built_with_inserted(
+ installed: Candidate, infos: Iterator[IndexCandidateInfo]
+) -> Iterator[Candidate]:
+ """Iterator for ``FoundCandidates``.
+
+ This iterator is used when the resolver prefers to upgrade an
+ already-installed package. Candidates from index are returned in their
+ normal ordering, except replaced when the version is already installed.
+
+ The implementation iterates through and yields other candidates, inserting
+ the installed candidate exactly once before we start yielding older or
+ equivalent candidates, or after all other candidates if they are all newer.
+ """
+ versions_found: Set[_BaseVersion] = set()
+ for version, func in infos:
+ if version in versions_found:
+ continue
+ # If the installed candidate is better, yield it first.
+ if installed.version >= version:
+ yield installed
+ versions_found.add(installed.version)
+ candidate = func()
+ if candidate is None:
+ continue
+ yield candidate
+ versions_found.add(version)
+
+ # If the installed candidate is older than all other candidates.
+ if installed.version not in versions_found:
+ yield installed
+
+
+class FoundCandidates(SequenceCandidate):
+ """A lazy sequence to provide candidates to the resolver.
+
+ The intended usage is to return this from `find_matches()` so the resolver
+ can iterate through the sequence multiple times, but only access the index
+ page when remote packages are actually needed. This improve performances
+ when suitable candidates are already installed on disk.
+ """
+
+ def __init__(
+ self,
+ get_infos: Callable[[], Iterator[IndexCandidateInfo]],
+ installed: Optional[Candidate],
+ prefers_installed: bool,
+ incompatible_ids: Set[int],
+ ):
+ self._get_infos = get_infos
+ self._installed = installed
+ self._prefers_installed = prefers_installed
+ self._incompatible_ids = incompatible_ids
+
+ def __getitem__(self, index: Any) -> Any:
+ # Implemented to satisfy the ABC check. This is not needed by the
+ # resolver, and should not be used by the provider either (for
+ # performance reasons).
+ raise NotImplementedError("don't do this")
+
+ def __iter__(self) -> Iterator[Candidate]:
+ infos = self._get_infos()
+ if not self._installed:
+ iterator = _iter_built(infos)
+ elif self._prefers_installed:
+ iterator = _iter_built_with_prepended(self._installed, infos)
+ else:
+ iterator = _iter_built_with_inserted(self._installed, infos)
+ return (c for c in iterator if id(c) not in self._incompatible_ids)
+
+ def __len__(self) -> int:
+ # Implemented to satisfy the ABC check. This is not needed by the
+ # resolver, and should not be used by the provider either (for
+ # performance reasons).
+ raise NotImplementedError("don't do this")
+
+ @functools.lru_cache(maxsize=1)
+ def __bool__(self) -> bool:
+ if self._prefers_installed and self._installed:
+ return True
+ return any(self)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/provider.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/provider.py
new file mode 100644
index 000000000..fb0dd85f1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/provider.py
@@ -0,0 +1,258 @@
+import collections
+import math
+from functools import lru_cache
+from typing import (
+ TYPE_CHECKING,
+ Dict,
+ Iterable,
+ Iterator,
+ Mapping,
+ Sequence,
+ TypeVar,
+ Union,
+)
+
+from pip._vendor.resolvelib.providers import AbstractProvider
+
+from .base import Candidate, Constraint, Requirement
+from .candidates import REQUIRES_PYTHON_IDENTIFIER
+from .factory import Factory
+
+if TYPE_CHECKING:
+ from pip._vendor.resolvelib.providers import Preference
+ from pip._vendor.resolvelib.resolvers import RequirementInformation
+
+ PreferenceInformation = RequirementInformation[Requirement, Candidate]
+
+ _ProviderBase = AbstractProvider[Requirement, Candidate, str]
+else:
+ _ProviderBase = AbstractProvider
+
+# Notes on the relationship between the provider, the factory, and the
+# candidate and requirement classes.
+#
+# The provider is a direct implementation of the resolvelib class. Its role
+# is to deliver the API that resolvelib expects.
+#
+# Rather than work with completely abstract "requirement" and "candidate"
+# concepts as resolvelib does, pip has concrete classes implementing these two
+# ideas. The API of Requirement and Candidate objects are defined in the base
+# classes, but essentially map fairly directly to the equivalent provider
+# methods. In particular, `find_matches` and `is_satisfied_by` are
+# requirement methods, and `get_dependencies` is a candidate method.
+#
+# The factory is the interface to pip's internal mechanisms. It is stateless,
+# and is created by the resolver and held as a property of the provider. It is
+# responsible for creating Requirement and Candidate objects, and provides
+# services to those objects (access to pip's finder and preparer).
+
+
+D = TypeVar("D")
+V = TypeVar("V")
+
+
+def _get_with_identifier(
+ mapping: Mapping[str, V],
+ identifier: str,
+ default: D,
+) -> Union[D, V]:
+ """Get item from a package name lookup mapping with a resolver identifier.
+
+ This extra logic is needed when the target mapping is keyed by package
+ name, which cannot be directly looked up with an identifier (which may
+ contain requested extras). Additional logic is added to also look up a value
+ by "cleaning up" the extras from the identifier.
+ """
+ if identifier in mapping:
+ return mapping[identifier]
+ # HACK: Theoretically we should check whether this identifier is a valid
+ # "NAME[EXTRAS]" format, and parse out the name part with packaging or
+ # some regular expression. But since pip's resolver only spits out three
+ # kinds of identifiers: normalized PEP 503 names, normalized names plus
+ # extras, and Requires-Python, we can cheat a bit here.
+ name, open_bracket, _ = identifier.partition("[")
+ if open_bracket and name in mapping:
+ return mapping[name]
+ return default
+
+
+class PipProvider(_ProviderBase):
+ """Pip's provider implementation for resolvelib.
+
+ :params constraints: A mapping of constraints specified by the user. Keys
+ are canonicalized project names.
+ :params ignore_dependencies: Whether the user specified ``--no-deps``.
+ :params upgrade_strategy: The user-specified upgrade strategy.
+ :params user_requested: A set of canonicalized package names that the user
+ supplied for pip to install/upgrade.
+ """
+
+ def __init__(
+ self,
+ factory: Factory,
+ constraints: Dict[str, Constraint],
+ ignore_dependencies: bool,
+ upgrade_strategy: str,
+ user_requested: Dict[str, int],
+ ) -> None:
+ self._factory = factory
+ self._constraints = constraints
+ self._ignore_dependencies = ignore_dependencies
+ self._upgrade_strategy = upgrade_strategy
+ self._user_requested = user_requested
+ self._known_depths: Dict[str, float] = collections.defaultdict(lambda: math.inf)
+
+ def identify(self, requirement_or_candidate: Union[Requirement, Candidate]) -> str:
+ return requirement_or_candidate.name
+
+ def get_preference(
+ self,
+ identifier: str,
+ resolutions: Mapping[str, Candidate],
+ candidates: Mapping[str, Iterator[Candidate]],
+ information: Mapping[str, Iterable["PreferenceInformation"]],
+ backtrack_causes: Sequence["PreferenceInformation"],
+ ) -> "Preference":
+ """Produce a sort key for given requirement based on preference.
+
+ The lower the return value is, the more preferred this group of
+ arguments is.
+
+ Currently pip considers the following in order:
+
+ * Prefer if any of the known requirements is "direct", e.g. points to an
+ explicit URL.
+ * If equal, prefer if any requirement is "pinned", i.e. contains
+ operator ``===`` or ``==``.
+ * If equal, calculate an approximate "depth" and resolve requirements
+ closer to the user-specified requirements first. If the depth cannot
+ by determined (eg: due to no matching parents), it is considered
+ infinite.
+ * Order user-specified requirements by the order they are specified.
+ * If equal, prefers "non-free" requirements, i.e. contains at least one
+ operator, such as ``>=`` or ``<``.
+ * If equal, order alphabetically for consistency (helps debuggability).
+ """
+ try:
+ next(iter(information[identifier]))
+ except StopIteration:
+ # There is no information for this identifier, so there's no known
+ # candidates.
+ has_information = False
+ else:
+ has_information = True
+
+ if has_information:
+ lookups = (r.get_candidate_lookup() for r, _ in information[identifier])
+ candidate, ireqs = zip(*lookups)
+ else:
+ candidate, ireqs = None, ()
+
+ operators = [
+ specifier.operator
+ for specifier_set in (ireq.specifier for ireq in ireqs if ireq)
+ for specifier in specifier_set
+ ]
+
+ direct = candidate is not None
+ pinned = any(op[:2] == "==" for op in operators)
+ unfree = bool(operators)
+
+ try:
+ requested_order: Union[int, float] = self._user_requested[identifier]
+ except KeyError:
+ requested_order = math.inf
+ if has_information:
+ parent_depths = (
+ self._known_depths[parent.name] if parent is not None else 0.0
+ for _, parent in information[identifier]
+ )
+ inferred_depth = min(d for d in parent_depths) + 1.0
+ else:
+ inferred_depth = math.inf
+ else:
+ inferred_depth = 1.0
+ self._known_depths[identifier] = inferred_depth
+
+ requested_order = self._user_requested.get(identifier, math.inf)
+
+ # Requires-Python has only one candidate and the check is basically
+ # free, so we always do it first to avoid needless work if it fails.
+ requires_python = identifier == REQUIRES_PYTHON_IDENTIFIER
+
+ # Prefer the causes of backtracking on the assumption that the problem
+ # resolving the dependency tree is related to the failures that caused
+ # the backtracking
+ backtrack_cause = self.is_backtrack_cause(identifier, backtrack_causes)
+
+ return (
+ not requires_python,
+ not direct,
+ not pinned,
+ not backtrack_cause,
+ inferred_depth,
+ requested_order,
+ not unfree,
+ identifier,
+ )
+
+ def find_matches(
+ self,
+ identifier: str,
+ requirements: Mapping[str, Iterator[Requirement]],
+ incompatibilities: Mapping[str, Iterator[Candidate]],
+ ) -> Iterable[Candidate]:
+ def _eligible_for_upgrade(identifier: str) -> bool:
+ """Are upgrades allowed for this project?
+
+ This checks the upgrade strategy, and whether the project was one
+ that the user specified in the command line, in order to decide
+ whether we should upgrade if there's a newer version available.
+
+ (Note that we don't need access to the `--upgrade` flag, because
+ an upgrade strategy of "to-satisfy-only" means that `--upgrade`
+ was not specified).
+ """
+ if self._upgrade_strategy == "eager":
+ return True
+ elif self._upgrade_strategy == "only-if-needed":
+ user_order = _get_with_identifier(
+ self._user_requested,
+ identifier,
+ default=None,
+ )
+ return user_order is not None
+ return False
+
+ constraint = _get_with_identifier(
+ self._constraints,
+ identifier,
+ default=Constraint.empty(),
+ )
+ return self._factory.find_candidates(
+ identifier=identifier,
+ requirements=requirements,
+ constraint=constraint,
+ prefers_installed=(not _eligible_for_upgrade(identifier)),
+ incompatibilities=incompatibilities,
+ is_satisfied_by=self.is_satisfied_by,
+ )
+
+ @lru_cache(maxsize=None)
+ def is_satisfied_by(self, requirement: Requirement, candidate: Candidate) -> bool:
+ return requirement.is_satisfied_by(candidate)
+
+ def get_dependencies(self, candidate: Candidate) -> Sequence[Requirement]:
+ with_requires = not self._ignore_dependencies
+ return [r for r in candidate.iter_dependencies(with_requires) if r is not None]
+
+ @staticmethod
+ def is_backtrack_cause(
+ identifier: str, backtrack_causes: Sequence["PreferenceInformation"]
+ ) -> bool:
+ for backtrack_cause in backtrack_causes:
+ if identifier == backtrack_cause.requirement.name:
+ return True
+ if backtrack_cause.parent and identifier == backtrack_cause.parent.name:
+ return True
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/reporter.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/reporter.py
new file mode 100644
index 000000000..0594569d8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/reporter.py
@@ -0,0 +1,81 @@
+from collections import defaultdict
+from logging import getLogger
+from typing import Any, DefaultDict
+
+from pip._vendor.resolvelib.reporters import BaseReporter
+
+from .base import Candidate, Requirement
+
+logger = getLogger(__name__)
+
+
+class PipReporter(BaseReporter):
+ def __init__(self) -> None:
+ self.reject_count_by_package: DefaultDict[str, int] = defaultdict(int)
+
+ self._messages_at_reject_count = {
+ 1: (
+ "pip is looking at multiple versions of {package_name} to "
+ "determine which version is compatible with other "
+ "requirements. This could take a while."
+ ),
+ 8: (
+ "pip is still looking at multiple versions of {package_name} to "
+ "determine which version is compatible with other "
+ "requirements. This could take a while."
+ ),
+ 13: (
+ "This is taking longer than usual. You might need to provide "
+ "the dependency resolver with stricter constraints to reduce "
+ "runtime. See https://pip.pypa.io/warnings/backtracking for "
+ "guidance. If you want to abort this run, press Ctrl + C."
+ ),
+ }
+
+ def rejecting_candidate(self, criterion: Any, candidate: Candidate) -> None:
+ self.reject_count_by_package[candidate.name] += 1
+
+ count = self.reject_count_by_package[candidate.name]
+ if count not in self._messages_at_reject_count:
+ return
+
+ message = self._messages_at_reject_count[count]
+ logger.info("INFO: %s", message.format(package_name=candidate.name))
+
+ msg = "Will try a different candidate, due to conflict:"
+ for req_info in criterion.information:
+ req, parent = req_info.requirement, req_info.parent
+ # Inspired by Factory.get_installation_error
+ msg += "\n "
+ if parent:
+ msg += f"{parent.name} {parent.version} depends on "
+ else:
+ msg += "The user requested "
+ msg += req.format_for_error()
+ logger.debug(msg)
+
+
+class PipDebuggingReporter(BaseReporter):
+ """A reporter that does an info log for every event it sees."""
+
+ def starting(self) -> None:
+ logger.info("Reporter.starting()")
+
+ def starting_round(self, index: int) -> None:
+ logger.info("Reporter.starting_round(%r)", index)
+
+ def ending_round(self, index: int, state: Any) -> None:
+ logger.info("Reporter.ending_round(%r, state)", index)
+ logger.debug("Reporter.ending_round(%r, %r)", index, state)
+
+ def ending(self, state: Any) -> None:
+ logger.info("Reporter.ending(%r)", state)
+
+ def adding_requirement(self, requirement: Requirement, parent: Candidate) -> None:
+ logger.info("Reporter.adding_requirement(%r, %r)", requirement, parent)
+
+ def rejecting_candidate(self, criterion: Any, candidate: Candidate) -> None:
+ logger.info("Reporter.rejecting_candidate(%r, %r)", criterion, candidate)
+
+ def pinning(self, candidate: Candidate) -> None:
+ logger.info("Reporter.pinning(%r)", candidate)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/requirements.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/requirements.py
new file mode 100644
index 000000000..b04f41b21
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/requirements.py
@@ -0,0 +1,245 @@
+from typing import Any, Optional
+
+from pip._vendor.packaging.specifiers import SpecifierSet
+from pip._vendor.packaging.utils import NormalizedName, canonicalize_name
+
+from pip._internal.req.constructors import install_req_drop_extras
+from pip._internal.req.req_install import InstallRequirement
+
+from .base import Candidate, CandidateLookup, Requirement, format_name
+
+
+class ExplicitRequirement(Requirement):
+ def __init__(self, candidate: Candidate) -> None:
+ self.candidate = candidate
+
+ def __str__(self) -> str:
+ return str(self.candidate)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({self.candidate!r})"
+
+ def __hash__(self) -> int:
+ return hash(self.candidate)
+
+ def __eq__(self, other: Any) -> bool:
+ if not isinstance(other, ExplicitRequirement):
+ return False
+ return self.candidate == other.candidate
+
+ @property
+ def project_name(self) -> NormalizedName:
+ # No need to canonicalize - the candidate did this
+ return self.candidate.project_name
+
+ @property
+ def name(self) -> str:
+ # No need to canonicalize - the candidate did this
+ return self.candidate.name
+
+ def format_for_error(self) -> str:
+ return self.candidate.format_for_error()
+
+ def get_candidate_lookup(self) -> CandidateLookup:
+ return self.candidate, None
+
+ def is_satisfied_by(self, candidate: Candidate) -> bool:
+ return candidate == self.candidate
+
+
+class SpecifierRequirement(Requirement):
+ def __init__(self, ireq: InstallRequirement) -> None:
+ assert ireq.link is None, "This is a link, not a specifier"
+ self._ireq = ireq
+ self._equal_cache: Optional[str] = None
+ self._hash: Optional[int] = None
+ self._extras = frozenset(canonicalize_name(e) for e in self._ireq.extras)
+
+ @property
+ def _equal(self) -> str:
+ if self._equal_cache is not None:
+ return self._equal_cache
+
+ self._equal_cache = str(self._ireq)
+ return self._equal_cache
+
+ def __str__(self) -> str:
+ return str(self._ireq.req)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({str(self._ireq.req)!r})"
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, SpecifierRequirement):
+ return NotImplemented
+ return self._equal == other._equal
+
+ def __hash__(self) -> int:
+ if self._hash is not None:
+ return self._hash
+
+ self._hash = hash(self._equal)
+ return self._hash
+
+ @property
+ def project_name(self) -> NormalizedName:
+ assert self._ireq.req, "Specifier-backed ireq is always PEP 508"
+ return canonicalize_name(self._ireq.req.name)
+
+ @property
+ def name(self) -> str:
+ return format_name(self.project_name, self._extras)
+
+ def format_for_error(self) -> str:
+ # Convert comma-separated specifiers into "A, B, ..., F and G"
+ # This makes the specifier a bit more "human readable", without
+ # risking a change in meaning. (Hopefully! Not all edge cases have
+ # been checked)
+ parts = [s.strip() for s in str(self).split(",")]
+ if len(parts) == 0:
+ return ""
+ elif len(parts) == 1:
+ return parts[0]
+
+ return ", ".join(parts[:-1]) + " and " + parts[-1]
+
+ def get_candidate_lookup(self) -> CandidateLookup:
+ return None, self._ireq
+
+ def is_satisfied_by(self, candidate: Candidate) -> bool:
+ assert candidate.name == self.name, (
+ f"Internal issue: Candidate is not for this requirement "
+ f"{candidate.name} vs {self.name}"
+ )
+ # We can safely always allow prereleases here since PackageFinder
+ # already implements the prerelease logic, and would have filtered out
+ # prerelease candidates if the user does not expect them.
+ assert self._ireq.req, "Specifier-backed ireq is always PEP 508"
+ spec = self._ireq.req.specifier
+ return spec.contains(candidate.version, prereleases=True)
+
+
+class SpecifierWithoutExtrasRequirement(SpecifierRequirement):
+ """
+ Requirement backed by an install requirement on a base package.
+ Trims extras from its install requirement if there are any.
+ """
+
+ def __init__(self, ireq: InstallRequirement) -> None:
+ assert ireq.link is None, "This is a link, not a specifier"
+ self._ireq = install_req_drop_extras(ireq)
+ self._equal_cache: Optional[str] = None
+ self._hash: Optional[int] = None
+ self._extras = frozenset(canonicalize_name(e) for e in self._ireq.extras)
+
+ @property
+ def _equal(self) -> str:
+ if self._equal_cache is not None:
+ return self._equal_cache
+
+ self._equal_cache = str(self._ireq)
+ return self._equal_cache
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, SpecifierWithoutExtrasRequirement):
+ return NotImplemented
+ return self._equal == other._equal
+
+ def __hash__(self) -> int:
+ if self._hash is not None:
+ return self._hash
+
+ self._hash = hash(self._equal)
+ return self._hash
+
+
+class RequiresPythonRequirement(Requirement):
+ """A requirement representing Requires-Python metadata."""
+
+ def __init__(self, specifier: SpecifierSet, match: Candidate) -> None:
+ self.specifier = specifier
+ self._specifier_string = str(specifier) # for faster __eq__
+ self._hash: Optional[int] = None
+ self._candidate = match
+
+ def __str__(self) -> str:
+ return f"Python {self.specifier}"
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({str(self.specifier)!r})"
+
+ def __hash__(self) -> int:
+ if self._hash is not None:
+ return self._hash
+
+ self._hash = hash((self._specifier_string, self._candidate))
+ return self._hash
+
+ def __eq__(self, other: Any) -> bool:
+ if not isinstance(other, RequiresPythonRequirement):
+ return False
+ return (
+ self._specifier_string == other._specifier_string
+ and self._candidate == other._candidate
+ )
+
+ @property
+ def project_name(self) -> NormalizedName:
+ return self._candidate.project_name
+
+ @property
+ def name(self) -> str:
+ return self._candidate.name
+
+ def format_for_error(self) -> str:
+ return str(self)
+
+ def get_candidate_lookup(self) -> CandidateLookup:
+ if self.specifier.contains(self._candidate.version, prereleases=True):
+ return self._candidate, None
+ return None, None
+
+ def is_satisfied_by(self, candidate: Candidate) -> bool:
+ assert candidate.name == self._candidate.name, "Not Python candidate"
+ # We can safely always allow prereleases here since PackageFinder
+ # already implements the prerelease logic, and would have filtered out
+ # prerelease candidates if the user does not expect them.
+ return self.specifier.contains(candidate.version, prereleases=True)
+
+
+class UnsatisfiableRequirement(Requirement):
+ """A requirement that cannot be satisfied."""
+
+ def __init__(self, name: NormalizedName) -> None:
+ self._name = name
+
+ def __str__(self) -> str:
+ return f"{self._name} (unavailable)"
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({str(self._name)!r})"
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, UnsatisfiableRequirement):
+ return NotImplemented
+ return self._name == other._name
+
+ def __hash__(self) -> int:
+ return hash(self._name)
+
+ @property
+ def project_name(self) -> NormalizedName:
+ return self._name
+
+ @property
+ def name(self) -> str:
+ return self._name
+
+ def format_for_error(self) -> str:
+ return str(self)
+
+ def get_candidate_lookup(self) -> CandidateLookup:
+ return None, None
+
+ def is_satisfied_by(self, candidate: Candidate) -> bool:
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/resolver.py b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/resolver.py
new file mode 100644
index 000000000..c12beef0b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/resolution/resolvelib/resolver.py
@@ -0,0 +1,317 @@
+import contextlib
+import functools
+import logging
+import os
+from typing import TYPE_CHECKING, Dict, List, Optional, Set, Tuple, cast
+
+from pip._vendor.packaging.utils import canonicalize_name
+from pip._vendor.resolvelib import BaseReporter, ResolutionImpossible
+from pip._vendor.resolvelib import Resolver as RLResolver
+from pip._vendor.resolvelib.structs import DirectedGraph
+
+from pip._internal.cache import WheelCache
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.operations.prepare import RequirementPreparer
+from pip._internal.req.constructors import install_req_extend_extras
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.req.req_set import RequirementSet
+from pip._internal.resolution.base import BaseResolver, InstallRequirementProvider
+from pip._internal.resolution.resolvelib.provider import PipProvider
+from pip._internal.resolution.resolvelib.reporter import (
+ PipDebuggingReporter,
+ PipReporter,
+)
+from pip._internal.utils.packaging import get_requirement
+
+from .base import Candidate, Requirement
+from .factory import Factory
+
+if TYPE_CHECKING:
+ from pip._vendor.resolvelib.resolvers import Result as RLResult
+
+ Result = RLResult[Requirement, Candidate, str]
+
+
+logger = logging.getLogger(__name__)
+
+
+class Resolver(BaseResolver):
+ _allowed_strategies = {"eager", "only-if-needed", "to-satisfy-only"}
+
+ def __init__(
+ self,
+ preparer: RequirementPreparer,
+ finder: PackageFinder,
+ wheel_cache: Optional[WheelCache],
+ make_install_req: InstallRequirementProvider,
+ use_user_site: bool,
+ ignore_dependencies: bool,
+ ignore_installed: bool,
+ ignore_requires_python: bool,
+ force_reinstall: bool,
+ upgrade_strategy: str,
+ py_version_info: Optional[Tuple[int, ...]] = None,
+ ):
+ super().__init__()
+ assert upgrade_strategy in self._allowed_strategies
+
+ self.factory = Factory(
+ finder=finder,
+ preparer=preparer,
+ make_install_req=make_install_req,
+ wheel_cache=wheel_cache,
+ use_user_site=use_user_site,
+ force_reinstall=force_reinstall,
+ ignore_installed=ignore_installed,
+ ignore_requires_python=ignore_requires_python,
+ py_version_info=py_version_info,
+ )
+ self.ignore_dependencies = ignore_dependencies
+ self.upgrade_strategy = upgrade_strategy
+ self._result: Optional[Result] = None
+
+ def resolve(
+ self, root_reqs: List[InstallRequirement], check_supported_wheels: bool
+ ) -> RequirementSet:
+ collected = self.factory.collect_root_requirements(root_reqs)
+ provider = PipProvider(
+ factory=self.factory,
+ constraints=collected.constraints,
+ ignore_dependencies=self.ignore_dependencies,
+ upgrade_strategy=self.upgrade_strategy,
+ user_requested=collected.user_requested,
+ )
+ if "PIP_RESOLVER_DEBUG" in os.environ:
+ reporter: BaseReporter = PipDebuggingReporter()
+ else:
+ reporter = PipReporter()
+ resolver: RLResolver[Requirement, Candidate, str] = RLResolver(
+ provider,
+ reporter,
+ )
+
+ try:
+ limit_how_complex_resolution_can_be = 200000
+ result = self._result = resolver.resolve(
+ collected.requirements, max_rounds=limit_how_complex_resolution_can_be
+ )
+
+ except ResolutionImpossible as e:
+ error = self.factory.get_installation_error(
+ cast("ResolutionImpossible[Requirement, Candidate]", e),
+ collected.constraints,
+ )
+ raise error from e
+
+ req_set = RequirementSet(check_supported_wheels=check_supported_wheels)
+ # process candidates with extras last to ensure their base equivalent is
+ # already in the req_set if appropriate.
+ # Python's sort is stable so using a binary key function keeps relative order
+ # within both subsets.
+ for candidate in sorted(
+ result.mapping.values(), key=lambda c: c.name != c.project_name
+ ):
+ ireq = candidate.get_install_requirement()
+ if ireq is None:
+ if candidate.name != candidate.project_name:
+ # extend existing req's extras
+ with contextlib.suppress(KeyError):
+ req = req_set.get_requirement(candidate.project_name)
+ req_set.add_named_requirement(
+ install_req_extend_extras(
+ req, get_requirement(candidate.name).extras
+ )
+ )
+ continue
+
+ # Check if there is already an installation under the same name,
+ # and set a flag for later stages to uninstall it, if needed.
+ installed_dist = self.factory.get_dist_to_uninstall(candidate)
+ if installed_dist is None:
+ # There is no existing installation -- nothing to uninstall.
+ ireq.should_reinstall = False
+ elif self.factory.force_reinstall:
+ # The --force-reinstall flag is set -- reinstall.
+ ireq.should_reinstall = True
+ elif installed_dist.version != candidate.version:
+ # The installation is different in version -- reinstall.
+ ireq.should_reinstall = True
+ elif candidate.is_editable or installed_dist.editable:
+ # The incoming distribution is editable, or different in
+ # editable-ness to installation -- reinstall.
+ ireq.should_reinstall = True
+ elif candidate.source_link and candidate.source_link.is_file:
+ # The incoming distribution is under file://
+ if candidate.source_link.is_wheel:
+ # is a local wheel -- do nothing.
+ logger.info(
+ "%s is already installed with the same version as the "
+ "provided wheel. Use --force-reinstall to force an "
+ "installation of the wheel.",
+ ireq.name,
+ )
+ continue
+
+ # is a local sdist or path -- reinstall
+ ireq.should_reinstall = True
+ else:
+ continue
+
+ link = candidate.source_link
+ if link and link.is_yanked:
+ # The reason can contain non-ASCII characters, Unicode
+ # is required for Python 2.
+ msg = (
+ "The candidate selected for download or install is a "
+ "yanked version: {name!r} candidate (version {version} "
+ "at {link})\nReason for being yanked: {reason}"
+ ).format(
+ name=candidate.name,
+ version=candidate.version,
+ link=link,
+ reason=link.yanked_reason or "<none given>",
+ )
+ logger.warning(msg)
+
+ req_set.add_named_requirement(ireq)
+
+ reqs = req_set.all_requirements
+ self.factory.preparer.prepare_linked_requirements_more(reqs)
+ for req in reqs:
+ req.prepared = True
+ req.needs_more_preparation = False
+ return req_set
+
+ def get_installation_order(
+ self, req_set: RequirementSet
+ ) -> List[InstallRequirement]:
+ """Get order for installation of requirements in RequirementSet.
+
+ The returned list contains a requirement before another that depends on
+ it. This helps ensure that the environment is kept consistent as they
+ get installed one-by-one.
+
+ The current implementation creates a topological ordering of the
+ dependency graph, giving more weight to packages with less
+ or no dependencies, while breaking any cycles in the graph at
+ arbitrary points. We make no guarantees about where the cycle
+ would be broken, other than it *would* be broken.
+ """
+ assert self._result is not None, "must call resolve() first"
+
+ if not req_set.requirements:
+ # Nothing is left to install, so we do not need an order.
+ return []
+
+ graph = self._result.graph
+ weights = get_topological_weights(graph, set(req_set.requirements.keys()))
+
+ sorted_items = sorted(
+ req_set.requirements.items(),
+ key=functools.partial(_req_set_item_sorter, weights=weights),
+ reverse=True,
+ )
+ return [ireq for _, ireq in sorted_items]
+
+
+def get_topological_weights(
+ graph: "DirectedGraph[Optional[str]]", requirement_keys: Set[str]
+) -> Dict[Optional[str], int]:
+ """Assign weights to each node based on how "deep" they are.
+
+ This implementation may change at any point in the future without prior
+ notice.
+
+ We first simplify the dependency graph by pruning any leaves and giving them
+ the highest weight: a package without any dependencies should be installed
+ first. This is done again and again in the same way, giving ever less weight
+ to the newly found leaves. The loop stops when no leaves are left: all
+ remaining packages have at least one dependency left in the graph.
+
+ Then we continue with the remaining graph, by taking the length for the
+ longest path to any node from root, ignoring any paths that contain a single
+ node twice (i.e. cycles). This is done through a depth-first search through
+ the graph, while keeping track of the path to the node.
+
+ Cycles in the graph result would result in node being revisited while also
+ being on its own path. In this case, take no action. This helps ensure we
+ don't get stuck in a cycle.
+
+ When assigning weight, the longer path (i.e. larger length) is preferred.
+
+ We are only interested in the weights of packages that are in the
+ requirement_keys.
+ """
+ path: Set[Optional[str]] = set()
+ weights: Dict[Optional[str], int] = {}
+
+ def visit(node: Optional[str]) -> None:
+ if node in path:
+ # We hit a cycle, so we'll break it here.
+ return
+
+ # Time to visit the children!
+ path.add(node)
+ for child in graph.iter_children(node):
+ visit(child)
+ path.remove(node)
+
+ if node not in requirement_keys:
+ return
+
+ last_known_parent_count = weights.get(node, 0)
+ weights[node] = max(last_known_parent_count, len(path))
+
+ # Simplify the graph, pruning leaves that have no dependencies.
+ # This is needed for large graphs (say over 200 packages) because the
+ # `visit` function is exponentially slower then, taking minutes.
+ # See https://github.com/pypa/pip/issues/10557
+ # We will loop until we explicitly break the loop.
+ while True:
+ leaves = set()
+ for key in graph:
+ if key is None:
+ continue
+ for _child in graph.iter_children(key):
+ # This means we have at least one child
+ break
+ else:
+ # No child.
+ leaves.add(key)
+ if not leaves:
+ # We are done simplifying.
+ break
+ # Calculate the weight for the leaves.
+ weight = len(graph) - 1
+ for leaf in leaves:
+ if leaf not in requirement_keys:
+ continue
+ weights[leaf] = weight
+ # Remove the leaves from the graph, making it simpler.
+ for leaf in leaves:
+ graph.remove(leaf)
+
+ # Visit the remaining graph.
+ # `None` is guaranteed to be the root node by resolvelib.
+ visit(None)
+
+ # Sanity check: all requirement keys should be in the weights,
+ # and no other keys should be in the weights.
+ difference = set(weights.keys()).difference(requirement_keys)
+ assert not difference, difference
+
+ return weights
+
+
+def _req_set_item_sorter(
+ item: Tuple[str, InstallRequirement],
+ weights: Dict[Optional[str], int],
+) -> Tuple[int, str]:
+ """Key function used to sort install requirements for installation.
+
+ Based on the "weight" mapping calculated in ``get_installation_order()``.
+ The canonical package name is returned as the second member as a tie-
+ breaker to ensure the result is predictable, which is useful in tests.
+ """
+ name = canonicalize_name(item[0])
+ return weights[name], name
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/self_outdated_check.py b/solutions/.venv/Lib/site-packages/pip/_internal/self_outdated_check.py
new file mode 100644
index 000000000..f9a91af9d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/self_outdated_check.py
@@ -0,0 +1,244 @@
+import datetime
+import functools
+import hashlib
+import json
+import logging
+import optparse
+import os.path
+import sys
+from dataclasses import dataclass
+from typing import Any, Callable, Dict, Optional
+
+from pip._vendor.packaging.version import Version
+from pip._vendor.packaging.version import parse as parse_version
+from pip._vendor.rich.console import Group
+from pip._vendor.rich.markup import escape
+from pip._vendor.rich.text import Text
+
+from pip._internal.index.collector import LinkCollector
+from pip._internal.index.package_finder import PackageFinder
+from pip._internal.metadata import get_default_environment
+from pip._internal.models.selection_prefs import SelectionPreferences
+from pip._internal.network.session import PipSession
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.entrypoints import (
+ get_best_invocation_for_this_pip,
+ get_best_invocation_for_this_python,
+)
+from pip._internal.utils.filesystem import adjacent_tmp_file, check_path_owner, replace
+from pip._internal.utils.misc import ensure_dir
+
+_WEEK = datetime.timedelta(days=7)
+
+logger = logging.getLogger(__name__)
+
+
+def _get_statefile_name(key: str) -> str:
+ key_bytes = key.encode()
+ name = hashlib.sha224(key_bytes).hexdigest()
+ return name
+
+
+def _convert_date(isodate: str) -> datetime.datetime:
+ """Convert an ISO format string to a date.
+
+ Handles the format 2020-01-22T14:24:01Z (trailing Z)
+ which is not supported by older versions of fromisoformat.
+ """
+ return datetime.datetime.fromisoformat(isodate.replace("Z", "+00:00"))
+
+
+class SelfCheckState:
+ def __init__(self, cache_dir: str) -> None:
+ self._state: Dict[str, Any] = {}
+ self._statefile_path = None
+
+ # Try to load the existing state
+ if cache_dir:
+ self._statefile_path = os.path.join(
+ cache_dir, "selfcheck", _get_statefile_name(self.key)
+ )
+ try:
+ with open(self._statefile_path, encoding="utf-8") as statefile:
+ self._state = json.load(statefile)
+ except (OSError, ValueError, KeyError):
+ # Explicitly suppressing exceptions, since we don't want to
+ # error out if the cache file is invalid.
+ pass
+
+ @property
+ def key(self) -> str:
+ return sys.prefix
+
+ def get(self, current_time: datetime.datetime) -> Optional[str]:
+ """Check if we have a not-outdated version loaded already."""
+ if not self._state:
+ return None
+
+ if "last_check" not in self._state:
+ return None
+
+ if "pypi_version" not in self._state:
+ return None
+
+ # Determine if we need to refresh the state
+ last_check = _convert_date(self._state["last_check"])
+ time_since_last_check = current_time - last_check
+ if time_since_last_check > _WEEK:
+ return None
+
+ return self._state["pypi_version"]
+
+ def set(self, pypi_version: str, current_time: datetime.datetime) -> None:
+ # If we do not have a path to cache in, don't bother saving.
+ if not self._statefile_path:
+ return
+
+ # Check to make sure that we own the directory
+ if not check_path_owner(os.path.dirname(self._statefile_path)):
+ return
+
+ # Now that we've ensured the directory is owned by this user, we'll go
+ # ahead and make sure that all our directories are created.
+ ensure_dir(os.path.dirname(self._statefile_path))
+
+ state = {
+ # Include the key so it's easy to tell which pip wrote the
+ # file.
+ "key": self.key,
+ "last_check": current_time.isoformat(),
+ "pypi_version": pypi_version,
+ }
+
+ text = json.dumps(state, sort_keys=True, separators=(",", ":"))
+
+ with adjacent_tmp_file(self._statefile_path) as f:
+ f.write(text.encode())
+
+ try:
+ # Since we have a prefix-specific state file, we can just
+ # overwrite whatever is there, no need to check.
+ replace(f.name, self._statefile_path)
+ except OSError:
+ # Best effort.
+ pass
+
+
+@dataclass
+class UpgradePrompt:
+ old: str
+ new: str
+
+ def __rich__(self) -> Group:
+ if WINDOWS:
+ pip_cmd = f"{get_best_invocation_for_this_python()} -m pip"
+ else:
+ pip_cmd = get_best_invocation_for_this_pip()
+
+ notice = "[bold][[reset][blue]notice[reset][bold]][reset]"
+ return Group(
+ Text(),
+ Text.from_markup(
+ f"{notice} A new release of pip is available: "
+ f"[red]{self.old}[reset] -> [green]{self.new}[reset]"
+ ),
+ Text.from_markup(
+ f"{notice} To update, run: "
+ f"[green]{escape(pip_cmd)} install --upgrade pip"
+ ),
+ )
+
+
+def was_installed_by_pip(pkg: str) -> bool:
+ """Checks whether pkg was installed by pip
+
+ This is used not to display the upgrade message when pip is in fact
+ installed by system package manager, such as dnf on Fedora.
+ """
+ dist = get_default_environment().get_distribution(pkg)
+ return dist is not None and "pip" == dist.installer
+
+
+def _get_current_remote_pip_version(
+ session: PipSession, options: optparse.Values
+) -> Optional[str]:
+ # Lets use PackageFinder to see what the latest pip version is
+ link_collector = LinkCollector.create(
+ session,
+ options=options,
+ suppress_no_index=True,
+ )
+
+ # Pass allow_yanked=False so we don't suggest upgrading to a
+ # yanked version.
+ selection_prefs = SelectionPreferences(
+ allow_yanked=False,
+ allow_all_prereleases=False, # Explicitly set to False
+ )
+
+ finder = PackageFinder.create(
+ link_collector=link_collector,
+ selection_prefs=selection_prefs,
+ )
+ best_candidate = finder.find_best_candidate("pip").best_candidate
+ if best_candidate is None:
+ return None
+
+ return str(best_candidate.version)
+
+
+def _self_version_check_logic(
+ *,
+ state: SelfCheckState,
+ current_time: datetime.datetime,
+ local_version: Version,
+ get_remote_version: Callable[[], Optional[str]],
+) -> Optional[UpgradePrompt]:
+ remote_version_str = state.get(current_time)
+ if remote_version_str is None:
+ remote_version_str = get_remote_version()
+ if remote_version_str is None:
+ logger.debug("No remote pip version found")
+ return None
+ state.set(remote_version_str, current_time)
+
+ remote_version = parse_version(remote_version_str)
+ logger.debug("Remote version of pip: %s", remote_version)
+ logger.debug("Local version of pip: %s", local_version)
+
+ pip_installed_by_pip = was_installed_by_pip("pip")
+ logger.debug("Was pip installed by pip? %s", pip_installed_by_pip)
+ if not pip_installed_by_pip:
+ return None # Only suggest upgrade if pip is installed by pip.
+
+ local_version_is_older = (
+ local_version < remote_version
+ and local_version.base_version != remote_version.base_version
+ )
+ if local_version_is_older:
+ return UpgradePrompt(old=str(local_version), new=remote_version_str)
+
+ return None
+
+
+def pip_self_version_check(session: PipSession, options: optparse.Values) -> None:
+ """Check for an update for pip.
+
+ Limit the frequency of checks to once per week. State is stored either in
+ the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix
+ of the pip script path.
+ """
+ installed_dist = get_default_environment().get_distribution("pip")
+ if not installed_dist:
+ return
+
+ upgrade_prompt = _self_version_check_logic(
+ state=SelfCheckState(cache_dir=options.cache_dir),
+ current_time=datetime.datetime.now(datetime.timezone.utc),
+ local_version=installed_dist.version,
+ get_remote_version=functools.partial(
+ _get_current_remote_pip_version, session, options
+ ),
+ )
+ if upgrade_prompt is not None:
+ logger.warning("%s", upgrade_prompt, extra={"rich": True})
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/_jaraco_text.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/_jaraco_text.py
new file mode 100644
index 000000000..6ccf53b7a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/_jaraco_text.py
@@ -0,0 +1,109 @@
+"""Functions brought over from jaraco.text.
+
+These functions are not supposed to be used within `pip._internal`. These are
+helper functions brought over from `jaraco.text` to enable vendoring newer
+copies of `pkg_resources` without having to vendor `jaraco.text` and its entire
+dependency cone; something that our vendoring setup is not currently capable of
+handling.
+
+License reproduced from original source below:
+
+Copyright Jason R. Coombs
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to
+deal in the Software without restriction, including without limitation the
+rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
+sell copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
+FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
+IN THE SOFTWARE.
+"""
+
+import functools
+import itertools
+
+
+def _nonblank(str):
+ return str and not str.startswith("#")
+
+
+@functools.singledispatch
+def yield_lines(iterable):
+ r"""
+ Yield valid lines of a string or iterable.
+
+ >>> list(yield_lines(''))
+ []
+ >>> list(yield_lines(['foo', 'bar']))
+ ['foo', 'bar']
+ >>> list(yield_lines('foo\nbar'))
+ ['foo', 'bar']
+ >>> list(yield_lines('\nfoo\n#bar\nbaz #comment'))
+ ['foo', 'baz #comment']
+ >>> list(yield_lines(['foo\nbar', 'baz', 'bing\n\n\n']))
+ ['foo', 'bar', 'baz', 'bing']
+ """
+ return itertools.chain.from_iterable(map(yield_lines, iterable))
+
+
+@yield_lines.register(str)
+def _(text):
+ return filter(_nonblank, map(str.strip, text.splitlines()))
+
+
+def drop_comment(line):
+ """
+ Drop comments.
+
+ >>> drop_comment('foo # bar')
+ 'foo'
+
+ A hash without a space may be in a URL.
+
+ >>> drop_comment('http://example.com/foo#bar')
+ 'http://example.com/foo#bar'
+ """
+ return line.partition(" #")[0]
+
+
+def join_continuation(lines):
+ r"""
+ Join lines continued by a trailing backslash.
+
+ >>> list(join_continuation(['foo \\', 'bar', 'baz']))
+ ['foobar', 'baz']
+ >>> list(join_continuation(['foo \\', 'bar', 'baz']))
+ ['foobar', 'baz']
+ >>> list(join_continuation(['foo \\', 'bar \\', 'baz']))
+ ['foobarbaz']
+
+ Not sure why, but...
+ The character preceding the backslash is also elided.
+
+ >>> list(join_continuation(['goo\\', 'dly']))
+ ['godly']
+
+ A terrible idea, but...
+ If no line is available to continue, suppress the lines.
+
+ >>> list(join_continuation(['foo', 'bar\\', 'baz\\']))
+ ['foo']
+ """
+ lines = iter(lines)
+ for item in lines:
+ while item.endswith("\\"):
+ try:
+ item = item[:-2].strip() + next(lines)
+ except StopIteration:
+ return
+ yield item
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/_log.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/_log.py
new file mode 100644
index 000000000..92c4c6a19
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/_log.py
@@ -0,0 +1,38 @@
+"""Customize logging
+
+Defines custom logger class for the `logger.verbose(...)` method.
+
+init_logging() must be called before any other modules that call logging.getLogger.
+"""
+
+import logging
+from typing import Any, cast
+
+# custom log level for `--verbose` output
+# between DEBUG and INFO
+VERBOSE = 15
+
+
+class VerboseLogger(logging.Logger):
+ """Custom Logger, defining a verbose log-level
+
+ VERBOSE is between INFO and DEBUG.
+ """
+
+ def verbose(self, msg: str, *args: Any, **kwargs: Any) -> None:
+ return self.log(VERBOSE, msg, *args, **kwargs)
+
+
+def getLogger(name: str) -> VerboseLogger:
+ """logging.getLogger, but ensures our VerboseLogger class is returned"""
+ return cast(VerboseLogger, logging.getLogger(name))
+
+
+def init_logging() -> None:
+ """Register our VerboseLogger and VERBOSE log level.
+
+ Should be called before any calls to getLogger(),
+ i.e. in pip._internal.__init__
+ """
+ logging.setLoggerClass(VerboseLogger)
+ logging.addLevelName(VERBOSE, "VERBOSE")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/appdirs.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/appdirs.py
new file mode 100644
index 000000000..16933bf8a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/appdirs.py
@@ -0,0 +1,52 @@
+"""
+This code wraps the vendored appdirs module to so the return values are
+compatible for the current pip code base.
+
+The intention is to rewrite current usages gradually, keeping the tests pass,
+and eventually drop this after all usages are changed.
+"""
+
+import os
+import sys
+from typing import List
+
+from pip._vendor import platformdirs as _appdirs
+
+
+def user_cache_dir(appname: str) -> str:
+ return _appdirs.user_cache_dir(appname, appauthor=False)
+
+
+def _macos_user_config_dir(appname: str, roaming: bool = True) -> str:
+ # Use ~/Application Support/pip, if the directory exists.
+ path = _appdirs.user_data_dir(appname, appauthor=False, roaming=roaming)
+ if os.path.isdir(path):
+ return path
+
+ # Use a Linux-like ~/.config/pip, by default.
+ linux_like_path = "~/.config/"
+ if appname:
+ linux_like_path = os.path.join(linux_like_path, appname)
+
+ return os.path.expanduser(linux_like_path)
+
+
+def user_config_dir(appname: str, roaming: bool = True) -> str:
+ if sys.platform == "darwin":
+ return _macos_user_config_dir(appname, roaming)
+
+ return _appdirs.user_config_dir(appname, appauthor=False, roaming=roaming)
+
+
+# for the discussion regarding site_config_dir locations
+# see <https://github.com/pypa/pip/issues/1733>
+def site_config_dirs(appname: str) -> List[str]:
+ if sys.platform == "darwin":
+ return [_appdirs.site_data_dir(appname, appauthor=False, multipath=True)]
+
+ dirval = _appdirs.site_config_dir(appname, appauthor=False, multipath=True)
+ if sys.platform == "win32":
+ return [dirval]
+
+ # Unix-y system. Look in /etc as well.
+ return dirval.split(os.pathsep) + ["/etc"]
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/compat.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/compat.py
new file mode 100644
index 000000000..d8b54e4ee
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/compat.py
@@ -0,0 +1,79 @@
+"""Stuff that differs in different Python versions and platform
+distributions."""
+
+import importlib.resources
+import logging
+import os
+import sys
+from typing import IO
+
+__all__ = ["get_path_uid", "stdlib_pkgs", "WINDOWS"]
+
+
+logger = logging.getLogger(__name__)
+
+
+def has_tls() -> bool:
+ try:
+ import _ssl # noqa: F401 # ignore unused
+
+ return True
+ except ImportError:
+ pass
+
+ from pip._vendor.urllib3.util import IS_PYOPENSSL
+
+ return IS_PYOPENSSL
+
+
+def get_path_uid(path: str) -> int:
+ """
+ Return path's uid.
+
+ Does not follow symlinks:
+ https://github.com/pypa/pip/pull/935#discussion_r5307003
+
+ Placed this function in compat due to differences on AIX and
+ Jython, that should eventually go away.
+
+ :raises OSError: When path is a symlink or can't be read.
+ """
+ if hasattr(os, "O_NOFOLLOW"):
+ fd = os.open(path, os.O_RDONLY | os.O_NOFOLLOW)
+ file_uid = os.fstat(fd).st_uid
+ os.close(fd)
+ else: # AIX and Jython
+ # WARNING: time of check vulnerability, but best we can do w/o NOFOLLOW
+ if not os.path.islink(path):
+ # older versions of Jython don't have `os.fstat`
+ file_uid = os.stat(path).st_uid
+ else:
+ # raise OSError for parity with os.O_NOFOLLOW above
+ raise OSError(f"{path} is a symlink; Will not return uid for symlinks")
+ return file_uid
+
+
+# The importlib.resources.open_text function was deprecated in 3.11 with suggested
+# replacement we use below.
+if sys.version_info < (3, 11):
+ open_text_resource = importlib.resources.open_text
+else:
+
+ def open_text_resource(
+ package: str, resource: str, encoding: str = "utf-8", errors: str = "strict"
+ ) -> IO[str]:
+ return (importlib.resources.files(package) / resource).open(
+ "r", encoding=encoding, errors=errors
+ )
+
+
+# packages in the stdlib that may have installation metadata, but should not be
+# considered 'installed'. this theoretically could be determined based on
+# dist.location (py27:`sysconfig.get_paths()['stdlib']`,
+# py26:sysconfig.get_config_vars('LIBDEST')), but fear platform variation may
+# make this ineffective, so hard-coding
+stdlib_pkgs = {"python", "wsgiref", "argparse"}
+
+
+# windows detection, covers cpython and ironpython
+WINDOWS = sys.platform.startswith("win") or (sys.platform == "cli" and os.name == "nt")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/compatibility_tags.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/compatibility_tags.py
new file mode 100644
index 000000000..2e7b7450d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/compatibility_tags.py
@@ -0,0 +1,188 @@
+"""Generate and work with PEP 425 Compatibility Tags.
+"""
+
+import re
+from typing import List, Optional, Tuple
+
+from pip._vendor.packaging.tags import (
+ PythonVersion,
+ Tag,
+ compatible_tags,
+ cpython_tags,
+ generic_tags,
+ interpreter_name,
+ interpreter_version,
+ ios_platforms,
+ mac_platforms,
+)
+
+_apple_arch_pat = re.compile(r"(.+)_(\d+)_(\d+)_(.+)")
+
+
+def version_info_to_nodot(version_info: Tuple[int, ...]) -> str:
+ # Only use up to the first two numbers.
+ return "".join(map(str, version_info[:2]))
+
+
+def _mac_platforms(arch: str) -> List[str]:
+ match = _apple_arch_pat.match(arch)
+ if match:
+ name, major, minor, actual_arch = match.groups()
+ mac_version = (int(major), int(minor))
+ arches = [
+ # Since we have always only checked that the platform starts
+ # with "macosx", for backwards-compatibility we extract the
+ # actual prefix provided by the user in case they provided
+ # something like "macosxcustom_". It may be good to remove
+ # this as undocumented or deprecate it in the future.
+ "{}_{}".format(name, arch[len("macosx_") :])
+ for arch in mac_platforms(mac_version, actual_arch)
+ ]
+ else:
+ # arch pattern didn't match (?!)
+ arches = [arch]
+ return arches
+
+
+def _ios_platforms(arch: str) -> List[str]:
+ match = _apple_arch_pat.match(arch)
+ if match:
+ name, major, minor, actual_multiarch = match.groups()
+ ios_version = (int(major), int(minor))
+ arches = [
+ # Since we have always only checked that the platform starts
+ # with "ios", for backwards-compatibility we extract the
+ # actual prefix provided by the user in case they provided
+ # something like "ioscustom_". It may be good to remove
+ # this as undocumented or deprecate it in the future.
+ "{}_{}".format(name, arch[len("ios_") :])
+ for arch in ios_platforms(ios_version, actual_multiarch)
+ ]
+ else:
+ # arch pattern didn't match (?!)
+ arches = [arch]
+ return arches
+
+
+def _custom_manylinux_platforms(arch: str) -> List[str]:
+ arches = [arch]
+ arch_prefix, arch_sep, arch_suffix = arch.partition("_")
+ if arch_prefix == "manylinux2014":
+ # manylinux1/manylinux2010 wheels run on most manylinux2014 systems
+ # with the exception of wheels depending on ncurses. PEP 599 states
+ # manylinux1/manylinux2010 wheels should be considered
+ # manylinux2014 wheels:
+ # https://www.python.org/dev/peps/pep-0599/#backwards-compatibility-with-manylinux2010-wheels
+ if arch_suffix in {"i686", "x86_64"}:
+ arches.append("manylinux2010" + arch_sep + arch_suffix)
+ arches.append("manylinux1" + arch_sep + arch_suffix)
+ elif arch_prefix == "manylinux2010":
+ # manylinux1 wheels run on most manylinux2010 systems with the
+ # exception of wheels depending on ncurses. PEP 571 states
+ # manylinux1 wheels should be considered manylinux2010 wheels:
+ # https://www.python.org/dev/peps/pep-0571/#backwards-compatibility-with-manylinux1-wheels
+ arches.append("manylinux1" + arch_sep + arch_suffix)
+ return arches
+
+
+def _get_custom_platforms(arch: str) -> List[str]:
+ arch_prefix, arch_sep, arch_suffix = arch.partition("_")
+ if arch.startswith("macosx"):
+ arches = _mac_platforms(arch)
+ elif arch.startswith("ios"):
+ arches = _ios_platforms(arch)
+ elif arch_prefix in ["manylinux2014", "manylinux2010"]:
+ arches = _custom_manylinux_platforms(arch)
+ else:
+ arches = [arch]
+ return arches
+
+
+def _expand_allowed_platforms(platforms: Optional[List[str]]) -> Optional[List[str]]:
+ if not platforms:
+ return None
+
+ seen = set()
+ result = []
+
+ for p in platforms:
+ if p in seen:
+ continue
+ additions = [c for c in _get_custom_platforms(p) if c not in seen]
+ seen.update(additions)
+ result.extend(additions)
+
+ return result
+
+
+def _get_python_version(version: str) -> PythonVersion:
+ if len(version) > 1:
+ return int(version[0]), int(version[1:])
+ else:
+ return (int(version[0]),)
+
+
+def _get_custom_interpreter(
+ implementation: Optional[str] = None, version: Optional[str] = None
+) -> str:
+ if implementation is None:
+ implementation = interpreter_name()
+ if version is None:
+ version = interpreter_version()
+ return f"{implementation}{version}"
+
+
+def get_supported(
+ version: Optional[str] = None,
+ platforms: Optional[List[str]] = None,
+ impl: Optional[str] = None,
+ abis: Optional[List[str]] = None,
+) -> List[Tag]:
+ """Return a list of supported tags for each version specified in
+ `versions`.
+
+ :param version: a string version, of the form "33" or "32",
+ or None. The version will be assumed to support our ABI.
+ :param platform: specify a list of platforms you want valid
+ tags for, or None. If None, use the local system platform.
+ :param impl: specify the exact implementation you want valid
+ tags for, or None. If None, use the local interpreter impl.
+ :param abis: specify a list of abis you want valid
+ tags for, or None. If None, use the local interpreter abi.
+ """
+ supported: List[Tag] = []
+
+ python_version: Optional[PythonVersion] = None
+ if version is not None:
+ python_version = _get_python_version(version)
+
+ interpreter = _get_custom_interpreter(impl, version)
+
+ platforms = _expand_allowed_platforms(platforms)
+
+ is_cpython = (impl or interpreter_name()) == "cp"
+ if is_cpython:
+ supported.extend(
+ cpython_tags(
+ python_version=python_version,
+ abis=abis,
+ platforms=platforms,
+ )
+ )
+ else:
+ supported.extend(
+ generic_tags(
+ interpreter=interpreter,
+ abis=abis,
+ platforms=platforms,
+ )
+ )
+ supported.extend(
+ compatible_tags(
+ python_version=python_version,
+ interpreter=interpreter,
+ platforms=platforms,
+ )
+ )
+
+ return supported
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/datetime.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/datetime.py
new file mode 100644
index 000000000..8668b3b0e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/datetime.py
@@ -0,0 +1,11 @@
+"""For when pip wants to check the date or time.
+"""
+
+import datetime
+
+
+def today_is_later_than(year: int, month: int, day: int) -> bool:
+ today = datetime.date.today()
+ given = datetime.date(year, month, day)
+
+ return today > given
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/deprecation.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/deprecation.py
new file mode 100644
index 000000000..0911147e7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/deprecation.py
@@ -0,0 +1,124 @@
+"""
+A module that implements tooling to enable easy warnings about deprecations.
+"""
+
+import logging
+import warnings
+from typing import Any, Optional, TextIO, Type, Union
+
+from pip._vendor.packaging.version import parse
+
+from pip import __version__ as current_version # NOTE: tests patch this name.
+
+DEPRECATION_MSG_PREFIX = "DEPRECATION: "
+
+
+class PipDeprecationWarning(Warning):
+ pass
+
+
+_original_showwarning: Any = None
+
+
+# Warnings <-> Logging Integration
+def _showwarning(
+ message: Union[Warning, str],
+ category: Type[Warning],
+ filename: str,
+ lineno: int,
+ file: Optional[TextIO] = None,
+ line: Optional[str] = None,
+) -> None:
+ if file is not None:
+ if _original_showwarning is not None:
+ _original_showwarning(message, category, filename, lineno, file, line)
+ elif issubclass(category, PipDeprecationWarning):
+ # We use a specially named logger which will handle all of the
+ # deprecation messages for pip.
+ logger = logging.getLogger("pip._internal.deprecations")
+ logger.warning(message)
+ else:
+ _original_showwarning(message, category, filename, lineno, file, line)
+
+
+def install_warning_logger() -> None:
+ # Enable our Deprecation Warnings
+ warnings.simplefilter("default", PipDeprecationWarning, append=True)
+
+ global _original_showwarning
+
+ if _original_showwarning is None:
+ _original_showwarning = warnings.showwarning
+ warnings.showwarning = _showwarning
+
+
+def deprecated(
+ *,
+ reason: str,
+ replacement: Optional[str],
+ gone_in: Optional[str],
+ feature_flag: Optional[str] = None,
+ issue: Optional[int] = None,
+) -> None:
+ """Helper to deprecate existing functionality.
+
+ reason:
+ Textual reason shown to the user about why this functionality has
+ been deprecated. Should be a complete sentence.
+ replacement:
+ Textual suggestion shown to the user about what alternative
+ functionality they can use.
+ gone_in:
+ The version of pip does this functionality should get removed in.
+ Raises an error if pip's current version is greater than or equal to
+ this.
+ feature_flag:
+ Command-line flag of the form --use-feature={feature_flag} for testing
+ upcoming functionality.
+ issue:
+ Issue number on the tracker that would serve as a useful place for
+ users to find related discussion and provide feedback.
+ """
+
+ # Determine whether or not the feature is already gone in this version.
+ is_gone = gone_in is not None and parse(current_version) >= parse(gone_in)
+
+ message_parts = [
+ (reason, f"{DEPRECATION_MSG_PREFIX}{{}}"),
+ (
+ gone_in,
+ (
+ "pip {} will enforce this behaviour change."
+ if not is_gone
+ else "Since pip {}, this is no longer supported."
+ ),
+ ),
+ (
+ replacement,
+ "A possible replacement is {}.",
+ ),
+ (
+ feature_flag,
+ (
+ "You can use the flag --use-feature={} to test the upcoming behaviour."
+ if not is_gone
+ else None
+ ),
+ ),
+ (
+ issue,
+ "Discussion can be found at https://github.com/pypa/pip/issues/{}",
+ ),
+ ]
+
+ message = " ".join(
+ format_str.format(value)
+ for value, format_str in message_parts
+ if format_str is not None and value is not None
+ )
+
+ # Raise as an error if this behaviour is deprecated.
+ if is_gone:
+ raise PipDeprecationWarning(message)
+
+ warnings.warn(message, category=PipDeprecationWarning, stacklevel=2)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/direct_url_helpers.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/direct_url_helpers.py
new file mode 100644
index 000000000..66020d396
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/direct_url_helpers.py
@@ -0,0 +1,87 @@
+from typing import Optional
+
+from pip._internal.models.direct_url import ArchiveInfo, DirectUrl, DirInfo, VcsInfo
+from pip._internal.models.link import Link
+from pip._internal.utils.urls import path_to_url
+from pip._internal.vcs import vcs
+
+
+def direct_url_as_pep440_direct_reference(direct_url: DirectUrl, name: str) -> str:
+ """Convert a DirectUrl to a pip requirement string."""
+ direct_url.validate() # if invalid, this is a pip bug
+ requirement = name + " @ "
+ fragments = []
+ if isinstance(direct_url.info, VcsInfo):
+ requirement += (
+ f"{direct_url.info.vcs}+{direct_url.url}@{direct_url.info.commit_id}"
+ )
+ elif isinstance(direct_url.info, ArchiveInfo):
+ requirement += direct_url.url
+ if direct_url.info.hash:
+ fragments.append(direct_url.info.hash)
+ else:
+ assert isinstance(direct_url.info, DirInfo)
+ requirement += direct_url.url
+ if direct_url.subdirectory:
+ fragments.append("subdirectory=" + direct_url.subdirectory)
+ if fragments:
+ requirement += "#" + "&".join(fragments)
+ return requirement
+
+
+def direct_url_for_editable(source_dir: str) -> DirectUrl:
+ return DirectUrl(
+ url=path_to_url(source_dir),
+ info=DirInfo(editable=True),
+ )
+
+
+def direct_url_from_link(
+ link: Link, source_dir: Optional[str] = None, link_is_in_wheel_cache: bool = False
+) -> DirectUrl:
+ if link.is_vcs:
+ vcs_backend = vcs.get_backend_for_scheme(link.scheme)
+ assert vcs_backend
+ url, requested_revision, _ = vcs_backend.get_url_rev_and_auth(
+ link.url_without_fragment
+ )
+ # For VCS links, we need to find out and add commit_id.
+ if link_is_in_wheel_cache:
+ # If the requested VCS link corresponds to a cached
+ # wheel, it means the requested revision was an
+ # immutable commit hash, otherwise it would not have
+ # been cached. In that case we don't have a source_dir
+ # with the VCS checkout.
+ assert requested_revision
+ commit_id = requested_revision
+ else:
+ # If the wheel was not in cache, it means we have
+ # had to checkout from VCS to build and we have a source_dir
+ # which we can inspect to find out the commit id.
+ assert source_dir
+ commit_id = vcs_backend.get_revision(source_dir)
+ return DirectUrl(
+ url=url,
+ info=VcsInfo(
+ vcs=vcs_backend.name,
+ commit_id=commit_id,
+ requested_revision=requested_revision,
+ ),
+ subdirectory=link.subdirectory_fragment,
+ )
+ elif link.is_existing_dir():
+ return DirectUrl(
+ url=link.url_without_fragment,
+ info=DirInfo(),
+ subdirectory=link.subdirectory_fragment,
+ )
+ else:
+ hash = None
+ hash_name = link.hash_name
+ if hash_name:
+ hash = f"{hash_name}={link.hash}"
+ return DirectUrl(
+ url=link.url_without_fragment,
+ info=ArchiveInfo(hash=hash),
+ subdirectory=link.subdirectory_fragment,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/egg_link.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/egg_link.py
new file mode 100644
index 000000000..4a384a636
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/egg_link.py
@@ -0,0 +1,80 @@
+import os
+import re
+import sys
+from typing import List, Optional
+
+from pip._internal.locations import site_packages, user_site
+from pip._internal.utils.virtualenv import (
+ running_under_virtualenv,
+ virtualenv_no_global,
+)
+
+__all__ = [
+ "egg_link_path_from_sys_path",
+ "egg_link_path_from_location",
+]
+
+
+def _egg_link_names(raw_name: str) -> List[str]:
+ """
+ Convert a Name metadata value to a .egg-link name, by applying
+ the same substitution as pkg_resources's safe_name function.
+ Note: we cannot use canonicalize_name because it has a different logic.
+
+ We also look for the raw name (without normalization) as setuptools 69 changed
+ the way it names .egg-link files (https://github.com/pypa/setuptools/issues/4167).
+ """
+ return [
+ re.sub("[^A-Za-z0-9.]+", "-", raw_name) + ".egg-link",
+ f"{raw_name}.egg-link",
+ ]
+
+
+def egg_link_path_from_sys_path(raw_name: str) -> Optional[str]:
+ """
+ Look for a .egg-link file for project name, by walking sys.path.
+ """
+ egg_link_names = _egg_link_names(raw_name)
+ for path_item in sys.path:
+ for egg_link_name in egg_link_names:
+ egg_link = os.path.join(path_item, egg_link_name)
+ if os.path.isfile(egg_link):
+ return egg_link
+ return None
+
+
+def egg_link_path_from_location(raw_name: str) -> Optional[str]:
+ """
+ Return the path for the .egg-link file if it exists, otherwise, None.
+
+ There's 3 scenarios:
+ 1) not in a virtualenv
+ try to find in site.USER_SITE, then site_packages
+ 2) in a no-global virtualenv
+ try to find in site_packages
+ 3) in a yes-global virtualenv
+ try to find in site_packages, then site.USER_SITE
+ (don't look in global location)
+
+ For #1 and #3, there could be odd cases, where there's an egg-link in 2
+ locations.
+
+ This method will just return the first one found.
+ """
+ sites: List[str] = []
+ if running_under_virtualenv():
+ sites.append(site_packages)
+ if not virtualenv_no_global() and user_site:
+ sites.append(user_site)
+ else:
+ if user_site:
+ sites.append(user_site)
+ sites.append(site_packages)
+
+ egg_link_names = _egg_link_names(raw_name)
+ for site in sites:
+ for egg_link_name in egg_link_names:
+ egglink = os.path.join(site, egg_link_name)
+ if os.path.isfile(egglink):
+ return egglink
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/encoding.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/encoding.py
new file mode 100644
index 000000000..008f06a79
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/encoding.py
@@ -0,0 +1,36 @@
+import codecs
+import locale
+import re
+import sys
+from typing import List, Tuple
+
+BOMS: List[Tuple[bytes, str]] = [
+ (codecs.BOM_UTF8, "utf-8"),
+ (codecs.BOM_UTF16, "utf-16"),
+ (codecs.BOM_UTF16_BE, "utf-16-be"),
+ (codecs.BOM_UTF16_LE, "utf-16-le"),
+ (codecs.BOM_UTF32, "utf-32"),
+ (codecs.BOM_UTF32_BE, "utf-32-be"),
+ (codecs.BOM_UTF32_LE, "utf-32-le"),
+]
+
+ENCODING_RE = re.compile(rb"coding[:=]\s*([-\w.]+)")
+
+
+def auto_decode(data: bytes) -> str:
+ """Check a bytes string for a BOM to correctly detect the encoding
+
+ Fallback to locale.getpreferredencoding(False) like open() on Python3"""
+ for bom, encoding in BOMS:
+ if data.startswith(bom):
+ return data[len(bom) :].decode(encoding)
+ # Lets check the first two lines as in PEP263
+ for line in data.split(b"\n")[:2]:
+ if line[0:1] == b"#" and ENCODING_RE.search(line):
+ result = ENCODING_RE.search(line)
+ assert result is not None
+ encoding = result.groups()[0].decode("ascii")
+ return data.decode(encoding)
+ return data.decode(
+ locale.getpreferredencoding(False) or sys.getdefaultencoding(),
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/entrypoints.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/entrypoints.py
new file mode 100644
index 000000000..150136938
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/entrypoints.py
@@ -0,0 +1,84 @@
+import itertools
+import os
+import shutil
+import sys
+from typing import List, Optional
+
+from pip._internal.cli.main import main
+from pip._internal.utils.compat import WINDOWS
+
+_EXECUTABLE_NAMES = [
+ "pip",
+ f"pip{sys.version_info.major}",
+ f"pip{sys.version_info.major}.{sys.version_info.minor}",
+]
+if WINDOWS:
+ _allowed_extensions = {"", ".exe"}
+ _EXECUTABLE_NAMES = [
+ "".join(parts)
+ for parts in itertools.product(_EXECUTABLE_NAMES, _allowed_extensions)
+ ]
+
+
+def _wrapper(args: Optional[List[str]] = None) -> int:
+ """Central wrapper for all old entrypoints.
+
+ Historically pip has had several entrypoints defined. Because of issues
+ arising from PATH, sys.path, multiple Pythons, their interactions, and most
+ of them having a pip installed, users suffer every time an entrypoint gets
+ moved.
+
+ To alleviate this pain, and provide a mechanism for warning users and
+ directing them to an appropriate place for help, we now define all of
+ our old entrypoints as wrappers for the current one.
+ """
+ sys.stderr.write(
+ "WARNING: pip is being invoked by an old script wrapper. This will "
+ "fail in a future version of pip.\n"
+ "Please see https://github.com/pypa/pip/issues/5599 for advice on "
+ "fixing the underlying issue.\n"
+ "To avoid this problem you can invoke Python with '-m pip' instead of "
+ "running pip directly.\n"
+ )
+ return main(args)
+
+
+def get_best_invocation_for_this_pip() -> str:
+ """Try to figure out the best way to invoke pip in the current environment."""
+ binary_directory = "Scripts" if WINDOWS else "bin"
+ binary_prefix = os.path.join(sys.prefix, binary_directory)
+
+ # Try to use pip[X[.Y]] names, if those executables for this environment are
+ # the first on PATH with that name.
+ path_parts = os.path.normcase(os.environ.get("PATH", "")).split(os.pathsep)
+ exe_are_in_PATH = os.path.normcase(binary_prefix) in path_parts
+ if exe_are_in_PATH:
+ for exe_name in _EXECUTABLE_NAMES:
+ found_executable = shutil.which(exe_name)
+ binary_executable = os.path.join(binary_prefix, exe_name)
+ if (
+ found_executable
+ and os.path.exists(binary_executable)
+ and os.path.samefile(
+ found_executable,
+ binary_executable,
+ )
+ ):
+ return exe_name
+
+ # Use the `-m` invocation, if there's no "nice" invocation.
+ return f"{get_best_invocation_for_this_python()} -m pip"
+
+
+def get_best_invocation_for_this_python() -> str:
+ """Try to figure out the best way to invoke the current Python."""
+ exe = sys.executable
+ exe_name = os.path.basename(exe)
+
+ # Try to use the basename, if it's the first executable.
+ found_executable = shutil.which(exe_name)
+ if found_executable and os.path.samefile(found_executable, exe):
+ return exe_name
+
+ # Use the full executable name, because we couldn't find something simpler.
+ return exe
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/filesystem.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/filesystem.py
new file mode 100644
index 000000000..22e356cdd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/filesystem.py
@@ -0,0 +1,149 @@
+import fnmatch
+import os
+import os.path
+import random
+import sys
+from contextlib import contextmanager
+from tempfile import NamedTemporaryFile
+from typing import Any, BinaryIO, Generator, List, Union, cast
+
+from pip._internal.utils.compat import get_path_uid
+from pip._internal.utils.misc import format_size
+from pip._internal.utils.retry import retry
+
+
+def check_path_owner(path: str) -> bool:
+ # If we don't have a way to check the effective uid of this process, then
+ # we'll just assume that we own the directory.
+ if sys.platform == "win32" or not hasattr(os, "geteuid"):
+ return True
+
+ assert os.path.isabs(path)
+
+ previous = None
+ while path != previous:
+ if os.path.lexists(path):
+ # Check if path is writable by current user.
+ if os.geteuid() == 0:
+ # Special handling for root user in order to handle properly
+ # cases where users use sudo without -H flag.
+ try:
+ path_uid = get_path_uid(path)
+ except OSError:
+ return False
+ return path_uid == 0
+ else:
+ return os.access(path, os.W_OK)
+ else:
+ previous, path = path, os.path.dirname(path)
+ return False # assume we don't own the path
+
+
+@contextmanager
+def adjacent_tmp_file(path: str, **kwargs: Any) -> Generator[BinaryIO, None, None]:
+ """Return a file-like object pointing to a tmp file next to path.
+
+ The file is created securely and is ensured to be written to disk
+ after the context reaches its end.
+
+ kwargs will be passed to tempfile.NamedTemporaryFile to control
+ the way the temporary file will be opened.
+ """
+ with NamedTemporaryFile(
+ delete=False,
+ dir=os.path.dirname(path),
+ prefix=os.path.basename(path),
+ suffix=".tmp",
+ **kwargs,
+ ) as f:
+ result = cast(BinaryIO, f)
+ try:
+ yield result
+ finally:
+ result.flush()
+ os.fsync(result.fileno())
+
+
+replace = retry(stop_after_delay=1, wait=0.25)(os.replace)
+
+
+# test_writable_dir and _test_writable_dir_win are copied from Flit,
+# with the author's agreement to also place them under pip's license.
+def test_writable_dir(path: str) -> bool:
+ """Check if a directory is writable.
+
+ Uses os.access() on POSIX, tries creating files on Windows.
+ """
+ # If the directory doesn't exist, find the closest parent that does.
+ while not os.path.isdir(path):
+ parent = os.path.dirname(path)
+ if parent == path:
+ break # Should never get here, but infinite loops are bad
+ path = parent
+
+ if os.name == "posix":
+ return os.access(path, os.W_OK)
+
+ return _test_writable_dir_win(path)
+
+
+def _test_writable_dir_win(path: str) -> bool:
+ # os.access doesn't work on Windows: http://bugs.python.org/issue2528
+ # and we can't use tempfile: http://bugs.python.org/issue22107
+ basename = "accesstest_deleteme_fishfingers_custard_"
+ alphabet = "abcdefghijklmnopqrstuvwxyz0123456789"
+ for _ in range(10):
+ name = basename + "".join(random.choice(alphabet) for _ in range(6))
+ file = os.path.join(path, name)
+ try:
+ fd = os.open(file, os.O_RDWR | os.O_CREAT | os.O_EXCL)
+ except FileExistsError:
+ pass
+ except PermissionError:
+ # This could be because there's a directory with the same name.
+ # But it's highly unlikely there's a directory called that,
+ # so we'll assume it's because the parent dir is not writable.
+ # This could as well be because the parent dir is not readable,
+ # due to non-privileged user access.
+ return False
+ else:
+ os.close(fd)
+ os.unlink(file)
+ return True
+
+ # This should never be reached
+ raise OSError("Unexpected condition testing for writable directory")
+
+
+def find_files(path: str, pattern: str) -> List[str]:
+ """Returns a list of absolute paths of files beneath path, recursively,
+ with filenames which match the UNIX-style shell glob pattern."""
+ result: List[str] = []
+ for root, _, files in os.walk(path):
+ matches = fnmatch.filter(files, pattern)
+ result.extend(os.path.join(root, f) for f in matches)
+ return result
+
+
+def file_size(path: str) -> Union[int, float]:
+ # If it's a symlink, return 0.
+ if os.path.islink(path):
+ return 0
+ return os.path.getsize(path)
+
+
+def format_file_size(path: str) -> str:
+ return format_size(file_size(path))
+
+
+def directory_size(path: str) -> Union[int, float]:
+ size = 0.0
+ for root, _dirs, files in os.walk(path):
+ for filename in files:
+ file_path = os.path.join(root, filename)
+ size += file_size(file_path)
+ return size
+
+
+def format_directory_size(path: str) -> str:
+ return format_size(directory_size(path))
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/filetypes.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/filetypes.py
new file mode 100644
index 000000000..594857017
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/filetypes.py
@@ -0,0 +1,27 @@
+"""Filetype information.
+"""
+
+from typing import Tuple
+
+from pip._internal.utils.misc import splitext
+
+WHEEL_EXTENSION = ".whl"
+BZ2_EXTENSIONS: Tuple[str, ...] = (".tar.bz2", ".tbz")
+XZ_EXTENSIONS: Tuple[str, ...] = (
+ ".tar.xz",
+ ".txz",
+ ".tlz",
+ ".tar.lz",
+ ".tar.lzma",
+)
+ZIP_EXTENSIONS: Tuple[str, ...] = (".zip", WHEEL_EXTENSION)
+TAR_EXTENSIONS: Tuple[str, ...] = (".tar.gz", ".tgz", ".tar")
+ARCHIVE_EXTENSIONS = ZIP_EXTENSIONS + BZ2_EXTENSIONS + TAR_EXTENSIONS + XZ_EXTENSIONS
+
+
+def is_archive_file(name: str) -> bool:
+ """Return True if `name` is a considered as an archive file."""
+ ext = splitext(name)[1].lower()
+ if ext in ARCHIVE_EXTENSIONS:
+ return True
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/glibc.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/glibc.py
new file mode 100644
index 000000000..998868ff2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/glibc.py
@@ -0,0 +1,101 @@
+import os
+import sys
+from typing import Optional, Tuple
+
+
+def glibc_version_string() -> Optional[str]:
+ "Returns glibc version string, or None if not using glibc."
+ return glibc_version_string_confstr() or glibc_version_string_ctypes()
+
+
+def glibc_version_string_confstr() -> Optional[str]:
+ "Primary implementation of glibc_version_string using os.confstr."
+ # os.confstr is quite a bit faster than ctypes.DLL. It's also less likely
+ # to be broken or missing. This strategy is used in the standard library
+ # platform module:
+ # https://github.com/python/cpython/blob/fcf1d003bf4f0100c9d0921ff3d70e1127ca1b71/Lib/platform.py#L175-L183
+ if sys.platform == "win32":
+ return None
+ try:
+ gnu_libc_version = os.confstr("CS_GNU_LIBC_VERSION")
+ if gnu_libc_version is None:
+ return None
+ # os.confstr("CS_GNU_LIBC_VERSION") returns a string like "glibc 2.17":
+ _, version = gnu_libc_version.split()
+ except (AttributeError, OSError, ValueError):
+ # os.confstr() or CS_GNU_LIBC_VERSION not available (or a bad value)...
+ return None
+ return version
+
+
+def glibc_version_string_ctypes() -> Optional[str]:
+ "Fallback implementation of glibc_version_string using ctypes."
+
+ try:
+ import ctypes
+ except ImportError:
+ return None
+
+ # ctypes.CDLL(None) internally calls dlopen(NULL), and as the dlopen
+ # manpage says, "If filename is NULL, then the returned handle is for the
+ # main program". This way we can let the linker do the work to figure out
+ # which libc our process is actually using.
+ #
+ # We must also handle the special case where the executable is not a
+ # dynamically linked executable. This can occur when using musl libc,
+ # for example. In this situation, dlopen() will error, leading to an
+ # OSError. Interestingly, at least in the case of musl, there is no
+ # errno set on the OSError. The single string argument used to construct
+ # OSError comes from libc itself and is therefore not portable to
+ # hard code here. In any case, failure to call dlopen() means we
+ # can't proceed, so we bail on our attempt.
+ try:
+ process_namespace = ctypes.CDLL(None)
+ except OSError:
+ return None
+
+ try:
+ gnu_get_libc_version = process_namespace.gnu_get_libc_version
+ except AttributeError:
+ # Symbol doesn't exist -> therefore, we are not linked to
+ # glibc.
+ return None
+
+ # Call gnu_get_libc_version, which returns a string like "2.5"
+ gnu_get_libc_version.restype = ctypes.c_char_p
+ version_str: str = gnu_get_libc_version()
+ # py2 / py3 compatibility:
+ if not isinstance(version_str, str):
+ version_str = version_str.decode("ascii")
+
+ return version_str
+
+
+# platform.libc_ver regularly returns completely nonsensical glibc
+# versions. E.g. on my computer, platform says:
+#
+# ~$ python2.7 -c 'import platform; print(platform.libc_ver())'
+# ('glibc', '2.7')
+# ~$ python3.5 -c 'import platform; print(platform.libc_ver())'
+# ('glibc', '2.9')
+#
+# But the truth is:
+#
+# ~$ ldd --version
+# ldd (Debian GLIBC 2.22-11) 2.22
+#
+# This is unfortunate, because it means that the linehaul data on libc
+# versions that was generated by pip 8.1.2 and earlier is useless and
+# misleading. Solution: instead of using platform, use our code that actually
+# works.
+def libc_ver() -> Tuple[str, str]:
+ """Try to determine the glibc version
+
+ Returns a tuple of strings (lib, version) which default to empty strings
+ in case the lookup fails.
+ """
+ glibc_version = glibc_version_string()
+ if glibc_version is None:
+ return ("", "")
+ else:
+ return ("glibc", glibc_version)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/hashes.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/hashes.py
new file mode 100644
index 000000000..535e94fca
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/hashes.py
@@ -0,0 +1,147 @@
+import hashlib
+from typing import TYPE_CHECKING, BinaryIO, Dict, Iterable, List, NoReturn, Optional
+
+from pip._internal.exceptions import HashMismatch, HashMissing, InstallationError
+from pip._internal.utils.misc import read_chunks
+
+if TYPE_CHECKING:
+ from hashlib import _Hash
+
+
+# The recommended hash algo of the moment. Change this whenever the state of
+# the art changes; it won't hurt backward compatibility.
+FAVORITE_HASH = "sha256"
+
+
+# Names of hashlib algorithms allowed by the --hash option and ``pip hash``
+# Currently, those are the ones at least as collision-resistant as sha256.
+STRONG_HASHES = ["sha256", "sha384", "sha512"]
+
+
+class Hashes:
+ """A wrapper that builds multiple hashes at once and checks them against
+ known-good values
+
+ """
+
+ def __init__(self, hashes: Optional[Dict[str, List[str]]] = None) -> None:
+ """
+ :param hashes: A dict of algorithm names pointing to lists of allowed
+ hex digests
+ """
+ allowed = {}
+ if hashes is not None:
+ for alg, keys in hashes.items():
+ # Make sure values are always sorted (to ease equality checks)
+ allowed[alg] = [k.lower() for k in sorted(keys)]
+ self._allowed = allowed
+
+ def __and__(self, other: "Hashes") -> "Hashes":
+ if not isinstance(other, Hashes):
+ return NotImplemented
+
+ # If either of the Hashes object is entirely empty (i.e. no hash
+ # specified at all), all hashes from the other object are allowed.
+ if not other:
+ return self
+ if not self:
+ return other
+
+ # Otherwise only hashes that present in both objects are allowed.
+ new = {}
+ for alg, values in other._allowed.items():
+ if alg not in self._allowed:
+ continue
+ new[alg] = [v for v in values if v in self._allowed[alg]]
+ return Hashes(new)
+
+ @property
+ def digest_count(self) -> int:
+ return sum(len(digests) for digests in self._allowed.values())
+
+ def is_hash_allowed(self, hash_name: str, hex_digest: str) -> bool:
+ """Return whether the given hex digest is allowed."""
+ return hex_digest in self._allowed.get(hash_name, [])
+
+ def check_against_chunks(self, chunks: Iterable[bytes]) -> None:
+ """Check good hashes against ones built from iterable of chunks of
+ data.
+
+ Raise HashMismatch if none match.
+
+ """
+ gots = {}
+ for hash_name in self._allowed.keys():
+ try:
+ gots[hash_name] = hashlib.new(hash_name)
+ except (ValueError, TypeError):
+ raise InstallationError(f"Unknown hash name: {hash_name}")
+
+ for chunk in chunks:
+ for hash in gots.values():
+ hash.update(chunk)
+
+ for hash_name, got in gots.items():
+ if got.hexdigest() in self._allowed[hash_name]:
+ return
+ self._raise(gots)
+
+ def _raise(self, gots: Dict[str, "_Hash"]) -> "NoReturn":
+ raise HashMismatch(self._allowed, gots)
+
+ def check_against_file(self, file: BinaryIO) -> None:
+ """Check good hashes against a file-like object
+
+ Raise HashMismatch if none match.
+
+ """
+ return self.check_against_chunks(read_chunks(file))
+
+ def check_against_path(self, path: str) -> None:
+ with open(path, "rb") as file:
+ return self.check_against_file(file)
+
+ def has_one_of(self, hashes: Dict[str, str]) -> bool:
+ """Return whether any of the given hashes are allowed."""
+ for hash_name, hex_digest in hashes.items():
+ if self.is_hash_allowed(hash_name, hex_digest):
+ return True
+ return False
+
+ def __bool__(self) -> bool:
+ """Return whether I know any known-good hashes."""
+ return bool(self._allowed)
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, Hashes):
+ return NotImplemented
+ return self._allowed == other._allowed
+
+ def __hash__(self) -> int:
+ return hash(
+ ",".join(
+ sorted(
+ ":".join((alg, digest))
+ for alg, digest_list in self._allowed.items()
+ for digest in digest_list
+ )
+ )
+ )
+
+
+class MissingHashes(Hashes):
+ """A workalike for Hashes used when we're missing a hash for a requirement
+
+ It computes the actual hash of the requirement and raises a HashMissing
+ exception showing it to the user.
+
+ """
+
+ def __init__(self) -> None:
+ """Don't offer the ``hashes`` kwarg."""
+ # Pass our favorite hash in to generate a "gotten hash". With the
+ # empty list, it will never match, so an error will always raise.
+ super().__init__(hashes={FAVORITE_HASH: []})
+
+ def _raise(self, gots: Dict[str, "_Hash"]) -> "NoReturn":
+ raise HashMissing(gots[FAVORITE_HASH].hexdigest())
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/logging.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/logging.py
new file mode 100644
index 000000000..41f6eb51a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/logging.py
@@ -0,0 +1,347 @@
+import contextlib
+import errno
+import logging
+import logging.handlers
+import os
+import sys
+import threading
+from dataclasses import dataclass
+from io import TextIOWrapper
+from logging import Filter
+from typing import Any, ClassVar, Generator, List, Optional, TextIO, Type
+
+from pip._vendor.rich.console import (
+ Console,
+ ConsoleOptions,
+ ConsoleRenderable,
+ RenderableType,
+ RenderResult,
+ RichCast,
+)
+from pip._vendor.rich.highlighter import NullHighlighter
+from pip._vendor.rich.logging import RichHandler
+from pip._vendor.rich.segment import Segment
+from pip._vendor.rich.style import Style
+
+from pip._internal.utils._log import VERBOSE, getLogger
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.deprecation import DEPRECATION_MSG_PREFIX
+from pip._internal.utils.misc import ensure_dir
+
+_log_state = threading.local()
+subprocess_logger = getLogger("pip.subprocessor")
+
+
+class BrokenStdoutLoggingError(Exception):
+ """
+ Raised if BrokenPipeError occurs for the stdout stream while logging.
+ """
+
+
+def _is_broken_pipe_error(exc_class: Type[BaseException], exc: BaseException) -> bool:
+ if exc_class is BrokenPipeError:
+ return True
+
+ # On Windows, a broken pipe can show up as EINVAL rather than EPIPE:
+ # https://bugs.python.org/issue19612
+ # https://bugs.python.org/issue30418
+ if not WINDOWS:
+ return False
+
+ return isinstance(exc, OSError) and exc.errno in (errno.EINVAL, errno.EPIPE)
+
+
+@contextlib.contextmanager
+def indent_log(num: int = 2) -> Generator[None, None, None]:
+ """
+ A context manager which will cause the log output to be indented for any
+ log messages emitted inside it.
+ """
+ # For thread-safety
+ _log_state.indentation = get_indentation()
+ _log_state.indentation += num
+ try:
+ yield
+ finally:
+ _log_state.indentation -= num
+
+
+def get_indentation() -> int:
+ return getattr(_log_state, "indentation", 0)
+
+
+class IndentingFormatter(logging.Formatter):
+ default_time_format = "%Y-%m-%dT%H:%M:%S"
+
+ def __init__(
+ self,
+ *args: Any,
+ add_timestamp: bool = False,
+ **kwargs: Any,
+ ) -> None:
+ """
+ A logging.Formatter that obeys the indent_log() context manager.
+
+ :param add_timestamp: A bool indicating output lines should be prefixed
+ with their record's timestamp.
+ """
+ self.add_timestamp = add_timestamp
+ super().__init__(*args, **kwargs)
+
+ def get_message_start(self, formatted: str, levelno: int) -> str:
+ """
+ Return the start of the formatted log message (not counting the
+ prefix to add to each line).
+ """
+ if levelno < logging.WARNING:
+ return ""
+ if formatted.startswith(DEPRECATION_MSG_PREFIX):
+ # Then the message already has a prefix. We don't want it to
+ # look like "WARNING: DEPRECATION: ...."
+ return ""
+ if levelno < logging.ERROR:
+ return "WARNING: "
+
+ return "ERROR: "
+
+ def format(self, record: logging.LogRecord) -> str:
+ """
+ Calls the standard formatter, but will indent all of the log message
+ lines by our current indentation level.
+ """
+ formatted = super().format(record)
+ message_start = self.get_message_start(formatted, record.levelno)
+ formatted = message_start + formatted
+
+ prefix = ""
+ if self.add_timestamp:
+ prefix = f"{self.formatTime(record)} "
+ prefix += " " * get_indentation()
+ formatted = "".join([prefix + line for line in formatted.splitlines(True)])
+ return formatted
+
+
+@dataclass
+class IndentedRenderable:
+ renderable: RenderableType
+ indent: int
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ segments = console.render(self.renderable, options)
+ lines = Segment.split_lines(segments)
+ for line in lines:
+ yield Segment(" " * self.indent)
+ yield from line
+ yield Segment("\n")
+
+
+class RichPipStreamHandler(RichHandler):
+ KEYWORDS: ClassVar[Optional[List[str]]] = []
+
+ def __init__(self, stream: Optional[TextIO], no_color: bool) -> None:
+ super().__init__(
+ console=Console(file=stream, no_color=no_color, soft_wrap=True),
+ show_time=False,
+ show_level=False,
+ show_path=False,
+ highlighter=NullHighlighter(),
+ )
+
+ # Our custom override on Rich's logger, to make things work as we need them to.
+ def emit(self, record: logging.LogRecord) -> None:
+ style: Optional[Style] = None
+
+ # If we are given a diagnostic error to present, present it with indentation.
+ if getattr(record, "rich", False):
+ assert isinstance(record.args, tuple)
+ (rich_renderable,) = record.args
+ assert isinstance(
+ rich_renderable, (ConsoleRenderable, RichCast, str)
+ ), f"{rich_renderable} is not rich-console-renderable"
+
+ renderable: RenderableType = IndentedRenderable(
+ rich_renderable, indent=get_indentation()
+ )
+ else:
+ message = self.format(record)
+ renderable = self.render_message(record, message)
+ if record.levelno is not None:
+ if record.levelno >= logging.ERROR:
+ style = Style(color="red")
+ elif record.levelno >= logging.WARNING:
+ style = Style(color="yellow")
+
+ try:
+ self.console.print(renderable, overflow="ignore", crop=False, style=style)
+ except Exception:
+ self.handleError(record)
+
+ def handleError(self, record: logging.LogRecord) -> None:
+ """Called when logging is unable to log some output."""
+
+ exc_class, exc = sys.exc_info()[:2]
+ # If a broken pipe occurred while calling write() or flush() on the
+ # stdout stream in logging's Handler.emit(), then raise our special
+ # exception so we can handle it in main() instead of logging the
+ # broken pipe error and continuing.
+ if (
+ exc_class
+ and exc
+ and self.console.file is sys.stdout
+ and _is_broken_pipe_error(exc_class, exc)
+ ):
+ raise BrokenStdoutLoggingError()
+
+ return super().handleError(record)
+
+
+class BetterRotatingFileHandler(logging.handlers.RotatingFileHandler):
+ def _open(self) -> TextIOWrapper:
+ ensure_dir(os.path.dirname(self.baseFilename))
+ return super()._open()
+
+
+class MaxLevelFilter(Filter):
+ def __init__(self, level: int) -> None:
+ self.level = level
+
+ def filter(self, record: logging.LogRecord) -> bool:
+ return record.levelno < self.level
+
+
+class ExcludeLoggerFilter(Filter):
+ """
+ A logging Filter that excludes records from a logger (or its children).
+ """
+
+ def filter(self, record: logging.LogRecord) -> bool:
+ # The base Filter class allows only records from a logger (or its
+ # children).
+ return not super().filter(record)
+
+
+def setup_logging(verbosity: int, no_color: bool, user_log_file: Optional[str]) -> int:
+ """Configures and sets up all of the logging
+
+ Returns the requested logging level, as its integer value.
+ """
+
+ # Determine the level to be logging at.
+ if verbosity >= 2:
+ level_number = logging.DEBUG
+ elif verbosity == 1:
+ level_number = VERBOSE
+ elif verbosity == -1:
+ level_number = logging.WARNING
+ elif verbosity == -2:
+ level_number = logging.ERROR
+ elif verbosity <= -3:
+ level_number = logging.CRITICAL
+ else:
+ level_number = logging.INFO
+
+ level = logging.getLevelName(level_number)
+
+ # The "root" logger should match the "console" level *unless* we also need
+ # to log to a user log file.
+ include_user_log = user_log_file is not None
+ if include_user_log:
+ additional_log_file = user_log_file
+ root_level = "DEBUG"
+ else:
+ additional_log_file = "/dev/null"
+ root_level = level
+
+ # Disable any logging besides WARNING unless we have DEBUG level logging
+ # enabled for vendored libraries.
+ vendored_log_level = "WARNING" if level in ["INFO", "ERROR"] else "DEBUG"
+
+ # Shorthands for clarity
+ log_streams = {
+ "stdout": "ext://sys.stdout",
+ "stderr": "ext://sys.stderr",
+ }
+ handler_classes = {
+ "stream": "pip._internal.utils.logging.RichPipStreamHandler",
+ "file": "pip._internal.utils.logging.BetterRotatingFileHandler",
+ }
+ handlers = ["console", "console_errors", "console_subprocess"] + (
+ ["user_log"] if include_user_log else []
+ )
+
+ logging.config.dictConfig(
+ {
+ "version": 1,
+ "disable_existing_loggers": False,
+ "filters": {
+ "exclude_warnings": {
+ "()": "pip._internal.utils.logging.MaxLevelFilter",
+ "level": logging.WARNING,
+ },
+ "restrict_to_subprocess": {
+ "()": "logging.Filter",
+ "name": subprocess_logger.name,
+ },
+ "exclude_subprocess": {
+ "()": "pip._internal.utils.logging.ExcludeLoggerFilter",
+ "name": subprocess_logger.name,
+ },
+ },
+ "formatters": {
+ "indent": {
+ "()": IndentingFormatter,
+ "format": "%(message)s",
+ },
+ "indent_with_timestamp": {
+ "()": IndentingFormatter,
+ "format": "%(message)s",
+ "add_timestamp": True,
+ },
+ },
+ "handlers": {
+ "console": {
+ "level": level,
+ "class": handler_classes["stream"],
+ "no_color": no_color,
+ "stream": log_streams["stdout"],
+ "filters": ["exclude_subprocess", "exclude_warnings"],
+ "formatter": "indent",
+ },
+ "console_errors": {
+ "level": "WARNING",
+ "class": handler_classes["stream"],
+ "no_color": no_color,
+ "stream": log_streams["stderr"],
+ "filters": ["exclude_subprocess"],
+ "formatter": "indent",
+ },
+ # A handler responsible for logging to the console messages
+ # from the "subprocessor" logger.
+ "console_subprocess": {
+ "level": level,
+ "class": handler_classes["stream"],
+ "stream": log_streams["stderr"],
+ "no_color": no_color,
+ "filters": ["restrict_to_subprocess"],
+ "formatter": "indent",
+ },
+ "user_log": {
+ "level": "DEBUG",
+ "class": handler_classes["file"],
+ "filename": additional_log_file,
+ "encoding": "utf-8",
+ "delay": True,
+ "formatter": "indent_with_timestamp",
+ },
+ },
+ "root": {
+ "level": root_level,
+ "handlers": handlers,
+ },
+ "loggers": {"pip._vendor": {"level": vendored_log_level}},
+ }
+ )
+
+ return level_number
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/misc.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/misc.py
new file mode 100644
index 000000000..c0a3e4d3b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/misc.py
@@ -0,0 +1,772 @@
+import errno
+import getpass
+import hashlib
+import logging
+import os
+import posixpath
+import shutil
+import stat
+import sys
+import sysconfig
+import urllib.parse
+from dataclasses import dataclass
+from functools import partial
+from io import StringIO
+from itertools import filterfalse, tee, zip_longest
+from pathlib import Path
+from types import FunctionType, TracebackType
+from typing import (
+ Any,
+ BinaryIO,
+ Callable,
+ Dict,
+ Generator,
+ Iterable,
+ Iterator,
+ List,
+ Optional,
+ TextIO,
+ Tuple,
+ Type,
+ TypeVar,
+ Union,
+ cast,
+)
+
+from pip._vendor.packaging.requirements import Requirement
+from pip._vendor.pyproject_hooks import BuildBackendHookCaller
+
+from pip import __version__
+from pip._internal.exceptions import CommandError, ExternallyManagedEnvironment
+from pip._internal.locations import get_major_minor_version
+from pip._internal.utils.compat import WINDOWS
+from pip._internal.utils.retry import retry
+from pip._internal.utils.virtualenv import running_under_virtualenv
+
+__all__ = [
+ "rmtree",
+ "display_path",
+ "backup_dir",
+ "ask",
+ "splitext",
+ "format_size",
+ "is_installable_dir",
+ "normalize_path",
+ "renames",
+ "get_prog",
+ "ensure_dir",
+ "remove_auth_from_url",
+ "check_externally_managed",
+ "ConfiguredBuildBackendHookCaller",
+]
+
+logger = logging.getLogger(__name__)
+
+T = TypeVar("T")
+ExcInfo = Tuple[Type[BaseException], BaseException, TracebackType]
+VersionInfo = Tuple[int, int, int]
+NetlocTuple = Tuple[str, Tuple[Optional[str], Optional[str]]]
+OnExc = Callable[[FunctionType, Path, BaseException], Any]
+OnErr = Callable[[FunctionType, Path, ExcInfo], Any]
+
+FILE_CHUNK_SIZE = 1024 * 1024
+
+
+def get_pip_version() -> str:
+ pip_pkg_dir = os.path.join(os.path.dirname(__file__), "..", "..")
+ pip_pkg_dir = os.path.abspath(pip_pkg_dir)
+
+ return f"pip {__version__} from {pip_pkg_dir} (python {get_major_minor_version()})"
+
+
+def normalize_version_info(py_version_info: Tuple[int, ...]) -> Tuple[int, int, int]:
+ """
+ Convert a tuple of ints representing a Python version to one of length
+ three.
+
+ :param py_version_info: a tuple of ints representing a Python version,
+ or None to specify no version. The tuple can have any length.
+
+ :return: a tuple of length three if `py_version_info` is non-None.
+ Otherwise, return `py_version_info` unchanged (i.e. None).
+ """
+ if len(py_version_info) < 3:
+ py_version_info += (3 - len(py_version_info)) * (0,)
+ elif len(py_version_info) > 3:
+ py_version_info = py_version_info[:3]
+
+ return cast("VersionInfo", py_version_info)
+
+
+def ensure_dir(path: str) -> None:
+ """os.path.makedirs without EEXIST."""
+ try:
+ os.makedirs(path)
+ except OSError as e:
+ # Windows can raise spurious ENOTEMPTY errors. See #6426.
+ if e.errno != errno.EEXIST and e.errno != errno.ENOTEMPTY:
+ raise
+
+
+def get_prog() -> str:
+ try:
+ prog = os.path.basename(sys.argv[0])
+ if prog in ("__main__.py", "-c"):
+ return f"{sys.executable} -m pip"
+ else:
+ return prog
+ except (AttributeError, TypeError, IndexError):
+ pass
+ return "pip"
+
+
+# Retry every half second for up to 3 seconds
+@retry(stop_after_delay=3, wait=0.5)
+def rmtree(
+ dir: str, ignore_errors: bool = False, onexc: Optional[OnExc] = None
+) -> None:
+ if ignore_errors:
+ onexc = _onerror_ignore
+ if onexc is None:
+ onexc = _onerror_reraise
+ handler: OnErr = partial(rmtree_errorhandler, onexc=onexc)
+ if sys.version_info >= (3, 12):
+ # See https://docs.python.org/3.12/whatsnew/3.12.html#shutil.
+ shutil.rmtree(dir, onexc=handler) # type: ignore
+ else:
+ shutil.rmtree(dir, onerror=handler) # type: ignore
+
+
+def _onerror_ignore(*_args: Any) -> None:
+ pass
+
+
+def _onerror_reraise(*_args: Any) -> None:
+ raise # noqa: PLE0704 - Bare exception used to reraise existing exception
+
+
+def rmtree_errorhandler(
+ func: FunctionType,
+ path: Path,
+ exc_info: Union[ExcInfo, BaseException],
+ *,
+ onexc: OnExc = _onerror_reraise,
+) -> None:
+ """
+ `rmtree` error handler to 'force' a file remove (i.e. like `rm -f`).
+
+ * If a file is readonly then it's write flag is set and operation is
+ retried.
+
+ * `onerror` is the original callback from `rmtree(... onerror=onerror)`
+ that is chained at the end if the "rm -f" still fails.
+ """
+ try:
+ st_mode = os.stat(path).st_mode
+ except OSError:
+ # it's equivalent to os.path.exists
+ return
+
+ if not st_mode & stat.S_IWRITE:
+ # convert to read/write
+ try:
+ os.chmod(path, st_mode | stat.S_IWRITE)
+ except OSError:
+ pass
+ else:
+ # use the original function to repeat the operation
+ try:
+ func(path)
+ return
+ except OSError:
+ pass
+
+ if not isinstance(exc_info, BaseException):
+ _, exc_info, _ = exc_info
+ onexc(func, path, exc_info)
+
+
+def display_path(path: str) -> str:
+ """Gives the display value for a given path, making it relative to cwd
+ if possible."""
+ path = os.path.normcase(os.path.abspath(path))
+ if path.startswith(os.getcwd() + os.path.sep):
+ path = "." + path[len(os.getcwd()) :]
+ return path
+
+
+def backup_dir(dir: str, ext: str = ".bak") -> str:
+ """Figure out the name of a directory to back up the given dir to
+ (adding .bak, .bak2, etc)"""
+ n = 1
+ extension = ext
+ while os.path.exists(dir + extension):
+ n += 1
+ extension = ext + str(n)
+ return dir + extension
+
+
+def ask_path_exists(message: str, options: Iterable[str]) -> str:
+ for action in os.environ.get("PIP_EXISTS_ACTION", "").split():
+ if action in options:
+ return action
+ return ask(message, options)
+
+
+def _check_no_input(message: str) -> None:
+ """Raise an error if no input is allowed."""
+ if os.environ.get("PIP_NO_INPUT"):
+ raise Exception(
+ f"No input was expected ($PIP_NO_INPUT set); question: {message}"
+ )
+
+
+def ask(message: str, options: Iterable[str]) -> str:
+ """Ask the message interactively, with the given possible responses"""
+ while 1:
+ _check_no_input(message)
+ response = input(message)
+ response = response.strip().lower()
+ if response not in options:
+ print(
+ "Your response ({!r}) was not one of the expected responses: "
+ "{}".format(response, ", ".join(options))
+ )
+ else:
+ return response
+
+
+def ask_input(message: str) -> str:
+ """Ask for input interactively."""
+ _check_no_input(message)
+ return input(message)
+
+
+def ask_password(message: str) -> str:
+ """Ask for a password interactively."""
+ _check_no_input(message)
+ return getpass.getpass(message)
+
+
+def strtobool(val: str) -> int:
+ """Convert a string representation of truth to true (1) or false (0).
+
+ True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values
+ are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if
+ 'val' is anything else.
+ """
+ val = val.lower()
+ if val in ("y", "yes", "t", "true", "on", "1"):
+ return 1
+ elif val in ("n", "no", "f", "false", "off", "0"):
+ return 0
+ else:
+ raise ValueError(f"invalid truth value {val!r}")
+
+
+def format_size(bytes: float) -> str:
+ if bytes > 1000 * 1000:
+ return f"{bytes / 1000.0 / 1000:.1f} MB"
+ elif bytes > 10 * 1000:
+ return f"{int(bytes / 1000)} kB"
+ elif bytes > 1000:
+ return f"{bytes / 1000.0:.1f} kB"
+ else:
+ return f"{int(bytes)} bytes"
+
+
+def tabulate(rows: Iterable[Iterable[Any]]) -> Tuple[List[str], List[int]]:
+ """Return a list of formatted rows and a list of column sizes.
+
+ For example::
+
+ >>> tabulate([['foobar', 2000], [0xdeadbeef]])
+ (['foobar 2000', '3735928559'], [10, 4])
+ """
+ rows = [tuple(map(str, row)) for row in rows]
+ sizes = [max(map(len, col)) for col in zip_longest(*rows, fillvalue="")]
+ table = [" ".join(map(str.ljust, row, sizes)).rstrip() for row in rows]
+ return table, sizes
+
+
+def is_installable_dir(path: str) -> bool:
+ """Is path is a directory containing pyproject.toml or setup.py?
+
+ If pyproject.toml exists, this is a PEP 517 project. Otherwise we look for
+ a legacy setuptools layout by identifying setup.py. We don't check for the
+ setup.cfg because using it without setup.py is only available for PEP 517
+ projects, which are already covered by the pyproject.toml check.
+ """
+ if not os.path.isdir(path):
+ return False
+ if os.path.isfile(os.path.join(path, "pyproject.toml")):
+ return True
+ if os.path.isfile(os.path.join(path, "setup.py")):
+ return True
+ return False
+
+
+def read_chunks(
+ file: BinaryIO, size: int = FILE_CHUNK_SIZE
+) -> Generator[bytes, None, None]:
+ """Yield pieces of data from a file-like object until EOF."""
+ while True:
+ chunk = file.read(size)
+ if not chunk:
+ break
+ yield chunk
+
+
+def normalize_path(path: str, resolve_symlinks: bool = True) -> str:
+ """
+ Convert a path to its canonical, case-normalized, absolute version.
+
+ """
+ path = os.path.expanduser(path)
+ if resolve_symlinks:
+ path = os.path.realpath(path)
+ else:
+ path = os.path.abspath(path)
+ return os.path.normcase(path)
+
+
+def splitext(path: str) -> Tuple[str, str]:
+ """Like os.path.splitext, but take off .tar too"""
+ base, ext = posixpath.splitext(path)
+ if base.lower().endswith(".tar"):
+ ext = base[-4:] + ext
+ base = base[:-4]
+ return base, ext
+
+
+def renames(old: str, new: str) -> None:
+ """Like os.renames(), but handles renaming across devices."""
+ # Implementation borrowed from os.renames().
+ head, tail = os.path.split(new)
+ if head and tail and not os.path.exists(head):
+ os.makedirs(head)
+
+ shutil.move(old, new)
+
+ head, tail = os.path.split(old)
+ if head and tail:
+ try:
+ os.removedirs(head)
+ except OSError:
+ pass
+
+
+def is_local(path: str) -> bool:
+ """
+ Return True if path is within sys.prefix, if we're running in a virtualenv.
+
+ If we're not in a virtualenv, all paths are considered "local."
+
+ Caution: this function assumes the head of path has been normalized
+ with normalize_path.
+ """
+ if not running_under_virtualenv():
+ return True
+ return path.startswith(normalize_path(sys.prefix))
+
+
+def write_output(msg: Any, *args: Any) -> None:
+ logger.info(msg, *args)
+
+
+class StreamWrapper(StringIO):
+ orig_stream: TextIO
+
+ @classmethod
+ def from_stream(cls, orig_stream: TextIO) -> "StreamWrapper":
+ ret = cls()
+ ret.orig_stream = orig_stream
+ return ret
+
+ # compileall.compile_dir() needs stdout.encoding to print to stdout
+ # type ignore is because TextIOBase.encoding is writeable
+ @property
+ def encoding(self) -> str: # type: ignore
+ return self.orig_stream.encoding
+
+
+# Simulates an enum
+def enum(*sequential: Any, **named: Any) -> Type[Any]:
+ enums = dict(zip(sequential, range(len(sequential))), **named)
+ reverse = {value: key for key, value in enums.items()}
+ enums["reverse_mapping"] = reverse
+ return type("Enum", (), enums)
+
+
+def build_netloc(host: str, port: Optional[int]) -> str:
+ """
+ Build a netloc from a host-port pair
+ """
+ if port is None:
+ return host
+ if ":" in host:
+ # Only wrap host with square brackets when it is IPv6
+ host = f"[{host}]"
+ return f"{host}:{port}"
+
+
+def build_url_from_netloc(netloc: str, scheme: str = "https") -> str:
+ """
+ Build a full URL from a netloc.
+ """
+ if netloc.count(":") >= 2 and "@" not in netloc and "[" not in netloc:
+ # It must be a bare IPv6 address, so wrap it with brackets.
+ netloc = f"[{netloc}]"
+ return f"{scheme}://{netloc}"
+
+
+def parse_netloc(netloc: str) -> Tuple[Optional[str], Optional[int]]:
+ """
+ Return the host-port pair from a netloc.
+ """
+ url = build_url_from_netloc(netloc)
+ parsed = urllib.parse.urlparse(url)
+ return parsed.hostname, parsed.port
+
+
+def split_auth_from_netloc(netloc: str) -> NetlocTuple:
+ """
+ Parse out and remove the auth information from a netloc.
+
+ Returns: (netloc, (username, password)).
+ """
+ if "@" not in netloc:
+ return netloc, (None, None)
+
+ # Split from the right because that's how urllib.parse.urlsplit()
+ # behaves if more than one @ is present (which can be checked using
+ # the password attribute of urlsplit()'s return value).
+ auth, netloc = netloc.rsplit("@", 1)
+ pw: Optional[str] = None
+ if ":" in auth:
+ # Split from the left because that's how urllib.parse.urlsplit()
+ # behaves if more than one : is present (which again can be checked
+ # using the password attribute of the return value)
+ user, pw = auth.split(":", 1)
+ else:
+ user, pw = auth, None
+
+ user = urllib.parse.unquote(user)
+ if pw is not None:
+ pw = urllib.parse.unquote(pw)
+
+ return netloc, (user, pw)
+
+
+def redact_netloc(netloc: str) -> str:
+ """
+ Replace the sensitive data in a netloc with "****", if it exists.
+
+ For example:
+ - "user:pass@example.com" returns "user:****@example.com"
+ - "accesstoken@example.com" returns "****@example.com"
+ """
+ netloc, (user, password) = split_auth_from_netloc(netloc)
+ if user is None:
+ return netloc
+ if password is None:
+ user = "****"
+ password = ""
+ else:
+ user = urllib.parse.quote(user)
+ password = ":****"
+ return f"{user}{password}@{netloc}"
+
+
+def _transform_url(
+ url: str, transform_netloc: Callable[[str], Tuple[Any, ...]]
+) -> Tuple[str, NetlocTuple]:
+ """Transform and replace netloc in a url.
+
+ transform_netloc is a function taking the netloc and returning a
+ tuple. The first element of this tuple is the new netloc. The
+ entire tuple is returned.
+
+ Returns a tuple containing the transformed url as item 0 and the
+ original tuple returned by transform_netloc as item 1.
+ """
+ purl = urllib.parse.urlsplit(url)
+ netloc_tuple = transform_netloc(purl.netloc)
+ # stripped url
+ url_pieces = (purl.scheme, netloc_tuple[0], purl.path, purl.query, purl.fragment)
+ surl = urllib.parse.urlunsplit(url_pieces)
+ return surl, cast("NetlocTuple", netloc_tuple)
+
+
+def _get_netloc(netloc: str) -> NetlocTuple:
+ return split_auth_from_netloc(netloc)
+
+
+def _redact_netloc(netloc: str) -> Tuple[str]:
+ return (redact_netloc(netloc),)
+
+
+def split_auth_netloc_from_url(
+ url: str,
+) -> Tuple[str, str, Tuple[Optional[str], Optional[str]]]:
+ """
+ Parse a url into separate netloc, auth, and url with no auth.
+
+ Returns: (url_without_auth, netloc, (username, password))
+ """
+ url_without_auth, (netloc, auth) = _transform_url(url, _get_netloc)
+ return url_without_auth, netloc, auth
+
+
+def remove_auth_from_url(url: str) -> str:
+ """Return a copy of url with 'username:password@' removed."""
+ # username/pass params are passed to subversion through flags
+ # and are not recognized in the url.
+ return _transform_url(url, _get_netloc)[0]
+
+
+def redact_auth_from_url(url: str) -> str:
+ """Replace the password in a given url with ****."""
+ return _transform_url(url, _redact_netloc)[0]
+
+
+def redact_auth_from_requirement(req: Requirement) -> str:
+ """Replace the password in a given requirement url with ****."""
+ if not req.url:
+ return str(req)
+ return str(req).replace(req.url, redact_auth_from_url(req.url))
+
+
+@dataclass(frozen=True)
+class HiddenText:
+ secret: str
+ redacted: str
+
+ def __repr__(self) -> str:
+ return f"<HiddenText {str(self)!r}>"
+
+ def __str__(self) -> str:
+ return self.redacted
+
+ # This is useful for testing.
+ def __eq__(self, other: Any) -> bool:
+ if type(self) is not type(other):
+ return False
+
+ # The string being used for redaction doesn't also have to match,
+ # just the raw, original string.
+ return self.secret == other.secret
+
+
+def hide_value(value: str) -> HiddenText:
+ return HiddenText(value, redacted="****")
+
+
+def hide_url(url: str) -> HiddenText:
+ redacted = redact_auth_from_url(url)
+ return HiddenText(url, redacted=redacted)
+
+
+def protect_pip_from_modification_on_windows(modifying_pip: bool) -> None:
+ """Protection of pip.exe from modification on Windows
+
+ On Windows, any operation modifying pip should be run as:
+ python -m pip ...
+ """
+ pip_names = [
+ "pip",
+ f"pip{sys.version_info.major}",
+ f"pip{sys.version_info.major}.{sys.version_info.minor}",
+ ]
+
+ # See https://github.com/pypa/pip/issues/1299 for more discussion
+ should_show_use_python_msg = (
+ modifying_pip and WINDOWS and os.path.basename(sys.argv[0]) in pip_names
+ )
+
+ if should_show_use_python_msg:
+ new_command = [sys.executable, "-m", "pip"] + sys.argv[1:]
+ raise CommandError(
+ "To modify pip, please run the following command:\n{}".format(
+ " ".join(new_command)
+ )
+ )
+
+
+def check_externally_managed() -> None:
+ """Check whether the current environment is externally managed.
+
+ If the ``EXTERNALLY-MANAGED`` config file is found, the current environment
+ is considered externally managed, and an ExternallyManagedEnvironment is
+ raised.
+ """
+ if running_under_virtualenv():
+ return
+ marker = os.path.join(sysconfig.get_path("stdlib"), "EXTERNALLY-MANAGED")
+ if not os.path.isfile(marker):
+ return
+ raise ExternallyManagedEnvironment.from_config(marker)
+
+
+def is_console_interactive() -> bool:
+ """Is this console interactive?"""
+ return sys.stdin is not None and sys.stdin.isatty()
+
+
+def hash_file(path: str, blocksize: int = 1 << 20) -> Tuple[Any, int]:
+ """Return (hash, length) for path using hashlib.sha256()"""
+
+ h = hashlib.sha256()
+ length = 0
+ with open(path, "rb") as f:
+ for block in read_chunks(f, size=blocksize):
+ length += len(block)
+ h.update(block)
+ return h, length
+
+
+def pairwise(iterable: Iterable[Any]) -> Iterator[Tuple[Any, Any]]:
+ """
+ Return paired elements.
+
+ For example:
+ s -> (s0, s1), (s2, s3), (s4, s5), ...
+ """
+ iterable = iter(iterable)
+ return zip_longest(iterable, iterable)
+
+
+def partition(
+ pred: Callable[[T], bool], iterable: Iterable[T]
+) -> Tuple[Iterable[T], Iterable[T]]:
+ """
+ Use a predicate to partition entries into false entries and true entries,
+ like
+
+ partition(is_odd, range(10)) --> 0 2 4 6 8 and 1 3 5 7 9
+ """
+ t1, t2 = tee(iterable)
+ return filterfalse(pred, t1), filter(pred, t2)
+
+
+class ConfiguredBuildBackendHookCaller(BuildBackendHookCaller):
+ def __init__(
+ self,
+ config_holder: Any,
+ source_dir: str,
+ build_backend: str,
+ backend_path: Optional[str] = None,
+ runner: Optional[Callable[..., None]] = None,
+ python_executable: Optional[str] = None,
+ ):
+ super().__init__(
+ source_dir, build_backend, backend_path, runner, python_executable
+ )
+ self.config_holder = config_holder
+
+ def build_wheel(
+ self,
+ wheel_directory: str,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+ metadata_directory: Optional[str] = None,
+ ) -> str:
+ cs = self.config_holder.config_settings
+ return super().build_wheel(
+ wheel_directory, config_settings=cs, metadata_directory=metadata_directory
+ )
+
+ def build_sdist(
+ self,
+ sdist_directory: str,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+ ) -> str:
+ cs = self.config_holder.config_settings
+ return super().build_sdist(sdist_directory, config_settings=cs)
+
+ def build_editable(
+ self,
+ wheel_directory: str,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+ metadata_directory: Optional[str] = None,
+ ) -> str:
+ cs = self.config_holder.config_settings
+ return super().build_editable(
+ wheel_directory, config_settings=cs, metadata_directory=metadata_directory
+ )
+
+ def get_requires_for_build_wheel(
+ self, config_settings: Optional[Dict[str, Union[str, List[str]]]] = None
+ ) -> List[str]:
+ cs = self.config_holder.config_settings
+ return super().get_requires_for_build_wheel(config_settings=cs)
+
+ def get_requires_for_build_sdist(
+ self, config_settings: Optional[Dict[str, Union[str, List[str]]]] = None
+ ) -> List[str]:
+ cs = self.config_holder.config_settings
+ return super().get_requires_for_build_sdist(config_settings=cs)
+
+ def get_requires_for_build_editable(
+ self, config_settings: Optional[Dict[str, Union[str, List[str]]]] = None
+ ) -> List[str]:
+ cs = self.config_holder.config_settings
+ return super().get_requires_for_build_editable(config_settings=cs)
+
+ def prepare_metadata_for_build_wheel(
+ self,
+ metadata_directory: str,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+ _allow_fallback: bool = True,
+ ) -> str:
+ cs = self.config_holder.config_settings
+ return super().prepare_metadata_for_build_wheel(
+ metadata_directory=metadata_directory,
+ config_settings=cs,
+ _allow_fallback=_allow_fallback,
+ )
+
+ def prepare_metadata_for_build_editable(
+ self,
+ metadata_directory: str,
+ config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
+ _allow_fallback: bool = True,
+ ) -> str:
+ cs = self.config_holder.config_settings
+ return super().prepare_metadata_for_build_editable(
+ metadata_directory=metadata_directory,
+ config_settings=cs,
+ _allow_fallback=_allow_fallback,
+ )
+
+
+def warn_if_run_as_root() -> None:
+ """Output a warning for sudo users on Unix.
+
+ In a virtual environment, sudo pip still writes to virtualenv.
+ On Windows, users may run pip as Administrator without issues.
+ This warning only applies to Unix root users outside of virtualenv.
+ """
+ if running_under_virtualenv():
+ return
+ if not hasattr(os, "getuid"):
+ return
+ # On Windows, there are no "system managed" Python packages. Installing as
+ # Administrator via pip is the correct way of updating system environments.
+ #
+ # We choose sys.platform over utils.compat.WINDOWS here to enable Mypy platform
+ # checks: https://mypy.readthedocs.io/en/stable/common_issues.html
+ if sys.platform == "win32" or sys.platform == "cygwin":
+ return
+
+ if os.getuid() != 0:
+ return
+
+ logger.warning(
+ "Running pip as the 'root' user can result in broken permissions and "
+ "conflicting behaviour with the system package manager, possibly "
+ "rendering your system unusable."
+ "It is recommended to use a virtual environment instead: "
+ "https://pip.pypa.io/warnings/venv. "
+ "Use the --root-user-action option if you know what you are doing and "
+ "want to suppress this warning."
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/packaging.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/packaging.py
new file mode 100644
index 000000000..4b8fa0fe3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/packaging.py
@@ -0,0 +1,57 @@
+import functools
+import logging
+import re
+from typing import NewType, Optional, Tuple, cast
+
+from pip._vendor.packaging import specifiers, version
+from pip._vendor.packaging.requirements import Requirement
+
+NormalizedExtra = NewType("NormalizedExtra", str)
+
+logger = logging.getLogger(__name__)
+
+
+def check_requires_python(
+ requires_python: Optional[str], version_info: Tuple[int, ...]
+) -> bool:
+ """
+ Check if the given Python version matches a "Requires-Python" specifier.
+
+ :param version_info: A 3-tuple of ints representing a Python
+ major-minor-micro version to check (e.g. `sys.version_info[:3]`).
+
+ :return: `True` if the given Python version satisfies the requirement.
+ Otherwise, return `False`.
+
+ :raises InvalidSpecifier: If `requires_python` has an invalid format.
+ """
+ if requires_python is None:
+ # The package provides no information
+ return True
+ requires_python_specifier = specifiers.SpecifierSet(requires_python)
+
+ python_version = version.parse(".".join(map(str, version_info)))
+ return python_version in requires_python_specifier
+
+
+@functools.lru_cache(maxsize=2048)
+def get_requirement(req_string: str) -> Requirement:
+ """Construct a packaging.Requirement object with caching"""
+ # Parsing requirement strings is expensive, and is also expected to happen
+ # with a low diversity of different arguments (at least relative the number
+ # constructed). This method adds a cache to requirement object creation to
+ # minimize repeated parsing of the same string to construct equivalent
+ # Requirement objects.
+ return Requirement(req_string)
+
+
+def safe_extra(extra: str) -> NormalizedExtra:
+ """Convert an arbitrary string to a standard 'extra' name
+
+ Any runs of non-alphanumeric characters are replaced with a single '_',
+ and the result is always lowercased.
+
+ This function is duplicated from ``pkg_resources``. Note that this is not
+ the same to either ``canonicalize_name`` or ``_egg_link_name``.
+ """
+ return cast(NormalizedExtra, re.sub("[^A-Za-z0-9.-]+", "_", extra).lower())
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/retry.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/retry.py
new file mode 100644
index 000000000..abfe07286
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/retry.py
@@ -0,0 +1,42 @@
+import functools
+from time import perf_counter, sleep
+from typing import Callable, TypeVar
+
+from pip._vendor.typing_extensions import ParamSpec
+
+T = TypeVar("T")
+P = ParamSpec("P")
+
+
+def retry(
+ wait: float, stop_after_delay: float
+) -> Callable[[Callable[P, T]], Callable[P, T]]:
+ """Decorator to automatically retry a function on error.
+
+ If the function raises, the function is recalled with the same arguments
+ until it returns or the time limit is reached. When the time limit is
+ surpassed, the last exception raised is reraised.
+
+ :param wait: The time to wait after an error before retrying, in seconds.
+ :param stop_after_delay: The time limit after which retries will cease,
+ in seconds.
+ """
+
+ def wrapper(func: Callable[P, T]) -> Callable[P, T]:
+
+ @functools.wraps(func)
+ def retry_wrapped(*args: P.args, **kwargs: P.kwargs) -> T:
+ # The performance counter is monotonic on all platforms we care
+ # about and has much better resolution than time.monotonic().
+ start_time = perf_counter()
+ while True:
+ try:
+ return func(*args, **kwargs)
+ except Exception:
+ if perf_counter() - start_time > stop_after_delay:
+ raise
+ sleep(wait)
+
+ return retry_wrapped
+
+ return wrapper
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/setuptools_build.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/setuptools_build.py
new file mode 100644
index 000000000..96d1b2460
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/setuptools_build.py
@@ -0,0 +1,146 @@
+import sys
+import textwrap
+from typing import List, Optional, Sequence
+
+# Shim to wrap setup.py invocation with setuptools
+# Note that __file__ is handled via two {!r} *and* %r, to ensure that paths on
+# Windows are correctly handled (it should be "C:\\Users" not "C:\Users").
+_SETUPTOOLS_SHIM = textwrap.dedent(
+ """
+ exec(compile('''
+ # This is <pip-setuptools-caller> -- a caller that pip uses to run setup.py
+ #
+ # - It imports setuptools before invoking setup.py, to enable projects that directly
+ # import from `distutils.core` to work with newer packaging standards.
+ # - It provides a clear error message when setuptools is not installed.
+ # - It sets `sys.argv[0]` to the underlying `setup.py`, when invoking `setup.py` so
+ # setuptools doesn't think the script is `-c`. This avoids the following warning:
+ # manifest_maker: standard file '-c' not found".
+ # - It generates a shim setup.py, for handling setup.cfg-only projects.
+ import os, sys, tokenize
+
+ try:
+ import setuptools
+ except ImportError as error:
+ print(
+ "ERROR: Can not execute `setup.py` since setuptools is not available in "
+ "the build environment.",
+ file=sys.stderr,
+ )
+ sys.exit(1)
+
+ __file__ = %r
+ sys.argv[0] = __file__
+
+ if os.path.exists(__file__):
+ filename = __file__
+ with tokenize.open(__file__) as f:
+ setup_py_code = f.read()
+ else:
+ filename = "<auto-generated setuptools caller>"
+ setup_py_code = "from setuptools import setup; setup()"
+
+ exec(compile(setup_py_code, filename, "exec"))
+ ''' % ({!r},), "<pip-setuptools-caller>", "exec"))
+ """
+).rstrip()
+
+
+def make_setuptools_shim_args(
+ setup_py_path: str,
+ global_options: Optional[Sequence[str]] = None,
+ no_user_config: bool = False,
+ unbuffered_output: bool = False,
+) -> List[str]:
+ """
+ Get setuptools command arguments with shim wrapped setup file invocation.
+
+ :param setup_py_path: The path to setup.py to be wrapped.
+ :param global_options: Additional global options.
+ :param no_user_config: If True, disables personal user configuration.
+ :param unbuffered_output: If True, adds the unbuffered switch to the
+ argument list.
+ """
+ args = [sys.executable]
+ if unbuffered_output:
+ args += ["-u"]
+ args += ["-c", _SETUPTOOLS_SHIM.format(setup_py_path)]
+ if global_options:
+ args += global_options
+ if no_user_config:
+ args += ["--no-user-cfg"]
+ return args
+
+
+def make_setuptools_bdist_wheel_args(
+ setup_py_path: str,
+ global_options: Sequence[str],
+ build_options: Sequence[str],
+ destination_dir: str,
+) -> List[str]:
+ # NOTE: Eventually, we'd want to also -S to the flags here, when we're
+ # isolating. Currently, it breaks Python in virtualenvs, because it
+ # relies on site.py to find parts of the standard library outside the
+ # virtualenv.
+ args = make_setuptools_shim_args(
+ setup_py_path, global_options=global_options, unbuffered_output=True
+ )
+ args += ["bdist_wheel", "-d", destination_dir]
+ args += build_options
+ return args
+
+
+def make_setuptools_clean_args(
+ setup_py_path: str,
+ global_options: Sequence[str],
+) -> List[str]:
+ args = make_setuptools_shim_args(
+ setup_py_path, global_options=global_options, unbuffered_output=True
+ )
+ args += ["clean", "--all"]
+ return args
+
+
+def make_setuptools_develop_args(
+ setup_py_path: str,
+ *,
+ global_options: Sequence[str],
+ no_user_config: bool,
+ prefix: Optional[str],
+ home: Optional[str],
+ use_user_site: bool,
+) -> List[str]:
+ assert not (use_user_site and prefix)
+
+ args = make_setuptools_shim_args(
+ setup_py_path,
+ global_options=global_options,
+ no_user_config=no_user_config,
+ )
+
+ args += ["develop", "--no-deps"]
+
+ if prefix:
+ args += ["--prefix", prefix]
+ if home is not None:
+ args += ["--install-dir", home]
+
+ if use_user_site:
+ args += ["--user", "--prefix="]
+
+ return args
+
+
+def make_setuptools_egg_info_args(
+ setup_py_path: str,
+ egg_info_dir: Optional[str],
+ no_user_config: bool,
+) -> List[str]:
+ args = make_setuptools_shim_args(setup_py_path, no_user_config=no_user_config)
+
+ args += ["egg_info"]
+
+ if egg_info_dir:
+ args += ["--egg-base", egg_info_dir]
+
+ return args
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/subprocess.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/subprocess.py
new file mode 100644
index 000000000..cb2e23f00
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/subprocess.py
@@ -0,0 +1,245 @@
+import logging
+import os
+import shlex
+import subprocess
+from typing import Any, Callable, Iterable, List, Literal, Mapping, Optional, Union
+
+from pip._vendor.rich.markup import escape
+
+from pip._internal.cli.spinners import SpinnerInterface, open_spinner
+from pip._internal.exceptions import InstallationSubprocessError
+from pip._internal.utils.logging import VERBOSE, subprocess_logger
+from pip._internal.utils.misc import HiddenText
+
+CommandArgs = List[Union[str, HiddenText]]
+
+
+def make_command(*args: Union[str, HiddenText, CommandArgs]) -> CommandArgs:
+ """
+ Create a CommandArgs object.
+ """
+ command_args: CommandArgs = []
+ for arg in args:
+ # Check for list instead of CommandArgs since CommandArgs is
+ # only known during type-checking.
+ if isinstance(arg, list):
+ command_args.extend(arg)
+ else:
+ # Otherwise, arg is str or HiddenText.
+ command_args.append(arg)
+
+ return command_args
+
+
+def format_command_args(args: Union[List[str], CommandArgs]) -> str:
+ """
+ Format command arguments for display.
+ """
+ # For HiddenText arguments, display the redacted form by calling str().
+ # Also, we don't apply str() to arguments that aren't HiddenText since
+ # this can trigger a UnicodeDecodeError in Python 2 if the argument
+ # has type unicode and includes a non-ascii character. (The type
+ # checker doesn't ensure the annotations are correct in all cases.)
+ return " ".join(
+ shlex.quote(str(arg)) if isinstance(arg, HiddenText) else shlex.quote(arg)
+ for arg in args
+ )
+
+
+def reveal_command_args(args: Union[List[str], CommandArgs]) -> List[str]:
+ """
+ Return the arguments in their raw, unredacted form.
+ """
+ return [arg.secret if isinstance(arg, HiddenText) else arg for arg in args]
+
+
+def call_subprocess(
+ cmd: Union[List[str], CommandArgs],
+ show_stdout: bool = False,
+ cwd: Optional[str] = None,
+ on_returncode: 'Literal["raise", "warn", "ignore"]' = "raise",
+ extra_ok_returncodes: Optional[Iterable[int]] = None,
+ extra_environ: Optional[Mapping[str, Any]] = None,
+ unset_environ: Optional[Iterable[str]] = None,
+ spinner: Optional[SpinnerInterface] = None,
+ log_failed_cmd: Optional[bool] = True,
+ stdout_only: Optional[bool] = False,
+ *,
+ command_desc: str,
+) -> str:
+ """
+ Args:
+ show_stdout: if true, use INFO to log the subprocess's stderr and
+ stdout streams. Otherwise, use DEBUG. Defaults to False.
+ extra_ok_returncodes: an iterable of integer return codes that are
+ acceptable, in addition to 0. Defaults to None, which means [].
+ unset_environ: an iterable of environment variable names to unset
+ prior to calling subprocess.Popen().
+ log_failed_cmd: if false, failed commands are not logged, only raised.
+ stdout_only: if true, return only stdout, else return both. When true,
+ logging of both stdout and stderr occurs when the subprocess has
+ terminated, else logging occurs as subprocess output is produced.
+ """
+ if extra_ok_returncodes is None:
+ extra_ok_returncodes = []
+ if unset_environ is None:
+ unset_environ = []
+ # Most places in pip use show_stdout=False. What this means is--
+ #
+ # - We connect the child's output (combined stderr and stdout) to a
+ # single pipe, which we read.
+ # - We log this output to stderr at DEBUG level as it is received.
+ # - If DEBUG logging isn't enabled (e.g. if --verbose logging wasn't
+ # requested), then we show a spinner so the user can still see the
+ # subprocess is in progress.
+ # - If the subprocess exits with an error, we log the output to stderr
+ # at ERROR level if it hasn't already been displayed to the console
+ # (e.g. if --verbose logging wasn't enabled). This way we don't log
+ # the output to the console twice.
+ #
+ # If show_stdout=True, then the above is still done, but with DEBUG
+ # replaced by INFO.
+ if show_stdout:
+ # Then log the subprocess output at INFO level.
+ log_subprocess: Callable[..., None] = subprocess_logger.info
+ used_level = logging.INFO
+ else:
+ # Then log the subprocess output using VERBOSE. This also ensures
+ # it will be logged to the log file (aka user_log), if enabled.
+ log_subprocess = subprocess_logger.verbose
+ used_level = VERBOSE
+
+ # Whether the subprocess will be visible in the console.
+ showing_subprocess = subprocess_logger.getEffectiveLevel() <= used_level
+
+ # Only use the spinner if we're not showing the subprocess output
+ # and we have a spinner.
+ use_spinner = not showing_subprocess and spinner is not None
+
+ log_subprocess("Running command %s", command_desc)
+ env = os.environ.copy()
+ if extra_environ:
+ env.update(extra_environ)
+ for name in unset_environ:
+ env.pop(name, None)
+ try:
+ proc = subprocess.Popen(
+ # Convert HiddenText objects to the underlying str.
+ reveal_command_args(cmd),
+ stdin=subprocess.PIPE,
+ stdout=subprocess.PIPE,
+ stderr=subprocess.STDOUT if not stdout_only else subprocess.PIPE,
+ cwd=cwd,
+ env=env,
+ errors="backslashreplace",
+ )
+ except Exception as exc:
+ if log_failed_cmd:
+ subprocess_logger.critical(
+ "Error %s while executing command %s",
+ exc,
+ command_desc,
+ )
+ raise
+ all_output = []
+ if not stdout_only:
+ assert proc.stdout
+ assert proc.stdin
+ proc.stdin.close()
+ # In this mode, stdout and stderr are in the same pipe.
+ while True:
+ line: str = proc.stdout.readline()
+ if not line:
+ break
+ line = line.rstrip()
+ all_output.append(line + "\n")
+
+ # Show the line immediately.
+ log_subprocess(line)
+ # Update the spinner.
+ if use_spinner:
+ assert spinner
+ spinner.spin()
+ try:
+ proc.wait()
+ finally:
+ if proc.stdout:
+ proc.stdout.close()
+ output = "".join(all_output)
+ else:
+ # In this mode, stdout and stderr are in different pipes.
+ # We must use communicate() which is the only safe way to read both.
+ out, err = proc.communicate()
+ # log line by line to preserve pip log indenting
+ for out_line in out.splitlines():
+ log_subprocess(out_line)
+ all_output.append(out)
+ for err_line in err.splitlines():
+ log_subprocess(err_line)
+ all_output.append(err)
+ output = out
+
+ proc_had_error = proc.returncode and proc.returncode not in extra_ok_returncodes
+ if use_spinner:
+ assert spinner
+ if proc_had_error:
+ spinner.finish("error")
+ else:
+ spinner.finish("done")
+ if proc_had_error:
+ if on_returncode == "raise":
+ error = InstallationSubprocessError(
+ command_description=command_desc,
+ exit_code=proc.returncode,
+ output_lines=all_output if not showing_subprocess else None,
+ )
+ if log_failed_cmd:
+ subprocess_logger.error("%s", error, extra={"rich": True})
+ subprocess_logger.verbose(
+ "[bold magenta]full command[/]: [blue]%s[/]",
+ escape(format_command_args(cmd)),
+ extra={"markup": True},
+ )
+ subprocess_logger.verbose(
+ "[bold magenta]cwd[/]: %s",
+ escape(cwd or "[inherit]"),
+ extra={"markup": True},
+ )
+
+ raise error
+ elif on_returncode == "warn":
+ subprocess_logger.warning(
+ 'Command "%s" had error code %s in %s',
+ command_desc,
+ proc.returncode,
+ cwd,
+ )
+ elif on_returncode == "ignore":
+ pass
+ else:
+ raise ValueError(f"Invalid value: on_returncode={on_returncode!r}")
+ return output
+
+
+def runner_with_spinner_message(message: str) -> Callable[..., None]:
+ """Provide a subprocess_runner that shows a spinner message.
+
+ Intended for use with for BuildBackendHookCaller. Thus, the runner has
+ an API that matches what's expected by BuildBackendHookCaller.subprocess_runner.
+ """
+
+ def runner(
+ cmd: List[str],
+ cwd: Optional[str] = None,
+ extra_environ: Optional[Mapping[str, Any]] = None,
+ ) -> None:
+ with open_spinner(message) as spinner:
+ call_subprocess(
+ cmd,
+ command_desc=message,
+ cwd=cwd,
+ extra_environ=extra_environ,
+ spinner=spinner,
+ )
+
+ return runner
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/temp_dir.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/temp_dir.py
new file mode 100644
index 000000000..06668e8ab
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/temp_dir.py
@@ -0,0 +1,296 @@
+import errno
+import itertools
+import logging
+import os.path
+import tempfile
+import traceback
+from contextlib import ExitStack, contextmanager
+from pathlib import Path
+from typing import (
+ Any,
+ Callable,
+ Dict,
+ Generator,
+ List,
+ Optional,
+ TypeVar,
+ Union,
+)
+
+from pip._internal.utils.misc import enum, rmtree
+
+logger = logging.getLogger(__name__)
+
+_T = TypeVar("_T", bound="TempDirectory")
+
+
+# Kinds of temporary directories. Only needed for ones that are
+# globally-managed.
+tempdir_kinds = enum(
+ BUILD_ENV="build-env",
+ EPHEM_WHEEL_CACHE="ephem-wheel-cache",
+ REQ_BUILD="req-build",
+)
+
+
+_tempdir_manager: Optional[ExitStack] = None
+
+
+@contextmanager
+def global_tempdir_manager() -> Generator[None, None, None]:
+ global _tempdir_manager
+ with ExitStack() as stack:
+ old_tempdir_manager, _tempdir_manager = _tempdir_manager, stack
+ try:
+ yield
+ finally:
+ _tempdir_manager = old_tempdir_manager
+
+
+class TempDirectoryTypeRegistry:
+ """Manages temp directory behavior"""
+
+ def __init__(self) -> None:
+ self._should_delete: Dict[str, bool] = {}
+
+ def set_delete(self, kind: str, value: bool) -> None:
+ """Indicate whether a TempDirectory of the given kind should be
+ auto-deleted.
+ """
+ self._should_delete[kind] = value
+
+ def get_delete(self, kind: str) -> bool:
+ """Get configured auto-delete flag for a given TempDirectory type,
+ default True.
+ """
+ return self._should_delete.get(kind, True)
+
+
+_tempdir_registry: Optional[TempDirectoryTypeRegistry] = None
+
+
+@contextmanager
+def tempdir_registry() -> Generator[TempDirectoryTypeRegistry, None, None]:
+ """Provides a scoped global tempdir registry that can be used to dictate
+ whether directories should be deleted.
+ """
+ global _tempdir_registry
+ old_tempdir_registry = _tempdir_registry
+ _tempdir_registry = TempDirectoryTypeRegistry()
+ try:
+ yield _tempdir_registry
+ finally:
+ _tempdir_registry = old_tempdir_registry
+
+
+class _Default:
+ pass
+
+
+_default = _Default()
+
+
+class TempDirectory:
+ """Helper class that owns and cleans up a temporary directory.
+
+ This class can be used as a context manager or as an OO representation of a
+ temporary directory.
+
+ Attributes:
+ path
+ Location to the created temporary directory
+ delete
+ Whether the directory should be deleted when exiting
+ (when used as a contextmanager)
+
+ Methods:
+ cleanup()
+ Deletes the temporary directory
+
+ When used as a context manager, if the delete attribute is True, on
+ exiting the context the temporary directory is deleted.
+ """
+
+ def __init__(
+ self,
+ path: Optional[str] = None,
+ delete: Union[bool, None, _Default] = _default,
+ kind: str = "temp",
+ globally_managed: bool = False,
+ ignore_cleanup_errors: bool = True,
+ ):
+ super().__init__()
+
+ if delete is _default:
+ if path is not None:
+ # If we were given an explicit directory, resolve delete option
+ # now.
+ delete = False
+ else:
+ # Otherwise, we wait until cleanup and see what
+ # tempdir_registry says.
+ delete = None
+
+ # The only time we specify path is in for editables where it
+ # is the value of the --src option.
+ if path is None:
+ path = self._create(kind)
+
+ self._path = path
+ self._deleted = False
+ self.delete = delete
+ self.kind = kind
+ self.ignore_cleanup_errors = ignore_cleanup_errors
+
+ if globally_managed:
+ assert _tempdir_manager is not None
+ _tempdir_manager.enter_context(self)
+
+ @property
+ def path(self) -> str:
+ assert not self._deleted, f"Attempted to access deleted path: {self._path}"
+ return self._path
+
+ def __repr__(self) -> str:
+ return f"<{self.__class__.__name__} {self.path!r}>"
+
+ def __enter__(self: _T) -> _T:
+ return self
+
+ def __exit__(self, exc: Any, value: Any, tb: Any) -> None:
+ if self.delete is not None:
+ delete = self.delete
+ elif _tempdir_registry:
+ delete = _tempdir_registry.get_delete(self.kind)
+ else:
+ delete = True
+
+ if delete:
+ self.cleanup()
+
+ def _create(self, kind: str) -> str:
+ """Create a temporary directory and store its path in self.path"""
+ # We realpath here because some systems have their default tmpdir
+ # symlinked to another directory. This tends to confuse build
+ # scripts, so we canonicalize the path by traversing potential
+ # symlinks here.
+ path = os.path.realpath(tempfile.mkdtemp(prefix=f"pip-{kind}-"))
+ logger.debug("Created temporary directory: %s", path)
+ return path
+
+ def cleanup(self) -> None:
+ """Remove the temporary directory created and reset state"""
+ self._deleted = True
+ if not os.path.exists(self._path):
+ return
+
+ errors: List[BaseException] = []
+
+ def onerror(
+ func: Callable[..., Any],
+ path: Path,
+ exc_val: BaseException,
+ ) -> None:
+ """Log a warning for a `rmtree` error and continue"""
+ formatted_exc = "\n".join(
+ traceback.format_exception_only(type(exc_val), exc_val)
+ )
+ formatted_exc = formatted_exc.rstrip() # remove trailing new line
+ if func in (os.unlink, os.remove, os.rmdir):
+ logger.debug(
+ "Failed to remove a temporary file '%s' due to %s.\n",
+ path,
+ formatted_exc,
+ )
+ else:
+ logger.debug("%s failed with %s.", func.__qualname__, formatted_exc)
+ errors.append(exc_val)
+
+ if self.ignore_cleanup_errors:
+ try:
+ # first try with @retry; retrying to handle ephemeral errors
+ rmtree(self._path, ignore_errors=False)
+ except OSError:
+ # last pass ignore/log all errors
+ rmtree(self._path, onexc=onerror)
+ if errors:
+ logger.warning(
+ "Failed to remove contents in a temporary directory '%s'.\n"
+ "You can safely remove it manually.",
+ self._path,
+ )
+ else:
+ rmtree(self._path)
+
+
+class AdjacentTempDirectory(TempDirectory):
+ """Helper class that creates a temporary directory adjacent to a real one.
+
+ Attributes:
+ original
+ The original directory to create a temp directory for.
+ path
+ After calling create() or entering, contains the full
+ path to the temporary directory.
+ delete
+ Whether the directory should be deleted when exiting
+ (when used as a contextmanager)
+
+ """
+
+ # The characters that may be used to name the temp directory
+ # We always prepend a ~ and then rotate through these until
+ # a usable name is found.
+ # pkg_resources raises a different error for .dist-info folder
+ # with leading '-' and invalid metadata
+ LEADING_CHARS = "-~.=%0123456789"
+
+ def __init__(self, original: str, delete: Optional[bool] = None) -> None:
+ self.original = original.rstrip("/\\")
+ super().__init__(delete=delete)
+
+ @classmethod
+ def _generate_names(cls, name: str) -> Generator[str, None, None]:
+ """Generates a series of temporary names.
+
+ The algorithm replaces the leading characters in the name
+ with ones that are valid filesystem characters, but are not
+ valid package names (for both Python and pip definitions of
+ package).
+ """
+ for i in range(1, len(name)):
+ for candidate in itertools.combinations_with_replacement(
+ cls.LEADING_CHARS, i - 1
+ ):
+ new_name = "~" + "".join(candidate) + name[i:]
+ if new_name != name:
+ yield new_name
+
+ # If we make it this far, we will have to make a longer name
+ for i in range(len(cls.LEADING_CHARS)):
+ for candidate in itertools.combinations_with_replacement(
+ cls.LEADING_CHARS, i
+ ):
+ new_name = "~" + "".join(candidate) + name
+ if new_name != name:
+ yield new_name
+
+ def _create(self, kind: str) -> str:
+ root, name = os.path.split(self.original)
+ for candidate in self._generate_names(name):
+ path = os.path.join(root, candidate)
+ try:
+ os.mkdir(path)
+ except OSError as ex:
+ # Continue if the name exists already
+ if ex.errno != errno.EEXIST:
+ raise
+ else:
+ path = os.path.realpath(path)
+ break
+ else:
+ # Final fallback on the default behavior.
+ path = os.path.realpath(tempfile.mkdtemp(prefix=f"pip-{kind}-"))
+
+ logger.debug("Created temporary directory: %s", path)
+ return path
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/unpacking.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/unpacking.py
new file mode 100644
index 000000000..875e30e13
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/unpacking.py
@@ -0,0 +1,337 @@
+"""Utilities related archives.
+"""
+
+import logging
+import os
+import shutil
+import stat
+import sys
+import tarfile
+import zipfile
+from typing import Iterable, List, Optional
+from zipfile import ZipInfo
+
+from pip._internal.exceptions import InstallationError
+from pip._internal.utils.filetypes import (
+ BZ2_EXTENSIONS,
+ TAR_EXTENSIONS,
+ XZ_EXTENSIONS,
+ ZIP_EXTENSIONS,
+)
+from pip._internal.utils.misc import ensure_dir
+
+logger = logging.getLogger(__name__)
+
+
+SUPPORTED_EXTENSIONS = ZIP_EXTENSIONS + TAR_EXTENSIONS
+
+try:
+ import bz2 # noqa
+
+ SUPPORTED_EXTENSIONS += BZ2_EXTENSIONS
+except ImportError:
+ logger.debug("bz2 module is not available")
+
+try:
+ # Only for Python 3.3+
+ import lzma # noqa
+
+ SUPPORTED_EXTENSIONS += XZ_EXTENSIONS
+except ImportError:
+ logger.debug("lzma module is not available")
+
+
+def current_umask() -> int:
+ """Get the current umask which involves having to set it temporarily."""
+ mask = os.umask(0)
+ os.umask(mask)
+ return mask
+
+
+def split_leading_dir(path: str) -> List[str]:
+ path = path.lstrip("/").lstrip("\\")
+ if "/" in path and (
+ ("\\" in path and path.find("/") < path.find("\\")) or "\\" not in path
+ ):
+ return path.split("/", 1)
+ elif "\\" in path:
+ return path.split("\\", 1)
+ else:
+ return [path, ""]
+
+
+def has_leading_dir(paths: Iterable[str]) -> bool:
+ """Returns true if all the paths have the same leading path name
+ (i.e., everything is in one subdirectory in an archive)"""
+ common_prefix = None
+ for path in paths:
+ prefix, rest = split_leading_dir(path)
+ if not prefix:
+ return False
+ elif common_prefix is None:
+ common_prefix = prefix
+ elif prefix != common_prefix:
+ return False
+ return True
+
+
+def is_within_directory(directory: str, target: str) -> bool:
+ """
+ Return true if the absolute path of target is within the directory
+ """
+ abs_directory = os.path.abspath(directory)
+ abs_target = os.path.abspath(target)
+
+ prefix = os.path.commonprefix([abs_directory, abs_target])
+ return prefix == abs_directory
+
+
+def _get_default_mode_plus_executable() -> int:
+ return 0o777 & ~current_umask() | 0o111
+
+
+def set_extracted_file_to_default_mode_plus_executable(path: str) -> None:
+ """
+ Make file present at path have execute for user/group/world
+ (chmod +x) is no-op on windows per python docs
+ """
+ os.chmod(path, _get_default_mode_plus_executable())
+
+
+def zip_item_is_executable(info: ZipInfo) -> bool:
+ mode = info.external_attr >> 16
+ # if mode and regular file and any execute permissions for
+ # user/group/world?
+ return bool(mode and stat.S_ISREG(mode) and mode & 0o111)
+
+
+def unzip_file(filename: str, location: str, flatten: bool = True) -> None:
+ """
+ Unzip the file (with path `filename`) to the destination `location`. All
+ files are written based on system defaults and umask (i.e. permissions are
+ not preserved), except that regular file members with any execute
+ permissions (user, group, or world) have "chmod +x" applied after being
+ written. Note that for windows, any execute changes using os.chmod are
+ no-ops per the python docs.
+ """
+ ensure_dir(location)
+ zipfp = open(filename, "rb")
+ try:
+ zip = zipfile.ZipFile(zipfp, allowZip64=True)
+ leading = has_leading_dir(zip.namelist()) and flatten
+ for info in zip.infolist():
+ name = info.filename
+ fn = name
+ if leading:
+ fn = split_leading_dir(name)[1]
+ fn = os.path.join(location, fn)
+ dir = os.path.dirname(fn)
+ if not is_within_directory(location, fn):
+ message = (
+ "The zip file ({}) has a file ({}) trying to install "
+ "outside target directory ({})"
+ )
+ raise InstallationError(message.format(filename, fn, location))
+ if fn.endswith("/") or fn.endswith("\\"):
+ # A directory
+ ensure_dir(fn)
+ else:
+ ensure_dir(dir)
+ # Don't use read() to avoid allocating an arbitrarily large
+ # chunk of memory for the file's content
+ fp = zip.open(name)
+ try:
+ with open(fn, "wb") as destfp:
+ shutil.copyfileobj(fp, destfp)
+ finally:
+ fp.close()
+ if zip_item_is_executable(info):
+ set_extracted_file_to_default_mode_plus_executable(fn)
+ finally:
+ zipfp.close()
+
+
+def untar_file(filename: str, location: str) -> None:
+ """
+ Untar the file (with path `filename`) to the destination `location`.
+ All files are written based on system defaults and umask (i.e. permissions
+ are not preserved), except that regular file members with any execute
+ permissions (user, group, or world) have "chmod +x" applied on top of the
+ default. Note that for windows, any execute changes using os.chmod are
+ no-ops per the python docs.
+ """
+ ensure_dir(location)
+ if filename.lower().endswith(".gz") or filename.lower().endswith(".tgz"):
+ mode = "r:gz"
+ elif filename.lower().endswith(BZ2_EXTENSIONS):
+ mode = "r:bz2"
+ elif filename.lower().endswith(XZ_EXTENSIONS):
+ mode = "r:xz"
+ elif filename.lower().endswith(".tar"):
+ mode = "r"
+ else:
+ logger.warning(
+ "Cannot determine compression type for file %s",
+ filename,
+ )
+ mode = "r:*"
+
+ tar = tarfile.open(filename, mode, encoding="utf-8")
+ try:
+ leading = has_leading_dir([member.name for member in tar.getmembers()])
+
+ # PEP 706 added `tarfile.data_filter`, and made some other changes to
+ # Python's tarfile module (see below). The features were backported to
+ # security releases.
+ try:
+ data_filter = tarfile.data_filter
+ except AttributeError:
+ _untar_without_filter(filename, location, tar, leading)
+ else:
+ default_mode_plus_executable = _get_default_mode_plus_executable()
+
+ if leading:
+ # Strip the leading directory from all files in the archive,
+ # including hardlink targets (which are relative to the
+ # unpack location).
+ for member in tar.getmembers():
+ name_lead, name_rest = split_leading_dir(member.name)
+ member.name = name_rest
+ if member.islnk():
+ lnk_lead, lnk_rest = split_leading_dir(member.linkname)
+ if lnk_lead == name_lead:
+ member.linkname = lnk_rest
+
+ def pip_filter(member: tarfile.TarInfo, path: str) -> tarfile.TarInfo:
+ orig_mode = member.mode
+ try:
+ try:
+ member = data_filter(member, location)
+ except tarfile.LinkOutsideDestinationError:
+ if sys.version_info[:3] in {
+ (3, 8, 17),
+ (3, 9, 17),
+ (3, 10, 12),
+ (3, 11, 4),
+ }:
+ # The tarfile filter in specific Python versions
+ # raises LinkOutsideDestinationError on valid input
+ # (https://github.com/python/cpython/issues/107845)
+ # Ignore the error there, but do use the
+ # more lax `tar_filter`
+ member = tarfile.tar_filter(member, location)
+ else:
+ raise
+ except tarfile.TarError as exc:
+ message = "Invalid member in the tar file {}: {}"
+ # Filter error messages mention the member name.
+ # No need to add it here.
+ raise InstallationError(
+ message.format(
+ filename,
+ exc,
+ )
+ )
+ if member.isfile() and orig_mode & 0o111:
+ member.mode = default_mode_plus_executable
+ else:
+ # See PEP 706 note above.
+ # The PEP changed this from `int` to `Optional[int]`,
+ # where None means "use the default". Mypy doesn't
+ # know this yet.
+ member.mode = None # type: ignore [assignment]
+ return member
+
+ tar.extractall(location, filter=pip_filter)
+
+ finally:
+ tar.close()
+
+
+def _untar_without_filter(
+ filename: str,
+ location: str,
+ tar: tarfile.TarFile,
+ leading: bool,
+) -> None:
+ """Fallback for Python without tarfile.data_filter"""
+ for member in tar.getmembers():
+ fn = member.name
+ if leading:
+ fn = split_leading_dir(fn)[1]
+ path = os.path.join(location, fn)
+ if not is_within_directory(location, path):
+ message = (
+ "The tar file ({}) has a file ({}) trying to install "
+ "outside target directory ({})"
+ )
+ raise InstallationError(message.format(filename, path, location))
+ if member.isdir():
+ ensure_dir(path)
+ elif member.issym():
+ try:
+ tar._extract_member(member, path)
+ except Exception as exc:
+ # Some corrupt tar files seem to produce this
+ # (specifically bad symlinks)
+ logger.warning(
+ "In the tar file %s the member %s is invalid: %s",
+ filename,
+ member.name,
+ exc,
+ )
+ continue
+ else:
+ try:
+ fp = tar.extractfile(member)
+ except (KeyError, AttributeError) as exc:
+ # Some corrupt tar files seem to produce this
+ # (specifically bad symlinks)
+ logger.warning(
+ "In the tar file %s the member %s is invalid: %s",
+ filename,
+ member.name,
+ exc,
+ )
+ continue
+ ensure_dir(os.path.dirname(path))
+ assert fp is not None
+ with open(path, "wb") as destfp:
+ shutil.copyfileobj(fp, destfp)
+ fp.close()
+ # Update the timestamp (useful for cython compiled files)
+ tar.utime(member, path)
+ # member have any execute permissions for user/group/world?
+ if member.mode & 0o111:
+ set_extracted_file_to_default_mode_plus_executable(path)
+
+
+def unpack_file(
+ filename: str,
+ location: str,
+ content_type: Optional[str] = None,
+) -> None:
+ filename = os.path.realpath(filename)
+ if (
+ content_type == "application/zip"
+ or filename.lower().endswith(ZIP_EXTENSIONS)
+ or zipfile.is_zipfile(filename)
+ ):
+ unzip_file(filename, location, flatten=not filename.endswith(".whl"))
+ elif (
+ content_type == "application/x-gzip"
+ or tarfile.is_tarfile(filename)
+ or filename.lower().endswith(TAR_EXTENSIONS + BZ2_EXTENSIONS + XZ_EXTENSIONS)
+ ):
+ untar_file(filename, location)
+ else:
+ # FIXME: handle?
+ # FIXME: magic signatures?
+ logger.critical(
+ "Cannot unpack file %s (downloaded from %s, content-type: %s); "
+ "cannot detect archive format",
+ filename,
+ location,
+ content_type,
+ )
+ raise InstallationError(f"Cannot determine archive format of {location}")
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/urls.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/urls.py
new file mode 100644
index 000000000..9f34f882a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/urls.py
@@ -0,0 +1,55 @@
+import os
+import string
+import urllib.parse
+import urllib.request
+
+from .compat import WINDOWS
+
+
+def path_to_url(path: str) -> str:
+ """
+ Convert a path to a file: URL. The path will be made absolute and have
+ quoted path parts.
+ """
+ path = os.path.normpath(os.path.abspath(path))
+ url = urllib.parse.urljoin("file:", urllib.request.pathname2url(path))
+ return url
+
+
+def url_to_path(url: str) -> str:
+ """
+ Convert a file: URL to a path.
+ """
+ assert url.startswith(
+ "file:"
+ ), f"You can only turn file: urls into filenames (not {url!r})"
+
+ _, netloc, path, _, _ = urllib.parse.urlsplit(url)
+
+ if not netloc or netloc == "localhost":
+ # According to RFC 8089, same as empty authority.
+ netloc = ""
+ elif WINDOWS:
+ # If we have a UNC path, prepend UNC share notation.
+ netloc = "\\\\" + netloc
+ else:
+ raise ValueError(
+ f"non-local file URIs are not supported on this platform: {url!r}"
+ )
+
+ path = urllib.request.url2pathname(netloc + path)
+
+ # On Windows, urlsplit parses the path as something like "/C:/Users/foo".
+ # This creates issues for path-related functions like io.open(), so we try
+ # to detect and strip the leading slash.
+ if (
+ WINDOWS
+ and not netloc # Not UNC.
+ and len(path) >= 3
+ and path[0] == "/" # Leading slash to strip.
+ and path[1] in string.ascii_letters # Drive letter.
+ and path[2:4] in (":", ":/") # Colon + end of string, or colon + absolute path.
+ ):
+ path = path[1:]
+
+ return path
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/virtualenv.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/virtualenv.py
new file mode 100644
index 000000000..882e36f5c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/virtualenv.py
@@ -0,0 +1,104 @@
+import logging
+import os
+import re
+import site
+import sys
+from typing import List, Optional
+
+logger = logging.getLogger(__name__)
+_INCLUDE_SYSTEM_SITE_PACKAGES_REGEX = re.compile(
+ r"include-system-site-packages\s*=\s*(?P<value>true|false)"
+)
+
+
+def _running_under_venv() -> bool:
+ """Checks if sys.base_prefix and sys.prefix match.
+
+ This handles PEP 405 compliant virtual environments.
+ """
+ return sys.prefix != getattr(sys, "base_prefix", sys.prefix)
+
+
+def _running_under_legacy_virtualenv() -> bool:
+ """Checks if sys.real_prefix is set.
+
+ This handles virtual environments created with pypa's virtualenv.
+ """
+ # pypa/virtualenv case
+ return hasattr(sys, "real_prefix")
+
+
+def running_under_virtualenv() -> bool:
+ """True if we're running inside a virtual environment, False otherwise."""
+ return _running_under_venv() or _running_under_legacy_virtualenv()
+
+
+def _get_pyvenv_cfg_lines() -> Optional[List[str]]:
+ """Reads {sys.prefix}/pyvenv.cfg and returns its contents as list of lines
+
+ Returns None, if it could not read/access the file.
+ """
+ pyvenv_cfg_file = os.path.join(sys.prefix, "pyvenv.cfg")
+ try:
+ # Although PEP 405 does not specify, the built-in venv module always
+ # writes with UTF-8. (pypa/pip#8717)
+ with open(pyvenv_cfg_file, encoding="utf-8") as f:
+ return f.read().splitlines() # avoids trailing newlines
+ except OSError:
+ return None
+
+
+def _no_global_under_venv() -> bool:
+ """Check `{sys.prefix}/pyvenv.cfg` for system site-packages inclusion
+
+ PEP 405 specifies that when system site-packages are not supposed to be
+ visible from a virtual environment, `pyvenv.cfg` must contain the following
+ line:
+
+ include-system-site-packages = false
+
+ Additionally, log a warning if accessing the file fails.
+ """
+ cfg_lines = _get_pyvenv_cfg_lines()
+ if cfg_lines is None:
+ # We're not in a "sane" venv, so assume there is no system
+ # site-packages access (since that's PEP 405's default state).
+ logger.warning(
+ "Could not access 'pyvenv.cfg' despite a virtual environment "
+ "being active. Assuming global site-packages is not accessible "
+ "in this environment."
+ )
+ return True
+
+ for line in cfg_lines:
+ match = _INCLUDE_SYSTEM_SITE_PACKAGES_REGEX.match(line)
+ if match is not None and match.group("value") == "false":
+ return True
+ return False
+
+
+def _no_global_under_legacy_virtualenv() -> bool:
+ """Check if "no-global-site-packages.txt" exists beside site.py
+
+ This mirrors logic in pypa/virtualenv for determining whether system
+ site-packages are visible in the virtual environment.
+ """
+ site_mod_dir = os.path.dirname(os.path.abspath(site.__file__))
+ no_global_site_packages_file = os.path.join(
+ site_mod_dir,
+ "no-global-site-packages.txt",
+ )
+ return os.path.exists(no_global_site_packages_file)
+
+
+def virtualenv_no_global() -> bool:
+ """Returns a boolean, whether running in venv with no system site-packages."""
+ # PEP 405 compliance needs to be checked first since virtualenv >=20 would
+ # return True for both checks, but is only able to use the PEP 405 config.
+ if _running_under_venv():
+ return _no_global_under_venv()
+
+ if _running_under_legacy_virtualenv():
+ return _no_global_under_legacy_virtualenv()
+
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/utils/wheel.py b/solutions/.venv/Lib/site-packages/pip/_internal/utils/wheel.py
new file mode 100644
index 000000000..f85aee8a3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/utils/wheel.py
@@ -0,0 +1,134 @@
+"""Support functions for working with wheel files.
+"""
+
+import logging
+from email.message import Message
+from email.parser import Parser
+from typing import Tuple
+from zipfile import BadZipFile, ZipFile
+
+from pip._vendor.packaging.utils import canonicalize_name
+
+from pip._internal.exceptions import UnsupportedWheel
+
+VERSION_COMPATIBLE = (1, 0)
+
+
+logger = logging.getLogger(__name__)
+
+
+def parse_wheel(wheel_zip: ZipFile, name: str) -> Tuple[str, Message]:
+ """Extract information from the provided wheel, ensuring it meets basic
+ standards.
+
+ Returns the name of the .dist-info directory and the parsed WHEEL metadata.
+ """
+ try:
+ info_dir = wheel_dist_info_dir(wheel_zip, name)
+ metadata = wheel_metadata(wheel_zip, info_dir)
+ version = wheel_version(metadata)
+ except UnsupportedWheel as e:
+ raise UnsupportedWheel(f"{name} has an invalid wheel, {e}")
+
+ check_compatibility(version, name)
+
+ return info_dir, metadata
+
+
+def wheel_dist_info_dir(source: ZipFile, name: str) -> str:
+ """Returns the name of the contained .dist-info directory.
+
+ Raises AssertionError or UnsupportedWheel if not found, >1 found, or
+ it doesn't match the provided name.
+ """
+ # Zip file path separators must be /
+ subdirs = {p.split("/", 1)[0] for p in source.namelist()}
+
+ info_dirs = [s for s in subdirs if s.endswith(".dist-info")]
+
+ if not info_dirs:
+ raise UnsupportedWheel(".dist-info directory not found")
+
+ if len(info_dirs) > 1:
+ raise UnsupportedWheel(
+ "multiple .dist-info directories found: {}".format(", ".join(info_dirs))
+ )
+
+ info_dir = info_dirs[0]
+
+ info_dir_name = canonicalize_name(info_dir)
+ canonical_name = canonicalize_name(name)
+ if not info_dir_name.startswith(canonical_name):
+ raise UnsupportedWheel(
+ f".dist-info directory {info_dir!r} does not start with {canonical_name!r}"
+ )
+
+ return info_dir
+
+
+def read_wheel_metadata_file(source: ZipFile, path: str) -> bytes:
+ try:
+ return source.read(path)
+ # BadZipFile for general corruption, KeyError for missing entry,
+ # and RuntimeError for password-protected files
+ except (BadZipFile, KeyError, RuntimeError) as e:
+ raise UnsupportedWheel(f"could not read {path!r} file: {e!r}")
+
+
+def wheel_metadata(source: ZipFile, dist_info_dir: str) -> Message:
+ """Return the WHEEL metadata of an extracted wheel, if possible.
+ Otherwise, raise UnsupportedWheel.
+ """
+ path = f"{dist_info_dir}/WHEEL"
+ # Zip file path separators must be /
+ wheel_contents = read_wheel_metadata_file(source, path)
+
+ try:
+ wheel_text = wheel_contents.decode()
+ except UnicodeDecodeError as e:
+ raise UnsupportedWheel(f"error decoding {path!r}: {e!r}")
+
+ # FeedParser (used by Parser) does not raise any exceptions. The returned
+ # message may have .defects populated, but for backwards-compatibility we
+ # currently ignore them.
+ return Parser().parsestr(wheel_text)
+
+
+def wheel_version(wheel_data: Message) -> Tuple[int, ...]:
+ """Given WHEEL metadata, return the parsed Wheel-Version.
+ Otherwise, raise UnsupportedWheel.
+ """
+ version_text = wheel_data["Wheel-Version"]
+ if version_text is None:
+ raise UnsupportedWheel("WHEEL is missing Wheel-Version")
+
+ version = version_text.strip()
+
+ try:
+ return tuple(map(int, version.split(".")))
+ except ValueError:
+ raise UnsupportedWheel(f"invalid Wheel-Version: {version!r}")
+
+
+def check_compatibility(version: Tuple[int, ...], name: str) -> None:
+ """Raises errors or warns if called with an incompatible Wheel-Version.
+
+ pip should refuse to install a Wheel-Version that's a major series
+ ahead of what it's compatible with (e.g 2.0 > 1.1); and warn when
+ installing a version only minor version ahead (e.g 1.2 > 1.1).
+
+ version: a 2-tuple representing a Wheel-Version (Major, Minor)
+ name: name of wheel or package to raise exception about
+
+ :raises UnsupportedWheel: when an incompatible Wheel-Version is given
+ """
+ if version[0] > VERSION_COMPATIBLE[0]:
+ raise UnsupportedWheel(
+ "{}'s Wheel-Version ({}) is not compatible with this version "
+ "of pip".format(name, ".".join(map(str, version)))
+ )
+ elif version > VERSION_COMPATIBLE:
+ logger.warning(
+ "Installing from a newer Wheel-Version (%s)",
+ ".".join(map(str, version)),
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/vcs/__init__.py b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/__init__.py
new file mode 100644
index 000000000..b6beddbe6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/__init__.py
@@ -0,0 +1,15 @@
+# Expose a limited set of classes and functions so callers outside of
+# the vcs package don't need to import deeper than `pip._internal.vcs`.
+# (The test directory may still need to import from a vcs sub-package.)
+# Import all vcs modules to register each VCS in the VcsSupport object.
+import pip._internal.vcs.bazaar
+import pip._internal.vcs.git
+import pip._internal.vcs.mercurial
+import pip._internal.vcs.subversion # noqa: F401
+from pip._internal.vcs.versioncontrol import ( # noqa: F401
+ RemoteNotFoundError,
+ RemoteNotValidError,
+ is_url,
+ make_vcs_requirement_url,
+ vcs,
+)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/vcs/bazaar.py b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/bazaar.py
new file mode 100644
index 000000000..c754b7cc5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/bazaar.py
@@ -0,0 +1,112 @@
+import logging
+from typing import List, Optional, Tuple
+
+from pip._internal.utils.misc import HiddenText, display_path
+from pip._internal.utils.subprocess import make_command
+from pip._internal.utils.urls import path_to_url
+from pip._internal.vcs.versioncontrol import (
+ AuthInfo,
+ RemoteNotFoundError,
+ RevOptions,
+ VersionControl,
+ vcs,
+)
+
+logger = logging.getLogger(__name__)
+
+
+class Bazaar(VersionControl):
+ name = "bzr"
+ dirname = ".bzr"
+ repo_name = "branch"
+ schemes = (
+ "bzr+http",
+ "bzr+https",
+ "bzr+ssh",
+ "bzr+sftp",
+ "bzr+ftp",
+ "bzr+lp",
+ "bzr+file",
+ )
+
+ @staticmethod
+ def get_base_rev_args(rev: str) -> List[str]:
+ return ["-r", rev]
+
+ def fetch_new(
+ self, dest: str, url: HiddenText, rev_options: RevOptions, verbosity: int
+ ) -> None:
+ rev_display = rev_options.to_display()
+ logger.info(
+ "Checking out %s%s to %s",
+ url,
+ rev_display,
+ display_path(dest),
+ )
+ if verbosity <= 0:
+ flags = ["--quiet"]
+ elif verbosity == 1:
+ flags = []
+ else:
+ flags = [f"-{'v'*verbosity}"]
+ cmd_args = make_command(
+ "checkout", "--lightweight", *flags, rev_options.to_args(), url, dest
+ )
+ self.run_command(cmd_args)
+
+ def switch(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ self.run_command(make_command("switch", url), cwd=dest)
+
+ def update(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ output = self.run_command(
+ make_command("info"), show_stdout=False, stdout_only=True, cwd=dest
+ )
+ if output.startswith("Standalone "):
+ # Older versions of pip used to create standalone branches.
+ # Convert the standalone branch to a checkout by calling "bzr bind".
+ cmd_args = make_command("bind", "-q", url)
+ self.run_command(cmd_args, cwd=dest)
+
+ cmd_args = make_command("update", "-q", rev_options.to_args())
+ self.run_command(cmd_args, cwd=dest)
+
+ @classmethod
+ def get_url_rev_and_auth(cls, url: str) -> Tuple[str, Optional[str], AuthInfo]:
+ # hotfix the URL scheme after removing bzr+ from bzr+ssh:// re-add it
+ url, rev, user_pass = super().get_url_rev_and_auth(url)
+ if url.startswith("ssh://"):
+ url = "bzr+" + url
+ return url, rev, user_pass
+
+ @classmethod
+ def get_remote_url(cls, location: str) -> str:
+ urls = cls.run_command(
+ ["info"], show_stdout=False, stdout_only=True, cwd=location
+ )
+ for line in urls.splitlines():
+ line = line.strip()
+ for x in ("checkout of branch: ", "parent branch: "):
+ if line.startswith(x):
+ repo = line.split(x)[1]
+ if cls._is_local_repository(repo):
+ return path_to_url(repo)
+ return repo
+ raise RemoteNotFoundError
+
+ @classmethod
+ def get_revision(cls, location: str) -> str:
+ revision = cls.run_command(
+ ["revno"],
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ )
+ return revision.splitlines()[-1]
+
+ @classmethod
+ def is_commit_id_equal(cls, dest: str, name: Optional[str]) -> bool:
+ """Always assume the versions don't match"""
+ return False
+
+
+vcs.register(Bazaar)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/vcs/git.py b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/git.py
new file mode 100644
index 000000000..0425debb3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/git.py
@@ -0,0 +1,527 @@
+import logging
+import os.path
+import pathlib
+import re
+import urllib.parse
+import urllib.request
+from dataclasses import replace
+from typing import List, Optional, Tuple
+
+from pip._internal.exceptions import BadCommand, InstallationError
+from pip._internal.utils.misc import HiddenText, display_path, hide_url
+from pip._internal.utils.subprocess import make_command
+from pip._internal.vcs.versioncontrol import (
+ AuthInfo,
+ RemoteNotFoundError,
+ RemoteNotValidError,
+ RevOptions,
+ VersionControl,
+ find_path_to_project_root_from_repo_root,
+ vcs,
+)
+
+urlsplit = urllib.parse.urlsplit
+urlunsplit = urllib.parse.urlunsplit
+
+
+logger = logging.getLogger(__name__)
+
+
+GIT_VERSION_REGEX = re.compile(
+ r"^git version " # Prefix.
+ r"(\d+)" # Major.
+ r"\.(\d+)" # Dot, minor.
+ r"(?:\.(\d+))?" # Optional dot, patch.
+ r".*$" # Suffix, including any pre- and post-release segments we don't care about.
+)
+
+HASH_REGEX = re.compile("^[a-fA-F0-9]{40}$")
+
+# SCP (Secure copy protocol) shorthand. e.g. 'git@example.com:foo/bar.git'
+SCP_REGEX = re.compile(
+ r"""^
+ # Optional user, e.g. 'git@'
+ (\w+@)?
+ # Server, e.g. 'github.com'.
+ ([^/:]+):
+ # The server-side path. e.g. 'user/project.git'. Must start with an
+ # alphanumeric character so as not to be confusable with a Windows paths
+ # like 'C:/foo/bar' or 'C:\foo\bar'.
+ (\w[^:]*)
+ $""",
+ re.VERBOSE,
+)
+
+
+def looks_like_hash(sha: str) -> bool:
+ return bool(HASH_REGEX.match(sha))
+
+
+class Git(VersionControl):
+ name = "git"
+ dirname = ".git"
+ repo_name = "clone"
+ schemes = (
+ "git+http",
+ "git+https",
+ "git+ssh",
+ "git+git",
+ "git+file",
+ )
+ # Prevent the user's environment variables from interfering with pip:
+ # https://github.com/pypa/pip/issues/1130
+ unset_environ = ("GIT_DIR", "GIT_WORK_TREE")
+ default_arg_rev = "HEAD"
+
+ @staticmethod
+ def get_base_rev_args(rev: str) -> List[str]:
+ return [rev]
+
+ def is_immutable_rev_checkout(self, url: str, dest: str) -> bool:
+ _, rev_options = self.get_url_rev_options(hide_url(url))
+ if not rev_options.rev:
+ return False
+ if not self.is_commit_id_equal(dest, rev_options.rev):
+ # the current commit is different from rev,
+ # which means rev was something else than a commit hash
+ return False
+ # return False in the rare case rev is both a commit hash
+ # and a tag or a branch; we don't want to cache in that case
+ # because that branch/tag could point to something else in the future
+ is_tag_or_branch = bool(self.get_revision_sha(dest, rev_options.rev)[0])
+ return not is_tag_or_branch
+
+ def get_git_version(self) -> Tuple[int, ...]:
+ version = self.run_command(
+ ["version"],
+ command_desc="git version",
+ show_stdout=False,
+ stdout_only=True,
+ )
+ match = GIT_VERSION_REGEX.match(version)
+ if not match:
+ logger.warning("Can't parse git version: %s", version)
+ return ()
+ return (int(match.group(1)), int(match.group(2)))
+
+ @classmethod
+ def get_current_branch(cls, location: str) -> Optional[str]:
+ """
+ Return the current branch, or None if HEAD isn't at a branch
+ (e.g. detached HEAD).
+ """
+ # git-symbolic-ref exits with empty stdout if "HEAD" is a detached
+ # HEAD rather than a symbolic ref. In addition, the -q causes the
+ # command to exit with status code 1 instead of 128 in this case
+ # and to suppress the message to stderr.
+ args = ["symbolic-ref", "-q", "HEAD"]
+ output = cls.run_command(
+ args,
+ extra_ok_returncodes=(1,),
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ )
+ ref = output.strip()
+
+ if ref.startswith("refs/heads/"):
+ return ref[len("refs/heads/") :]
+
+ return None
+
+ @classmethod
+ def get_revision_sha(cls, dest: str, rev: str) -> Tuple[Optional[str], bool]:
+ """
+ Return (sha_or_none, is_branch), where sha_or_none is a commit hash
+ if the revision names a remote branch or tag, otherwise None.
+
+ Args:
+ dest: the repository directory.
+ rev: the revision name.
+ """
+ # Pass rev to pre-filter the list.
+ output = cls.run_command(
+ ["show-ref", rev],
+ cwd=dest,
+ show_stdout=False,
+ stdout_only=True,
+ on_returncode="ignore",
+ )
+ refs = {}
+ # NOTE: We do not use splitlines here since that would split on other
+ # unicode separators, which can be maliciously used to install a
+ # different revision.
+ for line in output.strip().split("\n"):
+ line = line.rstrip("\r")
+ if not line:
+ continue
+ try:
+ ref_sha, ref_name = line.split(" ", maxsplit=2)
+ except ValueError:
+ # Include the offending line to simplify troubleshooting if
+ # this error ever occurs.
+ raise ValueError(f"unexpected show-ref line: {line!r}")
+
+ refs[ref_name] = ref_sha
+
+ branch_ref = f"refs/remotes/origin/{rev}"
+ tag_ref = f"refs/tags/{rev}"
+
+ sha = refs.get(branch_ref)
+ if sha is not None:
+ return (sha, True)
+
+ sha = refs.get(tag_ref)
+
+ return (sha, False)
+
+ @classmethod
+ def _should_fetch(cls, dest: str, rev: str) -> bool:
+ """
+ Return true if rev is a ref or is a commit that we don't have locally.
+
+ Branches and tags are not considered in this method because they are
+ assumed to be always available locally (which is a normal outcome of
+ ``git clone`` and ``git fetch --tags``).
+ """
+ if rev.startswith("refs/"):
+ # Always fetch remote refs.
+ return True
+
+ if not looks_like_hash(rev):
+ # Git fetch would fail with abbreviated commits.
+ return False
+
+ if cls.has_commit(dest, rev):
+ # Don't fetch if we have the commit locally.
+ return False
+
+ return True
+
+ @classmethod
+ def resolve_revision(
+ cls, dest: str, url: HiddenText, rev_options: RevOptions
+ ) -> RevOptions:
+ """
+ Resolve a revision to a new RevOptions object with the SHA1 of the
+ branch, tag, or ref if found.
+
+ Args:
+ rev_options: a RevOptions object.
+ """
+ rev = rev_options.arg_rev
+ # The arg_rev property's implementation for Git ensures that the
+ # rev return value is always non-None.
+ assert rev is not None
+
+ sha, is_branch = cls.get_revision_sha(dest, rev)
+
+ if sha is not None:
+ rev_options = rev_options.make_new(sha)
+ rev_options = replace(rev_options, branch_name=(rev if is_branch else None))
+
+ return rev_options
+
+ # Do not show a warning for the common case of something that has
+ # the form of a Git commit hash.
+ if not looks_like_hash(rev):
+ logger.warning(
+ "Did not find branch or tag '%s', assuming revision or ref.",
+ rev,
+ )
+
+ if not cls._should_fetch(dest, rev):
+ return rev_options
+
+ # fetch the requested revision
+ cls.run_command(
+ make_command("fetch", "-q", url, rev_options.to_args()),
+ cwd=dest,
+ )
+ # Change the revision to the SHA of the ref we fetched
+ sha = cls.get_revision(dest, rev="FETCH_HEAD")
+ rev_options = rev_options.make_new(sha)
+
+ return rev_options
+
+ @classmethod
+ def is_commit_id_equal(cls, dest: str, name: Optional[str]) -> bool:
+ """
+ Return whether the current commit hash equals the given name.
+
+ Args:
+ dest: the repository directory.
+ name: a string name.
+ """
+ if not name:
+ # Then avoid an unnecessary subprocess call.
+ return False
+
+ return cls.get_revision(dest) == name
+
+ def fetch_new(
+ self, dest: str, url: HiddenText, rev_options: RevOptions, verbosity: int
+ ) -> None:
+ rev_display = rev_options.to_display()
+ logger.info("Cloning %s%s to %s", url, rev_display, display_path(dest))
+ if verbosity <= 0:
+ flags: Tuple[str, ...] = ("--quiet",)
+ elif verbosity == 1:
+ flags = ()
+ else:
+ flags = ("--verbose", "--progress")
+ if self.get_git_version() >= (2, 17):
+ # Git added support for partial clone in 2.17
+ # https://git-scm.com/docs/partial-clone
+ # Speeds up cloning by functioning without a complete copy of repository
+ self.run_command(
+ make_command(
+ "clone",
+ "--filter=blob:none",
+ *flags,
+ url,
+ dest,
+ )
+ )
+ else:
+ self.run_command(make_command("clone", *flags, url, dest))
+
+ if rev_options.rev:
+ # Then a specific revision was requested.
+ rev_options = self.resolve_revision(dest, url, rev_options)
+ branch_name = getattr(rev_options, "branch_name", None)
+ logger.debug("Rev options %s, branch_name %s", rev_options, branch_name)
+ if branch_name is None:
+ # Only do a checkout if the current commit id doesn't match
+ # the requested revision.
+ if not self.is_commit_id_equal(dest, rev_options.rev):
+ cmd_args = make_command(
+ "checkout",
+ "-q",
+ rev_options.to_args(),
+ )
+ self.run_command(cmd_args, cwd=dest)
+ elif self.get_current_branch(dest) != branch_name:
+ # Then a specific branch was requested, and that branch
+ # is not yet checked out.
+ track_branch = f"origin/{branch_name}"
+ cmd_args = [
+ "checkout",
+ "-b",
+ branch_name,
+ "--track",
+ track_branch,
+ ]
+ self.run_command(cmd_args, cwd=dest)
+ else:
+ sha = self.get_revision(dest)
+ rev_options = rev_options.make_new(sha)
+
+ logger.info("Resolved %s to commit %s", url, rev_options.rev)
+
+ #: repo may contain submodules
+ self.update_submodules(dest)
+
+ def switch(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ self.run_command(
+ make_command("config", "remote.origin.url", url),
+ cwd=dest,
+ )
+ cmd_args = make_command("checkout", "-q", rev_options.to_args())
+ self.run_command(cmd_args, cwd=dest)
+
+ self.update_submodules(dest)
+
+ def update(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ # First fetch changes from the default remote
+ if self.get_git_version() >= (1, 9):
+ # fetch tags in addition to everything else
+ self.run_command(["fetch", "-q", "--tags"], cwd=dest)
+ else:
+ self.run_command(["fetch", "-q"], cwd=dest)
+ # Then reset to wanted revision (maybe even origin/master)
+ rev_options = self.resolve_revision(dest, url, rev_options)
+ cmd_args = make_command("reset", "--hard", "-q", rev_options.to_args())
+ self.run_command(cmd_args, cwd=dest)
+ #: update submodules
+ self.update_submodules(dest)
+
+ @classmethod
+ def get_remote_url(cls, location: str) -> str:
+ """
+ Return URL of the first remote encountered.
+
+ Raises RemoteNotFoundError if the repository does not have a remote
+ url configured.
+ """
+ # We need to pass 1 for extra_ok_returncodes since the command
+ # exits with return code 1 if there are no matching lines.
+ stdout = cls.run_command(
+ ["config", "--get-regexp", r"remote\..*\.url"],
+ extra_ok_returncodes=(1,),
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ )
+ remotes = stdout.splitlines()
+ try:
+ found_remote = remotes[0]
+ except IndexError:
+ raise RemoteNotFoundError
+
+ for remote in remotes:
+ if remote.startswith("remote.origin.url "):
+ found_remote = remote
+ break
+ url = found_remote.split(" ")[1]
+ return cls._git_remote_to_pip_url(url.strip())
+
+ @staticmethod
+ def _git_remote_to_pip_url(url: str) -> str:
+ """
+ Convert a remote url from what git uses to what pip accepts.
+
+ There are 3 legal forms **url** may take:
+
+ 1. A fully qualified url: ssh://git@example.com/foo/bar.git
+ 2. A local project.git folder: /path/to/bare/repository.git
+ 3. SCP shorthand for form 1: git@example.com:foo/bar.git
+
+ Form 1 is output as-is. Form 2 must be converted to URI and form 3 must
+ be converted to form 1.
+
+ See the corresponding test test_git_remote_url_to_pip() for examples of
+ sample inputs/outputs.
+ """
+ if re.match(r"\w+://", url):
+ # This is already valid. Pass it though as-is.
+ return url
+ if os.path.exists(url):
+ # A local bare remote (git clone --mirror).
+ # Needs a file:// prefix.
+ return pathlib.PurePath(url).as_uri()
+ scp_match = SCP_REGEX.match(url)
+ if scp_match:
+ # Add an ssh:// prefix and replace the ':' with a '/'.
+ return scp_match.expand(r"ssh://\1\2/\3")
+ # Otherwise, bail out.
+ raise RemoteNotValidError(url)
+
+ @classmethod
+ def has_commit(cls, location: str, rev: str) -> bool:
+ """
+ Check if rev is a commit that is available in the local repository.
+ """
+ try:
+ cls.run_command(
+ ["rev-parse", "-q", "--verify", "sha^" + rev],
+ cwd=location,
+ log_failed_cmd=False,
+ )
+ except InstallationError:
+ return False
+ else:
+ return True
+
+ @classmethod
+ def get_revision(cls, location: str, rev: Optional[str] = None) -> str:
+ if rev is None:
+ rev = "HEAD"
+ current_rev = cls.run_command(
+ ["rev-parse", rev],
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ )
+ return current_rev.strip()
+
+ @classmethod
+ def get_subdirectory(cls, location: str) -> Optional[str]:
+ """
+ Return the path to Python project root, relative to the repo root.
+ Return None if the project root is in the repo root.
+ """
+ # find the repo root
+ git_dir = cls.run_command(
+ ["rev-parse", "--git-dir"],
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ ).strip()
+ if not os.path.isabs(git_dir):
+ git_dir = os.path.join(location, git_dir)
+ repo_root = os.path.abspath(os.path.join(git_dir, ".."))
+ return find_path_to_project_root_from_repo_root(location, repo_root)
+
+ @classmethod
+ def get_url_rev_and_auth(cls, url: str) -> Tuple[str, Optional[str], AuthInfo]:
+ """
+ Prefixes stub URLs like 'user@hostname:user/repo.git' with 'ssh://'.
+ That's required because although they use SSH they sometimes don't
+ work with a ssh:// scheme (e.g. GitHub). But we need a scheme for
+ parsing. Hence we remove it again afterwards and return it as a stub.
+ """
+ # Works around an apparent Git bug
+ # (see https://article.gmane.org/gmane.comp.version-control.git/146500)
+ scheme, netloc, path, query, fragment = urlsplit(url)
+ if scheme.endswith("file"):
+ initial_slashes = path[: -len(path.lstrip("/"))]
+ newpath = initial_slashes + urllib.request.url2pathname(path).replace(
+ "\\", "/"
+ ).lstrip("/")
+ after_plus = scheme.find("+") + 1
+ url = scheme[:after_plus] + urlunsplit(
+ (scheme[after_plus:], netloc, newpath, query, fragment),
+ )
+
+ if "://" not in url:
+ assert "file:" not in url
+ url = url.replace("git+", "git+ssh://")
+ url, rev, user_pass = super().get_url_rev_and_auth(url)
+ url = url.replace("ssh://", "")
+ else:
+ url, rev, user_pass = super().get_url_rev_and_auth(url)
+
+ return url, rev, user_pass
+
+ @classmethod
+ def update_submodules(cls, location: str) -> None:
+ if not os.path.exists(os.path.join(location, ".gitmodules")):
+ return
+ cls.run_command(
+ ["submodule", "update", "--init", "--recursive", "-q"],
+ cwd=location,
+ )
+
+ @classmethod
+ def get_repository_root(cls, location: str) -> Optional[str]:
+ loc = super().get_repository_root(location)
+ if loc:
+ return loc
+ try:
+ r = cls.run_command(
+ ["rev-parse", "--show-toplevel"],
+ cwd=location,
+ show_stdout=False,
+ stdout_only=True,
+ on_returncode="raise",
+ log_failed_cmd=False,
+ )
+ except BadCommand:
+ logger.debug(
+ "could not determine if %s is under git control "
+ "because git is not available",
+ location,
+ )
+ return None
+ except InstallationError:
+ return None
+ return os.path.normpath(r.rstrip("\r\n"))
+
+ @staticmethod
+ def should_add_vcs_url_prefix(repo_url: str) -> bool:
+ """In either https or ssh form, requirements must be prefixed with git+."""
+ return True
+
+
+vcs.register(Git)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/vcs/mercurial.py b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/mercurial.py
new file mode 100644
index 000000000..c183d41d0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/mercurial.py
@@ -0,0 +1,163 @@
+import configparser
+import logging
+import os
+from typing import List, Optional, Tuple
+
+from pip._internal.exceptions import BadCommand, InstallationError
+from pip._internal.utils.misc import HiddenText, display_path
+from pip._internal.utils.subprocess import make_command
+from pip._internal.utils.urls import path_to_url
+from pip._internal.vcs.versioncontrol import (
+ RevOptions,
+ VersionControl,
+ find_path_to_project_root_from_repo_root,
+ vcs,
+)
+
+logger = logging.getLogger(__name__)
+
+
+class Mercurial(VersionControl):
+ name = "hg"
+ dirname = ".hg"
+ repo_name = "clone"
+ schemes = (
+ "hg+file",
+ "hg+http",
+ "hg+https",
+ "hg+ssh",
+ "hg+static-http",
+ )
+
+ @staticmethod
+ def get_base_rev_args(rev: str) -> List[str]:
+ return [f"--rev={rev}"]
+
+ def fetch_new(
+ self, dest: str, url: HiddenText, rev_options: RevOptions, verbosity: int
+ ) -> None:
+ rev_display = rev_options.to_display()
+ logger.info(
+ "Cloning hg %s%s to %s",
+ url,
+ rev_display,
+ display_path(dest),
+ )
+ if verbosity <= 0:
+ flags: Tuple[str, ...] = ("--quiet",)
+ elif verbosity == 1:
+ flags = ()
+ elif verbosity == 2:
+ flags = ("--verbose",)
+ else:
+ flags = ("--verbose", "--debug")
+ self.run_command(make_command("clone", "--noupdate", *flags, url, dest))
+ self.run_command(
+ make_command("update", *flags, rev_options.to_args()),
+ cwd=dest,
+ )
+
+ def switch(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ repo_config = os.path.join(dest, self.dirname, "hgrc")
+ config = configparser.RawConfigParser()
+ try:
+ config.read(repo_config)
+ config.set("paths", "default", url.secret)
+ with open(repo_config, "w") as config_file:
+ config.write(config_file)
+ except (OSError, configparser.NoSectionError) as exc:
+ logger.warning("Could not switch Mercurial repository to %s: %s", url, exc)
+ else:
+ cmd_args = make_command("update", "-q", rev_options.to_args())
+ self.run_command(cmd_args, cwd=dest)
+
+ def update(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ self.run_command(["pull", "-q"], cwd=dest)
+ cmd_args = make_command("update", "-q", rev_options.to_args())
+ self.run_command(cmd_args, cwd=dest)
+
+ @classmethod
+ def get_remote_url(cls, location: str) -> str:
+ url = cls.run_command(
+ ["showconfig", "paths.default"],
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ ).strip()
+ if cls._is_local_repository(url):
+ url = path_to_url(url)
+ return url.strip()
+
+ @classmethod
+ def get_revision(cls, location: str) -> str:
+ """
+ Return the repository-local changeset revision number, as an integer.
+ """
+ current_revision = cls.run_command(
+ ["parents", "--template={rev}"],
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ ).strip()
+ return current_revision
+
+ @classmethod
+ def get_requirement_revision(cls, location: str) -> str:
+ """
+ Return the changeset identification hash, as a 40-character
+ hexadecimal string
+ """
+ current_rev_hash = cls.run_command(
+ ["parents", "--template={node}"],
+ show_stdout=False,
+ stdout_only=True,
+ cwd=location,
+ ).strip()
+ return current_rev_hash
+
+ @classmethod
+ def is_commit_id_equal(cls, dest: str, name: Optional[str]) -> bool:
+ """Always assume the versions don't match"""
+ return False
+
+ @classmethod
+ def get_subdirectory(cls, location: str) -> Optional[str]:
+ """
+ Return the path to Python project root, relative to the repo root.
+ Return None if the project root is in the repo root.
+ """
+ # find the repo root
+ repo_root = cls.run_command(
+ ["root"], show_stdout=False, stdout_only=True, cwd=location
+ ).strip()
+ if not os.path.isabs(repo_root):
+ repo_root = os.path.abspath(os.path.join(location, repo_root))
+ return find_path_to_project_root_from_repo_root(location, repo_root)
+
+ @classmethod
+ def get_repository_root(cls, location: str) -> Optional[str]:
+ loc = super().get_repository_root(location)
+ if loc:
+ return loc
+ try:
+ r = cls.run_command(
+ ["root"],
+ cwd=location,
+ show_stdout=False,
+ stdout_only=True,
+ on_returncode="raise",
+ log_failed_cmd=False,
+ )
+ except BadCommand:
+ logger.debug(
+ "could not determine if %s is under hg control "
+ "because hg is not available",
+ location,
+ )
+ return None
+ except InstallationError:
+ return None
+ return os.path.normpath(r.rstrip("\r\n"))
+
+
+vcs.register(Mercurial)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/vcs/subversion.py b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/subversion.py
new file mode 100644
index 000000000..f359266d9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/subversion.py
@@ -0,0 +1,324 @@
+import logging
+import os
+import re
+from typing import List, Optional, Tuple
+
+from pip._internal.utils.misc import (
+ HiddenText,
+ display_path,
+ is_console_interactive,
+ is_installable_dir,
+ split_auth_from_netloc,
+)
+from pip._internal.utils.subprocess import CommandArgs, make_command
+from pip._internal.vcs.versioncontrol import (
+ AuthInfo,
+ RemoteNotFoundError,
+ RevOptions,
+ VersionControl,
+ vcs,
+)
+
+logger = logging.getLogger(__name__)
+
+_svn_xml_url_re = re.compile('url="([^"]+)"')
+_svn_rev_re = re.compile(r'committed-rev="(\d+)"')
+_svn_info_xml_rev_re = re.compile(r'\s*revision="(\d+)"')
+_svn_info_xml_url_re = re.compile(r"<url>(.*)</url>")
+
+
+class Subversion(VersionControl):
+ name = "svn"
+ dirname = ".svn"
+ repo_name = "checkout"
+ schemes = ("svn+ssh", "svn+http", "svn+https", "svn+svn", "svn+file")
+
+ @classmethod
+ def should_add_vcs_url_prefix(cls, remote_url: str) -> bool:
+ return True
+
+ @staticmethod
+ def get_base_rev_args(rev: str) -> List[str]:
+ return ["-r", rev]
+
+ @classmethod
+ def get_revision(cls, location: str) -> str:
+ """
+ Return the maximum revision for all files under a given location
+ """
+ # Note: taken from setuptools.command.egg_info
+ revision = 0
+
+ for base, dirs, _ in os.walk(location):
+ if cls.dirname not in dirs:
+ dirs[:] = []
+ continue # no sense walking uncontrolled subdirs
+ dirs.remove(cls.dirname)
+ entries_fn = os.path.join(base, cls.dirname, "entries")
+ if not os.path.exists(entries_fn):
+ # FIXME: should we warn?
+ continue
+
+ dirurl, localrev = cls._get_svn_url_rev(base)
+
+ if base == location:
+ assert dirurl is not None
+ base = dirurl + "/" # save the root url
+ elif not dirurl or not dirurl.startswith(base):
+ dirs[:] = []
+ continue # not part of the same svn tree, skip it
+ revision = max(revision, localrev)
+ return str(revision)
+
+ @classmethod
+ def get_netloc_and_auth(
+ cls, netloc: str, scheme: str
+ ) -> Tuple[str, Tuple[Optional[str], Optional[str]]]:
+ """
+ This override allows the auth information to be passed to svn via the
+ --username and --password options instead of via the URL.
+ """
+ if scheme == "ssh":
+ # The --username and --password options can't be used for
+ # svn+ssh URLs, so keep the auth information in the URL.
+ return super().get_netloc_and_auth(netloc, scheme)
+
+ return split_auth_from_netloc(netloc)
+
+ @classmethod
+ def get_url_rev_and_auth(cls, url: str) -> Tuple[str, Optional[str], AuthInfo]:
+ # hotfix the URL scheme after removing svn+ from svn+ssh:// re-add it
+ url, rev, user_pass = super().get_url_rev_and_auth(url)
+ if url.startswith("ssh://"):
+ url = "svn+" + url
+ return url, rev, user_pass
+
+ @staticmethod
+ def make_rev_args(
+ username: Optional[str], password: Optional[HiddenText]
+ ) -> CommandArgs:
+ extra_args: CommandArgs = []
+ if username:
+ extra_args += ["--username", username]
+ if password:
+ extra_args += ["--password", password]
+
+ return extra_args
+
+ @classmethod
+ def get_remote_url(cls, location: str) -> str:
+ # In cases where the source is in a subdirectory, we have to look up in
+ # the location until we find a valid project root.
+ orig_location = location
+ while not is_installable_dir(location):
+ last_location = location
+ location = os.path.dirname(location)
+ if location == last_location:
+ # We've traversed up to the root of the filesystem without
+ # finding a Python project.
+ logger.warning(
+ "Could not find Python project for directory %s (tried all "
+ "parent directories)",
+ orig_location,
+ )
+ raise RemoteNotFoundError
+
+ url, _rev = cls._get_svn_url_rev(location)
+ if url is None:
+ raise RemoteNotFoundError
+
+ return url
+
+ @classmethod
+ def _get_svn_url_rev(cls, location: str) -> Tuple[Optional[str], int]:
+ from pip._internal.exceptions import InstallationError
+
+ entries_path = os.path.join(location, cls.dirname, "entries")
+ if os.path.exists(entries_path):
+ with open(entries_path) as f:
+ data = f.read()
+ else: # subversion >= 1.7 does not have the 'entries' file
+ data = ""
+
+ url = None
+ if data.startswith("8") or data.startswith("9") or data.startswith("10"):
+ entries = list(map(str.splitlines, data.split("\n\x0c\n")))
+ del entries[0][0] # get rid of the '8'
+ url = entries[0][3]
+ revs = [int(d[9]) for d in entries if len(d) > 9 and d[9]] + [0]
+ elif data.startswith("<?xml"):
+ match = _svn_xml_url_re.search(data)
+ if not match:
+ raise ValueError(f"Badly formatted data: {data!r}")
+ url = match.group(1) # get repository URL
+ revs = [int(m.group(1)) for m in _svn_rev_re.finditer(data)] + [0]
+ else:
+ try:
+ # subversion >= 1.7
+ # Note that using get_remote_call_options is not necessary here
+ # because `svn info` is being run against a local directory.
+ # We don't need to worry about making sure interactive mode
+ # is being used to prompt for passwords, because passwords
+ # are only potentially needed for remote server requests.
+ xml = cls.run_command(
+ ["info", "--xml", location],
+ show_stdout=False,
+ stdout_only=True,
+ )
+ match = _svn_info_xml_url_re.search(xml)
+ assert match is not None
+ url = match.group(1)
+ revs = [int(m.group(1)) for m in _svn_info_xml_rev_re.finditer(xml)]
+ except InstallationError:
+ url, revs = None, []
+
+ if revs:
+ rev = max(revs)
+ else:
+ rev = 0
+
+ return url, rev
+
+ @classmethod
+ def is_commit_id_equal(cls, dest: str, name: Optional[str]) -> bool:
+ """Always assume the versions don't match"""
+ return False
+
+ def __init__(self, use_interactive: Optional[bool] = None) -> None:
+ if use_interactive is None:
+ use_interactive = is_console_interactive()
+ self.use_interactive = use_interactive
+
+ # This member is used to cache the fetched version of the current
+ # ``svn`` client.
+ # Special value definitions:
+ # None: Not evaluated yet.
+ # Empty tuple: Could not parse version.
+ self._vcs_version: Optional[Tuple[int, ...]] = None
+
+ super().__init__()
+
+ def call_vcs_version(self) -> Tuple[int, ...]:
+ """Query the version of the currently installed Subversion client.
+
+ :return: A tuple containing the parts of the version information or
+ ``()`` if the version returned from ``svn`` could not be parsed.
+ :raises: BadCommand: If ``svn`` is not installed.
+ """
+ # Example versions:
+ # svn, version 1.10.3 (r1842928)
+ # compiled Feb 25 2019, 14:20:39 on x86_64-apple-darwin17.0.0
+ # svn, version 1.7.14 (r1542130)
+ # compiled Mar 28 2018, 08:49:13 on x86_64-pc-linux-gnu
+ # svn, version 1.12.0-SlikSvn (SlikSvn/1.12.0)
+ # compiled May 28 2019, 13:44:56 on x86_64-microsoft-windows6.2
+ version_prefix = "svn, version "
+ version = self.run_command(["--version"], show_stdout=False, stdout_only=True)
+ if not version.startswith(version_prefix):
+ return ()
+
+ version = version[len(version_prefix) :].split()[0]
+ version_list = version.partition("-")[0].split(".")
+ try:
+ parsed_version = tuple(map(int, version_list))
+ except ValueError:
+ return ()
+
+ return parsed_version
+
+ def get_vcs_version(self) -> Tuple[int, ...]:
+ """Return the version of the currently installed Subversion client.
+
+ If the version of the Subversion client has already been queried,
+ a cached value will be used.
+
+ :return: A tuple containing the parts of the version information or
+ ``()`` if the version returned from ``svn`` could not be parsed.
+ :raises: BadCommand: If ``svn`` is not installed.
+ """
+ if self._vcs_version is not None:
+ # Use cached version, if available.
+ # If parsing the version failed previously (empty tuple),
+ # do not attempt to parse it again.
+ return self._vcs_version
+
+ vcs_version = self.call_vcs_version()
+ self._vcs_version = vcs_version
+ return vcs_version
+
+ def get_remote_call_options(self) -> CommandArgs:
+ """Return options to be used on calls to Subversion that contact the server.
+
+ These options are applicable for the following ``svn`` subcommands used
+ in this class.
+
+ - checkout
+ - switch
+ - update
+
+ :return: A list of command line arguments to pass to ``svn``.
+ """
+ if not self.use_interactive:
+ # --non-interactive switch is available since Subversion 0.14.4.
+ # Subversion < 1.8 runs in interactive mode by default.
+ return ["--non-interactive"]
+
+ svn_version = self.get_vcs_version()
+ # By default, Subversion >= 1.8 runs in non-interactive mode if
+ # stdin is not a TTY. Since that is how pip invokes SVN, in
+ # call_subprocess(), pip must pass --force-interactive to ensure
+ # the user can be prompted for a password, if required.
+ # SVN added the --force-interactive option in SVN 1.8. Since
+ # e.g. RHEL/CentOS 7, which is supported until 2024, ships with
+ # SVN 1.7, pip should continue to support SVN 1.7. Therefore, pip
+ # can't safely add the option if the SVN version is < 1.8 (or unknown).
+ if svn_version >= (1, 8):
+ return ["--force-interactive"]
+
+ return []
+
+ def fetch_new(
+ self, dest: str, url: HiddenText, rev_options: RevOptions, verbosity: int
+ ) -> None:
+ rev_display = rev_options.to_display()
+ logger.info(
+ "Checking out %s%s to %s",
+ url,
+ rev_display,
+ display_path(dest),
+ )
+ if verbosity <= 0:
+ flags = ["--quiet"]
+ else:
+ flags = []
+ cmd_args = make_command(
+ "checkout",
+ *flags,
+ self.get_remote_call_options(),
+ rev_options.to_args(),
+ url,
+ dest,
+ )
+ self.run_command(cmd_args)
+
+ def switch(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ cmd_args = make_command(
+ "switch",
+ self.get_remote_call_options(),
+ rev_options.to_args(),
+ url,
+ dest,
+ )
+ self.run_command(cmd_args)
+
+ def update(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ cmd_args = make_command(
+ "update",
+ self.get_remote_call_options(),
+ rev_options.to_args(),
+ dest,
+ )
+ self.run_command(cmd_args)
+
+
+vcs.register(Subversion)
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/vcs/versioncontrol.py b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/versioncontrol.py
new file mode 100644
index 000000000..a4133165e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/vcs/versioncontrol.py
@@ -0,0 +1,688 @@
+"""Handles all VCS (version control) support"""
+
+import logging
+import os
+import shutil
+import sys
+import urllib.parse
+from dataclasses import dataclass, field
+from typing import (
+ Any,
+ Dict,
+ Iterable,
+ Iterator,
+ List,
+ Literal,
+ Mapping,
+ Optional,
+ Tuple,
+ Type,
+ Union,
+)
+
+from pip._internal.cli.spinners import SpinnerInterface
+from pip._internal.exceptions import BadCommand, InstallationError
+from pip._internal.utils.misc import (
+ HiddenText,
+ ask_path_exists,
+ backup_dir,
+ display_path,
+ hide_url,
+ hide_value,
+ is_installable_dir,
+ rmtree,
+)
+from pip._internal.utils.subprocess import (
+ CommandArgs,
+ call_subprocess,
+ format_command_args,
+ make_command,
+)
+
+__all__ = ["vcs"]
+
+
+logger = logging.getLogger(__name__)
+
+AuthInfo = Tuple[Optional[str], Optional[str]]
+
+
+def is_url(name: str) -> bool:
+ """
+ Return true if the name looks like a URL.
+ """
+ scheme = urllib.parse.urlsplit(name).scheme
+ if not scheme:
+ return False
+ return scheme in ["http", "https", "file", "ftp"] + vcs.all_schemes
+
+
+def make_vcs_requirement_url(
+ repo_url: str, rev: str, project_name: str, subdir: Optional[str] = None
+) -> str:
+ """
+ Return the URL for a VCS requirement.
+
+ Args:
+ repo_url: the remote VCS url, with any needed VCS prefix (e.g. "git+").
+ project_name: the (unescaped) project name.
+ """
+ egg_project_name = project_name.replace("-", "_")
+ req = f"{repo_url}@{rev}#egg={egg_project_name}"
+ if subdir:
+ req += f"&subdirectory={subdir}"
+
+ return req
+
+
+def find_path_to_project_root_from_repo_root(
+ location: str, repo_root: str
+) -> Optional[str]:
+ """
+ Find the the Python project's root by searching up the filesystem from
+ `location`. Return the path to project root relative to `repo_root`.
+ Return None if the project root is `repo_root`, or cannot be found.
+ """
+ # find project root.
+ orig_location = location
+ while not is_installable_dir(location):
+ last_location = location
+ location = os.path.dirname(location)
+ if location == last_location:
+ # We've traversed up to the root of the filesystem without
+ # finding a Python project.
+ logger.warning(
+ "Could not find a Python project for directory %s (tried all "
+ "parent directories)",
+ orig_location,
+ )
+ return None
+
+ if os.path.samefile(repo_root, location):
+ return None
+
+ return os.path.relpath(location, repo_root)
+
+
+class RemoteNotFoundError(Exception):
+ pass
+
+
+class RemoteNotValidError(Exception):
+ def __init__(self, url: str):
+ super().__init__(url)
+ self.url = url
+
+
+@dataclass(frozen=True)
+class RevOptions:
+ """
+ Encapsulates a VCS-specific revision to install, along with any VCS
+ install options.
+
+ Args:
+ vc_class: a VersionControl subclass.
+ rev: the name of the revision to install.
+ extra_args: a list of extra options.
+ """
+
+ vc_class: Type["VersionControl"]
+ rev: Optional[str] = None
+ extra_args: CommandArgs = field(default_factory=list)
+ branch_name: Optional[str] = None
+
+ def __repr__(self) -> str:
+ return f"<RevOptions {self.vc_class.name}: rev={self.rev!r}>"
+
+ @property
+ def arg_rev(self) -> Optional[str]:
+ if self.rev is None:
+ return self.vc_class.default_arg_rev
+
+ return self.rev
+
+ def to_args(self) -> CommandArgs:
+ """
+ Return the VCS-specific command arguments.
+ """
+ args: CommandArgs = []
+ rev = self.arg_rev
+ if rev is not None:
+ args += self.vc_class.get_base_rev_args(rev)
+ args += self.extra_args
+
+ return args
+
+ def to_display(self) -> str:
+ if not self.rev:
+ return ""
+
+ return f" (to revision {self.rev})"
+
+ def make_new(self, rev: str) -> "RevOptions":
+ """
+ Make a copy of the current instance, but with a new rev.
+
+ Args:
+ rev: the name of the revision for the new object.
+ """
+ return self.vc_class.make_rev_options(rev, extra_args=self.extra_args)
+
+
+class VcsSupport:
+ _registry: Dict[str, "VersionControl"] = {}
+ schemes = ["ssh", "git", "hg", "bzr", "sftp", "svn"]
+
+ def __init__(self) -> None:
+ # Register more schemes with urlparse for various version control
+ # systems
+ urllib.parse.uses_netloc.extend(self.schemes)
+ super().__init__()
+
+ def __iter__(self) -> Iterator[str]:
+ return self._registry.__iter__()
+
+ @property
+ def backends(self) -> List["VersionControl"]:
+ return list(self._registry.values())
+
+ @property
+ def dirnames(self) -> List[str]:
+ return [backend.dirname for backend in self.backends]
+
+ @property
+ def all_schemes(self) -> List[str]:
+ schemes: List[str] = []
+ for backend in self.backends:
+ schemes.extend(backend.schemes)
+ return schemes
+
+ def register(self, cls: Type["VersionControl"]) -> None:
+ if not hasattr(cls, "name"):
+ logger.warning("Cannot register VCS %s", cls.__name__)
+ return
+ if cls.name not in self._registry:
+ self._registry[cls.name] = cls()
+ logger.debug("Registered VCS backend: %s", cls.name)
+
+ def unregister(self, name: str) -> None:
+ if name in self._registry:
+ del self._registry[name]
+
+ def get_backend_for_dir(self, location: str) -> Optional["VersionControl"]:
+ """
+ Return a VersionControl object if a repository of that type is found
+ at the given directory.
+ """
+ vcs_backends = {}
+ for vcs_backend in self._registry.values():
+ repo_path = vcs_backend.get_repository_root(location)
+ if not repo_path:
+ continue
+ logger.debug("Determine that %s uses VCS: %s", location, vcs_backend.name)
+ vcs_backends[repo_path] = vcs_backend
+
+ if not vcs_backends:
+ return None
+
+ # Choose the VCS in the inner-most directory. Since all repository
+ # roots found here would be either `location` or one of its
+ # parents, the longest path should have the most path components,
+ # i.e. the backend representing the inner-most repository.
+ inner_most_repo_path = max(vcs_backends, key=len)
+ return vcs_backends[inner_most_repo_path]
+
+ def get_backend_for_scheme(self, scheme: str) -> Optional["VersionControl"]:
+ """
+ Return a VersionControl object or None.
+ """
+ for vcs_backend in self._registry.values():
+ if scheme in vcs_backend.schemes:
+ return vcs_backend
+ return None
+
+ def get_backend(self, name: str) -> Optional["VersionControl"]:
+ """
+ Return a VersionControl object or None.
+ """
+ name = name.lower()
+ return self._registry.get(name)
+
+
+vcs = VcsSupport()
+
+
+class VersionControl:
+ name = ""
+ dirname = ""
+ repo_name = ""
+ # List of supported schemes for this Version Control
+ schemes: Tuple[str, ...] = ()
+ # Iterable of environment variable names to pass to call_subprocess().
+ unset_environ: Tuple[str, ...] = ()
+ default_arg_rev: Optional[str] = None
+
+ @classmethod
+ def should_add_vcs_url_prefix(cls, remote_url: str) -> bool:
+ """
+ Return whether the vcs prefix (e.g. "git+") should be added to a
+ repository's remote url when used in a requirement.
+ """
+ return not remote_url.lower().startswith(f"{cls.name}:")
+
+ @classmethod
+ def get_subdirectory(cls, location: str) -> Optional[str]:
+ """
+ Return the path to Python project root, relative to the repo root.
+ Return None if the project root is in the repo root.
+ """
+ return None
+
+ @classmethod
+ def get_requirement_revision(cls, repo_dir: str) -> str:
+ """
+ Return the revision string that should be used in a requirement.
+ """
+ return cls.get_revision(repo_dir)
+
+ @classmethod
+ def get_src_requirement(cls, repo_dir: str, project_name: str) -> str:
+ """
+ Return the requirement string to use to redownload the files
+ currently at the given repository directory.
+
+ Args:
+ project_name: the (unescaped) project name.
+
+ The return value has a form similar to the following:
+
+ {repository_url}@{revision}#egg={project_name}
+ """
+ repo_url = cls.get_remote_url(repo_dir)
+
+ if cls.should_add_vcs_url_prefix(repo_url):
+ repo_url = f"{cls.name}+{repo_url}"
+
+ revision = cls.get_requirement_revision(repo_dir)
+ subdir = cls.get_subdirectory(repo_dir)
+ req = make_vcs_requirement_url(repo_url, revision, project_name, subdir=subdir)
+
+ return req
+
+ @staticmethod
+ def get_base_rev_args(rev: str) -> List[str]:
+ """
+ Return the base revision arguments for a vcs command.
+
+ Args:
+ rev: the name of a revision to install. Cannot be None.
+ """
+ raise NotImplementedError
+
+ def is_immutable_rev_checkout(self, url: str, dest: str) -> bool:
+ """
+ Return true if the commit hash checked out at dest matches
+ the revision in url.
+
+ Always return False, if the VCS does not support immutable commit
+ hashes.
+
+ This method does not check if there are local uncommitted changes
+ in dest after checkout, as pip currently has no use case for that.
+ """
+ return False
+
+ @classmethod
+ def make_rev_options(
+ cls, rev: Optional[str] = None, extra_args: Optional[CommandArgs] = None
+ ) -> RevOptions:
+ """
+ Return a RevOptions object.
+
+ Args:
+ rev: the name of a revision to install.
+ extra_args: a list of extra options.
+ """
+ return RevOptions(cls, rev, extra_args=extra_args or [])
+
+ @classmethod
+ def _is_local_repository(cls, repo: str) -> bool:
+ """
+ posix absolute paths start with os.path.sep,
+ win32 ones start with drive (like c:\\folder)
+ """
+ drive, tail = os.path.splitdrive(repo)
+ return repo.startswith(os.path.sep) or bool(drive)
+
+ @classmethod
+ def get_netloc_and_auth(
+ cls, netloc: str, scheme: str
+ ) -> Tuple[str, Tuple[Optional[str], Optional[str]]]:
+ """
+ Parse the repository URL's netloc, and return the new netloc to use
+ along with auth information.
+
+ Args:
+ netloc: the original repository URL netloc.
+ scheme: the repository URL's scheme without the vcs prefix.
+
+ This is mainly for the Subversion class to override, so that auth
+ information can be provided via the --username and --password options
+ instead of through the URL. For other subclasses like Git without
+ such an option, auth information must stay in the URL.
+
+ Returns: (netloc, (username, password)).
+ """
+ return netloc, (None, None)
+
+ @classmethod
+ def get_url_rev_and_auth(cls, url: str) -> Tuple[str, Optional[str], AuthInfo]:
+ """
+ Parse the repository URL to use, and return the URL, revision,
+ and auth info to use.
+
+ Returns: (url, rev, (username, password)).
+ """
+ scheme, netloc, path, query, frag = urllib.parse.urlsplit(url)
+ if "+" not in scheme:
+ raise ValueError(
+ f"Sorry, {url!r} is a malformed VCS url. "
+ "The format is <vcs>+<protocol>://<url>, "
+ "e.g. svn+http://myrepo/svn/MyApp#egg=MyApp"
+ )
+ # Remove the vcs prefix.
+ scheme = scheme.split("+", 1)[1]
+ netloc, user_pass = cls.get_netloc_and_auth(netloc, scheme)
+ rev = None
+ if "@" in path:
+ path, rev = path.rsplit("@", 1)
+ if not rev:
+ raise InstallationError(
+ f"The URL {url!r} has an empty revision (after @) "
+ "which is not supported. Include a revision after @ "
+ "or remove @ from the URL."
+ )
+ url = urllib.parse.urlunsplit((scheme, netloc, path, query, ""))
+ return url, rev, user_pass
+
+ @staticmethod
+ def make_rev_args(
+ username: Optional[str], password: Optional[HiddenText]
+ ) -> CommandArgs:
+ """
+ Return the RevOptions "extra arguments" to use in obtain().
+ """
+ return []
+
+ def get_url_rev_options(self, url: HiddenText) -> Tuple[HiddenText, RevOptions]:
+ """
+ Return the URL and RevOptions object to use in obtain(),
+ as a tuple (url, rev_options).
+ """
+ secret_url, rev, user_pass = self.get_url_rev_and_auth(url.secret)
+ username, secret_password = user_pass
+ password: Optional[HiddenText] = None
+ if secret_password is not None:
+ password = hide_value(secret_password)
+ extra_args = self.make_rev_args(username, password)
+ rev_options = self.make_rev_options(rev, extra_args=extra_args)
+
+ return hide_url(secret_url), rev_options
+
+ @staticmethod
+ def normalize_url(url: str) -> str:
+ """
+ Normalize a URL for comparison by unquoting it and removing any
+ trailing slash.
+ """
+ return urllib.parse.unquote(url).rstrip("/")
+
+ @classmethod
+ def compare_urls(cls, url1: str, url2: str) -> bool:
+ """
+ Compare two repo URLs for identity, ignoring incidental differences.
+ """
+ return cls.normalize_url(url1) == cls.normalize_url(url2)
+
+ def fetch_new(
+ self, dest: str, url: HiddenText, rev_options: RevOptions, verbosity: int
+ ) -> None:
+ """
+ Fetch a revision from a repository, in the case that this is the
+ first fetch from the repository.
+
+ Args:
+ dest: the directory to fetch the repository to.
+ rev_options: a RevOptions object.
+ verbosity: verbosity level.
+ """
+ raise NotImplementedError
+
+ def switch(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ """
+ Switch the repo at ``dest`` to point to ``URL``.
+
+ Args:
+ rev_options: a RevOptions object.
+ """
+ raise NotImplementedError
+
+ def update(self, dest: str, url: HiddenText, rev_options: RevOptions) -> None:
+ """
+ Update an already-existing repo to the given ``rev_options``.
+
+ Args:
+ rev_options: a RevOptions object.
+ """
+ raise NotImplementedError
+
+ @classmethod
+ def is_commit_id_equal(cls, dest: str, name: Optional[str]) -> bool:
+ """
+ Return whether the id of the current commit equals the given name.
+
+ Args:
+ dest: the repository directory.
+ name: a string name.
+ """
+ raise NotImplementedError
+
+ def obtain(self, dest: str, url: HiddenText, verbosity: int) -> None:
+ """
+ Install or update in editable mode the package represented by this
+ VersionControl object.
+
+ :param dest: the repository directory in which to install or update.
+ :param url: the repository URL starting with a vcs prefix.
+ :param verbosity: verbosity level.
+ """
+ url, rev_options = self.get_url_rev_options(url)
+
+ if not os.path.exists(dest):
+ self.fetch_new(dest, url, rev_options, verbosity=verbosity)
+ return
+
+ rev_display = rev_options.to_display()
+ if self.is_repository_directory(dest):
+ existing_url = self.get_remote_url(dest)
+ if self.compare_urls(existing_url, url.secret):
+ logger.debug(
+ "%s in %s exists, and has correct URL (%s)",
+ self.repo_name.title(),
+ display_path(dest),
+ url,
+ )
+ if not self.is_commit_id_equal(dest, rev_options.rev):
+ logger.info(
+ "Updating %s %s%s",
+ display_path(dest),
+ self.repo_name,
+ rev_display,
+ )
+ self.update(dest, url, rev_options)
+ else:
+ logger.info("Skipping because already up-to-date.")
+ return
+
+ logger.warning(
+ "%s %s in %s exists with URL %s",
+ self.name,
+ self.repo_name,
+ display_path(dest),
+ existing_url,
+ )
+ prompt = ("(s)witch, (i)gnore, (w)ipe, (b)ackup ", ("s", "i", "w", "b"))
+ else:
+ logger.warning(
+ "Directory %s already exists, and is not a %s %s.",
+ dest,
+ self.name,
+ self.repo_name,
+ )
+ # https://github.com/python/mypy/issues/1174
+ prompt = ("(i)gnore, (w)ipe, (b)ackup ", ("i", "w", "b")) # type: ignore
+
+ logger.warning(
+ "The plan is to install the %s repository %s",
+ self.name,
+ url,
+ )
+ response = ask_path_exists(f"What to do? {prompt[0]}", prompt[1])
+
+ if response == "a":
+ sys.exit(-1)
+
+ if response == "w":
+ logger.warning("Deleting %s", display_path(dest))
+ rmtree(dest)
+ self.fetch_new(dest, url, rev_options, verbosity=verbosity)
+ return
+
+ if response == "b":
+ dest_dir = backup_dir(dest)
+ logger.warning("Backing up %s to %s", display_path(dest), dest_dir)
+ shutil.move(dest, dest_dir)
+ self.fetch_new(dest, url, rev_options, verbosity=verbosity)
+ return
+
+ # Do nothing if the response is "i".
+ if response == "s":
+ logger.info(
+ "Switching %s %s to %s%s",
+ self.repo_name,
+ display_path(dest),
+ url,
+ rev_display,
+ )
+ self.switch(dest, url, rev_options)
+
+ def unpack(self, location: str, url: HiddenText, verbosity: int) -> None:
+ """
+ Clean up current location and download the url repository
+ (and vcs infos) into location
+
+ :param url: the repository URL starting with a vcs prefix.
+ :param verbosity: verbosity level.
+ """
+ if os.path.exists(location):
+ rmtree(location)
+ self.obtain(location, url=url, verbosity=verbosity)
+
+ @classmethod
+ def get_remote_url(cls, location: str) -> str:
+ """
+ Return the url used at location
+
+ Raises RemoteNotFoundError if the repository does not have a remote
+ url configured.
+ """
+ raise NotImplementedError
+
+ @classmethod
+ def get_revision(cls, location: str) -> str:
+ """
+ Return the current commit id of the files at the given location.
+ """
+ raise NotImplementedError
+
+ @classmethod
+ def run_command(
+ cls,
+ cmd: Union[List[str], CommandArgs],
+ show_stdout: bool = True,
+ cwd: Optional[str] = None,
+ on_returncode: 'Literal["raise", "warn", "ignore"]' = "raise",
+ extra_ok_returncodes: Optional[Iterable[int]] = None,
+ command_desc: Optional[str] = None,
+ extra_environ: Optional[Mapping[str, Any]] = None,
+ spinner: Optional[SpinnerInterface] = None,
+ log_failed_cmd: bool = True,
+ stdout_only: bool = False,
+ ) -> str:
+ """
+ Run a VCS subcommand
+ This is simply a wrapper around call_subprocess that adds the VCS
+ command name, and checks that the VCS is available
+ """
+ cmd = make_command(cls.name, *cmd)
+ if command_desc is None:
+ command_desc = format_command_args(cmd)
+ try:
+ return call_subprocess(
+ cmd,
+ show_stdout,
+ cwd,
+ on_returncode=on_returncode,
+ extra_ok_returncodes=extra_ok_returncodes,
+ command_desc=command_desc,
+ extra_environ=extra_environ,
+ unset_environ=cls.unset_environ,
+ spinner=spinner,
+ log_failed_cmd=log_failed_cmd,
+ stdout_only=stdout_only,
+ )
+ except NotADirectoryError:
+ raise BadCommand(f"Cannot find command {cls.name!r} - invalid PATH")
+ except FileNotFoundError:
+ # errno.ENOENT = no such file or directory
+ # In other words, the VCS executable isn't available
+ raise BadCommand(
+ f"Cannot find command {cls.name!r} - do you have "
+ f"{cls.name!r} installed and in your PATH?"
+ )
+ except PermissionError:
+ # errno.EACCES = Permission denied
+ # This error occurs, for instance, when the command is installed
+ # only for another user. So, the current user don't have
+ # permission to call the other user command.
+ raise BadCommand(
+ f"No permission to execute {cls.name!r} - install it "
+ f"locally, globally (ask admin), or check your PATH. "
+ f"See possible solutions at "
+ f"https://pip.pypa.io/en/latest/reference/pip_freeze/"
+ f"#fixing-permission-denied."
+ )
+
+ @classmethod
+ def is_repository_directory(cls, path: str) -> bool:
+ """
+ Return whether a directory path is a repository directory.
+ """
+ logger.debug("Checking in %s for %s (%s)...", path, cls.dirname, cls.name)
+ return os.path.exists(os.path.join(path, cls.dirname))
+
+ @classmethod
+ def get_repository_root(cls, location: str) -> Optional[str]:
+ """
+ Return the "root" (top-level) directory controlled by the vcs,
+ or `None` if the directory is not in any.
+
+ It is meant to be overridden to implement smarter detection
+ mechanisms for specific vcs.
+
+ This can do more than is_repository_directory() alone. For
+ example, the Git override checks that Git is actually available.
+ """
+ if cls.is_repository_directory(location):
+ return location
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_internal/wheel_builder.py b/solutions/.venv/Lib/site-packages/pip/_internal/wheel_builder.py
new file mode 100644
index 000000000..93f8e1f5b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_internal/wheel_builder.py
@@ -0,0 +1,354 @@
+"""Orchestrator for building wheels from InstallRequirements.
+"""
+
+import logging
+import os.path
+import re
+import shutil
+from typing import Iterable, List, Optional, Tuple
+
+from pip._vendor.packaging.utils import canonicalize_name, canonicalize_version
+from pip._vendor.packaging.version import InvalidVersion, Version
+
+from pip._internal.cache import WheelCache
+from pip._internal.exceptions import InvalidWheelFilename, UnsupportedWheel
+from pip._internal.metadata import FilesystemWheel, get_wheel_distribution
+from pip._internal.models.link import Link
+from pip._internal.models.wheel import Wheel
+from pip._internal.operations.build.wheel import build_wheel_pep517
+from pip._internal.operations.build.wheel_editable import build_wheel_editable
+from pip._internal.operations.build.wheel_legacy import build_wheel_legacy
+from pip._internal.req.req_install import InstallRequirement
+from pip._internal.utils.logging import indent_log
+from pip._internal.utils.misc import ensure_dir, hash_file
+from pip._internal.utils.setuptools_build import make_setuptools_clean_args
+from pip._internal.utils.subprocess import call_subprocess
+from pip._internal.utils.temp_dir import TempDirectory
+from pip._internal.utils.urls import path_to_url
+from pip._internal.vcs import vcs
+
+logger = logging.getLogger(__name__)
+
+_egg_info_re = re.compile(r"([a-z0-9_.]+)-([a-z0-9_.!+-]+)", re.IGNORECASE)
+
+BuildResult = Tuple[List[InstallRequirement], List[InstallRequirement]]
+
+
+def _contains_egg_info(s: str) -> bool:
+ """Determine whether the string looks like an egg_info.
+
+ :param s: The string to parse. E.g. foo-2.1
+ """
+ return bool(_egg_info_re.search(s))
+
+
+def _should_build(
+ req: InstallRequirement,
+ need_wheel: bool,
+) -> bool:
+ """Return whether an InstallRequirement should be built into a wheel."""
+ if req.constraint:
+ # never build requirements that are merely constraints
+ return False
+ if req.is_wheel:
+ if need_wheel:
+ logger.info(
+ "Skipping %s, due to already being wheel.",
+ req.name,
+ )
+ return False
+
+ if need_wheel:
+ # i.e. pip wheel, not pip install
+ return True
+
+ # From this point, this concerns the pip install command only
+ # (need_wheel=False).
+
+ if not req.source_dir:
+ return False
+
+ if req.editable:
+ # we only build PEP 660 editable requirements
+ return req.supports_pyproject_editable
+
+ return True
+
+
+def should_build_for_wheel_command(
+ req: InstallRequirement,
+) -> bool:
+ return _should_build(req, need_wheel=True)
+
+
+def should_build_for_install_command(
+ req: InstallRequirement,
+) -> bool:
+ return _should_build(req, need_wheel=False)
+
+
+def _should_cache(
+ req: InstallRequirement,
+) -> Optional[bool]:
+ """
+ Return whether a built InstallRequirement can be stored in the persistent
+ wheel cache, assuming the wheel cache is available, and _should_build()
+ has determined a wheel needs to be built.
+ """
+ if req.editable or not req.source_dir:
+ # never cache editable requirements
+ return False
+
+ if req.link and req.link.is_vcs:
+ # VCS checkout. Do not cache
+ # unless it points to an immutable commit hash.
+ assert not req.editable
+ assert req.source_dir
+ vcs_backend = vcs.get_backend_for_scheme(req.link.scheme)
+ assert vcs_backend
+ if vcs_backend.is_immutable_rev_checkout(req.link.url, req.source_dir):
+ return True
+ return False
+
+ assert req.link
+ base, ext = req.link.splitext()
+ if _contains_egg_info(base):
+ return True
+
+ # Otherwise, do not cache.
+ return False
+
+
+def _get_cache_dir(
+ req: InstallRequirement,
+ wheel_cache: WheelCache,
+) -> str:
+ """Return the persistent or temporary cache directory where the built
+ wheel need to be stored.
+ """
+ cache_available = bool(wheel_cache.cache_dir)
+ assert req.link
+ if cache_available and _should_cache(req):
+ cache_dir = wheel_cache.get_path_for_link(req.link)
+ else:
+ cache_dir = wheel_cache.get_ephem_path_for_link(req.link)
+ return cache_dir
+
+
+def _verify_one(req: InstallRequirement, wheel_path: str) -> None:
+ canonical_name = canonicalize_name(req.name or "")
+ w = Wheel(os.path.basename(wheel_path))
+ if canonicalize_name(w.name) != canonical_name:
+ raise InvalidWheelFilename(
+ f"Wheel has unexpected file name: expected {canonical_name!r}, "
+ f"got {w.name!r}",
+ )
+ dist = get_wheel_distribution(FilesystemWheel(wheel_path), canonical_name)
+ dist_verstr = str(dist.version)
+ if canonicalize_version(dist_verstr) != canonicalize_version(w.version):
+ raise InvalidWheelFilename(
+ f"Wheel has unexpected file name: expected {dist_verstr!r}, "
+ f"got {w.version!r}",
+ )
+ metadata_version_value = dist.metadata_version
+ if metadata_version_value is None:
+ raise UnsupportedWheel("Missing Metadata-Version")
+ try:
+ metadata_version = Version(metadata_version_value)
+ except InvalidVersion:
+ msg = f"Invalid Metadata-Version: {metadata_version_value}"
+ raise UnsupportedWheel(msg)
+ if metadata_version >= Version("1.2") and not isinstance(dist.version, Version):
+ raise UnsupportedWheel(
+ f"Metadata 1.2 mandates PEP 440 version, but {dist_verstr!r} is not"
+ )
+
+
+def _build_one(
+ req: InstallRequirement,
+ output_dir: str,
+ verify: bool,
+ build_options: List[str],
+ global_options: List[str],
+ editable: bool,
+) -> Optional[str]:
+ """Build one wheel.
+
+ :return: The filename of the built wheel, or None if the build failed.
+ """
+ artifact = "editable" if editable else "wheel"
+ try:
+ ensure_dir(output_dir)
+ except OSError as e:
+ logger.warning(
+ "Building %s for %s failed: %s",
+ artifact,
+ req.name,
+ e,
+ )
+ return None
+
+ # Install build deps into temporary directory (PEP 518)
+ with req.build_env:
+ wheel_path = _build_one_inside_env(
+ req, output_dir, build_options, global_options, editable
+ )
+ if wheel_path and verify:
+ try:
+ _verify_one(req, wheel_path)
+ except (InvalidWheelFilename, UnsupportedWheel) as e:
+ logger.warning("Built %s for %s is invalid: %s", artifact, req.name, e)
+ return None
+ return wheel_path
+
+
+def _build_one_inside_env(
+ req: InstallRequirement,
+ output_dir: str,
+ build_options: List[str],
+ global_options: List[str],
+ editable: bool,
+) -> Optional[str]:
+ with TempDirectory(kind="wheel") as temp_dir:
+ assert req.name
+ if req.use_pep517:
+ assert req.metadata_directory
+ assert req.pep517_backend
+ if global_options:
+ logger.warning(
+ "Ignoring --global-option when building %s using PEP 517", req.name
+ )
+ if build_options:
+ logger.warning(
+ "Ignoring --build-option when building %s using PEP 517", req.name
+ )
+ if editable:
+ wheel_path = build_wheel_editable(
+ name=req.name,
+ backend=req.pep517_backend,
+ metadata_directory=req.metadata_directory,
+ tempd=temp_dir.path,
+ )
+ else:
+ wheel_path = build_wheel_pep517(
+ name=req.name,
+ backend=req.pep517_backend,
+ metadata_directory=req.metadata_directory,
+ tempd=temp_dir.path,
+ )
+ else:
+ wheel_path = build_wheel_legacy(
+ name=req.name,
+ setup_py_path=req.setup_py_path,
+ source_dir=req.unpacked_source_directory,
+ global_options=global_options,
+ build_options=build_options,
+ tempd=temp_dir.path,
+ )
+
+ if wheel_path is not None:
+ wheel_name = os.path.basename(wheel_path)
+ dest_path = os.path.join(output_dir, wheel_name)
+ try:
+ wheel_hash, length = hash_file(wheel_path)
+ shutil.move(wheel_path, dest_path)
+ logger.info(
+ "Created wheel for %s: filename=%s size=%d sha256=%s",
+ req.name,
+ wheel_name,
+ length,
+ wheel_hash.hexdigest(),
+ )
+ logger.info("Stored in directory: %s", output_dir)
+ return dest_path
+ except Exception as e:
+ logger.warning(
+ "Building wheel for %s failed: %s",
+ req.name,
+ e,
+ )
+ # Ignore return, we can't do anything else useful.
+ if not req.use_pep517:
+ _clean_one_legacy(req, global_options)
+ return None
+
+
+def _clean_one_legacy(req: InstallRequirement, global_options: List[str]) -> bool:
+ clean_args = make_setuptools_clean_args(
+ req.setup_py_path,
+ global_options=global_options,
+ )
+
+ logger.info("Running setup.py clean for %s", req.name)
+ try:
+ call_subprocess(
+ clean_args, command_desc="python setup.py clean", cwd=req.source_dir
+ )
+ return True
+ except Exception:
+ logger.error("Failed cleaning build dir for %s", req.name)
+ return False
+
+
+def build(
+ requirements: Iterable[InstallRequirement],
+ wheel_cache: WheelCache,
+ verify: bool,
+ build_options: List[str],
+ global_options: List[str],
+) -> BuildResult:
+ """Build wheels.
+
+ :return: The list of InstallRequirement that succeeded to build and
+ the list of InstallRequirement that failed to build.
+ """
+ if not requirements:
+ return [], []
+
+ # Build the wheels.
+ logger.info(
+ "Building wheels for collected packages: %s",
+ ", ".join(req.name for req in requirements), # type: ignore
+ )
+
+ with indent_log():
+ build_successes, build_failures = [], []
+ for req in requirements:
+ assert req.name
+ cache_dir = _get_cache_dir(req, wheel_cache)
+ wheel_file = _build_one(
+ req,
+ cache_dir,
+ verify,
+ build_options,
+ global_options,
+ req.editable and req.permit_editable_wheels,
+ )
+ if wheel_file:
+ # Record the download origin in the cache
+ if req.download_info is not None:
+ # download_info is guaranteed to be set because when we build an
+ # InstallRequirement it has been through the preparer before, but
+ # let's be cautious.
+ wheel_cache.record_download_origin(cache_dir, req.download_info)
+ # Update the link for this.
+ req.link = Link(path_to_url(wheel_file))
+ req.local_file_path = req.link.file_path
+ assert req.link.is_wheel
+ build_successes.append(req)
+ else:
+ build_failures.append(req)
+
+ # notify success/failure
+ if build_successes:
+ logger.info(
+ "Successfully built %s",
+ " ".join([req.name for req in build_successes]), # type: ignore
+ )
+ if build_failures:
+ logger.info(
+ "Failed to build %s",
+ " ".join([req.name for req in build_failures]), # type: ignore
+ )
+ # Return a list of requirements that failed to build
+ return build_successes, build_failures
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/__init__.py
new file mode 100644
index 000000000..561089ccc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/__init__.py
@@ -0,0 +1,116 @@
+"""
+pip._vendor is for vendoring dependencies of pip to prevent needing pip to
+depend on something external.
+
+Files inside of pip._vendor should be considered immutable and should only be
+updated to versions from upstream.
+"""
+from __future__ import absolute_import
+
+import glob
+import os.path
+import sys
+
+# Downstream redistributors which have debundled our dependencies should also
+# patch this value to be true. This will trigger the additional patching
+# to cause things like "six" to be available as pip.
+DEBUNDLED = False
+
+# By default, look in this directory for a bunch of .whl files which we will
+# add to the beginning of sys.path before attempting to import anything. This
+# is done to support downstream re-distributors like Debian and Fedora who
+# wish to create their own Wheels for our dependencies to aid in debundling.
+WHEEL_DIR = os.path.abspath(os.path.dirname(__file__))
+
+
+# Define a small helper function to alias our vendored modules to the real ones
+# if the vendored ones do not exist. This idea of this was taken from
+# https://github.com/kennethreitz/requests/pull/2567.
+def vendored(modulename):
+ vendored_name = "{0}.{1}".format(__name__, modulename)
+
+ try:
+ __import__(modulename, globals(), locals(), level=0)
+ except ImportError:
+ # We can just silently allow import failures to pass here. If we
+ # got to this point it means that ``import pip._vendor.whatever``
+ # failed and so did ``import whatever``. Since we're importing this
+ # upfront in an attempt to alias imports, not erroring here will
+ # just mean we get a regular import error whenever pip *actually*
+ # tries to import one of these modules to use it, which actually
+ # gives us a better error message than we would have otherwise
+ # gotten.
+ pass
+ else:
+ sys.modules[vendored_name] = sys.modules[modulename]
+ base, head = vendored_name.rsplit(".", 1)
+ setattr(sys.modules[base], head, sys.modules[modulename])
+
+
+# If we're operating in a debundled setup, then we want to go ahead and trigger
+# the aliasing of our vendored libraries as well as looking for wheels to add
+# to our sys.path. This will cause all of this code to be a no-op typically
+# however downstream redistributors can enable it in a consistent way across
+# all platforms.
+if DEBUNDLED:
+ # Actually look inside of WHEEL_DIR to find .whl files and add them to the
+ # front of our sys.path.
+ sys.path[:] = glob.glob(os.path.join(WHEEL_DIR, "*.whl")) + sys.path
+
+ # Actually alias all of our vendored dependencies.
+ vendored("cachecontrol")
+ vendored("certifi")
+ vendored("distlib")
+ vendored("distro")
+ vendored("packaging")
+ vendored("packaging.version")
+ vendored("packaging.specifiers")
+ vendored("pkg_resources")
+ vendored("platformdirs")
+ vendored("progress")
+ vendored("pyproject_hooks")
+ vendored("requests")
+ vendored("requests.exceptions")
+ vendored("requests.packages")
+ vendored("requests.packages.urllib3")
+ vendored("requests.packages.urllib3._collections")
+ vendored("requests.packages.urllib3.connection")
+ vendored("requests.packages.urllib3.connectionpool")
+ vendored("requests.packages.urllib3.contrib")
+ vendored("requests.packages.urllib3.contrib.ntlmpool")
+ vendored("requests.packages.urllib3.contrib.pyopenssl")
+ vendored("requests.packages.urllib3.exceptions")
+ vendored("requests.packages.urllib3.fields")
+ vendored("requests.packages.urllib3.filepost")
+ vendored("requests.packages.urllib3.packages")
+ vendored("requests.packages.urllib3.packages.ordered_dict")
+ vendored("requests.packages.urllib3.packages.six")
+ vendored("requests.packages.urllib3.packages.ssl_match_hostname")
+ vendored("requests.packages.urllib3.packages.ssl_match_hostname."
+ "_implementation")
+ vendored("requests.packages.urllib3.poolmanager")
+ vendored("requests.packages.urllib3.request")
+ vendored("requests.packages.urllib3.response")
+ vendored("requests.packages.urllib3.util")
+ vendored("requests.packages.urllib3.util.connection")
+ vendored("requests.packages.urllib3.util.request")
+ vendored("requests.packages.urllib3.util.response")
+ vendored("requests.packages.urllib3.util.retry")
+ vendored("requests.packages.urllib3.util.ssl_")
+ vendored("requests.packages.urllib3.util.timeout")
+ vendored("requests.packages.urllib3.util.url")
+ vendored("resolvelib")
+ vendored("rich")
+ vendored("rich.console")
+ vendored("rich.highlighter")
+ vendored("rich.logging")
+ vendored("rich.markup")
+ vendored("rich.progress")
+ vendored("rich.segment")
+ vendored("rich.style")
+ vendored("rich.text")
+ vendored("rich.traceback")
+ if sys.version_info < (3, 11):
+ vendored("tomli")
+ vendored("truststore")
+ vendored("urllib3")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/__init__.py
new file mode 100644
index 000000000..b34b0fcbd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/__init__.py
@@ -0,0 +1,28 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+
+"""CacheControl import Interface.
+
+Make it easy to import from cachecontrol without long namespaces.
+"""
+__author__ = "Eric Larson"
+__email__ = "eric@ionrock.org"
+__version__ = "0.14.0"
+
+from pip._vendor.cachecontrol.adapter import CacheControlAdapter
+from pip._vendor.cachecontrol.controller import CacheController
+from pip._vendor.cachecontrol.wrapper import CacheControl
+
+__all__ = [
+ "__author__",
+ "__email__",
+ "__version__",
+ "CacheControlAdapter",
+ "CacheController",
+ "CacheControl",
+]
+
+import logging
+
+logging.getLogger(__name__).addHandler(logging.NullHandler())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/_cmd.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/_cmd.py
new file mode 100644
index 000000000..2c84208a5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/_cmd.py
@@ -0,0 +1,70 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+import logging
+from argparse import ArgumentParser
+from typing import TYPE_CHECKING
+
+from pip._vendor import requests
+
+from pip._vendor.cachecontrol.adapter import CacheControlAdapter
+from pip._vendor.cachecontrol.cache import DictCache
+from pip._vendor.cachecontrol.controller import logger
+
+if TYPE_CHECKING:
+ from argparse import Namespace
+
+ from pip._vendor.cachecontrol.controller import CacheController
+
+
+def setup_logging() -> None:
+ logger.setLevel(logging.DEBUG)
+ handler = logging.StreamHandler()
+ logger.addHandler(handler)
+
+
+def get_session() -> requests.Session:
+ adapter = CacheControlAdapter(
+ DictCache(), cache_etags=True, serializer=None, heuristic=None
+ )
+ sess = requests.Session()
+ sess.mount("http://", adapter)
+ sess.mount("https://", adapter)
+
+ sess.cache_controller = adapter.controller # type: ignore[attr-defined]
+ return sess
+
+
+def get_args() -> Namespace:
+ parser = ArgumentParser()
+ parser.add_argument("url", help="The URL to try and cache")
+ return parser.parse_args()
+
+
+def main() -> None:
+ args = get_args()
+ sess = get_session()
+
+ # Make a request to get a response
+ resp = sess.get(args.url)
+
+ # Turn on logging
+ setup_logging()
+
+ # try setting the cache
+ cache_controller: CacheController = (
+ sess.cache_controller # type: ignore[attr-defined]
+ )
+ cache_controller.cache_response(resp.request, resp.raw)
+
+ # Now try to get it
+ if cache_controller.cached_request(resp.request):
+ print("Cached!")
+ else:
+ print("Not cached :(")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/adapter.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/adapter.py
new file mode 100644
index 000000000..fbb4ecc88
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/adapter.py
@@ -0,0 +1,161 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+import functools
+import types
+import zlib
+from typing import TYPE_CHECKING, Any, Collection, Mapping
+
+from pip._vendor.requests.adapters import HTTPAdapter
+
+from pip._vendor.cachecontrol.cache import DictCache
+from pip._vendor.cachecontrol.controller import PERMANENT_REDIRECT_STATUSES, CacheController
+from pip._vendor.cachecontrol.filewrapper import CallbackFileWrapper
+
+if TYPE_CHECKING:
+ from pip._vendor.requests import PreparedRequest, Response
+ from pip._vendor.urllib3 import HTTPResponse
+
+ from pip._vendor.cachecontrol.cache import BaseCache
+ from pip._vendor.cachecontrol.heuristics import BaseHeuristic
+ from pip._vendor.cachecontrol.serialize import Serializer
+
+
+class CacheControlAdapter(HTTPAdapter):
+ invalidating_methods = {"PUT", "PATCH", "DELETE"}
+
+ def __init__(
+ self,
+ cache: BaseCache | None = None,
+ cache_etags: bool = True,
+ controller_class: type[CacheController] | None = None,
+ serializer: Serializer | None = None,
+ heuristic: BaseHeuristic | None = None,
+ cacheable_methods: Collection[str] | None = None,
+ *args: Any,
+ **kw: Any,
+ ) -> None:
+ super().__init__(*args, **kw)
+ self.cache = DictCache() if cache is None else cache
+ self.heuristic = heuristic
+ self.cacheable_methods = cacheable_methods or ("GET",)
+
+ controller_factory = controller_class or CacheController
+ self.controller = controller_factory(
+ self.cache, cache_etags=cache_etags, serializer=serializer
+ )
+
+ def send(
+ self,
+ request: PreparedRequest,
+ stream: bool = False,
+ timeout: None | float | tuple[float, float] | tuple[float, None] = None,
+ verify: bool | str = True,
+ cert: (None | bytes | str | tuple[bytes | str, bytes | str]) = None,
+ proxies: Mapping[str, str] | None = None,
+ cacheable_methods: Collection[str] | None = None,
+ ) -> Response:
+ """
+ Send a request. Use the request information to see if it
+ exists in the cache and cache the response if we need to and can.
+ """
+ cacheable = cacheable_methods or self.cacheable_methods
+ if request.method in cacheable:
+ try:
+ cached_response = self.controller.cached_request(request)
+ except zlib.error:
+ cached_response = None
+ if cached_response:
+ return self.build_response(request, cached_response, from_cache=True)
+
+ # check for etags and add headers if appropriate
+ request.headers.update(self.controller.conditional_headers(request))
+
+ resp = super().send(request, stream, timeout, verify, cert, proxies)
+
+ return resp
+
+ def build_response(
+ self,
+ request: PreparedRequest,
+ response: HTTPResponse,
+ from_cache: bool = False,
+ cacheable_methods: Collection[str] | None = None,
+ ) -> Response:
+ """
+ Build a response by making a request or using the cache.
+
+ This will end up calling send and returning a potentially
+ cached response
+ """
+ cacheable = cacheable_methods or self.cacheable_methods
+ if not from_cache and request.method in cacheable:
+ # Check for any heuristics that might update headers
+ # before trying to cache.
+ if self.heuristic:
+ response = self.heuristic.apply(response)
+
+ # apply any expiration heuristics
+ if response.status == 304:
+ # We must have sent an ETag request. This could mean
+ # that we've been expired already or that we simply
+ # have an etag. In either case, we want to try and
+ # update the cache if that is the case.
+ cached_response = self.controller.update_cached_response(
+ request, response
+ )
+
+ if cached_response is not response:
+ from_cache = True
+
+ # We are done with the server response, read a
+ # possible response body (compliant servers will
+ # not return one, but we cannot be 100% sure) and
+ # release the connection back to the pool.
+ response.read(decode_content=False)
+ response.release_conn()
+
+ response = cached_response
+
+ # We always cache the 301 responses
+ elif int(response.status) in PERMANENT_REDIRECT_STATUSES:
+ self.controller.cache_response(request, response)
+ else:
+ # Wrap the response file with a wrapper that will cache the
+ # response when the stream has been consumed.
+ response._fp = CallbackFileWrapper( # type: ignore[assignment]
+ response._fp, # type: ignore[arg-type]
+ functools.partial(
+ self.controller.cache_response, request, response
+ ),
+ )
+ if response.chunked:
+ super_update_chunk_length = response._update_chunk_length
+
+ def _update_chunk_length(self: HTTPResponse) -> None:
+ super_update_chunk_length()
+ if self.chunk_left == 0:
+ self._fp._close() # type: ignore[union-attr]
+
+ response._update_chunk_length = types.MethodType( # type: ignore[method-assign]
+ _update_chunk_length, response
+ )
+
+ resp: Response = super().build_response(request, response) # type: ignore[no-untyped-call]
+
+ # See if we should invalidate the cache.
+ if request.method in self.invalidating_methods and resp.ok:
+ assert request.url is not None
+ cache_url = self.controller.cache_url(request.url)
+ self.cache.delete(cache_url)
+
+ # Give the request a from_cache attr to let people use it
+ resp.from_cache = from_cache # type: ignore[attr-defined]
+
+ return resp
+
+ def close(self) -> None:
+ self.cache.close()
+ super().close() # type: ignore[no-untyped-call]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/cache.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/cache.py
new file mode 100644
index 000000000..3293b0057
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/cache.py
@@ -0,0 +1,74 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+
+"""
+The cache object API for implementing caches. The default is a thread
+safe in-memory dictionary.
+"""
+from __future__ import annotations
+
+from threading import Lock
+from typing import IO, TYPE_CHECKING, MutableMapping
+
+if TYPE_CHECKING:
+ from datetime import datetime
+
+
+class BaseCache:
+ def get(self, key: str) -> bytes | None:
+ raise NotImplementedError()
+
+ def set(
+ self, key: str, value: bytes, expires: int | datetime | None = None
+ ) -> None:
+ raise NotImplementedError()
+
+ def delete(self, key: str) -> None:
+ raise NotImplementedError()
+
+ def close(self) -> None:
+ pass
+
+
+class DictCache(BaseCache):
+ def __init__(self, init_dict: MutableMapping[str, bytes] | None = None) -> None:
+ self.lock = Lock()
+ self.data = init_dict or {}
+
+ def get(self, key: str) -> bytes | None:
+ return self.data.get(key, None)
+
+ def set(
+ self, key: str, value: bytes, expires: int | datetime | None = None
+ ) -> None:
+ with self.lock:
+ self.data.update({key: value})
+
+ def delete(self, key: str) -> None:
+ with self.lock:
+ if key in self.data:
+ self.data.pop(key)
+
+
+class SeparateBodyBaseCache(BaseCache):
+ """
+ In this variant, the body is not stored mixed in with the metadata, but is
+ passed in (as a bytes-like object) in a separate call to ``set_body()``.
+
+ That is, the expected interaction pattern is::
+
+ cache.set(key, serialized_metadata)
+ cache.set_body(key)
+
+ Similarly, the body should be loaded separately via ``get_body()``.
+ """
+
+ def set_body(self, key: str, body: bytes) -> None:
+ raise NotImplementedError()
+
+ def get_body(self, key: str) -> IO[bytes] | None:
+ """
+ Return the body as file-like object.
+ """
+ raise NotImplementedError()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/__init__.py
new file mode 100644
index 000000000..24ff469ff
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/__init__.py
@@ -0,0 +1,8 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+
+from pip._vendor.cachecontrol.caches.file_cache import FileCache, SeparateBodyFileCache
+from pip._vendor.cachecontrol.caches.redis_cache import RedisCache
+
+__all__ = ["FileCache", "SeparateBodyFileCache", "RedisCache"]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/file_cache.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/file_cache.py
new file mode 100644
index 000000000..e6e3a5794
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/file_cache.py
@@ -0,0 +1,182 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+import hashlib
+import os
+from textwrap import dedent
+from typing import IO, TYPE_CHECKING, Union
+from pathlib import Path
+
+from pip._vendor.cachecontrol.cache import BaseCache, SeparateBodyBaseCache
+from pip._vendor.cachecontrol.controller import CacheController
+
+if TYPE_CHECKING:
+ from datetime import datetime
+
+ from filelock import BaseFileLock
+
+
+def _secure_open_write(filename: str, fmode: int) -> IO[bytes]:
+ # We only want to write to this file, so open it in write only mode
+ flags = os.O_WRONLY
+
+ # os.O_CREAT | os.O_EXCL will fail if the file already exists, so we only
+ # will open *new* files.
+ # We specify this because we want to ensure that the mode we pass is the
+ # mode of the file.
+ flags |= os.O_CREAT | os.O_EXCL
+
+ # Do not follow symlinks to prevent someone from making a symlink that
+ # we follow and insecurely open a cache file.
+ if hasattr(os, "O_NOFOLLOW"):
+ flags |= os.O_NOFOLLOW
+
+ # On Windows we'll mark this file as binary
+ if hasattr(os, "O_BINARY"):
+ flags |= os.O_BINARY
+
+ # Before we open our file, we want to delete any existing file that is
+ # there
+ try:
+ os.remove(filename)
+ except OSError:
+ # The file must not exist already, so we can just skip ahead to opening
+ pass
+
+ # Open our file, the use of os.O_CREAT | os.O_EXCL will ensure that if a
+ # race condition happens between the os.remove and this line, that an
+ # error will be raised. Because we utilize a lockfile this should only
+ # happen if someone is attempting to attack us.
+ fd = os.open(filename, flags, fmode)
+ try:
+ return os.fdopen(fd, "wb")
+
+ except:
+ # An error occurred wrapping our FD in a file object
+ os.close(fd)
+ raise
+
+
+class _FileCacheMixin:
+ """Shared implementation for both FileCache variants."""
+
+ def __init__(
+ self,
+ directory: str | Path,
+ forever: bool = False,
+ filemode: int = 0o0600,
+ dirmode: int = 0o0700,
+ lock_class: type[BaseFileLock] | None = None,
+ ) -> None:
+ try:
+ if lock_class is None:
+ from filelock import FileLock
+
+ lock_class = FileLock
+ except ImportError:
+ notice = dedent(
+ """
+ NOTE: In order to use the FileCache you must have
+ filelock installed. You can install it via pip:
+ pip install cachecontrol[filecache]
+ """
+ )
+ raise ImportError(notice)
+
+ self.directory = directory
+ self.forever = forever
+ self.filemode = filemode
+ self.dirmode = dirmode
+ self.lock_class = lock_class
+
+ @staticmethod
+ def encode(x: str) -> str:
+ return hashlib.sha224(x.encode()).hexdigest()
+
+ def _fn(self, name: str) -> str:
+ # NOTE: This method should not change as some may depend on it.
+ # See: https://github.com/ionrock/cachecontrol/issues/63
+ hashed = self.encode(name)
+ parts = list(hashed[:5]) + [hashed]
+ return os.path.join(self.directory, *parts)
+
+ def get(self, key: str) -> bytes | None:
+ name = self._fn(key)
+ try:
+ with open(name, "rb") as fh:
+ return fh.read()
+
+ except FileNotFoundError:
+ return None
+
+ def set(
+ self, key: str, value: bytes, expires: int | datetime | None = None
+ ) -> None:
+ name = self._fn(key)
+ self._write(name, value)
+
+ def _write(self, path: str, data: bytes) -> None:
+ """
+ Safely write the data to the given path.
+ """
+ # Make sure the directory exists
+ try:
+ os.makedirs(os.path.dirname(path), self.dirmode)
+ except OSError:
+ pass
+
+ with self.lock_class(path + ".lock"):
+ # Write our actual file
+ with _secure_open_write(path, self.filemode) as fh:
+ fh.write(data)
+
+ def _delete(self, key: str, suffix: str) -> None:
+ name = self._fn(key) + suffix
+ if not self.forever:
+ try:
+ os.remove(name)
+ except FileNotFoundError:
+ pass
+
+
+class FileCache(_FileCacheMixin, BaseCache):
+ """
+ Traditional FileCache: body is stored in memory, so not suitable for large
+ downloads.
+ """
+
+ def delete(self, key: str) -> None:
+ self._delete(key, "")
+
+
+class SeparateBodyFileCache(_FileCacheMixin, SeparateBodyBaseCache):
+ """
+ Memory-efficient FileCache: body is stored in a separate file, reducing
+ peak memory usage.
+ """
+
+ def get_body(self, key: str) -> IO[bytes] | None:
+ name = self._fn(key) + ".body"
+ try:
+ return open(name, "rb")
+ except FileNotFoundError:
+ return None
+
+ def set_body(self, key: str, body: bytes) -> None:
+ name = self._fn(key) + ".body"
+ self._write(name, body)
+
+ def delete(self, key: str) -> None:
+ self._delete(key, "")
+ self._delete(key, ".body")
+
+
+def url_to_file_path(url: str, filecache: FileCache) -> str:
+ """Return the file cache path based on the URL.
+
+ This does not ensure the file exists!
+ """
+ key = CacheController.cache_url(url)
+ return filecache._fn(key)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/redis_cache.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/redis_cache.py
new file mode 100644
index 000000000..f4f68c47b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/caches/redis_cache.py
@@ -0,0 +1,48 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+
+from datetime import datetime, timezone
+from typing import TYPE_CHECKING
+
+from pip._vendor.cachecontrol.cache import BaseCache
+
+if TYPE_CHECKING:
+ from redis import Redis
+
+
+class RedisCache(BaseCache):
+ def __init__(self, conn: Redis[bytes]) -> None:
+ self.conn = conn
+
+ def get(self, key: str) -> bytes | None:
+ return self.conn.get(key)
+
+ def set(
+ self, key: str, value: bytes, expires: int | datetime | None = None
+ ) -> None:
+ if not expires:
+ self.conn.set(key, value)
+ elif isinstance(expires, datetime):
+ now_utc = datetime.now(timezone.utc)
+ if expires.tzinfo is None:
+ now_utc = now_utc.replace(tzinfo=None)
+ delta = expires - now_utc
+ self.conn.setex(key, int(delta.total_seconds()), value)
+ else:
+ self.conn.setex(key, expires, value)
+
+ def delete(self, key: str) -> None:
+ self.conn.delete(key)
+
+ def clear(self) -> None:
+ """Helper for clearing all the keys in a database. Use with
+ caution!"""
+ for key in self.conn.keys():
+ self.conn.delete(key)
+
+ def close(self) -> None:
+ """Redis uses connection pooling, no need to close the connection."""
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/controller.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/controller.py
new file mode 100644
index 000000000..d7dd86e5f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/controller.py
@@ -0,0 +1,499 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+
+"""
+The httplib2 algorithms ported for use with requests.
+"""
+from __future__ import annotations
+
+import calendar
+import logging
+import re
+import time
+from email.utils import parsedate_tz
+from typing import TYPE_CHECKING, Collection, Mapping
+
+from pip._vendor.requests.structures import CaseInsensitiveDict
+
+from pip._vendor.cachecontrol.cache import DictCache, SeparateBodyBaseCache
+from pip._vendor.cachecontrol.serialize import Serializer
+
+if TYPE_CHECKING:
+ from typing import Literal
+
+ from pip._vendor.requests import PreparedRequest
+ from pip._vendor.urllib3 import HTTPResponse
+
+ from pip._vendor.cachecontrol.cache import BaseCache
+
+logger = logging.getLogger(__name__)
+
+URI = re.compile(r"^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))?")
+
+PERMANENT_REDIRECT_STATUSES = (301, 308)
+
+
+def parse_uri(uri: str) -> tuple[str, str, str, str, str]:
+ """Parses a URI using the regex given in Appendix B of RFC 3986.
+
+ (scheme, authority, path, query, fragment) = parse_uri(uri)
+ """
+ match = URI.match(uri)
+ assert match is not None
+ groups = match.groups()
+ return (groups[1], groups[3], groups[4], groups[6], groups[8])
+
+
+class CacheController:
+ """An interface to see if request should cached or not."""
+
+ def __init__(
+ self,
+ cache: BaseCache | None = None,
+ cache_etags: bool = True,
+ serializer: Serializer | None = None,
+ status_codes: Collection[int] | None = None,
+ ):
+ self.cache = DictCache() if cache is None else cache
+ self.cache_etags = cache_etags
+ self.serializer = serializer or Serializer()
+ self.cacheable_status_codes = status_codes or (200, 203, 300, 301, 308)
+
+ @classmethod
+ def _urlnorm(cls, uri: str) -> str:
+ """Normalize the URL to create a safe key for the cache"""
+ (scheme, authority, path, query, fragment) = parse_uri(uri)
+ if not scheme or not authority:
+ raise Exception("Only absolute URIs are allowed. uri = %s" % uri)
+
+ scheme = scheme.lower()
+ authority = authority.lower()
+
+ if not path:
+ path = "/"
+
+ # Could do syntax based normalization of the URI before
+ # computing the digest. See Section 6.2.2 of Std 66.
+ request_uri = query and "?".join([path, query]) or path
+ defrag_uri = scheme + "://" + authority + request_uri
+
+ return defrag_uri
+
+ @classmethod
+ def cache_url(cls, uri: str) -> str:
+ return cls._urlnorm(uri)
+
+ def parse_cache_control(self, headers: Mapping[str, str]) -> dict[str, int | None]:
+ known_directives = {
+ # https://tools.ietf.org/html/rfc7234#section-5.2
+ "max-age": (int, True),
+ "max-stale": (int, False),
+ "min-fresh": (int, True),
+ "no-cache": (None, False),
+ "no-store": (None, False),
+ "no-transform": (None, False),
+ "only-if-cached": (None, False),
+ "must-revalidate": (None, False),
+ "public": (None, False),
+ "private": (None, False),
+ "proxy-revalidate": (None, False),
+ "s-maxage": (int, True),
+ }
+
+ cc_headers = headers.get("cache-control", headers.get("Cache-Control", ""))
+
+ retval: dict[str, int | None] = {}
+
+ for cc_directive in cc_headers.split(","):
+ if not cc_directive.strip():
+ continue
+
+ parts = cc_directive.split("=", 1)
+ directive = parts[0].strip()
+
+ try:
+ typ, required = known_directives[directive]
+ except KeyError:
+ logger.debug("Ignoring unknown cache-control directive: %s", directive)
+ continue
+
+ if not typ or not required:
+ retval[directive] = None
+ if typ:
+ try:
+ retval[directive] = typ(parts[1].strip())
+ except IndexError:
+ if required:
+ logger.debug(
+ "Missing value for cache-control " "directive: %s",
+ directive,
+ )
+ except ValueError:
+ logger.debug(
+ "Invalid value for cache-control directive " "%s, must be %s",
+ directive,
+ typ.__name__,
+ )
+
+ return retval
+
+ def _load_from_cache(self, request: PreparedRequest) -> HTTPResponse | None:
+ """
+ Load a cached response, or return None if it's not available.
+ """
+ # We do not support caching of partial content: so if the request contains a
+ # Range header then we don't want to load anything from the cache.
+ if "Range" in request.headers:
+ return None
+
+ cache_url = request.url
+ assert cache_url is not None
+ cache_data = self.cache.get(cache_url)
+ if cache_data is None:
+ logger.debug("No cache entry available")
+ return None
+
+ if isinstance(self.cache, SeparateBodyBaseCache):
+ body_file = self.cache.get_body(cache_url)
+ else:
+ body_file = None
+
+ result = self.serializer.loads(request, cache_data, body_file)
+ if result is None:
+ logger.warning("Cache entry deserialization failed, entry ignored")
+ return result
+
+ def cached_request(self, request: PreparedRequest) -> HTTPResponse | Literal[False]:
+ """
+ Return a cached response if it exists in the cache, otherwise
+ return False.
+ """
+ assert request.url is not None
+ cache_url = self.cache_url(request.url)
+ logger.debug('Looking up "%s" in the cache', cache_url)
+ cc = self.parse_cache_control(request.headers)
+
+ # Bail out if the request insists on fresh data
+ if "no-cache" in cc:
+ logger.debug('Request header has "no-cache", cache bypassed')
+ return False
+
+ if "max-age" in cc and cc["max-age"] == 0:
+ logger.debug('Request header has "max_age" as 0, cache bypassed')
+ return False
+
+ # Check whether we can load the response from the cache:
+ resp = self._load_from_cache(request)
+ if not resp:
+ return False
+
+ # If we have a cached permanent redirect, return it immediately. We
+ # don't need to test our response for other headers b/c it is
+ # intrinsically "cacheable" as it is Permanent.
+ #
+ # See:
+ # https://tools.ietf.org/html/rfc7231#section-6.4.2
+ #
+ # Client can try to refresh the value by repeating the request
+ # with cache busting headers as usual (ie no-cache).
+ if int(resp.status) in PERMANENT_REDIRECT_STATUSES:
+ msg = (
+ "Returning cached permanent redirect response "
+ "(ignoring date and etag information)"
+ )
+ logger.debug(msg)
+ return resp
+
+ headers: CaseInsensitiveDict[str] = CaseInsensitiveDict(resp.headers)
+ if not headers or "date" not in headers:
+ if "etag" not in headers:
+ # Without date or etag, the cached response can never be used
+ # and should be deleted.
+ logger.debug("Purging cached response: no date or etag")
+ self.cache.delete(cache_url)
+ logger.debug("Ignoring cached response: no date")
+ return False
+
+ now = time.time()
+ time_tuple = parsedate_tz(headers["date"])
+ assert time_tuple is not None
+ date = calendar.timegm(time_tuple[:6])
+ current_age = max(0, now - date)
+ logger.debug("Current age based on date: %i", current_age)
+
+ # TODO: There is an assumption that the result will be a
+ # urllib3 response object. This may not be best since we
+ # could probably avoid instantiating or constructing the
+ # response until we know we need it.
+ resp_cc = self.parse_cache_control(headers)
+
+ # determine freshness
+ freshness_lifetime = 0
+
+ # Check the max-age pragma in the cache control header
+ max_age = resp_cc.get("max-age")
+ if max_age is not None:
+ freshness_lifetime = max_age
+ logger.debug("Freshness lifetime from max-age: %i", freshness_lifetime)
+
+ # If there isn't a max-age, check for an expires header
+ elif "expires" in headers:
+ expires = parsedate_tz(headers["expires"])
+ if expires is not None:
+ expire_time = calendar.timegm(expires[:6]) - date
+ freshness_lifetime = max(0, expire_time)
+ logger.debug("Freshness lifetime from expires: %i", freshness_lifetime)
+
+ # Determine if we are setting freshness limit in the
+ # request. Note, this overrides what was in the response.
+ max_age = cc.get("max-age")
+ if max_age is not None:
+ freshness_lifetime = max_age
+ logger.debug(
+ "Freshness lifetime from request max-age: %i", freshness_lifetime
+ )
+
+ min_fresh = cc.get("min-fresh")
+ if min_fresh is not None:
+ # adjust our current age by our min fresh
+ current_age += min_fresh
+ logger.debug("Adjusted current age from min-fresh: %i", current_age)
+
+ # Return entry if it is fresh enough
+ if freshness_lifetime > current_age:
+ logger.debug('The response is "fresh", returning cached response')
+ logger.debug("%i > %i", freshness_lifetime, current_age)
+ return resp
+
+ # we're not fresh. If we don't have an Etag, clear it out
+ if "etag" not in headers:
+ logger.debug('The cached response is "stale" with no etag, purging')
+ self.cache.delete(cache_url)
+
+ # return the original handler
+ return False
+
+ def conditional_headers(self, request: PreparedRequest) -> dict[str, str]:
+ resp = self._load_from_cache(request)
+ new_headers = {}
+
+ if resp:
+ headers: CaseInsensitiveDict[str] = CaseInsensitiveDict(resp.headers)
+
+ if "etag" in headers:
+ new_headers["If-None-Match"] = headers["ETag"]
+
+ if "last-modified" in headers:
+ new_headers["If-Modified-Since"] = headers["Last-Modified"]
+
+ return new_headers
+
+ def _cache_set(
+ self,
+ cache_url: str,
+ request: PreparedRequest,
+ response: HTTPResponse,
+ body: bytes | None = None,
+ expires_time: int | None = None,
+ ) -> None:
+ """
+ Store the data in the cache.
+ """
+ if isinstance(self.cache, SeparateBodyBaseCache):
+ # We pass in the body separately; just put a placeholder empty
+ # string in the metadata.
+ self.cache.set(
+ cache_url,
+ self.serializer.dumps(request, response, b""),
+ expires=expires_time,
+ )
+ # body is None can happen when, for example, we're only updating
+ # headers, as is the case in update_cached_response().
+ if body is not None:
+ self.cache.set_body(cache_url, body)
+ else:
+ self.cache.set(
+ cache_url,
+ self.serializer.dumps(request, response, body),
+ expires=expires_time,
+ )
+
+ def cache_response(
+ self,
+ request: PreparedRequest,
+ response: HTTPResponse,
+ body: bytes | None = None,
+ status_codes: Collection[int] | None = None,
+ ) -> None:
+ """
+ Algorithm for caching requests.
+
+ This assumes a requests Response object.
+ """
+ # From httplib2: Don't cache 206's since we aren't going to
+ # handle byte range requests
+ cacheable_status_codes = status_codes or self.cacheable_status_codes
+ if response.status not in cacheable_status_codes:
+ logger.debug(
+ "Status code %s not in %s", response.status, cacheable_status_codes
+ )
+ return
+
+ response_headers: CaseInsensitiveDict[str] = CaseInsensitiveDict(
+ response.headers
+ )
+
+ if "date" in response_headers:
+ time_tuple = parsedate_tz(response_headers["date"])
+ assert time_tuple is not None
+ date = calendar.timegm(time_tuple[:6])
+ else:
+ date = 0
+
+ # If we've been given a body, our response has a Content-Length, that
+ # Content-Length is valid then we can check to see if the body we've
+ # been given matches the expected size, and if it doesn't we'll just
+ # skip trying to cache it.
+ if (
+ body is not None
+ and "content-length" in response_headers
+ and response_headers["content-length"].isdigit()
+ and int(response_headers["content-length"]) != len(body)
+ ):
+ return
+
+ cc_req = self.parse_cache_control(request.headers)
+ cc = self.parse_cache_control(response_headers)
+
+ assert request.url is not None
+ cache_url = self.cache_url(request.url)
+ logger.debug('Updating cache with response from "%s"', cache_url)
+
+ # Delete it from the cache if we happen to have it stored there
+ no_store = False
+ if "no-store" in cc:
+ no_store = True
+ logger.debug('Response header has "no-store"')
+ if "no-store" in cc_req:
+ no_store = True
+ logger.debug('Request header has "no-store"')
+ if no_store and self.cache.get(cache_url):
+ logger.debug('Purging existing cache entry to honor "no-store"')
+ self.cache.delete(cache_url)
+ if no_store:
+ return
+
+ # https://tools.ietf.org/html/rfc7234#section-4.1:
+ # A Vary header field-value of "*" always fails to match.
+ # Storing such a response leads to a deserialization warning
+ # during cache lookup and is not allowed to ever be served,
+ # so storing it can be avoided.
+ if "*" in response_headers.get("vary", ""):
+ logger.debug('Response header has "Vary: *"')
+ return
+
+ # If we've been given an etag, then keep the response
+ if self.cache_etags and "etag" in response_headers:
+ expires_time = 0
+ if response_headers.get("expires"):
+ expires = parsedate_tz(response_headers["expires"])
+ if expires is not None:
+ expires_time = calendar.timegm(expires[:6]) - date
+
+ expires_time = max(expires_time, 14 * 86400)
+
+ logger.debug(f"etag object cached for {expires_time} seconds")
+ logger.debug("Caching due to etag")
+ self._cache_set(cache_url, request, response, body, expires_time)
+
+ # Add to the cache any permanent redirects. We do this before looking
+ # that the Date headers.
+ elif int(response.status) in PERMANENT_REDIRECT_STATUSES:
+ logger.debug("Caching permanent redirect")
+ self._cache_set(cache_url, request, response, b"")
+
+ # Add to the cache if the response headers demand it. If there
+ # is no date header then we can't do anything about expiring
+ # the cache.
+ elif "date" in response_headers:
+ time_tuple = parsedate_tz(response_headers["date"])
+ assert time_tuple is not None
+ date = calendar.timegm(time_tuple[:6])
+ # cache when there is a max-age > 0
+ max_age = cc.get("max-age")
+ if max_age is not None and max_age > 0:
+ logger.debug("Caching b/c date exists and max-age > 0")
+ expires_time = max_age
+ self._cache_set(
+ cache_url,
+ request,
+ response,
+ body,
+ expires_time,
+ )
+
+ # If the request can expire, it means we should cache it
+ # in the meantime.
+ elif "expires" in response_headers:
+ if response_headers["expires"]:
+ expires = parsedate_tz(response_headers["expires"])
+ if expires is not None:
+ expires_time = calendar.timegm(expires[:6]) - date
+ else:
+ expires_time = None
+
+ logger.debug(
+ "Caching b/c of expires header. expires in {} seconds".format(
+ expires_time
+ )
+ )
+ self._cache_set(
+ cache_url,
+ request,
+ response,
+ body,
+ expires_time,
+ )
+
+ def update_cached_response(
+ self, request: PreparedRequest, response: HTTPResponse
+ ) -> HTTPResponse:
+ """On a 304 we will get a new set of headers that we want to
+ update our cached value with, assuming we have one.
+
+ This should only ever be called when we've sent an ETag and
+ gotten a 304 as the response.
+ """
+ assert request.url is not None
+ cache_url = self.cache_url(request.url)
+ cached_response = self._load_from_cache(request)
+
+ if not cached_response:
+ # we didn't have a cached response
+ return response
+
+ # Lets update our headers with the headers from the new request:
+ # http://tools.ietf.org/html/draft-ietf-httpbis-p4-conditional-26#section-4.1
+ #
+ # The server isn't supposed to send headers that would make
+ # the cached body invalid. But... just in case, we'll be sure
+ # to strip out ones we know that might be problmatic due to
+ # typical assumptions.
+ excluded_headers = ["content-length"]
+
+ cached_response.headers.update(
+ {
+ k: v
+ for k, v in response.headers.items()
+ if k.lower() not in excluded_headers
+ }
+ )
+
+ # we want a 200 b/c we have content via the cache
+ cached_response.status = 200
+
+ # update our cache
+ self._cache_set(cache_url, request, cached_response)
+
+ return cached_response
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/filewrapper.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/filewrapper.py
new file mode 100644
index 000000000..25143902a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/filewrapper.py
@@ -0,0 +1,119 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+import mmap
+from tempfile import NamedTemporaryFile
+from typing import TYPE_CHECKING, Any, Callable
+
+if TYPE_CHECKING:
+ from http.client import HTTPResponse
+
+
+class CallbackFileWrapper:
+ """
+ Small wrapper around a fp object which will tee everything read into a
+ buffer, and when that file is closed it will execute a callback with the
+ contents of that buffer.
+
+ All attributes are proxied to the underlying file object.
+
+ This class uses members with a double underscore (__) leading prefix so as
+ not to accidentally shadow an attribute.
+
+ The data is stored in a temporary file until it is all available. As long
+ as the temporary files directory is disk-based (sometimes it's a
+ memory-backed-``tmpfs`` on Linux), data will be unloaded to disk if memory
+ pressure is high. For small files the disk usually won't be used at all,
+ it'll all be in the filesystem memory cache, so there should be no
+ performance impact.
+ """
+
+ def __init__(
+ self, fp: HTTPResponse, callback: Callable[[bytes], None] | None
+ ) -> None:
+ self.__buf = NamedTemporaryFile("rb+", delete=True)
+ self.__fp = fp
+ self.__callback = callback
+
+ def __getattr__(self, name: str) -> Any:
+ # The vaguaries of garbage collection means that self.__fp is
+ # not always set. By using __getattribute__ and the private
+ # name[0] allows looking up the attribute value and raising an
+ # AttributeError when it doesn't exist. This stop thigns from
+ # infinitely recursing calls to getattr in the case where
+ # self.__fp hasn't been set.
+ #
+ # [0] https://docs.python.org/2/reference/expressions.html#atom-identifiers
+ fp = self.__getattribute__("_CallbackFileWrapper__fp")
+ return getattr(fp, name)
+
+ def __is_fp_closed(self) -> bool:
+ try:
+ return self.__fp.fp is None
+
+ except AttributeError:
+ pass
+
+ try:
+ closed: bool = self.__fp.closed
+ return closed
+
+ except AttributeError:
+ pass
+
+ # We just don't cache it then.
+ # TODO: Add some logging here...
+ return False
+
+ def _close(self) -> None:
+ if self.__callback:
+ if self.__buf.tell() == 0:
+ # Empty file:
+ result = b""
+ else:
+ # Return the data without actually loading it into memory,
+ # relying on Python's buffer API and mmap(). mmap() just gives
+ # a view directly into the filesystem's memory cache, so it
+ # doesn't result in duplicate memory use.
+ self.__buf.seek(0, 0)
+ result = memoryview(
+ mmap.mmap(self.__buf.fileno(), 0, access=mmap.ACCESS_READ)
+ )
+ self.__callback(result)
+
+ # We assign this to None here, because otherwise we can get into
+ # really tricky problems where the CPython interpreter dead locks
+ # because the callback is holding a reference to something which
+ # has a __del__ method. Setting this to None breaks the cycle
+ # and allows the garbage collector to do it's thing normally.
+ self.__callback = None
+
+ # Closing the temporary file releases memory and frees disk space.
+ # Important when caching big files.
+ self.__buf.close()
+
+ def read(self, amt: int | None = None) -> bytes:
+ data: bytes = self.__fp.read(amt)
+ if data:
+ # We may be dealing with b'', a sign that things are over:
+ # it's passed e.g. after we've already closed self.__buf.
+ self.__buf.write(data)
+ if self.__is_fp_closed():
+ self._close()
+
+ return data
+
+ def _safe_read(self, amt: int) -> bytes:
+ data: bytes = self.__fp._safe_read(amt) # type: ignore[attr-defined]
+ if amt == 2 and data == b"\r\n":
+ # urllib executes this read to toss the CRLF at the end
+ # of the chunk.
+ return data
+
+ self.__buf.write(data)
+ if self.__is_fp_closed():
+ self._close()
+
+ return data
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/heuristics.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/heuristics.py
new file mode 100644
index 000000000..f6e5634e3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/heuristics.py
@@ -0,0 +1,154 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+import calendar
+import time
+from datetime import datetime, timedelta, timezone
+from email.utils import formatdate, parsedate, parsedate_tz
+from typing import TYPE_CHECKING, Any, Mapping
+
+if TYPE_CHECKING:
+ from pip._vendor.urllib3 import HTTPResponse
+
+TIME_FMT = "%a, %d %b %Y %H:%M:%S GMT"
+
+
+def expire_after(delta: timedelta, date: datetime | None = None) -> datetime:
+ date = date or datetime.now(timezone.utc)
+ return date + delta
+
+
+def datetime_to_header(dt: datetime) -> str:
+ return formatdate(calendar.timegm(dt.timetuple()))
+
+
+class BaseHeuristic:
+ def warning(self, response: HTTPResponse) -> str | None:
+ """
+ Return a valid 1xx warning header value describing the cache
+ adjustments.
+
+ The response is provided too allow warnings like 113
+ http://tools.ietf.org/html/rfc7234#section-5.5.4 where we need
+ to explicitly say response is over 24 hours old.
+ """
+ return '110 - "Response is Stale"'
+
+ def update_headers(self, response: HTTPResponse) -> dict[str, str]:
+ """Update the response headers with any new headers.
+
+ NOTE: This SHOULD always include some Warning header to
+ signify that the response was cached by the client, not
+ by way of the provided headers.
+ """
+ return {}
+
+ def apply(self, response: HTTPResponse) -> HTTPResponse:
+ updated_headers = self.update_headers(response)
+
+ if updated_headers:
+ response.headers.update(updated_headers)
+ warning_header_value = self.warning(response)
+ if warning_header_value is not None:
+ response.headers.update({"Warning": warning_header_value})
+
+ return response
+
+
+class OneDayCache(BaseHeuristic):
+ """
+ Cache the response by providing an expires 1 day in the
+ future.
+ """
+
+ def update_headers(self, response: HTTPResponse) -> dict[str, str]:
+ headers = {}
+
+ if "expires" not in response.headers:
+ date = parsedate(response.headers["date"])
+ expires = expire_after(timedelta(days=1), date=datetime(*date[:6], tzinfo=timezone.utc)) # type: ignore[index,misc]
+ headers["expires"] = datetime_to_header(expires)
+ headers["cache-control"] = "public"
+ return headers
+
+
+class ExpiresAfter(BaseHeuristic):
+ """
+ Cache **all** requests for a defined time period.
+ """
+
+ def __init__(self, **kw: Any) -> None:
+ self.delta = timedelta(**kw)
+
+ def update_headers(self, response: HTTPResponse) -> dict[str, str]:
+ expires = expire_after(self.delta)
+ return {"expires": datetime_to_header(expires), "cache-control": "public"}
+
+ def warning(self, response: HTTPResponse) -> str | None:
+ tmpl = "110 - Automatically cached for %s. Response might be stale"
+ return tmpl % self.delta
+
+
+class LastModified(BaseHeuristic):
+ """
+ If there is no Expires header already, fall back on Last-Modified
+ using the heuristic from
+ http://tools.ietf.org/html/rfc7234#section-4.2.2
+ to calculate a reasonable value.
+
+ Firefox also does something like this per
+ https://developer.mozilla.org/en-US/docs/Web/HTTP/Caching_FAQ
+ http://lxr.mozilla.org/mozilla-release/source/netwerk/protocol/http/nsHttpResponseHead.cpp#397
+ Unlike mozilla we limit this to 24-hr.
+ """
+
+ cacheable_by_default_statuses = {
+ 200,
+ 203,
+ 204,
+ 206,
+ 300,
+ 301,
+ 404,
+ 405,
+ 410,
+ 414,
+ 501,
+ }
+
+ def update_headers(self, resp: HTTPResponse) -> dict[str, str]:
+ headers: Mapping[str, str] = resp.headers
+
+ if "expires" in headers:
+ return {}
+
+ if "cache-control" in headers and headers["cache-control"] != "public":
+ return {}
+
+ if resp.status not in self.cacheable_by_default_statuses:
+ return {}
+
+ if "date" not in headers or "last-modified" not in headers:
+ return {}
+
+ time_tuple = parsedate_tz(headers["date"])
+ assert time_tuple is not None
+ date = calendar.timegm(time_tuple[:6])
+ last_modified = parsedate(headers["last-modified"])
+ if last_modified is None:
+ return {}
+
+ now = time.time()
+ current_age = max(0, now - date)
+ delta = date - calendar.timegm(last_modified)
+ freshness_lifetime = max(0, min(delta / 10, 24 * 3600))
+ if freshness_lifetime <= current_age:
+ return {}
+
+ expires = date + freshness_lifetime
+ return {"expires": time.strftime(TIME_FMT, time.gmtime(expires))}
+
+ def warning(self, resp: HTTPResponse) -> str | None:
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/serialize.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/serialize.py
new file mode 100644
index 000000000..a49487a14
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/serialize.py
@@ -0,0 +1,146 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+import io
+from typing import IO, TYPE_CHECKING, Any, Mapping, cast
+
+from pip._vendor import msgpack
+from pip._vendor.requests.structures import CaseInsensitiveDict
+from pip._vendor.urllib3 import HTTPResponse
+
+if TYPE_CHECKING:
+ from pip._vendor.requests import PreparedRequest
+
+
+class Serializer:
+ serde_version = "4"
+
+ def dumps(
+ self,
+ request: PreparedRequest,
+ response: HTTPResponse,
+ body: bytes | None = None,
+ ) -> bytes:
+ response_headers: CaseInsensitiveDict[str] = CaseInsensitiveDict(
+ response.headers
+ )
+
+ if body is None:
+ # When a body isn't passed in, we'll read the response. We
+ # also update the response with a new file handler to be
+ # sure it acts as though it was never read.
+ body = response.read(decode_content=False)
+ response._fp = io.BytesIO(body) # type: ignore[assignment]
+ response.length_remaining = len(body)
+
+ data = {
+ "response": {
+ "body": body, # Empty bytestring if body is stored separately
+ "headers": {str(k): str(v) for k, v in response.headers.items()},
+ "status": response.status,
+ "version": response.version,
+ "reason": str(response.reason),
+ "decode_content": response.decode_content,
+ }
+ }
+
+ # Construct our vary headers
+ data["vary"] = {}
+ if "vary" in response_headers:
+ varied_headers = response_headers["vary"].split(",")
+ for header in varied_headers:
+ header = str(header).strip()
+ header_value = request.headers.get(header, None)
+ if header_value is not None:
+ header_value = str(header_value)
+ data["vary"][header] = header_value
+
+ return b",".join([f"cc={self.serde_version}".encode(), self.serialize(data)])
+
+ def serialize(self, data: dict[str, Any]) -> bytes:
+ return cast(bytes, msgpack.dumps(data, use_bin_type=True))
+
+ def loads(
+ self,
+ request: PreparedRequest,
+ data: bytes,
+ body_file: IO[bytes] | None = None,
+ ) -> HTTPResponse | None:
+ # Short circuit if we've been given an empty set of data
+ if not data:
+ return None
+
+ # Previous versions of this library supported other serialization
+ # formats, but these have all been removed.
+ if not data.startswith(f"cc={self.serde_version},".encode()):
+ return None
+
+ data = data[5:]
+ return self._loads_v4(request, data, body_file)
+
+ def prepare_response(
+ self,
+ request: PreparedRequest,
+ cached: Mapping[str, Any],
+ body_file: IO[bytes] | None = None,
+ ) -> HTTPResponse | None:
+ """Verify our vary headers match and construct a real urllib3
+ HTTPResponse object.
+ """
+ # Special case the '*' Vary value as it means we cannot actually
+ # determine if the cached response is suitable for this request.
+ # This case is also handled in the controller code when creating
+ # a cache entry, but is left here for backwards compatibility.
+ if "*" in cached.get("vary", {}):
+ return None
+
+ # Ensure that the Vary headers for the cached response match our
+ # request
+ for header, value in cached.get("vary", {}).items():
+ if request.headers.get(header, None) != value:
+ return None
+
+ body_raw = cached["response"].pop("body")
+
+ headers: CaseInsensitiveDict[str] = CaseInsensitiveDict(
+ data=cached["response"]["headers"]
+ )
+ if headers.get("transfer-encoding", "") == "chunked":
+ headers.pop("transfer-encoding")
+
+ cached["response"]["headers"] = headers
+
+ try:
+ body: IO[bytes]
+ if body_file is None:
+ body = io.BytesIO(body_raw)
+ else:
+ body = body_file
+ except TypeError:
+ # This can happen if cachecontrol serialized to v1 format (pickle)
+ # using Python 2. A Python 2 str(byte string) will be unpickled as
+ # a Python 3 str (unicode string), which will cause the above to
+ # fail with:
+ #
+ # TypeError: 'str' does not support the buffer interface
+ body = io.BytesIO(body_raw.encode("utf8"))
+
+ # Discard any `strict` parameter serialized by older version of cachecontrol.
+ cached["response"].pop("strict", None)
+
+ return HTTPResponse(body=body, preload_content=False, **cached["response"])
+
+ def _loads_v4(
+ self,
+ request: PreparedRequest,
+ data: bytes,
+ body_file: IO[bytes] | None = None,
+ ) -> HTTPResponse | None:
+ try:
+ cached = msgpack.loads(data, raw=False)
+ except ValueError:
+ return None
+
+ return self.prepare_response(request, cached, body_file)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/wrapper.py b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/wrapper.py
new file mode 100644
index 000000000..f618bc363
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/cachecontrol/wrapper.py
@@ -0,0 +1,43 @@
+# SPDX-FileCopyrightText: 2015 Eric Larson
+#
+# SPDX-License-Identifier: Apache-2.0
+from __future__ import annotations
+
+from typing import TYPE_CHECKING, Collection
+
+from pip._vendor.cachecontrol.adapter import CacheControlAdapter
+from pip._vendor.cachecontrol.cache import DictCache
+
+if TYPE_CHECKING:
+ from pip._vendor import requests
+
+ from pip._vendor.cachecontrol.cache import BaseCache
+ from pip._vendor.cachecontrol.controller import CacheController
+ from pip._vendor.cachecontrol.heuristics import BaseHeuristic
+ from pip._vendor.cachecontrol.serialize import Serializer
+
+
+def CacheControl(
+ sess: requests.Session,
+ cache: BaseCache | None = None,
+ cache_etags: bool = True,
+ serializer: Serializer | None = None,
+ heuristic: BaseHeuristic | None = None,
+ controller_class: type[CacheController] | None = None,
+ adapter_class: type[CacheControlAdapter] | None = None,
+ cacheable_methods: Collection[str] | None = None,
+) -> requests.Session:
+ cache = DictCache() if cache is None else cache
+ adapter_class = adapter_class or CacheControlAdapter
+ adapter = adapter_class(
+ cache,
+ cache_etags=cache_etags,
+ serializer=serializer,
+ heuristic=heuristic,
+ controller_class=controller_class,
+ cacheable_methods=cacheable_methods,
+ )
+ sess.mount("http://", adapter)
+ sess.mount("https://", adapter)
+
+ return sess
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/__init__.py
new file mode 100644
index 000000000..f61d77fa3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/__init__.py
@@ -0,0 +1,4 @@
+from .core import contents, where
+
+__all__ = ["contents", "where"]
+__version__ = "2024.08.30"
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/__main__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/__main__.py
new file mode 100644
index 000000000..00376349e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/__main__.py
@@ -0,0 +1,12 @@
+import argparse
+
+from pip._vendor.certifi import contents, where
+
+parser = argparse.ArgumentParser()
+parser.add_argument("-c", "--contents", action="store_true")
+args = parser.parse_args()
+
+if args.contents:
+ print(contents())
+else:
+ print(where())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/cacert.pem b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/cacert.pem
new file mode 100644
index 000000000..3c165a1b8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/cacert.pem
@@ -0,0 +1,4929 @@
+
+# Issuer: CN=GlobalSign Root CA O=GlobalSign nv-sa OU=Root CA
+# Subject: CN=GlobalSign Root CA O=GlobalSign nv-sa OU=Root CA
+# Label: "GlobalSign Root CA"
+# Serial: 4835703278459707669005204
+# MD5 Fingerprint: 3e:45:52:15:09:51:92:e1:b7:5d:37:9f:b1:87:29:8a
+# SHA1 Fingerprint: b1:bc:96:8b:d4:f4:9d:62:2a:a8:9a:81:f2:15:01:52:a4:1d:82:9c
+# SHA256 Fingerprint: eb:d4:10:40:e4:bb:3e:c7:42:c9:e3:81:d3:1e:f2:a4:1a:48:b6:68:5c:96:e7:ce:f3:c1:df:6c:d4:33:1c:99
+-----BEGIN CERTIFICATE-----
+MIIDdTCCAl2gAwIBAgILBAAAAAABFUtaw5QwDQYJKoZIhvcNAQEFBQAwVzELMAkG
+A1UEBhMCQkUxGTAXBgNVBAoTEEdsb2JhbFNpZ24gbnYtc2ExEDAOBgNVBAsTB1Jv
+b3QgQ0ExGzAZBgNVBAMTEkdsb2JhbFNpZ24gUm9vdCBDQTAeFw05ODA5MDExMjAw
+MDBaFw0yODAxMjgxMjAwMDBaMFcxCzAJBgNVBAYTAkJFMRkwFwYDVQQKExBHbG9i
+YWxTaWduIG52LXNhMRAwDgYDVQQLEwdSb290IENBMRswGQYDVQQDExJHbG9iYWxT
+aWduIFJvb3QgQ0EwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQDaDuaZ
+jc6j40+Kfvvxi4Mla+pIH/EqsLmVEQS98GPR4mdmzxzdzxtIK+6NiY6arymAZavp
+xy0Sy6scTHAHoT0KMM0VjU/43dSMUBUc71DuxC73/OlS8pF94G3VNTCOXkNz8kHp
+1Wrjsok6Vjk4bwY8iGlbKk3Fp1S4bInMm/k8yuX9ifUSPJJ4ltbcdG6TRGHRjcdG
+snUOhugZitVtbNV4FpWi6cgKOOvyJBNPc1STE4U6G7weNLWLBYy5d4ux2x8gkasJ
+U26Qzns3dLlwR5EiUWMWea6xrkEmCMgZK9FGqkjWZCrXgzT/LCrBbBlDSgeF59N8
+9iFo7+ryUp9/k5DPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMBAf8E
+BTADAQH/MB0GA1UdDgQWBBRge2YaRQ2XyolQL30EzTSo//z9SzANBgkqhkiG9w0B
+AQUFAAOCAQEA1nPnfE920I2/7LqivjTFKDK1fPxsnCwrvQmeU79rXqoRSLblCKOz
+yj1hTdNGCbM+w6DjY1Ub8rrvrTnhQ7k4o+YviiY776BQVvnGCv04zcQLcFGUl5gE
+38NflNUVyRRBnMRddWQVDf9VMOyGj/8N7yy5Y0b2qvzfvGn9LhJIZJrglfCm7ymP
+AbEVtQwdpf5pLGkkeB6zpxxxYu7KyJesF12KwvhHhm4qxFYxldBniYUr+WymXUad
+DKqC5JlR3XC321Y9YeRq4VzW9v493kHMB65jUr9TU/Qr6cf9tveCX4XSQRjbgbME
+HMUfpIBvFSDJ3gyICh3WZlXi/EjJKSZp4A==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Entrust.net Certification Authority (2048) O=Entrust.net OU=www.entrust.net/CPS_2048 incorp. by ref. (limits liab.)/(c) 1999 Entrust.net Limited
+# Subject: CN=Entrust.net Certification Authority (2048) O=Entrust.net OU=www.entrust.net/CPS_2048 incorp. by ref. (limits liab.)/(c) 1999 Entrust.net Limited
+# Label: "Entrust.net Premium 2048 Secure Server CA"
+# Serial: 946069240
+# MD5 Fingerprint: ee:29:31:bc:32:7e:9a:e6:e8:b5:f7:51:b4:34:71:90
+# SHA1 Fingerprint: 50:30:06:09:1d:97:d4:f5:ae:39:f7:cb:e7:92:7d:7d:65:2d:34:31
+# SHA256 Fingerprint: 6d:c4:71:72:e0:1c:bc:b0:bf:62:58:0d:89:5f:e2:b8:ac:9a:d4:f8:73:80:1e:0c:10:b9:c8:37:d2:1e:b1:77
+-----BEGIN CERTIFICATE-----
+MIIEKjCCAxKgAwIBAgIEOGPe+DANBgkqhkiG9w0BAQUFADCBtDEUMBIGA1UEChML
+RW50cnVzdC5uZXQxQDA+BgNVBAsUN3d3dy5lbnRydXN0Lm5ldC9DUFNfMjA0OCBp
+bmNvcnAuIGJ5IHJlZi4gKGxpbWl0cyBsaWFiLikxJTAjBgNVBAsTHChjKSAxOTk5
+IEVudHJ1c3QubmV0IExpbWl0ZWQxMzAxBgNVBAMTKkVudHJ1c3QubmV0IENlcnRp
+ZmljYXRpb24gQXV0aG9yaXR5ICgyMDQ4KTAeFw05OTEyMjQxNzUwNTFaFw0yOTA3
+MjQxNDE1MTJaMIG0MRQwEgYDVQQKEwtFbnRydXN0Lm5ldDFAMD4GA1UECxQ3d3d3
+LmVudHJ1c3QubmV0L0NQU18yMDQ4IGluY29ycC4gYnkgcmVmLiAobGltaXRzIGxp
+YWIuKTElMCMGA1UECxMcKGMpIDE5OTkgRW50cnVzdC5uZXQgTGltaXRlZDEzMDEG
+A1UEAxMqRW50cnVzdC5uZXQgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkgKDIwNDgp
+MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArU1LqRKGsuqjIAcVFmQq
+K0vRvwtKTY7tgHalZ7d4QMBzQshowNtTK91euHaYNZOLGp18EzoOH1u3Hs/lJBQe
+sYGpjX24zGtLA/ECDNyrpUAkAH90lKGdCCmziAv1h3edVc3kw37XamSrhRSGlVuX
+MlBvPci6Zgzj/L24ScF2iUkZ/cCovYmjZy/Gn7xxGWC4LeksyZB2ZnuU4q941mVT
+XTzWnLLPKQP5L6RQstRIzgUyVYr9smRMDuSYB3Xbf9+5CFVghTAp+XtIpGmG4zU/
+HoZdenoVve8AjhUiVBcAkCaTvA5JaJG/+EfTnZVCwQ5N328mz8MYIWJmQ3DW1cAH
+4QIDAQABo0IwQDAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB/zAdBgNV
+HQ4EFgQUVeSB0RGAvtiJuQijMfmhJAkWuXAwDQYJKoZIhvcNAQEFBQADggEBADub
+j1abMOdTmXx6eadNl9cZlZD7Bh/KM3xGY4+WZiT6QBshJ8rmcnPyT/4xmf3IDExo
+U8aAghOY+rat2l098c5u9hURlIIM7j+VrxGrD9cv3h8Dj1csHsm7mhpElesYT6Yf
+zX1XEC+bBAlahLVu2B064dae0Wx5XnkcFMXj0EyTO2U87d89vqbllRrDtRnDvV5b
+u/8j72gZyxKTJ1wDLW8w0B62GqzeWvfRqqgnpv55gcR5mTNXuhKwqeBCbJPKVt7+
+bYQLCIt+jerXmCHG8+c8eS9enNFMFY3h7CI3zJpDC5fcgJCNs2ebb0gIFVbPv/Er
+fF6adulZkMV8gzURZVE=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Baltimore CyberTrust Root O=Baltimore OU=CyberTrust
+# Subject: CN=Baltimore CyberTrust Root O=Baltimore OU=CyberTrust
+# Label: "Baltimore CyberTrust Root"
+# Serial: 33554617
+# MD5 Fingerprint: ac:b6:94:a5:9c:17:e0:d7:91:52:9b:b1:97:06:a6:e4
+# SHA1 Fingerprint: d4:de:20:d0:5e:66:fc:53:fe:1a:50:88:2c:78:db:28:52:ca:e4:74
+# SHA256 Fingerprint: 16:af:57:a9:f6:76:b0:ab:12:60:95:aa:5e:ba:de:f2:2a:b3:11:19:d6:44:ac:95:cd:4b:93:db:f3:f2:6a:eb
+-----BEGIN CERTIFICATE-----
+MIIDdzCCAl+gAwIBAgIEAgAAuTANBgkqhkiG9w0BAQUFADBaMQswCQYDVQQGEwJJ
+RTESMBAGA1UEChMJQmFsdGltb3JlMRMwEQYDVQQLEwpDeWJlclRydXN0MSIwIAYD
+VQQDExlCYWx0aW1vcmUgQ3liZXJUcnVzdCBSb290MB4XDTAwMDUxMjE4NDYwMFoX
+DTI1MDUxMjIzNTkwMFowWjELMAkGA1UEBhMCSUUxEjAQBgNVBAoTCUJhbHRpbW9y
+ZTETMBEGA1UECxMKQ3liZXJUcnVzdDEiMCAGA1UEAxMZQmFsdGltb3JlIEN5YmVy
+VHJ1c3QgUm9vdDCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAKMEuyKr
+mD1X6CZymrV51Cni4eiVgLGw41uOKymaZN+hXe2wCQVt2yguzmKiYv60iNoS6zjr
+IZ3AQSsBUnuId9Mcj8e6uYi1agnnc+gRQKfRzMpijS3ljwumUNKoUMMo6vWrJYeK
+mpYcqWe4PwzV9/lSEy/CG9VwcPCPwBLKBsua4dnKM3p31vjsufFoREJIE9LAwqSu
+XmD+tqYF/LTdB1kC1FkYmGP1pWPgkAx9XbIGevOF6uvUA65ehD5f/xXtabz5OTZy
+dc93Uk3zyZAsuT3lySNTPx8kmCFcB5kpvcY67Oduhjprl3RjM71oGDHweI12v/ye
+jl0qhqdNkNwnGjkCAwEAAaNFMEMwHQYDVR0OBBYEFOWdWTCCR1jMrPoIVDaGezq1
+BE3wMBIGA1UdEwEB/wQIMAYBAf8CAQMwDgYDVR0PAQH/BAQDAgEGMA0GCSqGSIb3
+DQEBBQUAA4IBAQCFDF2O5G9RaEIFoN27TyclhAO992T9Ldcw46QQF+vaKSm2eT92
+9hkTI7gQCvlYpNRhcL0EYWoSihfVCr3FvDB81ukMJY2GQE/szKN+OMY3EU/t3Wgx
+jkzSswF07r51XgdIGn9w/xZchMB5hbgF/X++ZRGjD8ACtPhSNzkE1akxehi/oCr0
+Epn3o0WC4zxe9Z2etciefC7IpJ5OCBRLbf1wbWsaY71k5h+3zvDyny67G7fyUIhz
+ksLi4xaNmjICq44Y3ekQEe5+NauQrz4wlHrQMz2nZQ/1/I6eYs9HRCwBXbsdtTLS
+R9I4LtD+gdwyah617jzV/OeBHRnDJELqYzmp
+-----END CERTIFICATE-----
+
+# Issuer: CN=Entrust Root Certification Authority O=Entrust, Inc. OU=www.entrust.net/CPS is incorporated by reference/(c) 2006 Entrust, Inc.
+# Subject: CN=Entrust Root Certification Authority O=Entrust, Inc. OU=www.entrust.net/CPS is incorporated by reference/(c) 2006 Entrust, Inc.
+# Label: "Entrust Root Certification Authority"
+# Serial: 1164660820
+# MD5 Fingerprint: d6:a5:c3:ed:5d:dd:3e:00:c1:3d:87:92:1f:1d:3f:e4
+# SHA1 Fingerprint: b3:1e:b1:b7:40:e3:6c:84:02:da:dc:37:d4:4d:f5:d4:67:49:52:f9
+# SHA256 Fingerprint: 73:c1:76:43:4f:1b:c6:d5:ad:f4:5b:0e:76:e7:27:28:7c:8d:e5:76:16:c1:e6:e6:14:1a:2b:2c:bc:7d:8e:4c
+-----BEGIN CERTIFICATE-----
+MIIEkTCCA3mgAwIBAgIERWtQVDANBgkqhkiG9w0BAQUFADCBsDELMAkGA1UEBhMC
+VVMxFjAUBgNVBAoTDUVudHJ1c3QsIEluYy4xOTA3BgNVBAsTMHd3dy5lbnRydXN0
+Lm5ldC9DUFMgaXMgaW5jb3Jwb3JhdGVkIGJ5IHJlZmVyZW5jZTEfMB0GA1UECxMW
+KGMpIDIwMDYgRW50cnVzdCwgSW5jLjEtMCsGA1UEAxMkRW50cnVzdCBSb290IENl
+cnRpZmljYXRpb24gQXV0aG9yaXR5MB4XDTA2MTEyNzIwMjM0MloXDTI2MTEyNzIw
+NTM0MlowgbAxCzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1FbnRydXN0LCBJbmMuMTkw
+NwYDVQQLEzB3d3cuZW50cnVzdC5uZXQvQ1BTIGlzIGluY29ycG9yYXRlZCBieSBy
+ZWZlcmVuY2UxHzAdBgNVBAsTFihjKSAyMDA2IEVudHJ1c3QsIEluYy4xLTArBgNV
+BAMTJEVudHJ1c3QgUm9vdCBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTCCASIwDQYJ
+KoZIhvcNAQEBBQADggEPADCCAQoCggEBALaVtkNC+sZtKm9I35RMOVcF7sN5EUFo
+Nu3s/poBj6E4KPz3EEZmLk0eGrEaTsbRwJWIsMn/MYszA9u3g3s+IIRe7bJWKKf4
+4LlAcTfFy0cOlypowCKVYhXbR9n10Cv/gkvJrT7eTNuQgFA/CYqEAOwwCj0Yzfv9
+KlmaI5UXLEWeH25DeW0MXJj+SKfFI0dcXv1u5x609mhF0YaDW6KKjbHjKYD+JXGI
+rb68j6xSlkuqUY3kEzEZ6E5Nn9uss2rVvDlUccp6en+Q3X0dgNmBu1kmwhH+5pPi
+94DkZfs0Nw4pgHBNrziGLp5/V6+eF67rHMsoIV+2HNjnogQi+dPa2MsCAwEAAaOB
+sDCBrTAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB/zArBgNVHRAEJDAi
+gA8yMDA2MTEyNzIwMjM0MlqBDzIwMjYxMTI3MjA1MzQyWjAfBgNVHSMEGDAWgBRo
+kORnpKZTgMeGZqTx90tD+4S9bTAdBgNVHQ4EFgQUaJDkZ6SmU4DHhmak8fdLQ/uE
+vW0wHQYJKoZIhvZ9B0EABBAwDhsIVjcuMTo0LjADAgSQMA0GCSqGSIb3DQEBBQUA
+A4IBAQCT1DCw1wMgKtD5Y+iRDAUgqV8ZyntyTtSx29CW+1RaGSwMCPeyvIWonX9t
+O1KzKtvn1ISMY/YPyyYBkVBs9F8U4pN0wBOeMDpQ47RgxRzwIkSNcUesyBrJ6Zua
+AGAT/3B+XxFNSRuzFVJ7yVTav52Vr2ua2J7p8eRDjeIRRDq/r72DQnNSi6q7pynP
+9WQcCk3RvKqsnyrQ/39/2n3qse0wJcGE2jTSW3iDVuycNsMm4hH2Z0kdkquM++v/
+eu6FSqdQgPCnXEqULl8FmTxSQeDNtGPPAUO6nIPcj2A781q0tHuu2guQOHXvgR1m
+0vdXcDazv/wor3ElhVsT/h5/WrQ8
+-----END CERTIFICATE-----
+
+# Issuer: CN=AAA Certificate Services O=Comodo CA Limited
+# Subject: CN=AAA Certificate Services O=Comodo CA Limited
+# Label: "Comodo AAA Services root"
+# Serial: 1
+# MD5 Fingerprint: 49:79:04:b0:eb:87:19:ac:47:b0:bc:11:51:9b:74:d0
+# SHA1 Fingerprint: d1:eb:23:a4:6d:17:d6:8f:d9:25:64:c2:f1:f1:60:17:64:d8:e3:49
+# SHA256 Fingerprint: d7:a7:a0:fb:5d:7e:27:31:d7:71:e9:48:4e:bc:de:f7:1d:5f:0c:3e:0a:29:48:78:2b:c8:3e:e0:ea:69:9e:f4
+-----BEGIN CERTIFICATE-----
+MIIEMjCCAxqgAwIBAgIBATANBgkqhkiG9w0BAQUFADB7MQswCQYDVQQGEwJHQjEb
+MBkGA1UECAwSR3JlYXRlciBNYW5jaGVzdGVyMRAwDgYDVQQHDAdTYWxmb3JkMRow
+GAYDVQQKDBFDb21vZG8gQ0EgTGltaXRlZDEhMB8GA1UEAwwYQUFBIENlcnRpZmlj
+YXRlIFNlcnZpY2VzMB4XDTA0MDEwMTAwMDAwMFoXDTI4MTIzMTIzNTk1OVowezEL
+MAkGA1UEBhMCR0IxGzAZBgNVBAgMEkdyZWF0ZXIgTWFuY2hlc3RlcjEQMA4GA1UE
+BwwHU2FsZm9yZDEaMBgGA1UECgwRQ29tb2RvIENBIExpbWl0ZWQxITAfBgNVBAMM
+GEFBQSBDZXJ0aWZpY2F0ZSBTZXJ2aWNlczCCASIwDQYJKoZIhvcNAQEBBQADggEP
+ADCCAQoCggEBAL5AnfRu4ep2hxxNRUSOvkbIgwadwSr+GB+O5AL686tdUIoWMQua
+BtDFcCLNSS1UY8y2bmhGC1Pqy0wkwLxyTurxFa70VJoSCsN6sjNg4tqJVfMiWPPe
+3M/vg4aijJRPn2jymJBGhCfHdr/jzDUsi14HZGWCwEiwqJH5YZ92IFCokcdmtet4
+YgNW8IoaE+oxox6gmf049vYnMlhvB/VruPsUK6+3qszWY19zjNoFmag4qMsXeDZR
+rOme9Hg6jc8P2ULimAyrL58OAd7vn5lJ8S3frHRNG5i1R8XlKdH5kBjHYpy+g8cm
+ez6KJcfA3Z3mNWgQIJ2P2N7Sw4ScDV7oL8kCAwEAAaOBwDCBvTAdBgNVHQ4EFgQU
+oBEKIz6W8Qfs4q8p74Klf9AwpLQwDgYDVR0PAQH/BAQDAgEGMA8GA1UdEwEB/wQF
+MAMBAf8wewYDVR0fBHQwcjA4oDagNIYyaHR0cDovL2NybC5jb21vZG9jYS5jb20v
+QUFBQ2VydGlmaWNhdGVTZXJ2aWNlcy5jcmwwNqA0oDKGMGh0dHA6Ly9jcmwuY29t
+b2RvLm5ldC9BQUFDZXJ0aWZpY2F0ZVNlcnZpY2VzLmNybDANBgkqhkiG9w0BAQUF
+AAOCAQEACFb8AvCb6P+k+tZ7xkSAzk/ExfYAWMymtrwUSWgEdujm7l3sAg9g1o1Q
+GE8mTgHj5rCl7r+8dFRBv/38ErjHT1r0iWAFf2C3BUrz9vHCv8S5dIa2LX1rzNLz
+Rt0vxuBqw8M0Ayx9lt1awg6nCpnBBYurDC/zXDrPbDdVCYfeU0BsWO/8tqtlbgT2
+G9w84FoVxp7Z8VlIMCFlA2zs6SFz7JsDoeA3raAVGI/6ugLOpyypEBMs1OUIJqsi
+l2D4kF501KKaU73yqWjgom7C12yxow+ev+to51byrvLjKzg6CYG1a4XXvi3tPxq3
+smPi9WIsgtRqAEFQ8TmDn5XpNpaYbg==
+-----END CERTIFICATE-----
+
+# Issuer: CN=QuoVadis Root CA 2 O=QuoVadis Limited
+# Subject: CN=QuoVadis Root CA 2 O=QuoVadis Limited
+# Label: "QuoVadis Root CA 2"
+# Serial: 1289
+# MD5 Fingerprint: 5e:39:7b:dd:f8:ba:ec:82:e9:ac:62:ba:0c:54:00:2b
+# SHA1 Fingerprint: ca:3a:fb:cf:12:40:36:4b:44:b2:16:20:88:80:48:39:19:93:7c:f7
+# SHA256 Fingerprint: 85:a0:dd:7d:d7:20:ad:b7:ff:05:f8:3d:54:2b:20:9d:c7:ff:45:28:f7:d6:77:b1:83:89:fe:a5:e5:c4:9e:86
+-----BEGIN CERTIFICATE-----
+MIIFtzCCA5+gAwIBAgICBQkwDQYJKoZIhvcNAQEFBQAwRTELMAkGA1UEBhMCQk0x
+GTAXBgNVBAoTEFF1b1ZhZGlzIExpbWl0ZWQxGzAZBgNVBAMTElF1b1ZhZGlzIFJv
+b3QgQ0EgMjAeFw0wNjExMjQxODI3MDBaFw0zMTExMjQxODIzMzNaMEUxCzAJBgNV
+BAYTAkJNMRkwFwYDVQQKExBRdW9WYWRpcyBMaW1pdGVkMRswGQYDVQQDExJRdW9W
+YWRpcyBSb290IENBIDIwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCa
+GMpLlA0ALa8DKYrwD4HIrkwZhR0In6spRIXzL4GtMh6QRr+jhiYaHv5+HBg6XJxg
+Fyo6dIMzMH1hVBHL7avg5tKifvVrbxi3Cgst/ek+7wrGsxDp3MJGF/hd/aTa/55J
+WpzmM+Yklvc/ulsrHHo1wtZn/qtmUIttKGAr79dgw8eTvI02kfN/+NsRE8Scd3bB
+rrcCaoF6qUWD4gXmuVbBlDePSHFjIuwXZQeVikvfj8ZaCuWw419eaxGrDPmF60Tp
++ARz8un+XJiM9XOva7R+zdRcAitMOeGylZUtQofX1bOQQ7dsE/He3fbE+Ik/0XX1
+ksOR1YqI0JDs3G3eicJlcZaLDQP9nL9bFqyS2+r+eXyt66/3FsvbzSUr5R/7mp/i
+Ucw6UwxI5g69ybR2BlLmEROFcmMDBOAENisgGQLodKcftslWZvB1JdxnwQ5hYIiz
+PtGo/KPaHbDRsSNU30R2be1B2MGyIrZTHN81Hdyhdyox5C315eXbyOD/5YDXC2Og
+/zOhD7osFRXql7PSorW+8oyWHhqPHWykYTe5hnMz15eWniN9gqRMgeKh0bpnX5UH
+oycR7hYQe7xFSkyyBNKr79X9DFHOUGoIMfmR2gyPZFwDwzqLID9ujWc9Otb+fVuI
+yV77zGHcizN300QyNQliBJIWENieJ0f7OyHj+OsdWwIDAQABo4GwMIGtMA8GA1Ud
+EwEB/wQFMAMBAf8wCwYDVR0PBAQDAgEGMB0GA1UdDgQWBBQahGK8SEwzJQTU7tD2
+A8QZRtGUazBuBgNVHSMEZzBlgBQahGK8SEwzJQTU7tD2A8QZRtGUa6FJpEcwRTEL
+MAkGA1UEBhMCQk0xGTAXBgNVBAoTEFF1b1ZhZGlzIExpbWl0ZWQxGzAZBgNVBAMT
+ElF1b1ZhZGlzIFJvb3QgQ0EgMoICBQkwDQYJKoZIhvcNAQEFBQADggIBAD4KFk2f
+BluornFdLwUvZ+YTRYPENvbzwCYMDbVHZF34tHLJRqUDGCdViXh9duqWNIAXINzn
+g/iN/Ae42l9NLmeyhP3ZRPx3UIHmfLTJDQtyU/h2BwdBR5YM++CCJpNVjP4iH2Bl
+fF/nJrP3MpCYUNQ3cVX2kiF495V5+vgtJodmVjB3pjd4M1IQWK4/YY7yarHvGH5K
+WWPKjaJW1acvvFYfzznB4vsKqBUsfU16Y8Zsl0Q80m/DShcK+JDSV6IZUaUtl0Ha
+B0+pUNqQjZRG4T7wlP0QADj1O+hA4bRuVhogzG9Yje0uRY/W6ZM/57Es3zrWIozc
+hLsib9D45MY56QSIPMO661V6bYCZJPVsAfv4l7CUW+v90m/xd2gNNWQjrLhVoQPR
+TUIZ3Ph1WVaj+ahJefivDrkRoHy3au000LYmYjgahwz46P0u05B/B5EqHdZ+XIWD
+mbA4CD/pXvk1B+TJYm5Xf6dQlfe6yJvmjqIBxdZmv3lh8zwc4bmCXF2gw+nYSL0Z
+ohEUGW6yhhtoPkg3Goi3XZZenMfvJ2II4pEZXNLxId26F0KCl3GBUzGpn/Z9Yr9y
+4aOTHcyKJloJONDO1w2AFrR4pTqHTI2KpdVGl/IsELm8VCLAAVBpQ570su9t+Oza
+8eOx79+Rj1QqCyXBJhnEUhAFZdWCEOrCMc0u
+-----END CERTIFICATE-----
+
+# Issuer: CN=QuoVadis Root CA 3 O=QuoVadis Limited
+# Subject: CN=QuoVadis Root CA 3 O=QuoVadis Limited
+# Label: "QuoVadis Root CA 3"
+# Serial: 1478
+# MD5 Fingerprint: 31:85:3c:62:94:97:63:b9:aa:fd:89:4e:af:6f:e0:cf
+# SHA1 Fingerprint: 1f:49:14:f7:d8:74:95:1d:dd:ae:02:c0:be:fd:3a:2d:82:75:51:85
+# SHA256 Fingerprint: 18:f1:fc:7f:20:5d:f8:ad:dd:eb:7f:e0:07:dd:57:e3:af:37:5a:9c:4d:8d:73:54:6b:f4:f1:fe:d1:e1:8d:35
+-----BEGIN CERTIFICATE-----
+MIIGnTCCBIWgAwIBAgICBcYwDQYJKoZIhvcNAQEFBQAwRTELMAkGA1UEBhMCQk0x
+GTAXBgNVBAoTEFF1b1ZhZGlzIExpbWl0ZWQxGzAZBgNVBAMTElF1b1ZhZGlzIFJv
+b3QgQ0EgMzAeFw0wNjExMjQxOTExMjNaFw0zMTExMjQxOTA2NDRaMEUxCzAJBgNV
+BAYTAkJNMRkwFwYDVQQKExBRdW9WYWRpcyBMaW1pdGVkMRswGQYDVQQDExJRdW9W
+YWRpcyBSb290IENBIDMwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDM
+V0IWVJzmmNPTTe7+7cefQzlKZbPoFog02w1ZkXTPkrgEQK0CSzGrvI2RaNggDhoB
+4hp7Thdd4oq3P5kazethq8Jlph+3t723j/z9cI8LoGe+AaJZz3HmDyl2/7FWeUUr
+H556VOijKTVopAFPD6QuN+8bv+OPEKhyq1hX51SGyMnzW9os2l2ObjyjPtr7guXd
+8lyyBTNvijbO0BNO/79KDDRMpsMhvVAEVeuxu537RR5kFd5VAYwCdrXLoT9Cabwv
+vWhDFlaJKjdhkf2mrk7AyxRllDdLkgbvBNDInIjbC3uBr7E9KsRlOni27tyAsdLT
+mZw67mtaa7ONt9XOnMK+pUsvFrGeaDsGb659n/je7Mwpp5ijJUMv7/FfJuGITfhe
+btfZFG4ZM2mnO4SJk8RTVROhUXhA+LjJou57ulJCg54U7QVSWllWp5f8nT8KKdjc
+T5EOE7zelaTfi5m+rJsziO+1ga8bxiJTyPbH7pcUsMV8eFLI8M5ud2CEpukqdiDt
+WAEXMJPpGovgc2PZapKUSU60rUqFxKMiMPwJ7Wgic6aIDFUhWMXhOp8q3crhkODZ
+c6tsgLjoC2SToJyMGf+z0gzskSaHirOi4XCPLArlzW1oUevaPwV/izLmE1xr/l9A
+4iLItLRkT9a6fUg+qGkM17uGcclzuD87nSVL2v9A6wIDAQABo4IBlTCCAZEwDwYD
+VR0TAQH/BAUwAwEB/zCB4QYDVR0gBIHZMIHWMIHTBgkrBgEEAb5YAAMwgcUwgZMG
+CCsGAQUFBwICMIGGGoGDQW55IHVzZSBvZiB0aGlzIENlcnRpZmljYXRlIGNvbnN0
+aXR1dGVzIGFjY2VwdGFuY2Ugb2YgdGhlIFF1b1ZhZGlzIFJvb3QgQ0EgMyBDZXJ0
+aWZpY2F0ZSBQb2xpY3kgLyBDZXJ0aWZpY2F0aW9uIFByYWN0aWNlIFN0YXRlbWVu
+dC4wLQYIKwYBBQUHAgEWIWh0dHA6Ly93d3cucXVvdmFkaXNnbG9iYWwuY29tL2Nw
+czALBgNVHQ8EBAMCAQYwHQYDVR0OBBYEFPLAE+CCQz777i9nMpY1XNu4ywLQMG4G
+A1UdIwRnMGWAFPLAE+CCQz777i9nMpY1XNu4ywLQoUmkRzBFMQswCQYDVQQGEwJC
+TTEZMBcGA1UEChMQUXVvVmFkaXMgTGltaXRlZDEbMBkGA1UEAxMSUXVvVmFkaXMg
+Um9vdCBDQSAzggIFxjANBgkqhkiG9w0BAQUFAAOCAgEAT62gLEz6wPJv92ZVqyM0
+7ucp2sNbtrCD2dDQ4iH782CnO11gUyeim/YIIirnv6By5ZwkajGxkHon24QRiSem
+d1o417+shvzuXYO8BsbRd2sPbSQvS3pspweWyuOEn62Iix2rFo1bZhfZFvSLgNLd
++LJ2w/w4E6oM3kJpK27zPOuAJ9v1pkQNn1pVWQvVDVJIxa6f8i+AxeoyUDUSly7B
+4f/xI4hROJ/yZlZ25w9Rl6VSDE1JUZU2Pb+iSwwQHYaZTKrzchGT5Or2m9qoXadN
+t54CrnMAyNojA+j56hl0YgCUyyIgvpSnWbWCar6ZeXqp8kokUvd0/bpO5qgdAm6x
+DYBEwa7TIzdfu4V8K5Iu6H6li92Z4b8nby1dqnuH/grdS/yO9SbkbnBCbjPsMZ57
+k8HkyWkaPcBrTiJt7qtYTcbQQcEr6k8Sh17rRdhs9ZgC06DYVYoGmRmioHfRMJ6s
+zHXug/WwYjnPbFfiTNKRCw51KBuav/0aQ/HKd/s7j2G4aSgWQgRecCocIdiP4b0j
+Wy10QJLZYxkNc91pvGJHvOB0K7Lrfb5BG7XARsWhIstfTsEokt4YutUqKLsRixeT
+mJlglFwjz1onl14LBQaTNx47aTbrqZ5hHY8y2o4M1nQ+ewkk2gF3R8Q7zTSMmfXK
+4SVhM7JZG+Ju1zdXtg2pEto=
+-----END CERTIFICATE-----
+
+# Issuer: CN=XRamp Global Certification Authority O=XRamp Security Services Inc OU=www.xrampsecurity.com
+# Subject: CN=XRamp Global Certification Authority O=XRamp Security Services Inc OU=www.xrampsecurity.com
+# Label: "XRamp Global CA Root"
+# Serial: 107108908803651509692980124233745014957
+# MD5 Fingerprint: a1:0b:44:b3:ca:10:d8:00:6e:9d:0f:d8:0f:92:0a:d1
+# SHA1 Fingerprint: b8:01:86:d1:eb:9c:86:a5:41:04:cf:30:54:f3:4c:52:b7:e5:58:c6
+# SHA256 Fingerprint: ce:cd:dc:90:50:99:d8:da:df:c5:b1:d2:09:b7:37:cb:e2:c1:8c:fb:2c:10:c0:ff:0b:cf:0d:32:86:fc:1a:a2
+-----BEGIN CERTIFICATE-----
+MIIEMDCCAxigAwIBAgIQUJRs7Bjq1ZxN1ZfvdY+grTANBgkqhkiG9w0BAQUFADCB
+gjELMAkGA1UEBhMCVVMxHjAcBgNVBAsTFXd3dy54cmFtcHNlY3VyaXR5LmNvbTEk
+MCIGA1UEChMbWFJhbXAgU2VjdXJpdHkgU2VydmljZXMgSW5jMS0wKwYDVQQDEyRY
+UmFtcCBHbG9iYWwgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwHhcNMDQxMTAxMTcx
+NDA0WhcNMzUwMTAxMDUzNzE5WjCBgjELMAkGA1UEBhMCVVMxHjAcBgNVBAsTFXd3
+dy54cmFtcHNlY3VyaXR5LmNvbTEkMCIGA1UEChMbWFJhbXAgU2VjdXJpdHkgU2Vy
+dmljZXMgSW5jMS0wKwYDVQQDEyRYUmFtcCBHbG9iYWwgQ2VydGlmaWNhdGlvbiBB
+dXRob3JpdHkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCYJB69FbS6
+38eMpSe2OAtp87ZOqCwuIR1cRN8hXX4jdP5efrRKt6atH67gBhbim1vZZ3RrXYCP
+KZ2GG9mcDZhtdhAoWORlsH9KmHmf4MMxfoArtYzAQDsRhtDLooY2YKTVMIJt2W7Q
+DxIEM5dfT2Fa8OT5kavnHTu86M/0ay00fOJIYRyO82FEzG+gSqmUsE3a56k0enI4
+qEHMPJQRfevIpoy3hsvKMzvZPTeL+3o+hiznc9cKV6xkmxnr9A8ECIqsAxcZZPRa
+JSKNNCyy9mgdEm3Tih4U2sSPpuIjhdV6Db1q4Ons7Be7QhtnqiXtRYMh/MHJfNVi
+PvryxS3T/dRlAgMBAAGjgZ8wgZwwEwYJKwYBBAGCNxQCBAYeBABDAEEwCwYDVR0P
+BAQDAgGGMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFMZPoj0GY4QJnM5i5ASs
+jVy16bYbMDYGA1UdHwQvMC0wK6ApoCeGJWh0dHA6Ly9jcmwueHJhbXBzZWN1cml0
+eS5jb20vWEdDQS5jcmwwEAYJKwYBBAGCNxUBBAMCAQEwDQYJKoZIhvcNAQEFBQAD
+ggEBAJEVOQMBG2f7Shz5CmBbodpNl2L5JFMn14JkTpAuw0kbK5rc/Kh4ZzXxHfAR
+vbdI4xD2Dd8/0sm2qlWkSLoC295ZLhVbO50WfUfXN+pfTXYSNrsf16GBBEYgoyxt
+qZ4Bfj8pzgCT3/3JknOJiWSe5yvkHJEs0rnOfc5vMZnT5r7SHpDwCRR5XCOrTdLa
+IR9NmXmd4c8nnxCbHIgNsIpkQTG4DmyQJKSbXHGPurt+HBvbaoAPIbzp26a3QPSy
+i6mx5O+aGtA9aZnuqCij4Tyz8LIRnM98QObd50N9otg6tamN8jSZxNQQ4Qb9CYQQ
+O+7ETPTsJ3xCwnR8gooJybQDJbw=
+-----END CERTIFICATE-----
+
+# Issuer: O=The Go Daddy Group, Inc. OU=Go Daddy Class 2 Certification Authority
+# Subject: O=The Go Daddy Group, Inc. OU=Go Daddy Class 2 Certification Authority
+# Label: "Go Daddy Class 2 CA"
+# Serial: 0
+# MD5 Fingerprint: 91:de:06:25:ab:da:fd:32:17:0c:bb:25:17:2a:84:67
+# SHA1 Fingerprint: 27:96:ba:e6:3f:18:01:e2:77:26:1b:a0:d7:77:70:02:8f:20:ee:e4
+# SHA256 Fingerprint: c3:84:6b:f2:4b:9e:93:ca:64:27:4c:0e:c6:7c:1e:cc:5e:02:4f:fc:ac:d2:d7:40:19:35:0e:81:fe:54:6a:e4
+-----BEGIN CERTIFICATE-----
+MIIEADCCAuigAwIBAgIBADANBgkqhkiG9w0BAQUFADBjMQswCQYDVQQGEwJVUzEh
+MB8GA1UEChMYVGhlIEdvIERhZGR5IEdyb3VwLCBJbmMuMTEwLwYDVQQLEyhHbyBE
+YWRkeSBDbGFzcyAyIENlcnRpZmljYXRpb24gQXV0aG9yaXR5MB4XDTA0MDYyOTE3
+MDYyMFoXDTM0MDYyOTE3MDYyMFowYzELMAkGA1UEBhMCVVMxITAfBgNVBAoTGFRo
+ZSBHbyBEYWRkeSBHcm91cCwgSW5jLjExMC8GA1UECxMoR28gRGFkZHkgQ2xhc3Mg
+MiBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTCCASAwDQYJKoZIhvcNAQEBBQADggEN
+ADCCAQgCggEBAN6d1+pXGEmhW+vXX0iG6r7d/+TvZxz0ZWizV3GgXne77ZtJ6XCA
+PVYYYwhv2vLM0D9/AlQiVBDYsoHUwHU9S3/Hd8M+eKsaA7Ugay9qK7HFiH7Eux6w
+wdhFJ2+qN1j3hybX2C32qRe3H3I2TqYXP2WYktsqbl2i/ojgC95/5Y0V4evLOtXi
+EqITLdiOr18SPaAIBQi2XKVlOARFmR6jYGB0xUGlcmIbYsUfb18aQr4CUWWoriMY
+avx4A6lNf4DD+qta/KFApMoZFv6yyO9ecw3ud72a9nmYvLEHZ6IVDd2gWMZEewo+
+YihfukEHU1jPEX44dMX4/7VpkI+EdOqXG68CAQOjgcAwgb0wHQYDVR0OBBYEFNLE
+sNKR1EwRcbNhyz2h/t2oatTjMIGNBgNVHSMEgYUwgYKAFNLEsNKR1EwRcbNhyz2h
+/t2oatTjoWekZTBjMQswCQYDVQQGEwJVUzEhMB8GA1UEChMYVGhlIEdvIERhZGR5
+IEdyb3VwLCBJbmMuMTEwLwYDVQQLEyhHbyBEYWRkeSBDbGFzcyAyIENlcnRpZmlj
+YXRpb24gQXV0aG9yaXR5ggEAMAwGA1UdEwQFMAMBAf8wDQYJKoZIhvcNAQEFBQAD
+ggEBADJL87LKPpH8EsahB4yOd6AzBhRckB4Y9wimPQoZ+YeAEW5p5JYXMP80kWNy
+OO7MHAGjHZQopDH2esRU1/blMVgDoszOYtuURXO1v0XJJLXVggKtI3lpjbi2Tc7P
+TMozI+gciKqdi0FuFskg5YmezTvacPd+mSYgFFQlq25zheabIZ0KbIIOqPjCDPoQ
+HmyW74cNxA9hi63ugyuV+I6ShHI56yDqg+2DzZduCLzrTia2cyvk0/ZM/iZx4mER
+dEr/VxqHD3VILs9RaRegAhJhldXRQLIQTO7ErBBDpqWeCtWVYpoNz4iCxTIM5Cuf
+ReYNnyicsbkqWletNw+vHX/bvZ8=
+-----END CERTIFICATE-----
+
+# Issuer: O=Starfield Technologies, Inc. OU=Starfield Class 2 Certification Authority
+# Subject: O=Starfield Technologies, Inc. OU=Starfield Class 2 Certification Authority
+# Label: "Starfield Class 2 CA"
+# Serial: 0
+# MD5 Fingerprint: 32:4a:4b:bb:c8:63:69:9b:be:74:9a:c6:dd:1d:46:24
+# SHA1 Fingerprint: ad:7e:1c:28:b0:64:ef:8f:60:03:40:20:14:c3:d0:e3:37:0e:b5:8a
+# SHA256 Fingerprint: 14:65:fa:20:53:97:b8:76:fa:a6:f0:a9:95:8e:55:90:e4:0f:cc:7f:aa:4f:b7:c2:c8:67:75:21:fb:5f:b6:58
+-----BEGIN CERTIFICATE-----
+MIIEDzCCAvegAwIBAgIBADANBgkqhkiG9w0BAQUFADBoMQswCQYDVQQGEwJVUzEl
+MCMGA1UEChMcU3RhcmZpZWxkIFRlY2hub2xvZ2llcywgSW5jLjEyMDAGA1UECxMp
+U3RhcmZpZWxkIENsYXNzIDIgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwHhcNMDQw
+NjI5MTczOTE2WhcNMzQwNjI5MTczOTE2WjBoMQswCQYDVQQGEwJVUzElMCMGA1UE
+ChMcU3RhcmZpZWxkIFRlY2hub2xvZ2llcywgSW5jLjEyMDAGA1UECxMpU3RhcmZp
+ZWxkIENsYXNzIDIgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwggEgMA0GCSqGSIb3
+DQEBAQUAA4IBDQAwggEIAoIBAQC3Msj+6XGmBIWtDBFk385N78gDGIc/oav7PKaf
+8MOh2tTYbitTkPskpD6E8J7oX+zlJ0T1KKY/e97gKvDIr1MvnsoFAZMej2YcOadN
++lq2cwQlZut3f+dZxkqZJRRU6ybH838Z1TBwj6+wRir/resp7defqgSHo9T5iaU0
+X9tDkYI22WY8sbi5gv2cOj4QyDvvBmVmepsZGD3/cVE8MC5fvj13c7JdBmzDI1aa
+K4UmkhynArPkPw2vCHmCuDY96pzTNbO8acr1zJ3o/WSNF4Azbl5KXZnJHoe0nRrA
+1W4TNSNe35tfPe/W93bC6j67eA0cQmdrBNj41tpvi/JEoAGrAgEDo4HFMIHCMB0G
+A1UdDgQWBBS/X7fRzt0fhvRbVazc1xDCDqmI5zCBkgYDVR0jBIGKMIGHgBS/X7fR
+zt0fhvRbVazc1xDCDqmI56FspGowaDELMAkGA1UEBhMCVVMxJTAjBgNVBAoTHFN0
+YXJmaWVsZCBUZWNobm9sb2dpZXMsIEluYy4xMjAwBgNVBAsTKVN0YXJmaWVsZCBD
+bGFzcyAyIENlcnRpZmljYXRpb24gQXV0aG9yaXR5ggEAMAwGA1UdEwQFMAMBAf8w
+DQYJKoZIhvcNAQEFBQADggEBAAWdP4id0ckaVaGsafPzWdqbAYcaT1epoXkJKtv3
+L7IezMdeatiDh6GX70k1PncGQVhiv45YuApnP+yz3SFmH8lU+nLMPUxA2IGvd56D
+eruix/U0F47ZEUD0/CwqTRV/p2JdLiXTAAsgGh1o+Re49L2L7ShZ3U0WixeDyLJl
+xy16paq8U4Zt3VekyvggQQto8PT7dL5WXXp59fkdheMtlb71cZBDzI0fmgAKhynp
+VSJYACPq4xJDKVtHCN2MQWplBqjlIapBtJUhlbl90TSrE9atvNziPTnNvT51cKEY
+WQPJIrSPnNVeKtelttQKbfi3QBFGmh95DmK/D5fs4C8fF5Q=
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert Assured ID Root CA O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert Assured ID Root CA O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert Assured ID Root CA"
+# Serial: 17154717934120587862167794914071425081
+# MD5 Fingerprint: 87:ce:0b:7b:2a:0e:49:00:e1:58:71:9b:37:a8:93:72
+# SHA1 Fingerprint: 05:63:b8:63:0d:62:d7:5a:bb:c8:ab:1e:4b:df:b5:a8:99:b2:4d:43
+# SHA256 Fingerprint: 3e:90:99:b5:01:5e:8f:48:6c:00:bc:ea:9d:11:1e:e7:21:fa:ba:35:5a:89:bc:f1:df:69:56:1e:3d:c6:32:5c
+-----BEGIN CERTIFICATE-----
+MIIDtzCCAp+gAwIBAgIQDOfg5RfYRv6P5WD8G/AwOTANBgkqhkiG9w0BAQUFADBl
+MQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3
+d3cuZGlnaWNlcnQuY29tMSQwIgYDVQQDExtEaWdpQ2VydCBBc3N1cmVkIElEIFJv
+b3QgQ0EwHhcNMDYxMTEwMDAwMDAwWhcNMzExMTEwMDAwMDAwWjBlMQswCQYDVQQG
+EwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cuZGlnaWNl
+cnQuY29tMSQwIgYDVQQDExtEaWdpQ2VydCBBc3N1cmVkIElEIFJvb3QgQ0EwggEi
+MA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCtDhXO5EOAXLGH87dg+XESpa7c
+JpSIqvTO9SA5KFhgDPiA2qkVlTJhPLWxKISKityfCgyDF3qPkKyK53lTXDGEKvYP
+mDI2dsze3Tyoou9q+yHyUmHfnyDXH+Kx2f4YZNISW1/5WBg1vEfNoTb5a3/UsDg+
+wRvDjDPZ2C8Y/igPs6eD1sNuRMBhNZYW/lmci3Zt1/GiSw0r/wty2p5g0I6QNcZ4
+VYcgoc/lbQrISXwxmDNsIumH0DJaoroTghHtORedmTpyoeb6pNnVFzF1roV9Iq4/
+AUaG9ih5yLHa5FcXxH4cDrC0kqZWs72yl+2qp/C3xag/lRbQ/6GW6whfGHdPAgMB
+AAGjYzBhMA4GA1UdDwEB/wQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQW
+BBRF66Kv9JLLgjEtUYunpyGd823IDzAfBgNVHSMEGDAWgBRF66Kv9JLLgjEtUYun
+pyGd823IDzANBgkqhkiG9w0BAQUFAAOCAQEAog683+Lt8ONyc3pklL/3cmbYMuRC
+dWKuh+vy1dneVrOfzM4UKLkNl2BcEkxY5NM9g0lFWJc1aRqoR+pWxnmrEthngYTf
+fwk8lOa4JiwgvT2zKIn3X/8i4peEH+ll74fg38FnSbNd67IJKusm7Xi+fT8r87cm
+NW1fiQG2SVufAQWbqz0lwcy2f8Lxb4bG+mRo64EtlOtCt/qMHt1i8b5QZ7dsvfPx
+H2sMNgcWfzd8qVttevESRmCD1ycEvkvOl77DZypoEd+A5wwzZr8TDRRu838fYxAe
++o0bJW1sj6W3YQGx0qMmoRBxna3iw/nDmVG3KwcIzi7mULKn+gpFL6Lw8g==
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert Global Root CA O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert Global Root CA O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert Global Root CA"
+# Serial: 10944719598952040374951832963794454346
+# MD5 Fingerprint: 79:e4:a9:84:0d:7d:3a:96:d7:c0:4f:e2:43:4c:89:2e
+# SHA1 Fingerprint: a8:98:5d:3a:65:e5:e5:c4:b2:d7:d6:6d:40:c6:dd:2f:b1:9c:54:36
+# SHA256 Fingerprint: 43:48:a0:e9:44:4c:78:cb:26:5e:05:8d:5e:89:44:b4:d8:4f:96:62:bd:26:db:25:7f:89:34:a4:43:c7:01:61
+-----BEGIN CERTIFICATE-----
+MIIDrzCCApegAwIBAgIQCDvgVpBCRrGhdWrJWZHHSjANBgkqhkiG9w0BAQUFADBh
+MQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3
+d3cuZGlnaWNlcnQuY29tMSAwHgYDVQQDExdEaWdpQ2VydCBHbG9iYWwgUm9vdCBD
+QTAeFw0wNjExMTAwMDAwMDBaFw0zMTExMTAwMDAwMDBaMGExCzAJBgNVBAYTAlVT
+MRUwEwYDVQQKEwxEaWdpQ2VydCBJbmMxGTAXBgNVBAsTEHd3dy5kaWdpY2VydC5j
+b20xIDAeBgNVBAMTF0RpZ2lDZXJ0IEdsb2JhbCBSb290IENBMIIBIjANBgkqhkiG
+9w0BAQEFAAOCAQ8AMIIBCgKCAQEA4jvhEXLeqKTTo1eqUKKPC3eQyaKl7hLOllsB
+CSDMAZOnTjC3U/dDxGkAV53ijSLdhwZAAIEJzs4bg7/fzTtxRuLWZscFs3YnFo97
+nh6Vfe63SKMI2tavegw5BmV/Sl0fvBf4q77uKNd0f3p4mVmFaG5cIzJLv07A6Fpt
+43C/dxC//AH2hdmoRBBYMql1GNXRor5H4idq9Joz+EkIYIvUX7Q6hL+hqkpMfT7P
+T19sdl6gSzeRntwi5m3OFBqOasv+zbMUZBfHWymeMr/y7vrTC0LUq7dBMtoM1O/4
+gdW7jVg/tRvoSSiicNoxBN33shbyTApOB6jtSj1etX+jkMOvJwIDAQABo2MwYTAO
+BgNVHQ8BAf8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQUA95QNVbR
+TLtm8KPiGxvDl7I90VUwHwYDVR0jBBgwFoAUA95QNVbRTLtm8KPiGxvDl7I90VUw
+DQYJKoZIhvcNAQEFBQADggEBAMucN6pIExIK+t1EnE9SsPTfrgT1eXkIoyQY/Esr
+hMAtudXH/vTBH1jLuG2cenTnmCmrEbXjcKChzUyImZOMkXDiqw8cvpOp/2PV5Adg
+06O/nVsJ8dWO41P0jmP6P6fbtGbfYmbW0W5BjfIttep3Sp+dWOIrWcBAI+0tKIJF
+PnlUkiaY4IBIqDfv8NZ5YBberOgOzW6sRBc4L0na4UU+Krk2U886UAb3LujEV0ls
+YSEY1QSteDwsOoBrp+uvFRTp2InBuThs4pFsiv9kuXclVzDAGySj4dzp30d8tbQk
+CAUw7C29C79Fv1C5qfPrmAESrciIxpg0X40KPMbp1ZWVbd4=
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert High Assurance EV Root CA O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert High Assurance EV Root CA O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert High Assurance EV Root CA"
+# Serial: 3553400076410547919724730734378100087
+# MD5 Fingerprint: d4:74:de:57:5c:39:b2:d3:9c:85:83:c5:c0:65:49:8a
+# SHA1 Fingerprint: 5f:b7:ee:06:33:e2:59:db:ad:0c:4c:9a:e6:d3:8f:1a:61:c7:dc:25
+# SHA256 Fingerprint: 74:31:e5:f4:c3:c1:ce:46:90:77:4f:0b:61:e0:54:40:88:3b:a9:a0:1e:d0:0b:a6:ab:d7:80:6e:d3:b1:18:cf
+-----BEGIN CERTIFICATE-----
+MIIDxTCCAq2gAwIBAgIQAqxcJmoLQJuPC3nyrkYldzANBgkqhkiG9w0BAQUFADBs
+MQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3
+d3cuZGlnaWNlcnQuY29tMSswKQYDVQQDEyJEaWdpQ2VydCBIaWdoIEFzc3VyYW5j
+ZSBFViBSb290IENBMB4XDTA2MTExMDAwMDAwMFoXDTMxMTExMDAwMDAwMFowbDEL
+MAkGA1UEBhMCVVMxFTATBgNVBAoTDERpZ2lDZXJ0IEluYzEZMBcGA1UECxMQd3d3
+LmRpZ2ljZXJ0LmNvbTErMCkGA1UEAxMiRGlnaUNlcnQgSGlnaCBBc3N1cmFuY2Ug
+RVYgUm9vdCBDQTCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAMbM5XPm
++9S75S0tMqbf5YE/yc0lSbZxKsPVlDRnogocsF9ppkCxxLeyj9CYpKlBWTrT3JTW
+PNt0OKRKzE0lgvdKpVMSOO7zSW1xkX5jtqumX8OkhPhPYlG++MXs2ziS4wblCJEM
+xChBVfvLWokVfnHoNb9Ncgk9vjo4UFt3MRuNs8ckRZqnrG0AFFoEt7oT61EKmEFB
+Ik5lYYeBQVCmeVyJ3hlKV9Uu5l0cUyx+mM0aBhakaHPQNAQTXKFx01p8VdteZOE3
+hzBWBOURtCmAEvF5OYiiAhF8J2a3iLd48soKqDirCmTCv2ZdlYTBoSUeh10aUAsg
+EsxBu24LUTi4S8sCAwEAAaNjMGEwDgYDVR0PAQH/BAQDAgGGMA8GA1UdEwEB/wQF
+MAMBAf8wHQYDVR0OBBYEFLE+w2kD+L9HAdSYJhoIAu9jZCvDMB8GA1UdIwQYMBaA
+FLE+w2kD+L9HAdSYJhoIAu9jZCvDMA0GCSqGSIb3DQEBBQUAA4IBAQAcGgaX3Nec
+nzyIZgYIVyHbIUf4KmeqvxgydkAQV8GK83rZEWWONfqe/EW1ntlMMUu4kehDLI6z
+eM7b41N5cdblIZQB2lWHmiRk9opmzN6cN82oNLFpmyPInngiK3BD41VHMWEZ71jF
+hS9OMPagMRYjyOfiZRYzy78aG6A9+MpeizGLYAiJLQwGXFK3xPkKmNEVX58Svnw2
+Yzi9RKR/5CYrCsSXaQ3pjOLAEFe4yHYSkVXySGnYvCoCWw9E1CAx2/S6cCZdkGCe
+vEsXCS+0yx5DaMkHJ8HSXPfqIbloEpw8nL+e/IBcm2PN7EeqJSdnoDfzAIJ9VNep
++OkuE6N36B9K
+-----END CERTIFICATE-----
+
+# Issuer: CN=SwissSign Gold CA - G2 O=SwissSign AG
+# Subject: CN=SwissSign Gold CA - G2 O=SwissSign AG
+# Label: "SwissSign Gold CA - G2"
+# Serial: 13492815561806991280
+# MD5 Fingerprint: 24:77:d9:a8:91:d1:3b:fa:88:2d:c2:ff:f8:cd:33:93
+# SHA1 Fingerprint: d8:c5:38:8a:b7:30:1b:1b:6e:d4:7a:e6:45:25:3a:6f:9f:1a:27:61
+# SHA256 Fingerprint: 62:dd:0b:e9:b9:f5:0a:16:3e:a0:f8:e7:5c:05:3b:1e:ca:57:ea:55:c8:68:8f:64:7c:68:81:f2:c8:35:7b:95
+-----BEGIN CERTIFICATE-----
+MIIFujCCA6KgAwIBAgIJALtAHEP1Xk+wMA0GCSqGSIb3DQEBBQUAMEUxCzAJBgNV
+BAYTAkNIMRUwEwYDVQQKEwxTd2lzc1NpZ24gQUcxHzAdBgNVBAMTFlN3aXNzU2ln
+biBHb2xkIENBIC0gRzIwHhcNMDYxMDI1MDgzMDM1WhcNMzYxMDI1MDgzMDM1WjBF
+MQswCQYDVQQGEwJDSDEVMBMGA1UEChMMU3dpc3NTaWduIEFHMR8wHQYDVQQDExZT
+d2lzc1NpZ24gR29sZCBDQSAtIEcyMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIIC
+CgKCAgEAr+TufoskDhJuqVAtFkQ7kpJcyrhdhJJCEyq8ZVeCQD5XJM1QiyUqt2/8
+76LQwB8CJEoTlo8jE+YoWACjR8cGp4QjK7u9lit/VcyLwVcfDmJlD909Vopz2q5+
+bbqBHH5CjCA12UNNhPqE21Is8w4ndwtrvxEvcnifLtg+5hg3Wipy+dpikJKVyh+c
+6bM8K8vzARO/Ws/BtQpgvd21mWRTuKCWs2/iJneRjOBiEAKfNA+k1ZIzUd6+jbqE
+emA8atufK+ze3gE/bk3lUIbLtK/tREDFylqM2tIrfKjuvqblCqoOpd8FUrdVxyJd
+MmqXl2MT28nbeTZ7hTpKxVKJ+STnnXepgv9VHKVxaSvRAiTysybUa9oEVeXBCsdt
+MDeQKuSeFDNeFhdVxVu1yzSJkvGdJo+hB9TGsnhQ2wwMC3wLjEHXuendjIj3o02y
+MszYF9rNt85mndT9Xv+9lz4pded+p2JYryU0pUHHPbwNUMoDAw8IWh+Vc3hiv69y
+FGkOpeUDDniOJihC8AcLYiAQZzlG+qkDzAQ4embvIIO1jEpWjpEA/I5cgt6IoMPi
+aG59je883WX0XaxR7ySArqpWl2/5rX3aYT+YdzylkbYcjCbaZaIJbcHiVOO5ykxM
+gI93e2CaHt+28kgeDrpOVG2Y4OGiGqJ3UM/EY5LsRxmd6+ZrzsECAwEAAaOBrDCB
+qTAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQUWyV7
+lqRlUX64OfPAeGZe6Drn8O4wHwYDVR0jBBgwFoAUWyV7lqRlUX64OfPAeGZe6Drn
+8O4wRgYDVR0gBD8wPTA7BglghXQBWQECAQEwLjAsBggrBgEFBQcCARYgaHR0cDov
+L3JlcG9zaXRvcnkuc3dpc3NzaWduLmNvbS8wDQYJKoZIhvcNAQEFBQADggIBACe6
+45R88a7A3hfm5djV9VSwg/S7zV4Fe0+fdWavPOhWfvxyeDgD2StiGwC5+OlgzczO
+UYrHUDFu4Up+GC9pWbY9ZIEr44OE5iKHjn3g7gKZYbge9LgriBIWhMIxkziWMaa5
+O1M/wySTVltpkuzFwbs4AOPsF6m43Md8AYOfMke6UiI0HTJ6CVanfCU2qT1L2sCC
+bwq7EsiHSycR+R4tx5M/nttfJmtS2S6K8RTGRI0Vqbe/vd6mGu6uLftIdxf+u+yv
+GPUqUfA5hJeVbG4bwyvEdGB5JbAKJ9/fXtI5z0V9QkvfsywexcZdylU6oJxpmo/a
+77KwPJ+HbBIrZXAVUjEaJM9vMSNQH4xPjyPDdEFjHFWoFN0+4FFQz/EbMFYOkrCC
+hdiDyyJkvC24JdVUorgG6q2SpCSgwYa1ShNqR88uC1aVVMvOmttqtKay20EIhid3
+92qgQmwLOM7XdVAyksLfKzAiSNDVQTglXaTpXZ/GlHXQRf0wl0OPkKsKx4ZzYEpp
+Ld6leNcG2mqeSz53OiATIgHQv2ieY2BrNU0LbbqhPcCT4H8js1WtciVORvnSFu+w
+ZMEBnunKoGqYDs/YYPIvSbjkQuE4NRb0yG5P94FW6LqjviOvrv1vA+ACOzB2+htt
+Qc8Bsem4yWb02ybzOqR08kkkW8mw0FfB+j564ZfJ
+-----END CERTIFICATE-----
+
+# Issuer: CN=SwissSign Silver CA - G2 O=SwissSign AG
+# Subject: CN=SwissSign Silver CA - G2 O=SwissSign AG
+# Label: "SwissSign Silver CA - G2"
+# Serial: 5700383053117599563
+# MD5 Fingerprint: e0:06:a1:c9:7d:cf:c9:fc:0d:c0:56:75:96:d8:62:13
+# SHA1 Fingerprint: 9b:aa:e5:9f:56:ee:21:cb:43:5a:be:25:93:df:a7:f0:40:d1:1d:cb
+# SHA256 Fingerprint: be:6c:4d:a2:bb:b9:ba:59:b6:f3:93:97:68:37:42:46:c3:c0:05:99:3f:a9:8f:02:0d:1d:ed:be:d4:8a:81:d5
+-----BEGIN CERTIFICATE-----
+MIIFvTCCA6WgAwIBAgIITxvUL1S7L0swDQYJKoZIhvcNAQEFBQAwRzELMAkGA1UE
+BhMCQ0gxFTATBgNVBAoTDFN3aXNzU2lnbiBBRzEhMB8GA1UEAxMYU3dpc3NTaWdu
+IFNpbHZlciBDQSAtIEcyMB4XDTA2MTAyNTA4MzI0NloXDTM2MTAyNTA4MzI0Nlow
+RzELMAkGA1UEBhMCQ0gxFTATBgNVBAoTDFN3aXNzU2lnbiBBRzEhMB8GA1UEAxMY
+U3dpc3NTaWduIFNpbHZlciBDQSAtIEcyMIICIjANBgkqhkiG9w0BAQEFAAOCAg8A
+MIICCgKCAgEAxPGHf9N4Mfc4yfjDmUO8x/e8N+dOcbpLj6VzHVxumK4DV644N0Mv
+Fz0fyM5oEMF4rhkDKxD6LHmD9ui5aLlV8gREpzn5/ASLHvGiTSf5YXu6t+WiE7br
+YT7QbNHm+/pe7R20nqA1W6GSy/BJkv6FCgU+5tkL4k+73JU3/JHpMjUi0R86TieF
+nbAVlDLaYQ1HTWBCrpJH6INaUFjpiou5XaHc3ZlKHzZnu0jkg7Y360g6rw9njxcH
+6ATK72oxh9TAtvmUcXtnZLi2kUpCe2UuMGoM9ZDulebyzYLs2aFK7PayS+VFheZt
+eJMELpyCbTapxDFkH4aDCyr0NQp4yVXPQbBH6TCfmb5hqAaEuSh6XzjZG6k4sIN/
+c8HDO0gqgg8hm7jMqDXDhBuDsz6+pJVpATqJAHgE2cn0mRmrVn5bi4Y5FZGkECwJ
+MoBgs5PAKrYYC51+jUnyEEp/+dVGLxmSo5mnJqy7jDzmDrxHB9xzUfFwZC8I+bRH
+HTBsROopN4WSaGa8gzj+ezku01DwH/teYLappvonQfGbGHLy9YR0SslnxFSuSGTf
+jNFusB3hB48IHpmccelM2KX3RxIfdNFRnobzwqIjQAtz20um53MGjMGg6cFZrEb6
+5i/4z3GcRm25xBWNOHkDRUjvxF3XCO6HOSKGsg0PWEP3calILv3q1h8CAwEAAaOB
+rDCBqTAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQU
+F6DNweRBtjpbO8tFnb0cwpj6hlgwHwYDVR0jBBgwFoAUF6DNweRBtjpbO8tFnb0c
+wpj6hlgwRgYDVR0gBD8wPTA7BglghXQBWQEDAQEwLjAsBggrBgEFBQcCARYgaHR0
+cDovL3JlcG9zaXRvcnkuc3dpc3NzaWduLmNvbS8wDQYJKoZIhvcNAQEFBQADggIB
+AHPGgeAn0i0P4JUw4ppBf1AsX19iYamGamkYDHRJ1l2E6kFSGG9YrVBWIGrGvShp
+WJHckRE1qTodvBqlYJ7YH39FkWnZfrt4csEGDyrOj4VwYaygzQu4OSlWhDJOhrs9
+xCrZ1x9y7v5RoSJBsXECYxqCsGKrXlcSH9/L3XWgwF15kIwb4FDm3jH+mHtwX6WQ
+2K34ArZv02DdQEsixT2tOnqfGhpHkXkzuoLcMmkDlm4fS/Bx/uNncqCxv1yL5PqZ
+IseEuRuNI5c/7SXgz2W79WEE790eslpBIlqhn10s6FvJbakMDHiqYMZWjwFaDGi8
+aRl5xB9+lwW/xekkUV7U1UtT7dkjWjYDZaPBA61BMPNGG4WQr2W11bHkFlt4dR2X
+em1ZqSqPe97Dh4kQmUlzeMg9vVE1dCrV8X5pGyq7O70luJpaPXJhkGaH7gzWTdQR
+dAtq/gsD/KNVV4n+SsuuWxcFyPKNIzFTONItaj+CuY0IavdeQXRuwxF+B6wpYJE/
+OMpXEA29MC/HpeZBoNquBYeaoKRlbEwJDIm6uNO5wJOKMPqN5ZprFQFOZ6raYlY+
+hAhm0sQ2fac+EPyI4NSA5QC9qvNOBqN6avlicuMJT+ubDgEj8Z+7fNzcbBGXJbLy
+tGMU0gYqZ4yD9c7qB9iaah7s5Aq7KkzrCWA5zspi2C5u
+-----END CERTIFICATE-----
+
+# Issuer: CN=SecureTrust CA O=SecureTrust Corporation
+# Subject: CN=SecureTrust CA O=SecureTrust Corporation
+# Label: "SecureTrust CA"
+# Serial: 17199774589125277788362757014266862032
+# MD5 Fingerprint: dc:32:c3:a7:6d:25:57:c7:68:09:9d:ea:2d:a9:a2:d1
+# SHA1 Fingerprint: 87:82:c6:c3:04:35:3b:cf:d2:96:92:d2:59:3e:7d:44:d9:34:ff:11
+# SHA256 Fingerprint: f1:c1:b5:0a:e5:a2:0d:d8:03:0e:c9:f6:bc:24:82:3d:d3:67:b5:25:57:59:b4:e7:1b:61:fc:e9:f7:37:5d:73
+-----BEGIN CERTIFICATE-----
+MIIDuDCCAqCgAwIBAgIQDPCOXAgWpa1Cf/DrJxhZ0DANBgkqhkiG9w0BAQUFADBI
+MQswCQYDVQQGEwJVUzEgMB4GA1UEChMXU2VjdXJlVHJ1c3QgQ29ycG9yYXRpb24x
+FzAVBgNVBAMTDlNlY3VyZVRydXN0IENBMB4XDTA2MTEwNzE5MzExOFoXDTI5MTIz
+MTE5NDA1NVowSDELMAkGA1UEBhMCVVMxIDAeBgNVBAoTF1NlY3VyZVRydXN0IENv
+cnBvcmF0aW9uMRcwFQYDVQQDEw5TZWN1cmVUcnVzdCBDQTCCASIwDQYJKoZIhvcN
+AQEBBQADggEPADCCAQoCggEBAKukgeWVzfX2FI7CT8rU4niVWJxB4Q2ZQCQXOZEz
+Zum+4YOvYlyJ0fwkW2Gz4BERQRwdbvC4u/jep4G6pkjGnx29vo6pQT64lO0pGtSO
+0gMdA+9tDWccV9cGrcrI9f4Or2YlSASWC12juhbDCE/RRvgUXPLIXgGZbf2IzIao
+wW8xQmxSPmjL8xk037uHGFaAJsTQ3MBv396gwpEWoGQRS0S8Hvbn+mPeZqx2pHGj
+7DaUaHp3pLHnDi+BeuK1cobvomuL8A/b01k/unK8RCSc43Oz969XL0Imnal0ugBS
+8kvNU3xHCzaFDmapCJcWNFfBZveA4+1wVMeT4C4oFVmHursCAwEAAaOBnTCBmjAT
+BgkrBgEEAYI3FAIEBh4EAEMAQTALBgNVHQ8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB
+/zAdBgNVHQ4EFgQUQjK2FvoE/f5dS3rD/fdMQB1aQ68wNAYDVR0fBC0wKzApoCeg
+JYYjaHR0cDovL2NybC5zZWN1cmV0cnVzdC5jb20vU1RDQS5jcmwwEAYJKwYBBAGC
+NxUBBAMCAQAwDQYJKoZIhvcNAQEFBQADggEBADDtT0rhWDpSclu1pqNlGKa7UTt3
+6Z3q059c4EVlew3KW+JwULKUBRSuSceNQQcSc5R+DCMh/bwQf2AQWnL1mA6s7Ll/
+3XpvXdMc9P+IBWlCqQVxyLesJugutIxq/3HcuLHfmbx8IVQr5Fiiu1cprp6poxkm
+D5kuCLDv/WnPmRoJjeOnnyvJNjR7JLN4TJUXpAYmHrZkUjZfYGfZnMUFdAvnZyPS
+CPyI6a6Lf+Ew9Dd+/cYy2i2eRDAwbO4H3tI0/NL/QPZL9GZGBlSm8jIKYyYwa5vR
+3ItHuuG51WLQoqD0ZwV4KWMabwTW+MZMo5qxN7SN5ShLHZ4swrhovO0C7jE=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Secure Global CA O=SecureTrust Corporation
+# Subject: CN=Secure Global CA O=SecureTrust Corporation
+# Label: "Secure Global CA"
+# Serial: 9751836167731051554232119481456978597
+# MD5 Fingerprint: cf:f4:27:0d:d4:ed:dc:65:16:49:6d:3d:da:bf:6e:de
+# SHA1 Fingerprint: 3a:44:73:5a:e5:81:90:1f:24:86:61:46:1e:3b:9c:c4:5f:f5:3a:1b
+# SHA256 Fingerprint: 42:00:f5:04:3a:c8:59:0e:bb:52:7d:20:9e:d1:50:30:29:fb:cb:d4:1c:a1:b5:06:ec:27:f1:5a:de:7d:ac:69
+-----BEGIN CERTIFICATE-----
+MIIDvDCCAqSgAwIBAgIQB1YipOjUiolN9BPI8PjqpTANBgkqhkiG9w0BAQUFADBK
+MQswCQYDVQQGEwJVUzEgMB4GA1UEChMXU2VjdXJlVHJ1c3QgQ29ycG9yYXRpb24x
+GTAXBgNVBAMTEFNlY3VyZSBHbG9iYWwgQ0EwHhcNMDYxMTA3MTk0MjI4WhcNMjkx
+MjMxMTk1MjA2WjBKMQswCQYDVQQGEwJVUzEgMB4GA1UEChMXU2VjdXJlVHJ1c3Qg
+Q29ycG9yYXRpb24xGTAXBgNVBAMTEFNlY3VyZSBHbG9iYWwgQ0EwggEiMA0GCSqG
+SIb3DQEBAQUAA4IBDwAwggEKAoIBAQCvNS7YrGxVaQZx5RNoJLNP2MwhR/jxYDiJ
+iQPpvepeRlMJ3Fz1Wuj3RSoC6zFh1ykzTM7HfAo3fg+6MpjhHZevj8fcyTiW89sa
+/FHtaMbQbqR8JNGuQsiWUGMu4P51/pinX0kuleM5M2SOHqRfkNJnPLLZ/kG5VacJ
+jnIFHovdRIWCQtBJwB1g8NEXLJXr9qXBkqPFwqcIYA1gBBCWeZ4WNOaptvolRTnI
+HmX5k/Wq8VLcmZg9pYYaDDUz+kulBAYVHDGA76oYa8J719rO+TMg1fW9ajMtgQT7
+sFzUnKPiXB3jqUJ1XnvUd+85VLrJChgbEplJL4hL/VBi0XPnj3pDAgMBAAGjgZ0w
+gZowEwYJKwYBBAGCNxQCBAYeBABDAEEwCwYDVR0PBAQDAgGGMA8GA1UdEwEB/wQF
+MAMBAf8wHQYDVR0OBBYEFK9EBMJBfkiD2045AuzshHrmzsmkMDQGA1UdHwQtMCsw
+KaAnoCWGI2h0dHA6Ly9jcmwuc2VjdXJldHJ1c3QuY29tL1NHQ0EuY3JsMBAGCSsG
+AQQBgjcVAQQDAgEAMA0GCSqGSIb3DQEBBQUAA4IBAQBjGghAfaReUw132HquHw0L
+URYD7xh8yOOvaliTFGCRsoTciE6+OYo68+aCiV0BN7OrJKQVDpI1WkpEXk5X+nXO
+H0jOZvQ8QCaSmGwb7iRGDBezUqXbpZGRzzfTb+cnCDpOGR86p1hcF895P4vkp9Mm
+I50mD1hp/Ed+stCNi5O/KU9DaXR2Z0vPB4zmAve14bRDtUstFJ/53CYNv6ZHdAbY
+iNE6KTCEztI5gGIbqMdXSbxqVVFnFUq+NQfk1XWYN3kwFNspnWzFacxHVaIw98xc
+f8LDmBxrThaA63p4ZUWiABqvDA1VZDRIuJK58bRQKfJPIx/abKwfROHdI3hRW8cW
+-----END CERTIFICATE-----
+
+# Issuer: CN=COMODO Certification Authority O=COMODO CA Limited
+# Subject: CN=COMODO Certification Authority O=COMODO CA Limited
+# Label: "COMODO Certification Authority"
+# Serial: 104350513648249232941998508985834464573
+# MD5 Fingerprint: 5c:48:dc:f7:42:72:ec:56:94:6d:1c:cc:71:35:80:75
+# SHA1 Fingerprint: 66:31:bf:9e:f7:4f:9e:b6:c9:d5:a6:0c:ba:6a:be:d1:f7:bd:ef:7b
+# SHA256 Fingerprint: 0c:2c:d6:3d:f7:80:6f:a3:99:ed:e8:09:11:6b:57:5b:f8:79:89:f0:65:18:f9:80:8c:86:05:03:17:8b:af:66
+-----BEGIN CERTIFICATE-----
+MIIEHTCCAwWgAwIBAgIQToEtioJl4AsC7j41AkblPTANBgkqhkiG9w0BAQUFADCB
+gTELMAkGA1UEBhMCR0IxGzAZBgNVBAgTEkdyZWF0ZXIgTWFuY2hlc3RlcjEQMA4G
+A1UEBxMHU2FsZm9yZDEaMBgGA1UEChMRQ09NT0RPIENBIExpbWl0ZWQxJzAlBgNV
+BAMTHkNPTU9ETyBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTAeFw0wNjEyMDEwMDAw
+MDBaFw0yOTEyMzEyMzU5NTlaMIGBMQswCQYDVQQGEwJHQjEbMBkGA1UECBMSR3Jl
+YXRlciBNYW5jaGVzdGVyMRAwDgYDVQQHEwdTYWxmb3JkMRowGAYDVQQKExFDT01P
+RE8gQ0EgTGltaXRlZDEnMCUGA1UEAxMeQ09NT0RPIENlcnRpZmljYXRpb24gQXV0
+aG9yaXR5MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA0ECLi3LjkRv3
+UcEbVASY06m/weaKXTuH+7uIzg3jLz8GlvCiKVCZrts7oVewdFFxze1CkU1B/qnI
+2GqGd0S7WWaXUF601CxwRM/aN5VCaTwwxHGzUvAhTaHYujl8HJ6jJJ3ygxaYqhZ8
+Q5sVW7euNJH+1GImGEaaP+vB+fGQV+useg2L23IwambV4EajcNxo2f8ESIl33rXp
++2dtQem8Ob0y2WIC8bGoPW43nOIv4tOiJovGuFVDiOEjPqXSJDlqR6sA1KGzqSX+
+DT+nHbrTUcELpNqsOO9VUCQFZUaTNE8tja3G1CEZ0o7KBWFxB3NH5YoZEr0ETc5O
+nKVIrLsm9wIDAQABo4GOMIGLMB0GA1UdDgQWBBQLWOWLxkwVN6RAqTCpIb5HNlpW
+/zAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB/zBJBgNVHR8EQjBAMD6g
+PKA6hjhodHRwOi8vY3JsLmNvbW9kb2NhLmNvbS9DT01PRE9DZXJ0aWZpY2F0aW9u
+QXV0aG9yaXR5LmNybDANBgkqhkiG9w0BAQUFAAOCAQEAPpiem/Yb6dc5t3iuHXIY
+SdOH5EOC6z/JqvWote9VfCFSZfnVDeFs9D6Mk3ORLgLETgdxb8CPOGEIqB6BCsAv
+IC9Bi5HcSEW88cbeunZrM8gALTFGTO3nnc+IlP8zwFboJIYmuNg4ON8qa90SzMc/
+RxdMosIGlgnW2/4/PEZB31jiVg88O8EckzXZOFKs7sjsLjBOlDW0JB9LeGna8gI4
+zJVSk/BwJVmcIGfE7vmLV2H0knZ9P4SNVbfo5azV8fUZVqZa+5Acr5Pr5RzUZ5dd
+BA6+C4OmF4O5MBKgxTMVBbkN+8cFduPYSo38NBejxiEovjBFMR7HeL5YYTisO+IB
+ZQ==
+-----END CERTIFICATE-----
+
+# Issuer: CN=COMODO ECC Certification Authority O=COMODO CA Limited
+# Subject: CN=COMODO ECC Certification Authority O=COMODO CA Limited
+# Label: "COMODO ECC Certification Authority"
+# Serial: 41578283867086692638256921589707938090
+# MD5 Fingerprint: 7c:62:ff:74:9d:31:53:5e:68:4a:d5:78:aa:1e:bf:23
+# SHA1 Fingerprint: 9f:74:4e:9f:2b:4d:ba:ec:0f:31:2c:50:b6:56:3b:8e:2d:93:c3:11
+# SHA256 Fingerprint: 17:93:92:7a:06:14:54:97:89:ad:ce:2f:8f:34:f7:f0:b6:6d:0f:3a:e3:a3:b8:4d:21:ec:15:db:ba:4f:ad:c7
+-----BEGIN CERTIFICATE-----
+MIICiTCCAg+gAwIBAgIQH0evqmIAcFBUTAGem2OZKjAKBggqhkjOPQQDAzCBhTEL
+MAkGA1UEBhMCR0IxGzAZBgNVBAgTEkdyZWF0ZXIgTWFuY2hlc3RlcjEQMA4GA1UE
+BxMHU2FsZm9yZDEaMBgGA1UEChMRQ09NT0RPIENBIExpbWl0ZWQxKzApBgNVBAMT
+IkNPTU9ETyBFQ0MgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwHhcNMDgwMzA2MDAw
+MDAwWhcNMzgwMTE4MjM1OTU5WjCBhTELMAkGA1UEBhMCR0IxGzAZBgNVBAgTEkdy
+ZWF0ZXIgTWFuY2hlc3RlcjEQMA4GA1UEBxMHU2FsZm9yZDEaMBgGA1UEChMRQ09N
+T0RPIENBIExpbWl0ZWQxKzApBgNVBAMTIkNPTU9ETyBFQ0MgQ2VydGlmaWNhdGlv
+biBBdXRob3JpdHkwdjAQBgcqhkjOPQIBBgUrgQQAIgNiAAQDR3svdcmCFYX7deSR
+FtSrYpn1PlILBs5BAH+X4QokPB0BBO490o0JlwzgdeT6+3eKKvUDYEs2ixYjFq0J
+cfRK9ChQtP6IHG4/bC8vCVlbpVsLM5niwz2J+Wos77LTBumjQjBAMB0GA1UdDgQW
+BBR1cacZSBm8nZ3qQUfflMRId5nTeTAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/
+BAUwAwEB/zAKBggqhkjOPQQDAwNoADBlAjEA7wNbeqy3eApyt4jf/7VGFAkK+qDm
+fQjGGoe9GKhzvSbKYAydzpmfz1wPMOG+FDHqAjAU9JM8SaczepBGR7NjfRObTrdv
+GDeAU/7dIOA1mjbRxwG55tzd8/8dLDoWV9mSOdY=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certigna O=Dhimyotis
+# Subject: CN=Certigna O=Dhimyotis
+# Label: "Certigna"
+# Serial: 18364802974209362175
+# MD5 Fingerprint: ab:57:a6:5b:7d:42:82:19:b5:d8:58:26:28:5e:fd:ff
+# SHA1 Fingerprint: b1:2e:13:63:45:86:a4:6f:1a:b2:60:68:37:58:2d:c4:ac:fd:94:97
+# SHA256 Fingerprint: e3:b6:a2:db:2e:d7:ce:48:84:2f:7a:c5:32:41:c7:b7:1d:54:14:4b:fb:40:c1:1f:3f:1d:0b:42:f5:ee:a1:2d
+-----BEGIN CERTIFICATE-----
+MIIDqDCCApCgAwIBAgIJAP7c4wEPyUj/MA0GCSqGSIb3DQEBBQUAMDQxCzAJBgNV
+BAYTAkZSMRIwEAYDVQQKDAlEaGlteW90aXMxETAPBgNVBAMMCENlcnRpZ25hMB4X
+DTA3MDYyOTE1MTMwNVoXDTI3MDYyOTE1MTMwNVowNDELMAkGA1UEBhMCRlIxEjAQ
+BgNVBAoMCURoaW15b3RpczERMA8GA1UEAwwIQ2VydGlnbmEwggEiMA0GCSqGSIb3
+DQEBAQUAA4IBDwAwggEKAoIBAQDIaPHJ1tazNHUmgh7stL7qXOEm7RFHYeGifBZ4
+QCHkYJ5ayGPhxLGWkv8YbWkj4Sti993iNi+RB7lIzw7sebYs5zRLcAglozyHGxny
+gQcPOJAZ0xH+hrTy0V4eHpbNgGzOOzGTtvKg0KmVEn2lmsxryIRWijOp5yIVUxbw
+zBfsV1/pogqYCd7jX5xv3EjjhQsVWqa6n6xI4wmy9/Qy3l40vhx4XUJbzg4ij02Q
+130yGLMLLGq/jj8UEYkgDncUtT2UCIf3JR7VsmAA7G8qKCVuKj4YYxclPz5EIBb2
+JsglrgVKtOdjLPOMFlN+XPsRGgjBRmKfIrjxwo1p3Po6WAbfAgMBAAGjgbwwgbkw
+DwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQUGu3+QTmQtCRZvgHyUtVF9lo53BEw
+ZAYDVR0jBF0wW4AUGu3+QTmQtCRZvgHyUtVF9lo53BGhOKQ2MDQxCzAJBgNVBAYT
+AkZSMRIwEAYDVQQKDAlEaGlteW90aXMxETAPBgNVBAMMCENlcnRpZ25hggkA/tzj
+AQ/JSP8wDgYDVR0PAQH/BAQDAgEGMBEGCWCGSAGG+EIBAQQEAwIABzANBgkqhkiG
+9w0BAQUFAAOCAQEAhQMeknH2Qq/ho2Ge6/PAD/Kl1NqV5ta+aDY9fm4fTIrv0Q8h
+bV6lUmPOEvjvKtpv6zf+EwLHyzs+ImvaYS5/1HI93TDhHkxAGYwP15zRgzB7mFnc
+fca5DClMoTOi62c6ZYTTluLtdkVwj7Ur3vkj1kluPBS1xp81HlDQwY9qcEQCYsuu
+HWhBp6pX6FOqB9IG9tUUBguRA3UsbHK1YZWaDYu5Def131TN3ubY1gkIl2PlwS6w
+t0QmwCbAr1UwnjvVNioZBPRcHv/PLLf/0P2HQBHVESO7SMAhqaQoLf0V+LBOK/Qw
+WyH8EZE0vkHve52Xdf+XlcCWWC/qu0bXu+TZLg==
+-----END CERTIFICATE-----
+
+# Issuer: O=Chunghwa Telecom Co., Ltd. OU=ePKI Root Certification Authority
+# Subject: O=Chunghwa Telecom Co., Ltd. OU=ePKI Root Certification Authority
+# Label: "ePKI Root Certification Authority"
+# Serial: 28956088682735189655030529057352760477
+# MD5 Fingerprint: 1b:2e:00:ca:26:06:90:3d:ad:fe:6f:15:68:d3:6b:b3
+# SHA1 Fingerprint: 67:65:0d:f1:7e:8e:7e:5b:82:40:a4:f4:56:4b:cf:e2:3d:69:c6:f0
+# SHA256 Fingerprint: c0:a6:f4:dc:63:a2:4b:fd:cf:54:ef:2a:6a:08:2a:0a:72:de:35:80:3e:2f:f5:ff:52:7a:e5:d8:72:06:df:d5
+-----BEGIN CERTIFICATE-----
+MIIFsDCCA5igAwIBAgIQFci9ZUdcr7iXAF7kBtK8nTANBgkqhkiG9w0BAQUFADBe
+MQswCQYDVQQGEwJUVzEjMCEGA1UECgwaQ2h1bmdod2EgVGVsZWNvbSBDby4sIEx0
+ZC4xKjAoBgNVBAsMIWVQS0kgUm9vdCBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTAe
+Fw0wNDEyMjAwMjMxMjdaFw0zNDEyMjAwMjMxMjdaMF4xCzAJBgNVBAYTAlRXMSMw
+IQYDVQQKDBpDaHVuZ2h3YSBUZWxlY29tIENvLiwgTHRkLjEqMCgGA1UECwwhZVBL
+SSBSb290IENlcnRpZmljYXRpb24gQXV0aG9yaXR5MIICIjANBgkqhkiG9w0BAQEF
+AAOCAg8AMIICCgKCAgEA4SUP7o3biDN1Z82tH306Tm2d0y8U82N0ywEhajfqhFAH
+SyZbCUNsIZ5qyNUD9WBpj8zwIuQf5/dqIjG3LBXy4P4AakP/h2XGtRrBp0xtInAh
+ijHyl3SJCRImHJ7K2RKilTza6We/CKBk49ZCt0Xvl/T29de1ShUCWH2YWEtgvM3X
+DZoTM1PRYfl61dd4s5oz9wCGzh1NlDivqOx4UXCKXBCDUSH3ET00hl7lSM2XgYI1
+TBnsZfZrxQWh7kcT1rMhJ5QQCtkkO7q+RBNGMD+XPNjX12ruOzjjK9SXDrkb5wdJ
+fzcq+Xd4z1TtW0ado4AOkUPB1ltfFLqfpo0kR0BZv3I4sjZsN/+Z0V0OWQqraffA
+sgRFelQArr5T9rXn4fg8ozHSqf4hUmTFpmfwdQcGlBSBVcYn5AGPF8Fqcde+S/uU
+WH1+ETOxQvdibBjWzwloPn9s9h6PYq2lY9sJpx8iQkEeb5mKPtf5P0B6ebClAZLS
+nT0IFaUQAS2zMnaolQ2zepr7BxB4EW/hj8e6DyUadCrlHJhBmd8hh+iVBmoKs2pH
+dmX2Os+PYhcZewoozRrSgx4hxyy/vv9haLdnG7t4TY3OZ+XkwY63I2binZB1NJip
+NiuKmpS5nezMirH4JYlcWrYvjB9teSSnUmjDhDXiZo1jDiVN1Rmy5nk3pyKdVDEC
+AwEAAaNqMGgwHQYDVR0OBBYEFB4M97Zn8uGSJglFwFU5Lnc/QkqiMAwGA1UdEwQF
+MAMBAf8wOQYEZyoHAAQxMC8wLQIBADAJBgUrDgMCGgUAMAcGBWcqAwAABBRFsMLH
+ClZ87lt4DJX5GFPBphzYEDANBgkqhkiG9w0BAQUFAAOCAgEACbODU1kBPpVJufGB
+uvl2ICO1J2B01GqZNF5sAFPZn/KmsSQHRGoqxqWOeBLoR9lYGxMqXnmbnwoqZ6Yl
+PwZpVnPDimZI+ymBV3QGypzqKOg4ZyYr8dW1P2WT+DZdjo2NQCCHGervJ8A9tDkP
+JXtoUHRVnAxZfVo9QZQlUgjgRywVMRnVvwdVxrsStZf0X4OFunHB2WyBEXYKCrC/
+gpf36j36+uwtqSiUO1bd0lEursC9CBWMd1I0ltabrNMdjmEPNXubrjlpC2JgQCA2
+j6/7Nu4tCEoduL+bXPjqpRugc6bY+G7gMwRfaKonh+3ZwZCc7b3jajWvY9+rGNm6
+5ulK6lCKD2GTHuItGeIwlDWSXQ62B68ZgI9HkFFLLk3dheLSClIKF5r8GrBQAuUB
+o2M3IUxExJtRmREOc5wGj1QupyheRDmHVi03vYVElOEMSyycw5KFNGHLD7ibSkNS
+/jQ6fbjpKdx2qcgw+BRxgMYeNkh0IkFch4LoGHGLQYlE535YW6i4jRPpp2zDR+2z
+Gp1iro2C6pSe3VkQw63d4k3jMdXH7OjysP6SHhYKGvzZ8/gntsm+HbRsZJB/9OTE
+W9c3rkIO3aQab3yIVMUWbuF6aC74Or8NpDyJO3inTmODBCEIZ43ygknQW/2xzQ+D
+hNQ+IIX3Sj0rnP0qCglN6oH4EZw=
+-----END CERTIFICATE-----
+
+# Issuer: O=certSIGN OU=certSIGN ROOT CA
+# Subject: O=certSIGN OU=certSIGN ROOT CA
+# Label: "certSIGN ROOT CA"
+# Serial: 35210227249154
+# MD5 Fingerprint: 18:98:c0:d6:e9:3a:fc:f9:b0:f5:0c:f7:4b:01:44:17
+# SHA1 Fingerprint: fa:b7:ee:36:97:26:62:fb:2d:b0:2a:f6:bf:03:fd:e8:7c:4b:2f:9b
+# SHA256 Fingerprint: ea:a9:62:c4:fa:4a:6b:af:eb:e4:15:19:6d:35:1c:cd:88:8d:4f:53:f3:fa:8a:e6:d7:c4:66:a9:4e:60:42:bb
+-----BEGIN CERTIFICATE-----
+MIIDODCCAiCgAwIBAgIGIAYFFnACMA0GCSqGSIb3DQEBBQUAMDsxCzAJBgNVBAYT
+AlJPMREwDwYDVQQKEwhjZXJ0U0lHTjEZMBcGA1UECxMQY2VydFNJR04gUk9PVCBD
+QTAeFw0wNjA3MDQxNzIwMDRaFw0zMTA3MDQxNzIwMDRaMDsxCzAJBgNVBAYTAlJP
+MREwDwYDVQQKEwhjZXJ0U0lHTjEZMBcGA1UECxMQY2VydFNJR04gUk9PVCBDQTCC
+ASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBALczuX7IJUqOtdu0KBuqV5Do
+0SLTZLrTk+jUrIZhQGpgV2hUhE28alQCBf/fm5oqrl0Hj0rDKH/v+yv6efHHrfAQ
+UySQi2bJqIirr1qjAOm+ukbuW3N7LBeCgV5iLKECZbO9xSsAfsT8AzNXDe3i+s5d
+RdY4zTW2ssHQnIFKquSyAVwdj1+ZxLGt24gh65AIgoDzMKND5pCCrlUoSe1b16kQ
+OA7+j0xbm0bqQfWwCHTD0IgztnzXdN/chNFDDnU5oSVAKOp4yw4sLjmdjItuFhwv
+JoIQ4uNllAoEwF73XVv4EOLQunpL+943AAAaWyjj0pxzPjKHmKHJUS/X3qwzs08C
+AwEAAaNCMEAwDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAcYwHQYDVR0O
+BBYEFOCMm9slSbPxfIbWskKHC9BroNnkMA0GCSqGSIb3DQEBBQUAA4IBAQA+0hyJ
+LjX8+HXd5n9liPRyTMks1zJO890ZeUe9jjtbkw9QSSQTaxQGcu8J06Gh40CEyecY
+MnQ8SG4Pn0vU9x7Tk4ZkVJdjclDVVc/6IJMCopvDI5NOFlV2oHB5bc0hH88vLbwZ
+44gx+FkagQnIl6Z0x2DEW8xXjrJ1/RsCCdtZb3KTafcxQdaIOL+Hsr0Wefmq5L6I
+Jd1hJyMctTEHBDa0GpC9oHRxUIltvBTjD4au8as+x6AJzKNI0eDbZOeStc+vckNw
+i/nDhDwTqn6Sm1dTk/pwwpEOMfmbZ13pljheX7NzTogVZ96edhBiIL5VaZVDADlN
+9u6wWk5JRFRYX0KD
+-----END CERTIFICATE-----
+
+# Issuer: CN=NetLock Arany (Class Gold) F\u0151tan\xfas\xedtv\xe1ny O=NetLock Kft. OU=Tan\xfas\xedtv\xe1nykiad\xf3k (Certification Services)
+# Subject: CN=NetLock Arany (Class Gold) F\u0151tan\xfas\xedtv\xe1ny O=NetLock Kft. OU=Tan\xfas\xedtv\xe1nykiad\xf3k (Certification Services)
+# Label: "NetLock Arany (Class Gold) F\u0151tan\xfas\xedtv\xe1ny"
+# Serial: 80544274841616
+# MD5 Fingerprint: c5:a1:b7:ff:73:dd:d6:d7:34:32:18:df:fc:3c:ad:88
+# SHA1 Fingerprint: 06:08:3f:59:3f:15:a1:04:a0:69:a4:6b:a9:03:d0:06:b7:97:09:91
+# SHA256 Fingerprint: 6c:61:da:c3:a2:de:f0:31:50:6b:e0:36:d2:a6:fe:40:19:94:fb:d1:3d:f9:c8:d4:66:59:92:74:c4:46:ec:98
+-----BEGIN CERTIFICATE-----
+MIIEFTCCAv2gAwIBAgIGSUEs5AAQMA0GCSqGSIb3DQEBCwUAMIGnMQswCQYDVQQG
+EwJIVTERMA8GA1UEBwwIQnVkYXBlc3QxFTATBgNVBAoMDE5ldExvY2sgS2Z0LjE3
+MDUGA1UECwwuVGFuw7pzw610dsOhbnlraWFkw7NrIChDZXJ0aWZpY2F0aW9uIFNl
+cnZpY2VzKTE1MDMGA1UEAwwsTmV0TG9jayBBcmFueSAoQ2xhc3MgR29sZCkgRsWR
+dGFuw7pzw610dsOhbnkwHhcNMDgxMjExMTUwODIxWhcNMjgxMjA2MTUwODIxWjCB
+pzELMAkGA1UEBhMCSFUxETAPBgNVBAcMCEJ1ZGFwZXN0MRUwEwYDVQQKDAxOZXRM
+b2NrIEtmdC4xNzA1BgNVBAsMLlRhbsO6c8OtdHbDoW55a2lhZMOzayAoQ2VydGlm
+aWNhdGlvbiBTZXJ2aWNlcykxNTAzBgNVBAMMLE5ldExvY2sgQXJhbnkgKENsYXNz
+IEdvbGQpIEbFkXRhbsO6c8OtdHbDoW55MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8A
+MIIBCgKCAQEAxCRec75LbRTDofTjl5Bu0jBFHjzuZ9lk4BqKf8owyoPjIMHj9DrT
+lF8afFttvzBPhCf2nx9JvMaZCpDyD/V/Q4Q3Y1GLeqVw/HpYzY6b7cNGbIRwXdrz
+AZAj/E4wqX7hJ2Pn7WQ8oLjJM2P+FpD/sLj916jAwJRDC7bVWaaeVtAkH3B5r9s5
+VA1lddkVQZQBr17s9o3x/61k/iCa11zr/qYfCGSji3ZVrR47KGAuhyXoqq8fxmRG
+ILdwfzzeSNuWU7c5d+Qa4scWhHaXWy+7GRWF+GmF9ZmnqfI0p6m2pgP8b4Y9VHx2
+BJtr+UBdADTHLpl1neWIA6pN+APSQnbAGwIDAKiLo0UwQzASBgNVHRMBAf8ECDAG
+AQH/AgEEMA4GA1UdDwEB/wQEAwIBBjAdBgNVHQ4EFgQUzPpnk/C2uNClwB7zU/2M
+U9+D15YwDQYJKoZIhvcNAQELBQADggEBAKt/7hwWqZw8UQCgwBEIBaeZ5m8BiFRh
+bvG5GK1Krf6BQCOUL/t1fC8oS2IkgYIL9WHxHG64YTjrgfpioTtaYtOUZcTh5m2C
++C8lcLIhJsFyUR+MLMOEkMNaj7rP9KdlpeuY0fsFskZ1FSNqb4VjMIDw1Z4fKRzC
+bLBQWV2QWzuoDTDPv31/zvGdg73JRm4gpvlhUbohL3u+pRVjodSVh/GeufOJ8z2F
+uLjbvrW5KfnaNwUASZQDhETnv0Mxz3WLJdH0pmT1kvarBes96aULNmLazAZfNou2
+XjG4Kvte9nHfRCaexOYNkbQudZWAUWpLMKawYqGT8ZvYzsRjdT9ZR7E=
+-----END CERTIFICATE-----
+
+# Issuer: CN=SecureSign RootCA11 O=Japan Certification Services, Inc.
+# Subject: CN=SecureSign RootCA11 O=Japan Certification Services, Inc.
+# Label: "SecureSign RootCA11"
+# Serial: 1
+# MD5 Fingerprint: b7:52:74:e2:92:b4:80:93:f2:75:e4:cc:d7:f2:ea:26
+# SHA1 Fingerprint: 3b:c4:9f:48:f8:f3:73:a0:9c:1e:bd:f8:5b:b1:c3:65:c7:d8:11:b3
+# SHA256 Fingerprint: bf:0f:ee:fb:9e:3a:58:1a:d5:f9:e9:db:75:89:98:57:43:d2:61:08:5c:4d:31:4f:6f:5d:72:59:aa:42:16:12
+-----BEGIN CERTIFICATE-----
+MIIDbTCCAlWgAwIBAgIBATANBgkqhkiG9w0BAQUFADBYMQswCQYDVQQGEwJKUDEr
+MCkGA1UEChMiSmFwYW4gQ2VydGlmaWNhdGlvbiBTZXJ2aWNlcywgSW5jLjEcMBoG
+A1UEAxMTU2VjdXJlU2lnbiBSb290Q0ExMTAeFw0wOTA0MDgwNDU2NDdaFw0yOTA0
+MDgwNDU2NDdaMFgxCzAJBgNVBAYTAkpQMSswKQYDVQQKEyJKYXBhbiBDZXJ0aWZp
+Y2F0aW9uIFNlcnZpY2VzLCBJbmMuMRwwGgYDVQQDExNTZWN1cmVTaWduIFJvb3RD
+QTExMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA/XeqpRyQBTvLTJsz
+i1oURaTnkBbR31fSIRCkF/3frNYfp+TbfPfs37gD2pRY/V1yfIw/XwFndBWW4wI8
+h9uuywGOwvNmxoVF9ALGOrVisq/6nL+k5tSAMJjzDbaTj6nU2DbysPyKyiyhFTOV
+MdrAG/LuYpmGYz+/3ZMqg6h2uRMft85OQoWPIucuGvKVCbIFtUROd6EgvanyTgp9
+UK31BQ1FT0Zx/Sg+U/sE2C3XZR1KG/rPO7AxmjVuyIsG0wCR8pQIZUyxNAYAeoni
+8McDWc/V1uinMrPmmECGxc0nEovMe863ETxiYAcjPitAbpSACW22s293bzUIUPsC
+h8U+iQIDAQABo0IwQDAdBgNVHQ4EFgQUW/hNT7KlhtQ60vFjmqC+CfZXt94wDgYD
+VR0PAQH/BAQDAgEGMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQEFBQADggEB
+AKChOBZmLqdWHyGcBvod7bkixTgm2E5P7KN/ed5GIaGHd48HCJqypMWvDzKYC3xm
+KbabfSVSSUOrTC4rbnpwrxYO4wJs+0LmGJ1F2FXI6Dvd5+H0LgscNFxsWEr7jIhQ
+X5Ucv+2rIrVls4W6ng+4reV6G4pQOh29Dbx7VFALuUKvVaAYga1lme++5Jy/xIWr
+QbJUb9wlze144o4MjQlJ3WN7WmmWAiGovVJZ6X01y8hSyn+B/tlr0/cR7SXf+Of5
+pPpyl4RTDaXQMhhRdlkUbA/r7F+AjHVDg8OFmP9Mni0N5HeDk061lgeLKBObjBmN
+QSdJQO7e5iNEOdyhIta6A/I=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Microsec e-Szigno Root CA 2009 O=Microsec Ltd.
+# Subject: CN=Microsec e-Szigno Root CA 2009 O=Microsec Ltd.
+# Label: "Microsec e-Szigno Root CA 2009"
+# Serial: 14014712776195784473
+# MD5 Fingerprint: f8:49:f4:03:bc:44:2d:83:be:48:69:7d:29:64:fc:b1
+# SHA1 Fingerprint: 89:df:74:fe:5c:f4:0f:4a:80:f9:e3:37:7d:54:da:91:e1:01:31:8e
+# SHA256 Fingerprint: 3c:5f:81:fe:a5:fa:b8:2c:64:bf:a2:ea:ec:af:cd:e8:e0:77:fc:86:20:a7:ca:e5:37:16:3d:f3:6e:db:f3:78
+-----BEGIN CERTIFICATE-----
+MIIECjCCAvKgAwIBAgIJAMJ+QwRORz8ZMA0GCSqGSIb3DQEBCwUAMIGCMQswCQYD
+VQQGEwJIVTERMA8GA1UEBwwIQnVkYXBlc3QxFjAUBgNVBAoMDU1pY3Jvc2VjIEx0
+ZC4xJzAlBgNVBAMMHk1pY3Jvc2VjIGUtU3ppZ25vIFJvb3QgQ0EgMjAwOTEfMB0G
+CSqGSIb3DQEJARYQaW5mb0BlLXN6aWduby5odTAeFw0wOTA2MTYxMTMwMThaFw0y
+OTEyMzAxMTMwMThaMIGCMQswCQYDVQQGEwJIVTERMA8GA1UEBwwIQnVkYXBlc3Qx
+FjAUBgNVBAoMDU1pY3Jvc2VjIEx0ZC4xJzAlBgNVBAMMHk1pY3Jvc2VjIGUtU3pp
+Z25vIFJvb3QgQ0EgMjAwOTEfMB0GCSqGSIb3DQEJARYQaW5mb0BlLXN6aWduby5o
+dTCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAOn4j/NjrdqG2KfgQvvP
+kd6mJviZpWNwrZuuyjNAfW2WbqEORO7hE52UQlKavXWFdCyoDh2Tthi3jCyoz/tc
+cbna7P7ofo/kLx2yqHWH2Leh5TvPmUpG0IMZfcChEhyVbUr02MelTTMuhTlAdX4U
+fIASmFDHQWe4oIBhVKZsTh/gnQ4H6cm6M+f+wFUoLAKApxn1ntxVUwOXewdI/5n7
+N4okxFnMUBBjjqqpGrCEGob5X7uxUG6k0QrM1XF+H6cbfPVTbiJfyyvm1HxdrtbC
+xkzlBQHZ7Vf8wSN5/PrIJIOV87VqUQHQd9bpEqH5GoP7ghu5sJf0dgYzQ0mg/wu1
++rUCAwEAAaOBgDB+MA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgEGMB0G
+A1UdDgQWBBTLD8bfQkPMPcu1SCOhGnqmKrs0aDAfBgNVHSMEGDAWgBTLD8bfQkPM
+Pcu1SCOhGnqmKrs0aDAbBgNVHREEFDASgRBpbmZvQGUtc3ppZ25vLmh1MA0GCSqG
+SIb3DQEBCwUAA4IBAQDJ0Q5eLtXMs3w+y/w9/w0olZMEyL/azXm4Q5DwpL7v8u8h
+mLzU1F0G9u5C7DBsoKqpyvGvivo/C3NqPuouQH4frlRheesuCDfXI/OMn74dseGk
+ddug4lQUsbocKaQY9hK6ohQU4zE1yED/t+AFdlfBHFny+L/k7SViXITwfn4fs775
+tyERzAMBVnCnEJIeGzSBHq2cGsMEPO0CYdYeBvNfOofyK/FFh+U9rNHHV4S9a67c
+2Pm2G2JwCz02yULyMtd6YebS2z3PyKnJm9zbWETXbzivf3jTo60adbocwTZ8jx5t
+HMN1Rq41Bab2XD0h7lbwyYIiLXpUq3DDfSJlgnCW
+-----END CERTIFICATE-----
+
+# Issuer: CN=GlobalSign O=GlobalSign OU=GlobalSign Root CA - R3
+# Subject: CN=GlobalSign O=GlobalSign OU=GlobalSign Root CA - R3
+# Label: "GlobalSign Root CA - R3"
+# Serial: 4835703278459759426209954
+# MD5 Fingerprint: c5:df:b8:49:ca:05:13:55:ee:2d:ba:1a:c3:3e:b0:28
+# SHA1 Fingerprint: d6:9b:56:11:48:f0:1c:77:c5:45:78:c1:09:26:df:5b:85:69:76:ad
+# SHA256 Fingerprint: cb:b5:22:d7:b7:f1:27:ad:6a:01:13:86:5b:df:1c:d4:10:2e:7d:07:59:af:63:5a:7c:f4:72:0d:c9:63:c5:3b
+-----BEGIN CERTIFICATE-----
+MIIDXzCCAkegAwIBAgILBAAAAAABIVhTCKIwDQYJKoZIhvcNAQELBQAwTDEgMB4G
+A1UECxMXR2xvYmFsU2lnbiBSb290IENBIC0gUjMxEzARBgNVBAoTCkdsb2JhbFNp
+Z24xEzARBgNVBAMTCkdsb2JhbFNpZ24wHhcNMDkwMzE4MTAwMDAwWhcNMjkwMzE4
+MTAwMDAwWjBMMSAwHgYDVQQLExdHbG9iYWxTaWduIFJvb3QgQ0EgLSBSMzETMBEG
+A1UEChMKR2xvYmFsU2lnbjETMBEGA1UEAxMKR2xvYmFsU2lnbjCCASIwDQYJKoZI
+hvcNAQEBBQADggEPADCCAQoCggEBAMwldpB5BngiFvXAg7aEyiie/QV2EcWtiHL8
+RgJDx7KKnQRfJMsuS+FggkbhUqsMgUdwbN1k0ev1LKMPgj0MK66X17YUhhB5uzsT
+gHeMCOFJ0mpiLx9e+pZo34knlTifBtc+ycsmWQ1z3rDI6SYOgxXG71uL0gRgykmm
+KPZpO/bLyCiR5Z2KYVc3rHQU3HTgOu5yLy6c+9C7v/U9AOEGM+iCK65TpjoWc4zd
+QQ4gOsC0p6Hpsk+QLjJg6VfLuQSSaGjlOCZgdbKfd/+RFO+uIEn8rUAVSNECMWEZ
+XriX7613t2Saer9fwRPvm2L7DWzgVGkWqQPabumDk3F2xmmFghcCAwEAAaNCMEAw
+DgYDVR0PAQH/BAQDAgEGMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFI/wS3+o
+LkUkrk1Q+mOai97i3Ru8MA0GCSqGSIb3DQEBCwUAA4IBAQBLQNvAUKr+yAzv95ZU
+RUm7lgAJQayzE4aGKAczymvmdLm6AC2upArT9fHxD4q/c2dKg8dEe3jgr25sbwMp
+jjM5RcOO5LlXbKr8EpbsU8Yt5CRsuZRj+9xTaGdWPoO4zzUhw8lo/s7awlOqzJCK
+6fBdRoyV3XpYKBovHd7NADdBj+1EbddTKJd+82cEHhXXipa0095MJ6RMG3NzdvQX
+mcIfeg7jLQitChws/zyrVQ4PkX4268NXSb7hLi18YIvDQVETI53O9zJrlAGomecs
+Mx86OyXShkDOOyyGeMlhLxS67ttVb9+E7gUJTb0o2HLO02JQZR7rkpeDMdmztcpH
+WD9f
+-----END CERTIFICATE-----
+
+# Issuer: CN=Izenpe.com O=IZENPE S.A.
+# Subject: CN=Izenpe.com O=IZENPE S.A.
+# Label: "Izenpe.com"
+# Serial: 917563065490389241595536686991402621
+# MD5 Fingerprint: a6:b0:cd:85:80:da:5c:50:34:a3:39:90:2f:55:67:73
+# SHA1 Fingerprint: 2f:78:3d:25:52:18:a7:4a:65:39:71:b5:2c:a2:9c:45:15:6f:e9:19
+# SHA256 Fingerprint: 25:30:cc:8e:98:32:15:02:ba:d9:6f:9b:1f:ba:1b:09:9e:2d:29:9e:0f:45:48:bb:91:4f:36:3b:c0:d4:53:1f
+-----BEGIN CERTIFICATE-----
+MIIF8TCCA9mgAwIBAgIQALC3WhZIX7/hy/WL1xnmfTANBgkqhkiG9w0BAQsFADA4
+MQswCQYDVQQGEwJFUzEUMBIGA1UECgwLSVpFTlBFIFMuQS4xEzARBgNVBAMMCkl6
+ZW5wZS5jb20wHhcNMDcxMjEzMTMwODI4WhcNMzcxMjEzMDgyNzI1WjA4MQswCQYD
+VQQGEwJFUzEUMBIGA1UECgwLSVpFTlBFIFMuQS4xEzARBgNVBAMMCkl6ZW5wZS5j
+b20wggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDJ03rKDx6sp4boFmVq
+scIbRTJxldn+EFvMr+eleQGPicPK8lVx93e+d5TzcqQsRNiekpsUOqHnJJAKClaO
+xdgmlOHZSOEtPtoKct2jmRXagaKH9HtuJneJWK3W6wyyQXpzbm3benhB6QiIEn6H
+LmYRY2xU+zydcsC8Lv/Ct90NduM61/e0aL6i9eOBbsFGb12N4E3GVFWJGjMxCrFX
+uaOKmMPsOzTFlUFpfnXCPCDFYbpRR6AgkJOhkEvzTnyFRVSa0QUmQbC1TR0zvsQD
+yCV8wXDbO/QJLVQnSKwv4cSsPsjLkkxTOTcj7NMB+eAJRE1NZMDhDVqHIrytG6P+
+JrUV86f8hBnp7KGItERphIPzidF0BqnMC9bC3ieFUCbKF7jJeodWLBoBHmy+E60Q
+rLUk9TiRodZL2vG70t5HtfG8gfZZa88ZU+mNFctKy6lvROUbQc/hhqfK0GqfvEyN
+BjNaooXlkDWgYlwWTvDjovoDGrQscbNYLN57C9saD+veIR8GdwYDsMnvmfzAuU8L
+hij+0rnq49qlw0dpEuDb8PYZi+17cNcC1u2HGCgsBCRMd+RIihrGO5rUD8r6ddIB
+QFqNeb+Lz0vPqhbBleStTIo+F5HUsWLlguWABKQDfo2/2n+iD5dPDNMN+9fR5XJ+
+HMh3/1uaD7euBUbl8agW7EekFwIDAQABo4H2MIHzMIGwBgNVHREEgagwgaWBD2lu
+Zm9AaXplbnBlLmNvbaSBkTCBjjFHMEUGA1UECgw+SVpFTlBFIFMuQS4gLSBDSUYg
+QTAxMzM3MjYwLVJNZXJjLlZpdG9yaWEtR2FzdGVpeiBUMTA1NSBGNjIgUzgxQzBB
+BgNVBAkMOkF2ZGEgZGVsIE1lZGl0ZXJyYW5lbyBFdG9yYmlkZWEgMTQgLSAwMTAx
+MCBWaXRvcmlhLUdhc3RlaXowDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMC
+AQYwHQYDVR0OBBYEFB0cZQ6o8iV7tJHP5LGx5r1VdGwFMA0GCSqGSIb3DQEBCwUA
+A4ICAQB4pgwWSp9MiDrAyw6lFn2fuUhfGI8NYjb2zRlrrKvV9pF9rnHzP7MOeIWb
+laQnIUdCSnxIOvVFfLMMjlF4rJUT3sb9fbgakEyrkgPH7UIBzg/YsfqikuFgba56
+awmqxinuaElnMIAkejEWOVt+8Rwu3WwJrfIxwYJOubv5vr8qhT/AQKM6WfxZSzwo
+JNu0FXWuDYi6LnPAvViH5ULy617uHjAimcs30cQhbIHsvm0m5hzkQiCeR7Csg1lw
+LDXWrzY0tM07+DKo7+N4ifuNRSzanLh+QBxh5z6ikixL8s36mLYp//Pye6kfLqCT
+VyvehQP5aTfLnnhqBbTFMXiJ7HqnheG5ezzevh55hM6fcA5ZwjUukCox2eRFekGk
+LhObNA5me0mrZJfQRsN5nXJQY6aYWwa9SG3YOYNw6DXwBdGqvOPbyALqfP2C2sJb
+UjWumDqtujWTI6cfSN01RpiyEGjkpTHCClguGYEQyVB1/OpaFs4R1+7vUIgtYf8/
+QnMFlEPVjjxOAToZpR9GTnfQXeWBIiGH/pR9hNiTrdZoQ0iy2+tzJOeRf1SktoA+
+naM8THLCV8Sg1Mw4J87VBp6iSNnpn86CcDaTmjvfliHjWbcM2pE38P1ZWrOZyGls
+QyYBNWNgVYkDOnXYukrZVP/u3oDYLdE41V4tC5h9Pmzb/CaIxw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Go Daddy Root Certificate Authority - G2 O=GoDaddy.com, Inc.
+# Subject: CN=Go Daddy Root Certificate Authority - G2 O=GoDaddy.com, Inc.
+# Label: "Go Daddy Root Certificate Authority - G2"
+# Serial: 0
+# MD5 Fingerprint: 80:3a:bc:22:c1:e6:fb:8d:9b:3b:27:4a:32:1b:9a:01
+# SHA1 Fingerprint: 47:be:ab:c9:22:ea:e8:0e:78:78:34:62:a7:9f:45:c2:54:fd:e6:8b
+# SHA256 Fingerprint: 45:14:0b:32:47:eb:9c:c8:c5:b4:f0:d7:b5:30:91:f7:32:92:08:9e:6e:5a:63:e2:74:9d:d3:ac:a9:19:8e:da
+-----BEGIN CERTIFICATE-----
+MIIDxTCCAq2gAwIBAgIBADANBgkqhkiG9w0BAQsFADCBgzELMAkGA1UEBhMCVVMx
+EDAOBgNVBAgTB0FyaXpvbmExEzARBgNVBAcTClNjb3R0c2RhbGUxGjAYBgNVBAoT
+EUdvRGFkZHkuY29tLCBJbmMuMTEwLwYDVQQDEyhHbyBEYWRkeSBSb290IENlcnRp
+ZmljYXRlIEF1dGhvcml0eSAtIEcyMB4XDTA5MDkwMTAwMDAwMFoXDTM3MTIzMTIz
+NTk1OVowgYMxCzAJBgNVBAYTAlVTMRAwDgYDVQQIEwdBcml6b25hMRMwEQYDVQQH
+EwpTY290dHNkYWxlMRowGAYDVQQKExFHb0RhZGR5LmNvbSwgSW5jLjExMC8GA1UE
+AxMoR28gRGFkZHkgUm9vdCBDZXJ0aWZpY2F0ZSBBdXRob3JpdHkgLSBHMjCCASIw
+DQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAL9xYgjx+lk09xvJGKP3gElY6SKD
+E6bFIEMBO4Tx5oVJnyfq9oQbTqC023CYxzIBsQU+B07u9PpPL1kwIuerGVZr4oAH
+/PMWdYA5UXvl+TW2dE6pjYIT5LY/qQOD+qK+ihVqf94Lw7YZFAXK6sOoBJQ7Rnwy
+DfMAZiLIjWltNowRGLfTshxgtDj6AozO091GB94KPutdfMh8+7ArU6SSYmlRJQVh
+GkSBjCypQ5Yj36w6gZoOKcUcqeldHraenjAKOc7xiID7S13MMuyFYkMlNAJWJwGR
+tDtwKj9useiciAF9n9T521NtYJ2/LOdYq7hfRvzOxBsDPAnrSTFcaUaz4EcCAwEA
+AaNCMEAwDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwHQYDVR0OBBYE
+FDqahQcQZyi27/a9BUFuIMGU2g/eMA0GCSqGSIb3DQEBCwUAA4IBAQCZ21151fmX
+WWcDYfF+OwYxdS2hII5PZYe096acvNjpL9DbWu7PdIxztDhC2gV7+AJ1uP2lsdeu
+9tfeE8tTEH6KRtGX+rcuKxGrkLAngPnon1rpN5+r5N9ss4UXnT3ZJE95kTXWXwTr
+gIOrmgIttRD02JDHBHNA7XIloKmf7J6raBKZV8aPEjoJpL1E/QYVN8Gb5DKj7Tjo
+2GTzLH4U/ALqn83/B2gX2yKQOC16jdFU8WnjXzPKej17CuPKf1855eJ1usV2GDPO
+LPAvTK33sefOT6jEm0pUBsV/fdUID+Ic/n4XuKxe9tQWskMJDE32p2u0mYRlynqI
+4uJEvlz36hz1
+-----END CERTIFICATE-----
+
+# Issuer: CN=Starfield Root Certificate Authority - G2 O=Starfield Technologies, Inc.
+# Subject: CN=Starfield Root Certificate Authority - G2 O=Starfield Technologies, Inc.
+# Label: "Starfield Root Certificate Authority - G2"
+# Serial: 0
+# MD5 Fingerprint: d6:39:81:c6:52:7e:96:69:fc:fc:ca:66:ed:05:f2:96
+# SHA1 Fingerprint: b5:1c:06:7c:ee:2b:0c:3d:f8:55:ab:2d:92:f4:fe:39:d4:e7:0f:0e
+# SHA256 Fingerprint: 2c:e1:cb:0b:f9:d2:f9:e1:02:99:3f:be:21:51:52:c3:b2:dd:0c:ab:de:1c:68:e5:31:9b:83:91:54:db:b7:f5
+-----BEGIN CERTIFICATE-----
+MIID3TCCAsWgAwIBAgIBADANBgkqhkiG9w0BAQsFADCBjzELMAkGA1UEBhMCVVMx
+EDAOBgNVBAgTB0FyaXpvbmExEzARBgNVBAcTClNjb3R0c2RhbGUxJTAjBgNVBAoT
+HFN0YXJmaWVsZCBUZWNobm9sb2dpZXMsIEluYy4xMjAwBgNVBAMTKVN0YXJmaWVs
+ZCBSb290IENlcnRpZmljYXRlIEF1dGhvcml0eSAtIEcyMB4XDTA5MDkwMTAwMDAw
+MFoXDTM3MTIzMTIzNTk1OVowgY8xCzAJBgNVBAYTAlVTMRAwDgYDVQQIEwdBcml6
+b25hMRMwEQYDVQQHEwpTY290dHNkYWxlMSUwIwYDVQQKExxTdGFyZmllbGQgVGVj
+aG5vbG9naWVzLCBJbmMuMTIwMAYDVQQDEylTdGFyZmllbGQgUm9vdCBDZXJ0aWZp
+Y2F0ZSBBdXRob3JpdHkgLSBHMjCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoC
+ggEBAL3twQP89o/8ArFvW59I2Z154qK3A2FWGMNHttfKPTUuiUP3oWmb3ooa/RMg
+nLRJdzIpVv257IzdIvpy3Cdhl+72WoTsbhm5iSzchFvVdPtrX8WJpRBSiUZV9Lh1
+HOZ/5FSuS/hVclcCGfgXcVnrHigHdMWdSL5stPSksPNkN3mSwOxGXn/hbVNMYq/N
+Hwtjuzqd+/x5AJhhdM8mgkBj87JyahkNmcrUDnXMN/uLicFZ8WJ/X7NfZTD4p7dN
+dloedl40wOiWVpmKs/B/pM293DIxfJHP4F8R+GuqSVzRmZTRouNjWwl2tVZi4Ut0
+HZbUJtQIBFnQmA4O5t78w+wfkPECAwEAAaNCMEAwDwYDVR0TAQH/BAUwAwEB/zAO
+BgNVHQ8BAf8EBAMCAQYwHQYDVR0OBBYEFHwMMh+n2TB/xH1oo2Kooc6rB1snMA0G
+CSqGSIb3DQEBCwUAA4IBAQARWfolTwNvlJk7mh+ChTnUdgWUXuEok21iXQnCoKjU
+sHU48TRqneSfioYmUeYs0cYtbpUgSpIB7LiKZ3sx4mcujJUDJi5DnUox9g61DLu3
+4jd/IroAow57UvtruzvE03lRTs2Q9GcHGcg8RnoNAX3FWOdt5oUwF5okxBDgBPfg
+8n/Uqgr/Qh037ZTlZFkSIHc40zI+OIF1lnP6aI+xy84fxez6nH7PfrHxBy22/L/K
+pL/QlwVKvOoYKAKQvVR4CSFx09F9HdkWsKlhPdAKACL8x3vLCWRFCztAgfd9fDL1
+mMpYjn0q7pBZc2T5NnReJaH1ZgUufzkVqSr7UIuOhWn0
+-----END CERTIFICATE-----
+
+# Issuer: CN=Starfield Services Root Certificate Authority - G2 O=Starfield Technologies, Inc.
+# Subject: CN=Starfield Services Root Certificate Authority - G2 O=Starfield Technologies, Inc.
+# Label: "Starfield Services Root Certificate Authority - G2"
+# Serial: 0
+# MD5 Fingerprint: 17:35:74:af:7b:61:1c:eb:f4:f9:3c:e2:ee:40:f9:a2
+# SHA1 Fingerprint: 92:5a:8f:8d:2c:6d:04:e0:66:5f:59:6a:ff:22:d8:63:e8:25:6f:3f
+# SHA256 Fingerprint: 56:8d:69:05:a2:c8:87:08:a4:b3:02:51:90:ed:cf:ed:b1:97:4a:60:6a:13:c6:e5:29:0f:cb:2a:e6:3e:da:b5
+-----BEGIN CERTIFICATE-----
+MIID7zCCAtegAwIBAgIBADANBgkqhkiG9w0BAQsFADCBmDELMAkGA1UEBhMCVVMx
+EDAOBgNVBAgTB0FyaXpvbmExEzARBgNVBAcTClNjb3R0c2RhbGUxJTAjBgNVBAoT
+HFN0YXJmaWVsZCBUZWNobm9sb2dpZXMsIEluYy4xOzA5BgNVBAMTMlN0YXJmaWVs
+ZCBTZXJ2aWNlcyBSb290IENlcnRpZmljYXRlIEF1dGhvcml0eSAtIEcyMB4XDTA5
+MDkwMTAwMDAwMFoXDTM3MTIzMTIzNTk1OVowgZgxCzAJBgNVBAYTAlVTMRAwDgYD
+VQQIEwdBcml6b25hMRMwEQYDVQQHEwpTY290dHNkYWxlMSUwIwYDVQQKExxTdGFy
+ZmllbGQgVGVjaG5vbG9naWVzLCBJbmMuMTswOQYDVQQDEzJTdGFyZmllbGQgU2Vy
+dmljZXMgUm9vdCBDZXJ0aWZpY2F0ZSBBdXRob3JpdHkgLSBHMjCCASIwDQYJKoZI
+hvcNAQEBBQADggEPADCCAQoCggEBANUMOsQq+U7i9b4Zl1+OiFOxHz/Lz58gE20p
+OsgPfTz3a3Y4Y9k2YKibXlwAgLIvWX/2h/klQ4bnaRtSmpDhcePYLQ1Ob/bISdm2
+8xpWriu2dBTrz/sm4xq6HZYuajtYlIlHVv8loJNwU4PahHQUw2eeBGg6345AWh1K
+Ts9DkTvnVtYAcMtS7nt9rjrnvDH5RfbCYM8TWQIrgMw0R9+53pBlbQLPLJGmpufe
+hRhJfGZOozptqbXuNC66DQO4M99H67FrjSXZm86B0UVGMpZwh94CDklDhbZsc7tk
+6mFBrMnUVN+HL8cisibMn1lUaJ/8viovxFUcdUBgF4UCVTmLfwUCAwEAAaNCMEAw
+DwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwHQYDVR0OBBYEFJxfAN+q
+AdcwKziIorhtSpzyEZGDMA0GCSqGSIb3DQEBCwUAA4IBAQBLNqaEd2ndOxmfZyMI
+bw5hyf2E3F/YNoHN2BtBLZ9g3ccaaNnRbobhiCPPE95Dz+I0swSdHynVv/heyNXB
+ve6SbzJ08pGCL72CQnqtKrcgfU28elUSwhXqvfdqlS5sdJ/PHLTyxQGjhdByPq1z
+qwubdQxtRbeOlKyWN7Wg0I8VRw7j6IPdj/3vQQF3zCepYoUz8jcI73HPdwbeyBkd
+iEDPfUYd/x7H4c7/I9vG+o1VTqkC50cRRj70/b17KSa7qWFiNyi2LSr2EIZkyXCn
+0q23KXB56jzaYyWf/Wi3MOxw+3WKt21gZ7IeyLnp2KhvAotnDU0mV3HaIPzBSlCN
+sSi6
+-----END CERTIFICATE-----
+
+# Issuer: CN=AffirmTrust Commercial O=AffirmTrust
+# Subject: CN=AffirmTrust Commercial O=AffirmTrust
+# Label: "AffirmTrust Commercial"
+# Serial: 8608355977964138876
+# MD5 Fingerprint: 82:92:ba:5b:ef:cd:8a:6f:a6:3d:55:f9:84:f6:d6:b7
+# SHA1 Fingerprint: f9:b5:b6:32:45:5f:9c:be:ec:57:5f:80:dc:e9:6e:2c:c7:b2:78:b7
+# SHA256 Fingerprint: 03:76:ab:1d:54:c5:f9:80:3c:e4:b2:e2:01:a0:ee:7e:ef:7b:57:b6:36:e8:a9:3c:9b:8d:48:60:c9:6f:5f:a7
+-----BEGIN CERTIFICATE-----
+MIIDTDCCAjSgAwIBAgIId3cGJyapsXwwDQYJKoZIhvcNAQELBQAwRDELMAkGA1UE
+BhMCVVMxFDASBgNVBAoMC0FmZmlybVRydXN0MR8wHQYDVQQDDBZBZmZpcm1UcnVz
+dCBDb21tZXJjaWFsMB4XDTEwMDEyOTE0MDYwNloXDTMwMTIzMTE0MDYwNlowRDEL
+MAkGA1UEBhMCVVMxFDASBgNVBAoMC0FmZmlybVRydXN0MR8wHQYDVQQDDBZBZmZp
+cm1UcnVzdCBDb21tZXJjaWFsMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKC
+AQEA9htPZwcroRX1BiLLHwGy43NFBkRJLLtJJRTWzsO3qyxPxkEylFf6EqdbDuKP
+Hx6GGaeqtS25Xw2Kwq+FNXkyLbscYjfysVtKPcrNcV/pQr6U6Mje+SJIZMblq8Yr
+ba0F8PrVC8+a5fBQpIs7R6UjW3p6+DM/uO+Zl+MgwdYoic+U+7lF7eNAFxHUdPAL
+MeIrJmqbTFeurCA+ukV6BfO9m2kVrn1OIGPENXY6BwLJN/3HR+7o8XYdcxXyl6S1
+yHp52UKqK39c/s4mT6NmgTWvRLpUHhwwMmWd5jyTXlBOeuM61G7MGvv50jeuJCqr
+VwMiKA1JdX+3KNp1v47j3A55MQIDAQABo0IwQDAdBgNVHQ4EFgQUnZPGU4teyq8/
+nx4P5ZmVvCT2lI8wDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwDQYJ
+KoZIhvcNAQELBQADggEBAFis9AQOzcAN/wr91LoWXym9e2iZWEnStB03TX8nfUYG
+XUPGhi4+c7ImfU+TqbbEKpqrIZcUsd6M06uJFdhrJNTxFq7YpFzUf1GO7RgBsZNj
+vbz4YYCanrHOQnDiqX0GJX0nof5v7LMeJNrjS1UaADs1tDvZ110w/YETifLCBivt
+Z8SOyUOyXGsViQK8YvxO8rUzqrJv0wqiUOP2O+guRMLbZjipM1ZI8W0bM40NjD9g
+N53Tym1+NH4Nn3J2ixufcv1SNUFFApYvHLKac0khsUlHRUe072o0EclNmsxZt9YC
+nlpOZbWUrhvfKbAW8b8Angc6F2S1BLUjIZkKlTuXfO8=
+-----END CERTIFICATE-----
+
+# Issuer: CN=AffirmTrust Networking O=AffirmTrust
+# Subject: CN=AffirmTrust Networking O=AffirmTrust
+# Label: "AffirmTrust Networking"
+# Serial: 8957382827206547757
+# MD5 Fingerprint: 42:65:ca:be:01:9a:9a:4c:a9:8c:41:49:cd:c0:d5:7f
+# SHA1 Fingerprint: 29:36:21:02:8b:20:ed:02:f5:66:c5:32:d1:d6:ed:90:9f:45:00:2f
+# SHA256 Fingerprint: 0a:81:ec:5a:92:97:77:f1:45:90:4a:f3:8d:5d:50:9f:66:b5:e2:c5:8f:cd:b5:31:05:8b:0e:17:f3:f0:b4:1b
+-----BEGIN CERTIFICATE-----
+MIIDTDCCAjSgAwIBAgIIfE8EORzUmS0wDQYJKoZIhvcNAQEFBQAwRDELMAkGA1UE
+BhMCVVMxFDASBgNVBAoMC0FmZmlybVRydXN0MR8wHQYDVQQDDBZBZmZpcm1UcnVz
+dCBOZXR3b3JraW5nMB4XDTEwMDEyOTE0MDgyNFoXDTMwMTIzMTE0MDgyNFowRDEL
+MAkGA1UEBhMCVVMxFDASBgNVBAoMC0FmZmlybVRydXN0MR8wHQYDVQQDDBZBZmZp
+cm1UcnVzdCBOZXR3b3JraW5nMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKC
+AQEAtITMMxcua5Rsa2FSoOujz3mUTOWUgJnLVWREZY9nZOIG41w3SfYvm4SEHi3y
+YJ0wTsyEheIszx6e/jarM3c1RNg1lho9Nuh6DtjVR6FqaYvZ/Ls6rnla1fTWcbua
+kCNrmreIdIcMHl+5ni36q1Mr3Lt2PpNMCAiMHqIjHNRqrSK6mQEubWXLviRmVSRL
+QESxG9fhwoXA3hA/Pe24/PHxI1Pcv2WXb9n5QHGNfb2V1M6+oF4nI979ptAmDgAp
+6zxG8D1gvz9Q0twmQVGeFDdCBKNwV6gbh+0t+nvujArjqWaJGctB+d1ENmHP4ndG
+yH329JKBNv3bNPFyfvMMFr20FQIDAQABo0IwQDAdBgNVHQ4EFgQUBx/S55zawm6i
+QLSwelAQUHTEyL0wDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwDQYJ
+KoZIhvcNAQEFBQADggEBAIlXshZ6qML91tmbmzTCnLQyFE2npN/svqe++EPbkTfO
+tDIuUFUaNU52Q3Eg75N3ThVwLofDwR1t3Mu1J9QsVtFSUzpE0nPIxBsFZVpikpzu
+QY0x2+c06lkh1QF612S4ZDnNye2v7UsDSKegmQGA3GWjNq5lWUhPgkvIZfFXHeVZ
+Lgo/bNjR9eUJtGxUAArgFU2HdW23WJZa3W3SAKD0m0i+wzekujbgfIeFlxoVot4u
+olu9rxj5kFDNcFn4J2dHy8egBzp90SxdbBk6ZrV9/ZFvgrG+CJPbFEfxojfHRZ48
+x3evZKiT3/Zpg4Jg8klCNO1aAFSFHBY2kgxc+qatv9s=
+-----END CERTIFICATE-----
+
+# Issuer: CN=AffirmTrust Premium O=AffirmTrust
+# Subject: CN=AffirmTrust Premium O=AffirmTrust
+# Label: "AffirmTrust Premium"
+# Serial: 7893706540734352110
+# MD5 Fingerprint: c4:5d:0e:48:b6:ac:28:30:4e:0a:bc:f9:38:16:87:57
+# SHA1 Fingerprint: d8:a6:33:2c:e0:03:6f:b1:85:f6:63:4f:7d:6a:06:65:26:32:28:27
+# SHA256 Fingerprint: 70:a7:3f:7f:37:6b:60:07:42:48:90:45:34:b1:14:82:d5:bf:0e:69:8e:cc:49:8d:f5:25:77:eb:f2:e9:3b:9a
+-----BEGIN CERTIFICATE-----
+MIIFRjCCAy6gAwIBAgIIbYwURrGmCu4wDQYJKoZIhvcNAQEMBQAwQTELMAkGA1UE
+BhMCVVMxFDASBgNVBAoMC0FmZmlybVRydXN0MRwwGgYDVQQDDBNBZmZpcm1UcnVz
+dCBQcmVtaXVtMB4XDTEwMDEyOTE0MTAzNloXDTQwMTIzMTE0MTAzNlowQTELMAkG
+A1UEBhMCVVMxFDASBgNVBAoMC0FmZmlybVRydXN0MRwwGgYDVQQDDBNBZmZpcm1U
+cnVzdCBQcmVtaXVtMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAxBLf
+qV/+Qd3d9Z+K4/as4Tx4mrzY8H96oDMq3I0gW64tb+eT2TZwamjPjlGjhVtnBKAQ
+JG9dKILBl1fYSCkTtuG+kU3fhQxTGJoeJKJPj/CihQvL9Cl/0qRY7iZNyaqoe5rZ
++jjeRFcV5fiMyNlI4g0WJx0eyIOFJbe6qlVBzAMiSy2RjYvmia9mx+n/K+k8rNrS
+s8PhaJyJ+HoAVt70VZVs+7pk3WKL3wt3MutizCaam7uqYoNMtAZ6MMgpv+0GTZe5
+HMQxK9VfvFMSF5yZVylmd2EhMQcuJUmdGPLu8ytxjLW6OQdJd/zvLpKQBY0tL3d7
+70O/Nbua2Plzpyzy0FfuKE4mX4+QaAkvuPjcBukumj5Rp9EixAqnOEhss/n/fauG
+V+O61oV4d7pD6kh/9ti+I20ev9E2bFhc8e6kGVQa9QPSdubhjL08s9NIS+LI+H+S
+qHZGnEJlPqQewQcDWkYtuJfzt9WyVSHvutxMAJf7FJUnM7/oQ0dG0giZFmA7mn7S
+5u046uwBHjxIVkkJx0w3AJ6IDsBz4W9m6XJHMD4Q5QsDyZpCAGzFlH5hxIrff4Ia
+C1nEWTJ3s7xgaVY5/bQGeyzWZDbZvUjthB9+pSKPKrhC9IK31FOQeE4tGv2Bb0TX
+OwF0lkLgAOIua+rF7nKsu7/+6qqo+Nz2snmKtmcCAwEAAaNCMEAwHQYDVR0OBBYE
+FJ3AZ6YMItkm9UWrpmVSESfYRaxjMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/
+BAQDAgEGMA0GCSqGSIb3DQEBDAUAA4ICAQCzV00QYk465KzquByvMiPIs0laUZx2
+KI15qldGF9X1Uva3ROgIRL8YhNILgM3FEv0AVQVhh0HctSSePMTYyPtwni94loMg
+Nt58D2kTiKV1NpgIpsbfrM7jWNa3Pt668+s0QNiigfV4Py/VpfzZotReBA4Xrf5B
+8OWycvpEgjNC6C1Y91aMYj+6QrCcDFx+LmUmXFNPALJ4fqENmS2NuB2OosSw/WDQ
+MKSOyARiqcTtNd56l+0OOF6SL5Nwpamcb6d9Ex1+xghIsV5n61EIJenmJWtSKZGc
+0jlzCFfemQa0W50QBuHCAKi4HEoCChTQwUHK+4w1IX2COPKpVJEZNZOUbWo6xbLQ
+u4mGk+ibyQ86p3q4ofB4Rvr8Ny/lioTz3/4E2aFooC8k4gmVBtWVyuEklut89pMF
+u+1z6S3RdTnX5yTb2E5fQ4+e0BQ5v1VwSJlXMbSc7kqYA5YwH2AG7hsj/oFgIxpH
+YoWlzBk0gG+zrBrjn/B7SK3VAdlntqlyk+otZrWyuOQ9PLLvTIzq6we/qzWaVYa8
+GKa1qF60g2xraUDTn9zxw2lrueFtCfTxqlB2Cnp9ehehVZZCmTEJ3WARjQUwfuaO
+RtGdFNrHF+QFlozEJLUbzxQHskD4o55BhrwE0GuWyCqANP2/7waj3VjFhT0+j/6e
+KeC2uAloGRwYQw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=AffirmTrust Premium ECC O=AffirmTrust
+# Subject: CN=AffirmTrust Premium ECC O=AffirmTrust
+# Label: "AffirmTrust Premium ECC"
+# Serial: 8401224907861490260
+# MD5 Fingerprint: 64:b0:09:55:cf:b1:d5:99:e2:be:13:ab:a6:5d:ea:4d
+# SHA1 Fingerprint: b8:23:6b:00:2f:1d:16:86:53:01:55:6c:11:a4:37:ca:eb:ff:c3:bb
+# SHA256 Fingerprint: bd:71:fd:f6:da:97:e4:cf:62:d1:64:7a:dd:25:81:b0:7d:79:ad:f8:39:7e:b4:ec:ba:9c:5e:84:88:82:14:23
+-----BEGIN CERTIFICATE-----
+MIIB/jCCAYWgAwIBAgIIdJclisc/elQwCgYIKoZIzj0EAwMwRTELMAkGA1UEBhMC
+VVMxFDASBgNVBAoMC0FmZmlybVRydXN0MSAwHgYDVQQDDBdBZmZpcm1UcnVzdCBQ
+cmVtaXVtIEVDQzAeFw0xMDAxMjkxNDIwMjRaFw00MDEyMzExNDIwMjRaMEUxCzAJ
+BgNVBAYTAlVTMRQwEgYDVQQKDAtBZmZpcm1UcnVzdDEgMB4GA1UEAwwXQWZmaXJt
+VHJ1c3QgUHJlbWl1bSBFQ0MwdjAQBgcqhkjOPQIBBgUrgQQAIgNiAAQNMF4bFZ0D
+0KF5Nbc6PJJ6yhUczWLznCZcBz3lVPqj1swS6vQUX+iOGasvLkjmrBhDeKzQN8O9
+ss0s5kfiGuZjuD0uL3jET9v0D6RoTFVya5UdThhClXjMNzyR4ptlKymjQjBAMB0G
+A1UdDgQWBBSaryl6wBE1NSZRMADDav5A1a7WPDAPBgNVHRMBAf8EBTADAQH/MA4G
+A1UdDwEB/wQEAwIBBjAKBggqhkjOPQQDAwNnADBkAjAXCfOHiFBar8jAQr9HX/Vs
+aobgxCd05DhT1wV/GzTjxi+zygk8N53X57hG8f2h4nECMEJZh0PUUd+60wkyWs6I
+flc9nF9Ca/UHLbXwgpP5WW+uZPpY5Yse42O+tYHNbwKMeQ==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certum Trusted Network CA O=Unizeto Technologies S.A. OU=Certum Certification Authority
+# Subject: CN=Certum Trusted Network CA O=Unizeto Technologies S.A. OU=Certum Certification Authority
+# Label: "Certum Trusted Network CA"
+# Serial: 279744
+# MD5 Fingerprint: d5:e9:81:40:c5:18:69:fc:46:2c:89:75:62:0f:aa:78
+# SHA1 Fingerprint: 07:e0:32:e0:20:b7:2c:3f:19:2f:06:28:a2:59:3a:19:a7:0f:06:9e
+# SHA256 Fingerprint: 5c:58:46:8d:55:f5:8e:49:7e:74:39:82:d2:b5:00:10:b6:d1:65:37:4a:cf:83:a7:d4:a3:2d:b7:68:c4:40:8e
+-----BEGIN CERTIFICATE-----
+MIIDuzCCAqOgAwIBAgIDBETAMA0GCSqGSIb3DQEBBQUAMH4xCzAJBgNVBAYTAlBM
+MSIwIAYDVQQKExlVbml6ZXRvIFRlY2hub2xvZ2llcyBTLkEuMScwJQYDVQQLEx5D
+ZXJ0dW0gQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkxIjAgBgNVBAMTGUNlcnR1bSBU
+cnVzdGVkIE5ldHdvcmsgQ0EwHhcNMDgxMDIyMTIwNzM3WhcNMjkxMjMxMTIwNzM3
+WjB+MQswCQYDVQQGEwJQTDEiMCAGA1UEChMZVW5pemV0byBUZWNobm9sb2dpZXMg
+Uy5BLjEnMCUGA1UECxMeQ2VydHVtIENlcnRpZmljYXRpb24gQXV0aG9yaXR5MSIw
+IAYDVQQDExlDZXJ0dW0gVHJ1c3RlZCBOZXR3b3JrIENBMIIBIjANBgkqhkiG9w0B
+AQEFAAOCAQ8AMIIBCgKCAQEA4/t9o3K6wvDJFIf1awFO4W5AB7ptJ11/91sts1rH
+UV+rpDKmYYe2bg+G0jACl/jXaVehGDldamR5xgFZrDwxSjh80gTSSyjoIF87B6LM
+TXPb865Px1bVWqeWifrzq2jUI4ZZJ88JJ7ysbnKDHDBy3+Ci6dLhdHUZvSqeexVU
+BBvXQzmtVSjF4hq79MDkrjhJM8x2hZ85RdKknvISjFH4fOQtf/WsX+sWn7Et0brM
+kUJ3TCXJkDhv2/DM+44el1k+1WBO5gUo7Ul5E0u6SNsv+XLTOcr+H9g0cvW0QM8x
+AcPs3hEtF10fuFDRXhmnad4HMyjKUJX5p1TLVIZQRan5SQIDAQABo0IwQDAPBgNV
+HRMBAf8EBTADAQH/MB0GA1UdDgQWBBQIds3LB/8k9sXN7buQvOKEN0Z19zAOBgNV
+HQ8BAf8EBAMCAQYwDQYJKoZIhvcNAQEFBQADggEBAKaorSLOAT2mo/9i0Eidi15y
+sHhE49wcrwn9I0j6vSrEuVUEtRCjjSfeC4Jj0O7eDDd5QVsisrCaQVymcODU0HfL
+I9MA4GxWL+FpDQ3Zqr8hgVDZBqWo/5U30Kr+4rP1mS1FhIrlQgnXdAIv94nYmem8
+J9RHjboNRhx3zxSkHLmkMcScKHQDNP8zGSal6Q10tz6XxnboJ5ajZt3hrvJBW8qY
+VoNzcOSGGtIxQbovvi0TWnZvTuhOgQ4/WwMioBK+ZlgRSssDxLQqKi2WF+A5VLxI
+03YnnZotBqbJ7DnSq9ufmgsnAjUpsUCV5/nonFWIGUbWtzT1fs45mtk48VH3Tyw=
+-----END CERTIFICATE-----
+
+# Issuer: CN=TWCA Root Certification Authority O=TAIWAN-CA OU=Root CA
+# Subject: CN=TWCA Root Certification Authority O=TAIWAN-CA OU=Root CA
+# Label: "TWCA Root Certification Authority"
+# Serial: 1
+# MD5 Fingerprint: aa:08:8f:f6:f9:7b:b7:f2:b1:a7:1e:9b:ea:ea:bd:79
+# SHA1 Fingerprint: cf:9e:87:6d:d3:eb:fc:42:26:97:a3:b5:a3:7a:a0:76:a9:06:23:48
+# SHA256 Fingerprint: bf:d8:8f:e1:10:1c:41:ae:3e:80:1b:f8:be:56:35:0e:e9:ba:d1:a6:b9:bd:51:5e:dc:5c:6d:5b:87:11:ac:44
+-----BEGIN CERTIFICATE-----
+MIIDezCCAmOgAwIBAgIBATANBgkqhkiG9w0BAQUFADBfMQswCQYDVQQGEwJUVzES
+MBAGA1UECgwJVEFJV0FOLUNBMRAwDgYDVQQLDAdSb290IENBMSowKAYDVQQDDCFU
+V0NBIFJvb3QgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwHhcNMDgwODI4MDcyNDMz
+WhcNMzAxMjMxMTU1OTU5WjBfMQswCQYDVQQGEwJUVzESMBAGA1UECgwJVEFJV0FO
+LUNBMRAwDgYDVQQLDAdSb290IENBMSowKAYDVQQDDCFUV0NBIFJvb3QgQ2VydGlm
+aWNhdGlvbiBBdXRob3JpdHkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIB
+AQCwfnK4pAOU5qfeCTiRShFAh6d8WWQUe7UREN3+v9XAu1bihSX0NXIP+FPQQeFE
+AcK0HMMxQhZHhTMidrIKbw/lJVBPhYa+v5guEGcevhEFhgWQxFnQfHgQsIBct+HH
+K3XLfJ+utdGdIzdjp9xCoi2SBBtQwXu4PhvJVgSLL1KbralW6cH/ralYhzC2gfeX
+RfwZVzsrb+RH9JlF/h3x+JejiB03HFyP4HYlmlD4oFT/RJB2I9IyxsOrBr/8+7/z
+rX2SYgJbKdM1o5OaQ2RgXbL6Mv87BK9NQGr5x+PvI/1ry+UPizgN7gr8/g+YnzAx
+3WxSZfmLgb4i4RxYA7qRG4kHAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
+HRMBAf8EBTADAQH/MB0GA1UdDgQWBBRqOFsmjd6LWvJPelSDGRjjCDWmujANBgkq
+hkiG9w0BAQUFAAOCAQEAPNV3PdrfibqHDAhUaiBQkr6wQT25JmSDCi/oQMCXKCeC
+MErJk/9q56YAf4lCmtYR5VPOL8zy2gXE/uJQxDqGfczafhAJO5I1KlOy/usrBdls
+XebQ79NqZp4VKIV66IIArB6nCWlWQtNoURi+VJq/REG6Sb4gumlc7rh3zc5sH62D
+lhh9DrUUOYTxKOkto557HnpyWoOzeW/vtPzQCqVYT0bf+215WfKEIlKuD8z7fDvn
+aspHYcN6+NOSBB+4IIThNlQWx0DeO4pz3N/GCUzf7Nr/1FNCocnyYh0igzyXxfkZ
+YiesZSLX0zzG5Y6yU8xJzrww/nsOM5D77dIUkR8Hrw==
+-----END CERTIFICATE-----
+
+# Issuer: O=SECOM Trust Systems CO.,LTD. OU=Security Communication RootCA2
+# Subject: O=SECOM Trust Systems CO.,LTD. OU=Security Communication RootCA2
+# Label: "Security Communication RootCA2"
+# Serial: 0
+# MD5 Fingerprint: 6c:39:7d:a4:0e:55:59:b2:3f:d6:41:b1:12:50:de:43
+# SHA1 Fingerprint: 5f:3b:8c:f2:f8:10:b3:7d:78:b4:ce:ec:19:19:c3:73:34:b9:c7:74
+# SHA256 Fingerprint: 51:3b:2c:ec:b8:10:d4:cd:e5:dd:85:39:1a:df:c6:c2:dd:60:d8:7b:b7:36:d2:b5:21:48:4a:a4:7a:0e:be:f6
+-----BEGIN CERTIFICATE-----
+MIIDdzCCAl+gAwIBAgIBADANBgkqhkiG9w0BAQsFADBdMQswCQYDVQQGEwJKUDEl
+MCMGA1UEChMcU0VDT00gVHJ1c3QgU3lzdGVtcyBDTy4sTFRELjEnMCUGA1UECxMe
+U2VjdXJpdHkgQ29tbXVuaWNhdGlvbiBSb290Q0EyMB4XDTA5MDUyOTA1MDAzOVoX
+DTI5MDUyOTA1MDAzOVowXTELMAkGA1UEBhMCSlAxJTAjBgNVBAoTHFNFQ09NIFRy
+dXN0IFN5c3RlbXMgQ08uLExURC4xJzAlBgNVBAsTHlNlY3VyaXR5IENvbW11bmlj
+YXRpb24gUm9vdENBMjCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBANAV
+OVKxUrO6xVmCxF1SrjpDZYBLx/KWvNs2l9amZIyoXvDjChz335c9S672XewhtUGr
+zbl+dp+++T42NKA7wfYxEUV0kz1XgMX5iZnK5atq1LXaQZAQwdbWQonCv/Q4EpVM
+VAX3NuRFg3sUZdbcDE3R3n4MqzvEFb46VqZab3ZpUql6ucjrappdUtAtCms1FgkQ
+hNBqyjoGADdH5H5XTz+L62e4iKrFvlNVspHEfbmwhRkGeC7bYRr6hfVKkaHnFtWO
+ojnflLhwHyg/i/xAXmODPIMqGplrz95Zajv8bxbXH/1KEOtOghY6rCcMU/Gt1SSw
+awNQwS08Ft1ENCcadfsCAwEAAaNCMEAwHQYDVR0OBBYEFAqFqXdlBZh8QIH4D5cs
+OPEK7DzPMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3
+DQEBCwUAA4IBAQBMOqNErLlFsceTfsgLCkLfZOoc7llsCLqJX2rKSpWeeo8HxdpF
+coJxDjrSzG+ntKEju/Ykn8sX/oymzsLS28yN/HH8AynBbF0zX2S2ZTuJbxh2ePXc
+okgfGT+Ok+vx+hfuzU7jBBJV1uXk3fs+BXziHV7Gp7yXT2g69ekuCkO2r1dcYmh8
+t/2jioSgrGK+KwmHNPBqAbubKVY8/gA3zyNs8U6qtnRGEmyR7jTV7JqR50S+kDFy
+1UkC9gLl9B/rfNmWVan/7Ir5mUf/NVoCqgTLiluHcSmRvaS0eg29mvVXIwAHIRc/
+SjnRBUkLp7Y3gaVdjKozXoEofKd9J+sAro03
+-----END CERTIFICATE-----
+
+# Issuer: CN=Actalis Authentication Root CA O=Actalis S.p.A./03358520967
+# Subject: CN=Actalis Authentication Root CA O=Actalis S.p.A./03358520967
+# Label: "Actalis Authentication Root CA"
+# Serial: 6271844772424770508
+# MD5 Fingerprint: 69:c1:0d:4f:07:a3:1b:c3:fe:56:3d:04:bc:11:f6:a6
+# SHA1 Fingerprint: f3:73:b3:87:06:5a:28:84:8a:f2:f3:4a:ce:19:2b:dd:c7:8e:9c:ac
+# SHA256 Fingerprint: 55:92:60:84:ec:96:3a:64:b9:6e:2a:be:01:ce:0b:a8:6a:64:fb:fe:bc:c7:aa:b5:af:c1:55:b3:7f:d7:60:66
+-----BEGIN CERTIFICATE-----
+MIIFuzCCA6OgAwIBAgIIVwoRl0LE48wwDQYJKoZIhvcNAQELBQAwazELMAkGA1UE
+BhMCSVQxDjAMBgNVBAcMBU1pbGFuMSMwIQYDVQQKDBpBY3RhbGlzIFMucC5BLi8w
+MzM1ODUyMDk2NzEnMCUGA1UEAwweQWN0YWxpcyBBdXRoZW50aWNhdGlvbiBSb290
+IENBMB4XDTExMDkyMjExMjIwMloXDTMwMDkyMjExMjIwMlowazELMAkGA1UEBhMC
+SVQxDjAMBgNVBAcMBU1pbGFuMSMwIQYDVQQKDBpBY3RhbGlzIFMucC5BLi8wMzM1
+ODUyMDk2NzEnMCUGA1UEAwweQWN0YWxpcyBBdXRoZW50aWNhdGlvbiBSb290IENB
+MIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAp8bEpSmkLO/lGMWwUKNv
+UTufClrJwkg4CsIcoBh/kbWHuUA/3R1oHwiD1S0eiKD4j1aPbZkCkpAW1V8IbInX
+4ay8IMKx4INRimlNAJZaby/ARH6jDuSRzVju3PvHHkVH3Se5CAGfpiEd9UEtL0z9
+KK3giq0itFZljoZUj5NDKd45RnijMCO6zfB9E1fAXdKDa0hMxKufgFpbOr3JpyI/
+gCczWw63igxdBzcIy2zSekciRDXFzMwujt0q7bd9Zg1fYVEiVRvjRuPjPdA1Yprb
+rxTIW6HMiRvhMCb8oJsfgadHHwTrozmSBp+Z07/T6k9QnBn+locePGX2oxgkg4YQ
+51Q+qDp2JE+BIcXjDwL4k5RHILv+1A7TaLndxHqEguNTVHnd25zS8gebLra8Pu2F
+be8lEfKXGkJh90qX6IuxEAf6ZYGyojnP9zz/GPvG8VqLWeICrHuS0E4UT1lF9gxe
+KF+w6D9Fz8+vm2/7hNN3WpVvrJSEnu68wEqPSpP4RCHiMUVhUE4Q2OM1fEwZtN4F
+v6MGn8i1zeQf1xcGDXqVdFUNaBr8EBtiZJ1t4JWgw5QHVw0U5r0F+7if5t+L4sbn
+fpb2U8WANFAoWPASUHEXMLrmeGO89LKtmyuy/uE5jF66CyCU3nuDuP/jVo23Eek7
+jPKxwV2dpAtMK9myGPW1n0sCAwEAAaNjMGEwHQYDVR0OBBYEFFLYiDrIn3hm7Ynz
+ezhwlMkCAjbQMA8GA1UdEwEB/wQFMAMBAf8wHwYDVR0jBBgwFoAUUtiIOsifeGbt
+ifN7OHCUyQICNtAwDgYDVR0PAQH/BAQDAgEGMA0GCSqGSIb3DQEBCwUAA4ICAQAL
+e3KHwGCmSUyIWOYdiPcUZEim2FgKDk8TNd81HdTtBjHIgT5q1d07GjLukD0R0i70
+jsNjLiNmsGe+b7bAEzlgqqI0JZN1Ut6nna0Oh4lScWoWPBkdg/iaKWW+9D+a2fDz
+WochcYBNy+A4mz+7+uAwTc+G02UQGRjRlwKxK3JCaKygvU5a2hi/a5iB0P2avl4V
+SM0RFbnAKVy06Ij3Pjaut2L9HmLecHgQHEhb2rykOLpn7VU+Xlff1ANATIGk0k9j
+pwlCCRT8AKnCgHNPLsBA2RF7SOp6AsDT6ygBJlh0wcBzIm2Tlf05fbsq4/aC4yyX
+X04fkZT6/iyj2HYauE2yOE+b+h1IYHkm4vP9qdCa6HCPSXrW5b0KDtst842/6+Ok
+fcvHlXHo2qN8xcL4dJIEG4aspCJTQLas/kx2z/uUMsA1n3Y/buWQbqCmJqK4LL7R
+K4X9p2jIugErsWx0Hbhzlefut8cl8ABMALJ+tguLHPPAUJ4lueAI3jZm/zel0btU
+ZCzJJ7VLkn5l/9Mt4blOvH+kQSGQQXemOR/qnuOf0GZvBeyqdn6/axag67XH/JJU
+LysRJyU3eExRarDzzFhdFPFqSBX/wge2sY0PjlxQRrM9vwGYT7JZVEc+NHt4bVaT
+LnPqZih4zR0Uv6CPLy64Lo7yFIrM6bV8+2ydDKXhlg==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Buypass Class 2 Root CA O=Buypass AS-983163327
+# Subject: CN=Buypass Class 2 Root CA O=Buypass AS-983163327
+# Label: "Buypass Class 2 Root CA"
+# Serial: 2
+# MD5 Fingerprint: 46:a7:d2:fe:45:fb:64:5a:a8:59:90:9b:78:44:9b:29
+# SHA1 Fingerprint: 49:0a:75:74:de:87:0a:47:fe:58:ee:f6:c7:6b:eb:c6:0b:12:40:99
+# SHA256 Fingerprint: 9a:11:40:25:19:7c:5b:b9:5d:94:e6:3d:55:cd:43:79:08:47:b6:46:b2:3c:df:11:ad:a4:a0:0e:ff:15:fb:48
+-----BEGIN CERTIFICATE-----
+MIIFWTCCA0GgAwIBAgIBAjANBgkqhkiG9w0BAQsFADBOMQswCQYDVQQGEwJOTzEd
+MBsGA1UECgwUQnV5cGFzcyBBUy05ODMxNjMzMjcxIDAeBgNVBAMMF0J1eXBhc3Mg
+Q2xhc3MgMiBSb290IENBMB4XDTEwMTAyNjA4MzgwM1oXDTQwMTAyNjA4MzgwM1ow
+TjELMAkGA1UEBhMCTk8xHTAbBgNVBAoMFEJ1eXBhc3MgQVMtOTgzMTYzMzI3MSAw
+HgYDVQQDDBdCdXlwYXNzIENsYXNzIDIgUm9vdCBDQTCCAiIwDQYJKoZIhvcNAQEB
+BQADggIPADCCAgoCggIBANfHXvfBB9R3+0Mh9PT1aeTuMgHbo4Yf5FkNuud1g1Lr
+6hxhFUi7HQfKjK6w3Jad6sNgkoaCKHOcVgb/S2TwDCo3SbXlzwx87vFKu3MwZfPV
+L4O2fuPn9Z6rYPnT8Z2SdIrkHJasW4DptfQxh6NR/Md+oW+OU3fUl8FVM5I+GC91
+1K2GScuVr1QGbNgGE41b/+EmGVnAJLqBcXmQRFBoJJRfuLMR8SlBYaNByyM21cHx
+MlAQTn/0hpPshNOOvEu/XAFOBz3cFIqUCqTqc/sLUegTBxj6DvEr0VQVfTzh97QZ
+QmdiXnfgolXsttlpF9U6r0TtSsWe5HonfOV116rLJeffawrbD02TTqigzXsu8lkB
+arcNuAeBfos4GzjmCleZPe4h6KP1DBbdi+w0jpwqHAAVF41og9JwnxgIzRFo1clr
+Us3ERo/ctfPYV3Me6ZQ5BL/T3jjetFPsaRyifsSP5BtwrfKi+fv3FmRmaZ9JUaLi
+FRhnBkp/1Wy1TbMz4GHrXb7pmA8y1x1LPC5aAVKRCfLf6o3YBkBjqhHk/sM3nhRS
+P/TizPJhk9H9Z2vXUq6/aKtAQ6BXNVN48FP4YUIHZMbXb5tMOA1jrGKvNouicwoN
+9SG9dKpN6nIDSdvHXx1iY8f93ZHsM+71bbRuMGjeyNYmsHVee7QHIJihdjK4TWxP
+AgMBAAGjQjBAMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFMmAd+BikoL1Rpzz
+uvdMw964o605MA4GA1UdDwEB/wQEAwIBBjANBgkqhkiG9w0BAQsFAAOCAgEAU18h
+9bqwOlI5LJKwbADJ784g7wbylp7ppHR/ehb8t/W2+xUbP6umwHJdELFx7rxP462s
+A20ucS6vxOOto70MEae0/0qyexAQH6dXQbLArvQsWdZHEIjzIVEpMMpghq9Gqx3t
+OluwlN5E40EIosHsHdb9T7bWR9AUC8rmyrV7d35BH16Dx7aMOZawP5aBQW9gkOLo
++fsicdl9sz1Gv7SEr5AcD48Saq/v7h56rgJKihcrdv6sVIkkLE8/trKnToyokZf7
+KcZ7XC25y2a2t6hbElGFtQl+Ynhw/qlqYLYdDnkM/crqJIByw5c/8nerQyIKx+u2
+DISCLIBrQYoIwOula9+ZEsuK1V6ADJHgJgg2SMX6OBE1/yWDLfJ6v9r9jv6ly0Us
+H8SIU653DtmadsWOLB2jutXsMq7Aqqz30XpN69QH4kj3Io6wpJ9qzo6ysmD0oyLQ
+I+uUWnpp3Q+/QFesa1lQ2aOZ4W7+jQF5JyMV3pKdewlNWudLSDBaGOYKbeaP4NK7
+5t98biGCwWg5TbSYWGZizEqQXsP6JwSxeRV0mcy+rSDeJmAc61ZRpqPq5KM/p/9h
+3PFaTWwyI0PurKju7koSCTxdccK+efrCh2gdC/1cacwG0Jp9VJkqyTkaGa9LKkPz
+Y11aWOIv4x3kqdbQCtCev9eBCfHJxyYNrJgWVqA=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Buypass Class 3 Root CA O=Buypass AS-983163327
+# Subject: CN=Buypass Class 3 Root CA O=Buypass AS-983163327
+# Label: "Buypass Class 3 Root CA"
+# Serial: 2
+# MD5 Fingerprint: 3d:3b:18:9e:2c:64:5a:e8:d5:88:ce:0e:f9:37:c2:ec
+# SHA1 Fingerprint: da:fa:f7:fa:66:84:ec:06:8f:14:50:bd:c7:c2:81:a5:bc:a9:64:57
+# SHA256 Fingerprint: ed:f7:eb:bc:a2:7a:2a:38:4d:38:7b:7d:40:10:c6:66:e2:ed:b4:84:3e:4c:29:b4:ae:1d:5b:93:32:e6:b2:4d
+-----BEGIN CERTIFICATE-----
+MIIFWTCCA0GgAwIBAgIBAjANBgkqhkiG9w0BAQsFADBOMQswCQYDVQQGEwJOTzEd
+MBsGA1UECgwUQnV5cGFzcyBBUy05ODMxNjMzMjcxIDAeBgNVBAMMF0J1eXBhc3Mg
+Q2xhc3MgMyBSb290IENBMB4XDTEwMTAyNjA4Mjg1OFoXDTQwMTAyNjA4Mjg1OFow
+TjELMAkGA1UEBhMCTk8xHTAbBgNVBAoMFEJ1eXBhc3MgQVMtOTgzMTYzMzI3MSAw
+HgYDVQQDDBdCdXlwYXNzIENsYXNzIDMgUm9vdCBDQTCCAiIwDQYJKoZIhvcNAQEB
+BQADggIPADCCAgoCggIBAKXaCpUWUOOV8l6ddjEGMnqb8RB2uACatVI2zSRHsJ8Y
+ZLya9vrVediQYkwiL944PdbgqOkcLNt4EemOaFEVcsfzM4fkoF0LXOBXByow9c3E
+N3coTRiR5r/VUv1xLXA+58bEiuPwKAv0dpihi4dVsjoT/Lc+JzeOIuOoTyrvYLs9
+tznDDgFHmV0ST9tD+leh7fmdvhFHJlsTmKtdFoqwNxxXnUX/iJY2v7vKB3tvh2PX
+0DJq1l1sDPGzbjniazEuOQAnFN44wOwZZoYS6J1yFhNkUsepNxz9gjDthBgd9K5c
+/3ATAOux9TN6S9ZV+AWNS2mw9bMoNlwUxFFzTWsL8TQH2xc519woe2v1n/MuwU8X
+KhDzzMro6/1rqy6any2CbgTUUgGTLT2G/H783+9CHaZr77kgxve9oKeV/afmiSTY
+zIw0bOIjL9kSGiG5VZFvC5F5GQytQIgLcOJ60g7YaEi7ghM5EFjp2CoHxhLbWNvS
+O1UQRwUVZ2J+GGOmRj8JDlQyXr8NYnon74Do29lLBlo3WiXQCBJ31G8JUJc9yB3D
+34xFMFbG02SrZvPAXpacw8Tvw3xrizp5f7NJzz3iiZ+gMEuFuZyUJHmPfWupRWgP
+K9Dx2hzLabjKSWJtyNBjYt1gD1iqj6G8BaVmos8bdrKEZLFMOVLAMLrwjEsCsLa3
+AgMBAAGjQjBAMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFEe4zf/lb+74suwv
+Tg75JbCOPGvDMA4GA1UdDwEB/wQEAwIBBjANBgkqhkiG9w0BAQsFAAOCAgEAACAj
+QTUEkMJAYmDv4jVM1z+s4jSQuKFvdvoWFqRINyzpkMLyPPgKn9iB5btb2iUspKdV
+cSQy9sgL8rxq+JOssgfCX5/bzMiKqr5qb+FJEMwx14C7u8jYog5kV+qi9cKpMRXS
+IGrs/CIBKM+GuIAeqcwRpTzyFrNHnfzSgCHEy9BHcEGhyoMZCCxt8l13nIoUE9Q2
+HJLw5QY33KbmkJs4j1xrG0aGQ0JfPgEHU1RdZX33inOhmlRaHylDFCfChQ+1iHsa
+O5S3HWCntZznKWlXWpuTekMwGwPXYshApqr8ZORK15FTAaggiG6cX0S5y2CBNOxv
+033aSF/rtJC8LakcC6wc1aJoIIAE1vyxjy+7SjENSoYc6+I2KSb12tjE8nVhz36u
+dmNKekBlk4f4HoCMhuWG1o8O/FMsYOgWYRqiPkN7zTlgVGr18okmAWiDSKIz6MkE
+kbIRNBE+6tBDGR8Dk5AM/1E9V/RBbuHLoL7ryWPNbczk+DaqaJ3tvV2XcEQNtg41
+3OEMXbugUZTLfhbrES+jkkXITHHZvMmZUldGL1DPvTVp9D0VzgalLA8+9oG6lLvD
+u79leNKGef9JOxqDDPDeeOzI8k1MGt6CKfjBWtrt7uYnXuhF0J0cUahoq0Tj0Itq
+4/g7u9xN12TyUb7mqqta6THuBrxzvxNiCp/HuZc=
+-----END CERTIFICATE-----
+
+# Issuer: CN=T-TeleSec GlobalRoot Class 3 O=T-Systems Enterprise Services GmbH OU=T-Systems Trust Center
+# Subject: CN=T-TeleSec GlobalRoot Class 3 O=T-Systems Enterprise Services GmbH OU=T-Systems Trust Center
+# Label: "T-TeleSec GlobalRoot Class 3"
+# Serial: 1
+# MD5 Fingerprint: ca:fb:40:a8:4e:39:92:8a:1d:fe:8e:2f:c4:27:ea:ef
+# SHA1 Fingerprint: 55:a6:72:3e:cb:f2:ec:cd:c3:23:74:70:19:9d:2a:be:11:e3:81:d1
+# SHA256 Fingerprint: fd:73:da:d3:1c:64:4f:f1:b4:3b:ef:0c:cd:da:96:71:0b:9c:d9:87:5e:ca:7e:31:70:7a:f3:e9:6d:52:2b:bd
+-----BEGIN CERTIFICATE-----
+MIIDwzCCAqugAwIBAgIBATANBgkqhkiG9w0BAQsFADCBgjELMAkGA1UEBhMCREUx
+KzApBgNVBAoMIlQtU3lzdGVtcyBFbnRlcnByaXNlIFNlcnZpY2VzIEdtYkgxHzAd
+BgNVBAsMFlQtU3lzdGVtcyBUcnVzdCBDZW50ZXIxJTAjBgNVBAMMHFQtVGVsZVNl
+YyBHbG9iYWxSb290IENsYXNzIDMwHhcNMDgxMDAxMTAyOTU2WhcNMzMxMDAxMjM1
+OTU5WjCBgjELMAkGA1UEBhMCREUxKzApBgNVBAoMIlQtU3lzdGVtcyBFbnRlcnBy
+aXNlIFNlcnZpY2VzIEdtYkgxHzAdBgNVBAsMFlQtU3lzdGVtcyBUcnVzdCBDZW50
+ZXIxJTAjBgNVBAMMHFQtVGVsZVNlYyBHbG9iYWxSb290IENsYXNzIDMwggEiMA0G
+CSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQC9dZPwYiJvJK7genasfb3ZJNW4t/zN
+8ELg63iIVl6bmlQdTQyK9tPPcPRStdiTBONGhnFBSivwKixVA9ZIw+A5OO3yXDw/
+RLyTPWGrTs0NvvAgJ1gORH8EGoel15YUNpDQSXuhdfsaa3Ox+M6pCSzyU9XDFES4
+hqX2iys52qMzVNn6chr3IhUciJFrf2blw2qAsCTz34ZFiP0Zf3WHHx+xGwpzJFu5
+ZeAsVMhg02YXP+HMVDNzkQI6pn97djmiH5a2OK61yJN0HZ65tOVgnS9W0eDrXltM
+EnAMbEQgqxHY9Bn20pxSN+f6tsIxO0rUFJmtxxr1XV/6B7h8DR/Wgx6zAgMBAAGj
+QjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgEGMB0GA1UdDgQWBBS1
+A/d2O2GCahKqGFPrAyGUv/7OyjANBgkqhkiG9w0BAQsFAAOCAQEAVj3vlNW92nOy
+WL6ukK2YJ5f+AbGwUgC4TeQbIXQbfsDuXmkqJa9c1h3a0nnJ85cp4IaH3gRZD/FZ
+1GSFS5mvJQQeyUapl96Cshtwn5z2r3Ex3XsFpSzTucpH9sry9uetuUg/vBa3wW30
+6gmv7PO15wWeph6KU1HWk4HMdJP2udqmJQV0eVp+QD6CSyYRMG7hP0HHRwA11fXT
+91Q+gT3aSWqas+8QPebrb9HIIkfLzM8BMZLZGOMivgkeGj5asuRrDFR6fUNOuIml
+e9eiPZaGzPImNC1qkp2aGtAw4l1OBLBfiyB+d8E9lYLRRpo7PHi4b6HQDWSieB4p
+TpPDpFQUWw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=D-TRUST Root Class 3 CA 2 2009 O=D-Trust GmbH
+# Subject: CN=D-TRUST Root Class 3 CA 2 2009 O=D-Trust GmbH
+# Label: "D-TRUST Root Class 3 CA 2 2009"
+# Serial: 623603
+# MD5 Fingerprint: cd:e0:25:69:8d:47:ac:9c:89:35:90:f7:fd:51:3d:2f
+# SHA1 Fingerprint: 58:e8:ab:b0:36:15:33:fb:80:f7:9b:1b:6d:29:d3:ff:8d:5f:00:f0
+# SHA256 Fingerprint: 49:e7:a4:42:ac:f0:ea:62:87:05:00:54:b5:25:64:b6:50:e4:f4:9e:42:e3:48:d6:aa:38:e0:39:e9:57:b1:c1
+-----BEGIN CERTIFICATE-----
+MIIEMzCCAxugAwIBAgIDCYPzMA0GCSqGSIb3DQEBCwUAME0xCzAJBgNVBAYTAkRF
+MRUwEwYDVQQKDAxELVRydXN0IEdtYkgxJzAlBgNVBAMMHkQtVFJVU1QgUm9vdCBD
+bGFzcyAzIENBIDIgMjAwOTAeFw0wOTExMDUwODM1NThaFw0yOTExMDUwODM1NTha
+ME0xCzAJBgNVBAYTAkRFMRUwEwYDVQQKDAxELVRydXN0IEdtYkgxJzAlBgNVBAMM
+HkQtVFJVU1QgUm9vdCBDbGFzcyAzIENBIDIgMjAwOTCCASIwDQYJKoZIhvcNAQEB
+BQADggEPADCCAQoCggEBANOySs96R+91myP6Oi/WUEWJNTrGa9v+2wBoqOADER03
+UAifTUpolDWzU9GUY6cgVq/eUXjsKj3zSEhQPgrfRlWLJ23DEE0NkVJD2IfgXU42
+tSHKXzlABF9bfsyjxiupQB7ZNoTWSPOSHjRGICTBpFGOShrvUD9pXRl/RcPHAY9R
+ySPocq60vFYJfxLLHLGvKZAKyVXMD9O0Gu1HNVpK7ZxzBCHQqr0ME7UAyiZsxGsM
+lFqVlNpQmvH/pStmMaTJOKDfHR+4CS7zp+hnUquVH+BGPtikw8paxTGA6Eian5Rp
+/hnd2HN8gcqW3o7tszIFZYQ05ub9VxC1X3a/L7AQDcUCAwEAAaOCARowggEWMA8G
+A1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFP3aFMSfMN4hvR5COfyrYyNJ4PGEMA4G
+A1UdDwEB/wQEAwIBBjCB0wYDVR0fBIHLMIHIMIGAoH6gfIZ6bGRhcDovL2RpcmVj
+dG9yeS5kLXRydXN0Lm5ldC9DTj1ELVRSVVNUJTIwUm9vdCUyMENsYXNzJTIwMyUy
+MENBJTIwMiUyMDIwMDksTz1ELVRydXN0JTIwR21iSCxDPURFP2NlcnRpZmljYXRl
+cmV2b2NhdGlvbmxpc3QwQ6BBoD+GPWh0dHA6Ly93d3cuZC10cnVzdC5uZXQvY3Js
+L2QtdHJ1c3Rfcm9vdF9jbGFzc18zX2NhXzJfMjAwOS5jcmwwDQYJKoZIhvcNAQEL
+BQADggEBAH+X2zDI36ScfSF6gHDOFBJpiBSVYEQBrLLpME+bUMJm2H6NMLVwMeni
+acfzcNsgFYbQDfC+rAF1hM5+n02/t2A7nPPKHeJeaNijnZflQGDSNiH+0LS4F9p0
+o3/U37CYAqxva2ssJSRyoWXuJVrl5jLn8t+rSfrzkGkj2wTZ51xY/GXUl77M/C4K
+zCUqNQT4YJEVdT1B/yMfGchs64JTBKbkTCJNjYy6zltz7GRUUG3RnFX7acM2w4y8
+PIWmawomDeCTmGCufsYkl4phX5GOZpIJhzbNi5stPvZR1FDUWSi9g/LMKHtThm3Y
+Johw1+qRzT65ysCQblrGXnRl11z+o+I=
+-----END CERTIFICATE-----
+
+# Issuer: CN=D-TRUST Root Class 3 CA 2 EV 2009 O=D-Trust GmbH
+# Subject: CN=D-TRUST Root Class 3 CA 2 EV 2009 O=D-Trust GmbH
+# Label: "D-TRUST Root Class 3 CA 2 EV 2009"
+# Serial: 623604
+# MD5 Fingerprint: aa:c6:43:2c:5e:2d:cd:c4:34:c0:50:4f:11:02:4f:b6
+# SHA1 Fingerprint: 96:c9:1b:0b:95:b4:10:98:42:fa:d0:d8:22:79:fe:60:fa:b9:16:83
+# SHA256 Fingerprint: ee:c5:49:6b:98:8c:e9:86:25:b9:34:09:2e:ec:29:08:be:d0:b0:f3:16:c2:d4:73:0c:84:ea:f1:f3:d3:48:81
+-----BEGIN CERTIFICATE-----
+MIIEQzCCAyugAwIBAgIDCYP0MA0GCSqGSIb3DQEBCwUAMFAxCzAJBgNVBAYTAkRF
+MRUwEwYDVQQKDAxELVRydXN0IEdtYkgxKjAoBgNVBAMMIUQtVFJVU1QgUm9vdCBD
+bGFzcyAzIENBIDIgRVYgMjAwOTAeFw0wOTExMDUwODUwNDZaFw0yOTExMDUwODUw
+NDZaMFAxCzAJBgNVBAYTAkRFMRUwEwYDVQQKDAxELVRydXN0IEdtYkgxKjAoBgNV
+BAMMIUQtVFJVU1QgUm9vdCBDbGFzcyAzIENBIDIgRVYgMjAwOTCCASIwDQYJKoZI
+hvcNAQEBBQADggEPADCCAQoCggEBAJnxhDRwui+3MKCOvXwEz75ivJn9gpfSegpn
+ljgJ9hBOlSJzmY3aFS3nBfwZcyK3jpgAvDw9rKFs+9Z5JUut8Mxk2og+KbgPCdM0
+3TP1YtHhzRnp7hhPTFiu4h7WDFsVWtg6uMQYZB7jM7K1iXdODL/ZlGsTl28So/6Z
+qQTMFexgaDbtCHu39b+T7WYxg4zGcTSHThfqr4uRjRxWQa4iN1438h3Z0S0NL2lR
+p75mpoo6Kr3HGrHhFPC+Oh25z1uxav60sUYgovseO3Dvk5h9jHOW8sXvhXCtKSb8
+HgQ+HKDYD8tSg2J87otTlZCpV6LqYQXY+U3EJ/pure3511H3a6UCAwEAAaOCASQw
+ggEgMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFNOUikxiEyoZLsyvcop9Ntea
+HNxnMA4GA1UdDwEB/wQEAwIBBjCB3QYDVR0fBIHVMIHSMIGHoIGEoIGBhn9sZGFw
+Oi8vZGlyZWN0b3J5LmQtdHJ1c3QubmV0L0NOPUQtVFJVU1QlMjBSb290JTIwQ2xh
+c3MlMjAzJTIwQ0ElMjAyJTIwRVYlMjAyMDA5LE89RC1UcnVzdCUyMEdtYkgsQz1E
+RT9jZXJ0aWZpY2F0ZXJldm9jYXRpb25saXN0MEagRKBChkBodHRwOi8vd3d3LmQt
+dHJ1c3QubmV0L2NybC9kLXRydXN0X3Jvb3RfY2xhc3NfM19jYV8yX2V2XzIwMDku
+Y3JsMA0GCSqGSIb3DQEBCwUAA4IBAQA07XtaPKSUiO8aEXUHL7P+PPoeUSbrh/Yp
+3uDx1MYkCenBz1UbtDDZzhr+BlGmFaQt77JLvyAoJUnRpjZ3NOhk31KxEcdzes05
+nsKtjHEh8lprr988TlWvsoRlFIm5d8sqMb7Po23Pb0iUMkZv53GMoKaEGTcH8gNF
+CSuGdXzfX2lXANtu2KZyIktQ1HWYVt+3GP9DQ1CuekR78HlR10M9p9OB0/DJT7na
+xpeG0ILD5EJt/rDiZE4OJudANCa1CInXCGNjOCd1HjPqbqjdn5lPdE2BiYBL3ZqX
+KVwvvoFBuYz/6n1gBp7N1z3TLqMVvKjmJuVvw9y4AyHqnxbxLFS1
+-----END CERTIFICATE-----
+
+# Issuer: CN=CA Disig Root R2 O=Disig a.s.
+# Subject: CN=CA Disig Root R2 O=Disig a.s.
+# Label: "CA Disig Root R2"
+# Serial: 10572350602393338211
+# MD5 Fingerprint: 26:01:fb:d8:27:a7:17:9a:45:54:38:1a:43:01:3b:03
+# SHA1 Fingerprint: b5:61:eb:ea:a4:de:e4:25:4b:69:1a:98:a5:57:47:c2:34:c7:d9:71
+# SHA256 Fingerprint: e2:3d:4a:03:6d:7b:70:e9:f5:95:b1:42:20:79:d2:b9:1e:df:bb:1f:b6:51:a0:63:3e:aa:8a:9d:c5:f8:07:03
+-----BEGIN CERTIFICATE-----
+MIIFaTCCA1GgAwIBAgIJAJK4iNuwisFjMA0GCSqGSIb3DQEBCwUAMFIxCzAJBgNV
+BAYTAlNLMRMwEQYDVQQHEwpCcmF0aXNsYXZhMRMwEQYDVQQKEwpEaXNpZyBhLnMu
+MRkwFwYDVQQDExBDQSBEaXNpZyBSb290IFIyMB4XDTEyMDcxOTA5MTUzMFoXDTQy
+MDcxOTA5MTUzMFowUjELMAkGA1UEBhMCU0sxEzARBgNVBAcTCkJyYXRpc2xhdmEx
+EzARBgNVBAoTCkRpc2lnIGEucy4xGTAXBgNVBAMTEENBIERpc2lnIFJvb3QgUjIw
+ggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCio8QACdaFXS1tFPbCw3Oe
+NcJxVX6B+6tGUODBfEl45qt5WDza/3wcn9iXAng+a0EE6UG9vgMsRfYvZNSrXaNH
+PWSb6WiaxswbP7q+sos0Ai6YVRn8jG+qX9pMzk0DIaPY0jSTVpbLTAwAFjxfGs3I
+x2ymrdMxp7zo5eFm1tL7A7RBZckQrg4FY8aAamkw/dLukO8NJ9+flXP04SXabBbe
+QTg06ov80egEFGEtQX6sx3dOy1FU+16SGBsEWmjGycT6txOgmLcRK7fWV8x8nhfR
+yyX+hk4kLlYMeE2eARKmK6cBZW58Yh2EhN/qwGu1pSqVg8NTEQxzHQuyRpDRQjrO
+QG6Vrf/GlK1ul4SOfW+eioANSW1z4nuSHsPzwfPrLgVv2RvPN3YEyLRa5Beny912
+H9AZdugsBbPWnDTYltxhh5EF5EQIM8HauQhl1K6yNg3ruji6DOWbnuuNZt2Zz9aJ
+QfYEkoopKW1rOhzndX0CcQ7zwOe9yxndnWCywmZgtrEE7snmhrmaZkCo5xHtgUUD
+i/ZnWejBBhG93c+AAk9lQHhcR1DIm+YfgXvkRKhbhZri3lrVx/k6RGZL5DJUfORs
+nLMOPReisjQS1n6yqEm70XooQL6iFh/f5DcfEXP7kAplQ6INfPgGAVUzfbANuPT1
+rqVCV3w2EYx7XsQDnYx5nQIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MA4GA1Ud
+DwEB/wQEAwIBBjAdBgNVHQ4EFgQUtZn4r7CU9eMg1gqtzk5WpC5uQu0wDQYJKoZI
+hvcNAQELBQADggIBACYGXnDnZTPIgm7ZnBc6G3pmsgH2eDtpXi/q/075KMOYKmFM
+tCQSin1tERT3nLXK5ryeJ45MGcipvXrA1zYObYVybqjGom32+nNjf7xueQgcnYqf
+GopTpti72TVVsRHFqQOzVju5hJMiXn7B9hJSi+osZ7z+Nkz1uM/Rs0mSO9MpDpkb
+lvdhuDvEK7Z4bLQjb/D907JedR+Zlais9trhxTF7+9FGs9K8Z7RiVLoJ92Owk6Ka
++elSLotgEqv89WBW7xBci8QaQtyDW2QOy7W81k/BfDxujRNt+3vrMNDcTa/F1bal
+TFtxyegxvug4BkihGuLq0t4SOVga/4AOgnXmt8kHbA7v/zjxmHHEt38OFdAlab0i
+nSvtBfZGR6ztwPDUO+Ls7pZbkBNOHlY667DvlruWIxG68kOGdGSVyCh13x01utI3
+gzhTODY7z2zp+WsO0PsE6E9312UBeIYMej4hYvF/Y3EMyZ9E26gnonW+boE+18Dr
+G5gPcFw0sorMwIUY6256s/daoQe/qUKS82Ail+QUoQebTnbAjn39pCXHR+3/H3Os
+zMOl6W8KjptlwlCFtaOgUxLMVYdh84GuEEZhvUQhuMI9dM9+JDX6HAcOmz0iyu8x
+L4ysEr3vQCj8KWefshNPZiTEUxnpHikV7+ZtsH8tZ/3zbBt1RqPlShfppNcL
+-----END CERTIFICATE-----
+
+# Issuer: CN=ACCVRAIZ1 O=ACCV OU=PKIACCV
+# Subject: CN=ACCVRAIZ1 O=ACCV OU=PKIACCV
+# Label: "ACCVRAIZ1"
+# Serial: 6828503384748696800
+# MD5 Fingerprint: d0:a0:5a:ee:05:b6:09:94:21:a1:7d:f1:b2:29:82:02
+# SHA1 Fingerprint: 93:05:7a:88:15:c6:4f:ce:88:2f:fa:91:16:52:28:78:bc:53:64:17
+# SHA256 Fingerprint: 9a:6e:c0:12:e1:a7:da:9d:be:34:19:4d:47:8a:d7:c0:db:18:22:fb:07:1d:f1:29:81:49:6e:d1:04:38:41:13
+-----BEGIN CERTIFICATE-----
+MIIH0zCCBbugAwIBAgIIXsO3pkN/pOAwDQYJKoZIhvcNAQEFBQAwQjESMBAGA1UE
+AwwJQUNDVlJBSVoxMRAwDgYDVQQLDAdQS0lBQ0NWMQ0wCwYDVQQKDARBQ0NWMQsw
+CQYDVQQGEwJFUzAeFw0xMTA1MDUwOTM3MzdaFw0zMDEyMzEwOTM3MzdaMEIxEjAQ
+BgNVBAMMCUFDQ1ZSQUlaMTEQMA4GA1UECwwHUEtJQUNDVjENMAsGA1UECgwEQUND
+VjELMAkGA1UEBhMCRVMwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCb
+qau/YUqXry+XZpp0X9DZlv3P4uRm7x8fRzPCRKPfmt4ftVTdFXxpNRFvu8gMjmoY
+HtiP2Ra8EEg2XPBjs5BaXCQ316PWywlxufEBcoSwfdtNgM3802/J+Nq2DoLSRYWo
+G2ioPej0RGy9ocLLA76MPhMAhN9KSMDjIgro6TenGEyxCQ0jVn8ETdkXhBilyNpA
+lHPrzg5XPAOBOp0KoVdDaaxXbXmQeOW1tDvYvEyNKKGno6e6Ak4l0Squ7a4DIrhr
+IA8wKFSVf+DuzgpmndFALW4ir50awQUZ0m/A8p/4e7MCQvtQqR0tkw8jq8bBD5L/
+0KIV9VMJcRz/RROE5iZe+OCIHAr8Fraocwa48GOEAqDGWuzndN9wrqODJerWx5eH
+k6fGioozl2A3ED6XPm4pFdahD9GILBKfb6qkxkLrQaLjlUPTAYVtjrs78yM2x/47
+4KElB0iryYl0/wiPgL/AlmXz7uxLaL2diMMxs0Dx6M/2OLuc5NF/1OVYm3z61PMO
+m3WR5LpSLhl+0fXNWhn8ugb2+1KoS5kE3fj5tItQo05iifCHJPqDQsGH+tUtKSpa
+cXpkatcnYGMN285J9Y0fkIkyF/hzQ7jSWpOGYdbhdQrqeWZ2iE9x6wQl1gpaepPl
+uUsXQA+xtrn13k/c4LOsOxFwYIRKQ26ZIMApcQrAZQIDAQABo4ICyzCCAscwfQYI
+KwYBBQUHAQEEcTBvMEwGCCsGAQUFBzAChkBodHRwOi8vd3d3LmFjY3YuZXMvZmls
+ZWFkbWluL0FyY2hpdm9zL2NlcnRpZmljYWRvcy9yYWl6YWNjdjEuY3J0MB8GCCsG
+AQUFBzABhhNodHRwOi8vb2NzcC5hY2N2LmVzMB0GA1UdDgQWBBTSh7Tj3zcnk1X2
+VuqB5TbMjB4/vTAPBgNVHRMBAf8EBTADAQH/MB8GA1UdIwQYMBaAFNKHtOPfNyeT
+VfZW6oHlNsyMHj+9MIIBcwYDVR0gBIIBajCCAWYwggFiBgRVHSAAMIIBWDCCASIG
+CCsGAQUFBwICMIIBFB6CARAAQQB1AHQAbwByAGkAZABhAGQAIABkAGUAIABDAGUA
+cgB0AGkAZgBpAGMAYQBjAGkA8wBuACAAUgBhAO0AegAgAGQAZQAgAGwAYQAgAEEA
+QwBDAFYAIAAoAEEAZwBlAG4AYwBpAGEAIABkAGUAIABUAGUAYwBuAG8AbABvAGcA
+7QBhACAAeQAgAEMAZQByAHQAaQBmAGkAYwBhAGMAaQDzAG4AIABFAGwAZQBjAHQA
+cgDzAG4AaQBjAGEALAAgAEMASQBGACAAUQA0ADYAMAAxADEANQA2AEUAKQAuACAA
+QwBQAFMAIABlAG4AIABoAHQAdABwADoALwAvAHcAdwB3AC4AYQBjAGMAdgAuAGUA
+czAwBggrBgEFBQcCARYkaHR0cDovL3d3dy5hY2N2LmVzL2xlZ2lzbGFjaW9uX2Mu
+aHRtMFUGA1UdHwROMEwwSqBIoEaGRGh0dHA6Ly93d3cuYWNjdi5lcy9maWxlYWRt
+aW4vQXJjaGl2b3MvY2VydGlmaWNhZG9zL3JhaXphY2N2MV9kZXIuY3JsMA4GA1Ud
+DwEB/wQEAwIBBjAXBgNVHREEEDAOgQxhY2N2QGFjY3YuZXMwDQYJKoZIhvcNAQEF
+BQADggIBAJcxAp/n/UNnSEQU5CmH7UwoZtCPNdpNYbdKl02125DgBS4OxnnQ8pdp
+D70ER9m+27Up2pvZrqmZ1dM8MJP1jaGo/AaNRPTKFpV8M9xii6g3+CfYCS0b78gU
+JyCpZET/LtZ1qmxNYEAZSUNUY9rizLpm5U9EelvZaoErQNV/+QEnWCzI7UiRfD+m
+AM/EKXMRNt6GGT6d7hmKG9Ww7Y49nCrADdg9ZuM8Db3VlFzi4qc1GwQA9j9ajepD
+vV+JHanBsMyZ4k0ACtrJJ1vnE5Bc5PUzolVt3OAJTS+xJlsndQAJxGJ3KQhfnlms
+tn6tn1QwIgPBHnFk/vk4CpYY3QIUrCPLBhwepH2NDd4nQeit2hW3sCPdK6jT2iWH
+7ehVRE2I9DZ+hJp4rPcOVkkO1jMl1oRQQmwgEh0q1b688nCBpHBgvgW1m54ERL5h
+I6zppSSMEYCUWqKiuUnSwdzRp+0xESyeGabu4VXhwOrPDYTkF7eifKXeVSUG7szA
+h1xA2syVP1XgNce4hL60Xc16gwFy7ofmXx2utYXGJt/mwZrpHgJHnyqobalbz+xF
+d3+YJ5oyXSrjhO7FmGYvliAd3djDJ9ew+f7Zfc3Qn48LFFhRny+Lwzgt3uiP1o2H
+pPVWQxaZLPSkVrQ0uGE3ycJYgBugl6H8WY3pEfbRD0tVNEYqi4Y7
+-----END CERTIFICATE-----
+
+# Issuer: CN=TWCA Global Root CA O=TAIWAN-CA OU=Root CA
+# Subject: CN=TWCA Global Root CA O=TAIWAN-CA OU=Root CA
+# Label: "TWCA Global Root CA"
+# Serial: 3262
+# MD5 Fingerprint: f9:03:7e:cf:e6:9e:3c:73:7a:2a:90:07:69:ff:2b:96
+# SHA1 Fingerprint: 9c:bb:48:53:f6:a4:f6:d3:52:a4:e8:32:52:55:60:13:f5:ad:af:65
+# SHA256 Fingerprint: 59:76:90:07:f7:68:5d:0f:cd:50:87:2f:9f:95:d5:75:5a:5b:2b:45:7d:81:f3:69:2b:61:0a:98:67:2f:0e:1b
+-----BEGIN CERTIFICATE-----
+MIIFQTCCAymgAwIBAgICDL4wDQYJKoZIhvcNAQELBQAwUTELMAkGA1UEBhMCVFcx
+EjAQBgNVBAoTCVRBSVdBTi1DQTEQMA4GA1UECxMHUm9vdCBDQTEcMBoGA1UEAxMT
+VFdDQSBHbG9iYWwgUm9vdCBDQTAeFw0xMjA2MjcwNjI4MzNaFw0zMDEyMzExNTU5
+NTlaMFExCzAJBgNVBAYTAlRXMRIwEAYDVQQKEwlUQUlXQU4tQ0ExEDAOBgNVBAsT
+B1Jvb3QgQ0ExHDAaBgNVBAMTE1RXQ0EgR2xvYmFsIFJvb3QgQ0EwggIiMA0GCSqG
+SIb3DQEBAQUAA4ICDwAwggIKAoICAQCwBdvI64zEbooh745NnHEKH1Jw7W2CnJfF
+10xORUnLQEK1EjRsGcJ0pDFfhQKX7EMzClPSnIyOt7h52yvVavKOZsTuKwEHktSz
+0ALfUPZVr2YOy+BHYC8rMjk1Ujoog/h7FsYYuGLWRyWRzvAZEk2tY/XTP3VfKfCh
+MBwqoJimFb3u/Rk28OKRQ4/6ytYQJ0lM793B8YVwm8rqqFpD/G2Gb3PpN0Wp8DbH
+zIh1HrtsBv+baz4X7GGqcXzGHaL3SekVtTzWoWH1EfcFbx39Eb7QMAfCKbAJTibc
+46KokWofwpFFiFzlmLhxpRUZyXx1EcxwdE8tmx2RRP1WKKD+u4ZqyPpcC1jcxkt2
+yKsi2XMPpfRaAok/T54igu6idFMqPVMnaR1sjjIsZAAmY2E2TqNGtz99sy2sbZCi
+laLOz9qC5wc0GZbpuCGqKX6mOL6OKUohZnkfs8O1CWfe1tQHRvMq2uYiN2DLgbYP
+oA/pyJV/v1WRBXrPPRXAb94JlAGD1zQbzECl8LibZ9WYkTunhHiVJqRaCPgrdLQA
+BDzfuBSO6N+pjWxnkjMdwLfS7JLIvgm/LCkFbwJrnu+8vyq8W8BQj0FwcYeyTbcE
+qYSjMq+u7msXi7Kx/mzhkIyIqJdIzshNy/MGz19qCkKxHh53L46g5pIOBvwFItIm
+4TFRfTLcDwIDAQABoyMwITAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB
+/zANBgkqhkiG9w0BAQsFAAOCAgEAXzSBdu+WHdXltdkCY4QWwa6gcFGn90xHNcgL
+1yg9iXHZqjNB6hQbbCEAwGxCGX6faVsgQt+i0trEfJdLjbDorMjupWkEmQqSpqsn
+LhpNgb+E1HAerUf+/UqdM+DyucRFCCEK2mlpc3INvjT+lIutwx4116KD7+U4x6WF
+H6vPNOw/KP4M8VeGTslV9xzU2KV9Bnpv1d8Q34FOIWWxtuEXeZVFBs5fzNxGiWNo
+RI2T9GRwoD2dKAXDOXC4Ynsg/eTb6QihuJ49CcdP+yz4k3ZB3lLg4VfSnQO8d57+
+nile98FRYB/e2guyLXW3Q0iT5/Z5xoRdgFlglPx4mI88k1HtQJAH32RjJMtOcQWh
+15QaiDLxInQirqWm2BJpTGCjAu4r7NRjkgtevi92a6O2JryPA9gK8kxkRr05YuWW
+6zRjESjMlfGt7+/cgFhI6Uu46mWs6fyAtbXIRfmswZ/ZuepiiI7E8UuDEq3mi4TW
+nsLrgxifarsbJGAzcMzs9zLzXNl5fe+epP7JI8Mk7hWSsT2RTyaGvWZzJBPqpK5j
+wa19hAM8EHiGG3njxPPyBJUgriOCxLM6AGK/5jYk4Ve6xx6QddVfP5VhK8E7zeWz
+aGHQRiapIVJpLesux+t3zqY6tQMzT3bR51xUAV3LePTJDL/PEo4XLSNolOer/qmy
+KwbQBM0=
+-----END CERTIFICATE-----
+
+# Issuer: CN=TeliaSonera Root CA v1 O=TeliaSonera
+# Subject: CN=TeliaSonera Root CA v1 O=TeliaSonera
+# Label: "TeliaSonera Root CA v1"
+# Serial: 199041966741090107964904287217786801558
+# MD5 Fingerprint: 37:41:49:1b:18:56:9a:26:f5:ad:c2:66:fb:40:a5:4c
+# SHA1 Fingerprint: 43:13:bb:96:f1:d5:86:9b:c1:4e:6a:92:f6:cf:f6:34:69:87:82:37
+# SHA256 Fingerprint: dd:69:36:fe:21:f8:f0:77:c1:23:a1:a5:21:c1:22:24:f7:22:55:b7:3e:03:a7:26:06:93:e8:a2:4b:0f:a3:89
+-----BEGIN CERTIFICATE-----
+MIIFODCCAyCgAwIBAgIRAJW+FqD3LkbxezmCcvqLzZYwDQYJKoZIhvcNAQEFBQAw
+NzEUMBIGA1UECgwLVGVsaWFTb25lcmExHzAdBgNVBAMMFlRlbGlhU29uZXJhIFJv
+b3QgQ0EgdjEwHhcNMDcxMDE4MTIwMDUwWhcNMzIxMDE4MTIwMDUwWjA3MRQwEgYD
+VQQKDAtUZWxpYVNvbmVyYTEfMB0GA1UEAwwWVGVsaWFTb25lcmEgUm9vdCBDQSB2
+MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAMK+6yfwIaPzaSZVfp3F
+VRaRXP3vIb9TgHot0pGMYzHw7CTww6XScnwQbfQ3t+XmfHnqjLWCi65ItqwA3GV1
+7CpNX8GH9SBlK4GoRz6JI5UwFpB/6FcHSOcZrr9FZ7E3GwYq/t75rH2D+1665I+X
+Z75Ljo1kB1c4VWk0Nj0TSO9P4tNmHqTPGrdeNjPUtAa9GAH9d4RQAEX1jF3oI7x+
+/jXh7VB7qTCNGdMJjmhnXb88lxhTuylixcpecsHHltTbLaC0H2kD7OriUPEMPPCs
+81Mt8Bz17Ww5OXOAFshSsCPN4D7c3TxHoLs1iuKYaIu+5b9y7tL6pe0S7fyYGKkm
+dtwoSxAgHNN/Fnct7W+A90m7UwW7XWjH1Mh1Fj+JWov3F0fUTPHSiXk+TT2YqGHe
+Oh7S+F4D4MHJHIzTjU3TlTazN19jY5szFPAtJmtTfImMMsJu7D0hADnJoWjiUIMu
+sDor8zagrC/kb2HCUQk5PotTubtn2txTuXZZNp1D5SDgPTJghSJRt8czu90VL6R4
+pgd7gUY2BIbdeTXHlSw7sKMXNeVzH7RcWe/a6hBle3rQf5+ztCo3O3CLm1u5K7fs
+slESl1MpWtTwEhDcTwK7EpIvYtQ/aUN8Ddb8WHUBiJ1YFkveupD/RwGJBmr2X7KQ
+arMCpgKIv7NHfirZ1fpoeDVNAgMBAAGjPzA9MA8GA1UdEwEB/wQFMAMBAf8wCwYD
+VR0PBAQDAgEGMB0GA1UdDgQWBBTwj1k4ALP1j5qWDNXr+nuqF+gTEjANBgkqhkiG
+9w0BAQUFAAOCAgEAvuRcYk4k9AwI//DTDGjkk0kiP0Qnb7tt3oNmzqjMDfz1mgbl
+dxSR651Be5kqhOX//CHBXfDkH1e3damhXwIm/9fH907eT/j3HEbAek9ALCI18Bmx
+0GtnLLCo4MBANzX2hFxc469CeP6nyQ1Q6g2EdvZR74NTxnr/DlZJLo961gzmJ1Tj
+TQpgcmLNkQfWpb/ImWvtxBnmq0wROMVvMeJuScg/doAmAyYp4Db29iBT4xdwNBed
+Y2gea+zDTYa4EzAvXUYNR0PVG6pZDrlcjQZIrXSHX8f8MVRBE+LHIQ6e4B4N4cB7
+Q4WQxYpYxmUKeFfyxiMPAdkgS94P+5KFdSpcc41teyWRyu5FrgZLAMzTsVlQ2jqI
+OylDRl6XK1TOU2+NSueW+r9xDkKLfP0ooNBIytrEgUy7onOTJsjrDNYmiLbAJM+7
+vVvrdX3pCI6GMyx5dwlppYn8s3CQh3aP0yK7Qs69cwsgJirQmz1wHiRszYd2qReW
+t88NkvuOGKmYSdGe/mBEciG5Ge3C9THxOUiIkCR1VBatzvT4aRRkOfujuLpwQMcn
+HL/EVlP6Y2XQ8xwOFvVrhlhNGNTkDY6lnVuR3HYkUD/GKvvZt5y11ubQ2egZixVx
+SK236thZiNSQvxaz2emsWWFUyBy6ysHK4bkgTI86k4mloMy/0/Z1pHWWbVY=
+-----END CERTIFICATE-----
+
+# Issuer: CN=T-TeleSec GlobalRoot Class 2 O=T-Systems Enterprise Services GmbH OU=T-Systems Trust Center
+# Subject: CN=T-TeleSec GlobalRoot Class 2 O=T-Systems Enterprise Services GmbH OU=T-Systems Trust Center
+# Label: "T-TeleSec GlobalRoot Class 2"
+# Serial: 1
+# MD5 Fingerprint: 2b:9b:9e:e4:7b:6c:1f:00:72:1a:cc:c1:77:79:df:6a
+# SHA1 Fingerprint: 59:0d:2d:7d:88:4f:40:2e:61:7e:a5:62:32:17:65:cf:17:d8:94:e9
+# SHA256 Fingerprint: 91:e2:f5:78:8d:58:10:eb:a7:ba:58:73:7d:e1:54:8a:8e:ca:cd:01:45:98:bc:0b:14:3e:04:1b:17:05:25:52
+-----BEGIN CERTIFICATE-----
+MIIDwzCCAqugAwIBAgIBATANBgkqhkiG9w0BAQsFADCBgjELMAkGA1UEBhMCREUx
+KzApBgNVBAoMIlQtU3lzdGVtcyBFbnRlcnByaXNlIFNlcnZpY2VzIEdtYkgxHzAd
+BgNVBAsMFlQtU3lzdGVtcyBUcnVzdCBDZW50ZXIxJTAjBgNVBAMMHFQtVGVsZVNl
+YyBHbG9iYWxSb290IENsYXNzIDIwHhcNMDgxMDAxMTA0MDE0WhcNMzMxMDAxMjM1
+OTU5WjCBgjELMAkGA1UEBhMCREUxKzApBgNVBAoMIlQtU3lzdGVtcyBFbnRlcnBy
+aXNlIFNlcnZpY2VzIEdtYkgxHzAdBgNVBAsMFlQtU3lzdGVtcyBUcnVzdCBDZW50
+ZXIxJTAjBgNVBAMMHFQtVGVsZVNlYyBHbG9iYWxSb290IENsYXNzIDIwggEiMA0G
+CSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCqX9obX+hzkeXaXPSi5kfl82hVYAUd
+AqSzm1nzHoqvNK38DcLZSBnuaY/JIPwhqgcZ7bBcrGXHX+0CfHt8LRvWurmAwhiC
+FoT6ZrAIxlQjgeTNuUk/9k9uN0goOA/FvudocP05l03Sx5iRUKrERLMjfTlH6VJi
+1hKTXrcxlkIF+3anHqP1wvzpesVsqXFP6st4vGCvx9702cu+fjOlbpSD8DT6Iavq
+jnKgP6TeMFvvhk1qlVtDRKgQFRzlAVfFmPHmBiiRqiDFt1MmUUOyCxGVWOHAD3bZ
+wI18gfNycJ5v/hqO2V81xrJvNHy+SE/iWjnX2J14np+GPgNeGYtEotXHAgMBAAGj
+QjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgEGMB0GA1UdDgQWBBS/
+WSA2AHmgoCJrjNXyYdK4LMuCSjANBgkqhkiG9w0BAQsFAAOCAQEAMQOiYQsfdOhy
+NsZt+U2e+iKo4YFWz827n+qrkRk4r6p8FU3ztqONpfSO9kSpp+ghla0+AGIWiPAC
+uvxhI+YzmzB6azZie60EI4RYZeLbK4rnJVM3YlNfvNoBYimipidx5joifsFvHZVw
+IEoHNN/q/xWA5brXethbdXwFeilHfkCoMRN3zUA7tFFHei4R40cR3p1m0IvVVGb6
+g1XqfMIpiRvpb7PO4gWEyS8+eIVibslfwXhjdFjASBgMmTnrpMwatXlajRWc2BQN
+9noHV8cigwUtPJslJj0Ys6lDfMjIq2SPDqO/nBudMNva0Bkuqjzx+zOAduTNrRlP
+BSeOE6Fuwg==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Atos TrustedRoot 2011 O=Atos
+# Subject: CN=Atos TrustedRoot 2011 O=Atos
+# Label: "Atos TrustedRoot 2011"
+# Serial: 6643877497813316402
+# MD5 Fingerprint: ae:b9:c4:32:4b:ac:7f:5d:66:cc:77:94:bb:2a:77:56
+# SHA1 Fingerprint: 2b:b1:f5:3e:55:0c:1d:c5:f1:d4:e6:b7:6a:46:4b:55:06:02:ac:21
+# SHA256 Fingerprint: f3:56:be:a2:44:b7:a9:1e:b3:5d:53:ca:9a:d7:86:4a:ce:01:8e:2d:35:d5:f8:f9:6d:df:68:a6:f4:1a:a4:74
+-----BEGIN CERTIFICATE-----
+MIIDdzCCAl+gAwIBAgIIXDPLYixfszIwDQYJKoZIhvcNAQELBQAwPDEeMBwGA1UE
+AwwVQXRvcyBUcnVzdGVkUm9vdCAyMDExMQ0wCwYDVQQKDARBdG9zMQswCQYDVQQG
+EwJERTAeFw0xMTA3MDcxNDU4MzBaFw0zMDEyMzEyMzU5NTlaMDwxHjAcBgNVBAMM
+FUF0b3MgVHJ1c3RlZFJvb3QgMjAxMTENMAsGA1UECgwEQXRvczELMAkGA1UEBhMC
+REUwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCVhTuXbyo7LjvPpvMp
+Nb7PGKw+qtn4TaA+Gke5vJrf8v7MPkfoepbCJI419KkM/IL9bcFyYie96mvr54rM
+VD6QUM+A1JX76LWC1BTFtqlVJVfbsVD2sGBkWXppzwO3bw2+yj5vdHLqqjAqc2K+
+SZFhyBH+DgMq92og3AIVDV4VavzjgsG1xZ1kCWyjWZgHJ8cblithdHFsQ/H3NYkQ
+4J7sVaE3IqKHBAUsR320HLliKWYoyrfhk/WklAOZuXCFteZI6o1Q/NnezG8HDt0L
+cp2AMBYHlT8oDv3FdU9T1nSatCQujgKRz3bFmx5VdJx4IbHwLfELn8LVlhgf8FQi
+eowHAgMBAAGjfTB7MB0GA1UdDgQWBBSnpQaxLKYJYO7Rl+lwrrw7GWzbITAPBgNV
+HRMBAf8EBTADAQH/MB8GA1UdIwQYMBaAFKelBrEspglg7tGX6XCuvDsZbNshMBgG
+A1UdIAQRMA8wDQYLKwYBBAGwLQMEAQEwDgYDVR0PAQH/BAQDAgGGMA0GCSqGSIb3
+DQEBCwUAA4IBAQAmdzTblEiGKkGdLD4GkGDEjKwLVLgfuXvTBznk+j57sj1O7Z8j
+vZfza1zv7v1Apt+hk6EKhqzvINB5Ab149xnYJDE0BAGmuhWawyfc2E8PzBhj/5kP
+DpFrdRbhIfzYJsdHt6bPWHJxfrrhTZVHO8mvbaG0weyJ9rQPOLXiZNwlz6bb65pc
+maHFCN795trV1lpFDMS3wrUU77QR/w4VtfX128a961qn8FYiqTxlVMYVqL2Gns2D
+lmh6cYGJ4Qvh6hEbaAjMaZ7snkGeRDImeuKHCnE96+RapNLbxc3G3mB/ufNPRJLv
+KrcYPqcZ2Qt9sTdBQrC6YB3y/gkRsPCHe6ed
+-----END CERTIFICATE-----
+
+# Issuer: CN=QuoVadis Root CA 1 G3 O=QuoVadis Limited
+# Subject: CN=QuoVadis Root CA 1 G3 O=QuoVadis Limited
+# Label: "QuoVadis Root CA 1 G3"
+# Serial: 687049649626669250736271037606554624078720034195
+# MD5 Fingerprint: a4:bc:5b:3f:fe:37:9a:fa:64:f0:e2:fa:05:3d:0b:ab
+# SHA1 Fingerprint: 1b:8e:ea:57:96:29:1a:c9:39:ea:b8:0a:81:1a:73:73:c0:93:79:67
+# SHA256 Fingerprint: 8a:86:6f:d1:b2:76:b5:7e:57:8e:92:1c:65:82:8a:2b:ed:58:e9:f2:f2:88:05:41:34:b7:f1:f4:bf:c9:cc:74
+-----BEGIN CERTIFICATE-----
+MIIFYDCCA0igAwIBAgIUeFhfLq0sGUvjNwc1NBMotZbUZZMwDQYJKoZIhvcNAQEL
+BQAwSDELMAkGA1UEBhMCQk0xGTAXBgNVBAoTEFF1b1ZhZGlzIExpbWl0ZWQxHjAc
+BgNVBAMTFVF1b1ZhZGlzIFJvb3QgQ0EgMSBHMzAeFw0xMjAxMTIxNzI3NDRaFw00
+MjAxMTIxNzI3NDRaMEgxCzAJBgNVBAYTAkJNMRkwFwYDVQQKExBRdW9WYWRpcyBM
+aW1pdGVkMR4wHAYDVQQDExVRdW9WYWRpcyBSb290IENBIDEgRzMwggIiMA0GCSqG
+SIb3DQEBAQUAA4ICDwAwggIKAoICAQCgvlAQjunybEC0BJyFuTHK3C3kEakEPBtV
+wedYMB0ktMPvhd6MLOHBPd+C5k+tR4ds7FtJwUrVu4/sh6x/gpqG7D0DmVIB0jWe
+rNrwU8lmPNSsAgHaJNM7qAJGr6Qc4/hzWHa39g6QDbXwz8z6+cZM5cOGMAqNF341
+68Xfuw6cwI2H44g4hWf6Pser4BOcBRiYz5P1sZK0/CPTz9XEJ0ngnjybCKOLXSoh
+4Pw5qlPafX7PGglTvF0FBM+hSo+LdoINofjSxxR3W5A2B4GbPgb6Ul5jxaYA/qXp
+UhtStZI5cgMJYr2wYBZupt0lwgNm3fME0UDiTouG9G/lg6AnhF4EwfWQvTA9xO+o
+abw4m6SkltFi2mnAAZauy8RRNOoMqv8hjlmPSlzkYZqn0ukqeI1RPToV7qJZjqlc
+3sX5kCLliEVx3ZGZbHqfPT2YfF72vhZooF6uCyP8Wg+qInYtyaEQHeTTRCOQiJ/G
+KubX9ZqzWB4vMIkIG1SitZgj7Ah3HJVdYdHLiZxfokqRmu8hqkkWCKi9YSgxyXSt
+hfbZxbGL0eUQMk1fiyA6PEkfM4VZDdvLCXVDaXP7a3F98N/ETH3Goy7IlXnLc6KO
+Tk0k+17kBL5yG6YnLUlamXrXXAkgt3+UuU/xDRxeiEIbEbfnkduebPRq34wGmAOt
+zCjvpUfzUwIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIB
+BjAdBgNVHQ4EFgQUo5fW816iEOGrRZ88F2Q87gFwnMwwDQYJKoZIhvcNAQELBQAD
+ggIBABj6W3X8PnrHX3fHyt/PX8MSxEBd1DKquGrX1RUVRpgjpeaQWxiZTOOtQqOC
+MTaIzen7xASWSIsBx40Bz1szBpZGZnQdT+3Btrm0DWHMY37XLneMlhwqI2hrhVd2
+cDMT/uFPpiN3GPoajOi9ZcnPP/TJF9zrx7zABC4tRi9pZsMbj/7sPtPKlL92CiUN
+qXsCHKnQO18LwIE6PWThv6ctTr1NxNgpxiIY0MWscgKCP6o6ojoilzHdCGPDdRS5
+YCgtW2jgFqlmgiNR9etT2DGbe+m3nUvriBbP+V04ikkwj+3x6xn0dxoxGE1nVGwv
+b2X52z3sIexe9PSLymBlVNFxZPT5pqOBMzYzcfCkeF9OrYMh3jRJjehZrJ3ydlo2
+8hP0r+AJx2EqbPfgna67hkooby7utHnNkDPDs3b69fBsnQGQ+p6Q9pxyz0fawx/k
+NSBT8lTR32GDpgLiJTjehTItXnOQUl1CxM49S+H5GYQd1aJQzEH7QRTDvdbJWqNj
+ZgKAvQU6O0ec7AAmTPWIUb+oI38YB7AL7YsmoWTTYUrrXJ/es69nA7Mf3W1daWhp
+q1467HxpvMc7hU6eFbm0FU/DlXpY18ls6Wy58yljXrQs8C097Vpl4KlbQMJImYFt
+nh8GKjwStIsPm6Ik8KaN1nrgS7ZklmOVhMJKzRwuJIczYOXD
+-----END CERTIFICATE-----
+
+# Issuer: CN=QuoVadis Root CA 2 G3 O=QuoVadis Limited
+# Subject: CN=QuoVadis Root CA 2 G3 O=QuoVadis Limited
+# Label: "QuoVadis Root CA 2 G3"
+# Serial: 390156079458959257446133169266079962026824725800
+# MD5 Fingerprint: af:0c:86:6e:bf:40:2d:7f:0b:3e:12:50:ba:12:3d:06
+# SHA1 Fingerprint: 09:3c:61:f3:8b:8b:dc:7d:55:df:75:38:02:05:00:e1:25:f5:c8:36
+# SHA256 Fingerprint: 8f:e4:fb:0a:f9:3a:4d:0d:67:db:0b:eb:b2:3e:37:c7:1b:f3:25:dc:bc:dd:24:0e:a0:4d:af:58:b4:7e:18:40
+-----BEGIN CERTIFICATE-----
+MIIFYDCCA0igAwIBAgIURFc0JFuBiZs18s64KztbpybwdSgwDQYJKoZIhvcNAQEL
+BQAwSDELMAkGA1UEBhMCQk0xGTAXBgNVBAoTEFF1b1ZhZGlzIExpbWl0ZWQxHjAc
+BgNVBAMTFVF1b1ZhZGlzIFJvb3QgQ0EgMiBHMzAeFw0xMjAxMTIxODU5MzJaFw00
+MjAxMTIxODU5MzJaMEgxCzAJBgNVBAYTAkJNMRkwFwYDVQQKExBRdW9WYWRpcyBM
+aW1pdGVkMR4wHAYDVQQDExVRdW9WYWRpcyBSb290IENBIDIgRzMwggIiMA0GCSqG
+SIb3DQEBAQUAA4ICDwAwggIKAoICAQChriWyARjcV4g/Ruv5r+LrI3HimtFhZiFf
+qq8nUeVuGxbULX1QsFN3vXg6YOJkApt8hpvWGo6t/x8Vf9WVHhLL5hSEBMHfNrMW
+n4rjyduYNM7YMxcoRvynyfDStNVNCXJJ+fKH46nafaF9a7I6JaltUkSs+L5u+9ym
+c5GQYaYDFCDy54ejiK2toIz/pgslUiXnFgHVy7g1gQyjO/Dh4fxaXc6AcW34Sas+
+O7q414AB+6XrW7PFXmAqMaCvN+ggOp+oMiwMzAkd056OXbxMmO7FGmh77FOm6RQ1
+o9/NgJ8MSPsc9PG/Srj61YxxSscfrf5BmrODXfKEVu+lV0POKa2Mq1W/xPtbAd0j
+IaFYAI7D0GoT7RPjEiuA3GfmlbLNHiJuKvhB1PLKFAeNilUSxmn1uIZoL1NesNKq
+IcGY5jDjZ1XHm26sGahVpkUG0CM62+tlXSoREfA7T8pt9DTEceT/AFr2XK4jYIVz
+8eQQsSWu1ZK7E8EM4DnatDlXtas1qnIhO4M15zHfeiFuuDIIfR0ykRVKYnLP43eh
+vNURG3YBZwjgQQvD6xVu+KQZ2aKrr+InUlYrAoosFCT5v0ICvybIxo/gbjh9Uy3l
+7ZizlWNof/k19N+IxWA1ksB8aRxhlRbQ694Lrz4EEEVlWFA4r0jyWbYW8jwNkALG
+cC4BrTwV1wIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIB
+BjAdBgNVHQ4EFgQU7edvdlq/YOxJW8ald7tyFnGbxD0wDQYJKoZIhvcNAQELBQAD
+ggIBAJHfgD9DCX5xwvfrs4iP4VGyvD11+ShdyLyZm3tdquXK4Qr36LLTn91nMX66
+AarHakE7kNQIXLJgapDwyM4DYvmL7ftuKtwGTTwpD4kWilhMSA/ohGHqPHKmd+RC
+roijQ1h5fq7KpVMNqT1wvSAZYaRsOPxDMuHBR//47PERIjKWnML2W2mWeyAMQ0Ga
+W/ZZGYjeVYg3UQt4XAoeo0L9x52ID8DyeAIkVJOviYeIyUqAHerQbj5hLja7NQ4n
+lv1mNDthcnPxFlxHBlRJAHpYErAK74X9sbgzdWqTHBLmYF5vHX/JHyPLhGGfHoJE
++V+tYlUkmlKY7VHnoX6XOuYvHxHaU4AshZ6rNRDbIl9qxV6XU/IyAgkwo1jwDQHV
+csaxfGl7w/U2Rcxhbl5MlMVerugOXou/983g7aEOGzPuVBj+D77vfoRrQ+NwmNtd
+dbINWQeFFSM51vHfqSYP1kjHs6Yi9TM3WpVHn3u6GBVv/9YUZINJ0gpnIdsPNWNg
+KCLjsZWDzYWm3S8P52dSbrsvhXz1SnPnxT7AvSESBT/8twNJAlvIJebiVDj1eYeM
+HVOyToV7BjjHLPj4sHKNJeV3UvQDHEimUF+IIDBu8oJDqz2XhOdT+yHBTw8imoa4
+WSr2Rz0ZiC3oheGe7IUIarFsNMkd7EgrO3jtZsSOeWmD3n+M
+-----END CERTIFICATE-----
+
+# Issuer: CN=QuoVadis Root CA 3 G3 O=QuoVadis Limited
+# Subject: CN=QuoVadis Root CA 3 G3 O=QuoVadis Limited
+# Label: "QuoVadis Root CA 3 G3"
+# Serial: 268090761170461462463995952157327242137089239581
+# MD5 Fingerprint: df:7d:b9:ad:54:6f:68:a1:df:89:57:03:97:43:b0:d7
+# SHA1 Fingerprint: 48:12:bd:92:3c:a8:c4:39:06:e7:30:6d:27:96:e6:a4:cf:22:2e:7d
+# SHA256 Fingerprint: 88:ef:81:de:20:2e:b0:18:45:2e:43:f8:64:72:5c:ea:5f:bd:1f:c2:d9:d2:05:73:07:09:c5:d8:b8:69:0f:46
+-----BEGIN CERTIFICATE-----
+MIIFYDCCA0igAwIBAgIULvWbAiin23r/1aOp7r0DoM8Sah0wDQYJKoZIhvcNAQEL
+BQAwSDELMAkGA1UEBhMCQk0xGTAXBgNVBAoTEFF1b1ZhZGlzIExpbWl0ZWQxHjAc
+BgNVBAMTFVF1b1ZhZGlzIFJvb3QgQ0EgMyBHMzAeFw0xMjAxMTIyMDI2MzJaFw00
+MjAxMTIyMDI2MzJaMEgxCzAJBgNVBAYTAkJNMRkwFwYDVQQKExBRdW9WYWRpcyBM
+aW1pdGVkMR4wHAYDVQQDExVRdW9WYWRpcyBSb290IENBIDMgRzMwggIiMA0GCSqG
+SIb3DQEBAQUAA4ICDwAwggIKAoICAQCzyw4QZ47qFJenMioKVjZ/aEzHs286IxSR
+/xl/pcqs7rN2nXrpixurazHb+gtTTK/FpRp5PIpM/6zfJd5O2YIyC0TeytuMrKNu
+FoM7pmRLMon7FhY4futD4tN0SsJiCnMK3UmzV9KwCoWdcTzeo8vAMvMBOSBDGzXR
+U7Ox7sWTaYI+FrUoRqHe6okJ7UO4BUaKhvVZR74bbwEhELn9qdIoyhA5CcoTNs+c
+ra1AdHkrAj80//ogaX3T7mH1urPnMNA3I4ZyYUUpSFlob3emLoG+B01vr87ERROR
+FHAGjx+f+IdpsQ7vw4kZ6+ocYfx6bIrc1gMLnia6Et3UVDmrJqMz6nWB2i3ND0/k
+A9HvFZcba5DFApCTZgIhsUfei5pKgLlVj7WiL8DWM2fafsSntARE60f75li59wzw
+eyuxwHApw0BiLTtIadwjPEjrewl5qW3aqDCYz4ByA4imW0aucnl8CAMhZa634Ryl
+sSqiMd5mBPfAdOhx3v89WcyWJhKLhZVXGqtrdQtEPREoPHtht+KPZ0/l7DxMYIBp
+VzgeAVuNVejH38DMdyM0SXV89pgR6y3e7UEuFAUCf+D+IOs15xGsIs5XPd7JMG0Q
+A4XN8f+MFrXBsj6IbGB/kE+V9/YtrQE5BwT6dYB9v0lQ7e/JxHwc64B+27bQ3RP+
+ydOc17KXqQIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIB
+BjAdBgNVHQ4EFgQUxhfQvKjqAkPyGwaZXSuQILnXnOQwDQYJKoZIhvcNAQELBQAD
+ggIBADRh2Va1EodVTd2jNTFGu6QHcrxfYWLopfsLN7E8trP6KZ1/AvWkyaiTt3px
+KGmPc+FSkNrVvjrlt3ZqVoAh313m6Tqe5T72omnHKgqwGEfcIHB9UqM+WXzBusnI
+FUBhynLWcKzSt/Ac5IYp8M7vaGPQtSCKFWGafoaYtMnCdvvMujAWzKNhxnQT5Wvv
+oxXqA/4Ti2Tk08HS6IT7SdEQTXlm66r99I0xHnAUrdzeZxNMgRVhvLfZkXdxGYFg
+u/BYpbWcC/ePIlUnwEsBbTuZDdQdm2NnL9DuDcpmvJRPpq3t/O5jrFc/ZSXPsoaP
+0Aj/uHYUbt7lJ+yreLVTubY/6CD50qi+YUbKh4yE8/nxoGibIh6BJpsQBJFxwAYf
+3KDTuVan45gtf4Od34wrnDKOMpTwATwiKp9Dwi7DmDkHOHv8XgBCH/MyJnmDhPbl
+8MFREsALHgQjDFSlTC9JxUrRtm5gDWv8a4uFJGS3iQ6rJUdbPM9+Sb3H6QrG2vd+
+DhcI00iX0HGS8A85PjRqHH3Y8iKuu2n0M7SmSFXRDw4m6Oy2Cy2nhTXN/VnIn9HN
+PlopNLk9hM6xZdRZkZFWdSHBd575euFgndOtBBj0fOtek49TSiIp+EgrPk2GrFt/
+ywaZWWDYWGWVjUTR939+J399roD1B0y2PpxxVJkES/1Y+Zj0
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert Assured ID Root G2 O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert Assured ID Root G2 O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert Assured ID Root G2"
+# Serial: 15385348160840213938643033620894905419
+# MD5 Fingerprint: 92:38:b9:f8:63:24:82:65:2c:57:33:e6:fe:81:8f:9d
+# SHA1 Fingerprint: a1:4b:48:d9:43:ee:0a:0e:40:90:4f:3c:e0:a4:c0:91:93:51:5d:3f
+# SHA256 Fingerprint: 7d:05:eb:b6:82:33:9f:8c:94:51:ee:09:4e:eb:fe:fa:79:53:a1:14:ed:b2:f4:49:49:45:2f:ab:7d:2f:c1:85
+-----BEGIN CERTIFICATE-----
+MIIDljCCAn6gAwIBAgIQC5McOtY5Z+pnI7/Dr5r0SzANBgkqhkiG9w0BAQsFADBl
+MQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3
+d3cuZGlnaWNlcnQuY29tMSQwIgYDVQQDExtEaWdpQ2VydCBBc3N1cmVkIElEIFJv
+b3QgRzIwHhcNMTMwODAxMTIwMDAwWhcNMzgwMTE1MTIwMDAwWjBlMQswCQYDVQQG
+EwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cuZGlnaWNl
+cnQuY29tMSQwIgYDVQQDExtEaWdpQ2VydCBBc3N1cmVkIElEIFJvb3QgRzIwggEi
+MA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQDZ5ygvUj82ckmIkzTz+GoeMVSA
+n61UQbVH35ao1K+ALbkKz3X9iaV9JPrjIgwrvJUXCzO/GU1BBpAAvQxNEP4Htecc
+biJVMWWXvdMX0h5i89vqbFCMP4QMls+3ywPgym2hFEwbid3tALBSfK+RbLE4E9Hp
+EgjAALAcKxHad3A2m67OeYfcgnDmCXRwVWmvo2ifv922ebPynXApVfSr/5Vh88lA
+bx3RvpO704gqu52/clpWcTs/1PPRCv4o76Pu2ZmvA9OPYLfykqGxvYmJHzDNw6Yu
+YjOuFgJ3RFrngQo8p0Quebg/BLxcoIfhG69Rjs3sLPr4/m3wOnyqi+RnlTGNAgMB
+AAGjQjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgGGMB0GA1UdDgQW
+BBTOw0q5mVXyuNtgv6l+vVa1lzan1jANBgkqhkiG9w0BAQsFAAOCAQEAyqVVjOPI
+QW5pJ6d1Ee88hjZv0p3GeDgdaZaikmkuOGybfQTUiaWxMTeKySHMq2zNixya1r9I
+0jJmwYrA8y8678Dj1JGG0VDjA9tzd29KOVPt3ibHtX2vK0LRdWLjSisCx1BL4Gni
+lmwORGYQRI+tBev4eaymG+g3NJ1TyWGqolKvSnAWhsI6yLETcDbYz+70CjTVW0z9
+B5yiutkBclzzTcHdDrEcDcRjvq30FPuJ7KJBDkzMyFdA0G4Dqs0MjomZmWzwPDCv
+ON9vvKO+KSAnq3T/EyJ43pdSVR6DtVQgA+6uwE9W3jfMw3+qBCe703e4YtsXfJwo
+IhNzbM8m9Yop5w==
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert Assured ID Root G3 O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert Assured ID Root G3 O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert Assured ID Root G3"
+# Serial: 15459312981008553731928384953135426796
+# MD5 Fingerprint: 7c:7f:65:31:0c:81:df:8d:ba:3e:99:e2:5c:ad:6e:fb
+# SHA1 Fingerprint: f5:17:a2:4f:9a:48:c6:c9:f8:a2:00:26:9f:dc:0f:48:2c:ab:30:89
+# SHA256 Fingerprint: 7e:37:cb:8b:4c:47:09:0c:ab:36:55:1b:a6:f4:5d:b8:40:68:0f:ba:16:6a:95:2d:b1:00:71:7f:43:05:3f:c2
+-----BEGIN CERTIFICATE-----
+MIICRjCCAc2gAwIBAgIQC6Fa+h3foLVJRK/NJKBs7DAKBggqhkjOPQQDAzBlMQsw
+CQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cu
+ZGlnaWNlcnQuY29tMSQwIgYDVQQDExtEaWdpQ2VydCBBc3N1cmVkIElEIFJvb3Qg
+RzMwHhcNMTMwODAxMTIwMDAwWhcNMzgwMTE1MTIwMDAwWjBlMQswCQYDVQQGEwJV
+UzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cuZGlnaWNlcnQu
+Y29tMSQwIgYDVQQDExtEaWdpQ2VydCBBc3N1cmVkIElEIFJvb3QgRzMwdjAQBgcq
+hkjOPQIBBgUrgQQAIgNiAAQZ57ysRGXtzbg/WPuNsVepRC0FFfLvC/8QdJ+1YlJf
+Zn4f5dwbRXkLzMZTCp2NXQLZqVneAlr2lSoOjThKiknGvMYDOAdfVdp+CW7if17Q
+RSAPWXYQ1qAk8C3eNvJsKTmjQjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/
+BAQDAgGGMB0GA1UdDgQWBBTL0L2p4ZgFUaFNN6KDec6NHSrkhDAKBggqhkjOPQQD
+AwNnADBkAjAlpIFFAmsSS3V0T8gj43DydXLefInwz5FyYZ5eEJJZVrmDxxDnOOlY
+JjZ91eQ0hjkCMHw2U/Aw5WJjOpnitqM7mzT6HtoQknFekROn3aRukswy1vUhZscv
+6pZjamVFkpUBtA==
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert Global Root G2 O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert Global Root G2 O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert Global Root G2"
+# Serial: 4293743540046975378534879503202253541
+# MD5 Fingerprint: e4:a6:8a:c8:54:ac:52:42:46:0a:fd:72:48:1b:2a:44
+# SHA1 Fingerprint: df:3c:24:f9:bf:d6:66:76:1b:26:80:73:fe:06:d1:cc:8d:4f:82:a4
+# SHA256 Fingerprint: cb:3c:cb:b7:60:31:e5:e0:13:8f:8d:d3:9a:23:f9:de:47:ff:c3:5e:43:c1:14:4c:ea:27:d4:6a:5a:b1:cb:5f
+-----BEGIN CERTIFICATE-----
+MIIDjjCCAnagAwIBAgIQAzrx5qcRqaC7KGSxHQn65TANBgkqhkiG9w0BAQsFADBh
+MQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3
+d3cuZGlnaWNlcnQuY29tMSAwHgYDVQQDExdEaWdpQ2VydCBHbG9iYWwgUm9vdCBH
+MjAeFw0xMzA4MDExMjAwMDBaFw0zODAxMTUxMjAwMDBaMGExCzAJBgNVBAYTAlVT
+MRUwEwYDVQQKEwxEaWdpQ2VydCBJbmMxGTAXBgNVBAsTEHd3dy5kaWdpY2VydC5j
+b20xIDAeBgNVBAMTF0RpZ2lDZXJ0IEdsb2JhbCBSb290IEcyMIIBIjANBgkqhkiG
+9w0BAQEFAAOCAQ8AMIIBCgKCAQEAuzfNNNx7a8myaJCtSnX/RrohCgiN9RlUyfuI
+2/Ou8jqJkTx65qsGGmvPrC3oXgkkRLpimn7Wo6h+4FR1IAWsULecYxpsMNzaHxmx
+1x7e/dfgy5SDN67sH0NO3Xss0r0upS/kqbitOtSZpLYl6ZtrAGCSYP9PIUkY92eQ
+q2EGnI/yuum06ZIya7XzV+hdG82MHauVBJVJ8zUtluNJbd134/tJS7SsVQepj5Wz
+tCO7TG1F8PapspUwtP1MVYwnSlcUfIKdzXOS0xZKBgyMUNGPHgm+F6HmIcr9g+UQ
+vIOlCsRnKPZzFBQ9RnbDhxSJITRNrw9FDKZJobq7nMWxM4MphQIDAQABo0IwQDAP
+BgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIBhjAdBgNVHQ4EFgQUTiJUIBiV
+5uNu5g/6+rkS7QYXjzkwDQYJKoZIhvcNAQELBQADggEBAGBnKJRvDkhj6zHd6mcY
+1Yl9PMWLSn/pvtsrF9+wX3N3KjITOYFnQoQj8kVnNeyIv/iPsGEMNKSuIEyExtv4
+NeF22d+mQrvHRAiGfzZ0JFrabA0UWTW98kndth/Jsw1HKj2ZL7tcu7XUIOGZX1NG
+Fdtom/DzMNU+MeKNhJ7jitralj41E6Vf8PlwUHBHQRFXGU7Aj64GxJUTFy8bJZ91
+8rGOmaFvE7FBcf6IKshPECBV1/MUReXgRPTqh5Uykw7+U0b6LJ3/iyK5S9kJRaTe
+pLiaWN0bfVKfjllDiIGknibVb63dDcY3fe0Dkhvld1927jyNxF1WW6LZZm6zNTfl
+MrY=
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert Global Root G3 O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert Global Root G3 O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert Global Root G3"
+# Serial: 7089244469030293291760083333884364146
+# MD5 Fingerprint: f5:5d:a4:50:a5:fb:28:7e:1e:0f:0d:cc:96:57:56:ca
+# SHA1 Fingerprint: 7e:04:de:89:6a:3e:66:6d:00:e6:87:d3:3f:fa:d9:3b:e8:3d:34:9e
+# SHA256 Fingerprint: 31:ad:66:48:f8:10:41:38:c7:38:f3:9e:a4:32:01:33:39:3e:3a:18:cc:02:29:6e:f9:7c:2a:c9:ef:67:31:d0
+-----BEGIN CERTIFICATE-----
+MIICPzCCAcWgAwIBAgIQBVVWvPJepDU1w6QP1atFcjAKBggqhkjOPQQDAzBhMQsw
+CQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cu
+ZGlnaWNlcnQuY29tMSAwHgYDVQQDExdEaWdpQ2VydCBHbG9iYWwgUm9vdCBHMzAe
+Fw0xMzA4MDExMjAwMDBaFw0zODAxMTUxMjAwMDBaMGExCzAJBgNVBAYTAlVTMRUw
+EwYDVQQKEwxEaWdpQ2VydCBJbmMxGTAXBgNVBAsTEHd3dy5kaWdpY2VydC5jb20x
+IDAeBgNVBAMTF0RpZ2lDZXJ0IEdsb2JhbCBSb290IEczMHYwEAYHKoZIzj0CAQYF
+K4EEACIDYgAE3afZu4q4C/sLfyHS8L6+c/MzXRq8NOrexpu80JX28MzQC7phW1FG
+fp4tn+6OYwwX7Adw9c+ELkCDnOg/QW07rdOkFFk2eJ0DQ+4QE2xy3q6Ip6FrtUPO
+Z9wj/wMco+I+o0IwQDAPBgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIBhjAd
+BgNVHQ4EFgQUs9tIpPmhxdiuNkHMEWNpYim8S8YwCgYIKoZIzj0EAwMDaAAwZQIx
+AK288mw/EkrRLTnDCgmXc/SINoyIJ7vmiI1Qhadj+Z4y3maTD/HMsQmP3Wyr+mt/
+oAIwOWZbwmSNuJ5Q3KjVSaLtx9zRSX8XAbjIho9OjIgrqJqpisXRAL34VOKa5Vt8
+sycX
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert Trusted Root G4 O=DigiCert Inc OU=www.digicert.com
+# Subject: CN=DigiCert Trusted Root G4 O=DigiCert Inc OU=www.digicert.com
+# Label: "DigiCert Trusted Root G4"
+# Serial: 7451500558977370777930084869016614236
+# MD5 Fingerprint: 78:f2:fc:aa:60:1f:2f:b4:eb:c9:37:ba:53:2e:75:49
+# SHA1 Fingerprint: dd:fb:16:cd:49:31:c9:73:a2:03:7d:3f:c8:3a:4d:7d:77:5d:05:e4
+# SHA256 Fingerprint: 55:2f:7b:dc:f1:a7:af:9e:6c:e6:72:01:7f:4f:12:ab:f7:72:40:c7:8e:76:1a:c2:03:d1:d9:d2:0a:c8:99:88
+-----BEGIN CERTIFICATE-----
+MIIFkDCCA3igAwIBAgIQBZsbV56OITLiOQe9p3d1XDANBgkqhkiG9w0BAQwFADBi
+MQswCQYDVQQGEwJVUzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3
+d3cuZGlnaWNlcnQuY29tMSEwHwYDVQQDExhEaWdpQ2VydCBUcnVzdGVkIFJvb3Qg
+RzQwHhcNMTMwODAxMTIwMDAwWhcNMzgwMTE1MTIwMDAwWjBiMQswCQYDVQQGEwJV
+UzEVMBMGA1UEChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cuZGlnaWNlcnQu
+Y29tMSEwHwYDVQQDExhEaWdpQ2VydCBUcnVzdGVkIFJvb3QgRzQwggIiMA0GCSqG
+SIb3DQEBAQUAA4ICDwAwggIKAoICAQC/5pBzaN675F1KPDAiMGkz7MKnJS7JIT3y
+ithZwuEppz1Yq3aaza57G4QNxDAf8xukOBbrVsaXbR2rsnnyyhHS5F/WBTxSD1If
+xp4VpX6+n6lXFllVcq9ok3DCsrp1mWpzMpTREEQQLt+C8weE5nQ7bXHiLQwb7iDV
+ySAdYyktzuxeTsiT+CFhmzTrBcZe7FsavOvJz82sNEBfsXpm7nfISKhmV1efVFiO
+DCu3T6cw2Vbuyntd463JT17lNecxy9qTXtyOj4DatpGYQJB5w3jHtrHEtWoYOAMQ
+jdjUN6QuBX2I9YI+EJFwq1WCQTLX2wRzKm6RAXwhTNS8rhsDdV14Ztk6MUSaM0C/
+CNdaSaTC5qmgZ92kJ7yhTzm1EVgX9yRcRo9k98FpiHaYdj1ZXUJ2h4mXaXpI8OCi
+EhtmmnTK3kse5w5jrubU75KSOp493ADkRSWJtppEGSt+wJS00mFt6zPZxd9LBADM
+fRyVw4/3IbKyEbe7f/LVjHAsQWCqsWMYRJUadmJ+9oCw++hkpjPRiQfhvbfmQ6QY
+uKZ3AeEPlAwhHbJUKSWJbOUOUlFHdL4mrLZBdd56rF+NP8m800ERElvlEFDrMcXK
+chYiCd98THU/Y+whX8QgUWtvsauGi0/C1kVfnSD8oR7FwI+isX4KJpn15GkvmB0t
+9dmpsh3lGwIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIB
+hjAdBgNVHQ4EFgQU7NfjgtJxXWRM3y5nP+e6mK4cD08wDQYJKoZIhvcNAQEMBQAD
+ggIBALth2X2pbL4XxJEbw6GiAI3jZGgPVs93rnD5/ZpKmbnJeFwMDF/k5hQpVgs2
+SV1EY+CtnJYYZhsjDT156W1r1lT40jzBQ0CuHVD1UvyQO7uYmWlrx8GnqGikJ9yd
++SeuMIW59mdNOj6PWTkiU0TryF0Dyu1Qen1iIQqAyHNm0aAFYF/opbSnr6j3bTWc
+fFqK1qI4mfN4i/RN0iAL3gTujJtHgXINwBQy7zBZLq7gcfJW5GqXb5JQbZaNaHqa
+sjYUegbyJLkJEVDXCLG4iXqEI2FCKeWjzaIgQdfRnGTZ6iahixTXTBmyUEFxPT9N
+cCOGDErcgdLMMpSEDQgJlxxPwO5rIHQw0uA5NBCFIRUBCOhVMt5xSdkoF1BN5r5N
+0XWs0Mr7QbhDparTwwVETyw2m+L64kW4I1NsBm9nVX9GtUw/bihaeSbSpKhil9Ie
+4u1Ki7wb/UdKDd9nZn6yW0HQO+T0O/QEY+nvwlQAUaCKKsnOeMzV6ocEGLPOr0mI
+r/OSmbaz5mEP0oUA51Aa5BuVnRmhuZyxm7EAHu/QD09CbMkKvO5D+jpxpchNJqU1
+/YldvIViHTLSoCtU7ZpXwdv6EM8Zt4tKG48BtieVU+i2iW1bvGjUI+iLUaJW+fCm
+gKDWHrO8Dw9TdSmq6hN35N6MgSGtBxBHEa2HPQfRdbzP82Z+
+-----END CERTIFICATE-----
+
+# Issuer: CN=COMODO RSA Certification Authority O=COMODO CA Limited
+# Subject: CN=COMODO RSA Certification Authority O=COMODO CA Limited
+# Label: "COMODO RSA Certification Authority"
+# Serial: 101909084537582093308941363524873193117
+# MD5 Fingerprint: 1b:31:b0:71:40:36:cc:14:36:91:ad:c4:3e:fd:ec:18
+# SHA1 Fingerprint: af:e5:d2:44:a8:d1:19:42:30:ff:47:9f:e2:f8:97:bb:cd:7a:8c:b4
+# SHA256 Fingerprint: 52:f0:e1:c4:e5:8e:c6:29:29:1b:60:31:7f:07:46:71:b8:5d:7e:a8:0d:5b:07:27:34:63:53:4b:32:b4:02:34
+-----BEGIN CERTIFICATE-----
+MIIF2DCCA8CgAwIBAgIQTKr5yttjb+Af907YWwOGnTANBgkqhkiG9w0BAQwFADCB
+hTELMAkGA1UEBhMCR0IxGzAZBgNVBAgTEkdyZWF0ZXIgTWFuY2hlc3RlcjEQMA4G
+A1UEBxMHU2FsZm9yZDEaMBgGA1UEChMRQ09NT0RPIENBIExpbWl0ZWQxKzApBgNV
+BAMTIkNPTU9ETyBSU0EgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwHhcNMTAwMTE5
+MDAwMDAwWhcNMzgwMTE4MjM1OTU5WjCBhTELMAkGA1UEBhMCR0IxGzAZBgNVBAgT
+EkdyZWF0ZXIgTWFuY2hlc3RlcjEQMA4GA1UEBxMHU2FsZm9yZDEaMBgGA1UEChMR
+Q09NT0RPIENBIExpbWl0ZWQxKzApBgNVBAMTIkNPTU9ETyBSU0EgQ2VydGlmaWNh
+dGlvbiBBdXRob3JpdHkwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCR
+6FSS0gpWsawNJN3Fz0RndJkrN6N9I3AAcbxT38T6KhKPS38QVr2fcHK3YX/JSw8X
+pz3jsARh7v8Rl8f0hj4K+j5c+ZPmNHrZFGvnnLOFoIJ6dq9xkNfs/Q36nGz637CC
+9BR++b7Epi9Pf5l/tfxnQ3K9DADWietrLNPtj5gcFKt+5eNu/Nio5JIk2kNrYrhV
+/erBvGy2i/MOjZrkm2xpmfh4SDBF1a3hDTxFYPwyllEnvGfDyi62a+pGx8cgoLEf
+Zd5ICLqkTqnyg0Y3hOvozIFIQ2dOciqbXL1MGyiKXCJ7tKuY2e7gUYPDCUZObT6Z
++pUX2nwzV0E8jVHtC7ZcryxjGt9XyD+86V3Em69FmeKjWiS0uqlWPc9vqv9JWL7w
+qP/0uK3pN/u6uPQLOvnoQ0IeidiEyxPx2bvhiWC4jChWrBQdnArncevPDt09qZah
+SL0896+1DSJMwBGB7FY79tOi4lu3sgQiUpWAk2nojkxl8ZEDLXB0AuqLZxUpaVIC
+u9ffUGpVRr+goyhhf3DQw6KqLCGqR84onAZFdr+CGCe01a60y1Dma/RMhnEw6abf
+Fobg2P9A3fvQQoh/ozM6LlweQRGBY84YcWsr7KaKtzFcOmpH4MN5WdYgGq/yapiq
+crxXStJLnbsQ/LBMQeXtHT1eKJ2czL+zUdqnR+WEUwIDAQABo0IwQDAdBgNVHQ4E
+FgQUu69+Aj36pvE8hI6t7jiY7NkyMtQwDgYDVR0PAQH/BAQDAgEGMA8GA1UdEwEB
+/wQFMAMBAf8wDQYJKoZIhvcNAQEMBQADggIBAArx1UaEt65Ru2yyTUEUAJNMnMvl
+wFTPoCWOAvn9sKIN9SCYPBMtrFaisNZ+EZLpLrqeLppysb0ZRGxhNaKatBYSaVqM
+4dc+pBroLwP0rmEdEBsqpIt6xf4FpuHA1sj+nq6PK7o9mfjYcwlYRm6mnPTXJ9OV
+2jeDchzTc+CiR5kDOF3VSXkAKRzH7JsgHAckaVd4sjn8OoSgtZx8jb8uk2Intzna
+FxiuvTwJaP+EmzzV1gsD41eeFPfR60/IvYcjt7ZJQ3mFXLrrkguhxuhoqEwWsRqZ
+CuhTLJK7oQkYdQxlqHvLI7cawiiFwxv/0Cti76R7CZGYZ4wUAc1oBmpjIXUDgIiK
+boHGhfKppC3n9KUkEEeDys30jXlYsQab5xoq2Z0B15R97QNKyvDb6KkBPvVWmcke
+jkk9u+UJueBPSZI9FoJAzMxZxuY67RIuaTxslbH9qh17f4a+Hg4yRvv7E491f0yL
+S0Zj/gA0QHDBw7mh3aZw4gSzQbzpgJHqZJx64SIDqZxubw5lT2yHh17zbqD5daWb
+QOhTsiedSrnAdyGN/4fy3ryM7xfft0kL0fJuMAsaDk527RH89elWsn2/x20Kk4yl
+0MC2Hb46TpSi125sC8KKfPog88Tk5c0NqMuRkrF8hey1FGlmDoLnzc7ILaZRfyHB
+NVOFBkpdn627G190
+-----END CERTIFICATE-----
+
+# Issuer: CN=USERTrust RSA Certification Authority O=The USERTRUST Network
+# Subject: CN=USERTrust RSA Certification Authority O=The USERTRUST Network
+# Label: "USERTrust RSA Certification Authority"
+# Serial: 2645093764781058787591871645665788717
+# MD5 Fingerprint: 1b:fe:69:d1:91:b7:19:33:a3:72:a8:0f:e1:55:e5:b5
+# SHA1 Fingerprint: 2b:8f:1b:57:33:0d:bb:a2:d0:7a:6c:51:f7:0e:e9:0d:da:b9:ad:8e
+# SHA256 Fingerprint: e7:93:c9:b0:2f:d8:aa:13:e2:1c:31:22:8a:cc:b0:81:19:64:3b:74:9c:89:89:64:b1:74:6d:46:c3:d4:cb:d2
+-----BEGIN CERTIFICATE-----
+MIIF3jCCA8agAwIBAgIQAf1tMPyjylGoG7xkDjUDLTANBgkqhkiG9w0BAQwFADCB
+iDELMAkGA1UEBhMCVVMxEzARBgNVBAgTCk5ldyBKZXJzZXkxFDASBgNVBAcTC0pl
+cnNleSBDaXR5MR4wHAYDVQQKExVUaGUgVVNFUlRSVVNUIE5ldHdvcmsxLjAsBgNV
+BAMTJVVTRVJUcnVzdCBSU0EgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwHhcNMTAw
+MjAxMDAwMDAwWhcNMzgwMTE4MjM1OTU5WjCBiDELMAkGA1UEBhMCVVMxEzARBgNV
+BAgTCk5ldyBKZXJzZXkxFDASBgNVBAcTC0plcnNleSBDaXR5MR4wHAYDVQQKExVU
+aGUgVVNFUlRSVVNUIE5ldHdvcmsxLjAsBgNVBAMTJVVTRVJUcnVzdCBSU0EgQ2Vy
+dGlmaWNhdGlvbiBBdXRob3JpdHkwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIK
+AoICAQCAEmUXNg7D2wiz0KxXDXbtzSfTTK1Qg2HiqiBNCS1kCdzOiZ/MPans9s/B
+3PHTsdZ7NygRK0faOca8Ohm0X6a9fZ2jY0K2dvKpOyuR+OJv0OwWIJAJPuLodMkY
+tJHUYmTbf6MG8YgYapAiPLz+E/CHFHv25B+O1ORRxhFnRghRy4YUVD+8M/5+bJz/
+Fp0YvVGONaanZshyZ9shZrHUm3gDwFA66Mzw3LyeTP6vBZY1H1dat//O+T23LLb2
+VN3I5xI6Ta5MirdcmrS3ID3KfyI0rn47aGYBROcBTkZTmzNg95S+UzeQc0PzMsNT
+79uq/nROacdrjGCT3sTHDN/hMq7MkztReJVni+49Vv4M0GkPGw/zJSZrM233bkf6
+c0Plfg6lZrEpfDKEY1WJxA3Bk1QwGROs0303p+tdOmw1XNtB1xLaqUkL39iAigmT
+Yo61Zs8liM2EuLE/pDkP2QKe6xJMlXzzawWpXhaDzLhn4ugTncxbgtNMs+1b/97l
+c6wjOy0AvzVVdAlJ2ElYGn+SNuZRkg7zJn0cTRe8yexDJtC/QV9AqURE9JnnV4ee
+UB9XVKg+/XRjL7FQZQnmWEIuQxpMtPAlR1n6BB6T1CZGSlCBst6+eLf8ZxXhyVeE
+Hg9j1uliutZfVS7qXMYoCAQlObgOK6nyTJccBz8NUvXt7y+CDwIDAQABo0IwQDAd
+BgNVHQ4EFgQUU3m/WqorSs9UgOHYm8Cd8rIDZsswDgYDVR0PAQH/BAQDAgEGMA8G
+A1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQEMBQADggIBAFzUfA3P9wF9QZllDHPF
+Up/L+M+ZBn8b2kMVn54CVVeWFPFSPCeHlCjtHzoBN6J2/FNQwISbxmtOuowhT6KO
+VWKR82kV2LyI48SqC/3vqOlLVSoGIG1VeCkZ7l8wXEskEVX/JJpuXior7gtNn3/3
+ATiUFJVDBwn7YKnuHKsSjKCaXqeYalltiz8I+8jRRa8YFWSQEg9zKC7F4iRO/Fjs
+8PRF/iKz6y+O0tlFYQXBl2+odnKPi4w2r78NBc5xjeambx9spnFixdjQg3IM8WcR
+iQycE0xyNN+81XHfqnHd4blsjDwSXWXavVcStkNr/+XeTWYRUc+ZruwXtuhxkYze
+Sf7dNXGiFSeUHM9h4ya7b6NnJSFd5t0dCy5oGzuCr+yDZ4XUmFF0sbmZgIn/f3gZ
+XHlKYC6SQK5MNyosycdiyA5d9zZbyuAlJQG03RoHnHcAP9Dc1ew91Pq7P8yF1m9/
+qS3fuQL39ZeatTXaw2ewh0qpKJ4jjv9cJ2vhsE/zB+4ALtRZh8tSQZXq9EfX7mRB
+VXyNWQKV3WKdwrnuWih0hKWbt5DHDAff9Yk2dDLWKMGwsAvgnEzDHNb842m1R0aB
+L6KCq9NjRHDEjf8tM7qtj3u1cIiuPhnPQCjY/MiQu12ZIvVS5ljFH4gxQ+6IHdfG
+jjxDah2nGN59PRbxYvnKkKj9
+-----END CERTIFICATE-----
+
+# Issuer: CN=USERTrust ECC Certification Authority O=The USERTRUST Network
+# Subject: CN=USERTrust ECC Certification Authority O=The USERTRUST Network
+# Label: "USERTrust ECC Certification Authority"
+# Serial: 123013823720199481456569720443997572134
+# MD5 Fingerprint: fa:68:bc:d9:b5:7f:ad:fd:c9:1d:06:83:28:cc:24:c1
+# SHA1 Fingerprint: d1:cb:ca:5d:b2:d5:2a:7f:69:3b:67:4d:e5:f0:5a:1d:0c:95:7d:f0
+# SHA256 Fingerprint: 4f:f4:60:d5:4b:9c:86:da:bf:bc:fc:57:12:e0:40:0d:2b:ed:3f:bc:4d:4f:bd:aa:86:e0:6a:dc:d2:a9:ad:7a
+-----BEGIN CERTIFICATE-----
+MIICjzCCAhWgAwIBAgIQXIuZxVqUxdJxVt7NiYDMJjAKBggqhkjOPQQDAzCBiDEL
+MAkGA1UEBhMCVVMxEzARBgNVBAgTCk5ldyBKZXJzZXkxFDASBgNVBAcTC0plcnNl
+eSBDaXR5MR4wHAYDVQQKExVUaGUgVVNFUlRSVVNUIE5ldHdvcmsxLjAsBgNVBAMT
+JVVTRVJUcnVzdCBFQ0MgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkwHhcNMTAwMjAx
+MDAwMDAwWhcNMzgwMTE4MjM1OTU5WjCBiDELMAkGA1UEBhMCVVMxEzARBgNVBAgT
+Ck5ldyBKZXJzZXkxFDASBgNVBAcTC0plcnNleSBDaXR5MR4wHAYDVQQKExVUaGUg
+VVNFUlRSVVNUIE5ldHdvcmsxLjAsBgNVBAMTJVVTRVJUcnVzdCBFQ0MgQ2VydGlm
+aWNhdGlvbiBBdXRob3JpdHkwdjAQBgcqhkjOPQIBBgUrgQQAIgNiAAQarFRaqflo
+I+d61SRvU8Za2EurxtW20eZzca7dnNYMYf3boIkDuAUU7FfO7l0/4iGzzvfUinng
+o4N+LZfQYcTxmdwlkWOrfzCjtHDix6EznPO/LlxTsV+zfTJ/ijTjeXmjQjBAMB0G
+A1UdDgQWBBQ64QmG1M8ZwpZ2dEl23OA1xmNjmjAOBgNVHQ8BAf8EBAMCAQYwDwYD
+VR0TAQH/BAUwAwEB/zAKBggqhkjOPQQDAwNoADBlAjA2Z6EWCNzklwBBHU6+4WMB
+zzuqQhFkoJ2UOQIReVx7Hfpkue4WQrO/isIJxOzksU0CMQDpKmFHjFJKS04YcPbW
+RNZu9YO6bVi9JNlWSOrvxKJGgYhqOkbRqZtNyWHa0V1Xahg=
+-----END CERTIFICATE-----
+
+# Issuer: CN=GlobalSign O=GlobalSign OU=GlobalSign ECC Root CA - R5
+# Subject: CN=GlobalSign O=GlobalSign OU=GlobalSign ECC Root CA - R5
+# Label: "GlobalSign ECC Root CA - R5"
+# Serial: 32785792099990507226680698011560947931244
+# MD5 Fingerprint: 9f:ad:3b:1c:02:1e:8a:ba:17:74:38:81:0c:a2:bc:08
+# SHA1 Fingerprint: 1f:24:c6:30:cd:a4:18:ef:20:69:ff:ad:4f:dd:5f:46:3a:1b:69:aa
+# SHA256 Fingerprint: 17:9f:bc:14:8a:3d:d0:0f:d2:4e:a1:34:58:cc:43:bf:a7:f5:9c:81:82:d7:83:a5:13:f6:eb:ec:10:0c:89:24
+-----BEGIN CERTIFICATE-----
+MIICHjCCAaSgAwIBAgIRYFlJ4CYuu1X5CneKcflK2GwwCgYIKoZIzj0EAwMwUDEk
+MCIGA1UECxMbR2xvYmFsU2lnbiBFQ0MgUm9vdCBDQSAtIFI1MRMwEQYDVQQKEwpH
+bG9iYWxTaWduMRMwEQYDVQQDEwpHbG9iYWxTaWduMB4XDTEyMTExMzAwMDAwMFoX
+DTM4MDExOTAzMTQwN1owUDEkMCIGA1UECxMbR2xvYmFsU2lnbiBFQ0MgUm9vdCBD
+QSAtIFI1MRMwEQYDVQQKEwpHbG9iYWxTaWduMRMwEQYDVQQDEwpHbG9iYWxTaWdu
+MHYwEAYHKoZIzj0CAQYFK4EEACIDYgAER0UOlvt9Xb/pOdEh+J8LttV7HpI6SFkc
+8GIxLcB6KP4ap1yztsyX50XUWPrRd21DosCHZTQKH3rd6zwzocWdTaRvQZU4f8ke
+hOvRnkmSh5SHDDqFSmafnVmTTZdhBoZKo0IwQDAOBgNVHQ8BAf8EBAMCAQYwDwYD
+VR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQUPeYpSJvqB8ohREom3m7e0oPQn1kwCgYI
+KoZIzj0EAwMDaAAwZQIxAOVpEslu28YxuglB4Zf4+/2a4n0Sye18ZNPLBSWLVtmg
+515dTguDnFt2KaAJJiFqYgIwcdK1j1zqO+F4CYWodZI7yFz9SO8NdCKoCOJuxUnO
+xwy8p2Fp8fc74SrL+SvzZpA3
+-----END CERTIFICATE-----
+
+# Issuer: CN=IdenTrust Commercial Root CA 1 O=IdenTrust
+# Subject: CN=IdenTrust Commercial Root CA 1 O=IdenTrust
+# Label: "IdenTrust Commercial Root CA 1"
+# Serial: 13298821034946342390520003877796839426
+# MD5 Fingerprint: b3:3e:77:73:75:ee:a0:d3:e3:7e:49:63:49:59:bb:c7
+# SHA1 Fingerprint: df:71:7e:aa:4a:d9:4e:c9:55:84:99:60:2d:48:de:5f:bc:f0:3a:25
+# SHA256 Fingerprint: 5d:56:49:9b:e4:d2:e0:8b:cf:ca:d0:8a:3e:38:72:3d:50:50:3b:de:70:69:48:e4:2f:55:60:30:19:e5:28:ae
+-----BEGIN CERTIFICATE-----
+MIIFYDCCA0igAwIBAgIQCgFCgAAAAUUjyES1AAAAAjANBgkqhkiG9w0BAQsFADBK
+MQswCQYDVQQGEwJVUzESMBAGA1UEChMJSWRlblRydXN0MScwJQYDVQQDEx5JZGVu
+VHJ1c3QgQ29tbWVyY2lhbCBSb290IENBIDEwHhcNMTQwMTE2MTgxMjIzWhcNMzQw
+MTE2MTgxMjIzWjBKMQswCQYDVQQGEwJVUzESMBAGA1UEChMJSWRlblRydXN0MScw
+JQYDVQQDEx5JZGVuVHJ1c3QgQ29tbWVyY2lhbCBSb290IENBIDEwggIiMA0GCSqG
+SIb3DQEBAQUAA4ICDwAwggIKAoICAQCnUBneP5k91DNG8W9RYYKyqU+PZ4ldhNlT
+3Qwo2dfw/66VQ3KZ+bVdfIrBQuExUHTRgQ18zZshq0PirK1ehm7zCYofWjK9ouuU
++ehcCuz/mNKvcbO0U59Oh++SvL3sTzIwiEsXXlfEU8L2ApeN2WIrvyQfYo3fw7gp
+S0l4PJNgiCL8mdo2yMKi1CxUAGc1bnO/AljwpN3lsKImesrgNqUZFvX9t++uP0D1
+bVoE/c40yiTcdCMbXTMTEl3EASX2MN0CXZ/g1Ue9tOsbobtJSdifWwLziuQkkORi
+T0/Br4sOdBeo0XKIanoBScy0RnnGF7HamB4HWfp1IYVl3ZBWzvurpWCdxJ35UrCL
+vYf5jysjCiN2O/cz4ckA82n5S6LgTrx+kzmEB/dEcH7+B1rlsazRGMzyNeVJSQjK
+Vsk9+w8YfYs7wRPCTY/JTw436R+hDmrfYi7LNQZReSzIJTj0+kuniVyc0uMNOYZK
+dHzVWYfCP04MXFL0PfdSgvHqo6z9STQaKPNBiDoT7uje/5kdX7rL6B7yuVBgwDHT
+c+XvvqDtMwt0viAgxGds8AgDelWAf0ZOlqf0Hj7h9tgJ4TNkK2PXMl6f+cB7D3hv
+l7yTmvmcEpB4eoCHFddydJxVdHixuuFucAS6T6C6aMN7/zHwcz09lCqxC0EOoP5N
+iGVreTO01wIDAQABo0IwQDAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB
+/zAdBgNVHQ4EFgQU7UQZwNPwBovupHu+QucmVMiONnYwDQYJKoZIhvcNAQELBQAD
+ggIBAA2ukDL2pkt8RHYZYR4nKM1eVO8lvOMIkPkp165oCOGUAFjvLi5+U1KMtlwH
+6oi6mYtQlNeCgN9hCQCTrQ0U5s7B8jeUeLBfnLOic7iPBZM4zY0+sLj7wM+x8uwt
+LRvM7Kqas6pgghstO8OEPVeKlh6cdbjTMM1gCIOQ045U8U1mwF10A0Cj7oV+wh93
+nAbowacYXVKV7cndJZ5t+qntozo00Fl72u1Q8zW/7esUTTHHYPTa8Yec4kjixsU3
++wYQ+nVZZjFHKdp2mhzpgq7vmrlR94gjmmmVYjzlVYA211QC//G5Xc7UI2/YRYRK
+W2XviQzdFKcgyxilJbQN+QHwotL0AMh0jqEqSI5l2xPE4iUXfeu+h1sXIFRRk0pT
+AwvsXcoz7WL9RccvW9xYoIA55vrX/hMUpu09lEpCdNTDd1lzzY9GvlU47/rokTLq
+l1gEIt44w8y8bckzOmoKaT+gyOpyj4xjhiO9bTyWnpXgSUyqorkqG5w2gXjtw+hG
+4iZZRHUe2XWJUc0QhJ1hYMtd+ZciTY6Y5uN/9lu7rs3KSoFrXgvzUeF0K+l+J6fZ
+mUlO+KWA2yUPHGNiiskzZ2s8EIPGrd6ozRaOjfAHN3Gf8qv8QfXBi+wAN10J5U6A
+7/qxXDgGpRtK4dw4LTzcqx+QGtVKnO7RcGzM7vRX+Bi6hG6H
+-----END CERTIFICATE-----
+
+# Issuer: CN=IdenTrust Public Sector Root CA 1 O=IdenTrust
+# Subject: CN=IdenTrust Public Sector Root CA 1 O=IdenTrust
+# Label: "IdenTrust Public Sector Root CA 1"
+# Serial: 13298821034946342390521976156843933698
+# MD5 Fingerprint: 37:06:a5:b0:fc:89:9d:ba:f4:6b:8c:1a:64:cd:d5:ba
+# SHA1 Fingerprint: ba:29:41:60:77:98:3f:f4:f3:ef:f2:31:05:3b:2e:ea:6d:4d:45:fd
+# SHA256 Fingerprint: 30:d0:89:5a:9a:44:8a:26:20:91:63:55:22:d1:f5:20:10:b5:86:7a:ca:e1:2c:78:ef:95:8f:d4:f4:38:9f:2f
+-----BEGIN CERTIFICATE-----
+MIIFZjCCA06gAwIBAgIQCgFCgAAAAUUjz0Z8AAAAAjANBgkqhkiG9w0BAQsFADBN
+MQswCQYDVQQGEwJVUzESMBAGA1UEChMJSWRlblRydXN0MSowKAYDVQQDEyFJZGVu
+VHJ1c3QgUHVibGljIFNlY3RvciBSb290IENBIDEwHhcNMTQwMTE2MTc1MzMyWhcN
+MzQwMTE2MTc1MzMyWjBNMQswCQYDVQQGEwJVUzESMBAGA1UEChMJSWRlblRydXN0
+MSowKAYDVQQDEyFJZGVuVHJ1c3QgUHVibGljIFNlY3RvciBSb290IENBIDEwggIi
+MA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQC2IpT8pEiv6EdrCvsnduTyP4o7
+ekosMSqMjbCpwzFrqHd2hCa2rIFCDQjrVVi7evi8ZX3yoG2LqEfpYnYeEe4IFNGy
+RBb06tD6Hi9e28tzQa68ALBKK0CyrOE7S8ItneShm+waOh7wCLPQ5CQ1B5+ctMlS
+bdsHyo+1W/CD80/HLaXIrcuVIKQxKFdYWuSNG5qrng0M8gozOSI5Cpcu81N3uURF
+/YTLNiCBWS2ab21ISGHKTN9T0a9SvESfqy9rg3LvdYDaBjMbXcjaY8ZNzaxmMc3R
+3j6HEDbhuaR672BQssvKplbgN6+rNBM5Jeg5ZuSYeqoSmJxZZoY+rfGwyj4GD3vw
+EUs3oERte8uojHH01bWRNszwFcYr3lEXsZdMUD2xlVl8BX0tIdUAvwFnol57plzy
+9yLxkA2T26pEUWbMfXYD62qoKjgZl3YNa4ph+bz27nb9cCvdKTz4Ch5bQhyLVi9V
+GxyhLrXHFub4qjySjmm2AcG1hp2JDws4lFTo6tyePSW8Uybt1as5qsVATFSrsrTZ
+2fjXctscvG29ZV/viDUqZi/u9rNl8DONfJhBaUYPQxxp+pu10GFqzcpL2UyQRqsV
+WaFHVCkugyhfHMKiq3IXAAaOReyL4jM9f9oZRORicsPfIsbyVtTdX5Vy7W1f90gD
+W/3FKqD2cyOEEBsB5wIDAQABo0IwQDAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/
+BAUwAwEB/zAdBgNVHQ4EFgQU43HgntinQtnbcZFrlJPrw6PRFKMwDQYJKoZIhvcN
+AQELBQADggIBAEf63QqwEZE4rU1d9+UOl1QZgkiHVIyqZJnYWv6IAcVYpZmxI1Qj
+t2odIFflAWJBF9MJ23XLblSQdf4an4EKwt3X9wnQW3IV5B4Jaj0z8yGa5hV+rVHV
+DRDtfULAj+7AmgjVQdZcDiFpboBhDhXAuM/FSRJSzL46zNQuOAXeNf0fb7iAaJg9
+TaDKQGXSc3z1i9kKlT/YPyNtGtEqJBnZhbMX73huqVjRI9PHE+1yJX9dsXNw0H8G
+lwmEKYBhHfpe/3OsoOOJuBxxFcbeMX8S3OFtm6/n6J91eEyrRjuazr8FGF1NFTwW
+mhlQBJqymm9li1JfPFgEKCXAZmExfrngdbkaqIHWchezxQMxNRF4eKLg6TCMf4Df
+WN88uieW4oA0beOY02QnrEh+KHdcxiVhJfiFDGX6xDIvpZgF5PgLZxYWxoK4Mhn5
++bl53B/N66+rDt0b20XkeucC4pVd/GnwU2lhlXV5C15V5jgclKlZM57IcXR5f1GJ
+tshquDDIajjDbp7hNxbqBWJMWxJH7ae0s1hWx0nzfxJoCTFx8G34Tkf71oXuxVhA
+GaQdp/lLQzfcaFpPz+vCZHTetBXZ9FRUGi8c15dxVJCO2SCdUyt/q4/i6jC8UDfv
+8Ue1fXwsBOxonbRJRBD0ckscZOf85muQ3Wl9af0AVqW3rLatt8o+Ae+c
+-----END CERTIFICATE-----
+
+# Issuer: CN=Entrust Root Certification Authority - G2 O=Entrust, Inc. OU=See www.entrust.net/legal-terms/(c) 2009 Entrust, Inc. - for authorized use only
+# Subject: CN=Entrust Root Certification Authority - G2 O=Entrust, Inc. OU=See www.entrust.net/legal-terms/(c) 2009 Entrust, Inc. - for authorized use only
+# Label: "Entrust Root Certification Authority - G2"
+# Serial: 1246989352
+# MD5 Fingerprint: 4b:e2:c9:91:96:65:0c:f4:0e:5a:93:92:a0:0a:fe:b2
+# SHA1 Fingerprint: 8c:f4:27:fd:79:0c:3a:d1:66:06:8d:e8:1e:57:ef:bb:93:22:72:d4
+# SHA256 Fingerprint: 43:df:57:74:b0:3e:7f:ef:5f:e4:0d:93:1a:7b:ed:f1:bb:2e:6b:42:73:8c:4e:6d:38:41:10:3d:3a:a7:f3:39
+-----BEGIN CERTIFICATE-----
+MIIEPjCCAyagAwIBAgIESlOMKDANBgkqhkiG9w0BAQsFADCBvjELMAkGA1UEBhMC
+VVMxFjAUBgNVBAoTDUVudHJ1c3QsIEluYy4xKDAmBgNVBAsTH1NlZSB3d3cuZW50
+cnVzdC5uZXQvbGVnYWwtdGVybXMxOTA3BgNVBAsTMChjKSAyMDA5IEVudHJ1c3Qs
+IEluYy4gLSBmb3IgYXV0aG9yaXplZCB1c2Ugb25seTEyMDAGA1UEAxMpRW50cnVz
+dCBSb290IENlcnRpZmljYXRpb24gQXV0aG9yaXR5IC0gRzIwHhcNMDkwNzA3MTcy
+NTU0WhcNMzAxMjA3MTc1NTU0WjCBvjELMAkGA1UEBhMCVVMxFjAUBgNVBAoTDUVu
+dHJ1c3QsIEluYy4xKDAmBgNVBAsTH1NlZSB3d3cuZW50cnVzdC5uZXQvbGVnYWwt
+dGVybXMxOTA3BgNVBAsTMChjKSAyMDA5IEVudHJ1c3QsIEluYy4gLSBmb3IgYXV0
+aG9yaXplZCB1c2Ugb25seTEyMDAGA1UEAxMpRW50cnVzdCBSb290IENlcnRpZmlj
+YXRpb24gQXV0aG9yaXR5IC0gRzIwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEK
+AoIBAQC6hLZy254Ma+KZ6TABp3bqMriVQRrJ2mFOWHLP/vaCeb9zYQYKpSfYs1/T
+RU4cctZOMvJyig/3gxnQaoCAAEUesMfnmr8SVycco2gvCoe9amsOXmXzHHfV1IWN
+cCG0szLni6LVhjkCsbjSR87kyUnEO6fe+1R9V77w6G7CebI6C1XiUJgWMhNcL3hW
+wcKUs/Ja5CeanyTXxuzQmyWC48zCxEXFjJd6BmsqEZ+pCm5IO2/b1BEZQvePB7/1
+U1+cPvQXLOZprE4yTGJ36rfo5bs0vBmLrpxR57d+tVOxMyLlbc9wPBr64ptntoP0
+jaWvYkxN4FisZDQSA/i2jZRjJKRxAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAP
+BgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBRqciZ60B7vfec7aVHUbI2fkBJmqzAN
+BgkqhkiG9w0BAQsFAAOCAQEAeZ8dlsa2eT8ijYfThwMEYGprmi5ZiXMRrEPR9RP/
+jTkrwPK9T3CMqS/qF8QLVJ7UG5aYMzyorWKiAHarWWluBh1+xLlEjZivEtRh2woZ
+Rkfz6/djwUAFQKXSt/S1mja/qYh2iARVBCuch38aNzx+LaUa2NSJXsq9rD1s2G2v
+1fN2D807iDginWyTmsQ9v4IbZT+mD12q/OWyFcq1rca8PdCE6OoGcrBNOTJ4vz4R
+nAuknZoh8/CbCzB428Hch0P+vGOaysXCHMnHjf87ElgI5rY97HosTvuDls4MPGmH
+VHOkc8KT/1EQrBVUAdj8BbGJoX90g5pJ19xOe4pIb4tF9g==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Entrust Root Certification Authority - EC1 O=Entrust, Inc. OU=See www.entrust.net/legal-terms/(c) 2012 Entrust, Inc. - for authorized use only
+# Subject: CN=Entrust Root Certification Authority - EC1 O=Entrust, Inc. OU=See www.entrust.net/legal-terms/(c) 2012 Entrust, Inc. - for authorized use only
+# Label: "Entrust Root Certification Authority - EC1"
+# Serial: 51543124481930649114116133369
+# MD5 Fingerprint: b6:7e:1d:f0:58:c5:49:6c:24:3b:3d:ed:98:18:ed:bc
+# SHA1 Fingerprint: 20:d8:06:40:df:9b:25:f5:12:25:3a:11:ea:f7:59:8a:eb:14:b5:47
+# SHA256 Fingerprint: 02:ed:0e:b2:8c:14:da:45:16:5c:56:67:91:70:0d:64:51:d7:fb:56:f0:b2:ab:1d:3b:8e:b0:70:e5:6e:df:f5
+-----BEGIN CERTIFICATE-----
+MIIC+TCCAoCgAwIBAgINAKaLeSkAAAAAUNCR+TAKBggqhkjOPQQDAzCBvzELMAkG
+A1UEBhMCVVMxFjAUBgNVBAoTDUVudHJ1c3QsIEluYy4xKDAmBgNVBAsTH1NlZSB3
+d3cuZW50cnVzdC5uZXQvbGVnYWwtdGVybXMxOTA3BgNVBAsTMChjKSAyMDEyIEVu
+dHJ1c3QsIEluYy4gLSBmb3IgYXV0aG9yaXplZCB1c2Ugb25seTEzMDEGA1UEAxMq
+RW50cnVzdCBSb290IENlcnRpZmljYXRpb24gQXV0aG9yaXR5IC0gRUMxMB4XDTEy
+MTIxODE1MjUzNloXDTM3MTIxODE1NTUzNlowgb8xCzAJBgNVBAYTAlVTMRYwFAYD
+VQQKEw1FbnRydXN0LCBJbmMuMSgwJgYDVQQLEx9TZWUgd3d3LmVudHJ1c3QubmV0
+L2xlZ2FsLXRlcm1zMTkwNwYDVQQLEzAoYykgMjAxMiBFbnRydXN0LCBJbmMuIC0g
+Zm9yIGF1dGhvcml6ZWQgdXNlIG9ubHkxMzAxBgNVBAMTKkVudHJ1c3QgUm9vdCBD
+ZXJ0aWZpY2F0aW9uIEF1dGhvcml0eSAtIEVDMTB2MBAGByqGSM49AgEGBSuBBAAi
+A2IABIQTydC6bUF74mzQ61VfZgIaJPRbiWlH47jCffHyAsWfoPZb1YsGGYZPUxBt
+ByQnoaD41UcZYUx9ypMn6nQM72+WCf5j7HBdNq1nd67JnXxVRDqiY1Ef9eNi1KlH
+Bz7MIKNCMEAwDgYDVR0PAQH/BAQDAgEGMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0O
+BBYEFLdj5xrdjekIplWDpOBqUEFlEUJJMAoGCCqGSM49BAMDA2cAMGQCMGF52OVC
+R98crlOZF7ZvHH3hvxGU0QOIdeSNiaSKd0bebWHvAvX7td/M/k7//qnmpwIwW5nX
+hTcGtXsI/esni0qU+eH6p44mCOh8kmhtc9hvJqwhAriZtyZBWyVgrtBIGu4G
+-----END CERTIFICATE-----
+
+# Issuer: CN=CFCA EV ROOT O=China Financial Certification Authority
+# Subject: CN=CFCA EV ROOT O=China Financial Certification Authority
+# Label: "CFCA EV ROOT"
+# Serial: 407555286
+# MD5 Fingerprint: 74:e1:b6:ed:26:7a:7a:44:30:33:94:ab:7b:27:81:30
+# SHA1 Fingerprint: e2:b8:29:4b:55:84:ab:6b:58:c2:90:46:6c:ac:3f:b8:39:8f:84:83
+# SHA256 Fingerprint: 5c:c3:d7:8e:4e:1d:5e:45:54:7a:04:e6:87:3e:64:f9:0c:f9:53:6d:1c:cc:2e:f8:00:f3:55:c4:c5:fd:70:fd
+-----BEGIN CERTIFICATE-----
+MIIFjTCCA3WgAwIBAgIEGErM1jANBgkqhkiG9w0BAQsFADBWMQswCQYDVQQGEwJD
+TjEwMC4GA1UECgwnQ2hpbmEgRmluYW5jaWFsIENlcnRpZmljYXRpb24gQXV0aG9y
+aXR5MRUwEwYDVQQDDAxDRkNBIEVWIFJPT1QwHhcNMTIwODA4MDMwNzAxWhcNMjkx
+MjMxMDMwNzAxWjBWMQswCQYDVQQGEwJDTjEwMC4GA1UECgwnQ2hpbmEgRmluYW5j
+aWFsIENlcnRpZmljYXRpb24gQXV0aG9yaXR5MRUwEwYDVQQDDAxDRkNBIEVWIFJP
+T1QwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDXXWvNED8fBVnVBU03
+sQ7smCuOFR36k0sXgiFxEFLXUWRwFsJVaU2OFW2fvwwbwuCjZ9YMrM8irq93VCpL
+TIpTUnrD7i7es3ElweldPe6hL6P3KjzJIx1qqx2hp/Hz7KDVRM8Vz3IvHWOX6Jn5
+/ZOkVIBMUtRSqy5J35DNuF++P96hyk0g1CXohClTt7GIH//62pCfCqktQT+x8Rgp
+7hZZLDRJGqgG16iI0gNyejLi6mhNbiyWZXvKWfry4t3uMCz7zEasxGPrb382KzRz
+EpR/38wmnvFyXVBlWY9ps4deMm/DGIq1lY+wejfeWkU7xzbh72fROdOXW3NiGUgt
+hxwG+3SYIElz8AXSG7Ggo7cbcNOIabla1jj0Ytwli3i/+Oh+uFzJlU9fpy25IGvP
+a931DfSCt/SyZi4QKPaXWnuWFo8BGS1sbn85WAZkgwGDg8NNkt0yxoekN+kWzqot
+aK8KgWU6cMGbrU1tVMoqLUuFG7OA5nBFDWteNfB/O7ic5ARwiRIlk9oKmSJgamNg
+TnYGmE69g60dWIolhdLHZR4tjsbftsbhf4oEIRUpdPA+nJCdDC7xij5aqgwJHsfV
+PKPtl8MeNPo4+QgO48BdK4PRVmrJtqhUUy54Mmc9gn900PvhtgVguXDbjgv5E1hv
+cWAQUhC5wUEJ73IfZzF4/5YFjQIDAQABo2MwYTAfBgNVHSMEGDAWgBTj/i39KNAL
+tbq2osS/BqoFjJP7LzAPBgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIBBjAd
+BgNVHQ4EFgQU4/4t/SjQC7W6tqLEvwaqBYyT+y8wDQYJKoZIhvcNAQELBQADggIB
+ACXGumvrh8vegjmWPfBEp2uEcwPenStPuiB/vHiyz5ewG5zz13ku9Ui20vsXiObT
+ej/tUxPQ4i9qecsAIyjmHjdXNYmEwnZPNDatZ8POQQaIxffu2Bq41gt/UP+TqhdL
+jOztUmCypAbqTuv0axn96/Ua4CUqmtzHQTb3yHQFhDmVOdYLO6Qn+gjYXB74BGBS
+ESgoA//vU2YApUo0FmZ8/Qmkrp5nGm9BC2sGE5uPhnEFtC+NiWYzKXZUmhH4J/qy
+P5Hgzg0b8zAarb8iXRvTvyUFTeGSGn+ZnzxEk8rUQElsgIfXBDrDMlI1Dlb4pd19
+xIsNER9Tyx6yF7Zod1rg1MvIB671Oi6ON7fQAUtDKXeMOZePglr4UeWJoBjnaH9d
+Ci77o0cOPaYjesYBx4/IXr9tgFa+iiS6M+qf4TIRnvHST4D2G0CvOJ4RUHlzEhLN
+5mydLIhyPDCBBpEi6lmt2hkuIsKNuYyH4Ga8cyNfIWRjgEj1oDwYPZTISEEdQLpe
+/v5WOaHIz16eGWRGENoXkbcFgKyLmZJ956LYBws2J+dIeWCKw9cTXPhyQN9Ky8+Z
+AAoACxGV2lZFA4gKn2fQ1XmxqI1AbQ3CekD6819kR5LLU7m7Wc5P/dAVUwHY3+vZ
+5nbv0CO7O6l5s9UCKc2Jo5YPSjXnTkLAdc0Hz+Ys63su
+-----END CERTIFICATE-----
+
+# Issuer: CN=OISTE WISeKey Global Root GB CA O=WISeKey OU=OISTE Foundation Endorsed
+# Subject: CN=OISTE WISeKey Global Root GB CA O=WISeKey OU=OISTE Foundation Endorsed
+# Label: "OISTE WISeKey Global Root GB CA"
+# Serial: 157768595616588414422159278966750757568
+# MD5 Fingerprint: a4:eb:b9:61:28:2e:b7:2f:98:b0:35:26:90:99:51:1d
+# SHA1 Fingerprint: 0f:f9:40:76:18:d3:d7:6a:4b:98:f0:a8:35:9e:0c:fd:27:ac:cc:ed
+# SHA256 Fingerprint: 6b:9c:08:e8:6e:b0:f7:67:cf:ad:65:cd:98:b6:21:49:e5:49:4a:67:f5:84:5e:7b:d1:ed:01:9f:27:b8:6b:d6
+-----BEGIN CERTIFICATE-----
+MIIDtTCCAp2gAwIBAgIQdrEgUnTwhYdGs/gjGvbCwDANBgkqhkiG9w0BAQsFADBt
+MQswCQYDVQQGEwJDSDEQMA4GA1UEChMHV0lTZUtleTEiMCAGA1UECxMZT0lTVEUg
+Rm91bmRhdGlvbiBFbmRvcnNlZDEoMCYGA1UEAxMfT0lTVEUgV0lTZUtleSBHbG9i
+YWwgUm9vdCBHQiBDQTAeFw0xNDEyMDExNTAwMzJaFw0zOTEyMDExNTEwMzFaMG0x
+CzAJBgNVBAYTAkNIMRAwDgYDVQQKEwdXSVNlS2V5MSIwIAYDVQQLExlPSVNURSBG
+b3VuZGF0aW9uIEVuZG9yc2VkMSgwJgYDVQQDEx9PSVNURSBXSVNlS2V5IEdsb2Jh
+bCBSb290IEdCIENBMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA2Be3
+HEokKtaXscriHvt9OO+Y9bI5mE4nuBFde9IllIiCFSZqGzG7qFshISvYD06fWvGx
+WuR51jIjK+FTzJlFXHtPrby/h0oLS5daqPZI7H17Dc0hBt+eFf1Biki3IPShehtX
+1F1Q/7pn2COZH8g/497/b1t3sWtuuMlk9+HKQUYOKXHQuSP8yYFfTvdv37+ErXNk
+u7dCjmn21HYdfp2nuFeKUWdy19SouJVUQHMD9ur06/4oQnc/nSMbsrY9gBQHTC5P
+99UKFg29ZkM3fiNDecNAhvVMKdqOmq0NpQSHiB6F4+lT1ZvIiwNjeOvgGUpuuy9r
+M2RYk61pv48b74JIxwIDAQABo1EwTzALBgNVHQ8EBAMCAYYwDwYDVR0TAQH/BAUw
+AwEB/zAdBgNVHQ4EFgQUNQ/INmNe4qPs+TtmFc5RUuORmj0wEAYJKwYBBAGCNxUB
+BAMCAQAwDQYJKoZIhvcNAQELBQADggEBAEBM+4eymYGQfp3FsLAmzYh7KzKNbrgh
+cViXfa43FK8+5/ea4n32cZiZBKpDdHij40lhPnOMTZTg+XHEthYOU3gf1qKHLwI5
+gSk8rxWYITD+KJAAjNHhy/peyP34EEY7onhCkRd0VQreUGdNZtGn//3ZwLWoo4rO
+ZvUPQ82nK1d7Y0Zqqi5S2PTt4W2tKZB4SLrhI6qjiey1q5bAtEuiHZeeevJuQHHf
+aPFlTc58Bd9TZaml8LGXBHAVRgOY1NK/VLSgWH1Sb9pWJmLU2NuJMW8c8CLC02Ic
+Nc1MaRVUGpCY3useX8p3x8uOPUNpnJpY0CQ73xtAln41rYHHTnG6iBM=
+-----END CERTIFICATE-----
+
+# Issuer: CN=SZAFIR ROOT CA2 O=Krajowa Izba Rozliczeniowa S.A.
+# Subject: CN=SZAFIR ROOT CA2 O=Krajowa Izba Rozliczeniowa S.A.
+# Label: "SZAFIR ROOT CA2"
+# Serial: 357043034767186914217277344587386743377558296292
+# MD5 Fingerprint: 11:64:c1:89:b0:24:b1:8c:b1:07:7e:89:9e:51:9e:99
+# SHA1 Fingerprint: e2:52:fa:95:3f:ed:db:24:60:bd:6e:28:f3:9c:cc:cf:5e:b3:3f:de
+# SHA256 Fingerprint: a1:33:9d:33:28:1a:0b:56:e5:57:d3:d3:2b:1c:e7:f9:36:7e:b0:94:bd:5f:a7:2a:7e:50:04:c8:de:d7:ca:fe
+-----BEGIN CERTIFICATE-----
+MIIDcjCCAlqgAwIBAgIUPopdB+xV0jLVt+O2XwHrLdzk1uQwDQYJKoZIhvcNAQEL
+BQAwUTELMAkGA1UEBhMCUEwxKDAmBgNVBAoMH0tyYWpvd2EgSXpiYSBSb3psaWN6
+ZW5pb3dhIFMuQS4xGDAWBgNVBAMMD1NaQUZJUiBST09UIENBMjAeFw0xNTEwMTkw
+NzQzMzBaFw0zNTEwMTkwNzQzMzBaMFExCzAJBgNVBAYTAlBMMSgwJgYDVQQKDB9L
+cmFqb3dhIEl6YmEgUm96bGljemVuaW93YSBTLkEuMRgwFgYDVQQDDA9TWkFGSVIg
+Uk9PVCBDQTIwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQC3vD5QqEvN
+QLXOYeeWyrSh2gwisPq1e3YAd4wLz32ohswmUeQgPYUM1ljj5/QqGJ3a0a4m7utT
+3PSQ1hNKDJA8w/Ta0o4NkjrcsbH/ON7Dui1fgLkCvUqdGw+0w8LBZwPd3BucPbOw
+3gAeqDRHu5rr/gsUvTaE2g0gv/pby6kWIK05YO4vdbbnl5z5Pv1+TW9NL++IDWr6
+3fE9biCloBK0TXC5ztdyO4mTp4CEHCdJckm1/zuVnsHMyAHs6A6KCpbns6aH5db5
+BSsNl0BwPLqsdVqc1U2dAgrSS5tmS0YHF2Wtn2yIANwiieDhZNRnvDF5YTy7ykHN
+XGoAyDw4jlivAgMBAAGjQjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQD
+AgEGMB0GA1UdDgQWBBQuFqlKGLXLzPVvUPMjX/hd56zwyDANBgkqhkiG9w0BAQsF
+AAOCAQEAtXP4A9xZWx126aMqe5Aosk3AM0+qmrHUuOQn/6mWmc5G4G18TKI4pAZw
+8PRBEew/R40/cof5O/2kbytTAOD/OblqBw7rHRz2onKQy4I9EYKL0rufKq8h5mOG
+nXkZ7/e7DDWQw4rtTw/1zBLZpD67oPwglV9PJi8RI4NOdQcPv5vRtB3pEAT+ymCP
+oky4rc/hkA/NrgrHXXu3UNLUYfrVFdvXn4dRVOul4+vJhaAlIDf7js4MNIThPIGy
+d05DpYhfhmehPea0XGG2Ptv+tyjFogeutcrKjSoS75ftwjCkySp6+/NNIxuZMzSg
+LvWpCz/UXeHPhJ/iGcJfitYgHuNztw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certum Trusted Network CA 2 O=Unizeto Technologies S.A. OU=Certum Certification Authority
+# Subject: CN=Certum Trusted Network CA 2 O=Unizeto Technologies S.A. OU=Certum Certification Authority
+# Label: "Certum Trusted Network CA 2"
+# Serial: 44979900017204383099463764357512596969
+# MD5 Fingerprint: 6d:46:9e:d9:25:6d:08:23:5b:5e:74:7d:1e:27:db:f2
+# SHA1 Fingerprint: d3:dd:48:3e:2b:bf:4c:05:e8:af:10:f5:fa:76:26:cf:d3:dc:30:92
+# SHA256 Fingerprint: b6:76:f2:ed:da:e8:77:5c:d3:6c:b0:f6:3c:d1:d4:60:39:61:f4:9e:62:65:ba:01:3a:2f:03:07:b6:d0:b8:04
+-----BEGIN CERTIFICATE-----
+MIIF0jCCA7qgAwIBAgIQIdbQSk8lD8kyN/yqXhKN6TANBgkqhkiG9w0BAQ0FADCB
+gDELMAkGA1UEBhMCUEwxIjAgBgNVBAoTGVVuaXpldG8gVGVjaG5vbG9naWVzIFMu
+QS4xJzAlBgNVBAsTHkNlcnR1bSBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTEkMCIG
+A1UEAxMbQ2VydHVtIFRydXN0ZWQgTmV0d29yayBDQSAyMCIYDzIwMTExMDA2MDgz
+OTU2WhgPMjA0NjEwMDYwODM5NTZaMIGAMQswCQYDVQQGEwJQTDEiMCAGA1UEChMZ
+VW5pemV0byBUZWNobm9sb2dpZXMgUy5BLjEnMCUGA1UECxMeQ2VydHVtIENlcnRp
+ZmljYXRpb24gQXV0aG9yaXR5MSQwIgYDVQQDExtDZXJ0dW0gVHJ1c3RlZCBOZXR3
+b3JrIENBIDIwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQC9+Xj45tWA
+DGSdhhuWZGc/IjoedQF97/tcZ4zJzFxrqZHmuULlIEub2pt7uZld2ZuAS9eEQCsn
+0+i6MLs+CRqnSZXvK0AkwpfHp+6bJe+oCgCXhVqqndwpyeI1B+twTUrWwbNWuKFB
+OJvR+zF/j+Bf4bE/D44WSWDXBo0Y+aomEKsq09DRZ40bRr5HMNUuctHFY9rnY3lE
+fktjJImGLjQ/KUxSiyqnwOKRKIm5wFv5HdnnJ63/mgKXwcZQkpsCLL2puTRZCr+E
+Sv/f/rOf69me4Jgj7KZrdxYq28ytOxykh9xGc14ZYmhFV+SQgkK7QtbwYeDBoz1m
+o130GO6IyY0XRSmZMnUCMe4pJshrAua1YkV/NxVaI2iJ1D7eTiew8EAMvE0Xy02i
+sx7QBlrd9pPPV3WZ9fqGGmd4s7+W/jTcvedSVuWz5XV710GRBdxdaeOVDUO5/IOW
+OZV7bIBaTxNyxtd9KXpEulKkKtVBRgkg/iKgtlswjbyJDNXXcPiHUv3a76xRLgez
+Tv7QCdpw75j6VuZt27VXS9zlLCUVyJ4ueE742pyehizKV/Ma5ciSixqClnrDvFAS
+adgOWkaLOusm+iPJtrCBvkIApPjW/jAux9JG9uWOdf3yzLnQh1vMBhBgu4M1t15n
+3kfsmUjxpKEV/q2MYo45VU85FrmxY53/twIDAQABo0IwQDAPBgNVHRMBAf8EBTAD
+AQH/MB0GA1UdDgQWBBS2oVQ5AsOgP46KvPrU+Bym0ToO/TAOBgNVHQ8BAf8EBAMC
+AQYwDQYJKoZIhvcNAQENBQADggIBAHGlDs7k6b8/ONWJWsQCYftMxRQXLYtPU2sQ
+F/xlhMcQSZDe28cmk4gmb3DWAl45oPePq5a1pRNcgRRtDoGCERuKTsZPpd1iHkTf
+CVn0W3cLN+mLIMb4Ck4uWBzrM9DPhmDJ2vuAL55MYIR4PSFk1vtBHxgP58l1cb29
+XN40hz5BsA72udY/CROWFC/emh1auVbONTqwX3BNXuMp8SMoclm2q8KMZiYcdywm
+djWLKKdpoPk79SPdhRB0yZADVpHnr7pH1BKXESLjokmUbOe3lEu6LaTaM4tMpkT/
+WjzGHWTYtTHkpjx6qFcL2+1hGsvxznN3Y6SHb0xRONbkX8eftoEq5IVIeVheO/jb
+AoJnwTnbw3RLPTYe+SmTiGhbqEQZIfCn6IENLOiTNrQ3ssqwGyZ6miUfmpqAnksq
+P/ujmv5zMnHCnsZy4YpoJ/HkD7TETKVhk/iXEAcqMCWpuchxuO9ozC1+9eB+D4Ko
+b7a6bINDd82Kkhehnlt4Fj1F4jNy3eFmypnTycUm/Q1oBEauttmbjL4ZvrHG8hnj
+XALKLNhvSgfZyTXaQHXyxKcZb55CEJh15pWLYLztxRLXis7VmFxWlgPF7ncGNf/P
+5O4/E2Hu29othfDNrp2yGAlFw5Khchf8R7agCyzxxN5DaAhqXzvwdmP7zAYspsbi
+DrW5viSP
+-----END CERTIFICATE-----
+
+# Issuer: CN=Hellenic Academic and Research Institutions RootCA 2015 O=Hellenic Academic and Research Institutions Cert. Authority
+# Subject: CN=Hellenic Academic and Research Institutions RootCA 2015 O=Hellenic Academic and Research Institutions Cert. Authority
+# Label: "Hellenic Academic and Research Institutions RootCA 2015"
+# Serial: 0
+# MD5 Fingerprint: ca:ff:e2:db:03:d9:cb:4b:e9:0f:ad:84:fd:7b:18:ce
+# SHA1 Fingerprint: 01:0c:06:95:a6:98:19:14:ff:bf:5f:c6:b0:b6:95:ea:29:e9:12:a6
+# SHA256 Fingerprint: a0:40:92:9a:02:ce:53:b4:ac:f4:f2:ff:c6:98:1c:e4:49:6f:75:5e:6d:45:fe:0b:2a:69:2b:cd:52:52:3f:36
+-----BEGIN CERTIFICATE-----
+MIIGCzCCA/OgAwIBAgIBADANBgkqhkiG9w0BAQsFADCBpjELMAkGA1UEBhMCR1Ix
+DzANBgNVBAcTBkF0aGVuczFEMEIGA1UEChM7SGVsbGVuaWMgQWNhZGVtaWMgYW5k
+IFJlc2VhcmNoIEluc3RpdHV0aW9ucyBDZXJ0LiBBdXRob3JpdHkxQDA+BgNVBAMT
+N0hlbGxlbmljIEFjYWRlbWljIGFuZCBSZXNlYXJjaCBJbnN0aXR1dGlvbnMgUm9v
+dENBIDIwMTUwHhcNMTUwNzA3MTAxMTIxWhcNNDAwNjMwMTAxMTIxWjCBpjELMAkG
+A1UEBhMCR1IxDzANBgNVBAcTBkF0aGVuczFEMEIGA1UEChM7SGVsbGVuaWMgQWNh
+ZGVtaWMgYW5kIFJlc2VhcmNoIEluc3RpdHV0aW9ucyBDZXJ0LiBBdXRob3JpdHkx
+QDA+BgNVBAMTN0hlbGxlbmljIEFjYWRlbWljIGFuZCBSZXNlYXJjaCBJbnN0aXR1
+dGlvbnMgUm9vdENBIDIwMTUwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoIC
+AQDC+Kk/G4n8PDwEXT2QNrCROnk8ZlrvbTkBSRq0t89/TSNTt5AA4xMqKKYx8ZEA
+4yjsriFBzh/a/X0SWwGDD7mwX5nh8hKDgE0GPt+sr+ehiGsxr/CL0BgzuNtFajT0
+AoAkKAoCFZVedioNmToUW/bLy1O8E00BiDeUJRtCvCLYjqOWXjrZMts+6PAQZe10
+4S+nfK8nNLspfZu2zwnI5dMK/IhlZXQK3HMcXM1AsRzUtoSMTFDPaI6oWa7CJ06C
+ojXdFPQf/7J31Ycvqm59JCfnxssm5uX+Zwdj2EUN3TpZZTlYepKZcj2chF6IIbjV
+9Cz82XBST3i4vTwri5WY9bPRaM8gFH5MXF/ni+X1NYEZN9cRCLdmvtNKzoNXADrD
+gfgXy5I2XdGj2HUb4Ysn6npIQf1FGQatJ5lOwXBH3bWfgVMS5bGMSF0xQxfjjMZ6
+Y5ZLKTBOhE5iGV48zpeQpX8B653g+IuJ3SWYPZK2fu/Z8VFRfS0myGlZYeCsargq
+NhEEelC9MoS+L9xy1dcdFkfkR2YgP/SWxa+OAXqlD3pk9Q0Yh9muiNX6hME6wGko
+LfINaFGq46V3xqSQDqE3izEjR8EJCOtu93ib14L8hCCZSRm2Ekax+0VVFqmjZayc
+Bw/qa9wfLgZy7IaIEuQt218FL+TwA9MmM+eAws1CoRc0CwIDAQABo0IwQDAPBgNV
+HRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIBBjAdBgNVHQ4EFgQUcRVnyMjJvXVd
+ctA4GGqd83EkVAswDQYJKoZIhvcNAQELBQADggIBAHW7bVRLqhBYRjTyYtcWNl0I
+XtVsyIe9tC5G8jH4fOpCtZMWVdyhDBKg2mF+D1hYc2Ryx+hFjtyp8iY/xnmMsVMI
+M4GwVhO+5lFc2JsKT0ucVlMC6U/2DWDqTUJV6HwbISHTGzrMd/K4kPFox/la/vot
+9L/J9UUbzjgQKjeKeaO04wlshYaT/4mWJ3iBj2fjRnRUjtkNaeJK9E10A/+yd+2V
+Z5fkscWrv2oj6NSU4kQoYsRL4vDY4ilrGnB+JGGTe08DMiUNRSQrlrRGar9KC/ea
+j8GsGsVn82800vpzY4zvFrCopEYq+OsS7HK07/grfoxSwIuEVPkvPuNVqNxmsdnh
+X9izjFk0WaSrT2y7HxjbdavYy5LNlDhhDgcGH0tGEPEVvo2FXDtKK4F5D7Rpn0lQ
+l033DlZdwJVqwjbDG2jJ9SrcR5q+ss7FJej6A7na+RZukYT1HCjI/CbM1xyQVqdf
+bzoEvM14iQuODy+jqk+iGxI9FghAD/FGTNeqewjBCvVtJ94Cj8rDtSvK6evIIVM4
+pcw72Hc3MKJP2W/R8kCtQXoXxdZKNYm3QdV8hn9VTYNKpXMgwDqvkPGaJI7ZjnHK
+e7iG2rKPmT4dEw0SEe7Uq/DpFXYC5ODfqiAeW2GFZECpkJcNrVPSWh2HagCXZWK0
+vm9qp/UsQu0yrbYhnr68
+-----END CERTIFICATE-----
+
+# Issuer: CN=Hellenic Academic and Research Institutions ECC RootCA 2015 O=Hellenic Academic and Research Institutions Cert. Authority
+# Subject: CN=Hellenic Academic and Research Institutions ECC RootCA 2015 O=Hellenic Academic and Research Institutions Cert. Authority
+# Label: "Hellenic Academic and Research Institutions ECC RootCA 2015"
+# Serial: 0
+# MD5 Fingerprint: 81:e5:b4:17:eb:c2:f5:e1:4b:0d:41:7b:49:92:fe:ef
+# SHA1 Fingerprint: 9f:f1:71:8d:92:d5:9a:f3:7d:74:97:b4:bc:6f:84:68:0b:ba:b6:66
+# SHA256 Fingerprint: 44:b5:45:aa:8a:25:e6:5a:73:ca:15:dc:27:fc:36:d2:4c:1c:b9:95:3a:06:65:39:b1:15:82:dc:48:7b:48:33
+-----BEGIN CERTIFICATE-----
+MIICwzCCAkqgAwIBAgIBADAKBggqhkjOPQQDAjCBqjELMAkGA1UEBhMCR1IxDzAN
+BgNVBAcTBkF0aGVuczFEMEIGA1UEChM7SGVsbGVuaWMgQWNhZGVtaWMgYW5kIFJl
+c2VhcmNoIEluc3RpdHV0aW9ucyBDZXJ0LiBBdXRob3JpdHkxRDBCBgNVBAMTO0hl
+bGxlbmljIEFjYWRlbWljIGFuZCBSZXNlYXJjaCBJbnN0aXR1dGlvbnMgRUNDIFJv
+b3RDQSAyMDE1MB4XDTE1MDcwNzEwMzcxMloXDTQwMDYzMDEwMzcxMlowgaoxCzAJ
+BgNVBAYTAkdSMQ8wDQYDVQQHEwZBdGhlbnMxRDBCBgNVBAoTO0hlbGxlbmljIEFj
+YWRlbWljIGFuZCBSZXNlYXJjaCBJbnN0aXR1dGlvbnMgQ2VydC4gQXV0aG9yaXR5
+MUQwQgYDVQQDEztIZWxsZW5pYyBBY2FkZW1pYyBhbmQgUmVzZWFyY2ggSW5zdGl0
+dXRpb25zIEVDQyBSb290Q0EgMjAxNTB2MBAGByqGSM49AgEGBSuBBAAiA2IABJKg
+QehLgoRc4vgxEZmGZE4JJS+dQS8KrjVPdJWyUWRrjWvmP3CV8AVER6ZyOFB2lQJa
+jq4onvktTpnvLEhvTCUp6NFxW98dwXU3tNf6e3pCnGoKVlp8aQuqgAkkbH7BRqNC
+MEAwDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwHQYDVR0OBBYEFLQi
+C4KZJAEOnLvkDv2/+5cgk5kqMAoGCCqGSM49BAMCA2cAMGQCMGfOFmI4oqxiRaep
+lSTAGiecMjvAwNW6qef4BENThe5SId6d9SWDPp5YSy/XZxMOIQIwBeF1Ad5o7Sof
+TUwJCA3sS61kFyjndc5FZXIhF8siQQ6ME5g4mlRtm8rifOoCWCKR
+-----END CERTIFICATE-----
+
+# Issuer: CN=ISRG Root X1 O=Internet Security Research Group
+# Subject: CN=ISRG Root X1 O=Internet Security Research Group
+# Label: "ISRG Root X1"
+# Serial: 172886928669790476064670243504169061120
+# MD5 Fingerprint: 0c:d2:f9:e0:da:17:73:e9:ed:86:4d:a5:e3:70:e7:4e
+# SHA1 Fingerprint: ca:bd:2a:79:a1:07:6a:31:f2:1d:25:36:35:cb:03:9d:43:29:a5:e8
+# SHA256 Fingerprint: 96:bc:ec:06:26:49:76:f3:74:60:77:9a:cf:28:c5:a7:cf:e8:a3:c0:aa:e1:1a:8f:fc:ee:05:c0:bd:df:08:c6
+-----BEGIN CERTIFICATE-----
+MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
+TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
+cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
+WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
+ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
+MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
+h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
+0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
+A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
+T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
+B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
+B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
+KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
+OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
+jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
+qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
+rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
+HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
+hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
+ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
+3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
+NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
+ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
+TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
+jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
+oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
+4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
+mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
+emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
+-----END CERTIFICATE-----
+
+# Issuer: O=FNMT-RCM OU=AC RAIZ FNMT-RCM
+# Subject: O=FNMT-RCM OU=AC RAIZ FNMT-RCM
+# Label: "AC RAIZ FNMT-RCM"
+# Serial: 485876308206448804701554682760554759
+# MD5 Fingerprint: e2:09:04:b4:d3:bd:d1:a0:14:fd:1a:d2:47:c4:57:1d
+# SHA1 Fingerprint: ec:50:35:07:b2:15:c4:95:62:19:e2:a8:9a:5b:42:99:2c:4c:2c:20
+# SHA256 Fingerprint: eb:c5:57:0c:29:01:8c:4d:67:b1:aa:12:7b:af:12:f7:03:b4:61:1e:bc:17:b7:da:b5:57:38:94:17:9b:93:fa
+-----BEGIN CERTIFICATE-----
+MIIFgzCCA2ugAwIBAgIPXZONMGc2yAYdGsdUhGkHMA0GCSqGSIb3DQEBCwUAMDsx
+CzAJBgNVBAYTAkVTMREwDwYDVQQKDAhGTk1ULVJDTTEZMBcGA1UECwwQQUMgUkFJ
+WiBGTk1ULVJDTTAeFw0wODEwMjkxNTU5NTZaFw0zMDAxMDEwMDAwMDBaMDsxCzAJ
+BgNVBAYTAkVTMREwDwYDVQQKDAhGTk1ULVJDTTEZMBcGA1UECwwQQUMgUkFJWiBG
+Tk1ULVJDTTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBALpxgHpMhm5/
+yBNtwMZ9HACXjywMI7sQmkCpGreHiPibVmr75nuOi5KOpyVdWRHbNi63URcfqQgf
+BBckWKo3Shjf5TnUV/3XwSyRAZHiItQDwFj8d0fsjz50Q7qsNI1NOHZnjrDIbzAz
+WHFctPVrbtQBULgTfmxKo0nRIBnuvMApGGWn3v7v3QqQIecaZ5JCEJhfTzC8PhxF
+tBDXaEAUwED653cXeuYLj2VbPNmaUtu1vZ5Gzz3rkQUCwJaydkxNEJY7kvqcfw+Z
+374jNUUeAlz+taibmSXaXvMiwzn15Cou08YfxGyqxRxqAQVKL9LFwag0Jl1mpdIC
+IfkYtwb1TplvqKtMUejPUBjFd8g5CSxJkjKZqLsXF3mwWsXmo8RZZUc1g16p6DUL
+mbvkzSDGm0oGObVo/CK67lWMK07q87Hj/LaZmtVC+nFNCM+HHmpxffnTtOmlcYF7
+wk5HlqX2doWjKI/pgG6BU6VtX7hI+cL5NqYuSf+4lsKMB7ObiFj86xsc3i1w4peS
+MKGJ47xVqCfWS+2QrYv6YyVZLag13cqXM7zlzced0ezvXg5KkAYmY6252TUtB7p2
+ZSysV4999AeU14ECll2jB0nVetBX+RvnU0Z1qrB5QstocQjpYL05ac70r8NWQMet
+UqIJ5G+GR4of6ygnXYMgrwTJbFaai0b1AgMBAAGjgYMwgYAwDwYDVR0TAQH/BAUw
+AwEB/zAOBgNVHQ8BAf8EBAMCAQYwHQYDVR0OBBYEFPd9xf3E6Jobd2Sn9R2gzL+H
+YJptMD4GA1UdIAQ3MDUwMwYEVR0gADArMCkGCCsGAQUFBwIBFh1odHRwOi8vd3d3
+LmNlcnQuZm5tdC5lcy9kcGNzLzANBgkqhkiG9w0BAQsFAAOCAgEAB5BK3/MjTvDD
+nFFlm5wioooMhfNzKWtN/gHiqQxjAb8EZ6WdmF/9ARP67Jpi6Yb+tmLSbkyU+8B1
+RXxlDPiyN8+sD8+Nb/kZ94/sHvJwnvDKuO+3/3Y3dlv2bojzr2IyIpMNOmqOFGYM
+LVN0V2Ue1bLdI4E7pWYjJ2cJj+F3qkPNZVEI7VFY/uY5+ctHhKQV8Xa7pO6kO8Rf
+77IzlhEYt8llvhjho6Tc+hj507wTmzl6NLrTQfv6MooqtyuGC2mDOL7Nii4LcK2N
+JpLuHvUBKwrZ1pebbuCoGRw6IYsMHkCtA+fdZn71uSANA+iW+YJF1DngoABd15jm
+fZ5nc8OaKveri6E6FO80vFIOiZiaBECEHX5FaZNXzuvO+FB8TxxuBEOb+dY7Ixjp
+6o7RTUaN8Tvkasq6+yO3m/qZASlaWFot4/nUbQ4mrcFuNLwy+AwF+mWj2zs3gyLp
+1txyM/1d8iC9djwj2ij3+RvrWWTV3F9yfiD8zYm1kGdNYno/Tq0dwzn+evQoFt9B
+9kiABdcPUXmsEKvU7ANm5mqwujGSQkBqvjrTcuFqN1W8rB2Vt2lh8kORdOag0wok
+RqEIr9baRRmW1FMdW4R58MD3R++Lj8UGrp1MYp3/RgT408m2ECVAdf4WqslKYIYv
+uu8wd+RU4riEmViAqhOLUTpPSPaLtrM=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Amazon Root CA 1 O=Amazon
+# Subject: CN=Amazon Root CA 1 O=Amazon
+# Label: "Amazon Root CA 1"
+# Serial: 143266978916655856878034712317230054538369994
+# MD5 Fingerprint: 43:c6:bf:ae:ec:fe:ad:2f:18:c6:88:68:30:fc:c8:e6
+# SHA1 Fingerprint: 8d:a7:f9:65:ec:5e:fc:37:91:0f:1c:6e:59:fd:c1:cc:6a:6e:de:16
+# SHA256 Fingerprint: 8e:cd:e6:88:4f:3d:87:b1:12:5b:a3:1a:c3:fc:b1:3d:70:16:de:7f:57:cc:90:4f:e1:cb:97:c6:ae:98:19:6e
+-----BEGIN CERTIFICATE-----
+MIIDQTCCAimgAwIBAgITBmyfz5m/jAo54vB4ikPmljZbyjANBgkqhkiG9w0BAQsF
+ADA5MQswCQYDVQQGEwJVUzEPMA0GA1UEChMGQW1hem9uMRkwFwYDVQQDExBBbWF6
+b24gUm9vdCBDQSAxMB4XDTE1MDUyNjAwMDAwMFoXDTM4MDExNzAwMDAwMFowOTEL
+MAkGA1UEBhMCVVMxDzANBgNVBAoTBkFtYXpvbjEZMBcGA1UEAxMQQW1hem9uIFJv
+b3QgQ0EgMTCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBALJ4gHHKeNXj
+ca9HgFB0fW7Y14h29Jlo91ghYPl0hAEvrAIthtOgQ3pOsqTQNroBvo3bSMgHFzZM
+9O6II8c+6zf1tRn4SWiw3te5djgdYZ6k/oI2peVKVuRF4fn9tBb6dNqcmzU5L/qw
+IFAGbHrQgLKm+a/sRxmPUDgH3KKHOVj4utWp+UhnMJbulHheb4mjUcAwhmahRWa6
+VOujw5H5SNz/0egwLX0tdHA114gk957EWW67c4cX8jJGKLhD+rcdqsq08p8kDi1L
+93FcXmn/6pUCyziKrlA4b9v7LWIbxcceVOF34GfID5yHI9Y/QCB/IIDEgEw+OyQm
+jgSubJrIqg0CAwEAAaNCMEAwDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMC
+AYYwHQYDVR0OBBYEFIQYzIU07LwMlJQuCFmcx7IQTgoIMA0GCSqGSIb3DQEBCwUA
+A4IBAQCY8jdaQZChGsV2USggNiMOruYou6r4lK5IpDB/G/wkjUu0yKGX9rbxenDI
+U5PMCCjjmCXPI6T53iHTfIUJrU6adTrCC2qJeHZERxhlbI1Bjjt/msv0tadQ1wUs
+N+gDS63pYaACbvXy8MWy7Vu33PqUXHeeE6V/Uq2V8viTO96LXFvKWlJbYK8U90vv
+o/ufQJVtMVT8QtPHRh8jrdkPSHCa2XV4cdFyQzR1bldZwgJcJmApzyMZFo6IQ6XU
+5MsI+yMRQ+hDKXJioaldXgjUkK642M4UwtBV8ob2xJNDd2ZhwLnoQdeXeGADbkpy
+rqXRfboQnoZsG4q5WTP468SQvvG5
+-----END CERTIFICATE-----
+
+# Issuer: CN=Amazon Root CA 2 O=Amazon
+# Subject: CN=Amazon Root CA 2 O=Amazon
+# Label: "Amazon Root CA 2"
+# Serial: 143266982885963551818349160658925006970653239
+# MD5 Fingerprint: c8:e5:8d:ce:a8:42:e2:7a:c0:2a:5c:7c:9e:26:bf:66
+# SHA1 Fingerprint: 5a:8c:ef:45:d7:a6:98:59:76:7a:8c:8b:44:96:b5:78:cf:47:4b:1a
+# SHA256 Fingerprint: 1b:a5:b2:aa:8c:65:40:1a:82:96:01:18:f8:0b:ec:4f:62:30:4d:83:ce:c4:71:3a:19:c3:9c:01:1e:a4:6d:b4
+-----BEGIN CERTIFICATE-----
+MIIFQTCCAymgAwIBAgITBmyf0pY1hp8KD+WGePhbJruKNzANBgkqhkiG9w0BAQwF
+ADA5MQswCQYDVQQGEwJVUzEPMA0GA1UEChMGQW1hem9uMRkwFwYDVQQDExBBbWF6
+b24gUm9vdCBDQSAyMB4XDTE1MDUyNjAwMDAwMFoXDTQwMDUyNjAwMDAwMFowOTEL
+MAkGA1UEBhMCVVMxDzANBgNVBAoTBkFtYXpvbjEZMBcGA1UEAxMQQW1hem9uIFJv
+b3QgQ0EgMjCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK2Wny2cSkxK
+gXlRmeyKy2tgURO8TW0G/LAIjd0ZEGrHJgw12MBvIITplLGbhQPDW9tK6Mj4kHbZ
+W0/jTOgGNk3Mmqw9DJArktQGGWCsN0R5hYGCrVo34A3MnaZMUnbqQ523BNFQ9lXg
+1dKmSYXpN+nKfq5clU1Imj+uIFptiJXZNLhSGkOQsL9sBbm2eLfq0OQ6PBJTYv9K
+8nu+NQWpEjTj82R0Yiw9AElaKP4yRLuH3WUnAnE72kr3H9rN9yFVkE8P7K6C4Z9r
+2UXTu/Bfh+08LDmG2j/e7HJV63mjrdvdfLC6HM783k81ds8P+HgfajZRRidhW+me
+z/CiVX18JYpvL7TFz4QuK/0NURBs+18bvBt+xa47mAExkv8LV/SasrlX6avvDXbR
+8O70zoan4G7ptGmh32n2M8ZpLpcTnqWHsFcQgTfJU7O7f/aS0ZzQGPSSbtqDT6Zj
+mUyl+17vIWR6IF9sZIUVyzfpYgwLKhbcAS4y2j5L9Z469hdAlO+ekQiG+r5jqFoz
+7Mt0Q5X5bGlSNscpb/xVA1wf+5+9R+vnSUeVC06JIglJ4PVhHvG/LopyboBZ/1c6
++XUyo05f7O0oYtlNc/LMgRdg7c3r3NunysV+Ar3yVAhU/bQtCSwXVEqY0VThUWcI
+0u1ufm8/0i2BWSlmy5A5lREedCf+3euvAgMBAAGjQjBAMA8GA1UdEwEB/wQFMAMB
+Af8wDgYDVR0PAQH/BAQDAgGGMB0GA1UdDgQWBBSwDPBMMPQFWAJI/TPlUq9LhONm
+UjANBgkqhkiG9w0BAQwFAAOCAgEAqqiAjw54o+Ci1M3m9Zh6O+oAA7CXDpO8Wqj2
+LIxyh6mx/H9z/WNxeKWHWc8w4Q0QshNabYL1auaAn6AFC2jkR2vHat+2/XcycuUY
++gn0oJMsXdKMdYV2ZZAMA3m3MSNjrXiDCYZohMr/+c8mmpJ5581LxedhpxfL86kS
+k5Nrp+gvU5LEYFiwzAJRGFuFjWJZY7attN6a+yb3ACfAXVU3dJnJUH/jWS5E4ywl
+7uxMMne0nxrpS10gxdr9HIcWxkPo1LsmmkVwXqkLN1PiRnsn/eBG8om3zEK2yygm
+btmlyTrIQRNg91CMFa6ybRoVGld45pIq2WWQgj9sAq+uEjonljYE1x2igGOpm/Hl
+urR8FLBOybEfdF849lHqm/osohHUqS0nGkWxr7JOcQ3AWEbWaQbLU8uz/mtBzUF+
+fUwPfHJ5elnNXkoOrJupmHN5fLT0zLm4BwyydFy4x2+IoZCn9Kr5v2c69BoVYh63
+n749sSmvZ6ES8lgQGVMDMBu4Gon2nL2XA46jCfMdiyHxtN/kHNGfZQIG6lzWE7OE
+76KlXIx3KadowGuuQNKotOrN8I1LOJwZmhsoVLiJkO/KdYE+HvJkJMcYr07/R54H
+9jVlpNMKVv/1F2Rs76giJUmTtt8AF9pYfl3uxRuw0dFfIRDH+fO6AgonB8Xx1sfT
+4PsJYGw=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Amazon Root CA 3 O=Amazon
+# Subject: CN=Amazon Root CA 3 O=Amazon
+# Label: "Amazon Root CA 3"
+# Serial: 143266986699090766294700635381230934788665930
+# MD5 Fingerprint: a0:d4:ef:0b:f7:b5:d8:49:95:2a:ec:f5:c4:fc:81:87
+# SHA1 Fingerprint: 0d:44:dd:8c:3c:8c:1a:1a:58:75:64:81:e9:0f:2e:2a:ff:b3:d2:6e
+# SHA256 Fingerprint: 18:ce:6c:fe:7b:f1:4e:60:b2:e3:47:b8:df:e8:68:cb:31:d0:2e:bb:3a:da:27:15:69:f5:03:43:b4:6d:b3:a4
+-----BEGIN CERTIFICATE-----
+MIIBtjCCAVugAwIBAgITBmyf1XSXNmY/Owua2eiedgPySjAKBggqhkjOPQQDAjA5
+MQswCQYDVQQGEwJVUzEPMA0GA1UEChMGQW1hem9uMRkwFwYDVQQDExBBbWF6b24g
+Um9vdCBDQSAzMB4XDTE1MDUyNjAwMDAwMFoXDTQwMDUyNjAwMDAwMFowOTELMAkG
+A1UEBhMCVVMxDzANBgNVBAoTBkFtYXpvbjEZMBcGA1UEAxMQQW1hem9uIFJvb3Qg
+Q0EgMzBZMBMGByqGSM49AgEGCCqGSM49AwEHA0IABCmXp8ZBf8ANm+gBG1bG8lKl
+ui2yEujSLtf6ycXYqm0fc4E7O5hrOXwzpcVOho6AF2hiRVd9RFgdszflZwjrZt6j
+QjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgGGMB0GA1UdDgQWBBSr
+ttvXBp43rDCGB5Fwx5zEGbF4wDAKBggqhkjOPQQDAgNJADBGAiEA4IWSoxe3jfkr
+BqWTrBqYaGFy+uGh0PsceGCmQ5nFuMQCIQCcAu/xlJyzlvnrxir4tiz+OpAUFteM
+YyRIHN8wfdVoOw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Amazon Root CA 4 O=Amazon
+# Subject: CN=Amazon Root CA 4 O=Amazon
+# Label: "Amazon Root CA 4"
+# Serial: 143266989758080763974105200630763877849284878
+# MD5 Fingerprint: 89:bc:27:d5:eb:17:8d:06:6a:69:d5:fd:89:47:b4:cd
+# SHA1 Fingerprint: f6:10:84:07:d6:f8:bb:67:98:0c:c2:e2:44:c2:eb:ae:1c:ef:63:be
+# SHA256 Fingerprint: e3:5d:28:41:9e:d0:20:25:cf:a6:90:38:cd:62:39:62:45:8d:a5:c6:95:fb:de:a3:c2:2b:0b:fb:25:89:70:92
+-----BEGIN CERTIFICATE-----
+MIIB8jCCAXigAwIBAgITBmyf18G7EEwpQ+Vxe3ssyBrBDjAKBggqhkjOPQQDAzA5
+MQswCQYDVQQGEwJVUzEPMA0GA1UEChMGQW1hem9uMRkwFwYDVQQDExBBbWF6b24g
+Um9vdCBDQSA0MB4XDTE1MDUyNjAwMDAwMFoXDTQwMDUyNjAwMDAwMFowOTELMAkG
+A1UEBhMCVVMxDzANBgNVBAoTBkFtYXpvbjEZMBcGA1UEAxMQQW1hem9uIFJvb3Qg
+Q0EgNDB2MBAGByqGSM49AgEGBSuBBAAiA2IABNKrijdPo1MN/sGKe0uoe0ZLY7Bi
+9i0b2whxIdIA6GO9mif78DluXeo9pcmBqqNbIJhFXRbb/egQbeOc4OO9X4Ri83Bk
+M6DLJC9wuoihKqB1+IGuYgbEgds5bimwHvouXKNCMEAwDwYDVR0TAQH/BAUwAwEB
+/zAOBgNVHQ8BAf8EBAMCAYYwHQYDVR0OBBYEFNPsxzplbszh2naaVvuc84ZtV+WB
+MAoGCCqGSM49BAMDA2gAMGUCMDqLIfG9fhGt0O9Yli/W651+kI0rz2ZVwyzjKKlw
+CkcO8DdZEv8tmZQoTipPNU0zWgIxAOp1AE47xDqUEpHJWEadIRNyp4iciuRMStuW
+1KyLa2tJElMzrdfkviT8tQp21KW8EA==
+-----END CERTIFICATE-----
+
+# Issuer: CN=TUBITAK Kamu SM SSL Kok Sertifikasi - Surum 1 O=Turkiye Bilimsel ve Teknolojik Arastirma Kurumu - TUBITAK OU=Kamu Sertifikasyon Merkezi - Kamu SM
+# Subject: CN=TUBITAK Kamu SM SSL Kok Sertifikasi - Surum 1 O=Turkiye Bilimsel ve Teknolojik Arastirma Kurumu - TUBITAK OU=Kamu Sertifikasyon Merkezi - Kamu SM
+# Label: "TUBITAK Kamu SM SSL Kok Sertifikasi - Surum 1"
+# Serial: 1
+# MD5 Fingerprint: dc:00:81:dc:69:2f:3e:2f:b0:3b:f6:3d:5a:91:8e:49
+# SHA1 Fingerprint: 31:43:64:9b:ec:ce:27:ec:ed:3a:3f:0b:8f:0d:e4:e8:91:dd:ee:ca
+# SHA256 Fingerprint: 46:ed:c3:68:90:46:d5:3a:45:3f:b3:10:4a:b8:0d:ca:ec:65:8b:26:60:ea:16:29:dd:7e:86:79:90:64:87:16
+-----BEGIN CERTIFICATE-----
+MIIEYzCCA0ugAwIBAgIBATANBgkqhkiG9w0BAQsFADCB0jELMAkGA1UEBhMCVFIx
+GDAWBgNVBAcTD0dlYnplIC0gS29jYWVsaTFCMEAGA1UEChM5VHVya2l5ZSBCaWxp
+bXNlbCB2ZSBUZWtub2xvamlrIEFyYXN0aXJtYSBLdXJ1bXUgLSBUVUJJVEFLMS0w
+KwYDVQQLEyRLYW11IFNlcnRpZmlrYXN5b24gTWVya2V6aSAtIEthbXUgU00xNjA0
+BgNVBAMTLVRVQklUQUsgS2FtdSBTTSBTU0wgS29rIFNlcnRpZmlrYXNpIC0gU3Vy
+dW0gMTAeFw0xMzExMjUwODI1NTVaFw00MzEwMjUwODI1NTVaMIHSMQswCQYDVQQG
+EwJUUjEYMBYGA1UEBxMPR2ViemUgLSBLb2NhZWxpMUIwQAYDVQQKEzlUdXJraXll
+IEJpbGltc2VsIHZlIFRla25vbG9qaWsgQXJhc3Rpcm1hIEt1cnVtdSAtIFRVQklU
+QUsxLTArBgNVBAsTJEthbXUgU2VydGlmaWthc3lvbiBNZXJrZXppIC0gS2FtdSBT
+TTE2MDQGA1UEAxMtVFVCSVRBSyBLYW11IFNNIFNTTCBLb2sgU2VydGlmaWthc2kg
+LSBTdXJ1bSAxMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAr3UwM6q7
+a9OZLBI3hNmNe5eA027n/5tQlT6QlVZC1xl8JoSNkvoBHToP4mQ4t4y86Ij5iySr
+LqP1N+RAjhgleYN1Hzv/bKjFxlb4tO2KRKOrbEz8HdDc72i9z+SqzvBV96I01INr
+N3wcwv61A+xXzry0tcXtAA9TNypN9E8Mg/uGz8v+jE69h/mniyFXnHrfA2eJLJ2X
+YacQuFWQfw4tJzh03+f92k4S400VIgLI4OD8D62K18lUUMw7D8oWgITQUVbDjlZ/
+iSIzL+aFCr2lqBs23tPcLG07xxO9WSMs5uWk99gL7eqQQESolbuT1dCANLZGeA4f
+AJNG4e7p+exPFwIDAQABo0IwQDAdBgNVHQ4EFgQUZT/HiobGPN08VFw1+DrtUgxH
+V8gwDgYDVR0PAQH/BAQDAgEGMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQEL
+BQADggEBACo/4fEyjq7hmFxLXs9rHmoJ0iKpEsdeV31zVmSAhHqT5Am5EM2fKifh
+AHe+SMg1qIGf5LgsyX8OsNJLN13qudULXjS99HMpw+0mFZx+CFOKWI3QSyjfwbPf
+IPP54+M638yclNhOT8NrF7f3cuitZjO1JVOr4PhMqZ398g26rrnZqsZr+ZO7rqu4
+lzwDGrpDxpa5RXI4s6ehlj2Re37AIVNMh+3yC1SVUZPVIqUNivGTDj5UDrDYyU7c
+8jEyVupk+eq1nRZmQnLzf9OxMUP8pI4X8W0jq5Rm+K37DwhuJi1/FwcJsoz7UMCf
+lo3Ptv0AnVoUmr8CRPXBwp8iXqIPoeM=
+-----END CERTIFICATE-----
+
+# Issuer: CN=GDCA TrustAUTH R5 ROOT O=GUANG DONG CERTIFICATE AUTHORITY CO.,LTD.
+# Subject: CN=GDCA TrustAUTH R5 ROOT O=GUANG DONG CERTIFICATE AUTHORITY CO.,LTD.
+# Label: "GDCA TrustAUTH R5 ROOT"
+# Serial: 9009899650740120186
+# MD5 Fingerprint: 63:cc:d9:3d:34:35:5c:6f:53:a3:e2:08:70:48:1f:b4
+# SHA1 Fingerprint: 0f:36:38:5b:81:1a:25:c3:9b:31:4e:83:ca:e9:34:66:70:cc:74:b4
+# SHA256 Fingerprint: bf:ff:8f:d0:44:33:48:7d:6a:8a:a6:0c:1a:29:76:7a:9f:c2:bb:b0:5e:42:0f:71:3a:13:b9:92:89:1d:38:93
+-----BEGIN CERTIFICATE-----
+MIIFiDCCA3CgAwIBAgIIfQmX/vBH6nowDQYJKoZIhvcNAQELBQAwYjELMAkGA1UE
+BhMCQ04xMjAwBgNVBAoMKUdVQU5HIERPTkcgQ0VSVElGSUNBVEUgQVVUSE9SSVRZ
+IENPLixMVEQuMR8wHQYDVQQDDBZHRENBIFRydXN0QVVUSCBSNSBST09UMB4XDTE0
+MTEyNjA1MTMxNVoXDTQwMTIzMTE1NTk1OVowYjELMAkGA1UEBhMCQ04xMjAwBgNV
+BAoMKUdVQU5HIERPTkcgQ0VSVElGSUNBVEUgQVVUSE9SSVRZIENPLixMVEQuMR8w
+HQYDVQQDDBZHRENBIFRydXN0QVVUSCBSNSBST09UMIICIjANBgkqhkiG9w0BAQEF
+AAOCAg8AMIICCgKCAgEA2aMW8Mh0dHeb7zMNOwZ+Vfy1YI92hhJCfVZmPoiC7XJj
+Dp6L3TQsAlFRwxn9WVSEyfFrs0yw6ehGXTjGoqcuEVe6ghWinI9tsJlKCvLriXBj
+TnnEt1u9ol2x8kECK62pOqPseQrsXzrj/e+APK00mxqriCZ7VqKChh/rNYmDf1+u
+KU49tm7srsHwJ5uu4/Ts765/94Y9cnrrpftZTqfrlYwiOXnhLQiPzLyRuEH3FMEj
+qcOtmkVEs7LXLM3GKeJQEK5cy4KOFxg2fZfmiJqwTTQJ9Cy5WmYqsBebnh52nUpm
+MUHfP/vFBu8btn4aRjb3ZGM74zkYI+dndRTVdVeSN72+ahsmUPI2JgaQxXABZG12
+ZuGR224HwGGALrIuL4xwp9E7PLOR5G62xDtw8mySlwnNR30YwPO7ng/Wi64HtloP
+zgsMR6flPri9fcebNaBhlzpBdRfMK5Z3KpIhHtmVdiBnaM8Nvd/WHwlqmuLMc3Gk
+L30SgLdTMEZeS1SZD2fJpcjyIMGC7J0R38IC+xo70e0gmu9lZJIQDSri3nDxGGeC
+jGHeuLzRL5z7D9Ar7Rt2ueQ5Vfj4oR24qoAATILnsn8JuLwwoC8N9VKejveSswoA
+HQBUlwbgsQfZxw9cZX08bVlX5O2ljelAU58VS6Bx9hoh49pwBiFYFIeFd3mqgnkC
+AwEAAaNCMEAwHQYDVR0OBBYEFOLJQJ9NzuiaoXzPDj9lxSmIahlRMA8GA1UdEwEB
+/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgGGMA0GCSqGSIb3DQEBCwUAA4ICAQDRSVfg
+p8xoWLoBDysZzY2wYUWsEe1jUGn4H3++Fo/9nesLqjJHdtJnJO29fDMylyrHBYZm
+DRd9FBUb1Ov9H5r2XpdptxolpAqzkT9fNqyL7FeoPueBihhXOYV0GkLH6VsTX4/5
+COmSdI31R9KrO9b7eGZONn356ZLpBN79SWP8bfsUcZNnL0dKt7n/HipzcEYwv1ry
+L3ml4Y0M2fmyYzeMN2WFcGpcWwlyua1jPLHd+PwyvzeG5LuOmCd+uh8W4XAR8gPf
+JWIyJyYYMoSf/wA6E7qaTfRPuBRwIrHKK5DOKcFw9C+df/KQHtZa37dG/OaG+svg
+IHZ6uqbL9XzeYqWxi+7egmaKTjowHz+Ay60nugxe19CxVsp3cbK1daFQqUBDF8Io
+2c9Si1vIY9RCPqAzekYu9wogRlR+ak8x8YF+QnQ4ZXMn7sZ8uI7XpTrXmKGcjBBV
+09tL7ECQ8s1uV9JiDnxXk7Gnbc2dg7sq5+W2O3FYrf3RRbxake5TFW/TRQl1brqQ
+XR4EzzffHqhmsYzmIGrv/EhOdJhCrylvLmrH+33RZjEizIYAfmaDDEL0vTSSwxrq
+T8p+ck0LcIymSLumoRT2+1hEmRSuqguTaaApJUqlyyvdimYHFngVV3Eb7PVHhPOe
+MTd61X8kreS8/f3MboPoDKi3QWwH3b08hpcv0g==
+-----END CERTIFICATE-----
+
+# Issuer: CN=SSL.com Root Certification Authority RSA O=SSL Corporation
+# Subject: CN=SSL.com Root Certification Authority RSA O=SSL Corporation
+# Label: "SSL.com Root Certification Authority RSA"
+# Serial: 8875640296558310041
+# MD5 Fingerprint: 86:69:12:c0:70:f1:ec:ac:ac:c2:d5:bc:a5:5b:a1:29
+# SHA1 Fingerprint: b7:ab:33:08:d1:ea:44:77:ba:14:80:12:5a:6f:bd:a9:36:49:0c:bb
+# SHA256 Fingerprint: 85:66:6a:56:2e:e0:be:5c:e9:25:c1:d8:89:0a:6f:76:a8:7e:c1:6d:4d:7d:5f:29:ea:74:19:cf:20:12:3b:69
+-----BEGIN CERTIFICATE-----
+MIIF3TCCA8WgAwIBAgIIeyyb0xaAMpkwDQYJKoZIhvcNAQELBQAwfDELMAkGA1UE
+BhMCVVMxDjAMBgNVBAgMBVRleGFzMRAwDgYDVQQHDAdIb3VzdG9uMRgwFgYDVQQK
+DA9TU0wgQ29ycG9yYXRpb24xMTAvBgNVBAMMKFNTTC5jb20gUm9vdCBDZXJ0aWZp
+Y2F0aW9uIEF1dGhvcml0eSBSU0EwHhcNMTYwMjEyMTczOTM5WhcNNDEwMjEyMTcz
+OTM5WjB8MQswCQYDVQQGEwJVUzEOMAwGA1UECAwFVGV4YXMxEDAOBgNVBAcMB0hv
+dXN0b24xGDAWBgNVBAoMD1NTTCBDb3Jwb3JhdGlvbjExMC8GA1UEAwwoU1NMLmNv
+bSBSb290IENlcnRpZmljYXRpb24gQXV0aG9yaXR5IFJTQTCCAiIwDQYJKoZIhvcN
+AQEBBQADggIPADCCAgoCggIBAPkP3aMrfcvQKv7sZ4Wm5y4bunfh4/WvpOz6Sl2R
+xFdHaxh3a3by/ZPkPQ/CFp4LZsNWlJ4Xg4XOVu/yFv0AYvUiCVToZRdOQbngT0aX
+qhvIuG5iXmmxX9sqAn78bMrzQdjt0Oj8P2FI7bADFB0QDksZ4LtO7IZl/zbzXmcC
+C52GVWH9ejjt/uIZALdvoVBidXQ8oPrIJZK0bnoix/geoeOy3ZExqysdBP+lSgQ3
+6YWkMyv94tZVNHwZpEpox7Ko07fKoZOI68GXvIz5HdkihCR0xwQ9aqkpk8zruFvh
+/l8lqjRYyMEjVJ0bmBHDOJx+PYZspQ9AhnwC9FwCTyjLrnGfDzrIM/4RJTXq/LrF
+YD3ZfBjVsqnTdXgDciLKOsMf7yzlLqn6niy2UUb9rwPW6mBo6oUWNmuF6R7As93E
+JNyAKoFBbZQ+yODJgUEAnl6/f8UImKIYLEJAs/lvOCdLToD0PYFH4Ih86hzOtXVc
+US4cK38acijnALXRdMbX5J+tB5O2UzU1/Dfkw/ZdFr4hc96SCvigY2q8lpJqPvi8
+ZVWb3vUNiSYE/CUapiVpy8JtynziWV+XrOvvLsi81xtZPCvM8hnIk2snYxnP/Okm
++Mpxm3+T/jRnhE6Z6/yzeAkzcLpmpnbtG3PrGqUNxCITIJRWCk4sbE6x/c+cCbqi
+M+2HAgMBAAGjYzBhMB0GA1UdDgQWBBTdBAkHovV6fVJTEpKV7jiAJQ2mWTAPBgNV
+HRMBAf8EBTADAQH/MB8GA1UdIwQYMBaAFN0ECQei9Xp9UlMSkpXuOIAlDaZZMA4G
+A1UdDwEB/wQEAwIBhjANBgkqhkiG9w0BAQsFAAOCAgEAIBgRlCn7Jp0cHh5wYfGV
+cpNxJK1ok1iOMq8bs3AD/CUrdIWQPXhq9LmLpZc7tRiRux6n+UBbkflVma8eEdBc
+Hadm47GUBwwyOabqG7B52B2ccETjit3E+ZUfijhDPwGFpUenPUayvOUiaPd7nNgs
+PgohyC0zrL/FgZkxdMF1ccW+sfAjRfSda/wZY52jvATGGAslu1OJD7OAUN5F7kR/
+q5R4ZJjT9ijdh9hwZXT7DrkT66cPYakylszeu+1jTBi7qUD3oFRuIIhxdRjqerQ0
+cuAjJ3dctpDqhiVAq+8zD8ufgr6iIPv2tS0a5sKFsXQP+8hlAqRSAUfdSSLBv9jr
+a6x+3uxjMxW3IwiPxg+NQVrdjsW5j+VFP3jbutIbQLH+cU0/4IGiul607BXgk90I
+H37hVZkLId6Tngr75qNJvTYw/ud3sqB1l7UtgYgXZSD32pAAn8lSzDLKNXz1PQ/Y
+K9f1JmzJBjSWFupwWRoyeXkLtoh/D1JIPb9s2KJELtFOt3JY04kTlf5Eq/jXixtu
+nLwsoFvVagCvXzfh1foQC5ichucmj87w7G6KVwuA406ywKBjYZC6VWg3dGq2ktuf
+oYYitmUnDuy2n0Jg5GfCtdpBC8TTi2EbvPofkSvXRAdeuims2cXp71NIWuuA8ShY
+Ic2wBlX7Jz9TkHCpBB5XJ7k=
+-----END CERTIFICATE-----
+
+# Issuer: CN=SSL.com Root Certification Authority ECC O=SSL Corporation
+# Subject: CN=SSL.com Root Certification Authority ECC O=SSL Corporation
+# Label: "SSL.com Root Certification Authority ECC"
+# Serial: 8495723813297216424
+# MD5 Fingerprint: 2e:da:e4:39:7f:9c:8f:37:d1:70:9f:26:17:51:3a:8e
+# SHA1 Fingerprint: c3:19:7c:39:24:e6:54:af:1b:c4:ab:20:95:7a:e2:c3:0e:13:02:6a
+# SHA256 Fingerprint: 34:17:bb:06:cc:60:07:da:1b:96:1c:92:0b:8a:b4:ce:3f:ad:82:0e:4a:a3:0b:9a:cb:c4:a7:4e:bd:ce:bc:65
+-----BEGIN CERTIFICATE-----
+MIICjTCCAhSgAwIBAgIIdebfy8FoW6gwCgYIKoZIzj0EAwIwfDELMAkGA1UEBhMC
+VVMxDjAMBgNVBAgMBVRleGFzMRAwDgYDVQQHDAdIb3VzdG9uMRgwFgYDVQQKDA9T
+U0wgQ29ycG9yYXRpb24xMTAvBgNVBAMMKFNTTC5jb20gUm9vdCBDZXJ0aWZpY2F0
+aW9uIEF1dGhvcml0eSBFQ0MwHhcNMTYwMjEyMTgxNDAzWhcNNDEwMjEyMTgxNDAz
+WjB8MQswCQYDVQQGEwJVUzEOMAwGA1UECAwFVGV4YXMxEDAOBgNVBAcMB0hvdXN0
+b24xGDAWBgNVBAoMD1NTTCBDb3Jwb3JhdGlvbjExMC8GA1UEAwwoU1NMLmNvbSBS
+b290IENlcnRpZmljYXRpb24gQXV0aG9yaXR5IEVDQzB2MBAGByqGSM49AgEGBSuB
+BAAiA2IABEVuqVDEpiM2nl8ojRfLliJkP9x6jh3MCLOicSS6jkm5BBtHllirLZXI
+7Z4INcgn64mMU1jrYor+8FsPazFSY0E7ic3s7LaNGdM0B9y7xgZ/wkWV7Mt/qCPg
+CemB+vNH06NjMGEwHQYDVR0OBBYEFILRhXMw5zUE044CkvvlpNHEIejNMA8GA1Ud
+EwEB/wQFMAMBAf8wHwYDVR0jBBgwFoAUgtGFczDnNQTTjgKS++Wk0cQh6M0wDgYD
+VR0PAQH/BAQDAgGGMAoGCCqGSM49BAMCA2cAMGQCMG/n61kRpGDPYbCWe+0F+S8T
+kdzt5fxQaxFGRrMcIQBiu77D5+jNB5n5DQtdcj7EqgIwH7y6C+IwJPt8bYBVCpk+
+gA0z5Wajs6O7pdWLjwkspl1+4vAHCGht0nxpbl/f5Wpl
+-----END CERTIFICATE-----
+
+# Issuer: CN=SSL.com EV Root Certification Authority RSA R2 O=SSL Corporation
+# Subject: CN=SSL.com EV Root Certification Authority RSA R2 O=SSL Corporation
+# Label: "SSL.com EV Root Certification Authority RSA R2"
+# Serial: 6248227494352943350
+# MD5 Fingerprint: e1:1e:31:58:1a:ae:54:53:02:f6:17:6a:11:7b:4d:95
+# SHA1 Fingerprint: 74:3a:f0:52:9b:d0:32:a0:f4:4a:83:cd:d4:ba:a9:7b:7c:2e:c4:9a
+# SHA256 Fingerprint: 2e:7b:f1:6c:c2:24:85:a7:bb:e2:aa:86:96:75:07:61:b0:ae:39:be:3b:2f:e9:d0:cc:6d:4e:f7:34:91:42:5c
+-----BEGIN CERTIFICATE-----
+MIIF6zCCA9OgAwIBAgIIVrYpzTS8ePYwDQYJKoZIhvcNAQELBQAwgYIxCzAJBgNV
+BAYTAlVTMQ4wDAYDVQQIDAVUZXhhczEQMA4GA1UEBwwHSG91c3RvbjEYMBYGA1UE
+CgwPU1NMIENvcnBvcmF0aW9uMTcwNQYDVQQDDC5TU0wuY29tIEVWIFJvb3QgQ2Vy
+dGlmaWNhdGlvbiBBdXRob3JpdHkgUlNBIFIyMB4XDTE3MDUzMTE4MTQzN1oXDTQy
+MDUzMDE4MTQzN1owgYIxCzAJBgNVBAYTAlVTMQ4wDAYDVQQIDAVUZXhhczEQMA4G
+A1UEBwwHSG91c3RvbjEYMBYGA1UECgwPU1NMIENvcnBvcmF0aW9uMTcwNQYDVQQD
+DC5TU0wuY29tIEVWIFJvb3QgQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkgUlNBIFIy
+MIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAjzZlQOHWTcDXtOlG2mvq
+M0fNTPl9fb69LT3w23jhhqXZuglXaO1XPqDQCEGD5yhBJB/jchXQARr7XnAjssuf
+OePPxU7Gkm0mxnu7s9onnQqG6YE3Bf7wcXHswxzpY6IXFJ3vG2fThVUCAtZJycxa
+4bH3bzKfydQ7iEGonL3Lq9ttewkfokxykNorCPzPPFTOZw+oz12WGQvE43LrrdF9
+HSfvkusQv1vrO6/PgN3B0pYEW3p+pKk8OHakYo6gOV7qd89dAFmPZiw+B6KjBSYR
+aZfqhbcPlgtLyEDhULouisv3D5oi53+aNxPN8k0TayHRwMwi8qFG9kRpnMphNQcA
+b9ZhCBHqurj26bNg5U257J8UZslXWNvNh2n4ioYSA0e/ZhN2rHd9NCSFg83XqpyQ
+Gp8hLH94t2S42Oim9HizVcuE0jLEeK6jj2HdzghTreyI/BXkmg3mnxp3zkyPuBQV
+PWKchjgGAGYS5Fl2WlPAApiiECtoRHuOec4zSnaqW4EWG7WK2NAAe15itAnWhmMO
+pgWVSbooi4iTsjQc2KRVbrcc0N6ZVTsj9CLg+SlmJuwgUHfbSguPvuUCYHBBXtSu
+UDkiFCbLsjtzdFVHB3mBOagwE0TlBIqulhMlQg+5U8Sb/M3kHN48+qvWBkofZ6aY
+MBzdLNvcGJVXZsb/XItW9XcCAwEAAaNjMGEwDwYDVR0TAQH/BAUwAwEB/zAfBgNV
+HSMEGDAWgBT5YLvU49U09rj1BoAlp3PbRmmonjAdBgNVHQ4EFgQU+WC71OPVNPa4
+9QaAJadz20ZpqJ4wDgYDVR0PAQH/BAQDAgGGMA0GCSqGSIb3DQEBCwUAA4ICAQBW
+s47LCp1Jjr+kxJG7ZhcFUZh1++VQLHqe8RT6q9OKPv+RKY9ji9i0qVQBDb6Thi/5
+Sm3HXvVX+cpVHBK+Rw82xd9qt9t1wkclf7nxY/hoLVUE0fKNsKTPvDxeH3jnpaAg
+cLAExbf3cqfeIg29MyVGjGSSJuM+LmOW2puMPfgYCdcDzH2GguDKBAdRUNf/ktUM
+79qGn5nX67evaOI5JpS6aLe/g9Pqemc9YmeuJeVy6OLk7K4S9ksrPJ/psEDzOFSz
+/bdoyNrGj1E8svuR3Bznm53htw1yj+KkxKl4+esUrMZDBcJlOSgYAsOCsp0FvmXt
+ll9ldDz7CTUue5wT/RsPXcdtgTpWD8w74a8CLyKsRspGPKAcTNZEtF4uXBVmCeEm
+Kf7GUmG6sXP/wwyc5WxqlD8UykAWlYTzWamsX0xhk23RO8yilQwipmdnRC652dKK
+QbNmC1r7fSOl8hqw/96bg5Qu0T/fkreRrwU7ZcegbLHNYhLDkBvjJc40vG93drEQ
+w/cFGsDWr3RiSBd3kmmQYRzelYB0VI8YHMPzA9C/pEN1hlMYegouCRw2n5H9gooi
+S9EOUCXdywMMF8mDAAhONU2Ki+3wApRmLER/y5UnlhetCTCstnEXbosX9hwJ1C07
+mKVx01QT2WDz9UtmT/rx7iASjbSsV7FFY6GsdqnC+w==
+-----END CERTIFICATE-----
+
+# Issuer: CN=SSL.com EV Root Certification Authority ECC O=SSL Corporation
+# Subject: CN=SSL.com EV Root Certification Authority ECC O=SSL Corporation
+# Label: "SSL.com EV Root Certification Authority ECC"
+# Serial: 3182246526754555285
+# MD5 Fingerprint: 59:53:22:65:83:42:01:54:c0:ce:42:b9:5a:7c:f2:90
+# SHA1 Fingerprint: 4c:dd:51:a3:d1:f5:20:32:14:b0:c6:c5:32:23:03:91:c7:46:42:6d
+# SHA256 Fingerprint: 22:a2:c1:f7:bd:ed:70:4c:c1:e7:01:b5:f4:08:c3:10:88:0f:e9:56:b5:de:2a:4a:44:f9:9c:87:3a:25:a7:c8
+-----BEGIN CERTIFICATE-----
+MIIClDCCAhqgAwIBAgIILCmcWxbtBZUwCgYIKoZIzj0EAwIwfzELMAkGA1UEBhMC
+VVMxDjAMBgNVBAgMBVRleGFzMRAwDgYDVQQHDAdIb3VzdG9uMRgwFgYDVQQKDA9T
+U0wgQ29ycG9yYXRpb24xNDAyBgNVBAMMK1NTTC5jb20gRVYgUm9vdCBDZXJ0aWZp
+Y2F0aW9uIEF1dGhvcml0eSBFQ0MwHhcNMTYwMjEyMTgxNTIzWhcNNDEwMjEyMTgx
+NTIzWjB/MQswCQYDVQQGEwJVUzEOMAwGA1UECAwFVGV4YXMxEDAOBgNVBAcMB0hv
+dXN0b24xGDAWBgNVBAoMD1NTTCBDb3Jwb3JhdGlvbjE0MDIGA1UEAwwrU1NMLmNv
+bSBFViBSb290IENlcnRpZmljYXRpb24gQXV0aG9yaXR5IEVDQzB2MBAGByqGSM49
+AgEGBSuBBAAiA2IABKoSR5CYG/vvw0AHgyBO8TCCogbR8pKGYfL2IWjKAMTH6kMA
+VIbc/R/fALhBYlzccBYy3h+Z1MzFB8gIH2EWB1E9fVwHU+M1OIzfzZ/ZLg1Kthku
+WnBaBu2+8KGwytAJKaNjMGEwHQYDVR0OBBYEFFvKXuXe0oGqzagtZFG22XKbl+ZP
+MA8GA1UdEwEB/wQFMAMBAf8wHwYDVR0jBBgwFoAUW8pe5d7SgarNqC1kUbbZcpuX
+5k8wDgYDVR0PAQH/BAQDAgGGMAoGCCqGSM49BAMCA2gAMGUCMQCK5kCJN+vp1RPZ
+ytRrJPOwPYdGWBrssd9v+1a6cGvHOMzosYxPD/fxZ3YOg9AeUY8CMD32IygmTMZg
+h5Mmm7I1HrrW9zzRHM76JTymGoEVW/MSD2zuZYrJh6j5B+BimoxcSg==
+-----END CERTIFICATE-----
+
+# Issuer: CN=GlobalSign O=GlobalSign OU=GlobalSign Root CA - R6
+# Subject: CN=GlobalSign O=GlobalSign OU=GlobalSign Root CA - R6
+# Label: "GlobalSign Root CA - R6"
+# Serial: 1417766617973444989252670301619537
+# MD5 Fingerprint: 4f:dd:07:e4:d4:22:64:39:1e:0c:37:42:ea:d1:c6:ae
+# SHA1 Fingerprint: 80:94:64:0e:b5:a7:a1:ca:11:9c:1f:dd:d5:9f:81:02:63:a7:fb:d1
+# SHA256 Fingerprint: 2c:ab:ea:fe:37:d0:6c:a2:2a:ba:73:91:c0:03:3d:25:98:29:52:c4:53:64:73:49:76:3a:3a:b5:ad:6c:cf:69
+-----BEGIN CERTIFICATE-----
+MIIFgzCCA2ugAwIBAgIORea7A4Mzw4VlSOb/RVEwDQYJKoZIhvcNAQEMBQAwTDEg
+MB4GA1UECxMXR2xvYmFsU2lnbiBSb290IENBIC0gUjYxEzARBgNVBAoTCkdsb2Jh
+bFNpZ24xEzARBgNVBAMTCkdsb2JhbFNpZ24wHhcNMTQxMjEwMDAwMDAwWhcNMzQx
+MjEwMDAwMDAwWjBMMSAwHgYDVQQLExdHbG9iYWxTaWduIFJvb3QgQ0EgLSBSNjET
+MBEGA1UEChMKR2xvYmFsU2lnbjETMBEGA1UEAxMKR2xvYmFsU2lnbjCCAiIwDQYJ
+KoZIhvcNAQEBBQADggIPADCCAgoCggIBAJUH6HPKZvnsFMp7PPcNCPG0RQssgrRI
+xutbPK6DuEGSMxSkb3/pKszGsIhrxbaJ0cay/xTOURQh7ErdG1rG1ofuTToVBu1k
+ZguSgMpE3nOUTvOniX9PeGMIyBJQbUJmL025eShNUhqKGoC3GYEOfsSKvGRMIRxD
+aNc9PIrFsmbVkJq3MQbFvuJtMgamHvm566qjuL++gmNQ0PAYid/kD3n16qIfKtJw
+LnvnvJO7bVPiSHyMEAc4/2ayd2F+4OqMPKq0pPbzlUoSB239jLKJz9CgYXfIWHSw
+1CM69106yqLbnQneXUQtkPGBzVeS+n68UARjNN9rkxi+azayOeSsJDa38O+2HBNX
+k7besvjihbdzorg1qkXy4J02oW9UivFyVm4uiMVRQkQVlO6jxTiWm05OWgtH8wY2
+SXcwvHE35absIQh1/OZhFj931dmRl4QKbNQCTXTAFO39OfuD8l4UoQSwC+n+7o/h
+bguyCLNhZglqsQY6ZZZZwPA1/cnaKI0aEYdwgQqomnUdnjqGBQCe24DWJfncBZ4n
+WUx2OVvq+aWh2IMP0f/fMBH5hc8zSPXKbWQULHpYT9NLCEnFlWQaYw55PfWzjMpY
+rZxCRXluDocZXFSxZba/jJvcE+kNb7gu3GduyYsRtYQUigAZcIN5kZeR1Bonvzce
+MgfYFGM8KEyvAgMBAAGjYzBhMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMBAf8EBTAD
+AQH/MB0GA1UdDgQWBBSubAWjkxPioufi1xzWx/B/yGdToDAfBgNVHSMEGDAWgBSu
+bAWjkxPioufi1xzWx/B/yGdToDANBgkqhkiG9w0BAQwFAAOCAgEAgyXt6NH9lVLN
+nsAEoJFp5lzQhN7craJP6Ed41mWYqVuoPId8AorRbrcWc+ZfwFSY1XS+wc3iEZGt
+Ixg93eFyRJa0lV7Ae46ZeBZDE1ZXs6KzO7V33EByrKPrmzU+sQghoefEQzd5Mr61
+55wsTLxDKZmOMNOsIeDjHfrYBzN2VAAiKrlNIC5waNrlU/yDXNOd8v9EDERm8tLj
+vUYAGm0CuiVdjaExUd1URhxN25mW7xocBFymFe944Hn+Xds+qkxV/ZoVqW/hpvvf
+cDDpw+5CRu3CkwWJ+n1jez/QcYF8AOiYrg54NMMl+68KnyBr3TsTjxKM4kEaSHpz
+oHdpx7Zcf4LIHv5YGygrqGytXm3ABdJ7t+uA/iU3/gKbaKxCXcPu9czc8FB10jZp
+nOZ7BN9uBmm23goJSFmH63sUYHpkqmlD75HHTOwY3WzvUy2MmeFe8nI+z1TIvWfs
+pA9MRf/TuTAjB0yPEL+GltmZWrSZVxykzLsViVO6LAUP5MSeGbEYNNVMnbrt9x+v
+JJUEeKgDu+6B5dpffItKoZB0JaezPkvILFa9x8jvOOJckvB595yEunQtYQEgfn7R
+8k8HWV+LLUNS60YMlOH1Zkd5d9VUWx+tJDfLRVpOoERIyNiwmcUVhAn21klJwGW4
+5hpxbqCo8YLoRT5s1gLXCmeDBVrJpBA=
+-----END CERTIFICATE-----
+
+# Issuer: CN=OISTE WISeKey Global Root GC CA O=WISeKey OU=OISTE Foundation Endorsed
+# Subject: CN=OISTE WISeKey Global Root GC CA O=WISeKey OU=OISTE Foundation Endorsed
+# Label: "OISTE WISeKey Global Root GC CA"
+# Serial: 44084345621038548146064804565436152554
+# MD5 Fingerprint: a9:d6:b9:2d:2f:93:64:f8:a5:69:ca:91:e9:68:07:23
+# SHA1 Fingerprint: e0:11:84:5e:34:de:be:88:81:b9:9c:f6:16:26:d1:96:1f:c3:b9:31
+# SHA256 Fingerprint: 85:60:f9:1c:36:24:da:ba:95:70:b5:fe:a0:db:e3:6f:f1:1a:83:23:be:94:86:85:4f:b3:f3:4a:55:71:19:8d
+-----BEGIN CERTIFICATE-----
+MIICaTCCAe+gAwIBAgIQISpWDK7aDKtARb8roi066jAKBggqhkjOPQQDAzBtMQsw
+CQYDVQQGEwJDSDEQMA4GA1UEChMHV0lTZUtleTEiMCAGA1UECxMZT0lTVEUgRm91
+bmRhdGlvbiBFbmRvcnNlZDEoMCYGA1UEAxMfT0lTVEUgV0lTZUtleSBHbG9iYWwg
+Um9vdCBHQyBDQTAeFw0xNzA1MDkwOTQ4MzRaFw00MjA1MDkwOTU4MzNaMG0xCzAJ
+BgNVBAYTAkNIMRAwDgYDVQQKEwdXSVNlS2V5MSIwIAYDVQQLExlPSVNURSBGb3Vu
+ZGF0aW9uIEVuZG9yc2VkMSgwJgYDVQQDEx9PSVNURSBXSVNlS2V5IEdsb2JhbCBS
+b290IEdDIENBMHYwEAYHKoZIzj0CAQYFK4EEACIDYgAETOlQwMYPchi82PG6s4ni
+eUqjFqdrVCTbUf/q9Akkwwsin8tqJ4KBDdLArzHkdIJuyiXZjHWd8dvQmqJLIX4W
+p2OQ0jnUsYd4XxiWD1AbNTcPasbc2RNNpI6QN+a9WzGRo1QwUjAOBgNVHQ8BAf8E
+BAMCAQYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQUSIcUrOPDnpBgOtfKie7T
+rYy0UGYwEAYJKwYBBAGCNxUBBAMCAQAwCgYIKoZIzj0EAwMDaAAwZQIwJsdpW9zV
+57LnyAyMjMPdeYwbY9XJUpROTYJKcx6ygISpJcBMWm1JKWB4E+J+SOtkAjEA2zQg
+Mgj/mkkCtojeFK9dbJlxjRo/i9fgojaGHAeCOnZT/cKi7e97sIBPWA9LUzm9
+-----END CERTIFICATE-----
+
+# Issuer: CN=UCA Global G2 Root O=UniTrust
+# Subject: CN=UCA Global G2 Root O=UniTrust
+# Label: "UCA Global G2 Root"
+# Serial: 124779693093741543919145257850076631279
+# MD5 Fingerprint: 80:fe:f0:c4:4a:f0:5c:62:32:9f:1c:ba:78:a9:50:f8
+# SHA1 Fingerprint: 28:f9:78:16:19:7a:ff:18:25:18:aa:44:fe:c1:a0:ce:5c:b6:4c:8a
+# SHA256 Fingerprint: 9b:ea:11:c9:76:fe:01:47:64:c1:be:56:a6:f9:14:b5:a5:60:31:7a:bd:99:88:39:33:82:e5:16:1a:a0:49:3c
+-----BEGIN CERTIFICATE-----
+MIIFRjCCAy6gAwIBAgIQXd+x2lqj7V2+WmUgZQOQ7zANBgkqhkiG9w0BAQsFADA9
+MQswCQYDVQQGEwJDTjERMA8GA1UECgwIVW5pVHJ1c3QxGzAZBgNVBAMMElVDQSBH
+bG9iYWwgRzIgUm9vdDAeFw0xNjAzMTEwMDAwMDBaFw00MDEyMzEwMDAwMDBaMD0x
+CzAJBgNVBAYTAkNOMREwDwYDVQQKDAhVbmlUcnVzdDEbMBkGA1UEAwwSVUNBIEds
+b2JhbCBHMiBSb290MIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAxeYr
+b3zvJgUno4Ek2m/LAfmZmqkywiKHYUGRO8vDaBsGxUypK8FnFyIdK+35KYmToni9
+kmugow2ifsqTs6bRjDXVdfkX9s9FxeV67HeToI8jrg4aA3++1NDtLnurRiNb/yzm
+VHqUwCoV8MmNsHo7JOHXaOIxPAYzRrZUEaalLyJUKlgNAQLx+hVRZ2zA+te2G3/R
+VogvGjqNO7uCEeBHANBSh6v7hn4PJGtAnTRnvI3HLYZveT6OqTwXS3+wmeOwcWDc
+C/Vkw85DvG1xudLeJ1uK6NjGruFZfc8oLTW4lVYa8bJYS7cSN8h8s+1LgOGN+jIj
+tm+3SJUIsUROhYw6AlQgL9+/V087OpAh18EmNVQg7Mc/R+zvWr9LesGtOxdQXGLY
+D0tK3Cv6brxzks3sx1DoQZbXqX5t2Okdj4q1uViSukqSKwxW/YDrCPBeKW4bHAyv
+j5OJrdu9o54hyokZ7N+1wxrrFv54NkzWbtA+FxyQF2smuvt6L78RHBgOLXMDj6Dl
+NaBa4kx1HXHhOThTeEDMg5PXCp6dW4+K5OXgSORIskfNTip1KnvyIvbJvgmRlld6
+iIis7nCs+dwp4wwcOxJORNanTrAmyPPZGpeRaOrvjUYG0lZFWJo8DA+DuAUlwznP
+O6Q0ibd5Ei9Hxeepl2n8pndntd978XplFeRhVmUCAwEAAaNCMEAwDgYDVR0PAQH/
+BAQDAgEGMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFIHEjMz15DD/pQwIX4wV
+ZyF0Ad/fMA0GCSqGSIb3DQEBCwUAA4ICAQATZSL1jiutROTL/7lo5sOASD0Ee/oj
+L3rtNtqyzm325p7lX1iPyzcyochltq44PTUbPrw7tgTQvPlJ9Zv3hcU2tsu8+Mg5
+1eRfB70VVJd0ysrtT7q6ZHafgbiERUlMjW+i67HM0cOU2kTC5uLqGOiiHycFutfl
+1qnN3e92mI0ADs0b+gO3joBYDic/UvuUospeZcnWhNq5NXHzJsBPd+aBJ9J3O5oU
+b3n09tDh05S60FdRvScFDcH9yBIw7m+NESsIndTUv4BFFJqIRNow6rSn4+7vW4LV
+PtateJLbXDzz2K36uGt/xDYotgIVilQsnLAXc47QN6MUPJiVAAwpBVueSUmxX8fj
+y88nZY41F7dXyDDZQVu5FLbowg+UMaeUmMxq67XhJ/UQqAHojhJi6IjMtX9Gl8Cb
+EGY4GjZGXyJoPd/JxhMnq1MGrKI8hgZlb7F+sSlEmqO6SWkoaY/X5V+tBIZkbxqg
+DMUIYs6Ao9Dz7GjevjPHF1t/gMRMTLGmhIrDO7gJzRSBuhjjVFc2/tsvfEehOjPI
++Vg7RE+xygKJBJYoaMVLuCaJu9YzL1DV/pqJuhgyklTGW+Cd+V7lDSKb9triyCGy
+YiGqhkCyLmTTX8jjfhFnRR8F/uOi77Oos/N9j/gMHyIfLXC0uAE0djAA5SN4p1bX
+UB+K+wb1whnw0A==
+-----END CERTIFICATE-----
+
+# Issuer: CN=UCA Extended Validation Root O=UniTrust
+# Subject: CN=UCA Extended Validation Root O=UniTrust
+# Label: "UCA Extended Validation Root"
+# Serial: 106100277556486529736699587978573607008
+# MD5 Fingerprint: a1:f3:5f:43:c6:34:9b:da:bf:8c:7e:05:53:ad:96:e2
+# SHA1 Fingerprint: a3:a1:b0:6f:24:61:23:4a:e3:36:a5:c2:37:fc:a6:ff:dd:f0:d7:3a
+# SHA256 Fingerprint: d4:3a:f9:b3:54:73:75:5c:96:84:fc:06:d7:d8:cb:70:ee:5c:28:e7:73:fb:29:4e:b4:1e:e7:17:22:92:4d:24
+-----BEGIN CERTIFICATE-----
+MIIFWjCCA0KgAwIBAgIQT9Irj/VkyDOeTzRYZiNwYDANBgkqhkiG9w0BAQsFADBH
+MQswCQYDVQQGEwJDTjERMA8GA1UECgwIVW5pVHJ1c3QxJTAjBgNVBAMMHFVDQSBF
+eHRlbmRlZCBWYWxpZGF0aW9uIFJvb3QwHhcNMTUwMzEzMDAwMDAwWhcNMzgxMjMx
+MDAwMDAwWjBHMQswCQYDVQQGEwJDTjERMA8GA1UECgwIVW5pVHJ1c3QxJTAjBgNV
+BAMMHFVDQSBFeHRlbmRlZCBWYWxpZGF0aW9uIFJvb3QwggIiMA0GCSqGSIb3DQEB
+AQUAA4ICDwAwggIKAoICAQCpCQcoEwKwmeBkqh5DFnpzsZGgdT6o+uM4AHrsiWog
+D4vFsJszA1qGxliG1cGFu0/GnEBNyr7uaZa4rYEwmnySBesFK5pI0Lh2PpbIILvS
+sPGP2KxFRv+qZ2C0d35qHzwaUnoEPQc8hQ2E0B92CvdqFN9y4zR8V05WAT558aop
+O2z6+I9tTcg1367r3CTueUWnhbYFiN6IXSV8l2RnCdm/WhUFhvMJHuxYMjMR83dk
+sHYf5BA1FxvyDrFspCqjc/wJHx4yGVMR59mzLC52LqGj3n5qiAno8geK+LLNEOfi
+c0CTuwjRP+H8C5SzJe98ptfRr5//lpr1kXuYC3fUfugH0mK1lTnj8/FtDw5lhIpj
+VMWAtuCeS31HJqcBCF3RiJ7XwzJE+oJKCmhUfzhTA8ykADNkUVkLo4KRel7sFsLz
+KuZi2irbWWIQJUoqgQtHB0MGcIfS+pMRKXpITeuUx3BNr2fVUbGAIAEBtHoIppB/
+TuDvB0GHr2qlXov7z1CymlSvw4m6WC31MJixNnI5fkkE/SmnTHnkBVfblLkWU41G
+sx2VYVdWf6/wFlthWG82UBEL2KwrlRYaDh8IzTY0ZRBiZtWAXxQgXy0MoHgKaNYs
+1+lvK9JKBZP8nm9rZ/+I8U6laUpSNwXqxhaN0sSZ0YIrO7o1dfdRUVjzyAfd5LQD
+fwIDAQABo0IwQDAdBgNVHQ4EFgQU2XQ65DA9DfcS3H5aBZ8eNJr34RQwDwYDVR0T
+AQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAYYwDQYJKoZIhvcNAQELBQADggIBADaN
+l8xCFWQpN5smLNb7rhVpLGsaGvdftvkHTFnq88nIua7Mui563MD1sC3AO6+fcAUR
+ap8lTwEpcOPlDOHqWnzcSbvBHiqB9RZLcpHIojG5qtr8nR/zXUACE/xOHAbKsxSQ
+VBcZEhrxH9cMaVr2cXj0lH2RC47skFSOvG+hTKv8dGT9cZr4QQehzZHkPJrgmzI5
+c6sq1WnIeJEmMX3ixzDx/BR4dxIOE/TdFpS/S2d7cFOFyrC78zhNLJA5wA3CXWvp
+4uXViI3WLL+rG761KIcSF3Ru/H38j9CHJrAb+7lsq+KePRXBOy5nAliRn+/4Qh8s
+t2j1da3Ptfb/EX3C8CSlrdP6oDyp+l3cpaDvRKS+1ujl5BOWF3sGPjLtx7dCvHaj
+2GU4Kzg1USEODm8uNBNA4StnDG1KQTAYI1oyVZnJF+A83vbsea0rWBmirSwiGpWO
+vpaQXUJXxPkUAzUrHC1RVwinOt4/5Mi0A3PCwSaAuwtCH60NryZy2sy+s6ODWA2C
+xR9GUeOcGMyNm43sSet1UNWMKFnKdDTajAshqx7qG+XH/RU+wBeq+yNuJkbL+vmx
+cmtpzyKEC2IPrNkZAJSidjzULZrtBJ4tBmIQN1IchXIbJ+XMxjHsN+xjWZsLHXbM
+fjKaiJUINlK73nZfdklJrX+9ZSCyycErdhh2n1ax
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certigna Root CA O=Dhimyotis OU=0002 48146308100036
+# Subject: CN=Certigna Root CA O=Dhimyotis OU=0002 48146308100036
+# Label: "Certigna Root CA"
+# Serial: 269714418870597844693661054334862075617
+# MD5 Fingerprint: 0e:5c:30:62:27:eb:5b:bc:d7:ae:62:ba:e9:d5:df:77
+# SHA1 Fingerprint: 2d:0d:52:14:ff:9e:ad:99:24:01:74:20:47:6e:6c:85:27:27:f5:43
+# SHA256 Fingerprint: d4:8d:3d:23:ee:db:50:a4:59:e5:51:97:60:1c:27:77:4b:9d:7b:18:c9:4d:5a:05:95:11:a1:02:50:b9:31:68
+-----BEGIN CERTIFICATE-----
+MIIGWzCCBEOgAwIBAgIRAMrpG4nxVQMNo+ZBbcTjpuEwDQYJKoZIhvcNAQELBQAw
+WjELMAkGA1UEBhMCRlIxEjAQBgNVBAoMCURoaW15b3RpczEcMBoGA1UECwwTMDAw
+MiA0ODE0NjMwODEwMDAzNjEZMBcGA1UEAwwQQ2VydGlnbmEgUm9vdCBDQTAeFw0x
+MzEwMDEwODMyMjdaFw0zMzEwMDEwODMyMjdaMFoxCzAJBgNVBAYTAkZSMRIwEAYD
+VQQKDAlEaGlteW90aXMxHDAaBgNVBAsMEzAwMDIgNDgxNDYzMDgxMDAwMzYxGTAX
+BgNVBAMMEENlcnRpZ25hIFJvb3QgQ0EwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAw
+ggIKAoICAQDNGDllGlmx6mQWDoyUJJV8g9PFOSbcDO8WV43X2KyjQn+Cyu3NW9sO
+ty3tRQgXstmzy9YXUnIo245Onoq2C/mehJpNdt4iKVzSs9IGPjA5qXSjklYcoW9M
+CiBtnyN6tMbaLOQdLNyzKNAT8kxOAkmhVECe5uUFoC2EyP+YbNDrihqECB63aCPu
+I9Vwzm1RaRDuoXrC0SIxwoKF0vJVdlB8JXrJhFwLrN1CTivngqIkicuQstDuI7pm
+TLtipPlTWmR7fJj6o0ieD5Wupxj0auwuA0Wv8HT4Ks16XdG+RCYyKfHx9WzMfgIh
+C59vpD++nVPiz32pLHxYGpfhPTc3GGYo0kDFUYqMwy3OU4gkWGQwFsWq4NYKpkDf
+ePb1BHxpE4S80dGnBs8B92jAqFe7OmGtBIyT46388NtEbVncSVmurJqZNjBBe3Yz
+IoejwpKGbvlw7q6Hh5UbxHq9MfPU0uWZ/75I7HX1eBYdpnDBfzwboZL7z8g81sWT
+Co/1VTp2lc5ZmIoJlXcymoO6LAQ6l73UL77XbJuiyn1tJslV1c/DeVIICZkHJC1k
+JWumIWmbat10TWuXekG9qxf5kBdIjzb5LdXF2+6qhUVB+s06RbFo5jZMm5BX7CO5
+hwjCxAnxl4YqKE3idMDaxIzb3+KhF1nOJFl0Mdp//TBt2dzhauH8XwIDAQABo4IB
+GjCCARYwDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwHQYDVR0OBBYE
+FBiHVuBud+4kNTxOc5of1uHieX4rMB8GA1UdIwQYMBaAFBiHVuBud+4kNTxOc5of
+1uHieX4rMEQGA1UdIAQ9MDswOQYEVR0gADAxMC8GCCsGAQUFBwIBFiNodHRwczov
+L3d3d3cuY2VydGlnbmEuZnIvYXV0b3JpdGVzLzBtBgNVHR8EZjBkMC+gLaArhilo
+dHRwOi8vY3JsLmNlcnRpZ25hLmZyL2NlcnRpZ25hcm9vdGNhLmNybDAxoC+gLYYr
+aHR0cDovL2NybC5kaGlteW90aXMuY29tL2NlcnRpZ25hcm9vdGNhLmNybDANBgkq
+hkiG9w0BAQsFAAOCAgEAlLieT/DjlQgi581oQfccVdV8AOItOoldaDgvUSILSo3L
+6btdPrtcPbEo/uRTVRPPoZAbAh1fZkYJMyjhDSSXcNMQH+pkV5a7XdrnxIxPTGRG
+HVyH41neQtGbqH6mid2PHMkwgu07nM3A6RngatgCdTer9zQoKJHyBApPNeNgJgH6
+0BGM+RFq7q89w1DTj18zeTyGqHNFkIwgtnJzFyO+B2XleJINugHA64wcZr+shncB
+lA2c5uk5jR+mUYyZDDl34bSb+hxnV29qao6pK0xXeXpXIs/NX2NGjVxZOob4Mkdi
+o2cNGJHc+6Zr9UhhcyNZjgKnvETq9Emd8VRY+WCv2hikLyhF3HqgiIZd8zvn/yk1
+gPxkQ5Tm4xxvvq0OKmOZK8l+hfZx6AYDlf7ej0gcWtSS6Cvu5zHbugRqh5jnxV/v
+faci9wHYTfmJ0A6aBVmknpjZbyvKcL5kwlWj9Omvw5Ip3IgWJJk8jSaYtlu3zM63
+Nwf9JtmYhST/WSMDmu2dnajkXjjO11INb9I/bbEFa0nOipFGc/T2L/Coc3cOZayh
+jWZSaX5LaAzHHjcng6WMxwLkFM1JAbBzs/3GkDpv0mztO+7skb6iQ12LAEpmJURw
+3kAP+HwV96LOPNdeE4yBFxgX0b3xdxA61GU5wSesVywlVP+i2k+KYTlerj1KjL0=
+-----END CERTIFICATE-----
+
+# Issuer: CN=emSign Root CA - G1 O=eMudhra Technologies Limited OU=emSign PKI
+# Subject: CN=emSign Root CA - G1 O=eMudhra Technologies Limited OU=emSign PKI
+# Label: "emSign Root CA - G1"
+# Serial: 235931866688319308814040
+# MD5 Fingerprint: 9c:42:84:57:dd:cb:0b:a7:2e:95:ad:b6:f3:da:bc:ac
+# SHA1 Fingerprint: 8a:c7:ad:8f:73:ac:4e:c1:b5:75:4d:a5:40:f4:fc:cf:7c:b5:8e:8c
+# SHA256 Fingerprint: 40:f6:af:03:46:a9:9a:a1:cd:1d:55:5a:4e:9c:ce:62:c7:f9:63:46:03:ee:40:66:15:83:3d:c8:c8:d0:03:67
+-----BEGIN CERTIFICATE-----
+MIIDlDCCAnygAwIBAgIKMfXkYgxsWO3W2DANBgkqhkiG9w0BAQsFADBnMQswCQYD
+VQQGEwJJTjETMBEGA1UECxMKZW1TaWduIFBLSTElMCMGA1UEChMcZU11ZGhyYSBU
+ZWNobm9sb2dpZXMgTGltaXRlZDEcMBoGA1UEAxMTZW1TaWduIFJvb3QgQ0EgLSBH
+MTAeFw0xODAyMTgxODMwMDBaFw00MzAyMTgxODMwMDBaMGcxCzAJBgNVBAYTAklO
+MRMwEQYDVQQLEwplbVNpZ24gUEtJMSUwIwYDVQQKExxlTXVkaHJhIFRlY2hub2xv
+Z2llcyBMaW1pdGVkMRwwGgYDVQQDExNlbVNpZ24gUm9vdCBDQSAtIEcxMIIBIjAN
+BgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAk0u76WaK7p1b1TST0Bsew+eeuGQz
+f2N4aLTNLnF115sgxk0pvLZoYIr3IZpWNVrzdr3YzZr/k1ZLpVkGoZM0Kd0WNHVO
+8oG0x5ZOrRkVUkr+PHB1cM2vK6sVmjM8qrOLqs1D/fXqcP/tzxE7lM5OMhbTI0Aq
+d7OvPAEsbO2ZLIvZTmmYsvePQbAyeGHWDV/D+qJAkh1cF+ZwPjXnorfCYuKrpDhM
+tTk1b+oDafo6VGiFbdbyL0NVHpENDtjVaqSW0RM8LHhQ6DqS0hdW5TUaQBw+jSzt
+Od9C4INBdN+jzcKGYEho42kLVACL5HZpIQ15TjQIXhTCzLG3rdd8cIrHhQIDAQAB
+o0IwQDAdBgNVHQ4EFgQU++8Nhp6w492pufEhF38+/PB3KxowDgYDVR0PAQH/BAQD
+AgEGMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQELBQADggEBAFn/8oz1h31x
+PaOfG1vR2vjTnGs2vZupYeveFix0PZ7mddrXuqe8QhfnPZHr5X3dPpzxz5KsbEjM
+wiI/aTvFthUvozXGaCocV685743QNcMYDHsAVhzNixl03r4PEuDQqqE/AjSxcM6d
+GNYIAwlG7mDgfrbESQRRfXBgvKqy/3lyeqYdPV8q+Mri/Tm3R7nrft8EI6/6nAYH
+6ftjk4BAtcZsCjEozgyfz7MjNYBBjWzEN3uBL4ChQEKF6dk4jeihU80Bv2noWgby
+RQuQ+q7hv53yrlc8pa6yVvSLZUDp/TGBLPQ5Cdjua6e0ph0VpZj3AYHYhX3zUVxx
+iN66zB+Afko=
+-----END CERTIFICATE-----
+
+# Issuer: CN=emSign ECC Root CA - G3 O=eMudhra Technologies Limited OU=emSign PKI
+# Subject: CN=emSign ECC Root CA - G3 O=eMudhra Technologies Limited OU=emSign PKI
+# Label: "emSign ECC Root CA - G3"
+# Serial: 287880440101571086945156
+# MD5 Fingerprint: ce:0b:72:d1:9f:88:8e:d0:50:03:e8:e3:b8:8b:67:40
+# SHA1 Fingerprint: 30:43:fa:4f:f2:57:dc:a0:c3:80:ee:2e:58:ea:78:b2:3f:e6:bb:c1
+# SHA256 Fingerprint: 86:a1:ec:ba:08:9c:4a:8d:3b:be:27:34:c6:12:ba:34:1d:81:3e:04:3c:f9:e8:a8:62:cd:5c:57:a3:6b:be:6b
+-----BEGIN CERTIFICATE-----
+MIICTjCCAdOgAwIBAgIKPPYHqWhwDtqLhDAKBggqhkjOPQQDAzBrMQswCQYDVQQG
+EwJJTjETMBEGA1UECxMKZW1TaWduIFBLSTElMCMGA1UEChMcZU11ZGhyYSBUZWNo
+bm9sb2dpZXMgTGltaXRlZDEgMB4GA1UEAxMXZW1TaWduIEVDQyBSb290IENBIC0g
+RzMwHhcNMTgwMjE4MTgzMDAwWhcNNDMwMjE4MTgzMDAwWjBrMQswCQYDVQQGEwJJ
+TjETMBEGA1UECxMKZW1TaWduIFBLSTElMCMGA1UEChMcZU11ZGhyYSBUZWNobm9s
+b2dpZXMgTGltaXRlZDEgMB4GA1UEAxMXZW1TaWduIEVDQyBSb290IENBIC0gRzMw
+djAQBgcqhkjOPQIBBgUrgQQAIgNiAAQjpQy4LRL1KPOxst3iAhKAnjlfSU2fySU0
+WXTsuwYc58Byr+iuL+FBVIcUqEqy6HyC5ltqtdyzdc6LBtCGI79G1Y4PPwT01xyS
+fvalY8L1X44uT6EYGQIrMgqCZH0Wk9GjQjBAMB0GA1UdDgQWBBR8XQKEE9TMipuB
+zhccLikenEhjQjAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUwAwEB/zAKBggq
+hkjOPQQDAwNpADBmAjEAvvNhzwIQHWSVB7gYboiFBS+DCBeQyh+KTOgNG3qxrdWB
+CUfvO6wIBHxcmbHtRwfSAjEAnbpV/KlK6O3t5nYBQnvI+GDZjVGLVTv7jHvrZQnD
++JbNR6iC8hZVdyR+EhCVBCyj
+-----END CERTIFICATE-----
+
+# Issuer: CN=emSign Root CA - C1 O=eMudhra Inc OU=emSign PKI
+# Subject: CN=emSign Root CA - C1 O=eMudhra Inc OU=emSign PKI
+# Label: "emSign Root CA - C1"
+# Serial: 825510296613316004955058
+# MD5 Fingerprint: d8:e3:5d:01:21:fa:78:5a:b0:df:ba:d2:ee:2a:5f:68
+# SHA1 Fingerprint: e7:2e:f1:df:fc:b2:09:28:cf:5d:d4:d5:67:37:b1:51:cb:86:4f:01
+# SHA256 Fingerprint: 12:56:09:aa:30:1d:a0:a2:49:b9:7a:82:39:cb:6a:34:21:6f:44:dc:ac:9f:39:54:b1:42:92:f2:e8:c8:60:8f
+-----BEGIN CERTIFICATE-----
+MIIDczCCAlugAwIBAgILAK7PALrEzzL4Q7IwDQYJKoZIhvcNAQELBQAwVjELMAkG
+A1UEBhMCVVMxEzARBgNVBAsTCmVtU2lnbiBQS0kxFDASBgNVBAoTC2VNdWRocmEg
+SW5jMRwwGgYDVQQDExNlbVNpZ24gUm9vdCBDQSAtIEMxMB4XDTE4MDIxODE4MzAw
+MFoXDTQzMDIxODE4MzAwMFowVjELMAkGA1UEBhMCVVMxEzARBgNVBAsTCmVtU2ln
+biBQS0kxFDASBgNVBAoTC2VNdWRocmEgSW5jMRwwGgYDVQQDExNlbVNpZ24gUm9v
+dCBDQSAtIEMxMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAz+upufGZ
+BczYKCFK83M0UYRWEPWgTywS4/oTmifQz/l5GnRfHXk5/Fv4cI7gklL35CX5VIPZ
+HdPIWoU/Xse2B+4+wM6ar6xWQio5JXDWv7V7Nq2s9nPczdcdioOl+yuQFTdrHCZH
+3DspVpNqs8FqOp099cGXOFgFixwR4+S0uF2FHYP+eF8LRWgYSKVGczQ7/g/IdrvH
+GPMF0Ybzhe3nudkyrVWIzqa2kbBPrH4VI5b2P/AgNBbeCsbEBEV5f6f9vtKppa+c
+xSMq9zwhbL2vj07FOrLzNBL834AaSaTUqZX3noleoomslMuoaJuvimUnzYnu3Yy1
+aylwQ6BpC+S5DwIDAQABo0IwQDAdBgNVHQ4EFgQU/qHgcB4qAzlSWkK+XJGFehiq
+TbUwDgYDVR0PAQH/BAQDAgEGMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQEL
+BQADggEBAMJKVvoVIXsoounlHfv4LcQ5lkFMOycsxGwYFYDGrK9HWS8mC+M2sO87
+/kOXSTKZEhVb3xEp/6tT+LvBeA+snFOvV71ojD1pM/CjoCNjO2RnIkSt1XHLVip4
+kqNPEjE2NuLe/gDEo2APJ62gsIq1NnpSob0n9CAnYuhNlCQT5AoE6TyrLshDCUrG
+YQTlSTR+08TI9Q/Aqum6VF7zYytPT1DU/rl7mYw9wC68AivTxEDkigcxHpvOJpkT
++xHqmiIMERnHXhuBUDDIlhJu58tBf5E7oke3VIAb3ADMmpDqw8NQBmIMMMAVSKeo
+WXzhriKi4gp6D/piq1JM4fHfyr6DDUI=
+-----END CERTIFICATE-----
+
+# Issuer: CN=emSign ECC Root CA - C3 O=eMudhra Inc OU=emSign PKI
+# Subject: CN=emSign ECC Root CA - C3 O=eMudhra Inc OU=emSign PKI
+# Label: "emSign ECC Root CA - C3"
+# Serial: 582948710642506000014504
+# MD5 Fingerprint: 3e:53:b3:a3:81:ee:d7:10:f8:d3:b0:1d:17:92:f5:d5
+# SHA1 Fingerprint: b6:af:43:c2:9b:81:53:7d:f6:ef:6b:c3:1f:1f:60:15:0c:ee:48:66
+# SHA256 Fingerprint: bc:4d:80:9b:15:18:9d:78:db:3e:1d:8c:f4:f9:72:6a:79:5d:a1:64:3c:a5:f1:35:8e:1d:db:0e:dc:0d:7e:b3
+-----BEGIN CERTIFICATE-----
+MIICKzCCAbGgAwIBAgIKe3G2gla4EnycqDAKBggqhkjOPQQDAzBaMQswCQYDVQQG
+EwJVUzETMBEGA1UECxMKZW1TaWduIFBLSTEUMBIGA1UEChMLZU11ZGhyYSBJbmMx
+IDAeBgNVBAMTF2VtU2lnbiBFQ0MgUm9vdCBDQSAtIEMzMB4XDTE4MDIxODE4MzAw
+MFoXDTQzMDIxODE4MzAwMFowWjELMAkGA1UEBhMCVVMxEzARBgNVBAsTCmVtU2ln
+biBQS0kxFDASBgNVBAoTC2VNdWRocmEgSW5jMSAwHgYDVQQDExdlbVNpZ24gRUND
+IFJvb3QgQ0EgLSBDMzB2MBAGByqGSM49AgEGBSuBBAAiA2IABP2lYa57JhAd6bci
+MK4G9IGzsUJxlTm801Ljr6/58pc1kjZGDoeVjbk5Wum739D+yAdBPLtVb4Ojavti
+sIGJAnB9SMVK4+kiVCJNk7tCDK93nCOmfddhEc5lx/h//vXyqaNCMEAwHQYDVR0O
+BBYEFPtaSNCAIEDyqOkAB2kZd6fmw/TPMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMB
+Af8EBTADAQH/MAoGCCqGSM49BAMDA2gAMGUCMQC02C8Cif22TGK6Q04ThHK1rt0c
+3ta13FaPWEBaLd4gTCKDypOofu4SQMfWh0/434UCMBwUZOR8loMRnLDRWmFLpg9J
+0wD8ofzkpf9/rdcw0Md3f76BB1UwUCAU9Vc4CqgxUQ==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Hongkong Post Root CA 3 O=Hongkong Post
+# Subject: CN=Hongkong Post Root CA 3 O=Hongkong Post
+# Label: "Hongkong Post Root CA 3"
+# Serial: 46170865288971385588281144162979347873371282084
+# MD5 Fingerprint: 11:fc:9f:bd:73:30:02:8a:fd:3f:f3:58:b9:cb:20:f0
+# SHA1 Fingerprint: 58:a2:d0:ec:20:52:81:5b:c1:f3:f8:64:02:24:4e:c2:8e:02:4b:02
+# SHA256 Fingerprint: 5a:2f:c0:3f:0c:83:b0:90:bb:fa:40:60:4b:09:88:44:6c:76:36:18:3d:f9:84:6e:17:10:1a:44:7f:b8:ef:d6
+-----BEGIN CERTIFICATE-----
+MIIFzzCCA7egAwIBAgIUCBZfikyl7ADJk0DfxMauI7gcWqQwDQYJKoZIhvcNAQEL
+BQAwbzELMAkGA1UEBhMCSEsxEjAQBgNVBAgTCUhvbmcgS29uZzESMBAGA1UEBxMJ
+SG9uZyBLb25nMRYwFAYDVQQKEw1Ib25na29uZyBQb3N0MSAwHgYDVQQDExdIb25n
+a29uZyBQb3N0IFJvb3QgQ0EgMzAeFw0xNzA2MDMwMjI5NDZaFw00MjA2MDMwMjI5
+NDZaMG8xCzAJBgNVBAYTAkhLMRIwEAYDVQQIEwlIb25nIEtvbmcxEjAQBgNVBAcT
+CUhvbmcgS29uZzEWMBQGA1UEChMNSG9uZ2tvbmcgUG9zdDEgMB4GA1UEAxMXSG9u
+Z2tvbmcgUG9zdCBSb290IENBIDMwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIK
+AoICAQCziNfqzg8gTr7m1gNt7ln8wlffKWihgw4+aMdoWJwcYEuJQwy51BWy7sFO
+dem1p+/l6TWZ5Mwc50tfjTMwIDNT2aa71T4Tjukfh0mtUC1Qyhi+AViiE3CWu4mI
+VoBc+L0sPOFMV4i707mV78vH9toxdCim5lSJ9UExyuUmGs2C4HDaOym71QP1mbpV
+9WTRYA6ziUm4ii8F0oRFKHyPaFASePwLtVPLwpgchKOesL4jpNrcyCse2m5FHomY
+2vkALgbpDDtw1VAliJnLzXNg99X/NWfFobxeq81KuEXryGgeDQ0URhLj0mRiikKY
+vLTGCAj4/ahMZJx2Ab0vqWwzD9g/KLg8aQFChn5pwckGyuV6RmXpwtZQQS4/t+Tt
+bNe/JgERohYpSms0BpDsE9K2+2p20jzt8NYt3eEV7KObLyzJPivkaTv/ciWxNoZb
+x39ri1UbSsUgYT2uy1DhCDq+sI9jQVMwCFk8mB13umOResoQUGC/8Ne8lYePl8X+
+l2oBlKN8W4UdKjk60FSh0Tlxnf0h+bV78OLgAo9uliQlLKAeLKjEiafv7ZkGL7YK
+TE/bosw3Gq9HhS2KX8Q0NEwA/RiTZxPRN+ZItIsGxVd7GYYKecsAyVKvQv83j+Gj
+Hno9UKtjBucVtT+2RTeUN7F+8kjDf8V1/peNRY8apxpyKBpADwIDAQABo2MwYTAP
+BgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQEAwIBBjAfBgNVHSMEGDAWgBQXnc0e
+i9Y5K3DTXNSguB+wAPzFYTAdBgNVHQ4EFgQUF53NHovWOStw01zUoLgfsAD8xWEw
+DQYJKoZIhvcNAQELBQADggIBAFbVe27mIgHSQpsY1Q7XZiNc4/6gx5LS6ZStS6LG
+7BJ8dNVI0lkUmcDrudHr9EgwW62nV3OZqdPlt9EuWSRY3GguLmLYauRwCy0gUCCk
+MpXRAJi70/33MvJJrsZ64Ee+bs7Lo3I6LWldy8joRTnU+kLBEUx3XZL7av9YROXr
+gZ6voJmtvqkBZss4HTzfQx/0TW60uhdG/H39h4F5ag0zD/ov+BS5gLNdTaqX4fnk
+GMX41TiMJjz98iji7lpJiCzfeT2OnpA8vUFKOt1b9pq0zj8lMH8yfaIDlNDceqFS
+3m6TjRgm/VWsvY+b0s+v54Ysyx8Jb6NvqYTUc79NoXQbTiNg8swOqn+knEwlqLJm
+Ozj/2ZQw9nKEvmhVEA/GcywWaZMH/rFF7buiVWqw2rVKAiUnhde3t4ZEFolsgCs+
+l6mc1X5VTMbeRRAc6uk7nwNT7u56AQIWeNTowr5GdogTPyK7SBIdUgC0An4hGh6c
+JfTzPV4e0hz5sy229zdcxsshTrD3mUcYhcErulWuBurQB7Lcq9CClnXO0lD+mefP
+L5/ndtFhKvshuzHQqp9HpLIiyhY6UFfEW0NnxWViA0kB60PZ2Pierc+xYw5F9KBa
+LJstxabArahH9CdMOA0uG0k7UvToiIMrVCjU8jVStDKDYmlkDJGcn5fqdBb9HxEG
+mpv0
+-----END CERTIFICATE-----
+
+# Issuer: CN=Entrust Root Certification Authority - G4 O=Entrust, Inc. OU=See www.entrust.net/legal-terms/(c) 2015 Entrust, Inc. - for authorized use only
+# Subject: CN=Entrust Root Certification Authority - G4 O=Entrust, Inc. OU=See www.entrust.net/legal-terms/(c) 2015 Entrust, Inc. - for authorized use only
+# Label: "Entrust Root Certification Authority - G4"
+# Serial: 289383649854506086828220374796556676440
+# MD5 Fingerprint: 89:53:f1:83:23:b7:7c:8e:05:f1:8c:71:38:4e:1f:88
+# SHA1 Fingerprint: 14:88:4e:86:26:37:b0:26:af:59:62:5c:40:77:ec:35:29:ba:96:01
+# SHA256 Fingerprint: db:35:17:d1:f6:73:2a:2d:5a:b9:7c:53:3e:c7:07:79:ee:32:70:a6:2f:b4:ac:42:38:37:24:60:e6:f0:1e:88
+-----BEGIN CERTIFICATE-----
+MIIGSzCCBDOgAwIBAgIRANm1Q3+vqTkPAAAAAFVlrVgwDQYJKoZIhvcNAQELBQAw
+gb4xCzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1FbnRydXN0LCBJbmMuMSgwJgYDVQQL
+Ex9TZWUgd3d3LmVudHJ1c3QubmV0L2xlZ2FsLXRlcm1zMTkwNwYDVQQLEzAoYykg
+MjAxNSBFbnRydXN0LCBJbmMuIC0gZm9yIGF1dGhvcml6ZWQgdXNlIG9ubHkxMjAw
+BgNVBAMTKUVudHJ1c3QgUm9vdCBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eSAtIEc0
+MB4XDTE1MDUyNzExMTExNloXDTM3MTIyNzExNDExNlowgb4xCzAJBgNVBAYTAlVT
+MRYwFAYDVQQKEw1FbnRydXN0LCBJbmMuMSgwJgYDVQQLEx9TZWUgd3d3LmVudHJ1
+c3QubmV0L2xlZ2FsLXRlcm1zMTkwNwYDVQQLEzAoYykgMjAxNSBFbnRydXN0LCBJ
+bmMuIC0gZm9yIGF1dGhvcml6ZWQgdXNlIG9ubHkxMjAwBgNVBAMTKUVudHJ1c3Qg
+Um9vdCBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eSAtIEc0MIICIjANBgkqhkiG9w0B
+AQEFAAOCAg8AMIICCgKCAgEAsewsQu7i0TD/pZJH4i3DumSXbcr3DbVZwbPLqGgZ
+2K+EbTBwXX7zLtJTmeH+H17ZSK9dE43b/2MzTdMAArzE+NEGCJR5WIoV3imz/f3E
+T+iq4qA7ec2/a0My3dl0ELn39GjUu9CH1apLiipvKgS1sqbHoHrmSKvS0VnM1n4j
+5pds8ELl3FFLFUHtSUrJ3hCX1nbB76W1NhSXNdh4IjVS70O92yfbYVaCNNzLiGAM
+C1rlLAHGVK/XqsEQe9IFWrhAnoanw5CGAlZSCXqc0ieCU0plUmr1POeo8pyvi73T
+DtTUXm6Hnmo9RR3RXRv06QqsYJn7ibT/mCzPfB3pAqoEmh643IhuJbNsZvc8kPNX
+wbMv9W3y+8qh+CmdRouzavbmZwe+LGcKKh9asj5XxNMhIWNlUpEbsZmOeX7m640A
+2Vqq6nPopIICR5b+W45UYaPrL0swsIsjdXJ8ITzI9vF01Bx7owVV7rtNOzK+mndm
+nqxpkCIHH2E6lr7lmk/MBTwoWdPBDFSoWWG9yHJM6Nyfh3+9nEg2XpWjDrk4JFX8
+dWbrAuMINClKxuMrLzOg2qOGpRKX/YAr2hRC45K9PvJdXmd0LhyIRyk0X+IyqJwl
+N4y6mACXi0mWHv0liqzc2thddG5msP9E36EYxr5ILzeUePiVSj9/E15dWf10hkNj
+c0kCAwEAAaNCMEAwDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwHQYD
+VR0OBBYEFJ84xFYjwznooHFs6FRM5Og6sb9nMA0GCSqGSIb3DQEBCwUAA4ICAQAS
+5UKme4sPDORGpbZgQIeMJX6tuGguW8ZAdjwD+MlZ9POrYs4QjbRaZIxowLByQzTS
+Gwv2LFPSypBLhmb8qoMi9IsabyZIrHZ3CL/FmFz0Jomee8O5ZDIBf9PD3Vht7LGr
+hFV0d4QEJ1JrhkzO3bll/9bGXp+aEJlLdWr+aumXIOTkdnrG0CSqkM0gkLpHZPt/
+B7NTeLUKYvJzQ85BK4FqLoUWlFPUa19yIqtRLULVAJyZv967lDtX/Zr1hstWO1uI
+AeV8KEsD+UmDfLJ/fOPtjqF/YFOOVZ1QNBIPt5d7bIdKROf1beyAN/BYGW5KaHbw
+H5Lk6rWS02FREAutp9lfx1/cH6NcjKF+m7ee01ZvZl4HliDtC3T7Zk6LERXpgUl+
+b7DUUH8i119lAg2m9IUe2K4GS0qn0jFmwvjO5QimpAKWRGhXxNUzzxkvFMSUHHuk
+2fCfDrGA4tGeEWSpiBE6doLlYsKA2KSD7ZPvfC+QsDJMlhVoSFLUmQjAJOgc47Ol
+IQ6SwJAfzyBfyjs4x7dtOvPmRLgOMWuIjnDrnBdSqEGULoe256YSxXXfW8AKbnuk
+5F6G+TaU33fD6Q3AOfF5u0aOq0NZJ7cguyPpVkAh7DE9ZapD8j3fcEThuk0mEDuY
+n/PIjhs4ViFqUZPTkcpG2om3PVODLAgfi49T3f+sHw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Microsoft ECC Root Certificate Authority 2017 O=Microsoft Corporation
+# Subject: CN=Microsoft ECC Root Certificate Authority 2017 O=Microsoft Corporation
+# Label: "Microsoft ECC Root Certificate Authority 2017"
+# Serial: 136839042543790627607696632466672567020
+# MD5 Fingerprint: dd:a1:03:e6:4a:93:10:d1:bf:f0:19:42:cb:fe:ed:67
+# SHA1 Fingerprint: 99:9a:64:c3:7f:f4:7d:9f:ab:95:f1:47:69:89:14:60:ee:c4:c3:c5
+# SHA256 Fingerprint: 35:8d:f3:9d:76:4a:f9:e1:b7:66:e9:c9:72:df:35:2e:e1:5c:fa:c2:27:af:6a:d1:d7:0e:8e:4a:6e:dc:ba:02
+-----BEGIN CERTIFICATE-----
+MIICWTCCAd+gAwIBAgIQZvI9r4fei7FK6gxXMQHC7DAKBggqhkjOPQQDAzBlMQsw
+CQYDVQQGEwJVUzEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMTYwNAYD
+VQQDEy1NaWNyb3NvZnQgRUNDIFJvb3QgQ2VydGlmaWNhdGUgQXV0aG9yaXR5IDIw
+MTcwHhcNMTkxMjE4MjMwNjQ1WhcNNDIwNzE4MjMxNjA0WjBlMQswCQYDVQQGEwJV
+UzEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMTYwNAYDVQQDEy1NaWNy
+b3NvZnQgRUNDIFJvb3QgQ2VydGlmaWNhdGUgQXV0aG9yaXR5IDIwMTcwdjAQBgcq
+hkjOPQIBBgUrgQQAIgNiAATUvD0CQnVBEyPNgASGAlEvaqiBYgtlzPbKnR5vSmZR
+ogPZnZH6thaxjG7efM3beaYvzrvOcS/lpaso7GMEZpn4+vKTEAXhgShC48Zo9OYb
+hGBKia/teQ87zvH2RPUBeMCjVDBSMA4GA1UdDwEB/wQEAwIBhjAPBgNVHRMBAf8E
+BTADAQH/MB0GA1UdDgQWBBTIy5lycFIM+Oa+sgRXKSrPQhDtNTAQBgkrBgEEAYI3
+FQEEAwIBADAKBggqhkjOPQQDAwNoADBlAjBY8k3qDPlfXu5gKcs68tvWMoQZP3zV
+L8KxzJOuULsJMsbG7X7JNpQS5GiFBqIb0C8CMQCZ6Ra0DvpWSNSkMBaReNtUjGUB
+iudQZsIxtzm6uBoiB078a1QWIP8rtedMDE2mT3M=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Microsoft RSA Root Certificate Authority 2017 O=Microsoft Corporation
+# Subject: CN=Microsoft RSA Root Certificate Authority 2017 O=Microsoft Corporation
+# Label: "Microsoft RSA Root Certificate Authority 2017"
+# Serial: 40975477897264996090493496164228220339
+# MD5 Fingerprint: 10:ff:00:ff:cf:c9:f8:c7:7a:c0:ee:35:8e:c9:0f:47
+# SHA1 Fingerprint: 73:a5:e6:4a:3b:ff:83:16:ff:0e:dc:cc:61:8a:90:6e:4e:ae:4d:74
+# SHA256 Fingerprint: c7:41:f7:0f:4b:2a:8d:88:bf:2e:71:c1:41:22:ef:53:ef:10:eb:a0:cf:a5:e6:4c:fa:20:f4:18:85:30:73:e0
+-----BEGIN CERTIFICATE-----
+MIIFqDCCA5CgAwIBAgIQHtOXCV/YtLNHcB6qvn9FszANBgkqhkiG9w0BAQwFADBl
+MQswCQYDVQQGEwJVUzEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMTYw
+NAYDVQQDEy1NaWNyb3NvZnQgUlNBIFJvb3QgQ2VydGlmaWNhdGUgQXV0aG9yaXR5
+IDIwMTcwHhcNMTkxMjE4MjI1MTIyWhcNNDIwNzE4MjMwMDIzWjBlMQswCQYDVQQG
+EwJVUzEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMTYwNAYDVQQDEy1N
+aWNyb3NvZnQgUlNBIFJvb3QgQ2VydGlmaWNhdGUgQXV0aG9yaXR5IDIwMTcwggIi
+MA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDKW76UM4wplZEWCpW9R2LBifOZ
+Nt9GkMml7Xhqb0eRaPgnZ1AzHaGm++DlQ6OEAlcBXZxIQIJTELy/xztokLaCLeX0
+ZdDMbRnMlfl7rEqUrQ7eS0MdhweSE5CAg2Q1OQT85elss7YfUJQ4ZVBcF0a5toW1
+HLUX6NZFndiyJrDKxHBKrmCk3bPZ7Pw71VdyvD/IybLeS2v4I2wDwAW9lcfNcztm
+gGTjGqwu+UcF8ga2m3P1eDNbx6H7JyqhtJqRjJHTOoI+dkC0zVJhUXAoP8XFWvLJ
+jEm7FFtNyP9nTUwSlq31/niol4fX/V4ggNyhSyL71Imtus5Hl0dVe49FyGcohJUc
+aDDv70ngNXtk55iwlNpNhTs+VcQor1fznhPbRiefHqJeRIOkpcrVE7NLP8TjwuaG
+YaRSMLl6IE9vDzhTyzMMEyuP1pq9KsgtsRx9S1HKR9FIJ3Jdh+vVReZIZZ2vUpC6
+W6IYZVcSn2i51BVrlMRpIpj0M+Dt+VGOQVDJNE92kKz8OMHY4Xu54+OU4UZpyw4K
+UGsTuqwPN1q3ErWQgR5WrlcihtnJ0tHXUeOrO8ZV/R4O03QK0dqq6mm4lyiPSMQH
++FJDOvTKVTUssKZqwJz58oHhEmrARdlns87/I6KJClTUFLkqqNfs+avNJVgyeY+Q
+W5g5xAgGwax/Dj0ApQIDAQABo1QwUjAOBgNVHQ8BAf8EBAMCAYYwDwYDVR0TAQH/
+BAUwAwEB/zAdBgNVHQ4EFgQUCctZf4aycI8awznjwNnpv7tNsiMwEAYJKwYBBAGC
+NxUBBAMCAQAwDQYJKoZIhvcNAQEMBQADggIBAKyvPl3CEZaJjqPnktaXFbgToqZC
+LgLNFgVZJ8og6Lq46BrsTaiXVq5lQ7GPAJtSzVXNUzltYkyLDVt8LkS/gxCP81OC
+gMNPOsduET/m4xaRhPtthH80dK2Jp86519efhGSSvpWhrQlTM93uCupKUY5vVau6
+tZRGrox/2KJQJWVggEbbMwSubLWYdFQl3JPk+ONVFT24bcMKpBLBaYVu32TxU5nh
+SnUgnZUP5NbcA/FZGOhHibJXWpS2qdgXKxdJ5XbLwVaZOjex/2kskZGT4d9Mozd2
+TaGf+G0eHdP67Pv0RR0Tbc/3WeUiJ3IrhvNXuzDtJE3cfVa7o7P4NHmJweDyAmH3
+pvwPuxwXC65B2Xy9J6P9LjrRk5Sxcx0ki69bIImtt2dmefU6xqaWM/5TkshGsRGR
+xpl/j8nWZjEgQRCHLQzWwa80mMpkg/sTV9HB8Dx6jKXB/ZUhoHHBk2dxEuqPiApp
+GWSZI1b7rCoucL5mxAyE7+WL85MB+GqQk2dLsmijtWKP6T+MejteD+eMuMZ87zf9
+dOLITzNy4ZQ5bb0Sr74MTnB8G2+NszKTc0QWbej09+CVgI+WXTik9KveCjCHk9hN
+AHFiRSdLOkKEW39lt2c0Ui2cFmuqqNh7o0JMcccMyj6D5KbvtwEwXlGjefVwaaZB
+RA+GsCyRxj3qrg+E
+-----END CERTIFICATE-----
+
+# Issuer: CN=e-Szigno Root CA 2017 O=Microsec Ltd.
+# Subject: CN=e-Szigno Root CA 2017 O=Microsec Ltd.
+# Label: "e-Szigno Root CA 2017"
+# Serial: 411379200276854331539784714
+# MD5 Fingerprint: de:1f:f6:9e:84:ae:a7:b4:21:ce:1e:58:7d:d1:84:98
+# SHA1 Fingerprint: 89:d4:83:03:4f:9e:9a:48:80:5f:72:37:d4:a9:a6:ef:cb:7c:1f:d1
+# SHA256 Fingerprint: be:b0:0b:30:83:9b:9b:c3:2c:32:e4:44:79:05:95:06:41:f2:64:21:b1:5e:d0:89:19:8b:51:8a:e2:ea:1b:99
+-----BEGIN CERTIFICATE-----
+MIICQDCCAeWgAwIBAgIMAVRI7yH9l1kN9QQKMAoGCCqGSM49BAMCMHExCzAJBgNV
+BAYTAkhVMREwDwYDVQQHDAhCdWRhcGVzdDEWMBQGA1UECgwNTWljcm9zZWMgTHRk
+LjEXMBUGA1UEYQwOVkFUSFUtMjM1ODQ0OTcxHjAcBgNVBAMMFWUtU3ppZ25vIFJv
+b3QgQ0EgMjAxNzAeFw0xNzA4MjIxMjA3MDZaFw00MjA4MjIxMjA3MDZaMHExCzAJ
+BgNVBAYTAkhVMREwDwYDVQQHDAhCdWRhcGVzdDEWMBQGA1UECgwNTWljcm9zZWMg
+THRkLjEXMBUGA1UEYQwOVkFUSFUtMjM1ODQ0OTcxHjAcBgNVBAMMFWUtU3ppZ25v
+IFJvb3QgQ0EgMjAxNzBZMBMGByqGSM49AgEGCCqGSM49AwEHA0IABJbcPYrYsHtv
+xie+RJCxs1YVe45DJH0ahFnuY2iyxl6H0BVIHqiQrb1TotreOpCmYF9oMrWGQd+H
+Wyx7xf58etqjYzBhMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgEGMB0G
+A1UdDgQWBBSHERUI0arBeAyxr87GyZDvvzAEwDAfBgNVHSMEGDAWgBSHERUI0arB
+eAyxr87GyZDvvzAEwDAKBggqhkjOPQQDAgNJADBGAiEAtVfd14pVCzbhhkT61Nlo
+jbjcI4qKDdQvfepz7L9NbKgCIQDLpbQS+ue16M9+k/zzNY9vTlp8tLxOsvxyqltZ
++efcMQ==
+-----END CERTIFICATE-----
+
+# Issuer: O=CERTSIGN SA OU=certSIGN ROOT CA G2
+# Subject: O=CERTSIGN SA OU=certSIGN ROOT CA G2
+# Label: "certSIGN Root CA G2"
+# Serial: 313609486401300475190
+# MD5 Fingerprint: 8c:f1:75:8a:c6:19:cf:94:b7:f7:65:20:87:c3:97:c7
+# SHA1 Fingerprint: 26:f9:93:b4:ed:3d:28:27:b0:b9:4b:a7:e9:15:1d:a3:8d:92:e5:32
+# SHA256 Fingerprint: 65:7c:fe:2f:a7:3f:aa:38:46:25:71:f3:32:a2:36:3a:46:fc:e7:02:09:51:71:07:02:cd:fb:b6:ee:da:33:05
+-----BEGIN CERTIFICATE-----
+MIIFRzCCAy+gAwIBAgIJEQA0tk7GNi02MA0GCSqGSIb3DQEBCwUAMEExCzAJBgNV
+BAYTAlJPMRQwEgYDVQQKEwtDRVJUU0lHTiBTQTEcMBoGA1UECxMTY2VydFNJR04g
+Uk9PVCBDQSBHMjAeFw0xNzAyMDYwOTI3MzVaFw00MjAyMDYwOTI3MzVaMEExCzAJ
+BgNVBAYTAlJPMRQwEgYDVQQKEwtDRVJUU0lHTiBTQTEcMBoGA1UECxMTY2VydFNJ
+R04gUk9PVCBDQSBHMjCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAMDF
+dRmRfUR0dIf+DjuW3NgBFszuY5HnC2/OOwppGnzC46+CjobXXo9X69MhWf05N0Iw
+vlDqtg+piNguLWkh59E3GE59kdUWX2tbAMI5Qw02hVK5U2UPHULlj88F0+7cDBrZ
+uIt4ImfkabBoxTzkbFpG583H+u/E7Eu9aqSs/cwoUe+StCmrqzWaTOTECMYmzPhp
+n+Sc8CnTXPnGFiWeI8MgwT0PPzhAsP6CRDiqWhqKa2NYOLQV07YRaXseVO6MGiKs
+cpc/I1mbySKEwQdPzH/iV8oScLumZfNpdWO9lfsbl83kqK/20U6o2YpxJM02PbyW
+xPFsqa7lzw1uKA2wDrXKUXt4FMMgL3/7FFXhEZn91QqhngLjYl/rNUssuHLoPj1P
+rCy7Lobio3aP5ZMqz6WryFyNSwb/EkaseMsUBzXgqd+L6a8VTxaJW732jcZZroiF
+DsGJ6x9nxUWO/203Nit4ZoORUSs9/1F3dmKh7Gc+PoGD4FapUB8fepmrY7+EF3fx
+DTvf95xhszWYijqy7DwaNz9+j5LP2RIUZNoQAhVB/0/E6xyjyfqZ90bp4RjZsbgy
+LcsUDFDYg2WD7rlcz8sFWkz6GZdr1l0T08JcVLwyc6B49fFtHsufpaafItzRUZ6C
+eWRgKRM+o/1Pcmqr4tTluCRVLERLiohEnMqE0yo7AgMBAAGjQjBAMA8GA1UdEwEB
+/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgEGMB0GA1UdDgQWBBSCIS1mxteg4BXrzkwJ
+d8RgnlRuAzANBgkqhkiG9w0BAQsFAAOCAgEAYN4auOfyYILVAzOBywaK8SJJ6ejq
+kX/GM15oGQOGO0MBzwdw5AgeZYWR5hEit/UCI46uuR59H35s5r0l1ZUa8gWmr4UC
+b6741jH/JclKyMeKqdmfS0mbEVeZkkMR3rYzpMzXjWR91M08KCy0mpbqTfXERMQl
+qiCA2ClV9+BB/AYm/7k29UMUA2Z44RGx2iBfRgB4ACGlHgAoYXhvqAEBj500mv/0
+OJD7uNGzcgbJceaBxXntC6Z58hMLnPddDnskk7RI24Zf3lCGeOdA5jGokHZwYa+c
+NywRtYK3qq4kNFtyDGkNzVmf9nGvnAvRCjj5BiKDUyUM/FHE5r7iOZULJK2v0ZXk
+ltd0ZGtxTgI8qoXzIKNDOXZbbFD+mpwUHmUUihW9o4JFWklWatKcsWMy5WHgUyIO
+pwpJ6st+H6jiYoD2EEVSmAYY3qXNL3+q1Ok+CHLsIwMCPKaq2LxndD0UF/tUSxfj
+03k9bWtJySgOLnRQvwzZRjoQhsmnP+mg7H/rpXdYaXHmgwo38oZJar55CJD2AhZk
+PuXaTH4MNMn5X7azKFGnpyuqSfqNZSlO42sTp5SjLVFteAxEy9/eCG/Oo2Sr05WE
+1LlSVHJ7liXMvGnjSG4N0MedJ5qq+BOS3R7fY581qRY27Iy4g/Q9iY/NtBde17MX
+QRBdJ3NghVdJIgc=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Trustwave Global Certification Authority O=Trustwave Holdings, Inc.
+# Subject: CN=Trustwave Global Certification Authority O=Trustwave Holdings, Inc.
+# Label: "Trustwave Global Certification Authority"
+# Serial: 1846098327275375458322922162
+# MD5 Fingerprint: f8:1c:18:2d:2f:ba:5f:6d:a1:6c:bc:c7:ab:91:c7:0e
+# SHA1 Fingerprint: 2f:8f:36:4f:e1:58:97:44:21:59:87:a5:2a:9a:d0:69:95:26:7f:b5
+# SHA256 Fingerprint: 97:55:20:15:f5:dd:fc:3c:87:88:c0:06:94:45:55:40:88:94:45:00:84:f1:00:86:70:86:bc:1a:2b:b5:8d:c8
+-----BEGIN CERTIFICATE-----
+MIIF2jCCA8KgAwIBAgIMBfcOhtpJ80Y1LrqyMA0GCSqGSIb3DQEBCwUAMIGIMQsw
+CQYDVQQGEwJVUzERMA8GA1UECAwISWxsaW5vaXMxEDAOBgNVBAcMB0NoaWNhZ28x
+ITAfBgNVBAoMGFRydXN0d2F2ZSBIb2xkaW5ncywgSW5jLjExMC8GA1UEAwwoVHJ1
+c3R3YXZlIEdsb2JhbCBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTAeFw0xNzA4MjMx
+OTM0MTJaFw00MjA4MjMxOTM0MTJaMIGIMQswCQYDVQQGEwJVUzERMA8GA1UECAwI
+SWxsaW5vaXMxEDAOBgNVBAcMB0NoaWNhZ28xITAfBgNVBAoMGFRydXN0d2F2ZSBI
+b2xkaW5ncywgSW5jLjExMC8GA1UEAwwoVHJ1c3R3YXZlIEdsb2JhbCBDZXJ0aWZp
+Y2F0aW9uIEF1dGhvcml0eTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIB
+ALldUShLPDeS0YLOvR29zd24q88KPuFd5dyqCblXAj7mY2Hf8g+CY66j96xz0Xzn
+swuvCAAJWX/NKSqIk4cXGIDtiLK0thAfLdZfVaITXdHG6wZWiYj+rDKd/VzDBcdu
+7oaJuogDnXIhhpCujwOl3J+IKMujkkkP7NAP4m1ET4BqstTnoApTAbqOl5F2brz8
+1Ws25kCI1nsvXwXoLG0R8+eyvpJETNKXpP7ScoFDB5zpET71ixpZfR9oWN0EACyW
+80OzfpgZdNmcc9kYvkHHNHnZ9GLCQ7mzJ7Aiy/k9UscwR7PJPrhq4ufogXBeQotP
+JqX+OsIgbrv4Fo7NDKm0G2x2EOFYeUY+VM6AqFcJNykbmROPDMjWLBz7BegIlT1l
+RtzuzWniTY+HKE40Cz7PFNm73bZQmq131BnW2hqIyE4bJ3XYsgjxroMwuREOzYfw
+hI0Vcnyh78zyiGG69Gm7DIwLdVcEuE4qFC49DxweMqZiNu5m4iK4BUBjECLzMx10
+coos9TkpoNPnG4CELcU9402x/RpvumUHO1jsQkUm+9jaJXLE9gCxInm943xZYkqc
+BW89zubWR2OZxiRvchLIrH+QtAuRcOi35hYQcRfO3gZPSEF9NUqjifLJS3tBEW1n
+twiYTOURGa5CgNz7kAXU+FDKvuStx8KU1xad5hePrzb7AgMBAAGjQjBAMA8GA1Ud
+EwEB/wQFMAMBAf8wHQYDVR0OBBYEFJngGWcNYtt2s9o9uFvo/ULSMQ6HMA4GA1Ud
+DwEB/wQEAwIBBjANBgkqhkiG9w0BAQsFAAOCAgEAmHNw4rDT7TnsTGDZqRKGFx6W
+0OhUKDtkLSGm+J1WE2pIPU/HPinbbViDVD2HfSMF1OQc3Og4ZYbFdada2zUFvXfe
+uyk3QAUHw5RSn8pk3fEbK9xGChACMf1KaA0HZJDmHvUqoai7PF35owgLEQzxPy0Q
+lG/+4jSHg9bP5Rs1bdID4bANqKCqRieCNqcVtgimQlRXtpla4gt5kNdXElE1GYhB
+aCXUNxeEFfsBctyV3lImIJgm4nb1J2/6ADtKYdkNy1GTKv0WBpanI5ojSP5RvbbE
+sLFUzt5sQa0WZ37b/TjNuThOssFgy50X31ieemKyJo90lZvkWx3SD92YHJtZuSPT
+MaCm/zjdzyBP6VhWOmfD0faZmZ26NraAL4hHT4a/RDqA5Dccprrql5gR0IRiR2Qe
+qu5AvzSxnI9O4fKSTx+O856X3vOmeWqJcU9LJxdI/uz0UA9PSX3MReO9ekDFQdxh
+VicGaeVyQYHTtgGJoC86cnn+OjC/QezHYj6RS8fZMXZC+fc8Y+wmjHMMfRod6qh8
+h6jCJ3zhM0EPz8/8AKAigJ5Kp28AsEFFtyLKaEjFQqKu3R3y4G5OBVixwJAWKqQ9
+EEC+j2Jjg6mcgn0tAumDMHzLJ8n9HmYAsC7TIS+OMxZsmO0QqAfWzJPP29FpHOTK
+yeC2nOnOcXHebD8WpHk=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Trustwave Global ECC P256 Certification Authority O=Trustwave Holdings, Inc.
+# Subject: CN=Trustwave Global ECC P256 Certification Authority O=Trustwave Holdings, Inc.
+# Label: "Trustwave Global ECC P256 Certification Authority"
+# Serial: 4151900041497450638097112925
+# MD5 Fingerprint: 5b:44:e3:8d:5d:36:86:26:e8:0d:05:d2:59:a7:83:54
+# SHA1 Fingerprint: b4:90:82:dd:45:0c:be:8b:5b:b1:66:d3:e2:a4:08:26:cd:ed:42:cf
+# SHA256 Fingerprint: 94:5b:bc:82:5e:a5:54:f4:89:d1:fd:51:a7:3d:df:2e:a6:24:ac:70:19:a0:52:05:22:5c:22:a7:8c:cf:a8:b4
+-----BEGIN CERTIFICATE-----
+MIICYDCCAgegAwIBAgIMDWpfCD8oXD5Rld9dMAoGCCqGSM49BAMCMIGRMQswCQYD
+VQQGEwJVUzERMA8GA1UECBMISWxsaW5vaXMxEDAOBgNVBAcTB0NoaWNhZ28xITAf
+BgNVBAoTGFRydXN0d2F2ZSBIb2xkaW5ncywgSW5jLjE6MDgGA1UEAxMxVHJ1c3R3
+YXZlIEdsb2JhbCBFQ0MgUDI1NiBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTAeFw0x
+NzA4MjMxOTM1MTBaFw00MjA4MjMxOTM1MTBaMIGRMQswCQYDVQQGEwJVUzERMA8G
+A1UECBMISWxsaW5vaXMxEDAOBgNVBAcTB0NoaWNhZ28xITAfBgNVBAoTGFRydXN0
+d2F2ZSBIb2xkaW5ncywgSW5jLjE6MDgGA1UEAxMxVHJ1c3R3YXZlIEdsb2JhbCBF
+Q0MgUDI1NiBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTBZMBMGByqGSM49AgEGCCqG
+SM49AwEHA0IABH77bOYj43MyCMpg5lOcunSNGLB4kFKA3TjASh3RqMyTpJcGOMoN
+FWLGjgEqZZ2q3zSRLoHB5DOSMcT9CTqmP62jQzBBMA8GA1UdEwEB/wQFMAMBAf8w
+DwYDVR0PAQH/BAUDAwcGADAdBgNVHQ4EFgQUo0EGrJBt0UrrdaVKEJmzsaGLSvcw
+CgYIKoZIzj0EAwIDRwAwRAIgB+ZU2g6gWrKuEZ+Hxbb/ad4lvvigtwjzRM4q3wgh
+DDcCIC0mA6AFvWvR9lz4ZcyGbbOcNEhjhAnFjXca4syc4XR7
+-----END CERTIFICATE-----
+
+# Issuer: CN=Trustwave Global ECC P384 Certification Authority O=Trustwave Holdings, Inc.
+# Subject: CN=Trustwave Global ECC P384 Certification Authority O=Trustwave Holdings, Inc.
+# Label: "Trustwave Global ECC P384 Certification Authority"
+# Serial: 2704997926503831671788816187
+# MD5 Fingerprint: ea:cf:60:c4:3b:b9:15:29:40:a1:97:ed:78:27:93:d6
+# SHA1 Fingerprint: e7:f3:a3:c8:cf:6f:c3:04:2e:6d:0e:67:32:c5:9e:68:95:0d:5e:d2
+# SHA256 Fingerprint: 55:90:38:59:c8:c0:c3:eb:b8:75:9e:ce:4e:25:57:22:5f:f5:75:8b:bd:38:eb:d4:82:76:60:1e:1b:d5:80:97
+-----BEGIN CERTIFICATE-----
+MIICnTCCAiSgAwIBAgIMCL2Fl2yZJ6SAaEc7MAoGCCqGSM49BAMDMIGRMQswCQYD
+VQQGEwJVUzERMA8GA1UECBMISWxsaW5vaXMxEDAOBgNVBAcTB0NoaWNhZ28xITAf
+BgNVBAoTGFRydXN0d2F2ZSBIb2xkaW5ncywgSW5jLjE6MDgGA1UEAxMxVHJ1c3R3
+YXZlIEdsb2JhbCBFQ0MgUDM4NCBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTAeFw0x
+NzA4MjMxOTM2NDNaFw00MjA4MjMxOTM2NDNaMIGRMQswCQYDVQQGEwJVUzERMA8G
+A1UECBMISWxsaW5vaXMxEDAOBgNVBAcTB0NoaWNhZ28xITAfBgNVBAoTGFRydXN0
+d2F2ZSBIb2xkaW5ncywgSW5jLjE6MDgGA1UEAxMxVHJ1c3R3YXZlIEdsb2JhbCBF
+Q0MgUDM4NCBDZXJ0aWZpY2F0aW9uIEF1dGhvcml0eTB2MBAGByqGSM49AgEGBSuB
+BAAiA2IABGvaDXU1CDFHBa5FmVXxERMuSvgQMSOjfoPTfygIOiYaOs+Xgh+AtycJ
+j9GOMMQKmw6sWASr9zZ9lCOkmwqKi6vr/TklZvFe/oyujUF5nQlgziip04pt89ZF
+1PKYhDhloKNDMEEwDwYDVR0TAQH/BAUwAwEB/zAPBgNVHQ8BAf8EBQMDBwYAMB0G
+A1UdDgQWBBRVqYSJ0sEyvRjLbKYHTsjnnb6CkDAKBggqhkjOPQQDAwNnADBkAjA3
+AZKXRRJ+oPM+rRk6ct30UJMDEr5E0k9BpIycnR+j9sKS50gU/k6bpZFXrsY3crsC
+MGclCrEMXu6pY5Jv5ZAL/mYiykf9ijH3g/56vxC+GCsej/YpHpRZ744hN8tRmKVu
+Sw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=NAVER Global Root Certification Authority O=NAVER BUSINESS PLATFORM Corp.
+# Subject: CN=NAVER Global Root Certification Authority O=NAVER BUSINESS PLATFORM Corp.
+# Label: "NAVER Global Root Certification Authority"
+# Serial: 9013692873798656336226253319739695165984492813
+# MD5 Fingerprint: c8:7e:41:f6:25:3b:f5:09:b3:17:e8:46:3d:bf:d0:9b
+# SHA1 Fingerprint: 8f:6b:f2:a9:27:4a:da:14:a0:c4:f4:8e:61:27:f9:c0:1e:78:5d:d1
+# SHA256 Fingerprint: 88:f4:38:dc:f8:ff:d1:fa:8f:42:91:15:ff:e5:f8:2a:e1:e0:6e:0c:70:c3:75:fa:ad:71:7b:34:a4:9e:72:65
+-----BEGIN CERTIFICATE-----
+MIIFojCCA4qgAwIBAgIUAZQwHqIL3fXFMyqxQ0Rx+NZQTQ0wDQYJKoZIhvcNAQEM
+BQAwaTELMAkGA1UEBhMCS1IxJjAkBgNVBAoMHU5BVkVSIEJVU0lORVNTIFBMQVRG
+T1JNIENvcnAuMTIwMAYDVQQDDClOQVZFUiBHbG9iYWwgUm9vdCBDZXJ0aWZpY2F0
+aW9uIEF1dGhvcml0eTAeFw0xNzA4MTgwODU4NDJaFw0zNzA4MTgyMzU5NTlaMGkx
+CzAJBgNVBAYTAktSMSYwJAYDVQQKDB1OQVZFUiBCVVNJTkVTUyBQTEFURk9STSBD
+b3JwLjEyMDAGA1UEAwwpTkFWRVIgR2xvYmFsIFJvb3QgQ2VydGlmaWNhdGlvbiBB
+dXRob3JpdHkwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQC21PGTXLVA
+iQqrDZBbUGOukJR0F0Vy1ntlWilLp1agS7gvQnXp2XskWjFlqxcX0TM62RHcQDaH
+38dq6SZeWYp34+hInDEW+j6RscrJo+KfziFTowI2MMtSAuXaMl3Dxeb57hHHi8lE
+HoSTGEq0n+USZGnQJoViAbbJAh2+g1G7XNr4rRVqmfeSVPc0W+m/6imBEtRTkZaz
+kVrd/pBzKPswRrXKCAfHcXLJZtM0l/aM9BhK4dA9WkW2aacp+yPOiNgSnABIqKYP
+szuSjXEOdMWLyEz59JuOuDxp7W87UC9Y7cSw0BwbagzivESq2M0UXZR4Yb8Obtoq
+vC8MC3GmsxY/nOb5zJ9TNeIDoKAYv7vxvvTWjIcNQvcGufFt7QSUqP620wbGQGHf
+nZ3zVHbOUzoBppJB7ASjjw2i1QnK1sua8e9DXcCrpUHPXFNwcMmIpi3Ua2FzUCaG
+YQ5fG8Ir4ozVu53BA0K6lNpfqbDKzE0K70dpAy8i+/Eozr9dUGWokG2zdLAIx6yo
+0es+nPxdGoMuK8u180SdOqcXYZaicdNwlhVNt0xz7hlcxVs+Qf6sdWA7G2POAN3a
+CJBitOUt7kinaxeZVL6HSuOpXgRM6xBtVNbv8ejyYhbLgGvtPe31HzClrkvJE+2K
+AQHJuFFYwGY6sWZLxNUxAmLpdIQM201GLQIDAQABo0IwQDAdBgNVHQ4EFgQU0p+I
+36HNLL3s9TsBAZMzJ7LrYEswDgYDVR0PAQH/BAQDAgEGMA8GA1UdEwEB/wQFMAMB
+Af8wDQYJKoZIhvcNAQEMBQADggIBADLKgLOdPVQG3dLSLvCkASELZ0jKbY7gyKoN
+qo0hV4/GPnrK21HUUrPUloSlWGB/5QuOH/XcChWB5Tu2tyIvCZwTFrFsDDUIbatj
+cu3cvuzHV+YwIHHW1xDBE1UBjCpD5EHxzzp6U5LOogMFDTjfArsQLtk70pt6wKGm
++LUx5vR1yblTmXVHIloUFcd4G7ad6Qz4G3bxhYTeodoS76TiEJd6eN4MUZeoIUCL
+hr0N8F5OSza7OyAfikJW4Qsav3vQIkMsRIz75Sq0bBwcupTgE34h5prCy8VCZLQe
+lHsIJchxzIdFV4XTnyliIoNRlwAYl3dqmJLJfGBs32x9SuRwTMKeuB330DTHD8z7
+p/8Dvq1wkNoL3chtl1+afwkyQf3NosxabUzyqkn+Zvjp2DXrDige7kgvOtB5CTh8
+piKCk5XQA76+AqAF3SAi428diDRgxuYKuQl1C/AH6GmWNcf7I4GOODm4RStDeKLR
+LBT/DShycpWbXgnbiUSYqqFJu3FS8r/2/yehNq+4tneI3TqkbZs0kNwUXTC/t+sX
+5Ie3cdCh13cV1ELX8vMxmV2b3RZtP+oGI/hGoiLtk/bdmuYqh7GYVPEi92tF4+KO
+dh2ajcQGjTa3FPOdVGm3jjzVpG2Tgbet9r1ke8LJaDmgkpzNNIaRkPpkUZ3+/uul
+9XXeifdy
+-----END CERTIFICATE-----
+
+# Issuer: CN=AC RAIZ FNMT-RCM SERVIDORES SEGUROS O=FNMT-RCM OU=Ceres
+# Subject: CN=AC RAIZ FNMT-RCM SERVIDORES SEGUROS O=FNMT-RCM OU=Ceres
+# Label: "AC RAIZ FNMT-RCM SERVIDORES SEGUROS"
+# Serial: 131542671362353147877283741781055151509
+# MD5 Fingerprint: 19:36:9c:52:03:2f:d2:d1:bb:23:cc:dd:1e:12:55:bb
+# SHA1 Fingerprint: 62:ff:d9:9e:c0:65:0d:03:ce:75:93:d2:ed:3f:2d:32:c9:e3:e5:4a
+# SHA256 Fingerprint: 55:41:53:b1:3d:2c:f9:dd:b7:53:bf:be:1a:4e:0a:e0:8d:0a:a4:18:70:58:fe:60:a2:b8:62:b2:e4:b8:7b:cb
+-----BEGIN CERTIFICATE-----
+MIICbjCCAfOgAwIBAgIQYvYybOXE42hcG2LdnC6dlTAKBggqhkjOPQQDAzB4MQsw
+CQYDVQQGEwJFUzERMA8GA1UECgwIRk5NVC1SQ00xDjAMBgNVBAsMBUNlcmVzMRgw
+FgYDVQRhDA9WQVRFUy1RMjgyNjAwNEoxLDAqBgNVBAMMI0FDIFJBSVogRk5NVC1S
+Q00gU0VSVklET1JFUyBTRUdVUk9TMB4XDTE4MTIyMDA5MzczM1oXDTQzMTIyMDA5
+MzczM1oweDELMAkGA1UEBhMCRVMxETAPBgNVBAoMCEZOTVQtUkNNMQ4wDAYDVQQL
+DAVDZXJlczEYMBYGA1UEYQwPVkFURVMtUTI4MjYwMDRKMSwwKgYDVQQDDCNBQyBS
+QUlaIEZOTVQtUkNNIFNFUlZJRE9SRVMgU0VHVVJPUzB2MBAGByqGSM49AgEGBSuB
+BAAiA2IABPa6V1PIyqvfNkpSIeSX0oNnnvBlUdBeh8dHsVnyV0ebAAKTRBdp20LH
+sbI6GA60XYyzZl2hNPk2LEnb80b8s0RpRBNm/dfF/a82Tc4DTQdxz69qBdKiQ1oK
+Um8BA06Oi6NCMEAwDwYDVR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwHQYD
+VR0OBBYEFAG5L++/EYZg8k/QQW6rcx/n0m5JMAoGCCqGSM49BAMDA2kAMGYCMQCu
+SuMrQMN0EfKVrRYj3k4MGuZdpSRea0R7/DjiT8ucRRcRTBQnJlU5dUoDzBOQn5IC
+MQD6SmxgiHPz7riYYqnOK8LZiqZwMR2vsJRM60/G49HzYqc8/5MuB1xJAWdpEgJy
+v+c=
+-----END CERTIFICATE-----
+
+# Issuer: CN=GlobalSign Root R46 O=GlobalSign nv-sa
+# Subject: CN=GlobalSign Root R46 O=GlobalSign nv-sa
+# Label: "GlobalSign Root R46"
+# Serial: 1552617688466950547958867513931858518042577
+# MD5 Fingerprint: c4:14:30:e4:fa:66:43:94:2a:6a:1b:24:5f:19:d0:ef
+# SHA1 Fingerprint: 53:a2:b0:4b:ca:6b:d6:45:e6:39:8a:8e:c4:0d:d2:bf:77:c3:a2:90
+# SHA256 Fingerprint: 4f:a3:12:6d:8d:3a:11:d1:c4:85:5a:4f:80:7c:ba:d6:cf:91:9d:3a:5a:88:b0:3b:ea:2c:63:72:d9:3c:40:c9
+-----BEGIN CERTIFICATE-----
+MIIFWjCCA0KgAwIBAgISEdK7udcjGJ5AXwqdLdDfJWfRMA0GCSqGSIb3DQEBDAUA
+MEYxCzAJBgNVBAYTAkJFMRkwFwYDVQQKExBHbG9iYWxTaWduIG52LXNhMRwwGgYD
+VQQDExNHbG9iYWxTaWduIFJvb3QgUjQ2MB4XDTE5MDMyMDAwMDAwMFoXDTQ2MDMy
+MDAwMDAwMFowRjELMAkGA1UEBhMCQkUxGTAXBgNVBAoTEEdsb2JhbFNpZ24gbnYt
+c2ExHDAaBgNVBAMTE0dsb2JhbFNpZ24gUm9vdCBSNDYwggIiMA0GCSqGSIb3DQEB
+AQUAA4ICDwAwggIKAoICAQCsrHQy6LNl5brtQyYdpokNRbopiLKkHWPd08EsCVeJ
+OaFV6Wc0dwxu5FUdUiXSE2te4R2pt32JMl8Nnp8semNgQB+msLZ4j5lUlghYruQG
+vGIFAha/r6gjA7aUD7xubMLL1aa7DOn2wQL7Id5m3RerdELv8HQvJfTqa1VbkNud
+316HCkD7rRlr+/fKYIje2sGP1q7Vf9Q8g+7XFkyDRTNrJ9CG0Bwta/OrffGFqfUo
+0q3v84RLHIf8E6M6cqJaESvWJ3En7YEtbWaBkoe0G1h6zD8K+kZPTXhc+CtI4wSE
+y132tGqzZfxCnlEmIyDLPRT5ge1lFgBPGmSXZgjPjHvjK8Cd+RTyG/FWaha/LIWF
+zXg4mutCagI0GIMXTpRW+LaCtfOW3T3zvn8gdz57GSNrLNRyc0NXfeD412lPFzYE
++cCQYDdF3uYM2HSNrpyibXRdQr4G9dlkbgIQrImwTDsHTUB+JMWKmIJ5jqSngiCN
+I/onccnfxkF0oE32kRbcRoxfKWMxWXEM2G/CtjJ9++ZdU6Z+Ffy7dXxd7Pj2Fxzs
+x2sZy/N78CsHpdlseVR2bJ0cpm4O6XkMqCNqo98bMDGfsVR7/mrLZqrcZdCinkqa
+ByFrgY/bxFn63iLABJzjqls2k+g9vXqhnQt2sQvHnf3PmKgGwvgqo6GDoLclcqUC
+4wIDAQABo0IwQDAOBgNVHQ8BAf8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB/zAdBgNV
+HQ4EFgQUA1yrc4GHqMywptWU4jaWSf8FmSwwDQYJKoZIhvcNAQEMBQADggIBAHx4
+7PYCLLtbfpIrXTncvtgdokIzTfnvpCo7RGkerNlFo048p9gkUbJUHJNOxO97k4Vg
+JuoJSOD1u8fpaNK7ajFxzHmuEajwmf3lH7wvqMxX63bEIaZHU1VNaL8FpO7XJqti
+2kM3S+LGteWygxk6x9PbTZ4IevPuzz5i+6zoYMzRx6Fcg0XERczzF2sUyQQCPtIk
+pnnpHs6i58FZFZ8d4kuaPp92CC1r2LpXFNqD6v6MVenQTqnMdzGxRBF6XLE+0xRF
+FRhiJBPSy03OXIPBNvIQtQ6IbbjhVp+J3pZmOUdkLG5NrmJ7v2B0GbhWrJKsFjLt
+rWhV/pi60zTe9Mlhww6G9kuEYO4Ne7UyWHmRVSyBQ7N0H3qqJZ4d16GLuc1CLgSk
+ZoNNiTW2bKg2SnkheCLQQrzRQDGQob4Ez8pn7fXwgNNgyYMqIgXQBztSvwyeqiv5
+u+YfjyW6hY0XHgL+XVAEV8/+LbzvXMAaq7afJMbfc2hIkCwU9D9SGuTSyxTDYWnP
+4vkYxboznxSjBF25cfe1lNj2M8FawTSLfJvdkzrnE6JwYZ+vj+vYxXX4M2bUdGc6
+N3ec592kD3ZDZopD8p/7DEJ4Y9HiD2971KE9dJeFt0g5QdYg/NA6s/rob8SKunE3
+vouXsXgxT7PntgMTzlSdriVZzH81Xwj3QEUxeCp6
+-----END CERTIFICATE-----
+
+# Issuer: CN=GlobalSign Root E46 O=GlobalSign nv-sa
+# Subject: CN=GlobalSign Root E46 O=GlobalSign nv-sa
+# Label: "GlobalSign Root E46"
+# Serial: 1552617690338932563915843282459653771421763
+# MD5 Fingerprint: b5:b8:66:ed:de:08:83:e3:c9:e2:01:34:06:ac:51:6f
+# SHA1 Fingerprint: 39:b4:6c:d5:fe:80:06:eb:e2:2f:4a:bb:08:33:a0:af:db:b9:dd:84
+# SHA256 Fingerprint: cb:b9:c4:4d:84:b8:04:3e:10:50:ea:31:a6:9f:51:49:55:d7:bf:d2:e2:c6:b4:93:01:01:9a:d6:1d:9f:50:58
+-----BEGIN CERTIFICATE-----
+MIICCzCCAZGgAwIBAgISEdK7ujNu1LzmJGjFDYQdmOhDMAoGCCqGSM49BAMDMEYx
+CzAJBgNVBAYTAkJFMRkwFwYDVQQKExBHbG9iYWxTaWduIG52LXNhMRwwGgYDVQQD
+ExNHbG9iYWxTaWduIFJvb3QgRTQ2MB4XDTE5MDMyMDAwMDAwMFoXDTQ2MDMyMDAw
+MDAwMFowRjELMAkGA1UEBhMCQkUxGTAXBgNVBAoTEEdsb2JhbFNpZ24gbnYtc2Ex
+HDAaBgNVBAMTE0dsb2JhbFNpZ24gUm9vdCBFNDYwdjAQBgcqhkjOPQIBBgUrgQQA
+IgNiAAScDrHPt+ieUnd1NPqlRqetMhkytAepJ8qUuwzSChDH2omwlwxwEwkBjtjq
+R+q+soArzfwoDdusvKSGN+1wCAB16pMLey5SnCNoIwZD7JIvU4Tb+0cUB+hflGdd
+yXqBPCCjQjBAMA4GA1UdDwEB/wQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1Ud
+DgQWBBQxCpCPtsad0kRLgLWi5h+xEk8blTAKBggqhkjOPQQDAwNoADBlAjEA31SQ
+7Zvvi5QCkxeCmb6zniz2C5GMn0oUsfZkvLtoURMMA/cVi4RguYv/Uo7njLwcAjA8
++RHUjE7AwWHCFUyqqx0LMV87HOIAl0Qx5v5zli/altP+CAezNIm8BZ/3Hobui3A=
+-----END CERTIFICATE-----
+
+# Issuer: CN=ANF Secure Server Root CA O=ANF Autoridad de Certificacion OU=ANF CA Raiz
+# Subject: CN=ANF Secure Server Root CA O=ANF Autoridad de Certificacion OU=ANF CA Raiz
+# Label: "ANF Secure Server Root CA"
+# Serial: 996390341000653745
+# MD5 Fingerprint: 26:a6:44:5a:d9:af:4e:2f:b2:1d:b6:65:b0:4e:e8:96
+# SHA1 Fingerprint: 5b:6e:68:d0:cc:15:b6:a0:5f:1e:c1:5f:ae:02:fc:6b:2f:5d:6f:74
+# SHA256 Fingerprint: fb:8f:ec:75:91:69:b9:10:6b:1e:51:16:44:c6:18:c5:13:04:37:3f:6c:06:43:08:8d:8b:ef:fd:1b:99:75:99
+-----BEGIN CERTIFICATE-----
+MIIF7zCCA9egAwIBAgIIDdPjvGz5a7EwDQYJKoZIhvcNAQELBQAwgYQxEjAQBgNV
+BAUTCUc2MzI4NzUxMDELMAkGA1UEBhMCRVMxJzAlBgNVBAoTHkFORiBBdXRvcmlk
+YWQgZGUgQ2VydGlmaWNhY2lvbjEUMBIGA1UECxMLQU5GIENBIFJhaXoxIjAgBgNV
+BAMTGUFORiBTZWN1cmUgU2VydmVyIFJvb3QgQ0EwHhcNMTkwOTA0MTAwMDM4WhcN
+MzkwODMwMTAwMDM4WjCBhDESMBAGA1UEBRMJRzYzMjg3NTEwMQswCQYDVQQGEwJF
+UzEnMCUGA1UEChMeQU5GIEF1dG9yaWRhZCBkZSBDZXJ0aWZpY2FjaW9uMRQwEgYD
+VQQLEwtBTkYgQ0EgUmFpejEiMCAGA1UEAxMZQU5GIFNlY3VyZSBTZXJ2ZXIgUm9v
+dCBDQTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBANvrayvmZFSVgpCj
+cqQZAZ2cC4Ffc0m6p6zzBE57lgvsEeBbphzOG9INgxwruJ4dfkUyYA8H6XdYfp9q
+yGFOtibBTI3/TO80sh9l2Ll49a2pcbnvT1gdpd50IJeh7WhM3pIXS7yr/2WanvtH
+2Vdy8wmhrnZEE26cLUQ5vPnHO6RYPUG9tMJJo8gN0pcvB2VSAKduyK9o7PQUlrZX
+H1bDOZ8rbeTzPvY1ZNoMHKGESy9LS+IsJJ1tk0DrtSOOMspvRdOoiXsezx76W0OL
+zc2oD2rKDF65nkeP8Nm2CgtYZRczuSPkdxl9y0oukntPLxB3sY0vaJxizOBQ+OyR
+p1RMVwnVdmPF6GUe7m1qzwmd+nxPrWAI/VaZDxUse6mAq4xhj0oHdkLePfTdsiQz
+W7i1o0TJrH93PB0j7IKppuLIBkwC/qxcmZkLLxCKpvR/1Yd0DVlJRfbwcVw5Kda/
+SiOL9V8BY9KHcyi1Swr1+KuCLH5zJTIdC2MKF4EA/7Z2Xue0sUDKIbvVgFHlSFJn
+LNJhiQcND85Cd8BEc5xEUKDbEAotlRyBr+Qc5RQe8TZBAQIvfXOn3kLMTOmJDVb3
+n5HUA8ZsyY/b2BzgQJhdZpmYgG4t/wHFzstGH6wCxkPmrqKEPMVOHj1tyRRM4y5B
+u8o5vzY8KhmqQYdOpc5LMnndkEl/AgMBAAGjYzBhMB8GA1UdIwQYMBaAFJxf0Gxj
+o1+TypOYCK2Mh6UsXME3MB0GA1UdDgQWBBScX9BsY6Nfk8qTmAitjIelLFzBNzAO
+BgNVHQ8BAf8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAAOC
+AgEATh65isagmD9uw2nAalxJUqzLK114OMHVVISfk/CHGT0sZonrDUL8zPB1hT+L
+9IBdeeUXZ701guLyPI59WzbLWoAAKfLOKyzxj6ptBZNscsdW699QIyjlRRA96Gej
+rw5VD5AJYu9LWaL2U/HANeQvwSS9eS9OICI7/RogsKQOLHDtdD+4E5UGUcjohybK
+pFtqFiGS3XNgnhAY3jyB6ugYw3yJ8otQPr0R4hUDqDZ9MwFsSBXXiJCZBMXM5gf0
+vPSQ7RPi6ovDj6MzD8EpTBNO2hVWcXNyglD2mjN8orGoGjR0ZVzO0eurU+AagNjq
+OknkJjCb5RyKqKkVMoaZkgoQI1YS4PbOTOK7vtuNknMBZi9iPrJyJ0U27U1W45eZ
+/zo1PqVUSlJZS2Db7v54EX9K3BR5YLZrZAPbFYPhor72I5dQ8AkzNqdxliXzuUJ9
+2zg/LFis6ELhDtjTO0wugumDLmsx2d1Hhk9tl5EuT+IocTUW0fJz/iUrB0ckYyfI
++PbZa/wSMVYIwFNCr5zQM378BvAxRAMU8Vjq8moNqRGyg77FGr8H6lnco4g175x2
+MjxNBiLOFeXdntiP2t7SxDnlF4HPOEfrf4htWRvfn0IUrn7PqLBmZdo3r5+qPeoo
+tt7VMVgWglvquxl1AnMaykgaIZOQCo6ThKd9OyMYkomgjaw=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certum EC-384 CA O=Asseco Data Systems S.A. OU=Certum Certification Authority
+# Subject: CN=Certum EC-384 CA O=Asseco Data Systems S.A. OU=Certum Certification Authority
+# Label: "Certum EC-384 CA"
+# Serial: 160250656287871593594747141429395092468
+# MD5 Fingerprint: b6:65:b3:96:60:97:12:a1:ec:4e:e1:3d:a3:c6:c9:f1
+# SHA1 Fingerprint: f3:3e:78:3c:ac:df:f4:a2:cc:ac:67:55:69:56:d7:e5:16:3c:e1:ed
+# SHA256 Fingerprint: 6b:32:80:85:62:53:18:aa:50:d1:73:c9:8d:8b:da:09:d5:7e:27:41:3d:11:4c:f7:87:a0:f5:d0:6c:03:0c:f6
+-----BEGIN CERTIFICATE-----
+MIICZTCCAeugAwIBAgIQeI8nXIESUiClBNAt3bpz9DAKBggqhkjOPQQDAzB0MQsw
+CQYDVQQGEwJQTDEhMB8GA1UEChMYQXNzZWNvIERhdGEgU3lzdGVtcyBTLkEuMScw
+JQYDVQQLEx5DZXJ0dW0gQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkxGTAXBgNVBAMT
+EENlcnR1bSBFQy0zODQgQ0EwHhcNMTgwMzI2MDcyNDU0WhcNNDMwMzI2MDcyNDU0
+WjB0MQswCQYDVQQGEwJQTDEhMB8GA1UEChMYQXNzZWNvIERhdGEgU3lzdGVtcyBT
+LkEuMScwJQYDVQQLEx5DZXJ0dW0gQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkxGTAX
+BgNVBAMTEENlcnR1bSBFQy0zODQgQ0EwdjAQBgcqhkjOPQIBBgUrgQQAIgNiAATE
+KI6rGFtqvm5kN2PkzeyrOvfMobgOgknXhimfoZTy42B4mIF4Bk3y7JoOV2CDn7Tm
+Fy8as10CW4kjPMIRBSqniBMY81CE1700LCeJVf/OTOffph8oxPBUw7l8t1Ot68Kj
+QjBAMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFI0GZnQkdjrzife81r1HfS+8
+EF9LMA4GA1UdDwEB/wQEAwIBBjAKBggqhkjOPQQDAwNoADBlAjADVS2m5hjEfO/J
+UG7BJw+ch69u1RsIGL2SKcHvlJF40jocVYli5RsJHrpka/F2tNQCMQC0QoSZ/6vn
+nvuRlydd3LBbMHHOXjgaatkl5+r3YZJW+OraNsKHZZYuciUvf9/DE8k=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certum Trusted Root CA O=Asseco Data Systems S.A. OU=Certum Certification Authority
+# Subject: CN=Certum Trusted Root CA O=Asseco Data Systems S.A. OU=Certum Certification Authority
+# Label: "Certum Trusted Root CA"
+# Serial: 40870380103424195783807378461123655149
+# MD5 Fingerprint: 51:e1:c2:e7:fe:4c:84:af:59:0e:2f:f4:54:6f:ea:29
+# SHA1 Fingerprint: c8:83:44:c0:18:ae:9f:cc:f1:87:b7:8f:22:d1:c5:d7:45:84:ba:e5
+# SHA256 Fingerprint: fe:76:96:57:38:55:77:3e:37:a9:5e:7a:d4:d9:cc:96:c3:01:57:c1:5d:31:76:5b:a9:b1:57:04:e1:ae:78:fd
+-----BEGIN CERTIFICATE-----
+MIIFwDCCA6igAwIBAgIQHr9ZULjJgDdMBvfrVU+17TANBgkqhkiG9w0BAQ0FADB6
+MQswCQYDVQQGEwJQTDEhMB8GA1UEChMYQXNzZWNvIERhdGEgU3lzdGVtcyBTLkEu
+MScwJQYDVQQLEx5DZXJ0dW0gQ2VydGlmaWNhdGlvbiBBdXRob3JpdHkxHzAdBgNV
+BAMTFkNlcnR1bSBUcnVzdGVkIFJvb3QgQ0EwHhcNMTgwMzE2MTIxMDEzWhcNNDMw
+MzE2MTIxMDEzWjB6MQswCQYDVQQGEwJQTDEhMB8GA1UEChMYQXNzZWNvIERhdGEg
+U3lzdGVtcyBTLkEuMScwJQYDVQQLEx5DZXJ0dW0gQ2VydGlmaWNhdGlvbiBBdXRo
+b3JpdHkxHzAdBgNVBAMTFkNlcnR1bSBUcnVzdGVkIFJvb3QgQ0EwggIiMA0GCSqG
+SIb3DQEBAQUAA4ICDwAwggIKAoICAQDRLY67tzbqbTeRn06TpwXkKQMlzhyC93yZ
+n0EGze2jusDbCSzBfN8pfktlL5On1AFrAygYo9idBcEq2EXxkd7fO9CAAozPOA/q
+p1x4EaTByIVcJdPTsuclzxFUl6s1wB52HO8AU5853BSlLCIls3Jy/I2z5T4IHhQq
+NwuIPMqw9MjCoa68wb4pZ1Xi/K1ZXP69VyywkI3C7Te2fJmItdUDmj0VDT06qKhF
+8JVOJVkdzZhpu9PMMsmN74H+rX2Ju7pgE8pllWeg8xn2A1bUatMn4qGtg/BKEiJ3
+HAVz4hlxQsDsdUaakFjgao4rpUYwBI4Zshfjvqm6f1bxJAPXsiEodg42MEx51UGa
+mqi4NboMOvJEGyCI98Ul1z3G4z5D3Yf+xOr1Uz5MZf87Sst4WmsXXw3Hw09Omiqi
+7VdNIuJGmj8PkTQkfVXjjJU30xrwCSss0smNtA0Aq2cpKNgB9RkEth2+dv5yXMSF
+ytKAQd8FqKPVhJBPC/PgP5sZ0jeJP/J7UhyM9uH3PAeXjA6iWYEMspA90+NZRu0P
+qafegGtaqge2Gcu8V/OXIXoMsSt0Puvap2ctTMSYnjYJdmZm/Bo/6khUHL4wvYBQ
+v3y1zgD2DGHZ5yQD4OMBgQ692IU0iL2yNqh7XAjlRICMb/gv1SHKHRzQ+8S1h9E6
+Tsd2tTVItQIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBSM+xx1
+vALTn04uSNn5YFSqxLNP+jAOBgNVHQ8BAf8EBAMCAQYwDQYJKoZIhvcNAQENBQAD
+ggIBAEii1QALLtA/vBzVtVRJHlpr9OTy4EA34MwUe7nJ+jW1dReTagVphZzNTxl4
+WxmB82M+w85bj/UvXgF2Ez8sALnNllI5SW0ETsXpD4YN4fqzX4IS8TrOZgYkNCvo
+zMrnadyHncI013nR03e4qllY/p0m+jiGPp2Kh2RX5Rc64vmNueMzeMGQ2Ljdt4NR
+5MTMI9UGfOZR0800McD2RrsLrfw9EAUqO0qRJe6M1ISHgCq8CYyqOhNf6DR5UMEQ
+GfnTKB7U0VEwKbOukGfWHwpjscWpxkIxYxeU72nLL/qMFH3EQxiJ2fAyQOaA4kZf
+5ePBAFmo+eggvIksDkc0C+pXwlM2/KfUrzHN/gLldfq5Jwn58/U7yn2fqSLLiMmq
+0Uc9NneoWWRrJ8/vJ8HjJLWG965+Mk2weWjROeiQWMODvA8s1pfrzgzhIMfatz7D
+P78v3DSk+yshzWePS/Tj6tQ/50+6uaWTRRxmHyH6ZF5v4HaUMst19W7l9o/HuKTM
+qJZ9ZPskWkoDbGs4xugDQ5r3V7mzKWmTOPQD8rv7gmsHINFSH5pkAnuYZttcTVoP
+0ISVoDwUQwbKytu4QTbaakRnh6+v40URFWkIsr4WOZckbxJF0WddCajJFdr60qZf
+E2Efv4WstK2tBZQIgx51F9NxO5NQI1mg7TyRVJ12AMXDuDjb
+-----END CERTIFICATE-----
+
+# Issuer: CN=TunTrust Root CA O=Agence Nationale de Certification Electronique
+# Subject: CN=TunTrust Root CA O=Agence Nationale de Certification Electronique
+# Label: "TunTrust Root CA"
+# Serial: 108534058042236574382096126452369648152337120275
+# MD5 Fingerprint: 85:13:b9:90:5b:36:5c:b6:5e:b8:5a:f8:e0:31:57:b4
+# SHA1 Fingerprint: cf:e9:70:84:0f:e0:73:0f:9d:f6:0c:7f:2c:4b:ee:20:46:34:9c:bb
+# SHA256 Fingerprint: 2e:44:10:2a:b5:8c:b8:54:19:45:1c:8e:19:d9:ac:f3:66:2c:af:bc:61:4b:6a:53:96:0a:30:f7:d0:e2:eb:41
+-----BEGIN CERTIFICATE-----
+MIIFszCCA5ugAwIBAgIUEwLV4kBMkkaGFmddtLu7sms+/BMwDQYJKoZIhvcNAQEL
+BQAwYTELMAkGA1UEBhMCVE4xNzA1BgNVBAoMLkFnZW5jZSBOYXRpb25hbGUgZGUg
+Q2VydGlmaWNhdGlvbiBFbGVjdHJvbmlxdWUxGTAXBgNVBAMMEFR1blRydXN0IFJv
+b3QgQ0EwHhcNMTkwNDI2MDg1NzU2WhcNNDQwNDI2MDg1NzU2WjBhMQswCQYDVQQG
+EwJUTjE3MDUGA1UECgwuQWdlbmNlIE5hdGlvbmFsZSBkZSBDZXJ0aWZpY2F0aW9u
+IEVsZWN0cm9uaXF1ZTEZMBcGA1UEAwwQVHVuVHJ1c3QgUm9vdCBDQTCCAiIwDQYJ
+KoZIhvcNAQEBBQADggIPADCCAgoCggIBAMPN0/y9BFPdDCA61YguBUtB9YOCfvdZ
+n56eY+hz2vYGqU8ftPkLHzmMmiDQfgbU7DTZhrx1W4eI8NLZ1KMKsmwb60ksPqxd
+2JQDoOw05TDENX37Jk0bbjBU2PWARZw5rZzJJQRNmpA+TkBuimvNKWfGzC3gdOgF
+VwpIUPp6Q9p+7FuaDmJ2/uqdHYVy7BG7NegfJ7/Boce7SBbdVtfMTqDhuazb1YMZ
+GoXRlJfXyqNlC/M4+QKu3fZnz8k/9YosRxqZbwUN/dAdgjH8KcwAWJeRTIAAHDOF
+li/LQcKLEITDCSSJH7UP2dl3RxiSlGBcx5kDPP73lad9UKGAwqmDrViWVSHbhlnU
+r8a83YFuB9tgYv7sEG7aaAH0gxupPqJbI9dkxt/con3YS7qC0lH4Zr8GRuR5KiY2
+eY8fTpkdso8MDhz/yV3A/ZAQprE38806JG60hZC/gLkMjNWb1sjxVj8agIl6qeIb
+MlEsPvLfe/ZdeikZjuXIvTZxi11Mwh0/rViizz1wTaZQmCXcI/m4WEEIcb9PuISg
+jwBUFfyRbVinljvrS5YnzWuioYasDXxU5mZMZl+QviGaAkYt5IPCgLnPSz7ofzwB
+7I9ezX/SKEIBlYrilz0QIX32nRzFNKHsLA4KUiwSVXAkPcvCFDVDXSdOvsC9qnyW
+5/yeYa1E0wCXAgMBAAGjYzBhMB0GA1UdDgQWBBQGmpsfU33x9aTI04Y+oXNZtPdE
+ITAPBgNVHRMBAf8EBTADAQH/MB8GA1UdIwQYMBaAFAaamx9TffH1pMjThj6hc1m0
+90QhMA4GA1UdDwEB/wQEAwIBBjANBgkqhkiG9w0BAQsFAAOCAgEAqgVutt0Vyb+z
+xiD2BkewhpMl0425yAA/l/VSJ4hxyXT968pk21vvHl26v9Hr7lxpuhbI87mP0zYu
+QEkHDVneixCwSQXi/5E/S7fdAo74gShczNxtr18UnH1YeA32gAm56Q6XKRm4t+v4
+FstVEuTGfbvE7Pi1HE4+Z7/FXxttbUcoqgRYYdZ2vyJ/0Adqp2RT8JeNnYA/u8EH
+22Wv5psymsNUk8QcCMNE+3tjEUPRahphanltkE8pjkcFwRJpadbGNjHh/PqAulxP
+xOu3Mqz4dWEX1xAZufHSCe96Qp1bWgvUxpVOKs7/B9dPfhgGiPEZtdmYu65xxBzn
+dFlY7wyJz4sfdZMaBBSSSFCp61cpABbjNhzI+L/wM9VBD8TMPN3pM0MBkRArHtG5
+Xc0yGYuPjCB31yLEQtyEFpslbei0VXF/sHyz03FJuc9SpAQ/3D2gu68zngowYI7b
+nV2UqL1g52KAdoGDDIzMMEZJ4gzSqK/rYXHv5yJiqfdcZGyfFoxnNidF9Ql7v/YQ
+CvGwjVRDjAS6oz/v4jXH+XTgbzRB0L9zZVcg+ZtnemZoJE6AZb0QmQZZ8mWvuMZH
+u/2QeItBcy6vVR/cO5JyboTT0GFMDcx2V+IthSIVNg3rAZ3r2OvEhJn7wAzMMujj
+d9qDRIueVSjAi1jTkD5OGwDxFa2DK5o=
+-----END CERTIFICATE-----
+
+# Issuer: CN=HARICA TLS RSA Root CA 2021 O=Hellenic Academic and Research Institutions CA
+# Subject: CN=HARICA TLS RSA Root CA 2021 O=Hellenic Academic and Research Institutions CA
+# Label: "HARICA TLS RSA Root CA 2021"
+# Serial: 76817823531813593706434026085292783742
+# MD5 Fingerprint: 65:47:9b:58:86:dd:2c:f0:fc:a2:84:1f:1e:96:c4:91
+# SHA1 Fingerprint: 02:2d:05:82:fa:88:ce:14:0c:06:79:de:7f:14:10:e9:45:d7:a5:6d
+# SHA256 Fingerprint: d9:5d:0e:8e:da:79:52:5b:f9:be:b1:1b:14:d2:10:0d:32:94:98:5f:0c:62:d9:fa:bd:9c:d9:99:ec:cb:7b:1d
+-----BEGIN CERTIFICATE-----
+MIIFpDCCA4ygAwIBAgIQOcqTHO9D88aOk8f0ZIk4fjANBgkqhkiG9w0BAQsFADBs
+MQswCQYDVQQGEwJHUjE3MDUGA1UECgwuSGVsbGVuaWMgQWNhZGVtaWMgYW5kIFJl
+c2VhcmNoIEluc3RpdHV0aW9ucyBDQTEkMCIGA1UEAwwbSEFSSUNBIFRMUyBSU0Eg
+Um9vdCBDQSAyMDIxMB4XDTIxMDIxOTEwNTUzOFoXDTQ1MDIxMzEwNTUzN1owbDEL
+MAkGA1UEBhMCR1IxNzA1BgNVBAoMLkhlbGxlbmljIEFjYWRlbWljIGFuZCBSZXNl
+YXJjaCBJbnN0aXR1dGlvbnMgQ0ExJDAiBgNVBAMMG0hBUklDQSBUTFMgUlNBIFJv
+b3QgQ0EgMjAyMTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAIvC569l
+mwVnlskNJLnQDmT8zuIkGCyEf3dRywQRNrhe7Wlxp57kJQmXZ8FHws+RFjZiPTgE
+4VGC/6zStGndLuwRo0Xua2s7TL+MjaQenRG56Tj5eg4MmOIjHdFOY9TnuEFE+2uv
+a9of08WRiFukiZLRgeaMOVig1mlDqa2YUlhu2wr7a89o+uOkXjpFc5gH6l8Cct4M
+pbOfrqkdtx2z/IpZ525yZa31MJQjB/OCFks1mJxTuy/K5FrZx40d/JiZ+yykgmvw
+Kh+OC19xXFyuQnspiYHLA6OZyoieC0AJQTPb5lh6/a6ZcMBaD9YThnEvdmn8kN3b
+LW7R8pv1GmuebxWMevBLKKAiOIAkbDakO/IwkfN4E8/BPzWr8R0RI7VDIp4BkrcY
+AuUR0YLbFQDMYTfBKnya4dC6s1BG7oKsnTH4+yPiAwBIcKMJJnkVU2DzOFytOOqB
+AGMUuTNe3QvboEUHGjMJ+E20pwKmafTCWQWIZYVWrkvL4N48fS0ayOn7H6NhStYq
+E613TBoYm5EPWNgGVMWX+Ko/IIqmhaZ39qb8HOLubpQzKoNQhArlT4b4UEV4AIHr
+W2jjJo3Me1xR9BQsQL4aYB16cmEdH2MtiKrOokWQCPxrvrNQKlr9qEgYRtaQQJKQ
+CoReaDH46+0N0x3GfZkYVVYnZS6NRcUk7M7jAgMBAAGjQjBAMA8GA1UdEwEB/wQF
+MAMBAf8wHQYDVR0OBBYEFApII6ZgpJIKM+qTW8VX6iVNvRLuMA4GA1UdDwEB/wQE
+AwIBhjANBgkqhkiG9w0BAQsFAAOCAgEAPpBIqm5iFSVmewzVjIuJndftTgfvnNAU
+X15QvWiWkKQUEapobQk1OUAJ2vQJLDSle1mESSmXdMgHHkdt8s4cUCbjnj1AUz/3
+f5Z2EMVGpdAgS1D0NTsY9FVqQRtHBmg8uwkIYtlfVUKqrFOFrJVWNlar5AWMxaja
+H6NpvVMPxP/cyuN+8kyIhkdGGvMA9YCRotxDQpSbIPDRzbLrLFPCU3hKTwSUQZqP
+JzLB5UkZv/HywouoCjkxKLR9YjYsTewfM7Z+d21+UPCfDtcRj88YxeMn/ibvBZ3P
+zzfF0HvaO7AWhAw6k9a+F9sPPg4ZeAnHqQJyIkv3N3a6dcSFA1pj1bF1BcK5vZSt
+jBWZp5N99sXzqnTPBIWUmAD04vnKJGW/4GKvyMX6ssmeVkjaef2WdhW+o45WxLM0
+/L5H9MG0qPzVMIho7suuyWPEdr6sOBjhXlzPrjoiUevRi7PzKzMHVIf6tLITe7pT
+BGIBnfHAT+7hOtSLIBD6Alfm78ELt5BGnBkpjNxvoEppaZS3JGWg/6w/zgH7IS79
+aPib8qXPMThcFarmlwDB31qlpzmq6YR/PFGoOtmUW4y/Twhx5duoXNTSpv4Ao8YW
+xw/ogM4cKGR0GQjTQuPOAF1/sdwTsOEFy9EgqoZ0njnnkf3/W9b3raYvAwtt41dU
+63ZTGI0RmLo=
+-----END CERTIFICATE-----
+
+# Issuer: CN=HARICA TLS ECC Root CA 2021 O=Hellenic Academic and Research Institutions CA
+# Subject: CN=HARICA TLS ECC Root CA 2021 O=Hellenic Academic and Research Institutions CA
+# Label: "HARICA TLS ECC Root CA 2021"
+# Serial: 137515985548005187474074462014555733966
+# MD5 Fingerprint: ae:f7:4c:e5:66:35:d1:b7:9b:8c:22:93:74:d3:4b:b0
+# SHA1 Fingerprint: bc:b0:c1:9d:e9:98:92:70:19:38:57:e9:8d:a7:b4:5d:6e:ee:01:48
+# SHA256 Fingerprint: 3f:99:cc:47:4a:cf:ce:4d:fe:d5:87:94:66:5e:47:8d:15:47:73:9f:2e:78:0f:1b:b4:ca:9b:13:30:97:d4:01
+-----BEGIN CERTIFICATE-----
+MIICVDCCAdugAwIBAgIQZ3SdjXfYO2rbIvT/WeK/zjAKBggqhkjOPQQDAzBsMQsw
+CQYDVQQGEwJHUjE3MDUGA1UECgwuSGVsbGVuaWMgQWNhZGVtaWMgYW5kIFJlc2Vh
+cmNoIEluc3RpdHV0aW9ucyBDQTEkMCIGA1UEAwwbSEFSSUNBIFRMUyBFQ0MgUm9v
+dCBDQSAyMDIxMB4XDTIxMDIxOTExMDExMFoXDTQ1MDIxMzExMDEwOVowbDELMAkG
+A1UEBhMCR1IxNzA1BgNVBAoMLkhlbGxlbmljIEFjYWRlbWljIGFuZCBSZXNlYXJj
+aCBJbnN0aXR1dGlvbnMgQ0ExJDAiBgNVBAMMG0hBUklDQSBUTFMgRUNDIFJvb3Qg
+Q0EgMjAyMTB2MBAGByqGSM49AgEGBSuBBAAiA2IABDgI/rGgltJ6rK9JOtDA4MM7
+KKrxcm1lAEeIhPyaJmuqS7psBAqIXhfyVYf8MLA04jRYVxqEU+kw2anylnTDUR9Y
+STHMmE5gEYd103KUkE+bECUqqHgtvpBBWJAVcqeht6NCMEAwDwYDVR0TAQH/BAUw
+AwEB/zAdBgNVHQ4EFgQUyRtTgRL+BNUW0aq8mm+3oJUZbsowDgYDVR0PAQH/BAQD
+AgGGMAoGCCqGSM49BAMDA2cAMGQCMBHervjcToiwqfAircJRQO9gcS3ujwLEXQNw
+SaSS6sUUiHCm0w2wqsosQJz76YJumgIwK0eaB8bRwoF8yguWGEEbo/QwCZ61IygN
+nxS2PFOiTAZpffpskcYqSUXm7LcT4Tps
+-----END CERTIFICATE-----
+
+# Issuer: CN=Autoridad de Certificacion Firmaprofesional CIF A62634068
+# Subject: CN=Autoridad de Certificacion Firmaprofesional CIF A62634068
+# Label: "Autoridad de Certificacion Firmaprofesional CIF A62634068"
+# Serial: 1977337328857672817
+# MD5 Fingerprint: 4e:6e:9b:54:4c:ca:b7:fa:48:e4:90:b1:15:4b:1c:a3
+# SHA1 Fingerprint: 0b:be:c2:27:22:49:cb:39:aa:db:35:5c:53:e3:8c:ae:78:ff:b6:fe
+# SHA256 Fingerprint: 57:de:05:83:ef:d2:b2:6e:03:61:da:99:da:9d:f4:64:8d:ef:7e:e8:44:1c:3b:72:8a:fa:9b:cd:e0:f9:b2:6a
+-----BEGIN CERTIFICATE-----
+MIIGFDCCA/ygAwIBAgIIG3Dp0v+ubHEwDQYJKoZIhvcNAQELBQAwUTELMAkGA1UE
+BhMCRVMxQjBABgNVBAMMOUF1dG9yaWRhZCBkZSBDZXJ0aWZpY2FjaW9uIEZpcm1h
+cHJvZmVzaW9uYWwgQ0lGIEE2MjYzNDA2ODAeFw0xNDA5MjMxNTIyMDdaFw0zNjA1
+MDUxNTIyMDdaMFExCzAJBgNVBAYTAkVTMUIwQAYDVQQDDDlBdXRvcmlkYWQgZGUg
+Q2VydGlmaWNhY2lvbiBGaXJtYXByb2Zlc2lvbmFsIENJRiBBNjI2MzQwNjgwggIi
+MA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDKlmuO6vj78aI14H9M2uDDUtd9
+thDIAl6zQyrET2qyyhxdKJp4ERppWVevtSBC5IsP5t9bpgOSL/UR5GLXMnE42QQM
+cas9UX4PB99jBVzpv5RvwSmCwLTaUbDBPLutN0pcyvFLNg4kq7/DhHf9qFD0sefG
+L9ItWY16Ck6WaVICqjaY7Pz6FIMMNx/Jkjd/14Et5cS54D40/mf0PmbR0/RAz15i
+NA9wBj4gGFrO93IbJWyTdBSTo3OxDqqHECNZXyAFGUftaI6SEspd/NYrspI8IM/h
+X68gvqB2f3bl7BqGYTM+53u0P6APjqK5am+5hyZvQWyIplD9amML9ZMWGxmPsu2b
+m8mQ9QEM3xk9Dz44I8kvjwzRAv4bVdZO0I08r0+k8/6vKtMFnXkIoctXMbScyJCy
+Z/QYFpM6/EfY0XiWMR+6KwxfXZmtY4laJCB22N/9q06mIqqdXuYnin1oKaPnirja
+EbsXLZmdEyRG98Xi2J+Of8ePdG1asuhy9azuJBCtLxTa/y2aRnFHvkLfuwHb9H/T
+KI8xWVvTyQKmtFLKbpf7Q8UIJm+K9Lv9nyiqDdVF8xM6HdjAeI9BZzwelGSuewvF
+6NkBiDkal4ZkQdU7hwxu+g/GvUgUvzlN1J5Bto+WHWOWk9mVBngxaJ43BjuAiUVh
+OSPHG0SjFeUc+JIwuwIDAQABo4HvMIHsMB0GA1UdDgQWBBRlzeurNR4APn7VdMAc
+tHNHDhpkLzASBgNVHRMBAf8ECDAGAQH/AgEBMIGmBgNVHSAEgZ4wgZswgZgGBFUd
+IAAwgY8wLwYIKwYBBQUHAgEWI2h0dHA6Ly93d3cuZmlybWFwcm9mZXNpb25hbC5j
+b20vY3BzMFwGCCsGAQUFBwICMFAeTgBQAGEAcwBlAG8AIABkAGUAIABsAGEAIABC
+AG8AbgBhAG4AbwB2AGEAIAA0ADcAIABCAGEAcgBjAGUAbABvAG4AYQAgADAAOAAw
+ADEANzAOBgNVHQ8BAf8EBAMCAQYwDQYJKoZIhvcNAQELBQADggIBAHSHKAIrdx9m
+iWTtj3QuRhy7qPj4Cx2Dtjqn6EWKB7fgPiDL4QjbEwj4KKE1soCzC1HA01aajTNF
+Sa9J8OA9B3pFE1r/yJfY0xgsfZb43aJlQ3CTkBW6kN/oGbDbLIpgD7dvlAceHabJ
+hfa9NPhAeGIQcDq+fUs5gakQ1JZBu/hfHAsdCPKxsIl68veg4MSPi3i1O1ilI45P
+Vf42O+AMt8oqMEEgtIDNrvx2ZnOorm7hfNoD6JQg5iKj0B+QXSBTFCZX2lSX3xZE
+EAEeiGaPcjiT3SC3NL7X8e5jjkd5KAb881lFJWAiMxujX6i6KtoaPc1A6ozuBRWV
+1aUsIC+nmCjuRfzxuIgALI9C2lHVnOUTaHFFQ4ueCyE8S1wF3BqfmI7avSKecs2t
+CsvMo2ebKHTEm9caPARYpoKdrcd7b/+Alun4jWq9GJAd/0kakFI3ky88Al2CdgtR
+5xbHV/g4+afNmyJU72OwFW1TZQNKXkqgsqeOSQBZONXH9IBk9W6VULgRfhVwOEqw
+f9DEMnDAGf/JOC0ULGb0QkTmVXYbgBVX/8Cnp6o5qtjTcNAuuuuUavpfNIbnYrX9
+ivAwhZTJryQCL2/W3Wf+47BVTwSYT6RBVuKT0Gro1vP7ZeDOdcQxWQzugsgMYDNK
+GbqEZycPvEJdvSRUDewdcAZfpLz6IHxV
+-----END CERTIFICATE-----
+
+# Issuer: CN=vTrus ECC Root CA O=iTrusChina Co.,Ltd.
+# Subject: CN=vTrus ECC Root CA O=iTrusChina Co.,Ltd.
+# Label: "vTrus ECC Root CA"
+# Serial: 630369271402956006249506845124680065938238527194
+# MD5 Fingerprint: de:4b:c1:f5:52:8c:9b:43:e1:3e:8f:55:54:17:8d:85
+# SHA1 Fingerprint: f6:9c:db:b0:fc:f6:02:13:b6:52:32:a6:a3:91:3f:16:70:da:c3:e1
+# SHA256 Fingerprint: 30:fb:ba:2c:32:23:8e:2a:98:54:7a:f9:79:31:e5:50:42:8b:9b:3f:1c:8e:eb:66:33:dc:fa:86:c5:b2:7d:d3
+-----BEGIN CERTIFICATE-----
+MIICDzCCAZWgAwIBAgIUbmq8WapTvpg5Z6LSa6Q75m0c1towCgYIKoZIzj0EAwMw
+RzELMAkGA1UEBhMCQ04xHDAaBgNVBAoTE2lUcnVzQ2hpbmEgQ28uLEx0ZC4xGjAY
+BgNVBAMTEXZUcnVzIEVDQyBSb290IENBMB4XDTE4MDczMTA3MjY0NFoXDTQzMDcz
+MTA3MjY0NFowRzELMAkGA1UEBhMCQ04xHDAaBgNVBAoTE2lUcnVzQ2hpbmEgQ28u
+LEx0ZC4xGjAYBgNVBAMTEXZUcnVzIEVDQyBSb290IENBMHYwEAYHKoZIzj0CAQYF
+K4EEACIDYgAEZVBKrox5lkqqHAjDo6LN/llWQXf9JpRCux3NCNtzslt188+cToL0
+v/hhJoVs1oVbcnDS/dtitN9Ti72xRFhiQgnH+n9bEOf+QP3A2MMrMudwpremIFUd
+e4BdS49nTPEQo0IwQDAdBgNVHQ4EFgQUmDnNvtiyjPeyq+GtJK97fKHbH88wDwYD
+VR0TAQH/BAUwAwEB/zAOBgNVHQ8BAf8EBAMCAQYwCgYIKoZIzj0EAwMDaAAwZQIw
+V53dVvHH4+m4SVBrm2nDb+zDfSXkV5UTQJtS0zvzQBm8JsctBp61ezaf9SXUY2sA
+AjEA6dPGnlaaKsyh2j/IZivTWJwghfqrkYpwcBE4YGQLYgmRWAD5Tfs0aNoJrSEG
+GJTO
+-----END CERTIFICATE-----
+
+# Issuer: CN=vTrus Root CA O=iTrusChina Co.,Ltd.
+# Subject: CN=vTrus Root CA O=iTrusChina Co.,Ltd.
+# Label: "vTrus Root CA"
+# Serial: 387574501246983434957692974888460947164905180485
+# MD5 Fingerprint: b8:c9:37:df:fa:6b:31:84:64:c5:ea:11:6a:1b:75:fc
+# SHA1 Fingerprint: 84:1a:69:fb:f5:cd:1a:25:34:13:3d:e3:f8:fc:b8:99:d0:c9:14:b7
+# SHA256 Fingerprint: 8a:71:de:65:59:33:6f:42:6c:26:e5:38:80:d0:0d:88:a1:8d:a4:c6:a9:1f:0d:cb:61:94:e2:06:c5:c9:63:87
+-----BEGIN CERTIFICATE-----
+MIIFVjCCAz6gAwIBAgIUQ+NxE9izWRRdt86M/TX9b7wFjUUwDQYJKoZIhvcNAQEL
+BQAwQzELMAkGA1UEBhMCQ04xHDAaBgNVBAoTE2lUcnVzQ2hpbmEgQ28uLEx0ZC4x
+FjAUBgNVBAMTDXZUcnVzIFJvb3QgQ0EwHhcNMTgwNzMxMDcyNDA1WhcNNDMwNzMx
+MDcyNDA1WjBDMQswCQYDVQQGEwJDTjEcMBoGA1UEChMTaVRydXNDaGluYSBDby4s
+THRkLjEWMBQGA1UEAxMNdlRydXMgUm9vdCBDQTCCAiIwDQYJKoZIhvcNAQEBBQAD
+ggIPADCCAgoCggIBAL1VfGHTuB0EYgWgrmy3cLRB6ksDXhA/kFocizuwZotsSKYc
+IrrVQJLuM7IjWcmOvFjai57QGfIvWcaMY1q6n6MLsLOaXLoRuBLpDLvPbmyAhykU
+AyyNJJrIZIO1aqwTLDPxn9wsYTwaP3BVm60AUn/PBLn+NvqcwBauYv6WTEN+VRS+
+GrPSbcKvdmaVayqwlHeFXgQPYh1jdfdr58tbmnDsPmcF8P4HCIDPKNsFxhQnL4Z9
+8Cfe/+Z+M0jnCx5Y0ScrUw5XSmXX+6KAYPxMvDVTAWqXcoKv8R1w6Jz1717CbMdH
+flqUhSZNO7rrTOiwCcJlwp2dCZtOtZcFrPUGoPc2BX70kLJrxLT5ZOrpGgrIDajt
+J8nU57O5q4IikCc9Kuh8kO+8T/3iCiSn3mUkpF3qwHYw03dQ+A0Em5Q2AXPKBlim
+0zvc+gRGE1WKyURHuFE5Gi7oNOJ5y1lKCn+8pu8fA2dqWSslYpPZUxlmPCdiKYZN
+pGvu/9ROutW04o5IWgAZCfEF2c6Rsffr6TlP9m8EQ5pV9T4FFL2/s1m02I4zhKOQ
+UqqzApVg+QxMaPnu1RcN+HFXtSXkKe5lXa/R7jwXC1pDxaWG6iSe4gUH3DRCEpHW
+OXSuTEGC2/KmSNGzm/MzqvOmwMVO9fSddmPmAsYiS8GVP1BkLFTltvA8Kc9XAgMB
+AAGjQjBAMB0GA1UdDgQWBBRUYnBj8XWEQ1iO0RYgscasGrz2iTAPBgNVHRMBAf8E
+BTADAQH/MA4GA1UdDwEB/wQEAwIBBjANBgkqhkiG9w0BAQsFAAOCAgEAKbqSSaet
+8PFww+SX8J+pJdVrnjT+5hpk9jprUrIQeBqfTNqK2uwcN1LgQkv7bHbKJAs5EhWd
+nxEt/Hlk3ODg9d3gV8mlsnZwUKT+twpw1aA08XXXTUm6EdGz2OyC/+sOxL9kLX1j
+bhd47F18iMjrjld22VkE+rxSH0Ws8HqA7Oxvdq6R2xCOBNyS36D25q5J08FsEhvM
+Kar5CKXiNxTKsbhm7xqC5PD48acWabfbqWE8n/Uxy+QARsIvdLGx14HuqCaVvIiv
+TDUHKgLKeBRtRytAVunLKmChZwOgzoy8sHJnxDHO2zTlJQNgJXtxmOTAGytfdELS
+S8VZCAeHvsXDf+eW2eHcKJfWjwXj9ZtOyh1QRwVTsMo554WgicEFOwE30z9J4nfr
+I8iIZjs9OXYhRvHsXyO466JmdXTBQPfYaJqT4i2pLr0cox7IdMakLXogqzu4sEb9
+b91fUlV1YvCXoHzXOP0l382gmxDPi7g4Xl7FtKYCNqEeXxzP4padKar9mK5S4fNB
+UvupLnKWnyfjqnN9+BojZns7q2WwMgFLFT49ok8MKzWixtlnEjUwzXYuFrOZnk1P
+Ti07NEPhmg4NpGaXutIcSkwsKouLgU9xGqndXHt7CMUADTdA43x7VF8vhV929ven
+sBxXVsFy6K2ir40zSbofitzmdHxghm+Hl3s=
+-----END CERTIFICATE-----
+
+# Issuer: CN=ISRG Root X2 O=Internet Security Research Group
+# Subject: CN=ISRG Root X2 O=Internet Security Research Group
+# Label: "ISRG Root X2"
+# Serial: 87493402998870891108772069816698636114
+# MD5 Fingerprint: d3:9e:c4:1e:23:3c:a6:df:cf:a3:7e:6d:e0:14:e6:e5
+# SHA1 Fingerprint: bd:b1:b9:3c:d5:97:8d:45:c6:26:14:55:f8:db:95:c7:5a:d1:53:af
+# SHA256 Fingerprint: 69:72:9b:8e:15:a8:6e:fc:17:7a:57:af:b7:17:1d:fc:64:ad:d2:8c:2f:ca:8c:f1:50:7e:34:45:3c:cb:14:70
+-----BEGIN CERTIFICATE-----
+MIICGzCCAaGgAwIBAgIQQdKd0XLq7qeAwSxs6S+HUjAKBggqhkjOPQQDAzBPMQsw
+CQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJuZXQgU2VjdXJpdHkgUmVzZWFyY2gg
+R3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBYMjAeFw0yMDA5MDQwMDAwMDBaFw00
+MDA5MTcxNjAwMDBaME8xCzAJBgNVBAYTAlVTMSkwJwYDVQQKEyBJbnRlcm5ldCBT
+ZWN1cml0eSBSZXNlYXJjaCBHcm91cDEVMBMGA1UEAxMMSVNSRyBSb290IFgyMHYw
+EAYHKoZIzj0CAQYFK4EEACIDYgAEzZvVn4CDCuwJSvMWSj5cz3es3mcFDR0HttwW
++1qLFNvicWDEukWVEYmO6gbf9yoWHKS5xcUy4APgHoIYOIvXRdgKam7mAHf7AlF9
+ItgKbppbd9/w+kHsOdx1ymgHDB/qo0IwQDAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0T
+AQH/BAUwAwEB/zAdBgNVHQ4EFgQUfEKWrt5LSDv6kviejM9ti6lyN5UwCgYIKoZI
+zj0EAwMDaAAwZQIwe3lORlCEwkSHRhtFcP9Ymd70/aTSVaYgLXTWNLxBo1BfASdW
+tL4ndQavEi51mI38AjEAi/V3bNTIZargCyzuFJ0nN6T5U6VR5CmD1/iQMVtCnwr1
+/q4AaOeMSQ+2b1tbFfLn
+-----END CERTIFICATE-----
+
+# Issuer: CN=HiPKI Root CA - G1 O=Chunghwa Telecom Co., Ltd.
+# Subject: CN=HiPKI Root CA - G1 O=Chunghwa Telecom Co., Ltd.
+# Label: "HiPKI Root CA - G1"
+# Serial: 60966262342023497858655262305426234976
+# MD5 Fingerprint: 69:45:df:16:65:4b:e8:68:9a:8f:76:5f:ff:80:9e:d3
+# SHA1 Fingerprint: 6a:92:e4:a8:ee:1b:ec:96:45:37:e3:29:57:49:cd:96:e3:e5:d2:60
+# SHA256 Fingerprint: f0:15:ce:3c:c2:39:bf:ef:06:4b:e9:f1:d2:c4:17:e1:a0:26:4a:0a:94:be:1f:0c:8d:12:18:64:eb:69:49:cc
+-----BEGIN CERTIFICATE-----
+MIIFajCCA1KgAwIBAgIQLd2szmKXlKFD6LDNdmpeYDANBgkqhkiG9w0BAQsFADBP
+MQswCQYDVQQGEwJUVzEjMCEGA1UECgwaQ2h1bmdod2EgVGVsZWNvbSBDby4sIEx0
+ZC4xGzAZBgNVBAMMEkhpUEtJIFJvb3QgQ0EgLSBHMTAeFw0xOTAyMjIwOTQ2MDRa
+Fw0zNzEyMzExNTU5NTlaME8xCzAJBgNVBAYTAlRXMSMwIQYDVQQKDBpDaHVuZ2h3
+YSBUZWxlY29tIENvLiwgTHRkLjEbMBkGA1UEAwwSSGlQS0kgUm9vdCBDQSAtIEcx
+MIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEA9B5/UnMyDHPkvRN0o9Qw
+qNCuS9i233VHZvR85zkEHmpwINJaR3JnVfSl6J3VHiGh8Ge6zCFovkRTv4354twv
+Vcg3Px+kwJyz5HdcoEb+d/oaoDjq7Zpy3iu9lFc6uux55199QmQ5eiY29yTw1S+6
+lZgRZq2XNdZ1AYDgr/SEYYwNHl98h5ZeQa/rh+r4XfEuiAU+TCK72h8q3VJGZDnz
+Qs7ZngyzsHeXZJzA9KMuH5UHsBffMNsAGJZMoYFL3QRtU6M9/Aes1MU3guvklQgZ
+KILSQjqj2FPseYlgSGDIcpJQ3AOPgz+yQlda22rpEZfdhSi8MEyr48KxRURHH+CK
+FgeW0iEPU8DtqX7UTuybCeyvQqww1r/REEXgphaypcXTT3OUM3ECoWqj1jOXTyFj
+HluP2cFeRXF3D4FdXyGarYPM+l7WjSNfGz1BryB1ZlpK9p/7qxj3ccC2HTHsOyDr
+y+K49a6SsvfhhEvyovKTmiKe0xRvNlS9H15ZFblzqMF8b3ti6RZsR1pl8w4Rm0bZ
+/W3c1pzAtH2lsN0/Vm+h+fbkEkj9Bn8SV7apI09bA8PgcSojt/ewsTu8mL3WmKgM
+a/aOEmem8rJY5AIJEzypuxC00jBF8ez3ABHfZfjcK0NVvxaXxA/VLGGEqnKG/uY6
+fsI/fe78LxQ+5oXdUG+3Se0CAwEAAaNCMEAwDwYDVR0TAQH/BAUwAwEB/zAdBgNV
+HQ4EFgQU8ncX+l6o/vY9cdVouslGDDjYr7AwDgYDVR0PAQH/BAQDAgGGMA0GCSqG
+SIb3DQEBCwUAA4ICAQBQUfB13HAE4/+qddRxosuej6ip0691x1TPOhwEmSKsxBHi
+7zNKpiMdDg1H2DfHb680f0+BazVP6XKlMeJ45/dOlBhbQH3PayFUhuaVevvGyuqc
+SE5XCV0vrPSltJczWNWseanMX/mF+lLFjfiRFOs6DRfQUsJ748JzjkZ4Bjgs6Fza
+ZsT0pPBWGTMpWmWSBUdGSquEwx4noR8RkpkndZMPvDY7l1ePJlsMu5wP1G4wB9Tc
+XzZoZjmDlicmisjEOf6aIW/Vcobpf2Lll07QJNBAsNB1CI69aO4I1258EHBGG3zg
+iLKecoaZAeO/n0kZtCW+VmWuF2PlHt/o/0elv+EmBYTksMCv5wiZqAxeJoBF1Pho
+L5aPruJKHJwWDBNvOIf2u8g0X5IDUXlwpt/L9ZlNec1OvFefQ05rLisY+GpzjLrF
+Ne85akEez3GoorKGB1s6yeHvP2UEgEcyRHCVTjFnanRbEEV16rCf0OY1/k6fi8wr
+kkVbbiVghUbN0aqwdmaTd5a+g744tiROJgvM7XpWGuDpWsZkrUx6AEhEL7lAuxM+
+vhV4nYWBSipX3tUZQ9rbyltHhoMLP7YNdnhzeSJesYAfz77RP1YQmCuVh6EfnWQU
+YDksswBVLuT1sw5XxJFBAJw/6KXf6vb/yPCtbVKoF6ubYfwSUTXkJf2vqmqGOQ==
+-----END CERTIFICATE-----
+
+# Issuer: CN=GlobalSign O=GlobalSign OU=GlobalSign ECC Root CA - R4
+# Subject: CN=GlobalSign O=GlobalSign OU=GlobalSign ECC Root CA - R4
+# Label: "GlobalSign ECC Root CA - R4"
+# Serial: 159662223612894884239637590694
+# MD5 Fingerprint: 26:29:f8:6d:e1:88:bf:a2:65:7f:aa:c4:cd:0f:7f:fc
+# SHA1 Fingerprint: 6b:a0:b0:98:e1:71:ef:5a:ad:fe:48:15:80:77:10:f4:bd:6f:0b:28
+# SHA256 Fingerprint: b0:85:d7:0b:96:4f:19:1a:73:e4:af:0d:54:ae:7a:0e:07:aa:fd:af:9b:71:dd:08:62:13:8a:b7:32:5a:24:a2
+-----BEGIN CERTIFICATE-----
+MIIB3DCCAYOgAwIBAgINAgPlfvU/k/2lCSGypjAKBggqhkjOPQQDAjBQMSQwIgYD
+VQQLExtHbG9iYWxTaWduIEVDQyBSb290IENBIC0gUjQxEzARBgNVBAoTCkdsb2Jh
+bFNpZ24xEzARBgNVBAMTCkdsb2JhbFNpZ24wHhcNMTIxMTEzMDAwMDAwWhcNMzgw
+MTE5MDMxNDA3WjBQMSQwIgYDVQQLExtHbG9iYWxTaWduIEVDQyBSb290IENBIC0g
+UjQxEzARBgNVBAoTCkdsb2JhbFNpZ24xEzARBgNVBAMTCkdsb2JhbFNpZ24wWTAT
+BgcqhkjOPQIBBggqhkjOPQMBBwNCAAS4xnnTj2wlDp8uORkcA6SumuU5BwkWymOx
+uYb4ilfBV85C+nOh92VC/x7BALJucw7/xyHlGKSq2XE/qNS5zowdo0IwQDAOBgNV
+HQ8BAf8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQUVLB7rUW44kB/
++wpu+74zyTyjhNUwCgYIKoZIzj0EAwIDRwAwRAIgIk90crlgr/HmnKAWBVBfw147
+bmF0774BxL4YSFlhgjICICadVGNA3jdgUM/I2O2dgq43mLyjj0xMqTQrbO/7lZsm
+-----END CERTIFICATE-----
+
+# Issuer: CN=GTS Root R1 O=Google Trust Services LLC
+# Subject: CN=GTS Root R1 O=Google Trust Services LLC
+# Label: "GTS Root R1"
+# Serial: 159662320309726417404178440727
+# MD5 Fingerprint: 05:fe:d0:bf:71:a8:a3:76:63:da:01:e0:d8:52:dc:40
+# SHA1 Fingerprint: e5:8c:1c:c4:91:3b:38:63:4b:e9:10:6e:e3:ad:8e:6b:9d:d9:81:4a
+# SHA256 Fingerprint: d9:47:43:2a:bd:e7:b7:fa:90:fc:2e:6b:59:10:1b:12:80:e0:e1:c7:e4:e4:0f:a3:c6:88:7f:ff:57:a7:f4:cf
+-----BEGIN CERTIFICATE-----
+MIIFVzCCAz+gAwIBAgINAgPlk28xsBNJiGuiFzANBgkqhkiG9w0BAQwFADBHMQsw
+CQYDVQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZpY2VzIExMQzEU
+MBIGA1UEAxMLR1RTIFJvb3QgUjEwHhcNMTYwNjIyMDAwMDAwWhcNMzYwNjIyMDAw
+MDAwWjBHMQswCQYDVQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZp
+Y2VzIExMQzEUMBIGA1UEAxMLR1RTIFJvb3QgUjEwggIiMA0GCSqGSIb3DQEBAQUA
+A4ICDwAwggIKAoICAQC2EQKLHuOhd5s73L+UPreVp0A8of2C+X0yBoJx9vaMf/vo
+27xqLpeXo4xL+Sv2sfnOhB2x+cWX3u+58qPpvBKJXqeqUqv4IyfLpLGcY9vXmX7w
+Cl7raKb0xlpHDU0QM+NOsROjyBhsS+z8CZDfnWQpJSMHobTSPS5g4M/SCYe7zUjw
+TcLCeoiKu7rPWRnWr4+wB7CeMfGCwcDfLqZtbBkOtdh+JhpFAz2weaSUKK0Pfybl
+qAj+lug8aJRT7oM6iCsVlgmy4HqMLnXWnOunVmSPlk9orj2XwoSPwLxAwAtcvfaH
+szVsrBhQf4TgTM2S0yDpM7xSma8ytSmzJSq0SPly4cpk9+aCEI3oncKKiPo4Zor8
+Y/kB+Xj9e1x3+naH+uzfsQ55lVe0vSbv1gHR6xYKu44LtcXFilWr06zqkUspzBmk
+MiVOKvFlRNACzqrOSbTqn3yDsEB750Orp2yjj32JgfpMpf/VjsPOS+C12LOORc92
+wO1AK/1TD7Cn1TsNsYqiA94xrcx36m97PtbfkSIS5r762DL8EGMUUXLeXdYWk70p
+aDPvOmbsB4om3xPXV2V4J95eSRQAogB/mqghtqmxlbCluQ0WEdrHbEg8QOB+DVrN
+VjzRlwW5y0vtOUucxD/SVRNuJLDWcfr0wbrM7Rv1/oFB2ACYPTrIrnqYNxgFlQID
+AQABo0IwQDAOBgNVHQ8BAf8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4E
+FgQU5K8rJnEaK0gnhS9SZizv8IkTcT4wDQYJKoZIhvcNAQEMBQADggIBAJ+qQibb
+C5u+/x6Wki4+omVKapi6Ist9wTrYggoGxval3sBOh2Z5ofmmWJyq+bXmYOfg6LEe
+QkEzCzc9zolwFcq1JKjPa7XSQCGYzyI0zzvFIoTgxQ6KfF2I5DUkzps+GlQebtuy
+h6f88/qBVRRiClmpIgUxPoLW7ttXNLwzldMXG+gnoot7TiYaelpkttGsN/H9oPM4
+7HLwEXWdyzRSjeZ2axfG34arJ45JK3VmgRAhpuo+9K4l/3wV3s6MJT/KYnAK9y8J
+ZgfIPxz88NtFMN9iiMG1D53Dn0reWVlHxYciNuaCp+0KueIHoI17eko8cdLiA6Ef
+MgfdG+RCzgwARWGAtQsgWSl4vflVy2PFPEz0tv/bal8xa5meLMFrUKTX5hgUvYU/
+Z6tGn6D/Qqc6f1zLXbBwHSs09dR2CQzreExZBfMzQsNhFRAbd03OIozUhfJFfbdT
+6u9AWpQKXCBfTkBdYiJ23//OYb2MI3jSNwLgjt7RETeJ9r/tSQdirpLsQBqvFAnZ
+0E6yove+7u7Y/9waLd64NnHi/Hm3lCXRSHNboTXns5lndcEZOitHTtNCjv0xyBZm
+2tIMPNuzjsmhDYAPexZ3FL//2wmUspO8IFgV6dtxQ/PeEMMA3KgqlbbC1j+Qa3bb
+bP6MvPJwNQzcmRk13NfIRmPVNnGuV/u3gm3c
+-----END CERTIFICATE-----
+
+# Issuer: CN=GTS Root R2 O=Google Trust Services LLC
+# Subject: CN=GTS Root R2 O=Google Trust Services LLC
+# Label: "GTS Root R2"
+# Serial: 159662449406622349769042896298
+# MD5 Fingerprint: 1e:39:c0:53:e6:1e:29:82:0b:ca:52:55:36:5d:57:dc
+# SHA1 Fingerprint: 9a:44:49:76:32:db:de:fa:d0:bc:fb:5a:7b:17:bd:9e:56:09:24:94
+# SHA256 Fingerprint: 8d:25:cd:97:22:9d:bf:70:35:6b:da:4e:b3:cc:73:40:31:e2:4c:f0:0f:af:cf:d3:2d:c7:6e:b5:84:1c:7e:a8
+-----BEGIN CERTIFICATE-----
+MIIFVzCCAz+gAwIBAgINAgPlrsWNBCUaqxElqjANBgkqhkiG9w0BAQwFADBHMQsw
+CQYDVQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZpY2VzIExMQzEU
+MBIGA1UEAxMLR1RTIFJvb3QgUjIwHhcNMTYwNjIyMDAwMDAwWhcNMzYwNjIyMDAw
+MDAwWjBHMQswCQYDVQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZp
+Y2VzIExMQzEUMBIGA1UEAxMLR1RTIFJvb3QgUjIwggIiMA0GCSqGSIb3DQEBAQUA
+A4ICDwAwggIKAoICAQDO3v2m++zsFDQ8BwZabFn3GTXd98GdVarTzTukk3LvCvpt
+nfbwhYBboUhSnznFt+4orO/LdmgUud+tAWyZH8QiHZ/+cnfgLFuv5AS/T3KgGjSY
+6Dlo7JUle3ah5mm5hRm9iYz+re026nO8/4Piy33B0s5Ks40FnotJk9/BW9BuXvAu
+MC6C/Pq8tBcKSOWIm8Wba96wyrQD8Nr0kLhlZPdcTK3ofmZemde4wj7I0BOdre7k
+RXuJVfeKH2JShBKzwkCX44ofR5GmdFrS+LFjKBC4swm4VndAoiaYecb+3yXuPuWg
+f9RhD1FLPD+M2uFwdNjCaKH5wQzpoeJ/u1U8dgbuak7MkogwTZq9TwtImoS1mKPV
++3PBV2HdKFZ1E66HjucMUQkQdYhMvI35ezzUIkgfKtzra7tEscszcTJGr61K8Yzo
+dDqs5xoic4DSMPclQsciOzsSrZYuxsN2B6ogtzVJV+mSSeh2FnIxZyuWfoqjx5RW
+Ir9qS34BIbIjMt/kmkRtWVtd9QCgHJvGeJeNkP+byKq0rxFROV7Z+2et1VsRnTKa
+G73VululycslaVNVJ1zgyjbLiGH7HrfQy+4W+9OmTN6SpdTi3/UGVN4unUu0kzCq
+gc7dGtxRcw1PcOnlthYhGXmy5okLdWTK1au8CcEYof/UVKGFPP0UJAOyh9OktwID
+AQABo0IwQDAOBgNVHQ8BAf8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4E
+FgQUu//KjiOfT5nK2+JopqUVJxce2Q4wDQYJKoZIhvcNAQEMBQADggIBAB/Kzt3H
+vqGf2SdMC9wXmBFqiN495nFWcrKeGk6c1SuYJF2ba3uwM4IJvd8lRuqYnrYb/oM8
+0mJhwQTtzuDFycgTE1XnqGOtjHsB/ncw4c5omwX4Eu55MaBBRTUoCnGkJE+M3DyC
+B19m3H0Q/gxhswWV7uGugQ+o+MePTagjAiZrHYNSVc61LwDKgEDg4XSsYPWHgJ2u
+NmSRXbBoGOqKYcl3qJfEycel/FVL8/B/uWU9J2jQzGv6U53hkRrJXRqWbTKH7QMg
+yALOWr7Z6v2yTcQvG99fevX4i8buMTolUVVnjWQye+mew4K6Ki3pHrTgSAai/Gev
+HyICc/sgCq+dVEuhzf9gR7A/Xe8bVr2XIZYtCtFenTgCR2y59PYjJbigapordwj6
+xLEokCZYCDzifqrXPW+6MYgKBesntaFJ7qBFVHvmJ2WZICGoo7z7GJa7Um8M7YNR
+TOlZ4iBgxcJlkoKM8xAfDoqXvneCbT+PHV28SSe9zE8P4c52hgQjxcCMElv924Sg
+JPFI/2R80L5cFtHvma3AH/vLrrw4IgYmZNralw4/KBVEqE8AyvCazM90arQ+POuV
+7LXTWtiBmelDGDfrs7vRWGJB82bSj6p4lVQgw1oudCvV0b4YacCs1aTPObpRhANl
+6WLAYv7YTVWW4tAR+kg0Eeye7QUd5MjWHYbL
+-----END CERTIFICATE-----
+
+# Issuer: CN=GTS Root R3 O=Google Trust Services LLC
+# Subject: CN=GTS Root R3 O=Google Trust Services LLC
+# Label: "GTS Root R3"
+# Serial: 159662495401136852707857743206
+# MD5 Fingerprint: 3e:e7:9d:58:02:94:46:51:94:e5:e0:22:4a:8b:e7:73
+# SHA1 Fingerprint: ed:e5:71:80:2b:c8:92:b9:5b:83:3c:d2:32:68:3f:09:cd:a0:1e:46
+# SHA256 Fingerprint: 34:d8:a7:3e:e2:08:d9:bc:db:0d:95:65:20:93:4b:4e:40:e6:94:82:59:6e:8b:6f:73:c8:42:6b:01:0a:6f:48
+-----BEGIN CERTIFICATE-----
+MIICCTCCAY6gAwIBAgINAgPluILrIPglJ209ZjAKBggqhkjOPQQDAzBHMQswCQYD
+VQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZpY2VzIExMQzEUMBIG
+A1UEAxMLR1RTIFJvb3QgUjMwHhcNMTYwNjIyMDAwMDAwWhcNMzYwNjIyMDAwMDAw
+WjBHMQswCQYDVQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZpY2Vz
+IExMQzEUMBIGA1UEAxMLR1RTIFJvb3QgUjMwdjAQBgcqhkjOPQIBBgUrgQQAIgNi
+AAQfTzOHMymKoYTey8chWEGJ6ladK0uFxh1MJ7x/JlFyb+Kf1qPKzEUURout736G
+jOyxfi//qXGdGIRFBEFVbivqJn+7kAHjSxm65FSWRQmx1WyRRK2EE46ajA2ADDL2
+4CejQjBAMA4GA1UdDwEB/wQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQW
+BBTB8Sa6oC2uhYHP0/EqEr24Cmf9vDAKBggqhkjOPQQDAwNpADBmAjEA9uEglRR7
+VKOQFhG/hMjqb2sXnh5GmCCbn9MN2azTL818+FsuVbu/3ZL3pAzcMeGiAjEA/Jdm
+ZuVDFhOD3cffL74UOO0BzrEXGhF16b0DjyZ+hOXJYKaV11RZt+cRLInUue4X
+-----END CERTIFICATE-----
+
+# Issuer: CN=GTS Root R4 O=Google Trust Services LLC
+# Subject: CN=GTS Root R4 O=Google Trust Services LLC
+# Label: "GTS Root R4"
+# Serial: 159662532700760215368942768210
+# MD5 Fingerprint: 43:96:83:77:19:4d:76:b3:9d:65:52:e4:1d:22:a5:e8
+# SHA1 Fingerprint: 77:d3:03:67:b5:e0:0c:15:f6:0c:38:61:df:7c:e1:3b:92:46:4d:47
+# SHA256 Fingerprint: 34:9d:fa:40:58:c5:e2:63:12:3b:39:8a:e7:95:57:3c:4e:13:13:c8:3f:e6:8f:93:55:6c:d5:e8:03:1b:3c:7d
+-----BEGIN CERTIFICATE-----
+MIICCTCCAY6gAwIBAgINAgPlwGjvYxqccpBQUjAKBggqhkjOPQQDAzBHMQswCQYD
+VQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZpY2VzIExMQzEUMBIG
+A1UEAxMLR1RTIFJvb3QgUjQwHhcNMTYwNjIyMDAwMDAwWhcNMzYwNjIyMDAwMDAw
+WjBHMQswCQYDVQQGEwJVUzEiMCAGA1UEChMZR29vZ2xlIFRydXN0IFNlcnZpY2Vz
+IExMQzEUMBIGA1UEAxMLR1RTIFJvb3QgUjQwdjAQBgcqhkjOPQIBBgUrgQQAIgNi
+AATzdHOnaItgrkO4NcWBMHtLSZ37wWHO5t5GvWvVYRg1rkDdc/eJkTBa6zzuhXyi
+QHY7qca4R9gq55KRanPpsXI5nymfopjTX15YhmUPoYRlBtHci8nHc8iMai/lxKvR
+HYqjQjBAMA4GA1UdDwEB/wQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQW
+BBSATNbrdP9JNqPV2Py1PsVq8JQdjDAKBggqhkjOPQQDAwNpADBmAjEA6ED/g94D
+9J+uHXqnLrmvT/aDHQ4thQEd0dlq7A/Cr8deVl5c1RxYIigL9zC2L7F8AjEA8GE8
+p/SgguMh1YQdc4acLa/KNJvxn7kjNuK8YAOdgLOaVsjh4rsUecrNIdSUtUlD
+-----END CERTIFICATE-----
+
+# Issuer: CN=Telia Root CA v2 O=Telia Finland Oyj
+# Subject: CN=Telia Root CA v2 O=Telia Finland Oyj
+# Label: "Telia Root CA v2"
+# Serial: 7288924052977061235122729490515358
+# MD5 Fingerprint: 0e:8f:ac:aa:82:df:85:b1:f4:dc:10:1c:fc:99:d9:48
+# SHA1 Fingerprint: b9:99:cd:d1:73:50:8a:c4:47:05:08:9c:8c:88:fb:be:a0:2b:40:cd
+# SHA256 Fingerprint: 24:2b:69:74:2f:cb:1e:5b:2a:bf:98:89:8b:94:57:21:87:54:4e:5b:4d:99:11:78:65:73:62:1f:6a:74:b8:2c
+-----BEGIN CERTIFICATE-----
+MIIFdDCCA1ygAwIBAgIPAWdfJ9b+euPkrL4JWwWeMA0GCSqGSIb3DQEBCwUAMEQx
+CzAJBgNVBAYTAkZJMRowGAYDVQQKDBFUZWxpYSBGaW5sYW5kIE95ajEZMBcGA1UE
+AwwQVGVsaWEgUm9vdCBDQSB2MjAeFw0xODExMjkxMTU1NTRaFw00MzExMjkxMTU1
+NTRaMEQxCzAJBgNVBAYTAkZJMRowGAYDVQQKDBFUZWxpYSBGaW5sYW5kIE95ajEZ
+MBcGA1UEAwwQVGVsaWEgUm9vdCBDQSB2MjCCAiIwDQYJKoZIhvcNAQEBBQADggIP
+ADCCAgoCggIBALLQPwe84nvQa5n44ndp586dpAO8gm2h/oFlH0wnrI4AuhZ76zBq
+AMCzdGh+sq/H1WKzej9Qyow2RCRj0jbpDIX2Q3bVTKFgcmfiKDOlyzG4OiIjNLh9
+vVYiQJ3q9HsDrWj8soFPmNB06o3lfc1jw6P23pLCWBnglrvFxKk9pXSW/q/5iaq9
+lRdU2HhE8Qx3FZLgmEKnpNaqIJLNwaCzlrI6hEKNfdWV5Nbb6WLEWLN5xYzTNTOD
+n3WhUidhOPFZPY5Q4L15POdslv5e2QJltI5c0BE0312/UqeBAMN/mUWZFdUXyApT
+7GPzmX3MaRKGwhfwAZ6/hLzRUssbkmbOpFPlob/E2wnW5olWK8jjfN7j/4nlNW4o
+6GwLI1GpJQXrSPjdscr6bAhR77cYbETKJuFzxokGgeWKrLDiKca5JLNrRBH0pUPC
+TEPlcDaMtjNXepUugqD0XBCzYYP2AgWGLnwtbNwDRm41k9V6lS/eINhbfpSQBGq6
+WT0EBXWdN6IOLj3rwaRSg/7Qa9RmjtzG6RJOHSpXqhC8fF6CfaamyfItufUXJ63R
+DolUK5X6wK0dmBR4M0KGCqlztft0DbcbMBnEWg4cJ7faGND/isgFuvGqHKI3t+ZI
+pEYslOqodmJHixBTB0hXbOKSTbauBcvcwUpej6w9GU7C7WB1K9vBykLVAgMBAAGj
+YzBhMB8GA1UdIwQYMBaAFHKs5DN5qkWH9v2sHZ7Wxy+G2CQ5MB0GA1UdDgQWBBRy
+rOQzeapFh/b9rB2e1scvhtgkOTAOBgNVHQ8BAf8EBAMCAQYwDwYDVR0TAQH/BAUw
+AwEB/zANBgkqhkiG9w0BAQsFAAOCAgEAoDtZpwmUPjaE0n4vOaWWl/oRrfxn83EJ
+8rKJhGdEr7nv7ZbsnGTbMjBvZ5qsfl+yqwE2foH65IRe0qw24GtixX1LDoJt0nZi
+0f6X+J8wfBj5tFJ3gh1229MdqfDBmgC9bXXYfef6xzijnHDoRnkDry5023X4blMM
+A8iZGok1GTzTyVR8qPAs5m4HeW9q4ebqkYJpCh3DflminmtGFZhb069GHWLIzoBS
+SRE/yQQSwxN8PzuKlts8oB4KtItUsiRnDe+Cy748fdHif64W1lZYudogsYMVoe+K
+TTJvQS8TUoKU1xrBeKJR3Stwbbca+few4GeXVtt8YVMJAygCQMez2P2ccGrGKMOF
+6eLtGpOg3kuYooQ+BXcBlj37tCAPnHICehIv1aO6UXivKitEZU61/Qrowc15h2Er
+3oBXRb9n8ZuRXqWk7FlIEA04x7D6w0RtBPV4UBySllva9bguulvP5fBqnUsvWHMt
+Ty3EHD70sz+rFQ47GUGKpMFXEmZxTPpT41frYpUJnlTd0cI8Vzy9OK2YZLe4A5pT
+VmBds9hCG1xLEooc6+t9xnppxyd/pPiL8uSUZodL6ZQHCRJ5irLrdATczvREWeAW
+ysUsWNc8e89ihmpQfTU2Zqf7N+cox9jQraVplI/owd8k+BsHMYeB2F326CjYSlKA
+rBPuUBQemMc=
+-----END CERTIFICATE-----
+
+# Issuer: CN=D-TRUST BR Root CA 1 2020 O=D-Trust GmbH
+# Subject: CN=D-TRUST BR Root CA 1 2020 O=D-Trust GmbH
+# Label: "D-TRUST BR Root CA 1 2020"
+# Serial: 165870826978392376648679885835942448534
+# MD5 Fingerprint: b5:aa:4b:d5:ed:f7:e3:55:2e:8f:72:0a:f3:75:b8:ed
+# SHA1 Fingerprint: 1f:5b:98:f0:e3:b5:f7:74:3c:ed:e6:b0:36:7d:32:cd:f4:09:41:67
+# SHA256 Fingerprint: e5:9a:aa:81:60:09:c2:2b:ff:5b:25:ba:d3:7d:f3:06:f0:49:79:7c:1f:81:d8:5a:b0:89:e6:57:bd:8f:00:44
+-----BEGIN CERTIFICATE-----
+MIIC2zCCAmCgAwIBAgIQfMmPK4TX3+oPyWWa00tNljAKBggqhkjOPQQDAzBIMQsw
+CQYDVQQGEwJERTEVMBMGA1UEChMMRC1UcnVzdCBHbWJIMSIwIAYDVQQDExlELVRS
+VVNUIEJSIFJvb3QgQ0EgMSAyMDIwMB4XDTIwMDIxMTA5NDUwMFoXDTM1MDIxMTA5
+NDQ1OVowSDELMAkGA1UEBhMCREUxFTATBgNVBAoTDEQtVHJ1c3QgR21iSDEiMCAG
+A1UEAxMZRC1UUlVTVCBCUiBSb290IENBIDEgMjAyMDB2MBAGByqGSM49AgEGBSuB
+BAAiA2IABMbLxyjR+4T1mu9CFCDhQ2tuda38KwOE1HaTJddZO0Flax7mNCq7dPYS
+zuht56vkPE4/RAiLzRZxy7+SmfSk1zxQVFKQhYN4lGdnoxwJGT11NIXe7WB9xwy0
+QVK5buXuQqOCAQ0wggEJMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFHOREKv/
+VbNafAkl1bK6CKBrqx9tMA4GA1UdDwEB/wQEAwIBBjCBxgYDVR0fBIG+MIG7MD6g
+PKA6hjhodHRwOi8vY3JsLmQtdHJ1c3QubmV0L2NybC9kLXRydXN0X2JyX3Jvb3Rf
+Y2FfMV8yMDIwLmNybDB5oHegdYZzbGRhcDovL2RpcmVjdG9yeS5kLXRydXN0Lm5l
+dC9DTj1ELVRSVVNUJTIwQlIlMjBSb290JTIwQ0ElMjAxJTIwMjAyMCxPPUQtVHJ1
+c3QlMjBHbWJILEM9REU/Y2VydGlmaWNhdGVyZXZvY2F0aW9ubGlzdDAKBggqhkjO
+PQQDAwNpADBmAjEAlJAtE/rhY/hhY+ithXhUkZy4kzg+GkHaQBZTQgjKL47xPoFW
+wKrY7RjEsK70PvomAjEA8yjixtsrmfu3Ubgko6SUeho/5jbiA1czijDLgsfWFBHV
+dWNbFJWcHwHP2NVypw87
+-----END CERTIFICATE-----
+
+# Issuer: CN=D-TRUST EV Root CA 1 2020 O=D-Trust GmbH
+# Subject: CN=D-TRUST EV Root CA 1 2020 O=D-Trust GmbH
+# Label: "D-TRUST EV Root CA 1 2020"
+# Serial: 126288379621884218666039612629459926992
+# MD5 Fingerprint: 8c:2d:9d:70:9f:48:99:11:06:11:fb:e9:cb:30:c0:6e
+# SHA1 Fingerprint: 61:db:8c:21:59:69:03:90:d8:7c:9c:12:86:54:cf:9d:3d:f4:dd:07
+# SHA256 Fingerprint: 08:17:0d:1a:a3:64:53:90:1a:2f:95:92:45:e3:47:db:0c:8d:37:ab:aa:bc:56:b8:1a:a1:00:dc:95:89:70:db
+-----BEGIN CERTIFICATE-----
+MIIC2zCCAmCgAwIBAgIQXwJB13qHfEwDo6yWjfv/0DAKBggqhkjOPQQDAzBIMQsw
+CQYDVQQGEwJERTEVMBMGA1UEChMMRC1UcnVzdCBHbWJIMSIwIAYDVQQDExlELVRS
+VVNUIEVWIFJvb3QgQ0EgMSAyMDIwMB4XDTIwMDIxMTEwMDAwMFoXDTM1MDIxMTA5
+NTk1OVowSDELMAkGA1UEBhMCREUxFTATBgNVBAoTDEQtVHJ1c3QgR21iSDEiMCAG
+A1UEAxMZRC1UUlVTVCBFViBSb290IENBIDEgMjAyMDB2MBAGByqGSM49AgEGBSuB
+BAAiA2IABPEL3YZDIBnfl4XoIkqbz52Yv7QFJsnL46bSj8WeeHsxiamJrSc8ZRCC
+/N/DnU7wMyPE0jL1HLDfMxddxfCxivnvubcUyilKwg+pf3VlSSowZ/Rk99Yad9rD
+wpdhQntJraOCAQ0wggEJMA8GA1UdEwEB/wQFMAMBAf8wHQYDVR0OBBYEFH8QARY3
+OqQo5FD4pPfsazK2/umLMA4GA1UdDwEB/wQEAwIBBjCBxgYDVR0fBIG+MIG7MD6g
+PKA6hjhodHRwOi8vY3JsLmQtdHJ1c3QubmV0L2NybC9kLXRydXN0X2V2X3Jvb3Rf
+Y2FfMV8yMDIwLmNybDB5oHegdYZzbGRhcDovL2RpcmVjdG9yeS5kLXRydXN0Lm5l
+dC9DTj1ELVRSVVNUJTIwRVYlMjBSb290JTIwQ0ElMjAxJTIwMjAyMCxPPUQtVHJ1
+c3QlMjBHbWJILEM9REU/Y2VydGlmaWNhdGVyZXZvY2F0aW9ubGlzdDAKBggqhkjO
+PQQDAwNpADBmAjEAyjzGKnXCXnViOTYAYFqLwZOZzNnbQTs7h5kXO9XMT8oi96CA
+y/m0sRtW9XLS/BnRAjEAkfcwkz8QRitxpNA7RJvAKQIFskF3UfN5Wp6OFKBOQtJb
+gfM0agPnIjhQW+0ZT0MW
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert TLS ECC P384 Root G5 O=DigiCert, Inc.
+# Subject: CN=DigiCert TLS ECC P384 Root G5 O=DigiCert, Inc.
+# Label: "DigiCert TLS ECC P384 Root G5"
+# Serial: 13129116028163249804115411775095713523
+# MD5 Fingerprint: d3:71:04:6a:43:1c:db:a6:59:e1:a8:a3:aa:c5:71:ed
+# SHA1 Fingerprint: 17:f3:de:5e:9f:0f:19:e9:8e:f6:1f:32:26:6e:20:c4:07:ae:30:ee
+# SHA256 Fingerprint: 01:8e:13:f0:77:25:32:cf:80:9b:d1:b1:72:81:86:72:83:fc:48:c6:e1:3b:e9:c6:98:12:85:4a:49:0c:1b:05
+-----BEGIN CERTIFICATE-----
+MIICGTCCAZ+gAwIBAgIQCeCTZaz32ci5PhwLBCou8zAKBggqhkjOPQQDAzBOMQsw
+CQYDVQQGEwJVUzEXMBUGA1UEChMORGlnaUNlcnQsIEluYy4xJjAkBgNVBAMTHURp
+Z2lDZXJ0IFRMUyBFQ0MgUDM4NCBSb290IEc1MB4XDTIxMDExNTAwMDAwMFoXDTQ2
+MDExNDIzNTk1OVowTjELMAkGA1UEBhMCVVMxFzAVBgNVBAoTDkRpZ2lDZXJ0LCBJ
+bmMuMSYwJAYDVQQDEx1EaWdpQ2VydCBUTFMgRUNDIFAzODQgUm9vdCBHNTB2MBAG
+ByqGSM49AgEGBSuBBAAiA2IABMFEoc8Rl1Ca3iOCNQfN0MsYndLxf3c1TzvdlHJS
+7cI7+Oz6e2tYIOyZrsn8aLN1udsJ7MgT9U7GCh1mMEy7H0cKPGEQQil8pQgO4CLp
+0zVozptjn4S1mU1YoI71VOeVyaNCMEAwHQYDVR0OBBYEFMFRRVBZqz7nLFr6ICIS
+B4CIfBFqMA4GA1UdDwEB/wQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MAoGCCqGSM49
+BAMDA2gAMGUCMQCJao1H5+z8blUD2WdsJk6Dxv3J+ysTvLd6jLRl0mlpYxNjOyZQ
+LgGheQaRnUi/wr4CMEfDFXuxoJGZSZOoPHzoRgaLLPIxAJSdYsiJvRmEFOml+wG4
+DXZDjC5Ty3zfDBeWUA==
+-----END CERTIFICATE-----
+
+# Issuer: CN=DigiCert TLS RSA4096 Root G5 O=DigiCert, Inc.
+# Subject: CN=DigiCert TLS RSA4096 Root G5 O=DigiCert, Inc.
+# Label: "DigiCert TLS RSA4096 Root G5"
+# Serial: 11930366277458970227240571539258396554
+# MD5 Fingerprint: ac:fe:f7:34:96:a9:f2:b3:b4:12:4b:e4:27:41:6f:e1
+# SHA1 Fingerprint: a7:88:49:dc:5d:7c:75:8c:8c:de:39:98:56:b3:aa:d0:b2:a5:71:35
+# SHA256 Fingerprint: 37:1a:00:dc:05:33:b3:72:1a:7e:eb:40:e8:41:9e:70:79:9d:2b:0a:0f:2c:1d:80:69:31:65:f7:ce:c4:ad:75
+-----BEGIN CERTIFICATE-----
+MIIFZjCCA06gAwIBAgIQCPm0eKj6ftpqMzeJ3nzPijANBgkqhkiG9w0BAQwFADBN
+MQswCQYDVQQGEwJVUzEXMBUGA1UEChMORGlnaUNlcnQsIEluYy4xJTAjBgNVBAMT
+HERpZ2lDZXJ0IFRMUyBSU0E0MDk2IFJvb3QgRzUwHhcNMjEwMTE1MDAwMDAwWhcN
+NDYwMTE0MjM1OTU5WjBNMQswCQYDVQQGEwJVUzEXMBUGA1UEChMORGlnaUNlcnQs
+IEluYy4xJTAjBgNVBAMTHERpZ2lDZXJ0IFRMUyBSU0E0MDk2IFJvb3QgRzUwggIi
+MA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCz0PTJeRGd/fxmgefM1eS87IE+
+ajWOLrfn3q/5B03PMJ3qCQuZvWxX2hhKuHisOjmopkisLnLlvevxGs3npAOpPxG0
+2C+JFvuUAT27L/gTBaF4HI4o4EXgg/RZG5Wzrn4DReW+wkL+7vI8toUTmDKdFqgp
+wgscONyfMXdcvyej/Cestyu9dJsXLfKB2l2w4SMXPohKEiPQ6s+d3gMXsUJKoBZM
+pG2T6T867jp8nVid9E6P/DsjyG244gXazOvswzH016cpVIDPRFtMbzCe88zdH5RD
+nU1/cHAN1DrRN/BsnZvAFJNY781BOHW8EwOVfH/jXOnVDdXifBBiqmvwPXbzP6Po
+sMH976pXTayGpxi0KcEsDr9kvimM2AItzVwv8n/vFfQMFawKsPHTDU9qTXeXAaDx
+Zre3zu/O7Oyldcqs4+Fj97ihBMi8ez9dLRYiVu1ISf6nL3kwJZu6ay0/nTvEF+cd
+Lvvyz6b84xQslpghjLSR6Rlgg/IwKwZzUNWYOwbpx4oMYIwo+FKbbuH2TbsGJJvX
+KyY//SovcfXWJL5/MZ4PbeiPT02jP/816t9JXkGPhvnxd3lLG7SjXi/7RgLQZhNe
+XoVPzthwiHvOAbWWl9fNff2C+MIkwcoBOU+NosEUQB+cZtUMCUbW8tDRSHZWOkPL
+tgoRObqME2wGtZ7P6wIDAQABo0IwQDAdBgNVHQ4EFgQUUTMc7TZArxfTJc1paPKv
+TiM+s0EwDgYDVR0PAQH/BAQDAgGGMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcN
+AQEMBQADggIBAGCmr1tfV9qJ20tQqcQjNSH/0GEwhJG3PxDPJY7Jv0Y02cEhJhxw
+GXIeo8mH/qlDZJY6yFMECrZBu8RHANmfGBg7sg7zNOok992vIGCukihfNudd5N7H
+PNtQOa27PShNlnx2xlv0wdsUpasZYgcYQF+Xkdycx6u1UQ3maVNVzDl92sURVXLF
+O4uJ+DQtpBflF+aZfTCIITfNMBc9uPK8qHWgQ9w+iUuQrm0D4ByjoJYJu32jtyoQ
+REtGBzRj7TG5BO6jm5qu5jF49OokYTurWGT/u4cnYiWB39yhL/btp/96j1EuMPik
+AdKFOV8BmZZvWltwGUb+hmA+rYAQCd05JS9Yf7vSdPD3Rh9GOUrYU9DzLjtxpdRv
+/PNn5AeP3SYZ4Y1b+qOTEZvpyDrDVWiakuFSdjjo4bq9+0/V77PnSIMx8IIh47a+
+p6tv75/fTM8BuGJqIz3nCU2AG3swpMPdB380vqQmsvZB6Akd4yCYqjdP//fx4ilw
+MUc/dNAUFvohigLVigmUdy7yWSiLfFCSCmZ4OIN1xLVaqBHG5cGdZlXPU8Sv13WF
+qUITVuwhd4GTWgzqltlJyqEI8pc7bZsEGCREjnwB8twl2F6GmrE52/WRMmrRpnCK
+ovfepEWFJqgejF0pW8hL2JpqA15w8oVPbEtoL8pU9ozaMv7Da4M/OMZ+
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certainly Root R1 O=Certainly
+# Subject: CN=Certainly Root R1 O=Certainly
+# Label: "Certainly Root R1"
+# Serial: 188833316161142517227353805653483829216
+# MD5 Fingerprint: 07:70:d4:3e:82:87:a0:fa:33:36:13:f4:fa:33:e7:12
+# SHA1 Fingerprint: a0:50:ee:0f:28:71:f4:27:b2:12:6d:6f:50:96:25:ba:cc:86:42:af
+# SHA256 Fingerprint: 77:b8:2c:d8:64:4c:43:05:f7:ac:c5:cb:15:6b:45:67:50:04:03:3d:51:c6:0c:62:02:a8:e0:c3:34:67:d3:a0
+-----BEGIN CERTIFICATE-----
+MIIFRzCCAy+gAwIBAgIRAI4P+UuQcWhlM1T01EQ5t+AwDQYJKoZIhvcNAQELBQAw
+PTELMAkGA1UEBhMCVVMxEjAQBgNVBAoTCUNlcnRhaW5seTEaMBgGA1UEAxMRQ2Vy
+dGFpbmx5IFJvb3QgUjEwHhcNMjEwNDAxMDAwMDAwWhcNNDYwNDAxMDAwMDAwWjA9
+MQswCQYDVQQGEwJVUzESMBAGA1UEChMJQ2VydGFpbmx5MRowGAYDVQQDExFDZXJ0
+YWlubHkgUm9vdCBSMTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBANA2
+1B/q3avk0bbm+yLA3RMNansiExyXPGhjZjKcA7WNpIGD2ngwEc/csiu+kr+O5MQT
+vqRoTNoCaBZ0vrLdBORrKt03H2As2/X3oXyVtwxwhi7xOu9S98zTm/mLvg7fMbed
+aFySpvXl8wo0tf97ouSHocavFwDvA5HtqRxOcT3Si2yJ9HiG5mpJoM610rCrm/b0
+1C7jcvk2xusVtyWMOvwlDbMicyF0yEqWYZL1LwsYpfSt4u5BvQF5+paMjRcCMLT5
+r3gajLQ2EBAHBXDQ9DGQilHFhiZ5shGIXsXwClTNSaa/ApzSRKft43jvRl5tcdF5
+cBxGX1HpyTfcX35pe0HfNEXgO4T0oYoKNp43zGJS4YkNKPl6I7ENPT2a/Z2B7yyQ
+wHtETrtJ4A5KVpK8y7XdeReJkd5hiXSSqOMyhb5OhaRLWcsrxXiOcVTQAjeZjOVJ
+6uBUcqQRBi8LjMFbvrWhsFNunLhgkR9Za/kt9JQKl7XsxXYDVBtlUrpMklZRNaBA
+2CnbrlJ2Oy0wQJuK0EJWtLeIAaSHO1OWzaMWj/Nmqhexx2DgwUMFDO6bW2BvBlyH
+Wyf5QBGenDPBt+U1VwV/J84XIIwc/PH72jEpSe31C4SnT8H2TsIonPru4K8H+zMR
+eiFPCyEQtkA6qyI6BJyLm4SGcprSp6XEtHWRqSsjAgMBAAGjQjBAMA4GA1UdDwEB
+/wQEAwIBBjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBTgqj8ljZ9EXME66C6u
+d0yEPmcM9DANBgkqhkiG9w0BAQsFAAOCAgEAuVevuBLaV4OPaAszHQNTVfSVcOQr
+PbA56/qJYv331hgELyE03fFo8NWWWt7CgKPBjcZq91l3rhVkz1t5BXdm6ozTaw3d
+8VkswTOlMIAVRQdFGjEitpIAq5lNOo93r6kiyi9jyhXWx8bwPWz8HA2YEGGeEaIi
+1wrykXprOQ4vMMM2SZ/g6Q8CRFA3lFV96p/2O7qUpUzpvD5RtOjKkjZUbVwlKNrd
+rRT90+7iIgXr0PK3aBLXWopBGsaSpVo7Y0VPv+E6dyIvXL9G+VoDhRNCX8reU9di
+taY1BMJH/5n9hN9czulegChB8n3nHpDYT3Y+gjwN/KUD+nsa2UUeYNrEjvn8K8l7
+lcUq/6qJ34IxD3L/DCfXCh5WAFAeDJDBlrXYFIW7pw0WwfgHJBu6haEaBQmAupVj
+yTrsJZ9/nbqkRxWbRHDxakvWOF5D8xh+UG7pWijmZeZ3Gzr9Hb4DJqPb1OG7fpYn
+Kx3upPvaJVQTA945xsMfTZDsjxtK0hzthZU4UHlG1sGQUDGpXJpuHfUzVounmdLy
+yCwzk5Iwx06MZTMQZBf9JBeW0Y3COmor6xOLRPIh80oat3df1+2IpHLlOR+Vnb5n
+wXARPbv0+Em34yaXOp/SX3z7wJl8OSngex2/DaeP0ik0biQVy96QXr8axGbqwua6
+OV+KmalBWQewLK8=
+-----END CERTIFICATE-----
+
+# Issuer: CN=Certainly Root E1 O=Certainly
+# Subject: CN=Certainly Root E1 O=Certainly
+# Label: "Certainly Root E1"
+# Serial: 8168531406727139161245376702891150584
+# MD5 Fingerprint: 0a:9e:ca:cd:3e:52:50:c6:36:f3:4b:a3:ed:a7:53:e9
+# SHA1 Fingerprint: f9:e1:6d:dc:01:89:cf:d5:82:45:63:3e:c5:37:7d:c2:eb:93:6f:2b
+# SHA256 Fingerprint: b4:58:5f:22:e4:ac:75:6a:4e:86:12:a1:36:1c:5d:9d:03:1a:93:fd:84:fe:bb:77:8f:a3:06:8b:0f:c4:2d:c2
+-----BEGIN CERTIFICATE-----
+MIIB9zCCAX2gAwIBAgIQBiUzsUcDMydc+Y2aub/M+DAKBggqhkjOPQQDAzA9MQsw
+CQYDVQQGEwJVUzESMBAGA1UEChMJQ2VydGFpbmx5MRowGAYDVQQDExFDZXJ0YWlu
+bHkgUm9vdCBFMTAeFw0yMTA0MDEwMDAwMDBaFw00NjA0MDEwMDAwMDBaMD0xCzAJ
+BgNVBAYTAlVTMRIwEAYDVQQKEwlDZXJ0YWlubHkxGjAYBgNVBAMTEUNlcnRhaW5s
+eSBSb290IEUxMHYwEAYHKoZIzj0CAQYFK4EEACIDYgAE3m/4fxzf7flHh4axpMCK
++IKXgOqPyEpeKn2IaKcBYhSRJHpcnqMXfYqGITQYUBsQ3tA3SybHGWCA6TS9YBk2
+QNYphwk8kXr2vBMj3VlOBF7PyAIcGFPBMdjaIOlEjeR2o0IwQDAOBgNVHQ8BAf8E
+BAMCAQYwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQU8ygYy2R17ikq6+2uI1g4
+hevIIgcwCgYIKoZIzj0EAwMDaAAwZQIxALGOWiDDshliTd6wT99u0nCK8Z9+aozm
+ut6Dacpps6kFtZaSF4fC0urQe87YQVt8rgIwRt7qy12a7DLCZRawTDBcMPPaTnOG
+BtjOiQRINzf43TNRnXCve1XYAS59BWQOhriR
+-----END CERTIFICATE-----
+
+# Issuer: CN=Security Communication RootCA3 O=SECOM Trust Systems CO.,LTD.
+# Subject: CN=Security Communication RootCA3 O=SECOM Trust Systems CO.,LTD.
+# Label: "Security Communication RootCA3"
+# Serial: 16247922307909811815
+# MD5 Fingerprint: 1c:9a:16:ff:9e:5c:e0:4d:8a:14:01:f4:35:5d:29:26
+# SHA1 Fingerprint: c3:03:c8:22:74:92:e5:61:a2:9c:5f:79:91:2b:1e:44:13:91:30:3a
+# SHA256 Fingerprint: 24:a5:5c:2a:b0:51:44:2d:06:17:76:65:41:23:9a:4a:d0:32:d7:c5:51:75:aa:34:ff:de:2f:bc:4f:5c:52:94
+-----BEGIN CERTIFICATE-----
+MIIFfzCCA2egAwIBAgIJAOF8N0D9G/5nMA0GCSqGSIb3DQEBDAUAMF0xCzAJBgNV
+BAYTAkpQMSUwIwYDVQQKExxTRUNPTSBUcnVzdCBTeXN0ZW1zIENPLixMVEQuMScw
+JQYDVQQDEx5TZWN1cml0eSBDb21tdW5pY2F0aW9uIFJvb3RDQTMwHhcNMTYwNjE2
+MDYxNzE2WhcNMzgwMTE4MDYxNzE2WjBdMQswCQYDVQQGEwJKUDElMCMGA1UEChMc
+U0VDT00gVHJ1c3QgU3lzdGVtcyBDTy4sTFRELjEnMCUGA1UEAxMeU2VjdXJpdHkg
+Q29tbXVuaWNhdGlvbiBSb290Q0EzMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIIC
+CgKCAgEA48lySfcw3gl8qUCBWNO0Ot26YQ+TUG5pPDXC7ltzkBtnTCHsXzW7OT4r
+CmDvu20rhvtxosis5FaU+cmvsXLUIKx00rgVrVH+hXShuRD+BYD5UpOzQD11EKzA
+lrenfna84xtSGc4RHwsENPXY9Wk8d/Nk9A2qhd7gCVAEF5aEt8iKvE1y/By7z/MG
+TfmfZPd+pmaGNXHIEYBMwXFAWB6+oHP2/D5Q4eAvJj1+XCO1eXDe+uDRpdYMQXF7
+9+qMHIjH7Iv10S9VlkZ8WjtYO/u62C21Jdp6Ts9EriGmnpjKIG58u4iFW/vAEGK7
+8vknR+/RiTlDxN/e4UG/VHMgly1s2vPUB6PmudhvrvyMGS7TZ2crldtYXLVqAvO4
+g160a75BflcJdURQVc1aEWEhCmHCqYj9E7wtiS/NYeCVvsq1e+F7NGcLH7YMx3we
+GVPKp7FKFSBWFHA9K4IsD50VHUeAR/94mQ4xr28+j+2GaR57GIgUssL8gjMunEst
++3A7caoreyYn8xrC3PsXuKHqy6C0rtOUfnrQq8PsOC0RLoi/1D+tEjtCrI8Cbn3M
+0V9hvqG8OmpI6iZVIhZdXw3/JzOfGAN0iltSIEdrRU0id4xVJ/CvHozJgyJUt5rQ
+T9nO/NkuHJYosQLTA70lUhw0Zk8jq/R3gpYd0VcwCBEF/VfR2ccCAwEAAaNCMEAw
+HQYDVR0OBBYEFGQUfPxYchamCik0FW8qy7z8r6irMA4GA1UdDwEB/wQEAwIBBjAP
+BgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBDAUAA4ICAQDcAiMI4u8hOscNtybS
+YpOnpSNyByCCYN8Y11StaSWSntkUz5m5UoHPrmyKO1o5yGwBQ8IibQLwYs1OY0PA
+FNr0Y/Dq9HHuTofjcan0yVflLl8cebsjqodEV+m9NU1Bu0soo5iyG9kLFwfl9+qd
+9XbXv8S2gVj/yP9kaWJ5rW4OH3/uHWnlt3Jxs/6lATWUVCvAUm2PVcTJ0rjLyjQI
+UYWg9by0F1jqClx6vWPGOi//lkkZhOpn2ASxYfQAW0q3nHE3GYV5v4GwxxMOdnE+
+OoAGrgYWp421wsTL/0ClXI2lyTrtcoHKXJg80jQDdwj98ClZXSEIx2C/pHF7uNke
+gr4Jr2VvKKu/S7XuPghHJ6APbw+LP6yVGPO5DtxnVW5inkYO0QR4ynKudtml+LLf
+iAlhi+8kTtFZP1rUPcmTPCtk9YENFpb3ksP+MW/oKjJ0DvRMmEoYDjBU1cXrvMUV
+nuiZIesnKwkK2/HmcBhWuwzkvvnoEKQTkrgc4NtnHVMDpCKn3F2SEDzq//wbEBrD
+2NCcnWXL0CsnMQMeNuE9dnUM/0Umud1RvCPHX9jYhxBAEg09ODfnRDwYwFMJZI//
+1ZqmfHAuc1Uh6N//g7kdPjIe1qZ9LPFm6Vwdp6POXiUyK+OVrCoHzrQoeIY8Laad
+TdJ0MN1kURXbg4NR16/9M51NZg==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Security Communication ECC RootCA1 O=SECOM Trust Systems CO.,LTD.
+# Subject: CN=Security Communication ECC RootCA1 O=SECOM Trust Systems CO.,LTD.
+# Label: "Security Communication ECC RootCA1"
+# Serial: 15446673492073852651
+# MD5 Fingerprint: 7e:43:b0:92:68:ec:05:43:4c:98:ab:5d:35:2e:7e:86
+# SHA1 Fingerprint: b8:0e:26:a9:bf:d2:b2:3b:c0:ef:46:c9:ba:c7:bb:f6:1d:0d:41:41
+# SHA256 Fingerprint: e7:4f:bd:a5:5b:d5:64:c4:73:a3:6b:44:1a:a7:99:c8:a6:8e:07:74:40:e8:28:8b:9f:a1:e5:0e:4b:ba:ca:11
+-----BEGIN CERTIFICATE-----
+MIICODCCAb6gAwIBAgIJANZdm7N4gS7rMAoGCCqGSM49BAMDMGExCzAJBgNVBAYT
+AkpQMSUwIwYDVQQKExxTRUNPTSBUcnVzdCBTeXN0ZW1zIENPLixMVEQuMSswKQYD
+VQQDEyJTZWN1cml0eSBDb21tdW5pY2F0aW9uIEVDQyBSb290Q0ExMB4XDTE2MDYx
+NjA1MTUyOFoXDTM4MDExODA1MTUyOFowYTELMAkGA1UEBhMCSlAxJTAjBgNVBAoT
+HFNFQ09NIFRydXN0IFN5c3RlbXMgQ08uLExURC4xKzApBgNVBAMTIlNlY3VyaXR5
+IENvbW11bmljYXRpb24gRUNDIFJvb3RDQTEwdjAQBgcqhkjOPQIBBgUrgQQAIgNi
+AASkpW9gAwPDvTH00xecK4R1rOX9PVdu12O/5gSJko6BnOPpR27KkBLIE+Cnnfdl
+dB9sELLo5OnvbYUymUSxXv3MdhDYW72ixvnWQuRXdtyQwjWpS4g8EkdtXP9JTxpK
+ULGjQjBAMB0GA1UdDgQWBBSGHOf+LaVKiwj+KBH6vqNm+GBZLzAOBgNVHQ8BAf8E
+BAMCAQYwDwYDVR0TAQH/BAUwAwEB/zAKBggqhkjOPQQDAwNoADBlAjAVXUI9/Lbu
+9zuxNuie9sRGKEkz0FhDKmMpzE2xtHqiuQ04pV1IKv3LsnNdo4gIxwwCMQDAqy0O
+be0YottT6SXbVQjgUMzfRGEWgqtJsLKB7HOHeLRMsmIbEvoWTSVLY70eN9k=
+-----END CERTIFICATE-----
+
+# Issuer: CN=BJCA Global Root CA1 O=BEIJING CERTIFICATE AUTHORITY
+# Subject: CN=BJCA Global Root CA1 O=BEIJING CERTIFICATE AUTHORITY
+# Label: "BJCA Global Root CA1"
+# Serial: 113562791157148395269083148143378328608
+# MD5 Fingerprint: 42:32:99:76:43:33:36:24:35:07:82:9b:28:f9:d0:90
+# SHA1 Fingerprint: d5:ec:8d:7b:4c:ba:79:f4:e7:e8:cb:9d:6b:ae:77:83:10:03:21:6a
+# SHA256 Fingerprint: f3:89:6f:88:fe:7c:0a:88:27:66:a7:fa:6a:d2:74:9f:b5:7a:7f:3e:98:fb:76:9c:1f:a7:b0:9c:2c:44:d5:ae
+-----BEGIN CERTIFICATE-----
+MIIFdDCCA1ygAwIBAgIQVW9l47TZkGobCdFsPsBsIDANBgkqhkiG9w0BAQsFADBU
+MQswCQYDVQQGEwJDTjEmMCQGA1UECgwdQkVJSklORyBDRVJUSUZJQ0FURSBBVVRI
+T1JJVFkxHTAbBgNVBAMMFEJKQ0EgR2xvYmFsIFJvb3QgQ0ExMB4XDTE5MTIxOTAz
+MTYxN1oXDTQ0MTIxMjAzMTYxN1owVDELMAkGA1UEBhMCQ04xJjAkBgNVBAoMHUJF
+SUpJTkcgQ0VSVElGSUNBVEUgQVVUSE9SSVRZMR0wGwYDVQQDDBRCSkNBIEdsb2Jh
+bCBSb290IENBMTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAPFmCL3Z
+xRVhy4QEQaVpN3cdwbB7+sN3SJATcmTRuHyQNZ0YeYjjlwE8R4HyDqKYDZ4/N+AZ
+spDyRhySsTphzvq3Rp4Dhtczbu33RYx2N95ulpH3134rhxfVizXuhJFyV9xgw8O5
+58dnJCNPYwpj9mZ9S1WnP3hkSWkSl+BMDdMJoDIwOvqfwPKcxRIqLhy1BDPapDgR
+at7GGPZHOiJBhyL8xIkoVNiMpTAK+BcWyqw3/XmnkRd4OJmtWO2y3syJfQOcs4ll
+5+M7sSKGjwZteAf9kRJ/sGsciQ35uMt0WwfCyPQ10WRjeulumijWML3mG90Vr4Tq
+nMfK9Q7q8l0ph49pczm+LiRvRSGsxdRpJQaDrXpIhRMsDQa4bHlW/KNnMoH1V6XK
+V0Jp6VwkYe/iMBhORJhVb3rCk9gZtt58R4oRTklH2yiUAguUSiz5EtBP6DF+bHq/
+pj+bOT0CFqMYs2esWz8sgytnOYFcuX6U1WTdno9uruh8W7TXakdI136z1C2OVnZO
+z2nxbkRs1CTqjSShGL+9V/6pmTW12xB3uD1IutbB5/EjPtffhZ0nPNRAvQoMvfXn
+jSXWgXSHRtQpdaJCbPdzied9v3pKH9MiyRVVz99vfFXQpIsHETdfg6YmV6YBW37+
+WGgHqel62bno/1Afq8K0wM7o6v0PvY1NuLxxAgMBAAGjQjBAMB0GA1UdDgQWBBTF
+7+3M2I0hxkjk49cULqcWk+WYATAPBgNVHRMBAf8EBTADAQH/MA4GA1UdDwEB/wQE
+AwIBBjANBgkqhkiG9w0BAQsFAAOCAgEAUoKsITQfI/Ki2Pm4rzc2IInRNwPWaZ+4
+YRC6ojGYWUfo0Q0lHhVBDOAqVdVXUsv45Mdpox1NcQJeXyFFYEhcCY5JEMEE3Kli
+awLwQ8hOnThJdMkycFRtwUf8jrQ2ntScvd0g1lPJGKm1Vrl2i5VnZu69mP6u775u
++2D2/VnGKhs/I0qUJDAnyIm860Qkmss9vk/Ves6OF8tiwdneHg56/0OGNFK8YT88
+X7vZdrRTvJez/opMEi4r89fO4aL/3Xtw+zuhTaRjAv04l5U/BXCga99igUOLtFkN
+SoxUnMW7gZ/NfaXvCyUeOiDbHPwfmGcCCtRzRBPbUYQaVQNW4AB+dAb/OMRyHdOo
+P2gxXdMJxy6MW2Pg6Nwe0uxhHvLe5e/2mXZgLR6UcnHGCyoyx5JO1UbXHfmpGQrI
++pXObSOYqgs4rZpWDW+N8TEAiMEXnM0ZNjX+VVOg4DwzX5Ze4jLp3zO7Bkqp2IRz
+znfSxqxx4VyjHQy7Ct9f4qNx2No3WqB4K/TUfet27fJhcKVlmtOJNBir+3I+17Q9
+eVzYH6Eze9mCUAyTF6ps3MKCuwJXNq+YJyo5UOGwifUll35HaBC07HPKs5fRJNz2
+YqAo07WjuGS3iGJCz51TzZm+ZGiPTx4SSPfSKcOYKMryMguTjClPPGAyzQWWYezy
+r/6zcCwupvI=
+-----END CERTIFICATE-----
+
+# Issuer: CN=BJCA Global Root CA2 O=BEIJING CERTIFICATE AUTHORITY
+# Subject: CN=BJCA Global Root CA2 O=BEIJING CERTIFICATE AUTHORITY
+# Label: "BJCA Global Root CA2"
+# Serial: 58605626836079930195615843123109055211
+# MD5 Fingerprint: 5e:0a:f6:47:5f:a6:14:e8:11:01:95:3f:4d:01:eb:3c
+# SHA1 Fingerprint: f4:27:86:eb:6e:b8:6d:88:31:67:02:fb:ba:66:a4:53:00:aa:7a:a6
+# SHA256 Fingerprint: 57:4d:f6:93:1e:27:80:39:66:7b:72:0a:fd:c1:60:0f:c2:7e:b6:6d:d3:09:29:79:fb:73:85:64:87:21:28:82
+-----BEGIN CERTIFICATE-----
+MIICJTCCAaugAwIBAgIQLBcIfWQqwP6FGFkGz7RK6zAKBggqhkjOPQQDAzBUMQsw
+CQYDVQQGEwJDTjEmMCQGA1UECgwdQkVJSklORyBDRVJUSUZJQ0FURSBBVVRIT1JJ
+VFkxHTAbBgNVBAMMFEJKQ0EgR2xvYmFsIFJvb3QgQ0EyMB4XDTE5MTIxOTAzMTgy
+MVoXDTQ0MTIxMjAzMTgyMVowVDELMAkGA1UEBhMCQ04xJjAkBgNVBAoMHUJFSUpJ
+TkcgQ0VSVElGSUNBVEUgQVVUSE9SSVRZMR0wGwYDVQQDDBRCSkNBIEdsb2JhbCBS
+b290IENBMjB2MBAGByqGSM49AgEGBSuBBAAiA2IABJ3LgJGNU2e1uVCxA/jlSR9B
+IgmwUVJY1is0j8USRhTFiy8shP8sbqjV8QnjAyEUxEM9fMEsxEtqSs3ph+B99iK+
++kpRuDCK/eHeGBIK9ke35xe/J4rUQUyWPGCWwf0VHKNCMEAwHQYDVR0OBBYEFNJK
+sVF/BvDRgh9Obl+rg/xI1LCRMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQD
+AgEGMAoGCCqGSM49BAMDA2gAMGUCMBq8W9f+qdJUDkpd0m2xQNz0Q9XSSpkZElaA
+94M04TVOSG0ED1cxMDAtsaqdAzjbBgIxAMvMh1PLet8gUXOQwKhbYdDFUDn9hf7B
+43j4ptZLvZuHjw/l1lOWqzzIQNph91Oj9w==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Sectigo Public Server Authentication Root E46 O=Sectigo Limited
+# Subject: CN=Sectigo Public Server Authentication Root E46 O=Sectigo Limited
+# Label: "Sectigo Public Server Authentication Root E46"
+# Serial: 88989738453351742415770396670917916916
+# MD5 Fingerprint: 28:23:f8:b2:98:5c:37:16:3b:3e:46:13:4e:b0:b3:01
+# SHA1 Fingerprint: ec:8a:39:6c:40:f0:2e:bc:42:75:d4:9f:ab:1c:1a:5b:67:be:d2:9a
+# SHA256 Fingerprint: c9:0f:26:f0:fb:1b:40:18:b2:22:27:51:9b:5c:a2:b5:3e:2c:a5:b3:be:5c:f1:8e:fe:1b:ef:47:38:0c:53:83
+-----BEGIN CERTIFICATE-----
+MIICOjCCAcGgAwIBAgIQQvLM2htpN0RfFf51KBC49DAKBggqhkjOPQQDAzBfMQsw
+CQYDVQQGEwJHQjEYMBYGA1UEChMPU2VjdGlnbyBMaW1pdGVkMTYwNAYDVQQDEy1T
+ZWN0aWdvIFB1YmxpYyBTZXJ2ZXIgQXV0aGVudGljYXRpb24gUm9vdCBFNDYwHhcN
+MjEwMzIyMDAwMDAwWhcNNDYwMzIxMjM1OTU5WjBfMQswCQYDVQQGEwJHQjEYMBYG
+A1UEChMPU2VjdGlnbyBMaW1pdGVkMTYwNAYDVQQDEy1TZWN0aWdvIFB1YmxpYyBT
+ZXJ2ZXIgQXV0aGVudGljYXRpb24gUm9vdCBFNDYwdjAQBgcqhkjOPQIBBgUrgQQA
+IgNiAAR2+pmpbiDt+dd34wc7qNs9Xzjoq1WmVk/WSOrsfy2qw7LFeeyZYX8QeccC
+WvkEN/U0NSt3zn8gj1KjAIns1aeibVvjS5KToID1AZTc8GgHHs3u/iVStSBDHBv+
+6xnOQ6OjQjBAMB0GA1UdDgQWBBTRItpMWfFLXyY4qp3W7usNw/upYTAOBgNVHQ8B
+Af8EBAMCAYYwDwYDVR0TAQH/BAUwAwEB/zAKBggqhkjOPQQDAwNnADBkAjAn7qRa
+qCG76UeXlImldCBteU/IvZNeWBj7LRoAasm4PdCkT0RHlAFWovgzJQxC36oCMB3q
+4S6ILuH5px0CMk7yn2xVdOOurvulGu7t0vzCAxHrRVxgED1cf5kDW21USAGKcw==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Sectigo Public Server Authentication Root R46 O=Sectigo Limited
+# Subject: CN=Sectigo Public Server Authentication Root R46 O=Sectigo Limited
+# Label: "Sectigo Public Server Authentication Root R46"
+# Serial: 156256931880233212765902055439220583700
+# MD5 Fingerprint: 32:10:09:52:00:d5:7e:6c:43:df:15:c0:b1:16:93:e5
+# SHA1 Fingerprint: ad:98:f9:f3:e4:7d:75:3b:65:d4:82:b3:a4:52:17:bb:6e:f5:e4:38
+# SHA256 Fingerprint: 7b:b6:47:a6:2a:ee:ac:88:bf:25:7a:a5:22:d0:1f:fe:a3:95:e0:ab:45:c7:3f:93:f6:56:54:ec:38:f2:5a:06
+-----BEGIN CERTIFICATE-----
+MIIFijCCA3KgAwIBAgIQdY39i658BwD6qSWn4cetFDANBgkqhkiG9w0BAQwFADBf
+MQswCQYDVQQGEwJHQjEYMBYGA1UEChMPU2VjdGlnbyBMaW1pdGVkMTYwNAYDVQQD
+Ey1TZWN0aWdvIFB1YmxpYyBTZXJ2ZXIgQXV0aGVudGljYXRpb24gUm9vdCBSNDYw
+HhcNMjEwMzIyMDAwMDAwWhcNNDYwMzIxMjM1OTU5WjBfMQswCQYDVQQGEwJHQjEY
+MBYGA1UEChMPU2VjdGlnbyBMaW1pdGVkMTYwNAYDVQQDEy1TZWN0aWdvIFB1Ymxp
+YyBTZXJ2ZXIgQXV0aGVudGljYXRpb24gUm9vdCBSNDYwggIiMA0GCSqGSIb3DQEB
+AQUAA4ICDwAwggIKAoICAQCTvtU2UnXYASOgHEdCSe5jtrch/cSV1UgrJnwUUxDa
+ef0rty2k1Cz66jLdScK5vQ9IPXtamFSvnl0xdE8H/FAh3aTPaE8bEmNtJZlMKpnz
+SDBh+oF8HqcIStw+KxwfGExxqjWMrfhu6DtK2eWUAtaJhBOqbchPM8xQljeSM9xf
+iOefVNlI8JhD1mb9nxc4Q8UBUQvX4yMPFF1bFOdLvt30yNoDN9HWOaEhUTCDsG3X
+ME6WW5HwcCSrv0WBZEMNvSE6Lzzpng3LILVCJ8zab5vuZDCQOc2TZYEhMbUjUDM3
+IuM47fgxMMxF/mL50V0yeUKH32rMVhlATc6qu/m1dkmU8Sf4kaWD5QazYw6A3OAS
+VYCmO2a0OYctyPDQ0RTp5A1NDvZdV3LFOxxHVp3i1fuBYYzMTYCQNFu31xR13NgE
+SJ/AwSiItOkcyqex8Va3e0lMWeUgFaiEAin6OJRpmkkGj80feRQXEgyDet4fsZfu
++Zd4KKTIRJLpfSYFplhym3kT2BFfrsU4YjRosoYwjviQYZ4ybPUHNs2iTG7sijbt
+8uaZFURww3y8nDnAtOFr94MlI1fZEoDlSfB1D++N6xybVCi0ITz8fAr/73trdf+L
+HaAZBav6+CuBQug4urv7qv094PPK306Xlynt8xhW6aWWrL3DkJiy4Pmi1KZHQ3xt
+zwIDAQABo0IwQDAdBgNVHQ4EFgQUVnNYZJX5khqwEioEYnmhQBWIIUkwDgYDVR0P
+AQH/BAQDAgGGMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQEMBQADggIBAC9c
+mTz8Bl6MlC5w6tIyMY208FHVvArzZJ8HXtXBc2hkeqK5Duj5XYUtqDdFqij0lgVQ
+YKlJfp/imTYpE0RHap1VIDzYm/EDMrraQKFz6oOht0SmDpkBm+S8f74TlH7Kph52
+gDY9hAaLMyZlbcp+nv4fjFg4exqDsQ+8FxG75gbMY/qB8oFM2gsQa6H61SilzwZA
+Fv97fRheORKkU55+MkIQpiGRqRxOF3yEvJ+M0ejf5lG5Nkc/kLnHvALcWxxPDkjB
+JYOcCj+esQMzEhonrPcibCTRAUH4WAP+JWgiH5paPHxsnnVI84HxZmduTILA7rpX
+DhjvLpr3Etiga+kFpaHpaPi8TD8SHkXoUsCjvxInebnMMTzD9joiFgOgyY9mpFui
+TdaBJQbpdqQACj7LzTWb4OE4y2BThihCQRxEV+ioratF4yUQvNs+ZUH7G6aXD+u5
+dHn5HrwdVw1Hr8Mvn4dGp+smWg9WY7ViYG4A++MnESLn/pmPNPW56MORcr3Ywx65
+LvKRRFHQV80MNNVIIb/bE/FmJUNS0nAiNs2fxBx1IK1jcmMGDw4nztJqDby1ORrp
+0XZ60Vzk50lJLVU3aPAaOpg+VBeHVOmmJ1CJeyAvP/+/oYtKR5j/K3tJPsMpRmAY
+QqszKbrAKbkTidOIijlBO8n9pu0f9GBj39ItVQGL
+-----END CERTIFICATE-----
+
+# Issuer: CN=SSL.com TLS RSA Root CA 2022 O=SSL Corporation
+# Subject: CN=SSL.com TLS RSA Root CA 2022 O=SSL Corporation
+# Label: "SSL.com TLS RSA Root CA 2022"
+# Serial: 148535279242832292258835760425842727825
+# MD5 Fingerprint: d8:4e:c6:59:30:d8:fe:a0:d6:7a:5a:2c:2c:69:78:da
+# SHA1 Fingerprint: ec:2c:83:40:72:af:26:95:10:ff:0e:f2:03:ee:31:70:f6:78:9d:ca
+# SHA256 Fingerprint: 8f:af:7d:2e:2c:b4:70:9b:b8:e0:b3:36:66:bf:75:a5:dd:45:b5:de:48:0f:8e:a8:d4:bf:e6:be:bc:17:f2:ed
+-----BEGIN CERTIFICATE-----
+MIIFiTCCA3GgAwIBAgIQb77arXO9CEDii02+1PdbkTANBgkqhkiG9w0BAQsFADBO
+MQswCQYDVQQGEwJVUzEYMBYGA1UECgwPU1NMIENvcnBvcmF0aW9uMSUwIwYDVQQD
+DBxTU0wuY29tIFRMUyBSU0EgUm9vdCBDQSAyMDIyMB4XDTIyMDgyNTE2MzQyMloX
+DTQ2MDgxOTE2MzQyMVowTjELMAkGA1UEBhMCVVMxGDAWBgNVBAoMD1NTTCBDb3Jw
+b3JhdGlvbjElMCMGA1UEAwwcU1NMLmNvbSBUTFMgUlNBIFJvb3QgQ0EgMjAyMjCC
+AiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBANCkCXJPQIgSYT41I57u9nTP
+L3tYPc48DRAokC+X94xI2KDYJbFMsBFMF3NQ0CJKY7uB0ylu1bUJPiYYf7ISf5OY
+t6/wNr/y7hienDtSxUcZXXTzZGbVXcdotL8bHAajvI9AI7YexoS9UcQbOcGV0ins
+S657Lb85/bRi3pZ7QcacoOAGcvvwB5cJOYF0r/c0WRFXCsJbwST0MXMwgsadugL3
+PnxEX4MN8/HdIGkWCVDi1FW24IBydm5MR7d1VVm0U3TZlMZBrViKMWYPHqIbKUBO
+L9975hYsLfy/7PO0+r4Y9ptJ1O4Fbtk085zx7AGL0SDGD6C1vBdOSHtRwvzpXGk3
+R2azaPgVKPC506QVzFpPulJwoxJF3ca6TvvC0PeoUidtbnm1jPx7jMEWTO6Af77w
+dr5BUxIzrlo4QqvXDz5BjXYHMtWrifZOZ9mxQnUjbvPNQrL8VfVThxc7wDNY8VLS
++YCk8OjwO4s4zKTGkH8PnP2L0aPP2oOnaclQNtVcBdIKQXTbYxE3waWglksejBYS
+d66UNHsef8JmAOSqg+qKkK3ONkRN0VHpvB/zagX9wHQfJRlAUW7qglFA35u5CCoG
+AtUjHBPW6dvbxrB6y3snm/vg1UYk7RBLY0ulBY+6uB0rpvqR4pJSvezrZ5dtmi2f
+gTIFZzL7SAg/2SW4BCUvAgMBAAGjYzBhMA8GA1UdEwEB/wQFMAMBAf8wHwYDVR0j
+BBgwFoAU+y437uOEeicuzRk1sTN8/9REQrkwHQYDVR0OBBYEFPsuN+7jhHonLs0Z
+NbEzfP/UREK5MA4GA1UdDwEB/wQEAwIBhjANBgkqhkiG9w0BAQsFAAOCAgEAjYlt
+hEUY8U+zoO9opMAdrDC8Z2awms22qyIZZtM7QbUQnRC6cm4pJCAcAZli05bg4vsM
+QtfhWsSWTVTNj8pDU/0quOr4ZcoBwq1gaAafORpR2eCNJvkLTqVTJXojpBzOCBvf
+R4iyrT7gJ4eLSYwfqUdYe5byiB0YrrPRpgqU+tvT5TgKa3kSM/tKWTcWQA673vWJ
+DPFs0/dRa1419dvAJuoSc06pkZCmF8NsLzjUo3KUQyxi4U5cMj29TH0ZR6LDSeeW
+P4+a0zvkEdiLA9z2tmBVGKaBUfPhqBVq6+AL8BQx1rmMRTqoENjwuSfr98t67wVy
+lrXEj5ZzxOhWc5y8aVFjvO9nHEMaX3cZHxj4HCUp+UmZKbaSPaKDN7EgkaibMOlq
+bLQjk2UEqxHzDh1TJElTHaE/nUiSEeJ9DU/1172iWD54nR4fK/4huxoTtrEoZP2w
+AgDHbICivRZQIA9ygV/MlP+7mea6kMvq+cYMwq7FGc4zoWtcu358NFcXrfA/rs3q
+r5nsLFR+jM4uElZI7xc7P0peYNLcdDa8pUNjyw9bowJWCZ4kLOGGgYz+qxcs+sji
+Mho6/4UIyYOf8kpIEFR3N+2ivEC+5BB09+Rbu7nzifmPQdjH5FCQNYA+HLhNkNPU
+98OwoX6EyneSMSy4kLGCenROmxMmtNVQZlR4rmA=
+-----END CERTIFICATE-----
+
+# Issuer: CN=SSL.com TLS ECC Root CA 2022 O=SSL Corporation
+# Subject: CN=SSL.com TLS ECC Root CA 2022 O=SSL Corporation
+# Label: "SSL.com TLS ECC Root CA 2022"
+# Serial: 26605119622390491762507526719404364228
+# MD5 Fingerprint: 99:d7:5c:f1:51:36:cc:e9:ce:d9:19:2e:77:71:56:c5
+# SHA1 Fingerprint: 9f:5f:d9:1a:54:6d:f5:0c:71:f0:ee:7a:bd:17:49:98:84:73:e2:39
+# SHA256 Fingerprint: c3:2f:fd:9f:46:f9:36:d1:6c:36:73:99:09:59:43:4b:9a:d6:0a:af:bb:9e:7c:f3:36:54:f1:44:cc:1b:a1:43
+-----BEGIN CERTIFICATE-----
+MIICOjCCAcCgAwIBAgIQFAP1q/s3ixdAW+JDsqXRxDAKBggqhkjOPQQDAzBOMQsw
+CQYDVQQGEwJVUzEYMBYGA1UECgwPU1NMIENvcnBvcmF0aW9uMSUwIwYDVQQDDBxT
+U0wuY29tIFRMUyBFQ0MgUm9vdCBDQSAyMDIyMB4XDTIyMDgyNTE2MzM0OFoXDTQ2
+MDgxOTE2MzM0N1owTjELMAkGA1UEBhMCVVMxGDAWBgNVBAoMD1NTTCBDb3Jwb3Jh
+dGlvbjElMCMGA1UEAwwcU1NMLmNvbSBUTFMgRUNDIFJvb3QgQ0EgMjAyMjB2MBAG
+ByqGSM49AgEGBSuBBAAiA2IABEUpNXP6wrgjzhR9qLFNoFs27iosU8NgCTWyJGYm
+acCzldZdkkAZDsalE3D07xJRKF3nzL35PIXBz5SQySvOkkJYWWf9lCcQZIxPBLFN
+SeR7T5v15wj4A4j3p8OSSxlUgaNjMGEwDwYDVR0TAQH/BAUwAwEB/zAfBgNVHSME
+GDAWgBSJjy+j6CugFFR781a4Jl9nOAuc0DAdBgNVHQ4EFgQUiY8vo+groBRUe/NW
+uCZfZzgLnNAwDgYDVR0PAQH/BAQDAgGGMAoGCCqGSM49BAMDA2gAMGUCMFXjIlbp
+15IkWE8elDIPDAI2wv2sdDJO4fscgIijzPvX6yv/N33w7deedWo1dlJF4AIxAMeN
+b0Igj762TVntd00pxCAgRWSGOlDGxK0tk/UYfXLtqc/ErFc2KAhl3zx5Zn6g6g==
+-----END CERTIFICATE-----
+
+# Issuer: CN=Atos TrustedRoot Root CA ECC TLS 2021 O=Atos
+# Subject: CN=Atos TrustedRoot Root CA ECC TLS 2021 O=Atos
+# Label: "Atos TrustedRoot Root CA ECC TLS 2021"
+# Serial: 81873346711060652204712539181482831616
+# MD5 Fingerprint: 16:9f:ad:f1:70:ad:79:d6:ed:29:b4:d1:c5:79:70:a8
+# SHA1 Fingerprint: 9e:bc:75:10:42:b3:02:f3:81:f4:f7:30:62:d4:8f:c3:a7:51:b2:dd
+# SHA256 Fingerprint: b2:fa:e5:3e:14:cc:d7:ab:92:12:06:47:01:ae:27:9c:1d:89:88:fa:cb:77:5f:a8:a0:08:91:4e:66:39:88:a8
+-----BEGIN CERTIFICATE-----
+MIICFTCCAZugAwIBAgIQPZg7pmY9kGP3fiZXOATvADAKBggqhkjOPQQDAzBMMS4w
+LAYDVQQDDCVBdG9zIFRydXN0ZWRSb290IFJvb3QgQ0EgRUNDIFRMUyAyMDIxMQ0w
+CwYDVQQKDARBdG9zMQswCQYDVQQGEwJERTAeFw0yMTA0MjIwOTI2MjNaFw00MTA0
+MTcwOTI2MjJaMEwxLjAsBgNVBAMMJUF0b3MgVHJ1c3RlZFJvb3QgUm9vdCBDQSBF
+Q0MgVExTIDIwMjExDTALBgNVBAoMBEF0b3MxCzAJBgNVBAYTAkRFMHYwEAYHKoZI
+zj0CAQYFK4EEACIDYgAEloZYKDcKZ9Cg3iQZGeHkBQcfl+3oZIK59sRxUM6KDP/X
+tXa7oWyTbIOiaG6l2b4siJVBzV3dscqDY4PMwL502eCdpO5KTlbgmClBk1IQ1SQ4
+AjJn8ZQSb+/Xxd4u/RmAo0IwQDAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBR2
+KCXWfeBmmnoJsmo7jjPXNtNPojAOBgNVHQ8BAf8EBAMCAYYwCgYIKoZIzj0EAwMD
+aAAwZQIwW5kp85wxtolrbNa9d+F851F+uDrNozZffPc8dz7kUK2o59JZDCaOMDtu
+CCrCp1rIAjEAmeMM56PDr9NJLkaCI2ZdyQAUEv049OGYa3cpetskz2VAv9LcjBHo
+9H1/IISpQuQo
+-----END CERTIFICATE-----
+
+# Issuer: CN=Atos TrustedRoot Root CA RSA TLS 2021 O=Atos
+# Subject: CN=Atos TrustedRoot Root CA RSA TLS 2021 O=Atos
+# Label: "Atos TrustedRoot Root CA RSA TLS 2021"
+# Serial: 111436099570196163832749341232207667876
+# MD5 Fingerprint: d4:d3:46:b8:9a:c0:9c:76:5d:9e:3a:c3:b9:99:31:d2
+# SHA1 Fingerprint: 18:52:3b:0d:06:37:e4:d6:3a:df:23:e4:98:fb:5b:16:fb:86:74:48
+# SHA256 Fingerprint: 81:a9:08:8e:a5:9f:b3:64:c5:48:a6:f8:55:59:09:9b:6f:04:05:ef:bf:18:e5:32:4e:c9:f4:57:ba:00:11:2f
+-----BEGIN CERTIFICATE-----
+MIIFZDCCA0ygAwIBAgIQU9XP5hmTC/srBRLYwiqipDANBgkqhkiG9w0BAQwFADBM
+MS4wLAYDVQQDDCVBdG9zIFRydXN0ZWRSb290IFJvb3QgQ0EgUlNBIFRMUyAyMDIx
+MQ0wCwYDVQQKDARBdG9zMQswCQYDVQQGEwJERTAeFw0yMTA0MjIwOTIxMTBaFw00
+MTA0MTcwOTIxMDlaMEwxLjAsBgNVBAMMJUF0b3MgVHJ1c3RlZFJvb3QgUm9vdCBD
+QSBSU0EgVExTIDIwMjExDTALBgNVBAoMBEF0b3MxCzAJBgNVBAYTAkRFMIICIjAN
+BgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAtoAOxHm9BYx9sKOdTSJNy/BBl01Z
+4NH+VoyX8te9j2y3I49f1cTYQcvyAh5x5en2XssIKl4w8i1mx4QbZFc4nXUtVsYv
+Ye+W/CBGvevUez8/fEc4BKkbqlLfEzfTFRVOvV98r61jx3ncCHvVoOX3W3WsgFWZ
+kmGbzSoXfduP9LVq6hdKZChmFSlsAvFr1bqjM9xaZ6cF4r9lthawEO3NUDPJcFDs
+GY6wx/J0W2tExn2WuZgIWWbeKQGb9Cpt0xU6kGpn8bRrZtkh68rZYnxGEFzedUln
+nkL5/nWpo63/dgpnQOPF943HhZpZnmKaau1Fh5hnstVKPNe0OwANwI8f4UDErmwh
+3El+fsqyjW22v5MvoVw+j8rtgI5Y4dtXz4U2OLJxpAmMkokIiEjxQGMYsluMWuPD
+0xeqqxmjLBvk1cbiZnrXghmmOxYsL3GHX0WelXOTwkKBIROW1527k2gV+p2kHYzy
+geBYBr3JtuP2iV2J+axEoctr+hbxx1A9JNr3w+SH1VbxT5Aw+kUJWdo0zuATHAR8
+ANSbhqRAvNncTFd+rrcztl524WWLZt+NyteYr842mIycg5kDcPOvdO3GDjbnvezB
+c6eUWsuSZIKmAMFwoW4sKeFYV+xafJlrJaSQOoD0IJ2azsct+bJLKZWD6TWNp0lI
+pw9MGZHQ9b8Q4HECAwEAAaNCMEAwDwYDVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQU
+dEmZ0f+0emhFdcN+tNzMzjkz2ggwDgYDVR0PAQH/BAQDAgGGMA0GCSqGSIb3DQEB
+DAUAA4ICAQAjQ1MkYlxt/T7Cz1UAbMVWiLkO3TriJQ2VSpfKgInuKs1l+NsW4AmS
+4BjHeJi78+xCUvuppILXTdiK/ORO/auQxDh1MoSf/7OwKwIzNsAQkG8dnK/haZPs
+o0UvFJ/1TCplQ3IM98P4lYsU84UgYt1UU90s3BiVaU+DR3BAM1h3Egyi61IxHkzJ
+qM7F78PRreBrAwA0JrRUITWXAdxfG/F851X6LWh3e9NpzNMOa7pNdkTWwhWaJuyw
+xfW70Xp0wmzNxbVe9kzmWy2B27O3Opee7c9GslA9hGCZcbUztVdF5kJHdWoOsAgM
+rr3e97sPWD2PAzHoPYJQyi9eDF20l74gNAf0xBLh7tew2VktafcxBPTy+av5EzH4
+AXcOPUIjJsyacmdRIXrMPIWo6iFqO9taPKU0nprALN+AnCng33eU0aKAQv9qTFsR
+0PXNor6uzFFcw9VUewyu1rkGd4Di7wcaaMxZUa1+XGdrudviB0JbuAEFWDlN5LuY
+o7Ey7Nmj1m+UI/87tyll5gfp77YZ6ufCOB0yiJA8EytuzO+rdwY0d4RPcuSBhPm5
+dDTedk+SKlOxJTnbPP/lPqYO5Wue/9vsL3SD3460s6neFE3/MaNFcyT6lSnMEpcE
+oji2jbDwN/zIIX8/syQbPYtuzE2wFg2WHYMfRsCbvUOZ58SWLs5fyQ==
+-----END CERTIFICATE-----
+
+# Issuer: CN=TrustAsia Global Root CA G3 O=TrustAsia Technologies, Inc.
+# Subject: CN=TrustAsia Global Root CA G3 O=TrustAsia Technologies, Inc.
+# Label: "TrustAsia Global Root CA G3"
+# Serial: 576386314500428537169965010905813481816650257167
+# MD5 Fingerprint: 30:42:1b:b7:bb:81:75:35:e4:16:4f:53:d2:94:de:04
+# SHA1 Fingerprint: 63:cf:b6:c1:27:2b:56:e4:88:8e:1c:23:9a:b6:2e:81:47:24:c3:c7
+# SHA256 Fingerprint: e0:d3:22:6a:eb:11:63:c2:e4:8f:f9:be:3b:50:b4:c6:43:1b:e7:bb:1e:ac:c5:c3:6b:5d:5e:c5:09:03:9a:08
+-----BEGIN CERTIFICATE-----
+MIIFpTCCA42gAwIBAgIUZPYOZXdhaqs7tOqFhLuxibhxkw8wDQYJKoZIhvcNAQEM
+BQAwWjELMAkGA1UEBhMCQ04xJTAjBgNVBAoMHFRydXN0QXNpYSBUZWNobm9sb2dp
+ZXMsIEluYy4xJDAiBgNVBAMMG1RydXN0QXNpYSBHbG9iYWwgUm9vdCBDQSBHMzAe
+Fw0yMTA1MjAwMjEwMTlaFw00NjA1MTkwMjEwMTlaMFoxCzAJBgNVBAYTAkNOMSUw
+IwYDVQQKDBxUcnVzdEFzaWEgVGVjaG5vbG9naWVzLCBJbmMuMSQwIgYDVQQDDBtU
+cnVzdEFzaWEgR2xvYmFsIFJvb3QgQ0EgRzMwggIiMA0GCSqGSIb3DQEBAQUAA4IC
+DwAwggIKAoICAQDAMYJhkuSUGwoqZdC+BqmHO1ES6nBBruL7dOoKjbmzTNyPtxNS
+T1QY4SxzlZHFZjtqz6xjbYdT8PfxObegQ2OwxANdV6nnRM7EoYNl9lA+sX4WuDqK
+AtCWHwDNBSHvBm3dIZwZQ0WhxeiAysKtQGIXBsaqvPPW5vxQfmZCHzyLpnl5hkA1
+nyDvP+uLRx+PjsXUjrYsyUQE49RDdT/VP68czH5GX6zfZBCK70bwkPAPLfSIC7Ep
+qq+FqklYqL9joDiR5rPmd2jE+SoZhLsO4fWvieylL1AgdB4SQXMeJNnKziyhWTXA
+yB1GJ2Faj/lN03J5Zh6fFZAhLf3ti1ZwA0pJPn9pMRJpxx5cynoTi+jm9WAPzJMs
+hH/x/Gr8m0ed262IPfN2dTPXS6TIi/n1Q1hPy8gDVI+lhXgEGvNz8teHHUGf59gX
+zhqcD0r83ERoVGjiQTz+LISGNzzNPy+i2+f3VANfWdP3kXjHi3dqFuVJhZBFcnAv
+kV34PmVACxmZySYgWmjBNb9Pp1Hx2BErW+Canig7CjoKH8GB5S7wprlppYiU5msT
+f9FkPz2ccEblooV7WIQn3MSAPmeamseaMQ4w7OYXQJXZRe0Blqq/DPNL0WP3E1jA
+uPP6Z92bfW1K/zJMtSU7/xxnD4UiWQWRkUF3gdCFTIcQcf+eQxuulXUtgQIDAQAB
+o2MwYTAPBgNVHRMBAf8EBTADAQH/MB8GA1UdIwQYMBaAFEDk5PIj7zjKsK5Xf/Ih
+MBY027ySMB0GA1UdDgQWBBRA5OTyI+84yrCuV3/yITAWNNu8kjAOBgNVHQ8BAf8E
+BAMCAQYwDQYJKoZIhvcNAQEMBQADggIBACY7UeFNOPMyGLS0XuFlXsSUT9SnYaP4
+wM8zAQLpw6o1D/GUE3d3NZ4tVlFEbuHGLige/9rsR82XRBf34EzC4Xx8MnpmyFq2
+XFNFV1pF1AWZLy4jVe5jaN/TG3inEpQGAHUNcoTpLrxaatXeL1nHo+zSh2bbt1S1
+JKv0Q3jbSwTEb93mPmY+KfJLaHEih6D4sTNjduMNhXJEIlU/HHzp/LgV6FL6qj6j
+ITk1dImmasI5+njPtqzn59ZW/yOSLlALqbUHM/Q4X6RJpstlcHboCoWASzY9M/eV
+VHUl2qzEc4Jl6VL1XP04lQJqaTDFHApXB64ipCz5xUG3uOyfT0gA+QEEVcys+TIx
+xHWVBqB/0Y0n3bOppHKH/lmLmnp0Ft0WpWIp6zqW3IunaFnT63eROfjXy9mPX1on
+AX1daBli2MjN9LdyR75bl87yraKZk62Uy5P2EgmVtqvXO9A/EcswFi55gORngS1d
+7XB4tmBZrOFdRWOPyN9yaFvqHbgB8X7754qz41SgOAngPN5C8sLtLpvzHzW2Ntjj
+gKGLzZlkD8Kqq7HK9W+eQ42EVJmzbsASZthwEPEGNTNDqJwuuhQxzhB/HIbjj9LV
++Hfsm6vxL2PZQl/gZ4FkkfGXL/xuJvYz+NO1+MRiqzFRJQJ6+N1rZdVtTTDIZbpo
+FGWsJwt0ivKH
+-----END CERTIFICATE-----
+
+# Issuer: CN=TrustAsia Global Root CA G4 O=TrustAsia Technologies, Inc.
+# Subject: CN=TrustAsia Global Root CA G4 O=TrustAsia Technologies, Inc.
+# Label: "TrustAsia Global Root CA G4"
+# Serial: 451799571007117016466790293371524403291602933463
+# MD5 Fingerprint: 54:dd:b2:d7:5f:d8:3e:ed:7c:e0:0b:2e:cc:ed:eb:eb
+# SHA1 Fingerprint: 57:73:a5:61:5d:80:b2:e6:ac:38:82:fc:68:07:31:ac:9f:b5:92:5a
+# SHA256 Fingerprint: be:4b:56:cb:50:56:c0:13:6a:52:6d:f4:44:50:8d:aa:36:a0:b5:4f:42:e4:ac:38:f7:2a:f4:70:e4:79:65:4c
+-----BEGIN CERTIFICATE-----
+MIICVTCCAdygAwIBAgIUTyNkuI6XY57GU4HBdk7LKnQV1tcwCgYIKoZIzj0EAwMw
+WjELMAkGA1UEBhMCQ04xJTAjBgNVBAoMHFRydXN0QXNpYSBUZWNobm9sb2dpZXMs
+IEluYy4xJDAiBgNVBAMMG1RydXN0QXNpYSBHbG9iYWwgUm9vdCBDQSBHNDAeFw0y
+MTA1MjAwMjEwMjJaFw00NjA1MTkwMjEwMjJaMFoxCzAJBgNVBAYTAkNOMSUwIwYD
+VQQKDBxUcnVzdEFzaWEgVGVjaG5vbG9naWVzLCBJbmMuMSQwIgYDVQQDDBtUcnVz
+dEFzaWEgR2xvYmFsIFJvb3QgQ0EgRzQwdjAQBgcqhkjOPQIBBgUrgQQAIgNiAATx
+s8045CVD5d4ZCbuBeaIVXxVjAd7Cq92zphtnS4CDr5nLrBfbK5bKfFJV4hrhPVbw
+LxYI+hW8m7tH5j/uqOFMjPXTNvk4XatwmkcN4oFBButJ+bAp3TPsUKV/eSm4IJij
+YzBhMA8GA1UdEwEB/wQFMAMBAf8wHwYDVR0jBBgwFoAUpbtKl86zK3+kMd6Xg1mD
+pm9xy94wHQYDVR0OBBYEFKW7SpfOsyt/pDHel4NZg6ZvccveMA4GA1UdDwEB/wQE
+AwIBBjAKBggqhkjOPQQDAwNnADBkAjBe8usGzEkxn0AAbbd+NvBNEU/zy4k6LHiR
+UKNbwMp1JvK/kF0LgoxgKJ/GcJpo5PECMFxYDlZ2z1jD1xCMuo6u47xkdUfFVZDj
+/bpV6wfEU6s3qe4hsiFbYI89MvHVI5TWWA==
+-----END CERTIFICATE-----
+
+# Issuer: CN=CommScope Public Trust ECC Root-01 O=CommScope
+# Subject: CN=CommScope Public Trust ECC Root-01 O=CommScope
+# Label: "CommScope Public Trust ECC Root-01"
+# Serial: 385011430473757362783587124273108818652468453534
+# MD5 Fingerprint: 3a:40:a7:fc:03:8c:9c:38:79:2f:3a:a2:6c:b6:0a:16
+# SHA1 Fingerprint: 07:86:c0:d8:dd:8e:c0:80:98:06:98:d0:58:7a:ef:de:a6:cc:a2:5d
+# SHA256 Fingerprint: 11:43:7c:da:7b:b4:5e:41:36:5f:45:b3:9a:38:98:6b:0d:e0:0d:ef:34:8e:0c:7b:b0:87:36:33:80:0b:c3:8b
+-----BEGIN CERTIFICATE-----
+MIICHTCCAaOgAwIBAgIUQ3CCd89NXTTxyq4yLzf39H91oJ4wCgYIKoZIzj0EAwMw
+TjELMAkGA1UEBhMCVVMxEjAQBgNVBAoMCUNvbW1TY29wZTErMCkGA1UEAwwiQ29t
+bVNjb3BlIFB1YmxpYyBUcnVzdCBFQ0MgUm9vdC0wMTAeFw0yMTA0MjgxNzM1NDNa
+Fw00NjA0MjgxNzM1NDJaME4xCzAJBgNVBAYTAlVTMRIwEAYDVQQKDAlDb21tU2Nv
+cGUxKzApBgNVBAMMIkNvbW1TY29wZSBQdWJsaWMgVHJ1c3QgRUNDIFJvb3QtMDEw
+djAQBgcqhkjOPQIBBgUrgQQAIgNiAARLNumuV16ocNfQj3Rid8NeeqrltqLxeP0C
+flfdkXmcbLlSiFS8LwS+uM32ENEp7LXQoMPwiXAZu1FlxUOcw5tjnSCDPgYLpkJE
+hRGnSjot6dZoL0hOUysHP029uax3OVejQjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYD
+VR0PAQH/BAQDAgEGMB0GA1UdDgQWBBSOB2LAUN3GGQYARnQE9/OufXVNMDAKBggq
+hkjOPQQDAwNoADBlAjEAnDPfQeMjqEI2Jpc1XHvr20v4qotzVRVcrHgpD7oh2MSg
+2NED3W3ROT3Ek2DS43KyAjB8xX6I01D1HiXo+k515liWpDVfG2XqYZpwI7UNo5uS
+Um9poIyNStDuiw7LR47QjRE=
+-----END CERTIFICATE-----
+
+# Issuer: CN=CommScope Public Trust ECC Root-02 O=CommScope
+# Subject: CN=CommScope Public Trust ECC Root-02 O=CommScope
+# Label: "CommScope Public Trust ECC Root-02"
+# Serial: 234015080301808452132356021271193974922492992893
+# MD5 Fingerprint: 59:b0:44:d5:65:4d:b8:5c:55:19:92:02:b6:d1:94:b2
+# SHA1 Fingerprint: 3c:3f:ef:57:0f:fe:65:93:86:9e:a0:fe:b0:f6:ed:8e:d1:13:c7:e5
+# SHA256 Fingerprint: 2f:fb:7f:81:3b:bb:b3:c8:9a:b4:e8:16:2d:0f:16:d7:15:09:a8:30:cc:9d:73:c2:62:e5:14:08:75:d1:ad:4a
+-----BEGIN CERTIFICATE-----
+MIICHDCCAaOgAwIBAgIUKP2ZYEFHpgE6yhR7H+/5aAiDXX0wCgYIKoZIzj0EAwMw
+TjELMAkGA1UEBhMCVVMxEjAQBgNVBAoMCUNvbW1TY29wZTErMCkGA1UEAwwiQ29t
+bVNjb3BlIFB1YmxpYyBUcnVzdCBFQ0MgUm9vdC0wMjAeFw0yMTA0MjgxNzQ0NTRa
+Fw00NjA0MjgxNzQ0NTNaME4xCzAJBgNVBAYTAlVTMRIwEAYDVQQKDAlDb21tU2Nv
+cGUxKzApBgNVBAMMIkNvbW1TY29wZSBQdWJsaWMgVHJ1c3QgRUNDIFJvb3QtMDIw
+djAQBgcqhkjOPQIBBgUrgQQAIgNiAAR4MIHoYx7l63FRD/cHB8o5mXxO1Q/MMDAL
+j2aTPs+9xYa9+bG3tD60B8jzljHz7aRP+KNOjSkVWLjVb3/ubCK1sK9IRQq9qEmU
+v4RDsNuESgMjGWdqb8FuvAY5N9GIIvejQjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYD
+VR0PAQH/BAQDAgEGMB0GA1UdDgQWBBTmGHX/72DehKT1RsfeSlXjMjZ59TAKBggq
+hkjOPQQDAwNnADBkAjAmc0l6tqvmSfR9Uj/UQQSugEODZXW5hYA4O9Zv5JOGq4/n
+ich/m35rChJVYaoR4HkCMHfoMXGsPHED1oQmHhS48zs73u1Z/GtMMH9ZzkXpc2AV
+mkzw5l4lIhVtwodZ0LKOag==
+-----END CERTIFICATE-----
+
+# Issuer: CN=CommScope Public Trust RSA Root-01 O=CommScope
+# Subject: CN=CommScope Public Trust RSA Root-01 O=CommScope
+# Label: "CommScope Public Trust RSA Root-01"
+# Serial: 354030733275608256394402989253558293562031411421
+# MD5 Fingerprint: 0e:b4:15:bc:87:63:5d:5d:02:73:d4:26:38:68:73:d8
+# SHA1 Fingerprint: 6d:0a:5f:f7:b4:23:06:b4:85:b3:b7:97:64:fc:ac:75:f5:33:f2:93
+# SHA256 Fingerprint: 02:bd:f9:6e:2a:45:dd:9b:f1:8f:c7:e1:db:df:21:a0:37:9b:a3:c9:c2:61:03:44:cf:d8:d6:06:fe:c1:ed:81
+-----BEGIN CERTIFICATE-----
+MIIFbDCCA1SgAwIBAgIUPgNJgXUWdDGOTKvVxZAplsU5EN0wDQYJKoZIhvcNAQEL
+BQAwTjELMAkGA1UEBhMCVVMxEjAQBgNVBAoMCUNvbW1TY29wZTErMCkGA1UEAwwi
+Q29tbVNjb3BlIFB1YmxpYyBUcnVzdCBSU0EgUm9vdC0wMTAeFw0yMTA0MjgxNjQ1
+NTRaFw00NjA0MjgxNjQ1NTNaME4xCzAJBgNVBAYTAlVTMRIwEAYDVQQKDAlDb21t
+U2NvcGUxKzApBgNVBAMMIkNvbW1TY29wZSBQdWJsaWMgVHJ1c3QgUlNBIFJvb3Qt
+MDEwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCwSGWjDR1C45FtnYSk
+YZYSwu3D2iM0GXb26v1VWvZVAVMP8syMl0+5UMuzAURWlv2bKOx7dAvnQmtVzslh
+suitQDy6uUEKBU8bJoWPQ7VAtYXR1HHcg0Hz9kXHgKKEUJdGzqAMxGBWBB0HW0al
+DrJLpA6lfO741GIDuZNqihS4cPgugkY4Iw50x2tBt9Apo52AsH53k2NC+zSDO3Oj
+WiE260f6GBfZumbCk6SP/F2krfxQapWsvCQz0b2If4b19bJzKo98rwjyGpg/qYFl
+P8GMicWWMJoKz/TUyDTtnS+8jTiGU+6Xn6myY5QXjQ/cZip8UlF1y5mO6D1cv547
+KI2DAg+pn3LiLCuz3GaXAEDQpFSOm117RTYm1nJD68/A6g3czhLmfTifBSeolz7p
+UcZsBSjBAg/pGG3svZwG1KdJ9FQFa2ww8esD1eo9anbCyxooSU1/ZOD6K9pzg4H/
+kQO9lLvkuI6cMmPNn7togbGEW682v3fuHX/3SZtS7NJ3Wn2RnU3COS3kuoL4b/JO
+Hg9O5j9ZpSPcPYeoKFgo0fEbNttPxP/hjFtyjMcmAyejOQoBqsCyMWCDIqFPEgkB
+Ea801M/XrmLTBQe0MXXgDW1XT2mH+VepuhX2yFJtocucH+X8eKg1mp9BFM6ltM6U
+CBwJrVbl2rZJmkrqYxhTnCwuwwIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MA4G
+A1UdDwEB/wQEAwIBBjAdBgNVHQ4EFgQUN12mmnQywsL5x6YVEFm45P3luG0wDQYJ
+KoZIhvcNAQELBQADggIBAK+nz97/4L1CjU3lIpbfaOp9TSp90K09FlxD533Ahuh6
+NWPxzIHIxgvoLlI1pKZJkGNRrDSsBTtXAOnTYtPZKdVUvhwQkZyybf5Z/Xn36lbQ
+nmhUQo8mUuJM3y+Xpi/SB5io82BdS5pYV4jvguX6r2yBS5KPQJqTRlnLX3gWsWc+
+QgvfKNmwrZggvkN80V4aCRckjXtdlemrwWCrWxhkgPut4AZ9HcpZuPN4KWfGVh2v
+trV0KnahP/t1MJ+UXjulYPPLXAziDslg+MkfFoom3ecnf+slpoq9uC02EJqxWE2a
+aE9gVOX2RhOOiKy8IUISrcZKiX2bwdgt6ZYD9KJ0DLwAHb/WNyVntHKLr4W96ioD
+j8z7PEQkguIBpQtZtjSNMgsSDesnwv1B10A8ckYpwIzqug/xBpMu95yo9GA+o/E4
+Xo4TwbM6l4c/ksp4qRyv0LAbJh6+cOx69TOY6lz/KwsETkPdY34Op054A5U+1C0w
+lREQKC6/oAI+/15Z0wUOlV9TRe9rh9VIzRamloPh37MG88EU26fsHItdkJANclHn
+YfkUyq+Dj7+vsQpZXdxc1+SWrVtgHdqul7I52Qb1dgAT+GhMIbA1xNxVssnBQVoc
+icCMb3SgazNNtQEo/a2tiRc7ppqEvOuM6sRxJKi6KfkIsidWNTJf6jn7MZrVGczw
+-----END CERTIFICATE-----
+
+# Issuer: CN=CommScope Public Trust RSA Root-02 O=CommScope
+# Subject: CN=CommScope Public Trust RSA Root-02 O=CommScope
+# Label: "CommScope Public Trust RSA Root-02"
+# Serial: 480062499834624527752716769107743131258796508494
+# MD5 Fingerprint: e1:29:f9:62:7b:76:e2:96:6d:f3:d4:d7:0f:ae:1f:aa
+# SHA1 Fingerprint: ea:b0:e2:52:1b:89:93:4c:11:68:f2:d8:9a:ac:22:4c:a3:8a:57:ae
+# SHA256 Fingerprint: ff:e9:43:d7:93:42:4b:4f:7c:44:0c:1c:3d:64:8d:53:63:f3:4b:82:dc:87:aa:7a:9f:11:8f:c5:de:e1:01:f1
+-----BEGIN CERTIFICATE-----
+MIIFbDCCA1SgAwIBAgIUVBa/O345lXGN0aoApYYNK496BU4wDQYJKoZIhvcNAQEL
+BQAwTjELMAkGA1UEBhMCVVMxEjAQBgNVBAoMCUNvbW1TY29wZTErMCkGA1UEAwwi
+Q29tbVNjb3BlIFB1YmxpYyBUcnVzdCBSU0EgUm9vdC0wMjAeFw0yMTA0MjgxNzE2
+NDNaFw00NjA0MjgxNzE2NDJaME4xCzAJBgNVBAYTAlVTMRIwEAYDVQQKDAlDb21t
+U2NvcGUxKzApBgNVBAMMIkNvbW1TY29wZSBQdWJsaWMgVHJ1c3QgUlNBIFJvb3Qt
+MDIwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDh+g77aAASyE3VrCLE
+NQE7xVTlWXZjpX/rwcRqmL0yjReA61260WI9JSMZNRTpf4mnG2I81lDnNJUDMrG0
+kyI9p+Kx7eZ7Ti6Hmw0zdQreqjXnfuU2mKKuJZ6VszKWpCtYHu8//mI0SFHRtI1C
+rWDaSWqVcN3SAOLMV2MCe5bdSZdbkk6V0/nLKR8YSvgBKtJjCW4k6YnS5cciTNxz
+hkcAqg2Ijq6FfUrpuzNPDlJwnZXjfG2WWy09X6GDRl224yW4fKcZgBzqZUPckXk2
+LHR88mcGyYnJ27/aaL8j7dxrrSiDeS/sOKUNNwFnJ5rpM9kzXzehxfCrPfp4sOcs
+n/Y+n2Dg70jpkEUeBVF4GiwSLFworA2iI540jwXmojPOEXcT1A6kHkIfhs1w/tku
+FT0du7jyU1fbzMZ0KZwYszZ1OC4PVKH4kh+Jlk+71O6d6Ts2QrUKOyrUZHk2EOH5
+kQMreyBUzQ0ZGshBMjTRsJnhkB4BQDa1t/qp5Xd1pCKBXbCL5CcSD1SIxtuFdOa3
+wNemKfrb3vOTlycEVS8KbzfFPROvCgCpLIscgSjX74Yxqa7ybrjKaixUR9gqiC6v
+wQcQeKwRoi9C8DfF8rhW3Q5iLc4tVn5V8qdE9isy9COoR+jUKgF4z2rDN6ieZdIs
+5fq6M8EGRPbmz6UNp2YINIos8wIDAQABo0IwQDAPBgNVHRMBAf8EBTADAQH/MA4G
+A1UdDwEB/wQEAwIBBjAdBgNVHQ4EFgQUR9DnsSL/nSz12Vdgs7GxcJXvYXowDQYJ
+KoZIhvcNAQELBQADggIBAIZpsU0v6Z9PIpNojuQhmaPORVMbc0RTAIFhzTHjCLqB
+KCh6krm2qMhDnscTJk3C2OVVnJJdUNjCK9v+5qiXz1I6JMNlZFxHMaNlNRPDk7n3
++VGXu6TwYofF1gbTl4MgqX67tiHCpQ2EAOHyJxCDut0DgdXdaMNmEMjRdrSzbyme
+APnCKfWxkxlSaRosTKCL4BWaMS/TiJVZbuXEs1DIFAhKm4sTg7GkcrI7djNB3Nyq
+pgdvHSQSn8h2vS/ZjvQs7rfSOBAkNlEv41xdgSGn2rtO/+YHqP65DSdsu3BaVXoT
+6fEqSWnHX4dXTEN5bTpl6TBcQe7rd6VzEojov32u5cSoHw2OHG1QAk8mGEPej1WF
+sQs3BWDJVTkSBKEqz3EWnzZRSb9wO55nnPt7eck5HHisd5FUmrh1CoFSl+NmYWvt
+PjgelmFV4ZFUjO2MJB+ByRCac5krFk5yAD9UG/iNuovnFNa2RU9g7Jauwy8CTl2d
+lklyALKrdVwPaFsdZcJfMw8eD/A7hvWwTruc9+olBdytoptLFwG+Qt81IR2tq670
+v64fG9PiO/yzcnMcmyiQiRM9HcEARwmWmjgb3bHPDcK0RPOWlc4yOo80nOAXx17O
+rg3bhzjlP1v9mxnhMUF6cKojawHhRUzNlM47ni3niAIi9G7oyOzWPPO5std3eqx7
+-----END CERTIFICATE-----
+
+# Issuer: CN=Telekom Security TLS ECC Root 2020 O=Deutsche Telekom Security GmbH
+# Subject: CN=Telekom Security TLS ECC Root 2020 O=Deutsche Telekom Security GmbH
+# Label: "Telekom Security TLS ECC Root 2020"
+# Serial: 72082518505882327255703894282316633856
+# MD5 Fingerprint: c1:ab:fe:6a:10:2c:03:8d:bc:1c:22:32:c0:85:a7:fd
+# SHA1 Fingerprint: c0:f8:96:c5:a9:3b:01:06:21:07:da:18:42:48:bc:e9:9d:88:d5:ec
+# SHA256 Fingerprint: 57:8a:f4:de:d0:85:3f:4e:59:98:db:4a:ea:f9:cb:ea:8d:94:5f:60:b6:20:a3:8d:1a:3c:13:b2:bc:7b:a8:e1
+-----BEGIN CERTIFICATE-----
+MIICQjCCAcmgAwIBAgIQNjqWjMlcsljN0AFdxeVXADAKBggqhkjOPQQDAzBjMQsw
+CQYDVQQGEwJERTEnMCUGA1UECgweRGV1dHNjaGUgVGVsZWtvbSBTZWN1cml0eSBH
+bWJIMSswKQYDVQQDDCJUZWxla29tIFNlY3VyaXR5IFRMUyBFQ0MgUm9vdCAyMDIw
+MB4XDTIwMDgyNTA3NDgyMFoXDTQ1MDgyNTIzNTk1OVowYzELMAkGA1UEBhMCREUx
+JzAlBgNVBAoMHkRldXRzY2hlIFRlbGVrb20gU2VjdXJpdHkgR21iSDErMCkGA1UE
+AwwiVGVsZWtvbSBTZWN1cml0eSBUTFMgRUNDIFJvb3QgMjAyMDB2MBAGByqGSM49
+AgEGBSuBBAAiA2IABM6//leov9Wq9xCazbzREaK9Z0LMkOsVGJDZos0MKiXrPk/O
+tdKPD/M12kOLAoC+b1EkHQ9rK8qfwm9QMuU3ILYg/4gND21Ju9sGpIeQkpT0CdDP
+f8iAC8GXs7s1J8nCG6NCMEAwHQYDVR0OBBYEFONyzG6VmUex5rNhTNHLq+O6zd6f
+MA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgEGMAoGCCqGSM49BAMDA2cA
+MGQCMHVSi7ekEE+uShCLsoRbQuHmKjYC2qBuGT8lv9pZMo7k+5Dck2TOrbRBR2Di
+z6fLHgIwN0GMZt9Ba9aDAEH9L1r3ULRn0SyocddDypwnJJGDSA3PzfdUga/sf+Rn
+27iQ7t0l
+-----END CERTIFICATE-----
+
+# Issuer: CN=Telekom Security TLS RSA Root 2023 O=Deutsche Telekom Security GmbH
+# Subject: CN=Telekom Security TLS RSA Root 2023 O=Deutsche Telekom Security GmbH
+# Label: "Telekom Security TLS RSA Root 2023"
+# Serial: 44676229530606711399881795178081572759
+# MD5 Fingerprint: bf:5b:eb:54:40:cd:48:71:c4:20:8d:7d:de:0a:42:f2
+# SHA1 Fingerprint: 54:d3:ac:b3:bd:57:56:f6:85:9d:ce:e5:c3:21:e2:d4:ad:83:d0:93
+# SHA256 Fingerprint: ef:c6:5c:ad:bb:59:ad:b6:ef:e8:4d:a2:23:11:b3:56:24:b7:1b:3b:1e:a0:da:8b:66:55:17:4e:c8:97:86:46
+-----BEGIN CERTIFICATE-----
+MIIFszCCA5ugAwIBAgIQIZxULej27HF3+k7ow3BXlzANBgkqhkiG9w0BAQwFADBj
+MQswCQYDVQQGEwJERTEnMCUGA1UECgweRGV1dHNjaGUgVGVsZWtvbSBTZWN1cml0
+eSBHbWJIMSswKQYDVQQDDCJUZWxla29tIFNlY3VyaXR5IFRMUyBSU0EgUm9vdCAy
+MDIzMB4XDTIzMDMyODEyMTY0NVoXDTQ4MDMyNzIzNTk1OVowYzELMAkGA1UEBhMC
+REUxJzAlBgNVBAoMHkRldXRzY2hlIFRlbGVrb20gU2VjdXJpdHkgR21iSDErMCkG
+A1UEAwwiVGVsZWtvbSBTZWN1cml0eSBUTFMgUlNBIFJvb3QgMjAyMzCCAiIwDQYJ
+KoZIhvcNAQEBBQADggIPADCCAgoCggIBAO01oYGA88tKaVvC+1GDrib94W7zgRJ9
+cUD/h3VCKSHtgVIs3xLBGYSJwb3FKNXVS2xE1kzbB5ZKVXrKNoIENqil/Cf2SfHV
+cp6R+SPWcHu79ZvB7JPPGeplfohwoHP89v+1VmLhc2o0mD6CuKyVU/QBoCcHcqMA
+U6DksquDOFczJZSfvkgdmOGjup5czQRxUX11eKvzWarE4GC+j4NSuHUaQTXtvPM6
+Y+mpFEXX5lLRbtLevOP1Czvm4MS9Q2QTps70mDdsipWol8hHD/BeEIvnHRz+sTug
+BTNoBUGCwQMrAcjnj02r6LX2zWtEtefdi+zqJbQAIldNsLGyMcEWzv/9FIS3R/qy
+8XDe24tsNlikfLMR0cN3f1+2JeANxdKz+bi4d9s3cXFH42AYTyS2dTd4uaNir73J
+co4vzLuu2+QVUhkHM/tqty1LkCiCc/4YizWN26cEar7qwU02OxY2kTLvtkCJkUPg
+8qKrBC7m8kwOFjQgrIfBLX7JZkcXFBGk8/ehJImr2BrIoVyxo/eMbcgByU/J7MT8
+rFEz0ciD0cmfHdRHNCk+y7AO+oMLKFjlKdw/fKifybYKu6boRhYPluV75Gp6SG12
+mAWl3G0eQh5C2hrgUve1g8Aae3g1LDj1H/1Joy7SWWO/gLCMk3PLNaaZlSJhZQNg
++y+TS/qanIA7AgMBAAGjYzBhMA4GA1UdDwEB/wQEAwIBBjAdBgNVHQ4EFgQUtqeX
+gj10hZv3PJ+TmpV5dVKMbUcwDwYDVR0TAQH/BAUwAwEB/zAfBgNVHSMEGDAWgBS2
+p5eCPXSFm/c8n5OalXl1UoxtRzANBgkqhkiG9w0BAQwFAAOCAgEAqMxhpr51nhVQ
+pGv7qHBFfLp+sVr8WyP6Cnf4mHGCDG3gXkaqk/QeoMPhk9tLrbKmXauw1GLLXrtm
+9S3ul0A8Yute1hTWjOKWi0FpkzXmuZlrYrShF2Y0pmtjxrlO8iLpWA1WQdH6DErw
+M807u20hOq6OcrXDSvvpfeWxm4bu4uB9tPcy/SKE8YXJN3nptT+/XOR0so8RYgDd
+GGah2XsjX/GO1WfoVNpbOms2b/mBsTNHM3dA+VKq3dSDz4V4mZqTuXNnQkYRIer+
+CqkbGmVps4+uFrb2S1ayLfmlyOw7YqPta9BO1UAJpB+Y1zqlklkg5LB9zVtzaL1t
+xKITDmcZuI1CfmwMmm6gJC3VRRvcxAIU/oVbZZfKTpBQCHpCNfnqwmbU+AGuHrS+
+w6jv/naaoqYfRvaE7fzbzsQCzndILIyy7MMAo+wsVRjBfhnu4S/yrYObnqsZ38aK
+L4x35bcF7DvB7L6Gs4a8wPfc5+pbrrLMtTWGS9DiP7bY+A4A7l3j941Y/8+LN+lj
+X273CXE2whJdV/LItM3z7gLfEdxquVeEHVlNjM7IDiPCtyaaEBRx/pOyiriA8A4Q
+ntOoUAw3gi/q4Iqd4Sw5/7W0cwDk90imc6y/st53BIe0o82bNSQ3+pCTE4FCxpgm
+dTdmQRCsu/WU48IxK63nI1bMNSWSs1A=
+-----END CERTIFICATE-----
+
+# Issuer: CN=FIRMAPROFESIONAL CA ROOT-A WEB O=Firmaprofesional SA
+# Subject: CN=FIRMAPROFESIONAL CA ROOT-A WEB O=Firmaprofesional SA
+# Label: "FIRMAPROFESIONAL CA ROOT-A WEB"
+# Serial: 65916896770016886708751106294915943533
+# MD5 Fingerprint: 82:b2:ad:45:00:82:b0:66:63:f8:5f:c3:67:4e:ce:a3
+# SHA1 Fingerprint: a8:31:11:74:a6:14:15:0d:ca:77:dd:0e:e4:0c:5d:58:fc:a0:72:a5
+# SHA256 Fingerprint: be:f2:56:da:f2:6e:9c:69:bd:ec:16:02:35:97:98:f3:ca:f7:18:21:a0:3e:01:82:57:c5:3c:65:61:7f:3d:4a
+-----BEGIN CERTIFICATE-----
+MIICejCCAgCgAwIBAgIQMZch7a+JQn81QYehZ1ZMbTAKBggqhkjOPQQDAzBuMQsw
+CQYDVQQGEwJFUzEcMBoGA1UECgwTRmlybWFwcm9mZXNpb25hbCBTQTEYMBYGA1UE
+YQwPVkFURVMtQTYyNjM0MDY4MScwJQYDVQQDDB5GSVJNQVBST0ZFU0lPTkFMIENB
+IFJPT1QtQSBXRUIwHhcNMjIwNDA2MDkwMTM2WhcNNDcwMzMxMDkwMTM2WjBuMQsw
+CQYDVQQGEwJFUzEcMBoGA1UECgwTRmlybWFwcm9mZXNpb25hbCBTQTEYMBYGA1UE
+YQwPVkFURVMtQTYyNjM0MDY4MScwJQYDVQQDDB5GSVJNQVBST0ZFU0lPTkFMIENB
+IFJPT1QtQSBXRUIwdjAQBgcqhkjOPQIBBgUrgQQAIgNiAARHU+osEaR3xyrq89Zf
+e9MEkVz6iMYiuYMQYneEMy3pA4jU4DP37XcsSmDq5G+tbbT4TIqk5B/K6k84Si6C
+cyvHZpsKjECcfIr28jlgst7L7Ljkb+qbXbdTkBgyVcUgt5SjYzBhMA8GA1UdEwEB
+/wQFMAMBAf8wHwYDVR0jBBgwFoAUk+FDY1w8ndYn81LsF7Kpryz3dvgwHQYDVR0O
+BBYEFJPhQ2NcPJ3WJ/NS7Beyqa8s93b4MA4GA1UdDwEB/wQEAwIBBjAKBggqhkjO
+PQQDAwNoADBlAjAdfKR7w4l1M+E7qUW/Runpod3JIha3RxEL2Jq68cgLcFBTApFw
+hVmpHqTm6iMxoAACMQD94vizrxa5HnPEluPBMBnYfubDl94cT7iJLzPrSA8Z94dG
+XSaQpYXFuXqUPoeovQA=
+-----END CERTIFICATE-----
+
+# Issuer: CN=TWCA CYBER Root CA O=TAIWAN-CA OU=Root CA
+# Subject: CN=TWCA CYBER Root CA O=TAIWAN-CA OU=Root CA
+# Label: "TWCA CYBER Root CA"
+# Serial: 85076849864375384482682434040119489222
+# MD5 Fingerprint: 0b:33:a0:97:52:95:d4:a9:fd:bb:db:6e:a3:55:5b:51
+# SHA1 Fingerprint: f6:b1:1c:1a:83:38:e9:7b:db:b3:a8:c8:33:24:e0:2d:9c:7f:26:66
+# SHA256 Fingerprint: 3f:63:bb:28:14:be:17:4e:c8:b6:43:9c:f0:8d:6d:56:f0:b7:c4:05:88:3a:56:48:a3:34:42:4d:6b:3e:c5:58
+-----BEGIN CERTIFICATE-----
+MIIFjTCCA3WgAwIBAgIQQAE0jMIAAAAAAAAAATzyxjANBgkqhkiG9w0BAQwFADBQ
+MQswCQYDVQQGEwJUVzESMBAGA1UEChMJVEFJV0FOLUNBMRAwDgYDVQQLEwdSb290
+IENBMRswGQYDVQQDExJUV0NBIENZQkVSIFJvb3QgQ0EwHhcNMjIxMTIyMDY1NDI5
+WhcNNDcxMTIyMTU1OTU5WjBQMQswCQYDVQQGEwJUVzESMBAGA1UEChMJVEFJV0FO
+LUNBMRAwDgYDVQQLEwdSb290IENBMRswGQYDVQQDExJUV0NBIENZQkVSIFJvb3Qg
+Q0EwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDG+Moe2Qkgfh1sTs6P
+40czRJzHyWmqOlt47nDSkvgEs1JSHWdyKKHfi12VCv7qze33Kc7wb3+szT3vsxxF
+avcokPFhV8UMxKNQXd7UtcsZyoC5dc4pztKFIuwCY8xEMCDa6pFbVuYdHNWdZsc/
+34bKS1PE2Y2yHer43CdTo0fhYcx9tbD47nORxc5zb87uEB8aBs/pJ2DFTxnk684i
+JkXXYJndzk834H/nY62wuFm40AZoNWDTNq5xQwTxaWV4fPMf88oon1oglWa0zbfu
+j3ikRRjpJi+NmykosaS3Om251Bw4ckVYsV7r8Cibt4LK/c/WMw+f+5eesRycnupf
+Xtuq3VTpMCEobY5583WSjCb+3MX2w7DfRFlDo7YDKPYIMKoNM+HvnKkHIuNZW0CP
+2oi3aQiotyMuRAlZN1vH4xfyIutuOVLF3lSnmMlLIJXcRolftBL5hSmO68gnFSDA
+S9TMfAxsNAwmmyYxpjyn9tnQS6Jk/zuZQXLB4HCX8SS7K8R0IrGsayIyJNN4KsDA
+oS/xUgXJP+92ZuJF2A09rZXIx4kmyA+upwMu+8Ff+iDhcK2wZSA3M2Cw1a/XDBzC
+kHDXShi8fgGwsOsVHkQGzaRP6AzRwyAQ4VRlnrZR0Bp2a0JaWHY06rc3Ga4udfmW
+5cFZ95RXKSWNOkyrTZpB0F8mAwIDAQABo2MwYTAOBgNVHQ8BAf8EBAMCAQYwDwYD
+VR0TAQH/BAUwAwEB/zAfBgNVHSMEGDAWgBSdhWEUfMFib5do5E83QOGt4A1WNzAd
+BgNVHQ4EFgQUnYVhFHzBYm+XaORPN0DhreANVjcwDQYJKoZIhvcNAQEMBQADggIB
+AGSPesRiDrWIzLjHhg6hShbNcAu3p4ULs3a2D6f/CIsLJc+o1IN1KriWiLb73y0t
+tGlTITVX1olNc79pj3CjYcya2x6a4CD4bLubIp1dhDGaLIrdaqHXKGnK/nZVekZn
+68xDiBaiA9a5F/gZbG0jAn/xX9AKKSM70aoK7akXJlQKTcKlTfjF/biBzysseKNn
+TKkHmvPfXvt89YnNdJdhEGoHK4Fa0o635yDRIG4kqIQnoVesqlVYL9zZyvpoBJ7t
+RCT5dEA7IzOrg1oYJkK2bVS1FmAwbLGg+LhBoF1JSdJlBTrq/p1hvIbZv97Tujqx
+f36SNI7JAG7cmL3c7IAFrQI932XtCwP39xaEBDG6k5TY8hL4iuO/Qq+n1M0RFxbI
+Qh0UqEL20kCGoE8jypZFVmAGzbdVAaYBlGX+bgUJurSkquLvWL69J1bY73NxW0Qz
+8ppy6rBePm6pUlvscG21h483XjyMnM7k8M4MZ0HMzvaAq07MTFb1wWFZk7Q+ptq4
+NxKfKjLji7gh7MMrZQzvIt6IKTtM1/r+t+FHvpw+PoP7UV31aPcuIYXcv/Fa4nzX
+xeSDwWrruoBa3lwtcHb4yOWHh8qgnaHlIhInD0Q9HWzq1MKLL295q39QpsQZp6F6
+t5b5wR9iWqJDB0BeJsas7a5wFsWqynKKTbDPAYsDP27X
+-----END CERTIFICATE-----
+
+# Issuer: CN=SecureSign Root CA12 O=Cybertrust Japan Co., Ltd.
+# Subject: CN=SecureSign Root CA12 O=Cybertrust Japan Co., Ltd.
+# Label: "SecureSign Root CA12"
+# Serial: 587887345431707215246142177076162061960426065942
+# MD5 Fingerprint: c6:89:ca:64:42:9b:62:08:49:0b:1e:7f:e9:07:3d:e8
+# SHA1 Fingerprint: 7a:22:1e:3d:de:1b:06:ac:9e:c8:47:70:16:8e:3c:e5:f7:6b:06:f4
+# SHA256 Fingerprint: 3f:03:4b:b5:70:4d:44:b2:d0:85:45:a0:20:57:de:93:eb:f3:90:5f:ce:72:1a:cb:c7:30:c0:6d:da:ee:90:4e
+-----BEGIN CERTIFICATE-----
+MIIDcjCCAlqgAwIBAgIUZvnHwa/swlG07VOX5uaCwysckBYwDQYJKoZIhvcNAQEL
+BQAwUTELMAkGA1UEBhMCSlAxIzAhBgNVBAoTGkN5YmVydHJ1c3QgSmFwYW4gQ28u
+LCBMdGQuMR0wGwYDVQQDExRTZWN1cmVTaWduIFJvb3QgQ0ExMjAeFw0yMDA0MDgw
+NTM2NDZaFw00MDA0MDgwNTM2NDZaMFExCzAJBgNVBAYTAkpQMSMwIQYDVQQKExpD
+eWJlcnRydXN0IEphcGFuIENvLiwgTHRkLjEdMBsGA1UEAxMUU2VjdXJlU2lnbiBS
+b290IENBMTIwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQC6OcE3emhF
+KxS06+QT61d1I02PJC0W6K6OyX2kVzsqdiUzg2zqMoqUm048luT9Ub+ZyZN+v/mt
+p7JIKwccJ/VMvHASd6SFVLX9kHrko+RRWAPNEHl57muTH2SOa2SroxPjcf59q5zd
+J1M3s6oYwlkm7Fsf0uZlfO+TvdhYXAvA42VvPMfKWeP+bl+sg779XSVOKik71gur
+FzJ4pOE+lEa+Ym6b3kaosRbnhW70CEBFEaCeVESE99g2zvVQR9wsMJvuwPWW0v4J
+hscGWa5Pro4RmHvzC1KqYiaqId+OJTN5lxZJjfU+1UefNzFJM3IFTQy2VYzxV4+K
+h9GtxRESOaCtAgMBAAGjQjBAMA8GA1UdEwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQD
+AgEGMB0GA1UdDgQWBBRXNPN0zwRL1SXm8UC2LEzZLemgrTANBgkqhkiG9w0BAQsF
+AAOCAQEAPrvbFxbS8hQBICw4g0utvsqFepq2m2um4fylOqyttCg6r9cBg0krY6Ld
+mmQOmFxv3Y67ilQiLUoT865AQ9tPkbeGGuwAtEGBpE/6aouIs3YIcipJQMPTw4WJ
+mBClnW8Zt7vPemVV2zfrPIpyMpcemik+rY3moxtt9XUa5rBouVui7mlHJzWhhpmA
+8zNL4WukJsPvdFlseqJkth5Ew1DgDzk9qTPxpfPSvWKErI4cqc1avTc7bgoitPQV
+55FYxTpE05Uo2cBl6XLK0A+9H7MV2anjpEcJnuDLN/v9vZfVvhgaaaI5gdka9at/
+yOPiZwud9AzqVN/Ssq+xIvEg37xEHA==
+-----END CERTIFICATE-----
+
+# Issuer: CN=SecureSign Root CA14 O=Cybertrust Japan Co., Ltd.
+# Subject: CN=SecureSign Root CA14 O=Cybertrust Japan Co., Ltd.
+# Label: "SecureSign Root CA14"
+# Serial: 575790784512929437950770173562378038616896959179
+# MD5 Fingerprint: 71:0d:72:fa:92:19:65:5e:89:04:ac:16:33:f0:bc:d5
+# SHA1 Fingerprint: dd:50:c0:f7:79:b3:64:2e:74:a2:b8:9d:9f:d3:40:dd:bb:f0:f2:4f
+# SHA256 Fingerprint: 4b:00:9c:10:34:49:4f:9a:b5:6b:ba:3b:a1:d6:27:31:fc:4d:20:d8:95:5a:dc:ec:10:a9:25:60:72:61:e3:38
+-----BEGIN CERTIFICATE-----
+MIIFcjCCA1qgAwIBAgIUZNtaDCBO6Ncpd8hQJ6JaJ90t8sswDQYJKoZIhvcNAQEM
+BQAwUTELMAkGA1UEBhMCSlAxIzAhBgNVBAoTGkN5YmVydHJ1c3QgSmFwYW4gQ28u
+LCBMdGQuMR0wGwYDVQQDExRTZWN1cmVTaWduIFJvb3QgQ0ExNDAeFw0yMDA0MDgw
+NzA2MTlaFw00NTA0MDgwNzA2MTlaMFExCzAJBgNVBAYTAkpQMSMwIQYDVQQKExpD
+eWJlcnRydXN0IEphcGFuIENvLiwgTHRkLjEdMBsGA1UEAxMUU2VjdXJlU2lnbiBS
+b290IENBMTQwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDF0nqh1oq/
+FjHQmNE6lPxauG4iwWL3pwon71D2LrGeaBLwbCRjOfHw3xDG3rdSINVSW0KZnvOg
+vlIfX8xnbacuUKLBl422+JX1sLrcneC+y9/3OPJH9aaakpUqYllQC6KxNedlsmGy
+6pJxaeQp8E+BgQQ8sqVb1MWoWWd7VRxJq3qdwudzTe/NCcLEVxLbAQ4jeQkHO6Lo
+/IrPj8BGJJw4J+CDnRugv3gVEOuGTgpa/d/aLIJ+7sr2KeH6caH3iGicnPCNvg9J
+kdjqOvn90Ghx2+m1K06Ckm9mH+Dw3EzsytHqunQG+bOEkJTRX45zGRBdAuVwpcAQ
+0BB8b8VYSbSwbprafZX1zNoCr7gsfXmPvkPx+SgojQlD+Ajda8iLLCSxjVIHvXib
+y8posqTdDEx5YMaZ0ZPxMBoH064iwurO8YQJzOAUbn8/ftKChazcqRZOhaBgy/ac
+18izju3Gm5h1DVXoX+WViwKkrkMpKBGk5hIwAUt1ax5mnXkvpXYvHUC0bcl9eQjs
+0Wq2XSqypWa9a4X0dFbD9ed1Uigspf9mR6XU/v6eVL9lfgHWMI+lNpyiUBzuOIAB
+SMbHdPTGrMNASRZhdCyvjG817XsYAFs2PJxQDcqSMxDxJklt33UkN4Ii1+iW/RVL
+ApY+B3KVfqs9TC7XyvDf4Fg/LS8EmjijAQIDAQABo0IwQDAPBgNVHRMBAf8EBTAD
+AQH/MA4GA1UdDwEB/wQEAwIBBjAdBgNVHQ4EFgQUBpOjCl4oaTeqYR3r6/wtbyPk
+86AwDQYJKoZIhvcNAQEMBQADggIBAJaAcgkGfpzMkwQWu6A6jZJOtxEaCnFxEM0E
+rX+lRVAQZk5KQaID2RFPeje5S+LGjzJmdSX7684/AykmjbgWHfYfM25I5uj4V7Ib
+ed87hwriZLoAymzvftAj63iP/2SbNDefNWWipAA9EiOWWF3KY4fGoweITedpdopT
+zfFP7ELyk+OZpDc8h7hi2/DsHzc/N19DzFGdtfCXwreFamgLRB7lUe6TzktuhsHS
+DCRZNhqfLJGP4xjblJUK7ZGqDpncllPjYYPGFrojutzdfhrGe0K22VoF3Jpf1d+4
+2kd92jjbrDnVHmtsKheMYc2xbXIBw8MgAGJoFjHVdqqGuw6qnsb58Nn4DSEC5MUo
+FlkRudlpcyqSeLiSV5sI8jrlL5WwWLdrIBRtFO8KvH7YVdiI2i/6GaX7i+B/OfVy
+K4XELKzvGUWSTLNhB9xNH27SgRNcmvMSZ4PPmz+Ln52kuaiWA3rF7iDeM9ovnhp6
+dB7h7sxaOgTdsxoEqBRjrLdHEoOabPXm6RUVkRqEGQ6UROcSjiVbgGcZ3GOTEAtl
+Lor6CZpO2oYofaphNdgOpygau1LgePhsumywbrmHXumZNTfxPWQrqaA0k89jL9WB
+365jJ6UeTo3cKXhZ+PmhIIynJkBugnLNeLLIjzwec+fBH7/PzqUqm9tEZDKgu39c
+JRNItX+S
+-----END CERTIFICATE-----
+
+# Issuer: CN=SecureSign Root CA15 O=Cybertrust Japan Co., Ltd.
+# Subject: CN=SecureSign Root CA15 O=Cybertrust Japan Co., Ltd.
+# Label: "SecureSign Root CA15"
+# Serial: 126083514594751269499665114766174399806381178503
+# MD5 Fingerprint: 13:30:fc:c4:62:a6:a9:de:b5:c1:68:af:b5:d2:31:47
+# SHA1 Fingerprint: cb:ba:83:c8:c1:5a:5d:f1:f9:73:6f:ca:d7:ef:28:13:06:4a:07:7d
+# SHA256 Fingerprint: e7:78:f0:f0:95:fe:84:37:29:cd:1a:00:82:17:9e:53:14:a9:c2:91:44:28:05:e1:fb:1d:8f:b6:b8:88:6c:3a
+-----BEGIN CERTIFICATE-----
+MIICIzCCAamgAwIBAgIUFhXHw9hJp75pDIqI7fBw+d23PocwCgYIKoZIzj0EAwMw
+UTELMAkGA1UEBhMCSlAxIzAhBgNVBAoTGkN5YmVydHJ1c3QgSmFwYW4gQ28uLCBM
+dGQuMR0wGwYDVQQDExRTZWN1cmVTaWduIFJvb3QgQ0ExNTAeFw0yMDA0MDgwODMy
+NTZaFw00NTA0MDgwODMyNTZaMFExCzAJBgNVBAYTAkpQMSMwIQYDVQQKExpDeWJl
+cnRydXN0IEphcGFuIENvLiwgTHRkLjEdMBsGA1UEAxMUU2VjdXJlU2lnbiBSb290
+IENBMTUwdjAQBgcqhkjOPQIBBgUrgQQAIgNiAAQLUHSNZDKZmbPSYAi4Io5GdCx4
+wCtELW1fHcmuS1Iggz24FG1Th2CeX2yF2wYUleDHKP+dX+Sq8bOLbe1PL0vJSpSR
+ZHX+AezB2Ot6lHhWGENfa4HL9rzatAy2KZMIaY+jQjBAMA8GA1UdEwEB/wQFMAMB
+Af8wDgYDVR0PAQH/BAQDAgEGMB0GA1UdDgQWBBTrQciu/NWeUUj1vYv0hyCTQSvT
+9DAKBggqhkjOPQQDAwNoADBlAjEA2S6Jfl5OpBEHvVnCB96rMjhTKkZEBhd6zlHp
+4P9mLQlO4E/0BdGF9jVg3PVys0Z9AjBEmEYagoUeYWmJSwdLZrWeqrqgHkHZAXQ6
+bkU6iYAZezKYVWOr62Nuk22rGwlgMU4=
+-----END CERTIFICATE-----
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/core.py b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/core.py
new file mode 100644
index 000000000..70e0c3bdb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/core.py
@@ -0,0 +1,114 @@
+"""
+certifi.py
+~~~~~~~~~~
+
+This module returns the installation location of cacert.pem or its contents.
+"""
+import sys
+import atexit
+
+def exit_cacert_ctx() -> None:
+ _CACERT_CTX.__exit__(None, None, None) # type: ignore[union-attr]
+
+
+if sys.version_info >= (3, 11):
+
+ from importlib.resources import as_file, files
+
+ _CACERT_CTX = None
+ _CACERT_PATH = None
+
+ def where() -> str:
+ # This is slightly terrible, but we want to delay extracting the file
+ # in cases where we're inside of a zipimport situation until someone
+ # actually calls where(), but we don't want to re-extract the file
+ # on every call of where(), so we'll do it once then store it in a
+ # global variable.
+ global _CACERT_CTX
+ global _CACERT_PATH
+ if _CACERT_PATH is None:
+ # This is slightly janky, the importlib.resources API wants you to
+ # manage the cleanup of this file, so it doesn't actually return a
+ # path, it returns a context manager that will give you the path
+ # when you enter it and will do any cleanup when you leave it. In
+ # the common case of not needing a temporary file, it will just
+ # return the file system location and the __exit__() is a no-op.
+ #
+ # We also have to hold onto the actual context manager, because
+ # it will do the cleanup whenever it gets garbage collected, so
+ # we will also store that at the global level as well.
+ _CACERT_CTX = as_file(files("pip._vendor.certifi").joinpath("cacert.pem"))
+ _CACERT_PATH = str(_CACERT_CTX.__enter__())
+ atexit.register(exit_cacert_ctx)
+
+ return _CACERT_PATH
+
+ def contents() -> str:
+ return files("pip._vendor.certifi").joinpath("cacert.pem").read_text(encoding="ascii")
+
+elif sys.version_info >= (3, 7):
+
+ from importlib.resources import path as get_path, read_text
+
+ _CACERT_CTX = None
+ _CACERT_PATH = None
+
+ def where() -> str:
+ # This is slightly terrible, but we want to delay extracting the
+ # file in cases where we're inside of a zipimport situation until
+ # someone actually calls where(), but we don't want to re-extract
+ # the file on every call of where(), so we'll do it once then store
+ # it in a global variable.
+ global _CACERT_CTX
+ global _CACERT_PATH
+ if _CACERT_PATH is None:
+ # This is slightly janky, the importlib.resources API wants you
+ # to manage the cleanup of this file, so it doesn't actually
+ # return a path, it returns a context manager that will give
+ # you the path when you enter it and will do any cleanup when
+ # you leave it. In the common case of not needing a temporary
+ # file, it will just return the file system location and the
+ # __exit__() is a no-op.
+ #
+ # We also have to hold onto the actual context manager, because
+ # it will do the cleanup whenever it gets garbage collected, so
+ # we will also store that at the global level as well.
+ _CACERT_CTX = get_path("pip._vendor.certifi", "cacert.pem")
+ _CACERT_PATH = str(_CACERT_CTX.__enter__())
+ atexit.register(exit_cacert_ctx)
+
+ return _CACERT_PATH
+
+ def contents() -> str:
+ return read_text("pip._vendor.certifi", "cacert.pem", encoding="ascii")
+
+else:
+ import os
+ import types
+ from typing import Union
+
+ Package = Union[types.ModuleType, str]
+ Resource = Union[str, "os.PathLike"]
+
+ # This fallback will work for Python versions prior to 3.7 that lack the
+ # importlib.resources module but relies on the existing `where` function
+ # so won't address issues with environments like PyOxidizer that don't set
+ # __file__ on modules.
+ def read_text(
+ package: Package,
+ resource: Resource,
+ encoding: str = 'utf-8',
+ errors: str = 'strict'
+ ) -> str:
+ with open(where(), encoding=encoding) as data:
+ return data.read()
+
+ # If we don't have importlib.resources, then we will just do the old logic
+ # of assuming we're on the filesystem and munge the path directly.
+ def where() -> str:
+ f = os.path.dirname(__file__)
+
+ return os.path.join(f, "cacert.pem")
+
+ def contents() -> str:
+ return read_text("pip._vendor.certifi", "cacert.pem", encoding="ascii")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/certifi/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/__init__.py
new file mode 100644
index 000000000..bf0d6c6d3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/__init__.py
@@ -0,0 +1,33 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2012-2023 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+import logging
+
+__version__ = '0.3.9'
+
+
+class DistlibException(Exception):
+ pass
+
+
+try:
+ from logging import NullHandler
+except ImportError: # pragma: no cover
+
+ class NullHandler(logging.Handler):
+
+ def handle(self, record):
+ pass
+
+ def emit(self, record):
+ pass
+
+ def createLock(self):
+ self.lock = None
+
+
+logger = logging.getLogger(__name__)
+logger.addHandler(NullHandler())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/compat.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/compat.py
new file mode 100644
index 000000000..ca561dd2e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/compat.py
@@ -0,0 +1,1137 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2013-2017 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+from __future__ import absolute_import
+
+import os
+import re
+import shutil
+import sys
+
+try:
+ import ssl
+except ImportError: # pragma: no cover
+ ssl = None
+
+if sys.version_info[0] < 3: # pragma: no cover
+ from StringIO import StringIO
+ string_types = basestring,
+ text_type = unicode
+ from types import FileType as file_type
+ import __builtin__ as builtins
+ import ConfigParser as configparser
+ from urlparse import urlparse, urlunparse, urljoin, urlsplit, urlunsplit
+ from urllib import (urlretrieve, quote as _quote, unquote, url2pathname,
+ pathname2url, ContentTooShortError, splittype)
+
+ def quote(s):
+ if isinstance(s, unicode):
+ s = s.encode('utf-8')
+ return _quote(s)
+
+ import urllib2
+ from urllib2 import (Request, urlopen, URLError, HTTPError,
+ HTTPBasicAuthHandler, HTTPPasswordMgr, HTTPHandler,
+ HTTPRedirectHandler, build_opener)
+ if ssl:
+ from urllib2 import HTTPSHandler
+ import httplib
+ import xmlrpclib
+ import Queue as queue
+ from HTMLParser import HTMLParser
+ import htmlentitydefs
+ raw_input = raw_input
+ from itertools import ifilter as filter
+ from itertools import ifilterfalse as filterfalse
+
+ # Leaving this around for now, in case it needs resurrecting in some way
+ # _userprog = None
+ # def splituser(host):
+ # """splituser('user[:passwd]@host[:port]') --> 'user[:passwd]', 'host[:port]'."""
+ # global _userprog
+ # if _userprog is None:
+ # import re
+ # _userprog = re.compile('^(.*)@(.*)$')
+
+ # match = _userprog.match(host)
+ # if match: return match.group(1, 2)
+ # return None, host
+
+else: # pragma: no cover
+ from io import StringIO
+ string_types = str,
+ text_type = str
+ from io import TextIOWrapper as file_type
+ import builtins
+ import configparser
+ from urllib.parse import (urlparse, urlunparse, urljoin, quote, unquote,
+ urlsplit, urlunsplit, splittype)
+ from urllib.request import (urlopen, urlretrieve, Request, url2pathname,
+ pathname2url, HTTPBasicAuthHandler,
+ HTTPPasswordMgr, HTTPHandler,
+ HTTPRedirectHandler, build_opener)
+ if ssl:
+ from urllib.request import HTTPSHandler
+ from urllib.error import HTTPError, URLError, ContentTooShortError
+ import http.client as httplib
+ import urllib.request as urllib2
+ import xmlrpc.client as xmlrpclib
+ import queue
+ from html.parser import HTMLParser
+ import html.entities as htmlentitydefs
+ raw_input = input
+ from itertools import filterfalse
+ filter = filter
+
+try:
+ from ssl import match_hostname, CertificateError
+except ImportError: # pragma: no cover
+
+ class CertificateError(ValueError):
+ pass
+
+ def _dnsname_match(dn, hostname, max_wildcards=1):
+ """Matching according to RFC 6125, section 6.4.3
+
+ http://tools.ietf.org/html/rfc6125#section-6.4.3
+ """
+ pats = []
+ if not dn:
+ return False
+
+ parts = dn.split('.')
+ leftmost, remainder = parts[0], parts[1:]
+
+ wildcards = leftmost.count('*')
+ if wildcards > max_wildcards:
+ # Issue #17980: avoid denials of service by refusing more
+ # than one wildcard per fragment. A survey of established
+ # policy among SSL implementations showed it to be a
+ # reasonable choice.
+ raise CertificateError(
+ "too many wildcards in certificate DNS name: " + repr(dn))
+
+ # speed up common case w/o wildcards
+ if not wildcards:
+ return dn.lower() == hostname.lower()
+
+ # RFC 6125, section 6.4.3, subitem 1.
+ # The client SHOULD NOT attempt to match a presented identifier in which
+ # the wildcard character comprises a label other than the left-most label.
+ if leftmost == '*':
+ # When '*' is a fragment by itself, it matches a non-empty dotless
+ # fragment.
+ pats.append('[^.]+')
+ elif leftmost.startswith('xn--') or hostname.startswith('xn--'):
+ # RFC 6125, section 6.4.3, subitem 3.
+ # The client SHOULD NOT attempt to match a presented identifier
+ # where the wildcard character is embedded within an A-label or
+ # U-label of an internationalized domain name.
+ pats.append(re.escape(leftmost))
+ else:
+ # Otherwise, '*' matches any dotless string, e.g. www*
+ pats.append(re.escape(leftmost).replace(r'\*', '[^.]*'))
+
+ # add the remaining fragments, ignore any wildcards
+ for frag in remainder:
+ pats.append(re.escape(frag))
+
+ pat = re.compile(r'\A' + r'\.'.join(pats) + r'\Z', re.IGNORECASE)
+ return pat.match(hostname)
+
+ def match_hostname(cert, hostname):
+ """Verify that *cert* (in decoded format as returned by
+ SSLSocket.getpeercert()) matches the *hostname*. RFC 2818 and RFC 6125
+ rules are followed, but IP addresses are not accepted for *hostname*.
+
+ CertificateError is raised on failure. On success, the function
+ returns nothing.
+ """
+ if not cert:
+ raise ValueError("empty or no certificate, match_hostname needs a "
+ "SSL socket or SSL context with either "
+ "CERT_OPTIONAL or CERT_REQUIRED")
+ dnsnames = []
+ san = cert.get('subjectAltName', ())
+ for key, value in san:
+ if key == 'DNS':
+ if _dnsname_match(value, hostname):
+ return
+ dnsnames.append(value)
+ if not dnsnames:
+ # The subject is only checked when there is no dNSName entry
+ # in subjectAltName
+ for sub in cert.get('subject', ()):
+ for key, value in sub:
+ # XXX according to RFC 2818, the most specific Common Name
+ # must be used.
+ if key == 'commonName':
+ if _dnsname_match(value, hostname):
+ return
+ dnsnames.append(value)
+ if len(dnsnames) > 1:
+ raise CertificateError("hostname %r "
+ "doesn't match either of %s" %
+ (hostname, ', '.join(map(repr, dnsnames))))
+ elif len(dnsnames) == 1:
+ raise CertificateError("hostname %r "
+ "doesn't match %r" %
+ (hostname, dnsnames[0]))
+ else:
+ raise CertificateError("no appropriate commonName or "
+ "subjectAltName fields were found")
+
+
+try:
+ from types import SimpleNamespace as Container
+except ImportError: # pragma: no cover
+
+ class Container(object):
+ """
+ A generic container for when multiple values need to be returned
+ """
+
+ def __init__(self, **kwargs):
+ self.__dict__.update(kwargs)
+
+
+try:
+ from shutil import which
+except ImportError: # pragma: no cover
+ # Implementation from Python 3.3
+ def which(cmd, mode=os.F_OK | os.X_OK, path=None):
+ """Given a command, mode, and a PATH string, return the path which
+ conforms to the given mode on the PATH, or None if there is no such
+ file.
+
+ `mode` defaults to os.F_OK | os.X_OK. `path` defaults to the result
+ of os.environ.get("PATH"), or can be overridden with a custom search
+ path.
+
+ """
+
+ # Check that a given file can be accessed with the correct mode.
+ # Additionally check that `file` is not a directory, as on Windows
+ # directories pass the os.access check.
+ def _access_check(fn, mode):
+ return (os.path.exists(fn) and os.access(fn, mode) and not os.path.isdir(fn))
+
+ # If we're given a path with a directory part, look it up directly rather
+ # than referring to PATH directories. This includes checking relative to the
+ # current directory, e.g. ./script
+ if os.path.dirname(cmd):
+ if _access_check(cmd, mode):
+ return cmd
+ return None
+
+ if path is None:
+ path = os.environ.get("PATH", os.defpath)
+ if not path:
+ return None
+ path = path.split(os.pathsep)
+
+ if sys.platform == "win32":
+ # The current directory takes precedence on Windows.
+ if os.curdir not in path:
+ path.insert(0, os.curdir)
+
+ # PATHEXT is necessary to check on Windows.
+ pathext = os.environ.get("PATHEXT", "").split(os.pathsep)
+ # See if the given file matches any of the expected path extensions.
+ # This will allow us to short circuit when given "python.exe".
+ # If it does match, only test that one, otherwise we have to try
+ # others.
+ if any(cmd.lower().endswith(ext.lower()) for ext in pathext):
+ files = [cmd]
+ else:
+ files = [cmd + ext for ext in pathext]
+ else:
+ # On other platforms you don't have things like PATHEXT to tell you
+ # what file suffixes are executable, so just pass on cmd as-is.
+ files = [cmd]
+
+ seen = set()
+ for dir in path:
+ normdir = os.path.normcase(dir)
+ if normdir not in seen:
+ seen.add(normdir)
+ for thefile in files:
+ name = os.path.join(dir, thefile)
+ if _access_check(name, mode):
+ return name
+ return None
+
+
+# ZipFile is a context manager in 2.7, but not in 2.6
+
+from zipfile import ZipFile as BaseZipFile
+
+if hasattr(BaseZipFile, '__enter__'): # pragma: no cover
+ ZipFile = BaseZipFile
+else: # pragma: no cover
+ from zipfile import ZipExtFile as BaseZipExtFile
+
+ class ZipExtFile(BaseZipExtFile):
+
+ def __init__(self, base):
+ self.__dict__.update(base.__dict__)
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, *exc_info):
+ self.close()
+ # return None, so if an exception occurred, it will propagate
+
+ class ZipFile(BaseZipFile):
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, *exc_info):
+ self.close()
+ # return None, so if an exception occurred, it will propagate
+
+ def open(self, *args, **kwargs):
+ base = BaseZipFile.open(self, *args, **kwargs)
+ return ZipExtFile(base)
+
+
+try:
+ from platform import python_implementation
+except ImportError: # pragma: no cover
+
+ def python_implementation():
+ """Return a string identifying the Python implementation."""
+ if 'PyPy' in sys.version:
+ return 'PyPy'
+ if os.name == 'java':
+ return 'Jython'
+ if sys.version.startswith('IronPython'):
+ return 'IronPython'
+ return 'CPython'
+
+
+import sysconfig
+
+try:
+ callable = callable
+except NameError: # pragma: no cover
+ from collections.abc import Callable
+
+ def callable(obj):
+ return isinstance(obj, Callable)
+
+
+try:
+ fsencode = os.fsencode
+ fsdecode = os.fsdecode
+except AttributeError: # pragma: no cover
+ # Issue #99: on some systems (e.g. containerised),
+ # sys.getfilesystemencoding() returns None, and we need a real value,
+ # so fall back to utf-8. From the CPython 2.7 docs relating to Unix and
+ # sys.getfilesystemencoding(): the return value is "the user’s preference
+ # according to the result of nl_langinfo(CODESET), or None if the
+ # nl_langinfo(CODESET) failed."
+ _fsencoding = sys.getfilesystemencoding() or 'utf-8'
+ if _fsencoding == 'mbcs':
+ _fserrors = 'strict'
+ else:
+ _fserrors = 'surrogateescape'
+
+ def fsencode(filename):
+ if isinstance(filename, bytes):
+ return filename
+ elif isinstance(filename, text_type):
+ return filename.encode(_fsencoding, _fserrors)
+ else:
+ raise TypeError("expect bytes or str, not %s" %
+ type(filename).__name__)
+
+ def fsdecode(filename):
+ if isinstance(filename, text_type):
+ return filename
+ elif isinstance(filename, bytes):
+ return filename.decode(_fsencoding, _fserrors)
+ else:
+ raise TypeError("expect bytes or str, not %s" %
+ type(filename).__name__)
+
+
+try:
+ from tokenize import detect_encoding
+except ImportError: # pragma: no cover
+ from codecs import BOM_UTF8, lookup
+
+ cookie_re = re.compile(r"coding[:=]\s*([-\w.]+)")
+
+ def _get_normal_name(orig_enc):
+ """Imitates get_normal_name in tokenizer.c."""
+ # Only care about the first 12 characters.
+ enc = orig_enc[:12].lower().replace("_", "-")
+ if enc == "utf-8" or enc.startswith("utf-8-"):
+ return "utf-8"
+ if enc in ("latin-1", "iso-8859-1", "iso-latin-1") or \
+ enc.startswith(("latin-1-", "iso-8859-1-", "iso-latin-1-")):
+ return "iso-8859-1"
+ return orig_enc
+
+ def detect_encoding(readline):
+ """
+ The detect_encoding() function is used to detect the encoding that should
+ be used to decode a Python source file. It requires one argument, readline,
+ in the same way as the tokenize() generator.
+
+ It will call readline a maximum of twice, and return the encoding used
+ (as a string) and a list of any lines (left as bytes) it has read in.
+
+ It detects the encoding from the presence of a utf-8 bom or an encoding
+ cookie as specified in pep-0263. If both a bom and a cookie are present,
+ but disagree, a SyntaxError will be raised. If the encoding cookie is an
+ invalid charset, raise a SyntaxError. Note that if a utf-8 bom is found,
+ 'utf-8-sig' is returned.
+
+ If no encoding is specified, then the default of 'utf-8' will be returned.
+ """
+ try:
+ filename = readline.__self__.name
+ except AttributeError:
+ filename = None
+ bom_found = False
+ encoding = None
+ default = 'utf-8'
+
+ def read_or_stop():
+ try:
+ return readline()
+ except StopIteration:
+ return b''
+
+ def find_cookie(line):
+ try:
+ # Decode as UTF-8. Either the line is an encoding declaration,
+ # in which case it should be pure ASCII, or it must be UTF-8
+ # per default encoding.
+ line_string = line.decode('utf-8')
+ except UnicodeDecodeError:
+ msg = "invalid or missing encoding declaration"
+ if filename is not None:
+ msg = '{} for {!r}'.format(msg, filename)
+ raise SyntaxError(msg)
+
+ matches = cookie_re.findall(line_string)
+ if not matches:
+ return None
+ encoding = _get_normal_name(matches[0])
+ try:
+ codec = lookup(encoding)
+ except LookupError:
+ # This behaviour mimics the Python interpreter
+ if filename is None:
+ msg = "unknown encoding: " + encoding
+ else:
+ msg = "unknown encoding for {!r}: {}".format(
+ filename, encoding)
+ raise SyntaxError(msg)
+
+ if bom_found:
+ if codec.name != 'utf-8':
+ # This behaviour mimics the Python interpreter
+ if filename is None:
+ msg = 'encoding problem: utf-8'
+ else:
+ msg = 'encoding problem for {!r}: utf-8'.format(
+ filename)
+ raise SyntaxError(msg)
+ encoding += '-sig'
+ return encoding
+
+ first = read_or_stop()
+ if first.startswith(BOM_UTF8):
+ bom_found = True
+ first = first[3:]
+ default = 'utf-8-sig'
+ if not first:
+ return default, []
+
+ encoding = find_cookie(first)
+ if encoding:
+ return encoding, [first]
+
+ second = read_or_stop()
+ if not second:
+ return default, [first]
+
+ encoding = find_cookie(second)
+ if encoding:
+ return encoding, [first, second]
+
+ return default, [first, second]
+
+
+# For converting & <-> & etc.
+try:
+ from html import escape
+except ImportError:
+ from cgi import escape
+if sys.version_info[:2] < (3, 4):
+ unescape = HTMLParser().unescape
+else:
+ from html import unescape
+
+try:
+ from collections import ChainMap
+except ImportError: # pragma: no cover
+ from collections import MutableMapping
+
+ try:
+ from reprlib import recursive_repr as _recursive_repr
+ except ImportError:
+
+ def _recursive_repr(fillvalue='...'):
+ '''
+ Decorator to make a repr function return fillvalue for a recursive
+ call
+ '''
+
+ def decorating_function(user_function):
+ repr_running = set()
+
+ def wrapper(self):
+ key = id(self), get_ident()
+ if key in repr_running:
+ return fillvalue
+ repr_running.add(key)
+ try:
+ result = user_function(self)
+ finally:
+ repr_running.discard(key)
+ return result
+
+ # Can't use functools.wraps() here because of bootstrap issues
+ wrapper.__module__ = getattr(user_function, '__module__')
+ wrapper.__doc__ = getattr(user_function, '__doc__')
+ wrapper.__name__ = getattr(user_function, '__name__')
+ wrapper.__annotations__ = getattr(user_function,
+ '__annotations__', {})
+ return wrapper
+
+ return decorating_function
+
+ class ChainMap(MutableMapping):
+ '''
+ A ChainMap groups multiple dicts (or other mappings) together
+ to create a single, updateable view.
+
+ The underlying mappings are stored in a list. That list is public and can
+ accessed or updated using the *maps* attribute. There is no other state.
+
+ Lookups search the underlying mappings successively until a key is found.
+ In contrast, writes, updates, and deletions only operate on the first
+ mapping.
+ '''
+
+ def __init__(self, *maps):
+ '''Initialize a ChainMap by setting *maps* to the given mappings.
+ If no mappings are provided, a single empty dictionary is used.
+
+ '''
+ self.maps = list(maps) or [{}] # always at least one map
+
+ def __missing__(self, key):
+ raise KeyError(key)
+
+ def __getitem__(self, key):
+ for mapping in self.maps:
+ try:
+ return mapping[
+ key] # can't use 'key in mapping' with defaultdict
+ except KeyError:
+ pass
+ return self.__missing__(
+ key) # support subclasses that define __missing__
+
+ def get(self, key, default=None):
+ return self[key] if key in self else default
+
+ def __len__(self):
+ return len(set().union(
+ *self.maps)) # reuses stored hash values if possible
+
+ def __iter__(self):
+ return iter(set().union(*self.maps))
+
+ def __contains__(self, key):
+ return any(key in m for m in self.maps)
+
+ def __bool__(self):
+ return any(self.maps)
+
+ @_recursive_repr()
+ def __repr__(self):
+ return '{0.__class__.__name__}({1})'.format(
+ self, ', '.join(map(repr, self.maps)))
+
+ @classmethod
+ def fromkeys(cls, iterable, *args):
+ 'Create a ChainMap with a single dict created from the iterable.'
+ return cls(dict.fromkeys(iterable, *args))
+
+ def copy(self):
+ 'New ChainMap or subclass with a new copy of maps[0] and refs to maps[1:]'
+ return self.__class__(self.maps[0].copy(), *self.maps[1:])
+
+ __copy__ = copy
+
+ def new_child(self): # like Django's Context.push()
+ 'New ChainMap with a new dict followed by all previous maps.'
+ return self.__class__({}, *self.maps)
+
+ @property
+ def parents(self): # like Django's Context.pop()
+ 'New ChainMap from maps[1:].'
+ return self.__class__(*self.maps[1:])
+
+ def __setitem__(self, key, value):
+ self.maps[0][key] = value
+
+ def __delitem__(self, key):
+ try:
+ del self.maps[0][key]
+ except KeyError:
+ raise KeyError(
+ 'Key not found in the first mapping: {!r}'.format(key))
+
+ def popitem(self):
+ 'Remove and return an item pair from maps[0]. Raise KeyError is maps[0] is empty.'
+ try:
+ return self.maps[0].popitem()
+ except KeyError:
+ raise KeyError('No keys found in the first mapping.')
+
+ def pop(self, key, *args):
+ 'Remove *key* from maps[0] and return its value. Raise KeyError if *key* not in maps[0].'
+ try:
+ return self.maps[0].pop(key, *args)
+ except KeyError:
+ raise KeyError(
+ 'Key not found in the first mapping: {!r}'.format(key))
+
+ def clear(self):
+ 'Clear maps[0], leaving maps[1:] intact.'
+ self.maps[0].clear()
+
+
+try:
+ from importlib.util import cache_from_source # Python >= 3.4
+except ImportError: # pragma: no cover
+
+ def cache_from_source(path, debug_override=None):
+ assert path.endswith('.py')
+ if debug_override is None:
+ debug_override = __debug__
+ if debug_override:
+ suffix = 'c'
+ else:
+ suffix = 'o'
+ return path + suffix
+
+
+try:
+ from collections import OrderedDict
+except ImportError: # pragma: no cover
+ # {{{ http://code.activestate.com/recipes/576693/ (r9)
+ # Backport of OrderedDict() class that runs on Python 2.4, 2.5, 2.6, 2.7 and pypy.
+ # Passes Python2.7's test suite and incorporates all the latest updates.
+ try:
+ from thread import get_ident as _get_ident
+ except ImportError:
+ from dummy_thread import get_ident as _get_ident
+
+ try:
+ from _abcoll import KeysView, ValuesView, ItemsView
+ except ImportError:
+ pass
+
+ class OrderedDict(dict):
+ 'Dictionary that remembers insertion order'
+
+ # An inherited dict maps keys to values.
+ # The inherited dict provides __getitem__, __len__, __contains__, and get.
+ # The remaining methods are order-aware.
+ # Big-O running times for all methods are the same as for regular dictionaries.
+
+ # The internal self.__map dictionary maps keys to links in a doubly linked list.
+ # The circular doubly linked list starts and ends with a sentinel element.
+ # The sentinel element never gets deleted (this simplifies the algorithm).
+ # Each link is stored as a list of length three: [PREV, NEXT, KEY].
+
+ def __init__(self, *args, **kwds):
+ '''Initialize an ordered dictionary. Signature is the same as for
+ regular dictionaries, but keyword arguments are not recommended
+ because their insertion order is arbitrary.
+
+ '''
+ if len(args) > 1:
+ raise TypeError('expected at most 1 arguments, got %d' %
+ len(args))
+ try:
+ self.__root
+ except AttributeError:
+ self.__root = root = [] # sentinel node
+ root[:] = [root, root, None]
+ self.__map = {}
+ self.__update(*args, **kwds)
+
+ def __setitem__(self, key, value, dict_setitem=dict.__setitem__):
+ 'od.__setitem__(i, y) <==> od[i]=y'
+ # Setting a new item creates a new link which goes at the end of the linked
+ # list, and the inherited dictionary is updated with the new key/value pair.
+ if key not in self:
+ root = self.__root
+ last = root[0]
+ last[1] = root[0] = self.__map[key] = [last, root, key]
+ dict_setitem(self, key, value)
+
+ def __delitem__(self, key, dict_delitem=dict.__delitem__):
+ 'od.__delitem__(y) <==> del od[y]'
+ # Deleting an existing item uses self.__map to find the link which is
+ # then removed by updating the links in the predecessor and successor nodes.
+ dict_delitem(self, key)
+ link_prev, link_next, key = self.__map.pop(key)
+ link_prev[1] = link_next
+ link_next[0] = link_prev
+
+ def __iter__(self):
+ 'od.__iter__() <==> iter(od)'
+ root = self.__root
+ curr = root[1]
+ while curr is not root:
+ yield curr[2]
+ curr = curr[1]
+
+ def __reversed__(self):
+ 'od.__reversed__() <==> reversed(od)'
+ root = self.__root
+ curr = root[0]
+ while curr is not root:
+ yield curr[2]
+ curr = curr[0]
+
+ def clear(self):
+ 'od.clear() -> None. Remove all items from od.'
+ try:
+ for node in self.__map.itervalues():
+ del node[:]
+ root = self.__root
+ root[:] = [root, root, None]
+ self.__map.clear()
+ except AttributeError:
+ pass
+ dict.clear(self)
+
+ def popitem(self, last=True):
+ '''od.popitem() -> (k, v), return and remove a (key, value) pair.
+ Pairs are returned in LIFO order if last is true or FIFO order if false.
+
+ '''
+ if not self:
+ raise KeyError('dictionary is empty')
+ root = self.__root
+ if last:
+ link = root[0]
+ link_prev = link[0]
+ link_prev[1] = root
+ root[0] = link_prev
+ else:
+ link = root[1]
+ link_next = link[1]
+ root[1] = link_next
+ link_next[0] = root
+ key = link[2]
+ del self.__map[key]
+ value = dict.pop(self, key)
+ return key, value
+
+ # -- the following methods do not depend on the internal structure --
+
+ def keys(self):
+ 'od.keys() -> list of keys in od'
+ return list(self)
+
+ def values(self):
+ 'od.values() -> list of values in od'
+ return [self[key] for key in self]
+
+ def items(self):
+ 'od.items() -> list of (key, value) pairs in od'
+ return [(key, self[key]) for key in self]
+
+ def iterkeys(self):
+ 'od.iterkeys() -> an iterator over the keys in od'
+ return iter(self)
+
+ def itervalues(self):
+ 'od.itervalues -> an iterator over the values in od'
+ for k in self:
+ yield self[k]
+
+ def iteritems(self):
+ 'od.iteritems -> an iterator over the (key, value) items in od'
+ for k in self:
+ yield (k, self[k])
+
+ def update(*args, **kwds):
+ '''od.update(E, **F) -> None. Update od from dict/iterable E and F.
+
+ If E is a dict instance, does: for k in E: od[k] = E[k]
+ If E has a .keys() method, does: for k in E.keys(): od[k] = E[k]
+ Or if E is an iterable of items, does: for k, v in E: od[k] = v
+ In either case, this is followed by: for k, v in F.items(): od[k] = v
+
+ '''
+ if len(args) > 2:
+ raise TypeError('update() takes at most 2 positional '
+ 'arguments (%d given)' % (len(args), ))
+ elif not args:
+ raise TypeError('update() takes at least 1 argument (0 given)')
+ self = args[0]
+ # Make progressively weaker assumptions about "other"
+ other = ()
+ if len(args) == 2:
+ other = args[1]
+ if isinstance(other, dict):
+ for key in other:
+ self[key] = other[key]
+ elif hasattr(other, 'keys'):
+ for key in other.keys():
+ self[key] = other[key]
+ else:
+ for key, value in other:
+ self[key] = value
+ for key, value in kwds.items():
+ self[key] = value
+
+ __update = update # let subclasses override update without breaking __init__
+
+ __marker = object()
+
+ def pop(self, key, default=__marker):
+ '''od.pop(k[,d]) -> v, remove specified key and return the corresponding value.
+ If key is not found, d is returned if given, otherwise KeyError is raised.
+
+ '''
+ if key in self:
+ result = self[key]
+ del self[key]
+ return result
+ if default is self.__marker:
+ raise KeyError(key)
+ return default
+
+ def setdefault(self, key, default=None):
+ 'od.setdefault(k[,d]) -> od.get(k,d), also set od[k]=d if k not in od'
+ if key in self:
+ return self[key]
+ self[key] = default
+ return default
+
+ def __repr__(self, _repr_running=None):
+ 'od.__repr__() <==> repr(od)'
+ if not _repr_running:
+ _repr_running = {}
+ call_key = id(self), _get_ident()
+ if call_key in _repr_running:
+ return '...'
+ _repr_running[call_key] = 1
+ try:
+ if not self:
+ return '%s()' % (self.__class__.__name__, )
+ return '%s(%r)' % (self.__class__.__name__, self.items())
+ finally:
+ del _repr_running[call_key]
+
+ def __reduce__(self):
+ 'Return state information for pickling'
+ items = [[k, self[k]] for k in self]
+ inst_dict = vars(self).copy()
+ for k in vars(OrderedDict()):
+ inst_dict.pop(k, None)
+ if inst_dict:
+ return (self.__class__, (items, ), inst_dict)
+ return self.__class__, (items, )
+
+ def copy(self):
+ 'od.copy() -> a shallow copy of od'
+ return self.__class__(self)
+
+ @classmethod
+ def fromkeys(cls, iterable, value=None):
+ '''OD.fromkeys(S[, v]) -> New ordered dictionary with keys from S
+ and values equal to v (which defaults to None).
+
+ '''
+ d = cls()
+ for key in iterable:
+ d[key] = value
+ return d
+
+ def __eq__(self, other):
+ '''od.__eq__(y) <==> od==y. Comparison to another OD is order-sensitive
+ while comparison to a regular mapping is order-insensitive.
+
+ '''
+ if isinstance(other, OrderedDict):
+ return len(self) == len(
+ other) and self.items() == other.items()
+ return dict.__eq__(self, other)
+
+ def __ne__(self, other):
+ return not self == other
+
+ # -- the following methods are only used in Python 2.7 --
+
+ def viewkeys(self):
+ "od.viewkeys() -> a set-like object providing a view on od's keys"
+ return KeysView(self)
+
+ def viewvalues(self):
+ "od.viewvalues() -> an object providing a view on od's values"
+ return ValuesView(self)
+
+ def viewitems(self):
+ "od.viewitems() -> a set-like object providing a view on od's items"
+ return ItemsView(self)
+
+
+try:
+ from logging.config import BaseConfigurator, valid_ident
+except ImportError: # pragma: no cover
+ IDENTIFIER = re.compile('^[a-z_][a-z0-9_]*$', re.I)
+
+ def valid_ident(s):
+ m = IDENTIFIER.match(s)
+ if not m:
+ raise ValueError('Not a valid Python identifier: %r' % s)
+ return True
+
+ # The ConvertingXXX classes are wrappers around standard Python containers,
+ # and they serve to convert any suitable values in the container. The
+ # conversion converts base dicts, lists and tuples to their wrapped
+ # equivalents, whereas strings which match a conversion format are converted
+ # appropriately.
+ #
+ # Each wrapper should have a configurator attribute holding the actual
+ # configurator to use for conversion.
+
+ class ConvertingDict(dict):
+ """A converting dictionary wrapper."""
+
+ def __getitem__(self, key):
+ value = dict.__getitem__(self, key)
+ result = self.configurator.convert(value)
+ # If the converted value is different, save for next time
+ if value is not result:
+ self[key] = result
+ if type(result) in (ConvertingDict, ConvertingList,
+ ConvertingTuple):
+ result.parent = self
+ result.key = key
+ return result
+
+ def get(self, key, default=None):
+ value = dict.get(self, key, default)
+ result = self.configurator.convert(value)
+ # If the converted value is different, save for next time
+ if value is not result:
+ self[key] = result
+ if type(result) in (ConvertingDict, ConvertingList,
+ ConvertingTuple):
+ result.parent = self
+ result.key = key
+ return result
+
+ def pop(self, key, default=None):
+ value = dict.pop(self, key, default)
+ result = self.configurator.convert(value)
+ if value is not result:
+ if type(result) in (ConvertingDict, ConvertingList,
+ ConvertingTuple):
+ result.parent = self
+ result.key = key
+ return result
+
+ class ConvertingList(list):
+ """A converting list wrapper."""
+
+ def __getitem__(self, key):
+ value = list.__getitem__(self, key)
+ result = self.configurator.convert(value)
+ # If the converted value is different, save for next time
+ if value is not result:
+ self[key] = result
+ if type(result) in (ConvertingDict, ConvertingList,
+ ConvertingTuple):
+ result.parent = self
+ result.key = key
+ return result
+
+ def pop(self, idx=-1):
+ value = list.pop(self, idx)
+ result = self.configurator.convert(value)
+ if value is not result:
+ if type(result) in (ConvertingDict, ConvertingList,
+ ConvertingTuple):
+ result.parent = self
+ return result
+
+ class ConvertingTuple(tuple):
+ """A converting tuple wrapper."""
+
+ def __getitem__(self, key):
+ value = tuple.__getitem__(self, key)
+ result = self.configurator.convert(value)
+ if value is not result:
+ if type(result) in (ConvertingDict, ConvertingList,
+ ConvertingTuple):
+ result.parent = self
+ result.key = key
+ return result
+
+ class BaseConfigurator(object):
+ """
+ The configurator base class which defines some useful defaults.
+ """
+
+ CONVERT_PATTERN = re.compile(r'^(?P<prefix>[a-z]+)://(?P<suffix>.*)$')
+
+ WORD_PATTERN = re.compile(r'^\s*(\w+)\s*')
+ DOT_PATTERN = re.compile(r'^\.\s*(\w+)\s*')
+ INDEX_PATTERN = re.compile(r'^\[\s*(\w+)\s*\]\s*')
+ DIGIT_PATTERN = re.compile(r'^\d+$')
+
+ value_converters = {
+ 'ext': 'ext_convert',
+ 'cfg': 'cfg_convert',
+ }
+
+ # We might want to use a different one, e.g. importlib
+ importer = staticmethod(__import__)
+
+ def __init__(self, config):
+ self.config = ConvertingDict(config)
+ self.config.configurator = self
+
+ def resolve(self, s):
+ """
+ Resolve strings to objects using standard import and attribute
+ syntax.
+ """
+ name = s.split('.')
+ used = name.pop(0)
+ try:
+ found = self.importer(used)
+ for frag in name:
+ used += '.' + frag
+ try:
+ found = getattr(found, frag)
+ except AttributeError:
+ self.importer(used)
+ found = getattr(found, frag)
+ return found
+ except ImportError:
+ e, tb = sys.exc_info()[1:]
+ v = ValueError('Cannot resolve %r: %s' % (s, e))
+ v.__cause__, v.__traceback__ = e, tb
+ raise v
+
+ def ext_convert(self, value):
+ """Default converter for the ext:// protocol."""
+ return self.resolve(value)
+
+ def cfg_convert(self, value):
+ """Default converter for the cfg:// protocol."""
+ rest = value
+ m = self.WORD_PATTERN.match(rest)
+ if m is None:
+ raise ValueError("Unable to convert %r" % value)
+ else:
+ rest = rest[m.end():]
+ d = self.config[m.groups()[0]]
+ while rest:
+ m = self.DOT_PATTERN.match(rest)
+ if m:
+ d = d[m.groups()[0]]
+ else:
+ m = self.INDEX_PATTERN.match(rest)
+ if m:
+ idx = m.groups()[0]
+ if not self.DIGIT_PATTERN.match(idx):
+ d = d[idx]
+ else:
+ try:
+ n = int(
+ idx
+ ) # try as number first (most likely)
+ d = d[n]
+ except TypeError:
+ d = d[idx]
+ if m:
+ rest = rest[m.end():]
+ else:
+ raise ValueError('Unable to convert '
+ '%r at %r' % (value, rest))
+ # rest should be empty
+ return d
+
+ def convert(self, value):
+ """
+ Convert values to an appropriate type. dicts, lists and tuples are
+ replaced by their converting alternatives. Strings are checked to
+ see if they have a conversion format and are converted if they do.
+ """
+ if not isinstance(value, ConvertingDict) and isinstance(
+ value, dict):
+ value = ConvertingDict(value)
+ value.configurator = self
+ elif not isinstance(value, ConvertingList) and isinstance(
+ value, list):
+ value = ConvertingList(value)
+ value.configurator = self
+ elif not isinstance(value, ConvertingTuple) and isinstance(value, tuple):
+ value = ConvertingTuple(value)
+ value.configurator = self
+ elif isinstance(value, string_types):
+ m = self.CONVERT_PATTERN.match(value)
+ if m:
+ d = m.groupdict()
+ prefix = d['prefix']
+ converter = self.value_converters.get(prefix, None)
+ if converter:
+ suffix = d['suffix']
+ converter = getattr(self, converter)
+ value = converter(suffix)
+ return value
+
+ def configure_custom(self, config):
+ """Configure an object with a user-supplied factory."""
+ c = config.pop('()')
+ if not callable(c):
+ c = self.resolve(c)
+ props = config.pop('.', None)
+ # Check for valid identifiers
+ kwargs = dict([(k, config[k]) for k in config if valid_ident(k)])
+ result = c(**kwargs)
+ if props:
+ for name, value in props.items():
+ setattr(result, name, value)
+ return result
+
+ def as_tuple(self, value):
+ """Utility function which converts lists to tuples."""
+ if isinstance(value, list):
+ value = tuple(value)
+ return value
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/database.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/database.py
new file mode 100644
index 000000000..c0f896a7d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/database.py
@@ -0,0 +1,1329 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2012-2023 The Python Software Foundation.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+"""PEP 376 implementation."""
+
+from __future__ import unicode_literals
+
+import base64
+import codecs
+import contextlib
+import hashlib
+import logging
+import os
+import posixpath
+import sys
+import zipimport
+
+from . import DistlibException, resources
+from .compat import StringIO
+from .version import get_scheme, UnsupportedVersionError
+from .metadata import (Metadata, METADATA_FILENAME, WHEEL_METADATA_FILENAME, LEGACY_METADATA_FILENAME)
+from .util import (parse_requirement, cached_property, parse_name_and_version, read_exports, write_exports, CSVReader,
+ CSVWriter)
+
+__all__ = [
+ 'Distribution', 'BaseInstalledDistribution', 'InstalledDistribution', 'EggInfoDistribution', 'DistributionPath'
+]
+
+logger = logging.getLogger(__name__)
+
+EXPORTS_FILENAME = 'pydist-exports.json'
+COMMANDS_FILENAME = 'pydist-commands.json'
+
+DIST_FILES = ('INSTALLER', METADATA_FILENAME, 'RECORD', 'REQUESTED', 'RESOURCES', EXPORTS_FILENAME, 'SHARED')
+
+DISTINFO_EXT = '.dist-info'
+
+
+class _Cache(object):
+ """
+ A simple cache mapping names and .dist-info paths to distributions
+ """
+
+ def __init__(self):
+ """
+ Initialise an instance. There is normally one for each DistributionPath.
+ """
+ self.name = {}
+ self.path = {}
+ self.generated = False
+
+ def clear(self):
+ """
+ Clear the cache, setting it to its initial state.
+ """
+ self.name.clear()
+ self.path.clear()
+ self.generated = False
+
+ def add(self, dist):
+ """
+ Add a distribution to the cache.
+ :param dist: The distribution to add.
+ """
+ if dist.path not in self.path:
+ self.path[dist.path] = dist
+ self.name.setdefault(dist.key, []).append(dist)
+
+
+class DistributionPath(object):
+ """
+ Represents a set of distributions installed on a path (typically sys.path).
+ """
+
+ def __init__(self, path=None, include_egg=False):
+ """
+ Create an instance from a path, optionally including legacy (distutils/
+ setuptools/distribute) distributions.
+ :param path: The path to use, as a list of directories. If not specified,
+ sys.path is used.
+ :param include_egg: If True, this instance will look for and return legacy
+ distributions as well as those based on PEP 376.
+ """
+ if path is None:
+ path = sys.path
+ self.path = path
+ self._include_dist = True
+ self._include_egg = include_egg
+
+ self._cache = _Cache()
+ self._cache_egg = _Cache()
+ self._cache_enabled = True
+ self._scheme = get_scheme('default')
+
+ def _get_cache_enabled(self):
+ return self._cache_enabled
+
+ def _set_cache_enabled(self, value):
+ self._cache_enabled = value
+
+ cache_enabled = property(_get_cache_enabled, _set_cache_enabled)
+
+ def clear_cache(self):
+ """
+ Clears the internal cache.
+ """
+ self._cache.clear()
+ self._cache_egg.clear()
+
+ def _yield_distributions(self):
+ """
+ Yield .dist-info and/or .egg(-info) distributions.
+ """
+ # We need to check if we've seen some resources already, because on
+ # some Linux systems (e.g. some Debian/Ubuntu variants) there are
+ # symlinks which alias other files in the environment.
+ seen = set()
+ for path in self.path:
+ finder = resources.finder_for_path(path)
+ if finder is None:
+ continue
+ r = finder.find('')
+ if not r or not r.is_container:
+ continue
+ rset = sorted(r.resources)
+ for entry in rset:
+ r = finder.find(entry)
+ if not r or r.path in seen:
+ continue
+ try:
+ if self._include_dist and entry.endswith(DISTINFO_EXT):
+ possible_filenames = [METADATA_FILENAME, WHEEL_METADATA_FILENAME, LEGACY_METADATA_FILENAME]
+ for metadata_filename in possible_filenames:
+ metadata_path = posixpath.join(entry, metadata_filename)
+ pydist = finder.find(metadata_path)
+ if pydist:
+ break
+ else:
+ continue
+
+ with contextlib.closing(pydist.as_stream()) as stream:
+ metadata = Metadata(fileobj=stream, scheme='legacy')
+ logger.debug('Found %s', r.path)
+ seen.add(r.path)
+ yield new_dist_class(r.path, metadata=metadata, env=self)
+ elif self._include_egg and entry.endswith(('.egg-info', '.egg')):
+ logger.debug('Found %s', r.path)
+ seen.add(r.path)
+ yield old_dist_class(r.path, self)
+ except Exception as e:
+ msg = 'Unable to read distribution at %s, perhaps due to bad metadata: %s'
+ logger.warning(msg, r.path, e)
+ import warnings
+ warnings.warn(msg % (r.path, e), stacklevel=2)
+
+ def _generate_cache(self):
+ """
+ Scan the path for distributions and populate the cache with
+ those that are found.
+ """
+ gen_dist = not self._cache.generated
+ gen_egg = self._include_egg and not self._cache_egg.generated
+ if gen_dist or gen_egg:
+ for dist in self._yield_distributions():
+ if isinstance(dist, InstalledDistribution):
+ self._cache.add(dist)
+ else:
+ self._cache_egg.add(dist)
+
+ if gen_dist:
+ self._cache.generated = True
+ if gen_egg:
+ self._cache_egg.generated = True
+
+ @classmethod
+ def distinfo_dirname(cls, name, version):
+ """
+ The *name* and *version* parameters are converted into their
+ filename-escaped form, i.e. any ``'-'`` characters are replaced
+ with ``'_'`` other than the one in ``'dist-info'`` and the one
+ separating the name from the version number.
+
+ :parameter name: is converted to a standard distribution name by replacing
+ any runs of non- alphanumeric characters with a single
+ ``'-'``.
+ :type name: string
+ :parameter version: is converted to a standard version string. Spaces
+ become dots, and all other non-alphanumeric characters
+ (except dots) become dashes, with runs of multiple
+ dashes condensed to a single dash.
+ :type version: string
+ :returns: directory name
+ :rtype: string"""
+ name = name.replace('-', '_')
+ return '-'.join([name, version]) + DISTINFO_EXT
+
+ def get_distributions(self):
+ """
+ Provides an iterator that looks for distributions and returns
+ :class:`InstalledDistribution` or
+ :class:`EggInfoDistribution` instances for each one of them.
+
+ :rtype: iterator of :class:`InstalledDistribution` and
+ :class:`EggInfoDistribution` instances
+ """
+ if not self._cache_enabled:
+ for dist in self._yield_distributions():
+ yield dist
+ else:
+ self._generate_cache()
+
+ for dist in self._cache.path.values():
+ yield dist
+
+ if self._include_egg:
+ for dist in self._cache_egg.path.values():
+ yield dist
+
+ def get_distribution(self, name):
+ """
+ Looks for a named distribution on the path.
+
+ This function only returns the first result found, as no more than one
+ value is expected. If nothing is found, ``None`` is returned.
+
+ :rtype: :class:`InstalledDistribution`, :class:`EggInfoDistribution`
+ or ``None``
+ """
+ result = None
+ name = name.lower()
+ if not self._cache_enabled:
+ for dist in self._yield_distributions():
+ if dist.key == name:
+ result = dist
+ break
+ else:
+ self._generate_cache()
+
+ if name in self._cache.name:
+ result = self._cache.name[name][0]
+ elif self._include_egg and name in self._cache_egg.name:
+ result = self._cache_egg.name[name][0]
+ return result
+
+ def provides_distribution(self, name, version=None):
+ """
+ Iterates over all distributions to find which distributions provide *name*.
+ If a *version* is provided, it will be used to filter the results.
+
+ This function only returns the first result found, since no more than
+ one values are expected. If the directory is not found, returns ``None``.
+
+ :parameter version: a version specifier that indicates the version
+ required, conforming to the format in ``PEP-345``
+
+ :type name: string
+ :type version: string
+ """
+ matcher = None
+ if version is not None:
+ try:
+ matcher = self._scheme.matcher('%s (%s)' % (name, version))
+ except ValueError:
+ raise DistlibException('invalid name or version: %r, %r' % (name, version))
+
+ for dist in self.get_distributions():
+ # We hit a problem on Travis where enum34 was installed and doesn't
+ # have a provides attribute ...
+ if not hasattr(dist, 'provides'):
+ logger.debug('No "provides": %s', dist)
+ else:
+ provided = dist.provides
+
+ for p in provided:
+ p_name, p_ver = parse_name_and_version(p)
+ if matcher is None:
+ if p_name == name:
+ yield dist
+ break
+ else:
+ if p_name == name and matcher.match(p_ver):
+ yield dist
+ break
+
+ def get_file_path(self, name, relative_path):
+ """
+ Return the path to a resource file.
+ """
+ dist = self.get_distribution(name)
+ if dist is None:
+ raise LookupError('no distribution named %r found' % name)
+ return dist.get_resource_path(relative_path)
+
+ def get_exported_entries(self, category, name=None):
+ """
+ Return all of the exported entries in a particular category.
+
+ :param category: The category to search for entries.
+ :param name: If specified, only entries with that name are returned.
+ """
+ for dist in self.get_distributions():
+ r = dist.exports
+ if category in r:
+ d = r[category]
+ if name is not None:
+ if name in d:
+ yield d[name]
+ else:
+ for v in d.values():
+ yield v
+
+
+class Distribution(object):
+ """
+ A base class for distributions, whether installed or from indexes.
+ Either way, it must have some metadata, so that's all that's needed
+ for construction.
+ """
+
+ build_time_dependency = False
+ """
+ Set to True if it's known to be only a build-time dependency (i.e.
+ not needed after installation).
+ """
+
+ requested = False
+ """A boolean that indicates whether the ``REQUESTED`` metadata file is
+ present (in other words, whether the package was installed by user
+ request or it was installed as a dependency)."""
+
+ def __init__(self, metadata):
+ """
+ Initialise an instance.
+ :param metadata: The instance of :class:`Metadata` describing this
+ distribution.
+ """
+ self.metadata = metadata
+ self.name = metadata.name
+ self.key = self.name.lower() # for case-insensitive comparisons
+ self.version = metadata.version
+ self.locator = None
+ self.digest = None
+ self.extras = None # additional features requested
+ self.context = None # environment marker overrides
+ self.download_urls = set()
+ self.digests = {}
+
+ @property
+ def source_url(self):
+ """
+ The source archive download URL for this distribution.
+ """
+ return self.metadata.source_url
+
+ download_url = source_url # Backward compatibility
+
+ @property
+ def name_and_version(self):
+ """
+ A utility property which displays the name and version in parentheses.
+ """
+ return '%s (%s)' % (self.name, self.version)
+
+ @property
+ def provides(self):
+ """
+ A set of distribution names and versions provided by this distribution.
+ :return: A set of "name (version)" strings.
+ """
+ plist = self.metadata.provides
+ s = '%s (%s)' % (self.name, self.version)
+ if s not in plist:
+ plist.append(s)
+ return plist
+
+ def _get_requirements(self, req_attr):
+ md = self.metadata
+ reqts = getattr(md, req_attr)
+ logger.debug('%s: got requirements %r from metadata: %r', self.name, req_attr, reqts)
+ return set(md.get_requirements(reqts, extras=self.extras, env=self.context))
+
+ @property
+ def run_requires(self):
+ return self._get_requirements('run_requires')
+
+ @property
+ def meta_requires(self):
+ return self._get_requirements('meta_requires')
+
+ @property
+ def build_requires(self):
+ return self._get_requirements('build_requires')
+
+ @property
+ def test_requires(self):
+ return self._get_requirements('test_requires')
+
+ @property
+ def dev_requires(self):
+ return self._get_requirements('dev_requires')
+
+ def matches_requirement(self, req):
+ """
+ Say if this instance matches (fulfills) a requirement.
+ :param req: The requirement to match.
+ :rtype req: str
+ :return: True if it matches, else False.
+ """
+ # Requirement may contain extras - parse to lose those
+ # from what's passed to the matcher
+ r = parse_requirement(req)
+ scheme = get_scheme(self.metadata.scheme)
+ try:
+ matcher = scheme.matcher(r.requirement)
+ except UnsupportedVersionError:
+ # XXX compat-mode if cannot read the version
+ logger.warning('could not read version %r - using name only', req)
+ name = req.split()[0]
+ matcher = scheme.matcher(name)
+
+ name = matcher.key # case-insensitive
+
+ result = False
+ for p in self.provides:
+ p_name, p_ver = parse_name_and_version(p)
+ if p_name != name:
+ continue
+ try:
+ result = matcher.match(p_ver)
+ break
+ except UnsupportedVersionError:
+ pass
+ return result
+
+ def __repr__(self):
+ """
+ Return a textual representation of this instance,
+ """
+ if self.source_url:
+ suffix = ' [%s]' % self.source_url
+ else:
+ suffix = ''
+ return '<Distribution %s (%s)%s>' % (self.name, self.version, suffix)
+
+ def __eq__(self, other):
+ """
+ See if this distribution is the same as another.
+ :param other: The distribution to compare with. To be equal to one
+ another. distributions must have the same type, name,
+ version and source_url.
+ :return: True if it is the same, else False.
+ """
+ if type(other) is not type(self):
+ result = False
+ else:
+ result = (self.name == other.name and self.version == other.version and self.source_url == other.source_url)
+ return result
+
+ def __hash__(self):
+ """
+ Compute hash in a way which matches the equality test.
+ """
+ return hash(self.name) + hash(self.version) + hash(self.source_url)
+
+
+class BaseInstalledDistribution(Distribution):
+ """
+ This is the base class for installed distributions (whether PEP 376 or
+ legacy).
+ """
+
+ hasher = None
+
+ def __init__(self, metadata, path, env=None):
+ """
+ Initialise an instance.
+ :param metadata: An instance of :class:`Metadata` which describes the
+ distribution. This will normally have been initialised
+ from a metadata file in the ``path``.
+ :param path: The path of the ``.dist-info`` or ``.egg-info``
+ directory for the distribution.
+ :param env: This is normally the :class:`DistributionPath`
+ instance where this distribution was found.
+ """
+ super(BaseInstalledDistribution, self).__init__(metadata)
+ self.path = path
+ self.dist_path = env
+
+ def get_hash(self, data, hasher=None):
+ """
+ Get the hash of some data, using a particular hash algorithm, if
+ specified.
+
+ :param data: The data to be hashed.
+ :type data: bytes
+ :param hasher: The name of a hash implementation, supported by hashlib,
+ or ``None``. Examples of valid values are ``'sha1'``,
+ ``'sha224'``, ``'sha384'``, '``sha256'``, ``'md5'`` and
+ ``'sha512'``. If no hasher is specified, the ``hasher``
+ attribute of the :class:`InstalledDistribution` instance
+ is used. If the hasher is determined to be ``None``, MD5
+ is used as the hashing algorithm.
+ :returns: The hash of the data. If a hasher was explicitly specified,
+ the returned hash will be prefixed with the specified hasher
+ followed by '='.
+ :rtype: str
+ """
+ if hasher is None:
+ hasher = self.hasher
+ if hasher is None:
+ hasher = hashlib.md5
+ prefix = ''
+ else:
+ hasher = getattr(hashlib, hasher)
+ prefix = '%s=' % self.hasher
+ digest = hasher(data).digest()
+ digest = base64.urlsafe_b64encode(digest).rstrip(b'=').decode('ascii')
+ return '%s%s' % (prefix, digest)
+
+
+class InstalledDistribution(BaseInstalledDistribution):
+ """
+ Created with the *path* of the ``.dist-info`` directory provided to the
+ constructor. It reads the metadata contained in ``pydist.json`` when it is
+ instantiated., or uses a passed in Metadata instance (useful for when
+ dry-run mode is being used).
+ """
+
+ hasher = 'sha256'
+
+ def __init__(self, path, metadata=None, env=None):
+ self.modules = []
+ self.finder = finder = resources.finder_for_path(path)
+ if finder is None:
+ raise ValueError('finder unavailable for %s' % path)
+ if env and env._cache_enabled and path in env._cache.path:
+ metadata = env._cache.path[path].metadata
+ elif metadata is None:
+ r = finder.find(METADATA_FILENAME)
+ # Temporary - for Wheel 0.23 support
+ if r is None:
+ r = finder.find(WHEEL_METADATA_FILENAME)
+ # Temporary - for legacy support
+ if r is None:
+ r = finder.find(LEGACY_METADATA_FILENAME)
+ if r is None:
+ raise ValueError('no %s found in %s' % (METADATA_FILENAME, path))
+ with contextlib.closing(r.as_stream()) as stream:
+ metadata = Metadata(fileobj=stream, scheme='legacy')
+
+ super(InstalledDistribution, self).__init__(metadata, path, env)
+
+ if env and env._cache_enabled:
+ env._cache.add(self)
+
+ r = finder.find('REQUESTED')
+ self.requested = r is not None
+ p = os.path.join(path, 'top_level.txt')
+ if os.path.exists(p):
+ with open(p, 'rb') as f:
+ data = f.read().decode('utf-8')
+ self.modules = data.splitlines()
+
+ def __repr__(self):
+ return '<InstalledDistribution %r %s at %r>' % (self.name, self.version, self.path)
+
+ def __str__(self):
+ return "%s %s" % (self.name, self.version)
+
+ def _get_records(self):
+ """
+ Get the list of installed files for the distribution
+ :return: A list of tuples of path, hash and size. Note that hash and
+ size might be ``None`` for some entries. The path is exactly
+ as stored in the file (which is as in PEP 376).
+ """
+ results = []
+ r = self.get_distinfo_resource('RECORD')
+ with contextlib.closing(r.as_stream()) as stream:
+ with CSVReader(stream=stream) as record_reader:
+ # Base location is parent dir of .dist-info dir
+ # base_location = os.path.dirname(self.path)
+ # base_location = os.path.abspath(base_location)
+ for row in record_reader:
+ missing = [None for i in range(len(row), 3)]
+ path, checksum, size = row + missing
+ # if not os.path.isabs(path):
+ # path = path.replace('/', os.sep)
+ # path = os.path.join(base_location, path)
+ results.append((path, checksum, size))
+ return results
+
+ @cached_property
+ def exports(self):
+ """
+ Return the information exported by this distribution.
+ :return: A dictionary of exports, mapping an export category to a dict
+ of :class:`ExportEntry` instances describing the individual
+ export entries, and keyed by name.
+ """
+ result = {}
+ r = self.get_distinfo_resource(EXPORTS_FILENAME)
+ if r:
+ result = self.read_exports()
+ return result
+
+ def read_exports(self):
+ """
+ Read exports data from a file in .ini format.
+
+ :return: A dictionary of exports, mapping an export category to a list
+ of :class:`ExportEntry` instances describing the individual
+ export entries.
+ """
+ result = {}
+ r = self.get_distinfo_resource(EXPORTS_FILENAME)
+ if r:
+ with contextlib.closing(r.as_stream()) as stream:
+ result = read_exports(stream)
+ return result
+
+ def write_exports(self, exports):
+ """
+ Write a dictionary of exports to a file in .ini format.
+ :param exports: A dictionary of exports, mapping an export category to
+ a list of :class:`ExportEntry` instances describing the
+ individual export entries.
+ """
+ rf = self.get_distinfo_file(EXPORTS_FILENAME)
+ with open(rf, 'w') as f:
+ write_exports(exports, f)
+
+ def get_resource_path(self, relative_path):
+ """
+ NOTE: This API may change in the future.
+
+ Return the absolute path to a resource file with the given relative
+ path.
+
+ :param relative_path: The path, relative to .dist-info, of the resource
+ of interest.
+ :return: The absolute path where the resource is to be found.
+ """
+ r = self.get_distinfo_resource('RESOURCES')
+ with contextlib.closing(r.as_stream()) as stream:
+ with CSVReader(stream=stream) as resources_reader:
+ for relative, destination in resources_reader:
+ if relative == relative_path:
+ return destination
+ raise KeyError('no resource file with relative path %r '
+ 'is installed' % relative_path)
+
+ def list_installed_files(self):
+ """
+ Iterates over the ``RECORD`` entries and returns a tuple
+ ``(path, hash, size)`` for each line.
+
+ :returns: iterator of (path, hash, size)
+ """
+ for result in self._get_records():
+ yield result
+
+ def write_installed_files(self, paths, prefix, dry_run=False):
+ """
+ Writes the ``RECORD`` file, using the ``paths`` iterable passed in. Any
+ existing ``RECORD`` file is silently overwritten.
+
+ prefix is used to determine when to write absolute paths.
+ """
+ prefix = os.path.join(prefix, '')
+ base = os.path.dirname(self.path)
+ base_under_prefix = base.startswith(prefix)
+ base = os.path.join(base, '')
+ record_path = self.get_distinfo_file('RECORD')
+ logger.info('creating %s', record_path)
+ if dry_run:
+ return None
+ with CSVWriter(record_path) as writer:
+ for path in paths:
+ if os.path.isdir(path) or path.endswith(('.pyc', '.pyo')):
+ # do not put size and hash, as in PEP-376
+ hash_value = size = ''
+ else:
+ size = '%d' % os.path.getsize(path)
+ with open(path, 'rb') as fp:
+ hash_value = self.get_hash(fp.read())
+ if path.startswith(base) or (base_under_prefix and path.startswith(prefix)):
+ path = os.path.relpath(path, base)
+ writer.writerow((path, hash_value, size))
+
+ # add the RECORD file itself
+ if record_path.startswith(base):
+ record_path = os.path.relpath(record_path, base)
+ writer.writerow((record_path, '', ''))
+ return record_path
+
+ def check_installed_files(self):
+ """
+ Checks that the hashes and sizes of the files in ``RECORD`` are
+ matched by the files themselves. Returns a (possibly empty) list of
+ mismatches. Each entry in the mismatch list will be a tuple consisting
+ of the path, 'exists', 'size' or 'hash' according to what didn't match
+ (existence is checked first, then size, then hash), the expected
+ value and the actual value.
+ """
+ mismatches = []
+ base = os.path.dirname(self.path)
+ record_path = self.get_distinfo_file('RECORD')
+ for path, hash_value, size in self.list_installed_files():
+ if not os.path.isabs(path):
+ path = os.path.join(base, path)
+ if path == record_path:
+ continue
+ if not os.path.exists(path):
+ mismatches.append((path, 'exists', True, False))
+ elif os.path.isfile(path):
+ actual_size = str(os.path.getsize(path))
+ if size and actual_size != size:
+ mismatches.append((path, 'size', size, actual_size))
+ elif hash_value:
+ if '=' in hash_value:
+ hasher = hash_value.split('=', 1)[0]
+ else:
+ hasher = None
+
+ with open(path, 'rb') as f:
+ actual_hash = self.get_hash(f.read(), hasher)
+ if actual_hash != hash_value:
+ mismatches.append((path, 'hash', hash_value, actual_hash))
+ return mismatches
+
+ @cached_property
+ def shared_locations(self):
+ """
+ A dictionary of shared locations whose keys are in the set 'prefix',
+ 'purelib', 'platlib', 'scripts', 'headers', 'data' and 'namespace'.
+ The corresponding value is the absolute path of that category for
+ this distribution, and takes into account any paths selected by the
+ user at installation time (e.g. via command-line arguments). In the
+ case of the 'namespace' key, this would be a list of absolute paths
+ for the roots of namespace packages in this distribution.
+
+ The first time this property is accessed, the relevant information is
+ read from the SHARED file in the .dist-info directory.
+ """
+ result = {}
+ shared_path = os.path.join(self.path, 'SHARED')
+ if os.path.isfile(shared_path):
+ with codecs.open(shared_path, 'r', encoding='utf-8') as f:
+ lines = f.read().splitlines()
+ for line in lines:
+ key, value = line.split('=', 1)
+ if key == 'namespace':
+ result.setdefault(key, []).append(value)
+ else:
+ result[key] = value
+ return result
+
+ def write_shared_locations(self, paths, dry_run=False):
+ """
+ Write shared location information to the SHARED file in .dist-info.
+ :param paths: A dictionary as described in the documentation for
+ :meth:`shared_locations`.
+ :param dry_run: If True, the action is logged but no file is actually
+ written.
+ :return: The path of the file written to.
+ """
+ shared_path = os.path.join(self.path, 'SHARED')
+ logger.info('creating %s', shared_path)
+ if dry_run:
+ return None
+ lines = []
+ for key in ('prefix', 'lib', 'headers', 'scripts', 'data'):
+ path = paths[key]
+ if os.path.isdir(paths[key]):
+ lines.append('%s=%s' % (key, path))
+ for ns in paths.get('namespace', ()):
+ lines.append('namespace=%s' % ns)
+
+ with codecs.open(shared_path, 'w', encoding='utf-8') as f:
+ f.write('\n'.join(lines))
+ return shared_path
+
+ def get_distinfo_resource(self, path):
+ if path not in DIST_FILES:
+ raise DistlibException('invalid path for a dist-info file: '
+ '%r at %r' % (path, self.path))
+ finder = resources.finder_for_path(self.path)
+ if finder is None:
+ raise DistlibException('Unable to get a finder for %s' % self.path)
+ return finder.find(path)
+
+ def get_distinfo_file(self, path):
+ """
+ Returns a path located under the ``.dist-info`` directory. Returns a
+ string representing the path.
+
+ :parameter path: a ``'/'``-separated path relative to the
+ ``.dist-info`` directory or an absolute path;
+ If *path* is an absolute path and doesn't start
+ with the ``.dist-info`` directory path,
+ a :class:`DistlibException` is raised
+ :type path: str
+ :rtype: str
+ """
+ # Check if it is an absolute path # XXX use relpath, add tests
+ if path.find(os.sep) >= 0:
+ # it's an absolute path?
+ distinfo_dirname, path = path.split(os.sep)[-2:]
+ if distinfo_dirname != self.path.split(os.sep)[-1]:
+ raise DistlibException('dist-info file %r does not belong to the %r %s '
+ 'distribution' % (path, self.name, self.version))
+
+ # The file must be relative
+ if path not in DIST_FILES:
+ raise DistlibException('invalid path for a dist-info file: '
+ '%r at %r' % (path, self.path))
+
+ return os.path.join(self.path, path)
+
+ def list_distinfo_files(self):
+ """
+ Iterates over the ``RECORD`` entries and returns paths for each line if
+ the path is pointing to a file located in the ``.dist-info`` directory
+ or one of its subdirectories.
+
+ :returns: iterator of paths
+ """
+ base = os.path.dirname(self.path)
+ for path, checksum, size in self._get_records():
+ # XXX add separator or use real relpath algo
+ if not os.path.isabs(path):
+ path = os.path.join(base, path)
+ if path.startswith(self.path):
+ yield path
+
+ def __eq__(self, other):
+ return (isinstance(other, InstalledDistribution) and self.path == other.path)
+
+ # See http://docs.python.org/reference/datamodel#object.__hash__
+ __hash__ = object.__hash__
+
+
+class EggInfoDistribution(BaseInstalledDistribution):
+ """Created with the *path* of the ``.egg-info`` directory or file provided
+ to the constructor. It reads the metadata contained in the file itself, or
+ if the given path happens to be a directory, the metadata is read from the
+ file ``PKG-INFO`` under that directory."""
+
+ requested = True # as we have no way of knowing, assume it was
+ shared_locations = {}
+
+ def __init__(self, path, env=None):
+
+ def set_name_and_version(s, n, v):
+ s.name = n
+ s.key = n.lower() # for case-insensitive comparisons
+ s.version = v
+
+ self.path = path
+ self.dist_path = env
+ if env and env._cache_enabled and path in env._cache_egg.path:
+ metadata = env._cache_egg.path[path].metadata
+ set_name_and_version(self, metadata.name, metadata.version)
+ else:
+ metadata = self._get_metadata(path)
+
+ # Need to be set before caching
+ set_name_and_version(self, metadata.name, metadata.version)
+
+ if env and env._cache_enabled:
+ env._cache_egg.add(self)
+ super(EggInfoDistribution, self).__init__(metadata, path, env)
+
+ def _get_metadata(self, path):
+ requires = None
+
+ def parse_requires_data(data):
+ """Create a list of dependencies from a requires.txt file.
+
+ *data*: the contents of a setuptools-produced requires.txt file.
+ """
+ reqs = []
+ lines = data.splitlines()
+ for line in lines:
+ line = line.strip()
+ # sectioned files have bare newlines (separating sections)
+ if not line: # pragma: no cover
+ continue
+ if line.startswith('['): # pragma: no cover
+ logger.warning('Unexpected line: quitting requirement scan: %r', line)
+ break
+ r = parse_requirement(line)
+ if not r: # pragma: no cover
+ logger.warning('Not recognised as a requirement: %r', line)
+ continue
+ if r.extras: # pragma: no cover
+ logger.warning('extra requirements in requires.txt are '
+ 'not supported')
+ if not r.constraints:
+ reqs.append(r.name)
+ else:
+ cons = ', '.join('%s%s' % c for c in r.constraints)
+ reqs.append('%s (%s)' % (r.name, cons))
+ return reqs
+
+ def parse_requires_path(req_path):
+ """Create a list of dependencies from a requires.txt file.
+
+ *req_path*: the path to a setuptools-produced requires.txt file.
+ """
+
+ reqs = []
+ try:
+ with codecs.open(req_path, 'r', 'utf-8') as fp:
+ reqs = parse_requires_data(fp.read())
+ except IOError:
+ pass
+ return reqs
+
+ tl_path = tl_data = None
+ if path.endswith('.egg'):
+ if os.path.isdir(path):
+ p = os.path.join(path, 'EGG-INFO')
+ meta_path = os.path.join(p, 'PKG-INFO')
+ metadata = Metadata(path=meta_path, scheme='legacy')
+ req_path = os.path.join(p, 'requires.txt')
+ tl_path = os.path.join(p, 'top_level.txt')
+ requires = parse_requires_path(req_path)
+ else:
+ # FIXME handle the case where zipfile is not available
+ zipf = zipimport.zipimporter(path)
+ fileobj = StringIO(zipf.get_data('EGG-INFO/PKG-INFO').decode('utf8'))
+ metadata = Metadata(fileobj=fileobj, scheme='legacy')
+ try:
+ data = zipf.get_data('EGG-INFO/requires.txt')
+ tl_data = zipf.get_data('EGG-INFO/top_level.txt').decode('utf-8')
+ requires = parse_requires_data(data.decode('utf-8'))
+ except IOError:
+ requires = None
+ elif path.endswith('.egg-info'):
+ if os.path.isdir(path):
+ req_path = os.path.join(path, 'requires.txt')
+ requires = parse_requires_path(req_path)
+ path = os.path.join(path, 'PKG-INFO')
+ tl_path = os.path.join(path, 'top_level.txt')
+ metadata = Metadata(path=path, scheme='legacy')
+ else:
+ raise DistlibException('path must end with .egg-info or .egg, '
+ 'got %r' % path)
+
+ if requires:
+ metadata.add_requirements(requires)
+ # look for top-level modules in top_level.txt, if present
+ if tl_data is None:
+ if tl_path is not None and os.path.exists(tl_path):
+ with open(tl_path, 'rb') as f:
+ tl_data = f.read().decode('utf-8')
+ if not tl_data:
+ tl_data = []
+ else:
+ tl_data = tl_data.splitlines()
+ self.modules = tl_data
+ return metadata
+
+ def __repr__(self):
+ return '<EggInfoDistribution %r %s at %r>' % (self.name, self.version, self.path)
+
+ def __str__(self):
+ return "%s %s" % (self.name, self.version)
+
+ def check_installed_files(self):
+ """
+ Checks that the hashes and sizes of the files in ``RECORD`` are
+ matched by the files themselves. Returns a (possibly empty) list of
+ mismatches. Each entry in the mismatch list will be a tuple consisting
+ of the path, 'exists', 'size' or 'hash' according to what didn't match
+ (existence is checked first, then size, then hash), the expected
+ value and the actual value.
+ """
+ mismatches = []
+ record_path = os.path.join(self.path, 'installed-files.txt')
+ if os.path.exists(record_path):
+ for path, _, _ in self.list_installed_files():
+ if path == record_path:
+ continue
+ if not os.path.exists(path):
+ mismatches.append((path, 'exists', True, False))
+ return mismatches
+
+ def list_installed_files(self):
+ """
+ Iterates over the ``installed-files.txt`` entries and returns a tuple
+ ``(path, hash, size)`` for each line.
+
+ :returns: a list of (path, hash, size)
+ """
+
+ def _md5(path):
+ f = open(path, 'rb')
+ try:
+ content = f.read()
+ finally:
+ f.close()
+ return hashlib.md5(content).hexdigest()
+
+ def _size(path):
+ return os.stat(path).st_size
+
+ record_path = os.path.join(self.path, 'installed-files.txt')
+ result = []
+ if os.path.exists(record_path):
+ with codecs.open(record_path, 'r', encoding='utf-8') as f:
+ for line in f:
+ line = line.strip()
+ p = os.path.normpath(os.path.join(self.path, line))
+ # "./" is present as a marker between installed files
+ # and installation metadata files
+ if not os.path.exists(p):
+ logger.warning('Non-existent file: %s', p)
+ if p.endswith(('.pyc', '.pyo')):
+ continue
+ # otherwise fall through and fail
+ if not os.path.isdir(p):
+ result.append((p, _md5(p), _size(p)))
+ result.append((record_path, None, None))
+ return result
+
+ def list_distinfo_files(self, absolute=False):
+ """
+ Iterates over the ``installed-files.txt`` entries and returns paths for
+ each line if the path is pointing to a file located in the
+ ``.egg-info`` directory or one of its subdirectories.
+
+ :parameter absolute: If *absolute* is ``True``, each returned path is
+ transformed into a local absolute path. Otherwise the
+ raw value from ``installed-files.txt`` is returned.
+ :type absolute: boolean
+ :returns: iterator of paths
+ """
+ record_path = os.path.join(self.path, 'installed-files.txt')
+ if os.path.exists(record_path):
+ skip = True
+ with codecs.open(record_path, 'r', encoding='utf-8') as f:
+ for line in f:
+ line = line.strip()
+ if line == './':
+ skip = False
+ continue
+ if not skip:
+ p = os.path.normpath(os.path.join(self.path, line))
+ if p.startswith(self.path):
+ if absolute:
+ yield p
+ else:
+ yield line
+
+ def __eq__(self, other):
+ return (isinstance(other, EggInfoDistribution) and self.path == other.path)
+
+ # See http://docs.python.org/reference/datamodel#object.__hash__
+ __hash__ = object.__hash__
+
+
+new_dist_class = InstalledDistribution
+old_dist_class = EggInfoDistribution
+
+
+class DependencyGraph(object):
+ """
+ Represents a dependency graph between distributions.
+
+ The dependency relationships are stored in an ``adjacency_list`` that maps
+ distributions to a list of ``(other, label)`` tuples where ``other``
+ is a distribution and the edge is labeled with ``label`` (i.e. the version
+ specifier, if such was provided). Also, for more efficient traversal, for
+ every distribution ``x``, a list of predecessors is kept in
+ ``reverse_list[x]``. An edge from distribution ``a`` to
+ distribution ``b`` means that ``a`` depends on ``b``. If any missing
+ dependencies are found, they are stored in ``missing``, which is a
+ dictionary that maps distributions to a list of requirements that were not
+ provided by any other distributions.
+ """
+
+ def __init__(self):
+ self.adjacency_list = {}
+ self.reverse_list = {}
+ self.missing = {}
+
+ def add_distribution(self, distribution):
+ """Add the *distribution* to the graph.
+
+ :type distribution: :class:`distutils2.database.InstalledDistribution`
+ or :class:`distutils2.database.EggInfoDistribution`
+ """
+ self.adjacency_list[distribution] = []
+ self.reverse_list[distribution] = []
+ # self.missing[distribution] = []
+
+ def add_edge(self, x, y, label=None):
+ """Add an edge from distribution *x* to distribution *y* with the given
+ *label*.
+
+ :type x: :class:`distutils2.database.InstalledDistribution` or
+ :class:`distutils2.database.EggInfoDistribution`
+ :type y: :class:`distutils2.database.InstalledDistribution` or
+ :class:`distutils2.database.EggInfoDistribution`
+ :type label: ``str`` or ``None``
+ """
+ self.adjacency_list[x].append((y, label))
+ # multiple edges are allowed, so be careful
+ if x not in self.reverse_list[y]:
+ self.reverse_list[y].append(x)
+
+ def add_missing(self, distribution, requirement):
+ """
+ Add a missing *requirement* for the given *distribution*.
+
+ :type distribution: :class:`distutils2.database.InstalledDistribution`
+ or :class:`distutils2.database.EggInfoDistribution`
+ :type requirement: ``str``
+ """
+ logger.debug('%s missing %r', distribution, requirement)
+ self.missing.setdefault(distribution, []).append(requirement)
+
+ def _repr_dist(self, dist):
+ return '%s %s' % (dist.name, dist.version)
+
+ def repr_node(self, dist, level=1):
+ """Prints only a subgraph"""
+ output = [self._repr_dist(dist)]
+ for other, label in self.adjacency_list[dist]:
+ dist = self._repr_dist(other)
+ if label is not None:
+ dist = '%s [%s]' % (dist, label)
+ output.append(' ' * level + str(dist))
+ suboutput = self.repr_node(other, level + 1)
+ subs = suboutput.split('\n')
+ output.extend(subs[1:])
+ return '\n'.join(output)
+
+ def to_dot(self, f, skip_disconnected=True):
+ """Writes a DOT output for the graph to the provided file *f*.
+
+ If *skip_disconnected* is set to ``True``, then all distributions
+ that are not dependent on any other distribution are skipped.
+
+ :type f: has to support ``file``-like operations
+ :type skip_disconnected: ``bool``
+ """
+ disconnected = []
+
+ f.write("digraph dependencies {\n")
+ for dist, adjs in self.adjacency_list.items():
+ if len(adjs) == 0 and not skip_disconnected:
+ disconnected.append(dist)
+ for other, label in adjs:
+ if label is not None:
+ f.write('"%s" -> "%s" [label="%s"]\n' % (dist.name, other.name, label))
+ else:
+ f.write('"%s" -> "%s"\n' % (dist.name, other.name))
+ if not skip_disconnected and len(disconnected) > 0:
+ f.write('subgraph disconnected {\n')
+ f.write('label = "Disconnected"\n')
+ f.write('bgcolor = red\n')
+
+ for dist in disconnected:
+ f.write('"%s"' % dist.name)
+ f.write('\n')
+ f.write('}\n')
+ f.write('}\n')
+
+ def topological_sort(self):
+ """
+ Perform a topological sort of the graph.
+ :return: A tuple, the first element of which is a topologically sorted
+ list of distributions, and the second element of which is a
+ list of distributions that cannot be sorted because they have
+ circular dependencies and so form a cycle.
+ """
+ result = []
+ # Make a shallow copy of the adjacency list
+ alist = {}
+ for k, v in self.adjacency_list.items():
+ alist[k] = v[:]
+ while True:
+ # See what we can remove in this run
+ to_remove = []
+ for k, v in list(alist.items())[:]:
+ if not v:
+ to_remove.append(k)
+ del alist[k]
+ if not to_remove:
+ # What's left in alist (if anything) is a cycle.
+ break
+ # Remove from the adjacency list of others
+ for k, v in alist.items():
+ alist[k] = [(d, r) for d, r in v if d not in to_remove]
+ logger.debug('Moving to result: %s', ['%s (%s)' % (d.name, d.version) for d in to_remove])
+ result.extend(to_remove)
+ return result, list(alist.keys())
+
+ def __repr__(self):
+ """Representation of the graph"""
+ output = []
+ for dist, adjs in self.adjacency_list.items():
+ output.append(self.repr_node(dist))
+ return '\n'.join(output)
+
+
+def make_graph(dists, scheme='default'):
+ """Makes a dependency graph from the given distributions.
+
+ :parameter dists: a list of distributions
+ :type dists: list of :class:`distutils2.database.InstalledDistribution` and
+ :class:`distutils2.database.EggInfoDistribution` instances
+ :rtype: a :class:`DependencyGraph` instance
+ """
+ scheme = get_scheme(scheme)
+ graph = DependencyGraph()
+ provided = {} # maps names to lists of (version, dist) tuples
+
+ # first, build the graph and find out what's provided
+ for dist in dists:
+ graph.add_distribution(dist)
+
+ for p in dist.provides:
+ name, version = parse_name_and_version(p)
+ logger.debug('Add to provided: %s, %s, %s', name, version, dist)
+ provided.setdefault(name, []).append((version, dist))
+
+ # now make the edges
+ for dist in dists:
+ requires = (dist.run_requires | dist.meta_requires | dist.build_requires | dist.dev_requires)
+ for req in requires:
+ try:
+ matcher = scheme.matcher(req)
+ except UnsupportedVersionError:
+ # XXX compat-mode if cannot read the version
+ logger.warning('could not read version %r - using name only', req)
+ name = req.split()[0]
+ matcher = scheme.matcher(name)
+
+ name = matcher.key # case-insensitive
+
+ matched = False
+ if name in provided:
+ for version, provider in provided[name]:
+ try:
+ match = matcher.match(version)
+ except UnsupportedVersionError:
+ match = False
+
+ if match:
+ graph.add_edge(dist, provider, req)
+ matched = True
+ break
+ if not matched:
+ graph.add_missing(dist, req)
+ return graph
+
+
+def get_dependent_dists(dists, dist):
+ """Recursively generate a list of distributions from *dists* that are
+ dependent on *dist*.
+
+ :param dists: a list of distributions
+ :param dist: a distribution, member of *dists* for which we are interested
+ """
+ if dist not in dists:
+ raise DistlibException('given distribution %r is not a member '
+ 'of the list' % dist.name)
+ graph = make_graph(dists)
+
+ dep = [dist] # dependent distributions
+ todo = graph.reverse_list[dist] # list of nodes we should inspect
+
+ while todo:
+ d = todo.pop()
+ dep.append(d)
+ for succ in graph.reverse_list[d]:
+ if succ not in dep:
+ todo.append(succ)
+
+ dep.pop(0) # remove dist from dep, was there to prevent infinite loops
+ return dep
+
+
+def get_required_dists(dists, dist):
+ """Recursively generate a list of distributions from *dists* that are
+ required by *dist*.
+
+ :param dists: a list of distributions
+ :param dist: a distribution, member of *dists* for which we are interested
+ in finding the dependencies.
+ """
+ if dist not in dists:
+ raise DistlibException('given distribution %r is not a member '
+ 'of the list' % dist.name)
+ graph = make_graph(dists)
+
+ req = set() # required distributions
+ todo = graph.adjacency_list[dist] # list of nodes we should inspect
+ seen = set(t[0] for t in todo) # already added to todo
+
+ while todo:
+ d = todo.pop()[0]
+ req.add(d)
+ pred_list = graph.adjacency_list[d]
+ for pred in pred_list:
+ d = pred[0]
+ if d not in req and d not in seen:
+ seen.add(d)
+ todo.append(pred)
+ return req
+
+
+def make_dist(name, version, **kwargs):
+ """
+ A convenience method for making a dist given just a name and version.
+ """
+ summary = kwargs.pop('summary', 'Placeholder for summary')
+ md = Metadata(**kwargs)
+ md.name = name
+ md.version = version
+ md.summary = summary or 'Placeholder for summary'
+ return Distribution(md)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/index.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/index.py
new file mode 100644
index 000000000..56cd28671
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/index.py
@@ -0,0 +1,508 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2013-2023 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+import hashlib
+import logging
+import os
+import shutil
+import subprocess
+import tempfile
+try:
+ from threading import Thread
+except ImportError: # pragma: no cover
+ from dummy_threading import Thread
+
+from . import DistlibException
+from .compat import (HTTPBasicAuthHandler, Request, HTTPPasswordMgr,
+ urlparse, build_opener, string_types)
+from .util import zip_dir, ServerProxy
+
+logger = logging.getLogger(__name__)
+
+DEFAULT_INDEX = 'https://pypi.org/pypi'
+DEFAULT_REALM = 'pypi'
+
+
+class PackageIndex(object):
+ """
+ This class represents a package index compatible with PyPI, the Python
+ Package Index.
+ """
+
+ boundary = b'----------ThIs_Is_tHe_distlib_index_bouNdaRY_$'
+
+ def __init__(self, url=None):
+ """
+ Initialise an instance.
+
+ :param url: The URL of the index. If not specified, the URL for PyPI is
+ used.
+ """
+ self.url = url or DEFAULT_INDEX
+ self.read_configuration()
+ scheme, netloc, path, params, query, frag = urlparse(self.url)
+ if params or query or frag or scheme not in ('http', 'https'):
+ raise DistlibException('invalid repository: %s' % self.url)
+ self.password_handler = None
+ self.ssl_verifier = None
+ self.gpg = None
+ self.gpg_home = None
+ with open(os.devnull, 'w') as sink:
+ # Use gpg by default rather than gpg2, as gpg2 insists on
+ # prompting for passwords
+ for s in ('gpg', 'gpg2'):
+ try:
+ rc = subprocess.check_call([s, '--version'], stdout=sink,
+ stderr=sink)
+ if rc == 0:
+ self.gpg = s
+ break
+ except OSError:
+ pass
+
+ def _get_pypirc_command(self):
+ """
+ Get the distutils command for interacting with PyPI configurations.
+ :return: the command.
+ """
+ from .util import _get_pypirc_command as cmd
+ return cmd()
+
+ def read_configuration(self):
+ """
+ Read the PyPI access configuration as supported by distutils. This populates
+ ``username``, ``password``, ``realm`` and ``url`` attributes from the
+ configuration.
+ """
+ from .util import _load_pypirc
+ cfg = _load_pypirc(self)
+ self.username = cfg.get('username')
+ self.password = cfg.get('password')
+ self.realm = cfg.get('realm', 'pypi')
+ self.url = cfg.get('repository', self.url)
+
+ def save_configuration(self):
+ """
+ Save the PyPI access configuration. You must have set ``username`` and
+ ``password`` attributes before calling this method.
+ """
+ self.check_credentials()
+ from .util import _store_pypirc
+ _store_pypirc(self)
+
+ def check_credentials(self):
+ """
+ Check that ``username`` and ``password`` have been set, and raise an
+ exception if not.
+ """
+ if self.username is None or self.password is None:
+ raise DistlibException('username and password must be set')
+ pm = HTTPPasswordMgr()
+ _, netloc, _, _, _, _ = urlparse(self.url)
+ pm.add_password(self.realm, netloc, self.username, self.password)
+ self.password_handler = HTTPBasicAuthHandler(pm)
+
+ def register(self, metadata): # pragma: no cover
+ """
+ Register a distribution on PyPI, using the provided metadata.
+
+ :param metadata: A :class:`Metadata` instance defining at least a name
+ and version number for the distribution to be
+ registered.
+ :return: The HTTP response received from PyPI upon submission of the
+ request.
+ """
+ self.check_credentials()
+ metadata.validate()
+ d = metadata.todict()
+ d[':action'] = 'verify'
+ request = self.encode_request(d.items(), [])
+ self.send_request(request)
+ d[':action'] = 'submit'
+ request = self.encode_request(d.items(), [])
+ return self.send_request(request)
+
+ def _reader(self, name, stream, outbuf):
+ """
+ Thread runner for reading lines of from a subprocess into a buffer.
+
+ :param name: The logical name of the stream (used for logging only).
+ :param stream: The stream to read from. This will typically a pipe
+ connected to the output stream of a subprocess.
+ :param outbuf: The list to append the read lines to.
+ """
+ while True:
+ s = stream.readline()
+ if not s:
+ break
+ s = s.decode('utf-8').rstrip()
+ outbuf.append(s)
+ logger.debug('%s: %s' % (name, s))
+ stream.close()
+
+ def get_sign_command(self, filename, signer, sign_password, keystore=None): # pragma: no cover
+ """
+ Return a suitable command for signing a file.
+
+ :param filename: The pathname to the file to be signed.
+ :param signer: The identifier of the signer of the file.
+ :param sign_password: The passphrase for the signer's
+ private key used for signing.
+ :param keystore: The path to a directory which contains the keys
+ used in verification. If not specified, the
+ instance's ``gpg_home`` attribute is used instead.
+ :return: The signing command as a list suitable to be
+ passed to :class:`subprocess.Popen`.
+ """
+ cmd = [self.gpg, '--status-fd', '2', '--no-tty']
+ if keystore is None:
+ keystore = self.gpg_home
+ if keystore:
+ cmd.extend(['--homedir', keystore])
+ if sign_password is not None:
+ cmd.extend(['--batch', '--passphrase-fd', '0'])
+ td = tempfile.mkdtemp()
+ sf = os.path.join(td, os.path.basename(filename) + '.asc')
+ cmd.extend(['--detach-sign', '--armor', '--local-user',
+ signer, '--output', sf, filename])
+ logger.debug('invoking: %s', ' '.join(cmd))
+ return cmd, sf
+
+ def run_command(self, cmd, input_data=None):
+ """
+ Run a command in a child process , passing it any input data specified.
+
+ :param cmd: The command to run.
+ :param input_data: If specified, this must be a byte string containing
+ data to be sent to the child process.
+ :return: A tuple consisting of the subprocess' exit code, a list of
+ lines read from the subprocess' ``stdout``, and a list of
+ lines read from the subprocess' ``stderr``.
+ """
+ kwargs = {
+ 'stdout': subprocess.PIPE,
+ 'stderr': subprocess.PIPE,
+ }
+ if input_data is not None:
+ kwargs['stdin'] = subprocess.PIPE
+ stdout = []
+ stderr = []
+ p = subprocess.Popen(cmd, **kwargs)
+ # We don't use communicate() here because we may need to
+ # get clever with interacting with the command
+ t1 = Thread(target=self._reader, args=('stdout', p.stdout, stdout))
+ t1.start()
+ t2 = Thread(target=self._reader, args=('stderr', p.stderr, stderr))
+ t2.start()
+ if input_data is not None:
+ p.stdin.write(input_data)
+ p.stdin.close()
+
+ p.wait()
+ t1.join()
+ t2.join()
+ return p.returncode, stdout, stderr
+
+ def sign_file(self, filename, signer, sign_password, keystore=None): # pragma: no cover
+ """
+ Sign a file.
+
+ :param filename: The pathname to the file to be signed.
+ :param signer: The identifier of the signer of the file.
+ :param sign_password: The passphrase for the signer's
+ private key used for signing.
+ :param keystore: The path to a directory which contains the keys
+ used in signing. If not specified, the instance's
+ ``gpg_home`` attribute is used instead.
+ :return: The absolute pathname of the file where the signature is
+ stored.
+ """
+ cmd, sig_file = self.get_sign_command(filename, signer, sign_password,
+ keystore)
+ rc, stdout, stderr = self.run_command(cmd,
+ sign_password.encode('utf-8'))
+ if rc != 0:
+ raise DistlibException('sign command failed with error '
+ 'code %s' % rc)
+ return sig_file
+
+ def upload_file(self, metadata, filename, signer=None, sign_password=None,
+ filetype='sdist', pyversion='source', keystore=None):
+ """
+ Upload a release file to the index.
+
+ :param metadata: A :class:`Metadata` instance defining at least a name
+ and version number for the file to be uploaded.
+ :param filename: The pathname of the file to be uploaded.
+ :param signer: The identifier of the signer of the file.
+ :param sign_password: The passphrase for the signer's
+ private key used for signing.
+ :param filetype: The type of the file being uploaded. This is the
+ distutils command which produced that file, e.g.
+ ``sdist`` or ``bdist_wheel``.
+ :param pyversion: The version of Python which the release relates
+ to. For code compatible with any Python, this would
+ be ``source``, otherwise it would be e.g. ``3.2``.
+ :param keystore: The path to a directory which contains the keys
+ used in signing. If not specified, the instance's
+ ``gpg_home`` attribute is used instead.
+ :return: The HTTP response received from PyPI upon submission of the
+ request.
+ """
+ self.check_credentials()
+ if not os.path.exists(filename):
+ raise DistlibException('not found: %s' % filename)
+ metadata.validate()
+ d = metadata.todict()
+ sig_file = None
+ if signer:
+ if not self.gpg:
+ logger.warning('no signing program available - not signed')
+ else:
+ sig_file = self.sign_file(filename, signer, sign_password,
+ keystore)
+ with open(filename, 'rb') as f:
+ file_data = f.read()
+ md5_digest = hashlib.md5(file_data).hexdigest()
+ sha256_digest = hashlib.sha256(file_data).hexdigest()
+ d.update({
+ ':action': 'file_upload',
+ 'protocol_version': '1',
+ 'filetype': filetype,
+ 'pyversion': pyversion,
+ 'md5_digest': md5_digest,
+ 'sha256_digest': sha256_digest,
+ })
+ files = [('content', os.path.basename(filename), file_data)]
+ if sig_file:
+ with open(sig_file, 'rb') as f:
+ sig_data = f.read()
+ files.append(('gpg_signature', os.path.basename(sig_file),
+ sig_data))
+ shutil.rmtree(os.path.dirname(sig_file))
+ request = self.encode_request(d.items(), files)
+ return self.send_request(request)
+
+ def upload_documentation(self, metadata, doc_dir): # pragma: no cover
+ """
+ Upload documentation to the index.
+
+ :param metadata: A :class:`Metadata` instance defining at least a name
+ and version number for the documentation to be
+ uploaded.
+ :param doc_dir: The pathname of the directory which contains the
+ documentation. This should be the directory that
+ contains the ``index.html`` for the documentation.
+ :return: The HTTP response received from PyPI upon submission of the
+ request.
+ """
+ self.check_credentials()
+ if not os.path.isdir(doc_dir):
+ raise DistlibException('not a directory: %r' % doc_dir)
+ fn = os.path.join(doc_dir, 'index.html')
+ if not os.path.exists(fn):
+ raise DistlibException('not found: %r' % fn)
+ metadata.validate()
+ name, version = metadata.name, metadata.version
+ zip_data = zip_dir(doc_dir).getvalue()
+ fields = [(':action', 'doc_upload'),
+ ('name', name), ('version', version)]
+ files = [('content', name, zip_data)]
+ request = self.encode_request(fields, files)
+ return self.send_request(request)
+
+ def get_verify_command(self, signature_filename, data_filename,
+ keystore=None):
+ """
+ Return a suitable command for verifying a file.
+
+ :param signature_filename: The pathname to the file containing the
+ signature.
+ :param data_filename: The pathname to the file containing the
+ signed data.
+ :param keystore: The path to a directory which contains the keys
+ used in verification. If not specified, the
+ instance's ``gpg_home`` attribute is used instead.
+ :return: The verifying command as a list suitable to be
+ passed to :class:`subprocess.Popen`.
+ """
+ cmd = [self.gpg, '--status-fd', '2', '--no-tty']
+ if keystore is None:
+ keystore = self.gpg_home
+ if keystore:
+ cmd.extend(['--homedir', keystore])
+ cmd.extend(['--verify', signature_filename, data_filename])
+ logger.debug('invoking: %s', ' '.join(cmd))
+ return cmd
+
+ def verify_signature(self, signature_filename, data_filename,
+ keystore=None):
+ """
+ Verify a signature for a file.
+
+ :param signature_filename: The pathname to the file containing the
+ signature.
+ :param data_filename: The pathname to the file containing the
+ signed data.
+ :param keystore: The path to a directory which contains the keys
+ used in verification. If not specified, the
+ instance's ``gpg_home`` attribute is used instead.
+ :return: True if the signature was verified, else False.
+ """
+ if not self.gpg:
+ raise DistlibException('verification unavailable because gpg '
+ 'unavailable')
+ cmd = self.get_verify_command(signature_filename, data_filename,
+ keystore)
+ rc, stdout, stderr = self.run_command(cmd)
+ if rc not in (0, 1):
+ raise DistlibException('verify command failed with error code %s' % rc)
+ return rc == 0
+
+ def download_file(self, url, destfile, digest=None, reporthook=None):
+ """
+ This is a convenience method for downloading a file from an URL.
+ Normally, this will be a file from the index, though currently
+ no check is made for this (i.e. a file can be downloaded from
+ anywhere).
+
+ The method is just like the :func:`urlretrieve` function in the
+ standard library, except that it allows digest computation to be
+ done during download and checking that the downloaded data
+ matched any expected value.
+
+ :param url: The URL of the file to be downloaded (assumed to be
+ available via an HTTP GET request).
+ :param destfile: The pathname where the downloaded file is to be
+ saved.
+ :param digest: If specified, this must be a (hasher, value)
+ tuple, where hasher is the algorithm used (e.g.
+ ``'md5'``) and ``value`` is the expected value.
+ :param reporthook: The same as for :func:`urlretrieve` in the
+ standard library.
+ """
+ if digest is None:
+ digester = None
+ logger.debug('No digest specified')
+ else:
+ if isinstance(digest, (list, tuple)):
+ hasher, digest = digest
+ else:
+ hasher = 'md5'
+ digester = getattr(hashlib, hasher)()
+ logger.debug('Digest specified: %s' % digest)
+ # The following code is equivalent to urlretrieve.
+ # We need to do it this way so that we can compute the
+ # digest of the file as we go.
+ with open(destfile, 'wb') as dfp:
+ # addinfourl is not a context manager on 2.x
+ # so we have to use try/finally
+ sfp = self.send_request(Request(url))
+ try:
+ headers = sfp.info()
+ blocksize = 8192
+ size = -1
+ read = 0
+ blocknum = 0
+ if "content-length" in headers:
+ size = int(headers["Content-Length"])
+ if reporthook:
+ reporthook(blocknum, blocksize, size)
+ while True:
+ block = sfp.read(blocksize)
+ if not block:
+ break
+ read += len(block)
+ dfp.write(block)
+ if digester:
+ digester.update(block)
+ blocknum += 1
+ if reporthook:
+ reporthook(blocknum, blocksize, size)
+ finally:
+ sfp.close()
+
+ # check that we got the whole file, if we can
+ if size >= 0 and read < size:
+ raise DistlibException(
+ 'retrieval incomplete: got only %d out of %d bytes'
+ % (read, size))
+ # if we have a digest, it must match.
+ if digester:
+ actual = digester.hexdigest()
+ if digest != actual:
+ raise DistlibException('%s digest mismatch for %s: expected '
+ '%s, got %s' % (hasher, destfile,
+ digest, actual))
+ logger.debug('Digest verified: %s', digest)
+
+ def send_request(self, req):
+ """
+ Send a standard library :class:`Request` to PyPI and return its
+ response.
+
+ :param req: The request to send.
+ :return: The HTTP response from PyPI (a standard library HTTPResponse).
+ """
+ handlers = []
+ if self.password_handler:
+ handlers.append(self.password_handler)
+ if self.ssl_verifier:
+ handlers.append(self.ssl_verifier)
+ opener = build_opener(*handlers)
+ return opener.open(req)
+
+ def encode_request(self, fields, files):
+ """
+ Encode fields and files for posting to an HTTP server.
+
+ :param fields: The fields to send as a list of (fieldname, value)
+ tuples.
+ :param files: The files to send as a list of (fieldname, filename,
+ file_bytes) tuple.
+ """
+ # Adapted from packaging, which in turn was adapted from
+ # http://code.activestate.com/recipes/146306
+
+ parts = []
+ boundary = self.boundary
+ for k, values in fields:
+ if not isinstance(values, (list, tuple)):
+ values = [values]
+
+ for v in values:
+ parts.extend((
+ b'--' + boundary,
+ ('Content-Disposition: form-data; name="%s"' %
+ k).encode('utf-8'),
+ b'',
+ v.encode('utf-8')))
+ for key, filename, value in files:
+ parts.extend((
+ b'--' + boundary,
+ ('Content-Disposition: form-data; name="%s"; filename="%s"' %
+ (key, filename)).encode('utf-8'),
+ b'',
+ value))
+
+ parts.extend((b'--' + boundary + b'--', b''))
+
+ body = b'\r\n'.join(parts)
+ ct = b'multipart/form-data; boundary=' + boundary
+ headers = {
+ 'Content-type': ct,
+ 'Content-length': str(len(body))
+ }
+ return Request(self.url, body, headers)
+
+ def search(self, terms, operator=None): # pragma: no cover
+ if isinstance(terms, string_types):
+ terms = {'name': terms}
+ rpc_proxy = ServerProxy(self.url, timeout=3.0)
+ try:
+ return rpc_proxy.search(terms, operator or 'and')
+ finally:
+ rpc_proxy('close')()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/locators.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/locators.py
new file mode 100644
index 000000000..222c1bf3e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/locators.py
@@ -0,0 +1,1295 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2012-2023 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+
+import gzip
+from io import BytesIO
+import json
+import logging
+import os
+import posixpath
+import re
+try:
+ import threading
+except ImportError: # pragma: no cover
+ import dummy_threading as threading
+import zlib
+
+from . import DistlibException
+from .compat import (urljoin, urlparse, urlunparse, url2pathname, pathname2url, queue, quote, unescape, build_opener,
+ HTTPRedirectHandler as BaseRedirectHandler, text_type, Request, HTTPError, URLError)
+from .database import Distribution, DistributionPath, make_dist
+from .metadata import Metadata, MetadataInvalidError
+from .util import (cached_property, ensure_slash, split_filename, get_project_data, parse_requirement,
+ parse_name_and_version, ServerProxy, normalize_name)
+from .version import get_scheme, UnsupportedVersionError
+from .wheel import Wheel, is_compatible
+
+logger = logging.getLogger(__name__)
+
+HASHER_HASH = re.compile(r'^(\w+)=([a-f0-9]+)')
+CHARSET = re.compile(r';\s*charset\s*=\s*(.*)\s*$', re.I)
+HTML_CONTENT_TYPE = re.compile('text/html|application/x(ht)?ml')
+DEFAULT_INDEX = 'https://pypi.org/pypi'
+
+
+def get_all_distribution_names(url=None):
+ """
+ Return all distribution names known by an index.
+ :param url: The URL of the index.
+ :return: A list of all known distribution names.
+ """
+ if url is None:
+ url = DEFAULT_INDEX
+ client = ServerProxy(url, timeout=3.0)
+ try:
+ return client.list_packages()
+ finally:
+ client('close')()
+
+
+class RedirectHandler(BaseRedirectHandler):
+ """
+ A class to work around a bug in some Python 3.2.x releases.
+ """
+
+ # There's a bug in the base version for some 3.2.x
+ # (e.g. 3.2.2 on Ubuntu Oneiric). If a Location header
+ # returns e.g. /abc, it bails because it says the scheme ''
+ # is bogus, when actually it should use the request's
+ # URL for the scheme. See Python issue #13696.
+ def http_error_302(self, req, fp, code, msg, headers):
+ # Some servers (incorrectly) return multiple Location headers
+ # (so probably same goes for URI). Use first header.
+ newurl = None
+ for key in ('location', 'uri'):
+ if key in headers:
+ newurl = headers[key]
+ break
+ if newurl is None: # pragma: no cover
+ return
+ urlparts = urlparse(newurl)
+ if urlparts.scheme == '':
+ newurl = urljoin(req.get_full_url(), newurl)
+ if hasattr(headers, 'replace_header'):
+ headers.replace_header(key, newurl)
+ else:
+ headers[key] = newurl
+ return BaseRedirectHandler.http_error_302(self, req, fp, code, msg, headers)
+
+ http_error_301 = http_error_303 = http_error_307 = http_error_302
+
+
+class Locator(object):
+ """
+ A base class for locators - things that locate distributions.
+ """
+ source_extensions = ('.tar.gz', '.tar.bz2', '.tar', '.zip', '.tgz', '.tbz')
+ binary_extensions = ('.egg', '.exe', '.whl')
+ excluded_extensions = ('.pdf', )
+
+ # A list of tags indicating which wheels you want to match. The default
+ # value of None matches against the tags compatible with the running
+ # Python. If you want to match other values, set wheel_tags on a locator
+ # instance to a list of tuples (pyver, abi, arch) which you want to match.
+ wheel_tags = None
+
+ downloadable_extensions = source_extensions + ('.whl', )
+
+ def __init__(self, scheme='default'):
+ """
+ Initialise an instance.
+ :param scheme: Because locators look for most recent versions, they
+ need to know the version scheme to use. This specifies
+ the current PEP-recommended scheme - use ``'legacy'``
+ if you need to support existing distributions on PyPI.
+ """
+ self._cache = {}
+ self.scheme = scheme
+ # Because of bugs in some of the handlers on some of the platforms,
+ # we use our own opener rather than just using urlopen.
+ self.opener = build_opener(RedirectHandler())
+ # If get_project() is called from locate(), the matcher instance
+ # is set from the requirement passed to locate(). See issue #18 for
+ # why this can be useful to know.
+ self.matcher = None
+ self.errors = queue.Queue()
+
+ def get_errors(self):
+ """
+ Return any errors which have occurred.
+ """
+ result = []
+ while not self.errors.empty(): # pragma: no cover
+ try:
+ e = self.errors.get(False)
+ result.append(e)
+ except self.errors.Empty:
+ continue
+ self.errors.task_done()
+ return result
+
+ def clear_errors(self):
+ """
+ Clear any errors which may have been logged.
+ """
+ # Just get the errors and throw them away
+ self.get_errors()
+
+ def clear_cache(self):
+ self._cache.clear()
+
+ def _get_scheme(self):
+ return self._scheme
+
+ def _set_scheme(self, value):
+ self._scheme = value
+
+ scheme = property(_get_scheme, _set_scheme)
+
+ def _get_project(self, name):
+ """
+ For a given project, get a dictionary mapping available versions to Distribution
+ instances.
+
+ This should be implemented in subclasses.
+
+ If called from a locate() request, self.matcher will be set to a
+ matcher for the requirement to satisfy, otherwise it will be None.
+ """
+ raise NotImplementedError('Please implement in the subclass')
+
+ def get_distribution_names(self):
+ """
+ Return all the distribution names known to this locator.
+ """
+ raise NotImplementedError('Please implement in the subclass')
+
+ def get_project(self, name):
+ """
+ For a given project, get a dictionary mapping available versions to Distribution
+ instances.
+
+ This calls _get_project to do all the work, and just implements a caching layer on top.
+ """
+ if self._cache is None: # pragma: no cover
+ result = self._get_project(name)
+ elif name in self._cache:
+ result = self._cache[name]
+ else:
+ self.clear_errors()
+ result = self._get_project(name)
+ self._cache[name] = result
+ return result
+
+ def score_url(self, url):
+ """
+ Give an url a score which can be used to choose preferred URLs
+ for a given project release.
+ """
+ t = urlparse(url)
+ basename = posixpath.basename(t.path)
+ compatible = True
+ is_wheel = basename.endswith('.whl')
+ is_downloadable = basename.endswith(self.downloadable_extensions)
+ if is_wheel:
+ compatible = is_compatible(Wheel(basename), self.wheel_tags)
+ return (t.scheme == 'https', 'pypi.org' in t.netloc, is_downloadable, is_wheel, compatible, basename)
+
+ def prefer_url(self, url1, url2):
+ """
+ Choose one of two URLs where both are candidates for distribution
+ archives for the same version of a distribution (for example,
+ .tar.gz vs. zip).
+
+ The current implementation favours https:// URLs over http://, archives
+ from PyPI over those from other locations, wheel compatibility (if a
+ wheel) and then the archive name.
+ """
+ result = url2
+ if url1:
+ s1 = self.score_url(url1)
+ s2 = self.score_url(url2)
+ if s1 > s2:
+ result = url1
+ if result != url2:
+ logger.debug('Not replacing %r with %r', url1, url2)
+ else:
+ logger.debug('Replacing %r with %r', url1, url2)
+ return result
+
+ def split_filename(self, filename, project_name):
+ """
+ Attempt to split a filename in project name, version and Python version.
+ """
+ return split_filename(filename, project_name)
+
+ def convert_url_to_download_info(self, url, project_name):
+ """
+ See if a URL is a candidate for a download URL for a project (the URL
+ has typically been scraped from an HTML page).
+
+ If it is, a dictionary is returned with keys "name", "version",
+ "filename" and "url"; otherwise, None is returned.
+ """
+
+ def same_project(name1, name2):
+ return normalize_name(name1) == normalize_name(name2)
+
+ result = None
+ scheme, netloc, path, params, query, frag = urlparse(url)
+ if frag.lower().startswith('egg='): # pragma: no cover
+ logger.debug('%s: version hint in fragment: %r', project_name, frag)
+ m = HASHER_HASH.match(frag)
+ if m:
+ algo, digest = m.groups()
+ else:
+ algo, digest = None, None
+ origpath = path
+ if path and path[-1] == '/': # pragma: no cover
+ path = path[:-1]
+ if path.endswith('.whl'):
+ try:
+ wheel = Wheel(path)
+ if not is_compatible(wheel, self.wheel_tags):
+ logger.debug('Wheel not compatible: %s', path)
+ else:
+ if project_name is None:
+ include = True
+ else:
+ include = same_project(wheel.name, project_name)
+ if include:
+ result = {
+ 'name': wheel.name,
+ 'version': wheel.version,
+ 'filename': wheel.filename,
+ 'url': urlunparse((scheme, netloc, origpath, params, query, '')),
+ 'python-version': ', '.join(['.'.join(list(v[2:])) for v in wheel.pyver]),
+ }
+ except Exception: # pragma: no cover
+ logger.warning('invalid path for wheel: %s', path)
+ elif not path.endswith(self.downloadable_extensions): # pragma: no cover
+ logger.debug('Not downloadable: %s', path)
+ else: # downloadable extension
+ path = filename = posixpath.basename(path)
+ for ext in self.downloadable_extensions:
+ if path.endswith(ext):
+ path = path[:-len(ext)]
+ t = self.split_filename(path, project_name)
+ if not t: # pragma: no cover
+ logger.debug('No match for project/version: %s', path)
+ else:
+ name, version, pyver = t
+ if not project_name or same_project(project_name, name):
+ result = {
+ 'name': name,
+ 'version': version,
+ 'filename': filename,
+ 'url': urlunparse((scheme, netloc, origpath, params, query, '')),
+ }
+ if pyver: # pragma: no cover
+ result['python-version'] = pyver
+ break
+ if result and algo:
+ result['%s_digest' % algo] = digest
+ return result
+
+ def _get_digest(self, info):
+ """
+ Get a digest from a dictionary by looking at a "digests" dictionary
+ or keys of the form 'algo_digest'.
+
+ Returns a 2-tuple (algo, digest) if found, else None. Currently
+ looks only for SHA256, then MD5.
+ """
+ result = None
+ if 'digests' in info:
+ digests = info['digests']
+ for algo in ('sha256', 'md5'):
+ if algo in digests:
+ result = (algo, digests[algo])
+ break
+ if not result:
+ for algo in ('sha256', 'md5'):
+ key = '%s_digest' % algo
+ if key in info:
+ result = (algo, info[key])
+ break
+ return result
+
+ def _update_version_data(self, result, info):
+ """
+ Update a result dictionary (the final result from _get_project) with a
+ dictionary for a specific version, which typically holds information
+ gleaned from a filename or URL for an archive for the distribution.
+ """
+ name = info.pop('name')
+ version = info.pop('version')
+ if version in result:
+ dist = result[version]
+ md = dist.metadata
+ else:
+ dist = make_dist(name, version, scheme=self.scheme)
+ md = dist.metadata
+ dist.digest = digest = self._get_digest(info)
+ url = info['url']
+ result['digests'][url] = digest
+ if md.source_url != info['url']:
+ md.source_url = self.prefer_url(md.source_url, url)
+ result['urls'].setdefault(version, set()).add(url)
+ dist.locator = self
+ result[version] = dist
+
+ def locate(self, requirement, prereleases=False):
+ """
+ Find the most recent distribution which matches the given
+ requirement.
+
+ :param requirement: A requirement of the form 'foo (1.0)' or perhaps
+ 'foo (>= 1.0, < 2.0, != 1.3)'
+ :param prereleases: If ``True``, allow pre-release versions
+ to be located. Otherwise, pre-release versions
+ are not returned.
+ :return: A :class:`Distribution` instance, or ``None`` if no such
+ distribution could be located.
+ """
+ result = None
+ r = parse_requirement(requirement)
+ if r is None: # pragma: no cover
+ raise DistlibException('Not a valid requirement: %r' % requirement)
+ scheme = get_scheme(self.scheme)
+ self.matcher = matcher = scheme.matcher(r.requirement)
+ logger.debug('matcher: %s (%s)', matcher, type(matcher).__name__)
+ versions = self.get_project(r.name)
+ if len(versions) > 2: # urls and digests keys are present
+ # sometimes, versions are invalid
+ slist = []
+ vcls = matcher.version_class
+ for k in versions:
+ if k in ('urls', 'digests'):
+ continue
+ try:
+ if not matcher.match(k):
+ pass # logger.debug('%s did not match %r', matcher, k)
+ else:
+ if prereleases or not vcls(k).is_prerelease:
+ slist.append(k)
+ except Exception: # pragma: no cover
+ logger.warning('error matching %s with %r', matcher, k)
+ pass # slist.append(k)
+ if len(slist) > 1:
+ slist = sorted(slist, key=scheme.key)
+ if slist:
+ logger.debug('sorted list: %s', slist)
+ version = slist[-1]
+ result = versions[version]
+ if result:
+ if r.extras:
+ result.extras = r.extras
+ result.download_urls = versions.get('urls', {}).get(version, set())
+ d = {}
+ sd = versions.get('digests', {})
+ for url in result.download_urls:
+ if url in sd: # pragma: no cover
+ d[url] = sd[url]
+ result.digests = d
+ self.matcher = None
+ return result
+
+
+class PyPIRPCLocator(Locator):
+ """
+ This locator uses XML-RPC to locate distributions. It therefore
+ cannot be used with simple mirrors (that only mirror file content).
+ """
+
+ def __init__(self, url, **kwargs):
+ """
+ Initialise an instance.
+
+ :param url: The URL to use for XML-RPC.
+ :param kwargs: Passed to the superclass constructor.
+ """
+ super(PyPIRPCLocator, self).__init__(**kwargs)
+ self.base_url = url
+ self.client = ServerProxy(url, timeout=3.0)
+
+ def get_distribution_names(self):
+ """
+ Return all the distribution names known to this locator.
+ """
+ return set(self.client.list_packages())
+
+ def _get_project(self, name):
+ result = {'urls': {}, 'digests': {}}
+ versions = self.client.package_releases(name, True)
+ for v in versions:
+ urls = self.client.release_urls(name, v)
+ data = self.client.release_data(name, v)
+ metadata = Metadata(scheme=self.scheme)
+ metadata.name = data['name']
+ metadata.version = data['version']
+ metadata.license = data.get('license')
+ metadata.keywords = data.get('keywords', [])
+ metadata.summary = data.get('summary')
+ dist = Distribution(metadata)
+ if urls:
+ info = urls[0]
+ metadata.source_url = info['url']
+ dist.digest = self._get_digest(info)
+ dist.locator = self
+ result[v] = dist
+ for info in urls:
+ url = info['url']
+ digest = self._get_digest(info)
+ result['urls'].setdefault(v, set()).add(url)
+ result['digests'][url] = digest
+ return result
+
+
+class PyPIJSONLocator(Locator):
+ """
+ This locator uses PyPI's JSON interface. It's very limited in functionality
+ and probably not worth using.
+ """
+
+ def __init__(self, url, **kwargs):
+ super(PyPIJSONLocator, self).__init__(**kwargs)
+ self.base_url = ensure_slash(url)
+
+ def get_distribution_names(self):
+ """
+ Return all the distribution names known to this locator.
+ """
+ raise NotImplementedError('Not available from this locator')
+
+ def _get_project(self, name):
+ result = {'urls': {}, 'digests': {}}
+ url = urljoin(self.base_url, '%s/json' % quote(name))
+ try:
+ resp = self.opener.open(url)
+ data = resp.read().decode() # for now
+ d = json.loads(data)
+ md = Metadata(scheme=self.scheme)
+ data = d['info']
+ md.name = data['name']
+ md.version = data['version']
+ md.license = data.get('license')
+ md.keywords = data.get('keywords', [])
+ md.summary = data.get('summary')
+ dist = Distribution(md)
+ dist.locator = self
+ # urls = d['urls']
+ result[md.version] = dist
+ for info in d['urls']:
+ url = info['url']
+ dist.download_urls.add(url)
+ dist.digests[url] = self._get_digest(info)
+ result['urls'].setdefault(md.version, set()).add(url)
+ result['digests'][url] = self._get_digest(info)
+ # Now get other releases
+ for version, infos in d['releases'].items():
+ if version == md.version:
+ continue # already done
+ omd = Metadata(scheme=self.scheme)
+ omd.name = md.name
+ omd.version = version
+ odist = Distribution(omd)
+ odist.locator = self
+ result[version] = odist
+ for info in infos:
+ url = info['url']
+ odist.download_urls.add(url)
+ odist.digests[url] = self._get_digest(info)
+ result['urls'].setdefault(version, set()).add(url)
+ result['digests'][url] = self._get_digest(info)
+
+
+# for info in urls:
+# md.source_url = info['url']
+# dist.digest = self._get_digest(info)
+# dist.locator = self
+# for info in urls:
+# url = info['url']
+# result['urls'].setdefault(md.version, set()).add(url)
+# result['digests'][url] = self._get_digest(info)
+ except Exception as e:
+ self.errors.put(text_type(e))
+ logger.exception('JSON fetch failed: %s', e)
+ return result
+
+
+class Page(object):
+ """
+ This class represents a scraped HTML page.
+ """
+ # The following slightly hairy-looking regex just looks for the contents of
+ # an anchor link, which has an attribute "href" either immediately preceded
+ # or immediately followed by a "rel" attribute. The attribute values can be
+ # declared with double quotes, single quotes or no quotes - which leads to
+ # the length of the expression.
+ _href = re.compile(
+ """
+(rel\\s*=\\s*(?:"(?P<rel1>[^"]*)"|'(?P<rel2>[^']*)'|(?P<rel3>[^>\\s\n]*))\\s+)?
+href\\s*=\\s*(?:"(?P<url1>[^"]*)"|'(?P<url2>[^']*)'|(?P<url3>[^>\\s\n]*))
+(\\s+rel\\s*=\\s*(?:"(?P<rel4>[^"]*)"|'(?P<rel5>[^']*)'|(?P<rel6>[^>\\s\n]*)))?
+""", re.I | re.S | re.X)
+ _base = re.compile(r"""<base\s+href\s*=\s*['"]?([^'">]+)""", re.I | re.S)
+
+ def __init__(self, data, url):
+ """
+ Initialise an instance with the Unicode page contents and the URL they
+ came from.
+ """
+ self.data = data
+ self.base_url = self.url = url
+ m = self._base.search(self.data)
+ if m:
+ self.base_url = m.group(1)
+
+ _clean_re = re.compile(r'[^a-z0-9$&+,/:;=?@.#%_\\|-]', re.I)
+
+ @cached_property
+ def links(self):
+ """
+ Return the URLs of all the links on a page together with information
+ about their "rel" attribute, for determining which ones to treat as
+ downloads and which ones to queue for further scraping.
+ """
+
+ def clean(url):
+ "Tidy up an URL."
+ scheme, netloc, path, params, query, frag = urlparse(url)
+ return urlunparse((scheme, netloc, quote(path), params, query, frag))
+
+ result = set()
+ for match in self._href.finditer(self.data):
+ d = match.groupdict('')
+ rel = (d['rel1'] or d['rel2'] or d['rel3'] or d['rel4'] or d['rel5'] or d['rel6'])
+ url = d['url1'] or d['url2'] or d['url3']
+ url = urljoin(self.base_url, url)
+ url = unescape(url)
+ url = self._clean_re.sub(lambda m: '%%%2x' % ord(m.group(0)), url)
+ result.add((url, rel))
+ # We sort the result, hoping to bring the most recent versions
+ # to the front
+ result = sorted(result, key=lambda t: t[0], reverse=True)
+ return result
+
+
+class SimpleScrapingLocator(Locator):
+ """
+ A locator which scrapes HTML pages to locate downloads for a distribution.
+ This runs multiple threads to do the I/O; performance is at least as good
+ as pip's PackageFinder, which works in an analogous fashion.
+ """
+
+ # These are used to deal with various Content-Encoding schemes.
+ decoders = {
+ 'deflate': zlib.decompress,
+ 'gzip': lambda b: gzip.GzipFile(fileobj=BytesIO(b)).read(),
+ 'none': lambda b: b,
+ }
+
+ def __init__(self, url, timeout=None, num_workers=10, **kwargs):
+ """
+ Initialise an instance.
+ :param url: The root URL to use for scraping.
+ :param timeout: The timeout, in seconds, to be applied to requests.
+ This defaults to ``None`` (no timeout specified).
+ :param num_workers: The number of worker threads you want to do I/O,
+ This defaults to 10.
+ :param kwargs: Passed to the superclass.
+ """
+ super(SimpleScrapingLocator, self).__init__(**kwargs)
+ self.base_url = ensure_slash(url)
+ self.timeout = timeout
+ self._page_cache = {}
+ self._seen = set()
+ self._to_fetch = queue.Queue()
+ self._bad_hosts = set()
+ self.skip_externals = False
+ self.num_workers = num_workers
+ self._lock = threading.RLock()
+ # See issue #45: we need to be resilient when the locator is used
+ # in a thread, e.g. with concurrent.futures. We can't use self._lock
+ # as it is for coordinating our internal threads - the ones created
+ # in _prepare_threads.
+ self._gplock = threading.RLock()
+ self.platform_check = False # See issue #112
+
+ def _prepare_threads(self):
+ """
+ Threads are created only when get_project is called, and terminate
+ before it returns. They are there primarily to parallelise I/O (i.e.
+ fetching web pages).
+ """
+ self._threads = []
+ for i in range(self.num_workers):
+ t = threading.Thread(target=self._fetch)
+ t.daemon = True
+ t.start()
+ self._threads.append(t)
+
+ def _wait_threads(self):
+ """
+ Tell all the threads to terminate (by sending a sentinel value) and
+ wait for them to do so.
+ """
+ # Note that you need two loops, since you can't say which
+ # thread will get each sentinel
+ for t in self._threads:
+ self._to_fetch.put(None) # sentinel
+ for t in self._threads:
+ t.join()
+ self._threads = []
+
+ def _get_project(self, name):
+ result = {'urls': {}, 'digests': {}}
+ with self._gplock:
+ self.result = result
+ self.project_name = name
+ url = urljoin(self.base_url, '%s/' % quote(name))
+ self._seen.clear()
+ self._page_cache.clear()
+ self._prepare_threads()
+ try:
+ logger.debug('Queueing %s', url)
+ self._to_fetch.put(url)
+ self._to_fetch.join()
+ finally:
+ self._wait_threads()
+ del self.result
+ return result
+
+ platform_dependent = re.compile(r'\b(linux_(i\d86|x86_64|arm\w+)|'
+ r'win(32|_amd64)|macosx_?\d+)\b', re.I)
+
+ def _is_platform_dependent(self, url):
+ """
+ Does an URL refer to a platform-specific download?
+ """
+ return self.platform_dependent.search(url)
+
+ def _process_download(self, url):
+ """
+ See if an URL is a suitable download for a project.
+
+ If it is, register information in the result dictionary (for
+ _get_project) about the specific version it's for.
+
+ Note that the return value isn't actually used other than as a boolean
+ value.
+ """
+ if self.platform_check and self._is_platform_dependent(url):
+ info = None
+ else:
+ info = self.convert_url_to_download_info(url, self.project_name)
+ logger.debug('process_download: %s -> %s', url, info)
+ if info:
+ with self._lock: # needed because self.result is shared
+ self._update_version_data(self.result, info)
+ return info
+
+ def _should_queue(self, link, referrer, rel):
+ """
+ Determine whether a link URL from a referring page and with a
+ particular "rel" attribute should be queued for scraping.
+ """
+ scheme, netloc, path, _, _, _ = urlparse(link)
+ if path.endswith(self.source_extensions + self.binary_extensions + self.excluded_extensions):
+ result = False
+ elif self.skip_externals and not link.startswith(self.base_url):
+ result = False
+ elif not referrer.startswith(self.base_url):
+ result = False
+ elif rel not in ('homepage', 'download'):
+ result = False
+ elif scheme not in ('http', 'https', 'ftp'):
+ result = False
+ elif self._is_platform_dependent(link):
+ result = False
+ else:
+ host = netloc.split(':', 1)[0]
+ if host.lower() == 'localhost':
+ result = False
+ else:
+ result = True
+ logger.debug('should_queue: %s (%s) from %s -> %s', link, rel, referrer, result)
+ return result
+
+ def _fetch(self):
+ """
+ Get a URL to fetch from the work queue, get the HTML page, examine its
+ links for download candidates and candidates for further scraping.
+
+ This is a handy method to run in a thread.
+ """
+ while True:
+ url = self._to_fetch.get()
+ try:
+ if url:
+ page = self.get_page(url)
+ if page is None: # e.g. after an error
+ continue
+ for link, rel in page.links:
+ if link not in self._seen:
+ try:
+ self._seen.add(link)
+ if (not self._process_download(link) and self._should_queue(link, url, rel)):
+ logger.debug('Queueing %s from %s', link, url)
+ self._to_fetch.put(link)
+ except MetadataInvalidError: # e.g. invalid versions
+ pass
+ except Exception as e: # pragma: no cover
+ self.errors.put(text_type(e))
+ finally:
+ # always do this, to avoid hangs :-)
+ self._to_fetch.task_done()
+ if not url:
+ # logger.debug('Sentinel seen, quitting.')
+ break
+
+ def get_page(self, url):
+ """
+ Get the HTML for an URL, possibly from an in-memory cache.
+
+ XXX TODO Note: this cache is never actually cleared. It's assumed that
+ the data won't get stale over the lifetime of a locator instance (not
+ necessarily true for the default_locator).
+ """
+ # http://peak.telecommunity.com/DevCenter/EasyInstall#package-index-api
+ scheme, netloc, path, _, _, _ = urlparse(url)
+ if scheme == 'file' and os.path.isdir(url2pathname(path)):
+ url = urljoin(ensure_slash(url), 'index.html')
+
+ if url in self._page_cache:
+ result = self._page_cache[url]
+ logger.debug('Returning %s from cache: %s', url, result)
+ else:
+ host = netloc.split(':', 1)[0]
+ result = None
+ if host in self._bad_hosts:
+ logger.debug('Skipping %s due to bad host %s', url, host)
+ else:
+ req = Request(url, headers={'Accept-encoding': 'identity'})
+ try:
+ logger.debug('Fetching %s', url)
+ resp = self.opener.open(req, timeout=self.timeout)
+ logger.debug('Fetched %s', url)
+ headers = resp.info()
+ content_type = headers.get('Content-Type', '')
+ if HTML_CONTENT_TYPE.match(content_type):
+ final_url = resp.geturl()
+ data = resp.read()
+ encoding = headers.get('Content-Encoding')
+ if encoding:
+ decoder = self.decoders[encoding] # fail if not found
+ data = decoder(data)
+ encoding = 'utf-8'
+ m = CHARSET.search(content_type)
+ if m:
+ encoding = m.group(1)
+ try:
+ data = data.decode(encoding)
+ except UnicodeError: # pragma: no cover
+ data = data.decode('latin-1') # fallback
+ result = Page(data, final_url)
+ self._page_cache[final_url] = result
+ except HTTPError as e:
+ if e.code != 404:
+ logger.exception('Fetch failed: %s: %s', url, e)
+ except URLError as e: # pragma: no cover
+ logger.exception('Fetch failed: %s: %s', url, e)
+ with self._lock:
+ self._bad_hosts.add(host)
+ except Exception as e: # pragma: no cover
+ logger.exception('Fetch failed: %s: %s', url, e)
+ finally:
+ self._page_cache[url] = result # even if None (failure)
+ return result
+
+ _distname_re = re.compile('<a href=[^>]*>([^<]+)<')
+
+ def get_distribution_names(self):
+ """
+ Return all the distribution names known to this locator.
+ """
+ result = set()
+ page = self.get_page(self.base_url)
+ if not page:
+ raise DistlibException('Unable to get %s' % self.base_url)
+ for match in self._distname_re.finditer(page.data):
+ result.add(match.group(1))
+ return result
+
+
+class DirectoryLocator(Locator):
+ """
+ This class locates distributions in a directory tree.
+ """
+
+ def __init__(self, path, **kwargs):
+ """
+ Initialise an instance.
+ :param path: The root of the directory tree to search.
+ :param kwargs: Passed to the superclass constructor,
+ except for:
+ * recursive - if True (the default), subdirectories are
+ recursed into. If False, only the top-level directory
+ is searched,
+ """
+ self.recursive = kwargs.pop('recursive', True)
+ super(DirectoryLocator, self).__init__(**kwargs)
+ path = os.path.abspath(path)
+ if not os.path.isdir(path): # pragma: no cover
+ raise DistlibException('Not a directory: %r' % path)
+ self.base_dir = path
+
+ def should_include(self, filename, parent):
+ """
+ Should a filename be considered as a candidate for a distribution
+ archive? As well as the filename, the directory which contains it
+ is provided, though not used by the current implementation.
+ """
+ return filename.endswith(self.downloadable_extensions)
+
+ def _get_project(self, name):
+ result = {'urls': {}, 'digests': {}}
+ for root, dirs, files in os.walk(self.base_dir):
+ for fn in files:
+ if self.should_include(fn, root):
+ fn = os.path.join(root, fn)
+ url = urlunparse(('file', '', pathname2url(os.path.abspath(fn)), '', '', ''))
+ info = self.convert_url_to_download_info(url, name)
+ if info:
+ self._update_version_data(result, info)
+ if not self.recursive:
+ break
+ return result
+
+ def get_distribution_names(self):
+ """
+ Return all the distribution names known to this locator.
+ """
+ result = set()
+ for root, dirs, files in os.walk(self.base_dir):
+ for fn in files:
+ if self.should_include(fn, root):
+ fn = os.path.join(root, fn)
+ url = urlunparse(('file', '', pathname2url(os.path.abspath(fn)), '', '', ''))
+ info = self.convert_url_to_download_info(url, None)
+ if info:
+ result.add(info['name'])
+ if not self.recursive:
+ break
+ return result
+
+
+class JSONLocator(Locator):
+ """
+ This locator uses special extended metadata (not available on PyPI) and is
+ the basis of performant dependency resolution in distlib. Other locators
+ require archive downloads before dependencies can be determined! As you
+ might imagine, that can be slow.
+ """
+
+ def get_distribution_names(self):
+ """
+ Return all the distribution names known to this locator.
+ """
+ raise NotImplementedError('Not available from this locator')
+
+ def _get_project(self, name):
+ result = {'urls': {}, 'digests': {}}
+ data = get_project_data(name)
+ if data:
+ for info in data.get('files', []):
+ if info['ptype'] != 'sdist' or info['pyversion'] != 'source':
+ continue
+ # We don't store summary in project metadata as it makes
+ # the data bigger for no benefit during dependency
+ # resolution
+ dist = make_dist(data['name'],
+ info['version'],
+ summary=data.get('summary', 'Placeholder for summary'),
+ scheme=self.scheme)
+ md = dist.metadata
+ md.source_url = info['url']
+ # TODO SHA256 digest
+ if 'digest' in info and info['digest']:
+ dist.digest = ('md5', info['digest'])
+ md.dependencies = info.get('requirements', {})
+ dist.exports = info.get('exports', {})
+ result[dist.version] = dist
+ result['urls'].setdefault(dist.version, set()).add(info['url'])
+ return result
+
+
+class DistPathLocator(Locator):
+ """
+ This locator finds installed distributions in a path. It can be useful for
+ adding to an :class:`AggregatingLocator`.
+ """
+
+ def __init__(self, distpath, **kwargs):
+ """
+ Initialise an instance.
+
+ :param distpath: A :class:`DistributionPath` instance to search.
+ """
+ super(DistPathLocator, self).__init__(**kwargs)
+ assert isinstance(distpath, DistributionPath)
+ self.distpath = distpath
+
+ def _get_project(self, name):
+ dist = self.distpath.get_distribution(name)
+ if dist is None:
+ result = {'urls': {}, 'digests': {}}
+ else:
+ result = {
+ dist.version: dist,
+ 'urls': {
+ dist.version: set([dist.source_url])
+ },
+ 'digests': {
+ dist.version: set([None])
+ }
+ }
+ return result
+
+
+class AggregatingLocator(Locator):
+ """
+ This class allows you to chain and/or merge a list of locators.
+ """
+
+ def __init__(self, *locators, **kwargs):
+ """
+ Initialise an instance.
+
+ :param locators: The list of locators to search.
+ :param kwargs: Passed to the superclass constructor,
+ except for:
+ * merge - if False (the default), the first successful
+ search from any of the locators is returned. If True,
+ the results from all locators are merged (this can be
+ slow).
+ """
+ self.merge = kwargs.pop('merge', False)
+ self.locators = locators
+ super(AggregatingLocator, self).__init__(**kwargs)
+
+ def clear_cache(self):
+ super(AggregatingLocator, self).clear_cache()
+ for locator in self.locators:
+ locator.clear_cache()
+
+ def _set_scheme(self, value):
+ self._scheme = value
+ for locator in self.locators:
+ locator.scheme = value
+
+ scheme = property(Locator.scheme.fget, _set_scheme)
+
+ def _get_project(self, name):
+ result = {}
+ for locator in self.locators:
+ d = locator.get_project(name)
+ if d:
+ if self.merge:
+ files = result.get('urls', {})
+ digests = result.get('digests', {})
+ # next line could overwrite result['urls'], result['digests']
+ result.update(d)
+ df = result.get('urls')
+ if files and df:
+ for k, v in files.items():
+ if k in df:
+ df[k] |= v
+ else:
+ df[k] = v
+ dd = result.get('digests')
+ if digests and dd:
+ dd.update(digests)
+ else:
+ # See issue #18. If any dists are found and we're looking
+ # for specific constraints, we only return something if
+ # a match is found. For example, if a DirectoryLocator
+ # returns just foo (1.0) while we're looking for
+ # foo (>= 2.0), we'll pretend there was nothing there so
+ # that subsequent locators can be queried. Otherwise we
+ # would just return foo (1.0) which would then lead to a
+ # failure to find foo (>= 2.0), because other locators
+ # weren't searched. Note that this only matters when
+ # merge=False.
+ if self.matcher is None:
+ found = True
+ else:
+ found = False
+ for k in d:
+ if self.matcher.match(k):
+ found = True
+ break
+ if found:
+ result = d
+ break
+ return result
+
+ def get_distribution_names(self):
+ """
+ Return all the distribution names known to this locator.
+ """
+ result = set()
+ for locator in self.locators:
+ try:
+ result |= locator.get_distribution_names()
+ except NotImplementedError:
+ pass
+ return result
+
+
+# We use a legacy scheme simply because most of the dists on PyPI use legacy
+# versions which don't conform to PEP 440.
+default_locator = AggregatingLocator(
+ # JSONLocator(), # don't use as PEP 426 is withdrawn
+ SimpleScrapingLocator('https://pypi.org/simple/', timeout=3.0),
+ scheme='legacy')
+
+locate = default_locator.locate
+
+
+class DependencyFinder(object):
+ """
+ Locate dependencies for distributions.
+ """
+
+ def __init__(self, locator=None):
+ """
+ Initialise an instance, using the specified locator
+ to locate distributions.
+ """
+ self.locator = locator or default_locator
+ self.scheme = get_scheme(self.locator.scheme)
+
+ def add_distribution(self, dist):
+ """
+ Add a distribution to the finder. This will update internal information
+ about who provides what.
+ :param dist: The distribution to add.
+ """
+ logger.debug('adding distribution %s', dist)
+ name = dist.key
+ self.dists_by_name[name] = dist
+ self.dists[(name, dist.version)] = dist
+ for p in dist.provides:
+ name, version = parse_name_and_version(p)
+ logger.debug('Add to provided: %s, %s, %s', name, version, dist)
+ self.provided.setdefault(name, set()).add((version, dist))
+
+ def remove_distribution(self, dist):
+ """
+ Remove a distribution from the finder. This will update internal
+ information about who provides what.
+ :param dist: The distribution to remove.
+ """
+ logger.debug('removing distribution %s', dist)
+ name = dist.key
+ del self.dists_by_name[name]
+ del self.dists[(name, dist.version)]
+ for p in dist.provides:
+ name, version = parse_name_and_version(p)
+ logger.debug('Remove from provided: %s, %s, %s', name, version, dist)
+ s = self.provided[name]
+ s.remove((version, dist))
+ if not s:
+ del self.provided[name]
+
+ def get_matcher(self, reqt):
+ """
+ Get a version matcher for a requirement.
+ :param reqt: The requirement
+ :type reqt: str
+ :return: A version matcher (an instance of
+ :class:`distlib.version.Matcher`).
+ """
+ try:
+ matcher = self.scheme.matcher(reqt)
+ except UnsupportedVersionError: # pragma: no cover
+ # XXX compat-mode if cannot read the version
+ name = reqt.split()[0]
+ matcher = self.scheme.matcher(name)
+ return matcher
+
+ def find_providers(self, reqt):
+ """
+ Find the distributions which can fulfill a requirement.
+
+ :param reqt: The requirement.
+ :type reqt: str
+ :return: A set of distribution which can fulfill the requirement.
+ """
+ matcher = self.get_matcher(reqt)
+ name = matcher.key # case-insensitive
+ result = set()
+ provided = self.provided
+ if name in provided:
+ for version, provider in provided[name]:
+ try:
+ match = matcher.match(version)
+ except UnsupportedVersionError:
+ match = False
+
+ if match:
+ result.add(provider)
+ break
+ return result
+
+ def try_to_replace(self, provider, other, problems):
+ """
+ Attempt to replace one provider with another. This is typically used
+ when resolving dependencies from multiple sources, e.g. A requires
+ (B >= 1.0) while C requires (B >= 1.1).
+
+ For successful replacement, ``provider`` must meet all the requirements
+ which ``other`` fulfills.
+
+ :param provider: The provider we are trying to replace with.
+ :param other: The provider we're trying to replace.
+ :param problems: If False is returned, this will contain what
+ problems prevented replacement. This is currently
+ a tuple of the literal string 'cantreplace',
+ ``provider``, ``other`` and the set of requirements
+ that ``provider`` couldn't fulfill.
+ :return: True if we can replace ``other`` with ``provider``, else
+ False.
+ """
+ rlist = self.reqts[other]
+ unmatched = set()
+ for s in rlist:
+ matcher = self.get_matcher(s)
+ if not matcher.match(provider.version):
+ unmatched.add(s)
+ if unmatched:
+ # can't replace other with provider
+ problems.add(('cantreplace', provider, other, frozenset(unmatched)))
+ result = False
+ else:
+ # can replace other with provider
+ self.remove_distribution(other)
+ del self.reqts[other]
+ for s in rlist:
+ self.reqts.setdefault(provider, set()).add(s)
+ self.add_distribution(provider)
+ result = True
+ return result
+
+ def find(self, requirement, meta_extras=None, prereleases=False):
+ """
+ Find a distribution and all distributions it depends on.
+
+ :param requirement: The requirement specifying the distribution to
+ find, or a Distribution instance.
+ :param meta_extras: A list of meta extras such as :test:, :build: and
+ so on.
+ :param prereleases: If ``True``, allow pre-release versions to be
+ returned - otherwise, don't return prereleases
+ unless they're all that's available.
+
+ Return a set of :class:`Distribution` instances and a set of
+ problems.
+
+ The distributions returned should be such that they have the
+ :attr:`required` attribute set to ``True`` if they were
+ from the ``requirement`` passed to ``find()``, and they have the
+ :attr:`build_time_dependency` attribute set to ``True`` unless they
+ are post-installation dependencies of the ``requirement``.
+
+ The problems should be a tuple consisting of the string
+ ``'unsatisfied'`` and the requirement which couldn't be satisfied
+ by any distribution known to the locator.
+ """
+
+ self.provided = {}
+ self.dists = {}
+ self.dists_by_name = {}
+ self.reqts = {}
+
+ meta_extras = set(meta_extras or [])
+ if ':*:' in meta_extras:
+ meta_extras.remove(':*:')
+ # :meta: and :run: are implicitly included
+ meta_extras |= set([':test:', ':build:', ':dev:'])
+
+ if isinstance(requirement, Distribution):
+ dist = odist = requirement
+ logger.debug('passed %s as requirement', odist)
+ else:
+ dist = odist = self.locator.locate(requirement, prereleases=prereleases)
+ if dist is None:
+ raise DistlibException('Unable to locate %r' % requirement)
+ logger.debug('located %s', odist)
+ dist.requested = True
+ problems = set()
+ todo = set([dist])
+ install_dists = set([odist])
+ while todo:
+ dist = todo.pop()
+ name = dist.key # case-insensitive
+ if name not in self.dists_by_name:
+ self.add_distribution(dist)
+ else:
+ # import pdb; pdb.set_trace()
+ other = self.dists_by_name[name]
+ if other != dist:
+ self.try_to_replace(dist, other, problems)
+
+ ireqts = dist.run_requires | dist.meta_requires
+ sreqts = dist.build_requires
+ ereqts = set()
+ if meta_extras and dist in install_dists:
+ for key in ('test', 'build', 'dev'):
+ e = ':%s:' % key
+ if e in meta_extras:
+ ereqts |= getattr(dist, '%s_requires' % key)
+ all_reqts = ireqts | sreqts | ereqts
+ for r in all_reqts:
+ providers = self.find_providers(r)
+ if not providers:
+ logger.debug('No providers found for %r', r)
+ provider = self.locator.locate(r, prereleases=prereleases)
+ # If no provider is found and we didn't consider
+ # prereleases, consider them now.
+ if provider is None and not prereleases:
+ provider = self.locator.locate(r, prereleases=True)
+ if provider is None:
+ logger.debug('Cannot satisfy %r', r)
+ problems.add(('unsatisfied', r))
+ else:
+ n, v = provider.key, provider.version
+ if (n, v) not in self.dists:
+ todo.add(provider)
+ providers.add(provider)
+ if r in ireqts and dist in install_dists:
+ install_dists.add(provider)
+ logger.debug('Adding %s to install_dists', provider.name_and_version)
+ for p in providers:
+ name = p.key
+ if name not in self.dists_by_name:
+ self.reqts.setdefault(p, set()).add(r)
+ else:
+ other = self.dists_by_name[name]
+ if other != p:
+ # see if other can be replaced by p
+ self.try_to_replace(p, other, problems)
+
+ dists = set(self.dists.values())
+ for dist in dists:
+ dist.build_time_dependency = dist not in install_dists
+ if dist.build_time_dependency:
+ logger.debug('%s is a build-time dependency only.', dist.name_and_version)
+ logger.debug('find done for %s', odist)
+ return dists, problems
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/manifest.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/manifest.py
new file mode 100644
index 000000000..420dcf12e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/manifest.py
@@ -0,0 +1,384 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2012-2023 Python Software Foundation.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+"""
+Class representing the list of files in a distribution.
+
+Equivalent to distutils.filelist, but fixes some problems.
+"""
+import fnmatch
+import logging
+import os
+import re
+import sys
+
+from . import DistlibException
+from .compat import fsdecode
+from .util import convert_path
+
+
+__all__ = ['Manifest']
+
+logger = logging.getLogger(__name__)
+
+# a \ followed by some spaces + EOL
+_COLLAPSE_PATTERN = re.compile('\\\\w*\n', re.M)
+_COMMENTED_LINE = re.compile('#.*?(?=\n)|\n(?=$)', re.M | re.S)
+
+#
+# Due to the different results returned by fnmatch.translate, we need
+# to do slightly different processing for Python 2.7 and 3.2 ... this needed
+# to be brought in for Python 3.6 onwards.
+#
+_PYTHON_VERSION = sys.version_info[:2]
+
+
+class Manifest(object):
+ """
+ A list of files built by exploring the filesystem and filtered by applying various
+ patterns to what we find there.
+ """
+
+ def __init__(self, base=None):
+ """
+ Initialise an instance.
+
+ :param base: The base directory to explore under.
+ """
+ self.base = os.path.abspath(os.path.normpath(base or os.getcwd()))
+ self.prefix = self.base + os.sep
+ self.allfiles = None
+ self.files = set()
+
+ #
+ # Public API
+ #
+
+ def findall(self):
+ """Find all files under the base and set ``allfiles`` to the absolute
+ pathnames of files found.
+ """
+ from stat import S_ISREG, S_ISDIR, S_ISLNK
+
+ self.allfiles = allfiles = []
+ root = self.base
+ stack = [root]
+ pop = stack.pop
+ push = stack.append
+
+ while stack:
+ root = pop()
+ names = os.listdir(root)
+
+ for name in names:
+ fullname = os.path.join(root, name)
+
+ # Avoid excess stat calls -- just one will do, thank you!
+ stat = os.stat(fullname)
+ mode = stat.st_mode
+ if S_ISREG(mode):
+ allfiles.append(fsdecode(fullname))
+ elif S_ISDIR(mode) and not S_ISLNK(mode):
+ push(fullname)
+
+ def add(self, item):
+ """
+ Add a file to the manifest.
+
+ :param item: The pathname to add. This can be relative to the base.
+ """
+ if not item.startswith(self.prefix):
+ item = os.path.join(self.base, item)
+ self.files.add(os.path.normpath(item))
+
+ def add_many(self, items):
+ """
+ Add a list of files to the manifest.
+
+ :param items: The pathnames to add. These can be relative to the base.
+ """
+ for item in items:
+ self.add(item)
+
+ def sorted(self, wantdirs=False):
+ """
+ Return sorted files in directory order
+ """
+
+ def add_dir(dirs, d):
+ dirs.add(d)
+ logger.debug('add_dir added %s', d)
+ if d != self.base:
+ parent, _ = os.path.split(d)
+ assert parent not in ('', '/')
+ add_dir(dirs, parent)
+
+ result = set(self.files) # make a copy!
+ if wantdirs:
+ dirs = set()
+ for f in result:
+ add_dir(dirs, os.path.dirname(f))
+ result |= dirs
+ return [os.path.join(*path_tuple) for path_tuple in
+ sorted(os.path.split(path) for path in result)]
+
+ def clear(self):
+ """Clear all collected files."""
+ self.files = set()
+ self.allfiles = []
+
+ def process_directive(self, directive):
+ """
+ Process a directive which either adds some files from ``allfiles`` to
+ ``files``, or removes some files from ``files``.
+
+ :param directive: The directive to process. This should be in a format
+ compatible with distutils ``MANIFEST.in`` files:
+
+ http://docs.python.org/distutils/sourcedist.html#commands
+ """
+ # Parse the line: split it up, make sure the right number of words
+ # is there, and return the relevant words. 'action' is always
+ # defined: it's the first word of the line. Which of the other
+ # three are defined depends on the action; it'll be either
+ # patterns, (dir and patterns), or (dirpattern).
+ action, patterns, thedir, dirpattern = self._parse_directive(directive)
+
+ # OK, now we know that the action is valid and we have the
+ # right number of words on the line for that action -- so we
+ # can proceed with minimal error-checking.
+ if action == 'include':
+ for pattern in patterns:
+ if not self._include_pattern(pattern, anchor=True):
+ logger.warning('no files found matching %r', pattern)
+
+ elif action == 'exclude':
+ for pattern in patterns:
+ self._exclude_pattern(pattern, anchor=True)
+
+ elif action == 'global-include':
+ for pattern in patterns:
+ if not self._include_pattern(pattern, anchor=False):
+ logger.warning('no files found matching %r '
+ 'anywhere in distribution', pattern)
+
+ elif action == 'global-exclude':
+ for pattern in patterns:
+ self._exclude_pattern(pattern, anchor=False)
+
+ elif action == 'recursive-include':
+ for pattern in patterns:
+ if not self._include_pattern(pattern, prefix=thedir):
+ logger.warning('no files found matching %r '
+ 'under directory %r', pattern, thedir)
+
+ elif action == 'recursive-exclude':
+ for pattern in patterns:
+ self._exclude_pattern(pattern, prefix=thedir)
+
+ elif action == 'graft':
+ if not self._include_pattern(None, prefix=dirpattern):
+ logger.warning('no directories found matching %r',
+ dirpattern)
+
+ elif action == 'prune':
+ if not self._exclude_pattern(None, prefix=dirpattern):
+ logger.warning('no previously-included directories found '
+ 'matching %r', dirpattern)
+ else: # pragma: no cover
+ # This should never happen, as it should be caught in
+ # _parse_template_line
+ raise DistlibException(
+ 'invalid action %r' % action)
+
+ #
+ # Private API
+ #
+
+ def _parse_directive(self, directive):
+ """
+ Validate a directive.
+ :param directive: The directive to validate.
+ :return: A tuple of action, patterns, thedir, dir_patterns
+ """
+ words = directive.split()
+ if len(words) == 1 and words[0] not in ('include', 'exclude',
+ 'global-include',
+ 'global-exclude',
+ 'recursive-include',
+ 'recursive-exclude',
+ 'graft', 'prune'):
+ # no action given, let's use the default 'include'
+ words.insert(0, 'include')
+
+ action = words[0]
+ patterns = thedir = dir_pattern = None
+
+ if action in ('include', 'exclude',
+ 'global-include', 'global-exclude'):
+ if len(words) < 2:
+ raise DistlibException(
+ '%r expects <pattern1> <pattern2> ...' % action)
+
+ patterns = [convert_path(word) for word in words[1:]]
+
+ elif action in ('recursive-include', 'recursive-exclude'):
+ if len(words) < 3:
+ raise DistlibException(
+ '%r expects <dir> <pattern1> <pattern2> ...' % action)
+
+ thedir = convert_path(words[1])
+ patterns = [convert_path(word) for word in words[2:]]
+
+ elif action in ('graft', 'prune'):
+ if len(words) != 2:
+ raise DistlibException(
+ '%r expects a single <dir_pattern>' % action)
+
+ dir_pattern = convert_path(words[1])
+
+ else:
+ raise DistlibException('unknown action %r' % action)
+
+ return action, patterns, thedir, dir_pattern
+
+ def _include_pattern(self, pattern, anchor=True, prefix=None,
+ is_regex=False):
+ """Select strings (presumably filenames) from 'self.files' that
+ match 'pattern', a Unix-style wildcard (glob) pattern.
+
+ Patterns are not quite the same as implemented by the 'fnmatch'
+ module: '*' and '?' match non-special characters, where "special"
+ is platform-dependent: slash on Unix; colon, slash, and backslash on
+ DOS/Windows; and colon on Mac OS.
+
+ If 'anchor' is true (the default), then the pattern match is more
+ stringent: "*.py" will match "foo.py" but not "foo/bar.py". If
+ 'anchor' is false, both of these will match.
+
+ If 'prefix' is supplied, then only filenames starting with 'prefix'
+ (itself a pattern) and ending with 'pattern', with anything in between
+ them, will match. 'anchor' is ignored in this case.
+
+ If 'is_regex' is true, 'anchor' and 'prefix' are ignored, and
+ 'pattern' is assumed to be either a string containing a regex or a
+ regex object -- no translation is done, the regex is just compiled
+ and used as-is.
+
+ Selected strings will be added to self.files.
+
+ Return True if files are found.
+ """
+ # XXX docstring lying about what the special chars are?
+ found = False
+ pattern_re = self._translate_pattern(pattern, anchor, prefix, is_regex)
+
+ # delayed loading of allfiles list
+ if self.allfiles is None:
+ self.findall()
+
+ for name in self.allfiles:
+ if pattern_re.search(name):
+ self.files.add(name)
+ found = True
+ return found
+
+ def _exclude_pattern(self, pattern, anchor=True, prefix=None,
+ is_regex=False):
+ """Remove strings (presumably filenames) from 'files' that match
+ 'pattern'.
+
+ Other parameters are the same as for 'include_pattern()', above.
+ The list 'self.files' is modified in place. Return True if files are
+ found.
+
+ This API is public to allow e.g. exclusion of SCM subdirs, e.g. when
+ packaging source distributions
+ """
+ found = False
+ pattern_re = self._translate_pattern(pattern, anchor, prefix, is_regex)
+ for f in list(self.files):
+ if pattern_re.search(f):
+ self.files.remove(f)
+ found = True
+ return found
+
+ def _translate_pattern(self, pattern, anchor=True, prefix=None,
+ is_regex=False):
+ """Translate a shell-like wildcard pattern to a compiled regular
+ expression.
+
+ Return the compiled regex. If 'is_regex' true,
+ then 'pattern' is directly compiled to a regex (if it's a string)
+ or just returned as-is (assumes it's a regex object).
+ """
+ if is_regex:
+ if isinstance(pattern, str):
+ return re.compile(pattern)
+ else:
+ return pattern
+
+ if _PYTHON_VERSION > (3, 2):
+ # ditch start and end characters
+ start, _, end = self._glob_to_re('_').partition('_')
+
+ if pattern:
+ pattern_re = self._glob_to_re(pattern)
+ if _PYTHON_VERSION > (3, 2):
+ assert pattern_re.startswith(start) and pattern_re.endswith(end)
+ else:
+ pattern_re = ''
+
+ base = re.escape(os.path.join(self.base, ''))
+ if prefix is not None:
+ # ditch end of pattern character
+ if _PYTHON_VERSION <= (3, 2):
+ empty_pattern = self._glob_to_re('')
+ prefix_re = self._glob_to_re(prefix)[:-len(empty_pattern)]
+ else:
+ prefix_re = self._glob_to_re(prefix)
+ assert prefix_re.startswith(start) and prefix_re.endswith(end)
+ prefix_re = prefix_re[len(start): len(prefix_re) - len(end)]
+ sep = os.sep
+ if os.sep == '\\':
+ sep = r'\\'
+ if _PYTHON_VERSION <= (3, 2):
+ pattern_re = '^' + base + sep.join((prefix_re,
+ '.*' + pattern_re))
+ else:
+ pattern_re = pattern_re[len(start): len(pattern_re) - len(end)]
+ pattern_re = r'%s%s%s%s.*%s%s' % (start, base, prefix_re, sep,
+ pattern_re, end)
+ else: # no prefix -- respect anchor flag
+ if anchor:
+ if _PYTHON_VERSION <= (3, 2):
+ pattern_re = '^' + base + pattern_re
+ else:
+ pattern_re = r'%s%s%s' % (start, base, pattern_re[len(start):])
+
+ return re.compile(pattern_re)
+
+ def _glob_to_re(self, pattern):
+ """Translate a shell-like glob pattern to a regular expression.
+
+ Return a string containing the regex. Differs from
+ 'fnmatch.translate()' in that '*' does not match "special characters"
+ (which are platform-specific).
+ """
+ pattern_re = fnmatch.translate(pattern)
+
+ # '?' and '*' in the glob pattern become '.' and '.*' in the RE, which
+ # IMHO is wrong -- '?' and '*' aren't supposed to match slash in Unix,
+ # and by extension they shouldn't match such "special characters" under
+ # any OS. So change all non-escaped dots in the RE to match any
+ # character except the special characters (currently: just os.sep).
+ sep = os.sep
+ if os.sep == '\\':
+ # we're using a regex to manipulate a regex, so we need
+ # to escape the backslash twice
+ sep = r'\\\\'
+ escaped = r'\1[^%s]' % sep
+ pattern_re = re.sub(r'((?<!\\)(\\\\)*)\.', escaped, pattern_re)
+ return pattern_re
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/markers.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/markers.py
new file mode 100644
index 000000000..3f5632be4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/markers.py
@@ -0,0 +1,162 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2012-2023 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+"""
+Parser for the environment markers micro-language defined in PEP 508.
+"""
+
+# Note: In PEP 345, the micro-language was Python compatible, so the ast
+# module could be used to parse it. However, PEP 508 introduced operators such
+# as ~= and === which aren't in Python, necessitating a different approach.
+
+import os
+import re
+import sys
+import platform
+
+from .compat import string_types
+from .util import in_venv, parse_marker
+from .version import LegacyVersion as LV
+
+__all__ = ['interpret']
+
+_VERSION_PATTERN = re.compile(r'((\d+(\.\d+)*\w*)|\'(\d+(\.\d+)*\w*)\'|\"(\d+(\.\d+)*\w*)\")')
+_VERSION_MARKERS = {'python_version', 'python_full_version'}
+
+
+def _is_version_marker(s):
+ return isinstance(s, string_types) and s in _VERSION_MARKERS
+
+
+def _is_literal(o):
+ if not isinstance(o, string_types) or not o:
+ return False
+ return o[0] in '\'"'
+
+
+def _get_versions(s):
+ return {LV(m.groups()[0]) for m in _VERSION_PATTERN.finditer(s)}
+
+
+class Evaluator(object):
+ """
+ This class is used to evaluate marker expressions.
+ """
+
+ operations = {
+ '==': lambda x, y: x == y,
+ '===': lambda x, y: x == y,
+ '~=': lambda x, y: x == y or x > y,
+ '!=': lambda x, y: x != y,
+ '<': lambda x, y: x < y,
+ '<=': lambda x, y: x == y or x < y,
+ '>': lambda x, y: x > y,
+ '>=': lambda x, y: x == y or x > y,
+ 'and': lambda x, y: x and y,
+ 'or': lambda x, y: x or y,
+ 'in': lambda x, y: x in y,
+ 'not in': lambda x, y: x not in y,
+ }
+
+ def evaluate(self, expr, context):
+ """
+ Evaluate a marker expression returned by the :func:`parse_requirement`
+ function in the specified context.
+ """
+ if isinstance(expr, string_types):
+ if expr[0] in '\'"':
+ result = expr[1:-1]
+ else:
+ if expr not in context:
+ raise SyntaxError('unknown variable: %s' % expr)
+ result = context[expr]
+ else:
+ assert isinstance(expr, dict)
+ op = expr['op']
+ if op not in self.operations:
+ raise NotImplementedError('op not implemented: %s' % op)
+ elhs = expr['lhs']
+ erhs = expr['rhs']
+ if _is_literal(expr['lhs']) and _is_literal(expr['rhs']):
+ raise SyntaxError('invalid comparison: %s %s %s' % (elhs, op, erhs))
+
+ lhs = self.evaluate(elhs, context)
+ rhs = self.evaluate(erhs, context)
+ if ((_is_version_marker(elhs) or _is_version_marker(erhs)) and
+ op in ('<', '<=', '>', '>=', '===', '==', '!=', '~=')):
+ lhs = LV(lhs)
+ rhs = LV(rhs)
+ elif _is_version_marker(elhs) and op in ('in', 'not in'):
+ lhs = LV(lhs)
+ rhs = _get_versions(rhs)
+ result = self.operations[op](lhs, rhs)
+ return result
+
+
+_DIGITS = re.compile(r'\d+\.\d+')
+
+
+def default_context():
+
+ def format_full_version(info):
+ version = '%s.%s.%s' % (info.major, info.minor, info.micro)
+ kind = info.releaselevel
+ if kind != 'final':
+ version += kind[0] + str(info.serial)
+ return version
+
+ if hasattr(sys, 'implementation'):
+ implementation_version = format_full_version(sys.implementation.version)
+ implementation_name = sys.implementation.name
+ else:
+ implementation_version = '0'
+ implementation_name = ''
+
+ ppv = platform.python_version()
+ m = _DIGITS.match(ppv)
+ pv = m.group(0)
+ result = {
+ 'implementation_name': implementation_name,
+ 'implementation_version': implementation_version,
+ 'os_name': os.name,
+ 'platform_machine': platform.machine(),
+ 'platform_python_implementation': platform.python_implementation(),
+ 'platform_release': platform.release(),
+ 'platform_system': platform.system(),
+ 'platform_version': platform.version(),
+ 'platform_in_venv': str(in_venv()),
+ 'python_full_version': ppv,
+ 'python_version': pv,
+ 'sys_platform': sys.platform,
+ }
+ return result
+
+
+DEFAULT_CONTEXT = default_context()
+del default_context
+
+evaluator = Evaluator()
+
+
+def interpret(marker, execution_context=None):
+ """
+ Interpret a marker and return a result depending on environment.
+
+ :param marker: The marker to interpret.
+ :type marker: str
+ :param execution_context: The context used for name lookup.
+ :type execution_context: mapping
+ """
+ try:
+ expr, rest = parse_marker(marker)
+ except Exception as e:
+ raise SyntaxError('Unable to interpret marker syntax: %s: %s' % (marker, e))
+ if rest and rest[0] != '#':
+ raise SyntaxError('unexpected trailing data in marker: %s: %s' % (marker, rest))
+ context = dict(DEFAULT_CONTEXT)
+ if execution_context:
+ context.update(execution_context)
+ return evaluator.evaluate(expr, context)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/metadata.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/metadata.py
new file mode 100644
index 000000000..ce9a34b3e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/metadata.py
@@ -0,0 +1,1031 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2012 The Python Software Foundation.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+"""Implementation of the Metadata for Python packages PEPs.
+
+Supports all metadata formats (1.0, 1.1, 1.2, 1.3/2.1 and 2.2).
+"""
+from __future__ import unicode_literals
+
+import codecs
+from email import message_from_file
+import json
+import logging
+import re
+
+from . import DistlibException, __version__
+from .compat import StringIO, string_types, text_type
+from .markers import interpret
+from .util import extract_by_key, get_extras
+from .version import get_scheme, PEP440_VERSION_RE
+
+logger = logging.getLogger(__name__)
+
+
+class MetadataMissingError(DistlibException):
+ """A required metadata is missing"""
+
+
+class MetadataConflictError(DistlibException):
+ """Attempt to read or write metadata fields that are conflictual."""
+
+
+class MetadataUnrecognizedVersionError(DistlibException):
+ """Unknown metadata version number."""
+
+
+class MetadataInvalidError(DistlibException):
+ """A metadata value is invalid"""
+
+
+# public API of this module
+__all__ = ['Metadata', 'PKG_INFO_ENCODING', 'PKG_INFO_PREFERRED_VERSION']
+
+# Encoding used for the PKG-INFO files
+PKG_INFO_ENCODING = 'utf-8'
+
+# preferred version. Hopefully will be changed
+# to 1.2 once PEP 345 is supported everywhere
+PKG_INFO_PREFERRED_VERSION = '1.1'
+
+_LINE_PREFIX_1_2 = re.compile('\n \\|')
+_LINE_PREFIX_PRE_1_2 = re.compile('\n ')
+_241_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform', 'Summary', 'Description', 'Keywords', 'Home-page',
+ 'Author', 'Author-email', 'License')
+
+_314_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform', 'Supported-Platform', 'Summary', 'Description',
+ 'Keywords', 'Home-page', 'Author', 'Author-email', 'License', 'Classifier', 'Download-URL', 'Obsoletes',
+ 'Provides', 'Requires')
+
+_314_MARKERS = ('Obsoletes', 'Provides', 'Requires', 'Classifier', 'Download-URL')
+
+_345_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform', 'Supported-Platform', 'Summary', 'Description',
+ 'Keywords', 'Home-page', 'Author', 'Author-email', 'Maintainer', 'Maintainer-email', 'License',
+ 'Classifier', 'Download-URL', 'Obsoletes-Dist', 'Project-URL', 'Provides-Dist', 'Requires-Dist',
+ 'Requires-Python', 'Requires-External')
+
+_345_MARKERS = ('Provides-Dist', 'Requires-Dist', 'Requires-Python', 'Obsoletes-Dist', 'Requires-External',
+ 'Maintainer', 'Maintainer-email', 'Project-URL')
+
+_426_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform', 'Supported-Platform', 'Summary', 'Description',
+ 'Keywords', 'Home-page', 'Author', 'Author-email', 'Maintainer', 'Maintainer-email', 'License',
+ 'Classifier', 'Download-URL', 'Obsoletes-Dist', 'Project-URL', 'Provides-Dist', 'Requires-Dist',
+ 'Requires-Python', 'Requires-External', 'Private-Version', 'Obsoleted-By', 'Setup-Requires-Dist',
+ 'Extension', 'Provides-Extra')
+
+_426_MARKERS = ('Private-Version', 'Provides-Extra', 'Obsoleted-By', 'Setup-Requires-Dist', 'Extension')
+
+# See issue #106: Sometimes 'Requires' and 'Provides' occur wrongly in
+# the metadata. Include them in the tuple literal below to allow them
+# (for now).
+# Ditto for Obsoletes - see issue #140.
+_566_FIELDS = _426_FIELDS + ('Description-Content-Type', 'Requires', 'Provides', 'Obsoletes')
+
+_566_MARKERS = ('Description-Content-Type', )
+
+_643_MARKERS = ('Dynamic', 'License-File')
+
+_643_FIELDS = _566_FIELDS + _643_MARKERS
+
+_ALL_FIELDS = set()
+_ALL_FIELDS.update(_241_FIELDS)
+_ALL_FIELDS.update(_314_FIELDS)
+_ALL_FIELDS.update(_345_FIELDS)
+_ALL_FIELDS.update(_426_FIELDS)
+_ALL_FIELDS.update(_566_FIELDS)
+_ALL_FIELDS.update(_643_FIELDS)
+
+EXTRA_RE = re.compile(r'''extra\s*==\s*("([^"]+)"|'([^']+)')''')
+
+
+def _version2fieldlist(version):
+ if version == '1.0':
+ return _241_FIELDS
+ elif version == '1.1':
+ return _314_FIELDS
+ elif version == '1.2':
+ return _345_FIELDS
+ elif version in ('1.3', '2.1'):
+ # avoid adding field names if already there
+ return _345_FIELDS + tuple(f for f in _566_FIELDS if f not in _345_FIELDS)
+ elif version == '2.0':
+ raise ValueError('Metadata 2.0 is withdrawn and not supported')
+ # return _426_FIELDS
+ elif version == '2.2':
+ return _643_FIELDS
+ raise MetadataUnrecognizedVersionError(version)
+
+
+def _best_version(fields):
+ """Detect the best version depending on the fields used."""
+
+ def _has_marker(keys, markers):
+ return any(marker in keys for marker in markers)
+
+ keys = [key for key, value in fields.items() if value not in ([], 'UNKNOWN', None)]
+ possible_versions = ['1.0', '1.1', '1.2', '1.3', '2.1', '2.2'] # 2.0 removed
+
+ # first let's try to see if a field is not part of one of the version
+ for key in keys:
+ if key not in _241_FIELDS and '1.0' in possible_versions:
+ possible_versions.remove('1.0')
+ logger.debug('Removed 1.0 due to %s', key)
+ if key not in _314_FIELDS and '1.1' in possible_versions:
+ possible_versions.remove('1.1')
+ logger.debug('Removed 1.1 due to %s', key)
+ if key not in _345_FIELDS and '1.2' in possible_versions:
+ possible_versions.remove('1.2')
+ logger.debug('Removed 1.2 due to %s', key)
+ if key not in _566_FIELDS and '1.3' in possible_versions:
+ possible_versions.remove('1.3')
+ logger.debug('Removed 1.3 due to %s', key)
+ if key not in _566_FIELDS and '2.1' in possible_versions:
+ if key != 'Description': # In 2.1, description allowed after headers
+ possible_versions.remove('2.1')
+ logger.debug('Removed 2.1 due to %s', key)
+ if key not in _643_FIELDS and '2.2' in possible_versions:
+ possible_versions.remove('2.2')
+ logger.debug('Removed 2.2 due to %s', key)
+ # if key not in _426_FIELDS and '2.0' in possible_versions:
+ # possible_versions.remove('2.0')
+ # logger.debug('Removed 2.0 due to %s', key)
+
+ # possible_version contains qualified versions
+ if len(possible_versions) == 1:
+ return possible_versions[0] # found !
+ elif len(possible_versions) == 0:
+ logger.debug('Out of options - unknown metadata set: %s', fields)
+ raise MetadataConflictError('Unknown metadata set')
+
+ # let's see if one unique marker is found
+ is_1_1 = '1.1' in possible_versions and _has_marker(keys, _314_MARKERS)
+ is_1_2 = '1.2' in possible_versions and _has_marker(keys, _345_MARKERS)
+ is_2_1 = '2.1' in possible_versions and _has_marker(keys, _566_MARKERS)
+ # is_2_0 = '2.0' in possible_versions and _has_marker(keys, _426_MARKERS)
+ is_2_2 = '2.2' in possible_versions and _has_marker(keys, _643_MARKERS)
+ if int(is_1_1) + int(is_1_2) + int(is_2_1) + int(is_2_2) > 1:
+ raise MetadataConflictError('You used incompatible 1.1/1.2/2.1/2.2 fields')
+
+ # we have the choice, 1.0, or 1.2, 2.1 or 2.2
+ # - 1.0 has a broken Summary field but works with all tools
+ # - 1.1 is to avoid
+ # - 1.2 fixes Summary but has little adoption
+ # - 2.1 adds more features
+ # - 2.2 is the latest
+ if not is_1_1 and not is_1_2 and not is_2_1 and not is_2_2:
+ # we couldn't find any specific marker
+ if PKG_INFO_PREFERRED_VERSION in possible_versions:
+ return PKG_INFO_PREFERRED_VERSION
+ if is_1_1:
+ return '1.1'
+ if is_1_2:
+ return '1.2'
+ if is_2_1:
+ return '2.1'
+ # if is_2_2:
+ # return '2.2'
+
+ return '2.2'
+
+
+# This follows the rules about transforming keys as described in
+# https://www.python.org/dev/peps/pep-0566/#id17
+_ATTR2FIELD = {name.lower().replace("-", "_"): name for name in _ALL_FIELDS}
+_FIELD2ATTR = {field: attr for attr, field in _ATTR2FIELD.items()}
+
+_PREDICATE_FIELDS = ('Requires-Dist', 'Obsoletes-Dist', 'Provides-Dist')
+_VERSIONS_FIELDS = ('Requires-Python', )
+_VERSION_FIELDS = ('Version', )
+_LISTFIELDS = ('Platform', 'Classifier', 'Obsoletes', 'Requires', 'Provides', 'Obsoletes-Dist', 'Provides-Dist',
+ 'Requires-Dist', 'Requires-External', 'Project-URL', 'Supported-Platform', 'Setup-Requires-Dist',
+ 'Provides-Extra', 'Extension', 'License-File')
+_LISTTUPLEFIELDS = ('Project-URL', )
+
+_ELEMENTSFIELD = ('Keywords', )
+
+_UNICODEFIELDS = ('Author', 'Maintainer', 'Summary', 'Description')
+
+_MISSING = object()
+
+_FILESAFE = re.compile('[^A-Za-z0-9.]+')
+
+
+def _get_name_and_version(name, version, for_filename=False):
+ """Return the distribution name with version.
+
+ If for_filename is true, return a filename-escaped form."""
+ if for_filename:
+ # For both name and version any runs of non-alphanumeric or '.'
+ # characters are replaced with a single '-'. Additionally any
+ # spaces in the version string become '.'
+ name = _FILESAFE.sub('-', name)
+ version = _FILESAFE.sub('-', version.replace(' ', '.'))
+ return '%s-%s' % (name, version)
+
+
+class LegacyMetadata(object):
+ """The legacy metadata of a release.
+
+ Supports versions 1.0, 1.1, 1.2, 2.0 and 1.3/2.1 (auto-detected). You can
+ instantiate the class with one of these arguments (or none):
+ - *path*, the path to a metadata file
+ - *fileobj* give a file-like object with metadata as content
+ - *mapping* is a dict-like object
+ - *scheme* is a version scheme name
+ """
+
+ # TODO document the mapping API and UNKNOWN default key
+
+ def __init__(self, path=None, fileobj=None, mapping=None, scheme='default'):
+ if [path, fileobj, mapping].count(None) < 2:
+ raise TypeError('path, fileobj and mapping are exclusive')
+ self._fields = {}
+ self.requires_files = []
+ self._dependencies = None
+ self.scheme = scheme
+ if path is not None:
+ self.read(path)
+ elif fileobj is not None:
+ self.read_file(fileobj)
+ elif mapping is not None:
+ self.update(mapping)
+ self.set_metadata_version()
+
+ def set_metadata_version(self):
+ self._fields['Metadata-Version'] = _best_version(self._fields)
+
+ def _write_field(self, fileobj, name, value):
+ fileobj.write('%s: %s\n' % (name, value))
+
+ def __getitem__(self, name):
+ return self.get(name)
+
+ def __setitem__(self, name, value):
+ return self.set(name, value)
+
+ def __delitem__(self, name):
+ field_name = self._convert_name(name)
+ try:
+ del self._fields[field_name]
+ except KeyError:
+ raise KeyError(name)
+
+ def __contains__(self, name):
+ return (name in self._fields or self._convert_name(name) in self._fields)
+
+ def _convert_name(self, name):
+ if name in _ALL_FIELDS:
+ return name
+ name = name.replace('-', '_').lower()
+ return _ATTR2FIELD.get(name, name)
+
+ def _default_value(self, name):
+ if name in _LISTFIELDS or name in _ELEMENTSFIELD:
+ return []
+ return 'UNKNOWN'
+
+ def _remove_line_prefix(self, value):
+ if self.metadata_version in ('1.0', '1.1'):
+ return _LINE_PREFIX_PRE_1_2.sub('\n', value)
+ else:
+ return _LINE_PREFIX_1_2.sub('\n', value)
+
+ def __getattr__(self, name):
+ if name in _ATTR2FIELD:
+ return self[name]
+ raise AttributeError(name)
+
+ #
+ # Public API
+ #
+
+ def get_fullname(self, filesafe=False):
+ """
+ Return the distribution name with version.
+
+ If filesafe is true, return a filename-escaped form.
+ """
+ return _get_name_and_version(self['Name'], self['Version'], filesafe)
+
+ def is_field(self, name):
+ """return True if name is a valid metadata key"""
+ name = self._convert_name(name)
+ return name in _ALL_FIELDS
+
+ def is_multi_field(self, name):
+ name = self._convert_name(name)
+ return name in _LISTFIELDS
+
+ def read(self, filepath):
+ """Read the metadata values from a file path."""
+ fp = codecs.open(filepath, 'r', encoding='utf-8')
+ try:
+ self.read_file(fp)
+ finally:
+ fp.close()
+
+ def read_file(self, fileob):
+ """Read the metadata values from a file object."""
+ msg = message_from_file(fileob)
+ self._fields['Metadata-Version'] = msg['metadata-version']
+
+ # When reading, get all the fields we can
+ for field in _ALL_FIELDS:
+ if field not in msg:
+ continue
+ if field in _LISTFIELDS:
+ # we can have multiple lines
+ values = msg.get_all(field)
+ if field in _LISTTUPLEFIELDS and values is not None:
+ values = [tuple(value.split(',')) for value in values]
+ self.set(field, values)
+ else:
+ # single line
+ value = msg[field]
+ if value is not None and value != 'UNKNOWN':
+ self.set(field, value)
+
+ # PEP 566 specifies that the body be used for the description, if
+ # available
+ body = msg.get_payload()
+ self["Description"] = body if body else self["Description"]
+ # logger.debug('Attempting to set metadata for %s', self)
+ # self.set_metadata_version()
+
+ def write(self, filepath, skip_unknown=False):
+ """Write the metadata fields to filepath."""
+ fp = codecs.open(filepath, 'w', encoding='utf-8')
+ try:
+ self.write_file(fp, skip_unknown)
+ finally:
+ fp.close()
+
+ def write_file(self, fileobject, skip_unknown=False):
+ """Write the PKG-INFO format data to a file object."""
+ self.set_metadata_version()
+
+ for field in _version2fieldlist(self['Metadata-Version']):
+ values = self.get(field)
+ if skip_unknown and values in ('UNKNOWN', [], ['UNKNOWN']):
+ continue
+ if field in _ELEMENTSFIELD:
+ self._write_field(fileobject, field, ','.join(values))
+ continue
+ if field not in _LISTFIELDS:
+ if field == 'Description':
+ if self.metadata_version in ('1.0', '1.1'):
+ values = values.replace('\n', '\n ')
+ else:
+ values = values.replace('\n', '\n |')
+ values = [values]
+
+ if field in _LISTTUPLEFIELDS:
+ values = [','.join(value) for value in values]
+
+ for value in values:
+ self._write_field(fileobject, field, value)
+
+ def update(self, other=None, **kwargs):
+ """Set metadata values from the given iterable `other` and kwargs.
+
+ Behavior is like `dict.update`: If `other` has a ``keys`` method,
+ they are looped over and ``self[key]`` is assigned ``other[key]``.
+ Else, ``other`` is an iterable of ``(key, value)`` iterables.
+
+ Keys that don't match a metadata field or that have an empty value are
+ dropped.
+ """
+
+ def _set(key, value):
+ if key in _ATTR2FIELD and value:
+ self.set(self._convert_name(key), value)
+
+ if not other:
+ # other is None or empty container
+ pass
+ elif hasattr(other, 'keys'):
+ for k in other.keys():
+ _set(k, other[k])
+ else:
+ for k, v in other:
+ _set(k, v)
+
+ if kwargs:
+ for k, v in kwargs.items():
+ _set(k, v)
+
+ def set(self, name, value):
+ """Control then set a metadata field."""
+ name = self._convert_name(name)
+
+ if ((name in _ELEMENTSFIELD or name == 'Platform') and not isinstance(value, (list, tuple))):
+ if isinstance(value, string_types):
+ value = [v.strip() for v in value.split(',')]
+ else:
+ value = []
+ elif (name in _LISTFIELDS and not isinstance(value, (list, tuple))):
+ if isinstance(value, string_types):
+ value = [value]
+ else:
+ value = []
+
+ if logger.isEnabledFor(logging.WARNING):
+ project_name = self['Name']
+
+ scheme = get_scheme(self.scheme)
+ if name in _PREDICATE_FIELDS and value is not None:
+ for v in value:
+ # check that the values are valid
+ if not scheme.is_valid_matcher(v.split(';')[0]):
+ logger.warning("'%s': '%s' is not valid (field '%s')", project_name, v, name)
+ # FIXME this rejects UNKNOWN, is that right?
+ elif name in _VERSIONS_FIELDS and value is not None:
+ if not scheme.is_valid_constraint_list(value):
+ logger.warning("'%s': '%s' is not a valid version (field '%s')", project_name, value, name)
+ elif name in _VERSION_FIELDS and value is not None:
+ if not scheme.is_valid_version(value):
+ logger.warning("'%s': '%s' is not a valid version (field '%s')", project_name, value, name)
+
+ if name in _UNICODEFIELDS:
+ if name == 'Description':
+ value = self._remove_line_prefix(value)
+
+ self._fields[name] = value
+
+ def get(self, name, default=_MISSING):
+ """Get a metadata field."""
+ name = self._convert_name(name)
+ if name not in self._fields:
+ if default is _MISSING:
+ default = self._default_value(name)
+ return default
+ if name in _UNICODEFIELDS:
+ value = self._fields[name]
+ return value
+ elif name in _LISTFIELDS:
+ value = self._fields[name]
+ if value is None:
+ return []
+ res = []
+ for val in value:
+ if name not in _LISTTUPLEFIELDS:
+ res.append(val)
+ else:
+ # That's for Project-URL
+ res.append((val[0], val[1]))
+ return res
+
+ elif name in _ELEMENTSFIELD:
+ value = self._fields[name]
+ if isinstance(value, string_types):
+ return value.split(',')
+ return self._fields[name]
+
+ def check(self, strict=False):
+ """Check if the metadata is compliant. If strict is True then raise if
+ no Name or Version are provided"""
+ self.set_metadata_version()
+
+ # XXX should check the versions (if the file was loaded)
+ missing, warnings = [], []
+
+ for attr in ('Name', 'Version'): # required by PEP 345
+ if attr not in self:
+ missing.append(attr)
+
+ if strict and missing != []:
+ msg = 'missing required metadata: %s' % ', '.join(missing)
+ raise MetadataMissingError(msg)
+
+ for attr in ('Home-page', 'Author'):
+ if attr not in self:
+ missing.append(attr)
+
+ # checking metadata 1.2 (XXX needs to check 1.1, 1.0)
+ if self['Metadata-Version'] != '1.2':
+ return missing, warnings
+
+ scheme = get_scheme(self.scheme)
+
+ def are_valid_constraints(value):
+ for v in value:
+ if not scheme.is_valid_matcher(v.split(';')[0]):
+ return False
+ return True
+
+ for fields, controller in ((_PREDICATE_FIELDS, are_valid_constraints),
+ (_VERSIONS_FIELDS, scheme.is_valid_constraint_list), (_VERSION_FIELDS,
+ scheme.is_valid_version)):
+ for field in fields:
+ value = self.get(field, None)
+ if value is not None and not controller(value):
+ warnings.append("Wrong value for '%s': %s" % (field, value))
+
+ return missing, warnings
+
+ def todict(self, skip_missing=False):
+ """Return fields as a dict.
+
+ Field names will be converted to use the underscore-lowercase style
+ instead of hyphen-mixed case (i.e. home_page instead of Home-page).
+ This is as per https://www.python.org/dev/peps/pep-0566/#id17.
+ """
+ self.set_metadata_version()
+
+ fields = _version2fieldlist(self['Metadata-Version'])
+
+ data = {}
+
+ for field_name in fields:
+ if not skip_missing or field_name in self._fields:
+ key = _FIELD2ATTR[field_name]
+ if key != 'project_url':
+ data[key] = self[field_name]
+ else:
+ data[key] = [','.join(u) for u in self[field_name]]
+
+ return data
+
+ def add_requirements(self, requirements):
+ if self['Metadata-Version'] == '1.1':
+ # we can't have 1.1 metadata *and* Setuptools requires
+ for field in ('Obsoletes', 'Requires', 'Provides'):
+ if field in self:
+ del self[field]
+ self['Requires-Dist'] += requirements
+
+ # Mapping API
+ # TODO could add iter* variants
+
+ def keys(self):
+ return list(_version2fieldlist(self['Metadata-Version']))
+
+ def __iter__(self):
+ for key in self.keys():
+ yield key
+
+ def values(self):
+ return [self[key] for key in self.keys()]
+
+ def items(self):
+ return [(key, self[key]) for key in self.keys()]
+
+ def __repr__(self):
+ return '<%s %s %s>' % (self.__class__.__name__, self.name, self.version)
+
+
+METADATA_FILENAME = 'pydist.json'
+WHEEL_METADATA_FILENAME = 'metadata.json'
+LEGACY_METADATA_FILENAME = 'METADATA'
+
+
+class Metadata(object):
+ """
+ The metadata of a release. This implementation uses 2.1
+ metadata where possible. If not possible, it wraps a LegacyMetadata
+ instance which handles the key-value metadata format.
+ """
+
+ METADATA_VERSION_MATCHER = re.compile(r'^\d+(\.\d+)*$')
+
+ NAME_MATCHER = re.compile('^[0-9A-Z]([0-9A-Z_.-]*[0-9A-Z])?$', re.I)
+
+ FIELDNAME_MATCHER = re.compile('^[A-Z]([0-9A-Z-]*[0-9A-Z])?$', re.I)
+
+ VERSION_MATCHER = PEP440_VERSION_RE
+
+ SUMMARY_MATCHER = re.compile('.{1,2047}')
+
+ METADATA_VERSION = '2.0'
+
+ GENERATOR = 'distlib (%s)' % __version__
+
+ MANDATORY_KEYS = {
+ 'name': (),
+ 'version': (),
+ 'summary': ('legacy', ),
+ }
+
+ INDEX_KEYS = ('name version license summary description author '
+ 'author_email keywords platform home_page classifiers '
+ 'download_url')
+
+ DEPENDENCY_KEYS = ('extras run_requires test_requires build_requires '
+ 'dev_requires provides meta_requires obsoleted_by '
+ 'supports_environments')
+
+ SYNTAX_VALIDATORS = {
+ 'metadata_version': (METADATA_VERSION_MATCHER, ()),
+ 'name': (NAME_MATCHER, ('legacy', )),
+ 'version': (VERSION_MATCHER, ('legacy', )),
+ 'summary': (SUMMARY_MATCHER, ('legacy', )),
+ 'dynamic': (FIELDNAME_MATCHER, ('legacy', )),
+ }
+
+ __slots__ = ('_legacy', '_data', 'scheme')
+
+ def __init__(self, path=None, fileobj=None, mapping=None, scheme='default'):
+ if [path, fileobj, mapping].count(None) < 2:
+ raise TypeError('path, fileobj and mapping are exclusive')
+ self._legacy = None
+ self._data = None
+ self.scheme = scheme
+ # import pdb; pdb.set_trace()
+ if mapping is not None:
+ try:
+ self._validate_mapping(mapping, scheme)
+ self._data = mapping
+ except MetadataUnrecognizedVersionError:
+ self._legacy = LegacyMetadata(mapping=mapping, scheme=scheme)
+ self.validate()
+ else:
+ data = None
+ if path:
+ with open(path, 'rb') as f:
+ data = f.read()
+ elif fileobj:
+ data = fileobj.read()
+ if data is None:
+ # Initialised with no args - to be added
+ self._data = {
+ 'metadata_version': self.METADATA_VERSION,
+ 'generator': self.GENERATOR,
+ }
+ else:
+ if not isinstance(data, text_type):
+ data = data.decode('utf-8')
+ try:
+ self._data = json.loads(data)
+ self._validate_mapping(self._data, scheme)
+ except ValueError:
+ # Note: MetadataUnrecognizedVersionError does not
+ # inherit from ValueError (it's a DistlibException,
+ # which should not inherit from ValueError).
+ # The ValueError comes from the json.load - if that
+ # succeeds and we get a validation error, we want
+ # that to propagate
+ self._legacy = LegacyMetadata(fileobj=StringIO(data), scheme=scheme)
+ self.validate()
+
+ common_keys = set(('name', 'version', 'license', 'keywords', 'summary'))
+
+ none_list = (None, list)
+ none_dict = (None, dict)
+
+ mapped_keys = {
+ 'run_requires': ('Requires-Dist', list),
+ 'build_requires': ('Setup-Requires-Dist', list),
+ 'dev_requires': none_list,
+ 'test_requires': none_list,
+ 'meta_requires': none_list,
+ 'extras': ('Provides-Extra', list),
+ 'modules': none_list,
+ 'namespaces': none_list,
+ 'exports': none_dict,
+ 'commands': none_dict,
+ 'classifiers': ('Classifier', list),
+ 'source_url': ('Download-URL', None),
+ 'metadata_version': ('Metadata-Version', None),
+ }
+
+ del none_list, none_dict
+
+ def __getattribute__(self, key):
+ common = object.__getattribute__(self, 'common_keys')
+ mapped = object.__getattribute__(self, 'mapped_keys')
+ if key in mapped:
+ lk, maker = mapped[key]
+ if self._legacy:
+ if lk is None:
+ result = None if maker is None else maker()
+ else:
+ result = self._legacy.get(lk)
+ else:
+ value = None if maker is None else maker()
+ if key not in ('commands', 'exports', 'modules', 'namespaces', 'classifiers'):
+ result = self._data.get(key, value)
+ else:
+ # special cases for PEP 459
+ sentinel = object()
+ result = sentinel
+ d = self._data.get('extensions')
+ if d:
+ if key == 'commands':
+ result = d.get('python.commands', value)
+ elif key == 'classifiers':
+ d = d.get('python.details')
+ if d:
+ result = d.get(key, value)
+ else:
+ d = d.get('python.exports')
+ if not d:
+ d = self._data.get('python.exports')
+ if d:
+ result = d.get(key, value)
+ if result is sentinel:
+ result = value
+ elif key not in common:
+ result = object.__getattribute__(self, key)
+ elif self._legacy:
+ result = self._legacy.get(key)
+ else:
+ result = self._data.get(key)
+ return result
+
+ def _validate_value(self, key, value, scheme=None):
+ if key in self.SYNTAX_VALIDATORS:
+ pattern, exclusions = self.SYNTAX_VALIDATORS[key]
+ if (scheme or self.scheme) not in exclusions:
+ m = pattern.match(value)
+ if not m:
+ raise MetadataInvalidError("'%s' is an invalid value for "
+ "the '%s' property" % (value, key))
+
+ def __setattr__(self, key, value):
+ self._validate_value(key, value)
+ common = object.__getattribute__(self, 'common_keys')
+ mapped = object.__getattribute__(self, 'mapped_keys')
+ if key in mapped:
+ lk, _ = mapped[key]
+ if self._legacy:
+ if lk is None:
+ raise NotImplementedError
+ self._legacy[lk] = value
+ elif key not in ('commands', 'exports', 'modules', 'namespaces', 'classifiers'):
+ self._data[key] = value
+ else:
+ # special cases for PEP 459
+ d = self._data.setdefault('extensions', {})
+ if key == 'commands':
+ d['python.commands'] = value
+ elif key == 'classifiers':
+ d = d.setdefault('python.details', {})
+ d[key] = value
+ else:
+ d = d.setdefault('python.exports', {})
+ d[key] = value
+ elif key not in common:
+ object.__setattr__(self, key, value)
+ else:
+ if key == 'keywords':
+ if isinstance(value, string_types):
+ value = value.strip()
+ if value:
+ value = value.split()
+ else:
+ value = []
+ if self._legacy:
+ self._legacy[key] = value
+ else:
+ self._data[key] = value
+
+ @property
+ def name_and_version(self):
+ return _get_name_and_version(self.name, self.version, True)
+
+ @property
+ def provides(self):
+ if self._legacy:
+ result = self._legacy['Provides-Dist']
+ else:
+ result = self._data.setdefault('provides', [])
+ s = '%s (%s)' % (self.name, self.version)
+ if s not in result:
+ result.append(s)
+ return result
+
+ @provides.setter
+ def provides(self, value):
+ if self._legacy:
+ self._legacy['Provides-Dist'] = value
+ else:
+ self._data['provides'] = value
+
+ def get_requirements(self, reqts, extras=None, env=None):
+ """
+ Base method to get dependencies, given a set of extras
+ to satisfy and an optional environment context.
+ :param reqts: A list of sometimes-wanted dependencies,
+ perhaps dependent on extras and environment.
+ :param extras: A list of optional components being requested.
+ :param env: An optional environment for marker evaluation.
+ """
+ if self._legacy:
+ result = reqts
+ else:
+ result = []
+ extras = get_extras(extras or [], self.extras)
+ for d in reqts:
+ if 'extra' not in d and 'environment' not in d:
+ # unconditional
+ include = True
+ else:
+ if 'extra' not in d:
+ # Not extra-dependent - only environment-dependent
+ include = True
+ else:
+ include = d.get('extra') in extras
+ if include:
+ # Not excluded because of extras, check environment
+ marker = d.get('environment')
+ if marker:
+ include = interpret(marker, env)
+ if include:
+ result.extend(d['requires'])
+ for key in ('build', 'dev', 'test'):
+ e = ':%s:' % key
+ if e in extras:
+ extras.remove(e)
+ # A recursive call, but it should terminate since 'test'
+ # has been removed from the extras
+ reqts = self._data.get('%s_requires' % key, [])
+ result.extend(self.get_requirements(reqts, extras=extras, env=env))
+ return result
+
+ @property
+ def dictionary(self):
+ if self._legacy:
+ return self._from_legacy()
+ return self._data
+
+ @property
+ def dependencies(self):
+ if self._legacy:
+ raise NotImplementedError
+ else:
+ return extract_by_key(self._data, self.DEPENDENCY_KEYS)
+
+ @dependencies.setter
+ def dependencies(self, value):
+ if self._legacy:
+ raise NotImplementedError
+ else:
+ self._data.update(value)
+
+ def _validate_mapping(self, mapping, scheme):
+ if mapping.get('metadata_version') != self.METADATA_VERSION:
+ raise MetadataUnrecognizedVersionError()
+ missing = []
+ for key, exclusions in self.MANDATORY_KEYS.items():
+ if key not in mapping:
+ if scheme not in exclusions:
+ missing.append(key)
+ if missing:
+ msg = 'Missing metadata items: %s' % ', '.join(missing)
+ raise MetadataMissingError(msg)
+ for k, v in mapping.items():
+ self._validate_value(k, v, scheme)
+
+ def validate(self):
+ if self._legacy:
+ missing, warnings = self._legacy.check(True)
+ if missing or warnings:
+ logger.warning('Metadata: missing: %s, warnings: %s', missing, warnings)
+ else:
+ self._validate_mapping(self._data, self.scheme)
+
+ def todict(self):
+ if self._legacy:
+ return self._legacy.todict(True)
+ else:
+ result = extract_by_key(self._data, self.INDEX_KEYS)
+ return result
+
+ def _from_legacy(self):
+ assert self._legacy and not self._data
+ result = {
+ 'metadata_version': self.METADATA_VERSION,
+ 'generator': self.GENERATOR,
+ }
+ lmd = self._legacy.todict(True) # skip missing ones
+ for k in ('name', 'version', 'license', 'summary', 'description', 'classifier'):
+ if k in lmd:
+ if k == 'classifier':
+ nk = 'classifiers'
+ else:
+ nk = k
+ result[nk] = lmd[k]
+ kw = lmd.get('Keywords', [])
+ if kw == ['']:
+ kw = []
+ result['keywords'] = kw
+ keys = (('requires_dist', 'run_requires'), ('setup_requires_dist', 'build_requires'))
+ for ok, nk in keys:
+ if ok in lmd and lmd[ok]:
+ result[nk] = [{'requires': lmd[ok]}]
+ result['provides'] = self.provides
+ # author = {}
+ # maintainer = {}
+ return result
+
+ LEGACY_MAPPING = {
+ 'name': 'Name',
+ 'version': 'Version',
+ ('extensions', 'python.details', 'license'): 'License',
+ 'summary': 'Summary',
+ 'description': 'Description',
+ ('extensions', 'python.project', 'project_urls', 'Home'): 'Home-page',
+ ('extensions', 'python.project', 'contacts', 0, 'name'): 'Author',
+ ('extensions', 'python.project', 'contacts', 0, 'email'): 'Author-email',
+ 'source_url': 'Download-URL',
+ ('extensions', 'python.details', 'classifiers'): 'Classifier',
+ }
+
+ def _to_legacy(self):
+
+ def process_entries(entries):
+ reqts = set()
+ for e in entries:
+ extra = e.get('extra')
+ env = e.get('environment')
+ rlist = e['requires']
+ for r in rlist:
+ if not env and not extra:
+ reqts.add(r)
+ else:
+ marker = ''
+ if extra:
+ marker = 'extra == "%s"' % extra
+ if env:
+ if marker:
+ marker = '(%s) and %s' % (env, marker)
+ else:
+ marker = env
+ reqts.add(';'.join((r, marker)))
+ return reqts
+
+ assert self._data and not self._legacy
+ result = LegacyMetadata()
+ nmd = self._data
+ # import pdb; pdb.set_trace()
+ for nk, ok in self.LEGACY_MAPPING.items():
+ if not isinstance(nk, tuple):
+ if nk in nmd:
+ result[ok] = nmd[nk]
+ else:
+ d = nmd
+ found = True
+ for k in nk:
+ try:
+ d = d[k]
+ except (KeyError, IndexError):
+ found = False
+ break
+ if found:
+ result[ok] = d
+ r1 = process_entries(self.run_requires + self.meta_requires)
+ r2 = process_entries(self.build_requires + self.dev_requires)
+ if self.extras:
+ result['Provides-Extra'] = sorted(self.extras)
+ result['Requires-Dist'] = sorted(r1)
+ result['Setup-Requires-Dist'] = sorted(r2)
+ # TODO: any other fields wanted
+ return result
+
+ def write(self, path=None, fileobj=None, legacy=False, skip_unknown=True):
+ if [path, fileobj].count(None) != 1:
+ raise ValueError('Exactly one of path and fileobj is needed')
+ self.validate()
+ if legacy:
+ if self._legacy:
+ legacy_md = self._legacy
+ else:
+ legacy_md = self._to_legacy()
+ if path:
+ legacy_md.write(path, skip_unknown=skip_unknown)
+ else:
+ legacy_md.write_file(fileobj, skip_unknown=skip_unknown)
+ else:
+ if self._legacy:
+ d = self._from_legacy()
+ else:
+ d = self._data
+ if fileobj:
+ json.dump(d, fileobj, ensure_ascii=True, indent=2, sort_keys=True)
+ else:
+ with codecs.open(path, 'w', 'utf-8') as f:
+ json.dump(d, f, ensure_ascii=True, indent=2, sort_keys=True)
+
+ def add_requirements(self, requirements):
+ if self._legacy:
+ self._legacy.add_requirements(requirements)
+ else:
+ run_requires = self._data.setdefault('run_requires', [])
+ always = None
+ for entry in run_requires:
+ if 'environment' not in entry and 'extra' not in entry:
+ always = entry
+ break
+ if always is None:
+ always = {'requires': requirements}
+ run_requires.insert(0, always)
+ else:
+ rset = set(always['requires']) | set(requirements)
+ always['requires'] = sorted(rset)
+
+ def __repr__(self):
+ name = self.name or '(no name)'
+ version = self.version or 'no version'
+ return '<%s %s %s (%s)>' % (self.__class__.__name__, self.metadata_version, name, version)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/resources.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/resources.py
new file mode 100644
index 000000000..fef52aa10
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/resources.py
@@ -0,0 +1,358 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2013-2017 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+from __future__ import unicode_literals
+
+import bisect
+import io
+import logging
+import os
+import pkgutil
+import sys
+import types
+import zipimport
+
+from . import DistlibException
+from .util import cached_property, get_cache_base, Cache
+
+logger = logging.getLogger(__name__)
+
+
+cache = None # created when needed
+
+
+class ResourceCache(Cache):
+ def __init__(self, base=None):
+ if base is None:
+ # Use native string to avoid issues on 2.x: see Python #20140.
+ base = os.path.join(get_cache_base(), str('resource-cache'))
+ super(ResourceCache, self).__init__(base)
+
+ def is_stale(self, resource, path):
+ """
+ Is the cache stale for the given resource?
+
+ :param resource: The :class:`Resource` being cached.
+ :param path: The path of the resource in the cache.
+ :return: True if the cache is stale.
+ """
+ # Cache invalidation is a hard problem :-)
+ return True
+
+ def get(self, resource):
+ """
+ Get a resource into the cache,
+
+ :param resource: A :class:`Resource` instance.
+ :return: The pathname of the resource in the cache.
+ """
+ prefix, path = resource.finder.get_cache_info(resource)
+ if prefix is None:
+ result = path
+ else:
+ result = os.path.join(self.base, self.prefix_to_dir(prefix), path)
+ dirname = os.path.dirname(result)
+ if not os.path.isdir(dirname):
+ os.makedirs(dirname)
+ if not os.path.exists(result):
+ stale = True
+ else:
+ stale = self.is_stale(resource, path)
+ if stale:
+ # write the bytes of the resource to the cache location
+ with open(result, 'wb') as f:
+ f.write(resource.bytes)
+ return result
+
+
+class ResourceBase(object):
+ def __init__(self, finder, name):
+ self.finder = finder
+ self.name = name
+
+
+class Resource(ResourceBase):
+ """
+ A class representing an in-package resource, such as a data file. This is
+ not normally instantiated by user code, but rather by a
+ :class:`ResourceFinder` which manages the resource.
+ """
+ is_container = False # Backwards compatibility
+
+ def as_stream(self):
+ """
+ Get the resource as a stream.
+
+ This is not a property to make it obvious that it returns a new stream
+ each time.
+ """
+ return self.finder.get_stream(self)
+
+ @cached_property
+ def file_path(self):
+ global cache
+ if cache is None:
+ cache = ResourceCache()
+ return cache.get(self)
+
+ @cached_property
+ def bytes(self):
+ return self.finder.get_bytes(self)
+
+ @cached_property
+ def size(self):
+ return self.finder.get_size(self)
+
+
+class ResourceContainer(ResourceBase):
+ is_container = True # Backwards compatibility
+
+ @cached_property
+ def resources(self):
+ return self.finder.get_resources(self)
+
+
+class ResourceFinder(object):
+ """
+ Resource finder for file system resources.
+ """
+
+ if sys.platform.startswith('java'):
+ skipped_extensions = ('.pyc', '.pyo', '.class')
+ else:
+ skipped_extensions = ('.pyc', '.pyo')
+
+ def __init__(self, module):
+ self.module = module
+ self.loader = getattr(module, '__loader__', None)
+ self.base = os.path.dirname(getattr(module, '__file__', ''))
+
+ def _adjust_path(self, path):
+ return os.path.realpath(path)
+
+ def _make_path(self, resource_name):
+ # Issue #50: need to preserve type of path on Python 2.x
+ # like os.path._get_sep
+ if isinstance(resource_name, bytes): # should only happen on 2.x
+ sep = b'/'
+ else:
+ sep = '/'
+ parts = resource_name.split(sep)
+ parts.insert(0, self.base)
+ result = os.path.join(*parts)
+ return self._adjust_path(result)
+
+ def _find(self, path):
+ return os.path.exists(path)
+
+ def get_cache_info(self, resource):
+ return None, resource.path
+
+ def find(self, resource_name):
+ path = self._make_path(resource_name)
+ if not self._find(path):
+ result = None
+ else:
+ if self._is_directory(path):
+ result = ResourceContainer(self, resource_name)
+ else:
+ result = Resource(self, resource_name)
+ result.path = path
+ return result
+
+ def get_stream(self, resource):
+ return open(resource.path, 'rb')
+
+ def get_bytes(self, resource):
+ with open(resource.path, 'rb') as f:
+ return f.read()
+
+ def get_size(self, resource):
+ return os.path.getsize(resource.path)
+
+ def get_resources(self, resource):
+ def allowed(f):
+ return (f != '__pycache__' and not
+ f.endswith(self.skipped_extensions))
+ return set([f for f in os.listdir(resource.path) if allowed(f)])
+
+ def is_container(self, resource):
+ return self._is_directory(resource.path)
+
+ _is_directory = staticmethod(os.path.isdir)
+
+ def iterator(self, resource_name):
+ resource = self.find(resource_name)
+ if resource is not None:
+ todo = [resource]
+ while todo:
+ resource = todo.pop(0)
+ yield resource
+ if resource.is_container:
+ rname = resource.name
+ for name in resource.resources:
+ if not rname:
+ new_name = name
+ else:
+ new_name = '/'.join([rname, name])
+ child = self.find(new_name)
+ if child.is_container:
+ todo.append(child)
+ else:
+ yield child
+
+
+class ZipResourceFinder(ResourceFinder):
+ """
+ Resource finder for resources in .zip files.
+ """
+ def __init__(self, module):
+ super(ZipResourceFinder, self).__init__(module)
+ archive = self.loader.archive
+ self.prefix_len = 1 + len(archive)
+ # PyPy doesn't have a _files attr on zipimporter, and you can't set one
+ if hasattr(self.loader, '_files'):
+ self._files = self.loader._files
+ else:
+ self._files = zipimport._zip_directory_cache[archive]
+ self.index = sorted(self._files)
+
+ def _adjust_path(self, path):
+ return path
+
+ def _find(self, path):
+ path = path[self.prefix_len:]
+ if path in self._files:
+ result = True
+ else:
+ if path and path[-1] != os.sep:
+ path = path + os.sep
+ i = bisect.bisect(self.index, path)
+ try:
+ result = self.index[i].startswith(path)
+ except IndexError:
+ result = False
+ if not result:
+ logger.debug('_find failed: %r %r', path, self.loader.prefix)
+ else:
+ logger.debug('_find worked: %r %r', path, self.loader.prefix)
+ return result
+
+ def get_cache_info(self, resource):
+ prefix = self.loader.archive
+ path = resource.path[1 + len(prefix):]
+ return prefix, path
+
+ def get_bytes(self, resource):
+ return self.loader.get_data(resource.path)
+
+ def get_stream(self, resource):
+ return io.BytesIO(self.get_bytes(resource))
+
+ def get_size(self, resource):
+ path = resource.path[self.prefix_len:]
+ return self._files[path][3]
+
+ def get_resources(self, resource):
+ path = resource.path[self.prefix_len:]
+ if path and path[-1] != os.sep:
+ path += os.sep
+ plen = len(path)
+ result = set()
+ i = bisect.bisect(self.index, path)
+ while i < len(self.index):
+ if not self.index[i].startswith(path):
+ break
+ s = self.index[i][plen:]
+ result.add(s.split(os.sep, 1)[0]) # only immediate children
+ i += 1
+ return result
+
+ def _is_directory(self, path):
+ path = path[self.prefix_len:]
+ if path and path[-1] != os.sep:
+ path += os.sep
+ i = bisect.bisect(self.index, path)
+ try:
+ result = self.index[i].startswith(path)
+ except IndexError:
+ result = False
+ return result
+
+
+_finder_registry = {
+ type(None): ResourceFinder,
+ zipimport.zipimporter: ZipResourceFinder
+}
+
+try:
+ # In Python 3.6, _frozen_importlib -> _frozen_importlib_external
+ try:
+ import _frozen_importlib_external as _fi
+ except ImportError:
+ import _frozen_importlib as _fi
+ _finder_registry[_fi.SourceFileLoader] = ResourceFinder
+ _finder_registry[_fi.FileFinder] = ResourceFinder
+ # See issue #146
+ _finder_registry[_fi.SourcelessFileLoader] = ResourceFinder
+ del _fi
+except (ImportError, AttributeError):
+ pass
+
+
+def register_finder(loader, finder_maker):
+ _finder_registry[type(loader)] = finder_maker
+
+
+_finder_cache = {}
+
+
+def finder(package):
+ """
+ Return a resource finder for a package.
+ :param package: The name of the package.
+ :return: A :class:`ResourceFinder` instance for the package.
+ """
+ if package in _finder_cache:
+ result = _finder_cache[package]
+ else:
+ if package not in sys.modules:
+ __import__(package)
+ module = sys.modules[package]
+ path = getattr(module, '__path__', None)
+ if path is None:
+ raise DistlibException('You cannot get a finder for a module, '
+ 'only for a package')
+ loader = getattr(module, '__loader__', None)
+ finder_maker = _finder_registry.get(type(loader))
+ if finder_maker is None:
+ raise DistlibException('Unable to locate finder for %r' % package)
+ result = finder_maker(module)
+ _finder_cache[package] = result
+ return result
+
+
+_dummy_module = types.ModuleType(str('__dummy__'))
+
+
+def finder_for_path(path):
+ """
+ Return a resource finder for a path, which should represent a container.
+
+ :param path: The path.
+ :return: A :class:`ResourceFinder` instance for the path.
+ """
+ result = None
+ # calls any path hooks, gets importer into cache
+ pkgutil.get_importer(path)
+ loader = sys.path_importer_cache.get(path)
+ finder = _finder_registry.get(type(loader))
+ if finder:
+ module = _dummy_module
+ module.__file__ = os.path.join(path, '')
+ module.__loader__ = loader
+ result = finder(module)
+ return result
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/scripts.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/scripts.py
new file mode 100644
index 000000000..b1fc705b7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/scripts.py
@@ -0,0 +1,447 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2013-2023 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+from io import BytesIO
+import logging
+import os
+import re
+import struct
+import sys
+import time
+from zipfile import ZipInfo
+
+from .compat import sysconfig, detect_encoding, ZipFile
+from .resources import finder
+from .util import (FileOperator, get_export_entry, convert_path, get_executable, get_platform, in_venv)
+
+logger = logging.getLogger(__name__)
+
+_DEFAULT_MANIFEST = '''
+<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
+<assembly xmlns="urn:schemas-microsoft-com:asm.v1" manifestVersion="1.0">
+ <assemblyIdentity version="1.0.0.0"
+ processorArchitecture="X86"
+ name="%s"
+ type="win32"/>
+
+ <!-- Identify the application security requirements. -->
+ <trustInfo xmlns="urn:schemas-microsoft-com:asm.v3">
+ <security>
+ <requestedPrivileges>
+ <requestedExecutionLevel level="asInvoker" uiAccess="false"/>
+ </requestedPrivileges>
+ </security>
+ </trustInfo>
+</assembly>'''.strip()
+
+# check if Python is called on the first line with this expression
+FIRST_LINE_RE = re.compile(b'^#!.*pythonw?[0-9.]*([ \t].*)?$')
+SCRIPT_TEMPLATE = r'''# -*- coding: utf-8 -*-
+import re
+import sys
+from %(module)s import %(import_name)s
+if __name__ == '__main__':
+ sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
+ sys.exit(%(func)s())
+'''
+
+# Pre-fetch the contents of all executable wrapper stubs.
+# This is to address https://github.com/pypa/pip/issues/12666.
+# When updating pip, we rename the old pip in place before installing the
+# new version. If we try to fetch a wrapper *after* that rename, the finder
+# machinery will be confused as the package is no longer available at the
+# location where it was imported from. So we load everything into memory in
+# advance.
+
+if os.name == 'nt' or (os.name == 'java' and os._name == 'nt'):
+ # Issue 31: don't hardcode an absolute package name, but
+ # determine it relative to the current package
+ DISTLIB_PACKAGE = __name__.rsplit('.', 1)[0]
+
+ WRAPPERS = {
+ r.name: r.bytes
+ for r in finder(DISTLIB_PACKAGE).iterator("")
+ if r.name.endswith(".exe")
+ }
+
+
+def enquote_executable(executable):
+ if ' ' in executable:
+ # make sure we quote only the executable in case of env
+ # for example /usr/bin/env "/dir with spaces/bin/jython"
+ # instead of "/usr/bin/env /dir with spaces/bin/jython"
+ # otherwise whole
+ if executable.startswith('/usr/bin/env '):
+ env, _executable = executable.split(' ', 1)
+ if ' ' in _executable and not _executable.startswith('"'):
+ executable = '%s "%s"' % (env, _executable)
+ else:
+ if not executable.startswith('"'):
+ executable = '"%s"' % executable
+ return executable
+
+
+# Keep the old name around (for now), as there is at least one project using it!
+_enquote_executable = enquote_executable
+
+
+class ScriptMaker(object):
+ """
+ A class to copy or create scripts from source scripts or callable
+ specifications.
+ """
+ script_template = SCRIPT_TEMPLATE
+
+ executable = None # for shebangs
+
+ def __init__(self, source_dir, target_dir, add_launchers=True, dry_run=False, fileop=None):
+ self.source_dir = source_dir
+ self.target_dir = target_dir
+ self.add_launchers = add_launchers
+ self.force = False
+ self.clobber = False
+ # It only makes sense to set mode bits on POSIX.
+ self.set_mode = (os.name == 'posix') or (os.name == 'java' and os._name == 'posix')
+ self.variants = set(('', 'X.Y'))
+ self._fileop = fileop or FileOperator(dry_run)
+
+ self._is_nt = os.name == 'nt' or (os.name == 'java' and os._name == 'nt')
+ self.version_info = sys.version_info
+
+ def _get_alternate_executable(self, executable, options):
+ if options.get('gui', False) and self._is_nt: # pragma: no cover
+ dn, fn = os.path.split(executable)
+ fn = fn.replace('python', 'pythonw')
+ executable = os.path.join(dn, fn)
+ return executable
+
+ if sys.platform.startswith('java'): # pragma: no cover
+
+ def _is_shell(self, executable):
+ """
+ Determine if the specified executable is a script
+ (contains a #! line)
+ """
+ try:
+ with open(executable) as fp:
+ return fp.read(2) == '#!'
+ except (OSError, IOError):
+ logger.warning('Failed to open %s', executable)
+ return False
+
+ def _fix_jython_executable(self, executable):
+ if self._is_shell(executable):
+ # Workaround for Jython is not needed on Linux systems.
+ import java
+
+ if java.lang.System.getProperty('os.name') == 'Linux':
+ return executable
+ elif executable.lower().endswith('jython.exe'):
+ # Use wrapper exe for Jython on Windows
+ return executable
+ return '/usr/bin/env %s' % executable
+
+ def _build_shebang(self, executable, post_interp):
+ """
+ Build a shebang line. In the simple case (on Windows, or a shebang line
+ which is not too long or contains spaces) use a simple formulation for
+ the shebang. Otherwise, use /bin/sh as the executable, with a contrived
+ shebang which allows the script to run either under Python or sh, using
+ suitable quoting. Thanks to Harald Nordgren for his input.
+
+ See also: http://www.in-ulm.de/~mascheck/various/shebang/#length
+ https://hg.mozilla.org/mozilla-central/file/tip/mach
+ """
+ if os.name != 'posix':
+ simple_shebang = True
+ elif getattr(sys, "cross_compiling", False):
+ # In a cross-compiling environment, the shebang will likely be a
+ # script; this *must* be invoked with the "safe" version of the
+ # shebang, or else using os.exec() to run the entry script will
+ # fail, raising "OSError 8 [Errno 8] Exec format error".
+ simple_shebang = False
+ else:
+ # Add 3 for '#!' prefix and newline suffix.
+ shebang_length = len(executable) + len(post_interp) + 3
+ if sys.platform == 'darwin':
+ max_shebang_length = 512
+ else:
+ max_shebang_length = 127
+ simple_shebang = ((b' ' not in executable) and (shebang_length <= max_shebang_length))
+
+ if simple_shebang:
+ result = b'#!' + executable + post_interp + b'\n'
+ else:
+ result = b'#!/bin/sh\n'
+ result += b"'''exec' " + executable + post_interp + b' "$0" "$@"\n'
+ result += b"' '''\n"
+ return result
+
+ def _get_shebang(self, encoding, post_interp=b'', options=None):
+ enquote = True
+ if self.executable:
+ executable = self.executable
+ enquote = False # assume this will be taken care of
+ elif not sysconfig.is_python_build():
+ executable = get_executable()
+ elif in_venv(): # pragma: no cover
+ executable = os.path.join(sysconfig.get_path('scripts'), 'python%s' % sysconfig.get_config_var('EXE'))
+ else: # pragma: no cover
+ if os.name == 'nt':
+ # for Python builds from source on Windows, no Python executables with
+ # a version suffix are created, so we use python.exe
+ executable = os.path.join(sysconfig.get_config_var('BINDIR'),
+ 'python%s' % (sysconfig.get_config_var('EXE')))
+ else:
+ executable = os.path.join(
+ sysconfig.get_config_var('BINDIR'),
+ 'python%s%s' % (sysconfig.get_config_var('VERSION'), sysconfig.get_config_var('EXE')))
+ if options:
+ executable = self._get_alternate_executable(executable, options)
+
+ if sys.platform.startswith('java'): # pragma: no cover
+ executable = self._fix_jython_executable(executable)
+
+ # Normalise case for Windows - COMMENTED OUT
+ # executable = os.path.normcase(executable)
+ # N.B. The normalising operation above has been commented out: See
+ # issue #124. Although paths in Windows are generally case-insensitive,
+ # they aren't always. For example, a path containing a ẞ (which is a
+ # LATIN CAPITAL LETTER SHARP S - U+1E9E) is normcased to ß (which is a
+ # LATIN SMALL LETTER SHARP S' - U+00DF). The two are not considered by
+ # Windows as equivalent in path names.
+
+ # If the user didn't specify an executable, it may be necessary to
+ # cater for executable paths with spaces (not uncommon on Windows)
+ if enquote:
+ executable = enquote_executable(executable)
+ # Issue #51: don't use fsencode, since we later try to
+ # check that the shebang is decodable using utf-8.
+ executable = executable.encode('utf-8')
+ # in case of IronPython, play safe and enable frames support
+ if (sys.platform == 'cli' and '-X:Frames' not in post_interp and
+ '-X:FullFrames' not in post_interp): # pragma: no cover
+ post_interp += b' -X:Frames'
+ shebang = self._build_shebang(executable, post_interp)
+ # Python parser starts to read a script using UTF-8 until
+ # it gets a #coding:xxx cookie. The shebang has to be the
+ # first line of a file, the #coding:xxx cookie cannot be
+ # written before. So the shebang has to be decodable from
+ # UTF-8.
+ try:
+ shebang.decode('utf-8')
+ except UnicodeDecodeError: # pragma: no cover
+ raise ValueError('The shebang (%r) is not decodable from utf-8' % shebang)
+ # If the script is encoded to a custom encoding (use a
+ # #coding:xxx cookie), the shebang has to be decodable from
+ # the script encoding too.
+ if encoding != 'utf-8':
+ try:
+ shebang.decode(encoding)
+ except UnicodeDecodeError: # pragma: no cover
+ raise ValueError('The shebang (%r) is not decodable '
+ 'from the script encoding (%r)' % (shebang, encoding))
+ return shebang
+
+ def _get_script_text(self, entry):
+ return self.script_template % dict(
+ module=entry.prefix, import_name=entry.suffix.split('.')[0], func=entry.suffix)
+
+ manifest = _DEFAULT_MANIFEST
+
+ def get_manifest(self, exename):
+ base = os.path.basename(exename)
+ return self.manifest % base
+
+ def _write_script(self, names, shebang, script_bytes, filenames, ext):
+ use_launcher = self.add_launchers and self._is_nt
+ if not use_launcher:
+ script_bytes = shebang + script_bytes
+ else: # pragma: no cover
+ if ext == 'py':
+ launcher = self._get_launcher('t')
+ else:
+ launcher = self._get_launcher('w')
+ stream = BytesIO()
+ with ZipFile(stream, 'w') as zf:
+ source_date_epoch = os.environ.get('SOURCE_DATE_EPOCH')
+ if source_date_epoch:
+ date_time = time.gmtime(int(source_date_epoch))[:6]
+ zinfo = ZipInfo(filename='__main__.py', date_time=date_time)
+ zf.writestr(zinfo, script_bytes)
+ else:
+ zf.writestr('__main__.py', script_bytes)
+ zip_data = stream.getvalue()
+ script_bytes = launcher + shebang + zip_data
+ for name in names:
+ outname = os.path.join(self.target_dir, name)
+ if use_launcher: # pragma: no cover
+ n, e = os.path.splitext(outname)
+ if e.startswith('.py'):
+ outname = n
+ outname = '%s.exe' % outname
+ try:
+ self._fileop.write_binary_file(outname, script_bytes)
+ except Exception:
+ # Failed writing an executable - it might be in use.
+ logger.warning('Failed to write executable - trying to '
+ 'use .deleteme logic')
+ dfname = '%s.deleteme' % outname
+ if os.path.exists(dfname):
+ os.remove(dfname) # Not allowed to fail here
+ os.rename(outname, dfname) # nor here
+ self._fileop.write_binary_file(outname, script_bytes)
+ logger.debug('Able to replace executable using '
+ '.deleteme logic')
+ try:
+ os.remove(dfname)
+ except Exception:
+ pass # still in use - ignore error
+ else:
+ if self._is_nt and not outname.endswith('.' + ext): # pragma: no cover
+ outname = '%s.%s' % (outname, ext)
+ if os.path.exists(outname) and not self.clobber:
+ logger.warning('Skipping existing file %s', outname)
+ continue
+ self._fileop.write_binary_file(outname, script_bytes)
+ if self.set_mode:
+ self._fileop.set_executable_mode([outname])
+ filenames.append(outname)
+
+ variant_separator = '-'
+
+ def get_script_filenames(self, name):
+ result = set()
+ if '' in self.variants:
+ result.add(name)
+ if 'X' in self.variants:
+ result.add('%s%s' % (name, self.version_info[0]))
+ if 'X.Y' in self.variants:
+ result.add('%s%s%s.%s' % (name, self.variant_separator, self.version_info[0], self.version_info[1]))
+ return result
+
+ def _make_script(self, entry, filenames, options=None):
+ post_interp = b''
+ if options:
+ args = options.get('interpreter_args', [])
+ if args:
+ args = ' %s' % ' '.join(args)
+ post_interp = args.encode('utf-8')
+ shebang = self._get_shebang('utf-8', post_interp, options=options)
+ script = self._get_script_text(entry).encode('utf-8')
+ scriptnames = self.get_script_filenames(entry.name)
+ if options and options.get('gui', False):
+ ext = 'pyw'
+ else:
+ ext = 'py'
+ self._write_script(scriptnames, shebang, script, filenames, ext)
+
+ def _copy_script(self, script, filenames):
+ adjust = False
+ script = os.path.join(self.source_dir, convert_path(script))
+ outname = os.path.join(self.target_dir, os.path.basename(script))
+ if not self.force and not self._fileop.newer(script, outname):
+ logger.debug('not copying %s (up-to-date)', script)
+ return
+
+ # Always open the file, but ignore failures in dry-run mode --
+ # that way, we'll get accurate feedback if we can read the
+ # script.
+ try:
+ f = open(script, 'rb')
+ except IOError: # pragma: no cover
+ if not self.dry_run:
+ raise
+ f = None
+ else:
+ first_line = f.readline()
+ if not first_line: # pragma: no cover
+ logger.warning('%s is an empty file (skipping)', script)
+ return
+
+ match = FIRST_LINE_RE.match(first_line.replace(b'\r\n', b'\n'))
+ if match:
+ adjust = True
+ post_interp = match.group(1) or b''
+
+ if not adjust:
+ if f:
+ f.close()
+ self._fileop.copy_file(script, outname)
+ if self.set_mode:
+ self._fileop.set_executable_mode([outname])
+ filenames.append(outname)
+ else:
+ logger.info('copying and adjusting %s -> %s', script, self.target_dir)
+ if not self._fileop.dry_run:
+ encoding, lines = detect_encoding(f.readline)
+ f.seek(0)
+ shebang = self._get_shebang(encoding, post_interp)
+ if b'pythonw' in first_line: # pragma: no cover
+ ext = 'pyw'
+ else:
+ ext = 'py'
+ n = os.path.basename(outname)
+ self._write_script([n], shebang, f.read(), filenames, ext)
+ if f:
+ f.close()
+
+ @property
+ def dry_run(self):
+ return self._fileop.dry_run
+
+ @dry_run.setter
+ def dry_run(self, value):
+ self._fileop.dry_run = value
+
+ if os.name == 'nt' or (os.name == 'java' and os._name == 'nt'): # pragma: no cover
+ # Executable launcher support.
+ # Launchers are from https://bitbucket.org/vinay.sajip/simple_launcher/
+
+ def _get_launcher(self, kind):
+ if struct.calcsize('P') == 8: # 64-bit
+ bits = '64'
+ else:
+ bits = '32'
+ platform_suffix = '-arm' if get_platform() == 'win-arm64' else ''
+ name = '%s%s%s.exe' % (kind, bits, platform_suffix)
+ if name not in WRAPPERS:
+ msg = ('Unable to find resource %s in package %s' %
+ (name, DISTLIB_PACKAGE))
+ raise ValueError(msg)
+ return WRAPPERS[name]
+
+ # Public API follows
+
+ def make(self, specification, options=None):
+ """
+ Make a script.
+
+ :param specification: The specification, which is either a valid export
+ entry specification (to make a script from a
+ callable) or a filename (to make a script by
+ copying from a source location).
+ :param options: A dictionary of options controlling script generation.
+ :return: A list of all absolute pathnames written to.
+ """
+ filenames = []
+ entry = get_export_entry(specification)
+ if entry is None:
+ self._copy_script(specification, filenames)
+ else:
+ self._make_script(entry, filenames, options=options)
+ return filenames
+
+ def make_multiple(self, specifications, options=None):
+ """
+ Take a list of specifications and make scripts from them,
+ :param specifications: A list of specifications.
+ :return: A list of all absolute pathnames written to,
+ """
+ filenames = []
+ for specification in specifications:
+ filenames.extend(self.make(specification, options))
+ return filenames
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t32.exe b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t32.exe
new file mode 100644
index 000000000..52154f0be
Binary files /dev/null and b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t32.exe differ
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t64-arm.exe b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t64-arm.exe
new file mode 100644
index 000000000..e1ab8f8f5
Binary files /dev/null and b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t64-arm.exe differ
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t64.exe b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t64.exe
new file mode 100644
index 000000000..e8bebdba6
Binary files /dev/null and b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/t64.exe differ
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/util.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/util.py
new file mode 100644
index 000000000..0d5bd7a8b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/util.py
@@ -0,0 +1,1984 @@
+#
+# Copyright (C) 2012-2023 The Python Software Foundation.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+import codecs
+from collections import deque
+import contextlib
+import csv
+from glob import iglob as std_iglob
+import io
+import json
+import logging
+import os
+import py_compile
+import re
+import socket
+try:
+ import ssl
+except ImportError: # pragma: no cover
+ ssl = None
+import subprocess
+import sys
+import tarfile
+import tempfile
+import textwrap
+
+try:
+ import threading
+except ImportError: # pragma: no cover
+ import dummy_threading as threading
+import time
+
+from . import DistlibException
+from .compat import (string_types, text_type, shutil, raw_input, StringIO, cache_from_source, urlopen, urljoin, httplib,
+ xmlrpclib, HTTPHandler, BaseConfigurator, valid_ident, Container, configparser, URLError, ZipFile,
+ fsdecode, unquote, urlparse)
+
+logger = logging.getLogger(__name__)
+
+#
+# Requirement parsing code as per PEP 508
+#
+
+IDENTIFIER = re.compile(r'^([\w\.-]+)\s*')
+VERSION_IDENTIFIER = re.compile(r'^([\w\.*+-]+)\s*')
+COMPARE_OP = re.compile(r'^(<=?|>=?|={2,3}|[~!]=)\s*')
+MARKER_OP = re.compile(r'^((<=?)|(>=?)|={2,3}|[~!]=|in|not\s+in)\s*')
+OR = re.compile(r'^or\b\s*')
+AND = re.compile(r'^and\b\s*')
+NON_SPACE = re.compile(r'(\S+)\s*')
+STRING_CHUNK = re.compile(r'([\s\w\.{}()*+#:;,/?!~`@$%^&=|<>\[\]-]+)')
+
+
+def parse_marker(marker_string):
+ """
+ Parse a marker string and return a dictionary containing a marker expression.
+
+ The dictionary will contain keys "op", "lhs" and "rhs" for non-terminals in
+ the expression grammar, or strings. A string contained in quotes is to be
+ interpreted as a literal string, and a string not contained in quotes is a
+ variable (such as os_name).
+ """
+
+ def marker_var(remaining):
+ # either identifier, or literal string
+ m = IDENTIFIER.match(remaining)
+ if m:
+ result = m.groups()[0]
+ remaining = remaining[m.end():]
+ elif not remaining:
+ raise SyntaxError('unexpected end of input')
+ else:
+ q = remaining[0]
+ if q not in '\'"':
+ raise SyntaxError('invalid expression: %s' % remaining)
+ oq = '\'"'.replace(q, '')
+ remaining = remaining[1:]
+ parts = [q]
+ while remaining:
+ # either a string chunk, or oq, or q to terminate
+ if remaining[0] == q:
+ break
+ elif remaining[0] == oq:
+ parts.append(oq)
+ remaining = remaining[1:]
+ else:
+ m = STRING_CHUNK.match(remaining)
+ if not m:
+ raise SyntaxError('error in string literal: %s' % remaining)
+ parts.append(m.groups()[0])
+ remaining = remaining[m.end():]
+ else:
+ s = ''.join(parts)
+ raise SyntaxError('unterminated string: %s' % s)
+ parts.append(q)
+ result = ''.join(parts)
+ remaining = remaining[1:].lstrip() # skip past closing quote
+ return result, remaining
+
+ def marker_expr(remaining):
+ if remaining and remaining[0] == '(':
+ result, remaining = marker(remaining[1:].lstrip())
+ if remaining[0] != ')':
+ raise SyntaxError('unterminated parenthesis: %s' % remaining)
+ remaining = remaining[1:].lstrip()
+ else:
+ lhs, remaining = marker_var(remaining)
+ while remaining:
+ m = MARKER_OP.match(remaining)
+ if not m:
+ break
+ op = m.groups()[0]
+ remaining = remaining[m.end():]
+ rhs, remaining = marker_var(remaining)
+ lhs = {'op': op, 'lhs': lhs, 'rhs': rhs}
+ result = lhs
+ return result, remaining
+
+ def marker_and(remaining):
+ lhs, remaining = marker_expr(remaining)
+ while remaining:
+ m = AND.match(remaining)
+ if not m:
+ break
+ remaining = remaining[m.end():]
+ rhs, remaining = marker_expr(remaining)
+ lhs = {'op': 'and', 'lhs': lhs, 'rhs': rhs}
+ return lhs, remaining
+
+ def marker(remaining):
+ lhs, remaining = marker_and(remaining)
+ while remaining:
+ m = OR.match(remaining)
+ if not m:
+ break
+ remaining = remaining[m.end():]
+ rhs, remaining = marker_and(remaining)
+ lhs = {'op': 'or', 'lhs': lhs, 'rhs': rhs}
+ return lhs, remaining
+
+ return marker(marker_string)
+
+
+def parse_requirement(req):
+ """
+ Parse a requirement passed in as a string. Return a Container
+ whose attributes contain the various parts of the requirement.
+ """
+ remaining = req.strip()
+ if not remaining or remaining.startswith('#'):
+ return None
+ m = IDENTIFIER.match(remaining)
+ if not m:
+ raise SyntaxError('name expected: %s' % remaining)
+ distname = m.groups()[0]
+ remaining = remaining[m.end():]
+ extras = mark_expr = versions = uri = None
+ if remaining and remaining[0] == '[':
+ i = remaining.find(']', 1)
+ if i < 0:
+ raise SyntaxError('unterminated extra: %s' % remaining)
+ s = remaining[1:i]
+ remaining = remaining[i + 1:].lstrip()
+ extras = []
+ while s:
+ m = IDENTIFIER.match(s)
+ if not m:
+ raise SyntaxError('malformed extra: %s' % s)
+ extras.append(m.groups()[0])
+ s = s[m.end():]
+ if not s:
+ break
+ if s[0] != ',':
+ raise SyntaxError('comma expected in extras: %s' % s)
+ s = s[1:].lstrip()
+ if not extras:
+ extras = None
+ if remaining:
+ if remaining[0] == '@':
+ # it's a URI
+ remaining = remaining[1:].lstrip()
+ m = NON_SPACE.match(remaining)
+ if not m:
+ raise SyntaxError('invalid URI: %s' % remaining)
+ uri = m.groups()[0]
+ t = urlparse(uri)
+ # there are issues with Python and URL parsing, so this test
+ # is a bit crude. See bpo-20271, bpo-23505. Python doesn't
+ # always parse invalid URLs correctly - it should raise
+ # exceptions for malformed URLs
+ if not (t.scheme and t.netloc):
+ raise SyntaxError('Invalid URL: %s' % uri)
+ remaining = remaining[m.end():].lstrip()
+ else:
+
+ def get_versions(ver_remaining):
+ """
+ Return a list of operator, version tuples if any are
+ specified, else None.
+ """
+ m = COMPARE_OP.match(ver_remaining)
+ versions = None
+ if m:
+ versions = []
+ while True:
+ op = m.groups()[0]
+ ver_remaining = ver_remaining[m.end():]
+ m = VERSION_IDENTIFIER.match(ver_remaining)
+ if not m:
+ raise SyntaxError('invalid version: %s' % ver_remaining)
+ v = m.groups()[0]
+ versions.append((op, v))
+ ver_remaining = ver_remaining[m.end():]
+ if not ver_remaining or ver_remaining[0] != ',':
+ break
+ ver_remaining = ver_remaining[1:].lstrip()
+ # Some packages have a trailing comma which would break things
+ # See issue #148
+ if not ver_remaining:
+ break
+ m = COMPARE_OP.match(ver_remaining)
+ if not m:
+ raise SyntaxError('invalid constraint: %s' % ver_remaining)
+ if not versions:
+ versions = None
+ return versions, ver_remaining
+
+ if remaining[0] != '(':
+ versions, remaining = get_versions(remaining)
+ else:
+ i = remaining.find(')', 1)
+ if i < 0:
+ raise SyntaxError('unterminated parenthesis: %s' % remaining)
+ s = remaining[1:i]
+ remaining = remaining[i + 1:].lstrip()
+ # As a special diversion from PEP 508, allow a version number
+ # a.b.c in parentheses as a synonym for ~= a.b.c (because this
+ # is allowed in earlier PEPs)
+ if COMPARE_OP.match(s):
+ versions, _ = get_versions(s)
+ else:
+ m = VERSION_IDENTIFIER.match(s)
+ if not m:
+ raise SyntaxError('invalid constraint: %s' % s)
+ v = m.groups()[0]
+ s = s[m.end():].lstrip()
+ if s:
+ raise SyntaxError('invalid constraint: %s' % s)
+ versions = [('~=', v)]
+
+ if remaining:
+ if remaining[0] != ';':
+ raise SyntaxError('invalid requirement: %s' % remaining)
+ remaining = remaining[1:].lstrip()
+
+ mark_expr, remaining = parse_marker(remaining)
+
+ if remaining and remaining[0] != '#':
+ raise SyntaxError('unexpected trailing data: %s' % remaining)
+
+ if not versions:
+ rs = distname
+ else:
+ rs = '%s %s' % (distname, ', '.join(['%s %s' % con for con in versions]))
+ return Container(name=distname, extras=extras, constraints=versions, marker=mark_expr, url=uri, requirement=rs)
+
+
+def get_resources_dests(resources_root, rules):
+ """Find destinations for resources files"""
+
+ def get_rel_path(root, path):
+ # normalizes and returns a lstripped-/-separated path
+ root = root.replace(os.path.sep, '/')
+ path = path.replace(os.path.sep, '/')
+ assert path.startswith(root)
+ return path[len(root):].lstrip('/')
+
+ destinations = {}
+ for base, suffix, dest in rules:
+ prefix = os.path.join(resources_root, base)
+ for abs_base in iglob(prefix):
+ abs_glob = os.path.join(abs_base, suffix)
+ for abs_path in iglob(abs_glob):
+ resource_file = get_rel_path(resources_root, abs_path)
+ if dest is None: # remove the entry if it was here
+ destinations.pop(resource_file, None)
+ else:
+ rel_path = get_rel_path(abs_base, abs_path)
+ rel_dest = dest.replace(os.path.sep, '/').rstrip('/')
+ destinations[resource_file] = rel_dest + '/' + rel_path
+ return destinations
+
+
+def in_venv():
+ if hasattr(sys, 'real_prefix'):
+ # virtualenv venvs
+ result = True
+ else:
+ # PEP 405 venvs
+ result = sys.prefix != getattr(sys, 'base_prefix', sys.prefix)
+ return result
+
+
+def get_executable():
+ # The __PYVENV_LAUNCHER__ dance is apparently no longer needed, as
+ # changes to the stub launcher mean that sys.executable always points
+ # to the stub on OS X
+ # if sys.platform == 'darwin' and ('__PYVENV_LAUNCHER__'
+ # in os.environ):
+ # result = os.environ['__PYVENV_LAUNCHER__']
+ # else:
+ # result = sys.executable
+ # return result
+ # Avoid normcasing: see issue #143
+ # result = os.path.normcase(sys.executable)
+ result = sys.executable
+ if not isinstance(result, text_type):
+ result = fsdecode(result)
+ return result
+
+
+def proceed(prompt, allowed_chars, error_prompt=None, default=None):
+ p = prompt
+ while True:
+ s = raw_input(p)
+ p = prompt
+ if not s and default:
+ s = default
+ if s:
+ c = s[0].lower()
+ if c in allowed_chars:
+ break
+ if error_prompt:
+ p = '%c: %s\n%s' % (c, error_prompt, prompt)
+ return c
+
+
+def extract_by_key(d, keys):
+ if isinstance(keys, string_types):
+ keys = keys.split()
+ result = {}
+ for key in keys:
+ if key in d:
+ result[key] = d[key]
+ return result
+
+
+def read_exports(stream):
+ if sys.version_info[0] >= 3:
+ # needs to be a text stream
+ stream = codecs.getreader('utf-8')(stream)
+ # Try to load as JSON, falling back on legacy format
+ data = stream.read()
+ stream = StringIO(data)
+ try:
+ jdata = json.load(stream)
+ result = jdata['extensions']['python.exports']['exports']
+ for group, entries in result.items():
+ for k, v in entries.items():
+ s = '%s = %s' % (k, v)
+ entry = get_export_entry(s)
+ assert entry is not None
+ entries[k] = entry
+ return result
+ except Exception:
+ stream.seek(0, 0)
+
+ def read_stream(cp, stream):
+ if hasattr(cp, 'read_file'):
+ cp.read_file(stream)
+ else:
+ cp.readfp(stream)
+
+ cp = configparser.ConfigParser()
+ try:
+ read_stream(cp, stream)
+ except configparser.MissingSectionHeaderError:
+ stream.close()
+ data = textwrap.dedent(data)
+ stream = StringIO(data)
+ read_stream(cp, stream)
+
+ result = {}
+ for key in cp.sections():
+ result[key] = entries = {}
+ for name, value in cp.items(key):
+ s = '%s = %s' % (name, value)
+ entry = get_export_entry(s)
+ assert entry is not None
+ # entry.dist = self
+ entries[name] = entry
+ return result
+
+
+def write_exports(exports, stream):
+ if sys.version_info[0] >= 3:
+ # needs to be a text stream
+ stream = codecs.getwriter('utf-8')(stream)
+ cp = configparser.ConfigParser()
+ for k, v in exports.items():
+ # TODO check k, v for valid values
+ cp.add_section(k)
+ for entry in v.values():
+ if entry.suffix is None:
+ s = entry.prefix
+ else:
+ s = '%s:%s' % (entry.prefix, entry.suffix)
+ if entry.flags:
+ s = '%s [%s]' % (s, ', '.join(entry.flags))
+ cp.set(k, entry.name, s)
+ cp.write(stream)
+
+
+@contextlib.contextmanager
+def tempdir():
+ td = tempfile.mkdtemp()
+ try:
+ yield td
+ finally:
+ shutil.rmtree(td)
+
+
+@contextlib.contextmanager
+def chdir(d):
+ cwd = os.getcwd()
+ try:
+ os.chdir(d)
+ yield
+ finally:
+ os.chdir(cwd)
+
+
+@contextlib.contextmanager
+def socket_timeout(seconds=15):
+ cto = socket.getdefaulttimeout()
+ try:
+ socket.setdefaulttimeout(seconds)
+ yield
+ finally:
+ socket.setdefaulttimeout(cto)
+
+
+class cached_property(object):
+
+ def __init__(self, func):
+ self.func = func
+ # for attr in ('__name__', '__module__', '__doc__'):
+ # setattr(self, attr, getattr(func, attr, None))
+
+ def __get__(self, obj, cls=None):
+ if obj is None:
+ return self
+ value = self.func(obj)
+ object.__setattr__(obj, self.func.__name__, value)
+ # obj.__dict__[self.func.__name__] = value = self.func(obj)
+ return value
+
+
+def convert_path(pathname):
+ """Return 'pathname' as a name that will work on the native filesystem.
+
+ The path is split on '/' and put back together again using the current
+ directory separator. Needed because filenames in the setup script are
+ always supplied in Unix style, and have to be converted to the local
+ convention before we can actually use them in the filesystem. Raises
+ ValueError on non-Unix-ish systems if 'pathname' either starts or
+ ends with a slash.
+ """
+ if os.sep == '/':
+ return pathname
+ if not pathname:
+ return pathname
+ if pathname[0] == '/':
+ raise ValueError("path '%s' cannot be absolute" % pathname)
+ if pathname[-1] == '/':
+ raise ValueError("path '%s' cannot end with '/'" % pathname)
+
+ paths = pathname.split('/')
+ while os.curdir in paths:
+ paths.remove(os.curdir)
+ if not paths:
+ return os.curdir
+ return os.path.join(*paths)
+
+
+class FileOperator(object):
+
+ def __init__(self, dry_run=False):
+ self.dry_run = dry_run
+ self.ensured = set()
+ self._init_record()
+
+ def _init_record(self):
+ self.record = False
+ self.files_written = set()
+ self.dirs_created = set()
+
+ def record_as_written(self, path):
+ if self.record:
+ self.files_written.add(path)
+
+ def newer(self, source, target):
+ """Tell if the target is newer than the source.
+
+ Returns true if 'source' exists and is more recently modified than
+ 'target', or if 'source' exists and 'target' doesn't.
+
+ Returns false if both exist and 'target' is the same age or younger
+ than 'source'. Raise PackagingFileError if 'source' does not exist.
+
+ Note that this test is not very accurate: files created in the same
+ second will have the same "age".
+ """
+ if not os.path.exists(source):
+ raise DistlibException("file '%r' does not exist" % os.path.abspath(source))
+ if not os.path.exists(target):
+ return True
+
+ return os.stat(source).st_mtime > os.stat(target).st_mtime
+
+ def copy_file(self, infile, outfile, check=True):
+ """Copy a file respecting dry-run and force flags.
+ """
+ self.ensure_dir(os.path.dirname(outfile))
+ logger.info('Copying %s to %s', infile, outfile)
+ if not self.dry_run:
+ msg = None
+ if check:
+ if os.path.islink(outfile):
+ msg = '%s is a symlink' % outfile
+ elif os.path.exists(outfile) and not os.path.isfile(outfile):
+ msg = '%s is a non-regular file' % outfile
+ if msg:
+ raise ValueError(msg + ' which would be overwritten')
+ shutil.copyfile(infile, outfile)
+ self.record_as_written(outfile)
+
+ def copy_stream(self, instream, outfile, encoding=None):
+ assert not os.path.isdir(outfile)
+ self.ensure_dir(os.path.dirname(outfile))
+ logger.info('Copying stream %s to %s', instream, outfile)
+ if not self.dry_run:
+ if encoding is None:
+ outstream = open(outfile, 'wb')
+ else:
+ outstream = codecs.open(outfile, 'w', encoding=encoding)
+ try:
+ shutil.copyfileobj(instream, outstream)
+ finally:
+ outstream.close()
+ self.record_as_written(outfile)
+
+ def write_binary_file(self, path, data):
+ self.ensure_dir(os.path.dirname(path))
+ if not self.dry_run:
+ if os.path.exists(path):
+ os.remove(path)
+ with open(path, 'wb') as f:
+ f.write(data)
+ self.record_as_written(path)
+
+ def write_text_file(self, path, data, encoding):
+ self.write_binary_file(path, data.encode(encoding))
+
+ def set_mode(self, bits, mask, files):
+ if os.name == 'posix' or (os.name == 'java' and os._name == 'posix'):
+ # Set the executable bits (owner, group, and world) on
+ # all the files specified.
+ for f in files:
+ if self.dry_run:
+ logger.info("changing mode of %s", f)
+ else:
+ mode = (os.stat(f).st_mode | bits) & mask
+ logger.info("changing mode of %s to %o", f, mode)
+ os.chmod(f, mode)
+
+ set_executable_mode = lambda s, f: s.set_mode(0o555, 0o7777, f)
+
+ def ensure_dir(self, path):
+ path = os.path.abspath(path)
+ if path not in self.ensured and not os.path.exists(path):
+ self.ensured.add(path)
+ d, f = os.path.split(path)
+ self.ensure_dir(d)
+ logger.info('Creating %s' % path)
+ if not self.dry_run:
+ os.mkdir(path)
+ if self.record:
+ self.dirs_created.add(path)
+
+ def byte_compile(self, path, optimize=False, force=False, prefix=None, hashed_invalidation=False):
+ dpath = cache_from_source(path, not optimize)
+ logger.info('Byte-compiling %s to %s', path, dpath)
+ if not self.dry_run:
+ if force or self.newer(path, dpath):
+ if not prefix:
+ diagpath = None
+ else:
+ assert path.startswith(prefix)
+ diagpath = path[len(prefix):]
+ compile_kwargs = {}
+ if hashed_invalidation and hasattr(py_compile, 'PycInvalidationMode'):
+ if not isinstance(hashed_invalidation, py_compile.PycInvalidationMode):
+ hashed_invalidation = py_compile.PycInvalidationMode.CHECKED_HASH
+ compile_kwargs['invalidation_mode'] = hashed_invalidation
+ py_compile.compile(path, dpath, diagpath, True, **compile_kwargs) # raise error
+ self.record_as_written(dpath)
+ return dpath
+
+ def ensure_removed(self, path):
+ if os.path.exists(path):
+ if os.path.isdir(path) and not os.path.islink(path):
+ logger.debug('Removing directory tree at %s', path)
+ if not self.dry_run:
+ shutil.rmtree(path)
+ if self.record:
+ if path in self.dirs_created:
+ self.dirs_created.remove(path)
+ else:
+ if os.path.islink(path):
+ s = 'link'
+ else:
+ s = 'file'
+ logger.debug('Removing %s %s', s, path)
+ if not self.dry_run:
+ os.remove(path)
+ if self.record:
+ if path in self.files_written:
+ self.files_written.remove(path)
+
+ def is_writable(self, path):
+ result = False
+ while not result:
+ if os.path.exists(path):
+ result = os.access(path, os.W_OK)
+ break
+ parent = os.path.dirname(path)
+ if parent == path:
+ break
+ path = parent
+ return result
+
+ def commit(self):
+ """
+ Commit recorded changes, turn off recording, return
+ changes.
+ """
+ assert self.record
+ result = self.files_written, self.dirs_created
+ self._init_record()
+ return result
+
+ def rollback(self):
+ if not self.dry_run:
+ for f in list(self.files_written):
+ if os.path.exists(f):
+ os.remove(f)
+ # dirs should all be empty now, except perhaps for
+ # __pycache__ subdirs
+ # reverse so that subdirs appear before their parents
+ dirs = sorted(self.dirs_created, reverse=True)
+ for d in dirs:
+ flist = os.listdir(d)
+ if flist:
+ assert flist == ['__pycache__']
+ sd = os.path.join(d, flist[0])
+ os.rmdir(sd)
+ os.rmdir(d) # should fail if non-empty
+ self._init_record()
+
+
+def resolve(module_name, dotted_path):
+ if module_name in sys.modules:
+ mod = sys.modules[module_name]
+ else:
+ mod = __import__(module_name)
+ if dotted_path is None:
+ result = mod
+ else:
+ parts = dotted_path.split('.')
+ result = getattr(mod, parts.pop(0))
+ for p in parts:
+ result = getattr(result, p)
+ return result
+
+
+class ExportEntry(object):
+
+ def __init__(self, name, prefix, suffix, flags):
+ self.name = name
+ self.prefix = prefix
+ self.suffix = suffix
+ self.flags = flags
+
+ @cached_property
+ def value(self):
+ return resolve(self.prefix, self.suffix)
+
+ def __repr__(self): # pragma: no cover
+ return '<ExportEntry %s = %s:%s %s>' % (self.name, self.prefix, self.suffix, self.flags)
+
+ def __eq__(self, other):
+ if not isinstance(other, ExportEntry):
+ result = False
+ else:
+ result = (self.name == other.name and self.prefix == other.prefix and self.suffix == other.suffix and
+ self.flags == other.flags)
+ return result
+
+ __hash__ = object.__hash__
+
+
+ENTRY_RE = re.compile(
+ r'''(?P<name>([^\[]\S*))
+ \s*=\s*(?P<callable>(\w+)([:\.]\w+)*)
+ \s*(\[\s*(?P<flags>[\w-]+(=\w+)?(,\s*\w+(=\w+)?)*)\s*\])?
+ ''', re.VERBOSE)
+
+
+def get_export_entry(specification):
+ m = ENTRY_RE.search(specification)
+ if not m:
+ result = None
+ if '[' in specification or ']' in specification:
+ raise DistlibException("Invalid specification "
+ "'%s'" % specification)
+ else:
+ d = m.groupdict()
+ name = d['name']
+ path = d['callable']
+ colons = path.count(':')
+ if colons == 0:
+ prefix, suffix = path, None
+ else:
+ if colons != 1:
+ raise DistlibException("Invalid specification "
+ "'%s'" % specification)
+ prefix, suffix = path.split(':')
+ flags = d['flags']
+ if flags is None:
+ if '[' in specification or ']' in specification:
+ raise DistlibException("Invalid specification "
+ "'%s'" % specification)
+ flags = []
+ else:
+ flags = [f.strip() for f in flags.split(',')]
+ result = ExportEntry(name, prefix, suffix, flags)
+ return result
+
+
+def get_cache_base(suffix=None):
+ """
+ Return the default base location for distlib caches. If the directory does
+ not exist, it is created. Use the suffix provided for the base directory,
+ and default to '.distlib' if it isn't provided.
+
+ On Windows, if LOCALAPPDATA is defined in the environment, then it is
+ assumed to be a directory, and will be the parent directory of the result.
+ On POSIX, and on Windows if LOCALAPPDATA is not defined, the user's home
+ directory - using os.expanduser('~') - will be the parent directory of
+ the result.
+
+ The result is just the directory '.distlib' in the parent directory as
+ determined above, or with the name specified with ``suffix``.
+ """
+ if suffix is None:
+ suffix = '.distlib'
+ if os.name == 'nt' and 'LOCALAPPDATA' in os.environ:
+ result = os.path.expandvars('$localappdata')
+ else:
+ # Assume posix, or old Windows
+ result = os.path.expanduser('~')
+ # we use 'isdir' instead of 'exists', because we want to
+ # fail if there's a file with that name
+ if os.path.isdir(result):
+ usable = os.access(result, os.W_OK)
+ if not usable:
+ logger.warning('Directory exists but is not writable: %s', result)
+ else:
+ try:
+ os.makedirs(result)
+ usable = True
+ except OSError:
+ logger.warning('Unable to create %s', result, exc_info=True)
+ usable = False
+ if not usable:
+ result = tempfile.mkdtemp()
+ logger.warning('Default location unusable, using %s', result)
+ return os.path.join(result, suffix)
+
+
+def path_to_cache_dir(path, use_abspath=True):
+ """
+ Convert an absolute path to a directory name for use in a cache.
+
+ The algorithm used is:
+
+ #. On Windows, any ``':'`` in the drive is replaced with ``'---'``.
+ #. Any occurrence of ``os.sep`` is replaced with ``'--'``.
+ #. ``'.cache'`` is appended.
+ """
+ d, p = os.path.splitdrive(os.path.abspath(path) if use_abspath else path)
+ if d:
+ d = d.replace(':', '---')
+ p = p.replace(os.sep, '--')
+ return d + p + '.cache'
+
+
+def ensure_slash(s):
+ if not s.endswith('/'):
+ return s + '/'
+ return s
+
+
+def parse_credentials(netloc):
+ username = password = None
+ if '@' in netloc:
+ prefix, netloc = netloc.rsplit('@', 1)
+ if ':' not in prefix:
+ username = prefix
+ else:
+ username, password = prefix.split(':', 1)
+ if username:
+ username = unquote(username)
+ if password:
+ password = unquote(password)
+ return username, password, netloc
+
+
+def get_process_umask():
+ result = os.umask(0o22)
+ os.umask(result)
+ return result
+
+
+def is_string_sequence(seq):
+ result = True
+ i = None
+ for i, s in enumerate(seq):
+ if not isinstance(s, string_types):
+ result = False
+ break
+ assert i is not None
+ return result
+
+
+PROJECT_NAME_AND_VERSION = re.compile('([a-z0-9_]+([.-][a-z_][a-z0-9_]*)*)-'
+ '([a-z0-9_.+-]+)', re.I)
+PYTHON_VERSION = re.compile(r'-py(\d\.?\d?)')
+
+
+def split_filename(filename, project_name=None):
+ """
+ Extract name, version, python version from a filename (no extension)
+
+ Return name, version, pyver or None
+ """
+ result = None
+ pyver = None
+ filename = unquote(filename).replace(' ', '-')
+ m = PYTHON_VERSION.search(filename)
+ if m:
+ pyver = m.group(1)
+ filename = filename[:m.start()]
+ if project_name and len(filename) > len(project_name) + 1:
+ m = re.match(re.escape(project_name) + r'\b', filename)
+ if m:
+ n = m.end()
+ result = filename[:n], filename[n + 1:], pyver
+ if result is None:
+ m = PROJECT_NAME_AND_VERSION.match(filename)
+ if m:
+ result = m.group(1), m.group(3), pyver
+ return result
+
+
+# Allow spaces in name because of legacy dists like "Twisted Core"
+NAME_VERSION_RE = re.compile(r'(?P<name>[\w .-]+)\s*'
+ r'\(\s*(?P<ver>[^\s)]+)\)$')
+
+
+def parse_name_and_version(p):
+ """
+ A utility method used to get name and version from a string.
+
+ From e.g. a Provides-Dist value.
+
+ :param p: A value in a form 'foo (1.0)'
+ :return: The name and version as a tuple.
+ """
+ m = NAME_VERSION_RE.match(p)
+ if not m:
+ raise DistlibException('Ill-formed name/version string: \'%s\'' % p)
+ d = m.groupdict()
+ return d['name'].strip().lower(), d['ver']
+
+
+def get_extras(requested, available):
+ result = set()
+ requested = set(requested or [])
+ available = set(available or [])
+ if '*' in requested:
+ requested.remove('*')
+ result |= available
+ for r in requested:
+ if r == '-':
+ result.add(r)
+ elif r.startswith('-'):
+ unwanted = r[1:]
+ if unwanted not in available:
+ logger.warning('undeclared extra: %s' % unwanted)
+ if unwanted in result:
+ result.remove(unwanted)
+ else:
+ if r not in available:
+ logger.warning('undeclared extra: %s' % r)
+ result.add(r)
+ return result
+
+
+#
+# Extended metadata functionality
+#
+
+
+def _get_external_data(url):
+ result = {}
+ try:
+ # urlopen might fail if it runs into redirections,
+ # because of Python issue #13696. Fixed in locators
+ # using a custom redirect handler.
+ resp = urlopen(url)
+ headers = resp.info()
+ ct = headers.get('Content-Type')
+ if not ct.startswith('application/json'):
+ logger.debug('Unexpected response for JSON request: %s', ct)
+ else:
+ reader = codecs.getreader('utf-8')(resp)
+ # data = reader.read().decode('utf-8')
+ # result = json.loads(data)
+ result = json.load(reader)
+ except Exception as e:
+ logger.exception('Failed to get external data for %s: %s', url, e)
+ return result
+
+
+_external_data_base_url = 'https://www.red-dove.com/pypi/projects/'
+
+
+def get_project_data(name):
+ url = '%s/%s/project.json' % (name[0].upper(), name)
+ url = urljoin(_external_data_base_url, url)
+ result = _get_external_data(url)
+ return result
+
+
+def get_package_data(name, version):
+ url = '%s/%s/package-%s.json' % (name[0].upper(), name, version)
+ url = urljoin(_external_data_base_url, url)
+ return _get_external_data(url)
+
+
+class Cache(object):
+ """
+ A class implementing a cache for resources that need to live in the file system
+ e.g. shared libraries. This class was moved from resources to here because it
+ could be used by other modules, e.g. the wheel module.
+ """
+
+ def __init__(self, base):
+ """
+ Initialise an instance.
+
+ :param base: The base directory where the cache should be located.
+ """
+ # we use 'isdir' instead of 'exists', because we want to
+ # fail if there's a file with that name
+ if not os.path.isdir(base): # pragma: no cover
+ os.makedirs(base)
+ if (os.stat(base).st_mode & 0o77) != 0:
+ logger.warning('Directory \'%s\' is not private', base)
+ self.base = os.path.abspath(os.path.normpath(base))
+
+ def prefix_to_dir(self, prefix, use_abspath=True):
+ """
+ Converts a resource prefix to a directory name in the cache.
+ """
+ return path_to_cache_dir(prefix, use_abspath=use_abspath)
+
+ def clear(self):
+ """
+ Clear the cache.
+ """
+ not_removed = []
+ for fn in os.listdir(self.base):
+ fn = os.path.join(self.base, fn)
+ try:
+ if os.path.islink(fn) or os.path.isfile(fn):
+ os.remove(fn)
+ elif os.path.isdir(fn):
+ shutil.rmtree(fn)
+ except Exception:
+ not_removed.append(fn)
+ return not_removed
+
+
+class EventMixin(object):
+ """
+ A very simple publish/subscribe system.
+ """
+
+ def __init__(self):
+ self._subscribers = {}
+
+ def add(self, event, subscriber, append=True):
+ """
+ Add a subscriber for an event.
+
+ :param event: The name of an event.
+ :param subscriber: The subscriber to be added (and called when the
+ event is published).
+ :param append: Whether to append or prepend the subscriber to an
+ existing subscriber list for the event.
+ """
+ subs = self._subscribers
+ if event not in subs:
+ subs[event] = deque([subscriber])
+ else:
+ sq = subs[event]
+ if append:
+ sq.append(subscriber)
+ else:
+ sq.appendleft(subscriber)
+
+ def remove(self, event, subscriber):
+ """
+ Remove a subscriber for an event.
+
+ :param event: The name of an event.
+ :param subscriber: The subscriber to be removed.
+ """
+ subs = self._subscribers
+ if event not in subs:
+ raise ValueError('No subscribers: %r' % event)
+ subs[event].remove(subscriber)
+
+ def get_subscribers(self, event):
+ """
+ Return an iterator for the subscribers for an event.
+ :param event: The event to return subscribers for.
+ """
+ return iter(self._subscribers.get(event, ()))
+
+ def publish(self, event, *args, **kwargs):
+ """
+ Publish a event and return a list of values returned by its
+ subscribers.
+
+ :param event: The event to publish.
+ :param args: The positional arguments to pass to the event's
+ subscribers.
+ :param kwargs: The keyword arguments to pass to the event's
+ subscribers.
+ """
+ result = []
+ for subscriber in self.get_subscribers(event):
+ try:
+ value = subscriber(event, *args, **kwargs)
+ except Exception:
+ logger.exception('Exception during event publication')
+ value = None
+ result.append(value)
+ logger.debug('publish %s: args = %s, kwargs = %s, result = %s', event, args, kwargs, result)
+ return result
+
+
+#
+# Simple sequencing
+#
+class Sequencer(object):
+
+ def __init__(self):
+ self._preds = {}
+ self._succs = {}
+ self._nodes = set() # nodes with no preds/succs
+
+ def add_node(self, node):
+ self._nodes.add(node)
+
+ def remove_node(self, node, edges=False):
+ if node in self._nodes:
+ self._nodes.remove(node)
+ if edges:
+ for p in set(self._preds.get(node, ())):
+ self.remove(p, node)
+ for s in set(self._succs.get(node, ())):
+ self.remove(node, s)
+ # Remove empties
+ for k, v in list(self._preds.items()):
+ if not v:
+ del self._preds[k]
+ for k, v in list(self._succs.items()):
+ if not v:
+ del self._succs[k]
+
+ def add(self, pred, succ):
+ assert pred != succ
+ self._preds.setdefault(succ, set()).add(pred)
+ self._succs.setdefault(pred, set()).add(succ)
+
+ def remove(self, pred, succ):
+ assert pred != succ
+ try:
+ preds = self._preds[succ]
+ succs = self._succs[pred]
+ except KeyError: # pragma: no cover
+ raise ValueError('%r not a successor of anything' % succ)
+ try:
+ preds.remove(pred)
+ succs.remove(succ)
+ except KeyError: # pragma: no cover
+ raise ValueError('%r not a successor of %r' % (succ, pred))
+
+ def is_step(self, step):
+ return (step in self._preds or step in self._succs or step in self._nodes)
+
+ def get_steps(self, final):
+ if not self.is_step(final):
+ raise ValueError('Unknown: %r' % final)
+ result = []
+ todo = []
+ seen = set()
+ todo.append(final)
+ while todo:
+ step = todo.pop(0)
+ if step in seen:
+ # if a step was already seen,
+ # move it to the end (so it will appear earlier
+ # when reversed on return) ... but not for the
+ # final step, as that would be confusing for
+ # users
+ if step != final:
+ result.remove(step)
+ result.append(step)
+ else:
+ seen.add(step)
+ result.append(step)
+ preds = self._preds.get(step, ())
+ todo.extend(preds)
+ return reversed(result)
+
+ @property
+ def strong_connections(self):
+ # http://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
+ index_counter = [0]
+ stack = []
+ lowlinks = {}
+ index = {}
+ result = []
+
+ graph = self._succs
+
+ def strongconnect(node):
+ # set the depth index for this node to the smallest unused index
+ index[node] = index_counter[0]
+ lowlinks[node] = index_counter[0]
+ index_counter[0] += 1
+ stack.append(node)
+
+ # Consider successors
+ try:
+ successors = graph[node]
+ except Exception:
+ successors = []
+ for successor in successors:
+ if successor not in lowlinks:
+ # Successor has not yet been visited
+ strongconnect(successor)
+ lowlinks[node] = min(lowlinks[node], lowlinks[successor])
+ elif successor in stack:
+ # the successor is in the stack and hence in the current
+ # strongly connected component (SCC)
+ lowlinks[node] = min(lowlinks[node], index[successor])
+
+ # If `node` is a root node, pop the stack and generate an SCC
+ if lowlinks[node] == index[node]:
+ connected_component = []
+
+ while True:
+ successor = stack.pop()
+ connected_component.append(successor)
+ if successor == node:
+ break
+ component = tuple(connected_component)
+ # storing the result
+ result.append(component)
+
+ for node in graph:
+ if node not in lowlinks:
+ strongconnect(node)
+
+ return result
+
+ @property
+ def dot(self):
+ result = ['digraph G {']
+ for succ in self._preds:
+ preds = self._preds[succ]
+ for pred in preds:
+ result.append(' %s -> %s;' % (pred, succ))
+ for node in self._nodes:
+ result.append(' %s;' % node)
+ result.append('}')
+ return '\n'.join(result)
+
+
+#
+# Unarchiving functionality for zip, tar, tgz, tbz, whl
+#
+
+ARCHIVE_EXTENSIONS = ('.tar.gz', '.tar.bz2', '.tar', '.zip', '.tgz', '.tbz', '.whl')
+
+
+def unarchive(archive_filename, dest_dir, format=None, check=True):
+
+ def check_path(path):
+ if not isinstance(path, text_type):
+ path = path.decode('utf-8')
+ p = os.path.abspath(os.path.join(dest_dir, path))
+ if not p.startswith(dest_dir) or p[plen] != os.sep:
+ raise ValueError('path outside destination: %r' % p)
+
+ dest_dir = os.path.abspath(dest_dir)
+ plen = len(dest_dir)
+ archive = None
+ if format is None:
+ if archive_filename.endswith(('.zip', '.whl')):
+ format = 'zip'
+ elif archive_filename.endswith(('.tar.gz', '.tgz')):
+ format = 'tgz'
+ mode = 'r:gz'
+ elif archive_filename.endswith(('.tar.bz2', '.tbz')):
+ format = 'tbz'
+ mode = 'r:bz2'
+ elif archive_filename.endswith('.tar'):
+ format = 'tar'
+ mode = 'r'
+ else: # pragma: no cover
+ raise ValueError('Unknown format for %r' % archive_filename)
+ try:
+ if format == 'zip':
+ archive = ZipFile(archive_filename, 'r')
+ if check:
+ names = archive.namelist()
+ for name in names:
+ check_path(name)
+ else:
+ archive = tarfile.open(archive_filename, mode)
+ if check:
+ names = archive.getnames()
+ for name in names:
+ check_path(name)
+ if format != 'zip' and sys.version_info[0] < 3:
+ # See Python issue 17153. If the dest path contains Unicode,
+ # tarfile extraction fails on Python 2.x if a member path name
+ # contains non-ASCII characters - it leads to an implicit
+ # bytes -> unicode conversion using ASCII to decode.
+ for tarinfo in archive.getmembers():
+ if not isinstance(tarinfo.name, text_type):
+ tarinfo.name = tarinfo.name.decode('utf-8')
+
+ # Limit extraction of dangerous items, if this Python
+ # allows it easily. If not, just trust the input.
+ # See: https://docs.python.org/3/library/tarfile.html#extraction-filters
+ def extraction_filter(member, path):
+ """Run tarfile.tar_filter, but raise the expected ValueError"""
+ # This is only called if the current Python has tarfile filters
+ try:
+ return tarfile.tar_filter(member, path)
+ except tarfile.FilterError as exc:
+ raise ValueError(str(exc))
+
+ archive.extraction_filter = extraction_filter
+
+ archive.extractall(dest_dir)
+
+ finally:
+ if archive:
+ archive.close()
+
+
+def zip_dir(directory):
+ """zip a directory tree into a BytesIO object"""
+ result = io.BytesIO()
+ dlen = len(directory)
+ with ZipFile(result, "w") as zf:
+ for root, dirs, files in os.walk(directory):
+ for name in files:
+ full = os.path.join(root, name)
+ rel = root[dlen:]
+ dest = os.path.join(rel, name)
+ zf.write(full, dest)
+ return result
+
+
+#
+# Simple progress bar
+#
+
+UNITS = ('', 'K', 'M', 'G', 'T', 'P')
+
+
+class Progress(object):
+ unknown = 'UNKNOWN'
+
+ def __init__(self, minval=0, maxval=100):
+ assert maxval is None or maxval >= minval
+ self.min = self.cur = minval
+ self.max = maxval
+ self.started = None
+ self.elapsed = 0
+ self.done = False
+
+ def update(self, curval):
+ assert self.min <= curval
+ assert self.max is None or curval <= self.max
+ self.cur = curval
+ now = time.time()
+ if self.started is None:
+ self.started = now
+ else:
+ self.elapsed = now - self.started
+
+ def increment(self, incr):
+ assert incr >= 0
+ self.update(self.cur + incr)
+
+ def start(self):
+ self.update(self.min)
+ return self
+
+ def stop(self):
+ if self.max is not None:
+ self.update(self.max)
+ self.done = True
+
+ @property
+ def maximum(self):
+ return self.unknown if self.max is None else self.max
+
+ @property
+ def percentage(self):
+ if self.done:
+ result = '100 %'
+ elif self.max is None:
+ result = ' ?? %'
+ else:
+ v = 100.0 * (self.cur - self.min) / (self.max - self.min)
+ result = '%3d %%' % v
+ return result
+
+ def format_duration(self, duration):
+ if (duration <= 0) and self.max is None or self.cur == self.min:
+ result = '??:??:??'
+ # elif duration < 1:
+ # result = '--:--:--'
+ else:
+ result = time.strftime('%H:%M:%S', time.gmtime(duration))
+ return result
+
+ @property
+ def ETA(self):
+ if self.done:
+ prefix = 'Done'
+ t = self.elapsed
+ # import pdb; pdb.set_trace()
+ else:
+ prefix = 'ETA '
+ if self.max is None:
+ t = -1
+ elif self.elapsed == 0 or (self.cur == self.min):
+ t = 0
+ else:
+ # import pdb; pdb.set_trace()
+ t = float(self.max - self.min)
+ t /= self.cur - self.min
+ t = (t - 1) * self.elapsed
+ return '%s: %s' % (prefix, self.format_duration(t))
+
+ @property
+ def speed(self):
+ if self.elapsed == 0:
+ result = 0.0
+ else:
+ result = (self.cur - self.min) / self.elapsed
+ for unit in UNITS:
+ if result < 1000:
+ break
+ result /= 1000.0
+ return '%d %sB/s' % (result, unit)
+
+
+#
+# Glob functionality
+#
+
+RICH_GLOB = re.compile(r'\{([^}]*)\}')
+_CHECK_RECURSIVE_GLOB = re.compile(r'[^/\\,{]\*\*|\*\*[^/\\,}]')
+_CHECK_MISMATCH_SET = re.compile(r'^[^{]*\}|\{[^}]*$')
+
+
+def iglob(path_glob):
+ """Extended globbing function that supports ** and {opt1,opt2,opt3}."""
+ if _CHECK_RECURSIVE_GLOB.search(path_glob):
+ msg = """invalid glob %r: recursive glob "**" must be used alone"""
+ raise ValueError(msg % path_glob)
+ if _CHECK_MISMATCH_SET.search(path_glob):
+ msg = """invalid glob %r: mismatching set marker '{' or '}'"""
+ raise ValueError(msg % path_glob)
+ return _iglob(path_glob)
+
+
+def _iglob(path_glob):
+ rich_path_glob = RICH_GLOB.split(path_glob, 1)
+ if len(rich_path_glob) > 1:
+ assert len(rich_path_glob) == 3, rich_path_glob
+ prefix, set, suffix = rich_path_glob
+ for item in set.split(','):
+ for path in _iglob(''.join((prefix, item, suffix))):
+ yield path
+ else:
+ if '**' not in path_glob:
+ for item in std_iglob(path_glob):
+ yield item
+ else:
+ prefix, radical = path_glob.split('**', 1)
+ if prefix == '':
+ prefix = '.'
+ if radical == '':
+ radical = '*'
+ else:
+ # we support both
+ radical = radical.lstrip('/')
+ radical = radical.lstrip('\\')
+ for path, dir, files in os.walk(prefix):
+ path = os.path.normpath(path)
+ for fn in _iglob(os.path.join(path, radical)):
+ yield fn
+
+
+if ssl:
+ from .compat import (HTTPSHandler as BaseHTTPSHandler, match_hostname, CertificateError)
+
+ #
+ # HTTPSConnection which verifies certificates/matches domains
+ #
+
+ class HTTPSConnection(httplib.HTTPSConnection):
+ ca_certs = None # set this to the path to the certs file (.pem)
+ check_domain = True # only used if ca_certs is not None
+
+ # noinspection PyPropertyAccess
+ def connect(self):
+ sock = socket.create_connection((self.host, self.port), self.timeout)
+ if getattr(self, '_tunnel_host', False):
+ self.sock = sock
+ self._tunnel()
+
+ context = ssl.SSLContext(ssl.PROTOCOL_SSLv23)
+ if hasattr(ssl, 'OP_NO_SSLv2'):
+ context.options |= ssl.OP_NO_SSLv2
+ if getattr(self, 'cert_file', None):
+ context.load_cert_chain(self.cert_file, self.key_file)
+ kwargs = {}
+ if self.ca_certs:
+ context.verify_mode = ssl.CERT_REQUIRED
+ context.load_verify_locations(cafile=self.ca_certs)
+ if getattr(ssl, 'HAS_SNI', False):
+ kwargs['server_hostname'] = self.host
+
+ self.sock = context.wrap_socket(sock, **kwargs)
+ if self.ca_certs and self.check_domain:
+ try:
+ match_hostname(self.sock.getpeercert(), self.host)
+ logger.debug('Host verified: %s', self.host)
+ except CertificateError: # pragma: no cover
+ self.sock.shutdown(socket.SHUT_RDWR)
+ self.sock.close()
+ raise
+
+ class HTTPSHandler(BaseHTTPSHandler):
+
+ def __init__(self, ca_certs, check_domain=True):
+ BaseHTTPSHandler.__init__(self)
+ self.ca_certs = ca_certs
+ self.check_domain = check_domain
+
+ def _conn_maker(self, *args, **kwargs):
+ """
+ This is called to create a connection instance. Normally you'd
+ pass a connection class to do_open, but it doesn't actually check for
+ a class, and just expects a callable. As long as we behave just as a
+ constructor would have, we should be OK. If it ever changes so that
+ we *must* pass a class, we'll create an UnsafeHTTPSConnection class
+ which just sets check_domain to False in the class definition, and
+ choose which one to pass to do_open.
+ """
+ result = HTTPSConnection(*args, **kwargs)
+ if self.ca_certs:
+ result.ca_certs = self.ca_certs
+ result.check_domain = self.check_domain
+ return result
+
+ def https_open(self, req):
+ try:
+ return self.do_open(self._conn_maker, req)
+ except URLError as e:
+ if 'certificate verify failed' in str(e.reason):
+ raise CertificateError('Unable to verify server certificate '
+ 'for %s' % req.host)
+ else:
+ raise
+
+ #
+ # To prevent against mixing HTTP traffic with HTTPS (examples: A Man-In-The-
+ # Middle proxy using HTTP listens on port 443, or an index mistakenly serves
+ # HTML containing a http://xyz link when it should be https://xyz),
+ # you can use the following handler class, which does not allow HTTP traffic.
+ #
+ # It works by inheriting from HTTPHandler - so build_opener won't add a
+ # handler for HTTP itself.
+ #
+ class HTTPSOnlyHandler(HTTPSHandler, HTTPHandler):
+
+ def http_open(self, req):
+ raise URLError('Unexpected HTTP request on what should be a secure '
+ 'connection: %s' % req)
+
+
+#
+# XML-RPC with timeouts
+#
+class Transport(xmlrpclib.Transport):
+
+ def __init__(self, timeout, use_datetime=0):
+ self.timeout = timeout
+ xmlrpclib.Transport.__init__(self, use_datetime)
+
+ def make_connection(self, host):
+ h, eh, x509 = self.get_host_info(host)
+ if not self._connection or host != self._connection[0]:
+ self._extra_headers = eh
+ self._connection = host, httplib.HTTPConnection(h)
+ return self._connection[1]
+
+
+if ssl:
+
+ class SafeTransport(xmlrpclib.SafeTransport):
+
+ def __init__(self, timeout, use_datetime=0):
+ self.timeout = timeout
+ xmlrpclib.SafeTransport.__init__(self, use_datetime)
+
+ def make_connection(self, host):
+ h, eh, kwargs = self.get_host_info(host)
+ if not kwargs:
+ kwargs = {}
+ kwargs['timeout'] = self.timeout
+ if not self._connection or host != self._connection[0]:
+ self._extra_headers = eh
+ self._connection = host, httplib.HTTPSConnection(h, None, **kwargs)
+ return self._connection[1]
+
+
+class ServerProxy(xmlrpclib.ServerProxy):
+
+ def __init__(self, uri, **kwargs):
+ self.timeout = timeout = kwargs.pop('timeout', None)
+ # The above classes only come into play if a timeout
+ # is specified
+ if timeout is not None:
+ # scheme = splittype(uri) # deprecated as of Python 3.8
+ scheme = urlparse(uri)[0]
+ use_datetime = kwargs.get('use_datetime', 0)
+ if scheme == 'https':
+ tcls = SafeTransport
+ else:
+ tcls = Transport
+ kwargs['transport'] = t = tcls(timeout, use_datetime=use_datetime)
+ self.transport = t
+ xmlrpclib.ServerProxy.__init__(self, uri, **kwargs)
+
+
+#
+# CSV functionality. This is provided because on 2.x, the csv module can't
+# handle Unicode. However, we need to deal with Unicode in e.g. RECORD files.
+#
+
+
+def _csv_open(fn, mode, **kwargs):
+ if sys.version_info[0] < 3:
+ mode += 'b'
+ else:
+ kwargs['newline'] = ''
+ # Python 3 determines encoding from locale. Force 'utf-8'
+ # file encoding to match other forced utf-8 encoding
+ kwargs['encoding'] = 'utf-8'
+ return open(fn, mode, **kwargs)
+
+
+class CSVBase(object):
+ defaults = {
+ 'delimiter': str(','), # The strs are used because we need native
+ 'quotechar': str('"'), # str in the csv API (2.x won't take
+ 'lineterminator': str('\n') # Unicode)
+ }
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, *exc_info):
+ self.stream.close()
+
+
+class CSVReader(CSVBase):
+
+ def __init__(self, **kwargs):
+ if 'stream' in kwargs:
+ stream = kwargs['stream']
+ if sys.version_info[0] >= 3:
+ # needs to be a text stream
+ stream = codecs.getreader('utf-8')(stream)
+ self.stream = stream
+ else:
+ self.stream = _csv_open(kwargs['path'], 'r')
+ self.reader = csv.reader(self.stream, **self.defaults)
+
+ def __iter__(self):
+ return self
+
+ def next(self):
+ result = next(self.reader)
+ if sys.version_info[0] < 3:
+ for i, item in enumerate(result):
+ if not isinstance(item, text_type):
+ result[i] = item.decode('utf-8')
+ return result
+
+ __next__ = next
+
+
+class CSVWriter(CSVBase):
+
+ def __init__(self, fn, **kwargs):
+ self.stream = _csv_open(fn, 'w')
+ self.writer = csv.writer(self.stream, **self.defaults)
+
+ def writerow(self, row):
+ if sys.version_info[0] < 3:
+ r = []
+ for item in row:
+ if isinstance(item, text_type):
+ item = item.encode('utf-8')
+ r.append(item)
+ row = r
+ self.writer.writerow(row)
+
+
+#
+# Configurator functionality
+#
+
+
+class Configurator(BaseConfigurator):
+
+ value_converters = dict(BaseConfigurator.value_converters)
+ value_converters['inc'] = 'inc_convert'
+
+ def __init__(self, config, base=None):
+ super(Configurator, self).__init__(config)
+ self.base = base or os.getcwd()
+
+ def configure_custom(self, config):
+
+ def convert(o):
+ if isinstance(o, (list, tuple)):
+ result = type(o)([convert(i) for i in o])
+ elif isinstance(o, dict):
+ if '()' in o:
+ result = self.configure_custom(o)
+ else:
+ result = {}
+ for k in o:
+ result[k] = convert(o[k])
+ else:
+ result = self.convert(o)
+ return result
+
+ c = config.pop('()')
+ if not callable(c):
+ c = self.resolve(c)
+ props = config.pop('.', None)
+ # Check for valid identifiers
+ args = config.pop('[]', ())
+ if args:
+ args = tuple([convert(o) for o in args])
+ items = [(k, convert(config[k])) for k in config if valid_ident(k)]
+ kwargs = dict(items)
+ result = c(*args, **kwargs)
+ if props:
+ for n, v in props.items():
+ setattr(result, n, convert(v))
+ return result
+
+ def __getitem__(self, key):
+ result = self.config[key]
+ if isinstance(result, dict) and '()' in result:
+ self.config[key] = result = self.configure_custom(result)
+ return result
+
+ def inc_convert(self, value):
+ """Default converter for the inc:// protocol."""
+ if not os.path.isabs(value):
+ value = os.path.join(self.base, value)
+ with codecs.open(value, 'r', encoding='utf-8') as f:
+ result = json.load(f)
+ return result
+
+
+class SubprocessMixin(object):
+ """
+ Mixin for running subprocesses and capturing their output
+ """
+
+ def __init__(self, verbose=False, progress=None):
+ self.verbose = verbose
+ self.progress = progress
+
+ def reader(self, stream, context):
+ """
+ Read lines from a subprocess' output stream and either pass to a progress
+ callable (if specified) or write progress information to sys.stderr.
+ """
+ progress = self.progress
+ verbose = self.verbose
+ while True:
+ s = stream.readline()
+ if not s:
+ break
+ if progress is not None:
+ progress(s, context)
+ else:
+ if not verbose:
+ sys.stderr.write('.')
+ else:
+ sys.stderr.write(s.decode('utf-8'))
+ sys.stderr.flush()
+ stream.close()
+
+ def run_command(self, cmd, **kwargs):
+ p = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, **kwargs)
+ t1 = threading.Thread(target=self.reader, args=(p.stdout, 'stdout'))
+ t1.start()
+ t2 = threading.Thread(target=self.reader, args=(p.stderr, 'stderr'))
+ t2.start()
+ p.wait()
+ t1.join()
+ t2.join()
+ if self.progress is not None:
+ self.progress('done.', 'main')
+ elif self.verbose:
+ sys.stderr.write('done.\n')
+ return p
+
+
+def normalize_name(name):
+ """Normalize a python package name a la PEP 503"""
+ # https://www.python.org/dev/peps/pep-0503/#normalized-names
+ return re.sub('[-_.]+', '-', name).lower()
+
+
+# def _get_pypirc_command():
+# """
+# Get the distutils command for interacting with PyPI configurations.
+# :return: the command.
+# """
+# from distutils.core import Distribution
+# from distutils.config import PyPIRCCommand
+# d = Distribution()
+# return PyPIRCCommand(d)
+
+
+class PyPIRCFile(object):
+
+ DEFAULT_REPOSITORY = 'https://upload.pypi.org/legacy/'
+ DEFAULT_REALM = 'pypi'
+
+ def __init__(self, fn=None, url=None):
+ if fn is None:
+ fn = os.path.join(os.path.expanduser('~'), '.pypirc')
+ self.filename = fn
+ self.url = url
+
+ def read(self):
+ result = {}
+
+ if os.path.exists(self.filename):
+ repository = self.url or self.DEFAULT_REPOSITORY
+
+ config = configparser.RawConfigParser()
+ config.read(self.filename)
+ sections = config.sections()
+ if 'distutils' in sections:
+ # let's get the list of servers
+ index_servers = config.get('distutils', 'index-servers')
+ _servers = [server.strip() for server in index_servers.split('\n') if server.strip() != '']
+ if _servers == []:
+ # nothing set, let's try to get the default pypi
+ if 'pypi' in sections:
+ _servers = ['pypi']
+ else:
+ for server in _servers:
+ result = {'server': server}
+ result['username'] = config.get(server, 'username')
+
+ # optional params
+ for key, default in (('repository', self.DEFAULT_REPOSITORY), ('realm', self.DEFAULT_REALM),
+ ('password', None)):
+ if config.has_option(server, key):
+ result[key] = config.get(server, key)
+ else:
+ result[key] = default
+
+ # work around people having "repository" for the "pypi"
+ # section of their config set to the HTTP (rather than
+ # HTTPS) URL
+ if (server == 'pypi' and repository in (self.DEFAULT_REPOSITORY, 'pypi')):
+ result['repository'] = self.DEFAULT_REPOSITORY
+ elif (result['server'] != repository and result['repository'] != repository):
+ result = {}
+ elif 'server-login' in sections:
+ # old format
+ server = 'server-login'
+ if config.has_option(server, 'repository'):
+ repository = config.get(server, 'repository')
+ else:
+ repository = self.DEFAULT_REPOSITORY
+ result = {
+ 'username': config.get(server, 'username'),
+ 'password': config.get(server, 'password'),
+ 'repository': repository,
+ 'server': server,
+ 'realm': self.DEFAULT_REALM
+ }
+ return result
+
+ def update(self, username, password):
+ # import pdb; pdb.set_trace()
+ config = configparser.RawConfigParser()
+ fn = self.filename
+ config.read(fn)
+ if not config.has_section('pypi'):
+ config.add_section('pypi')
+ config.set('pypi', 'username', username)
+ config.set('pypi', 'password', password)
+ with open(fn, 'w') as f:
+ config.write(f)
+
+
+def _load_pypirc(index):
+ """
+ Read the PyPI access configuration as supported by distutils.
+ """
+ return PyPIRCFile(url=index.url).read()
+
+
+def _store_pypirc(index):
+ PyPIRCFile().update(index.username, index.password)
+
+
+#
+# get_platform()/get_host_platform() copied from Python 3.10.a0 source, with some minor
+# tweaks
+#
+
+
+def get_host_platform():
+ """Return a string that identifies the current platform. This is used mainly to
+ distinguish platform-specific build directories and platform-specific built
+ distributions. Typically includes the OS name and version and the
+ architecture (as supplied by 'os.uname()'), although the exact information
+ included depends on the OS; eg. on Linux, the kernel version isn't
+ particularly important.
+
+ Examples of returned values:
+ linux-i586
+ linux-alpha (?)
+ solaris-2.6-sun4u
+
+ Windows will return one of:
+ win-amd64 (64bit Windows on AMD64 (aka x86_64, Intel64, EM64T, etc)
+ win32 (all others - specifically, sys.platform is returned)
+
+ For other non-POSIX platforms, currently just returns 'sys.platform'.
+
+ """
+ if os.name == 'nt':
+ if 'amd64' in sys.version.lower():
+ return 'win-amd64'
+ if '(arm)' in sys.version.lower():
+ return 'win-arm32'
+ if '(arm64)' in sys.version.lower():
+ return 'win-arm64'
+ return sys.platform
+
+ # Set for cross builds explicitly
+ if "_PYTHON_HOST_PLATFORM" in os.environ:
+ return os.environ["_PYTHON_HOST_PLATFORM"]
+
+ if os.name != 'posix' or not hasattr(os, 'uname'):
+ # XXX what about the architecture? NT is Intel or Alpha,
+ # Mac OS is M68k or PPC, etc.
+ return sys.platform
+
+ # Try to distinguish various flavours of Unix
+
+ (osname, host, release, version, machine) = os.uname()
+
+ # Convert the OS name to lowercase, remove '/' characters, and translate
+ # spaces (for "Power Macintosh")
+ osname = osname.lower().replace('/', '')
+ machine = machine.replace(' ', '_').replace('/', '-')
+
+ if osname[:5] == 'linux':
+ # At least on Linux/Intel, 'machine' is the processor --
+ # i386, etc.
+ # XXX what about Alpha, SPARC, etc?
+ return "%s-%s" % (osname, machine)
+
+ elif osname[:5] == 'sunos':
+ if release[0] >= '5': # SunOS 5 == Solaris 2
+ osname = 'solaris'
+ release = '%d.%s' % (int(release[0]) - 3, release[2:])
+ # We can't use 'platform.architecture()[0]' because a
+ # bootstrap problem. We use a dict to get an error
+ # if some suspicious happens.
+ bitness = {2147483647: '32bit', 9223372036854775807: '64bit'}
+ machine += '.%s' % bitness[sys.maxsize]
+ # fall through to standard osname-release-machine representation
+ elif osname[:3] == 'aix':
+ from _aix_support import aix_platform
+ return aix_platform()
+ elif osname[:6] == 'cygwin':
+ osname = 'cygwin'
+ rel_re = re.compile(r'[\d.]+', re.ASCII)
+ m = rel_re.match(release)
+ if m:
+ release = m.group()
+ elif osname[:6] == 'darwin':
+ import _osx_support
+ try:
+ from distutils import sysconfig
+ except ImportError:
+ import sysconfig
+ osname, release, machine = _osx_support.get_platform_osx(sysconfig.get_config_vars(), osname, release, machine)
+
+ return '%s-%s-%s' % (osname, release, machine)
+
+
+_TARGET_TO_PLAT = {
+ 'x86': 'win32',
+ 'x64': 'win-amd64',
+ 'arm': 'win-arm32',
+}
+
+
+def get_platform():
+ if os.name != 'nt':
+ return get_host_platform()
+ cross_compilation_target = os.environ.get('VSCMD_ARG_TGT_ARCH')
+ if cross_compilation_target not in _TARGET_TO_PLAT:
+ return get_host_platform()
+ return _TARGET_TO_PLAT[cross_compilation_target]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/version.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/version.py
new file mode 100644
index 000000000..d70a96ef5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/version.py
@@ -0,0 +1,750 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2012-2023 The Python Software Foundation.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+"""
+Implementation of a flexible versioning scheme providing support for PEP-440,
+setuptools-compatible and semantic versioning.
+"""
+
+import logging
+import re
+
+from .compat import string_types
+from .util import parse_requirement
+
+__all__ = ['NormalizedVersion', 'NormalizedMatcher',
+ 'LegacyVersion', 'LegacyMatcher',
+ 'SemanticVersion', 'SemanticMatcher',
+ 'UnsupportedVersionError', 'get_scheme']
+
+logger = logging.getLogger(__name__)
+
+
+class UnsupportedVersionError(ValueError):
+ """This is an unsupported version."""
+ pass
+
+
+class Version(object):
+ def __init__(self, s):
+ self._string = s = s.strip()
+ self._parts = parts = self.parse(s)
+ assert isinstance(parts, tuple)
+ assert len(parts) > 0
+
+ def parse(self, s):
+ raise NotImplementedError('please implement in a subclass')
+
+ def _check_compatible(self, other):
+ if type(self) != type(other):
+ raise TypeError('cannot compare %r and %r' % (self, other))
+
+ def __eq__(self, other):
+ self._check_compatible(other)
+ return self._parts == other._parts
+
+ def __ne__(self, other):
+ return not self.__eq__(other)
+
+ def __lt__(self, other):
+ self._check_compatible(other)
+ return self._parts < other._parts
+
+ def __gt__(self, other):
+ return not (self.__lt__(other) or self.__eq__(other))
+
+ def __le__(self, other):
+ return self.__lt__(other) or self.__eq__(other)
+
+ def __ge__(self, other):
+ return self.__gt__(other) or self.__eq__(other)
+
+ # See http://docs.python.org/reference/datamodel#object.__hash__
+ def __hash__(self):
+ return hash(self._parts)
+
+ def __repr__(self):
+ return "%s('%s')" % (self.__class__.__name__, self._string)
+
+ def __str__(self):
+ return self._string
+
+ @property
+ def is_prerelease(self):
+ raise NotImplementedError('Please implement in subclasses.')
+
+
+class Matcher(object):
+ version_class = None
+
+ # value is either a callable or the name of a method
+ _operators = {
+ '<': lambda v, c, p: v < c,
+ '>': lambda v, c, p: v > c,
+ '<=': lambda v, c, p: v == c or v < c,
+ '>=': lambda v, c, p: v == c or v > c,
+ '==': lambda v, c, p: v == c,
+ '===': lambda v, c, p: v == c,
+ # by default, compatible => >=.
+ '~=': lambda v, c, p: v == c or v > c,
+ '!=': lambda v, c, p: v != c,
+ }
+
+ # this is a method only to support alternative implementations
+ # via overriding
+ def parse_requirement(self, s):
+ return parse_requirement(s)
+
+ def __init__(self, s):
+ if self.version_class is None:
+ raise ValueError('Please specify a version class')
+ self._string = s = s.strip()
+ r = self.parse_requirement(s)
+ if not r:
+ raise ValueError('Not valid: %r' % s)
+ self.name = r.name
+ self.key = self.name.lower() # for case-insensitive comparisons
+ clist = []
+ if r.constraints:
+ # import pdb; pdb.set_trace()
+ for op, s in r.constraints:
+ if s.endswith('.*'):
+ if op not in ('==', '!='):
+ raise ValueError('\'.*\' not allowed for '
+ '%r constraints' % op)
+ # Could be a partial version (e.g. for '2.*') which
+ # won't parse as a version, so keep it as a string
+ vn, prefix = s[:-2], True
+ # Just to check that vn is a valid version
+ self.version_class(vn)
+ else:
+ # Should parse as a version, so we can create an
+ # instance for the comparison
+ vn, prefix = self.version_class(s), False
+ clist.append((op, vn, prefix))
+ self._parts = tuple(clist)
+
+ def match(self, version):
+ """
+ Check if the provided version matches the constraints.
+
+ :param version: The version to match against this instance.
+ :type version: String or :class:`Version` instance.
+ """
+ if isinstance(version, string_types):
+ version = self.version_class(version)
+ for operator, constraint, prefix in self._parts:
+ f = self._operators.get(operator)
+ if isinstance(f, string_types):
+ f = getattr(self, f)
+ if not f:
+ msg = ('%r not implemented '
+ 'for %s' % (operator, self.__class__.__name__))
+ raise NotImplementedError(msg)
+ if not f(version, constraint, prefix):
+ return False
+ return True
+
+ @property
+ def exact_version(self):
+ result = None
+ if len(self._parts) == 1 and self._parts[0][0] in ('==', '==='):
+ result = self._parts[0][1]
+ return result
+
+ def _check_compatible(self, other):
+ if type(self) != type(other) or self.name != other.name:
+ raise TypeError('cannot compare %s and %s' % (self, other))
+
+ def __eq__(self, other):
+ self._check_compatible(other)
+ return self.key == other.key and self._parts == other._parts
+
+ def __ne__(self, other):
+ return not self.__eq__(other)
+
+ # See http://docs.python.org/reference/datamodel#object.__hash__
+ def __hash__(self):
+ return hash(self.key) + hash(self._parts)
+
+ def __repr__(self):
+ return "%s(%r)" % (self.__class__.__name__, self._string)
+
+ def __str__(self):
+ return self._string
+
+
+PEP440_VERSION_RE = re.compile(r'^v?(\d+!)?(\d+(\.\d+)*)((a|alpha|b|beta|c|rc|pre|preview)(\d+)?)?'
+ r'(\.(post|r|rev)(\d+)?)?([._-]?(dev)(\d+)?)?'
+ r'(\+([a-zA-Z\d]+(\.[a-zA-Z\d]+)?))?$', re.I)
+
+
+def _pep_440_key(s):
+ s = s.strip()
+ m = PEP440_VERSION_RE.match(s)
+ if not m:
+ raise UnsupportedVersionError('Not a valid version: %s' % s)
+ groups = m.groups()
+ nums = tuple(int(v) for v in groups[1].split('.'))
+ while len(nums) > 1 and nums[-1] == 0:
+ nums = nums[:-1]
+
+ if not groups[0]:
+ epoch = 0
+ else:
+ epoch = int(groups[0][:-1])
+ pre = groups[4:6]
+ post = groups[7:9]
+ dev = groups[10:12]
+ local = groups[13]
+ if pre == (None, None):
+ pre = ()
+ else:
+ if pre[1] is None:
+ pre = pre[0], 0
+ else:
+ pre = pre[0], int(pre[1])
+ if post == (None, None):
+ post = ()
+ else:
+ if post[1] is None:
+ post = post[0], 0
+ else:
+ post = post[0], int(post[1])
+ if dev == (None, None):
+ dev = ()
+ else:
+ if dev[1] is None:
+ dev = dev[0], 0
+ else:
+ dev = dev[0], int(dev[1])
+ if local is None:
+ local = ()
+ else:
+ parts = []
+ for part in local.split('.'):
+ # to ensure that numeric compares as > lexicographic, avoid
+ # comparing them directly, but encode a tuple which ensures
+ # correct sorting
+ if part.isdigit():
+ part = (1, int(part))
+ else:
+ part = (0, part)
+ parts.append(part)
+ local = tuple(parts)
+ if not pre:
+ # either before pre-release, or final release and after
+ if not post and dev:
+ # before pre-release
+ pre = ('a', -1) # to sort before a0
+ else:
+ pre = ('z',) # to sort after all pre-releases
+ # now look at the state of post and dev.
+ if not post:
+ post = ('_',) # sort before 'a'
+ if not dev:
+ dev = ('final',)
+
+ return epoch, nums, pre, post, dev, local
+
+
+_normalized_key = _pep_440_key
+
+
+class NormalizedVersion(Version):
+ """A rational version.
+
+ Good:
+ 1.2 # equivalent to "1.2.0"
+ 1.2.0
+ 1.2a1
+ 1.2.3a2
+ 1.2.3b1
+ 1.2.3c1
+ 1.2.3.4
+ TODO: fill this out
+
+ Bad:
+ 1 # minimum two numbers
+ 1.2a # release level must have a release serial
+ 1.2.3b
+ """
+ def parse(self, s):
+ result = _normalized_key(s)
+ # _normalized_key loses trailing zeroes in the release
+ # clause, since that's needed to ensure that X.Y == X.Y.0 == X.Y.0.0
+ # However, PEP 440 prefix matching needs it: for example,
+ # (~= 1.4.5.0) matches differently to (~= 1.4.5.0.0).
+ m = PEP440_VERSION_RE.match(s) # must succeed
+ groups = m.groups()
+ self._release_clause = tuple(int(v) for v in groups[1].split('.'))
+ return result
+
+ PREREL_TAGS = set(['a', 'b', 'c', 'rc', 'dev'])
+
+ @property
+ def is_prerelease(self):
+ return any(t[0] in self.PREREL_TAGS for t in self._parts if t)
+
+
+def _match_prefix(x, y):
+ x = str(x)
+ y = str(y)
+ if x == y:
+ return True
+ if not x.startswith(y):
+ return False
+ n = len(y)
+ return x[n] == '.'
+
+
+class NormalizedMatcher(Matcher):
+ version_class = NormalizedVersion
+
+ # value is either a callable or the name of a method
+ _operators = {
+ '~=': '_match_compatible',
+ '<': '_match_lt',
+ '>': '_match_gt',
+ '<=': '_match_le',
+ '>=': '_match_ge',
+ '==': '_match_eq',
+ '===': '_match_arbitrary',
+ '!=': '_match_ne',
+ }
+
+ def _adjust_local(self, version, constraint, prefix):
+ if prefix:
+ strip_local = '+' not in constraint and version._parts[-1]
+ else:
+ # both constraint and version are
+ # NormalizedVersion instances.
+ # If constraint does not have a local component,
+ # ensure the version doesn't, either.
+ strip_local = not constraint._parts[-1] and version._parts[-1]
+ if strip_local:
+ s = version._string.split('+', 1)[0]
+ version = self.version_class(s)
+ return version, constraint
+
+ def _match_lt(self, version, constraint, prefix):
+ version, constraint = self._adjust_local(version, constraint, prefix)
+ if version >= constraint:
+ return False
+ release_clause = constraint._release_clause
+ pfx = '.'.join([str(i) for i in release_clause])
+ return not _match_prefix(version, pfx)
+
+ def _match_gt(self, version, constraint, prefix):
+ version, constraint = self._adjust_local(version, constraint, prefix)
+ if version <= constraint:
+ return False
+ release_clause = constraint._release_clause
+ pfx = '.'.join([str(i) for i in release_clause])
+ return not _match_prefix(version, pfx)
+
+ def _match_le(self, version, constraint, prefix):
+ version, constraint = self._adjust_local(version, constraint, prefix)
+ return version <= constraint
+
+ def _match_ge(self, version, constraint, prefix):
+ version, constraint = self._adjust_local(version, constraint, prefix)
+ return version >= constraint
+
+ def _match_eq(self, version, constraint, prefix):
+ version, constraint = self._adjust_local(version, constraint, prefix)
+ if not prefix:
+ result = (version == constraint)
+ else:
+ result = _match_prefix(version, constraint)
+ return result
+
+ def _match_arbitrary(self, version, constraint, prefix):
+ return str(version) == str(constraint)
+
+ def _match_ne(self, version, constraint, prefix):
+ version, constraint = self._adjust_local(version, constraint, prefix)
+ if not prefix:
+ result = (version != constraint)
+ else:
+ result = not _match_prefix(version, constraint)
+ return result
+
+ def _match_compatible(self, version, constraint, prefix):
+ version, constraint = self._adjust_local(version, constraint, prefix)
+ if version == constraint:
+ return True
+ if version < constraint:
+ return False
+# if not prefix:
+# return True
+ release_clause = constraint._release_clause
+ if len(release_clause) > 1:
+ release_clause = release_clause[:-1]
+ pfx = '.'.join([str(i) for i in release_clause])
+ return _match_prefix(version, pfx)
+
+
+_REPLACEMENTS = (
+ (re.compile('[.+-]$'), ''), # remove trailing puncts
+ (re.compile(r'^[.](\d)'), r'0.\1'), # .N -> 0.N at start
+ (re.compile('^[.-]'), ''), # remove leading puncts
+ (re.compile(r'^\((.*)\)$'), r'\1'), # remove parentheses
+ (re.compile(r'^v(ersion)?\s*(\d+)'), r'\2'), # remove leading v(ersion)
+ (re.compile(r'^r(ev)?\s*(\d+)'), r'\2'), # remove leading v(ersion)
+ (re.compile('[.]{2,}'), '.'), # multiple runs of '.'
+ (re.compile(r'\b(alfa|apha)\b'), 'alpha'), # misspelt alpha
+ (re.compile(r'\b(pre-alpha|prealpha)\b'),
+ 'pre.alpha'), # standardise
+ (re.compile(r'\(beta\)$'), 'beta'), # remove parentheses
+)
+
+_SUFFIX_REPLACEMENTS = (
+ (re.compile('^[:~._+-]+'), ''), # remove leading puncts
+ (re.compile('[,*")([\\]]'), ''), # remove unwanted chars
+ (re.compile('[~:+_ -]'), '.'), # replace illegal chars
+ (re.compile('[.]{2,}'), '.'), # multiple runs of '.'
+ (re.compile(r'\.$'), ''), # trailing '.'
+)
+
+_NUMERIC_PREFIX = re.compile(r'(\d+(\.\d+)*)')
+
+
+def _suggest_semantic_version(s):
+ """
+ Try to suggest a semantic form for a version for which
+ _suggest_normalized_version couldn't come up with anything.
+ """
+ result = s.strip().lower()
+ for pat, repl in _REPLACEMENTS:
+ result = pat.sub(repl, result)
+ if not result:
+ result = '0.0.0'
+
+ # Now look for numeric prefix, and separate it out from
+ # the rest.
+ # import pdb; pdb.set_trace()
+ m = _NUMERIC_PREFIX.match(result)
+ if not m:
+ prefix = '0.0.0'
+ suffix = result
+ else:
+ prefix = m.groups()[0].split('.')
+ prefix = [int(i) for i in prefix]
+ while len(prefix) < 3:
+ prefix.append(0)
+ if len(prefix) == 3:
+ suffix = result[m.end():]
+ else:
+ suffix = '.'.join([str(i) for i in prefix[3:]]) + result[m.end():]
+ prefix = prefix[:3]
+ prefix = '.'.join([str(i) for i in prefix])
+ suffix = suffix.strip()
+ if suffix:
+ # import pdb; pdb.set_trace()
+ # massage the suffix.
+ for pat, repl in _SUFFIX_REPLACEMENTS:
+ suffix = pat.sub(repl, suffix)
+
+ if not suffix:
+ result = prefix
+ else:
+ sep = '-' if 'dev' in suffix else '+'
+ result = prefix + sep + suffix
+ if not is_semver(result):
+ result = None
+ return result
+
+
+def _suggest_normalized_version(s):
+ """Suggest a normalized version close to the given version string.
+
+ If you have a version string that isn't rational (i.e. NormalizedVersion
+ doesn't like it) then you might be able to get an equivalent (or close)
+ rational version from this function.
+
+ This does a number of simple normalizations to the given string, based
+ on observation of versions currently in use on PyPI. Given a dump of
+ those version during PyCon 2009, 4287 of them:
+ - 2312 (53.93%) match NormalizedVersion without change
+ with the automatic suggestion
+ - 3474 (81.04%) match when using this suggestion method
+
+ @param s {str} An irrational version string.
+ @returns A rational version string, or None, if couldn't determine one.
+ """
+ try:
+ _normalized_key(s)
+ return s # already rational
+ except UnsupportedVersionError:
+ pass
+
+ rs = s.lower()
+
+ # part of this could use maketrans
+ for orig, repl in (('-alpha', 'a'), ('-beta', 'b'), ('alpha', 'a'),
+ ('beta', 'b'), ('rc', 'c'), ('-final', ''),
+ ('-pre', 'c'),
+ ('-release', ''), ('.release', ''), ('-stable', ''),
+ ('+', '.'), ('_', '.'), (' ', ''), ('.final', ''),
+ ('final', '')):
+ rs = rs.replace(orig, repl)
+
+ # if something ends with dev or pre, we add a 0
+ rs = re.sub(r"pre$", r"pre0", rs)
+ rs = re.sub(r"dev$", r"dev0", rs)
+
+ # if we have something like "b-2" or "a.2" at the end of the
+ # version, that is probably beta, alpha, etc
+ # let's remove the dash or dot
+ rs = re.sub(r"([abc]|rc)[\-\.](\d+)$", r"\1\2", rs)
+
+ # 1.0-dev-r371 -> 1.0.dev371
+ # 0.1-dev-r79 -> 0.1.dev79
+ rs = re.sub(r"[\-\.](dev)[\-\.]?r?(\d+)$", r".\1\2", rs)
+
+ # Clean: 2.0.a.3, 2.0.b1, 0.9.0~c1
+ rs = re.sub(r"[.~]?([abc])\.?", r"\1", rs)
+
+ # Clean: v0.3, v1.0
+ if rs.startswith('v'):
+ rs = rs[1:]
+
+ # Clean leading '0's on numbers.
+ # TODO: unintended side-effect on, e.g., "2003.05.09"
+ # PyPI stats: 77 (~2%) better
+ rs = re.sub(r"\b0+(\d+)(?!\d)", r"\1", rs)
+
+ # Clean a/b/c with no version. E.g. "1.0a" -> "1.0a0". Setuptools infers
+ # zero.
+ # PyPI stats: 245 (7.56%) better
+ rs = re.sub(r"(\d+[abc])$", r"\g<1>0", rs)
+
+ # the 'dev-rNNN' tag is a dev tag
+ rs = re.sub(r"\.?(dev-r|dev\.r)\.?(\d+)$", r".dev\2", rs)
+
+ # clean the - when used as a pre delimiter
+ rs = re.sub(r"-(a|b|c)(\d+)$", r"\1\2", rs)
+
+ # a terminal "dev" or "devel" can be changed into ".dev0"
+ rs = re.sub(r"[\.\-](dev|devel)$", r".dev0", rs)
+
+ # a terminal "dev" can be changed into ".dev0"
+ rs = re.sub(r"(?![\.\-])dev$", r".dev0", rs)
+
+ # a terminal "final" or "stable" can be removed
+ rs = re.sub(r"(final|stable)$", "", rs)
+
+ # The 'r' and the '-' tags are post release tags
+ # 0.4a1.r10 -> 0.4a1.post10
+ # 0.9.33-17222 -> 0.9.33.post17222
+ # 0.9.33-r17222 -> 0.9.33.post17222
+ rs = re.sub(r"\.?(r|-|-r)\.?(\d+)$", r".post\2", rs)
+
+ # Clean 'r' instead of 'dev' usage:
+ # 0.9.33+r17222 -> 0.9.33.dev17222
+ # 1.0dev123 -> 1.0.dev123
+ # 1.0.git123 -> 1.0.dev123
+ # 1.0.bzr123 -> 1.0.dev123
+ # 0.1a0dev.123 -> 0.1a0.dev123
+ # PyPI stats: ~150 (~4%) better
+ rs = re.sub(r"\.?(dev|git|bzr)\.?(\d+)$", r".dev\2", rs)
+
+ # Clean '.pre' (normalized from '-pre' above) instead of 'c' usage:
+ # 0.2.pre1 -> 0.2c1
+ # 0.2-c1 -> 0.2c1
+ # 1.0preview123 -> 1.0c123
+ # PyPI stats: ~21 (0.62%) better
+ rs = re.sub(r"\.?(pre|preview|-c)(\d+)$", r"c\g<2>", rs)
+
+ # Tcl/Tk uses "px" for their post release markers
+ rs = re.sub(r"p(\d+)$", r".post\1", rs)
+
+ try:
+ _normalized_key(rs)
+ except UnsupportedVersionError:
+ rs = None
+ return rs
+
+#
+# Legacy version processing (distribute-compatible)
+#
+
+
+_VERSION_PART = re.compile(r'([a-z]+|\d+|[\.-])', re.I)
+_VERSION_REPLACE = {
+ 'pre': 'c',
+ 'preview': 'c',
+ '-': 'final-',
+ 'rc': 'c',
+ 'dev': '@',
+ '': None,
+ '.': None,
+}
+
+
+def _legacy_key(s):
+ def get_parts(s):
+ result = []
+ for p in _VERSION_PART.split(s.lower()):
+ p = _VERSION_REPLACE.get(p, p)
+ if p:
+ if '0' <= p[:1] <= '9':
+ p = p.zfill(8)
+ else:
+ p = '*' + p
+ result.append(p)
+ result.append('*final')
+ return result
+
+ result = []
+ for p in get_parts(s):
+ if p.startswith('*'):
+ if p < '*final':
+ while result and result[-1] == '*final-':
+ result.pop()
+ while result and result[-1] == '00000000':
+ result.pop()
+ result.append(p)
+ return tuple(result)
+
+
+class LegacyVersion(Version):
+ def parse(self, s):
+ return _legacy_key(s)
+
+ @property
+ def is_prerelease(self):
+ result = False
+ for x in self._parts:
+ if (isinstance(x, string_types) and x.startswith('*') and x < '*final'):
+ result = True
+ break
+ return result
+
+
+class LegacyMatcher(Matcher):
+ version_class = LegacyVersion
+
+ _operators = dict(Matcher._operators)
+ _operators['~='] = '_match_compatible'
+
+ numeric_re = re.compile(r'^(\d+(\.\d+)*)')
+
+ def _match_compatible(self, version, constraint, prefix):
+ if version < constraint:
+ return False
+ m = self.numeric_re.match(str(constraint))
+ if not m:
+ logger.warning('Cannot compute compatible match for version %s '
+ ' and constraint %s', version, constraint)
+ return True
+ s = m.groups()[0]
+ if '.' in s:
+ s = s.rsplit('.', 1)[0]
+ return _match_prefix(version, s)
+
+#
+# Semantic versioning
+#
+
+
+_SEMVER_RE = re.compile(r'^(\d+)\.(\d+)\.(\d+)'
+ r'(-[a-z0-9]+(\.[a-z0-9-]+)*)?'
+ r'(\+[a-z0-9]+(\.[a-z0-9-]+)*)?$', re.I)
+
+
+def is_semver(s):
+ return _SEMVER_RE.match(s)
+
+
+def _semantic_key(s):
+ def make_tuple(s, absent):
+ if s is None:
+ result = (absent,)
+ else:
+ parts = s[1:].split('.')
+ # We can't compare ints and strings on Python 3, so fudge it
+ # by zero-filling numeric values so simulate a numeric comparison
+ result = tuple([p.zfill(8) if p.isdigit() else p for p in parts])
+ return result
+
+ m = is_semver(s)
+ if not m:
+ raise UnsupportedVersionError(s)
+ groups = m.groups()
+ major, minor, patch = [int(i) for i in groups[:3]]
+ # choose the '|' and '*' so that versions sort correctly
+ pre, build = make_tuple(groups[3], '|'), make_tuple(groups[5], '*')
+ return (major, minor, patch), pre, build
+
+
+class SemanticVersion(Version):
+ def parse(self, s):
+ return _semantic_key(s)
+
+ @property
+ def is_prerelease(self):
+ return self._parts[1][0] != '|'
+
+
+class SemanticMatcher(Matcher):
+ version_class = SemanticVersion
+
+
+class VersionScheme(object):
+ def __init__(self, key, matcher, suggester=None):
+ self.key = key
+ self.matcher = matcher
+ self.suggester = suggester
+
+ def is_valid_version(self, s):
+ try:
+ self.matcher.version_class(s)
+ result = True
+ except UnsupportedVersionError:
+ result = False
+ return result
+
+ def is_valid_matcher(self, s):
+ try:
+ self.matcher(s)
+ result = True
+ except UnsupportedVersionError:
+ result = False
+ return result
+
+ def is_valid_constraint_list(self, s):
+ """
+ Used for processing some metadata fields
+ """
+ # See issue #140. Be tolerant of a single trailing comma.
+ if s.endswith(','):
+ s = s[:-1]
+ return self.is_valid_matcher('dummy_name (%s)' % s)
+
+ def suggest(self, s):
+ if self.suggester is None:
+ result = None
+ else:
+ result = self.suggester(s)
+ return result
+
+
+_SCHEMES = {
+ 'normalized': VersionScheme(_normalized_key, NormalizedMatcher,
+ _suggest_normalized_version),
+ 'legacy': VersionScheme(_legacy_key, LegacyMatcher, lambda self, s: s),
+ 'semantic': VersionScheme(_semantic_key, SemanticMatcher,
+ _suggest_semantic_version),
+}
+
+_SCHEMES['default'] = _SCHEMES['normalized']
+
+
+def get_scheme(name):
+ if name not in _SCHEMES:
+ raise ValueError('unknown scheme name: %r' % name)
+ return _SCHEMES[name]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w32.exe b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w32.exe
new file mode 100644
index 000000000..4ee2d3a31
Binary files /dev/null and b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w32.exe differ
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w64-arm.exe b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w64-arm.exe
new file mode 100644
index 000000000..951d5817c
Binary files /dev/null and b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w64-arm.exe differ
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w64.exe b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w64.exe
new file mode 100644
index 000000000..5763076d2
Binary files /dev/null and b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/w64.exe differ
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/wheel.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/wheel.py
new file mode 100644
index 000000000..62ab10fb3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distlib/wheel.py
@@ -0,0 +1,1100 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2013-2023 Vinay Sajip.
+# Licensed to the Python Software Foundation under a contributor agreement.
+# See LICENSE.txt and CONTRIBUTORS.txt.
+#
+from __future__ import unicode_literals
+
+import base64
+import codecs
+import datetime
+from email import message_from_file
+import hashlib
+import json
+import logging
+import os
+import posixpath
+import re
+import shutil
+import sys
+import tempfile
+import zipfile
+
+from . import __version__, DistlibException
+from .compat import sysconfig, ZipFile, fsdecode, text_type, filter
+from .database import InstalledDistribution
+from .metadata import Metadata, WHEEL_METADATA_FILENAME, LEGACY_METADATA_FILENAME
+from .util import (FileOperator, convert_path, CSVReader, CSVWriter, Cache, cached_property, get_cache_base,
+ read_exports, tempdir, get_platform)
+from .version import NormalizedVersion, UnsupportedVersionError
+
+logger = logging.getLogger(__name__)
+
+cache = None # created when needed
+
+if hasattr(sys, 'pypy_version_info'): # pragma: no cover
+ IMP_PREFIX = 'pp'
+elif sys.platform.startswith('java'): # pragma: no cover
+ IMP_PREFIX = 'jy'
+elif sys.platform == 'cli': # pragma: no cover
+ IMP_PREFIX = 'ip'
+else:
+ IMP_PREFIX = 'cp'
+
+VER_SUFFIX = sysconfig.get_config_var('py_version_nodot')
+if not VER_SUFFIX: # pragma: no cover
+ VER_SUFFIX = '%s%s' % sys.version_info[:2]
+PYVER = 'py' + VER_SUFFIX
+IMPVER = IMP_PREFIX + VER_SUFFIX
+
+ARCH = get_platform().replace('-', '_').replace('.', '_')
+
+ABI = sysconfig.get_config_var('SOABI')
+if ABI and ABI.startswith('cpython-'):
+ ABI = ABI.replace('cpython-', 'cp').split('-')[0]
+else:
+
+ def _derive_abi():
+ parts = ['cp', VER_SUFFIX]
+ if sysconfig.get_config_var('Py_DEBUG'):
+ parts.append('d')
+ if IMP_PREFIX == 'cp':
+ vi = sys.version_info[:2]
+ if vi < (3, 8):
+ wpm = sysconfig.get_config_var('WITH_PYMALLOC')
+ if wpm is None:
+ wpm = True
+ if wpm:
+ parts.append('m')
+ if vi < (3, 3):
+ us = sysconfig.get_config_var('Py_UNICODE_SIZE')
+ if us == 4 or (us is None and sys.maxunicode == 0x10FFFF):
+ parts.append('u')
+ return ''.join(parts)
+
+ ABI = _derive_abi()
+ del _derive_abi
+
+FILENAME_RE = re.compile(
+ r'''
+(?P<nm>[^-]+)
+-(?P<vn>\d+[^-]*)
+(-(?P<bn>\d+[^-]*))?
+-(?P<py>\w+\d+(\.\w+\d+)*)
+-(?P<bi>\w+)
+-(?P<ar>\w+(\.\w+)*)
+\.whl$
+''', re.IGNORECASE | re.VERBOSE)
+
+NAME_VERSION_RE = re.compile(r'''
+(?P<nm>[^-]+)
+-(?P<vn>\d+[^-]*)
+(-(?P<bn>\d+[^-]*))?$
+''', re.IGNORECASE | re.VERBOSE)
+
+SHEBANG_RE = re.compile(br'\s*#![^\r\n]*')
+SHEBANG_DETAIL_RE = re.compile(br'^(\s*#!("[^"]+"|\S+))\s+(.*)$')
+SHEBANG_PYTHON = b'#!python'
+SHEBANG_PYTHONW = b'#!pythonw'
+
+if os.sep == '/':
+ to_posix = lambda o: o
+else:
+ to_posix = lambda o: o.replace(os.sep, '/')
+
+if sys.version_info[0] < 3:
+ import imp
+else:
+ imp = None
+ import importlib.machinery
+ import importlib.util
+
+
+def _get_suffixes():
+ if imp:
+ return [s[0] for s in imp.get_suffixes()]
+ else:
+ return importlib.machinery.EXTENSION_SUFFIXES
+
+
+def _load_dynamic(name, path):
+ # https://docs.python.org/3/library/importlib.html#importing-a-source-file-directly
+ if imp:
+ return imp.load_dynamic(name, path)
+ else:
+ spec = importlib.util.spec_from_file_location(name, path)
+ module = importlib.util.module_from_spec(spec)
+ sys.modules[name] = module
+ spec.loader.exec_module(module)
+ return module
+
+
+class Mounter(object):
+
+ def __init__(self):
+ self.impure_wheels = {}
+ self.libs = {}
+
+ def add(self, pathname, extensions):
+ self.impure_wheels[pathname] = extensions
+ self.libs.update(extensions)
+
+ def remove(self, pathname):
+ extensions = self.impure_wheels.pop(pathname)
+ for k, v in extensions:
+ if k in self.libs:
+ del self.libs[k]
+
+ def find_module(self, fullname, path=None):
+ if fullname in self.libs:
+ result = self
+ else:
+ result = None
+ return result
+
+ def load_module(self, fullname):
+ if fullname in sys.modules:
+ result = sys.modules[fullname]
+ else:
+ if fullname not in self.libs:
+ raise ImportError('unable to find extension for %s' % fullname)
+ result = _load_dynamic(fullname, self.libs[fullname])
+ result.__loader__ = self
+ parts = fullname.rsplit('.', 1)
+ if len(parts) > 1:
+ result.__package__ = parts[0]
+ return result
+
+
+_hook = Mounter()
+
+
+class Wheel(object):
+ """
+ Class to build and install from Wheel files (PEP 427).
+ """
+
+ wheel_version = (1, 1)
+ hash_kind = 'sha256'
+
+ def __init__(self, filename=None, sign=False, verify=False):
+ """
+ Initialise an instance using a (valid) filename.
+ """
+ self.sign = sign
+ self.should_verify = verify
+ self.buildver = ''
+ self.pyver = [PYVER]
+ self.abi = ['none']
+ self.arch = ['any']
+ self.dirname = os.getcwd()
+ if filename is None:
+ self.name = 'dummy'
+ self.version = '0.1'
+ self._filename = self.filename
+ else:
+ m = NAME_VERSION_RE.match(filename)
+ if m:
+ info = m.groupdict('')
+ self.name = info['nm']
+ # Reinstate the local version separator
+ self.version = info['vn'].replace('_', '-')
+ self.buildver = info['bn']
+ self._filename = self.filename
+ else:
+ dirname, filename = os.path.split(filename)
+ m = FILENAME_RE.match(filename)
+ if not m:
+ raise DistlibException('Invalid name or '
+ 'filename: %r' % filename)
+ if dirname:
+ self.dirname = os.path.abspath(dirname)
+ self._filename = filename
+ info = m.groupdict('')
+ self.name = info['nm']
+ self.version = info['vn']
+ self.buildver = info['bn']
+ self.pyver = info['py'].split('.')
+ self.abi = info['bi'].split('.')
+ self.arch = info['ar'].split('.')
+
+ @property
+ def filename(self):
+ """
+ Build and return a filename from the various components.
+ """
+ if self.buildver:
+ buildver = '-' + self.buildver
+ else:
+ buildver = ''
+ pyver = '.'.join(self.pyver)
+ abi = '.'.join(self.abi)
+ arch = '.'.join(self.arch)
+ # replace - with _ as a local version separator
+ version = self.version.replace('-', '_')
+ return '%s-%s%s-%s-%s-%s.whl' % (self.name, version, buildver, pyver, abi, arch)
+
+ @property
+ def exists(self):
+ path = os.path.join(self.dirname, self.filename)
+ return os.path.isfile(path)
+
+ @property
+ def tags(self):
+ for pyver in self.pyver:
+ for abi in self.abi:
+ for arch in self.arch:
+ yield pyver, abi, arch
+
+ @cached_property
+ def metadata(self):
+ pathname = os.path.join(self.dirname, self.filename)
+ name_ver = '%s-%s' % (self.name, self.version)
+ info_dir = '%s.dist-info' % name_ver
+ wrapper = codecs.getreader('utf-8')
+ with ZipFile(pathname, 'r') as zf:
+ self.get_wheel_metadata(zf)
+ # wv = wheel_metadata['Wheel-Version'].split('.', 1)
+ # file_version = tuple([int(i) for i in wv])
+ # if file_version < (1, 1):
+ # fns = [WHEEL_METADATA_FILENAME, METADATA_FILENAME,
+ # LEGACY_METADATA_FILENAME]
+ # else:
+ # fns = [WHEEL_METADATA_FILENAME, METADATA_FILENAME]
+ fns = [WHEEL_METADATA_FILENAME, LEGACY_METADATA_FILENAME]
+ result = None
+ for fn in fns:
+ try:
+ metadata_filename = posixpath.join(info_dir, fn)
+ with zf.open(metadata_filename) as bf:
+ wf = wrapper(bf)
+ result = Metadata(fileobj=wf)
+ if result:
+ break
+ except KeyError:
+ pass
+ if not result:
+ raise ValueError('Invalid wheel, because metadata is '
+ 'missing: looked in %s' % ', '.join(fns))
+ return result
+
+ def get_wheel_metadata(self, zf):
+ name_ver = '%s-%s' % (self.name, self.version)
+ info_dir = '%s.dist-info' % name_ver
+ metadata_filename = posixpath.join(info_dir, 'WHEEL')
+ with zf.open(metadata_filename) as bf:
+ wf = codecs.getreader('utf-8')(bf)
+ message = message_from_file(wf)
+ return dict(message)
+
+ @cached_property
+ def info(self):
+ pathname = os.path.join(self.dirname, self.filename)
+ with ZipFile(pathname, 'r') as zf:
+ result = self.get_wheel_metadata(zf)
+ return result
+
+ def process_shebang(self, data):
+ m = SHEBANG_RE.match(data)
+ if m:
+ end = m.end()
+ shebang, data_after_shebang = data[:end], data[end:]
+ # Preserve any arguments after the interpreter
+ if b'pythonw' in shebang.lower():
+ shebang_python = SHEBANG_PYTHONW
+ else:
+ shebang_python = SHEBANG_PYTHON
+ m = SHEBANG_DETAIL_RE.match(shebang)
+ if m:
+ args = b' ' + m.groups()[-1]
+ else:
+ args = b''
+ shebang = shebang_python + args
+ data = shebang + data_after_shebang
+ else:
+ cr = data.find(b'\r')
+ lf = data.find(b'\n')
+ if cr < 0 or cr > lf:
+ term = b'\n'
+ else:
+ if data[cr:cr + 2] == b'\r\n':
+ term = b'\r\n'
+ else:
+ term = b'\r'
+ data = SHEBANG_PYTHON + term + data
+ return data
+
+ def get_hash(self, data, hash_kind=None):
+ if hash_kind is None:
+ hash_kind = self.hash_kind
+ try:
+ hasher = getattr(hashlib, hash_kind)
+ except AttributeError:
+ raise DistlibException('Unsupported hash algorithm: %r' % hash_kind)
+ result = hasher(data).digest()
+ result = base64.urlsafe_b64encode(result).rstrip(b'=').decode('ascii')
+ return hash_kind, result
+
+ def write_record(self, records, record_path, archive_record_path):
+ records = list(records) # make a copy, as mutated
+ records.append((archive_record_path, '', ''))
+ with CSVWriter(record_path) as writer:
+ for row in records:
+ writer.writerow(row)
+
+ def write_records(self, info, libdir, archive_paths):
+ records = []
+ distinfo, info_dir = info
+ # hasher = getattr(hashlib, self.hash_kind)
+ for ap, p in archive_paths:
+ with open(p, 'rb') as f:
+ data = f.read()
+ digest = '%s=%s' % self.get_hash(data)
+ size = os.path.getsize(p)
+ records.append((ap, digest, size))
+
+ p = os.path.join(distinfo, 'RECORD')
+ ap = to_posix(os.path.join(info_dir, 'RECORD'))
+ self.write_record(records, p, ap)
+ archive_paths.append((ap, p))
+
+ def build_zip(self, pathname, archive_paths):
+ with ZipFile(pathname, 'w', zipfile.ZIP_DEFLATED) as zf:
+ for ap, p in archive_paths:
+ logger.debug('Wrote %s to %s in wheel', p, ap)
+ zf.write(p, ap)
+
+ def build(self, paths, tags=None, wheel_version=None):
+ """
+ Build a wheel from files in specified paths, and use any specified tags
+ when determining the name of the wheel.
+ """
+ if tags is None:
+ tags = {}
+
+ libkey = list(filter(lambda o: o in paths, ('purelib', 'platlib')))[0]
+ if libkey == 'platlib':
+ is_pure = 'false'
+ default_pyver = [IMPVER]
+ default_abi = [ABI]
+ default_arch = [ARCH]
+ else:
+ is_pure = 'true'
+ default_pyver = [PYVER]
+ default_abi = ['none']
+ default_arch = ['any']
+
+ self.pyver = tags.get('pyver', default_pyver)
+ self.abi = tags.get('abi', default_abi)
+ self.arch = tags.get('arch', default_arch)
+
+ libdir = paths[libkey]
+
+ name_ver = '%s-%s' % (self.name, self.version)
+ data_dir = '%s.data' % name_ver
+ info_dir = '%s.dist-info' % name_ver
+
+ archive_paths = []
+
+ # First, stuff which is not in site-packages
+ for key in ('data', 'headers', 'scripts'):
+ if key not in paths:
+ continue
+ path = paths[key]
+ if os.path.isdir(path):
+ for root, dirs, files in os.walk(path):
+ for fn in files:
+ p = fsdecode(os.path.join(root, fn))
+ rp = os.path.relpath(p, path)
+ ap = to_posix(os.path.join(data_dir, key, rp))
+ archive_paths.append((ap, p))
+ if key == 'scripts' and not p.endswith('.exe'):
+ with open(p, 'rb') as f:
+ data = f.read()
+ data = self.process_shebang(data)
+ with open(p, 'wb') as f:
+ f.write(data)
+
+ # Now, stuff which is in site-packages, other than the
+ # distinfo stuff.
+ path = libdir
+ distinfo = None
+ for root, dirs, files in os.walk(path):
+ if root == path:
+ # At the top level only, save distinfo for later
+ # and skip it for now
+ for i, dn in enumerate(dirs):
+ dn = fsdecode(dn)
+ if dn.endswith('.dist-info'):
+ distinfo = os.path.join(root, dn)
+ del dirs[i]
+ break
+ assert distinfo, '.dist-info directory expected, not found'
+
+ for fn in files:
+ # comment out next suite to leave .pyc files in
+ if fsdecode(fn).endswith(('.pyc', '.pyo')):
+ continue
+ p = os.path.join(root, fn)
+ rp = to_posix(os.path.relpath(p, path))
+ archive_paths.append((rp, p))
+
+ # Now distinfo. Assumed to be flat, i.e. os.listdir is enough.
+ files = os.listdir(distinfo)
+ for fn in files:
+ if fn not in ('RECORD', 'INSTALLER', 'SHARED', 'WHEEL'):
+ p = fsdecode(os.path.join(distinfo, fn))
+ ap = to_posix(os.path.join(info_dir, fn))
+ archive_paths.append((ap, p))
+
+ wheel_metadata = [
+ 'Wheel-Version: %d.%d' % (wheel_version or self.wheel_version),
+ 'Generator: distlib %s' % __version__,
+ 'Root-Is-Purelib: %s' % is_pure,
+ ]
+ for pyver, abi, arch in self.tags:
+ wheel_metadata.append('Tag: %s-%s-%s' % (pyver, abi, arch))
+ p = os.path.join(distinfo, 'WHEEL')
+ with open(p, 'w') as f:
+ f.write('\n'.join(wheel_metadata))
+ ap = to_posix(os.path.join(info_dir, 'WHEEL'))
+ archive_paths.append((ap, p))
+
+ # sort the entries by archive path. Not needed by any spec, but it
+ # keeps the archive listing and RECORD tidier than they would otherwise
+ # be. Use the number of path segments to keep directory entries together,
+ # and keep the dist-info stuff at the end.
+ def sorter(t):
+ ap = t[0]
+ n = ap.count('/')
+ if '.dist-info' in ap:
+ n += 10000
+ return (n, ap)
+
+ archive_paths = sorted(archive_paths, key=sorter)
+
+ # Now, at last, RECORD.
+ # Paths in here are archive paths - nothing else makes sense.
+ self.write_records((distinfo, info_dir), libdir, archive_paths)
+ # Now, ready to build the zip file
+ pathname = os.path.join(self.dirname, self.filename)
+ self.build_zip(pathname, archive_paths)
+ return pathname
+
+ def skip_entry(self, arcname):
+ """
+ Determine whether an archive entry should be skipped when verifying
+ or installing.
+ """
+ # The signature file won't be in RECORD,
+ # and we don't currently don't do anything with it
+ # We also skip directories, as they won't be in RECORD
+ # either. See:
+ #
+ # https://github.com/pypa/wheel/issues/294
+ # https://github.com/pypa/wheel/issues/287
+ # https://github.com/pypa/wheel/pull/289
+ #
+ return arcname.endswith(('/', '/RECORD.jws'))
+
+ def install(self, paths, maker, **kwargs):
+ """
+ Install a wheel to the specified paths. If kwarg ``warner`` is
+ specified, it should be a callable, which will be called with two
+ tuples indicating the wheel version of this software and the wheel
+ version in the file, if there is a discrepancy in the versions.
+ This can be used to issue any warnings to raise any exceptions.
+ If kwarg ``lib_only`` is True, only the purelib/platlib files are
+ installed, and the headers, scripts, data and dist-info metadata are
+ not written. If kwarg ``bytecode_hashed_invalidation`` is True, written
+ bytecode will try to use file-hash based invalidation (PEP-552) on
+ supported interpreter versions (CPython 3.7+).
+
+ The return value is a :class:`InstalledDistribution` instance unless
+ ``options.lib_only`` is True, in which case the return value is ``None``.
+ """
+
+ dry_run = maker.dry_run
+ warner = kwargs.get('warner')
+ lib_only = kwargs.get('lib_only', False)
+ bc_hashed_invalidation = kwargs.get('bytecode_hashed_invalidation', False)
+
+ pathname = os.path.join(self.dirname, self.filename)
+ name_ver = '%s-%s' % (self.name, self.version)
+ data_dir = '%s.data' % name_ver
+ info_dir = '%s.dist-info' % name_ver
+
+ metadata_name = posixpath.join(info_dir, LEGACY_METADATA_FILENAME)
+ wheel_metadata_name = posixpath.join(info_dir, 'WHEEL')
+ record_name = posixpath.join(info_dir, 'RECORD')
+
+ wrapper = codecs.getreader('utf-8')
+
+ with ZipFile(pathname, 'r') as zf:
+ with zf.open(wheel_metadata_name) as bwf:
+ wf = wrapper(bwf)
+ message = message_from_file(wf)
+ wv = message['Wheel-Version'].split('.', 1)
+ file_version = tuple([int(i) for i in wv])
+ if (file_version != self.wheel_version) and warner:
+ warner(self.wheel_version, file_version)
+
+ if message['Root-Is-Purelib'] == 'true':
+ libdir = paths['purelib']
+ else:
+ libdir = paths['platlib']
+
+ records = {}
+ with zf.open(record_name) as bf:
+ with CSVReader(stream=bf) as reader:
+ for row in reader:
+ p = row[0]
+ records[p] = row
+
+ data_pfx = posixpath.join(data_dir, '')
+ info_pfx = posixpath.join(info_dir, '')
+ script_pfx = posixpath.join(data_dir, 'scripts', '')
+
+ # make a new instance rather than a copy of maker's,
+ # as we mutate it
+ fileop = FileOperator(dry_run=dry_run)
+ fileop.record = True # so we can rollback if needed
+
+ bc = not sys.dont_write_bytecode # Double negatives. Lovely!
+
+ outfiles = [] # for RECORD writing
+
+ # for script copying/shebang processing
+ workdir = tempfile.mkdtemp()
+ # set target dir later
+ # we default add_launchers to False, as the
+ # Python Launcher should be used instead
+ maker.source_dir = workdir
+ maker.target_dir = None
+ try:
+ for zinfo in zf.infolist():
+ arcname = zinfo.filename
+ if isinstance(arcname, text_type):
+ u_arcname = arcname
+ else:
+ u_arcname = arcname.decode('utf-8')
+ if self.skip_entry(u_arcname):
+ continue
+ row = records[u_arcname]
+ if row[2] and str(zinfo.file_size) != row[2]:
+ raise DistlibException('size mismatch for '
+ '%s' % u_arcname)
+ if row[1]:
+ kind, value = row[1].split('=', 1)
+ with zf.open(arcname) as bf:
+ data = bf.read()
+ _, digest = self.get_hash(data, kind)
+ if digest != value:
+ raise DistlibException('digest mismatch for '
+ '%s' % arcname)
+
+ if lib_only and u_arcname.startswith((info_pfx, data_pfx)):
+ logger.debug('lib_only: skipping %s', u_arcname)
+ continue
+ is_script = (u_arcname.startswith(script_pfx) and not u_arcname.endswith('.exe'))
+
+ if u_arcname.startswith(data_pfx):
+ _, where, rp = u_arcname.split('/', 2)
+ outfile = os.path.join(paths[where], convert_path(rp))
+ else:
+ # meant for site-packages.
+ if u_arcname in (wheel_metadata_name, record_name):
+ continue
+ outfile = os.path.join(libdir, convert_path(u_arcname))
+ if not is_script:
+ with zf.open(arcname) as bf:
+ fileop.copy_stream(bf, outfile)
+ # Issue #147: permission bits aren't preserved. Using
+ # zf.extract(zinfo, libdir) should have worked, but didn't,
+ # see https://www.thetopsites.net/article/53834422.shtml
+ # So ... manually preserve permission bits as given in zinfo
+ if os.name == 'posix':
+ # just set the normal permission bits
+ os.chmod(outfile, (zinfo.external_attr >> 16) & 0x1FF)
+ outfiles.append(outfile)
+ # Double check the digest of the written file
+ if not dry_run and row[1]:
+ with open(outfile, 'rb') as bf:
+ data = bf.read()
+ _, newdigest = self.get_hash(data, kind)
+ if newdigest != digest:
+ raise DistlibException('digest mismatch '
+ 'on write for '
+ '%s' % outfile)
+ if bc and outfile.endswith('.py'):
+ try:
+ pyc = fileop.byte_compile(outfile, hashed_invalidation=bc_hashed_invalidation)
+ outfiles.append(pyc)
+ except Exception:
+ # Don't give up if byte-compilation fails,
+ # but log it and perhaps warn the user
+ logger.warning('Byte-compilation failed', exc_info=True)
+ else:
+ fn = os.path.basename(convert_path(arcname))
+ workname = os.path.join(workdir, fn)
+ with zf.open(arcname) as bf:
+ fileop.copy_stream(bf, workname)
+
+ dn, fn = os.path.split(outfile)
+ maker.target_dir = dn
+ filenames = maker.make(fn)
+ fileop.set_executable_mode(filenames)
+ outfiles.extend(filenames)
+
+ if lib_only:
+ logger.debug('lib_only: returning None')
+ dist = None
+ else:
+ # Generate scripts
+
+ # Try to get pydist.json so we can see if there are
+ # any commands to generate. If this fails (e.g. because
+ # of a legacy wheel), log a warning but don't give up.
+ commands = None
+ file_version = self.info['Wheel-Version']
+ if file_version == '1.0':
+ # Use legacy info
+ ep = posixpath.join(info_dir, 'entry_points.txt')
+ try:
+ with zf.open(ep) as bwf:
+ epdata = read_exports(bwf)
+ commands = {}
+ for key in ('console', 'gui'):
+ k = '%s_scripts' % key
+ if k in epdata:
+ commands['wrap_%s' % key] = d = {}
+ for v in epdata[k].values():
+ s = '%s:%s' % (v.prefix, v.suffix)
+ if v.flags:
+ s += ' [%s]' % ','.join(v.flags)
+ d[v.name] = s
+ except Exception:
+ logger.warning('Unable to read legacy script '
+ 'metadata, so cannot generate '
+ 'scripts')
+ else:
+ try:
+ with zf.open(metadata_name) as bwf:
+ wf = wrapper(bwf)
+ commands = json.load(wf).get('extensions')
+ if commands:
+ commands = commands.get('python.commands')
+ except Exception:
+ logger.warning('Unable to read JSON metadata, so '
+ 'cannot generate scripts')
+ if commands:
+ console_scripts = commands.get('wrap_console', {})
+ gui_scripts = commands.get('wrap_gui', {})
+ if console_scripts or gui_scripts:
+ script_dir = paths.get('scripts', '')
+ if not os.path.isdir(script_dir):
+ raise ValueError('Valid script path not '
+ 'specified')
+ maker.target_dir = script_dir
+ for k, v in console_scripts.items():
+ script = '%s = %s' % (k, v)
+ filenames = maker.make(script)
+ fileop.set_executable_mode(filenames)
+
+ if gui_scripts:
+ options = {'gui': True}
+ for k, v in gui_scripts.items():
+ script = '%s = %s' % (k, v)
+ filenames = maker.make(script, options)
+ fileop.set_executable_mode(filenames)
+
+ p = os.path.join(libdir, info_dir)
+ dist = InstalledDistribution(p)
+
+ # Write SHARED
+ paths = dict(paths) # don't change passed in dict
+ del paths['purelib']
+ del paths['platlib']
+ paths['lib'] = libdir
+ p = dist.write_shared_locations(paths, dry_run)
+ if p:
+ outfiles.append(p)
+
+ # Write RECORD
+ dist.write_installed_files(outfiles, paths['prefix'], dry_run)
+ return dist
+ except Exception: # pragma: no cover
+ logger.exception('installation failed.')
+ fileop.rollback()
+ raise
+ finally:
+ shutil.rmtree(workdir)
+
+ def _get_dylib_cache(self):
+ global cache
+ if cache is None:
+ # Use native string to avoid issues on 2.x: see Python #20140.
+ base = os.path.join(get_cache_base(), str('dylib-cache'), '%s.%s' % sys.version_info[:2])
+ cache = Cache(base)
+ return cache
+
+ def _get_extensions(self):
+ pathname = os.path.join(self.dirname, self.filename)
+ name_ver = '%s-%s' % (self.name, self.version)
+ info_dir = '%s.dist-info' % name_ver
+ arcname = posixpath.join(info_dir, 'EXTENSIONS')
+ wrapper = codecs.getreader('utf-8')
+ result = []
+ with ZipFile(pathname, 'r') as zf:
+ try:
+ with zf.open(arcname) as bf:
+ wf = wrapper(bf)
+ extensions = json.load(wf)
+ cache = self._get_dylib_cache()
+ prefix = cache.prefix_to_dir(self.filename, use_abspath=False)
+ cache_base = os.path.join(cache.base, prefix)
+ if not os.path.isdir(cache_base):
+ os.makedirs(cache_base)
+ for name, relpath in extensions.items():
+ dest = os.path.join(cache_base, convert_path(relpath))
+ if not os.path.exists(dest):
+ extract = True
+ else:
+ file_time = os.stat(dest).st_mtime
+ file_time = datetime.datetime.fromtimestamp(file_time)
+ info = zf.getinfo(relpath)
+ wheel_time = datetime.datetime(*info.date_time)
+ extract = wheel_time > file_time
+ if extract:
+ zf.extract(relpath, cache_base)
+ result.append((name, dest))
+ except KeyError:
+ pass
+ return result
+
+ def is_compatible(self):
+ """
+ Determine if a wheel is compatible with the running system.
+ """
+ return is_compatible(self)
+
+ def is_mountable(self):
+ """
+ Determine if a wheel is asserted as mountable by its metadata.
+ """
+ return True # for now - metadata details TBD
+
+ def mount(self, append=False):
+ pathname = os.path.abspath(os.path.join(self.dirname, self.filename))
+ if not self.is_compatible():
+ msg = 'Wheel %s not compatible with this Python.' % pathname
+ raise DistlibException(msg)
+ if not self.is_mountable():
+ msg = 'Wheel %s is marked as not mountable.' % pathname
+ raise DistlibException(msg)
+ if pathname in sys.path:
+ logger.debug('%s already in path', pathname)
+ else:
+ if append:
+ sys.path.append(pathname)
+ else:
+ sys.path.insert(0, pathname)
+ extensions = self._get_extensions()
+ if extensions:
+ if _hook not in sys.meta_path:
+ sys.meta_path.append(_hook)
+ _hook.add(pathname, extensions)
+
+ def unmount(self):
+ pathname = os.path.abspath(os.path.join(self.dirname, self.filename))
+ if pathname not in sys.path:
+ logger.debug('%s not in path', pathname)
+ else:
+ sys.path.remove(pathname)
+ if pathname in _hook.impure_wheels:
+ _hook.remove(pathname)
+ if not _hook.impure_wheels:
+ if _hook in sys.meta_path:
+ sys.meta_path.remove(_hook)
+
+ def verify(self):
+ pathname = os.path.join(self.dirname, self.filename)
+ name_ver = '%s-%s' % (self.name, self.version)
+ # data_dir = '%s.data' % name_ver
+ info_dir = '%s.dist-info' % name_ver
+
+ # metadata_name = posixpath.join(info_dir, LEGACY_METADATA_FILENAME)
+ wheel_metadata_name = posixpath.join(info_dir, 'WHEEL')
+ record_name = posixpath.join(info_dir, 'RECORD')
+
+ wrapper = codecs.getreader('utf-8')
+
+ with ZipFile(pathname, 'r') as zf:
+ with zf.open(wheel_metadata_name) as bwf:
+ wf = wrapper(bwf)
+ message_from_file(wf)
+ # wv = message['Wheel-Version'].split('.', 1)
+ # file_version = tuple([int(i) for i in wv])
+ # TODO version verification
+
+ records = {}
+ with zf.open(record_name) as bf:
+ with CSVReader(stream=bf) as reader:
+ for row in reader:
+ p = row[0]
+ records[p] = row
+
+ for zinfo in zf.infolist():
+ arcname = zinfo.filename
+ if isinstance(arcname, text_type):
+ u_arcname = arcname
+ else:
+ u_arcname = arcname.decode('utf-8')
+ # See issue #115: some wheels have .. in their entries, but
+ # in the filename ... e.g. __main__..py ! So the check is
+ # updated to look for .. in the directory portions
+ p = u_arcname.split('/')
+ if '..' in p:
+ raise DistlibException('invalid entry in '
+ 'wheel: %r' % u_arcname)
+
+ if self.skip_entry(u_arcname):
+ continue
+ row = records[u_arcname]
+ if row[2] and str(zinfo.file_size) != row[2]:
+ raise DistlibException('size mismatch for '
+ '%s' % u_arcname)
+ if row[1]:
+ kind, value = row[1].split('=', 1)
+ with zf.open(arcname) as bf:
+ data = bf.read()
+ _, digest = self.get_hash(data, kind)
+ if digest != value:
+ raise DistlibException('digest mismatch for '
+ '%s' % arcname)
+
+ def update(self, modifier, dest_dir=None, **kwargs):
+ """
+ Update the contents of a wheel in a generic way. The modifier should
+ be a callable which expects a dictionary argument: its keys are
+ archive-entry paths, and its values are absolute filesystem paths
+ where the contents the corresponding archive entries can be found. The
+ modifier is free to change the contents of the files pointed to, add
+ new entries and remove entries, before returning. This method will
+ extract the entire contents of the wheel to a temporary location, call
+ the modifier, and then use the passed (and possibly updated)
+ dictionary to write a new wheel. If ``dest_dir`` is specified, the new
+ wheel is written there -- otherwise, the original wheel is overwritten.
+
+ The modifier should return True if it updated the wheel, else False.
+ This method returns the same value the modifier returns.
+ """
+
+ def get_version(path_map, info_dir):
+ version = path = None
+ key = '%s/%s' % (info_dir, LEGACY_METADATA_FILENAME)
+ if key not in path_map:
+ key = '%s/PKG-INFO' % info_dir
+ if key in path_map:
+ path = path_map[key]
+ version = Metadata(path=path).version
+ return version, path
+
+ def update_version(version, path):
+ updated = None
+ try:
+ NormalizedVersion(version)
+ i = version.find('-')
+ if i < 0:
+ updated = '%s+1' % version
+ else:
+ parts = [int(s) for s in version[i + 1:].split('.')]
+ parts[-1] += 1
+ updated = '%s+%s' % (version[:i], '.'.join(str(i) for i in parts))
+ except UnsupportedVersionError:
+ logger.debug('Cannot update non-compliant (PEP-440) '
+ 'version %r', version)
+ if updated:
+ md = Metadata(path=path)
+ md.version = updated
+ legacy = path.endswith(LEGACY_METADATA_FILENAME)
+ md.write(path=path, legacy=legacy)
+ logger.debug('Version updated from %r to %r', version, updated)
+
+ pathname = os.path.join(self.dirname, self.filename)
+ name_ver = '%s-%s' % (self.name, self.version)
+ info_dir = '%s.dist-info' % name_ver
+ record_name = posixpath.join(info_dir, 'RECORD')
+ with tempdir() as workdir:
+ with ZipFile(pathname, 'r') as zf:
+ path_map = {}
+ for zinfo in zf.infolist():
+ arcname = zinfo.filename
+ if isinstance(arcname, text_type):
+ u_arcname = arcname
+ else:
+ u_arcname = arcname.decode('utf-8')
+ if u_arcname == record_name:
+ continue
+ if '..' in u_arcname:
+ raise DistlibException('invalid entry in '
+ 'wheel: %r' % u_arcname)
+ zf.extract(zinfo, workdir)
+ path = os.path.join(workdir, convert_path(u_arcname))
+ path_map[u_arcname] = path
+
+ # Remember the version.
+ original_version, _ = get_version(path_map, info_dir)
+ # Files extracted. Call the modifier.
+ modified = modifier(path_map, **kwargs)
+ if modified:
+ # Something changed - need to build a new wheel.
+ current_version, path = get_version(path_map, info_dir)
+ if current_version and (current_version == original_version):
+ # Add or update local version to signify changes.
+ update_version(current_version, path)
+ # Decide where the new wheel goes.
+ if dest_dir is None:
+ fd, newpath = tempfile.mkstemp(suffix='.whl', prefix='wheel-update-', dir=workdir)
+ os.close(fd)
+ else:
+ if not os.path.isdir(dest_dir):
+ raise DistlibException('Not a directory: %r' % dest_dir)
+ newpath = os.path.join(dest_dir, self.filename)
+ archive_paths = list(path_map.items())
+ distinfo = os.path.join(workdir, info_dir)
+ info = distinfo, info_dir
+ self.write_records(info, workdir, archive_paths)
+ self.build_zip(newpath, archive_paths)
+ if dest_dir is None:
+ shutil.copyfile(newpath, pathname)
+ return modified
+
+
+def _get_glibc_version():
+ import platform
+ ver = platform.libc_ver()
+ result = []
+ if ver[0] == 'glibc':
+ for s in ver[1].split('.'):
+ result.append(int(s) if s.isdigit() else 0)
+ result = tuple(result)
+ return result
+
+
+def compatible_tags():
+ """
+ Return (pyver, abi, arch) tuples compatible with this Python.
+ """
+ class _Version:
+ def __init__(self, major, minor):
+ self.major = major
+ self.major_minor = (major, minor)
+ self.string = ''.join((str(major), str(minor)))
+
+ def __str__(self):
+ return self.string
+
+
+ versions = [
+ _Version(sys.version_info.major, minor_version)
+ for minor_version in range(sys.version_info.minor, -1, -1)
+ ]
+ abis = []
+ for suffix in _get_suffixes():
+ if suffix.startswith('.abi'):
+ abis.append(suffix.split('.', 2)[1])
+ abis.sort()
+ if ABI != 'none':
+ abis.insert(0, ABI)
+ abis.append('none')
+ result = []
+
+ arches = [ARCH]
+ if sys.platform == 'darwin':
+ m = re.match(r'(\w+)_(\d+)_(\d+)_(\w+)$', ARCH)
+ if m:
+ name, major, minor, arch = m.groups()
+ minor = int(minor)
+ matches = [arch]
+ if arch in ('i386', 'ppc'):
+ matches.append('fat')
+ if arch in ('i386', 'ppc', 'x86_64'):
+ matches.append('fat3')
+ if arch in ('ppc64', 'x86_64'):
+ matches.append('fat64')
+ if arch in ('i386', 'x86_64'):
+ matches.append('intel')
+ if arch in ('i386', 'x86_64', 'intel', 'ppc', 'ppc64'):
+ matches.append('universal')
+ while minor >= 0:
+ for match in matches:
+ s = '%s_%s_%s_%s' % (name, major, minor, match)
+ if s != ARCH: # already there
+ arches.append(s)
+ minor -= 1
+
+ # Most specific - our Python version, ABI and arch
+ for i, version_object in enumerate(versions):
+ version = str(version_object)
+ add_abis = []
+
+ if i == 0:
+ add_abis = abis
+
+ if IMP_PREFIX == 'cp' and version_object.major_minor >= (3, 2):
+ limited_api_abi = 'abi' + str(version_object.major)
+ if limited_api_abi not in add_abis:
+ add_abis.append(limited_api_abi)
+
+ for abi in add_abis:
+ for arch in arches:
+ result.append((''.join((IMP_PREFIX, version)), abi, arch))
+ # manylinux
+ if abi != 'none' and sys.platform.startswith('linux'):
+ arch = arch.replace('linux_', '')
+ parts = _get_glibc_version()
+ if len(parts) == 2:
+ if parts >= (2, 5):
+ result.append((''.join((IMP_PREFIX, version)), abi, 'manylinux1_%s' % arch))
+ if parts >= (2, 12):
+ result.append((''.join((IMP_PREFIX, version)), abi, 'manylinux2010_%s' % arch))
+ if parts >= (2, 17):
+ result.append((''.join((IMP_PREFIX, version)), abi, 'manylinux2014_%s' % arch))
+ result.append((''.join(
+ (IMP_PREFIX, version)), abi, 'manylinux_%s_%s_%s' % (parts[0], parts[1], arch)))
+
+ # where no ABI / arch dependency, but IMP_PREFIX dependency
+ for i, version_object in enumerate(versions):
+ version = str(version_object)
+ result.append((''.join((IMP_PREFIX, version)), 'none', 'any'))
+ if i == 0:
+ result.append((''.join((IMP_PREFIX, version[0])), 'none', 'any'))
+
+ # no IMP_PREFIX, ABI or arch dependency
+ for i, version_object in enumerate(versions):
+ version = str(version_object)
+ result.append((''.join(('py', version)), 'none', 'any'))
+ if i == 0:
+ result.append((''.join(('py', version[0])), 'none', 'any'))
+
+ return set(result)
+
+
+COMPATIBLE_TAGS = compatible_tags()
+
+del compatible_tags
+
+
+def is_compatible(wheel, tags=None):
+ if not isinstance(wheel, Wheel):
+ wheel = Wheel(wheel) # assume it's a filename
+ result = False
+ if tags is None:
+ tags = COMPATIBLE_TAGS
+ for ver, abi, arch in tags:
+ if ver in wheel.pyver and abi in wheel.abi and arch in wheel.arch:
+ result = True
+ break
+ return result
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distro/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distro/__init__.py
new file mode 100644
index 000000000..7686fe85a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distro/__init__.py
@@ -0,0 +1,54 @@
+from .distro import (
+ NORMALIZED_DISTRO_ID,
+ NORMALIZED_LSB_ID,
+ NORMALIZED_OS_ID,
+ LinuxDistribution,
+ __version__,
+ build_number,
+ codename,
+ distro_release_attr,
+ distro_release_info,
+ id,
+ info,
+ like,
+ linux_distribution,
+ lsb_release_attr,
+ lsb_release_info,
+ major_version,
+ minor_version,
+ name,
+ os_release_attr,
+ os_release_info,
+ uname_attr,
+ uname_info,
+ version,
+ version_parts,
+)
+
+__all__ = [
+ "NORMALIZED_DISTRO_ID",
+ "NORMALIZED_LSB_ID",
+ "NORMALIZED_OS_ID",
+ "LinuxDistribution",
+ "build_number",
+ "codename",
+ "distro_release_attr",
+ "distro_release_info",
+ "id",
+ "info",
+ "like",
+ "linux_distribution",
+ "lsb_release_attr",
+ "lsb_release_info",
+ "major_version",
+ "minor_version",
+ "name",
+ "os_release_attr",
+ "os_release_info",
+ "uname_attr",
+ "uname_info",
+ "version",
+ "version_parts",
+]
+
+__version__ = __version__
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distro/__main__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distro/__main__.py
new file mode 100644
index 000000000..0c01d5b08
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distro/__main__.py
@@ -0,0 +1,4 @@
+from .distro import main
+
+if __name__ == "__main__":
+ main()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distro/distro.py b/solutions/.venv/Lib/site-packages/pip/_vendor/distro/distro.py
new file mode 100644
index 000000000..78ccdfa40
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/distro/distro.py
@@ -0,0 +1,1403 @@
+#!/usr/bin/env python
+# Copyright 2015-2021 Nir Cohen
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""
+The ``distro`` package (``distro`` stands for Linux Distribution) provides
+information about the Linux distribution it runs on, such as a reliable
+machine-readable distro ID, or version information.
+
+It is the recommended replacement for Python's original
+:py:func:`platform.linux_distribution` function, but it provides much more
+functionality. An alternative implementation became necessary because Python
+3.5 deprecated this function, and Python 3.8 removed it altogether. Its
+predecessor function :py:func:`platform.dist` was already deprecated since
+Python 2.6 and removed in Python 3.8. Still, there are many cases in which
+access to OS distribution information is needed. See `Python issue 1322
+<https://bugs.python.org/issue1322>`_ for more information.
+"""
+
+import argparse
+import json
+import logging
+import os
+import re
+import shlex
+import subprocess
+import sys
+import warnings
+from typing import (
+ Any,
+ Callable,
+ Dict,
+ Iterable,
+ Optional,
+ Sequence,
+ TextIO,
+ Tuple,
+ Type,
+)
+
+try:
+ from typing import TypedDict
+except ImportError:
+ # Python 3.7
+ TypedDict = dict
+
+__version__ = "1.9.0"
+
+
+class VersionDict(TypedDict):
+ major: str
+ minor: str
+ build_number: str
+
+
+class InfoDict(TypedDict):
+ id: str
+ version: str
+ version_parts: VersionDict
+ like: str
+ codename: str
+
+
+_UNIXCONFDIR = os.environ.get("UNIXCONFDIR", "/etc")
+_UNIXUSRLIBDIR = os.environ.get("UNIXUSRLIBDIR", "/usr/lib")
+_OS_RELEASE_BASENAME = "os-release"
+
+#: Translation table for normalizing the "ID" attribute defined in os-release
+#: files, for use by the :func:`distro.id` method.
+#:
+#: * Key: Value as defined in the os-release file, translated to lower case,
+#: with blanks translated to underscores.
+#:
+#: * Value: Normalized value.
+NORMALIZED_OS_ID = {
+ "ol": "oracle", # Oracle Linux
+ "opensuse-leap": "opensuse", # Newer versions of OpenSuSE report as opensuse-leap
+}
+
+#: Translation table for normalizing the "Distributor ID" attribute returned by
+#: the lsb_release command, for use by the :func:`distro.id` method.
+#:
+#: * Key: Value as returned by the lsb_release command, translated to lower
+#: case, with blanks translated to underscores.
+#:
+#: * Value: Normalized value.
+NORMALIZED_LSB_ID = {
+ "enterpriseenterpriseas": "oracle", # Oracle Enterprise Linux 4
+ "enterpriseenterpriseserver": "oracle", # Oracle Linux 5
+ "redhatenterpriseworkstation": "rhel", # RHEL 6, 7 Workstation
+ "redhatenterpriseserver": "rhel", # RHEL 6, 7 Server
+ "redhatenterprisecomputenode": "rhel", # RHEL 6 ComputeNode
+}
+
+#: Translation table for normalizing the distro ID derived from the file name
+#: of distro release files, for use by the :func:`distro.id` method.
+#:
+#: * Key: Value as derived from the file name of a distro release file,
+#: translated to lower case, with blanks translated to underscores.
+#:
+#: * Value: Normalized value.
+NORMALIZED_DISTRO_ID = {
+ "redhat": "rhel", # RHEL 6.x, 7.x
+}
+
+# Pattern for content of distro release file (reversed)
+_DISTRO_RELEASE_CONTENT_REVERSED_PATTERN = re.compile(
+ r"(?:[^)]*\)(.*)\()? *(?:STL )?([\d.+\-a-z]*\d) *(?:esaeler *)?(.+)"
+)
+
+# Pattern for base file name of distro release file
+_DISTRO_RELEASE_BASENAME_PATTERN = re.compile(r"(\w+)[-_](release|version)$")
+
+# Base file names to be looked up for if _UNIXCONFDIR is not readable.
+_DISTRO_RELEASE_BASENAMES = [
+ "SuSE-release",
+ "altlinux-release",
+ "arch-release",
+ "base-release",
+ "centos-release",
+ "fedora-release",
+ "gentoo-release",
+ "mageia-release",
+ "mandrake-release",
+ "mandriva-release",
+ "mandrivalinux-release",
+ "manjaro-release",
+ "oracle-release",
+ "redhat-release",
+ "rocky-release",
+ "sl-release",
+ "slackware-version",
+]
+
+# Base file names to be ignored when searching for distro release file
+_DISTRO_RELEASE_IGNORE_BASENAMES = (
+ "debian_version",
+ "lsb-release",
+ "oem-release",
+ _OS_RELEASE_BASENAME,
+ "system-release",
+ "plesk-release",
+ "iredmail-release",
+ "board-release",
+ "ec2_version",
+)
+
+
+def linux_distribution(full_distribution_name: bool = True) -> Tuple[str, str, str]:
+ """
+ .. deprecated:: 1.6.0
+
+ :func:`distro.linux_distribution()` is deprecated. It should only be
+ used as a compatibility shim with Python's
+ :py:func:`platform.linux_distribution()`. Please use :func:`distro.id`,
+ :func:`distro.version` and :func:`distro.name` instead.
+
+ Return information about the current OS distribution as a tuple
+ ``(id_name, version, codename)`` with items as follows:
+
+ * ``id_name``: If *full_distribution_name* is false, the result of
+ :func:`distro.id`. Otherwise, the result of :func:`distro.name`.
+
+ * ``version``: The result of :func:`distro.version`.
+
+ * ``codename``: The extra item (usually in parentheses) after the
+ os-release version number, or the result of :func:`distro.codename`.
+
+ The interface of this function is compatible with the original
+ :py:func:`platform.linux_distribution` function, supporting a subset of
+ its parameters.
+
+ The data it returns may not exactly be the same, because it uses more data
+ sources than the original function, and that may lead to different data if
+ the OS distribution is not consistent across multiple data sources it
+ provides (there are indeed such distributions ...).
+
+ Another reason for differences is the fact that the :func:`distro.id`
+ method normalizes the distro ID string to a reliable machine-readable value
+ for a number of popular OS distributions.
+ """
+ warnings.warn(
+ "distro.linux_distribution() is deprecated. It should only be used as a "
+ "compatibility shim with Python's platform.linux_distribution(). Please use "
+ "distro.id(), distro.version() and distro.name() instead.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ return _distro.linux_distribution(full_distribution_name)
+
+
+def id() -> str:
+ """
+ Return the distro ID of the current distribution, as a
+ machine-readable string.
+
+ For a number of OS distributions, the returned distro ID value is
+ *reliable*, in the sense that it is documented and that it does not change
+ across releases of the distribution.
+
+ This package maintains the following reliable distro ID values:
+
+ ============== =========================================
+ Distro ID Distribution
+ ============== =========================================
+ "ubuntu" Ubuntu
+ "debian" Debian
+ "rhel" RedHat Enterprise Linux
+ "centos" CentOS
+ "fedora" Fedora
+ "sles" SUSE Linux Enterprise Server
+ "opensuse" openSUSE
+ "amzn" Amazon Linux
+ "arch" Arch Linux
+ "buildroot" Buildroot
+ "cloudlinux" CloudLinux OS
+ "exherbo" Exherbo Linux
+ "gentoo" GenToo Linux
+ "ibm_powerkvm" IBM PowerKVM
+ "kvmibm" KVM for IBM z Systems
+ "linuxmint" Linux Mint
+ "mageia" Mageia
+ "mandriva" Mandriva Linux
+ "parallels" Parallels
+ "pidora" Pidora
+ "raspbian" Raspbian
+ "oracle" Oracle Linux (and Oracle Enterprise Linux)
+ "scientific" Scientific Linux
+ "slackware" Slackware
+ "xenserver" XenServer
+ "openbsd" OpenBSD
+ "netbsd" NetBSD
+ "freebsd" FreeBSD
+ "midnightbsd" MidnightBSD
+ "rocky" Rocky Linux
+ "aix" AIX
+ "guix" Guix System
+ "altlinux" ALT Linux
+ ============== =========================================
+
+ If you have a need to get distros for reliable IDs added into this set,
+ or if you find that the :func:`distro.id` function returns a different
+ distro ID for one of the listed distros, please create an issue in the
+ `distro issue tracker`_.
+
+ **Lookup hierarchy and transformations:**
+
+ First, the ID is obtained from the following sources, in the specified
+ order. The first available and non-empty value is used:
+
+ * the value of the "ID" attribute of the os-release file,
+
+ * the value of the "Distributor ID" attribute returned by the lsb_release
+ command,
+
+ * the first part of the file name of the distro release file,
+
+ The so determined ID value then passes the following transformations,
+ before it is returned by this method:
+
+ * it is translated to lower case,
+
+ * blanks (which should not be there anyway) are translated to underscores,
+
+ * a normalization of the ID is performed, based upon
+ `normalization tables`_. The purpose of this normalization is to ensure
+ that the ID is as reliable as possible, even across incompatible changes
+ in the OS distributions. A common reason for an incompatible change is
+ the addition of an os-release file, or the addition of the lsb_release
+ command, with ID values that differ from what was previously determined
+ from the distro release file name.
+ """
+ return _distro.id()
+
+
+def name(pretty: bool = False) -> str:
+ """
+ Return the name of the current OS distribution, as a human-readable
+ string.
+
+ If *pretty* is false, the name is returned without version or codename.
+ (e.g. "CentOS Linux")
+
+ If *pretty* is true, the version and codename are appended.
+ (e.g. "CentOS Linux 7.1.1503 (Core)")
+
+ **Lookup hierarchy:**
+
+ The name is obtained from the following sources, in the specified order.
+ The first available and non-empty value is used:
+
+ * If *pretty* is false:
+
+ - the value of the "NAME" attribute of the os-release file,
+
+ - the value of the "Distributor ID" attribute returned by the lsb_release
+ command,
+
+ - the value of the "<name>" field of the distro release file.
+
+ * If *pretty* is true:
+
+ - the value of the "PRETTY_NAME" attribute of the os-release file,
+
+ - the value of the "Description" attribute returned by the lsb_release
+ command,
+
+ - the value of the "<name>" field of the distro release file, appended
+ with the value of the pretty version ("<version_id>" and "<codename>"
+ fields) of the distro release file, if available.
+ """
+ return _distro.name(pretty)
+
+
+def version(pretty: bool = False, best: bool = False) -> str:
+ """
+ Return the version of the current OS distribution, as a human-readable
+ string.
+
+ If *pretty* is false, the version is returned without codename (e.g.
+ "7.0").
+
+ If *pretty* is true, the codename in parenthesis is appended, if the
+ codename is non-empty (e.g. "7.0 (Maipo)").
+
+ Some distributions provide version numbers with different precisions in
+ the different sources of distribution information. Examining the different
+ sources in a fixed priority order does not always yield the most precise
+ version (e.g. for Debian 8.2, or CentOS 7.1).
+
+ Some other distributions may not provide this kind of information. In these
+ cases, an empty string would be returned. This behavior can be observed
+ with rolling releases distributions (e.g. Arch Linux).
+
+ The *best* parameter can be used to control the approach for the returned
+ version:
+
+ If *best* is false, the first non-empty version number in priority order of
+ the examined sources is returned.
+
+ If *best* is true, the most precise version number out of all examined
+ sources is returned.
+
+ **Lookup hierarchy:**
+
+ In all cases, the version number is obtained from the following sources.
+ If *best* is false, this order represents the priority order:
+
+ * the value of the "VERSION_ID" attribute of the os-release file,
+ * the value of the "Release" attribute returned by the lsb_release
+ command,
+ * the version number parsed from the "<version_id>" field of the first line
+ of the distro release file,
+ * the version number parsed from the "PRETTY_NAME" attribute of the
+ os-release file, if it follows the format of the distro release files.
+ * the version number parsed from the "Description" attribute returned by
+ the lsb_release command, if it follows the format of the distro release
+ files.
+ """
+ return _distro.version(pretty, best)
+
+
+def version_parts(best: bool = False) -> Tuple[str, str, str]:
+ """
+ Return the version of the current OS distribution as a tuple
+ ``(major, minor, build_number)`` with items as follows:
+
+ * ``major``: The result of :func:`distro.major_version`.
+
+ * ``minor``: The result of :func:`distro.minor_version`.
+
+ * ``build_number``: The result of :func:`distro.build_number`.
+
+ For a description of the *best* parameter, see the :func:`distro.version`
+ method.
+ """
+ return _distro.version_parts(best)
+
+
+def major_version(best: bool = False) -> str:
+ """
+ Return the major version of the current OS distribution, as a string,
+ if provided.
+ Otherwise, the empty string is returned. The major version is the first
+ part of the dot-separated version string.
+
+ For a description of the *best* parameter, see the :func:`distro.version`
+ method.
+ """
+ return _distro.major_version(best)
+
+
+def minor_version(best: bool = False) -> str:
+ """
+ Return the minor version of the current OS distribution, as a string,
+ if provided.
+ Otherwise, the empty string is returned. The minor version is the second
+ part of the dot-separated version string.
+
+ For a description of the *best* parameter, see the :func:`distro.version`
+ method.
+ """
+ return _distro.minor_version(best)
+
+
+def build_number(best: bool = False) -> str:
+ """
+ Return the build number of the current OS distribution, as a string,
+ if provided.
+ Otherwise, the empty string is returned. The build number is the third part
+ of the dot-separated version string.
+
+ For a description of the *best* parameter, see the :func:`distro.version`
+ method.
+ """
+ return _distro.build_number(best)
+
+
+def like() -> str:
+ """
+ Return a space-separated list of distro IDs of distributions that are
+ closely related to the current OS distribution in regards to packaging
+ and programming interfaces, for example distributions the current
+ distribution is a derivative from.
+
+ **Lookup hierarchy:**
+
+ This information item is only provided by the os-release file.
+ For details, see the description of the "ID_LIKE" attribute in the
+ `os-release man page
+ <http://www.freedesktop.org/software/systemd/man/os-release.html>`_.
+ """
+ return _distro.like()
+
+
+def codename() -> str:
+ """
+ Return the codename for the release of the current OS distribution,
+ as a string.
+
+ If the distribution does not have a codename, an empty string is returned.
+
+ Note that the returned codename is not always really a codename. For
+ example, openSUSE returns "x86_64". This function does not handle such
+ cases in any special way and just returns the string it finds, if any.
+
+ **Lookup hierarchy:**
+
+ * the codename within the "VERSION" attribute of the os-release file, if
+ provided,
+
+ * the value of the "Codename" attribute returned by the lsb_release
+ command,
+
+ * the value of the "<codename>" field of the distro release file.
+ """
+ return _distro.codename()
+
+
+def info(pretty: bool = False, best: bool = False) -> InfoDict:
+ """
+ Return certain machine-readable information items about the current OS
+ distribution in a dictionary, as shown in the following example:
+
+ .. sourcecode:: python
+
+ {
+ 'id': 'rhel',
+ 'version': '7.0',
+ 'version_parts': {
+ 'major': '7',
+ 'minor': '0',
+ 'build_number': ''
+ },
+ 'like': 'fedora',
+ 'codename': 'Maipo'
+ }
+
+ The dictionary structure and keys are always the same, regardless of which
+ information items are available in the underlying data sources. The values
+ for the various keys are as follows:
+
+ * ``id``: The result of :func:`distro.id`.
+
+ * ``version``: The result of :func:`distro.version`.
+
+ * ``version_parts -> major``: The result of :func:`distro.major_version`.
+
+ * ``version_parts -> minor``: The result of :func:`distro.minor_version`.
+
+ * ``version_parts -> build_number``: The result of
+ :func:`distro.build_number`.
+
+ * ``like``: The result of :func:`distro.like`.
+
+ * ``codename``: The result of :func:`distro.codename`.
+
+ For a description of the *pretty* and *best* parameters, see the
+ :func:`distro.version` method.
+ """
+ return _distro.info(pretty, best)
+
+
+def os_release_info() -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information items
+ from the os-release file data source of the current OS distribution.
+
+ See `os-release file`_ for details about these information items.
+ """
+ return _distro.os_release_info()
+
+
+def lsb_release_info() -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information items
+ from the lsb_release command data source of the current OS distribution.
+
+ See `lsb_release command output`_ for details about these information
+ items.
+ """
+ return _distro.lsb_release_info()
+
+
+def distro_release_info() -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information items
+ from the distro release file data source of the current OS distribution.
+
+ See `distro release file`_ for details about these information items.
+ """
+ return _distro.distro_release_info()
+
+
+def uname_info() -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information items
+ from the distro release file data source of the current OS distribution.
+ """
+ return _distro.uname_info()
+
+
+def os_release_attr(attribute: str) -> str:
+ """
+ Return a single named information item from the os-release file data source
+ of the current OS distribution.
+
+ Parameters:
+
+ * ``attribute`` (string): Key of the information item.
+
+ Returns:
+
+ * (string): Value of the information item, if the item exists.
+ The empty string, if the item does not exist.
+
+ See `os-release file`_ for details about these information items.
+ """
+ return _distro.os_release_attr(attribute)
+
+
+def lsb_release_attr(attribute: str) -> str:
+ """
+ Return a single named information item from the lsb_release command output
+ data source of the current OS distribution.
+
+ Parameters:
+
+ * ``attribute`` (string): Key of the information item.
+
+ Returns:
+
+ * (string): Value of the information item, if the item exists.
+ The empty string, if the item does not exist.
+
+ See `lsb_release command output`_ for details about these information
+ items.
+ """
+ return _distro.lsb_release_attr(attribute)
+
+
+def distro_release_attr(attribute: str) -> str:
+ """
+ Return a single named information item from the distro release file
+ data source of the current OS distribution.
+
+ Parameters:
+
+ * ``attribute`` (string): Key of the information item.
+
+ Returns:
+
+ * (string): Value of the information item, if the item exists.
+ The empty string, if the item does not exist.
+
+ See `distro release file`_ for details about these information items.
+ """
+ return _distro.distro_release_attr(attribute)
+
+
+def uname_attr(attribute: str) -> str:
+ """
+ Return a single named information item from the distro release file
+ data source of the current OS distribution.
+
+ Parameters:
+
+ * ``attribute`` (string): Key of the information item.
+
+ Returns:
+
+ * (string): Value of the information item, if the item exists.
+ The empty string, if the item does not exist.
+ """
+ return _distro.uname_attr(attribute)
+
+
+try:
+ from functools import cached_property
+except ImportError:
+ # Python < 3.8
+ class cached_property: # type: ignore
+ """A version of @property which caches the value. On access, it calls the
+ underlying function and sets the value in `__dict__` so future accesses
+ will not re-call the property.
+ """
+
+ def __init__(self, f: Callable[[Any], Any]) -> None:
+ self._fname = f.__name__
+ self._f = f
+
+ def __get__(self, obj: Any, owner: Type[Any]) -> Any:
+ assert obj is not None, f"call {self._fname} on an instance"
+ ret = obj.__dict__[self._fname] = self._f(obj)
+ return ret
+
+
+class LinuxDistribution:
+ """
+ Provides information about a OS distribution.
+
+ This package creates a private module-global instance of this class with
+ default initialization arguments, that is used by the
+ `consolidated accessor functions`_ and `single source accessor functions`_.
+ By using default initialization arguments, that module-global instance
+ returns data about the current OS distribution (i.e. the distro this
+ package runs on).
+
+ Normally, it is not necessary to create additional instances of this class.
+ However, in situations where control is needed over the exact data sources
+ that are used, instances of this class can be created with a specific
+ distro release file, or a specific os-release file, or without invoking the
+ lsb_release command.
+ """
+
+ def __init__(
+ self,
+ include_lsb: Optional[bool] = None,
+ os_release_file: str = "",
+ distro_release_file: str = "",
+ include_uname: Optional[bool] = None,
+ root_dir: Optional[str] = None,
+ include_oslevel: Optional[bool] = None,
+ ) -> None:
+ """
+ The initialization method of this class gathers information from the
+ available data sources, and stores that in private instance attributes.
+ Subsequent access to the information items uses these private instance
+ attributes, so that the data sources are read only once.
+
+ Parameters:
+
+ * ``include_lsb`` (bool): Controls whether the
+ `lsb_release command output`_ is included as a data source.
+
+ If the lsb_release command is not available in the program execution
+ path, the data source for the lsb_release command will be empty.
+
+ * ``os_release_file`` (string): The path name of the
+ `os-release file`_ that is to be used as a data source.
+
+ An empty string (the default) will cause the default path name to
+ be used (see `os-release file`_ for details).
+
+ If the specified or defaulted os-release file does not exist, the
+ data source for the os-release file will be empty.
+
+ * ``distro_release_file`` (string): The path name of the
+ `distro release file`_ that is to be used as a data source.
+
+ An empty string (the default) will cause a default search algorithm
+ to be used (see `distro release file`_ for details).
+
+ If the specified distro release file does not exist, or if no default
+ distro release file can be found, the data source for the distro
+ release file will be empty.
+
+ * ``include_uname`` (bool): Controls whether uname command output is
+ included as a data source. If the uname command is not available in
+ the program execution path the data source for the uname command will
+ be empty.
+
+ * ``root_dir`` (string): The absolute path to the root directory to use
+ to find distro-related information files. Note that ``include_*``
+ parameters must not be enabled in combination with ``root_dir``.
+
+ * ``include_oslevel`` (bool): Controls whether (AIX) oslevel command
+ output is included as a data source. If the oslevel command is not
+ available in the program execution path the data source will be
+ empty.
+
+ Public instance attributes:
+
+ * ``os_release_file`` (string): The path name of the
+ `os-release file`_ that is actually used as a data source. The
+ empty string if no distro release file is used as a data source.
+
+ * ``distro_release_file`` (string): The path name of the
+ `distro release file`_ that is actually used as a data source. The
+ empty string if no distro release file is used as a data source.
+
+ * ``include_lsb`` (bool): The result of the ``include_lsb`` parameter.
+ This controls whether the lsb information will be loaded.
+
+ * ``include_uname`` (bool): The result of the ``include_uname``
+ parameter. This controls whether the uname information will
+ be loaded.
+
+ * ``include_oslevel`` (bool): The result of the ``include_oslevel``
+ parameter. This controls whether (AIX) oslevel information will be
+ loaded.
+
+ * ``root_dir`` (string): The result of the ``root_dir`` parameter.
+ The absolute path to the root directory to use to find distro-related
+ information files.
+
+ Raises:
+
+ * :py:exc:`ValueError`: Initialization parameters combination is not
+ supported.
+
+ * :py:exc:`OSError`: Some I/O issue with an os-release file or distro
+ release file.
+
+ * :py:exc:`UnicodeError`: A data source has unexpected characters or
+ uses an unexpected encoding.
+ """
+ self.root_dir = root_dir
+ self.etc_dir = os.path.join(root_dir, "etc") if root_dir else _UNIXCONFDIR
+ self.usr_lib_dir = (
+ os.path.join(root_dir, "usr/lib") if root_dir else _UNIXUSRLIBDIR
+ )
+
+ if os_release_file:
+ self.os_release_file = os_release_file
+ else:
+ etc_dir_os_release_file = os.path.join(self.etc_dir, _OS_RELEASE_BASENAME)
+ usr_lib_os_release_file = os.path.join(
+ self.usr_lib_dir, _OS_RELEASE_BASENAME
+ )
+
+ # NOTE: The idea is to respect order **and** have it set
+ # at all times for API backwards compatibility.
+ if os.path.isfile(etc_dir_os_release_file) or not os.path.isfile(
+ usr_lib_os_release_file
+ ):
+ self.os_release_file = etc_dir_os_release_file
+ else:
+ self.os_release_file = usr_lib_os_release_file
+
+ self.distro_release_file = distro_release_file or "" # updated later
+
+ is_root_dir_defined = root_dir is not None
+ if is_root_dir_defined and (include_lsb or include_uname or include_oslevel):
+ raise ValueError(
+ "Including subprocess data sources from specific root_dir is disallowed"
+ " to prevent false information"
+ )
+ self.include_lsb = (
+ include_lsb if include_lsb is not None else not is_root_dir_defined
+ )
+ self.include_uname = (
+ include_uname if include_uname is not None else not is_root_dir_defined
+ )
+ self.include_oslevel = (
+ include_oslevel if include_oslevel is not None else not is_root_dir_defined
+ )
+
+ def __repr__(self) -> str:
+ """Return repr of all info"""
+ return (
+ "LinuxDistribution("
+ "os_release_file={self.os_release_file!r}, "
+ "distro_release_file={self.distro_release_file!r}, "
+ "include_lsb={self.include_lsb!r}, "
+ "include_uname={self.include_uname!r}, "
+ "include_oslevel={self.include_oslevel!r}, "
+ "root_dir={self.root_dir!r}, "
+ "_os_release_info={self._os_release_info!r}, "
+ "_lsb_release_info={self._lsb_release_info!r}, "
+ "_distro_release_info={self._distro_release_info!r}, "
+ "_uname_info={self._uname_info!r}, "
+ "_oslevel_info={self._oslevel_info!r})".format(self=self)
+ )
+
+ def linux_distribution(
+ self, full_distribution_name: bool = True
+ ) -> Tuple[str, str, str]:
+ """
+ Return information about the OS distribution that is compatible
+ with Python's :func:`platform.linux_distribution`, supporting a subset
+ of its parameters.
+
+ For details, see :func:`distro.linux_distribution`.
+ """
+ return (
+ self.name() if full_distribution_name else self.id(),
+ self.version(),
+ self._os_release_info.get("release_codename") or self.codename(),
+ )
+
+ def id(self) -> str:
+ """Return the distro ID of the OS distribution, as a string.
+
+ For details, see :func:`distro.id`.
+ """
+
+ def normalize(distro_id: str, table: Dict[str, str]) -> str:
+ distro_id = distro_id.lower().replace(" ", "_")
+ return table.get(distro_id, distro_id)
+
+ distro_id = self.os_release_attr("id")
+ if distro_id:
+ return normalize(distro_id, NORMALIZED_OS_ID)
+
+ distro_id = self.lsb_release_attr("distributor_id")
+ if distro_id:
+ return normalize(distro_id, NORMALIZED_LSB_ID)
+
+ distro_id = self.distro_release_attr("id")
+ if distro_id:
+ return normalize(distro_id, NORMALIZED_DISTRO_ID)
+
+ distro_id = self.uname_attr("id")
+ if distro_id:
+ return normalize(distro_id, NORMALIZED_DISTRO_ID)
+
+ return ""
+
+ def name(self, pretty: bool = False) -> str:
+ """
+ Return the name of the OS distribution, as a string.
+
+ For details, see :func:`distro.name`.
+ """
+ name = (
+ self.os_release_attr("name")
+ or self.lsb_release_attr("distributor_id")
+ or self.distro_release_attr("name")
+ or self.uname_attr("name")
+ )
+ if pretty:
+ name = self.os_release_attr("pretty_name") or self.lsb_release_attr(
+ "description"
+ )
+ if not name:
+ name = self.distro_release_attr("name") or self.uname_attr("name")
+ version = self.version(pretty=True)
+ if version:
+ name = f"{name} {version}"
+ return name or ""
+
+ def version(self, pretty: bool = False, best: bool = False) -> str:
+ """
+ Return the version of the OS distribution, as a string.
+
+ For details, see :func:`distro.version`.
+ """
+ versions = [
+ self.os_release_attr("version_id"),
+ self.lsb_release_attr("release"),
+ self.distro_release_attr("version_id"),
+ self._parse_distro_release_content(self.os_release_attr("pretty_name")).get(
+ "version_id", ""
+ ),
+ self._parse_distro_release_content(
+ self.lsb_release_attr("description")
+ ).get("version_id", ""),
+ self.uname_attr("release"),
+ ]
+ if self.uname_attr("id").startswith("aix"):
+ # On AIX platforms, prefer oslevel command output.
+ versions.insert(0, self.oslevel_info())
+ elif self.id() == "debian" or "debian" in self.like().split():
+ # On Debian-like, add debian_version file content to candidates list.
+ versions.append(self._debian_version)
+ version = ""
+ if best:
+ # This algorithm uses the last version in priority order that has
+ # the best precision. If the versions are not in conflict, that
+ # does not matter; otherwise, using the last one instead of the
+ # first one might be considered a surprise.
+ for v in versions:
+ if v.count(".") > version.count(".") or version == "":
+ version = v
+ else:
+ for v in versions:
+ if v != "":
+ version = v
+ break
+ if pretty and version and self.codename():
+ version = f"{version} ({self.codename()})"
+ return version
+
+ def version_parts(self, best: bool = False) -> Tuple[str, str, str]:
+ """
+ Return the version of the OS distribution, as a tuple of version
+ numbers.
+
+ For details, see :func:`distro.version_parts`.
+ """
+ version_str = self.version(best=best)
+ if version_str:
+ version_regex = re.compile(r"(\d+)\.?(\d+)?\.?(\d+)?")
+ matches = version_regex.match(version_str)
+ if matches:
+ major, minor, build_number = matches.groups()
+ return major, minor or "", build_number or ""
+ return "", "", ""
+
+ def major_version(self, best: bool = False) -> str:
+ """
+ Return the major version number of the current distribution.
+
+ For details, see :func:`distro.major_version`.
+ """
+ return self.version_parts(best)[0]
+
+ def minor_version(self, best: bool = False) -> str:
+ """
+ Return the minor version number of the current distribution.
+
+ For details, see :func:`distro.minor_version`.
+ """
+ return self.version_parts(best)[1]
+
+ def build_number(self, best: bool = False) -> str:
+ """
+ Return the build number of the current distribution.
+
+ For details, see :func:`distro.build_number`.
+ """
+ return self.version_parts(best)[2]
+
+ def like(self) -> str:
+ """
+ Return the IDs of distributions that are like the OS distribution.
+
+ For details, see :func:`distro.like`.
+ """
+ return self.os_release_attr("id_like") or ""
+
+ def codename(self) -> str:
+ """
+ Return the codename of the OS distribution.
+
+ For details, see :func:`distro.codename`.
+ """
+ try:
+ # Handle os_release specially since distros might purposefully set
+ # this to empty string to have no codename
+ return self._os_release_info["codename"]
+ except KeyError:
+ return (
+ self.lsb_release_attr("codename")
+ or self.distro_release_attr("codename")
+ or ""
+ )
+
+ def info(self, pretty: bool = False, best: bool = False) -> InfoDict:
+ """
+ Return certain machine-readable information about the OS
+ distribution.
+
+ For details, see :func:`distro.info`.
+ """
+ return InfoDict(
+ id=self.id(),
+ version=self.version(pretty, best),
+ version_parts=VersionDict(
+ major=self.major_version(best),
+ minor=self.minor_version(best),
+ build_number=self.build_number(best),
+ ),
+ like=self.like(),
+ codename=self.codename(),
+ )
+
+ def os_release_info(self) -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information
+ items from the os-release file data source of the OS distribution.
+
+ For details, see :func:`distro.os_release_info`.
+ """
+ return self._os_release_info
+
+ def lsb_release_info(self) -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information
+ items from the lsb_release command data source of the OS
+ distribution.
+
+ For details, see :func:`distro.lsb_release_info`.
+ """
+ return self._lsb_release_info
+
+ def distro_release_info(self) -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information
+ items from the distro release file data source of the OS
+ distribution.
+
+ For details, see :func:`distro.distro_release_info`.
+ """
+ return self._distro_release_info
+
+ def uname_info(self) -> Dict[str, str]:
+ """
+ Return a dictionary containing key-value pairs for the information
+ items from the uname command data source of the OS distribution.
+
+ For details, see :func:`distro.uname_info`.
+ """
+ return self._uname_info
+
+ def oslevel_info(self) -> str:
+ """
+ Return AIX' oslevel command output.
+ """
+ return self._oslevel_info
+
+ def os_release_attr(self, attribute: str) -> str:
+ """
+ Return a single named information item from the os-release file data
+ source of the OS distribution.
+
+ For details, see :func:`distro.os_release_attr`.
+ """
+ return self._os_release_info.get(attribute, "")
+
+ def lsb_release_attr(self, attribute: str) -> str:
+ """
+ Return a single named information item from the lsb_release command
+ output data source of the OS distribution.
+
+ For details, see :func:`distro.lsb_release_attr`.
+ """
+ return self._lsb_release_info.get(attribute, "")
+
+ def distro_release_attr(self, attribute: str) -> str:
+ """
+ Return a single named information item from the distro release file
+ data source of the OS distribution.
+
+ For details, see :func:`distro.distro_release_attr`.
+ """
+ return self._distro_release_info.get(attribute, "")
+
+ def uname_attr(self, attribute: str) -> str:
+ """
+ Return a single named information item from the uname command
+ output data source of the OS distribution.
+
+ For details, see :func:`distro.uname_attr`.
+ """
+ return self._uname_info.get(attribute, "")
+
+ @cached_property
+ def _os_release_info(self) -> Dict[str, str]:
+ """
+ Get the information items from the specified os-release file.
+
+ Returns:
+ A dictionary containing all information items.
+ """
+ if os.path.isfile(self.os_release_file):
+ with open(self.os_release_file, encoding="utf-8") as release_file:
+ return self._parse_os_release_content(release_file)
+ return {}
+
+ @staticmethod
+ def _parse_os_release_content(lines: TextIO) -> Dict[str, str]:
+ """
+ Parse the lines of an os-release file.
+
+ Parameters:
+
+ * lines: Iterable through the lines in the os-release file.
+ Each line must be a unicode string or a UTF-8 encoded byte
+ string.
+
+ Returns:
+ A dictionary containing all information items.
+ """
+ props = {}
+ lexer = shlex.shlex(lines, posix=True)
+ lexer.whitespace_split = True
+
+ tokens = list(lexer)
+ for token in tokens:
+ # At this point, all shell-like parsing has been done (i.e.
+ # comments processed, quotes and backslash escape sequences
+ # processed, multi-line values assembled, trailing newlines
+ # stripped, etc.), so the tokens are now either:
+ # * variable assignments: var=value
+ # * commands or their arguments (not allowed in os-release)
+ # Ignore any tokens that are not variable assignments
+ if "=" in token:
+ k, v = token.split("=", 1)
+ props[k.lower()] = v
+
+ if "version" in props:
+ # extract release codename (if any) from version attribute
+ match = re.search(r"\((\D+)\)|,\s*(\D+)", props["version"])
+ if match:
+ release_codename = match.group(1) or match.group(2)
+ props["codename"] = props["release_codename"] = release_codename
+
+ if "version_codename" in props:
+ # os-release added a version_codename field. Use that in
+ # preference to anything else Note that some distros purposefully
+ # do not have code names. They should be setting
+ # version_codename=""
+ props["codename"] = props["version_codename"]
+ elif "ubuntu_codename" in props:
+ # Same as above but a non-standard field name used on older Ubuntus
+ props["codename"] = props["ubuntu_codename"]
+
+ return props
+
+ @cached_property
+ def _lsb_release_info(self) -> Dict[str, str]:
+ """
+ Get the information items from the lsb_release command output.
+
+ Returns:
+ A dictionary containing all information items.
+ """
+ if not self.include_lsb:
+ return {}
+ try:
+ cmd = ("lsb_release", "-a")
+ stdout = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)
+ # Command not found or lsb_release returned error
+ except (OSError, subprocess.CalledProcessError):
+ return {}
+ content = self._to_str(stdout).splitlines()
+ return self._parse_lsb_release_content(content)
+
+ @staticmethod
+ def _parse_lsb_release_content(lines: Iterable[str]) -> Dict[str, str]:
+ """
+ Parse the output of the lsb_release command.
+
+ Parameters:
+
+ * lines: Iterable through the lines of the lsb_release output.
+ Each line must be a unicode string or a UTF-8 encoded byte
+ string.
+
+ Returns:
+ A dictionary containing all information items.
+ """
+ props = {}
+ for line in lines:
+ kv = line.strip("\n").split(":", 1)
+ if len(kv) != 2:
+ # Ignore lines without colon.
+ continue
+ k, v = kv
+ props.update({k.replace(" ", "_").lower(): v.strip()})
+ return props
+
+ @cached_property
+ def _uname_info(self) -> Dict[str, str]:
+ if not self.include_uname:
+ return {}
+ try:
+ cmd = ("uname", "-rs")
+ stdout = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)
+ except OSError:
+ return {}
+ content = self._to_str(stdout).splitlines()
+ return self._parse_uname_content(content)
+
+ @cached_property
+ def _oslevel_info(self) -> str:
+ if not self.include_oslevel:
+ return ""
+ try:
+ stdout = subprocess.check_output("oslevel", stderr=subprocess.DEVNULL)
+ except (OSError, subprocess.CalledProcessError):
+ return ""
+ return self._to_str(stdout).strip()
+
+ @cached_property
+ def _debian_version(self) -> str:
+ try:
+ with open(
+ os.path.join(self.etc_dir, "debian_version"), encoding="ascii"
+ ) as fp:
+ return fp.readline().rstrip()
+ except FileNotFoundError:
+ return ""
+
+ @staticmethod
+ def _parse_uname_content(lines: Sequence[str]) -> Dict[str, str]:
+ if not lines:
+ return {}
+ props = {}
+ match = re.search(r"^([^\s]+)\s+([\d\.]+)", lines[0].strip())
+ if match:
+ name, version = match.groups()
+
+ # This is to prevent the Linux kernel version from
+ # appearing as the 'best' version on otherwise
+ # identifiable distributions.
+ if name == "Linux":
+ return {}
+ props["id"] = name.lower()
+ props["name"] = name
+ props["release"] = version
+ return props
+
+ @staticmethod
+ def _to_str(bytestring: bytes) -> str:
+ encoding = sys.getfilesystemencoding()
+ return bytestring.decode(encoding)
+
+ @cached_property
+ def _distro_release_info(self) -> Dict[str, str]:
+ """
+ Get the information items from the specified distro release file.
+
+ Returns:
+ A dictionary containing all information items.
+ """
+ if self.distro_release_file:
+ # If it was specified, we use it and parse what we can, even if
+ # its file name or content does not match the expected pattern.
+ distro_info = self._parse_distro_release_file(self.distro_release_file)
+ basename = os.path.basename(self.distro_release_file)
+ # The file name pattern for user-specified distro release files
+ # is somewhat more tolerant (compared to when searching for the
+ # file), because we want to use what was specified as best as
+ # possible.
+ match = _DISTRO_RELEASE_BASENAME_PATTERN.match(basename)
+ else:
+ try:
+ basenames = [
+ basename
+ for basename in os.listdir(self.etc_dir)
+ if basename not in _DISTRO_RELEASE_IGNORE_BASENAMES
+ and os.path.isfile(os.path.join(self.etc_dir, basename))
+ ]
+ # We sort for repeatability in cases where there are multiple
+ # distro specific files; e.g. CentOS, Oracle, Enterprise all
+ # containing `redhat-release` on top of their own.
+ basenames.sort()
+ except OSError:
+ # This may occur when /etc is not readable but we can't be
+ # sure about the *-release files. Check common entries of
+ # /etc for information. If they turn out to not be there the
+ # error is handled in `_parse_distro_release_file()`.
+ basenames = _DISTRO_RELEASE_BASENAMES
+ for basename in basenames:
+ match = _DISTRO_RELEASE_BASENAME_PATTERN.match(basename)
+ if match is None:
+ continue
+ filepath = os.path.join(self.etc_dir, basename)
+ distro_info = self._parse_distro_release_file(filepath)
+ # The name is always present if the pattern matches.
+ if "name" not in distro_info:
+ continue
+ self.distro_release_file = filepath
+ break
+ else: # the loop didn't "break": no candidate.
+ return {}
+
+ if match is not None:
+ distro_info["id"] = match.group(1)
+
+ # CloudLinux < 7: manually enrich info with proper id.
+ if "cloudlinux" in distro_info.get("name", "").lower():
+ distro_info["id"] = "cloudlinux"
+
+ return distro_info
+
+ def _parse_distro_release_file(self, filepath: str) -> Dict[str, str]:
+ """
+ Parse a distro release file.
+
+ Parameters:
+
+ * filepath: Path name of the distro release file.
+
+ Returns:
+ A dictionary containing all information items.
+ """
+ try:
+ with open(filepath, encoding="utf-8") as fp:
+ # Only parse the first line. For instance, on SLES there
+ # are multiple lines. We don't want them...
+ return self._parse_distro_release_content(fp.readline())
+ except OSError:
+ # Ignore not being able to read a specific, seemingly version
+ # related file.
+ # See https://github.com/python-distro/distro/issues/162
+ return {}
+
+ @staticmethod
+ def _parse_distro_release_content(line: str) -> Dict[str, str]:
+ """
+ Parse a line from a distro release file.
+
+ Parameters:
+ * line: Line from the distro release file. Must be a unicode string
+ or a UTF-8 encoded byte string.
+
+ Returns:
+ A dictionary containing all information items.
+ """
+ matches = _DISTRO_RELEASE_CONTENT_REVERSED_PATTERN.match(line.strip()[::-1])
+ distro_info = {}
+ if matches:
+ # regexp ensures non-None
+ distro_info["name"] = matches.group(3)[::-1]
+ if matches.group(2):
+ distro_info["version_id"] = matches.group(2)[::-1]
+ if matches.group(1):
+ distro_info["codename"] = matches.group(1)[::-1]
+ elif line:
+ distro_info["name"] = line.strip()
+ return distro_info
+
+
+_distro = LinuxDistribution()
+
+
+def main() -> None:
+ logger = logging.getLogger(__name__)
+ logger.setLevel(logging.DEBUG)
+ logger.addHandler(logging.StreamHandler(sys.stdout))
+
+ parser = argparse.ArgumentParser(description="OS distro info tool")
+ parser.add_argument(
+ "--json", "-j", help="Output in machine readable format", action="store_true"
+ )
+
+ parser.add_argument(
+ "--root-dir",
+ "-r",
+ type=str,
+ dest="root_dir",
+ help="Path to the root filesystem directory (defaults to /)",
+ )
+
+ args = parser.parse_args()
+
+ if args.root_dir:
+ dist = LinuxDistribution(
+ include_lsb=False,
+ include_uname=False,
+ include_oslevel=False,
+ root_dir=args.root_dir,
+ )
+ else:
+ dist = _distro
+
+ if args.json:
+ logger.info(json.dumps(dist.info(), indent=4, sort_keys=True))
+ else:
+ logger.info("Name: %s", dist.name(pretty=True))
+ distribution_version = dist.version(pretty=True)
+ logger.info("Version: %s", distribution_version)
+ distribution_codename = dist.codename()
+ logger.info("Codename: %s", distribution_codename)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/distro/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/distro/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/__init__.py
new file mode 100644
index 000000000..a40eeafcc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/__init__.py
@@ -0,0 +1,44 @@
+from .package_data import __version__
+from .core import (
+ IDNABidiError,
+ IDNAError,
+ InvalidCodepoint,
+ InvalidCodepointContext,
+ alabel,
+ check_bidi,
+ check_hyphen_ok,
+ check_initial_combiner,
+ check_label,
+ check_nfc,
+ decode,
+ encode,
+ ulabel,
+ uts46_remap,
+ valid_contextj,
+ valid_contexto,
+ valid_label_length,
+ valid_string_length,
+)
+from .intranges import intranges_contain
+
+__all__ = [
+ "IDNABidiError",
+ "IDNAError",
+ "InvalidCodepoint",
+ "InvalidCodepointContext",
+ "alabel",
+ "check_bidi",
+ "check_hyphen_ok",
+ "check_initial_combiner",
+ "check_label",
+ "check_nfc",
+ "decode",
+ "encode",
+ "intranges_contain",
+ "ulabel",
+ "uts46_remap",
+ "valid_contextj",
+ "valid_contexto",
+ "valid_label_length",
+ "valid_string_length",
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/codec.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/codec.py
new file mode 100644
index 000000000..c855a4de6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/codec.py
@@ -0,0 +1,118 @@
+from .core import encode, decode, alabel, ulabel, IDNAError
+import codecs
+import re
+from typing import Any, Tuple, Optional
+
+_unicode_dots_re = re.compile('[\u002e\u3002\uff0e\uff61]')
+
+class Codec(codecs.Codec):
+
+ def encode(self, data: str, errors: str = 'strict') -> Tuple[bytes, int]:
+ if errors != 'strict':
+ raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
+
+ if not data:
+ return b"", 0
+
+ return encode(data), len(data)
+
+ def decode(self, data: bytes, errors: str = 'strict') -> Tuple[str, int]:
+ if errors != 'strict':
+ raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
+
+ if not data:
+ return '', 0
+
+ return decode(data), len(data)
+
+class IncrementalEncoder(codecs.BufferedIncrementalEncoder):
+ def _buffer_encode(self, data: str, errors: str, final: bool) -> Tuple[bytes, int]:
+ if errors != 'strict':
+ raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
+
+ if not data:
+ return b'', 0
+
+ labels = _unicode_dots_re.split(data)
+ trailing_dot = b''
+ if labels:
+ if not labels[-1]:
+ trailing_dot = b'.'
+ del labels[-1]
+ elif not final:
+ # Keep potentially unfinished label until the next call
+ del labels[-1]
+ if labels:
+ trailing_dot = b'.'
+
+ result = []
+ size = 0
+ for label in labels:
+ result.append(alabel(label))
+ if size:
+ size += 1
+ size += len(label)
+
+ # Join with U+002E
+ result_bytes = b'.'.join(result) + trailing_dot
+ size += len(trailing_dot)
+ return result_bytes, size
+
+class IncrementalDecoder(codecs.BufferedIncrementalDecoder):
+ def _buffer_decode(self, data: Any, errors: str, final: bool) -> Tuple[str, int]:
+ if errors != 'strict':
+ raise IDNAError('Unsupported error handling \"{}\"'.format(errors))
+
+ if not data:
+ return ('', 0)
+
+ if not isinstance(data, str):
+ data = str(data, 'ascii')
+
+ labels = _unicode_dots_re.split(data)
+ trailing_dot = ''
+ if labels:
+ if not labels[-1]:
+ trailing_dot = '.'
+ del labels[-1]
+ elif not final:
+ # Keep potentially unfinished label until the next call
+ del labels[-1]
+ if labels:
+ trailing_dot = '.'
+
+ result = []
+ size = 0
+ for label in labels:
+ result.append(ulabel(label))
+ if size:
+ size += 1
+ size += len(label)
+
+ result_str = '.'.join(result) + trailing_dot
+ size += len(trailing_dot)
+ return (result_str, size)
+
+
+class StreamWriter(Codec, codecs.StreamWriter):
+ pass
+
+
+class StreamReader(Codec, codecs.StreamReader):
+ pass
+
+
+def search_function(name: str) -> Optional[codecs.CodecInfo]:
+ if name != 'idna2008':
+ return None
+ return codecs.CodecInfo(
+ name=name,
+ encode=Codec().encode,
+ decode=Codec().decode,
+ incrementalencoder=IncrementalEncoder,
+ incrementaldecoder=IncrementalDecoder,
+ streamwriter=StreamWriter,
+ streamreader=StreamReader,
+ )
+
+codecs.register(search_function)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/compat.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/compat.py
new file mode 100644
index 000000000..786e6bda6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/compat.py
@@ -0,0 +1,13 @@
+from .core import *
+from .codec import *
+from typing import Any, Union
+
+def ToASCII(label: str) -> bytes:
+ return encode(label)
+
+def ToUnicode(label: Union[bytes, bytearray]) -> str:
+ return decode(label)
+
+def nameprep(s: Any) -> None:
+ raise NotImplementedError('IDNA 2008 does not utilise nameprep protocol')
+
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/core.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/core.py
new file mode 100644
index 000000000..0dae61acd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/core.py
@@ -0,0 +1,395 @@
+from . import idnadata
+import bisect
+import unicodedata
+import re
+from typing import Union, Optional
+from .intranges import intranges_contain
+
+_virama_combining_class = 9
+_alabel_prefix = b'xn--'
+_unicode_dots_re = re.compile('[\u002e\u3002\uff0e\uff61]')
+
+class IDNAError(UnicodeError):
+ """ Base exception for all IDNA-encoding related problems """
+ pass
+
+
+class IDNABidiError(IDNAError):
+ """ Exception when bidirectional requirements are not satisfied """
+ pass
+
+
+class InvalidCodepoint(IDNAError):
+ """ Exception when a disallowed or unallocated codepoint is used """
+ pass
+
+
+class InvalidCodepointContext(IDNAError):
+ """ Exception when the codepoint is not valid in the context it is used """
+ pass
+
+
+def _combining_class(cp: int) -> int:
+ v = unicodedata.combining(chr(cp))
+ if v == 0:
+ if not unicodedata.name(chr(cp)):
+ raise ValueError('Unknown character in unicodedata')
+ return v
+
+def _is_script(cp: str, script: str) -> bool:
+ return intranges_contain(ord(cp), idnadata.scripts[script])
+
+def _punycode(s: str) -> bytes:
+ return s.encode('punycode')
+
+def _unot(s: int) -> str:
+ return 'U+{:04X}'.format(s)
+
+
+def valid_label_length(label: Union[bytes, str]) -> bool:
+ if len(label) > 63:
+ return False
+ return True
+
+
+def valid_string_length(label: Union[bytes, str], trailing_dot: bool) -> bool:
+ if len(label) > (254 if trailing_dot else 253):
+ return False
+ return True
+
+
+def check_bidi(label: str, check_ltr: bool = False) -> bool:
+ # Bidi rules should only be applied if string contains RTL characters
+ bidi_label = False
+ for (idx, cp) in enumerate(label, 1):
+ direction = unicodedata.bidirectional(cp)
+ if direction == '':
+ # String likely comes from a newer version of Unicode
+ raise IDNABidiError('Unknown directionality in label {} at position {}'.format(repr(label), idx))
+ if direction in ['R', 'AL', 'AN']:
+ bidi_label = True
+ if not bidi_label and not check_ltr:
+ return True
+
+ # Bidi rule 1
+ direction = unicodedata.bidirectional(label[0])
+ if direction in ['R', 'AL']:
+ rtl = True
+ elif direction == 'L':
+ rtl = False
+ else:
+ raise IDNABidiError('First codepoint in label {} must be directionality L, R or AL'.format(repr(label)))
+
+ valid_ending = False
+ number_type = None # type: Optional[str]
+ for (idx, cp) in enumerate(label, 1):
+ direction = unicodedata.bidirectional(cp)
+
+ if rtl:
+ # Bidi rule 2
+ if not direction in ['R', 'AL', 'AN', 'EN', 'ES', 'CS', 'ET', 'ON', 'BN', 'NSM']:
+ raise IDNABidiError('Invalid direction for codepoint at position {} in a right-to-left label'.format(idx))
+ # Bidi rule 3
+ if direction in ['R', 'AL', 'EN', 'AN']:
+ valid_ending = True
+ elif direction != 'NSM':
+ valid_ending = False
+ # Bidi rule 4
+ if direction in ['AN', 'EN']:
+ if not number_type:
+ number_type = direction
+ else:
+ if number_type != direction:
+ raise IDNABidiError('Can not mix numeral types in a right-to-left label')
+ else:
+ # Bidi rule 5
+ if not direction in ['L', 'EN', 'ES', 'CS', 'ET', 'ON', 'BN', 'NSM']:
+ raise IDNABidiError('Invalid direction for codepoint at position {} in a left-to-right label'.format(idx))
+ # Bidi rule 6
+ if direction in ['L', 'EN']:
+ valid_ending = True
+ elif direction != 'NSM':
+ valid_ending = False
+
+ if not valid_ending:
+ raise IDNABidiError('Label ends with illegal codepoint directionality')
+
+ return True
+
+
+def check_initial_combiner(label: str) -> bool:
+ if unicodedata.category(label[0])[0] == 'M':
+ raise IDNAError('Label begins with an illegal combining character')
+ return True
+
+
+def check_hyphen_ok(label: str) -> bool:
+ if label[2:4] == '--':
+ raise IDNAError('Label has disallowed hyphens in 3rd and 4th position')
+ if label[0] == '-' or label[-1] == '-':
+ raise IDNAError('Label must not start or end with a hyphen')
+ return True
+
+
+def check_nfc(label: str) -> None:
+ if unicodedata.normalize('NFC', label) != label:
+ raise IDNAError('Label must be in Normalization Form C')
+
+
+def valid_contextj(label: str, pos: int) -> bool:
+ cp_value = ord(label[pos])
+
+ if cp_value == 0x200c:
+
+ if pos > 0:
+ if _combining_class(ord(label[pos - 1])) == _virama_combining_class:
+ return True
+
+ ok = False
+ for i in range(pos-1, -1, -1):
+ joining_type = idnadata.joining_types.get(ord(label[i]))
+ if joining_type == ord('T'):
+ continue
+ elif joining_type in [ord('L'), ord('D')]:
+ ok = True
+ break
+ else:
+ break
+
+ if not ok:
+ return False
+
+ ok = False
+ for i in range(pos+1, len(label)):
+ joining_type = idnadata.joining_types.get(ord(label[i]))
+ if joining_type == ord('T'):
+ continue
+ elif joining_type in [ord('R'), ord('D')]:
+ ok = True
+ break
+ else:
+ break
+ return ok
+
+ if cp_value == 0x200d:
+
+ if pos > 0:
+ if _combining_class(ord(label[pos - 1])) == _virama_combining_class:
+ return True
+ return False
+
+ else:
+
+ return False
+
+
+def valid_contexto(label: str, pos: int, exception: bool = False) -> bool:
+ cp_value = ord(label[pos])
+
+ if cp_value == 0x00b7:
+ if 0 < pos < len(label)-1:
+ if ord(label[pos - 1]) == 0x006c and ord(label[pos + 1]) == 0x006c:
+ return True
+ return False
+
+ elif cp_value == 0x0375:
+ if pos < len(label)-1 and len(label) > 1:
+ return _is_script(label[pos + 1], 'Greek')
+ return False
+
+ elif cp_value == 0x05f3 or cp_value == 0x05f4:
+ if pos > 0:
+ return _is_script(label[pos - 1], 'Hebrew')
+ return False
+
+ elif cp_value == 0x30fb:
+ for cp in label:
+ if cp == '\u30fb':
+ continue
+ if _is_script(cp, 'Hiragana') or _is_script(cp, 'Katakana') or _is_script(cp, 'Han'):
+ return True
+ return False
+
+ elif 0x660 <= cp_value <= 0x669:
+ for cp in label:
+ if 0x6f0 <= ord(cp) <= 0x06f9:
+ return False
+ return True
+
+ elif 0x6f0 <= cp_value <= 0x6f9:
+ for cp in label:
+ if 0x660 <= ord(cp) <= 0x0669:
+ return False
+ return True
+
+ return False
+
+
+def check_label(label: Union[str, bytes, bytearray]) -> None:
+ if isinstance(label, (bytes, bytearray)):
+ label = label.decode('utf-8')
+ if len(label) == 0:
+ raise IDNAError('Empty Label')
+
+ check_nfc(label)
+ check_hyphen_ok(label)
+ check_initial_combiner(label)
+
+ for (pos, cp) in enumerate(label):
+ cp_value = ord(cp)
+ if intranges_contain(cp_value, idnadata.codepoint_classes['PVALID']):
+ continue
+ elif intranges_contain(cp_value, idnadata.codepoint_classes['CONTEXTJ']):
+ if not valid_contextj(label, pos):
+ raise InvalidCodepointContext('Joiner {} not allowed at position {} in {}'.format(
+ _unot(cp_value), pos+1, repr(label)))
+ elif intranges_contain(cp_value, idnadata.codepoint_classes['CONTEXTO']):
+ if not valid_contexto(label, pos):
+ raise InvalidCodepointContext('Codepoint {} not allowed at position {} in {}'.format(_unot(cp_value), pos+1, repr(label)))
+ else:
+ raise InvalidCodepoint('Codepoint {} at position {} of {} not allowed'.format(_unot(cp_value), pos+1, repr(label)))
+
+ check_bidi(label)
+
+
+def alabel(label: str) -> bytes:
+ try:
+ label_bytes = label.encode('ascii')
+ ulabel(label_bytes)
+ if not valid_label_length(label_bytes):
+ raise IDNAError('Label too long')
+ return label_bytes
+ except UnicodeEncodeError:
+ pass
+
+ check_label(label)
+ label_bytes = _alabel_prefix + _punycode(label)
+
+ if not valid_label_length(label_bytes):
+ raise IDNAError('Label too long')
+
+ return label_bytes
+
+
+def ulabel(label: Union[str, bytes, bytearray]) -> str:
+ if not isinstance(label, (bytes, bytearray)):
+ try:
+ label_bytes = label.encode('ascii')
+ except UnicodeEncodeError:
+ check_label(label)
+ return label
+ else:
+ label_bytes = label
+
+ label_bytes = label_bytes.lower()
+ if label_bytes.startswith(_alabel_prefix):
+ label_bytes = label_bytes[len(_alabel_prefix):]
+ if not label_bytes:
+ raise IDNAError('Malformed A-label, no Punycode eligible content found')
+ if label_bytes.decode('ascii')[-1] == '-':
+ raise IDNAError('A-label must not end with a hyphen')
+ else:
+ check_label(label_bytes)
+ return label_bytes.decode('ascii')
+
+ try:
+ label = label_bytes.decode('punycode')
+ except UnicodeError:
+ raise IDNAError('Invalid A-label')
+ check_label(label)
+ return label
+
+
+def uts46_remap(domain: str, std3_rules: bool = True, transitional: bool = False) -> str:
+ """Re-map the characters in the string according to UTS46 processing."""
+ from .uts46data import uts46data
+ output = ''
+
+ for pos, char in enumerate(domain):
+ code_point = ord(char)
+ try:
+ uts46row = uts46data[code_point if code_point < 256 else
+ bisect.bisect_left(uts46data, (code_point, 'Z')) - 1]
+ status = uts46row[1]
+ replacement = None # type: Optional[str]
+ if len(uts46row) == 3:
+ replacement = uts46row[2]
+ if (status == 'V' or
+ (status == 'D' and not transitional) or
+ (status == '3' and not std3_rules and replacement is None)):
+ output += char
+ elif replacement is not None and (status == 'M' or
+ (status == '3' and not std3_rules) or
+ (status == 'D' and transitional)):
+ output += replacement
+ elif status != 'I':
+ raise IndexError()
+ except IndexError:
+ raise InvalidCodepoint(
+ 'Codepoint {} not allowed at position {} in {}'.format(
+ _unot(code_point), pos + 1, repr(domain)))
+
+ return unicodedata.normalize('NFC', output)
+
+
+def encode(s: Union[str, bytes, bytearray], strict: bool = False, uts46: bool = False, std3_rules: bool = False, transitional: bool = False) -> bytes:
+ if not isinstance(s, str):
+ try:
+ s = str(s, 'ascii')
+ except UnicodeDecodeError:
+ raise IDNAError('should pass a unicode string to the function rather than a byte string.')
+ if uts46:
+ s = uts46_remap(s, std3_rules, transitional)
+ trailing_dot = False
+ result = []
+ if strict:
+ labels = s.split('.')
+ else:
+ labels = _unicode_dots_re.split(s)
+ if not labels or labels == ['']:
+ raise IDNAError('Empty domain')
+ if labels[-1] == '':
+ del labels[-1]
+ trailing_dot = True
+ for label in labels:
+ s = alabel(label)
+ if s:
+ result.append(s)
+ else:
+ raise IDNAError('Empty label')
+ if trailing_dot:
+ result.append(b'')
+ s = b'.'.join(result)
+ if not valid_string_length(s, trailing_dot):
+ raise IDNAError('Domain too long')
+ return s
+
+
+def decode(s: Union[str, bytes, bytearray], strict: bool = False, uts46: bool = False, std3_rules: bool = False) -> str:
+ try:
+ if not isinstance(s, str):
+ s = str(s, 'ascii')
+ except UnicodeDecodeError:
+ raise IDNAError('Invalid ASCII in A-label')
+ if uts46:
+ s = uts46_remap(s, std3_rules, False)
+ trailing_dot = False
+ result = []
+ if not strict:
+ labels = _unicode_dots_re.split(s)
+ else:
+ labels = s.split('.')
+ if not labels or labels == ['']:
+ raise IDNAError('Empty domain')
+ if not labels[-1]:
+ del labels[-1]
+ trailing_dot = True
+ for label in labels:
+ s = ulabel(label)
+ if s:
+ result.append(s)
+ else:
+ raise IDNAError('Empty label')
+ if trailing_dot:
+ result.append('')
+ return '.'.join(result)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/idnadata.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/idnadata.py
new file mode 100644
index 000000000..c61dcf977
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/idnadata.py
@@ -0,0 +1,4245 @@
+# This file is automatically generated by tools/idna-data
+
+__version__ = '15.1.0'
+scripts = {
+ 'Greek': (
+ 0x37000000374,
+ 0x37500000378,
+ 0x37a0000037e,
+ 0x37f00000380,
+ 0x38400000385,
+ 0x38600000387,
+ 0x3880000038b,
+ 0x38c0000038d,
+ 0x38e000003a2,
+ 0x3a3000003e2,
+ 0x3f000000400,
+ 0x1d2600001d2b,
+ 0x1d5d00001d62,
+ 0x1d6600001d6b,
+ 0x1dbf00001dc0,
+ 0x1f0000001f16,
+ 0x1f1800001f1e,
+ 0x1f2000001f46,
+ 0x1f4800001f4e,
+ 0x1f5000001f58,
+ 0x1f5900001f5a,
+ 0x1f5b00001f5c,
+ 0x1f5d00001f5e,
+ 0x1f5f00001f7e,
+ 0x1f8000001fb5,
+ 0x1fb600001fc5,
+ 0x1fc600001fd4,
+ 0x1fd600001fdc,
+ 0x1fdd00001ff0,
+ 0x1ff200001ff5,
+ 0x1ff600001fff,
+ 0x212600002127,
+ 0xab650000ab66,
+ 0x101400001018f,
+ 0x101a0000101a1,
+ 0x1d2000001d246,
+ ),
+ 'Han': (
+ 0x2e8000002e9a,
+ 0x2e9b00002ef4,
+ 0x2f0000002fd6,
+ 0x300500003006,
+ 0x300700003008,
+ 0x30210000302a,
+ 0x30380000303c,
+ 0x340000004dc0,
+ 0x4e000000a000,
+ 0xf9000000fa6e,
+ 0xfa700000fada,
+ 0x16fe200016fe4,
+ 0x16ff000016ff2,
+ 0x200000002a6e0,
+ 0x2a7000002b73a,
+ 0x2b7400002b81e,
+ 0x2b8200002cea2,
+ 0x2ceb00002ebe1,
+ 0x2ebf00002ee5e,
+ 0x2f8000002fa1e,
+ 0x300000003134b,
+ 0x31350000323b0,
+ ),
+ 'Hebrew': (
+ 0x591000005c8,
+ 0x5d0000005eb,
+ 0x5ef000005f5,
+ 0xfb1d0000fb37,
+ 0xfb380000fb3d,
+ 0xfb3e0000fb3f,
+ 0xfb400000fb42,
+ 0xfb430000fb45,
+ 0xfb460000fb50,
+ ),
+ 'Hiragana': (
+ 0x304100003097,
+ 0x309d000030a0,
+ 0x1b0010001b120,
+ 0x1b1320001b133,
+ 0x1b1500001b153,
+ 0x1f2000001f201,
+ ),
+ 'Katakana': (
+ 0x30a1000030fb,
+ 0x30fd00003100,
+ 0x31f000003200,
+ 0x32d0000032ff,
+ 0x330000003358,
+ 0xff660000ff70,
+ 0xff710000ff9e,
+ 0x1aff00001aff4,
+ 0x1aff50001affc,
+ 0x1affd0001afff,
+ 0x1b0000001b001,
+ 0x1b1200001b123,
+ 0x1b1550001b156,
+ 0x1b1640001b168,
+ ),
+}
+joining_types = {
+ 0xad: 84,
+ 0x300: 84,
+ 0x301: 84,
+ 0x302: 84,
+ 0x303: 84,
+ 0x304: 84,
+ 0x305: 84,
+ 0x306: 84,
+ 0x307: 84,
+ 0x308: 84,
+ 0x309: 84,
+ 0x30a: 84,
+ 0x30b: 84,
+ 0x30c: 84,
+ 0x30d: 84,
+ 0x30e: 84,
+ 0x30f: 84,
+ 0x310: 84,
+ 0x311: 84,
+ 0x312: 84,
+ 0x313: 84,
+ 0x314: 84,
+ 0x315: 84,
+ 0x316: 84,
+ 0x317: 84,
+ 0x318: 84,
+ 0x319: 84,
+ 0x31a: 84,
+ 0x31b: 84,
+ 0x31c: 84,
+ 0x31d: 84,
+ 0x31e: 84,
+ 0x31f: 84,
+ 0x320: 84,
+ 0x321: 84,
+ 0x322: 84,
+ 0x323: 84,
+ 0x324: 84,
+ 0x325: 84,
+ 0x326: 84,
+ 0x327: 84,
+ 0x328: 84,
+ 0x329: 84,
+ 0x32a: 84,
+ 0x32b: 84,
+ 0x32c: 84,
+ 0x32d: 84,
+ 0x32e: 84,
+ 0x32f: 84,
+ 0x330: 84,
+ 0x331: 84,
+ 0x332: 84,
+ 0x333: 84,
+ 0x334: 84,
+ 0x335: 84,
+ 0x336: 84,
+ 0x337: 84,
+ 0x338: 84,
+ 0x339: 84,
+ 0x33a: 84,
+ 0x33b: 84,
+ 0x33c: 84,
+ 0x33d: 84,
+ 0x33e: 84,
+ 0x33f: 84,
+ 0x340: 84,
+ 0x341: 84,
+ 0x342: 84,
+ 0x343: 84,
+ 0x344: 84,
+ 0x345: 84,
+ 0x346: 84,
+ 0x347: 84,
+ 0x348: 84,
+ 0x349: 84,
+ 0x34a: 84,
+ 0x34b: 84,
+ 0x34c: 84,
+ 0x34d: 84,
+ 0x34e: 84,
+ 0x34f: 84,
+ 0x350: 84,
+ 0x351: 84,
+ 0x352: 84,
+ 0x353: 84,
+ 0x354: 84,
+ 0x355: 84,
+ 0x356: 84,
+ 0x357: 84,
+ 0x358: 84,
+ 0x359: 84,
+ 0x35a: 84,
+ 0x35b: 84,
+ 0x35c: 84,
+ 0x35d: 84,
+ 0x35e: 84,
+ 0x35f: 84,
+ 0x360: 84,
+ 0x361: 84,
+ 0x362: 84,
+ 0x363: 84,
+ 0x364: 84,
+ 0x365: 84,
+ 0x366: 84,
+ 0x367: 84,
+ 0x368: 84,
+ 0x369: 84,
+ 0x36a: 84,
+ 0x36b: 84,
+ 0x36c: 84,
+ 0x36d: 84,
+ 0x36e: 84,
+ 0x36f: 84,
+ 0x483: 84,
+ 0x484: 84,
+ 0x485: 84,
+ 0x486: 84,
+ 0x487: 84,
+ 0x488: 84,
+ 0x489: 84,
+ 0x591: 84,
+ 0x592: 84,
+ 0x593: 84,
+ 0x594: 84,
+ 0x595: 84,
+ 0x596: 84,
+ 0x597: 84,
+ 0x598: 84,
+ 0x599: 84,
+ 0x59a: 84,
+ 0x59b: 84,
+ 0x59c: 84,
+ 0x59d: 84,
+ 0x59e: 84,
+ 0x59f: 84,
+ 0x5a0: 84,
+ 0x5a1: 84,
+ 0x5a2: 84,
+ 0x5a3: 84,
+ 0x5a4: 84,
+ 0x5a5: 84,
+ 0x5a6: 84,
+ 0x5a7: 84,
+ 0x5a8: 84,
+ 0x5a9: 84,
+ 0x5aa: 84,
+ 0x5ab: 84,
+ 0x5ac: 84,
+ 0x5ad: 84,
+ 0x5ae: 84,
+ 0x5af: 84,
+ 0x5b0: 84,
+ 0x5b1: 84,
+ 0x5b2: 84,
+ 0x5b3: 84,
+ 0x5b4: 84,
+ 0x5b5: 84,
+ 0x5b6: 84,
+ 0x5b7: 84,
+ 0x5b8: 84,
+ 0x5b9: 84,
+ 0x5ba: 84,
+ 0x5bb: 84,
+ 0x5bc: 84,
+ 0x5bd: 84,
+ 0x5bf: 84,
+ 0x5c1: 84,
+ 0x5c2: 84,
+ 0x5c4: 84,
+ 0x5c5: 84,
+ 0x5c7: 84,
+ 0x610: 84,
+ 0x611: 84,
+ 0x612: 84,
+ 0x613: 84,
+ 0x614: 84,
+ 0x615: 84,
+ 0x616: 84,
+ 0x617: 84,
+ 0x618: 84,
+ 0x619: 84,
+ 0x61a: 84,
+ 0x61c: 84,
+ 0x620: 68,
+ 0x622: 82,
+ 0x623: 82,
+ 0x624: 82,
+ 0x625: 82,
+ 0x626: 68,
+ 0x627: 82,
+ 0x628: 68,
+ 0x629: 82,
+ 0x62a: 68,
+ 0x62b: 68,
+ 0x62c: 68,
+ 0x62d: 68,
+ 0x62e: 68,
+ 0x62f: 82,
+ 0x630: 82,
+ 0x631: 82,
+ 0x632: 82,
+ 0x633: 68,
+ 0x634: 68,
+ 0x635: 68,
+ 0x636: 68,
+ 0x637: 68,
+ 0x638: 68,
+ 0x639: 68,
+ 0x63a: 68,
+ 0x63b: 68,
+ 0x63c: 68,
+ 0x63d: 68,
+ 0x63e: 68,
+ 0x63f: 68,
+ 0x640: 67,
+ 0x641: 68,
+ 0x642: 68,
+ 0x643: 68,
+ 0x644: 68,
+ 0x645: 68,
+ 0x646: 68,
+ 0x647: 68,
+ 0x648: 82,
+ 0x649: 68,
+ 0x64a: 68,
+ 0x64b: 84,
+ 0x64c: 84,
+ 0x64d: 84,
+ 0x64e: 84,
+ 0x64f: 84,
+ 0x650: 84,
+ 0x651: 84,
+ 0x652: 84,
+ 0x653: 84,
+ 0x654: 84,
+ 0x655: 84,
+ 0x656: 84,
+ 0x657: 84,
+ 0x658: 84,
+ 0x659: 84,
+ 0x65a: 84,
+ 0x65b: 84,
+ 0x65c: 84,
+ 0x65d: 84,
+ 0x65e: 84,
+ 0x65f: 84,
+ 0x66e: 68,
+ 0x66f: 68,
+ 0x670: 84,
+ 0x671: 82,
+ 0x672: 82,
+ 0x673: 82,
+ 0x675: 82,
+ 0x676: 82,
+ 0x677: 82,
+ 0x678: 68,
+ 0x679: 68,
+ 0x67a: 68,
+ 0x67b: 68,
+ 0x67c: 68,
+ 0x67d: 68,
+ 0x67e: 68,
+ 0x67f: 68,
+ 0x680: 68,
+ 0x681: 68,
+ 0x682: 68,
+ 0x683: 68,
+ 0x684: 68,
+ 0x685: 68,
+ 0x686: 68,
+ 0x687: 68,
+ 0x688: 82,
+ 0x689: 82,
+ 0x68a: 82,
+ 0x68b: 82,
+ 0x68c: 82,
+ 0x68d: 82,
+ 0x68e: 82,
+ 0x68f: 82,
+ 0x690: 82,
+ 0x691: 82,
+ 0x692: 82,
+ 0x693: 82,
+ 0x694: 82,
+ 0x695: 82,
+ 0x696: 82,
+ 0x697: 82,
+ 0x698: 82,
+ 0x699: 82,
+ 0x69a: 68,
+ 0x69b: 68,
+ 0x69c: 68,
+ 0x69d: 68,
+ 0x69e: 68,
+ 0x69f: 68,
+ 0x6a0: 68,
+ 0x6a1: 68,
+ 0x6a2: 68,
+ 0x6a3: 68,
+ 0x6a4: 68,
+ 0x6a5: 68,
+ 0x6a6: 68,
+ 0x6a7: 68,
+ 0x6a8: 68,
+ 0x6a9: 68,
+ 0x6aa: 68,
+ 0x6ab: 68,
+ 0x6ac: 68,
+ 0x6ad: 68,
+ 0x6ae: 68,
+ 0x6af: 68,
+ 0x6b0: 68,
+ 0x6b1: 68,
+ 0x6b2: 68,
+ 0x6b3: 68,
+ 0x6b4: 68,
+ 0x6b5: 68,
+ 0x6b6: 68,
+ 0x6b7: 68,
+ 0x6b8: 68,
+ 0x6b9: 68,
+ 0x6ba: 68,
+ 0x6bb: 68,
+ 0x6bc: 68,
+ 0x6bd: 68,
+ 0x6be: 68,
+ 0x6bf: 68,
+ 0x6c0: 82,
+ 0x6c1: 68,
+ 0x6c2: 68,
+ 0x6c3: 82,
+ 0x6c4: 82,
+ 0x6c5: 82,
+ 0x6c6: 82,
+ 0x6c7: 82,
+ 0x6c8: 82,
+ 0x6c9: 82,
+ 0x6ca: 82,
+ 0x6cb: 82,
+ 0x6cc: 68,
+ 0x6cd: 82,
+ 0x6ce: 68,
+ 0x6cf: 82,
+ 0x6d0: 68,
+ 0x6d1: 68,
+ 0x6d2: 82,
+ 0x6d3: 82,
+ 0x6d5: 82,
+ 0x6d6: 84,
+ 0x6d7: 84,
+ 0x6d8: 84,
+ 0x6d9: 84,
+ 0x6da: 84,
+ 0x6db: 84,
+ 0x6dc: 84,
+ 0x6df: 84,
+ 0x6e0: 84,
+ 0x6e1: 84,
+ 0x6e2: 84,
+ 0x6e3: 84,
+ 0x6e4: 84,
+ 0x6e7: 84,
+ 0x6e8: 84,
+ 0x6ea: 84,
+ 0x6eb: 84,
+ 0x6ec: 84,
+ 0x6ed: 84,
+ 0x6ee: 82,
+ 0x6ef: 82,
+ 0x6fa: 68,
+ 0x6fb: 68,
+ 0x6fc: 68,
+ 0x6ff: 68,
+ 0x70f: 84,
+ 0x710: 82,
+ 0x711: 84,
+ 0x712: 68,
+ 0x713: 68,
+ 0x714: 68,
+ 0x715: 82,
+ 0x716: 82,
+ 0x717: 82,
+ 0x718: 82,
+ 0x719: 82,
+ 0x71a: 68,
+ 0x71b: 68,
+ 0x71c: 68,
+ 0x71d: 68,
+ 0x71e: 82,
+ 0x71f: 68,
+ 0x720: 68,
+ 0x721: 68,
+ 0x722: 68,
+ 0x723: 68,
+ 0x724: 68,
+ 0x725: 68,
+ 0x726: 68,
+ 0x727: 68,
+ 0x728: 82,
+ 0x729: 68,
+ 0x72a: 82,
+ 0x72b: 68,
+ 0x72c: 82,
+ 0x72d: 68,
+ 0x72e: 68,
+ 0x72f: 82,
+ 0x730: 84,
+ 0x731: 84,
+ 0x732: 84,
+ 0x733: 84,
+ 0x734: 84,
+ 0x735: 84,
+ 0x736: 84,
+ 0x737: 84,
+ 0x738: 84,
+ 0x739: 84,
+ 0x73a: 84,
+ 0x73b: 84,
+ 0x73c: 84,
+ 0x73d: 84,
+ 0x73e: 84,
+ 0x73f: 84,
+ 0x740: 84,
+ 0x741: 84,
+ 0x742: 84,
+ 0x743: 84,
+ 0x744: 84,
+ 0x745: 84,
+ 0x746: 84,
+ 0x747: 84,
+ 0x748: 84,
+ 0x749: 84,
+ 0x74a: 84,
+ 0x74d: 82,
+ 0x74e: 68,
+ 0x74f: 68,
+ 0x750: 68,
+ 0x751: 68,
+ 0x752: 68,
+ 0x753: 68,
+ 0x754: 68,
+ 0x755: 68,
+ 0x756: 68,
+ 0x757: 68,
+ 0x758: 68,
+ 0x759: 82,
+ 0x75a: 82,
+ 0x75b: 82,
+ 0x75c: 68,
+ 0x75d: 68,
+ 0x75e: 68,
+ 0x75f: 68,
+ 0x760: 68,
+ 0x761: 68,
+ 0x762: 68,
+ 0x763: 68,
+ 0x764: 68,
+ 0x765: 68,
+ 0x766: 68,
+ 0x767: 68,
+ 0x768: 68,
+ 0x769: 68,
+ 0x76a: 68,
+ 0x76b: 82,
+ 0x76c: 82,
+ 0x76d: 68,
+ 0x76e: 68,
+ 0x76f: 68,
+ 0x770: 68,
+ 0x771: 82,
+ 0x772: 68,
+ 0x773: 82,
+ 0x774: 82,
+ 0x775: 68,
+ 0x776: 68,
+ 0x777: 68,
+ 0x778: 82,
+ 0x779: 82,
+ 0x77a: 68,
+ 0x77b: 68,
+ 0x77c: 68,
+ 0x77d: 68,
+ 0x77e: 68,
+ 0x77f: 68,
+ 0x7a6: 84,
+ 0x7a7: 84,
+ 0x7a8: 84,
+ 0x7a9: 84,
+ 0x7aa: 84,
+ 0x7ab: 84,
+ 0x7ac: 84,
+ 0x7ad: 84,
+ 0x7ae: 84,
+ 0x7af: 84,
+ 0x7b0: 84,
+ 0x7ca: 68,
+ 0x7cb: 68,
+ 0x7cc: 68,
+ 0x7cd: 68,
+ 0x7ce: 68,
+ 0x7cf: 68,
+ 0x7d0: 68,
+ 0x7d1: 68,
+ 0x7d2: 68,
+ 0x7d3: 68,
+ 0x7d4: 68,
+ 0x7d5: 68,
+ 0x7d6: 68,
+ 0x7d7: 68,
+ 0x7d8: 68,
+ 0x7d9: 68,
+ 0x7da: 68,
+ 0x7db: 68,
+ 0x7dc: 68,
+ 0x7dd: 68,
+ 0x7de: 68,
+ 0x7df: 68,
+ 0x7e0: 68,
+ 0x7e1: 68,
+ 0x7e2: 68,
+ 0x7e3: 68,
+ 0x7e4: 68,
+ 0x7e5: 68,
+ 0x7e6: 68,
+ 0x7e7: 68,
+ 0x7e8: 68,
+ 0x7e9: 68,
+ 0x7ea: 68,
+ 0x7eb: 84,
+ 0x7ec: 84,
+ 0x7ed: 84,
+ 0x7ee: 84,
+ 0x7ef: 84,
+ 0x7f0: 84,
+ 0x7f1: 84,
+ 0x7f2: 84,
+ 0x7f3: 84,
+ 0x7fa: 67,
+ 0x7fd: 84,
+ 0x816: 84,
+ 0x817: 84,
+ 0x818: 84,
+ 0x819: 84,
+ 0x81b: 84,
+ 0x81c: 84,
+ 0x81d: 84,
+ 0x81e: 84,
+ 0x81f: 84,
+ 0x820: 84,
+ 0x821: 84,
+ 0x822: 84,
+ 0x823: 84,
+ 0x825: 84,
+ 0x826: 84,
+ 0x827: 84,
+ 0x829: 84,
+ 0x82a: 84,
+ 0x82b: 84,
+ 0x82c: 84,
+ 0x82d: 84,
+ 0x840: 82,
+ 0x841: 68,
+ 0x842: 68,
+ 0x843: 68,
+ 0x844: 68,
+ 0x845: 68,
+ 0x846: 82,
+ 0x847: 82,
+ 0x848: 68,
+ 0x849: 82,
+ 0x84a: 68,
+ 0x84b: 68,
+ 0x84c: 68,
+ 0x84d: 68,
+ 0x84e: 68,
+ 0x84f: 68,
+ 0x850: 68,
+ 0x851: 68,
+ 0x852: 68,
+ 0x853: 68,
+ 0x854: 82,
+ 0x855: 68,
+ 0x856: 82,
+ 0x857: 82,
+ 0x858: 82,
+ 0x859: 84,
+ 0x85a: 84,
+ 0x85b: 84,
+ 0x860: 68,
+ 0x862: 68,
+ 0x863: 68,
+ 0x864: 68,
+ 0x865: 68,
+ 0x867: 82,
+ 0x868: 68,
+ 0x869: 82,
+ 0x86a: 82,
+ 0x870: 82,
+ 0x871: 82,
+ 0x872: 82,
+ 0x873: 82,
+ 0x874: 82,
+ 0x875: 82,
+ 0x876: 82,
+ 0x877: 82,
+ 0x878: 82,
+ 0x879: 82,
+ 0x87a: 82,
+ 0x87b: 82,
+ 0x87c: 82,
+ 0x87d: 82,
+ 0x87e: 82,
+ 0x87f: 82,
+ 0x880: 82,
+ 0x881: 82,
+ 0x882: 82,
+ 0x883: 67,
+ 0x884: 67,
+ 0x885: 67,
+ 0x886: 68,
+ 0x889: 68,
+ 0x88a: 68,
+ 0x88b: 68,
+ 0x88c: 68,
+ 0x88d: 68,
+ 0x88e: 82,
+ 0x898: 84,
+ 0x899: 84,
+ 0x89a: 84,
+ 0x89b: 84,
+ 0x89c: 84,
+ 0x89d: 84,
+ 0x89e: 84,
+ 0x89f: 84,
+ 0x8a0: 68,
+ 0x8a1: 68,
+ 0x8a2: 68,
+ 0x8a3: 68,
+ 0x8a4: 68,
+ 0x8a5: 68,
+ 0x8a6: 68,
+ 0x8a7: 68,
+ 0x8a8: 68,
+ 0x8a9: 68,
+ 0x8aa: 82,
+ 0x8ab: 82,
+ 0x8ac: 82,
+ 0x8ae: 82,
+ 0x8af: 68,
+ 0x8b0: 68,
+ 0x8b1: 82,
+ 0x8b2: 82,
+ 0x8b3: 68,
+ 0x8b4: 68,
+ 0x8b5: 68,
+ 0x8b6: 68,
+ 0x8b7: 68,
+ 0x8b8: 68,
+ 0x8b9: 82,
+ 0x8ba: 68,
+ 0x8bb: 68,
+ 0x8bc: 68,
+ 0x8bd: 68,
+ 0x8be: 68,
+ 0x8bf: 68,
+ 0x8c0: 68,
+ 0x8c1: 68,
+ 0x8c2: 68,
+ 0x8c3: 68,
+ 0x8c4: 68,
+ 0x8c5: 68,
+ 0x8c6: 68,
+ 0x8c7: 68,
+ 0x8c8: 68,
+ 0x8ca: 84,
+ 0x8cb: 84,
+ 0x8cc: 84,
+ 0x8cd: 84,
+ 0x8ce: 84,
+ 0x8cf: 84,
+ 0x8d0: 84,
+ 0x8d1: 84,
+ 0x8d2: 84,
+ 0x8d3: 84,
+ 0x8d4: 84,
+ 0x8d5: 84,
+ 0x8d6: 84,
+ 0x8d7: 84,
+ 0x8d8: 84,
+ 0x8d9: 84,
+ 0x8da: 84,
+ 0x8db: 84,
+ 0x8dc: 84,
+ 0x8dd: 84,
+ 0x8de: 84,
+ 0x8df: 84,
+ 0x8e0: 84,
+ 0x8e1: 84,
+ 0x8e3: 84,
+ 0x8e4: 84,
+ 0x8e5: 84,
+ 0x8e6: 84,
+ 0x8e7: 84,
+ 0x8e8: 84,
+ 0x8e9: 84,
+ 0x8ea: 84,
+ 0x8eb: 84,
+ 0x8ec: 84,
+ 0x8ed: 84,
+ 0x8ee: 84,
+ 0x8ef: 84,
+ 0x8f0: 84,
+ 0x8f1: 84,
+ 0x8f2: 84,
+ 0x8f3: 84,
+ 0x8f4: 84,
+ 0x8f5: 84,
+ 0x8f6: 84,
+ 0x8f7: 84,
+ 0x8f8: 84,
+ 0x8f9: 84,
+ 0x8fa: 84,
+ 0x8fb: 84,
+ 0x8fc: 84,
+ 0x8fd: 84,
+ 0x8fe: 84,
+ 0x8ff: 84,
+ 0x900: 84,
+ 0x901: 84,
+ 0x902: 84,
+ 0x93a: 84,
+ 0x93c: 84,
+ 0x941: 84,
+ 0x942: 84,
+ 0x943: 84,
+ 0x944: 84,
+ 0x945: 84,
+ 0x946: 84,
+ 0x947: 84,
+ 0x948: 84,
+ 0x94d: 84,
+ 0x951: 84,
+ 0x952: 84,
+ 0x953: 84,
+ 0x954: 84,
+ 0x955: 84,
+ 0x956: 84,
+ 0x957: 84,
+ 0x962: 84,
+ 0x963: 84,
+ 0x981: 84,
+ 0x9bc: 84,
+ 0x9c1: 84,
+ 0x9c2: 84,
+ 0x9c3: 84,
+ 0x9c4: 84,
+ 0x9cd: 84,
+ 0x9e2: 84,
+ 0x9e3: 84,
+ 0x9fe: 84,
+ 0xa01: 84,
+ 0xa02: 84,
+ 0xa3c: 84,
+ 0xa41: 84,
+ 0xa42: 84,
+ 0xa47: 84,
+ 0xa48: 84,
+ 0xa4b: 84,
+ 0xa4c: 84,
+ 0xa4d: 84,
+ 0xa51: 84,
+ 0xa70: 84,
+ 0xa71: 84,
+ 0xa75: 84,
+ 0xa81: 84,
+ 0xa82: 84,
+ 0xabc: 84,
+ 0xac1: 84,
+ 0xac2: 84,
+ 0xac3: 84,
+ 0xac4: 84,
+ 0xac5: 84,
+ 0xac7: 84,
+ 0xac8: 84,
+ 0xacd: 84,
+ 0xae2: 84,
+ 0xae3: 84,
+ 0xafa: 84,
+ 0xafb: 84,
+ 0xafc: 84,
+ 0xafd: 84,
+ 0xafe: 84,
+ 0xaff: 84,
+ 0xb01: 84,
+ 0xb3c: 84,
+ 0xb3f: 84,
+ 0xb41: 84,
+ 0xb42: 84,
+ 0xb43: 84,
+ 0xb44: 84,
+ 0xb4d: 84,
+ 0xb55: 84,
+ 0xb56: 84,
+ 0xb62: 84,
+ 0xb63: 84,
+ 0xb82: 84,
+ 0xbc0: 84,
+ 0xbcd: 84,
+ 0xc00: 84,
+ 0xc04: 84,
+ 0xc3c: 84,
+ 0xc3e: 84,
+ 0xc3f: 84,
+ 0xc40: 84,
+ 0xc46: 84,
+ 0xc47: 84,
+ 0xc48: 84,
+ 0xc4a: 84,
+ 0xc4b: 84,
+ 0xc4c: 84,
+ 0xc4d: 84,
+ 0xc55: 84,
+ 0xc56: 84,
+ 0xc62: 84,
+ 0xc63: 84,
+ 0xc81: 84,
+ 0xcbc: 84,
+ 0xcbf: 84,
+ 0xcc6: 84,
+ 0xccc: 84,
+ 0xccd: 84,
+ 0xce2: 84,
+ 0xce3: 84,
+ 0xd00: 84,
+ 0xd01: 84,
+ 0xd3b: 84,
+ 0xd3c: 84,
+ 0xd41: 84,
+ 0xd42: 84,
+ 0xd43: 84,
+ 0xd44: 84,
+ 0xd4d: 84,
+ 0xd62: 84,
+ 0xd63: 84,
+ 0xd81: 84,
+ 0xdca: 84,
+ 0xdd2: 84,
+ 0xdd3: 84,
+ 0xdd4: 84,
+ 0xdd6: 84,
+ 0xe31: 84,
+ 0xe34: 84,
+ 0xe35: 84,
+ 0xe36: 84,
+ 0xe37: 84,
+ 0xe38: 84,
+ 0xe39: 84,
+ 0xe3a: 84,
+ 0xe47: 84,
+ 0xe48: 84,
+ 0xe49: 84,
+ 0xe4a: 84,
+ 0xe4b: 84,
+ 0xe4c: 84,
+ 0xe4d: 84,
+ 0xe4e: 84,
+ 0xeb1: 84,
+ 0xeb4: 84,
+ 0xeb5: 84,
+ 0xeb6: 84,
+ 0xeb7: 84,
+ 0xeb8: 84,
+ 0xeb9: 84,
+ 0xeba: 84,
+ 0xebb: 84,
+ 0xebc: 84,
+ 0xec8: 84,
+ 0xec9: 84,
+ 0xeca: 84,
+ 0xecb: 84,
+ 0xecc: 84,
+ 0xecd: 84,
+ 0xece: 84,
+ 0xf18: 84,
+ 0xf19: 84,
+ 0xf35: 84,
+ 0xf37: 84,
+ 0xf39: 84,
+ 0xf71: 84,
+ 0xf72: 84,
+ 0xf73: 84,
+ 0xf74: 84,
+ 0xf75: 84,
+ 0xf76: 84,
+ 0xf77: 84,
+ 0xf78: 84,
+ 0xf79: 84,
+ 0xf7a: 84,
+ 0xf7b: 84,
+ 0xf7c: 84,
+ 0xf7d: 84,
+ 0xf7e: 84,
+ 0xf80: 84,
+ 0xf81: 84,
+ 0xf82: 84,
+ 0xf83: 84,
+ 0xf84: 84,
+ 0xf86: 84,
+ 0xf87: 84,
+ 0xf8d: 84,
+ 0xf8e: 84,
+ 0xf8f: 84,
+ 0xf90: 84,
+ 0xf91: 84,
+ 0xf92: 84,
+ 0xf93: 84,
+ 0xf94: 84,
+ 0xf95: 84,
+ 0xf96: 84,
+ 0xf97: 84,
+ 0xf99: 84,
+ 0xf9a: 84,
+ 0xf9b: 84,
+ 0xf9c: 84,
+ 0xf9d: 84,
+ 0xf9e: 84,
+ 0xf9f: 84,
+ 0xfa0: 84,
+ 0xfa1: 84,
+ 0xfa2: 84,
+ 0xfa3: 84,
+ 0xfa4: 84,
+ 0xfa5: 84,
+ 0xfa6: 84,
+ 0xfa7: 84,
+ 0xfa8: 84,
+ 0xfa9: 84,
+ 0xfaa: 84,
+ 0xfab: 84,
+ 0xfac: 84,
+ 0xfad: 84,
+ 0xfae: 84,
+ 0xfaf: 84,
+ 0xfb0: 84,
+ 0xfb1: 84,
+ 0xfb2: 84,
+ 0xfb3: 84,
+ 0xfb4: 84,
+ 0xfb5: 84,
+ 0xfb6: 84,
+ 0xfb7: 84,
+ 0xfb8: 84,
+ 0xfb9: 84,
+ 0xfba: 84,
+ 0xfbb: 84,
+ 0xfbc: 84,
+ 0xfc6: 84,
+ 0x102d: 84,
+ 0x102e: 84,
+ 0x102f: 84,
+ 0x1030: 84,
+ 0x1032: 84,
+ 0x1033: 84,
+ 0x1034: 84,
+ 0x1035: 84,
+ 0x1036: 84,
+ 0x1037: 84,
+ 0x1039: 84,
+ 0x103a: 84,
+ 0x103d: 84,
+ 0x103e: 84,
+ 0x1058: 84,
+ 0x1059: 84,
+ 0x105e: 84,
+ 0x105f: 84,
+ 0x1060: 84,
+ 0x1071: 84,
+ 0x1072: 84,
+ 0x1073: 84,
+ 0x1074: 84,
+ 0x1082: 84,
+ 0x1085: 84,
+ 0x1086: 84,
+ 0x108d: 84,
+ 0x109d: 84,
+ 0x135d: 84,
+ 0x135e: 84,
+ 0x135f: 84,
+ 0x1712: 84,
+ 0x1713: 84,
+ 0x1714: 84,
+ 0x1732: 84,
+ 0x1733: 84,
+ 0x1752: 84,
+ 0x1753: 84,
+ 0x1772: 84,
+ 0x1773: 84,
+ 0x17b4: 84,
+ 0x17b5: 84,
+ 0x17b7: 84,
+ 0x17b8: 84,
+ 0x17b9: 84,
+ 0x17ba: 84,
+ 0x17bb: 84,
+ 0x17bc: 84,
+ 0x17bd: 84,
+ 0x17c6: 84,
+ 0x17c9: 84,
+ 0x17ca: 84,
+ 0x17cb: 84,
+ 0x17cc: 84,
+ 0x17cd: 84,
+ 0x17ce: 84,
+ 0x17cf: 84,
+ 0x17d0: 84,
+ 0x17d1: 84,
+ 0x17d2: 84,
+ 0x17d3: 84,
+ 0x17dd: 84,
+ 0x1807: 68,
+ 0x180a: 67,
+ 0x180b: 84,
+ 0x180c: 84,
+ 0x180d: 84,
+ 0x180f: 84,
+ 0x1820: 68,
+ 0x1821: 68,
+ 0x1822: 68,
+ 0x1823: 68,
+ 0x1824: 68,
+ 0x1825: 68,
+ 0x1826: 68,
+ 0x1827: 68,
+ 0x1828: 68,
+ 0x1829: 68,
+ 0x182a: 68,
+ 0x182b: 68,
+ 0x182c: 68,
+ 0x182d: 68,
+ 0x182e: 68,
+ 0x182f: 68,
+ 0x1830: 68,
+ 0x1831: 68,
+ 0x1832: 68,
+ 0x1833: 68,
+ 0x1834: 68,
+ 0x1835: 68,
+ 0x1836: 68,
+ 0x1837: 68,
+ 0x1838: 68,
+ 0x1839: 68,
+ 0x183a: 68,
+ 0x183b: 68,
+ 0x183c: 68,
+ 0x183d: 68,
+ 0x183e: 68,
+ 0x183f: 68,
+ 0x1840: 68,
+ 0x1841: 68,
+ 0x1842: 68,
+ 0x1843: 68,
+ 0x1844: 68,
+ 0x1845: 68,
+ 0x1846: 68,
+ 0x1847: 68,
+ 0x1848: 68,
+ 0x1849: 68,
+ 0x184a: 68,
+ 0x184b: 68,
+ 0x184c: 68,
+ 0x184d: 68,
+ 0x184e: 68,
+ 0x184f: 68,
+ 0x1850: 68,
+ 0x1851: 68,
+ 0x1852: 68,
+ 0x1853: 68,
+ 0x1854: 68,
+ 0x1855: 68,
+ 0x1856: 68,
+ 0x1857: 68,
+ 0x1858: 68,
+ 0x1859: 68,
+ 0x185a: 68,
+ 0x185b: 68,
+ 0x185c: 68,
+ 0x185d: 68,
+ 0x185e: 68,
+ 0x185f: 68,
+ 0x1860: 68,
+ 0x1861: 68,
+ 0x1862: 68,
+ 0x1863: 68,
+ 0x1864: 68,
+ 0x1865: 68,
+ 0x1866: 68,
+ 0x1867: 68,
+ 0x1868: 68,
+ 0x1869: 68,
+ 0x186a: 68,
+ 0x186b: 68,
+ 0x186c: 68,
+ 0x186d: 68,
+ 0x186e: 68,
+ 0x186f: 68,
+ 0x1870: 68,
+ 0x1871: 68,
+ 0x1872: 68,
+ 0x1873: 68,
+ 0x1874: 68,
+ 0x1875: 68,
+ 0x1876: 68,
+ 0x1877: 68,
+ 0x1878: 68,
+ 0x1885: 84,
+ 0x1886: 84,
+ 0x1887: 68,
+ 0x1888: 68,
+ 0x1889: 68,
+ 0x188a: 68,
+ 0x188b: 68,
+ 0x188c: 68,
+ 0x188d: 68,
+ 0x188e: 68,
+ 0x188f: 68,
+ 0x1890: 68,
+ 0x1891: 68,
+ 0x1892: 68,
+ 0x1893: 68,
+ 0x1894: 68,
+ 0x1895: 68,
+ 0x1896: 68,
+ 0x1897: 68,
+ 0x1898: 68,
+ 0x1899: 68,
+ 0x189a: 68,
+ 0x189b: 68,
+ 0x189c: 68,
+ 0x189d: 68,
+ 0x189e: 68,
+ 0x189f: 68,
+ 0x18a0: 68,
+ 0x18a1: 68,
+ 0x18a2: 68,
+ 0x18a3: 68,
+ 0x18a4: 68,
+ 0x18a5: 68,
+ 0x18a6: 68,
+ 0x18a7: 68,
+ 0x18a8: 68,
+ 0x18a9: 84,
+ 0x18aa: 68,
+ 0x1920: 84,
+ 0x1921: 84,
+ 0x1922: 84,
+ 0x1927: 84,
+ 0x1928: 84,
+ 0x1932: 84,
+ 0x1939: 84,
+ 0x193a: 84,
+ 0x193b: 84,
+ 0x1a17: 84,
+ 0x1a18: 84,
+ 0x1a1b: 84,
+ 0x1a56: 84,
+ 0x1a58: 84,
+ 0x1a59: 84,
+ 0x1a5a: 84,
+ 0x1a5b: 84,
+ 0x1a5c: 84,
+ 0x1a5d: 84,
+ 0x1a5e: 84,
+ 0x1a60: 84,
+ 0x1a62: 84,
+ 0x1a65: 84,
+ 0x1a66: 84,
+ 0x1a67: 84,
+ 0x1a68: 84,
+ 0x1a69: 84,
+ 0x1a6a: 84,
+ 0x1a6b: 84,
+ 0x1a6c: 84,
+ 0x1a73: 84,
+ 0x1a74: 84,
+ 0x1a75: 84,
+ 0x1a76: 84,
+ 0x1a77: 84,
+ 0x1a78: 84,
+ 0x1a79: 84,
+ 0x1a7a: 84,
+ 0x1a7b: 84,
+ 0x1a7c: 84,
+ 0x1a7f: 84,
+ 0x1ab0: 84,
+ 0x1ab1: 84,
+ 0x1ab2: 84,
+ 0x1ab3: 84,
+ 0x1ab4: 84,
+ 0x1ab5: 84,
+ 0x1ab6: 84,
+ 0x1ab7: 84,
+ 0x1ab8: 84,
+ 0x1ab9: 84,
+ 0x1aba: 84,
+ 0x1abb: 84,
+ 0x1abc: 84,
+ 0x1abd: 84,
+ 0x1abe: 84,
+ 0x1abf: 84,
+ 0x1ac0: 84,
+ 0x1ac1: 84,
+ 0x1ac2: 84,
+ 0x1ac3: 84,
+ 0x1ac4: 84,
+ 0x1ac5: 84,
+ 0x1ac6: 84,
+ 0x1ac7: 84,
+ 0x1ac8: 84,
+ 0x1ac9: 84,
+ 0x1aca: 84,
+ 0x1acb: 84,
+ 0x1acc: 84,
+ 0x1acd: 84,
+ 0x1ace: 84,
+ 0x1b00: 84,
+ 0x1b01: 84,
+ 0x1b02: 84,
+ 0x1b03: 84,
+ 0x1b34: 84,
+ 0x1b36: 84,
+ 0x1b37: 84,
+ 0x1b38: 84,
+ 0x1b39: 84,
+ 0x1b3a: 84,
+ 0x1b3c: 84,
+ 0x1b42: 84,
+ 0x1b6b: 84,
+ 0x1b6c: 84,
+ 0x1b6d: 84,
+ 0x1b6e: 84,
+ 0x1b6f: 84,
+ 0x1b70: 84,
+ 0x1b71: 84,
+ 0x1b72: 84,
+ 0x1b73: 84,
+ 0x1b80: 84,
+ 0x1b81: 84,
+ 0x1ba2: 84,
+ 0x1ba3: 84,
+ 0x1ba4: 84,
+ 0x1ba5: 84,
+ 0x1ba8: 84,
+ 0x1ba9: 84,
+ 0x1bab: 84,
+ 0x1bac: 84,
+ 0x1bad: 84,
+ 0x1be6: 84,
+ 0x1be8: 84,
+ 0x1be9: 84,
+ 0x1bed: 84,
+ 0x1bef: 84,
+ 0x1bf0: 84,
+ 0x1bf1: 84,
+ 0x1c2c: 84,
+ 0x1c2d: 84,
+ 0x1c2e: 84,
+ 0x1c2f: 84,
+ 0x1c30: 84,
+ 0x1c31: 84,
+ 0x1c32: 84,
+ 0x1c33: 84,
+ 0x1c36: 84,
+ 0x1c37: 84,
+ 0x1cd0: 84,
+ 0x1cd1: 84,
+ 0x1cd2: 84,
+ 0x1cd4: 84,
+ 0x1cd5: 84,
+ 0x1cd6: 84,
+ 0x1cd7: 84,
+ 0x1cd8: 84,
+ 0x1cd9: 84,
+ 0x1cda: 84,
+ 0x1cdb: 84,
+ 0x1cdc: 84,
+ 0x1cdd: 84,
+ 0x1cde: 84,
+ 0x1cdf: 84,
+ 0x1ce0: 84,
+ 0x1ce2: 84,
+ 0x1ce3: 84,
+ 0x1ce4: 84,
+ 0x1ce5: 84,
+ 0x1ce6: 84,
+ 0x1ce7: 84,
+ 0x1ce8: 84,
+ 0x1ced: 84,
+ 0x1cf4: 84,
+ 0x1cf8: 84,
+ 0x1cf9: 84,
+ 0x1dc0: 84,
+ 0x1dc1: 84,
+ 0x1dc2: 84,
+ 0x1dc3: 84,
+ 0x1dc4: 84,
+ 0x1dc5: 84,
+ 0x1dc6: 84,
+ 0x1dc7: 84,
+ 0x1dc8: 84,
+ 0x1dc9: 84,
+ 0x1dca: 84,
+ 0x1dcb: 84,
+ 0x1dcc: 84,
+ 0x1dcd: 84,
+ 0x1dce: 84,
+ 0x1dcf: 84,
+ 0x1dd0: 84,
+ 0x1dd1: 84,
+ 0x1dd2: 84,
+ 0x1dd3: 84,
+ 0x1dd4: 84,
+ 0x1dd5: 84,
+ 0x1dd6: 84,
+ 0x1dd7: 84,
+ 0x1dd8: 84,
+ 0x1dd9: 84,
+ 0x1dda: 84,
+ 0x1ddb: 84,
+ 0x1ddc: 84,
+ 0x1ddd: 84,
+ 0x1dde: 84,
+ 0x1ddf: 84,
+ 0x1de0: 84,
+ 0x1de1: 84,
+ 0x1de2: 84,
+ 0x1de3: 84,
+ 0x1de4: 84,
+ 0x1de5: 84,
+ 0x1de6: 84,
+ 0x1de7: 84,
+ 0x1de8: 84,
+ 0x1de9: 84,
+ 0x1dea: 84,
+ 0x1deb: 84,
+ 0x1dec: 84,
+ 0x1ded: 84,
+ 0x1dee: 84,
+ 0x1def: 84,
+ 0x1df0: 84,
+ 0x1df1: 84,
+ 0x1df2: 84,
+ 0x1df3: 84,
+ 0x1df4: 84,
+ 0x1df5: 84,
+ 0x1df6: 84,
+ 0x1df7: 84,
+ 0x1df8: 84,
+ 0x1df9: 84,
+ 0x1dfa: 84,
+ 0x1dfb: 84,
+ 0x1dfc: 84,
+ 0x1dfd: 84,
+ 0x1dfe: 84,
+ 0x1dff: 84,
+ 0x200b: 84,
+ 0x200d: 67,
+ 0x200e: 84,
+ 0x200f: 84,
+ 0x202a: 84,
+ 0x202b: 84,
+ 0x202c: 84,
+ 0x202d: 84,
+ 0x202e: 84,
+ 0x2060: 84,
+ 0x2061: 84,
+ 0x2062: 84,
+ 0x2063: 84,
+ 0x2064: 84,
+ 0x206a: 84,
+ 0x206b: 84,
+ 0x206c: 84,
+ 0x206d: 84,
+ 0x206e: 84,
+ 0x206f: 84,
+ 0x20d0: 84,
+ 0x20d1: 84,
+ 0x20d2: 84,
+ 0x20d3: 84,
+ 0x20d4: 84,
+ 0x20d5: 84,
+ 0x20d6: 84,
+ 0x20d7: 84,
+ 0x20d8: 84,
+ 0x20d9: 84,
+ 0x20da: 84,
+ 0x20db: 84,
+ 0x20dc: 84,
+ 0x20dd: 84,
+ 0x20de: 84,
+ 0x20df: 84,
+ 0x20e0: 84,
+ 0x20e1: 84,
+ 0x20e2: 84,
+ 0x20e3: 84,
+ 0x20e4: 84,
+ 0x20e5: 84,
+ 0x20e6: 84,
+ 0x20e7: 84,
+ 0x20e8: 84,
+ 0x20e9: 84,
+ 0x20ea: 84,
+ 0x20eb: 84,
+ 0x20ec: 84,
+ 0x20ed: 84,
+ 0x20ee: 84,
+ 0x20ef: 84,
+ 0x20f0: 84,
+ 0x2cef: 84,
+ 0x2cf0: 84,
+ 0x2cf1: 84,
+ 0x2d7f: 84,
+ 0x2de0: 84,
+ 0x2de1: 84,
+ 0x2de2: 84,
+ 0x2de3: 84,
+ 0x2de4: 84,
+ 0x2de5: 84,
+ 0x2de6: 84,
+ 0x2de7: 84,
+ 0x2de8: 84,
+ 0x2de9: 84,
+ 0x2dea: 84,
+ 0x2deb: 84,
+ 0x2dec: 84,
+ 0x2ded: 84,
+ 0x2dee: 84,
+ 0x2def: 84,
+ 0x2df0: 84,
+ 0x2df1: 84,
+ 0x2df2: 84,
+ 0x2df3: 84,
+ 0x2df4: 84,
+ 0x2df5: 84,
+ 0x2df6: 84,
+ 0x2df7: 84,
+ 0x2df8: 84,
+ 0x2df9: 84,
+ 0x2dfa: 84,
+ 0x2dfb: 84,
+ 0x2dfc: 84,
+ 0x2dfd: 84,
+ 0x2dfe: 84,
+ 0x2dff: 84,
+ 0x302a: 84,
+ 0x302b: 84,
+ 0x302c: 84,
+ 0x302d: 84,
+ 0x3099: 84,
+ 0x309a: 84,
+ 0xa66f: 84,
+ 0xa670: 84,
+ 0xa671: 84,
+ 0xa672: 84,
+ 0xa674: 84,
+ 0xa675: 84,
+ 0xa676: 84,
+ 0xa677: 84,
+ 0xa678: 84,
+ 0xa679: 84,
+ 0xa67a: 84,
+ 0xa67b: 84,
+ 0xa67c: 84,
+ 0xa67d: 84,
+ 0xa69e: 84,
+ 0xa69f: 84,
+ 0xa6f0: 84,
+ 0xa6f1: 84,
+ 0xa802: 84,
+ 0xa806: 84,
+ 0xa80b: 84,
+ 0xa825: 84,
+ 0xa826: 84,
+ 0xa82c: 84,
+ 0xa840: 68,
+ 0xa841: 68,
+ 0xa842: 68,
+ 0xa843: 68,
+ 0xa844: 68,
+ 0xa845: 68,
+ 0xa846: 68,
+ 0xa847: 68,
+ 0xa848: 68,
+ 0xa849: 68,
+ 0xa84a: 68,
+ 0xa84b: 68,
+ 0xa84c: 68,
+ 0xa84d: 68,
+ 0xa84e: 68,
+ 0xa84f: 68,
+ 0xa850: 68,
+ 0xa851: 68,
+ 0xa852: 68,
+ 0xa853: 68,
+ 0xa854: 68,
+ 0xa855: 68,
+ 0xa856: 68,
+ 0xa857: 68,
+ 0xa858: 68,
+ 0xa859: 68,
+ 0xa85a: 68,
+ 0xa85b: 68,
+ 0xa85c: 68,
+ 0xa85d: 68,
+ 0xa85e: 68,
+ 0xa85f: 68,
+ 0xa860: 68,
+ 0xa861: 68,
+ 0xa862: 68,
+ 0xa863: 68,
+ 0xa864: 68,
+ 0xa865: 68,
+ 0xa866: 68,
+ 0xa867: 68,
+ 0xa868: 68,
+ 0xa869: 68,
+ 0xa86a: 68,
+ 0xa86b: 68,
+ 0xa86c: 68,
+ 0xa86d: 68,
+ 0xa86e: 68,
+ 0xa86f: 68,
+ 0xa870: 68,
+ 0xa871: 68,
+ 0xa872: 76,
+ 0xa8c4: 84,
+ 0xa8c5: 84,
+ 0xa8e0: 84,
+ 0xa8e1: 84,
+ 0xa8e2: 84,
+ 0xa8e3: 84,
+ 0xa8e4: 84,
+ 0xa8e5: 84,
+ 0xa8e6: 84,
+ 0xa8e7: 84,
+ 0xa8e8: 84,
+ 0xa8e9: 84,
+ 0xa8ea: 84,
+ 0xa8eb: 84,
+ 0xa8ec: 84,
+ 0xa8ed: 84,
+ 0xa8ee: 84,
+ 0xa8ef: 84,
+ 0xa8f0: 84,
+ 0xa8f1: 84,
+ 0xa8ff: 84,
+ 0xa926: 84,
+ 0xa927: 84,
+ 0xa928: 84,
+ 0xa929: 84,
+ 0xa92a: 84,
+ 0xa92b: 84,
+ 0xa92c: 84,
+ 0xa92d: 84,
+ 0xa947: 84,
+ 0xa948: 84,
+ 0xa949: 84,
+ 0xa94a: 84,
+ 0xa94b: 84,
+ 0xa94c: 84,
+ 0xa94d: 84,
+ 0xa94e: 84,
+ 0xa94f: 84,
+ 0xa950: 84,
+ 0xa951: 84,
+ 0xa980: 84,
+ 0xa981: 84,
+ 0xa982: 84,
+ 0xa9b3: 84,
+ 0xa9b6: 84,
+ 0xa9b7: 84,
+ 0xa9b8: 84,
+ 0xa9b9: 84,
+ 0xa9bc: 84,
+ 0xa9bd: 84,
+ 0xa9e5: 84,
+ 0xaa29: 84,
+ 0xaa2a: 84,
+ 0xaa2b: 84,
+ 0xaa2c: 84,
+ 0xaa2d: 84,
+ 0xaa2e: 84,
+ 0xaa31: 84,
+ 0xaa32: 84,
+ 0xaa35: 84,
+ 0xaa36: 84,
+ 0xaa43: 84,
+ 0xaa4c: 84,
+ 0xaa7c: 84,
+ 0xaab0: 84,
+ 0xaab2: 84,
+ 0xaab3: 84,
+ 0xaab4: 84,
+ 0xaab7: 84,
+ 0xaab8: 84,
+ 0xaabe: 84,
+ 0xaabf: 84,
+ 0xaac1: 84,
+ 0xaaec: 84,
+ 0xaaed: 84,
+ 0xaaf6: 84,
+ 0xabe5: 84,
+ 0xabe8: 84,
+ 0xabed: 84,
+ 0xfb1e: 84,
+ 0xfe00: 84,
+ 0xfe01: 84,
+ 0xfe02: 84,
+ 0xfe03: 84,
+ 0xfe04: 84,
+ 0xfe05: 84,
+ 0xfe06: 84,
+ 0xfe07: 84,
+ 0xfe08: 84,
+ 0xfe09: 84,
+ 0xfe0a: 84,
+ 0xfe0b: 84,
+ 0xfe0c: 84,
+ 0xfe0d: 84,
+ 0xfe0e: 84,
+ 0xfe0f: 84,
+ 0xfe20: 84,
+ 0xfe21: 84,
+ 0xfe22: 84,
+ 0xfe23: 84,
+ 0xfe24: 84,
+ 0xfe25: 84,
+ 0xfe26: 84,
+ 0xfe27: 84,
+ 0xfe28: 84,
+ 0xfe29: 84,
+ 0xfe2a: 84,
+ 0xfe2b: 84,
+ 0xfe2c: 84,
+ 0xfe2d: 84,
+ 0xfe2e: 84,
+ 0xfe2f: 84,
+ 0xfeff: 84,
+ 0xfff9: 84,
+ 0xfffa: 84,
+ 0xfffb: 84,
+ 0x101fd: 84,
+ 0x102e0: 84,
+ 0x10376: 84,
+ 0x10377: 84,
+ 0x10378: 84,
+ 0x10379: 84,
+ 0x1037a: 84,
+ 0x10a01: 84,
+ 0x10a02: 84,
+ 0x10a03: 84,
+ 0x10a05: 84,
+ 0x10a06: 84,
+ 0x10a0c: 84,
+ 0x10a0d: 84,
+ 0x10a0e: 84,
+ 0x10a0f: 84,
+ 0x10a38: 84,
+ 0x10a39: 84,
+ 0x10a3a: 84,
+ 0x10a3f: 84,
+ 0x10ac0: 68,
+ 0x10ac1: 68,
+ 0x10ac2: 68,
+ 0x10ac3: 68,
+ 0x10ac4: 68,
+ 0x10ac5: 82,
+ 0x10ac7: 82,
+ 0x10ac9: 82,
+ 0x10aca: 82,
+ 0x10acd: 76,
+ 0x10ace: 82,
+ 0x10acf: 82,
+ 0x10ad0: 82,
+ 0x10ad1: 82,
+ 0x10ad2: 82,
+ 0x10ad3: 68,
+ 0x10ad4: 68,
+ 0x10ad5: 68,
+ 0x10ad6: 68,
+ 0x10ad7: 76,
+ 0x10ad8: 68,
+ 0x10ad9: 68,
+ 0x10ada: 68,
+ 0x10adb: 68,
+ 0x10adc: 68,
+ 0x10add: 82,
+ 0x10ade: 68,
+ 0x10adf: 68,
+ 0x10ae0: 68,
+ 0x10ae1: 82,
+ 0x10ae4: 82,
+ 0x10ae5: 84,
+ 0x10ae6: 84,
+ 0x10aeb: 68,
+ 0x10aec: 68,
+ 0x10aed: 68,
+ 0x10aee: 68,
+ 0x10aef: 82,
+ 0x10b80: 68,
+ 0x10b81: 82,
+ 0x10b82: 68,
+ 0x10b83: 82,
+ 0x10b84: 82,
+ 0x10b85: 82,
+ 0x10b86: 68,
+ 0x10b87: 68,
+ 0x10b88: 68,
+ 0x10b89: 82,
+ 0x10b8a: 68,
+ 0x10b8b: 68,
+ 0x10b8c: 82,
+ 0x10b8d: 68,
+ 0x10b8e: 82,
+ 0x10b8f: 82,
+ 0x10b90: 68,
+ 0x10b91: 82,
+ 0x10ba9: 82,
+ 0x10baa: 82,
+ 0x10bab: 82,
+ 0x10bac: 82,
+ 0x10bad: 68,
+ 0x10bae: 68,
+ 0x10d00: 76,
+ 0x10d01: 68,
+ 0x10d02: 68,
+ 0x10d03: 68,
+ 0x10d04: 68,
+ 0x10d05: 68,
+ 0x10d06: 68,
+ 0x10d07: 68,
+ 0x10d08: 68,
+ 0x10d09: 68,
+ 0x10d0a: 68,
+ 0x10d0b: 68,
+ 0x10d0c: 68,
+ 0x10d0d: 68,
+ 0x10d0e: 68,
+ 0x10d0f: 68,
+ 0x10d10: 68,
+ 0x10d11: 68,
+ 0x10d12: 68,
+ 0x10d13: 68,
+ 0x10d14: 68,
+ 0x10d15: 68,
+ 0x10d16: 68,
+ 0x10d17: 68,
+ 0x10d18: 68,
+ 0x10d19: 68,
+ 0x10d1a: 68,
+ 0x10d1b: 68,
+ 0x10d1c: 68,
+ 0x10d1d: 68,
+ 0x10d1e: 68,
+ 0x10d1f: 68,
+ 0x10d20: 68,
+ 0x10d21: 68,
+ 0x10d22: 82,
+ 0x10d23: 68,
+ 0x10d24: 84,
+ 0x10d25: 84,
+ 0x10d26: 84,
+ 0x10d27: 84,
+ 0x10eab: 84,
+ 0x10eac: 84,
+ 0x10efd: 84,
+ 0x10efe: 84,
+ 0x10eff: 84,
+ 0x10f30: 68,
+ 0x10f31: 68,
+ 0x10f32: 68,
+ 0x10f33: 82,
+ 0x10f34: 68,
+ 0x10f35: 68,
+ 0x10f36: 68,
+ 0x10f37: 68,
+ 0x10f38: 68,
+ 0x10f39: 68,
+ 0x10f3a: 68,
+ 0x10f3b: 68,
+ 0x10f3c: 68,
+ 0x10f3d: 68,
+ 0x10f3e: 68,
+ 0x10f3f: 68,
+ 0x10f40: 68,
+ 0x10f41: 68,
+ 0x10f42: 68,
+ 0x10f43: 68,
+ 0x10f44: 68,
+ 0x10f46: 84,
+ 0x10f47: 84,
+ 0x10f48: 84,
+ 0x10f49: 84,
+ 0x10f4a: 84,
+ 0x10f4b: 84,
+ 0x10f4c: 84,
+ 0x10f4d: 84,
+ 0x10f4e: 84,
+ 0x10f4f: 84,
+ 0x10f50: 84,
+ 0x10f51: 68,
+ 0x10f52: 68,
+ 0x10f53: 68,
+ 0x10f54: 82,
+ 0x10f70: 68,
+ 0x10f71: 68,
+ 0x10f72: 68,
+ 0x10f73: 68,
+ 0x10f74: 82,
+ 0x10f75: 82,
+ 0x10f76: 68,
+ 0x10f77: 68,
+ 0x10f78: 68,
+ 0x10f79: 68,
+ 0x10f7a: 68,
+ 0x10f7b: 68,
+ 0x10f7c: 68,
+ 0x10f7d: 68,
+ 0x10f7e: 68,
+ 0x10f7f: 68,
+ 0x10f80: 68,
+ 0x10f81: 68,
+ 0x10f82: 84,
+ 0x10f83: 84,
+ 0x10f84: 84,
+ 0x10f85: 84,
+ 0x10fb0: 68,
+ 0x10fb2: 68,
+ 0x10fb3: 68,
+ 0x10fb4: 82,
+ 0x10fb5: 82,
+ 0x10fb6: 82,
+ 0x10fb8: 68,
+ 0x10fb9: 82,
+ 0x10fba: 82,
+ 0x10fbb: 68,
+ 0x10fbc: 68,
+ 0x10fbd: 82,
+ 0x10fbe: 68,
+ 0x10fbf: 68,
+ 0x10fc1: 68,
+ 0x10fc2: 82,
+ 0x10fc3: 82,
+ 0x10fc4: 68,
+ 0x10fc9: 82,
+ 0x10fca: 68,
+ 0x10fcb: 76,
+ 0x11001: 84,
+ 0x11038: 84,
+ 0x11039: 84,
+ 0x1103a: 84,
+ 0x1103b: 84,
+ 0x1103c: 84,
+ 0x1103d: 84,
+ 0x1103e: 84,
+ 0x1103f: 84,
+ 0x11040: 84,
+ 0x11041: 84,
+ 0x11042: 84,
+ 0x11043: 84,
+ 0x11044: 84,
+ 0x11045: 84,
+ 0x11046: 84,
+ 0x11070: 84,
+ 0x11073: 84,
+ 0x11074: 84,
+ 0x1107f: 84,
+ 0x11080: 84,
+ 0x11081: 84,
+ 0x110b3: 84,
+ 0x110b4: 84,
+ 0x110b5: 84,
+ 0x110b6: 84,
+ 0x110b9: 84,
+ 0x110ba: 84,
+ 0x110c2: 84,
+ 0x11100: 84,
+ 0x11101: 84,
+ 0x11102: 84,
+ 0x11127: 84,
+ 0x11128: 84,
+ 0x11129: 84,
+ 0x1112a: 84,
+ 0x1112b: 84,
+ 0x1112d: 84,
+ 0x1112e: 84,
+ 0x1112f: 84,
+ 0x11130: 84,
+ 0x11131: 84,
+ 0x11132: 84,
+ 0x11133: 84,
+ 0x11134: 84,
+ 0x11173: 84,
+ 0x11180: 84,
+ 0x11181: 84,
+ 0x111b6: 84,
+ 0x111b7: 84,
+ 0x111b8: 84,
+ 0x111b9: 84,
+ 0x111ba: 84,
+ 0x111bb: 84,
+ 0x111bc: 84,
+ 0x111bd: 84,
+ 0x111be: 84,
+ 0x111c9: 84,
+ 0x111ca: 84,
+ 0x111cb: 84,
+ 0x111cc: 84,
+ 0x111cf: 84,
+ 0x1122f: 84,
+ 0x11230: 84,
+ 0x11231: 84,
+ 0x11234: 84,
+ 0x11236: 84,
+ 0x11237: 84,
+ 0x1123e: 84,
+ 0x11241: 84,
+ 0x112df: 84,
+ 0x112e3: 84,
+ 0x112e4: 84,
+ 0x112e5: 84,
+ 0x112e6: 84,
+ 0x112e7: 84,
+ 0x112e8: 84,
+ 0x112e9: 84,
+ 0x112ea: 84,
+ 0x11300: 84,
+ 0x11301: 84,
+ 0x1133b: 84,
+ 0x1133c: 84,
+ 0x11340: 84,
+ 0x11366: 84,
+ 0x11367: 84,
+ 0x11368: 84,
+ 0x11369: 84,
+ 0x1136a: 84,
+ 0x1136b: 84,
+ 0x1136c: 84,
+ 0x11370: 84,
+ 0x11371: 84,
+ 0x11372: 84,
+ 0x11373: 84,
+ 0x11374: 84,
+ 0x11438: 84,
+ 0x11439: 84,
+ 0x1143a: 84,
+ 0x1143b: 84,
+ 0x1143c: 84,
+ 0x1143d: 84,
+ 0x1143e: 84,
+ 0x1143f: 84,
+ 0x11442: 84,
+ 0x11443: 84,
+ 0x11444: 84,
+ 0x11446: 84,
+ 0x1145e: 84,
+ 0x114b3: 84,
+ 0x114b4: 84,
+ 0x114b5: 84,
+ 0x114b6: 84,
+ 0x114b7: 84,
+ 0x114b8: 84,
+ 0x114ba: 84,
+ 0x114bf: 84,
+ 0x114c0: 84,
+ 0x114c2: 84,
+ 0x114c3: 84,
+ 0x115b2: 84,
+ 0x115b3: 84,
+ 0x115b4: 84,
+ 0x115b5: 84,
+ 0x115bc: 84,
+ 0x115bd: 84,
+ 0x115bf: 84,
+ 0x115c0: 84,
+ 0x115dc: 84,
+ 0x115dd: 84,
+ 0x11633: 84,
+ 0x11634: 84,
+ 0x11635: 84,
+ 0x11636: 84,
+ 0x11637: 84,
+ 0x11638: 84,
+ 0x11639: 84,
+ 0x1163a: 84,
+ 0x1163d: 84,
+ 0x1163f: 84,
+ 0x11640: 84,
+ 0x116ab: 84,
+ 0x116ad: 84,
+ 0x116b0: 84,
+ 0x116b1: 84,
+ 0x116b2: 84,
+ 0x116b3: 84,
+ 0x116b4: 84,
+ 0x116b5: 84,
+ 0x116b7: 84,
+ 0x1171d: 84,
+ 0x1171e: 84,
+ 0x1171f: 84,
+ 0x11722: 84,
+ 0x11723: 84,
+ 0x11724: 84,
+ 0x11725: 84,
+ 0x11727: 84,
+ 0x11728: 84,
+ 0x11729: 84,
+ 0x1172a: 84,
+ 0x1172b: 84,
+ 0x1182f: 84,
+ 0x11830: 84,
+ 0x11831: 84,
+ 0x11832: 84,
+ 0x11833: 84,
+ 0x11834: 84,
+ 0x11835: 84,
+ 0x11836: 84,
+ 0x11837: 84,
+ 0x11839: 84,
+ 0x1183a: 84,
+ 0x1193b: 84,
+ 0x1193c: 84,
+ 0x1193e: 84,
+ 0x11943: 84,
+ 0x119d4: 84,
+ 0x119d5: 84,
+ 0x119d6: 84,
+ 0x119d7: 84,
+ 0x119da: 84,
+ 0x119db: 84,
+ 0x119e0: 84,
+ 0x11a01: 84,
+ 0x11a02: 84,
+ 0x11a03: 84,
+ 0x11a04: 84,
+ 0x11a05: 84,
+ 0x11a06: 84,
+ 0x11a07: 84,
+ 0x11a08: 84,
+ 0x11a09: 84,
+ 0x11a0a: 84,
+ 0x11a33: 84,
+ 0x11a34: 84,
+ 0x11a35: 84,
+ 0x11a36: 84,
+ 0x11a37: 84,
+ 0x11a38: 84,
+ 0x11a3b: 84,
+ 0x11a3c: 84,
+ 0x11a3d: 84,
+ 0x11a3e: 84,
+ 0x11a47: 84,
+ 0x11a51: 84,
+ 0x11a52: 84,
+ 0x11a53: 84,
+ 0x11a54: 84,
+ 0x11a55: 84,
+ 0x11a56: 84,
+ 0x11a59: 84,
+ 0x11a5a: 84,
+ 0x11a5b: 84,
+ 0x11a8a: 84,
+ 0x11a8b: 84,
+ 0x11a8c: 84,
+ 0x11a8d: 84,
+ 0x11a8e: 84,
+ 0x11a8f: 84,
+ 0x11a90: 84,
+ 0x11a91: 84,
+ 0x11a92: 84,
+ 0x11a93: 84,
+ 0x11a94: 84,
+ 0x11a95: 84,
+ 0x11a96: 84,
+ 0x11a98: 84,
+ 0x11a99: 84,
+ 0x11c30: 84,
+ 0x11c31: 84,
+ 0x11c32: 84,
+ 0x11c33: 84,
+ 0x11c34: 84,
+ 0x11c35: 84,
+ 0x11c36: 84,
+ 0x11c38: 84,
+ 0x11c39: 84,
+ 0x11c3a: 84,
+ 0x11c3b: 84,
+ 0x11c3c: 84,
+ 0x11c3d: 84,
+ 0x11c3f: 84,
+ 0x11c92: 84,
+ 0x11c93: 84,
+ 0x11c94: 84,
+ 0x11c95: 84,
+ 0x11c96: 84,
+ 0x11c97: 84,
+ 0x11c98: 84,
+ 0x11c99: 84,
+ 0x11c9a: 84,
+ 0x11c9b: 84,
+ 0x11c9c: 84,
+ 0x11c9d: 84,
+ 0x11c9e: 84,
+ 0x11c9f: 84,
+ 0x11ca0: 84,
+ 0x11ca1: 84,
+ 0x11ca2: 84,
+ 0x11ca3: 84,
+ 0x11ca4: 84,
+ 0x11ca5: 84,
+ 0x11ca6: 84,
+ 0x11ca7: 84,
+ 0x11caa: 84,
+ 0x11cab: 84,
+ 0x11cac: 84,
+ 0x11cad: 84,
+ 0x11cae: 84,
+ 0x11caf: 84,
+ 0x11cb0: 84,
+ 0x11cb2: 84,
+ 0x11cb3: 84,
+ 0x11cb5: 84,
+ 0x11cb6: 84,
+ 0x11d31: 84,
+ 0x11d32: 84,
+ 0x11d33: 84,
+ 0x11d34: 84,
+ 0x11d35: 84,
+ 0x11d36: 84,
+ 0x11d3a: 84,
+ 0x11d3c: 84,
+ 0x11d3d: 84,
+ 0x11d3f: 84,
+ 0x11d40: 84,
+ 0x11d41: 84,
+ 0x11d42: 84,
+ 0x11d43: 84,
+ 0x11d44: 84,
+ 0x11d45: 84,
+ 0x11d47: 84,
+ 0x11d90: 84,
+ 0x11d91: 84,
+ 0x11d95: 84,
+ 0x11d97: 84,
+ 0x11ef3: 84,
+ 0x11ef4: 84,
+ 0x11f00: 84,
+ 0x11f01: 84,
+ 0x11f36: 84,
+ 0x11f37: 84,
+ 0x11f38: 84,
+ 0x11f39: 84,
+ 0x11f3a: 84,
+ 0x11f40: 84,
+ 0x11f42: 84,
+ 0x13430: 84,
+ 0x13431: 84,
+ 0x13432: 84,
+ 0x13433: 84,
+ 0x13434: 84,
+ 0x13435: 84,
+ 0x13436: 84,
+ 0x13437: 84,
+ 0x13438: 84,
+ 0x13439: 84,
+ 0x1343a: 84,
+ 0x1343b: 84,
+ 0x1343c: 84,
+ 0x1343d: 84,
+ 0x1343e: 84,
+ 0x1343f: 84,
+ 0x13440: 84,
+ 0x13447: 84,
+ 0x13448: 84,
+ 0x13449: 84,
+ 0x1344a: 84,
+ 0x1344b: 84,
+ 0x1344c: 84,
+ 0x1344d: 84,
+ 0x1344e: 84,
+ 0x1344f: 84,
+ 0x13450: 84,
+ 0x13451: 84,
+ 0x13452: 84,
+ 0x13453: 84,
+ 0x13454: 84,
+ 0x13455: 84,
+ 0x16af0: 84,
+ 0x16af1: 84,
+ 0x16af2: 84,
+ 0x16af3: 84,
+ 0x16af4: 84,
+ 0x16b30: 84,
+ 0x16b31: 84,
+ 0x16b32: 84,
+ 0x16b33: 84,
+ 0x16b34: 84,
+ 0x16b35: 84,
+ 0x16b36: 84,
+ 0x16f4f: 84,
+ 0x16f8f: 84,
+ 0x16f90: 84,
+ 0x16f91: 84,
+ 0x16f92: 84,
+ 0x16fe4: 84,
+ 0x1bc9d: 84,
+ 0x1bc9e: 84,
+ 0x1bca0: 84,
+ 0x1bca1: 84,
+ 0x1bca2: 84,
+ 0x1bca3: 84,
+ 0x1cf00: 84,
+ 0x1cf01: 84,
+ 0x1cf02: 84,
+ 0x1cf03: 84,
+ 0x1cf04: 84,
+ 0x1cf05: 84,
+ 0x1cf06: 84,
+ 0x1cf07: 84,
+ 0x1cf08: 84,
+ 0x1cf09: 84,
+ 0x1cf0a: 84,
+ 0x1cf0b: 84,
+ 0x1cf0c: 84,
+ 0x1cf0d: 84,
+ 0x1cf0e: 84,
+ 0x1cf0f: 84,
+ 0x1cf10: 84,
+ 0x1cf11: 84,
+ 0x1cf12: 84,
+ 0x1cf13: 84,
+ 0x1cf14: 84,
+ 0x1cf15: 84,
+ 0x1cf16: 84,
+ 0x1cf17: 84,
+ 0x1cf18: 84,
+ 0x1cf19: 84,
+ 0x1cf1a: 84,
+ 0x1cf1b: 84,
+ 0x1cf1c: 84,
+ 0x1cf1d: 84,
+ 0x1cf1e: 84,
+ 0x1cf1f: 84,
+ 0x1cf20: 84,
+ 0x1cf21: 84,
+ 0x1cf22: 84,
+ 0x1cf23: 84,
+ 0x1cf24: 84,
+ 0x1cf25: 84,
+ 0x1cf26: 84,
+ 0x1cf27: 84,
+ 0x1cf28: 84,
+ 0x1cf29: 84,
+ 0x1cf2a: 84,
+ 0x1cf2b: 84,
+ 0x1cf2c: 84,
+ 0x1cf2d: 84,
+ 0x1cf30: 84,
+ 0x1cf31: 84,
+ 0x1cf32: 84,
+ 0x1cf33: 84,
+ 0x1cf34: 84,
+ 0x1cf35: 84,
+ 0x1cf36: 84,
+ 0x1cf37: 84,
+ 0x1cf38: 84,
+ 0x1cf39: 84,
+ 0x1cf3a: 84,
+ 0x1cf3b: 84,
+ 0x1cf3c: 84,
+ 0x1cf3d: 84,
+ 0x1cf3e: 84,
+ 0x1cf3f: 84,
+ 0x1cf40: 84,
+ 0x1cf41: 84,
+ 0x1cf42: 84,
+ 0x1cf43: 84,
+ 0x1cf44: 84,
+ 0x1cf45: 84,
+ 0x1cf46: 84,
+ 0x1d167: 84,
+ 0x1d168: 84,
+ 0x1d169: 84,
+ 0x1d173: 84,
+ 0x1d174: 84,
+ 0x1d175: 84,
+ 0x1d176: 84,
+ 0x1d177: 84,
+ 0x1d178: 84,
+ 0x1d179: 84,
+ 0x1d17a: 84,
+ 0x1d17b: 84,
+ 0x1d17c: 84,
+ 0x1d17d: 84,
+ 0x1d17e: 84,
+ 0x1d17f: 84,
+ 0x1d180: 84,
+ 0x1d181: 84,
+ 0x1d182: 84,
+ 0x1d185: 84,
+ 0x1d186: 84,
+ 0x1d187: 84,
+ 0x1d188: 84,
+ 0x1d189: 84,
+ 0x1d18a: 84,
+ 0x1d18b: 84,
+ 0x1d1aa: 84,
+ 0x1d1ab: 84,
+ 0x1d1ac: 84,
+ 0x1d1ad: 84,
+ 0x1d242: 84,
+ 0x1d243: 84,
+ 0x1d244: 84,
+ 0x1da00: 84,
+ 0x1da01: 84,
+ 0x1da02: 84,
+ 0x1da03: 84,
+ 0x1da04: 84,
+ 0x1da05: 84,
+ 0x1da06: 84,
+ 0x1da07: 84,
+ 0x1da08: 84,
+ 0x1da09: 84,
+ 0x1da0a: 84,
+ 0x1da0b: 84,
+ 0x1da0c: 84,
+ 0x1da0d: 84,
+ 0x1da0e: 84,
+ 0x1da0f: 84,
+ 0x1da10: 84,
+ 0x1da11: 84,
+ 0x1da12: 84,
+ 0x1da13: 84,
+ 0x1da14: 84,
+ 0x1da15: 84,
+ 0x1da16: 84,
+ 0x1da17: 84,
+ 0x1da18: 84,
+ 0x1da19: 84,
+ 0x1da1a: 84,
+ 0x1da1b: 84,
+ 0x1da1c: 84,
+ 0x1da1d: 84,
+ 0x1da1e: 84,
+ 0x1da1f: 84,
+ 0x1da20: 84,
+ 0x1da21: 84,
+ 0x1da22: 84,
+ 0x1da23: 84,
+ 0x1da24: 84,
+ 0x1da25: 84,
+ 0x1da26: 84,
+ 0x1da27: 84,
+ 0x1da28: 84,
+ 0x1da29: 84,
+ 0x1da2a: 84,
+ 0x1da2b: 84,
+ 0x1da2c: 84,
+ 0x1da2d: 84,
+ 0x1da2e: 84,
+ 0x1da2f: 84,
+ 0x1da30: 84,
+ 0x1da31: 84,
+ 0x1da32: 84,
+ 0x1da33: 84,
+ 0x1da34: 84,
+ 0x1da35: 84,
+ 0x1da36: 84,
+ 0x1da3b: 84,
+ 0x1da3c: 84,
+ 0x1da3d: 84,
+ 0x1da3e: 84,
+ 0x1da3f: 84,
+ 0x1da40: 84,
+ 0x1da41: 84,
+ 0x1da42: 84,
+ 0x1da43: 84,
+ 0x1da44: 84,
+ 0x1da45: 84,
+ 0x1da46: 84,
+ 0x1da47: 84,
+ 0x1da48: 84,
+ 0x1da49: 84,
+ 0x1da4a: 84,
+ 0x1da4b: 84,
+ 0x1da4c: 84,
+ 0x1da4d: 84,
+ 0x1da4e: 84,
+ 0x1da4f: 84,
+ 0x1da50: 84,
+ 0x1da51: 84,
+ 0x1da52: 84,
+ 0x1da53: 84,
+ 0x1da54: 84,
+ 0x1da55: 84,
+ 0x1da56: 84,
+ 0x1da57: 84,
+ 0x1da58: 84,
+ 0x1da59: 84,
+ 0x1da5a: 84,
+ 0x1da5b: 84,
+ 0x1da5c: 84,
+ 0x1da5d: 84,
+ 0x1da5e: 84,
+ 0x1da5f: 84,
+ 0x1da60: 84,
+ 0x1da61: 84,
+ 0x1da62: 84,
+ 0x1da63: 84,
+ 0x1da64: 84,
+ 0x1da65: 84,
+ 0x1da66: 84,
+ 0x1da67: 84,
+ 0x1da68: 84,
+ 0x1da69: 84,
+ 0x1da6a: 84,
+ 0x1da6b: 84,
+ 0x1da6c: 84,
+ 0x1da75: 84,
+ 0x1da84: 84,
+ 0x1da9b: 84,
+ 0x1da9c: 84,
+ 0x1da9d: 84,
+ 0x1da9e: 84,
+ 0x1da9f: 84,
+ 0x1daa1: 84,
+ 0x1daa2: 84,
+ 0x1daa3: 84,
+ 0x1daa4: 84,
+ 0x1daa5: 84,
+ 0x1daa6: 84,
+ 0x1daa7: 84,
+ 0x1daa8: 84,
+ 0x1daa9: 84,
+ 0x1daaa: 84,
+ 0x1daab: 84,
+ 0x1daac: 84,
+ 0x1daad: 84,
+ 0x1daae: 84,
+ 0x1daaf: 84,
+ 0x1e000: 84,
+ 0x1e001: 84,
+ 0x1e002: 84,
+ 0x1e003: 84,
+ 0x1e004: 84,
+ 0x1e005: 84,
+ 0x1e006: 84,
+ 0x1e008: 84,
+ 0x1e009: 84,
+ 0x1e00a: 84,
+ 0x1e00b: 84,
+ 0x1e00c: 84,
+ 0x1e00d: 84,
+ 0x1e00e: 84,
+ 0x1e00f: 84,
+ 0x1e010: 84,
+ 0x1e011: 84,
+ 0x1e012: 84,
+ 0x1e013: 84,
+ 0x1e014: 84,
+ 0x1e015: 84,
+ 0x1e016: 84,
+ 0x1e017: 84,
+ 0x1e018: 84,
+ 0x1e01b: 84,
+ 0x1e01c: 84,
+ 0x1e01d: 84,
+ 0x1e01e: 84,
+ 0x1e01f: 84,
+ 0x1e020: 84,
+ 0x1e021: 84,
+ 0x1e023: 84,
+ 0x1e024: 84,
+ 0x1e026: 84,
+ 0x1e027: 84,
+ 0x1e028: 84,
+ 0x1e029: 84,
+ 0x1e02a: 84,
+ 0x1e08f: 84,
+ 0x1e130: 84,
+ 0x1e131: 84,
+ 0x1e132: 84,
+ 0x1e133: 84,
+ 0x1e134: 84,
+ 0x1e135: 84,
+ 0x1e136: 84,
+ 0x1e2ae: 84,
+ 0x1e2ec: 84,
+ 0x1e2ed: 84,
+ 0x1e2ee: 84,
+ 0x1e2ef: 84,
+ 0x1e4ec: 84,
+ 0x1e4ed: 84,
+ 0x1e4ee: 84,
+ 0x1e4ef: 84,
+ 0x1e8d0: 84,
+ 0x1e8d1: 84,
+ 0x1e8d2: 84,
+ 0x1e8d3: 84,
+ 0x1e8d4: 84,
+ 0x1e8d5: 84,
+ 0x1e8d6: 84,
+ 0x1e900: 68,
+ 0x1e901: 68,
+ 0x1e902: 68,
+ 0x1e903: 68,
+ 0x1e904: 68,
+ 0x1e905: 68,
+ 0x1e906: 68,
+ 0x1e907: 68,
+ 0x1e908: 68,
+ 0x1e909: 68,
+ 0x1e90a: 68,
+ 0x1e90b: 68,
+ 0x1e90c: 68,
+ 0x1e90d: 68,
+ 0x1e90e: 68,
+ 0x1e90f: 68,
+ 0x1e910: 68,
+ 0x1e911: 68,
+ 0x1e912: 68,
+ 0x1e913: 68,
+ 0x1e914: 68,
+ 0x1e915: 68,
+ 0x1e916: 68,
+ 0x1e917: 68,
+ 0x1e918: 68,
+ 0x1e919: 68,
+ 0x1e91a: 68,
+ 0x1e91b: 68,
+ 0x1e91c: 68,
+ 0x1e91d: 68,
+ 0x1e91e: 68,
+ 0x1e91f: 68,
+ 0x1e920: 68,
+ 0x1e921: 68,
+ 0x1e922: 68,
+ 0x1e923: 68,
+ 0x1e924: 68,
+ 0x1e925: 68,
+ 0x1e926: 68,
+ 0x1e927: 68,
+ 0x1e928: 68,
+ 0x1e929: 68,
+ 0x1e92a: 68,
+ 0x1e92b: 68,
+ 0x1e92c: 68,
+ 0x1e92d: 68,
+ 0x1e92e: 68,
+ 0x1e92f: 68,
+ 0x1e930: 68,
+ 0x1e931: 68,
+ 0x1e932: 68,
+ 0x1e933: 68,
+ 0x1e934: 68,
+ 0x1e935: 68,
+ 0x1e936: 68,
+ 0x1e937: 68,
+ 0x1e938: 68,
+ 0x1e939: 68,
+ 0x1e93a: 68,
+ 0x1e93b: 68,
+ 0x1e93c: 68,
+ 0x1e93d: 68,
+ 0x1e93e: 68,
+ 0x1e93f: 68,
+ 0x1e940: 68,
+ 0x1e941: 68,
+ 0x1e942: 68,
+ 0x1e943: 68,
+ 0x1e944: 84,
+ 0x1e945: 84,
+ 0x1e946: 84,
+ 0x1e947: 84,
+ 0x1e948: 84,
+ 0x1e949: 84,
+ 0x1e94a: 84,
+ 0x1e94b: 84,
+ 0xe0001: 84,
+ 0xe0020: 84,
+ 0xe0021: 84,
+ 0xe0022: 84,
+ 0xe0023: 84,
+ 0xe0024: 84,
+ 0xe0025: 84,
+ 0xe0026: 84,
+ 0xe0027: 84,
+ 0xe0028: 84,
+ 0xe0029: 84,
+ 0xe002a: 84,
+ 0xe002b: 84,
+ 0xe002c: 84,
+ 0xe002d: 84,
+ 0xe002e: 84,
+ 0xe002f: 84,
+ 0xe0030: 84,
+ 0xe0031: 84,
+ 0xe0032: 84,
+ 0xe0033: 84,
+ 0xe0034: 84,
+ 0xe0035: 84,
+ 0xe0036: 84,
+ 0xe0037: 84,
+ 0xe0038: 84,
+ 0xe0039: 84,
+ 0xe003a: 84,
+ 0xe003b: 84,
+ 0xe003c: 84,
+ 0xe003d: 84,
+ 0xe003e: 84,
+ 0xe003f: 84,
+ 0xe0040: 84,
+ 0xe0041: 84,
+ 0xe0042: 84,
+ 0xe0043: 84,
+ 0xe0044: 84,
+ 0xe0045: 84,
+ 0xe0046: 84,
+ 0xe0047: 84,
+ 0xe0048: 84,
+ 0xe0049: 84,
+ 0xe004a: 84,
+ 0xe004b: 84,
+ 0xe004c: 84,
+ 0xe004d: 84,
+ 0xe004e: 84,
+ 0xe004f: 84,
+ 0xe0050: 84,
+ 0xe0051: 84,
+ 0xe0052: 84,
+ 0xe0053: 84,
+ 0xe0054: 84,
+ 0xe0055: 84,
+ 0xe0056: 84,
+ 0xe0057: 84,
+ 0xe0058: 84,
+ 0xe0059: 84,
+ 0xe005a: 84,
+ 0xe005b: 84,
+ 0xe005c: 84,
+ 0xe005d: 84,
+ 0xe005e: 84,
+ 0xe005f: 84,
+ 0xe0060: 84,
+ 0xe0061: 84,
+ 0xe0062: 84,
+ 0xe0063: 84,
+ 0xe0064: 84,
+ 0xe0065: 84,
+ 0xe0066: 84,
+ 0xe0067: 84,
+ 0xe0068: 84,
+ 0xe0069: 84,
+ 0xe006a: 84,
+ 0xe006b: 84,
+ 0xe006c: 84,
+ 0xe006d: 84,
+ 0xe006e: 84,
+ 0xe006f: 84,
+ 0xe0070: 84,
+ 0xe0071: 84,
+ 0xe0072: 84,
+ 0xe0073: 84,
+ 0xe0074: 84,
+ 0xe0075: 84,
+ 0xe0076: 84,
+ 0xe0077: 84,
+ 0xe0078: 84,
+ 0xe0079: 84,
+ 0xe007a: 84,
+ 0xe007b: 84,
+ 0xe007c: 84,
+ 0xe007d: 84,
+ 0xe007e: 84,
+ 0xe007f: 84,
+ 0xe0100: 84,
+ 0xe0101: 84,
+ 0xe0102: 84,
+ 0xe0103: 84,
+ 0xe0104: 84,
+ 0xe0105: 84,
+ 0xe0106: 84,
+ 0xe0107: 84,
+ 0xe0108: 84,
+ 0xe0109: 84,
+ 0xe010a: 84,
+ 0xe010b: 84,
+ 0xe010c: 84,
+ 0xe010d: 84,
+ 0xe010e: 84,
+ 0xe010f: 84,
+ 0xe0110: 84,
+ 0xe0111: 84,
+ 0xe0112: 84,
+ 0xe0113: 84,
+ 0xe0114: 84,
+ 0xe0115: 84,
+ 0xe0116: 84,
+ 0xe0117: 84,
+ 0xe0118: 84,
+ 0xe0119: 84,
+ 0xe011a: 84,
+ 0xe011b: 84,
+ 0xe011c: 84,
+ 0xe011d: 84,
+ 0xe011e: 84,
+ 0xe011f: 84,
+ 0xe0120: 84,
+ 0xe0121: 84,
+ 0xe0122: 84,
+ 0xe0123: 84,
+ 0xe0124: 84,
+ 0xe0125: 84,
+ 0xe0126: 84,
+ 0xe0127: 84,
+ 0xe0128: 84,
+ 0xe0129: 84,
+ 0xe012a: 84,
+ 0xe012b: 84,
+ 0xe012c: 84,
+ 0xe012d: 84,
+ 0xe012e: 84,
+ 0xe012f: 84,
+ 0xe0130: 84,
+ 0xe0131: 84,
+ 0xe0132: 84,
+ 0xe0133: 84,
+ 0xe0134: 84,
+ 0xe0135: 84,
+ 0xe0136: 84,
+ 0xe0137: 84,
+ 0xe0138: 84,
+ 0xe0139: 84,
+ 0xe013a: 84,
+ 0xe013b: 84,
+ 0xe013c: 84,
+ 0xe013d: 84,
+ 0xe013e: 84,
+ 0xe013f: 84,
+ 0xe0140: 84,
+ 0xe0141: 84,
+ 0xe0142: 84,
+ 0xe0143: 84,
+ 0xe0144: 84,
+ 0xe0145: 84,
+ 0xe0146: 84,
+ 0xe0147: 84,
+ 0xe0148: 84,
+ 0xe0149: 84,
+ 0xe014a: 84,
+ 0xe014b: 84,
+ 0xe014c: 84,
+ 0xe014d: 84,
+ 0xe014e: 84,
+ 0xe014f: 84,
+ 0xe0150: 84,
+ 0xe0151: 84,
+ 0xe0152: 84,
+ 0xe0153: 84,
+ 0xe0154: 84,
+ 0xe0155: 84,
+ 0xe0156: 84,
+ 0xe0157: 84,
+ 0xe0158: 84,
+ 0xe0159: 84,
+ 0xe015a: 84,
+ 0xe015b: 84,
+ 0xe015c: 84,
+ 0xe015d: 84,
+ 0xe015e: 84,
+ 0xe015f: 84,
+ 0xe0160: 84,
+ 0xe0161: 84,
+ 0xe0162: 84,
+ 0xe0163: 84,
+ 0xe0164: 84,
+ 0xe0165: 84,
+ 0xe0166: 84,
+ 0xe0167: 84,
+ 0xe0168: 84,
+ 0xe0169: 84,
+ 0xe016a: 84,
+ 0xe016b: 84,
+ 0xe016c: 84,
+ 0xe016d: 84,
+ 0xe016e: 84,
+ 0xe016f: 84,
+ 0xe0170: 84,
+ 0xe0171: 84,
+ 0xe0172: 84,
+ 0xe0173: 84,
+ 0xe0174: 84,
+ 0xe0175: 84,
+ 0xe0176: 84,
+ 0xe0177: 84,
+ 0xe0178: 84,
+ 0xe0179: 84,
+ 0xe017a: 84,
+ 0xe017b: 84,
+ 0xe017c: 84,
+ 0xe017d: 84,
+ 0xe017e: 84,
+ 0xe017f: 84,
+ 0xe0180: 84,
+ 0xe0181: 84,
+ 0xe0182: 84,
+ 0xe0183: 84,
+ 0xe0184: 84,
+ 0xe0185: 84,
+ 0xe0186: 84,
+ 0xe0187: 84,
+ 0xe0188: 84,
+ 0xe0189: 84,
+ 0xe018a: 84,
+ 0xe018b: 84,
+ 0xe018c: 84,
+ 0xe018d: 84,
+ 0xe018e: 84,
+ 0xe018f: 84,
+ 0xe0190: 84,
+ 0xe0191: 84,
+ 0xe0192: 84,
+ 0xe0193: 84,
+ 0xe0194: 84,
+ 0xe0195: 84,
+ 0xe0196: 84,
+ 0xe0197: 84,
+ 0xe0198: 84,
+ 0xe0199: 84,
+ 0xe019a: 84,
+ 0xe019b: 84,
+ 0xe019c: 84,
+ 0xe019d: 84,
+ 0xe019e: 84,
+ 0xe019f: 84,
+ 0xe01a0: 84,
+ 0xe01a1: 84,
+ 0xe01a2: 84,
+ 0xe01a3: 84,
+ 0xe01a4: 84,
+ 0xe01a5: 84,
+ 0xe01a6: 84,
+ 0xe01a7: 84,
+ 0xe01a8: 84,
+ 0xe01a9: 84,
+ 0xe01aa: 84,
+ 0xe01ab: 84,
+ 0xe01ac: 84,
+ 0xe01ad: 84,
+ 0xe01ae: 84,
+ 0xe01af: 84,
+ 0xe01b0: 84,
+ 0xe01b1: 84,
+ 0xe01b2: 84,
+ 0xe01b3: 84,
+ 0xe01b4: 84,
+ 0xe01b5: 84,
+ 0xe01b6: 84,
+ 0xe01b7: 84,
+ 0xe01b8: 84,
+ 0xe01b9: 84,
+ 0xe01ba: 84,
+ 0xe01bb: 84,
+ 0xe01bc: 84,
+ 0xe01bd: 84,
+ 0xe01be: 84,
+ 0xe01bf: 84,
+ 0xe01c0: 84,
+ 0xe01c1: 84,
+ 0xe01c2: 84,
+ 0xe01c3: 84,
+ 0xe01c4: 84,
+ 0xe01c5: 84,
+ 0xe01c6: 84,
+ 0xe01c7: 84,
+ 0xe01c8: 84,
+ 0xe01c9: 84,
+ 0xe01ca: 84,
+ 0xe01cb: 84,
+ 0xe01cc: 84,
+ 0xe01cd: 84,
+ 0xe01ce: 84,
+ 0xe01cf: 84,
+ 0xe01d0: 84,
+ 0xe01d1: 84,
+ 0xe01d2: 84,
+ 0xe01d3: 84,
+ 0xe01d4: 84,
+ 0xe01d5: 84,
+ 0xe01d6: 84,
+ 0xe01d7: 84,
+ 0xe01d8: 84,
+ 0xe01d9: 84,
+ 0xe01da: 84,
+ 0xe01db: 84,
+ 0xe01dc: 84,
+ 0xe01dd: 84,
+ 0xe01de: 84,
+ 0xe01df: 84,
+ 0xe01e0: 84,
+ 0xe01e1: 84,
+ 0xe01e2: 84,
+ 0xe01e3: 84,
+ 0xe01e4: 84,
+ 0xe01e5: 84,
+ 0xe01e6: 84,
+ 0xe01e7: 84,
+ 0xe01e8: 84,
+ 0xe01e9: 84,
+ 0xe01ea: 84,
+ 0xe01eb: 84,
+ 0xe01ec: 84,
+ 0xe01ed: 84,
+ 0xe01ee: 84,
+ 0xe01ef: 84,
+}
+codepoint_classes = {
+ 'PVALID': (
+ 0x2d0000002e,
+ 0x300000003a,
+ 0x610000007b,
+ 0xdf000000f7,
+ 0xf800000100,
+ 0x10100000102,
+ 0x10300000104,
+ 0x10500000106,
+ 0x10700000108,
+ 0x1090000010a,
+ 0x10b0000010c,
+ 0x10d0000010e,
+ 0x10f00000110,
+ 0x11100000112,
+ 0x11300000114,
+ 0x11500000116,
+ 0x11700000118,
+ 0x1190000011a,
+ 0x11b0000011c,
+ 0x11d0000011e,
+ 0x11f00000120,
+ 0x12100000122,
+ 0x12300000124,
+ 0x12500000126,
+ 0x12700000128,
+ 0x1290000012a,
+ 0x12b0000012c,
+ 0x12d0000012e,
+ 0x12f00000130,
+ 0x13100000132,
+ 0x13500000136,
+ 0x13700000139,
+ 0x13a0000013b,
+ 0x13c0000013d,
+ 0x13e0000013f,
+ 0x14200000143,
+ 0x14400000145,
+ 0x14600000147,
+ 0x14800000149,
+ 0x14b0000014c,
+ 0x14d0000014e,
+ 0x14f00000150,
+ 0x15100000152,
+ 0x15300000154,
+ 0x15500000156,
+ 0x15700000158,
+ 0x1590000015a,
+ 0x15b0000015c,
+ 0x15d0000015e,
+ 0x15f00000160,
+ 0x16100000162,
+ 0x16300000164,
+ 0x16500000166,
+ 0x16700000168,
+ 0x1690000016a,
+ 0x16b0000016c,
+ 0x16d0000016e,
+ 0x16f00000170,
+ 0x17100000172,
+ 0x17300000174,
+ 0x17500000176,
+ 0x17700000178,
+ 0x17a0000017b,
+ 0x17c0000017d,
+ 0x17e0000017f,
+ 0x18000000181,
+ 0x18300000184,
+ 0x18500000186,
+ 0x18800000189,
+ 0x18c0000018e,
+ 0x19200000193,
+ 0x19500000196,
+ 0x1990000019c,
+ 0x19e0000019f,
+ 0x1a1000001a2,
+ 0x1a3000001a4,
+ 0x1a5000001a6,
+ 0x1a8000001a9,
+ 0x1aa000001ac,
+ 0x1ad000001ae,
+ 0x1b0000001b1,
+ 0x1b4000001b5,
+ 0x1b6000001b7,
+ 0x1b9000001bc,
+ 0x1bd000001c4,
+ 0x1ce000001cf,
+ 0x1d0000001d1,
+ 0x1d2000001d3,
+ 0x1d4000001d5,
+ 0x1d6000001d7,
+ 0x1d8000001d9,
+ 0x1da000001db,
+ 0x1dc000001de,
+ 0x1df000001e0,
+ 0x1e1000001e2,
+ 0x1e3000001e4,
+ 0x1e5000001e6,
+ 0x1e7000001e8,
+ 0x1e9000001ea,
+ 0x1eb000001ec,
+ 0x1ed000001ee,
+ 0x1ef000001f1,
+ 0x1f5000001f6,
+ 0x1f9000001fa,
+ 0x1fb000001fc,
+ 0x1fd000001fe,
+ 0x1ff00000200,
+ 0x20100000202,
+ 0x20300000204,
+ 0x20500000206,
+ 0x20700000208,
+ 0x2090000020a,
+ 0x20b0000020c,
+ 0x20d0000020e,
+ 0x20f00000210,
+ 0x21100000212,
+ 0x21300000214,
+ 0x21500000216,
+ 0x21700000218,
+ 0x2190000021a,
+ 0x21b0000021c,
+ 0x21d0000021e,
+ 0x21f00000220,
+ 0x22100000222,
+ 0x22300000224,
+ 0x22500000226,
+ 0x22700000228,
+ 0x2290000022a,
+ 0x22b0000022c,
+ 0x22d0000022e,
+ 0x22f00000230,
+ 0x23100000232,
+ 0x2330000023a,
+ 0x23c0000023d,
+ 0x23f00000241,
+ 0x24200000243,
+ 0x24700000248,
+ 0x2490000024a,
+ 0x24b0000024c,
+ 0x24d0000024e,
+ 0x24f000002b0,
+ 0x2b9000002c2,
+ 0x2c6000002d2,
+ 0x2ec000002ed,
+ 0x2ee000002ef,
+ 0x30000000340,
+ 0x34200000343,
+ 0x3460000034f,
+ 0x35000000370,
+ 0x37100000372,
+ 0x37300000374,
+ 0x37700000378,
+ 0x37b0000037e,
+ 0x39000000391,
+ 0x3ac000003cf,
+ 0x3d7000003d8,
+ 0x3d9000003da,
+ 0x3db000003dc,
+ 0x3dd000003de,
+ 0x3df000003e0,
+ 0x3e1000003e2,
+ 0x3e3000003e4,
+ 0x3e5000003e6,
+ 0x3e7000003e8,
+ 0x3e9000003ea,
+ 0x3eb000003ec,
+ 0x3ed000003ee,
+ 0x3ef000003f0,
+ 0x3f3000003f4,
+ 0x3f8000003f9,
+ 0x3fb000003fd,
+ 0x43000000460,
+ 0x46100000462,
+ 0x46300000464,
+ 0x46500000466,
+ 0x46700000468,
+ 0x4690000046a,
+ 0x46b0000046c,
+ 0x46d0000046e,
+ 0x46f00000470,
+ 0x47100000472,
+ 0x47300000474,
+ 0x47500000476,
+ 0x47700000478,
+ 0x4790000047a,
+ 0x47b0000047c,
+ 0x47d0000047e,
+ 0x47f00000480,
+ 0x48100000482,
+ 0x48300000488,
+ 0x48b0000048c,
+ 0x48d0000048e,
+ 0x48f00000490,
+ 0x49100000492,
+ 0x49300000494,
+ 0x49500000496,
+ 0x49700000498,
+ 0x4990000049a,
+ 0x49b0000049c,
+ 0x49d0000049e,
+ 0x49f000004a0,
+ 0x4a1000004a2,
+ 0x4a3000004a4,
+ 0x4a5000004a6,
+ 0x4a7000004a8,
+ 0x4a9000004aa,
+ 0x4ab000004ac,
+ 0x4ad000004ae,
+ 0x4af000004b0,
+ 0x4b1000004b2,
+ 0x4b3000004b4,
+ 0x4b5000004b6,
+ 0x4b7000004b8,
+ 0x4b9000004ba,
+ 0x4bb000004bc,
+ 0x4bd000004be,
+ 0x4bf000004c0,
+ 0x4c2000004c3,
+ 0x4c4000004c5,
+ 0x4c6000004c7,
+ 0x4c8000004c9,
+ 0x4ca000004cb,
+ 0x4cc000004cd,
+ 0x4ce000004d0,
+ 0x4d1000004d2,
+ 0x4d3000004d4,
+ 0x4d5000004d6,
+ 0x4d7000004d8,
+ 0x4d9000004da,
+ 0x4db000004dc,
+ 0x4dd000004de,
+ 0x4df000004e0,
+ 0x4e1000004e2,
+ 0x4e3000004e4,
+ 0x4e5000004e6,
+ 0x4e7000004e8,
+ 0x4e9000004ea,
+ 0x4eb000004ec,
+ 0x4ed000004ee,
+ 0x4ef000004f0,
+ 0x4f1000004f2,
+ 0x4f3000004f4,
+ 0x4f5000004f6,
+ 0x4f7000004f8,
+ 0x4f9000004fa,
+ 0x4fb000004fc,
+ 0x4fd000004fe,
+ 0x4ff00000500,
+ 0x50100000502,
+ 0x50300000504,
+ 0x50500000506,
+ 0x50700000508,
+ 0x5090000050a,
+ 0x50b0000050c,
+ 0x50d0000050e,
+ 0x50f00000510,
+ 0x51100000512,
+ 0x51300000514,
+ 0x51500000516,
+ 0x51700000518,
+ 0x5190000051a,
+ 0x51b0000051c,
+ 0x51d0000051e,
+ 0x51f00000520,
+ 0x52100000522,
+ 0x52300000524,
+ 0x52500000526,
+ 0x52700000528,
+ 0x5290000052a,
+ 0x52b0000052c,
+ 0x52d0000052e,
+ 0x52f00000530,
+ 0x5590000055a,
+ 0x56000000587,
+ 0x58800000589,
+ 0x591000005be,
+ 0x5bf000005c0,
+ 0x5c1000005c3,
+ 0x5c4000005c6,
+ 0x5c7000005c8,
+ 0x5d0000005eb,
+ 0x5ef000005f3,
+ 0x6100000061b,
+ 0x62000000640,
+ 0x64100000660,
+ 0x66e00000675,
+ 0x679000006d4,
+ 0x6d5000006dd,
+ 0x6df000006e9,
+ 0x6ea000006f0,
+ 0x6fa00000700,
+ 0x7100000074b,
+ 0x74d000007b2,
+ 0x7c0000007f6,
+ 0x7fd000007fe,
+ 0x8000000082e,
+ 0x8400000085c,
+ 0x8600000086b,
+ 0x87000000888,
+ 0x8890000088f,
+ 0x898000008e2,
+ 0x8e300000958,
+ 0x96000000964,
+ 0x96600000970,
+ 0x97100000984,
+ 0x9850000098d,
+ 0x98f00000991,
+ 0x993000009a9,
+ 0x9aa000009b1,
+ 0x9b2000009b3,
+ 0x9b6000009ba,
+ 0x9bc000009c5,
+ 0x9c7000009c9,
+ 0x9cb000009cf,
+ 0x9d7000009d8,
+ 0x9e0000009e4,
+ 0x9e6000009f2,
+ 0x9fc000009fd,
+ 0x9fe000009ff,
+ 0xa0100000a04,
+ 0xa0500000a0b,
+ 0xa0f00000a11,
+ 0xa1300000a29,
+ 0xa2a00000a31,
+ 0xa3200000a33,
+ 0xa3500000a36,
+ 0xa3800000a3a,
+ 0xa3c00000a3d,
+ 0xa3e00000a43,
+ 0xa4700000a49,
+ 0xa4b00000a4e,
+ 0xa5100000a52,
+ 0xa5c00000a5d,
+ 0xa6600000a76,
+ 0xa8100000a84,
+ 0xa8500000a8e,
+ 0xa8f00000a92,
+ 0xa9300000aa9,
+ 0xaaa00000ab1,
+ 0xab200000ab4,
+ 0xab500000aba,
+ 0xabc00000ac6,
+ 0xac700000aca,
+ 0xacb00000ace,
+ 0xad000000ad1,
+ 0xae000000ae4,
+ 0xae600000af0,
+ 0xaf900000b00,
+ 0xb0100000b04,
+ 0xb0500000b0d,
+ 0xb0f00000b11,
+ 0xb1300000b29,
+ 0xb2a00000b31,
+ 0xb3200000b34,
+ 0xb3500000b3a,
+ 0xb3c00000b45,
+ 0xb4700000b49,
+ 0xb4b00000b4e,
+ 0xb5500000b58,
+ 0xb5f00000b64,
+ 0xb6600000b70,
+ 0xb7100000b72,
+ 0xb8200000b84,
+ 0xb8500000b8b,
+ 0xb8e00000b91,
+ 0xb9200000b96,
+ 0xb9900000b9b,
+ 0xb9c00000b9d,
+ 0xb9e00000ba0,
+ 0xba300000ba5,
+ 0xba800000bab,
+ 0xbae00000bba,
+ 0xbbe00000bc3,
+ 0xbc600000bc9,
+ 0xbca00000bce,
+ 0xbd000000bd1,
+ 0xbd700000bd8,
+ 0xbe600000bf0,
+ 0xc0000000c0d,
+ 0xc0e00000c11,
+ 0xc1200000c29,
+ 0xc2a00000c3a,
+ 0xc3c00000c45,
+ 0xc4600000c49,
+ 0xc4a00000c4e,
+ 0xc5500000c57,
+ 0xc5800000c5b,
+ 0xc5d00000c5e,
+ 0xc6000000c64,
+ 0xc6600000c70,
+ 0xc8000000c84,
+ 0xc8500000c8d,
+ 0xc8e00000c91,
+ 0xc9200000ca9,
+ 0xcaa00000cb4,
+ 0xcb500000cba,
+ 0xcbc00000cc5,
+ 0xcc600000cc9,
+ 0xcca00000cce,
+ 0xcd500000cd7,
+ 0xcdd00000cdf,
+ 0xce000000ce4,
+ 0xce600000cf0,
+ 0xcf100000cf4,
+ 0xd0000000d0d,
+ 0xd0e00000d11,
+ 0xd1200000d45,
+ 0xd4600000d49,
+ 0xd4a00000d4f,
+ 0xd5400000d58,
+ 0xd5f00000d64,
+ 0xd6600000d70,
+ 0xd7a00000d80,
+ 0xd8100000d84,
+ 0xd8500000d97,
+ 0xd9a00000db2,
+ 0xdb300000dbc,
+ 0xdbd00000dbe,
+ 0xdc000000dc7,
+ 0xdca00000dcb,
+ 0xdcf00000dd5,
+ 0xdd600000dd7,
+ 0xdd800000de0,
+ 0xde600000df0,
+ 0xdf200000df4,
+ 0xe0100000e33,
+ 0xe3400000e3b,
+ 0xe4000000e4f,
+ 0xe5000000e5a,
+ 0xe8100000e83,
+ 0xe8400000e85,
+ 0xe8600000e8b,
+ 0xe8c00000ea4,
+ 0xea500000ea6,
+ 0xea700000eb3,
+ 0xeb400000ebe,
+ 0xec000000ec5,
+ 0xec600000ec7,
+ 0xec800000ecf,
+ 0xed000000eda,
+ 0xede00000ee0,
+ 0xf0000000f01,
+ 0xf0b00000f0c,
+ 0xf1800000f1a,
+ 0xf2000000f2a,
+ 0xf3500000f36,
+ 0xf3700000f38,
+ 0xf3900000f3a,
+ 0xf3e00000f43,
+ 0xf4400000f48,
+ 0xf4900000f4d,
+ 0xf4e00000f52,
+ 0xf5300000f57,
+ 0xf5800000f5c,
+ 0xf5d00000f69,
+ 0xf6a00000f6d,
+ 0xf7100000f73,
+ 0xf7400000f75,
+ 0xf7a00000f81,
+ 0xf8200000f85,
+ 0xf8600000f93,
+ 0xf9400000f98,
+ 0xf9900000f9d,
+ 0xf9e00000fa2,
+ 0xfa300000fa7,
+ 0xfa800000fac,
+ 0xfad00000fb9,
+ 0xfba00000fbd,
+ 0xfc600000fc7,
+ 0x10000000104a,
+ 0x10500000109e,
+ 0x10d0000010fb,
+ 0x10fd00001100,
+ 0x120000001249,
+ 0x124a0000124e,
+ 0x125000001257,
+ 0x125800001259,
+ 0x125a0000125e,
+ 0x126000001289,
+ 0x128a0000128e,
+ 0x1290000012b1,
+ 0x12b2000012b6,
+ 0x12b8000012bf,
+ 0x12c0000012c1,
+ 0x12c2000012c6,
+ 0x12c8000012d7,
+ 0x12d800001311,
+ 0x131200001316,
+ 0x13180000135b,
+ 0x135d00001360,
+ 0x138000001390,
+ 0x13a0000013f6,
+ 0x14010000166d,
+ 0x166f00001680,
+ 0x16810000169b,
+ 0x16a0000016eb,
+ 0x16f1000016f9,
+ 0x170000001716,
+ 0x171f00001735,
+ 0x174000001754,
+ 0x17600000176d,
+ 0x176e00001771,
+ 0x177200001774,
+ 0x1780000017b4,
+ 0x17b6000017d4,
+ 0x17d7000017d8,
+ 0x17dc000017de,
+ 0x17e0000017ea,
+ 0x18100000181a,
+ 0x182000001879,
+ 0x1880000018ab,
+ 0x18b0000018f6,
+ 0x19000000191f,
+ 0x19200000192c,
+ 0x19300000193c,
+ 0x19460000196e,
+ 0x197000001975,
+ 0x1980000019ac,
+ 0x19b0000019ca,
+ 0x19d0000019da,
+ 0x1a0000001a1c,
+ 0x1a2000001a5f,
+ 0x1a6000001a7d,
+ 0x1a7f00001a8a,
+ 0x1a9000001a9a,
+ 0x1aa700001aa8,
+ 0x1ab000001abe,
+ 0x1abf00001acf,
+ 0x1b0000001b4d,
+ 0x1b5000001b5a,
+ 0x1b6b00001b74,
+ 0x1b8000001bf4,
+ 0x1c0000001c38,
+ 0x1c4000001c4a,
+ 0x1c4d00001c7e,
+ 0x1cd000001cd3,
+ 0x1cd400001cfb,
+ 0x1d0000001d2c,
+ 0x1d2f00001d30,
+ 0x1d3b00001d3c,
+ 0x1d4e00001d4f,
+ 0x1d6b00001d78,
+ 0x1d7900001d9b,
+ 0x1dc000001e00,
+ 0x1e0100001e02,
+ 0x1e0300001e04,
+ 0x1e0500001e06,
+ 0x1e0700001e08,
+ 0x1e0900001e0a,
+ 0x1e0b00001e0c,
+ 0x1e0d00001e0e,
+ 0x1e0f00001e10,
+ 0x1e1100001e12,
+ 0x1e1300001e14,
+ 0x1e1500001e16,
+ 0x1e1700001e18,
+ 0x1e1900001e1a,
+ 0x1e1b00001e1c,
+ 0x1e1d00001e1e,
+ 0x1e1f00001e20,
+ 0x1e2100001e22,
+ 0x1e2300001e24,
+ 0x1e2500001e26,
+ 0x1e2700001e28,
+ 0x1e2900001e2a,
+ 0x1e2b00001e2c,
+ 0x1e2d00001e2e,
+ 0x1e2f00001e30,
+ 0x1e3100001e32,
+ 0x1e3300001e34,
+ 0x1e3500001e36,
+ 0x1e3700001e38,
+ 0x1e3900001e3a,
+ 0x1e3b00001e3c,
+ 0x1e3d00001e3e,
+ 0x1e3f00001e40,
+ 0x1e4100001e42,
+ 0x1e4300001e44,
+ 0x1e4500001e46,
+ 0x1e4700001e48,
+ 0x1e4900001e4a,
+ 0x1e4b00001e4c,
+ 0x1e4d00001e4e,
+ 0x1e4f00001e50,
+ 0x1e5100001e52,
+ 0x1e5300001e54,
+ 0x1e5500001e56,
+ 0x1e5700001e58,
+ 0x1e5900001e5a,
+ 0x1e5b00001e5c,
+ 0x1e5d00001e5e,
+ 0x1e5f00001e60,
+ 0x1e6100001e62,
+ 0x1e6300001e64,
+ 0x1e6500001e66,
+ 0x1e6700001e68,
+ 0x1e6900001e6a,
+ 0x1e6b00001e6c,
+ 0x1e6d00001e6e,
+ 0x1e6f00001e70,
+ 0x1e7100001e72,
+ 0x1e7300001e74,
+ 0x1e7500001e76,
+ 0x1e7700001e78,
+ 0x1e7900001e7a,
+ 0x1e7b00001e7c,
+ 0x1e7d00001e7e,
+ 0x1e7f00001e80,
+ 0x1e8100001e82,
+ 0x1e8300001e84,
+ 0x1e8500001e86,
+ 0x1e8700001e88,
+ 0x1e8900001e8a,
+ 0x1e8b00001e8c,
+ 0x1e8d00001e8e,
+ 0x1e8f00001e90,
+ 0x1e9100001e92,
+ 0x1e9300001e94,
+ 0x1e9500001e9a,
+ 0x1e9c00001e9e,
+ 0x1e9f00001ea0,
+ 0x1ea100001ea2,
+ 0x1ea300001ea4,
+ 0x1ea500001ea6,
+ 0x1ea700001ea8,
+ 0x1ea900001eaa,
+ 0x1eab00001eac,
+ 0x1ead00001eae,
+ 0x1eaf00001eb0,
+ 0x1eb100001eb2,
+ 0x1eb300001eb4,
+ 0x1eb500001eb6,
+ 0x1eb700001eb8,
+ 0x1eb900001eba,
+ 0x1ebb00001ebc,
+ 0x1ebd00001ebe,
+ 0x1ebf00001ec0,
+ 0x1ec100001ec2,
+ 0x1ec300001ec4,
+ 0x1ec500001ec6,
+ 0x1ec700001ec8,
+ 0x1ec900001eca,
+ 0x1ecb00001ecc,
+ 0x1ecd00001ece,
+ 0x1ecf00001ed0,
+ 0x1ed100001ed2,
+ 0x1ed300001ed4,
+ 0x1ed500001ed6,
+ 0x1ed700001ed8,
+ 0x1ed900001eda,
+ 0x1edb00001edc,
+ 0x1edd00001ede,
+ 0x1edf00001ee0,
+ 0x1ee100001ee2,
+ 0x1ee300001ee4,
+ 0x1ee500001ee6,
+ 0x1ee700001ee8,
+ 0x1ee900001eea,
+ 0x1eeb00001eec,
+ 0x1eed00001eee,
+ 0x1eef00001ef0,
+ 0x1ef100001ef2,
+ 0x1ef300001ef4,
+ 0x1ef500001ef6,
+ 0x1ef700001ef8,
+ 0x1ef900001efa,
+ 0x1efb00001efc,
+ 0x1efd00001efe,
+ 0x1eff00001f08,
+ 0x1f1000001f16,
+ 0x1f2000001f28,
+ 0x1f3000001f38,
+ 0x1f4000001f46,
+ 0x1f5000001f58,
+ 0x1f6000001f68,
+ 0x1f7000001f71,
+ 0x1f7200001f73,
+ 0x1f7400001f75,
+ 0x1f7600001f77,
+ 0x1f7800001f79,
+ 0x1f7a00001f7b,
+ 0x1f7c00001f7d,
+ 0x1fb000001fb2,
+ 0x1fb600001fb7,
+ 0x1fc600001fc7,
+ 0x1fd000001fd3,
+ 0x1fd600001fd8,
+ 0x1fe000001fe3,
+ 0x1fe400001fe8,
+ 0x1ff600001ff7,
+ 0x214e0000214f,
+ 0x218400002185,
+ 0x2c3000002c60,
+ 0x2c6100002c62,
+ 0x2c6500002c67,
+ 0x2c6800002c69,
+ 0x2c6a00002c6b,
+ 0x2c6c00002c6d,
+ 0x2c7100002c72,
+ 0x2c7300002c75,
+ 0x2c7600002c7c,
+ 0x2c8100002c82,
+ 0x2c8300002c84,
+ 0x2c8500002c86,
+ 0x2c8700002c88,
+ 0x2c8900002c8a,
+ 0x2c8b00002c8c,
+ 0x2c8d00002c8e,
+ 0x2c8f00002c90,
+ 0x2c9100002c92,
+ 0x2c9300002c94,
+ 0x2c9500002c96,
+ 0x2c9700002c98,
+ 0x2c9900002c9a,
+ 0x2c9b00002c9c,
+ 0x2c9d00002c9e,
+ 0x2c9f00002ca0,
+ 0x2ca100002ca2,
+ 0x2ca300002ca4,
+ 0x2ca500002ca6,
+ 0x2ca700002ca8,
+ 0x2ca900002caa,
+ 0x2cab00002cac,
+ 0x2cad00002cae,
+ 0x2caf00002cb0,
+ 0x2cb100002cb2,
+ 0x2cb300002cb4,
+ 0x2cb500002cb6,
+ 0x2cb700002cb8,
+ 0x2cb900002cba,
+ 0x2cbb00002cbc,
+ 0x2cbd00002cbe,
+ 0x2cbf00002cc0,
+ 0x2cc100002cc2,
+ 0x2cc300002cc4,
+ 0x2cc500002cc6,
+ 0x2cc700002cc8,
+ 0x2cc900002cca,
+ 0x2ccb00002ccc,
+ 0x2ccd00002cce,
+ 0x2ccf00002cd0,
+ 0x2cd100002cd2,
+ 0x2cd300002cd4,
+ 0x2cd500002cd6,
+ 0x2cd700002cd8,
+ 0x2cd900002cda,
+ 0x2cdb00002cdc,
+ 0x2cdd00002cde,
+ 0x2cdf00002ce0,
+ 0x2ce100002ce2,
+ 0x2ce300002ce5,
+ 0x2cec00002ced,
+ 0x2cee00002cf2,
+ 0x2cf300002cf4,
+ 0x2d0000002d26,
+ 0x2d2700002d28,
+ 0x2d2d00002d2e,
+ 0x2d3000002d68,
+ 0x2d7f00002d97,
+ 0x2da000002da7,
+ 0x2da800002daf,
+ 0x2db000002db7,
+ 0x2db800002dbf,
+ 0x2dc000002dc7,
+ 0x2dc800002dcf,
+ 0x2dd000002dd7,
+ 0x2dd800002ddf,
+ 0x2de000002e00,
+ 0x2e2f00002e30,
+ 0x300500003008,
+ 0x302a0000302e,
+ 0x303c0000303d,
+ 0x304100003097,
+ 0x30990000309b,
+ 0x309d0000309f,
+ 0x30a1000030fb,
+ 0x30fc000030ff,
+ 0x310500003130,
+ 0x31a0000031c0,
+ 0x31f000003200,
+ 0x340000004dc0,
+ 0x4e000000a48d,
+ 0xa4d00000a4fe,
+ 0xa5000000a60d,
+ 0xa6100000a62c,
+ 0xa6410000a642,
+ 0xa6430000a644,
+ 0xa6450000a646,
+ 0xa6470000a648,
+ 0xa6490000a64a,
+ 0xa64b0000a64c,
+ 0xa64d0000a64e,
+ 0xa64f0000a650,
+ 0xa6510000a652,
+ 0xa6530000a654,
+ 0xa6550000a656,
+ 0xa6570000a658,
+ 0xa6590000a65a,
+ 0xa65b0000a65c,
+ 0xa65d0000a65e,
+ 0xa65f0000a660,
+ 0xa6610000a662,
+ 0xa6630000a664,
+ 0xa6650000a666,
+ 0xa6670000a668,
+ 0xa6690000a66a,
+ 0xa66b0000a66c,
+ 0xa66d0000a670,
+ 0xa6740000a67e,
+ 0xa67f0000a680,
+ 0xa6810000a682,
+ 0xa6830000a684,
+ 0xa6850000a686,
+ 0xa6870000a688,
+ 0xa6890000a68a,
+ 0xa68b0000a68c,
+ 0xa68d0000a68e,
+ 0xa68f0000a690,
+ 0xa6910000a692,
+ 0xa6930000a694,
+ 0xa6950000a696,
+ 0xa6970000a698,
+ 0xa6990000a69a,
+ 0xa69b0000a69c,
+ 0xa69e0000a6e6,
+ 0xa6f00000a6f2,
+ 0xa7170000a720,
+ 0xa7230000a724,
+ 0xa7250000a726,
+ 0xa7270000a728,
+ 0xa7290000a72a,
+ 0xa72b0000a72c,
+ 0xa72d0000a72e,
+ 0xa72f0000a732,
+ 0xa7330000a734,
+ 0xa7350000a736,
+ 0xa7370000a738,
+ 0xa7390000a73a,
+ 0xa73b0000a73c,
+ 0xa73d0000a73e,
+ 0xa73f0000a740,
+ 0xa7410000a742,
+ 0xa7430000a744,
+ 0xa7450000a746,
+ 0xa7470000a748,
+ 0xa7490000a74a,
+ 0xa74b0000a74c,
+ 0xa74d0000a74e,
+ 0xa74f0000a750,
+ 0xa7510000a752,
+ 0xa7530000a754,
+ 0xa7550000a756,
+ 0xa7570000a758,
+ 0xa7590000a75a,
+ 0xa75b0000a75c,
+ 0xa75d0000a75e,
+ 0xa75f0000a760,
+ 0xa7610000a762,
+ 0xa7630000a764,
+ 0xa7650000a766,
+ 0xa7670000a768,
+ 0xa7690000a76a,
+ 0xa76b0000a76c,
+ 0xa76d0000a76e,
+ 0xa76f0000a770,
+ 0xa7710000a779,
+ 0xa77a0000a77b,
+ 0xa77c0000a77d,
+ 0xa77f0000a780,
+ 0xa7810000a782,
+ 0xa7830000a784,
+ 0xa7850000a786,
+ 0xa7870000a789,
+ 0xa78c0000a78d,
+ 0xa78e0000a790,
+ 0xa7910000a792,
+ 0xa7930000a796,
+ 0xa7970000a798,
+ 0xa7990000a79a,
+ 0xa79b0000a79c,
+ 0xa79d0000a79e,
+ 0xa79f0000a7a0,
+ 0xa7a10000a7a2,
+ 0xa7a30000a7a4,
+ 0xa7a50000a7a6,
+ 0xa7a70000a7a8,
+ 0xa7a90000a7aa,
+ 0xa7af0000a7b0,
+ 0xa7b50000a7b6,
+ 0xa7b70000a7b8,
+ 0xa7b90000a7ba,
+ 0xa7bb0000a7bc,
+ 0xa7bd0000a7be,
+ 0xa7bf0000a7c0,
+ 0xa7c10000a7c2,
+ 0xa7c30000a7c4,
+ 0xa7c80000a7c9,
+ 0xa7ca0000a7cb,
+ 0xa7d10000a7d2,
+ 0xa7d30000a7d4,
+ 0xa7d50000a7d6,
+ 0xa7d70000a7d8,
+ 0xa7d90000a7da,
+ 0xa7f60000a7f8,
+ 0xa7fa0000a828,
+ 0xa82c0000a82d,
+ 0xa8400000a874,
+ 0xa8800000a8c6,
+ 0xa8d00000a8da,
+ 0xa8e00000a8f8,
+ 0xa8fb0000a8fc,
+ 0xa8fd0000a92e,
+ 0xa9300000a954,
+ 0xa9800000a9c1,
+ 0xa9cf0000a9da,
+ 0xa9e00000a9ff,
+ 0xaa000000aa37,
+ 0xaa400000aa4e,
+ 0xaa500000aa5a,
+ 0xaa600000aa77,
+ 0xaa7a0000aac3,
+ 0xaadb0000aade,
+ 0xaae00000aaf0,
+ 0xaaf20000aaf7,
+ 0xab010000ab07,
+ 0xab090000ab0f,
+ 0xab110000ab17,
+ 0xab200000ab27,
+ 0xab280000ab2f,
+ 0xab300000ab5b,
+ 0xab600000ab69,
+ 0xabc00000abeb,
+ 0xabec0000abee,
+ 0xabf00000abfa,
+ 0xac000000d7a4,
+ 0xfa0e0000fa10,
+ 0xfa110000fa12,
+ 0xfa130000fa15,
+ 0xfa1f0000fa20,
+ 0xfa210000fa22,
+ 0xfa230000fa25,
+ 0xfa270000fa2a,
+ 0xfb1e0000fb1f,
+ 0xfe200000fe30,
+ 0xfe730000fe74,
+ 0x100000001000c,
+ 0x1000d00010027,
+ 0x100280001003b,
+ 0x1003c0001003e,
+ 0x1003f0001004e,
+ 0x100500001005e,
+ 0x10080000100fb,
+ 0x101fd000101fe,
+ 0x102800001029d,
+ 0x102a0000102d1,
+ 0x102e0000102e1,
+ 0x1030000010320,
+ 0x1032d00010341,
+ 0x103420001034a,
+ 0x103500001037b,
+ 0x103800001039e,
+ 0x103a0000103c4,
+ 0x103c8000103d0,
+ 0x104280001049e,
+ 0x104a0000104aa,
+ 0x104d8000104fc,
+ 0x1050000010528,
+ 0x1053000010564,
+ 0x10597000105a2,
+ 0x105a3000105b2,
+ 0x105b3000105ba,
+ 0x105bb000105bd,
+ 0x1060000010737,
+ 0x1074000010756,
+ 0x1076000010768,
+ 0x1078000010781,
+ 0x1080000010806,
+ 0x1080800010809,
+ 0x1080a00010836,
+ 0x1083700010839,
+ 0x1083c0001083d,
+ 0x1083f00010856,
+ 0x1086000010877,
+ 0x108800001089f,
+ 0x108e0000108f3,
+ 0x108f4000108f6,
+ 0x1090000010916,
+ 0x109200001093a,
+ 0x10980000109b8,
+ 0x109be000109c0,
+ 0x10a0000010a04,
+ 0x10a0500010a07,
+ 0x10a0c00010a14,
+ 0x10a1500010a18,
+ 0x10a1900010a36,
+ 0x10a3800010a3b,
+ 0x10a3f00010a40,
+ 0x10a6000010a7d,
+ 0x10a8000010a9d,
+ 0x10ac000010ac8,
+ 0x10ac900010ae7,
+ 0x10b0000010b36,
+ 0x10b4000010b56,
+ 0x10b6000010b73,
+ 0x10b8000010b92,
+ 0x10c0000010c49,
+ 0x10cc000010cf3,
+ 0x10d0000010d28,
+ 0x10d3000010d3a,
+ 0x10e8000010eaa,
+ 0x10eab00010ead,
+ 0x10eb000010eb2,
+ 0x10efd00010f1d,
+ 0x10f2700010f28,
+ 0x10f3000010f51,
+ 0x10f7000010f86,
+ 0x10fb000010fc5,
+ 0x10fe000010ff7,
+ 0x1100000011047,
+ 0x1106600011076,
+ 0x1107f000110bb,
+ 0x110c2000110c3,
+ 0x110d0000110e9,
+ 0x110f0000110fa,
+ 0x1110000011135,
+ 0x1113600011140,
+ 0x1114400011148,
+ 0x1115000011174,
+ 0x1117600011177,
+ 0x11180000111c5,
+ 0x111c9000111cd,
+ 0x111ce000111db,
+ 0x111dc000111dd,
+ 0x1120000011212,
+ 0x1121300011238,
+ 0x1123e00011242,
+ 0x1128000011287,
+ 0x1128800011289,
+ 0x1128a0001128e,
+ 0x1128f0001129e,
+ 0x1129f000112a9,
+ 0x112b0000112eb,
+ 0x112f0000112fa,
+ 0x1130000011304,
+ 0x113050001130d,
+ 0x1130f00011311,
+ 0x1131300011329,
+ 0x1132a00011331,
+ 0x1133200011334,
+ 0x113350001133a,
+ 0x1133b00011345,
+ 0x1134700011349,
+ 0x1134b0001134e,
+ 0x1135000011351,
+ 0x1135700011358,
+ 0x1135d00011364,
+ 0x113660001136d,
+ 0x1137000011375,
+ 0x114000001144b,
+ 0x114500001145a,
+ 0x1145e00011462,
+ 0x11480000114c6,
+ 0x114c7000114c8,
+ 0x114d0000114da,
+ 0x11580000115b6,
+ 0x115b8000115c1,
+ 0x115d8000115de,
+ 0x1160000011641,
+ 0x1164400011645,
+ 0x116500001165a,
+ 0x11680000116b9,
+ 0x116c0000116ca,
+ 0x117000001171b,
+ 0x1171d0001172c,
+ 0x117300001173a,
+ 0x1174000011747,
+ 0x118000001183b,
+ 0x118c0000118ea,
+ 0x118ff00011907,
+ 0x119090001190a,
+ 0x1190c00011914,
+ 0x1191500011917,
+ 0x1191800011936,
+ 0x1193700011939,
+ 0x1193b00011944,
+ 0x119500001195a,
+ 0x119a0000119a8,
+ 0x119aa000119d8,
+ 0x119da000119e2,
+ 0x119e3000119e5,
+ 0x11a0000011a3f,
+ 0x11a4700011a48,
+ 0x11a5000011a9a,
+ 0x11a9d00011a9e,
+ 0x11ab000011af9,
+ 0x11c0000011c09,
+ 0x11c0a00011c37,
+ 0x11c3800011c41,
+ 0x11c5000011c5a,
+ 0x11c7200011c90,
+ 0x11c9200011ca8,
+ 0x11ca900011cb7,
+ 0x11d0000011d07,
+ 0x11d0800011d0a,
+ 0x11d0b00011d37,
+ 0x11d3a00011d3b,
+ 0x11d3c00011d3e,
+ 0x11d3f00011d48,
+ 0x11d5000011d5a,
+ 0x11d6000011d66,
+ 0x11d6700011d69,
+ 0x11d6a00011d8f,
+ 0x11d9000011d92,
+ 0x11d9300011d99,
+ 0x11da000011daa,
+ 0x11ee000011ef7,
+ 0x11f0000011f11,
+ 0x11f1200011f3b,
+ 0x11f3e00011f43,
+ 0x11f5000011f5a,
+ 0x11fb000011fb1,
+ 0x120000001239a,
+ 0x1248000012544,
+ 0x12f9000012ff1,
+ 0x1300000013430,
+ 0x1344000013456,
+ 0x1440000014647,
+ 0x1680000016a39,
+ 0x16a4000016a5f,
+ 0x16a6000016a6a,
+ 0x16a7000016abf,
+ 0x16ac000016aca,
+ 0x16ad000016aee,
+ 0x16af000016af5,
+ 0x16b0000016b37,
+ 0x16b4000016b44,
+ 0x16b5000016b5a,
+ 0x16b6300016b78,
+ 0x16b7d00016b90,
+ 0x16e6000016e80,
+ 0x16f0000016f4b,
+ 0x16f4f00016f88,
+ 0x16f8f00016fa0,
+ 0x16fe000016fe2,
+ 0x16fe300016fe5,
+ 0x16ff000016ff2,
+ 0x17000000187f8,
+ 0x1880000018cd6,
+ 0x18d0000018d09,
+ 0x1aff00001aff4,
+ 0x1aff50001affc,
+ 0x1affd0001afff,
+ 0x1b0000001b123,
+ 0x1b1320001b133,
+ 0x1b1500001b153,
+ 0x1b1550001b156,
+ 0x1b1640001b168,
+ 0x1b1700001b2fc,
+ 0x1bc000001bc6b,
+ 0x1bc700001bc7d,
+ 0x1bc800001bc89,
+ 0x1bc900001bc9a,
+ 0x1bc9d0001bc9f,
+ 0x1cf000001cf2e,
+ 0x1cf300001cf47,
+ 0x1da000001da37,
+ 0x1da3b0001da6d,
+ 0x1da750001da76,
+ 0x1da840001da85,
+ 0x1da9b0001daa0,
+ 0x1daa10001dab0,
+ 0x1df000001df1f,
+ 0x1df250001df2b,
+ 0x1e0000001e007,
+ 0x1e0080001e019,
+ 0x1e01b0001e022,
+ 0x1e0230001e025,
+ 0x1e0260001e02b,
+ 0x1e08f0001e090,
+ 0x1e1000001e12d,
+ 0x1e1300001e13e,
+ 0x1e1400001e14a,
+ 0x1e14e0001e14f,
+ 0x1e2900001e2af,
+ 0x1e2c00001e2fa,
+ 0x1e4d00001e4fa,
+ 0x1e7e00001e7e7,
+ 0x1e7e80001e7ec,
+ 0x1e7ed0001e7ef,
+ 0x1e7f00001e7ff,
+ 0x1e8000001e8c5,
+ 0x1e8d00001e8d7,
+ 0x1e9220001e94c,
+ 0x1e9500001e95a,
+ 0x200000002a6e0,
+ 0x2a7000002b73a,
+ 0x2b7400002b81e,
+ 0x2b8200002cea2,
+ 0x2ceb00002ebe1,
+ 0x2ebf00002ee5e,
+ 0x300000003134b,
+ 0x31350000323b0,
+ ),
+ 'CONTEXTJ': (
+ 0x200c0000200e,
+ ),
+ 'CONTEXTO': (
+ 0xb7000000b8,
+ 0x37500000376,
+ 0x5f3000005f5,
+ 0x6600000066a,
+ 0x6f0000006fa,
+ 0x30fb000030fc,
+ ),
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/intranges.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/intranges.py
new file mode 100644
index 000000000..6a43b0475
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/intranges.py
@@ -0,0 +1,54 @@
+"""
+Given a list of integers, made up of (hopefully) a small number of long runs
+of consecutive integers, compute a representation of the form
+((start1, end1), (start2, end2) ...). Then answer the question "was x present
+in the original list?" in time O(log(# runs)).
+"""
+
+import bisect
+from typing import List, Tuple
+
+def intranges_from_list(list_: List[int]) -> Tuple[int, ...]:
+ """Represent a list of integers as a sequence of ranges:
+ ((start_0, end_0), (start_1, end_1), ...), such that the original
+ integers are exactly those x such that start_i <= x < end_i for some i.
+
+ Ranges are encoded as single integers (start << 32 | end), not as tuples.
+ """
+
+ sorted_list = sorted(list_)
+ ranges = []
+ last_write = -1
+ for i in range(len(sorted_list)):
+ if i+1 < len(sorted_list):
+ if sorted_list[i] == sorted_list[i+1]-1:
+ continue
+ current_range = sorted_list[last_write+1:i+1]
+ ranges.append(_encode_range(current_range[0], current_range[-1] + 1))
+ last_write = i
+
+ return tuple(ranges)
+
+def _encode_range(start: int, end: int) -> int:
+ return (start << 32) | end
+
+def _decode_range(r: int) -> Tuple[int, int]:
+ return (r >> 32), (r & ((1 << 32) - 1))
+
+
+def intranges_contain(int_: int, ranges: Tuple[int, ...]) -> bool:
+ """Determine if `int_` falls into one of the ranges in `ranges`."""
+ tuple_ = _encode_range(int_, 0)
+ pos = bisect.bisect_left(ranges, tuple_)
+ # we could be immediately ahead of a tuple (start, end)
+ # with start < int_ <= end
+ if pos > 0:
+ left, right = _decode_range(ranges[pos-1])
+ if left <= int_ < right:
+ return True
+ # or we could be immediately behind a tuple (int_, end)
+ if pos < len(ranges):
+ left, _ = _decode_range(ranges[pos])
+ if left == int_:
+ return True
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/package_data.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/package_data.py
new file mode 100644
index 000000000..ed8111336
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/package_data.py
@@ -0,0 +1,2 @@
+__version__ = '3.7'
+
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/idna/uts46data.py b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/uts46data.py
new file mode 100644
index 000000000..6a1eddbfd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/idna/uts46data.py
@@ -0,0 +1,8598 @@
+# This file is automatically generated by tools/idna-data
+# vim: set fileencoding=utf-8 :
+
+from typing import List, Tuple, Union
+
+
+"""IDNA Mapping Table from UTS46."""
+
+
+__version__ = '15.1.0'
+def _seg_0() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x0, '3'),
+ (0x1, '3'),
+ (0x2, '3'),
+ (0x3, '3'),
+ (0x4, '3'),
+ (0x5, '3'),
+ (0x6, '3'),
+ (0x7, '3'),
+ (0x8, '3'),
+ (0x9, '3'),
+ (0xA, '3'),
+ (0xB, '3'),
+ (0xC, '3'),
+ (0xD, '3'),
+ (0xE, '3'),
+ (0xF, '3'),
+ (0x10, '3'),
+ (0x11, '3'),
+ (0x12, '3'),
+ (0x13, '3'),
+ (0x14, '3'),
+ (0x15, '3'),
+ (0x16, '3'),
+ (0x17, '3'),
+ (0x18, '3'),
+ (0x19, '3'),
+ (0x1A, '3'),
+ (0x1B, '3'),
+ (0x1C, '3'),
+ (0x1D, '3'),
+ (0x1E, '3'),
+ (0x1F, '3'),
+ (0x20, '3'),
+ (0x21, '3'),
+ (0x22, '3'),
+ (0x23, '3'),
+ (0x24, '3'),
+ (0x25, '3'),
+ (0x26, '3'),
+ (0x27, '3'),
+ (0x28, '3'),
+ (0x29, '3'),
+ (0x2A, '3'),
+ (0x2B, '3'),
+ (0x2C, '3'),
+ (0x2D, 'V'),
+ (0x2E, 'V'),
+ (0x2F, '3'),
+ (0x30, 'V'),
+ (0x31, 'V'),
+ (0x32, 'V'),
+ (0x33, 'V'),
+ (0x34, 'V'),
+ (0x35, 'V'),
+ (0x36, 'V'),
+ (0x37, 'V'),
+ (0x38, 'V'),
+ (0x39, 'V'),
+ (0x3A, '3'),
+ (0x3B, '3'),
+ (0x3C, '3'),
+ (0x3D, '3'),
+ (0x3E, '3'),
+ (0x3F, '3'),
+ (0x40, '3'),
+ (0x41, 'M', 'a'),
+ (0x42, 'M', 'b'),
+ (0x43, 'M', 'c'),
+ (0x44, 'M', 'd'),
+ (0x45, 'M', 'e'),
+ (0x46, 'M', 'f'),
+ (0x47, 'M', 'g'),
+ (0x48, 'M', 'h'),
+ (0x49, 'M', 'i'),
+ (0x4A, 'M', 'j'),
+ (0x4B, 'M', 'k'),
+ (0x4C, 'M', 'l'),
+ (0x4D, 'M', 'm'),
+ (0x4E, 'M', 'n'),
+ (0x4F, 'M', 'o'),
+ (0x50, 'M', 'p'),
+ (0x51, 'M', 'q'),
+ (0x52, 'M', 'r'),
+ (0x53, 'M', 's'),
+ (0x54, 'M', 't'),
+ (0x55, 'M', 'u'),
+ (0x56, 'M', 'v'),
+ (0x57, 'M', 'w'),
+ (0x58, 'M', 'x'),
+ (0x59, 'M', 'y'),
+ (0x5A, 'M', 'z'),
+ (0x5B, '3'),
+ (0x5C, '3'),
+ (0x5D, '3'),
+ (0x5E, '3'),
+ (0x5F, '3'),
+ (0x60, '3'),
+ (0x61, 'V'),
+ (0x62, 'V'),
+ (0x63, 'V'),
+ ]
+
+def _seg_1() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x64, 'V'),
+ (0x65, 'V'),
+ (0x66, 'V'),
+ (0x67, 'V'),
+ (0x68, 'V'),
+ (0x69, 'V'),
+ (0x6A, 'V'),
+ (0x6B, 'V'),
+ (0x6C, 'V'),
+ (0x6D, 'V'),
+ (0x6E, 'V'),
+ (0x6F, 'V'),
+ (0x70, 'V'),
+ (0x71, 'V'),
+ (0x72, 'V'),
+ (0x73, 'V'),
+ (0x74, 'V'),
+ (0x75, 'V'),
+ (0x76, 'V'),
+ (0x77, 'V'),
+ (0x78, 'V'),
+ (0x79, 'V'),
+ (0x7A, 'V'),
+ (0x7B, '3'),
+ (0x7C, '3'),
+ (0x7D, '3'),
+ (0x7E, '3'),
+ (0x7F, '3'),
+ (0x80, 'X'),
+ (0x81, 'X'),
+ (0x82, 'X'),
+ (0x83, 'X'),
+ (0x84, 'X'),
+ (0x85, 'X'),
+ (0x86, 'X'),
+ (0x87, 'X'),
+ (0x88, 'X'),
+ (0x89, 'X'),
+ (0x8A, 'X'),
+ (0x8B, 'X'),
+ (0x8C, 'X'),
+ (0x8D, 'X'),
+ (0x8E, 'X'),
+ (0x8F, 'X'),
+ (0x90, 'X'),
+ (0x91, 'X'),
+ (0x92, 'X'),
+ (0x93, 'X'),
+ (0x94, 'X'),
+ (0x95, 'X'),
+ (0x96, 'X'),
+ (0x97, 'X'),
+ (0x98, 'X'),
+ (0x99, 'X'),
+ (0x9A, 'X'),
+ (0x9B, 'X'),
+ (0x9C, 'X'),
+ (0x9D, 'X'),
+ (0x9E, 'X'),
+ (0x9F, 'X'),
+ (0xA0, '3', ' '),
+ (0xA1, 'V'),
+ (0xA2, 'V'),
+ (0xA3, 'V'),
+ (0xA4, 'V'),
+ (0xA5, 'V'),
+ (0xA6, 'V'),
+ (0xA7, 'V'),
+ (0xA8, '3', ' ̈'),
+ (0xA9, 'V'),
+ (0xAA, 'M', 'a'),
+ (0xAB, 'V'),
+ (0xAC, 'V'),
+ (0xAD, 'I'),
+ (0xAE, 'V'),
+ (0xAF, '3', ' ̄'),
+ (0xB0, 'V'),
+ (0xB1, 'V'),
+ (0xB2, 'M', '2'),
+ (0xB3, 'M', '3'),
+ (0xB4, '3', ' ́'),
+ (0xB5, 'M', 'μ'),
+ (0xB6, 'V'),
+ (0xB7, 'V'),
+ (0xB8, '3', ' ̧'),
+ (0xB9, 'M', '1'),
+ (0xBA, 'M', 'o'),
+ (0xBB, 'V'),
+ (0xBC, 'M', '1⁄4'),
+ (0xBD, 'M', '1⁄2'),
+ (0xBE, 'M', '3⁄4'),
+ (0xBF, 'V'),
+ (0xC0, 'M', 'à'),
+ (0xC1, 'M', 'á'),
+ (0xC2, 'M', 'â'),
+ (0xC3, 'M', 'ã'),
+ (0xC4, 'M', 'ä'),
+ (0xC5, 'M', 'å'),
+ (0xC6, 'M', 'æ'),
+ (0xC7, 'M', 'ç'),
+ ]
+
+def _seg_2() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xC8, 'M', 'è'),
+ (0xC9, 'M', 'é'),
+ (0xCA, 'M', 'ê'),
+ (0xCB, 'M', 'ë'),
+ (0xCC, 'M', 'ì'),
+ (0xCD, 'M', 'í'),
+ (0xCE, 'M', 'î'),
+ (0xCF, 'M', 'ï'),
+ (0xD0, 'M', 'ð'),
+ (0xD1, 'M', 'ñ'),
+ (0xD2, 'M', 'ò'),
+ (0xD3, 'M', 'ó'),
+ (0xD4, 'M', 'ô'),
+ (0xD5, 'M', 'õ'),
+ (0xD6, 'M', 'ö'),
+ (0xD7, 'V'),
+ (0xD8, 'M', 'ø'),
+ (0xD9, 'M', 'ù'),
+ (0xDA, 'M', 'ú'),
+ (0xDB, 'M', 'û'),
+ (0xDC, 'M', 'ü'),
+ (0xDD, 'M', 'ý'),
+ (0xDE, 'M', 'þ'),
+ (0xDF, 'D', 'ss'),
+ (0xE0, 'V'),
+ (0xE1, 'V'),
+ (0xE2, 'V'),
+ (0xE3, 'V'),
+ (0xE4, 'V'),
+ (0xE5, 'V'),
+ (0xE6, 'V'),
+ (0xE7, 'V'),
+ (0xE8, 'V'),
+ (0xE9, 'V'),
+ (0xEA, 'V'),
+ (0xEB, 'V'),
+ (0xEC, 'V'),
+ (0xED, 'V'),
+ (0xEE, 'V'),
+ (0xEF, 'V'),
+ (0xF0, 'V'),
+ (0xF1, 'V'),
+ (0xF2, 'V'),
+ (0xF3, 'V'),
+ (0xF4, 'V'),
+ (0xF5, 'V'),
+ (0xF6, 'V'),
+ (0xF7, 'V'),
+ (0xF8, 'V'),
+ (0xF9, 'V'),
+ (0xFA, 'V'),
+ (0xFB, 'V'),
+ (0xFC, 'V'),
+ (0xFD, 'V'),
+ (0xFE, 'V'),
+ (0xFF, 'V'),
+ (0x100, 'M', 'ā'),
+ (0x101, 'V'),
+ (0x102, 'M', 'ă'),
+ (0x103, 'V'),
+ (0x104, 'M', 'ą'),
+ (0x105, 'V'),
+ (0x106, 'M', 'ć'),
+ (0x107, 'V'),
+ (0x108, 'M', 'ĉ'),
+ (0x109, 'V'),
+ (0x10A, 'M', 'ċ'),
+ (0x10B, 'V'),
+ (0x10C, 'M', 'č'),
+ (0x10D, 'V'),
+ (0x10E, 'M', 'ď'),
+ (0x10F, 'V'),
+ (0x110, 'M', 'đ'),
+ (0x111, 'V'),
+ (0x112, 'M', 'ē'),
+ (0x113, 'V'),
+ (0x114, 'M', 'ĕ'),
+ (0x115, 'V'),
+ (0x116, 'M', 'ė'),
+ (0x117, 'V'),
+ (0x118, 'M', 'ę'),
+ (0x119, 'V'),
+ (0x11A, 'M', 'ě'),
+ (0x11B, 'V'),
+ (0x11C, 'M', 'ĝ'),
+ (0x11D, 'V'),
+ (0x11E, 'M', 'ğ'),
+ (0x11F, 'V'),
+ (0x120, 'M', 'ġ'),
+ (0x121, 'V'),
+ (0x122, 'M', 'ģ'),
+ (0x123, 'V'),
+ (0x124, 'M', 'ĥ'),
+ (0x125, 'V'),
+ (0x126, 'M', 'ħ'),
+ (0x127, 'V'),
+ (0x128, 'M', 'ĩ'),
+ (0x129, 'V'),
+ (0x12A, 'M', 'ī'),
+ (0x12B, 'V'),
+ ]
+
+def _seg_3() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x12C, 'M', 'ĭ'),
+ (0x12D, 'V'),
+ (0x12E, 'M', 'į'),
+ (0x12F, 'V'),
+ (0x130, 'M', 'i̇'),
+ (0x131, 'V'),
+ (0x132, 'M', 'ij'),
+ (0x134, 'M', 'ĵ'),
+ (0x135, 'V'),
+ (0x136, 'M', 'ķ'),
+ (0x137, 'V'),
+ (0x139, 'M', 'ĺ'),
+ (0x13A, 'V'),
+ (0x13B, 'M', 'ļ'),
+ (0x13C, 'V'),
+ (0x13D, 'M', 'ľ'),
+ (0x13E, 'V'),
+ (0x13F, 'M', 'l·'),
+ (0x141, 'M', 'ł'),
+ (0x142, 'V'),
+ (0x143, 'M', 'ń'),
+ (0x144, 'V'),
+ (0x145, 'M', 'ņ'),
+ (0x146, 'V'),
+ (0x147, 'M', 'ň'),
+ (0x148, 'V'),
+ (0x149, 'M', 'ʼn'),
+ (0x14A, 'M', 'ŋ'),
+ (0x14B, 'V'),
+ (0x14C, 'M', 'ō'),
+ (0x14D, 'V'),
+ (0x14E, 'M', 'ŏ'),
+ (0x14F, 'V'),
+ (0x150, 'M', 'ő'),
+ (0x151, 'V'),
+ (0x152, 'M', 'œ'),
+ (0x153, 'V'),
+ (0x154, 'M', 'ŕ'),
+ (0x155, 'V'),
+ (0x156, 'M', 'ŗ'),
+ (0x157, 'V'),
+ (0x158, 'M', 'ř'),
+ (0x159, 'V'),
+ (0x15A, 'M', 'ś'),
+ (0x15B, 'V'),
+ (0x15C, 'M', 'ŝ'),
+ (0x15D, 'V'),
+ (0x15E, 'M', 'ş'),
+ (0x15F, 'V'),
+ (0x160, 'M', 'š'),
+ (0x161, 'V'),
+ (0x162, 'M', 'ţ'),
+ (0x163, 'V'),
+ (0x164, 'M', 'ť'),
+ (0x165, 'V'),
+ (0x166, 'M', 'ŧ'),
+ (0x167, 'V'),
+ (0x168, 'M', 'ũ'),
+ (0x169, 'V'),
+ (0x16A, 'M', 'ū'),
+ (0x16B, 'V'),
+ (0x16C, 'M', 'ŭ'),
+ (0x16D, 'V'),
+ (0x16E, 'M', 'ů'),
+ (0x16F, 'V'),
+ (0x170, 'M', 'ű'),
+ (0x171, 'V'),
+ (0x172, 'M', 'ų'),
+ (0x173, 'V'),
+ (0x174, 'M', 'ŵ'),
+ (0x175, 'V'),
+ (0x176, 'M', 'ŷ'),
+ (0x177, 'V'),
+ (0x178, 'M', 'ÿ'),
+ (0x179, 'M', 'ź'),
+ (0x17A, 'V'),
+ (0x17B, 'M', 'ż'),
+ (0x17C, 'V'),
+ (0x17D, 'M', 'ž'),
+ (0x17E, 'V'),
+ (0x17F, 'M', 's'),
+ (0x180, 'V'),
+ (0x181, 'M', 'ɓ'),
+ (0x182, 'M', 'ƃ'),
+ (0x183, 'V'),
+ (0x184, 'M', 'ƅ'),
+ (0x185, 'V'),
+ (0x186, 'M', 'ɔ'),
+ (0x187, 'M', 'ƈ'),
+ (0x188, 'V'),
+ (0x189, 'M', 'ɖ'),
+ (0x18A, 'M', 'ɗ'),
+ (0x18B, 'M', 'ƌ'),
+ (0x18C, 'V'),
+ (0x18E, 'M', 'ǝ'),
+ (0x18F, 'M', 'ə'),
+ (0x190, 'M', 'ɛ'),
+ (0x191, 'M', 'ƒ'),
+ (0x192, 'V'),
+ (0x193, 'M', 'ɠ'),
+ ]
+
+def _seg_4() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x194, 'M', 'ɣ'),
+ (0x195, 'V'),
+ (0x196, 'M', 'ɩ'),
+ (0x197, 'M', 'ɨ'),
+ (0x198, 'M', 'ƙ'),
+ (0x199, 'V'),
+ (0x19C, 'M', 'ɯ'),
+ (0x19D, 'M', 'ɲ'),
+ (0x19E, 'V'),
+ (0x19F, 'M', 'ɵ'),
+ (0x1A0, 'M', 'ơ'),
+ (0x1A1, 'V'),
+ (0x1A2, 'M', 'ƣ'),
+ (0x1A3, 'V'),
+ (0x1A4, 'M', 'ƥ'),
+ (0x1A5, 'V'),
+ (0x1A6, 'M', 'ʀ'),
+ (0x1A7, 'M', 'ƨ'),
+ (0x1A8, 'V'),
+ (0x1A9, 'M', 'ʃ'),
+ (0x1AA, 'V'),
+ (0x1AC, 'M', 'ƭ'),
+ (0x1AD, 'V'),
+ (0x1AE, 'M', 'ʈ'),
+ (0x1AF, 'M', 'ư'),
+ (0x1B0, 'V'),
+ (0x1B1, 'M', 'ʊ'),
+ (0x1B2, 'M', 'ʋ'),
+ (0x1B3, 'M', 'ƴ'),
+ (0x1B4, 'V'),
+ (0x1B5, 'M', 'ƶ'),
+ (0x1B6, 'V'),
+ (0x1B7, 'M', 'ʒ'),
+ (0x1B8, 'M', 'ƹ'),
+ (0x1B9, 'V'),
+ (0x1BC, 'M', 'ƽ'),
+ (0x1BD, 'V'),
+ (0x1C4, 'M', 'dž'),
+ (0x1C7, 'M', 'lj'),
+ (0x1CA, 'M', 'nj'),
+ (0x1CD, 'M', 'ǎ'),
+ (0x1CE, 'V'),
+ (0x1CF, 'M', 'ǐ'),
+ (0x1D0, 'V'),
+ (0x1D1, 'M', 'ǒ'),
+ (0x1D2, 'V'),
+ (0x1D3, 'M', 'ǔ'),
+ (0x1D4, 'V'),
+ (0x1D5, 'M', 'ǖ'),
+ (0x1D6, 'V'),
+ (0x1D7, 'M', 'ǘ'),
+ (0x1D8, 'V'),
+ (0x1D9, 'M', 'ǚ'),
+ (0x1DA, 'V'),
+ (0x1DB, 'M', 'ǜ'),
+ (0x1DC, 'V'),
+ (0x1DE, 'M', 'ǟ'),
+ (0x1DF, 'V'),
+ (0x1E0, 'M', 'ǡ'),
+ (0x1E1, 'V'),
+ (0x1E2, 'M', 'ǣ'),
+ (0x1E3, 'V'),
+ (0x1E4, 'M', 'ǥ'),
+ (0x1E5, 'V'),
+ (0x1E6, 'M', 'ǧ'),
+ (0x1E7, 'V'),
+ (0x1E8, 'M', 'ǩ'),
+ (0x1E9, 'V'),
+ (0x1EA, 'M', 'ǫ'),
+ (0x1EB, 'V'),
+ (0x1EC, 'M', 'ǭ'),
+ (0x1ED, 'V'),
+ (0x1EE, 'M', 'ǯ'),
+ (0x1EF, 'V'),
+ (0x1F1, 'M', 'dz'),
+ (0x1F4, 'M', 'ǵ'),
+ (0x1F5, 'V'),
+ (0x1F6, 'M', 'ƕ'),
+ (0x1F7, 'M', 'ƿ'),
+ (0x1F8, 'M', 'ǹ'),
+ (0x1F9, 'V'),
+ (0x1FA, 'M', 'ǻ'),
+ (0x1FB, 'V'),
+ (0x1FC, 'M', 'ǽ'),
+ (0x1FD, 'V'),
+ (0x1FE, 'M', 'ǿ'),
+ (0x1FF, 'V'),
+ (0x200, 'M', 'ȁ'),
+ (0x201, 'V'),
+ (0x202, 'M', 'ȃ'),
+ (0x203, 'V'),
+ (0x204, 'M', 'ȅ'),
+ (0x205, 'V'),
+ (0x206, 'M', 'ȇ'),
+ (0x207, 'V'),
+ (0x208, 'M', 'ȉ'),
+ (0x209, 'V'),
+ (0x20A, 'M', 'ȋ'),
+ (0x20B, 'V'),
+ (0x20C, 'M', 'ȍ'),
+ ]
+
+def _seg_5() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x20D, 'V'),
+ (0x20E, 'M', 'ȏ'),
+ (0x20F, 'V'),
+ (0x210, 'M', 'ȑ'),
+ (0x211, 'V'),
+ (0x212, 'M', 'ȓ'),
+ (0x213, 'V'),
+ (0x214, 'M', 'ȕ'),
+ (0x215, 'V'),
+ (0x216, 'M', 'ȗ'),
+ (0x217, 'V'),
+ (0x218, 'M', 'ș'),
+ (0x219, 'V'),
+ (0x21A, 'M', 'ț'),
+ (0x21B, 'V'),
+ (0x21C, 'M', 'ȝ'),
+ (0x21D, 'V'),
+ (0x21E, 'M', 'ȟ'),
+ (0x21F, 'V'),
+ (0x220, 'M', 'ƞ'),
+ (0x221, 'V'),
+ (0x222, 'M', 'ȣ'),
+ (0x223, 'V'),
+ (0x224, 'M', 'ȥ'),
+ (0x225, 'V'),
+ (0x226, 'M', 'ȧ'),
+ (0x227, 'V'),
+ (0x228, 'M', 'ȩ'),
+ (0x229, 'V'),
+ (0x22A, 'M', 'ȫ'),
+ (0x22B, 'V'),
+ (0x22C, 'M', 'ȭ'),
+ (0x22D, 'V'),
+ (0x22E, 'M', 'ȯ'),
+ (0x22F, 'V'),
+ (0x230, 'M', 'ȱ'),
+ (0x231, 'V'),
+ (0x232, 'M', 'ȳ'),
+ (0x233, 'V'),
+ (0x23A, 'M', 'ⱥ'),
+ (0x23B, 'M', 'ȼ'),
+ (0x23C, 'V'),
+ (0x23D, 'M', 'ƚ'),
+ (0x23E, 'M', 'ⱦ'),
+ (0x23F, 'V'),
+ (0x241, 'M', 'ɂ'),
+ (0x242, 'V'),
+ (0x243, 'M', 'ƀ'),
+ (0x244, 'M', 'ʉ'),
+ (0x245, 'M', 'ʌ'),
+ (0x246, 'M', 'ɇ'),
+ (0x247, 'V'),
+ (0x248, 'M', 'ɉ'),
+ (0x249, 'V'),
+ (0x24A, 'M', 'ɋ'),
+ (0x24B, 'V'),
+ (0x24C, 'M', 'ɍ'),
+ (0x24D, 'V'),
+ (0x24E, 'M', 'ɏ'),
+ (0x24F, 'V'),
+ (0x2B0, 'M', 'h'),
+ (0x2B1, 'M', 'ɦ'),
+ (0x2B2, 'M', 'j'),
+ (0x2B3, 'M', 'r'),
+ (0x2B4, 'M', 'ɹ'),
+ (0x2B5, 'M', 'ɻ'),
+ (0x2B6, 'M', 'ʁ'),
+ (0x2B7, 'M', 'w'),
+ (0x2B8, 'M', 'y'),
+ (0x2B9, 'V'),
+ (0x2D8, '3', ' ̆'),
+ (0x2D9, '3', ' ̇'),
+ (0x2DA, '3', ' ̊'),
+ (0x2DB, '3', ' ̨'),
+ (0x2DC, '3', ' ̃'),
+ (0x2DD, '3', ' ̋'),
+ (0x2DE, 'V'),
+ (0x2E0, 'M', 'ɣ'),
+ (0x2E1, 'M', 'l'),
+ (0x2E2, 'M', 's'),
+ (0x2E3, 'M', 'x'),
+ (0x2E4, 'M', 'ʕ'),
+ (0x2E5, 'V'),
+ (0x340, 'M', '̀'),
+ (0x341, 'M', '́'),
+ (0x342, 'V'),
+ (0x343, 'M', '̓'),
+ (0x344, 'M', '̈́'),
+ (0x345, 'M', 'ι'),
+ (0x346, 'V'),
+ (0x34F, 'I'),
+ (0x350, 'V'),
+ (0x370, 'M', 'ͱ'),
+ (0x371, 'V'),
+ (0x372, 'M', 'ͳ'),
+ (0x373, 'V'),
+ (0x374, 'M', 'ʹ'),
+ (0x375, 'V'),
+ (0x376, 'M', 'ͷ'),
+ (0x377, 'V'),
+ ]
+
+def _seg_6() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x378, 'X'),
+ (0x37A, '3', ' ι'),
+ (0x37B, 'V'),
+ (0x37E, '3', ';'),
+ (0x37F, 'M', 'ϳ'),
+ (0x380, 'X'),
+ (0x384, '3', ' ́'),
+ (0x385, '3', ' ̈́'),
+ (0x386, 'M', 'ά'),
+ (0x387, 'M', '·'),
+ (0x388, 'M', 'έ'),
+ (0x389, 'M', 'ή'),
+ (0x38A, 'M', 'ί'),
+ (0x38B, 'X'),
+ (0x38C, 'M', 'ό'),
+ (0x38D, 'X'),
+ (0x38E, 'M', 'ύ'),
+ (0x38F, 'M', 'ώ'),
+ (0x390, 'V'),
+ (0x391, 'M', 'α'),
+ (0x392, 'M', 'β'),
+ (0x393, 'M', 'γ'),
+ (0x394, 'M', 'δ'),
+ (0x395, 'M', 'ε'),
+ (0x396, 'M', 'ζ'),
+ (0x397, 'M', 'η'),
+ (0x398, 'M', 'θ'),
+ (0x399, 'M', 'ι'),
+ (0x39A, 'M', 'κ'),
+ (0x39B, 'M', 'λ'),
+ (0x39C, 'M', 'μ'),
+ (0x39D, 'M', 'ν'),
+ (0x39E, 'M', 'ξ'),
+ (0x39F, 'M', 'ο'),
+ (0x3A0, 'M', 'π'),
+ (0x3A1, 'M', 'ρ'),
+ (0x3A2, 'X'),
+ (0x3A3, 'M', 'σ'),
+ (0x3A4, 'M', 'τ'),
+ (0x3A5, 'M', 'υ'),
+ (0x3A6, 'M', 'φ'),
+ (0x3A7, 'M', 'χ'),
+ (0x3A8, 'M', 'ψ'),
+ (0x3A9, 'M', 'ω'),
+ (0x3AA, 'M', 'ϊ'),
+ (0x3AB, 'M', 'ϋ'),
+ (0x3AC, 'V'),
+ (0x3C2, 'D', 'σ'),
+ (0x3C3, 'V'),
+ (0x3CF, 'M', 'ϗ'),
+ (0x3D0, 'M', 'β'),
+ (0x3D1, 'M', 'θ'),
+ (0x3D2, 'M', 'υ'),
+ (0x3D3, 'M', 'ύ'),
+ (0x3D4, 'M', 'ϋ'),
+ (0x3D5, 'M', 'φ'),
+ (0x3D6, 'M', 'π'),
+ (0x3D7, 'V'),
+ (0x3D8, 'M', 'ϙ'),
+ (0x3D9, 'V'),
+ (0x3DA, 'M', 'ϛ'),
+ (0x3DB, 'V'),
+ (0x3DC, 'M', 'ϝ'),
+ (0x3DD, 'V'),
+ (0x3DE, 'M', 'ϟ'),
+ (0x3DF, 'V'),
+ (0x3E0, 'M', 'ϡ'),
+ (0x3E1, 'V'),
+ (0x3E2, 'M', 'ϣ'),
+ (0x3E3, 'V'),
+ (0x3E4, 'M', 'ϥ'),
+ (0x3E5, 'V'),
+ (0x3E6, 'M', 'ϧ'),
+ (0x3E7, 'V'),
+ (0x3E8, 'M', 'ϩ'),
+ (0x3E9, 'V'),
+ (0x3EA, 'M', 'ϫ'),
+ (0x3EB, 'V'),
+ (0x3EC, 'M', 'ϭ'),
+ (0x3ED, 'V'),
+ (0x3EE, 'M', 'ϯ'),
+ (0x3EF, 'V'),
+ (0x3F0, 'M', 'κ'),
+ (0x3F1, 'M', 'ρ'),
+ (0x3F2, 'M', 'σ'),
+ (0x3F3, 'V'),
+ (0x3F4, 'M', 'θ'),
+ (0x3F5, 'M', 'ε'),
+ (0x3F6, 'V'),
+ (0x3F7, 'M', 'ϸ'),
+ (0x3F8, 'V'),
+ (0x3F9, 'M', 'σ'),
+ (0x3FA, 'M', 'ϻ'),
+ (0x3FB, 'V'),
+ (0x3FD, 'M', 'ͻ'),
+ (0x3FE, 'M', 'ͼ'),
+ (0x3FF, 'M', 'ͽ'),
+ (0x400, 'M', 'ѐ'),
+ (0x401, 'M', 'ё'),
+ (0x402, 'M', 'ђ'),
+ ]
+
+def _seg_7() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x403, 'M', 'ѓ'),
+ (0x404, 'M', 'є'),
+ (0x405, 'M', 'ѕ'),
+ (0x406, 'M', 'і'),
+ (0x407, 'M', 'ї'),
+ (0x408, 'M', 'ј'),
+ (0x409, 'M', 'љ'),
+ (0x40A, 'M', 'њ'),
+ (0x40B, 'M', 'ћ'),
+ (0x40C, 'M', 'ќ'),
+ (0x40D, 'M', 'ѝ'),
+ (0x40E, 'M', 'ў'),
+ (0x40F, 'M', 'џ'),
+ (0x410, 'M', 'а'),
+ (0x411, 'M', 'б'),
+ (0x412, 'M', 'в'),
+ (0x413, 'M', 'г'),
+ (0x414, 'M', 'д'),
+ (0x415, 'M', 'е'),
+ (0x416, 'M', 'ж'),
+ (0x417, 'M', 'з'),
+ (0x418, 'M', 'и'),
+ (0x419, 'M', 'й'),
+ (0x41A, 'M', 'к'),
+ (0x41B, 'M', 'л'),
+ (0x41C, 'M', 'м'),
+ (0x41D, 'M', 'н'),
+ (0x41E, 'M', 'о'),
+ (0x41F, 'M', 'п'),
+ (0x420, 'M', 'р'),
+ (0x421, 'M', 'с'),
+ (0x422, 'M', 'т'),
+ (0x423, 'M', 'у'),
+ (0x424, 'M', 'ф'),
+ (0x425, 'M', 'х'),
+ (0x426, 'M', 'ц'),
+ (0x427, 'M', 'ч'),
+ (0x428, 'M', 'ш'),
+ (0x429, 'M', 'щ'),
+ (0x42A, 'M', 'ъ'),
+ (0x42B, 'M', 'ы'),
+ (0x42C, 'M', 'ь'),
+ (0x42D, 'M', 'э'),
+ (0x42E, 'M', 'ю'),
+ (0x42F, 'M', 'я'),
+ (0x430, 'V'),
+ (0x460, 'M', 'ѡ'),
+ (0x461, 'V'),
+ (0x462, 'M', 'ѣ'),
+ (0x463, 'V'),
+ (0x464, 'M', 'ѥ'),
+ (0x465, 'V'),
+ (0x466, 'M', 'ѧ'),
+ (0x467, 'V'),
+ (0x468, 'M', 'ѩ'),
+ (0x469, 'V'),
+ (0x46A, 'M', 'ѫ'),
+ (0x46B, 'V'),
+ (0x46C, 'M', 'ѭ'),
+ (0x46D, 'V'),
+ (0x46E, 'M', 'ѯ'),
+ (0x46F, 'V'),
+ (0x470, 'M', 'ѱ'),
+ (0x471, 'V'),
+ (0x472, 'M', 'ѳ'),
+ (0x473, 'V'),
+ (0x474, 'M', 'ѵ'),
+ (0x475, 'V'),
+ (0x476, 'M', 'ѷ'),
+ (0x477, 'V'),
+ (0x478, 'M', 'ѹ'),
+ (0x479, 'V'),
+ (0x47A, 'M', 'ѻ'),
+ (0x47B, 'V'),
+ (0x47C, 'M', 'ѽ'),
+ (0x47D, 'V'),
+ (0x47E, 'M', 'ѿ'),
+ (0x47F, 'V'),
+ (0x480, 'M', 'ҁ'),
+ (0x481, 'V'),
+ (0x48A, 'M', 'ҋ'),
+ (0x48B, 'V'),
+ (0x48C, 'M', 'ҍ'),
+ (0x48D, 'V'),
+ (0x48E, 'M', 'ҏ'),
+ (0x48F, 'V'),
+ (0x490, 'M', 'ґ'),
+ (0x491, 'V'),
+ (0x492, 'M', 'ғ'),
+ (0x493, 'V'),
+ (0x494, 'M', 'ҕ'),
+ (0x495, 'V'),
+ (0x496, 'M', 'җ'),
+ (0x497, 'V'),
+ (0x498, 'M', 'ҙ'),
+ (0x499, 'V'),
+ (0x49A, 'M', 'қ'),
+ (0x49B, 'V'),
+ (0x49C, 'M', 'ҝ'),
+ (0x49D, 'V'),
+ ]
+
+def _seg_8() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x49E, 'M', 'ҟ'),
+ (0x49F, 'V'),
+ (0x4A0, 'M', 'ҡ'),
+ (0x4A1, 'V'),
+ (0x4A2, 'M', 'ң'),
+ (0x4A3, 'V'),
+ (0x4A4, 'M', 'ҥ'),
+ (0x4A5, 'V'),
+ (0x4A6, 'M', 'ҧ'),
+ (0x4A7, 'V'),
+ (0x4A8, 'M', 'ҩ'),
+ (0x4A9, 'V'),
+ (0x4AA, 'M', 'ҫ'),
+ (0x4AB, 'V'),
+ (0x4AC, 'M', 'ҭ'),
+ (0x4AD, 'V'),
+ (0x4AE, 'M', 'ү'),
+ (0x4AF, 'V'),
+ (0x4B0, 'M', 'ұ'),
+ (0x4B1, 'V'),
+ (0x4B2, 'M', 'ҳ'),
+ (0x4B3, 'V'),
+ (0x4B4, 'M', 'ҵ'),
+ (0x4B5, 'V'),
+ (0x4B6, 'M', 'ҷ'),
+ (0x4B7, 'V'),
+ (0x4B8, 'M', 'ҹ'),
+ (0x4B9, 'V'),
+ (0x4BA, 'M', 'һ'),
+ (0x4BB, 'V'),
+ (0x4BC, 'M', 'ҽ'),
+ (0x4BD, 'V'),
+ (0x4BE, 'M', 'ҿ'),
+ (0x4BF, 'V'),
+ (0x4C0, 'X'),
+ (0x4C1, 'M', 'ӂ'),
+ (0x4C2, 'V'),
+ (0x4C3, 'M', 'ӄ'),
+ (0x4C4, 'V'),
+ (0x4C5, 'M', 'ӆ'),
+ (0x4C6, 'V'),
+ (0x4C7, 'M', 'ӈ'),
+ (0x4C8, 'V'),
+ (0x4C9, 'M', 'ӊ'),
+ (0x4CA, 'V'),
+ (0x4CB, 'M', 'ӌ'),
+ (0x4CC, 'V'),
+ (0x4CD, 'M', 'ӎ'),
+ (0x4CE, 'V'),
+ (0x4D0, 'M', 'ӑ'),
+ (0x4D1, 'V'),
+ (0x4D2, 'M', 'ӓ'),
+ (0x4D3, 'V'),
+ (0x4D4, 'M', 'ӕ'),
+ (0x4D5, 'V'),
+ (0x4D6, 'M', 'ӗ'),
+ (0x4D7, 'V'),
+ (0x4D8, 'M', 'ә'),
+ (0x4D9, 'V'),
+ (0x4DA, 'M', 'ӛ'),
+ (0x4DB, 'V'),
+ (0x4DC, 'M', 'ӝ'),
+ (0x4DD, 'V'),
+ (0x4DE, 'M', 'ӟ'),
+ (0x4DF, 'V'),
+ (0x4E0, 'M', 'ӡ'),
+ (0x4E1, 'V'),
+ (0x4E2, 'M', 'ӣ'),
+ (0x4E3, 'V'),
+ (0x4E4, 'M', 'ӥ'),
+ (0x4E5, 'V'),
+ (0x4E6, 'M', 'ӧ'),
+ (0x4E7, 'V'),
+ (0x4E8, 'M', 'ө'),
+ (0x4E9, 'V'),
+ (0x4EA, 'M', 'ӫ'),
+ (0x4EB, 'V'),
+ (0x4EC, 'M', 'ӭ'),
+ (0x4ED, 'V'),
+ (0x4EE, 'M', 'ӯ'),
+ (0x4EF, 'V'),
+ (0x4F0, 'M', 'ӱ'),
+ (0x4F1, 'V'),
+ (0x4F2, 'M', 'ӳ'),
+ (0x4F3, 'V'),
+ (0x4F4, 'M', 'ӵ'),
+ (0x4F5, 'V'),
+ (0x4F6, 'M', 'ӷ'),
+ (0x4F7, 'V'),
+ (0x4F8, 'M', 'ӹ'),
+ (0x4F9, 'V'),
+ (0x4FA, 'M', 'ӻ'),
+ (0x4FB, 'V'),
+ (0x4FC, 'M', 'ӽ'),
+ (0x4FD, 'V'),
+ (0x4FE, 'M', 'ӿ'),
+ (0x4FF, 'V'),
+ (0x500, 'M', 'ԁ'),
+ (0x501, 'V'),
+ (0x502, 'M', 'ԃ'),
+ ]
+
+def _seg_9() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x503, 'V'),
+ (0x504, 'M', 'ԅ'),
+ (0x505, 'V'),
+ (0x506, 'M', 'ԇ'),
+ (0x507, 'V'),
+ (0x508, 'M', 'ԉ'),
+ (0x509, 'V'),
+ (0x50A, 'M', 'ԋ'),
+ (0x50B, 'V'),
+ (0x50C, 'M', 'ԍ'),
+ (0x50D, 'V'),
+ (0x50E, 'M', 'ԏ'),
+ (0x50F, 'V'),
+ (0x510, 'M', 'ԑ'),
+ (0x511, 'V'),
+ (0x512, 'M', 'ԓ'),
+ (0x513, 'V'),
+ (0x514, 'M', 'ԕ'),
+ (0x515, 'V'),
+ (0x516, 'M', 'ԗ'),
+ (0x517, 'V'),
+ (0x518, 'M', 'ԙ'),
+ (0x519, 'V'),
+ (0x51A, 'M', 'ԛ'),
+ (0x51B, 'V'),
+ (0x51C, 'M', 'ԝ'),
+ (0x51D, 'V'),
+ (0x51E, 'M', 'ԟ'),
+ (0x51F, 'V'),
+ (0x520, 'M', 'ԡ'),
+ (0x521, 'V'),
+ (0x522, 'M', 'ԣ'),
+ (0x523, 'V'),
+ (0x524, 'M', 'ԥ'),
+ (0x525, 'V'),
+ (0x526, 'M', 'ԧ'),
+ (0x527, 'V'),
+ (0x528, 'M', 'ԩ'),
+ (0x529, 'V'),
+ (0x52A, 'M', 'ԫ'),
+ (0x52B, 'V'),
+ (0x52C, 'M', 'ԭ'),
+ (0x52D, 'V'),
+ (0x52E, 'M', 'ԯ'),
+ (0x52F, 'V'),
+ (0x530, 'X'),
+ (0x531, 'M', 'ա'),
+ (0x532, 'M', 'բ'),
+ (0x533, 'M', 'գ'),
+ (0x534, 'M', 'դ'),
+ (0x535, 'M', 'ե'),
+ (0x536, 'M', 'զ'),
+ (0x537, 'M', 'է'),
+ (0x538, 'M', 'ը'),
+ (0x539, 'M', 'թ'),
+ (0x53A, 'M', 'ժ'),
+ (0x53B, 'M', 'ի'),
+ (0x53C, 'M', 'լ'),
+ (0x53D, 'M', 'խ'),
+ (0x53E, 'M', 'ծ'),
+ (0x53F, 'M', 'կ'),
+ (0x540, 'M', 'հ'),
+ (0x541, 'M', 'ձ'),
+ (0x542, 'M', 'ղ'),
+ (0x543, 'M', 'ճ'),
+ (0x544, 'M', 'մ'),
+ (0x545, 'M', 'յ'),
+ (0x546, 'M', 'ն'),
+ (0x547, 'M', 'շ'),
+ (0x548, 'M', 'ո'),
+ (0x549, 'M', 'չ'),
+ (0x54A, 'M', 'պ'),
+ (0x54B, 'M', 'ջ'),
+ (0x54C, 'M', 'ռ'),
+ (0x54D, 'M', 'ս'),
+ (0x54E, 'M', 'վ'),
+ (0x54F, 'M', 'տ'),
+ (0x550, 'M', 'ր'),
+ (0x551, 'M', 'ց'),
+ (0x552, 'M', 'ւ'),
+ (0x553, 'M', 'փ'),
+ (0x554, 'M', 'ք'),
+ (0x555, 'M', 'օ'),
+ (0x556, 'M', 'ֆ'),
+ (0x557, 'X'),
+ (0x559, 'V'),
+ (0x587, 'M', 'եւ'),
+ (0x588, 'V'),
+ (0x58B, 'X'),
+ (0x58D, 'V'),
+ (0x590, 'X'),
+ (0x591, 'V'),
+ (0x5C8, 'X'),
+ (0x5D0, 'V'),
+ (0x5EB, 'X'),
+ (0x5EF, 'V'),
+ (0x5F5, 'X'),
+ (0x606, 'V'),
+ (0x61C, 'X'),
+ (0x61D, 'V'),
+ ]
+
+def _seg_10() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x675, 'M', 'اٴ'),
+ (0x676, 'M', 'وٴ'),
+ (0x677, 'M', 'ۇٴ'),
+ (0x678, 'M', 'يٴ'),
+ (0x679, 'V'),
+ (0x6DD, 'X'),
+ (0x6DE, 'V'),
+ (0x70E, 'X'),
+ (0x710, 'V'),
+ (0x74B, 'X'),
+ (0x74D, 'V'),
+ (0x7B2, 'X'),
+ (0x7C0, 'V'),
+ (0x7FB, 'X'),
+ (0x7FD, 'V'),
+ (0x82E, 'X'),
+ (0x830, 'V'),
+ (0x83F, 'X'),
+ (0x840, 'V'),
+ (0x85C, 'X'),
+ (0x85E, 'V'),
+ (0x85F, 'X'),
+ (0x860, 'V'),
+ (0x86B, 'X'),
+ (0x870, 'V'),
+ (0x88F, 'X'),
+ (0x898, 'V'),
+ (0x8E2, 'X'),
+ (0x8E3, 'V'),
+ (0x958, 'M', 'क़'),
+ (0x959, 'M', 'ख़'),
+ (0x95A, 'M', 'ग़'),
+ (0x95B, 'M', 'ज़'),
+ (0x95C, 'M', 'ड़'),
+ (0x95D, 'M', 'ढ़'),
+ (0x95E, 'M', 'फ़'),
+ (0x95F, 'M', 'य़'),
+ (0x960, 'V'),
+ (0x984, 'X'),
+ (0x985, 'V'),
+ (0x98D, 'X'),
+ (0x98F, 'V'),
+ (0x991, 'X'),
+ (0x993, 'V'),
+ (0x9A9, 'X'),
+ (0x9AA, 'V'),
+ (0x9B1, 'X'),
+ (0x9B2, 'V'),
+ (0x9B3, 'X'),
+ (0x9B6, 'V'),
+ (0x9BA, 'X'),
+ (0x9BC, 'V'),
+ (0x9C5, 'X'),
+ (0x9C7, 'V'),
+ (0x9C9, 'X'),
+ (0x9CB, 'V'),
+ (0x9CF, 'X'),
+ (0x9D7, 'V'),
+ (0x9D8, 'X'),
+ (0x9DC, 'M', 'ড়'),
+ (0x9DD, 'M', 'ঢ়'),
+ (0x9DE, 'X'),
+ (0x9DF, 'M', 'য়'),
+ (0x9E0, 'V'),
+ (0x9E4, 'X'),
+ (0x9E6, 'V'),
+ (0x9FF, 'X'),
+ (0xA01, 'V'),
+ (0xA04, 'X'),
+ (0xA05, 'V'),
+ (0xA0B, 'X'),
+ (0xA0F, 'V'),
+ (0xA11, 'X'),
+ (0xA13, 'V'),
+ (0xA29, 'X'),
+ (0xA2A, 'V'),
+ (0xA31, 'X'),
+ (0xA32, 'V'),
+ (0xA33, 'M', 'ਲ਼'),
+ (0xA34, 'X'),
+ (0xA35, 'V'),
+ (0xA36, 'M', 'ਸ਼'),
+ (0xA37, 'X'),
+ (0xA38, 'V'),
+ (0xA3A, 'X'),
+ (0xA3C, 'V'),
+ (0xA3D, 'X'),
+ (0xA3E, 'V'),
+ (0xA43, 'X'),
+ (0xA47, 'V'),
+ (0xA49, 'X'),
+ (0xA4B, 'V'),
+ (0xA4E, 'X'),
+ (0xA51, 'V'),
+ (0xA52, 'X'),
+ (0xA59, 'M', 'ਖ਼'),
+ (0xA5A, 'M', 'ਗ਼'),
+ (0xA5B, 'M', 'ਜ਼'),
+ (0xA5C, 'V'),
+ (0xA5D, 'X'),
+ ]
+
+def _seg_11() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xA5E, 'M', 'ਫ਼'),
+ (0xA5F, 'X'),
+ (0xA66, 'V'),
+ (0xA77, 'X'),
+ (0xA81, 'V'),
+ (0xA84, 'X'),
+ (0xA85, 'V'),
+ (0xA8E, 'X'),
+ (0xA8F, 'V'),
+ (0xA92, 'X'),
+ (0xA93, 'V'),
+ (0xAA9, 'X'),
+ (0xAAA, 'V'),
+ (0xAB1, 'X'),
+ (0xAB2, 'V'),
+ (0xAB4, 'X'),
+ (0xAB5, 'V'),
+ (0xABA, 'X'),
+ (0xABC, 'V'),
+ (0xAC6, 'X'),
+ (0xAC7, 'V'),
+ (0xACA, 'X'),
+ (0xACB, 'V'),
+ (0xACE, 'X'),
+ (0xAD0, 'V'),
+ (0xAD1, 'X'),
+ (0xAE0, 'V'),
+ (0xAE4, 'X'),
+ (0xAE6, 'V'),
+ (0xAF2, 'X'),
+ (0xAF9, 'V'),
+ (0xB00, 'X'),
+ (0xB01, 'V'),
+ (0xB04, 'X'),
+ (0xB05, 'V'),
+ (0xB0D, 'X'),
+ (0xB0F, 'V'),
+ (0xB11, 'X'),
+ (0xB13, 'V'),
+ (0xB29, 'X'),
+ (0xB2A, 'V'),
+ (0xB31, 'X'),
+ (0xB32, 'V'),
+ (0xB34, 'X'),
+ (0xB35, 'V'),
+ (0xB3A, 'X'),
+ (0xB3C, 'V'),
+ (0xB45, 'X'),
+ (0xB47, 'V'),
+ (0xB49, 'X'),
+ (0xB4B, 'V'),
+ (0xB4E, 'X'),
+ (0xB55, 'V'),
+ (0xB58, 'X'),
+ (0xB5C, 'M', 'ଡ଼'),
+ (0xB5D, 'M', 'ଢ଼'),
+ (0xB5E, 'X'),
+ (0xB5F, 'V'),
+ (0xB64, 'X'),
+ (0xB66, 'V'),
+ (0xB78, 'X'),
+ (0xB82, 'V'),
+ (0xB84, 'X'),
+ (0xB85, 'V'),
+ (0xB8B, 'X'),
+ (0xB8E, 'V'),
+ (0xB91, 'X'),
+ (0xB92, 'V'),
+ (0xB96, 'X'),
+ (0xB99, 'V'),
+ (0xB9B, 'X'),
+ (0xB9C, 'V'),
+ (0xB9D, 'X'),
+ (0xB9E, 'V'),
+ (0xBA0, 'X'),
+ (0xBA3, 'V'),
+ (0xBA5, 'X'),
+ (0xBA8, 'V'),
+ (0xBAB, 'X'),
+ (0xBAE, 'V'),
+ (0xBBA, 'X'),
+ (0xBBE, 'V'),
+ (0xBC3, 'X'),
+ (0xBC6, 'V'),
+ (0xBC9, 'X'),
+ (0xBCA, 'V'),
+ (0xBCE, 'X'),
+ (0xBD0, 'V'),
+ (0xBD1, 'X'),
+ (0xBD7, 'V'),
+ (0xBD8, 'X'),
+ (0xBE6, 'V'),
+ (0xBFB, 'X'),
+ (0xC00, 'V'),
+ (0xC0D, 'X'),
+ (0xC0E, 'V'),
+ (0xC11, 'X'),
+ (0xC12, 'V'),
+ (0xC29, 'X'),
+ (0xC2A, 'V'),
+ ]
+
+def _seg_12() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xC3A, 'X'),
+ (0xC3C, 'V'),
+ (0xC45, 'X'),
+ (0xC46, 'V'),
+ (0xC49, 'X'),
+ (0xC4A, 'V'),
+ (0xC4E, 'X'),
+ (0xC55, 'V'),
+ (0xC57, 'X'),
+ (0xC58, 'V'),
+ (0xC5B, 'X'),
+ (0xC5D, 'V'),
+ (0xC5E, 'X'),
+ (0xC60, 'V'),
+ (0xC64, 'X'),
+ (0xC66, 'V'),
+ (0xC70, 'X'),
+ (0xC77, 'V'),
+ (0xC8D, 'X'),
+ (0xC8E, 'V'),
+ (0xC91, 'X'),
+ (0xC92, 'V'),
+ (0xCA9, 'X'),
+ (0xCAA, 'V'),
+ (0xCB4, 'X'),
+ (0xCB5, 'V'),
+ (0xCBA, 'X'),
+ (0xCBC, 'V'),
+ (0xCC5, 'X'),
+ (0xCC6, 'V'),
+ (0xCC9, 'X'),
+ (0xCCA, 'V'),
+ (0xCCE, 'X'),
+ (0xCD5, 'V'),
+ (0xCD7, 'X'),
+ (0xCDD, 'V'),
+ (0xCDF, 'X'),
+ (0xCE0, 'V'),
+ (0xCE4, 'X'),
+ (0xCE6, 'V'),
+ (0xCF0, 'X'),
+ (0xCF1, 'V'),
+ (0xCF4, 'X'),
+ (0xD00, 'V'),
+ (0xD0D, 'X'),
+ (0xD0E, 'V'),
+ (0xD11, 'X'),
+ (0xD12, 'V'),
+ (0xD45, 'X'),
+ (0xD46, 'V'),
+ (0xD49, 'X'),
+ (0xD4A, 'V'),
+ (0xD50, 'X'),
+ (0xD54, 'V'),
+ (0xD64, 'X'),
+ (0xD66, 'V'),
+ (0xD80, 'X'),
+ (0xD81, 'V'),
+ (0xD84, 'X'),
+ (0xD85, 'V'),
+ (0xD97, 'X'),
+ (0xD9A, 'V'),
+ (0xDB2, 'X'),
+ (0xDB3, 'V'),
+ (0xDBC, 'X'),
+ (0xDBD, 'V'),
+ (0xDBE, 'X'),
+ (0xDC0, 'V'),
+ (0xDC7, 'X'),
+ (0xDCA, 'V'),
+ (0xDCB, 'X'),
+ (0xDCF, 'V'),
+ (0xDD5, 'X'),
+ (0xDD6, 'V'),
+ (0xDD7, 'X'),
+ (0xDD8, 'V'),
+ (0xDE0, 'X'),
+ (0xDE6, 'V'),
+ (0xDF0, 'X'),
+ (0xDF2, 'V'),
+ (0xDF5, 'X'),
+ (0xE01, 'V'),
+ (0xE33, 'M', 'ํา'),
+ (0xE34, 'V'),
+ (0xE3B, 'X'),
+ (0xE3F, 'V'),
+ (0xE5C, 'X'),
+ (0xE81, 'V'),
+ (0xE83, 'X'),
+ (0xE84, 'V'),
+ (0xE85, 'X'),
+ (0xE86, 'V'),
+ (0xE8B, 'X'),
+ (0xE8C, 'V'),
+ (0xEA4, 'X'),
+ (0xEA5, 'V'),
+ (0xEA6, 'X'),
+ (0xEA7, 'V'),
+ (0xEB3, 'M', 'ໍາ'),
+ (0xEB4, 'V'),
+ ]
+
+def _seg_13() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xEBE, 'X'),
+ (0xEC0, 'V'),
+ (0xEC5, 'X'),
+ (0xEC6, 'V'),
+ (0xEC7, 'X'),
+ (0xEC8, 'V'),
+ (0xECF, 'X'),
+ (0xED0, 'V'),
+ (0xEDA, 'X'),
+ (0xEDC, 'M', 'ຫນ'),
+ (0xEDD, 'M', 'ຫມ'),
+ (0xEDE, 'V'),
+ (0xEE0, 'X'),
+ (0xF00, 'V'),
+ (0xF0C, 'M', '་'),
+ (0xF0D, 'V'),
+ (0xF43, 'M', 'གྷ'),
+ (0xF44, 'V'),
+ (0xF48, 'X'),
+ (0xF49, 'V'),
+ (0xF4D, 'M', 'ཌྷ'),
+ (0xF4E, 'V'),
+ (0xF52, 'M', 'དྷ'),
+ (0xF53, 'V'),
+ (0xF57, 'M', 'བྷ'),
+ (0xF58, 'V'),
+ (0xF5C, 'M', 'ཛྷ'),
+ (0xF5D, 'V'),
+ (0xF69, 'M', 'ཀྵ'),
+ (0xF6A, 'V'),
+ (0xF6D, 'X'),
+ (0xF71, 'V'),
+ (0xF73, 'M', 'ཱི'),
+ (0xF74, 'V'),
+ (0xF75, 'M', 'ཱུ'),
+ (0xF76, 'M', 'ྲྀ'),
+ (0xF77, 'M', 'ྲཱྀ'),
+ (0xF78, 'M', 'ླྀ'),
+ (0xF79, 'M', 'ླཱྀ'),
+ (0xF7A, 'V'),
+ (0xF81, 'M', 'ཱྀ'),
+ (0xF82, 'V'),
+ (0xF93, 'M', 'ྒྷ'),
+ (0xF94, 'V'),
+ (0xF98, 'X'),
+ (0xF99, 'V'),
+ (0xF9D, 'M', 'ྜྷ'),
+ (0xF9E, 'V'),
+ (0xFA2, 'M', 'ྡྷ'),
+ (0xFA3, 'V'),
+ (0xFA7, 'M', 'ྦྷ'),
+ (0xFA8, 'V'),
+ (0xFAC, 'M', 'ྫྷ'),
+ (0xFAD, 'V'),
+ (0xFB9, 'M', 'ྐྵ'),
+ (0xFBA, 'V'),
+ (0xFBD, 'X'),
+ (0xFBE, 'V'),
+ (0xFCD, 'X'),
+ (0xFCE, 'V'),
+ (0xFDB, 'X'),
+ (0x1000, 'V'),
+ (0x10A0, 'X'),
+ (0x10C7, 'M', 'ⴧ'),
+ (0x10C8, 'X'),
+ (0x10CD, 'M', 'ⴭ'),
+ (0x10CE, 'X'),
+ (0x10D0, 'V'),
+ (0x10FC, 'M', 'ნ'),
+ (0x10FD, 'V'),
+ (0x115F, 'X'),
+ (0x1161, 'V'),
+ (0x1249, 'X'),
+ (0x124A, 'V'),
+ (0x124E, 'X'),
+ (0x1250, 'V'),
+ (0x1257, 'X'),
+ (0x1258, 'V'),
+ (0x1259, 'X'),
+ (0x125A, 'V'),
+ (0x125E, 'X'),
+ (0x1260, 'V'),
+ (0x1289, 'X'),
+ (0x128A, 'V'),
+ (0x128E, 'X'),
+ (0x1290, 'V'),
+ (0x12B1, 'X'),
+ (0x12B2, 'V'),
+ (0x12B6, 'X'),
+ (0x12B8, 'V'),
+ (0x12BF, 'X'),
+ (0x12C0, 'V'),
+ (0x12C1, 'X'),
+ (0x12C2, 'V'),
+ (0x12C6, 'X'),
+ (0x12C8, 'V'),
+ (0x12D7, 'X'),
+ (0x12D8, 'V'),
+ (0x1311, 'X'),
+ (0x1312, 'V'),
+ ]
+
+def _seg_14() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1316, 'X'),
+ (0x1318, 'V'),
+ (0x135B, 'X'),
+ (0x135D, 'V'),
+ (0x137D, 'X'),
+ (0x1380, 'V'),
+ (0x139A, 'X'),
+ (0x13A0, 'V'),
+ (0x13F6, 'X'),
+ (0x13F8, 'M', 'Ᏸ'),
+ (0x13F9, 'M', 'Ᏹ'),
+ (0x13FA, 'M', 'Ᏺ'),
+ (0x13FB, 'M', 'Ᏻ'),
+ (0x13FC, 'M', 'Ᏼ'),
+ (0x13FD, 'M', 'Ᏽ'),
+ (0x13FE, 'X'),
+ (0x1400, 'V'),
+ (0x1680, 'X'),
+ (0x1681, 'V'),
+ (0x169D, 'X'),
+ (0x16A0, 'V'),
+ (0x16F9, 'X'),
+ (0x1700, 'V'),
+ (0x1716, 'X'),
+ (0x171F, 'V'),
+ (0x1737, 'X'),
+ (0x1740, 'V'),
+ (0x1754, 'X'),
+ (0x1760, 'V'),
+ (0x176D, 'X'),
+ (0x176E, 'V'),
+ (0x1771, 'X'),
+ (0x1772, 'V'),
+ (0x1774, 'X'),
+ (0x1780, 'V'),
+ (0x17B4, 'X'),
+ (0x17B6, 'V'),
+ (0x17DE, 'X'),
+ (0x17E0, 'V'),
+ (0x17EA, 'X'),
+ (0x17F0, 'V'),
+ (0x17FA, 'X'),
+ (0x1800, 'V'),
+ (0x1806, 'X'),
+ (0x1807, 'V'),
+ (0x180B, 'I'),
+ (0x180E, 'X'),
+ (0x180F, 'I'),
+ (0x1810, 'V'),
+ (0x181A, 'X'),
+ (0x1820, 'V'),
+ (0x1879, 'X'),
+ (0x1880, 'V'),
+ (0x18AB, 'X'),
+ (0x18B0, 'V'),
+ (0x18F6, 'X'),
+ (0x1900, 'V'),
+ (0x191F, 'X'),
+ (0x1920, 'V'),
+ (0x192C, 'X'),
+ (0x1930, 'V'),
+ (0x193C, 'X'),
+ (0x1940, 'V'),
+ (0x1941, 'X'),
+ (0x1944, 'V'),
+ (0x196E, 'X'),
+ (0x1970, 'V'),
+ (0x1975, 'X'),
+ (0x1980, 'V'),
+ (0x19AC, 'X'),
+ (0x19B0, 'V'),
+ (0x19CA, 'X'),
+ (0x19D0, 'V'),
+ (0x19DB, 'X'),
+ (0x19DE, 'V'),
+ (0x1A1C, 'X'),
+ (0x1A1E, 'V'),
+ (0x1A5F, 'X'),
+ (0x1A60, 'V'),
+ (0x1A7D, 'X'),
+ (0x1A7F, 'V'),
+ (0x1A8A, 'X'),
+ (0x1A90, 'V'),
+ (0x1A9A, 'X'),
+ (0x1AA0, 'V'),
+ (0x1AAE, 'X'),
+ (0x1AB0, 'V'),
+ (0x1ACF, 'X'),
+ (0x1B00, 'V'),
+ (0x1B4D, 'X'),
+ (0x1B50, 'V'),
+ (0x1B7F, 'X'),
+ (0x1B80, 'V'),
+ (0x1BF4, 'X'),
+ (0x1BFC, 'V'),
+ (0x1C38, 'X'),
+ (0x1C3B, 'V'),
+ (0x1C4A, 'X'),
+ (0x1C4D, 'V'),
+ (0x1C80, 'M', 'в'),
+ ]
+
+def _seg_15() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1C81, 'M', 'д'),
+ (0x1C82, 'M', 'о'),
+ (0x1C83, 'M', 'с'),
+ (0x1C84, 'M', 'т'),
+ (0x1C86, 'M', 'ъ'),
+ (0x1C87, 'M', 'ѣ'),
+ (0x1C88, 'M', 'ꙋ'),
+ (0x1C89, 'X'),
+ (0x1C90, 'M', 'ა'),
+ (0x1C91, 'M', 'ბ'),
+ (0x1C92, 'M', 'გ'),
+ (0x1C93, 'M', 'დ'),
+ (0x1C94, 'M', 'ე'),
+ (0x1C95, 'M', 'ვ'),
+ (0x1C96, 'M', 'ზ'),
+ (0x1C97, 'M', 'თ'),
+ (0x1C98, 'M', 'ი'),
+ (0x1C99, 'M', 'კ'),
+ (0x1C9A, 'M', 'ლ'),
+ (0x1C9B, 'M', 'მ'),
+ (0x1C9C, 'M', 'ნ'),
+ (0x1C9D, 'M', 'ო'),
+ (0x1C9E, 'M', 'პ'),
+ (0x1C9F, 'M', 'ჟ'),
+ (0x1CA0, 'M', 'რ'),
+ (0x1CA1, 'M', 'ს'),
+ (0x1CA2, 'M', 'ტ'),
+ (0x1CA3, 'M', 'უ'),
+ (0x1CA4, 'M', 'ფ'),
+ (0x1CA5, 'M', 'ქ'),
+ (0x1CA6, 'M', 'ღ'),
+ (0x1CA7, 'M', 'ყ'),
+ (0x1CA8, 'M', 'შ'),
+ (0x1CA9, 'M', 'ჩ'),
+ (0x1CAA, 'M', 'ც'),
+ (0x1CAB, 'M', 'ძ'),
+ (0x1CAC, 'M', 'წ'),
+ (0x1CAD, 'M', 'ჭ'),
+ (0x1CAE, 'M', 'ხ'),
+ (0x1CAF, 'M', 'ჯ'),
+ (0x1CB0, 'M', 'ჰ'),
+ (0x1CB1, 'M', 'ჱ'),
+ (0x1CB2, 'M', 'ჲ'),
+ (0x1CB3, 'M', 'ჳ'),
+ (0x1CB4, 'M', 'ჴ'),
+ (0x1CB5, 'M', 'ჵ'),
+ (0x1CB6, 'M', 'ჶ'),
+ (0x1CB7, 'M', 'ჷ'),
+ (0x1CB8, 'M', 'ჸ'),
+ (0x1CB9, 'M', 'ჹ'),
+ (0x1CBA, 'M', 'ჺ'),
+ (0x1CBB, 'X'),
+ (0x1CBD, 'M', 'ჽ'),
+ (0x1CBE, 'M', 'ჾ'),
+ (0x1CBF, 'M', 'ჿ'),
+ (0x1CC0, 'V'),
+ (0x1CC8, 'X'),
+ (0x1CD0, 'V'),
+ (0x1CFB, 'X'),
+ (0x1D00, 'V'),
+ (0x1D2C, 'M', 'a'),
+ (0x1D2D, 'M', 'æ'),
+ (0x1D2E, 'M', 'b'),
+ (0x1D2F, 'V'),
+ (0x1D30, 'M', 'd'),
+ (0x1D31, 'M', 'e'),
+ (0x1D32, 'M', 'ǝ'),
+ (0x1D33, 'M', 'g'),
+ (0x1D34, 'M', 'h'),
+ (0x1D35, 'M', 'i'),
+ (0x1D36, 'M', 'j'),
+ (0x1D37, 'M', 'k'),
+ (0x1D38, 'M', 'l'),
+ (0x1D39, 'M', 'm'),
+ (0x1D3A, 'M', 'n'),
+ (0x1D3B, 'V'),
+ (0x1D3C, 'M', 'o'),
+ (0x1D3D, 'M', 'ȣ'),
+ (0x1D3E, 'M', 'p'),
+ (0x1D3F, 'M', 'r'),
+ (0x1D40, 'M', 't'),
+ (0x1D41, 'M', 'u'),
+ (0x1D42, 'M', 'w'),
+ (0x1D43, 'M', 'a'),
+ (0x1D44, 'M', 'ɐ'),
+ (0x1D45, 'M', 'ɑ'),
+ (0x1D46, 'M', 'ᴂ'),
+ (0x1D47, 'M', 'b'),
+ (0x1D48, 'M', 'd'),
+ (0x1D49, 'M', 'e'),
+ (0x1D4A, 'M', 'ə'),
+ (0x1D4B, 'M', 'ɛ'),
+ (0x1D4C, 'M', 'ɜ'),
+ (0x1D4D, 'M', 'g'),
+ (0x1D4E, 'V'),
+ (0x1D4F, 'M', 'k'),
+ (0x1D50, 'M', 'm'),
+ (0x1D51, 'M', 'ŋ'),
+ (0x1D52, 'M', 'o'),
+ (0x1D53, 'M', 'ɔ'),
+ ]
+
+def _seg_16() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D54, 'M', 'ᴖ'),
+ (0x1D55, 'M', 'ᴗ'),
+ (0x1D56, 'M', 'p'),
+ (0x1D57, 'M', 't'),
+ (0x1D58, 'M', 'u'),
+ (0x1D59, 'M', 'ᴝ'),
+ (0x1D5A, 'M', 'ɯ'),
+ (0x1D5B, 'M', 'v'),
+ (0x1D5C, 'M', 'ᴥ'),
+ (0x1D5D, 'M', 'β'),
+ (0x1D5E, 'M', 'γ'),
+ (0x1D5F, 'M', 'δ'),
+ (0x1D60, 'M', 'φ'),
+ (0x1D61, 'M', 'χ'),
+ (0x1D62, 'M', 'i'),
+ (0x1D63, 'M', 'r'),
+ (0x1D64, 'M', 'u'),
+ (0x1D65, 'M', 'v'),
+ (0x1D66, 'M', 'β'),
+ (0x1D67, 'M', 'γ'),
+ (0x1D68, 'M', 'ρ'),
+ (0x1D69, 'M', 'φ'),
+ (0x1D6A, 'M', 'χ'),
+ (0x1D6B, 'V'),
+ (0x1D78, 'M', 'н'),
+ (0x1D79, 'V'),
+ (0x1D9B, 'M', 'ɒ'),
+ (0x1D9C, 'M', 'c'),
+ (0x1D9D, 'M', 'ɕ'),
+ (0x1D9E, 'M', 'ð'),
+ (0x1D9F, 'M', 'ɜ'),
+ (0x1DA0, 'M', 'f'),
+ (0x1DA1, 'M', 'ɟ'),
+ (0x1DA2, 'M', 'ɡ'),
+ (0x1DA3, 'M', 'ɥ'),
+ (0x1DA4, 'M', 'ɨ'),
+ (0x1DA5, 'M', 'ɩ'),
+ (0x1DA6, 'M', 'ɪ'),
+ (0x1DA7, 'M', 'ᵻ'),
+ (0x1DA8, 'M', 'ʝ'),
+ (0x1DA9, 'M', 'ɭ'),
+ (0x1DAA, 'M', 'ᶅ'),
+ (0x1DAB, 'M', 'ʟ'),
+ (0x1DAC, 'M', 'ɱ'),
+ (0x1DAD, 'M', 'ɰ'),
+ (0x1DAE, 'M', 'ɲ'),
+ (0x1DAF, 'M', 'ɳ'),
+ (0x1DB0, 'M', 'ɴ'),
+ (0x1DB1, 'M', 'ɵ'),
+ (0x1DB2, 'M', 'ɸ'),
+ (0x1DB3, 'M', 'ʂ'),
+ (0x1DB4, 'M', 'ʃ'),
+ (0x1DB5, 'M', 'ƫ'),
+ (0x1DB6, 'M', 'ʉ'),
+ (0x1DB7, 'M', 'ʊ'),
+ (0x1DB8, 'M', 'ᴜ'),
+ (0x1DB9, 'M', 'ʋ'),
+ (0x1DBA, 'M', 'ʌ'),
+ (0x1DBB, 'M', 'z'),
+ (0x1DBC, 'M', 'ʐ'),
+ (0x1DBD, 'M', 'ʑ'),
+ (0x1DBE, 'M', 'ʒ'),
+ (0x1DBF, 'M', 'θ'),
+ (0x1DC0, 'V'),
+ (0x1E00, 'M', 'ḁ'),
+ (0x1E01, 'V'),
+ (0x1E02, 'M', 'ḃ'),
+ (0x1E03, 'V'),
+ (0x1E04, 'M', 'ḅ'),
+ (0x1E05, 'V'),
+ (0x1E06, 'M', 'ḇ'),
+ (0x1E07, 'V'),
+ (0x1E08, 'M', 'ḉ'),
+ (0x1E09, 'V'),
+ (0x1E0A, 'M', 'ḋ'),
+ (0x1E0B, 'V'),
+ (0x1E0C, 'M', 'ḍ'),
+ (0x1E0D, 'V'),
+ (0x1E0E, 'M', 'ḏ'),
+ (0x1E0F, 'V'),
+ (0x1E10, 'M', 'ḑ'),
+ (0x1E11, 'V'),
+ (0x1E12, 'M', 'ḓ'),
+ (0x1E13, 'V'),
+ (0x1E14, 'M', 'ḕ'),
+ (0x1E15, 'V'),
+ (0x1E16, 'M', 'ḗ'),
+ (0x1E17, 'V'),
+ (0x1E18, 'M', 'ḙ'),
+ (0x1E19, 'V'),
+ (0x1E1A, 'M', 'ḛ'),
+ (0x1E1B, 'V'),
+ (0x1E1C, 'M', 'ḝ'),
+ (0x1E1D, 'V'),
+ (0x1E1E, 'M', 'ḟ'),
+ (0x1E1F, 'V'),
+ (0x1E20, 'M', 'ḡ'),
+ (0x1E21, 'V'),
+ (0x1E22, 'M', 'ḣ'),
+ (0x1E23, 'V'),
+ ]
+
+def _seg_17() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1E24, 'M', 'ḥ'),
+ (0x1E25, 'V'),
+ (0x1E26, 'M', 'ḧ'),
+ (0x1E27, 'V'),
+ (0x1E28, 'M', 'ḩ'),
+ (0x1E29, 'V'),
+ (0x1E2A, 'M', 'ḫ'),
+ (0x1E2B, 'V'),
+ (0x1E2C, 'M', 'ḭ'),
+ (0x1E2D, 'V'),
+ (0x1E2E, 'M', 'ḯ'),
+ (0x1E2F, 'V'),
+ (0x1E30, 'M', 'ḱ'),
+ (0x1E31, 'V'),
+ (0x1E32, 'M', 'ḳ'),
+ (0x1E33, 'V'),
+ (0x1E34, 'M', 'ḵ'),
+ (0x1E35, 'V'),
+ (0x1E36, 'M', 'ḷ'),
+ (0x1E37, 'V'),
+ (0x1E38, 'M', 'ḹ'),
+ (0x1E39, 'V'),
+ (0x1E3A, 'M', 'ḻ'),
+ (0x1E3B, 'V'),
+ (0x1E3C, 'M', 'ḽ'),
+ (0x1E3D, 'V'),
+ (0x1E3E, 'M', 'ḿ'),
+ (0x1E3F, 'V'),
+ (0x1E40, 'M', 'ṁ'),
+ (0x1E41, 'V'),
+ (0x1E42, 'M', 'ṃ'),
+ (0x1E43, 'V'),
+ (0x1E44, 'M', 'ṅ'),
+ (0x1E45, 'V'),
+ (0x1E46, 'M', 'ṇ'),
+ (0x1E47, 'V'),
+ (0x1E48, 'M', 'ṉ'),
+ (0x1E49, 'V'),
+ (0x1E4A, 'M', 'ṋ'),
+ (0x1E4B, 'V'),
+ (0x1E4C, 'M', 'ṍ'),
+ (0x1E4D, 'V'),
+ (0x1E4E, 'M', 'ṏ'),
+ (0x1E4F, 'V'),
+ (0x1E50, 'M', 'ṑ'),
+ (0x1E51, 'V'),
+ (0x1E52, 'M', 'ṓ'),
+ (0x1E53, 'V'),
+ (0x1E54, 'M', 'ṕ'),
+ (0x1E55, 'V'),
+ (0x1E56, 'M', 'ṗ'),
+ (0x1E57, 'V'),
+ (0x1E58, 'M', 'ṙ'),
+ (0x1E59, 'V'),
+ (0x1E5A, 'M', 'ṛ'),
+ (0x1E5B, 'V'),
+ (0x1E5C, 'M', 'ṝ'),
+ (0x1E5D, 'V'),
+ (0x1E5E, 'M', 'ṟ'),
+ (0x1E5F, 'V'),
+ (0x1E60, 'M', 'ṡ'),
+ (0x1E61, 'V'),
+ (0x1E62, 'M', 'ṣ'),
+ (0x1E63, 'V'),
+ (0x1E64, 'M', 'ṥ'),
+ (0x1E65, 'V'),
+ (0x1E66, 'M', 'ṧ'),
+ (0x1E67, 'V'),
+ (0x1E68, 'M', 'ṩ'),
+ (0x1E69, 'V'),
+ (0x1E6A, 'M', 'ṫ'),
+ (0x1E6B, 'V'),
+ (0x1E6C, 'M', 'ṭ'),
+ (0x1E6D, 'V'),
+ (0x1E6E, 'M', 'ṯ'),
+ (0x1E6F, 'V'),
+ (0x1E70, 'M', 'ṱ'),
+ (0x1E71, 'V'),
+ (0x1E72, 'M', 'ṳ'),
+ (0x1E73, 'V'),
+ (0x1E74, 'M', 'ṵ'),
+ (0x1E75, 'V'),
+ (0x1E76, 'M', 'ṷ'),
+ (0x1E77, 'V'),
+ (0x1E78, 'M', 'ṹ'),
+ (0x1E79, 'V'),
+ (0x1E7A, 'M', 'ṻ'),
+ (0x1E7B, 'V'),
+ (0x1E7C, 'M', 'ṽ'),
+ (0x1E7D, 'V'),
+ (0x1E7E, 'M', 'ṿ'),
+ (0x1E7F, 'V'),
+ (0x1E80, 'M', 'ẁ'),
+ (0x1E81, 'V'),
+ (0x1E82, 'M', 'ẃ'),
+ (0x1E83, 'V'),
+ (0x1E84, 'M', 'ẅ'),
+ (0x1E85, 'V'),
+ (0x1E86, 'M', 'ẇ'),
+ (0x1E87, 'V'),
+ ]
+
+def _seg_18() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1E88, 'M', 'ẉ'),
+ (0x1E89, 'V'),
+ (0x1E8A, 'M', 'ẋ'),
+ (0x1E8B, 'V'),
+ (0x1E8C, 'M', 'ẍ'),
+ (0x1E8D, 'V'),
+ (0x1E8E, 'M', 'ẏ'),
+ (0x1E8F, 'V'),
+ (0x1E90, 'M', 'ẑ'),
+ (0x1E91, 'V'),
+ (0x1E92, 'M', 'ẓ'),
+ (0x1E93, 'V'),
+ (0x1E94, 'M', 'ẕ'),
+ (0x1E95, 'V'),
+ (0x1E9A, 'M', 'aʾ'),
+ (0x1E9B, 'M', 'ṡ'),
+ (0x1E9C, 'V'),
+ (0x1E9E, 'M', 'ß'),
+ (0x1E9F, 'V'),
+ (0x1EA0, 'M', 'ạ'),
+ (0x1EA1, 'V'),
+ (0x1EA2, 'M', 'ả'),
+ (0x1EA3, 'V'),
+ (0x1EA4, 'M', 'ấ'),
+ (0x1EA5, 'V'),
+ (0x1EA6, 'M', 'ầ'),
+ (0x1EA7, 'V'),
+ (0x1EA8, 'M', 'ẩ'),
+ (0x1EA9, 'V'),
+ (0x1EAA, 'M', 'ẫ'),
+ (0x1EAB, 'V'),
+ (0x1EAC, 'M', 'ậ'),
+ (0x1EAD, 'V'),
+ (0x1EAE, 'M', 'ắ'),
+ (0x1EAF, 'V'),
+ (0x1EB0, 'M', 'ằ'),
+ (0x1EB1, 'V'),
+ (0x1EB2, 'M', 'ẳ'),
+ (0x1EB3, 'V'),
+ (0x1EB4, 'M', 'ẵ'),
+ (0x1EB5, 'V'),
+ (0x1EB6, 'M', 'ặ'),
+ (0x1EB7, 'V'),
+ (0x1EB8, 'M', 'ẹ'),
+ (0x1EB9, 'V'),
+ (0x1EBA, 'M', 'ẻ'),
+ (0x1EBB, 'V'),
+ (0x1EBC, 'M', 'ẽ'),
+ (0x1EBD, 'V'),
+ (0x1EBE, 'M', 'ế'),
+ (0x1EBF, 'V'),
+ (0x1EC0, 'M', 'ề'),
+ (0x1EC1, 'V'),
+ (0x1EC2, 'M', 'ể'),
+ (0x1EC3, 'V'),
+ (0x1EC4, 'M', 'ễ'),
+ (0x1EC5, 'V'),
+ (0x1EC6, 'M', 'ệ'),
+ (0x1EC7, 'V'),
+ (0x1EC8, 'M', 'ỉ'),
+ (0x1EC9, 'V'),
+ (0x1ECA, 'M', 'ị'),
+ (0x1ECB, 'V'),
+ (0x1ECC, 'M', 'ọ'),
+ (0x1ECD, 'V'),
+ (0x1ECE, 'M', 'ỏ'),
+ (0x1ECF, 'V'),
+ (0x1ED0, 'M', 'ố'),
+ (0x1ED1, 'V'),
+ (0x1ED2, 'M', 'ồ'),
+ (0x1ED3, 'V'),
+ (0x1ED4, 'M', 'ổ'),
+ (0x1ED5, 'V'),
+ (0x1ED6, 'M', 'ỗ'),
+ (0x1ED7, 'V'),
+ (0x1ED8, 'M', 'ộ'),
+ (0x1ED9, 'V'),
+ (0x1EDA, 'M', 'ớ'),
+ (0x1EDB, 'V'),
+ (0x1EDC, 'M', 'ờ'),
+ (0x1EDD, 'V'),
+ (0x1EDE, 'M', 'ở'),
+ (0x1EDF, 'V'),
+ (0x1EE0, 'M', 'ỡ'),
+ (0x1EE1, 'V'),
+ (0x1EE2, 'M', 'ợ'),
+ (0x1EE3, 'V'),
+ (0x1EE4, 'M', 'ụ'),
+ (0x1EE5, 'V'),
+ (0x1EE6, 'M', 'ủ'),
+ (0x1EE7, 'V'),
+ (0x1EE8, 'M', 'ứ'),
+ (0x1EE9, 'V'),
+ (0x1EEA, 'M', 'ừ'),
+ (0x1EEB, 'V'),
+ (0x1EEC, 'M', 'ử'),
+ (0x1EED, 'V'),
+ (0x1EEE, 'M', 'ữ'),
+ (0x1EEF, 'V'),
+ (0x1EF0, 'M', 'ự'),
+ ]
+
+def _seg_19() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1EF1, 'V'),
+ (0x1EF2, 'M', 'ỳ'),
+ (0x1EF3, 'V'),
+ (0x1EF4, 'M', 'ỵ'),
+ (0x1EF5, 'V'),
+ (0x1EF6, 'M', 'ỷ'),
+ (0x1EF7, 'V'),
+ (0x1EF8, 'M', 'ỹ'),
+ (0x1EF9, 'V'),
+ (0x1EFA, 'M', 'ỻ'),
+ (0x1EFB, 'V'),
+ (0x1EFC, 'M', 'ỽ'),
+ (0x1EFD, 'V'),
+ (0x1EFE, 'M', 'ỿ'),
+ (0x1EFF, 'V'),
+ (0x1F08, 'M', 'ἀ'),
+ (0x1F09, 'M', 'ἁ'),
+ (0x1F0A, 'M', 'ἂ'),
+ (0x1F0B, 'M', 'ἃ'),
+ (0x1F0C, 'M', 'ἄ'),
+ (0x1F0D, 'M', 'ἅ'),
+ (0x1F0E, 'M', 'ἆ'),
+ (0x1F0F, 'M', 'ἇ'),
+ (0x1F10, 'V'),
+ (0x1F16, 'X'),
+ (0x1F18, 'M', 'ἐ'),
+ (0x1F19, 'M', 'ἑ'),
+ (0x1F1A, 'M', 'ἒ'),
+ (0x1F1B, 'M', 'ἓ'),
+ (0x1F1C, 'M', 'ἔ'),
+ (0x1F1D, 'M', 'ἕ'),
+ (0x1F1E, 'X'),
+ (0x1F20, 'V'),
+ (0x1F28, 'M', 'ἠ'),
+ (0x1F29, 'M', 'ἡ'),
+ (0x1F2A, 'M', 'ἢ'),
+ (0x1F2B, 'M', 'ἣ'),
+ (0x1F2C, 'M', 'ἤ'),
+ (0x1F2D, 'M', 'ἥ'),
+ (0x1F2E, 'M', 'ἦ'),
+ (0x1F2F, 'M', 'ἧ'),
+ (0x1F30, 'V'),
+ (0x1F38, 'M', 'ἰ'),
+ (0x1F39, 'M', 'ἱ'),
+ (0x1F3A, 'M', 'ἲ'),
+ (0x1F3B, 'M', 'ἳ'),
+ (0x1F3C, 'M', 'ἴ'),
+ (0x1F3D, 'M', 'ἵ'),
+ (0x1F3E, 'M', 'ἶ'),
+ (0x1F3F, 'M', 'ἷ'),
+ (0x1F40, 'V'),
+ (0x1F46, 'X'),
+ (0x1F48, 'M', 'ὀ'),
+ (0x1F49, 'M', 'ὁ'),
+ (0x1F4A, 'M', 'ὂ'),
+ (0x1F4B, 'M', 'ὃ'),
+ (0x1F4C, 'M', 'ὄ'),
+ (0x1F4D, 'M', 'ὅ'),
+ (0x1F4E, 'X'),
+ (0x1F50, 'V'),
+ (0x1F58, 'X'),
+ (0x1F59, 'M', 'ὑ'),
+ (0x1F5A, 'X'),
+ (0x1F5B, 'M', 'ὓ'),
+ (0x1F5C, 'X'),
+ (0x1F5D, 'M', 'ὕ'),
+ (0x1F5E, 'X'),
+ (0x1F5F, 'M', 'ὗ'),
+ (0x1F60, 'V'),
+ (0x1F68, 'M', 'ὠ'),
+ (0x1F69, 'M', 'ὡ'),
+ (0x1F6A, 'M', 'ὢ'),
+ (0x1F6B, 'M', 'ὣ'),
+ (0x1F6C, 'M', 'ὤ'),
+ (0x1F6D, 'M', 'ὥ'),
+ (0x1F6E, 'M', 'ὦ'),
+ (0x1F6F, 'M', 'ὧ'),
+ (0x1F70, 'V'),
+ (0x1F71, 'M', 'ά'),
+ (0x1F72, 'V'),
+ (0x1F73, 'M', 'έ'),
+ (0x1F74, 'V'),
+ (0x1F75, 'M', 'ή'),
+ (0x1F76, 'V'),
+ (0x1F77, 'M', 'ί'),
+ (0x1F78, 'V'),
+ (0x1F79, 'M', 'ό'),
+ (0x1F7A, 'V'),
+ (0x1F7B, 'M', 'ύ'),
+ (0x1F7C, 'V'),
+ (0x1F7D, 'M', 'ώ'),
+ (0x1F7E, 'X'),
+ (0x1F80, 'M', 'ἀι'),
+ (0x1F81, 'M', 'ἁι'),
+ (0x1F82, 'M', 'ἂι'),
+ (0x1F83, 'M', 'ἃι'),
+ (0x1F84, 'M', 'ἄι'),
+ (0x1F85, 'M', 'ἅι'),
+ (0x1F86, 'M', 'ἆι'),
+ (0x1F87, 'M', 'ἇι'),
+ ]
+
+def _seg_20() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1F88, 'M', 'ἀι'),
+ (0x1F89, 'M', 'ἁι'),
+ (0x1F8A, 'M', 'ἂι'),
+ (0x1F8B, 'M', 'ἃι'),
+ (0x1F8C, 'M', 'ἄι'),
+ (0x1F8D, 'M', 'ἅι'),
+ (0x1F8E, 'M', 'ἆι'),
+ (0x1F8F, 'M', 'ἇι'),
+ (0x1F90, 'M', 'ἠι'),
+ (0x1F91, 'M', 'ἡι'),
+ (0x1F92, 'M', 'ἢι'),
+ (0x1F93, 'M', 'ἣι'),
+ (0x1F94, 'M', 'ἤι'),
+ (0x1F95, 'M', 'ἥι'),
+ (0x1F96, 'M', 'ἦι'),
+ (0x1F97, 'M', 'ἧι'),
+ (0x1F98, 'M', 'ἠι'),
+ (0x1F99, 'M', 'ἡι'),
+ (0x1F9A, 'M', 'ἢι'),
+ (0x1F9B, 'M', 'ἣι'),
+ (0x1F9C, 'M', 'ἤι'),
+ (0x1F9D, 'M', 'ἥι'),
+ (0x1F9E, 'M', 'ἦι'),
+ (0x1F9F, 'M', 'ἧι'),
+ (0x1FA0, 'M', 'ὠι'),
+ (0x1FA1, 'M', 'ὡι'),
+ (0x1FA2, 'M', 'ὢι'),
+ (0x1FA3, 'M', 'ὣι'),
+ (0x1FA4, 'M', 'ὤι'),
+ (0x1FA5, 'M', 'ὥι'),
+ (0x1FA6, 'M', 'ὦι'),
+ (0x1FA7, 'M', 'ὧι'),
+ (0x1FA8, 'M', 'ὠι'),
+ (0x1FA9, 'M', 'ὡι'),
+ (0x1FAA, 'M', 'ὢι'),
+ (0x1FAB, 'M', 'ὣι'),
+ (0x1FAC, 'M', 'ὤι'),
+ (0x1FAD, 'M', 'ὥι'),
+ (0x1FAE, 'M', 'ὦι'),
+ (0x1FAF, 'M', 'ὧι'),
+ (0x1FB0, 'V'),
+ (0x1FB2, 'M', 'ὰι'),
+ (0x1FB3, 'M', 'αι'),
+ (0x1FB4, 'M', 'άι'),
+ (0x1FB5, 'X'),
+ (0x1FB6, 'V'),
+ (0x1FB7, 'M', 'ᾶι'),
+ (0x1FB8, 'M', 'ᾰ'),
+ (0x1FB9, 'M', 'ᾱ'),
+ (0x1FBA, 'M', 'ὰ'),
+ (0x1FBB, 'M', 'ά'),
+ (0x1FBC, 'M', 'αι'),
+ (0x1FBD, '3', ' ̓'),
+ (0x1FBE, 'M', 'ι'),
+ (0x1FBF, '3', ' ̓'),
+ (0x1FC0, '3', ' ͂'),
+ (0x1FC1, '3', ' ̈͂'),
+ (0x1FC2, 'M', 'ὴι'),
+ (0x1FC3, 'M', 'ηι'),
+ (0x1FC4, 'M', 'ήι'),
+ (0x1FC5, 'X'),
+ (0x1FC6, 'V'),
+ (0x1FC7, 'M', 'ῆι'),
+ (0x1FC8, 'M', 'ὲ'),
+ (0x1FC9, 'M', 'έ'),
+ (0x1FCA, 'M', 'ὴ'),
+ (0x1FCB, 'M', 'ή'),
+ (0x1FCC, 'M', 'ηι'),
+ (0x1FCD, '3', ' ̓̀'),
+ (0x1FCE, '3', ' ̓́'),
+ (0x1FCF, '3', ' ̓͂'),
+ (0x1FD0, 'V'),
+ (0x1FD3, 'M', 'ΐ'),
+ (0x1FD4, 'X'),
+ (0x1FD6, 'V'),
+ (0x1FD8, 'M', 'ῐ'),
+ (0x1FD9, 'M', 'ῑ'),
+ (0x1FDA, 'M', 'ὶ'),
+ (0x1FDB, 'M', 'ί'),
+ (0x1FDC, 'X'),
+ (0x1FDD, '3', ' ̔̀'),
+ (0x1FDE, '3', ' ̔́'),
+ (0x1FDF, '3', ' ̔͂'),
+ (0x1FE0, 'V'),
+ (0x1FE3, 'M', 'ΰ'),
+ (0x1FE4, 'V'),
+ (0x1FE8, 'M', 'ῠ'),
+ (0x1FE9, 'M', 'ῡ'),
+ (0x1FEA, 'M', 'ὺ'),
+ (0x1FEB, 'M', 'ύ'),
+ (0x1FEC, 'M', 'ῥ'),
+ (0x1FED, '3', ' ̈̀'),
+ (0x1FEE, '3', ' ̈́'),
+ (0x1FEF, '3', '`'),
+ (0x1FF0, 'X'),
+ (0x1FF2, 'M', 'ὼι'),
+ (0x1FF3, 'M', 'ωι'),
+ (0x1FF4, 'M', 'ώι'),
+ (0x1FF5, 'X'),
+ (0x1FF6, 'V'),
+ ]
+
+def _seg_21() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1FF7, 'M', 'ῶι'),
+ (0x1FF8, 'M', 'ὸ'),
+ (0x1FF9, 'M', 'ό'),
+ (0x1FFA, 'M', 'ὼ'),
+ (0x1FFB, 'M', 'ώ'),
+ (0x1FFC, 'M', 'ωι'),
+ (0x1FFD, '3', ' ́'),
+ (0x1FFE, '3', ' ̔'),
+ (0x1FFF, 'X'),
+ (0x2000, '3', ' '),
+ (0x200B, 'I'),
+ (0x200C, 'D', ''),
+ (0x200E, 'X'),
+ (0x2010, 'V'),
+ (0x2011, 'M', '‐'),
+ (0x2012, 'V'),
+ (0x2017, '3', ' ̳'),
+ (0x2018, 'V'),
+ (0x2024, 'X'),
+ (0x2027, 'V'),
+ (0x2028, 'X'),
+ (0x202F, '3', ' '),
+ (0x2030, 'V'),
+ (0x2033, 'M', '′′'),
+ (0x2034, 'M', '′′′'),
+ (0x2035, 'V'),
+ (0x2036, 'M', '‵‵'),
+ (0x2037, 'M', '‵‵‵'),
+ (0x2038, 'V'),
+ (0x203C, '3', '!!'),
+ (0x203D, 'V'),
+ (0x203E, '3', ' ̅'),
+ (0x203F, 'V'),
+ (0x2047, '3', '??'),
+ (0x2048, '3', '?!'),
+ (0x2049, '3', '!?'),
+ (0x204A, 'V'),
+ (0x2057, 'M', '′′′′'),
+ (0x2058, 'V'),
+ (0x205F, '3', ' '),
+ (0x2060, 'I'),
+ (0x2061, 'X'),
+ (0x2064, 'I'),
+ (0x2065, 'X'),
+ (0x2070, 'M', '0'),
+ (0x2071, 'M', 'i'),
+ (0x2072, 'X'),
+ (0x2074, 'M', '4'),
+ (0x2075, 'M', '5'),
+ (0x2076, 'M', '6'),
+ (0x2077, 'M', '7'),
+ (0x2078, 'M', '8'),
+ (0x2079, 'M', '9'),
+ (0x207A, '3', '+'),
+ (0x207B, 'M', '−'),
+ (0x207C, '3', '='),
+ (0x207D, '3', '('),
+ (0x207E, '3', ')'),
+ (0x207F, 'M', 'n'),
+ (0x2080, 'M', '0'),
+ (0x2081, 'M', '1'),
+ (0x2082, 'M', '2'),
+ (0x2083, 'M', '3'),
+ (0x2084, 'M', '4'),
+ (0x2085, 'M', '5'),
+ (0x2086, 'M', '6'),
+ (0x2087, 'M', '7'),
+ (0x2088, 'M', '8'),
+ (0x2089, 'M', '9'),
+ (0x208A, '3', '+'),
+ (0x208B, 'M', '−'),
+ (0x208C, '3', '='),
+ (0x208D, '3', '('),
+ (0x208E, '3', ')'),
+ (0x208F, 'X'),
+ (0x2090, 'M', 'a'),
+ (0x2091, 'M', 'e'),
+ (0x2092, 'M', 'o'),
+ (0x2093, 'M', 'x'),
+ (0x2094, 'M', 'ə'),
+ (0x2095, 'M', 'h'),
+ (0x2096, 'M', 'k'),
+ (0x2097, 'M', 'l'),
+ (0x2098, 'M', 'm'),
+ (0x2099, 'M', 'n'),
+ (0x209A, 'M', 'p'),
+ (0x209B, 'M', 's'),
+ (0x209C, 'M', 't'),
+ (0x209D, 'X'),
+ (0x20A0, 'V'),
+ (0x20A8, 'M', 'rs'),
+ (0x20A9, 'V'),
+ (0x20C1, 'X'),
+ (0x20D0, 'V'),
+ (0x20F1, 'X'),
+ (0x2100, '3', 'a/c'),
+ (0x2101, '3', 'a/s'),
+ (0x2102, 'M', 'c'),
+ (0x2103, 'M', '°c'),
+ (0x2104, 'V'),
+ ]
+
+def _seg_22() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2105, '3', 'c/o'),
+ (0x2106, '3', 'c/u'),
+ (0x2107, 'M', 'ɛ'),
+ (0x2108, 'V'),
+ (0x2109, 'M', '°f'),
+ (0x210A, 'M', 'g'),
+ (0x210B, 'M', 'h'),
+ (0x210F, 'M', 'ħ'),
+ (0x2110, 'M', 'i'),
+ (0x2112, 'M', 'l'),
+ (0x2114, 'V'),
+ (0x2115, 'M', 'n'),
+ (0x2116, 'M', 'no'),
+ (0x2117, 'V'),
+ (0x2119, 'M', 'p'),
+ (0x211A, 'M', 'q'),
+ (0x211B, 'M', 'r'),
+ (0x211E, 'V'),
+ (0x2120, 'M', 'sm'),
+ (0x2121, 'M', 'tel'),
+ (0x2122, 'M', 'tm'),
+ (0x2123, 'V'),
+ (0x2124, 'M', 'z'),
+ (0x2125, 'V'),
+ (0x2126, 'M', 'ω'),
+ (0x2127, 'V'),
+ (0x2128, 'M', 'z'),
+ (0x2129, 'V'),
+ (0x212A, 'M', 'k'),
+ (0x212B, 'M', 'å'),
+ (0x212C, 'M', 'b'),
+ (0x212D, 'M', 'c'),
+ (0x212E, 'V'),
+ (0x212F, 'M', 'e'),
+ (0x2131, 'M', 'f'),
+ (0x2132, 'X'),
+ (0x2133, 'M', 'm'),
+ (0x2134, 'M', 'o'),
+ (0x2135, 'M', 'א'),
+ (0x2136, 'M', 'ב'),
+ (0x2137, 'M', 'ג'),
+ (0x2138, 'M', 'ד'),
+ (0x2139, 'M', 'i'),
+ (0x213A, 'V'),
+ (0x213B, 'M', 'fax'),
+ (0x213C, 'M', 'π'),
+ (0x213D, 'M', 'γ'),
+ (0x213F, 'M', 'π'),
+ (0x2140, 'M', '∑'),
+ (0x2141, 'V'),
+ (0x2145, 'M', 'd'),
+ (0x2147, 'M', 'e'),
+ (0x2148, 'M', 'i'),
+ (0x2149, 'M', 'j'),
+ (0x214A, 'V'),
+ (0x2150, 'M', '1⁄7'),
+ (0x2151, 'M', '1⁄9'),
+ (0x2152, 'M', '1⁄10'),
+ (0x2153, 'M', '1⁄3'),
+ (0x2154, 'M', '2⁄3'),
+ (0x2155, 'M', '1⁄5'),
+ (0x2156, 'M', '2⁄5'),
+ (0x2157, 'M', '3⁄5'),
+ (0x2158, 'M', '4⁄5'),
+ (0x2159, 'M', '1⁄6'),
+ (0x215A, 'M', '5⁄6'),
+ (0x215B, 'M', '1⁄8'),
+ (0x215C, 'M', '3⁄8'),
+ (0x215D, 'M', '5⁄8'),
+ (0x215E, 'M', '7⁄8'),
+ (0x215F, 'M', '1⁄'),
+ (0x2160, 'M', 'i'),
+ (0x2161, 'M', 'ii'),
+ (0x2162, 'M', 'iii'),
+ (0x2163, 'M', 'iv'),
+ (0x2164, 'M', 'v'),
+ (0x2165, 'M', 'vi'),
+ (0x2166, 'M', 'vii'),
+ (0x2167, 'M', 'viii'),
+ (0x2168, 'M', 'ix'),
+ (0x2169, 'M', 'x'),
+ (0x216A, 'M', 'xi'),
+ (0x216B, 'M', 'xii'),
+ (0x216C, 'M', 'l'),
+ (0x216D, 'M', 'c'),
+ (0x216E, 'M', 'd'),
+ (0x216F, 'M', 'm'),
+ (0x2170, 'M', 'i'),
+ (0x2171, 'M', 'ii'),
+ (0x2172, 'M', 'iii'),
+ (0x2173, 'M', 'iv'),
+ (0x2174, 'M', 'v'),
+ (0x2175, 'M', 'vi'),
+ (0x2176, 'M', 'vii'),
+ (0x2177, 'M', 'viii'),
+ (0x2178, 'M', 'ix'),
+ (0x2179, 'M', 'x'),
+ (0x217A, 'M', 'xi'),
+ (0x217B, 'M', 'xii'),
+ (0x217C, 'M', 'l'),
+ ]
+
+def _seg_23() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x217D, 'M', 'c'),
+ (0x217E, 'M', 'd'),
+ (0x217F, 'M', 'm'),
+ (0x2180, 'V'),
+ (0x2183, 'X'),
+ (0x2184, 'V'),
+ (0x2189, 'M', '0⁄3'),
+ (0x218A, 'V'),
+ (0x218C, 'X'),
+ (0x2190, 'V'),
+ (0x222C, 'M', '∫∫'),
+ (0x222D, 'M', '∫∫∫'),
+ (0x222E, 'V'),
+ (0x222F, 'M', '∮∮'),
+ (0x2230, 'M', '∮∮∮'),
+ (0x2231, 'V'),
+ (0x2329, 'M', '〈'),
+ (0x232A, 'M', '〉'),
+ (0x232B, 'V'),
+ (0x2427, 'X'),
+ (0x2440, 'V'),
+ (0x244B, 'X'),
+ (0x2460, 'M', '1'),
+ (0x2461, 'M', '2'),
+ (0x2462, 'M', '3'),
+ (0x2463, 'M', '4'),
+ (0x2464, 'M', '5'),
+ (0x2465, 'M', '6'),
+ (0x2466, 'M', '7'),
+ (0x2467, 'M', '8'),
+ (0x2468, 'M', '9'),
+ (0x2469, 'M', '10'),
+ (0x246A, 'M', '11'),
+ (0x246B, 'M', '12'),
+ (0x246C, 'M', '13'),
+ (0x246D, 'M', '14'),
+ (0x246E, 'M', '15'),
+ (0x246F, 'M', '16'),
+ (0x2470, 'M', '17'),
+ (0x2471, 'M', '18'),
+ (0x2472, 'M', '19'),
+ (0x2473, 'M', '20'),
+ (0x2474, '3', '(1)'),
+ (0x2475, '3', '(2)'),
+ (0x2476, '3', '(3)'),
+ (0x2477, '3', '(4)'),
+ (0x2478, '3', '(5)'),
+ (0x2479, '3', '(6)'),
+ (0x247A, '3', '(7)'),
+ (0x247B, '3', '(8)'),
+ (0x247C, '3', '(9)'),
+ (0x247D, '3', '(10)'),
+ (0x247E, '3', '(11)'),
+ (0x247F, '3', '(12)'),
+ (0x2480, '3', '(13)'),
+ (0x2481, '3', '(14)'),
+ (0x2482, '3', '(15)'),
+ (0x2483, '3', '(16)'),
+ (0x2484, '3', '(17)'),
+ (0x2485, '3', '(18)'),
+ (0x2486, '3', '(19)'),
+ (0x2487, '3', '(20)'),
+ (0x2488, 'X'),
+ (0x249C, '3', '(a)'),
+ (0x249D, '3', '(b)'),
+ (0x249E, '3', '(c)'),
+ (0x249F, '3', '(d)'),
+ (0x24A0, '3', '(e)'),
+ (0x24A1, '3', '(f)'),
+ (0x24A2, '3', '(g)'),
+ (0x24A3, '3', '(h)'),
+ (0x24A4, '3', '(i)'),
+ (0x24A5, '3', '(j)'),
+ (0x24A6, '3', '(k)'),
+ (0x24A7, '3', '(l)'),
+ (0x24A8, '3', '(m)'),
+ (0x24A9, '3', '(n)'),
+ (0x24AA, '3', '(o)'),
+ (0x24AB, '3', '(p)'),
+ (0x24AC, '3', '(q)'),
+ (0x24AD, '3', '(r)'),
+ (0x24AE, '3', '(s)'),
+ (0x24AF, '3', '(t)'),
+ (0x24B0, '3', '(u)'),
+ (0x24B1, '3', '(v)'),
+ (0x24B2, '3', '(w)'),
+ (0x24B3, '3', '(x)'),
+ (0x24B4, '3', '(y)'),
+ (0x24B5, '3', '(z)'),
+ (0x24B6, 'M', 'a'),
+ (0x24B7, 'M', 'b'),
+ (0x24B8, 'M', 'c'),
+ (0x24B9, 'M', 'd'),
+ (0x24BA, 'M', 'e'),
+ (0x24BB, 'M', 'f'),
+ (0x24BC, 'M', 'g'),
+ (0x24BD, 'M', 'h'),
+ (0x24BE, 'M', 'i'),
+ (0x24BF, 'M', 'j'),
+ (0x24C0, 'M', 'k'),
+ ]
+
+def _seg_24() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x24C1, 'M', 'l'),
+ (0x24C2, 'M', 'm'),
+ (0x24C3, 'M', 'n'),
+ (0x24C4, 'M', 'o'),
+ (0x24C5, 'M', 'p'),
+ (0x24C6, 'M', 'q'),
+ (0x24C7, 'M', 'r'),
+ (0x24C8, 'M', 's'),
+ (0x24C9, 'M', 't'),
+ (0x24CA, 'M', 'u'),
+ (0x24CB, 'M', 'v'),
+ (0x24CC, 'M', 'w'),
+ (0x24CD, 'M', 'x'),
+ (0x24CE, 'M', 'y'),
+ (0x24CF, 'M', 'z'),
+ (0x24D0, 'M', 'a'),
+ (0x24D1, 'M', 'b'),
+ (0x24D2, 'M', 'c'),
+ (0x24D3, 'M', 'd'),
+ (0x24D4, 'M', 'e'),
+ (0x24D5, 'M', 'f'),
+ (0x24D6, 'M', 'g'),
+ (0x24D7, 'M', 'h'),
+ (0x24D8, 'M', 'i'),
+ (0x24D9, 'M', 'j'),
+ (0x24DA, 'M', 'k'),
+ (0x24DB, 'M', 'l'),
+ (0x24DC, 'M', 'm'),
+ (0x24DD, 'M', 'n'),
+ (0x24DE, 'M', 'o'),
+ (0x24DF, 'M', 'p'),
+ (0x24E0, 'M', 'q'),
+ (0x24E1, 'M', 'r'),
+ (0x24E2, 'M', 's'),
+ (0x24E3, 'M', 't'),
+ (0x24E4, 'M', 'u'),
+ (0x24E5, 'M', 'v'),
+ (0x24E6, 'M', 'w'),
+ (0x24E7, 'M', 'x'),
+ (0x24E8, 'M', 'y'),
+ (0x24E9, 'M', 'z'),
+ (0x24EA, 'M', '0'),
+ (0x24EB, 'V'),
+ (0x2A0C, 'M', '∫∫∫∫'),
+ (0x2A0D, 'V'),
+ (0x2A74, '3', '::='),
+ (0x2A75, '3', '=='),
+ (0x2A76, '3', '==='),
+ (0x2A77, 'V'),
+ (0x2ADC, 'M', '⫝̸'),
+ (0x2ADD, 'V'),
+ (0x2B74, 'X'),
+ (0x2B76, 'V'),
+ (0x2B96, 'X'),
+ (0x2B97, 'V'),
+ (0x2C00, 'M', 'ⰰ'),
+ (0x2C01, 'M', 'ⰱ'),
+ (0x2C02, 'M', 'ⰲ'),
+ (0x2C03, 'M', 'ⰳ'),
+ (0x2C04, 'M', 'ⰴ'),
+ (0x2C05, 'M', 'ⰵ'),
+ (0x2C06, 'M', 'ⰶ'),
+ (0x2C07, 'M', 'ⰷ'),
+ (0x2C08, 'M', 'ⰸ'),
+ (0x2C09, 'M', 'ⰹ'),
+ (0x2C0A, 'M', 'ⰺ'),
+ (0x2C0B, 'M', 'ⰻ'),
+ (0x2C0C, 'M', 'ⰼ'),
+ (0x2C0D, 'M', 'ⰽ'),
+ (0x2C0E, 'M', 'ⰾ'),
+ (0x2C0F, 'M', 'ⰿ'),
+ (0x2C10, 'M', 'ⱀ'),
+ (0x2C11, 'M', 'ⱁ'),
+ (0x2C12, 'M', 'ⱂ'),
+ (0x2C13, 'M', 'ⱃ'),
+ (0x2C14, 'M', 'ⱄ'),
+ (0x2C15, 'M', 'ⱅ'),
+ (0x2C16, 'M', 'ⱆ'),
+ (0x2C17, 'M', 'ⱇ'),
+ (0x2C18, 'M', 'ⱈ'),
+ (0x2C19, 'M', 'ⱉ'),
+ (0x2C1A, 'M', 'ⱊ'),
+ (0x2C1B, 'M', 'ⱋ'),
+ (0x2C1C, 'M', 'ⱌ'),
+ (0x2C1D, 'M', 'ⱍ'),
+ (0x2C1E, 'M', 'ⱎ'),
+ (0x2C1F, 'M', 'ⱏ'),
+ (0x2C20, 'M', 'ⱐ'),
+ (0x2C21, 'M', 'ⱑ'),
+ (0x2C22, 'M', 'ⱒ'),
+ (0x2C23, 'M', 'ⱓ'),
+ (0x2C24, 'M', 'ⱔ'),
+ (0x2C25, 'M', 'ⱕ'),
+ (0x2C26, 'M', 'ⱖ'),
+ (0x2C27, 'M', 'ⱗ'),
+ (0x2C28, 'M', 'ⱘ'),
+ (0x2C29, 'M', 'ⱙ'),
+ (0x2C2A, 'M', 'ⱚ'),
+ (0x2C2B, 'M', 'ⱛ'),
+ (0x2C2C, 'M', 'ⱜ'),
+ ]
+
+def _seg_25() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2C2D, 'M', 'ⱝ'),
+ (0x2C2E, 'M', 'ⱞ'),
+ (0x2C2F, 'M', 'ⱟ'),
+ (0x2C30, 'V'),
+ (0x2C60, 'M', 'ⱡ'),
+ (0x2C61, 'V'),
+ (0x2C62, 'M', 'ɫ'),
+ (0x2C63, 'M', 'ᵽ'),
+ (0x2C64, 'M', 'ɽ'),
+ (0x2C65, 'V'),
+ (0x2C67, 'M', 'ⱨ'),
+ (0x2C68, 'V'),
+ (0x2C69, 'M', 'ⱪ'),
+ (0x2C6A, 'V'),
+ (0x2C6B, 'M', 'ⱬ'),
+ (0x2C6C, 'V'),
+ (0x2C6D, 'M', 'ɑ'),
+ (0x2C6E, 'M', 'ɱ'),
+ (0x2C6F, 'M', 'ɐ'),
+ (0x2C70, 'M', 'ɒ'),
+ (0x2C71, 'V'),
+ (0x2C72, 'M', 'ⱳ'),
+ (0x2C73, 'V'),
+ (0x2C75, 'M', 'ⱶ'),
+ (0x2C76, 'V'),
+ (0x2C7C, 'M', 'j'),
+ (0x2C7D, 'M', 'v'),
+ (0x2C7E, 'M', 'ȿ'),
+ (0x2C7F, 'M', 'ɀ'),
+ (0x2C80, 'M', 'ⲁ'),
+ (0x2C81, 'V'),
+ (0x2C82, 'M', 'ⲃ'),
+ (0x2C83, 'V'),
+ (0x2C84, 'M', 'ⲅ'),
+ (0x2C85, 'V'),
+ (0x2C86, 'M', 'ⲇ'),
+ (0x2C87, 'V'),
+ (0x2C88, 'M', 'ⲉ'),
+ (0x2C89, 'V'),
+ (0x2C8A, 'M', 'ⲋ'),
+ (0x2C8B, 'V'),
+ (0x2C8C, 'M', 'ⲍ'),
+ (0x2C8D, 'V'),
+ (0x2C8E, 'M', 'ⲏ'),
+ (0x2C8F, 'V'),
+ (0x2C90, 'M', 'ⲑ'),
+ (0x2C91, 'V'),
+ (0x2C92, 'M', 'ⲓ'),
+ (0x2C93, 'V'),
+ (0x2C94, 'M', 'ⲕ'),
+ (0x2C95, 'V'),
+ (0x2C96, 'M', 'ⲗ'),
+ (0x2C97, 'V'),
+ (0x2C98, 'M', 'ⲙ'),
+ (0x2C99, 'V'),
+ (0x2C9A, 'M', 'ⲛ'),
+ (0x2C9B, 'V'),
+ (0x2C9C, 'M', 'ⲝ'),
+ (0x2C9D, 'V'),
+ (0x2C9E, 'M', 'ⲟ'),
+ (0x2C9F, 'V'),
+ (0x2CA0, 'M', 'ⲡ'),
+ (0x2CA1, 'V'),
+ (0x2CA2, 'M', 'ⲣ'),
+ (0x2CA3, 'V'),
+ (0x2CA4, 'M', 'ⲥ'),
+ (0x2CA5, 'V'),
+ (0x2CA6, 'M', 'ⲧ'),
+ (0x2CA7, 'V'),
+ (0x2CA8, 'M', 'ⲩ'),
+ (0x2CA9, 'V'),
+ (0x2CAA, 'M', 'ⲫ'),
+ (0x2CAB, 'V'),
+ (0x2CAC, 'M', 'ⲭ'),
+ (0x2CAD, 'V'),
+ (0x2CAE, 'M', 'ⲯ'),
+ (0x2CAF, 'V'),
+ (0x2CB0, 'M', 'ⲱ'),
+ (0x2CB1, 'V'),
+ (0x2CB2, 'M', 'ⲳ'),
+ (0x2CB3, 'V'),
+ (0x2CB4, 'M', 'ⲵ'),
+ (0x2CB5, 'V'),
+ (0x2CB6, 'M', 'ⲷ'),
+ (0x2CB7, 'V'),
+ (0x2CB8, 'M', 'ⲹ'),
+ (0x2CB9, 'V'),
+ (0x2CBA, 'M', 'ⲻ'),
+ (0x2CBB, 'V'),
+ (0x2CBC, 'M', 'ⲽ'),
+ (0x2CBD, 'V'),
+ (0x2CBE, 'M', 'ⲿ'),
+ (0x2CBF, 'V'),
+ (0x2CC0, 'M', 'ⳁ'),
+ (0x2CC1, 'V'),
+ (0x2CC2, 'M', 'ⳃ'),
+ (0x2CC3, 'V'),
+ (0x2CC4, 'M', 'ⳅ'),
+ (0x2CC5, 'V'),
+ (0x2CC6, 'M', 'ⳇ'),
+ ]
+
+def _seg_26() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2CC7, 'V'),
+ (0x2CC8, 'M', 'ⳉ'),
+ (0x2CC9, 'V'),
+ (0x2CCA, 'M', 'ⳋ'),
+ (0x2CCB, 'V'),
+ (0x2CCC, 'M', 'ⳍ'),
+ (0x2CCD, 'V'),
+ (0x2CCE, 'M', 'ⳏ'),
+ (0x2CCF, 'V'),
+ (0x2CD0, 'M', 'ⳑ'),
+ (0x2CD1, 'V'),
+ (0x2CD2, 'M', 'ⳓ'),
+ (0x2CD3, 'V'),
+ (0x2CD4, 'M', 'ⳕ'),
+ (0x2CD5, 'V'),
+ (0x2CD6, 'M', 'ⳗ'),
+ (0x2CD7, 'V'),
+ (0x2CD8, 'M', 'ⳙ'),
+ (0x2CD9, 'V'),
+ (0x2CDA, 'M', 'ⳛ'),
+ (0x2CDB, 'V'),
+ (0x2CDC, 'M', 'ⳝ'),
+ (0x2CDD, 'V'),
+ (0x2CDE, 'M', 'ⳟ'),
+ (0x2CDF, 'V'),
+ (0x2CE0, 'M', 'ⳡ'),
+ (0x2CE1, 'V'),
+ (0x2CE2, 'M', 'ⳣ'),
+ (0x2CE3, 'V'),
+ (0x2CEB, 'M', 'ⳬ'),
+ (0x2CEC, 'V'),
+ (0x2CED, 'M', 'ⳮ'),
+ (0x2CEE, 'V'),
+ (0x2CF2, 'M', 'ⳳ'),
+ (0x2CF3, 'V'),
+ (0x2CF4, 'X'),
+ (0x2CF9, 'V'),
+ (0x2D26, 'X'),
+ (0x2D27, 'V'),
+ (0x2D28, 'X'),
+ (0x2D2D, 'V'),
+ (0x2D2E, 'X'),
+ (0x2D30, 'V'),
+ (0x2D68, 'X'),
+ (0x2D6F, 'M', 'ⵡ'),
+ (0x2D70, 'V'),
+ (0x2D71, 'X'),
+ (0x2D7F, 'V'),
+ (0x2D97, 'X'),
+ (0x2DA0, 'V'),
+ (0x2DA7, 'X'),
+ (0x2DA8, 'V'),
+ (0x2DAF, 'X'),
+ (0x2DB0, 'V'),
+ (0x2DB7, 'X'),
+ (0x2DB8, 'V'),
+ (0x2DBF, 'X'),
+ (0x2DC0, 'V'),
+ (0x2DC7, 'X'),
+ (0x2DC8, 'V'),
+ (0x2DCF, 'X'),
+ (0x2DD0, 'V'),
+ (0x2DD7, 'X'),
+ (0x2DD8, 'V'),
+ (0x2DDF, 'X'),
+ (0x2DE0, 'V'),
+ (0x2E5E, 'X'),
+ (0x2E80, 'V'),
+ (0x2E9A, 'X'),
+ (0x2E9B, 'V'),
+ (0x2E9F, 'M', '母'),
+ (0x2EA0, 'V'),
+ (0x2EF3, 'M', '龟'),
+ (0x2EF4, 'X'),
+ (0x2F00, 'M', '一'),
+ (0x2F01, 'M', '丨'),
+ (0x2F02, 'M', '丶'),
+ (0x2F03, 'M', '丿'),
+ (0x2F04, 'M', '乙'),
+ (0x2F05, 'M', '亅'),
+ (0x2F06, 'M', '二'),
+ (0x2F07, 'M', '亠'),
+ (0x2F08, 'M', '人'),
+ (0x2F09, 'M', '儿'),
+ (0x2F0A, 'M', '入'),
+ (0x2F0B, 'M', '八'),
+ (0x2F0C, 'M', '冂'),
+ (0x2F0D, 'M', '冖'),
+ (0x2F0E, 'M', '冫'),
+ (0x2F0F, 'M', '几'),
+ (0x2F10, 'M', '凵'),
+ (0x2F11, 'M', '刀'),
+ (0x2F12, 'M', '力'),
+ (0x2F13, 'M', '勹'),
+ (0x2F14, 'M', '匕'),
+ (0x2F15, 'M', '匚'),
+ (0x2F16, 'M', '匸'),
+ (0x2F17, 'M', '十'),
+ (0x2F18, 'M', '卜'),
+ (0x2F19, 'M', '卩'),
+ ]
+
+def _seg_27() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2F1A, 'M', '厂'),
+ (0x2F1B, 'M', '厶'),
+ (0x2F1C, 'M', '又'),
+ (0x2F1D, 'M', '口'),
+ (0x2F1E, 'M', '囗'),
+ (0x2F1F, 'M', '土'),
+ (0x2F20, 'M', '士'),
+ (0x2F21, 'M', '夂'),
+ (0x2F22, 'M', '夊'),
+ (0x2F23, 'M', '夕'),
+ (0x2F24, 'M', '大'),
+ (0x2F25, 'M', '女'),
+ (0x2F26, 'M', '子'),
+ (0x2F27, 'M', '宀'),
+ (0x2F28, 'M', '寸'),
+ (0x2F29, 'M', '小'),
+ (0x2F2A, 'M', '尢'),
+ (0x2F2B, 'M', '尸'),
+ (0x2F2C, 'M', '屮'),
+ (0x2F2D, 'M', '山'),
+ (0x2F2E, 'M', '巛'),
+ (0x2F2F, 'M', '工'),
+ (0x2F30, 'M', '己'),
+ (0x2F31, 'M', '巾'),
+ (0x2F32, 'M', '干'),
+ (0x2F33, 'M', '幺'),
+ (0x2F34, 'M', '广'),
+ (0x2F35, 'M', '廴'),
+ (0x2F36, 'M', '廾'),
+ (0x2F37, 'M', '弋'),
+ (0x2F38, 'M', '弓'),
+ (0x2F39, 'M', '彐'),
+ (0x2F3A, 'M', '彡'),
+ (0x2F3B, 'M', '彳'),
+ (0x2F3C, 'M', '心'),
+ (0x2F3D, 'M', '戈'),
+ (0x2F3E, 'M', '戶'),
+ (0x2F3F, 'M', '手'),
+ (0x2F40, 'M', '支'),
+ (0x2F41, 'M', '攴'),
+ (0x2F42, 'M', '文'),
+ (0x2F43, 'M', '斗'),
+ (0x2F44, 'M', '斤'),
+ (0x2F45, 'M', '方'),
+ (0x2F46, 'M', '无'),
+ (0x2F47, 'M', '日'),
+ (0x2F48, 'M', '曰'),
+ (0x2F49, 'M', '月'),
+ (0x2F4A, 'M', '木'),
+ (0x2F4B, 'M', '欠'),
+ (0x2F4C, 'M', '止'),
+ (0x2F4D, 'M', '歹'),
+ (0x2F4E, 'M', '殳'),
+ (0x2F4F, 'M', '毋'),
+ (0x2F50, 'M', '比'),
+ (0x2F51, 'M', '毛'),
+ (0x2F52, 'M', '氏'),
+ (0x2F53, 'M', '气'),
+ (0x2F54, 'M', '水'),
+ (0x2F55, 'M', '火'),
+ (0x2F56, 'M', '爪'),
+ (0x2F57, 'M', '父'),
+ (0x2F58, 'M', '爻'),
+ (0x2F59, 'M', '爿'),
+ (0x2F5A, 'M', '片'),
+ (0x2F5B, 'M', '牙'),
+ (0x2F5C, 'M', '牛'),
+ (0x2F5D, 'M', '犬'),
+ (0x2F5E, 'M', '玄'),
+ (0x2F5F, 'M', '玉'),
+ (0x2F60, 'M', '瓜'),
+ (0x2F61, 'M', '瓦'),
+ (0x2F62, 'M', '甘'),
+ (0x2F63, 'M', '生'),
+ (0x2F64, 'M', '用'),
+ (0x2F65, 'M', '田'),
+ (0x2F66, 'M', '疋'),
+ (0x2F67, 'M', '疒'),
+ (0x2F68, 'M', '癶'),
+ (0x2F69, 'M', '白'),
+ (0x2F6A, 'M', '皮'),
+ (0x2F6B, 'M', '皿'),
+ (0x2F6C, 'M', '目'),
+ (0x2F6D, 'M', '矛'),
+ (0x2F6E, 'M', '矢'),
+ (0x2F6F, 'M', '石'),
+ (0x2F70, 'M', '示'),
+ (0x2F71, 'M', '禸'),
+ (0x2F72, 'M', '禾'),
+ (0x2F73, 'M', '穴'),
+ (0x2F74, 'M', '立'),
+ (0x2F75, 'M', '竹'),
+ (0x2F76, 'M', '米'),
+ (0x2F77, 'M', '糸'),
+ (0x2F78, 'M', '缶'),
+ (0x2F79, 'M', '网'),
+ (0x2F7A, 'M', '羊'),
+ (0x2F7B, 'M', '羽'),
+ (0x2F7C, 'M', '老'),
+ (0x2F7D, 'M', '而'),
+ ]
+
+def _seg_28() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2F7E, 'M', '耒'),
+ (0x2F7F, 'M', '耳'),
+ (0x2F80, 'M', '聿'),
+ (0x2F81, 'M', '肉'),
+ (0x2F82, 'M', '臣'),
+ (0x2F83, 'M', '自'),
+ (0x2F84, 'M', '至'),
+ (0x2F85, 'M', '臼'),
+ (0x2F86, 'M', '舌'),
+ (0x2F87, 'M', '舛'),
+ (0x2F88, 'M', '舟'),
+ (0x2F89, 'M', '艮'),
+ (0x2F8A, 'M', '色'),
+ (0x2F8B, 'M', '艸'),
+ (0x2F8C, 'M', '虍'),
+ (0x2F8D, 'M', '虫'),
+ (0x2F8E, 'M', '血'),
+ (0x2F8F, 'M', '行'),
+ (0x2F90, 'M', '衣'),
+ (0x2F91, 'M', '襾'),
+ (0x2F92, 'M', '見'),
+ (0x2F93, 'M', '角'),
+ (0x2F94, 'M', '言'),
+ (0x2F95, 'M', '谷'),
+ (0x2F96, 'M', '豆'),
+ (0x2F97, 'M', '豕'),
+ (0x2F98, 'M', '豸'),
+ (0x2F99, 'M', '貝'),
+ (0x2F9A, 'M', '赤'),
+ (0x2F9B, 'M', '走'),
+ (0x2F9C, 'M', '足'),
+ (0x2F9D, 'M', '身'),
+ (0x2F9E, 'M', '車'),
+ (0x2F9F, 'M', '辛'),
+ (0x2FA0, 'M', '辰'),
+ (0x2FA1, 'M', '辵'),
+ (0x2FA2, 'M', '邑'),
+ (0x2FA3, 'M', '酉'),
+ (0x2FA4, 'M', '釆'),
+ (0x2FA5, 'M', '里'),
+ (0x2FA6, 'M', '金'),
+ (0x2FA7, 'M', '長'),
+ (0x2FA8, 'M', '門'),
+ (0x2FA9, 'M', '阜'),
+ (0x2FAA, 'M', '隶'),
+ (0x2FAB, 'M', '隹'),
+ (0x2FAC, 'M', '雨'),
+ (0x2FAD, 'M', '靑'),
+ (0x2FAE, 'M', '非'),
+ (0x2FAF, 'M', '面'),
+ (0x2FB0, 'M', '革'),
+ (0x2FB1, 'M', '韋'),
+ (0x2FB2, 'M', '韭'),
+ (0x2FB3, 'M', '音'),
+ (0x2FB4, 'M', '頁'),
+ (0x2FB5, 'M', '風'),
+ (0x2FB6, 'M', '飛'),
+ (0x2FB7, 'M', '食'),
+ (0x2FB8, 'M', '首'),
+ (0x2FB9, 'M', '香'),
+ (0x2FBA, 'M', '馬'),
+ (0x2FBB, 'M', '骨'),
+ (0x2FBC, 'M', '高'),
+ (0x2FBD, 'M', '髟'),
+ (0x2FBE, 'M', '鬥'),
+ (0x2FBF, 'M', '鬯'),
+ (0x2FC0, 'M', '鬲'),
+ (0x2FC1, 'M', '鬼'),
+ (0x2FC2, 'M', '魚'),
+ (0x2FC3, 'M', '鳥'),
+ (0x2FC4, 'M', '鹵'),
+ (0x2FC5, 'M', '鹿'),
+ (0x2FC6, 'M', '麥'),
+ (0x2FC7, 'M', '麻'),
+ (0x2FC8, 'M', '黃'),
+ (0x2FC9, 'M', '黍'),
+ (0x2FCA, 'M', '黑'),
+ (0x2FCB, 'M', '黹'),
+ (0x2FCC, 'M', '黽'),
+ (0x2FCD, 'M', '鼎'),
+ (0x2FCE, 'M', '鼓'),
+ (0x2FCF, 'M', '鼠'),
+ (0x2FD0, 'M', '鼻'),
+ (0x2FD1, 'M', '齊'),
+ (0x2FD2, 'M', '齒'),
+ (0x2FD3, 'M', '龍'),
+ (0x2FD4, 'M', '龜'),
+ (0x2FD5, 'M', '龠'),
+ (0x2FD6, 'X'),
+ (0x3000, '3', ' '),
+ (0x3001, 'V'),
+ (0x3002, 'M', '.'),
+ (0x3003, 'V'),
+ (0x3036, 'M', '〒'),
+ (0x3037, 'V'),
+ (0x3038, 'M', '十'),
+ (0x3039, 'M', '卄'),
+ (0x303A, 'M', '卅'),
+ (0x303B, 'V'),
+ (0x3040, 'X'),
+ ]
+
+def _seg_29() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x3041, 'V'),
+ (0x3097, 'X'),
+ (0x3099, 'V'),
+ (0x309B, '3', ' ゙'),
+ (0x309C, '3', ' ゚'),
+ (0x309D, 'V'),
+ (0x309F, 'M', 'より'),
+ (0x30A0, 'V'),
+ (0x30FF, 'M', 'コト'),
+ (0x3100, 'X'),
+ (0x3105, 'V'),
+ (0x3130, 'X'),
+ (0x3131, 'M', 'ᄀ'),
+ (0x3132, 'M', 'ᄁ'),
+ (0x3133, 'M', 'ᆪ'),
+ (0x3134, 'M', 'ᄂ'),
+ (0x3135, 'M', 'ᆬ'),
+ (0x3136, 'M', 'ᆭ'),
+ (0x3137, 'M', 'ᄃ'),
+ (0x3138, 'M', 'ᄄ'),
+ (0x3139, 'M', 'ᄅ'),
+ (0x313A, 'M', 'ᆰ'),
+ (0x313B, 'M', 'ᆱ'),
+ (0x313C, 'M', 'ᆲ'),
+ (0x313D, 'M', 'ᆳ'),
+ (0x313E, 'M', 'ᆴ'),
+ (0x313F, 'M', 'ᆵ'),
+ (0x3140, 'M', 'ᄚ'),
+ (0x3141, 'M', 'ᄆ'),
+ (0x3142, 'M', 'ᄇ'),
+ (0x3143, 'M', 'ᄈ'),
+ (0x3144, 'M', 'ᄡ'),
+ (0x3145, 'M', 'ᄉ'),
+ (0x3146, 'M', 'ᄊ'),
+ (0x3147, 'M', 'ᄋ'),
+ (0x3148, 'M', 'ᄌ'),
+ (0x3149, 'M', 'ᄍ'),
+ (0x314A, 'M', 'ᄎ'),
+ (0x314B, 'M', 'ᄏ'),
+ (0x314C, 'M', 'ᄐ'),
+ (0x314D, 'M', 'ᄑ'),
+ (0x314E, 'M', 'ᄒ'),
+ (0x314F, 'M', 'ᅡ'),
+ (0x3150, 'M', 'ᅢ'),
+ (0x3151, 'M', 'ᅣ'),
+ (0x3152, 'M', 'ᅤ'),
+ (0x3153, 'M', 'ᅥ'),
+ (0x3154, 'M', 'ᅦ'),
+ (0x3155, 'M', 'ᅧ'),
+ (0x3156, 'M', 'ᅨ'),
+ (0x3157, 'M', 'ᅩ'),
+ (0x3158, 'M', 'ᅪ'),
+ (0x3159, 'M', 'ᅫ'),
+ (0x315A, 'M', 'ᅬ'),
+ (0x315B, 'M', 'ᅭ'),
+ (0x315C, 'M', 'ᅮ'),
+ (0x315D, 'M', 'ᅯ'),
+ (0x315E, 'M', 'ᅰ'),
+ (0x315F, 'M', 'ᅱ'),
+ (0x3160, 'M', 'ᅲ'),
+ (0x3161, 'M', 'ᅳ'),
+ (0x3162, 'M', 'ᅴ'),
+ (0x3163, 'M', 'ᅵ'),
+ (0x3164, 'X'),
+ (0x3165, 'M', 'ᄔ'),
+ (0x3166, 'M', 'ᄕ'),
+ (0x3167, 'M', 'ᇇ'),
+ (0x3168, 'M', 'ᇈ'),
+ (0x3169, 'M', 'ᇌ'),
+ (0x316A, 'M', 'ᇎ'),
+ (0x316B, 'M', 'ᇓ'),
+ (0x316C, 'M', 'ᇗ'),
+ (0x316D, 'M', 'ᇙ'),
+ (0x316E, 'M', 'ᄜ'),
+ (0x316F, 'M', 'ᇝ'),
+ (0x3170, 'M', 'ᇟ'),
+ (0x3171, 'M', 'ᄝ'),
+ (0x3172, 'M', 'ᄞ'),
+ (0x3173, 'M', 'ᄠ'),
+ (0x3174, 'M', 'ᄢ'),
+ (0x3175, 'M', 'ᄣ'),
+ (0x3176, 'M', 'ᄧ'),
+ (0x3177, 'M', 'ᄩ'),
+ (0x3178, 'M', 'ᄫ'),
+ (0x3179, 'M', 'ᄬ'),
+ (0x317A, 'M', 'ᄭ'),
+ (0x317B, 'M', 'ᄮ'),
+ (0x317C, 'M', 'ᄯ'),
+ (0x317D, 'M', 'ᄲ'),
+ (0x317E, 'M', 'ᄶ'),
+ (0x317F, 'M', 'ᅀ'),
+ (0x3180, 'M', 'ᅇ'),
+ (0x3181, 'M', 'ᅌ'),
+ (0x3182, 'M', 'ᇱ'),
+ (0x3183, 'M', 'ᇲ'),
+ (0x3184, 'M', 'ᅗ'),
+ (0x3185, 'M', 'ᅘ'),
+ (0x3186, 'M', 'ᅙ'),
+ (0x3187, 'M', 'ᆄ'),
+ (0x3188, 'M', 'ᆅ'),
+ ]
+
+def _seg_30() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x3189, 'M', 'ᆈ'),
+ (0x318A, 'M', 'ᆑ'),
+ (0x318B, 'M', 'ᆒ'),
+ (0x318C, 'M', 'ᆔ'),
+ (0x318D, 'M', 'ᆞ'),
+ (0x318E, 'M', 'ᆡ'),
+ (0x318F, 'X'),
+ (0x3190, 'V'),
+ (0x3192, 'M', '一'),
+ (0x3193, 'M', '二'),
+ (0x3194, 'M', '三'),
+ (0x3195, 'M', '四'),
+ (0x3196, 'M', '上'),
+ (0x3197, 'M', '中'),
+ (0x3198, 'M', '下'),
+ (0x3199, 'M', '甲'),
+ (0x319A, 'M', '乙'),
+ (0x319B, 'M', '丙'),
+ (0x319C, 'M', '丁'),
+ (0x319D, 'M', '天'),
+ (0x319E, 'M', '地'),
+ (0x319F, 'M', '人'),
+ (0x31A0, 'V'),
+ (0x31E4, 'X'),
+ (0x31F0, 'V'),
+ (0x3200, '3', '(ᄀ)'),
+ (0x3201, '3', '(ᄂ)'),
+ (0x3202, '3', '(ᄃ)'),
+ (0x3203, '3', '(ᄅ)'),
+ (0x3204, '3', '(ᄆ)'),
+ (0x3205, '3', '(ᄇ)'),
+ (0x3206, '3', '(ᄉ)'),
+ (0x3207, '3', '(ᄋ)'),
+ (0x3208, '3', '(ᄌ)'),
+ (0x3209, '3', '(ᄎ)'),
+ (0x320A, '3', '(ᄏ)'),
+ (0x320B, '3', '(ᄐ)'),
+ (0x320C, '3', '(ᄑ)'),
+ (0x320D, '3', '(ᄒ)'),
+ (0x320E, '3', '(가)'),
+ (0x320F, '3', '(나)'),
+ (0x3210, '3', '(다)'),
+ (0x3211, '3', '(라)'),
+ (0x3212, '3', '(마)'),
+ (0x3213, '3', '(바)'),
+ (0x3214, '3', '(사)'),
+ (0x3215, '3', '(아)'),
+ (0x3216, '3', '(자)'),
+ (0x3217, '3', '(차)'),
+ (0x3218, '3', '(카)'),
+ (0x3219, '3', '(타)'),
+ (0x321A, '3', '(파)'),
+ (0x321B, '3', '(하)'),
+ (0x321C, '3', '(주)'),
+ (0x321D, '3', '(오전)'),
+ (0x321E, '3', '(오후)'),
+ (0x321F, 'X'),
+ (0x3220, '3', '(一)'),
+ (0x3221, '3', '(二)'),
+ (0x3222, '3', '(三)'),
+ (0x3223, '3', '(四)'),
+ (0x3224, '3', '(五)'),
+ (0x3225, '3', '(六)'),
+ (0x3226, '3', '(七)'),
+ (0x3227, '3', '(八)'),
+ (0x3228, '3', '(九)'),
+ (0x3229, '3', '(十)'),
+ (0x322A, '3', '(月)'),
+ (0x322B, '3', '(火)'),
+ (0x322C, '3', '(水)'),
+ (0x322D, '3', '(木)'),
+ (0x322E, '3', '(金)'),
+ (0x322F, '3', '(土)'),
+ (0x3230, '3', '(日)'),
+ (0x3231, '3', '(株)'),
+ (0x3232, '3', '(有)'),
+ (0x3233, '3', '(社)'),
+ (0x3234, '3', '(名)'),
+ (0x3235, '3', '(特)'),
+ (0x3236, '3', '(財)'),
+ (0x3237, '3', '(祝)'),
+ (0x3238, '3', '(労)'),
+ (0x3239, '3', '(代)'),
+ (0x323A, '3', '(呼)'),
+ (0x323B, '3', '(学)'),
+ (0x323C, '3', '(監)'),
+ (0x323D, '3', '(企)'),
+ (0x323E, '3', '(資)'),
+ (0x323F, '3', '(協)'),
+ (0x3240, '3', '(祭)'),
+ (0x3241, '3', '(休)'),
+ (0x3242, '3', '(自)'),
+ (0x3243, '3', '(至)'),
+ (0x3244, 'M', '問'),
+ (0x3245, 'M', '幼'),
+ (0x3246, 'M', '文'),
+ (0x3247, 'M', '箏'),
+ (0x3248, 'V'),
+ (0x3250, 'M', 'pte'),
+ (0x3251, 'M', '21'),
+ ]
+
+def _seg_31() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x3252, 'M', '22'),
+ (0x3253, 'M', '23'),
+ (0x3254, 'M', '24'),
+ (0x3255, 'M', '25'),
+ (0x3256, 'M', '26'),
+ (0x3257, 'M', '27'),
+ (0x3258, 'M', '28'),
+ (0x3259, 'M', '29'),
+ (0x325A, 'M', '30'),
+ (0x325B, 'M', '31'),
+ (0x325C, 'M', '32'),
+ (0x325D, 'M', '33'),
+ (0x325E, 'M', '34'),
+ (0x325F, 'M', '35'),
+ (0x3260, 'M', 'ᄀ'),
+ (0x3261, 'M', 'ᄂ'),
+ (0x3262, 'M', 'ᄃ'),
+ (0x3263, 'M', 'ᄅ'),
+ (0x3264, 'M', 'ᄆ'),
+ (0x3265, 'M', 'ᄇ'),
+ (0x3266, 'M', 'ᄉ'),
+ (0x3267, 'M', 'ᄋ'),
+ (0x3268, 'M', 'ᄌ'),
+ (0x3269, 'M', 'ᄎ'),
+ (0x326A, 'M', 'ᄏ'),
+ (0x326B, 'M', 'ᄐ'),
+ (0x326C, 'M', 'ᄑ'),
+ (0x326D, 'M', 'ᄒ'),
+ (0x326E, 'M', '가'),
+ (0x326F, 'M', '나'),
+ (0x3270, 'M', '다'),
+ (0x3271, 'M', '라'),
+ (0x3272, 'M', '마'),
+ (0x3273, 'M', '바'),
+ (0x3274, 'M', '사'),
+ (0x3275, 'M', '아'),
+ (0x3276, 'M', '자'),
+ (0x3277, 'M', '차'),
+ (0x3278, 'M', '카'),
+ (0x3279, 'M', '타'),
+ (0x327A, 'M', '파'),
+ (0x327B, 'M', '하'),
+ (0x327C, 'M', '참고'),
+ (0x327D, 'M', '주의'),
+ (0x327E, 'M', '우'),
+ (0x327F, 'V'),
+ (0x3280, 'M', '一'),
+ (0x3281, 'M', '二'),
+ (0x3282, 'M', '三'),
+ (0x3283, 'M', '四'),
+ (0x3284, 'M', '五'),
+ (0x3285, 'M', '六'),
+ (0x3286, 'M', '七'),
+ (0x3287, 'M', '八'),
+ (0x3288, 'M', '九'),
+ (0x3289, 'M', '十'),
+ (0x328A, 'M', '月'),
+ (0x328B, 'M', '火'),
+ (0x328C, 'M', '水'),
+ (0x328D, 'M', '木'),
+ (0x328E, 'M', '金'),
+ (0x328F, 'M', '土'),
+ (0x3290, 'M', '日'),
+ (0x3291, 'M', '株'),
+ (0x3292, 'M', '有'),
+ (0x3293, 'M', '社'),
+ (0x3294, 'M', '名'),
+ (0x3295, 'M', '特'),
+ (0x3296, 'M', '財'),
+ (0x3297, 'M', '祝'),
+ (0x3298, 'M', '労'),
+ (0x3299, 'M', '秘'),
+ (0x329A, 'M', '男'),
+ (0x329B, 'M', '女'),
+ (0x329C, 'M', '適'),
+ (0x329D, 'M', '優'),
+ (0x329E, 'M', '印'),
+ (0x329F, 'M', '注'),
+ (0x32A0, 'M', '項'),
+ (0x32A1, 'M', '休'),
+ (0x32A2, 'M', '写'),
+ (0x32A3, 'M', '正'),
+ (0x32A4, 'M', '上'),
+ (0x32A5, 'M', '中'),
+ (0x32A6, 'M', '下'),
+ (0x32A7, 'M', '左'),
+ (0x32A8, 'M', '右'),
+ (0x32A9, 'M', '医'),
+ (0x32AA, 'M', '宗'),
+ (0x32AB, 'M', '学'),
+ (0x32AC, 'M', '監'),
+ (0x32AD, 'M', '企'),
+ (0x32AE, 'M', '資'),
+ (0x32AF, 'M', '協'),
+ (0x32B0, 'M', '夜'),
+ (0x32B1, 'M', '36'),
+ (0x32B2, 'M', '37'),
+ (0x32B3, 'M', '38'),
+ (0x32B4, 'M', '39'),
+ (0x32B5, 'M', '40'),
+ ]
+
+def _seg_32() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x32B6, 'M', '41'),
+ (0x32B7, 'M', '42'),
+ (0x32B8, 'M', '43'),
+ (0x32B9, 'M', '44'),
+ (0x32BA, 'M', '45'),
+ (0x32BB, 'M', '46'),
+ (0x32BC, 'M', '47'),
+ (0x32BD, 'M', '48'),
+ (0x32BE, 'M', '49'),
+ (0x32BF, 'M', '50'),
+ (0x32C0, 'M', '1月'),
+ (0x32C1, 'M', '2月'),
+ (0x32C2, 'M', '3月'),
+ (0x32C3, 'M', '4月'),
+ (0x32C4, 'M', '5月'),
+ (0x32C5, 'M', '6月'),
+ (0x32C6, 'M', '7月'),
+ (0x32C7, 'M', '8月'),
+ (0x32C8, 'M', '9月'),
+ (0x32C9, 'M', '10月'),
+ (0x32CA, 'M', '11月'),
+ (0x32CB, 'M', '12月'),
+ (0x32CC, 'M', 'hg'),
+ (0x32CD, 'M', 'erg'),
+ (0x32CE, 'M', 'ev'),
+ (0x32CF, 'M', 'ltd'),
+ (0x32D0, 'M', 'ア'),
+ (0x32D1, 'M', 'イ'),
+ (0x32D2, 'M', 'ウ'),
+ (0x32D3, 'M', 'エ'),
+ (0x32D4, 'M', 'オ'),
+ (0x32D5, 'M', 'カ'),
+ (0x32D6, 'M', 'キ'),
+ (0x32D7, 'M', 'ク'),
+ (0x32D8, 'M', 'ケ'),
+ (0x32D9, 'M', 'コ'),
+ (0x32DA, 'M', 'サ'),
+ (0x32DB, 'M', 'シ'),
+ (0x32DC, 'M', 'ス'),
+ (0x32DD, 'M', 'セ'),
+ (0x32DE, 'M', 'ソ'),
+ (0x32DF, 'M', 'タ'),
+ (0x32E0, 'M', 'チ'),
+ (0x32E1, 'M', 'ツ'),
+ (0x32E2, 'M', 'テ'),
+ (0x32E3, 'M', 'ト'),
+ (0x32E4, 'M', 'ナ'),
+ (0x32E5, 'M', 'ニ'),
+ (0x32E6, 'M', 'ヌ'),
+ (0x32E7, 'M', 'ネ'),
+ (0x32E8, 'M', 'ノ'),
+ (0x32E9, 'M', 'ハ'),
+ (0x32EA, 'M', 'ヒ'),
+ (0x32EB, 'M', 'フ'),
+ (0x32EC, 'M', 'ヘ'),
+ (0x32ED, 'M', 'ホ'),
+ (0x32EE, 'M', 'マ'),
+ (0x32EF, 'M', 'ミ'),
+ (0x32F0, 'M', 'ム'),
+ (0x32F1, 'M', 'メ'),
+ (0x32F2, 'M', 'モ'),
+ (0x32F3, 'M', 'ヤ'),
+ (0x32F4, 'M', 'ユ'),
+ (0x32F5, 'M', 'ヨ'),
+ (0x32F6, 'M', 'ラ'),
+ (0x32F7, 'M', 'リ'),
+ (0x32F8, 'M', 'ル'),
+ (0x32F9, 'M', 'レ'),
+ (0x32FA, 'M', 'ロ'),
+ (0x32FB, 'M', 'ワ'),
+ (0x32FC, 'M', 'ヰ'),
+ (0x32FD, 'M', 'ヱ'),
+ (0x32FE, 'M', 'ヲ'),
+ (0x32FF, 'M', '令和'),
+ (0x3300, 'M', 'アパート'),
+ (0x3301, 'M', 'アルファ'),
+ (0x3302, 'M', 'アンペア'),
+ (0x3303, 'M', 'アール'),
+ (0x3304, 'M', 'イニング'),
+ (0x3305, 'M', 'インチ'),
+ (0x3306, 'M', 'ウォン'),
+ (0x3307, 'M', 'エスクード'),
+ (0x3308, 'M', 'エーカー'),
+ (0x3309, 'M', 'オンス'),
+ (0x330A, 'M', 'オーム'),
+ (0x330B, 'M', 'カイリ'),
+ (0x330C, 'M', 'カラット'),
+ (0x330D, 'M', 'カロリー'),
+ (0x330E, 'M', 'ガロン'),
+ (0x330F, 'M', 'ガンマ'),
+ (0x3310, 'M', 'ギガ'),
+ (0x3311, 'M', 'ギニー'),
+ (0x3312, 'M', 'キュリー'),
+ (0x3313, 'M', 'ギルダー'),
+ (0x3314, 'M', 'キロ'),
+ (0x3315, 'M', 'キログラム'),
+ (0x3316, 'M', 'キロメートル'),
+ (0x3317, 'M', 'キロワット'),
+ (0x3318, 'M', 'グラム'),
+ (0x3319, 'M', 'グラムトン'),
+ ]
+
+def _seg_33() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x331A, 'M', 'クルゼイロ'),
+ (0x331B, 'M', 'クローネ'),
+ (0x331C, 'M', 'ケース'),
+ (0x331D, 'M', 'コルナ'),
+ (0x331E, 'M', 'コーポ'),
+ (0x331F, 'M', 'サイクル'),
+ (0x3320, 'M', 'サンチーム'),
+ (0x3321, 'M', 'シリング'),
+ (0x3322, 'M', 'センチ'),
+ (0x3323, 'M', 'セント'),
+ (0x3324, 'M', 'ダース'),
+ (0x3325, 'M', 'デシ'),
+ (0x3326, 'M', 'ドル'),
+ (0x3327, 'M', 'トン'),
+ (0x3328, 'M', 'ナノ'),
+ (0x3329, 'M', 'ノット'),
+ (0x332A, 'M', 'ハイツ'),
+ (0x332B, 'M', 'パーセント'),
+ (0x332C, 'M', 'パーツ'),
+ (0x332D, 'M', 'バーレル'),
+ (0x332E, 'M', 'ピアストル'),
+ (0x332F, 'M', 'ピクル'),
+ (0x3330, 'M', 'ピコ'),
+ (0x3331, 'M', 'ビル'),
+ (0x3332, 'M', 'ファラッド'),
+ (0x3333, 'M', 'フィート'),
+ (0x3334, 'M', 'ブッシェル'),
+ (0x3335, 'M', 'フラン'),
+ (0x3336, 'M', 'ヘクタール'),
+ (0x3337, 'M', 'ペソ'),
+ (0x3338, 'M', 'ペニヒ'),
+ (0x3339, 'M', 'ヘルツ'),
+ (0x333A, 'M', 'ペンス'),
+ (0x333B, 'M', 'ページ'),
+ (0x333C, 'M', 'ベータ'),
+ (0x333D, 'M', 'ポイント'),
+ (0x333E, 'M', 'ボルト'),
+ (0x333F, 'M', 'ホン'),
+ (0x3340, 'M', 'ポンド'),
+ (0x3341, 'M', 'ホール'),
+ (0x3342, 'M', 'ホーン'),
+ (0x3343, 'M', 'マイクロ'),
+ (0x3344, 'M', 'マイル'),
+ (0x3345, 'M', 'マッハ'),
+ (0x3346, 'M', 'マルク'),
+ (0x3347, 'M', 'マンション'),
+ (0x3348, 'M', 'ミクロン'),
+ (0x3349, 'M', 'ミリ'),
+ (0x334A, 'M', 'ミリバール'),
+ (0x334B, 'M', 'メガ'),
+ (0x334C, 'M', 'メガトン'),
+ (0x334D, 'M', 'メートル'),
+ (0x334E, 'M', 'ヤード'),
+ (0x334F, 'M', 'ヤール'),
+ (0x3350, 'M', 'ユアン'),
+ (0x3351, 'M', 'リットル'),
+ (0x3352, 'M', 'リラ'),
+ (0x3353, 'M', 'ルピー'),
+ (0x3354, 'M', 'ルーブル'),
+ (0x3355, 'M', 'レム'),
+ (0x3356, 'M', 'レントゲン'),
+ (0x3357, 'M', 'ワット'),
+ (0x3358, 'M', '0点'),
+ (0x3359, 'M', '1点'),
+ (0x335A, 'M', '2点'),
+ (0x335B, 'M', '3点'),
+ (0x335C, 'M', '4点'),
+ (0x335D, 'M', '5点'),
+ (0x335E, 'M', '6点'),
+ (0x335F, 'M', '7点'),
+ (0x3360, 'M', '8点'),
+ (0x3361, 'M', '9点'),
+ (0x3362, 'M', '10点'),
+ (0x3363, 'M', '11点'),
+ (0x3364, 'M', '12点'),
+ (0x3365, 'M', '13点'),
+ (0x3366, 'M', '14点'),
+ (0x3367, 'M', '15点'),
+ (0x3368, 'M', '16点'),
+ (0x3369, 'M', '17点'),
+ (0x336A, 'M', '18点'),
+ (0x336B, 'M', '19点'),
+ (0x336C, 'M', '20点'),
+ (0x336D, 'M', '21点'),
+ (0x336E, 'M', '22点'),
+ (0x336F, 'M', '23点'),
+ (0x3370, 'M', '24点'),
+ (0x3371, 'M', 'hpa'),
+ (0x3372, 'M', 'da'),
+ (0x3373, 'M', 'au'),
+ (0x3374, 'M', 'bar'),
+ (0x3375, 'M', 'ov'),
+ (0x3376, 'M', 'pc'),
+ (0x3377, 'M', 'dm'),
+ (0x3378, 'M', 'dm2'),
+ (0x3379, 'M', 'dm3'),
+ (0x337A, 'M', 'iu'),
+ (0x337B, 'M', '平成'),
+ (0x337C, 'M', '昭和'),
+ (0x337D, 'M', '大正'),
+ ]
+
+def _seg_34() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x337E, 'M', '明治'),
+ (0x337F, 'M', '株式会社'),
+ (0x3380, 'M', 'pa'),
+ (0x3381, 'M', 'na'),
+ (0x3382, 'M', 'μa'),
+ (0x3383, 'M', 'ma'),
+ (0x3384, 'M', 'ka'),
+ (0x3385, 'M', 'kb'),
+ (0x3386, 'M', 'mb'),
+ (0x3387, 'M', 'gb'),
+ (0x3388, 'M', 'cal'),
+ (0x3389, 'M', 'kcal'),
+ (0x338A, 'M', 'pf'),
+ (0x338B, 'M', 'nf'),
+ (0x338C, 'M', 'μf'),
+ (0x338D, 'M', 'μg'),
+ (0x338E, 'M', 'mg'),
+ (0x338F, 'M', 'kg'),
+ (0x3390, 'M', 'hz'),
+ (0x3391, 'M', 'khz'),
+ (0x3392, 'M', 'mhz'),
+ (0x3393, 'M', 'ghz'),
+ (0x3394, 'M', 'thz'),
+ (0x3395, 'M', 'μl'),
+ (0x3396, 'M', 'ml'),
+ (0x3397, 'M', 'dl'),
+ (0x3398, 'M', 'kl'),
+ (0x3399, 'M', 'fm'),
+ (0x339A, 'M', 'nm'),
+ (0x339B, 'M', 'μm'),
+ (0x339C, 'M', 'mm'),
+ (0x339D, 'M', 'cm'),
+ (0x339E, 'M', 'km'),
+ (0x339F, 'M', 'mm2'),
+ (0x33A0, 'M', 'cm2'),
+ (0x33A1, 'M', 'm2'),
+ (0x33A2, 'M', 'km2'),
+ (0x33A3, 'M', 'mm3'),
+ (0x33A4, 'M', 'cm3'),
+ (0x33A5, 'M', 'm3'),
+ (0x33A6, 'M', 'km3'),
+ (0x33A7, 'M', 'm∕s'),
+ (0x33A8, 'M', 'm∕s2'),
+ (0x33A9, 'M', 'pa'),
+ (0x33AA, 'M', 'kpa'),
+ (0x33AB, 'M', 'mpa'),
+ (0x33AC, 'M', 'gpa'),
+ (0x33AD, 'M', 'rad'),
+ (0x33AE, 'M', 'rad∕s'),
+ (0x33AF, 'M', 'rad∕s2'),
+ (0x33B0, 'M', 'ps'),
+ (0x33B1, 'M', 'ns'),
+ (0x33B2, 'M', 'μs'),
+ (0x33B3, 'M', 'ms'),
+ (0x33B4, 'M', 'pv'),
+ (0x33B5, 'M', 'nv'),
+ (0x33B6, 'M', 'μv'),
+ (0x33B7, 'M', 'mv'),
+ (0x33B8, 'M', 'kv'),
+ (0x33B9, 'M', 'mv'),
+ (0x33BA, 'M', 'pw'),
+ (0x33BB, 'M', 'nw'),
+ (0x33BC, 'M', 'μw'),
+ (0x33BD, 'M', 'mw'),
+ (0x33BE, 'M', 'kw'),
+ (0x33BF, 'M', 'mw'),
+ (0x33C0, 'M', 'kω'),
+ (0x33C1, 'M', 'mω'),
+ (0x33C2, 'X'),
+ (0x33C3, 'M', 'bq'),
+ (0x33C4, 'M', 'cc'),
+ (0x33C5, 'M', 'cd'),
+ (0x33C6, 'M', 'c∕kg'),
+ (0x33C7, 'X'),
+ (0x33C8, 'M', 'db'),
+ (0x33C9, 'M', 'gy'),
+ (0x33CA, 'M', 'ha'),
+ (0x33CB, 'M', 'hp'),
+ (0x33CC, 'M', 'in'),
+ (0x33CD, 'M', 'kk'),
+ (0x33CE, 'M', 'km'),
+ (0x33CF, 'M', 'kt'),
+ (0x33D0, 'M', 'lm'),
+ (0x33D1, 'M', 'ln'),
+ (0x33D2, 'M', 'log'),
+ (0x33D3, 'M', 'lx'),
+ (0x33D4, 'M', 'mb'),
+ (0x33D5, 'M', 'mil'),
+ (0x33D6, 'M', 'mol'),
+ (0x33D7, 'M', 'ph'),
+ (0x33D8, 'X'),
+ (0x33D9, 'M', 'ppm'),
+ (0x33DA, 'M', 'pr'),
+ (0x33DB, 'M', 'sr'),
+ (0x33DC, 'M', 'sv'),
+ (0x33DD, 'M', 'wb'),
+ (0x33DE, 'M', 'v∕m'),
+ (0x33DF, 'M', 'a∕m'),
+ (0x33E0, 'M', '1日'),
+ (0x33E1, 'M', '2日'),
+ ]
+
+def _seg_35() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x33E2, 'M', '3日'),
+ (0x33E3, 'M', '4日'),
+ (0x33E4, 'M', '5日'),
+ (0x33E5, 'M', '6日'),
+ (0x33E6, 'M', '7日'),
+ (0x33E7, 'M', '8日'),
+ (0x33E8, 'M', '9日'),
+ (0x33E9, 'M', '10日'),
+ (0x33EA, 'M', '11日'),
+ (0x33EB, 'M', '12日'),
+ (0x33EC, 'M', '13日'),
+ (0x33ED, 'M', '14日'),
+ (0x33EE, 'M', '15日'),
+ (0x33EF, 'M', '16日'),
+ (0x33F0, 'M', '17日'),
+ (0x33F1, 'M', '18日'),
+ (0x33F2, 'M', '19日'),
+ (0x33F3, 'M', '20日'),
+ (0x33F4, 'M', '21日'),
+ (0x33F5, 'M', '22日'),
+ (0x33F6, 'M', '23日'),
+ (0x33F7, 'M', '24日'),
+ (0x33F8, 'M', '25日'),
+ (0x33F9, 'M', '26日'),
+ (0x33FA, 'M', '27日'),
+ (0x33FB, 'M', '28日'),
+ (0x33FC, 'M', '29日'),
+ (0x33FD, 'M', '30日'),
+ (0x33FE, 'M', '31日'),
+ (0x33FF, 'M', 'gal'),
+ (0x3400, 'V'),
+ (0xA48D, 'X'),
+ (0xA490, 'V'),
+ (0xA4C7, 'X'),
+ (0xA4D0, 'V'),
+ (0xA62C, 'X'),
+ (0xA640, 'M', 'ꙁ'),
+ (0xA641, 'V'),
+ (0xA642, 'M', 'ꙃ'),
+ (0xA643, 'V'),
+ (0xA644, 'M', 'ꙅ'),
+ (0xA645, 'V'),
+ (0xA646, 'M', 'ꙇ'),
+ (0xA647, 'V'),
+ (0xA648, 'M', 'ꙉ'),
+ (0xA649, 'V'),
+ (0xA64A, 'M', 'ꙋ'),
+ (0xA64B, 'V'),
+ (0xA64C, 'M', 'ꙍ'),
+ (0xA64D, 'V'),
+ (0xA64E, 'M', 'ꙏ'),
+ (0xA64F, 'V'),
+ (0xA650, 'M', 'ꙑ'),
+ (0xA651, 'V'),
+ (0xA652, 'M', 'ꙓ'),
+ (0xA653, 'V'),
+ (0xA654, 'M', 'ꙕ'),
+ (0xA655, 'V'),
+ (0xA656, 'M', 'ꙗ'),
+ (0xA657, 'V'),
+ (0xA658, 'M', 'ꙙ'),
+ (0xA659, 'V'),
+ (0xA65A, 'M', 'ꙛ'),
+ (0xA65B, 'V'),
+ (0xA65C, 'M', 'ꙝ'),
+ (0xA65D, 'V'),
+ (0xA65E, 'M', 'ꙟ'),
+ (0xA65F, 'V'),
+ (0xA660, 'M', 'ꙡ'),
+ (0xA661, 'V'),
+ (0xA662, 'M', 'ꙣ'),
+ (0xA663, 'V'),
+ (0xA664, 'M', 'ꙥ'),
+ (0xA665, 'V'),
+ (0xA666, 'M', 'ꙧ'),
+ (0xA667, 'V'),
+ (0xA668, 'M', 'ꙩ'),
+ (0xA669, 'V'),
+ (0xA66A, 'M', 'ꙫ'),
+ (0xA66B, 'V'),
+ (0xA66C, 'M', 'ꙭ'),
+ (0xA66D, 'V'),
+ (0xA680, 'M', 'ꚁ'),
+ (0xA681, 'V'),
+ (0xA682, 'M', 'ꚃ'),
+ (0xA683, 'V'),
+ (0xA684, 'M', 'ꚅ'),
+ (0xA685, 'V'),
+ (0xA686, 'M', 'ꚇ'),
+ (0xA687, 'V'),
+ (0xA688, 'M', 'ꚉ'),
+ (0xA689, 'V'),
+ (0xA68A, 'M', 'ꚋ'),
+ (0xA68B, 'V'),
+ (0xA68C, 'M', 'ꚍ'),
+ (0xA68D, 'V'),
+ (0xA68E, 'M', 'ꚏ'),
+ (0xA68F, 'V'),
+ (0xA690, 'M', 'ꚑ'),
+ (0xA691, 'V'),
+ ]
+
+def _seg_36() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xA692, 'M', 'ꚓ'),
+ (0xA693, 'V'),
+ (0xA694, 'M', 'ꚕ'),
+ (0xA695, 'V'),
+ (0xA696, 'M', 'ꚗ'),
+ (0xA697, 'V'),
+ (0xA698, 'M', 'ꚙ'),
+ (0xA699, 'V'),
+ (0xA69A, 'M', 'ꚛ'),
+ (0xA69B, 'V'),
+ (0xA69C, 'M', 'ъ'),
+ (0xA69D, 'M', 'ь'),
+ (0xA69E, 'V'),
+ (0xA6F8, 'X'),
+ (0xA700, 'V'),
+ (0xA722, 'M', 'ꜣ'),
+ (0xA723, 'V'),
+ (0xA724, 'M', 'ꜥ'),
+ (0xA725, 'V'),
+ (0xA726, 'M', 'ꜧ'),
+ (0xA727, 'V'),
+ (0xA728, 'M', 'ꜩ'),
+ (0xA729, 'V'),
+ (0xA72A, 'M', 'ꜫ'),
+ (0xA72B, 'V'),
+ (0xA72C, 'M', 'ꜭ'),
+ (0xA72D, 'V'),
+ (0xA72E, 'M', 'ꜯ'),
+ (0xA72F, 'V'),
+ (0xA732, 'M', 'ꜳ'),
+ (0xA733, 'V'),
+ (0xA734, 'M', 'ꜵ'),
+ (0xA735, 'V'),
+ (0xA736, 'M', 'ꜷ'),
+ (0xA737, 'V'),
+ (0xA738, 'M', 'ꜹ'),
+ (0xA739, 'V'),
+ (0xA73A, 'M', 'ꜻ'),
+ (0xA73B, 'V'),
+ (0xA73C, 'M', 'ꜽ'),
+ (0xA73D, 'V'),
+ (0xA73E, 'M', 'ꜿ'),
+ (0xA73F, 'V'),
+ (0xA740, 'M', 'ꝁ'),
+ (0xA741, 'V'),
+ (0xA742, 'M', 'ꝃ'),
+ (0xA743, 'V'),
+ (0xA744, 'M', 'ꝅ'),
+ (0xA745, 'V'),
+ (0xA746, 'M', 'ꝇ'),
+ (0xA747, 'V'),
+ (0xA748, 'M', 'ꝉ'),
+ (0xA749, 'V'),
+ (0xA74A, 'M', 'ꝋ'),
+ (0xA74B, 'V'),
+ (0xA74C, 'M', 'ꝍ'),
+ (0xA74D, 'V'),
+ (0xA74E, 'M', 'ꝏ'),
+ (0xA74F, 'V'),
+ (0xA750, 'M', 'ꝑ'),
+ (0xA751, 'V'),
+ (0xA752, 'M', 'ꝓ'),
+ (0xA753, 'V'),
+ (0xA754, 'M', 'ꝕ'),
+ (0xA755, 'V'),
+ (0xA756, 'M', 'ꝗ'),
+ (0xA757, 'V'),
+ (0xA758, 'M', 'ꝙ'),
+ (0xA759, 'V'),
+ (0xA75A, 'M', 'ꝛ'),
+ (0xA75B, 'V'),
+ (0xA75C, 'M', 'ꝝ'),
+ (0xA75D, 'V'),
+ (0xA75E, 'M', 'ꝟ'),
+ (0xA75F, 'V'),
+ (0xA760, 'M', 'ꝡ'),
+ (0xA761, 'V'),
+ (0xA762, 'M', 'ꝣ'),
+ (0xA763, 'V'),
+ (0xA764, 'M', 'ꝥ'),
+ (0xA765, 'V'),
+ (0xA766, 'M', 'ꝧ'),
+ (0xA767, 'V'),
+ (0xA768, 'M', 'ꝩ'),
+ (0xA769, 'V'),
+ (0xA76A, 'M', 'ꝫ'),
+ (0xA76B, 'V'),
+ (0xA76C, 'M', 'ꝭ'),
+ (0xA76D, 'V'),
+ (0xA76E, 'M', 'ꝯ'),
+ (0xA76F, 'V'),
+ (0xA770, 'M', 'ꝯ'),
+ (0xA771, 'V'),
+ (0xA779, 'M', 'ꝺ'),
+ (0xA77A, 'V'),
+ (0xA77B, 'M', 'ꝼ'),
+ (0xA77C, 'V'),
+ (0xA77D, 'M', 'ᵹ'),
+ (0xA77E, 'M', 'ꝿ'),
+ (0xA77F, 'V'),
+ ]
+
+def _seg_37() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xA780, 'M', 'ꞁ'),
+ (0xA781, 'V'),
+ (0xA782, 'M', 'ꞃ'),
+ (0xA783, 'V'),
+ (0xA784, 'M', 'ꞅ'),
+ (0xA785, 'V'),
+ (0xA786, 'M', 'ꞇ'),
+ (0xA787, 'V'),
+ (0xA78B, 'M', 'ꞌ'),
+ (0xA78C, 'V'),
+ (0xA78D, 'M', 'ɥ'),
+ (0xA78E, 'V'),
+ (0xA790, 'M', 'ꞑ'),
+ (0xA791, 'V'),
+ (0xA792, 'M', 'ꞓ'),
+ (0xA793, 'V'),
+ (0xA796, 'M', 'ꞗ'),
+ (0xA797, 'V'),
+ (0xA798, 'M', 'ꞙ'),
+ (0xA799, 'V'),
+ (0xA79A, 'M', 'ꞛ'),
+ (0xA79B, 'V'),
+ (0xA79C, 'M', 'ꞝ'),
+ (0xA79D, 'V'),
+ (0xA79E, 'M', 'ꞟ'),
+ (0xA79F, 'V'),
+ (0xA7A0, 'M', 'ꞡ'),
+ (0xA7A1, 'V'),
+ (0xA7A2, 'M', 'ꞣ'),
+ (0xA7A3, 'V'),
+ (0xA7A4, 'M', 'ꞥ'),
+ (0xA7A5, 'V'),
+ (0xA7A6, 'M', 'ꞧ'),
+ (0xA7A7, 'V'),
+ (0xA7A8, 'M', 'ꞩ'),
+ (0xA7A9, 'V'),
+ (0xA7AA, 'M', 'ɦ'),
+ (0xA7AB, 'M', 'ɜ'),
+ (0xA7AC, 'M', 'ɡ'),
+ (0xA7AD, 'M', 'ɬ'),
+ (0xA7AE, 'M', 'ɪ'),
+ (0xA7AF, 'V'),
+ (0xA7B0, 'M', 'ʞ'),
+ (0xA7B1, 'M', 'ʇ'),
+ (0xA7B2, 'M', 'ʝ'),
+ (0xA7B3, 'M', 'ꭓ'),
+ (0xA7B4, 'M', 'ꞵ'),
+ (0xA7B5, 'V'),
+ (0xA7B6, 'M', 'ꞷ'),
+ (0xA7B7, 'V'),
+ (0xA7B8, 'M', 'ꞹ'),
+ (0xA7B9, 'V'),
+ (0xA7BA, 'M', 'ꞻ'),
+ (0xA7BB, 'V'),
+ (0xA7BC, 'M', 'ꞽ'),
+ (0xA7BD, 'V'),
+ (0xA7BE, 'M', 'ꞿ'),
+ (0xA7BF, 'V'),
+ (0xA7C0, 'M', 'ꟁ'),
+ (0xA7C1, 'V'),
+ (0xA7C2, 'M', 'ꟃ'),
+ (0xA7C3, 'V'),
+ (0xA7C4, 'M', 'ꞔ'),
+ (0xA7C5, 'M', 'ʂ'),
+ (0xA7C6, 'M', 'ᶎ'),
+ (0xA7C7, 'M', 'ꟈ'),
+ (0xA7C8, 'V'),
+ (0xA7C9, 'M', 'ꟊ'),
+ (0xA7CA, 'V'),
+ (0xA7CB, 'X'),
+ (0xA7D0, 'M', 'ꟑ'),
+ (0xA7D1, 'V'),
+ (0xA7D2, 'X'),
+ (0xA7D3, 'V'),
+ (0xA7D4, 'X'),
+ (0xA7D5, 'V'),
+ (0xA7D6, 'M', 'ꟗ'),
+ (0xA7D7, 'V'),
+ (0xA7D8, 'M', 'ꟙ'),
+ (0xA7D9, 'V'),
+ (0xA7DA, 'X'),
+ (0xA7F2, 'M', 'c'),
+ (0xA7F3, 'M', 'f'),
+ (0xA7F4, 'M', 'q'),
+ (0xA7F5, 'M', 'ꟶ'),
+ (0xA7F6, 'V'),
+ (0xA7F8, 'M', 'ħ'),
+ (0xA7F9, 'M', 'œ'),
+ (0xA7FA, 'V'),
+ (0xA82D, 'X'),
+ (0xA830, 'V'),
+ (0xA83A, 'X'),
+ (0xA840, 'V'),
+ (0xA878, 'X'),
+ (0xA880, 'V'),
+ (0xA8C6, 'X'),
+ (0xA8CE, 'V'),
+ (0xA8DA, 'X'),
+ (0xA8E0, 'V'),
+ (0xA954, 'X'),
+ ]
+
+def _seg_38() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xA95F, 'V'),
+ (0xA97D, 'X'),
+ (0xA980, 'V'),
+ (0xA9CE, 'X'),
+ (0xA9CF, 'V'),
+ (0xA9DA, 'X'),
+ (0xA9DE, 'V'),
+ (0xA9FF, 'X'),
+ (0xAA00, 'V'),
+ (0xAA37, 'X'),
+ (0xAA40, 'V'),
+ (0xAA4E, 'X'),
+ (0xAA50, 'V'),
+ (0xAA5A, 'X'),
+ (0xAA5C, 'V'),
+ (0xAAC3, 'X'),
+ (0xAADB, 'V'),
+ (0xAAF7, 'X'),
+ (0xAB01, 'V'),
+ (0xAB07, 'X'),
+ (0xAB09, 'V'),
+ (0xAB0F, 'X'),
+ (0xAB11, 'V'),
+ (0xAB17, 'X'),
+ (0xAB20, 'V'),
+ (0xAB27, 'X'),
+ (0xAB28, 'V'),
+ (0xAB2F, 'X'),
+ (0xAB30, 'V'),
+ (0xAB5C, 'M', 'ꜧ'),
+ (0xAB5D, 'M', 'ꬷ'),
+ (0xAB5E, 'M', 'ɫ'),
+ (0xAB5F, 'M', 'ꭒ'),
+ (0xAB60, 'V'),
+ (0xAB69, 'M', 'ʍ'),
+ (0xAB6A, 'V'),
+ (0xAB6C, 'X'),
+ (0xAB70, 'M', 'Ꭰ'),
+ (0xAB71, 'M', 'Ꭱ'),
+ (0xAB72, 'M', 'Ꭲ'),
+ (0xAB73, 'M', 'Ꭳ'),
+ (0xAB74, 'M', 'Ꭴ'),
+ (0xAB75, 'M', 'Ꭵ'),
+ (0xAB76, 'M', 'Ꭶ'),
+ (0xAB77, 'M', 'Ꭷ'),
+ (0xAB78, 'M', 'Ꭸ'),
+ (0xAB79, 'M', 'Ꭹ'),
+ (0xAB7A, 'M', 'Ꭺ'),
+ (0xAB7B, 'M', 'Ꭻ'),
+ (0xAB7C, 'M', 'Ꭼ'),
+ (0xAB7D, 'M', 'Ꭽ'),
+ (0xAB7E, 'M', 'Ꭾ'),
+ (0xAB7F, 'M', 'Ꭿ'),
+ (0xAB80, 'M', 'Ꮀ'),
+ (0xAB81, 'M', 'Ꮁ'),
+ (0xAB82, 'M', 'Ꮂ'),
+ (0xAB83, 'M', 'Ꮃ'),
+ (0xAB84, 'M', 'Ꮄ'),
+ (0xAB85, 'M', 'Ꮅ'),
+ (0xAB86, 'M', 'Ꮆ'),
+ (0xAB87, 'M', 'Ꮇ'),
+ (0xAB88, 'M', 'Ꮈ'),
+ (0xAB89, 'M', 'Ꮉ'),
+ (0xAB8A, 'M', 'Ꮊ'),
+ (0xAB8B, 'M', 'Ꮋ'),
+ (0xAB8C, 'M', 'Ꮌ'),
+ (0xAB8D, 'M', 'Ꮍ'),
+ (0xAB8E, 'M', 'Ꮎ'),
+ (0xAB8F, 'M', 'Ꮏ'),
+ (0xAB90, 'M', 'Ꮐ'),
+ (0xAB91, 'M', 'Ꮑ'),
+ (0xAB92, 'M', 'Ꮒ'),
+ (0xAB93, 'M', 'Ꮓ'),
+ (0xAB94, 'M', 'Ꮔ'),
+ (0xAB95, 'M', 'Ꮕ'),
+ (0xAB96, 'M', 'Ꮖ'),
+ (0xAB97, 'M', 'Ꮗ'),
+ (0xAB98, 'M', 'Ꮘ'),
+ (0xAB99, 'M', 'Ꮙ'),
+ (0xAB9A, 'M', 'Ꮚ'),
+ (0xAB9B, 'M', 'Ꮛ'),
+ (0xAB9C, 'M', 'Ꮜ'),
+ (0xAB9D, 'M', 'Ꮝ'),
+ (0xAB9E, 'M', 'Ꮞ'),
+ (0xAB9F, 'M', 'Ꮟ'),
+ (0xABA0, 'M', 'Ꮠ'),
+ (0xABA1, 'M', 'Ꮡ'),
+ (0xABA2, 'M', 'Ꮢ'),
+ (0xABA3, 'M', 'Ꮣ'),
+ (0xABA4, 'M', 'Ꮤ'),
+ (0xABA5, 'M', 'Ꮥ'),
+ (0xABA6, 'M', 'Ꮦ'),
+ (0xABA7, 'M', 'Ꮧ'),
+ (0xABA8, 'M', 'Ꮨ'),
+ (0xABA9, 'M', 'Ꮩ'),
+ (0xABAA, 'M', 'Ꮪ'),
+ (0xABAB, 'M', 'Ꮫ'),
+ (0xABAC, 'M', 'Ꮬ'),
+ (0xABAD, 'M', 'Ꮭ'),
+ (0xABAE, 'M', 'Ꮮ'),
+ ]
+
+def _seg_39() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xABAF, 'M', 'Ꮯ'),
+ (0xABB0, 'M', 'Ꮰ'),
+ (0xABB1, 'M', 'Ꮱ'),
+ (0xABB2, 'M', 'Ꮲ'),
+ (0xABB3, 'M', 'Ꮳ'),
+ (0xABB4, 'M', 'Ꮴ'),
+ (0xABB5, 'M', 'Ꮵ'),
+ (0xABB6, 'M', 'Ꮶ'),
+ (0xABB7, 'M', 'Ꮷ'),
+ (0xABB8, 'M', 'Ꮸ'),
+ (0xABB9, 'M', 'Ꮹ'),
+ (0xABBA, 'M', 'Ꮺ'),
+ (0xABBB, 'M', 'Ꮻ'),
+ (0xABBC, 'M', 'Ꮼ'),
+ (0xABBD, 'M', 'Ꮽ'),
+ (0xABBE, 'M', 'Ꮾ'),
+ (0xABBF, 'M', 'Ꮿ'),
+ (0xABC0, 'V'),
+ (0xABEE, 'X'),
+ (0xABF0, 'V'),
+ (0xABFA, 'X'),
+ (0xAC00, 'V'),
+ (0xD7A4, 'X'),
+ (0xD7B0, 'V'),
+ (0xD7C7, 'X'),
+ (0xD7CB, 'V'),
+ (0xD7FC, 'X'),
+ (0xF900, 'M', '豈'),
+ (0xF901, 'M', '更'),
+ (0xF902, 'M', '車'),
+ (0xF903, 'M', '賈'),
+ (0xF904, 'M', '滑'),
+ (0xF905, 'M', '串'),
+ (0xF906, 'M', '句'),
+ (0xF907, 'M', '龜'),
+ (0xF909, 'M', '契'),
+ (0xF90A, 'M', '金'),
+ (0xF90B, 'M', '喇'),
+ (0xF90C, 'M', '奈'),
+ (0xF90D, 'M', '懶'),
+ (0xF90E, 'M', '癩'),
+ (0xF90F, 'M', '羅'),
+ (0xF910, 'M', '蘿'),
+ (0xF911, 'M', '螺'),
+ (0xF912, 'M', '裸'),
+ (0xF913, 'M', '邏'),
+ (0xF914, 'M', '樂'),
+ (0xF915, 'M', '洛'),
+ (0xF916, 'M', '烙'),
+ (0xF917, 'M', '珞'),
+ (0xF918, 'M', '落'),
+ (0xF919, 'M', '酪'),
+ (0xF91A, 'M', '駱'),
+ (0xF91B, 'M', '亂'),
+ (0xF91C, 'M', '卵'),
+ (0xF91D, 'M', '欄'),
+ (0xF91E, 'M', '爛'),
+ (0xF91F, 'M', '蘭'),
+ (0xF920, 'M', '鸞'),
+ (0xF921, 'M', '嵐'),
+ (0xF922, 'M', '濫'),
+ (0xF923, 'M', '藍'),
+ (0xF924, 'M', '襤'),
+ (0xF925, 'M', '拉'),
+ (0xF926, 'M', '臘'),
+ (0xF927, 'M', '蠟'),
+ (0xF928, 'M', '廊'),
+ (0xF929, 'M', '朗'),
+ (0xF92A, 'M', '浪'),
+ (0xF92B, 'M', '狼'),
+ (0xF92C, 'M', '郎'),
+ (0xF92D, 'M', '來'),
+ (0xF92E, 'M', '冷'),
+ (0xF92F, 'M', '勞'),
+ (0xF930, 'M', '擄'),
+ (0xF931, 'M', '櫓'),
+ (0xF932, 'M', '爐'),
+ (0xF933, 'M', '盧'),
+ (0xF934, 'M', '老'),
+ (0xF935, 'M', '蘆'),
+ (0xF936, 'M', '虜'),
+ (0xF937, 'M', '路'),
+ (0xF938, 'M', '露'),
+ (0xF939, 'M', '魯'),
+ (0xF93A, 'M', '鷺'),
+ (0xF93B, 'M', '碌'),
+ (0xF93C, 'M', '祿'),
+ (0xF93D, 'M', '綠'),
+ (0xF93E, 'M', '菉'),
+ (0xF93F, 'M', '錄'),
+ (0xF940, 'M', '鹿'),
+ (0xF941, 'M', '論'),
+ (0xF942, 'M', '壟'),
+ (0xF943, 'M', '弄'),
+ (0xF944, 'M', '籠'),
+ (0xF945, 'M', '聾'),
+ (0xF946, 'M', '牢'),
+ (0xF947, 'M', '磊'),
+ (0xF948, 'M', '賂'),
+ (0xF949, 'M', '雷'),
+ ]
+
+def _seg_40() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xF94A, 'M', '壘'),
+ (0xF94B, 'M', '屢'),
+ (0xF94C, 'M', '樓'),
+ (0xF94D, 'M', '淚'),
+ (0xF94E, 'M', '漏'),
+ (0xF94F, 'M', '累'),
+ (0xF950, 'M', '縷'),
+ (0xF951, 'M', '陋'),
+ (0xF952, 'M', '勒'),
+ (0xF953, 'M', '肋'),
+ (0xF954, 'M', '凜'),
+ (0xF955, 'M', '凌'),
+ (0xF956, 'M', '稜'),
+ (0xF957, 'M', '綾'),
+ (0xF958, 'M', '菱'),
+ (0xF959, 'M', '陵'),
+ (0xF95A, 'M', '讀'),
+ (0xF95B, 'M', '拏'),
+ (0xF95C, 'M', '樂'),
+ (0xF95D, 'M', '諾'),
+ (0xF95E, 'M', '丹'),
+ (0xF95F, 'M', '寧'),
+ (0xF960, 'M', '怒'),
+ (0xF961, 'M', '率'),
+ (0xF962, 'M', '異'),
+ (0xF963, 'M', '北'),
+ (0xF964, 'M', '磻'),
+ (0xF965, 'M', '便'),
+ (0xF966, 'M', '復'),
+ (0xF967, 'M', '不'),
+ (0xF968, 'M', '泌'),
+ (0xF969, 'M', '數'),
+ (0xF96A, 'M', '索'),
+ (0xF96B, 'M', '參'),
+ (0xF96C, 'M', '塞'),
+ (0xF96D, 'M', '省'),
+ (0xF96E, 'M', '葉'),
+ (0xF96F, 'M', '說'),
+ (0xF970, 'M', '殺'),
+ (0xF971, 'M', '辰'),
+ (0xF972, 'M', '沈'),
+ (0xF973, 'M', '拾'),
+ (0xF974, 'M', '若'),
+ (0xF975, 'M', '掠'),
+ (0xF976, 'M', '略'),
+ (0xF977, 'M', '亮'),
+ (0xF978, 'M', '兩'),
+ (0xF979, 'M', '凉'),
+ (0xF97A, 'M', '梁'),
+ (0xF97B, 'M', '糧'),
+ (0xF97C, 'M', '良'),
+ (0xF97D, 'M', '諒'),
+ (0xF97E, 'M', '量'),
+ (0xF97F, 'M', '勵'),
+ (0xF980, 'M', '呂'),
+ (0xF981, 'M', '女'),
+ (0xF982, 'M', '廬'),
+ (0xF983, 'M', '旅'),
+ (0xF984, 'M', '濾'),
+ (0xF985, 'M', '礪'),
+ (0xF986, 'M', '閭'),
+ (0xF987, 'M', '驪'),
+ (0xF988, 'M', '麗'),
+ (0xF989, 'M', '黎'),
+ (0xF98A, 'M', '力'),
+ (0xF98B, 'M', '曆'),
+ (0xF98C, 'M', '歷'),
+ (0xF98D, 'M', '轢'),
+ (0xF98E, 'M', '年'),
+ (0xF98F, 'M', '憐'),
+ (0xF990, 'M', '戀'),
+ (0xF991, 'M', '撚'),
+ (0xF992, 'M', '漣'),
+ (0xF993, 'M', '煉'),
+ (0xF994, 'M', '璉'),
+ (0xF995, 'M', '秊'),
+ (0xF996, 'M', '練'),
+ (0xF997, 'M', '聯'),
+ (0xF998, 'M', '輦'),
+ (0xF999, 'M', '蓮'),
+ (0xF99A, 'M', '連'),
+ (0xF99B, 'M', '鍊'),
+ (0xF99C, 'M', '列'),
+ (0xF99D, 'M', '劣'),
+ (0xF99E, 'M', '咽'),
+ (0xF99F, 'M', '烈'),
+ (0xF9A0, 'M', '裂'),
+ (0xF9A1, 'M', '說'),
+ (0xF9A2, 'M', '廉'),
+ (0xF9A3, 'M', '念'),
+ (0xF9A4, 'M', '捻'),
+ (0xF9A5, 'M', '殮'),
+ (0xF9A6, 'M', '簾'),
+ (0xF9A7, 'M', '獵'),
+ (0xF9A8, 'M', '令'),
+ (0xF9A9, 'M', '囹'),
+ (0xF9AA, 'M', '寧'),
+ (0xF9AB, 'M', '嶺'),
+ (0xF9AC, 'M', '怜'),
+ (0xF9AD, 'M', '玲'),
+ ]
+
+def _seg_41() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xF9AE, 'M', '瑩'),
+ (0xF9AF, 'M', '羚'),
+ (0xF9B0, 'M', '聆'),
+ (0xF9B1, 'M', '鈴'),
+ (0xF9B2, 'M', '零'),
+ (0xF9B3, 'M', '靈'),
+ (0xF9B4, 'M', '領'),
+ (0xF9B5, 'M', '例'),
+ (0xF9B6, 'M', '禮'),
+ (0xF9B7, 'M', '醴'),
+ (0xF9B8, 'M', '隸'),
+ (0xF9B9, 'M', '惡'),
+ (0xF9BA, 'M', '了'),
+ (0xF9BB, 'M', '僚'),
+ (0xF9BC, 'M', '寮'),
+ (0xF9BD, 'M', '尿'),
+ (0xF9BE, 'M', '料'),
+ (0xF9BF, 'M', '樂'),
+ (0xF9C0, 'M', '燎'),
+ (0xF9C1, 'M', '療'),
+ (0xF9C2, 'M', '蓼'),
+ (0xF9C3, 'M', '遼'),
+ (0xF9C4, 'M', '龍'),
+ (0xF9C5, 'M', '暈'),
+ (0xF9C6, 'M', '阮'),
+ (0xF9C7, 'M', '劉'),
+ (0xF9C8, 'M', '杻'),
+ (0xF9C9, 'M', '柳'),
+ (0xF9CA, 'M', '流'),
+ (0xF9CB, 'M', '溜'),
+ (0xF9CC, 'M', '琉'),
+ (0xF9CD, 'M', '留'),
+ (0xF9CE, 'M', '硫'),
+ (0xF9CF, 'M', '紐'),
+ (0xF9D0, 'M', '類'),
+ (0xF9D1, 'M', '六'),
+ (0xF9D2, 'M', '戮'),
+ (0xF9D3, 'M', '陸'),
+ (0xF9D4, 'M', '倫'),
+ (0xF9D5, 'M', '崙'),
+ (0xF9D6, 'M', '淪'),
+ (0xF9D7, 'M', '輪'),
+ (0xF9D8, 'M', '律'),
+ (0xF9D9, 'M', '慄'),
+ (0xF9DA, 'M', '栗'),
+ (0xF9DB, 'M', '率'),
+ (0xF9DC, 'M', '隆'),
+ (0xF9DD, 'M', '利'),
+ (0xF9DE, 'M', '吏'),
+ (0xF9DF, 'M', '履'),
+ (0xF9E0, 'M', '易'),
+ (0xF9E1, 'M', '李'),
+ (0xF9E2, 'M', '梨'),
+ (0xF9E3, 'M', '泥'),
+ (0xF9E4, 'M', '理'),
+ (0xF9E5, 'M', '痢'),
+ (0xF9E6, 'M', '罹'),
+ (0xF9E7, 'M', '裏'),
+ (0xF9E8, 'M', '裡'),
+ (0xF9E9, 'M', '里'),
+ (0xF9EA, 'M', '離'),
+ (0xF9EB, 'M', '匿'),
+ (0xF9EC, 'M', '溺'),
+ (0xF9ED, 'M', '吝'),
+ (0xF9EE, 'M', '燐'),
+ (0xF9EF, 'M', '璘'),
+ (0xF9F0, 'M', '藺'),
+ (0xF9F1, 'M', '隣'),
+ (0xF9F2, 'M', '鱗'),
+ (0xF9F3, 'M', '麟'),
+ (0xF9F4, 'M', '林'),
+ (0xF9F5, 'M', '淋'),
+ (0xF9F6, 'M', '臨'),
+ (0xF9F7, 'M', '立'),
+ (0xF9F8, 'M', '笠'),
+ (0xF9F9, 'M', '粒'),
+ (0xF9FA, 'M', '狀'),
+ (0xF9FB, 'M', '炙'),
+ (0xF9FC, 'M', '識'),
+ (0xF9FD, 'M', '什'),
+ (0xF9FE, 'M', '茶'),
+ (0xF9FF, 'M', '刺'),
+ (0xFA00, 'M', '切'),
+ (0xFA01, 'M', '度'),
+ (0xFA02, 'M', '拓'),
+ (0xFA03, 'M', '糖'),
+ (0xFA04, 'M', '宅'),
+ (0xFA05, 'M', '洞'),
+ (0xFA06, 'M', '暴'),
+ (0xFA07, 'M', '輻'),
+ (0xFA08, 'M', '行'),
+ (0xFA09, 'M', '降'),
+ (0xFA0A, 'M', '見'),
+ (0xFA0B, 'M', '廓'),
+ (0xFA0C, 'M', '兀'),
+ (0xFA0D, 'M', '嗀'),
+ (0xFA0E, 'V'),
+ (0xFA10, 'M', '塚'),
+ (0xFA11, 'V'),
+ (0xFA12, 'M', '晴'),
+ ]
+
+def _seg_42() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFA13, 'V'),
+ (0xFA15, 'M', '凞'),
+ (0xFA16, 'M', '猪'),
+ (0xFA17, 'M', '益'),
+ (0xFA18, 'M', '礼'),
+ (0xFA19, 'M', '神'),
+ (0xFA1A, 'M', '祥'),
+ (0xFA1B, 'M', '福'),
+ (0xFA1C, 'M', '靖'),
+ (0xFA1D, 'M', '精'),
+ (0xFA1E, 'M', '羽'),
+ (0xFA1F, 'V'),
+ (0xFA20, 'M', '蘒'),
+ (0xFA21, 'V'),
+ (0xFA22, 'M', '諸'),
+ (0xFA23, 'V'),
+ (0xFA25, 'M', '逸'),
+ (0xFA26, 'M', '都'),
+ (0xFA27, 'V'),
+ (0xFA2A, 'M', '飯'),
+ (0xFA2B, 'M', '飼'),
+ (0xFA2C, 'M', '館'),
+ (0xFA2D, 'M', '鶴'),
+ (0xFA2E, 'M', '郞'),
+ (0xFA2F, 'M', '隷'),
+ (0xFA30, 'M', '侮'),
+ (0xFA31, 'M', '僧'),
+ (0xFA32, 'M', '免'),
+ (0xFA33, 'M', '勉'),
+ (0xFA34, 'M', '勤'),
+ (0xFA35, 'M', '卑'),
+ (0xFA36, 'M', '喝'),
+ (0xFA37, 'M', '嘆'),
+ (0xFA38, 'M', '器'),
+ (0xFA39, 'M', '塀'),
+ (0xFA3A, 'M', '墨'),
+ (0xFA3B, 'M', '層'),
+ (0xFA3C, 'M', '屮'),
+ (0xFA3D, 'M', '悔'),
+ (0xFA3E, 'M', '慨'),
+ (0xFA3F, 'M', '憎'),
+ (0xFA40, 'M', '懲'),
+ (0xFA41, 'M', '敏'),
+ (0xFA42, 'M', '既'),
+ (0xFA43, 'M', '暑'),
+ (0xFA44, 'M', '梅'),
+ (0xFA45, 'M', '海'),
+ (0xFA46, 'M', '渚'),
+ (0xFA47, 'M', '漢'),
+ (0xFA48, 'M', '煮'),
+ (0xFA49, 'M', '爫'),
+ (0xFA4A, 'M', '琢'),
+ (0xFA4B, 'M', '碑'),
+ (0xFA4C, 'M', '社'),
+ (0xFA4D, 'M', '祉'),
+ (0xFA4E, 'M', '祈'),
+ (0xFA4F, 'M', '祐'),
+ (0xFA50, 'M', '祖'),
+ (0xFA51, 'M', '祝'),
+ (0xFA52, 'M', '禍'),
+ (0xFA53, 'M', '禎'),
+ (0xFA54, 'M', '穀'),
+ (0xFA55, 'M', '突'),
+ (0xFA56, 'M', '節'),
+ (0xFA57, 'M', '練'),
+ (0xFA58, 'M', '縉'),
+ (0xFA59, 'M', '繁'),
+ (0xFA5A, 'M', '署'),
+ (0xFA5B, 'M', '者'),
+ (0xFA5C, 'M', '臭'),
+ (0xFA5D, 'M', '艹'),
+ (0xFA5F, 'M', '著'),
+ (0xFA60, 'M', '褐'),
+ (0xFA61, 'M', '視'),
+ (0xFA62, 'M', '謁'),
+ (0xFA63, 'M', '謹'),
+ (0xFA64, 'M', '賓'),
+ (0xFA65, 'M', '贈'),
+ (0xFA66, 'M', '辶'),
+ (0xFA67, 'M', '逸'),
+ (0xFA68, 'M', '難'),
+ (0xFA69, 'M', '響'),
+ (0xFA6A, 'M', '頻'),
+ (0xFA6B, 'M', '恵'),
+ (0xFA6C, 'M', '𤋮'),
+ (0xFA6D, 'M', '舘'),
+ (0xFA6E, 'X'),
+ (0xFA70, 'M', '並'),
+ (0xFA71, 'M', '况'),
+ (0xFA72, 'M', '全'),
+ (0xFA73, 'M', '侀'),
+ (0xFA74, 'M', '充'),
+ (0xFA75, 'M', '冀'),
+ (0xFA76, 'M', '勇'),
+ (0xFA77, 'M', '勺'),
+ (0xFA78, 'M', '喝'),
+ (0xFA79, 'M', '啕'),
+ (0xFA7A, 'M', '喙'),
+ (0xFA7B, 'M', '嗢'),
+ (0xFA7C, 'M', '塚'),
+ ]
+
+def _seg_43() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFA7D, 'M', '墳'),
+ (0xFA7E, 'M', '奄'),
+ (0xFA7F, 'M', '奔'),
+ (0xFA80, 'M', '婢'),
+ (0xFA81, 'M', '嬨'),
+ (0xFA82, 'M', '廒'),
+ (0xFA83, 'M', '廙'),
+ (0xFA84, 'M', '彩'),
+ (0xFA85, 'M', '徭'),
+ (0xFA86, 'M', '惘'),
+ (0xFA87, 'M', '慎'),
+ (0xFA88, 'M', '愈'),
+ (0xFA89, 'M', '憎'),
+ (0xFA8A, 'M', '慠'),
+ (0xFA8B, 'M', '懲'),
+ (0xFA8C, 'M', '戴'),
+ (0xFA8D, 'M', '揄'),
+ (0xFA8E, 'M', '搜'),
+ (0xFA8F, 'M', '摒'),
+ (0xFA90, 'M', '敖'),
+ (0xFA91, 'M', '晴'),
+ (0xFA92, 'M', '朗'),
+ (0xFA93, 'M', '望'),
+ (0xFA94, 'M', '杖'),
+ (0xFA95, 'M', '歹'),
+ (0xFA96, 'M', '殺'),
+ (0xFA97, 'M', '流'),
+ (0xFA98, 'M', '滛'),
+ (0xFA99, 'M', '滋'),
+ (0xFA9A, 'M', '漢'),
+ (0xFA9B, 'M', '瀞'),
+ (0xFA9C, 'M', '煮'),
+ (0xFA9D, 'M', '瞧'),
+ (0xFA9E, 'M', '爵'),
+ (0xFA9F, 'M', '犯'),
+ (0xFAA0, 'M', '猪'),
+ (0xFAA1, 'M', '瑱'),
+ (0xFAA2, 'M', '甆'),
+ (0xFAA3, 'M', '画'),
+ (0xFAA4, 'M', '瘝'),
+ (0xFAA5, 'M', '瘟'),
+ (0xFAA6, 'M', '益'),
+ (0xFAA7, 'M', '盛'),
+ (0xFAA8, 'M', '直'),
+ (0xFAA9, 'M', '睊'),
+ (0xFAAA, 'M', '着'),
+ (0xFAAB, 'M', '磌'),
+ (0xFAAC, 'M', '窱'),
+ (0xFAAD, 'M', '節'),
+ (0xFAAE, 'M', '类'),
+ (0xFAAF, 'M', '絛'),
+ (0xFAB0, 'M', '練'),
+ (0xFAB1, 'M', '缾'),
+ (0xFAB2, 'M', '者'),
+ (0xFAB3, 'M', '荒'),
+ (0xFAB4, 'M', '華'),
+ (0xFAB5, 'M', '蝹'),
+ (0xFAB6, 'M', '襁'),
+ (0xFAB7, 'M', '覆'),
+ (0xFAB8, 'M', '視'),
+ (0xFAB9, 'M', '調'),
+ (0xFABA, 'M', '諸'),
+ (0xFABB, 'M', '請'),
+ (0xFABC, 'M', '謁'),
+ (0xFABD, 'M', '諾'),
+ (0xFABE, 'M', '諭'),
+ (0xFABF, 'M', '謹'),
+ (0xFAC0, 'M', '變'),
+ (0xFAC1, 'M', '贈'),
+ (0xFAC2, 'M', '輸'),
+ (0xFAC3, 'M', '遲'),
+ (0xFAC4, 'M', '醙'),
+ (0xFAC5, 'M', '鉶'),
+ (0xFAC6, 'M', '陼'),
+ (0xFAC7, 'M', '難'),
+ (0xFAC8, 'M', '靖'),
+ (0xFAC9, 'M', '韛'),
+ (0xFACA, 'M', '響'),
+ (0xFACB, 'M', '頋'),
+ (0xFACC, 'M', '頻'),
+ (0xFACD, 'M', '鬒'),
+ (0xFACE, 'M', '龜'),
+ (0xFACF, 'M', '𢡊'),
+ (0xFAD0, 'M', '𢡄'),
+ (0xFAD1, 'M', '𣏕'),
+ (0xFAD2, 'M', '㮝'),
+ (0xFAD3, 'M', '䀘'),
+ (0xFAD4, 'M', '䀹'),
+ (0xFAD5, 'M', '𥉉'),
+ (0xFAD6, 'M', '𥳐'),
+ (0xFAD7, 'M', '𧻓'),
+ (0xFAD8, 'M', '齃'),
+ (0xFAD9, 'M', '龎'),
+ (0xFADA, 'X'),
+ (0xFB00, 'M', 'ff'),
+ (0xFB01, 'M', 'fi'),
+ (0xFB02, 'M', 'fl'),
+ (0xFB03, 'M', 'ffi'),
+ (0xFB04, 'M', 'ffl'),
+ (0xFB05, 'M', 'st'),
+ ]
+
+def _seg_44() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFB07, 'X'),
+ (0xFB13, 'M', 'մն'),
+ (0xFB14, 'M', 'մե'),
+ (0xFB15, 'M', 'մի'),
+ (0xFB16, 'M', 'վն'),
+ (0xFB17, 'M', 'մխ'),
+ (0xFB18, 'X'),
+ (0xFB1D, 'M', 'יִ'),
+ (0xFB1E, 'V'),
+ (0xFB1F, 'M', 'ײַ'),
+ (0xFB20, 'M', 'ע'),
+ (0xFB21, 'M', 'א'),
+ (0xFB22, 'M', 'ד'),
+ (0xFB23, 'M', 'ה'),
+ (0xFB24, 'M', 'כ'),
+ (0xFB25, 'M', 'ל'),
+ (0xFB26, 'M', 'ם'),
+ (0xFB27, 'M', 'ר'),
+ (0xFB28, 'M', 'ת'),
+ (0xFB29, '3', '+'),
+ (0xFB2A, 'M', 'שׁ'),
+ (0xFB2B, 'M', 'שׂ'),
+ (0xFB2C, 'M', 'שּׁ'),
+ (0xFB2D, 'M', 'שּׂ'),
+ (0xFB2E, 'M', 'אַ'),
+ (0xFB2F, 'M', 'אָ'),
+ (0xFB30, 'M', 'אּ'),
+ (0xFB31, 'M', 'בּ'),
+ (0xFB32, 'M', 'גּ'),
+ (0xFB33, 'M', 'דּ'),
+ (0xFB34, 'M', 'הּ'),
+ (0xFB35, 'M', 'וּ'),
+ (0xFB36, 'M', 'זּ'),
+ (0xFB37, 'X'),
+ (0xFB38, 'M', 'טּ'),
+ (0xFB39, 'M', 'יּ'),
+ (0xFB3A, 'M', 'ךּ'),
+ (0xFB3B, 'M', 'כּ'),
+ (0xFB3C, 'M', 'לּ'),
+ (0xFB3D, 'X'),
+ (0xFB3E, 'M', 'מּ'),
+ (0xFB3F, 'X'),
+ (0xFB40, 'M', 'נּ'),
+ (0xFB41, 'M', 'סּ'),
+ (0xFB42, 'X'),
+ (0xFB43, 'M', 'ףּ'),
+ (0xFB44, 'M', 'פּ'),
+ (0xFB45, 'X'),
+ (0xFB46, 'M', 'צּ'),
+ (0xFB47, 'M', 'קּ'),
+ (0xFB48, 'M', 'רּ'),
+ (0xFB49, 'M', 'שּ'),
+ (0xFB4A, 'M', 'תּ'),
+ (0xFB4B, 'M', 'וֹ'),
+ (0xFB4C, 'M', 'בֿ'),
+ (0xFB4D, 'M', 'כֿ'),
+ (0xFB4E, 'M', 'פֿ'),
+ (0xFB4F, 'M', 'אל'),
+ (0xFB50, 'M', 'ٱ'),
+ (0xFB52, 'M', 'ٻ'),
+ (0xFB56, 'M', 'پ'),
+ (0xFB5A, 'M', 'ڀ'),
+ (0xFB5E, 'M', 'ٺ'),
+ (0xFB62, 'M', 'ٿ'),
+ (0xFB66, 'M', 'ٹ'),
+ (0xFB6A, 'M', 'ڤ'),
+ (0xFB6E, 'M', 'ڦ'),
+ (0xFB72, 'M', 'ڄ'),
+ (0xFB76, 'M', 'ڃ'),
+ (0xFB7A, 'M', 'چ'),
+ (0xFB7E, 'M', 'ڇ'),
+ (0xFB82, 'M', 'ڍ'),
+ (0xFB84, 'M', 'ڌ'),
+ (0xFB86, 'M', 'ڎ'),
+ (0xFB88, 'M', 'ڈ'),
+ (0xFB8A, 'M', 'ژ'),
+ (0xFB8C, 'M', 'ڑ'),
+ (0xFB8E, 'M', 'ک'),
+ (0xFB92, 'M', 'گ'),
+ (0xFB96, 'M', 'ڳ'),
+ (0xFB9A, 'M', 'ڱ'),
+ (0xFB9E, 'M', 'ں'),
+ (0xFBA0, 'M', 'ڻ'),
+ (0xFBA4, 'M', 'ۀ'),
+ (0xFBA6, 'M', 'ہ'),
+ (0xFBAA, 'M', 'ھ'),
+ (0xFBAE, 'M', 'ے'),
+ (0xFBB0, 'M', 'ۓ'),
+ (0xFBB2, 'V'),
+ (0xFBC3, 'X'),
+ (0xFBD3, 'M', 'ڭ'),
+ (0xFBD7, 'M', 'ۇ'),
+ (0xFBD9, 'M', 'ۆ'),
+ (0xFBDB, 'M', 'ۈ'),
+ (0xFBDD, 'M', 'ۇٴ'),
+ (0xFBDE, 'M', 'ۋ'),
+ (0xFBE0, 'M', 'ۅ'),
+ (0xFBE2, 'M', 'ۉ'),
+ (0xFBE4, 'M', 'ې'),
+ (0xFBE8, 'M', 'ى'),
+ ]
+
+def _seg_45() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFBEA, 'M', 'ئا'),
+ (0xFBEC, 'M', 'ئە'),
+ (0xFBEE, 'M', 'ئو'),
+ (0xFBF0, 'M', 'ئۇ'),
+ (0xFBF2, 'M', 'ئۆ'),
+ (0xFBF4, 'M', 'ئۈ'),
+ (0xFBF6, 'M', 'ئې'),
+ (0xFBF9, 'M', 'ئى'),
+ (0xFBFC, 'M', 'ی'),
+ (0xFC00, 'M', 'ئج'),
+ (0xFC01, 'M', 'ئح'),
+ (0xFC02, 'M', 'ئم'),
+ (0xFC03, 'M', 'ئى'),
+ (0xFC04, 'M', 'ئي'),
+ (0xFC05, 'M', 'بج'),
+ (0xFC06, 'M', 'بح'),
+ (0xFC07, 'M', 'بخ'),
+ (0xFC08, 'M', 'بم'),
+ (0xFC09, 'M', 'بى'),
+ (0xFC0A, 'M', 'بي'),
+ (0xFC0B, 'M', 'تج'),
+ (0xFC0C, 'M', 'تح'),
+ (0xFC0D, 'M', 'تخ'),
+ (0xFC0E, 'M', 'تم'),
+ (0xFC0F, 'M', 'تى'),
+ (0xFC10, 'M', 'تي'),
+ (0xFC11, 'M', 'ثج'),
+ (0xFC12, 'M', 'ثم'),
+ (0xFC13, 'M', 'ثى'),
+ (0xFC14, 'M', 'ثي'),
+ (0xFC15, 'M', 'جح'),
+ (0xFC16, 'M', 'جم'),
+ (0xFC17, 'M', 'حج'),
+ (0xFC18, 'M', 'حم'),
+ (0xFC19, 'M', 'خج'),
+ (0xFC1A, 'M', 'خح'),
+ (0xFC1B, 'M', 'خم'),
+ (0xFC1C, 'M', 'سج'),
+ (0xFC1D, 'M', 'سح'),
+ (0xFC1E, 'M', 'سخ'),
+ (0xFC1F, 'M', 'سم'),
+ (0xFC20, 'M', 'صح'),
+ (0xFC21, 'M', 'صم'),
+ (0xFC22, 'M', 'ضج'),
+ (0xFC23, 'M', 'ضح'),
+ (0xFC24, 'M', 'ضخ'),
+ (0xFC25, 'M', 'ضم'),
+ (0xFC26, 'M', 'طح'),
+ (0xFC27, 'M', 'طم'),
+ (0xFC28, 'M', 'ظم'),
+ (0xFC29, 'M', 'عج'),
+ (0xFC2A, 'M', 'عم'),
+ (0xFC2B, 'M', 'غج'),
+ (0xFC2C, 'M', 'غم'),
+ (0xFC2D, 'M', 'فج'),
+ (0xFC2E, 'M', 'فح'),
+ (0xFC2F, 'M', 'فخ'),
+ (0xFC30, 'M', 'فم'),
+ (0xFC31, 'M', 'فى'),
+ (0xFC32, 'M', 'في'),
+ (0xFC33, 'M', 'قح'),
+ (0xFC34, 'M', 'قم'),
+ (0xFC35, 'M', 'قى'),
+ (0xFC36, 'M', 'قي'),
+ (0xFC37, 'M', 'كا'),
+ (0xFC38, 'M', 'كج'),
+ (0xFC39, 'M', 'كح'),
+ (0xFC3A, 'M', 'كخ'),
+ (0xFC3B, 'M', 'كل'),
+ (0xFC3C, 'M', 'كم'),
+ (0xFC3D, 'M', 'كى'),
+ (0xFC3E, 'M', 'كي'),
+ (0xFC3F, 'M', 'لج'),
+ (0xFC40, 'M', 'لح'),
+ (0xFC41, 'M', 'لخ'),
+ (0xFC42, 'M', 'لم'),
+ (0xFC43, 'M', 'لى'),
+ (0xFC44, 'M', 'لي'),
+ (0xFC45, 'M', 'مج'),
+ (0xFC46, 'M', 'مح'),
+ (0xFC47, 'M', 'مخ'),
+ (0xFC48, 'M', 'مم'),
+ (0xFC49, 'M', 'مى'),
+ (0xFC4A, 'M', 'مي'),
+ (0xFC4B, 'M', 'نج'),
+ (0xFC4C, 'M', 'نح'),
+ (0xFC4D, 'M', 'نخ'),
+ (0xFC4E, 'M', 'نم'),
+ (0xFC4F, 'M', 'نى'),
+ (0xFC50, 'M', 'ني'),
+ (0xFC51, 'M', 'هج'),
+ (0xFC52, 'M', 'هم'),
+ (0xFC53, 'M', 'هى'),
+ (0xFC54, 'M', 'هي'),
+ (0xFC55, 'M', 'يج'),
+ (0xFC56, 'M', 'يح'),
+ (0xFC57, 'M', 'يخ'),
+ (0xFC58, 'M', 'يم'),
+ (0xFC59, 'M', 'يى'),
+ (0xFC5A, 'M', 'يي'),
+ ]
+
+def _seg_46() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFC5B, 'M', 'ذٰ'),
+ (0xFC5C, 'M', 'رٰ'),
+ (0xFC5D, 'M', 'ىٰ'),
+ (0xFC5E, '3', ' ٌّ'),
+ (0xFC5F, '3', ' ٍّ'),
+ (0xFC60, '3', ' َّ'),
+ (0xFC61, '3', ' ُّ'),
+ (0xFC62, '3', ' ِّ'),
+ (0xFC63, '3', ' ّٰ'),
+ (0xFC64, 'M', 'ئر'),
+ (0xFC65, 'M', 'ئز'),
+ (0xFC66, 'M', 'ئم'),
+ (0xFC67, 'M', 'ئن'),
+ (0xFC68, 'M', 'ئى'),
+ (0xFC69, 'M', 'ئي'),
+ (0xFC6A, 'M', 'بر'),
+ (0xFC6B, 'M', 'بز'),
+ (0xFC6C, 'M', 'بم'),
+ (0xFC6D, 'M', 'بن'),
+ (0xFC6E, 'M', 'بى'),
+ (0xFC6F, 'M', 'بي'),
+ (0xFC70, 'M', 'تر'),
+ (0xFC71, 'M', 'تز'),
+ (0xFC72, 'M', 'تم'),
+ (0xFC73, 'M', 'تن'),
+ (0xFC74, 'M', 'تى'),
+ (0xFC75, 'M', 'تي'),
+ (0xFC76, 'M', 'ثر'),
+ (0xFC77, 'M', 'ثز'),
+ (0xFC78, 'M', 'ثم'),
+ (0xFC79, 'M', 'ثن'),
+ (0xFC7A, 'M', 'ثى'),
+ (0xFC7B, 'M', 'ثي'),
+ (0xFC7C, 'M', 'فى'),
+ (0xFC7D, 'M', 'في'),
+ (0xFC7E, 'M', 'قى'),
+ (0xFC7F, 'M', 'قي'),
+ (0xFC80, 'M', 'كا'),
+ (0xFC81, 'M', 'كل'),
+ (0xFC82, 'M', 'كم'),
+ (0xFC83, 'M', 'كى'),
+ (0xFC84, 'M', 'كي'),
+ (0xFC85, 'M', 'لم'),
+ (0xFC86, 'M', 'لى'),
+ (0xFC87, 'M', 'لي'),
+ (0xFC88, 'M', 'ما'),
+ (0xFC89, 'M', 'مم'),
+ (0xFC8A, 'M', 'نر'),
+ (0xFC8B, 'M', 'نز'),
+ (0xFC8C, 'M', 'نم'),
+ (0xFC8D, 'M', 'نن'),
+ (0xFC8E, 'M', 'نى'),
+ (0xFC8F, 'M', 'ني'),
+ (0xFC90, 'M', 'ىٰ'),
+ (0xFC91, 'M', 'ير'),
+ (0xFC92, 'M', 'يز'),
+ (0xFC93, 'M', 'يم'),
+ (0xFC94, 'M', 'ين'),
+ (0xFC95, 'M', 'يى'),
+ (0xFC96, 'M', 'يي'),
+ (0xFC97, 'M', 'ئج'),
+ (0xFC98, 'M', 'ئح'),
+ (0xFC99, 'M', 'ئخ'),
+ (0xFC9A, 'M', 'ئم'),
+ (0xFC9B, 'M', 'ئه'),
+ (0xFC9C, 'M', 'بج'),
+ (0xFC9D, 'M', 'بح'),
+ (0xFC9E, 'M', 'بخ'),
+ (0xFC9F, 'M', 'بم'),
+ (0xFCA0, 'M', 'به'),
+ (0xFCA1, 'M', 'تج'),
+ (0xFCA2, 'M', 'تح'),
+ (0xFCA3, 'M', 'تخ'),
+ (0xFCA4, 'M', 'تم'),
+ (0xFCA5, 'M', 'ته'),
+ (0xFCA6, 'M', 'ثم'),
+ (0xFCA7, 'M', 'جح'),
+ (0xFCA8, 'M', 'جم'),
+ (0xFCA9, 'M', 'حج'),
+ (0xFCAA, 'M', 'حم'),
+ (0xFCAB, 'M', 'خج'),
+ (0xFCAC, 'M', 'خم'),
+ (0xFCAD, 'M', 'سج'),
+ (0xFCAE, 'M', 'سح'),
+ (0xFCAF, 'M', 'سخ'),
+ (0xFCB0, 'M', 'سم'),
+ (0xFCB1, 'M', 'صح'),
+ (0xFCB2, 'M', 'صخ'),
+ (0xFCB3, 'M', 'صم'),
+ (0xFCB4, 'M', 'ضج'),
+ (0xFCB5, 'M', 'ضح'),
+ (0xFCB6, 'M', 'ضخ'),
+ (0xFCB7, 'M', 'ضم'),
+ (0xFCB8, 'M', 'طح'),
+ (0xFCB9, 'M', 'ظم'),
+ (0xFCBA, 'M', 'عج'),
+ (0xFCBB, 'M', 'عم'),
+ (0xFCBC, 'M', 'غج'),
+ (0xFCBD, 'M', 'غم'),
+ (0xFCBE, 'M', 'فج'),
+ ]
+
+def _seg_47() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFCBF, 'M', 'فح'),
+ (0xFCC0, 'M', 'فخ'),
+ (0xFCC1, 'M', 'فم'),
+ (0xFCC2, 'M', 'قح'),
+ (0xFCC3, 'M', 'قم'),
+ (0xFCC4, 'M', 'كج'),
+ (0xFCC5, 'M', 'كح'),
+ (0xFCC6, 'M', 'كخ'),
+ (0xFCC7, 'M', 'كل'),
+ (0xFCC8, 'M', 'كم'),
+ (0xFCC9, 'M', 'لج'),
+ (0xFCCA, 'M', 'لح'),
+ (0xFCCB, 'M', 'لخ'),
+ (0xFCCC, 'M', 'لم'),
+ (0xFCCD, 'M', 'له'),
+ (0xFCCE, 'M', 'مج'),
+ (0xFCCF, 'M', 'مح'),
+ (0xFCD0, 'M', 'مخ'),
+ (0xFCD1, 'M', 'مم'),
+ (0xFCD2, 'M', 'نج'),
+ (0xFCD3, 'M', 'نح'),
+ (0xFCD4, 'M', 'نخ'),
+ (0xFCD5, 'M', 'نم'),
+ (0xFCD6, 'M', 'نه'),
+ (0xFCD7, 'M', 'هج'),
+ (0xFCD8, 'M', 'هم'),
+ (0xFCD9, 'M', 'هٰ'),
+ (0xFCDA, 'M', 'يج'),
+ (0xFCDB, 'M', 'يح'),
+ (0xFCDC, 'M', 'يخ'),
+ (0xFCDD, 'M', 'يم'),
+ (0xFCDE, 'M', 'يه'),
+ (0xFCDF, 'M', 'ئم'),
+ (0xFCE0, 'M', 'ئه'),
+ (0xFCE1, 'M', 'بم'),
+ (0xFCE2, 'M', 'به'),
+ (0xFCE3, 'M', 'تم'),
+ (0xFCE4, 'M', 'ته'),
+ (0xFCE5, 'M', 'ثم'),
+ (0xFCE6, 'M', 'ثه'),
+ (0xFCE7, 'M', 'سم'),
+ (0xFCE8, 'M', 'سه'),
+ (0xFCE9, 'M', 'شم'),
+ (0xFCEA, 'M', 'شه'),
+ (0xFCEB, 'M', 'كل'),
+ (0xFCEC, 'M', 'كم'),
+ (0xFCED, 'M', 'لم'),
+ (0xFCEE, 'M', 'نم'),
+ (0xFCEF, 'M', 'نه'),
+ (0xFCF0, 'M', 'يم'),
+ (0xFCF1, 'M', 'يه'),
+ (0xFCF2, 'M', 'ـَّ'),
+ (0xFCF3, 'M', 'ـُّ'),
+ (0xFCF4, 'M', 'ـِّ'),
+ (0xFCF5, 'M', 'طى'),
+ (0xFCF6, 'M', 'طي'),
+ (0xFCF7, 'M', 'عى'),
+ (0xFCF8, 'M', 'عي'),
+ (0xFCF9, 'M', 'غى'),
+ (0xFCFA, 'M', 'غي'),
+ (0xFCFB, 'M', 'سى'),
+ (0xFCFC, 'M', 'سي'),
+ (0xFCFD, 'M', 'شى'),
+ (0xFCFE, 'M', 'شي'),
+ (0xFCFF, 'M', 'حى'),
+ (0xFD00, 'M', 'حي'),
+ (0xFD01, 'M', 'جى'),
+ (0xFD02, 'M', 'جي'),
+ (0xFD03, 'M', 'خى'),
+ (0xFD04, 'M', 'خي'),
+ (0xFD05, 'M', 'صى'),
+ (0xFD06, 'M', 'صي'),
+ (0xFD07, 'M', 'ضى'),
+ (0xFD08, 'M', 'ضي'),
+ (0xFD09, 'M', 'شج'),
+ (0xFD0A, 'M', 'شح'),
+ (0xFD0B, 'M', 'شخ'),
+ (0xFD0C, 'M', 'شم'),
+ (0xFD0D, 'M', 'شر'),
+ (0xFD0E, 'M', 'سر'),
+ (0xFD0F, 'M', 'صر'),
+ (0xFD10, 'M', 'ضر'),
+ (0xFD11, 'M', 'طى'),
+ (0xFD12, 'M', 'طي'),
+ (0xFD13, 'M', 'عى'),
+ (0xFD14, 'M', 'عي'),
+ (0xFD15, 'M', 'غى'),
+ (0xFD16, 'M', 'غي'),
+ (0xFD17, 'M', 'سى'),
+ (0xFD18, 'M', 'سي'),
+ (0xFD19, 'M', 'شى'),
+ (0xFD1A, 'M', 'شي'),
+ (0xFD1B, 'M', 'حى'),
+ (0xFD1C, 'M', 'حي'),
+ (0xFD1D, 'M', 'جى'),
+ (0xFD1E, 'M', 'جي'),
+ (0xFD1F, 'M', 'خى'),
+ (0xFD20, 'M', 'خي'),
+ (0xFD21, 'M', 'صى'),
+ (0xFD22, 'M', 'صي'),
+ ]
+
+def _seg_48() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFD23, 'M', 'ضى'),
+ (0xFD24, 'M', 'ضي'),
+ (0xFD25, 'M', 'شج'),
+ (0xFD26, 'M', 'شح'),
+ (0xFD27, 'M', 'شخ'),
+ (0xFD28, 'M', 'شم'),
+ (0xFD29, 'M', 'شر'),
+ (0xFD2A, 'M', 'سر'),
+ (0xFD2B, 'M', 'صر'),
+ (0xFD2C, 'M', 'ضر'),
+ (0xFD2D, 'M', 'شج'),
+ (0xFD2E, 'M', 'شح'),
+ (0xFD2F, 'M', 'شخ'),
+ (0xFD30, 'M', 'شم'),
+ (0xFD31, 'M', 'سه'),
+ (0xFD32, 'M', 'شه'),
+ (0xFD33, 'M', 'طم'),
+ (0xFD34, 'M', 'سج'),
+ (0xFD35, 'M', 'سح'),
+ (0xFD36, 'M', 'سخ'),
+ (0xFD37, 'M', 'شج'),
+ (0xFD38, 'M', 'شح'),
+ (0xFD39, 'M', 'شخ'),
+ (0xFD3A, 'M', 'طم'),
+ (0xFD3B, 'M', 'ظم'),
+ (0xFD3C, 'M', 'اً'),
+ (0xFD3E, 'V'),
+ (0xFD50, 'M', 'تجم'),
+ (0xFD51, 'M', 'تحج'),
+ (0xFD53, 'M', 'تحم'),
+ (0xFD54, 'M', 'تخم'),
+ (0xFD55, 'M', 'تمج'),
+ (0xFD56, 'M', 'تمح'),
+ (0xFD57, 'M', 'تمخ'),
+ (0xFD58, 'M', 'جمح'),
+ (0xFD5A, 'M', 'حمي'),
+ (0xFD5B, 'M', 'حمى'),
+ (0xFD5C, 'M', 'سحج'),
+ (0xFD5D, 'M', 'سجح'),
+ (0xFD5E, 'M', 'سجى'),
+ (0xFD5F, 'M', 'سمح'),
+ (0xFD61, 'M', 'سمج'),
+ (0xFD62, 'M', 'سمم'),
+ (0xFD64, 'M', 'صحح'),
+ (0xFD66, 'M', 'صمم'),
+ (0xFD67, 'M', 'شحم'),
+ (0xFD69, 'M', 'شجي'),
+ (0xFD6A, 'M', 'شمخ'),
+ (0xFD6C, 'M', 'شمم'),
+ (0xFD6E, 'M', 'ضحى'),
+ (0xFD6F, 'M', 'ضخم'),
+ (0xFD71, 'M', 'طمح'),
+ (0xFD73, 'M', 'طمم'),
+ (0xFD74, 'M', 'طمي'),
+ (0xFD75, 'M', 'عجم'),
+ (0xFD76, 'M', 'عمم'),
+ (0xFD78, 'M', 'عمى'),
+ (0xFD79, 'M', 'غمم'),
+ (0xFD7A, 'M', 'غمي'),
+ (0xFD7B, 'M', 'غمى'),
+ (0xFD7C, 'M', 'فخم'),
+ (0xFD7E, 'M', 'قمح'),
+ (0xFD7F, 'M', 'قمم'),
+ (0xFD80, 'M', 'لحم'),
+ (0xFD81, 'M', 'لحي'),
+ (0xFD82, 'M', 'لحى'),
+ (0xFD83, 'M', 'لجج'),
+ (0xFD85, 'M', 'لخم'),
+ (0xFD87, 'M', 'لمح'),
+ (0xFD89, 'M', 'محج'),
+ (0xFD8A, 'M', 'محم'),
+ (0xFD8B, 'M', 'محي'),
+ (0xFD8C, 'M', 'مجح'),
+ (0xFD8D, 'M', 'مجم'),
+ (0xFD8E, 'M', 'مخج'),
+ (0xFD8F, 'M', 'مخم'),
+ (0xFD90, 'X'),
+ (0xFD92, 'M', 'مجخ'),
+ (0xFD93, 'M', 'همج'),
+ (0xFD94, 'M', 'همم'),
+ (0xFD95, 'M', 'نحم'),
+ (0xFD96, 'M', 'نحى'),
+ (0xFD97, 'M', 'نجم'),
+ (0xFD99, 'M', 'نجى'),
+ (0xFD9A, 'M', 'نمي'),
+ (0xFD9B, 'M', 'نمى'),
+ (0xFD9C, 'M', 'يمم'),
+ (0xFD9E, 'M', 'بخي'),
+ (0xFD9F, 'M', 'تجي'),
+ (0xFDA0, 'M', 'تجى'),
+ (0xFDA1, 'M', 'تخي'),
+ (0xFDA2, 'M', 'تخى'),
+ (0xFDA3, 'M', 'تمي'),
+ (0xFDA4, 'M', 'تمى'),
+ (0xFDA5, 'M', 'جمي'),
+ (0xFDA6, 'M', 'جحى'),
+ (0xFDA7, 'M', 'جمى'),
+ (0xFDA8, 'M', 'سخى'),
+ (0xFDA9, 'M', 'صحي'),
+ (0xFDAA, 'M', 'شحي'),
+ ]
+
+def _seg_49() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFDAB, 'M', 'ضحي'),
+ (0xFDAC, 'M', 'لجي'),
+ (0xFDAD, 'M', 'لمي'),
+ (0xFDAE, 'M', 'يحي'),
+ (0xFDAF, 'M', 'يجي'),
+ (0xFDB0, 'M', 'يمي'),
+ (0xFDB1, 'M', 'ممي'),
+ (0xFDB2, 'M', 'قمي'),
+ (0xFDB3, 'M', 'نحي'),
+ (0xFDB4, 'M', 'قمح'),
+ (0xFDB5, 'M', 'لحم'),
+ (0xFDB6, 'M', 'عمي'),
+ (0xFDB7, 'M', 'كمي'),
+ (0xFDB8, 'M', 'نجح'),
+ (0xFDB9, 'M', 'مخي'),
+ (0xFDBA, 'M', 'لجم'),
+ (0xFDBB, 'M', 'كمم'),
+ (0xFDBC, 'M', 'لجم'),
+ (0xFDBD, 'M', 'نجح'),
+ (0xFDBE, 'M', 'جحي'),
+ (0xFDBF, 'M', 'حجي'),
+ (0xFDC0, 'M', 'مجي'),
+ (0xFDC1, 'M', 'فمي'),
+ (0xFDC2, 'M', 'بحي'),
+ (0xFDC3, 'M', 'كمم'),
+ (0xFDC4, 'M', 'عجم'),
+ (0xFDC5, 'M', 'صمم'),
+ (0xFDC6, 'M', 'سخي'),
+ (0xFDC7, 'M', 'نجي'),
+ (0xFDC8, 'X'),
+ (0xFDCF, 'V'),
+ (0xFDD0, 'X'),
+ (0xFDF0, 'M', 'صلے'),
+ (0xFDF1, 'M', 'قلے'),
+ (0xFDF2, 'M', 'الله'),
+ (0xFDF3, 'M', 'اكبر'),
+ (0xFDF4, 'M', 'محمد'),
+ (0xFDF5, 'M', 'صلعم'),
+ (0xFDF6, 'M', 'رسول'),
+ (0xFDF7, 'M', 'عليه'),
+ (0xFDF8, 'M', 'وسلم'),
+ (0xFDF9, 'M', 'صلى'),
+ (0xFDFA, '3', 'صلى الله عليه وسلم'),
+ (0xFDFB, '3', 'جل جلاله'),
+ (0xFDFC, 'M', 'ریال'),
+ (0xFDFD, 'V'),
+ (0xFE00, 'I'),
+ (0xFE10, '3', ','),
+ (0xFE11, 'M', '、'),
+ (0xFE12, 'X'),
+ (0xFE13, '3', ':'),
+ (0xFE14, '3', ';'),
+ (0xFE15, '3', '!'),
+ (0xFE16, '3', '?'),
+ (0xFE17, 'M', '〖'),
+ (0xFE18, 'M', '〗'),
+ (0xFE19, 'X'),
+ (0xFE20, 'V'),
+ (0xFE30, 'X'),
+ (0xFE31, 'M', '—'),
+ (0xFE32, 'M', '–'),
+ (0xFE33, '3', '_'),
+ (0xFE35, '3', '('),
+ (0xFE36, '3', ')'),
+ (0xFE37, '3', '{'),
+ (0xFE38, '3', '}'),
+ (0xFE39, 'M', '〔'),
+ (0xFE3A, 'M', '〕'),
+ (0xFE3B, 'M', '【'),
+ (0xFE3C, 'M', '】'),
+ (0xFE3D, 'M', '《'),
+ (0xFE3E, 'M', '》'),
+ (0xFE3F, 'M', '〈'),
+ (0xFE40, 'M', '〉'),
+ (0xFE41, 'M', '「'),
+ (0xFE42, 'M', '」'),
+ (0xFE43, 'M', '『'),
+ (0xFE44, 'M', '』'),
+ (0xFE45, 'V'),
+ (0xFE47, '3', '['),
+ (0xFE48, '3', ']'),
+ (0xFE49, '3', ' ̅'),
+ (0xFE4D, '3', '_'),
+ (0xFE50, '3', ','),
+ (0xFE51, 'M', '、'),
+ (0xFE52, 'X'),
+ (0xFE54, '3', ';'),
+ (0xFE55, '3', ':'),
+ (0xFE56, '3', '?'),
+ (0xFE57, '3', '!'),
+ (0xFE58, 'M', '—'),
+ (0xFE59, '3', '('),
+ (0xFE5A, '3', ')'),
+ (0xFE5B, '3', '{'),
+ (0xFE5C, '3', '}'),
+ (0xFE5D, 'M', '〔'),
+ (0xFE5E, 'M', '〕'),
+ (0xFE5F, '3', '#'),
+ (0xFE60, '3', '&'),
+ (0xFE61, '3', '*'),
+ ]
+
+def _seg_50() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFE62, '3', '+'),
+ (0xFE63, 'M', '-'),
+ (0xFE64, '3', '<'),
+ (0xFE65, '3', '>'),
+ (0xFE66, '3', '='),
+ (0xFE67, 'X'),
+ (0xFE68, '3', '\\'),
+ (0xFE69, '3', '$'),
+ (0xFE6A, '3', '%'),
+ (0xFE6B, '3', '@'),
+ (0xFE6C, 'X'),
+ (0xFE70, '3', ' ً'),
+ (0xFE71, 'M', 'ـً'),
+ (0xFE72, '3', ' ٌ'),
+ (0xFE73, 'V'),
+ (0xFE74, '3', ' ٍ'),
+ (0xFE75, 'X'),
+ (0xFE76, '3', ' َ'),
+ (0xFE77, 'M', 'ـَ'),
+ (0xFE78, '3', ' ُ'),
+ (0xFE79, 'M', 'ـُ'),
+ (0xFE7A, '3', ' ِ'),
+ (0xFE7B, 'M', 'ـِ'),
+ (0xFE7C, '3', ' ّ'),
+ (0xFE7D, 'M', 'ـّ'),
+ (0xFE7E, '3', ' ْ'),
+ (0xFE7F, 'M', 'ـْ'),
+ (0xFE80, 'M', 'ء'),
+ (0xFE81, 'M', 'آ'),
+ (0xFE83, 'M', 'أ'),
+ (0xFE85, 'M', 'ؤ'),
+ (0xFE87, 'M', 'إ'),
+ (0xFE89, 'M', 'ئ'),
+ (0xFE8D, 'M', 'ا'),
+ (0xFE8F, 'M', 'ب'),
+ (0xFE93, 'M', 'ة'),
+ (0xFE95, 'M', 'ت'),
+ (0xFE99, 'M', 'ث'),
+ (0xFE9D, 'M', 'ج'),
+ (0xFEA1, 'M', 'ح'),
+ (0xFEA5, 'M', 'خ'),
+ (0xFEA9, 'M', 'د'),
+ (0xFEAB, 'M', 'ذ'),
+ (0xFEAD, 'M', 'ر'),
+ (0xFEAF, 'M', 'ز'),
+ (0xFEB1, 'M', 'س'),
+ (0xFEB5, 'M', 'ش'),
+ (0xFEB9, 'M', 'ص'),
+ (0xFEBD, 'M', 'ض'),
+ (0xFEC1, 'M', 'ط'),
+ (0xFEC5, 'M', 'ظ'),
+ (0xFEC9, 'M', 'ع'),
+ (0xFECD, 'M', 'غ'),
+ (0xFED1, 'M', 'ف'),
+ (0xFED5, 'M', 'ق'),
+ (0xFED9, 'M', 'ك'),
+ (0xFEDD, 'M', 'ل'),
+ (0xFEE1, 'M', 'م'),
+ (0xFEE5, 'M', 'ن'),
+ (0xFEE9, 'M', 'ه'),
+ (0xFEED, 'M', 'و'),
+ (0xFEEF, 'M', 'ى'),
+ (0xFEF1, 'M', 'ي'),
+ (0xFEF5, 'M', 'لآ'),
+ (0xFEF7, 'M', 'لأ'),
+ (0xFEF9, 'M', 'لإ'),
+ (0xFEFB, 'M', 'لا'),
+ (0xFEFD, 'X'),
+ (0xFEFF, 'I'),
+ (0xFF00, 'X'),
+ (0xFF01, '3', '!'),
+ (0xFF02, '3', '"'),
+ (0xFF03, '3', '#'),
+ (0xFF04, '3', '$'),
+ (0xFF05, '3', '%'),
+ (0xFF06, '3', '&'),
+ (0xFF07, '3', '\''),
+ (0xFF08, '3', '('),
+ (0xFF09, '3', ')'),
+ (0xFF0A, '3', '*'),
+ (0xFF0B, '3', '+'),
+ (0xFF0C, '3', ','),
+ (0xFF0D, 'M', '-'),
+ (0xFF0E, 'M', '.'),
+ (0xFF0F, '3', '/'),
+ (0xFF10, 'M', '0'),
+ (0xFF11, 'M', '1'),
+ (0xFF12, 'M', '2'),
+ (0xFF13, 'M', '3'),
+ (0xFF14, 'M', '4'),
+ (0xFF15, 'M', '5'),
+ (0xFF16, 'M', '6'),
+ (0xFF17, 'M', '7'),
+ (0xFF18, 'M', '8'),
+ (0xFF19, 'M', '9'),
+ (0xFF1A, '3', ':'),
+ (0xFF1B, '3', ';'),
+ (0xFF1C, '3', '<'),
+ (0xFF1D, '3', '='),
+ (0xFF1E, '3', '>'),
+ ]
+
+def _seg_51() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFF1F, '3', '?'),
+ (0xFF20, '3', '@'),
+ (0xFF21, 'M', 'a'),
+ (0xFF22, 'M', 'b'),
+ (0xFF23, 'M', 'c'),
+ (0xFF24, 'M', 'd'),
+ (0xFF25, 'M', 'e'),
+ (0xFF26, 'M', 'f'),
+ (0xFF27, 'M', 'g'),
+ (0xFF28, 'M', 'h'),
+ (0xFF29, 'M', 'i'),
+ (0xFF2A, 'M', 'j'),
+ (0xFF2B, 'M', 'k'),
+ (0xFF2C, 'M', 'l'),
+ (0xFF2D, 'M', 'm'),
+ (0xFF2E, 'M', 'n'),
+ (0xFF2F, 'M', 'o'),
+ (0xFF30, 'M', 'p'),
+ (0xFF31, 'M', 'q'),
+ (0xFF32, 'M', 'r'),
+ (0xFF33, 'M', 's'),
+ (0xFF34, 'M', 't'),
+ (0xFF35, 'M', 'u'),
+ (0xFF36, 'M', 'v'),
+ (0xFF37, 'M', 'w'),
+ (0xFF38, 'M', 'x'),
+ (0xFF39, 'M', 'y'),
+ (0xFF3A, 'M', 'z'),
+ (0xFF3B, '3', '['),
+ (0xFF3C, '3', '\\'),
+ (0xFF3D, '3', ']'),
+ (0xFF3E, '3', '^'),
+ (0xFF3F, '3', '_'),
+ (0xFF40, '3', '`'),
+ (0xFF41, 'M', 'a'),
+ (0xFF42, 'M', 'b'),
+ (0xFF43, 'M', 'c'),
+ (0xFF44, 'M', 'd'),
+ (0xFF45, 'M', 'e'),
+ (0xFF46, 'M', 'f'),
+ (0xFF47, 'M', 'g'),
+ (0xFF48, 'M', 'h'),
+ (0xFF49, 'M', 'i'),
+ (0xFF4A, 'M', 'j'),
+ (0xFF4B, 'M', 'k'),
+ (0xFF4C, 'M', 'l'),
+ (0xFF4D, 'M', 'm'),
+ (0xFF4E, 'M', 'n'),
+ (0xFF4F, 'M', 'o'),
+ (0xFF50, 'M', 'p'),
+ (0xFF51, 'M', 'q'),
+ (0xFF52, 'M', 'r'),
+ (0xFF53, 'M', 's'),
+ (0xFF54, 'M', 't'),
+ (0xFF55, 'M', 'u'),
+ (0xFF56, 'M', 'v'),
+ (0xFF57, 'M', 'w'),
+ (0xFF58, 'M', 'x'),
+ (0xFF59, 'M', 'y'),
+ (0xFF5A, 'M', 'z'),
+ (0xFF5B, '3', '{'),
+ (0xFF5C, '3', '|'),
+ (0xFF5D, '3', '}'),
+ (0xFF5E, '3', '~'),
+ (0xFF5F, 'M', '⦅'),
+ (0xFF60, 'M', '⦆'),
+ (0xFF61, 'M', '.'),
+ (0xFF62, 'M', '「'),
+ (0xFF63, 'M', '」'),
+ (0xFF64, 'M', '、'),
+ (0xFF65, 'M', '・'),
+ (0xFF66, 'M', 'ヲ'),
+ (0xFF67, 'M', 'ァ'),
+ (0xFF68, 'M', 'ィ'),
+ (0xFF69, 'M', 'ゥ'),
+ (0xFF6A, 'M', 'ェ'),
+ (0xFF6B, 'M', 'ォ'),
+ (0xFF6C, 'M', 'ャ'),
+ (0xFF6D, 'M', 'ュ'),
+ (0xFF6E, 'M', 'ョ'),
+ (0xFF6F, 'M', 'ッ'),
+ (0xFF70, 'M', 'ー'),
+ (0xFF71, 'M', 'ア'),
+ (0xFF72, 'M', 'イ'),
+ (0xFF73, 'M', 'ウ'),
+ (0xFF74, 'M', 'エ'),
+ (0xFF75, 'M', 'オ'),
+ (0xFF76, 'M', 'カ'),
+ (0xFF77, 'M', 'キ'),
+ (0xFF78, 'M', 'ク'),
+ (0xFF79, 'M', 'ケ'),
+ (0xFF7A, 'M', 'コ'),
+ (0xFF7B, 'M', 'サ'),
+ (0xFF7C, 'M', 'シ'),
+ (0xFF7D, 'M', 'ス'),
+ (0xFF7E, 'M', 'セ'),
+ (0xFF7F, 'M', 'ソ'),
+ (0xFF80, 'M', 'タ'),
+ (0xFF81, 'M', 'チ'),
+ (0xFF82, 'M', 'ツ'),
+ ]
+
+def _seg_52() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFF83, 'M', 'テ'),
+ (0xFF84, 'M', 'ト'),
+ (0xFF85, 'M', 'ナ'),
+ (0xFF86, 'M', 'ニ'),
+ (0xFF87, 'M', 'ヌ'),
+ (0xFF88, 'M', 'ネ'),
+ (0xFF89, 'M', 'ノ'),
+ (0xFF8A, 'M', 'ハ'),
+ (0xFF8B, 'M', 'ヒ'),
+ (0xFF8C, 'M', 'フ'),
+ (0xFF8D, 'M', 'ヘ'),
+ (0xFF8E, 'M', 'ホ'),
+ (0xFF8F, 'M', 'マ'),
+ (0xFF90, 'M', 'ミ'),
+ (0xFF91, 'M', 'ム'),
+ (0xFF92, 'M', 'メ'),
+ (0xFF93, 'M', 'モ'),
+ (0xFF94, 'M', 'ヤ'),
+ (0xFF95, 'M', 'ユ'),
+ (0xFF96, 'M', 'ヨ'),
+ (0xFF97, 'M', 'ラ'),
+ (0xFF98, 'M', 'リ'),
+ (0xFF99, 'M', 'ル'),
+ (0xFF9A, 'M', 'レ'),
+ (0xFF9B, 'M', 'ロ'),
+ (0xFF9C, 'M', 'ワ'),
+ (0xFF9D, 'M', 'ン'),
+ (0xFF9E, 'M', '゙'),
+ (0xFF9F, 'M', '゚'),
+ (0xFFA0, 'X'),
+ (0xFFA1, 'M', 'ᄀ'),
+ (0xFFA2, 'M', 'ᄁ'),
+ (0xFFA3, 'M', 'ᆪ'),
+ (0xFFA4, 'M', 'ᄂ'),
+ (0xFFA5, 'M', 'ᆬ'),
+ (0xFFA6, 'M', 'ᆭ'),
+ (0xFFA7, 'M', 'ᄃ'),
+ (0xFFA8, 'M', 'ᄄ'),
+ (0xFFA9, 'M', 'ᄅ'),
+ (0xFFAA, 'M', 'ᆰ'),
+ (0xFFAB, 'M', 'ᆱ'),
+ (0xFFAC, 'M', 'ᆲ'),
+ (0xFFAD, 'M', 'ᆳ'),
+ (0xFFAE, 'M', 'ᆴ'),
+ (0xFFAF, 'M', 'ᆵ'),
+ (0xFFB0, 'M', 'ᄚ'),
+ (0xFFB1, 'M', 'ᄆ'),
+ (0xFFB2, 'M', 'ᄇ'),
+ (0xFFB3, 'M', 'ᄈ'),
+ (0xFFB4, 'M', 'ᄡ'),
+ (0xFFB5, 'M', 'ᄉ'),
+ (0xFFB6, 'M', 'ᄊ'),
+ (0xFFB7, 'M', 'ᄋ'),
+ (0xFFB8, 'M', 'ᄌ'),
+ (0xFFB9, 'M', 'ᄍ'),
+ (0xFFBA, 'M', 'ᄎ'),
+ (0xFFBB, 'M', 'ᄏ'),
+ (0xFFBC, 'M', 'ᄐ'),
+ (0xFFBD, 'M', 'ᄑ'),
+ (0xFFBE, 'M', 'ᄒ'),
+ (0xFFBF, 'X'),
+ (0xFFC2, 'M', 'ᅡ'),
+ (0xFFC3, 'M', 'ᅢ'),
+ (0xFFC4, 'M', 'ᅣ'),
+ (0xFFC5, 'M', 'ᅤ'),
+ (0xFFC6, 'M', 'ᅥ'),
+ (0xFFC7, 'M', 'ᅦ'),
+ (0xFFC8, 'X'),
+ (0xFFCA, 'M', 'ᅧ'),
+ (0xFFCB, 'M', 'ᅨ'),
+ (0xFFCC, 'M', 'ᅩ'),
+ (0xFFCD, 'M', 'ᅪ'),
+ (0xFFCE, 'M', 'ᅫ'),
+ (0xFFCF, 'M', 'ᅬ'),
+ (0xFFD0, 'X'),
+ (0xFFD2, 'M', 'ᅭ'),
+ (0xFFD3, 'M', 'ᅮ'),
+ (0xFFD4, 'M', 'ᅯ'),
+ (0xFFD5, 'M', 'ᅰ'),
+ (0xFFD6, 'M', 'ᅱ'),
+ (0xFFD7, 'M', 'ᅲ'),
+ (0xFFD8, 'X'),
+ (0xFFDA, 'M', 'ᅳ'),
+ (0xFFDB, 'M', 'ᅴ'),
+ (0xFFDC, 'M', 'ᅵ'),
+ (0xFFDD, 'X'),
+ (0xFFE0, 'M', '¢'),
+ (0xFFE1, 'M', '£'),
+ (0xFFE2, 'M', '¬'),
+ (0xFFE3, '3', ' ̄'),
+ (0xFFE4, 'M', '¦'),
+ (0xFFE5, 'M', '¥'),
+ (0xFFE6, 'M', '₩'),
+ (0xFFE7, 'X'),
+ (0xFFE8, 'M', '│'),
+ (0xFFE9, 'M', '←'),
+ (0xFFEA, 'M', '↑'),
+ (0xFFEB, 'M', '→'),
+ (0xFFEC, 'M', '↓'),
+ (0xFFED, 'M', '■'),
+ ]
+
+def _seg_53() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0xFFEE, 'M', '○'),
+ (0xFFEF, 'X'),
+ (0x10000, 'V'),
+ (0x1000C, 'X'),
+ (0x1000D, 'V'),
+ (0x10027, 'X'),
+ (0x10028, 'V'),
+ (0x1003B, 'X'),
+ (0x1003C, 'V'),
+ (0x1003E, 'X'),
+ (0x1003F, 'V'),
+ (0x1004E, 'X'),
+ (0x10050, 'V'),
+ (0x1005E, 'X'),
+ (0x10080, 'V'),
+ (0x100FB, 'X'),
+ (0x10100, 'V'),
+ (0x10103, 'X'),
+ (0x10107, 'V'),
+ (0x10134, 'X'),
+ (0x10137, 'V'),
+ (0x1018F, 'X'),
+ (0x10190, 'V'),
+ (0x1019D, 'X'),
+ (0x101A0, 'V'),
+ (0x101A1, 'X'),
+ (0x101D0, 'V'),
+ (0x101FE, 'X'),
+ (0x10280, 'V'),
+ (0x1029D, 'X'),
+ (0x102A0, 'V'),
+ (0x102D1, 'X'),
+ (0x102E0, 'V'),
+ (0x102FC, 'X'),
+ (0x10300, 'V'),
+ (0x10324, 'X'),
+ (0x1032D, 'V'),
+ (0x1034B, 'X'),
+ (0x10350, 'V'),
+ (0x1037B, 'X'),
+ (0x10380, 'V'),
+ (0x1039E, 'X'),
+ (0x1039F, 'V'),
+ (0x103C4, 'X'),
+ (0x103C8, 'V'),
+ (0x103D6, 'X'),
+ (0x10400, 'M', '𐐨'),
+ (0x10401, 'M', '𐐩'),
+ (0x10402, 'M', '𐐪'),
+ (0x10403, 'M', '𐐫'),
+ (0x10404, 'M', '𐐬'),
+ (0x10405, 'M', '𐐭'),
+ (0x10406, 'M', '𐐮'),
+ (0x10407, 'M', '𐐯'),
+ (0x10408, 'M', '𐐰'),
+ (0x10409, 'M', '𐐱'),
+ (0x1040A, 'M', '𐐲'),
+ (0x1040B, 'M', '𐐳'),
+ (0x1040C, 'M', '𐐴'),
+ (0x1040D, 'M', '𐐵'),
+ (0x1040E, 'M', '𐐶'),
+ (0x1040F, 'M', '𐐷'),
+ (0x10410, 'M', '𐐸'),
+ (0x10411, 'M', '𐐹'),
+ (0x10412, 'M', '𐐺'),
+ (0x10413, 'M', '𐐻'),
+ (0x10414, 'M', '𐐼'),
+ (0x10415, 'M', '𐐽'),
+ (0x10416, 'M', '𐐾'),
+ (0x10417, 'M', '𐐿'),
+ (0x10418, 'M', '𐑀'),
+ (0x10419, 'M', '𐑁'),
+ (0x1041A, 'M', '𐑂'),
+ (0x1041B, 'M', '𐑃'),
+ (0x1041C, 'M', '𐑄'),
+ (0x1041D, 'M', '𐑅'),
+ (0x1041E, 'M', '𐑆'),
+ (0x1041F, 'M', '𐑇'),
+ (0x10420, 'M', '𐑈'),
+ (0x10421, 'M', '𐑉'),
+ (0x10422, 'M', '𐑊'),
+ (0x10423, 'M', '𐑋'),
+ (0x10424, 'M', '𐑌'),
+ (0x10425, 'M', '𐑍'),
+ (0x10426, 'M', '𐑎'),
+ (0x10427, 'M', '𐑏'),
+ (0x10428, 'V'),
+ (0x1049E, 'X'),
+ (0x104A0, 'V'),
+ (0x104AA, 'X'),
+ (0x104B0, 'M', '𐓘'),
+ (0x104B1, 'M', '𐓙'),
+ (0x104B2, 'M', '𐓚'),
+ (0x104B3, 'M', '𐓛'),
+ (0x104B4, 'M', '𐓜'),
+ (0x104B5, 'M', '𐓝'),
+ (0x104B6, 'M', '𐓞'),
+ (0x104B7, 'M', '𐓟'),
+ (0x104B8, 'M', '𐓠'),
+ (0x104B9, 'M', '𐓡'),
+ ]
+
+def _seg_54() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x104BA, 'M', '𐓢'),
+ (0x104BB, 'M', '𐓣'),
+ (0x104BC, 'M', '𐓤'),
+ (0x104BD, 'M', '𐓥'),
+ (0x104BE, 'M', '𐓦'),
+ (0x104BF, 'M', '𐓧'),
+ (0x104C0, 'M', '𐓨'),
+ (0x104C1, 'M', '𐓩'),
+ (0x104C2, 'M', '𐓪'),
+ (0x104C3, 'M', '𐓫'),
+ (0x104C4, 'M', '𐓬'),
+ (0x104C5, 'M', '𐓭'),
+ (0x104C6, 'M', '𐓮'),
+ (0x104C7, 'M', '𐓯'),
+ (0x104C8, 'M', '𐓰'),
+ (0x104C9, 'M', '𐓱'),
+ (0x104CA, 'M', '𐓲'),
+ (0x104CB, 'M', '𐓳'),
+ (0x104CC, 'M', '𐓴'),
+ (0x104CD, 'M', '𐓵'),
+ (0x104CE, 'M', '𐓶'),
+ (0x104CF, 'M', '𐓷'),
+ (0x104D0, 'M', '𐓸'),
+ (0x104D1, 'M', '𐓹'),
+ (0x104D2, 'M', '𐓺'),
+ (0x104D3, 'M', '𐓻'),
+ (0x104D4, 'X'),
+ (0x104D8, 'V'),
+ (0x104FC, 'X'),
+ (0x10500, 'V'),
+ (0x10528, 'X'),
+ (0x10530, 'V'),
+ (0x10564, 'X'),
+ (0x1056F, 'V'),
+ (0x10570, 'M', '𐖗'),
+ (0x10571, 'M', '𐖘'),
+ (0x10572, 'M', '𐖙'),
+ (0x10573, 'M', '𐖚'),
+ (0x10574, 'M', '𐖛'),
+ (0x10575, 'M', '𐖜'),
+ (0x10576, 'M', '𐖝'),
+ (0x10577, 'M', '𐖞'),
+ (0x10578, 'M', '𐖟'),
+ (0x10579, 'M', '𐖠'),
+ (0x1057A, 'M', '𐖡'),
+ (0x1057B, 'X'),
+ (0x1057C, 'M', '𐖣'),
+ (0x1057D, 'M', '𐖤'),
+ (0x1057E, 'M', '𐖥'),
+ (0x1057F, 'M', '𐖦'),
+ (0x10580, 'M', '𐖧'),
+ (0x10581, 'M', '𐖨'),
+ (0x10582, 'M', '𐖩'),
+ (0x10583, 'M', '𐖪'),
+ (0x10584, 'M', '𐖫'),
+ (0x10585, 'M', '𐖬'),
+ (0x10586, 'M', '𐖭'),
+ (0x10587, 'M', '𐖮'),
+ (0x10588, 'M', '𐖯'),
+ (0x10589, 'M', '𐖰'),
+ (0x1058A, 'M', '𐖱'),
+ (0x1058B, 'X'),
+ (0x1058C, 'M', '𐖳'),
+ (0x1058D, 'M', '𐖴'),
+ (0x1058E, 'M', '𐖵'),
+ (0x1058F, 'M', '𐖶'),
+ (0x10590, 'M', '𐖷'),
+ (0x10591, 'M', '𐖸'),
+ (0x10592, 'M', '𐖹'),
+ (0x10593, 'X'),
+ (0x10594, 'M', '𐖻'),
+ (0x10595, 'M', '𐖼'),
+ (0x10596, 'X'),
+ (0x10597, 'V'),
+ (0x105A2, 'X'),
+ (0x105A3, 'V'),
+ (0x105B2, 'X'),
+ (0x105B3, 'V'),
+ (0x105BA, 'X'),
+ (0x105BB, 'V'),
+ (0x105BD, 'X'),
+ (0x10600, 'V'),
+ (0x10737, 'X'),
+ (0x10740, 'V'),
+ (0x10756, 'X'),
+ (0x10760, 'V'),
+ (0x10768, 'X'),
+ (0x10780, 'V'),
+ (0x10781, 'M', 'ː'),
+ (0x10782, 'M', 'ˑ'),
+ (0x10783, 'M', 'æ'),
+ (0x10784, 'M', 'ʙ'),
+ (0x10785, 'M', 'ɓ'),
+ (0x10786, 'X'),
+ (0x10787, 'M', 'ʣ'),
+ (0x10788, 'M', 'ꭦ'),
+ (0x10789, 'M', 'ʥ'),
+ (0x1078A, 'M', 'ʤ'),
+ (0x1078B, 'M', 'ɖ'),
+ (0x1078C, 'M', 'ɗ'),
+ ]
+
+def _seg_55() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1078D, 'M', 'ᶑ'),
+ (0x1078E, 'M', 'ɘ'),
+ (0x1078F, 'M', 'ɞ'),
+ (0x10790, 'M', 'ʩ'),
+ (0x10791, 'M', 'ɤ'),
+ (0x10792, 'M', 'ɢ'),
+ (0x10793, 'M', 'ɠ'),
+ (0x10794, 'M', 'ʛ'),
+ (0x10795, 'M', 'ħ'),
+ (0x10796, 'M', 'ʜ'),
+ (0x10797, 'M', 'ɧ'),
+ (0x10798, 'M', 'ʄ'),
+ (0x10799, 'M', 'ʪ'),
+ (0x1079A, 'M', 'ʫ'),
+ (0x1079B, 'M', 'ɬ'),
+ (0x1079C, 'M', '𝼄'),
+ (0x1079D, 'M', 'ꞎ'),
+ (0x1079E, 'M', 'ɮ'),
+ (0x1079F, 'M', '𝼅'),
+ (0x107A0, 'M', 'ʎ'),
+ (0x107A1, 'M', '𝼆'),
+ (0x107A2, 'M', 'ø'),
+ (0x107A3, 'M', 'ɶ'),
+ (0x107A4, 'M', 'ɷ'),
+ (0x107A5, 'M', 'q'),
+ (0x107A6, 'M', 'ɺ'),
+ (0x107A7, 'M', '𝼈'),
+ (0x107A8, 'M', 'ɽ'),
+ (0x107A9, 'M', 'ɾ'),
+ (0x107AA, 'M', 'ʀ'),
+ (0x107AB, 'M', 'ʨ'),
+ (0x107AC, 'M', 'ʦ'),
+ (0x107AD, 'M', 'ꭧ'),
+ (0x107AE, 'M', 'ʧ'),
+ (0x107AF, 'M', 'ʈ'),
+ (0x107B0, 'M', 'ⱱ'),
+ (0x107B1, 'X'),
+ (0x107B2, 'M', 'ʏ'),
+ (0x107B3, 'M', 'ʡ'),
+ (0x107B4, 'M', 'ʢ'),
+ (0x107B5, 'M', 'ʘ'),
+ (0x107B6, 'M', 'ǀ'),
+ (0x107B7, 'M', 'ǁ'),
+ (0x107B8, 'M', 'ǂ'),
+ (0x107B9, 'M', '𝼊'),
+ (0x107BA, 'M', '𝼞'),
+ (0x107BB, 'X'),
+ (0x10800, 'V'),
+ (0x10806, 'X'),
+ (0x10808, 'V'),
+ (0x10809, 'X'),
+ (0x1080A, 'V'),
+ (0x10836, 'X'),
+ (0x10837, 'V'),
+ (0x10839, 'X'),
+ (0x1083C, 'V'),
+ (0x1083D, 'X'),
+ (0x1083F, 'V'),
+ (0x10856, 'X'),
+ (0x10857, 'V'),
+ (0x1089F, 'X'),
+ (0x108A7, 'V'),
+ (0x108B0, 'X'),
+ (0x108E0, 'V'),
+ (0x108F3, 'X'),
+ (0x108F4, 'V'),
+ (0x108F6, 'X'),
+ (0x108FB, 'V'),
+ (0x1091C, 'X'),
+ (0x1091F, 'V'),
+ (0x1093A, 'X'),
+ (0x1093F, 'V'),
+ (0x10940, 'X'),
+ (0x10980, 'V'),
+ (0x109B8, 'X'),
+ (0x109BC, 'V'),
+ (0x109D0, 'X'),
+ (0x109D2, 'V'),
+ (0x10A04, 'X'),
+ (0x10A05, 'V'),
+ (0x10A07, 'X'),
+ (0x10A0C, 'V'),
+ (0x10A14, 'X'),
+ (0x10A15, 'V'),
+ (0x10A18, 'X'),
+ (0x10A19, 'V'),
+ (0x10A36, 'X'),
+ (0x10A38, 'V'),
+ (0x10A3B, 'X'),
+ (0x10A3F, 'V'),
+ (0x10A49, 'X'),
+ (0x10A50, 'V'),
+ (0x10A59, 'X'),
+ (0x10A60, 'V'),
+ (0x10AA0, 'X'),
+ (0x10AC0, 'V'),
+ (0x10AE7, 'X'),
+ (0x10AEB, 'V'),
+ (0x10AF7, 'X'),
+ (0x10B00, 'V'),
+ ]
+
+def _seg_56() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x10B36, 'X'),
+ (0x10B39, 'V'),
+ (0x10B56, 'X'),
+ (0x10B58, 'V'),
+ (0x10B73, 'X'),
+ (0x10B78, 'V'),
+ (0x10B92, 'X'),
+ (0x10B99, 'V'),
+ (0x10B9D, 'X'),
+ (0x10BA9, 'V'),
+ (0x10BB0, 'X'),
+ (0x10C00, 'V'),
+ (0x10C49, 'X'),
+ (0x10C80, 'M', '𐳀'),
+ (0x10C81, 'M', '𐳁'),
+ (0x10C82, 'M', '𐳂'),
+ (0x10C83, 'M', '𐳃'),
+ (0x10C84, 'M', '𐳄'),
+ (0x10C85, 'M', '𐳅'),
+ (0x10C86, 'M', '𐳆'),
+ (0x10C87, 'M', '𐳇'),
+ (0x10C88, 'M', '𐳈'),
+ (0x10C89, 'M', '𐳉'),
+ (0x10C8A, 'M', '𐳊'),
+ (0x10C8B, 'M', '𐳋'),
+ (0x10C8C, 'M', '𐳌'),
+ (0x10C8D, 'M', '𐳍'),
+ (0x10C8E, 'M', '𐳎'),
+ (0x10C8F, 'M', '𐳏'),
+ (0x10C90, 'M', '𐳐'),
+ (0x10C91, 'M', '𐳑'),
+ (0x10C92, 'M', '𐳒'),
+ (0x10C93, 'M', '𐳓'),
+ (0x10C94, 'M', '𐳔'),
+ (0x10C95, 'M', '𐳕'),
+ (0x10C96, 'M', '𐳖'),
+ (0x10C97, 'M', '𐳗'),
+ (0x10C98, 'M', '𐳘'),
+ (0x10C99, 'M', '𐳙'),
+ (0x10C9A, 'M', '𐳚'),
+ (0x10C9B, 'M', '𐳛'),
+ (0x10C9C, 'M', '𐳜'),
+ (0x10C9D, 'M', '𐳝'),
+ (0x10C9E, 'M', '𐳞'),
+ (0x10C9F, 'M', '𐳟'),
+ (0x10CA0, 'M', '𐳠'),
+ (0x10CA1, 'M', '𐳡'),
+ (0x10CA2, 'M', '𐳢'),
+ (0x10CA3, 'M', '𐳣'),
+ (0x10CA4, 'M', '𐳤'),
+ (0x10CA5, 'M', '𐳥'),
+ (0x10CA6, 'M', '𐳦'),
+ (0x10CA7, 'M', '𐳧'),
+ (0x10CA8, 'M', '𐳨'),
+ (0x10CA9, 'M', '𐳩'),
+ (0x10CAA, 'M', '𐳪'),
+ (0x10CAB, 'M', '𐳫'),
+ (0x10CAC, 'M', '𐳬'),
+ (0x10CAD, 'M', '𐳭'),
+ (0x10CAE, 'M', '𐳮'),
+ (0x10CAF, 'M', '𐳯'),
+ (0x10CB0, 'M', '𐳰'),
+ (0x10CB1, 'M', '𐳱'),
+ (0x10CB2, 'M', '𐳲'),
+ (0x10CB3, 'X'),
+ (0x10CC0, 'V'),
+ (0x10CF3, 'X'),
+ (0x10CFA, 'V'),
+ (0x10D28, 'X'),
+ (0x10D30, 'V'),
+ (0x10D3A, 'X'),
+ (0x10E60, 'V'),
+ (0x10E7F, 'X'),
+ (0x10E80, 'V'),
+ (0x10EAA, 'X'),
+ (0x10EAB, 'V'),
+ (0x10EAE, 'X'),
+ (0x10EB0, 'V'),
+ (0x10EB2, 'X'),
+ (0x10EFD, 'V'),
+ (0x10F28, 'X'),
+ (0x10F30, 'V'),
+ (0x10F5A, 'X'),
+ (0x10F70, 'V'),
+ (0x10F8A, 'X'),
+ (0x10FB0, 'V'),
+ (0x10FCC, 'X'),
+ (0x10FE0, 'V'),
+ (0x10FF7, 'X'),
+ (0x11000, 'V'),
+ (0x1104E, 'X'),
+ (0x11052, 'V'),
+ (0x11076, 'X'),
+ (0x1107F, 'V'),
+ (0x110BD, 'X'),
+ (0x110BE, 'V'),
+ (0x110C3, 'X'),
+ (0x110D0, 'V'),
+ (0x110E9, 'X'),
+ (0x110F0, 'V'),
+ ]
+
+def _seg_57() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x110FA, 'X'),
+ (0x11100, 'V'),
+ (0x11135, 'X'),
+ (0x11136, 'V'),
+ (0x11148, 'X'),
+ (0x11150, 'V'),
+ (0x11177, 'X'),
+ (0x11180, 'V'),
+ (0x111E0, 'X'),
+ (0x111E1, 'V'),
+ (0x111F5, 'X'),
+ (0x11200, 'V'),
+ (0x11212, 'X'),
+ (0x11213, 'V'),
+ (0x11242, 'X'),
+ (0x11280, 'V'),
+ (0x11287, 'X'),
+ (0x11288, 'V'),
+ (0x11289, 'X'),
+ (0x1128A, 'V'),
+ (0x1128E, 'X'),
+ (0x1128F, 'V'),
+ (0x1129E, 'X'),
+ (0x1129F, 'V'),
+ (0x112AA, 'X'),
+ (0x112B0, 'V'),
+ (0x112EB, 'X'),
+ (0x112F0, 'V'),
+ (0x112FA, 'X'),
+ (0x11300, 'V'),
+ (0x11304, 'X'),
+ (0x11305, 'V'),
+ (0x1130D, 'X'),
+ (0x1130F, 'V'),
+ (0x11311, 'X'),
+ (0x11313, 'V'),
+ (0x11329, 'X'),
+ (0x1132A, 'V'),
+ (0x11331, 'X'),
+ (0x11332, 'V'),
+ (0x11334, 'X'),
+ (0x11335, 'V'),
+ (0x1133A, 'X'),
+ (0x1133B, 'V'),
+ (0x11345, 'X'),
+ (0x11347, 'V'),
+ (0x11349, 'X'),
+ (0x1134B, 'V'),
+ (0x1134E, 'X'),
+ (0x11350, 'V'),
+ (0x11351, 'X'),
+ (0x11357, 'V'),
+ (0x11358, 'X'),
+ (0x1135D, 'V'),
+ (0x11364, 'X'),
+ (0x11366, 'V'),
+ (0x1136D, 'X'),
+ (0x11370, 'V'),
+ (0x11375, 'X'),
+ (0x11400, 'V'),
+ (0x1145C, 'X'),
+ (0x1145D, 'V'),
+ (0x11462, 'X'),
+ (0x11480, 'V'),
+ (0x114C8, 'X'),
+ (0x114D0, 'V'),
+ (0x114DA, 'X'),
+ (0x11580, 'V'),
+ (0x115B6, 'X'),
+ (0x115B8, 'V'),
+ (0x115DE, 'X'),
+ (0x11600, 'V'),
+ (0x11645, 'X'),
+ (0x11650, 'V'),
+ (0x1165A, 'X'),
+ (0x11660, 'V'),
+ (0x1166D, 'X'),
+ (0x11680, 'V'),
+ (0x116BA, 'X'),
+ (0x116C0, 'V'),
+ (0x116CA, 'X'),
+ (0x11700, 'V'),
+ (0x1171B, 'X'),
+ (0x1171D, 'V'),
+ (0x1172C, 'X'),
+ (0x11730, 'V'),
+ (0x11747, 'X'),
+ (0x11800, 'V'),
+ (0x1183C, 'X'),
+ (0x118A0, 'M', '𑣀'),
+ (0x118A1, 'M', '𑣁'),
+ (0x118A2, 'M', '𑣂'),
+ (0x118A3, 'M', '𑣃'),
+ (0x118A4, 'M', '𑣄'),
+ (0x118A5, 'M', '𑣅'),
+ (0x118A6, 'M', '𑣆'),
+ (0x118A7, 'M', '𑣇'),
+ (0x118A8, 'M', '𑣈'),
+ (0x118A9, 'M', '𑣉'),
+ (0x118AA, 'M', '𑣊'),
+ ]
+
+def _seg_58() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x118AB, 'M', '𑣋'),
+ (0x118AC, 'M', '𑣌'),
+ (0x118AD, 'M', '𑣍'),
+ (0x118AE, 'M', '𑣎'),
+ (0x118AF, 'M', '𑣏'),
+ (0x118B0, 'M', '𑣐'),
+ (0x118B1, 'M', '𑣑'),
+ (0x118B2, 'M', '𑣒'),
+ (0x118B3, 'M', '𑣓'),
+ (0x118B4, 'M', '𑣔'),
+ (0x118B5, 'M', '𑣕'),
+ (0x118B6, 'M', '𑣖'),
+ (0x118B7, 'M', '𑣗'),
+ (0x118B8, 'M', '𑣘'),
+ (0x118B9, 'M', '𑣙'),
+ (0x118BA, 'M', '𑣚'),
+ (0x118BB, 'M', '𑣛'),
+ (0x118BC, 'M', '𑣜'),
+ (0x118BD, 'M', '𑣝'),
+ (0x118BE, 'M', '𑣞'),
+ (0x118BF, 'M', '𑣟'),
+ (0x118C0, 'V'),
+ (0x118F3, 'X'),
+ (0x118FF, 'V'),
+ (0x11907, 'X'),
+ (0x11909, 'V'),
+ (0x1190A, 'X'),
+ (0x1190C, 'V'),
+ (0x11914, 'X'),
+ (0x11915, 'V'),
+ (0x11917, 'X'),
+ (0x11918, 'V'),
+ (0x11936, 'X'),
+ (0x11937, 'V'),
+ (0x11939, 'X'),
+ (0x1193B, 'V'),
+ (0x11947, 'X'),
+ (0x11950, 'V'),
+ (0x1195A, 'X'),
+ (0x119A0, 'V'),
+ (0x119A8, 'X'),
+ (0x119AA, 'V'),
+ (0x119D8, 'X'),
+ (0x119DA, 'V'),
+ (0x119E5, 'X'),
+ (0x11A00, 'V'),
+ (0x11A48, 'X'),
+ (0x11A50, 'V'),
+ (0x11AA3, 'X'),
+ (0x11AB0, 'V'),
+ (0x11AF9, 'X'),
+ (0x11B00, 'V'),
+ (0x11B0A, 'X'),
+ (0x11C00, 'V'),
+ (0x11C09, 'X'),
+ (0x11C0A, 'V'),
+ (0x11C37, 'X'),
+ (0x11C38, 'V'),
+ (0x11C46, 'X'),
+ (0x11C50, 'V'),
+ (0x11C6D, 'X'),
+ (0x11C70, 'V'),
+ (0x11C90, 'X'),
+ (0x11C92, 'V'),
+ (0x11CA8, 'X'),
+ (0x11CA9, 'V'),
+ (0x11CB7, 'X'),
+ (0x11D00, 'V'),
+ (0x11D07, 'X'),
+ (0x11D08, 'V'),
+ (0x11D0A, 'X'),
+ (0x11D0B, 'V'),
+ (0x11D37, 'X'),
+ (0x11D3A, 'V'),
+ (0x11D3B, 'X'),
+ (0x11D3C, 'V'),
+ (0x11D3E, 'X'),
+ (0x11D3F, 'V'),
+ (0x11D48, 'X'),
+ (0x11D50, 'V'),
+ (0x11D5A, 'X'),
+ (0x11D60, 'V'),
+ (0x11D66, 'X'),
+ (0x11D67, 'V'),
+ (0x11D69, 'X'),
+ (0x11D6A, 'V'),
+ (0x11D8F, 'X'),
+ (0x11D90, 'V'),
+ (0x11D92, 'X'),
+ (0x11D93, 'V'),
+ (0x11D99, 'X'),
+ (0x11DA0, 'V'),
+ (0x11DAA, 'X'),
+ (0x11EE0, 'V'),
+ (0x11EF9, 'X'),
+ (0x11F00, 'V'),
+ (0x11F11, 'X'),
+ (0x11F12, 'V'),
+ (0x11F3B, 'X'),
+ (0x11F3E, 'V'),
+ ]
+
+def _seg_59() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x11F5A, 'X'),
+ (0x11FB0, 'V'),
+ (0x11FB1, 'X'),
+ (0x11FC0, 'V'),
+ (0x11FF2, 'X'),
+ (0x11FFF, 'V'),
+ (0x1239A, 'X'),
+ (0x12400, 'V'),
+ (0x1246F, 'X'),
+ (0x12470, 'V'),
+ (0x12475, 'X'),
+ (0x12480, 'V'),
+ (0x12544, 'X'),
+ (0x12F90, 'V'),
+ (0x12FF3, 'X'),
+ (0x13000, 'V'),
+ (0x13430, 'X'),
+ (0x13440, 'V'),
+ (0x13456, 'X'),
+ (0x14400, 'V'),
+ (0x14647, 'X'),
+ (0x16800, 'V'),
+ (0x16A39, 'X'),
+ (0x16A40, 'V'),
+ (0x16A5F, 'X'),
+ (0x16A60, 'V'),
+ (0x16A6A, 'X'),
+ (0x16A6E, 'V'),
+ (0x16ABF, 'X'),
+ (0x16AC0, 'V'),
+ (0x16ACA, 'X'),
+ (0x16AD0, 'V'),
+ (0x16AEE, 'X'),
+ (0x16AF0, 'V'),
+ (0x16AF6, 'X'),
+ (0x16B00, 'V'),
+ (0x16B46, 'X'),
+ (0x16B50, 'V'),
+ (0x16B5A, 'X'),
+ (0x16B5B, 'V'),
+ (0x16B62, 'X'),
+ (0x16B63, 'V'),
+ (0x16B78, 'X'),
+ (0x16B7D, 'V'),
+ (0x16B90, 'X'),
+ (0x16E40, 'M', '𖹠'),
+ (0x16E41, 'M', '𖹡'),
+ (0x16E42, 'M', '𖹢'),
+ (0x16E43, 'M', '𖹣'),
+ (0x16E44, 'M', '𖹤'),
+ (0x16E45, 'M', '𖹥'),
+ (0x16E46, 'M', '𖹦'),
+ (0x16E47, 'M', '𖹧'),
+ (0x16E48, 'M', '𖹨'),
+ (0x16E49, 'M', '𖹩'),
+ (0x16E4A, 'M', '𖹪'),
+ (0x16E4B, 'M', '𖹫'),
+ (0x16E4C, 'M', '𖹬'),
+ (0x16E4D, 'M', '𖹭'),
+ (0x16E4E, 'M', '𖹮'),
+ (0x16E4F, 'M', '𖹯'),
+ (0x16E50, 'M', '𖹰'),
+ (0x16E51, 'M', '𖹱'),
+ (0x16E52, 'M', '𖹲'),
+ (0x16E53, 'M', '𖹳'),
+ (0x16E54, 'M', '𖹴'),
+ (0x16E55, 'M', '𖹵'),
+ (0x16E56, 'M', '𖹶'),
+ (0x16E57, 'M', '𖹷'),
+ (0x16E58, 'M', '𖹸'),
+ (0x16E59, 'M', '𖹹'),
+ (0x16E5A, 'M', '𖹺'),
+ (0x16E5B, 'M', '𖹻'),
+ (0x16E5C, 'M', '𖹼'),
+ (0x16E5D, 'M', '𖹽'),
+ (0x16E5E, 'M', '𖹾'),
+ (0x16E5F, 'M', '𖹿'),
+ (0x16E60, 'V'),
+ (0x16E9B, 'X'),
+ (0x16F00, 'V'),
+ (0x16F4B, 'X'),
+ (0x16F4F, 'V'),
+ (0x16F88, 'X'),
+ (0x16F8F, 'V'),
+ (0x16FA0, 'X'),
+ (0x16FE0, 'V'),
+ (0x16FE5, 'X'),
+ (0x16FF0, 'V'),
+ (0x16FF2, 'X'),
+ (0x17000, 'V'),
+ (0x187F8, 'X'),
+ (0x18800, 'V'),
+ (0x18CD6, 'X'),
+ (0x18D00, 'V'),
+ (0x18D09, 'X'),
+ (0x1AFF0, 'V'),
+ (0x1AFF4, 'X'),
+ (0x1AFF5, 'V'),
+ (0x1AFFC, 'X'),
+ (0x1AFFD, 'V'),
+ ]
+
+def _seg_60() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1AFFF, 'X'),
+ (0x1B000, 'V'),
+ (0x1B123, 'X'),
+ (0x1B132, 'V'),
+ (0x1B133, 'X'),
+ (0x1B150, 'V'),
+ (0x1B153, 'X'),
+ (0x1B155, 'V'),
+ (0x1B156, 'X'),
+ (0x1B164, 'V'),
+ (0x1B168, 'X'),
+ (0x1B170, 'V'),
+ (0x1B2FC, 'X'),
+ (0x1BC00, 'V'),
+ (0x1BC6B, 'X'),
+ (0x1BC70, 'V'),
+ (0x1BC7D, 'X'),
+ (0x1BC80, 'V'),
+ (0x1BC89, 'X'),
+ (0x1BC90, 'V'),
+ (0x1BC9A, 'X'),
+ (0x1BC9C, 'V'),
+ (0x1BCA0, 'I'),
+ (0x1BCA4, 'X'),
+ (0x1CF00, 'V'),
+ (0x1CF2E, 'X'),
+ (0x1CF30, 'V'),
+ (0x1CF47, 'X'),
+ (0x1CF50, 'V'),
+ (0x1CFC4, 'X'),
+ (0x1D000, 'V'),
+ (0x1D0F6, 'X'),
+ (0x1D100, 'V'),
+ (0x1D127, 'X'),
+ (0x1D129, 'V'),
+ (0x1D15E, 'M', '𝅗𝅥'),
+ (0x1D15F, 'M', '𝅘𝅥'),
+ (0x1D160, 'M', '𝅘𝅥𝅮'),
+ (0x1D161, 'M', '𝅘𝅥𝅯'),
+ (0x1D162, 'M', '𝅘𝅥𝅰'),
+ (0x1D163, 'M', '𝅘𝅥𝅱'),
+ (0x1D164, 'M', '𝅘𝅥𝅲'),
+ (0x1D165, 'V'),
+ (0x1D173, 'X'),
+ (0x1D17B, 'V'),
+ (0x1D1BB, 'M', '𝆹𝅥'),
+ (0x1D1BC, 'M', '𝆺𝅥'),
+ (0x1D1BD, 'M', '𝆹𝅥𝅮'),
+ (0x1D1BE, 'M', '𝆺𝅥𝅮'),
+ (0x1D1BF, 'M', '𝆹𝅥𝅯'),
+ (0x1D1C0, 'M', '𝆺𝅥𝅯'),
+ (0x1D1C1, 'V'),
+ (0x1D1EB, 'X'),
+ (0x1D200, 'V'),
+ (0x1D246, 'X'),
+ (0x1D2C0, 'V'),
+ (0x1D2D4, 'X'),
+ (0x1D2E0, 'V'),
+ (0x1D2F4, 'X'),
+ (0x1D300, 'V'),
+ (0x1D357, 'X'),
+ (0x1D360, 'V'),
+ (0x1D379, 'X'),
+ (0x1D400, 'M', 'a'),
+ (0x1D401, 'M', 'b'),
+ (0x1D402, 'M', 'c'),
+ (0x1D403, 'M', 'd'),
+ (0x1D404, 'M', 'e'),
+ (0x1D405, 'M', 'f'),
+ (0x1D406, 'M', 'g'),
+ (0x1D407, 'M', 'h'),
+ (0x1D408, 'M', 'i'),
+ (0x1D409, 'M', 'j'),
+ (0x1D40A, 'M', 'k'),
+ (0x1D40B, 'M', 'l'),
+ (0x1D40C, 'M', 'm'),
+ (0x1D40D, 'M', 'n'),
+ (0x1D40E, 'M', 'o'),
+ (0x1D40F, 'M', 'p'),
+ (0x1D410, 'M', 'q'),
+ (0x1D411, 'M', 'r'),
+ (0x1D412, 'M', 's'),
+ (0x1D413, 'M', 't'),
+ (0x1D414, 'M', 'u'),
+ (0x1D415, 'M', 'v'),
+ (0x1D416, 'M', 'w'),
+ (0x1D417, 'M', 'x'),
+ (0x1D418, 'M', 'y'),
+ (0x1D419, 'M', 'z'),
+ (0x1D41A, 'M', 'a'),
+ (0x1D41B, 'M', 'b'),
+ (0x1D41C, 'M', 'c'),
+ (0x1D41D, 'M', 'd'),
+ (0x1D41E, 'M', 'e'),
+ (0x1D41F, 'M', 'f'),
+ (0x1D420, 'M', 'g'),
+ (0x1D421, 'M', 'h'),
+ (0x1D422, 'M', 'i'),
+ (0x1D423, 'M', 'j'),
+ (0x1D424, 'M', 'k'),
+ ]
+
+def _seg_61() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D425, 'M', 'l'),
+ (0x1D426, 'M', 'm'),
+ (0x1D427, 'M', 'n'),
+ (0x1D428, 'M', 'o'),
+ (0x1D429, 'M', 'p'),
+ (0x1D42A, 'M', 'q'),
+ (0x1D42B, 'M', 'r'),
+ (0x1D42C, 'M', 's'),
+ (0x1D42D, 'M', 't'),
+ (0x1D42E, 'M', 'u'),
+ (0x1D42F, 'M', 'v'),
+ (0x1D430, 'M', 'w'),
+ (0x1D431, 'M', 'x'),
+ (0x1D432, 'M', 'y'),
+ (0x1D433, 'M', 'z'),
+ (0x1D434, 'M', 'a'),
+ (0x1D435, 'M', 'b'),
+ (0x1D436, 'M', 'c'),
+ (0x1D437, 'M', 'd'),
+ (0x1D438, 'M', 'e'),
+ (0x1D439, 'M', 'f'),
+ (0x1D43A, 'M', 'g'),
+ (0x1D43B, 'M', 'h'),
+ (0x1D43C, 'M', 'i'),
+ (0x1D43D, 'M', 'j'),
+ (0x1D43E, 'M', 'k'),
+ (0x1D43F, 'M', 'l'),
+ (0x1D440, 'M', 'm'),
+ (0x1D441, 'M', 'n'),
+ (0x1D442, 'M', 'o'),
+ (0x1D443, 'M', 'p'),
+ (0x1D444, 'M', 'q'),
+ (0x1D445, 'M', 'r'),
+ (0x1D446, 'M', 's'),
+ (0x1D447, 'M', 't'),
+ (0x1D448, 'M', 'u'),
+ (0x1D449, 'M', 'v'),
+ (0x1D44A, 'M', 'w'),
+ (0x1D44B, 'M', 'x'),
+ (0x1D44C, 'M', 'y'),
+ (0x1D44D, 'M', 'z'),
+ (0x1D44E, 'M', 'a'),
+ (0x1D44F, 'M', 'b'),
+ (0x1D450, 'M', 'c'),
+ (0x1D451, 'M', 'd'),
+ (0x1D452, 'M', 'e'),
+ (0x1D453, 'M', 'f'),
+ (0x1D454, 'M', 'g'),
+ (0x1D455, 'X'),
+ (0x1D456, 'M', 'i'),
+ (0x1D457, 'M', 'j'),
+ (0x1D458, 'M', 'k'),
+ (0x1D459, 'M', 'l'),
+ (0x1D45A, 'M', 'm'),
+ (0x1D45B, 'M', 'n'),
+ (0x1D45C, 'M', 'o'),
+ (0x1D45D, 'M', 'p'),
+ (0x1D45E, 'M', 'q'),
+ (0x1D45F, 'M', 'r'),
+ (0x1D460, 'M', 's'),
+ (0x1D461, 'M', 't'),
+ (0x1D462, 'M', 'u'),
+ (0x1D463, 'M', 'v'),
+ (0x1D464, 'M', 'w'),
+ (0x1D465, 'M', 'x'),
+ (0x1D466, 'M', 'y'),
+ (0x1D467, 'M', 'z'),
+ (0x1D468, 'M', 'a'),
+ (0x1D469, 'M', 'b'),
+ (0x1D46A, 'M', 'c'),
+ (0x1D46B, 'M', 'd'),
+ (0x1D46C, 'M', 'e'),
+ (0x1D46D, 'M', 'f'),
+ (0x1D46E, 'M', 'g'),
+ (0x1D46F, 'M', 'h'),
+ (0x1D470, 'M', 'i'),
+ (0x1D471, 'M', 'j'),
+ (0x1D472, 'M', 'k'),
+ (0x1D473, 'M', 'l'),
+ (0x1D474, 'M', 'm'),
+ (0x1D475, 'M', 'n'),
+ (0x1D476, 'M', 'o'),
+ (0x1D477, 'M', 'p'),
+ (0x1D478, 'M', 'q'),
+ (0x1D479, 'M', 'r'),
+ (0x1D47A, 'M', 's'),
+ (0x1D47B, 'M', 't'),
+ (0x1D47C, 'M', 'u'),
+ (0x1D47D, 'M', 'v'),
+ (0x1D47E, 'M', 'w'),
+ (0x1D47F, 'M', 'x'),
+ (0x1D480, 'M', 'y'),
+ (0x1D481, 'M', 'z'),
+ (0x1D482, 'M', 'a'),
+ (0x1D483, 'M', 'b'),
+ (0x1D484, 'M', 'c'),
+ (0x1D485, 'M', 'd'),
+ (0x1D486, 'M', 'e'),
+ (0x1D487, 'M', 'f'),
+ (0x1D488, 'M', 'g'),
+ ]
+
+def _seg_62() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D489, 'M', 'h'),
+ (0x1D48A, 'M', 'i'),
+ (0x1D48B, 'M', 'j'),
+ (0x1D48C, 'M', 'k'),
+ (0x1D48D, 'M', 'l'),
+ (0x1D48E, 'M', 'm'),
+ (0x1D48F, 'M', 'n'),
+ (0x1D490, 'M', 'o'),
+ (0x1D491, 'M', 'p'),
+ (0x1D492, 'M', 'q'),
+ (0x1D493, 'M', 'r'),
+ (0x1D494, 'M', 's'),
+ (0x1D495, 'M', 't'),
+ (0x1D496, 'M', 'u'),
+ (0x1D497, 'M', 'v'),
+ (0x1D498, 'M', 'w'),
+ (0x1D499, 'M', 'x'),
+ (0x1D49A, 'M', 'y'),
+ (0x1D49B, 'M', 'z'),
+ (0x1D49C, 'M', 'a'),
+ (0x1D49D, 'X'),
+ (0x1D49E, 'M', 'c'),
+ (0x1D49F, 'M', 'd'),
+ (0x1D4A0, 'X'),
+ (0x1D4A2, 'M', 'g'),
+ (0x1D4A3, 'X'),
+ (0x1D4A5, 'M', 'j'),
+ (0x1D4A6, 'M', 'k'),
+ (0x1D4A7, 'X'),
+ (0x1D4A9, 'M', 'n'),
+ (0x1D4AA, 'M', 'o'),
+ (0x1D4AB, 'M', 'p'),
+ (0x1D4AC, 'M', 'q'),
+ (0x1D4AD, 'X'),
+ (0x1D4AE, 'M', 's'),
+ (0x1D4AF, 'M', 't'),
+ (0x1D4B0, 'M', 'u'),
+ (0x1D4B1, 'M', 'v'),
+ (0x1D4B2, 'M', 'w'),
+ (0x1D4B3, 'M', 'x'),
+ (0x1D4B4, 'M', 'y'),
+ (0x1D4B5, 'M', 'z'),
+ (0x1D4B6, 'M', 'a'),
+ (0x1D4B7, 'M', 'b'),
+ (0x1D4B8, 'M', 'c'),
+ (0x1D4B9, 'M', 'd'),
+ (0x1D4BA, 'X'),
+ (0x1D4BB, 'M', 'f'),
+ (0x1D4BC, 'X'),
+ (0x1D4BD, 'M', 'h'),
+ (0x1D4BE, 'M', 'i'),
+ (0x1D4BF, 'M', 'j'),
+ (0x1D4C0, 'M', 'k'),
+ (0x1D4C1, 'M', 'l'),
+ (0x1D4C2, 'M', 'm'),
+ (0x1D4C3, 'M', 'n'),
+ (0x1D4C4, 'X'),
+ (0x1D4C5, 'M', 'p'),
+ (0x1D4C6, 'M', 'q'),
+ (0x1D4C7, 'M', 'r'),
+ (0x1D4C8, 'M', 's'),
+ (0x1D4C9, 'M', 't'),
+ (0x1D4CA, 'M', 'u'),
+ (0x1D4CB, 'M', 'v'),
+ (0x1D4CC, 'M', 'w'),
+ (0x1D4CD, 'M', 'x'),
+ (0x1D4CE, 'M', 'y'),
+ (0x1D4CF, 'M', 'z'),
+ (0x1D4D0, 'M', 'a'),
+ (0x1D4D1, 'M', 'b'),
+ (0x1D4D2, 'M', 'c'),
+ (0x1D4D3, 'M', 'd'),
+ (0x1D4D4, 'M', 'e'),
+ (0x1D4D5, 'M', 'f'),
+ (0x1D4D6, 'M', 'g'),
+ (0x1D4D7, 'M', 'h'),
+ (0x1D4D8, 'M', 'i'),
+ (0x1D4D9, 'M', 'j'),
+ (0x1D4DA, 'M', 'k'),
+ (0x1D4DB, 'M', 'l'),
+ (0x1D4DC, 'M', 'm'),
+ (0x1D4DD, 'M', 'n'),
+ (0x1D4DE, 'M', 'o'),
+ (0x1D4DF, 'M', 'p'),
+ (0x1D4E0, 'M', 'q'),
+ (0x1D4E1, 'M', 'r'),
+ (0x1D4E2, 'M', 's'),
+ (0x1D4E3, 'M', 't'),
+ (0x1D4E4, 'M', 'u'),
+ (0x1D4E5, 'M', 'v'),
+ (0x1D4E6, 'M', 'w'),
+ (0x1D4E7, 'M', 'x'),
+ (0x1D4E8, 'M', 'y'),
+ (0x1D4E9, 'M', 'z'),
+ (0x1D4EA, 'M', 'a'),
+ (0x1D4EB, 'M', 'b'),
+ (0x1D4EC, 'M', 'c'),
+ (0x1D4ED, 'M', 'd'),
+ (0x1D4EE, 'M', 'e'),
+ (0x1D4EF, 'M', 'f'),
+ ]
+
+def _seg_63() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D4F0, 'M', 'g'),
+ (0x1D4F1, 'M', 'h'),
+ (0x1D4F2, 'M', 'i'),
+ (0x1D4F3, 'M', 'j'),
+ (0x1D4F4, 'M', 'k'),
+ (0x1D4F5, 'M', 'l'),
+ (0x1D4F6, 'M', 'm'),
+ (0x1D4F7, 'M', 'n'),
+ (0x1D4F8, 'M', 'o'),
+ (0x1D4F9, 'M', 'p'),
+ (0x1D4FA, 'M', 'q'),
+ (0x1D4FB, 'M', 'r'),
+ (0x1D4FC, 'M', 's'),
+ (0x1D4FD, 'M', 't'),
+ (0x1D4FE, 'M', 'u'),
+ (0x1D4FF, 'M', 'v'),
+ (0x1D500, 'M', 'w'),
+ (0x1D501, 'M', 'x'),
+ (0x1D502, 'M', 'y'),
+ (0x1D503, 'M', 'z'),
+ (0x1D504, 'M', 'a'),
+ (0x1D505, 'M', 'b'),
+ (0x1D506, 'X'),
+ (0x1D507, 'M', 'd'),
+ (0x1D508, 'M', 'e'),
+ (0x1D509, 'M', 'f'),
+ (0x1D50A, 'M', 'g'),
+ (0x1D50B, 'X'),
+ (0x1D50D, 'M', 'j'),
+ (0x1D50E, 'M', 'k'),
+ (0x1D50F, 'M', 'l'),
+ (0x1D510, 'M', 'm'),
+ (0x1D511, 'M', 'n'),
+ (0x1D512, 'M', 'o'),
+ (0x1D513, 'M', 'p'),
+ (0x1D514, 'M', 'q'),
+ (0x1D515, 'X'),
+ (0x1D516, 'M', 's'),
+ (0x1D517, 'M', 't'),
+ (0x1D518, 'M', 'u'),
+ (0x1D519, 'M', 'v'),
+ (0x1D51A, 'M', 'w'),
+ (0x1D51B, 'M', 'x'),
+ (0x1D51C, 'M', 'y'),
+ (0x1D51D, 'X'),
+ (0x1D51E, 'M', 'a'),
+ (0x1D51F, 'M', 'b'),
+ (0x1D520, 'M', 'c'),
+ (0x1D521, 'M', 'd'),
+ (0x1D522, 'M', 'e'),
+ (0x1D523, 'M', 'f'),
+ (0x1D524, 'M', 'g'),
+ (0x1D525, 'M', 'h'),
+ (0x1D526, 'M', 'i'),
+ (0x1D527, 'M', 'j'),
+ (0x1D528, 'M', 'k'),
+ (0x1D529, 'M', 'l'),
+ (0x1D52A, 'M', 'm'),
+ (0x1D52B, 'M', 'n'),
+ (0x1D52C, 'M', 'o'),
+ (0x1D52D, 'M', 'p'),
+ (0x1D52E, 'M', 'q'),
+ (0x1D52F, 'M', 'r'),
+ (0x1D530, 'M', 's'),
+ (0x1D531, 'M', 't'),
+ (0x1D532, 'M', 'u'),
+ (0x1D533, 'M', 'v'),
+ (0x1D534, 'M', 'w'),
+ (0x1D535, 'M', 'x'),
+ (0x1D536, 'M', 'y'),
+ (0x1D537, 'M', 'z'),
+ (0x1D538, 'M', 'a'),
+ (0x1D539, 'M', 'b'),
+ (0x1D53A, 'X'),
+ (0x1D53B, 'M', 'd'),
+ (0x1D53C, 'M', 'e'),
+ (0x1D53D, 'M', 'f'),
+ (0x1D53E, 'M', 'g'),
+ (0x1D53F, 'X'),
+ (0x1D540, 'M', 'i'),
+ (0x1D541, 'M', 'j'),
+ (0x1D542, 'M', 'k'),
+ (0x1D543, 'M', 'l'),
+ (0x1D544, 'M', 'm'),
+ (0x1D545, 'X'),
+ (0x1D546, 'M', 'o'),
+ (0x1D547, 'X'),
+ (0x1D54A, 'M', 's'),
+ (0x1D54B, 'M', 't'),
+ (0x1D54C, 'M', 'u'),
+ (0x1D54D, 'M', 'v'),
+ (0x1D54E, 'M', 'w'),
+ (0x1D54F, 'M', 'x'),
+ (0x1D550, 'M', 'y'),
+ (0x1D551, 'X'),
+ (0x1D552, 'M', 'a'),
+ (0x1D553, 'M', 'b'),
+ (0x1D554, 'M', 'c'),
+ (0x1D555, 'M', 'd'),
+ (0x1D556, 'M', 'e'),
+ ]
+
+def _seg_64() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D557, 'M', 'f'),
+ (0x1D558, 'M', 'g'),
+ (0x1D559, 'M', 'h'),
+ (0x1D55A, 'M', 'i'),
+ (0x1D55B, 'M', 'j'),
+ (0x1D55C, 'M', 'k'),
+ (0x1D55D, 'M', 'l'),
+ (0x1D55E, 'M', 'm'),
+ (0x1D55F, 'M', 'n'),
+ (0x1D560, 'M', 'o'),
+ (0x1D561, 'M', 'p'),
+ (0x1D562, 'M', 'q'),
+ (0x1D563, 'M', 'r'),
+ (0x1D564, 'M', 's'),
+ (0x1D565, 'M', 't'),
+ (0x1D566, 'M', 'u'),
+ (0x1D567, 'M', 'v'),
+ (0x1D568, 'M', 'w'),
+ (0x1D569, 'M', 'x'),
+ (0x1D56A, 'M', 'y'),
+ (0x1D56B, 'M', 'z'),
+ (0x1D56C, 'M', 'a'),
+ (0x1D56D, 'M', 'b'),
+ (0x1D56E, 'M', 'c'),
+ (0x1D56F, 'M', 'd'),
+ (0x1D570, 'M', 'e'),
+ (0x1D571, 'M', 'f'),
+ (0x1D572, 'M', 'g'),
+ (0x1D573, 'M', 'h'),
+ (0x1D574, 'M', 'i'),
+ (0x1D575, 'M', 'j'),
+ (0x1D576, 'M', 'k'),
+ (0x1D577, 'M', 'l'),
+ (0x1D578, 'M', 'm'),
+ (0x1D579, 'M', 'n'),
+ (0x1D57A, 'M', 'o'),
+ (0x1D57B, 'M', 'p'),
+ (0x1D57C, 'M', 'q'),
+ (0x1D57D, 'M', 'r'),
+ (0x1D57E, 'M', 's'),
+ (0x1D57F, 'M', 't'),
+ (0x1D580, 'M', 'u'),
+ (0x1D581, 'M', 'v'),
+ (0x1D582, 'M', 'w'),
+ (0x1D583, 'M', 'x'),
+ (0x1D584, 'M', 'y'),
+ (0x1D585, 'M', 'z'),
+ (0x1D586, 'M', 'a'),
+ (0x1D587, 'M', 'b'),
+ (0x1D588, 'M', 'c'),
+ (0x1D589, 'M', 'd'),
+ (0x1D58A, 'M', 'e'),
+ (0x1D58B, 'M', 'f'),
+ (0x1D58C, 'M', 'g'),
+ (0x1D58D, 'M', 'h'),
+ (0x1D58E, 'M', 'i'),
+ (0x1D58F, 'M', 'j'),
+ (0x1D590, 'M', 'k'),
+ (0x1D591, 'M', 'l'),
+ (0x1D592, 'M', 'm'),
+ (0x1D593, 'M', 'n'),
+ (0x1D594, 'M', 'o'),
+ (0x1D595, 'M', 'p'),
+ (0x1D596, 'M', 'q'),
+ (0x1D597, 'M', 'r'),
+ (0x1D598, 'M', 's'),
+ (0x1D599, 'M', 't'),
+ (0x1D59A, 'M', 'u'),
+ (0x1D59B, 'M', 'v'),
+ (0x1D59C, 'M', 'w'),
+ (0x1D59D, 'M', 'x'),
+ (0x1D59E, 'M', 'y'),
+ (0x1D59F, 'M', 'z'),
+ (0x1D5A0, 'M', 'a'),
+ (0x1D5A1, 'M', 'b'),
+ (0x1D5A2, 'M', 'c'),
+ (0x1D5A3, 'M', 'd'),
+ (0x1D5A4, 'M', 'e'),
+ (0x1D5A5, 'M', 'f'),
+ (0x1D5A6, 'M', 'g'),
+ (0x1D5A7, 'M', 'h'),
+ (0x1D5A8, 'M', 'i'),
+ (0x1D5A9, 'M', 'j'),
+ (0x1D5AA, 'M', 'k'),
+ (0x1D5AB, 'M', 'l'),
+ (0x1D5AC, 'M', 'm'),
+ (0x1D5AD, 'M', 'n'),
+ (0x1D5AE, 'M', 'o'),
+ (0x1D5AF, 'M', 'p'),
+ (0x1D5B0, 'M', 'q'),
+ (0x1D5B1, 'M', 'r'),
+ (0x1D5B2, 'M', 's'),
+ (0x1D5B3, 'M', 't'),
+ (0x1D5B4, 'M', 'u'),
+ (0x1D5B5, 'M', 'v'),
+ (0x1D5B6, 'M', 'w'),
+ (0x1D5B7, 'M', 'x'),
+ (0x1D5B8, 'M', 'y'),
+ (0x1D5B9, 'M', 'z'),
+ (0x1D5BA, 'M', 'a'),
+ ]
+
+def _seg_65() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D5BB, 'M', 'b'),
+ (0x1D5BC, 'M', 'c'),
+ (0x1D5BD, 'M', 'd'),
+ (0x1D5BE, 'M', 'e'),
+ (0x1D5BF, 'M', 'f'),
+ (0x1D5C0, 'M', 'g'),
+ (0x1D5C1, 'M', 'h'),
+ (0x1D5C2, 'M', 'i'),
+ (0x1D5C3, 'M', 'j'),
+ (0x1D5C4, 'M', 'k'),
+ (0x1D5C5, 'M', 'l'),
+ (0x1D5C6, 'M', 'm'),
+ (0x1D5C7, 'M', 'n'),
+ (0x1D5C8, 'M', 'o'),
+ (0x1D5C9, 'M', 'p'),
+ (0x1D5CA, 'M', 'q'),
+ (0x1D5CB, 'M', 'r'),
+ (0x1D5CC, 'M', 's'),
+ (0x1D5CD, 'M', 't'),
+ (0x1D5CE, 'M', 'u'),
+ (0x1D5CF, 'M', 'v'),
+ (0x1D5D0, 'M', 'w'),
+ (0x1D5D1, 'M', 'x'),
+ (0x1D5D2, 'M', 'y'),
+ (0x1D5D3, 'M', 'z'),
+ (0x1D5D4, 'M', 'a'),
+ (0x1D5D5, 'M', 'b'),
+ (0x1D5D6, 'M', 'c'),
+ (0x1D5D7, 'M', 'd'),
+ (0x1D5D8, 'M', 'e'),
+ (0x1D5D9, 'M', 'f'),
+ (0x1D5DA, 'M', 'g'),
+ (0x1D5DB, 'M', 'h'),
+ (0x1D5DC, 'M', 'i'),
+ (0x1D5DD, 'M', 'j'),
+ (0x1D5DE, 'M', 'k'),
+ (0x1D5DF, 'M', 'l'),
+ (0x1D5E0, 'M', 'm'),
+ (0x1D5E1, 'M', 'n'),
+ (0x1D5E2, 'M', 'o'),
+ (0x1D5E3, 'M', 'p'),
+ (0x1D5E4, 'M', 'q'),
+ (0x1D5E5, 'M', 'r'),
+ (0x1D5E6, 'M', 's'),
+ (0x1D5E7, 'M', 't'),
+ (0x1D5E8, 'M', 'u'),
+ (0x1D5E9, 'M', 'v'),
+ (0x1D5EA, 'M', 'w'),
+ (0x1D5EB, 'M', 'x'),
+ (0x1D5EC, 'M', 'y'),
+ (0x1D5ED, 'M', 'z'),
+ (0x1D5EE, 'M', 'a'),
+ (0x1D5EF, 'M', 'b'),
+ (0x1D5F0, 'M', 'c'),
+ (0x1D5F1, 'M', 'd'),
+ (0x1D5F2, 'M', 'e'),
+ (0x1D5F3, 'M', 'f'),
+ (0x1D5F4, 'M', 'g'),
+ (0x1D5F5, 'M', 'h'),
+ (0x1D5F6, 'M', 'i'),
+ (0x1D5F7, 'M', 'j'),
+ (0x1D5F8, 'M', 'k'),
+ (0x1D5F9, 'M', 'l'),
+ (0x1D5FA, 'M', 'm'),
+ (0x1D5FB, 'M', 'n'),
+ (0x1D5FC, 'M', 'o'),
+ (0x1D5FD, 'M', 'p'),
+ (0x1D5FE, 'M', 'q'),
+ (0x1D5FF, 'M', 'r'),
+ (0x1D600, 'M', 's'),
+ (0x1D601, 'M', 't'),
+ (0x1D602, 'M', 'u'),
+ (0x1D603, 'M', 'v'),
+ (0x1D604, 'M', 'w'),
+ (0x1D605, 'M', 'x'),
+ (0x1D606, 'M', 'y'),
+ (0x1D607, 'M', 'z'),
+ (0x1D608, 'M', 'a'),
+ (0x1D609, 'M', 'b'),
+ (0x1D60A, 'M', 'c'),
+ (0x1D60B, 'M', 'd'),
+ (0x1D60C, 'M', 'e'),
+ (0x1D60D, 'M', 'f'),
+ (0x1D60E, 'M', 'g'),
+ (0x1D60F, 'M', 'h'),
+ (0x1D610, 'M', 'i'),
+ (0x1D611, 'M', 'j'),
+ (0x1D612, 'M', 'k'),
+ (0x1D613, 'M', 'l'),
+ (0x1D614, 'M', 'm'),
+ (0x1D615, 'M', 'n'),
+ (0x1D616, 'M', 'o'),
+ (0x1D617, 'M', 'p'),
+ (0x1D618, 'M', 'q'),
+ (0x1D619, 'M', 'r'),
+ (0x1D61A, 'M', 's'),
+ (0x1D61B, 'M', 't'),
+ (0x1D61C, 'M', 'u'),
+ (0x1D61D, 'M', 'v'),
+ (0x1D61E, 'M', 'w'),
+ ]
+
+def _seg_66() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D61F, 'M', 'x'),
+ (0x1D620, 'M', 'y'),
+ (0x1D621, 'M', 'z'),
+ (0x1D622, 'M', 'a'),
+ (0x1D623, 'M', 'b'),
+ (0x1D624, 'M', 'c'),
+ (0x1D625, 'M', 'd'),
+ (0x1D626, 'M', 'e'),
+ (0x1D627, 'M', 'f'),
+ (0x1D628, 'M', 'g'),
+ (0x1D629, 'M', 'h'),
+ (0x1D62A, 'M', 'i'),
+ (0x1D62B, 'M', 'j'),
+ (0x1D62C, 'M', 'k'),
+ (0x1D62D, 'M', 'l'),
+ (0x1D62E, 'M', 'm'),
+ (0x1D62F, 'M', 'n'),
+ (0x1D630, 'M', 'o'),
+ (0x1D631, 'M', 'p'),
+ (0x1D632, 'M', 'q'),
+ (0x1D633, 'M', 'r'),
+ (0x1D634, 'M', 's'),
+ (0x1D635, 'M', 't'),
+ (0x1D636, 'M', 'u'),
+ (0x1D637, 'M', 'v'),
+ (0x1D638, 'M', 'w'),
+ (0x1D639, 'M', 'x'),
+ (0x1D63A, 'M', 'y'),
+ (0x1D63B, 'M', 'z'),
+ (0x1D63C, 'M', 'a'),
+ (0x1D63D, 'M', 'b'),
+ (0x1D63E, 'M', 'c'),
+ (0x1D63F, 'M', 'd'),
+ (0x1D640, 'M', 'e'),
+ (0x1D641, 'M', 'f'),
+ (0x1D642, 'M', 'g'),
+ (0x1D643, 'M', 'h'),
+ (0x1D644, 'M', 'i'),
+ (0x1D645, 'M', 'j'),
+ (0x1D646, 'M', 'k'),
+ (0x1D647, 'M', 'l'),
+ (0x1D648, 'M', 'm'),
+ (0x1D649, 'M', 'n'),
+ (0x1D64A, 'M', 'o'),
+ (0x1D64B, 'M', 'p'),
+ (0x1D64C, 'M', 'q'),
+ (0x1D64D, 'M', 'r'),
+ (0x1D64E, 'M', 's'),
+ (0x1D64F, 'M', 't'),
+ (0x1D650, 'M', 'u'),
+ (0x1D651, 'M', 'v'),
+ (0x1D652, 'M', 'w'),
+ (0x1D653, 'M', 'x'),
+ (0x1D654, 'M', 'y'),
+ (0x1D655, 'M', 'z'),
+ (0x1D656, 'M', 'a'),
+ (0x1D657, 'M', 'b'),
+ (0x1D658, 'M', 'c'),
+ (0x1D659, 'M', 'd'),
+ (0x1D65A, 'M', 'e'),
+ (0x1D65B, 'M', 'f'),
+ (0x1D65C, 'M', 'g'),
+ (0x1D65D, 'M', 'h'),
+ (0x1D65E, 'M', 'i'),
+ (0x1D65F, 'M', 'j'),
+ (0x1D660, 'M', 'k'),
+ (0x1D661, 'M', 'l'),
+ (0x1D662, 'M', 'm'),
+ (0x1D663, 'M', 'n'),
+ (0x1D664, 'M', 'o'),
+ (0x1D665, 'M', 'p'),
+ (0x1D666, 'M', 'q'),
+ (0x1D667, 'M', 'r'),
+ (0x1D668, 'M', 's'),
+ (0x1D669, 'M', 't'),
+ (0x1D66A, 'M', 'u'),
+ (0x1D66B, 'M', 'v'),
+ (0x1D66C, 'M', 'w'),
+ (0x1D66D, 'M', 'x'),
+ (0x1D66E, 'M', 'y'),
+ (0x1D66F, 'M', 'z'),
+ (0x1D670, 'M', 'a'),
+ (0x1D671, 'M', 'b'),
+ (0x1D672, 'M', 'c'),
+ (0x1D673, 'M', 'd'),
+ (0x1D674, 'M', 'e'),
+ (0x1D675, 'M', 'f'),
+ (0x1D676, 'M', 'g'),
+ (0x1D677, 'M', 'h'),
+ (0x1D678, 'M', 'i'),
+ (0x1D679, 'M', 'j'),
+ (0x1D67A, 'M', 'k'),
+ (0x1D67B, 'M', 'l'),
+ (0x1D67C, 'M', 'm'),
+ (0x1D67D, 'M', 'n'),
+ (0x1D67E, 'M', 'o'),
+ (0x1D67F, 'M', 'p'),
+ (0x1D680, 'M', 'q'),
+ (0x1D681, 'M', 'r'),
+ (0x1D682, 'M', 's'),
+ ]
+
+def _seg_67() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D683, 'M', 't'),
+ (0x1D684, 'M', 'u'),
+ (0x1D685, 'M', 'v'),
+ (0x1D686, 'M', 'w'),
+ (0x1D687, 'M', 'x'),
+ (0x1D688, 'M', 'y'),
+ (0x1D689, 'M', 'z'),
+ (0x1D68A, 'M', 'a'),
+ (0x1D68B, 'M', 'b'),
+ (0x1D68C, 'M', 'c'),
+ (0x1D68D, 'M', 'd'),
+ (0x1D68E, 'M', 'e'),
+ (0x1D68F, 'M', 'f'),
+ (0x1D690, 'M', 'g'),
+ (0x1D691, 'M', 'h'),
+ (0x1D692, 'M', 'i'),
+ (0x1D693, 'M', 'j'),
+ (0x1D694, 'M', 'k'),
+ (0x1D695, 'M', 'l'),
+ (0x1D696, 'M', 'm'),
+ (0x1D697, 'M', 'n'),
+ (0x1D698, 'M', 'o'),
+ (0x1D699, 'M', 'p'),
+ (0x1D69A, 'M', 'q'),
+ (0x1D69B, 'M', 'r'),
+ (0x1D69C, 'M', 's'),
+ (0x1D69D, 'M', 't'),
+ (0x1D69E, 'M', 'u'),
+ (0x1D69F, 'M', 'v'),
+ (0x1D6A0, 'M', 'w'),
+ (0x1D6A1, 'M', 'x'),
+ (0x1D6A2, 'M', 'y'),
+ (0x1D6A3, 'M', 'z'),
+ (0x1D6A4, 'M', 'ı'),
+ (0x1D6A5, 'M', 'ȷ'),
+ (0x1D6A6, 'X'),
+ (0x1D6A8, 'M', 'α'),
+ (0x1D6A9, 'M', 'β'),
+ (0x1D6AA, 'M', 'γ'),
+ (0x1D6AB, 'M', 'δ'),
+ (0x1D6AC, 'M', 'ε'),
+ (0x1D6AD, 'M', 'ζ'),
+ (0x1D6AE, 'M', 'η'),
+ (0x1D6AF, 'M', 'θ'),
+ (0x1D6B0, 'M', 'ι'),
+ (0x1D6B1, 'M', 'κ'),
+ (0x1D6B2, 'M', 'λ'),
+ (0x1D6B3, 'M', 'μ'),
+ (0x1D6B4, 'M', 'ν'),
+ (0x1D6B5, 'M', 'ξ'),
+ (0x1D6B6, 'M', 'ο'),
+ (0x1D6B7, 'M', 'π'),
+ (0x1D6B8, 'M', 'ρ'),
+ (0x1D6B9, 'M', 'θ'),
+ (0x1D6BA, 'M', 'σ'),
+ (0x1D6BB, 'M', 'τ'),
+ (0x1D6BC, 'M', 'υ'),
+ (0x1D6BD, 'M', 'φ'),
+ (0x1D6BE, 'M', 'χ'),
+ (0x1D6BF, 'M', 'ψ'),
+ (0x1D6C0, 'M', 'ω'),
+ (0x1D6C1, 'M', '∇'),
+ (0x1D6C2, 'M', 'α'),
+ (0x1D6C3, 'M', 'β'),
+ (0x1D6C4, 'M', 'γ'),
+ (0x1D6C5, 'M', 'δ'),
+ (0x1D6C6, 'M', 'ε'),
+ (0x1D6C7, 'M', 'ζ'),
+ (0x1D6C8, 'M', 'η'),
+ (0x1D6C9, 'M', 'θ'),
+ (0x1D6CA, 'M', 'ι'),
+ (0x1D6CB, 'M', 'κ'),
+ (0x1D6CC, 'M', 'λ'),
+ (0x1D6CD, 'M', 'μ'),
+ (0x1D6CE, 'M', 'ν'),
+ (0x1D6CF, 'M', 'ξ'),
+ (0x1D6D0, 'M', 'ο'),
+ (0x1D6D1, 'M', 'π'),
+ (0x1D6D2, 'M', 'ρ'),
+ (0x1D6D3, 'M', 'σ'),
+ (0x1D6D5, 'M', 'τ'),
+ (0x1D6D6, 'M', 'υ'),
+ (0x1D6D7, 'M', 'φ'),
+ (0x1D6D8, 'M', 'χ'),
+ (0x1D6D9, 'M', 'ψ'),
+ (0x1D6DA, 'M', 'ω'),
+ (0x1D6DB, 'M', '∂'),
+ (0x1D6DC, 'M', 'ε'),
+ (0x1D6DD, 'M', 'θ'),
+ (0x1D6DE, 'M', 'κ'),
+ (0x1D6DF, 'M', 'φ'),
+ (0x1D6E0, 'M', 'ρ'),
+ (0x1D6E1, 'M', 'π'),
+ (0x1D6E2, 'M', 'α'),
+ (0x1D6E3, 'M', 'β'),
+ (0x1D6E4, 'M', 'γ'),
+ (0x1D6E5, 'M', 'δ'),
+ (0x1D6E6, 'M', 'ε'),
+ (0x1D6E7, 'M', 'ζ'),
+ (0x1D6E8, 'M', 'η'),
+ ]
+
+def _seg_68() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D6E9, 'M', 'θ'),
+ (0x1D6EA, 'M', 'ι'),
+ (0x1D6EB, 'M', 'κ'),
+ (0x1D6EC, 'M', 'λ'),
+ (0x1D6ED, 'M', 'μ'),
+ (0x1D6EE, 'M', 'ν'),
+ (0x1D6EF, 'M', 'ξ'),
+ (0x1D6F0, 'M', 'ο'),
+ (0x1D6F1, 'M', 'π'),
+ (0x1D6F2, 'M', 'ρ'),
+ (0x1D6F3, 'M', 'θ'),
+ (0x1D6F4, 'M', 'σ'),
+ (0x1D6F5, 'M', 'τ'),
+ (0x1D6F6, 'M', 'υ'),
+ (0x1D6F7, 'M', 'φ'),
+ (0x1D6F8, 'M', 'χ'),
+ (0x1D6F9, 'M', 'ψ'),
+ (0x1D6FA, 'M', 'ω'),
+ (0x1D6FB, 'M', '∇'),
+ (0x1D6FC, 'M', 'α'),
+ (0x1D6FD, 'M', 'β'),
+ (0x1D6FE, 'M', 'γ'),
+ (0x1D6FF, 'M', 'δ'),
+ (0x1D700, 'M', 'ε'),
+ (0x1D701, 'M', 'ζ'),
+ (0x1D702, 'M', 'η'),
+ (0x1D703, 'M', 'θ'),
+ (0x1D704, 'M', 'ι'),
+ (0x1D705, 'M', 'κ'),
+ (0x1D706, 'M', 'λ'),
+ (0x1D707, 'M', 'μ'),
+ (0x1D708, 'M', 'ν'),
+ (0x1D709, 'M', 'ξ'),
+ (0x1D70A, 'M', 'ο'),
+ (0x1D70B, 'M', 'π'),
+ (0x1D70C, 'M', 'ρ'),
+ (0x1D70D, 'M', 'σ'),
+ (0x1D70F, 'M', 'τ'),
+ (0x1D710, 'M', 'υ'),
+ (0x1D711, 'M', 'φ'),
+ (0x1D712, 'M', 'χ'),
+ (0x1D713, 'M', 'ψ'),
+ (0x1D714, 'M', 'ω'),
+ (0x1D715, 'M', '∂'),
+ (0x1D716, 'M', 'ε'),
+ (0x1D717, 'M', 'θ'),
+ (0x1D718, 'M', 'κ'),
+ (0x1D719, 'M', 'φ'),
+ (0x1D71A, 'M', 'ρ'),
+ (0x1D71B, 'M', 'π'),
+ (0x1D71C, 'M', 'α'),
+ (0x1D71D, 'M', 'β'),
+ (0x1D71E, 'M', 'γ'),
+ (0x1D71F, 'M', 'δ'),
+ (0x1D720, 'M', 'ε'),
+ (0x1D721, 'M', 'ζ'),
+ (0x1D722, 'M', 'η'),
+ (0x1D723, 'M', 'θ'),
+ (0x1D724, 'M', 'ι'),
+ (0x1D725, 'M', 'κ'),
+ (0x1D726, 'M', 'λ'),
+ (0x1D727, 'M', 'μ'),
+ (0x1D728, 'M', 'ν'),
+ (0x1D729, 'M', 'ξ'),
+ (0x1D72A, 'M', 'ο'),
+ (0x1D72B, 'M', 'π'),
+ (0x1D72C, 'M', 'ρ'),
+ (0x1D72D, 'M', 'θ'),
+ (0x1D72E, 'M', 'σ'),
+ (0x1D72F, 'M', 'τ'),
+ (0x1D730, 'M', 'υ'),
+ (0x1D731, 'M', 'φ'),
+ (0x1D732, 'M', 'χ'),
+ (0x1D733, 'M', 'ψ'),
+ (0x1D734, 'M', 'ω'),
+ (0x1D735, 'M', '∇'),
+ (0x1D736, 'M', 'α'),
+ (0x1D737, 'M', 'β'),
+ (0x1D738, 'M', 'γ'),
+ (0x1D739, 'M', 'δ'),
+ (0x1D73A, 'M', 'ε'),
+ (0x1D73B, 'M', 'ζ'),
+ (0x1D73C, 'M', 'η'),
+ (0x1D73D, 'M', 'θ'),
+ (0x1D73E, 'M', 'ι'),
+ (0x1D73F, 'M', 'κ'),
+ (0x1D740, 'M', 'λ'),
+ (0x1D741, 'M', 'μ'),
+ (0x1D742, 'M', 'ν'),
+ (0x1D743, 'M', 'ξ'),
+ (0x1D744, 'M', 'ο'),
+ (0x1D745, 'M', 'π'),
+ (0x1D746, 'M', 'ρ'),
+ (0x1D747, 'M', 'σ'),
+ (0x1D749, 'M', 'τ'),
+ (0x1D74A, 'M', 'υ'),
+ (0x1D74B, 'M', 'φ'),
+ (0x1D74C, 'M', 'χ'),
+ (0x1D74D, 'M', 'ψ'),
+ (0x1D74E, 'M', 'ω'),
+ ]
+
+def _seg_69() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D74F, 'M', '∂'),
+ (0x1D750, 'M', 'ε'),
+ (0x1D751, 'M', 'θ'),
+ (0x1D752, 'M', 'κ'),
+ (0x1D753, 'M', 'φ'),
+ (0x1D754, 'M', 'ρ'),
+ (0x1D755, 'M', 'π'),
+ (0x1D756, 'M', 'α'),
+ (0x1D757, 'M', 'β'),
+ (0x1D758, 'M', 'γ'),
+ (0x1D759, 'M', 'δ'),
+ (0x1D75A, 'M', 'ε'),
+ (0x1D75B, 'M', 'ζ'),
+ (0x1D75C, 'M', 'η'),
+ (0x1D75D, 'M', 'θ'),
+ (0x1D75E, 'M', 'ι'),
+ (0x1D75F, 'M', 'κ'),
+ (0x1D760, 'M', 'λ'),
+ (0x1D761, 'M', 'μ'),
+ (0x1D762, 'M', 'ν'),
+ (0x1D763, 'M', 'ξ'),
+ (0x1D764, 'M', 'ο'),
+ (0x1D765, 'M', 'π'),
+ (0x1D766, 'M', 'ρ'),
+ (0x1D767, 'M', 'θ'),
+ (0x1D768, 'M', 'σ'),
+ (0x1D769, 'M', 'τ'),
+ (0x1D76A, 'M', 'υ'),
+ (0x1D76B, 'M', 'φ'),
+ (0x1D76C, 'M', 'χ'),
+ (0x1D76D, 'M', 'ψ'),
+ (0x1D76E, 'M', 'ω'),
+ (0x1D76F, 'M', '∇'),
+ (0x1D770, 'M', 'α'),
+ (0x1D771, 'M', 'β'),
+ (0x1D772, 'M', 'γ'),
+ (0x1D773, 'M', 'δ'),
+ (0x1D774, 'M', 'ε'),
+ (0x1D775, 'M', 'ζ'),
+ (0x1D776, 'M', 'η'),
+ (0x1D777, 'M', 'θ'),
+ (0x1D778, 'M', 'ι'),
+ (0x1D779, 'M', 'κ'),
+ (0x1D77A, 'M', 'λ'),
+ (0x1D77B, 'M', 'μ'),
+ (0x1D77C, 'M', 'ν'),
+ (0x1D77D, 'M', 'ξ'),
+ (0x1D77E, 'M', 'ο'),
+ (0x1D77F, 'M', 'π'),
+ (0x1D780, 'M', 'ρ'),
+ (0x1D781, 'M', 'σ'),
+ (0x1D783, 'M', 'τ'),
+ (0x1D784, 'M', 'υ'),
+ (0x1D785, 'M', 'φ'),
+ (0x1D786, 'M', 'χ'),
+ (0x1D787, 'M', 'ψ'),
+ (0x1D788, 'M', 'ω'),
+ (0x1D789, 'M', '∂'),
+ (0x1D78A, 'M', 'ε'),
+ (0x1D78B, 'M', 'θ'),
+ (0x1D78C, 'M', 'κ'),
+ (0x1D78D, 'M', 'φ'),
+ (0x1D78E, 'M', 'ρ'),
+ (0x1D78F, 'M', 'π'),
+ (0x1D790, 'M', 'α'),
+ (0x1D791, 'M', 'β'),
+ (0x1D792, 'M', 'γ'),
+ (0x1D793, 'M', 'δ'),
+ (0x1D794, 'M', 'ε'),
+ (0x1D795, 'M', 'ζ'),
+ (0x1D796, 'M', 'η'),
+ (0x1D797, 'M', 'θ'),
+ (0x1D798, 'M', 'ι'),
+ (0x1D799, 'M', 'κ'),
+ (0x1D79A, 'M', 'λ'),
+ (0x1D79B, 'M', 'μ'),
+ (0x1D79C, 'M', 'ν'),
+ (0x1D79D, 'M', 'ξ'),
+ (0x1D79E, 'M', 'ο'),
+ (0x1D79F, 'M', 'π'),
+ (0x1D7A0, 'M', 'ρ'),
+ (0x1D7A1, 'M', 'θ'),
+ (0x1D7A2, 'M', 'σ'),
+ (0x1D7A3, 'M', 'τ'),
+ (0x1D7A4, 'M', 'υ'),
+ (0x1D7A5, 'M', 'φ'),
+ (0x1D7A6, 'M', 'χ'),
+ (0x1D7A7, 'M', 'ψ'),
+ (0x1D7A8, 'M', 'ω'),
+ (0x1D7A9, 'M', '∇'),
+ (0x1D7AA, 'M', 'α'),
+ (0x1D7AB, 'M', 'β'),
+ (0x1D7AC, 'M', 'γ'),
+ (0x1D7AD, 'M', 'δ'),
+ (0x1D7AE, 'M', 'ε'),
+ (0x1D7AF, 'M', 'ζ'),
+ (0x1D7B0, 'M', 'η'),
+ (0x1D7B1, 'M', 'θ'),
+ (0x1D7B2, 'M', 'ι'),
+ (0x1D7B3, 'M', 'κ'),
+ ]
+
+def _seg_70() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1D7B4, 'M', 'λ'),
+ (0x1D7B5, 'M', 'μ'),
+ (0x1D7B6, 'M', 'ν'),
+ (0x1D7B7, 'M', 'ξ'),
+ (0x1D7B8, 'M', 'ο'),
+ (0x1D7B9, 'M', 'π'),
+ (0x1D7BA, 'M', 'ρ'),
+ (0x1D7BB, 'M', 'σ'),
+ (0x1D7BD, 'M', 'τ'),
+ (0x1D7BE, 'M', 'υ'),
+ (0x1D7BF, 'M', 'φ'),
+ (0x1D7C0, 'M', 'χ'),
+ (0x1D7C1, 'M', 'ψ'),
+ (0x1D7C2, 'M', 'ω'),
+ (0x1D7C3, 'M', '∂'),
+ (0x1D7C4, 'M', 'ε'),
+ (0x1D7C5, 'M', 'θ'),
+ (0x1D7C6, 'M', 'κ'),
+ (0x1D7C7, 'M', 'φ'),
+ (0x1D7C8, 'M', 'ρ'),
+ (0x1D7C9, 'M', 'π'),
+ (0x1D7CA, 'M', 'ϝ'),
+ (0x1D7CC, 'X'),
+ (0x1D7CE, 'M', '0'),
+ (0x1D7CF, 'M', '1'),
+ (0x1D7D0, 'M', '2'),
+ (0x1D7D1, 'M', '3'),
+ (0x1D7D2, 'M', '4'),
+ (0x1D7D3, 'M', '5'),
+ (0x1D7D4, 'M', '6'),
+ (0x1D7D5, 'M', '7'),
+ (0x1D7D6, 'M', '8'),
+ (0x1D7D7, 'M', '9'),
+ (0x1D7D8, 'M', '0'),
+ (0x1D7D9, 'M', '1'),
+ (0x1D7DA, 'M', '2'),
+ (0x1D7DB, 'M', '3'),
+ (0x1D7DC, 'M', '4'),
+ (0x1D7DD, 'M', '5'),
+ (0x1D7DE, 'M', '6'),
+ (0x1D7DF, 'M', '7'),
+ (0x1D7E0, 'M', '8'),
+ (0x1D7E1, 'M', '9'),
+ (0x1D7E2, 'M', '0'),
+ (0x1D7E3, 'M', '1'),
+ (0x1D7E4, 'M', '2'),
+ (0x1D7E5, 'M', '3'),
+ (0x1D7E6, 'M', '4'),
+ (0x1D7E7, 'M', '5'),
+ (0x1D7E8, 'M', '6'),
+ (0x1D7E9, 'M', '7'),
+ (0x1D7EA, 'M', '8'),
+ (0x1D7EB, 'M', '9'),
+ (0x1D7EC, 'M', '0'),
+ (0x1D7ED, 'M', '1'),
+ (0x1D7EE, 'M', '2'),
+ (0x1D7EF, 'M', '3'),
+ (0x1D7F0, 'M', '4'),
+ (0x1D7F1, 'M', '5'),
+ (0x1D7F2, 'M', '6'),
+ (0x1D7F3, 'M', '7'),
+ (0x1D7F4, 'M', '8'),
+ (0x1D7F5, 'M', '9'),
+ (0x1D7F6, 'M', '0'),
+ (0x1D7F7, 'M', '1'),
+ (0x1D7F8, 'M', '2'),
+ (0x1D7F9, 'M', '3'),
+ (0x1D7FA, 'M', '4'),
+ (0x1D7FB, 'M', '5'),
+ (0x1D7FC, 'M', '6'),
+ (0x1D7FD, 'M', '7'),
+ (0x1D7FE, 'M', '8'),
+ (0x1D7FF, 'M', '9'),
+ (0x1D800, 'V'),
+ (0x1DA8C, 'X'),
+ (0x1DA9B, 'V'),
+ (0x1DAA0, 'X'),
+ (0x1DAA1, 'V'),
+ (0x1DAB0, 'X'),
+ (0x1DF00, 'V'),
+ (0x1DF1F, 'X'),
+ (0x1DF25, 'V'),
+ (0x1DF2B, 'X'),
+ (0x1E000, 'V'),
+ (0x1E007, 'X'),
+ (0x1E008, 'V'),
+ (0x1E019, 'X'),
+ (0x1E01B, 'V'),
+ (0x1E022, 'X'),
+ (0x1E023, 'V'),
+ (0x1E025, 'X'),
+ (0x1E026, 'V'),
+ (0x1E02B, 'X'),
+ (0x1E030, 'M', 'а'),
+ (0x1E031, 'M', 'б'),
+ (0x1E032, 'M', 'в'),
+ (0x1E033, 'M', 'г'),
+ (0x1E034, 'M', 'д'),
+ (0x1E035, 'M', 'е'),
+ (0x1E036, 'M', 'ж'),
+ ]
+
+def _seg_71() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1E037, 'M', 'з'),
+ (0x1E038, 'M', 'и'),
+ (0x1E039, 'M', 'к'),
+ (0x1E03A, 'M', 'л'),
+ (0x1E03B, 'M', 'м'),
+ (0x1E03C, 'M', 'о'),
+ (0x1E03D, 'M', 'п'),
+ (0x1E03E, 'M', 'р'),
+ (0x1E03F, 'M', 'с'),
+ (0x1E040, 'M', 'т'),
+ (0x1E041, 'M', 'у'),
+ (0x1E042, 'M', 'ф'),
+ (0x1E043, 'M', 'х'),
+ (0x1E044, 'M', 'ц'),
+ (0x1E045, 'M', 'ч'),
+ (0x1E046, 'M', 'ш'),
+ (0x1E047, 'M', 'ы'),
+ (0x1E048, 'M', 'э'),
+ (0x1E049, 'M', 'ю'),
+ (0x1E04A, 'M', 'ꚉ'),
+ (0x1E04B, 'M', 'ә'),
+ (0x1E04C, 'M', 'і'),
+ (0x1E04D, 'M', 'ј'),
+ (0x1E04E, 'M', 'ө'),
+ (0x1E04F, 'M', 'ү'),
+ (0x1E050, 'M', 'ӏ'),
+ (0x1E051, 'M', 'а'),
+ (0x1E052, 'M', 'б'),
+ (0x1E053, 'M', 'в'),
+ (0x1E054, 'M', 'г'),
+ (0x1E055, 'M', 'д'),
+ (0x1E056, 'M', 'е'),
+ (0x1E057, 'M', 'ж'),
+ (0x1E058, 'M', 'з'),
+ (0x1E059, 'M', 'и'),
+ (0x1E05A, 'M', 'к'),
+ (0x1E05B, 'M', 'л'),
+ (0x1E05C, 'M', 'о'),
+ (0x1E05D, 'M', 'п'),
+ (0x1E05E, 'M', 'с'),
+ (0x1E05F, 'M', 'у'),
+ (0x1E060, 'M', 'ф'),
+ (0x1E061, 'M', 'х'),
+ (0x1E062, 'M', 'ц'),
+ (0x1E063, 'M', 'ч'),
+ (0x1E064, 'M', 'ш'),
+ (0x1E065, 'M', 'ъ'),
+ (0x1E066, 'M', 'ы'),
+ (0x1E067, 'M', 'ґ'),
+ (0x1E068, 'M', 'і'),
+ (0x1E069, 'M', 'ѕ'),
+ (0x1E06A, 'M', 'џ'),
+ (0x1E06B, 'M', 'ҫ'),
+ (0x1E06C, 'M', 'ꙑ'),
+ (0x1E06D, 'M', 'ұ'),
+ (0x1E06E, 'X'),
+ (0x1E08F, 'V'),
+ (0x1E090, 'X'),
+ (0x1E100, 'V'),
+ (0x1E12D, 'X'),
+ (0x1E130, 'V'),
+ (0x1E13E, 'X'),
+ (0x1E140, 'V'),
+ (0x1E14A, 'X'),
+ (0x1E14E, 'V'),
+ (0x1E150, 'X'),
+ (0x1E290, 'V'),
+ (0x1E2AF, 'X'),
+ (0x1E2C0, 'V'),
+ (0x1E2FA, 'X'),
+ (0x1E2FF, 'V'),
+ (0x1E300, 'X'),
+ (0x1E4D0, 'V'),
+ (0x1E4FA, 'X'),
+ (0x1E7E0, 'V'),
+ (0x1E7E7, 'X'),
+ (0x1E7E8, 'V'),
+ (0x1E7EC, 'X'),
+ (0x1E7ED, 'V'),
+ (0x1E7EF, 'X'),
+ (0x1E7F0, 'V'),
+ (0x1E7FF, 'X'),
+ (0x1E800, 'V'),
+ (0x1E8C5, 'X'),
+ (0x1E8C7, 'V'),
+ (0x1E8D7, 'X'),
+ (0x1E900, 'M', '𞤢'),
+ (0x1E901, 'M', '𞤣'),
+ (0x1E902, 'M', '𞤤'),
+ (0x1E903, 'M', '𞤥'),
+ (0x1E904, 'M', '𞤦'),
+ (0x1E905, 'M', '𞤧'),
+ (0x1E906, 'M', '𞤨'),
+ (0x1E907, 'M', '𞤩'),
+ (0x1E908, 'M', '𞤪'),
+ (0x1E909, 'M', '𞤫'),
+ (0x1E90A, 'M', '𞤬'),
+ (0x1E90B, 'M', '𞤭'),
+ (0x1E90C, 'M', '𞤮'),
+ (0x1E90D, 'M', '𞤯'),
+ ]
+
+def _seg_72() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1E90E, 'M', '𞤰'),
+ (0x1E90F, 'M', '𞤱'),
+ (0x1E910, 'M', '𞤲'),
+ (0x1E911, 'M', '𞤳'),
+ (0x1E912, 'M', '𞤴'),
+ (0x1E913, 'M', '𞤵'),
+ (0x1E914, 'M', '𞤶'),
+ (0x1E915, 'M', '𞤷'),
+ (0x1E916, 'M', '𞤸'),
+ (0x1E917, 'M', '𞤹'),
+ (0x1E918, 'M', '𞤺'),
+ (0x1E919, 'M', '𞤻'),
+ (0x1E91A, 'M', '𞤼'),
+ (0x1E91B, 'M', '𞤽'),
+ (0x1E91C, 'M', '𞤾'),
+ (0x1E91D, 'M', '𞤿'),
+ (0x1E91E, 'M', '𞥀'),
+ (0x1E91F, 'M', '𞥁'),
+ (0x1E920, 'M', '𞥂'),
+ (0x1E921, 'M', '𞥃'),
+ (0x1E922, 'V'),
+ (0x1E94C, 'X'),
+ (0x1E950, 'V'),
+ (0x1E95A, 'X'),
+ (0x1E95E, 'V'),
+ (0x1E960, 'X'),
+ (0x1EC71, 'V'),
+ (0x1ECB5, 'X'),
+ (0x1ED01, 'V'),
+ (0x1ED3E, 'X'),
+ (0x1EE00, 'M', 'ا'),
+ (0x1EE01, 'M', 'ب'),
+ (0x1EE02, 'M', 'ج'),
+ (0x1EE03, 'M', 'د'),
+ (0x1EE04, 'X'),
+ (0x1EE05, 'M', 'و'),
+ (0x1EE06, 'M', 'ز'),
+ (0x1EE07, 'M', 'ح'),
+ (0x1EE08, 'M', 'ط'),
+ (0x1EE09, 'M', 'ي'),
+ (0x1EE0A, 'M', 'ك'),
+ (0x1EE0B, 'M', 'ل'),
+ (0x1EE0C, 'M', 'م'),
+ (0x1EE0D, 'M', 'ن'),
+ (0x1EE0E, 'M', 'س'),
+ (0x1EE0F, 'M', 'ع'),
+ (0x1EE10, 'M', 'ف'),
+ (0x1EE11, 'M', 'ص'),
+ (0x1EE12, 'M', 'ق'),
+ (0x1EE13, 'M', 'ر'),
+ (0x1EE14, 'M', 'ش'),
+ (0x1EE15, 'M', 'ت'),
+ (0x1EE16, 'M', 'ث'),
+ (0x1EE17, 'M', 'خ'),
+ (0x1EE18, 'M', 'ذ'),
+ (0x1EE19, 'M', 'ض'),
+ (0x1EE1A, 'M', 'ظ'),
+ (0x1EE1B, 'M', 'غ'),
+ (0x1EE1C, 'M', 'ٮ'),
+ (0x1EE1D, 'M', 'ں'),
+ (0x1EE1E, 'M', 'ڡ'),
+ (0x1EE1F, 'M', 'ٯ'),
+ (0x1EE20, 'X'),
+ (0x1EE21, 'M', 'ب'),
+ (0x1EE22, 'M', 'ج'),
+ (0x1EE23, 'X'),
+ (0x1EE24, 'M', 'ه'),
+ (0x1EE25, 'X'),
+ (0x1EE27, 'M', 'ح'),
+ (0x1EE28, 'X'),
+ (0x1EE29, 'M', 'ي'),
+ (0x1EE2A, 'M', 'ك'),
+ (0x1EE2B, 'M', 'ل'),
+ (0x1EE2C, 'M', 'م'),
+ (0x1EE2D, 'M', 'ن'),
+ (0x1EE2E, 'M', 'س'),
+ (0x1EE2F, 'M', 'ع'),
+ (0x1EE30, 'M', 'ف'),
+ (0x1EE31, 'M', 'ص'),
+ (0x1EE32, 'M', 'ق'),
+ (0x1EE33, 'X'),
+ (0x1EE34, 'M', 'ش'),
+ (0x1EE35, 'M', 'ت'),
+ (0x1EE36, 'M', 'ث'),
+ (0x1EE37, 'M', 'خ'),
+ (0x1EE38, 'X'),
+ (0x1EE39, 'M', 'ض'),
+ (0x1EE3A, 'X'),
+ (0x1EE3B, 'M', 'غ'),
+ (0x1EE3C, 'X'),
+ (0x1EE42, 'M', 'ج'),
+ (0x1EE43, 'X'),
+ (0x1EE47, 'M', 'ح'),
+ (0x1EE48, 'X'),
+ (0x1EE49, 'M', 'ي'),
+ (0x1EE4A, 'X'),
+ (0x1EE4B, 'M', 'ل'),
+ (0x1EE4C, 'X'),
+ (0x1EE4D, 'M', 'ن'),
+ (0x1EE4E, 'M', 'س'),
+ ]
+
+def _seg_73() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1EE4F, 'M', 'ع'),
+ (0x1EE50, 'X'),
+ (0x1EE51, 'M', 'ص'),
+ (0x1EE52, 'M', 'ق'),
+ (0x1EE53, 'X'),
+ (0x1EE54, 'M', 'ش'),
+ (0x1EE55, 'X'),
+ (0x1EE57, 'M', 'خ'),
+ (0x1EE58, 'X'),
+ (0x1EE59, 'M', 'ض'),
+ (0x1EE5A, 'X'),
+ (0x1EE5B, 'M', 'غ'),
+ (0x1EE5C, 'X'),
+ (0x1EE5D, 'M', 'ں'),
+ (0x1EE5E, 'X'),
+ (0x1EE5F, 'M', 'ٯ'),
+ (0x1EE60, 'X'),
+ (0x1EE61, 'M', 'ب'),
+ (0x1EE62, 'M', 'ج'),
+ (0x1EE63, 'X'),
+ (0x1EE64, 'M', 'ه'),
+ (0x1EE65, 'X'),
+ (0x1EE67, 'M', 'ح'),
+ (0x1EE68, 'M', 'ط'),
+ (0x1EE69, 'M', 'ي'),
+ (0x1EE6A, 'M', 'ك'),
+ (0x1EE6B, 'X'),
+ (0x1EE6C, 'M', 'م'),
+ (0x1EE6D, 'M', 'ن'),
+ (0x1EE6E, 'M', 'س'),
+ (0x1EE6F, 'M', 'ع'),
+ (0x1EE70, 'M', 'ف'),
+ (0x1EE71, 'M', 'ص'),
+ (0x1EE72, 'M', 'ق'),
+ (0x1EE73, 'X'),
+ (0x1EE74, 'M', 'ش'),
+ (0x1EE75, 'M', 'ت'),
+ (0x1EE76, 'M', 'ث'),
+ (0x1EE77, 'M', 'خ'),
+ (0x1EE78, 'X'),
+ (0x1EE79, 'M', 'ض'),
+ (0x1EE7A, 'M', 'ظ'),
+ (0x1EE7B, 'M', 'غ'),
+ (0x1EE7C, 'M', 'ٮ'),
+ (0x1EE7D, 'X'),
+ (0x1EE7E, 'M', 'ڡ'),
+ (0x1EE7F, 'X'),
+ (0x1EE80, 'M', 'ا'),
+ (0x1EE81, 'M', 'ب'),
+ (0x1EE82, 'M', 'ج'),
+ (0x1EE83, 'M', 'د'),
+ (0x1EE84, 'M', 'ه'),
+ (0x1EE85, 'M', 'و'),
+ (0x1EE86, 'M', 'ز'),
+ (0x1EE87, 'M', 'ح'),
+ (0x1EE88, 'M', 'ط'),
+ (0x1EE89, 'M', 'ي'),
+ (0x1EE8A, 'X'),
+ (0x1EE8B, 'M', 'ل'),
+ (0x1EE8C, 'M', 'م'),
+ (0x1EE8D, 'M', 'ن'),
+ (0x1EE8E, 'M', 'س'),
+ (0x1EE8F, 'M', 'ع'),
+ (0x1EE90, 'M', 'ف'),
+ (0x1EE91, 'M', 'ص'),
+ (0x1EE92, 'M', 'ق'),
+ (0x1EE93, 'M', 'ر'),
+ (0x1EE94, 'M', 'ش'),
+ (0x1EE95, 'M', 'ت'),
+ (0x1EE96, 'M', 'ث'),
+ (0x1EE97, 'M', 'خ'),
+ (0x1EE98, 'M', 'ذ'),
+ (0x1EE99, 'M', 'ض'),
+ (0x1EE9A, 'M', 'ظ'),
+ (0x1EE9B, 'M', 'غ'),
+ (0x1EE9C, 'X'),
+ (0x1EEA1, 'M', 'ب'),
+ (0x1EEA2, 'M', 'ج'),
+ (0x1EEA3, 'M', 'د'),
+ (0x1EEA4, 'X'),
+ (0x1EEA5, 'M', 'و'),
+ (0x1EEA6, 'M', 'ز'),
+ (0x1EEA7, 'M', 'ح'),
+ (0x1EEA8, 'M', 'ط'),
+ (0x1EEA9, 'M', 'ي'),
+ (0x1EEAA, 'X'),
+ (0x1EEAB, 'M', 'ل'),
+ (0x1EEAC, 'M', 'م'),
+ (0x1EEAD, 'M', 'ن'),
+ (0x1EEAE, 'M', 'س'),
+ (0x1EEAF, 'M', 'ع'),
+ (0x1EEB0, 'M', 'ف'),
+ (0x1EEB1, 'M', 'ص'),
+ (0x1EEB2, 'M', 'ق'),
+ (0x1EEB3, 'M', 'ر'),
+ (0x1EEB4, 'M', 'ش'),
+ (0x1EEB5, 'M', 'ت'),
+ (0x1EEB6, 'M', 'ث'),
+ (0x1EEB7, 'M', 'خ'),
+ (0x1EEB8, 'M', 'ذ'),
+ ]
+
+def _seg_74() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1EEB9, 'M', 'ض'),
+ (0x1EEBA, 'M', 'ظ'),
+ (0x1EEBB, 'M', 'غ'),
+ (0x1EEBC, 'X'),
+ (0x1EEF0, 'V'),
+ (0x1EEF2, 'X'),
+ (0x1F000, 'V'),
+ (0x1F02C, 'X'),
+ (0x1F030, 'V'),
+ (0x1F094, 'X'),
+ (0x1F0A0, 'V'),
+ (0x1F0AF, 'X'),
+ (0x1F0B1, 'V'),
+ (0x1F0C0, 'X'),
+ (0x1F0C1, 'V'),
+ (0x1F0D0, 'X'),
+ (0x1F0D1, 'V'),
+ (0x1F0F6, 'X'),
+ (0x1F101, '3', '0,'),
+ (0x1F102, '3', '1,'),
+ (0x1F103, '3', '2,'),
+ (0x1F104, '3', '3,'),
+ (0x1F105, '3', '4,'),
+ (0x1F106, '3', '5,'),
+ (0x1F107, '3', '6,'),
+ (0x1F108, '3', '7,'),
+ (0x1F109, '3', '8,'),
+ (0x1F10A, '3', '9,'),
+ (0x1F10B, 'V'),
+ (0x1F110, '3', '(a)'),
+ (0x1F111, '3', '(b)'),
+ (0x1F112, '3', '(c)'),
+ (0x1F113, '3', '(d)'),
+ (0x1F114, '3', '(e)'),
+ (0x1F115, '3', '(f)'),
+ (0x1F116, '3', '(g)'),
+ (0x1F117, '3', '(h)'),
+ (0x1F118, '3', '(i)'),
+ (0x1F119, '3', '(j)'),
+ (0x1F11A, '3', '(k)'),
+ (0x1F11B, '3', '(l)'),
+ (0x1F11C, '3', '(m)'),
+ (0x1F11D, '3', '(n)'),
+ (0x1F11E, '3', '(o)'),
+ (0x1F11F, '3', '(p)'),
+ (0x1F120, '3', '(q)'),
+ (0x1F121, '3', '(r)'),
+ (0x1F122, '3', '(s)'),
+ (0x1F123, '3', '(t)'),
+ (0x1F124, '3', '(u)'),
+ (0x1F125, '3', '(v)'),
+ (0x1F126, '3', '(w)'),
+ (0x1F127, '3', '(x)'),
+ (0x1F128, '3', '(y)'),
+ (0x1F129, '3', '(z)'),
+ (0x1F12A, 'M', '〔s〕'),
+ (0x1F12B, 'M', 'c'),
+ (0x1F12C, 'M', 'r'),
+ (0x1F12D, 'M', 'cd'),
+ (0x1F12E, 'M', 'wz'),
+ (0x1F12F, 'V'),
+ (0x1F130, 'M', 'a'),
+ (0x1F131, 'M', 'b'),
+ (0x1F132, 'M', 'c'),
+ (0x1F133, 'M', 'd'),
+ (0x1F134, 'M', 'e'),
+ (0x1F135, 'M', 'f'),
+ (0x1F136, 'M', 'g'),
+ (0x1F137, 'M', 'h'),
+ (0x1F138, 'M', 'i'),
+ (0x1F139, 'M', 'j'),
+ (0x1F13A, 'M', 'k'),
+ (0x1F13B, 'M', 'l'),
+ (0x1F13C, 'M', 'm'),
+ (0x1F13D, 'M', 'n'),
+ (0x1F13E, 'M', 'o'),
+ (0x1F13F, 'M', 'p'),
+ (0x1F140, 'M', 'q'),
+ (0x1F141, 'M', 'r'),
+ (0x1F142, 'M', 's'),
+ (0x1F143, 'M', 't'),
+ (0x1F144, 'M', 'u'),
+ (0x1F145, 'M', 'v'),
+ (0x1F146, 'M', 'w'),
+ (0x1F147, 'M', 'x'),
+ (0x1F148, 'M', 'y'),
+ (0x1F149, 'M', 'z'),
+ (0x1F14A, 'M', 'hv'),
+ (0x1F14B, 'M', 'mv'),
+ (0x1F14C, 'M', 'sd'),
+ (0x1F14D, 'M', 'ss'),
+ (0x1F14E, 'M', 'ppv'),
+ (0x1F14F, 'M', 'wc'),
+ (0x1F150, 'V'),
+ (0x1F16A, 'M', 'mc'),
+ (0x1F16B, 'M', 'md'),
+ (0x1F16C, 'M', 'mr'),
+ (0x1F16D, 'V'),
+ (0x1F190, 'M', 'dj'),
+ (0x1F191, 'V'),
+ ]
+
+def _seg_75() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1F1AE, 'X'),
+ (0x1F1E6, 'V'),
+ (0x1F200, 'M', 'ほか'),
+ (0x1F201, 'M', 'ココ'),
+ (0x1F202, 'M', 'サ'),
+ (0x1F203, 'X'),
+ (0x1F210, 'M', '手'),
+ (0x1F211, 'M', '字'),
+ (0x1F212, 'M', '双'),
+ (0x1F213, 'M', 'デ'),
+ (0x1F214, 'M', '二'),
+ (0x1F215, 'M', '多'),
+ (0x1F216, 'M', '解'),
+ (0x1F217, 'M', '天'),
+ (0x1F218, 'M', '交'),
+ (0x1F219, 'M', '映'),
+ (0x1F21A, 'M', '無'),
+ (0x1F21B, 'M', '料'),
+ (0x1F21C, 'M', '前'),
+ (0x1F21D, 'M', '後'),
+ (0x1F21E, 'M', '再'),
+ (0x1F21F, 'M', '新'),
+ (0x1F220, 'M', '初'),
+ (0x1F221, 'M', '終'),
+ (0x1F222, 'M', '生'),
+ (0x1F223, 'M', '販'),
+ (0x1F224, 'M', '声'),
+ (0x1F225, 'M', '吹'),
+ (0x1F226, 'M', '演'),
+ (0x1F227, 'M', '投'),
+ (0x1F228, 'M', '捕'),
+ (0x1F229, 'M', '一'),
+ (0x1F22A, 'M', '三'),
+ (0x1F22B, 'M', '遊'),
+ (0x1F22C, 'M', '左'),
+ (0x1F22D, 'M', '中'),
+ (0x1F22E, 'M', '右'),
+ (0x1F22F, 'M', '指'),
+ (0x1F230, 'M', '走'),
+ (0x1F231, 'M', '打'),
+ (0x1F232, 'M', '禁'),
+ (0x1F233, 'M', '空'),
+ (0x1F234, 'M', '合'),
+ (0x1F235, 'M', '満'),
+ (0x1F236, 'M', '有'),
+ (0x1F237, 'M', '月'),
+ (0x1F238, 'M', '申'),
+ (0x1F239, 'M', '割'),
+ (0x1F23A, 'M', '営'),
+ (0x1F23B, 'M', '配'),
+ (0x1F23C, 'X'),
+ (0x1F240, 'M', '〔本〕'),
+ (0x1F241, 'M', '〔三〕'),
+ (0x1F242, 'M', '〔二〕'),
+ (0x1F243, 'M', '〔安〕'),
+ (0x1F244, 'M', '〔点〕'),
+ (0x1F245, 'M', '〔打〕'),
+ (0x1F246, 'M', '〔盗〕'),
+ (0x1F247, 'M', '〔勝〕'),
+ (0x1F248, 'M', '〔敗〕'),
+ (0x1F249, 'X'),
+ (0x1F250, 'M', '得'),
+ (0x1F251, 'M', '可'),
+ (0x1F252, 'X'),
+ (0x1F260, 'V'),
+ (0x1F266, 'X'),
+ (0x1F300, 'V'),
+ (0x1F6D8, 'X'),
+ (0x1F6DC, 'V'),
+ (0x1F6ED, 'X'),
+ (0x1F6F0, 'V'),
+ (0x1F6FD, 'X'),
+ (0x1F700, 'V'),
+ (0x1F777, 'X'),
+ (0x1F77B, 'V'),
+ (0x1F7DA, 'X'),
+ (0x1F7E0, 'V'),
+ (0x1F7EC, 'X'),
+ (0x1F7F0, 'V'),
+ (0x1F7F1, 'X'),
+ (0x1F800, 'V'),
+ (0x1F80C, 'X'),
+ (0x1F810, 'V'),
+ (0x1F848, 'X'),
+ (0x1F850, 'V'),
+ (0x1F85A, 'X'),
+ (0x1F860, 'V'),
+ (0x1F888, 'X'),
+ (0x1F890, 'V'),
+ (0x1F8AE, 'X'),
+ (0x1F8B0, 'V'),
+ (0x1F8B2, 'X'),
+ (0x1F900, 'V'),
+ (0x1FA54, 'X'),
+ (0x1FA60, 'V'),
+ (0x1FA6E, 'X'),
+ (0x1FA70, 'V'),
+ (0x1FA7D, 'X'),
+ (0x1FA80, 'V'),
+ (0x1FA89, 'X'),
+ ]
+
+def _seg_76() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x1FA90, 'V'),
+ (0x1FABE, 'X'),
+ (0x1FABF, 'V'),
+ (0x1FAC6, 'X'),
+ (0x1FACE, 'V'),
+ (0x1FADC, 'X'),
+ (0x1FAE0, 'V'),
+ (0x1FAE9, 'X'),
+ (0x1FAF0, 'V'),
+ (0x1FAF9, 'X'),
+ (0x1FB00, 'V'),
+ (0x1FB93, 'X'),
+ (0x1FB94, 'V'),
+ (0x1FBCB, 'X'),
+ (0x1FBF0, 'M', '0'),
+ (0x1FBF1, 'M', '1'),
+ (0x1FBF2, 'M', '2'),
+ (0x1FBF3, 'M', '3'),
+ (0x1FBF4, 'M', '4'),
+ (0x1FBF5, 'M', '5'),
+ (0x1FBF6, 'M', '6'),
+ (0x1FBF7, 'M', '7'),
+ (0x1FBF8, 'M', '8'),
+ (0x1FBF9, 'M', '9'),
+ (0x1FBFA, 'X'),
+ (0x20000, 'V'),
+ (0x2A6E0, 'X'),
+ (0x2A700, 'V'),
+ (0x2B73A, 'X'),
+ (0x2B740, 'V'),
+ (0x2B81E, 'X'),
+ (0x2B820, 'V'),
+ (0x2CEA2, 'X'),
+ (0x2CEB0, 'V'),
+ (0x2EBE1, 'X'),
+ (0x2EBF0, 'V'),
+ (0x2EE5E, 'X'),
+ (0x2F800, 'M', '丽'),
+ (0x2F801, 'M', '丸'),
+ (0x2F802, 'M', '乁'),
+ (0x2F803, 'M', '𠄢'),
+ (0x2F804, 'M', '你'),
+ (0x2F805, 'M', '侮'),
+ (0x2F806, 'M', '侻'),
+ (0x2F807, 'M', '倂'),
+ (0x2F808, 'M', '偺'),
+ (0x2F809, 'M', '備'),
+ (0x2F80A, 'M', '僧'),
+ (0x2F80B, 'M', '像'),
+ (0x2F80C, 'M', '㒞'),
+ (0x2F80D, 'M', '𠘺'),
+ (0x2F80E, 'M', '免'),
+ (0x2F80F, 'M', '兔'),
+ (0x2F810, 'M', '兤'),
+ (0x2F811, 'M', '具'),
+ (0x2F812, 'M', '𠔜'),
+ (0x2F813, 'M', '㒹'),
+ (0x2F814, 'M', '內'),
+ (0x2F815, 'M', '再'),
+ (0x2F816, 'M', '𠕋'),
+ (0x2F817, 'M', '冗'),
+ (0x2F818, 'M', '冤'),
+ (0x2F819, 'M', '仌'),
+ (0x2F81A, 'M', '冬'),
+ (0x2F81B, 'M', '况'),
+ (0x2F81C, 'M', '𩇟'),
+ (0x2F81D, 'M', '凵'),
+ (0x2F81E, 'M', '刃'),
+ (0x2F81F, 'M', '㓟'),
+ (0x2F820, 'M', '刻'),
+ (0x2F821, 'M', '剆'),
+ (0x2F822, 'M', '割'),
+ (0x2F823, 'M', '剷'),
+ (0x2F824, 'M', '㔕'),
+ (0x2F825, 'M', '勇'),
+ (0x2F826, 'M', '勉'),
+ (0x2F827, 'M', '勤'),
+ (0x2F828, 'M', '勺'),
+ (0x2F829, 'M', '包'),
+ (0x2F82A, 'M', '匆'),
+ (0x2F82B, 'M', '北'),
+ (0x2F82C, 'M', '卉'),
+ (0x2F82D, 'M', '卑'),
+ (0x2F82E, 'M', '博'),
+ (0x2F82F, 'M', '即'),
+ (0x2F830, 'M', '卽'),
+ (0x2F831, 'M', '卿'),
+ (0x2F834, 'M', '𠨬'),
+ (0x2F835, 'M', '灰'),
+ (0x2F836, 'M', '及'),
+ (0x2F837, 'M', '叟'),
+ (0x2F838, 'M', '𠭣'),
+ (0x2F839, 'M', '叫'),
+ (0x2F83A, 'M', '叱'),
+ (0x2F83B, 'M', '吆'),
+ (0x2F83C, 'M', '咞'),
+ (0x2F83D, 'M', '吸'),
+ (0x2F83E, 'M', '呈'),
+ (0x2F83F, 'M', '周'),
+ (0x2F840, 'M', '咢'),
+ ]
+
+def _seg_77() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2F841, 'M', '哶'),
+ (0x2F842, 'M', '唐'),
+ (0x2F843, 'M', '啓'),
+ (0x2F844, 'M', '啣'),
+ (0x2F845, 'M', '善'),
+ (0x2F847, 'M', '喙'),
+ (0x2F848, 'M', '喫'),
+ (0x2F849, 'M', '喳'),
+ (0x2F84A, 'M', '嗂'),
+ (0x2F84B, 'M', '圖'),
+ (0x2F84C, 'M', '嘆'),
+ (0x2F84D, 'M', '圗'),
+ (0x2F84E, 'M', '噑'),
+ (0x2F84F, 'M', '噴'),
+ (0x2F850, 'M', '切'),
+ (0x2F851, 'M', '壮'),
+ (0x2F852, 'M', '城'),
+ (0x2F853, 'M', '埴'),
+ (0x2F854, 'M', '堍'),
+ (0x2F855, 'M', '型'),
+ (0x2F856, 'M', '堲'),
+ (0x2F857, 'M', '報'),
+ (0x2F858, 'M', '墬'),
+ (0x2F859, 'M', '𡓤'),
+ (0x2F85A, 'M', '売'),
+ (0x2F85B, 'M', '壷'),
+ (0x2F85C, 'M', '夆'),
+ (0x2F85D, 'M', '多'),
+ (0x2F85E, 'M', '夢'),
+ (0x2F85F, 'M', '奢'),
+ (0x2F860, 'M', '𡚨'),
+ (0x2F861, 'M', '𡛪'),
+ (0x2F862, 'M', '姬'),
+ (0x2F863, 'M', '娛'),
+ (0x2F864, 'M', '娧'),
+ (0x2F865, 'M', '姘'),
+ (0x2F866, 'M', '婦'),
+ (0x2F867, 'M', '㛮'),
+ (0x2F868, 'X'),
+ (0x2F869, 'M', '嬈'),
+ (0x2F86A, 'M', '嬾'),
+ (0x2F86C, 'M', '𡧈'),
+ (0x2F86D, 'M', '寃'),
+ (0x2F86E, 'M', '寘'),
+ (0x2F86F, 'M', '寧'),
+ (0x2F870, 'M', '寳'),
+ (0x2F871, 'M', '𡬘'),
+ (0x2F872, 'M', '寿'),
+ (0x2F873, 'M', '将'),
+ (0x2F874, 'X'),
+ (0x2F875, 'M', '尢'),
+ (0x2F876, 'M', '㞁'),
+ (0x2F877, 'M', '屠'),
+ (0x2F878, 'M', '屮'),
+ (0x2F879, 'M', '峀'),
+ (0x2F87A, 'M', '岍'),
+ (0x2F87B, 'M', '𡷤'),
+ (0x2F87C, 'M', '嵃'),
+ (0x2F87D, 'M', '𡷦'),
+ (0x2F87E, 'M', '嵮'),
+ (0x2F87F, 'M', '嵫'),
+ (0x2F880, 'M', '嵼'),
+ (0x2F881, 'M', '巡'),
+ (0x2F882, 'M', '巢'),
+ (0x2F883, 'M', '㠯'),
+ (0x2F884, 'M', '巽'),
+ (0x2F885, 'M', '帨'),
+ (0x2F886, 'M', '帽'),
+ (0x2F887, 'M', '幩'),
+ (0x2F888, 'M', '㡢'),
+ (0x2F889, 'M', '𢆃'),
+ (0x2F88A, 'M', '㡼'),
+ (0x2F88B, 'M', '庰'),
+ (0x2F88C, 'M', '庳'),
+ (0x2F88D, 'M', '庶'),
+ (0x2F88E, 'M', '廊'),
+ (0x2F88F, 'M', '𪎒'),
+ (0x2F890, 'M', '廾'),
+ (0x2F891, 'M', '𢌱'),
+ (0x2F893, 'M', '舁'),
+ (0x2F894, 'M', '弢'),
+ (0x2F896, 'M', '㣇'),
+ (0x2F897, 'M', '𣊸'),
+ (0x2F898, 'M', '𦇚'),
+ (0x2F899, 'M', '形'),
+ (0x2F89A, 'M', '彫'),
+ (0x2F89B, 'M', '㣣'),
+ (0x2F89C, 'M', '徚'),
+ (0x2F89D, 'M', '忍'),
+ (0x2F89E, 'M', '志'),
+ (0x2F89F, 'M', '忹'),
+ (0x2F8A0, 'M', '悁'),
+ (0x2F8A1, 'M', '㤺'),
+ (0x2F8A2, 'M', '㤜'),
+ (0x2F8A3, 'M', '悔'),
+ (0x2F8A4, 'M', '𢛔'),
+ (0x2F8A5, 'M', '惇'),
+ (0x2F8A6, 'M', '慈'),
+ (0x2F8A7, 'M', '慌'),
+ (0x2F8A8, 'M', '慎'),
+ ]
+
+def _seg_78() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2F8A9, 'M', '慌'),
+ (0x2F8AA, 'M', '慺'),
+ (0x2F8AB, 'M', '憎'),
+ (0x2F8AC, 'M', '憲'),
+ (0x2F8AD, 'M', '憤'),
+ (0x2F8AE, 'M', '憯'),
+ (0x2F8AF, 'M', '懞'),
+ (0x2F8B0, 'M', '懲'),
+ (0x2F8B1, 'M', '懶'),
+ (0x2F8B2, 'M', '成'),
+ (0x2F8B3, 'M', '戛'),
+ (0x2F8B4, 'M', '扝'),
+ (0x2F8B5, 'M', '抱'),
+ (0x2F8B6, 'M', '拔'),
+ (0x2F8B7, 'M', '捐'),
+ (0x2F8B8, 'M', '𢬌'),
+ (0x2F8B9, 'M', '挽'),
+ (0x2F8BA, 'M', '拼'),
+ (0x2F8BB, 'M', '捨'),
+ (0x2F8BC, 'M', '掃'),
+ (0x2F8BD, 'M', '揤'),
+ (0x2F8BE, 'M', '𢯱'),
+ (0x2F8BF, 'M', '搢'),
+ (0x2F8C0, 'M', '揅'),
+ (0x2F8C1, 'M', '掩'),
+ (0x2F8C2, 'M', '㨮'),
+ (0x2F8C3, 'M', '摩'),
+ (0x2F8C4, 'M', '摾'),
+ (0x2F8C5, 'M', '撝'),
+ (0x2F8C6, 'M', '摷'),
+ (0x2F8C7, 'M', '㩬'),
+ (0x2F8C8, 'M', '敏'),
+ (0x2F8C9, 'M', '敬'),
+ (0x2F8CA, 'M', '𣀊'),
+ (0x2F8CB, 'M', '旣'),
+ (0x2F8CC, 'M', '書'),
+ (0x2F8CD, 'M', '晉'),
+ (0x2F8CE, 'M', '㬙'),
+ (0x2F8CF, 'M', '暑'),
+ (0x2F8D0, 'M', '㬈'),
+ (0x2F8D1, 'M', '㫤'),
+ (0x2F8D2, 'M', '冒'),
+ (0x2F8D3, 'M', '冕'),
+ (0x2F8D4, 'M', '最'),
+ (0x2F8D5, 'M', '暜'),
+ (0x2F8D6, 'M', '肭'),
+ (0x2F8D7, 'M', '䏙'),
+ (0x2F8D8, 'M', '朗'),
+ (0x2F8D9, 'M', '望'),
+ (0x2F8DA, 'M', '朡'),
+ (0x2F8DB, 'M', '杞'),
+ (0x2F8DC, 'M', '杓'),
+ (0x2F8DD, 'M', '𣏃'),
+ (0x2F8DE, 'M', '㭉'),
+ (0x2F8DF, 'M', '柺'),
+ (0x2F8E0, 'M', '枅'),
+ (0x2F8E1, 'M', '桒'),
+ (0x2F8E2, 'M', '梅'),
+ (0x2F8E3, 'M', '𣑭'),
+ (0x2F8E4, 'M', '梎'),
+ (0x2F8E5, 'M', '栟'),
+ (0x2F8E6, 'M', '椔'),
+ (0x2F8E7, 'M', '㮝'),
+ (0x2F8E8, 'M', '楂'),
+ (0x2F8E9, 'M', '榣'),
+ (0x2F8EA, 'M', '槪'),
+ (0x2F8EB, 'M', '檨'),
+ (0x2F8EC, 'M', '𣚣'),
+ (0x2F8ED, 'M', '櫛'),
+ (0x2F8EE, 'M', '㰘'),
+ (0x2F8EF, 'M', '次'),
+ (0x2F8F0, 'M', '𣢧'),
+ (0x2F8F1, 'M', '歔'),
+ (0x2F8F2, 'M', '㱎'),
+ (0x2F8F3, 'M', '歲'),
+ (0x2F8F4, 'M', '殟'),
+ (0x2F8F5, 'M', '殺'),
+ (0x2F8F6, 'M', '殻'),
+ (0x2F8F7, 'M', '𣪍'),
+ (0x2F8F8, 'M', '𡴋'),
+ (0x2F8F9, 'M', '𣫺'),
+ (0x2F8FA, 'M', '汎'),
+ (0x2F8FB, 'M', '𣲼'),
+ (0x2F8FC, 'M', '沿'),
+ (0x2F8FD, 'M', '泍'),
+ (0x2F8FE, 'M', '汧'),
+ (0x2F8FF, 'M', '洖'),
+ (0x2F900, 'M', '派'),
+ (0x2F901, 'M', '海'),
+ (0x2F902, 'M', '流'),
+ (0x2F903, 'M', '浩'),
+ (0x2F904, 'M', '浸'),
+ (0x2F905, 'M', '涅'),
+ (0x2F906, 'M', '𣴞'),
+ (0x2F907, 'M', '洴'),
+ (0x2F908, 'M', '港'),
+ (0x2F909, 'M', '湮'),
+ (0x2F90A, 'M', '㴳'),
+ (0x2F90B, 'M', '滋'),
+ (0x2F90C, 'M', '滇'),
+ ]
+
+def _seg_79() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2F90D, 'M', '𣻑'),
+ (0x2F90E, 'M', '淹'),
+ (0x2F90F, 'M', '潮'),
+ (0x2F910, 'M', '𣽞'),
+ (0x2F911, 'M', '𣾎'),
+ (0x2F912, 'M', '濆'),
+ (0x2F913, 'M', '瀹'),
+ (0x2F914, 'M', '瀞'),
+ (0x2F915, 'M', '瀛'),
+ (0x2F916, 'M', '㶖'),
+ (0x2F917, 'M', '灊'),
+ (0x2F918, 'M', '災'),
+ (0x2F919, 'M', '灷'),
+ (0x2F91A, 'M', '炭'),
+ (0x2F91B, 'M', '𠔥'),
+ (0x2F91C, 'M', '煅'),
+ (0x2F91D, 'M', '𤉣'),
+ (0x2F91E, 'M', '熜'),
+ (0x2F91F, 'X'),
+ (0x2F920, 'M', '爨'),
+ (0x2F921, 'M', '爵'),
+ (0x2F922, 'M', '牐'),
+ (0x2F923, 'M', '𤘈'),
+ (0x2F924, 'M', '犀'),
+ (0x2F925, 'M', '犕'),
+ (0x2F926, 'M', '𤜵'),
+ (0x2F927, 'M', '𤠔'),
+ (0x2F928, 'M', '獺'),
+ (0x2F929, 'M', '王'),
+ (0x2F92A, 'M', '㺬'),
+ (0x2F92B, 'M', '玥'),
+ (0x2F92C, 'M', '㺸'),
+ (0x2F92E, 'M', '瑇'),
+ (0x2F92F, 'M', '瑜'),
+ (0x2F930, 'M', '瑱'),
+ (0x2F931, 'M', '璅'),
+ (0x2F932, 'M', '瓊'),
+ (0x2F933, 'M', '㼛'),
+ (0x2F934, 'M', '甤'),
+ (0x2F935, 'M', '𤰶'),
+ (0x2F936, 'M', '甾'),
+ (0x2F937, 'M', '𤲒'),
+ (0x2F938, 'M', '異'),
+ (0x2F939, 'M', '𢆟'),
+ (0x2F93A, 'M', '瘐'),
+ (0x2F93B, 'M', '𤾡'),
+ (0x2F93C, 'M', '𤾸'),
+ (0x2F93D, 'M', '𥁄'),
+ (0x2F93E, 'M', '㿼'),
+ (0x2F93F, 'M', '䀈'),
+ (0x2F940, 'M', '直'),
+ (0x2F941, 'M', '𥃳'),
+ (0x2F942, 'M', '𥃲'),
+ (0x2F943, 'M', '𥄙'),
+ (0x2F944, 'M', '𥄳'),
+ (0x2F945, 'M', '眞'),
+ (0x2F946, 'M', '真'),
+ (0x2F948, 'M', '睊'),
+ (0x2F949, 'M', '䀹'),
+ (0x2F94A, 'M', '瞋'),
+ (0x2F94B, 'M', '䁆'),
+ (0x2F94C, 'M', '䂖'),
+ (0x2F94D, 'M', '𥐝'),
+ (0x2F94E, 'M', '硎'),
+ (0x2F94F, 'M', '碌'),
+ (0x2F950, 'M', '磌'),
+ (0x2F951, 'M', '䃣'),
+ (0x2F952, 'M', '𥘦'),
+ (0x2F953, 'M', '祖'),
+ (0x2F954, 'M', '𥚚'),
+ (0x2F955, 'M', '𥛅'),
+ (0x2F956, 'M', '福'),
+ (0x2F957, 'M', '秫'),
+ (0x2F958, 'M', '䄯'),
+ (0x2F959, 'M', '穀'),
+ (0x2F95A, 'M', '穊'),
+ (0x2F95B, 'M', '穏'),
+ (0x2F95C, 'M', '𥥼'),
+ (0x2F95D, 'M', '𥪧'),
+ (0x2F95F, 'X'),
+ (0x2F960, 'M', '䈂'),
+ (0x2F961, 'M', '𥮫'),
+ (0x2F962, 'M', '篆'),
+ (0x2F963, 'M', '築'),
+ (0x2F964, 'M', '䈧'),
+ (0x2F965, 'M', '𥲀'),
+ (0x2F966, 'M', '糒'),
+ (0x2F967, 'M', '䊠'),
+ (0x2F968, 'M', '糨'),
+ (0x2F969, 'M', '糣'),
+ (0x2F96A, 'M', '紀'),
+ (0x2F96B, 'M', '𥾆'),
+ (0x2F96C, 'M', '絣'),
+ (0x2F96D, 'M', '䌁'),
+ (0x2F96E, 'M', '緇'),
+ (0x2F96F, 'M', '縂'),
+ (0x2F970, 'M', '繅'),
+ (0x2F971, 'M', '䌴'),
+ (0x2F972, 'M', '𦈨'),
+ (0x2F973, 'M', '𦉇'),
+ ]
+
+def _seg_80() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2F974, 'M', '䍙'),
+ (0x2F975, 'M', '𦋙'),
+ (0x2F976, 'M', '罺'),
+ (0x2F977, 'M', '𦌾'),
+ (0x2F978, 'M', '羕'),
+ (0x2F979, 'M', '翺'),
+ (0x2F97A, 'M', '者'),
+ (0x2F97B, 'M', '𦓚'),
+ (0x2F97C, 'M', '𦔣'),
+ (0x2F97D, 'M', '聠'),
+ (0x2F97E, 'M', '𦖨'),
+ (0x2F97F, 'M', '聰'),
+ (0x2F980, 'M', '𣍟'),
+ (0x2F981, 'M', '䏕'),
+ (0x2F982, 'M', '育'),
+ (0x2F983, 'M', '脃'),
+ (0x2F984, 'M', '䐋'),
+ (0x2F985, 'M', '脾'),
+ (0x2F986, 'M', '媵'),
+ (0x2F987, 'M', '𦞧'),
+ (0x2F988, 'M', '𦞵'),
+ (0x2F989, 'M', '𣎓'),
+ (0x2F98A, 'M', '𣎜'),
+ (0x2F98B, 'M', '舁'),
+ (0x2F98C, 'M', '舄'),
+ (0x2F98D, 'M', '辞'),
+ (0x2F98E, 'M', '䑫'),
+ (0x2F98F, 'M', '芑'),
+ (0x2F990, 'M', '芋'),
+ (0x2F991, 'M', '芝'),
+ (0x2F992, 'M', '劳'),
+ (0x2F993, 'M', '花'),
+ (0x2F994, 'M', '芳'),
+ (0x2F995, 'M', '芽'),
+ (0x2F996, 'M', '苦'),
+ (0x2F997, 'M', '𦬼'),
+ (0x2F998, 'M', '若'),
+ (0x2F999, 'M', '茝'),
+ (0x2F99A, 'M', '荣'),
+ (0x2F99B, 'M', '莭'),
+ (0x2F99C, 'M', '茣'),
+ (0x2F99D, 'M', '莽'),
+ (0x2F99E, 'M', '菧'),
+ (0x2F99F, 'M', '著'),
+ (0x2F9A0, 'M', '荓'),
+ (0x2F9A1, 'M', '菊'),
+ (0x2F9A2, 'M', '菌'),
+ (0x2F9A3, 'M', '菜'),
+ (0x2F9A4, 'M', '𦰶'),
+ (0x2F9A5, 'M', '𦵫'),
+ (0x2F9A6, 'M', '𦳕'),
+ (0x2F9A7, 'M', '䔫'),
+ (0x2F9A8, 'M', '蓱'),
+ (0x2F9A9, 'M', '蓳'),
+ (0x2F9AA, 'M', '蔖'),
+ (0x2F9AB, 'M', '𧏊'),
+ (0x2F9AC, 'M', '蕤'),
+ (0x2F9AD, 'M', '𦼬'),
+ (0x2F9AE, 'M', '䕝'),
+ (0x2F9AF, 'M', '䕡'),
+ (0x2F9B0, 'M', '𦾱'),
+ (0x2F9B1, 'M', '𧃒'),
+ (0x2F9B2, 'M', '䕫'),
+ (0x2F9B3, 'M', '虐'),
+ (0x2F9B4, 'M', '虜'),
+ (0x2F9B5, 'M', '虧'),
+ (0x2F9B6, 'M', '虩'),
+ (0x2F9B7, 'M', '蚩'),
+ (0x2F9B8, 'M', '蚈'),
+ (0x2F9B9, 'M', '蜎'),
+ (0x2F9BA, 'M', '蛢'),
+ (0x2F9BB, 'M', '蝹'),
+ (0x2F9BC, 'M', '蜨'),
+ (0x2F9BD, 'M', '蝫'),
+ (0x2F9BE, 'M', '螆'),
+ (0x2F9BF, 'X'),
+ (0x2F9C0, 'M', '蟡'),
+ (0x2F9C1, 'M', '蠁'),
+ (0x2F9C2, 'M', '䗹'),
+ (0x2F9C3, 'M', '衠'),
+ (0x2F9C4, 'M', '衣'),
+ (0x2F9C5, 'M', '𧙧'),
+ (0x2F9C6, 'M', '裗'),
+ (0x2F9C7, 'M', '裞'),
+ (0x2F9C8, 'M', '䘵'),
+ (0x2F9C9, 'M', '裺'),
+ (0x2F9CA, 'M', '㒻'),
+ (0x2F9CB, 'M', '𧢮'),
+ (0x2F9CC, 'M', '𧥦'),
+ (0x2F9CD, 'M', '䚾'),
+ (0x2F9CE, 'M', '䛇'),
+ (0x2F9CF, 'M', '誠'),
+ (0x2F9D0, 'M', '諭'),
+ (0x2F9D1, 'M', '變'),
+ (0x2F9D2, 'M', '豕'),
+ (0x2F9D3, 'M', '𧲨'),
+ (0x2F9D4, 'M', '貫'),
+ (0x2F9D5, 'M', '賁'),
+ (0x2F9D6, 'M', '贛'),
+ (0x2F9D7, 'M', '起'),
+ ]
+
+def _seg_81() -> List[Union[Tuple[int, str], Tuple[int, str, str]]]:
+ return [
+ (0x2F9D8, 'M', '𧼯'),
+ (0x2F9D9, 'M', '𠠄'),
+ (0x2F9DA, 'M', '跋'),
+ (0x2F9DB, 'M', '趼'),
+ (0x2F9DC, 'M', '跰'),
+ (0x2F9DD, 'M', '𠣞'),
+ (0x2F9DE, 'M', '軔'),
+ (0x2F9DF, 'M', '輸'),
+ (0x2F9E0, 'M', '𨗒'),
+ (0x2F9E1, 'M', '𨗭'),
+ (0x2F9E2, 'M', '邔'),
+ (0x2F9E3, 'M', '郱'),
+ (0x2F9E4, 'M', '鄑'),
+ (0x2F9E5, 'M', '𨜮'),
+ (0x2F9E6, 'M', '鄛'),
+ (0x2F9E7, 'M', '鈸'),
+ (0x2F9E8, 'M', '鋗'),
+ (0x2F9E9, 'M', '鋘'),
+ (0x2F9EA, 'M', '鉼'),
+ (0x2F9EB, 'M', '鏹'),
+ (0x2F9EC, 'M', '鐕'),
+ (0x2F9ED, 'M', '𨯺'),
+ (0x2F9EE, 'M', '開'),
+ (0x2F9EF, 'M', '䦕'),
+ (0x2F9F0, 'M', '閷'),
+ (0x2F9F1, 'M', '𨵷'),
+ (0x2F9F2, 'M', '䧦'),
+ (0x2F9F3, 'M', '雃'),
+ (0x2F9F4, 'M', '嶲'),
+ (0x2F9F5, 'M', '霣'),
+ (0x2F9F6, 'M', '𩅅'),
+ (0x2F9F7, 'M', '𩈚'),
+ (0x2F9F8, 'M', '䩮'),
+ (0x2F9F9, 'M', '䩶'),
+ (0x2F9FA, 'M', '韠'),
+ (0x2F9FB, 'M', '𩐊'),
+ (0x2F9FC, 'M', '䪲'),
+ (0x2F9FD, 'M', '𩒖'),
+ (0x2F9FE, 'M', '頋'),
+ (0x2FA00, 'M', '頩'),
+ (0x2FA01, 'M', '𩖶'),
+ (0x2FA02, 'M', '飢'),
+ (0x2FA03, 'M', '䬳'),
+ (0x2FA04, 'M', '餩'),
+ (0x2FA05, 'M', '馧'),
+ (0x2FA06, 'M', '駂'),
+ (0x2FA07, 'M', '駾'),
+ (0x2FA08, 'M', '䯎'),
+ (0x2FA09, 'M', '𩬰'),
+ (0x2FA0A, 'M', '鬒'),
+ (0x2FA0B, 'M', '鱀'),
+ (0x2FA0C, 'M', '鳽'),
+ (0x2FA0D, 'M', '䳎'),
+ (0x2FA0E, 'M', '䳭'),
+ (0x2FA0F, 'M', '鵧'),
+ (0x2FA10, 'M', '𪃎'),
+ (0x2FA11, 'M', '䳸'),
+ (0x2FA12, 'M', '𪄅'),
+ (0x2FA13, 'M', '𪈎'),
+ (0x2FA14, 'M', '𪊑'),
+ (0x2FA15, 'M', '麻'),
+ (0x2FA16, 'M', '䵖'),
+ (0x2FA17, 'M', '黹'),
+ (0x2FA18, 'M', '黾'),
+ (0x2FA19, 'M', '鼅'),
+ (0x2FA1A, 'M', '鼏'),
+ (0x2FA1B, 'M', '鼖'),
+ (0x2FA1C, 'M', '鼻'),
+ (0x2FA1D, 'M', '𪘀'),
+ (0x2FA1E, 'X'),
+ (0x30000, 'V'),
+ (0x3134B, 'X'),
+ (0x31350, 'V'),
+ (0x323B0, 'X'),
+ (0xE0100, 'I'),
+ (0xE01F0, 'X'),
+ ]
+
+uts46data = tuple(
+ _seg_0()
+ + _seg_1()
+ + _seg_2()
+ + _seg_3()
+ + _seg_4()
+ + _seg_5()
+ + _seg_6()
+ + _seg_7()
+ + _seg_8()
+ + _seg_9()
+ + _seg_10()
+ + _seg_11()
+ + _seg_12()
+ + _seg_13()
+ + _seg_14()
+ + _seg_15()
+ + _seg_16()
+ + _seg_17()
+ + _seg_18()
+ + _seg_19()
+ + _seg_20()
+ + _seg_21()
+ + _seg_22()
+ + _seg_23()
+ + _seg_24()
+ + _seg_25()
+ + _seg_26()
+ + _seg_27()
+ + _seg_28()
+ + _seg_29()
+ + _seg_30()
+ + _seg_31()
+ + _seg_32()
+ + _seg_33()
+ + _seg_34()
+ + _seg_35()
+ + _seg_36()
+ + _seg_37()
+ + _seg_38()
+ + _seg_39()
+ + _seg_40()
+ + _seg_41()
+ + _seg_42()
+ + _seg_43()
+ + _seg_44()
+ + _seg_45()
+ + _seg_46()
+ + _seg_47()
+ + _seg_48()
+ + _seg_49()
+ + _seg_50()
+ + _seg_51()
+ + _seg_52()
+ + _seg_53()
+ + _seg_54()
+ + _seg_55()
+ + _seg_56()
+ + _seg_57()
+ + _seg_58()
+ + _seg_59()
+ + _seg_60()
+ + _seg_61()
+ + _seg_62()
+ + _seg_63()
+ + _seg_64()
+ + _seg_65()
+ + _seg_66()
+ + _seg_67()
+ + _seg_68()
+ + _seg_69()
+ + _seg_70()
+ + _seg_71()
+ + _seg_72()
+ + _seg_73()
+ + _seg_74()
+ + _seg_75()
+ + _seg_76()
+ + _seg_77()
+ + _seg_78()
+ + _seg_79()
+ + _seg_80()
+ + _seg_81()
+) # type: Tuple[Union[Tuple[int, str], Tuple[int, str, str]], ...]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/__init__.py
new file mode 100644
index 000000000..919b86f17
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/__init__.py
@@ -0,0 +1,55 @@
+from .exceptions import *
+from .ext import ExtType, Timestamp
+
+import os
+
+
+version = (1, 0, 8)
+__version__ = "1.0.8"
+
+
+if os.environ.get("MSGPACK_PUREPYTHON"):
+ from .fallback import Packer, unpackb, Unpacker
+else:
+ try:
+ from ._cmsgpack import Packer, unpackb, Unpacker
+ except ImportError:
+ from .fallback import Packer, unpackb, Unpacker
+
+
+def pack(o, stream, **kwargs):
+ """
+ Pack object `o` and write it to `stream`
+
+ See :class:`Packer` for options.
+ """
+ packer = Packer(**kwargs)
+ stream.write(packer.pack(o))
+
+
+def packb(o, **kwargs):
+ """
+ Pack object `o` and return packed bytes
+
+ See :class:`Packer` for options.
+ """
+ return Packer(**kwargs).pack(o)
+
+
+def unpack(stream, **kwargs):
+ """
+ Unpack an object from `stream`.
+
+ Raises `ExtraData` when `stream` contains extra bytes.
+ See :class:`Unpacker` for options.
+ """
+ data = stream.read()
+ return unpackb(data, **kwargs)
+
+
+# alias for compatibility to simplejson/marshal/pickle.
+load = unpack
+loads = unpackb
+
+dump = pack
+dumps = packb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/exceptions.py b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/exceptions.py
new file mode 100644
index 000000000..d6d2615cf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/exceptions.py
@@ -0,0 +1,48 @@
+class UnpackException(Exception):
+ """Base class for some exceptions raised while unpacking.
+
+ NOTE: unpack may raise exception other than subclass of
+ UnpackException. If you want to catch all error, catch
+ Exception instead.
+ """
+
+
+class BufferFull(UnpackException):
+ pass
+
+
+class OutOfData(UnpackException):
+ pass
+
+
+class FormatError(ValueError, UnpackException):
+ """Invalid msgpack format"""
+
+
+class StackError(ValueError, UnpackException):
+ """Too nested"""
+
+
+# Deprecated. Use ValueError instead
+UnpackValueError = ValueError
+
+
+class ExtraData(UnpackValueError):
+ """ExtraData is raised when there is trailing data.
+
+ This exception is raised while only one-shot (not streaming)
+ unpack.
+ """
+
+ def __init__(self, unpacked, extra):
+ self.unpacked = unpacked
+ self.extra = extra
+
+ def __str__(self):
+ return "unpack(b) received extra data."
+
+
+# Deprecated. Use Exception instead to catch all exception during packing.
+PackException = Exception
+PackValueError = ValueError
+PackOverflowError = OverflowError
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/ext.py b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/ext.py
new file mode 100644
index 000000000..02c2c4300
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/ext.py
@@ -0,0 +1,168 @@
+from collections import namedtuple
+import datetime
+import struct
+
+
+class ExtType(namedtuple("ExtType", "code data")):
+ """ExtType represents ext type in msgpack."""
+
+ def __new__(cls, code, data):
+ if not isinstance(code, int):
+ raise TypeError("code must be int")
+ if not isinstance(data, bytes):
+ raise TypeError("data must be bytes")
+ if not 0 <= code <= 127:
+ raise ValueError("code must be 0~127")
+ return super().__new__(cls, code, data)
+
+
+class Timestamp:
+ """Timestamp represents the Timestamp extension type in msgpack.
+
+ When built with Cython, msgpack uses C methods to pack and unpack `Timestamp`.
+ When using pure-Python msgpack, :func:`to_bytes` and :func:`from_bytes` are used to pack and
+ unpack `Timestamp`.
+
+ This class is immutable: Do not override seconds and nanoseconds.
+ """
+
+ __slots__ = ["seconds", "nanoseconds"]
+
+ def __init__(self, seconds, nanoseconds=0):
+ """Initialize a Timestamp object.
+
+ :param int seconds:
+ Number of seconds since the UNIX epoch (00:00:00 UTC Jan 1 1970, minus leap seconds).
+ May be negative.
+
+ :param int nanoseconds:
+ Number of nanoseconds to add to `seconds` to get fractional time.
+ Maximum is 999_999_999. Default is 0.
+
+ Note: Negative times (before the UNIX epoch) are represented as neg. seconds + pos. ns.
+ """
+ if not isinstance(seconds, int):
+ raise TypeError("seconds must be an integer")
+ if not isinstance(nanoseconds, int):
+ raise TypeError("nanoseconds must be an integer")
+ if not (0 <= nanoseconds < 10**9):
+ raise ValueError("nanoseconds must be a non-negative integer less than 999999999.")
+ self.seconds = seconds
+ self.nanoseconds = nanoseconds
+
+ def __repr__(self):
+ """String representation of Timestamp."""
+ return f"Timestamp(seconds={self.seconds}, nanoseconds={self.nanoseconds})"
+
+ def __eq__(self, other):
+ """Check for equality with another Timestamp object"""
+ if type(other) is self.__class__:
+ return self.seconds == other.seconds and self.nanoseconds == other.nanoseconds
+ return False
+
+ def __ne__(self, other):
+ """not-equals method (see :func:`__eq__()`)"""
+ return not self.__eq__(other)
+
+ def __hash__(self):
+ return hash((self.seconds, self.nanoseconds))
+
+ @staticmethod
+ def from_bytes(b):
+ """Unpack bytes into a `Timestamp` object.
+
+ Used for pure-Python msgpack unpacking.
+
+ :param b: Payload from msgpack ext message with code -1
+ :type b: bytes
+
+ :returns: Timestamp object unpacked from msgpack ext payload
+ :rtype: Timestamp
+ """
+ if len(b) == 4:
+ seconds = struct.unpack("!L", b)[0]
+ nanoseconds = 0
+ elif len(b) == 8:
+ data64 = struct.unpack("!Q", b)[0]
+ seconds = data64 & 0x00000003FFFFFFFF
+ nanoseconds = data64 >> 34
+ elif len(b) == 12:
+ nanoseconds, seconds = struct.unpack("!Iq", b)
+ else:
+ raise ValueError(
+ "Timestamp type can only be created from 32, 64, or 96-bit byte objects"
+ )
+ return Timestamp(seconds, nanoseconds)
+
+ def to_bytes(self):
+ """Pack this Timestamp object into bytes.
+
+ Used for pure-Python msgpack packing.
+
+ :returns data: Payload for EXT message with code -1 (timestamp type)
+ :rtype: bytes
+ """
+ if (self.seconds >> 34) == 0: # seconds is non-negative and fits in 34 bits
+ data64 = self.nanoseconds << 34 | self.seconds
+ if data64 & 0xFFFFFFFF00000000 == 0:
+ # nanoseconds is zero and seconds < 2**32, so timestamp 32
+ data = struct.pack("!L", data64)
+ else:
+ # timestamp 64
+ data = struct.pack("!Q", data64)
+ else:
+ # timestamp 96
+ data = struct.pack("!Iq", self.nanoseconds, self.seconds)
+ return data
+
+ @staticmethod
+ def from_unix(unix_sec):
+ """Create a Timestamp from posix timestamp in seconds.
+
+ :param unix_float: Posix timestamp in seconds.
+ :type unix_float: int or float
+ """
+ seconds = int(unix_sec // 1)
+ nanoseconds = int((unix_sec % 1) * 10**9)
+ return Timestamp(seconds, nanoseconds)
+
+ def to_unix(self):
+ """Get the timestamp as a floating-point value.
+
+ :returns: posix timestamp
+ :rtype: float
+ """
+ return self.seconds + self.nanoseconds / 1e9
+
+ @staticmethod
+ def from_unix_nano(unix_ns):
+ """Create a Timestamp from posix timestamp in nanoseconds.
+
+ :param int unix_ns: Posix timestamp in nanoseconds.
+ :rtype: Timestamp
+ """
+ return Timestamp(*divmod(unix_ns, 10**9))
+
+ def to_unix_nano(self):
+ """Get the timestamp as a unixtime in nanoseconds.
+
+ :returns: posix timestamp in nanoseconds
+ :rtype: int
+ """
+ return self.seconds * 10**9 + self.nanoseconds
+
+ def to_datetime(self):
+ """Get the timestamp as a UTC datetime.
+
+ :rtype: `datetime.datetime`
+ """
+ utc = datetime.timezone.utc
+ return datetime.datetime.fromtimestamp(0, utc) + datetime.timedelta(seconds=self.to_unix())
+
+ @staticmethod
+ def from_datetime(dt):
+ """Create a Timestamp from datetime with tzinfo.
+
+ :rtype: Timestamp
+ """
+ return Timestamp.from_unix(dt.timestamp())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/fallback.py b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/fallback.py
new file mode 100644
index 000000000..a174162af
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/msgpack/fallback.py
@@ -0,0 +1,951 @@
+"""Fallback pure Python implementation of msgpack"""
+from datetime import datetime as _DateTime
+import sys
+import struct
+
+
+if hasattr(sys, "pypy_version_info"):
+ # StringIO is slow on PyPy, StringIO is faster. However: PyPy's own
+ # StringBuilder is fastest.
+ from __pypy__ import newlist_hint
+
+ try:
+ from __pypy__.builders import BytesBuilder as StringBuilder
+ except ImportError:
+ from __pypy__.builders import StringBuilder
+ USING_STRINGBUILDER = True
+
+ class StringIO:
+ def __init__(self, s=b""):
+ if s:
+ self.builder = StringBuilder(len(s))
+ self.builder.append(s)
+ else:
+ self.builder = StringBuilder()
+
+ def write(self, s):
+ if isinstance(s, memoryview):
+ s = s.tobytes()
+ elif isinstance(s, bytearray):
+ s = bytes(s)
+ self.builder.append(s)
+
+ def getvalue(self):
+ return self.builder.build()
+
+else:
+ USING_STRINGBUILDER = False
+ from io import BytesIO as StringIO
+
+ newlist_hint = lambda size: []
+
+
+from .exceptions import BufferFull, OutOfData, ExtraData, FormatError, StackError
+
+from .ext import ExtType, Timestamp
+
+
+EX_SKIP = 0
+EX_CONSTRUCT = 1
+EX_READ_ARRAY_HEADER = 2
+EX_READ_MAP_HEADER = 3
+
+TYPE_IMMEDIATE = 0
+TYPE_ARRAY = 1
+TYPE_MAP = 2
+TYPE_RAW = 3
+TYPE_BIN = 4
+TYPE_EXT = 5
+
+DEFAULT_RECURSE_LIMIT = 511
+
+
+def _check_type_strict(obj, t, type=type, tuple=tuple):
+ if type(t) is tuple:
+ return type(obj) in t
+ else:
+ return type(obj) is t
+
+
+def _get_data_from_buffer(obj):
+ view = memoryview(obj)
+ if view.itemsize != 1:
+ raise ValueError("cannot unpack from multi-byte object")
+ return view
+
+
+def unpackb(packed, **kwargs):
+ """
+ Unpack an object from `packed`.
+
+ Raises ``ExtraData`` when *packed* contains extra bytes.
+ Raises ``ValueError`` when *packed* is incomplete.
+ Raises ``FormatError`` when *packed* is not valid msgpack.
+ Raises ``StackError`` when *packed* contains too nested.
+ Other exceptions can be raised during unpacking.
+
+ See :class:`Unpacker` for options.
+ """
+ unpacker = Unpacker(None, max_buffer_size=len(packed), **kwargs)
+ unpacker.feed(packed)
+ try:
+ ret = unpacker._unpack()
+ except OutOfData:
+ raise ValueError("Unpack failed: incomplete input")
+ except RecursionError:
+ raise StackError
+ if unpacker._got_extradata():
+ raise ExtraData(ret, unpacker._get_extradata())
+ return ret
+
+
+_NO_FORMAT_USED = ""
+_MSGPACK_HEADERS = {
+ 0xC4: (1, _NO_FORMAT_USED, TYPE_BIN),
+ 0xC5: (2, ">H", TYPE_BIN),
+ 0xC6: (4, ">I", TYPE_BIN),
+ 0xC7: (2, "Bb", TYPE_EXT),
+ 0xC8: (3, ">Hb", TYPE_EXT),
+ 0xC9: (5, ">Ib", TYPE_EXT),
+ 0xCA: (4, ">f"),
+ 0xCB: (8, ">d"),
+ 0xCC: (1, _NO_FORMAT_USED),
+ 0xCD: (2, ">H"),
+ 0xCE: (4, ">I"),
+ 0xCF: (8, ">Q"),
+ 0xD0: (1, "b"),
+ 0xD1: (2, ">h"),
+ 0xD2: (4, ">i"),
+ 0xD3: (8, ">q"),
+ 0xD4: (1, "b1s", TYPE_EXT),
+ 0xD5: (2, "b2s", TYPE_EXT),
+ 0xD6: (4, "b4s", TYPE_EXT),
+ 0xD7: (8, "b8s", TYPE_EXT),
+ 0xD8: (16, "b16s", TYPE_EXT),
+ 0xD9: (1, _NO_FORMAT_USED, TYPE_RAW),
+ 0xDA: (2, ">H", TYPE_RAW),
+ 0xDB: (4, ">I", TYPE_RAW),
+ 0xDC: (2, ">H", TYPE_ARRAY),
+ 0xDD: (4, ">I", TYPE_ARRAY),
+ 0xDE: (2, ">H", TYPE_MAP),
+ 0xDF: (4, ">I", TYPE_MAP),
+}
+
+
+class Unpacker:
+ """Streaming unpacker.
+
+ Arguments:
+
+ :param file_like:
+ File-like object having `.read(n)` method.
+ If specified, unpacker reads serialized data from it and `.feed()` is not usable.
+
+ :param int read_size:
+ Used as `file_like.read(read_size)`. (default: `min(16*1024, max_buffer_size)`)
+
+ :param bool use_list:
+ If true, unpack msgpack array to Python list.
+ Otherwise, unpack to Python tuple. (default: True)
+
+ :param bool raw:
+ If true, unpack msgpack raw to Python bytes.
+ Otherwise, unpack to Python str by decoding with UTF-8 encoding (default).
+
+ :param int timestamp:
+ Control how timestamp type is unpacked:
+
+ 0 - Timestamp
+ 1 - float (Seconds from the EPOCH)
+ 2 - int (Nanoseconds from the EPOCH)
+ 3 - datetime.datetime (UTC).
+
+ :param bool strict_map_key:
+ If true (default), only str or bytes are accepted for map (dict) keys.
+
+ :param object_hook:
+ When specified, it should be callable.
+ Unpacker calls it with a dict argument after unpacking msgpack map.
+ (See also simplejson)
+
+ :param object_pairs_hook:
+ When specified, it should be callable.
+ Unpacker calls it with a list of key-value pairs after unpacking msgpack map.
+ (See also simplejson)
+
+ :param str unicode_errors:
+ The error handler for decoding unicode. (default: 'strict')
+ This option should be used only when you have msgpack data which
+ contains invalid UTF-8 string.
+
+ :param int max_buffer_size:
+ Limits size of data waiting unpacked. 0 means 2**32-1.
+ The default value is 100*1024*1024 (100MiB).
+ Raises `BufferFull` exception when it is insufficient.
+ You should set this parameter when unpacking data from untrusted source.
+
+ :param int max_str_len:
+ Deprecated, use *max_buffer_size* instead.
+ Limits max length of str. (default: max_buffer_size)
+
+ :param int max_bin_len:
+ Deprecated, use *max_buffer_size* instead.
+ Limits max length of bin. (default: max_buffer_size)
+
+ :param int max_array_len:
+ Limits max length of array.
+ (default: max_buffer_size)
+
+ :param int max_map_len:
+ Limits max length of map.
+ (default: max_buffer_size//2)
+
+ :param int max_ext_len:
+ Deprecated, use *max_buffer_size* instead.
+ Limits max size of ext type. (default: max_buffer_size)
+
+ Example of streaming deserialize from file-like object::
+
+ unpacker = Unpacker(file_like)
+ for o in unpacker:
+ process(o)
+
+ Example of streaming deserialize from socket::
+
+ unpacker = Unpacker()
+ while True:
+ buf = sock.recv(1024**2)
+ if not buf:
+ break
+ unpacker.feed(buf)
+ for o in unpacker:
+ process(o)
+
+ Raises ``ExtraData`` when *packed* contains extra bytes.
+ Raises ``OutOfData`` when *packed* is incomplete.
+ Raises ``FormatError`` when *packed* is not valid msgpack.
+ Raises ``StackError`` when *packed* contains too nested.
+ Other exceptions can be raised during unpacking.
+ """
+
+ def __init__(
+ self,
+ file_like=None,
+ read_size=0,
+ use_list=True,
+ raw=False,
+ timestamp=0,
+ strict_map_key=True,
+ object_hook=None,
+ object_pairs_hook=None,
+ list_hook=None,
+ unicode_errors=None,
+ max_buffer_size=100 * 1024 * 1024,
+ ext_hook=ExtType,
+ max_str_len=-1,
+ max_bin_len=-1,
+ max_array_len=-1,
+ max_map_len=-1,
+ max_ext_len=-1,
+ ):
+ if unicode_errors is None:
+ unicode_errors = "strict"
+
+ if file_like is None:
+ self._feeding = True
+ else:
+ if not callable(file_like.read):
+ raise TypeError("`file_like.read` must be callable")
+ self.file_like = file_like
+ self._feeding = False
+
+ #: array of bytes fed.
+ self._buffer = bytearray()
+ #: Which position we currently reads
+ self._buff_i = 0
+
+ # When Unpacker is used as an iterable, between the calls to next(),
+ # the buffer is not "consumed" completely, for efficiency sake.
+ # Instead, it is done sloppily. To make sure we raise BufferFull at
+ # the correct moments, we have to keep track of how sloppy we were.
+ # Furthermore, when the buffer is incomplete (that is: in the case
+ # we raise an OutOfData) we need to rollback the buffer to the correct
+ # state, which _buf_checkpoint records.
+ self._buf_checkpoint = 0
+
+ if not max_buffer_size:
+ max_buffer_size = 2**31 - 1
+ if max_str_len == -1:
+ max_str_len = max_buffer_size
+ if max_bin_len == -1:
+ max_bin_len = max_buffer_size
+ if max_array_len == -1:
+ max_array_len = max_buffer_size
+ if max_map_len == -1:
+ max_map_len = max_buffer_size // 2
+ if max_ext_len == -1:
+ max_ext_len = max_buffer_size
+
+ self._max_buffer_size = max_buffer_size
+ if read_size > self._max_buffer_size:
+ raise ValueError("read_size must be smaller than max_buffer_size")
+ self._read_size = read_size or min(self._max_buffer_size, 16 * 1024)
+ self._raw = bool(raw)
+ self._strict_map_key = bool(strict_map_key)
+ self._unicode_errors = unicode_errors
+ self._use_list = use_list
+ if not (0 <= timestamp <= 3):
+ raise ValueError("timestamp must be 0..3")
+ self._timestamp = timestamp
+ self._list_hook = list_hook
+ self._object_hook = object_hook
+ self._object_pairs_hook = object_pairs_hook
+ self._ext_hook = ext_hook
+ self._max_str_len = max_str_len
+ self._max_bin_len = max_bin_len
+ self._max_array_len = max_array_len
+ self._max_map_len = max_map_len
+ self._max_ext_len = max_ext_len
+ self._stream_offset = 0
+
+ if list_hook is not None and not callable(list_hook):
+ raise TypeError("`list_hook` is not callable")
+ if object_hook is not None and not callable(object_hook):
+ raise TypeError("`object_hook` is not callable")
+ if object_pairs_hook is not None and not callable(object_pairs_hook):
+ raise TypeError("`object_pairs_hook` is not callable")
+ if object_hook is not None and object_pairs_hook is not None:
+ raise TypeError("object_pairs_hook and object_hook are mutually exclusive")
+ if not callable(ext_hook):
+ raise TypeError("`ext_hook` is not callable")
+
+ def feed(self, next_bytes):
+ assert self._feeding
+ view = _get_data_from_buffer(next_bytes)
+ if len(self._buffer) - self._buff_i + len(view) > self._max_buffer_size:
+ raise BufferFull
+
+ # Strip buffer before checkpoint before reading file.
+ if self._buf_checkpoint > 0:
+ del self._buffer[: self._buf_checkpoint]
+ self._buff_i -= self._buf_checkpoint
+ self._buf_checkpoint = 0
+
+ # Use extend here: INPLACE_ADD += doesn't reliably typecast memoryview in jython
+ self._buffer.extend(view)
+
+ def _consume(self):
+ """Gets rid of the used parts of the buffer."""
+ self._stream_offset += self._buff_i - self._buf_checkpoint
+ self._buf_checkpoint = self._buff_i
+
+ def _got_extradata(self):
+ return self._buff_i < len(self._buffer)
+
+ def _get_extradata(self):
+ return self._buffer[self._buff_i :]
+
+ def read_bytes(self, n):
+ ret = self._read(n, raise_outofdata=False)
+ self._consume()
+ return ret
+
+ def _read(self, n, raise_outofdata=True):
+ # (int) -> bytearray
+ self._reserve(n, raise_outofdata=raise_outofdata)
+ i = self._buff_i
+ ret = self._buffer[i : i + n]
+ self._buff_i = i + len(ret)
+ return ret
+
+ def _reserve(self, n, raise_outofdata=True):
+ remain_bytes = len(self._buffer) - self._buff_i - n
+
+ # Fast path: buffer has n bytes already
+ if remain_bytes >= 0:
+ return
+
+ if self._feeding:
+ self._buff_i = self._buf_checkpoint
+ raise OutOfData
+
+ # Strip buffer before checkpoint before reading file.
+ if self._buf_checkpoint > 0:
+ del self._buffer[: self._buf_checkpoint]
+ self._buff_i -= self._buf_checkpoint
+ self._buf_checkpoint = 0
+
+ # Read from file
+ remain_bytes = -remain_bytes
+ if remain_bytes + len(self._buffer) > self._max_buffer_size:
+ raise BufferFull
+ while remain_bytes > 0:
+ to_read_bytes = max(self._read_size, remain_bytes)
+ read_data = self.file_like.read(to_read_bytes)
+ if not read_data:
+ break
+ assert isinstance(read_data, bytes)
+ self._buffer += read_data
+ remain_bytes -= len(read_data)
+
+ if len(self._buffer) < n + self._buff_i and raise_outofdata:
+ self._buff_i = 0 # rollback
+ raise OutOfData
+
+ def _read_header(self):
+ typ = TYPE_IMMEDIATE
+ n = 0
+ obj = None
+ self._reserve(1)
+ b = self._buffer[self._buff_i]
+ self._buff_i += 1
+ if b & 0b10000000 == 0:
+ obj = b
+ elif b & 0b11100000 == 0b11100000:
+ obj = -1 - (b ^ 0xFF)
+ elif b & 0b11100000 == 0b10100000:
+ n = b & 0b00011111
+ typ = TYPE_RAW
+ if n > self._max_str_len:
+ raise ValueError(f"{n} exceeds max_str_len({self._max_str_len})")
+ obj = self._read(n)
+ elif b & 0b11110000 == 0b10010000:
+ n = b & 0b00001111
+ typ = TYPE_ARRAY
+ if n > self._max_array_len:
+ raise ValueError(f"{n} exceeds max_array_len({self._max_array_len})")
+ elif b & 0b11110000 == 0b10000000:
+ n = b & 0b00001111
+ typ = TYPE_MAP
+ if n > self._max_map_len:
+ raise ValueError(f"{n} exceeds max_map_len({self._max_map_len})")
+ elif b == 0xC0:
+ obj = None
+ elif b == 0xC2:
+ obj = False
+ elif b == 0xC3:
+ obj = True
+ elif 0xC4 <= b <= 0xC6:
+ size, fmt, typ = _MSGPACK_HEADERS[b]
+ self._reserve(size)
+ if len(fmt) > 0:
+ n = struct.unpack_from(fmt, self._buffer, self._buff_i)[0]
+ else:
+ n = self._buffer[self._buff_i]
+ self._buff_i += size
+ if n > self._max_bin_len:
+ raise ValueError(f"{n} exceeds max_bin_len({self._max_bin_len})")
+ obj = self._read(n)
+ elif 0xC7 <= b <= 0xC9:
+ size, fmt, typ = _MSGPACK_HEADERS[b]
+ self._reserve(size)
+ L, n = struct.unpack_from(fmt, self._buffer, self._buff_i)
+ self._buff_i += size
+ if L > self._max_ext_len:
+ raise ValueError(f"{L} exceeds max_ext_len({self._max_ext_len})")
+ obj = self._read(L)
+ elif 0xCA <= b <= 0xD3:
+ size, fmt = _MSGPACK_HEADERS[b]
+ self._reserve(size)
+ if len(fmt) > 0:
+ obj = struct.unpack_from(fmt, self._buffer, self._buff_i)[0]
+ else:
+ obj = self._buffer[self._buff_i]
+ self._buff_i += size
+ elif 0xD4 <= b <= 0xD8:
+ size, fmt, typ = _MSGPACK_HEADERS[b]
+ if self._max_ext_len < size:
+ raise ValueError(f"{size} exceeds max_ext_len({self._max_ext_len})")
+ self._reserve(size + 1)
+ n, obj = struct.unpack_from(fmt, self._buffer, self._buff_i)
+ self._buff_i += size + 1
+ elif 0xD9 <= b <= 0xDB:
+ size, fmt, typ = _MSGPACK_HEADERS[b]
+ self._reserve(size)
+ if len(fmt) > 0:
+ (n,) = struct.unpack_from(fmt, self._buffer, self._buff_i)
+ else:
+ n = self._buffer[self._buff_i]
+ self._buff_i += size
+ if n > self._max_str_len:
+ raise ValueError(f"{n} exceeds max_str_len({self._max_str_len})")
+ obj = self._read(n)
+ elif 0xDC <= b <= 0xDD:
+ size, fmt, typ = _MSGPACK_HEADERS[b]
+ self._reserve(size)
+ (n,) = struct.unpack_from(fmt, self._buffer, self._buff_i)
+ self._buff_i += size
+ if n > self._max_array_len:
+ raise ValueError(f"{n} exceeds max_array_len({self._max_array_len})")
+ elif 0xDE <= b <= 0xDF:
+ size, fmt, typ = _MSGPACK_HEADERS[b]
+ self._reserve(size)
+ (n,) = struct.unpack_from(fmt, self._buffer, self._buff_i)
+ self._buff_i += size
+ if n > self._max_map_len:
+ raise ValueError(f"{n} exceeds max_map_len({self._max_map_len})")
+ else:
+ raise FormatError("Unknown header: 0x%x" % b)
+ return typ, n, obj
+
+ def _unpack(self, execute=EX_CONSTRUCT):
+ typ, n, obj = self._read_header()
+
+ if execute == EX_READ_ARRAY_HEADER:
+ if typ != TYPE_ARRAY:
+ raise ValueError("Expected array")
+ return n
+ if execute == EX_READ_MAP_HEADER:
+ if typ != TYPE_MAP:
+ raise ValueError("Expected map")
+ return n
+ # TODO should we eliminate the recursion?
+ if typ == TYPE_ARRAY:
+ if execute == EX_SKIP:
+ for i in range(n):
+ # TODO check whether we need to call `list_hook`
+ self._unpack(EX_SKIP)
+ return
+ ret = newlist_hint(n)
+ for i in range(n):
+ ret.append(self._unpack(EX_CONSTRUCT))
+ if self._list_hook is not None:
+ ret = self._list_hook(ret)
+ # TODO is the interaction between `list_hook` and `use_list` ok?
+ return ret if self._use_list else tuple(ret)
+ if typ == TYPE_MAP:
+ if execute == EX_SKIP:
+ for i in range(n):
+ # TODO check whether we need to call hooks
+ self._unpack(EX_SKIP)
+ self._unpack(EX_SKIP)
+ return
+ if self._object_pairs_hook is not None:
+ ret = self._object_pairs_hook(
+ (self._unpack(EX_CONSTRUCT), self._unpack(EX_CONSTRUCT)) for _ in range(n)
+ )
+ else:
+ ret = {}
+ for _ in range(n):
+ key = self._unpack(EX_CONSTRUCT)
+ if self._strict_map_key and type(key) not in (str, bytes):
+ raise ValueError("%s is not allowed for map key" % str(type(key)))
+ if isinstance(key, str):
+ key = sys.intern(key)
+ ret[key] = self._unpack(EX_CONSTRUCT)
+ if self._object_hook is not None:
+ ret = self._object_hook(ret)
+ return ret
+ if execute == EX_SKIP:
+ return
+ if typ == TYPE_RAW:
+ if self._raw:
+ obj = bytes(obj)
+ else:
+ obj = obj.decode("utf_8", self._unicode_errors)
+ return obj
+ if typ == TYPE_BIN:
+ return bytes(obj)
+ if typ == TYPE_EXT:
+ if n == -1: # timestamp
+ ts = Timestamp.from_bytes(bytes(obj))
+ if self._timestamp == 1:
+ return ts.to_unix()
+ elif self._timestamp == 2:
+ return ts.to_unix_nano()
+ elif self._timestamp == 3:
+ return ts.to_datetime()
+ else:
+ return ts
+ else:
+ return self._ext_hook(n, bytes(obj))
+ assert typ == TYPE_IMMEDIATE
+ return obj
+
+ def __iter__(self):
+ return self
+
+ def __next__(self):
+ try:
+ ret = self._unpack(EX_CONSTRUCT)
+ self._consume()
+ return ret
+ except OutOfData:
+ self._consume()
+ raise StopIteration
+ except RecursionError:
+ raise StackError
+
+ next = __next__
+
+ def skip(self):
+ self._unpack(EX_SKIP)
+ self._consume()
+
+ def unpack(self):
+ try:
+ ret = self._unpack(EX_CONSTRUCT)
+ except RecursionError:
+ raise StackError
+ self._consume()
+ return ret
+
+ def read_array_header(self):
+ ret = self._unpack(EX_READ_ARRAY_HEADER)
+ self._consume()
+ return ret
+
+ def read_map_header(self):
+ ret = self._unpack(EX_READ_MAP_HEADER)
+ self._consume()
+ return ret
+
+ def tell(self):
+ return self._stream_offset
+
+
+class Packer:
+ """
+ MessagePack Packer
+
+ Usage::
+
+ packer = Packer()
+ astream.write(packer.pack(a))
+ astream.write(packer.pack(b))
+
+ Packer's constructor has some keyword arguments:
+
+ :param default:
+ When specified, it should be callable.
+ Convert user type to builtin type that Packer supports.
+ See also simplejson's document.
+
+ :param bool use_single_float:
+ Use single precision float type for float. (default: False)
+
+ :param bool autoreset:
+ Reset buffer after each pack and return its content as `bytes`. (default: True).
+ If set this to false, use `bytes()` to get content and `.reset()` to clear buffer.
+
+ :param bool use_bin_type:
+ Use bin type introduced in msgpack spec 2.0 for bytes.
+ It also enables str8 type for unicode. (default: True)
+
+ :param bool strict_types:
+ If set to true, types will be checked to be exact. Derived classes
+ from serializable types will not be serialized and will be
+ treated as unsupported type and forwarded to default.
+ Additionally tuples will not be serialized as lists.
+ This is useful when trying to implement accurate serialization
+ for python types.
+
+ :param bool datetime:
+ If set to true, datetime with tzinfo is packed into Timestamp type.
+ Note that the tzinfo is stripped in the timestamp.
+ You can get UTC datetime with `timestamp=3` option of the Unpacker.
+
+ :param str unicode_errors:
+ The error handler for encoding unicode. (default: 'strict')
+ DO NOT USE THIS!! This option is kept for very specific usage.
+
+ Example of streaming deserialize from file-like object::
+
+ unpacker = Unpacker(file_like)
+ for o in unpacker:
+ process(o)
+
+ Example of streaming deserialize from socket::
+
+ unpacker = Unpacker()
+ while True:
+ buf = sock.recv(1024**2)
+ if not buf:
+ break
+ unpacker.feed(buf)
+ for o in unpacker:
+ process(o)
+
+ Raises ``ExtraData`` when *packed* contains extra bytes.
+ Raises ``OutOfData`` when *packed* is incomplete.
+ Raises ``FormatError`` when *packed* is not valid msgpack.
+ Raises ``StackError`` when *packed* contains too nested.
+ Other exceptions can be raised during unpacking.
+ """
+
+ def __init__(
+ self,
+ default=None,
+ use_single_float=False,
+ autoreset=True,
+ use_bin_type=True,
+ strict_types=False,
+ datetime=False,
+ unicode_errors=None,
+ ):
+ self._strict_types = strict_types
+ self._use_float = use_single_float
+ self._autoreset = autoreset
+ self._use_bin_type = use_bin_type
+ self._buffer = StringIO()
+ self._datetime = bool(datetime)
+ self._unicode_errors = unicode_errors or "strict"
+ if default is not None:
+ if not callable(default):
+ raise TypeError("default must be callable")
+ self._default = default
+
+ def _pack(
+ self,
+ obj,
+ nest_limit=DEFAULT_RECURSE_LIMIT,
+ check=isinstance,
+ check_type_strict=_check_type_strict,
+ ):
+ default_used = False
+ if self._strict_types:
+ check = check_type_strict
+ list_types = list
+ else:
+ list_types = (list, tuple)
+ while True:
+ if nest_limit < 0:
+ raise ValueError("recursion limit exceeded")
+ if obj is None:
+ return self._buffer.write(b"\xc0")
+ if check(obj, bool):
+ if obj:
+ return self._buffer.write(b"\xc3")
+ return self._buffer.write(b"\xc2")
+ if check(obj, int):
+ if 0 <= obj < 0x80:
+ return self._buffer.write(struct.pack("B", obj))
+ if -0x20 <= obj < 0:
+ return self._buffer.write(struct.pack("b", obj))
+ if 0x80 <= obj <= 0xFF:
+ return self._buffer.write(struct.pack("BB", 0xCC, obj))
+ if -0x80 <= obj < 0:
+ return self._buffer.write(struct.pack(">Bb", 0xD0, obj))
+ if 0xFF < obj <= 0xFFFF:
+ return self._buffer.write(struct.pack(">BH", 0xCD, obj))
+ if -0x8000 <= obj < -0x80:
+ return self._buffer.write(struct.pack(">Bh", 0xD1, obj))
+ if 0xFFFF < obj <= 0xFFFFFFFF:
+ return self._buffer.write(struct.pack(">BI", 0xCE, obj))
+ if -0x80000000 <= obj < -0x8000:
+ return self._buffer.write(struct.pack(">Bi", 0xD2, obj))
+ if 0xFFFFFFFF < obj <= 0xFFFFFFFFFFFFFFFF:
+ return self._buffer.write(struct.pack(">BQ", 0xCF, obj))
+ if -0x8000000000000000 <= obj < -0x80000000:
+ return self._buffer.write(struct.pack(">Bq", 0xD3, obj))
+ if not default_used and self._default is not None:
+ obj = self._default(obj)
+ default_used = True
+ continue
+ raise OverflowError("Integer value out of range")
+ if check(obj, (bytes, bytearray)):
+ n = len(obj)
+ if n >= 2**32:
+ raise ValueError("%s is too large" % type(obj).__name__)
+ self._pack_bin_header(n)
+ return self._buffer.write(obj)
+ if check(obj, str):
+ obj = obj.encode("utf-8", self._unicode_errors)
+ n = len(obj)
+ if n >= 2**32:
+ raise ValueError("String is too large")
+ self._pack_raw_header(n)
+ return self._buffer.write(obj)
+ if check(obj, memoryview):
+ n = obj.nbytes
+ if n >= 2**32:
+ raise ValueError("Memoryview is too large")
+ self._pack_bin_header(n)
+ return self._buffer.write(obj)
+ if check(obj, float):
+ if self._use_float:
+ return self._buffer.write(struct.pack(">Bf", 0xCA, obj))
+ return self._buffer.write(struct.pack(">Bd", 0xCB, obj))
+ if check(obj, (ExtType, Timestamp)):
+ if check(obj, Timestamp):
+ code = -1
+ data = obj.to_bytes()
+ else:
+ code = obj.code
+ data = obj.data
+ assert isinstance(code, int)
+ assert isinstance(data, bytes)
+ L = len(data)
+ if L == 1:
+ self._buffer.write(b"\xd4")
+ elif L == 2:
+ self._buffer.write(b"\xd5")
+ elif L == 4:
+ self._buffer.write(b"\xd6")
+ elif L == 8:
+ self._buffer.write(b"\xd7")
+ elif L == 16:
+ self._buffer.write(b"\xd8")
+ elif L <= 0xFF:
+ self._buffer.write(struct.pack(">BB", 0xC7, L))
+ elif L <= 0xFFFF:
+ self._buffer.write(struct.pack(">BH", 0xC8, L))
+ else:
+ self._buffer.write(struct.pack(">BI", 0xC9, L))
+ self._buffer.write(struct.pack("b", code))
+ self._buffer.write(data)
+ return
+ if check(obj, list_types):
+ n = len(obj)
+ self._pack_array_header(n)
+ for i in range(n):
+ self._pack(obj[i], nest_limit - 1)
+ return
+ if check(obj, dict):
+ return self._pack_map_pairs(len(obj), obj.items(), nest_limit - 1)
+
+ if self._datetime and check(obj, _DateTime) and obj.tzinfo is not None:
+ obj = Timestamp.from_datetime(obj)
+ default_used = 1
+ continue
+
+ if not default_used and self._default is not None:
+ obj = self._default(obj)
+ default_used = 1
+ continue
+
+ if self._datetime and check(obj, _DateTime):
+ raise ValueError(f"Cannot serialize {obj!r} where tzinfo=None")
+
+ raise TypeError(f"Cannot serialize {obj!r}")
+
+ def pack(self, obj):
+ try:
+ self._pack(obj)
+ except:
+ self._buffer = StringIO() # force reset
+ raise
+ if self._autoreset:
+ ret = self._buffer.getvalue()
+ self._buffer = StringIO()
+ return ret
+
+ def pack_map_pairs(self, pairs):
+ self._pack_map_pairs(len(pairs), pairs)
+ if self._autoreset:
+ ret = self._buffer.getvalue()
+ self._buffer = StringIO()
+ return ret
+
+ def pack_array_header(self, n):
+ if n >= 2**32:
+ raise ValueError
+ self._pack_array_header(n)
+ if self._autoreset:
+ ret = self._buffer.getvalue()
+ self._buffer = StringIO()
+ return ret
+
+ def pack_map_header(self, n):
+ if n >= 2**32:
+ raise ValueError
+ self._pack_map_header(n)
+ if self._autoreset:
+ ret = self._buffer.getvalue()
+ self._buffer = StringIO()
+ return ret
+
+ def pack_ext_type(self, typecode, data):
+ if not isinstance(typecode, int):
+ raise TypeError("typecode must have int type.")
+ if not 0 <= typecode <= 127:
+ raise ValueError("typecode should be 0-127")
+ if not isinstance(data, bytes):
+ raise TypeError("data must have bytes type")
+ L = len(data)
+ if L > 0xFFFFFFFF:
+ raise ValueError("Too large data")
+ if L == 1:
+ self._buffer.write(b"\xd4")
+ elif L == 2:
+ self._buffer.write(b"\xd5")
+ elif L == 4:
+ self._buffer.write(b"\xd6")
+ elif L == 8:
+ self._buffer.write(b"\xd7")
+ elif L == 16:
+ self._buffer.write(b"\xd8")
+ elif L <= 0xFF:
+ self._buffer.write(b"\xc7" + struct.pack("B", L))
+ elif L <= 0xFFFF:
+ self._buffer.write(b"\xc8" + struct.pack(">H", L))
+ else:
+ self._buffer.write(b"\xc9" + struct.pack(">I", L))
+ self._buffer.write(struct.pack("B", typecode))
+ self._buffer.write(data)
+
+ def _pack_array_header(self, n):
+ if n <= 0x0F:
+ return self._buffer.write(struct.pack("B", 0x90 + n))
+ if n <= 0xFFFF:
+ return self._buffer.write(struct.pack(">BH", 0xDC, n))
+ if n <= 0xFFFFFFFF:
+ return self._buffer.write(struct.pack(">BI", 0xDD, n))
+ raise ValueError("Array is too large")
+
+ def _pack_map_header(self, n):
+ if n <= 0x0F:
+ return self._buffer.write(struct.pack("B", 0x80 + n))
+ if n <= 0xFFFF:
+ return self._buffer.write(struct.pack(">BH", 0xDE, n))
+ if n <= 0xFFFFFFFF:
+ return self._buffer.write(struct.pack(">BI", 0xDF, n))
+ raise ValueError("Dict is too large")
+
+ def _pack_map_pairs(self, n, pairs, nest_limit=DEFAULT_RECURSE_LIMIT):
+ self._pack_map_header(n)
+ for k, v in pairs:
+ self._pack(k, nest_limit - 1)
+ self._pack(v, nest_limit - 1)
+
+ def _pack_raw_header(self, n):
+ if n <= 0x1F:
+ self._buffer.write(struct.pack("B", 0xA0 + n))
+ elif self._use_bin_type and n <= 0xFF:
+ self._buffer.write(struct.pack(">BB", 0xD9, n))
+ elif n <= 0xFFFF:
+ self._buffer.write(struct.pack(">BH", 0xDA, n))
+ elif n <= 0xFFFFFFFF:
+ self._buffer.write(struct.pack(">BI", 0xDB, n))
+ else:
+ raise ValueError("Raw is too large")
+
+ def _pack_bin_header(self, n):
+ if not self._use_bin_type:
+ return self._pack_raw_header(n)
+ elif n <= 0xFF:
+ return self._buffer.write(struct.pack(">BB", 0xC4, n))
+ elif n <= 0xFFFF:
+ return self._buffer.write(struct.pack(">BH", 0xC5, n))
+ elif n <= 0xFFFFFFFF:
+ return self._buffer.write(struct.pack(">BI", 0xC6, n))
+ else:
+ raise ValueError("Bin is too large")
+
+ def bytes(self):
+ """Return internal buffer contents as bytes object"""
+ return self._buffer.getvalue()
+
+ def reset(self):
+ """Reset internal buffer.
+
+ This method is useful only when autoreset=False.
+ """
+ self._buffer = StringIO()
+
+ def getbuffer(self):
+ """Return view of internal buffer."""
+ if USING_STRINGBUILDER:
+ return memoryview(self.bytes())
+ else:
+ return self._buffer.getbuffer()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/__init__.py
new file mode 100644
index 000000000..9ba41d835
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/__init__.py
@@ -0,0 +1,15 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+
+__title__ = "packaging"
+__summary__ = "Core utilities for Python packages"
+__uri__ = "https://github.com/pypa/packaging"
+
+__version__ = "24.1"
+
+__author__ = "Donald Stufft and individual contributors"
+__email__ = "donald@stufft.io"
+
+__license__ = "BSD-2-Clause or Apache-2.0"
+__copyright__ = "2014 %s" % __author__
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_elffile.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_elffile.py
new file mode 100644
index 000000000..f7a02180b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_elffile.py
@@ -0,0 +1,110 @@
+"""
+ELF file parser.
+
+This provides a class ``ELFFile`` that parses an ELF executable in a similar
+interface to ``ZipFile``. Only the read interface is implemented.
+
+Based on: https://gist.github.com/lyssdod/f51579ae8d93c8657a5564aefc2ffbca
+ELF header: https://refspecs.linuxfoundation.org/elf/gabi4+/ch4.eheader.html
+"""
+
+from __future__ import annotations
+
+import enum
+import os
+import struct
+from typing import IO
+
+
+class ELFInvalid(ValueError):
+ pass
+
+
+class EIClass(enum.IntEnum):
+ C32 = 1
+ C64 = 2
+
+
+class EIData(enum.IntEnum):
+ Lsb = 1
+ Msb = 2
+
+
+class EMachine(enum.IntEnum):
+ I386 = 3
+ S390 = 22
+ Arm = 40
+ X8664 = 62
+ AArc64 = 183
+
+
+class ELFFile:
+ """
+ Representation of an ELF executable.
+ """
+
+ def __init__(self, f: IO[bytes]) -> None:
+ self._f = f
+
+ try:
+ ident = self._read("16B")
+ except struct.error:
+ raise ELFInvalid("unable to parse identification")
+ magic = bytes(ident[:4])
+ if magic != b"\x7fELF":
+ raise ELFInvalid(f"invalid magic: {magic!r}")
+
+ self.capacity = ident[4] # Format for program header (bitness).
+ self.encoding = ident[5] # Data structure encoding (endianness).
+
+ try:
+ # e_fmt: Format for program header.
+ # p_fmt: Format for section header.
+ # p_idx: Indexes to find p_type, p_offset, and p_filesz.
+ e_fmt, self._p_fmt, self._p_idx = {
+ (1, 1): ("<HHIIIIIHHH", "<IIIIIIII", (0, 1, 4)), # 32-bit LSB.
+ (1, 2): (">HHIIIIIHHH", ">IIIIIIII", (0, 1, 4)), # 32-bit MSB.
+ (2, 1): ("<HHIQQQIHHH", "<IIQQQQQQ", (0, 2, 5)), # 64-bit LSB.
+ (2, 2): (">HHIQQQIHHH", ">IIQQQQQQ", (0, 2, 5)), # 64-bit MSB.
+ }[(self.capacity, self.encoding)]
+ except KeyError:
+ raise ELFInvalid(
+ f"unrecognized capacity ({self.capacity}) or "
+ f"encoding ({self.encoding})"
+ )
+
+ try:
+ (
+ _,
+ self.machine, # Architecture type.
+ _,
+ _,
+ self._e_phoff, # Offset of program header.
+ _,
+ self.flags, # Processor-specific flags.
+ _,
+ self._e_phentsize, # Size of section.
+ self._e_phnum, # Number of sections.
+ ) = self._read(e_fmt)
+ except struct.error as e:
+ raise ELFInvalid("unable to parse machine and section information") from e
+
+ def _read(self, fmt: str) -> tuple[int, ...]:
+ return struct.unpack(fmt, self._f.read(struct.calcsize(fmt)))
+
+ @property
+ def interpreter(self) -> str | None:
+ """
+ The path recorded in the ``PT_INTERP`` section header.
+ """
+ for index in range(self._e_phnum):
+ self._f.seek(self._e_phoff + self._e_phentsize * index)
+ try:
+ data = self._read(self._p_fmt)
+ except struct.error:
+ continue
+ if data[self._p_idx[0]] != 3: # Not PT_INTERP.
+ continue
+ self._f.seek(data[self._p_idx[1]])
+ return os.fsdecode(self._f.read(data[self._p_idx[2]])).strip("\0")
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_manylinux.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_manylinux.py
new file mode 100644
index 000000000..08f651fbd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_manylinux.py
@@ -0,0 +1,262 @@
+from __future__ import annotations
+
+import collections
+import contextlib
+import functools
+import os
+import re
+import sys
+import warnings
+from typing import Generator, Iterator, NamedTuple, Sequence
+
+from ._elffile import EIClass, EIData, ELFFile, EMachine
+
+EF_ARM_ABIMASK = 0xFF000000
+EF_ARM_ABI_VER5 = 0x05000000
+EF_ARM_ABI_FLOAT_HARD = 0x00000400
+
+
+# `os.PathLike` not a generic type until Python 3.9, so sticking with `str`
+# as the type for `path` until then.
+@contextlib.contextmanager
+def _parse_elf(path: str) -> Generator[ELFFile | None, None, None]:
+ try:
+ with open(path, "rb") as f:
+ yield ELFFile(f)
+ except (OSError, TypeError, ValueError):
+ yield None
+
+
+def _is_linux_armhf(executable: str) -> bool:
+ # hard-float ABI can be detected from the ELF header of the running
+ # process
+ # https://static.docs.arm.com/ihi0044/g/aaelf32.pdf
+ with _parse_elf(executable) as f:
+ return (
+ f is not None
+ and f.capacity == EIClass.C32
+ and f.encoding == EIData.Lsb
+ and f.machine == EMachine.Arm
+ and f.flags & EF_ARM_ABIMASK == EF_ARM_ABI_VER5
+ and f.flags & EF_ARM_ABI_FLOAT_HARD == EF_ARM_ABI_FLOAT_HARD
+ )
+
+
+def _is_linux_i686(executable: str) -> bool:
+ with _parse_elf(executable) as f:
+ return (
+ f is not None
+ and f.capacity == EIClass.C32
+ and f.encoding == EIData.Lsb
+ and f.machine == EMachine.I386
+ )
+
+
+def _have_compatible_abi(executable: str, archs: Sequence[str]) -> bool:
+ if "armv7l" in archs:
+ return _is_linux_armhf(executable)
+ if "i686" in archs:
+ return _is_linux_i686(executable)
+ allowed_archs = {
+ "x86_64",
+ "aarch64",
+ "ppc64",
+ "ppc64le",
+ "s390x",
+ "loongarch64",
+ "riscv64",
+ }
+ return any(arch in allowed_archs for arch in archs)
+
+
+# If glibc ever changes its major version, we need to know what the last
+# minor version was, so we can build the complete list of all versions.
+# For now, guess what the highest minor version might be, assume it will
+# be 50 for testing. Once this actually happens, update the dictionary
+# with the actual value.
+_LAST_GLIBC_MINOR: dict[int, int] = collections.defaultdict(lambda: 50)
+
+
+class _GLibCVersion(NamedTuple):
+ major: int
+ minor: int
+
+
+def _glibc_version_string_confstr() -> str | None:
+ """
+ Primary implementation of glibc_version_string using os.confstr.
+ """
+ # os.confstr is quite a bit faster than ctypes.DLL. It's also less likely
+ # to be broken or missing. This strategy is used in the standard library
+ # platform module.
+ # https://github.com/python/cpython/blob/fcf1d003bf4f0100c/Lib/platform.py#L175-L183
+ try:
+ # Should be a string like "glibc 2.17".
+ version_string: str | None = os.confstr("CS_GNU_LIBC_VERSION")
+ assert version_string is not None
+ _, version = version_string.rsplit()
+ except (AssertionError, AttributeError, OSError, ValueError):
+ # os.confstr() or CS_GNU_LIBC_VERSION not available (or a bad value)...
+ return None
+ return version
+
+
+def _glibc_version_string_ctypes() -> str | None:
+ """
+ Fallback implementation of glibc_version_string using ctypes.
+ """
+ try:
+ import ctypes
+ except ImportError:
+ return None
+
+ # ctypes.CDLL(None) internally calls dlopen(NULL), and as the dlopen
+ # manpage says, "If filename is NULL, then the returned handle is for the
+ # main program". This way we can let the linker do the work to figure out
+ # which libc our process is actually using.
+ #
+ # We must also handle the special case where the executable is not a
+ # dynamically linked executable. This can occur when using musl libc,
+ # for example. In this situation, dlopen() will error, leading to an
+ # OSError. Interestingly, at least in the case of musl, there is no
+ # errno set on the OSError. The single string argument used to construct
+ # OSError comes from libc itself and is therefore not portable to
+ # hard code here. In any case, failure to call dlopen() means we
+ # can proceed, so we bail on our attempt.
+ try:
+ process_namespace = ctypes.CDLL(None)
+ except OSError:
+ return None
+
+ try:
+ gnu_get_libc_version = process_namespace.gnu_get_libc_version
+ except AttributeError:
+ # Symbol doesn't exist -> therefore, we are not linked to
+ # glibc.
+ return None
+
+ # Call gnu_get_libc_version, which returns a string like "2.5"
+ gnu_get_libc_version.restype = ctypes.c_char_p
+ version_str: str = gnu_get_libc_version()
+ # py2 / py3 compatibility:
+ if not isinstance(version_str, str):
+ version_str = version_str.decode("ascii")
+
+ return version_str
+
+
+def _glibc_version_string() -> str | None:
+ """Returns glibc version string, or None if not using glibc."""
+ return _glibc_version_string_confstr() or _glibc_version_string_ctypes()
+
+
+def _parse_glibc_version(version_str: str) -> tuple[int, int]:
+ """Parse glibc version.
+
+ We use a regexp instead of str.split because we want to discard any
+ random junk that might come after the minor version -- this might happen
+ in patched/forked versions of glibc (e.g. Linaro's version of glibc
+ uses version strings like "2.20-2014.11"). See gh-3588.
+ """
+ m = re.match(r"(?P<major>[0-9]+)\.(?P<minor>[0-9]+)", version_str)
+ if not m:
+ warnings.warn(
+ f"Expected glibc version with 2 components major.minor,"
+ f" got: {version_str}",
+ RuntimeWarning,
+ )
+ return -1, -1
+ return int(m.group("major")), int(m.group("minor"))
+
+
+@functools.lru_cache
+def _get_glibc_version() -> tuple[int, int]:
+ version_str = _glibc_version_string()
+ if version_str is None:
+ return (-1, -1)
+ return _parse_glibc_version(version_str)
+
+
+# From PEP 513, PEP 600
+def _is_compatible(arch: str, version: _GLibCVersion) -> bool:
+ sys_glibc = _get_glibc_version()
+ if sys_glibc < version:
+ return False
+ # Check for presence of _manylinux module.
+ try:
+ import _manylinux
+ except ImportError:
+ return True
+ if hasattr(_manylinux, "manylinux_compatible"):
+ result = _manylinux.manylinux_compatible(version[0], version[1], arch)
+ if result is not None:
+ return bool(result)
+ return True
+ if version == _GLibCVersion(2, 5):
+ if hasattr(_manylinux, "manylinux1_compatible"):
+ return bool(_manylinux.manylinux1_compatible)
+ if version == _GLibCVersion(2, 12):
+ if hasattr(_manylinux, "manylinux2010_compatible"):
+ return bool(_manylinux.manylinux2010_compatible)
+ if version == _GLibCVersion(2, 17):
+ if hasattr(_manylinux, "manylinux2014_compatible"):
+ return bool(_manylinux.manylinux2014_compatible)
+ return True
+
+
+_LEGACY_MANYLINUX_MAP = {
+ # CentOS 7 w/ glibc 2.17 (PEP 599)
+ (2, 17): "manylinux2014",
+ # CentOS 6 w/ glibc 2.12 (PEP 571)
+ (2, 12): "manylinux2010",
+ # CentOS 5 w/ glibc 2.5 (PEP 513)
+ (2, 5): "manylinux1",
+}
+
+
+def platform_tags(archs: Sequence[str]) -> Iterator[str]:
+ """Generate manylinux tags compatible to the current platform.
+
+ :param archs: Sequence of compatible architectures.
+ The first one shall be the closest to the actual architecture and be the part of
+ platform tag after the ``linux_`` prefix, e.g. ``x86_64``.
+ The ``linux_`` prefix is assumed as a prerequisite for the current platform to
+ be manylinux-compatible.
+
+ :returns: An iterator of compatible manylinux tags.
+ """
+ if not _have_compatible_abi(sys.executable, archs):
+ return
+ # Oldest glibc to be supported regardless of architecture is (2, 17).
+ too_old_glibc2 = _GLibCVersion(2, 16)
+ if set(archs) & {"x86_64", "i686"}:
+ # On x86/i686 also oldest glibc to be supported is (2, 5).
+ too_old_glibc2 = _GLibCVersion(2, 4)
+ current_glibc = _GLibCVersion(*_get_glibc_version())
+ glibc_max_list = [current_glibc]
+ # We can assume compatibility across glibc major versions.
+ # https://sourceware.org/bugzilla/show_bug.cgi?id=24636
+ #
+ # Build a list of maximum glibc versions so that we can
+ # output the canonical list of all glibc from current_glibc
+ # down to too_old_glibc2, including all intermediary versions.
+ for glibc_major in range(current_glibc.major - 1, 1, -1):
+ glibc_minor = _LAST_GLIBC_MINOR[glibc_major]
+ glibc_max_list.append(_GLibCVersion(glibc_major, glibc_minor))
+ for arch in archs:
+ for glibc_max in glibc_max_list:
+ if glibc_max.major == too_old_glibc2.major:
+ min_minor = too_old_glibc2.minor
+ else:
+ # For other glibc major versions oldest supported is (x, 0).
+ min_minor = -1
+ for glibc_minor in range(glibc_max.minor, min_minor, -1):
+ glibc_version = _GLibCVersion(glibc_max.major, glibc_minor)
+ tag = "manylinux_{}_{}".format(*glibc_version)
+ if _is_compatible(arch, glibc_version):
+ yield f"{tag}_{arch}"
+ # Handle the legacy manylinux1, manylinux2010, manylinux2014 tags.
+ if glibc_version in _LEGACY_MANYLINUX_MAP:
+ legacy_tag = _LEGACY_MANYLINUX_MAP[glibc_version]
+ if _is_compatible(arch, glibc_version):
+ yield f"{legacy_tag}_{arch}"
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_musllinux.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_musllinux.py
new file mode 100644
index 000000000..d2bf30b56
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_musllinux.py
@@ -0,0 +1,85 @@
+"""PEP 656 support.
+
+This module implements logic to detect if the currently running Python is
+linked against musl, and what musl version is used.
+"""
+
+from __future__ import annotations
+
+import functools
+import re
+import subprocess
+import sys
+from typing import Iterator, NamedTuple, Sequence
+
+from ._elffile import ELFFile
+
+
+class _MuslVersion(NamedTuple):
+ major: int
+ minor: int
+
+
+def _parse_musl_version(output: str) -> _MuslVersion | None:
+ lines = [n for n in (n.strip() for n in output.splitlines()) if n]
+ if len(lines) < 2 or lines[0][:4] != "musl":
+ return None
+ m = re.match(r"Version (\d+)\.(\d+)", lines[1])
+ if not m:
+ return None
+ return _MuslVersion(major=int(m.group(1)), minor=int(m.group(2)))
+
+
+@functools.lru_cache
+def _get_musl_version(executable: str) -> _MuslVersion | None:
+ """Detect currently-running musl runtime version.
+
+ This is done by checking the specified executable's dynamic linking
+ information, and invoking the loader to parse its output for a version
+ string. If the loader is musl, the output would be something like::
+
+ musl libc (x86_64)
+ Version 1.2.2
+ Dynamic Program Loader
+ """
+ try:
+ with open(executable, "rb") as f:
+ ld = ELFFile(f).interpreter
+ except (OSError, TypeError, ValueError):
+ return None
+ if ld is None or "musl" not in ld:
+ return None
+ proc = subprocess.run([ld], stderr=subprocess.PIPE, text=True)
+ return _parse_musl_version(proc.stderr)
+
+
+def platform_tags(archs: Sequence[str]) -> Iterator[str]:
+ """Generate musllinux tags compatible to the current platform.
+
+ :param archs: Sequence of compatible architectures.
+ The first one shall be the closest to the actual architecture and be the part of
+ platform tag after the ``linux_`` prefix, e.g. ``x86_64``.
+ The ``linux_`` prefix is assumed as a prerequisite for the current platform to
+ be musllinux-compatible.
+
+ :returns: An iterator of compatible musllinux tags.
+ """
+ sys_musl = _get_musl_version(sys.executable)
+ if sys_musl is None: # Python not dynamically linked against musl.
+ return
+ for arch in archs:
+ for minor in range(sys_musl.minor, -1, -1):
+ yield f"musllinux_{sys_musl.major}_{minor}_{arch}"
+
+
+if __name__ == "__main__": # pragma: no cover
+ import sysconfig
+
+ plat = sysconfig.get_platform()
+ assert plat.startswith("linux-"), "not linux"
+
+ print("plat:", plat)
+ print("musl:", _get_musl_version(sys.executable))
+ print("tags:", end=" ")
+ for t in platform_tags(re.sub(r"[.-]", "_", plat.split("-", 1)[-1])):
+ print(t, end="\n ")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_parser.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_parser.py
new file mode 100644
index 000000000..c1238c06e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_parser.py
@@ -0,0 +1,354 @@
+"""Handwritten parser of dependency specifiers.
+
+The docstring for each __parse_* function contains EBNF-inspired grammar representing
+the implementation.
+"""
+
+from __future__ import annotations
+
+import ast
+from typing import NamedTuple, Sequence, Tuple, Union
+
+from ._tokenizer import DEFAULT_RULES, Tokenizer
+
+
+class Node:
+ def __init__(self, value: str) -> None:
+ self.value = value
+
+ def __str__(self) -> str:
+ return self.value
+
+ def __repr__(self) -> str:
+ return f"<{self.__class__.__name__}('{self}')>"
+
+ def serialize(self) -> str:
+ raise NotImplementedError
+
+
+class Variable(Node):
+ def serialize(self) -> str:
+ return str(self)
+
+
+class Value(Node):
+ def serialize(self) -> str:
+ return f'"{self}"'
+
+
+class Op(Node):
+ def serialize(self) -> str:
+ return str(self)
+
+
+MarkerVar = Union[Variable, Value]
+MarkerItem = Tuple[MarkerVar, Op, MarkerVar]
+MarkerAtom = Union[MarkerItem, Sequence["MarkerAtom"]]
+MarkerList = Sequence[Union["MarkerList", MarkerAtom, str]]
+
+
+class ParsedRequirement(NamedTuple):
+ name: str
+ url: str
+ extras: list[str]
+ specifier: str
+ marker: MarkerList | None
+
+
+# --------------------------------------------------------------------------------------
+# Recursive descent parser for dependency specifier
+# --------------------------------------------------------------------------------------
+def parse_requirement(source: str) -> ParsedRequirement:
+ return _parse_requirement(Tokenizer(source, rules=DEFAULT_RULES))
+
+
+def _parse_requirement(tokenizer: Tokenizer) -> ParsedRequirement:
+ """
+ requirement = WS? IDENTIFIER WS? extras WS? requirement_details
+ """
+ tokenizer.consume("WS")
+
+ name_token = tokenizer.expect(
+ "IDENTIFIER", expected="package name at the start of dependency specifier"
+ )
+ name = name_token.text
+ tokenizer.consume("WS")
+
+ extras = _parse_extras(tokenizer)
+ tokenizer.consume("WS")
+
+ url, specifier, marker = _parse_requirement_details(tokenizer)
+ tokenizer.expect("END", expected="end of dependency specifier")
+
+ return ParsedRequirement(name, url, extras, specifier, marker)
+
+
+def _parse_requirement_details(
+ tokenizer: Tokenizer,
+) -> tuple[str, str, MarkerList | None]:
+ """
+ requirement_details = AT URL (WS requirement_marker?)?
+ | specifier WS? (requirement_marker)?
+ """
+
+ specifier = ""
+ url = ""
+ marker = None
+
+ if tokenizer.check("AT"):
+ tokenizer.read()
+ tokenizer.consume("WS")
+
+ url_start = tokenizer.position
+ url = tokenizer.expect("URL", expected="URL after @").text
+ if tokenizer.check("END", peek=True):
+ return (url, specifier, marker)
+
+ tokenizer.expect("WS", expected="whitespace after URL")
+
+ # The input might end after whitespace.
+ if tokenizer.check("END", peek=True):
+ return (url, specifier, marker)
+
+ marker = _parse_requirement_marker(
+ tokenizer, span_start=url_start, after="URL and whitespace"
+ )
+ else:
+ specifier_start = tokenizer.position
+ specifier = _parse_specifier(tokenizer)
+ tokenizer.consume("WS")
+
+ if tokenizer.check("END", peek=True):
+ return (url, specifier, marker)
+
+ marker = _parse_requirement_marker(
+ tokenizer,
+ span_start=specifier_start,
+ after=(
+ "version specifier"
+ if specifier
+ else "name and no valid version specifier"
+ ),
+ )
+
+ return (url, specifier, marker)
+
+
+def _parse_requirement_marker(
+ tokenizer: Tokenizer, *, span_start: int, after: str
+) -> MarkerList:
+ """
+ requirement_marker = SEMICOLON marker WS?
+ """
+
+ if not tokenizer.check("SEMICOLON"):
+ tokenizer.raise_syntax_error(
+ f"Expected end or semicolon (after {after})",
+ span_start=span_start,
+ )
+ tokenizer.read()
+
+ marker = _parse_marker(tokenizer)
+ tokenizer.consume("WS")
+
+ return marker
+
+
+def _parse_extras(tokenizer: Tokenizer) -> list[str]:
+ """
+ extras = (LEFT_BRACKET wsp* extras_list? wsp* RIGHT_BRACKET)?
+ """
+ if not tokenizer.check("LEFT_BRACKET", peek=True):
+ return []
+
+ with tokenizer.enclosing_tokens(
+ "LEFT_BRACKET",
+ "RIGHT_BRACKET",
+ around="extras",
+ ):
+ tokenizer.consume("WS")
+ extras = _parse_extras_list(tokenizer)
+ tokenizer.consume("WS")
+
+ return extras
+
+
+def _parse_extras_list(tokenizer: Tokenizer) -> list[str]:
+ """
+ extras_list = identifier (wsp* ',' wsp* identifier)*
+ """
+ extras: list[str] = []
+
+ if not tokenizer.check("IDENTIFIER"):
+ return extras
+
+ extras.append(tokenizer.read().text)
+
+ while True:
+ tokenizer.consume("WS")
+ if tokenizer.check("IDENTIFIER", peek=True):
+ tokenizer.raise_syntax_error("Expected comma between extra names")
+ elif not tokenizer.check("COMMA"):
+ break
+
+ tokenizer.read()
+ tokenizer.consume("WS")
+
+ extra_token = tokenizer.expect("IDENTIFIER", expected="extra name after comma")
+ extras.append(extra_token.text)
+
+ return extras
+
+
+def _parse_specifier(tokenizer: Tokenizer) -> str:
+ """
+ specifier = LEFT_PARENTHESIS WS? version_many WS? RIGHT_PARENTHESIS
+ | WS? version_many WS?
+ """
+ with tokenizer.enclosing_tokens(
+ "LEFT_PARENTHESIS",
+ "RIGHT_PARENTHESIS",
+ around="version specifier",
+ ):
+ tokenizer.consume("WS")
+ parsed_specifiers = _parse_version_many(tokenizer)
+ tokenizer.consume("WS")
+
+ return parsed_specifiers
+
+
+def _parse_version_many(tokenizer: Tokenizer) -> str:
+ """
+ version_many = (SPECIFIER (WS? COMMA WS? SPECIFIER)*)?
+ """
+ parsed_specifiers = ""
+ while tokenizer.check("SPECIFIER"):
+ span_start = tokenizer.position
+ parsed_specifiers += tokenizer.read().text
+ if tokenizer.check("VERSION_PREFIX_TRAIL", peek=True):
+ tokenizer.raise_syntax_error(
+ ".* suffix can only be used with `==` or `!=` operators",
+ span_start=span_start,
+ span_end=tokenizer.position + 1,
+ )
+ if tokenizer.check("VERSION_LOCAL_LABEL_TRAIL", peek=True):
+ tokenizer.raise_syntax_error(
+ "Local version label can only be used with `==` or `!=` operators",
+ span_start=span_start,
+ span_end=tokenizer.position,
+ )
+ tokenizer.consume("WS")
+ if not tokenizer.check("COMMA"):
+ break
+ parsed_specifiers += tokenizer.read().text
+ tokenizer.consume("WS")
+
+ return parsed_specifiers
+
+
+# --------------------------------------------------------------------------------------
+# Recursive descent parser for marker expression
+# --------------------------------------------------------------------------------------
+def parse_marker(source: str) -> MarkerList:
+ return _parse_full_marker(Tokenizer(source, rules=DEFAULT_RULES))
+
+
+def _parse_full_marker(tokenizer: Tokenizer) -> MarkerList:
+ retval = _parse_marker(tokenizer)
+ tokenizer.expect("END", expected="end of marker expression")
+ return retval
+
+
+def _parse_marker(tokenizer: Tokenizer) -> MarkerList:
+ """
+ marker = marker_atom (BOOLOP marker_atom)+
+ """
+ expression = [_parse_marker_atom(tokenizer)]
+ while tokenizer.check("BOOLOP"):
+ token = tokenizer.read()
+ expr_right = _parse_marker_atom(tokenizer)
+ expression.extend((token.text, expr_right))
+ return expression
+
+
+def _parse_marker_atom(tokenizer: Tokenizer) -> MarkerAtom:
+ """
+ marker_atom = WS? LEFT_PARENTHESIS WS? marker WS? RIGHT_PARENTHESIS WS?
+ | WS? marker_item WS?
+ """
+
+ tokenizer.consume("WS")
+ if tokenizer.check("LEFT_PARENTHESIS", peek=True):
+ with tokenizer.enclosing_tokens(
+ "LEFT_PARENTHESIS",
+ "RIGHT_PARENTHESIS",
+ around="marker expression",
+ ):
+ tokenizer.consume("WS")
+ marker: MarkerAtom = _parse_marker(tokenizer)
+ tokenizer.consume("WS")
+ else:
+ marker = _parse_marker_item(tokenizer)
+ tokenizer.consume("WS")
+ return marker
+
+
+def _parse_marker_item(tokenizer: Tokenizer) -> MarkerItem:
+ """
+ marker_item = WS? marker_var WS? marker_op WS? marker_var WS?
+ """
+ tokenizer.consume("WS")
+ marker_var_left = _parse_marker_var(tokenizer)
+ tokenizer.consume("WS")
+ marker_op = _parse_marker_op(tokenizer)
+ tokenizer.consume("WS")
+ marker_var_right = _parse_marker_var(tokenizer)
+ tokenizer.consume("WS")
+ return (marker_var_left, marker_op, marker_var_right)
+
+
+def _parse_marker_var(tokenizer: Tokenizer) -> MarkerVar:
+ """
+ marker_var = VARIABLE | QUOTED_STRING
+ """
+ if tokenizer.check("VARIABLE"):
+ return process_env_var(tokenizer.read().text.replace(".", "_"))
+ elif tokenizer.check("QUOTED_STRING"):
+ return process_python_str(tokenizer.read().text)
+ else:
+ tokenizer.raise_syntax_error(
+ message="Expected a marker variable or quoted string"
+ )
+
+
+def process_env_var(env_var: str) -> Variable:
+ if env_var in ("platform_python_implementation", "python_implementation"):
+ return Variable("platform_python_implementation")
+ else:
+ return Variable(env_var)
+
+
+def process_python_str(python_str: str) -> Value:
+ value = ast.literal_eval(python_str)
+ return Value(str(value))
+
+
+def _parse_marker_op(tokenizer: Tokenizer) -> Op:
+ """
+ marker_op = IN | NOT IN | OP
+ """
+ if tokenizer.check("IN"):
+ tokenizer.read()
+ return Op("in")
+ elif tokenizer.check("NOT"):
+ tokenizer.read()
+ tokenizer.expect("WS", expected="whitespace after 'not'")
+ tokenizer.expect("IN", expected="'in' after 'not'")
+ return Op("not in")
+ elif tokenizer.check("OP"):
+ return Op(tokenizer.read().text)
+ else:
+ return tokenizer.raise_syntax_error(
+ "Expected marker operator, one of "
+ "<=, <, !=, ==, >=, >, ~=, ===, in, not in"
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_structures.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_structures.py
new file mode 100644
index 000000000..90a6465f9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_structures.py
@@ -0,0 +1,61 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+
+
+class InfinityType:
+ def __repr__(self) -> str:
+ return "Infinity"
+
+ def __hash__(self) -> int:
+ return hash(repr(self))
+
+ def __lt__(self, other: object) -> bool:
+ return False
+
+ def __le__(self, other: object) -> bool:
+ return False
+
+ def __eq__(self, other: object) -> bool:
+ return isinstance(other, self.__class__)
+
+ def __gt__(self, other: object) -> bool:
+ return True
+
+ def __ge__(self, other: object) -> bool:
+ return True
+
+ def __neg__(self: object) -> "NegativeInfinityType":
+ return NegativeInfinity
+
+
+Infinity = InfinityType()
+
+
+class NegativeInfinityType:
+ def __repr__(self) -> str:
+ return "-Infinity"
+
+ def __hash__(self) -> int:
+ return hash(repr(self))
+
+ def __lt__(self, other: object) -> bool:
+ return True
+
+ def __le__(self, other: object) -> bool:
+ return True
+
+ def __eq__(self, other: object) -> bool:
+ return isinstance(other, self.__class__)
+
+ def __gt__(self, other: object) -> bool:
+ return False
+
+ def __ge__(self, other: object) -> bool:
+ return False
+
+ def __neg__(self: object) -> InfinityType:
+ return Infinity
+
+
+NegativeInfinity = NegativeInfinityType()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_tokenizer.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_tokenizer.py
new file mode 100644
index 000000000..89d041605
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/_tokenizer.py
@@ -0,0 +1,194 @@
+from __future__ import annotations
+
+import contextlib
+import re
+from dataclasses import dataclass
+from typing import Iterator, NoReturn
+
+from .specifiers import Specifier
+
+
+@dataclass
+class Token:
+ name: str
+ text: str
+ position: int
+
+
+class ParserSyntaxError(Exception):
+ """The provided source text could not be parsed correctly."""
+
+ def __init__(
+ self,
+ message: str,
+ *,
+ source: str,
+ span: tuple[int, int],
+ ) -> None:
+ self.span = span
+ self.message = message
+ self.source = source
+
+ super().__init__()
+
+ def __str__(self) -> str:
+ marker = " " * self.span[0] + "~" * (self.span[1] - self.span[0]) + "^"
+ return "\n ".join([self.message, self.source, marker])
+
+
+DEFAULT_RULES: dict[str, str | re.Pattern[str]] = {
+ "LEFT_PARENTHESIS": r"\(",
+ "RIGHT_PARENTHESIS": r"\)",
+ "LEFT_BRACKET": r"\[",
+ "RIGHT_BRACKET": r"\]",
+ "SEMICOLON": r";",
+ "COMMA": r",",
+ "QUOTED_STRING": re.compile(
+ r"""
+ (
+ ('[^']*')
+ |
+ ("[^"]*")
+ )
+ """,
+ re.VERBOSE,
+ ),
+ "OP": r"(===|==|~=|!=|<=|>=|<|>)",
+ "BOOLOP": r"\b(or|and)\b",
+ "IN": r"\bin\b",
+ "NOT": r"\bnot\b",
+ "VARIABLE": re.compile(
+ r"""
+ \b(
+ python_version
+ |python_full_version
+ |os[._]name
+ |sys[._]platform
+ |platform_(release|system)
+ |platform[._](version|machine|python_implementation)
+ |python_implementation
+ |implementation_(name|version)
+ |extra
+ )\b
+ """,
+ re.VERBOSE,
+ ),
+ "SPECIFIER": re.compile(
+ Specifier._operator_regex_str + Specifier._version_regex_str,
+ re.VERBOSE | re.IGNORECASE,
+ ),
+ "AT": r"\@",
+ "URL": r"[^ \t]+",
+ "IDENTIFIER": r"\b[a-zA-Z0-9][a-zA-Z0-9._-]*\b",
+ "VERSION_PREFIX_TRAIL": r"\.\*",
+ "VERSION_LOCAL_LABEL_TRAIL": r"\+[a-z0-9]+(?:[-_\.][a-z0-9]+)*",
+ "WS": r"[ \t]+",
+ "END": r"$",
+}
+
+
+class Tokenizer:
+ """Context-sensitive token parsing.
+
+ Provides methods to examine the input stream to check whether the next token
+ matches.
+ """
+
+ def __init__(
+ self,
+ source: str,
+ *,
+ rules: dict[str, str | re.Pattern[str]],
+ ) -> None:
+ self.source = source
+ self.rules: dict[str, re.Pattern[str]] = {
+ name: re.compile(pattern) for name, pattern in rules.items()
+ }
+ self.next_token: Token | None = None
+ self.position = 0
+
+ def consume(self, name: str) -> None:
+ """Move beyond provided token name, if at current position."""
+ if self.check(name):
+ self.read()
+
+ def check(self, name: str, *, peek: bool = False) -> bool:
+ """Check whether the next token has the provided name.
+
+ By default, if the check succeeds, the token *must* be read before
+ another check. If `peek` is set to `True`, the token is not loaded and
+ would need to be checked again.
+ """
+ assert (
+ self.next_token is None
+ ), f"Cannot check for {name!r}, already have {self.next_token!r}"
+ assert name in self.rules, f"Unknown token name: {name!r}"
+
+ expression = self.rules[name]
+
+ match = expression.match(self.source, self.position)
+ if match is None:
+ return False
+ if not peek:
+ self.next_token = Token(name, match[0], self.position)
+ return True
+
+ def expect(self, name: str, *, expected: str) -> Token:
+ """Expect a certain token name next, failing with a syntax error otherwise.
+
+ The token is *not* read.
+ """
+ if not self.check(name):
+ raise self.raise_syntax_error(f"Expected {expected}")
+ return self.read()
+
+ def read(self) -> Token:
+ """Consume the next token and return it."""
+ token = self.next_token
+ assert token is not None
+
+ self.position += len(token.text)
+ self.next_token = None
+
+ return token
+
+ def raise_syntax_error(
+ self,
+ message: str,
+ *,
+ span_start: int | None = None,
+ span_end: int | None = None,
+ ) -> NoReturn:
+ """Raise ParserSyntaxError at the given position."""
+ span = (
+ self.position if span_start is None else span_start,
+ self.position if span_end is None else span_end,
+ )
+ raise ParserSyntaxError(
+ message,
+ source=self.source,
+ span=span,
+ )
+
+ @contextlib.contextmanager
+ def enclosing_tokens(
+ self, open_token: str, close_token: str, *, around: str
+ ) -> Iterator[None]:
+ if self.check(open_token):
+ open_position = self.position
+ self.read()
+ else:
+ open_position = None
+
+ yield
+
+ if open_position is None:
+ return
+
+ if not self.check(close_token):
+ self.raise_syntax_error(
+ f"Expected matching {close_token} for {open_token}, after {around}",
+ span_start=open_position,
+ )
+
+ self.read()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/markers.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/markers.py
new file mode 100644
index 000000000..7ac7bb69a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/markers.py
@@ -0,0 +1,325 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+
+from __future__ import annotations
+
+import operator
+import os
+import platform
+import sys
+from typing import Any, Callable, TypedDict, cast
+
+from ._parser import MarkerAtom, MarkerList, Op, Value, Variable
+from ._parser import parse_marker as _parse_marker
+from ._tokenizer import ParserSyntaxError
+from .specifiers import InvalidSpecifier, Specifier
+from .utils import canonicalize_name
+
+__all__ = [
+ "InvalidMarker",
+ "UndefinedComparison",
+ "UndefinedEnvironmentName",
+ "Marker",
+ "default_environment",
+]
+
+Operator = Callable[[str, str], bool]
+
+
+class InvalidMarker(ValueError):
+ """
+ An invalid marker was found, users should refer to PEP 508.
+ """
+
+
+class UndefinedComparison(ValueError):
+ """
+ An invalid operation was attempted on a value that doesn't support it.
+ """
+
+
+class UndefinedEnvironmentName(ValueError):
+ """
+ A name was attempted to be used that does not exist inside of the
+ environment.
+ """
+
+
+class Environment(TypedDict):
+ implementation_name: str
+ """The implementation's identifier, e.g. ``'cpython'``."""
+
+ implementation_version: str
+ """
+ The implementation's version, e.g. ``'3.13.0a2'`` for CPython 3.13.0a2, or
+ ``'7.3.13'`` for PyPy3.10 v7.3.13.
+ """
+
+ os_name: str
+ """
+ The value of :py:data:`os.name`. The name of the operating system dependent module
+ imported, e.g. ``'posix'``.
+ """
+
+ platform_machine: str
+ """
+ Returns the machine type, e.g. ``'i386'``.
+
+ An empty string if the value cannot be determined.
+ """
+
+ platform_release: str
+ """
+ The system's release, e.g. ``'2.2.0'`` or ``'NT'``.
+
+ An empty string if the value cannot be determined.
+ """
+
+ platform_system: str
+ """
+ The system/OS name, e.g. ``'Linux'``, ``'Windows'`` or ``'Java'``.
+
+ An empty string if the value cannot be determined.
+ """
+
+ platform_version: str
+ """
+ The system's release version, e.g. ``'#3 on degas'``.
+
+ An empty string if the value cannot be determined.
+ """
+
+ python_full_version: str
+ """
+ The Python version as string ``'major.minor.patchlevel'``.
+
+ Note that unlike the Python :py:data:`sys.version`, this value will always include
+ the patchlevel (it defaults to 0).
+ """
+
+ platform_python_implementation: str
+ """
+ A string identifying the Python implementation, e.g. ``'CPython'``.
+ """
+
+ python_version: str
+ """The Python version as string ``'major.minor'``."""
+
+ sys_platform: str
+ """
+ This string contains a platform identifier that can be used to append
+ platform-specific components to :py:data:`sys.path`, for instance.
+
+ For Unix systems, except on Linux and AIX, this is the lowercased OS name as
+ returned by ``uname -s`` with the first part of the version as returned by
+ ``uname -r`` appended, e.g. ``'sunos5'`` or ``'freebsd8'``, at the time when Python
+ was built.
+ """
+
+
+def _normalize_extra_values(results: Any) -> Any:
+ """
+ Normalize extra values.
+ """
+ if isinstance(results[0], tuple):
+ lhs, op, rhs = results[0]
+ if isinstance(lhs, Variable) and lhs.value == "extra":
+ normalized_extra = canonicalize_name(rhs.value)
+ rhs = Value(normalized_extra)
+ elif isinstance(rhs, Variable) and rhs.value == "extra":
+ normalized_extra = canonicalize_name(lhs.value)
+ lhs = Value(normalized_extra)
+ results[0] = lhs, op, rhs
+ return results
+
+
+def _format_marker(
+ marker: list[str] | MarkerAtom | str, first: bool | None = True
+) -> str:
+ assert isinstance(marker, (list, tuple, str))
+
+ # Sometimes we have a structure like [[...]] which is a single item list
+ # where the single item is itself it's own list. In that case we want skip
+ # the rest of this function so that we don't get extraneous () on the
+ # outside.
+ if (
+ isinstance(marker, list)
+ and len(marker) == 1
+ and isinstance(marker[0], (list, tuple))
+ ):
+ return _format_marker(marker[0])
+
+ if isinstance(marker, list):
+ inner = (_format_marker(m, first=False) for m in marker)
+ if first:
+ return " ".join(inner)
+ else:
+ return "(" + " ".join(inner) + ")"
+ elif isinstance(marker, tuple):
+ return " ".join([m.serialize() for m in marker])
+ else:
+ return marker
+
+
+_operators: dict[str, Operator] = {
+ "in": lambda lhs, rhs: lhs in rhs,
+ "not in": lambda lhs, rhs: lhs not in rhs,
+ "<": operator.lt,
+ "<=": operator.le,
+ "==": operator.eq,
+ "!=": operator.ne,
+ ">=": operator.ge,
+ ">": operator.gt,
+}
+
+
+def _eval_op(lhs: str, op: Op, rhs: str) -> bool:
+ try:
+ spec = Specifier("".join([op.serialize(), rhs]))
+ except InvalidSpecifier:
+ pass
+ else:
+ return spec.contains(lhs, prereleases=True)
+
+ oper: Operator | None = _operators.get(op.serialize())
+ if oper is None:
+ raise UndefinedComparison(f"Undefined {op!r} on {lhs!r} and {rhs!r}.")
+
+ return oper(lhs, rhs)
+
+
+def _normalize(*values: str, key: str) -> tuple[str, ...]:
+ # PEP 685 – Comparison of extra names for optional distribution dependencies
+ # https://peps.python.org/pep-0685/
+ # > When comparing extra names, tools MUST normalize the names being
+ # > compared using the semantics outlined in PEP 503 for names
+ if key == "extra":
+ return tuple(canonicalize_name(v) for v in values)
+
+ # other environment markers don't have such standards
+ return values
+
+
+def _evaluate_markers(markers: MarkerList, environment: dict[str, str]) -> bool:
+ groups: list[list[bool]] = [[]]
+
+ for marker in markers:
+ assert isinstance(marker, (list, tuple, str))
+
+ if isinstance(marker, list):
+ groups[-1].append(_evaluate_markers(marker, environment))
+ elif isinstance(marker, tuple):
+ lhs, op, rhs = marker
+
+ if isinstance(lhs, Variable):
+ environment_key = lhs.value
+ lhs_value = environment[environment_key]
+ rhs_value = rhs.value
+ else:
+ lhs_value = lhs.value
+ environment_key = rhs.value
+ rhs_value = environment[environment_key]
+
+ lhs_value, rhs_value = _normalize(lhs_value, rhs_value, key=environment_key)
+ groups[-1].append(_eval_op(lhs_value, op, rhs_value))
+ else:
+ assert marker in ["and", "or"]
+ if marker == "or":
+ groups.append([])
+
+ return any(all(item) for item in groups)
+
+
+def format_full_version(info: sys._version_info) -> str:
+ version = "{0.major}.{0.minor}.{0.micro}".format(info)
+ kind = info.releaselevel
+ if kind != "final":
+ version += kind[0] + str(info.serial)
+ return version
+
+
+def default_environment() -> Environment:
+ iver = format_full_version(sys.implementation.version)
+ implementation_name = sys.implementation.name
+ return {
+ "implementation_name": implementation_name,
+ "implementation_version": iver,
+ "os_name": os.name,
+ "platform_machine": platform.machine(),
+ "platform_release": platform.release(),
+ "platform_system": platform.system(),
+ "platform_version": platform.version(),
+ "python_full_version": platform.python_version(),
+ "platform_python_implementation": platform.python_implementation(),
+ "python_version": ".".join(platform.python_version_tuple()[:2]),
+ "sys_platform": sys.platform,
+ }
+
+
+class Marker:
+ def __init__(self, marker: str) -> None:
+ # Note: We create a Marker object without calling this constructor in
+ # packaging.requirements.Requirement. If any additional logic is
+ # added here, make sure to mirror/adapt Requirement.
+ try:
+ self._markers = _normalize_extra_values(_parse_marker(marker))
+ # The attribute `_markers` can be described in terms of a recursive type:
+ # MarkerList = List[Union[Tuple[Node, ...], str, MarkerList]]
+ #
+ # For example, the following expression:
+ # python_version > "3.6" or (python_version == "3.6" and os_name == "unix")
+ #
+ # is parsed into:
+ # [
+ # (<Variable('python_version')>, <Op('>')>, <Value('3.6')>),
+ # 'and',
+ # [
+ # (<Variable('python_version')>, <Op('==')>, <Value('3.6')>),
+ # 'or',
+ # (<Variable('os_name')>, <Op('==')>, <Value('unix')>)
+ # ]
+ # ]
+ except ParserSyntaxError as e:
+ raise InvalidMarker(str(e)) from e
+
+ def __str__(self) -> str:
+ return _format_marker(self._markers)
+
+ def __repr__(self) -> str:
+ return f"<Marker('{self}')>"
+
+ def __hash__(self) -> int:
+ return hash((self.__class__.__name__, str(self)))
+
+ def __eq__(self, other: Any) -> bool:
+ if not isinstance(other, Marker):
+ return NotImplemented
+
+ return str(self) == str(other)
+
+ def evaluate(self, environment: dict[str, str] | None = None) -> bool:
+ """Evaluate a marker.
+
+ Return the boolean from evaluating the given marker against the
+ environment. environment is an optional argument to override all or
+ part of the determined environment.
+
+ The environment is determined from the current Python process.
+ """
+ current_environment = cast("dict[str, str]", default_environment())
+ current_environment["extra"] = ""
+ # Work around platform.python_version() returning something that is not PEP 440
+ # compliant for non-tagged Python builds. We preserve default_environment()'s
+ # behavior of returning platform.python_version() verbatim, and leave it to the
+ # caller to provide a syntactically valid version if they want to override it.
+ if current_environment["python_full_version"].endswith("+"):
+ current_environment["python_full_version"] += "local"
+ if environment is not None:
+ current_environment.update(environment)
+ # The API used to allow setting extra to None. We need to handle this
+ # case for backwards compatibility.
+ if current_environment["extra"] is None:
+ current_environment["extra"] = ""
+
+ return _evaluate_markers(self._markers, current_environment)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/metadata.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/metadata.py
new file mode 100644
index 000000000..eb8dc844d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/metadata.py
@@ -0,0 +1,804 @@
+from __future__ import annotations
+
+import email.feedparser
+import email.header
+import email.message
+import email.parser
+import email.policy
+import typing
+from typing import (
+ Any,
+ Callable,
+ Generic,
+ Literal,
+ TypedDict,
+ cast,
+)
+
+from . import requirements, specifiers, utils
+from . import version as version_module
+
+T = typing.TypeVar("T")
+
+
+try:
+ ExceptionGroup
+except NameError: # pragma: no cover
+
+ class ExceptionGroup(Exception):
+ """A minimal implementation of :external:exc:`ExceptionGroup` from Python 3.11.
+
+ If :external:exc:`ExceptionGroup` is already defined by Python itself,
+ that version is used instead.
+ """
+
+ message: str
+ exceptions: list[Exception]
+
+ def __init__(self, message: str, exceptions: list[Exception]) -> None:
+ self.message = message
+ self.exceptions = exceptions
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}({self.message!r}, {self.exceptions!r})"
+
+else: # pragma: no cover
+ ExceptionGroup = ExceptionGroup
+
+
+class InvalidMetadata(ValueError):
+ """A metadata field contains invalid data."""
+
+ field: str
+ """The name of the field that contains invalid data."""
+
+ def __init__(self, field: str, message: str) -> None:
+ self.field = field
+ super().__init__(message)
+
+
+# The RawMetadata class attempts to make as few assumptions about the underlying
+# serialization formats as possible. The idea is that as long as a serialization
+# formats offer some very basic primitives in *some* way then we can support
+# serializing to and from that format.
+class RawMetadata(TypedDict, total=False):
+ """A dictionary of raw core metadata.
+
+ Each field in core metadata maps to a key of this dictionary (when data is
+ provided). The key is lower-case and underscores are used instead of dashes
+ compared to the equivalent core metadata field. Any core metadata field that
+ can be specified multiple times or can hold multiple values in a single
+ field have a key with a plural name. See :class:`Metadata` whose attributes
+ match the keys of this dictionary.
+
+ Core metadata fields that can be specified multiple times are stored as a
+ list or dict depending on which is appropriate for the field. Any fields
+ which hold multiple values in a single field are stored as a list.
+
+ """
+
+ # Metadata 1.0 - PEP 241
+ metadata_version: str
+ name: str
+ version: str
+ platforms: list[str]
+ summary: str
+ description: str
+ keywords: list[str]
+ home_page: str
+ author: str
+ author_email: str
+ license: str
+
+ # Metadata 1.1 - PEP 314
+ supported_platforms: list[str]
+ download_url: str
+ classifiers: list[str]
+ requires: list[str]
+ provides: list[str]
+ obsoletes: list[str]
+
+ # Metadata 1.2 - PEP 345
+ maintainer: str
+ maintainer_email: str
+ requires_dist: list[str]
+ provides_dist: list[str]
+ obsoletes_dist: list[str]
+ requires_python: str
+ requires_external: list[str]
+ project_urls: dict[str, str]
+
+ # Metadata 2.0
+ # PEP 426 attempted to completely revamp the metadata format
+ # but got stuck without ever being able to build consensus on
+ # it and ultimately ended up withdrawn.
+ #
+ # However, a number of tools had started emitting METADATA with
+ # `2.0` Metadata-Version, so for historical reasons, this version
+ # was skipped.
+
+ # Metadata 2.1 - PEP 566
+ description_content_type: str
+ provides_extra: list[str]
+
+ # Metadata 2.2 - PEP 643
+ dynamic: list[str]
+
+ # Metadata 2.3 - PEP 685
+ # No new fields were added in PEP 685, just some edge case were
+ # tightened up to provide better interoptability.
+
+
+_STRING_FIELDS = {
+ "author",
+ "author_email",
+ "description",
+ "description_content_type",
+ "download_url",
+ "home_page",
+ "license",
+ "maintainer",
+ "maintainer_email",
+ "metadata_version",
+ "name",
+ "requires_python",
+ "summary",
+ "version",
+}
+
+_LIST_FIELDS = {
+ "classifiers",
+ "dynamic",
+ "obsoletes",
+ "obsoletes_dist",
+ "platforms",
+ "provides",
+ "provides_dist",
+ "provides_extra",
+ "requires",
+ "requires_dist",
+ "requires_external",
+ "supported_platforms",
+}
+
+_DICT_FIELDS = {
+ "project_urls",
+}
+
+
+def _parse_keywords(data: str) -> list[str]:
+ """Split a string of comma-separate keyboards into a list of keywords."""
+ return [k.strip() for k in data.split(",")]
+
+
+def _parse_project_urls(data: list[str]) -> dict[str, str]:
+ """Parse a list of label/URL string pairings separated by a comma."""
+ urls = {}
+ for pair in data:
+ # Our logic is slightly tricky here as we want to try and do
+ # *something* reasonable with malformed data.
+ #
+ # The main thing that we have to worry about, is data that does
+ # not have a ',' at all to split the label from the Value. There
+ # isn't a singular right answer here, and we will fail validation
+ # later on (if the caller is validating) so it doesn't *really*
+ # matter, but since the missing value has to be an empty str
+ # and our return value is dict[str, str], if we let the key
+ # be the missing value, then they'd have multiple '' values that
+ # overwrite each other in a accumulating dict.
+ #
+ # The other potentional issue is that it's possible to have the
+ # same label multiple times in the metadata, with no solid "right"
+ # answer with what to do in that case. As such, we'll do the only
+ # thing we can, which is treat the field as unparseable and add it
+ # to our list of unparsed fields.
+ parts = [p.strip() for p in pair.split(",", 1)]
+ parts.extend([""] * (max(0, 2 - len(parts)))) # Ensure 2 items
+
+ # TODO: The spec doesn't say anything about if the keys should be
+ # considered case sensitive or not... logically they should
+ # be case-preserving and case-insensitive, but doing that
+ # would open up more cases where we might have duplicate
+ # entries.
+ label, url = parts
+ if label in urls:
+ # The label already exists in our set of urls, so this field
+ # is unparseable, and we can just add the whole thing to our
+ # unparseable data and stop processing it.
+ raise KeyError("duplicate labels in project urls")
+ urls[label] = url
+
+ return urls
+
+
+def _get_payload(msg: email.message.Message, source: bytes | str) -> str:
+ """Get the body of the message."""
+ # If our source is a str, then our caller has managed encodings for us,
+ # and we don't need to deal with it.
+ if isinstance(source, str):
+ payload: str = msg.get_payload()
+ return payload
+ # If our source is a bytes, then we're managing the encoding and we need
+ # to deal with it.
+ else:
+ bpayload: bytes = msg.get_payload(decode=True)
+ try:
+ return bpayload.decode("utf8", "strict")
+ except UnicodeDecodeError:
+ raise ValueError("payload in an invalid encoding")
+
+
+# The various parse_FORMAT functions here are intended to be as lenient as
+# possible in their parsing, while still returning a correctly typed
+# RawMetadata.
+#
+# To aid in this, we also generally want to do as little touching of the
+# data as possible, except where there are possibly some historic holdovers
+# that make valid data awkward to work with.
+#
+# While this is a lower level, intermediate format than our ``Metadata``
+# class, some light touch ups can make a massive difference in usability.
+
+# Map METADATA fields to RawMetadata.
+_EMAIL_TO_RAW_MAPPING = {
+ "author": "author",
+ "author-email": "author_email",
+ "classifier": "classifiers",
+ "description": "description",
+ "description-content-type": "description_content_type",
+ "download-url": "download_url",
+ "dynamic": "dynamic",
+ "home-page": "home_page",
+ "keywords": "keywords",
+ "license": "license",
+ "maintainer": "maintainer",
+ "maintainer-email": "maintainer_email",
+ "metadata-version": "metadata_version",
+ "name": "name",
+ "obsoletes": "obsoletes",
+ "obsoletes-dist": "obsoletes_dist",
+ "platform": "platforms",
+ "project-url": "project_urls",
+ "provides": "provides",
+ "provides-dist": "provides_dist",
+ "provides-extra": "provides_extra",
+ "requires": "requires",
+ "requires-dist": "requires_dist",
+ "requires-external": "requires_external",
+ "requires-python": "requires_python",
+ "summary": "summary",
+ "supported-platform": "supported_platforms",
+ "version": "version",
+}
+_RAW_TO_EMAIL_MAPPING = {raw: email for email, raw in _EMAIL_TO_RAW_MAPPING.items()}
+
+
+def parse_email(data: bytes | str) -> tuple[RawMetadata, dict[str, list[str]]]:
+ """Parse a distribution's metadata stored as email headers (e.g. from ``METADATA``).
+
+ This function returns a two-item tuple of dicts. The first dict is of
+ recognized fields from the core metadata specification. Fields that can be
+ parsed and translated into Python's built-in types are converted
+ appropriately. All other fields are left as-is. Fields that are allowed to
+ appear multiple times are stored as lists.
+
+ The second dict contains all other fields from the metadata. This includes
+ any unrecognized fields. It also includes any fields which are expected to
+ be parsed into a built-in type but were not formatted appropriately. Finally,
+ any fields that are expected to appear only once but are repeated are
+ included in this dict.
+
+ """
+ raw: dict[str, str | list[str] | dict[str, str]] = {}
+ unparsed: dict[str, list[str]] = {}
+
+ if isinstance(data, str):
+ parsed = email.parser.Parser(policy=email.policy.compat32).parsestr(data)
+ else:
+ parsed = email.parser.BytesParser(policy=email.policy.compat32).parsebytes(data)
+
+ # We have to wrap parsed.keys() in a set, because in the case of multiple
+ # values for a key (a list), the key will appear multiple times in the
+ # list of keys, but we're avoiding that by using get_all().
+ for name in frozenset(parsed.keys()):
+ # Header names in RFC are case insensitive, so we'll normalize to all
+ # lower case to make comparisons easier.
+ name = name.lower()
+
+ # We use get_all() here, even for fields that aren't multiple use,
+ # because otherwise someone could have e.g. two Name fields, and we
+ # would just silently ignore it rather than doing something about it.
+ headers = parsed.get_all(name) or []
+
+ # The way the email module works when parsing bytes is that it
+ # unconditionally decodes the bytes as ascii using the surrogateescape
+ # handler. When you pull that data back out (such as with get_all() ),
+ # it looks to see if the str has any surrogate escapes, and if it does
+ # it wraps it in a Header object instead of returning the string.
+ #
+ # As such, we'll look for those Header objects, and fix up the encoding.
+ value = []
+ # Flag if we have run into any issues processing the headers, thus
+ # signalling that the data belongs in 'unparsed'.
+ valid_encoding = True
+ for h in headers:
+ # It's unclear if this can return more types than just a Header or
+ # a str, so we'll just assert here to make sure.
+ assert isinstance(h, (email.header.Header, str))
+
+ # If it's a header object, we need to do our little dance to get
+ # the real data out of it. In cases where there is invalid data
+ # we're going to end up with mojibake, but there's no obvious, good
+ # way around that without reimplementing parts of the Header object
+ # ourselves.
+ #
+ # That should be fine since, if mojibacked happens, this key is
+ # going into the unparsed dict anyways.
+ if isinstance(h, email.header.Header):
+ # The Header object stores it's data as chunks, and each chunk
+ # can be independently encoded, so we'll need to check each
+ # of them.
+ chunks: list[tuple[bytes, str | None]] = []
+ for bin, encoding in email.header.decode_header(h):
+ try:
+ bin.decode("utf8", "strict")
+ except UnicodeDecodeError:
+ # Enable mojibake.
+ encoding = "latin1"
+ valid_encoding = False
+ else:
+ encoding = "utf8"
+ chunks.append((bin, encoding))
+
+ # Turn our chunks back into a Header object, then let that
+ # Header object do the right thing to turn them into a
+ # string for us.
+ value.append(str(email.header.make_header(chunks)))
+ # This is already a string, so just add it.
+ else:
+ value.append(h)
+
+ # We've processed all of our values to get them into a list of str,
+ # but we may have mojibake data, in which case this is an unparsed
+ # field.
+ if not valid_encoding:
+ unparsed[name] = value
+ continue
+
+ raw_name = _EMAIL_TO_RAW_MAPPING.get(name)
+ if raw_name is None:
+ # This is a bit of a weird situation, we've encountered a key that
+ # we don't know what it means, so we don't know whether it's meant
+ # to be a list or not.
+ #
+ # Since we can't really tell one way or another, we'll just leave it
+ # as a list, even though it may be a single item list, because that's
+ # what makes the most sense for email headers.
+ unparsed[name] = value
+ continue
+
+ # If this is one of our string fields, then we'll check to see if our
+ # value is a list of a single item. If it is then we'll assume that
+ # it was emitted as a single string, and unwrap the str from inside
+ # the list.
+ #
+ # If it's any other kind of data, then we haven't the faintest clue
+ # what we should parse it as, and we have to just add it to our list
+ # of unparsed stuff.
+ if raw_name in _STRING_FIELDS and len(value) == 1:
+ raw[raw_name] = value[0]
+ # If this is one of our list of string fields, then we can just assign
+ # the value, since email *only* has strings, and our get_all() call
+ # above ensures that this is a list.
+ elif raw_name in _LIST_FIELDS:
+ raw[raw_name] = value
+ # Special Case: Keywords
+ # The keywords field is implemented in the metadata spec as a str,
+ # but it conceptually is a list of strings, and is serialized using
+ # ", ".join(keywords), so we'll do some light data massaging to turn
+ # this into what it logically is.
+ elif raw_name == "keywords" and len(value) == 1:
+ raw[raw_name] = _parse_keywords(value[0])
+ # Special Case: Project-URL
+ # The project urls is implemented in the metadata spec as a list of
+ # specially-formatted strings that represent a key and a value, which
+ # is fundamentally a mapping, however the email format doesn't support
+ # mappings in a sane way, so it was crammed into a list of strings
+ # instead.
+ #
+ # We will do a little light data massaging to turn this into a map as
+ # it logically should be.
+ elif raw_name == "project_urls":
+ try:
+ raw[raw_name] = _parse_project_urls(value)
+ except KeyError:
+ unparsed[name] = value
+ # Nothing that we've done has managed to parse this, so it'll just
+ # throw it in our unparseable data and move on.
+ else:
+ unparsed[name] = value
+
+ # We need to support getting the Description from the message payload in
+ # addition to getting it from the the headers. This does mean, though, there
+ # is the possibility of it being set both ways, in which case we put both
+ # in 'unparsed' since we don't know which is right.
+ try:
+ payload = _get_payload(parsed, data)
+ except ValueError:
+ unparsed.setdefault("description", []).append(
+ parsed.get_payload(decode=isinstance(data, bytes))
+ )
+ else:
+ if payload:
+ # Check to see if we've already got a description, if so then both
+ # it, and this body move to unparseable.
+ if "description" in raw:
+ description_header = cast(str, raw.pop("description"))
+ unparsed.setdefault("description", []).extend(
+ [description_header, payload]
+ )
+ elif "description" in unparsed:
+ unparsed["description"].append(payload)
+ else:
+ raw["description"] = payload
+
+ # We need to cast our `raw` to a metadata, because a TypedDict only support
+ # literal key names, but we're computing our key names on purpose, but the
+ # way this function is implemented, our `TypedDict` can only have valid key
+ # names.
+ return cast(RawMetadata, raw), unparsed
+
+
+_NOT_FOUND = object()
+
+
+# Keep the two values in sync.
+_VALID_METADATA_VERSIONS = ["1.0", "1.1", "1.2", "2.1", "2.2", "2.3"]
+_MetadataVersion = Literal["1.0", "1.1", "1.2", "2.1", "2.2", "2.3"]
+
+_REQUIRED_ATTRS = frozenset(["metadata_version", "name", "version"])
+
+
+class _Validator(Generic[T]):
+ """Validate a metadata field.
+
+ All _process_*() methods correspond to a core metadata field. The method is
+ called with the field's raw value. If the raw value is valid it is returned
+ in its "enriched" form (e.g. ``version.Version`` for the ``Version`` field).
+ If the raw value is invalid, :exc:`InvalidMetadata` is raised (with a cause
+ as appropriate).
+ """
+
+ name: str
+ raw_name: str
+ added: _MetadataVersion
+
+ def __init__(
+ self,
+ *,
+ added: _MetadataVersion = "1.0",
+ ) -> None:
+ self.added = added
+
+ def __set_name__(self, _owner: Metadata, name: str) -> None:
+ self.name = name
+ self.raw_name = _RAW_TO_EMAIL_MAPPING[name]
+
+ def __get__(self, instance: Metadata, _owner: type[Metadata]) -> T:
+ # With Python 3.8, the caching can be replaced with functools.cached_property().
+ # No need to check the cache as attribute lookup will resolve into the
+ # instance's __dict__ before __get__ is called.
+ cache = instance.__dict__
+ value = instance._raw.get(self.name)
+
+ # To make the _process_* methods easier, we'll check if the value is None
+ # and if this field is NOT a required attribute, and if both of those
+ # things are true, we'll skip the the converter. This will mean that the
+ # converters never have to deal with the None union.
+ if self.name in _REQUIRED_ATTRS or value is not None:
+ try:
+ converter: Callable[[Any], T] = getattr(self, f"_process_{self.name}")
+ except AttributeError:
+ pass
+ else:
+ value = converter(value)
+
+ cache[self.name] = value
+ try:
+ del instance._raw[self.name] # type: ignore[misc]
+ except KeyError:
+ pass
+
+ return cast(T, value)
+
+ def _invalid_metadata(
+ self, msg: str, cause: Exception | None = None
+ ) -> InvalidMetadata:
+ exc = InvalidMetadata(
+ self.raw_name, msg.format_map({"field": repr(self.raw_name)})
+ )
+ exc.__cause__ = cause
+ return exc
+
+ def _process_metadata_version(self, value: str) -> _MetadataVersion:
+ # Implicitly makes Metadata-Version required.
+ if value not in _VALID_METADATA_VERSIONS:
+ raise self._invalid_metadata(f"{value!r} is not a valid metadata version")
+ return cast(_MetadataVersion, value)
+
+ def _process_name(self, value: str) -> str:
+ if not value:
+ raise self._invalid_metadata("{field} is a required field")
+ # Validate the name as a side-effect.
+ try:
+ utils.canonicalize_name(value, validate=True)
+ except utils.InvalidName as exc:
+ raise self._invalid_metadata(
+ f"{value!r} is invalid for {{field}}", cause=exc
+ )
+ else:
+ return value
+
+ def _process_version(self, value: str) -> version_module.Version:
+ if not value:
+ raise self._invalid_metadata("{field} is a required field")
+ try:
+ return version_module.parse(value)
+ except version_module.InvalidVersion as exc:
+ raise self._invalid_metadata(
+ f"{value!r} is invalid for {{field}}", cause=exc
+ )
+
+ def _process_summary(self, value: str) -> str:
+ """Check the field contains no newlines."""
+ if "\n" in value:
+ raise self._invalid_metadata("{field} must be a single line")
+ return value
+
+ def _process_description_content_type(self, value: str) -> str:
+ content_types = {"text/plain", "text/x-rst", "text/markdown"}
+ message = email.message.EmailMessage()
+ message["content-type"] = value
+
+ content_type, parameters = (
+ # Defaults to `text/plain` if parsing failed.
+ message.get_content_type().lower(),
+ message["content-type"].params,
+ )
+ # Check if content-type is valid or defaulted to `text/plain` and thus was
+ # not parseable.
+ if content_type not in content_types or content_type not in value.lower():
+ raise self._invalid_metadata(
+ f"{{field}} must be one of {list(content_types)}, not {value!r}"
+ )
+
+ charset = parameters.get("charset", "UTF-8")
+ if charset != "UTF-8":
+ raise self._invalid_metadata(
+ f"{{field}} can only specify the UTF-8 charset, not {list(charset)}"
+ )
+
+ markdown_variants = {"GFM", "CommonMark"}
+ variant = parameters.get("variant", "GFM") # Use an acceptable default.
+ if content_type == "text/markdown" and variant not in markdown_variants:
+ raise self._invalid_metadata(
+ f"valid Markdown variants for {{field}} are {list(markdown_variants)}, "
+ f"not {variant!r}",
+ )
+ return value
+
+ def _process_dynamic(self, value: list[str]) -> list[str]:
+ for dynamic_field in map(str.lower, value):
+ if dynamic_field in {"name", "version", "metadata-version"}:
+ raise self._invalid_metadata(
+ f"{value!r} is not allowed as a dynamic field"
+ )
+ elif dynamic_field not in _EMAIL_TO_RAW_MAPPING:
+ raise self._invalid_metadata(f"{value!r} is not a valid dynamic field")
+ return list(map(str.lower, value))
+
+ def _process_provides_extra(
+ self,
+ value: list[str],
+ ) -> list[utils.NormalizedName]:
+ normalized_names = []
+ try:
+ for name in value:
+ normalized_names.append(utils.canonicalize_name(name, validate=True))
+ except utils.InvalidName as exc:
+ raise self._invalid_metadata(
+ f"{name!r} is invalid for {{field}}", cause=exc
+ )
+ else:
+ return normalized_names
+
+ def _process_requires_python(self, value: str) -> specifiers.SpecifierSet:
+ try:
+ return specifiers.SpecifierSet(value)
+ except specifiers.InvalidSpecifier as exc:
+ raise self._invalid_metadata(
+ f"{value!r} is invalid for {{field}}", cause=exc
+ )
+
+ def _process_requires_dist(
+ self,
+ value: list[str],
+ ) -> list[requirements.Requirement]:
+ reqs = []
+ try:
+ for req in value:
+ reqs.append(requirements.Requirement(req))
+ except requirements.InvalidRequirement as exc:
+ raise self._invalid_metadata(f"{req!r} is invalid for {{field}}", cause=exc)
+ else:
+ return reqs
+
+
+class Metadata:
+ """Representation of distribution metadata.
+
+ Compared to :class:`RawMetadata`, this class provides objects representing
+ metadata fields instead of only using built-in types. Any invalid metadata
+ will cause :exc:`InvalidMetadata` to be raised (with a
+ :py:attr:`~BaseException.__cause__` attribute as appropriate).
+ """
+
+ _raw: RawMetadata
+
+ @classmethod
+ def from_raw(cls, data: RawMetadata, *, validate: bool = True) -> Metadata:
+ """Create an instance from :class:`RawMetadata`.
+
+ If *validate* is true, all metadata will be validated. All exceptions
+ related to validation will be gathered and raised as an :class:`ExceptionGroup`.
+ """
+ ins = cls()
+ ins._raw = data.copy() # Mutations occur due to caching enriched values.
+
+ if validate:
+ exceptions: list[Exception] = []
+ try:
+ metadata_version = ins.metadata_version
+ metadata_age = _VALID_METADATA_VERSIONS.index(metadata_version)
+ except InvalidMetadata as metadata_version_exc:
+ exceptions.append(metadata_version_exc)
+ metadata_version = None
+
+ # Make sure to check for the fields that are present, the required
+ # fields (so their absence can be reported).
+ fields_to_check = frozenset(ins._raw) | _REQUIRED_ATTRS
+ # Remove fields that have already been checked.
+ fields_to_check -= {"metadata_version"}
+
+ for key in fields_to_check:
+ try:
+ if metadata_version:
+ # Can't use getattr() as that triggers descriptor protocol which
+ # will fail due to no value for the instance argument.
+ try:
+ field_metadata_version = cls.__dict__[key].added
+ except KeyError:
+ exc = InvalidMetadata(key, f"unrecognized field: {key!r}")
+ exceptions.append(exc)
+ continue
+ field_age = _VALID_METADATA_VERSIONS.index(
+ field_metadata_version
+ )
+ if field_age > metadata_age:
+ field = _RAW_TO_EMAIL_MAPPING[key]
+ exc = InvalidMetadata(
+ field,
+ "{field} introduced in metadata version "
+ "{field_metadata_version}, not {metadata_version}",
+ )
+ exceptions.append(exc)
+ continue
+ getattr(ins, key)
+ except InvalidMetadata as exc:
+ exceptions.append(exc)
+
+ if exceptions:
+ raise ExceptionGroup("invalid metadata", exceptions)
+
+ return ins
+
+ @classmethod
+ def from_email(cls, data: bytes | str, *, validate: bool = True) -> Metadata:
+ """Parse metadata from email headers.
+
+ If *validate* is true, the metadata will be validated. All exceptions
+ related to validation will be gathered and raised as an :class:`ExceptionGroup`.
+ """
+ raw, unparsed = parse_email(data)
+
+ if validate:
+ exceptions: list[Exception] = []
+ for unparsed_key in unparsed:
+ if unparsed_key in _EMAIL_TO_RAW_MAPPING:
+ message = f"{unparsed_key!r} has invalid data"
+ else:
+ message = f"unrecognized field: {unparsed_key!r}"
+ exceptions.append(InvalidMetadata(unparsed_key, message))
+
+ if exceptions:
+ raise ExceptionGroup("unparsed", exceptions)
+
+ try:
+ return cls.from_raw(raw, validate=validate)
+ except ExceptionGroup as exc_group:
+ raise ExceptionGroup(
+ "invalid or unparsed metadata", exc_group.exceptions
+ ) from None
+
+ metadata_version: _Validator[_MetadataVersion] = _Validator()
+ """:external:ref:`core-metadata-metadata-version`
+ (required; validated to be a valid metadata version)"""
+ name: _Validator[str] = _Validator()
+ """:external:ref:`core-metadata-name`
+ (required; validated using :func:`~packaging.utils.canonicalize_name` and its
+ *validate* parameter)"""
+ version: _Validator[version_module.Version] = _Validator()
+ """:external:ref:`core-metadata-version` (required)"""
+ dynamic: _Validator[list[str] | None] = _Validator(
+ added="2.2",
+ )
+ """:external:ref:`core-metadata-dynamic`
+ (validated against core metadata field names and lowercased)"""
+ platforms: _Validator[list[str] | None] = _Validator()
+ """:external:ref:`core-metadata-platform`"""
+ supported_platforms: _Validator[list[str] | None] = _Validator(added="1.1")
+ """:external:ref:`core-metadata-supported-platform`"""
+ summary: _Validator[str | None] = _Validator()
+ """:external:ref:`core-metadata-summary` (validated to contain no newlines)"""
+ description: _Validator[str | None] = _Validator() # TODO 2.1: can be in body
+ """:external:ref:`core-metadata-description`"""
+ description_content_type: _Validator[str | None] = _Validator(added="2.1")
+ """:external:ref:`core-metadata-description-content-type` (validated)"""
+ keywords: _Validator[list[str] | None] = _Validator()
+ """:external:ref:`core-metadata-keywords`"""
+ home_page: _Validator[str | None] = _Validator()
+ """:external:ref:`core-metadata-home-page`"""
+ download_url: _Validator[str | None] = _Validator(added="1.1")
+ """:external:ref:`core-metadata-download-url`"""
+ author: _Validator[str | None] = _Validator()
+ """:external:ref:`core-metadata-author`"""
+ author_email: _Validator[str | None] = _Validator()
+ """:external:ref:`core-metadata-author-email`"""
+ maintainer: _Validator[str | None] = _Validator(added="1.2")
+ """:external:ref:`core-metadata-maintainer`"""
+ maintainer_email: _Validator[str | None] = _Validator(added="1.2")
+ """:external:ref:`core-metadata-maintainer-email`"""
+ license: _Validator[str | None] = _Validator()
+ """:external:ref:`core-metadata-license`"""
+ classifiers: _Validator[list[str] | None] = _Validator(added="1.1")
+ """:external:ref:`core-metadata-classifier`"""
+ requires_dist: _Validator[list[requirements.Requirement] | None] = _Validator(
+ added="1.2"
+ )
+ """:external:ref:`core-metadata-requires-dist`"""
+ requires_python: _Validator[specifiers.SpecifierSet | None] = _Validator(
+ added="1.2"
+ )
+ """:external:ref:`core-metadata-requires-python`"""
+ # Because `Requires-External` allows for non-PEP 440 version specifiers, we
+ # don't do any processing on the values.
+ requires_external: _Validator[list[str] | None] = _Validator(added="1.2")
+ """:external:ref:`core-metadata-requires-external`"""
+ project_urls: _Validator[dict[str, str] | None] = _Validator(added="1.2")
+ """:external:ref:`core-metadata-project-url`"""
+ # PEP 685 lets us raise an error if an extra doesn't pass `Name` validation
+ # regardless of metadata version.
+ provides_extra: _Validator[list[utils.NormalizedName] | None] = _Validator(
+ added="2.1",
+ )
+ """:external:ref:`core-metadata-provides-extra`"""
+ provides_dist: _Validator[list[str] | None] = _Validator(added="1.2")
+ """:external:ref:`core-metadata-provides-dist`"""
+ obsoletes_dist: _Validator[list[str] | None] = _Validator(added="1.2")
+ """:external:ref:`core-metadata-obsoletes-dist`"""
+ requires: _Validator[list[str] | None] = _Validator(added="1.1")
+ """``Requires`` (deprecated)"""
+ provides: _Validator[list[str] | None] = _Validator(added="1.1")
+ """``Provides`` (deprecated)"""
+ obsoletes: _Validator[list[str] | None] = _Validator(added="1.1")
+ """``Obsoletes`` (deprecated)"""
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/requirements.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/requirements.py
new file mode 100644
index 000000000..4e068c956
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/requirements.py
@@ -0,0 +1,91 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+from __future__ import annotations
+
+from typing import Any, Iterator
+
+from ._parser import parse_requirement as _parse_requirement
+from ._tokenizer import ParserSyntaxError
+from .markers import Marker, _normalize_extra_values
+from .specifiers import SpecifierSet
+from .utils import canonicalize_name
+
+
+class InvalidRequirement(ValueError):
+ """
+ An invalid requirement was found, users should refer to PEP 508.
+ """
+
+
+class Requirement:
+ """Parse a requirement.
+
+ Parse a given requirement string into its parts, such as name, specifier,
+ URL, and extras. Raises InvalidRequirement on a badly-formed requirement
+ string.
+ """
+
+ # TODO: Can we test whether something is contained within a requirement?
+ # If so how do we do that? Do we need to test against the _name_ of
+ # the thing as well as the version? What about the markers?
+ # TODO: Can we normalize the name and extra name?
+
+ def __init__(self, requirement_string: str) -> None:
+ try:
+ parsed = _parse_requirement(requirement_string)
+ except ParserSyntaxError as e:
+ raise InvalidRequirement(str(e)) from e
+
+ self.name: str = parsed.name
+ self.url: str | None = parsed.url or None
+ self.extras: set[str] = set(parsed.extras or [])
+ self.specifier: SpecifierSet = SpecifierSet(parsed.specifier)
+ self.marker: Marker | None = None
+ if parsed.marker is not None:
+ self.marker = Marker.__new__(Marker)
+ self.marker._markers = _normalize_extra_values(parsed.marker)
+
+ def _iter_parts(self, name: str) -> Iterator[str]:
+ yield name
+
+ if self.extras:
+ formatted_extras = ",".join(sorted(self.extras))
+ yield f"[{formatted_extras}]"
+
+ if self.specifier:
+ yield str(self.specifier)
+
+ if self.url:
+ yield f"@ {self.url}"
+ if self.marker:
+ yield " "
+
+ if self.marker:
+ yield f"; {self.marker}"
+
+ def __str__(self) -> str:
+ return "".join(self._iter_parts(self.name))
+
+ def __repr__(self) -> str:
+ return f"<Requirement('{self}')>"
+
+ def __hash__(self) -> int:
+ return hash(
+ (
+ self.__class__.__name__,
+ *self._iter_parts(canonicalize_name(self.name)),
+ )
+ )
+
+ def __eq__(self, other: Any) -> bool:
+ if not isinstance(other, Requirement):
+ return NotImplemented
+
+ return (
+ canonicalize_name(self.name) == canonicalize_name(other.name)
+ and self.extras == other.extras
+ and self.specifier == other.specifier
+ and self.url == other.url
+ and self.marker == other.marker
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/specifiers.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/specifiers.py
new file mode 100644
index 000000000..f3ac480fa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/specifiers.py
@@ -0,0 +1,1009 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+"""
+.. testsetup::
+
+ from pip._vendor.packaging.specifiers import Specifier, SpecifierSet, InvalidSpecifier
+ from pip._vendor.packaging.version import Version
+"""
+
+from __future__ import annotations
+
+import abc
+import itertools
+import re
+from typing import Callable, Iterable, Iterator, TypeVar, Union
+
+from .utils import canonicalize_version
+from .version import Version
+
+UnparsedVersion = Union[Version, str]
+UnparsedVersionVar = TypeVar("UnparsedVersionVar", bound=UnparsedVersion)
+CallableOperator = Callable[[Version, str], bool]
+
+
+def _coerce_version(version: UnparsedVersion) -> Version:
+ if not isinstance(version, Version):
+ version = Version(version)
+ return version
+
+
+class InvalidSpecifier(ValueError):
+ """
+ Raised when attempting to create a :class:`Specifier` with a specifier
+ string that is invalid.
+
+ >>> Specifier("lolwat")
+ Traceback (most recent call last):
+ ...
+ packaging.specifiers.InvalidSpecifier: Invalid specifier: 'lolwat'
+ """
+
+
+class BaseSpecifier(metaclass=abc.ABCMeta):
+ @abc.abstractmethod
+ def __str__(self) -> str:
+ """
+ Returns the str representation of this Specifier-like object. This
+ should be representative of the Specifier itself.
+ """
+
+ @abc.abstractmethod
+ def __hash__(self) -> int:
+ """
+ Returns a hash value for this Specifier-like object.
+ """
+
+ @abc.abstractmethod
+ def __eq__(self, other: object) -> bool:
+ """
+ Returns a boolean representing whether or not the two Specifier-like
+ objects are equal.
+
+ :param other: The other object to check against.
+ """
+
+ @property
+ @abc.abstractmethod
+ def prereleases(self) -> bool | None:
+ """Whether or not pre-releases as a whole are allowed.
+
+ This can be set to either ``True`` or ``False`` to explicitly enable or disable
+ prereleases or it can be set to ``None`` (the default) to use default semantics.
+ """
+
+ @prereleases.setter
+ def prereleases(self, value: bool) -> None:
+ """Setter for :attr:`prereleases`.
+
+ :param value: The value to set.
+ """
+
+ @abc.abstractmethod
+ def contains(self, item: str, prereleases: bool | None = None) -> bool:
+ """
+ Determines if the given item is contained within this specifier.
+ """
+
+ @abc.abstractmethod
+ def filter(
+ self, iterable: Iterable[UnparsedVersionVar], prereleases: bool | None = None
+ ) -> Iterator[UnparsedVersionVar]:
+ """
+ Takes an iterable of items and filters them so that only items which
+ are contained within this specifier are allowed in it.
+ """
+
+
+class Specifier(BaseSpecifier):
+ """This class abstracts handling of version specifiers.
+
+ .. tip::
+
+ It is generally not required to instantiate this manually. You should instead
+ prefer to work with :class:`SpecifierSet` instead, which can parse
+ comma-separated version specifiers (which is what package metadata contains).
+ """
+
+ _operator_regex_str = r"""
+ (?P<operator>(~=|==|!=|<=|>=|<|>|===))
+ """
+ _version_regex_str = r"""
+ (?P<version>
+ (?:
+ # The identity operators allow for an escape hatch that will
+ # do an exact string match of the version you wish to install.
+ # This will not be parsed by PEP 440 and we cannot determine
+ # any semantic meaning from it. This operator is discouraged
+ # but included entirely as an escape hatch.
+ (?<====) # Only match for the identity operator
+ \s*
+ [^\s;)]* # The arbitrary version can be just about anything,
+ # we match everything except for whitespace, a
+ # semi-colon for marker support, and a closing paren
+ # since versions can be enclosed in them.
+ )
+ |
+ (?:
+ # The (non)equality operators allow for wild card and local
+ # versions to be specified so we have to define these two
+ # operators separately to enable that.
+ (?<===|!=) # Only match for equals and not equals
+
+ \s*
+ v?
+ (?:[0-9]+!)? # epoch
+ [0-9]+(?:\.[0-9]+)* # release
+
+ # You cannot use a wild card and a pre-release, post-release, a dev or
+ # local version together so group them with a | and make them optional.
+ (?:
+ \.\* # Wild card syntax of .*
+ |
+ (?: # pre release
+ [-_\.]?
+ (alpha|beta|preview|pre|a|b|c|rc)
+ [-_\.]?
+ [0-9]*
+ )?
+ (?: # post release
+ (?:-[0-9]+)|(?:[-_\.]?(post|rev|r)[-_\.]?[0-9]*)
+ )?
+ (?:[-_\.]?dev[-_\.]?[0-9]*)? # dev release
+ (?:\+[a-z0-9]+(?:[-_\.][a-z0-9]+)*)? # local
+ )?
+ )
+ |
+ (?:
+ # The compatible operator requires at least two digits in the
+ # release segment.
+ (?<=~=) # Only match for the compatible operator
+
+ \s*
+ v?
+ (?:[0-9]+!)? # epoch
+ [0-9]+(?:\.[0-9]+)+ # release (We have a + instead of a *)
+ (?: # pre release
+ [-_\.]?
+ (alpha|beta|preview|pre|a|b|c|rc)
+ [-_\.]?
+ [0-9]*
+ )?
+ (?: # post release
+ (?:-[0-9]+)|(?:[-_\.]?(post|rev|r)[-_\.]?[0-9]*)
+ )?
+ (?:[-_\.]?dev[-_\.]?[0-9]*)? # dev release
+ )
+ |
+ (?:
+ # All other operators only allow a sub set of what the
+ # (non)equality operators do. Specifically they do not allow
+ # local versions to be specified nor do they allow the prefix
+ # matching wild cards.
+ (?<!==|!=|~=) # We have special cases for these
+ # operators so we want to make sure they
+ # don't match here.
+
+ \s*
+ v?
+ (?:[0-9]+!)? # epoch
+ [0-9]+(?:\.[0-9]+)* # release
+ (?: # pre release
+ [-_\.]?
+ (alpha|beta|preview|pre|a|b|c|rc)
+ [-_\.]?
+ [0-9]*
+ )?
+ (?: # post release
+ (?:-[0-9]+)|(?:[-_\.]?(post|rev|r)[-_\.]?[0-9]*)
+ )?
+ (?:[-_\.]?dev[-_\.]?[0-9]*)? # dev release
+ )
+ )
+ """
+
+ _regex = re.compile(
+ r"^\s*" + _operator_regex_str + _version_regex_str + r"\s*$",
+ re.VERBOSE | re.IGNORECASE,
+ )
+
+ _operators = {
+ "~=": "compatible",
+ "==": "equal",
+ "!=": "not_equal",
+ "<=": "less_than_equal",
+ ">=": "greater_than_equal",
+ "<": "less_than",
+ ">": "greater_than",
+ "===": "arbitrary",
+ }
+
+ def __init__(self, spec: str = "", prereleases: bool | None = None) -> None:
+ """Initialize a Specifier instance.
+
+ :param spec:
+ The string representation of a specifier which will be parsed and
+ normalized before use.
+ :param prereleases:
+ This tells the specifier if it should accept prerelease versions if
+ applicable or not. The default of ``None`` will autodetect it from the
+ given specifiers.
+ :raises InvalidSpecifier:
+ If the given specifier is invalid (i.e. bad syntax).
+ """
+ match = self._regex.search(spec)
+ if not match:
+ raise InvalidSpecifier(f"Invalid specifier: '{spec}'")
+
+ self._spec: tuple[str, str] = (
+ match.group("operator").strip(),
+ match.group("version").strip(),
+ )
+
+ # Store whether or not this Specifier should accept prereleases
+ self._prereleases = prereleases
+
+ # https://github.com/python/mypy/pull/13475#pullrequestreview-1079784515
+ @property # type: ignore[override]
+ def prereleases(self) -> bool:
+ # If there is an explicit prereleases set for this, then we'll just
+ # blindly use that.
+ if self._prereleases is not None:
+ return self._prereleases
+
+ # Look at all of our specifiers and determine if they are inclusive
+ # operators, and if they are if they are including an explicit
+ # prerelease.
+ operator, version = self._spec
+ if operator in ["==", ">=", "<=", "~=", "==="]:
+ # The == specifier can include a trailing .*, if it does we
+ # want to remove before parsing.
+ if operator == "==" and version.endswith(".*"):
+ version = version[:-2]
+
+ # Parse the version, and if it is a pre-release than this
+ # specifier allows pre-releases.
+ if Version(version).is_prerelease:
+ return True
+
+ return False
+
+ @prereleases.setter
+ def prereleases(self, value: bool) -> None:
+ self._prereleases = value
+
+ @property
+ def operator(self) -> str:
+ """The operator of this specifier.
+
+ >>> Specifier("==1.2.3").operator
+ '=='
+ """
+ return self._spec[0]
+
+ @property
+ def version(self) -> str:
+ """The version of this specifier.
+
+ >>> Specifier("==1.2.3").version
+ '1.2.3'
+ """
+ return self._spec[1]
+
+ def __repr__(self) -> str:
+ """A representation of the Specifier that shows all internal state.
+
+ >>> Specifier('>=1.0.0')
+ <Specifier('>=1.0.0')>
+ >>> Specifier('>=1.0.0', prereleases=False)
+ <Specifier('>=1.0.0', prereleases=False)>
+ >>> Specifier('>=1.0.0', prereleases=True)
+ <Specifier('>=1.0.0', prereleases=True)>
+ """
+ pre = (
+ f", prereleases={self.prereleases!r}"
+ if self._prereleases is not None
+ else ""
+ )
+
+ return f"<{self.__class__.__name__}({str(self)!r}{pre})>"
+
+ def __str__(self) -> str:
+ """A string representation of the Specifier that can be round-tripped.
+
+ >>> str(Specifier('>=1.0.0'))
+ '>=1.0.0'
+ >>> str(Specifier('>=1.0.0', prereleases=False))
+ '>=1.0.0'
+ """
+ return "{}{}".format(*self._spec)
+
+ @property
+ def _canonical_spec(self) -> tuple[str, str]:
+ canonical_version = canonicalize_version(
+ self._spec[1],
+ strip_trailing_zero=(self._spec[0] != "~="),
+ )
+ return self._spec[0], canonical_version
+
+ def __hash__(self) -> int:
+ return hash(self._canonical_spec)
+
+ def __eq__(self, other: object) -> bool:
+ """Whether or not the two Specifier-like objects are equal.
+
+ :param other: The other object to check against.
+
+ The value of :attr:`prereleases` is ignored.
+
+ >>> Specifier("==1.2.3") == Specifier("== 1.2.3.0")
+ True
+ >>> (Specifier("==1.2.3", prereleases=False) ==
+ ... Specifier("==1.2.3", prereleases=True))
+ True
+ >>> Specifier("==1.2.3") == "==1.2.3"
+ True
+ >>> Specifier("==1.2.3") == Specifier("==1.2.4")
+ False
+ >>> Specifier("==1.2.3") == Specifier("~=1.2.3")
+ False
+ """
+ if isinstance(other, str):
+ try:
+ other = self.__class__(str(other))
+ except InvalidSpecifier:
+ return NotImplemented
+ elif not isinstance(other, self.__class__):
+ return NotImplemented
+
+ return self._canonical_spec == other._canonical_spec
+
+ def _get_operator(self, op: str) -> CallableOperator:
+ operator_callable: CallableOperator = getattr(
+ self, f"_compare_{self._operators[op]}"
+ )
+ return operator_callable
+
+ def _compare_compatible(self, prospective: Version, spec: str) -> bool:
+ # Compatible releases have an equivalent combination of >= and ==. That
+ # is that ~=2.2 is equivalent to >=2.2,==2.*. This allows us to
+ # implement this in terms of the other specifiers instead of
+ # implementing it ourselves. The only thing we need to do is construct
+ # the other specifiers.
+
+ # We want everything but the last item in the version, but we want to
+ # ignore suffix segments.
+ prefix = _version_join(
+ list(itertools.takewhile(_is_not_suffix, _version_split(spec)))[:-1]
+ )
+
+ # Add the prefix notation to the end of our string
+ prefix += ".*"
+
+ return self._get_operator(">=")(prospective, spec) and self._get_operator("==")(
+ prospective, prefix
+ )
+
+ def _compare_equal(self, prospective: Version, spec: str) -> bool:
+ # We need special logic to handle prefix matching
+ if spec.endswith(".*"):
+ # In the case of prefix matching we want to ignore local segment.
+ normalized_prospective = canonicalize_version(
+ prospective.public, strip_trailing_zero=False
+ )
+ # Get the normalized version string ignoring the trailing .*
+ normalized_spec = canonicalize_version(spec[:-2], strip_trailing_zero=False)
+ # Split the spec out by bangs and dots, and pretend that there is
+ # an implicit dot in between a release segment and a pre-release segment.
+ split_spec = _version_split(normalized_spec)
+
+ # Split the prospective version out by bangs and dots, and pretend
+ # that there is an implicit dot in between a release segment and
+ # a pre-release segment.
+ split_prospective = _version_split(normalized_prospective)
+
+ # 0-pad the prospective version before shortening it to get the correct
+ # shortened version.
+ padded_prospective, _ = _pad_version(split_prospective, split_spec)
+
+ # Shorten the prospective version to be the same length as the spec
+ # so that we can determine if the specifier is a prefix of the
+ # prospective version or not.
+ shortened_prospective = padded_prospective[: len(split_spec)]
+
+ return shortened_prospective == split_spec
+ else:
+ # Convert our spec string into a Version
+ spec_version = Version(spec)
+
+ # If the specifier does not have a local segment, then we want to
+ # act as if the prospective version also does not have a local
+ # segment.
+ if not spec_version.local:
+ prospective = Version(prospective.public)
+
+ return prospective == spec_version
+
+ def _compare_not_equal(self, prospective: Version, spec: str) -> bool:
+ return not self._compare_equal(prospective, spec)
+
+ def _compare_less_than_equal(self, prospective: Version, spec: str) -> bool:
+ # NB: Local version identifiers are NOT permitted in the version
+ # specifier, so local version labels can be universally removed from
+ # the prospective version.
+ return Version(prospective.public) <= Version(spec)
+
+ def _compare_greater_than_equal(self, prospective: Version, spec: str) -> bool:
+ # NB: Local version identifiers are NOT permitted in the version
+ # specifier, so local version labels can be universally removed from
+ # the prospective version.
+ return Version(prospective.public) >= Version(spec)
+
+ def _compare_less_than(self, prospective: Version, spec_str: str) -> bool:
+ # Convert our spec to a Version instance, since we'll want to work with
+ # it as a version.
+ spec = Version(spec_str)
+
+ # Check to see if the prospective version is less than the spec
+ # version. If it's not we can short circuit and just return False now
+ # instead of doing extra unneeded work.
+ if not prospective < spec:
+ return False
+
+ # This special case is here so that, unless the specifier itself
+ # includes is a pre-release version, that we do not accept pre-release
+ # versions for the version mentioned in the specifier (e.g. <3.1 should
+ # not match 3.1.dev0, but should match 3.0.dev0).
+ if not spec.is_prerelease and prospective.is_prerelease:
+ if Version(prospective.base_version) == Version(spec.base_version):
+ return False
+
+ # If we've gotten to here, it means that prospective version is both
+ # less than the spec version *and* it's not a pre-release of the same
+ # version in the spec.
+ return True
+
+ def _compare_greater_than(self, prospective: Version, spec_str: str) -> bool:
+ # Convert our spec to a Version instance, since we'll want to work with
+ # it as a version.
+ spec = Version(spec_str)
+
+ # Check to see if the prospective version is greater than the spec
+ # version. If it's not we can short circuit and just return False now
+ # instead of doing extra unneeded work.
+ if not prospective > spec:
+ return False
+
+ # This special case is here so that, unless the specifier itself
+ # includes is a post-release version, that we do not accept
+ # post-release versions for the version mentioned in the specifier
+ # (e.g. >3.1 should not match 3.0.post0, but should match 3.2.post0).
+ if not spec.is_postrelease and prospective.is_postrelease:
+ if Version(prospective.base_version) == Version(spec.base_version):
+ return False
+
+ # Ensure that we do not allow a local version of the version mentioned
+ # in the specifier, which is technically greater than, to match.
+ if prospective.local is not None:
+ if Version(prospective.base_version) == Version(spec.base_version):
+ return False
+
+ # If we've gotten to here, it means that prospective version is both
+ # greater than the spec version *and* it's not a pre-release of the
+ # same version in the spec.
+ return True
+
+ def _compare_arbitrary(self, prospective: Version, spec: str) -> bool:
+ return str(prospective).lower() == str(spec).lower()
+
+ def __contains__(self, item: str | Version) -> bool:
+ """Return whether or not the item is contained in this specifier.
+
+ :param item: The item to check for.
+
+ This is used for the ``in`` operator and behaves the same as
+ :meth:`contains` with no ``prereleases`` argument passed.
+
+ >>> "1.2.3" in Specifier(">=1.2.3")
+ True
+ >>> Version("1.2.3") in Specifier(">=1.2.3")
+ True
+ >>> "1.0.0" in Specifier(">=1.2.3")
+ False
+ >>> "1.3.0a1" in Specifier(">=1.2.3")
+ False
+ >>> "1.3.0a1" in Specifier(">=1.2.3", prereleases=True)
+ True
+ """
+ return self.contains(item)
+
+ def contains(self, item: UnparsedVersion, prereleases: bool | None = None) -> bool:
+ """Return whether or not the item is contained in this specifier.
+
+ :param item:
+ The item to check for, which can be a version string or a
+ :class:`Version` instance.
+ :param prereleases:
+ Whether or not to match prereleases with this Specifier. If set to
+ ``None`` (the default), it uses :attr:`prereleases` to determine
+ whether or not prereleases are allowed.
+
+ >>> Specifier(">=1.2.3").contains("1.2.3")
+ True
+ >>> Specifier(">=1.2.3").contains(Version("1.2.3"))
+ True
+ >>> Specifier(">=1.2.3").contains("1.0.0")
+ False
+ >>> Specifier(">=1.2.3").contains("1.3.0a1")
+ False
+ >>> Specifier(">=1.2.3", prereleases=True).contains("1.3.0a1")
+ True
+ >>> Specifier(">=1.2.3").contains("1.3.0a1", prereleases=True)
+ True
+ """
+
+ # Determine if prereleases are to be allowed or not.
+ if prereleases is None:
+ prereleases = self.prereleases
+
+ # Normalize item to a Version, this allows us to have a shortcut for
+ # "2.0" in Specifier(">=2")
+ normalized_item = _coerce_version(item)
+
+ # Determine if we should be supporting prereleases in this specifier
+ # or not, if we do not support prereleases than we can short circuit
+ # logic if this version is a prereleases.
+ if normalized_item.is_prerelease and not prereleases:
+ return False
+
+ # Actually do the comparison to determine if this item is contained
+ # within this Specifier or not.
+ operator_callable: CallableOperator = self._get_operator(self.operator)
+ return operator_callable(normalized_item, self.version)
+
+ def filter(
+ self, iterable: Iterable[UnparsedVersionVar], prereleases: bool | None = None
+ ) -> Iterator[UnparsedVersionVar]:
+ """Filter items in the given iterable, that match the specifier.
+
+ :param iterable:
+ An iterable that can contain version strings and :class:`Version` instances.
+ The items in the iterable will be filtered according to the specifier.
+ :param prereleases:
+ Whether or not to allow prereleases in the returned iterator. If set to
+ ``None`` (the default), it will be intelligently decide whether to allow
+ prereleases or not (based on the :attr:`prereleases` attribute, and
+ whether the only versions matching are prereleases).
+
+ This method is smarter than just ``filter(Specifier().contains, [...])``
+ because it implements the rule from :pep:`440` that a prerelease item
+ SHOULD be accepted if no other versions match the given specifier.
+
+ >>> list(Specifier(">=1.2.3").filter(["1.2", "1.3", "1.5a1"]))
+ ['1.3']
+ >>> list(Specifier(">=1.2.3").filter(["1.2", "1.2.3", "1.3", Version("1.4")]))
+ ['1.2.3', '1.3', <Version('1.4')>]
+ >>> list(Specifier(">=1.2.3").filter(["1.2", "1.5a1"]))
+ ['1.5a1']
+ >>> list(Specifier(">=1.2.3").filter(["1.3", "1.5a1"], prereleases=True))
+ ['1.3', '1.5a1']
+ >>> list(Specifier(">=1.2.3", prereleases=True).filter(["1.3", "1.5a1"]))
+ ['1.3', '1.5a1']
+ """
+
+ yielded = False
+ found_prereleases = []
+
+ kw = {"prereleases": prereleases if prereleases is not None else True}
+
+ # Attempt to iterate over all the values in the iterable and if any of
+ # them match, yield them.
+ for version in iterable:
+ parsed_version = _coerce_version(version)
+
+ if self.contains(parsed_version, **kw):
+ # If our version is a prerelease, and we were not set to allow
+ # prereleases, then we'll store it for later in case nothing
+ # else matches this specifier.
+ if parsed_version.is_prerelease and not (
+ prereleases or self.prereleases
+ ):
+ found_prereleases.append(version)
+ # Either this is not a prerelease, or we should have been
+ # accepting prereleases from the beginning.
+ else:
+ yielded = True
+ yield version
+
+ # Now that we've iterated over everything, determine if we've yielded
+ # any values, and if we have not and we have any prereleases stored up
+ # then we will go ahead and yield the prereleases.
+ if not yielded and found_prereleases:
+ for version in found_prereleases:
+ yield version
+
+
+_prefix_regex = re.compile(r"^([0-9]+)((?:a|b|c|rc)[0-9]+)$")
+
+
+def _version_split(version: str) -> list[str]:
+ """Split version into components.
+
+ The split components are intended for version comparison. The logic does
+ not attempt to retain the original version string, so joining the
+ components back with :func:`_version_join` may not produce the original
+ version string.
+ """
+ result: list[str] = []
+
+ epoch, _, rest = version.rpartition("!")
+ result.append(epoch or "0")
+
+ for item in rest.split("."):
+ match = _prefix_regex.search(item)
+ if match:
+ result.extend(match.groups())
+ else:
+ result.append(item)
+ return result
+
+
+def _version_join(components: list[str]) -> str:
+ """Join split version components into a version string.
+
+ This function assumes the input came from :func:`_version_split`, where the
+ first component must be the epoch (either empty or numeric), and all other
+ components numeric.
+ """
+ epoch, *rest = components
+ return f"{epoch}!{'.'.join(rest)}"
+
+
+def _is_not_suffix(segment: str) -> bool:
+ return not any(
+ segment.startswith(prefix) for prefix in ("dev", "a", "b", "rc", "post")
+ )
+
+
+def _pad_version(left: list[str], right: list[str]) -> tuple[list[str], list[str]]:
+ left_split, right_split = [], []
+
+ # Get the release segment of our versions
+ left_split.append(list(itertools.takewhile(lambda x: x.isdigit(), left)))
+ right_split.append(list(itertools.takewhile(lambda x: x.isdigit(), right)))
+
+ # Get the rest of our versions
+ left_split.append(left[len(left_split[0]) :])
+ right_split.append(right[len(right_split[0]) :])
+
+ # Insert our padding
+ left_split.insert(1, ["0"] * max(0, len(right_split[0]) - len(left_split[0])))
+ right_split.insert(1, ["0"] * max(0, len(left_split[0]) - len(right_split[0])))
+
+ return (
+ list(itertools.chain.from_iterable(left_split)),
+ list(itertools.chain.from_iterable(right_split)),
+ )
+
+
+class SpecifierSet(BaseSpecifier):
+ """This class abstracts handling of a set of version specifiers.
+
+ It can be passed a single specifier (``>=3.0``), a comma-separated list of
+ specifiers (``>=3.0,!=3.1``), or no specifier at all.
+ """
+
+ def __init__(self, specifiers: str = "", prereleases: bool | None = None) -> None:
+ """Initialize a SpecifierSet instance.
+
+ :param specifiers:
+ The string representation of a specifier or a comma-separated list of
+ specifiers which will be parsed and normalized before use.
+ :param prereleases:
+ This tells the SpecifierSet if it should accept prerelease versions if
+ applicable or not. The default of ``None`` will autodetect it from the
+ given specifiers.
+
+ :raises InvalidSpecifier:
+ If the given ``specifiers`` are not parseable than this exception will be
+ raised.
+ """
+
+ # Split on `,` to break each individual specifier into it's own item, and
+ # strip each item to remove leading/trailing whitespace.
+ split_specifiers = [s.strip() for s in specifiers.split(",") if s.strip()]
+
+ # Make each individual specifier a Specifier and save in a frozen set for later.
+ self._specs = frozenset(map(Specifier, split_specifiers))
+
+ # Store our prereleases value so we can use it later to determine if
+ # we accept prereleases or not.
+ self._prereleases = prereleases
+
+ @property
+ def prereleases(self) -> bool | None:
+ # If we have been given an explicit prerelease modifier, then we'll
+ # pass that through here.
+ if self._prereleases is not None:
+ return self._prereleases
+
+ # If we don't have any specifiers, and we don't have a forced value,
+ # then we'll just return None since we don't know if this should have
+ # pre-releases or not.
+ if not self._specs:
+ return None
+
+ # Otherwise we'll see if any of the given specifiers accept
+ # prereleases, if any of them do we'll return True, otherwise False.
+ return any(s.prereleases for s in self._specs)
+
+ @prereleases.setter
+ def prereleases(self, value: bool) -> None:
+ self._prereleases = value
+
+ def __repr__(self) -> str:
+ """A representation of the specifier set that shows all internal state.
+
+ Note that the ordering of the individual specifiers within the set may not
+ match the input string.
+
+ >>> SpecifierSet('>=1.0.0,!=2.0.0')
+ <SpecifierSet('!=2.0.0,>=1.0.0')>
+ >>> SpecifierSet('>=1.0.0,!=2.0.0', prereleases=False)
+ <SpecifierSet('!=2.0.0,>=1.0.0', prereleases=False)>
+ >>> SpecifierSet('>=1.0.0,!=2.0.0', prereleases=True)
+ <SpecifierSet('!=2.0.0,>=1.0.0', prereleases=True)>
+ """
+ pre = (
+ f", prereleases={self.prereleases!r}"
+ if self._prereleases is not None
+ else ""
+ )
+
+ return f"<SpecifierSet({str(self)!r}{pre})>"
+
+ def __str__(self) -> str:
+ """A string representation of the specifier set that can be round-tripped.
+
+ Note that the ordering of the individual specifiers within the set may not
+ match the input string.
+
+ >>> str(SpecifierSet(">=1.0.0,!=1.0.1"))
+ '!=1.0.1,>=1.0.0'
+ >>> str(SpecifierSet(">=1.0.0,!=1.0.1", prereleases=False))
+ '!=1.0.1,>=1.0.0'
+ """
+ return ",".join(sorted(str(s) for s in self._specs))
+
+ def __hash__(self) -> int:
+ return hash(self._specs)
+
+ def __and__(self, other: SpecifierSet | str) -> SpecifierSet:
+ """Return a SpecifierSet which is a combination of the two sets.
+
+ :param other: The other object to combine with.
+
+ >>> SpecifierSet(">=1.0.0,!=1.0.1") & '<=2.0.0,!=2.0.1'
+ <SpecifierSet('!=1.0.1,!=2.0.1,<=2.0.0,>=1.0.0')>
+ >>> SpecifierSet(">=1.0.0,!=1.0.1") & SpecifierSet('<=2.0.0,!=2.0.1')
+ <SpecifierSet('!=1.0.1,!=2.0.1,<=2.0.0,>=1.0.0')>
+ """
+ if isinstance(other, str):
+ other = SpecifierSet(other)
+ elif not isinstance(other, SpecifierSet):
+ return NotImplemented
+
+ specifier = SpecifierSet()
+ specifier._specs = frozenset(self._specs | other._specs)
+
+ if self._prereleases is None and other._prereleases is not None:
+ specifier._prereleases = other._prereleases
+ elif self._prereleases is not None and other._prereleases is None:
+ specifier._prereleases = self._prereleases
+ elif self._prereleases == other._prereleases:
+ specifier._prereleases = self._prereleases
+ else:
+ raise ValueError(
+ "Cannot combine SpecifierSets with True and False prerelease "
+ "overrides."
+ )
+
+ return specifier
+
+ def __eq__(self, other: object) -> bool:
+ """Whether or not the two SpecifierSet-like objects are equal.
+
+ :param other: The other object to check against.
+
+ The value of :attr:`prereleases` is ignored.
+
+ >>> SpecifierSet(">=1.0.0,!=1.0.1") == SpecifierSet(">=1.0.0,!=1.0.1")
+ True
+ >>> (SpecifierSet(">=1.0.0,!=1.0.1", prereleases=False) ==
+ ... SpecifierSet(">=1.0.0,!=1.0.1", prereleases=True))
+ True
+ >>> SpecifierSet(">=1.0.0,!=1.0.1") == ">=1.0.0,!=1.0.1"
+ True
+ >>> SpecifierSet(">=1.0.0,!=1.0.1") == SpecifierSet(">=1.0.0")
+ False
+ >>> SpecifierSet(">=1.0.0,!=1.0.1") == SpecifierSet(">=1.0.0,!=1.0.2")
+ False
+ """
+ if isinstance(other, (str, Specifier)):
+ other = SpecifierSet(str(other))
+ elif not isinstance(other, SpecifierSet):
+ return NotImplemented
+
+ return self._specs == other._specs
+
+ def __len__(self) -> int:
+ """Returns the number of specifiers in this specifier set."""
+ return len(self._specs)
+
+ def __iter__(self) -> Iterator[Specifier]:
+ """
+ Returns an iterator over all the underlying :class:`Specifier` instances
+ in this specifier set.
+
+ >>> sorted(SpecifierSet(">=1.0.0,!=1.0.1"), key=str)
+ [<Specifier('!=1.0.1')>, <Specifier('>=1.0.0')>]
+ """
+ return iter(self._specs)
+
+ def __contains__(self, item: UnparsedVersion) -> bool:
+ """Return whether or not the item is contained in this specifier.
+
+ :param item: The item to check for.
+
+ This is used for the ``in`` operator and behaves the same as
+ :meth:`contains` with no ``prereleases`` argument passed.
+
+ >>> "1.2.3" in SpecifierSet(">=1.0.0,!=1.0.1")
+ True
+ >>> Version("1.2.3") in SpecifierSet(">=1.0.0,!=1.0.1")
+ True
+ >>> "1.0.1" in SpecifierSet(">=1.0.0,!=1.0.1")
+ False
+ >>> "1.3.0a1" in SpecifierSet(">=1.0.0,!=1.0.1")
+ False
+ >>> "1.3.0a1" in SpecifierSet(">=1.0.0,!=1.0.1", prereleases=True)
+ True
+ """
+ return self.contains(item)
+
+ def contains(
+ self,
+ item: UnparsedVersion,
+ prereleases: bool | None = None,
+ installed: bool | None = None,
+ ) -> bool:
+ """Return whether or not the item is contained in this SpecifierSet.
+
+ :param item:
+ The item to check for, which can be a version string or a
+ :class:`Version` instance.
+ :param prereleases:
+ Whether or not to match prereleases with this SpecifierSet. If set to
+ ``None`` (the default), it uses :attr:`prereleases` to determine
+ whether or not prereleases are allowed.
+
+ >>> SpecifierSet(">=1.0.0,!=1.0.1").contains("1.2.3")
+ True
+ >>> SpecifierSet(">=1.0.0,!=1.0.1").contains(Version("1.2.3"))
+ True
+ >>> SpecifierSet(">=1.0.0,!=1.0.1").contains("1.0.1")
+ False
+ >>> SpecifierSet(">=1.0.0,!=1.0.1").contains("1.3.0a1")
+ False
+ >>> SpecifierSet(">=1.0.0,!=1.0.1", prereleases=True).contains("1.3.0a1")
+ True
+ >>> SpecifierSet(">=1.0.0,!=1.0.1").contains("1.3.0a1", prereleases=True)
+ True
+ """
+ # Ensure that our item is a Version instance.
+ if not isinstance(item, Version):
+ item = Version(item)
+
+ # Determine if we're forcing a prerelease or not, if we're not forcing
+ # one for this particular filter call, then we'll use whatever the
+ # SpecifierSet thinks for whether or not we should support prereleases.
+ if prereleases is None:
+ prereleases = self.prereleases
+
+ # We can determine if we're going to allow pre-releases by looking to
+ # see if any of the underlying items supports them. If none of them do
+ # and this item is a pre-release then we do not allow it and we can
+ # short circuit that here.
+ # Note: This means that 1.0.dev1 would not be contained in something
+ # like >=1.0.devabc however it would be in >=1.0.debabc,>0.0.dev0
+ if not prereleases and item.is_prerelease:
+ return False
+
+ if installed and item.is_prerelease:
+ item = Version(item.base_version)
+
+ # We simply dispatch to the underlying specs here to make sure that the
+ # given version is contained within all of them.
+ # Note: This use of all() here means that an empty set of specifiers
+ # will always return True, this is an explicit design decision.
+ return all(s.contains(item, prereleases=prereleases) for s in self._specs)
+
+ def filter(
+ self, iterable: Iterable[UnparsedVersionVar], prereleases: bool | None = None
+ ) -> Iterator[UnparsedVersionVar]:
+ """Filter items in the given iterable, that match the specifiers in this set.
+
+ :param iterable:
+ An iterable that can contain version strings and :class:`Version` instances.
+ The items in the iterable will be filtered according to the specifier.
+ :param prereleases:
+ Whether or not to allow prereleases in the returned iterator. If set to
+ ``None`` (the default), it will be intelligently decide whether to allow
+ prereleases or not (based on the :attr:`prereleases` attribute, and
+ whether the only versions matching are prereleases).
+
+ This method is smarter than just ``filter(SpecifierSet(...).contains, [...])``
+ because it implements the rule from :pep:`440` that a prerelease item
+ SHOULD be accepted if no other versions match the given specifier.
+
+ >>> list(SpecifierSet(">=1.2.3").filter(["1.2", "1.3", "1.5a1"]))
+ ['1.3']
+ >>> list(SpecifierSet(">=1.2.3").filter(["1.2", "1.3", Version("1.4")]))
+ ['1.3', <Version('1.4')>]
+ >>> list(SpecifierSet(">=1.2.3").filter(["1.2", "1.5a1"]))
+ []
+ >>> list(SpecifierSet(">=1.2.3").filter(["1.3", "1.5a1"], prereleases=True))
+ ['1.3', '1.5a1']
+ >>> list(SpecifierSet(">=1.2.3", prereleases=True).filter(["1.3", "1.5a1"]))
+ ['1.3', '1.5a1']
+
+ An "empty" SpecifierSet will filter items based on the presence of prerelease
+ versions in the set.
+
+ >>> list(SpecifierSet("").filter(["1.3", "1.5a1"]))
+ ['1.3']
+ >>> list(SpecifierSet("").filter(["1.5a1"]))
+ ['1.5a1']
+ >>> list(SpecifierSet("", prereleases=True).filter(["1.3", "1.5a1"]))
+ ['1.3', '1.5a1']
+ >>> list(SpecifierSet("").filter(["1.3", "1.5a1"], prereleases=True))
+ ['1.3', '1.5a1']
+ """
+ # Determine if we're forcing a prerelease or not, if we're not forcing
+ # one for this particular filter call, then we'll use whatever the
+ # SpecifierSet thinks for whether or not we should support prereleases.
+ if prereleases is None:
+ prereleases = self.prereleases
+
+ # If we have any specifiers, then we want to wrap our iterable in the
+ # filter method for each one, this will act as a logical AND amongst
+ # each specifier.
+ if self._specs:
+ for spec in self._specs:
+ iterable = spec.filter(iterable, prereleases=bool(prereleases))
+ return iter(iterable)
+ # If we do not have any specifiers, then we need to have a rough filter
+ # which will filter out any pre-releases, unless there are no final
+ # releases.
+ else:
+ filtered: list[UnparsedVersionVar] = []
+ found_prereleases: list[UnparsedVersionVar] = []
+
+ for item in iterable:
+ parsed_version = _coerce_version(item)
+
+ # Store any item which is a pre-release for later unless we've
+ # already found a final version or we are accepting prereleases
+ if parsed_version.is_prerelease and not prereleases:
+ if not filtered:
+ found_prereleases.append(item)
+ else:
+ filtered.append(item)
+
+ # If we've found no items except for pre-releases, then we'll go
+ # ahead and use the pre-releases
+ if not filtered and found_prereleases and prereleases is None:
+ return iter(found_prereleases)
+
+ return iter(filtered)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/tags.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/tags.py
new file mode 100644
index 000000000..703f0ed53
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/tags.py
@@ -0,0 +1,627 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+
+from __future__ import annotations
+
+import logging
+import platform
+import re
+import struct
+import subprocess
+import sys
+import sysconfig
+from importlib.machinery import EXTENSION_SUFFIXES
+from typing import (
+ Iterable,
+ Iterator,
+ Sequence,
+ Tuple,
+ cast,
+)
+
+from . import _manylinux, _musllinux
+
+logger = logging.getLogger(__name__)
+
+PythonVersion = Sequence[int]
+AppleVersion = Tuple[int, int]
+
+INTERPRETER_SHORT_NAMES: dict[str, str] = {
+ "python": "py", # Generic.
+ "cpython": "cp",
+ "pypy": "pp",
+ "ironpython": "ip",
+ "jython": "jy",
+}
+
+
+_32_BIT_INTERPRETER = struct.calcsize("P") == 4
+
+
+class Tag:
+ """
+ A representation of the tag triple for a wheel.
+
+ Instances are considered immutable and thus are hashable. Equality checking
+ is also supported.
+ """
+
+ __slots__ = ["_interpreter", "_abi", "_platform", "_hash"]
+
+ def __init__(self, interpreter: str, abi: str, platform: str) -> None:
+ self._interpreter = interpreter.lower()
+ self._abi = abi.lower()
+ self._platform = platform.lower()
+ # The __hash__ of every single element in a Set[Tag] will be evaluated each time
+ # that a set calls its `.disjoint()` method, which may be called hundreds of
+ # times when scanning a page of links for packages with tags matching that
+ # Set[Tag]. Pre-computing the value here produces significant speedups for
+ # downstream consumers.
+ self._hash = hash((self._interpreter, self._abi, self._platform))
+
+ @property
+ def interpreter(self) -> str:
+ return self._interpreter
+
+ @property
+ def abi(self) -> str:
+ return self._abi
+
+ @property
+ def platform(self) -> str:
+ return self._platform
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, Tag):
+ return NotImplemented
+
+ return (
+ (self._hash == other._hash) # Short-circuit ASAP for perf reasons.
+ and (self._platform == other._platform)
+ and (self._abi == other._abi)
+ and (self._interpreter == other._interpreter)
+ )
+
+ def __hash__(self) -> int:
+ return self._hash
+
+ def __str__(self) -> str:
+ return f"{self._interpreter}-{self._abi}-{self._platform}"
+
+ def __repr__(self) -> str:
+ return f"<{self} @ {id(self)}>"
+
+
+def parse_tag(tag: str) -> frozenset[Tag]:
+ """
+ Parses the provided tag (e.g. `py3-none-any`) into a frozenset of Tag instances.
+
+ Returning a set is required due to the possibility that the tag is a
+ compressed tag set.
+ """
+ tags = set()
+ interpreters, abis, platforms = tag.split("-")
+ for interpreter in interpreters.split("."):
+ for abi in abis.split("."):
+ for platform_ in platforms.split("."):
+ tags.add(Tag(interpreter, abi, platform_))
+ return frozenset(tags)
+
+
+def _get_config_var(name: str, warn: bool = False) -> int | str | None:
+ value: int | str | None = sysconfig.get_config_var(name)
+ if value is None and warn:
+ logger.debug(
+ "Config variable '%s' is unset, Python ABI tag may be incorrect", name
+ )
+ return value
+
+
+def _normalize_string(string: str) -> str:
+ return string.replace(".", "_").replace("-", "_").replace(" ", "_")
+
+
+def _is_threaded_cpython(abis: list[str]) -> bool:
+ """
+ Determine if the ABI corresponds to a threaded (`--disable-gil`) build.
+
+ The threaded builds are indicated by a "t" in the abiflags.
+ """
+ if len(abis) == 0:
+ return False
+ # expect e.g., cp313
+ m = re.match(r"cp\d+(.*)", abis[0])
+ if not m:
+ return False
+ abiflags = m.group(1)
+ return "t" in abiflags
+
+
+def _abi3_applies(python_version: PythonVersion, threading: bool) -> bool:
+ """
+ Determine if the Python version supports abi3.
+
+ PEP 384 was first implemented in Python 3.2. The threaded (`--disable-gil`)
+ builds do not support abi3.
+ """
+ return len(python_version) > 1 and tuple(python_version) >= (3, 2) and not threading
+
+
+def _cpython_abis(py_version: PythonVersion, warn: bool = False) -> list[str]:
+ py_version = tuple(py_version) # To allow for version comparison.
+ abis = []
+ version = _version_nodot(py_version[:2])
+ threading = debug = pymalloc = ucs4 = ""
+ with_debug = _get_config_var("Py_DEBUG", warn)
+ has_refcount = hasattr(sys, "gettotalrefcount")
+ # Windows doesn't set Py_DEBUG, so checking for support of debug-compiled
+ # extension modules is the best option.
+ # https://github.com/pypa/pip/issues/3383#issuecomment-173267692
+ has_ext = "_d.pyd" in EXTENSION_SUFFIXES
+ if with_debug or (with_debug is None and (has_refcount or has_ext)):
+ debug = "d"
+ if py_version >= (3, 13) and _get_config_var("Py_GIL_DISABLED", warn):
+ threading = "t"
+ if py_version < (3, 8):
+ with_pymalloc = _get_config_var("WITH_PYMALLOC", warn)
+ if with_pymalloc or with_pymalloc is None:
+ pymalloc = "m"
+ if py_version < (3, 3):
+ unicode_size = _get_config_var("Py_UNICODE_SIZE", warn)
+ if unicode_size == 4 or (
+ unicode_size is None and sys.maxunicode == 0x10FFFF
+ ):
+ ucs4 = "u"
+ elif debug:
+ # Debug builds can also load "normal" extension modules.
+ # We can also assume no UCS-4 or pymalloc requirement.
+ abis.append(f"cp{version}{threading}")
+ abis.insert(0, f"cp{version}{threading}{debug}{pymalloc}{ucs4}")
+ return abis
+
+
+def cpython_tags(
+ python_version: PythonVersion | None = None,
+ abis: Iterable[str] | None = None,
+ platforms: Iterable[str] | None = None,
+ *,
+ warn: bool = False,
+) -> Iterator[Tag]:
+ """
+ Yields the tags for a CPython interpreter.
+
+ The tags consist of:
+ - cp<python_version>-<abi>-<platform>
+ - cp<python_version>-abi3-<platform>
+ - cp<python_version>-none-<platform>
+ - cp<less than python_version>-abi3-<platform> # Older Python versions down to 3.2.
+
+ If python_version only specifies a major version then user-provided ABIs and
+ the 'none' ABItag will be used.
+
+ If 'abi3' or 'none' are specified in 'abis' then they will be yielded at
+ their normal position and not at the beginning.
+ """
+ if not python_version:
+ python_version = sys.version_info[:2]
+
+ interpreter = f"cp{_version_nodot(python_version[:2])}"
+
+ if abis is None:
+ if len(python_version) > 1:
+ abis = _cpython_abis(python_version, warn)
+ else:
+ abis = []
+ abis = list(abis)
+ # 'abi3' and 'none' are explicitly handled later.
+ for explicit_abi in ("abi3", "none"):
+ try:
+ abis.remove(explicit_abi)
+ except ValueError:
+ pass
+
+ platforms = list(platforms or platform_tags())
+ for abi in abis:
+ for platform_ in platforms:
+ yield Tag(interpreter, abi, platform_)
+
+ threading = _is_threaded_cpython(abis)
+ use_abi3 = _abi3_applies(python_version, threading)
+ if use_abi3:
+ yield from (Tag(interpreter, "abi3", platform_) for platform_ in platforms)
+ yield from (Tag(interpreter, "none", platform_) for platform_ in platforms)
+
+ if use_abi3:
+ for minor_version in range(python_version[1] - 1, 1, -1):
+ for platform_ in platforms:
+ interpreter = "cp{version}".format(
+ version=_version_nodot((python_version[0], minor_version))
+ )
+ yield Tag(interpreter, "abi3", platform_)
+
+
+def _generic_abi() -> list[str]:
+ """
+ Return the ABI tag based on EXT_SUFFIX.
+ """
+ # The following are examples of `EXT_SUFFIX`.
+ # We want to keep the parts which are related to the ABI and remove the
+ # parts which are related to the platform:
+ # - linux: '.cpython-310-x86_64-linux-gnu.so' => cp310
+ # - mac: '.cpython-310-darwin.so' => cp310
+ # - win: '.cp310-win_amd64.pyd' => cp310
+ # - win: '.pyd' => cp37 (uses _cpython_abis())
+ # - pypy: '.pypy38-pp73-x86_64-linux-gnu.so' => pypy38_pp73
+ # - graalpy: '.graalpy-38-native-x86_64-darwin.dylib'
+ # => graalpy_38_native
+
+ ext_suffix = _get_config_var("EXT_SUFFIX", warn=True)
+ if not isinstance(ext_suffix, str) or ext_suffix[0] != ".":
+ raise SystemError("invalid sysconfig.get_config_var('EXT_SUFFIX')")
+ parts = ext_suffix.split(".")
+ if len(parts) < 3:
+ # CPython3.7 and earlier uses ".pyd" on Windows.
+ return _cpython_abis(sys.version_info[:2])
+ soabi = parts[1]
+ if soabi.startswith("cpython"):
+ # non-windows
+ abi = "cp" + soabi.split("-")[1]
+ elif soabi.startswith("cp"):
+ # windows
+ abi = soabi.split("-")[0]
+ elif soabi.startswith("pypy"):
+ abi = "-".join(soabi.split("-")[:2])
+ elif soabi.startswith("graalpy"):
+ abi = "-".join(soabi.split("-")[:3])
+ elif soabi:
+ # pyston, ironpython, others?
+ abi = soabi
+ else:
+ return []
+ return [_normalize_string(abi)]
+
+
+def generic_tags(
+ interpreter: str | None = None,
+ abis: Iterable[str] | None = None,
+ platforms: Iterable[str] | None = None,
+ *,
+ warn: bool = False,
+) -> Iterator[Tag]:
+ """
+ Yields the tags for a generic interpreter.
+
+ The tags consist of:
+ - <interpreter>-<abi>-<platform>
+
+ The "none" ABI will be added if it was not explicitly provided.
+ """
+ if not interpreter:
+ interp_name = interpreter_name()
+ interp_version = interpreter_version(warn=warn)
+ interpreter = "".join([interp_name, interp_version])
+ if abis is None:
+ abis = _generic_abi()
+ else:
+ abis = list(abis)
+ platforms = list(platforms or platform_tags())
+ if "none" not in abis:
+ abis.append("none")
+ for abi in abis:
+ for platform_ in platforms:
+ yield Tag(interpreter, abi, platform_)
+
+
+def _py_interpreter_range(py_version: PythonVersion) -> Iterator[str]:
+ """
+ Yields Python versions in descending order.
+
+ After the latest version, the major-only version will be yielded, and then
+ all previous versions of that major version.
+ """
+ if len(py_version) > 1:
+ yield f"py{_version_nodot(py_version[:2])}"
+ yield f"py{py_version[0]}"
+ if len(py_version) > 1:
+ for minor in range(py_version[1] - 1, -1, -1):
+ yield f"py{_version_nodot((py_version[0], minor))}"
+
+
+def compatible_tags(
+ python_version: PythonVersion | None = None,
+ interpreter: str | None = None,
+ platforms: Iterable[str] | None = None,
+) -> Iterator[Tag]:
+ """
+ Yields the sequence of tags that are compatible with a specific version of Python.
+
+ The tags consist of:
+ - py*-none-<platform>
+ - <interpreter>-none-any # ... if `interpreter` is provided.
+ - py*-none-any
+ """
+ if not python_version:
+ python_version = sys.version_info[:2]
+ platforms = list(platforms or platform_tags())
+ for version in _py_interpreter_range(python_version):
+ for platform_ in platforms:
+ yield Tag(version, "none", platform_)
+ if interpreter:
+ yield Tag(interpreter, "none", "any")
+ for version in _py_interpreter_range(python_version):
+ yield Tag(version, "none", "any")
+
+
+def _mac_arch(arch: str, is_32bit: bool = _32_BIT_INTERPRETER) -> str:
+ if not is_32bit:
+ return arch
+
+ if arch.startswith("ppc"):
+ return "ppc"
+
+ return "i386"
+
+
+def _mac_binary_formats(version: AppleVersion, cpu_arch: str) -> list[str]:
+ formats = [cpu_arch]
+ if cpu_arch == "x86_64":
+ if version < (10, 4):
+ return []
+ formats.extend(["intel", "fat64", "fat32"])
+
+ elif cpu_arch == "i386":
+ if version < (10, 4):
+ return []
+ formats.extend(["intel", "fat32", "fat"])
+
+ elif cpu_arch == "ppc64":
+ # TODO: Need to care about 32-bit PPC for ppc64 through 10.2?
+ if version > (10, 5) or version < (10, 4):
+ return []
+ formats.append("fat64")
+
+ elif cpu_arch == "ppc":
+ if version > (10, 6):
+ return []
+ formats.extend(["fat32", "fat"])
+
+ if cpu_arch in {"arm64", "x86_64"}:
+ formats.append("universal2")
+
+ if cpu_arch in {"x86_64", "i386", "ppc64", "ppc", "intel"}:
+ formats.append("universal")
+
+ return formats
+
+
+def mac_platforms(
+ version: AppleVersion | None = None, arch: str | None = None
+) -> Iterator[str]:
+ """
+ Yields the platform tags for a macOS system.
+
+ The `version` parameter is a two-item tuple specifying the macOS version to
+ generate platform tags for. The `arch` parameter is the CPU architecture to
+ generate platform tags for. Both parameters default to the appropriate value
+ for the current system.
+ """
+ version_str, _, cpu_arch = platform.mac_ver()
+ if version is None:
+ version = cast("AppleVersion", tuple(map(int, version_str.split(".")[:2])))
+ if version == (10, 16):
+ # When built against an older macOS SDK, Python will report macOS 10.16
+ # instead of the real version.
+ version_str = subprocess.run(
+ [
+ sys.executable,
+ "-sS",
+ "-c",
+ "import platform; print(platform.mac_ver()[0])",
+ ],
+ check=True,
+ env={"SYSTEM_VERSION_COMPAT": "0"},
+ stdout=subprocess.PIPE,
+ text=True,
+ ).stdout
+ version = cast("AppleVersion", tuple(map(int, version_str.split(".")[:2])))
+ else:
+ version = version
+ if arch is None:
+ arch = _mac_arch(cpu_arch)
+ else:
+ arch = arch
+
+ if (10, 0) <= version and version < (11, 0):
+ # Prior to Mac OS 11, each yearly release of Mac OS bumped the
+ # "minor" version number. The major version was always 10.
+ for minor_version in range(version[1], -1, -1):
+ compat_version = 10, minor_version
+ binary_formats = _mac_binary_formats(compat_version, arch)
+ for binary_format in binary_formats:
+ yield "macosx_{major}_{minor}_{binary_format}".format(
+ major=10, minor=minor_version, binary_format=binary_format
+ )
+
+ if version >= (11, 0):
+ # Starting with Mac OS 11, each yearly release bumps the major version
+ # number. The minor versions are now the midyear updates.
+ for major_version in range(version[0], 10, -1):
+ compat_version = major_version, 0
+ binary_formats = _mac_binary_formats(compat_version, arch)
+ for binary_format in binary_formats:
+ yield "macosx_{major}_{minor}_{binary_format}".format(
+ major=major_version, minor=0, binary_format=binary_format
+ )
+
+ if version >= (11, 0):
+ # Mac OS 11 on x86_64 is compatible with binaries from previous releases.
+ # Arm64 support was introduced in 11.0, so no Arm binaries from previous
+ # releases exist.
+ #
+ # However, the "universal2" binary format can have a
+ # macOS version earlier than 11.0 when the x86_64 part of the binary supports
+ # that version of macOS.
+ if arch == "x86_64":
+ for minor_version in range(16, 3, -1):
+ compat_version = 10, minor_version
+ binary_formats = _mac_binary_formats(compat_version, arch)
+ for binary_format in binary_formats:
+ yield "macosx_{major}_{minor}_{binary_format}".format(
+ major=compat_version[0],
+ minor=compat_version[1],
+ binary_format=binary_format,
+ )
+ else:
+ for minor_version in range(16, 3, -1):
+ compat_version = 10, minor_version
+ binary_format = "universal2"
+ yield "macosx_{major}_{minor}_{binary_format}".format(
+ major=compat_version[0],
+ minor=compat_version[1],
+ binary_format=binary_format,
+ )
+
+
+def ios_platforms(
+ version: AppleVersion | None = None, multiarch: str | None = None
+) -> Iterator[str]:
+ """
+ Yields the platform tags for an iOS system.
+
+ :param version: A two-item tuple specifying the iOS version to generate
+ platform tags for. Defaults to the current iOS version.
+ :param multiarch: The CPU architecture+ABI to generate platform tags for -
+ (the value used by `sys.implementation._multiarch` e.g.,
+ `arm64_iphoneos` or `x84_64_iphonesimulator`). Defaults to the current
+ multiarch value.
+ """
+ if version is None:
+ # if iOS is the current platform, ios_ver *must* be defined. However,
+ # it won't exist for CPython versions before 3.13, which causes a mypy
+ # error.
+ _, release, _, _ = platform.ios_ver() # type: ignore[attr-defined]
+ version = cast("AppleVersion", tuple(map(int, release.split(".")[:2])))
+
+ if multiarch is None:
+ multiarch = sys.implementation._multiarch
+ multiarch = multiarch.replace("-", "_")
+
+ ios_platform_template = "ios_{major}_{minor}_{multiarch}"
+
+ # Consider any iOS major.minor version from the version requested, down to
+ # 12.0. 12.0 is the first iOS version that is known to have enough features
+ # to support CPython. Consider every possible minor release up to X.9. There
+ # highest the minor has ever gone is 8 (14.8 and 15.8) but having some extra
+ # candidates that won't ever match doesn't really hurt, and it saves us from
+ # having to keep an explicit list of known iOS versions in the code. Return
+ # the results descending order of version number.
+
+ # If the requested major version is less than 12, there won't be any matches.
+ if version[0] < 12:
+ return
+
+ # Consider the actual X.Y version that was requested.
+ yield ios_platform_template.format(
+ major=version[0], minor=version[1], multiarch=multiarch
+ )
+
+ # Consider every minor version from X.0 to the minor version prior to the
+ # version requested by the platform.
+ for minor in range(version[1] - 1, -1, -1):
+ yield ios_platform_template.format(
+ major=version[0], minor=minor, multiarch=multiarch
+ )
+
+ for major in range(version[0] - 1, 11, -1):
+ for minor in range(9, -1, -1):
+ yield ios_platform_template.format(
+ major=major, minor=minor, multiarch=multiarch
+ )
+
+
+def _linux_platforms(is_32bit: bool = _32_BIT_INTERPRETER) -> Iterator[str]:
+ linux = _normalize_string(sysconfig.get_platform())
+ if not linux.startswith("linux_"):
+ # we should never be here, just yield the sysconfig one and return
+ yield linux
+ return
+ if is_32bit:
+ if linux == "linux_x86_64":
+ linux = "linux_i686"
+ elif linux == "linux_aarch64":
+ linux = "linux_armv8l"
+ _, arch = linux.split("_", 1)
+ archs = {"armv8l": ["armv8l", "armv7l"]}.get(arch, [arch])
+ yield from _manylinux.platform_tags(archs)
+ yield from _musllinux.platform_tags(archs)
+ for arch in archs:
+ yield f"linux_{arch}"
+
+
+def _generic_platforms() -> Iterator[str]:
+ yield _normalize_string(sysconfig.get_platform())
+
+
+def platform_tags() -> Iterator[str]:
+ """
+ Provides the platform tags for this installation.
+ """
+ if platform.system() == "Darwin":
+ return mac_platforms()
+ elif platform.system() == "iOS":
+ return ios_platforms()
+ elif platform.system() == "Linux":
+ return _linux_platforms()
+ else:
+ return _generic_platforms()
+
+
+def interpreter_name() -> str:
+ """
+ Returns the name of the running interpreter.
+
+ Some implementations have a reserved, two-letter abbreviation which will
+ be returned when appropriate.
+ """
+ name = sys.implementation.name
+ return INTERPRETER_SHORT_NAMES.get(name) or name
+
+
+def interpreter_version(*, warn: bool = False) -> str:
+ """
+ Returns the version of the running interpreter.
+ """
+ version = _get_config_var("py_version_nodot", warn=warn)
+ if version:
+ version = str(version)
+ else:
+ version = _version_nodot(sys.version_info[:2])
+ return version
+
+
+def _version_nodot(version: PythonVersion) -> str:
+ return "".join(map(str, version))
+
+
+def sys_tags(*, warn: bool = False) -> Iterator[Tag]:
+ """
+ Returns the sequence of tag triples for the running interpreter.
+
+ The order of the sequence corresponds to priority order for the
+ interpreter, from most to least important.
+ """
+
+ interp_name = interpreter_name()
+ if interp_name == "cp":
+ yield from cpython_tags(warn=warn)
+ else:
+ yield from generic_tags()
+
+ if interp_name == "pp":
+ interp = "pp3"
+ elif interp_name == "cp":
+ interp = "cp" + interpreter_version(warn=warn)
+ else:
+ interp = None
+ yield from compatible_tags(interpreter=interp)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/utils.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/utils.py
new file mode 100644
index 000000000..d33da5bb8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/utils.py
@@ -0,0 +1,174 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+
+from __future__ import annotations
+
+import re
+from typing import NewType, Tuple, Union, cast
+
+from .tags import Tag, parse_tag
+from .version import InvalidVersion, Version
+
+BuildTag = Union[Tuple[()], Tuple[int, str]]
+NormalizedName = NewType("NormalizedName", str)
+
+
+class InvalidName(ValueError):
+ """
+ An invalid distribution name; users should refer to the packaging user guide.
+ """
+
+
+class InvalidWheelFilename(ValueError):
+ """
+ An invalid wheel filename was found, users should refer to PEP 427.
+ """
+
+
+class InvalidSdistFilename(ValueError):
+ """
+ An invalid sdist filename was found, users should refer to the packaging user guide.
+ """
+
+
+# Core metadata spec for `Name`
+_validate_regex = re.compile(
+ r"^([A-Z0-9]|[A-Z0-9][A-Z0-9._-]*[A-Z0-9])$", re.IGNORECASE
+)
+_canonicalize_regex = re.compile(r"[-_.]+")
+_normalized_regex = re.compile(r"^([a-z0-9]|[a-z0-9]([a-z0-9-](?!--))*[a-z0-9])$")
+# PEP 427: The build number must start with a digit.
+_build_tag_regex = re.compile(r"(\d+)(.*)")
+
+
+def canonicalize_name(name: str, *, validate: bool = False) -> NormalizedName:
+ if validate and not _validate_regex.match(name):
+ raise InvalidName(f"name is invalid: {name!r}")
+ # This is taken from PEP 503.
+ value = _canonicalize_regex.sub("-", name).lower()
+ return cast(NormalizedName, value)
+
+
+def is_normalized_name(name: str) -> bool:
+ return _normalized_regex.match(name) is not None
+
+
+def canonicalize_version(
+ version: Version | str, *, strip_trailing_zero: bool = True
+) -> str:
+ """
+ This is very similar to Version.__str__, but has one subtle difference
+ with the way it handles the release segment.
+ """
+ if isinstance(version, str):
+ try:
+ parsed = Version(version)
+ except InvalidVersion:
+ # Legacy versions cannot be normalized
+ return version
+ else:
+ parsed = version
+
+ parts = []
+
+ # Epoch
+ if parsed.epoch != 0:
+ parts.append(f"{parsed.epoch}!")
+
+ # Release segment
+ release_segment = ".".join(str(x) for x in parsed.release)
+ if strip_trailing_zero:
+ # NB: This strips trailing '.0's to normalize
+ release_segment = re.sub(r"(\.0)+$", "", release_segment)
+ parts.append(release_segment)
+
+ # Pre-release
+ if parsed.pre is not None:
+ parts.append("".join(str(x) for x in parsed.pre))
+
+ # Post-release
+ if parsed.post is not None:
+ parts.append(f".post{parsed.post}")
+
+ # Development release
+ if parsed.dev is not None:
+ parts.append(f".dev{parsed.dev}")
+
+ # Local version segment
+ if parsed.local is not None:
+ parts.append(f"+{parsed.local}")
+
+ return "".join(parts)
+
+
+def parse_wheel_filename(
+ filename: str,
+) -> tuple[NormalizedName, Version, BuildTag, frozenset[Tag]]:
+ if not filename.endswith(".whl"):
+ raise InvalidWheelFilename(
+ f"Invalid wheel filename (extension must be '.whl'): {filename}"
+ )
+
+ filename = filename[:-4]
+ dashes = filename.count("-")
+ if dashes not in (4, 5):
+ raise InvalidWheelFilename(
+ f"Invalid wheel filename (wrong number of parts): {filename}"
+ )
+
+ parts = filename.split("-", dashes - 2)
+ name_part = parts[0]
+ # See PEP 427 for the rules on escaping the project name.
+ if "__" in name_part or re.match(r"^[\w\d._]*$", name_part, re.UNICODE) is None:
+ raise InvalidWheelFilename(f"Invalid project name: {filename}")
+ name = canonicalize_name(name_part)
+
+ try:
+ version = Version(parts[1])
+ except InvalidVersion as e:
+ raise InvalidWheelFilename(
+ f"Invalid wheel filename (invalid version): {filename}"
+ ) from e
+
+ if dashes == 5:
+ build_part = parts[2]
+ build_match = _build_tag_regex.match(build_part)
+ if build_match is None:
+ raise InvalidWheelFilename(
+ f"Invalid build number: {build_part} in '{filename}'"
+ )
+ build = cast(BuildTag, (int(build_match.group(1)), build_match.group(2)))
+ else:
+ build = ()
+ tags = parse_tag(parts[-1])
+ return (name, version, build, tags)
+
+
+def parse_sdist_filename(filename: str) -> tuple[NormalizedName, Version]:
+ if filename.endswith(".tar.gz"):
+ file_stem = filename[: -len(".tar.gz")]
+ elif filename.endswith(".zip"):
+ file_stem = filename[: -len(".zip")]
+ else:
+ raise InvalidSdistFilename(
+ f"Invalid sdist filename (extension must be '.tar.gz' or '.zip'):"
+ f" {filename}"
+ )
+
+ # We are requiring a PEP 440 version, which cannot contain dashes,
+ # so we split on the last dash.
+ name_part, sep, version_part = file_stem.rpartition("-")
+ if not sep:
+ raise InvalidSdistFilename(f"Invalid sdist filename: {filename}")
+
+ name = canonicalize_name(name_part)
+
+ try:
+ version = Version(version_part)
+ except InvalidVersion as e:
+ raise InvalidSdistFilename(
+ f"Invalid sdist filename (invalid version): {filename}"
+ ) from e
+
+ return (name, version)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/version.py b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/version.py
new file mode 100644
index 000000000..8b0a04084
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/packaging/version.py
@@ -0,0 +1,563 @@
+# This file is dual licensed under the terms of the Apache License, Version
+# 2.0, and the BSD License. See the LICENSE file in the root of this repository
+# for complete details.
+"""
+.. testsetup::
+
+ from pip._vendor.packaging.version import parse, Version
+"""
+
+from __future__ import annotations
+
+import itertools
+import re
+from typing import Any, Callable, NamedTuple, SupportsInt, Tuple, Union
+
+from ._structures import Infinity, InfinityType, NegativeInfinity, NegativeInfinityType
+
+__all__ = ["VERSION_PATTERN", "parse", "Version", "InvalidVersion"]
+
+LocalType = Tuple[Union[int, str], ...]
+
+CmpPrePostDevType = Union[InfinityType, NegativeInfinityType, Tuple[str, int]]
+CmpLocalType = Union[
+ NegativeInfinityType,
+ Tuple[Union[Tuple[int, str], Tuple[NegativeInfinityType, Union[int, str]]], ...],
+]
+CmpKey = Tuple[
+ int,
+ Tuple[int, ...],
+ CmpPrePostDevType,
+ CmpPrePostDevType,
+ CmpPrePostDevType,
+ CmpLocalType,
+]
+VersionComparisonMethod = Callable[[CmpKey, CmpKey], bool]
+
+
+class _Version(NamedTuple):
+ epoch: int
+ release: tuple[int, ...]
+ dev: tuple[str, int] | None
+ pre: tuple[str, int] | None
+ post: tuple[str, int] | None
+ local: LocalType | None
+
+
+def parse(version: str) -> Version:
+ """Parse the given version string.
+
+ >>> parse('1.0.dev1')
+ <Version('1.0.dev1')>
+
+ :param version: The version string to parse.
+ :raises InvalidVersion: When the version string is not a valid version.
+ """
+ return Version(version)
+
+
+class InvalidVersion(ValueError):
+ """Raised when a version string is not a valid version.
+
+ >>> Version("invalid")
+ Traceback (most recent call last):
+ ...
+ packaging.version.InvalidVersion: Invalid version: 'invalid'
+ """
+
+
+class _BaseVersion:
+ _key: tuple[Any, ...]
+
+ def __hash__(self) -> int:
+ return hash(self._key)
+
+ # Please keep the duplicated `isinstance` check
+ # in the six comparisons hereunder
+ # unless you find a way to avoid adding overhead function calls.
+ def __lt__(self, other: _BaseVersion) -> bool:
+ if not isinstance(other, _BaseVersion):
+ return NotImplemented
+
+ return self._key < other._key
+
+ def __le__(self, other: _BaseVersion) -> bool:
+ if not isinstance(other, _BaseVersion):
+ return NotImplemented
+
+ return self._key <= other._key
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, _BaseVersion):
+ return NotImplemented
+
+ return self._key == other._key
+
+ def __ge__(self, other: _BaseVersion) -> bool:
+ if not isinstance(other, _BaseVersion):
+ return NotImplemented
+
+ return self._key >= other._key
+
+ def __gt__(self, other: _BaseVersion) -> bool:
+ if not isinstance(other, _BaseVersion):
+ return NotImplemented
+
+ return self._key > other._key
+
+ def __ne__(self, other: object) -> bool:
+ if not isinstance(other, _BaseVersion):
+ return NotImplemented
+
+ return self._key != other._key
+
+
+# Deliberately not anchored to the start and end of the string, to make it
+# easier for 3rd party code to reuse
+_VERSION_PATTERN = r"""
+ v?
+ (?:
+ (?:(?P<epoch>[0-9]+)!)? # epoch
+ (?P<release>[0-9]+(?:\.[0-9]+)*) # release segment
+ (?P<pre> # pre-release
+ [-_\.]?
+ (?P<pre_l>alpha|a|beta|b|preview|pre|c|rc)
+ [-_\.]?
+ (?P<pre_n>[0-9]+)?
+ )?
+ (?P<post> # post release
+ (?:-(?P<post_n1>[0-9]+))
+ |
+ (?:
+ [-_\.]?
+ (?P<post_l>post|rev|r)
+ [-_\.]?
+ (?P<post_n2>[0-9]+)?
+ )
+ )?
+ (?P<dev> # dev release
+ [-_\.]?
+ (?P<dev_l>dev)
+ [-_\.]?
+ (?P<dev_n>[0-9]+)?
+ )?
+ )
+ (?:\+(?P<local>[a-z0-9]+(?:[-_\.][a-z0-9]+)*))? # local version
+"""
+
+VERSION_PATTERN = _VERSION_PATTERN
+"""
+A string containing the regular expression used to match a valid version.
+
+The pattern is not anchored at either end, and is intended for embedding in larger
+expressions (for example, matching a version number as part of a file name). The
+regular expression should be compiled with the ``re.VERBOSE`` and ``re.IGNORECASE``
+flags set.
+
+:meta hide-value:
+"""
+
+
+class Version(_BaseVersion):
+ """This class abstracts handling of a project's versions.
+
+ A :class:`Version` instance is comparison aware and can be compared and
+ sorted using the standard Python interfaces.
+
+ >>> v1 = Version("1.0a5")
+ >>> v2 = Version("1.0")
+ >>> v1
+ <Version('1.0a5')>
+ >>> v2
+ <Version('1.0')>
+ >>> v1 < v2
+ True
+ >>> v1 == v2
+ False
+ >>> v1 > v2
+ False
+ >>> v1 >= v2
+ False
+ >>> v1 <= v2
+ True
+ """
+
+ _regex = re.compile(r"^\s*" + VERSION_PATTERN + r"\s*$", re.VERBOSE | re.IGNORECASE)
+ _key: CmpKey
+
+ def __init__(self, version: str) -> None:
+ """Initialize a Version object.
+
+ :param version:
+ The string representation of a version which will be parsed and normalized
+ before use.
+ :raises InvalidVersion:
+ If the ``version`` does not conform to PEP 440 in any way then this
+ exception will be raised.
+ """
+
+ # Validate the version and parse it into pieces
+ match = self._regex.search(version)
+ if not match:
+ raise InvalidVersion(f"Invalid version: '{version}'")
+
+ # Store the parsed out pieces of the version
+ self._version = _Version(
+ epoch=int(match.group("epoch")) if match.group("epoch") else 0,
+ release=tuple(int(i) for i in match.group("release").split(".")),
+ pre=_parse_letter_version(match.group("pre_l"), match.group("pre_n")),
+ post=_parse_letter_version(
+ match.group("post_l"), match.group("post_n1") or match.group("post_n2")
+ ),
+ dev=_parse_letter_version(match.group("dev_l"), match.group("dev_n")),
+ local=_parse_local_version(match.group("local")),
+ )
+
+ # Generate a key which will be used for sorting
+ self._key = _cmpkey(
+ self._version.epoch,
+ self._version.release,
+ self._version.pre,
+ self._version.post,
+ self._version.dev,
+ self._version.local,
+ )
+
+ def __repr__(self) -> str:
+ """A representation of the Version that shows all internal state.
+
+ >>> Version('1.0.0')
+ <Version('1.0.0')>
+ """
+ return f"<Version('{self}')>"
+
+ def __str__(self) -> str:
+ """A string representation of the version that can be rounded-tripped.
+
+ >>> str(Version("1.0a5"))
+ '1.0a5'
+ """
+ parts = []
+
+ # Epoch
+ if self.epoch != 0:
+ parts.append(f"{self.epoch}!")
+
+ # Release segment
+ parts.append(".".join(str(x) for x in self.release))
+
+ # Pre-release
+ if self.pre is not None:
+ parts.append("".join(str(x) for x in self.pre))
+
+ # Post-release
+ if self.post is not None:
+ parts.append(f".post{self.post}")
+
+ # Development release
+ if self.dev is not None:
+ parts.append(f".dev{self.dev}")
+
+ # Local version segment
+ if self.local is not None:
+ parts.append(f"+{self.local}")
+
+ return "".join(parts)
+
+ @property
+ def epoch(self) -> int:
+ """The epoch of the version.
+
+ >>> Version("2.0.0").epoch
+ 0
+ >>> Version("1!2.0.0").epoch
+ 1
+ """
+ return self._version.epoch
+
+ @property
+ def release(self) -> tuple[int, ...]:
+ """The components of the "release" segment of the version.
+
+ >>> Version("1.2.3").release
+ (1, 2, 3)
+ >>> Version("2.0.0").release
+ (2, 0, 0)
+ >>> Version("1!2.0.0.post0").release
+ (2, 0, 0)
+
+ Includes trailing zeroes but not the epoch or any pre-release / development /
+ post-release suffixes.
+ """
+ return self._version.release
+
+ @property
+ def pre(self) -> tuple[str, int] | None:
+ """The pre-release segment of the version.
+
+ >>> print(Version("1.2.3").pre)
+ None
+ >>> Version("1.2.3a1").pre
+ ('a', 1)
+ >>> Version("1.2.3b1").pre
+ ('b', 1)
+ >>> Version("1.2.3rc1").pre
+ ('rc', 1)
+ """
+ return self._version.pre
+
+ @property
+ def post(self) -> int | None:
+ """The post-release number of the version.
+
+ >>> print(Version("1.2.3").post)
+ None
+ >>> Version("1.2.3.post1").post
+ 1
+ """
+ return self._version.post[1] if self._version.post else None
+
+ @property
+ def dev(self) -> int | None:
+ """The development number of the version.
+
+ >>> print(Version("1.2.3").dev)
+ None
+ >>> Version("1.2.3.dev1").dev
+ 1
+ """
+ return self._version.dev[1] if self._version.dev else None
+
+ @property
+ def local(self) -> str | None:
+ """The local version segment of the version.
+
+ >>> print(Version("1.2.3").local)
+ None
+ >>> Version("1.2.3+abc").local
+ 'abc'
+ """
+ if self._version.local:
+ return ".".join(str(x) for x in self._version.local)
+ else:
+ return None
+
+ @property
+ def public(self) -> str:
+ """The public portion of the version.
+
+ >>> Version("1.2.3").public
+ '1.2.3'
+ >>> Version("1.2.3+abc").public
+ '1.2.3'
+ >>> Version("1.2.3+abc.dev1").public
+ '1.2.3'
+ """
+ return str(self).split("+", 1)[0]
+
+ @property
+ def base_version(self) -> str:
+ """The "base version" of the version.
+
+ >>> Version("1.2.3").base_version
+ '1.2.3'
+ >>> Version("1.2.3+abc").base_version
+ '1.2.3'
+ >>> Version("1!1.2.3+abc.dev1").base_version
+ '1!1.2.3'
+
+ The "base version" is the public version of the project without any pre or post
+ release markers.
+ """
+ parts = []
+
+ # Epoch
+ if self.epoch != 0:
+ parts.append(f"{self.epoch}!")
+
+ # Release segment
+ parts.append(".".join(str(x) for x in self.release))
+
+ return "".join(parts)
+
+ @property
+ def is_prerelease(self) -> bool:
+ """Whether this version is a pre-release.
+
+ >>> Version("1.2.3").is_prerelease
+ False
+ >>> Version("1.2.3a1").is_prerelease
+ True
+ >>> Version("1.2.3b1").is_prerelease
+ True
+ >>> Version("1.2.3rc1").is_prerelease
+ True
+ >>> Version("1.2.3dev1").is_prerelease
+ True
+ """
+ return self.dev is not None or self.pre is not None
+
+ @property
+ def is_postrelease(self) -> bool:
+ """Whether this version is a post-release.
+
+ >>> Version("1.2.3").is_postrelease
+ False
+ >>> Version("1.2.3.post1").is_postrelease
+ True
+ """
+ return self.post is not None
+
+ @property
+ def is_devrelease(self) -> bool:
+ """Whether this version is a development release.
+
+ >>> Version("1.2.3").is_devrelease
+ False
+ >>> Version("1.2.3.dev1").is_devrelease
+ True
+ """
+ return self.dev is not None
+
+ @property
+ def major(self) -> int:
+ """The first item of :attr:`release` or ``0`` if unavailable.
+
+ >>> Version("1.2.3").major
+ 1
+ """
+ return self.release[0] if len(self.release) >= 1 else 0
+
+ @property
+ def minor(self) -> int:
+ """The second item of :attr:`release` or ``0`` if unavailable.
+
+ >>> Version("1.2.3").minor
+ 2
+ >>> Version("1").minor
+ 0
+ """
+ return self.release[1] if len(self.release) >= 2 else 0
+
+ @property
+ def micro(self) -> int:
+ """The third item of :attr:`release` or ``0`` if unavailable.
+
+ >>> Version("1.2.3").micro
+ 3
+ >>> Version("1").micro
+ 0
+ """
+ return self.release[2] if len(self.release) >= 3 else 0
+
+
+def _parse_letter_version(
+ letter: str | None, number: str | bytes | SupportsInt | None
+) -> tuple[str, int] | None:
+ if letter:
+ # We consider there to be an implicit 0 in a pre-release if there is
+ # not a numeral associated with it.
+ if number is None:
+ number = 0
+
+ # We normalize any letters to their lower case form
+ letter = letter.lower()
+
+ # We consider some words to be alternate spellings of other words and
+ # in those cases we want to normalize the spellings to our preferred
+ # spelling.
+ if letter == "alpha":
+ letter = "a"
+ elif letter == "beta":
+ letter = "b"
+ elif letter in ["c", "pre", "preview"]:
+ letter = "rc"
+ elif letter in ["rev", "r"]:
+ letter = "post"
+
+ return letter, int(number)
+ if not letter and number:
+ # We assume if we are given a number, but we are not given a letter
+ # then this is using the implicit post release syntax (e.g. 1.0-1)
+ letter = "post"
+
+ return letter, int(number)
+
+ return None
+
+
+_local_version_separators = re.compile(r"[\._-]")
+
+
+def _parse_local_version(local: str | None) -> LocalType | None:
+ """
+ Takes a string like abc.1.twelve and turns it into ("abc", 1, "twelve").
+ """
+ if local is not None:
+ return tuple(
+ part.lower() if not part.isdigit() else int(part)
+ for part in _local_version_separators.split(local)
+ )
+ return None
+
+
+def _cmpkey(
+ epoch: int,
+ release: tuple[int, ...],
+ pre: tuple[str, int] | None,
+ post: tuple[str, int] | None,
+ dev: tuple[str, int] | None,
+ local: LocalType | None,
+) -> CmpKey:
+ # When we compare a release version, we want to compare it with all of the
+ # trailing zeros removed. So we'll use a reverse the list, drop all the now
+ # leading zeros until we come to something non zero, then take the rest
+ # re-reverse it back into the correct order and make it a tuple and use
+ # that for our sorting key.
+ _release = tuple(
+ reversed(list(itertools.dropwhile(lambda x: x == 0, reversed(release))))
+ )
+
+ # We need to "trick" the sorting algorithm to put 1.0.dev0 before 1.0a0.
+ # We'll do this by abusing the pre segment, but we _only_ want to do this
+ # if there is not a pre or a post segment. If we have one of those then
+ # the normal sorting rules will handle this case correctly.
+ if pre is None and post is None and dev is not None:
+ _pre: CmpPrePostDevType = NegativeInfinity
+ # Versions without a pre-release (except as noted above) should sort after
+ # those with one.
+ elif pre is None:
+ _pre = Infinity
+ else:
+ _pre = pre
+
+ # Versions without a post segment should sort before those with one.
+ if post is None:
+ _post: CmpPrePostDevType = NegativeInfinity
+
+ else:
+ _post = post
+
+ # Versions without a development segment should sort after those with one.
+ if dev is None:
+ _dev: CmpPrePostDevType = Infinity
+
+ else:
+ _dev = dev
+
+ if local is None:
+ # Versions without a local segment should sort before those with one.
+ _local: CmpLocalType = NegativeInfinity
+ else:
+ # Versions with a local segment need that segment parsed to implement
+ # the sorting rules in PEP440.
+ # - Alpha numeric segments sort before numeric segments
+ # - Alpha numeric segments sort lexicographically
+ # - Numeric segments sort numerically
+ # - Shorter versions sort before longer versions when the prefixes
+ # match exactly
+ _local = tuple(
+ (i, "") if isinstance(i, int) else (NegativeInfinity, i) for i in local
+ )
+
+ return epoch, _release, _pre, _post, _dev, _local
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pkg_resources/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pkg_resources/__init__.py
new file mode 100644
index 000000000..57ce7f100
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pkg_resources/__init__.py
@@ -0,0 +1,3676 @@
+# TODO: Add Generic type annotations to initialized collections.
+# For now we'd simply use implicit Any/Unknown which would add redundant annotations
+# mypy: disable-error-code="var-annotated"
+"""
+Package resource API
+--------------------
+
+A resource is a logical file contained within a package, or a logical
+subdirectory thereof. The package resource API expects resource names
+to have their path parts separated with ``/``, *not* whatever the local
+path separator is. Do not use os.path operations to manipulate resource
+names being passed into the API.
+
+The package resource API is designed to work with normal filesystem packages,
+.egg files, and unpacked .egg files. It can also work in a limited way with
+.zip files and with custom PEP 302 loaders that support the ``get_data()``
+method.
+
+This module is deprecated. Users are directed to :mod:`importlib.resources`,
+:mod:`importlib.metadata` and :pypi:`packaging` instead.
+"""
+
+from __future__ import annotations
+
+import sys
+
+if sys.version_info < (3, 8): # noqa: UP036 # Check for unsupported versions
+ raise RuntimeError("Python 3.8 or later is required")
+
+import os
+import io
+import time
+import re
+import types
+from typing import (
+ Any,
+ Literal,
+ Dict,
+ Iterator,
+ Mapping,
+ MutableSequence,
+ NamedTuple,
+ NoReturn,
+ Tuple,
+ Union,
+ TYPE_CHECKING,
+ Protocol,
+ Callable,
+ Iterable,
+ TypeVar,
+ overload,
+)
+import zipfile
+import zipimport
+import warnings
+import stat
+import functools
+import pkgutil
+import operator
+import platform
+import collections
+import plistlib
+import email.parser
+import errno
+import tempfile
+import textwrap
+import inspect
+import ntpath
+import posixpath
+import importlib
+import importlib.abc
+import importlib.machinery
+from pkgutil import get_importer
+
+import _imp
+
+# capture these to bypass sandboxing
+from os import utime
+from os import open as os_open
+from os.path import isdir, split
+
+try:
+ from os import mkdir, rename, unlink
+
+ WRITE_SUPPORT = True
+except ImportError:
+ # no write support, probably under GAE
+ WRITE_SUPPORT = False
+
+from pip._internal.utils._jaraco_text import (
+ yield_lines,
+ drop_comment,
+ join_continuation,
+)
+from pip._vendor.packaging import markers as _packaging_markers
+from pip._vendor.packaging import requirements as _packaging_requirements
+from pip._vendor.packaging import utils as _packaging_utils
+from pip._vendor.packaging import version as _packaging_version
+from pip._vendor.platformdirs import user_cache_dir as _user_cache_dir
+
+if TYPE_CHECKING:
+ from _typeshed import BytesPath, StrPath, StrOrBytesPath
+ from pip._vendor.typing_extensions import Self
+
+
+# Patch: Remove deprecation warning from vendored pkg_resources.
+# Setting PYTHONWARNINGS=error to verify builds produce no warnings
+# causes immediate exceptions.
+# See https://github.com/pypa/pip/issues/12243
+
+
+_T = TypeVar("_T")
+_DistributionT = TypeVar("_DistributionT", bound="Distribution")
+# Type aliases
+_NestedStr = Union[str, Iterable[Union[str, Iterable["_NestedStr"]]]]
+_InstallerTypeT = Callable[["Requirement"], "_DistributionT"]
+_InstallerType = Callable[["Requirement"], Union["Distribution", None]]
+_PkgReqType = Union[str, "Requirement"]
+_EPDistType = Union["Distribution", _PkgReqType]
+_MetadataType = Union["IResourceProvider", None]
+_ResolvedEntryPoint = Any # Can be any attribute in the module
+_ResourceStream = Any # TODO / Incomplete: A readable file-like object
+# Any object works, but let's indicate we expect something like a module (optionally has __loader__ or __file__)
+_ModuleLike = Union[object, types.ModuleType]
+# Any: Should be _ModuleLike but we end up with issues where _ModuleLike doesn't have _ZipLoaderModule's __loader__
+_ProviderFactoryType = Callable[[Any], "IResourceProvider"]
+_DistFinderType = Callable[[_T, str, bool], Iterable["Distribution"]]
+_NSHandlerType = Callable[[_T, str, str, types.ModuleType], Union[str, None]]
+_AdapterT = TypeVar(
+ "_AdapterT", _DistFinderType[Any], _ProviderFactoryType, _NSHandlerType[Any]
+)
+
+
+# Use _typeshed.importlib.LoaderProtocol once available https://github.com/python/typeshed/pull/11890
+class _LoaderProtocol(Protocol):
+ def load_module(self, fullname: str, /) -> types.ModuleType: ...
+
+
+class _ZipLoaderModule(Protocol):
+ __loader__: zipimport.zipimporter
+
+
+_PEP440_FALLBACK = re.compile(r"^v?(?P<safe>(?:[0-9]+!)?[0-9]+(?:\.[0-9]+)*)", re.I)
+
+
+class PEP440Warning(RuntimeWarning):
+ """
+ Used when there is an issue with a version or specifier not complying with
+ PEP 440.
+ """
+
+
+parse_version = _packaging_version.Version
+
+
+_state_vars: dict[str, str] = {}
+
+
+def _declare_state(vartype: str, varname: str, initial_value: _T) -> _T:
+ _state_vars[varname] = vartype
+ return initial_value
+
+
+def __getstate__() -> dict[str, Any]:
+ state = {}
+ g = globals()
+ for k, v in _state_vars.items():
+ state[k] = g['_sget_' + v](g[k])
+ return state
+
+
+def __setstate__(state: dict[str, Any]) -> dict[str, Any]:
+ g = globals()
+ for k, v in state.items():
+ g['_sset_' + _state_vars[k]](k, g[k], v)
+ return state
+
+
+def _sget_dict(val):
+ return val.copy()
+
+
+def _sset_dict(key, ob, state):
+ ob.clear()
+ ob.update(state)
+
+
+def _sget_object(val):
+ return val.__getstate__()
+
+
+def _sset_object(key, ob, state):
+ ob.__setstate__(state)
+
+
+_sget_none = _sset_none = lambda *args: None
+
+
+def get_supported_platform():
+ """Return this platform's maximum compatible version.
+
+ distutils.util.get_platform() normally reports the minimum version
+ of macOS that would be required to *use* extensions produced by
+ distutils. But what we want when checking compatibility is to know the
+ version of macOS that we are *running*. To allow usage of packages that
+ explicitly require a newer version of macOS, we must also know the
+ current version of the OS.
+
+ If this condition occurs for any other platform with a version in its
+ platform strings, this function should be extended accordingly.
+ """
+ plat = get_build_platform()
+ m = macosVersionString.match(plat)
+ if m is not None and sys.platform == "darwin":
+ try:
+ plat = 'macosx-%s-%s' % ('.'.join(_macos_vers()[:2]), m.group(3))
+ except ValueError:
+ # not macOS
+ pass
+ return plat
+
+
+__all__ = [
+ # Basic resource access and distribution/entry point discovery
+ 'require',
+ 'run_script',
+ 'get_provider',
+ 'get_distribution',
+ 'load_entry_point',
+ 'get_entry_map',
+ 'get_entry_info',
+ 'iter_entry_points',
+ 'resource_string',
+ 'resource_stream',
+ 'resource_filename',
+ 'resource_listdir',
+ 'resource_exists',
+ 'resource_isdir',
+ # Environmental control
+ 'declare_namespace',
+ 'working_set',
+ 'add_activation_listener',
+ 'find_distributions',
+ 'set_extraction_path',
+ 'cleanup_resources',
+ 'get_default_cache',
+ # Primary implementation classes
+ 'Environment',
+ 'WorkingSet',
+ 'ResourceManager',
+ 'Distribution',
+ 'Requirement',
+ 'EntryPoint',
+ # Exceptions
+ 'ResolutionError',
+ 'VersionConflict',
+ 'DistributionNotFound',
+ 'UnknownExtra',
+ 'ExtractionError',
+ # Warnings
+ 'PEP440Warning',
+ # Parsing functions and string utilities
+ 'parse_requirements',
+ 'parse_version',
+ 'safe_name',
+ 'safe_version',
+ 'get_platform',
+ 'compatible_platforms',
+ 'yield_lines',
+ 'split_sections',
+ 'safe_extra',
+ 'to_filename',
+ 'invalid_marker',
+ 'evaluate_marker',
+ # filesystem utilities
+ 'ensure_directory',
+ 'normalize_path',
+ # Distribution "precedence" constants
+ 'EGG_DIST',
+ 'BINARY_DIST',
+ 'SOURCE_DIST',
+ 'CHECKOUT_DIST',
+ 'DEVELOP_DIST',
+ # "Provider" interfaces, implementations, and registration/lookup APIs
+ 'IMetadataProvider',
+ 'IResourceProvider',
+ 'FileMetadata',
+ 'PathMetadata',
+ 'EggMetadata',
+ 'EmptyProvider',
+ 'empty_provider',
+ 'NullProvider',
+ 'EggProvider',
+ 'DefaultProvider',
+ 'ZipProvider',
+ 'register_finder',
+ 'register_namespace_handler',
+ 'register_loader_type',
+ 'fixup_namespace_packages',
+ 'get_importer',
+ # Warnings
+ 'PkgResourcesDeprecationWarning',
+ # Deprecated/backward compatibility only
+ 'run_main',
+ 'AvailableDistributions',
+]
+
+
+class ResolutionError(Exception):
+ """Abstract base for dependency resolution errors"""
+
+ def __repr__(self):
+ return self.__class__.__name__ + repr(self.args)
+
+
+class VersionConflict(ResolutionError):
+ """
+ An already-installed version conflicts with the requested version.
+
+ Should be initialized with the installed Distribution and the requested
+ Requirement.
+ """
+
+ _template = "{self.dist} is installed but {self.req} is required"
+
+ @property
+ def dist(self) -> Distribution:
+ return self.args[0]
+
+ @property
+ def req(self) -> Requirement:
+ return self.args[1]
+
+ def report(self):
+ return self._template.format(**locals())
+
+ def with_context(self, required_by: set[Distribution | str]):
+ """
+ If required_by is non-empty, return a version of self that is a
+ ContextualVersionConflict.
+ """
+ if not required_by:
+ return self
+ args = self.args + (required_by,)
+ return ContextualVersionConflict(*args)
+
+
+class ContextualVersionConflict(VersionConflict):
+ """
+ A VersionConflict that accepts a third parameter, the set of the
+ requirements that required the installed Distribution.
+ """
+
+ _template = VersionConflict._template + ' by {self.required_by}'
+
+ @property
+ def required_by(self) -> set[str]:
+ return self.args[2]
+
+
+class DistributionNotFound(ResolutionError):
+ """A requested distribution was not found"""
+
+ _template = (
+ "The '{self.req}' distribution was not found "
+ "and is required by {self.requirers_str}"
+ )
+
+ @property
+ def req(self) -> Requirement:
+ return self.args[0]
+
+ @property
+ def requirers(self) -> set[str] | None:
+ return self.args[1]
+
+ @property
+ def requirers_str(self):
+ if not self.requirers:
+ return 'the application'
+ return ', '.join(self.requirers)
+
+ def report(self):
+ return self._template.format(**locals())
+
+ def __str__(self):
+ return self.report()
+
+
+class UnknownExtra(ResolutionError):
+ """Distribution doesn't have an "extra feature" of the given name"""
+
+
+_provider_factories: dict[type[_ModuleLike], _ProviderFactoryType] = {}
+
+PY_MAJOR = '{}.{}'.format(*sys.version_info)
+EGG_DIST = 3
+BINARY_DIST = 2
+SOURCE_DIST = 1
+CHECKOUT_DIST = 0
+DEVELOP_DIST = -1
+
+
+def register_loader_type(
+ loader_type: type[_ModuleLike], provider_factory: _ProviderFactoryType
+):
+ """Register `provider_factory` to make providers for `loader_type`
+
+ `loader_type` is the type or class of a PEP 302 ``module.__loader__``,
+ and `provider_factory` is a function that, passed a *module* object,
+ returns an ``IResourceProvider`` for that module.
+ """
+ _provider_factories[loader_type] = provider_factory
+
+
+@overload
+def get_provider(moduleOrReq: str) -> IResourceProvider: ...
+@overload
+def get_provider(moduleOrReq: Requirement) -> Distribution: ...
+def get_provider(moduleOrReq: str | Requirement) -> IResourceProvider | Distribution:
+ """Return an IResourceProvider for the named module or requirement"""
+ if isinstance(moduleOrReq, Requirement):
+ return working_set.find(moduleOrReq) or require(str(moduleOrReq))[0]
+ try:
+ module = sys.modules[moduleOrReq]
+ except KeyError:
+ __import__(moduleOrReq)
+ module = sys.modules[moduleOrReq]
+ loader = getattr(module, '__loader__', None)
+ return _find_adapter(_provider_factories, loader)(module)
+
+
+@functools.lru_cache(maxsize=None)
+def _macos_vers():
+ version = platform.mac_ver()[0]
+ # fallback for MacPorts
+ if version == '':
+ plist = '/System/Library/CoreServices/SystemVersion.plist'
+ if os.path.exists(plist):
+ with open(plist, 'rb') as fh:
+ plist_content = plistlib.load(fh)
+ if 'ProductVersion' in plist_content:
+ version = plist_content['ProductVersion']
+ return version.split('.')
+
+
+def _macos_arch(machine):
+ return {'PowerPC': 'ppc', 'Power_Macintosh': 'ppc'}.get(machine, machine)
+
+
+def get_build_platform():
+ """Return this platform's string for platform-specific distributions
+
+ XXX Currently this is the same as ``distutils.util.get_platform()``, but it
+ needs some hacks for Linux and macOS.
+ """
+ from sysconfig import get_platform
+
+ plat = get_platform()
+ if sys.platform == "darwin" and not plat.startswith('macosx-'):
+ try:
+ version = _macos_vers()
+ machine = os.uname()[4].replace(" ", "_")
+ return "macosx-%d.%d-%s" % (
+ int(version[0]),
+ int(version[1]),
+ _macos_arch(machine),
+ )
+ except ValueError:
+ # if someone is running a non-Mac darwin system, this will fall
+ # through to the default implementation
+ pass
+ return plat
+
+
+macosVersionString = re.compile(r"macosx-(\d+)\.(\d+)-(.*)")
+darwinVersionString = re.compile(r"darwin-(\d+)\.(\d+)\.(\d+)-(.*)")
+# XXX backward compat
+get_platform = get_build_platform
+
+
+def compatible_platforms(provided: str | None, required: str | None):
+ """Can code for the `provided` platform run on the `required` platform?
+
+ Returns true if either platform is ``None``, or the platforms are equal.
+
+ XXX Needs compatibility checks for Linux and other unixy OSes.
+ """
+ if provided is None or required is None or provided == required:
+ # easy case
+ return True
+
+ # macOS special cases
+ reqMac = macosVersionString.match(required)
+ if reqMac:
+ provMac = macosVersionString.match(provided)
+
+ # is this a Mac package?
+ if not provMac:
+ # this is backwards compatibility for packages built before
+ # setuptools 0.6. All packages built after this point will
+ # use the new macOS designation.
+ provDarwin = darwinVersionString.match(provided)
+ if provDarwin:
+ dversion = int(provDarwin.group(1))
+ macosversion = "%s.%s" % (reqMac.group(1), reqMac.group(2))
+ if (
+ dversion == 7
+ and macosversion >= "10.3"
+ or dversion == 8
+ and macosversion >= "10.4"
+ ):
+ return True
+ # egg isn't macOS or legacy darwin
+ return False
+
+ # are they the same major version and machine type?
+ if provMac.group(1) != reqMac.group(1) or provMac.group(3) != reqMac.group(3):
+ return False
+
+ # is the required OS major update >= the provided one?
+ if int(provMac.group(2)) > int(reqMac.group(2)):
+ return False
+
+ return True
+
+ # XXX Linux and other platforms' special cases should go here
+ return False
+
+
+@overload
+def get_distribution(dist: _DistributionT) -> _DistributionT: ...
+@overload
+def get_distribution(dist: _PkgReqType) -> Distribution: ...
+def get_distribution(dist: Distribution | _PkgReqType) -> Distribution:
+ """Return a current distribution object for a Requirement or string"""
+ if isinstance(dist, str):
+ dist = Requirement.parse(dist)
+ if isinstance(dist, Requirement):
+ # Bad type narrowing, dist has to be a Requirement here, so get_provider has to return Distribution
+ dist = get_provider(dist) # type: ignore[assignment]
+ if not isinstance(dist, Distribution):
+ raise TypeError("Expected str, Requirement, or Distribution", dist)
+ return dist
+
+
+def load_entry_point(dist: _EPDistType, group: str, name: str) -> _ResolvedEntryPoint:
+ """Return `name` entry point of `group` for `dist` or raise ImportError"""
+ return get_distribution(dist).load_entry_point(group, name)
+
+
+@overload
+def get_entry_map(
+ dist: _EPDistType, group: None = None
+) -> dict[str, dict[str, EntryPoint]]: ...
+@overload
+def get_entry_map(dist: _EPDistType, group: str) -> dict[str, EntryPoint]: ...
+def get_entry_map(dist: _EPDistType, group: str | None = None):
+ """Return the entry point map for `group`, or the full entry map"""
+ return get_distribution(dist).get_entry_map(group)
+
+
+def get_entry_info(dist: _EPDistType, group: str, name: str):
+ """Return the EntryPoint object for `group`+`name`, or ``None``"""
+ return get_distribution(dist).get_entry_info(group, name)
+
+
+class IMetadataProvider(Protocol):
+ def has_metadata(self, name: str) -> bool:
+ """Does the package's distribution contain the named metadata?"""
+
+ def get_metadata(self, name: str) -> str:
+ """The named metadata resource as a string"""
+
+ def get_metadata_lines(self, name: str) -> Iterator[str]:
+ """Yield named metadata resource as list of non-blank non-comment lines
+
+ Leading and trailing whitespace is stripped from each line, and lines
+ with ``#`` as the first non-blank character are omitted."""
+
+ def metadata_isdir(self, name: str) -> bool:
+ """Is the named metadata a directory? (like ``os.path.isdir()``)"""
+
+ def metadata_listdir(self, name: str) -> list[str]:
+ """List of metadata names in the directory (like ``os.listdir()``)"""
+
+ def run_script(self, script_name: str, namespace: dict[str, Any]) -> None:
+ """Execute the named script in the supplied namespace dictionary"""
+
+
+class IResourceProvider(IMetadataProvider, Protocol):
+ """An object that provides access to package resources"""
+
+ def get_resource_filename(
+ self, manager: ResourceManager, resource_name: str
+ ) -> str:
+ """Return a true filesystem path for `resource_name`
+
+ `manager` must be a ``ResourceManager``"""
+
+ def get_resource_stream(
+ self, manager: ResourceManager, resource_name: str
+ ) -> _ResourceStream:
+ """Return a readable file-like object for `resource_name`
+
+ `manager` must be a ``ResourceManager``"""
+
+ def get_resource_string(
+ self, manager: ResourceManager, resource_name: str
+ ) -> bytes:
+ """Return the contents of `resource_name` as :obj:`bytes`
+
+ `manager` must be a ``ResourceManager``"""
+
+ def has_resource(self, resource_name: str) -> bool:
+ """Does the package contain the named resource?"""
+
+ def resource_isdir(self, resource_name: str) -> bool:
+ """Is the named resource a directory? (like ``os.path.isdir()``)"""
+
+ def resource_listdir(self, resource_name: str) -> list[str]:
+ """List of resource names in the directory (like ``os.listdir()``)"""
+
+
+class WorkingSet:
+ """A collection of active distributions on sys.path (or a similar list)"""
+
+ def __init__(self, entries: Iterable[str] | None = None):
+ """Create working set from list of path entries (default=sys.path)"""
+ self.entries: list[str] = []
+ self.entry_keys = {}
+ self.by_key = {}
+ self.normalized_to_canonical_keys = {}
+ self.callbacks = []
+
+ if entries is None:
+ entries = sys.path
+
+ for entry in entries:
+ self.add_entry(entry)
+
+ @classmethod
+ def _build_master(cls):
+ """
+ Prepare the master working set.
+ """
+ ws = cls()
+ try:
+ from __main__ import __requires__
+ except ImportError:
+ # The main program does not list any requirements
+ return ws
+
+ # ensure the requirements are met
+ try:
+ ws.require(__requires__)
+ except VersionConflict:
+ return cls._build_from_requirements(__requires__)
+
+ return ws
+
+ @classmethod
+ def _build_from_requirements(cls, req_spec):
+ """
+ Build a working set from a requirement spec. Rewrites sys.path.
+ """
+ # try it without defaults already on sys.path
+ # by starting with an empty path
+ ws = cls([])
+ reqs = parse_requirements(req_spec)
+ dists = ws.resolve(reqs, Environment())
+ for dist in dists:
+ ws.add(dist)
+
+ # add any missing entries from sys.path
+ for entry in sys.path:
+ if entry not in ws.entries:
+ ws.add_entry(entry)
+
+ # then copy back to sys.path
+ sys.path[:] = ws.entries
+ return ws
+
+ def add_entry(self, entry: str):
+ """Add a path item to ``.entries``, finding any distributions on it
+
+ ``find_distributions(entry, True)`` is used to find distributions
+ corresponding to the path entry, and they are added. `entry` is
+ always appended to ``.entries``, even if it is already present.
+ (This is because ``sys.path`` can contain the same value more than
+ once, and the ``.entries`` of the ``sys.path`` WorkingSet should always
+ equal ``sys.path``.)
+ """
+ self.entry_keys.setdefault(entry, [])
+ self.entries.append(entry)
+ for dist in find_distributions(entry, True):
+ self.add(dist, entry, False)
+
+ def __contains__(self, dist: Distribution) -> bool:
+ """True if `dist` is the active distribution for its project"""
+ return self.by_key.get(dist.key) == dist
+
+ def find(self, req: Requirement) -> Distribution | None:
+ """Find a distribution matching requirement `req`
+
+ If there is an active distribution for the requested project, this
+ returns it as long as it meets the version requirement specified by
+ `req`. But, if there is an active distribution for the project and it
+ does *not* meet the `req` requirement, ``VersionConflict`` is raised.
+ If there is no active distribution for the requested project, ``None``
+ is returned.
+ """
+ dist = self.by_key.get(req.key)
+
+ if dist is None:
+ canonical_key = self.normalized_to_canonical_keys.get(req.key)
+
+ if canonical_key is not None:
+ req.key = canonical_key
+ dist = self.by_key.get(canonical_key)
+
+ if dist is not None and dist not in req:
+ # XXX add more info
+ raise VersionConflict(dist, req)
+ return dist
+
+ def iter_entry_points(self, group: str, name: str | None = None):
+ """Yield entry point objects from `group` matching `name`
+
+ If `name` is None, yields all entry points in `group` from all
+ distributions in the working set, otherwise only ones matching
+ both `group` and `name` are yielded (in distribution order).
+ """
+ return (
+ entry
+ for dist in self
+ for entry in dist.get_entry_map(group).values()
+ if name is None or name == entry.name
+ )
+
+ def run_script(self, requires: str, script_name: str):
+ """Locate distribution for `requires` and run `script_name` script"""
+ ns = sys._getframe(1).f_globals
+ name = ns['__name__']
+ ns.clear()
+ ns['__name__'] = name
+ self.require(requires)[0].run_script(script_name, ns)
+
+ def __iter__(self) -> Iterator[Distribution]:
+ """Yield distributions for non-duplicate projects in the working set
+
+ The yield order is the order in which the items' path entries were
+ added to the working set.
+ """
+ seen = set()
+ for item in self.entries:
+ if item not in self.entry_keys:
+ # workaround a cache issue
+ continue
+
+ for key in self.entry_keys[item]:
+ if key not in seen:
+ seen.add(key)
+ yield self.by_key[key]
+
+ def add(
+ self,
+ dist: Distribution,
+ entry: str | None = None,
+ insert: bool = True,
+ replace: bool = False,
+ ):
+ """Add `dist` to working set, associated with `entry`
+
+ If `entry` is unspecified, it defaults to the ``.location`` of `dist`.
+ On exit from this routine, `entry` is added to the end of the working
+ set's ``.entries`` (if it wasn't already present).
+
+ `dist` is only added to the working set if it's for a project that
+ doesn't already have a distribution in the set, unless `replace=True`.
+ If it's added, any callbacks registered with the ``subscribe()`` method
+ will be called.
+ """
+ if insert:
+ dist.insert_on(self.entries, entry, replace=replace)
+
+ if entry is None:
+ entry = dist.location
+ keys = self.entry_keys.setdefault(entry, [])
+ keys2 = self.entry_keys.setdefault(dist.location, [])
+ if not replace and dist.key in self.by_key:
+ # ignore hidden distros
+ return
+
+ self.by_key[dist.key] = dist
+ normalized_name = _packaging_utils.canonicalize_name(dist.key)
+ self.normalized_to_canonical_keys[normalized_name] = dist.key
+ if dist.key not in keys:
+ keys.append(dist.key)
+ if dist.key not in keys2:
+ keys2.append(dist.key)
+ self._added_new(dist)
+
+ @overload
+ def resolve(
+ self,
+ requirements: Iterable[Requirement],
+ env: Environment | None,
+ installer: _InstallerTypeT[_DistributionT],
+ replace_conflicting: bool = False,
+ extras: tuple[str, ...] | None = None,
+ ) -> list[_DistributionT]: ...
+ @overload
+ def resolve(
+ self,
+ requirements: Iterable[Requirement],
+ env: Environment | None = None,
+ *,
+ installer: _InstallerTypeT[_DistributionT],
+ replace_conflicting: bool = False,
+ extras: tuple[str, ...] | None = None,
+ ) -> list[_DistributionT]: ...
+ @overload
+ def resolve(
+ self,
+ requirements: Iterable[Requirement],
+ env: Environment | None = None,
+ installer: _InstallerType | None = None,
+ replace_conflicting: bool = False,
+ extras: tuple[str, ...] | None = None,
+ ) -> list[Distribution]: ...
+ def resolve(
+ self,
+ requirements: Iterable[Requirement],
+ env: Environment | None = None,
+ installer: _InstallerType | None | _InstallerTypeT[_DistributionT] = None,
+ replace_conflicting: bool = False,
+ extras: tuple[str, ...] | None = None,
+ ) -> list[Distribution] | list[_DistributionT]:
+ """List all distributions needed to (recursively) meet `requirements`
+
+ `requirements` must be a sequence of ``Requirement`` objects. `env`,
+ if supplied, should be an ``Environment`` instance. If
+ not supplied, it defaults to all distributions available within any
+ entry or distribution in the working set. `installer`, if supplied,
+ will be invoked with each requirement that cannot be met by an
+ already-installed distribution; it should return a ``Distribution`` or
+ ``None``.
+
+ Unless `replace_conflicting=True`, raises a VersionConflict exception
+ if
+ any requirements are found on the path that have the correct name but
+ the wrong version. Otherwise, if an `installer` is supplied it will be
+ invoked to obtain the correct version of the requirement and activate
+ it.
+
+ `extras` is a list of the extras to be used with these requirements.
+ This is important because extra requirements may look like `my_req;
+ extra = "my_extra"`, which would otherwise be interpreted as a purely
+ optional requirement. Instead, we want to be able to assert that these
+ requirements are truly required.
+ """
+
+ # set up the stack
+ requirements = list(requirements)[::-1]
+ # set of processed requirements
+ processed = set()
+ # key -> dist
+ best = {}
+ to_activate = []
+
+ req_extras = _ReqExtras()
+
+ # Mapping of requirement to set of distributions that required it;
+ # useful for reporting info about conflicts.
+ required_by = collections.defaultdict(set)
+
+ while requirements:
+ # process dependencies breadth-first
+ req = requirements.pop(0)
+ if req in processed:
+ # Ignore cyclic or redundant dependencies
+ continue
+
+ if not req_extras.markers_pass(req, extras):
+ continue
+
+ dist = self._resolve_dist(
+ req, best, replace_conflicting, env, installer, required_by, to_activate
+ )
+
+ # push the new requirements onto the stack
+ new_requirements = dist.requires(req.extras)[::-1]
+ requirements.extend(new_requirements)
+
+ # Register the new requirements needed by req
+ for new_requirement in new_requirements:
+ required_by[new_requirement].add(req.project_name)
+ req_extras[new_requirement] = req.extras
+
+ processed.add(req)
+
+ # return list of distros to activate
+ return to_activate
+
+ def _resolve_dist(
+ self, req, best, replace_conflicting, env, installer, required_by, to_activate
+ ) -> Distribution:
+ dist = best.get(req.key)
+ if dist is None:
+ # Find the best distribution and add it to the map
+ dist = self.by_key.get(req.key)
+ if dist is None or (dist not in req and replace_conflicting):
+ ws = self
+ if env is None:
+ if dist is None:
+ env = Environment(self.entries)
+ else:
+ # Use an empty environment and workingset to avoid
+ # any further conflicts with the conflicting
+ # distribution
+ env = Environment([])
+ ws = WorkingSet([])
+ dist = best[req.key] = env.best_match(
+ req, ws, installer, replace_conflicting=replace_conflicting
+ )
+ if dist is None:
+ requirers = required_by.get(req, None)
+ raise DistributionNotFound(req, requirers)
+ to_activate.append(dist)
+ if dist not in req:
+ # Oops, the "best" so far conflicts with a dependency
+ dependent_req = required_by[req]
+ raise VersionConflict(dist, req).with_context(dependent_req)
+ return dist
+
+ @overload
+ def find_plugins(
+ self,
+ plugin_env: Environment,
+ full_env: Environment | None,
+ installer: _InstallerTypeT[_DistributionT],
+ fallback: bool = True,
+ ) -> tuple[list[_DistributionT], dict[Distribution, Exception]]: ...
+ @overload
+ def find_plugins(
+ self,
+ plugin_env: Environment,
+ full_env: Environment | None = None,
+ *,
+ installer: _InstallerTypeT[_DistributionT],
+ fallback: bool = True,
+ ) -> tuple[list[_DistributionT], dict[Distribution, Exception]]: ...
+ @overload
+ def find_plugins(
+ self,
+ plugin_env: Environment,
+ full_env: Environment | None = None,
+ installer: _InstallerType | None = None,
+ fallback: bool = True,
+ ) -> tuple[list[Distribution], dict[Distribution, Exception]]: ...
+ def find_plugins(
+ self,
+ plugin_env: Environment,
+ full_env: Environment | None = None,
+ installer: _InstallerType | None | _InstallerTypeT[_DistributionT] = None,
+ fallback: bool = True,
+ ) -> tuple[
+ list[Distribution] | list[_DistributionT],
+ dict[Distribution, Exception],
+ ]:
+ """Find all activatable distributions in `plugin_env`
+
+ Example usage::
+
+ distributions, errors = working_set.find_plugins(
+ Environment(plugin_dirlist)
+ )
+ # add plugins+libs to sys.path
+ map(working_set.add, distributions)
+ # display errors
+ print('Could not load', errors)
+
+ The `plugin_env` should be an ``Environment`` instance that contains
+ only distributions that are in the project's "plugin directory" or
+ directories. The `full_env`, if supplied, should be an ``Environment``
+ contains all currently-available distributions. If `full_env` is not
+ supplied, one is created automatically from the ``WorkingSet`` this
+ method is called on, which will typically mean that every directory on
+ ``sys.path`` will be scanned for distributions.
+
+ `installer` is a standard installer callback as used by the
+ ``resolve()`` method. The `fallback` flag indicates whether we should
+ attempt to resolve older versions of a plugin if the newest version
+ cannot be resolved.
+
+ This method returns a 2-tuple: (`distributions`, `error_info`), where
+ `distributions` is a list of the distributions found in `plugin_env`
+ that were loadable, along with any other distributions that are needed
+ to resolve their dependencies. `error_info` is a dictionary mapping
+ unloadable plugin distributions to an exception instance describing the
+ error that occurred. Usually this will be a ``DistributionNotFound`` or
+ ``VersionConflict`` instance.
+ """
+
+ plugin_projects = list(plugin_env)
+ # scan project names in alphabetic order
+ plugin_projects.sort()
+
+ error_info: dict[Distribution, Exception] = {}
+ distributions: dict[Distribution, Exception | None] = {}
+
+ if full_env is None:
+ env = Environment(self.entries)
+ env += plugin_env
+ else:
+ env = full_env + plugin_env
+
+ shadow_set = self.__class__([])
+ # put all our entries in shadow_set
+ list(map(shadow_set.add, self))
+
+ for project_name in plugin_projects:
+ for dist in plugin_env[project_name]:
+ req = [dist.as_requirement()]
+
+ try:
+ resolvees = shadow_set.resolve(req, env, installer)
+
+ except ResolutionError as v:
+ # save error info
+ error_info[dist] = v
+ if fallback:
+ # try the next older version of project
+ continue
+ else:
+ # give up on this project, keep going
+ break
+
+ else:
+ list(map(shadow_set.add, resolvees))
+ distributions.update(dict.fromkeys(resolvees))
+
+ # success, no need to try any more versions of this project
+ break
+
+ sorted_distributions = list(distributions)
+ sorted_distributions.sort()
+
+ return sorted_distributions, error_info
+
+ def require(self, *requirements: _NestedStr):
+ """Ensure that distributions matching `requirements` are activated
+
+ `requirements` must be a string or a (possibly-nested) sequence
+ thereof, specifying the distributions and versions required. The
+ return value is a sequence of the distributions that needed to be
+ activated to fulfill the requirements; all relevant distributions are
+ included, even if they were already activated in this working set.
+ """
+ needed = self.resolve(parse_requirements(requirements))
+
+ for dist in needed:
+ self.add(dist)
+
+ return needed
+
+ def subscribe(
+ self, callback: Callable[[Distribution], object], existing: bool = True
+ ):
+ """Invoke `callback` for all distributions
+
+ If `existing=True` (default),
+ call on all existing ones, as well.
+ """
+ if callback in self.callbacks:
+ return
+ self.callbacks.append(callback)
+ if not existing:
+ return
+ for dist in self:
+ callback(dist)
+
+ def _added_new(self, dist):
+ for callback in self.callbacks:
+ callback(dist)
+
+ def __getstate__(self):
+ return (
+ self.entries[:],
+ self.entry_keys.copy(),
+ self.by_key.copy(),
+ self.normalized_to_canonical_keys.copy(),
+ self.callbacks[:],
+ )
+
+ def __setstate__(self, e_k_b_n_c):
+ entries, keys, by_key, normalized_to_canonical_keys, callbacks = e_k_b_n_c
+ self.entries = entries[:]
+ self.entry_keys = keys.copy()
+ self.by_key = by_key.copy()
+ self.normalized_to_canonical_keys = normalized_to_canonical_keys.copy()
+ self.callbacks = callbacks[:]
+
+
+class _ReqExtras(Dict["Requirement", Tuple[str, ...]]):
+ """
+ Map each requirement to the extras that demanded it.
+ """
+
+ def markers_pass(self, req: Requirement, extras: tuple[str, ...] | None = None):
+ """
+ Evaluate markers for req against each extra that
+ demanded it.
+
+ Return False if the req has a marker and fails
+ evaluation. Otherwise, return True.
+ """
+ extra_evals = (
+ req.marker.evaluate({'extra': extra})
+ for extra in self.get(req, ()) + (extras or (None,))
+ )
+ return not req.marker or any(extra_evals)
+
+
+class Environment:
+ """Searchable snapshot of distributions on a search path"""
+
+ def __init__(
+ self,
+ search_path: Iterable[str] | None = None,
+ platform: str | None = get_supported_platform(),
+ python: str | None = PY_MAJOR,
+ ):
+ """Snapshot distributions available on a search path
+
+ Any distributions found on `search_path` are added to the environment.
+ `search_path` should be a sequence of ``sys.path`` items. If not
+ supplied, ``sys.path`` is used.
+
+ `platform` is an optional string specifying the name of the platform
+ that platform-specific distributions must be compatible with. If
+ unspecified, it defaults to the current platform. `python` is an
+ optional string naming the desired version of Python (e.g. ``'3.6'``);
+ it defaults to the current version.
+
+ You may explicitly set `platform` (and/or `python`) to ``None`` if you
+ wish to map *all* distributions, not just those compatible with the
+ running platform or Python version.
+ """
+ self._distmap = {}
+ self.platform = platform
+ self.python = python
+ self.scan(search_path)
+
+ def can_add(self, dist: Distribution):
+ """Is distribution `dist` acceptable for this environment?
+
+ The distribution must match the platform and python version
+ requirements specified when this environment was created, or False
+ is returned.
+ """
+ py_compat = (
+ self.python is None
+ or dist.py_version is None
+ or dist.py_version == self.python
+ )
+ return py_compat and compatible_platforms(dist.platform, self.platform)
+
+ def remove(self, dist: Distribution):
+ """Remove `dist` from the environment"""
+ self._distmap[dist.key].remove(dist)
+
+ def scan(self, search_path: Iterable[str] | None = None):
+ """Scan `search_path` for distributions usable in this environment
+
+ Any distributions found are added to the environment.
+ `search_path` should be a sequence of ``sys.path`` items. If not
+ supplied, ``sys.path`` is used. Only distributions conforming to
+ the platform/python version defined at initialization are added.
+ """
+ if search_path is None:
+ search_path = sys.path
+
+ for item in search_path:
+ for dist in find_distributions(item):
+ self.add(dist)
+
+ def __getitem__(self, project_name: str) -> list[Distribution]:
+ """Return a newest-to-oldest list of distributions for `project_name`
+
+ Uses case-insensitive `project_name` comparison, assuming all the
+ project's distributions use their project's name converted to all
+ lowercase as their key.
+
+ """
+ distribution_key = project_name.lower()
+ return self._distmap.get(distribution_key, [])
+
+ def add(self, dist: Distribution):
+ """Add `dist` if we ``can_add()`` it and it has not already been added"""
+ if self.can_add(dist) and dist.has_version():
+ dists = self._distmap.setdefault(dist.key, [])
+ if dist not in dists:
+ dists.append(dist)
+ dists.sort(key=operator.attrgetter('hashcmp'), reverse=True)
+
+ @overload
+ def best_match(
+ self,
+ req: Requirement,
+ working_set: WorkingSet,
+ installer: _InstallerTypeT[_DistributionT],
+ replace_conflicting: bool = False,
+ ) -> _DistributionT: ...
+ @overload
+ def best_match(
+ self,
+ req: Requirement,
+ working_set: WorkingSet,
+ installer: _InstallerType | None = None,
+ replace_conflicting: bool = False,
+ ) -> Distribution | None: ...
+ def best_match(
+ self,
+ req: Requirement,
+ working_set: WorkingSet,
+ installer: _InstallerType | None | _InstallerTypeT[_DistributionT] = None,
+ replace_conflicting: bool = False,
+ ) -> Distribution | None:
+ """Find distribution best matching `req` and usable on `working_set`
+
+ This calls the ``find(req)`` method of the `working_set` to see if a
+ suitable distribution is already active. (This may raise
+ ``VersionConflict`` if an unsuitable version of the project is already
+ active in the specified `working_set`.) If a suitable distribution
+ isn't active, this method returns the newest distribution in the
+ environment that meets the ``Requirement`` in `req`. If no suitable
+ distribution is found, and `installer` is supplied, then the result of
+ calling the environment's ``obtain(req, installer)`` method will be
+ returned.
+ """
+ try:
+ dist = working_set.find(req)
+ except VersionConflict:
+ if not replace_conflicting:
+ raise
+ dist = None
+ if dist is not None:
+ return dist
+ for dist in self[req.key]:
+ if dist in req:
+ return dist
+ # try to download/install
+ return self.obtain(req, installer)
+
+ @overload
+ def obtain(
+ self,
+ requirement: Requirement,
+ installer: _InstallerTypeT[_DistributionT],
+ ) -> _DistributionT: ...
+ @overload
+ def obtain(
+ self,
+ requirement: Requirement,
+ installer: Callable[[Requirement], None] | None = None,
+ ) -> None: ...
+ @overload
+ def obtain(
+ self,
+ requirement: Requirement,
+ installer: _InstallerType | None = None,
+ ) -> Distribution | None: ...
+ def obtain(
+ self,
+ requirement: Requirement,
+ installer: Callable[[Requirement], None]
+ | _InstallerType
+ | None
+ | _InstallerTypeT[_DistributionT] = None,
+ ) -> Distribution | None:
+ """Obtain a distribution matching `requirement` (e.g. via download)
+
+ Obtain a distro that matches requirement (e.g. via download). In the
+ base ``Environment`` class, this routine just returns
+ ``installer(requirement)``, unless `installer` is None, in which case
+ None is returned instead. This method is a hook that allows subclasses
+ to attempt other ways of obtaining a distribution before falling back
+ to the `installer` argument."""
+ return installer(requirement) if installer else None
+
+ def __iter__(self) -> Iterator[str]:
+ """Yield the unique project names of the available distributions"""
+ for key in self._distmap.keys():
+ if self[key]:
+ yield key
+
+ def __iadd__(self, other: Distribution | Environment):
+ """In-place addition of a distribution or environment"""
+ if isinstance(other, Distribution):
+ self.add(other)
+ elif isinstance(other, Environment):
+ for project in other:
+ for dist in other[project]:
+ self.add(dist)
+ else:
+ raise TypeError("Can't add %r to environment" % (other,))
+ return self
+
+ def __add__(self, other: Distribution | Environment):
+ """Add an environment or distribution to an environment"""
+ new = self.__class__([], platform=None, python=None)
+ for env in self, other:
+ new += env
+ return new
+
+
+# XXX backward compatibility
+AvailableDistributions = Environment
+
+
+class ExtractionError(RuntimeError):
+ """An error occurred extracting a resource
+
+ The following attributes are available from instances of this exception:
+
+ manager
+ The resource manager that raised this exception
+
+ cache_path
+ The base directory for resource extraction
+
+ original_error
+ The exception instance that caused extraction to fail
+ """
+
+ manager: ResourceManager
+ cache_path: str
+ original_error: BaseException | None
+
+
+class ResourceManager:
+ """Manage resource extraction and packages"""
+
+ extraction_path: str | None = None
+
+ def __init__(self):
+ self.cached_files = {}
+
+ def resource_exists(self, package_or_requirement: _PkgReqType, resource_name: str):
+ """Does the named resource exist?"""
+ return get_provider(package_or_requirement).has_resource(resource_name)
+
+ def resource_isdir(self, package_or_requirement: _PkgReqType, resource_name: str):
+ """Is the named resource an existing directory?"""
+ return get_provider(package_or_requirement).resource_isdir(resource_name)
+
+ def resource_filename(
+ self, package_or_requirement: _PkgReqType, resource_name: str
+ ):
+ """Return a true filesystem path for specified resource"""
+ return get_provider(package_or_requirement).get_resource_filename(
+ self, resource_name
+ )
+
+ def resource_stream(self, package_or_requirement: _PkgReqType, resource_name: str):
+ """Return a readable file-like object for specified resource"""
+ return get_provider(package_or_requirement).get_resource_stream(
+ self, resource_name
+ )
+
+ def resource_string(
+ self, package_or_requirement: _PkgReqType, resource_name: str
+ ) -> bytes:
+ """Return specified resource as :obj:`bytes`"""
+ return get_provider(package_or_requirement).get_resource_string(
+ self, resource_name
+ )
+
+ def resource_listdir(self, package_or_requirement: _PkgReqType, resource_name: str):
+ """List the contents of the named resource directory"""
+ return get_provider(package_or_requirement).resource_listdir(resource_name)
+
+ def extraction_error(self) -> NoReturn:
+ """Give an error message for problems extracting file(s)"""
+
+ old_exc = sys.exc_info()[1]
+ cache_path = self.extraction_path or get_default_cache()
+
+ tmpl = textwrap.dedent(
+ """
+ Can't extract file(s) to egg cache
+
+ The following error occurred while trying to extract file(s)
+ to the Python egg cache:
+
+ {old_exc}
+
+ The Python egg cache directory is currently set to:
+
+ {cache_path}
+
+ Perhaps your account does not have write access to this directory?
+ You can change the cache directory by setting the PYTHON_EGG_CACHE
+ environment variable to point to an accessible directory.
+ """
+ ).lstrip()
+ err = ExtractionError(tmpl.format(**locals()))
+ err.manager = self
+ err.cache_path = cache_path
+ err.original_error = old_exc
+ raise err
+
+ def get_cache_path(self, archive_name: str, names: Iterable[StrPath] = ()):
+ """Return absolute location in cache for `archive_name` and `names`
+
+ The parent directory of the resulting path will be created if it does
+ not already exist. `archive_name` should be the base filename of the
+ enclosing egg (which may not be the name of the enclosing zipfile!),
+ including its ".egg" extension. `names`, if provided, should be a
+ sequence of path name parts "under" the egg's extraction location.
+
+ This method should only be called by resource providers that need to
+ obtain an extraction location, and only for names they intend to
+ extract, as it tracks the generated names for possible cleanup later.
+ """
+ extract_path = self.extraction_path or get_default_cache()
+ target_path = os.path.join(extract_path, archive_name + '-tmp', *names)
+ try:
+ _bypass_ensure_directory(target_path)
+ except Exception:
+ self.extraction_error()
+
+ self._warn_unsafe_extraction_path(extract_path)
+
+ self.cached_files[target_path] = True
+ return target_path
+
+ @staticmethod
+ def _warn_unsafe_extraction_path(path):
+ """
+ If the default extraction path is overridden and set to an insecure
+ location, such as /tmp, it opens up an opportunity for an attacker to
+ replace an extracted file with an unauthorized payload. Warn the user
+ if a known insecure location is used.
+
+ See Distribute #375 for more details.
+ """
+ if os.name == 'nt' and not path.startswith(os.environ['windir']):
+ # On Windows, permissions are generally restrictive by default
+ # and temp directories are not writable by other users, so
+ # bypass the warning.
+ return
+ mode = os.stat(path).st_mode
+ if mode & stat.S_IWOTH or mode & stat.S_IWGRP:
+ msg = (
+ "Extraction path is writable by group/others "
+ "and vulnerable to attack when "
+ "used with get_resource_filename ({path}). "
+ "Consider a more secure "
+ "location (set with .set_extraction_path or the "
+ "PYTHON_EGG_CACHE environment variable)."
+ ).format(**locals())
+ warnings.warn(msg, UserWarning)
+
+ def postprocess(self, tempname: StrOrBytesPath, filename: StrOrBytesPath):
+ """Perform any platform-specific postprocessing of `tempname`
+
+ This is where Mac header rewrites should be done; other platforms don't
+ have anything special they should do.
+
+ Resource providers should call this method ONLY after successfully
+ extracting a compressed resource. They must NOT call it on resources
+ that are already in the filesystem.
+
+ `tempname` is the current (temporary) name of the file, and `filename`
+ is the name it will be renamed to by the caller after this routine
+ returns.
+ """
+
+ if os.name == 'posix':
+ # Make the resource executable
+ mode = ((os.stat(tempname).st_mode) | 0o555) & 0o7777
+ os.chmod(tempname, mode)
+
+ def set_extraction_path(self, path: str):
+ """Set the base path where resources will be extracted to, if needed.
+
+ If you do not call this routine before any extractions take place, the
+ path defaults to the return value of ``get_default_cache()``. (Which
+ is based on the ``PYTHON_EGG_CACHE`` environment variable, with various
+ platform-specific fallbacks. See that routine's documentation for more
+ details.)
+
+ Resources are extracted to subdirectories of this path based upon
+ information given by the ``IResourceProvider``. You may set this to a
+ temporary directory, but then you must call ``cleanup_resources()`` to
+ delete the extracted files when done. There is no guarantee that
+ ``cleanup_resources()`` will be able to remove all extracted files.
+
+ (Note: you may not change the extraction path for a given resource
+ manager once resources have been extracted, unless you first call
+ ``cleanup_resources()``.)
+ """
+ if self.cached_files:
+ raise ValueError("Can't change extraction path, files already extracted")
+
+ self.extraction_path = path
+
+ def cleanup_resources(self, force: bool = False) -> list[str]:
+ """
+ Delete all extracted resource files and directories, returning a list
+ of the file and directory names that could not be successfully removed.
+ This function does not have any concurrency protection, so it should
+ generally only be called when the extraction path is a temporary
+ directory exclusive to a single process. This method is not
+ automatically called; you must call it explicitly or register it as an
+ ``atexit`` function if you wish to ensure cleanup of a temporary
+ directory used for extractions.
+ """
+ # XXX
+ return []
+
+
+def get_default_cache() -> str:
+ """
+ Return the ``PYTHON_EGG_CACHE`` environment variable
+ or a platform-relevant user cache dir for an app
+ named "Python-Eggs".
+ """
+ return os.environ.get('PYTHON_EGG_CACHE') or _user_cache_dir(appname='Python-Eggs')
+
+
+def safe_name(name: str):
+ """Convert an arbitrary string to a standard distribution name
+
+ Any runs of non-alphanumeric/. characters are replaced with a single '-'.
+ """
+ return re.sub('[^A-Za-z0-9.]+', '-', name)
+
+
+def safe_version(version: str):
+ """
+ Convert an arbitrary string to a standard version string
+ """
+ try:
+ # normalize the version
+ return str(_packaging_version.Version(version))
+ except _packaging_version.InvalidVersion:
+ version = version.replace(' ', '.')
+ return re.sub('[^A-Za-z0-9.]+', '-', version)
+
+
+def _forgiving_version(version):
+ """Fallback when ``safe_version`` is not safe enough
+ >>> parse_version(_forgiving_version('0.23ubuntu1'))
+ <Version('0.23.dev0+sanitized.ubuntu1')>
+ >>> parse_version(_forgiving_version('0.23-'))
+ <Version('0.23.dev0+sanitized')>
+ >>> parse_version(_forgiving_version('0.-_'))
+ <Version('0.dev0+sanitized')>
+ >>> parse_version(_forgiving_version('42.+?1'))
+ <Version('42.dev0+sanitized.1')>
+ >>> parse_version(_forgiving_version('hello world'))
+ <Version('0.dev0+sanitized.hello.world')>
+ """
+ version = version.replace(' ', '.')
+ match = _PEP440_FALLBACK.search(version)
+ if match:
+ safe = match["safe"]
+ rest = version[len(safe) :]
+ else:
+ safe = "0"
+ rest = version
+ local = f"sanitized.{_safe_segment(rest)}".strip(".")
+ return f"{safe}.dev0+{local}"
+
+
+def _safe_segment(segment):
+ """Convert an arbitrary string into a safe segment"""
+ segment = re.sub('[^A-Za-z0-9.]+', '-', segment)
+ segment = re.sub('-[^A-Za-z0-9]+', '-', segment)
+ return re.sub(r'\.[^A-Za-z0-9]+', '.', segment).strip(".-")
+
+
+def safe_extra(extra: str):
+ """Convert an arbitrary string to a standard 'extra' name
+
+ Any runs of non-alphanumeric characters are replaced with a single '_',
+ and the result is always lowercased.
+ """
+ return re.sub('[^A-Za-z0-9.-]+', '_', extra).lower()
+
+
+def to_filename(name: str):
+ """Convert a project or version name to its filename-escaped form
+
+ Any '-' characters are currently replaced with '_'.
+ """
+ return name.replace('-', '_')
+
+
+def invalid_marker(text: str):
+ """
+ Validate text as a PEP 508 environment marker; return an exception
+ if invalid or False otherwise.
+ """
+ try:
+ evaluate_marker(text)
+ except SyntaxError as e:
+ e.filename = None
+ e.lineno = None
+ return e
+ return False
+
+
+def evaluate_marker(text: str, extra: str | None = None) -> bool:
+ """
+ Evaluate a PEP 508 environment marker.
+ Return a boolean indicating the marker result in this environment.
+ Raise SyntaxError if marker is invalid.
+
+ This implementation uses the 'pyparsing' module.
+ """
+ try:
+ marker = _packaging_markers.Marker(text)
+ return marker.evaluate()
+ except _packaging_markers.InvalidMarker as e:
+ raise SyntaxError(e) from e
+
+
+class NullProvider:
+ """Try to implement resources and metadata for arbitrary PEP 302 loaders"""
+
+ egg_name: str | None = None
+ egg_info: str | None = None
+ loader: _LoaderProtocol | None = None
+
+ def __init__(self, module: _ModuleLike):
+ self.loader = getattr(module, '__loader__', None)
+ self.module_path = os.path.dirname(getattr(module, '__file__', ''))
+
+ def get_resource_filename(self, manager: ResourceManager, resource_name: str):
+ return self._fn(self.module_path, resource_name)
+
+ def get_resource_stream(self, manager: ResourceManager, resource_name: str):
+ return io.BytesIO(self.get_resource_string(manager, resource_name))
+
+ def get_resource_string(
+ self, manager: ResourceManager, resource_name: str
+ ) -> bytes:
+ return self._get(self._fn(self.module_path, resource_name))
+
+ def has_resource(self, resource_name: str):
+ return self._has(self._fn(self.module_path, resource_name))
+
+ def _get_metadata_path(self, name):
+ return self._fn(self.egg_info, name)
+
+ def has_metadata(self, name: str) -> bool:
+ if not self.egg_info:
+ return False
+
+ path = self._get_metadata_path(name)
+ return self._has(path)
+
+ def get_metadata(self, name: str):
+ if not self.egg_info:
+ return ""
+ path = self._get_metadata_path(name)
+ value = self._get(path)
+ try:
+ return value.decode('utf-8')
+ except UnicodeDecodeError as exc:
+ # Include the path in the error message to simplify
+ # troubleshooting, and without changing the exception type.
+ exc.reason += ' in {} file at path: {}'.format(name, path)
+ raise
+
+ def get_metadata_lines(self, name: str) -> Iterator[str]:
+ return yield_lines(self.get_metadata(name))
+
+ def resource_isdir(self, resource_name: str):
+ return self._isdir(self._fn(self.module_path, resource_name))
+
+ def metadata_isdir(self, name: str) -> bool:
+ return bool(self.egg_info and self._isdir(self._fn(self.egg_info, name)))
+
+ def resource_listdir(self, resource_name: str):
+ return self._listdir(self._fn(self.module_path, resource_name))
+
+ def metadata_listdir(self, name: str) -> list[str]:
+ if self.egg_info:
+ return self._listdir(self._fn(self.egg_info, name))
+ return []
+
+ def run_script(self, script_name: str, namespace: dict[str, Any]):
+ script = 'scripts/' + script_name
+ if not self.has_metadata(script):
+ raise ResolutionError(
+ "Script {script!r} not found in metadata at {self.egg_info!r}".format(
+ **locals()
+ ),
+ )
+
+ script_text = self.get_metadata(script).replace('\r\n', '\n')
+ script_text = script_text.replace('\r', '\n')
+ script_filename = self._fn(self.egg_info, script)
+ namespace['__file__'] = script_filename
+ if os.path.exists(script_filename):
+ source = _read_utf8_with_fallback(script_filename)
+ code = compile(source, script_filename, 'exec')
+ exec(code, namespace, namespace)
+ else:
+ from linecache import cache
+
+ cache[script_filename] = (
+ len(script_text),
+ 0,
+ script_text.split('\n'),
+ script_filename,
+ )
+ script_code = compile(script_text, script_filename, 'exec')
+ exec(script_code, namespace, namespace)
+
+ def _has(self, path) -> bool:
+ raise NotImplementedError(
+ "Can't perform this operation for unregistered loader type"
+ )
+
+ def _isdir(self, path) -> bool:
+ raise NotImplementedError(
+ "Can't perform this operation for unregistered loader type"
+ )
+
+ def _listdir(self, path) -> list[str]:
+ raise NotImplementedError(
+ "Can't perform this operation for unregistered loader type"
+ )
+
+ def _fn(self, base: str | None, resource_name: str):
+ if base is None:
+ raise TypeError(
+ "`base` parameter in `_fn` is `None`. Either override this method or check the parameter first."
+ )
+ self._validate_resource_path(resource_name)
+ if resource_name:
+ return os.path.join(base, *resource_name.split('/'))
+ return base
+
+ @staticmethod
+ def _validate_resource_path(path):
+ """
+ Validate the resource paths according to the docs.
+ https://setuptools.pypa.io/en/latest/pkg_resources.html#basic-resource-access
+
+ >>> warned = getfixture('recwarn')
+ >>> warnings.simplefilter('always')
+ >>> vrp = NullProvider._validate_resource_path
+ >>> vrp('foo/bar.txt')
+ >>> bool(warned)
+ False
+ >>> vrp('../foo/bar.txt')
+ >>> bool(warned)
+ True
+ >>> warned.clear()
+ >>> vrp('/foo/bar.txt')
+ >>> bool(warned)
+ True
+ >>> vrp('foo/../../bar.txt')
+ >>> bool(warned)
+ True
+ >>> warned.clear()
+ >>> vrp('foo/f../bar.txt')
+ >>> bool(warned)
+ False
+
+ Windows path separators are straight-up disallowed.
+ >>> vrp(r'\\foo/bar.txt')
+ Traceback (most recent call last):
+ ...
+ ValueError: Use of .. or absolute path in a resource path \
+is not allowed.
+
+ >>> vrp(r'C:\\foo/bar.txt')
+ Traceback (most recent call last):
+ ...
+ ValueError: Use of .. or absolute path in a resource path \
+is not allowed.
+
+ Blank values are allowed
+
+ >>> vrp('')
+ >>> bool(warned)
+ False
+
+ Non-string values are not.
+
+ >>> vrp(None)
+ Traceback (most recent call last):
+ ...
+ AttributeError: ...
+ """
+ invalid = (
+ os.path.pardir in path.split(posixpath.sep)
+ or posixpath.isabs(path)
+ or ntpath.isabs(path)
+ or path.startswith("\\")
+ )
+ if not invalid:
+ return
+
+ msg = "Use of .. or absolute path in a resource path is not allowed."
+
+ # Aggressively disallow Windows absolute paths
+ if (path.startswith("\\") or ntpath.isabs(path)) and not posixpath.isabs(path):
+ raise ValueError(msg)
+
+ # for compatibility, warn; in future
+ # raise ValueError(msg)
+ issue_warning(
+ msg[:-1] + " and will raise exceptions in a future release.",
+ DeprecationWarning,
+ )
+
+ def _get(self, path) -> bytes:
+ if hasattr(self.loader, 'get_data') and self.loader:
+ # Already checked get_data exists
+ return self.loader.get_data(path) # type: ignore[attr-defined]
+ raise NotImplementedError(
+ "Can't perform this operation for loaders without 'get_data()'"
+ )
+
+
+register_loader_type(object, NullProvider)
+
+
+def _parents(path):
+ """
+ yield all parents of path including path
+ """
+ last = None
+ while path != last:
+ yield path
+ last = path
+ path, _ = os.path.split(path)
+
+
+class EggProvider(NullProvider):
+ """Provider based on a virtual filesystem"""
+
+ def __init__(self, module: _ModuleLike):
+ super().__init__(module)
+ self._setup_prefix()
+
+ def _setup_prefix(self):
+ # Assume that metadata may be nested inside a "basket"
+ # of multiple eggs and use module_path instead of .archive.
+ eggs = filter(_is_egg_path, _parents(self.module_path))
+ egg = next(eggs, None)
+ egg and self._set_egg(egg)
+
+ def _set_egg(self, path: str):
+ self.egg_name = os.path.basename(path)
+ self.egg_info = os.path.join(path, 'EGG-INFO')
+ self.egg_root = path
+
+
+class DefaultProvider(EggProvider):
+ """Provides access to package resources in the filesystem"""
+
+ def _has(self, path) -> bool:
+ return os.path.exists(path)
+
+ def _isdir(self, path) -> bool:
+ return os.path.isdir(path)
+
+ def _listdir(self, path):
+ return os.listdir(path)
+
+ def get_resource_stream(self, manager: object, resource_name: str):
+ return open(self._fn(self.module_path, resource_name), 'rb')
+
+ def _get(self, path) -> bytes:
+ with open(path, 'rb') as stream:
+ return stream.read()
+
+ @classmethod
+ def _register(cls):
+ loader_names = (
+ 'SourceFileLoader',
+ 'SourcelessFileLoader',
+ )
+ for name in loader_names:
+ loader_cls = getattr(importlib.machinery, name, type(None))
+ register_loader_type(loader_cls, cls)
+
+
+DefaultProvider._register()
+
+
+class EmptyProvider(NullProvider):
+ """Provider that returns nothing for all requests"""
+
+ # A special case, we don't want all Providers inheriting from NullProvider to have a potentially None module_path
+ module_path: str | None = None # type: ignore[assignment]
+
+ _isdir = _has = lambda self, path: False
+
+ def _get(self, path) -> bytes:
+ return b''
+
+ def _listdir(self, path):
+ return []
+
+ def __init__(self):
+ pass
+
+
+empty_provider = EmptyProvider()
+
+
+class ZipManifests(Dict[str, "MemoizedZipManifests.manifest_mod"]):
+ """
+ zip manifest builder
+ """
+
+ # `path` could be `StrPath | IO[bytes]` but that violates the LSP for `MemoizedZipManifests.load`
+ @classmethod
+ def build(cls, path: str):
+ """
+ Build a dictionary similar to the zipimport directory
+ caches, except instead of tuples, store ZipInfo objects.
+
+ Use a platform-specific path separator (os.sep) for the path keys
+ for compatibility with pypy on Windows.
+ """
+ with zipfile.ZipFile(path) as zfile:
+ items = (
+ (
+ name.replace('/', os.sep),
+ zfile.getinfo(name),
+ )
+ for name in zfile.namelist()
+ )
+ return dict(items)
+
+ load = build
+
+
+class MemoizedZipManifests(ZipManifests):
+ """
+ Memoized zipfile manifests.
+ """
+
+ class manifest_mod(NamedTuple):
+ manifest: dict[str, zipfile.ZipInfo]
+ mtime: float
+
+ def load(self, path: str) -> dict[str, zipfile.ZipInfo]: # type: ignore[override] # ZipManifests.load is a classmethod
+ """
+ Load a manifest at path or return a suitable manifest already loaded.
+ """
+ path = os.path.normpath(path)
+ mtime = os.stat(path).st_mtime
+
+ if path not in self or self[path].mtime != mtime:
+ manifest = self.build(path)
+ self[path] = self.manifest_mod(manifest, mtime)
+
+ return self[path].manifest
+
+
+class ZipProvider(EggProvider):
+ """Resource support for zips and eggs"""
+
+ eagers: list[str] | None = None
+ _zip_manifests = MemoizedZipManifests()
+ # ZipProvider's loader should always be a zipimporter or equivalent
+ loader: zipimport.zipimporter
+
+ def __init__(self, module: _ZipLoaderModule):
+ super().__init__(module)
+ self.zip_pre = self.loader.archive + os.sep
+
+ def _zipinfo_name(self, fspath):
+ # Convert a virtual filename (full path to file) into a zipfile subpath
+ # usable with the zipimport directory cache for our target archive
+ fspath = fspath.rstrip(os.sep)
+ if fspath == self.loader.archive:
+ return ''
+ if fspath.startswith(self.zip_pre):
+ return fspath[len(self.zip_pre) :]
+ raise AssertionError("%s is not a subpath of %s" % (fspath, self.zip_pre))
+
+ def _parts(self, zip_path):
+ # Convert a zipfile subpath into an egg-relative path part list.
+ # pseudo-fs path
+ fspath = self.zip_pre + zip_path
+ if fspath.startswith(self.egg_root + os.sep):
+ return fspath[len(self.egg_root) + 1 :].split(os.sep)
+ raise AssertionError("%s is not a subpath of %s" % (fspath, self.egg_root))
+
+ @property
+ def zipinfo(self):
+ return self._zip_manifests.load(self.loader.archive)
+
+ def get_resource_filename(self, manager: ResourceManager, resource_name: str):
+ if not self.egg_name:
+ raise NotImplementedError(
+ "resource_filename() only supported for .egg, not .zip"
+ )
+ # no need to lock for extraction, since we use temp names
+ zip_path = self._resource_to_zip(resource_name)
+ eagers = self._get_eager_resources()
+ if '/'.join(self._parts(zip_path)) in eagers:
+ for name in eagers:
+ self._extract_resource(manager, self._eager_to_zip(name))
+ return self._extract_resource(manager, zip_path)
+
+ @staticmethod
+ def _get_date_and_size(zip_stat):
+ size = zip_stat.file_size
+ # ymdhms+wday, yday, dst
+ date_time = zip_stat.date_time + (0, 0, -1)
+ # 1980 offset already done
+ timestamp = time.mktime(date_time)
+ return timestamp, size
+
+ # FIXME: 'ZipProvider._extract_resource' is too complex (12)
+ def _extract_resource(self, manager: ResourceManager, zip_path) -> str: # noqa: C901
+ if zip_path in self._index():
+ for name in self._index()[zip_path]:
+ last = self._extract_resource(manager, os.path.join(zip_path, name))
+ # return the extracted directory name
+ return os.path.dirname(last)
+
+ timestamp, size = self._get_date_and_size(self.zipinfo[zip_path])
+
+ if not WRITE_SUPPORT:
+ raise OSError(
+ '"os.rename" and "os.unlink" are not supported on this platform'
+ )
+ try:
+ if not self.egg_name:
+ raise OSError(
+ '"egg_name" is empty. This likely means no egg could be found from the "module_path".'
+ )
+ real_path = manager.get_cache_path(self.egg_name, self._parts(zip_path))
+
+ if self._is_current(real_path, zip_path):
+ return real_path
+
+ outf, tmpnam = _mkstemp(
+ ".$extract",
+ dir=os.path.dirname(real_path),
+ )
+ os.write(outf, self.loader.get_data(zip_path))
+ os.close(outf)
+ utime(tmpnam, (timestamp, timestamp))
+ manager.postprocess(tmpnam, real_path)
+
+ try:
+ rename(tmpnam, real_path)
+
+ except OSError:
+ if os.path.isfile(real_path):
+ if self._is_current(real_path, zip_path):
+ # the file became current since it was checked above,
+ # so proceed.
+ return real_path
+ # Windows, del old file and retry
+ elif os.name == 'nt':
+ unlink(real_path)
+ rename(tmpnam, real_path)
+ return real_path
+ raise
+
+ except OSError:
+ # report a user-friendly error
+ manager.extraction_error()
+
+ return real_path
+
+ def _is_current(self, file_path, zip_path):
+ """
+ Return True if the file_path is current for this zip_path
+ """
+ timestamp, size = self._get_date_and_size(self.zipinfo[zip_path])
+ if not os.path.isfile(file_path):
+ return False
+ stat = os.stat(file_path)
+ if stat.st_size != size or stat.st_mtime != timestamp:
+ return False
+ # check that the contents match
+ zip_contents = self.loader.get_data(zip_path)
+ with open(file_path, 'rb') as f:
+ file_contents = f.read()
+ return zip_contents == file_contents
+
+ def _get_eager_resources(self):
+ if self.eagers is None:
+ eagers = []
+ for name in ('native_libs.txt', 'eager_resources.txt'):
+ if self.has_metadata(name):
+ eagers.extend(self.get_metadata_lines(name))
+ self.eagers = eagers
+ return self.eagers
+
+ def _index(self):
+ try:
+ return self._dirindex
+ except AttributeError:
+ ind = {}
+ for path in self.zipinfo:
+ parts = path.split(os.sep)
+ while parts:
+ parent = os.sep.join(parts[:-1])
+ if parent in ind:
+ ind[parent].append(parts[-1])
+ break
+ else:
+ ind[parent] = [parts.pop()]
+ self._dirindex = ind
+ return ind
+
+ def _has(self, fspath) -> bool:
+ zip_path = self._zipinfo_name(fspath)
+ return zip_path in self.zipinfo or zip_path in self._index()
+
+ def _isdir(self, fspath) -> bool:
+ return self._zipinfo_name(fspath) in self._index()
+
+ def _listdir(self, fspath):
+ return list(self._index().get(self._zipinfo_name(fspath), ()))
+
+ def _eager_to_zip(self, resource_name: str):
+ return self._zipinfo_name(self._fn(self.egg_root, resource_name))
+
+ def _resource_to_zip(self, resource_name: str):
+ return self._zipinfo_name(self._fn(self.module_path, resource_name))
+
+
+register_loader_type(zipimport.zipimporter, ZipProvider)
+
+
+class FileMetadata(EmptyProvider):
+ """Metadata handler for standalone PKG-INFO files
+
+ Usage::
+
+ metadata = FileMetadata("/path/to/PKG-INFO")
+
+ This provider rejects all data and metadata requests except for PKG-INFO,
+ which is treated as existing, and will be the contents of the file at
+ the provided location.
+ """
+
+ def __init__(self, path: StrPath):
+ self.path = path
+
+ def _get_metadata_path(self, name):
+ return self.path
+
+ def has_metadata(self, name: str) -> bool:
+ return name == 'PKG-INFO' and os.path.isfile(self.path)
+
+ def get_metadata(self, name: str):
+ if name != 'PKG-INFO':
+ raise KeyError("No metadata except PKG-INFO is available")
+
+ with open(self.path, encoding='utf-8', errors="replace") as f:
+ metadata = f.read()
+ self._warn_on_replacement(metadata)
+ return metadata
+
+ def _warn_on_replacement(self, metadata):
+ replacement_char = '�'
+ if replacement_char in metadata:
+ tmpl = "{self.path} could not be properly decoded in UTF-8"
+ msg = tmpl.format(**locals())
+ warnings.warn(msg)
+
+ def get_metadata_lines(self, name: str) -> Iterator[str]:
+ return yield_lines(self.get_metadata(name))
+
+
+class PathMetadata(DefaultProvider):
+ """Metadata provider for egg directories
+
+ Usage::
+
+ # Development eggs:
+
+ egg_info = "/path/to/PackageName.egg-info"
+ base_dir = os.path.dirname(egg_info)
+ metadata = PathMetadata(base_dir, egg_info)
+ dist_name = os.path.splitext(os.path.basename(egg_info))[0]
+ dist = Distribution(basedir, project_name=dist_name, metadata=metadata)
+
+ # Unpacked egg directories:
+
+ egg_path = "/path/to/PackageName-ver-pyver-etc.egg"
+ metadata = PathMetadata(egg_path, os.path.join(egg_path,'EGG-INFO'))
+ dist = Distribution.from_filename(egg_path, metadata=metadata)
+ """
+
+ def __init__(self, path: str, egg_info: str):
+ self.module_path = path
+ self.egg_info = egg_info
+
+
+class EggMetadata(ZipProvider):
+ """Metadata provider for .egg files"""
+
+ def __init__(self, importer: zipimport.zipimporter):
+ """Create a metadata provider from a zipimporter"""
+
+ self.zip_pre = importer.archive + os.sep
+ self.loader = importer
+ if importer.prefix:
+ self.module_path = os.path.join(importer.archive, importer.prefix)
+ else:
+ self.module_path = importer.archive
+ self._setup_prefix()
+
+
+_distribution_finders: dict[type, _DistFinderType[Any]] = _declare_state(
+ 'dict', '_distribution_finders', {}
+)
+
+
+def register_finder(importer_type: type[_T], distribution_finder: _DistFinderType[_T]):
+ """Register `distribution_finder` to find distributions in sys.path items
+
+ `importer_type` is the type or class of a PEP 302 "Importer" (sys.path item
+ handler), and `distribution_finder` is a callable that, passed a path
+ item and the importer instance, yields ``Distribution`` instances found on
+ that path item. See ``pkg_resources.find_on_path`` for an example."""
+ _distribution_finders[importer_type] = distribution_finder
+
+
+def find_distributions(path_item: str, only: bool = False):
+ """Yield distributions accessible via `path_item`"""
+ importer = get_importer(path_item)
+ finder = _find_adapter(_distribution_finders, importer)
+ return finder(importer, path_item, only)
+
+
+def find_eggs_in_zip(
+ importer: zipimport.zipimporter, path_item: str, only: bool = False
+) -> Iterator[Distribution]:
+ """
+ Find eggs in zip files; possibly multiple nested eggs.
+ """
+ if importer.archive.endswith('.whl'):
+ # wheels are not supported with this finder
+ # they don't have PKG-INFO metadata, and won't ever contain eggs
+ return
+ metadata = EggMetadata(importer)
+ if metadata.has_metadata('PKG-INFO'):
+ yield Distribution.from_filename(path_item, metadata=metadata)
+ if only:
+ # don't yield nested distros
+ return
+ for subitem in metadata.resource_listdir(''):
+ if _is_egg_path(subitem):
+ subpath = os.path.join(path_item, subitem)
+ dists = find_eggs_in_zip(zipimport.zipimporter(subpath), subpath)
+ yield from dists
+ elif subitem.lower().endswith(('.dist-info', '.egg-info')):
+ subpath = os.path.join(path_item, subitem)
+ submeta = EggMetadata(zipimport.zipimporter(subpath))
+ submeta.egg_info = subpath
+ yield Distribution.from_location(path_item, subitem, submeta)
+
+
+register_finder(zipimport.zipimporter, find_eggs_in_zip)
+
+
+def find_nothing(
+ importer: object | None, path_item: str | None, only: bool | None = False
+):
+ return ()
+
+
+register_finder(object, find_nothing)
+
+
+def find_on_path(importer: object | None, path_item, only=False):
+ """Yield distributions accessible on a sys.path directory"""
+ path_item = _normalize_cached(path_item)
+
+ if _is_unpacked_egg(path_item):
+ yield Distribution.from_filename(
+ path_item,
+ metadata=PathMetadata(path_item, os.path.join(path_item, 'EGG-INFO')),
+ )
+ return
+
+ entries = (os.path.join(path_item, child) for child in safe_listdir(path_item))
+
+ # scan for .egg and .egg-info in directory
+ for entry in sorted(entries):
+ fullpath = os.path.join(path_item, entry)
+ factory = dist_factory(path_item, entry, only)
+ yield from factory(fullpath)
+
+
+def dist_factory(path_item, entry, only):
+ """Return a dist_factory for the given entry."""
+ lower = entry.lower()
+ is_egg_info = lower.endswith('.egg-info')
+ is_dist_info = lower.endswith('.dist-info') and os.path.isdir(
+ os.path.join(path_item, entry)
+ )
+ is_meta = is_egg_info or is_dist_info
+ return (
+ distributions_from_metadata
+ if is_meta
+ else find_distributions
+ if not only and _is_egg_path(entry)
+ else resolve_egg_link
+ if not only and lower.endswith('.egg-link')
+ else NoDists()
+ )
+
+
+class NoDists:
+ """
+ >>> bool(NoDists())
+ False
+
+ >>> list(NoDists()('anything'))
+ []
+ """
+
+ def __bool__(self):
+ return False
+
+ def __call__(self, fullpath):
+ return iter(())
+
+
+def safe_listdir(path: StrOrBytesPath):
+ """
+ Attempt to list contents of path, but suppress some exceptions.
+ """
+ try:
+ return os.listdir(path)
+ except (PermissionError, NotADirectoryError):
+ pass
+ except OSError as e:
+ # Ignore the directory if does not exist, not a directory or
+ # permission denied
+ if e.errno not in (errno.ENOTDIR, errno.EACCES, errno.ENOENT):
+ raise
+ return ()
+
+
+def distributions_from_metadata(path: str):
+ root = os.path.dirname(path)
+ if os.path.isdir(path):
+ if len(os.listdir(path)) == 0:
+ # empty metadata dir; skip
+ return
+ metadata: _MetadataType = PathMetadata(root, path)
+ else:
+ metadata = FileMetadata(path)
+ entry = os.path.basename(path)
+ yield Distribution.from_location(
+ root,
+ entry,
+ metadata,
+ precedence=DEVELOP_DIST,
+ )
+
+
+def non_empty_lines(path):
+ """
+ Yield non-empty lines from file at path
+ """
+ for line in _read_utf8_with_fallback(path).splitlines():
+ line = line.strip()
+ if line:
+ yield line
+
+
+def resolve_egg_link(path):
+ """
+ Given a path to an .egg-link, resolve distributions
+ present in the referenced path.
+ """
+ referenced_paths = non_empty_lines(path)
+ resolved_paths = (
+ os.path.join(os.path.dirname(path), ref) for ref in referenced_paths
+ )
+ dist_groups = map(find_distributions, resolved_paths)
+ return next(dist_groups, ())
+
+
+if hasattr(pkgutil, 'ImpImporter'):
+ register_finder(pkgutil.ImpImporter, find_on_path)
+
+register_finder(importlib.machinery.FileFinder, find_on_path)
+
+_namespace_handlers: dict[type, _NSHandlerType[Any]] = _declare_state(
+ 'dict', '_namespace_handlers', {}
+)
+_namespace_packages: dict[str | None, list[str]] = _declare_state(
+ 'dict', '_namespace_packages', {}
+)
+
+
+def register_namespace_handler(
+ importer_type: type[_T], namespace_handler: _NSHandlerType[_T]
+):
+ """Register `namespace_handler` to declare namespace packages
+
+ `importer_type` is the type or class of a PEP 302 "Importer" (sys.path item
+ handler), and `namespace_handler` is a callable like this::
+
+ def namespace_handler(importer, path_entry, moduleName, module):
+ # return a path_entry to use for child packages
+
+ Namespace handlers are only called if the importer object has already
+ agreed that it can handle the relevant path item, and they should only
+ return a subpath if the module __path__ does not already contain an
+ equivalent subpath. For an example namespace handler, see
+ ``pkg_resources.file_ns_handler``.
+ """
+ _namespace_handlers[importer_type] = namespace_handler
+
+
+def _handle_ns(packageName, path_item):
+ """Ensure that named package includes a subpath of path_item (if needed)"""
+
+ importer = get_importer(path_item)
+ if importer is None:
+ return None
+
+ # use find_spec (PEP 451) and fall-back to find_module (PEP 302)
+ try:
+ spec = importer.find_spec(packageName)
+ except AttributeError:
+ # capture warnings due to #1111
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ loader = importer.find_module(packageName)
+ else:
+ loader = spec.loader if spec else None
+
+ if loader is None:
+ return None
+ module = sys.modules.get(packageName)
+ if module is None:
+ module = sys.modules[packageName] = types.ModuleType(packageName)
+ module.__path__ = []
+ _set_parent_ns(packageName)
+ elif not hasattr(module, '__path__'):
+ raise TypeError("Not a package:", packageName)
+ handler = _find_adapter(_namespace_handlers, importer)
+ subpath = handler(importer, path_item, packageName, module)
+ if subpath is not None:
+ path = module.__path__
+ path.append(subpath)
+ importlib.import_module(packageName)
+ _rebuild_mod_path(path, packageName, module)
+ return subpath
+
+
+def _rebuild_mod_path(orig_path, package_name, module: types.ModuleType):
+ """
+ Rebuild module.__path__ ensuring that all entries are ordered
+ corresponding to their sys.path order
+ """
+ sys_path = [_normalize_cached(p) for p in sys.path]
+
+ def safe_sys_path_index(entry):
+ """
+ Workaround for #520 and #513.
+ """
+ try:
+ return sys_path.index(entry)
+ except ValueError:
+ return float('inf')
+
+ def position_in_sys_path(path):
+ """
+ Return the ordinal of the path based on its position in sys.path
+ """
+ path_parts = path.split(os.sep)
+ module_parts = package_name.count('.') + 1
+ parts = path_parts[:-module_parts]
+ return safe_sys_path_index(_normalize_cached(os.sep.join(parts)))
+
+ new_path = sorted(orig_path, key=position_in_sys_path)
+ new_path = [_normalize_cached(p) for p in new_path]
+
+ if isinstance(module.__path__, list):
+ module.__path__[:] = new_path
+ else:
+ module.__path__ = new_path
+
+
+def declare_namespace(packageName: str):
+ """Declare that package 'packageName' is a namespace package"""
+
+ msg = (
+ f"Deprecated call to `pkg_resources.declare_namespace({packageName!r})`.\n"
+ "Implementing implicit namespace packages (as specified in PEP 420) "
+ "is preferred to `pkg_resources.declare_namespace`. "
+ "See https://setuptools.pypa.io/en/latest/references/"
+ "keywords.html#keyword-namespace-packages"
+ )
+ warnings.warn(msg, DeprecationWarning, stacklevel=2)
+
+ _imp.acquire_lock()
+ try:
+ if packageName in _namespace_packages:
+ return
+
+ path: MutableSequence[str] = sys.path
+ parent, _, _ = packageName.rpartition('.')
+
+ if parent:
+ declare_namespace(parent)
+ if parent not in _namespace_packages:
+ __import__(parent)
+ try:
+ path = sys.modules[parent].__path__
+ except AttributeError as e:
+ raise TypeError("Not a package:", parent) from e
+
+ # Track what packages are namespaces, so when new path items are added,
+ # they can be updated
+ _namespace_packages.setdefault(parent or None, []).append(packageName)
+ _namespace_packages.setdefault(packageName, [])
+
+ for path_item in path:
+ # Ensure all the parent's path items are reflected in the child,
+ # if they apply
+ _handle_ns(packageName, path_item)
+
+ finally:
+ _imp.release_lock()
+
+
+def fixup_namespace_packages(path_item: str, parent: str | None = None):
+ """Ensure that previously-declared namespace packages include path_item"""
+ _imp.acquire_lock()
+ try:
+ for package in _namespace_packages.get(parent, ()):
+ subpath = _handle_ns(package, path_item)
+ if subpath:
+ fixup_namespace_packages(subpath, package)
+ finally:
+ _imp.release_lock()
+
+
+def file_ns_handler(
+ importer: object,
+ path_item: StrPath,
+ packageName: str,
+ module: types.ModuleType,
+):
+ """Compute an ns-package subpath for a filesystem or zipfile importer"""
+
+ subpath = os.path.join(path_item, packageName.split('.')[-1])
+ normalized = _normalize_cached(subpath)
+ for item in module.__path__:
+ if _normalize_cached(item) == normalized:
+ break
+ else:
+ # Only return the path if it's not already there
+ return subpath
+
+
+if hasattr(pkgutil, 'ImpImporter'):
+ register_namespace_handler(pkgutil.ImpImporter, file_ns_handler)
+
+register_namespace_handler(zipimport.zipimporter, file_ns_handler)
+register_namespace_handler(importlib.machinery.FileFinder, file_ns_handler)
+
+
+def null_ns_handler(
+ importer: object,
+ path_item: str | None,
+ packageName: str | None,
+ module: _ModuleLike | None,
+):
+ return None
+
+
+register_namespace_handler(object, null_ns_handler)
+
+
+@overload
+def normalize_path(filename: StrPath) -> str: ...
+@overload
+def normalize_path(filename: BytesPath) -> bytes: ...
+def normalize_path(filename: StrOrBytesPath):
+ """Normalize a file/dir name for comparison purposes"""
+ return os.path.normcase(os.path.realpath(os.path.normpath(_cygwin_patch(filename))))
+
+
+def _cygwin_patch(filename: StrOrBytesPath): # pragma: nocover
+ """
+ Contrary to POSIX 2008, on Cygwin, getcwd (3) contains
+ symlink components. Using
+ os.path.abspath() works around this limitation. A fix in os.getcwd()
+ would probably better, in Cygwin even more so, except
+ that this seems to be by design...
+ """
+ return os.path.abspath(filename) if sys.platform == 'cygwin' else filename
+
+
+if TYPE_CHECKING:
+ # https://github.com/python/mypy/issues/16261
+ # https://github.com/python/typeshed/issues/6347
+ @overload
+ def _normalize_cached(filename: StrPath) -> str: ...
+ @overload
+ def _normalize_cached(filename: BytesPath) -> bytes: ...
+ def _normalize_cached(filename: StrOrBytesPath) -> str | bytes: ...
+else:
+
+ @functools.lru_cache(maxsize=None)
+ def _normalize_cached(filename):
+ return normalize_path(filename)
+
+
+def _is_egg_path(path):
+ """
+ Determine if given path appears to be an egg.
+ """
+ return _is_zip_egg(path) or _is_unpacked_egg(path)
+
+
+def _is_zip_egg(path):
+ return (
+ path.lower().endswith('.egg')
+ and os.path.isfile(path)
+ and zipfile.is_zipfile(path)
+ )
+
+
+def _is_unpacked_egg(path):
+ """
+ Determine if given path appears to be an unpacked egg.
+ """
+ return path.lower().endswith('.egg') and os.path.isfile(
+ os.path.join(path, 'EGG-INFO', 'PKG-INFO')
+ )
+
+
+def _set_parent_ns(packageName):
+ parts = packageName.split('.')
+ name = parts.pop()
+ if parts:
+ parent = '.'.join(parts)
+ setattr(sys.modules[parent], name, sys.modules[packageName])
+
+
+MODULE = re.compile(r"\w+(\.\w+)*$").match
+EGG_NAME = re.compile(
+ r"""
+ (?P<name>[^-]+) (
+ -(?P<ver>[^-]+) (
+ -py(?P<pyver>[^-]+) (
+ -(?P<plat>.+)
+ )?
+ )?
+ )?
+ """,
+ re.VERBOSE | re.IGNORECASE,
+).match
+
+
+class EntryPoint:
+ """Object representing an advertised importable object"""
+
+ def __init__(
+ self,
+ name: str,
+ module_name: str,
+ attrs: Iterable[str] = (),
+ extras: Iterable[str] = (),
+ dist: Distribution | None = None,
+ ):
+ if not MODULE(module_name):
+ raise ValueError("Invalid module name", module_name)
+ self.name = name
+ self.module_name = module_name
+ self.attrs = tuple(attrs)
+ self.extras = tuple(extras)
+ self.dist = dist
+
+ def __str__(self):
+ s = "%s = %s" % (self.name, self.module_name)
+ if self.attrs:
+ s += ':' + '.'.join(self.attrs)
+ if self.extras:
+ s += ' [%s]' % ','.join(self.extras)
+ return s
+
+ def __repr__(self):
+ return "EntryPoint.parse(%r)" % str(self)
+
+ @overload
+ def load(
+ self,
+ require: Literal[True] = True,
+ env: Environment | None = None,
+ installer: _InstallerType | None = None,
+ ) -> _ResolvedEntryPoint: ...
+ @overload
+ def load(
+ self,
+ require: Literal[False],
+ *args: Any,
+ **kwargs: Any,
+ ) -> _ResolvedEntryPoint: ...
+ def load(
+ self,
+ require: bool = True,
+ *args: Environment | _InstallerType | None,
+ **kwargs: Environment | _InstallerType | None,
+ ) -> _ResolvedEntryPoint:
+ """
+ Require packages for this EntryPoint, then resolve it.
+ """
+ if not require or args or kwargs:
+ warnings.warn(
+ "Parameters to load are deprecated. Call .resolve and "
+ ".require separately.",
+ PkgResourcesDeprecationWarning,
+ stacklevel=2,
+ )
+ if require:
+ # We could pass `env` and `installer` directly,
+ # but keeping `*args` and `**kwargs` for backwards compatibility
+ self.require(*args, **kwargs) # type: ignore
+ return self.resolve()
+
+ def resolve(self) -> _ResolvedEntryPoint:
+ """
+ Resolve the entry point from its module and attrs.
+ """
+ module = __import__(self.module_name, fromlist=['__name__'], level=0)
+ try:
+ return functools.reduce(getattr, self.attrs, module)
+ except AttributeError as exc:
+ raise ImportError(str(exc)) from exc
+
+ def require(
+ self,
+ env: Environment | None = None,
+ installer: _InstallerType | None = None,
+ ):
+ if not self.dist:
+ error_cls = UnknownExtra if self.extras else AttributeError
+ raise error_cls("Can't require() without a distribution", self)
+
+ # Get the requirements for this entry point with all its extras and
+ # then resolve them. We have to pass `extras` along when resolving so
+ # that the working set knows what extras we want. Otherwise, for
+ # dist-info distributions, the working set will assume that the
+ # requirements for that extra are purely optional and skip over them.
+ reqs = self.dist.requires(self.extras)
+ items = working_set.resolve(reqs, env, installer, extras=self.extras)
+ list(map(working_set.add, items))
+
+ pattern = re.compile(
+ r'\s*'
+ r'(?P<name>.+?)\s*'
+ r'=\s*'
+ r'(?P<module>[\w.]+)\s*'
+ r'(:\s*(?P<attr>[\w.]+))?\s*'
+ r'(?P<extras>\[.*\])?\s*$'
+ )
+
+ @classmethod
+ def parse(cls, src: str, dist: Distribution | None = None):
+ """Parse a single entry point from string `src`
+
+ Entry point syntax follows the form::
+
+ name = some.module:some.attr [extra1, extra2]
+
+ The entry name and module name are required, but the ``:attrs`` and
+ ``[extras]`` parts are optional
+ """
+ m = cls.pattern.match(src)
+ if not m:
+ msg = "EntryPoint must be in 'name=module:attrs [extras]' format"
+ raise ValueError(msg, src)
+ res = m.groupdict()
+ extras = cls._parse_extras(res['extras'])
+ attrs = res['attr'].split('.') if res['attr'] else ()
+ return cls(res['name'], res['module'], attrs, extras, dist)
+
+ @classmethod
+ def _parse_extras(cls, extras_spec):
+ if not extras_spec:
+ return ()
+ req = Requirement.parse('x' + extras_spec)
+ if req.specs:
+ raise ValueError
+ return req.extras
+
+ @classmethod
+ def parse_group(
+ cls,
+ group: str,
+ lines: _NestedStr,
+ dist: Distribution | None = None,
+ ):
+ """Parse an entry point group"""
+ if not MODULE(group):
+ raise ValueError("Invalid group name", group)
+ this: dict[str, Self] = {}
+ for line in yield_lines(lines):
+ ep = cls.parse(line, dist)
+ if ep.name in this:
+ raise ValueError("Duplicate entry point", group, ep.name)
+ this[ep.name] = ep
+ return this
+
+ @classmethod
+ def parse_map(
+ cls,
+ data: str | Iterable[str] | dict[str, str | Iterable[str]],
+ dist: Distribution | None = None,
+ ):
+ """Parse a map of entry point groups"""
+ _data: Iterable[tuple[str | None, str | Iterable[str]]]
+ if isinstance(data, dict):
+ _data = data.items()
+ else:
+ _data = split_sections(data)
+ maps: dict[str, dict[str, Self]] = {}
+ for group, lines in _data:
+ if group is None:
+ if not lines:
+ continue
+ raise ValueError("Entry points must be listed in groups")
+ group = group.strip()
+ if group in maps:
+ raise ValueError("Duplicate group name", group)
+ maps[group] = cls.parse_group(group, lines, dist)
+ return maps
+
+
+def _version_from_file(lines):
+ """
+ Given an iterable of lines from a Metadata file, return
+ the value of the Version field, if present, or None otherwise.
+ """
+
+ def is_version_line(line):
+ return line.lower().startswith('version:')
+
+ version_lines = filter(is_version_line, lines)
+ line = next(iter(version_lines), '')
+ _, _, value = line.partition(':')
+ return safe_version(value.strip()) or None
+
+
+class Distribution:
+ """Wrap an actual or potential sys.path entry w/metadata"""
+
+ PKG_INFO = 'PKG-INFO'
+
+ def __init__(
+ self,
+ location: str | None = None,
+ metadata: _MetadataType = None,
+ project_name: str | None = None,
+ version: str | None = None,
+ py_version: str | None = PY_MAJOR,
+ platform: str | None = None,
+ precedence: int = EGG_DIST,
+ ):
+ self.project_name = safe_name(project_name or 'Unknown')
+ if version is not None:
+ self._version = safe_version(version)
+ self.py_version = py_version
+ self.platform = platform
+ self.location = location
+ self.precedence = precedence
+ self._provider = metadata or empty_provider
+
+ @classmethod
+ def from_location(
+ cls,
+ location: str,
+ basename: StrPath,
+ metadata: _MetadataType = None,
+ **kw: int, # We could set `precedence` explicitly, but keeping this as `**kw` for full backwards and subclassing compatibility
+ ) -> Distribution:
+ project_name, version, py_version, platform = [None] * 4
+ basename, ext = os.path.splitext(basename)
+ if ext.lower() in _distributionImpl:
+ cls = _distributionImpl[ext.lower()]
+
+ match = EGG_NAME(basename)
+ if match:
+ project_name, version, py_version, platform = match.group(
+ 'name', 'ver', 'pyver', 'plat'
+ )
+ return cls(
+ location,
+ metadata,
+ project_name=project_name,
+ version=version,
+ py_version=py_version,
+ platform=platform,
+ **kw,
+ )._reload_version()
+
+ def _reload_version(self):
+ return self
+
+ @property
+ def hashcmp(self):
+ return (
+ self._forgiving_parsed_version,
+ self.precedence,
+ self.key,
+ self.location,
+ self.py_version or '',
+ self.platform or '',
+ )
+
+ def __hash__(self):
+ return hash(self.hashcmp)
+
+ def __lt__(self, other: Distribution):
+ return self.hashcmp < other.hashcmp
+
+ def __le__(self, other: Distribution):
+ return self.hashcmp <= other.hashcmp
+
+ def __gt__(self, other: Distribution):
+ return self.hashcmp > other.hashcmp
+
+ def __ge__(self, other: Distribution):
+ return self.hashcmp >= other.hashcmp
+
+ def __eq__(self, other: object):
+ if not isinstance(other, self.__class__):
+ # It's not a Distribution, so they are not equal
+ return False
+ return self.hashcmp == other.hashcmp
+
+ def __ne__(self, other: object):
+ return not self == other
+
+ # These properties have to be lazy so that we don't have to load any
+ # metadata until/unless it's actually needed. (i.e., some distributions
+ # may not know their name or version without loading PKG-INFO)
+
+ @property
+ def key(self):
+ try:
+ return self._key
+ except AttributeError:
+ self._key = key = self.project_name.lower()
+ return key
+
+ @property
+ def parsed_version(self):
+ if not hasattr(self, "_parsed_version"):
+ try:
+ self._parsed_version = parse_version(self.version)
+ except _packaging_version.InvalidVersion as ex:
+ info = f"(package: {self.project_name})"
+ if hasattr(ex, "add_note"):
+ ex.add_note(info) # PEP 678
+ raise
+ raise _packaging_version.InvalidVersion(f"{str(ex)} {info}") from None
+
+ return self._parsed_version
+
+ @property
+ def _forgiving_parsed_version(self):
+ try:
+ return self.parsed_version
+ except _packaging_version.InvalidVersion as ex:
+ self._parsed_version = parse_version(_forgiving_version(self.version))
+
+ notes = "\n".join(getattr(ex, "__notes__", [])) # PEP 678
+ msg = f"""!!\n\n
+ *************************************************************************
+ {str(ex)}\n{notes}
+
+ This is a long overdue deprecation.
+ For the time being, `pkg_resources` will use `{self._parsed_version}`
+ as a replacement to avoid breaking existing environments,
+ but no future compatibility is guaranteed.
+
+ If you maintain package {self.project_name} you should implement
+ the relevant changes to adequate the project to PEP 440 immediately.
+ *************************************************************************
+ \n\n!!
+ """
+ warnings.warn(msg, DeprecationWarning)
+
+ return self._parsed_version
+
+ @property
+ def version(self):
+ try:
+ return self._version
+ except AttributeError as e:
+ version = self._get_version()
+ if version is None:
+ path = self._get_metadata_path_for_display(self.PKG_INFO)
+ msg = ("Missing 'Version:' header and/or {} file at path: {}").format(
+ self.PKG_INFO, path
+ )
+ raise ValueError(msg, self) from e
+
+ return version
+
+ @property
+ def _dep_map(self):
+ """
+ A map of extra to its list of (direct) requirements
+ for this distribution, including the null extra.
+ """
+ try:
+ return self.__dep_map
+ except AttributeError:
+ self.__dep_map = self._filter_extras(self._build_dep_map())
+ return self.__dep_map
+
+ @staticmethod
+ def _filter_extras(dm: dict[str | None, list[Requirement]]):
+ """
+ Given a mapping of extras to dependencies, strip off
+ environment markers and filter out any dependencies
+ not matching the markers.
+ """
+ for extra in list(filter(None, dm)):
+ new_extra: str | None = extra
+ reqs = dm.pop(extra)
+ new_extra, _, marker = extra.partition(':')
+ fails_marker = marker and (
+ invalid_marker(marker) or not evaluate_marker(marker)
+ )
+ if fails_marker:
+ reqs = []
+ new_extra = safe_extra(new_extra) or None
+
+ dm.setdefault(new_extra, []).extend(reqs)
+ return dm
+
+ def _build_dep_map(self):
+ dm = {}
+ for name in 'requires.txt', 'depends.txt':
+ for extra, reqs in split_sections(self._get_metadata(name)):
+ dm.setdefault(extra, []).extend(parse_requirements(reqs))
+ return dm
+
+ def requires(self, extras: Iterable[str] = ()):
+ """List of Requirements needed for this distro if `extras` are used"""
+ dm = self._dep_map
+ deps: list[Requirement] = []
+ deps.extend(dm.get(None, ()))
+ for ext in extras:
+ try:
+ deps.extend(dm[safe_extra(ext)])
+ except KeyError as e:
+ raise UnknownExtra(
+ "%s has no such extra feature %r" % (self, ext)
+ ) from e
+ return deps
+
+ def _get_metadata_path_for_display(self, name):
+ """
+ Return the path to the given metadata file, if available.
+ """
+ try:
+ # We need to access _get_metadata_path() on the provider object
+ # directly rather than through this class's __getattr__()
+ # since _get_metadata_path() is marked private.
+ path = self._provider._get_metadata_path(name)
+
+ # Handle exceptions e.g. in case the distribution's metadata
+ # provider doesn't support _get_metadata_path().
+ except Exception:
+ return '[could not detect]'
+
+ return path
+
+ def _get_metadata(self, name):
+ if self.has_metadata(name):
+ yield from self.get_metadata_lines(name)
+
+ def _get_version(self):
+ lines = self._get_metadata(self.PKG_INFO)
+ return _version_from_file(lines)
+
+ def activate(self, path: list[str] | None = None, replace: bool = False):
+ """Ensure distribution is importable on `path` (default=sys.path)"""
+ if path is None:
+ path = sys.path
+ self.insert_on(path, replace=replace)
+ if path is sys.path and self.location is not None:
+ fixup_namespace_packages(self.location)
+ for pkg in self._get_metadata('namespace_packages.txt'):
+ if pkg in sys.modules:
+ declare_namespace(pkg)
+
+ def egg_name(self):
+ """Return what this distribution's standard .egg filename should be"""
+ filename = "%s-%s-py%s" % (
+ to_filename(self.project_name),
+ to_filename(self.version),
+ self.py_version or PY_MAJOR,
+ )
+
+ if self.platform:
+ filename += '-' + self.platform
+ return filename
+
+ def __repr__(self):
+ if self.location:
+ return "%s (%s)" % (self, self.location)
+ else:
+ return str(self)
+
+ def __str__(self):
+ try:
+ version = getattr(self, 'version', None)
+ except ValueError:
+ version = None
+ version = version or "[unknown version]"
+ return "%s %s" % (self.project_name, version)
+
+ def __getattr__(self, attr):
+ """Delegate all unrecognized public attributes to .metadata provider"""
+ if attr.startswith('_'):
+ raise AttributeError(attr)
+ return getattr(self._provider, attr)
+
+ def __dir__(self):
+ return list(
+ set(super().__dir__())
+ | set(attr for attr in self._provider.__dir__() if not attr.startswith('_'))
+ )
+
+ @classmethod
+ def from_filename(
+ cls,
+ filename: StrPath,
+ metadata: _MetadataType = None,
+ **kw: int, # We could set `precedence` explicitly, but keeping this as `**kw` for full backwards and subclassing compatibility
+ ):
+ return cls.from_location(
+ _normalize_cached(filename), os.path.basename(filename), metadata, **kw
+ )
+
+ def as_requirement(self):
+ """Return a ``Requirement`` that matches this distribution exactly"""
+ if isinstance(self.parsed_version, _packaging_version.Version):
+ spec = "%s==%s" % (self.project_name, self.parsed_version)
+ else:
+ spec = "%s===%s" % (self.project_name, self.parsed_version)
+
+ return Requirement.parse(spec)
+
+ def load_entry_point(self, group: str, name: str) -> _ResolvedEntryPoint:
+ """Return the `name` entry point of `group` or raise ImportError"""
+ ep = self.get_entry_info(group, name)
+ if ep is None:
+ raise ImportError("Entry point %r not found" % ((group, name),))
+ return ep.load()
+
+ @overload
+ def get_entry_map(self, group: None = None) -> dict[str, dict[str, EntryPoint]]: ...
+ @overload
+ def get_entry_map(self, group: str) -> dict[str, EntryPoint]: ...
+ def get_entry_map(self, group: str | None = None):
+ """Return the entry point map for `group`, or the full entry map"""
+ if not hasattr(self, "_ep_map"):
+ self._ep_map = EntryPoint.parse_map(
+ self._get_metadata('entry_points.txt'), self
+ )
+ if group is not None:
+ return self._ep_map.get(group, {})
+ return self._ep_map
+
+ def get_entry_info(self, group: str, name: str):
+ """Return the EntryPoint object for `group`+`name`, or ``None``"""
+ return self.get_entry_map(group).get(name)
+
+ # FIXME: 'Distribution.insert_on' is too complex (13)
+ def insert_on( # noqa: C901
+ self,
+ path: list[str],
+ loc=None,
+ replace: bool = False,
+ ):
+ """Ensure self.location is on path
+
+ If replace=False (default):
+ - If location is already in path anywhere, do nothing.
+ - Else:
+ - If it's an egg and its parent directory is on path,
+ insert just ahead of the parent.
+ - Else: add to the end of path.
+ If replace=True:
+ - If location is already on path anywhere (not eggs)
+ or higher priority than its parent (eggs)
+ do nothing.
+ - Else:
+ - If it's an egg and its parent directory is on path,
+ insert just ahead of the parent,
+ removing any lower-priority entries.
+ - Else: add it to the front of path.
+ """
+
+ loc = loc or self.location
+ if not loc:
+ return
+
+ nloc = _normalize_cached(loc)
+ bdir = os.path.dirname(nloc)
+ npath = [(p and _normalize_cached(p) or p) for p in path]
+
+ for p, item in enumerate(npath):
+ if item == nloc:
+ if replace:
+ break
+ else:
+ # don't modify path (even removing duplicates) if
+ # found and not replace
+ return
+ elif item == bdir and self.precedence == EGG_DIST:
+ # if it's an .egg, give it precedence over its directory
+ # UNLESS it's already been added to sys.path and replace=False
+ if (not replace) and nloc in npath[p:]:
+ return
+ if path is sys.path:
+ self.check_version_conflict()
+ path.insert(p, loc)
+ npath.insert(p, nloc)
+ break
+ else:
+ if path is sys.path:
+ self.check_version_conflict()
+ if replace:
+ path.insert(0, loc)
+ else:
+ path.append(loc)
+ return
+
+ # p is the spot where we found or inserted loc; now remove duplicates
+ while True:
+ try:
+ np = npath.index(nloc, p + 1)
+ except ValueError:
+ break
+ else:
+ del npath[np], path[np]
+ # ha!
+ p = np
+
+ return
+
+ def check_version_conflict(self):
+ if self.key == 'setuptools':
+ # ignore the inevitable setuptools self-conflicts :(
+ return
+
+ nsp = dict.fromkeys(self._get_metadata('namespace_packages.txt'))
+ loc = normalize_path(self.location)
+ for modname in self._get_metadata('top_level.txt'):
+ if (
+ modname not in sys.modules
+ or modname in nsp
+ or modname in _namespace_packages
+ ):
+ continue
+ if modname in ('pkg_resources', 'setuptools', 'site'):
+ continue
+ fn = getattr(sys.modules[modname], '__file__', None)
+ if fn and (
+ normalize_path(fn).startswith(loc) or fn.startswith(self.location)
+ ):
+ continue
+ issue_warning(
+ "Module %s was already imported from %s, but %s is being added"
+ " to sys.path" % (modname, fn, self.location),
+ )
+
+ def has_version(self):
+ try:
+ self.version
+ except ValueError:
+ issue_warning("Unbuilt egg for " + repr(self))
+ return False
+ except SystemError:
+ # TODO: remove this except clause when python/cpython#103632 is fixed.
+ return False
+ return True
+
+ def clone(self, **kw: str | int | IResourceProvider | None):
+ """Copy this distribution, substituting in any changed keyword args"""
+ names = 'project_name version py_version platform location precedence'
+ for attr in names.split():
+ kw.setdefault(attr, getattr(self, attr, None))
+ kw.setdefault('metadata', self._provider)
+ # Unsafely unpacking. But keeping **kw for backwards and subclassing compatibility
+ return self.__class__(**kw) # type:ignore[arg-type]
+
+ @property
+ def extras(self):
+ return [dep for dep in self._dep_map if dep]
+
+
+class EggInfoDistribution(Distribution):
+ def _reload_version(self):
+ """
+ Packages installed by distutils (e.g. numpy or scipy),
+ which uses an old safe_version, and so
+ their version numbers can get mangled when
+ converted to filenames (e.g., 1.11.0.dev0+2329eae to
+ 1.11.0.dev0_2329eae). These distributions will not be
+ parsed properly
+ downstream by Distribution and safe_version, so
+ take an extra step and try to get the version number from
+ the metadata file itself instead of the filename.
+ """
+ md_version = self._get_version()
+ if md_version:
+ self._version = md_version
+ return self
+
+
+class DistInfoDistribution(Distribution):
+ """
+ Wrap an actual or potential sys.path entry
+ w/metadata, .dist-info style.
+ """
+
+ PKG_INFO = 'METADATA'
+ EQEQ = re.compile(r"([\(,])\s*(\d.*?)\s*([,\)])")
+
+ @property
+ def _parsed_pkg_info(self):
+ """Parse and cache metadata"""
+ try:
+ return self._pkg_info
+ except AttributeError:
+ metadata = self.get_metadata(self.PKG_INFO)
+ self._pkg_info = email.parser.Parser().parsestr(metadata)
+ return self._pkg_info
+
+ @property
+ def _dep_map(self):
+ try:
+ return self.__dep_map
+ except AttributeError:
+ self.__dep_map = self._compute_dependencies()
+ return self.__dep_map
+
+ def _compute_dependencies(self) -> dict[str | None, list[Requirement]]:
+ """Recompute this distribution's dependencies."""
+ self.__dep_map: dict[str | None, list[Requirement]] = {None: []}
+
+ reqs: list[Requirement] = []
+ # Including any condition expressions
+ for req in self._parsed_pkg_info.get_all('Requires-Dist') or []:
+ reqs.extend(parse_requirements(req))
+
+ def reqs_for_extra(extra):
+ for req in reqs:
+ if not req.marker or req.marker.evaluate({'extra': extra}):
+ yield req
+
+ common = types.MappingProxyType(dict.fromkeys(reqs_for_extra(None)))
+ self.__dep_map[None].extend(common)
+
+ for extra in self._parsed_pkg_info.get_all('Provides-Extra') or []:
+ s_extra = safe_extra(extra.strip())
+ self.__dep_map[s_extra] = [
+ r for r in reqs_for_extra(extra) if r not in common
+ ]
+
+ return self.__dep_map
+
+
+_distributionImpl = {
+ '.egg': Distribution,
+ '.egg-info': EggInfoDistribution,
+ '.dist-info': DistInfoDistribution,
+}
+
+
+def issue_warning(*args, **kw):
+ level = 1
+ g = globals()
+ try:
+ # find the first stack frame that is *not* code in
+ # the pkg_resources module, to use for the warning
+ while sys._getframe(level).f_globals is g:
+ level += 1
+ except ValueError:
+ pass
+ warnings.warn(stacklevel=level + 1, *args, **kw)
+
+
+def parse_requirements(strs: _NestedStr):
+ """
+ Yield ``Requirement`` objects for each specification in `strs`.
+
+ `strs` must be a string, or a (possibly-nested) iterable thereof.
+ """
+ return map(Requirement, join_continuation(map(drop_comment, yield_lines(strs))))
+
+
+class RequirementParseError(_packaging_requirements.InvalidRequirement):
+ "Compatibility wrapper for InvalidRequirement"
+
+
+class Requirement(_packaging_requirements.Requirement):
+ def __init__(self, requirement_string: str):
+ """DO NOT CALL THIS UNDOCUMENTED METHOD; use Requirement.parse()!"""
+ super().__init__(requirement_string)
+ self.unsafe_name = self.name
+ project_name = safe_name(self.name)
+ self.project_name, self.key = project_name, project_name.lower()
+ self.specs = [(spec.operator, spec.version) for spec in self.specifier]
+ # packaging.requirements.Requirement uses a set for its extras. We use a variable-length tuple
+ self.extras: tuple[str] = tuple(map(safe_extra, self.extras))
+ self.hashCmp = (
+ self.key,
+ self.url,
+ self.specifier,
+ frozenset(self.extras),
+ str(self.marker) if self.marker else None,
+ )
+ self.__hash = hash(self.hashCmp)
+
+ def __eq__(self, other: object):
+ return isinstance(other, Requirement) and self.hashCmp == other.hashCmp
+
+ def __ne__(self, other):
+ return not self == other
+
+ def __contains__(self, item: Distribution | str | tuple[str, ...]) -> bool:
+ if isinstance(item, Distribution):
+ if item.key != self.key:
+ return False
+
+ item = item.version
+
+ # Allow prereleases always in order to match the previous behavior of
+ # this method. In the future this should be smarter and follow PEP 440
+ # more accurately.
+ return self.specifier.contains(item, prereleases=True)
+
+ def __hash__(self):
+ return self.__hash
+
+ def __repr__(self):
+ return "Requirement.parse(%r)" % str(self)
+
+ @staticmethod
+ def parse(s: str | Iterable[str]):
+ (req,) = parse_requirements(s)
+ return req
+
+
+def _always_object(classes):
+ """
+ Ensure object appears in the mro even
+ for old-style classes.
+ """
+ if object not in classes:
+ return classes + (object,)
+ return classes
+
+
+def _find_adapter(registry: Mapping[type, _AdapterT], ob: object) -> _AdapterT:
+ """Return an adapter factory for `ob` from `registry`"""
+ types = _always_object(inspect.getmro(getattr(ob, '__class__', type(ob))))
+ for t in types:
+ if t in registry:
+ return registry[t]
+ # _find_adapter would previously return None, and immediately be called.
+ # So we're raising a TypeError to keep backward compatibility if anyone depended on that behaviour.
+ raise TypeError(f"Could not find adapter for {registry} and {ob}")
+
+
+def ensure_directory(path: StrOrBytesPath):
+ """Ensure that the parent directory of `path` exists"""
+ dirname = os.path.dirname(path)
+ os.makedirs(dirname, exist_ok=True)
+
+
+def _bypass_ensure_directory(path):
+ """Sandbox-bypassing version of ensure_directory()"""
+ if not WRITE_SUPPORT:
+ raise OSError('"os.mkdir" not supported on this platform.')
+ dirname, filename = split(path)
+ if dirname and filename and not isdir(dirname):
+ _bypass_ensure_directory(dirname)
+ try:
+ mkdir(dirname, 0o755)
+ except FileExistsError:
+ pass
+
+
+def split_sections(s: _NestedStr) -> Iterator[tuple[str | None, list[str]]]:
+ """Split a string or iterable thereof into (section, content) pairs
+
+ Each ``section`` is a stripped version of the section header ("[section]")
+ and each ``content`` is a list of stripped lines excluding blank lines and
+ comment-only lines. If there are any such lines before the first section
+ header, they're returned in a first ``section`` of ``None``.
+ """
+ section = None
+ content = []
+ for line in yield_lines(s):
+ if line.startswith("["):
+ if line.endswith("]"):
+ if section or content:
+ yield section, content
+ section = line[1:-1].strip()
+ content = []
+ else:
+ raise ValueError("Invalid section heading", line)
+ else:
+ content.append(line)
+
+ # wrap up last segment
+ yield section, content
+
+
+def _mkstemp(*args, **kw):
+ old_open = os.open
+ try:
+ # temporarily bypass sandboxing
+ os.open = os_open
+ return tempfile.mkstemp(*args, **kw)
+ finally:
+ # and then put it back
+ os.open = old_open
+
+
+# Silence the PEP440Warning by default, so that end users don't get hit by it
+# randomly just because they use pkg_resources. We want to append the rule
+# because we want earlier uses of filterwarnings to take precedence over this
+# one.
+warnings.filterwarnings("ignore", category=PEP440Warning, append=True)
+
+
+class PkgResourcesDeprecationWarning(Warning):
+ """
+ Base class for warning about deprecations in ``pkg_resources``
+
+ This class is not derived from ``DeprecationWarning``, and as such is
+ visible by default.
+ """
+
+
+# Ported from ``setuptools`` to avoid introducing an import inter-dependency:
+_LOCALE_ENCODING = "locale" if sys.version_info >= (3, 10) else None
+
+
+def _read_utf8_with_fallback(file: str, fallback_encoding=_LOCALE_ENCODING) -> str:
+ """See setuptools.unicode_utils._read_utf8_with_fallback"""
+ try:
+ with open(file, "r", encoding="utf-8") as f:
+ return f.read()
+ except UnicodeDecodeError: # pragma: no cover
+ msg = f"""\
+ ********************************************************************************
+ `encoding="utf-8"` fails with {file!r}, trying `encoding={fallback_encoding!r}`.
+
+ This fallback behaviour is considered **deprecated** and future versions of
+ `setuptools/pkg_resources` may not implement it.
+
+ Please encode {file!r} with "utf-8" to ensure future builds will succeed.
+
+ If this file was produced by `setuptools` itself, cleaning up the cached files
+ and re-building/re-installing the package with a newer version of `setuptools`
+ (e.g. by updating `build-system.requires` in its `pyproject.toml`)
+ might solve the problem.
+ ********************************************************************************
+ """
+ # TODO: Add a deadline?
+ # See comment in setuptools.unicode_utils._Utf8EncodingNeeded
+ warnings.warn(msg, PkgResourcesDeprecationWarning, stacklevel=2)
+ with open(file, "r", encoding=fallback_encoding) as f:
+ return f.read()
+
+
+# from jaraco.functools 1.3
+def _call_aside(f, *args, **kwargs):
+ f(*args, **kwargs)
+ return f
+
+
+@_call_aside
+def _initialize(g=globals()):
+ "Set up global resource manager (deliberately not state-saved)"
+ manager = ResourceManager()
+ g['_manager'] = manager
+ g.update(
+ (name, getattr(manager, name))
+ for name in dir(manager)
+ if not name.startswith('_')
+ )
+
+
+@_call_aside
+def _initialize_master_working_set():
+ """
+ Prepare the master working set and make the ``require()``
+ API available.
+
+ This function has explicit effects on the global state
+ of pkg_resources. It is intended to be invoked once at
+ the initialization of this module.
+
+ Invocation by other packages is unsupported and done
+ at their own risk.
+ """
+ working_set = _declare_state('object', 'working_set', WorkingSet._build_master())
+
+ require = working_set.require
+ iter_entry_points = working_set.iter_entry_points
+ add_activation_listener = working_set.subscribe
+ run_script = working_set.run_script
+ # backward compatibility
+ run_main = run_script
+ # Activate all distributions already on sys.path with replace=False and
+ # ensure that all distributions added to the working set in the future
+ # (e.g. by calling ``require()``) will get activated as well,
+ # with higher priority (replace=True).
+ tuple(dist.activate(replace=False) for dist in working_set)
+ add_activation_listener(
+ lambda dist: dist.activate(replace=True),
+ existing=False,
+ )
+ working_set.entries = []
+ # match order
+ list(map(working_set.add_entry, sys.path))
+ globals().update(locals())
+
+
+if TYPE_CHECKING:
+ # All of these are set by the @_call_aside methods above
+ __resource_manager = ResourceManager() # Won't exist at runtime
+ resource_exists = __resource_manager.resource_exists
+ resource_isdir = __resource_manager.resource_isdir
+ resource_filename = __resource_manager.resource_filename
+ resource_stream = __resource_manager.resource_stream
+ resource_string = __resource_manager.resource_string
+ resource_listdir = __resource_manager.resource_listdir
+ set_extraction_path = __resource_manager.set_extraction_path
+ cleanup_resources = __resource_manager.cleanup_resources
+
+ working_set = WorkingSet()
+ require = working_set.require
+ iter_entry_points = working_set.iter_entry_points
+ add_activation_listener = working_set.subscribe
+ run_script = working_set.run_script
+ run_main = run_script
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/__init__.py
new file mode 100644
index 000000000..d58dd2b7d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/__init__.py
@@ -0,0 +1,627 @@
+"""
+Utilities for determining application-specific dirs.
+
+See <https://github.com/platformdirs/platformdirs> for details and usage.
+
+"""
+
+from __future__ import annotations
+
+import os
+import sys
+from typing import TYPE_CHECKING
+
+from .api import PlatformDirsABC
+from .version import __version__
+from .version import __version_tuple__ as __version_info__
+
+if TYPE_CHECKING:
+ from pathlib import Path
+ from typing import Literal
+
+
+def _set_platform_dir_class() -> type[PlatformDirsABC]:
+ if sys.platform == "win32":
+ from pip._vendor.platformdirs.windows import Windows as Result # noqa: PLC0415
+ elif sys.platform == "darwin":
+ from pip._vendor.platformdirs.macos import MacOS as Result # noqa: PLC0415
+ else:
+ from pip._vendor.platformdirs.unix import Unix as Result # noqa: PLC0415
+
+ if os.getenv("ANDROID_DATA") == "/data" and os.getenv("ANDROID_ROOT") == "/system":
+ if os.getenv("SHELL") or os.getenv("PREFIX"):
+ return Result
+
+ from pip._vendor.platformdirs.android import _android_folder # noqa: PLC0415
+
+ if _android_folder() is not None:
+ from pip._vendor.platformdirs.android import Android # noqa: PLC0415
+
+ return Android # return to avoid redefinition of a result
+
+ return Result
+
+
+PlatformDirs = _set_platform_dir_class() #: Currently active platform
+AppDirs = PlatformDirs #: Backwards compatibility with appdirs
+
+
+def user_data_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_data_dir
+
+
+def site_data_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `roaming <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data directory shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_data_dir
+
+
+def user_config_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_config_dir
+
+
+def site_config_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `roaming <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config directory shared by the users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_config_dir
+
+
+def user_cache_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_cache_dir
+
+
+def site_cache_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_cache_dir
+
+
+def user_state_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: state directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_state_dir
+
+
+def user_log_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: log directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_log_dir
+
+
+def user_documents_dir() -> str:
+ """:returns: documents directory tied to the user"""
+ return PlatformDirs().user_documents_dir
+
+
+def user_downloads_dir() -> str:
+ """:returns: downloads directory tied to the user"""
+ return PlatformDirs().user_downloads_dir
+
+
+def user_pictures_dir() -> str:
+ """:returns: pictures directory tied to the user"""
+ return PlatformDirs().user_pictures_dir
+
+
+def user_videos_dir() -> str:
+ """:returns: videos directory tied to the user"""
+ return PlatformDirs().user_videos_dir
+
+
+def user_music_dir() -> str:
+ """:returns: music directory tied to the user"""
+ return PlatformDirs().user_music_dir
+
+
+def user_desktop_dir() -> str:
+ """:returns: desktop directory tied to the user"""
+ return PlatformDirs().user_desktop_dir
+
+
+def user_runtime_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_runtime_dir
+
+
+def site_runtime_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime directory shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_runtime_dir
+
+
+def user_data_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_data_path
+
+
+def site_data_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `multipath <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data path shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_data_path
+
+
+def user_config_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_config_path
+
+
+def site_config_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `roaming <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config path shared by the users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_config_path
+
+
+def site_cache_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_cache_path
+
+
+def user_cache_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_cache_path
+
+
+def user_state_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: state path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_state_path
+
+
+def user_log_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: log path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_log_path
+
+
+def user_documents_path() -> Path:
+ """:returns: documents a path tied to the user"""
+ return PlatformDirs().user_documents_path
+
+
+def user_downloads_path() -> Path:
+ """:returns: downloads path tied to the user"""
+ return PlatformDirs().user_downloads_path
+
+
+def user_pictures_path() -> Path:
+ """:returns: pictures path tied to the user"""
+ return PlatformDirs().user_pictures_path
+
+
+def user_videos_path() -> Path:
+ """:returns: videos path tied to the user"""
+ return PlatformDirs().user_videos_path
+
+
+def user_music_path() -> Path:
+ """:returns: music path tied to the user"""
+ return PlatformDirs().user_music_path
+
+
+def user_desktop_path() -> Path:
+ """:returns: desktop path tied to the user"""
+ return PlatformDirs().user_desktop_path
+
+
+def user_runtime_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_runtime_path
+
+
+def site_runtime_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime path shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_runtime_path
+
+
+__all__ = [
+ "AppDirs",
+ "PlatformDirs",
+ "PlatformDirsABC",
+ "__version__",
+ "__version_info__",
+ "site_cache_dir",
+ "site_cache_path",
+ "site_config_dir",
+ "site_config_path",
+ "site_data_dir",
+ "site_data_path",
+ "site_runtime_dir",
+ "site_runtime_path",
+ "user_cache_dir",
+ "user_cache_path",
+ "user_config_dir",
+ "user_config_path",
+ "user_data_dir",
+ "user_data_path",
+ "user_desktop_dir",
+ "user_desktop_path",
+ "user_documents_dir",
+ "user_documents_path",
+ "user_downloads_dir",
+ "user_downloads_path",
+ "user_log_dir",
+ "user_log_path",
+ "user_music_dir",
+ "user_music_path",
+ "user_pictures_dir",
+ "user_pictures_path",
+ "user_runtime_dir",
+ "user_runtime_path",
+ "user_state_dir",
+ "user_state_path",
+ "user_videos_dir",
+ "user_videos_path",
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/__main__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/__main__.py
new file mode 100644
index 000000000..fa8a677a3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/__main__.py
@@ -0,0 +1,55 @@
+"""Main entry point."""
+
+from __future__ import annotations
+
+from pip._vendor.platformdirs import PlatformDirs, __version__
+
+PROPS = (
+ "user_data_dir",
+ "user_config_dir",
+ "user_cache_dir",
+ "user_state_dir",
+ "user_log_dir",
+ "user_documents_dir",
+ "user_downloads_dir",
+ "user_pictures_dir",
+ "user_videos_dir",
+ "user_music_dir",
+ "user_runtime_dir",
+ "site_data_dir",
+ "site_config_dir",
+ "site_cache_dir",
+ "site_runtime_dir",
+)
+
+
+def main() -> None:
+ """Run the main entry point."""
+ app_name = "MyApp"
+ app_author = "MyCompany"
+
+ print(f"-- platformdirs {__version__} --") # noqa: T201
+
+ print("-- app dirs (with optional 'version')") # noqa: T201
+ dirs = PlatformDirs(app_name, app_author, version="1.0")
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+ print("\n-- app dirs (without optional 'version')") # noqa: T201
+ dirs = PlatformDirs(app_name, app_author)
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+ print("\n-- app dirs (without optional 'appauthor')") # noqa: T201
+ dirs = PlatformDirs(app_name)
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+ print("\n-- app dirs (with disabled 'appauthor')") # noqa: T201
+ dirs = PlatformDirs(app_name, appauthor=False)
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+
+if __name__ == "__main__":
+ main()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/android.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/android.py
new file mode 100644
index 000000000..afd3141c7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/android.py
@@ -0,0 +1,249 @@
+"""Android."""
+
+from __future__ import annotations
+
+import os
+import re
+import sys
+from functools import lru_cache
+from typing import TYPE_CHECKING, cast
+
+from .api import PlatformDirsABC
+
+
+class Android(PlatformDirsABC):
+ """
+ Follows the guidance `from here <https://android.stackexchange.com/a/216132>`_.
+
+ Makes use of the `appname <platformdirs.api.PlatformDirsABC.appname>`, `version
+ <platformdirs.api.PlatformDirsABC.version>`, `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """:return: data directory tied to the user, e.g. ``/data/user/<userid>/<packagename>/files/<AppName>``"""
+ return self._append_app_name_and_version(cast(str, _android_folder()), "files")
+
+ @property
+ def site_data_dir(self) -> str:
+ """:return: data directory shared by users, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_config_dir(self) -> str:
+ """
+ :return: config directory tied to the user, e.g. \
+ ``/data/user/<userid>/<packagename>/shared_prefs/<AppName>``
+ """
+ return self._append_app_name_and_version(cast(str, _android_folder()), "shared_prefs")
+
+ @property
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users, same as `user_config_dir`"""
+ return self.user_config_dir
+
+ @property
+ def user_cache_dir(self) -> str:
+ """:return: cache directory tied to the user, e.g.,``/data/user/<userid>/<packagename>/cache/<AppName>``"""
+ return self._append_app_name_and_version(cast(str, _android_folder()), "cache")
+
+ @property
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users, same as `user_cache_dir`"""
+ return self.user_cache_dir
+
+ @property
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_log_dir(self) -> str:
+ """
+ :return: log directory tied to the user, same as `user_cache_dir` if not opinionated else ``log`` in it,
+ e.g. ``/data/user/<userid>/<packagename>/cache/<AppName>/log``
+ """
+ path = self.user_cache_dir
+ if self.opinion:
+ path = os.path.join(path, "log") # noqa: PTH118
+ return path
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user e.g. ``/storage/emulated/0/Documents``"""
+ return _android_documents_folder()
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user e.g. ``/storage/emulated/0/Downloads``"""
+ return _android_downloads_folder()
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user e.g. ``/storage/emulated/0/Pictures``"""
+ return _android_pictures_folder()
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user e.g. ``/storage/emulated/0/DCIM/Camera``"""
+ return _android_videos_folder()
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user e.g. ``/storage/emulated/0/Music``"""
+ return _android_music_folder()
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user e.g. ``/storage/emulated/0/Desktop``"""
+ return "/storage/emulated/0/Desktop"
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """
+ :return: runtime directory tied to the user, same as `user_cache_dir` if not opinionated else ``tmp`` in it,
+ e.g. ``/data/user/<userid>/<packagename>/cache/<AppName>/tmp``
+ """
+ path = self.user_cache_dir
+ if self.opinion:
+ path = os.path.join(path, "tmp") # noqa: PTH118
+ return path
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users, same as `user_runtime_dir`"""
+ return self.user_runtime_dir
+
+
+@lru_cache(maxsize=1)
+def _android_folder() -> str | None: # noqa: C901, PLR0912
+ """:return: base folder for the Android OS or None if it cannot be found"""
+ result: str | None = None
+ # type checker isn't happy with our "import android", just don't do this when type checking see
+ # https://stackoverflow.com/a/61394121
+ if not TYPE_CHECKING:
+ try:
+ # First try to get a path to android app using python4android (if available)...
+ from android import mActivity # noqa: PLC0415
+
+ context = cast("android.content.Context", mActivity.getApplicationContext()) # noqa: F821
+ result = context.getFilesDir().getParentFile().getAbsolutePath()
+ except Exception: # noqa: BLE001
+ result = None
+ if result is None:
+ try:
+ # ...and fall back to using plain pyjnius, if python4android isn't available or doesn't deliver any useful
+ # result...
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ result = context.getFilesDir().getParentFile().getAbsolutePath()
+ except Exception: # noqa: BLE001
+ result = None
+ if result is None:
+ # and if that fails, too, find an android folder looking at path on the sys.path
+ # warning: only works for apps installed under /data, not adopted storage etc.
+ pattern = re.compile(r"/data/(data|user/\d+)/(.+)/files")
+ for path in sys.path:
+ if pattern.match(path):
+ result = path.split("/files")[0]
+ break
+ else:
+ result = None
+ if result is None:
+ # one last try: find an android folder looking at path on the sys.path taking adopted storage paths into
+ # account
+ pattern = re.compile(r"/mnt/expand/[a-fA-F0-9-]{36}/(data|user/\d+)/(.+)/files")
+ for path in sys.path:
+ if pattern.match(path):
+ result = path.split("/files")[0]
+ break
+ else:
+ result = None
+ return result
+
+
+@lru_cache(maxsize=1)
+def _android_documents_folder() -> str:
+ """:return: documents folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ documents_dir: str = context.getExternalFilesDir(environment.DIRECTORY_DOCUMENTS).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ documents_dir = "/storage/emulated/0/Documents"
+
+ return documents_dir
+
+
+@lru_cache(maxsize=1)
+def _android_downloads_folder() -> str:
+ """:return: downloads folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ downloads_dir: str = context.getExternalFilesDir(environment.DIRECTORY_DOWNLOADS).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ downloads_dir = "/storage/emulated/0/Downloads"
+
+ return downloads_dir
+
+
+@lru_cache(maxsize=1)
+def _android_pictures_folder() -> str:
+ """:return: pictures folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ pictures_dir: str = context.getExternalFilesDir(environment.DIRECTORY_PICTURES).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ pictures_dir = "/storage/emulated/0/Pictures"
+
+ return pictures_dir
+
+
+@lru_cache(maxsize=1)
+def _android_videos_folder() -> str:
+ """:return: videos folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ videos_dir: str = context.getExternalFilesDir(environment.DIRECTORY_DCIM).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ videos_dir = "/storage/emulated/0/DCIM/Camera"
+
+ return videos_dir
+
+
+@lru_cache(maxsize=1)
+def _android_music_folder() -> str:
+ """:return: music folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ music_dir: str = context.getExternalFilesDir(environment.DIRECTORY_MUSIC).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ music_dir = "/storage/emulated/0/Music"
+
+ return music_dir
+
+
+__all__ = [
+ "Android",
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/api.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/api.py
new file mode 100644
index 000000000..c50caa648
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/api.py
@@ -0,0 +1,292 @@
+"""Base API."""
+
+from __future__ import annotations
+
+import os
+from abc import ABC, abstractmethod
+from pathlib import Path
+from typing import TYPE_CHECKING
+
+if TYPE_CHECKING:
+ from typing import Iterator, Literal
+
+
+class PlatformDirsABC(ABC): # noqa: PLR0904
+ """Abstract base class for platform directories."""
+
+ def __init__( # noqa: PLR0913, PLR0917
+ self,
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ multipath: bool = False, # noqa: FBT001, FBT002
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+ ) -> None:
+ """
+ Create a new platform directory.
+
+ :param appname: See `appname`.
+ :param appauthor: See `appauthor`.
+ :param version: See `version`.
+ :param roaming: See `roaming`.
+ :param multipath: See `multipath`.
+ :param opinion: See `opinion`.
+ :param ensure_exists: See `ensure_exists`.
+
+ """
+ self.appname = appname #: The name of application.
+ self.appauthor = appauthor
+ """
+ The name of the app author or distributing body for this application.
+
+ Typically, it is the owning company name. Defaults to `appname`. You may pass ``False`` to disable it.
+
+ """
+ self.version = version
+ """
+ An optional version path element to append to the path.
+
+ You might want to use this if you want multiple versions of your app to be able to run independently. If used,
+ this would typically be ``<major>.<minor>``.
+
+ """
+ self.roaming = roaming
+ """
+ Whether to use the roaming appdata directory on Windows.
+
+ That means that for users on a Windows network setup for roaming profiles, this user data will be synced on
+ login (see
+ `here <https://technet.microsoft.com/en-us/library/cc766489(WS.10).aspx>`_).
+
+ """
+ self.multipath = multipath
+ """
+ An optional parameter which indicates that the entire list of data dirs should be returned.
+
+ By default, the first item would only be returned.
+
+ """
+ self.opinion = opinion #: A flag to indicating to use opinionated values.
+ self.ensure_exists = ensure_exists
+ """
+ Optionally create the directory (and any missing parents) upon access if it does not exist.
+
+ By default, no directories are created.
+
+ """
+
+ def _append_app_name_and_version(self, *base: str) -> str:
+ params = list(base[1:])
+ if self.appname:
+ params.append(self.appname)
+ if self.version:
+ params.append(self.version)
+ path = os.path.join(base[0], *params) # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ def _optionally_create_directory(self, path: str) -> None:
+ if self.ensure_exists:
+ Path(path).mkdir(parents=True, exist_ok=True)
+
+ @property
+ @abstractmethod
+ def user_data_dir(self) -> str:
+ """:return: data directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_data_dir(self) -> str:
+ """:return: data directory shared by users"""
+
+ @property
+ @abstractmethod
+ def user_config_dir(self) -> str:
+ """:return: config directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users"""
+
+ @property
+ @abstractmethod
+ def user_cache_dir(self) -> str:
+ """:return: cache directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users"""
+
+ @property
+ @abstractmethod
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_runtime_dir(self) -> str:
+ """:return: runtime directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users"""
+
+ @property
+ def user_data_path(self) -> Path:
+ """:return: data path tied to the user"""
+ return Path(self.user_data_dir)
+
+ @property
+ def site_data_path(self) -> Path:
+ """:return: data path shared by users"""
+ return Path(self.site_data_dir)
+
+ @property
+ def user_config_path(self) -> Path:
+ """:return: config path tied to the user"""
+ return Path(self.user_config_dir)
+
+ @property
+ def site_config_path(self) -> Path:
+ """:return: config path shared by the users"""
+ return Path(self.site_config_dir)
+
+ @property
+ def user_cache_path(self) -> Path:
+ """:return: cache path tied to the user"""
+ return Path(self.user_cache_dir)
+
+ @property
+ def site_cache_path(self) -> Path:
+ """:return: cache path shared by users"""
+ return Path(self.site_cache_dir)
+
+ @property
+ def user_state_path(self) -> Path:
+ """:return: state path tied to the user"""
+ return Path(self.user_state_dir)
+
+ @property
+ def user_log_path(self) -> Path:
+ """:return: log path tied to the user"""
+ return Path(self.user_log_dir)
+
+ @property
+ def user_documents_path(self) -> Path:
+ """:return: documents a path tied to the user"""
+ return Path(self.user_documents_dir)
+
+ @property
+ def user_downloads_path(self) -> Path:
+ """:return: downloads path tied to the user"""
+ return Path(self.user_downloads_dir)
+
+ @property
+ def user_pictures_path(self) -> Path:
+ """:return: pictures path tied to the user"""
+ return Path(self.user_pictures_dir)
+
+ @property
+ def user_videos_path(self) -> Path:
+ """:return: videos path tied to the user"""
+ return Path(self.user_videos_dir)
+
+ @property
+ def user_music_path(self) -> Path:
+ """:return: music path tied to the user"""
+ return Path(self.user_music_dir)
+
+ @property
+ def user_desktop_path(self) -> Path:
+ """:return: desktop path tied to the user"""
+ return Path(self.user_desktop_dir)
+
+ @property
+ def user_runtime_path(self) -> Path:
+ """:return: runtime path tied to the user"""
+ return Path(self.user_runtime_dir)
+
+ @property
+ def site_runtime_path(self) -> Path:
+ """:return: runtime path shared by users"""
+ return Path(self.site_runtime_dir)
+
+ def iter_config_dirs(self) -> Iterator[str]:
+ """:yield: all user and site configuration directories."""
+ yield self.user_config_dir
+ yield self.site_config_dir
+
+ def iter_data_dirs(self) -> Iterator[str]:
+ """:yield: all user and site data directories."""
+ yield self.user_data_dir
+ yield self.site_data_dir
+
+ def iter_cache_dirs(self) -> Iterator[str]:
+ """:yield: all user and site cache directories."""
+ yield self.user_cache_dir
+ yield self.site_cache_dir
+
+ def iter_runtime_dirs(self) -> Iterator[str]:
+ """:yield: all user and site runtime directories."""
+ yield self.user_runtime_dir
+ yield self.site_runtime_dir
+
+ def iter_config_paths(self) -> Iterator[Path]:
+ """:yield: all user and site configuration paths."""
+ for path in self.iter_config_dirs():
+ yield Path(path)
+
+ def iter_data_paths(self) -> Iterator[Path]:
+ """:yield: all user and site data paths."""
+ for path in self.iter_data_dirs():
+ yield Path(path)
+
+ def iter_cache_paths(self) -> Iterator[Path]:
+ """:yield: all user and site cache paths."""
+ for path in self.iter_cache_dirs():
+ yield Path(path)
+
+ def iter_runtime_paths(self) -> Iterator[Path]:
+ """:yield: all user and site runtime paths."""
+ for path in self.iter_runtime_dirs():
+ yield Path(path)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/macos.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/macos.py
new file mode 100644
index 000000000..eb1ba5df1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/macos.py
@@ -0,0 +1,130 @@
+"""macOS."""
+
+from __future__ import annotations
+
+import os.path
+import sys
+
+from .api import PlatformDirsABC
+
+
+class MacOS(PlatformDirsABC):
+ """
+ Platform directories for the macOS operating system.
+
+ Follows the guidance from
+ `Apple documentation <https://developer.apple.com/library/archive/documentation/FileManagement/Conceptual/FileSystemProgrammingGuide/MacOSXDirectories/MacOSXDirectories.html>`_.
+ Makes use of the `appname <platformdirs.api.PlatformDirsABC.appname>`,
+ `version <platformdirs.api.PlatformDirsABC.version>`,
+ `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """:return: data directory tied to the user, e.g. ``~/Library/Application Support/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Application Support")) # noqa: PTH111
+
+ @property
+ def site_data_dir(self) -> str:
+ """
+ :return: data directory shared by users, e.g. ``/Library/Application Support/$appname/$version``.
+ If we're using a Python binary managed by `Homebrew <https://brew.sh>`_, the directory
+ will be under the Homebrew prefix, e.g. ``/opt/homebrew/share/$appname/$version``.
+ If `multipath <platformdirs.api.PlatformDirsABC.multipath>` is enabled, and we're in Homebrew,
+ the response is a multi-path string separated by ":", e.g.
+ ``/opt/homebrew/share/$appname/$version:/Library/Application Support/$appname/$version``
+ """
+ is_homebrew = sys.prefix.startswith("/opt/homebrew")
+ path_list = [self._append_app_name_and_version("/opt/homebrew/share")] if is_homebrew else []
+ path_list.append(self._append_app_name_and_version("/Library/Application Support"))
+ if self.multipath:
+ return os.pathsep.join(path_list)
+ return path_list[0]
+
+ @property
+ def user_config_dir(self) -> str:
+ """:return: config directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users, same as `site_data_dir`"""
+ return self.site_data_dir
+
+ @property
+ def user_cache_dir(self) -> str:
+ """:return: cache directory tied to the user, e.g. ``~/Library/Caches/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Caches")) # noqa: PTH111
+
+ @property
+ def site_cache_dir(self) -> str:
+ """
+ :return: cache directory shared by users, e.g. ``/Library/Caches/$appname/$version``.
+ If we're using a Python binary managed by `Homebrew <https://brew.sh>`_, the directory
+ will be under the Homebrew prefix, e.g. ``/opt/homebrew/var/cache/$appname/$version``.
+ If `multipath <platformdirs.api.PlatformDirsABC.multipath>` is enabled, and we're in Homebrew,
+ the response is a multi-path string separated by ":", e.g.
+ ``/opt/homebrew/var/cache/$appname/$version:/Library/Caches/$appname/$version``
+ """
+ is_homebrew = sys.prefix.startswith("/opt/homebrew")
+ path_list = [self._append_app_name_and_version("/opt/homebrew/var/cache")] if is_homebrew else []
+ path_list.append(self._append_app_name_and_version("/Library/Caches"))
+ if self.multipath:
+ return os.pathsep.join(path_list)
+ return path_list[0]
+
+ @property
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user, e.g. ``~/Library/Logs/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Logs")) # noqa: PTH111
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user, e.g. ``~/Documents``"""
+ return os.path.expanduser("~/Documents") # noqa: PTH111
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user, e.g. ``~/Downloads``"""
+ return os.path.expanduser("~/Downloads") # noqa: PTH111
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user, e.g. ``~/Pictures``"""
+ return os.path.expanduser("~/Pictures") # noqa: PTH111
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user, e.g. ``~/Movies``"""
+ return os.path.expanduser("~/Movies") # noqa: PTH111
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user, e.g. ``~/Music``"""
+ return os.path.expanduser("~/Music") # noqa: PTH111
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user, e.g. ``~/Desktop``"""
+ return os.path.expanduser("~/Desktop") # noqa: PTH111
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """:return: runtime directory tied to the user, e.g. ``~/Library/Caches/TemporaryItems/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Caches/TemporaryItems")) # noqa: PTH111
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users, same as `user_runtime_dir`"""
+ return self.user_runtime_dir
+
+
+__all__ = [
+ "MacOS",
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/unix.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/unix.py
new file mode 100644
index 000000000..9500ade61
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/unix.py
@@ -0,0 +1,275 @@
+"""Unix."""
+
+from __future__ import annotations
+
+import os
+import sys
+from configparser import ConfigParser
+from pathlib import Path
+from typing import Iterator, NoReturn
+
+from .api import PlatformDirsABC
+
+if sys.platform == "win32":
+
+ def getuid() -> NoReturn:
+ msg = "should only be used on Unix"
+ raise RuntimeError(msg)
+
+else:
+ from os import getuid
+
+
+class Unix(PlatformDirsABC): # noqa: PLR0904
+ """
+ On Unix/Linux, we follow the `XDG Basedir Spec <https://specifications.freedesktop.org/basedir-spec/basedir-spec-
+ latest.html>`_.
+
+ The spec allows overriding directories with environment variables. The examples shown are the default values,
+ alongside the name of the environment variable that overrides them. Makes use of the `appname
+ <platformdirs.api.PlatformDirsABC.appname>`, `version <platformdirs.api.PlatformDirsABC.version>`, `multipath
+ <platformdirs.api.PlatformDirsABC.multipath>`, `opinion <platformdirs.api.PlatformDirsABC.opinion>`, `ensure_exists
+ <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """
+ :return: data directory tied to the user, e.g. ``~/.local/share/$appname/$version`` or
+ ``$XDG_DATA_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_DATA_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.local/share") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def _site_data_dirs(self) -> list[str]:
+ path = os.environ.get("XDG_DATA_DIRS", "")
+ if not path.strip():
+ path = f"/usr/local/share{os.pathsep}/usr/share"
+ return [self._append_app_name_and_version(p) for p in path.split(os.pathsep)]
+
+ @property
+ def site_data_dir(self) -> str:
+ """
+ :return: data directories shared by users (if `multipath <platformdirs.api.PlatformDirsABC.multipath>` is
+ enabled and ``XDG_DATA_DIRS`` is set and a multi path the response is also a multi path separated by the
+ OS path separator), e.g. ``/usr/local/share/$appname/$version`` or ``/usr/share/$appname/$version``
+ """
+ # XDG default for $XDG_DATA_DIRS; only first, if multipath is False
+ dirs = self._site_data_dirs
+ if not self.multipath:
+ return dirs[0]
+ return os.pathsep.join(dirs)
+
+ @property
+ def user_config_dir(self) -> str:
+ """
+ :return: config directory tied to the user, e.g. ``~/.config/$appname/$version`` or
+ ``$XDG_CONFIG_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_CONFIG_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.config") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def _site_config_dirs(self) -> list[str]:
+ path = os.environ.get("XDG_CONFIG_DIRS", "")
+ if not path.strip():
+ path = "/etc/xdg"
+ return [self._append_app_name_and_version(p) for p in path.split(os.pathsep)]
+
+ @property
+ def site_config_dir(self) -> str:
+ """
+ :return: config directories shared by users (if `multipath <platformdirs.api.PlatformDirsABC.multipath>`
+ is enabled and ``XDG_CONFIG_DIRS`` is set and a multi path the response is also a multi path separated by
+ the OS path separator), e.g. ``/etc/xdg/$appname/$version``
+ """
+ # XDG default for $XDG_CONFIG_DIRS only first, if multipath is False
+ dirs = self._site_config_dirs
+ if not self.multipath:
+ return dirs[0]
+ return os.pathsep.join(dirs)
+
+ @property
+ def user_cache_dir(self) -> str:
+ """
+ :return: cache directory tied to the user, e.g. ``~/.cache/$appname/$version`` or
+ ``~/$XDG_CACHE_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_CACHE_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.cache") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users, e.g. ``/var/cache/$appname/$version``"""
+ return self._append_app_name_and_version("/var/cache")
+
+ @property
+ def user_state_dir(self) -> str:
+ """
+ :return: state directory tied to the user, e.g. ``~/.local/state/$appname/$version`` or
+ ``$XDG_STATE_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_STATE_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.local/state") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user, same as `user_state_dir` if not opinionated else ``log`` in it"""
+ path = self.user_state_dir
+ if self.opinion:
+ path = os.path.join(path, "log") # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user, e.g. ``~/Documents``"""
+ return _get_user_media_dir("XDG_DOCUMENTS_DIR", "~/Documents")
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user, e.g. ``~/Downloads``"""
+ return _get_user_media_dir("XDG_DOWNLOAD_DIR", "~/Downloads")
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user, e.g. ``~/Pictures``"""
+ return _get_user_media_dir("XDG_PICTURES_DIR", "~/Pictures")
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user, e.g. ``~/Videos``"""
+ return _get_user_media_dir("XDG_VIDEOS_DIR", "~/Videos")
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user, e.g. ``~/Music``"""
+ return _get_user_media_dir("XDG_MUSIC_DIR", "~/Music")
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user, e.g. ``~/Desktop``"""
+ return _get_user_media_dir("XDG_DESKTOP_DIR", "~/Desktop")
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """
+ :return: runtime directory tied to the user, e.g. ``/run/user/$(id -u)/$appname/$version`` or
+ ``$XDG_RUNTIME_DIR/$appname/$version``.
+
+ For FreeBSD/OpenBSD/NetBSD, it would return ``/var/run/user/$(id -u)/$appname/$version`` if
+ exists, otherwise ``/tmp/runtime-$(id -u)/$appname/$version``, if``$XDG_RUNTIME_DIR``
+ is not set.
+ """
+ path = os.environ.get("XDG_RUNTIME_DIR", "")
+ if not path.strip():
+ if sys.platform.startswith(("freebsd", "openbsd", "netbsd")):
+ path = f"/var/run/user/{getuid()}"
+ if not Path(path).exists():
+ path = f"/tmp/runtime-{getuid()}" # noqa: S108
+ else:
+ path = f"/run/user/{getuid()}"
+ return self._append_app_name_and_version(path)
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """
+ :return: runtime directory shared by users, e.g. ``/run/$appname/$version`` or \
+ ``$XDG_RUNTIME_DIR/$appname/$version``.
+
+ Note that this behaves almost exactly like `user_runtime_dir` if ``$XDG_RUNTIME_DIR`` is set, but will
+ fall back to paths associated to the root user instead of a regular logged-in user if it's not set.
+
+ If you wish to ensure that a logged-in root user path is returned e.g. ``/run/user/0``, use `user_runtime_dir`
+ instead.
+
+ For FreeBSD/OpenBSD/NetBSD, it would return ``/var/run/$appname/$version`` if ``$XDG_RUNTIME_DIR`` is not set.
+ """
+ path = os.environ.get("XDG_RUNTIME_DIR", "")
+ if not path.strip():
+ if sys.platform.startswith(("freebsd", "openbsd", "netbsd")):
+ path = "/var/run"
+ else:
+ path = "/run"
+ return self._append_app_name_and_version(path)
+
+ @property
+ def site_data_path(self) -> Path:
+ """:return: data path shared by users. Only return the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_data_dir)
+
+ @property
+ def site_config_path(self) -> Path:
+ """:return: config path shared by the users, returns the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_config_dir)
+
+ @property
+ def site_cache_path(self) -> Path:
+ """:return: cache path shared by users. Only return the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_cache_dir)
+
+ def _first_item_as_path_if_multipath(self, directory: str) -> Path:
+ if self.multipath:
+ # If multipath is True, the first path is returned.
+ directory = directory.split(os.pathsep)[0]
+ return Path(directory)
+
+ def iter_config_dirs(self) -> Iterator[str]:
+ """:yield: all user and site configuration directories."""
+ yield self.user_config_dir
+ yield from self._site_config_dirs
+
+ def iter_data_dirs(self) -> Iterator[str]:
+ """:yield: all user and site data directories."""
+ yield self.user_data_dir
+ yield from self._site_data_dirs
+
+
+def _get_user_media_dir(env_var: str, fallback_tilde_path: str) -> str:
+ media_dir = _get_user_dirs_folder(env_var)
+ if media_dir is None:
+ media_dir = os.environ.get(env_var, "").strip()
+ if not media_dir:
+ media_dir = os.path.expanduser(fallback_tilde_path) # noqa: PTH111
+
+ return media_dir
+
+
+def _get_user_dirs_folder(key: str) -> str | None:
+ """
+ Return directory from user-dirs.dirs config file.
+
+ See https://freedesktop.org/wiki/Software/xdg-user-dirs/.
+
+ """
+ user_dirs_config_path = Path(Unix().user_config_dir) / "user-dirs.dirs"
+ if user_dirs_config_path.exists():
+ parser = ConfigParser()
+
+ with user_dirs_config_path.open() as stream:
+ # Add fake section header, so ConfigParser doesn't complain
+ parser.read_string(f"[top]\n{stream.read()}")
+
+ if key not in parser["top"]:
+ return None
+
+ path = parser["top"][key].strip('"')
+ # Handle relative home paths
+ return path.replace("$HOME", os.path.expanduser("~")) # noqa: PTH111
+
+ return None
+
+
+__all__ = [
+ "Unix",
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/version.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/version.py
new file mode 100644
index 000000000..6483ddce0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/version.py
@@ -0,0 +1,16 @@
+# file generated by setuptools_scm
+# don't change, don't track in version control
+TYPE_CHECKING = False
+if TYPE_CHECKING:
+ from typing import Tuple, Union
+ VERSION_TUPLE = Tuple[Union[int, str], ...]
+else:
+ VERSION_TUPLE = object
+
+version: str
+__version__: str
+__version_tuple__: VERSION_TUPLE
+version_tuple: VERSION_TUPLE
+
+__version__ = version = '4.2.2'
+__version_tuple__ = version_tuple = (4, 2, 2)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/windows.py b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/windows.py
new file mode 100644
index 000000000..d7bc96091
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/platformdirs/windows.py
@@ -0,0 +1,272 @@
+"""Windows."""
+
+from __future__ import annotations
+
+import os
+import sys
+from functools import lru_cache
+from typing import TYPE_CHECKING
+
+from .api import PlatformDirsABC
+
+if TYPE_CHECKING:
+ from collections.abc import Callable
+
+
+class Windows(PlatformDirsABC):
+ """
+ `MSDN on where to store app data files <https://learn.microsoft.com/en-us/windows/win32/shell/knownfolderid>`_.
+
+ Makes use of the `appname <platformdirs.api.PlatformDirsABC.appname>`, `appauthor
+ <platformdirs.api.PlatformDirsABC.appauthor>`, `version <platformdirs.api.PlatformDirsABC.version>`, `roaming
+ <platformdirs.api.PlatformDirsABC.roaming>`, `opinion <platformdirs.api.PlatformDirsABC.opinion>`, `ensure_exists
+ <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """
+ :return: data directory tied to the user, e.g.
+ ``%USERPROFILE%\\AppData\\Local\\$appauthor\\$appname`` (not roaming) or
+ ``%USERPROFILE%\\AppData\\Roaming\\$appauthor\\$appname`` (roaming)
+ """
+ const = "CSIDL_APPDATA" if self.roaming else "CSIDL_LOCAL_APPDATA"
+ path = os.path.normpath(get_win_folder(const))
+ return self._append_parts(path)
+
+ def _append_parts(self, path: str, *, opinion_value: str | None = None) -> str:
+ params = []
+ if self.appname:
+ if self.appauthor is not False:
+ author = self.appauthor or self.appname
+ params.append(author)
+ params.append(self.appname)
+ if opinion_value is not None and self.opinion:
+ params.append(opinion_value)
+ if self.version:
+ params.append(self.version)
+ path = os.path.join(path, *params) # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ @property
+ def site_data_dir(self) -> str:
+ """:return: data directory shared by users, e.g. ``C:\\ProgramData\\$appauthor\\$appname``"""
+ path = os.path.normpath(get_win_folder("CSIDL_COMMON_APPDATA"))
+ return self._append_parts(path)
+
+ @property
+ def user_config_dir(self) -> str:
+ """:return: config directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users, same as `site_data_dir`"""
+ return self.site_data_dir
+
+ @property
+ def user_cache_dir(self) -> str:
+ """
+ :return: cache directory tied to the user (if opinionated with ``Cache`` folder within ``$appname``) e.g.
+ ``%USERPROFILE%\\AppData\\Local\\$appauthor\\$appname\\Cache\\$version``
+ """
+ path = os.path.normpath(get_win_folder("CSIDL_LOCAL_APPDATA"))
+ return self._append_parts(path, opinion_value="Cache")
+
+ @property
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users, e.g. ``C:\\ProgramData\\$appauthor\\$appname\\Cache\\$version``"""
+ path = os.path.normpath(get_win_folder("CSIDL_COMMON_APPDATA"))
+ return self._append_parts(path, opinion_value="Cache")
+
+ @property
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user, same as `user_data_dir` if not opinionated else ``Logs`` in it"""
+ path = self.user_data_dir
+ if self.opinion:
+ path = os.path.join(path, "Logs") # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user e.g. ``%USERPROFILE%\\Documents``"""
+ return os.path.normpath(get_win_folder("CSIDL_PERSONAL"))
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user e.g. ``%USERPROFILE%\\Downloads``"""
+ return os.path.normpath(get_win_folder("CSIDL_DOWNLOADS"))
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user e.g. ``%USERPROFILE%\\Pictures``"""
+ return os.path.normpath(get_win_folder("CSIDL_MYPICTURES"))
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user e.g. ``%USERPROFILE%\\Videos``"""
+ return os.path.normpath(get_win_folder("CSIDL_MYVIDEO"))
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user e.g. ``%USERPROFILE%\\Music``"""
+ return os.path.normpath(get_win_folder("CSIDL_MYMUSIC"))
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user, e.g. ``%USERPROFILE%\\Desktop``"""
+ return os.path.normpath(get_win_folder("CSIDL_DESKTOPDIRECTORY"))
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """
+ :return: runtime directory tied to the user, e.g.
+ ``%USERPROFILE%\\AppData\\Local\\Temp\\$appauthor\\$appname``
+ """
+ path = os.path.normpath(os.path.join(get_win_folder("CSIDL_LOCAL_APPDATA"), "Temp")) # noqa: PTH118
+ return self._append_parts(path)
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users, same as `user_runtime_dir`"""
+ return self.user_runtime_dir
+
+
+def get_win_folder_from_env_vars(csidl_name: str) -> str:
+ """Get folder from environment variables."""
+ result = get_win_folder_if_csidl_name_not_env_var(csidl_name)
+ if result is not None:
+ return result
+
+ env_var_name = {
+ "CSIDL_APPDATA": "APPDATA",
+ "CSIDL_COMMON_APPDATA": "ALLUSERSPROFILE",
+ "CSIDL_LOCAL_APPDATA": "LOCALAPPDATA",
+ }.get(csidl_name)
+ if env_var_name is None:
+ msg = f"Unknown CSIDL name: {csidl_name}"
+ raise ValueError(msg)
+ result = os.environ.get(env_var_name)
+ if result is None:
+ msg = f"Unset environment variable: {env_var_name}"
+ raise ValueError(msg)
+ return result
+
+
+def get_win_folder_if_csidl_name_not_env_var(csidl_name: str) -> str | None:
+ """Get a folder for a CSIDL name that does not exist as an environment variable."""
+ if csidl_name == "CSIDL_PERSONAL":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Documents") # noqa: PTH118
+
+ if csidl_name == "CSIDL_DOWNLOADS":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Downloads") # noqa: PTH118
+
+ if csidl_name == "CSIDL_MYPICTURES":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Pictures") # noqa: PTH118
+
+ if csidl_name == "CSIDL_MYVIDEO":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Videos") # noqa: PTH118
+
+ if csidl_name == "CSIDL_MYMUSIC":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Music") # noqa: PTH118
+ return None
+
+
+def get_win_folder_from_registry(csidl_name: str) -> str:
+ """
+ Get folder from the registry.
+
+ This is a fallback technique at best. I'm not sure if using the registry for these guarantees us the correct answer
+ for all CSIDL_* names.
+
+ """
+ shell_folder_name = {
+ "CSIDL_APPDATA": "AppData",
+ "CSIDL_COMMON_APPDATA": "Common AppData",
+ "CSIDL_LOCAL_APPDATA": "Local AppData",
+ "CSIDL_PERSONAL": "Personal",
+ "CSIDL_DOWNLOADS": "{374DE290-123F-4565-9164-39C4925E467B}",
+ "CSIDL_MYPICTURES": "My Pictures",
+ "CSIDL_MYVIDEO": "My Video",
+ "CSIDL_MYMUSIC": "My Music",
+ }.get(csidl_name)
+ if shell_folder_name is None:
+ msg = f"Unknown CSIDL name: {csidl_name}"
+ raise ValueError(msg)
+ if sys.platform != "win32": # only needed for mypy type checker to know that this code runs only on Windows
+ raise NotImplementedError
+ import winreg # noqa: PLC0415
+
+ key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r"Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders")
+ directory, _ = winreg.QueryValueEx(key, shell_folder_name)
+ return str(directory)
+
+
+def get_win_folder_via_ctypes(csidl_name: str) -> str:
+ """Get folder with ctypes."""
+ # There is no 'CSIDL_DOWNLOADS'.
+ # Use 'CSIDL_PROFILE' (40) and append the default folder 'Downloads' instead.
+ # https://learn.microsoft.com/en-us/windows/win32/shell/knownfolderid
+
+ import ctypes # noqa: PLC0415
+
+ csidl_const = {
+ "CSIDL_APPDATA": 26,
+ "CSIDL_COMMON_APPDATA": 35,
+ "CSIDL_LOCAL_APPDATA": 28,
+ "CSIDL_PERSONAL": 5,
+ "CSIDL_MYPICTURES": 39,
+ "CSIDL_MYVIDEO": 14,
+ "CSIDL_MYMUSIC": 13,
+ "CSIDL_DOWNLOADS": 40,
+ "CSIDL_DESKTOPDIRECTORY": 16,
+ }.get(csidl_name)
+ if csidl_const is None:
+ msg = f"Unknown CSIDL name: {csidl_name}"
+ raise ValueError(msg)
+
+ buf = ctypes.create_unicode_buffer(1024)
+ windll = getattr(ctypes, "windll") # noqa: B009 # using getattr to avoid false positive with mypy type checker
+ windll.shell32.SHGetFolderPathW(None, csidl_const, None, 0, buf)
+
+ # Downgrade to short path name if it has high-bit chars.
+ if any(ord(c) > 255 for c in buf): # noqa: PLR2004
+ buf2 = ctypes.create_unicode_buffer(1024)
+ if windll.kernel32.GetShortPathNameW(buf.value, buf2, 1024):
+ buf = buf2
+
+ if csidl_name == "CSIDL_DOWNLOADS":
+ return os.path.join(buf.value, "Downloads") # noqa: PTH118
+
+ return buf.value
+
+
+def _pick_get_win_folder() -> Callable[[str], str]:
+ try:
+ import ctypes # noqa: PLC0415
+ except ImportError:
+ pass
+ else:
+ if hasattr(ctypes, "windll"):
+ return get_win_folder_via_ctypes
+ try:
+ import winreg # noqa: PLC0415, F401
+ except ImportError:
+ return get_win_folder_from_env_vars
+ else:
+ return get_win_folder_from_registry
+
+
+get_win_folder = lru_cache(maxsize=None)(_pick_get_win_folder())
+
+__all__ = [
+ "Windows",
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/__init__.py
new file mode 100644
index 000000000..60ae9bb85
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/__init__.py
@@ -0,0 +1,82 @@
+"""
+ Pygments
+ ~~~~~~~~
+
+ Pygments is a syntax highlighting package written in Python.
+
+ It is a generic syntax highlighter for general use in all kinds of software
+ such as forum systems, wikis or other applications that need to prettify
+ source code. Highlights are:
+
+ * a wide range of common languages and markup formats is supported
+ * special attention is paid to details, increasing quality by a fair amount
+ * support for new languages and formats are added easily
+ * a number of output formats, presently HTML, LaTeX, RTF, SVG, all image
+ formats that PIL supports, and ANSI sequences
+ * it is usable as a command-line tool and as a library
+ * ... and it highlights even Brainfuck!
+
+ The `Pygments master branch`_ is installable with ``easy_install Pygments==dev``.
+
+ .. _Pygments master branch:
+ https://github.com/pygments/pygments/archive/master.zip#egg=Pygments-dev
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+from io import StringIO, BytesIO
+
+__version__ = '2.18.0'
+__docformat__ = 'restructuredtext'
+
+__all__ = ['lex', 'format', 'highlight']
+
+
+def lex(code, lexer):
+ """
+ Lex `code` with the `lexer` (must be a `Lexer` instance)
+ and return an iterable of tokens. Currently, this only calls
+ `lexer.get_tokens()`.
+ """
+ try:
+ return lexer.get_tokens(code)
+ except TypeError:
+ # Heuristic to catch a common mistake.
+ from pip._vendor.pygments.lexer import RegexLexer
+ if isinstance(lexer, type) and issubclass(lexer, RegexLexer):
+ raise TypeError('lex() argument must be a lexer instance, '
+ 'not a class')
+ raise
+
+
+def format(tokens, formatter, outfile=None): # pylint: disable=redefined-builtin
+ """
+ Format ``tokens`` (an iterable of tokens) with the formatter ``formatter``
+ (a `Formatter` instance).
+
+ If ``outfile`` is given and a valid file object (an object with a
+ ``write`` method), the result will be written to it, otherwise it
+ is returned as a string.
+ """
+ try:
+ if not outfile:
+ realoutfile = getattr(formatter, 'encoding', None) and BytesIO() or StringIO()
+ formatter.format(tokens, realoutfile)
+ return realoutfile.getvalue()
+ else:
+ formatter.format(tokens, outfile)
+ except TypeError:
+ # Heuristic to catch a common mistake.
+ from pip._vendor.pygments.formatter import Formatter
+ if isinstance(formatter, type) and issubclass(formatter, Formatter):
+ raise TypeError('format() argument must be a formatter instance, '
+ 'not a class')
+ raise
+
+
+def highlight(code, lexer, formatter, outfile=None):
+ """
+ This is the most high-level highlighting function. It combines `lex` and
+ `format` in one function.
+ """
+ return format(lex(code, lexer), formatter, outfile)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/__main__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/__main__.py
new file mode 100644
index 000000000..dcc6e5add
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/__main__.py
@@ -0,0 +1,17 @@
+"""
+ pygments.__main__
+ ~~~~~~~~~~~~~~~~~
+
+ Main entry point for ``python -m pygments``.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import sys
+from pip._vendor.pygments.cmdline import main
+
+try:
+ sys.exit(main(sys.argv))
+except KeyboardInterrupt:
+ sys.exit(1)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/cmdline.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/cmdline.py
new file mode 100644
index 000000000..0a7072eff
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/cmdline.py
@@ -0,0 +1,668 @@
+"""
+ pygments.cmdline
+ ~~~~~~~~~~~~~~~~
+
+ Command line interface.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import os
+import sys
+import shutil
+import argparse
+from textwrap import dedent
+
+from pip._vendor.pygments import __version__, highlight
+from pip._vendor.pygments.util import ClassNotFound, OptionError, docstring_headline, \
+ guess_decode, guess_decode_from_terminal, terminal_encoding, \
+ UnclosingTextIOWrapper
+from pip._vendor.pygments.lexers import get_all_lexers, get_lexer_by_name, guess_lexer, \
+ load_lexer_from_file, get_lexer_for_filename, find_lexer_class_for_filename
+from pip._vendor.pygments.lexers.special import TextLexer
+from pip._vendor.pygments.formatters.latex import LatexEmbeddedLexer, LatexFormatter
+from pip._vendor.pygments.formatters import get_all_formatters, get_formatter_by_name, \
+ load_formatter_from_file, get_formatter_for_filename, find_formatter_class
+from pip._vendor.pygments.formatters.terminal import TerminalFormatter
+from pip._vendor.pygments.formatters.terminal256 import Terminal256Formatter, TerminalTrueColorFormatter
+from pip._vendor.pygments.filters import get_all_filters, find_filter_class
+from pip._vendor.pygments.styles import get_all_styles, get_style_by_name
+
+
+def _parse_options(o_strs):
+ opts = {}
+ if not o_strs:
+ return opts
+ for o_str in o_strs:
+ if not o_str.strip():
+ continue
+ o_args = o_str.split(',')
+ for o_arg in o_args:
+ o_arg = o_arg.strip()
+ try:
+ o_key, o_val = o_arg.split('=', 1)
+ o_key = o_key.strip()
+ o_val = o_val.strip()
+ except ValueError:
+ opts[o_arg] = True
+ else:
+ opts[o_key] = o_val
+ return opts
+
+
+def _parse_filters(f_strs):
+ filters = []
+ if not f_strs:
+ return filters
+ for f_str in f_strs:
+ if ':' in f_str:
+ fname, fopts = f_str.split(':', 1)
+ filters.append((fname, _parse_options([fopts])))
+ else:
+ filters.append((f_str, {}))
+ return filters
+
+
+def _print_help(what, name):
+ try:
+ if what == 'lexer':
+ cls = get_lexer_by_name(name)
+ print(f"Help on the {cls.name} lexer:")
+ print(dedent(cls.__doc__))
+ elif what == 'formatter':
+ cls = find_formatter_class(name)
+ print(f"Help on the {cls.name} formatter:")
+ print(dedent(cls.__doc__))
+ elif what == 'filter':
+ cls = find_filter_class(name)
+ print(f"Help on the {name} filter:")
+ print(dedent(cls.__doc__))
+ return 0
+ except (AttributeError, ValueError):
+ print(f"{what} not found!", file=sys.stderr)
+ return 1
+
+
+def _print_list(what):
+ if what == 'lexer':
+ print()
+ print("Lexers:")
+ print("~~~~~~~")
+
+ info = []
+ for fullname, names, exts, _ in get_all_lexers():
+ tup = (', '.join(names)+':', fullname,
+ exts and '(filenames ' + ', '.join(exts) + ')' or '')
+ info.append(tup)
+ info.sort()
+ for i in info:
+ print(('* {}\n {} {}').format(*i))
+
+ elif what == 'formatter':
+ print()
+ print("Formatters:")
+ print("~~~~~~~~~~~")
+
+ info = []
+ for cls in get_all_formatters():
+ doc = docstring_headline(cls)
+ tup = (', '.join(cls.aliases) + ':', doc, cls.filenames and
+ '(filenames ' + ', '.join(cls.filenames) + ')' or '')
+ info.append(tup)
+ info.sort()
+ for i in info:
+ print(('* {}\n {} {}').format(*i))
+
+ elif what == 'filter':
+ print()
+ print("Filters:")
+ print("~~~~~~~~")
+
+ for name in get_all_filters():
+ cls = find_filter_class(name)
+ print("* " + name + ':')
+ print(f" {docstring_headline(cls)}")
+
+ elif what == 'style':
+ print()
+ print("Styles:")
+ print("~~~~~~~")
+
+ for name in get_all_styles():
+ cls = get_style_by_name(name)
+ print("* " + name + ':')
+ print(f" {docstring_headline(cls)}")
+
+
+def _print_list_as_json(requested_items):
+ import json
+ result = {}
+ if 'lexer' in requested_items:
+ info = {}
+ for fullname, names, filenames, mimetypes in get_all_lexers():
+ info[fullname] = {
+ 'aliases': names,
+ 'filenames': filenames,
+ 'mimetypes': mimetypes
+ }
+ result['lexers'] = info
+
+ if 'formatter' in requested_items:
+ info = {}
+ for cls in get_all_formatters():
+ doc = docstring_headline(cls)
+ info[cls.name] = {
+ 'aliases': cls.aliases,
+ 'filenames': cls.filenames,
+ 'doc': doc
+ }
+ result['formatters'] = info
+
+ if 'filter' in requested_items:
+ info = {}
+ for name in get_all_filters():
+ cls = find_filter_class(name)
+ info[name] = {
+ 'doc': docstring_headline(cls)
+ }
+ result['filters'] = info
+
+ if 'style' in requested_items:
+ info = {}
+ for name in get_all_styles():
+ cls = get_style_by_name(name)
+ info[name] = {
+ 'doc': docstring_headline(cls)
+ }
+ result['styles'] = info
+
+ json.dump(result, sys.stdout)
+
+def main_inner(parser, argns):
+ if argns.help:
+ parser.print_help()
+ return 0
+
+ if argns.V:
+ print(f'Pygments version {__version__}, (c) 2006-2024 by Georg Brandl, Matthäus '
+ 'Chajdas and contributors.')
+ return 0
+
+ def is_only_option(opt):
+ return not any(v for (k, v) in vars(argns).items() if k != opt)
+
+ # handle ``pygmentize -L``
+ if argns.L is not None:
+ arg_set = set()
+ for k, v in vars(argns).items():
+ if v:
+ arg_set.add(k)
+
+ arg_set.discard('L')
+ arg_set.discard('json')
+
+ if arg_set:
+ parser.print_help(sys.stderr)
+ return 2
+
+ # print version
+ if not argns.json:
+ main(['', '-V'])
+ allowed_types = {'lexer', 'formatter', 'filter', 'style'}
+ largs = [arg.rstrip('s') for arg in argns.L]
+ if any(arg not in allowed_types for arg in largs):
+ parser.print_help(sys.stderr)
+ return 0
+ if not largs:
+ largs = allowed_types
+ if not argns.json:
+ for arg in largs:
+ _print_list(arg)
+ else:
+ _print_list_as_json(largs)
+ return 0
+
+ # handle ``pygmentize -H``
+ if argns.H:
+ if not is_only_option('H'):
+ parser.print_help(sys.stderr)
+ return 2
+ what, name = argns.H
+ if what not in ('lexer', 'formatter', 'filter'):
+ parser.print_help(sys.stderr)
+ return 2
+ return _print_help(what, name)
+
+ # parse -O options
+ parsed_opts = _parse_options(argns.O or [])
+
+ # parse -P options
+ for p_opt in argns.P or []:
+ try:
+ name, value = p_opt.split('=', 1)
+ except ValueError:
+ parsed_opts[p_opt] = True
+ else:
+ parsed_opts[name] = value
+
+ # encodings
+ inencoding = parsed_opts.get('inencoding', parsed_opts.get('encoding'))
+ outencoding = parsed_opts.get('outencoding', parsed_opts.get('encoding'))
+
+ # handle ``pygmentize -N``
+ if argns.N:
+ lexer = find_lexer_class_for_filename(argns.N)
+ if lexer is None:
+ lexer = TextLexer
+
+ print(lexer.aliases[0])
+ return 0
+
+ # handle ``pygmentize -C``
+ if argns.C:
+ inp = sys.stdin.buffer.read()
+ try:
+ lexer = guess_lexer(inp, inencoding=inencoding)
+ except ClassNotFound:
+ lexer = TextLexer
+
+ print(lexer.aliases[0])
+ return 0
+
+ # handle ``pygmentize -S``
+ S_opt = argns.S
+ a_opt = argns.a
+ if S_opt is not None:
+ f_opt = argns.f
+ if not f_opt:
+ parser.print_help(sys.stderr)
+ return 2
+ if argns.l or argns.INPUTFILE:
+ parser.print_help(sys.stderr)
+ return 2
+
+ try:
+ parsed_opts['style'] = S_opt
+ fmter = get_formatter_by_name(f_opt, **parsed_opts)
+ except ClassNotFound as err:
+ print(err, file=sys.stderr)
+ return 1
+
+ print(fmter.get_style_defs(a_opt or ''))
+ return 0
+
+ # if no -S is given, -a is not allowed
+ if argns.a is not None:
+ parser.print_help(sys.stderr)
+ return 2
+
+ # parse -F options
+ F_opts = _parse_filters(argns.F or [])
+
+ # -x: allow custom (eXternal) lexers and formatters
+ allow_custom_lexer_formatter = bool(argns.x)
+
+ # select lexer
+ lexer = None
+
+ # given by name?
+ lexername = argns.l
+ if lexername:
+ # custom lexer, located relative to user's cwd
+ if allow_custom_lexer_formatter and '.py' in lexername:
+ try:
+ filename = None
+ name = None
+ if ':' in lexername:
+ filename, name = lexername.rsplit(':', 1)
+
+ if '.py' in name:
+ # This can happen on Windows: If the lexername is
+ # C:\lexer.py -- return to normal load path in that case
+ name = None
+
+ if filename and name:
+ lexer = load_lexer_from_file(filename, name,
+ **parsed_opts)
+ else:
+ lexer = load_lexer_from_file(lexername, **parsed_opts)
+ except ClassNotFound as err:
+ print('Error:', err, file=sys.stderr)
+ return 1
+ else:
+ try:
+ lexer = get_lexer_by_name(lexername, **parsed_opts)
+ except (OptionError, ClassNotFound) as err:
+ print('Error:', err, file=sys.stderr)
+ return 1
+
+ # read input code
+ code = None
+
+ if argns.INPUTFILE:
+ if argns.s:
+ print('Error: -s option not usable when input file specified',
+ file=sys.stderr)
+ return 2
+
+ infn = argns.INPUTFILE
+ try:
+ with open(infn, 'rb') as infp:
+ code = infp.read()
+ except Exception as err:
+ print('Error: cannot read infile:', err, file=sys.stderr)
+ return 1
+ if not inencoding:
+ code, inencoding = guess_decode(code)
+
+ # do we have to guess the lexer?
+ if not lexer:
+ try:
+ lexer = get_lexer_for_filename(infn, code, **parsed_opts)
+ except ClassNotFound as err:
+ if argns.g:
+ try:
+ lexer = guess_lexer(code, **parsed_opts)
+ except ClassNotFound:
+ lexer = TextLexer(**parsed_opts)
+ else:
+ print('Error:', err, file=sys.stderr)
+ return 1
+ except OptionError as err:
+ print('Error:', err, file=sys.stderr)
+ return 1
+
+ elif not argns.s: # treat stdin as full file (-s support is later)
+ # read code from terminal, always in binary mode since we want to
+ # decode ourselves and be tolerant with it
+ code = sys.stdin.buffer.read() # use .buffer to get a binary stream
+ if not inencoding:
+ code, inencoding = guess_decode_from_terminal(code, sys.stdin)
+ # else the lexer will do the decoding
+ if not lexer:
+ try:
+ lexer = guess_lexer(code, **parsed_opts)
+ except ClassNotFound:
+ lexer = TextLexer(**parsed_opts)
+
+ else: # -s option needs a lexer with -l
+ if not lexer:
+ print('Error: when using -s a lexer has to be selected with -l',
+ file=sys.stderr)
+ return 2
+
+ # process filters
+ for fname, fopts in F_opts:
+ try:
+ lexer.add_filter(fname, **fopts)
+ except ClassNotFound as err:
+ print('Error:', err, file=sys.stderr)
+ return 1
+
+ # select formatter
+ outfn = argns.o
+ fmter = argns.f
+ if fmter:
+ # custom formatter, located relative to user's cwd
+ if allow_custom_lexer_formatter and '.py' in fmter:
+ try:
+ filename = None
+ name = None
+ if ':' in fmter:
+ # Same logic as above for custom lexer
+ filename, name = fmter.rsplit(':', 1)
+
+ if '.py' in name:
+ name = None
+
+ if filename and name:
+ fmter = load_formatter_from_file(filename, name,
+ **parsed_opts)
+ else:
+ fmter = load_formatter_from_file(fmter, **parsed_opts)
+ except ClassNotFound as err:
+ print('Error:', err, file=sys.stderr)
+ return 1
+ else:
+ try:
+ fmter = get_formatter_by_name(fmter, **parsed_opts)
+ except (OptionError, ClassNotFound) as err:
+ print('Error:', err, file=sys.stderr)
+ return 1
+
+ if outfn:
+ if not fmter:
+ try:
+ fmter = get_formatter_for_filename(outfn, **parsed_opts)
+ except (OptionError, ClassNotFound) as err:
+ print('Error:', err, file=sys.stderr)
+ return 1
+ try:
+ outfile = open(outfn, 'wb')
+ except Exception as err:
+ print('Error: cannot open outfile:', err, file=sys.stderr)
+ return 1
+ else:
+ if not fmter:
+ if os.environ.get('COLORTERM','') in ('truecolor', '24bit'):
+ fmter = TerminalTrueColorFormatter(**parsed_opts)
+ elif '256' in os.environ.get('TERM', ''):
+ fmter = Terminal256Formatter(**parsed_opts)
+ else:
+ fmter = TerminalFormatter(**parsed_opts)
+ outfile = sys.stdout.buffer
+
+ # determine output encoding if not explicitly selected
+ if not outencoding:
+ if outfn:
+ # output file? use lexer encoding for now (can still be None)
+ fmter.encoding = inencoding
+ else:
+ # else use terminal encoding
+ fmter.encoding = terminal_encoding(sys.stdout)
+
+ # provide coloring under Windows, if possible
+ if not outfn and sys.platform in ('win32', 'cygwin') and \
+ fmter.name in ('Terminal', 'Terminal256'): # pragma: no cover
+ # unfortunately colorama doesn't support binary streams on Py3
+ outfile = UnclosingTextIOWrapper(outfile, encoding=fmter.encoding)
+ fmter.encoding = None
+ try:
+ import colorama.initialise
+ except ImportError:
+ pass
+ else:
+ outfile = colorama.initialise.wrap_stream(
+ outfile, convert=None, strip=None, autoreset=False, wrap=True)
+
+ # When using the LaTeX formatter and the option `escapeinside` is
+ # specified, we need a special lexer which collects escaped text
+ # before running the chosen language lexer.
+ escapeinside = parsed_opts.get('escapeinside', '')
+ if len(escapeinside) == 2 and isinstance(fmter, LatexFormatter):
+ left = escapeinside[0]
+ right = escapeinside[1]
+ lexer = LatexEmbeddedLexer(left, right, lexer)
+
+ # ... and do it!
+ if not argns.s:
+ # process whole input as per normal...
+ try:
+ highlight(code, lexer, fmter, outfile)
+ finally:
+ if outfn:
+ outfile.close()
+ return 0
+ else:
+ # line by line processing of stdin (eg: for 'tail -f')...
+ try:
+ while 1:
+ line = sys.stdin.buffer.readline()
+ if not line:
+ break
+ if not inencoding:
+ line = guess_decode_from_terminal(line, sys.stdin)[0]
+ highlight(line, lexer, fmter, outfile)
+ if hasattr(outfile, 'flush'):
+ outfile.flush()
+ return 0
+ except KeyboardInterrupt: # pragma: no cover
+ return 0
+ finally:
+ if outfn:
+ outfile.close()
+
+
+class HelpFormatter(argparse.HelpFormatter):
+ def __init__(self, prog, indent_increment=2, max_help_position=16, width=None):
+ if width is None:
+ try:
+ width = shutil.get_terminal_size().columns - 2
+ except Exception:
+ pass
+ argparse.HelpFormatter.__init__(self, prog, indent_increment,
+ max_help_position, width)
+
+
+def main(args=sys.argv):
+ """
+ Main command line entry point.
+ """
+ desc = "Highlight an input file and write the result to an output file."
+ parser = argparse.ArgumentParser(description=desc, add_help=False,
+ formatter_class=HelpFormatter)
+
+ operation = parser.add_argument_group('Main operation')
+ lexersel = operation.add_mutually_exclusive_group()
+ lexersel.add_argument(
+ '-l', metavar='LEXER',
+ help='Specify the lexer to use. (Query names with -L.) If not '
+ 'given and -g is not present, the lexer is guessed from the filename.')
+ lexersel.add_argument(
+ '-g', action='store_true',
+ help='Guess the lexer from the file contents, or pass through '
+ 'as plain text if nothing can be guessed.')
+ operation.add_argument(
+ '-F', metavar='FILTER[:options]', action='append',
+ help='Add a filter to the token stream. (Query names with -L.) '
+ 'Filter options are given after a colon if necessary.')
+ operation.add_argument(
+ '-f', metavar='FORMATTER',
+ help='Specify the formatter to use. (Query names with -L.) '
+ 'If not given, the formatter is guessed from the output filename, '
+ 'and defaults to the terminal formatter if the output is to the '
+ 'terminal or an unknown file extension.')
+ operation.add_argument(
+ '-O', metavar='OPTION=value[,OPTION=value,...]', action='append',
+ help='Give options to the lexer and formatter as a comma-separated '
+ 'list of key-value pairs. '
+ 'Example: `-O bg=light,python=cool`.')
+ operation.add_argument(
+ '-P', metavar='OPTION=value', action='append',
+ help='Give a single option to the lexer and formatter - with this '
+ 'you can pass options whose value contains commas and equal signs. '
+ 'Example: `-P "heading=Pygments, the Python highlighter"`.')
+ operation.add_argument(
+ '-o', metavar='OUTPUTFILE',
+ help='Where to write the output. Defaults to standard output.')
+
+ operation.add_argument(
+ 'INPUTFILE', nargs='?',
+ help='Where to read the input. Defaults to standard input.')
+
+ flags = parser.add_argument_group('Operation flags')
+ flags.add_argument(
+ '-v', action='store_true',
+ help='Print a detailed traceback on unhandled exceptions, which '
+ 'is useful for debugging and bug reports.')
+ flags.add_argument(
+ '-s', action='store_true',
+ help='Process lines one at a time until EOF, rather than waiting to '
+ 'process the entire file. This only works for stdin, only for lexers '
+ 'with no line-spanning constructs, and is intended for streaming '
+ 'input such as you get from `tail -f`. '
+ 'Example usage: `tail -f sql.log | pygmentize -s -l sql`.')
+ flags.add_argument(
+ '-x', action='store_true',
+ help='Allow custom lexers and formatters to be loaded from a .py file '
+ 'relative to the current working directory. For example, '
+ '`-l ./customlexer.py -x`. By default, this option expects a file '
+ 'with a class named CustomLexer or CustomFormatter; you can also '
+ 'specify your own class name with a colon (`-l ./lexer.py:MyLexer`). '
+ 'Users should be very careful not to use this option with untrusted '
+ 'files, because it will import and run them.')
+ flags.add_argument('--json', help='Output as JSON. This can '
+ 'be only used in conjunction with -L.',
+ default=False,
+ action='store_true')
+
+ special_modes_group = parser.add_argument_group(
+ 'Special modes - do not do any highlighting')
+ special_modes = special_modes_group.add_mutually_exclusive_group()
+ special_modes.add_argument(
+ '-S', metavar='STYLE -f formatter',
+ help='Print style definitions for STYLE for a formatter '
+ 'given with -f. The argument given by -a is formatter '
+ 'dependent.')
+ special_modes.add_argument(
+ '-L', nargs='*', metavar='WHAT',
+ help='List lexers, formatters, styles or filters -- '
+ 'give additional arguments for the thing(s) you want to list '
+ '(e.g. "styles"), or omit them to list everything.')
+ special_modes.add_argument(
+ '-N', metavar='FILENAME',
+ help='Guess and print out a lexer name based solely on the given '
+ 'filename. Does not take input or highlight anything. If no specific '
+ 'lexer can be determined, "text" is printed.')
+ special_modes.add_argument(
+ '-C', action='store_true',
+ help='Like -N, but print out a lexer name based solely on '
+ 'a given content from standard input.')
+ special_modes.add_argument(
+ '-H', action='store', nargs=2, metavar=('NAME', 'TYPE'),
+ help='Print detailed help for the object <name> of type <type>, '
+ 'where <type> is one of "lexer", "formatter" or "filter".')
+ special_modes.add_argument(
+ '-V', action='store_true',
+ help='Print the package version.')
+ special_modes.add_argument(
+ '-h', '--help', action='store_true',
+ help='Print this help.')
+ special_modes_group.add_argument(
+ '-a', metavar='ARG',
+ help='Formatter-specific additional argument for the -S (print '
+ 'style sheet) mode.')
+
+ argns = parser.parse_args(args[1:])
+
+ try:
+ return main_inner(parser, argns)
+ except BrokenPipeError:
+ # someone closed our stdout, e.g. by quitting a pager.
+ return 0
+ except Exception:
+ if argns.v:
+ print(file=sys.stderr)
+ print('*' * 65, file=sys.stderr)
+ print('An unhandled exception occurred while highlighting.',
+ file=sys.stderr)
+ print('Please report the whole traceback to the issue tracker at',
+ file=sys.stderr)
+ print('<https://github.com/pygments/pygments/issues>.',
+ file=sys.stderr)
+ print('*' * 65, file=sys.stderr)
+ print(file=sys.stderr)
+ raise
+ import traceback
+ info = traceback.format_exception(*sys.exc_info())
+ msg = info[-1].strip()
+ if len(info) >= 3:
+ # extract relevant file and position info
+ msg += '\n (f{})'.format(info[-2].split('\n')[0].strip()[1:])
+ print(file=sys.stderr)
+ print('*** Error while highlighting:', file=sys.stderr)
+ print(msg, file=sys.stderr)
+ print('*** If this is a bug you want to report, please rerun with -v.',
+ file=sys.stderr)
+ return 1
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/console.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/console.py
new file mode 100644
index 000000000..4c1a06219
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/console.py
@@ -0,0 +1,70 @@
+"""
+ pygments.console
+ ~~~~~~~~~~~~~~~~
+
+ Format colored console output.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+esc = "\x1b["
+
+codes = {}
+codes[""] = ""
+codes["reset"] = esc + "39;49;00m"
+
+codes["bold"] = esc + "01m"
+codes["faint"] = esc + "02m"
+codes["standout"] = esc + "03m"
+codes["underline"] = esc + "04m"
+codes["blink"] = esc + "05m"
+codes["overline"] = esc + "06m"
+
+dark_colors = ["black", "red", "green", "yellow", "blue",
+ "magenta", "cyan", "gray"]
+light_colors = ["brightblack", "brightred", "brightgreen", "brightyellow", "brightblue",
+ "brightmagenta", "brightcyan", "white"]
+
+x = 30
+for dark, light in zip(dark_colors, light_colors):
+ codes[dark] = esc + "%im" % x
+ codes[light] = esc + "%im" % (60 + x)
+ x += 1
+
+del dark, light, x
+
+codes["white"] = codes["bold"]
+
+
+def reset_color():
+ return codes["reset"]
+
+
+def colorize(color_key, text):
+ return codes[color_key] + text + codes["reset"]
+
+
+def ansiformat(attr, text):
+ """
+ Format ``text`` with a color and/or some attributes::
+
+ color normal color
+ *color* bold color
+ _color_ underlined color
+ +color+ blinking color
+ """
+ result = []
+ if attr[:1] == attr[-1:] == '+':
+ result.append(codes['blink'])
+ attr = attr[1:-1]
+ if attr[:1] == attr[-1:] == '*':
+ result.append(codes['bold'])
+ attr = attr[1:-1]
+ if attr[:1] == attr[-1:] == '_':
+ result.append(codes['underline'])
+ attr = attr[1:-1]
+ result.append(codes[attr])
+ result.append(text)
+ result.append(codes['reset'])
+ return ''.join(result)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/filter.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/filter.py
new file mode 100644
index 000000000..aa6f76041
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/filter.py
@@ -0,0 +1,70 @@
+"""
+ pygments.filter
+ ~~~~~~~~~~~~~~~
+
+ Module that implements the default filter.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+
+def apply_filters(stream, filters, lexer=None):
+ """
+ Use this method to apply an iterable of filters to
+ a stream. If lexer is given it's forwarded to the
+ filter, otherwise the filter receives `None`.
+ """
+ def _apply(filter_, stream):
+ yield from filter_.filter(lexer, stream)
+ for filter_ in filters:
+ stream = _apply(filter_, stream)
+ return stream
+
+
+def simplefilter(f):
+ """
+ Decorator that converts a function into a filter::
+
+ @simplefilter
+ def lowercase(self, lexer, stream, options):
+ for ttype, value in stream:
+ yield ttype, value.lower()
+ """
+ return type(f.__name__, (FunctionFilter,), {
+ '__module__': getattr(f, '__module__'),
+ '__doc__': f.__doc__,
+ 'function': f,
+ })
+
+
+class Filter:
+ """
+ Default filter. Subclass this class or use the `simplefilter`
+ decorator to create own filters.
+ """
+
+ def __init__(self, **options):
+ self.options = options
+
+ def filter(self, lexer, stream):
+ raise NotImplementedError()
+
+
+class FunctionFilter(Filter):
+ """
+ Abstract class used by `simplefilter` to create simple
+ function filters on the fly. The `simplefilter` decorator
+ automatically creates subclasses of this class for
+ functions passed to it.
+ """
+ function = None
+
+ def __init__(self, **options):
+ if not hasattr(self, 'function'):
+ raise TypeError(f'{self.__class__.__name__!r} used without bound function')
+ Filter.__init__(self, **options)
+
+ def filter(self, lexer, stream):
+ # pylint: disable=not-callable
+ yield from self.function(lexer, stream, self.options)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/filters/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/filters/__init__.py
new file mode 100644
index 000000000..9255ca224
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/filters/__init__.py
@@ -0,0 +1,940 @@
+"""
+ pygments.filters
+ ~~~~~~~~~~~~~~~~
+
+ Module containing filter lookup functions and default
+ filters.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import re
+
+from pip._vendor.pygments.token import String, Comment, Keyword, Name, Error, Whitespace, \
+ string_to_tokentype
+from pip._vendor.pygments.filter import Filter
+from pip._vendor.pygments.util import get_list_opt, get_int_opt, get_bool_opt, \
+ get_choice_opt, ClassNotFound, OptionError
+from pip._vendor.pygments.plugin import find_plugin_filters
+
+
+def find_filter_class(filtername):
+ """Lookup a filter by name. Return None if not found."""
+ if filtername in FILTERS:
+ return FILTERS[filtername]
+ for name, cls in find_plugin_filters():
+ if name == filtername:
+ return cls
+ return None
+
+
+def get_filter_by_name(filtername, **options):
+ """Return an instantiated filter.
+
+ Options are passed to the filter initializer if wanted.
+ Raise a ClassNotFound if not found.
+ """
+ cls = find_filter_class(filtername)
+ if cls:
+ return cls(**options)
+ else:
+ raise ClassNotFound(f'filter {filtername!r} not found')
+
+
+def get_all_filters():
+ """Return a generator of all filter names."""
+ yield from FILTERS
+ for name, _ in find_plugin_filters():
+ yield name
+
+
+def _replace_special(ttype, value, regex, specialttype,
+ replacefunc=lambda x: x):
+ last = 0
+ for match in regex.finditer(value):
+ start, end = match.start(), match.end()
+ if start != last:
+ yield ttype, value[last:start]
+ yield specialttype, replacefunc(value[start:end])
+ last = end
+ if last != len(value):
+ yield ttype, value[last:]
+
+
+class CodeTagFilter(Filter):
+ """Highlight special code tags in comments and docstrings.
+
+ Options accepted:
+
+ `codetags` : list of strings
+ A list of strings that are flagged as code tags. The default is to
+ highlight ``XXX``, ``TODO``, ``FIXME``, ``BUG`` and ``NOTE``.
+
+ .. versionchanged:: 2.13
+ Now recognizes ``FIXME`` by default.
+ """
+
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+ tags = get_list_opt(options, 'codetags',
+ ['XXX', 'TODO', 'FIXME', 'BUG', 'NOTE'])
+ self.tag_re = re.compile(r'\b({})\b'.format('|'.join([
+ re.escape(tag) for tag in tags if tag
+ ])))
+
+ def filter(self, lexer, stream):
+ regex = self.tag_re
+ for ttype, value in stream:
+ if ttype in String.Doc or \
+ ttype in Comment and \
+ ttype not in Comment.Preproc:
+ yield from _replace_special(ttype, value, regex, Comment.Special)
+ else:
+ yield ttype, value
+
+
+class SymbolFilter(Filter):
+ """Convert mathematical symbols such as \\<longrightarrow> in Isabelle
+ or \\longrightarrow in LaTeX into Unicode characters.
+
+ This is mostly useful for HTML or console output when you want to
+ approximate the source rendering you'd see in an IDE.
+
+ Options accepted:
+
+ `lang` : string
+ The symbol language. Must be one of ``'isabelle'`` or
+ ``'latex'``. The default is ``'isabelle'``.
+ """
+
+ latex_symbols = {
+ '\\alpha' : '\U000003b1',
+ '\\beta' : '\U000003b2',
+ '\\gamma' : '\U000003b3',
+ '\\delta' : '\U000003b4',
+ '\\varepsilon' : '\U000003b5',
+ '\\zeta' : '\U000003b6',
+ '\\eta' : '\U000003b7',
+ '\\vartheta' : '\U000003b8',
+ '\\iota' : '\U000003b9',
+ '\\kappa' : '\U000003ba',
+ '\\lambda' : '\U000003bb',
+ '\\mu' : '\U000003bc',
+ '\\nu' : '\U000003bd',
+ '\\xi' : '\U000003be',
+ '\\pi' : '\U000003c0',
+ '\\varrho' : '\U000003c1',
+ '\\sigma' : '\U000003c3',
+ '\\tau' : '\U000003c4',
+ '\\upsilon' : '\U000003c5',
+ '\\varphi' : '\U000003c6',
+ '\\chi' : '\U000003c7',
+ '\\psi' : '\U000003c8',
+ '\\omega' : '\U000003c9',
+ '\\Gamma' : '\U00000393',
+ '\\Delta' : '\U00000394',
+ '\\Theta' : '\U00000398',
+ '\\Lambda' : '\U0000039b',
+ '\\Xi' : '\U0000039e',
+ '\\Pi' : '\U000003a0',
+ '\\Sigma' : '\U000003a3',
+ '\\Upsilon' : '\U000003a5',
+ '\\Phi' : '\U000003a6',
+ '\\Psi' : '\U000003a8',
+ '\\Omega' : '\U000003a9',
+ '\\leftarrow' : '\U00002190',
+ '\\longleftarrow' : '\U000027f5',
+ '\\rightarrow' : '\U00002192',
+ '\\longrightarrow' : '\U000027f6',
+ '\\Leftarrow' : '\U000021d0',
+ '\\Longleftarrow' : '\U000027f8',
+ '\\Rightarrow' : '\U000021d2',
+ '\\Longrightarrow' : '\U000027f9',
+ '\\leftrightarrow' : '\U00002194',
+ '\\longleftrightarrow' : '\U000027f7',
+ '\\Leftrightarrow' : '\U000021d4',
+ '\\Longleftrightarrow' : '\U000027fa',
+ '\\mapsto' : '\U000021a6',
+ '\\longmapsto' : '\U000027fc',
+ '\\relbar' : '\U00002500',
+ '\\Relbar' : '\U00002550',
+ '\\hookleftarrow' : '\U000021a9',
+ '\\hookrightarrow' : '\U000021aa',
+ '\\leftharpoondown' : '\U000021bd',
+ '\\rightharpoondown' : '\U000021c1',
+ '\\leftharpoonup' : '\U000021bc',
+ '\\rightharpoonup' : '\U000021c0',
+ '\\rightleftharpoons' : '\U000021cc',
+ '\\leadsto' : '\U0000219d',
+ '\\downharpoonleft' : '\U000021c3',
+ '\\downharpoonright' : '\U000021c2',
+ '\\upharpoonleft' : '\U000021bf',
+ '\\upharpoonright' : '\U000021be',
+ '\\restriction' : '\U000021be',
+ '\\uparrow' : '\U00002191',
+ '\\Uparrow' : '\U000021d1',
+ '\\downarrow' : '\U00002193',
+ '\\Downarrow' : '\U000021d3',
+ '\\updownarrow' : '\U00002195',
+ '\\Updownarrow' : '\U000021d5',
+ '\\langle' : '\U000027e8',
+ '\\rangle' : '\U000027e9',
+ '\\lceil' : '\U00002308',
+ '\\rceil' : '\U00002309',
+ '\\lfloor' : '\U0000230a',
+ '\\rfloor' : '\U0000230b',
+ '\\flqq' : '\U000000ab',
+ '\\frqq' : '\U000000bb',
+ '\\bot' : '\U000022a5',
+ '\\top' : '\U000022a4',
+ '\\wedge' : '\U00002227',
+ '\\bigwedge' : '\U000022c0',
+ '\\vee' : '\U00002228',
+ '\\bigvee' : '\U000022c1',
+ '\\forall' : '\U00002200',
+ '\\exists' : '\U00002203',
+ '\\nexists' : '\U00002204',
+ '\\neg' : '\U000000ac',
+ '\\Box' : '\U000025a1',
+ '\\Diamond' : '\U000025c7',
+ '\\vdash' : '\U000022a2',
+ '\\models' : '\U000022a8',
+ '\\dashv' : '\U000022a3',
+ '\\surd' : '\U0000221a',
+ '\\le' : '\U00002264',
+ '\\ge' : '\U00002265',
+ '\\ll' : '\U0000226a',
+ '\\gg' : '\U0000226b',
+ '\\lesssim' : '\U00002272',
+ '\\gtrsim' : '\U00002273',
+ '\\lessapprox' : '\U00002a85',
+ '\\gtrapprox' : '\U00002a86',
+ '\\in' : '\U00002208',
+ '\\notin' : '\U00002209',
+ '\\subset' : '\U00002282',
+ '\\supset' : '\U00002283',
+ '\\subseteq' : '\U00002286',
+ '\\supseteq' : '\U00002287',
+ '\\sqsubset' : '\U0000228f',
+ '\\sqsupset' : '\U00002290',
+ '\\sqsubseteq' : '\U00002291',
+ '\\sqsupseteq' : '\U00002292',
+ '\\cap' : '\U00002229',
+ '\\bigcap' : '\U000022c2',
+ '\\cup' : '\U0000222a',
+ '\\bigcup' : '\U000022c3',
+ '\\sqcup' : '\U00002294',
+ '\\bigsqcup' : '\U00002a06',
+ '\\sqcap' : '\U00002293',
+ '\\Bigsqcap' : '\U00002a05',
+ '\\setminus' : '\U00002216',
+ '\\propto' : '\U0000221d',
+ '\\uplus' : '\U0000228e',
+ '\\bigplus' : '\U00002a04',
+ '\\sim' : '\U0000223c',
+ '\\doteq' : '\U00002250',
+ '\\simeq' : '\U00002243',
+ '\\approx' : '\U00002248',
+ '\\asymp' : '\U0000224d',
+ '\\cong' : '\U00002245',
+ '\\equiv' : '\U00002261',
+ '\\Join' : '\U000022c8',
+ '\\bowtie' : '\U00002a1d',
+ '\\prec' : '\U0000227a',
+ '\\succ' : '\U0000227b',
+ '\\preceq' : '\U0000227c',
+ '\\succeq' : '\U0000227d',
+ '\\parallel' : '\U00002225',
+ '\\mid' : '\U000000a6',
+ '\\pm' : '\U000000b1',
+ '\\mp' : '\U00002213',
+ '\\times' : '\U000000d7',
+ '\\div' : '\U000000f7',
+ '\\cdot' : '\U000022c5',
+ '\\star' : '\U000022c6',
+ '\\circ' : '\U00002218',
+ '\\dagger' : '\U00002020',
+ '\\ddagger' : '\U00002021',
+ '\\lhd' : '\U000022b2',
+ '\\rhd' : '\U000022b3',
+ '\\unlhd' : '\U000022b4',
+ '\\unrhd' : '\U000022b5',
+ '\\triangleleft' : '\U000025c3',
+ '\\triangleright' : '\U000025b9',
+ '\\triangle' : '\U000025b3',
+ '\\triangleq' : '\U0000225c',
+ '\\oplus' : '\U00002295',
+ '\\bigoplus' : '\U00002a01',
+ '\\otimes' : '\U00002297',
+ '\\bigotimes' : '\U00002a02',
+ '\\odot' : '\U00002299',
+ '\\bigodot' : '\U00002a00',
+ '\\ominus' : '\U00002296',
+ '\\oslash' : '\U00002298',
+ '\\dots' : '\U00002026',
+ '\\cdots' : '\U000022ef',
+ '\\sum' : '\U00002211',
+ '\\prod' : '\U0000220f',
+ '\\coprod' : '\U00002210',
+ '\\infty' : '\U0000221e',
+ '\\int' : '\U0000222b',
+ '\\oint' : '\U0000222e',
+ '\\clubsuit' : '\U00002663',
+ '\\diamondsuit' : '\U00002662',
+ '\\heartsuit' : '\U00002661',
+ '\\spadesuit' : '\U00002660',
+ '\\aleph' : '\U00002135',
+ '\\emptyset' : '\U00002205',
+ '\\nabla' : '\U00002207',
+ '\\partial' : '\U00002202',
+ '\\flat' : '\U0000266d',
+ '\\natural' : '\U0000266e',
+ '\\sharp' : '\U0000266f',
+ '\\angle' : '\U00002220',
+ '\\copyright' : '\U000000a9',
+ '\\textregistered' : '\U000000ae',
+ '\\textonequarter' : '\U000000bc',
+ '\\textonehalf' : '\U000000bd',
+ '\\textthreequarters' : '\U000000be',
+ '\\textordfeminine' : '\U000000aa',
+ '\\textordmasculine' : '\U000000ba',
+ '\\euro' : '\U000020ac',
+ '\\pounds' : '\U000000a3',
+ '\\yen' : '\U000000a5',
+ '\\textcent' : '\U000000a2',
+ '\\textcurrency' : '\U000000a4',
+ '\\textdegree' : '\U000000b0',
+ }
+
+ isabelle_symbols = {
+ '\\<zero>' : '\U0001d7ec',
+ '\\<one>' : '\U0001d7ed',
+ '\\<two>' : '\U0001d7ee',
+ '\\<three>' : '\U0001d7ef',
+ '\\<four>' : '\U0001d7f0',
+ '\\<five>' : '\U0001d7f1',
+ '\\<six>' : '\U0001d7f2',
+ '\\<seven>' : '\U0001d7f3',
+ '\\<eight>' : '\U0001d7f4',
+ '\\<nine>' : '\U0001d7f5',
+ '\\<A>' : '\U0001d49c',
+ '\\<B>' : '\U0000212c',
+ '\\<C>' : '\U0001d49e',
+ '\\<D>' : '\U0001d49f',
+ '\\<E>' : '\U00002130',
+ '\\<F>' : '\U00002131',
+ '\\<G>' : '\U0001d4a2',
+ '\\<H>' : '\U0000210b',
+ '\\<I>' : '\U00002110',
+ '\\<J>' : '\U0001d4a5',
+ '\\<K>' : '\U0001d4a6',
+ '\\<L>' : '\U00002112',
+ '\\<M>' : '\U00002133',
+ '\\<N>' : '\U0001d4a9',
+ '\\<O>' : '\U0001d4aa',
+ '\\<P>' : '\U0001d4ab',
+ '\\<Q>' : '\U0001d4ac',
+ '\\<R>' : '\U0000211b',
+ '\\<S>' : '\U0001d4ae',
+ '\\<T>' : '\U0001d4af',
+ '\\<U>' : '\U0001d4b0',
+ '\\<V>' : '\U0001d4b1',
+ '\\<W>' : '\U0001d4b2',
+ '\\<X>' : '\U0001d4b3',
+ '\\<Y>' : '\U0001d4b4',
+ '\\<Z>' : '\U0001d4b5',
+ '\\<a>' : '\U0001d5ba',
+ '\\<b>' : '\U0001d5bb',
+ '\\<c>' : '\U0001d5bc',
+ '\\<d>' : '\U0001d5bd',
+ '\\<e>' : '\U0001d5be',
+ '\\<f>' : '\U0001d5bf',
+ '\\<g>' : '\U0001d5c0',
+ '\\<h>' : '\U0001d5c1',
+ '\\<i>' : '\U0001d5c2',
+ '\\<j>' : '\U0001d5c3',
+ '\\<k>' : '\U0001d5c4',
+ '\\<l>' : '\U0001d5c5',
+ '\\<m>' : '\U0001d5c6',
+ '\\<n>' : '\U0001d5c7',
+ '\\<o>' : '\U0001d5c8',
+ '\\<p>' : '\U0001d5c9',
+ '\\<q>' : '\U0001d5ca',
+ '\\<r>' : '\U0001d5cb',
+ '\\<s>' : '\U0001d5cc',
+ '\\<t>' : '\U0001d5cd',
+ '\\<u>' : '\U0001d5ce',
+ '\\<v>' : '\U0001d5cf',
+ '\\<w>' : '\U0001d5d0',
+ '\\<x>' : '\U0001d5d1',
+ '\\<y>' : '\U0001d5d2',
+ '\\<z>' : '\U0001d5d3',
+ '\\<AA>' : '\U0001d504',
+ '\\<BB>' : '\U0001d505',
+ '\\<CC>' : '\U0000212d',
+ '\\<DD>' : '\U0001d507',
+ '\\<EE>' : '\U0001d508',
+ '\\<FF>' : '\U0001d509',
+ '\\<GG>' : '\U0001d50a',
+ '\\<HH>' : '\U0000210c',
+ '\\<II>' : '\U00002111',
+ '\\<JJ>' : '\U0001d50d',
+ '\\<KK>' : '\U0001d50e',
+ '\\<LL>' : '\U0001d50f',
+ '\\<MM>' : '\U0001d510',
+ '\\<NN>' : '\U0001d511',
+ '\\<OO>' : '\U0001d512',
+ '\\<PP>' : '\U0001d513',
+ '\\<QQ>' : '\U0001d514',
+ '\\<RR>' : '\U0000211c',
+ '\\<SS>' : '\U0001d516',
+ '\\<TT>' : '\U0001d517',
+ '\\<UU>' : '\U0001d518',
+ '\\<VV>' : '\U0001d519',
+ '\\<WW>' : '\U0001d51a',
+ '\\<XX>' : '\U0001d51b',
+ '\\<YY>' : '\U0001d51c',
+ '\\<ZZ>' : '\U00002128',
+ '\\<aa>' : '\U0001d51e',
+ '\\<bb>' : '\U0001d51f',
+ '\\<cc>' : '\U0001d520',
+ '\\<dd>' : '\U0001d521',
+ '\\<ee>' : '\U0001d522',
+ '\\<ff>' : '\U0001d523',
+ '\\<gg>' : '\U0001d524',
+ '\\<hh>' : '\U0001d525',
+ '\\<ii>' : '\U0001d526',
+ '\\<jj>' : '\U0001d527',
+ '\\<kk>' : '\U0001d528',
+ '\\<ll>' : '\U0001d529',
+ '\\<mm>' : '\U0001d52a',
+ '\\<nn>' : '\U0001d52b',
+ '\\<oo>' : '\U0001d52c',
+ '\\<pp>' : '\U0001d52d',
+ '\\<qq>' : '\U0001d52e',
+ '\\<rr>' : '\U0001d52f',
+ '\\<ss>' : '\U0001d530',
+ '\\<tt>' : '\U0001d531',
+ '\\<uu>' : '\U0001d532',
+ '\\<vv>' : '\U0001d533',
+ '\\<ww>' : '\U0001d534',
+ '\\<xx>' : '\U0001d535',
+ '\\<yy>' : '\U0001d536',
+ '\\<zz>' : '\U0001d537',
+ '\\<alpha>' : '\U000003b1',
+ '\\<beta>' : '\U000003b2',
+ '\\<gamma>' : '\U000003b3',
+ '\\<delta>' : '\U000003b4',
+ '\\<epsilon>' : '\U000003b5',
+ '\\<zeta>' : '\U000003b6',
+ '\\<eta>' : '\U000003b7',
+ '\\<theta>' : '\U000003b8',
+ '\\<iota>' : '\U000003b9',
+ '\\<kappa>' : '\U000003ba',
+ '\\<lambda>' : '\U000003bb',
+ '\\<mu>' : '\U000003bc',
+ '\\<nu>' : '\U000003bd',
+ '\\<xi>' : '\U000003be',
+ '\\<pi>' : '\U000003c0',
+ '\\<rho>' : '\U000003c1',
+ '\\<sigma>' : '\U000003c3',
+ '\\<tau>' : '\U000003c4',
+ '\\<upsilon>' : '\U000003c5',
+ '\\<phi>' : '\U000003c6',
+ '\\<chi>' : '\U000003c7',
+ '\\<psi>' : '\U000003c8',
+ '\\<omega>' : '\U000003c9',
+ '\\<Gamma>' : '\U00000393',
+ '\\<Delta>' : '\U00000394',
+ '\\<Theta>' : '\U00000398',
+ '\\<Lambda>' : '\U0000039b',
+ '\\<Xi>' : '\U0000039e',
+ '\\<Pi>' : '\U000003a0',
+ '\\<Sigma>' : '\U000003a3',
+ '\\<Upsilon>' : '\U000003a5',
+ '\\<Phi>' : '\U000003a6',
+ '\\<Psi>' : '\U000003a8',
+ '\\<Omega>' : '\U000003a9',
+ '\\<bool>' : '\U0001d539',
+ '\\<complex>' : '\U00002102',
+ '\\<nat>' : '\U00002115',
+ '\\<rat>' : '\U0000211a',
+ '\\<real>' : '\U0000211d',
+ '\\<int>' : '\U00002124',
+ '\\<leftarrow>' : '\U00002190',
+ '\\<longleftarrow>' : '\U000027f5',
+ '\\<rightarrow>' : '\U00002192',
+ '\\<longrightarrow>' : '\U000027f6',
+ '\\<Leftarrow>' : '\U000021d0',
+ '\\<Longleftarrow>' : '\U000027f8',
+ '\\<Rightarrow>' : '\U000021d2',
+ '\\<Longrightarrow>' : '\U000027f9',
+ '\\<leftrightarrow>' : '\U00002194',
+ '\\<longleftrightarrow>' : '\U000027f7',
+ '\\<Leftrightarrow>' : '\U000021d4',
+ '\\<Longleftrightarrow>' : '\U000027fa',
+ '\\<mapsto>' : '\U000021a6',
+ '\\<longmapsto>' : '\U000027fc',
+ '\\<midarrow>' : '\U00002500',
+ '\\<Midarrow>' : '\U00002550',
+ '\\<hookleftarrow>' : '\U000021a9',
+ '\\<hookrightarrow>' : '\U000021aa',
+ '\\<leftharpoondown>' : '\U000021bd',
+ '\\<rightharpoondown>' : '\U000021c1',
+ '\\<leftharpoonup>' : '\U000021bc',
+ '\\<rightharpoonup>' : '\U000021c0',
+ '\\<rightleftharpoons>' : '\U000021cc',
+ '\\<leadsto>' : '\U0000219d',
+ '\\<downharpoonleft>' : '\U000021c3',
+ '\\<downharpoonright>' : '\U000021c2',
+ '\\<upharpoonleft>' : '\U000021bf',
+ '\\<upharpoonright>' : '\U000021be',
+ '\\<restriction>' : '\U000021be',
+ '\\<Colon>' : '\U00002237',
+ '\\<up>' : '\U00002191',
+ '\\<Up>' : '\U000021d1',
+ '\\<down>' : '\U00002193',
+ '\\<Down>' : '\U000021d3',
+ '\\<updown>' : '\U00002195',
+ '\\<Updown>' : '\U000021d5',
+ '\\<langle>' : '\U000027e8',
+ '\\<rangle>' : '\U000027e9',
+ '\\<lceil>' : '\U00002308',
+ '\\<rceil>' : '\U00002309',
+ '\\<lfloor>' : '\U0000230a',
+ '\\<rfloor>' : '\U0000230b',
+ '\\<lparr>' : '\U00002987',
+ '\\<rparr>' : '\U00002988',
+ '\\<lbrakk>' : '\U000027e6',
+ '\\<rbrakk>' : '\U000027e7',
+ '\\<lbrace>' : '\U00002983',
+ '\\<rbrace>' : '\U00002984',
+ '\\<guillemotleft>' : '\U000000ab',
+ '\\<guillemotright>' : '\U000000bb',
+ '\\<bottom>' : '\U000022a5',
+ '\\<top>' : '\U000022a4',
+ '\\<and>' : '\U00002227',
+ '\\<And>' : '\U000022c0',
+ '\\<or>' : '\U00002228',
+ '\\<Or>' : '\U000022c1',
+ '\\<forall>' : '\U00002200',
+ '\\<exists>' : '\U00002203',
+ '\\<nexists>' : '\U00002204',
+ '\\<not>' : '\U000000ac',
+ '\\<box>' : '\U000025a1',
+ '\\<diamond>' : '\U000025c7',
+ '\\<turnstile>' : '\U000022a2',
+ '\\<Turnstile>' : '\U000022a8',
+ '\\<tturnstile>' : '\U000022a9',
+ '\\<TTurnstile>' : '\U000022ab',
+ '\\<stileturn>' : '\U000022a3',
+ '\\<surd>' : '\U0000221a',
+ '\\<le>' : '\U00002264',
+ '\\<ge>' : '\U00002265',
+ '\\<lless>' : '\U0000226a',
+ '\\<ggreater>' : '\U0000226b',
+ '\\<lesssim>' : '\U00002272',
+ '\\<greatersim>' : '\U00002273',
+ '\\<lessapprox>' : '\U00002a85',
+ '\\<greaterapprox>' : '\U00002a86',
+ '\\<in>' : '\U00002208',
+ '\\<notin>' : '\U00002209',
+ '\\<subset>' : '\U00002282',
+ '\\<supset>' : '\U00002283',
+ '\\<subseteq>' : '\U00002286',
+ '\\<supseteq>' : '\U00002287',
+ '\\<sqsubset>' : '\U0000228f',
+ '\\<sqsupset>' : '\U00002290',
+ '\\<sqsubseteq>' : '\U00002291',
+ '\\<sqsupseteq>' : '\U00002292',
+ '\\<inter>' : '\U00002229',
+ '\\<Inter>' : '\U000022c2',
+ '\\<union>' : '\U0000222a',
+ '\\<Union>' : '\U000022c3',
+ '\\<squnion>' : '\U00002294',
+ '\\<Squnion>' : '\U00002a06',
+ '\\<sqinter>' : '\U00002293',
+ '\\<Sqinter>' : '\U00002a05',
+ '\\<setminus>' : '\U00002216',
+ '\\<propto>' : '\U0000221d',
+ '\\<uplus>' : '\U0000228e',
+ '\\<Uplus>' : '\U00002a04',
+ '\\<noteq>' : '\U00002260',
+ '\\<sim>' : '\U0000223c',
+ '\\<doteq>' : '\U00002250',
+ '\\<simeq>' : '\U00002243',
+ '\\<approx>' : '\U00002248',
+ '\\<asymp>' : '\U0000224d',
+ '\\<cong>' : '\U00002245',
+ '\\<smile>' : '\U00002323',
+ '\\<equiv>' : '\U00002261',
+ '\\<frown>' : '\U00002322',
+ '\\<Join>' : '\U000022c8',
+ '\\<bowtie>' : '\U00002a1d',
+ '\\<prec>' : '\U0000227a',
+ '\\<succ>' : '\U0000227b',
+ '\\<preceq>' : '\U0000227c',
+ '\\<succeq>' : '\U0000227d',
+ '\\<parallel>' : '\U00002225',
+ '\\<bar>' : '\U000000a6',
+ '\\<plusminus>' : '\U000000b1',
+ '\\<minusplus>' : '\U00002213',
+ '\\<times>' : '\U000000d7',
+ '\\<div>' : '\U000000f7',
+ '\\<cdot>' : '\U000022c5',
+ '\\<star>' : '\U000022c6',
+ '\\<bullet>' : '\U00002219',
+ '\\<circ>' : '\U00002218',
+ '\\<dagger>' : '\U00002020',
+ '\\<ddagger>' : '\U00002021',
+ '\\<lhd>' : '\U000022b2',
+ '\\<rhd>' : '\U000022b3',
+ '\\<unlhd>' : '\U000022b4',
+ '\\<unrhd>' : '\U000022b5',
+ '\\<triangleleft>' : '\U000025c3',
+ '\\<triangleright>' : '\U000025b9',
+ '\\<triangle>' : '\U000025b3',
+ '\\<triangleq>' : '\U0000225c',
+ '\\<oplus>' : '\U00002295',
+ '\\<Oplus>' : '\U00002a01',
+ '\\<otimes>' : '\U00002297',
+ '\\<Otimes>' : '\U00002a02',
+ '\\<odot>' : '\U00002299',
+ '\\<Odot>' : '\U00002a00',
+ '\\<ominus>' : '\U00002296',
+ '\\<oslash>' : '\U00002298',
+ '\\<dots>' : '\U00002026',
+ '\\<cdots>' : '\U000022ef',
+ '\\<Sum>' : '\U00002211',
+ '\\<Prod>' : '\U0000220f',
+ '\\<Coprod>' : '\U00002210',
+ '\\<infinity>' : '\U0000221e',
+ '\\<integral>' : '\U0000222b',
+ '\\<ointegral>' : '\U0000222e',
+ '\\<clubsuit>' : '\U00002663',
+ '\\<diamondsuit>' : '\U00002662',
+ '\\<heartsuit>' : '\U00002661',
+ '\\<spadesuit>' : '\U00002660',
+ '\\<aleph>' : '\U00002135',
+ '\\<emptyset>' : '\U00002205',
+ '\\<nabla>' : '\U00002207',
+ '\\<partial>' : '\U00002202',
+ '\\<flat>' : '\U0000266d',
+ '\\<natural>' : '\U0000266e',
+ '\\<sharp>' : '\U0000266f',
+ '\\<angle>' : '\U00002220',
+ '\\<copyright>' : '\U000000a9',
+ '\\<registered>' : '\U000000ae',
+ '\\<hyphen>' : '\U000000ad',
+ '\\<inverse>' : '\U000000af',
+ '\\<onequarter>' : '\U000000bc',
+ '\\<onehalf>' : '\U000000bd',
+ '\\<threequarters>' : '\U000000be',
+ '\\<ordfeminine>' : '\U000000aa',
+ '\\<ordmasculine>' : '\U000000ba',
+ '\\<section>' : '\U000000a7',
+ '\\<paragraph>' : '\U000000b6',
+ '\\<exclamdown>' : '\U000000a1',
+ '\\<questiondown>' : '\U000000bf',
+ '\\<euro>' : '\U000020ac',
+ '\\<pounds>' : '\U000000a3',
+ '\\<yen>' : '\U000000a5',
+ '\\<cent>' : '\U000000a2',
+ '\\<currency>' : '\U000000a4',
+ '\\<degree>' : '\U000000b0',
+ '\\<amalg>' : '\U00002a3f',
+ '\\<mho>' : '\U00002127',
+ '\\<lozenge>' : '\U000025ca',
+ '\\<wp>' : '\U00002118',
+ '\\<wrong>' : '\U00002240',
+ '\\<struct>' : '\U000022c4',
+ '\\<acute>' : '\U000000b4',
+ '\\<index>' : '\U00000131',
+ '\\<dieresis>' : '\U000000a8',
+ '\\<cedilla>' : '\U000000b8',
+ '\\<hungarumlaut>' : '\U000002dd',
+ '\\<some>' : '\U000003f5',
+ '\\<newline>' : '\U000023ce',
+ '\\<open>' : '\U00002039',
+ '\\<close>' : '\U0000203a',
+ '\\<here>' : '\U00002302',
+ '\\<^sub>' : '\U000021e9',
+ '\\<^sup>' : '\U000021e7',
+ '\\<^bold>' : '\U00002759',
+ '\\<^bsub>' : '\U000021d8',
+ '\\<^esub>' : '\U000021d9',
+ '\\<^bsup>' : '\U000021d7',
+ '\\<^esup>' : '\U000021d6',
+ }
+
+ lang_map = {'isabelle' : isabelle_symbols, 'latex' : latex_symbols}
+
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+ lang = get_choice_opt(options, 'lang',
+ ['isabelle', 'latex'], 'isabelle')
+ self.symbols = self.lang_map[lang]
+
+ def filter(self, lexer, stream):
+ for ttype, value in stream:
+ if value in self.symbols:
+ yield ttype, self.symbols[value]
+ else:
+ yield ttype, value
+
+
+class KeywordCaseFilter(Filter):
+ """Convert keywords to lowercase or uppercase or capitalize them, which
+ means first letter uppercase, rest lowercase.
+
+ This can be useful e.g. if you highlight Pascal code and want to adapt the
+ code to your styleguide.
+
+ Options accepted:
+
+ `case` : string
+ The casing to convert keywords to. Must be one of ``'lower'``,
+ ``'upper'`` or ``'capitalize'``. The default is ``'lower'``.
+ """
+
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+ case = get_choice_opt(options, 'case',
+ ['lower', 'upper', 'capitalize'], 'lower')
+ self.convert = getattr(str, case)
+
+ def filter(self, lexer, stream):
+ for ttype, value in stream:
+ if ttype in Keyword:
+ yield ttype, self.convert(value)
+ else:
+ yield ttype, value
+
+
+class NameHighlightFilter(Filter):
+ """Highlight a normal Name (and Name.*) token with a different token type.
+
+ Example::
+
+ filter = NameHighlightFilter(
+ names=['foo', 'bar', 'baz'],
+ tokentype=Name.Function,
+ )
+
+ This would highlight the names "foo", "bar" and "baz"
+ as functions. `Name.Function` is the default token type.
+
+ Options accepted:
+
+ `names` : list of strings
+ A list of names that should be given the different token type.
+ There is no default.
+ `tokentype` : TokenType or string
+ A token type or a string containing a token type name that is
+ used for highlighting the strings in `names`. The default is
+ `Name.Function`.
+ """
+
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+ self.names = set(get_list_opt(options, 'names', []))
+ tokentype = options.get('tokentype')
+ if tokentype:
+ self.tokentype = string_to_tokentype(tokentype)
+ else:
+ self.tokentype = Name.Function
+
+ def filter(self, lexer, stream):
+ for ttype, value in stream:
+ if ttype in Name and value in self.names:
+ yield self.tokentype, value
+ else:
+ yield ttype, value
+
+
+class ErrorToken(Exception):
+ pass
+
+
+class RaiseOnErrorTokenFilter(Filter):
+ """Raise an exception when the lexer generates an error token.
+
+ Options accepted:
+
+ `excclass` : Exception class
+ The exception class to raise.
+ The default is `pygments.filters.ErrorToken`.
+
+ .. versionadded:: 0.8
+ """
+
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+ self.exception = options.get('excclass', ErrorToken)
+ try:
+ # issubclass() will raise TypeError if first argument is not a class
+ if not issubclass(self.exception, Exception):
+ raise TypeError
+ except TypeError:
+ raise OptionError('excclass option is not an exception class')
+
+ def filter(self, lexer, stream):
+ for ttype, value in stream:
+ if ttype is Error:
+ raise self.exception(value)
+ yield ttype, value
+
+
+class VisibleWhitespaceFilter(Filter):
+ """Convert tabs, newlines and/or spaces to visible characters.
+
+ Options accepted:
+
+ `spaces` : string or bool
+ If this is a one-character string, spaces will be replaces by this string.
+ If it is another true value, spaces will be replaced by ``·`` (unicode
+ MIDDLE DOT). If it is a false value, spaces will not be replaced. The
+ default is ``False``.
+ `tabs` : string or bool
+ The same as for `spaces`, but the default replacement character is ``»``
+ (unicode RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK). The default value
+ is ``False``. Note: this will not work if the `tabsize` option for the
+ lexer is nonzero, as tabs will already have been expanded then.
+ `tabsize` : int
+ If tabs are to be replaced by this filter (see the `tabs` option), this
+ is the total number of characters that a tab should be expanded to.
+ The default is ``8``.
+ `newlines` : string or bool
+ The same as for `spaces`, but the default replacement character is ``¶``
+ (unicode PILCROW SIGN). The default value is ``False``.
+ `wstokentype` : bool
+ If true, give whitespace the special `Whitespace` token type. This allows
+ styling the visible whitespace differently (e.g. greyed out), but it can
+ disrupt background colors. The default is ``True``.
+
+ .. versionadded:: 0.8
+ """
+
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+ for name, default in [('spaces', '·'),
+ ('tabs', '»'),
+ ('newlines', '¶')]:
+ opt = options.get(name, False)
+ if isinstance(opt, str) and len(opt) == 1:
+ setattr(self, name, opt)
+ else:
+ setattr(self, name, (opt and default or ''))
+ tabsize = get_int_opt(options, 'tabsize', 8)
+ if self.tabs:
+ self.tabs += ' ' * (tabsize - 1)
+ if self.newlines:
+ self.newlines += '\n'
+ self.wstt = get_bool_opt(options, 'wstokentype', True)
+
+ def filter(self, lexer, stream):
+ if self.wstt:
+ spaces = self.spaces or ' '
+ tabs = self.tabs or '\t'
+ newlines = self.newlines or '\n'
+ regex = re.compile(r'\s')
+
+ def replacefunc(wschar):
+ if wschar == ' ':
+ return spaces
+ elif wschar == '\t':
+ return tabs
+ elif wschar == '\n':
+ return newlines
+ return wschar
+
+ for ttype, value in stream:
+ yield from _replace_special(ttype, value, regex, Whitespace,
+ replacefunc)
+ else:
+ spaces, tabs, newlines = self.spaces, self.tabs, self.newlines
+ # simpler processing
+ for ttype, value in stream:
+ if spaces:
+ value = value.replace(' ', spaces)
+ if tabs:
+ value = value.replace('\t', tabs)
+ if newlines:
+ value = value.replace('\n', newlines)
+ yield ttype, value
+
+
+class GobbleFilter(Filter):
+ """Gobbles source code lines (eats initial characters).
+
+ This filter drops the first ``n`` characters off every line of code. This
+ may be useful when the source code fed to the lexer is indented by a fixed
+ amount of space that isn't desired in the output.
+
+ Options accepted:
+
+ `n` : int
+ The number of characters to gobble.
+
+ .. versionadded:: 1.2
+ """
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+ self.n = get_int_opt(options, 'n', 0)
+
+ def gobble(self, value, left):
+ if left < len(value):
+ return value[left:], 0
+ else:
+ return '', left - len(value)
+
+ def filter(self, lexer, stream):
+ n = self.n
+ left = n # How many characters left to gobble.
+ for ttype, value in stream:
+ # Remove ``left`` tokens from first line, ``n`` from all others.
+ parts = value.split('\n')
+ (parts[0], left) = self.gobble(parts[0], left)
+ for i in range(1, len(parts)):
+ (parts[i], left) = self.gobble(parts[i], n)
+ value = '\n'.join(parts)
+
+ if value != '':
+ yield ttype, value
+
+
+class TokenMergeFilter(Filter):
+ """Merges consecutive tokens with the same token type in the output
+ stream of a lexer.
+
+ .. versionadded:: 1.2
+ """
+ def __init__(self, **options):
+ Filter.__init__(self, **options)
+
+ def filter(self, lexer, stream):
+ current_type = None
+ current_value = None
+ for ttype, value in stream:
+ if ttype is current_type:
+ current_value += value
+ else:
+ if current_type is not None:
+ yield current_type, current_value
+ current_type = ttype
+ current_value = value
+ if current_type is not None:
+ yield current_type, current_value
+
+
+FILTERS = {
+ 'codetagify': CodeTagFilter,
+ 'keywordcase': KeywordCaseFilter,
+ 'highlight': NameHighlightFilter,
+ 'raiseonerror': RaiseOnErrorTokenFilter,
+ 'whitespace': VisibleWhitespaceFilter,
+ 'gobble': GobbleFilter,
+ 'tokenmerge': TokenMergeFilter,
+ 'symbols': SymbolFilter,
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatter.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatter.py
new file mode 100644
index 000000000..d2666037f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatter.py
@@ -0,0 +1,129 @@
+"""
+ pygments.formatter
+ ~~~~~~~~~~~~~~~~~~
+
+ Base formatter class.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import codecs
+
+from pip._vendor.pygments.util import get_bool_opt
+from pip._vendor.pygments.styles import get_style_by_name
+
+__all__ = ['Formatter']
+
+
+def _lookup_style(style):
+ if isinstance(style, str):
+ return get_style_by_name(style)
+ return style
+
+
+class Formatter:
+ """
+ Converts a token stream to text.
+
+ Formatters should have attributes to help selecting them. These
+ are similar to the corresponding :class:`~pygments.lexer.Lexer`
+ attributes.
+
+ .. autoattribute:: name
+ :no-value:
+
+ .. autoattribute:: aliases
+ :no-value:
+
+ .. autoattribute:: filenames
+ :no-value:
+
+ You can pass options as keyword arguments to the constructor.
+ All formatters accept these basic options:
+
+ ``style``
+ The style to use, can be a string or a Style subclass
+ (default: "default"). Not used by e.g. the
+ TerminalFormatter.
+ ``full``
+ Tells the formatter to output a "full" document, i.e.
+ a complete self-contained document. This doesn't have
+ any effect for some formatters (default: false).
+ ``title``
+ If ``full`` is true, the title that should be used to
+ caption the document (default: '').
+ ``encoding``
+ If given, must be an encoding name. This will be used to
+ convert the Unicode token strings to byte strings in the
+ output. If it is "" or None, Unicode strings will be written
+ to the output file, which most file-like objects do not
+ support (default: None).
+ ``outencoding``
+ Overrides ``encoding`` if given.
+
+ """
+
+ #: Full name for the formatter, in human-readable form.
+ name = None
+
+ #: A list of short, unique identifiers that can be used to lookup
+ #: the formatter from a list, e.g. using :func:`.get_formatter_by_name()`.
+ aliases = []
+
+ #: A list of fnmatch patterns that match filenames for which this
+ #: formatter can produce output. The patterns in this list should be unique
+ #: among all formatters.
+ filenames = []
+
+ #: If True, this formatter outputs Unicode strings when no encoding
+ #: option is given.
+ unicodeoutput = True
+
+ def __init__(self, **options):
+ """
+ As with lexers, this constructor takes arbitrary optional arguments,
+ and if you override it, you should first process your own options, then
+ call the base class implementation.
+ """
+ self.style = _lookup_style(options.get('style', 'default'))
+ self.full = get_bool_opt(options, 'full', False)
+ self.title = options.get('title', '')
+ self.encoding = options.get('encoding', None) or None
+ if self.encoding in ('guess', 'chardet'):
+ # can happen for e.g. pygmentize -O encoding=guess
+ self.encoding = 'utf-8'
+ self.encoding = options.get('outencoding') or self.encoding
+ self.options = options
+
+ def get_style_defs(self, arg=''):
+ """
+ This method must return statements or declarations suitable to define
+ the current style for subsequent highlighted text (e.g. CSS classes
+ in the `HTMLFormatter`).
+
+ The optional argument `arg` can be used to modify the generation and
+ is formatter dependent (it is standardized because it can be given on
+ the command line).
+
+ This method is called by the ``-S`` :doc:`command-line option <cmdline>`,
+ the `arg` is then given by the ``-a`` option.
+ """
+ return ''
+
+ def format(self, tokensource, outfile):
+ """
+ This method must format the tokens from the `tokensource` iterable and
+ write the formatted version to the file object `outfile`.
+
+ Formatter options can control how exactly the tokens are converted.
+ """
+ if self.encoding:
+ # wrap the outfile in a StreamWriter
+ outfile = codecs.lookup(self.encoding)[3](outfile)
+ return self.format_unencoded(tokensource, outfile)
+
+ # Allow writing Formatter[str] or Formatter[bytes]. That's equivalent to
+ # Formatter. This helps when using third-party type stubs from typeshed.
+ def __class_getitem__(cls, name):
+ return cls
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/__init__.py
new file mode 100644
index 000000000..f19e9931f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/__init__.py
@@ -0,0 +1,157 @@
+"""
+ pygments.formatters
+ ~~~~~~~~~~~~~~~~~~~
+
+ Pygments formatters.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import re
+import sys
+import types
+import fnmatch
+from os.path import basename
+
+from pip._vendor.pygments.formatters._mapping import FORMATTERS
+from pip._vendor.pygments.plugin import find_plugin_formatters
+from pip._vendor.pygments.util import ClassNotFound
+
+__all__ = ['get_formatter_by_name', 'get_formatter_for_filename',
+ 'get_all_formatters', 'load_formatter_from_file'] + list(FORMATTERS)
+
+_formatter_cache = {} # classes by name
+_pattern_cache = {}
+
+
+def _fn_matches(fn, glob):
+ """Return whether the supplied file name fn matches pattern filename."""
+ if glob not in _pattern_cache:
+ pattern = _pattern_cache[glob] = re.compile(fnmatch.translate(glob))
+ return pattern.match(fn)
+ return _pattern_cache[glob].match(fn)
+
+
+def _load_formatters(module_name):
+ """Load a formatter (and all others in the module too)."""
+ mod = __import__(module_name, None, None, ['__all__'])
+ for formatter_name in mod.__all__:
+ cls = getattr(mod, formatter_name)
+ _formatter_cache[cls.name] = cls
+
+
+def get_all_formatters():
+ """Return a generator for all formatter classes."""
+ # NB: this returns formatter classes, not info like get_all_lexers().
+ for info in FORMATTERS.values():
+ if info[1] not in _formatter_cache:
+ _load_formatters(info[0])
+ yield _formatter_cache[info[1]]
+ for _, formatter in find_plugin_formatters():
+ yield formatter
+
+
+def find_formatter_class(alias):
+ """Lookup a formatter by alias.
+
+ Returns None if not found.
+ """
+ for module_name, name, aliases, _, _ in FORMATTERS.values():
+ if alias in aliases:
+ if name not in _formatter_cache:
+ _load_formatters(module_name)
+ return _formatter_cache[name]
+ for _, cls in find_plugin_formatters():
+ if alias in cls.aliases:
+ return cls
+
+
+def get_formatter_by_name(_alias, **options):
+ """
+ Return an instance of a :class:`.Formatter` subclass that has `alias` in its
+ aliases list. The formatter is given the `options` at its instantiation.
+
+ Will raise :exc:`pygments.util.ClassNotFound` if no formatter with that
+ alias is found.
+ """
+ cls = find_formatter_class(_alias)
+ if cls is None:
+ raise ClassNotFound(f"no formatter found for name {_alias!r}")
+ return cls(**options)
+
+
+def load_formatter_from_file(filename, formattername="CustomFormatter", **options):
+ """
+ Return a `Formatter` subclass instance loaded from the provided file, relative
+ to the current directory.
+
+ The file is expected to contain a Formatter class named ``formattername``
+ (by default, CustomFormatter). Users should be very careful with the input, because
+ this method is equivalent to running ``eval()`` on the input file. The formatter is
+ given the `options` at its instantiation.
+
+ :exc:`pygments.util.ClassNotFound` is raised if there are any errors loading
+ the formatter.
+
+ .. versionadded:: 2.2
+ """
+ try:
+ # This empty dict will contain the namespace for the exec'd file
+ custom_namespace = {}
+ with open(filename, 'rb') as f:
+ exec(f.read(), custom_namespace)
+ # Retrieve the class `formattername` from that namespace
+ if formattername not in custom_namespace:
+ raise ClassNotFound(f'no valid {formattername} class found in {filename}')
+ formatter_class = custom_namespace[formattername]
+ # And finally instantiate it with the options
+ return formatter_class(**options)
+ except OSError as err:
+ raise ClassNotFound(f'cannot read {filename}: {err}')
+ except ClassNotFound:
+ raise
+ except Exception as err:
+ raise ClassNotFound(f'error when loading custom formatter: {err}')
+
+
+def get_formatter_for_filename(fn, **options):
+ """
+ Return a :class:`.Formatter` subclass instance that has a filename pattern
+ matching `fn`. The formatter is given the `options` at its instantiation.
+
+ Will raise :exc:`pygments.util.ClassNotFound` if no formatter for that filename
+ is found.
+ """
+ fn = basename(fn)
+ for modname, name, _, filenames, _ in FORMATTERS.values():
+ for filename in filenames:
+ if _fn_matches(fn, filename):
+ if name not in _formatter_cache:
+ _load_formatters(modname)
+ return _formatter_cache[name](**options)
+ for _name, cls in find_plugin_formatters():
+ for filename in cls.filenames:
+ if _fn_matches(fn, filename):
+ return cls(**options)
+ raise ClassNotFound(f"no formatter found for file name {fn!r}")
+
+
+class _automodule(types.ModuleType):
+ """Automatically import formatters."""
+
+ def __getattr__(self, name):
+ info = FORMATTERS.get(name)
+ if info:
+ _load_formatters(info[0])
+ cls = _formatter_cache[info[1]]
+ setattr(self, name, cls)
+ return cls
+ raise AttributeError(name)
+
+
+oldmod = sys.modules[__name__]
+newmod = _automodule(__name__)
+newmod.__dict__.update(oldmod.__dict__)
+sys.modules[__name__] = newmod
+del newmod.newmod, newmod.oldmod, newmod.sys, newmod.types
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/_mapping.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/_mapping.py
new file mode 100644
index 000000000..72ca84040
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/_mapping.py
@@ -0,0 +1,23 @@
+# Automatically generated by scripts/gen_mapfiles.py.
+# DO NOT EDIT BY HAND; run `tox -e mapfiles` instead.
+
+FORMATTERS = {
+ 'BBCodeFormatter': ('pygments.formatters.bbcode', 'BBCode', ('bbcode', 'bb'), (), 'Format tokens with BBcodes. These formatting codes are used by many bulletin boards, so you can highlight your sourcecode with pygments before posting it there.'),
+ 'BmpImageFormatter': ('pygments.formatters.img', 'img_bmp', ('bmp', 'bitmap'), ('*.bmp',), 'Create a bitmap image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
+ 'GifImageFormatter': ('pygments.formatters.img', 'img_gif', ('gif',), ('*.gif',), 'Create a GIF image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
+ 'GroffFormatter': ('pygments.formatters.groff', 'groff', ('groff', 'troff', 'roff'), (), 'Format tokens with groff escapes to change their color and font style.'),
+ 'HtmlFormatter': ('pygments.formatters.html', 'HTML', ('html',), ('*.html', '*.htm'), "Format tokens as HTML 4 ``<span>`` tags. By default, the content is enclosed in a ``<pre>`` tag, itself wrapped in a ``<div>`` tag (but see the `nowrap` option). The ``<div>``'s CSS class can be set by the `cssclass` option."),
+ 'IRCFormatter': ('pygments.formatters.irc', 'IRC', ('irc', 'IRC'), (), 'Format tokens with IRC color sequences'),
+ 'ImageFormatter': ('pygments.formatters.img', 'img', ('img', 'IMG', 'png'), ('*.png',), 'Create a PNG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
+ 'JpgImageFormatter': ('pygments.formatters.img', 'img_jpg', ('jpg', 'jpeg'), ('*.jpg',), 'Create a JPEG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
+ 'LatexFormatter': ('pygments.formatters.latex', 'LaTeX', ('latex', 'tex'), ('*.tex',), 'Format tokens as LaTeX code. This needs the `fancyvrb` and `color` standard packages.'),
+ 'NullFormatter': ('pygments.formatters.other', 'Text only', ('text', 'null'), ('*.txt',), 'Output the text unchanged without any formatting.'),
+ 'PangoMarkupFormatter': ('pygments.formatters.pangomarkup', 'Pango Markup', ('pango', 'pangomarkup'), (), 'Format tokens as Pango Markup code. It can then be rendered to an SVG.'),
+ 'RawTokenFormatter': ('pygments.formatters.other', 'Raw tokens', ('raw', 'tokens'), ('*.raw',), 'Format tokens as a raw representation for storing token streams.'),
+ 'RtfFormatter': ('pygments.formatters.rtf', 'RTF', ('rtf',), ('*.rtf',), 'Format tokens as RTF markup. This formatter automatically outputs full RTF documents with color information and other useful stuff. Perfect for Copy and Paste into Microsoft(R) Word(R) documents.'),
+ 'SvgFormatter': ('pygments.formatters.svg', 'SVG', ('svg',), ('*.svg',), 'Format tokens as an SVG graphics file. This formatter is still experimental. Each line of code is a ``<text>`` element with explicit ``x`` and ``y`` coordinates containing ``<tspan>`` elements with the individual token styles.'),
+ 'Terminal256Formatter': ('pygments.formatters.terminal256', 'Terminal256', ('terminal256', 'console256', '256'), (), 'Format tokens with ANSI color sequences, for output in a 256-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
+ 'TerminalFormatter': ('pygments.formatters.terminal', 'Terminal', ('terminal', 'console'), (), 'Format tokens with ANSI color sequences, for output in a text console. Color sequences are terminated at newlines, so that paging the output works correctly.'),
+ 'TerminalTrueColorFormatter': ('pygments.formatters.terminal256', 'TerminalTrueColor', ('terminal16m', 'console16m', '16m'), (), 'Format tokens with ANSI color sequences, for output in a true-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
+ 'TestcaseFormatter': ('pygments.formatters.other', 'Testcase', ('testcase',), (), 'Format tokens as appropriate for a new testcase.'),
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/bbcode.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/bbcode.py
new file mode 100644
index 000000000..5a05bd961
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/bbcode.py
@@ -0,0 +1,108 @@
+"""
+ pygments.formatters.bbcode
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+ BBcode formatter.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.util import get_bool_opt
+
+__all__ = ['BBCodeFormatter']
+
+
+class BBCodeFormatter(Formatter):
+ """
+ Format tokens with BBcodes. These formatting codes are used by many
+ bulletin boards, so you can highlight your sourcecode with pygments before
+ posting it there.
+
+ This formatter has no support for background colors and borders, as there
+ are no common BBcode tags for that.
+
+ Some board systems (e.g. phpBB) don't support colors in their [code] tag,
+ so you can't use the highlighting together with that tag.
+ Text in a [code] tag usually is shown with a monospace font (which this
+ formatter can do with the ``monofont`` option) and no spaces (which you
+ need for indentation) are removed.
+
+ Additional options accepted:
+
+ `style`
+ The style to use, can be a string or a Style subclass (default:
+ ``'default'``).
+
+ `codetag`
+ If set to true, put the output into ``[code]`` tags (default:
+ ``false``)
+
+ `monofont`
+ If set to true, add a tag to show the code with a monospace font
+ (default: ``false``).
+ """
+ name = 'BBCode'
+ aliases = ['bbcode', 'bb']
+ filenames = []
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ self._code = get_bool_opt(options, 'codetag', False)
+ self._mono = get_bool_opt(options, 'monofont', False)
+
+ self.styles = {}
+ self._make_styles()
+
+ def _make_styles(self):
+ for ttype, ndef in self.style:
+ start = end = ''
+ if ndef['color']:
+ start += '[color=#{}]'.format(ndef['color'])
+ end = '[/color]' + end
+ if ndef['bold']:
+ start += '[b]'
+ end = '[/b]' + end
+ if ndef['italic']:
+ start += '[i]'
+ end = '[/i]' + end
+ if ndef['underline']:
+ start += '[u]'
+ end = '[/u]' + end
+ # there are no common BBcodes for background-color and border
+
+ self.styles[ttype] = start, end
+
+ def format_unencoded(self, tokensource, outfile):
+ if self._code:
+ outfile.write('[code]')
+ if self._mono:
+ outfile.write('[font=monospace]')
+
+ lastval = ''
+ lasttype = None
+
+ for ttype, value in tokensource:
+ while ttype not in self.styles:
+ ttype = ttype.parent
+ if ttype == lasttype:
+ lastval += value
+ else:
+ if lastval:
+ start, end = self.styles[lasttype]
+ outfile.write(''.join((start, lastval, end)))
+ lastval = value
+ lasttype = ttype
+
+ if lastval:
+ start, end = self.styles[lasttype]
+ outfile.write(''.join((start, lastval, end)))
+
+ if self._mono:
+ outfile.write('[/font]')
+ if self._code:
+ outfile.write('[/code]')
+ if self._code or self._mono:
+ outfile.write('\n')
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/groff.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/groff.py
new file mode 100644
index 000000000..5c8a958f8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/groff.py
@@ -0,0 +1,170 @@
+"""
+ pygments.formatters.groff
+ ~~~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for groff output.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import math
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.util import get_bool_opt, get_int_opt
+
+__all__ = ['GroffFormatter']
+
+
+class GroffFormatter(Formatter):
+ """
+ Format tokens with groff escapes to change their color and font style.
+
+ .. versionadded:: 2.11
+
+ Additional options accepted:
+
+ `style`
+ The style to use, can be a string or a Style subclass (default:
+ ``'default'``).
+
+ `monospaced`
+ If set to true, monospace font will be used (default: ``true``).
+
+ `linenos`
+ If set to true, print the line numbers (default: ``false``).
+
+ `wrap`
+ Wrap lines to the specified number of characters. Disabled if set to 0
+ (default: ``0``).
+ """
+
+ name = 'groff'
+ aliases = ['groff','troff','roff']
+ filenames = []
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+
+ self.monospaced = get_bool_opt(options, 'monospaced', True)
+ self.linenos = get_bool_opt(options, 'linenos', False)
+ self._lineno = 0
+ self.wrap = get_int_opt(options, 'wrap', 0)
+ self._linelen = 0
+
+ self.styles = {}
+ self._make_styles()
+
+
+ def _make_styles(self):
+ regular = '\\f[CR]' if self.monospaced else '\\f[R]'
+ bold = '\\f[CB]' if self.monospaced else '\\f[B]'
+ italic = '\\f[CI]' if self.monospaced else '\\f[I]'
+
+ for ttype, ndef in self.style:
+ start = end = ''
+ if ndef['color']:
+ start += '\\m[{}]'.format(ndef['color'])
+ end = '\\m[]' + end
+ if ndef['bold']:
+ start += bold
+ end = regular + end
+ if ndef['italic']:
+ start += italic
+ end = regular + end
+ if ndef['bgcolor']:
+ start += '\\M[{}]'.format(ndef['bgcolor'])
+ end = '\\M[]' + end
+
+ self.styles[ttype] = start, end
+
+
+ def _define_colors(self, outfile):
+ colors = set()
+ for _, ndef in self.style:
+ if ndef['color'] is not None:
+ colors.add(ndef['color'])
+
+ for color in sorted(colors):
+ outfile.write('.defcolor ' + color + ' rgb #' + color + '\n')
+
+
+ def _write_lineno(self, outfile):
+ self._lineno += 1
+ outfile.write("%s% 4d " % (self._lineno != 1 and '\n' or '', self._lineno))
+
+
+ def _wrap_line(self, line):
+ length = len(line.rstrip('\n'))
+ space = ' ' if self.linenos else ''
+ newline = ''
+
+ if length > self.wrap:
+ for i in range(0, math.floor(length / self.wrap)):
+ chunk = line[i*self.wrap:i*self.wrap+self.wrap]
+ newline += (chunk + '\n' + space)
+ remainder = length % self.wrap
+ if remainder > 0:
+ newline += line[-remainder-1:]
+ self._linelen = remainder
+ elif self._linelen + length > self.wrap:
+ newline = ('\n' + space) + line
+ self._linelen = length
+ else:
+ newline = line
+ self._linelen += length
+
+ return newline
+
+
+ def _escape_chars(self, text):
+ text = text.replace('\\', '\\[u005C]'). \
+ replace('.', '\\[char46]'). \
+ replace('\'', '\\[u0027]'). \
+ replace('`', '\\[u0060]'). \
+ replace('~', '\\[u007E]')
+ copy = text
+
+ for char in copy:
+ if len(char) != len(char.encode()):
+ uni = char.encode('unicode_escape') \
+ .decode()[1:] \
+ .replace('x', 'u00') \
+ .upper()
+ text = text.replace(char, '\\[u' + uni[1:] + ']')
+
+ return text
+
+
+ def format_unencoded(self, tokensource, outfile):
+ self._define_colors(outfile)
+
+ outfile.write('.nf\n\\f[CR]\n')
+
+ if self.linenos:
+ self._write_lineno(outfile)
+
+ for ttype, value in tokensource:
+ while ttype not in self.styles:
+ ttype = ttype.parent
+ start, end = self.styles[ttype]
+
+ for line in value.splitlines(True):
+ if self.wrap > 0:
+ line = self._wrap_line(line)
+
+ if start and end:
+ text = self._escape_chars(line.rstrip('\n'))
+ if text != '':
+ outfile.write(''.join((start, text, end)))
+ else:
+ outfile.write(self._escape_chars(line.rstrip('\n')))
+
+ if line.endswith('\n'):
+ if self.linenos:
+ self._write_lineno(outfile)
+ self._linelen = 0
+ else:
+ outfile.write('\n')
+ self._linelen = 0
+
+ outfile.write('\n.fi')
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/html.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/html.py
new file mode 100644
index 000000000..7aa938f51
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/html.py
@@ -0,0 +1,987 @@
+"""
+ pygments.formatters.html
+ ~~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for HTML output.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import functools
+import os
+import sys
+import os.path
+from io import StringIO
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.token import Token, Text, STANDARD_TYPES
+from pip._vendor.pygments.util import get_bool_opt, get_int_opt, get_list_opt
+
+try:
+ import ctags
+except ImportError:
+ ctags = None
+
+__all__ = ['HtmlFormatter']
+
+
+_escape_html_table = {
+ ord('&'): '&',
+ ord('<'): '<',
+ ord('>'): '>',
+ ord('"'): '"',
+ ord("'"): ''',
+}
+
+
+def escape_html(text, table=_escape_html_table):
+ """Escape &, <, > as well as single and double quotes for HTML."""
+ return text.translate(table)
+
+
+def webify(color):
+ if color.startswith('calc') or color.startswith('var'):
+ return color
+ else:
+ return '#' + color
+
+
+def _get_ttype_class(ttype):
+ fname = STANDARD_TYPES.get(ttype)
+ if fname:
+ return fname
+ aname = ''
+ while fname is None:
+ aname = '-' + ttype[-1] + aname
+ ttype = ttype.parent
+ fname = STANDARD_TYPES.get(ttype)
+ return fname + aname
+
+
+CSSFILE_TEMPLATE = '''\
+/*
+generated by Pygments <https://pygments.org/>
+Copyright 2006-2024 by the Pygments team.
+Licensed under the BSD license, see LICENSE for details.
+*/
+%(styledefs)s
+'''
+
+DOC_HEADER = '''\
+<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN"
+ "http://www.w3.org/TR/html4/strict.dtd">
+<!--
+generated by Pygments <https://pygments.org/>
+Copyright 2006-2024 by the Pygments team.
+Licensed under the BSD license, see LICENSE for details.
+-->
+<html>
+<head>
+ <title>%(title)s</title>
+ <meta http-equiv="content-type" content="text/html; charset=%(encoding)s">
+ <style type="text/css">
+''' + CSSFILE_TEMPLATE + '''
+ </style>
+</head>
+<body>
+<h2>%(title)s</h2>
+
+'''
+
+DOC_HEADER_EXTERNALCSS = '''\
+<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN"
+ "http://www.w3.org/TR/html4/strict.dtd">
+
+<html>
+<head>
+ <title>%(title)s</title>
+ <meta http-equiv="content-type" content="text/html; charset=%(encoding)s">
+ <link rel="stylesheet" href="%(cssfile)s" type="text/css">
+</head>
+<body>
+<h2>%(title)s</h2>
+
+'''
+
+DOC_FOOTER = '''\
+</body>
+</html>
+'''
+
+
+class HtmlFormatter(Formatter):
+ r"""
+ Format tokens as HTML 4 ``<span>`` tags. By default, the content is enclosed
+ in a ``<pre>`` tag, itself wrapped in a ``<div>`` tag (but see the `nowrap` option).
+ The ``<div>``'s CSS class can be set by the `cssclass` option.
+
+ If the `linenos` option is set to ``"table"``, the ``<pre>`` is
+ additionally wrapped inside a ``<table>`` which has one row and two
+ cells: one containing the line numbers and one containing the code.
+ Example:
+
+ .. sourcecode:: html
+
+ <div class="highlight" >
+ <table><tr>
+ <td class="linenos" title="click to toggle"
+ onclick="with (this.firstChild.style)
+ { display = (display == '') ? 'none' : '' }">
+ <pre>1
+ 2</pre>
+ </td>
+ <td class="code">
+ <pre><span class="Ke">def </span><span class="NaFu">foo</span>(bar):
+ <span class="Ke">pass</span>
+ </pre>
+ </td>
+ </tr></table></div>
+
+ (whitespace added to improve clarity).
+
+ A list of lines can be specified using the `hl_lines` option to make these
+ lines highlighted (as of Pygments 0.11).
+
+ With the `full` option, a complete HTML 4 document is output, including
+ the style definitions inside a ``<style>`` tag, or in a separate file if
+ the `cssfile` option is given.
+
+ When `tagsfile` is set to the path of a ctags index file, it is used to
+ generate hyperlinks from names to their definition. You must enable
+ `lineanchors` and run ctags with the `-n` option for this to work. The
+ `python-ctags` module from PyPI must be installed to use this feature;
+ otherwise a `RuntimeError` will be raised.
+
+ The `get_style_defs(arg='')` method of a `HtmlFormatter` returns a string
+ containing CSS rules for the CSS classes used by the formatter. The
+ argument `arg` can be used to specify additional CSS selectors that
+ are prepended to the classes. A call `fmter.get_style_defs('td .code')`
+ would result in the following CSS classes:
+
+ .. sourcecode:: css
+
+ td .code .kw { font-weight: bold; color: #00FF00 }
+ td .code .cm { color: #999999 }
+ ...
+
+ If you have Pygments 0.6 or higher, you can also pass a list or tuple to the
+ `get_style_defs()` method to request multiple prefixes for the tokens:
+
+ .. sourcecode:: python
+
+ formatter.get_style_defs(['div.syntax pre', 'pre.syntax'])
+
+ The output would then look like this:
+
+ .. sourcecode:: css
+
+ div.syntax pre .kw,
+ pre.syntax .kw { font-weight: bold; color: #00FF00 }
+ div.syntax pre .cm,
+ pre.syntax .cm { color: #999999 }
+ ...
+
+ Additional options accepted:
+
+ `nowrap`
+ If set to ``True``, don't add a ``<pre>`` and a ``<div>`` tag
+ around the tokens. This disables most other options (default: ``False``).
+
+ `full`
+ Tells the formatter to output a "full" document, i.e. a complete
+ self-contained document (default: ``False``).
+
+ `title`
+ If `full` is true, the title that should be used to caption the
+ document (default: ``''``).
+
+ `style`
+ The style to use, can be a string or a Style subclass (default:
+ ``'default'``). This option has no effect if the `cssfile`
+ and `noclobber_cssfile` option are given and the file specified in
+ `cssfile` exists.
+
+ `noclasses`
+ If set to true, token ``<span>`` tags (as well as line number elements)
+ will not use CSS classes, but inline styles. This is not recommended
+ for larger pieces of code since it increases output size by quite a bit
+ (default: ``False``).
+
+ `classprefix`
+ Since the token types use relatively short class names, they may clash
+ with some of your own class names. In this case you can use the
+ `classprefix` option to give a string to prepend to all Pygments-generated
+ CSS class names for token types.
+ Note that this option also affects the output of `get_style_defs()`.
+
+ `cssclass`
+ CSS class for the wrapping ``<div>`` tag (default: ``'highlight'``).
+ If you set this option, the default selector for `get_style_defs()`
+ will be this class.
+
+ .. versionadded:: 0.9
+ If you select the ``'table'`` line numbers, the wrapping table will
+ have a CSS class of this string plus ``'table'``, the default is
+ accordingly ``'highlighttable'``.
+
+ `cssstyles`
+ Inline CSS styles for the wrapping ``<div>`` tag (default: ``''``).
+
+ `prestyles`
+ Inline CSS styles for the ``<pre>`` tag (default: ``''``).
+
+ .. versionadded:: 0.11
+
+ `cssfile`
+ If the `full` option is true and this option is given, it must be the
+ name of an external file. If the filename does not include an absolute
+ path, the file's path will be assumed to be relative to the main output
+ file's path, if the latter can be found. The stylesheet is then written
+ to this file instead of the HTML file.
+
+ .. versionadded:: 0.6
+
+ `noclobber_cssfile`
+ If `cssfile` is given and the specified file exists, the css file will
+ not be overwritten. This allows the use of the `full` option in
+ combination with a user specified css file. Default is ``False``.
+
+ .. versionadded:: 1.1
+
+ `linenos`
+ If set to ``'table'``, output line numbers as a table with two cells,
+ one containing the line numbers, the other the whole code. This is
+ copy-and-paste-friendly, but may cause alignment problems with some
+ browsers or fonts. If set to ``'inline'``, the line numbers will be
+ integrated in the ``<pre>`` tag that contains the code (that setting
+ is *new in Pygments 0.8*).
+
+ For compatibility with Pygments 0.7 and earlier, every true value
+ except ``'inline'`` means the same as ``'table'`` (in particular, that
+ means also ``True``).
+
+ The default value is ``False``, which means no line numbers at all.
+
+ **Note:** with the default ("table") line number mechanism, the line
+ numbers and code can have different line heights in Internet Explorer
+ unless you give the enclosing ``<pre>`` tags an explicit ``line-height``
+ CSS property (you get the default line spacing with ``line-height:
+ 125%``).
+
+ `hl_lines`
+ Specify a list of lines to be highlighted. The line numbers are always
+ relative to the input (i.e. the first line is line 1) and are
+ independent of `linenostart`.
+
+ .. versionadded:: 0.11
+
+ `linenostart`
+ The line number for the first line (default: ``1``).
+
+ `linenostep`
+ If set to a number n > 1, only every nth line number is printed.
+
+ `linenospecial`
+ If set to a number n > 0, every nth line number is given the CSS
+ class ``"special"`` (default: ``0``).
+
+ `nobackground`
+ If set to ``True``, the formatter won't output the background color
+ for the wrapping element (this automatically defaults to ``False``
+ when there is no wrapping element [eg: no argument for the
+ `get_syntax_defs` method given]) (default: ``False``).
+
+ .. versionadded:: 0.6
+
+ `lineseparator`
+ This string is output between lines of code. It defaults to ``"\n"``,
+ which is enough to break a line inside ``<pre>`` tags, but you can
+ e.g. set it to ``"<br>"`` to get HTML line breaks.
+
+ .. versionadded:: 0.7
+
+ `lineanchors`
+ If set to a nonempty string, e.g. ``foo``, the formatter will wrap each
+ output line in an anchor tag with an ``id`` (and `name`) of ``foo-linenumber``.
+ This allows easy linking to certain lines.
+
+ .. versionadded:: 0.9
+
+ `linespans`
+ If set to a nonempty string, e.g. ``foo``, the formatter will wrap each
+ output line in a span tag with an ``id`` of ``foo-linenumber``.
+ This allows easy access to lines via javascript.
+
+ .. versionadded:: 1.6
+
+ `anchorlinenos`
+ If set to `True`, will wrap line numbers in <a> tags. Used in
+ combination with `linenos` and `lineanchors`.
+
+ `tagsfile`
+ If set to the path of a ctags file, wrap names in anchor tags that
+ link to their definitions. `lineanchors` should be used, and the
+ tags file should specify line numbers (see the `-n` option to ctags).
+ The tags file is assumed to be encoded in UTF-8.
+
+ .. versionadded:: 1.6
+
+ `tagurlformat`
+ A string formatting pattern used to generate links to ctags definitions.
+ Available variables are `%(path)s`, `%(fname)s` and `%(fext)s`.
+ Defaults to an empty string, resulting in just `#prefix-number` links.
+
+ .. versionadded:: 1.6
+
+ `filename`
+ A string used to generate a filename when rendering ``<pre>`` blocks,
+ for example if displaying source code. If `linenos` is set to
+ ``'table'`` then the filename will be rendered in an initial row
+ containing a single `<th>` which spans both columns.
+
+ .. versionadded:: 2.1
+
+ `wrapcode`
+ Wrap the code inside ``<pre>`` blocks using ``<code>``, as recommended
+ by the HTML5 specification.
+
+ .. versionadded:: 2.4
+
+ `debug_token_types`
+ Add ``title`` attributes to all token ``<span>`` tags that show the
+ name of the token.
+
+ .. versionadded:: 2.10
+
+
+ **Subclassing the HTML formatter**
+
+ .. versionadded:: 0.7
+
+ The HTML formatter is now built in a way that allows easy subclassing, thus
+ customizing the output HTML code. The `format()` method calls
+ `self._format_lines()` which returns a generator that yields tuples of ``(1,
+ line)``, where the ``1`` indicates that the ``line`` is a line of the
+ formatted source code.
+
+ If the `nowrap` option is set, the generator is the iterated over and the
+ resulting HTML is output.
+
+ Otherwise, `format()` calls `self.wrap()`, which wraps the generator with
+ other generators. These may add some HTML code to the one generated by
+ `_format_lines()`, either by modifying the lines generated by the latter,
+ then yielding them again with ``(1, line)``, and/or by yielding other HTML
+ code before or after the lines, with ``(0, html)``. The distinction between
+ source lines and other code makes it possible to wrap the generator multiple
+ times.
+
+ The default `wrap()` implementation adds a ``<div>`` and a ``<pre>`` tag.
+
+ A custom `HtmlFormatter` subclass could look like this:
+
+ .. sourcecode:: python
+
+ class CodeHtmlFormatter(HtmlFormatter):
+
+ def wrap(self, source, *, include_div):
+ return self._wrap_code(source)
+
+ def _wrap_code(self, source):
+ yield 0, '<code>'
+ for i, t in source:
+ if i == 1:
+ # it's a line of formatted code
+ t += '<br>'
+ yield i, t
+ yield 0, '</code>'
+
+ This results in wrapping the formatted lines with a ``<code>`` tag, where the
+ source lines are broken using ``<br>`` tags.
+
+ After calling `wrap()`, the `format()` method also adds the "line numbers"
+ and/or "full document" wrappers if the respective options are set. Then, all
+ HTML yielded by the wrapped generator is output.
+ """
+
+ name = 'HTML'
+ aliases = ['html']
+ filenames = ['*.html', '*.htm']
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ self.title = self._decodeifneeded(self.title)
+ self.nowrap = get_bool_opt(options, 'nowrap', False)
+ self.noclasses = get_bool_opt(options, 'noclasses', False)
+ self.classprefix = options.get('classprefix', '')
+ self.cssclass = self._decodeifneeded(options.get('cssclass', 'highlight'))
+ self.cssstyles = self._decodeifneeded(options.get('cssstyles', ''))
+ self.prestyles = self._decodeifneeded(options.get('prestyles', ''))
+ self.cssfile = self._decodeifneeded(options.get('cssfile', ''))
+ self.noclobber_cssfile = get_bool_opt(options, 'noclobber_cssfile', False)
+ self.tagsfile = self._decodeifneeded(options.get('tagsfile', ''))
+ self.tagurlformat = self._decodeifneeded(options.get('tagurlformat', ''))
+ self.filename = self._decodeifneeded(options.get('filename', ''))
+ self.wrapcode = get_bool_opt(options, 'wrapcode', False)
+ self.span_element_openers = {}
+ self.debug_token_types = get_bool_opt(options, 'debug_token_types', False)
+
+ if self.tagsfile:
+ if not ctags:
+ raise RuntimeError('The "ctags" package must to be installed '
+ 'to be able to use the "tagsfile" feature.')
+ self._ctags = ctags.CTags(self.tagsfile)
+
+ linenos = options.get('linenos', False)
+ if linenos == 'inline':
+ self.linenos = 2
+ elif linenos:
+ # compatibility with <= 0.7
+ self.linenos = 1
+ else:
+ self.linenos = 0
+ self.linenostart = abs(get_int_opt(options, 'linenostart', 1))
+ self.linenostep = abs(get_int_opt(options, 'linenostep', 1))
+ self.linenospecial = abs(get_int_opt(options, 'linenospecial', 0))
+ self.nobackground = get_bool_opt(options, 'nobackground', False)
+ self.lineseparator = options.get('lineseparator', '\n')
+ self.lineanchors = options.get('lineanchors', '')
+ self.linespans = options.get('linespans', '')
+ self.anchorlinenos = get_bool_opt(options, 'anchorlinenos', False)
+ self.hl_lines = set()
+ for lineno in get_list_opt(options, 'hl_lines', []):
+ try:
+ self.hl_lines.add(int(lineno))
+ except ValueError:
+ pass
+
+ self._create_stylesheet()
+
+ def _get_css_class(self, ttype):
+ """Return the css class of this token type prefixed with
+ the classprefix option."""
+ ttypeclass = _get_ttype_class(ttype)
+ if ttypeclass:
+ return self.classprefix + ttypeclass
+ return ''
+
+ def _get_css_classes(self, ttype):
+ """Return the CSS classes of this token type prefixed with the classprefix option."""
+ cls = self._get_css_class(ttype)
+ while ttype not in STANDARD_TYPES:
+ ttype = ttype.parent
+ cls = self._get_css_class(ttype) + ' ' + cls
+ return cls or ''
+
+ def _get_css_inline_styles(self, ttype):
+ """Return the inline CSS styles for this token type."""
+ cclass = self.ttype2class.get(ttype)
+ while cclass is None:
+ ttype = ttype.parent
+ cclass = self.ttype2class.get(ttype)
+ return cclass or ''
+
+ def _create_stylesheet(self):
+ t2c = self.ttype2class = {Token: ''}
+ c2s = self.class2style = {}
+ for ttype, ndef in self.style:
+ name = self._get_css_class(ttype)
+ style = ''
+ if ndef['color']:
+ style += 'color: {}; '.format(webify(ndef['color']))
+ if ndef['bold']:
+ style += 'font-weight: bold; '
+ if ndef['italic']:
+ style += 'font-style: italic; '
+ if ndef['underline']:
+ style += 'text-decoration: underline; '
+ if ndef['bgcolor']:
+ style += 'background-color: {}; '.format(webify(ndef['bgcolor']))
+ if ndef['border']:
+ style += 'border: 1px solid {}; '.format(webify(ndef['border']))
+ if style:
+ t2c[ttype] = name
+ # save len(ttype) to enable ordering the styles by
+ # hierarchy (necessary for CSS cascading rules!)
+ c2s[name] = (style[:-2], ttype, len(ttype))
+
+ def get_style_defs(self, arg=None):
+ """
+ Return CSS style definitions for the classes produced by the current
+ highlighting style. ``arg`` can be a string or list of selectors to
+ insert before the token type classes.
+ """
+ style_lines = []
+
+ style_lines.extend(self.get_linenos_style_defs())
+ style_lines.extend(self.get_background_style_defs(arg))
+ style_lines.extend(self.get_token_style_defs(arg))
+
+ return '\n'.join(style_lines)
+
+ def get_token_style_defs(self, arg=None):
+ prefix = self.get_css_prefix(arg)
+
+ styles = [
+ (level, ttype, cls, style)
+ for cls, (style, ttype, level) in self.class2style.items()
+ if cls and style
+ ]
+ styles.sort()
+
+ lines = [
+ f'{prefix(cls)} {{ {style} }} /* {repr(ttype)[6:]} */'
+ for (level, ttype, cls, style) in styles
+ ]
+
+ return lines
+
+ def get_background_style_defs(self, arg=None):
+ prefix = self.get_css_prefix(arg)
+ bg_color = self.style.background_color
+ hl_color = self.style.highlight_color
+
+ lines = []
+
+ if arg and not self.nobackground and bg_color is not None:
+ text_style = ''
+ if Text in self.ttype2class:
+ text_style = ' ' + self.class2style[self.ttype2class[Text]][0]
+ lines.insert(
+ 0, '{}{{ background: {};{} }}'.format(
+ prefix(''), bg_color, text_style
+ )
+ )
+ if hl_color is not None:
+ lines.insert(
+ 0, '{} {{ background-color: {} }}'.format(prefix('hll'), hl_color)
+ )
+
+ return lines
+
+ def get_linenos_style_defs(self):
+ lines = [
+ f'pre {{ {self._pre_style} }}',
+ f'td.linenos .normal {{ {self._linenos_style} }}',
+ f'span.linenos {{ {self._linenos_style} }}',
+ f'td.linenos .special {{ {self._linenos_special_style} }}',
+ f'span.linenos.special {{ {self._linenos_special_style} }}',
+ ]
+
+ return lines
+
+ def get_css_prefix(self, arg):
+ if arg is None:
+ arg = ('cssclass' in self.options and '.'+self.cssclass or '')
+ if isinstance(arg, str):
+ args = [arg]
+ else:
+ args = list(arg)
+
+ def prefix(cls):
+ if cls:
+ cls = '.' + cls
+ tmp = []
+ for arg in args:
+ tmp.append((arg and arg + ' ' or '') + cls)
+ return ', '.join(tmp)
+
+ return prefix
+
+ @property
+ def _pre_style(self):
+ return 'line-height: 125%;'
+
+ @property
+ def _linenos_style(self):
+ color = self.style.line_number_color
+ background_color = self.style.line_number_background_color
+ return f'color: {color}; background-color: {background_color}; padding-left: 5px; padding-right: 5px;'
+
+ @property
+ def _linenos_special_style(self):
+ color = self.style.line_number_special_color
+ background_color = self.style.line_number_special_background_color
+ return f'color: {color}; background-color: {background_color}; padding-left: 5px; padding-right: 5px;'
+
+ def _decodeifneeded(self, value):
+ if isinstance(value, bytes):
+ if self.encoding:
+ return value.decode(self.encoding)
+ return value.decode()
+ return value
+
+ def _wrap_full(self, inner, outfile):
+ if self.cssfile:
+ if os.path.isabs(self.cssfile):
+ # it's an absolute filename
+ cssfilename = self.cssfile
+ else:
+ try:
+ filename = outfile.name
+ if not filename or filename[0] == '<':
+ # pseudo files, e.g. name == '<fdopen>'
+ raise AttributeError
+ cssfilename = os.path.join(os.path.dirname(filename),
+ self.cssfile)
+ except AttributeError:
+ print('Note: Cannot determine output file name, '
+ 'using current directory as base for the CSS file name',
+ file=sys.stderr)
+ cssfilename = self.cssfile
+ # write CSS file only if noclobber_cssfile isn't given as an option.
+ try:
+ if not os.path.exists(cssfilename) or not self.noclobber_cssfile:
+ with open(cssfilename, "w", encoding="utf-8") as cf:
+ cf.write(CSSFILE_TEMPLATE %
+ {'styledefs': self.get_style_defs('body')})
+ except OSError as err:
+ err.strerror = 'Error writing CSS file: ' + err.strerror
+ raise
+
+ yield 0, (DOC_HEADER_EXTERNALCSS %
+ dict(title=self.title,
+ cssfile=self.cssfile,
+ encoding=self.encoding))
+ else:
+ yield 0, (DOC_HEADER %
+ dict(title=self.title,
+ styledefs=self.get_style_defs('body'),
+ encoding=self.encoding))
+
+ yield from inner
+ yield 0, DOC_FOOTER
+
+ def _wrap_tablelinenos(self, inner):
+ dummyoutfile = StringIO()
+ lncount = 0
+ for t, line in inner:
+ if t:
+ lncount += 1
+ dummyoutfile.write(line)
+
+ fl = self.linenostart
+ mw = len(str(lncount + fl - 1))
+ sp = self.linenospecial
+ st = self.linenostep
+ anchor_name = self.lineanchors or self.linespans
+ aln = self.anchorlinenos
+ nocls = self.noclasses
+
+ lines = []
+
+ for i in range(fl, fl+lncount):
+ print_line = i % st == 0
+ special_line = sp and i % sp == 0
+
+ if print_line:
+ line = '%*d' % (mw, i)
+ if aln:
+ line = '<a href="#%s-%d">%s</a>' % (anchor_name, i, line)
+ else:
+ line = ' ' * mw
+
+ if nocls:
+ if special_line:
+ style = f' style="{self._linenos_special_style}"'
+ else:
+ style = f' style="{self._linenos_style}"'
+ else:
+ if special_line:
+ style = ' class="special"'
+ else:
+ style = ' class="normal"'
+
+ if style:
+ line = f'<span{style}>{line}</span>'
+
+ lines.append(line)
+
+ ls = '\n'.join(lines)
+
+ # If a filename was specified, we can't put it into the code table as it
+ # would misalign the line numbers. Hence we emit a separate row for it.
+ filename_tr = ""
+ if self.filename:
+ filename_tr = (
+ '<tr><th colspan="2" class="filename">'
+ '<span class="filename">' + self.filename + '</span>'
+ '</th></tr>')
+
+ # in case you wonder about the seemingly redundant <div> here: since the
+ # content in the other cell also is wrapped in a div, some browsers in
+ # some configurations seem to mess up the formatting...
+ yield 0, (f'<table class="{self.cssclass}table">' + filename_tr +
+ '<tr><td class="linenos"><div class="linenodiv"><pre>' +
+ ls + '</pre></div></td><td class="code">')
+ yield 0, '<div>'
+ yield 0, dummyoutfile.getvalue()
+ yield 0, '</div>'
+ yield 0, '</td></tr></table>'
+
+
+ def _wrap_inlinelinenos(self, inner):
+ # need a list of lines since we need the width of a single number :(
+ inner_lines = list(inner)
+ sp = self.linenospecial
+ st = self.linenostep
+ num = self.linenostart
+ mw = len(str(len(inner_lines) + num - 1))
+ anchor_name = self.lineanchors or self.linespans
+ aln = self.anchorlinenos
+ nocls = self.noclasses
+
+ for _, inner_line in inner_lines:
+ print_line = num % st == 0
+ special_line = sp and num % sp == 0
+
+ if print_line:
+ line = '%*d' % (mw, num)
+ else:
+ line = ' ' * mw
+
+ if nocls:
+ if special_line:
+ style = f' style="{self._linenos_special_style}"'
+ else:
+ style = f' style="{self._linenos_style}"'
+ else:
+ if special_line:
+ style = ' class="linenos special"'
+ else:
+ style = ' class="linenos"'
+
+ if style:
+ linenos = f'<span{style}>{line}</span>'
+ else:
+ linenos = line
+
+ if aln:
+ yield 1, ('<a href="#%s-%d">%s</a>' % (anchor_name, num, linenos) +
+ inner_line)
+ else:
+ yield 1, linenos + inner_line
+ num += 1
+
+ def _wrap_lineanchors(self, inner):
+ s = self.lineanchors
+ # subtract 1 since we have to increment i *before* yielding
+ i = self.linenostart - 1
+ for t, line in inner:
+ if t:
+ i += 1
+ href = "" if self.linenos else ' href="#%s-%d"' % (s, i)
+ yield 1, '<a id="%s-%d" name="%s-%d"%s></a>' % (s, i, s, i, href) + line
+ else:
+ yield 0, line
+
+ def _wrap_linespans(self, inner):
+ s = self.linespans
+ i = self.linenostart - 1
+ for t, line in inner:
+ if t:
+ i += 1
+ yield 1, '<span id="%s-%d">%s</span>' % (s, i, line)
+ else:
+ yield 0, line
+
+ def _wrap_div(self, inner):
+ style = []
+ if (self.noclasses and not self.nobackground and
+ self.style.background_color is not None):
+ style.append(f'background: {self.style.background_color}')
+ if self.cssstyles:
+ style.append(self.cssstyles)
+ style = '; '.join(style)
+
+ yield 0, ('<div' + (self.cssclass and f' class="{self.cssclass}"') +
+ (style and (f' style="{style}"')) + '>')
+ yield from inner
+ yield 0, '</div>\n'
+
+ def _wrap_pre(self, inner):
+ style = []
+ if self.prestyles:
+ style.append(self.prestyles)
+ if self.noclasses:
+ style.append(self._pre_style)
+ style = '; '.join(style)
+
+ if self.filename and self.linenos != 1:
+ yield 0, ('<span class="filename">' + self.filename + '</span>')
+
+ # the empty span here is to keep leading empty lines from being
+ # ignored by HTML parsers
+ yield 0, ('<pre' + (style and f' style="{style}"') + '><span></span>')
+ yield from inner
+ yield 0, '</pre>'
+
+ def _wrap_code(self, inner):
+ yield 0, '<code>'
+ yield from inner
+ yield 0, '</code>'
+
+ @functools.lru_cache(maxsize=100)
+ def _translate_parts(self, value):
+ """HTML-escape a value and split it by newlines."""
+ return value.translate(_escape_html_table).split('\n')
+
+ def _format_lines(self, tokensource):
+ """
+ Just format the tokens, without any wrapping tags.
+ Yield individual lines.
+ """
+ nocls = self.noclasses
+ lsep = self.lineseparator
+ tagsfile = self.tagsfile
+
+ lspan = ''
+ line = []
+ for ttype, value in tokensource:
+ try:
+ cspan = self.span_element_openers[ttype]
+ except KeyError:
+ title = ' title="{}"'.format('.'.join(ttype)) if self.debug_token_types else ''
+ if nocls:
+ css_style = self._get_css_inline_styles(ttype)
+ if css_style:
+ css_style = self.class2style[css_style][0]
+ cspan = f'<span style="{css_style}"{title}>'
+ else:
+ cspan = ''
+ else:
+ css_class = self._get_css_classes(ttype)
+ if css_class:
+ cspan = f'<span class="{css_class}"{title}>'
+ else:
+ cspan = ''
+ self.span_element_openers[ttype] = cspan
+
+ parts = self._translate_parts(value)
+
+ if tagsfile and ttype in Token.Name:
+ filename, linenumber = self._lookup_ctag(value)
+ if linenumber:
+ base, filename = os.path.split(filename)
+ if base:
+ base += '/'
+ filename, extension = os.path.splitext(filename)
+ url = self.tagurlformat % {'path': base, 'fname': filename,
+ 'fext': extension}
+ parts[0] = "<a href=\"%s#%s-%d\">%s" % \
+ (url, self.lineanchors, linenumber, parts[0])
+ parts[-1] = parts[-1] + "</a>"
+
+ # for all but the last line
+ for part in parts[:-1]:
+ if line:
+ # Also check for part being non-empty, so we avoid creating
+ # empty <span> tags
+ if lspan != cspan and part:
+ line.extend(((lspan and '</span>'), cspan, part,
+ (cspan and '</span>'), lsep))
+ else: # both are the same, or the current part was empty
+ line.extend((part, (lspan and '</span>'), lsep))
+ yield 1, ''.join(line)
+ line = []
+ elif part:
+ yield 1, ''.join((cspan, part, (cspan and '</span>'), lsep))
+ else:
+ yield 1, lsep
+ # for the last line
+ if line and parts[-1]:
+ if lspan != cspan:
+ line.extend(((lspan and '</span>'), cspan, parts[-1]))
+ lspan = cspan
+ else:
+ line.append(parts[-1])
+ elif parts[-1]:
+ line = [cspan, parts[-1]]
+ lspan = cspan
+ # else we neither have to open a new span nor set lspan
+
+ if line:
+ line.extend(((lspan and '</span>'), lsep))
+ yield 1, ''.join(line)
+
+ def _lookup_ctag(self, token):
+ entry = ctags.TagEntry()
+ if self._ctags.find(entry, token.encode(), 0):
+ return entry['file'].decode(), entry['lineNumber']
+ else:
+ return None, None
+
+ def _highlight_lines(self, tokensource):
+ """
+ Highlighted the lines specified in the `hl_lines` option by
+ post-processing the token stream coming from `_format_lines`.
+ """
+ hls = self.hl_lines
+
+ for i, (t, value) in enumerate(tokensource):
+ if t != 1:
+ yield t, value
+ if i + 1 in hls: # i + 1 because Python indexes start at 0
+ if self.noclasses:
+ style = ''
+ if self.style.highlight_color is not None:
+ style = (f' style="background-color: {self.style.highlight_color}"')
+ yield 1, f'<span{style}>{value}</span>'
+ else:
+ yield 1, f'<span class="hll">{value}</span>'
+ else:
+ yield 1, value
+
+ def wrap(self, source):
+ """
+ Wrap the ``source``, which is a generator yielding
+ individual lines, in custom generators. See docstring
+ for `format`. Can be overridden.
+ """
+
+ output = source
+ if self.wrapcode:
+ output = self._wrap_code(output)
+
+ output = self._wrap_pre(output)
+
+ return output
+
+ def format_unencoded(self, tokensource, outfile):
+ """
+ The formatting process uses several nested generators; which of
+ them are used is determined by the user's options.
+
+ Each generator should take at least one argument, ``inner``,
+ and wrap the pieces of text generated by this.
+
+ Always yield 2-tuples: (code, text). If "code" is 1, the text
+ is part of the original tokensource being highlighted, if it's
+ 0, the text is some piece of wrapping. This makes it possible to
+ use several different wrappers that process the original source
+ linewise, e.g. line number generators.
+ """
+ source = self._format_lines(tokensource)
+
+ # As a special case, we wrap line numbers before line highlighting
+ # so the line numbers get wrapped in the highlighting tag.
+ if not self.nowrap and self.linenos == 2:
+ source = self._wrap_inlinelinenos(source)
+
+ if self.hl_lines:
+ source = self._highlight_lines(source)
+
+ if not self.nowrap:
+ if self.lineanchors:
+ source = self._wrap_lineanchors(source)
+ if self.linespans:
+ source = self._wrap_linespans(source)
+ source = self.wrap(source)
+ if self.linenos == 1:
+ source = self._wrap_tablelinenos(source)
+ source = self._wrap_div(source)
+ if self.full:
+ source = self._wrap_full(source, outfile)
+
+ for t, piece in source:
+ outfile.write(piece)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/img.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/img.py
new file mode 100644
index 000000000..7542cfad9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/img.py
@@ -0,0 +1,685 @@
+"""
+ pygments.formatters.img
+ ~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for Pixmap output.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+import os
+import sys
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
+ get_choice_opt
+
+import subprocess
+
+# Import this carefully
+try:
+ from PIL import Image, ImageDraw, ImageFont
+ pil_available = True
+except ImportError:
+ pil_available = False
+
+try:
+ import _winreg
+except ImportError:
+ try:
+ import winreg as _winreg
+ except ImportError:
+ _winreg = None
+
+__all__ = ['ImageFormatter', 'GifImageFormatter', 'JpgImageFormatter',
+ 'BmpImageFormatter']
+
+
+# For some unknown reason every font calls it something different
+STYLES = {
+ 'NORMAL': ['', 'Roman', 'Book', 'Normal', 'Regular', 'Medium'],
+ 'ITALIC': ['Oblique', 'Italic'],
+ 'BOLD': ['Bold'],
+ 'BOLDITALIC': ['Bold Oblique', 'Bold Italic'],
+}
+
+# A sane default for modern systems
+DEFAULT_FONT_NAME_NIX = 'DejaVu Sans Mono'
+DEFAULT_FONT_NAME_WIN = 'Courier New'
+DEFAULT_FONT_NAME_MAC = 'Menlo'
+
+
+class PilNotAvailable(ImportError):
+ """When Python imaging library is not available"""
+
+
+class FontNotFound(Exception):
+ """When there are no usable fonts specified"""
+
+
+class FontManager:
+ """
+ Manages a set of fonts: normal, italic, bold, etc...
+ """
+
+ def __init__(self, font_name, font_size=14):
+ self.font_name = font_name
+ self.font_size = font_size
+ self.fonts = {}
+ self.encoding = None
+ self.variable = False
+ if hasattr(font_name, 'read') or os.path.isfile(font_name):
+ font = ImageFont.truetype(font_name, self.font_size)
+ self.variable = True
+ for style in STYLES:
+ self.fonts[style] = font
+
+ return
+
+ if sys.platform.startswith('win'):
+ if not font_name:
+ self.font_name = DEFAULT_FONT_NAME_WIN
+ self._create_win()
+ elif sys.platform.startswith('darwin'):
+ if not font_name:
+ self.font_name = DEFAULT_FONT_NAME_MAC
+ self._create_mac()
+ else:
+ if not font_name:
+ self.font_name = DEFAULT_FONT_NAME_NIX
+ self._create_nix()
+
+ def _get_nix_font_path(self, name, style):
+ proc = subprocess.Popen(['fc-list', f"{name}:style={style}", 'file'],
+ stdout=subprocess.PIPE, stderr=None)
+ stdout, _ = proc.communicate()
+ if proc.returncode == 0:
+ lines = stdout.splitlines()
+ for line in lines:
+ if line.startswith(b'Fontconfig warning:'):
+ continue
+ path = line.decode().strip().strip(':')
+ if path:
+ return path
+ return None
+
+ def _create_nix(self):
+ for name in STYLES['NORMAL']:
+ path = self._get_nix_font_path(self.font_name, name)
+ if path is not None:
+ self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
+ break
+ else:
+ raise FontNotFound(f'No usable fonts named: "{self.font_name}"')
+ for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
+ for stylename in STYLES[style]:
+ path = self._get_nix_font_path(self.font_name, stylename)
+ if path is not None:
+ self.fonts[style] = ImageFont.truetype(path, self.font_size)
+ break
+ else:
+ if style == 'BOLDITALIC':
+ self.fonts[style] = self.fonts['BOLD']
+ else:
+ self.fonts[style] = self.fonts['NORMAL']
+
+ def _get_mac_font_path(self, font_map, name, style):
+ return font_map.get((name + ' ' + style).strip().lower())
+
+ def _create_mac(self):
+ font_map = {}
+ for font_dir in (os.path.join(os.getenv("HOME"), 'Library/Fonts/'),
+ '/Library/Fonts/', '/System/Library/Fonts/'):
+ font_map.update(
+ (os.path.splitext(f)[0].lower(), os.path.join(font_dir, f))
+ for f in os.listdir(font_dir)
+ if f.lower().endswith(('ttf', 'ttc')))
+
+ for name in STYLES['NORMAL']:
+ path = self._get_mac_font_path(font_map, self.font_name, name)
+ if path is not None:
+ self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
+ break
+ else:
+ raise FontNotFound(f'No usable fonts named: "{self.font_name}"')
+ for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
+ for stylename in STYLES[style]:
+ path = self._get_mac_font_path(font_map, self.font_name, stylename)
+ if path is not None:
+ self.fonts[style] = ImageFont.truetype(path, self.font_size)
+ break
+ else:
+ if style == 'BOLDITALIC':
+ self.fonts[style] = self.fonts['BOLD']
+ else:
+ self.fonts[style] = self.fonts['NORMAL']
+
+ def _lookup_win(self, key, basename, styles, fail=False):
+ for suffix in ('', ' (TrueType)'):
+ for style in styles:
+ try:
+ valname = '{}{}{}'.format(basename, style and ' '+style, suffix)
+ val, _ = _winreg.QueryValueEx(key, valname)
+ return val
+ except OSError:
+ continue
+ else:
+ if fail:
+ raise FontNotFound(f'Font {basename} ({styles[0]}) not found in registry')
+ return None
+
+ def _create_win(self):
+ lookuperror = None
+ keynames = [ (_winreg.HKEY_CURRENT_USER, r'Software\Microsoft\Windows NT\CurrentVersion\Fonts'),
+ (_winreg.HKEY_CURRENT_USER, r'Software\Microsoft\Windows\CurrentVersion\Fonts'),
+ (_winreg.HKEY_LOCAL_MACHINE, r'Software\Microsoft\Windows NT\CurrentVersion\Fonts'),
+ (_winreg.HKEY_LOCAL_MACHINE, r'Software\Microsoft\Windows\CurrentVersion\Fonts') ]
+ for keyname in keynames:
+ try:
+ key = _winreg.OpenKey(*keyname)
+ try:
+ path = self._lookup_win(key, self.font_name, STYLES['NORMAL'], True)
+ self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
+ for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
+ path = self._lookup_win(key, self.font_name, STYLES[style])
+ if path:
+ self.fonts[style] = ImageFont.truetype(path, self.font_size)
+ else:
+ if style == 'BOLDITALIC':
+ self.fonts[style] = self.fonts['BOLD']
+ else:
+ self.fonts[style] = self.fonts['NORMAL']
+ return
+ except FontNotFound as err:
+ lookuperror = err
+ finally:
+ _winreg.CloseKey(key)
+ except OSError:
+ pass
+ else:
+ # If we get here, we checked all registry keys and had no luck
+ # We can be in one of two situations now:
+ # * All key lookups failed. In this case lookuperror is None and we
+ # will raise a generic error
+ # * At least one lookup failed with a FontNotFound error. In this
+ # case, we will raise that as a more specific error
+ if lookuperror:
+ raise lookuperror
+ raise FontNotFound('Can\'t open Windows font registry key')
+
+ def get_char_size(self):
+ """
+ Get the character size.
+ """
+ return self.get_text_size('M')
+
+ def get_text_size(self, text):
+ """
+ Get the text size (width, height).
+ """
+ font = self.fonts['NORMAL']
+ if hasattr(font, 'getbbox'): # Pillow >= 9.2.0
+ return font.getbbox(text)[2:4]
+ else:
+ return font.getsize(text)
+
+ def get_font(self, bold, oblique):
+ """
+ Get the font based on bold and italic flags.
+ """
+ if bold and oblique:
+ if self.variable:
+ return self.get_style('BOLDITALIC')
+
+ return self.fonts['BOLDITALIC']
+ elif bold:
+ if self.variable:
+ return self.get_style('BOLD')
+
+ return self.fonts['BOLD']
+ elif oblique:
+ if self.variable:
+ return self.get_style('ITALIC')
+
+ return self.fonts['ITALIC']
+ else:
+ if self.variable:
+ return self.get_style('NORMAL')
+
+ return self.fonts['NORMAL']
+
+ def get_style(self, style):
+ """
+ Get the specified style of the font if it is a variable font.
+ If not found, return the normal font.
+ """
+ font = self.fonts[style]
+ for style_name in STYLES[style]:
+ try:
+ font.set_variation_by_name(style_name)
+ return font
+ except ValueError:
+ pass
+ except OSError:
+ return font
+
+ return font
+
+
+class ImageFormatter(Formatter):
+ """
+ Create a PNG image from source code. This uses the Python Imaging Library to
+ generate a pixmap from the source code.
+
+ .. versionadded:: 0.10
+
+ Additional options accepted:
+
+ `image_format`
+ An image format to output to that is recognised by PIL, these include:
+
+ * "PNG" (default)
+ * "JPEG"
+ * "BMP"
+ * "GIF"
+
+ `line_pad`
+ The extra spacing (in pixels) between each line of text.
+
+ Default: 2
+
+ `font_name`
+ The font name to be used as the base font from which others, such as
+ bold and italic fonts will be generated. This really should be a
+ monospace font to look sane.
+ If a filename or a file-like object is specified, the user must
+ provide different styles of the font.
+
+ Default: "Courier New" on Windows, "Menlo" on Mac OS, and
+ "DejaVu Sans Mono" on \\*nix
+
+ `font_size`
+ The font size in points to be used.
+
+ Default: 14
+
+ `image_pad`
+ The padding, in pixels to be used at each edge of the resulting image.
+
+ Default: 10
+
+ `line_numbers`
+ Whether line numbers should be shown: True/False
+
+ Default: True
+
+ `line_number_start`
+ The line number of the first line.
+
+ Default: 1
+
+ `line_number_step`
+ The step used when printing line numbers.
+
+ Default: 1
+
+ `line_number_bg`
+ The background colour (in "#123456" format) of the line number bar, or
+ None to use the style background color.
+
+ Default: "#eed"
+
+ `line_number_fg`
+ The text color of the line numbers (in "#123456"-like format).
+
+ Default: "#886"
+
+ `line_number_chars`
+ The number of columns of line numbers allowable in the line number
+ margin.
+
+ Default: 2
+
+ `line_number_bold`
+ Whether line numbers will be bold: True/False
+
+ Default: False
+
+ `line_number_italic`
+ Whether line numbers will be italicized: True/False
+
+ Default: False
+
+ `line_number_separator`
+ Whether a line will be drawn between the line number area and the
+ source code area: True/False
+
+ Default: True
+
+ `line_number_pad`
+ The horizontal padding (in pixels) between the line number margin, and
+ the source code area.
+
+ Default: 6
+
+ `hl_lines`
+ Specify a list of lines to be highlighted.
+
+ .. versionadded:: 1.2
+
+ Default: empty list
+
+ `hl_color`
+ Specify the color for highlighting lines.
+
+ .. versionadded:: 1.2
+
+ Default: highlight color of the selected style
+ """
+
+ # Required by the pygments mapper
+ name = 'img'
+ aliases = ['img', 'IMG', 'png']
+ filenames = ['*.png']
+
+ unicodeoutput = False
+
+ default_image_format = 'png'
+
+ def __init__(self, **options):
+ """
+ See the class docstring for explanation of options.
+ """
+ if not pil_available:
+ raise PilNotAvailable(
+ 'Python Imaging Library is required for this formatter')
+ Formatter.__init__(self, **options)
+ self.encoding = 'latin1' # let pygments.format() do the right thing
+ # Read the style
+ self.styles = dict(self.style)
+ if self.style.background_color is None:
+ self.background_color = '#fff'
+ else:
+ self.background_color = self.style.background_color
+ # Image options
+ self.image_format = get_choice_opt(
+ options, 'image_format', ['png', 'jpeg', 'gif', 'bmp'],
+ self.default_image_format, normcase=True)
+ self.image_pad = get_int_opt(options, 'image_pad', 10)
+ self.line_pad = get_int_opt(options, 'line_pad', 2)
+ # The fonts
+ fontsize = get_int_opt(options, 'font_size', 14)
+ self.fonts = FontManager(options.get('font_name', ''), fontsize)
+ self.fontw, self.fonth = self.fonts.get_char_size()
+ # Line number options
+ self.line_number_fg = options.get('line_number_fg', '#886')
+ self.line_number_bg = options.get('line_number_bg', '#eed')
+ self.line_number_chars = get_int_opt(options,
+ 'line_number_chars', 2)
+ self.line_number_bold = get_bool_opt(options,
+ 'line_number_bold', False)
+ self.line_number_italic = get_bool_opt(options,
+ 'line_number_italic', False)
+ self.line_number_pad = get_int_opt(options, 'line_number_pad', 6)
+ self.line_numbers = get_bool_opt(options, 'line_numbers', True)
+ self.line_number_separator = get_bool_opt(options,
+ 'line_number_separator', True)
+ self.line_number_step = get_int_opt(options, 'line_number_step', 1)
+ self.line_number_start = get_int_opt(options, 'line_number_start', 1)
+ if self.line_numbers:
+ self.line_number_width = (self.fontw * self.line_number_chars +
+ self.line_number_pad * 2)
+ else:
+ self.line_number_width = 0
+ self.hl_lines = []
+ hl_lines_str = get_list_opt(options, 'hl_lines', [])
+ for line in hl_lines_str:
+ try:
+ self.hl_lines.append(int(line))
+ except ValueError:
+ pass
+ self.hl_color = options.get('hl_color',
+ self.style.highlight_color) or '#f90'
+ self.drawables = []
+
+ def get_style_defs(self, arg=''):
+ raise NotImplementedError('The -S option is meaningless for the image '
+ 'formatter. Use -O style=<stylename> instead.')
+
+ def _get_line_height(self):
+ """
+ Get the height of a line.
+ """
+ return self.fonth + self.line_pad
+
+ def _get_line_y(self, lineno):
+ """
+ Get the Y coordinate of a line number.
+ """
+ return lineno * self._get_line_height() + self.image_pad
+
+ def _get_char_width(self):
+ """
+ Get the width of a character.
+ """
+ return self.fontw
+
+ def _get_char_x(self, linelength):
+ """
+ Get the X coordinate of a character position.
+ """
+ return linelength + self.image_pad + self.line_number_width
+
+ def _get_text_pos(self, linelength, lineno):
+ """
+ Get the actual position for a character and line position.
+ """
+ return self._get_char_x(linelength), self._get_line_y(lineno)
+
+ def _get_linenumber_pos(self, lineno):
+ """
+ Get the actual position for the start of a line number.
+ """
+ return (self.image_pad, self._get_line_y(lineno))
+
+ def _get_text_color(self, style):
+ """
+ Get the correct color for the token from the style.
+ """
+ if style['color'] is not None:
+ fill = '#' + style['color']
+ else:
+ fill = '#000'
+ return fill
+
+ def _get_text_bg_color(self, style):
+ """
+ Get the correct background color for the token from the style.
+ """
+ if style['bgcolor'] is not None:
+ bg_color = '#' + style['bgcolor']
+ else:
+ bg_color = None
+ return bg_color
+
+ def _get_style_font(self, style):
+ """
+ Get the correct font for the style.
+ """
+ return self.fonts.get_font(style['bold'], style['italic'])
+
+ def _get_image_size(self, maxlinelength, maxlineno):
+ """
+ Get the required image size.
+ """
+ return (self._get_char_x(maxlinelength) + self.image_pad,
+ self._get_line_y(maxlineno + 0) + self.image_pad)
+
+ def _draw_linenumber(self, posno, lineno):
+ """
+ Remember a line number drawable to paint later.
+ """
+ self._draw_text(
+ self._get_linenumber_pos(posno),
+ str(lineno).rjust(self.line_number_chars),
+ font=self.fonts.get_font(self.line_number_bold,
+ self.line_number_italic),
+ text_fg=self.line_number_fg,
+ text_bg=None,
+ )
+
+ def _draw_text(self, pos, text, font, text_fg, text_bg):
+ """
+ Remember a single drawable tuple to paint later.
+ """
+ self.drawables.append((pos, text, font, text_fg, text_bg))
+
+ def _create_drawables(self, tokensource):
+ """
+ Create drawables for the token content.
+ """
+ lineno = charno = maxcharno = 0
+ maxlinelength = linelength = 0
+ for ttype, value in tokensource:
+ while ttype not in self.styles:
+ ttype = ttype.parent
+ style = self.styles[ttype]
+ # TODO: make sure tab expansion happens earlier in the chain. It
+ # really ought to be done on the input, as to do it right here is
+ # quite complex.
+ value = value.expandtabs(4)
+ lines = value.splitlines(True)
+ # print lines
+ for i, line in enumerate(lines):
+ temp = line.rstrip('\n')
+ if temp:
+ self._draw_text(
+ self._get_text_pos(linelength, lineno),
+ temp,
+ font = self._get_style_font(style),
+ text_fg = self._get_text_color(style),
+ text_bg = self._get_text_bg_color(style),
+ )
+ temp_width, _ = self.fonts.get_text_size(temp)
+ linelength += temp_width
+ maxlinelength = max(maxlinelength, linelength)
+ charno += len(temp)
+ maxcharno = max(maxcharno, charno)
+ if line.endswith('\n'):
+ # add a line for each extra line in the value
+ linelength = 0
+ charno = 0
+ lineno += 1
+ self.maxlinelength = maxlinelength
+ self.maxcharno = maxcharno
+ self.maxlineno = lineno
+
+ def _draw_line_numbers(self):
+ """
+ Create drawables for the line numbers.
+ """
+ if not self.line_numbers:
+ return
+ for p in range(self.maxlineno):
+ n = p + self.line_number_start
+ if (n % self.line_number_step) == 0:
+ self._draw_linenumber(p, n)
+
+ def _paint_line_number_bg(self, im):
+ """
+ Paint the line number background on the image.
+ """
+ if not self.line_numbers:
+ return
+ if self.line_number_fg is None:
+ return
+ draw = ImageDraw.Draw(im)
+ recth = im.size[-1]
+ rectw = self.image_pad + self.line_number_width - self.line_number_pad
+ draw.rectangle([(0, 0), (rectw, recth)],
+ fill=self.line_number_bg)
+ if self.line_number_separator:
+ draw.line([(rectw, 0), (rectw, recth)], fill=self.line_number_fg)
+ del draw
+
+ def format(self, tokensource, outfile):
+ """
+ Format ``tokensource``, an iterable of ``(tokentype, tokenstring)``
+ tuples and write it into ``outfile``.
+
+ This implementation calculates where it should draw each token on the
+ pixmap, then calculates the required pixmap size and draws the items.
+ """
+ self._create_drawables(tokensource)
+ self._draw_line_numbers()
+ im = Image.new(
+ 'RGB',
+ self._get_image_size(self.maxlinelength, self.maxlineno),
+ self.background_color
+ )
+ self._paint_line_number_bg(im)
+ draw = ImageDraw.Draw(im)
+ # Highlight
+ if self.hl_lines:
+ x = self.image_pad + self.line_number_width - self.line_number_pad + 1
+ recth = self._get_line_height()
+ rectw = im.size[0] - x
+ for linenumber in self.hl_lines:
+ y = self._get_line_y(linenumber - 1)
+ draw.rectangle([(x, y), (x + rectw, y + recth)],
+ fill=self.hl_color)
+ for pos, value, font, text_fg, text_bg in self.drawables:
+ if text_bg:
+ # see deprecations https://pillow.readthedocs.io/en/stable/releasenotes/9.2.0.html#font-size-and-offset-methods
+ if hasattr(draw, 'textsize'):
+ text_size = draw.textsize(text=value, font=font)
+ else:
+ text_size = font.getbbox(value)[2:]
+ draw.rectangle([pos[0], pos[1], pos[0] + text_size[0], pos[1] + text_size[1]], fill=text_bg)
+ draw.text(pos, value, font=font, fill=text_fg)
+ im.save(outfile, self.image_format.upper())
+
+
+# Add one formatter per format, so that the "-f gif" option gives the correct result
+# when used in pygmentize.
+
+class GifImageFormatter(ImageFormatter):
+ """
+ Create a GIF image from source code. This uses the Python Imaging Library to
+ generate a pixmap from the source code.
+
+ .. versionadded:: 1.0
+ """
+
+ name = 'img_gif'
+ aliases = ['gif']
+ filenames = ['*.gif']
+ default_image_format = 'gif'
+
+
+class JpgImageFormatter(ImageFormatter):
+ """
+ Create a JPEG image from source code. This uses the Python Imaging Library to
+ generate a pixmap from the source code.
+
+ .. versionadded:: 1.0
+ """
+
+ name = 'img_jpg'
+ aliases = ['jpg', 'jpeg']
+ filenames = ['*.jpg']
+ default_image_format = 'jpeg'
+
+
+class BmpImageFormatter(ImageFormatter):
+ """
+ Create a bitmap image from source code. This uses the Python Imaging Library to
+ generate a pixmap from the source code.
+
+ .. versionadded:: 1.0
+ """
+
+ name = 'img_bmp'
+ aliases = ['bmp', 'bitmap']
+ filenames = ['*.bmp']
+ default_image_format = 'bmp'
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/irc.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/irc.py
new file mode 100644
index 000000000..468c28760
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/irc.py
@@ -0,0 +1,154 @@
+"""
+ pygments.formatters.irc
+ ~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for IRC output
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.token import Keyword, Name, Comment, String, Error, \
+ Number, Operator, Generic, Token, Whitespace
+from pip._vendor.pygments.util import get_choice_opt
+
+
+__all__ = ['IRCFormatter']
+
+
+#: Map token types to a tuple of color values for light and dark
+#: backgrounds.
+IRC_COLORS = {
+ Token: ('', ''),
+
+ Whitespace: ('gray', 'brightblack'),
+ Comment: ('gray', 'brightblack'),
+ Comment.Preproc: ('cyan', 'brightcyan'),
+ Keyword: ('blue', 'brightblue'),
+ Keyword.Type: ('cyan', 'brightcyan'),
+ Operator.Word: ('magenta', 'brightcyan'),
+ Name.Builtin: ('cyan', 'brightcyan'),
+ Name.Function: ('green', 'brightgreen'),
+ Name.Namespace: ('_cyan_', '_brightcyan_'),
+ Name.Class: ('_green_', '_brightgreen_'),
+ Name.Exception: ('cyan', 'brightcyan'),
+ Name.Decorator: ('brightblack', 'gray'),
+ Name.Variable: ('red', 'brightred'),
+ Name.Constant: ('red', 'brightred'),
+ Name.Attribute: ('cyan', 'brightcyan'),
+ Name.Tag: ('brightblue', 'brightblue'),
+ String: ('yellow', 'yellow'),
+ Number: ('blue', 'brightblue'),
+
+ Generic.Deleted: ('brightred', 'brightred'),
+ Generic.Inserted: ('green', 'brightgreen'),
+ Generic.Heading: ('**', '**'),
+ Generic.Subheading: ('*magenta*', '*brightmagenta*'),
+ Generic.Error: ('brightred', 'brightred'),
+
+ Error: ('_brightred_', '_brightred_'),
+}
+
+
+IRC_COLOR_MAP = {
+ 'white': 0,
+ 'black': 1,
+ 'blue': 2,
+ 'brightgreen': 3,
+ 'brightred': 4,
+ 'yellow': 5,
+ 'magenta': 6,
+ 'orange': 7,
+ 'green': 7, #compat w/ ansi
+ 'brightyellow': 8,
+ 'lightgreen': 9,
+ 'brightcyan': 9, # compat w/ ansi
+ 'cyan': 10,
+ 'lightblue': 11,
+ 'red': 11, # compat w/ ansi
+ 'brightblue': 12,
+ 'brightmagenta': 13,
+ 'brightblack': 14,
+ 'gray': 15,
+}
+
+def ircformat(color, text):
+ if len(color) < 1:
+ return text
+ add = sub = ''
+ if '_' in color: # italic
+ add += '\x1D'
+ sub = '\x1D' + sub
+ color = color.strip('_')
+ if '*' in color: # bold
+ add += '\x02'
+ sub = '\x02' + sub
+ color = color.strip('*')
+ # underline (\x1F) not supported
+ # backgrounds (\x03FF,BB) not supported
+ if len(color) > 0: # actual color - may have issues with ircformat("red", "blah")+"10" type stuff
+ add += '\x03' + str(IRC_COLOR_MAP[color]).zfill(2)
+ sub = '\x03' + sub
+ return add + text + sub
+ return '<'+add+'>'+text+'</'+sub+'>'
+
+
+class IRCFormatter(Formatter):
+ r"""
+ Format tokens with IRC color sequences
+
+ The `get_style_defs()` method doesn't do anything special since there is
+ no support for common styles.
+
+ Options accepted:
+
+ `bg`
+ Set to ``"light"`` or ``"dark"`` depending on the terminal's background
+ (default: ``"light"``).
+
+ `colorscheme`
+ A dictionary mapping token types to (lightbg, darkbg) color names or
+ ``None`` (default: ``None`` = use builtin colorscheme).
+
+ `linenos`
+ Set to ``True`` to have line numbers in the output as well
+ (default: ``False`` = no line numbers).
+ """
+ name = 'IRC'
+ aliases = ['irc', 'IRC']
+ filenames = []
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ self.darkbg = get_choice_opt(options, 'bg',
+ ['light', 'dark'], 'light') == 'dark'
+ self.colorscheme = options.get('colorscheme', None) or IRC_COLORS
+ self.linenos = options.get('linenos', False)
+ self._lineno = 0
+
+ def _write_lineno(self, outfile):
+ if self.linenos:
+ self._lineno += 1
+ outfile.write("%04d: " % self._lineno)
+
+ def format_unencoded(self, tokensource, outfile):
+ self._write_lineno(outfile)
+
+ for ttype, value in tokensource:
+ color = self.colorscheme.get(ttype)
+ while color is None:
+ ttype = ttype[:-1]
+ color = self.colorscheme.get(ttype)
+ if color:
+ color = color[self.darkbg]
+ spl = value.split('\n')
+ for line in spl[:-1]:
+ if line:
+ outfile.write(ircformat(color, line))
+ outfile.write('\n')
+ self._write_lineno(outfile)
+ if spl[-1]:
+ outfile.write(ircformat(color, spl[-1]))
+ else:
+ outfile.write(value)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/latex.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/latex.py
new file mode 100644
index 000000000..0ec9089b9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/latex.py
@@ -0,0 +1,518 @@
+"""
+ pygments.formatters.latex
+ ~~~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for LaTeX fancyvrb output.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from io import StringIO
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.lexer import Lexer, do_insertions
+from pip._vendor.pygments.token import Token, STANDARD_TYPES
+from pip._vendor.pygments.util import get_bool_opt, get_int_opt
+
+
+__all__ = ['LatexFormatter']
+
+
+def escape_tex(text, commandprefix):
+ return text.replace('\\', '\x00'). \
+ replace('{', '\x01'). \
+ replace('}', '\x02'). \
+ replace('\x00', rf'\{commandprefix}Zbs{{}}'). \
+ replace('\x01', rf'\{commandprefix}Zob{{}}'). \
+ replace('\x02', rf'\{commandprefix}Zcb{{}}'). \
+ replace('^', rf'\{commandprefix}Zca{{}}'). \
+ replace('_', rf'\{commandprefix}Zus{{}}'). \
+ replace('&', rf'\{commandprefix}Zam{{}}'). \
+ replace('<', rf'\{commandprefix}Zlt{{}}'). \
+ replace('>', rf'\{commandprefix}Zgt{{}}'). \
+ replace('#', rf'\{commandprefix}Zsh{{}}'). \
+ replace('%', rf'\{commandprefix}Zpc{{}}'). \
+ replace('$', rf'\{commandprefix}Zdl{{}}'). \
+ replace('-', rf'\{commandprefix}Zhy{{}}'). \
+ replace("'", rf'\{commandprefix}Zsq{{}}'). \
+ replace('"', rf'\{commandprefix}Zdq{{}}'). \
+ replace('~', rf'\{commandprefix}Zti{{}}')
+
+
+DOC_TEMPLATE = r'''
+\documentclass{%(docclass)s}
+\usepackage{fancyvrb}
+\usepackage{color}
+\usepackage[%(encoding)s]{inputenc}
+%(preamble)s
+
+%(styledefs)s
+
+\begin{document}
+
+\section*{%(title)s}
+
+%(code)s
+\end{document}
+'''
+
+## Small explanation of the mess below :)
+#
+# The previous version of the LaTeX formatter just assigned a command to
+# each token type defined in the current style. That obviously is
+# problematic if the highlighted code is produced for a different style
+# than the style commands themselves.
+#
+# This version works much like the HTML formatter which assigns multiple
+# CSS classes to each <span> tag, from the most specific to the least
+# specific token type, thus falling back to the parent token type if one
+# is not defined. Here, the classes are there too and use the same short
+# forms given in token.STANDARD_TYPES.
+#
+# Highlighted code now only uses one custom command, which by default is
+# \PY and selectable by the commandprefix option (and in addition the
+# escapes \PYZat, \PYZlb and \PYZrb which haven't been renamed for
+# backwards compatibility purposes).
+#
+# \PY has two arguments: the classes, separated by +, and the text to
+# render in that style. The classes are resolved into the respective
+# style commands by magic, which serves to ignore unknown classes.
+#
+# The magic macros are:
+# * \PY@it, \PY@bf, etc. are unconditionally wrapped around the text
+# to render in \PY@do. Their definition determines the style.
+# * \PY@reset resets \PY@it etc. to do nothing.
+# * \PY@toks parses the list of classes, using magic inspired by the
+# keyval package (but modified to use plusses instead of commas
+# because fancyvrb redefines commas inside its environments).
+# * \PY@tok processes one class, calling the \PY@tok@classname command
+# if it exists.
+# * \PY@tok@classname sets the \PY@it etc. to reflect the chosen style
+# for its class.
+# * \PY resets the style, parses the classnames and then calls \PY@do.
+#
+# Tip: to read this code, print it out in substituted form using e.g.
+# >>> print STYLE_TEMPLATE % {'cp': 'PY'}
+
+STYLE_TEMPLATE = r'''
+\makeatletter
+\def\%(cp)s@reset{\let\%(cp)s@it=\relax \let\%(cp)s@bf=\relax%%
+ \let\%(cp)s@ul=\relax \let\%(cp)s@tc=\relax%%
+ \let\%(cp)s@bc=\relax \let\%(cp)s@ff=\relax}
+\def\%(cp)s@tok#1{\csname %(cp)s@tok@#1\endcsname}
+\def\%(cp)s@toks#1+{\ifx\relax#1\empty\else%%
+ \%(cp)s@tok{#1}\expandafter\%(cp)s@toks\fi}
+\def\%(cp)s@do#1{\%(cp)s@bc{\%(cp)s@tc{\%(cp)s@ul{%%
+ \%(cp)s@it{\%(cp)s@bf{\%(cp)s@ff{#1}}}}}}}
+\def\%(cp)s#1#2{\%(cp)s@reset\%(cp)s@toks#1+\relax+\%(cp)s@do{#2}}
+
+%(styles)s
+
+\def\%(cp)sZbs{\char`\\}
+\def\%(cp)sZus{\char`\_}
+\def\%(cp)sZob{\char`\{}
+\def\%(cp)sZcb{\char`\}}
+\def\%(cp)sZca{\char`\^}
+\def\%(cp)sZam{\char`\&}
+\def\%(cp)sZlt{\char`\<}
+\def\%(cp)sZgt{\char`\>}
+\def\%(cp)sZsh{\char`\#}
+\def\%(cp)sZpc{\char`\%%}
+\def\%(cp)sZdl{\char`\$}
+\def\%(cp)sZhy{\char`\-}
+\def\%(cp)sZsq{\char`\'}
+\def\%(cp)sZdq{\char`\"}
+\def\%(cp)sZti{\char`\~}
+%% for compatibility with earlier versions
+\def\%(cp)sZat{@}
+\def\%(cp)sZlb{[}
+\def\%(cp)sZrb{]}
+\makeatother
+'''
+
+
+def _get_ttype_name(ttype):
+ fname = STANDARD_TYPES.get(ttype)
+ if fname:
+ return fname
+ aname = ''
+ while fname is None:
+ aname = ttype[-1] + aname
+ ttype = ttype.parent
+ fname = STANDARD_TYPES.get(ttype)
+ return fname + aname
+
+
+class LatexFormatter(Formatter):
+ r"""
+ Format tokens as LaTeX code. This needs the `fancyvrb` and `color`
+ standard packages.
+
+ Without the `full` option, code is formatted as one ``Verbatim``
+ environment, like this:
+
+ .. sourcecode:: latex
+
+ \begin{Verbatim}[commandchars=\\\{\}]
+ \PY{k}{def }\PY{n+nf}{foo}(\PY{n}{bar}):
+ \PY{k}{pass}
+ \end{Verbatim}
+
+ Wrapping can be disabled using the `nowrap` option.
+
+ The special command used here (``\PY``) and all the other macros it needs
+ are output by the `get_style_defs` method.
+
+ With the `full` option, a complete LaTeX document is output, including
+ the command definitions in the preamble.
+
+ The `get_style_defs()` method of a `LatexFormatter` returns a string
+ containing ``\def`` commands defining the macros needed inside the
+ ``Verbatim`` environments.
+
+ Additional options accepted:
+
+ `nowrap`
+ If set to ``True``, don't wrap the tokens at all, not even inside a
+ ``\begin{Verbatim}`` environment. This disables most other options
+ (default: ``False``).
+
+ `style`
+ The style to use, can be a string or a Style subclass (default:
+ ``'default'``).
+
+ `full`
+ Tells the formatter to output a "full" document, i.e. a complete
+ self-contained document (default: ``False``).
+
+ `title`
+ If `full` is true, the title that should be used to caption the
+ document (default: ``''``).
+
+ `docclass`
+ If the `full` option is enabled, this is the document class to use
+ (default: ``'article'``).
+
+ `preamble`
+ If the `full` option is enabled, this can be further preamble commands,
+ e.g. ``\usepackage`` (default: ``''``).
+
+ `linenos`
+ If set to ``True``, output line numbers (default: ``False``).
+
+ `linenostart`
+ The line number for the first line (default: ``1``).
+
+ `linenostep`
+ If set to a number n > 1, only every nth line number is printed.
+
+ `verboptions`
+ Additional options given to the Verbatim environment (see the *fancyvrb*
+ docs for possible values) (default: ``''``).
+
+ `commandprefix`
+ The LaTeX commands used to produce colored output are constructed
+ using this prefix and some letters (default: ``'PY'``).
+
+ .. versionadded:: 0.7
+ .. versionchanged:: 0.10
+ The default is now ``'PY'`` instead of ``'C'``.
+
+ `texcomments`
+ If set to ``True``, enables LaTeX comment lines. That is, LaTex markup
+ in comment tokens is not escaped so that LaTeX can render it (default:
+ ``False``).
+
+ .. versionadded:: 1.2
+
+ `mathescape`
+ If set to ``True``, enables LaTeX math mode escape in comments. That
+ is, ``'$...$'`` inside a comment will trigger math mode (default:
+ ``False``).
+
+ .. versionadded:: 1.2
+
+ `escapeinside`
+ If set to a string of length 2, enables escaping to LaTeX. Text
+ delimited by these 2 characters is read as LaTeX code and
+ typeset accordingly. It has no effect in string literals. It has
+ no effect in comments if `texcomments` or `mathescape` is
+ set. (default: ``''``).
+
+ .. versionadded:: 2.0
+
+ `envname`
+ Allows you to pick an alternative environment name replacing Verbatim.
+ The alternate environment still has to support Verbatim's option syntax.
+ (default: ``'Verbatim'``).
+
+ .. versionadded:: 2.0
+ """
+ name = 'LaTeX'
+ aliases = ['latex', 'tex']
+ filenames = ['*.tex']
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ self.nowrap = get_bool_opt(options, 'nowrap', False)
+ self.docclass = options.get('docclass', 'article')
+ self.preamble = options.get('preamble', '')
+ self.linenos = get_bool_opt(options, 'linenos', False)
+ self.linenostart = abs(get_int_opt(options, 'linenostart', 1))
+ self.linenostep = abs(get_int_opt(options, 'linenostep', 1))
+ self.verboptions = options.get('verboptions', '')
+ self.nobackground = get_bool_opt(options, 'nobackground', False)
+ self.commandprefix = options.get('commandprefix', 'PY')
+ self.texcomments = get_bool_opt(options, 'texcomments', False)
+ self.mathescape = get_bool_opt(options, 'mathescape', False)
+ self.escapeinside = options.get('escapeinside', '')
+ if len(self.escapeinside) == 2:
+ self.left = self.escapeinside[0]
+ self.right = self.escapeinside[1]
+ else:
+ self.escapeinside = ''
+ self.envname = options.get('envname', 'Verbatim')
+
+ self._create_stylesheet()
+
+ def _create_stylesheet(self):
+ t2n = self.ttype2name = {Token: ''}
+ c2d = self.cmd2def = {}
+ cp = self.commandprefix
+
+ def rgbcolor(col):
+ if col:
+ return ','.join(['%.2f' % (int(col[i] + col[i + 1], 16) / 255.0)
+ for i in (0, 2, 4)])
+ else:
+ return '1,1,1'
+
+ for ttype, ndef in self.style:
+ name = _get_ttype_name(ttype)
+ cmndef = ''
+ if ndef['bold']:
+ cmndef += r'\let\$$@bf=\textbf'
+ if ndef['italic']:
+ cmndef += r'\let\$$@it=\textit'
+ if ndef['underline']:
+ cmndef += r'\let\$$@ul=\underline'
+ if ndef['roman']:
+ cmndef += r'\let\$$@ff=\textrm'
+ if ndef['sans']:
+ cmndef += r'\let\$$@ff=\textsf'
+ if ndef['mono']:
+ cmndef += r'\let\$$@ff=\textsf'
+ if ndef['color']:
+ cmndef += (r'\def\$$@tc##1{{\textcolor[rgb]{{{}}}{{##1}}}}'.format(rgbcolor(ndef['color'])))
+ if ndef['border']:
+ cmndef += (r'\def\$$@bc##1{{{{\setlength{{\fboxsep}}{{\string -\fboxrule}}'
+ r'\fcolorbox[rgb]{{{}}}{{{}}}{{\strut ##1}}}}}}'.format(rgbcolor(ndef['border']),
+ rgbcolor(ndef['bgcolor'])))
+ elif ndef['bgcolor']:
+ cmndef += (r'\def\$$@bc##1{{{{\setlength{{\fboxsep}}{{0pt}}'
+ r'\colorbox[rgb]{{{}}}{{\strut ##1}}}}}}'.format(rgbcolor(ndef['bgcolor'])))
+ if cmndef == '':
+ continue
+ cmndef = cmndef.replace('$$', cp)
+ t2n[ttype] = name
+ c2d[name] = cmndef
+
+ def get_style_defs(self, arg=''):
+ """
+ Return the command sequences needed to define the commands
+ used to format text in the verbatim environment. ``arg`` is ignored.
+ """
+ cp = self.commandprefix
+ styles = []
+ for name, definition in self.cmd2def.items():
+ styles.append(rf'\@namedef{{{cp}@tok@{name}}}{{{definition}}}')
+ return STYLE_TEMPLATE % {'cp': self.commandprefix,
+ 'styles': '\n'.join(styles)}
+
+ def format_unencoded(self, tokensource, outfile):
+ # TODO: add support for background colors
+ t2n = self.ttype2name
+ cp = self.commandprefix
+
+ if self.full:
+ realoutfile = outfile
+ outfile = StringIO()
+
+ if not self.nowrap:
+ outfile.write('\\begin{' + self.envname + '}[commandchars=\\\\\\{\\}')
+ if self.linenos:
+ start, step = self.linenostart, self.linenostep
+ outfile.write(',numbers=left' +
+ (start and ',firstnumber=%d' % start or '') +
+ (step and ',stepnumber=%d' % step or ''))
+ if self.mathescape or self.texcomments or self.escapeinside:
+ outfile.write(',codes={\\catcode`\\$=3\\catcode`\\^=7'
+ '\\catcode`\\_=8\\relax}')
+ if self.verboptions:
+ outfile.write(',' + self.verboptions)
+ outfile.write(']\n')
+
+ for ttype, value in tokensource:
+ if ttype in Token.Comment:
+ if self.texcomments:
+ # Try to guess comment starting lexeme and escape it ...
+ start = value[0:1]
+ for i in range(1, len(value)):
+ if start[0] != value[i]:
+ break
+ start += value[i]
+
+ value = value[len(start):]
+ start = escape_tex(start, cp)
+
+ # ... but do not escape inside comment.
+ value = start + value
+ elif self.mathescape:
+ # Only escape parts not inside a math environment.
+ parts = value.split('$')
+ in_math = False
+ for i, part in enumerate(parts):
+ if not in_math:
+ parts[i] = escape_tex(part, cp)
+ in_math = not in_math
+ value = '$'.join(parts)
+ elif self.escapeinside:
+ text = value
+ value = ''
+ while text:
+ a, sep1, text = text.partition(self.left)
+ if sep1:
+ b, sep2, text = text.partition(self.right)
+ if sep2:
+ value += escape_tex(a, cp) + b
+ else:
+ value += escape_tex(a + sep1 + b, cp)
+ else:
+ value += escape_tex(a, cp)
+ else:
+ value = escape_tex(value, cp)
+ elif ttype not in Token.Escape:
+ value = escape_tex(value, cp)
+ styles = []
+ while ttype is not Token:
+ try:
+ styles.append(t2n[ttype])
+ except KeyError:
+ # not in current style
+ styles.append(_get_ttype_name(ttype))
+ ttype = ttype.parent
+ styleval = '+'.join(reversed(styles))
+ if styleval:
+ spl = value.split('\n')
+ for line in spl[:-1]:
+ if line:
+ outfile.write(f"\\{cp}{{{styleval}}}{{{line}}}")
+ outfile.write('\n')
+ if spl[-1]:
+ outfile.write(f"\\{cp}{{{styleval}}}{{{spl[-1]}}}")
+ else:
+ outfile.write(value)
+
+ if not self.nowrap:
+ outfile.write('\\end{' + self.envname + '}\n')
+
+ if self.full:
+ encoding = self.encoding or 'utf8'
+ # map known existings encodings from LaTeX distribution
+ encoding = {
+ 'utf_8': 'utf8',
+ 'latin_1': 'latin1',
+ 'iso_8859_1': 'latin1',
+ }.get(encoding.replace('-', '_'), encoding)
+ realoutfile.write(DOC_TEMPLATE %
+ dict(docclass = self.docclass,
+ preamble = self.preamble,
+ title = self.title,
+ encoding = encoding,
+ styledefs = self.get_style_defs(),
+ code = outfile.getvalue()))
+
+
+class LatexEmbeddedLexer(Lexer):
+ """
+ This lexer takes one lexer as argument, the lexer for the language
+ being formatted, and the left and right delimiters for escaped text.
+
+ First everything is scanned using the language lexer to obtain
+ strings and comments. All other consecutive tokens are merged and
+ the resulting text is scanned for escaped segments, which are given
+ the Token.Escape type. Finally text that is not escaped is scanned
+ again with the language lexer.
+ """
+ def __init__(self, left, right, lang, **options):
+ self.left = left
+ self.right = right
+ self.lang = lang
+ Lexer.__init__(self, **options)
+
+ def get_tokens_unprocessed(self, text):
+ # find and remove all the escape tokens (replace with an empty string)
+ # this is very similar to DelegatingLexer.get_tokens_unprocessed.
+ buffered = ''
+ insertions = []
+ insertion_buf = []
+ for i, t, v in self._find_safe_escape_tokens(text):
+ if t is None:
+ if insertion_buf:
+ insertions.append((len(buffered), insertion_buf))
+ insertion_buf = []
+ buffered += v
+ else:
+ insertion_buf.append((i, t, v))
+ if insertion_buf:
+ insertions.append((len(buffered), insertion_buf))
+ return do_insertions(insertions,
+ self.lang.get_tokens_unprocessed(buffered))
+
+ def _find_safe_escape_tokens(self, text):
+ """ find escape tokens that are not in strings or comments """
+ for i, t, v in self._filter_to(
+ self.lang.get_tokens_unprocessed(text),
+ lambda t: t in Token.Comment or t in Token.String
+ ):
+ if t is None:
+ for i2, t2, v2 in self._find_escape_tokens(v):
+ yield i + i2, t2, v2
+ else:
+ yield i, None, v
+
+ def _filter_to(self, it, pred):
+ """ Keep only the tokens that match `pred`, merge the others together """
+ buf = ''
+ idx = 0
+ for i, t, v in it:
+ if pred(t):
+ if buf:
+ yield idx, None, buf
+ buf = ''
+ yield i, t, v
+ else:
+ if not buf:
+ idx = i
+ buf += v
+ if buf:
+ yield idx, None, buf
+
+ def _find_escape_tokens(self, text):
+ """ Find escape tokens within text, give token=None otherwise """
+ index = 0
+ while text:
+ a, sep1, text = text.partition(self.left)
+ if a:
+ yield index, None, a
+ index += len(a)
+ if sep1:
+ b, sep2, text = text.partition(self.right)
+ if sep2:
+ yield index + len(sep1), Token.Escape, b
+ index += len(sep1) + len(b) + len(sep2)
+ else:
+ yield index, Token.Error, sep1
+ index += len(sep1)
+ text = b
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/other.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/other.py
new file mode 100644
index 000000000..de8d9dcf8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/other.py
@@ -0,0 +1,160 @@
+"""
+ pygments.formatters.other
+ ~~~~~~~~~~~~~~~~~~~~~~~~~
+
+ Other formatters: NullFormatter, RawTokenFormatter.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.util import get_choice_opt
+from pip._vendor.pygments.token import Token
+from pip._vendor.pygments.console import colorize
+
+__all__ = ['NullFormatter', 'RawTokenFormatter', 'TestcaseFormatter']
+
+
+class NullFormatter(Formatter):
+ """
+ Output the text unchanged without any formatting.
+ """
+ name = 'Text only'
+ aliases = ['text', 'null']
+ filenames = ['*.txt']
+
+ def format(self, tokensource, outfile):
+ enc = self.encoding
+ for ttype, value in tokensource:
+ if enc:
+ outfile.write(value.encode(enc))
+ else:
+ outfile.write(value)
+
+
+class RawTokenFormatter(Formatter):
+ r"""
+ Format tokens as a raw representation for storing token streams.
+
+ The format is ``tokentype<TAB>repr(tokenstring)\n``. The output can later
+ be converted to a token stream with the `RawTokenLexer`, described in the
+ :doc:`lexer list <lexers>`.
+
+ Only two options are accepted:
+
+ `compress`
+ If set to ``'gz'`` or ``'bz2'``, compress the output with the given
+ compression algorithm after encoding (default: ``''``).
+ `error_color`
+ If set to a color name, highlight error tokens using that color. If
+ set but with no value, defaults to ``'red'``.
+
+ .. versionadded:: 0.11
+
+ """
+ name = 'Raw tokens'
+ aliases = ['raw', 'tokens']
+ filenames = ['*.raw']
+
+ unicodeoutput = False
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ # We ignore self.encoding if it is set, since it gets set for lexer
+ # and formatter if given with -Oencoding on the command line.
+ # The RawTokenFormatter outputs only ASCII. Override here.
+ self.encoding = 'ascii' # let pygments.format() do the right thing
+ self.compress = get_choice_opt(options, 'compress',
+ ['', 'none', 'gz', 'bz2'], '')
+ self.error_color = options.get('error_color', None)
+ if self.error_color is True:
+ self.error_color = 'red'
+ if self.error_color is not None:
+ try:
+ colorize(self.error_color, '')
+ except KeyError:
+ raise ValueError(f"Invalid color {self.error_color!r} specified")
+
+ def format(self, tokensource, outfile):
+ try:
+ outfile.write(b'')
+ except TypeError:
+ raise TypeError('The raw tokens formatter needs a binary '
+ 'output file')
+ if self.compress == 'gz':
+ import gzip
+ outfile = gzip.GzipFile('', 'wb', 9, outfile)
+
+ write = outfile.write
+ flush = outfile.close
+ elif self.compress == 'bz2':
+ import bz2
+ compressor = bz2.BZ2Compressor(9)
+
+ def write(text):
+ outfile.write(compressor.compress(text))
+
+ def flush():
+ outfile.write(compressor.flush())
+ outfile.flush()
+ else:
+ write = outfile.write
+ flush = outfile.flush
+
+ if self.error_color:
+ for ttype, value in tokensource:
+ line = b"%r\t%r\n" % (ttype, value)
+ if ttype is Token.Error:
+ write(colorize(self.error_color, line))
+ else:
+ write(line)
+ else:
+ for ttype, value in tokensource:
+ write(b"%r\t%r\n" % (ttype, value))
+ flush()
+
+
+TESTCASE_BEFORE = '''\
+ def testNeedsName(lexer):
+ fragment = %r
+ tokens = [
+'''
+TESTCASE_AFTER = '''\
+ ]
+ assert list(lexer.get_tokens(fragment)) == tokens
+'''
+
+
+class TestcaseFormatter(Formatter):
+ """
+ Format tokens as appropriate for a new testcase.
+
+ .. versionadded:: 2.0
+ """
+ name = 'Testcase'
+ aliases = ['testcase']
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ if self.encoding is not None and self.encoding != 'utf-8':
+ raise ValueError("Only None and utf-8 are allowed encodings.")
+
+ def format(self, tokensource, outfile):
+ indentation = ' ' * 12
+ rawbuf = []
+ outbuf = []
+ for ttype, value in tokensource:
+ rawbuf.append(value)
+ outbuf.append(f'{indentation}({ttype}, {value!r}),\n')
+
+ before = TESTCASE_BEFORE % (''.join(rawbuf),)
+ during = ''.join(outbuf)
+ after = TESTCASE_AFTER
+ if self.encoding is None:
+ outfile.write(before + during + after)
+ else:
+ outfile.write(before.encode('utf-8'))
+ outfile.write(during.encode('utf-8'))
+ outfile.write(after.encode('utf-8'))
+ outfile.flush()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/pangomarkup.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/pangomarkup.py
new file mode 100644
index 000000000..dfed53ab7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/pangomarkup.py
@@ -0,0 +1,83 @@
+"""
+ pygments.formatters.pangomarkup
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for Pango markup output.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from pip._vendor.pygments.formatter import Formatter
+
+
+__all__ = ['PangoMarkupFormatter']
+
+
+_escape_table = {
+ ord('&'): '&',
+ ord('<'): '<',
+}
+
+
+def escape_special_chars(text, table=_escape_table):
+ """Escape & and < for Pango Markup."""
+ return text.translate(table)
+
+
+class PangoMarkupFormatter(Formatter):
+ """
+ Format tokens as Pango Markup code. It can then be rendered to an SVG.
+
+ .. versionadded:: 2.9
+ """
+
+ name = 'Pango Markup'
+ aliases = ['pango', 'pangomarkup']
+ filenames = []
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+
+ self.styles = {}
+
+ for token, style in self.style:
+ start = ''
+ end = ''
+ if style['color']:
+ start += '<span fgcolor="#{}">'.format(style['color'])
+ end = '</span>' + end
+ if style['bold']:
+ start += '<b>'
+ end = '</b>' + end
+ if style['italic']:
+ start += '<i>'
+ end = '</i>' + end
+ if style['underline']:
+ start += '<u>'
+ end = '</u>' + end
+ self.styles[token] = (start, end)
+
+ def format_unencoded(self, tokensource, outfile):
+ lastval = ''
+ lasttype = None
+
+ outfile.write('<tt>')
+
+ for ttype, value in tokensource:
+ while ttype not in self.styles:
+ ttype = ttype.parent
+ if ttype == lasttype:
+ lastval += escape_special_chars(value)
+ else:
+ if lastval:
+ stylebegin, styleend = self.styles[lasttype]
+ outfile.write(stylebegin + lastval + styleend)
+ lastval = escape_special_chars(value)
+ lasttype = ttype
+
+ if lastval:
+ stylebegin, styleend = self.styles[lasttype]
+ outfile.write(stylebegin + lastval + styleend)
+
+ outfile.write('</tt>')
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/rtf.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/rtf.py
new file mode 100644
index 000000000..eca2a41a1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/rtf.py
@@ -0,0 +1,349 @@
+"""
+ pygments.formatters.rtf
+ ~~~~~~~~~~~~~~~~~~~~~~~
+
+ A formatter that generates RTF files.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from collections import OrderedDict
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.style import _ansimap
+from pip._vendor.pygments.util import get_bool_opt, get_int_opt, get_list_opt, surrogatepair
+
+
+__all__ = ['RtfFormatter']
+
+
+class RtfFormatter(Formatter):
+ """
+ Format tokens as RTF markup. This formatter automatically outputs full RTF
+ documents with color information and other useful stuff. Perfect for Copy and
+ Paste into Microsoft(R) Word(R) documents.
+
+ Please note that ``encoding`` and ``outencoding`` options are ignored.
+ The RTF format is ASCII natively, but handles unicode characters correctly
+ thanks to escape sequences.
+
+ .. versionadded:: 0.6
+
+ Additional options accepted:
+
+ `style`
+ The style to use, can be a string or a Style subclass (default:
+ ``'default'``).
+
+ `fontface`
+ The used font family, for example ``Bitstream Vera Sans``. Defaults to
+ some generic font which is supposed to have fixed width.
+
+ `fontsize`
+ Size of the font used. Size is specified in half points. The
+ default is 24 half-points, giving a size 12 font.
+
+ .. versionadded:: 2.0
+
+ `linenos`
+ Turn on line numbering (default: ``False``).
+
+ .. versionadded:: 2.18
+
+ `lineno_fontsize`
+ Font size for line numbers. Size is specified in half points
+ (default: `fontsize`).
+
+ .. versionadded:: 2.18
+
+ `lineno_padding`
+ Number of spaces between the (inline) line numbers and the
+ source code (default: ``2``).
+
+ .. versionadded:: 2.18
+
+ `linenostart`
+ The line number for the first line (default: ``1``).
+
+ .. versionadded:: 2.18
+
+ `linenostep`
+ If set to a number n > 1, only every nth line number is printed.
+
+ .. versionadded:: 2.18
+
+ `lineno_color`
+ Color for line numbers specified as a hex triplet, e.g. ``'5e5e5e'``.
+ Defaults to the style's line number color if it is a hex triplet,
+ otherwise ansi bright black.
+
+ .. versionadded:: 2.18
+
+ `hl_lines`
+ Specify a list of lines to be highlighted, as line numbers separated by
+ spaces, e.g. ``'3 7 8'``. The line numbers are relative to the input
+ (i.e. the first line is line 1) unless `hl_linenostart` is set.
+
+ .. versionadded:: 2.18
+
+ `hl_color`
+ Color for highlighting the lines specified in `hl_lines`, specified as
+ a hex triplet (default: style's `highlight_color`).
+
+ .. versionadded:: 2.18
+
+ `hl_linenostart`
+ If set to ``True`` line numbers in `hl_lines` are specified
+ relative to `linenostart` (default ``False``).
+
+ .. versionadded:: 2.18
+ """
+ name = 'RTF'
+ aliases = ['rtf']
+ filenames = ['*.rtf']
+
+ def __init__(self, **options):
+ r"""
+ Additional options accepted:
+
+ ``fontface``
+ Name of the font used. Could for example be ``'Courier New'``
+ to further specify the default which is ``'\fmodern'``. The RTF
+ specification claims that ``\fmodern`` are "Fixed-pitch serif
+ and sans serif fonts". Hope every RTF implementation thinks
+ the same about modern...
+
+ """
+ Formatter.__init__(self, **options)
+ self.fontface = options.get('fontface') or ''
+ self.fontsize = get_int_opt(options, 'fontsize', 0)
+ self.linenos = get_bool_opt(options, 'linenos', False)
+ self.lineno_fontsize = get_int_opt(options, 'lineno_fontsize',
+ self.fontsize)
+ self.lineno_padding = get_int_opt(options, 'lineno_padding', 2)
+ self.linenostart = abs(get_int_opt(options, 'linenostart', 1))
+ self.linenostep = abs(get_int_opt(options, 'linenostep', 1))
+ self.hl_linenostart = get_bool_opt(options, 'hl_linenostart', False)
+
+ self.hl_color = options.get('hl_color', '')
+ if not self.hl_color:
+ self.hl_color = self.style.highlight_color
+
+ self.hl_lines = []
+ for lineno in get_list_opt(options, 'hl_lines', []):
+ try:
+ lineno = int(lineno)
+ if self.hl_linenostart:
+ lineno = lineno - self.linenostart + 1
+ self.hl_lines.append(lineno)
+ except ValueError:
+ pass
+
+ self.lineno_color = options.get('lineno_color', '')
+ if not self.lineno_color:
+ if self.style.line_number_color == 'inherit':
+ # style color is the css value 'inherit'
+ # default to ansi bright-black
+ self.lineno_color = _ansimap['ansibrightblack']
+ else:
+ # style color is assumed to be a hex triplet as other
+ # colors in pygments/style.py
+ self.lineno_color = self.style.line_number_color
+
+ self.color_mapping = self._create_color_mapping()
+
+ def _escape(self, text):
+ return text.replace('\\', '\\\\') \
+ .replace('{', '\\{') \
+ .replace('}', '\\}')
+
+ def _escape_text(self, text):
+ # empty strings, should give a small performance improvement
+ if not text:
+ return ''
+
+ # escape text
+ text = self._escape(text)
+
+ buf = []
+ for c in text:
+ cn = ord(c)
+ if cn < (2**7):
+ # ASCII character
+ buf.append(str(c))
+ elif (2**7) <= cn < (2**16):
+ # single unicode escape sequence
+ buf.append('{\\u%d}' % cn)
+ elif (2**16) <= cn:
+ # RTF limits unicode to 16 bits.
+ # Force surrogate pairs
+ buf.append('{\\u%d}{\\u%d}' % surrogatepair(cn))
+
+ return ''.join(buf).replace('\n', '\\par')
+
+ @staticmethod
+ def hex_to_rtf_color(hex_color):
+ if hex_color[0] == "#":
+ hex_color = hex_color[1:]
+
+ return '\\red%d\\green%d\\blue%d;' % (
+ int(hex_color[0:2], 16),
+ int(hex_color[2:4], 16),
+ int(hex_color[4:6], 16)
+ )
+
+ def _split_tokens_on_newlines(self, tokensource):
+ """
+ Split tokens containing newline characters into multiple token
+ each representing a line of the input file. Needed for numbering
+ lines of e.g. multiline comments.
+ """
+ for ttype, value in tokensource:
+ if value == '\n':
+ yield (ttype, value)
+ elif "\n" in value:
+ lines = value.split("\n")
+ for line in lines[:-1]:
+ yield (ttype, line+"\n")
+ if lines[-1]:
+ yield (ttype, lines[-1])
+ else:
+ yield (ttype, value)
+
+ def _create_color_mapping(self):
+ """
+ Create a mapping of style hex colors to index/offset in
+ the RTF color table.
+ """
+ color_mapping = OrderedDict()
+ offset = 1
+
+ if self.linenos:
+ color_mapping[self.lineno_color] = offset
+ offset += 1
+
+ if self.hl_lines:
+ color_mapping[self.hl_color] = offset
+ offset += 1
+
+ for _, style in self.style:
+ for color in style['color'], style['bgcolor'], style['border']:
+ if color and color not in color_mapping:
+ color_mapping[color] = offset
+ offset += 1
+
+ return color_mapping
+
+ @property
+ def _lineno_template(self):
+ if self.lineno_fontsize != self.fontsize:
+ return '{{\\fs{} \\cf{} %s{}}}'.format(self.lineno_fontsize,
+ self.color_mapping[self.lineno_color],
+ " " * self.lineno_padding)
+
+ return '{{\\cf{} %s{}}}'.format(self.color_mapping[self.lineno_color],
+ " " * self.lineno_padding)
+
+ @property
+ def _hl_open_str(self):
+ return rf'{{\highlight{self.color_mapping[self.hl_color]} '
+
+ @property
+ def _rtf_header(self):
+ lines = []
+ # rtf 1.8 header
+ lines.append('{\\rtf1\\ansi\\uc0\\deff0'
+ '{\\fonttbl{\\f0\\fmodern\\fprq1\\fcharset0%s;}}'
+ % (self.fontface and ' '
+ + self._escape(self.fontface) or ''))
+
+ # color table
+ lines.append('{\\colortbl;')
+ for color, _ in self.color_mapping.items():
+ lines.append(self.hex_to_rtf_color(color))
+ lines.append('}')
+
+ # font and fontsize
+ lines.append('\\f0\\sa0')
+ if self.fontsize:
+ lines.append('\\fs%d' % self.fontsize)
+
+ # ensure Libre Office Writer imports and renders consecutive
+ # space characters the same width, needed for line numbering.
+ # https://bugs.documentfoundation.org/show_bug.cgi?id=144050
+ lines.append('\\dntblnsbdb')
+
+ return lines
+
+ def format_unencoded(self, tokensource, outfile):
+ for line in self._rtf_header:
+ outfile.write(line + "\n")
+
+ tokensource = self._split_tokens_on_newlines(tokensource)
+
+ # first pass of tokens to count lines, needed for line numbering
+ if self.linenos:
+ line_count = 0
+ tokens = [] # for copying the token source generator
+ for ttype, value in tokensource:
+ tokens.append((ttype, value))
+ if value.endswith("\n"):
+ line_count += 1
+
+ # width of line number strings (for padding with spaces)
+ linenos_width = len(str(line_count+self.linenostart-1))
+
+ tokensource = tokens
+
+ # highlight stream
+ lineno = 1
+ start_new_line = True
+ for ttype, value in tokensource:
+ if start_new_line and lineno in self.hl_lines:
+ outfile.write(self._hl_open_str)
+
+ if start_new_line and self.linenos:
+ if (lineno-self.linenostart+1)%self.linenostep == 0:
+ current_lineno = lineno + self.linenostart - 1
+ lineno_str = str(current_lineno).rjust(linenos_width)
+ else:
+ lineno_str = "".rjust(linenos_width)
+ outfile.write(self._lineno_template % lineno_str)
+
+ while not self.style.styles_token(ttype) and ttype.parent:
+ ttype = ttype.parent
+ style = self.style.style_for_token(ttype)
+ buf = []
+ if style['bgcolor']:
+ buf.append('\\cb%d' % self.color_mapping[style['bgcolor']])
+ if style['color']:
+ buf.append('\\cf%d' % self.color_mapping[style['color']])
+ if style['bold']:
+ buf.append('\\b')
+ if style['italic']:
+ buf.append('\\i')
+ if style['underline']:
+ buf.append('\\ul')
+ if style['border']:
+ buf.append('\\chbrdr\\chcfpat%d' %
+ self.color_mapping[style['border']])
+ start = ''.join(buf)
+ if start:
+ outfile.write(f'{{{start} ')
+ outfile.write(self._escape_text(value))
+ if start:
+ outfile.write('}')
+ start_new_line = False
+
+ # complete line of input
+ if value.endswith("\n"):
+ # close line highlighting
+ if lineno in self.hl_lines:
+ outfile.write('}')
+ # newline in RTF file after closing }
+ outfile.write("\n")
+
+ start_new_line = True
+ lineno += 1
+
+ outfile.write('}\n')
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/svg.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/svg.py
new file mode 100644
index 000000000..d3e018ffd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/svg.py
@@ -0,0 +1,185 @@
+"""
+ pygments.formatters.svg
+ ~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for SVG output.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.token import Comment
+from pip._vendor.pygments.util import get_bool_opt, get_int_opt
+
+__all__ = ['SvgFormatter']
+
+
+def escape_html(text):
+ """Escape &, <, > as well as single and double quotes for HTML."""
+ return text.replace('&', '&'). \
+ replace('<', '<'). \
+ replace('>', '>'). \
+ replace('"', '"'). \
+ replace("'", ''')
+
+
+class2style = {}
+
+class SvgFormatter(Formatter):
+ """
+ Format tokens as an SVG graphics file. This formatter is still experimental.
+ Each line of code is a ``<text>`` element with explicit ``x`` and ``y``
+ coordinates containing ``<tspan>`` elements with the individual token styles.
+
+ By default, this formatter outputs a full SVG document including doctype
+ declaration and the ``<svg>`` root element.
+
+ .. versionadded:: 0.9
+
+ Additional options accepted:
+
+ `nowrap`
+ Don't wrap the SVG ``<text>`` elements in ``<svg><g>`` elements and
+ don't add a XML declaration and a doctype. If true, the `fontfamily`
+ and `fontsize` options are ignored. Defaults to ``False``.
+
+ `fontfamily`
+ The value to give the wrapping ``<g>`` element's ``font-family``
+ attribute, defaults to ``"monospace"``.
+
+ `fontsize`
+ The value to give the wrapping ``<g>`` element's ``font-size``
+ attribute, defaults to ``"14px"``.
+
+ `linenos`
+ If ``True``, add line numbers (default: ``False``).
+
+ `linenostart`
+ The line number for the first line (default: ``1``).
+
+ `linenostep`
+ If set to a number n > 1, only every nth line number is printed.
+
+ `linenowidth`
+ Maximum width devoted to line numbers (default: ``3*ystep``, sufficient
+ for up to 4-digit line numbers. Increase width for longer code blocks).
+
+ `xoffset`
+ Starting offset in X direction, defaults to ``0``.
+
+ `yoffset`
+ Starting offset in Y direction, defaults to the font size if it is given
+ in pixels, or ``20`` else. (This is necessary since text coordinates
+ refer to the text baseline, not the top edge.)
+
+ `ystep`
+ Offset to add to the Y coordinate for each subsequent line. This should
+ roughly be the text size plus 5. It defaults to that value if the text
+ size is given in pixels, or ``25`` else.
+
+ `spacehack`
+ Convert spaces in the source to `` ``, which are non-breaking
+ spaces. SVG provides the ``xml:space`` attribute to control how
+ whitespace inside tags is handled, in theory, the ``preserve`` value
+ could be used to keep all whitespace as-is. However, many current SVG
+ viewers don't obey that rule, so this option is provided as a workaround
+ and defaults to ``True``.
+ """
+ name = 'SVG'
+ aliases = ['svg']
+ filenames = ['*.svg']
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ self.nowrap = get_bool_opt(options, 'nowrap', False)
+ self.fontfamily = options.get('fontfamily', 'monospace')
+ self.fontsize = options.get('fontsize', '14px')
+ self.xoffset = get_int_opt(options, 'xoffset', 0)
+ fs = self.fontsize.strip()
+ if fs.endswith('px'):
+ fs = fs[:-2].strip()
+ try:
+ int_fs = int(fs)
+ except ValueError:
+ int_fs = 20
+ self.yoffset = get_int_opt(options, 'yoffset', int_fs)
+ self.ystep = get_int_opt(options, 'ystep', int_fs + 5)
+ self.spacehack = get_bool_opt(options, 'spacehack', True)
+ self.linenos = get_bool_opt(options,'linenos',False)
+ self.linenostart = get_int_opt(options,'linenostart',1)
+ self.linenostep = get_int_opt(options,'linenostep',1)
+ self.linenowidth = get_int_opt(options,'linenowidth', 3*self.ystep)
+ self._stylecache = {}
+
+ def format_unencoded(self, tokensource, outfile):
+ """
+ Format ``tokensource``, an iterable of ``(tokentype, tokenstring)``
+ tuples and write it into ``outfile``.
+
+ For our implementation we put all lines in their own 'line group'.
+ """
+ x = self.xoffset
+ y = self.yoffset
+ if not self.nowrap:
+ if self.encoding:
+ outfile.write(f'<?xml version="1.0" encoding="{self.encoding}"?>\n')
+ else:
+ outfile.write('<?xml version="1.0"?>\n')
+ outfile.write('<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.0//EN" '
+ '"http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/'
+ 'svg10.dtd">\n')
+ outfile.write('<svg xmlns="http://www.w3.org/2000/svg">\n')
+ outfile.write(f'<g font-family="{self.fontfamily}" font-size="{self.fontsize}">\n')
+
+ counter = self.linenostart
+ counter_step = self.linenostep
+ counter_style = self._get_style(Comment)
+ line_x = x
+
+ if self.linenos:
+ if counter % counter_step == 0:
+ outfile.write(f'<text x="{x+self.linenowidth}" y="{y}" {counter_style} text-anchor="end">{counter}</text>')
+ line_x += self.linenowidth + self.ystep
+ counter += 1
+
+ outfile.write(f'<text x="{line_x}" y="{y}" xml:space="preserve">')
+ for ttype, value in tokensource:
+ style = self._get_style(ttype)
+ tspan = style and '<tspan' + style + '>' or ''
+ tspanend = tspan and '</tspan>' or ''
+ value = escape_html(value)
+ if self.spacehack:
+ value = value.expandtabs().replace(' ', ' ')
+ parts = value.split('\n')
+ for part in parts[:-1]:
+ outfile.write(tspan + part + tspanend)
+ y += self.ystep
+ outfile.write('</text>\n')
+ if self.linenos and counter % counter_step == 0:
+ outfile.write(f'<text x="{x+self.linenowidth}" y="{y}" text-anchor="end" {counter_style}>{counter}</text>')
+
+ counter += 1
+ outfile.write(f'<text x="{line_x}" y="{y}" ' 'xml:space="preserve">')
+ outfile.write(tspan + parts[-1] + tspanend)
+ outfile.write('</text>')
+
+ if not self.nowrap:
+ outfile.write('</g></svg>\n')
+
+ def _get_style(self, tokentype):
+ if tokentype in self._stylecache:
+ return self._stylecache[tokentype]
+ otokentype = tokentype
+ while not self.style.styles_token(tokentype):
+ tokentype = tokentype.parent
+ value = self.style.style_for_token(tokentype)
+ result = ''
+ if value['color']:
+ result = ' fill="#' + value['color'] + '"'
+ if value['bold']:
+ result += ' font-weight="bold"'
+ if value['italic']:
+ result += ' font-style="italic"'
+ self._stylecache[otokentype] = result
+ return result
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/terminal.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/terminal.py
new file mode 100644
index 000000000..51b902d3e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/terminal.py
@@ -0,0 +1,127 @@
+"""
+ pygments.formatters.terminal
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for terminal output with ANSI sequences.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.token import Keyword, Name, Comment, String, Error, \
+ Number, Operator, Generic, Token, Whitespace
+from pip._vendor.pygments.console import ansiformat
+from pip._vendor.pygments.util import get_choice_opt
+
+
+__all__ = ['TerminalFormatter']
+
+
+#: Map token types to a tuple of color values for light and dark
+#: backgrounds.
+TERMINAL_COLORS = {
+ Token: ('', ''),
+
+ Whitespace: ('gray', 'brightblack'),
+ Comment: ('gray', 'brightblack'),
+ Comment.Preproc: ('cyan', 'brightcyan'),
+ Keyword: ('blue', 'brightblue'),
+ Keyword.Type: ('cyan', 'brightcyan'),
+ Operator.Word: ('magenta', 'brightmagenta'),
+ Name.Builtin: ('cyan', 'brightcyan'),
+ Name.Function: ('green', 'brightgreen'),
+ Name.Namespace: ('_cyan_', '_brightcyan_'),
+ Name.Class: ('_green_', '_brightgreen_'),
+ Name.Exception: ('cyan', 'brightcyan'),
+ Name.Decorator: ('brightblack', 'gray'),
+ Name.Variable: ('red', 'brightred'),
+ Name.Constant: ('red', 'brightred'),
+ Name.Attribute: ('cyan', 'brightcyan'),
+ Name.Tag: ('brightblue', 'brightblue'),
+ String: ('yellow', 'yellow'),
+ Number: ('blue', 'brightblue'),
+
+ Generic.Deleted: ('brightred', 'brightred'),
+ Generic.Inserted: ('green', 'brightgreen'),
+ Generic.Heading: ('**', '**'),
+ Generic.Subheading: ('*magenta*', '*brightmagenta*'),
+ Generic.Prompt: ('**', '**'),
+ Generic.Error: ('brightred', 'brightred'),
+
+ Error: ('_brightred_', '_brightred_'),
+}
+
+
+class TerminalFormatter(Formatter):
+ r"""
+ Format tokens with ANSI color sequences, for output in a text console.
+ Color sequences are terminated at newlines, so that paging the output
+ works correctly.
+
+ The `get_style_defs()` method doesn't do anything special since there is
+ no support for common styles.
+
+ Options accepted:
+
+ `bg`
+ Set to ``"light"`` or ``"dark"`` depending on the terminal's background
+ (default: ``"light"``).
+
+ `colorscheme`
+ A dictionary mapping token types to (lightbg, darkbg) color names or
+ ``None`` (default: ``None`` = use builtin colorscheme).
+
+ `linenos`
+ Set to ``True`` to have line numbers on the terminal output as well
+ (default: ``False`` = no line numbers).
+ """
+ name = 'Terminal'
+ aliases = ['terminal', 'console']
+ filenames = []
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+ self.darkbg = get_choice_opt(options, 'bg',
+ ['light', 'dark'], 'light') == 'dark'
+ self.colorscheme = options.get('colorscheme', None) or TERMINAL_COLORS
+ self.linenos = options.get('linenos', False)
+ self._lineno = 0
+
+ def format(self, tokensource, outfile):
+ return Formatter.format(self, tokensource, outfile)
+
+ def _write_lineno(self, outfile):
+ self._lineno += 1
+ outfile.write("%s%04d: " % (self._lineno != 1 and '\n' or '', self._lineno))
+
+ def _get_color(self, ttype):
+ # self.colorscheme is a dict containing usually generic types, so we
+ # have to walk the tree of dots. The base Token type must be a key,
+ # even if it's empty string, as in the default above.
+ colors = self.colorscheme.get(ttype)
+ while colors is None:
+ ttype = ttype.parent
+ colors = self.colorscheme.get(ttype)
+ return colors[self.darkbg]
+
+ def format_unencoded(self, tokensource, outfile):
+ if self.linenos:
+ self._write_lineno(outfile)
+
+ for ttype, value in tokensource:
+ color = self._get_color(ttype)
+
+ for line in value.splitlines(True):
+ if color:
+ outfile.write(ansiformat(color, line.rstrip('\n')))
+ else:
+ outfile.write(line.rstrip('\n'))
+ if line.endswith('\n'):
+ if self.linenos:
+ self._write_lineno(outfile)
+ else:
+ outfile.write('\n')
+
+ if self.linenos:
+ outfile.write("\n")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/terminal256.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/terminal256.py
new file mode 100644
index 000000000..5f254051a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/formatters/terminal256.py
@@ -0,0 +1,338 @@
+"""
+ pygments.formatters.terminal256
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+ Formatter for 256-color terminal output with ANSI sequences.
+
+ RGB-to-XTERM color conversion routines adapted from xterm256-conv
+ tool (http://frexx.de/xterm-256-notes/data/xterm256-conv2.tar.bz2)
+ by Wolfgang Frisch.
+
+ Formatter version 1.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+# TODO:
+# - Options to map style's bold/underline/italic/border attributes
+# to some ANSI attrbutes (something like 'italic=underline')
+# - An option to output "style RGB to xterm RGB/index" conversion table
+# - An option to indicate that we are running in "reverse background"
+# xterm. This means that default colors are white-on-black, not
+# black-on-while, so colors like "white background" need to be converted
+# to "white background, black foreground", etc...
+
+from pip._vendor.pygments.formatter import Formatter
+from pip._vendor.pygments.console import codes
+from pip._vendor.pygments.style import ansicolors
+
+
+__all__ = ['Terminal256Formatter', 'TerminalTrueColorFormatter']
+
+
+class EscapeSequence:
+ def __init__(self, fg=None, bg=None, bold=False, underline=False, italic=False):
+ self.fg = fg
+ self.bg = bg
+ self.bold = bold
+ self.underline = underline
+ self.italic = italic
+
+ def escape(self, attrs):
+ if len(attrs):
+ return "\x1b[" + ";".join(attrs) + "m"
+ return ""
+
+ def color_string(self):
+ attrs = []
+ if self.fg is not None:
+ if self.fg in ansicolors:
+ esc = codes[self.fg.replace('ansi','')]
+ if ';01m' in esc:
+ self.bold = True
+ # extract fg color code.
+ attrs.append(esc[2:4])
+ else:
+ attrs.extend(("38", "5", "%i" % self.fg))
+ if self.bg is not None:
+ if self.bg in ansicolors:
+ esc = codes[self.bg.replace('ansi','')]
+ # extract fg color code, add 10 for bg.
+ attrs.append(str(int(esc[2:4])+10))
+ else:
+ attrs.extend(("48", "5", "%i" % self.bg))
+ if self.bold:
+ attrs.append("01")
+ if self.underline:
+ attrs.append("04")
+ if self.italic:
+ attrs.append("03")
+ return self.escape(attrs)
+
+ def true_color_string(self):
+ attrs = []
+ if self.fg:
+ attrs.extend(("38", "2", str(self.fg[0]), str(self.fg[1]), str(self.fg[2])))
+ if self.bg:
+ attrs.extend(("48", "2", str(self.bg[0]), str(self.bg[1]), str(self.bg[2])))
+ if self.bold:
+ attrs.append("01")
+ if self.underline:
+ attrs.append("04")
+ if self.italic:
+ attrs.append("03")
+ return self.escape(attrs)
+
+ def reset_string(self):
+ attrs = []
+ if self.fg is not None:
+ attrs.append("39")
+ if self.bg is not None:
+ attrs.append("49")
+ if self.bold or self.underline or self.italic:
+ attrs.append("00")
+ return self.escape(attrs)
+
+
+class Terminal256Formatter(Formatter):
+ """
+ Format tokens with ANSI color sequences, for output in a 256-color
+ terminal or console. Like in `TerminalFormatter` color sequences
+ are terminated at newlines, so that paging the output works correctly.
+
+ The formatter takes colors from a style defined by the `style` option
+ and converts them to nearest ANSI 256-color escape sequences. Bold and
+ underline attributes from the style are preserved (and displayed).
+
+ .. versionadded:: 0.9
+
+ .. versionchanged:: 2.2
+ If the used style defines foreground colors in the form ``#ansi*``, then
+ `Terminal256Formatter` will map these to non extended foreground color.
+ See :ref:`AnsiTerminalStyle` for more information.
+
+ .. versionchanged:: 2.4
+ The ANSI color names have been updated with names that are easier to
+ understand and align with colornames of other projects and terminals.
+ See :ref:`this table <new-ansi-color-names>` for more information.
+
+
+ Options accepted:
+
+ `style`
+ The style to use, can be a string or a Style subclass (default:
+ ``'default'``).
+
+ `linenos`
+ Set to ``True`` to have line numbers on the terminal output as well
+ (default: ``False`` = no line numbers).
+ """
+ name = 'Terminal256'
+ aliases = ['terminal256', 'console256', '256']
+ filenames = []
+
+ def __init__(self, **options):
+ Formatter.__init__(self, **options)
+
+ self.xterm_colors = []
+ self.best_match = {}
+ self.style_string = {}
+
+ self.usebold = 'nobold' not in options
+ self.useunderline = 'nounderline' not in options
+ self.useitalic = 'noitalic' not in options
+
+ self._build_color_table() # build an RGB-to-256 color conversion table
+ self._setup_styles() # convert selected style's colors to term. colors
+
+ self.linenos = options.get('linenos', False)
+ self._lineno = 0
+
+ def _build_color_table(self):
+ # colors 0..15: 16 basic colors
+
+ self.xterm_colors.append((0x00, 0x00, 0x00)) # 0
+ self.xterm_colors.append((0xcd, 0x00, 0x00)) # 1
+ self.xterm_colors.append((0x00, 0xcd, 0x00)) # 2
+ self.xterm_colors.append((0xcd, 0xcd, 0x00)) # 3
+ self.xterm_colors.append((0x00, 0x00, 0xee)) # 4
+ self.xterm_colors.append((0xcd, 0x00, 0xcd)) # 5
+ self.xterm_colors.append((0x00, 0xcd, 0xcd)) # 6
+ self.xterm_colors.append((0xe5, 0xe5, 0xe5)) # 7
+ self.xterm_colors.append((0x7f, 0x7f, 0x7f)) # 8
+ self.xterm_colors.append((0xff, 0x00, 0x00)) # 9
+ self.xterm_colors.append((0x00, 0xff, 0x00)) # 10
+ self.xterm_colors.append((0xff, 0xff, 0x00)) # 11
+ self.xterm_colors.append((0x5c, 0x5c, 0xff)) # 12
+ self.xterm_colors.append((0xff, 0x00, 0xff)) # 13
+ self.xterm_colors.append((0x00, 0xff, 0xff)) # 14
+ self.xterm_colors.append((0xff, 0xff, 0xff)) # 15
+
+ # colors 16..232: the 6x6x6 color cube
+
+ valuerange = (0x00, 0x5f, 0x87, 0xaf, 0xd7, 0xff)
+
+ for i in range(217):
+ r = valuerange[(i // 36) % 6]
+ g = valuerange[(i // 6) % 6]
+ b = valuerange[i % 6]
+ self.xterm_colors.append((r, g, b))
+
+ # colors 233..253: grayscale
+
+ for i in range(1, 22):
+ v = 8 + i * 10
+ self.xterm_colors.append((v, v, v))
+
+ def _closest_color(self, r, g, b):
+ distance = 257*257*3 # "infinity" (>distance from #000000 to #ffffff)
+ match = 0
+
+ for i in range(0, 254):
+ values = self.xterm_colors[i]
+
+ rd = r - values[0]
+ gd = g - values[1]
+ bd = b - values[2]
+ d = rd*rd + gd*gd + bd*bd
+
+ if d < distance:
+ match = i
+ distance = d
+ return match
+
+ def _color_index(self, color):
+ index = self.best_match.get(color, None)
+ if color in ansicolors:
+ # strip the `ansi/#ansi` part and look up code
+ index = color
+ self.best_match[color] = index
+ if index is None:
+ try:
+ rgb = int(str(color), 16)
+ except ValueError:
+ rgb = 0
+
+ r = (rgb >> 16) & 0xff
+ g = (rgb >> 8) & 0xff
+ b = rgb & 0xff
+ index = self._closest_color(r, g, b)
+ self.best_match[color] = index
+ return index
+
+ def _setup_styles(self):
+ for ttype, ndef in self.style:
+ escape = EscapeSequence()
+ # get foreground from ansicolor if set
+ if ndef['ansicolor']:
+ escape.fg = self._color_index(ndef['ansicolor'])
+ elif ndef['color']:
+ escape.fg = self._color_index(ndef['color'])
+ if ndef['bgansicolor']:
+ escape.bg = self._color_index(ndef['bgansicolor'])
+ elif ndef['bgcolor']:
+ escape.bg = self._color_index(ndef['bgcolor'])
+ if self.usebold and ndef['bold']:
+ escape.bold = True
+ if self.useunderline and ndef['underline']:
+ escape.underline = True
+ if self.useitalic and ndef['italic']:
+ escape.italic = True
+ self.style_string[str(ttype)] = (escape.color_string(),
+ escape.reset_string())
+
+ def _write_lineno(self, outfile):
+ self._lineno += 1
+ outfile.write("%s%04d: " % (self._lineno != 1 and '\n' or '', self._lineno))
+
+ def format(self, tokensource, outfile):
+ return Formatter.format(self, tokensource, outfile)
+
+ def format_unencoded(self, tokensource, outfile):
+ if self.linenos:
+ self._write_lineno(outfile)
+
+ for ttype, value in tokensource:
+ not_found = True
+ while ttype and not_found:
+ try:
+ # outfile.write( "<" + str(ttype) + ">" )
+ on, off = self.style_string[str(ttype)]
+
+ # Like TerminalFormatter, add "reset colors" escape sequence
+ # on newline.
+ spl = value.split('\n')
+ for line in spl[:-1]:
+ if line:
+ outfile.write(on + line + off)
+ if self.linenos:
+ self._write_lineno(outfile)
+ else:
+ outfile.write('\n')
+
+ if spl[-1]:
+ outfile.write(on + spl[-1] + off)
+
+ not_found = False
+ # outfile.write( '#' + str(ttype) + '#' )
+
+ except KeyError:
+ # ottype = ttype
+ ttype = ttype.parent
+ # outfile.write( '!' + str(ottype) + '->' + str(ttype) + '!' )
+
+ if not_found:
+ outfile.write(value)
+
+ if self.linenos:
+ outfile.write("\n")
+
+
+
+class TerminalTrueColorFormatter(Terminal256Formatter):
+ r"""
+ Format tokens with ANSI color sequences, for output in a true-color
+ terminal or console. Like in `TerminalFormatter` color sequences
+ are terminated at newlines, so that paging the output works correctly.
+
+ .. versionadded:: 2.1
+
+ Options accepted:
+
+ `style`
+ The style to use, can be a string or a Style subclass (default:
+ ``'default'``).
+ """
+ name = 'TerminalTrueColor'
+ aliases = ['terminal16m', 'console16m', '16m']
+ filenames = []
+
+ def _build_color_table(self):
+ pass
+
+ def _color_tuple(self, color):
+ try:
+ rgb = int(str(color), 16)
+ except ValueError:
+ return None
+ r = (rgb >> 16) & 0xff
+ g = (rgb >> 8) & 0xff
+ b = rgb & 0xff
+ return (r, g, b)
+
+ def _setup_styles(self):
+ for ttype, ndef in self.style:
+ escape = EscapeSequence()
+ if ndef['color']:
+ escape.fg = self._color_tuple(ndef['color'])
+ if ndef['bgcolor']:
+ escape.bg = self._color_tuple(ndef['bgcolor'])
+ if self.usebold and ndef['bold']:
+ escape.bold = True
+ if self.useunderline and ndef['underline']:
+ escape.underline = True
+ if self.useitalic and ndef['italic']:
+ escape.italic = True
+ self.style_string[str(ttype)] = (escape.true_color_string(),
+ escape.reset_string())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexer.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexer.py
new file mode 100644
index 000000000..1348be587
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexer.py
@@ -0,0 +1,963 @@
+"""
+ pygments.lexer
+ ~~~~~~~~~~~~~~
+
+ Base lexer classes.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import re
+import sys
+import time
+
+from pip._vendor.pygments.filter import apply_filters, Filter
+from pip._vendor.pygments.filters import get_filter_by_name
+from pip._vendor.pygments.token import Error, Text, Other, Whitespace, _TokenType
+from pip._vendor.pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
+ make_analysator, Future, guess_decode
+from pip._vendor.pygments.regexopt import regex_opt
+
+__all__ = ['Lexer', 'RegexLexer', 'ExtendedRegexLexer', 'DelegatingLexer',
+ 'LexerContext', 'include', 'inherit', 'bygroups', 'using', 'this',
+ 'default', 'words', 'line_re']
+
+line_re = re.compile('.*?\n')
+
+_encoding_map = [(b'\xef\xbb\xbf', 'utf-8'),
+ (b'\xff\xfe\0\0', 'utf-32'),
+ (b'\0\0\xfe\xff', 'utf-32be'),
+ (b'\xff\xfe', 'utf-16'),
+ (b'\xfe\xff', 'utf-16be')]
+
+_default_analyse = staticmethod(lambda x: 0.0)
+
+
+class LexerMeta(type):
+ """
+ This metaclass automagically converts ``analyse_text`` methods into
+ static methods which always return float values.
+ """
+
+ def __new__(mcs, name, bases, d):
+ if 'analyse_text' in d:
+ d['analyse_text'] = make_analysator(d['analyse_text'])
+ return type.__new__(mcs, name, bases, d)
+
+
+class Lexer(metaclass=LexerMeta):
+ """
+ Lexer for a specific language.
+
+ See also :doc:`lexerdevelopment`, a high-level guide to writing
+ lexers.
+
+ Lexer classes have attributes used for choosing the most appropriate
+ lexer based on various criteria.
+
+ .. autoattribute:: name
+ :no-value:
+ .. autoattribute:: aliases
+ :no-value:
+ .. autoattribute:: filenames
+ :no-value:
+ .. autoattribute:: alias_filenames
+ .. autoattribute:: mimetypes
+ :no-value:
+ .. autoattribute:: priority
+
+ Lexers included in Pygments should have two additional attributes:
+
+ .. autoattribute:: url
+ :no-value:
+ .. autoattribute:: version_added
+ :no-value:
+
+ Lexers included in Pygments may have additional attributes:
+
+ .. autoattribute:: _example
+ :no-value:
+
+ You can pass options to the constructor. The basic options recognized
+ by all lexers and processed by the base `Lexer` class are:
+
+ ``stripnl``
+ Strip leading and trailing newlines from the input (default: True).
+ ``stripall``
+ Strip all leading and trailing whitespace from the input
+ (default: False).
+ ``ensurenl``
+ Make sure that the input ends with a newline (default: True). This
+ is required for some lexers that consume input linewise.
+
+ .. versionadded:: 1.3
+
+ ``tabsize``
+ If given and greater than 0, expand tabs in the input (default: 0).
+ ``encoding``
+ If given, must be an encoding name. This encoding will be used to
+ convert the input string to Unicode, if it is not already a Unicode
+ string (default: ``'guess'``, which uses a simple UTF-8 / Locale /
+ Latin1 detection. Can also be ``'chardet'`` to use the chardet
+ library, if it is installed.
+ ``inencoding``
+ Overrides the ``encoding`` if given.
+ """
+
+ #: Full name of the lexer, in human-readable form
+ name = None
+
+ #: A list of short, unique identifiers that can be used to look
+ #: up the lexer from a list, e.g., using `get_lexer_by_name()`.
+ aliases = []
+
+ #: A list of `fnmatch` patterns that match filenames which contain
+ #: content for this lexer. The patterns in this list should be unique among
+ #: all lexers.
+ filenames = []
+
+ #: A list of `fnmatch` patterns that match filenames which may or may not
+ #: contain content for this lexer. This list is used by the
+ #: :func:`.guess_lexer_for_filename()` function, to determine which lexers
+ #: are then included in guessing the correct one. That means that
+ #: e.g. every lexer for HTML and a template language should include
+ #: ``\*.html`` in this list.
+ alias_filenames = []
+
+ #: A list of MIME types for content that can be lexed with this lexer.
+ mimetypes = []
+
+ #: Priority, should multiple lexers match and no content is provided
+ priority = 0
+
+ #: URL of the language specification/definition. Used in the Pygments
+ #: documentation. Set to an empty string to disable.
+ url = None
+
+ #: Version of Pygments in which the lexer was added.
+ version_added = None
+
+ #: Example file name. Relative to the ``tests/examplefiles`` directory.
+ #: This is used by the documentation generator to show an example.
+ _example = None
+
+ def __init__(self, **options):
+ """
+ This constructor takes arbitrary options as keyword arguments.
+ Every subclass must first process its own options and then call
+ the `Lexer` constructor, since it processes the basic
+ options like `stripnl`.
+
+ An example looks like this:
+
+ .. sourcecode:: python
+
+ def __init__(self, **options):
+ self.compress = options.get('compress', '')
+ Lexer.__init__(self, **options)
+
+ As these options must all be specifiable as strings (due to the
+ command line usage), there are various utility functions
+ available to help with that, see `Utilities`_.
+ """
+ self.options = options
+ self.stripnl = get_bool_opt(options, 'stripnl', True)
+ self.stripall = get_bool_opt(options, 'stripall', False)
+ self.ensurenl = get_bool_opt(options, 'ensurenl', True)
+ self.tabsize = get_int_opt(options, 'tabsize', 0)
+ self.encoding = options.get('encoding', 'guess')
+ self.encoding = options.get('inencoding') or self.encoding
+ self.filters = []
+ for filter_ in get_list_opt(options, 'filters', ()):
+ self.add_filter(filter_)
+
+ def __repr__(self):
+ if self.options:
+ return f'<pygments.lexers.{self.__class__.__name__} with {self.options!r}>'
+ else:
+ return f'<pygments.lexers.{self.__class__.__name__}>'
+
+ def add_filter(self, filter_, **options):
+ """
+ Add a new stream filter to this lexer.
+ """
+ if not isinstance(filter_, Filter):
+ filter_ = get_filter_by_name(filter_, **options)
+ self.filters.append(filter_)
+
+ def analyse_text(text):
+ """
+ A static method which is called for lexer guessing.
+
+ It should analyse the text and return a float in the range
+ from ``0.0`` to ``1.0``. If it returns ``0.0``, the lexer
+ will not be selected as the most probable one, if it returns
+ ``1.0``, it will be selected immediately. This is used by
+ `guess_lexer`.
+
+ The `LexerMeta` metaclass automatically wraps this function so
+ that it works like a static method (no ``self`` or ``cls``
+ parameter) and the return value is automatically converted to
+ `float`. If the return value is an object that is boolean `False`
+ it's the same as if the return values was ``0.0``.
+ """
+
+ def _preprocess_lexer_input(self, text):
+ """Apply preprocessing such as decoding the input, removing BOM and normalizing newlines."""
+
+ if not isinstance(text, str):
+ if self.encoding == 'guess':
+ text, _ = guess_decode(text)
+ elif self.encoding == 'chardet':
+ try:
+ # pip vendoring note: this code is not reachable by pip,
+ # removed import of chardet to make it clear.
+ raise ImportError('chardet is not vendored by pip')
+ except ImportError as e:
+ raise ImportError('To enable chardet encoding guessing, '
+ 'please install the chardet library '
+ 'from http://chardet.feedparser.org/') from e
+ # check for BOM first
+ decoded = None
+ for bom, encoding in _encoding_map:
+ if text.startswith(bom):
+ decoded = text[len(bom):].decode(encoding, 'replace')
+ break
+ # no BOM found, so use chardet
+ if decoded is None:
+ enc = chardet.detect(text[:1024]) # Guess using first 1KB
+ decoded = text.decode(enc.get('encoding') or 'utf-8',
+ 'replace')
+ text = decoded
+ else:
+ text = text.decode(self.encoding)
+ if text.startswith('\ufeff'):
+ text = text[len('\ufeff'):]
+ else:
+ if text.startswith('\ufeff'):
+ text = text[len('\ufeff'):]
+
+ # text now *is* a unicode string
+ text = text.replace('\r\n', '\n')
+ text = text.replace('\r', '\n')
+ if self.stripall:
+ text = text.strip()
+ elif self.stripnl:
+ text = text.strip('\n')
+ if self.tabsize > 0:
+ text = text.expandtabs(self.tabsize)
+ if self.ensurenl and not text.endswith('\n'):
+ text += '\n'
+
+ return text
+
+ def get_tokens(self, text, unfiltered=False):
+ """
+ This method is the basic interface of a lexer. It is called by
+ the `highlight()` function. It must process the text and return an
+ iterable of ``(tokentype, value)`` pairs from `text`.
+
+ Normally, you don't need to override this method. The default
+ implementation processes the options recognized by all lexers
+ (`stripnl`, `stripall` and so on), and then yields all tokens
+ from `get_tokens_unprocessed()`, with the ``index`` dropped.
+
+ If `unfiltered` is set to `True`, the filtering mechanism is
+ bypassed even if filters are defined.
+ """
+ text = self._preprocess_lexer_input(text)
+
+ def streamer():
+ for _, t, v in self.get_tokens_unprocessed(text):
+ yield t, v
+ stream = streamer()
+ if not unfiltered:
+ stream = apply_filters(stream, self.filters, self)
+ return stream
+
+ def get_tokens_unprocessed(self, text):
+ """
+ This method should process the text and return an iterable of
+ ``(index, tokentype, value)`` tuples where ``index`` is the starting
+ position of the token within the input text.
+
+ It must be overridden by subclasses. It is recommended to
+ implement it as a generator to maximize effectiveness.
+ """
+ raise NotImplementedError
+
+
+class DelegatingLexer(Lexer):
+ """
+ This lexer takes two lexer as arguments. A root lexer and
+ a language lexer. First everything is scanned using the language
+ lexer, afterwards all ``Other`` tokens are lexed using the root
+ lexer.
+
+ The lexers from the ``template`` lexer package use this base lexer.
+ """
+
+ def __init__(self, _root_lexer, _language_lexer, _needle=Other, **options):
+ self.root_lexer = _root_lexer(**options)
+ self.language_lexer = _language_lexer(**options)
+ self.needle = _needle
+ Lexer.__init__(self, **options)
+
+ def get_tokens_unprocessed(self, text):
+ buffered = ''
+ insertions = []
+ lng_buffer = []
+ for i, t, v in self.language_lexer.get_tokens_unprocessed(text):
+ if t is self.needle:
+ if lng_buffer:
+ insertions.append((len(buffered), lng_buffer))
+ lng_buffer = []
+ buffered += v
+ else:
+ lng_buffer.append((i, t, v))
+ if lng_buffer:
+ insertions.append((len(buffered), lng_buffer))
+ return do_insertions(insertions,
+ self.root_lexer.get_tokens_unprocessed(buffered))
+
+
+# ------------------------------------------------------------------------------
+# RegexLexer and ExtendedRegexLexer
+#
+
+
+class include(str): # pylint: disable=invalid-name
+ """
+ Indicates that a state should include rules from another state.
+ """
+ pass
+
+
+class _inherit:
+ """
+ Indicates the a state should inherit from its superclass.
+ """
+ def __repr__(self):
+ return 'inherit'
+
+inherit = _inherit() # pylint: disable=invalid-name
+
+
+class combined(tuple): # pylint: disable=invalid-name
+ """
+ Indicates a state combined from multiple states.
+ """
+
+ def __new__(cls, *args):
+ return tuple.__new__(cls, args)
+
+ def __init__(self, *args):
+ # tuple.__init__ doesn't do anything
+ pass
+
+
+class _PseudoMatch:
+ """
+ A pseudo match object constructed from a string.
+ """
+
+ def __init__(self, start, text):
+ self._text = text
+ self._start = start
+
+ def start(self, arg=None):
+ return self._start
+
+ def end(self, arg=None):
+ return self._start + len(self._text)
+
+ def group(self, arg=None):
+ if arg:
+ raise IndexError('No such group')
+ return self._text
+
+ def groups(self):
+ return (self._text,)
+
+ def groupdict(self):
+ return {}
+
+
+def bygroups(*args):
+ """
+ Callback that yields multiple actions for each group in the match.
+ """
+ def callback(lexer, match, ctx=None):
+ for i, action in enumerate(args):
+ if action is None:
+ continue
+ elif type(action) is _TokenType:
+ data = match.group(i + 1)
+ if data:
+ yield match.start(i + 1), action, data
+ else:
+ data = match.group(i + 1)
+ if data is not None:
+ if ctx:
+ ctx.pos = match.start(i + 1)
+ for item in action(lexer,
+ _PseudoMatch(match.start(i + 1), data), ctx):
+ if item:
+ yield item
+ if ctx:
+ ctx.pos = match.end()
+ return callback
+
+
+class _This:
+ """
+ Special singleton used for indicating the caller class.
+ Used by ``using``.
+ """
+
+this = _This()
+
+
+def using(_other, **kwargs):
+ """
+ Callback that processes the match with a different lexer.
+
+ The keyword arguments are forwarded to the lexer, except `state` which
+ is handled separately.
+
+ `state` specifies the state that the new lexer will start in, and can
+ be an enumerable such as ('root', 'inline', 'string') or a simple
+ string which is assumed to be on top of the root state.
+
+ Note: For that to work, `_other` must not be an `ExtendedRegexLexer`.
+ """
+ gt_kwargs = {}
+ if 'state' in kwargs:
+ s = kwargs.pop('state')
+ if isinstance(s, (list, tuple)):
+ gt_kwargs['stack'] = s
+ else:
+ gt_kwargs['stack'] = ('root', s)
+
+ if _other is this:
+ def callback(lexer, match, ctx=None):
+ # if keyword arguments are given the callback
+ # function has to create a new lexer instance
+ if kwargs:
+ # XXX: cache that somehow
+ kwargs.update(lexer.options)
+ lx = lexer.__class__(**kwargs)
+ else:
+ lx = lexer
+ s = match.start()
+ for i, t, v in lx.get_tokens_unprocessed(match.group(), **gt_kwargs):
+ yield i + s, t, v
+ if ctx:
+ ctx.pos = match.end()
+ else:
+ def callback(lexer, match, ctx=None):
+ # XXX: cache that somehow
+ kwargs.update(lexer.options)
+ lx = _other(**kwargs)
+
+ s = match.start()
+ for i, t, v in lx.get_tokens_unprocessed(match.group(), **gt_kwargs):
+ yield i + s, t, v
+ if ctx:
+ ctx.pos = match.end()
+ return callback
+
+
+class default:
+ """
+ Indicates a state or state action (e.g. #pop) to apply.
+ For example default('#pop') is equivalent to ('', Token, '#pop')
+ Note that state tuples may be used as well.
+
+ .. versionadded:: 2.0
+ """
+ def __init__(self, state):
+ self.state = state
+
+
+class words(Future):
+ """
+ Indicates a list of literal words that is transformed into an optimized
+ regex that matches any of the words.
+
+ .. versionadded:: 2.0
+ """
+ def __init__(self, words, prefix='', suffix=''):
+ self.words = words
+ self.prefix = prefix
+ self.suffix = suffix
+
+ def get(self):
+ return regex_opt(self.words, prefix=self.prefix, suffix=self.suffix)
+
+
+class RegexLexerMeta(LexerMeta):
+ """
+ Metaclass for RegexLexer, creates the self._tokens attribute from
+ self.tokens on the first instantiation.
+ """
+
+ def _process_regex(cls, regex, rflags, state):
+ """Preprocess the regular expression component of a token definition."""
+ if isinstance(regex, Future):
+ regex = regex.get()
+ return re.compile(regex, rflags).match
+
+ def _process_token(cls, token):
+ """Preprocess the token component of a token definition."""
+ assert type(token) is _TokenType or callable(token), \
+ f'token type must be simple type or callable, not {token!r}'
+ return token
+
+ def _process_new_state(cls, new_state, unprocessed, processed):
+ """Preprocess the state transition action of a token definition."""
+ if isinstance(new_state, str):
+ # an existing state
+ if new_state == '#pop':
+ return -1
+ elif new_state in unprocessed:
+ return (new_state,)
+ elif new_state == '#push':
+ return new_state
+ elif new_state[:5] == '#pop:':
+ return -int(new_state[5:])
+ else:
+ assert False, f'unknown new state {new_state!r}'
+ elif isinstance(new_state, combined):
+ # combine a new state from existing ones
+ tmp_state = '_tmp_%d' % cls._tmpname
+ cls._tmpname += 1
+ itokens = []
+ for istate in new_state:
+ assert istate != new_state, f'circular state ref {istate!r}'
+ itokens.extend(cls._process_state(unprocessed,
+ processed, istate))
+ processed[tmp_state] = itokens
+ return (tmp_state,)
+ elif isinstance(new_state, tuple):
+ # push more than one state
+ for istate in new_state:
+ assert (istate in unprocessed or
+ istate in ('#pop', '#push')), \
+ 'unknown new state ' + istate
+ return new_state
+ else:
+ assert False, f'unknown new state def {new_state!r}'
+
+ def _process_state(cls, unprocessed, processed, state):
+ """Preprocess a single state definition."""
+ assert isinstance(state, str), f"wrong state name {state!r}"
+ assert state[0] != '#', f"invalid state name {state!r}"
+ if state in processed:
+ return processed[state]
+ tokens = processed[state] = []
+ rflags = cls.flags
+ for tdef in unprocessed[state]:
+ if isinstance(tdef, include):
+ # it's a state reference
+ assert tdef != state, f"circular state reference {state!r}"
+ tokens.extend(cls._process_state(unprocessed, processed,
+ str(tdef)))
+ continue
+ if isinstance(tdef, _inherit):
+ # should be processed already, but may not in the case of:
+ # 1. the state has no counterpart in any parent
+ # 2. the state includes more than one 'inherit'
+ continue
+ if isinstance(tdef, default):
+ new_state = cls._process_new_state(tdef.state, unprocessed, processed)
+ tokens.append((re.compile('').match, None, new_state))
+ continue
+
+ assert type(tdef) is tuple, f"wrong rule def {tdef!r}"
+
+ try:
+ rex = cls._process_regex(tdef[0], rflags, state)
+ except Exception as err:
+ raise ValueError(f"uncompilable regex {tdef[0]!r} in state {state!r} of {cls!r}: {err}") from err
+
+ token = cls._process_token(tdef[1])
+
+ if len(tdef) == 2:
+ new_state = None
+ else:
+ new_state = cls._process_new_state(tdef[2],
+ unprocessed, processed)
+
+ tokens.append((rex, token, new_state))
+ return tokens
+
+ def process_tokendef(cls, name, tokendefs=None):
+ """Preprocess a dictionary of token definitions."""
+ processed = cls._all_tokens[name] = {}
+ tokendefs = tokendefs or cls.tokens[name]
+ for state in list(tokendefs):
+ cls._process_state(tokendefs, processed, state)
+ return processed
+
+ def get_tokendefs(cls):
+ """
+ Merge tokens from superclasses in MRO order, returning a single tokendef
+ dictionary.
+
+ Any state that is not defined by a subclass will be inherited
+ automatically. States that *are* defined by subclasses will, by
+ default, override that state in the superclass. If a subclass wishes to
+ inherit definitions from a superclass, it can use the special value
+ "inherit", which will cause the superclass' state definition to be
+ included at that point in the state.
+ """
+ tokens = {}
+ inheritable = {}
+ for c in cls.__mro__:
+ toks = c.__dict__.get('tokens', {})
+
+ for state, items in toks.items():
+ curitems = tokens.get(state)
+ if curitems is None:
+ # N.b. because this is assigned by reference, sufficiently
+ # deep hierarchies are processed incrementally (e.g. for
+ # A(B), B(C), C(RegexLexer), B will be premodified so X(B)
+ # will not see any inherits in B).
+ tokens[state] = items
+ try:
+ inherit_ndx = items.index(inherit)
+ except ValueError:
+ continue
+ inheritable[state] = inherit_ndx
+ continue
+
+ inherit_ndx = inheritable.pop(state, None)
+ if inherit_ndx is None:
+ continue
+
+ # Replace the "inherit" value with the items
+ curitems[inherit_ndx:inherit_ndx+1] = items
+ try:
+ # N.b. this is the index in items (that is, the superclass
+ # copy), so offset required when storing below.
+ new_inh_ndx = items.index(inherit)
+ except ValueError:
+ pass
+ else:
+ inheritable[state] = inherit_ndx + new_inh_ndx
+
+ return tokens
+
+ def __call__(cls, *args, **kwds):
+ """Instantiate cls after preprocessing its token definitions."""
+ if '_tokens' not in cls.__dict__:
+ cls._all_tokens = {}
+ cls._tmpname = 0
+ if hasattr(cls, 'token_variants') and cls.token_variants:
+ # don't process yet
+ pass
+ else:
+ cls._tokens = cls.process_tokendef('', cls.get_tokendefs())
+
+ return type.__call__(cls, *args, **kwds)
+
+
+class RegexLexer(Lexer, metaclass=RegexLexerMeta):
+ """
+ Base for simple stateful regular expression-based lexers.
+ Simplifies the lexing process so that you need only
+ provide a list of states and regular expressions.
+ """
+
+ #: Flags for compiling the regular expressions.
+ #: Defaults to MULTILINE.
+ flags = re.MULTILINE
+
+ #: At all time there is a stack of states. Initially, the stack contains
+ #: a single state 'root'. The top of the stack is called "the current state".
+ #:
+ #: Dict of ``{'state': [(regex, tokentype, new_state), ...], ...}``
+ #:
+ #: ``new_state`` can be omitted to signify no state transition.
+ #: If ``new_state`` is a string, it is pushed on the stack. This ensure
+ #: the new current state is ``new_state``.
+ #: If ``new_state`` is a tuple of strings, all of those strings are pushed
+ #: on the stack and the current state will be the last element of the list.
+ #: ``new_state`` can also be ``combined('state1', 'state2', ...)``
+ #: to signify a new, anonymous state combined from the rules of two
+ #: or more existing ones.
+ #: Furthermore, it can be '#pop' to signify going back one step in
+ #: the state stack, or '#push' to push the current state on the stack
+ #: again. Note that if you push while in a combined state, the combined
+ #: state itself is pushed, and not only the state in which the rule is
+ #: defined.
+ #:
+ #: The tuple can also be replaced with ``include('state')``, in which
+ #: case the rules from the state named by the string are included in the
+ #: current one.
+ tokens = {}
+
+ def get_tokens_unprocessed(self, text, stack=('root',)):
+ """
+ Split ``text`` into (tokentype, text) pairs.
+
+ ``stack`` is the initial stack (default: ``['root']``)
+ """
+ pos = 0
+ tokendefs = self._tokens
+ statestack = list(stack)
+ statetokens = tokendefs[statestack[-1]]
+ while 1:
+ for rexmatch, action, new_state in statetokens:
+ m = rexmatch(text, pos)
+ if m:
+ if action is not None:
+ if type(action) is _TokenType:
+ yield pos, action, m.group()
+ else:
+ yield from action(self, m)
+ pos = m.end()
+ if new_state is not None:
+ # state transition
+ if isinstance(new_state, tuple):
+ for state in new_state:
+ if state == '#pop':
+ if len(statestack) > 1:
+ statestack.pop()
+ elif state == '#push':
+ statestack.append(statestack[-1])
+ else:
+ statestack.append(state)
+ elif isinstance(new_state, int):
+ # pop, but keep at least one state on the stack
+ # (random code leading to unexpected pops should
+ # not allow exceptions)
+ if abs(new_state) >= len(statestack):
+ del statestack[1:]
+ else:
+ del statestack[new_state:]
+ elif new_state == '#push':
+ statestack.append(statestack[-1])
+ else:
+ assert False, f"wrong state def: {new_state!r}"
+ statetokens = tokendefs[statestack[-1]]
+ break
+ else:
+ # We are here only if all state tokens have been considered
+ # and there was not a match on any of them.
+ try:
+ if text[pos] == '\n':
+ # at EOL, reset state to "root"
+ statestack = ['root']
+ statetokens = tokendefs['root']
+ yield pos, Whitespace, '\n'
+ pos += 1
+ continue
+ yield pos, Error, text[pos]
+ pos += 1
+ except IndexError:
+ break
+
+
+class LexerContext:
+ """
+ A helper object that holds lexer position data.
+ """
+
+ def __init__(self, text, pos, stack=None, end=None):
+ self.text = text
+ self.pos = pos
+ self.end = end or len(text) # end=0 not supported ;-)
+ self.stack = stack or ['root']
+
+ def __repr__(self):
+ return f'LexerContext({self.text!r}, {self.pos!r}, {self.stack!r})'
+
+
+class ExtendedRegexLexer(RegexLexer):
+ """
+ A RegexLexer that uses a context object to store its state.
+ """
+
+ def get_tokens_unprocessed(self, text=None, context=None):
+ """
+ Split ``text`` into (tokentype, text) pairs.
+ If ``context`` is given, use this lexer context instead.
+ """
+ tokendefs = self._tokens
+ if not context:
+ ctx = LexerContext(text, 0)
+ statetokens = tokendefs['root']
+ else:
+ ctx = context
+ statetokens = tokendefs[ctx.stack[-1]]
+ text = ctx.text
+ while 1:
+ for rexmatch, action, new_state in statetokens:
+ m = rexmatch(text, ctx.pos, ctx.end)
+ if m:
+ if action is not None:
+ if type(action) is _TokenType:
+ yield ctx.pos, action, m.group()
+ ctx.pos = m.end()
+ else:
+ yield from action(self, m, ctx)
+ if not new_state:
+ # altered the state stack?
+ statetokens = tokendefs[ctx.stack[-1]]
+ # CAUTION: callback must set ctx.pos!
+ if new_state is not None:
+ # state transition
+ if isinstance(new_state, tuple):
+ for state in new_state:
+ if state == '#pop':
+ if len(ctx.stack) > 1:
+ ctx.stack.pop()
+ elif state == '#push':
+ ctx.stack.append(ctx.stack[-1])
+ else:
+ ctx.stack.append(state)
+ elif isinstance(new_state, int):
+ # see RegexLexer for why this check is made
+ if abs(new_state) >= len(ctx.stack):
+ del ctx.stack[1:]
+ else:
+ del ctx.stack[new_state:]
+ elif new_state == '#push':
+ ctx.stack.append(ctx.stack[-1])
+ else:
+ assert False, f"wrong state def: {new_state!r}"
+ statetokens = tokendefs[ctx.stack[-1]]
+ break
+ else:
+ try:
+ if ctx.pos >= ctx.end:
+ break
+ if text[ctx.pos] == '\n':
+ # at EOL, reset state to "root"
+ ctx.stack = ['root']
+ statetokens = tokendefs['root']
+ yield ctx.pos, Text, '\n'
+ ctx.pos += 1
+ continue
+ yield ctx.pos, Error, text[ctx.pos]
+ ctx.pos += 1
+ except IndexError:
+ break
+
+
+def do_insertions(insertions, tokens):
+ """
+ Helper for lexers which must combine the results of several
+ sublexers.
+
+ ``insertions`` is a list of ``(index, itokens)`` pairs.
+ Each ``itokens`` iterable should be inserted at position
+ ``index`` into the token stream given by the ``tokens``
+ argument.
+
+ The result is a combined token stream.
+
+ TODO: clean up the code here.
+ """
+ insertions = iter(insertions)
+ try:
+ index, itokens = next(insertions)
+ except StopIteration:
+ # no insertions
+ yield from tokens
+ return
+
+ realpos = None
+ insleft = True
+
+ # iterate over the token stream where we want to insert
+ # the tokens from the insertion list.
+ for i, t, v in tokens:
+ # first iteration. store the position of first item
+ if realpos is None:
+ realpos = i
+ oldi = 0
+ while insleft and i + len(v) >= index:
+ tmpval = v[oldi:index - i]
+ if tmpval:
+ yield realpos, t, tmpval
+ realpos += len(tmpval)
+ for it_index, it_token, it_value in itokens:
+ yield realpos, it_token, it_value
+ realpos += len(it_value)
+ oldi = index - i
+ try:
+ index, itokens = next(insertions)
+ except StopIteration:
+ insleft = False
+ break # not strictly necessary
+ if oldi < len(v):
+ yield realpos, t, v[oldi:]
+ realpos += len(v) - oldi
+
+ # leftover tokens
+ while insleft:
+ # no normal tokens, set realpos to zero
+ realpos = realpos or 0
+ for p, t, v in itokens:
+ yield realpos, t, v
+ realpos += len(v)
+ try:
+ index, itokens = next(insertions)
+ except StopIteration:
+ insleft = False
+ break # not strictly necessary
+
+
+class ProfilingRegexLexerMeta(RegexLexerMeta):
+ """Metaclass for ProfilingRegexLexer, collects regex timing info."""
+
+ def _process_regex(cls, regex, rflags, state):
+ if isinstance(regex, words):
+ rex = regex_opt(regex.words, prefix=regex.prefix,
+ suffix=regex.suffix)
+ else:
+ rex = regex
+ compiled = re.compile(rex, rflags)
+
+ def match_func(text, pos, endpos=sys.maxsize):
+ info = cls._prof_data[-1].setdefault((state, rex), [0, 0.0])
+ t0 = time.time()
+ res = compiled.match(text, pos, endpos)
+ t1 = time.time()
+ info[0] += 1
+ info[1] += t1 - t0
+ return res
+ return match_func
+
+
+class ProfilingRegexLexer(RegexLexer, metaclass=ProfilingRegexLexerMeta):
+ """Drop-in replacement for RegexLexer that does profiling of its regexes."""
+
+ _prof_data = []
+ _prof_sort_index = 4 # defaults to time per call
+
+ def get_tokens_unprocessed(self, text, stack=('root',)):
+ # this needs to be a stack, since using(this) will produce nested calls
+ self.__class__._prof_data.append({})
+ yield from RegexLexer.get_tokens_unprocessed(self, text, stack)
+ rawdata = self.__class__._prof_data.pop()
+ data = sorted(((s, repr(r).strip('u\'').replace('\\\\', '\\')[:65],
+ n, 1000 * t, 1000 * t / n)
+ for ((s, r), (n, t)) in rawdata.items()),
+ key=lambda x: x[self._prof_sort_index],
+ reverse=True)
+ sum_total = sum(x[3] for x in data)
+
+ print()
+ print('Profiling result for %s lexing %d chars in %.3f ms' %
+ (self.__class__.__name__, len(text), sum_total))
+ print('=' * 110)
+ print('%-20s %-64s ncalls tottime percall' % ('state', 'regex'))
+ print('-' * 110)
+ for d in data:
+ print('%-20s %-65s %5d %8.4f %8.4f' % d)
+ print('=' * 110)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/__init__.py
new file mode 100644
index 000000000..ac88645a1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/__init__.py
@@ -0,0 +1,362 @@
+"""
+ pygments.lexers
+ ~~~~~~~~~~~~~~~
+
+ Pygments lexers.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import re
+import sys
+import types
+import fnmatch
+from os.path import basename
+
+from pip._vendor.pygments.lexers._mapping import LEXERS
+from pip._vendor.pygments.modeline import get_filetype_from_buffer
+from pip._vendor.pygments.plugin import find_plugin_lexers
+from pip._vendor.pygments.util import ClassNotFound, guess_decode
+
+COMPAT = {
+ 'Python3Lexer': 'PythonLexer',
+ 'Python3TracebackLexer': 'PythonTracebackLexer',
+ 'LeanLexer': 'Lean3Lexer',
+}
+
+__all__ = ['get_lexer_by_name', 'get_lexer_for_filename', 'find_lexer_class',
+ 'guess_lexer', 'load_lexer_from_file'] + list(LEXERS) + list(COMPAT)
+
+_lexer_cache = {}
+_pattern_cache = {}
+
+
+def _fn_matches(fn, glob):
+ """Return whether the supplied file name fn matches pattern filename."""
+ if glob not in _pattern_cache:
+ pattern = _pattern_cache[glob] = re.compile(fnmatch.translate(glob))
+ return pattern.match(fn)
+ return _pattern_cache[glob].match(fn)
+
+
+def _load_lexers(module_name):
+ """Load a lexer (and all others in the module too)."""
+ mod = __import__(module_name, None, None, ['__all__'])
+ for lexer_name in mod.__all__:
+ cls = getattr(mod, lexer_name)
+ _lexer_cache[cls.name] = cls
+
+
+def get_all_lexers(plugins=True):
+ """Return a generator of tuples in the form ``(name, aliases,
+ filenames, mimetypes)`` of all know lexers.
+
+ If *plugins* is true (the default), plugin lexers supplied by entrypoints
+ are also returned. Otherwise, only builtin ones are considered.
+ """
+ for item in LEXERS.values():
+ yield item[1:]
+ if plugins:
+ for lexer in find_plugin_lexers():
+ yield lexer.name, lexer.aliases, lexer.filenames, lexer.mimetypes
+
+
+def find_lexer_class(name):
+ """
+ Return the `Lexer` subclass that with the *name* attribute as given by
+ the *name* argument.
+ """
+ if name in _lexer_cache:
+ return _lexer_cache[name]
+ # lookup builtin lexers
+ for module_name, lname, aliases, _, _ in LEXERS.values():
+ if name == lname:
+ _load_lexers(module_name)
+ return _lexer_cache[name]
+ # continue with lexers from setuptools entrypoints
+ for cls in find_plugin_lexers():
+ if cls.name == name:
+ return cls
+
+
+def find_lexer_class_by_name(_alias):
+ """
+ Return the `Lexer` subclass that has `alias` in its aliases list, without
+ instantiating it.
+
+ Like `get_lexer_by_name`, but does not instantiate the class.
+
+ Will raise :exc:`pygments.util.ClassNotFound` if no lexer with that alias is
+ found.
+
+ .. versionadded:: 2.2
+ """
+ if not _alias:
+ raise ClassNotFound(f'no lexer for alias {_alias!r} found')
+ # lookup builtin lexers
+ for module_name, name, aliases, _, _ in LEXERS.values():
+ if _alias.lower() in aliases:
+ if name not in _lexer_cache:
+ _load_lexers(module_name)
+ return _lexer_cache[name]
+ # continue with lexers from setuptools entrypoints
+ for cls in find_plugin_lexers():
+ if _alias.lower() in cls.aliases:
+ return cls
+ raise ClassNotFound(f'no lexer for alias {_alias!r} found')
+
+
+def get_lexer_by_name(_alias, **options):
+ """
+ Return an instance of a `Lexer` subclass that has `alias` in its
+ aliases list. The lexer is given the `options` at its
+ instantiation.
+
+ Will raise :exc:`pygments.util.ClassNotFound` if no lexer with that alias is
+ found.
+ """
+ if not _alias:
+ raise ClassNotFound(f'no lexer for alias {_alias!r} found')
+
+ # lookup builtin lexers
+ for module_name, name, aliases, _, _ in LEXERS.values():
+ if _alias.lower() in aliases:
+ if name not in _lexer_cache:
+ _load_lexers(module_name)
+ return _lexer_cache[name](**options)
+ # continue with lexers from setuptools entrypoints
+ for cls in find_plugin_lexers():
+ if _alias.lower() in cls.aliases:
+ return cls(**options)
+ raise ClassNotFound(f'no lexer for alias {_alias!r} found')
+
+
+def load_lexer_from_file(filename, lexername="CustomLexer", **options):
+ """Load a lexer from a file.
+
+ This method expects a file located relative to the current working
+ directory, which contains a Lexer class. By default, it expects the
+ Lexer to be name CustomLexer; you can specify your own class name
+ as the second argument to this function.
+
+ Users should be very careful with the input, because this method
+ is equivalent to running eval on the input file.
+
+ Raises ClassNotFound if there are any problems importing the Lexer.
+
+ .. versionadded:: 2.2
+ """
+ try:
+ # This empty dict will contain the namespace for the exec'd file
+ custom_namespace = {}
+ with open(filename, 'rb') as f:
+ exec(f.read(), custom_namespace)
+ # Retrieve the class `lexername` from that namespace
+ if lexername not in custom_namespace:
+ raise ClassNotFound(f'no valid {lexername} class found in {filename}')
+ lexer_class = custom_namespace[lexername]
+ # And finally instantiate it with the options
+ return lexer_class(**options)
+ except OSError as err:
+ raise ClassNotFound(f'cannot read {filename}: {err}')
+ except ClassNotFound:
+ raise
+ except Exception as err:
+ raise ClassNotFound(f'error when loading custom lexer: {err}')
+
+
+def find_lexer_class_for_filename(_fn, code=None):
+ """Get a lexer for a filename.
+
+ If multiple lexers match the filename pattern, use ``analyse_text()`` to
+ figure out which one is more appropriate.
+
+ Returns None if not found.
+ """
+ matches = []
+ fn = basename(_fn)
+ for modname, name, _, filenames, _ in LEXERS.values():
+ for filename in filenames:
+ if _fn_matches(fn, filename):
+ if name not in _lexer_cache:
+ _load_lexers(modname)
+ matches.append((_lexer_cache[name], filename))
+ for cls in find_plugin_lexers():
+ for filename in cls.filenames:
+ if _fn_matches(fn, filename):
+ matches.append((cls, filename))
+
+ if isinstance(code, bytes):
+ # decode it, since all analyse_text functions expect unicode
+ code = guess_decode(code)
+
+ def get_rating(info):
+ cls, filename = info
+ # explicit patterns get a bonus
+ bonus = '*' not in filename and 0.5 or 0
+ # The class _always_ defines analyse_text because it's included in
+ # the Lexer class. The default implementation returns None which
+ # gets turned into 0.0. Run scripts/detect_missing_analyse_text.py
+ # to find lexers which need it overridden.
+ if code:
+ return cls.analyse_text(code) + bonus, cls.__name__
+ return cls.priority + bonus, cls.__name__
+
+ if matches:
+ matches.sort(key=get_rating)
+ # print "Possible lexers, after sort:", matches
+ return matches[-1][0]
+
+
+def get_lexer_for_filename(_fn, code=None, **options):
+ """Get a lexer for a filename.
+
+ Return a `Lexer` subclass instance that has a filename pattern
+ matching `fn`. The lexer is given the `options` at its
+ instantiation.
+
+ Raise :exc:`pygments.util.ClassNotFound` if no lexer for that filename
+ is found.
+
+ If multiple lexers match the filename pattern, use their ``analyse_text()``
+ methods to figure out which one is more appropriate.
+ """
+ res = find_lexer_class_for_filename(_fn, code)
+ if not res:
+ raise ClassNotFound(f'no lexer for filename {_fn!r} found')
+ return res(**options)
+
+
+def get_lexer_for_mimetype(_mime, **options):
+ """
+ Return a `Lexer` subclass instance that has `mime` in its mimetype
+ list. The lexer is given the `options` at its instantiation.
+
+ Will raise :exc:`pygments.util.ClassNotFound` if not lexer for that mimetype
+ is found.
+ """
+ for modname, name, _, _, mimetypes in LEXERS.values():
+ if _mime in mimetypes:
+ if name not in _lexer_cache:
+ _load_lexers(modname)
+ return _lexer_cache[name](**options)
+ for cls in find_plugin_lexers():
+ if _mime in cls.mimetypes:
+ return cls(**options)
+ raise ClassNotFound(f'no lexer for mimetype {_mime!r} found')
+
+
+def _iter_lexerclasses(plugins=True):
+ """Return an iterator over all lexer classes."""
+ for key in sorted(LEXERS):
+ module_name, name = LEXERS[key][:2]
+ if name not in _lexer_cache:
+ _load_lexers(module_name)
+ yield _lexer_cache[name]
+ if plugins:
+ yield from find_plugin_lexers()
+
+
+def guess_lexer_for_filename(_fn, _text, **options):
+ """
+ As :func:`guess_lexer()`, but only lexers which have a pattern in `filenames`
+ or `alias_filenames` that matches `filename` are taken into consideration.
+
+ :exc:`pygments.util.ClassNotFound` is raised if no lexer thinks it can
+ handle the content.
+ """
+ fn = basename(_fn)
+ primary = {}
+ matching_lexers = set()
+ for lexer in _iter_lexerclasses():
+ for filename in lexer.filenames:
+ if _fn_matches(fn, filename):
+ matching_lexers.add(lexer)
+ primary[lexer] = True
+ for filename in lexer.alias_filenames:
+ if _fn_matches(fn, filename):
+ matching_lexers.add(lexer)
+ primary[lexer] = False
+ if not matching_lexers:
+ raise ClassNotFound(f'no lexer for filename {fn!r} found')
+ if len(matching_lexers) == 1:
+ return matching_lexers.pop()(**options)
+ result = []
+ for lexer in matching_lexers:
+ rv = lexer.analyse_text(_text)
+ if rv == 1.0:
+ return lexer(**options)
+ result.append((rv, lexer))
+
+ def type_sort(t):
+ # sort by:
+ # - analyse score
+ # - is primary filename pattern?
+ # - priority
+ # - last resort: class name
+ return (t[0], primary[t[1]], t[1].priority, t[1].__name__)
+ result.sort(key=type_sort)
+
+ return result[-1][1](**options)
+
+
+def guess_lexer(_text, **options):
+ """
+ Return a `Lexer` subclass instance that's guessed from the text in
+ `text`. For that, the :meth:`.analyse_text()` method of every known lexer
+ class is called with the text as argument, and the lexer which returned the
+ highest value will be instantiated and returned.
+
+ :exc:`pygments.util.ClassNotFound` is raised if no lexer thinks it can
+ handle the content.
+ """
+
+ if not isinstance(_text, str):
+ inencoding = options.get('inencoding', options.get('encoding'))
+ if inencoding:
+ _text = _text.decode(inencoding or 'utf8')
+ else:
+ _text, _ = guess_decode(_text)
+
+ # try to get a vim modeline first
+ ft = get_filetype_from_buffer(_text)
+
+ if ft is not None:
+ try:
+ return get_lexer_by_name(ft, **options)
+ except ClassNotFound:
+ pass
+
+ best_lexer = [0.0, None]
+ for lexer in _iter_lexerclasses():
+ rv = lexer.analyse_text(_text)
+ if rv == 1.0:
+ return lexer(**options)
+ if rv > best_lexer[0]:
+ best_lexer[:] = (rv, lexer)
+ if not best_lexer[0] or best_lexer[1] is None:
+ raise ClassNotFound('no lexer matching the text found')
+ return best_lexer[1](**options)
+
+
+class _automodule(types.ModuleType):
+ """Automatically import lexers."""
+
+ def __getattr__(self, name):
+ info = LEXERS.get(name)
+ if info:
+ _load_lexers(info[0])
+ cls = _lexer_cache[info[1]]
+ setattr(self, name, cls)
+ return cls
+ if name in COMPAT:
+ return getattr(self, COMPAT[name])
+ raise AttributeError(name)
+
+
+oldmod = sys.modules[__name__]
+newmod = _automodule(__name__)
+newmod.__dict__.update(oldmod.__dict__)
+sys.modules[__name__] = newmod
+del newmod.newmod, newmod.oldmod, newmod.sys, newmod.types
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/_mapping.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/_mapping.py
new file mode 100644
index 000000000..f3e5c460d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/_mapping.py
@@ -0,0 +1,589 @@
+# Automatically generated by scripts/gen_mapfiles.py.
+# DO NOT EDIT BY HAND; run `tox -e mapfiles` instead.
+
+LEXERS = {
+ 'ABAPLexer': ('pip._vendor.pygments.lexers.business', 'ABAP', ('abap',), ('*.abap', '*.ABAP'), ('text/x-abap',)),
+ 'AMDGPULexer': ('pip._vendor.pygments.lexers.amdgpu', 'AMDGPU', ('amdgpu',), ('*.isa',), ()),
+ 'APLLexer': ('pip._vendor.pygments.lexers.apl', 'APL', ('apl',), ('*.apl', '*.aplf', '*.aplo', '*.apln', '*.aplc', '*.apli', '*.dyalog'), ()),
+ 'AbnfLexer': ('pip._vendor.pygments.lexers.grammar_notation', 'ABNF', ('abnf',), ('*.abnf',), ('text/x-abnf',)),
+ 'ActionScript3Lexer': ('pip._vendor.pygments.lexers.actionscript', 'ActionScript 3', ('actionscript3', 'as3'), ('*.as',), ('application/x-actionscript3', 'text/x-actionscript3', 'text/actionscript3')),
+ 'ActionScriptLexer': ('pip._vendor.pygments.lexers.actionscript', 'ActionScript', ('actionscript', 'as'), ('*.as',), ('application/x-actionscript', 'text/x-actionscript', 'text/actionscript')),
+ 'AdaLexer': ('pip._vendor.pygments.lexers.ada', 'Ada', ('ada', 'ada95', 'ada2005'), ('*.adb', '*.ads', '*.ada'), ('text/x-ada',)),
+ 'AdlLexer': ('pip._vendor.pygments.lexers.archetype', 'ADL', ('adl',), ('*.adl', '*.adls', '*.adlf', '*.adlx'), ()),
+ 'AgdaLexer': ('pip._vendor.pygments.lexers.haskell', 'Agda', ('agda',), ('*.agda',), ('text/x-agda',)),
+ 'AheuiLexer': ('pip._vendor.pygments.lexers.esoteric', 'Aheui', ('aheui',), ('*.aheui',), ()),
+ 'AlloyLexer': ('pip._vendor.pygments.lexers.dsls', 'Alloy', ('alloy',), ('*.als',), ('text/x-alloy',)),
+ 'AmbientTalkLexer': ('pip._vendor.pygments.lexers.ambient', 'AmbientTalk', ('ambienttalk', 'ambienttalk/2', 'at'), ('*.at',), ('text/x-ambienttalk',)),
+ 'AmplLexer': ('pip._vendor.pygments.lexers.ampl', 'Ampl', ('ampl',), ('*.run',), ()),
+ 'Angular2HtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML + Angular2', ('html+ng2',), ('*.ng2',), ()),
+ 'Angular2Lexer': ('pip._vendor.pygments.lexers.templates', 'Angular2', ('ng2',), (), ()),
+ 'AntlrActionScriptLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With ActionScript Target', ('antlr-actionscript', 'antlr-as'), ('*.G', '*.g'), ()),
+ 'AntlrCSharpLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With C# Target', ('antlr-csharp', 'antlr-c#'), ('*.G', '*.g'), ()),
+ 'AntlrCppLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With CPP Target', ('antlr-cpp',), ('*.G', '*.g'), ()),
+ 'AntlrJavaLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With Java Target', ('antlr-java',), ('*.G', '*.g'), ()),
+ 'AntlrLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR', ('antlr',), (), ()),
+ 'AntlrObjectiveCLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With ObjectiveC Target', ('antlr-objc',), ('*.G', '*.g'), ()),
+ 'AntlrPerlLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With Perl Target', ('antlr-perl',), ('*.G', '*.g'), ()),
+ 'AntlrPythonLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With Python Target', ('antlr-python',), ('*.G', '*.g'), ()),
+ 'AntlrRubyLexer': ('pip._vendor.pygments.lexers.parsers', 'ANTLR With Ruby Target', ('antlr-ruby', 'antlr-rb'), ('*.G', '*.g'), ()),
+ 'ApacheConfLexer': ('pip._vendor.pygments.lexers.configs', 'ApacheConf', ('apacheconf', 'aconf', 'apache'), ('.htaccess', 'apache.conf', 'apache2.conf'), ('text/x-apacheconf',)),
+ 'AppleScriptLexer': ('pip._vendor.pygments.lexers.scripting', 'AppleScript', ('applescript',), ('*.applescript',), ()),
+ 'ArduinoLexer': ('pip._vendor.pygments.lexers.c_like', 'Arduino', ('arduino',), ('*.ino',), ('text/x-arduino',)),
+ 'ArrowLexer': ('pip._vendor.pygments.lexers.arrow', 'Arrow', ('arrow',), ('*.arw',), ()),
+ 'ArturoLexer': ('pip._vendor.pygments.lexers.arturo', 'Arturo', ('arturo', 'art'), ('*.art',), ()),
+ 'AscLexer': ('pip._vendor.pygments.lexers.asc', 'ASCII armored', ('asc', 'pem'), ('*.asc', '*.pem', 'id_dsa', 'id_ecdsa', 'id_ecdsa_sk', 'id_ed25519', 'id_ed25519_sk', 'id_rsa'), ('application/pgp-keys', 'application/pgp-encrypted', 'application/pgp-signature', 'application/pem-certificate-chain')),
+ 'Asn1Lexer': ('pip._vendor.pygments.lexers.asn1', 'ASN.1', ('asn1',), ('*.asn1',), ()),
+ 'AspectJLexer': ('pip._vendor.pygments.lexers.jvm', 'AspectJ', ('aspectj',), ('*.aj',), ('text/x-aspectj',)),
+ 'AsymptoteLexer': ('pip._vendor.pygments.lexers.graphics', 'Asymptote', ('asymptote', 'asy'), ('*.asy',), ('text/x-asymptote',)),
+ 'AugeasLexer': ('pip._vendor.pygments.lexers.configs', 'Augeas', ('augeas',), ('*.aug',), ()),
+ 'AutoItLexer': ('pip._vendor.pygments.lexers.automation', 'AutoIt', ('autoit',), ('*.au3',), ('text/x-autoit',)),
+ 'AutohotkeyLexer': ('pip._vendor.pygments.lexers.automation', 'autohotkey', ('autohotkey', 'ahk'), ('*.ahk', '*.ahkl'), ('text/x-autohotkey',)),
+ 'AwkLexer': ('pip._vendor.pygments.lexers.textedit', 'Awk', ('awk', 'gawk', 'mawk', 'nawk'), ('*.awk',), ('application/x-awk',)),
+ 'BBCBasicLexer': ('pip._vendor.pygments.lexers.basic', 'BBC Basic', ('bbcbasic',), ('*.bbc',), ()),
+ 'BBCodeLexer': ('pip._vendor.pygments.lexers.markup', 'BBCode', ('bbcode',), (), ('text/x-bbcode',)),
+ 'BCLexer': ('pip._vendor.pygments.lexers.algebra', 'BC', ('bc',), ('*.bc',), ()),
+ 'BQNLexer': ('pip._vendor.pygments.lexers.bqn', 'BQN', ('bqn',), ('*.bqn',), ()),
+ 'BSTLexer': ('pip._vendor.pygments.lexers.bibtex', 'BST', ('bst', 'bst-pybtex'), ('*.bst',), ()),
+ 'BareLexer': ('pip._vendor.pygments.lexers.bare', 'BARE', ('bare',), ('*.bare',), ()),
+ 'BaseMakefileLexer': ('pip._vendor.pygments.lexers.make', 'Base Makefile', ('basemake',), (), ()),
+ 'BashLexer': ('pip._vendor.pygments.lexers.shell', 'Bash', ('bash', 'sh', 'ksh', 'zsh', 'shell', 'openrc'), ('*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass', '*.exheres-0', '*.exlib', '*.zsh', '.bashrc', 'bashrc', '.bash_*', 'bash_*', 'zshrc', '.zshrc', '.kshrc', 'kshrc', 'PKGBUILD'), ('application/x-sh', 'application/x-shellscript', 'text/x-shellscript')),
+ 'BashSessionLexer': ('pip._vendor.pygments.lexers.shell', 'Bash Session', ('console', 'shell-session'), ('*.sh-session', '*.shell-session'), ('application/x-shell-session', 'application/x-sh-session')),
+ 'BatchLexer': ('pip._vendor.pygments.lexers.shell', 'Batchfile', ('batch', 'bat', 'dosbatch', 'winbatch'), ('*.bat', '*.cmd'), ('application/x-dos-batch',)),
+ 'BddLexer': ('pip._vendor.pygments.lexers.bdd', 'Bdd', ('bdd',), ('*.feature',), ('text/x-bdd',)),
+ 'BefungeLexer': ('pip._vendor.pygments.lexers.esoteric', 'Befunge', ('befunge',), ('*.befunge',), ('application/x-befunge',)),
+ 'BerryLexer': ('pip._vendor.pygments.lexers.berry', 'Berry', ('berry', 'be'), ('*.be',), ('text/x-berry', 'application/x-berry')),
+ 'BibTeXLexer': ('pip._vendor.pygments.lexers.bibtex', 'BibTeX', ('bibtex', 'bib'), ('*.bib',), ('text/x-bibtex',)),
+ 'BlitzBasicLexer': ('pip._vendor.pygments.lexers.basic', 'BlitzBasic', ('blitzbasic', 'b3d', 'bplus'), ('*.bb', '*.decls'), ('text/x-bb',)),
+ 'BlitzMaxLexer': ('pip._vendor.pygments.lexers.basic', 'BlitzMax', ('blitzmax', 'bmax'), ('*.bmx',), ('text/x-bmx',)),
+ 'BlueprintLexer': ('pip._vendor.pygments.lexers.blueprint', 'Blueprint', ('blueprint',), ('*.blp',), ('text/x-blueprint',)),
+ 'BnfLexer': ('pip._vendor.pygments.lexers.grammar_notation', 'BNF', ('bnf',), ('*.bnf',), ('text/x-bnf',)),
+ 'BoaLexer': ('pip._vendor.pygments.lexers.boa', 'Boa', ('boa',), ('*.boa',), ()),
+ 'BooLexer': ('pip._vendor.pygments.lexers.dotnet', 'Boo', ('boo',), ('*.boo',), ('text/x-boo',)),
+ 'BoogieLexer': ('pip._vendor.pygments.lexers.verification', 'Boogie', ('boogie',), ('*.bpl',), ()),
+ 'BrainfuckLexer': ('pip._vendor.pygments.lexers.esoteric', 'Brainfuck', ('brainfuck', 'bf'), ('*.bf', '*.b'), ('application/x-brainfuck',)),
+ 'BugsLexer': ('pip._vendor.pygments.lexers.modeling', 'BUGS', ('bugs', 'winbugs', 'openbugs'), ('*.bug',), ()),
+ 'CAmkESLexer': ('pip._vendor.pygments.lexers.esoteric', 'CAmkES', ('camkes', 'idl4'), ('*.camkes', '*.idl4'), ()),
+ 'CLexer': ('pip._vendor.pygments.lexers.c_cpp', 'C', ('c',), ('*.c', '*.h', '*.idc', '*.x[bp]m'), ('text/x-chdr', 'text/x-csrc', 'image/x-xbitmap', 'image/x-xpixmap')),
+ 'CMakeLexer': ('pip._vendor.pygments.lexers.make', 'CMake', ('cmake',), ('*.cmake', 'CMakeLists.txt'), ('text/x-cmake',)),
+ 'CObjdumpLexer': ('pip._vendor.pygments.lexers.asm', 'c-objdump', ('c-objdump',), ('*.c-objdump',), ('text/x-c-objdump',)),
+ 'CPSALexer': ('pip._vendor.pygments.lexers.lisp', 'CPSA', ('cpsa',), ('*.cpsa',), ()),
+ 'CSSUL4Lexer': ('pip._vendor.pygments.lexers.ul4', 'CSS+UL4', ('css+ul4',), ('*.cssul4',), ()),
+ 'CSharpAspxLexer': ('pip._vendor.pygments.lexers.dotnet', 'aspx-cs', ('aspx-cs',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
+ 'CSharpLexer': ('pip._vendor.pygments.lexers.dotnet', 'C#', ('csharp', 'c#', 'cs'), ('*.cs',), ('text/x-csharp',)),
+ 'Ca65Lexer': ('pip._vendor.pygments.lexers.asm', 'ca65 assembler', ('ca65',), ('*.s',), ()),
+ 'CadlLexer': ('pip._vendor.pygments.lexers.archetype', 'cADL', ('cadl',), ('*.cadl',), ()),
+ 'CapDLLexer': ('pip._vendor.pygments.lexers.esoteric', 'CapDL', ('capdl',), ('*.cdl',), ()),
+ 'CapnProtoLexer': ('pip._vendor.pygments.lexers.capnproto', "Cap'n Proto", ('capnp',), ('*.capnp',), ()),
+ 'CarbonLexer': ('pip._vendor.pygments.lexers.carbon', 'Carbon', ('carbon',), ('*.carbon',), ('text/x-carbon',)),
+ 'CbmBasicV2Lexer': ('pip._vendor.pygments.lexers.basic', 'CBM BASIC V2', ('cbmbas',), ('*.bas',), ()),
+ 'CddlLexer': ('pip._vendor.pygments.lexers.cddl', 'CDDL', ('cddl',), ('*.cddl',), ('text/x-cddl',)),
+ 'CeylonLexer': ('pip._vendor.pygments.lexers.jvm', 'Ceylon', ('ceylon',), ('*.ceylon',), ('text/x-ceylon',)),
+ 'Cfengine3Lexer': ('pip._vendor.pygments.lexers.configs', 'CFEngine3', ('cfengine3', 'cf3'), ('*.cf',), ()),
+ 'ChaiscriptLexer': ('pip._vendor.pygments.lexers.scripting', 'ChaiScript', ('chaiscript', 'chai'), ('*.chai',), ('text/x-chaiscript', 'application/x-chaiscript')),
+ 'ChapelLexer': ('pip._vendor.pygments.lexers.chapel', 'Chapel', ('chapel', 'chpl'), ('*.chpl',), ()),
+ 'CharmciLexer': ('pip._vendor.pygments.lexers.c_like', 'Charmci', ('charmci',), ('*.ci',), ()),
+ 'CheetahHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Cheetah', ('html+cheetah', 'html+spitfire', 'htmlcheetah'), (), ('text/html+cheetah', 'text/html+spitfire')),
+ 'CheetahJavascriptLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Cheetah', ('javascript+cheetah', 'js+cheetah', 'javascript+spitfire', 'js+spitfire'), (), ('application/x-javascript+cheetah', 'text/x-javascript+cheetah', 'text/javascript+cheetah', 'application/x-javascript+spitfire', 'text/x-javascript+spitfire', 'text/javascript+spitfire')),
+ 'CheetahLexer': ('pip._vendor.pygments.lexers.templates', 'Cheetah', ('cheetah', 'spitfire'), ('*.tmpl', '*.spt'), ('application/x-cheetah', 'application/x-spitfire')),
+ 'CheetahXmlLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Cheetah', ('xml+cheetah', 'xml+spitfire'), (), ('application/xml+cheetah', 'application/xml+spitfire')),
+ 'CirruLexer': ('pip._vendor.pygments.lexers.webmisc', 'Cirru', ('cirru',), ('*.cirru',), ('text/x-cirru',)),
+ 'ClayLexer': ('pip._vendor.pygments.lexers.c_like', 'Clay', ('clay',), ('*.clay',), ('text/x-clay',)),
+ 'CleanLexer': ('pip._vendor.pygments.lexers.clean', 'Clean', ('clean',), ('*.icl', '*.dcl'), ()),
+ 'ClojureLexer': ('pip._vendor.pygments.lexers.jvm', 'Clojure', ('clojure', 'clj'), ('*.clj', '*.cljc'), ('text/x-clojure', 'application/x-clojure')),
+ 'ClojureScriptLexer': ('pip._vendor.pygments.lexers.jvm', 'ClojureScript', ('clojurescript', 'cljs'), ('*.cljs',), ('text/x-clojurescript', 'application/x-clojurescript')),
+ 'CobolFreeformatLexer': ('pip._vendor.pygments.lexers.business', 'COBOLFree', ('cobolfree',), ('*.cbl', '*.CBL'), ()),
+ 'CobolLexer': ('pip._vendor.pygments.lexers.business', 'COBOL', ('cobol',), ('*.cob', '*.COB', '*.cpy', '*.CPY'), ('text/x-cobol',)),
+ 'CoffeeScriptLexer': ('pip._vendor.pygments.lexers.javascript', 'CoffeeScript', ('coffeescript', 'coffee-script', 'coffee'), ('*.coffee',), ('text/coffeescript',)),
+ 'ColdfusionCFCLexer': ('pip._vendor.pygments.lexers.templates', 'Coldfusion CFC', ('cfc',), ('*.cfc',), ()),
+ 'ColdfusionHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'Coldfusion HTML', ('cfm',), ('*.cfm', '*.cfml'), ('application/x-coldfusion',)),
+ 'ColdfusionLexer': ('pip._vendor.pygments.lexers.templates', 'cfstatement', ('cfs',), (), ()),
+ 'Comal80Lexer': ('pip._vendor.pygments.lexers.comal', 'COMAL-80', ('comal', 'comal80'), ('*.cml', '*.comal'), ()),
+ 'CommonLispLexer': ('pip._vendor.pygments.lexers.lisp', 'Common Lisp', ('common-lisp', 'cl', 'lisp'), ('*.cl', '*.lisp'), ('text/x-common-lisp',)),
+ 'ComponentPascalLexer': ('pip._vendor.pygments.lexers.oberon', 'Component Pascal', ('componentpascal', 'cp'), ('*.cp', '*.cps'), ('text/x-component-pascal',)),
+ 'CoqLexer': ('pip._vendor.pygments.lexers.theorem', 'Coq', ('coq',), ('*.v',), ('text/x-coq',)),
+ 'CplintLexer': ('pip._vendor.pygments.lexers.cplint', 'cplint', ('cplint',), ('*.ecl', '*.prolog', '*.pro', '*.pl', '*.P', '*.lpad', '*.cpl'), ('text/x-cplint',)),
+ 'CppLexer': ('pip._vendor.pygments.lexers.c_cpp', 'C++', ('cpp', 'c++'), ('*.cpp', '*.hpp', '*.c++', '*.h++', '*.cc', '*.hh', '*.cxx', '*.hxx', '*.C', '*.H', '*.cp', '*.CPP', '*.tpp'), ('text/x-c++hdr', 'text/x-c++src')),
+ 'CppObjdumpLexer': ('pip._vendor.pygments.lexers.asm', 'cpp-objdump', ('cpp-objdump', 'c++-objdumb', 'cxx-objdump'), ('*.cpp-objdump', '*.c++-objdump', '*.cxx-objdump'), ('text/x-cpp-objdump',)),
+ 'CrmshLexer': ('pip._vendor.pygments.lexers.dsls', 'Crmsh', ('crmsh', 'pcmk'), ('*.crmsh', '*.pcmk'), ()),
+ 'CrocLexer': ('pip._vendor.pygments.lexers.d', 'Croc', ('croc',), ('*.croc',), ('text/x-crocsrc',)),
+ 'CryptolLexer': ('pip._vendor.pygments.lexers.haskell', 'Cryptol', ('cryptol', 'cry'), ('*.cry',), ('text/x-cryptol',)),
+ 'CrystalLexer': ('pip._vendor.pygments.lexers.crystal', 'Crystal', ('cr', 'crystal'), ('*.cr',), ('text/x-crystal',)),
+ 'CsoundDocumentLexer': ('pip._vendor.pygments.lexers.csound', 'Csound Document', ('csound-document', 'csound-csd'), ('*.csd',), ()),
+ 'CsoundOrchestraLexer': ('pip._vendor.pygments.lexers.csound', 'Csound Orchestra', ('csound', 'csound-orc'), ('*.orc', '*.udo'), ()),
+ 'CsoundScoreLexer': ('pip._vendor.pygments.lexers.csound', 'Csound Score', ('csound-score', 'csound-sco'), ('*.sco',), ()),
+ 'CssDjangoLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+Django/Jinja', ('css+django', 'css+jinja'), ('*.css.j2', '*.css.jinja2'), ('text/css+django', 'text/css+jinja')),
+ 'CssErbLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+Ruby', ('css+ruby', 'css+erb'), (), ('text/css+ruby',)),
+ 'CssGenshiLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+Genshi Text', ('css+genshitext', 'css+genshi'), (), ('text/css+genshi',)),
+ 'CssLexer': ('pip._vendor.pygments.lexers.css', 'CSS', ('css',), ('*.css',), ('text/css',)),
+ 'CssPhpLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+PHP', ('css+php',), (), ('text/css+php',)),
+ 'CssSmartyLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+Smarty', ('css+smarty',), (), ('text/css+smarty',)),
+ 'CudaLexer': ('pip._vendor.pygments.lexers.c_like', 'CUDA', ('cuda', 'cu'), ('*.cu', '*.cuh'), ('text/x-cuda',)),
+ 'CypherLexer': ('pip._vendor.pygments.lexers.graph', 'Cypher', ('cypher',), ('*.cyp', '*.cypher'), ()),
+ 'CythonLexer': ('pip._vendor.pygments.lexers.python', 'Cython', ('cython', 'pyx', 'pyrex'), ('*.pyx', '*.pxd', '*.pxi'), ('text/x-cython', 'application/x-cython')),
+ 'DLexer': ('pip._vendor.pygments.lexers.d', 'D', ('d',), ('*.d', '*.di'), ('text/x-dsrc',)),
+ 'DObjdumpLexer': ('pip._vendor.pygments.lexers.asm', 'd-objdump', ('d-objdump',), ('*.d-objdump',), ('text/x-d-objdump',)),
+ 'DarcsPatchLexer': ('pip._vendor.pygments.lexers.diff', 'Darcs Patch', ('dpatch',), ('*.dpatch', '*.darcspatch'), ()),
+ 'DartLexer': ('pip._vendor.pygments.lexers.javascript', 'Dart', ('dart',), ('*.dart',), ('text/x-dart',)),
+ 'Dasm16Lexer': ('pip._vendor.pygments.lexers.asm', 'DASM16', ('dasm16',), ('*.dasm16', '*.dasm'), ('text/x-dasm16',)),
+ 'DaxLexer': ('pip._vendor.pygments.lexers.dax', 'Dax', ('dax',), ('*.dax',), ()),
+ 'DebianControlLexer': ('pip._vendor.pygments.lexers.installers', 'Debian Control file', ('debcontrol', 'control'), ('control',), ()),
+ 'DelphiLexer': ('pip._vendor.pygments.lexers.pascal', 'Delphi', ('delphi', 'pas', 'pascal', 'objectpascal'), ('*.pas', '*.dpr'), ('text/x-pascal',)),
+ 'DesktopLexer': ('pip._vendor.pygments.lexers.configs', 'Desktop file', ('desktop',), ('*.desktop',), ('application/x-desktop',)),
+ 'DevicetreeLexer': ('pip._vendor.pygments.lexers.devicetree', 'Devicetree', ('devicetree', 'dts'), ('*.dts', '*.dtsi'), ('text/x-c',)),
+ 'DgLexer': ('pip._vendor.pygments.lexers.python', 'dg', ('dg',), ('*.dg',), ('text/x-dg',)),
+ 'DiffLexer': ('pip._vendor.pygments.lexers.diff', 'Diff', ('diff', 'udiff'), ('*.diff', '*.patch'), ('text/x-diff', 'text/x-patch')),
+ 'DjangoLexer': ('pip._vendor.pygments.lexers.templates', 'Django/Jinja', ('django', 'jinja'), (), ('application/x-django-templating', 'application/x-jinja')),
+ 'DnsZoneLexer': ('pip._vendor.pygments.lexers.dns', 'Zone', ('zone',), ('*.zone',), ('text/dns',)),
+ 'DockerLexer': ('pip._vendor.pygments.lexers.configs', 'Docker', ('docker', 'dockerfile'), ('Dockerfile', '*.docker'), ('text/x-dockerfile-config',)),
+ 'DtdLexer': ('pip._vendor.pygments.lexers.html', 'DTD', ('dtd',), ('*.dtd',), ('application/xml-dtd',)),
+ 'DuelLexer': ('pip._vendor.pygments.lexers.webmisc', 'Duel', ('duel', 'jbst', 'jsonml+bst'), ('*.duel', '*.jbst'), ('text/x-duel', 'text/x-jbst')),
+ 'DylanConsoleLexer': ('pip._vendor.pygments.lexers.dylan', 'Dylan session', ('dylan-console', 'dylan-repl'), ('*.dylan-console',), ('text/x-dylan-console',)),
+ 'DylanLexer': ('pip._vendor.pygments.lexers.dylan', 'Dylan', ('dylan',), ('*.dylan', '*.dyl', '*.intr'), ('text/x-dylan',)),
+ 'DylanLidLexer': ('pip._vendor.pygments.lexers.dylan', 'DylanLID', ('dylan-lid', 'lid'), ('*.lid', '*.hdp'), ('text/x-dylan-lid',)),
+ 'ECLLexer': ('pip._vendor.pygments.lexers.ecl', 'ECL', ('ecl',), ('*.ecl',), ('application/x-ecl',)),
+ 'ECLexer': ('pip._vendor.pygments.lexers.c_like', 'eC', ('ec',), ('*.ec', '*.eh'), ('text/x-echdr', 'text/x-ecsrc')),
+ 'EarlGreyLexer': ('pip._vendor.pygments.lexers.javascript', 'Earl Grey', ('earl-grey', 'earlgrey', 'eg'), ('*.eg',), ('text/x-earl-grey',)),
+ 'EasytrieveLexer': ('pip._vendor.pygments.lexers.scripting', 'Easytrieve', ('easytrieve',), ('*.ezt', '*.mac'), ('text/x-easytrieve',)),
+ 'EbnfLexer': ('pip._vendor.pygments.lexers.parsers', 'EBNF', ('ebnf',), ('*.ebnf',), ('text/x-ebnf',)),
+ 'EiffelLexer': ('pip._vendor.pygments.lexers.eiffel', 'Eiffel', ('eiffel',), ('*.e',), ('text/x-eiffel',)),
+ 'ElixirConsoleLexer': ('pip._vendor.pygments.lexers.erlang', 'Elixir iex session', ('iex',), (), ('text/x-elixir-shellsession',)),
+ 'ElixirLexer': ('pip._vendor.pygments.lexers.erlang', 'Elixir', ('elixir', 'ex', 'exs'), ('*.ex', '*.eex', '*.exs', '*.leex'), ('text/x-elixir',)),
+ 'ElmLexer': ('pip._vendor.pygments.lexers.elm', 'Elm', ('elm',), ('*.elm',), ('text/x-elm',)),
+ 'ElpiLexer': ('pip._vendor.pygments.lexers.elpi', 'Elpi', ('elpi',), ('*.elpi',), ('text/x-elpi',)),
+ 'EmacsLispLexer': ('pip._vendor.pygments.lexers.lisp', 'EmacsLisp', ('emacs-lisp', 'elisp', 'emacs'), ('*.el',), ('text/x-elisp', 'application/x-elisp')),
+ 'EmailLexer': ('pip._vendor.pygments.lexers.email', 'E-mail', ('email', 'eml'), ('*.eml',), ('message/rfc822',)),
+ 'ErbLexer': ('pip._vendor.pygments.lexers.templates', 'ERB', ('erb',), (), ('application/x-ruby-templating',)),
+ 'ErlangLexer': ('pip._vendor.pygments.lexers.erlang', 'Erlang', ('erlang',), ('*.erl', '*.hrl', '*.es', '*.escript'), ('text/x-erlang',)),
+ 'ErlangShellLexer': ('pip._vendor.pygments.lexers.erlang', 'Erlang erl session', ('erl',), ('*.erl-sh',), ('text/x-erl-shellsession',)),
+ 'EvoqueHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Evoque', ('html+evoque',), ('*.html',), ('text/html+evoque',)),
+ 'EvoqueLexer': ('pip._vendor.pygments.lexers.templates', 'Evoque', ('evoque',), ('*.evoque',), ('application/x-evoque',)),
+ 'EvoqueXmlLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Evoque', ('xml+evoque',), ('*.xml',), ('application/xml+evoque',)),
+ 'ExeclineLexer': ('pip._vendor.pygments.lexers.shell', 'execline', ('execline',), ('*.exec',), ()),
+ 'EzhilLexer': ('pip._vendor.pygments.lexers.ezhil', 'Ezhil', ('ezhil',), ('*.n',), ('text/x-ezhil',)),
+ 'FSharpLexer': ('pip._vendor.pygments.lexers.dotnet', 'F#', ('fsharp', 'f#'), ('*.fs', '*.fsi', '*.fsx'), ('text/x-fsharp',)),
+ 'FStarLexer': ('pip._vendor.pygments.lexers.ml', 'FStar', ('fstar',), ('*.fst', '*.fsti'), ('text/x-fstar',)),
+ 'FactorLexer': ('pip._vendor.pygments.lexers.factor', 'Factor', ('factor',), ('*.factor',), ('text/x-factor',)),
+ 'FancyLexer': ('pip._vendor.pygments.lexers.ruby', 'Fancy', ('fancy', 'fy'), ('*.fy', '*.fancypack'), ('text/x-fancysrc',)),
+ 'FantomLexer': ('pip._vendor.pygments.lexers.fantom', 'Fantom', ('fan',), ('*.fan',), ('application/x-fantom',)),
+ 'FelixLexer': ('pip._vendor.pygments.lexers.felix', 'Felix', ('felix', 'flx'), ('*.flx', '*.flxh'), ('text/x-felix',)),
+ 'FennelLexer': ('pip._vendor.pygments.lexers.lisp', 'Fennel', ('fennel', 'fnl'), ('*.fnl',), ()),
+ 'FiftLexer': ('pip._vendor.pygments.lexers.fift', 'Fift', ('fift', 'fif'), ('*.fif',), ()),
+ 'FishShellLexer': ('pip._vendor.pygments.lexers.shell', 'Fish', ('fish', 'fishshell'), ('*.fish', '*.load'), ('application/x-fish',)),
+ 'FlatlineLexer': ('pip._vendor.pygments.lexers.dsls', 'Flatline', ('flatline',), (), ('text/x-flatline',)),
+ 'FloScriptLexer': ('pip._vendor.pygments.lexers.floscript', 'FloScript', ('floscript', 'flo'), ('*.flo',), ()),
+ 'ForthLexer': ('pip._vendor.pygments.lexers.forth', 'Forth', ('forth',), ('*.frt', '*.fs'), ('application/x-forth',)),
+ 'FortranFixedLexer': ('pip._vendor.pygments.lexers.fortran', 'FortranFixed', ('fortranfixed',), ('*.f', '*.F'), ()),
+ 'FortranLexer': ('pip._vendor.pygments.lexers.fortran', 'Fortran', ('fortran', 'f90'), ('*.f03', '*.f90', '*.F03', '*.F90'), ('text/x-fortran',)),
+ 'FoxProLexer': ('pip._vendor.pygments.lexers.foxpro', 'FoxPro', ('foxpro', 'vfp', 'clipper', 'xbase'), ('*.PRG', '*.prg'), ()),
+ 'FreeFemLexer': ('pip._vendor.pygments.lexers.freefem', 'Freefem', ('freefem',), ('*.edp',), ('text/x-freefem',)),
+ 'FuncLexer': ('pip._vendor.pygments.lexers.func', 'FunC', ('func', 'fc'), ('*.fc', '*.func'), ()),
+ 'FutharkLexer': ('pip._vendor.pygments.lexers.futhark', 'Futhark', ('futhark',), ('*.fut',), ('text/x-futhark',)),
+ 'GAPConsoleLexer': ('pip._vendor.pygments.lexers.algebra', 'GAP session', ('gap-console', 'gap-repl'), ('*.tst',), ()),
+ 'GAPLexer': ('pip._vendor.pygments.lexers.algebra', 'GAP', ('gap',), ('*.g', '*.gd', '*.gi', '*.gap'), ()),
+ 'GDScriptLexer': ('pip._vendor.pygments.lexers.gdscript', 'GDScript', ('gdscript', 'gd'), ('*.gd',), ('text/x-gdscript', 'application/x-gdscript')),
+ 'GLShaderLexer': ('pip._vendor.pygments.lexers.graphics', 'GLSL', ('glsl',), ('*.vert', '*.frag', '*.geo'), ('text/x-glslsrc',)),
+ 'GSQLLexer': ('pip._vendor.pygments.lexers.gsql', 'GSQL', ('gsql',), ('*.gsql',), ()),
+ 'GasLexer': ('pip._vendor.pygments.lexers.asm', 'GAS', ('gas', 'asm'), ('*.s', '*.S'), ('text/x-gas',)),
+ 'GcodeLexer': ('pip._vendor.pygments.lexers.gcodelexer', 'g-code', ('gcode',), ('*.gcode',), ()),
+ 'GenshiLexer': ('pip._vendor.pygments.lexers.templates', 'Genshi', ('genshi', 'kid', 'xml+genshi', 'xml+kid'), ('*.kid',), ('application/x-genshi', 'application/x-kid')),
+ 'GenshiTextLexer': ('pip._vendor.pygments.lexers.templates', 'Genshi Text', ('genshitext',), (), ('application/x-genshi-text', 'text/x-genshi')),
+ 'GettextLexer': ('pip._vendor.pygments.lexers.textfmts', 'Gettext Catalog', ('pot', 'po'), ('*.pot', '*.po'), ('application/x-gettext', 'text/x-gettext', 'text/gettext')),
+ 'GherkinLexer': ('pip._vendor.pygments.lexers.testing', 'Gherkin', ('gherkin', 'cucumber'), ('*.feature',), ('text/x-gherkin',)),
+ 'GnuplotLexer': ('pip._vendor.pygments.lexers.graphics', 'Gnuplot', ('gnuplot',), ('*.plot', '*.plt'), ('text/x-gnuplot',)),
+ 'GoLexer': ('pip._vendor.pygments.lexers.go', 'Go', ('go', 'golang'), ('*.go',), ('text/x-gosrc',)),
+ 'GoloLexer': ('pip._vendor.pygments.lexers.jvm', 'Golo', ('golo',), ('*.golo',), ()),
+ 'GoodDataCLLexer': ('pip._vendor.pygments.lexers.business', 'GoodData-CL', ('gooddata-cl',), ('*.gdc',), ('text/x-gooddata-cl',)),
+ 'GosuLexer': ('pip._vendor.pygments.lexers.jvm', 'Gosu', ('gosu',), ('*.gs', '*.gsx', '*.gsp', '*.vark'), ('text/x-gosu',)),
+ 'GosuTemplateLexer': ('pip._vendor.pygments.lexers.jvm', 'Gosu Template', ('gst',), ('*.gst',), ('text/x-gosu-template',)),
+ 'GraphQLLexer': ('pip._vendor.pygments.lexers.graphql', 'GraphQL', ('graphql',), ('*.graphql',), ()),
+ 'GraphvizLexer': ('pip._vendor.pygments.lexers.graphviz', 'Graphviz', ('graphviz', 'dot'), ('*.gv', '*.dot'), ('text/x-graphviz', 'text/vnd.graphviz')),
+ 'GroffLexer': ('pip._vendor.pygments.lexers.markup', 'Groff', ('groff', 'nroff', 'man'), ('*.[1-9]', '*.man', '*.1p', '*.3pm'), ('application/x-troff', 'text/troff')),
+ 'GroovyLexer': ('pip._vendor.pygments.lexers.jvm', 'Groovy', ('groovy',), ('*.groovy', '*.gradle'), ('text/x-groovy',)),
+ 'HLSLShaderLexer': ('pip._vendor.pygments.lexers.graphics', 'HLSL', ('hlsl',), ('*.hlsl', '*.hlsli'), ('text/x-hlsl',)),
+ 'HTMLUL4Lexer': ('pip._vendor.pygments.lexers.ul4', 'HTML+UL4', ('html+ul4',), ('*.htmlul4',), ()),
+ 'HamlLexer': ('pip._vendor.pygments.lexers.html', 'Haml', ('haml',), ('*.haml',), ('text/x-haml',)),
+ 'HandlebarsHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Handlebars', ('html+handlebars',), ('*.handlebars', '*.hbs'), ('text/html+handlebars', 'text/x-handlebars-template')),
+ 'HandlebarsLexer': ('pip._vendor.pygments.lexers.templates', 'Handlebars', ('handlebars',), (), ()),
+ 'HaskellLexer': ('pip._vendor.pygments.lexers.haskell', 'Haskell', ('haskell', 'hs'), ('*.hs',), ('text/x-haskell',)),
+ 'HaxeLexer': ('pip._vendor.pygments.lexers.haxe', 'Haxe', ('haxe', 'hxsl', 'hx'), ('*.hx', '*.hxsl'), ('text/haxe', 'text/x-haxe', 'text/x-hx')),
+ 'HexdumpLexer': ('pip._vendor.pygments.lexers.hexdump', 'Hexdump', ('hexdump',), (), ()),
+ 'HsailLexer': ('pip._vendor.pygments.lexers.asm', 'HSAIL', ('hsail', 'hsa'), ('*.hsail',), ('text/x-hsail',)),
+ 'HspecLexer': ('pip._vendor.pygments.lexers.haskell', 'Hspec', ('hspec',), ('*Spec.hs',), ()),
+ 'HtmlDjangoLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Django/Jinja', ('html+django', 'html+jinja', 'htmldjango'), ('*.html.j2', '*.htm.j2', '*.xhtml.j2', '*.html.jinja2', '*.htm.jinja2', '*.xhtml.jinja2'), ('text/html+django', 'text/html+jinja')),
+ 'HtmlGenshiLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Genshi', ('html+genshi', 'html+kid'), (), ('text/html+genshi',)),
+ 'HtmlLexer': ('pip._vendor.pygments.lexers.html', 'HTML', ('html',), ('*.html', '*.htm', '*.xhtml', '*.xslt'), ('text/html', 'application/xhtml+xml')),
+ 'HtmlPhpLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+PHP', ('html+php',), ('*.phtml',), ('application/x-php', 'application/x-httpd-php', 'application/x-httpd-php3', 'application/x-httpd-php4', 'application/x-httpd-php5')),
+ 'HtmlSmartyLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Smarty', ('html+smarty',), (), ('text/html+smarty',)),
+ 'HttpLexer': ('pip._vendor.pygments.lexers.textfmts', 'HTTP', ('http',), (), ()),
+ 'HxmlLexer': ('pip._vendor.pygments.lexers.haxe', 'Hxml', ('haxeml', 'hxml'), ('*.hxml',), ()),
+ 'HyLexer': ('pip._vendor.pygments.lexers.lisp', 'Hy', ('hylang', 'hy'), ('*.hy',), ('text/x-hy', 'application/x-hy')),
+ 'HybrisLexer': ('pip._vendor.pygments.lexers.scripting', 'Hybris', ('hybris',), ('*.hyb',), ('text/x-hybris', 'application/x-hybris')),
+ 'IDLLexer': ('pip._vendor.pygments.lexers.idl', 'IDL', ('idl',), ('*.pro',), ('text/idl',)),
+ 'IconLexer': ('pip._vendor.pygments.lexers.unicon', 'Icon', ('icon',), ('*.icon', '*.ICON'), ()),
+ 'IdrisLexer': ('pip._vendor.pygments.lexers.haskell', 'Idris', ('idris', 'idr'), ('*.idr',), ('text/x-idris',)),
+ 'IgorLexer': ('pip._vendor.pygments.lexers.igor', 'Igor', ('igor', 'igorpro'), ('*.ipf',), ('text/ipf',)),
+ 'Inform6Lexer': ('pip._vendor.pygments.lexers.int_fiction', 'Inform 6', ('inform6', 'i6'), ('*.inf',), ()),
+ 'Inform6TemplateLexer': ('pip._vendor.pygments.lexers.int_fiction', 'Inform 6 template', ('i6t',), ('*.i6t',), ()),
+ 'Inform7Lexer': ('pip._vendor.pygments.lexers.int_fiction', 'Inform 7', ('inform7', 'i7'), ('*.ni', '*.i7x'), ()),
+ 'IniLexer': ('pip._vendor.pygments.lexers.configs', 'INI', ('ini', 'cfg', 'dosini'), ('*.ini', '*.cfg', '*.inf', '.editorconfig'), ('text/x-ini', 'text/inf')),
+ 'IoLexer': ('pip._vendor.pygments.lexers.iolang', 'Io', ('io',), ('*.io',), ('text/x-iosrc',)),
+ 'IokeLexer': ('pip._vendor.pygments.lexers.jvm', 'Ioke', ('ioke', 'ik'), ('*.ik',), ('text/x-iokesrc',)),
+ 'IrcLogsLexer': ('pip._vendor.pygments.lexers.textfmts', 'IRC logs', ('irc',), ('*.weechatlog',), ('text/x-irclog',)),
+ 'IsabelleLexer': ('pip._vendor.pygments.lexers.theorem', 'Isabelle', ('isabelle',), ('*.thy',), ('text/x-isabelle',)),
+ 'JLexer': ('pip._vendor.pygments.lexers.j', 'J', ('j',), ('*.ijs',), ('text/x-j',)),
+ 'JMESPathLexer': ('pip._vendor.pygments.lexers.jmespath', 'JMESPath', ('jmespath', 'jp'), ('*.jp',), ()),
+ 'JSLTLexer': ('pip._vendor.pygments.lexers.jslt', 'JSLT', ('jslt',), ('*.jslt',), ('text/x-jslt',)),
+ 'JagsLexer': ('pip._vendor.pygments.lexers.modeling', 'JAGS', ('jags',), ('*.jag', '*.bug'), ()),
+ 'JanetLexer': ('pip._vendor.pygments.lexers.lisp', 'Janet', ('janet',), ('*.janet', '*.jdn'), ('text/x-janet', 'application/x-janet')),
+ 'JasminLexer': ('pip._vendor.pygments.lexers.jvm', 'Jasmin', ('jasmin', 'jasminxt'), ('*.j',), ()),
+ 'JavaLexer': ('pip._vendor.pygments.lexers.jvm', 'Java', ('java',), ('*.java',), ('text/x-java',)),
+ 'JavascriptDjangoLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Django/Jinja', ('javascript+django', 'js+django', 'javascript+jinja', 'js+jinja'), ('*.js.j2', '*.js.jinja2'), ('application/x-javascript+django', 'application/x-javascript+jinja', 'text/x-javascript+django', 'text/x-javascript+jinja', 'text/javascript+django', 'text/javascript+jinja')),
+ 'JavascriptErbLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Ruby', ('javascript+ruby', 'js+ruby', 'javascript+erb', 'js+erb'), (), ('application/x-javascript+ruby', 'text/x-javascript+ruby', 'text/javascript+ruby')),
+ 'JavascriptGenshiLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Genshi Text', ('js+genshitext', 'js+genshi', 'javascript+genshitext', 'javascript+genshi'), (), ('application/x-javascript+genshi', 'text/x-javascript+genshi', 'text/javascript+genshi')),
+ 'JavascriptLexer': ('pip._vendor.pygments.lexers.javascript', 'JavaScript', ('javascript', 'js'), ('*.js', '*.jsm', '*.mjs', '*.cjs'), ('application/javascript', 'application/x-javascript', 'text/x-javascript', 'text/javascript')),
+ 'JavascriptPhpLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+PHP', ('javascript+php', 'js+php'), (), ('application/x-javascript+php', 'text/x-javascript+php', 'text/javascript+php')),
+ 'JavascriptSmartyLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Smarty', ('javascript+smarty', 'js+smarty'), (), ('application/x-javascript+smarty', 'text/x-javascript+smarty', 'text/javascript+smarty')),
+ 'JavascriptUL4Lexer': ('pip._vendor.pygments.lexers.ul4', 'Javascript+UL4', ('js+ul4',), ('*.jsul4',), ()),
+ 'JclLexer': ('pip._vendor.pygments.lexers.scripting', 'JCL', ('jcl',), ('*.jcl',), ('text/x-jcl',)),
+ 'JsgfLexer': ('pip._vendor.pygments.lexers.grammar_notation', 'JSGF', ('jsgf',), ('*.jsgf',), ('application/jsgf', 'application/x-jsgf', 'text/jsgf')),
+ 'JsonBareObjectLexer': ('pip._vendor.pygments.lexers.data', 'JSONBareObject', (), (), ()),
+ 'JsonLdLexer': ('pip._vendor.pygments.lexers.data', 'JSON-LD', ('jsonld', 'json-ld'), ('*.jsonld',), ('application/ld+json',)),
+ 'JsonLexer': ('pip._vendor.pygments.lexers.data', 'JSON', ('json', 'json-object'), ('*.json', '*.jsonl', '*.ndjson', 'Pipfile.lock'), ('application/json', 'application/json-object', 'application/x-ndjson', 'application/jsonl', 'application/json-seq')),
+ 'JsonnetLexer': ('pip._vendor.pygments.lexers.jsonnet', 'Jsonnet', ('jsonnet',), ('*.jsonnet', '*.libsonnet'), ()),
+ 'JspLexer': ('pip._vendor.pygments.lexers.templates', 'Java Server Page', ('jsp',), ('*.jsp',), ('application/x-jsp',)),
+ 'JsxLexer': ('pip._vendor.pygments.lexers.jsx', 'JSX', ('jsx', 'react'), ('*.jsx', '*.react'), ('text/jsx', 'text/typescript-jsx')),
+ 'JuliaConsoleLexer': ('pip._vendor.pygments.lexers.julia', 'Julia console', ('jlcon', 'julia-repl'), (), ()),
+ 'JuliaLexer': ('pip._vendor.pygments.lexers.julia', 'Julia', ('julia', 'jl'), ('*.jl',), ('text/x-julia', 'application/x-julia')),
+ 'JuttleLexer': ('pip._vendor.pygments.lexers.javascript', 'Juttle', ('juttle',), ('*.juttle',), ('application/juttle', 'application/x-juttle', 'text/x-juttle', 'text/juttle')),
+ 'KLexer': ('pip._vendor.pygments.lexers.q', 'K', ('k',), ('*.k',), ()),
+ 'KalLexer': ('pip._vendor.pygments.lexers.javascript', 'Kal', ('kal',), ('*.kal',), ('text/kal', 'application/kal')),
+ 'KconfigLexer': ('pip._vendor.pygments.lexers.configs', 'Kconfig', ('kconfig', 'menuconfig', 'linux-config', 'kernel-config'), ('Kconfig*', '*Config.in*', 'external.in*', 'standard-modules.in'), ('text/x-kconfig',)),
+ 'KernelLogLexer': ('pip._vendor.pygments.lexers.textfmts', 'Kernel log', ('kmsg', 'dmesg'), ('*.kmsg', '*.dmesg'), ()),
+ 'KokaLexer': ('pip._vendor.pygments.lexers.haskell', 'Koka', ('koka',), ('*.kk', '*.kki'), ('text/x-koka',)),
+ 'KotlinLexer': ('pip._vendor.pygments.lexers.jvm', 'Kotlin', ('kotlin',), ('*.kt', '*.kts'), ('text/x-kotlin',)),
+ 'KuinLexer': ('pip._vendor.pygments.lexers.kuin', 'Kuin', ('kuin',), ('*.kn',), ()),
+ 'KustoLexer': ('pip._vendor.pygments.lexers.kusto', 'Kusto', ('kql', 'kusto'), ('*.kql', '*.kusto', '.csl'), ()),
+ 'LSLLexer': ('pip._vendor.pygments.lexers.scripting', 'LSL', ('lsl',), ('*.lsl',), ('text/x-lsl',)),
+ 'LassoCssLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+Lasso', ('css+lasso',), (), ('text/css+lasso',)),
+ 'LassoHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Lasso', ('html+lasso',), (), ('text/html+lasso', 'application/x-httpd-lasso', 'application/x-httpd-lasso[89]')),
+ 'LassoJavascriptLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Lasso', ('javascript+lasso', 'js+lasso'), (), ('application/x-javascript+lasso', 'text/x-javascript+lasso', 'text/javascript+lasso')),
+ 'LassoLexer': ('pip._vendor.pygments.lexers.javascript', 'Lasso', ('lasso', 'lassoscript'), ('*.lasso', '*.lasso[89]'), ('text/x-lasso',)),
+ 'LassoXmlLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Lasso', ('xml+lasso',), (), ('application/xml+lasso',)),
+ 'LdaprcLexer': ('pip._vendor.pygments.lexers.ldap', 'LDAP configuration file', ('ldapconf', 'ldaprc'), ('.ldaprc', 'ldaprc', 'ldap.conf'), ('text/x-ldapconf',)),
+ 'LdifLexer': ('pip._vendor.pygments.lexers.ldap', 'LDIF', ('ldif',), ('*.ldif',), ('text/x-ldif',)),
+ 'Lean3Lexer': ('pip._vendor.pygments.lexers.lean', 'Lean', ('lean', 'lean3'), ('*.lean',), ('text/x-lean', 'text/x-lean3')),
+ 'Lean4Lexer': ('pip._vendor.pygments.lexers.lean', 'Lean4', ('lean4',), ('*.lean',), ('text/x-lean4',)),
+ 'LessCssLexer': ('pip._vendor.pygments.lexers.css', 'LessCss', ('less',), ('*.less',), ('text/x-less-css',)),
+ 'LighttpdConfLexer': ('pip._vendor.pygments.lexers.configs', 'Lighttpd configuration file', ('lighttpd', 'lighty'), ('lighttpd.conf',), ('text/x-lighttpd-conf',)),
+ 'LilyPondLexer': ('pip._vendor.pygments.lexers.lilypond', 'LilyPond', ('lilypond',), ('*.ly',), ()),
+ 'LimboLexer': ('pip._vendor.pygments.lexers.inferno', 'Limbo', ('limbo',), ('*.b',), ('text/limbo',)),
+ 'LiquidLexer': ('pip._vendor.pygments.lexers.templates', 'liquid', ('liquid',), ('*.liquid',), ()),
+ 'LiterateAgdaLexer': ('pip._vendor.pygments.lexers.haskell', 'Literate Agda', ('literate-agda', 'lagda'), ('*.lagda',), ('text/x-literate-agda',)),
+ 'LiterateCryptolLexer': ('pip._vendor.pygments.lexers.haskell', 'Literate Cryptol', ('literate-cryptol', 'lcryptol', 'lcry'), ('*.lcry',), ('text/x-literate-cryptol',)),
+ 'LiterateHaskellLexer': ('pip._vendor.pygments.lexers.haskell', 'Literate Haskell', ('literate-haskell', 'lhaskell', 'lhs'), ('*.lhs',), ('text/x-literate-haskell',)),
+ 'LiterateIdrisLexer': ('pip._vendor.pygments.lexers.haskell', 'Literate Idris', ('literate-idris', 'lidris', 'lidr'), ('*.lidr',), ('text/x-literate-idris',)),
+ 'LiveScriptLexer': ('pip._vendor.pygments.lexers.javascript', 'LiveScript', ('livescript', 'live-script'), ('*.ls',), ('text/livescript',)),
+ 'LlvmLexer': ('pip._vendor.pygments.lexers.asm', 'LLVM', ('llvm',), ('*.ll',), ('text/x-llvm',)),
+ 'LlvmMirBodyLexer': ('pip._vendor.pygments.lexers.asm', 'LLVM-MIR Body', ('llvm-mir-body',), (), ()),
+ 'LlvmMirLexer': ('pip._vendor.pygments.lexers.asm', 'LLVM-MIR', ('llvm-mir',), ('*.mir',), ()),
+ 'LogosLexer': ('pip._vendor.pygments.lexers.objective', 'Logos', ('logos',), ('*.x', '*.xi', '*.xm', '*.xmi'), ('text/x-logos',)),
+ 'LogtalkLexer': ('pip._vendor.pygments.lexers.prolog', 'Logtalk', ('logtalk',), ('*.lgt', '*.logtalk'), ('text/x-logtalk',)),
+ 'LuaLexer': ('pip._vendor.pygments.lexers.scripting', 'Lua', ('lua',), ('*.lua', '*.wlua'), ('text/x-lua', 'application/x-lua')),
+ 'LuauLexer': ('pip._vendor.pygments.lexers.scripting', 'Luau', ('luau',), ('*.luau',), ()),
+ 'MCFunctionLexer': ('pip._vendor.pygments.lexers.minecraft', 'MCFunction', ('mcfunction', 'mcf'), ('*.mcfunction',), ('text/mcfunction',)),
+ 'MCSchemaLexer': ('pip._vendor.pygments.lexers.minecraft', 'MCSchema', ('mcschema',), ('*.mcschema',), ('text/mcschema',)),
+ 'MIMELexer': ('pip._vendor.pygments.lexers.mime', 'MIME', ('mime',), (), ('multipart/mixed', 'multipart/related', 'multipart/alternative')),
+ 'MIPSLexer': ('pip._vendor.pygments.lexers.mips', 'MIPS', ('mips',), ('*.mips', '*.MIPS'), ()),
+ 'MOOCodeLexer': ('pip._vendor.pygments.lexers.scripting', 'MOOCode', ('moocode', 'moo'), ('*.moo',), ('text/x-moocode',)),
+ 'MSDOSSessionLexer': ('pip._vendor.pygments.lexers.shell', 'MSDOS Session', ('doscon',), (), ()),
+ 'Macaulay2Lexer': ('pip._vendor.pygments.lexers.macaulay2', 'Macaulay2', ('macaulay2',), ('*.m2',), ()),
+ 'MakefileLexer': ('pip._vendor.pygments.lexers.make', 'Makefile', ('make', 'makefile', 'mf', 'bsdmake'), ('*.mak', '*.mk', 'Makefile', 'makefile', 'Makefile.*', 'GNUmakefile'), ('text/x-makefile',)),
+ 'MakoCssLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+Mako', ('css+mako',), (), ('text/css+mako',)),
+ 'MakoHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Mako', ('html+mako',), (), ('text/html+mako',)),
+ 'MakoJavascriptLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Mako', ('javascript+mako', 'js+mako'), (), ('application/x-javascript+mako', 'text/x-javascript+mako', 'text/javascript+mako')),
+ 'MakoLexer': ('pip._vendor.pygments.lexers.templates', 'Mako', ('mako',), ('*.mao',), ('application/x-mako',)),
+ 'MakoXmlLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Mako', ('xml+mako',), (), ('application/xml+mako',)),
+ 'MaqlLexer': ('pip._vendor.pygments.lexers.business', 'MAQL', ('maql',), ('*.maql',), ('text/x-gooddata-maql', 'application/x-gooddata-maql')),
+ 'MarkdownLexer': ('pip._vendor.pygments.lexers.markup', 'Markdown', ('markdown', 'md'), ('*.md', '*.markdown'), ('text/x-markdown',)),
+ 'MaskLexer': ('pip._vendor.pygments.lexers.javascript', 'Mask', ('mask',), ('*.mask',), ('text/x-mask',)),
+ 'MasonLexer': ('pip._vendor.pygments.lexers.templates', 'Mason', ('mason',), ('*.m', '*.mhtml', '*.mc', '*.mi', 'autohandler', 'dhandler'), ('application/x-mason',)),
+ 'MathematicaLexer': ('pip._vendor.pygments.lexers.algebra', 'Mathematica', ('mathematica', 'mma', 'nb'), ('*.nb', '*.cdf', '*.nbp', '*.ma'), ('application/mathematica', 'application/vnd.wolfram.mathematica', 'application/vnd.wolfram.mathematica.package', 'application/vnd.wolfram.cdf')),
+ 'MatlabLexer': ('pip._vendor.pygments.lexers.matlab', 'Matlab', ('matlab',), ('*.m',), ('text/matlab',)),
+ 'MatlabSessionLexer': ('pip._vendor.pygments.lexers.matlab', 'Matlab session', ('matlabsession',), (), ()),
+ 'MaximaLexer': ('pip._vendor.pygments.lexers.maxima', 'Maxima', ('maxima', 'macsyma'), ('*.mac', '*.max'), ()),
+ 'MesonLexer': ('pip._vendor.pygments.lexers.meson', 'Meson', ('meson', 'meson.build'), ('meson.build', 'meson_options.txt'), ('text/x-meson',)),
+ 'MiniDLexer': ('pip._vendor.pygments.lexers.d', 'MiniD', ('minid',), (), ('text/x-minidsrc',)),
+ 'MiniScriptLexer': ('pip._vendor.pygments.lexers.scripting', 'MiniScript', ('miniscript', 'ms'), ('*.ms',), ('text/x-minicript', 'application/x-miniscript')),
+ 'ModelicaLexer': ('pip._vendor.pygments.lexers.modeling', 'Modelica', ('modelica',), ('*.mo',), ('text/x-modelica',)),
+ 'Modula2Lexer': ('pip._vendor.pygments.lexers.modula2', 'Modula-2', ('modula2', 'm2'), ('*.def', '*.mod'), ('text/x-modula2',)),
+ 'MoinWikiLexer': ('pip._vendor.pygments.lexers.markup', 'MoinMoin/Trac Wiki markup', ('trac-wiki', 'moin'), (), ('text/x-trac-wiki',)),
+ 'MojoLexer': ('pip._vendor.pygments.lexers.mojo', 'Mojo', ('mojo', '🔥'), ('*.mojo', '*.🔥'), ('text/x-mojo', 'application/x-mojo')),
+ 'MonkeyLexer': ('pip._vendor.pygments.lexers.basic', 'Monkey', ('monkey',), ('*.monkey',), ('text/x-monkey',)),
+ 'MonteLexer': ('pip._vendor.pygments.lexers.monte', 'Monte', ('monte',), ('*.mt',), ()),
+ 'MoonScriptLexer': ('pip._vendor.pygments.lexers.scripting', 'MoonScript', ('moonscript', 'moon'), ('*.moon',), ('text/x-moonscript', 'application/x-moonscript')),
+ 'MoselLexer': ('pip._vendor.pygments.lexers.mosel', 'Mosel', ('mosel',), ('*.mos',), ()),
+ 'MozPreprocCssLexer': ('pip._vendor.pygments.lexers.markup', 'CSS+mozpreproc', ('css+mozpreproc',), ('*.css.in',), ()),
+ 'MozPreprocHashLexer': ('pip._vendor.pygments.lexers.markup', 'mozhashpreproc', ('mozhashpreproc',), (), ()),
+ 'MozPreprocJavascriptLexer': ('pip._vendor.pygments.lexers.markup', 'Javascript+mozpreproc', ('javascript+mozpreproc',), ('*.js.in',), ()),
+ 'MozPreprocPercentLexer': ('pip._vendor.pygments.lexers.markup', 'mozpercentpreproc', ('mozpercentpreproc',), (), ()),
+ 'MozPreprocXulLexer': ('pip._vendor.pygments.lexers.markup', 'XUL+mozpreproc', ('xul+mozpreproc',), ('*.xul.in',), ()),
+ 'MqlLexer': ('pip._vendor.pygments.lexers.c_like', 'MQL', ('mql', 'mq4', 'mq5', 'mql4', 'mql5'), ('*.mq4', '*.mq5', '*.mqh'), ('text/x-mql',)),
+ 'MscgenLexer': ('pip._vendor.pygments.lexers.dsls', 'Mscgen', ('mscgen', 'msc'), ('*.msc',), ()),
+ 'MuPADLexer': ('pip._vendor.pygments.lexers.algebra', 'MuPAD', ('mupad',), ('*.mu',), ()),
+ 'MxmlLexer': ('pip._vendor.pygments.lexers.actionscript', 'MXML', ('mxml',), ('*.mxml',), ()),
+ 'MySqlLexer': ('pip._vendor.pygments.lexers.sql', 'MySQL', ('mysql',), (), ('text/x-mysql',)),
+ 'MyghtyCssLexer': ('pip._vendor.pygments.lexers.templates', 'CSS+Myghty', ('css+myghty',), (), ('text/css+myghty',)),
+ 'MyghtyHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Myghty', ('html+myghty',), (), ('text/html+myghty',)),
+ 'MyghtyJavascriptLexer': ('pip._vendor.pygments.lexers.templates', 'JavaScript+Myghty', ('javascript+myghty', 'js+myghty'), (), ('application/x-javascript+myghty', 'text/x-javascript+myghty', 'text/javascript+mygthy')),
+ 'MyghtyLexer': ('pip._vendor.pygments.lexers.templates', 'Myghty', ('myghty',), ('*.myt', 'autodelegate'), ('application/x-myghty',)),
+ 'MyghtyXmlLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Myghty', ('xml+myghty',), (), ('application/xml+myghty',)),
+ 'NCLLexer': ('pip._vendor.pygments.lexers.ncl', 'NCL', ('ncl',), ('*.ncl',), ('text/ncl',)),
+ 'NSISLexer': ('pip._vendor.pygments.lexers.installers', 'NSIS', ('nsis', 'nsi', 'nsh'), ('*.nsi', '*.nsh'), ('text/x-nsis',)),
+ 'NasmLexer': ('pip._vendor.pygments.lexers.asm', 'NASM', ('nasm',), ('*.asm', '*.ASM', '*.nasm'), ('text/x-nasm',)),
+ 'NasmObjdumpLexer': ('pip._vendor.pygments.lexers.asm', 'objdump-nasm', ('objdump-nasm',), ('*.objdump-intel',), ('text/x-nasm-objdump',)),
+ 'NemerleLexer': ('pip._vendor.pygments.lexers.dotnet', 'Nemerle', ('nemerle',), ('*.n',), ('text/x-nemerle',)),
+ 'NesCLexer': ('pip._vendor.pygments.lexers.c_like', 'nesC', ('nesc',), ('*.nc',), ('text/x-nescsrc',)),
+ 'NestedTextLexer': ('pip._vendor.pygments.lexers.configs', 'NestedText', ('nestedtext', 'nt'), ('*.nt',), ()),
+ 'NewLispLexer': ('pip._vendor.pygments.lexers.lisp', 'NewLisp', ('newlisp',), ('*.lsp', '*.nl', '*.kif'), ('text/x-newlisp', 'application/x-newlisp')),
+ 'NewspeakLexer': ('pip._vendor.pygments.lexers.smalltalk', 'Newspeak', ('newspeak',), ('*.ns2',), ('text/x-newspeak',)),
+ 'NginxConfLexer': ('pip._vendor.pygments.lexers.configs', 'Nginx configuration file', ('nginx',), ('nginx.conf',), ('text/x-nginx-conf',)),
+ 'NimrodLexer': ('pip._vendor.pygments.lexers.nimrod', 'Nimrod', ('nimrod', 'nim'), ('*.nim', '*.nimrod'), ('text/x-nim',)),
+ 'NitLexer': ('pip._vendor.pygments.lexers.nit', 'Nit', ('nit',), ('*.nit',), ()),
+ 'NixLexer': ('pip._vendor.pygments.lexers.nix', 'Nix', ('nixos', 'nix'), ('*.nix',), ('text/x-nix',)),
+ 'NodeConsoleLexer': ('pip._vendor.pygments.lexers.javascript', 'Node.js REPL console session', ('nodejsrepl',), (), ('text/x-nodejsrepl',)),
+ 'NotmuchLexer': ('pip._vendor.pygments.lexers.textfmts', 'Notmuch', ('notmuch',), (), ()),
+ 'NuSMVLexer': ('pip._vendor.pygments.lexers.smv', 'NuSMV', ('nusmv',), ('*.smv',), ()),
+ 'NumPyLexer': ('pip._vendor.pygments.lexers.python', 'NumPy', ('numpy',), (), ()),
+ 'ObjdumpLexer': ('pip._vendor.pygments.lexers.asm', 'objdump', ('objdump',), ('*.objdump',), ('text/x-objdump',)),
+ 'ObjectiveCLexer': ('pip._vendor.pygments.lexers.objective', 'Objective-C', ('objective-c', 'objectivec', 'obj-c', 'objc'), ('*.m', '*.h'), ('text/x-objective-c',)),
+ 'ObjectiveCppLexer': ('pip._vendor.pygments.lexers.objective', 'Objective-C++', ('objective-c++', 'objectivec++', 'obj-c++', 'objc++'), ('*.mm', '*.hh'), ('text/x-objective-c++',)),
+ 'ObjectiveJLexer': ('pip._vendor.pygments.lexers.javascript', 'Objective-J', ('objective-j', 'objectivej', 'obj-j', 'objj'), ('*.j',), ('text/x-objective-j',)),
+ 'OcamlLexer': ('pip._vendor.pygments.lexers.ml', 'OCaml', ('ocaml',), ('*.ml', '*.mli', '*.mll', '*.mly'), ('text/x-ocaml',)),
+ 'OctaveLexer': ('pip._vendor.pygments.lexers.matlab', 'Octave', ('octave',), ('*.m',), ('text/octave',)),
+ 'OdinLexer': ('pip._vendor.pygments.lexers.archetype', 'ODIN', ('odin',), ('*.odin',), ('text/odin',)),
+ 'OmgIdlLexer': ('pip._vendor.pygments.lexers.c_like', 'OMG Interface Definition Language', ('omg-idl',), ('*.idl', '*.pidl'), ()),
+ 'OocLexer': ('pip._vendor.pygments.lexers.ooc', 'Ooc', ('ooc',), ('*.ooc',), ('text/x-ooc',)),
+ 'OpaLexer': ('pip._vendor.pygments.lexers.ml', 'Opa', ('opa',), ('*.opa',), ('text/x-opa',)),
+ 'OpenEdgeLexer': ('pip._vendor.pygments.lexers.business', 'OpenEdge ABL', ('openedge', 'abl', 'progress'), ('*.p', '*.cls'), ('text/x-openedge', 'application/x-openedge')),
+ 'OpenScadLexer': ('pip._vendor.pygments.lexers.openscad', 'OpenSCAD', ('openscad',), ('*.scad',), ('application/x-openscad',)),
+ 'OrgLexer': ('pip._vendor.pygments.lexers.markup', 'Org Mode', ('org', 'orgmode', 'org-mode'), ('*.org',), ('text/org',)),
+ 'OutputLexer': ('pip._vendor.pygments.lexers.special', 'Text output', ('output',), (), ()),
+ 'PacmanConfLexer': ('pip._vendor.pygments.lexers.configs', 'PacmanConf', ('pacmanconf',), ('pacman.conf',), ()),
+ 'PanLexer': ('pip._vendor.pygments.lexers.dsls', 'Pan', ('pan',), ('*.pan',), ()),
+ 'ParaSailLexer': ('pip._vendor.pygments.lexers.parasail', 'ParaSail', ('parasail',), ('*.psi', '*.psl'), ('text/x-parasail',)),
+ 'PawnLexer': ('pip._vendor.pygments.lexers.pawn', 'Pawn', ('pawn',), ('*.p', '*.pwn', '*.inc'), ('text/x-pawn',)),
+ 'PegLexer': ('pip._vendor.pygments.lexers.grammar_notation', 'PEG', ('peg',), ('*.peg',), ('text/x-peg',)),
+ 'Perl6Lexer': ('pip._vendor.pygments.lexers.perl', 'Perl6', ('perl6', 'pl6', 'raku'), ('*.pl', '*.pm', '*.nqp', '*.p6', '*.6pl', '*.p6l', '*.pl6', '*.6pm', '*.p6m', '*.pm6', '*.t', '*.raku', '*.rakumod', '*.rakutest', '*.rakudoc'), ('text/x-perl6', 'application/x-perl6')),
+ 'PerlLexer': ('pip._vendor.pygments.lexers.perl', 'Perl', ('perl', 'pl'), ('*.pl', '*.pm', '*.t', '*.perl'), ('text/x-perl', 'application/x-perl')),
+ 'PhixLexer': ('pip._vendor.pygments.lexers.phix', 'Phix', ('phix',), ('*.exw',), ('text/x-phix',)),
+ 'PhpLexer': ('pip._vendor.pygments.lexers.php', 'PHP', ('php', 'php3', 'php4', 'php5'), ('*.php', '*.php[345]', '*.inc'), ('text/x-php',)),
+ 'PigLexer': ('pip._vendor.pygments.lexers.jvm', 'Pig', ('pig',), ('*.pig',), ('text/x-pig',)),
+ 'PikeLexer': ('pip._vendor.pygments.lexers.c_like', 'Pike', ('pike',), ('*.pike', '*.pmod'), ('text/x-pike',)),
+ 'PkgConfigLexer': ('pip._vendor.pygments.lexers.configs', 'PkgConfig', ('pkgconfig',), ('*.pc',), ()),
+ 'PlPgsqlLexer': ('pip._vendor.pygments.lexers.sql', 'PL/pgSQL', ('plpgsql',), (), ('text/x-plpgsql',)),
+ 'PointlessLexer': ('pip._vendor.pygments.lexers.pointless', 'Pointless', ('pointless',), ('*.ptls',), ()),
+ 'PonyLexer': ('pip._vendor.pygments.lexers.pony', 'Pony', ('pony',), ('*.pony',), ()),
+ 'PortugolLexer': ('pip._vendor.pygments.lexers.pascal', 'Portugol', ('portugol',), ('*.alg', '*.portugol'), ()),
+ 'PostScriptLexer': ('pip._vendor.pygments.lexers.graphics', 'PostScript', ('postscript', 'postscr'), ('*.ps', '*.eps'), ('application/postscript',)),
+ 'PostgresConsoleLexer': ('pip._vendor.pygments.lexers.sql', 'PostgreSQL console (psql)', ('psql', 'postgresql-console', 'postgres-console'), (), ('text/x-postgresql-psql',)),
+ 'PostgresExplainLexer': ('pip._vendor.pygments.lexers.sql', 'PostgreSQL EXPLAIN dialect', ('postgres-explain',), ('*.explain',), ('text/x-postgresql-explain',)),
+ 'PostgresLexer': ('pip._vendor.pygments.lexers.sql', 'PostgreSQL SQL dialect', ('postgresql', 'postgres'), (), ('text/x-postgresql',)),
+ 'PovrayLexer': ('pip._vendor.pygments.lexers.graphics', 'POVRay', ('pov',), ('*.pov', '*.inc'), ('text/x-povray',)),
+ 'PowerShellLexer': ('pip._vendor.pygments.lexers.shell', 'PowerShell', ('powershell', 'pwsh', 'posh', 'ps1', 'psm1'), ('*.ps1', '*.psm1'), ('text/x-powershell',)),
+ 'PowerShellSessionLexer': ('pip._vendor.pygments.lexers.shell', 'PowerShell Session', ('pwsh-session', 'ps1con'), (), ()),
+ 'PraatLexer': ('pip._vendor.pygments.lexers.praat', 'Praat', ('praat',), ('*.praat', '*.proc', '*.psc'), ()),
+ 'ProcfileLexer': ('pip._vendor.pygments.lexers.procfile', 'Procfile', ('procfile',), ('Procfile',), ()),
+ 'PrologLexer': ('pip._vendor.pygments.lexers.prolog', 'Prolog', ('prolog',), ('*.ecl', '*.prolog', '*.pro', '*.pl'), ('text/x-prolog',)),
+ 'PromQLLexer': ('pip._vendor.pygments.lexers.promql', 'PromQL', ('promql',), ('*.promql',), ()),
+ 'PromelaLexer': ('pip._vendor.pygments.lexers.c_like', 'Promela', ('promela',), ('*.pml', '*.prom', '*.prm', '*.promela', '*.pr', '*.pm'), ('text/x-promela',)),
+ 'PropertiesLexer': ('pip._vendor.pygments.lexers.configs', 'Properties', ('properties', 'jproperties'), ('*.properties',), ('text/x-java-properties',)),
+ 'ProtoBufLexer': ('pip._vendor.pygments.lexers.dsls', 'Protocol Buffer', ('protobuf', 'proto'), ('*.proto',), ()),
+ 'PrqlLexer': ('pip._vendor.pygments.lexers.prql', 'PRQL', ('prql',), ('*.prql',), ('application/prql', 'application/x-prql')),
+ 'PsyshConsoleLexer': ('pip._vendor.pygments.lexers.php', 'PsySH console session for PHP', ('psysh',), (), ()),
+ 'PtxLexer': ('pip._vendor.pygments.lexers.ptx', 'PTX', ('ptx',), ('*.ptx',), ('text/x-ptx',)),
+ 'PugLexer': ('pip._vendor.pygments.lexers.html', 'Pug', ('pug', 'jade'), ('*.pug', '*.jade'), ('text/x-pug', 'text/x-jade')),
+ 'PuppetLexer': ('pip._vendor.pygments.lexers.dsls', 'Puppet', ('puppet',), ('*.pp',), ()),
+ 'PyPyLogLexer': ('pip._vendor.pygments.lexers.console', 'PyPy Log', ('pypylog', 'pypy'), ('*.pypylog',), ('application/x-pypylog',)),
+ 'Python2Lexer': ('pip._vendor.pygments.lexers.python', 'Python 2.x', ('python2', 'py2'), (), ('text/x-python2', 'application/x-python2')),
+ 'Python2TracebackLexer': ('pip._vendor.pygments.lexers.python', 'Python 2.x Traceback', ('py2tb',), ('*.py2tb',), ('text/x-python2-traceback',)),
+ 'PythonConsoleLexer': ('pip._vendor.pygments.lexers.python', 'Python console session', ('pycon', 'python-console'), (), ('text/x-python-doctest',)),
+ 'PythonLexer': ('pip._vendor.pygments.lexers.python', 'Python', ('python', 'py', 'sage', 'python3', 'py3', 'bazel', 'starlark'), ('*.py', '*.pyw', '*.pyi', '*.jy', '*.sage', '*.sc', 'SConstruct', 'SConscript', '*.bzl', 'BUCK', 'BUILD', 'BUILD.bazel', 'WORKSPACE', '*.tac'), ('text/x-python', 'application/x-python', 'text/x-python3', 'application/x-python3')),
+ 'PythonTracebackLexer': ('pip._vendor.pygments.lexers.python', 'Python Traceback', ('pytb', 'py3tb'), ('*.pytb', '*.py3tb'), ('text/x-python-traceback', 'text/x-python3-traceback')),
+ 'PythonUL4Lexer': ('pip._vendor.pygments.lexers.ul4', 'Python+UL4', ('py+ul4',), ('*.pyul4',), ()),
+ 'QBasicLexer': ('pip._vendor.pygments.lexers.basic', 'QBasic', ('qbasic', 'basic'), ('*.BAS', '*.bas'), ('text/basic',)),
+ 'QLexer': ('pip._vendor.pygments.lexers.q', 'Q', ('q',), ('*.q',), ()),
+ 'QVToLexer': ('pip._vendor.pygments.lexers.qvt', 'QVTO', ('qvto', 'qvt'), ('*.qvto',), ()),
+ 'QlikLexer': ('pip._vendor.pygments.lexers.qlik', 'Qlik', ('qlik', 'qlikview', 'qliksense', 'qlikscript'), ('*.qvs', '*.qvw'), ()),
+ 'QmlLexer': ('pip._vendor.pygments.lexers.webmisc', 'QML', ('qml', 'qbs'), ('*.qml', '*.qbs'), ('application/x-qml', 'application/x-qt.qbs+qml')),
+ 'RConsoleLexer': ('pip._vendor.pygments.lexers.r', 'RConsole', ('rconsole', 'rout'), ('*.Rout',), ()),
+ 'RNCCompactLexer': ('pip._vendor.pygments.lexers.rnc', 'Relax-NG Compact', ('rng-compact', 'rnc'), ('*.rnc',), ()),
+ 'RPMSpecLexer': ('pip._vendor.pygments.lexers.installers', 'RPMSpec', ('spec',), ('*.spec',), ('text/x-rpm-spec',)),
+ 'RacketLexer': ('pip._vendor.pygments.lexers.lisp', 'Racket', ('racket', 'rkt'), ('*.rkt', '*.rktd', '*.rktl'), ('text/x-racket', 'application/x-racket')),
+ 'RagelCLexer': ('pip._vendor.pygments.lexers.parsers', 'Ragel in C Host', ('ragel-c',), ('*.rl',), ()),
+ 'RagelCppLexer': ('pip._vendor.pygments.lexers.parsers', 'Ragel in CPP Host', ('ragel-cpp',), ('*.rl',), ()),
+ 'RagelDLexer': ('pip._vendor.pygments.lexers.parsers', 'Ragel in D Host', ('ragel-d',), ('*.rl',), ()),
+ 'RagelEmbeddedLexer': ('pip._vendor.pygments.lexers.parsers', 'Embedded Ragel', ('ragel-em',), ('*.rl',), ()),
+ 'RagelJavaLexer': ('pip._vendor.pygments.lexers.parsers', 'Ragel in Java Host', ('ragel-java',), ('*.rl',), ()),
+ 'RagelLexer': ('pip._vendor.pygments.lexers.parsers', 'Ragel', ('ragel',), (), ()),
+ 'RagelObjectiveCLexer': ('pip._vendor.pygments.lexers.parsers', 'Ragel in Objective C Host', ('ragel-objc',), ('*.rl',), ()),
+ 'RagelRubyLexer': ('pip._vendor.pygments.lexers.parsers', 'Ragel in Ruby Host', ('ragel-ruby', 'ragel-rb'), ('*.rl',), ()),
+ 'RawTokenLexer': ('pip._vendor.pygments.lexers.special', 'Raw token data', (), (), ('application/x-pygments-tokens',)),
+ 'RdLexer': ('pip._vendor.pygments.lexers.r', 'Rd', ('rd',), ('*.Rd',), ('text/x-r-doc',)),
+ 'ReasonLexer': ('pip._vendor.pygments.lexers.ml', 'ReasonML', ('reasonml', 'reason'), ('*.re', '*.rei'), ('text/x-reasonml',)),
+ 'RebolLexer': ('pip._vendor.pygments.lexers.rebol', 'REBOL', ('rebol',), ('*.r', '*.r3', '*.reb'), ('text/x-rebol',)),
+ 'RedLexer': ('pip._vendor.pygments.lexers.rebol', 'Red', ('red', 'red/system'), ('*.red', '*.reds'), ('text/x-red', 'text/x-red-system')),
+ 'RedcodeLexer': ('pip._vendor.pygments.lexers.esoteric', 'Redcode', ('redcode',), ('*.cw',), ()),
+ 'RegeditLexer': ('pip._vendor.pygments.lexers.configs', 'reg', ('registry',), ('*.reg',), ('text/x-windows-registry',)),
+ 'ResourceLexer': ('pip._vendor.pygments.lexers.resource', 'ResourceBundle', ('resourcebundle', 'resource'), (), ()),
+ 'RexxLexer': ('pip._vendor.pygments.lexers.scripting', 'Rexx', ('rexx', 'arexx'), ('*.rexx', '*.rex', '*.rx', '*.arexx'), ('text/x-rexx',)),
+ 'RhtmlLexer': ('pip._vendor.pygments.lexers.templates', 'RHTML', ('rhtml', 'html+erb', 'html+ruby'), ('*.rhtml',), ('text/html+ruby',)),
+ 'RideLexer': ('pip._vendor.pygments.lexers.ride', 'Ride', ('ride',), ('*.ride',), ('text/x-ride',)),
+ 'RitaLexer': ('pip._vendor.pygments.lexers.rita', 'Rita', ('rita',), ('*.rita',), ('text/rita',)),
+ 'RoboconfGraphLexer': ('pip._vendor.pygments.lexers.roboconf', 'Roboconf Graph', ('roboconf-graph',), ('*.graph',), ()),
+ 'RoboconfInstancesLexer': ('pip._vendor.pygments.lexers.roboconf', 'Roboconf Instances', ('roboconf-instances',), ('*.instances',), ()),
+ 'RobotFrameworkLexer': ('pip._vendor.pygments.lexers.robotframework', 'RobotFramework', ('robotframework',), ('*.robot', '*.resource'), ('text/x-robotframework',)),
+ 'RqlLexer': ('pip._vendor.pygments.lexers.sql', 'RQL', ('rql',), ('*.rql',), ('text/x-rql',)),
+ 'RslLexer': ('pip._vendor.pygments.lexers.dsls', 'RSL', ('rsl',), ('*.rsl',), ('text/rsl',)),
+ 'RstLexer': ('pip._vendor.pygments.lexers.markup', 'reStructuredText', ('restructuredtext', 'rst', 'rest'), ('*.rst', '*.rest'), ('text/x-rst', 'text/prs.fallenstein.rst')),
+ 'RtsLexer': ('pip._vendor.pygments.lexers.trafficscript', 'TrafficScript', ('trafficscript', 'rts'), ('*.rts',), ()),
+ 'RubyConsoleLexer': ('pip._vendor.pygments.lexers.ruby', 'Ruby irb session', ('rbcon', 'irb'), (), ('text/x-ruby-shellsession',)),
+ 'RubyLexer': ('pip._vendor.pygments.lexers.ruby', 'Ruby', ('ruby', 'rb', 'duby'), ('*.rb', '*.rbw', 'Rakefile', '*.rake', '*.gemspec', '*.rbx', '*.duby', 'Gemfile', 'Vagrantfile'), ('text/x-ruby', 'application/x-ruby')),
+ 'RustLexer': ('pip._vendor.pygments.lexers.rust', 'Rust', ('rust', 'rs'), ('*.rs', '*.rs.in'), ('text/rust', 'text/x-rust')),
+ 'SASLexer': ('pip._vendor.pygments.lexers.sas', 'SAS', ('sas',), ('*.SAS', '*.sas'), ('text/x-sas', 'text/sas', 'application/x-sas')),
+ 'SLexer': ('pip._vendor.pygments.lexers.r', 'S', ('splus', 's', 'r'), ('*.S', '*.R', '.Rhistory', '.Rprofile', '.Renviron'), ('text/S-plus', 'text/S', 'text/x-r-source', 'text/x-r', 'text/x-R', 'text/x-r-history', 'text/x-r-profile')),
+ 'SMLLexer': ('pip._vendor.pygments.lexers.ml', 'Standard ML', ('sml',), ('*.sml', '*.sig', '*.fun'), ('text/x-standardml', 'application/x-standardml')),
+ 'SNBTLexer': ('pip._vendor.pygments.lexers.minecraft', 'SNBT', ('snbt',), ('*.snbt',), ('text/snbt',)),
+ 'SarlLexer': ('pip._vendor.pygments.lexers.jvm', 'SARL', ('sarl',), ('*.sarl',), ('text/x-sarl',)),
+ 'SassLexer': ('pip._vendor.pygments.lexers.css', 'Sass', ('sass',), ('*.sass',), ('text/x-sass',)),
+ 'SaviLexer': ('pip._vendor.pygments.lexers.savi', 'Savi', ('savi',), ('*.savi',), ()),
+ 'ScalaLexer': ('pip._vendor.pygments.lexers.jvm', 'Scala', ('scala',), ('*.scala',), ('text/x-scala',)),
+ 'ScamlLexer': ('pip._vendor.pygments.lexers.html', 'Scaml', ('scaml',), ('*.scaml',), ('text/x-scaml',)),
+ 'ScdocLexer': ('pip._vendor.pygments.lexers.scdoc', 'scdoc', ('scdoc', 'scd'), ('*.scd', '*.scdoc'), ()),
+ 'SchemeLexer': ('pip._vendor.pygments.lexers.lisp', 'Scheme', ('scheme', 'scm'), ('*.scm', '*.ss'), ('text/x-scheme', 'application/x-scheme')),
+ 'ScilabLexer': ('pip._vendor.pygments.lexers.matlab', 'Scilab', ('scilab',), ('*.sci', '*.sce', '*.tst'), ('text/scilab',)),
+ 'ScssLexer': ('pip._vendor.pygments.lexers.css', 'SCSS', ('scss',), ('*.scss',), ('text/x-scss',)),
+ 'SedLexer': ('pip._vendor.pygments.lexers.textedit', 'Sed', ('sed', 'gsed', 'ssed'), ('*.sed', '*.[gs]sed'), ('text/x-sed',)),
+ 'ShExCLexer': ('pip._vendor.pygments.lexers.rdf', 'ShExC', ('shexc', 'shex'), ('*.shex',), ('text/shex',)),
+ 'ShenLexer': ('pip._vendor.pygments.lexers.lisp', 'Shen', ('shen',), ('*.shen',), ('text/x-shen', 'application/x-shen')),
+ 'SieveLexer': ('pip._vendor.pygments.lexers.sieve', 'Sieve', ('sieve',), ('*.siv', '*.sieve'), ()),
+ 'SilverLexer': ('pip._vendor.pygments.lexers.verification', 'Silver', ('silver',), ('*.sil', '*.vpr'), ()),
+ 'SingularityLexer': ('pip._vendor.pygments.lexers.configs', 'Singularity', ('singularity',), ('*.def', 'Singularity'), ()),
+ 'SlashLexer': ('pip._vendor.pygments.lexers.slash', 'Slash', ('slash',), ('*.sla',), ()),
+ 'SlimLexer': ('pip._vendor.pygments.lexers.webmisc', 'Slim', ('slim',), ('*.slim',), ('text/x-slim',)),
+ 'SlurmBashLexer': ('pip._vendor.pygments.lexers.shell', 'Slurm', ('slurm', 'sbatch'), ('*.sl',), ()),
+ 'SmaliLexer': ('pip._vendor.pygments.lexers.dalvik', 'Smali', ('smali',), ('*.smali',), ('text/smali',)),
+ 'SmalltalkLexer': ('pip._vendor.pygments.lexers.smalltalk', 'Smalltalk', ('smalltalk', 'squeak', 'st'), ('*.st',), ('text/x-smalltalk',)),
+ 'SmartGameFormatLexer': ('pip._vendor.pygments.lexers.sgf', 'SmartGameFormat', ('sgf',), ('*.sgf',), ()),
+ 'SmartyLexer': ('pip._vendor.pygments.lexers.templates', 'Smarty', ('smarty',), ('*.tpl',), ('application/x-smarty',)),
+ 'SmithyLexer': ('pip._vendor.pygments.lexers.smithy', 'Smithy', ('smithy',), ('*.smithy',), ()),
+ 'SnobolLexer': ('pip._vendor.pygments.lexers.snobol', 'Snobol', ('snobol',), ('*.snobol',), ('text/x-snobol',)),
+ 'SnowballLexer': ('pip._vendor.pygments.lexers.dsls', 'Snowball', ('snowball',), ('*.sbl',), ()),
+ 'SolidityLexer': ('pip._vendor.pygments.lexers.solidity', 'Solidity', ('solidity',), ('*.sol',), ()),
+ 'SoongLexer': ('pip._vendor.pygments.lexers.soong', 'Soong', ('androidbp', 'bp', 'soong'), ('Android.bp',), ()),
+ 'SophiaLexer': ('pip._vendor.pygments.lexers.sophia', 'Sophia', ('sophia',), ('*.aes',), ()),
+ 'SourcePawnLexer': ('pip._vendor.pygments.lexers.pawn', 'SourcePawn', ('sp',), ('*.sp',), ('text/x-sourcepawn',)),
+ 'SourcesListLexer': ('pip._vendor.pygments.lexers.installers', 'Debian Sourcelist', ('debsources', 'sourceslist', 'sources.list'), ('sources.list',), ()),
+ 'SparqlLexer': ('pip._vendor.pygments.lexers.rdf', 'SPARQL', ('sparql',), ('*.rq', '*.sparql'), ('application/sparql-query',)),
+ 'SpiceLexer': ('pip._vendor.pygments.lexers.spice', 'Spice', ('spice', 'spicelang'), ('*.spice',), ('text/x-spice',)),
+ 'SqlJinjaLexer': ('pip._vendor.pygments.lexers.templates', 'SQL+Jinja', ('sql+jinja',), ('*.sql', '*.sql.j2', '*.sql.jinja2'), ()),
+ 'SqlLexer': ('pip._vendor.pygments.lexers.sql', 'SQL', ('sql',), ('*.sql',), ('text/x-sql',)),
+ 'SqliteConsoleLexer': ('pip._vendor.pygments.lexers.sql', 'sqlite3con', ('sqlite3',), ('*.sqlite3-console',), ('text/x-sqlite3-console',)),
+ 'SquidConfLexer': ('pip._vendor.pygments.lexers.configs', 'SquidConf', ('squidconf', 'squid.conf', 'squid'), ('squid.conf',), ('text/x-squidconf',)),
+ 'SrcinfoLexer': ('pip._vendor.pygments.lexers.srcinfo', 'Srcinfo', ('srcinfo',), ('.SRCINFO',), ()),
+ 'SspLexer': ('pip._vendor.pygments.lexers.templates', 'Scalate Server Page', ('ssp',), ('*.ssp',), ('application/x-ssp',)),
+ 'StanLexer': ('pip._vendor.pygments.lexers.modeling', 'Stan', ('stan',), ('*.stan',), ()),
+ 'StataLexer': ('pip._vendor.pygments.lexers.stata', 'Stata', ('stata', 'do'), ('*.do', '*.ado'), ('text/x-stata', 'text/stata', 'application/x-stata')),
+ 'SuperColliderLexer': ('pip._vendor.pygments.lexers.supercollider', 'SuperCollider', ('supercollider', 'sc'), ('*.sc', '*.scd'), ('application/supercollider', 'text/supercollider')),
+ 'SwiftLexer': ('pip._vendor.pygments.lexers.objective', 'Swift', ('swift',), ('*.swift',), ('text/x-swift',)),
+ 'SwigLexer': ('pip._vendor.pygments.lexers.c_like', 'SWIG', ('swig',), ('*.swg', '*.i'), ('text/swig',)),
+ 'SystemVerilogLexer': ('pip._vendor.pygments.lexers.hdl', 'systemverilog', ('systemverilog', 'sv'), ('*.sv', '*.svh'), ('text/x-systemverilog',)),
+ 'SystemdLexer': ('pip._vendor.pygments.lexers.configs', 'Systemd', ('systemd',), ('*.service', '*.socket', '*.device', '*.mount', '*.automount', '*.swap', '*.target', '*.path', '*.timer', '*.slice', '*.scope'), ()),
+ 'TAPLexer': ('pip._vendor.pygments.lexers.testing', 'TAP', ('tap',), ('*.tap',), ()),
+ 'TNTLexer': ('pip._vendor.pygments.lexers.tnt', 'Typographic Number Theory', ('tnt',), ('*.tnt',), ()),
+ 'TOMLLexer': ('pip._vendor.pygments.lexers.configs', 'TOML', ('toml',), ('*.toml', 'Pipfile', 'poetry.lock'), ('application/toml',)),
+ 'TactLexer': ('pip._vendor.pygments.lexers.tact', 'Tact', ('tact',), ('*.tact',), ()),
+ 'Tads3Lexer': ('pip._vendor.pygments.lexers.int_fiction', 'TADS 3', ('tads3',), ('*.t',), ()),
+ 'TalLexer': ('pip._vendor.pygments.lexers.tal', 'Tal', ('tal', 'uxntal'), ('*.tal',), ('text/x-uxntal',)),
+ 'TasmLexer': ('pip._vendor.pygments.lexers.asm', 'TASM', ('tasm',), ('*.asm', '*.ASM', '*.tasm'), ('text/x-tasm',)),
+ 'TclLexer': ('pip._vendor.pygments.lexers.tcl', 'Tcl', ('tcl',), ('*.tcl', '*.rvt'), ('text/x-tcl', 'text/x-script.tcl', 'application/x-tcl')),
+ 'TcshLexer': ('pip._vendor.pygments.lexers.shell', 'Tcsh', ('tcsh', 'csh'), ('*.tcsh', '*.csh'), ('application/x-csh',)),
+ 'TcshSessionLexer': ('pip._vendor.pygments.lexers.shell', 'Tcsh Session', ('tcshcon',), (), ()),
+ 'TeaTemplateLexer': ('pip._vendor.pygments.lexers.templates', 'Tea', ('tea',), ('*.tea',), ('text/x-tea',)),
+ 'TealLexer': ('pip._vendor.pygments.lexers.teal', 'teal', ('teal',), ('*.teal',), ()),
+ 'TeraTermLexer': ('pip._vendor.pygments.lexers.teraterm', 'Tera Term macro', ('teratermmacro', 'teraterm', 'ttl'), ('*.ttl',), ('text/x-teratermmacro',)),
+ 'TermcapLexer': ('pip._vendor.pygments.lexers.configs', 'Termcap', ('termcap',), ('termcap', 'termcap.src'), ()),
+ 'TerminfoLexer': ('pip._vendor.pygments.lexers.configs', 'Terminfo', ('terminfo',), ('terminfo', 'terminfo.src'), ()),
+ 'TerraformLexer': ('pip._vendor.pygments.lexers.configs', 'Terraform', ('terraform', 'tf', 'hcl'), ('*.tf', '*.hcl'), ('application/x-tf', 'application/x-terraform')),
+ 'TexLexer': ('pip._vendor.pygments.lexers.markup', 'TeX', ('tex', 'latex'), ('*.tex', '*.aux', '*.toc'), ('text/x-tex', 'text/x-latex')),
+ 'TextLexer': ('pip._vendor.pygments.lexers.special', 'Text only', ('text',), ('*.txt',), ('text/plain',)),
+ 'ThingsDBLexer': ('pip._vendor.pygments.lexers.thingsdb', 'ThingsDB', ('ti', 'thingsdb'), ('*.ti',), ()),
+ 'ThriftLexer': ('pip._vendor.pygments.lexers.dsls', 'Thrift', ('thrift',), ('*.thrift',), ('application/x-thrift',)),
+ 'TiddlyWiki5Lexer': ('pip._vendor.pygments.lexers.markup', 'tiddler', ('tid',), ('*.tid',), ('text/vnd.tiddlywiki',)),
+ 'TlbLexer': ('pip._vendor.pygments.lexers.tlb', 'Tl-b', ('tlb',), ('*.tlb',), ()),
+ 'TlsLexer': ('pip._vendor.pygments.lexers.tls', 'TLS Presentation Language', ('tls',), (), ()),
+ 'TodotxtLexer': ('pip._vendor.pygments.lexers.textfmts', 'Todotxt', ('todotxt',), ('todo.txt', '*.todotxt'), ('text/x-todo',)),
+ 'TransactSqlLexer': ('pip._vendor.pygments.lexers.sql', 'Transact-SQL', ('tsql', 't-sql'), ('*.sql',), ('text/x-tsql',)),
+ 'TreetopLexer': ('pip._vendor.pygments.lexers.parsers', 'Treetop', ('treetop',), ('*.treetop', '*.tt'), ()),
+ 'TurtleLexer': ('pip._vendor.pygments.lexers.rdf', 'Turtle', ('turtle',), ('*.ttl',), ('text/turtle', 'application/x-turtle')),
+ 'TwigHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Twig', ('html+twig',), ('*.twig',), ('text/html+twig',)),
+ 'TwigLexer': ('pip._vendor.pygments.lexers.templates', 'Twig', ('twig',), (), ('application/x-twig',)),
+ 'TypeScriptLexer': ('pip._vendor.pygments.lexers.javascript', 'TypeScript', ('typescript', 'ts'), ('*.ts',), ('application/x-typescript', 'text/x-typescript')),
+ 'TypoScriptCssDataLexer': ('pip._vendor.pygments.lexers.typoscript', 'TypoScriptCssData', ('typoscriptcssdata',), (), ()),
+ 'TypoScriptHtmlDataLexer': ('pip._vendor.pygments.lexers.typoscript', 'TypoScriptHtmlData', ('typoscripthtmldata',), (), ()),
+ 'TypoScriptLexer': ('pip._vendor.pygments.lexers.typoscript', 'TypoScript', ('typoscript',), ('*.typoscript',), ('text/x-typoscript',)),
+ 'TypstLexer': ('pip._vendor.pygments.lexers.typst', 'Typst', ('typst',), ('*.typ',), ('text/x-typst',)),
+ 'UL4Lexer': ('pip._vendor.pygments.lexers.ul4', 'UL4', ('ul4',), ('*.ul4',), ()),
+ 'UcodeLexer': ('pip._vendor.pygments.lexers.unicon', 'ucode', ('ucode',), ('*.u', '*.u1', '*.u2'), ()),
+ 'UniconLexer': ('pip._vendor.pygments.lexers.unicon', 'Unicon', ('unicon',), ('*.icn',), ('text/unicon',)),
+ 'UnixConfigLexer': ('pip._vendor.pygments.lexers.configs', 'Unix/Linux config files', ('unixconfig', 'linuxconfig'), (), ()),
+ 'UrbiscriptLexer': ('pip._vendor.pygments.lexers.urbi', 'UrbiScript', ('urbiscript',), ('*.u',), ('application/x-urbiscript',)),
+ 'UrlEncodedLexer': ('pip._vendor.pygments.lexers.html', 'urlencoded', ('urlencoded',), (), ('application/x-www-form-urlencoded',)),
+ 'UsdLexer': ('pip._vendor.pygments.lexers.usd', 'USD', ('usd', 'usda'), ('*.usd', '*.usda'), ()),
+ 'VBScriptLexer': ('pip._vendor.pygments.lexers.basic', 'VBScript', ('vbscript',), ('*.vbs', '*.VBS'), ()),
+ 'VCLLexer': ('pip._vendor.pygments.lexers.varnish', 'VCL', ('vcl',), ('*.vcl',), ('text/x-vclsrc',)),
+ 'VCLSnippetLexer': ('pip._vendor.pygments.lexers.varnish', 'VCLSnippets', ('vclsnippets', 'vclsnippet'), (), ('text/x-vclsnippet',)),
+ 'VCTreeStatusLexer': ('pip._vendor.pygments.lexers.console', 'VCTreeStatus', ('vctreestatus',), (), ()),
+ 'VGLLexer': ('pip._vendor.pygments.lexers.dsls', 'VGL', ('vgl',), ('*.rpf',), ()),
+ 'ValaLexer': ('pip._vendor.pygments.lexers.c_like', 'Vala', ('vala', 'vapi'), ('*.vala', '*.vapi'), ('text/x-vala',)),
+ 'VbNetAspxLexer': ('pip._vendor.pygments.lexers.dotnet', 'aspx-vb', ('aspx-vb',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
+ 'VbNetLexer': ('pip._vendor.pygments.lexers.dotnet', 'VB.net', ('vb.net', 'vbnet', 'lobas', 'oobas', 'sobas', 'visual-basic', 'visualbasic'), ('*.vb', '*.bas'), ('text/x-vbnet', 'text/x-vba')),
+ 'VelocityHtmlLexer': ('pip._vendor.pygments.lexers.templates', 'HTML+Velocity', ('html+velocity',), (), ('text/html+velocity',)),
+ 'VelocityLexer': ('pip._vendor.pygments.lexers.templates', 'Velocity', ('velocity',), ('*.vm', '*.fhtml'), ()),
+ 'VelocityXmlLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Velocity', ('xml+velocity',), (), ('application/xml+velocity',)),
+ 'VerifpalLexer': ('pip._vendor.pygments.lexers.verifpal', 'Verifpal', ('verifpal',), ('*.vp',), ('text/x-verifpal',)),
+ 'VerilogLexer': ('pip._vendor.pygments.lexers.hdl', 'verilog', ('verilog', 'v'), ('*.v',), ('text/x-verilog',)),
+ 'VhdlLexer': ('pip._vendor.pygments.lexers.hdl', 'vhdl', ('vhdl',), ('*.vhdl', '*.vhd'), ('text/x-vhdl',)),
+ 'VimLexer': ('pip._vendor.pygments.lexers.textedit', 'VimL', ('vim',), ('*.vim', '.vimrc', '.exrc', '.gvimrc', '_vimrc', '_exrc', '_gvimrc', 'vimrc', 'gvimrc'), ('text/x-vim',)),
+ 'VisualPrologGrammarLexer': ('pip._vendor.pygments.lexers.vip', 'Visual Prolog Grammar', ('visualprologgrammar',), ('*.vipgrm',), ()),
+ 'VisualPrologLexer': ('pip._vendor.pygments.lexers.vip', 'Visual Prolog', ('visualprolog',), ('*.pro', '*.cl', '*.i', '*.pack', '*.ph'), ()),
+ 'VyperLexer': ('pip._vendor.pygments.lexers.vyper', 'Vyper', ('vyper',), ('*.vy',), ()),
+ 'WDiffLexer': ('pip._vendor.pygments.lexers.diff', 'WDiff', ('wdiff',), ('*.wdiff',), ()),
+ 'WatLexer': ('pip._vendor.pygments.lexers.webassembly', 'WebAssembly', ('wast', 'wat'), ('*.wat', '*.wast'), ()),
+ 'WebIDLLexer': ('pip._vendor.pygments.lexers.webidl', 'Web IDL', ('webidl',), ('*.webidl',), ()),
+ 'WgslLexer': ('pip._vendor.pygments.lexers.wgsl', 'WebGPU Shading Language', ('wgsl',), ('*.wgsl',), ('text/wgsl',)),
+ 'WhileyLexer': ('pip._vendor.pygments.lexers.whiley', 'Whiley', ('whiley',), ('*.whiley',), ('text/x-whiley',)),
+ 'WikitextLexer': ('pip._vendor.pygments.lexers.markup', 'Wikitext', ('wikitext', 'mediawiki'), (), ('text/x-wiki',)),
+ 'WoWTocLexer': ('pip._vendor.pygments.lexers.wowtoc', 'World of Warcraft TOC', ('wowtoc',), ('*.toc',), ()),
+ 'WrenLexer': ('pip._vendor.pygments.lexers.wren', 'Wren', ('wren',), ('*.wren',), ()),
+ 'X10Lexer': ('pip._vendor.pygments.lexers.x10', 'X10', ('x10', 'xten'), ('*.x10',), ('text/x-x10',)),
+ 'XMLUL4Lexer': ('pip._vendor.pygments.lexers.ul4', 'XML+UL4', ('xml+ul4',), ('*.xmlul4',), ()),
+ 'XQueryLexer': ('pip._vendor.pygments.lexers.webmisc', 'XQuery', ('xquery', 'xqy', 'xq', 'xql', 'xqm'), ('*.xqy', '*.xquery', '*.xq', '*.xql', '*.xqm'), ('text/xquery', 'application/xquery')),
+ 'XmlDjangoLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Django/Jinja', ('xml+django', 'xml+jinja'), ('*.xml.j2', '*.xml.jinja2'), ('application/xml+django', 'application/xml+jinja')),
+ 'XmlErbLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Ruby', ('xml+ruby', 'xml+erb'), (), ('application/xml+ruby',)),
+ 'XmlLexer': ('pip._vendor.pygments.lexers.html', 'XML', ('xml',), ('*.xml', '*.xsl', '*.rss', '*.xslt', '*.xsd', '*.wsdl', '*.wsf'), ('text/xml', 'application/xml', 'image/svg+xml', 'application/rss+xml', 'application/atom+xml')),
+ 'XmlPhpLexer': ('pip._vendor.pygments.lexers.templates', 'XML+PHP', ('xml+php',), (), ('application/xml+php',)),
+ 'XmlSmartyLexer': ('pip._vendor.pygments.lexers.templates', 'XML+Smarty', ('xml+smarty',), (), ('application/xml+smarty',)),
+ 'XorgLexer': ('pip._vendor.pygments.lexers.xorg', 'Xorg', ('xorg.conf',), ('xorg.conf',), ()),
+ 'XppLexer': ('pip._vendor.pygments.lexers.dotnet', 'X++', ('xpp', 'x++'), ('*.xpp',), ()),
+ 'XsltLexer': ('pip._vendor.pygments.lexers.html', 'XSLT', ('xslt',), ('*.xsl', '*.xslt', '*.xpl'), ('application/xsl+xml', 'application/xslt+xml')),
+ 'XtendLexer': ('pip._vendor.pygments.lexers.jvm', 'Xtend', ('xtend',), ('*.xtend',), ('text/x-xtend',)),
+ 'XtlangLexer': ('pip._vendor.pygments.lexers.lisp', 'xtlang', ('extempore',), ('*.xtm',), ()),
+ 'YamlJinjaLexer': ('pip._vendor.pygments.lexers.templates', 'YAML+Jinja', ('yaml+jinja', 'salt', 'sls'), ('*.sls', '*.yaml.j2', '*.yml.j2', '*.yaml.jinja2', '*.yml.jinja2'), ('text/x-yaml+jinja', 'text/x-sls')),
+ 'YamlLexer': ('pip._vendor.pygments.lexers.data', 'YAML', ('yaml',), ('*.yaml', '*.yml'), ('text/x-yaml',)),
+ 'YangLexer': ('pip._vendor.pygments.lexers.yang', 'YANG', ('yang',), ('*.yang',), ('application/yang',)),
+ 'YaraLexer': ('pip._vendor.pygments.lexers.yara', 'YARA', ('yara', 'yar'), ('*.yar',), ('text/x-yara',)),
+ 'ZeekLexer': ('pip._vendor.pygments.lexers.dsls', 'Zeek', ('zeek', 'bro'), ('*.zeek', '*.bro'), ()),
+ 'ZephirLexer': ('pip._vendor.pygments.lexers.php', 'Zephir', ('zephir',), ('*.zep',), ()),
+ 'ZigLexer': ('pip._vendor.pygments.lexers.zig', 'Zig', ('zig',), ('*.zig',), ('text/zig',)),
+ 'apdlexer': ('pip._vendor.pygments.lexers.apdlexer', 'ANSYS parametric design language', ('ansys', 'apdl'), ('*.ans',), ()),
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/python.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/python.py
new file mode 100644
index 000000000..b2d07f208
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/lexers/python.py
@@ -0,0 +1,1198 @@
+"""
+ pygments.lexers.python
+ ~~~~~~~~~~~~~~~~~~~~~~
+
+ Lexers for Python and related languages.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import keyword
+
+from pip._vendor.pygments.lexer import DelegatingLexer, RegexLexer, include, \
+ bygroups, using, default, words, combined, this
+from pip._vendor.pygments.util import get_bool_opt, shebang_matches
+from pip._vendor.pygments.token import Text, Comment, Operator, Keyword, Name, String, \
+ Number, Punctuation, Generic, Other, Error, Whitespace
+from pip._vendor.pygments import unistring as uni
+
+__all__ = ['PythonLexer', 'PythonConsoleLexer', 'PythonTracebackLexer',
+ 'Python2Lexer', 'Python2TracebackLexer',
+ 'CythonLexer', 'DgLexer', 'NumPyLexer']
+
+
+class PythonLexer(RegexLexer):
+ """
+ For Python source code (version 3.x).
+
+ .. versionchanged:: 2.5
+ This is now the default ``PythonLexer``. It is still available as the
+ alias ``Python3Lexer``.
+ """
+
+ name = 'Python'
+ url = 'https://www.python.org'
+ aliases = ['python', 'py', 'sage', 'python3', 'py3', 'bazel', 'starlark']
+ filenames = [
+ '*.py',
+ '*.pyw',
+ # Type stubs
+ '*.pyi',
+ # Jython
+ '*.jy',
+ # Sage
+ '*.sage',
+ # SCons
+ '*.sc',
+ 'SConstruct',
+ 'SConscript',
+ # Skylark/Starlark (used by Bazel, Buck, and Pants)
+ '*.bzl',
+ 'BUCK',
+ 'BUILD',
+ 'BUILD.bazel',
+ 'WORKSPACE',
+ # Twisted Application infrastructure
+ '*.tac',
+ ]
+ mimetypes = ['text/x-python', 'application/x-python',
+ 'text/x-python3', 'application/x-python3']
+ version_added = '0.10'
+
+ uni_name = f"[{uni.xid_start}][{uni.xid_continue}]*"
+
+ def innerstring_rules(ttype):
+ return [
+ # the old style '%s' % (...) string formatting (still valid in Py3)
+ (r'%(\(\w+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
+ '[hlL]?[E-GXc-giorsaux%]', String.Interpol),
+ # the new style '{}'.format(...) string formatting
+ (r'\{'
+ r'((\w+)((\.\w+)|(\[[^\]]+\]))*)?' # field name
+ r'(\![sra])?' # conversion
+ r'(\:(.?[<>=\^])?[-+ ]?#?0?(\d+)?,?(\.\d+)?[E-GXb-gnosx%]?)?'
+ r'\}', String.Interpol),
+
+ # backslashes, quotes and formatting signs must be parsed one at a time
+ (r'[^\\\'"%{\n]+', ttype),
+ (r'[\'"\\]', ttype),
+ # unhandled string formatting sign
+ (r'%|(\{{1,2})', ttype)
+ # newlines are an error (use "nl" state)
+ ]
+
+ def fstring_rules(ttype):
+ return [
+ # Assuming that a '}' is the closing brace after format specifier.
+ # Sadly, this means that we won't detect syntax error. But it's
+ # more important to parse correct syntax correctly, than to
+ # highlight invalid syntax.
+ (r'\}', String.Interpol),
+ (r'\{', String.Interpol, 'expr-inside-fstring'),
+ # backslashes, quotes and formatting signs must be parsed one at a time
+ (r'[^\\\'"{}\n]+', ttype),
+ (r'[\'"\\]', ttype),
+ # newlines are an error (use "nl" state)
+ ]
+
+ tokens = {
+ 'root': [
+ (r'\n', Whitespace),
+ (r'^(\s*)([rRuUbB]{,2})("""(?:.|\n)*?""")',
+ bygroups(Whitespace, String.Affix, String.Doc)),
+ (r"^(\s*)([rRuUbB]{,2})('''(?:.|\n)*?''')",
+ bygroups(Whitespace, String.Affix, String.Doc)),
+ (r'\A#!.+$', Comment.Hashbang),
+ (r'#.*$', Comment.Single),
+ (r'\\\n', Text),
+ (r'\\', Text),
+ include('keywords'),
+ include('soft-keywords'),
+ (r'(def)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'funcname'),
+ (r'(class)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'classname'),
+ (r'(from)((?:\s|\\\s)+)', bygroups(Keyword.Namespace, Text),
+ 'fromimport'),
+ (r'(import)((?:\s|\\\s)+)', bygroups(Keyword.Namespace, Text),
+ 'import'),
+ include('expr'),
+ ],
+ 'expr': [
+ # raw f-strings
+ ('(?i)(rf|fr)(""")',
+ bygroups(String.Affix, String.Double),
+ combined('rfstringescape', 'tdqf')),
+ ("(?i)(rf|fr)(''')",
+ bygroups(String.Affix, String.Single),
+ combined('rfstringescape', 'tsqf')),
+ ('(?i)(rf|fr)(")',
+ bygroups(String.Affix, String.Double),
+ combined('rfstringescape', 'dqf')),
+ ("(?i)(rf|fr)(')",
+ bygroups(String.Affix, String.Single),
+ combined('rfstringescape', 'sqf')),
+ # non-raw f-strings
+ ('([fF])(""")', bygroups(String.Affix, String.Double),
+ combined('fstringescape', 'tdqf')),
+ ("([fF])(''')", bygroups(String.Affix, String.Single),
+ combined('fstringescape', 'tsqf')),
+ ('([fF])(")', bygroups(String.Affix, String.Double),
+ combined('fstringescape', 'dqf')),
+ ("([fF])(')", bygroups(String.Affix, String.Single),
+ combined('fstringescape', 'sqf')),
+ # raw bytes and strings
+ ('(?i)(rb|br|r)(""")',
+ bygroups(String.Affix, String.Double), 'tdqs'),
+ ("(?i)(rb|br|r)(''')",
+ bygroups(String.Affix, String.Single), 'tsqs'),
+ ('(?i)(rb|br|r)(")',
+ bygroups(String.Affix, String.Double), 'dqs'),
+ ("(?i)(rb|br|r)(')",
+ bygroups(String.Affix, String.Single), 'sqs'),
+ # non-raw strings
+ ('([uU]?)(""")', bygroups(String.Affix, String.Double),
+ combined('stringescape', 'tdqs')),
+ ("([uU]?)(''')", bygroups(String.Affix, String.Single),
+ combined('stringescape', 'tsqs')),
+ ('([uU]?)(")', bygroups(String.Affix, String.Double),
+ combined('stringescape', 'dqs')),
+ ("([uU]?)(')", bygroups(String.Affix, String.Single),
+ combined('stringescape', 'sqs')),
+ # non-raw bytes
+ ('([bB])(""")', bygroups(String.Affix, String.Double),
+ combined('bytesescape', 'tdqs')),
+ ("([bB])(''')", bygroups(String.Affix, String.Single),
+ combined('bytesescape', 'tsqs')),
+ ('([bB])(")', bygroups(String.Affix, String.Double),
+ combined('bytesescape', 'dqs')),
+ ("([bB])(')", bygroups(String.Affix, String.Single),
+ combined('bytesescape', 'sqs')),
+
+ (r'[^\S\n]+', Text),
+ include('numbers'),
+ (r'!=|==|<<|>>|:=|[-~+/*%=<>&^|.]', Operator),
+ (r'[]{}:(),;[]', Punctuation),
+ (r'(in|is|and|or|not)\b', Operator.Word),
+ include('expr-keywords'),
+ include('builtins'),
+ include('magicfuncs'),
+ include('magicvars'),
+ include('name'),
+ ],
+ 'expr-inside-fstring': [
+ (r'[{([]', Punctuation, 'expr-inside-fstring-inner'),
+ # without format specifier
+ (r'(=\s*)?' # debug (https://bugs.python.org/issue36817)
+ r'(\![sraf])?' # conversion
+ r'\}', String.Interpol, '#pop'),
+ # with format specifier
+ # we'll catch the remaining '}' in the outer scope
+ (r'(=\s*)?' # debug (https://bugs.python.org/issue36817)
+ r'(\![sraf])?' # conversion
+ r':', String.Interpol, '#pop'),
+ (r'\s+', Whitespace), # allow new lines
+ include('expr'),
+ ],
+ 'expr-inside-fstring-inner': [
+ (r'[{([]', Punctuation, 'expr-inside-fstring-inner'),
+ (r'[])}]', Punctuation, '#pop'),
+ (r'\s+', Whitespace), # allow new lines
+ include('expr'),
+ ],
+ 'expr-keywords': [
+ # Based on https://docs.python.org/3/reference/expressions.html
+ (words((
+ 'async for', 'await', 'else', 'for', 'if', 'lambda',
+ 'yield', 'yield from'), suffix=r'\b'),
+ Keyword),
+ (words(('True', 'False', 'None'), suffix=r'\b'), Keyword.Constant),
+ ],
+ 'keywords': [
+ (words((
+ 'assert', 'async', 'await', 'break', 'continue', 'del', 'elif',
+ 'else', 'except', 'finally', 'for', 'global', 'if', 'lambda',
+ 'pass', 'raise', 'nonlocal', 'return', 'try', 'while', 'yield',
+ 'yield from', 'as', 'with'), suffix=r'\b'),
+ Keyword),
+ (words(('True', 'False', 'None'), suffix=r'\b'), Keyword.Constant),
+ ],
+ 'soft-keywords': [
+ # `match`, `case` and `_` soft keywords
+ (r'(^[ \t]*)' # at beginning of line + possible indentation
+ r'(match|case)\b' # a possible keyword
+ r'(?![ \t]*(?:' # not followed by...
+ r'[:,;=^&|@~)\]}]|(?:' + # characters and keywords that mean this isn't
+ # pattern matching (but None/True/False is ok)
+ r'|'.join(k for k in keyword.kwlist if k[0].islower()) + r')\b))',
+ bygroups(Text, Keyword), 'soft-keywords-inner'),
+ ],
+ 'soft-keywords-inner': [
+ # optional `_` keyword
+ (r'(\s+)([^\n_]*)(_\b)', bygroups(Whitespace, using(this), Keyword)),
+ default('#pop')
+ ],
+ 'builtins': [
+ (words((
+ '__import__', 'abs', 'aiter', 'all', 'any', 'bin', 'bool', 'bytearray',
+ 'breakpoint', 'bytes', 'callable', 'chr', 'classmethod', 'compile',
+ 'complex', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval',
+ 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals',
+ 'hasattr', 'hash', 'hex', 'id', 'input', 'int', 'isinstance',
+ 'issubclass', 'iter', 'len', 'list', 'locals', 'map', 'max',
+ 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow',
+ 'print', 'property', 'range', 'repr', 'reversed', 'round', 'set',
+ 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super',
+ 'tuple', 'type', 'vars', 'zip'), prefix=r'(?<!\.)', suffix=r'\b'),
+ Name.Builtin),
+ (r'(?<!\.)(self|Ellipsis|NotImplemented|cls)\b', Name.Builtin.Pseudo),
+ (words((
+ 'ArithmeticError', 'AssertionError', 'AttributeError',
+ 'BaseException', 'BufferError', 'BytesWarning', 'DeprecationWarning',
+ 'EOFError', 'EnvironmentError', 'Exception', 'FloatingPointError',
+ 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError',
+ 'ImportWarning', 'IndentationError', 'IndexError', 'KeyError',
+ 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'NameError',
+ 'NotImplementedError', 'OSError', 'OverflowError',
+ 'PendingDeprecationWarning', 'ReferenceError', 'ResourceWarning',
+ 'RuntimeError', 'RuntimeWarning', 'StopIteration',
+ 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit',
+ 'TabError', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError',
+ 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError',
+ 'UnicodeWarning', 'UserWarning', 'ValueError', 'VMSError',
+ 'Warning', 'WindowsError', 'ZeroDivisionError',
+ # new builtin exceptions from PEP 3151
+ 'BlockingIOError', 'ChildProcessError', 'ConnectionError',
+ 'BrokenPipeError', 'ConnectionAbortedError', 'ConnectionRefusedError',
+ 'ConnectionResetError', 'FileExistsError', 'FileNotFoundError',
+ 'InterruptedError', 'IsADirectoryError', 'NotADirectoryError',
+ 'PermissionError', 'ProcessLookupError', 'TimeoutError',
+ # others new in Python 3
+ 'StopAsyncIteration', 'ModuleNotFoundError', 'RecursionError',
+ 'EncodingWarning'),
+ prefix=r'(?<!\.)', suffix=r'\b'),
+ Name.Exception),
+ ],
+ 'magicfuncs': [
+ (words((
+ '__abs__', '__add__', '__aenter__', '__aexit__', '__aiter__',
+ '__and__', '__anext__', '__await__', '__bool__', '__bytes__',
+ '__call__', '__complex__', '__contains__', '__del__', '__delattr__',
+ '__delete__', '__delitem__', '__dir__', '__divmod__', '__enter__',
+ '__eq__', '__exit__', '__float__', '__floordiv__', '__format__',
+ '__ge__', '__get__', '__getattr__', '__getattribute__',
+ '__getitem__', '__gt__', '__hash__', '__iadd__', '__iand__',
+ '__ifloordiv__', '__ilshift__', '__imatmul__', '__imod__',
+ '__imul__', '__index__', '__init__', '__instancecheck__',
+ '__int__', '__invert__', '__ior__', '__ipow__', '__irshift__',
+ '__isub__', '__iter__', '__itruediv__', '__ixor__', '__le__',
+ '__len__', '__length_hint__', '__lshift__', '__lt__', '__matmul__',
+ '__missing__', '__mod__', '__mul__', '__ne__', '__neg__',
+ '__new__', '__next__', '__or__', '__pos__', '__pow__',
+ '__prepare__', '__radd__', '__rand__', '__rdivmod__', '__repr__',
+ '__reversed__', '__rfloordiv__', '__rlshift__', '__rmatmul__',
+ '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__',
+ '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__',
+ '__rxor__', '__set__', '__setattr__', '__setitem__', '__str__',
+ '__sub__', '__subclasscheck__', '__truediv__',
+ '__xor__'), suffix=r'\b'),
+ Name.Function.Magic),
+ ],
+ 'magicvars': [
+ (words((
+ '__annotations__', '__bases__', '__class__', '__closure__',
+ '__code__', '__defaults__', '__dict__', '__doc__', '__file__',
+ '__func__', '__globals__', '__kwdefaults__', '__module__',
+ '__mro__', '__name__', '__objclass__', '__qualname__',
+ '__self__', '__slots__', '__weakref__'), suffix=r'\b'),
+ Name.Variable.Magic),
+ ],
+ 'numbers': [
+ (r'(\d(?:_?\d)*\.(?:\d(?:_?\d)*)?|(?:\d(?:_?\d)*)?\.\d(?:_?\d)*)'
+ r'([eE][+-]?\d(?:_?\d)*)?', Number.Float),
+ (r'\d(?:_?\d)*[eE][+-]?\d(?:_?\d)*j?', Number.Float),
+ (r'0[oO](?:_?[0-7])+', Number.Oct),
+ (r'0[bB](?:_?[01])+', Number.Bin),
+ (r'0[xX](?:_?[a-fA-F0-9])+', Number.Hex),
+ (r'\d(?:_?\d)*', Number.Integer),
+ ],
+ 'name': [
+ (r'@' + uni_name, Name.Decorator),
+ (r'@', Operator), # new matrix multiplication operator
+ (uni_name, Name),
+ ],
+ 'funcname': [
+ include('magicfuncs'),
+ (uni_name, Name.Function, '#pop'),
+ default('#pop'),
+ ],
+ 'classname': [
+ (uni_name, Name.Class, '#pop'),
+ ],
+ 'import': [
+ (r'(\s+)(as)(\s+)', bygroups(Text, Keyword, Text)),
+ (r'\.', Name.Namespace),
+ (uni_name, Name.Namespace),
+ (r'(\s*)(,)(\s*)', bygroups(Text, Operator, Text)),
+ default('#pop') # all else: go back
+ ],
+ 'fromimport': [
+ (r'(\s+)(import)\b', bygroups(Text, Keyword.Namespace), '#pop'),
+ (r'\.', Name.Namespace),
+ # if None occurs here, it's "raise x from None", since None can
+ # never be a module name
+ (r'None\b', Keyword.Constant, '#pop'),
+ (uni_name, Name.Namespace),
+ default('#pop'),
+ ],
+ 'rfstringescape': [
+ (r'\{\{', String.Escape),
+ (r'\}\}', String.Escape),
+ ],
+ 'fstringescape': [
+ include('rfstringescape'),
+ include('stringescape'),
+ ],
+ 'bytesescape': [
+ (r'\\([\\abfnrtv"\']|\n|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
+ ],
+ 'stringescape': [
+ (r'\\(N\{.*?\}|u[a-fA-F0-9]{4}|U[a-fA-F0-9]{8})', String.Escape),
+ include('bytesescape')
+ ],
+ 'fstrings-single': fstring_rules(String.Single),
+ 'fstrings-double': fstring_rules(String.Double),
+ 'strings-single': innerstring_rules(String.Single),
+ 'strings-double': innerstring_rules(String.Double),
+ 'dqf': [
+ (r'"', String.Double, '#pop'),
+ (r'\\\\|\\"|\\\n', String.Escape), # included here for raw strings
+ include('fstrings-double')
+ ],
+ 'sqf': [
+ (r"'", String.Single, '#pop'),
+ (r"\\\\|\\'|\\\n", String.Escape), # included here for raw strings
+ include('fstrings-single')
+ ],
+ 'dqs': [
+ (r'"', String.Double, '#pop'),
+ (r'\\\\|\\"|\\\n', String.Escape), # included here for raw strings
+ include('strings-double')
+ ],
+ 'sqs': [
+ (r"'", String.Single, '#pop'),
+ (r"\\\\|\\'|\\\n", String.Escape), # included here for raw strings
+ include('strings-single')
+ ],
+ 'tdqf': [
+ (r'"""', String.Double, '#pop'),
+ include('fstrings-double'),
+ (r'\n', String.Double)
+ ],
+ 'tsqf': [
+ (r"'''", String.Single, '#pop'),
+ include('fstrings-single'),
+ (r'\n', String.Single)
+ ],
+ 'tdqs': [
+ (r'"""', String.Double, '#pop'),
+ include('strings-double'),
+ (r'\n', String.Double)
+ ],
+ 'tsqs': [
+ (r"'''", String.Single, '#pop'),
+ include('strings-single'),
+ (r'\n', String.Single)
+ ],
+ }
+
+ def analyse_text(text):
+ return shebang_matches(text, r'pythonw?(3(\.\d)?)?') or \
+ 'import ' in text[:1000]
+
+
+Python3Lexer = PythonLexer
+
+
+class Python2Lexer(RegexLexer):
+ """
+ For Python 2.x source code.
+
+ .. versionchanged:: 2.5
+ This class has been renamed from ``PythonLexer``. ``PythonLexer`` now
+ refers to the Python 3 variant. File name patterns like ``*.py`` have
+ been moved to Python 3 as well.
+ """
+
+ name = 'Python 2.x'
+ url = 'https://www.python.org'
+ aliases = ['python2', 'py2']
+ filenames = [] # now taken over by PythonLexer (3.x)
+ mimetypes = ['text/x-python2', 'application/x-python2']
+ version_added = ''
+
+ def innerstring_rules(ttype):
+ return [
+ # the old style '%s' % (...) string formatting
+ (r'%(\(\w+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
+ '[hlL]?[E-GXc-giorsux%]', String.Interpol),
+ # backslashes, quotes and formatting signs must be parsed one at a time
+ (r'[^\\\'"%\n]+', ttype),
+ (r'[\'"\\]', ttype),
+ # unhandled string formatting sign
+ (r'%', ttype),
+ # newlines are an error (use "nl" state)
+ ]
+
+ tokens = {
+ 'root': [
+ (r'\n', Whitespace),
+ (r'^(\s*)([rRuUbB]{,2})("""(?:.|\n)*?""")',
+ bygroups(Whitespace, String.Affix, String.Doc)),
+ (r"^(\s*)([rRuUbB]{,2})('''(?:.|\n)*?''')",
+ bygroups(Whitespace, String.Affix, String.Doc)),
+ (r'[^\S\n]+', Text),
+ (r'\A#!.+$', Comment.Hashbang),
+ (r'#.*$', Comment.Single),
+ (r'[]{}:(),;[]', Punctuation),
+ (r'\\\n', Text),
+ (r'\\', Text),
+ (r'(in|is|and|or|not)\b', Operator.Word),
+ (r'!=|==|<<|>>|[-~+/*%=<>&^|.]', Operator),
+ include('keywords'),
+ (r'(def)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'funcname'),
+ (r'(class)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'classname'),
+ (r'(from)((?:\s|\\\s)+)', bygroups(Keyword.Namespace, Text),
+ 'fromimport'),
+ (r'(import)((?:\s|\\\s)+)', bygroups(Keyword.Namespace, Text),
+ 'import'),
+ include('builtins'),
+ include('magicfuncs'),
+ include('magicvars'),
+ include('backtick'),
+ ('([rR]|[uUbB][rR]|[rR][uUbB])(""")',
+ bygroups(String.Affix, String.Double), 'tdqs'),
+ ("([rR]|[uUbB][rR]|[rR][uUbB])(''')",
+ bygroups(String.Affix, String.Single), 'tsqs'),
+ ('([rR]|[uUbB][rR]|[rR][uUbB])(")',
+ bygroups(String.Affix, String.Double), 'dqs'),
+ ("([rR]|[uUbB][rR]|[rR][uUbB])(')",
+ bygroups(String.Affix, String.Single), 'sqs'),
+ ('([uUbB]?)(""")', bygroups(String.Affix, String.Double),
+ combined('stringescape', 'tdqs')),
+ ("([uUbB]?)(''')", bygroups(String.Affix, String.Single),
+ combined('stringescape', 'tsqs')),
+ ('([uUbB]?)(")', bygroups(String.Affix, String.Double),
+ combined('stringescape', 'dqs')),
+ ("([uUbB]?)(')", bygroups(String.Affix, String.Single),
+ combined('stringescape', 'sqs')),
+ include('name'),
+ include('numbers'),
+ ],
+ 'keywords': [
+ (words((
+ 'assert', 'break', 'continue', 'del', 'elif', 'else', 'except',
+ 'exec', 'finally', 'for', 'global', 'if', 'lambda', 'pass',
+ 'print', 'raise', 'return', 'try', 'while', 'yield',
+ 'yield from', 'as', 'with'), suffix=r'\b'),
+ Keyword),
+ ],
+ 'builtins': [
+ (words((
+ '__import__', 'abs', 'all', 'any', 'apply', 'basestring', 'bin',
+ 'bool', 'buffer', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod',
+ 'cmp', 'coerce', 'compile', 'complex', 'delattr', 'dict', 'dir', 'divmod',
+ 'enumerate', 'eval', 'execfile', 'exit', 'file', 'filter', 'float',
+ 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'hex', 'id',
+ 'input', 'int', 'intern', 'isinstance', 'issubclass', 'iter', 'len',
+ 'list', 'locals', 'long', 'map', 'max', 'min', 'next', 'object',
+ 'oct', 'open', 'ord', 'pow', 'property', 'range', 'raw_input', 'reduce',
+ 'reload', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice',
+ 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type',
+ 'unichr', 'unicode', 'vars', 'xrange', 'zip'),
+ prefix=r'(?<!\.)', suffix=r'\b'),
+ Name.Builtin),
+ (r'(?<!\.)(self|None|Ellipsis|NotImplemented|False|True|cls'
+ r')\b', Name.Builtin.Pseudo),
+ (words((
+ 'ArithmeticError', 'AssertionError', 'AttributeError',
+ 'BaseException', 'DeprecationWarning', 'EOFError', 'EnvironmentError',
+ 'Exception', 'FloatingPointError', 'FutureWarning', 'GeneratorExit',
+ 'IOError', 'ImportError', 'ImportWarning', 'IndentationError',
+ 'IndexError', 'KeyError', 'KeyboardInterrupt', 'LookupError',
+ 'MemoryError', 'NameError',
+ 'NotImplementedError', 'OSError', 'OverflowError', 'OverflowWarning',
+ 'PendingDeprecationWarning', 'ReferenceError',
+ 'RuntimeError', 'RuntimeWarning', 'StandardError', 'StopIteration',
+ 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit',
+ 'TabError', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError',
+ 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError',
+ 'UnicodeWarning', 'UserWarning', 'ValueError', 'VMSError', 'Warning',
+ 'WindowsError', 'ZeroDivisionError'), prefix=r'(?<!\.)', suffix=r'\b'),
+ Name.Exception),
+ ],
+ 'magicfuncs': [
+ (words((
+ '__abs__', '__add__', '__and__', '__call__', '__cmp__', '__coerce__',
+ '__complex__', '__contains__', '__del__', '__delattr__', '__delete__',
+ '__delitem__', '__delslice__', '__div__', '__divmod__', '__enter__',
+ '__eq__', '__exit__', '__float__', '__floordiv__', '__ge__', '__get__',
+ '__getattr__', '__getattribute__', '__getitem__', '__getslice__', '__gt__',
+ '__hash__', '__hex__', '__iadd__', '__iand__', '__idiv__', '__ifloordiv__',
+ '__ilshift__', '__imod__', '__imul__', '__index__', '__init__',
+ '__instancecheck__', '__int__', '__invert__', '__iop__', '__ior__',
+ '__ipow__', '__irshift__', '__isub__', '__iter__', '__itruediv__',
+ '__ixor__', '__le__', '__len__', '__long__', '__lshift__', '__lt__',
+ '__missing__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__',
+ '__nonzero__', '__oct__', '__op__', '__or__', '__pos__', '__pow__',
+ '__radd__', '__rand__', '__rcmp__', '__rdiv__', '__rdivmod__', '__repr__',
+ '__reversed__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__',
+ '__rop__', '__ror__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__',
+ '__rtruediv__', '__rxor__', '__set__', '__setattr__', '__setitem__',
+ '__setslice__', '__str__', '__sub__', '__subclasscheck__', '__truediv__',
+ '__unicode__', '__xor__'), suffix=r'\b'),
+ Name.Function.Magic),
+ ],
+ 'magicvars': [
+ (words((
+ '__bases__', '__class__', '__closure__', '__code__', '__defaults__',
+ '__dict__', '__doc__', '__file__', '__func__', '__globals__',
+ '__metaclass__', '__module__', '__mro__', '__name__', '__self__',
+ '__slots__', '__weakref__'),
+ suffix=r'\b'),
+ Name.Variable.Magic),
+ ],
+ 'numbers': [
+ (r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?j?', Number.Float),
+ (r'\d+[eE][+-]?[0-9]+j?', Number.Float),
+ (r'0[0-7]+j?', Number.Oct),
+ (r'0[bB][01]+', Number.Bin),
+ (r'0[xX][a-fA-F0-9]+', Number.Hex),
+ (r'\d+L', Number.Integer.Long),
+ (r'\d+j?', Number.Integer)
+ ],
+ 'backtick': [
+ ('`.*?`', String.Backtick),
+ ],
+ 'name': [
+ (r'@[\w.]+', Name.Decorator),
+ (r'[a-zA-Z_]\w*', Name),
+ ],
+ 'funcname': [
+ include('magicfuncs'),
+ (r'[a-zA-Z_]\w*', Name.Function, '#pop'),
+ default('#pop'),
+ ],
+ 'classname': [
+ (r'[a-zA-Z_]\w*', Name.Class, '#pop')
+ ],
+ 'import': [
+ (r'(?:[ \t]|\\\n)+', Text),
+ (r'as\b', Keyword.Namespace),
+ (r',', Operator),
+ (r'[a-zA-Z_][\w.]*', Name.Namespace),
+ default('#pop') # all else: go back
+ ],
+ 'fromimport': [
+ (r'(?:[ \t]|\\\n)+', Text),
+ (r'import\b', Keyword.Namespace, '#pop'),
+ # if None occurs here, it's "raise x from None", since None can
+ # never be a module name
+ (r'None\b', Name.Builtin.Pseudo, '#pop'),
+ # sadly, in "raise x from y" y will be highlighted as namespace too
+ (r'[a-zA-Z_.][\w.]*', Name.Namespace),
+ # anything else here also means "raise x from y" and is therefore
+ # not an error
+ default('#pop'),
+ ],
+ 'stringescape': [
+ (r'\\([\\abfnrtv"\']|\n|N\{.*?\}|u[a-fA-F0-9]{4}|'
+ r'U[a-fA-F0-9]{8}|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
+ ],
+ 'strings-single': innerstring_rules(String.Single),
+ 'strings-double': innerstring_rules(String.Double),
+ 'dqs': [
+ (r'"', String.Double, '#pop'),
+ (r'\\\\|\\"|\\\n', String.Escape), # included here for raw strings
+ include('strings-double')
+ ],
+ 'sqs': [
+ (r"'", String.Single, '#pop'),
+ (r"\\\\|\\'|\\\n", String.Escape), # included here for raw strings
+ include('strings-single')
+ ],
+ 'tdqs': [
+ (r'"""', String.Double, '#pop'),
+ include('strings-double'),
+ (r'\n', String.Double)
+ ],
+ 'tsqs': [
+ (r"'''", String.Single, '#pop'),
+ include('strings-single'),
+ (r'\n', String.Single)
+ ],
+ }
+
+ def analyse_text(text):
+ return shebang_matches(text, r'pythonw?2(\.\d)?')
+
+class _PythonConsoleLexerBase(RegexLexer):
+ name = 'Python console session'
+ aliases = ['pycon', 'python-console']
+ mimetypes = ['text/x-python-doctest']
+
+ """Auxiliary lexer for `PythonConsoleLexer`.
+
+ Code tokens are output as ``Token.Other.Code``, traceback tokens as
+ ``Token.Other.Traceback``.
+ """
+ tokens = {
+ 'root': [
+ (r'(>>> )(.*\n)', bygroups(Generic.Prompt, Other.Code), 'continuations'),
+ # This happens, e.g., when tracebacks are embedded in documentation;
+ # trailing whitespaces are often stripped in such contexts.
+ (r'(>>>)(\n)', bygroups(Generic.Prompt, Whitespace)),
+ (r'(\^C)?Traceback \(most recent call last\):\n', Other.Traceback, 'traceback'),
+ # SyntaxError starts with this
+ (r' File "[^"]+", line \d+', Other.Traceback, 'traceback'),
+ (r'.*\n', Generic.Output),
+ ],
+ 'continuations': [
+ (r'(\.\.\. )(.*\n)', bygroups(Generic.Prompt, Other.Code)),
+ # See above.
+ (r'(\.\.\.)(\n)', bygroups(Generic.Prompt, Whitespace)),
+ default('#pop'),
+ ],
+ 'traceback': [
+ # As soon as we see a traceback, consume everything until the next
+ # >>> prompt.
+ (r'(?=>>>( |$))', Text, '#pop'),
+ (r'(KeyboardInterrupt)(\n)', bygroups(Name.Class, Whitespace)),
+ (r'.*\n', Other.Traceback),
+ ],
+ }
+
+class PythonConsoleLexer(DelegatingLexer):
+ """
+ For Python console output or doctests, such as:
+
+ .. sourcecode:: pycon
+
+ >>> a = 'foo'
+ >>> print(a)
+ foo
+ >>> 1 / 0
+ Traceback (most recent call last):
+ File "<stdin>", line 1, in <module>
+ ZeroDivisionError: integer division or modulo by zero
+
+ Additional options:
+
+ `python3`
+ Use Python 3 lexer for code. Default is ``True``.
+
+ .. versionadded:: 1.0
+ .. versionchanged:: 2.5
+ Now defaults to ``True``.
+ """
+
+ name = 'Python console session'
+ aliases = ['pycon', 'python-console']
+ mimetypes = ['text/x-python-doctest']
+ url = 'https://python.org'
+ version_added = ''
+
+ def __init__(self, **options):
+ python3 = get_bool_opt(options, 'python3', True)
+ if python3:
+ pylexer = PythonLexer
+ tblexer = PythonTracebackLexer
+ else:
+ pylexer = Python2Lexer
+ tblexer = Python2TracebackLexer
+ # We have two auxiliary lexers. Use DelegatingLexer twice with
+ # different tokens. TODO: DelegatingLexer should support this
+ # directly, by accepting a tuplet of auxiliary lexers and a tuple of
+ # distinguishing tokens. Then we wouldn't need this intermediary
+ # class.
+ class _ReplaceInnerCode(DelegatingLexer):
+ def __init__(self, **options):
+ super().__init__(pylexer, _PythonConsoleLexerBase, Other.Code, **options)
+ super().__init__(tblexer, _ReplaceInnerCode, Other.Traceback, **options)
+
+class PythonTracebackLexer(RegexLexer):
+ """
+ For Python 3.x tracebacks, with support for chained exceptions.
+
+ .. versionchanged:: 2.5
+ This is now the default ``PythonTracebackLexer``. It is still available
+ as the alias ``Python3TracebackLexer``.
+ """
+
+ name = 'Python Traceback'
+ aliases = ['pytb', 'py3tb']
+ filenames = ['*.pytb', '*.py3tb']
+ mimetypes = ['text/x-python-traceback', 'text/x-python3-traceback']
+ url = 'https://python.org'
+ version_added = '1.0'
+
+ tokens = {
+ 'root': [
+ (r'\n', Whitespace),
+ (r'^(\^C)?Traceback \(most recent call last\):\n', Generic.Traceback, 'intb'),
+ (r'^During handling of the above exception, another '
+ r'exception occurred:\n\n', Generic.Traceback),
+ (r'^The above exception was the direct cause of the '
+ r'following exception:\n\n', Generic.Traceback),
+ (r'^(?= File "[^"]+", line \d+)', Generic.Traceback, 'intb'),
+ (r'^.*\n', Other),
+ ],
+ 'intb': [
+ (r'^( File )("[^"]+")(, line )(\d+)(, in )(.+)(\n)',
+ bygroups(Text, Name.Builtin, Text, Number, Text, Name, Whitespace)),
+ (r'^( File )("[^"]+")(, line )(\d+)(\n)',
+ bygroups(Text, Name.Builtin, Text, Number, Whitespace)),
+ (r'^( )(.+)(\n)',
+ bygroups(Whitespace, using(PythonLexer), Whitespace), 'markers'),
+ (r'^([ \t]*)(\.\.\.)(\n)',
+ bygroups(Whitespace, Comment, Whitespace)), # for doctests...
+ (r'^([^:]+)(: )(.+)(\n)',
+ bygroups(Generic.Error, Text, Name, Whitespace), '#pop'),
+ (r'^([a-zA-Z_][\w.]*)(:?\n)',
+ bygroups(Generic.Error, Whitespace), '#pop'),
+ default('#pop'),
+ ],
+ 'markers': [
+ # Either `PEP 657 <https://www.python.org/dev/peps/pep-0657/>`
+ # error locations in Python 3.11+, or single-caret markers
+ # for syntax errors before that.
+ (r'^( {4,})([~^]+)(\n)',
+ bygroups(Whitespace, Punctuation.Marker, Whitespace),
+ '#pop'),
+ default('#pop'),
+ ],
+ }
+
+
+Python3TracebackLexer = PythonTracebackLexer
+
+
+class Python2TracebackLexer(RegexLexer):
+ """
+ For Python tracebacks.
+
+ .. versionchanged:: 2.5
+ This class has been renamed from ``PythonTracebackLexer``.
+ ``PythonTracebackLexer`` now refers to the Python 3 variant.
+ """
+
+ name = 'Python 2.x Traceback'
+ aliases = ['py2tb']
+ filenames = ['*.py2tb']
+ mimetypes = ['text/x-python2-traceback']
+ url = 'https://python.org'
+ version_added = '0.7'
+
+ tokens = {
+ 'root': [
+ # Cover both (most recent call last) and (innermost last)
+ # The optional ^C allows us to catch keyboard interrupt signals.
+ (r'^(\^C)?(Traceback.*\n)',
+ bygroups(Text, Generic.Traceback), 'intb'),
+ # SyntaxError starts with this.
+ (r'^(?= File "[^"]+", line \d+)', Generic.Traceback, 'intb'),
+ (r'^.*\n', Other),
+ ],
+ 'intb': [
+ (r'^( File )("[^"]+")(, line )(\d+)(, in )(.+)(\n)',
+ bygroups(Text, Name.Builtin, Text, Number, Text, Name, Whitespace)),
+ (r'^( File )("[^"]+")(, line )(\d+)(\n)',
+ bygroups(Text, Name.Builtin, Text, Number, Whitespace)),
+ (r'^( )(.+)(\n)',
+ bygroups(Text, using(Python2Lexer), Whitespace), 'marker'),
+ (r'^([ \t]*)(\.\.\.)(\n)',
+ bygroups(Text, Comment, Whitespace)), # for doctests...
+ (r'^([^:]+)(: )(.+)(\n)',
+ bygroups(Generic.Error, Text, Name, Whitespace), '#pop'),
+ (r'^([a-zA-Z_]\w*)(:?\n)',
+ bygroups(Generic.Error, Whitespace), '#pop')
+ ],
+ 'marker': [
+ # For syntax errors.
+ (r'( {4,})(\^)', bygroups(Text, Punctuation.Marker), '#pop'),
+ default('#pop'),
+ ],
+ }
+
+
+class CythonLexer(RegexLexer):
+ """
+ For Pyrex and Cython source code.
+ """
+
+ name = 'Cython'
+ url = 'https://cython.org'
+ aliases = ['cython', 'pyx', 'pyrex']
+ filenames = ['*.pyx', '*.pxd', '*.pxi']
+ mimetypes = ['text/x-cython', 'application/x-cython']
+ version_added = '1.1'
+
+ tokens = {
+ 'root': [
+ (r'\n', Whitespace),
+ (r'^(\s*)("""(?:.|\n)*?""")', bygroups(Whitespace, String.Doc)),
+ (r"^(\s*)('''(?:.|\n)*?''')", bygroups(Whitespace, String.Doc)),
+ (r'[^\S\n]+', Text),
+ (r'#.*$', Comment),
+ (r'[]{}:(),;[]', Punctuation),
+ (r'\\\n', Whitespace),
+ (r'\\', Text),
+ (r'(in|is|and|or|not)\b', Operator.Word),
+ (r'(<)([a-zA-Z0-9.?]+)(>)',
+ bygroups(Punctuation, Keyword.Type, Punctuation)),
+ (r'!=|==|<<|>>|[-~+/*%=<>&^|.?]', Operator),
+ (r'(from)(\d+)(<=)(\s+)(<)(\d+)(:)',
+ bygroups(Keyword, Number.Integer, Operator, Name, Operator,
+ Name, Punctuation)),
+ include('keywords'),
+ (r'(def|property)(\s+)', bygroups(Keyword, Text), 'funcname'),
+ (r'(cp?def)(\s+)', bygroups(Keyword, Text), 'cdef'),
+ # (should actually start a block with only cdefs)
+ (r'(cdef)(:)', bygroups(Keyword, Punctuation)),
+ (r'(class|struct)(\s+)', bygroups(Keyword, Text), 'classname'),
+ (r'(from)(\s+)', bygroups(Keyword, Text), 'fromimport'),
+ (r'(c?import)(\s+)', bygroups(Keyword, Text), 'import'),
+ include('builtins'),
+ include('backtick'),
+ ('(?:[rR]|[uU][rR]|[rR][uU])"""', String, 'tdqs'),
+ ("(?:[rR]|[uU][rR]|[rR][uU])'''", String, 'tsqs'),
+ ('(?:[rR]|[uU][rR]|[rR][uU])"', String, 'dqs'),
+ ("(?:[rR]|[uU][rR]|[rR][uU])'", String, 'sqs'),
+ ('[uU]?"""', String, combined('stringescape', 'tdqs')),
+ ("[uU]?'''", String, combined('stringescape', 'tsqs')),
+ ('[uU]?"', String, combined('stringescape', 'dqs')),
+ ("[uU]?'", String, combined('stringescape', 'sqs')),
+ include('name'),
+ include('numbers'),
+ ],
+ 'keywords': [
+ (words((
+ 'assert', 'async', 'await', 'break', 'by', 'continue', 'ctypedef', 'del', 'elif',
+ 'else', 'except', 'except?', 'exec', 'finally', 'for', 'fused', 'gil',
+ 'global', 'if', 'include', 'lambda', 'nogil', 'pass', 'print',
+ 'raise', 'return', 'try', 'while', 'yield', 'as', 'with'), suffix=r'\b'),
+ Keyword),
+ (r'(DEF|IF|ELIF|ELSE)\b', Comment.Preproc),
+ ],
+ 'builtins': [
+ (words((
+ '__import__', 'abs', 'all', 'any', 'apply', 'basestring', 'bin', 'bint',
+ 'bool', 'buffer', 'bytearray', 'bytes', 'callable', 'chr',
+ 'classmethod', 'cmp', 'coerce', 'compile', 'complex', 'delattr',
+ 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'execfile', 'exit',
+ 'file', 'filter', 'float', 'frozenset', 'getattr', 'globals',
+ 'hasattr', 'hash', 'hex', 'id', 'input', 'int', 'intern', 'isinstance',
+ 'issubclass', 'iter', 'len', 'list', 'locals', 'long', 'map', 'max',
+ 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'property', 'Py_ssize_t',
+ 'range', 'raw_input', 'reduce', 'reload', 'repr', 'reversed',
+ 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod',
+ 'str', 'sum', 'super', 'tuple', 'type', 'unichr', 'unicode', 'unsigned',
+ 'vars', 'xrange', 'zip'), prefix=r'(?<!\.)', suffix=r'\b'),
+ Name.Builtin),
+ (r'(?<!\.)(self|None|Ellipsis|NotImplemented|False|True|NULL'
+ r')\b', Name.Builtin.Pseudo),
+ (words((
+ 'ArithmeticError', 'AssertionError', 'AttributeError',
+ 'BaseException', 'DeprecationWarning', 'EOFError', 'EnvironmentError',
+ 'Exception', 'FloatingPointError', 'FutureWarning', 'GeneratorExit',
+ 'IOError', 'ImportError', 'ImportWarning', 'IndentationError',
+ 'IndexError', 'KeyError', 'KeyboardInterrupt', 'LookupError',
+ 'MemoryError', 'NameError', 'NotImplemented', 'NotImplementedError',
+ 'OSError', 'OverflowError', 'OverflowWarning',
+ 'PendingDeprecationWarning', 'ReferenceError', 'RuntimeError',
+ 'RuntimeWarning', 'StandardError', 'StopIteration', 'SyntaxError',
+ 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError',
+ 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError',
+ 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError',
+ 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning',
+ 'ZeroDivisionError'), prefix=r'(?<!\.)', suffix=r'\b'),
+ Name.Exception),
+ ],
+ 'numbers': [
+ (r'(\d+\.?\d*|\d*\.\d+)([eE][+-]?[0-9]+)?', Number.Float),
+ (r'0\d+', Number.Oct),
+ (r'0[xX][a-fA-F0-9]+', Number.Hex),
+ (r'\d+L', Number.Integer.Long),
+ (r'\d+', Number.Integer)
+ ],
+ 'backtick': [
+ ('`.*?`', String.Backtick),
+ ],
+ 'name': [
+ (r'@\w+', Name.Decorator),
+ (r'[a-zA-Z_]\w*', Name),
+ ],
+ 'funcname': [
+ (r'[a-zA-Z_]\w*', Name.Function, '#pop')
+ ],
+ 'cdef': [
+ (r'(public|readonly|extern|api|inline)\b', Keyword.Reserved),
+ (r'(struct|enum|union|class)\b', Keyword),
+ (r'([a-zA-Z_]\w*)(\s*)(?=[(:#=]|$)',
+ bygroups(Name.Function, Text), '#pop'),
+ (r'([a-zA-Z_]\w*)(\s*)(,)',
+ bygroups(Name.Function, Text, Punctuation)),
+ (r'from\b', Keyword, '#pop'),
+ (r'as\b', Keyword),
+ (r':', Punctuation, '#pop'),
+ (r'(?=["\'])', Text, '#pop'),
+ (r'[a-zA-Z_]\w*', Keyword.Type),
+ (r'.', Text),
+ ],
+ 'classname': [
+ (r'[a-zA-Z_]\w*', Name.Class, '#pop')
+ ],
+ 'import': [
+ (r'(\s+)(as)(\s+)', bygroups(Text, Keyword, Text)),
+ (r'[a-zA-Z_][\w.]*', Name.Namespace),
+ (r'(\s*)(,)(\s*)', bygroups(Text, Operator, Text)),
+ default('#pop') # all else: go back
+ ],
+ 'fromimport': [
+ (r'(\s+)(c?import)\b', bygroups(Text, Keyword), '#pop'),
+ (r'[a-zA-Z_.][\w.]*', Name.Namespace),
+ # ``cdef foo from "header"``, or ``for foo from 0 < i < 10``
+ default('#pop'),
+ ],
+ 'stringescape': [
+ (r'\\([\\abfnrtv"\']|\n|N\{.*?\}|u[a-fA-F0-9]{4}|'
+ r'U[a-fA-F0-9]{8}|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
+ ],
+ 'strings': [
+ (r'%(\([a-zA-Z0-9]+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
+ '[hlL]?[E-GXc-giorsux%]', String.Interpol),
+ (r'[^\\\'"%\n]+', String),
+ # quotes, percents and backslashes must be parsed one at a time
+ (r'[\'"\\]', String),
+ # unhandled string formatting sign
+ (r'%', String)
+ # newlines are an error (use "nl" state)
+ ],
+ 'nl': [
+ (r'\n', String)
+ ],
+ 'dqs': [
+ (r'"', String, '#pop'),
+ (r'\\\\|\\"|\\\n', String.Escape), # included here again for raw strings
+ include('strings')
+ ],
+ 'sqs': [
+ (r"'", String, '#pop'),
+ (r"\\\\|\\'|\\\n", String.Escape), # included here again for raw strings
+ include('strings')
+ ],
+ 'tdqs': [
+ (r'"""', String, '#pop'),
+ include('strings'),
+ include('nl')
+ ],
+ 'tsqs': [
+ (r"'''", String, '#pop'),
+ include('strings'),
+ include('nl')
+ ],
+ }
+
+
+class DgLexer(RegexLexer):
+ """
+ Lexer for dg,
+ a functional and object-oriented programming language
+ running on the CPython 3 VM.
+ """
+ name = 'dg'
+ aliases = ['dg']
+ filenames = ['*.dg']
+ mimetypes = ['text/x-dg']
+ url = 'http://pyos.github.io/dg'
+ version_added = '1.6'
+
+ tokens = {
+ 'root': [
+ (r'\s+', Text),
+ (r'#.*?$', Comment.Single),
+
+ (r'(?i)0b[01]+', Number.Bin),
+ (r'(?i)0o[0-7]+', Number.Oct),
+ (r'(?i)0x[0-9a-f]+', Number.Hex),
+ (r'(?i)[+-]?[0-9]+\.[0-9]+(e[+-]?[0-9]+)?j?', Number.Float),
+ (r'(?i)[+-]?[0-9]+e[+-]?\d+j?', Number.Float),
+ (r'(?i)[+-]?[0-9]+j?', Number.Integer),
+
+ (r"(?i)(br|r?b?)'''", String, combined('stringescape', 'tsqs', 'string')),
+ (r'(?i)(br|r?b?)"""', String, combined('stringescape', 'tdqs', 'string')),
+ (r"(?i)(br|r?b?)'", String, combined('stringescape', 'sqs', 'string')),
+ (r'(?i)(br|r?b?)"', String, combined('stringescape', 'dqs', 'string')),
+
+ (r"`\w+'*`", Operator),
+ (r'\b(and|in|is|or|where)\b', Operator.Word),
+ (r'[!$%&*+\-./:<-@\\^|~;,]+', Operator),
+
+ (words((
+ 'bool', 'bytearray', 'bytes', 'classmethod', 'complex', 'dict', 'dict\'',
+ 'float', 'frozenset', 'int', 'list', 'list\'', 'memoryview', 'object',
+ 'property', 'range', 'set', 'set\'', 'slice', 'staticmethod', 'str',
+ 'super', 'tuple', 'tuple\'', 'type'),
+ prefix=r'(?<!\.)', suffix=r'(?![\'\w])'),
+ Name.Builtin),
+ (words((
+ '__import__', 'abs', 'all', 'any', 'bin', 'bind', 'chr', 'cmp', 'compile',
+ 'complex', 'delattr', 'dir', 'divmod', 'drop', 'dropwhile', 'enumerate',
+ 'eval', 'exhaust', 'filter', 'flip', 'foldl1?', 'format', 'fst',
+ 'getattr', 'globals', 'hasattr', 'hash', 'head', 'hex', 'id', 'init',
+ 'input', 'isinstance', 'issubclass', 'iter', 'iterate', 'last', 'len',
+ 'locals', 'map', 'max', 'min', 'next', 'oct', 'open', 'ord', 'pow',
+ 'print', 'repr', 'reversed', 'round', 'setattr', 'scanl1?', 'snd',
+ 'sorted', 'sum', 'tail', 'take', 'takewhile', 'vars', 'zip'),
+ prefix=r'(?<!\.)', suffix=r'(?![\'\w])'),
+ Name.Builtin),
+ (r"(?<!\.)(self|Ellipsis|NotImplemented|None|True|False)(?!['\w])",
+ Name.Builtin.Pseudo),
+
+ (r"(?<!\.)[A-Z]\w*(Error|Exception|Warning)'*(?!['\w])",
+ Name.Exception),
+ (r"(?<!\.)(Exception|GeneratorExit|KeyboardInterrupt|StopIteration|"
+ r"SystemExit)(?!['\w])", Name.Exception),
+
+ (r"(?<![\w.])(except|finally|for|if|import|not|otherwise|raise|"
+ r"subclass|while|with|yield)(?!['\w])", Keyword.Reserved),
+
+ (r"[A-Z_]+'*(?!['\w])", Name),
+ (r"[A-Z]\w+'*(?!['\w])", Keyword.Type),
+ (r"\w+'*", Name),
+
+ (r'[()]', Punctuation),
+ (r'.', Error),
+ ],
+ 'stringescape': [
+ (r'\\([\\abfnrtv"\']|\n|N\{.*?\}|u[a-fA-F0-9]{4}|'
+ r'U[a-fA-F0-9]{8}|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
+ ],
+ 'string': [
+ (r'%(\(\w+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
+ '[hlL]?[E-GXc-giorsux%]', String.Interpol),
+ (r'[^\\\'"%\n]+', String),
+ # quotes, percents and backslashes must be parsed one at a time
+ (r'[\'"\\]', String),
+ # unhandled string formatting sign
+ (r'%', String),
+ (r'\n', String)
+ ],
+ 'dqs': [
+ (r'"', String, '#pop')
+ ],
+ 'sqs': [
+ (r"'", String, '#pop')
+ ],
+ 'tdqs': [
+ (r'"""', String, '#pop')
+ ],
+ 'tsqs': [
+ (r"'''", String, '#pop')
+ ],
+ }
+
+
+class NumPyLexer(PythonLexer):
+ """
+ A Python lexer recognizing Numerical Python builtins.
+ """
+
+ name = 'NumPy'
+ url = 'https://numpy.org/'
+ aliases = ['numpy']
+ version_added = '0.10'
+
+ # override the mimetypes to not inherit them from python
+ mimetypes = []
+ filenames = []
+
+ EXTRA_KEYWORDS = {
+ 'abs', 'absolute', 'accumulate', 'add', 'alen', 'all', 'allclose',
+ 'alltrue', 'alterdot', 'amax', 'amin', 'angle', 'any', 'append',
+ 'apply_along_axis', 'apply_over_axes', 'arange', 'arccos', 'arccosh',
+ 'arcsin', 'arcsinh', 'arctan', 'arctan2', 'arctanh', 'argmax', 'argmin',
+ 'argsort', 'argwhere', 'around', 'array', 'array2string', 'array_equal',
+ 'array_equiv', 'array_repr', 'array_split', 'array_str', 'arrayrange',
+ 'asanyarray', 'asarray', 'asarray_chkfinite', 'ascontiguousarray',
+ 'asfarray', 'asfortranarray', 'asmatrix', 'asscalar', 'astype',
+ 'atleast_1d', 'atleast_2d', 'atleast_3d', 'average', 'bartlett',
+ 'base_repr', 'beta', 'binary_repr', 'bincount', 'binomial',
+ 'bitwise_and', 'bitwise_not', 'bitwise_or', 'bitwise_xor', 'blackman',
+ 'bmat', 'broadcast', 'byte_bounds', 'bytes', 'byteswap', 'c_',
+ 'can_cast', 'ceil', 'choose', 'clip', 'column_stack', 'common_type',
+ 'compare_chararrays', 'compress', 'concatenate', 'conj', 'conjugate',
+ 'convolve', 'copy', 'corrcoef', 'correlate', 'cos', 'cosh', 'cov',
+ 'cross', 'cumprod', 'cumproduct', 'cumsum', 'delete', 'deprecate',
+ 'diag', 'diagflat', 'diagonal', 'diff', 'digitize', 'disp', 'divide',
+ 'dot', 'dsplit', 'dstack', 'dtype', 'dump', 'dumps', 'ediff1d', 'empty',
+ 'empty_like', 'equal', 'exp', 'expand_dims', 'expm1', 'extract', 'eye',
+ 'fabs', 'fastCopyAndTranspose', 'fft', 'fftfreq', 'fftshift', 'fill',
+ 'finfo', 'fix', 'flat', 'flatnonzero', 'flatten', 'fliplr', 'flipud',
+ 'floor', 'floor_divide', 'fmod', 'frexp', 'fromarrays', 'frombuffer',
+ 'fromfile', 'fromfunction', 'fromiter', 'frompyfunc', 'fromstring',
+ 'generic', 'get_array_wrap', 'get_include', 'get_numarray_include',
+ 'get_numpy_include', 'get_printoptions', 'getbuffer', 'getbufsize',
+ 'geterr', 'geterrcall', 'geterrobj', 'getfield', 'gradient', 'greater',
+ 'greater_equal', 'gumbel', 'hamming', 'hanning', 'histogram',
+ 'histogram2d', 'histogramdd', 'hsplit', 'hstack', 'hypot', 'i0',
+ 'identity', 'ifft', 'imag', 'index_exp', 'indices', 'inf', 'info',
+ 'inner', 'insert', 'int_asbuffer', 'interp', 'intersect1d',
+ 'intersect1d_nu', 'inv', 'invert', 'iscomplex', 'iscomplexobj',
+ 'isfinite', 'isfortran', 'isinf', 'isnan', 'isneginf', 'isposinf',
+ 'isreal', 'isrealobj', 'isscalar', 'issctype', 'issubclass_',
+ 'issubdtype', 'issubsctype', 'item', 'itemset', 'iterable', 'ix_',
+ 'kaiser', 'kron', 'ldexp', 'left_shift', 'less', 'less_equal', 'lexsort',
+ 'linspace', 'load', 'loads', 'loadtxt', 'log', 'log10', 'log1p', 'log2',
+ 'logical_and', 'logical_not', 'logical_or', 'logical_xor', 'logspace',
+ 'lstsq', 'mat', 'matrix', 'max', 'maximum', 'maximum_sctype',
+ 'may_share_memory', 'mean', 'median', 'meshgrid', 'mgrid', 'min',
+ 'minimum', 'mintypecode', 'mod', 'modf', 'msort', 'multiply', 'nan',
+ 'nan_to_num', 'nanargmax', 'nanargmin', 'nanmax', 'nanmin', 'nansum',
+ 'ndenumerate', 'ndim', 'ndindex', 'negative', 'newaxis', 'newbuffer',
+ 'newbyteorder', 'nonzero', 'not_equal', 'obj2sctype', 'ogrid', 'ones',
+ 'ones_like', 'outer', 'permutation', 'piecewise', 'pinv', 'pkgload',
+ 'place', 'poisson', 'poly', 'poly1d', 'polyadd', 'polyder', 'polydiv',
+ 'polyfit', 'polyint', 'polymul', 'polysub', 'polyval', 'power', 'prod',
+ 'product', 'ptp', 'put', 'putmask', 'r_', 'randint', 'random_integers',
+ 'random_sample', 'ranf', 'rank', 'ravel', 'real', 'real_if_close',
+ 'recarray', 'reciprocal', 'reduce', 'remainder', 'repeat', 'require',
+ 'reshape', 'resize', 'restoredot', 'right_shift', 'rint', 'roll',
+ 'rollaxis', 'roots', 'rot90', 'round', 'round_', 'row_stack', 's_',
+ 'sample', 'savetxt', 'sctype2char', 'searchsorted', 'seed', 'select',
+ 'set_numeric_ops', 'set_printoptions', 'set_string_function',
+ 'setbufsize', 'setdiff1d', 'seterr', 'seterrcall', 'seterrobj',
+ 'setfield', 'setflags', 'setmember1d', 'setxor1d', 'shape',
+ 'show_config', 'shuffle', 'sign', 'signbit', 'sin', 'sinc', 'sinh',
+ 'size', 'slice', 'solve', 'sometrue', 'sort', 'sort_complex', 'source',
+ 'split', 'sqrt', 'square', 'squeeze', 'standard_normal', 'std',
+ 'subtract', 'sum', 'svd', 'swapaxes', 'take', 'tan', 'tanh', 'tensordot',
+ 'test', 'tile', 'tofile', 'tolist', 'tostring', 'trace', 'transpose',
+ 'trapz', 'tri', 'tril', 'trim_zeros', 'triu', 'true_divide', 'typeDict',
+ 'typename', 'uniform', 'union1d', 'unique', 'unique1d', 'unravel_index',
+ 'unwrap', 'vander', 'var', 'vdot', 'vectorize', 'view', 'vonmises',
+ 'vsplit', 'vstack', 'weibull', 'where', 'who', 'zeros', 'zeros_like'
+ }
+
+ def get_tokens_unprocessed(self, text):
+ for index, token, value in \
+ PythonLexer.get_tokens_unprocessed(self, text):
+ if token is Name and value in self.EXTRA_KEYWORDS:
+ yield index, Keyword.Pseudo, value
+ else:
+ yield index, token, value
+
+ def analyse_text(text):
+ ltext = text[:1000]
+ return (shebang_matches(text, r'pythonw?(3(\.\d)?)?') or
+ 'import ' in ltext) \
+ and ('import numpy' in ltext or 'from numpy import' in ltext)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/modeline.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/modeline.py
new file mode 100644
index 000000000..e4d9fe167
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/modeline.py
@@ -0,0 +1,43 @@
+"""
+ pygments.modeline
+ ~~~~~~~~~~~~~~~~~
+
+ A simple modeline parser (based on pymodeline).
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import re
+
+__all__ = ['get_filetype_from_buffer']
+
+
+modeline_re = re.compile(r'''
+ (?: vi | vim | ex ) (?: [<=>]? \d* )? :
+ .* (?: ft | filetype | syn | syntax ) = ( [^:\s]+ )
+''', re.VERBOSE)
+
+
+def get_filetype_from_line(l): # noqa: E741
+ m = modeline_re.search(l)
+ if m:
+ return m.group(1)
+
+
+def get_filetype_from_buffer(buf, max_lines=5):
+ """
+ Scan the buffer for modelines and return filetype if one is found.
+ """
+ lines = buf.splitlines()
+ for line in lines[-1:-max_lines-1:-1]:
+ ret = get_filetype_from_line(line)
+ if ret:
+ return ret
+ for i in range(max_lines, -1, -1):
+ if i < len(lines):
+ ret = get_filetype_from_line(lines[i])
+ if ret:
+ return ret
+
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/plugin.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/plugin.py
new file mode 100644
index 000000000..2e462f2c2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/plugin.py
@@ -0,0 +1,72 @@
+"""
+ pygments.plugin
+ ~~~~~~~~~~~~~~~
+
+ Pygments plugin interface.
+
+ lexer plugins::
+
+ [pygments.lexers]
+ yourlexer = yourmodule:YourLexer
+
+ formatter plugins::
+
+ [pygments.formatters]
+ yourformatter = yourformatter:YourFormatter
+ /.ext = yourformatter:YourFormatter
+
+ As you can see, you can define extensions for the formatter
+ with a leading slash.
+
+ syntax plugins::
+
+ [pygments.styles]
+ yourstyle = yourstyle:YourStyle
+
+ filter plugin::
+
+ [pygments.filter]
+ yourfilter = yourfilter:YourFilter
+
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+from importlib.metadata import entry_points
+
+LEXER_ENTRY_POINT = 'pygments.lexers'
+FORMATTER_ENTRY_POINT = 'pygments.formatters'
+STYLE_ENTRY_POINT = 'pygments.styles'
+FILTER_ENTRY_POINT = 'pygments.filters'
+
+
+def iter_entry_points(group_name):
+ groups = entry_points()
+ if hasattr(groups, 'select'):
+ # New interface in Python 3.10 and newer versions of the
+ # importlib_metadata backport.
+ return groups.select(group=group_name)
+ else:
+ # Older interface, deprecated in Python 3.10 and recent
+ # importlib_metadata, but we need it in Python 3.8 and 3.9.
+ return groups.get(group_name, [])
+
+
+def find_plugin_lexers():
+ for entrypoint in iter_entry_points(LEXER_ENTRY_POINT):
+ yield entrypoint.load()
+
+
+def find_plugin_formatters():
+ for entrypoint in iter_entry_points(FORMATTER_ENTRY_POINT):
+ yield entrypoint.name, entrypoint.load()
+
+
+def find_plugin_styles():
+ for entrypoint in iter_entry_points(STYLE_ENTRY_POINT):
+ yield entrypoint.name, entrypoint.load()
+
+
+def find_plugin_filters():
+ for entrypoint in iter_entry_points(FILTER_ENTRY_POINT):
+ yield entrypoint.name, entrypoint.load()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/regexopt.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/regexopt.py
new file mode 100644
index 000000000..c44eedbf2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/regexopt.py
@@ -0,0 +1,91 @@
+"""
+ pygments.regexopt
+ ~~~~~~~~~~~~~~~~~
+
+ An algorithm that generates optimized regexes for matching long lists of
+ literal strings.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import re
+from re import escape
+from os.path import commonprefix
+from itertools import groupby
+from operator import itemgetter
+
+CS_ESCAPE = re.compile(r'[\[\^\\\-\]]')
+FIRST_ELEMENT = itemgetter(0)
+
+
+def make_charset(letters):
+ return '[' + CS_ESCAPE.sub(lambda m: '\\' + m.group(), ''.join(letters)) + ']'
+
+
+def regex_opt_inner(strings, open_paren):
+ """Return a regex that matches any string in the sorted list of strings."""
+ close_paren = open_paren and ')' or ''
+ # print strings, repr(open_paren)
+ if not strings:
+ # print '-> nothing left'
+ return ''
+ first = strings[0]
+ if len(strings) == 1:
+ # print '-> only 1 string'
+ return open_paren + escape(first) + close_paren
+ if not first:
+ # print '-> first string empty'
+ return open_paren + regex_opt_inner(strings[1:], '(?:') \
+ + '?' + close_paren
+ if len(first) == 1:
+ # multiple one-char strings? make a charset
+ oneletter = []
+ rest = []
+ for s in strings:
+ if len(s) == 1:
+ oneletter.append(s)
+ else:
+ rest.append(s)
+ if len(oneletter) > 1: # do we have more than one oneletter string?
+ if rest:
+ # print '-> 1-character + rest'
+ return open_paren + regex_opt_inner(rest, '') + '|' \
+ + make_charset(oneletter) + close_paren
+ # print '-> only 1-character'
+ return open_paren + make_charset(oneletter) + close_paren
+ prefix = commonprefix(strings)
+ if prefix:
+ plen = len(prefix)
+ # we have a prefix for all strings
+ # print '-> prefix:', prefix
+ return open_paren + escape(prefix) \
+ + regex_opt_inner([s[plen:] for s in strings], '(?:') \
+ + close_paren
+ # is there a suffix?
+ strings_rev = [s[::-1] for s in strings]
+ suffix = commonprefix(strings_rev)
+ if suffix:
+ slen = len(suffix)
+ # print '-> suffix:', suffix[::-1]
+ return open_paren \
+ + regex_opt_inner(sorted(s[:-slen] for s in strings), '(?:') \
+ + escape(suffix[::-1]) + close_paren
+ # recurse on common 1-string prefixes
+ # print '-> last resort'
+ return open_paren + \
+ '|'.join(regex_opt_inner(list(group[1]), '')
+ for group in groupby(strings, lambda s: s[0] == first[0])) \
+ + close_paren
+
+
+def regex_opt(strings, prefix='', suffix=''):
+ """Return a compiled regex that matches any string in the given list.
+
+ The strings to match must be literal strings, not regexes. They will be
+ regex-escaped.
+
+ *prefix* and *suffix* are pre- and appended to the final regex.
+ """
+ strings = sorted(strings)
+ return prefix + regex_opt_inner(strings, '(') + suffix
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/scanner.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/scanner.py
new file mode 100644
index 000000000..112da3491
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/scanner.py
@@ -0,0 +1,104 @@
+"""
+ pygments.scanner
+ ~~~~~~~~~~~~~~~~
+
+ This library implements a regex based scanner. Some languages
+ like Pascal are easy to parse but have some keywords that
+ depend on the context. Because of this it's impossible to lex
+ that just by using a regular expression lexer like the
+ `RegexLexer`.
+
+ Have a look at the `DelphiLexer` to get an idea of how to use
+ this scanner.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+import re
+
+
+class EndOfText(RuntimeError):
+ """
+ Raise if end of text is reached and the user
+ tried to call a match function.
+ """
+
+
+class Scanner:
+ """
+ Simple scanner
+
+ All method patterns are regular expression strings (not
+ compiled expressions!)
+ """
+
+ def __init__(self, text, flags=0):
+ """
+ :param text: The text which should be scanned
+ :param flags: default regular expression flags
+ """
+ self.data = text
+ self.data_length = len(text)
+ self.start_pos = 0
+ self.pos = 0
+ self.flags = flags
+ self.last = None
+ self.match = None
+ self._re_cache = {}
+
+ def eos(self):
+ """`True` if the scanner reached the end of text."""
+ return self.pos >= self.data_length
+ eos = property(eos, eos.__doc__)
+
+ def check(self, pattern):
+ """
+ Apply `pattern` on the current position and return
+ the match object. (Doesn't touch pos). Use this for
+ lookahead.
+ """
+ if self.eos:
+ raise EndOfText()
+ if pattern not in self._re_cache:
+ self._re_cache[pattern] = re.compile(pattern, self.flags)
+ return self._re_cache[pattern].match(self.data, self.pos)
+
+ def test(self, pattern):
+ """Apply a pattern on the current position and check
+ if it patches. Doesn't touch pos.
+ """
+ return self.check(pattern) is not None
+
+ def scan(self, pattern):
+ """
+ Scan the text for the given pattern and update pos/match
+ and related fields. The return value is a boolean that
+ indicates if the pattern matched. The matched value is
+ stored on the instance as ``match``, the last value is
+ stored as ``last``. ``start_pos`` is the position of the
+ pointer before the pattern was matched, ``pos`` is the
+ end position.
+ """
+ if self.eos:
+ raise EndOfText()
+ if pattern not in self._re_cache:
+ self._re_cache[pattern] = re.compile(pattern, self.flags)
+ self.last = self.match
+ m = self._re_cache[pattern].match(self.data, self.pos)
+ if m is None:
+ return False
+ self.start_pos = m.start()
+ self.pos = m.end()
+ self.match = m.group()
+ return True
+
+ def get_char(self):
+ """Scan exactly one char."""
+ self.scan('.')
+
+ def __repr__(self):
+ return '<%s %d/%d>' % (
+ self.__class__.__name__,
+ self.pos,
+ self.data_length
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/sphinxext.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/sphinxext.py
new file mode 100644
index 000000000..34077a2ae
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/sphinxext.py
@@ -0,0 +1,247 @@
+"""
+ pygments.sphinxext
+ ~~~~~~~~~~~~~~~~~~
+
+ Sphinx extension to generate automatic documentation of lexers,
+ formatters and filters.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import sys
+
+from docutils import nodes
+from docutils.statemachine import ViewList
+from docutils.parsers.rst import Directive
+from sphinx.util.nodes import nested_parse_with_titles
+
+
+MODULEDOC = '''
+.. module:: %s
+
+%s
+%s
+'''
+
+LEXERDOC = '''
+.. class:: %s
+
+ :Short names: %s
+ :Filenames: %s
+ :MIME types: %s
+
+ %s
+
+ %s
+
+'''
+
+FMTERDOC = '''
+.. class:: %s
+
+ :Short names: %s
+ :Filenames: %s
+
+ %s
+
+'''
+
+FILTERDOC = '''
+.. class:: %s
+
+ :Name: %s
+
+ %s
+
+'''
+
+
+class PygmentsDoc(Directive):
+ """
+ A directive to collect all lexers/formatters/filters and generate
+ autoclass directives for them.
+ """
+ has_content = False
+ required_arguments = 1
+ optional_arguments = 0
+ final_argument_whitespace = False
+ option_spec = {}
+
+ def run(self):
+ self.filenames = set()
+ if self.arguments[0] == 'lexers':
+ out = self.document_lexers()
+ elif self.arguments[0] == 'formatters':
+ out = self.document_formatters()
+ elif self.arguments[0] == 'filters':
+ out = self.document_filters()
+ elif self.arguments[0] == 'lexers_overview':
+ out = self.document_lexers_overview()
+ else:
+ raise Exception('invalid argument for "pygmentsdoc" directive')
+ node = nodes.compound()
+ vl = ViewList(out.split('\n'), source='')
+ nested_parse_with_titles(self.state, vl, node)
+ for fn in self.filenames:
+ self.state.document.settings.record_dependencies.add(fn)
+ return node.children
+
+ def document_lexers_overview(self):
+ """Generate a tabular overview of all lexers.
+
+ The columns are the lexer name, the extensions handled by this lexer
+ (or "None"), the aliases and a link to the lexer class."""
+ from pip._vendor.pygments.lexers._mapping import LEXERS
+ from pip._vendor.pygments.lexers import find_lexer_class
+ out = []
+
+ table = []
+
+ def format_link(name, url):
+ if url:
+ return f'`{name} <{url}>`_'
+ return name
+
+ for classname, data in sorted(LEXERS.items(), key=lambda x: x[1][1].lower()):
+ lexer_cls = find_lexer_class(data[1])
+ extensions = lexer_cls.filenames + lexer_cls.alias_filenames
+
+ table.append({
+ 'name': format_link(data[1], lexer_cls.url),
+ 'extensions': ', '.join(extensions).replace('*', '\\*').replace('_', '\\') or 'None',
+ 'aliases': ', '.join(data[2]),
+ 'class': f'{data[0]}.{classname}'
+ })
+
+ column_names = ['name', 'extensions', 'aliases', 'class']
+ column_lengths = [max([len(row[column]) for row in table if row[column]])
+ for column in column_names]
+
+ def write_row(*columns):
+ """Format a table row"""
+ out = []
+ for length, col in zip(column_lengths, columns):
+ if col:
+ out.append(col.ljust(length))
+ else:
+ out.append(' '*length)
+
+ return ' '.join(out)
+
+ def write_seperator():
+ """Write a table separator row"""
+ sep = ['='*c for c in column_lengths]
+ return write_row(*sep)
+
+ out.append(write_seperator())
+ out.append(write_row('Name', 'Extension(s)', 'Short name(s)', 'Lexer class'))
+ out.append(write_seperator())
+ for row in table:
+ out.append(write_row(
+ row['name'],
+ row['extensions'],
+ row['aliases'],
+ f':class:`~{row["class"]}`'))
+ out.append(write_seperator())
+
+ return '\n'.join(out)
+
+ def document_lexers(self):
+ from pip._vendor.pygments.lexers._mapping import LEXERS
+ from pip._vendor import pygments
+ import inspect
+ import pathlib
+
+ out = []
+ modules = {}
+ moduledocstrings = {}
+ for classname, data in sorted(LEXERS.items(), key=lambda x: x[0]):
+ module = data[0]
+ mod = __import__(module, None, None, [classname])
+ self.filenames.add(mod.__file__)
+ cls = getattr(mod, classname)
+ if not cls.__doc__:
+ print(f"Warning: {classname} does not have a docstring.")
+ docstring = cls.__doc__
+ if isinstance(docstring, bytes):
+ docstring = docstring.decode('utf8')
+
+ example_file = getattr(cls, '_example', None)
+ if example_file:
+ p = pathlib.Path(inspect.getabsfile(pygments)).parent.parent /\
+ 'tests' / 'examplefiles' / example_file
+ content = p.read_text(encoding='utf-8')
+ if not content:
+ raise Exception(
+ f"Empty example file '{example_file}' for lexer "
+ f"{classname}")
+
+ if data[2]:
+ lexer_name = data[2][0]
+ docstring += '\n\n .. admonition:: Example\n'
+ docstring += f'\n .. code-block:: {lexer_name}\n\n'
+ for line in content.splitlines():
+ docstring += f' {line}\n'
+
+ if cls.version_added:
+ version_line = f'.. versionadded:: {cls.version_added}'
+ else:
+ version_line = ''
+
+ modules.setdefault(module, []).append((
+ classname,
+ ', '.join(data[2]) or 'None',
+ ', '.join(data[3]).replace('*', '\\*').replace('_', '\\') or 'None',
+ ', '.join(data[4]) or 'None',
+ docstring,
+ version_line))
+ if module not in moduledocstrings:
+ moddoc = mod.__doc__
+ if isinstance(moddoc, bytes):
+ moddoc = moddoc.decode('utf8')
+ moduledocstrings[module] = moddoc
+
+ for module, lexers in sorted(modules.items(), key=lambda x: x[0]):
+ if moduledocstrings[module] is None:
+ raise Exception(f"Missing docstring for {module}")
+ heading = moduledocstrings[module].splitlines()[4].strip().rstrip('.')
+ out.append(MODULEDOC % (module, heading, '-'*len(heading)))
+ for data in lexers:
+ out.append(LEXERDOC % data)
+
+ return ''.join(out)
+
+ def document_formatters(self):
+ from pip._vendor.pygments.formatters import FORMATTERS
+
+ out = []
+ for classname, data in sorted(FORMATTERS.items(), key=lambda x: x[0]):
+ module = data[0]
+ mod = __import__(module, None, None, [classname])
+ self.filenames.add(mod.__file__)
+ cls = getattr(mod, classname)
+ docstring = cls.__doc__
+ if isinstance(docstring, bytes):
+ docstring = docstring.decode('utf8')
+ heading = cls.__name__
+ out.append(FMTERDOC % (heading, ', '.join(data[2]) or 'None',
+ ', '.join(data[3]).replace('*', '\\*') or 'None',
+ docstring))
+ return ''.join(out)
+
+ def document_filters(self):
+ from pip._vendor.pygments.filters import FILTERS
+
+ out = []
+ for name, cls in FILTERS.items():
+ self.filenames.add(sys.modules[cls.__module__].__file__)
+ docstring = cls.__doc__
+ if isinstance(docstring, bytes):
+ docstring = docstring.decode('utf8')
+ out.append(FILTERDOC % (cls.__name__, name, docstring))
+ return ''.join(out)
+
+
+def setup(app):
+ app.add_directive('pygmentsdoc', PygmentsDoc)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/style.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/style.py
new file mode 100644
index 000000000..076e63f83
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/style.py
@@ -0,0 +1,203 @@
+"""
+ pygments.style
+ ~~~~~~~~~~~~~~
+
+ Basic style object.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from pip._vendor.pygments.token import Token, STANDARD_TYPES
+
+# Default mapping of ansixxx to RGB colors.
+_ansimap = {
+ # dark
+ 'ansiblack': '000000',
+ 'ansired': '7f0000',
+ 'ansigreen': '007f00',
+ 'ansiyellow': '7f7fe0',
+ 'ansiblue': '00007f',
+ 'ansimagenta': '7f007f',
+ 'ansicyan': '007f7f',
+ 'ansigray': 'e5e5e5',
+ # normal
+ 'ansibrightblack': '555555',
+ 'ansibrightred': 'ff0000',
+ 'ansibrightgreen': '00ff00',
+ 'ansibrightyellow': 'ffff00',
+ 'ansibrightblue': '0000ff',
+ 'ansibrightmagenta': 'ff00ff',
+ 'ansibrightcyan': '00ffff',
+ 'ansiwhite': 'ffffff',
+}
+# mapping of deprecated #ansixxx colors to new color names
+_deprecated_ansicolors = {
+ # dark
+ '#ansiblack': 'ansiblack',
+ '#ansidarkred': 'ansired',
+ '#ansidarkgreen': 'ansigreen',
+ '#ansibrown': 'ansiyellow',
+ '#ansidarkblue': 'ansiblue',
+ '#ansipurple': 'ansimagenta',
+ '#ansiteal': 'ansicyan',
+ '#ansilightgray': 'ansigray',
+ # normal
+ '#ansidarkgray': 'ansibrightblack',
+ '#ansired': 'ansibrightred',
+ '#ansigreen': 'ansibrightgreen',
+ '#ansiyellow': 'ansibrightyellow',
+ '#ansiblue': 'ansibrightblue',
+ '#ansifuchsia': 'ansibrightmagenta',
+ '#ansiturquoise': 'ansibrightcyan',
+ '#ansiwhite': 'ansiwhite',
+}
+ansicolors = set(_ansimap)
+
+
+class StyleMeta(type):
+
+ def __new__(mcs, name, bases, dct):
+ obj = type.__new__(mcs, name, bases, dct)
+ for token in STANDARD_TYPES:
+ if token not in obj.styles:
+ obj.styles[token] = ''
+
+ def colorformat(text):
+ if text in ansicolors:
+ return text
+ if text[0:1] == '#':
+ col = text[1:]
+ if len(col) == 6:
+ return col
+ elif len(col) == 3:
+ return col[0] * 2 + col[1] * 2 + col[2] * 2
+ elif text == '':
+ return ''
+ elif text.startswith('var') or text.startswith('calc'):
+ return text
+ assert False, f"wrong color format {text!r}"
+
+ _styles = obj._styles = {}
+
+ for ttype in obj.styles:
+ for token in ttype.split():
+ if token in _styles:
+ continue
+ ndef = _styles.get(token.parent, None)
+ styledefs = obj.styles.get(token, '').split()
+ if not ndef or token is None:
+ ndef = ['', 0, 0, 0, '', '', 0, 0, 0]
+ elif 'noinherit' in styledefs and token is not Token:
+ ndef = _styles[Token][:]
+ else:
+ ndef = ndef[:]
+ _styles[token] = ndef
+ for styledef in obj.styles.get(token, '').split():
+ if styledef == 'noinherit':
+ pass
+ elif styledef == 'bold':
+ ndef[1] = 1
+ elif styledef == 'nobold':
+ ndef[1] = 0
+ elif styledef == 'italic':
+ ndef[2] = 1
+ elif styledef == 'noitalic':
+ ndef[2] = 0
+ elif styledef == 'underline':
+ ndef[3] = 1
+ elif styledef == 'nounderline':
+ ndef[3] = 0
+ elif styledef[:3] == 'bg:':
+ ndef[4] = colorformat(styledef[3:])
+ elif styledef[:7] == 'border:':
+ ndef[5] = colorformat(styledef[7:])
+ elif styledef == 'roman':
+ ndef[6] = 1
+ elif styledef == 'sans':
+ ndef[7] = 1
+ elif styledef == 'mono':
+ ndef[8] = 1
+ else:
+ ndef[0] = colorformat(styledef)
+
+ return obj
+
+ def style_for_token(cls, token):
+ t = cls._styles[token]
+ ansicolor = bgansicolor = None
+ color = t[0]
+ if color in _deprecated_ansicolors:
+ color = _deprecated_ansicolors[color]
+ if color in ansicolors:
+ ansicolor = color
+ color = _ansimap[color]
+ bgcolor = t[4]
+ if bgcolor in _deprecated_ansicolors:
+ bgcolor = _deprecated_ansicolors[bgcolor]
+ if bgcolor in ansicolors:
+ bgansicolor = bgcolor
+ bgcolor = _ansimap[bgcolor]
+
+ return {
+ 'color': color or None,
+ 'bold': bool(t[1]),
+ 'italic': bool(t[2]),
+ 'underline': bool(t[3]),
+ 'bgcolor': bgcolor or None,
+ 'border': t[5] or None,
+ 'roman': bool(t[6]) or None,
+ 'sans': bool(t[7]) or None,
+ 'mono': bool(t[8]) or None,
+ 'ansicolor': ansicolor,
+ 'bgansicolor': bgansicolor,
+ }
+
+ def list_styles(cls):
+ return list(cls)
+
+ def styles_token(cls, ttype):
+ return ttype in cls._styles
+
+ def __iter__(cls):
+ for token in cls._styles:
+ yield token, cls.style_for_token(token)
+
+ def __len__(cls):
+ return len(cls._styles)
+
+
+class Style(metaclass=StyleMeta):
+
+ #: overall background color (``None`` means transparent)
+ background_color = '#ffffff'
+
+ #: highlight background color
+ highlight_color = '#ffffcc'
+
+ #: line number font color
+ line_number_color = 'inherit'
+
+ #: line number background color
+ line_number_background_color = 'transparent'
+
+ #: special line number font color
+ line_number_special_color = '#000000'
+
+ #: special line number background color
+ line_number_special_background_color = '#ffffc0'
+
+ #: Style definitions for individual token types.
+ styles = {}
+
+ #: user-friendly style name (used when selecting the style, so this
+ # should be all-lowercase, no spaces, hyphens)
+ name = 'unnamed'
+
+ aliases = []
+
+ # Attribute for lexers defined within Pygments. If set
+ # to True, the style is not shown in the style gallery
+ # on the website. This is intended for language-specific
+ # styles.
+ web_style_gallery_exclude = False
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/styles/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/styles/__init__.py
new file mode 100644
index 000000000..712f6e699
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/styles/__init__.py
@@ -0,0 +1,61 @@
+"""
+ pygments.styles
+ ~~~~~~~~~~~~~~~
+
+ Contains built-in styles.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+from pip._vendor.pygments.plugin import find_plugin_styles
+from pip._vendor.pygments.util import ClassNotFound
+from pip._vendor.pygments.styles._mapping import STYLES
+
+#: A dictionary of built-in styles, mapping style names to
+#: ``'submodule::classname'`` strings.
+#: This list is deprecated. Use `pygments.styles.STYLES` instead
+STYLE_MAP = {v[1]: v[0].split('.')[-1] + '::' + k for k, v in STYLES.items()}
+
+#: Internal reverse mapping to make `get_style_by_name` more efficient
+_STYLE_NAME_TO_MODULE_MAP = {v[1]: (v[0], k) for k, v in STYLES.items()}
+
+
+def get_style_by_name(name):
+ """
+ Return a style class by its short name. The names of the builtin styles
+ are listed in :data:`pygments.styles.STYLE_MAP`.
+
+ Will raise :exc:`pygments.util.ClassNotFound` if no style of that name is
+ found.
+ """
+ if name in _STYLE_NAME_TO_MODULE_MAP:
+ mod, cls = _STYLE_NAME_TO_MODULE_MAP[name]
+ builtin = "yes"
+ else:
+ for found_name, style in find_plugin_styles():
+ if name == found_name:
+ return style
+ # perhaps it got dropped into our styles package
+ builtin = ""
+ mod = 'pygments.styles.' + name
+ cls = name.title() + "Style"
+
+ try:
+ mod = __import__(mod, None, None, [cls])
+ except ImportError:
+ raise ClassNotFound(f"Could not find style module {mod!r}" +
+ (builtin and ", though it should be builtin")
+ + ".")
+ try:
+ return getattr(mod, cls)
+ except AttributeError:
+ raise ClassNotFound(f"Could not find style class {cls!r} in style module.")
+
+
+def get_all_styles():
+ """Return a generator for all styles by name, both builtin and plugin."""
+ for v in STYLES.values():
+ yield v[1]
+ for name, _ in find_plugin_styles():
+ yield name
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/styles/_mapping.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/styles/_mapping.py
new file mode 100644
index 000000000..49a7fae92
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/styles/_mapping.py
@@ -0,0 +1,54 @@
+# Automatically generated by scripts/gen_mapfiles.py.
+# DO NOT EDIT BY HAND; run `tox -e mapfiles` instead.
+
+STYLES = {
+ 'AbapStyle': ('pygments.styles.abap', 'abap', ()),
+ 'AlgolStyle': ('pygments.styles.algol', 'algol', ()),
+ 'Algol_NuStyle': ('pygments.styles.algol_nu', 'algol_nu', ()),
+ 'ArduinoStyle': ('pygments.styles.arduino', 'arduino', ()),
+ 'AutumnStyle': ('pygments.styles.autumn', 'autumn', ()),
+ 'BlackWhiteStyle': ('pygments.styles.bw', 'bw', ()),
+ 'BorlandStyle': ('pygments.styles.borland', 'borland', ()),
+ 'CoffeeStyle': ('pygments.styles.coffee', 'coffee', ()),
+ 'ColorfulStyle': ('pygments.styles.colorful', 'colorful', ()),
+ 'DefaultStyle': ('pygments.styles.default', 'default', ()),
+ 'DraculaStyle': ('pygments.styles.dracula', 'dracula', ()),
+ 'EmacsStyle': ('pygments.styles.emacs', 'emacs', ()),
+ 'FriendlyGrayscaleStyle': ('pygments.styles.friendly_grayscale', 'friendly_grayscale', ()),
+ 'FriendlyStyle': ('pygments.styles.friendly', 'friendly', ()),
+ 'FruityStyle': ('pygments.styles.fruity', 'fruity', ()),
+ 'GhDarkStyle': ('pygments.styles.gh_dark', 'github-dark', ()),
+ 'GruvboxDarkStyle': ('pygments.styles.gruvbox', 'gruvbox-dark', ()),
+ 'GruvboxLightStyle': ('pygments.styles.gruvbox', 'gruvbox-light', ()),
+ 'IgorStyle': ('pygments.styles.igor', 'igor', ()),
+ 'InkPotStyle': ('pygments.styles.inkpot', 'inkpot', ()),
+ 'LightbulbStyle': ('pygments.styles.lightbulb', 'lightbulb', ()),
+ 'LilyPondStyle': ('pygments.styles.lilypond', 'lilypond', ()),
+ 'LovelaceStyle': ('pygments.styles.lovelace', 'lovelace', ()),
+ 'ManniStyle': ('pygments.styles.manni', 'manni', ()),
+ 'MaterialStyle': ('pygments.styles.material', 'material', ()),
+ 'MonokaiStyle': ('pygments.styles.monokai', 'monokai', ()),
+ 'MurphyStyle': ('pygments.styles.murphy', 'murphy', ()),
+ 'NativeStyle': ('pygments.styles.native', 'native', ()),
+ 'NordDarkerStyle': ('pygments.styles.nord', 'nord-darker', ()),
+ 'NordStyle': ('pygments.styles.nord', 'nord', ()),
+ 'OneDarkStyle': ('pygments.styles.onedark', 'one-dark', ()),
+ 'ParaisoDarkStyle': ('pygments.styles.paraiso_dark', 'paraiso-dark', ()),
+ 'ParaisoLightStyle': ('pygments.styles.paraiso_light', 'paraiso-light', ()),
+ 'PastieStyle': ('pygments.styles.pastie', 'pastie', ()),
+ 'PerldocStyle': ('pygments.styles.perldoc', 'perldoc', ()),
+ 'RainbowDashStyle': ('pygments.styles.rainbow_dash', 'rainbow_dash', ()),
+ 'RrtStyle': ('pygments.styles.rrt', 'rrt', ()),
+ 'SasStyle': ('pygments.styles.sas', 'sas', ()),
+ 'SolarizedDarkStyle': ('pygments.styles.solarized', 'solarized-dark', ()),
+ 'SolarizedLightStyle': ('pygments.styles.solarized', 'solarized-light', ()),
+ 'StarofficeStyle': ('pygments.styles.staroffice', 'staroffice', ()),
+ 'StataDarkStyle': ('pygments.styles.stata_dark', 'stata-dark', ()),
+ 'StataLightStyle': ('pygments.styles.stata_light', 'stata-light', ()),
+ 'TangoStyle': ('pygments.styles.tango', 'tango', ()),
+ 'TracStyle': ('pygments.styles.trac', 'trac', ()),
+ 'VimStyle': ('pygments.styles.vim', 'vim', ()),
+ 'VisualStudioStyle': ('pygments.styles.vs', 'vs', ()),
+ 'XcodeStyle': ('pygments.styles.xcode', 'xcode', ()),
+ 'ZenburnStyle': ('pygments.styles.zenburn', 'zenburn', ()),
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/token.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/token.py
new file mode 100644
index 000000000..f78018a7a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/token.py
@@ -0,0 +1,214 @@
+"""
+ pygments.token
+ ~~~~~~~~~~~~~~
+
+ Basic token types and the standard tokens.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+
+class _TokenType(tuple):
+ parent = None
+
+ def split(self):
+ buf = []
+ node = self
+ while node is not None:
+ buf.append(node)
+ node = node.parent
+ buf.reverse()
+ return buf
+
+ def __init__(self, *args):
+ # no need to call super.__init__
+ self.subtypes = set()
+
+ def __contains__(self, val):
+ return self is val or (
+ type(val) is self.__class__ and
+ val[:len(self)] == self
+ )
+
+ def __getattr__(self, val):
+ if not val or not val[0].isupper():
+ return tuple.__getattribute__(self, val)
+ new = _TokenType(self + (val,))
+ setattr(self, val, new)
+ self.subtypes.add(new)
+ new.parent = self
+ return new
+
+ def __repr__(self):
+ return 'Token' + (self and '.' or '') + '.'.join(self)
+
+ def __copy__(self):
+ # These instances are supposed to be singletons
+ return self
+
+ def __deepcopy__(self, memo):
+ # These instances are supposed to be singletons
+ return self
+
+
+Token = _TokenType()
+
+# Special token types
+Text = Token.Text
+Whitespace = Text.Whitespace
+Escape = Token.Escape
+Error = Token.Error
+# Text that doesn't belong to this lexer (e.g. HTML in PHP)
+Other = Token.Other
+
+# Common token types for source code
+Keyword = Token.Keyword
+Name = Token.Name
+Literal = Token.Literal
+String = Literal.String
+Number = Literal.Number
+Punctuation = Token.Punctuation
+Operator = Token.Operator
+Comment = Token.Comment
+
+# Generic types for non-source code
+Generic = Token.Generic
+
+# String and some others are not direct children of Token.
+# alias them:
+Token.Token = Token
+Token.String = String
+Token.Number = Number
+
+
+def is_token_subtype(ttype, other):
+ """
+ Return True if ``ttype`` is a subtype of ``other``.
+
+ exists for backwards compatibility. use ``ttype in other`` now.
+ """
+ return ttype in other
+
+
+def string_to_tokentype(s):
+ """
+ Convert a string into a token type::
+
+ >>> string_to_token('String.Double')
+ Token.Literal.String.Double
+ >>> string_to_token('Token.Literal.Number')
+ Token.Literal.Number
+ >>> string_to_token('')
+ Token
+
+ Tokens that are already tokens are returned unchanged:
+
+ >>> string_to_token(String)
+ Token.Literal.String
+ """
+ if isinstance(s, _TokenType):
+ return s
+ if not s:
+ return Token
+ node = Token
+ for item in s.split('.'):
+ node = getattr(node, item)
+ return node
+
+
+# Map standard token types to short names, used in CSS class naming.
+# If you add a new item, please be sure to run this file to perform
+# a consistency check for duplicate values.
+STANDARD_TYPES = {
+ Token: '',
+
+ Text: '',
+ Whitespace: 'w',
+ Escape: 'esc',
+ Error: 'err',
+ Other: 'x',
+
+ Keyword: 'k',
+ Keyword.Constant: 'kc',
+ Keyword.Declaration: 'kd',
+ Keyword.Namespace: 'kn',
+ Keyword.Pseudo: 'kp',
+ Keyword.Reserved: 'kr',
+ Keyword.Type: 'kt',
+
+ Name: 'n',
+ Name.Attribute: 'na',
+ Name.Builtin: 'nb',
+ Name.Builtin.Pseudo: 'bp',
+ Name.Class: 'nc',
+ Name.Constant: 'no',
+ Name.Decorator: 'nd',
+ Name.Entity: 'ni',
+ Name.Exception: 'ne',
+ Name.Function: 'nf',
+ Name.Function.Magic: 'fm',
+ Name.Property: 'py',
+ Name.Label: 'nl',
+ Name.Namespace: 'nn',
+ Name.Other: 'nx',
+ Name.Tag: 'nt',
+ Name.Variable: 'nv',
+ Name.Variable.Class: 'vc',
+ Name.Variable.Global: 'vg',
+ Name.Variable.Instance: 'vi',
+ Name.Variable.Magic: 'vm',
+
+ Literal: 'l',
+ Literal.Date: 'ld',
+
+ String: 's',
+ String.Affix: 'sa',
+ String.Backtick: 'sb',
+ String.Char: 'sc',
+ String.Delimiter: 'dl',
+ String.Doc: 'sd',
+ String.Double: 's2',
+ String.Escape: 'se',
+ String.Heredoc: 'sh',
+ String.Interpol: 'si',
+ String.Other: 'sx',
+ String.Regex: 'sr',
+ String.Single: 's1',
+ String.Symbol: 'ss',
+
+ Number: 'm',
+ Number.Bin: 'mb',
+ Number.Float: 'mf',
+ Number.Hex: 'mh',
+ Number.Integer: 'mi',
+ Number.Integer.Long: 'il',
+ Number.Oct: 'mo',
+
+ Operator: 'o',
+ Operator.Word: 'ow',
+
+ Punctuation: 'p',
+ Punctuation.Marker: 'pm',
+
+ Comment: 'c',
+ Comment.Hashbang: 'ch',
+ Comment.Multiline: 'cm',
+ Comment.Preproc: 'cp',
+ Comment.PreprocFile: 'cpf',
+ Comment.Single: 'c1',
+ Comment.Special: 'cs',
+
+ Generic: 'g',
+ Generic.Deleted: 'gd',
+ Generic.Emph: 'ge',
+ Generic.Error: 'gr',
+ Generic.Heading: 'gh',
+ Generic.Inserted: 'gi',
+ Generic.Output: 'go',
+ Generic.Prompt: 'gp',
+ Generic.Strong: 'gs',
+ Generic.Subheading: 'gu',
+ Generic.EmphStrong: 'ges',
+ Generic.Traceback: 'gt',
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/unistring.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/unistring.py
new file mode 100644
index 000000000..e2c3523e4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/unistring.py
@@ -0,0 +1,153 @@
+"""
+ pygments.unistring
+ ~~~~~~~~~~~~~~~~~~
+
+ Strings of all Unicode characters of a certain category.
+ Used for matching in Unicode-aware languages. Run to regenerate.
+
+ Inspired by chartypes_create.py from the MoinMoin project.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+Cc = '\x00-\x1f\x7f-\x9f'
+
+Cf = '\xad\u0600-\u0605\u061c\u06dd\u070f\u08e2\u180e\u200b-\u200f\u202a-\u202e\u2060-\u2064\u2066-\u206f\ufeff\ufff9-\ufffb\U000110bd\U000110cd\U0001bca0-\U0001bca3\U0001d173-\U0001d17a\U000e0001\U000e0020-\U000e007f'
+
+Cn = '\u0378-\u0379\u0380-\u0383\u038b\u038d\u03a2\u0530\u0557-\u0558\u058b-\u058c\u0590\u05c8-\u05cf\u05eb-\u05ee\u05f5-\u05ff\u061d\u070e\u074b-\u074c\u07b2-\u07bf\u07fb-\u07fc\u082e-\u082f\u083f\u085c-\u085d\u085f\u086b-\u089f\u08b5\u08be-\u08d2\u0984\u098d-\u098e\u0991-\u0992\u09a9\u09b1\u09b3-\u09b5\u09ba-\u09bb\u09c5-\u09c6\u09c9-\u09ca\u09cf-\u09d6\u09d8-\u09db\u09de\u09e4-\u09e5\u09ff-\u0a00\u0a04\u0a0b-\u0a0e\u0a11-\u0a12\u0a29\u0a31\u0a34\u0a37\u0a3a-\u0a3b\u0a3d\u0a43-\u0a46\u0a49-\u0a4a\u0a4e-\u0a50\u0a52-\u0a58\u0a5d\u0a5f-\u0a65\u0a77-\u0a80\u0a84\u0a8e\u0a92\u0aa9\u0ab1\u0ab4\u0aba-\u0abb\u0ac6\u0aca\u0ace-\u0acf\u0ad1-\u0adf\u0ae4-\u0ae5\u0af2-\u0af8\u0b00\u0b04\u0b0d-\u0b0e\u0b11-\u0b12\u0b29\u0b31\u0b34\u0b3a-\u0b3b\u0b45-\u0b46\u0b49-\u0b4a\u0b4e-\u0b55\u0b58-\u0b5b\u0b5e\u0b64-\u0b65\u0b78-\u0b81\u0b84\u0b8b-\u0b8d\u0b91\u0b96-\u0b98\u0b9b\u0b9d\u0ba0-\u0ba2\u0ba5-\u0ba7\u0bab-\u0bad\u0bba-\u0bbd\u0bc3-\u0bc5\u0bc9\u0bce-\u0bcf\u0bd1-\u0bd6\u0bd8-\u0be5\u0bfb-\u0bff\u0c0d\u0c11\u0c29\u0c3a-\u0c3c\u0c45\u0c49\u0c4e-\u0c54\u0c57\u0c5b-\u0c5f\u0c64-\u0c65\u0c70-\u0c77\u0c8d\u0c91\u0ca9\u0cb4\u0cba-\u0cbb\u0cc5\u0cc9\u0cce-\u0cd4\u0cd7-\u0cdd\u0cdf\u0ce4-\u0ce5\u0cf0\u0cf3-\u0cff\u0d04\u0d0d\u0d11\u0d45\u0d49\u0d50-\u0d53\u0d64-\u0d65\u0d80-\u0d81\u0d84\u0d97-\u0d99\u0db2\u0dbc\u0dbe-\u0dbf\u0dc7-\u0dc9\u0dcb-\u0dce\u0dd5\u0dd7\u0de0-\u0de5\u0df0-\u0df1\u0df5-\u0e00\u0e3b-\u0e3e\u0e5c-\u0e80\u0e83\u0e85-\u0e86\u0e89\u0e8b-\u0e8c\u0e8e-\u0e93\u0e98\u0ea0\u0ea4\u0ea6\u0ea8-\u0ea9\u0eac\u0eba\u0ebe-\u0ebf\u0ec5\u0ec7\u0ece-\u0ecf\u0eda-\u0edb\u0ee0-\u0eff\u0f48\u0f6d-\u0f70\u0f98\u0fbd\u0fcd\u0fdb-\u0fff\u10c6\u10c8-\u10cc\u10ce-\u10cf\u1249\u124e-\u124f\u1257\u1259\u125e-\u125f\u1289\u128e-\u128f\u12b1\u12b6-\u12b7\u12bf\u12c1\u12c6-\u12c7\u12d7\u1311\u1316-\u1317\u135b-\u135c\u137d-\u137f\u139a-\u139f\u13f6-\u13f7\u13fe-\u13ff\u169d-\u169f\u16f9-\u16ff\u170d\u1715-\u171f\u1737-\u173f\u1754-\u175f\u176d\u1771\u1774-\u177f\u17de-\u17df\u17ea-\u17ef\u17fa-\u17ff\u180f\u181a-\u181f\u1879-\u187f\u18ab-\u18af\u18f6-\u18ff\u191f\u192c-\u192f\u193c-\u193f\u1941-\u1943\u196e-\u196f\u1975-\u197f\u19ac-\u19af\u19ca-\u19cf\u19db-\u19dd\u1a1c-\u1a1d\u1a5f\u1a7d-\u1a7e\u1a8a-\u1a8f\u1a9a-\u1a9f\u1aae-\u1aaf\u1abf-\u1aff\u1b4c-\u1b4f\u1b7d-\u1b7f\u1bf4-\u1bfb\u1c38-\u1c3a\u1c4a-\u1c4c\u1c89-\u1c8f\u1cbb-\u1cbc\u1cc8-\u1ccf\u1cfa-\u1cff\u1dfa\u1f16-\u1f17\u1f1e-\u1f1f\u1f46-\u1f47\u1f4e-\u1f4f\u1f58\u1f5a\u1f5c\u1f5e\u1f7e-\u1f7f\u1fb5\u1fc5\u1fd4-\u1fd5\u1fdc\u1ff0-\u1ff1\u1ff5\u1fff\u2065\u2072-\u2073\u208f\u209d-\u209f\u20c0-\u20cf\u20f1-\u20ff\u218c-\u218f\u2427-\u243f\u244b-\u245f\u2b74-\u2b75\u2b96-\u2b97\u2bc9\u2bff\u2c2f\u2c5f\u2cf4-\u2cf8\u2d26\u2d28-\u2d2c\u2d2e-\u2d2f\u2d68-\u2d6e\u2d71-\u2d7e\u2d97-\u2d9f\u2da7\u2daf\u2db7\u2dbf\u2dc7\u2dcf\u2dd7\u2ddf\u2e4f-\u2e7f\u2e9a\u2ef4-\u2eff\u2fd6-\u2fef\u2ffc-\u2fff\u3040\u3097-\u3098\u3100-\u3104\u3130\u318f\u31bb-\u31bf\u31e4-\u31ef\u321f\u32ff\u4db6-\u4dbf\u9ff0-\u9fff\ua48d-\ua48f\ua4c7-\ua4cf\ua62c-\ua63f\ua6f8-\ua6ff\ua7ba-\ua7f6\ua82c-\ua82f\ua83a-\ua83f\ua878-\ua87f\ua8c6-\ua8cd\ua8da-\ua8df\ua954-\ua95e\ua97d-\ua97f\ua9ce\ua9da-\ua9dd\ua9ff\uaa37-\uaa3f\uaa4e-\uaa4f\uaa5a-\uaa5b\uaac3-\uaada\uaaf7-\uab00\uab07-\uab08\uab0f-\uab10\uab17-\uab1f\uab27\uab2f\uab66-\uab6f\uabee-\uabef\uabfa-\uabff\ud7a4-\ud7af\ud7c7-\ud7ca\ud7fc-\ud7ff\ufa6e-\ufa6f\ufada-\ufaff\ufb07-\ufb12\ufb18-\ufb1c\ufb37\ufb3d\ufb3f\ufb42\ufb45\ufbc2-\ufbd2\ufd40-\ufd4f\ufd90-\ufd91\ufdc8-\ufdef\ufdfe-\ufdff\ufe1a-\ufe1f\ufe53\ufe67\ufe6c-\ufe6f\ufe75\ufefd-\ufefe\uff00\uffbf-\uffc1\uffc8-\uffc9\uffd0-\uffd1\uffd8-\uffd9\uffdd-\uffdf\uffe7\uffef-\ufff8\ufffe-\uffff\U0001000c\U00010027\U0001003b\U0001003e\U0001004e-\U0001004f\U0001005e-\U0001007f\U000100fb-\U000100ff\U00010103-\U00010106\U00010134-\U00010136\U0001018f\U0001019c-\U0001019f\U000101a1-\U000101cf\U000101fe-\U0001027f\U0001029d-\U0001029f\U000102d1-\U000102df\U000102fc-\U000102ff\U00010324-\U0001032c\U0001034b-\U0001034f\U0001037b-\U0001037f\U0001039e\U000103c4-\U000103c7\U000103d6-\U000103ff\U0001049e-\U0001049f\U000104aa-\U000104af\U000104d4-\U000104d7\U000104fc-\U000104ff\U00010528-\U0001052f\U00010564-\U0001056e\U00010570-\U000105ff\U00010737-\U0001073f\U00010756-\U0001075f\U00010768-\U000107ff\U00010806-\U00010807\U00010809\U00010836\U00010839-\U0001083b\U0001083d-\U0001083e\U00010856\U0001089f-\U000108a6\U000108b0-\U000108df\U000108f3\U000108f6-\U000108fa\U0001091c-\U0001091e\U0001093a-\U0001093e\U00010940-\U0001097f\U000109b8-\U000109bb\U000109d0-\U000109d1\U00010a04\U00010a07-\U00010a0b\U00010a14\U00010a18\U00010a36-\U00010a37\U00010a3b-\U00010a3e\U00010a49-\U00010a4f\U00010a59-\U00010a5f\U00010aa0-\U00010abf\U00010ae7-\U00010aea\U00010af7-\U00010aff\U00010b36-\U00010b38\U00010b56-\U00010b57\U00010b73-\U00010b77\U00010b92-\U00010b98\U00010b9d-\U00010ba8\U00010bb0-\U00010bff\U00010c49-\U00010c7f\U00010cb3-\U00010cbf\U00010cf3-\U00010cf9\U00010d28-\U00010d2f\U00010d3a-\U00010e5f\U00010e7f-\U00010eff\U00010f28-\U00010f2f\U00010f5a-\U00010fff\U0001104e-\U00011051\U00011070-\U0001107e\U000110c2-\U000110cc\U000110ce-\U000110cf\U000110e9-\U000110ef\U000110fa-\U000110ff\U00011135\U00011147-\U0001114f\U00011177-\U0001117f\U000111ce-\U000111cf\U000111e0\U000111f5-\U000111ff\U00011212\U0001123f-\U0001127f\U00011287\U00011289\U0001128e\U0001129e\U000112aa-\U000112af\U000112eb-\U000112ef\U000112fa-\U000112ff\U00011304\U0001130d-\U0001130e\U00011311-\U00011312\U00011329\U00011331\U00011334\U0001133a\U00011345-\U00011346\U00011349-\U0001134a\U0001134e-\U0001134f\U00011351-\U00011356\U00011358-\U0001135c\U00011364-\U00011365\U0001136d-\U0001136f\U00011375-\U000113ff\U0001145a\U0001145c\U0001145f-\U0001147f\U000114c8-\U000114cf\U000114da-\U0001157f\U000115b6-\U000115b7\U000115de-\U000115ff\U00011645-\U0001164f\U0001165a-\U0001165f\U0001166d-\U0001167f\U000116b8-\U000116bf\U000116ca-\U000116ff\U0001171b-\U0001171c\U0001172c-\U0001172f\U00011740-\U000117ff\U0001183c-\U0001189f\U000118f3-\U000118fe\U00011900-\U000119ff\U00011a48-\U00011a4f\U00011a84-\U00011a85\U00011aa3-\U00011abf\U00011af9-\U00011bff\U00011c09\U00011c37\U00011c46-\U00011c4f\U00011c6d-\U00011c6f\U00011c90-\U00011c91\U00011ca8\U00011cb7-\U00011cff\U00011d07\U00011d0a\U00011d37-\U00011d39\U00011d3b\U00011d3e\U00011d48-\U00011d4f\U00011d5a-\U00011d5f\U00011d66\U00011d69\U00011d8f\U00011d92\U00011d99-\U00011d9f\U00011daa-\U00011edf\U00011ef9-\U00011fff\U0001239a-\U000123ff\U0001246f\U00012475-\U0001247f\U00012544-\U00012fff\U0001342f-\U000143ff\U00014647-\U000167ff\U00016a39-\U00016a3f\U00016a5f\U00016a6a-\U00016a6d\U00016a70-\U00016acf\U00016aee-\U00016aef\U00016af6-\U00016aff\U00016b46-\U00016b4f\U00016b5a\U00016b62\U00016b78-\U00016b7c\U00016b90-\U00016e3f\U00016e9b-\U00016eff\U00016f45-\U00016f4f\U00016f7f-\U00016f8e\U00016fa0-\U00016fdf\U00016fe2-\U00016fff\U000187f2-\U000187ff\U00018af3-\U0001afff\U0001b11f-\U0001b16f\U0001b2fc-\U0001bbff\U0001bc6b-\U0001bc6f\U0001bc7d-\U0001bc7f\U0001bc89-\U0001bc8f\U0001bc9a-\U0001bc9b\U0001bca4-\U0001cfff\U0001d0f6-\U0001d0ff\U0001d127-\U0001d128\U0001d1e9-\U0001d1ff\U0001d246-\U0001d2df\U0001d2f4-\U0001d2ff\U0001d357-\U0001d35f\U0001d379-\U0001d3ff\U0001d455\U0001d49d\U0001d4a0-\U0001d4a1\U0001d4a3-\U0001d4a4\U0001d4a7-\U0001d4a8\U0001d4ad\U0001d4ba\U0001d4bc\U0001d4c4\U0001d506\U0001d50b-\U0001d50c\U0001d515\U0001d51d\U0001d53a\U0001d53f\U0001d545\U0001d547-\U0001d549\U0001d551\U0001d6a6-\U0001d6a7\U0001d7cc-\U0001d7cd\U0001da8c-\U0001da9a\U0001daa0\U0001dab0-\U0001dfff\U0001e007\U0001e019-\U0001e01a\U0001e022\U0001e025\U0001e02b-\U0001e7ff\U0001e8c5-\U0001e8c6\U0001e8d7-\U0001e8ff\U0001e94b-\U0001e94f\U0001e95a-\U0001e95d\U0001e960-\U0001ec70\U0001ecb5-\U0001edff\U0001ee04\U0001ee20\U0001ee23\U0001ee25-\U0001ee26\U0001ee28\U0001ee33\U0001ee38\U0001ee3a\U0001ee3c-\U0001ee41\U0001ee43-\U0001ee46\U0001ee48\U0001ee4a\U0001ee4c\U0001ee50\U0001ee53\U0001ee55-\U0001ee56\U0001ee58\U0001ee5a\U0001ee5c\U0001ee5e\U0001ee60\U0001ee63\U0001ee65-\U0001ee66\U0001ee6b\U0001ee73\U0001ee78\U0001ee7d\U0001ee7f\U0001ee8a\U0001ee9c-\U0001eea0\U0001eea4\U0001eeaa\U0001eebc-\U0001eeef\U0001eef2-\U0001efff\U0001f02c-\U0001f02f\U0001f094-\U0001f09f\U0001f0af-\U0001f0b0\U0001f0c0\U0001f0d0\U0001f0f6-\U0001f0ff\U0001f10d-\U0001f10f\U0001f16c-\U0001f16f\U0001f1ad-\U0001f1e5\U0001f203-\U0001f20f\U0001f23c-\U0001f23f\U0001f249-\U0001f24f\U0001f252-\U0001f25f\U0001f266-\U0001f2ff\U0001f6d5-\U0001f6df\U0001f6ed-\U0001f6ef\U0001f6fa-\U0001f6ff\U0001f774-\U0001f77f\U0001f7d9-\U0001f7ff\U0001f80c-\U0001f80f\U0001f848-\U0001f84f\U0001f85a-\U0001f85f\U0001f888-\U0001f88f\U0001f8ae-\U0001f8ff\U0001f90c-\U0001f90f\U0001f93f\U0001f971-\U0001f972\U0001f977-\U0001f979\U0001f97b\U0001f9a3-\U0001f9af\U0001f9ba-\U0001f9bf\U0001f9c3-\U0001f9cf\U0001fa00-\U0001fa5f\U0001fa6e-\U0001ffff\U0002a6d7-\U0002a6ff\U0002b735-\U0002b73f\U0002b81e-\U0002b81f\U0002cea2-\U0002ceaf\U0002ebe1-\U0002f7ff\U0002fa1e-\U000e0000\U000e0002-\U000e001f\U000e0080-\U000e00ff\U000e01f0-\U000effff\U000ffffe-\U000fffff\U0010fffe-\U0010ffff'
+
+Co = '\ue000-\uf8ff\U000f0000-\U000ffffd\U00100000-\U0010fffd'
+
+Cs = '\ud800-\udbff\\\udc00\udc01-\udfff'
+
+Ll = 'a-z\xb5\xdf-\xf6\xf8-\xff\u0101\u0103\u0105\u0107\u0109\u010b\u010d\u010f\u0111\u0113\u0115\u0117\u0119\u011b\u011d\u011f\u0121\u0123\u0125\u0127\u0129\u012b\u012d\u012f\u0131\u0133\u0135\u0137-\u0138\u013a\u013c\u013e\u0140\u0142\u0144\u0146\u0148-\u0149\u014b\u014d\u014f\u0151\u0153\u0155\u0157\u0159\u015b\u015d\u015f\u0161\u0163\u0165\u0167\u0169\u016b\u016d\u016f\u0171\u0173\u0175\u0177\u017a\u017c\u017e-\u0180\u0183\u0185\u0188\u018c-\u018d\u0192\u0195\u0199-\u019b\u019e\u01a1\u01a3\u01a5\u01a8\u01aa-\u01ab\u01ad\u01b0\u01b4\u01b6\u01b9-\u01ba\u01bd-\u01bf\u01c6\u01c9\u01cc\u01ce\u01d0\u01d2\u01d4\u01d6\u01d8\u01da\u01dc-\u01dd\u01df\u01e1\u01e3\u01e5\u01e7\u01e9\u01eb\u01ed\u01ef-\u01f0\u01f3\u01f5\u01f9\u01fb\u01fd\u01ff\u0201\u0203\u0205\u0207\u0209\u020b\u020d\u020f\u0211\u0213\u0215\u0217\u0219\u021b\u021d\u021f\u0221\u0223\u0225\u0227\u0229\u022b\u022d\u022f\u0231\u0233-\u0239\u023c\u023f-\u0240\u0242\u0247\u0249\u024b\u024d\u024f-\u0293\u0295-\u02af\u0371\u0373\u0377\u037b-\u037d\u0390\u03ac-\u03ce\u03d0-\u03d1\u03d5-\u03d7\u03d9\u03db\u03dd\u03df\u03e1\u03e3\u03e5\u03e7\u03e9\u03eb\u03ed\u03ef-\u03f3\u03f5\u03f8\u03fb-\u03fc\u0430-\u045f\u0461\u0463\u0465\u0467\u0469\u046b\u046d\u046f\u0471\u0473\u0475\u0477\u0479\u047b\u047d\u047f\u0481\u048b\u048d\u048f\u0491\u0493\u0495\u0497\u0499\u049b\u049d\u049f\u04a1\u04a3\u04a5\u04a7\u04a9\u04ab\u04ad\u04af\u04b1\u04b3\u04b5\u04b7\u04b9\u04bb\u04bd\u04bf\u04c2\u04c4\u04c6\u04c8\u04ca\u04cc\u04ce-\u04cf\u04d1\u04d3\u04d5\u04d7\u04d9\u04db\u04dd\u04df\u04e1\u04e3\u04e5\u04e7\u04e9\u04eb\u04ed\u04ef\u04f1\u04f3\u04f5\u04f7\u04f9\u04fb\u04fd\u04ff\u0501\u0503\u0505\u0507\u0509\u050b\u050d\u050f\u0511\u0513\u0515\u0517\u0519\u051b\u051d\u051f\u0521\u0523\u0525\u0527\u0529\u052b\u052d\u052f\u0560-\u0588\u10d0-\u10fa\u10fd-\u10ff\u13f8-\u13fd\u1c80-\u1c88\u1d00-\u1d2b\u1d6b-\u1d77\u1d79-\u1d9a\u1e01\u1e03\u1e05\u1e07\u1e09\u1e0b\u1e0d\u1e0f\u1e11\u1e13\u1e15\u1e17\u1e19\u1e1b\u1e1d\u1e1f\u1e21\u1e23\u1e25\u1e27\u1e29\u1e2b\u1e2d\u1e2f\u1e31\u1e33\u1e35\u1e37\u1e39\u1e3b\u1e3d\u1e3f\u1e41\u1e43\u1e45\u1e47\u1e49\u1e4b\u1e4d\u1e4f\u1e51\u1e53\u1e55\u1e57\u1e59\u1e5b\u1e5d\u1e5f\u1e61\u1e63\u1e65\u1e67\u1e69\u1e6b\u1e6d\u1e6f\u1e71\u1e73\u1e75\u1e77\u1e79\u1e7b\u1e7d\u1e7f\u1e81\u1e83\u1e85\u1e87\u1e89\u1e8b\u1e8d\u1e8f\u1e91\u1e93\u1e95-\u1e9d\u1e9f\u1ea1\u1ea3\u1ea5\u1ea7\u1ea9\u1eab\u1ead\u1eaf\u1eb1\u1eb3\u1eb5\u1eb7\u1eb9\u1ebb\u1ebd\u1ebf\u1ec1\u1ec3\u1ec5\u1ec7\u1ec9\u1ecb\u1ecd\u1ecf\u1ed1\u1ed3\u1ed5\u1ed7\u1ed9\u1edb\u1edd\u1edf\u1ee1\u1ee3\u1ee5\u1ee7\u1ee9\u1eeb\u1eed\u1eef\u1ef1\u1ef3\u1ef5\u1ef7\u1ef9\u1efb\u1efd\u1eff-\u1f07\u1f10-\u1f15\u1f20-\u1f27\u1f30-\u1f37\u1f40-\u1f45\u1f50-\u1f57\u1f60-\u1f67\u1f70-\u1f7d\u1f80-\u1f87\u1f90-\u1f97\u1fa0-\u1fa7\u1fb0-\u1fb4\u1fb6-\u1fb7\u1fbe\u1fc2-\u1fc4\u1fc6-\u1fc7\u1fd0-\u1fd3\u1fd6-\u1fd7\u1fe0-\u1fe7\u1ff2-\u1ff4\u1ff6-\u1ff7\u210a\u210e-\u210f\u2113\u212f\u2134\u2139\u213c-\u213d\u2146-\u2149\u214e\u2184\u2c30-\u2c5e\u2c61\u2c65-\u2c66\u2c68\u2c6a\u2c6c\u2c71\u2c73-\u2c74\u2c76-\u2c7b\u2c81\u2c83\u2c85\u2c87\u2c89\u2c8b\u2c8d\u2c8f\u2c91\u2c93\u2c95\u2c97\u2c99\u2c9b\u2c9d\u2c9f\u2ca1\u2ca3\u2ca5\u2ca7\u2ca9\u2cab\u2cad\u2caf\u2cb1\u2cb3\u2cb5\u2cb7\u2cb9\u2cbb\u2cbd\u2cbf\u2cc1\u2cc3\u2cc5\u2cc7\u2cc9\u2ccb\u2ccd\u2ccf\u2cd1\u2cd3\u2cd5\u2cd7\u2cd9\u2cdb\u2cdd\u2cdf\u2ce1\u2ce3-\u2ce4\u2cec\u2cee\u2cf3\u2d00-\u2d25\u2d27\u2d2d\ua641\ua643\ua645\ua647\ua649\ua64b\ua64d\ua64f\ua651\ua653\ua655\ua657\ua659\ua65b\ua65d\ua65f\ua661\ua663\ua665\ua667\ua669\ua66b\ua66d\ua681\ua683\ua685\ua687\ua689\ua68b\ua68d\ua68f\ua691\ua693\ua695\ua697\ua699\ua69b\ua723\ua725\ua727\ua729\ua72b\ua72d\ua72f-\ua731\ua733\ua735\ua737\ua739\ua73b\ua73d\ua73f\ua741\ua743\ua745\ua747\ua749\ua74b\ua74d\ua74f\ua751\ua753\ua755\ua757\ua759\ua75b\ua75d\ua75f\ua761\ua763\ua765\ua767\ua769\ua76b\ua76d\ua76f\ua771-\ua778\ua77a\ua77c\ua77f\ua781\ua783\ua785\ua787\ua78c\ua78e\ua791\ua793-\ua795\ua797\ua799\ua79b\ua79d\ua79f\ua7a1\ua7a3\ua7a5\ua7a7\ua7a9\ua7af\ua7b5\ua7b7\ua7b9\ua7fa\uab30-\uab5a\uab60-\uab65\uab70-\uabbf\ufb00-\ufb06\ufb13-\ufb17\uff41-\uff5a\U00010428-\U0001044f\U000104d8-\U000104fb\U00010cc0-\U00010cf2\U000118c0-\U000118df\U00016e60-\U00016e7f\U0001d41a-\U0001d433\U0001d44e-\U0001d454\U0001d456-\U0001d467\U0001d482-\U0001d49b\U0001d4b6-\U0001d4b9\U0001d4bb\U0001d4bd-\U0001d4c3\U0001d4c5-\U0001d4cf\U0001d4ea-\U0001d503\U0001d51e-\U0001d537\U0001d552-\U0001d56b\U0001d586-\U0001d59f\U0001d5ba-\U0001d5d3\U0001d5ee-\U0001d607\U0001d622-\U0001d63b\U0001d656-\U0001d66f\U0001d68a-\U0001d6a5\U0001d6c2-\U0001d6da\U0001d6dc-\U0001d6e1\U0001d6fc-\U0001d714\U0001d716-\U0001d71b\U0001d736-\U0001d74e\U0001d750-\U0001d755\U0001d770-\U0001d788\U0001d78a-\U0001d78f\U0001d7aa-\U0001d7c2\U0001d7c4-\U0001d7c9\U0001d7cb\U0001e922-\U0001e943'
+
+Lm = '\u02b0-\u02c1\u02c6-\u02d1\u02e0-\u02e4\u02ec\u02ee\u0374\u037a\u0559\u0640\u06e5-\u06e6\u07f4-\u07f5\u07fa\u081a\u0824\u0828\u0971\u0e46\u0ec6\u10fc\u17d7\u1843\u1aa7\u1c78-\u1c7d\u1d2c-\u1d6a\u1d78\u1d9b-\u1dbf\u2071\u207f\u2090-\u209c\u2c7c-\u2c7d\u2d6f\u2e2f\u3005\u3031-\u3035\u303b\u309d-\u309e\u30fc-\u30fe\ua015\ua4f8-\ua4fd\ua60c\ua67f\ua69c-\ua69d\ua717-\ua71f\ua770\ua788\ua7f8-\ua7f9\ua9cf\ua9e6\uaa70\uaadd\uaaf3-\uaaf4\uab5c-\uab5f\uff70\uff9e-\uff9f\U00016b40-\U00016b43\U00016f93-\U00016f9f\U00016fe0-\U00016fe1'
+
+Lo = '\xaa\xba\u01bb\u01c0-\u01c3\u0294\u05d0-\u05ea\u05ef-\u05f2\u0620-\u063f\u0641-\u064a\u066e-\u066f\u0671-\u06d3\u06d5\u06ee-\u06ef\u06fa-\u06fc\u06ff\u0710\u0712-\u072f\u074d-\u07a5\u07b1\u07ca-\u07ea\u0800-\u0815\u0840-\u0858\u0860-\u086a\u08a0-\u08b4\u08b6-\u08bd\u0904-\u0939\u093d\u0950\u0958-\u0961\u0972-\u0980\u0985-\u098c\u098f-\u0990\u0993-\u09a8\u09aa-\u09b0\u09b2\u09b6-\u09b9\u09bd\u09ce\u09dc-\u09dd\u09df-\u09e1\u09f0-\u09f1\u09fc\u0a05-\u0a0a\u0a0f-\u0a10\u0a13-\u0a28\u0a2a-\u0a30\u0a32-\u0a33\u0a35-\u0a36\u0a38-\u0a39\u0a59-\u0a5c\u0a5e\u0a72-\u0a74\u0a85-\u0a8d\u0a8f-\u0a91\u0a93-\u0aa8\u0aaa-\u0ab0\u0ab2-\u0ab3\u0ab5-\u0ab9\u0abd\u0ad0\u0ae0-\u0ae1\u0af9\u0b05-\u0b0c\u0b0f-\u0b10\u0b13-\u0b28\u0b2a-\u0b30\u0b32-\u0b33\u0b35-\u0b39\u0b3d\u0b5c-\u0b5d\u0b5f-\u0b61\u0b71\u0b83\u0b85-\u0b8a\u0b8e-\u0b90\u0b92-\u0b95\u0b99-\u0b9a\u0b9c\u0b9e-\u0b9f\u0ba3-\u0ba4\u0ba8-\u0baa\u0bae-\u0bb9\u0bd0\u0c05-\u0c0c\u0c0e-\u0c10\u0c12-\u0c28\u0c2a-\u0c39\u0c3d\u0c58-\u0c5a\u0c60-\u0c61\u0c80\u0c85-\u0c8c\u0c8e-\u0c90\u0c92-\u0ca8\u0caa-\u0cb3\u0cb5-\u0cb9\u0cbd\u0cde\u0ce0-\u0ce1\u0cf1-\u0cf2\u0d05-\u0d0c\u0d0e-\u0d10\u0d12-\u0d3a\u0d3d\u0d4e\u0d54-\u0d56\u0d5f-\u0d61\u0d7a-\u0d7f\u0d85-\u0d96\u0d9a-\u0db1\u0db3-\u0dbb\u0dbd\u0dc0-\u0dc6\u0e01-\u0e30\u0e32-\u0e33\u0e40-\u0e45\u0e81-\u0e82\u0e84\u0e87-\u0e88\u0e8a\u0e8d\u0e94-\u0e97\u0e99-\u0e9f\u0ea1-\u0ea3\u0ea5\u0ea7\u0eaa-\u0eab\u0ead-\u0eb0\u0eb2-\u0eb3\u0ebd\u0ec0-\u0ec4\u0edc-\u0edf\u0f00\u0f40-\u0f47\u0f49-\u0f6c\u0f88-\u0f8c\u1000-\u102a\u103f\u1050-\u1055\u105a-\u105d\u1061\u1065-\u1066\u106e-\u1070\u1075-\u1081\u108e\u1100-\u1248\u124a-\u124d\u1250-\u1256\u1258\u125a-\u125d\u1260-\u1288\u128a-\u128d\u1290-\u12b0\u12b2-\u12b5\u12b8-\u12be\u12c0\u12c2-\u12c5\u12c8-\u12d6\u12d8-\u1310\u1312-\u1315\u1318-\u135a\u1380-\u138f\u1401-\u166c\u166f-\u167f\u1681-\u169a\u16a0-\u16ea\u16f1-\u16f8\u1700-\u170c\u170e-\u1711\u1720-\u1731\u1740-\u1751\u1760-\u176c\u176e-\u1770\u1780-\u17b3\u17dc\u1820-\u1842\u1844-\u1878\u1880-\u1884\u1887-\u18a8\u18aa\u18b0-\u18f5\u1900-\u191e\u1950-\u196d\u1970-\u1974\u1980-\u19ab\u19b0-\u19c9\u1a00-\u1a16\u1a20-\u1a54\u1b05-\u1b33\u1b45-\u1b4b\u1b83-\u1ba0\u1bae-\u1baf\u1bba-\u1be5\u1c00-\u1c23\u1c4d-\u1c4f\u1c5a-\u1c77\u1ce9-\u1cec\u1cee-\u1cf1\u1cf5-\u1cf6\u2135-\u2138\u2d30-\u2d67\u2d80-\u2d96\u2da0-\u2da6\u2da8-\u2dae\u2db0-\u2db6\u2db8-\u2dbe\u2dc0-\u2dc6\u2dc8-\u2dce\u2dd0-\u2dd6\u2dd8-\u2dde\u3006\u303c\u3041-\u3096\u309f\u30a1-\u30fa\u30ff\u3105-\u312f\u3131-\u318e\u31a0-\u31ba\u31f0-\u31ff\u3400-\u4db5\u4e00-\u9fef\ua000-\ua014\ua016-\ua48c\ua4d0-\ua4f7\ua500-\ua60b\ua610-\ua61f\ua62a-\ua62b\ua66e\ua6a0-\ua6e5\ua78f\ua7f7\ua7fb-\ua801\ua803-\ua805\ua807-\ua80a\ua80c-\ua822\ua840-\ua873\ua882-\ua8b3\ua8f2-\ua8f7\ua8fb\ua8fd-\ua8fe\ua90a-\ua925\ua930-\ua946\ua960-\ua97c\ua984-\ua9b2\ua9e0-\ua9e4\ua9e7-\ua9ef\ua9fa-\ua9fe\uaa00-\uaa28\uaa40-\uaa42\uaa44-\uaa4b\uaa60-\uaa6f\uaa71-\uaa76\uaa7a\uaa7e-\uaaaf\uaab1\uaab5-\uaab6\uaab9-\uaabd\uaac0\uaac2\uaadb-\uaadc\uaae0-\uaaea\uaaf2\uab01-\uab06\uab09-\uab0e\uab11-\uab16\uab20-\uab26\uab28-\uab2e\uabc0-\uabe2\uac00-\ud7a3\ud7b0-\ud7c6\ud7cb-\ud7fb\uf900-\ufa6d\ufa70-\ufad9\ufb1d\ufb1f-\ufb28\ufb2a-\ufb36\ufb38-\ufb3c\ufb3e\ufb40-\ufb41\ufb43-\ufb44\ufb46-\ufbb1\ufbd3-\ufd3d\ufd50-\ufd8f\ufd92-\ufdc7\ufdf0-\ufdfb\ufe70-\ufe74\ufe76-\ufefc\uff66-\uff6f\uff71-\uff9d\uffa0-\uffbe\uffc2-\uffc7\uffca-\uffcf\uffd2-\uffd7\uffda-\uffdc\U00010000-\U0001000b\U0001000d-\U00010026\U00010028-\U0001003a\U0001003c-\U0001003d\U0001003f-\U0001004d\U00010050-\U0001005d\U00010080-\U000100fa\U00010280-\U0001029c\U000102a0-\U000102d0\U00010300-\U0001031f\U0001032d-\U00010340\U00010342-\U00010349\U00010350-\U00010375\U00010380-\U0001039d\U000103a0-\U000103c3\U000103c8-\U000103cf\U00010450-\U0001049d\U00010500-\U00010527\U00010530-\U00010563\U00010600-\U00010736\U00010740-\U00010755\U00010760-\U00010767\U00010800-\U00010805\U00010808\U0001080a-\U00010835\U00010837-\U00010838\U0001083c\U0001083f-\U00010855\U00010860-\U00010876\U00010880-\U0001089e\U000108e0-\U000108f2\U000108f4-\U000108f5\U00010900-\U00010915\U00010920-\U00010939\U00010980-\U000109b7\U000109be-\U000109bf\U00010a00\U00010a10-\U00010a13\U00010a15-\U00010a17\U00010a19-\U00010a35\U00010a60-\U00010a7c\U00010a80-\U00010a9c\U00010ac0-\U00010ac7\U00010ac9-\U00010ae4\U00010b00-\U00010b35\U00010b40-\U00010b55\U00010b60-\U00010b72\U00010b80-\U00010b91\U00010c00-\U00010c48\U00010d00-\U00010d23\U00010f00-\U00010f1c\U00010f27\U00010f30-\U00010f45\U00011003-\U00011037\U00011083-\U000110af\U000110d0-\U000110e8\U00011103-\U00011126\U00011144\U00011150-\U00011172\U00011176\U00011183-\U000111b2\U000111c1-\U000111c4\U000111da\U000111dc\U00011200-\U00011211\U00011213-\U0001122b\U00011280-\U00011286\U00011288\U0001128a-\U0001128d\U0001128f-\U0001129d\U0001129f-\U000112a8\U000112b0-\U000112de\U00011305-\U0001130c\U0001130f-\U00011310\U00011313-\U00011328\U0001132a-\U00011330\U00011332-\U00011333\U00011335-\U00011339\U0001133d\U00011350\U0001135d-\U00011361\U00011400-\U00011434\U00011447-\U0001144a\U00011480-\U000114af\U000114c4-\U000114c5\U000114c7\U00011580-\U000115ae\U000115d8-\U000115db\U00011600-\U0001162f\U00011644\U00011680-\U000116aa\U00011700-\U0001171a\U00011800-\U0001182b\U000118ff\U00011a00\U00011a0b-\U00011a32\U00011a3a\U00011a50\U00011a5c-\U00011a83\U00011a86-\U00011a89\U00011a9d\U00011ac0-\U00011af8\U00011c00-\U00011c08\U00011c0a-\U00011c2e\U00011c40\U00011c72-\U00011c8f\U00011d00-\U00011d06\U00011d08-\U00011d09\U00011d0b-\U00011d30\U00011d46\U00011d60-\U00011d65\U00011d67-\U00011d68\U00011d6a-\U00011d89\U00011d98\U00011ee0-\U00011ef2\U00012000-\U00012399\U00012480-\U00012543\U00013000-\U0001342e\U00014400-\U00014646\U00016800-\U00016a38\U00016a40-\U00016a5e\U00016ad0-\U00016aed\U00016b00-\U00016b2f\U00016b63-\U00016b77\U00016b7d-\U00016b8f\U00016f00-\U00016f44\U00016f50\U00017000-\U000187f1\U00018800-\U00018af2\U0001b000-\U0001b11e\U0001b170-\U0001b2fb\U0001bc00-\U0001bc6a\U0001bc70-\U0001bc7c\U0001bc80-\U0001bc88\U0001bc90-\U0001bc99\U0001e800-\U0001e8c4\U0001ee00-\U0001ee03\U0001ee05-\U0001ee1f\U0001ee21-\U0001ee22\U0001ee24\U0001ee27\U0001ee29-\U0001ee32\U0001ee34-\U0001ee37\U0001ee39\U0001ee3b\U0001ee42\U0001ee47\U0001ee49\U0001ee4b\U0001ee4d-\U0001ee4f\U0001ee51-\U0001ee52\U0001ee54\U0001ee57\U0001ee59\U0001ee5b\U0001ee5d\U0001ee5f\U0001ee61-\U0001ee62\U0001ee64\U0001ee67-\U0001ee6a\U0001ee6c-\U0001ee72\U0001ee74-\U0001ee77\U0001ee79-\U0001ee7c\U0001ee7e\U0001ee80-\U0001ee89\U0001ee8b-\U0001ee9b\U0001eea1-\U0001eea3\U0001eea5-\U0001eea9\U0001eeab-\U0001eebb\U00020000-\U0002a6d6\U0002a700-\U0002b734\U0002b740-\U0002b81d\U0002b820-\U0002cea1\U0002ceb0-\U0002ebe0\U0002f800-\U0002fa1d'
+
+Lt = '\u01c5\u01c8\u01cb\u01f2\u1f88-\u1f8f\u1f98-\u1f9f\u1fa8-\u1faf\u1fbc\u1fcc\u1ffc'
+
+Lu = 'A-Z\xc0-\xd6\xd8-\xde\u0100\u0102\u0104\u0106\u0108\u010a\u010c\u010e\u0110\u0112\u0114\u0116\u0118\u011a\u011c\u011e\u0120\u0122\u0124\u0126\u0128\u012a\u012c\u012e\u0130\u0132\u0134\u0136\u0139\u013b\u013d\u013f\u0141\u0143\u0145\u0147\u014a\u014c\u014e\u0150\u0152\u0154\u0156\u0158\u015a\u015c\u015e\u0160\u0162\u0164\u0166\u0168\u016a\u016c\u016e\u0170\u0172\u0174\u0176\u0178-\u0179\u017b\u017d\u0181-\u0182\u0184\u0186-\u0187\u0189-\u018b\u018e-\u0191\u0193-\u0194\u0196-\u0198\u019c-\u019d\u019f-\u01a0\u01a2\u01a4\u01a6-\u01a7\u01a9\u01ac\u01ae-\u01af\u01b1-\u01b3\u01b5\u01b7-\u01b8\u01bc\u01c4\u01c7\u01ca\u01cd\u01cf\u01d1\u01d3\u01d5\u01d7\u01d9\u01db\u01de\u01e0\u01e2\u01e4\u01e6\u01e8\u01ea\u01ec\u01ee\u01f1\u01f4\u01f6-\u01f8\u01fa\u01fc\u01fe\u0200\u0202\u0204\u0206\u0208\u020a\u020c\u020e\u0210\u0212\u0214\u0216\u0218\u021a\u021c\u021e\u0220\u0222\u0224\u0226\u0228\u022a\u022c\u022e\u0230\u0232\u023a-\u023b\u023d-\u023e\u0241\u0243-\u0246\u0248\u024a\u024c\u024e\u0370\u0372\u0376\u037f\u0386\u0388-\u038a\u038c\u038e-\u038f\u0391-\u03a1\u03a3-\u03ab\u03cf\u03d2-\u03d4\u03d8\u03da\u03dc\u03de\u03e0\u03e2\u03e4\u03e6\u03e8\u03ea\u03ec\u03ee\u03f4\u03f7\u03f9-\u03fa\u03fd-\u042f\u0460\u0462\u0464\u0466\u0468\u046a\u046c\u046e\u0470\u0472\u0474\u0476\u0478\u047a\u047c\u047e\u0480\u048a\u048c\u048e\u0490\u0492\u0494\u0496\u0498\u049a\u049c\u049e\u04a0\u04a2\u04a4\u04a6\u04a8\u04aa\u04ac\u04ae\u04b0\u04b2\u04b4\u04b6\u04b8\u04ba\u04bc\u04be\u04c0-\u04c1\u04c3\u04c5\u04c7\u04c9\u04cb\u04cd\u04d0\u04d2\u04d4\u04d6\u04d8\u04da\u04dc\u04de\u04e0\u04e2\u04e4\u04e6\u04e8\u04ea\u04ec\u04ee\u04f0\u04f2\u04f4\u04f6\u04f8\u04fa\u04fc\u04fe\u0500\u0502\u0504\u0506\u0508\u050a\u050c\u050e\u0510\u0512\u0514\u0516\u0518\u051a\u051c\u051e\u0520\u0522\u0524\u0526\u0528\u052a\u052c\u052e\u0531-\u0556\u10a0-\u10c5\u10c7\u10cd\u13a0-\u13f5\u1c90-\u1cba\u1cbd-\u1cbf\u1e00\u1e02\u1e04\u1e06\u1e08\u1e0a\u1e0c\u1e0e\u1e10\u1e12\u1e14\u1e16\u1e18\u1e1a\u1e1c\u1e1e\u1e20\u1e22\u1e24\u1e26\u1e28\u1e2a\u1e2c\u1e2e\u1e30\u1e32\u1e34\u1e36\u1e38\u1e3a\u1e3c\u1e3e\u1e40\u1e42\u1e44\u1e46\u1e48\u1e4a\u1e4c\u1e4e\u1e50\u1e52\u1e54\u1e56\u1e58\u1e5a\u1e5c\u1e5e\u1e60\u1e62\u1e64\u1e66\u1e68\u1e6a\u1e6c\u1e6e\u1e70\u1e72\u1e74\u1e76\u1e78\u1e7a\u1e7c\u1e7e\u1e80\u1e82\u1e84\u1e86\u1e88\u1e8a\u1e8c\u1e8e\u1e90\u1e92\u1e94\u1e9e\u1ea0\u1ea2\u1ea4\u1ea6\u1ea8\u1eaa\u1eac\u1eae\u1eb0\u1eb2\u1eb4\u1eb6\u1eb8\u1eba\u1ebc\u1ebe\u1ec0\u1ec2\u1ec4\u1ec6\u1ec8\u1eca\u1ecc\u1ece\u1ed0\u1ed2\u1ed4\u1ed6\u1ed8\u1eda\u1edc\u1ede\u1ee0\u1ee2\u1ee4\u1ee6\u1ee8\u1eea\u1eec\u1eee\u1ef0\u1ef2\u1ef4\u1ef6\u1ef8\u1efa\u1efc\u1efe\u1f08-\u1f0f\u1f18-\u1f1d\u1f28-\u1f2f\u1f38-\u1f3f\u1f48-\u1f4d\u1f59\u1f5b\u1f5d\u1f5f\u1f68-\u1f6f\u1fb8-\u1fbb\u1fc8-\u1fcb\u1fd8-\u1fdb\u1fe8-\u1fec\u1ff8-\u1ffb\u2102\u2107\u210b-\u210d\u2110-\u2112\u2115\u2119-\u211d\u2124\u2126\u2128\u212a-\u212d\u2130-\u2133\u213e-\u213f\u2145\u2183\u2c00-\u2c2e\u2c60\u2c62-\u2c64\u2c67\u2c69\u2c6b\u2c6d-\u2c70\u2c72\u2c75\u2c7e-\u2c80\u2c82\u2c84\u2c86\u2c88\u2c8a\u2c8c\u2c8e\u2c90\u2c92\u2c94\u2c96\u2c98\u2c9a\u2c9c\u2c9e\u2ca0\u2ca2\u2ca4\u2ca6\u2ca8\u2caa\u2cac\u2cae\u2cb0\u2cb2\u2cb4\u2cb6\u2cb8\u2cba\u2cbc\u2cbe\u2cc0\u2cc2\u2cc4\u2cc6\u2cc8\u2cca\u2ccc\u2cce\u2cd0\u2cd2\u2cd4\u2cd6\u2cd8\u2cda\u2cdc\u2cde\u2ce0\u2ce2\u2ceb\u2ced\u2cf2\ua640\ua642\ua644\ua646\ua648\ua64a\ua64c\ua64e\ua650\ua652\ua654\ua656\ua658\ua65a\ua65c\ua65e\ua660\ua662\ua664\ua666\ua668\ua66a\ua66c\ua680\ua682\ua684\ua686\ua688\ua68a\ua68c\ua68e\ua690\ua692\ua694\ua696\ua698\ua69a\ua722\ua724\ua726\ua728\ua72a\ua72c\ua72e\ua732\ua734\ua736\ua738\ua73a\ua73c\ua73e\ua740\ua742\ua744\ua746\ua748\ua74a\ua74c\ua74e\ua750\ua752\ua754\ua756\ua758\ua75a\ua75c\ua75e\ua760\ua762\ua764\ua766\ua768\ua76a\ua76c\ua76e\ua779\ua77b\ua77d-\ua77e\ua780\ua782\ua784\ua786\ua78b\ua78d\ua790\ua792\ua796\ua798\ua79a\ua79c\ua79e\ua7a0\ua7a2\ua7a4\ua7a6\ua7a8\ua7aa-\ua7ae\ua7b0-\ua7b4\ua7b6\ua7b8\uff21-\uff3a\U00010400-\U00010427\U000104b0-\U000104d3\U00010c80-\U00010cb2\U000118a0-\U000118bf\U00016e40-\U00016e5f\U0001d400-\U0001d419\U0001d434-\U0001d44d\U0001d468-\U0001d481\U0001d49c\U0001d49e-\U0001d49f\U0001d4a2\U0001d4a5-\U0001d4a6\U0001d4a9-\U0001d4ac\U0001d4ae-\U0001d4b5\U0001d4d0-\U0001d4e9\U0001d504-\U0001d505\U0001d507-\U0001d50a\U0001d50d-\U0001d514\U0001d516-\U0001d51c\U0001d538-\U0001d539\U0001d53b-\U0001d53e\U0001d540-\U0001d544\U0001d546\U0001d54a-\U0001d550\U0001d56c-\U0001d585\U0001d5a0-\U0001d5b9\U0001d5d4-\U0001d5ed\U0001d608-\U0001d621\U0001d63c-\U0001d655\U0001d670-\U0001d689\U0001d6a8-\U0001d6c0\U0001d6e2-\U0001d6fa\U0001d71c-\U0001d734\U0001d756-\U0001d76e\U0001d790-\U0001d7a8\U0001d7ca\U0001e900-\U0001e921'
+
+Mc = '\u0903\u093b\u093e-\u0940\u0949-\u094c\u094e-\u094f\u0982-\u0983\u09be-\u09c0\u09c7-\u09c8\u09cb-\u09cc\u09d7\u0a03\u0a3e-\u0a40\u0a83\u0abe-\u0ac0\u0ac9\u0acb-\u0acc\u0b02-\u0b03\u0b3e\u0b40\u0b47-\u0b48\u0b4b-\u0b4c\u0b57\u0bbe-\u0bbf\u0bc1-\u0bc2\u0bc6-\u0bc8\u0bca-\u0bcc\u0bd7\u0c01-\u0c03\u0c41-\u0c44\u0c82-\u0c83\u0cbe\u0cc0-\u0cc4\u0cc7-\u0cc8\u0cca-\u0ccb\u0cd5-\u0cd6\u0d02-\u0d03\u0d3e-\u0d40\u0d46-\u0d48\u0d4a-\u0d4c\u0d57\u0d82-\u0d83\u0dcf-\u0dd1\u0dd8-\u0ddf\u0df2-\u0df3\u0f3e-\u0f3f\u0f7f\u102b-\u102c\u1031\u1038\u103b-\u103c\u1056-\u1057\u1062-\u1064\u1067-\u106d\u1083-\u1084\u1087-\u108c\u108f\u109a-\u109c\u17b6\u17be-\u17c5\u17c7-\u17c8\u1923-\u1926\u1929-\u192b\u1930-\u1931\u1933-\u1938\u1a19-\u1a1a\u1a55\u1a57\u1a61\u1a63-\u1a64\u1a6d-\u1a72\u1b04\u1b35\u1b3b\u1b3d-\u1b41\u1b43-\u1b44\u1b82\u1ba1\u1ba6-\u1ba7\u1baa\u1be7\u1bea-\u1bec\u1bee\u1bf2-\u1bf3\u1c24-\u1c2b\u1c34-\u1c35\u1ce1\u1cf2-\u1cf3\u1cf7\u302e-\u302f\ua823-\ua824\ua827\ua880-\ua881\ua8b4-\ua8c3\ua952-\ua953\ua983\ua9b4-\ua9b5\ua9ba-\ua9bb\ua9bd-\ua9c0\uaa2f-\uaa30\uaa33-\uaa34\uaa4d\uaa7b\uaa7d\uaaeb\uaaee-\uaaef\uaaf5\uabe3-\uabe4\uabe6-\uabe7\uabe9-\uabea\uabec\U00011000\U00011002\U00011082\U000110b0-\U000110b2\U000110b7-\U000110b8\U0001112c\U00011145-\U00011146\U00011182\U000111b3-\U000111b5\U000111bf-\U000111c0\U0001122c-\U0001122e\U00011232-\U00011233\U00011235\U000112e0-\U000112e2\U00011302-\U00011303\U0001133e-\U0001133f\U00011341-\U00011344\U00011347-\U00011348\U0001134b-\U0001134d\U00011357\U00011362-\U00011363\U00011435-\U00011437\U00011440-\U00011441\U00011445\U000114b0-\U000114b2\U000114b9\U000114bb-\U000114be\U000114c1\U000115af-\U000115b1\U000115b8-\U000115bb\U000115be\U00011630-\U00011632\U0001163b-\U0001163c\U0001163e\U000116ac\U000116ae-\U000116af\U000116b6\U00011720-\U00011721\U00011726\U0001182c-\U0001182e\U00011838\U00011a39\U00011a57-\U00011a58\U00011a97\U00011c2f\U00011c3e\U00011ca9\U00011cb1\U00011cb4\U00011d8a-\U00011d8e\U00011d93-\U00011d94\U00011d96\U00011ef5-\U00011ef6\U00016f51-\U00016f7e\U0001d165-\U0001d166\U0001d16d-\U0001d172'
+
+Me = '\u0488-\u0489\u1abe\u20dd-\u20e0\u20e2-\u20e4\ua670-\ua672'
+
+Mn = '\u0300-\u036f\u0483-\u0487\u0591-\u05bd\u05bf\u05c1-\u05c2\u05c4-\u05c5\u05c7\u0610-\u061a\u064b-\u065f\u0670\u06d6-\u06dc\u06df-\u06e4\u06e7-\u06e8\u06ea-\u06ed\u0711\u0730-\u074a\u07a6-\u07b0\u07eb-\u07f3\u07fd\u0816-\u0819\u081b-\u0823\u0825-\u0827\u0829-\u082d\u0859-\u085b\u08d3-\u08e1\u08e3-\u0902\u093a\u093c\u0941-\u0948\u094d\u0951-\u0957\u0962-\u0963\u0981\u09bc\u09c1-\u09c4\u09cd\u09e2-\u09e3\u09fe\u0a01-\u0a02\u0a3c\u0a41-\u0a42\u0a47-\u0a48\u0a4b-\u0a4d\u0a51\u0a70-\u0a71\u0a75\u0a81-\u0a82\u0abc\u0ac1-\u0ac5\u0ac7-\u0ac8\u0acd\u0ae2-\u0ae3\u0afa-\u0aff\u0b01\u0b3c\u0b3f\u0b41-\u0b44\u0b4d\u0b56\u0b62-\u0b63\u0b82\u0bc0\u0bcd\u0c00\u0c04\u0c3e-\u0c40\u0c46-\u0c48\u0c4a-\u0c4d\u0c55-\u0c56\u0c62-\u0c63\u0c81\u0cbc\u0cbf\u0cc6\u0ccc-\u0ccd\u0ce2-\u0ce3\u0d00-\u0d01\u0d3b-\u0d3c\u0d41-\u0d44\u0d4d\u0d62-\u0d63\u0dca\u0dd2-\u0dd4\u0dd6\u0e31\u0e34-\u0e3a\u0e47-\u0e4e\u0eb1\u0eb4-\u0eb9\u0ebb-\u0ebc\u0ec8-\u0ecd\u0f18-\u0f19\u0f35\u0f37\u0f39\u0f71-\u0f7e\u0f80-\u0f84\u0f86-\u0f87\u0f8d-\u0f97\u0f99-\u0fbc\u0fc6\u102d-\u1030\u1032-\u1037\u1039-\u103a\u103d-\u103e\u1058-\u1059\u105e-\u1060\u1071-\u1074\u1082\u1085-\u1086\u108d\u109d\u135d-\u135f\u1712-\u1714\u1732-\u1734\u1752-\u1753\u1772-\u1773\u17b4-\u17b5\u17b7-\u17bd\u17c6\u17c9-\u17d3\u17dd\u180b-\u180d\u1885-\u1886\u18a9\u1920-\u1922\u1927-\u1928\u1932\u1939-\u193b\u1a17-\u1a18\u1a1b\u1a56\u1a58-\u1a5e\u1a60\u1a62\u1a65-\u1a6c\u1a73-\u1a7c\u1a7f\u1ab0-\u1abd\u1b00-\u1b03\u1b34\u1b36-\u1b3a\u1b3c\u1b42\u1b6b-\u1b73\u1b80-\u1b81\u1ba2-\u1ba5\u1ba8-\u1ba9\u1bab-\u1bad\u1be6\u1be8-\u1be9\u1bed\u1bef-\u1bf1\u1c2c-\u1c33\u1c36-\u1c37\u1cd0-\u1cd2\u1cd4-\u1ce0\u1ce2-\u1ce8\u1ced\u1cf4\u1cf8-\u1cf9\u1dc0-\u1df9\u1dfb-\u1dff\u20d0-\u20dc\u20e1\u20e5-\u20f0\u2cef-\u2cf1\u2d7f\u2de0-\u2dff\u302a-\u302d\u3099-\u309a\ua66f\ua674-\ua67d\ua69e-\ua69f\ua6f0-\ua6f1\ua802\ua806\ua80b\ua825-\ua826\ua8c4-\ua8c5\ua8e0-\ua8f1\ua8ff\ua926-\ua92d\ua947-\ua951\ua980-\ua982\ua9b3\ua9b6-\ua9b9\ua9bc\ua9e5\uaa29-\uaa2e\uaa31-\uaa32\uaa35-\uaa36\uaa43\uaa4c\uaa7c\uaab0\uaab2-\uaab4\uaab7-\uaab8\uaabe-\uaabf\uaac1\uaaec-\uaaed\uaaf6\uabe5\uabe8\uabed\ufb1e\ufe00-\ufe0f\ufe20-\ufe2f\U000101fd\U000102e0\U00010376-\U0001037a\U00010a01-\U00010a03\U00010a05-\U00010a06\U00010a0c-\U00010a0f\U00010a38-\U00010a3a\U00010a3f\U00010ae5-\U00010ae6\U00010d24-\U00010d27\U00010f46-\U00010f50\U00011001\U00011038-\U00011046\U0001107f-\U00011081\U000110b3-\U000110b6\U000110b9-\U000110ba\U00011100-\U00011102\U00011127-\U0001112b\U0001112d-\U00011134\U00011173\U00011180-\U00011181\U000111b6-\U000111be\U000111c9-\U000111cc\U0001122f-\U00011231\U00011234\U00011236-\U00011237\U0001123e\U000112df\U000112e3-\U000112ea\U00011300-\U00011301\U0001133b-\U0001133c\U00011340\U00011366-\U0001136c\U00011370-\U00011374\U00011438-\U0001143f\U00011442-\U00011444\U00011446\U0001145e\U000114b3-\U000114b8\U000114ba\U000114bf-\U000114c0\U000114c2-\U000114c3\U000115b2-\U000115b5\U000115bc-\U000115bd\U000115bf-\U000115c0\U000115dc-\U000115dd\U00011633-\U0001163a\U0001163d\U0001163f-\U00011640\U000116ab\U000116ad\U000116b0-\U000116b5\U000116b7\U0001171d-\U0001171f\U00011722-\U00011725\U00011727-\U0001172b\U0001182f-\U00011837\U00011839-\U0001183a\U00011a01-\U00011a0a\U00011a33-\U00011a38\U00011a3b-\U00011a3e\U00011a47\U00011a51-\U00011a56\U00011a59-\U00011a5b\U00011a8a-\U00011a96\U00011a98-\U00011a99\U00011c30-\U00011c36\U00011c38-\U00011c3d\U00011c3f\U00011c92-\U00011ca7\U00011caa-\U00011cb0\U00011cb2-\U00011cb3\U00011cb5-\U00011cb6\U00011d31-\U00011d36\U00011d3a\U00011d3c-\U00011d3d\U00011d3f-\U00011d45\U00011d47\U00011d90-\U00011d91\U00011d95\U00011d97\U00011ef3-\U00011ef4\U00016af0-\U00016af4\U00016b30-\U00016b36\U00016f8f-\U00016f92\U0001bc9d-\U0001bc9e\U0001d167-\U0001d169\U0001d17b-\U0001d182\U0001d185-\U0001d18b\U0001d1aa-\U0001d1ad\U0001d242-\U0001d244\U0001da00-\U0001da36\U0001da3b-\U0001da6c\U0001da75\U0001da84\U0001da9b-\U0001da9f\U0001daa1-\U0001daaf\U0001e000-\U0001e006\U0001e008-\U0001e018\U0001e01b-\U0001e021\U0001e023-\U0001e024\U0001e026-\U0001e02a\U0001e8d0-\U0001e8d6\U0001e944-\U0001e94a\U000e0100-\U000e01ef'
+
+Nd = '0-9\u0660-\u0669\u06f0-\u06f9\u07c0-\u07c9\u0966-\u096f\u09e6-\u09ef\u0a66-\u0a6f\u0ae6-\u0aef\u0b66-\u0b6f\u0be6-\u0bef\u0c66-\u0c6f\u0ce6-\u0cef\u0d66-\u0d6f\u0de6-\u0def\u0e50-\u0e59\u0ed0-\u0ed9\u0f20-\u0f29\u1040-\u1049\u1090-\u1099\u17e0-\u17e9\u1810-\u1819\u1946-\u194f\u19d0-\u19d9\u1a80-\u1a89\u1a90-\u1a99\u1b50-\u1b59\u1bb0-\u1bb9\u1c40-\u1c49\u1c50-\u1c59\ua620-\ua629\ua8d0-\ua8d9\ua900-\ua909\ua9d0-\ua9d9\ua9f0-\ua9f9\uaa50-\uaa59\uabf0-\uabf9\uff10-\uff19\U000104a0-\U000104a9\U00010d30-\U00010d39\U00011066-\U0001106f\U000110f0-\U000110f9\U00011136-\U0001113f\U000111d0-\U000111d9\U000112f0-\U000112f9\U00011450-\U00011459\U000114d0-\U000114d9\U00011650-\U00011659\U000116c0-\U000116c9\U00011730-\U00011739\U000118e0-\U000118e9\U00011c50-\U00011c59\U00011d50-\U00011d59\U00011da0-\U00011da9\U00016a60-\U00016a69\U00016b50-\U00016b59\U0001d7ce-\U0001d7ff\U0001e950-\U0001e959'
+
+Nl = '\u16ee-\u16f0\u2160-\u2182\u2185-\u2188\u3007\u3021-\u3029\u3038-\u303a\ua6e6-\ua6ef\U00010140-\U00010174\U00010341\U0001034a\U000103d1-\U000103d5\U00012400-\U0001246e'
+
+No = '\xb2-\xb3\xb9\xbc-\xbe\u09f4-\u09f9\u0b72-\u0b77\u0bf0-\u0bf2\u0c78-\u0c7e\u0d58-\u0d5e\u0d70-\u0d78\u0f2a-\u0f33\u1369-\u137c\u17f0-\u17f9\u19da\u2070\u2074-\u2079\u2080-\u2089\u2150-\u215f\u2189\u2460-\u249b\u24ea-\u24ff\u2776-\u2793\u2cfd\u3192-\u3195\u3220-\u3229\u3248-\u324f\u3251-\u325f\u3280-\u3289\u32b1-\u32bf\ua830-\ua835\U00010107-\U00010133\U00010175-\U00010178\U0001018a-\U0001018b\U000102e1-\U000102fb\U00010320-\U00010323\U00010858-\U0001085f\U00010879-\U0001087f\U000108a7-\U000108af\U000108fb-\U000108ff\U00010916-\U0001091b\U000109bc-\U000109bd\U000109c0-\U000109cf\U000109d2-\U000109ff\U00010a40-\U00010a48\U00010a7d-\U00010a7e\U00010a9d-\U00010a9f\U00010aeb-\U00010aef\U00010b58-\U00010b5f\U00010b78-\U00010b7f\U00010ba9-\U00010baf\U00010cfa-\U00010cff\U00010e60-\U00010e7e\U00010f1d-\U00010f26\U00010f51-\U00010f54\U00011052-\U00011065\U000111e1-\U000111f4\U0001173a-\U0001173b\U000118ea-\U000118f2\U00011c5a-\U00011c6c\U00016b5b-\U00016b61\U00016e80-\U00016e96\U0001d2e0-\U0001d2f3\U0001d360-\U0001d378\U0001e8c7-\U0001e8cf\U0001ec71-\U0001ecab\U0001ecad-\U0001ecaf\U0001ecb1-\U0001ecb4\U0001f100-\U0001f10c'
+
+Pc = '_\u203f-\u2040\u2054\ufe33-\ufe34\ufe4d-\ufe4f\uff3f'
+
+Pd = '\\-\u058a\u05be\u1400\u1806\u2010-\u2015\u2e17\u2e1a\u2e3a-\u2e3b\u2e40\u301c\u3030\u30a0\ufe31-\ufe32\ufe58\ufe63\uff0d'
+
+Pe = ')\\]}\u0f3b\u0f3d\u169c\u2046\u207e\u208e\u2309\u230b\u232a\u2769\u276b\u276d\u276f\u2771\u2773\u2775\u27c6\u27e7\u27e9\u27eb\u27ed\u27ef\u2984\u2986\u2988\u298a\u298c\u298e\u2990\u2992\u2994\u2996\u2998\u29d9\u29db\u29fd\u2e23\u2e25\u2e27\u2e29\u3009\u300b\u300d\u300f\u3011\u3015\u3017\u3019\u301b\u301e-\u301f\ufd3e\ufe18\ufe36\ufe38\ufe3a\ufe3c\ufe3e\ufe40\ufe42\ufe44\ufe48\ufe5a\ufe5c\ufe5e\uff09\uff3d\uff5d\uff60\uff63'
+
+Pf = '\xbb\u2019\u201d\u203a\u2e03\u2e05\u2e0a\u2e0d\u2e1d\u2e21'
+
+Pi = '\xab\u2018\u201b-\u201c\u201f\u2039\u2e02\u2e04\u2e09\u2e0c\u2e1c\u2e20'
+
+Po = "!-#%-'*,.-/:-;?-@\\\\\xa1\xa7\xb6-\xb7\xbf\u037e\u0387\u055a-\u055f\u0589\u05c0\u05c3\u05c6\u05f3-\u05f4\u0609-\u060a\u060c-\u060d\u061b\u061e-\u061f\u066a-\u066d\u06d4\u0700-\u070d\u07f7-\u07f9\u0830-\u083e\u085e\u0964-\u0965\u0970\u09fd\u0a76\u0af0\u0c84\u0df4\u0e4f\u0e5a-\u0e5b\u0f04-\u0f12\u0f14\u0f85\u0fd0-\u0fd4\u0fd9-\u0fda\u104a-\u104f\u10fb\u1360-\u1368\u166d-\u166e\u16eb-\u16ed\u1735-\u1736\u17d4-\u17d6\u17d8-\u17da\u1800-\u1805\u1807-\u180a\u1944-\u1945\u1a1e-\u1a1f\u1aa0-\u1aa6\u1aa8-\u1aad\u1b5a-\u1b60\u1bfc-\u1bff\u1c3b-\u1c3f\u1c7e-\u1c7f\u1cc0-\u1cc7\u1cd3\u2016-\u2017\u2020-\u2027\u2030-\u2038\u203b-\u203e\u2041-\u2043\u2047-\u2051\u2053\u2055-\u205e\u2cf9-\u2cfc\u2cfe-\u2cff\u2d70\u2e00-\u2e01\u2e06-\u2e08\u2e0b\u2e0e-\u2e16\u2e18-\u2e19\u2e1b\u2e1e-\u2e1f\u2e2a-\u2e2e\u2e30-\u2e39\u2e3c-\u2e3f\u2e41\u2e43-\u2e4e\u3001-\u3003\u303d\u30fb\ua4fe-\ua4ff\ua60d-\ua60f\ua673\ua67e\ua6f2-\ua6f7\ua874-\ua877\ua8ce-\ua8cf\ua8f8-\ua8fa\ua8fc\ua92e-\ua92f\ua95f\ua9c1-\ua9cd\ua9de-\ua9df\uaa5c-\uaa5f\uaade-\uaadf\uaaf0-\uaaf1\uabeb\ufe10-\ufe16\ufe19\ufe30\ufe45-\ufe46\ufe49-\ufe4c\ufe50-\ufe52\ufe54-\ufe57\ufe5f-\ufe61\ufe68\ufe6a-\ufe6b\uff01-\uff03\uff05-\uff07\uff0a\uff0c\uff0e-\uff0f\uff1a-\uff1b\uff1f-\uff20\uff3c\uff61\uff64-\uff65\U00010100-\U00010102\U0001039f\U000103d0\U0001056f\U00010857\U0001091f\U0001093f\U00010a50-\U00010a58\U00010a7f\U00010af0-\U00010af6\U00010b39-\U00010b3f\U00010b99-\U00010b9c\U00010f55-\U00010f59\U00011047-\U0001104d\U000110bb-\U000110bc\U000110be-\U000110c1\U00011140-\U00011143\U00011174-\U00011175\U000111c5-\U000111c8\U000111cd\U000111db\U000111dd-\U000111df\U00011238-\U0001123d\U000112a9\U0001144b-\U0001144f\U0001145b\U0001145d\U000114c6\U000115c1-\U000115d7\U00011641-\U00011643\U00011660-\U0001166c\U0001173c-\U0001173e\U0001183b\U00011a3f-\U00011a46\U00011a9a-\U00011a9c\U00011a9e-\U00011aa2\U00011c41-\U00011c45\U00011c70-\U00011c71\U00011ef7-\U00011ef8\U00012470-\U00012474\U00016a6e-\U00016a6f\U00016af5\U00016b37-\U00016b3b\U00016b44\U00016e97-\U00016e9a\U0001bc9f\U0001da87-\U0001da8b\U0001e95e-\U0001e95f"
+
+Ps = '(\\[{\u0f3a\u0f3c\u169b\u201a\u201e\u2045\u207d\u208d\u2308\u230a\u2329\u2768\u276a\u276c\u276e\u2770\u2772\u2774\u27c5\u27e6\u27e8\u27ea\u27ec\u27ee\u2983\u2985\u2987\u2989\u298b\u298d\u298f\u2991\u2993\u2995\u2997\u29d8\u29da\u29fc\u2e22\u2e24\u2e26\u2e28\u2e42\u3008\u300a\u300c\u300e\u3010\u3014\u3016\u3018\u301a\u301d\ufd3f\ufe17\ufe35\ufe37\ufe39\ufe3b\ufe3d\ufe3f\ufe41\ufe43\ufe47\ufe59\ufe5b\ufe5d\uff08\uff3b\uff5b\uff5f\uff62'
+
+Sc = '$\xa2-\xa5\u058f\u060b\u07fe-\u07ff\u09f2-\u09f3\u09fb\u0af1\u0bf9\u0e3f\u17db\u20a0-\u20bf\ua838\ufdfc\ufe69\uff04\uffe0-\uffe1\uffe5-\uffe6\U0001ecb0'
+
+Sk = '\\^`\xa8\xaf\xb4\xb8\u02c2-\u02c5\u02d2-\u02df\u02e5-\u02eb\u02ed\u02ef-\u02ff\u0375\u0384-\u0385\u1fbd\u1fbf-\u1fc1\u1fcd-\u1fcf\u1fdd-\u1fdf\u1fed-\u1fef\u1ffd-\u1ffe\u309b-\u309c\ua700-\ua716\ua720-\ua721\ua789-\ua78a\uab5b\ufbb2-\ufbc1\uff3e\uff40\uffe3\U0001f3fb-\U0001f3ff'
+
+Sm = '+<->|~\xac\xb1\xd7\xf7\u03f6\u0606-\u0608\u2044\u2052\u207a-\u207c\u208a-\u208c\u2118\u2140-\u2144\u214b\u2190-\u2194\u219a-\u219b\u21a0\u21a3\u21a6\u21ae\u21ce-\u21cf\u21d2\u21d4\u21f4-\u22ff\u2320-\u2321\u237c\u239b-\u23b3\u23dc-\u23e1\u25b7\u25c1\u25f8-\u25ff\u266f\u27c0-\u27c4\u27c7-\u27e5\u27f0-\u27ff\u2900-\u2982\u2999-\u29d7\u29dc-\u29fb\u29fe-\u2aff\u2b30-\u2b44\u2b47-\u2b4c\ufb29\ufe62\ufe64-\ufe66\uff0b\uff1c-\uff1e\uff5c\uff5e\uffe2\uffe9-\uffec\U0001d6c1\U0001d6db\U0001d6fb\U0001d715\U0001d735\U0001d74f\U0001d76f\U0001d789\U0001d7a9\U0001d7c3\U0001eef0-\U0001eef1'
+
+So = '\xa6\xa9\xae\xb0\u0482\u058d-\u058e\u060e-\u060f\u06de\u06e9\u06fd-\u06fe\u07f6\u09fa\u0b70\u0bf3-\u0bf8\u0bfa\u0c7f\u0d4f\u0d79\u0f01-\u0f03\u0f13\u0f15-\u0f17\u0f1a-\u0f1f\u0f34\u0f36\u0f38\u0fbe-\u0fc5\u0fc7-\u0fcc\u0fce-\u0fcf\u0fd5-\u0fd8\u109e-\u109f\u1390-\u1399\u1940\u19de-\u19ff\u1b61-\u1b6a\u1b74-\u1b7c\u2100-\u2101\u2103-\u2106\u2108-\u2109\u2114\u2116-\u2117\u211e-\u2123\u2125\u2127\u2129\u212e\u213a-\u213b\u214a\u214c-\u214d\u214f\u218a-\u218b\u2195-\u2199\u219c-\u219f\u21a1-\u21a2\u21a4-\u21a5\u21a7-\u21ad\u21af-\u21cd\u21d0-\u21d1\u21d3\u21d5-\u21f3\u2300-\u2307\u230c-\u231f\u2322-\u2328\u232b-\u237b\u237d-\u239a\u23b4-\u23db\u23e2-\u2426\u2440-\u244a\u249c-\u24e9\u2500-\u25b6\u25b8-\u25c0\u25c2-\u25f7\u2600-\u266e\u2670-\u2767\u2794-\u27bf\u2800-\u28ff\u2b00-\u2b2f\u2b45-\u2b46\u2b4d-\u2b73\u2b76-\u2b95\u2b98-\u2bc8\u2bca-\u2bfe\u2ce5-\u2cea\u2e80-\u2e99\u2e9b-\u2ef3\u2f00-\u2fd5\u2ff0-\u2ffb\u3004\u3012-\u3013\u3020\u3036-\u3037\u303e-\u303f\u3190-\u3191\u3196-\u319f\u31c0-\u31e3\u3200-\u321e\u322a-\u3247\u3250\u3260-\u327f\u328a-\u32b0\u32c0-\u32fe\u3300-\u33ff\u4dc0-\u4dff\ua490-\ua4c6\ua828-\ua82b\ua836-\ua837\ua839\uaa77-\uaa79\ufdfd\uffe4\uffe8\uffed-\uffee\ufffc-\ufffd\U00010137-\U0001013f\U00010179-\U00010189\U0001018c-\U0001018e\U00010190-\U0001019b\U000101a0\U000101d0-\U000101fc\U00010877-\U00010878\U00010ac8\U0001173f\U00016b3c-\U00016b3f\U00016b45\U0001bc9c\U0001d000-\U0001d0f5\U0001d100-\U0001d126\U0001d129-\U0001d164\U0001d16a-\U0001d16c\U0001d183-\U0001d184\U0001d18c-\U0001d1a9\U0001d1ae-\U0001d1e8\U0001d200-\U0001d241\U0001d245\U0001d300-\U0001d356\U0001d800-\U0001d9ff\U0001da37-\U0001da3a\U0001da6d-\U0001da74\U0001da76-\U0001da83\U0001da85-\U0001da86\U0001ecac\U0001f000-\U0001f02b\U0001f030-\U0001f093\U0001f0a0-\U0001f0ae\U0001f0b1-\U0001f0bf\U0001f0c1-\U0001f0cf\U0001f0d1-\U0001f0f5\U0001f110-\U0001f16b\U0001f170-\U0001f1ac\U0001f1e6-\U0001f202\U0001f210-\U0001f23b\U0001f240-\U0001f248\U0001f250-\U0001f251\U0001f260-\U0001f265\U0001f300-\U0001f3fa\U0001f400-\U0001f6d4\U0001f6e0-\U0001f6ec\U0001f6f0-\U0001f6f9\U0001f700-\U0001f773\U0001f780-\U0001f7d8\U0001f800-\U0001f80b\U0001f810-\U0001f847\U0001f850-\U0001f859\U0001f860-\U0001f887\U0001f890-\U0001f8ad\U0001f900-\U0001f90b\U0001f910-\U0001f93e\U0001f940-\U0001f970\U0001f973-\U0001f976\U0001f97a\U0001f97c-\U0001f9a2\U0001f9b0-\U0001f9b9\U0001f9c0-\U0001f9c2\U0001f9d0-\U0001f9ff\U0001fa60-\U0001fa6d'
+
+Zl = '\u2028'
+
+Zp = '\u2029'
+
+Zs = ' \xa0\u1680\u2000-\u200a\u202f\u205f\u3000'
+
+xid_continue = '0-9A-Z_a-z\xaa\xb5\xb7\xba\xc0-\xd6\xd8-\xf6\xf8-\u02c1\u02c6-\u02d1\u02e0-\u02e4\u02ec\u02ee\u0300-\u0374\u0376-\u0377\u037b-\u037d\u037f\u0386-\u038a\u038c\u038e-\u03a1\u03a3-\u03f5\u03f7-\u0481\u0483-\u0487\u048a-\u052f\u0531-\u0556\u0559\u0560-\u0588\u0591-\u05bd\u05bf\u05c1-\u05c2\u05c4-\u05c5\u05c7\u05d0-\u05ea\u05ef-\u05f2\u0610-\u061a\u0620-\u0669\u066e-\u06d3\u06d5-\u06dc\u06df-\u06e8\u06ea-\u06fc\u06ff\u0710-\u074a\u074d-\u07b1\u07c0-\u07f5\u07fa\u07fd\u0800-\u082d\u0840-\u085b\u0860-\u086a\u08a0-\u08b4\u08b6-\u08bd\u08d3-\u08e1\u08e3-\u0963\u0966-\u096f\u0971-\u0983\u0985-\u098c\u098f-\u0990\u0993-\u09a8\u09aa-\u09b0\u09b2\u09b6-\u09b9\u09bc-\u09c4\u09c7-\u09c8\u09cb-\u09ce\u09d7\u09dc-\u09dd\u09df-\u09e3\u09e6-\u09f1\u09fc\u09fe\u0a01-\u0a03\u0a05-\u0a0a\u0a0f-\u0a10\u0a13-\u0a28\u0a2a-\u0a30\u0a32-\u0a33\u0a35-\u0a36\u0a38-\u0a39\u0a3c\u0a3e-\u0a42\u0a47-\u0a48\u0a4b-\u0a4d\u0a51\u0a59-\u0a5c\u0a5e\u0a66-\u0a75\u0a81-\u0a83\u0a85-\u0a8d\u0a8f-\u0a91\u0a93-\u0aa8\u0aaa-\u0ab0\u0ab2-\u0ab3\u0ab5-\u0ab9\u0abc-\u0ac5\u0ac7-\u0ac9\u0acb-\u0acd\u0ad0\u0ae0-\u0ae3\u0ae6-\u0aef\u0af9-\u0aff\u0b01-\u0b03\u0b05-\u0b0c\u0b0f-\u0b10\u0b13-\u0b28\u0b2a-\u0b30\u0b32-\u0b33\u0b35-\u0b39\u0b3c-\u0b44\u0b47-\u0b48\u0b4b-\u0b4d\u0b56-\u0b57\u0b5c-\u0b5d\u0b5f-\u0b63\u0b66-\u0b6f\u0b71\u0b82-\u0b83\u0b85-\u0b8a\u0b8e-\u0b90\u0b92-\u0b95\u0b99-\u0b9a\u0b9c\u0b9e-\u0b9f\u0ba3-\u0ba4\u0ba8-\u0baa\u0bae-\u0bb9\u0bbe-\u0bc2\u0bc6-\u0bc8\u0bca-\u0bcd\u0bd0\u0bd7\u0be6-\u0bef\u0c00-\u0c0c\u0c0e-\u0c10\u0c12-\u0c28\u0c2a-\u0c39\u0c3d-\u0c44\u0c46-\u0c48\u0c4a-\u0c4d\u0c55-\u0c56\u0c58-\u0c5a\u0c60-\u0c63\u0c66-\u0c6f\u0c80-\u0c83\u0c85-\u0c8c\u0c8e-\u0c90\u0c92-\u0ca8\u0caa-\u0cb3\u0cb5-\u0cb9\u0cbc-\u0cc4\u0cc6-\u0cc8\u0cca-\u0ccd\u0cd5-\u0cd6\u0cde\u0ce0-\u0ce3\u0ce6-\u0cef\u0cf1-\u0cf2\u0d00-\u0d03\u0d05-\u0d0c\u0d0e-\u0d10\u0d12-\u0d44\u0d46-\u0d48\u0d4a-\u0d4e\u0d54-\u0d57\u0d5f-\u0d63\u0d66-\u0d6f\u0d7a-\u0d7f\u0d82-\u0d83\u0d85-\u0d96\u0d9a-\u0db1\u0db3-\u0dbb\u0dbd\u0dc0-\u0dc6\u0dca\u0dcf-\u0dd4\u0dd6\u0dd8-\u0ddf\u0de6-\u0def\u0df2-\u0df3\u0e01-\u0e3a\u0e40-\u0e4e\u0e50-\u0e59\u0e81-\u0e82\u0e84\u0e87-\u0e88\u0e8a\u0e8d\u0e94-\u0e97\u0e99-\u0e9f\u0ea1-\u0ea3\u0ea5\u0ea7\u0eaa-\u0eab\u0ead-\u0eb9\u0ebb-\u0ebd\u0ec0-\u0ec4\u0ec6\u0ec8-\u0ecd\u0ed0-\u0ed9\u0edc-\u0edf\u0f00\u0f18-\u0f19\u0f20-\u0f29\u0f35\u0f37\u0f39\u0f3e-\u0f47\u0f49-\u0f6c\u0f71-\u0f84\u0f86-\u0f97\u0f99-\u0fbc\u0fc6\u1000-\u1049\u1050-\u109d\u10a0-\u10c5\u10c7\u10cd\u10d0-\u10fa\u10fc-\u1248\u124a-\u124d\u1250-\u1256\u1258\u125a-\u125d\u1260-\u1288\u128a-\u128d\u1290-\u12b0\u12b2-\u12b5\u12b8-\u12be\u12c0\u12c2-\u12c5\u12c8-\u12d6\u12d8-\u1310\u1312-\u1315\u1318-\u135a\u135d-\u135f\u1369-\u1371\u1380-\u138f\u13a0-\u13f5\u13f8-\u13fd\u1401-\u166c\u166f-\u167f\u1681-\u169a\u16a0-\u16ea\u16ee-\u16f8\u1700-\u170c\u170e-\u1714\u1720-\u1734\u1740-\u1753\u1760-\u176c\u176e-\u1770\u1772-\u1773\u1780-\u17d3\u17d7\u17dc-\u17dd\u17e0-\u17e9\u180b-\u180d\u1810-\u1819\u1820-\u1878\u1880-\u18aa\u18b0-\u18f5\u1900-\u191e\u1920-\u192b\u1930-\u193b\u1946-\u196d\u1970-\u1974\u1980-\u19ab\u19b0-\u19c9\u19d0-\u19da\u1a00-\u1a1b\u1a20-\u1a5e\u1a60-\u1a7c\u1a7f-\u1a89\u1a90-\u1a99\u1aa7\u1ab0-\u1abd\u1b00-\u1b4b\u1b50-\u1b59\u1b6b-\u1b73\u1b80-\u1bf3\u1c00-\u1c37\u1c40-\u1c49\u1c4d-\u1c7d\u1c80-\u1c88\u1c90-\u1cba\u1cbd-\u1cbf\u1cd0-\u1cd2\u1cd4-\u1cf9\u1d00-\u1df9\u1dfb-\u1f15\u1f18-\u1f1d\u1f20-\u1f45\u1f48-\u1f4d\u1f50-\u1f57\u1f59\u1f5b\u1f5d\u1f5f-\u1f7d\u1f80-\u1fb4\u1fb6-\u1fbc\u1fbe\u1fc2-\u1fc4\u1fc6-\u1fcc\u1fd0-\u1fd3\u1fd6-\u1fdb\u1fe0-\u1fec\u1ff2-\u1ff4\u1ff6-\u1ffc\u203f-\u2040\u2054\u2071\u207f\u2090-\u209c\u20d0-\u20dc\u20e1\u20e5-\u20f0\u2102\u2107\u210a-\u2113\u2115\u2118-\u211d\u2124\u2126\u2128\u212a-\u2139\u213c-\u213f\u2145-\u2149\u214e\u2160-\u2188\u2c00-\u2c2e\u2c30-\u2c5e\u2c60-\u2ce4\u2ceb-\u2cf3\u2d00-\u2d25\u2d27\u2d2d\u2d30-\u2d67\u2d6f\u2d7f-\u2d96\u2da0-\u2da6\u2da8-\u2dae\u2db0-\u2db6\u2db8-\u2dbe\u2dc0-\u2dc6\u2dc8-\u2dce\u2dd0-\u2dd6\u2dd8-\u2dde\u2de0-\u2dff\u3005-\u3007\u3021-\u302f\u3031-\u3035\u3038-\u303c\u3041-\u3096\u3099-\u309a\u309d-\u309f\u30a1-\u30fa\u30fc-\u30ff\u3105-\u312f\u3131-\u318e\u31a0-\u31ba\u31f0-\u31ff\u3400-\u4db5\u4e00-\u9fef\ua000-\ua48c\ua4d0-\ua4fd\ua500-\ua60c\ua610-\ua62b\ua640-\ua66f\ua674-\ua67d\ua67f-\ua6f1\ua717-\ua71f\ua722-\ua788\ua78b-\ua7b9\ua7f7-\ua827\ua840-\ua873\ua880-\ua8c5\ua8d0-\ua8d9\ua8e0-\ua8f7\ua8fb\ua8fd-\ua92d\ua930-\ua953\ua960-\ua97c\ua980-\ua9c0\ua9cf-\ua9d9\ua9e0-\ua9fe\uaa00-\uaa36\uaa40-\uaa4d\uaa50-\uaa59\uaa60-\uaa76\uaa7a-\uaac2\uaadb-\uaadd\uaae0-\uaaef\uaaf2-\uaaf6\uab01-\uab06\uab09-\uab0e\uab11-\uab16\uab20-\uab26\uab28-\uab2e\uab30-\uab5a\uab5c-\uab65\uab70-\uabea\uabec-\uabed\uabf0-\uabf9\uac00-\ud7a3\ud7b0-\ud7c6\ud7cb-\ud7fb\uf900-\ufa6d\ufa70-\ufad9\ufb00-\ufb06\ufb13-\ufb17\ufb1d-\ufb28\ufb2a-\ufb36\ufb38-\ufb3c\ufb3e\ufb40-\ufb41\ufb43-\ufb44\ufb46-\ufbb1\ufbd3-\ufc5d\ufc64-\ufd3d\ufd50-\ufd8f\ufd92-\ufdc7\ufdf0-\ufdf9\ufe00-\ufe0f\ufe20-\ufe2f\ufe33-\ufe34\ufe4d-\ufe4f\ufe71\ufe73\ufe77\ufe79\ufe7b\ufe7d\ufe7f-\ufefc\uff10-\uff19\uff21-\uff3a\uff3f\uff41-\uff5a\uff66-\uffbe\uffc2-\uffc7\uffca-\uffcf\uffd2-\uffd7\uffda-\uffdc\U00010000-\U0001000b\U0001000d-\U00010026\U00010028-\U0001003a\U0001003c-\U0001003d\U0001003f-\U0001004d\U00010050-\U0001005d\U00010080-\U000100fa\U00010140-\U00010174\U000101fd\U00010280-\U0001029c\U000102a0-\U000102d0\U000102e0\U00010300-\U0001031f\U0001032d-\U0001034a\U00010350-\U0001037a\U00010380-\U0001039d\U000103a0-\U000103c3\U000103c8-\U000103cf\U000103d1-\U000103d5\U00010400-\U0001049d\U000104a0-\U000104a9\U000104b0-\U000104d3\U000104d8-\U000104fb\U00010500-\U00010527\U00010530-\U00010563\U00010600-\U00010736\U00010740-\U00010755\U00010760-\U00010767\U00010800-\U00010805\U00010808\U0001080a-\U00010835\U00010837-\U00010838\U0001083c\U0001083f-\U00010855\U00010860-\U00010876\U00010880-\U0001089e\U000108e0-\U000108f2\U000108f4-\U000108f5\U00010900-\U00010915\U00010920-\U00010939\U00010980-\U000109b7\U000109be-\U000109bf\U00010a00-\U00010a03\U00010a05-\U00010a06\U00010a0c-\U00010a13\U00010a15-\U00010a17\U00010a19-\U00010a35\U00010a38-\U00010a3a\U00010a3f\U00010a60-\U00010a7c\U00010a80-\U00010a9c\U00010ac0-\U00010ac7\U00010ac9-\U00010ae6\U00010b00-\U00010b35\U00010b40-\U00010b55\U00010b60-\U00010b72\U00010b80-\U00010b91\U00010c00-\U00010c48\U00010c80-\U00010cb2\U00010cc0-\U00010cf2\U00010d00-\U00010d27\U00010d30-\U00010d39\U00010f00-\U00010f1c\U00010f27\U00010f30-\U00010f50\U00011000-\U00011046\U00011066-\U0001106f\U0001107f-\U000110ba\U000110d0-\U000110e8\U000110f0-\U000110f9\U00011100-\U00011134\U00011136-\U0001113f\U00011144-\U00011146\U00011150-\U00011173\U00011176\U00011180-\U000111c4\U000111c9-\U000111cc\U000111d0-\U000111da\U000111dc\U00011200-\U00011211\U00011213-\U00011237\U0001123e\U00011280-\U00011286\U00011288\U0001128a-\U0001128d\U0001128f-\U0001129d\U0001129f-\U000112a8\U000112b0-\U000112ea\U000112f0-\U000112f9\U00011300-\U00011303\U00011305-\U0001130c\U0001130f-\U00011310\U00011313-\U00011328\U0001132a-\U00011330\U00011332-\U00011333\U00011335-\U00011339\U0001133b-\U00011344\U00011347-\U00011348\U0001134b-\U0001134d\U00011350\U00011357\U0001135d-\U00011363\U00011366-\U0001136c\U00011370-\U00011374\U00011400-\U0001144a\U00011450-\U00011459\U0001145e\U00011480-\U000114c5\U000114c7\U000114d0-\U000114d9\U00011580-\U000115b5\U000115b8-\U000115c0\U000115d8-\U000115dd\U00011600-\U00011640\U00011644\U00011650-\U00011659\U00011680-\U000116b7\U000116c0-\U000116c9\U00011700-\U0001171a\U0001171d-\U0001172b\U00011730-\U00011739\U00011800-\U0001183a\U000118a0-\U000118e9\U000118ff\U00011a00-\U00011a3e\U00011a47\U00011a50-\U00011a83\U00011a86-\U00011a99\U00011a9d\U00011ac0-\U00011af8\U00011c00-\U00011c08\U00011c0a-\U00011c36\U00011c38-\U00011c40\U00011c50-\U00011c59\U00011c72-\U00011c8f\U00011c92-\U00011ca7\U00011ca9-\U00011cb6\U00011d00-\U00011d06\U00011d08-\U00011d09\U00011d0b-\U00011d36\U00011d3a\U00011d3c-\U00011d3d\U00011d3f-\U00011d47\U00011d50-\U00011d59\U00011d60-\U00011d65\U00011d67-\U00011d68\U00011d6a-\U00011d8e\U00011d90-\U00011d91\U00011d93-\U00011d98\U00011da0-\U00011da9\U00011ee0-\U00011ef6\U00012000-\U00012399\U00012400-\U0001246e\U00012480-\U00012543\U00013000-\U0001342e\U00014400-\U00014646\U00016800-\U00016a38\U00016a40-\U00016a5e\U00016a60-\U00016a69\U00016ad0-\U00016aed\U00016af0-\U00016af4\U00016b00-\U00016b36\U00016b40-\U00016b43\U00016b50-\U00016b59\U00016b63-\U00016b77\U00016b7d-\U00016b8f\U00016e40-\U00016e7f\U00016f00-\U00016f44\U00016f50-\U00016f7e\U00016f8f-\U00016f9f\U00016fe0-\U00016fe1\U00017000-\U000187f1\U00018800-\U00018af2\U0001b000-\U0001b11e\U0001b170-\U0001b2fb\U0001bc00-\U0001bc6a\U0001bc70-\U0001bc7c\U0001bc80-\U0001bc88\U0001bc90-\U0001bc99\U0001bc9d-\U0001bc9e\U0001d165-\U0001d169\U0001d16d-\U0001d172\U0001d17b-\U0001d182\U0001d185-\U0001d18b\U0001d1aa-\U0001d1ad\U0001d242-\U0001d244\U0001d400-\U0001d454\U0001d456-\U0001d49c\U0001d49e-\U0001d49f\U0001d4a2\U0001d4a5-\U0001d4a6\U0001d4a9-\U0001d4ac\U0001d4ae-\U0001d4b9\U0001d4bb\U0001d4bd-\U0001d4c3\U0001d4c5-\U0001d505\U0001d507-\U0001d50a\U0001d50d-\U0001d514\U0001d516-\U0001d51c\U0001d51e-\U0001d539\U0001d53b-\U0001d53e\U0001d540-\U0001d544\U0001d546\U0001d54a-\U0001d550\U0001d552-\U0001d6a5\U0001d6a8-\U0001d6c0\U0001d6c2-\U0001d6da\U0001d6dc-\U0001d6fa\U0001d6fc-\U0001d714\U0001d716-\U0001d734\U0001d736-\U0001d74e\U0001d750-\U0001d76e\U0001d770-\U0001d788\U0001d78a-\U0001d7a8\U0001d7aa-\U0001d7c2\U0001d7c4-\U0001d7cb\U0001d7ce-\U0001d7ff\U0001da00-\U0001da36\U0001da3b-\U0001da6c\U0001da75\U0001da84\U0001da9b-\U0001da9f\U0001daa1-\U0001daaf\U0001e000-\U0001e006\U0001e008-\U0001e018\U0001e01b-\U0001e021\U0001e023-\U0001e024\U0001e026-\U0001e02a\U0001e800-\U0001e8c4\U0001e8d0-\U0001e8d6\U0001e900-\U0001e94a\U0001e950-\U0001e959\U0001ee00-\U0001ee03\U0001ee05-\U0001ee1f\U0001ee21-\U0001ee22\U0001ee24\U0001ee27\U0001ee29-\U0001ee32\U0001ee34-\U0001ee37\U0001ee39\U0001ee3b\U0001ee42\U0001ee47\U0001ee49\U0001ee4b\U0001ee4d-\U0001ee4f\U0001ee51-\U0001ee52\U0001ee54\U0001ee57\U0001ee59\U0001ee5b\U0001ee5d\U0001ee5f\U0001ee61-\U0001ee62\U0001ee64\U0001ee67-\U0001ee6a\U0001ee6c-\U0001ee72\U0001ee74-\U0001ee77\U0001ee79-\U0001ee7c\U0001ee7e\U0001ee80-\U0001ee89\U0001ee8b-\U0001ee9b\U0001eea1-\U0001eea3\U0001eea5-\U0001eea9\U0001eeab-\U0001eebb\U00020000-\U0002a6d6\U0002a700-\U0002b734\U0002b740-\U0002b81d\U0002b820-\U0002cea1\U0002ceb0-\U0002ebe0\U0002f800-\U0002fa1d\U000e0100-\U000e01ef'
+
+xid_start = 'A-Z_a-z\xaa\xb5\xba\xc0-\xd6\xd8-\xf6\xf8-\u02c1\u02c6-\u02d1\u02e0-\u02e4\u02ec\u02ee\u0370-\u0374\u0376-\u0377\u037b-\u037d\u037f\u0386\u0388-\u038a\u038c\u038e-\u03a1\u03a3-\u03f5\u03f7-\u0481\u048a-\u052f\u0531-\u0556\u0559\u0560-\u0588\u05d0-\u05ea\u05ef-\u05f2\u0620-\u064a\u066e-\u066f\u0671-\u06d3\u06d5\u06e5-\u06e6\u06ee-\u06ef\u06fa-\u06fc\u06ff\u0710\u0712-\u072f\u074d-\u07a5\u07b1\u07ca-\u07ea\u07f4-\u07f5\u07fa\u0800-\u0815\u081a\u0824\u0828\u0840-\u0858\u0860-\u086a\u08a0-\u08b4\u08b6-\u08bd\u0904-\u0939\u093d\u0950\u0958-\u0961\u0971-\u0980\u0985-\u098c\u098f-\u0990\u0993-\u09a8\u09aa-\u09b0\u09b2\u09b6-\u09b9\u09bd\u09ce\u09dc-\u09dd\u09df-\u09e1\u09f0-\u09f1\u09fc\u0a05-\u0a0a\u0a0f-\u0a10\u0a13-\u0a28\u0a2a-\u0a30\u0a32-\u0a33\u0a35-\u0a36\u0a38-\u0a39\u0a59-\u0a5c\u0a5e\u0a72-\u0a74\u0a85-\u0a8d\u0a8f-\u0a91\u0a93-\u0aa8\u0aaa-\u0ab0\u0ab2-\u0ab3\u0ab5-\u0ab9\u0abd\u0ad0\u0ae0-\u0ae1\u0af9\u0b05-\u0b0c\u0b0f-\u0b10\u0b13-\u0b28\u0b2a-\u0b30\u0b32-\u0b33\u0b35-\u0b39\u0b3d\u0b5c-\u0b5d\u0b5f-\u0b61\u0b71\u0b83\u0b85-\u0b8a\u0b8e-\u0b90\u0b92-\u0b95\u0b99-\u0b9a\u0b9c\u0b9e-\u0b9f\u0ba3-\u0ba4\u0ba8-\u0baa\u0bae-\u0bb9\u0bd0\u0c05-\u0c0c\u0c0e-\u0c10\u0c12-\u0c28\u0c2a-\u0c39\u0c3d\u0c58-\u0c5a\u0c60-\u0c61\u0c80\u0c85-\u0c8c\u0c8e-\u0c90\u0c92-\u0ca8\u0caa-\u0cb3\u0cb5-\u0cb9\u0cbd\u0cde\u0ce0-\u0ce1\u0cf1-\u0cf2\u0d05-\u0d0c\u0d0e-\u0d10\u0d12-\u0d3a\u0d3d\u0d4e\u0d54-\u0d56\u0d5f-\u0d61\u0d7a-\u0d7f\u0d85-\u0d96\u0d9a-\u0db1\u0db3-\u0dbb\u0dbd\u0dc0-\u0dc6\u0e01-\u0e30\u0e32\u0e40-\u0e46\u0e81-\u0e82\u0e84\u0e87-\u0e88\u0e8a\u0e8d\u0e94-\u0e97\u0e99-\u0e9f\u0ea1-\u0ea3\u0ea5\u0ea7\u0eaa-\u0eab\u0ead-\u0eb0\u0eb2\u0ebd\u0ec0-\u0ec4\u0ec6\u0edc-\u0edf\u0f00\u0f40-\u0f47\u0f49-\u0f6c\u0f88-\u0f8c\u1000-\u102a\u103f\u1050-\u1055\u105a-\u105d\u1061\u1065-\u1066\u106e-\u1070\u1075-\u1081\u108e\u10a0-\u10c5\u10c7\u10cd\u10d0-\u10fa\u10fc-\u1248\u124a-\u124d\u1250-\u1256\u1258\u125a-\u125d\u1260-\u1288\u128a-\u128d\u1290-\u12b0\u12b2-\u12b5\u12b8-\u12be\u12c0\u12c2-\u12c5\u12c8-\u12d6\u12d8-\u1310\u1312-\u1315\u1318-\u135a\u1380-\u138f\u13a0-\u13f5\u13f8-\u13fd\u1401-\u166c\u166f-\u167f\u1681-\u169a\u16a0-\u16ea\u16ee-\u16f8\u1700-\u170c\u170e-\u1711\u1720-\u1731\u1740-\u1751\u1760-\u176c\u176e-\u1770\u1780-\u17b3\u17d7\u17dc\u1820-\u1878\u1880-\u18a8\u18aa\u18b0-\u18f5\u1900-\u191e\u1950-\u196d\u1970-\u1974\u1980-\u19ab\u19b0-\u19c9\u1a00-\u1a16\u1a20-\u1a54\u1aa7\u1b05-\u1b33\u1b45-\u1b4b\u1b83-\u1ba0\u1bae-\u1baf\u1bba-\u1be5\u1c00-\u1c23\u1c4d-\u1c4f\u1c5a-\u1c7d\u1c80-\u1c88\u1c90-\u1cba\u1cbd-\u1cbf\u1ce9-\u1cec\u1cee-\u1cf1\u1cf5-\u1cf6\u1d00-\u1dbf\u1e00-\u1f15\u1f18-\u1f1d\u1f20-\u1f45\u1f48-\u1f4d\u1f50-\u1f57\u1f59\u1f5b\u1f5d\u1f5f-\u1f7d\u1f80-\u1fb4\u1fb6-\u1fbc\u1fbe\u1fc2-\u1fc4\u1fc6-\u1fcc\u1fd0-\u1fd3\u1fd6-\u1fdb\u1fe0-\u1fec\u1ff2-\u1ff4\u1ff6-\u1ffc\u2071\u207f\u2090-\u209c\u2102\u2107\u210a-\u2113\u2115\u2118-\u211d\u2124\u2126\u2128\u212a-\u2139\u213c-\u213f\u2145-\u2149\u214e\u2160-\u2188\u2c00-\u2c2e\u2c30-\u2c5e\u2c60-\u2ce4\u2ceb-\u2cee\u2cf2-\u2cf3\u2d00-\u2d25\u2d27\u2d2d\u2d30-\u2d67\u2d6f\u2d80-\u2d96\u2da0-\u2da6\u2da8-\u2dae\u2db0-\u2db6\u2db8-\u2dbe\u2dc0-\u2dc6\u2dc8-\u2dce\u2dd0-\u2dd6\u2dd8-\u2dde\u3005-\u3007\u3021-\u3029\u3031-\u3035\u3038-\u303c\u3041-\u3096\u309d-\u309f\u30a1-\u30fa\u30fc-\u30ff\u3105-\u312f\u3131-\u318e\u31a0-\u31ba\u31f0-\u31ff\u3400-\u4db5\u4e00-\u9fef\ua000-\ua48c\ua4d0-\ua4fd\ua500-\ua60c\ua610-\ua61f\ua62a-\ua62b\ua640-\ua66e\ua67f-\ua69d\ua6a0-\ua6ef\ua717-\ua71f\ua722-\ua788\ua78b-\ua7b9\ua7f7-\ua801\ua803-\ua805\ua807-\ua80a\ua80c-\ua822\ua840-\ua873\ua882-\ua8b3\ua8f2-\ua8f7\ua8fb\ua8fd-\ua8fe\ua90a-\ua925\ua930-\ua946\ua960-\ua97c\ua984-\ua9b2\ua9cf\ua9e0-\ua9e4\ua9e6-\ua9ef\ua9fa-\ua9fe\uaa00-\uaa28\uaa40-\uaa42\uaa44-\uaa4b\uaa60-\uaa76\uaa7a\uaa7e-\uaaaf\uaab1\uaab5-\uaab6\uaab9-\uaabd\uaac0\uaac2\uaadb-\uaadd\uaae0-\uaaea\uaaf2-\uaaf4\uab01-\uab06\uab09-\uab0e\uab11-\uab16\uab20-\uab26\uab28-\uab2e\uab30-\uab5a\uab5c-\uab65\uab70-\uabe2\uac00-\ud7a3\ud7b0-\ud7c6\ud7cb-\ud7fb\uf900-\ufa6d\ufa70-\ufad9\ufb00-\ufb06\ufb13-\ufb17\ufb1d\ufb1f-\ufb28\ufb2a-\ufb36\ufb38-\ufb3c\ufb3e\ufb40-\ufb41\ufb43-\ufb44\ufb46-\ufbb1\ufbd3-\ufc5d\ufc64-\ufd3d\ufd50-\ufd8f\ufd92-\ufdc7\ufdf0-\ufdf9\ufe71\ufe73\ufe77\ufe79\ufe7b\ufe7d\ufe7f-\ufefc\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d\uffa0-\uffbe\uffc2-\uffc7\uffca-\uffcf\uffd2-\uffd7\uffda-\uffdc\U00010000-\U0001000b\U0001000d-\U00010026\U00010028-\U0001003a\U0001003c-\U0001003d\U0001003f-\U0001004d\U00010050-\U0001005d\U00010080-\U000100fa\U00010140-\U00010174\U00010280-\U0001029c\U000102a0-\U000102d0\U00010300-\U0001031f\U0001032d-\U0001034a\U00010350-\U00010375\U00010380-\U0001039d\U000103a0-\U000103c3\U000103c8-\U000103cf\U000103d1-\U000103d5\U00010400-\U0001049d\U000104b0-\U000104d3\U000104d8-\U000104fb\U00010500-\U00010527\U00010530-\U00010563\U00010600-\U00010736\U00010740-\U00010755\U00010760-\U00010767\U00010800-\U00010805\U00010808\U0001080a-\U00010835\U00010837-\U00010838\U0001083c\U0001083f-\U00010855\U00010860-\U00010876\U00010880-\U0001089e\U000108e0-\U000108f2\U000108f4-\U000108f5\U00010900-\U00010915\U00010920-\U00010939\U00010980-\U000109b7\U000109be-\U000109bf\U00010a00\U00010a10-\U00010a13\U00010a15-\U00010a17\U00010a19-\U00010a35\U00010a60-\U00010a7c\U00010a80-\U00010a9c\U00010ac0-\U00010ac7\U00010ac9-\U00010ae4\U00010b00-\U00010b35\U00010b40-\U00010b55\U00010b60-\U00010b72\U00010b80-\U00010b91\U00010c00-\U00010c48\U00010c80-\U00010cb2\U00010cc0-\U00010cf2\U00010d00-\U00010d23\U00010f00-\U00010f1c\U00010f27\U00010f30-\U00010f45\U00011003-\U00011037\U00011083-\U000110af\U000110d0-\U000110e8\U00011103-\U00011126\U00011144\U00011150-\U00011172\U00011176\U00011183-\U000111b2\U000111c1-\U000111c4\U000111da\U000111dc\U00011200-\U00011211\U00011213-\U0001122b\U00011280-\U00011286\U00011288\U0001128a-\U0001128d\U0001128f-\U0001129d\U0001129f-\U000112a8\U000112b0-\U000112de\U00011305-\U0001130c\U0001130f-\U00011310\U00011313-\U00011328\U0001132a-\U00011330\U00011332-\U00011333\U00011335-\U00011339\U0001133d\U00011350\U0001135d-\U00011361\U00011400-\U00011434\U00011447-\U0001144a\U00011480-\U000114af\U000114c4-\U000114c5\U000114c7\U00011580-\U000115ae\U000115d8-\U000115db\U00011600-\U0001162f\U00011644\U00011680-\U000116aa\U00011700-\U0001171a\U00011800-\U0001182b\U000118a0-\U000118df\U000118ff\U00011a00\U00011a0b-\U00011a32\U00011a3a\U00011a50\U00011a5c-\U00011a83\U00011a86-\U00011a89\U00011a9d\U00011ac0-\U00011af8\U00011c00-\U00011c08\U00011c0a-\U00011c2e\U00011c40\U00011c72-\U00011c8f\U00011d00-\U00011d06\U00011d08-\U00011d09\U00011d0b-\U00011d30\U00011d46\U00011d60-\U00011d65\U00011d67-\U00011d68\U00011d6a-\U00011d89\U00011d98\U00011ee0-\U00011ef2\U00012000-\U00012399\U00012400-\U0001246e\U00012480-\U00012543\U00013000-\U0001342e\U00014400-\U00014646\U00016800-\U00016a38\U00016a40-\U00016a5e\U00016ad0-\U00016aed\U00016b00-\U00016b2f\U00016b40-\U00016b43\U00016b63-\U00016b77\U00016b7d-\U00016b8f\U00016e40-\U00016e7f\U00016f00-\U00016f44\U00016f50\U00016f93-\U00016f9f\U00016fe0-\U00016fe1\U00017000-\U000187f1\U00018800-\U00018af2\U0001b000-\U0001b11e\U0001b170-\U0001b2fb\U0001bc00-\U0001bc6a\U0001bc70-\U0001bc7c\U0001bc80-\U0001bc88\U0001bc90-\U0001bc99\U0001d400-\U0001d454\U0001d456-\U0001d49c\U0001d49e-\U0001d49f\U0001d4a2\U0001d4a5-\U0001d4a6\U0001d4a9-\U0001d4ac\U0001d4ae-\U0001d4b9\U0001d4bb\U0001d4bd-\U0001d4c3\U0001d4c5-\U0001d505\U0001d507-\U0001d50a\U0001d50d-\U0001d514\U0001d516-\U0001d51c\U0001d51e-\U0001d539\U0001d53b-\U0001d53e\U0001d540-\U0001d544\U0001d546\U0001d54a-\U0001d550\U0001d552-\U0001d6a5\U0001d6a8-\U0001d6c0\U0001d6c2-\U0001d6da\U0001d6dc-\U0001d6fa\U0001d6fc-\U0001d714\U0001d716-\U0001d734\U0001d736-\U0001d74e\U0001d750-\U0001d76e\U0001d770-\U0001d788\U0001d78a-\U0001d7a8\U0001d7aa-\U0001d7c2\U0001d7c4-\U0001d7cb\U0001e800-\U0001e8c4\U0001e900-\U0001e943\U0001ee00-\U0001ee03\U0001ee05-\U0001ee1f\U0001ee21-\U0001ee22\U0001ee24\U0001ee27\U0001ee29-\U0001ee32\U0001ee34-\U0001ee37\U0001ee39\U0001ee3b\U0001ee42\U0001ee47\U0001ee49\U0001ee4b\U0001ee4d-\U0001ee4f\U0001ee51-\U0001ee52\U0001ee54\U0001ee57\U0001ee59\U0001ee5b\U0001ee5d\U0001ee5f\U0001ee61-\U0001ee62\U0001ee64\U0001ee67-\U0001ee6a\U0001ee6c-\U0001ee72\U0001ee74-\U0001ee77\U0001ee79-\U0001ee7c\U0001ee7e\U0001ee80-\U0001ee89\U0001ee8b-\U0001ee9b\U0001eea1-\U0001eea3\U0001eea5-\U0001eea9\U0001eeab-\U0001eebb\U00020000-\U0002a6d6\U0002a700-\U0002b734\U0002b740-\U0002b81d\U0002b820-\U0002cea1\U0002ceb0-\U0002ebe0\U0002f800-\U0002fa1d'
+
+cats = ['Cc', 'Cf', 'Cn', 'Co', 'Cs', 'Ll', 'Lm', 'Lo', 'Lt', 'Lu', 'Mc', 'Me', 'Mn', 'Nd', 'Nl', 'No', 'Pc', 'Pd', 'Pe', 'Pf', 'Pi', 'Po', 'Ps', 'Sc', 'Sk', 'Sm', 'So', 'Zl', 'Zp', 'Zs']
+
+# Generated from unidata 11.0.0
+
+def combine(*args):
+ return ''.join(globals()[cat] for cat in args)
+
+
+def allexcept(*args):
+ newcats = cats[:]
+ for arg in args:
+ newcats.remove(arg)
+ return ''.join(globals()[cat] for cat in newcats)
+
+
+def _handle_runs(char_list): # pragma: no cover
+ buf = []
+ for c in char_list:
+ if len(c) == 1:
+ if buf and buf[-1][1] == chr(ord(c)-1):
+ buf[-1] = (buf[-1][0], c)
+ else:
+ buf.append((c, c))
+ else:
+ buf.append((c, c))
+ for a, b in buf:
+ if a == b:
+ yield a
+ else:
+ yield f'{a}-{b}'
+
+
+if __name__ == '__main__': # pragma: no cover
+ import unicodedata
+
+ categories = {'xid_start': [], 'xid_continue': []}
+
+ with open(__file__, encoding='utf-8') as fp:
+ content = fp.read()
+
+ header = content[:content.find('Cc =')]
+ footer = content[content.find("def combine("):]
+
+ for code in range(0x110000):
+ c = chr(code)
+ cat = unicodedata.category(c)
+ if ord(c) == 0xdc00:
+ # Hack to avoid combining this combining with the preceding high
+ # surrogate, 0xdbff, when doing a repr.
+ c = '\\' + c
+ elif ord(c) in (0x2d, 0x5b, 0x5c, 0x5d, 0x5e):
+ # Escape regex metachars.
+ c = '\\' + c
+ categories.setdefault(cat, []).append(c)
+ # XID_START and XID_CONTINUE are special categories used for matching
+ # identifiers in Python 3.
+ if c.isidentifier():
+ categories['xid_start'].append(c)
+ if ('a' + c).isidentifier():
+ categories['xid_continue'].append(c)
+
+ with open(__file__, 'w', encoding='utf-8') as fp:
+ fp.write(header)
+
+ for cat in sorted(categories):
+ val = ''.join(_handle_runs(categories[cat]))
+ fp.write(f'{cat} = {val!a}\n\n')
+
+ cats = sorted(categories)
+ cats.remove('xid_start')
+ cats.remove('xid_continue')
+ fp.write(f'cats = {cats!r}\n\n')
+
+ fp.write(f'# Generated from unidata {unicodedata.unidata_version}\n\n')
+
+ fp.write(footer)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/util.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/util.py
new file mode 100644
index 000000000..83cf10492
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pygments/util.py
@@ -0,0 +1,324 @@
+"""
+ pygments.util
+ ~~~~~~~~~~~~~
+
+ Utility functions.
+
+ :copyright: Copyright 2006-2024 by the Pygments team, see AUTHORS.
+ :license: BSD, see LICENSE for details.
+"""
+
+import re
+from io import TextIOWrapper
+
+
+split_path_re = re.compile(r'[/\\ ]')
+doctype_lookup_re = re.compile(r'''
+ <!DOCTYPE\s+(
+ [a-zA-Z_][a-zA-Z0-9]*
+ (?: \s+ # optional in HTML5
+ [a-zA-Z_][a-zA-Z0-9]*\s+
+ "[^"]*")?
+ )
+ [^>]*>
+''', re.DOTALL | re.MULTILINE | re.VERBOSE)
+tag_re = re.compile(r'<(.+?)(\s.*?)?>.*?</.+?>',
+ re.IGNORECASE | re.DOTALL | re.MULTILINE)
+xml_decl_re = re.compile(r'\s*<\?xml[^>]*\?>', re.I)
+
+
+class ClassNotFound(ValueError):
+ """Raised if one of the lookup functions didn't find a matching class."""
+
+
+class OptionError(Exception):
+ """
+ This exception will be raised by all option processing functions if
+ the type or value of the argument is not correct.
+ """
+
+def get_choice_opt(options, optname, allowed, default=None, normcase=False):
+ """
+ If the key `optname` from the dictionary is not in the sequence
+ `allowed`, raise an error, otherwise return it.
+ """
+ string = options.get(optname, default)
+ if normcase:
+ string = string.lower()
+ if string not in allowed:
+ raise OptionError('Value for option {} must be one of {}'.format(optname, ', '.join(map(str, allowed))))
+ return string
+
+
+def get_bool_opt(options, optname, default=None):
+ """
+ Intuitively, this is `options.get(optname, default)`, but restricted to
+ Boolean value. The Booleans can be represented as string, in order to accept
+ Boolean value from the command line arguments. If the key `optname` is
+ present in the dictionary `options` and is not associated with a Boolean,
+ raise an `OptionError`. If it is absent, `default` is returned instead.
+
+ The valid string values for ``True`` are ``1``, ``yes``, ``true`` and
+ ``on``, the ones for ``False`` are ``0``, ``no``, ``false`` and ``off``
+ (matched case-insensitively).
+ """
+ string = options.get(optname, default)
+ if isinstance(string, bool):
+ return string
+ elif isinstance(string, int):
+ return bool(string)
+ elif not isinstance(string, str):
+ raise OptionError(f'Invalid type {string!r} for option {optname}; use '
+ '1/0, yes/no, true/false, on/off')
+ elif string.lower() in ('1', 'yes', 'true', 'on'):
+ return True
+ elif string.lower() in ('0', 'no', 'false', 'off'):
+ return False
+ else:
+ raise OptionError(f'Invalid value {string!r} for option {optname}; use '
+ '1/0, yes/no, true/false, on/off')
+
+
+def get_int_opt(options, optname, default=None):
+ """As :func:`get_bool_opt`, but interpret the value as an integer."""
+ string = options.get(optname, default)
+ try:
+ return int(string)
+ except TypeError:
+ raise OptionError(f'Invalid type {string!r} for option {optname}; you '
+ 'must give an integer value')
+ except ValueError:
+ raise OptionError(f'Invalid value {string!r} for option {optname}; you '
+ 'must give an integer value')
+
+def get_list_opt(options, optname, default=None):
+ """
+ If the key `optname` from the dictionary `options` is a string,
+ split it at whitespace and return it. If it is already a list
+ or a tuple, it is returned as a list.
+ """
+ val = options.get(optname, default)
+ if isinstance(val, str):
+ return val.split()
+ elif isinstance(val, (list, tuple)):
+ return list(val)
+ else:
+ raise OptionError(f'Invalid type {val!r} for option {optname}; you '
+ 'must give a list value')
+
+
+def docstring_headline(obj):
+ if not obj.__doc__:
+ return ''
+ res = []
+ for line in obj.__doc__.strip().splitlines():
+ if line.strip():
+ res.append(" " + line.strip())
+ else:
+ break
+ return ''.join(res).lstrip()
+
+
+def make_analysator(f):
+ """Return a static text analyser function that returns float values."""
+ def text_analyse(text):
+ try:
+ rv = f(text)
+ except Exception:
+ return 0.0
+ if not rv:
+ return 0.0
+ try:
+ return min(1.0, max(0.0, float(rv)))
+ except (ValueError, TypeError):
+ return 0.0
+ text_analyse.__doc__ = f.__doc__
+ return staticmethod(text_analyse)
+
+
+def shebang_matches(text, regex):
+ r"""Check if the given regular expression matches the last part of the
+ shebang if one exists.
+
+ >>> from pygments.util import shebang_matches
+ >>> shebang_matches('#!/usr/bin/env python', r'python(2\.\d)?')
+ True
+ >>> shebang_matches('#!/usr/bin/python2.4', r'python(2\.\d)?')
+ True
+ >>> shebang_matches('#!/usr/bin/python-ruby', r'python(2\.\d)?')
+ False
+ >>> shebang_matches('#!/usr/bin/python/ruby', r'python(2\.\d)?')
+ False
+ >>> shebang_matches('#!/usr/bin/startsomethingwith python',
+ ... r'python(2\.\d)?')
+ True
+
+ It also checks for common windows executable file extensions::
+
+ >>> shebang_matches('#!C:\\Python2.4\\Python.exe', r'python(2\.\d)?')
+ True
+
+ Parameters (``'-f'`` or ``'--foo'`` are ignored so ``'perl'`` does
+ the same as ``'perl -e'``)
+
+ Note that this method automatically searches the whole string (eg:
+ the regular expression is wrapped in ``'^$'``)
+ """
+ index = text.find('\n')
+ if index >= 0:
+ first_line = text[:index].lower()
+ else:
+ first_line = text.lower()
+ if first_line.startswith('#!'):
+ try:
+ found = [x for x in split_path_re.split(first_line[2:].strip())
+ if x and not x.startswith('-')][-1]
+ except IndexError:
+ return False
+ regex = re.compile(rf'^{regex}(\.(exe|cmd|bat|bin))?$', re.IGNORECASE)
+ if regex.search(found) is not None:
+ return True
+ return False
+
+
+def doctype_matches(text, regex):
+ """Check if the doctype matches a regular expression (if present).
+
+ Note that this method only checks the first part of a DOCTYPE.
+ eg: 'html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"'
+ """
+ m = doctype_lookup_re.search(text)
+ if m is None:
+ return False
+ doctype = m.group(1)
+ return re.compile(regex, re.I).match(doctype.strip()) is not None
+
+
+def html_doctype_matches(text):
+ """Check if the file looks like it has a html doctype."""
+ return doctype_matches(text, r'html')
+
+
+_looks_like_xml_cache = {}
+
+
+def looks_like_xml(text):
+ """Check if a doctype exists or if we have some tags."""
+ if xml_decl_re.match(text):
+ return True
+ key = hash(text)
+ try:
+ return _looks_like_xml_cache[key]
+ except KeyError:
+ m = doctype_lookup_re.search(text)
+ if m is not None:
+ return True
+ rv = tag_re.search(text[:1000]) is not None
+ _looks_like_xml_cache[key] = rv
+ return rv
+
+
+def surrogatepair(c):
+ """Given a unicode character code with length greater than 16 bits,
+ return the two 16 bit surrogate pair.
+ """
+ # From example D28 of:
+ # http://www.unicode.org/book/ch03.pdf
+ return (0xd7c0 + (c >> 10), (0xdc00 + (c & 0x3ff)))
+
+
+def format_lines(var_name, seq, raw=False, indent_level=0):
+ """Formats a sequence of strings for output."""
+ lines = []
+ base_indent = ' ' * indent_level * 4
+ inner_indent = ' ' * (indent_level + 1) * 4
+ lines.append(base_indent + var_name + ' = (')
+ if raw:
+ # These should be preformatted reprs of, say, tuples.
+ for i in seq:
+ lines.append(inner_indent + i + ',')
+ else:
+ for i in seq:
+ # Force use of single quotes
+ r = repr(i + '"')
+ lines.append(inner_indent + r[:-2] + r[-1] + ',')
+ lines.append(base_indent + ')')
+ return '\n'.join(lines)
+
+
+def duplicates_removed(it, already_seen=()):
+ """
+ Returns a list with duplicates removed from the iterable `it`.
+
+ Order is preserved.
+ """
+ lst = []
+ seen = set()
+ for i in it:
+ if i in seen or i in already_seen:
+ continue
+ lst.append(i)
+ seen.add(i)
+ return lst
+
+
+class Future:
+ """Generic class to defer some work.
+
+ Handled specially in RegexLexerMeta, to support regex string construction at
+ first use.
+ """
+ def get(self):
+ raise NotImplementedError
+
+
+def guess_decode(text):
+ """Decode *text* with guessed encoding.
+
+ First try UTF-8; this should fail for non-UTF-8 encodings.
+ Then try the preferred locale encoding.
+ Fall back to latin-1, which always works.
+ """
+ try:
+ text = text.decode('utf-8')
+ return text, 'utf-8'
+ except UnicodeDecodeError:
+ try:
+ import locale
+ prefencoding = locale.getpreferredencoding()
+ text = text.decode()
+ return text, prefencoding
+ except (UnicodeDecodeError, LookupError):
+ text = text.decode('latin1')
+ return text, 'latin1'
+
+
+def guess_decode_from_terminal(text, term):
+ """Decode *text* coming from terminal *term*.
+
+ First try the terminal encoding, if given.
+ Then try UTF-8. Then try the preferred locale encoding.
+ Fall back to latin-1, which always works.
+ """
+ if getattr(term, 'encoding', None):
+ try:
+ text = text.decode(term.encoding)
+ except UnicodeDecodeError:
+ pass
+ else:
+ return text, term.encoding
+ return guess_decode(text)
+
+
+def terminal_encoding(term):
+ """Return our best guess of encoding for the given *term*."""
+ if getattr(term, 'encoding', None):
+ return term.encoding
+ import locale
+ return locale.getpreferredencoding()
+
+
+class UnclosingTextIOWrapper(TextIOWrapper):
+ # Don't close underlying buffer on destruction.
+ def close(self):
+ self.flush()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/__init__.py
new file mode 100644
index 000000000..ddfcf7f72
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/__init__.py
@@ -0,0 +1,23 @@
+"""Wrappers to call pyproject.toml-based build backend hooks.
+"""
+
+from ._impl import (
+ BackendInvalid,
+ BackendUnavailable,
+ BuildBackendHookCaller,
+ HookMissing,
+ UnsupportedOperation,
+ default_subprocess_runner,
+ quiet_subprocess_runner,
+)
+
+__version__ = '1.0.0'
+__all__ = [
+ 'BackendUnavailable',
+ 'BackendInvalid',
+ 'HookMissing',
+ 'UnsupportedOperation',
+ 'default_subprocess_runner',
+ 'quiet_subprocess_runner',
+ 'BuildBackendHookCaller',
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_compat.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_compat.py
new file mode 100644
index 000000000..95e509c01
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_compat.py
@@ -0,0 +1,8 @@
+__all__ = ("tomllib",)
+
+import sys
+
+if sys.version_info >= (3, 11):
+ import tomllib
+else:
+ from pip._vendor import tomli as tomllib
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_impl.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_impl.py
new file mode 100644
index 000000000..37b0e6531
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_impl.py
@@ -0,0 +1,330 @@
+import json
+import os
+import sys
+import tempfile
+from contextlib import contextmanager
+from os.path import abspath
+from os.path import join as pjoin
+from subprocess import STDOUT, check_call, check_output
+
+from ._in_process import _in_proc_script_path
+
+
+def write_json(obj, path, **kwargs):
+ with open(path, 'w', encoding='utf-8') as f:
+ json.dump(obj, f, **kwargs)
+
+
+def read_json(path):
+ with open(path, encoding='utf-8') as f:
+ return json.load(f)
+
+
+class BackendUnavailable(Exception):
+ """Will be raised if the backend cannot be imported in the hook process."""
+ def __init__(self, traceback):
+ self.traceback = traceback
+
+
+class BackendInvalid(Exception):
+ """Will be raised if the backend is invalid."""
+ def __init__(self, backend_name, backend_path, message):
+ super().__init__(message)
+ self.backend_name = backend_name
+ self.backend_path = backend_path
+
+
+class HookMissing(Exception):
+ """Will be raised on missing hooks (if a fallback can't be used)."""
+ def __init__(self, hook_name):
+ super().__init__(hook_name)
+ self.hook_name = hook_name
+
+
+class UnsupportedOperation(Exception):
+ """May be raised by build_sdist if the backend indicates that it can't."""
+ def __init__(self, traceback):
+ self.traceback = traceback
+
+
+def default_subprocess_runner(cmd, cwd=None, extra_environ=None):
+ """The default method of calling the wrapper subprocess.
+
+ This uses :func:`subprocess.check_call` under the hood.
+ """
+ env = os.environ.copy()
+ if extra_environ:
+ env.update(extra_environ)
+
+ check_call(cmd, cwd=cwd, env=env)
+
+
+def quiet_subprocess_runner(cmd, cwd=None, extra_environ=None):
+ """Call the subprocess while suppressing output.
+
+ This uses :func:`subprocess.check_output` under the hood.
+ """
+ env = os.environ.copy()
+ if extra_environ:
+ env.update(extra_environ)
+
+ check_output(cmd, cwd=cwd, env=env, stderr=STDOUT)
+
+
+def norm_and_check(source_tree, requested):
+ """Normalise and check a backend path.
+
+ Ensure that the requested backend path is specified as a relative path,
+ and resolves to a location under the given source tree.
+
+ Return an absolute version of the requested path.
+ """
+ if os.path.isabs(requested):
+ raise ValueError("paths must be relative")
+
+ abs_source = os.path.abspath(source_tree)
+ abs_requested = os.path.normpath(os.path.join(abs_source, requested))
+ # We have to use commonprefix for Python 2.7 compatibility. So we
+ # normalise case to avoid problems because commonprefix is a character
+ # based comparison :-(
+ norm_source = os.path.normcase(abs_source)
+ norm_requested = os.path.normcase(abs_requested)
+ if os.path.commonprefix([norm_source, norm_requested]) != norm_source:
+ raise ValueError("paths must be inside source tree")
+
+ return abs_requested
+
+
+class BuildBackendHookCaller:
+ """A wrapper to call the build backend hooks for a source directory.
+ """
+
+ def __init__(
+ self,
+ source_dir,
+ build_backend,
+ backend_path=None,
+ runner=None,
+ python_executable=None,
+ ):
+ """
+ :param source_dir: The source directory to invoke the build backend for
+ :param build_backend: The build backend spec
+ :param backend_path: Additional path entries for the build backend spec
+ :param runner: The :ref:`subprocess runner <Subprocess Runners>` to use
+ :param python_executable:
+ The Python executable used to invoke the build backend
+ """
+ if runner is None:
+ runner = default_subprocess_runner
+
+ self.source_dir = abspath(source_dir)
+ self.build_backend = build_backend
+ if backend_path:
+ backend_path = [
+ norm_and_check(self.source_dir, p) for p in backend_path
+ ]
+ self.backend_path = backend_path
+ self._subprocess_runner = runner
+ if not python_executable:
+ python_executable = sys.executable
+ self.python_executable = python_executable
+
+ @contextmanager
+ def subprocess_runner(self, runner):
+ """A context manager for temporarily overriding the default
+ :ref:`subprocess runner <Subprocess Runners>`.
+
+ .. code-block:: python
+
+ hook_caller = BuildBackendHookCaller(...)
+ with hook_caller.subprocess_runner(quiet_subprocess_runner):
+ ...
+ """
+ prev = self._subprocess_runner
+ self._subprocess_runner = runner
+ try:
+ yield
+ finally:
+ self._subprocess_runner = prev
+
+ def _supported_features(self):
+ """Return the list of optional features supported by the backend."""
+ return self._call_hook('_supported_features', {})
+
+ def get_requires_for_build_wheel(self, config_settings=None):
+ """Get additional dependencies required for building a wheel.
+
+ :returns: A list of :pep:`dependency specifiers <508>`.
+ :rtype: list[str]
+
+ .. admonition:: Fallback
+
+ If the build backend does not defined a hook with this name, an
+ empty list will be returned.
+ """
+ return self._call_hook('get_requires_for_build_wheel', {
+ 'config_settings': config_settings
+ })
+
+ def prepare_metadata_for_build_wheel(
+ self, metadata_directory, config_settings=None,
+ _allow_fallback=True):
+ """Prepare a ``*.dist-info`` folder with metadata for this project.
+
+ :returns: Name of the newly created subfolder within
+ ``metadata_directory``, containing the metadata.
+ :rtype: str
+
+ .. admonition:: Fallback
+
+ If the build backend does not define a hook with this name and
+ ``_allow_fallback`` is truthy, the backend will be asked to build a
+ wheel via the ``build_wheel`` hook and the dist-info extracted from
+ that will be returned.
+ """
+ return self._call_hook('prepare_metadata_for_build_wheel', {
+ 'metadata_directory': abspath(metadata_directory),
+ 'config_settings': config_settings,
+ '_allow_fallback': _allow_fallback,
+ })
+
+ def build_wheel(
+ self, wheel_directory, config_settings=None,
+ metadata_directory=None):
+ """Build a wheel from this project.
+
+ :returns:
+ The name of the newly created wheel within ``wheel_directory``.
+
+ .. admonition:: Interaction with fallback
+
+ If the ``build_wheel`` hook was called in the fallback for
+ :meth:`prepare_metadata_for_build_wheel`, the build backend would
+ not be invoked. Instead, the previously built wheel will be copied
+ to ``wheel_directory`` and the name of that file will be returned.
+ """
+ if metadata_directory is not None:
+ metadata_directory = abspath(metadata_directory)
+ return self._call_hook('build_wheel', {
+ 'wheel_directory': abspath(wheel_directory),
+ 'config_settings': config_settings,
+ 'metadata_directory': metadata_directory,
+ })
+
+ def get_requires_for_build_editable(self, config_settings=None):
+ """Get additional dependencies required for building an editable wheel.
+
+ :returns: A list of :pep:`dependency specifiers <508>`.
+ :rtype: list[str]
+
+ .. admonition:: Fallback
+
+ If the build backend does not defined a hook with this name, an
+ empty list will be returned.
+ """
+ return self._call_hook('get_requires_for_build_editable', {
+ 'config_settings': config_settings
+ })
+
+ def prepare_metadata_for_build_editable(
+ self, metadata_directory, config_settings=None,
+ _allow_fallback=True):
+ """Prepare a ``*.dist-info`` folder with metadata for this project.
+
+ :returns: Name of the newly created subfolder within
+ ``metadata_directory``, containing the metadata.
+ :rtype: str
+
+ .. admonition:: Fallback
+
+ If the build backend does not define a hook with this name and
+ ``_allow_fallback`` is truthy, the backend will be asked to build a
+ wheel via the ``build_editable`` hook and the dist-info
+ extracted from that will be returned.
+ """
+ return self._call_hook('prepare_metadata_for_build_editable', {
+ 'metadata_directory': abspath(metadata_directory),
+ 'config_settings': config_settings,
+ '_allow_fallback': _allow_fallback,
+ })
+
+ def build_editable(
+ self, wheel_directory, config_settings=None,
+ metadata_directory=None):
+ """Build an editable wheel from this project.
+
+ :returns:
+ The name of the newly created wheel within ``wheel_directory``.
+
+ .. admonition:: Interaction with fallback
+
+ If the ``build_editable`` hook was called in the fallback for
+ :meth:`prepare_metadata_for_build_editable`, the build backend
+ would not be invoked. Instead, the previously built wheel will be
+ copied to ``wheel_directory`` and the name of that file will be
+ returned.
+ """
+ if metadata_directory is not None:
+ metadata_directory = abspath(metadata_directory)
+ return self._call_hook('build_editable', {
+ 'wheel_directory': abspath(wheel_directory),
+ 'config_settings': config_settings,
+ 'metadata_directory': metadata_directory,
+ })
+
+ def get_requires_for_build_sdist(self, config_settings=None):
+ """Get additional dependencies required for building an sdist.
+
+ :returns: A list of :pep:`dependency specifiers <508>`.
+ :rtype: list[str]
+ """
+ return self._call_hook('get_requires_for_build_sdist', {
+ 'config_settings': config_settings
+ })
+
+ def build_sdist(self, sdist_directory, config_settings=None):
+ """Build an sdist from this project.
+
+ :returns:
+ The name of the newly created sdist within ``wheel_directory``.
+ """
+ return self._call_hook('build_sdist', {
+ 'sdist_directory': abspath(sdist_directory),
+ 'config_settings': config_settings,
+ })
+
+ def _call_hook(self, hook_name, kwargs):
+ extra_environ = {'PEP517_BUILD_BACKEND': self.build_backend}
+
+ if self.backend_path:
+ backend_path = os.pathsep.join(self.backend_path)
+ extra_environ['PEP517_BACKEND_PATH'] = backend_path
+
+ with tempfile.TemporaryDirectory() as td:
+ hook_input = {'kwargs': kwargs}
+ write_json(hook_input, pjoin(td, 'input.json'), indent=2)
+
+ # Run the hook in a subprocess
+ with _in_proc_script_path() as script:
+ python = self.python_executable
+ self._subprocess_runner(
+ [python, abspath(str(script)), hook_name, td],
+ cwd=self.source_dir,
+ extra_environ=extra_environ
+ )
+
+ data = read_json(pjoin(td, 'output.json'))
+ if data.get('unsupported'):
+ raise UnsupportedOperation(data.get('traceback', ''))
+ if data.get('no_backend'):
+ raise BackendUnavailable(data.get('traceback', ''))
+ if data.get('backend_invalid'):
+ raise BackendInvalid(
+ backend_name=self.build_backend,
+ backend_path=self.backend_path,
+ message=data.get('backend_error', '')
+ )
+ if data.get('hook_missing'):
+ raise HookMissing(data.get('missing_hook_name') or hook_name)
+ return data['return_val']
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_in_process/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_in_process/__init__.py
new file mode 100644
index 000000000..917fa065b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_in_process/__init__.py
@@ -0,0 +1,18 @@
+"""This is a subpackage because the directory is on sys.path for _in_process.py
+
+The subpackage should stay as empty as possible to avoid shadowing modules that
+the backend might import.
+"""
+
+import importlib.resources as resources
+
+try:
+ resources.files
+except AttributeError:
+ # Python 3.8 compatibility
+ def _in_proc_script_path():
+ return resources.path(__package__, '_in_process.py')
+else:
+ def _in_proc_script_path():
+ return resources.as_file(
+ resources.files(__package__).joinpath('_in_process.py'))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py
new file mode 100644
index 000000000..ee511ff20
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py
@@ -0,0 +1,353 @@
+"""This is invoked in a subprocess to call the build backend hooks.
+
+It expects:
+- Command line args: hook_name, control_dir
+- Environment variables:
+ PEP517_BUILD_BACKEND=entry.point:spec
+ PEP517_BACKEND_PATH=paths (separated with os.pathsep)
+- control_dir/input.json:
+ - {"kwargs": {...}}
+
+Results:
+- control_dir/output.json
+ - {"return_val": ...}
+"""
+import json
+import os
+import os.path
+import re
+import shutil
+import sys
+import traceback
+from glob import glob
+from importlib import import_module
+from os.path import join as pjoin
+
+# This file is run as a script, and `import wrappers` is not zip-safe, so we
+# include write_json() and read_json() from wrappers.py.
+
+
+def write_json(obj, path, **kwargs):
+ with open(path, 'w', encoding='utf-8') as f:
+ json.dump(obj, f, **kwargs)
+
+
+def read_json(path):
+ with open(path, encoding='utf-8') as f:
+ return json.load(f)
+
+
+class BackendUnavailable(Exception):
+ """Raised if we cannot import the backend"""
+ def __init__(self, traceback):
+ self.traceback = traceback
+
+
+class BackendInvalid(Exception):
+ """Raised if the backend is invalid"""
+ def __init__(self, message):
+ self.message = message
+
+
+class HookMissing(Exception):
+ """Raised if a hook is missing and we are not executing the fallback"""
+ def __init__(self, hook_name=None):
+ super().__init__(hook_name)
+ self.hook_name = hook_name
+
+
+def contained_in(filename, directory):
+ """Test if a file is located within the given directory."""
+ filename = os.path.normcase(os.path.abspath(filename))
+ directory = os.path.normcase(os.path.abspath(directory))
+ return os.path.commonprefix([filename, directory]) == directory
+
+
+def _build_backend():
+ """Find and load the build backend"""
+ # Add in-tree backend directories to the front of sys.path.
+ backend_path = os.environ.get('PEP517_BACKEND_PATH')
+ if backend_path:
+ extra_pathitems = backend_path.split(os.pathsep)
+ sys.path[:0] = extra_pathitems
+
+ ep = os.environ['PEP517_BUILD_BACKEND']
+ mod_path, _, obj_path = ep.partition(':')
+ try:
+ obj = import_module(mod_path)
+ except ImportError:
+ raise BackendUnavailable(traceback.format_exc())
+
+ if backend_path:
+ if not any(
+ contained_in(obj.__file__, path)
+ for path in extra_pathitems
+ ):
+ raise BackendInvalid("Backend was not loaded from backend-path")
+
+ if obj_path:
+ for path_part in obj_path.split('.'):
+ obj = getattr(obj, path_part)
+ return obj
+
+
+def _supported_features():
+ """Return the list of options features supported by the backend.
+
+ Returns a list of strings.
+ The only possible value is 'build_editable'.
+ """
+ backend = _build_backend()
+ features = []
+ if hasattr(backend, "build_editable"):
+ features.append("build_editable")
+ return features
+
+
+def get_requires_for_build_wheel(config_settings):
+ """Invoke the optional get_requires_for_build_wheel hook
+
+ Returns [] if the hook is not defined.
+ """
+ backend = _build_backend()
+ try:
+ hook = backend.get_requires_for_build_wheel
+ except AttributeError:
+ return []
+ else:
+ return hook(config_settings)
+
+
+def get_requires_for_build_editable(config_settings):
+ """Invoke the optional get_requires_for_build_editable hook
+
+ Returns [] if the hook is not defined.
+ """
+ backend = _build_backend()
+ try:
+ hook = backend.get_requires_for_build_editable
+ except AttributeError:
+ return []
+ else:
+ return hook(config_settings)
+
+
+def prepare_metadata_for_build_wheel(
+ metadata_directory, config_settings, _allow_fallback):
+ """Invoke optional prepare_metadata_for_build_wheel
+
+ Implements a fallback by building a wheel if the hook isn't defined,
+ unless _allow_fallback is False in which case HookMissing is raised.
+ """
+ backend = _build_backend()
+ try:
+ hook = backend.prepare_metadata_for_build_wheel
+ except AttributeError:
+ if not _allow_fallback:
+ raise HookMissing()
+ else:
+ return hook(metadata_directory, config_settings)
+ # fallback to build_wheel outside the try block to avoid exception chaining
+ # which can be confusing to users and is not relevant
+ whl_basename = backend.build_wheel(metadata_directory, config_settings)
+ return _get_wheel_metadata_from_wheel(whl_basename, metadata_directory,
+ config_settings)
+
+
+def prepare_metadata_for_build_editable(
+ metadata_directory, config_settings, _allow_fallback):
+ """Invoke optional prepare_metadata_for_build_editable
+
+ Implements a fallback by building an editable wheel if the hook isn't
+ defined, unless _allow_fallback is False in which case HookMissing is
+ raised.
+ """
+ backend = _build_backend()
+ try:
+ hook = backend.prepare_metadata_for_build_editable
+ except AttributeError:
+ if not _allow_fallback:
+ raise HookMissing()
+ try:
+ build_hook = backend.build_editable
+ except AttributeError:
+ raise HookMissing(hook_name='build_editable')
+ else:
+ whl_basename = build_hook(metadata_directory, config_settings)
+ return _get_wheel_metadata_from_wheel(whl_basename,
+ metadata_directory,
+ config_settings)
+ else:
+ return hook(metadata_directory, config_settings)
+
+
+WHEEL_BUILT_MARKER = 'PEP517_ALREADY_BUILT_WHEEL'
+
+
+def _dist_info_files(whl_zip):
+ """Identify the .dist-info folder inside a wheel ZipFile."""
+ res = []
+ for path in whl_zip.namelist():
+ m = re.match(r'[^/\\]+-[^/\\]+\.dist-info/', path)
+ if m:
+ res.append(path)
+ if res:
+ return res
+ raise Exception("No .dist-info folder found in wheel")
+
+
+def _get_wheel_metadata_from_wheel(
+ whl_basename, metadata_directory, config_settings):
+ """Extract the metadata from a wheel.
+
+ Fallback for when the build backend does not
+ define the 'get_wheel_metadata' hook.
+ """
+ from zipfile import ZipFile
+ with open(os.path.join(metadata_directory, WHEEL_BUILT_MARKER), 'wb'):
+ pass # Touch marker file
+
+ whl_file = os.path.join(metadata_directory, whl_basename)
+ with ZipFile(whl_file) as zipf:
+ dist_info = _dist_info_files(zipf)
+ zipf.extractall(path=metadata_directory, members=dist_info)
+ return dist_info[0].split('/')[0]
+
+
+def _find_already_built_wheel(metadata_directory):
+ """Check for a wheel already built during the get_wheel_metadata hook.
+ """
+ if not metadata_directory:
+ return None
+ metadata_parent = os.path.dirname(metadata_directory)
+ if not os.path.isfile(pjoin(metadata_parent, WHEEL_BUILT_MARKER)):
+ return None
+
+ whl_files = glob(os.path.join(metadata_parent, '*.whl'))
+ if not whl_files:
+ print('Found wheel built marker, but no .whl files')
+ return None
+ if len(whl_files) > 1:
+ print('Found multiple .whl files; unspecified behaviour. '
+ 'Will call build_wheel.')
+ return None
+
+ # Exactly one .whl file
+ return whl_files[0]
+
+
+def build_wheel(wheel_directory, config_settings, metadata_directory=None):
+ """Invoke the mandatory build_wheel hook.
+
+ If a wheel was already built in the
+ prepare_metadata_for_build_wheel fallback, this
+ will copy it rather than rebuilding the wheel.
+ """
+ prebuilt_whl = _find_already_built_wheel(metadata_directory)
+ if prebuilt_whl:
+ shutil.copy2(prebuilt_whl, wheel_directory)
+ return os.path.basename(prebuilt_whl)
+
+ return _build_backend().build_wheel(wheel_directory, config_settings,
+ metadata_directory)
+
+
+def build_editable(wheel_directory, config_settings, metadata_directory=None):
+ """Invoke the optional build_editable hook.
+
+ If a wheel was already built in the
+ prepare_metadata_for_build_editable fallback, this
+ will copy it rather than rebuilding the wheel.
+ """
+ backend = _build_backend()
+ try:
+ hook = backend.build_editable
+ except AttributeError:
+ raise HookMissing()
+ else:
+ prebuilt_whl = _find_already_built_wheel(metadata_directory)
+ if prebuilt_whl:
+ shutil.copy2(prebuilt_whl, wheel_directory)
+ return os.path.basename(prebuilt_whl)
+
+ return hook(wheel_directory, config_settings, metadata_directory)
+
+
+def get_requires_for_build_sdist(config_settings):
+ """Invoke the optional get_requires_for_build_wheel hook
+
+ Returns [] if the hook is not defined.
+ """
+ backend = _build_backend()
+ try:
+ hook = backend.get_requires_for_build_sdist
+ except AttributeError:
+ return []
+ else:
+ return hook(config_settings)
+
+
+class _DummyException(Exception):
+ """Nothing should ever raise this exception"""
+
+
+class GotUnsupportedOperation(Exception):
+ """For internal use when backend raises UnsupportedOperation"""
+ def __init__(self, traceback):
+ self.traceback = traceback
+
+
+def build_sdist(sdist_directory, config_settings):
+ """Invoke the mandatory build_sdist hook."""
+ backend = _build_backend()
+ try:
+ return backend.build_sdist(sdist_directory, config_settings)
+ except getattr(backend, 'UnsupportedOperation', _DummyException):
+ raise GotUnsupportedOperation(traceback.format_exc())
+
+
+HOOK_NAMES = {
+ 'get_requires_for_build_wheel',
+ 'prepare_metadata_for_build_wheel',
+ 'build_wheel',
+ 'get_requires_for_build_editable',
+ 'prepare_metadata_for_build_editable',
+ 'build_editable',
+ 'get_requires_for_build_sdist',
+ 'build_sdist',
+ '_supported_features',
+}
+
+
+def main():
+ if len(sys.argv) < 3:
+ sys.exit("Needs args: hook_name, control_dir")
+ hook_name = sys.argv[1]
+ control_dir = sys.argv[2]
+ if hook_name not in HOOK_NAMES:
+ sys.exit("Unknown hook: %s" % hook_name)
+ hook = globals()[hook_name]
+
+ hook_input = read_json(pjoin(control_dir, 'input.json'))
+
+ json_out = {'unsupported': False, 'return_val': None}
+ try:
+ json_out['return_val'] = hook(**hook_input['kwargs'])
+ except BackendUnavailable as e:
+ json_out['no_backend'] = True
+ json_out['traceback'] = e.traceback
+ except BackendInvalid as e:
+ json_out['backend_invalid'] = True
+ json_out['backend_error'] = e.message
+ except GotUnsupportedOperation as e:
+ json_out['unsupported'] = True
+ json_out['traceback'] = e.traceback
+ except HookMissing as e:
+ json_out['hook_missing'] = True
+ json_out['missing_hook_name'] = e.hook_name or hook_name
+
+ write_json(json_out, pjoin(control_dir, 'output.json'), indent=2)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/__init__.py
new file mode 100644
index 000000000..04230fc8d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/__init__.py
@@ -0,0 +1,179 @@
+# __
+# /__) _ _ _ _ _/ _
+# / ( (- (/ (/ (- _) / _)
+# /
+
+"""
+Requests HTTP Library
+~~~~~~~~~~~~~~~~~~~~~
+
+Requests is an HTTP library, written in Python, for human beings.
+Basic GET usage:
+
+ >>> import requests
+ >>> r = requests.get('https://www.python.org')
+ >>> r.status_code
+ 200
+ >>> b'Python is a programming language' in r.content
+ True
+
+... or POST:
+
+ >>> payload = dict(key1='value1', key2='value2')
+ >>> r = requests.post('https://httpbin.org/post', data=payload)
+ >>> print(r.text)
+ {
+ ...
+ "form": {
+ "key1": "value1",
+ "key2": "value2"
+ },
+ ...
+ }
+
+The other HTTP methods are supported - see `requests.api`. Full documentation
+is at <https://requests.readthedocs.io>.
+
+:copyright: (c) 2017 by Kenneth Reitz.
+:license: Apache 2.0, see LICENSE for more details.
+"""
+
+import warnings
+
+from pip._vendor import urllib3
+
+from .exceptions import RequestsDependencyWarning
+
+charset_normalizer_version = None
+chardet_version = None
+
+
+def check_compatibility(urllib3_version, chardet_version, charset_normalizer_version):
+ urllib3_version = urllib3_version.split(".")
+ assert urllib3_version != ["dev"] # Verify urllib3 isn't installed from git.
+
+ # Sometimes, urllib3 only reports its version as 16.1.
+ if len(urllib3_version) == 2:
+ urllib3_version.append("0")
+
+ # Check urllib3 for compatibility.
+ major, minor, patch = urllib3_version # noqa: F811
+ major, minor, patch = int(major), int(minor), int(patch)
+ # urllib3 >= 1.21.1
+ assert major >= 1
+ if major == 1:
+ assert minor >= 21
+
+ # Check charset_normalizer for compatibility.
+ if chardet_version:
+ major, minor, patch = chardet_version.split(".")[:3]
+ major, minor, patch = int(major), int(minor), int(patch)
+ # chardet_version >= 3.0.2, < 6.0.0
+ assert (3, 0, 2) <= (major, minor, patch) < (6, 0, 0)
+ elif charset_normalizer_version:
+ major, minor, patch = charset_normalizer_version.split(".")[:3]
+ major, minor, patch = int(major), int(minor), int(patch)
+ # charset_normalizer >= 2.0.0 < 4.0.0
+ assert (2, 0, 0) <= (major, minor, patch) < (4, 0, 0)
+ else:
+ # pip does not need or use character detection
+ pass
+
+
+def _check_cryptography(cryptography_version):
+ # cryptography < 1.3.4
+ try:
+ cryptography_version = list(map(int, cryptography_version.split(".")))
+ except ValueError:
+ return
+
+ if cryptography_version < [1, 3, 4]:
+ warning = "Old version of cryptography ({}) may cause slowdown.".format(
+ cryptography_version
+ )
+ warnings.warn(warning, RequestsDependencyWarning)
+
+
+# Check imported dependencies for compatibility.
+try:
+ check_compatibility(
+ urllib3.__version__, chardet_version, charset_normalizer_version
+ )
+except (AssertionError, ValueError):
+ warnings.warn(
+ "urllib3 ({}) or chardet ({})/charset_normalizer ({}) doesn't match a supported "
+ "version!".format(
+ urllib3.__version__, chardet_version, charset_normalizer_version
+ ),
+ RequestsDependencyWarning,
+ )
+
+# Attempt to enable urllib3's fallback for SNI support
+# if the standard library doesn't support SNI or the
+# 'ssl' library isn't available.
+try:
+ # Note: This logic prevents upgrading cryptography on Windows, if imported
+ # as part of pip.
+ from pip._internal.utils.compat import WINDOWS
+ if not WINDOWS:
+ raise ImportError("pip internals: don't import cryptography on Windows")
+ try:
+ import ssl
+ except ImportError:
+ ssl = None
+
+ if not getattr(ssl, "HAS_SNI", False):
+ from pip._vendor.urllib3.contrib import pyopenssl
+
+ pyopenssl.inject_into_urllib3()
+
+ # Check cryptography version
+ from cryptography import __version__ as cryptography_version
+
+ _check_cryptography(cryptography_version)
+except ImportError:
+ pass
+
+# urllib3's DependencyWarnings should be silenced.
+from pip._vendor.urllib3.exceptions import DependencyWarning
+
+warnings.simplefilter("ignore", DependencyWarning)
+
+# Set default logging handler to avoid "No handler found" warnings.
+import logging
+from logging import NullHandler
+
+from . import packages, utils
+from .__version__ import (
+ __author__,
+ __author_email__,
+ __build__,
+ __cake__,
+ __copyright__,
+ __description__,
+ __license__,
+ __title__,
+ __url__,
+ __version__,
+)
+from .api import delete, get, head, options, patch, post, put, request
+from .exceptions import (
+ ConnectionError,
+ ConnectTimeout,
+ FileModeWarning,
+ HTTPError,
+ JSONDecodeError,
+ ReadTimeout,
+ RequestException,
+ Timeout,
+ TooManyRedirects,
+ URLRequired,
+)
+from .models import PreparedRequest, Request, Response
+from .sessions import Session, session
+from .status_codes import codes
+
+logging.getLogger(__name__).addHandler(NullHandler())
+
+# FileModeWarnings go off per the default.
+warnings.simplefilter("default", FileModeWarning, append=True)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/__version__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/__version__.py
new file mode 100644
index 000000000..2c105aca7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/__version__.py
@@ -0,0 +1,14 @@
+# .-. .-. .-. . . .-. .-. .-. .-.
+# |( |- |.| | | |- `-. | `-.
+# ' ' `-' `-`.`-' `-' `-' ' `-'
+
+__title__ = "requests"
+__description__ = "Python HTTP for Humans."
+__url__ = "https://requests.readthedocs.io"
+__version__ = "2.32.3"
+__build__ = 0x023203
+__author__ = "Kenneth Reitz"
+__author_email__ = "me@kennethreitz.org"
+__license__ = "Apache-2.0"
+__copyright__ = "Copyright Kenneth Reitz"
+__cake__ = "\u2728 \U0001f370 \u2728"
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/_internal_utils.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/_internal_utils.py
new file mode 100644
index 000000000..f2cf635e2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/_internal_utils.py
@@ -0,0 +1,50 @@
+"""
+requests._internal_utils
+~~~~~~~~~~~~~~
+
+Provides utility functions that are consumed internally by Requests
+which depend on extremely few external helpers (such as compat)
+"""
+import re
+
+from .compat import builtin_str
+
+_VALID_HEADER_NAME_RE_BYTE = re.compile(rb"^[^:\s][^:\r\n]*$")
+_VALID_HEADER_NAME_RE_STR = re.compile(r"^[^:\s][^:\r\n]*$")
+_VALID_HEADER_VALUE_RE_BYTE = re.compile(rb"^\S[^\r\n]*$|^$")
+_VALID_HEADER_VALUE_RE_STR = re.compile(r"^\S[^\r\n]*$|^$")
+
+_HEADER_VALIDATORS_STR = (_VALID_HEADER_NAME_RE_STR, _VALID_HEADER_VALUE_RE_STR)
+_HEADER_VALIDATORS_BYTE = (_VALID_HEADER_NAME_RE_BYTE, _VALID_HEADER_VALUE_RE_BYTE)
+HEADER_VALIDATORS = {
+ bytes: _HEADER_VALIDATORS_BYTE,
+ str: _HEADER_VALIDATORS_STR,
+}
+
+
+def to_native_string(string, encoding="ascii"):
+ """Given a string object, regardless of type, returns a representation of
+ that string in the native string type, encoding and decoding where
+ necessary. This assumes ASCII unless told otherwise.
+ """
+ if isinstance(string, builtin_str):
+ out = string
+ else:
+ out = string.decode(encoding)
+
+ return out
+
+
+def unicode_is_ascii(u_string):
+ """Determine if unicode string only contains ASCII characters.
+
+ :param str u_string: unicode string to check. Must be unicode
+ and not Python 2 `str`.
+ :rtype: bool
+ """
+ assert isinstance(u_string, str)
+ try:
+ u_string.encode("ascii")
+ return True
+ except UnicodeEncodeError:
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/adapters.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/adapters.py
new file mode 100644
index 000000000..703077746
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/adapters.py
@@ -0,0 +1,719 @@
+"""
+requests.adapters
+~~~~~~~~~~~~~~~~~
+
+This module contains the transport adapters that Requests uses to define
+and maintain connections.
+"""
+
+import os.path
+import socket # noqa: F401
+import typing
+import warnings
+
+from pip._vendor.urllib3.exceptions import ClosedPoolError, ConnectTimeoutError
+from pip._vendor.urllib3.exceptions import HTTPError as _HTTPError
+from pip._vendor.urllib3.exceptions import InvalidHeader as _InvalidHeader
+from pip._vendor.urllib3.exceptions import (
+ LocationValueError,
+ MaxRetryError,
+ NewConnectionError,
+ ProtocolError,
+)
+from pip._vendor.urllib3.exceptions import ProxyError as _ProxyError
+from pip._vendor.urllib3.exceptions import ReadTimeoutError, ResponseError
+from pip._vendor.urllib3.exceptions import SSLError as _SSLError
+from pip._vendor.urllib3.poolmanager import PoolManager, proxy_from_url
+from pip._vendor.urllib3.util import Timeout as TimeoutSauce
+from pip._vendor.urllib3.util import parse_url
+from pip._vendor.urllib3.util.retry import Retry
+from pip._vendor.urllib3.util.ssl_ import create_urllib3_context
+
+from .auth import _basic_auth_str
+from .compat import basestring, urlparse
+from .cookies import extract_cookies_to_jar
+from .exceptions import (
+ ConnectionError,
+ ConnectTimeout,
+ InvalidHeader,
+ InvalidProxyURL,
+ InvalidSchema,
+ InvalidURL,
+ ProxyError,
+ ReadTimeout,
+ RetryError,
+ SSLError,
+)
+from .models import Response
+from .structures import CaseInsensitiveDict
+from .utils import (
+ DEFAULT_CA_BUNDLE_PATH,
+ extract_zipped_paths,
+ get_auth_from_url,
+ get_encoding_from_headers,
+ prepend_scheme_if_needed,
+ select_proxy,
+ urldefragauth,
+)
+
+try:
+ from pip._vendor.urllib3.contrib.socks import SOCKSProxyManager
+except ImportError:
+
+ def SOCKSProxyManager(*args, **kwargs):
+ raise InvalidSchema("Missing dependencies for SOCKS support.")
+
+
+if typing.TYPE_CHECKING:
+ from .models import PreparedRequest
+
+
+DEFAULT_POOLBLOCK = False
+DEFAULT_POOLSIZE = 10
+DEFAULT_RETRIES = 0
+DEFAULT_POOL_TIMEOUT = None
+
+
+try:
+ import ssl # noqa: F401
+
+ _preloaded_ssl_context = create_urllib3_context()
+ _preloaded_ssl_context.load_verify_locations(
+ extract_zipped_paths(DEFAULT_CA_BUNDLE_PATH)
+ )
+except ImportError:
+ # Bypass default SSLContext creation when Python
+ # interpreter isn't built with the ssl module.
+ _preloaded_ssl_context = None
+
+
+def _urllib3_request_context(
+ request: "PreparedRequest",
+ verify: "bool | str | None",
+ client_cert: "typing.Tuple[str, str] | str | None",
+ poolmanager: "PoolManager",
+) -> "(typing.Dict[str, typing.Any], typing.Dict[str, typing.Any])":
+ host_params = {}
+ pool_kwargs = {}
+ parsed_request_url = urlparse(request.url)
+ scheme = parsed_request_url.scheme.lower()
+ port = parsed_request_url.port
+
+ # Determine if we have and should use our default SSLContext
+ # to optimize performance on standard requests.
+ poolmanager_kwargs = getattr(poolmanager, "connection_pool_kw", {})
+ has_poolmanager_ssl_context = poolmanager_kwargs.get("ssl_context")
+ should_use_default_ssl_context = (
+ _preloaded_ssl_context is not None and not has_poolmanager_ssl_context
+ )
+
+ cert_reqs = "CERT_REQUIRED"
+ if verify is False:
+ cert_reqs = "CERT_NONE"
+ elif verify is True and should_use_default_ssl_context:
+ pool_kwargs["ssl_context"] = _preloaded_ssl_context
+ elif isinstance(verify, str):
+ if not os.path.isdir(verify):
+ pool_kwargs["ca_certs"] = verify
+ else:
+ pool_kwargs["ca_cert_dir"] = verify
+ pool_kwargs["cert_reqs"] = cert_reqs
+ if client_cert is not None:
+ if isinstance(client_cert, tuple) and len(client_cert) == 2:
+ pool_kwargs["cert_file"] = client_cert[0]
+ pool_kwargs["key_file"] = client_cert[1]
+ else:
+ # According to our docs, we allow users to specify just the client
+ # cert path
+ pool_kwargs["cert_file"] = client_cert
+ host_params = {
+ "scheme": scheme,
+ "host": parsed_request_url.hostname,
+ "port": port,
+ }
+ return host_params, pool_kwargs
+
+
+class BaseAdapter:
+ """The Base Transport Adapter"""
+
+ def __init__(self):
+ super().__init__()
+
+ def send(
+ self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None
+ ):
+ """Sends PreparedRequest object. Returns Response object.
+
+ :param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
+ :param stream: (optional) Whether to stream the request content.
+ :param timeout: (optional) How long to wait for the server to send
+ data before giving up, as a float, or a :ref:`(connect timeout,
+ read timeout) <timeouts>` tuple.
+ :type timeout: float or tuple
+ :param verify: (optional) Either a boolean, in which case it controls whether we verify
+ the server's TLS certificate, or a string, in which case it must be a path
+ to a CA bundle to use
+ :param cert: (optional) Any user-provided SSL certificate to be trusted.
+ :param proxies: (optional) The proxies dictionary to apply to the request.
+ """
+ raise NotImplementedError
+
+ def close(self):
+ """Cleans up adapter specific items."""
+ raise NotImplementedError
+
+
+class HTTPAdapter(BaseAdapter):
+ """The built-in HTTP Adapter for urllib3.
+
+ Provides a general-case interface for Requests sessions to contact HTTP and
+ HTTPS urls by implementing the Transport Adapter interface. This class will
+ usually be created by the :class:`Session <Session>` class under the
+ covers.
+
+ :param pool_connections: The number of urllib3 connection pools to cache.
+ :param pool_maxsize: The maximum number of connections to save in the pool.
+ :param max_retries: The maximum number of retries each connection
+ should attempt. Note, this applies only to failed DNS lookups, socket
+ connections and connection timeouts, never to requests where data has
+ made it to the server. By default, Requests does not retry failed
+ connections. If you need granular control over the conditions under
+ which we retry a request, import urllib3's ``Retry`` class and pass
+ that instead.
+ :param pool_block: Whether the connection pool should block for connections.
+
+ Usage::
+
+ >>> import requests
+ >>> s = requests.Session()
+ >>> a = requests.adapters.HTTPAdapter(max_retries=3)
+ >>> s.mount('http://', a)
+ """
+
+ __attrs__ = [
+ "max_retries",
+ "config",
+ "_pool_connections",
+ "_pool_maxsize",
+ "_pool_block",
+ ]
+
+ def __init__(
+ self,
+ pool_connections=DEFAULT_POOLSIZE,
+ pool_maxsize=DEFAULT_POOLSIZE,
+ max_retries=DEFAULT_RETRIES,
+ pool_block=DEFAULT_POOLBLOCK,
+ ):
+ if max_retries == DEFAULT_RETRIES:
+ self.max_retries = Retry(0, read=False)
+ else:
+ self.max_retries = Retry.from_int(max_retries)
+ self.config = {}
+ self.proxy_manager = {}
+
+ super().__init__()
+
+ self._pool_connections = pool_connections
+ self._pool_maxsize = pool_maxsize
+ self._pool_block = pool_block
+
+ self.init_poolmanager(pool_connections, pool_maxsize, block=pool_block)
+
+ def __getstate__(self):
+ return {attr: getattr(self, attr, None) for attr in self.__attrs__}
+
+ def __setstate__(self, state):
+ # Can't handle by adding 'proxy_manager' to self.__attrs__ because
+ # self.poolmanager uses a lambda function, which isn't pickleable.
+ self.proxy_manager = {}
+ self.config = {}
+
+ for attr, value in state.items():
+ setattr(self, attr, value)
+
+ self.init_poolmanager(
+ self._pool_connections, self._pool_maxsize, block=self._pool_block
+ )
+
+ def init_poolmanager(
+ self, connections, maxsize, block=DEFAULT_POOLBLOCK, **pool_kwargs
+ ):
+ """Initializes a urllib3 PoolManager.
+
+ This method should not be called from user code, and is only
+ exposed for use when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param connections: The number of urllib3 connection pools to cache.
+ :param maxsize: The maximum number of connections to save in the pool.
+ :param block: Block when no free connections are available.
+ :param pool_kwargs: Extra keyword arguments used to initialize the Pool Manager.
+ """
+ # save these values for pickling
+ self._pool_connections = connections
+ self._pool_maxsize = maxsize
+ self._pool_block = block
+
+ self.poolmanager = PoolManager(
+ num_pools=connections,
+ maxsize=maxsize,
+ block=block,
+ **pool_kwargs,
+ )
+
+ def proxy_manager_for(self, proxy, **proxy_kwargs):
+ """Return urllib3 ProxyManager for the given proxy.
+
+ This method should not be called from user code, and is only
+ exposed for use when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param proxy: The proxy to return a urllib3 ProxyManager for.
+ :param proxy_kwargs: Extra keyword arguments used to configure the Proxy Manager.
+ :returns: ProxyManager
+ :rtype: urllib3.ProxyManager
+ """
+ if proxy in self.proxy_manager:
+ manager = self.proxy_manager[proxy]
+ elif proxy.lower().startswith("socks"):
+ username, password = get_auth_from_url(proxy)
+ manager = self.proxy_manager[proxy] = SOCKSProxyManager(
+ proxy,
+ username=username,
+ password=password,
+ num_pools=self._pool_connections,
+ maxsize=self._pool_maxsize,
+ block=self._pool_block,
+ **proxy_kwargs,
+ )
+ else:
+ proxy_headers = self.proxy_headers(proxy)
+ manager = self.proxy_manager[proxy] = proxy_from_url(
+ proxy,
+ proxy_headers=proxy_headers,
+ num_pools=self._pool_connections,
+ maxsize=self._pool_maxsize,
+ block=self._pool_block,
+ **proxy_kwargs,
+ )
+
+ return manager
+
+ def cert_verify(self, conn, url, verify, cert):
+ """Verify a SSL certificate. This method should not be called from user
+ code, and is only exposed for use when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param conn: The urllib3 connection object associated with the cert.
+ :param url: The requested URL.
+ :param verify: Either a boolean, in which case it controls whether we verify
+ the server's TLS certificate, or a string, in which case it must be a path
+ to a CA bundle to use
+ :param cert: The SSL certificate to verify.
+ """
+ if url.lower().startswith("https") and verify:
+ conn.cert_reqs = "CERT_REQUIRED"
+
+ # Only load the CA certificates if 'verify' is a string indicating the CA bundle to use.
+ # Otherwise, if verify is a boolean, we don't load anything since
+ # the connection will be using a context with the default certificates already loaded,
+ # and this avoids a call to the slow load_verify_locations()
+ if verify is not True:
+ # `verify` must be a str with a path then
+ cert_loc = verify
+
+ if not os.path.exists(cert_loc):
+ raise OSError(
+ f"Could not find a suitable TLS CA certificate bundle, "
+ f"invalid path: {cert_loc}"
+ )
+
+ if not os.path.isdir(cert_loc):
+ conn.ca_certs = cert_loc
+ else:
+ conn.ca_cert_dir = cert_loc
+ else:
+ conn.cert_reqs = "CERT_NONE"
+ conn.ca_certs = None
+ conn.ca_cert_dir = None
+
+ if cert:
+ if not isinstance(cert, basestring):
+ conn.cert_file = cert[0]
+ conn.key_file = cert[1]
+ else:
+ conn.cert_file = cert
+ conn.key_file = None
+ if conn.cert_file and not os.path.exists(conn.cert_file):
+ raise OSError(
+ f"Could not find the TLS certificate file, "
+ f"invalid path: {conn.cert_file}"
+ )
+ if conn.key_file and not os.path.exists(conn.key_file):
+ raise OSError(
+ f"Could not find the TLS key file, invalid path: {conn.key_file}"
+ )
+
+ def build_response(self, req, resp):
+ """Builds a :class:`Response <requests.Response>` object from a urllib3
+ response. This should not be called from user code, and is only exposed
+ for use when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`
+
+ :param req: The :class:`PreparedRequest <PreparedRequest>` used to generate the response.
+ :param resp: The urllib3 response object.
+ :rtype: requests.Response
+ """
+ response = Response()
+
+ # Fallback to None if there's no status_code, for whatever reason.
+ response.status_code = getattr(resp, "status", None)
+
+ # Make headers case-insensitive.
+ response.headers = CaseInsensitiveDict(getattr(resp, "headers", {}))
+
+ # Set encoding.
+ response.encoding = get_encoding_from_headers(response.headers)
+ response.raw = resp
+ response.reason = response.raw.reason
+
+ if isinstance(req.url, bytes):
+ response.url = req.url.decode("utf-8")
+ else:
+ response.url = req.url
+
+ # Add new cookies from the server.
+ extract_cookies_to_jar(response.cookies, req, resp)
+
+ # Give the Response some context.
+ response.request = req
+ response.connection = self
+
+ return response
+
+ def build_connection_pool_key_attributes(self, request, verify, cert=None):
+ """Build the PoolKey attributes used by urllib3 to return a connection.
+
+ This looks at the PreparedRequest, the user-specified verify value,
+ and the value of the cert parameter to determine what PoolKey values
+ to use to select a connection from a given urllib3 Connection Pool.
+
+ The SSL related pool key arguments are not consistently set. As of
+ this writing, use the following to determine what keys may be in that
+ dictionary:
+
+ * If ``verify`` is ``True``, ``"ssl_context"`` will be set and will be the
+ default Requests SSL Context
+ * If ``verify`` is ``False``, ``"ssl_context"`` will not be set but
+ ``"cert_reqs"`` will be set
+ * If ``verify`` is a string, (i.e., it is a user-specified trust bundle)
+ ``"ca_certs"`` will be set if the string is not a directory recognized
+ by :py:func:`os.path.isdir`, otherwise ``"ca_certs_dir"`` will be
+ set.
+ * If ``"cert"`` is specified, ``"cert_file"`` will always be set. If
+ ``"cert"`` is a tuple with a second item, ``"key_file"`` will also
+ be present
+
+ To override these settings, one may subclass this class, call this
+ method and use the above logic to change parameters as desired. For
+ example, if one wishes to use a custom :py:class:`ssl.SSLContext` one
+ must both set ``"ssl_context"`` and based on what else they require,
+ alter the other keys to ensure the desired behaviour.
+
+ :param request:
+ The PreparedReqest being sent over the connection.
+ :type request:
+ :class:`~requests.models.PreparedRequest`
+ :param verify:
+ Either a boolean, in which case it controls whether
+ we verify the server's TLS certificate, or a string, in which case it
+ must be a path to a CA bundle to use.
+ :param cert:
+ (optional) Any user-provided SSL certificate for client
+ authentication (a.k.a., mTLS). This may be a string (i.e., just
+ the path to a file which holds both certificate and key) or a
+ tuple of length 2 with the certificate file path and key file
+ path.
+ :returns:
+ A tuple of two dictionaries. The first is the "host parameters"
+ portion of the Pool Key including scheme, hostname, and port. The
+ second is a dictionary of SSLContext related parameters.
+ """
+ return _urllib3_request_context(request, verify, cert, self.poolmanager)
+
+ def get_connection_with_tls_context(self, request, verify, proxies=None, cert=None):
+ """Returns a urllib3 connection for the given request and TLS settings.
+ This should not be called from user code, and is only exposed for use
+ when subclassing the :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param request:
+ The :class:`PreparedRequest <PreparedRequest>` object to be sent
+ over the connection.
+ :param verify:
+ Either a boolean, in which case it controls whether we verify the
+ server's TLS certificate, or a string, in which case it must be a
+ path to a CA bundle to use.
+ :param proxies:
+ (optional) The proxies dictionary to apply to the request.
+ :param cert:
+ (optional) Any user-provided SSL certificate to be used for client
+ authentication (a.k.a., mTLS).
+ :rtype:
+ urllib3.ConnectionPool
+ """
+ proxy = select_proxy(request.url, proxies)
+ try:
+ host_params, pool_kwargs = self.build_connection_pool_key_attributes(
+ request,
+ verify,
+ cert,
+ )
+ except ValueError as e:
+ raise InvalidURL(e, request=request)
+ if proxy:
+ proxy = prepend_scheme_if_needed(proxy, "http")
+ proxy_url = parse_url(proxy)
+ if not proxy_url.host:
+ raise InvalidProxyURL(
+ "Please check proxy URL. It is malformed "
+ "and could be missing the host."
+ )
+ proxy_manager = self.proxy_manager_for(proxy)
+ conn = proxy_manager.connection_from_host(
+ **host_params, pool_kwargs=pool_kwargs
+ )
+ else:
+ # Only scheme should be lower case
+ conn = self.poolmanager.connection_from_host(
+ **host_params, pool_kwargs=pool_kwargs
+ )
+
+ return conn
+
+ def get_connection(self, url, proxies=None):
+ """DEPRECATED: Users should move to `get_connection_with_tls_context`
+ for all subclasses of HTTPAdapter using Requests>=2.32.2.
+
+ Returns a urllib3 connection for the given URL. This should not be
+ called from user code, and is only exposed for use when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param url: The URL to connect to.
+ :param proxies: (optional) A Requests-style dictionary of proxies used on this request.
+ :rtype: urllib3.ConnectionPool
+ """
+ warnings.warn(
+ (
+ "`get_connection` has been deprecated in favor of "
+ "`get_connection_with_tls_context`. Custom HTTPAdapter subclasses "
+ "will need to migrate for Requests>=2.32.2. Please see "
+ "https://github.com/psf/requests/pull/6710 for more details."
+ ),
+ DeprecationWarning,
+ )
+ proxy = select_proxy(url, proxies)
+
+ if proxy:
+ proxy = prepend_scheme_if_needed(proxy, "http")
+ proxy_url = parse_url(proxy)
+ if not proxy_url.host:
+ raise InvalidProxyURL(
+ "Please check proxy URL. It is malformed "
+ "and could be missing the host."
+ )
+ proxy_manager = self.proxy_manager_for(proxy)
+ conn = proxy_manager.connection_from_url(url)
+ else:
+ # Only scheme should be lower case
+ parsed = urlparse(url)
+ url = parsed.geturl()
+ conn = self.poolmanager.connection_from_url(url)
+
+ return conn
+
+ def close(self):
+ """Disposes of any internal state.
+
+ Currently, this closes the PoolManager and any active ProxyManager,
+ which closes any pooled connections.
+ """
+ self.poolmanager.clear()
+ for proxy in self.proxy_manager.values():
+ proxy.clear()
+
+ def request_url(self, request, proxies):
+ """Obtain the url to use when making the final request.
+
+ If the message is being sent through a HTTP proxy, the full URL has to
+ be used. Otherwise, we should only use the path portion of the URL.
+
+ This should not be called from user code, and is only exposed for use
+ when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
+ :param proxies: A dictionary of schemes or schemes and hosts to proxy URLs.
+ :rtype: str
+ """
+ proxy = select_proxy(request.url, proxies)
+ scheme = urlparse(request.url).scheme
+
+ is_proxied_http_request = proxy and scheme != "https"
+ using_socks_proxy = False
+ if proxy:
+ proxy_scheme = urlparse(proxy).scheme.lower()
+ using_socks_proxy = proxy_scheme.startswith("socks")
+
+ url = request.path_url
+ if url.startswith("//"): # Don't confuse urllib3
+ url = f"/{url.lstrip('/')}"
+
+ if is_proxied_http_request and not using_socks_proxy:
+ url = urldefragauth(request.url)
+
+ return url
+
+ def add_headers(self, request, **kwargs):
+ """Add any headers needed by the connection. As of v2.0 this does
+ nothing by default, but is left for overriding by users that subclass
+ the :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ This should not be called from user code, and is only exposed for use
+ when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param request: The :class:`PreparedRequest <PreparedRequest>` to add headers to.
+ :param kwargs: The keyword arguments from the call to send().
+ """
+ pass
+
+ def proxy_headers(self, proxy):
+ """Returns a dictionary of the headers to add to any request sent
+ through a proxy. This works with urllib3 magic to ensure that they are
+ correctly sent to the proxy, rather than in a tunnelled request if
+ CONNECT is being used.
+
+ This should not be called from user code, and is only exposed for use
+ when subclassing the
+ :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
+
+ :param proxy: The url of the proxy being used for this request.
+ :rtype: dict
+ """
+ headers = {}
+ username, password = get_auth_from_url(proxy)
+
+ if username:
+ headers["Proxy-Authorization"] = _basic_auth_str(username, password)
+
+ return headers
+
+ def send(
+ self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None
+ ):
+ """Sends PreparedRequest object. Returns Response object.
+
+ :param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
+ :param stream: (optional) Whether to stream the request content.
+ :param timeout: (optional) How long to wait for the server to send
+ data before giving up, as a float, or a :ref:`(connect timeout,
+ read timeout) <timeouts>` tuple.
+ :type timeout: float or tuple or urllib3 Timeout object
+ :param verify: (optional) Either a boolean, in which case it controls whether
+ we verify the server's TLS certificate, or a string, in which case it
+ must be a path to a CA bundle to use
+ :param cert: (optional) Any user-provided SSL certificate to be trusted.
+ :param proxies: (optional) The proxies dictionary to apply to the request.
+ :rtype: requests.Response
+ """
+
+ try:
+ conn = self.get_connection_with_tls_context(
+ request, verify, proxies=proxies, cert=cert
+ )
+ except LocationValueError as e:
+ raise InvalidURL(e, request=request)
+
+ self.cert_verify(conn, request.url, verify, cert)
+ url = self.request_url(request, proxies)
+ self.add_headers(
+ request,
+ stream=stream,
+ timeout=timeout,
+ verify=verify,
+ cert=cert,
+ proxies=proxies,
+ )
+
+ chunked = not (request.body is None or "Content-Length" in request.headers)
+
+ if isinstance(timeout, tuple):
+ try:
+ connect, read = timeout
+ timeout = TimeoutSauce(connect=connect, read=read)
+ except ValueError:
+ raise ValueError(
+ f"Invalid timeout {timeout}. Pass a (connect, read) timeout tuple, "
+ f"or a single float to set both timeouts to the same value."
+ )
+ elif isinstance(timeout, TimeoutSauce):
+ pass
+ else:
+ timeout = TimeoutSauce(connect=timeout, read=timeout)
+
+ try:
+ resp = conn.urlopen(
+ method=request.method,
+ url=url,
+ body=request.body,
+ headers=request.headers,
+ redirect=False,
+ assert_same_host=False,
+ preload_content=False,
+ decode_content=False,
+ retries=self.max_retries,
+ timeout=timeout,
+ chunked=chunked,
+ )
+
+ except (ProtocolError, OSError) as err:
+ raise ConnectionError(err, request=request)
+
+ except MaxRetryError as e:
+ if isinstance(e.reason, ConnectTimeoutError):
+ # TODO: Remove this in 3.0.0: see #2811
+ if not isinstance(e.reason, NewConnectionError):
+ raise ConnectTimeout(e, request=request)
+
+ if isinstance(e.reason, ResponseError):
+ raise RetryError(e, request=request)
+
+ if isinstance(e.reason, _ProxyError):
+ raise ProxyError(e, request=request)
+
+ if isinstance(e.reason, _SSLError):
+ # This branch is for urllib3 v1.22 and later.
+ raise SSLError(e, request=request)
+
+ raise ConnectionError(e, request=request)
+
+ except ClosedPoolError as e:
+ raise ConnectionError(e, request=request)
+
+ except _ProxyError as e:
+ raise ProxyError(e)
+
+ except (_SSLError, _HTTPError) as e:
+ if isinstance(e, _SSLError):
+ # This branch is for urllib3 versions earlier than v1.22
+ raise SSLError(e, request=request)
+ elif isinstance(e, ReadTimeoutError):
+ raise ReadTimeout(e, request=request)
+ elif isinstance(e, _InvalidHeader):
+ raise InvalidHeader(e, request=request)
+ else:
+ raise
+
+ return self.build_response(request, resp)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/api.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/api.py
new file mode 100644
index 000000000..596074455
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/api.py
@@ -0,0 +1,157 @@
+"""
+requests.api
+~~~~~~~~~~~~
+
+This module implements the Requests API.
+
+:copyright: (c) 2012 by Kenneth Reitz.
+:license: Apache2, see LICENSE for more details.
+"""
+
+from . import sessions
+
+
+def request(method, url, **kwargs):
+ """Constructs and sends a :class:`Request <Request>`.
+
+ :param method: method for the new :class:`Request` object: ``GET``, ``OPTIONS``, ``HEAD``, ``POST``, ``PUT``, ``PATCH``, or ``DELETE``.
+ :param url: URL for the new :class:`Request` object.
+ :param params: (optional) Dictionary, list of tuples or bytes to send
+ in the query string for the :class:`Request`.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
+ :param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
+ :param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
+ :param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
+ ``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
+ or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content_type'`` is a string
+ defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
+ to add for the file.
+ :param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
+ :param timeout: (optional) How many seconds to wait for the server to send data
+ before giving up, as a float, or a :ref:`(connect timeout, read
+ timeout) <timeouts>` tuple.
+ :type timeout: float or tuple
+ :param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
+ :type allow_redirects: bool
+ :param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
+ :param verify: (optional) Either a boolean, in which case it controls whether we verify
+ the server's TLS certificate, or a string, in which case it must be a path
+ to a CA bundle to use. Defaults to ``True``.
+ :param stream: (optional) if ``False``, the response content will be immediately downloaded.
+ :param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+
+ Usage::
+
+ >>> import requests
+ >>> req = requests.request('GET', 'https://httpbin.org/get')
+ >>> req
+ <Response [200]>
+ """
+
+ # By using the 'with' statement we are sure the session is closed, thus we
+ # avoid leaving sockets open which can trigger a ResourceWarning in some
+ # cases, and look like a memory leak in others.
+ with sessions.Session() as session:
+ return session.request(method=method, url=url, **kwargs)
+
+
+def get(url, params=None, **kwargs):
+ r"""Sends a GET request.
+
+ :param url: URL for the new :class:`Request` object.
+ :param params: (optional) Dictionary, list of tuples or bytes to send
+ in the query string for the :class:`Request`.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+ """
+
+ return request("get", url, params=params, **kwargs)
+
+
+def options(url, **kwargs):
+ r"""Sends an OPTIONS request.
+
+ :param url: URL for the new :class:`Request` object.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+ """
+
+ return request("options", url, **kwargs)
+
+
+def head(url, **kwargs):
+ r"""Sends a HEAD request.
+
+ :param url: URL for the new :class:`Request` object.
+ :param \*\*kwargs: Optional arguments that ``request`` takes. If
+ `allow_redirects` is not provided, it will be set to `False` (as
+ opposed to the default :meth:`request` behavior).
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+ """
+
+ kwargs.setdefault("allow_redirects", False)
+ return request("head", url, **kwargs)
+
+
+def post(url, data=None, json=None, **kwargs):
+ r"""Sends a POST request.
+
+ :param url: URL for the new :class:`Request` object.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+ """
+
+ return request("post", url, data=data, json=json, **kwargs)
+
+
+def put(url, data=None, **kwargs):
+ r"""Sends a PUT request.
+
+ :param url: URL for the new :class:`Request` object.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+ """
+
+ return request("put", url, data=data, **kwargs)
+
+
+def patch(url, data=None, **kwargs):
+ r"""Sends a PATCH request.
+
+ :param url: URL for the new :class:`Request` object.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+ """
+
+ return request("patch", url, data=data, **kwargs)
+
+
+def delete(url, **kwargs):
+ r"""Sends a DELETE request.
+
+ :param url: URL for the new :class:`Request` object.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :return: :class:`Response <Response>` object
+ :rtype: requests.Response
+ """
+
+ return request("delete", url, **kwargs)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/auth.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/auth.py
new file mode 100644
index 000000000..4a7ce6dc1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/auth.py
@@ -0,0 +1,314 @@
+"""
+requests.auth
+~~~~~~~~~~~~~
+
+This module contains the authentication handlers for Requests.
+"""
+
+import hashlib
+import os
+import re
+import threading
+import time
+import warnings
+from base64 import b64encode
+
+from ._internal_utils import to_native_string
+from .compat import basestring, str, urlparse
+from .cookies import extract_cookies_to_jar
+from .utils import parse_dict_header
+
+CONTENT_TYPE_FORM_URLENCODED = "application/x-www-form-urlencoded"
+CONTENT_TYPE_MULTI_PART = "multipart/form-data"
+
+
+def _basic_auth_str(username, password):
+ """Returns a Basic Auth string."""
+
+ # "I want us to put a big-ol' comment on top of it that
+ # says that this behaviour is dumb but we need to preserve
+ # it because people are relying on it."
+ # - Lukasa
+ #
+ # These are here solely to maintain backwards compatibility
+ # for things like ints. This will be removed in 3.0.0.
+ if not isinstance(username, basestring):
+ warnings.warn(
+ "Non-string usernames will no longer be supported in Requests "
+ "3.0.0. Please convert the object you've passed in ({!r}) to "
+ "a string or bytes object in the near future to avoid "
+ "problems.".format(username),
+ category=DeprecationWarning,
+ )
+ username = str(username)
+
+ if not isinstance(password, basestring):
+ warnings.warn(
+ "Non-string passwords will no longer be supported in Requests "
+ "3.0.0. Please convert the object you've passed in ({!r}) to "
+ "a string or bytes object in the near future to avoid "
+ "problems.".format(type(password)),
+ category=DeprecationWarning,
+ )
+ password = str(password)
+ # -- End Removal --
+
+ if isinstance(username, str):
+ username = username.encode("latin1")
+
+ if isinstance(password, str):
+ password = password.encode("latin1")
+
+ authstr = "Basic " + to_native_string(
+ b64encode(b":".join((username, password))).strip()
+ )
+
+ return authstr
+
+
+class AuthBase:
+ """Base class that all auth implementations derive from"""
+
+ def __call__(self, r):
+ raise NotImplementedError("Auth hooks must be callable.")
+
+
+class HTTPBasicAuth(AuthBase):
+ """Attaches HTTP Basic Authentication to the given Request object."""
+
+ def __init__(self, username, password):
+ self.username = username
+ self.password = password
+
+ def __eq__(self, other):
+ return all(
+ [
+ self.username == getattr(other, "username", None),
+ self.password == getattr(other, "password", None),
+ ]
+ )
+
+ def __ne__(self, other):
+ return not self == other
+
+ def __call__(self, r):
+ r.headers["Authorization"] = _basic_auth_str(self.username, self.password)
+ return r
+
+
+class HTTPProxyAuth(HTTPBasicAuth):
+ """Attaches HTTP Proxy Authentication to a given Request object."""
+
+ def __call__(self, r):
+ r.headers["Proxy-Authorization"] = _basic_auth_str(self.username, self.password)
+ return r
+
+
+class HTTPDigestAuth(AuthBase):
+ """Attaches HTTP Digest Authentication to the given Request object."""
+
+ def __init__(self, username, password):
+ self.username = username
+ self.password = password
+ # Keep state in per-thread local storage
+ self._thread_local = threading.local()
+
+ def init_per_thread_state(self):
+ # Ensure state is initialized just once per-thread
+ if not hasattr(self._thread_local, "init"):
+ self._thread_local.init = True
+ self._thread_local.last_nonce = ""
+ self._thread_local.nonce_count = 0
+ self._thread_local.chal = {}
+ self._thread_local.pos = None
+ self._thread_local.num_401_calls = None
+
+ def build_digest_header(self, method, url):
+ """
+ :rtype: str
+ """
+
+ realm = self._thread_local.chal["realm"]
+ nonce = self._thread_local.chal["nonce"]
+ qop = self._thread_local.chal.get("qop")
+ algorithm = self._thread_local.chal.get("algorithm")
+ opaque = self._thread_local.chal.get("opaque")
+ hash_utf8 = None
+
+ if algorithm is None:
+ _algorithm = "MD5"
+ else:
+ _algorithm = algorithm.upper()
+ # lambdas assume digest modules are imported at the top level
+ if _algorithm == "MD5" or _algorithm == "MD5-SESS":
+
+ def md5_utf8(x):
+ if isinstance(x, str):
+ x = x.encode("utf-8")
+ return hashlib.md5(x).hexdigest()
+
+ hash_utf8 = md5_utf8
+ elif _algorithm == "SHA":
+
+ def sha_utf8(x):
+ if isinstance(x, str):
+ x = x.encode("utf-8")
+ return hashlib.sha1(x).hexdigest()
+
+ hash_utf8 = sha_utf8
+ elif _algorithm == "SHA-256":
+
+ def sha256_utf8(x):
+ if isinstance(x, str):
+ x = x.encode("utf-8")
+ return hashlib.sha256(x).hexdigest()
+
+ hash_utf8 = sha256_utf8
+ elif _algorithm == "SHA-512":
+
+ def sha512_utf8(x):
+ if isinstance(x, str):
+ x = x.encode("utf-8")
+ return hashlib.sha512(x).hexdigest()
+
+ hash_utf8 = sha512_utf8
+
+ KD = lambda s, d: hash_utf8(f"{s}:{d}") # noqa:E731
+
+ if hash_utf8 is None:
+ return None
+
+ # XXX not implemented yet
+ entdig = None
+ p_parsed = urlparse(url)
+ #: path is request-uri defined in RFC 2616 which should not be empty
+ path = p_parsed.path or "/"
+ if p_parsed.query:
+ path += f"?{p_parsed.query}"
+
+ A1 = f"{self.username}:{realm}:{self.password}"
+ A2 = f"{method}:{path}"
+
+ HA1 = hash_utf8(A1)
+ HA2 = hash_utf8(A2)
+
+ if nonce == self._thread_local.last_nonce:
+ self._thread_local.nonce_count += 1
+ else:
+ self._thread_local.nonce_count = 1
+ ncvalue = f"{self._thread_local.nonce_count:08x}"
+ s = str(self._thread_local.nonce_count).encode("utf-8")
+ s += nonce.encode("utf-8")
+ s += time.ctime().encode("utf-8")
+ s += os.urandom(8)
+
+ cnonce = hashlib.sha1(s).hexdigest()[:16]
+ if _algorithm == "MD5-SESS":
+ HA1 = hash_utf8(f"{HA1}:{nonce}:{cnonce}")
+
+ if not qop:
+ respdig = KD(HA1, f"{nonce}:{HA2}")
+ elif qop == "auth" or "auth" in qop.split(","):
+ noncebit = f"{nonce}:{ncvalue}:{cnonce}:auth:{HA2}"
+ respdig = KD(HA1, noncebit)
+ else:
+ # XXX handle auth-int.
+ return None
+
+ self._thread_local.last_nonce = nonce
+
+ # XXX should the partial digests be encoded too?
+ base = (
+ f'username="{self.username}", realm="{realm}", nonce="{nonce}", '
+ f'uri="{path}", response="{respdig}"'
+ )
+ if opaque:
+ base += f', opaque="{opaque}"'
+ if algorithm:
+ base += f', algorithm="{algorithm}"'
+ if entdig:
+ base += f', digest="{entdig}"'
+ if qop:
+ base += f', qop="auth", nc={ncvalue}, cnonce="{cnonce}"'
+
+ return f"Digest {base}"
+
+ def handle_redirect(self, r, **kwargs):
+ """Reset num_401_calls counter on redirects."""
+ if r.is_redirect:
+ self._thread_local.num_401_calls = 1
+
+ def handle_401(self, r, **kwargs):
+ """
+ Takes the given response and tries digest-auth, if needed.
+
+ :rtype: requests.Response
+ """
+
+ # If response is not 4xx, do not auth
+ # See https://github.com/psf/requests/issues/3772
+ if not 400 <= r.status_code < 500:
+ self._thread_local.num_401_calls = 1
+ return r
+
+ if self._thread_local.pos is not None:
+ # Rewind the file position indicator of the body to where
+ # it was to resend the request.
+ r.request.body.seek(self._thread_local.pos)
+ s_auth = r.headers.get("www-authenticate", "")
+
+ if "digest" in s_auth.lower() and self._thread_local.num_401_calls < 2:
+ self._thread_local.num_401_calls += 1
+ pat = re.compile(r"digest ", flags=re.IGNORECASE)
+ self._thread_local.chal = parse_dict_header(pat.sub("", s_auth, count=1))
+
+ # Consume content and release the original connection
+ # to allow our new request to reuse the same one.
+ r.content
+ r.close()
+ prep = r.request.copy()
+ extract_cookies_to_jar(prep._cookies, r.request, r.raw)
+ prep.prepare_cookies(prep._cookies)
+
+ prep.headers["Authorization"] = self.build_digest_header(
+ prep.method, prep.url
+ )
+ _r = r.connection.send(prep, **kwargs)
+ _r.history.append(r)
+ _r.request = prep
+
+ return _r
+
+ self._thread_local.num_401_calls = 1
+ return r
+
+ def __call__(self, r):
+ # Initialize per-thread state, if needed
+ self.init_per_thread_state()
+ # If we have a saved nonce, skip the 401
+ if self._thread_local.last_nonce:
+ r.headers["Authorization"] = self.build_digest_header(r.method, r.url)
+ try:
+ self._thread_local.pos = r.body.tell()
+ except AttributeError:
+ # In the case of HTTPDigestAuth being reused and the body of
+ # the previous request was a file-like object, pos has the
+ # file position of the previous body. Ensure it's set to
+ # None.
+ self._thread_local.pos = None
+ r.register_hook("response", self.handle_401)
+ r.register_hook("response", self.handle_redirect)
+ self._thread_local.num_401_calls = 1
+
+ return r
+
+ def __eq__(self, other):
+ return all(
+ [
+ self.username == getattr(other, "username", None),
+ self.password == getattr(other, "password", None),
+ ]
+ )
+
+ def __ne__(self, other):
+ return not self == other
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/certs.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/certs.py
new file mode 100644
index 000000000..38696a1fb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/certs.py
@@ -0,0 +1,24 @@
+#!/usr/bin/env python
+
+"""
+requests.certs
+~~~~~~~~~~~~~~
+
+This module returns the preferred default CA certificate bundle. There is
+only one — the one from the certifi package.
+
+If you are packaging Requests, e.g., for a Linux distribution or a managed
+environment, you can change the definition of where() to return a separately
+packaged CA bundle.
+"""
+
+import os
+
+if "_PIP_STANDALONE_CERT" not in os.environ:
+ from pip._vendor.certifi import where
+else:
+ def where():
+ return os.environ["_PIP_STANDALONE_CERT"]
+
+if __name__ == "__main__":
+ print(where())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/compat.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/compat.py
new file mode 100644
index 000000000..7081da756
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/compat.py
@@ -0,0 +1,78 @@
+"""
+requests.compat
+~~~~~~~~~~~~~~~
+
+This module previously handled import compatibility issues
+between Python 2 and Python 3. It remains for backwards
+compatibility until the next major version.
+"""
+
+import sys
+
+# -------------------
+# Character Detection
+# -------------------
+
+
+def _resolve_char_detection():
+ """Find supported character detection libraries."""
+ chardet = None
+ return chardet
+
+
+chardet = _resolve_char_detection()
+
+# -------
+# Pythons
+# -------
+
+# Syntax sugar.
+_ver = sys.version_info
+
+#: Python 2.x?
+is_py2 = _ver[0] == 2
+
+#: Python 3.x?
+is_py3 = _ver[0] == 3
+
+# Note: We've patched out simplejson support in pip because it prevents
+# upgrading simplejson on Windows.
+import json
+from json import JSONDecodeError
+
+# Keep OrderedDict for backwards compatibility.
+from collections import OrderedDict
+from collections.abc import Callable, Mapping, MutableMapping
+from http import cookiejar as cookielib
+from http.cookies import Morsel
+from io import StringIO
+
+# --------------
+# Legacy Imports
+# --------------
+from urllib.parse import (
+ quote,
+ quote_plus,
+ unquote,
+ unquote_plus,
+ urldefrag,
+ urlencode,
+ urljoin,
+ urlparse,
+ urlsplit,
+ urlunparse,
+)
+from urllib.request import (
+ getproxies,
+ getproxies_environment,
+ parse_http_list,
+ proxy_bypass,
+ proxy_bypass_environment,
+)
+
+builtin_str = str
+str = str
+bytes = bytes
+basestring = (str, bytes)
+numeric_types = (int, float)
+integer_types = (int,)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/cookies.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/cookies.py
new file mode 100644
index 000000000..f69d0cda9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/cookies.py
@@ -0,0 +1,561 @@
+"""
+requests.cookies
+~~~~~~~~~~~~~~~~
+
+Compatibility code to be able to use `http.cookiejar.CookieJar` with requests.
+
+requests.utils imports from here, so be careful with imports.
+"""
+
+import calendar
+import copy
+import time
+
+from ._internal_utils import to_native_string
+from .compat import Morsel, MutableMapping, cookielib, urlparse, urlunparse
+
+try:
+ import threading
+except ImportError:
+ import dummy_threading as threading
+
+
+class MockRequest:
+ """Wraps a `requests.Request` to mimic a `urllib2.Request`.
+
+ The code in `http.cookiejar.CookieJar` expects this interface in order to correctly
+ manage cookie policies, i.e., determine whether a cookie can be set, given the
+ domains of the request and the cookie.
+
+ The original request object is read-only. The client is responsible for collecting
+ the new headers via `get_new_headers()` and interpreting them appropriately. You
+ probably want `get_cookie_header`, defined below.
+ """
+
+ def __init__(self, request):
+ self._r = request
+ self._new_headers = {}
+ self.type = urlparse(self._r.url).scheme
+
+ def get_type(self):
+ return self.type
+
+ def get_host(self):
+ return urlparse(self._r.url).netloc
+
+ def get_origin_req_host(self):
+ return self.get_host()
+
+ def get_full_url(self):
+ # Only return the response's URL if the user hadn't set the Host
+ # header
+ if not self._r.headers.get("Host"):
+ return self._r.url
+ # If they did set it, retrieve it and reconstruct the expected domain
+ host = to_native_string(self._r.headers["Host"], encoding="utf-8")
+ parsed = urlparse(self._r.url)
+ # Reconstruct the URL as we expect it
+ return urlunparse(
+ [
+ parsed.scheme,
+ host,
+ parsed.path,
+ parsed.params,
+ parsed.query,
+ parsed.fragment,
+ ]
+ )
+
+ def is_unverifiable(self):
+ return True
+
+ def has_header(self, name):
+ return name in self._r.headers or name in self._new_headers
+
+ def get_header(self, name, default=None):
+ return self._r.headers.get(name, self._new_headers.get(name, default))
+
+ def add_header(self, key, val):
+ """cookiejar has no legitimate use for this method; add it back if you find one."""
+ raise NotImplementedError(
+ "Cookie headers should be added with add_unredirected_header()"
+ )
+
+ def add_unredirected_header(self, name, value):
+ self._new_headers[name] = value
+
+ def get_new_headers(self):
+ return self._new_headers
+
+ @property
+ def unverifiable(self):
+ return self.is_unverifiable()
+
+ @property
+ def origin_req_host(self):
+ return self.get_origin_req_host()
+
+ @property
+ def host(self):
+ return self.get_host()
+
+
+class MockResponse:
+ """Wraps a `httplib.HTTPMessage` to mimic a `urllib.addinfourl`.
+
+ ...what? Basically, expose the parsed HTTP headers from the server response
+ the way `http.cookiejar` expects to see them.
+ """
+
+ def __init__(self, headers):
+ """Make a MockResponse for `cookiejar` to read.
+
+ :param headers: a httplib.HTTPMessage or analogous carrying the headers
+ """
+ self._headers = headers
+
+ def info(self):
+ return self._headers
+
+ def getheaders(self, name):
+ self._headers.getheaders(name)
+
+
+def extract_cookies_to_jar(jar, request, response):
+ """Extract the cookies from the response into a CookieJar.
+
+ :param jar: http.cookiejar.CookieJar (not necessarily a RequestsCookieJar)
+ :param request: our own requests.Request object
+ :param response: urllib3.HTTPResponse object
+ """
+ if not (hasattr(response, "_original_response") and response._original_response):
+ return
+ # the _original_response field is the wrapped httplib.HTTPResponse object,
+ req = MockRequest(request)
+ # pull out the HTTPMessage with the headers and put it in the mock:
+ res = MockResponse(response._original_response.msg)
+ jar.extract_cookies(res, req)
+
+
+def get_cookie_header(jar, request):
+ """
+ Produce an appropriate Cookie header string to be sent with `request`, or None.
+
+ :rtype: str
+ """
+ r = MockRequest(request)
+ jar.add_cookie_header(r)
+ return r.get_new_headers().get("Cookie")
+
+
+def remove_cookie_by_name(cookiejar, name, domain=None, path=None):
+ """Unsets a cookie by name, by default over all domains and paths.
+
+ Wraps CookieJar.clear(), is O(n).
+ """
+ clearables = []
+ for cookie in cookiejar:
+ if cookie.name != name:
+ continue
+ if domain is not None and domain != cookie.domain:
+ continue
+ if path is not None and path != cookie.path:
+ continue
+ clearables.append((cookie.domain, cookie.path, cookie.name))
+
+ for domain, path, name in clearables:
+ cookiejar.clear(domain, path, name)
+
+
+class CookieConflictError(RuntimeError):
+ """There are two cookies that meet the criteria specified in the cookie jar.
+ Use .get and .set and include domain and path args in order to be more specific.
+ """
+
+
+class RequestsCookieJar(cookielib.CookieJar, MutableMapping):
+ """Compatibility class; is a http.cookiejar.CookieJar, but exposes a dict
+ interface.
+
+ This is the CookieJar we create by default for requests and sessions that
+ don't specify one, since some clients may expect response.cookies and
+ session.cookies to support dict operations.
+
+ Requests does not use the dict interface internally; it's just for
+ compatibility with external client code. All requests code should work
+ out of the box with externally provided instances of ``CookieJar``, e.g.
+ ``LWPCookieJar`` and ``FileCookieJar``.
+
+ Unlike a regular CookieJar, this class is pickleable.
+
+ .. warning:: dictionary operations that are normally O(1) may be O(n).
+ """
+
+ def get(self, name, default=None, domain=None, path=None):
+ """Dict-like get() that also supports optional domain and path args in
+ order to resolve naming collisions from using one cookie jar over
+ multiple domains.
+
+ .. warning:: operation is O(n), not O(1).
+ """
+ try:
+ return self._find_no_duplicates(name, domain, path)
+ except KeyError:
+ return default
+
+ def set(self, name, value, **kwargs):
+ """Dict-like set() that also supports optional domain and path args in
+ order to resolve naming collisions from using one cookie jar over
+ multiple domains.
+ """
+ # support client code that unsets cookies by assignment of a None value:
+ if value is None:
+ remove_cookie_by_name(
+ self, name, domain=kwargs.get("domain"), path=kwargs.get("path")
+ )
+ return
+
+ if isinstance(value, Morsel):
+ c = morsel_to_cookie(value)
+ else:
+ c = create_cookie(name, value, **kwargs)
+ self.set_cookie(c)
+ return c
+
+ def iterkeys(self):
+ """Dict-like iterkeys() that returns an iterator of names of cookies
+ from the jar.
+
+ .. seealso:: itervalues() and iteritems().
+ """
+ for cookie in iter(self):
+ yield cookie.name
+
+ def keys(self):
+ """Dict-like keys() that returns a list of names of cookies from the
+ jar.
+
+ .. seealso:: values() and items().
+ """
+ return list(self.iterkeys())
+
+ def itervalues(self):
+ """Dict-like itervalues() that returns an iterator of values of cookies
+ from the jar.
+
+ .. seealso:: iterkeys() and iteritems().
+ """
+ for cookie in iter(self):
+ yield cookie.value
+
+ def values(self):
+ """Dict-like values() that returns a list of values of cookies from the
+ jar.
+
+ .. seealso:: keys() and items().
+ """
+ return list(self.itervalues())
+
+ def iteritems(self):
+ """Dict-like iteritems() that returns an iterator of name-value tuples
+ from the jar.
+
+ .. seealso:: iterkeys() and itervalues().
+ """
+ for cookie in iter(self):
+ yield cookie.name, cookie.value
+
+ def items(self):
+ """Dict-like items() that returns a list of name-value tuples from the
+ jar. Allows client-code to call ``dict(RequestsCookieJar)`` and get a
+ vanilla python dict of key value pairs.
+
+ .. seealso:: keys() and values().
+ """
+ return list(self.iteritems())
+
+ def list_domains(self):
+ """Utility method to list all the domains in the jar."""
+ domains = []
+ for cookie in iter(self):
+ if cookie.domain not in domains:
+ domains.append(cookie.domain)
+ return domains
+
+ def list_paths(self):
+ """Utility method to list all the paths in the jar."""
+ paths = []
+ for cookie in iter(self):
+ if cookie.path not in paths:
+ paths.append(cookie.path)
+ return paths
+
+ def multiple_domains(self):
+ """Returns True if there are multiple domains in the jar.
+ Returns False otherwise.
+
+ :rtype: bool
+ """
+ domains = []
+ for cookie in iter(self):
+ if cookie.domain is not None and cookie.domain in domains:
+ return True
+ domains.append(cookie.domain)
+ return False # there is only one domain in jar
+
+ def get_dict(self, domain=None, path=None):
+ """Takes as an argument an optional domain and path and returns a plain
+ old Python dict of name-value pairs of cookies that meet the
+ requirements.
+
+ :rtype: dict
+ """
+ dictionary = {}
+ for cookie in iter(self):
+ if (domain is None or cookie.domain == domain) and (
+ path is None or cookie.path == path
+ ):
+ dictionary[cookie.name] = cookie.value
+ return dictionary
+
+ def __contains__(self, name):
+ try:
+ return super().__contains__(name)
+ except CookieConflictError:
+ return True
+
+ def __getitem__(self, name):
+ """Dict-like __getitem__() for compatibility with client code. Throws
+ exception if there are more than one cookie with name. In that case,
+ use the more explicit get() method instead.
+
+ .. warning:: operation is O(n), not O(1).
+ """
+ return self._find_no_duplicates(name)
+
+ def __setitem__(self, name, value):
+ """Dict-like __setitem__ for compatibility with client code. Throws
+ exception if there is already a cookie of that name in the jar. In that
+ case, use the more explicit set() method instead.
+ """
+ self.set(name, value)
+
+ def __delitem__(self, name):
+ """Deletes a cookie given a name. Wraps ``http.cookiejar.CookieJar``'s
+ ``remove_cookie_by_name()``.
+ """
+ remove_cookie_by_name(self, name)
+
+ def set_cookie(self, cookie, *args, **kwargs):
+ if (
+ hasattr(cookie.value, "startswith")
+ and cookie.value.startswith('"')
+ and cookie.value.endswith('"')
+ ):
+ cookie.value = cookie.value.replace('\\"', "")
+ return super().set_cookie(cookie, *args, **kwargs)
+
+ def update(self, other):
+ """Updates this jar with cookies from another CookieJar or dict-like"""
+ if isinstance(other, cookielib.CookieJar):
+ for cookie in other:
+ self.set_cookie(copy.copy(cookie))
+ else:
+ super().update(other)
+
+ def _find(self, name, domain=None, path=None):
+ """Requests uses this method internally to get cookie values.
+
+ If there are conflicting cookies, _find arbitrarily chooses one.
+ See _find_no_duplicates if you want an exception thrown if there are
+ conflicting cookies.
+
+ :param name: a string containing name of cookie
+ :param domain: (optional) string containing domain of cookie
+ :param path: (optional) string containing path of cookie
+ :return: cookie.value
+ """
+ for cookie in iter(self):
+ if cookie.name == name:
+ if domain is None or cookie.domain == domain:
+ if path is None or cookie.path == path:
+ return cookie.value
+
+ raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
+
+ def _find_no_duplicates(self, name, domain=None, path=None):
+ """Both ``__get_item__`` and ``get`` call this function: it's never
+ used elsewhere in Requests.
+
+ :param name: a string containing name of cookie
+ :param domain: (optional) string containing domain of cookie
+ :param path: (optional) string containing path of cookie
+ :raises KeyError: if cookie is not found
+ :raises CookieConflictError: if there are multiple cookies
+ that match name and optionally domain and path
+ :return: cookie.value
+ """
+ toReturn = None
+ for cookie in iter(self):
+ if cookie.name == name:
+ if domain is None or cookie.domain == domain:
+ if path is None or cookie.path == path:
+ if toReturn is not None:
+ # if there are multiple cookies that meet passed in criteria
+ raise CookieConflictError(
+ f"There are multiple cookies with name, {name!r}"
+ )
+ # we will eventually return this as long as no cookie conflict
+ toReturn = cookie.value
+
+ if toReturn:
+ return toReturn
+ raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
+
+ def __getstate__(self):
+ """Unlike a normal CookieJar, this class is pickleable."""
+ state = self.__dict__.copy()
+ # remove the unpickleable RLock object
+ state.pop("_cookies_lock")
+ return state
+
+ def __setstate__(self, state):
+ """Unlike a normal CookieJar, this class is pickleable."""
+ self.__dict__.update(state)
+ if "_cookies_lock" not in self.__dict__:
+ self._cookies_lock = threading.RLock()
+
+ def copy(self):
+ """Return a copy of this RequestsCookieJar."""
+ new_cj = RequestsCookieJar()
+ new_cj.set_policy(self.get_policy())
+ new_cj.update(self)
+ return new_cj
+
+ def get_policy(self):
+ """Return the CookiePolicy instance used."""
+ return self._policy
+
+
+def _copy_cookie_jar(jar):
+ if jar is None:
+ return None
+
+ if hasattr(jar, "copy"):
+ # We're dealing with an instance of RequestsCookieJar
+ return jar.copy()
+ # We're dealing with a generic CookieJar instance
+ new_jar = copy.copy(jar)
+ new_jar.clear()
+ for cookie in jar:
+ new_jar.set_cookie(copy.copy(cookie))
+ return new_jar
+
+
+def create_cookie(name, value, **kwargs):
+ """Make a cookie from underspecified parameters.
+
+ By default, the pair of `name` and `value` will be set for the domain ''
+ and sent on every request (this is sometimes called a "supercookie").
+ """
+ result = {
+ "version": 0,
+ "name": name,
+ "value": value,
+ "port": None,
+ "domain": "",
+ "path": "/",
+ "secure": False,
+ "expires": None,
+ "discard": True,
+ "comment": None,
+ "comment_url": None,
+ "rest": {"HttpOnly": None},
+ "rfc2109": False,
+ }
+
+ badargs = set(kwargs) - set(result)
+ if badargs:
+ raise TypeError(
+ f"create_cookie() got unexpected keyword arguments: {list(badargs)}"
+ )
+
+ result.update(kwargs)
+ result["port_specified"] = bool(result["port"])
+ result["domain_specified"] = bool(result["domain"])
+ result["domain_initial_dot"] = result["domain"].startswith(".")
+ result["path_specified"] = bool(result["path"])
+
+ return cookielib.Cookie(**result)
+
+
+def morsel_to_cookie(morsel):
+ """Convert a Morsel object into a Cookie containing the one k/v pair."""
+
+ expires = None
+ if morsel["max-age"]:
+ try:
+ expires = int(time.time() + int(morsel["max-age"]))
+ except ValueError:
+ raise TypeError(f"max-age: {morsel['max-age']} must be integer")
+ elif morsel["expires"]:
+ time_template = "%a, %d-%b-%Y %H:%M:%S GMT"
+ expires = calendar.timegm(time.strptime(morsel["expires"], time_template))
+ return create_cookie(
+ comment=morsel["comment"],
+ comment_url=bool(morsel["comment"]),
+ discard=False,
+ domain=morsel["domain"],
+ expires=expires,
+ name=morsel.key,
+ path=morsel["path"],
+ port=None,
+ rest={"HttpOnly": morsel["httponly"]},
+ rfc2109=False,
+ secure=bool(morsel["secure"]),
+ value=morsel.value,
+ version=morsel["version"] or 0,
+ )
+
+
+def cookiejar_from_dict(cookie_dict, cookiejar=None, overwrite=True):
+ """Returns a CookieJar from a key/value dictionary.
+
+ :param cookie_dict: Dict of key/values to insert into CookieJar.
+ :param cookiejar: (optional) A cookiejar to add the cookies to.
+ :param overwrite: (optional) If False, will not replace cookies
+ already in the jar with new ones.
+ :rtype: CookieJar
+ """
+ if cookiejar is None:
+ cookiejar = RequestsCookieJar()
+
+ if cookie_dict is not None:
+ names_from_jar = [cookie.name for cookie in cookiejar]
+ for name in cookie_dict:
+ if overwrite or (name not in names_from_jar):
+ cookiejar.set_cookie(create_cookie(name, cookie_dict[name]))
+
+ return cookiejar
+
+
+def merge_cookies(cookiejar, cookies):
+ """Add cookies to cookiejar and returns a merged CookieJar.
+
+ :param cookiejar: CookieJar object to add the cookies to.
+ :param cookies: Dictionary or CookieJar object to be added.
+ :rtype: CookieJar
+ """
+ if not isinstance(cookiejar, cookielib.CookieJar):
+ raise ValueError("You can only merge into CookieJar")
+
+ if isinstance(cookies, dict):
+ cookiejar = cookiejar_from_dict(cookies, cookiejar=cookiejar, overwrite=False)
+ elif isinstance(cookies, cookielib.CookieJar):
+ try:
+ cookiejar.update(cookies)
+ except AttributeError:
+ for cookie_in_jar in cookies:
+ cookiejar.set_cookie(cookie_in_jar)
+
+ return cookiejar
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/exceptions.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/exceptions.py
new file mode 100644
index 000000000..7f3660f00
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/exceptions.py
@@ -0,0 +1,151 @@
+"""
+requests.exceptions
+~~~~~~~~~~~~~~~~~~~
+
+This module contains the set of Requests' exceptions.
+"""
+from pip._vendor.urllib3.exceptions import HTTPError as BaseHTTPError
+
+from .compat import JSONDecodeError as CompatJSONDecodeError
+
+
+class RequestException(IOError):
+ """There was an ambiguous exception that occurred while handling your
+ request.
+ """
+
+ def __init__(self, *args, **kwargs):
+ """Initialize RequestException with `request` and `response` objects."""
+ response = kwargs.pop("response", None)
+ self.response = response
+ self.request = kwargs.pop("request", None)
+ if response is not None and not self.request and hasattr(response, "request"):
+ self.request = self.response.request
+ super().__init__(*args, **kwargs)
+
+
+class InvalidJSONError(RequestException):
+ """A JSON error occurred."""
+
+
+class JSONDecodeError(InvalidJSONError, CompatJSONDecodeError):
+ """Couldn't decode the text into json"""
+
+ def __init__(self, *args, **kwargs):
+ """
+ Construct the JSONDecodeError instance first with all
+ args. Then use it's args to construct the IOError so that
+ the json specific args aren't used as IOError specific args
+ and the error message from JSONDecodeError is preserved.
+ """
+ CompatJSONDecodeError.__init__(self, *args)
+ InvalidJSONError.__init__(self, *self.args, **kwargs)
+
+ def __reduce__(self):
+ """
+ The __reduce__ method called when pickling the object must
+ be the one from the JSONDecodeError (be it json/simplejson)
+ as it expects all the arguments for instantiation, not just
+ one like the IOError, and the MRO would by default call the
+ __reduce__ method from the IOError due to the inheritance order.
+ """
+ return CompatJSONDecodeError.__reduce__(self)
+
+
+class HTTPError(RequestException):
+ """An HTTP error occurred."""
+
+
+class ConnectionError(RequestException):
+ """A Connection error occurred."""
+
+
+class ProxyError(ConnectionError):
+ """A proxy error occurred."""
+
+
+class SSLError(ConnectionError):
+ """An SSL error occurred."""
+
+
+class Timeout(RequestException):
+ """The request timed out.
+
+ Catching this error will catch both
+ :exc:`~requests.exceptions.ConnectTimeout` and
+ :exc:`~requests.exceptions.ReadTimeout` errors.
+ """
+
+
+class ConnectTimeout(ConnectionError, Timeout):
+ """The request timed out while trying to connect to the remote server.
+
+ Requests that produced this error are safe to retry.
+ """
+
+
+class ReadTimeout(Timeout):
+ """The server did not send any data in the allotted amount of time."""
+
+
+class URLRequired(RequestException):
+ """A valid URL is required to make a request."""
+
+
+class TooManyRedirects(RequestException):
+ """Too many redirects."""
+
+
+class MissingSchema(RequestException, ValueError):
+ """The URL scheme (e.g. http or https) is missing."""
+
+
+class InvalidSchema(RequestException, ValueError):
+ """The URL scheme provided is either invalid or unsupported."""
+
+
+class InvalidURL(RequestException, ValueError):
+ """The URL provided was somehow invalid."""
+
+
+class InvalidHeader(RequestException, ValueError):
+ """The header value provided was somehow invalid."""
+
+
+class InvalidProxyURL(InvalidURL):
+ """The proxy URL provided is invalid."""
+
+
+class ChunkedEncodingError(RequestException):
+ """The server declared chunked encoding but sent an invalid chunk."""
+
+
+class ContentDecodingError(RequestException, BaseHTTPError):
+ """Failed to decode response content."""
+
+
+class StreamConsumedError(RequestException, TypeError):
+ """The content for this response was already consumed."""
+
+
+class RetryError(RequestException):
+ """Custom retries logic failed"""
+
+
+class UnrewindableBodyError(RequestException):
+ """Requests encountered an error when trying to rewind a body."""
+
+
+# Warnings
+
+
+class RequestsWarning(Warning):
+ """Base warning for Requests."""
+
+
+class FileModeWarning(RequestsWarning, DeprecationWarning):
+ """A file was opened in text mode, but Requests determined its binary length."""
+
+
+class RequestsDependencyWarning(RequestsWarning):
+ """An imported dependency doesn't match the expected version range."""
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/help.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/help.py
new file mode 100644
index 000000000..ddbb6150d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/help.py
@@ -0,0 +1,127 @@
+"""Module containing bug report helper(s)."""
+
+import json
+import platform
+import ssl
+import sys
+
+from pip._vendor import idna
+from pip._vendor import urllib3
+
+from . import __version__ as requests_version
+
+charset_normalizer = None
+chardet = None
+
+try:
+ from pip._vendor.urllib3.contrib import pyopenssl
+except ImportError:
+ pyopenssl = None
+ OpenSSL = None
+ cryptography = None
+else:
+ import cryptography
+ import OpenSSL
+
+
+def _implementation():
+ """Return a dict with the Python implementation and version.
+
+ Provide both the name and the version of the Python implementation
+ currently running. For example, on CPython 3.10.3 it will return
+ {'name': 'CPython', 'version': '3.10.3'}.
+
+ This function works best on CPython and PyPy: in particular, it probably
+ doesn't work for Jython or IronPython. Future investigation should be done
+ to work out the correct shape of the code for those platforms.
+ """
+ implementation = platform.python_implementation()
+
+ if implementation == "CPython":
+ implementation_version = platform.python_version()
+ elif implementation == "PyPy":
+ implementation_version = "{}.{}.{}".format(
+ sys.pypy_version_info.major,
+ sys.pypy_version_info.minor,
+ sys.pypy_version_info.micro,
+ )
+ if sys.pypy_version_info.releaselevel != "final":
+ implementation_version = "".join(
+ [implementation_version, sys.pypy_version_info.releaselevel]
+ )
+ elif implementation == "Jython":
+ implementation_version = platform.python_version() # Complete Guess
+ elif implementation == "IronPython":
+ implementation_version = platform.python_version() # Complete Guess
+ else:
+ implementation_version = "Unknown"
+
+ return {"name": implementation, "version": implementation_version}
+
+
+def info():
+ """Generate information for a bug report."""
+ try:
+ platform_info = {
+ "system": platform.system(),
+ "release": platform.release(),
+ }
+ except OSError:
+ platform_info = {
+ "system": "Unknown",
+ "release": "Unknown",
+ }
+
+ implementation_info = _implementation()
+ urllib3_info = {"version": urllib3.__version__}
+ charset_normalizer_info = {"version": None}
+ chardet_info = {"version": None}
+ if charset_normalizer:
+ charset_normalizer_info = {"version": charset_normalizer.__version__}
+ if chardet:
+ chardet_info = {"version": chardet.__version__}
+
+ pyopenssl_info = {
+ "version": None,
+ "openssl_version": "",
+ }
+ if OpenSSL:
+ pyopenssl_info = {
+ "version": OpenSSL.__version__,
+ "openssl_version": f"{OpenSSL.SSL.OPENSSL_VERSION_NUMBER:x}",
+ }
+ cryptography_info = {
+ "version": getattr(cryptography, "__version__", ""),
+ }
+ idna_info = {
+ "version": getattr(idna, "__version__", ""),
+ }
+
+ system_ssl = ssl.OPENSSL_VERSION_NUMBER
+ system_ssl_info = {"version": f"{system_ssl:x}" if system_ssl is not None else ""}
+
+ return {
+ "platform": platform_info,
+ "implementation": implementation_info,
+ "system_ssl": system_ssl_info,
+ "using_pyopenssl": pyopenssl is not None,
+ "using_charset_normalizer": chardet is None,
+ "pyOpenSSL": pyopenssl_info,
+ "urllib3": urllib3_info,
+ "chardet": chardet_info,
+ "charset_normalizer": charset_normalizer_info,
+ "cryptography": cryptography_info,
+ "idna": idna_info,
+ "requests": {
+ "version": requests_version,
+ },
+ }
+
+
+def main():
+ """Pretty-print the bug information as JSON."""
+ print(json.dumps(info(), sort_keys=True, indent=2))
+
+
+if __name__ == "__main__":
+ main()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/hooks.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/hooks.py
new file mode 100644
index 000000000..d181ba2ec
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/hooks.py
@@ -0,0 +1,33 @@
+"""
+requests.hooks
+~~~~~~~~~~~~~~
+
+This module provides the capabilities for the Requests hooks system.
+
+Available hooks:
+
+``response``:
+ The response generated from a Request.
+"""
+HOOKS = ["response"]
+
+
+def default_hooks():
+ return {event: [] for event in HOOKS}
+
+
+# TODO: response is the only one
+
+
+def dispatch_hook(key, hooks, hook_data, **kwargs):
+ """Dispatches a hook dictionary on a given piece of data."""
+ hooks = hooks or {}
+ hooks = hooks.get(key)
+ if hooks:
+ if hasattr(hooks, "__call__"):
+ hooks = [hooks]
+ for hook in hooks:
+ _hook_data = hook(hook_data, **kwargs)
+ if _hook_data is not None:
+ hook_data = _hook_data
+ return hook_data
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/models.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/models.py
new file mode 100644
index 000000000..85a008cfb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/models.py
@@ -0,0 +1,1037 @@
+"""
+requests.models
+~~~~~~~~~~~~~~~
+
+This module contains the primary objects that power Requests.
+"""
+
+import datetime
+
+# Import encoding now, to avoid implicit import later.
+# Implicit import within threads may cause LookupError when standard library is in a ZIP,
+# such as in Embedded Python. See https://github.com/psf/requests/issues/3578.
+import encodings.idna # noqa: F401
+from io import UnsupportedOperation
+
+from pip._vendor.urllib3.exceptions import (
+ DecodeError,
+ LocationParseError,
+ ProtocolError,
+ ReadTimeoutError,
+ SSLError,
+)
+from pip._vendor.urllib3.fields import RequestField
+from pip._vendor.urllib3.filepost import encode_multipart_formdata
+from pip._vendor.urllib3.util import parse_url
+
+from ._internal_utils import to_native_string, unicode_is_ascii
+from .auth import HTTPBasicAuth
+from .compat import (
+ Callable,
+ JSONDecodeError,
+ Mapping,
+ basestring,
+ builtin_str,
+ chardet,
+ cookielib,
+)
+from .compat import json as complexjson
+from .compat import urlencode, urlsplit, urlunparse
+from .cookies import _copy_cookie_jar, cookiejar_from_dict, get_cookie_header
+from .exceptions import (
+ ChunkedEncodingError,
+ ConnectionError,
+ ContentDecodingError,
+ HTTPError,
+ InvalidJSONError,
+ InvalidURL,
+)
+from .exceptions import JSONDecodeError as RequestsJSONDecodeError
+from .exceptions import MissingSchema
+from .exceptions import SSLError as RequestsSSLError
+from .exceptions import StreamConsumedError
+from .hooks import default_hooks
+from .status_codes import codes
+from .structures import CaseInsensitiveDict
+from .utils import (
+ check_header_validity,
+ get_auth_from_url,
+ guess_filename,
+ guess_json_utf,
+ iter_slices,
+ parse_header_links,
+ requote_uri,
+ stream_decode_response_unicode,
+ super_len,
+ to_key_val_list,
+)
+
+#: The set of HTTP status codes that indicate an automatically
+#: processable redirect.
+REDIRECT_STATI = (
+ codes.moved, # 301
+ codes.found, # 302
+ codes.other, # 303
+ codes.temporary_redirect, # 307
+ codes.permanent_redirect, # 308
+)
+
+DEFAULT_REDIRECT_LIMIT = 30
+CONTENT_CHUNK_SIZE = 10 * 1024
+ITER_CHUNK_SIZE = 512
+
+
+class RequestEncodingMixin:
+ @property
+ def path_url(self):
+ """Build the path URL to use."""
+
+ url = []
+
+ p = urlsplit(self.url)
+
+ path = p.path
+ if not path:
+ path = "/"
+
+ url.append(path)
+
+ query = p.query
+ if query:
+ url.append("?")
+ url.append(query)
+
+ return "".join(url)
+
+ @staticmethod
+ def _encode_params(data):
+ """Encode parameters in a piece of data.
+
+ Will successfully encode parameters when passed as a dict or a list of
+ 2-tuples. Order is retained if data is a list of 2-tuples but arbitrary
+ if parameters are supplied as a dict.
+ """
+
+ if isinstance(data, (str, bytes)):
+ return data
+ elif hasattr(data, "read"):
+ return data
+ elif hasattr(data, "__iter__"):
+ result = []
+ for k, vs in to_key_val_list(data):
+ if isinstance(vs, basestring) or not hasattr(vs, "__iter__"):
+ vs = [vs]
+ for v in vs:
+ if v is not None:
+ result.append(
+ (
+ k.encode("utf-8") if isinstance(k, str) else k,
+ v.encode("utf-8") if isinstance(v, str) else v,
+ )
+ )
+ return urlencode(result, doseq=True)
+ else:
+ return data
+
+ @staticmethod
+ def _encode_files(files, data):
+ """Build the body for a multipart/form-data request.
+
+ Will successfully encode files when passed as a dict or a list of
+ tuples. Order is retained if data is a list of tuples but arbitrary
+ if parameters are supplied as a dict.
+ The tuples may be 2-tuples (filename, fileobj), 3-tuples (filename, fileobj, contentype)
+ or 4-tuples (filename, fileobj, contentype, custom_headers).
+ """
+ if not files:
+ raise ValueError("Files must be provided.")
+ elif isinstance(data, basestring):
+ raise ValueError("Data must not be a string.")
+
+ new_fields = []
+ fields = to_key_val_list(data or {})
+ files = to_key_val_list(files or {})
+
+ for field, val in fields:
+ if isinstance(val, basestring) or not hasattr(val, "__iter__"):
+ val = [val]
+ for v in val:
+ if v is not None:
+ # Don't call str() on bytestrings: in Py3 it all goes wrong.
+ if not isinstance(v, bytes):
+ v = str(v)
+
+ new_fields.append(
+ (
+ field.decode("utf-8")
+ if isinstance(field, bytes)
+ else field,
+ v.encode("utf-8") if isinstance(v, str) else v,
+ )
+ )
+
+ for k, v in files:
+ # support for explicit filename
+ ft = None
+ fh = None
+ if isinstance(v, (tuple, list)):
+ if len(v) == 2:
+ fn, fp = v
+ elif len(v) == 3:
+ fn, fp, ft = v
+ else:
+ fn, fp, ft, fh = v
+ else:
+ fn = guess_filename(v) or k
+ fp = v
+
+ if isinstance(fp, (str, bytes, bytearray)):
+ fdata = fp
+ elif hasattr(fp, "read"):
+ fdata = fp.read()
+ elif fp is None:
+ continue
+ else:
+ fdata = fp
+
+ rf = RequestField(name=k, data=fdata, filename=fn, headers=fh)
+ rf.make_multipart(content_type=ft)
+ new_fields.append(rf)
+
+ body, content_type = encode_multipart_formdata(new_fields)
+
+ return body, content_type
+
+
+class RequestHooksMixin:
+ def register_hook(self, event, hook):
+ """Properly register a hook."""
+
+ if event not in self.hooks:
+ raise ValueError(f'Unsupported event specified, with event name "{event}"')
+
+ if isinstance(hook, Callable):
+ self.hooks[event].append(hook)
+ elif hasattr(hook, "__iter__"):
+ self.hooks[event].extend(h for h in hook if isinstance(h, Callable))
+
+ def deregister_hook(self, event, hook):
+ """Deregister a previously registered hook.
+ Returns True if the hook existed, False if not.
+ """
+
+ try:
+ self.hooks[event].remove(hook)
+ return True
+ except ValueError:
+ return False
+
+
+class Request(RequestHooksMixin):
+ """A user-created :class:`Request <Request>` object.
+
+ Used to prepare a :class:`PreparedRequest <PreparedRequest>`, which is sent to the server.
+
+ :param method: HTTP method to use.
+ :param url: URL to send.
+ :param headers: dictionary of headers to send.
+ :param files: dictionary of {filename: fileobject} files to multipart upload.
+ :param data: the body to attach to the request. If a dictionary or
+ list of tuples ``[(key, value)]`` is provided, form-encoding will
+ take place.
+ :param json: json for the body to attach to the request (if files or data is not specified).
+ :param params: URL parameters to append to the URL. If a dictionary or
+ list of tuples ``[(key, value)]`` is provided, form-encoding will
+ take place.
+ :param auth: Auth handler or (user, pass) tuple.
+ :param cookies: dictionary or CookieJar of cookies to attach to this request.
+ :param hooks: dictionary of callback hooks, for internal usage.
+
+ Usage::
+
+ >>> import requests
+ >>> req = requests.Request('GET', 'https://httpbin.org/get')
+ >>> req.prepare()
+ <PreparedRequest [GET]>
+ """
+
+ def __init__(
+ self,
+ method=None,
+ url=None,
+ headers=None,
+ files=None,
+ data=None,
+ params=None,
+ auth=None,
+ cookies=None,
+ hooks=None,
+ json=None,
+ ):
+ # Default empty dicts for dict params.
+ data = [] if data is None else data
+ files = [] if files is None else files
+ headers = {} if headers is None else headers
+ params = {} if params is None else params
+ hooks = {} if hooks is None else hooks
+
+ self.hooks = default_hooks()
+ for k, v in list(hooks.items()):
+ self.register_hook(event=k, hook=v)
+
+ self.method = method
+ self.url = url
+ self.headers = headers
+ self.files = files
+ self.data = data
+ self.json = json
+ self.params = params
+ self.auth = auth
+ self.cookies = cookies
+
+ def __repr__(self):
+ return f"<Request [{self.method}]>"
+
+ def prepare(self):
+ """Constructs a :class:`PreparedRequest <PreparedRequest>` for transmission and returns it."""
+ p = PreparedRequest()
+ p.prepare(
+ method=self.method,
+ url=self.url,
+ headers=self.headers,
+ files=self.files,
+ data=self.data,
+ json=self.json,
+ params=self.params,
+ auth=self.auth,
+ cookies=self.cookies,
+ hooks=self.hooks,
+ )
+ return p
+
+
+class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
+ """The fully mutable :class:`PreparedRequest <PreparedRequest>` object,
+ containing the exact bytes that will be sent to the server.
+
+ Instances are generated from a :class:`Request <Request>` object, and
+ should not be instantiated manually; doing so may produce undesirable
+ effects.
+
+ Usage::
+
+ >>> import requests
+ >>> req = requests.Request('GET', 'https://httpbin.org/get')
+ >>> r = req.prepare()
+ >>> r
+ <PreparedRequest [GET]>
+
+ >>> s = requests.Session()
+ >>> s.send(r)
+ <Response [200]>
+ """
+
+ def __init__(self):
+ #: HTTP verb to send to the server.
+ self.method = None
+ #: HTTP URL to send the request to.
+ self.url = None
+ #: dictionary of HTTP headers.
+ self.headers = None
+ # The `CookieJar` used to create the Cookie header will be stored here
+ # after prepare_cookies is called
+ self._cookies = None
+ #: request body to send to the server.
+ self.body = None
+ #: dictionary of callback hooks, for internal usage.
+ self.hooks = default_hooks()
+ #: integer denoting starting position of a readable file-like body.
+ self._body_position = None
+
+ def prepare(
+ self,
+ method=None,
+ url=None,
+ headers=None,
+ files=None,
+ data=None,
+ params=None,
+ auth=None,
+ cookies=None,
+ hooks=None,
+ json=None,
+ ):
+ """Prepares the entire request with the given parameters."""
+
+ self.prepare_method(method)
+ self.prepare_url(url, params)
+ self.prepare_headers(headers)
+ self.prepare_cookies(cookies)
+ self.prepare_body(data, files, json)
+ self.prepare_auth(auth, url)
+
+ # Note that prepare_auth must be last to enable authentication schemes
+ # such as OAuth to work on a fully prepared request.
+
+ # This MUST go after prepare_auth. Authenticators could add a hook
+ self.prepare_hooks(hooks)
+
+ def __repr__(self):
+ return f"<PreparedRequest [{self.method}]>"
+
+ def copy(self):
+ p = PreparedRequest()
+ p.method = self.method
+ p.url = self.url
+ p.headers = self.headers.copy() if self.headers is not None else None
+ p._cookies = _copy_cookie_jar(self._cookies)
+ p.body = self.body
+ p.hooks = self.hooks
+ p._body_position = self._body_position
+ return p
+
+ def prepare_method(self, method):
+ """Prepares the given HTTP method."""
+ self.method = method
+ if self.method is not None:
+ self.method = to_native_string(self.method.upper())
+
+ @staticmethod
+ def _get_idna_encoded_host(host):
+ from pip._vendor import idna
+
+ try:
+ host = idna.encode(host, uts46=True).decode("utf-8")
+ except idna.IDNAError:
+ raise UnicodeError
+ return host
+
+ def prepare_url(self, url, params):
+ """Prepares the given HTTP URL."""
+ #: Accept objects that have string representations.
+ #: We're unable to blindly call unicode/str functions
+ #: as this will include the bytestring indicator (b'')
+ #: on python 3.x.
+ #: https://github.com/psf/requests/pull/2238
+ if isinstance(url, bytes):
+ url = url.decode("utf8")
+ else:
+ url = str(url)
+
+ # Remove leading whitespaces from url
+ url = url.lstrip()
+
+ # Don't do any URL preparation for non-HTTP schemes like `mailto`,
+ # `data` etc to work around exceptions from `url_parse`, which
+ # handles RFC 3986 only.
+ if ":" in url and not url.lower().startswith("http"):
+ self.url = url
+ return
+
+ # Support for unicode domain names and paths.
+ try:
+ scheme, auth, host, port, path, query, fragment = parse_url(url)
+ except LocationParseError as e:
+ raise InvalidURL(*e.args)
+
+ if not scheme:
+ raise MissingSchema(
+ f"Invalid URL {url!r}: No scheme supplied. "
+ f"Perhaps you meant https://{url}?"
+ )
+
+ if not host:
+ raise InvalidURL(f"Invalid URL {url!r}: No host supplied")
+
+ # In general, we want to try IDNA encoding the hostname if the string contains
+ # non-ASCII characters. This allows users to automatically get the correct IDNA
+ # behaviour. For strings containing only ASCII characters, we need to also verify
+ # it doesn't start with a wildcard (*), before allowing the unencoded hostname.
+ if not unicode_is_ascii(host):
+ try:
+ host = self._get_idna_encoded_host(host)
+ except UnicodeError:
+ raise InvalidURL("URL has an invalid label.")
+ elif host.startswith(("*", ".")):
+ raise InvalidURL("URL has an invalid label.")
+
+ # Carefully reconstruct the network location
+ netloc = auth or ""
+ if netloc:
+ netloc += "@"
+ netloc += host
+ if port:
+ netloc += f":{port}"
+
+ # Bare domains aren't valid URLs.
+ if not path:
+ path = "/"
+
+ if isinstance(params, (str, bytes)):
+ params = to_native_string(params)
+
+ enc_params = self._encode_params(params)
+ if enc_params:
+ if query:
+ query = f"{query}&{enc_params}"
+ else:
+ query = enc_params
+
+ url = requote_uri(urlunparse([scheme, netloc, path, None, query, fragment]))
+ self.url = url
+
+ def prepare_headers(self, headers):
+ """Prepares the given HTTP headers."""
+
+ self.headers = CaseInsensitiveDict()
+ if headers:
+ for header in headers.items():
+ # Raise exception on invalid header value.
+ check_header_validity(header)
+ name, value = header
+ self.headers[to_native_string(name)] = value
+
+ def prepare_body(self, data, files, json=None):
+ """Prepares the given HTTP body data."""
+
+ # Check if file, fo, generator, iterator.
+ # If not, run through normal process.
+
+ # Nottin' on you.
+ body = None
+ content_type = None
+
+ if not data and json is not None:
+ # urllib3 requires a bytes-like body. Python 2's json.dumps
+ # provides this natively, but Python 3 gives a Unicode string.
+ content_type = "application/json"
+
+ try:
+ body = complexjson.dumps(json, allow_nan=False)
+ except ValueError as ve:
+ raise InvalidJSONError(ve, request=self)
+
+ if not isinstance(body, bytes):
+ body = body.encode("utf-8")
+
+ is_stream = all(
+ [
+ hasattr(data, "__iter__"),
+ not isinstance(data, (basestring, list, tuple, Mapping)),
+ ]
+ )
+
+ if is_stream:
+ try:
+ length = super_len(data)
+ except (TypeError, AttributeError, UnsupportedOperation):
+ length = None
+
+ body = data
+
+ if getattr(body, "tell", None) is not None:
+ # Record the current file position before reading.
+ # This will allow us to rewind a file in the event
+ # of a redirect.
+ try:
+ self._body_position = body.tell()
+ except OSError:
+ # This differentiates from None, allowing us to catch
+ # a failed `tell()` later when trying to rewind the body
+ self._body_position = object()
+
+ if files:
+ raise NotImplementedError(
+ "Streamed bodies and files are mutually exclusive."
+ )
+
+ if length:
+ self.headers["Content-Length"] = builtin_str(length)
+ else:
+ self.headers["Transfer-Encoding"] = "chunked"
+ else:
+ # Multi-part file uploads.
+ if files:
+ (body, content_type) = self._encode_files(files, data)
+ else:
+ if data:
+ body = self._encode_params(data)
+ if isinstance(data, basestring) or hasattr(data, "read"):
+ content_type = None
+ else:
+ content_type = "application/x-www-form-urlencoded"
+
+ self.prepare_content_length(body)
+
+ # Add content-type if it wasn't explicitly provided.
+ if content_type and ("content-type" not in self.headers):
+ self.headers["Content-Type"] = content_type
+
+ self.body = body
+
+ def prepare_content_length(self, body):
+ """Prepare Content-Length header based on request method and body"""
+ if body is not None:
+ length = super_len(body)
+ if length:
+ # If length exists, set it. Otherwise, we fallback
+ # to Transfer-Encoding: chunked.
+ self.headers["Content-Length"] = builtin_str(length)
+ elif (
+ self.method not in ("GET", "HEAD")
+ and self.headers.get("Content-Length") is None
+ ):
+ # Set Content-Length to 0 for methods that can have a body
+ # but don't provide one. (i.e. not GET or HEAD)
+ self.headers["Content-Length"] = "0"
+
+ def prepare_auth(self, auth, url=""):
+ """Prepares the given HTTP auth data."""
+
+ # If no Auth is explicitly provided, extract it from the URL first.
+ if auth is None:
+ url_auth = get_auth_from_url(self.url)
+ auth = url_auth if any(url_auth) else None
+
+ if auth:
+ if isinstance(auth, tuple) and len(auth) == 2:
+ # special-case basic HTTP auth
+ auth = HTTPBasicAuth(*auth)
+
+ # Allow auth to make its changes.
+ r = auth(self)
+
+ # Update self to reflect the auth changes.
+ self.__dict__.update(r.__dict__)
+
+ # Recompute Content-Length
+ self.prepare_content_length(self.body)
+
+ def prepare_cookies(self, cookies):
+ """Prepares the given HTTP cookie data.
+
+ This function eventually generates a ``Cookie`` header from the
+ given cookies using cookielib. Due to cookielib's design, the header
+ will not be regenerated if it already exists, meaning this function
+ can only be called once for the life of the
+ :class:`PreparedRequest <PreparedRequest>` object. Any subsequent calls
+ to ``prepare_cookies`` will have no actual effect, unless the "Cookie"
+ header is removed beforehand.
+ """
+ if isinstance(cookies, cookielib.CookieJar):
+ self._cookies = cookies
+ else:
+ self._cookies = cookiejar_from_dict(cookies)
+
+ cookie_header = get_cookie_header(self._cookies, self)
+ if cookie_header is not None:
+ self.headers["Cookie"] = cookie_header
+
+ def prepare_hooks(self, hooks):
+ """Prepares the given hooks."""
+ # hooks can be passed as None to the prepare method and to this
+ # method. To prevent iterating over None, simply use an empty list
+ # if hooks is False-y
+ hooks = hooks or []
+ for event in hooks:
+ self.register_hook(event, hooks[event])
+
+
+class Response:
+ """The :class:`Response <Response>` object, which contains a
+ server's response to an HTTP request.
+ """
+
+ __attrs__ = [
+ "_content",
+ "status_code",
+ "headers",
+ "url",
+ "history",
+ "encoding",
+ "reason",
+ "cookies",
+ "elapsed",
+ "request",
+ ]
+
+ def __init__(self):
+ self._content = False
+ self._content_consumed = False
+ self._next = None
+
+ #: Integer Code of responded HTTP Status, e.g. 404 or 200.
+ self.status_code = None
+
+ #: Case-insensitive Dictionary of Response Headers.
+ #: For example, ``headers['content-encoding']`` will return the
+ #: value of a ``'Content-Encoding'`` response header.
+ self.headers = CaseInsensitiveDict()
+
+ #: File-like object representation of response (for advanced usage).
+ #: Use of ``raw`` requires that ``stream=True`` be set on the request.
+ #: This requirement does not apply for use internally to Requests.
+ self.raw = None
+
+ #: Final URL location of Response.
+ self.url = None
+
+ #: Encoding to decode with when accessing r.text.
+ self.encoding = None
+
+ #: A list of :class:`Response <Response>` objects from
+ #: the history of the Request. Any redirect responses will end
+ #: up here. The list is sorted from the oldest to the most recent request.
+ self.history = []
+
+ #: Textual reason of responded HTTP Status, e.g. "Not Found" or "OK".
+ self.reason = None
+
+ #: A CookieJar of Cookies the server sent back.
+ self.cookies = cookiejar_from_dict({})
+
+ #: The amount of time elapsed between sending the request
+ #: and the arrival of the response (as a timedelta).
+ #: This property specifically measures the time taken between sending
+ #: the first byte of the request and finishing parsing the headers. It
+ #: is therefore unaffected by consuming the response content or the
+ #: value of the ``stream`` keyword argument.
+ self.elapsed = datetime.timedelta(0)
+
+ #: The :class:`PreparedRequest <PreparedRequest>` object to which this
+ #: is a response.
+ self.request = None
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, *args):
+ self.close()
+
+ def __getstate__(self):
+ # Consume everything; accessing the content attribute makes
+ # sure the content has been fully read.
+ if not self._content_consumed:
+ self.content
+
+ return {attr: getattr(self, attr, None) for attr in self.__attrs__}
+
+ def __setstate__(self, state):
+ for name, value in state.items():
+ setattr(self, name, value)
+
+ # pickled objects do not have .raw
+ setattr(self, "_content_consumed", True)
+ setattr(self, "raw", None)
+
+ def __repr__(self):
+ return f"<Response [{self.status_code}]>"
+
+ def __bool__(self):
+ """Returns True if :attr:`status_code` is less than 400.
+
+ This attribute checks if the status code of the response is between
+ 400 and 600 to see if there was a client error or a server error. If
+ the status code, is between 200 and 400, this will return True. This
+ is **not** a check to see if the response code is ``200 OK``.
+ """
+ return self.ok
+
+ def __nonzero__(self):
+ """Returns True if :attr:`status_code` is less than 400.
+
+ This attribute checks if the status code of the response is between
+ 400 and 600 to see if there was a client error or a server error. If
+ the status code, is between 200 and 400, this will return True. This
+ is **not** a check to see if the response code is ``200 OK``.
+ """
+ return self.ok
+
+ def __iter__(self):
+ """Allows you to use a response as an iterator."""
+ return self.iter_content(128)
+
+ @property
+ def ok(self):
+ """Returns True if :attr:`status_code` is less than 400, False if not.
+
+ This attribute checks if the status code of the response is between
+ 400 and 600 to see if there was a client error or a server error. If
+ the status code is between 200 and 400, this will return True. This
+ is **not** a check to see if the response code is ``200 OK``.
+ """
+ try:
+ self.raise_for_status()
+ except HTTPError:
+ return False
+ return True
+
+ @property
+ def is_redirect(self):
+ """True if this Response is a well-formed HTTP redirect that could have
+ been processed automatically (by :meth:`Session.resolve_redirects`).
+ """
+ return "location" in self.headers and self.status_code in REDIRECT_STATI
+
+ @property
+ def is_permanent_redirect(self):
+ """True if this Response one of the permanent versions of redirect."""
+ return "location" in self.headers and self.status_code in (
+ codes.moved_permanently,
+ codes.permanent_redirect,
+ )
+
+ @property
+ def next(self):
+ """Returns a PreparedRequest for the next request in a redirect chain, if there is one."""
+ return self._next
+
+ @property
+ def apparent_encoding(self):
+ """The apparent encoding, provided by the charset_normalizer or chardet libraries."""
+ if chardet is not None:
+ return chardet.detect(self.content)["encoding"]
+ else:
+ # If no character detection library is available, we'll fall back
+ # to a standard Python utf-8 str.
+ return "utf-8"
+
+ def iter_content(self, chunk_size=1, decode_unicode=False):
+ """Iterates over the response data. When stream=True is set on the
+ request, this avoids reading the content at once into memory for
+ large responses. The chunk size is the number of bytes it should
+ read into memory. This is not necessarily the length of each item
+ returned as decoding can take place.
+
+ chunk_size must be of type int or None. A value of None will
+ function differently depending on the value of `stream`.
+ stream=True will read data as it arrives in whatever size the
+ chunks are received. If stream=False, data is returned as
+ a single chunk.
+
+ If decode_unicode is True, content will be decoded using the best
+ available encoding based on the response.
+ """
+
+ def generate():
+ # Special case for urllib3.
+ if hasattr(self.raw, "stream"):
+ try:
+ yield from self.raw.stream(chunk_size, decode_content=True)
+ except ProtocolError as e:
+ raise ChunkedEncodingError(e)
+ except DecodeError as e:
+ raise ContentDecodingError(e)
+ except ReadTimeoutError as e:
+ raise ConnectionError(e)
+ except SSLError as e:
+ raise RequestsSSLError(e)
+ else:
+ # Standard file-like object.
+ while True:
+ chunk = self.raw.read(chunk_size)
+ if not chunk:
+ break
+ yield chunk
+
+ self._content_consumed = True
+
+ if self._content_consumed and isinstance(self._content, bool):
+ raise StreamConsumedError()
+ elif chunk_size is not None and not isinstance(chunk_size, int):
+ raise TypeError(
+ f"chunk_size must be an int, it is instead a {type(chunk_size)}."
+ )
+ # simulate reading small chunks of the content
+ reused_chunks = iter_slices(self._content, chunk_size)
+
+ stream_chunks = generate()
+
+ chunks = reused_chunks if self._content_consumed else stream_chunks
+
+ if decode_unicode:
+ chunks = stream_decode_response_unicode(chunks, self)
+
+ return chunks
+
+ def iter_lines(
+ self, chunk_size=ITER_CHUNK_SIZE, decode_unicode=False, delimiter=None
+ ):
+ """Iterates over the response data, one line at a time. When
+ stream=True is set on the request, this avoids reading the
+ content at once into memory for large responses.
+
+ .. note:: This method is not reentrant safe.
+ """
+
+ pending = None
+
+ for chunk in self.iter_content(
+ chunk_size=chunk_size, decode_unicode=decode_unicode
+ ):
+ if pending is not None:
+ chunk = pending + chunk
+
+ if delimiter:
+ lines = chunk.split(delimiter)
+ else:
+ lines = chunk.splitlines()
+
+ if lines and lines[-1] and chunk and lines[-1][-1] == chunk[-1]:
+ pending = lines.pop()
+ else:
+ pending = None
+
+ yield from lines
+
+ if pending is not None:
+ yield pending
+
+ @property
+ def content(self):
+ """Content of the response, in bytes."""
+
+ if self._content is False:
+ # Read the contents.
+ if self._content_consumed:
+ raise RuntimeError("The content for this response was already consumed")
+
+ if self.status_code == 0 or self.raw is None:
+ self._content = None
+ else:
+ self._content = b"".join(self.iter_content(CONTENT_CHUNK_SIZE)) or b""
+
+ self._content_consumed = True
+ # don't need to release the connection; that's been handled by urllib3
+ # since we exhausted the data.
+ return self._content
+
+ @property
+ def text(self):
+ """Content of the response, in unicode.
+
+ If Response.encoding is None, encoding will be guessed using
+ ``charset_normalizer`` or ``chardet``.
+
+ The encoding of the response content is determined based solely on HTTP
+ headers, following RFC 2616 to the letter. If you can take advantage of
+ non-HTTP knowledge to make a better guess at the encoding, you should
+ set ``r.encoding`` appropriately before accessing this property.
+ """
+
+ # Try charset from content-type
+ content = None
+ encoding = self.encoding
+
+ if not self.content:
+ return ""
+
+ # Fallback to auto-detected encoding.
+ if self.encoding is None:
+ encoding = self.apparent_encoding
+
+ # Decode unicode from given encoding.
+ try:
+ content = str(self.content, encoding, errors="replace")
+ except (LookupError, TypeError):
+ # A LookupError is raised if the encoding was not found which could
+ # indicate a misspelling or similar mistake.
+ #
+ # A TypeError can be raised if encoding is None
+ #
+ # So we try blindly encoding.
+ content = str(self.content, errors="replace")
+
+ return content
+
+ def json(self, **kwargs):
+ r"""Returns the json-encoded content of a response, if any.
+
+ :param \*\*kwargs: Optional arguments that ``json.loads`` takes.
+ :raises requests.exceptions.JSONDecodeError: If the response body does not
+ contain valid json.
+ """
+
+ if not self.encoding and self.content and len(self.content) > 3:
+ # No encoding set. JSON RFC 4627 section 3 states we should expect
+ # UTF-8, -16 or -32. Detect which one to use; If the detection or
+ # decoding fails, fall back to `self.text` (using charset_normalizer to make
+ # a best guess).
+ encoding = guess_json_utf(self.content)
+ if encoding is not None:
+ try:
+ return complexjson.loads(self.content.decode(encoding), **kwargs)
+ except UnicodeDecodeError:
+ # Wrong UTF codec detected; usually because it's not UTF-8
+ # but some other 8-bit codec. This is an RFC violation,
+ # and the server didn't bother to tell us what codec *was*
+ # used.
+ pass
+ except JSONDecodeError as e:
+ raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
+
+ try:
+ return complexjson.loads(self.text, **kwargs)
+ except JSONDecodeError as e:
+ # Catch JSON-related errors and raise as requests.JSONDecodeError
+ # This aliases json.JSONDecodeError and simplejson.JSONDecodeError
+ raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
+
+ @property
+ def links(self):
+ """Returns the parsed header links of the response, if any."""
+
+ header = self.headers.get("link")
+
+ resolved_links = {}
+
+ if header:
+ links = parse_header_links(header)
+
+ for link in links:
+ key = link.get("rel") or link.get("url")
+ resolved_links[key] = link
+
+ return resolved_links
+
+ def raise_for_status(self):
+ """Raises :class:`HTTPError`, if one occurred."""
+
+ http_error_msg = ""
+ if isinstance(self.reason, bytes):
+ # We attempt to decode utf-8 first because some servers
+ # choose to localize their reason strings. If the string
+ # isn't utf-8, we fall back to iso-8859-1 for all other
+ # encodings. (See PR #3538)
+ try:
+ reason = self.reason.decode("utf-8")
+ except UnicodeDecodeError:
+ reason = self.reason.decode("iso-8859-1")
+ else:
+ reason = self.reason
+
+ if 400 <= self.status_code < 500:
+ http_error_msg = (
+ f"{self.status_code} Client Error: {reason} for url: {self.url}"
+ )
+
+ elif 500 <= self.status_code < 600:
+ http_error_msg = (
+ f"{self.status_code} Server Error: {reason} for url: {self.url}"
+ )
+
+ if http_error_msg:
+ raise HTTPError(http_error_msg, response=self)
+
+ def close(self):
+ """Releases the connection back to the pool. Once this method has been
+ called the underlying ``raw`` object must not be accessed again.
+
+ *Note: Should not normally need to be called explicitly.*
+ """
+ if not self._content_consumed:
+ self.raw.close()
+
+ release_conn = getattr(self.raw, "release_conn", None)
+ if release_conn is not None:
+ release_conn()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/packages.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/packages.py
new file mode 100644
index 000000000..200c38287
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/packages.py
@@ -0,0 +1,25 @@
+import sys
+
+from .compat import chardet
+
+# This code exists for backwards compatibility reasons.
+# I don't like it either. Just look the other way. :)
+
+for package in ("urllib3", "idna"):
+ vendored_package = "pip._vendor." + package
+ locals()[package] = __import__(vendored_package)
+ # This traversal is apparently necessary such that the identities are
+ # preserved (requests.packages.urllib3.* is urllib3.*)
+ for mod in list(sys.modules):
+ if mod == vendored_package or mod.startswith(vendored_package + '.'):
+ unprefixed_mod = mod[len("pip._vendor."):]
+ sys.modules['pip._vendor.requests.packages.' + unprefixed_mod] = sys.modules[mod]
+
+if chardet is not None:
+ target = chardet.__name__
+ for mod in list(sys.modules):
+ if mod == target or mod.startswith(f"{target}."):
+ imported_mod = sys.modules[mod]
+ sys.modules[f"requests.packages.{mod}"] = imported_mod
+ mod = mod.replace(target, "chardet")
+ sys.modules[f"requests.packages.{mod}"] = imported_mod
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/sessions.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/sessions.py
new file mode 100644
index 000000000..b387bc36d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/sessions.py
@@ -0,0 +1,831 @@
+"""
+requests.sessions
+~~~~~~~~~~~~~~~~~
+
+This module provides a Session object to manage and persist settings across
+requests (cookies, auth, proxies).
+"""
+import os
+import sys
+import time
+from collections import OrderedDict
+from datetime import timedelta
+
+from ._internal_utils import to_native_string
+from .adapters import HTTPAdapter
+from .auth import _basic_auth_str
+from .compat import Mapping, cookielib, urljoin, urlparse
+from .cookies import (
+ RequestsCookieJar,
+ cookiejar_from_dict,
+ extract_cookies_to_jar,
+ merge_cookies,
+)
+from .exceptions import (
+ ChunkedEncodingError,
+ ContentDecodingError,
+ InvalidSchema,
+ TooManyRedirects,
+)
+from .hooks import default_hooks, dispatch_hook
+
+# formerly defined here, reexposed here for backward compatibility
+from .models import ( # noqa: F401
+ DEFAULT_REDIRECT_LIMIT,
+ REDIRECT_STATI,
+ PreparedRequest,
+ Request,
+)
+from .status_codes import codes
+from .structures import CaseInsensitiveDict
+from .utils import ( # noqa: F401
+ DEFAULT_PORTS,
+ default_headers,
+ get_auth_from_url,
+ get_environ_proxies,
+ get_netrc_auth,
+ requote_uri,
+ resolve_proxies,
+ rewind_body,
+ should_bypass_proxies,
+ to_key_val_list,
+)
+
+# Preferred clock, based on which one is more accurate on a given system.
+if sys.platform == "win32":
+ preferred_clock = time.perf_counter
+else:
+ preferred_clock = time.time
+
+
+def merge_setting(request_setting, session_setting, dict_class=OrderedDict):
+ """Determines appropriate setting for a given request, taking into account
+ the explicit setting on that request, and the setting in the session. If a
+ setting is a dictionary, they will be merged together using `dict_class`
+ """
+
+ if session_setting is None:
+ return request_setting
+
+ if request_setting is None:
+ return session_setting
+
+ # Bypass if not a dictionary (e.g. verify)
+ if not (
+ isinstance(session_setting, Mapping) and isinstance(request_setting, Mapping)
+ ):
+ return request_setting
+
+ merged_setting = dict_class(to_key_val_list(session_setting))
+ merged_setting.update(to_key_val_list(request_setting))
+
+ # Remove keys that are set to None. Extract keys first to avoid altering
+ # the dictionary during iteration.
+ none_keys = [k for (k, v) in merged_setting.items() if v is None]
+ for key in none_keys:
+ del merged_setting[key]
+
+ return merged_setting
+
+
+def merge_hooks(request_hooks, session_hooks, dict_class=OrderedDict):
+ """Properly merges both requests and session hooks.
+
+ This is necessary because when request_hooks == {'response': []}, the
+ merge breaks Session hooks entirely.
+ """
+ if session_hooks is None or session_hooks.get("response") == []:
+ return request_hooks
+
+ if request_hooks is None or request_hooks.get("response") == []:
+ return session_hooks
+
+ return merge_setting(request_hooks, session_hooks, dict_class)
+
+
+class SessionRedirectMixin:
+ def get_redirect_target(self, resp):
+ """Receives a Response. Returns a redirect URI or ``None``"""
+ # Due to the nature of how requests processes redirects this method will
+ # be called at least once upon the original response and at least twice
+ # on each subsequent redirect response (if any).
+ # If a custom mixin is used to handle this logic, it may be advantageous
+ # to cache the redirect location onto the response object as a private
+ # attribute.
+ if resp.is_redirect:
+ location = resp.headers["location"]
+ # Currently the underlying http module on py3 decode headers
+ # in latin1, but empirical evidence suggests that latin1 is very
+ # rarely used with non-ASCII characters in HTTP headers.
+ # It is more likely to get UTF8 header rather than latin1.
+ # This causes incorrect handling of UTF8 encoded location headers.
+ # To solve this, we re-encode the location in latin1.
+ location = location.encode("latin1")
+ return to_native_string(location, "utf8")
+ return None
+
+ def should_strip_auth(self, old_url, new_url):
+ """Decide whether Authorization header should be removed when redirecting"""
+ old_parsed = urlparse(old_url)
+ new_parsed = urlparse(new_url)
+ if old_parsed.hostname != new_parsed.hostname:
+ return True
+ # Special case: allow http -> https redirect when using the standard
+ # ports. This isn't specified by RFC 7235, but is kept to avoid
+ # breaking backwards compatibility with older versions of requests
+ # that allowed any redirects on the same host.
+ if (
+ old_parsed.scheme == "http"
+ and old_parsed.port in (80, None)
+ and new_parsed.scheme == "https"
+ and new_parsed.port in (443, None)
+ ):
+ return False
+
+ # Handle default port usage corresponding to scheme.
+ changed_port = old_parsed.port != new_parsed.port
+ changed_scheme = old_parsed.scheme != new_parsed.scheme
+ default_port = (DEFAULT_PORTS.get(old_parsed.scheme, None), None)
+ if (
+ not changed_scheme
+ and old_parsed.port in default_port
+ and new_parsed.port in default_port
+ ):
+ return False
+
+ # Standard case: root URI must match
+ return changed_port or changed_scheme
+
+ def resolve_redirects(
+ self,
+ resp,
+ req,
+ stream=False,
+ timeout=None,
+ verify=True,
+ cert=None,
+ proxies=None,
+ yield_requests=False,
+ **adapter_kwargs,
+ ):
+ """Receives a Response. Returns a generator of Responses or Requests."""
+
+ hist = [] # keep track of history
+
+ url = self.get_redirect_target(resp)
+ previous_fragment = urlparse(req.url).fragment
+ while url:
+ prepared_request = req.copy()
+
+ # Update history and keep track of redirects.
+ # resp.history must ignore the original request in this loop
+ hist.append(resp)
+ resp.history = hist[1:]
+
+ try:
+ resp.content # Consume socket so it can be released
+ except (ChunkedEncodingError, ContentDecodingError, RuntimeError):
+ resp.raw.read(decode_content=False)
+
+ if len(resp.history) >= self.max_redirects:
+ raise TooManyRedirects(
+ f"Exceeded {self.max_redirects} redirects.", response=resp
+ )
+
+ # Release the connection back into the pool.
+ resp.close()
+
+ # Handle redirection without scheme (see: RFC 1808 Section 4)
+ if url.startswith("//"):
+ parsed_rurl = urlparse(resp.url)
+ url = ":".join([to_native_string(parsed_rurl.scheme), url])
+
+ # Normalize url case and attach previous fragment if needed (RFC 7231 7.1.2)
+ parsed = urlparse(url)
+ if parsed.fragment == "" and previous_fragment:
+ parsed = parsed._replace(fragment=previous_fragment)
+ elif parsed.fragment:
+ previous_fragment = parsed.fragment
+ url = parsed.geturl()
+
+ # Facilitate relative 'location' headers, as allowed by RFC 7231.
+ # (e.g. '/path/to/resource' instead of 'http://domain.tld/path/to/resource')
+ # Compliant with RFC3986, we percent encode the url.
+ if not parsed.netloc:
+ url = urljoin(resp.url, requote_uri(url))
+ else:
+ url = requote_uri(url)
+
+ prepared_request.url = to_native_string(url)
+
+ self.rebuild_method(prepared_request, resp)
+
+ # https://github.com/psf/requests/issues/1084
+ if resp.status_code not in (
+ codes.temporary_redirect,
+ codes.permanent_redirect,
+ ):
+ # https://github.com/psf/requests/issues/3490
+ purged_headers = ("Content-Length", "Content-Type", "Transfer-Encoding")
+ for header in purged_headers:
+ prepared_request.headers.pop(header, None)
+ prepared_request.body = None
+
+ headers = prepared_request.headers
+ headers.pop("Cookie", None)
+
+ # Extract any cookies sent on the response to the cookiejar
+ # in the new request. Because we've mutated our copied prepared
+ # request, use the old one that we haven't yet touched.
+ extract_cookies_to_jar(prepared_request._cookies, req, resp.raw)
+ merge_cookies(prepared_request._cookies, self.cookies)
+ prepared_request.prepare_cookies(prepared_request._cookies)
+
+ # Rebuild auth and proxy information.
+ proxies = self.rebuild_proxies(prepared_request, proxies)
+ self.rebuild_auth(prepared_request, resp)
+
+ # A failed tell() sets `_body_position` to `object()`. This non-None
+ # value ensures `rewindable` will be True, allowing us to raise an
+ # UnrewindableBodyError, instead of hanging the connection.
+ rewindable = prepared_request._body_position is not None and (
+ "Content-Length" in headers or "Transfer-Encoding" in headers
+ )
+
+ # Attempt to rewind consumed file-like object.
+ if rewindable:
+ rewind_body(prepared_request)
+
+ # Override the original request.
+ req = prepared_request
+
+ if yield_requests:
+ yield req
+ else:
+ resp = self.send(
+ req,
+ stream=stream,
+ timeout=timeout,
+ verify=verify,
+ cert=cert,
+ proxies=proxies,
+ allow_redirects=False,
+ **adapter_kwargs,
+ )
+
+ extract_cookies_to_jar(self.cookies, prepared_request, resp.raw)
+
+ # extract redirect url, if any, for the next loop
+ url = self.get_redirect_target(resp)
+ yield resp
+
+ def rebuild_auth(self, prepared_request, response):
+ """When being redirected we may want to strip authentication from the
+ request to avoid leaking credentials. This method intelligently removes
+ and reapplies authentication where possible to avoid credential loss.
+ """
+ headers = prepared_request.headers
+ url = prepared_request.url
+
+ if "Authorization" in headers and self.should_strip_auth(
+ response.request.url, url
+ ):
+ # If we get redirected to a new host, we should strip out any
+ # authentication headers.
+ del headers["Authorization"]
+
+ # .netrc might have more auth for us on our new host.
+ new_auth = get_netrc_auth(url) if self.trust_env else None
+ if new_auth is not None:
+ prepared_request.prepare_auth(new_auth)
+
+ def rebuild_proxies(self, prepared_request, proxies):
+ """This method re-evaluates the proxy configuration by considering the
+ environment variables. If we are redirected to a URL covered by
+ NO_PROXY, we strip the proxy configuration. Otherwise, we set missing
+ proxy keys for this URL (in case they were stripped by a previous
+ redirect).
+
+ This method also replaces the Proxy-Authorization header where
+ necessary.
+
+ :rtype: dict
+ """
+ headers = prepared_request.headers
+ scheme = urlparse(prepared_request.url).scheme
+ new_proxies = resolve_proxies(prepared_request, proxies, self.trust_env)
+
+ if "Proxy-Authorization" in headers:
+ del headers["Proxy-Authorization"]
+
+ try:
+ username, password = get_auth_from_url(new_proxies[scheme])
+ except KeyError:
+ username, password = None, None
+
+ # urllib3 handles proxy authorization for us in the standard adapter.
+ # Avoid appending this to TLS tunneled requests where it may be leaked.
+ if not scheme.startswith("https") and username and password:
+ headers["Proxy-Authorization"] = _basic_auth_str(username, password)
+
+ return new_proxies
+
+ def rebuild_method(self, prepared_request, response):
+ """When being redirected we may want to change the method of the request
+ based on certain specs or browser behavior.
+ """
+ method = prepared_request.method
+
+ # https://tools.ietf.org/html/rfc7231#section-6.4.4
+ if response.status_code == codes.see_other and method != "HEAD":
+ method = "GET"
+
+ # Do what the browsers do, despite standards...
+ # First, turn 302s into GETs.
+ if response.status_code == codes.found and method != "HEAD":
+ method = "GET"
+
+ # Second, if a POST is responded to with a 301, turn it into a GET.
+ # This bizarre behaviour is explained in Issue 1704.
+ if response.status_code == codes.moved and method == "POST":
+ method = "GET"
+
+ prepared_request.method = method
+
+
+class Session(SessionRedirectMixin):
+ """A Requests session.
+
+ Provides cookie persistence, connection-pooling, and configuration.
+
+ Basic Usage::
+
+ >>> import requests
+ >>> s = requests.Session()
+ >>> s.get('https://httpbin.org/get')
+ <Response [200]>
+
+ Or as a context manager::
+
+ >>> with requests.Session() as s:
+ ... s.get('https://httpbin.org/get')
+ <Response [200]>
+ """
+
+ __attrs__ = [
+ "headers",
+ "cookies",
+ "auth",
+ "proxies",
+ "hooks",
+ "params",
+ "verify",
+ "cert",
+ "adapters",
+ "stream",
+ "trust_env",
+ "max_redirects",
+ ]
+
+ def __init__(self):
+ #: A case-insensitive dictionary of headers to be sent on each
+ #: :class:`Request <Request>` sent from this
+ #: :class:`Session <Session>`.
+ self.headers = default_headers()
+
+ #: Default Authentication tuple or object to attach to
+ #: :class:`Request <Request>`.
+ self.auth = None
+
+ #: Dictionary mapping protocol or protocol and host to the URL of the proxy
+ #: (e.g. {'http': 'foo.bar:3128', 'http://host.name': 'foo.bar:4012'}) to
+ #: be used on each :class:`Request <Request>`.
+ self.proxies = {}
+
+ #: Event-handling hooks.
+ self.hooks = default_hooks()
+
+ #: Dictionary of querystring data to attach to each
+ #: :class:`Request <Request>`. The dictionary values may be lists for
+ #: representing multivalued query parameters.
+ self.params = {}
+
+ #: Stream response content default.
+ self.stream = False
+
+ #: SSL Verification default.
+ #: Defaults to `True`, requiring requests to verify the TLS certificate at the
+ #: remote end.
+ #: If verify is set to `False`, requests will accept any TLS certificate
+ #: presented by the server, and will ignore hostname mismatches and/or
+ #: expired certificates, which will make your application vulnerable to
+ #: man-in-the-middle (MitM) attacks.
+ #: Only set this to `False` for testing.
+ self.verify = True
+
+ #: SSL client certificate default, if String, path to ssl client
+ #: cert file (.pem). If Tuple, ('cert', 'key') pair.
+ self.cert = None
+
+ #: Maximum number of redirects allowed. If the request exceeds this
+ #: limit, a :class:`TooManyRedirects` exception is raised.
+ #: This defaults to requests.models.DEFAULT_REDIRECT_LIMIT, which is
+ #: 30.
+ self.max_redirects = DEFAULT_REDIRECT_LIMIT
+
+ #: Trust environment settings for proxy configuration, default
+ #: authentication and similar.
+ self.trust_env = True
+
+ #: A CookieJar containing all currently outstanding cookies set on this
+ #: session. By default it is a
+ #: :class:`RequestsCookieJar <requests.cookies.RequestsCookieJar>`, but
+ #: may be any other ``cookielib.CookieJar`` compatible object.
+ self.cookies = cookiejar_from_dict({})
+
+ # Default connection adapters.
+ self.adapters = OrderedDict()
+ self.mount("https://", HTTPAdapter())
+ self.mount("http://", HTTPAdapter())
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, *args):
+ self.close()
+
+ def prepare_request(self, request):
+ """Constructs a :class:`PreparedRequest <PreparedRequest>` for
+ transmission and returns it. The :class:`PreparedRequest` has settings
+ merged from the :class:`Request <Request>` instance and those of the
+ :class:`Session`.
+
+ :param request: :class:`Request` instance to prepare with this
+ session's settings.
+ :rtype: requests.PreparedRequest
+ """
+ cookies = request.cookies or {}
+
+ # Bootstrap CookieJar.
+ if not isinstance(cookies, cookielib.CookieJar):
+ cookies = cookiejar_from_dict(cookies)
+
+ # Merge with session cookies
+ merged_cookies = merge_cookies(
+ merge_cookies(RequestsCookieJar(), self.cookies), cookies
+ )
+
+ # Set environment's basic authentication if not explicitly set.
+ auth = request.auth
+ if self.trust_env and not auth and not self.auth:
+ auth = get_netrc_auth(request.url)
+
+ p = PreparedRequest()
+ p.prepare(
+ method=request.method.upper(),
+ url=request.url,
+ files=request.files,
+ data=request.data,
+ json=request.json,
+ headers=merge_setting(
+ request.headers, self.headers, dict_class=CaseInsensitiveDict
+ ),
+ params=merge_setting(request.params, self.params),
+ auth=merge_setting(auth, self.auth),
+ cookies=merged_cookies,
+ hooks=merge_hooks(request.hooks, self.hooks),
+ )
+ return p
+
+ def request(
+ self,
+ method,
+ url,
+ params=None,
+ data=None,
+ headers=None,
+ cookies=None,
+ files=None,
+ auth=None,
+ timeout=None,
+ allow_redirects=True,
+ proxies=None,
+ hooks=None,
+ stream=None,
+ verify=None,
+ cert=None,
+ json=None,
+ ):
+ """Constructs a :class:`Request <Request>`, prepares it and sends it.
+ Returns :class:`Response <Response>` object.
+
+ :param method: method for the new :class:`Request` object.
+ :param url: URL for the new :class:`Request` object.
+ :param params: (optional) Dictionary or bytes to be sent in the query
+ string for the :class:`Request`.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param json: (optional) json to send in the body of the
+ :class:`Request`.
+ :param headers: (optional) Dictionary of HTTP Headers to send with the
+ :class:`Request`.
+ :param cookies: (optional) Dict or CookieJar object to send with the
+ :class:`Request`.
+ :param files: (optional) Dictionary of ``'filename': file-like-objects``
+ for multipart encoding upload.
+ :param auth: (optional) Auth tuple or callable to enable
+ Basic/Digest/Custom HTTP Auth.
+ :param timeout: (optional) How long to wait for the server to send
+ data before giving up, as a float, or a :ref:`(connect timeout,
+ read timeout) <timeouts>` tuple.
+ :type timeout: float or tuple
+ :param allow_redirects: (optional) Set to True by default.
+ :type allow_redirects: bool
+ :param proxies: (optional) Dictionary mapping protocol or protocol and
+ hostname to the URL of the proxy.
+ :param hooks: (optional) Dictionary mapping hook name to one event or
+ list of events, event must be callable.
+ :param stream: (optional) whether to immediately download the response
+ content. Defaults to ``False``.
+ :param verify: (optional) Either a boolean, in which case it controls whether we verify
+ the server's TLS certificate, or a string, in which case it must be a path
+ to a CA bundle to use. Defaults to ``True``. When set to
+ ``False``, requests will accept any TLS certificate presented by
+ the server, and will ignore hostname mismatches and/or expired
+ certificates, which will make your application vulnerable to
+ man-in-the-middle (MitM) attacks. Setting verify to ``False``
+ may be useful during local development or testing.
+ :param cert: (optional) if String, path to ssl client cert file (.pem).
+ If Tuple, ('cert', 'key') pair.
+ :rtype: requests.Response
+ """
+ # Create the Request.
+ req = Request(
+ method=method.upper(),
+ url=url,
+ headers=headers,
+ files=files,
+ data=data or {},
+ json=json,
+ params=params or {},
+ auth=auth,
+ cookies=cookies,
+ hooks=hooks,
+ )
+ prep = self.prepare_request(req)
+
+ proxies = proxies or {}
+
+ settings = self.merge_environment_settings(
+ prep.url, proxies, stream, verify, cert
+ )
+
+ # Send the request.
+ send_kwargs = {
+ "timeout": timeout,
+ "allow_redirects": allow_redirects,
+ }
+ send_kwargs.update(settings)
+ resp = self.send(prep, **send_kwargs)
+
+ return resp
+
+ def get(self, url, **kwargs):
+ r"""Sends a GET request. Returns :class:`Response` object.
+
+ :param url: URL for the new :class:`Request` object.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :rtype: requests.Response
+ """
+
+ kwargs.setdefault("allow_redirects", True)
+ return self.request("GET", url, **kwargs)
+
+ def options(self, url, **kwargs):
+ r"""Sends a OPTIONS request. Returns :class:`Response` object.
+
+ :param url: URL for the new :class:`Request` object.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :rtype: requests.Response
+ """
+
+ kwargs.setdefault("allow_redirects", True)
+ return self.request("OPTIONS", url, **kwargs)
+
+ def head(self, url, **kwargs):
+ r"""Sends a HEAD request. Returns :class:`Response` object.
+
+ :param url: URL for the new :class:`Request` object.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :rtype: requests.Response
+ """
+
+ kwargs.setdefault("allow_redirects", False)
+ return self.request("HEAD", url, **kwargs)
+
+ def post(self, url, data=None, json=None, **kwargs):
+ r"""Sends a POST request. Returns :class:`Response` object.
+
+ :param url: URL for the new :class:`Request` object.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param json: (optional) json to send in the body of the :class:`Request`.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :rtype: requests.Response
+ """
+
+ return self.request("POST", url, data=data, json=json, **kwargs)
+
+ def put(self, url, data=None, **kwargs):
+ r"""Sends a PUT request. Returns :class:`Response` object.
+
+ :param url: URL for the new :class:`Request` object.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :rtype: requests.Response
+ """
+
+ return self.request("PUT", url, data=data, **kwargs)
+
+ def patch(self, url, data=None, **kwargs):
+ r"""Sends a PATCH request. Returns :class:`Response` object.
+
+ :param url: URL for the new :class:`Request` object.
+ :param data: (optional) Dictionary, list of tuples, bytes, or file-like
+ object to send in the body of the :class:`Request`.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :rtype: requests.Response
+ """
+
+ return self.request("PATCH", url, data=data, **kwargs)
+
+ def delete(self, url, **kwargs):
+ r"""Sends a DELETE request. Returns :class:`Response` object.
+
+ :param url: URL for the new :class:`Request` object.
+ :param \*\*kwargs: Optional arguments that ``request`` takes.
+ :rtype: requests.Response
+ """
+
+ return self.request("DELETE", url, **kwargs)
+
+ def send(self, request, **kwargs):
+ """Send a given PreparedRequest.
+
+ :rtype: requests.Response
+ """
+ # Set defaults that the hooks can utilize to ensure they always have
+ # the correct parameters to reproduce the previous request.
+ kwargs.setdefault("stream", self.stream)
+ kwargs.setdefault("verify", self.verify)
+ kwargs.setdefault("cert", self.cert)
+ if "proxies" not in kwargs:
+ kwargs["proxies"] = resolve_proxies(request, self.proxies, self.trust_env)
+
+ # It's possible that users might accidentally send a Request object.
+ # Guard against that specific failure case.
+ if isinstance(request, Request):
+ raise ValueError("You can only send PreparedRequests.")
+
+ # Set up variables needed for resolve_redirects and dispatching of hooks
+ allow_redirects = kwargs.pop("allow_redirects", True)
+ stream = kwargs.get("stream")
+ hooks = request.hooks
+
+ # Get the appropriate adapter to use
+ adapter = self.get_adapter(url=request.url)
+
+ # Start time (approximately) of the request
+ start = preferred_clock()
+
+ # Send the request
+ r = adapter.send(request, **kwargs)
+
+ # Total elapsed time of the request (approximately)
+ elapsed = preferred_clock() - start
+ r.elapsed = timedelta(seconds=elapsed)
+
+ # Response manipulation hooks
+ r = dispatch_hook("response", hooks, r, **kwargs)
+
+ # Persist cookies
+ if r.history:
+ # If the hooks create history then we want those cookies too
+ for resp in r.history:
+ extract_cookies_to_jar(self.cookies, resp.request, resp.raw)
+
+ extract_cookies_to_jar(self.cookies, request, r.raw)
+
+ # Resolve redirects if allowed.
+ if allow_redirects:
+ # Redirect resolving generator.
+ gen = self.resolve_redirects(r, request, **kwargs)
+ history = [resp for resp in gen]
+ else:
+ history = []
+
+ # Shuffle things around if there's history.
+ if history:
+ # Insert the first (original) request at the start
+ history.insert(0, r)
+ # Get the last request made
+ r = history.pop()
+ r.history = history
+
+ # If redirects aren't being followed, store the response on the Request for Response.next().
+ if not allow_redirects:
+ try:
+ r._next = next(
+ self.resolve_redirects(r, request, yield_requests=True, **kwargs)
+ )
+ except StopIteration:
+ pass
+
+ if not stream:
+ r.content
+
+ return r
+
+ def merge_environment_settings(self, url, proxies, stream, verify, cert):
+ """
+ Check the environment and merge it with some settings.
+
+ :rtype: dict
+ """
+ # Gather clues from the surrounding environment.
+ if self.trust_env:
+ # Set environment's proxies.
+ no_proxy = proxies.get("no_proxy") if proxies is not None else None
+ env_proxies = get_environ_proxies(url, no_proxy=no_proxy)
+ for k, v in env_proxies.items():
+ proxies.setdefault(k, v)
+
+ # Look for requests environment configuration
+ # and be compatible with cURL.
+ if verify is True or verify is None:
+ verify = (
+ os.environ.get("REQUESTS_CA_BUNDLE")
+ or os.environ.get("CURL_CA_BUNDLE")
+ or verify
+ )
+
+ # Merge all the kwargs.
+ proxies = merge_setting(proxies, self.proxies)
+ stream = merge_setting(stream, self.stream)
+ verify = merge_setting(verify, self.verify)
+ cert = merge_setting(cert, self.cert)
+
+ return {"proxies": proxies, "stream": stream, "verify": verify, "cert": cert}
+
+ def get_adapter(self, url):
+ """
+ Returns the appropriate connection adapter for the given URL.
+
+ :rtype: requests.adapters.BaseAdapter
+ """
+ for prefix, adapter in self.adapters.items():
+ if url.lower().startswith(prefix.lower()):
+ return adapter
+
+ # Nothing matches :-/
+ raise InvalidSchema(f"No connection adapters were found for {url!r}")
+
+ def close(self):
+ """Closes all adapters and as such the session"""
+ for v in self.adapters.values():
+ v.close()
+
+ def mount(self, prefix, adapter):
+ """Registers a connection adapter to a prefix.
+
+ Adapters are sorted in descending order by prefix length.
+ """
+ self.adapters[prefix] = adapter
+ keys_to_move = [k for k in self.adapters if len(k) < len(prefix)]
+
+ for key in keys_to_move:
+ self.adapters[key] = self.adapters.pop(key)
+
+ def __getstate__(self):
+ state = {attr: getattr(self, attr, None) for attr in self.__attrs__}
+ return state
+
+ def __setstate__(self, state):
+ for attr, value in state.items():
+ setattr(self, attr, value)
+
+
+def session():
+ """
+ Returns a :class:`Session` for context-management.
+
+ .. deprecated:: 1.0.0
+
+ This method has been deprecated since version 1.0.0 and is only kept for
+ backwards compatibility. New code should use :class:`~requests.sessions.Session`
+ to create a session. This may be removed at a future date.
+
+ :rtype: Session
+ """
+ return Session()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/status_codes.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/status_codes.py
new file mode 100644
index 000000000..c7945a2f0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/status_codes.py
@@ -0,0 +1,128 @@
+r"""
+The ``codes`` object defines a mapping from common names for HTTP statuses
+to their numerical codes, accessible either as attributes or as dictionary
+items.
+
+Example::
+
+ >>> import requests
+ >>> requests.codes['temporary_redirect']
+ 307
+ >>> requests.codes.teapot
+ 418
+ >>> requests.codes['\o/']
+ 200
+
+Some codes have multiple names, and both upper- and lower-case versions of
+the names are allowed. For example, ``codes.ok``, ``codes.OK``, and
+``codes.okay`` all correspond to the HTTP status code 200.
+"""
+
+from .structures import LookupDict
+
+_codes = {
+ # Informational.
+ 100: ("continue",),
+ 101: ("switching_protocols",),
+ 102: ("processing", "early-hints"),
+ 103: ("checkpoint",),
+ 122: ("uri_too_long", "request_uri_too_long"),
+ 200: ("ok", "okay", "all_ok", "all_okay", "all_good", "\\o/", "✓"),
+ 201: ("created",),
+ 202: ("accepted",),
+ 203: ("non_authoritative_info", "non_authoritative_information"),
+ 204: ("no_content",),
+ 205: ("reset_content", "reset"),
+ 206: ("partial_content", "partial"),
+ 207: ("multi_status", "multiple_status", "multi_stati", "multiple_stati"),
+ 208: ("already_reported",),
+ 226: ("im_used",),
+ # Redirection.
+ 300: ("multiple_choices",),
+ 301: ("moved_permanently", "moved", "\\o-"),
+ 302: ("found",),
+ 303: ("see_other", "other"),
+ 304: ("not_modified",),
+ 305: ("use_proxy",),
+ 306: ("switch_proxy",),
+ 307: ("temporary_redirect", "temporary_moved", "temporary"),
+ 308: (
+ "permanent_redirect",
+ "resume_incomplete",
+ "resume",
+ ), # "resume" and "resume_incomplete" to be removed in 3.0
+ # Client Error.
+ 400: ("bad_request", "bad"),
+ 401: ("unauthorized",),
+ 402: ("payment_required", "payment"),
+ 403: ("forbidden",),
+ 404: ("not_found", "-o-"),
+ 405: ("method_not_allowed", "not_allowed"),
+ 406: ("not_acceptable",),
+ 407: ("proxy_authentication_required", "proxy_auth", "proxy_authentication"),
+ 408: ("request_timeout", "timeout"),
+ 409: ("conflict",),
+ 410: ("gone",),
+ 411: ("length_required",),
+ 412: ("precondition_failed", "precondition"),
+ 413: ("request_entity_too_large", "content_too_large"),
+ 414: ("request_uri_too_large", "uri_too_long"),
+ 415: ("unsupported_media_type", "unsupported_media", "media_type"),
+ 416: (
+ "requested_range_not_satisfiable",
+ "requested_range",
+ "range_not_satisfiable",
+ ),
+ 417: ("expectation_failed",),
+ 418: ("im_a_teapot", "teapot", "i_am_a_teapot"),
+ 421: ("misdirected_request",),
+ 422: ("unprocessable_entity", "unprocessable", "unprocessable_content"),
+ 423: ("locked",),
+ 424: ("failed_dependency", "dependency"),
+ 425: ("unordered_collection", "unordered", "too_early"),
+ 426: ("upgrade_required", "upgrade"),
+ 428: ("precondition_required", "precondition"),
+ 429: ("too_many_requests", "too_many"),
+ 431: ("header_fields_too_large", "fields_too_large"),
+ 444: ("no_response", "none"),
+ 449: ("retry_with", "retry"),
+ 450: ("blocked_by_windows_parental_controls", "parental_controls"),
+ 451: ("unavailable_for_legal_reasons", "legal_reasons"),
+ 499: ("client_closed_request",),
+ # Server Error.
+ 500: ("internal_server_error", "server_error", "/o\\", "✗"),
+ 501: ("not_implemented",),
+ 502: ("bad_gateway",),
+ 503: ("service_unavailable", "unavailable"),
+ 504: ("gateway_timeout",),
+ 505: ("http_version_not_supported", "http_version"),
+ 506: ("variant_also_negotiates",),
+ 507: ("insufficient_storage",),
+ 509: ("bandwidth_limit_exceeded", "bandwidth"),
+ 510: ("not_extended",),
+ 511: ("network_authentication_required", "network_auth", "network_authentication"),
+}
+
+codes = LookupDict(name="status_codes")
+
+
+def _init():
+ for code, titles in _codes.items():
+ for title in titles:
+ setattr(codes, title, code)
+ if not title.startswith(("\\", "/")):
+ setattr(codes, title.upper(), code)
+
+ def doc(code):
+ names = ", ".join(f"``{n}``" for n in _codes[code])
+ return "* %d: %s" % (code, names)
+
+ global __doc__
+ __doc__ = (
+ __doc__ + "\n" + "\n".join(doc(code) for code in sorted(_codes))
+ if __doc__ is not None
+ else None
+ )
+
+
+_init()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/structures.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/structures.py
new file mode 100644
index 000000000..188e13e48
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/structures.py
@@ -0,0 +1,99 @@
+"""
+requests.structures
+~~~~~~~~~~~~~~~~~~~
+
+Data structures that power Requests.
+"""
+
+from collections import OrderedDict
+
+from .compat import Mapping, MutableMapping
+
+
+class CaseInsensitiveDict(MutableMapping):
+ """A case-insensitive ``dict``-like object.
+
+ Implements all methods and operations of
+ ``MutableMapping`` as well as dict's ``copy``. Also
+ provides ``lower_items``.
+
+ All keys are expected to be strings. The structure remembers the
+ case of the last key to be set, and ``iter(instance)``,
+ ``keys()``, ``items()``, ``iterkeys()``, and ``iteritems()``
+ will contain case-sensitive keys. However, querying and contains
+ testing is case insensitive::
+
+ cid = CaseInsensitiveDict()
+ cid['Accept'] = 'application/json'
+ cid['aCCEPT'] == 'application/json' # True
+ list(cid) == ['Accept'] # True
+
+ For example, ``headers['content-encoding']`` will return the
+ value of a ``'Content-Encoding'`` response header, regardless
+ of how the header name was originally stored.
+
+ If the constructor, ``.update``, or equality comparison
+ operations are given keys that have equal ``.lower()``s, the
+ behavior is undefined.
+ """
+
+ def __init__(self, data=None, **kwargs):
+ self._store = OrderedDict()
+ if data is None:
+ data = {}
+ self.update(data, **kwargs)
+
+ def __setitem__(self, key, value):
+ # Use the lowercased key for lookups, but store the actual
+ # key alongside the value.
+ self._store[key.lower()] = (key, value)
+
+ def __getitem__(self, key):
+ return self._store[key.lower()][1]
+
+ def __delitem__(self, key):
+ del self._store[key.lower()]
+
+ def __iter__(self):
+ return (casedkey for casedkey, mappedvalue in self._store.values())
+
+ def __len__(self):
+ return len(self._store)
+
+ def lower_items(self):
+ """Like iteritems(), but with all lowercase keys."""
+ return ((lowerkey, keyval[1]) for (lowerkey, keyval) in self._store.items())
+
+ def __eq__(self, other):
+ if isinstance(other, Mapping):
+ other = CaseInsensitiveDict(other)
+ else:
+ return NotImplemented
+ # Compare insensitively
+ return dict(self.lower_items()) == dict(other.lower_items())
+
+ # Copy is required
+ def copy(self):
+ return CaseInsensitiveDict(self._store.values())
+
+ def __repr__(self):
+ return str(dict(self.items()))
+
+
+class LookupDict(dict):
+ """Dictionary lookup object."""
+
+ def __init__(self, name=None):
+ self.name = name
+ super().__init__()
+
+ def __repr__(self):
+ return f"<lookup '{self.name}'>"
+
+ def __getitem__(self, key):
+ # We allow fall-through here, so values default to None
+
+ return self.__dict__.get(key, None)
+
+ def get(self, key, default=None):
+ return self.__dict__.get(key, default)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/requests/utils.py b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/utils.py
new file mode 100644
index 000000000..a35ce4786
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/requests/utils.py
@@ -0,0 +1,1096 @@
+"""
+requests.utils
+~~~~~~~~~~~~~~
+
+This module provides utility functions that are used within Requests
+that are also useful for external consumption.
+"""
+
+import codecs
+import contextlib
+import io
+import os
+import re
+import socket
+import struct
+import sys
+import tempfile
+import warnings
+import zipfile
+from collections import OrderedDict
+
+from pip._vendor.urllib3.util import make_headers, parse_url
+
+from . import certs
+from .__version__ import __version__
+
+# to_native_string is unused here, but imported here for backwards compatibility
+from ._internal_utils import ( # noqa: F401
+ _HEADER_VALIDATORS_BYTE,
+ _HEADER_VALIDATORS_STR,
+ HEADER_VALIDATORS,
+ to_native_string,
+)
+from .compat import (
+ Mapping,
+ basestring,
+ bytes,
+ getproxies,
+ getproxies_environment,
+ integer_types,
+)
+from .compat import parse_http_list as _parse_list_header
+from .compat import (
+ proxy_bypass,
+ proxy_bypass_environment,
+ quote,
+ str,
+ unquote,
+ urlparse,
+ urlunparse,
+)
+from .cookies import cookiejar_from_dict
+from .exceptions import (
+ FileModeWarning,
+ InvalidHeader,
+ InvalidURL,
+ UnrewindableBodyError,
+)
+from .structures import CaseInsensitiveDict
+
+NETRC_FILES = (".netrc", "_netrc")
+
+DEFAULT_CA_BUNDLE_PATH = certs.where()
+
+DEFAULT_PORTS = {"http": 80, "https": 443}
+
+# Ensure that ', ' is used to preserve previous delimiter behavior.
+DEFAULT_ACCEPT_ENCODING = ", ".join(
+ re.split(r",\s*", make_headers(accept_encoding=True)["accept-encoding"])
+)
+
+
+if sys.platform == "win32":
+ # provide a proxy_bypass version on Windows without DNS lookups
+
+ def proxy_bypass_registry(host):
+ try:
+ import winreg
+ except ImportError:
+ return False
+
+ try:
+ internetSettings = winreg.OpenKey(
+ winreg.HKEY_CURRENT_USER,
+ r"Software\Microsoft\Windows\CurrentVersion\Internet Settings",
+ )
+ # ProxyEnable could be REG_SZ or REG_DWORD, normalizing it
+ proxyEnable = int(winreg.QueryValueEx(internetSettings, "ProxyEnable")[0])
+ # ProxyOverride is almost always a string
+ proxyOverride = winreg.QueryValueEx(internetSettings, "ProxyOverride")[0]
+ except (OSError, ValueError):
+ return False
+ if not proxyEnable or not proxyOverride:
+ return False
+
+ # make a check value list from the registry entry: replace the
+ # '<local>' string by the localhost entry and the corresponding
+ # canonical entry.
+ proxyOverride = proxyOverride.split(";")
+ # filter out empty strings to avoid re.match return true in the following code.
+ proxyOverride = filter(None, proxyOverride)
+ # now check if we match one of the registry values.
+ for test in proxyOverride:
+ if test == "<local>":
+ if "." not in host:
+ return True
+ test = test.replace(".", r"\.") # mask dots
+ test = test.replace("*", r".*") # change glob sequence
+ test = test.replace("?", r".") # change glob char
+ if re.match(test, host, re.I):
+ return True
+ return False
+
+ def proxy_bypass(host): # noqa
+ """Return True, if the host should be bypassed.
+
+ Checks proxy settings gathered from the environment, if specified,
+ or the registry.
+ """
+ if getproxies_environment():
+ return proxy_bypass_environment(host)
+ else:
+ return proxy_bypass_registry(host)
+
+
+def dict_to_sequence(d):
+ """Returns an internal sequence dictionary update."""
+
+ if hasattr(d, "items"):
+ d = d.items()
+
+ return d
+
+
+def super_len(o):
+ total_length = None
+ current_position = 0
+
+ if isinstance(o, str):
+ o = o.encode("utf-8")
+
+ if hasattr(o, "__len__"):
+ total_length = len(o)
+
+ elif hasattr(o, "len"):
+ total_length = o.len
+
+ elif hasattr(o, "fileno"):
+ try:
+ fileno = o.fileno()
+ except (io.UnsupportedOperation, AttributeError):
+ # AttributeError is a surprising exception, seeing as how we've just checked
+ # that `hasattr(o, 'fileno')`. It happens for objects obtained via
+ # `Tarfile.extractfile()`, per issue 5229.
+ pass
+ else:
+ total_length = os.fstat(fileno).st_size
+
+ # Having used fstat to determine the file length, we need to
+ # confirm that this file was opened up in binary mode.
+ if "b" not in o.mode:
+ warnings.warn(
+ (
+ "Requests has determined the content-length for this "
+ "request using the binary size of the file: however, the "
+ "file has been opened in text mode (i.e. without the 'b' "
+ "flag in the mode). This may lead to an incorrect "
+ "content-length. In Requests 3.0, support will be removed "
+ "for files in text mode."
+ ),
+ FileModeWarning,
+ )
+
+ if hasattr(o, "tell"):
+ try:
+ current_position = o.tell()
+ except OSError:
+ # This can happen in some weird situations, such as when the file
+ # is actually a special file descriptor like stdin. In this
+ # instance, we don't know what the length is, so set it to zero and
+ # let requests chunk it instead.
+ if total_length is not None:
+ current_position = total_length
+ else:
+ if hasattr(o, "seek") and total_length is None:
+ # StringIO and BytesIO have seek but no usable fileno
+ try:
+ # seek to end of file
+ o.seek(0, 2)
+ total_length = o.tell()
+
+ # seek back to current position to support
+ # partially read file-like objects
+ o.seek(current_position or 0)
+ except OSError:
+ total_length = 0
+
+ if total_length is None:
+ total_length = 0
+
+ return max(0, total_length - current_position)
+
+
+def get_netrc_auth(url, raise_errors=False):
+ """Returns the Requests tuple auth for a given url from netrc."""
+
+ netrc_file = os.environ.get("NETRC")
+ if netrc_file is not None:
+ netrc_locations = (netrc_file,)
+ else:
+ netrc_locations = (f"~/{f}" for f in NETRC_FILES)
+
+ try:
+ from netrc import NetrcParseError, netrc
+
+ netrc_path = None
+
+ for f in netrc_locations:
+ try:
+ loc = os.path.expanduser(f)
+ except KeyError:
+ # os.path.expanduser can fail when $HOME is undefined and
+ # getpwuid fails. See https://bugs.python.org/issue20164 &
+ # https://github.com/psf/requests/issues/1846
+ return
+
+ if os.path.exists(loc):
+ netrc_path = loc
+ break
+
+ # Abort early if there isn't one.
+ if netrc_path is None:
+ return
+
+ ri = urlparse(url)
+
+ # Strip port numbers from netloc. This weird `if...encode`` dance is
+ # used for Python 3.2, which doesn't support unicode literals.
+ splitstr = b":"
+ if isinstance(url, str):
+ splitstr = splitstr.decode("ascii")
+ host = ri.netloc.split(splitstr)[0]
+
+ try:
+ _netrc = netrc(netrc_path).authenticators(host)
+ if _netrc:
+ # Return with login / password
+ login_i = 0 if _netrc[0] else 1
+ return (_netrc[login_i], _netrc[2])
+ except (NetrcParseError, OSError):
+ # If there was a parsing error or a permissions issue reading the file,
+ # we'll just skip netrc auth unless explicitly asked to raise errors.
+ if raise_errors:
+ raise
+
+ # App Engine hackiness.
+ except (ImportError, AttributeError):
+ pass
+
+
+def guess_filename(obj):
+ """Tries to guess the filename of the given object."""
+ name = getattr(obj, "name", None)
+ if name and isinstance(name, basestring) and name[0] != "<" and name[-1] != ">":
+ return os.path.basename(name)
+
+
+def extract_zipped_paths(path):
+ """Replace nonexistent paths that look like they refer to a member of a zip
+ archive with the location of an extracted copy of the target, or else
+ just return the provided path unchanged.
+ """
+ if os.path.exists(path):
+ # this is already a valid path, no need to do anything further
+ return path
+
+ # find the first valid part of the provided path and treat that as a zip archive
+ # assume the rest of the path is the name of a member in the archive
+ archive, member = os.path.split(path)
+ while archive and not os.path.exists(archive):
+ archive, prefix = os.path.split(archive)
+ if not prefix:
+ # If we don't check for an empty prefix after the split (in other words, archive remains unchanged after the split),
+ # we _can_ end up in an infinite loop on a rare corner case affecting a small number of users
+ break
+ member = "/".join([prefix, member])
+
+ if not zipfile.is_zipfile(archive):
+ return path
+
+ zip_file = zipfile.ZipFile(archive)
+ if member not in zip_file.namelist():
+ return path
+
+ # we have a valid zip archive and a valid member of that archive
+ tmp = tempfile.gettempdir()
+ extracted_path = os.path.join(tmp, member.split("/")[-1])
+ if not os.path.exists(extracted_path):
+ # use read + write to avoid the creating nested folders, we only want the file, avoids mkdir racing condition
+ with atomic_open(extracted_path) as file_handler:
+ file_handler.write(zip_file.read(member))
+ return extracted_path
+
+
+@contextlib.contextmanager
+def atomic_open(filename):
+ """Write a file to the disk in an atomic fashion"""
+ tmp_descriptor, tmp_name = tempfile.mkstemp(dir=os.path.dirname(filename))
+ try:
+ with os.fdopen(tmp_descriptor, "wb") as tmp_handler:
+ yield tmp_handler
+ os.replace(tmp_name, filename)
+ except BaseException:
+ os.remove(tmp_name)
+ raise
+
+
+def from_key_val_list(value):
+ """Take an object and test to see if it can be represented as a
+ dictionary. Unless it can not be represented as such, return an
+ OrderedDict, e.g.,
+
+ ::
+
+ >>> from_key_val_list([('key', 'val')])
+ OrderedDict([('key', 'val')])
+ >>> from_key_val_list('string')
+ Traceback (most recent call last):
+ ...
+ ValueError: cannot encode objects that are not 2-tuples
+ >>> from_key_val_list({'key': 'val'})
+ OrderedDict([('key', 'val')])
+
+ :rtype: OrderedDict
+ """
+ if value is None:
+ return None
+
+ if isinstance(value, (str, bytes, bool, int)):
+ raise ValueError("cannot encode objects that are not 2-tuples")
+
+ return OrderedDict(value)
+
+
+def to_key_val_list(value):
+ """Take an object and test to see if it can be represented as a
+ dictionary. If it can be, return a list of tuples, e.g.,
+
+ ::
+
+ >>> to_key_val_list([('key', 'val')])
+ [('key', 'val')]
+ >>> to_key_val_list({'key': 'val'})
+ [('key', 'val')]
+ >>> to_key_val_list('string')
+ Traceback (most recent call last):
+ ...
+ ValueError: cannot encode objects that are not 2-tuples
+
+ :rtype: list
+ """
+ if value is None:
+ return None
+
+ if isinstance(value, (str, bytes, bool, int)):
+ raise ValueError("cannot encode objects that are not 2-tuples")
+
+ if isinstance(value, Mapping):
+ value = value.items()
+
+ return list(value)
+
+
+# From mitsuhiko/werkzeug (used with permission).
+def parse_list_header(value):
+ """Parse lists as described by RFC 2068 Section 2.
+
+ In particular, parse comma-separated lists where the elements of
+ the list may include quoted-strings. A quoted-string could
+ contain a comma. A non-quoted string could have quotes in the
+ middle. Quotes are removed automatically after parsing.
+
+ It basically works like :func:`parse_set_header` just that items
+ may appear multiple times and case sensitivity is preserved.
+
+ The return value is a standard :class:`list`:
+
+ >>> parse_list_header('token, "quoted value"')
+ ['token', 'quoted value']
+
+ To create a header from the :class:`list` again, use the
+ :func:`dump_header` function.
+
+ :param value: a string with a list header.
+ :return: :class:`list`
+ :rtype: list
+ """
+ result = []
+ for item in _parse_list_header(value):
+ if item[:1] == item[-1:] == '"':
+ item = unquote_header_value(item[1:-1])
+ result.append(item)
+ return result
+
+
+# From mitsuhiko/werkzeug (used with permission).
+def parse_dict_header(value):
+ """Parse lists of key, value pairs as described by RFC 2068 Section 2 and
+ convert them into a python dict:
+
+ >>> d = parse_dict_header('foo="is a fish", bar="as well"')
+ >>> type(d) is dict
+ True
+ >>> sorted(d.items())
+ [('bar', 'as well'), ('foo', 'is a fish')]
+
+ If there is no value for a key it will be `None`:
+
+ >>> parse_dict_header('key_without_value')
+ {'key_without_value': None}
+
+ To create a header from the :class:`dict` again, use the
+ :func:`dump_header` function.
+
+ :param value: a string with a dict header.
+ :return: :class:`dict`
+ :rtype: dict
+ """
+ result = {}
+ for item in _parse_list_header(value):
+ if "=" not in item:
+ result[item] = None
+ continue
+ name, value = item.split("=", 1)
+ if value[:1] == value[-1:] == '"':
+ value = unquote_header_value(value[1:-1])
+ result[name] = value
+ return result
+
+
+# From mitsuhiko/werkzeug (used with permission).
+def unquote_header_value(value, is_filename=False):
+ r"""Unquotes a header value. (Reversal of :func:`quote_header_value`).
+ This does not use the real unquoting but what browsers are actually
+ using for quoting.
+
+ :param value: the header value to unquote.
+ :rtype: str
+ """
+ if value and value[0] == value[-1] == '"':
+ # this is not the real unquoting, but fixing this so that the
+ # RFC is met will result in bugs with internet explorer and
+ # probably some other browsers as well. IE for example is
+ # uploading files with "C:\foo\bar.txt" as filename
+ value = value[1:-1]
+
+ # if this is a filename and the starting characters look like
+ # a UNC path, then just return the value without quotes. Using the
+ # replace sequence below on a UNC path has the effect of turning
+ # the leading double slash into a single slash and then
+ # _fix_ie_filename() doesn't work correctly. See #458.
+ if not is_filename or value[:2] != "\\\\":
+ return value.replace("\\\\", "\\").replace('\\"', '"')
+ return value
+
+
+def dict_from_cookiejar(cj):
+ """Returns a key/value dictionary from a CookieJar.
+
+ :param cj: CookieJar object to extract cookies from.
+ :rtype: dict
+ """
+
+ cookie_dict = {cookie.name: cookie.value for cookie in cj}
+ return cookie_dict
+
+
+def add_dict_to_cookiejar(cj, cookie_dict):
+ """Returns a CookieJar from a key/value dictionary.
+
+ :param cj: CookieJar to insert cookies into.
+ :param cookie_dict: Dict of key/values to insert into CookieJar.
+ :rtype: CookieJar
+ """
+
+ return cookiejar_from_dict(cookie_dict, cj)
+
+
+def get_encodings_from_content(content):
+ """Returns encodings from given content string.
+
+ :param content: bytestring to extract encodings from.
+ """
+ warnings.warn(
+ (
+ "In requests 3.0, get_encodings_from_content will be removed. For "
+ "more information, please see the discussion on issue #2266. (This"
+ " warning should only appear once.)"
+ ),
+ DeprecationWarning,
+ )
+
+ charset_re = re.compile(r'<meta.*?charset=["\']*(.+?)["\'>]', flags=re.I)
+ pragma_re = re.compile(r'<meta.*?content=["\']*;?charset=(.+?)["\'>]', flags=re.I)
+ xml_re = re.compile(r'^<\?xml.*?encoding=["\']*(.+?)["\'>]')
+
+ return (
+ charset_re.findall(content)
+ + pragma_re.findall(content)
+ + xml_re.findall(content)
+ )
+
+
+def _parse_content_type_header(header):
+ """Returns content type and parameters from given header
+
+ :param header: string
+ :return: tuple containing content type and dictionary of
+ parameters
+ """
+
+ tokens = header.split(";")
+ content_type, params = tokens[0].strip(), tokens[1:]
+ params_dict = {}
+ items_to_strip = "\"' "
+
+ for param in params:
+ param = param.strip()
+ if param:
+ key, value = param, True
+ index_of_equals = param.find("=")
+ if index_of_equals != -1:
+ key = param[:index_of_equals].strip(items_to_strip)
+ value = param[index_of_equals + 1 :].strip(items_to_strip)
+ params_dict[key.lower()] = value
+ return content_type, params_dict
+
+
+def get_encoding_from_headers(headers):
+ """Returns encodings from given HTTP Header Dict.
+
+ :param headers: dictionary to extract encoding from.
+ :rtype: str
+ """
+
+ content_type = headers.get("content-type")
+
+ if not content_type:
+ return None
+
+ content_type, params = _parse_content_type_header(content_type)
+
+ if "charset" in params:
+ return params["charset"].strip("'\"")
+
+ if "text" in content_type:
+ return "ISO-8859-1"
+
+ if "application/json" in content_type:
+ # Assume UTF-8 based on RFC 4627: https://www.ietf.org/rfc/rfc4627.txt since the charset was unset
+ return "utf-8"
+
+
+def stream_decode_response_unicode(iterator, r):
+ """Stream decodes an iterator."""
+
+ if r.encoding is None:
+ yield from iterator
+ return
+
+ decoder = codecs.getincrementaldecoder(r.encoding)(errors="replace")
+ for chunk in iterator:
+ rv = decoder.decode(chunk)
+ if rv:
+ yield rv
+ rv = decoder.decode(b"", final=True)
+ if rv:
+ yield rv
+
+
+def iter_slices(string, slice_length):
+ """Iterate over slices of a string."""
+ pos = 0
+ if slice_length is None or slice_length <= 0:
+ slice_length = len(string)
+ while pos < len(string):
+ yield string[pos : pos + slice_length]
+ pos += slice_length
+
+
+def get_unicode_from_response(r):
+ """Returns the requested content back in unicode.
+
+ :param r: Response object to get unicode content from.
+
+ Tried:
+
+ 1. charset from content-type
+ 2. fall back and replace all unicode characters
+
+ :rtype: str
+ """
+ warnings.warn(
+ (
+ "In requests 3.0, get_unicode_from_response will be removed. For "
+ "more information, please see the discussion on issue #2266. (This"
+ " warning should only appear once.)"
+ ),
+ DeprecationWarning,
+ )
+
+ tried_encodings = []
+
+ # Try charset from content-type
+ encoding = get_encoding_from_headers(r.headers)
+
+ if encoding:
+ try:
+ return str(r.content, encoding)
+ except UnicodeError:
+ tried_encodings.append(encoding)
+
+ # Fall back:
+ try:
+ return str(r.content, encoding, errors="replace")
+ except TypeError:
+ return r.content
+
+
+# The unreserved URI characters (RFC 3986)
+UNRESERVED_SET = frozenset(
+ "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" + "0123456789-._~"
+)
+
+
+def unquote_unreserved(uri):
+ """Un-escape any percent-escape sequences in a URI that are unreserved
+ characters. This leaves all reserved, illegal and non-ASCII bytes encoded.
+
+ :rtype: str
+ """
+ parts = uri.split("%")
+ for i in range(1, len(parts)):
+ h = parts[i][0:2]
+ if len(h) == 2 and h.isalnum():
+ try:
+ c = chr(int(h, 16))
+ except ValueError:
+ raise InvalidURL(f"Invalid percent-escape sequence: '{h}'")
+
+ if c in UNRESERVED_SET:
+ parts[i] = c + parts[i][2:]
+ else:
+ parts[i] = f"%{parts[i]}"
+ else:
+ parts[i] = f"%{parts[i]}"
+ return "".join(parts)
+
+
+def requote_uri(uri):
+ """Re-quote the given URI.
+
+ This function passes the given URI through an unquote/quote cycle to
+ ensure that it is fully and consistently quoted.
+
+ :rtype: str
+ """
+ safe_with_percent = "!#$%&'()*+,/:;=?@[]~"
+ safe_without_percent = "!#$&'()*+,/:;=?@[]~"
+ try:
+ # Unquote only the unreserved characters
+ # Then quote only illegal characters (do not quote reserved,
+ # unreserved, or '%')
+ return quote(unquote_unreserved(uri), safe=safe_with_percent)
+ except InvalidURL:
+ # We couldn't unquote the given URI, so let's try quoting it, but
+ # there may be unquoted '%'s in the URI. We need to make sure they're
+ # properly quoted so they do not cause issues elsewhere.
+ return quote(uri, safe=safe_without_percent)
+
+
+def address_in_network(ip, net):
+ """This function allows you to check if an IP belongs to a network subnet
+
+ Example: returns True if ip = 192.168.1.1 and net = 192.168.1.0/24
+ returns False if ip = 192.168.1.1 and net = 192.168.100.0/24
+
+ :rtype: bool
+ """
+ ipaddr = struct.unpack("=L", socket.inet_aton(ip))[0]
+ netaddr, bits = net.split("/")
+ netmask = struct.unpack("=L", socket.inet_aton(dotted_netmask(int(bits))))[0]
+ network = struct.unpack("=L", socket.inet_aton(netaddr))[0] & netmask
+ return (ipaddr & netmask) == (network & netmask)
+
+
+def dotted_netmask(mask):
+ """Converts mask from /xx format to xxx.xxx.xxx.xxx
+
+ Example: if mask is 24 function returns 255.255.255.0
+
+ :rtype: str
+ """
+ bits = 0xFFFFFFFF ^ (1 << 32 - mask) - 1
+ return socket.inet_ntoa(struct.pack(">I", bits))
+
+
+def is_ipv4_address(string_ip):
+ """
+ :rtype: bool
+ """
+ try:
+ socket.inet_aton(string_ip)
+ except OSError:
+ return False
+ return True
+
+
+def is_valid_cidr(string_network):
+ """
+ Very simple check of the cidr format in no_proxy variable.
+
+ :rtype: bool
+ """
+ if string_network.count("/") == 1:
+ try:
+ mask = int(string_network.split("/")[1])
+ except ValueError:
+ return False
+
+ if mask < 1 or mask > 32:
+ return False
+
+ try:
+ socket.inet_aton(string_network.split("/")[0])
+ except OSError:
+ return False
+ else:
+ return False
+ return True
+
+
+@contextlib.contextmanager
+def set_environ(env_name, value):
+ """Set the environment variable 'env_name' to 'value'
+
+ Save previous value, yield, and then restore the previous value stored in
+ the environment variable 'env_name'.
+
+ If 'value' is None, do nothing"""
+ value_changed = value is not None
+ if value_changed:
+ old_value = os.environ.get(env_name)
+ os.environ[env_name] = value
+ try:
+ yield
+ finally:
+ if value_changed:
+ if old_value is None:
+ del os.environ[env_name]
+ else:
+ os.environ[env_name] = old_value
+
+
+def should_bypass_proxies(url, no_proxy):
+ """
+ Returns whether we should bypass proxies or not.
+
+ :rtype: bool
+ """
+
+ # Prioritize lowercase environment variables over uppercase
+ # to keep a consistent behaviour with other http projects (curl, wget).
+ def get_proxy(key):
+ return os.environ.get(key) or os.environ.get(key.upper())
+
+ # First check whether no_proxy is defined. If it is, check that the URL
+ # we're getting isn't in the no_proxy list.
+ no_proxy_arg = no_proxy
+ if no_proxy is None:
+ no_proxy = get_proxy("no_proxy")
+ parsed = urlparse(url)
+
+ if parsed.hostname is None:
+ # URLs don't always have hostnames, e.g. file:/// urls.
+ return True
+
+ if no_proxy:
+ # We need to check whether we match here. We need to see if we match
+ # the end of the hostname, both with and without the port.
+ no_proxy = (host for host in no_proxy.replace(" ", "").split(",") if host)
+
+ if is_ipv4_address(parsed.hostname):
+ for proxy_ip in no_proxy:
+ if is_valid_cidr(proxy_ip):
+ if address_in_network(parsed.hostname, proxy_ip):
+ return True
+ elif parsed.hostname == proxy_ip:
+ # If no_proxy ip was defined in plain IP notation instead of cidr notation &
+ # matches the IP of the index
+ return True
+ else:
+ host_with_port = parsed.hostname
+ if parsed.port:
+ host_with_port += f":{parsed.port}"
+
+ for host in no_proxy:
+ if parsed.hostname.endswith(host) or host_with_port.endswith(host):
+ # The URL does match something in no_proxy, so we don't want
+ # to apply the proxies on this URL.
+ return True
+
+ with set_environ("no_proxy", no_proxy_arg):
+ # parsed.hostname can be `None` in cases such as a file URI.
+ try:
+ bypass = proxy_bypass(parsed.hostname)
+ except (TypeError, socket.gaierror):
+ bypass = False
+
+ if bypass:
+ return True
+
+ return False
+
+
+def get_environ_proxies(url, no_proxy=None):
+ """
+ Return a dict of environment proxies.
+
+ :rtype: dict
+ """
+ if should_bypass_proxies(url, no_proxy=no_proxy):
+ return {}
+ else:
+ return getproxies()
+
+
+def select_proxy(url, proxies):
+ """Select a proxy for the url, if applicable.
+
+ :param url: The url being for the request
+ :param proxies: A dictionary of schemes or schemes and hosts to proxy URLs
+ """
+ proxies = proxies or {}
+ urlparts = urlparse(url)
+ if urlparts.hostname is None:
+ return proxies.get(urlparts.scheme, proxies.get("all"))
+
+ proxy_keys = [
+ urlparts.scheme + "://" + urlparts.hostname,
+ urlparts.scheme,
+ "all://" + urlparts.hostname,
+ "all",
+ ]
+ proxy = None
+ for proxy_key in proxy_keys:
+ if proxy_key in proxies:
+ proxy = proxies[proxy_key]
+ break
+
+ return proxy
+
+
+def resolve_proxies(request, proxies, trust_env=True):
+ """This method takes proxy information from a request and configuration
+ input to resolve a mapping of target proxies. This will consider settings
+ such as NO_PROXY to strip proxy configurations.
+
+ :param request: Request or PreparedRequest
+ :param proxies: A dictionary of schemes or schemes and hosts to proxy URLs
+ :param trust_env: Boolean declaring whether to trust environment configs
+
+ :rtype: dict
+ """
+ proxies = proxies if proxies is not None else {}
+ url = request.url
+ scheme = urlparse(url).scheme
+ no_proxy = proxies.get("no_proxy")
+ new_proxies = proxies.copy()
+
+ if trust_env and not should_bypass_proxies(url, no_proxy=no_proxy):
+ environ_proxies = get_environ_proxies(url, no_proxy=no_proxy)
+
+ proxy = environ_proxies.get(scheme, environ_proxies.get("all"))
+
+ if proxy:
+ new_proxies.setdefault(scheme, proxy)
+ return new_proxies
+
+
+def default_user_agent(name="python-requests"):
+ """
+ Return a string representing the default user agent.
+
+ :rtype: str
+ """
+ return f"{name}/{__version__}"
+
+
+def default_headers():
+ """
+ :rtype: requests.structures.CaseInsensitiveDict
+ """
+ return CaseInsensitiveDict(
+ {
+ "User-Agent": default_user_agent(),
+ "Accept-Encoding": DEFAULT_ACCEPT_ENCODING,
+ "Accept": "*/*",
+ "Connection": "keep-alive",
+ }
+ )
+
+
+def parse_header_links(value):
+ """Return a list of parsed link headers proxies.
+
+ i.e. Link: <http:/.../front.jpeg>; rel=front; type="image/jpeg",<http://.../back.jpeg>; rel=back;type="image/jpeg"
+
+ :rtype: list
+ """
+
+ links = []
+
+ replace_chars = " '\""
+
+ value = value.strip(replace_chars)
+ if not value:
+ return links
+
+ for val in re.split(", *<", value):
+ try:
+ url, params = val.split(";", 1)
+ except ValueError:
+ url, params = val, ""
+
+ link = {"url": url.strip("<> '\"")}
+
+ for param in params.split(";"):
+ try:
+ key, value = param.split("=")
+ except ValueError:
+ break
+
+ link[key.strip(replace_chars)] = value.strip(replace_chars)
+
+ links.append(link)
+
+ return links
+
+
+# Null bytes; no need to recreate these on each call to guess_json_utf
+_null = "\x00".encode("ascii") # encoding to ASCII for Python 3
+_null2 = _null * 2
+_null3 = _null * 3
+
+
+def guess_json_utf(data):
+ """
+ :rtype: str
+ """
+ # JSON always starts with two ASCII characters, so detection is as
+ # easy as counting the nulls and from their location and count
+ # determine the encoding. Also detect a BOM, if present.
+ sample = data[:4]
+ if sample in (codecs.BOM_UTF32_LE, codecs.BOM_UTF32_BE):
+ return "utf-32" # BOM included
+ if sample[:3] == codecs.BOM_UTF8:
+ return "utf-8-sig" # BOM included, MS style (discouraged)
+ if sample[:2] in (codecs.BOM_UTF16_LE, codecs.BOM_UTF16_BE):
+ return "utf-16" # BOM included
+ nullcount = sample.count(_null)
+ if nullcount == 0:
+ return "utf-8"
+ if nullcount == 2:
+ if sample[::2] == _null2: # 1st and 3rd are null
+ return "utf-16-be"
+ if sample[1::2] == _null2: # 2nd and 4th are null
+ return "utf-16-le"
+ # Did not detect 2 valid UTF-16 ascii-range characters
+ if nullcount == 3:
+ if sample[:3] == _null3:
+ return "utf-32-be"
+ if sample[1:] == _null3:
+ return "utf-32-le"
+ # Did not detect a valid UTF-32 ascii-range character
+ return None
+
+
+def prepend_scheme_if_needed(url, new_scheme):
+ """Given a URL that may or may not have a scheme, prepend the given scheme.
+ Does not replace a present scheme with the one provided as an argument.
+
+ :rtype: str
+ """
+ parsed = parse_url(url)
+ scheme, auth, host, port, path, query, fragment = parsed
+
+ # A defect in urlparse determines that there isn't a netloc present in some
+ # urls. We previously assumed parsing was overly cautious, and swapped the
+ # netloc and path. Due to a lack of tests on the original defect, this is
+ # maintained with parse_url for backwards compatibility.
+ netloc = parsed.netloc
+ if not netloc:
+ netloc, path = path, netloc
+
+ if auth:
+ # parse_url doesn't provide the netloc with auth
+ # so we'll add it ourselves.
+ netloc = "@".join([auth, netloc])
+ if scheme is None:
+ scheme = new_scheme
+ if path is None:
+ path = ""
+
+ return urlunparse((scheme, netloc, path, "", query, fragment))
+
+
+def get_auth_from_url(url):
+ """Given a url with authentication components, extract them into a tuple of
+ username,password.
+
+ :rtype: (str,str)
+ """
+ parsed = urlparse(url)
+
+ try:
+ auth = (unquote(parsed.username), unquote(parsed.password))
+ except (AttributeError, TypeError):
+ auth = ("", "")
+
+ return auth
+
+
+def check_header_validity(header):
+ """Verifies that header parts don't contain leading whitespace
+ reserved characters, or return characters.
+
+ :param header: tuple, in the format (name, value).
+ """
+ name, value = header
+ _validate_header_part(header, name, 0)
+ _validate_header_part(header, value, 1)
+
+
+def _validate_header_part(header, header_part, header_validator_index):
+ if isinstance(header_part, str):
+ validator = _HEADER_VALIDATORS_STR[header_validator_index]
+ elif isinstance(header_part, bytes):
+ validator = _HEADER_VALIDATORS_BYTE[header_validator_index]
+ else:
+ raise InvalidHeader(
+ f"Header part ({header_part!r}) from {header} "
+ f"must be of type str or bytes, not {type(header_part)}"
+ )
+
+ if not validator.match(header_part):
+ header_kind = "name" if header_validator_index == 0 else "value"
+ raise InvalidHeader(
+ f"Invalid leading whitespace, reserved character(s), or return "
+ f"character(s) in header {header_kind}: {header_part!r}"
+ )
+
+
+def urldefragauth(url):
+ """
+ Given a url remove the fragment and the authentication part.
+
+ :rtype: str
+ """
+ scheme, netloc, path, params, query, fragment = urlparse(url)
+
+ # see func:`prepend_scheme_if_needed`
+ if not netloc:
+ netloc, path = path, netloc
+
+ netloc = netloc.rsplit("@", 1)[-1]
+
+ return urlunparse((scheme, netloc, path, params, query, ""))
+
+
+def rewind_body(prepared_request):
+ """Move file pointer back to its recorded starting position
+ so it can be read again on redirect.
+ """
+ body_seek = getattr(prepared_request.body, "seek", None)
+ if body_seek is not None and isinstance(
+ prepared_request._body_position, integer_types
+ ):
+ try:
+ body_seek(prepared_request._body_position)
+ except OSError:
+ raise UnrewindableBodyError(
+ "An error occurred when rewinding request body for redirect."
+ )
+ else:
+ raise UnrewindableBodyError("Unable to rewind request body for redirect.")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/__init__.py
new file mode 100644
index 000000000..d92acc7be
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/__init__.py
@@ -0,0 +1,26 @@
+__all__ = [
+ "__version__",
+ "AbstractProvider",
+ "AbstractResolver",
+ "BaseReporter",
+ "InconsistentCandidate",
+ "Resolver",
+ "RequirementsConflicted",
+ "ResolutionError",
+ "ResolutionImpossible",
+ "ResolutionTooDeep",
+]
+
+__version__ = "1.0.1"
+
+
+from .providers import AbstractProvider, AbstractResolver
+from .reporters import BaseReporter
+from .resolvers import (
+ InconsistentCandidate,
+ RequirementsConflicted,
+ ResolutionError,
+ ResolutionImpossible,
+ ResolutionTooDeep,
+ Resolver,
+)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/compat/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/compat/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/compat/collections_abc.py b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/compat/collections_abc.py
new file mode 100644
index 000000000..1becc5093
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/compat/collections_abc.py
@@ -0,0 +1,6 @@
+__all__ = ["Mapping", "Sequence"]
+
+try:
+ from collections.abc import Mapping, Sequence
+except ImportError:
+ from collections import Mapping, Sequence
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/providers.py b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/providers.py
new file mode 100644
index 000000000..e99d87ee7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/providers.py
@@ -0,0 +1,133 @@
+class AbstractProvider(object):
+ """Delegate class to provide the required interface for the resolver."""
+
+ def identify(self, requirement_or_candidate):
+ """Given a requirement, return an identifier for it.
+
+ This is used to identify a requirement, e.g. whether two requirements
+ should have their specifier parts merged.
+ """
+ raise NotImplementedError
+
+ def get_preference(
+ self,
+ identifier,
+ resolutions,
+ candidates,
+ information,
+ backtrack_causes,
+ ):
+ """Produce a sort key for given requirement based on preference.
+
+ The preference is defined as "I think this requirement should be
+ resolved first". The lower the return value is, the more preferred
+ this group of arguments is.
+
+ :param identifier: An identifier as returned by ``identify()``. This
+ identifies the dependency matches which should be returned.
+ :param resolutions: Mapping of candidates currently pinned by the
+ resolver. Each key is an identifier, and the value is a candidate.
+ The candidate may conflict with requirements from ``information``.
+ :param candidates: Mapping of each dependency's possible candidates.
+ Each value is an iterator of candidates.
+ :param information: Mapping of requirement information of each package.
+ Each value is an iterator of *requirement information*.
+ :param backtrack_causes: Sequence of requirement information that were
+ the requirements that caused the resolver to most recently backtrack.
+
+ A *requirement information* instance is a named tuple with two members:
+
+ * ``requirement`` specifies a requirement contributing to the current
+ list of candidates.
+ * ``parent`` specifies the candidate that provides (depended on) the
+ requirement, or ``None`` to indicate a root requirement.
+
+ The preference could depend on various issues, including (not
+ necessarily in this order):
+
+ * Is this package pinned in the current resolution result?
+ * How relaxed is the requirement? Stricter ones should probably be
+ worked on first? (I don't know, actually.)
+ * How many possibilities are there to satisfy this requirement? Those
+ with few left should likely be worked on first, I guess?
+ * Are there any known conflicts for this requirement? We should
+ probably work on those with the most known conflicts.
+
+ A sortable value should be returned (this will be used as the ``key``
+ parameter of the built-in sorting function). The smaller the value is,
+ the more preferred this requirement is (i.e. the sorting function
+ is called with ``reverse=False``).
+ """
+ raise NotImplementedError
+
+ def find_matches(self, identifier, requirements, incompatibilities):
+ """Find all possible candidates that satisfy the given constraints.
+
+ :param identifier: An identifier as returned by ``identify()``. This
+ identifies the dependency matches of which should be returned.
+ :param requirements: A mapping of requirements that all returned
+ candidates must satisfy. Each key is an identifier, and the value
+ an iterator of requirements for that dependency.
+ :param incompatibilities: A mapping of known incompatibilities of
+ each dependency. Each key is an identifier, and the value an
+ iterator of incompatibilities known to the resolver. All
+ incompatibilities *must* be excluded from the return value.
+
+ This should try to get candidates based on the requirements' types.
+ For VCS, local, and archive requirements, the one-and-only match is
+ returned, and for a "named" requirement, the index(es) should be
+ consulted to find concrete candidates for this requirement.
+
+ The return value should produce candidates ordered by preference; the
+ most preferred candidate should come first. The return type may be one
+ of the following:
+
+ * A callable that returns an iterator that yields candidates.
+ * An collection of candidates.
+ * An iterable of candidates. This will be consumed immediately into a
+ list of candidates.
+ """
+ raise NotImplementedError
+
+ def is_satisfied_by(self, requirement, candidate):
+ """Whether the given requirement can be satisfied by a candidate.
+
+ The candidate is guaranteed to have been generated from the
+ requirement.
+
+ A boolean should be returned to indicate whether ``candidate`` is a
+ viable solution to the requirement.
+ """
+ raise NotImplementedError
+
+ def get_dependencies(self, candidate):
+ """Get dependencies of a candidate.
+
+ This should return a collection of requirements that `candidate`
+ specifies as its dependencies.
+ """
+ raise NotImplementedError
+
+
+class AbstractResolver(object):
+ """The thing that performs the actual resolution work."""
+
+ base_exception = Exception
+
+ def __init__(self, provider, reporter):
+ self.provider = provider
+ self.reporter = reporter
+
+ def resolve(self, requirements, **kwargs):
+ """Take a collection of constraints, spit out the resolution result.
+
+ This returns a representation of the final resolution state, with one
+ guarenteed attribute ``mapping`` that contains resolved candidates as
+ values. The keys are their respective identifiers.
+
+ :param requirements: A collection of constraints.
+ :param kwargs: Additional keyword arguments that subclasses may accept.
+
+ :raises: ``self.base_exception`` or its subclass.
+ """
+ raise NotImplementedError
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/reporters.py b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/reporters.py
new file mode 100644
index 000000000..688b5e10d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/reporters.py
@@ -0,0 +1,43 @@
+class BaseReporter(object):
+ """Delegate class to provider progress reporting for the resolver."""
+
+ def starting(self):
+ """Called before the resolution actually starts."""
+
+ def starting_round(self, index):
+ """Called before each round of resolution starts.
+
+ The index is zero-based.
+ """
+
+ def ending_round(self, index, state):
+ """Called before each round of resolution ends.
+
+ This is NOT called if the resolution ends at this round. Use `ending`
+ if you want to report finalization. The index is zero-based.
+ """
+
+ def ending(self, state):
+ """Called before the resolution ends successfully."""
+
+ def adding_requirement(self, requirement, parent):
+ """Called when adding a new requirement into the resolve criteria.
+
+ :param requirement: The additional requirement to be applied to filter
+ the available candidaites.
+ :param parent: The candidate that requires ``requirement`` as a
+ dependency, or None if ``requirement`` is one of the root
+ requirements passed in from ``Resolver.resolve()``.
+ """
+
+ def resolving_conflicts(self, causes):
+ """Called when starting to attempt requirement conflict resolution.
+
+ :param causes: The information on the collision that caused the backtracking.
+ """
+
+ def rejecting_candidate(self, criterion, candidate):
+ """Called when rejecting a candidate during backtracking."""
+
+ def pinning(self, candidate):
+ """Called when adding a candidate to the potential solution."""
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/resolvers.py b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/resolvers.py
new file mode 100644
index 000000000..2c3d0e306
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/resolvers.py
@@ -0,0 +1,547 @@
+import collections
+import itertools
+import operator
+
+from .providers import AbstractResolver
+from .structs import DirectedGraph, IteratorMapping, build_iter_view
+
+RequirementInformation = collections.namedtuple(
+ "RequirementInformation", ["requirement", "parent"]
+)
+
+
+class ResolverException(Exception):
+ """A base class for all exceptions raised by this module.
+
+ Exceptions derived by this class should all be handled in this module. Any
+ bubbling pass the resolver should be treated as a bug.
+ """
+
+
+class RequirementsConflicted(ResolverException):
+ def __init__(self, criterion):
+ super(RequirementsConflicted, self).__init__(criterion)
+ self.criterion = criterion
+
+ def __str__(self):
+ return "Requirements conflict: {}".format(
+ ", ".join(repr(r) for r in self.criterion.iter_requirement()),
+ )
+
+
+class InconsistentCandidate(ResolverException):
+ def __init__(self, candidate, criterion):
+ super(InconsistentCandidate, self).__init__(candidate, criterion)
+ self.candidate = candidate
+ self.criterion = criterion
+
+ def __str__(self):
+ return "Provided candidate {!r} does not satisfy {}".format(
+ self.candidate,
+ ", ".join(repr(r) for r in self.criterion.iter_requirement()),
+ )
+
+
+class Criterion(object):
+ """Representation of possible resolution results of a package.
+
+ This holds three attributes:
+
+ * `information` is a collection of `RequirementInformation` pairs.
+ Each pair is a requirement contributing to this criterion, and the
+ candidate that provides the requirement.
+ * `incompatibilities` is a collection of all known not-to-work candidates
+ to exclude from consideration.
+ * `candidates` is a collection containing all possible candidates deducted
+ from the union of contributing requirements and known incompatibilities.
+ It should never be empty, except when the criterion is an attribute of a
+ raised `RequirementsConflicted` (in which case it is always empty).
+
+ .. note::
+ This class is intended to be externally immutable. **Do not** mutate
+ any of its attribute containers.
+ """
+
+ def __init__(self, candidates, information, incompatibilities):
+ self.candidates = candidates
+ self.information = information
+ self.incompatibilities = incompatibilities
+
+ def __repr__(self):
+ requirements = ", ".join(
+ "({!r}, via={!r})".format(req, parent)
+ for req, parent in self.information
+ )
+ return "Criterion({})".format(requirements)
+
+ def iter_requirement(self):
+ return (i.requirement for i in self.information)
+
+ def iter_parent(self):
+ return (i.parent for i in self.information)
+
+
+class ResolutionError(ResolverException):
+ pass
+
+
+class ResolutionImpossible(ResolutionError):
+ def __init__(self, causes):
+ super(ResolutionImpossible, self).__init__(causes)
+ # causes is a list of RequirementInformation objects
+ self.causes = causes
+
+
+class ResolutionTooDeep(ResolutionError):
+ def __init__(self, round_count):
+ super(ResolutionTooDeep, self).__init__(round_count)
+ self.round_count = round_count
+
+
+# Resolution state in a round.
+State = collections.namedtuple("State", "mapping criteria backtrack_causes")
+
+
+class Resolution(object):
+ """Stateful resolution object.
+
+ This is designed as a one-off object that holds information to kick start
+ the resolution process, and holds the results afterwards.
+ """
+
+ def __init__(self, provider, reporter):
+ self._p = provider
+ self._r = reporter
+ self._states = []
+
+ @property
+ def state(self):
+ try:
+ return self._states[-1]
+ except IndexError:
+ raise AttributeError("state")
+
+ def _push_new_state(self):
+ """Push a new state into history.
+
+ This new state will be used to hold resolution results of the next
+ coming round.
+ """
+ base = self._states[-1]
+ state = State(
+ mapping=base.mapping.copy(),
+ criteria=base.criteria.copy(),
+ backtrack_causes=base.backtrack_causes[:],
+ )
+ self._states.append(state)
+
+ def _add_to_criteria(self, criteria, requirement, parent):
+ self._r.adding_requirement(requirement=requirement, parent=parent)
+
+ identifier = self._p.identify(requirement_or_candidate=requirement)
+ criterion = criteria.get(identifier)
+ if criterion:
+ incompatibilities = list(criterion.incompatibilities)
+ else:
+ incompatibilities = []
+
+ matches = self._p.find_matches(
+ identifier=identifier,
+ requirements=IteratorMapping(
+ criteria,
+ operator.methodcaller("iter_requirement"),
+ {identifier: [requirement]},
+ ),
+ incompatibilities=IteratorMapping(
+ criteria,
+ operator.attrgetter("incompatibilities"),
+ {identifier: incompatibilities},
+ ),
+ )
+
+ if criterion:
+ information = list(criterion.information)
+ information.append(RequirementInformation(requirement, parent))
+ else:
+ information = [RequirementInformation(requirement, parent)]
+
+ criterion = Criterion(
+ candidates=build_iter_view(matches),
+ information=information,
+ incompatibilities=incompatibilities,
+ )
+ if not criterion.candidates:
+ raise RequirementsConflicted(criterion)
+ criteria[identifier] = criterion
+
+ def _remove_information_from_criteria(self, criteria, parents):
+ """Remove information from parents of criteria.
+
+ Concretely, removes all values from each criterion's ``information``
+ field that have one of ``parents`` as provider of the requirement.
+
+ :param criteria: The criteria to update.
+ :param parents: Identifiers for which to remove information from all criteria.
+ """
+ if not parents:
+ return
+ for key, criterion in criteria.items():
+ criteria[key] = Criterion(
+ criterion.candidates,
+ [
+ information
+ for information in criterion.information
+ if (
+ information.parent is None
+ or self._p.identify(information.parent) not in parents
+ )
+ ],
+ criterion.incompatibilities,
+ )
+
+ def _get_preference(self, name):
+ return self._p.get_preference(
+ identifier=name,
+ resolutions=self.state.mapping,
+ candidates=IteratorMapping(
+ self.state.criteria,
+ operator.attrgetter("candidates"),
+ ),
+ information=IteratorMapping(
+ self.state.criteria,
+ operator.attrgetter("information"),
+ ),
+ backtrack_causes=self.state.backtrack_causes,
+ )
+
+ def _is_current_pin_satisfying(self, name, criterion):
+ try:
+ current_pin = self.state.mapping[name]
+ except KeyError:
+ return False
+ return all(
+ self._p.is_satisfied_by(requirement=r, candidate=current_pin)
+ for r in criterion.iter_requirement()
+ )
+
+ def _get_updated_criteria(self, candidate):
+ criteria = self.state.criteria.copy()
+ for requirement in self._p.get_dependencies(candidate=candidate):
+ self._add_to_criteria(criteria, requirement, parent=candidate)
+ return criteria
+
+ def _attempt_to_pin_criterion(self, name):
+ criterion = self.state.criteria[name]
+
+ causes = []
+ for candidate in criterion.candidates:
+ try:
+ criteria = self._get_updated_criteria(candidate)
+ except RequirementsConflicted as e:
+ self._r.rejecting_candidate(e.criterion, candidate)
+ causes.append(e.criterion)
+ continue
+
+ # Check the newly-pinned candidate actually works. This should
+ # always pass under normal circumstances, but in the case of a
+ # faulty provider, we will raise an error to notify the implementer
+ # to fix find_matches() and/or is_satisfied_by().
+ satisfied = all(
+ self._p.is_satisfied_by(requirement=r, candidate=candidate)
+ for r in criterion.iter_requirement()
+ )
+ if not satisfied:
+ raise InconsistentCandidate(candidate, criterion)
+
+ self._r.pinning(candidate=candidate)
+ self.state.criteria.update(criteria)
+
+ # Put newly-pinned candidate at the end. This is essential because
+ # backtracking looks at this mapping to get the last pin.
+ self.state.mapping.pop(name, None)
+ self.state.mapping[name] = candidate
+
+ return []
+
+ # All candidates tried, nothing works. This criterion is a dead
+ # end, signal for backtracking.
+ return causes
+
+ def _backjump(self, causes):
+ """Perform backjumping.
+
+ When we enter here, the stack is like this::
+
+ [ state Z ]
+ [ state Y ]
+ [ state X ]
+ .... earlier states are irrelevant.
+
+ 1. No pins worked for Z, so it does not have a pin.
+ 2. We want to reset state Y to unpinned, and pin another candidate.
+ 3. State X holds what state Y was before the pin, but does not
+ have the incompatibility information gathered in state Y.
+
+ Each iteration of the loop will:
+
+ 1. Identify Z. The incompatibility is not always caused by the latest
+ state. For example, given three requirements A, B and C, with
+ dependencies A1, B1 and C1, where A1 and B1 are incompatible: the
+ last state might be related to C, so we want to discard the
+ previous state.
+ 2. Discard Z.
+ 3. Discard Y but remember its incompatibility information gathered
+ previously, and the failure we're dealing with right now.
+ 4. Push a new state Y' based on X, and apply the incompatibility
+ information from Y to Y'.
+ 5a. If this causes Y' to conflict, we need to backtrack again. Make Y'
+ the new Z and go back to step 2.
+ 5b. If the incompatibilities apply cleanly, end backtracking.
+ """
+ incompatible_reqs = itertools.chain(
+ (c.parent for c in causes if c.parent is not None),
+ (c.requirement for c in causes),
+ )
+ incompatible_deps = {self._p.identify(r) for r in incompatible_reqs}
+ while len(self._states) >= 3:
+ # Remove the state that triggered backtracking.
+ del self._states[-1]
+
+ # Ensure to backtrack to a state that caused the incompatibility
+ incompatible_state = False
+ while not incompatible_state:
+ # Retrieve the last candidate pin and known incompatibilities.
+ try:
+ broken_state = self._states.pop()
+ name, candidate = broken_state.mapping.popitem()
+ except (IndexError, KeyError):
+ raise ResolutionImpossible(causes)
+ current_dependencies = {
+ self._p.identify(d)
+ for d in self._p.get_dependencies(candidate)
+ }
+ incompatible_state = not current_dependencies.isdisjoint(
+ incompatible_deps
+ )
+
+ incompatibilities_from_broken = [
+ (k, list(v.incompatibilities))
+ for k, v in broken_state.criteria.items()
+ ]
+
+ # Also mark the newly known incompatibility.
+ incompatibilities_from_broken.append((name, [candidate]))
+
+ # Create a new state from the last known-to-work one, and apply
+ # the previously gathered incompatibility information.
+ def _patch_criteria():
+ for k, incompatibilities in incompatibilities_from_broken:
+ if not incompatibilities:
+ continue
+ try:
+ criterion = self.state.criteria[k]
+ except KeyError:
+ continue
+ matches = self._p.find_matches(
+ identifier=k,
+ requirements=IteratorMapping(
+ self.state.criteria,
+ operator.methodcaller("iter_requirement"),
+ ),
+ incompatibilities=IteratorMapping(
+ self.state.criteria,
+ operator.attrgetter("incompatibilities"),
+ {k: incompatibilities},
+ ),
+ )
+ candidates = build_iter_view(matches)
+ if not candidates:
+ return False
+ incompatibilities.extend(criterion.incompatibilities)
+ self.state.criteria[k] = Criterion(
+ candidates=candidates,
+ information=list(criterion.information),
+ incompatibilities=incompatibilities,
+ )
+ return True
+
+ self._push_new_state()
+ success = _patch_criteria()
+
+ # It works! Let's work on this new state.
+ if success:
+ return True
+
+ # State does not work after applying known incompatibilities.
+ # Try the still previous state.
+
+ # No way to backtrack anymore.
+ return False
+
+ def resolve(self, requirements, max_rounds):
+ if self._states:
+ raise RuntimeError("already resolved")
+
+ self._r.starting()
+
+ # Initialize the root state.
+ self._states = [
+ State(
+ mapping=collections.OrderedDict(),
+ criteria={},
+ backtrack_causes=[],
+ )
+ ]
+ for r in requirements:
+ try:
+ self._add_to_criteria(self.state.criteria, r, parent=None)
+ except RequirementsConflicted as e:
+ raise ResolutionImpossible(e.criterion.information)
+
+ # The root state is saved as a sentinel so the first ever pin can have
+ # something to backtrack to if it fails. The root state is basically
+ # pinning the virtual "root" package in the graph.
+ self._push_new_state()
+
+ for round_index in range(max_rounds):
+ self._r.starting_round(index=round_index)
+
+ unsatisfied_names = [
+ key
+ for key, criterion in self.state.criteria.items()
+ if not self._is_current_pin_satisfying(key, criterion)
+ ]
+
+ # All criteria are accounted for. Nothing more to pin, we are done!
+ if not unsatisfied_names:
+ self._r.ending(state=self.state)
+ return self.state
+
+ # keep track of satisfied names to calculate diff after pinning
+ satisfied_names = set(self.state.criteria.keys()) - set(
+ unsatisfied_names
+ )
+
+ # Choose the most preferred unpinned criterion to try.
+ name = min(unsatisfied_names, key=self._get_preference)
+ failure_causes = self._attempt_to_pin_criterion(name)
+
+ if failure_causes:
+ causes = [i for c in failure_causes for i in c.information]
+ # Backjump if pinning fails. The backjump process puts us in
+ # an unpinned state, so we can work on it in the next round.
+ self._r.resolving_conflicts(causes=causes)
+ success = self._backjump(causes)
+ self.state.backtrack_causes[:] = causes
+
+ # Dead ends everywhere. Give up.
+ if not success:
+ raise ResolutionImpossible(self.state.backtrack_causes)
+ else:
+ # discard as information sources any invalidated names
+ # (unsatisfied names that were previously satisfied)
+ newly_unsatisfied_names = {
+ key
+ for key, criterion in self.state.criteria.items()
+ if key in satisfied_names
+ and not self._is_current_pin_satisfying(key, criterion)
+ }
+ self._remove_information_from_criteria(
+ self.state.criteria, newly_unsatisfied_names
+ )
+ # Pinning was successful. Push a new state to do another pin.
+ self._push_new_state()
+
+ self._r.ending_round(index=round_index, state=self.state)
+
+ raise ResolutionTooDeep(max_rounds)
+
+
+def _has_route_to_root(criteria, key, all_keys, connected):
+ if key in connected:
+ return True
+ if key not in criteria:
+ return False
+ for p in criteria[key].iter_parent():
+ try:
+ pkey = all_keys[id(p)]
+ except KeyError:
+ continue
+ if pkey in connected:
+ connected.add(key)
+ return True
+ if _has_route_to_root(criteria, pkey, all_keys, connected):
+ connected.add(key)
+ return True
+ return False
+
+
+Result = collections.namedtuple("Result", "mapping graph criteria")
+
+
+def _build_result(state):
+ mapping = state.mapping
+ all_keys = {id(v): k for k, v in mapping.items()}
+ all_keys[id(None)] = None
+
+ graph = DirectedGraph()
+ graph.add(None) # Sentinel as root dependencies' parent.
+
+ connected = {None}
+ for key, criterion in state.criteria.items():
+ if not _has_route_to_root(state.criteria, key, all_keys, connected):
+ continue
+ if key not in graph:
+ graph.add(key)
+ for p in criterion.iter_parent():
+ try:
+ pkey = all_keys[id(p)]
+ except KeyError:
+ continue
+ if pkey not in graph:
+ graph.add(pkey)
+ graph.connect(pkey, key)
+
+ return Result(
+ mapping={k: v for k, v in mapping.items() if k in connected},
+ graph=graph,
+ criteria=state.criteria,
+ )
+
+
+class Resolver(AbstractResolver):
+ """The thing that performs the actual resolution work."""
+
+ base_exception = ResolverException
+
+ def resolve(self, requirements, max_rounds=100):
+ """Take a collection of constraints, spit out the resolution result.
+
+ The return value is a representation to the final resolution result. It
+ is a tuple subclass with three public members:
+
+ * `mapping`: A dict of resolved candidates. Each key is an identifier
+ of a requirement (as returned by the provider's `identify` method),
+ and the value is the resolved candidate.
+ * `graph`: A `DirectedGraph` instance representing the dependency tree.
+ The vertices are keys of `mapping`, and each edge represents *why*
+ a particular package is included. A special vertex `None` is
+ included to represent parents of user-supplied requirements.
+ * `criteria`: A dict of "criteria" that hold detailed information on
+ how edges in the graph are derived. Each key is an identifier of a
+ requirement, and the value is a `Criterion` instance.
+
+ The following exceptions may be raised if a resolution cannot be found:
+
+ * `ResolutionImpossible`: A resolution cannot be found for the given
+ combination of requirements. The `causes` attribute of the
+ exception is a list of (requirement, parent), giving the
+ requirements that could not be satisfied.
+ * `ResolutionTooDeep`: The dependency tree is too deeply nested and
+ the resolver gave up. This is usually caused by a circular
+ dependency, but you can try to resolve this by increasing the
+ `max_rounds` argument.
+ """
+ resolution = Resolution(self.provider, self.reporter)
+ state = resolution.resolve(requirements, max_rounds=max_rounds)
+ return _build_result(state)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/structs.py b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/structs.py
new file mode 100644
index 000000000..359a34f60
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/resolvelib/structs.py
@@ -0,0 +1,170 @@
+import itertools
+
+from .compat import collections_abc
+
+
+class DirectedGraph(object):
+ """A graph structure with directed edges."""
+
+ def __init__(self):
+ self._vertices = set()
+ self._forwards = {} # <key> -> Set[<key>]
+ self._backwards = {} # <key> -> Set[<key>]
+
+ def __iter__(self):
+ return iter(self._vertices)
+
+ def __len__(self):
+ return len(self._vertices)
+
+ def __contains__(self, key):
+ return key in self._vertices
+
+ def copy(self):
+ """Return a shallow copy of this graph."""
+ other = DirectedGraph()
+ other._vertices = set(self._vertices)
+ other._forwards = {k: set(v) for k, v in self._forwards.items()}
+ other._backwards = {k: set(v) for k, v in self._backwards.items()}
+ return other
+
+ def add(self, key):
+ """Add a new vertex to the graph."""
+ if key in self._vertices:
+ raise ValueError("vertex exists")
+ self._vertices.add(key)
+ self._forwards[key] = set()
+ self._backwards[key] = set()
+
+ def remove(self, key):
+ """Remove a vertex from the graph, disconnecting all edges from/to it."""
+ self._vertices.remove(key)
+ for f in self._forwards.pop(key):
+ self._backwards[f].remove(key)
+ for t in self._backwards.pop(key):
+ self._forwards[t].remove(key)
+
+ def connected(self, f, t):
+ return f in self._backwards[t] and t in self._forwards[f]
+
+ def connect(self, f, t):
+ """Connect two existing vertices.
+
+ Nothing happens if the vertices are already connected.
+ """
+ if t not in self._vertices:
+ raise KeyError(t)
+ self._forwards[f].add(t)
+ self._backwards[t].add(f)
+
+ def iter_edges(self):
+ for f, children in self._forwards.items():
+ for t in children:
+ yield f, t
+
+ def iter_children(self, key):
+ return iter(self._forwards[key])
+
+ def iter_parents(self, key):
+ return iter(self._backwards[key])
+
+
+class IteratorMapping(collections_abc.Mapping):
+ def __init__(self, mapping, accessor, appends=None):
+ self._mapping = mapping
+ self._accessor = accessor
+ self._appends = appends or {}
+
+ def __repr__(self):
+ return "IteratorMapping({!r}, {!r}, {!r})".format(
+ self._mapping,
+ self._accessor,
+ self._appends,
+ )
+
+ def __bool__(self):
+ return bool(self._mapping or self._appends)
+
+ __nonzero__ = __bool__ # XXX: Python 2.
+
+ def __contains__(self, key):
+ return key in self._mapping or key in self._appends
+
+ def __getitem__(self, k):
+ try:
+ v = self._mapping[k]
+ except KeyError:
+ return iter(self._appends[k])
+ return itertools.chain(self._accessor(v), self._appends.get(k, ()))
+
+ def __iter__(self):
+ more = (k for k in self._appends if k not in self._mapping)
+ return itertools.chain(self._mapping, more)
+
+ def __len__(self):
+ more = sum(1 for k in self._appends if k not in self._mapping)
+ return len(self._mapping) + more
+
+
+class _FactoryIterableView(object):
+ """Wrap an iterator factory returned by `find_matches()`.
+
+ Calling `iter()` on this class would invoke the underlying iterator
+ factory, making it a "collection with ordering" that can be iterated
+ through multiple times, but lacks random access methods presented in
+ built-in Python sequence types.
+ """
+
+ def __init__(self, factory):
+ self._factory = factory
+ self._iterable = None
+
+ def __repr__(self):
+ return "{}({})".format(type(self).__name__, list(self))
+
+ def __bool__(self):
+ try:
+ next(iter(self))
+ except StopIteration:
+ return False
+ return True
+
+ __nonzero__ = __bool__ # XXX: Python 2.
+
+ def __iter__(self):
+ iterable = (
+ self._factory() if self._iterable is None else self._iterable
+ )
+ self._iterable, current = itertools.tee(iterable)
+ return current
+
+
+class _SequenceIterableView(object):
+ """Wrap an iterable returned by find_matches().
+
+ This is essentially just a proxy to the underlying sequence that provides
+ the same interface as `_FactoryIterableView`.
+ """
+
+ def __init__(self, sequence):
+ self._sequence = sequence
+
+ def __repr__(self):
+ return "{}({})".format(type(self).__name__, self._sequence)
+
+ def __bool__(self):
+ return bool(self._sequence)
+
+ __nonzero__ = __bool__ # XXX: Python 2.
+
+ def __iter__(self):
+ return iter(self._sequence)
+
+
+def build_iter_view(matches):
+ """Build an iterable view from the value returned by `find_matches()`."""
+ if callable(matches):
+ return _FactoryIterableView(matches)
+ if not isinstance(matches, collections_abc.Sequence):
+ matches = list(matches)
+ return _SequenceIterableView(matches)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/__init__.py
new file mode 100644
index 000000000..73f58d774
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/__init__.py
@@ -0,0 +1,177 @@
+"""Rich text and beautiful formatting in the terminal."""
+
+import os
+from typing import IO, TYPE_CHECKING, Any, Callable, Optional, Union
+
+from ._extension import load_ipython_extension # noqa: F401
+
+__all__ = ["get_console", "reconfigure", "print", "inspect", "print_json"]
+
+if TYPE_CHECKING:
+ from .console import Console
+
+# Global console used by alternative print
+_console: Optional["Console"] = None
+
+try:
+ _IMPORT_CWD = os.path.abspath(os.getcwd())
+except FileNotFoundError:
+ # Can happen if the cwd has been deleted
+ _IMPORT_CWD = ""
+
+
+def get_console() -> "Console":
+ """Get a global :class:`~rich.console.Console` instance. This function is used when Rich requires a Console,
+ and hasn't been explicitly given one.
+
+ Returns:
+ Console: A console instance.
+ """
+ global _console
+ if _console is None:
+ from .console import Console
+
+ _console = Console()
+
+ return _console
+
+
+def reconfigure(*args: Any, **kwargs: Any) -> None:
+ """Reconfigures the global console by replacing it with another.
+
+ Args:
+ *args (Any): Positional arguments for the replacement :class:`~rich.console.Console`.
+ **kwargs (Any): Keyword arguments for the replacement :class:`~rich.console.Console`.
+ """
+ from pip._vendor.rich.console import Console
+
+ new_console = Console(*args, **kwargs)
+ _console = get_console()
+ _console.__dict__ = new_console.__dict__
+
+
+def print(
+ *objects: Any,
+ sep: str = " ",
+ end: str = "\n",
+ file: Optional[IO[str]] = None,
+ flush: bool = False,
+) -> None:
+ r"""Print object(s) supplied via positional arguments.
+ This function has an identical signature to the built-in print.
+ For more advanced features, see the :class:`~rich.console.Console` class.
+
+ Args:
+ sep (str, optional): Separator between printed objects. Defaults to " ".
+ end (str, optional): Character to write at end of output. Defaults to "\\n".
+ file (IO[str], optional): File to write to, or None for stdout. Defaults to None.
+ flush (bool, optional): Has no effect as Rich always flushes output. Defaults to False.
+
+ """
+ from .console import Console
+
+ write_console = get_console() if file is None else Console(file=file)
+ return write_console.print(*objects, sep=sep, end=end)
+
+
+def print_json(
+ json: Optional[str] = None,
+ *,
+ data: Any = None,
+ indent: Union[None, int, str] = 2,
+ highlight: bool = True,
+ skip_keys: bool = False,
+ ensure_ascii: bool = False,
+ check_circular: bool = True,
+ allow_nan: bool = True,
+ default: Optional[Callable[[Any], Any]] = None,
+ sort_keys: bool = False,
+) -> None:
+ """Pretty prints JSON. Output will be valid JSON.
+
+ Args:
+ json (str): A string containing JSON.
+ data (Any): If json is not supplied, then encode this data.
+ indent (int, optional): Number of spaces to indent. Defaults to 2.
+ highlight (bool, optional): Enable highlighting of output: Defaults to True.
+ skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.
+ ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.
+ check_circular (bool, optional): Check for circular references. Defaults to True.
+ allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.
+ default (Callable, optional): A callable that converts values that can not be encoded
+ in to something that can be JSON encoded. Defaults to None.
+ sort_keys (bool, optional): Sort dictionary keys. Defaults to False.
+ """
+
+ get_console().print_json(
+ json,
+ data=data,
+ indent=indent,
+ highlight=highlight,
+ skip_keys=skip_keys,
+ ensure_ascii=ensure_ascii,
+ check_circular=check_circular,
+ allow_nan=allow_nan,
+ default=default,
+ sort_keys=sort_keys,
+ )
+
+
+def inspect(
+ obj: Any,
+ *,
+ console: Optional["Console"] = None,
+ title: Optional[str] = None,
+ help: bool = False,
+ methods: bool = False,
+ docs: bool = True,
+ private: bool = False,
+ dunder: bool = False,
+ sort: bool = True,
+ all: bool = False,
+ value: bool = True,
+) -> None:
+ """Inspect any Python object.
+
+ * inspect(<OBJECT>) to see summarized info.
+ * inspect(<OBJECT>, methods=True) to see methods.
+ * inspect(<OBJECT>, help=True) to see full (non-abbreviated) help.
+ * inspect(<OBJECT>, private=True) to see private attributes (single underscore).
+ * inspect(<OBJECT>, dunder=True) to see attributes beginning with double underscore.
+ * inspect(<OBJECT>, all=True) to see all attributes.
+
+ Args:
+ obj (Any): An object to inspect.
+ title (str, optional): Title to display over inspect result, or None use type. Defaults to None.
+ help (bool, optional): Show full help text rather than just first paragraph. Defaults to False.
+ methods (bool, optional): Enable inspection of callables. Defaults to False.
+ docs (bool, optional): Also render doc strings. Defaults to True.
+ private (bool, optional): Show private attributes (beginning with underscore). Defaults to False.
+ dunder (bool, optional): Show attributes starting with double underscore. Defaults to False.
+ sort (bool, optional): Sort attributes alphabetically. Defaults to True.
+ all (bool, optional): Show all attributes. Defaults to False.
+ value (bool, optional): Pretty print value. Defaults to True.
+ """
+ _console = console or get_console()
+ from pip._vendor.rich._inspect import Inspect
+
+ # Special case for inspect(inspect)
+ is_inspect = obj is inspect
+
+ _inspect = Inspect(
+ obj,
+ title=title,
+ help=is_inspect or help,
+ methods=is_inspect or methods,
+ docs=is_inspect or docs,
+ private=private,
+ dunder=dunder,
+ sort=sort,
+ all=all,
+ value=value,
+ )
+ _console.print(_inspect)
+
+
+if __name__ == "__main__": # pragma: no cover
+ print("Hello, **World**")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/__main__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/__main__.py
new file mode 100644
index 000000000..efb7fb79b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/__main__.py
@@ -0,0 +1,273 @@
+import colorsys
+import io
+from time import process_time
+
+from pip._vendor.rich import box
+from pip._vendor.rich.color import Color
+from pip._vendor.rich.console import Console, ConsoleOptions, Group, RenderableType, RenderResult
+from pip._vendor.rich.markdown import Markdown
+from pip._vendor.rich.measure import Measurement
+from pip._vendor.rich.pretty import Pretty
+from pip._vendor.rich.segment import Segment
+from pip._vendor.rich.style import Style
+from pip._vendor.rich.syntax import Syntax
+from pip._vendor.rich.table import Table
+from pip._vendor.rich.text import Text
+
+
+class ColorBox:
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ for y in range(0, 5):
+ for x in range(options.max_width):
+ h = x / options.max_width
+ l = 0.1 + ((y / 5) * 0.7)
+ r1, g1, b1 = colorsys.hls_to_rgb(h, l, 1.0)
+ r2, g2, b2 = colorsys.hls_to_rgb(h, l + 0.7 / 10, 1.0)
+ bgcolor = Color.from_rgb(r1 * 255, g1 * 255, b1 * 255)
+ color = Color.from_rgb(r2 * 255, g2 * 255, b2 * 255)
+ yield Segment("▄", Style(color=color, bgcolor=bgcolor))
+ yield Segment.line()
+
+ def __rich_measure__(
+ self, console: "Console", options: ConsoleOptions
+ ) -> Measurement:
+ return Measurement(1, options.max_width)
+
+
+def make_test_card() -> Table:
+ """Get a renderable that demonstrates a number of features."""
+ table = Table.grid(padding=1, pad_edge=True)
+ table.title = "Rich features"
+ table.add_column("Feature", no_wrap=True, justify="center", style="bold red")
+ table.add_column("Demonstration")
+
+ color_table = Table(
+ box=None,
+ expand=False,
+ show_header=False,
+ show_edge=False,
+ pad_edge=False,
+ )
+ color_table.add_row(
+ (
+ "✓ [bold green]4-bit color[/]\n"
+ "✓ [bold blue]8-bit color[/]\n"
+ "✓ [bold magenta]Truecolor (16.7 million)[/]\n"
+ "✓ [bold yellow]Dumb terminals[/]\n"
+ "✓ [bold cyan]Automatic color conversion"
+ ),
+ ColorBox(),
+ )
+
+ table.add_row("Colors", color_table)
+
+ table.add_row(
+ "Styles",
+ "All ansi styles: [bold]bold[/], [dim]dim[/], [italic]italic[/italic], [underline]underline[/], [strike]strikethrough[/], [reverse]reverse[/], and even [blink]blink[/].",
+ )
+
+ lorem = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque in metus sed sapien ultricies pretium a at justo. Maecenas luctus velit et auctor maximus."
+ lorem_table = Table.grid(padding=1, collapse_padding=True)
+ lorem_table.pad_edge = False
+ lorem_table.add_row(
+ Text(lorem, justify="left", style="green"),
+ Text(lorem, justify="center", style="yellow"),
+ Text(lorem, justify="right", style="blue"),
+ Text(lorem, justify="full", style="red"),
+ )
+ table.add_row(
+ "Text",
+ Group(
+ Text.from_markup(
+ """Word wrap text. Justify [green]left[/], [yellow]center[/], [blue]right[/] or [red]full[/].\n"""
+ ),
+ lorem_table,
+ ),
+ )
+
+ def comparison(renderable1: RenderableType, renderable2: RenderableType) -> Table:
+ table = Table(show_header=False, pad_edge=False, box=None, expand=True)
+ table.add_column("1", ratio=1)
+ table.add_column("2", ratio=1)
+ table.add_row(renderable1, renderable2)
+ return table
+
+ table.add_row(
+ "Asian\nlanguage\nsupport",
+ ":flag_for_china: 该库支持中文,日文和韩文文本!\n:flag_for_japan: ライブラリは中国語、日本語、韓国語のテキストをサポートしています\n:flag_for_south_korea: 이 라이브러리는 중국어, 일본어 및 한국어 텍스트를 지원합니다",
+ )
+
+ markup_example = (
+ "[bold magenta]Rich[/] supports a simple [i]bbcode[/i]-like [b]markup[/b] for [yellow]color[/], [underline]style[/], and emoji! "
+ ":+1: :apple: :ant: :bear: :baguette_bread: :bus: "
+ )
+ table.add_row("Markup", markup_example)
+
+ example_table = Table(
+ show_edge=False,
+ show_header=True,
+ expand=False,
+ row_styles=["none", "dim"],
+ box=box.SIMPLE,
+ )
+ example_table.add_column("[green]Date", style="green", no_wrap=True)
+ example_table.add_column("[blue]Title", style="blue")
+ example_table.add_column(
+ "[cyan]Production Budget",
+ style="cyan",
+ justify="right",
+ no_wrap=True,
+ )
+ example_table.add_column(
+ "[magenta]Box Office",
+ style="magenta",
+ justify="right",
+ no_wrap=True,
+ )
+ example_table.add_row(
+ "Dec 20, 2019",
+ "Star Wars: The Rise of Skywalker",
+ "$275,000,000",
+ "$375,126,118",
+ )
+ example_table.add_row(
+ "May 25, 2018",
+ "[b]Solo[/]: A Star Wars Story",
+ "$275,000,000",
+ "$393,151,347",
+ )
+ example_table.add_row(
+ "Dec 15, 2017",
+ "Star Wars Ep. VIII: The Last Jedi",
+ "$262,000,000",
+ "[bold]$1,332,539,889[/bold]",
+ )
+ example_table.add_row(
+ "May 19, 1999",
+ "Star Wars Ep. [b]I[/b]: [i]The phantom Menace",
+ "$115,000,000",
+ "$1,027,044,677",
+ )
+
+ table.add_row("Tables", example_table)
+
+ code = '''\
+def iter_last(values: Iterable[T]) -> Iterable[Tuple[bool, T]]:
+ """Iterate and generate a tuple with a flag for last value."""
+ iter_values = iter(values)
+ try:
+ previous_value = next(iter_values)
+ except StopIteration:
+ return
+ for value in iter_values:
+ yield False, previous_value
+ previous_value = value
+ yield True, previous_value'''
+
+ pretty_data = {
+ "foo": [
+ 3.1427,
+ (
+ "Paul Atreides",
+ "Vladimir Harkonnen",
+ "Thufir Hawat",
+ ),
+ ],
+ "atomic": (False, True, None),
+ }
+ table.add_row(
+ "Syntax\nhighlighting\n&\npretty\nprinting",
+ comparison(
+ Syntax(code, "python3", line_numbers=True, indent_guides=True),
+ Pretty(pretty_data, indent_guides=True),
+ ),
+ )
+
+ markdown_example = """\
+# Markdown
+
+Supports much of the *markdown* __syntax__!
+
+- Headers
+- Basic formatting: **bold**, *italic*, `code`
+- Block quotes
+- Lists, and more...
+ """
+ table.add_row(
+ "Markdown", comparison("[cyan]" + markdown_example, Markdown(markdown_example))
+ )
+
+ table.add_row(
+ "+more!",
+ """Progress bars, columns, styled logging handler, tracebacks, etc...""",
+ )
+ return table
+
+
+if __name__ == "__main__": # pragma: no cover
+ console = Console(
+ file=io.StringIO(),
+ force_terminal=True,
+ )
+ test_card = make_test_card()
+
+ # Print once to warm cache
+ start = process_time()
+ console.print(test_card)
+ pre_cache_taken = round((process_time() - start) * 1000.0, 1)
+
+ console.file = io.StringIO()
+
+ start = process_time()
+ console.print(test_card)
+ taken = round((process_time() - start) * 1000.0, 1)
+
+ c = Console(record=True)
+ c.print(test_card)
+
+ print(f"rendered in {pre_cache_taken}ms (cold cache)")
+ print(f"rendered in {taken}ms (warm cache)")
+
+ from pip._vendor.rich.panel import Panel
+
+ console = Console()
+
+ sponsor_message = Table.grid(padding=1)
+ sponsor_message.add_column(style="green", justify="right")
+ sponsor_message.add_column(no_wrap=True)
+
+ sponsor_message.add_row(
+ "Textualize",
+ "[u blue link=https://github.com/textualize]https://github.com/textualize",
+ )
+ sponsor_message.add_row(
+ "Twitter",
+ "[u blue link=https://twitter.com/willmcgugan]https://twitter.com/willmcgugan",
+ )
+
+ intro_message = Text.from_markup(
+ """\
+We hope you enjoy using Rich!
+
+Rich is maintained with [red]:heart:[/] by [link=https://www.textualize.io]Textualize.io[/]
+
+- Will McGugan"""
+ )
+
+ message = Table.grid(padding=2)
+ message.add_column()
+ message.add_column(no_wrap=True)
+ message.add_row(intro_message, sponsor_message)
+
+ console.print(
+ Panel.fit(
+ message,
+ box=box.ROUNDED,
+ padding=(1, 2),
+ title="[b red]Thanks for trying out Rich!",
+ border_style="bright_blue",
+ ),
+ justify="center",
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_cell_widths.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_cell_widths.py
new file mode 100644
index 000000000..608ae3a75
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_cell_widths.py
@@ -0,0 +1,454 @@
+# Auto generated by make_terminal_widths.py
+
+CELL_WIDTHS = [
+ (0, 0, 0),
+ (1, 31, -1),
+ (127, 159, -1),
+ (173, 173, 0),
+ (768, 879, 0),
+ (1155, 1161, 0),
+ (1425, 1469, 0),
+ (1471, 1471, 0),
+ (1473, 1474, 0),
+ (1476, 1477, 0),
+ (1479, 1479, 0),
+ (1536, 1541, 0),
+ (1552, 1562, 0),
+ (1564, 1564, 0),
+ (1611, 1631, 0),
+ (1648, 1648, 0),
+ (1750, 1757, 0),
+ (1759, 1764, 0),
+ (1767, 1768, 0),
+ (1770, 1773, 0),
+ (1807, 1807, 0),
+ (1809, 1809, 0),
+ (1840, 1866, 0),
+ (1958, 1968, 0),
+ (2027, 2035, 0),
+ (2045, 2045, 0),
+ (2070, 2073, 0),
+ (2075, 2083, 0),
+ (2085, 2087, 0),
+ (2089, 2093, 0),
+ (2137, 2139, 0),
+ (2192, 2193, 0),
+ (2200, 2207, 0),
+ (2250, 2307, 0),
+ (2362, 2364, 0),
+ (2366, 2383, 0),
+ (2385, 2391, 0),
+ (2402, 2403, 0),
+ (2433, 2435, 0),
+ (2492, 2492, 0),
+ (2494, 2500, 0),
+ (2503, 2504, 0),
+ (2507, 2509, 0),
+ (2519, 2519, 0),
+ (2530, 2531, 0),
+ (2558, 2558, 0),
+ (2561, 2563, 0),
+ (2620, 2620, 0),
+ (2622, 2626, 0),
+ (2631, 2632, 0),
+ (2635, 2637, 0),
+ (2641, 2641, 0),
+ (2672, 2673, 0),
+ (2677, 2677, 0),
+ (2689, 2691, 0),
+ (2748, 2748, 0),
+ (2750, 2757, 0),
+ (2759, 2761, 0),
+ (2763, 2765, 0),
+ (2786, 2787, 0),
+ (2810, 2815, 0),
+ (2817, 2819, 0),
+ (2876, 2876, 0),
+ (2878, 2884, 0),
+ (2887, 2888, 0),
+ (2891, 2893, 0),
+ (2901, 2903, 0),
+ (2914, 2915, 0),
+ (2946, 2946, 0),
+ (3006, 3010, 0),
+ (3014, 3016, 0),
+ (3018, 3021, 0),
+ (3031, 3031, 0),
+ (3072, 3076, 0),
+ (3132, 3132, 0),
+ (3134, 3140, 0),
+ (3142, 3144, 0),
+ (3146, 3149, 0),
+ (3157, 3158, 0),
+ (3170, 3171, 0),
+ (3201, 3203, 0),
+ (3260, 3260, 0),
+ (3262, 3268, 0),
+ (3270, 3272, 0),
+ (3274, 3277, 0),
+ (3285, 3286, 0),
+ (3298, 3299, 0),
+ (3315, 3315, 0),
+ (3328, 3331, 0),
+ (3387, 3388, 0),
+ (3390, 3396, 0),
+ (3398, 3400, 0),
+ (3402, 3405, 0),
+ (3415, 3415, 0),
+ (3426, 3427, 0),
+ (3457, 3459, 0),
+ (3530, 3530, 0),
+ (3535, 3540, 0),
+ (3542, 3542, 0),
+ (3544, 3551, 0),
+ (3570, 3571, 0),
+ (3633, 3633, 0),
+ (3636, 3642, 0),
+ (3655, 3662, 0),
+ (3761, 3761, 0),
+ (3764, 3772, 0),
+ (3784, 3790, 0),
+ (3864, 3865, 0),
+ (3893, 3893, 0),
+ (3895, 3895, 0),
+ (3897, 3897, 0),
+ (3902, 3903, 0),
+ (3953, 3972, 0),
+ (3974, 3975, 0),
+ (3981, 3991, 0),
+ (3993, 4028, 0),
+ (4038, 4038, 0),
+ (4139, 4158, 0),
+ (4182, 4185, 0),
+ (4190, 4192, 0),
+ (4194, 4196, 0),
+ (4199, 4205, 0),
+ (4209, 4212, 0),
+ (4226, 4237, 0),
+ (4239, 4239, 0),
+ (4250, 4253, 0),
+ (4352, 4447, 2),
+ (4448, 4607, 0),
+ (4957, 4959, 0),
+ (5906, 5909, 0),
+ (5938, 5940, 0),
+ (5970, 5971, 0),
+ (6002, 6003, 0),
+ (6068, 6099, 0),
+ (6109, 6109, 0),
+ (6155, 6159, 0),
+ (6277, 6278, 0),
+ (6313, 6313, 0),
+ (6432, 6443, 0),
+ (6448, 6459, 0),
+ (6679, 6683, 0),
+ (6741, 6750, 0),
+ (6752, 6780, 0),
+ (6783, 6783, 0),
+ (6832, 6862, 0),
+ (6912, 6916, 0),
+ (6964, 6980, 0),
+ (7019, 7027, 0),
+ (7040, 7042, 0),
+ (7073, 7085, 0),
+ (7142, 7155, 0),
+ (7204, 7223, 0),
+ (7376, 7378, 0),
+ (7380, 7400, 0),
+ (7405, 7405, 0),
+ (7412, 7412, 0),
+ (7415, 7417, 0),
+ (7616, 7679, 0),
+ (8203, 8207, 0),
+ (8232, 8238, 0),
+ (8288, 8292, 0),
+ (8294, 8303, 0),
+ (8400, 8432, 0),
+ (8986, 8987, 2),
+ (9001, 9002, 2),
+ (9193, 9196, 2),
+ (9200, 9200, 2),
+ (9203, 9203, 2),
+ (9725, 9726, 2),
+ (9748, 9749, 2),
+ (9800, 9811, 2),
+ (9855, 9855, 2),
+ (9875, 9875, 2),
+ (9889, 9889, 2),
+ (9898, 9899, 2),
+ (9917, 9918, 2),
+ (9924, 9925, 2),
+ (9934, 9934, 2),
+ (9940, 9940, 2),
+ (9962, 9962, 2),
+ (9970, 9971, 2),
+ (9973, 9973, 2),
+ (9978, 9978, 2),
+ (9981, 9981, 2),
+ (9989, 9989, 2),
+ (9994, 9995, 2),
+ (10024, 10024, 2),
+ (10060, 10060, 2),
+ (10062, 10062, 2),
+ (10067, 10069, 2),
+ (10071, 10071, 2),
+ (10133, 10135, 2),
+ (10160, 10160, 2),
+ (10175, 10175, 2),
+ (11035, 11036, 2),
+ (11088, 11088, 2),
+ (11093, 11093, 2),
+ (11503, 11505, 0),
+ (11647, 11647, 0),
+ (11744, 11775, 0),
+ (11904, 11929, 2),
+ (11931, 12019, 2),
+ (12032, 12245, 2),
+ (12272, 12329, 2),
+ (12330, 12335, 0),
+ (12336, 12350, 2),
+ (12353, 12438, 2),
+ (12441, 12442, 0),
+ (12443, 12543, 2),
+ (12549, 12591, 2),
+ (12593, 12686, 2),
+ (12688, 12771, 2),
+ (12783, 12830, 2),
+ (12832, 12871, 2),
+ (12880, 19903, 2),
+ (19968, 42124, 2),
+ (42128, 42182, 2),
+ (42607, 42610, 0),
+ (42612, 42621, 0),
+ (42654, 42655, 0),
+ (42736, 42737, 0),
+ (43010, 43010, 0),
+ (43014, 43014, 0),
+ (43019, 43019, 0),
+ (43043, 43047, 0),
+ (43052, 43052, 0),
+ (43136, 43137, 0),
+ (43188, 43205, 0),
+ (43232, 43249, 0),
+ (43263, 43263, 0),
+ (43302, 43309, 0),
+ (43335, 43347, 0),
+ (43360, 43388, 2),
+ (43392, 43395, 0),
+ (43443, 43456, 0),
+ (43493, 43493, 0),
+ (43561, 43574, 0),
+ (43587, 43587, 0),
+ (43596, 43597, 0),
+ (43643, 43645, 0),
+ (43696, 43696, 0),
+ (43698, 43700, 0),
+ (43703, 43704, 0),
+ (43710, 43711, 0),
+ (43713, 43713, 0),
+ (43755, 43759, 0),
+ (43765, 43766, 0),
+ (44003, 44010, 0),
+ (44012, 44013, 0),
+ (44032, 55203, 2),
+ (55216, 55295, 0),
+ (63744, 64255, 2),
+ (64286, 64286, 0),
+ (65024, 65039, 0),
+ (65040, 65049, 2),
+ (65056, 65071, 0),
+ (65072, 65106, 2),
+ (65108, 65126, 2),
+ (65128, 65131, 2),
+ (65279, 65279, 0),
+ (65281, 65376, 2),
+ (65504, 65510, 2),
+ (65529, 65531, 0),
+ (66045, 66045, 0),
+ (66272, 66272, 0),
+ (66422, 66426, 0),
+ (68097, 68099, 0),
+ (68101, 68102, 0),
+ (68108, 68111, 0),
+ (68152, 68154, 0),
+ (68159, 68159, 0),
+ (68325, 68326, 0),
+ (68900, 68903, 0),
+ (69291, 69292, 0),
+ (69373, 69375, 0),
+ (69446, 69456, 0),
+ (69506, 69509, 0),
+ (69632, 69634, 0),
+ (69688, 69702, 0),
+ (69744, 69744, 0),
+ (69747, 69748, 0),
+ (69759, 69762, 0),
+ (69808, 69818, 0),
+ (69821, 69821, 0),
+ (69826, 69826, 0),
+ (69837, 69837, 0),
+ (69888, 69890, 0),
+ (69927, 69940, 0),
+ (69957, 69958, 0),
+ (70003, 70003, 0),
+ (70016, 70018, 0),
+ (70067, 70080, 0),
+ (70089, 70092, 0),
+ (70094, 70095, 0),
+ (70188, 70199, 0),
+ (70206, 70206, 0),
+ (70209, 70209, 0),
+ (70367, 70378, 0),
+ (70400, 70403, 0),
+ (70459, 70460, 0),
+ (70462, 70468, 0),
+ (70471, 70472, 0),
+ (70475, 70477, 0),
+ (70487, 70487, 0),
+ (70498, 70499, 0),
+ (70502, 70508, 0),
+ (70512, 70516, 0),
+ (70709, 70726, 0),
+ (70750, 70750, 0),
+ (70832, 70851, 0),
+ (71087, 71093, 0),
+ (71096, 71104, 0),
+ (71132, 71133, 0),
+ (71216, 71232, 0),
+ (71339, 71351, 0),
+ (71453, 71467, 0),
+ (71724, 71738, 0),
+ (71984, 71989, 0),
+ (71991, 71992, 0),
+ (71995, 71998, 0),
+ (72000, 72000, 0),
+ (72002, 72003, 0),
+ (72145, 72151, 0),
+ (72154, 72160, 0),
+ (72164, 72164, 0),
+ (72193, 72202, 0),
+ (72243, 72249, 0),
+ (72251, 72254, 0),
+ (72263, 72263, 0),
+ (72273, 72283, 0),
+ (72330, 72345, 0),
+ (72751, 72758, 0),
+ (72760, 72767, 0),
+ (72850, 72871, 0),
+ (72873, 72886, 0),
+ (73009, 73014, 0),
+ (73018, 73018, 0),
+ (73020, 73021, 0),
+ (73023, 73029, 0),
+ (73031, 73031, 0),
+ (73098, 73102, 0),
+ (73104, 73105, 0),
+ (73107, 73111, 0),
+ (73459, 73462, 0),
+ (73472, 73473, 0),
+ (73475, 73475, 0),
+ (73524, 73530, 0),
+ (73534, 73538, 0),
+ (78896, 78912, 0),
+ (78919, 78933, 0),
+ (92912, 92916, 0),
+ (92976, 92982, 0),
+ (94031, 94031, 0),
+ (94033, 94087, 0),
+ (94095, 94098, 0),
+ (94176, 94179, 2),
+ (94180, 94180, 0),
+ (94192, 94193, 0),
+ (94208, 100343, 2),
+ (100352, 101589, 2),
+ (101632, 101640, 2),
+ (110576, 110579, 2),
+ (110581, 110587, 2),
+ (110589, 110590, 2),
+ (110592, 110882, 2),
+ (110898, 110898, 2),
+ (110928, 110930, 2),
+ (110933, 110933, 2),
+ (110948, 110951, 2),
+ (110960, 111355, 2),
+ (113821, 113822, 0),
+ (113824, 113827, 0),
+ (118528, 118573, 0),
+ (118576, 118598, 0),
+ (119141, 119145, 0),
+ (119149, 119170, 0),
+ (119173, 119179, 0),
+ (119210, 119213, 0),
+ (119362, 119364, 0),
+ (121344, 121398, 0),
+ (121403, 121452, 0),
+ (121461, 121461, 0),
+ (121476, 121476, 0),
+ (121499, 121503, 0),
+ (121505, 121519, 0),
+ (122880, 122886, 0),
+ (122888, 122904, 0),
+ (122907, 122913, 0),
+ (122915, 122916, 0),
+ (122918, 122922, 0),
+ (123023, 123023, 0),
+ (123184, 123190, 0),
+ (123566, 123566, 0),
+ (123628, 123631, 0),
+ (124140, 124143, 0),
+ (125136, 125142, 0),
+ (125252, 125258, 0),
+ (126980, 126980, 2),
+ (127183, 127183, 2),
+ (127374, 127374, 2),
+ (127377, 127386, 2),
+ (127488, 127490, 2),
+ (127504, 127547, 2),
+ (127552, 127560, 2),
+ (127568, 127569, 2),
+ (127584, 127589, 2),
+ (127744, 127776, 2),
+ (127789, 127797, 2),
+ (127799, 127868, 2),
+ (127870, 127891, 2),
+ (127904, 127946, 2),
+ (127951, 127955, 2),
+ (127968, 127984, 2),
+ (127988, 127988, 2),
+ (127992, 127994, 2),
+ (127995, 127999, 0),
+ (128000, 128062, 2),
+ (128064, 128064, 2),
+ (128066, 128252, 2),
+ (128255, 128317, 2),
+ (128331, 128334, 2),
+ (128336, 128359, 2),
+ (128378, 128378, 2),
+ (128405, 128406, 2),
+ (128420, 128420, 2),
+ (128507, 128591, 2),
+ (128640, 128709, 2),
+ (128716, 128716, 2),
+ (128720, 128722, 2),
+ (128725, 128727, 2),
+ (128732, 128735, 2),
+ (128747, 128748, 2),
+ (128756, 128764, 2),
+ (128992, 129003, 2),
+ (129008, 129008, 2),
+ (129292, 129338, 2),
+ (129340, 129349, 2),
+ (129351, 129535, 2),
+ (129648, 129660, 2),
+ (129664, 129672, 2),
+ (129680, 129725, 2),
+ (129727, 129733, 2),
+ (129742, 129755, 2),
+ (129760, 129768, 2),
+ (129776, 129784, 2),
+ (131072, 196605, 2),
+ (196608, 262141, 2),
+ (917505, 917505, 0),
+ (917536, 917631, 0),
+ (917760, 917999, 0),
+]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_emoji_codes.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_emoji_codes.py
new file mode 100644
index 000000000..1f2877bb2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_emoji_codes.py
@@ -0,0 +1,3610 @@
+EMOJI = {
+ "1st_place_medal": "🥇",
+ "2nd_place_medal": "🥈",
+ "3rd_place_medal": "🥉",
+ "ab_button_(blood_type)": "🆎",
+ "atm_sign": "🏧",
+ "a_button_(blood_type)": "🅰",
+ "afghanistan": "🇦🇫",
+ "albania": "🇦🇱",
+ "algeria": "🇩🇿",
+ "american_samoa": "🇦🇸",
+ "andorra": "🇦🇩",
+ "angola": "🇦🇴",
+ "anguilla": "🇦🇮",
+ "antarctica": "🇦🇶",
+ "antigua_&_barbuda": "🇦🇬",
+ "aquarius": "♒",
+ "argentina": "🇦🇷",
+ "aries": "♈",
+ "armenia": "🇦🇲",
+ "aruba": "🇦🇼",
+ "ascension_island": "🇦🇨",
+ "australia": "🇦🇺",
+ "austria": "🇦🇹",
+ "azerbaijan": "🇦🇿",
+ "back_arrow": "🔙",
+ "b_button_(blood_type)": "🅱",
+ "bahamas": "🇧🇸",
+ "bahrain": "🇧🇭",
+ "bangladesh": "🇧🇩",
+ "barbados": "🇧🇧",
+ "belarus": "🇧🇾",
+ "belgium": "🇧🇪",
+ "belize": "🇧🇿",
+ "benin": "🇧🇯",
+ "bermuda": "🇧🇲",
+ "bhutan": "🇧🇹",
+ "bolivia": "🇧🇴",
+ "bosnia_&_herzegovina": "🇧🇦",
+ "botswana": "🇧🇼",
+ "bouvet_island": "🇧🇻",
+ "brazil": "🇧🇷",
+ "british_indian_ocean_territory": "🇮🇴",
+ "british_virgin_islands": "🇻🇬",
+ "brunei": "🇧🇳",
+ "bulgaria": "🇧🇬",
+ "burkina_faso": "🇧🇫",
+ "burundi": "🇧🇮",
+ "cl_button": "🆑",
+ "cool_button": "🆒",
+ "cambodia": "🇰🇭",
+ "cameroon": "🇨🇲",
+ "canada": "🇨🇦",
+ "canary_islands": "🇮🇨",
+ "cancer": "♋",
+ "cape_verde": "🇨🇻",
+ "capricorn": "♑",
+ "caribbean_netherlands": "🇧🇶",
+ "cayman_islands": "🇰🇾",
+ "central_african_republic": "🇨🇫",
+ "ceuta_&_melilla": "🇪🇦",
+ "chad": "🇹🇩",
+ "chile": "🇨🇱",
+ "china": "🇨🇳",
+ "christmas_island": "🇨🇽",
+ "christmas_tree": "🎄",
+ "clipperton_island": "🇨🇵",
+ "cocos_(keeling)_islands": "🇨🇨",
+ "colombia": "🇨🇴",
+ "comoros": "🇰🇲",
+ "congo_-_brazzaville": "🇨🇬",
+ "congo_-_kinshasa": "🇨🇩",
+ "cook_islands": "🇨🇰",
+ "costa_rica": "🇨🇷",
+ "croatia": "🇭🇷",
+ "cuba": "🇨🇺",
+ "curaçao": "🇨🇼",
+ "cyprus": "🇨🇾",
+ "czechia": "🇨🇿",
+ "côte_d’ivoire": "🇨🇮",
+ "denmark": "🇩🇰",
+ "diego_garcia": "🇩🇬",
+ "djibouti": "🇩🇯",
+ "dominica": "🇩🇲",
+ "dominican_republic": "🇩🇴",
+ "end_arrow": "🔚",
+ "ecuador": "🇪🇨",
+ "egypt": "🇪🇬",
+ "el_salvador": "🇸🇻",
+ "england": "🏴\U000e0067\U000e0062\U000e0065\U000e006e\U000e0067\U000e007f",
+ "equatorial_guinea": "🇬🇶",
+ "eritrea": "🇪🇷",
+ "estonia": "🇪🇪",
+ "ethiopia": "🇪🇹",
+ "european_union": "🇪🇺",
+ "free_button": "🆓",
+ "falkland_islands": "🇫🇰",
+ "faroe_islands": "🇫🇴",
+ "fiji": "🇫🇯",
+ "finland": "🇫🇮",
+ "france": "🇫🇷",
+ "french_guiana": "🇬🇫",
+ "french_polynesia": "🇵🇫",
+ "french_southern_territories": "🇹🇫",
+ "gabon": "🇬🇦",
+ "gambia": "🇬🇲",
+ "gemini": "♊",
+ "georgia": "🇬🇪",
+ "germany": "🇩🇪",
+ "ghana": "🇬🇭",
+ "gibraltar": "🇬🇮",
+ "greece": "🇬🇷",
+ "greenland": "🇬🇱",
+ "grenada": "🇬🇩",
+ "guadeloupe": "🇬🇵",
+ "guam": "🇬🇺",
+ "guatemala": "🇬🇹",
+ "guernsey": "🇬🇬",
+ "guinea": "🇬🇳",
+ "guinea-bissau": "🇬🇼",
+ "guyana": "🇬🇾",
+ "haiti": "🇭🇹",
+ "heard_&_mcdonald_islands": "🇭🇲",
+ "honduras": "🇭🇳",
+ "hong_kong_sar_china": "🇭🇰",
+ "hungary": "🇭🇺",
+ "id_button": "🆔",
+ "iceland": "🇮🇸",
+ "india": "🇮🇳",
+ "indonesia": "🇮🇩",
+ "iran": "🇮🇷",
+ "iraq": "🇮🇶",
+ "ireland": "🇮🇪",
+ "isle_of_man": "🇮🇲",
+ "israel": "🇮🇱",
+ "italy": "🇮🇹",
+ "jamaica": "🇯🇲",
+ "japan": "🗾",
+ "japanese_acceptable_button": "🉑",
+ "japanese_application_button": "🈸",
+ "japanese_bargain_button": "🉐",
+ "japanese_castle": "🏯",
+ "japanese_congratulations_button": "㊗",
+ "japanese_discount_button": "🈹",
+ "japanese_dolls": "🎎",
+ "japanese_free_of_charge_button": "🈚",
+ "japanese_here_button": "🈁",
+ "japanese_monthly_amount_button": "🈷",
+ "japanese_no_vacancy_button": "🈵",
+ "japanese_not_free_of_charge_button": "🈶",
+ "japanese_open_for_business_button": "🈺",
+ "japanese_passing_grade_button": "🈴",
+ "japanese_post_office": "🏣",
+ "japanese_prohibited_button": "🈲",
+ "japanese_reserved_button": "🈯",
+ "japanese_secret_button": "㊙",
+ "japanese_service_charge_button": "🈂",
+ "japanese_symbol_for_beginner": "🔰",
+ "japanese_vacancy_button": "🈳",
+ "jersey": "🇯🇪",
+ "jordan": "🇯🇴",
+ "kazakhstan": "🇰🇿",
+ "kenya": "🇰🇪",
+ "kiribati": "🇰🇮",
+ "kosovo": "🇽🇰",
+ "kuwait": "🇰🇼",
+ "kyrgyzstan": "🇰🇬",
+ "laos": "🇱🇦",
+ "latvia": "🇱🇻",
+ "lebanon": "🇱🇧",
+ "leo": "♌",
+ "lesotho": "🇱🇸",
+ "liberia": "🇱🇷",
+ "libra": "♎",
+ "libya": "🇱🇾",
+ "liechtenstein": "🇱🇮",
+ "lithuania": "🇱🇹",
+ "luxembourg": "🇱🇺",
+ "macau_sar_china": "🇲🇴",
+ "macedonia": "🇲🇰",
+ "madagascar": "🇲🇬",
+ "malawi": "🇲🇼",
+ "malaysia": "🇲🇾",
+ "maldives": "🇲🇻",
+ "mali": "🇲🇱",
+ "malta": "🇲🇹",
+ "marshall_islands": "🇲🇭",
+ "martinique": "🇲🇶",
+ "mauritania": "🇲🇷",
+ "mauritius": "🇲🇺",
+ "mayotte": "🇾🇹",
+ "mexico": "🇲🇽",
+ "micronesia": "🇫🇲",
+ "moldova": "🇲🇩",
+ "monaco": "🇲🇨",
+ "mongolia": "🇲🇳",
+ "montenegro": "🇲🇪",
+ "montserrat": "🇲🇸",
+ "morocco": "🇲🇦",
+ "mozambique": "🇲🇿",
+ "mrs._claus": "🤶",
+ "mrs._claus_dark_skin_tone": "🤶🏿",
+ "mrs._claus_light_skin_tone": "🤶🏻",
+ "mrs._claus_medium-dark_skin_tone": "🤶🏾",
+ "mrs._claus_medium-light_skin_tone": "🤶🏼",
+ "mrs._claus_medium_skin_tone": "🤶🏽",
+ "myanmar_(burma)": "🇲🇲",
+ "new_button": "🆕",
+ "ng_button": "🆖",
+ "namibia": "🇳🇦",
+ "nauru": "🇳🇷",
+ "nepal": "🇳🇵",
+ "netherlands": "🇳🇱",
+ "new_caledonia": "🇳🇨",
+ "new_zealand": "🇳🇿",
+ "nicaragua": "🇳🇮",
+ "niger": "🇳🇪",
+ "nigeria": "🇳🇬",
+ "niue": "🇳🇺",
+ "norfolk_island": "🇳🇫",
+ "north_korea": "🇰🇵",
+ "northern_mariana_islands": "🇲🇵",
+ "norway": "🇳🇴",
+ "ok_button": "🆗",
+ "ok_hand": "👌",
+ "ok_hand_dark_skin_tone": "👌🏿",
+ "ok_hand_light_skin_tone": "👌🏻",
+ "ok_hand_medium-dark_skin_tone": "👌🏾",
+ "ok_hand_medium-light_skin_tone": "👌🏼",
+ "ok_hand_medium_skin_tone": "👌🏽",
+ "on!_arrow": "🔛",
+ "o_button_(blood_type)": "🅾",
+ "oman": "🇴🇲",
+ "ophiuchus": "⛎",
+ "p_button": "🅿",
+ "pakistan": "🇵🇰",
+ "palau": "🇵🇼",
+ "palestinian_territories": "🇵🇸",
+ "panama": "🇵🇦",
+ "papua_new_guinea": "🇵🇬",
+ "paraguay": "🇵🇾",
+ "peru": "🇵🇪",
+ "philippines": "🇵🇭",
+ "pisces": "♓",
+ "pitcairn_islands": "🇵🇳",
+ "poland": "🇵🇱",
+ "portugal": "🇵🇹",
+ "puerto_rico": "🇵🇷",
+ "qatar": "🇶🇦",
+ "romania": "🇷🇴",
+ "russia": "🇷🇺",
+ "rwanda": "🇷🇼",
+ "réunion": "🇷🇪",
+ "soon_arrow": "🔜",
+ "sos_button": "🆘",
+ "sagittarius": "♐",
+ "samoa": "🇼🇸",
+ "san_marino": "🇸🇲",
+ "santa_claus": "🎅",
+ "santa_claus_dark_skin_tone": "🎅🏿",
+ "santa_claus_light_skin_tone": "🎅🏻",
+ "santa_claus_medium-dark_skin_tone": "🎅🏾",
+ "santa_claus_medium-light_skin_tone": "🎅🏼",
+ "santa_claus_medium_skin_tone": "🎅🏽",
+ "saudi_arabia": "🇸🇦",
+ "scorpio": "♏",
+ "scotland": "🏴\U000e0067\U000e0062\U000e0073\U000e0063\U000e0074\U000e007f",
+ "senegal": "🇸🇳",
+ "serbia": "🇷🇸",
+ "seychelles": "🇸🇨",
+ "sierra_leone": "🇸🇱",
+ "singapore": "🇸🇬",
+ "sint_maarten": "🇸🇽",
+ "slovakia": "🇸🇰",
+ "slovenia": "🇸🇮",
+ "solomon_islands": "🇸🇧",
+ "somalia": "🇸🇴",
+ "south_africa": "🇿🇦",
+ "south_georgia_&_south_sandwich_islands": "🇬🇸",
+ "south_korea": "🇰🇷",
+ "south_sudan": "🇸🇸",
+ "spain": "🇪🇸",
+ "sri_lanka": "🇱🇰",
+ "st._barthélemy": "🇧🇱",
+ "st._helena": "🇸🇭",
+ "st._kitts_&_nevis": "🇰🇳",
+ "st._lucia": "🇱🇨",
+ "st._martin": "🇲🇫",
+ "st._pierre_&_miquelon": "🇵🇲",
+ "st._vincent_&_grenadines": "🇻🇨",
+ "statue_of_liberty": "🗽",
+ "sudan": "🇸🇩",
+ "suriname": "🇸🇷",
+ "svalbard_&_jan_mayen": "🇸🇯",
+ "swaziland": "🇸🇿",
+ "sweden": "🇸🇪",
+ "switzerland": "🇨🇭",
+ "syria": "🇸🇾",
+ "são_tomé_&_príncipe": "🇸🇹",
+ "t-rex": "🦖",
+ "top_arrow": "🔝",
+ "taiwan": "🇹🇼",
+ "tajikistan": "🇹🇯",
+ "tanzania": "🇹🇿",
+ "taurus": "♉",
+ "thailand": "🇹🇭",
+ "timor-leste": "🇹🇱",
+ "togo": "🇹🇬",
+ "tokelau": "🇹🇰",
+ "tokyo_tower": "🗼",
+ "tonga": "🇹🇴",
+ "trinidad_&_tobago": "🇹🇹",
+ "tristan_da_cunha": "🇹🇦",
+ "tunisia": "🇹🇳",
+ "turkey": "🦃",
+ "turkmenistan": "🇹🇲",
+ "turks_&_caicos_islands": "🇹🇨",
+ "tuvalu": "🇹🇻",
+ "u.s._outlying_islands": "🇺🇲",
+ "u.s._virgin_islands": "🇻🇮",
+ "up!_button": "🆙",
+ "uganda": "🇺🇬",
+ "ukraine": "🇺🇦",
+ "united_arab_emirates": "🇦🇪",
+ "united_kingdom": "🇬🇧",
+ "united_nations": "🇺🇳",
+ "united_states": "🇺🇸",
+ "uruguay": "🇺🇾",
+ "uzbekistan": "🇺🇿",
+ "vs_button": "🆚",
+ "vanuatu": "🇻🇺",
+ "vatican_city": "🇻🇦",
+ "venezuela": "🇻🇪",
+ "vietnam": "🇻🇳",
+ "virgo": "♍",
+ "wales": "🏴\U000e0067\U000e0062\U000e0077\U000e006c\U000e0073\U000e007f",
+ "wallis_&_futuna": "🇼🇫",
+ "western_sahara": "🇪🇭",
+ "yemen": "🇾🇪",
+ "zambia": "🇿🇲",
+ "zimbabwe": "🇿🇼",
+ "abacus": "🧮",
+ "adhesive_bandage": "🩹",
+ "admission_tickets": "🎟",
+ "adult": "🧑",
+ "adult_dark_skin_tone": "🧑🏿",
+ "adult_light_skin_tone": "🧑🏻",
+ "adult_medium-dark_skin_tone": "🧑🏾",
+ "adult_medium-light_skin_tone": "🧑🏼",
+ "adult_medium_skin_tone": "🧑🏽",
+ "aerial_tramway": "🚡",
+ "airplane": "✈",
+ "airplane_arrival": "🛬",
+ "airplane_departure": "🛫",
+ "alarm_clock": "⏰",
+ "alembic": "⚗",
+ "alien": "👽",
+ "alien_monster": "👾",
+ "ambulance": "🚑",
+ "american_football": "🏈",
+ "amphora": "🏺",
+ "anchor": "⚓",
+ "anger_symbol": "💢",
+ "angry_face": "😠",
+ "angry_face_with_horns": "👿",
+ "anguished_face": "😧",
+ "ant": "🐜",
+ "antenna_bars": "📶",
+ "anxious_face_with_sweat": "😰",
+ "articulated_lorry": "🚛",
+ "artist_palette": "🎨",
+ "astonished_face": "😲",
+ "atom_symbol": "⚛",
+ "auto_rickshaw": "🛺",
+ "automobile": "🚗",
+ "avocado": "🥑",
+ "axe": "🪓",
+ "baby": "👶",
+ "baby_angel": "👼",
+ "baby_angel_dark_skin_tone": "👼🏿",
+ "baby_angel_light_skin_tone": "👼🏻",
+ "baby_angel_medium-dark_skin_tone": "👼🏾",
+ "baby_angel_medium-light_skin_tone": "👼🏼",
+ "baby_angel_medium_skin_tone": "👼🏽",
+ "baby_bottle": "🍼",
+ "baby_chick": "🐤",
+ "baby_dark_skin_tone": "👶🏿",
+ "baby_light_skin_tone": "👶🏻",
+ "baby_medium-dark_skin_tone": "👶🏾",
+ "baby_medium-light_skin_tone": "👶🏼",
+ "baby_medium_skin_tone": "👶🏽",
+ "baby_symbol": "🚼",
+ "backhand_index_pointing_down": "👇",
+ "backhand_index_pointing_down_dark_skin_tone": "👇🏿",
+ "backhand_index_pointing_down_light_skin_tone": "👇🏻",
+ "backhand_index_pointing_down_medium-dark_skin_tone": "👇🏾",
+ "backhand_index_pointing_down_medium-light_skin_tone": "👇🏼",
+ "backhand_index_pointing_down_medium_skin_tone": "👇🏽",
+ "backhand_index_pointing_left": "👈",
+ "backhand_index_pointing_left_dark_skin_tone": "👈🏿",
+ "backhand_index_pointing_left_light_skin_tone": "👈🏻",
+ "backhand_index_pointing_left_medium-dark_skin_tone": "👈🏾",
+ "backhand_index_pointing_left_medium-light_skin_tone": "👈🏼",
+ "backhand_index_pointing_left_medium_skin_tone": "👈🏽",
+ "backhand_index_pointing_right": "👉",
+ "backhand_index_pointing_right_dark_skin_tone": "👉🏿",
+ "backhand_index_pointing_right_light_skin_tone": "👉🏻",
+ "backhand_index_pointing_right_medium-dark_skin_tone": "👉🏾",
+ "backhand_index_pointing_right_medium-light_skin_tone": "👉🏼",
+ "backhand_index_pointing_right_medium_skin_tone": "👉🏽",
+ "backhand_index_pointing_up": "👆",
+ "backhand_index_pointing_up_dark_skin_tone": "👆🏿",
+ "backhand_index_pointing_up_light_skin_tone": "👆🏻",
+ "backhand_index_pointing_up_medium-dark_skin_tone": "👆🏾",
+ "backhand_index_pointing_up_medium-light_skin_tone": "👆🏼",
+ "backhand_index_pointing_up_medium_skin_tone": "👆🏽",
+ "bacon": "🥓",
+ "badger": "🦡",
+ "badminton": "🏸",
+ "bagel": "🥯",
+ "baggage_claim": "🛄",
+ "baguette_bread": "🥖",
+ "balance_scale": "⚖",
+ "bald": "🦲",
+ "bald_man": "👨\u200d🦲",
+ "bald_woman": "👩\u200d🦲",
+ "ballet_shoes": "🩰",
+ "balloon": "🎈",
+ "ballot_box_with_ballot": "🗳",
+ "ballot_box_with_check": "☑",
+ "banana": "🍌",
+ "banjo": "🪕",
+ "bank": "🏦",
+ "bar_chart": "📊",
+ "barber_pole": "💈",
+ "baseball": "⚾",
+ "basket": "🧺",
+ "basketball": "🏀",
+ "bat": "🦇",
+ "bathtub": "🛁",
+ "battery": "🔋",
+ "beach_with_umbrella": "🏖",
+ "beaming_face_with_smiling_eyes": "😁",
+ "bear_face": "🐻",
+ "bearded_person": "🧔",
+ "bearded_person_dark_skin_tone": "🧔🏿",
+ "bearded_person_light_skin_tone": "🧔🏻",
+ "bearded_person_medium-dark_skin_tone": "🧔🏾",
+ "bearded_person_medium-light_skin_tone": "🧔🏼",
+ "bearded_person_medium_skin_tone": "🧔🏽",
+ "beating_heart": "💓",
+ "bed": "🛏",
+ "beer_mug": "🍺",
+ "bell": "🔔",
+ "bell_with_slash": "🔕",
+ "bellhop_bell": "🛎",
+ "bento_box": "🍱",
+ "beverage_box": "🧃",
+ "bicycle": "🚲",
+ "bikini": "👙",
+ "billed_cap": "🧢",
+ "biohazard": "☣",
+ "bird": "🐦",
+ "birthday_cake": "🎂",
+ "black_circle": "⚫",
+ "black_flag": "🏴",
+ "black_heart": "🖤",
+ "black_large_square": "⬛",
+ "black_medium-small_square": "◾",
+ "black_medium_square": "◼",
+ "black_nib": "✒",
+ "black_small_square": "▪",
+ "black_square_button": "🔲",
+ "blond-haired_man": "👱\u200d♂️",
+ "blond-haired_man_dark_skin_tone": "👱🏿\u200d♂️",
+ "blond-haired_man_light_skin_tone": "👱🏻\u200d♂️",
+ "blond-haired_man_medium-dark_skin_tone": "👱🏾\u200d♂️",
+ "blond-haired_man_medium-light_skin_tone": "👱🏼\u200d♂️",
+ "blond-haired_man_medium_skin_tone": "👱🏽\u200d♂️",
+ "blond-haired_person": "👱",
+ "blond-haired_person_dark_skin_tone": "👱🏿",
+ "blond-haired_person_light_skin_tone": "👱🏻",
+ "blond-haired_person_medium-dark_skin_tone": "👱🏾",
+ "blond-haired_person_medium-light_skin_tone": "👱🏼",
+ "blond-haired_person_medium_skin_tone": "👱🏽",
+ "blond-haired_woman": "👱\u200d♀️",
+ "blond-haired_woman_dark_skin_tone": "👱🏿\u200d♀️",
+ "blond-haired_woman_light_skin_tone": "👱🏻\u200d♀️",
+ "blond-haired_woman_medium-dark_skin_tone": "👱🏾\u200d♀️",
+ "blond-haired_woman_medium-light_skin_tone": "👱🏼\u200d♀️",
+ "blond-haired_woman_medium_skin_tone": "👱🏽\u200d♀️",
+ "blossom": "🌼",
+ "blowfish": "🐡",
+ "blue_book": "📘",
+ "blue_circle": "🔵",
+ "blue_heart": "💙",
+ "blue_square": "🟦",
+ "boar": "🐗",
+ "bomb": "💣",
+ "bone": "🦴",
+ "bookmark": "🔖",
+ "bookmark_tabs": "📑",
+ "books": "📚",
+ "bottle_with_popping_cork": "🍾",
+ "bouquet": "💐",
+ "bow_and_arrow": "🏹",
+ "bowl_with_spoon": "🥣",
+ "bowling": "🎳",
+ "boxing_glove": "🥊",
+ "boy": "👦",
+ "boy_dark_skin_tone": "👦🏿",
+ "boy_light_skin_tone": "👦🏻",
+ "boy_medium-dark_skin_tone": "👦🏾",
+ "boy_medium-light_skin_tone": "👦🏼",
+ "boy_medium_skin_tone": "👦🏽",
+ "brain": "🧠",
+ "bread": "🍞",
+ "breast-feeding": "🤱",
+ "breast-feeding_dark_skin_tone": "🤱🏿",
+ "breast-feeding_light_skin_tone": "🤱🏻",
+ "breast-feeding_medium-dark_skin_tone": "🤱🏾",
+ "breast-feeding_medium-light_skin_tone": "🤱🏼",
+ "breast-feeding_medium_skin_tone": "🤱🏽",
+ "brick": "🧱",
+ "bride_with_veil": "👰",
+ "bride_with_veil_dark_skin_tone": "👰🏿",
+ "bride_with_veil_light_skin_tone": "👰🏻",
+ "bride_with_veil_medium-dark_skin_tone": "👰🏾",
+ "bride_with_veil_medium-light_skin_tone": "👰🏼",
+ "bride_with_veil_medium_skin_tone": "👰🏽",
+ "bridge_at_night": "🌉",
+ "briefcase": "💼",
+ "briefs": "🩲",
+ "bright_button": "🔆",
+ "broccoli": "🥦",
+ "broken_heart": "💔",
+ "broom": "🧹",
+ "brown_circle": "🟤",
+ "brown_heart": "🤎",
+ "brown_square": "🟫",
+ "bug": "🐛",
+ "building_construction": "🏗",
+ "bullet_train": "🚅",
+ "burrito": "🌯",
+ "bus": "🚌",
+ "bus_stop": "🚏",
+ "bust_in_silhouette": "👤",
+ "busts_in_silhouette": "👥",
+ "butter": "🧈",
+ "butterfly": "🦋",
+ "cactus": "🌵",
+ "calendar": "📆",
+ "call_me_hand": "🤙",
+ "call_me_hand_dark_skin_tone": "🤙🏿",
+ "call_me_hand_light_skin_tone": "🤙🏻",
+ "call_me_hand_medium-dark_skin_tone": "🤙🏾",
+ "call_me_hand_medium-light_skin_tone": "🤙🏼",
+ "call_me_hand_medium_skin_tone": "🤙🏽",
+ "camel": "🐫",
+ "camera": "📷",
+ "camera_with_flash": "📸",
+ "camping": "🏕",
+ "candle": "🕯",
+ "candy": "🍬",
+ "canned_food": "🥫",
+ "canoe": "🛶",
+ "card_file_box": "🗃",
+ "card_index": "📇",
+ "card_index_dividers": "🗂",
+ "carousel_horse": "🎠",
+ "carp_streamer": "🎏",
+ "carrot": "🥕",
+ "castle": "🏰",
+ "cat": "🐱",
+ "cat_face": "🐱",
+ "cat_face_with_tears_of_joy": "😹",
+ "cat_face_with_wry_smile": "😼",
+ "chains": "⛓",
+ "chair": "🪑",
+ "chart_decreasing": "📉",
+ "chart_increasing": "📈",
+ "chart_increasing_with_yen": "💹",
+ "cheese_wedge": "🧀",
+ "chequered_flag": "🏁",
+ "cherries": "🍒",
+ "cherry_blossom": "🌸",
+ "chess_pawn": "♟",
+ "chestnut": "🌰",
+ "chicken": "🐔",
+ "child": "🧒",
+ "child_dark_skin_tone": "🧒🏿",
+ "child_light_skin_tone": "🧒🏻",
+ "child_medium-dark_skin_tone": "🧒🏾",
+ "child_medium-light_skin_tone": "🧒🏼",
+ "child_medium_skin_tone": "🧒🏽",
+ "children_crossing": "🚸",
+ "chipmunk": "🐿",
+ "chocolate_bar": "🍫",
+ "chopsticks": "🥢",
+ "church": "⛪",
+ "cigarette": "🚬",
+ "cinema": "🎦",
+ "circled_m": "Ⓜ",
+ "circus_tent": "🎪",
+ "cityscape": "🏙",
+ "cityscape_at_dusk": "🌆",
+ "clamp": "🗜",
+ "clapper_board": "🎬",
+ "clapping_hands": "👏",
+ "clapping_hands_dark_skin_tone": "👏🏿",
+ "clapping_hands_light_skin_tone": "👏🏻",
+ "clapping_hands_medium-dark_skin_tone": "👏🏾",
+ "clapping_hands_medium-light_skin_tone": "👏🏼",
+ "clapping_hands_medium_skin_tone": "👏🏽",
+ "classical_building": "🏛",
+ "clinking_beer_mugs": "🍻",
+ "clinking_glasses": "🥂",
+ "clipboard": "📋",
+ "clockwise_vertical_arrows": "🔃",
+ "closed_book": "📕",
+ "closed_mailbox_with_lowered_flag": "📪",
+ "closed_mailbox_with_raised_flag": "📫",
+ "closed_umbrella": "🌂",
+ "cloud": "☁",
+ "cloud_with_lightning": "🌩",
+ "cloud_with_lightning_and_rain": "⛈",
+ "cloud_with_rain": "🌧",
+ "cloud_with_snow": "🌨",
+ "clown_face": "🤡",
+ "club_suit": "♣",
+ "clutch_bag": "👝",
+ "coat": "🧥",
+ "cocktail_glass": "🍸",
+ "coconut": "🥥",
+ "coffin": "⚰",
+ "cold_face": "🥶",
+ "collision": "💥",
+ "comet": "☄",
+ "compass": "🧭",
+ "computer_disk": "💽",
+ "computer_mouse": "🖱",
+ "confetti_ball": "🎊",
+ "confounded_face": "😖",
+ "confused_face": "😕",
+ "construction": "🚧",
+ "construction_worker": "👷",
+ "construction_worker_dark_skin_tone": "👷🏿",
+ "construction_worker_light_skin_tone": "👷🏻",
+ "construction_worker_medium-dark_skin_tone": "👷🏾",
+ "construction_worker_medium-light_skin_tone": "👷🏼",
+ "construction_worker_medium_skin_tone": "👷🏽",
+ "control_knobs": "🎛",
+ "convenience_store": "🏪",
+ "cooked_rice": "🍚",
+ "cookie": "🍪",
+ "cooking": "🍳",
+ "copyright": "©",
+ "couch_and_lamp": "🛋",
+ "counterclockwise_arrows_button": "🔄",
+ "couple_with_heart": "💑",
+ "couple_with_heart_man_man": "👨\u200d❤️\u200d👨",
+ "couple_with_heart_woman_man": "👩\u200d❤️\u200d👨",
+ "couple_with_heart_woman_woman": "👩\u200d❤️\u200d👩",
+ "cow": "🐮",
+ "cow_face": "🐮",
+ "cowboy_hat_face": "🤠",
+ "crab": "🦀",
+ "crayon": "🖍",
+ "credit_card": "💳",
+ "crescent_moon": "🌙",
+ "cricket": "🦗",
+ "cricket_game": "🏏",
+ "crocodile": "🐊",
+ "croissant": "🥐",
+ "cross_mark": "❌",
+ "cross_mark_button": "❎",
+ "crossed_fingers": "🤞",
+ "crossed_fingers_dark_skin_tone": "🤞🏿",
+ "crossed_fingers_light_skin_tone": "🤞🏻",
+ "crossed_fingers_medium-dark_skin_tone": "🤞🏾",
+ "crossed_fingers_medium-light_skin_tone": "🤞🏼",
+ "crossed_fingers_medium_skin_tone": "🤞🏽",
+ "crossed_flags": "🎌",
+ "crossed_swords": "⚔",
+ "crown": "👑",
+ "crying_cat_face": "😿",
+ "crying_face": "😢",
+ "crystal_ball": "🔮",
+ "cucumber": "🥒",
+ "cupcake": "🧁",
+ "cup_with_straw": "🥤",
+ "curling_stone": "🥌",
+ "curly_hair": "🦱",
+ "curly-haired_man": "👨\u200d🦱",
+ "curly-haired_woman": "👩\u200d🦱",
+ "curly_loop": "➰",
+ "currency_exchange": "💱",
+ "curry_rice": "🍛",
+ "custard": "🍮",
+ "customs": "🛃",
+ "cut_of_meat": "🥩",
+ "cyclone": "🌀",
+ "dagger": "🗡",
+ "dango": "🍡",
+ "dashing_away": "💨",
+ "deaf_person": "🧏",
+ "deciduous_tree": "🌳",
+ "deer": "🦌",
+ "delivery_truck": "🚚",
+ "department_store": "🏬",
+ "derelict_house": "🏚",
+ "desert": "🏜",
+ "desert_island": "🏝",
+ "desktop_computer": "🖥",
+ "detective": "🕵",
+ "detective_dark_skin_tone": "🕵🏿",
+ "detective_light_skin_tone": "🕵🏻",
+ "detective_medium-dark_skin_tone": "🕵🏾",
+ "detective_medium-light_skin_tone": "🕵🏼",
+ "detective_medium_skin_tone": "🕵🏽",
+ "diamond_suit": "♦",
+ "diamond_with_a_dot": "💠",
+ "dim_button": "🔅",
+ "direct_hit": "🎯",
+ "disappointed_face": "😞",
+ "diving_mask": "🤿",
+ "diya_lamp": "🪔",
+ "dizzy": "💫",
+ "dizzy_face": "😵",
+ "dna": "🧬",
+ "dog": "🐶",
+ "dog_face": "🐶",
+ "dollar_banknote": "💵",
+ "dolphin": "🐬",
+ "door": "🚪",
+ "dotted_six-pointed_star": "🔯",
+ "double_curly_loop": "➿",
+ "double_exclamation_mark": "‼",
+ "doughnut": "🍩",
+ "dove": "🕊",
+ "down-left_arrow": "↙",
+ "down-right_arrow": "↘",
+ "down_arrow": "⬇",
+ "downcast_face_with_sweat": "😓",
+ "downwards_button": "🔽",
+ "dragon": "🐉",
+ "dragon_face": "🐲",
+ "dress": "👗",
+ "drooling_face": "🤤",
+ "drop_of_blood": "🩸",
+ "droplet": "💧",
+ "drum": "🥁",
+ "duck": "🦆",
+ "dumpling": "🥟",
+ "dvd": "📀",
+ "e-mail": "📧",
+ "eagle": "🦅",
+ "ear": "👂",
+ "ear_dark_skin_tone": "👂🏿",
+ "ear_light_skin_tone": "👂🏻",
+ "ear_medium-dark_skin_tone": "👂🏾",
+ "ear_medium-light_skin_tone": "👂🏼",
+ "ear_medium_skin_tone": "👂🏽",
+ "ear_of_corn": "🌽",
+ "ear_with_hearing_aid": "🦻",
+ "egg": "🍳",
+ "eggplant": "🍆",
+ "eight-pointed_star": "✴",
+ "eight-spoked_asterisk": "✳",
+ "eight-thirty": "🕣",
+ "eight_o’clock": "🕗",
+ "eject_button": "⏏",
+ "electric_plug": "🔌",
+ "elephant": "🐘",
+ "eleven-thirty": "🕦",
+ "eleven_o’clock": "🕚",
+ "elf": "🧝",
+ "elf_dark_skin_tone": "🧝🏿",
+ "elf_light_skin_tone": "🧝🏻",
+ "elf_medium-dark_skin_tone": "🧝🏾",
+ "elf_medium-light_skin_tone": "🧝🏼",
+ "elf_medium_skin_tone": "🧝🏽",
+ "envelope": "✉",
+ "envelope_with_arrow": "📩",
+ "euro_banknote": "💶",
+ "evergreen_tree": "🌲",
+ "ewe": "🐑",
+ "exclamation_mark": "❗",
+ "exclamation_question_mark": "⁉",
+ "exploding_head": "🤯",
+ "expressionless_face": "😑",
+ "eye": "👁",
+ "eye_in_speech_bubble": "👁️\u200d🗨️",
+ "eyes": "👀",
+ "face_blowing_a_kiss": "😘",
+ "face_savoring_food": "😋",
+ "face_screaming_in_fear": "😱",
+ "face_vomiting": "🤮",
+ "face_with_hand_over_mouth": "🤭",
+ "face_with_head-bandage": "🤕",
+ "face_with_medical_mask": "😷",
+ "face_with_monocle": "🧐",
+ "face_with_open_mouth": "😮",
+ "face_with_raised_eyebrow": "🤨",
+ "face_with_rolling_eyes": "🙄",
+ "face_with_steam_from_nose": "😤",
+ "face_with_symbols_on_mouth": "🤬",
+ "face_with_tears_of_joy": "😂",
+ "face_with_thermometer": "🤒",
+ "face_with_tongue": "😛",
+ "face_without_mouth": "😶",
+ "factory": "🏭",
+ "fairy": "🧚",
+ "fairy_dark_skin_tone": "🧚🏿",
+ "fairy_light_skin_tone": "🧚🏻",
+ "fairy_medium-dark_skin_tone": "🧚🏾",
+ "fairy_medium-light_skin_tone": "🧚🏼",
+ "fairy_medium_skin_tone": "🧚🏽",
+ "falafel": "🧆",
+ "fallen_leaf": "🍂",
+ "family": "👪",
+ "family_man_boy": "👨\u200d👦",
+ "family_man_boy_boy": "👨\u200d👦\u200d👦",
+ "family_man_girl": "👨\u200d👧",
+ "family_man_girl_boy": "👨\u200d👧\u200d👦",
+ "family_man_girl_girl": "👨\u200d👧\u200d👧",
+ "family_man_man_boy": "👨\u200d👨\u200d👦",
+ "family_man_man_boy_boy": "👨\u200d👨\u200d👦\u200d👦",
+ "family_man_man_girl": "👨\u200d👨\u200d👧",
+ "family_man_man_girl_boy": "👨\u200d👨\u200d👧\u200d👦",
+ "family_man_man_girl_girl": "👨\u200d👨\u200d👧\u200d👧",
+ "family_man_woman_boy": "👨\u200d👩\u200d👦",
+ "family_man_woman_boy_boy": "👨\u200d👩\u200d👦\u200d👦",
+ "family_man_woman_girl": "👨\u200d👩\u200d👧",
+ "family_man_woman_girl_boy": "👨\u200d👩\u200d👧\u200d👦",
+ "family_man_woman_girl_girl": "👨\u200d👩\u200d👧\u200d👧",
+ "family_woman_boy": "👩\u200d👦",
+ "family_woman_boy_boy": "👩\u200d👦\u200d👦",
+ "family_woman_girl": "👩\u200d👧",
+ "family_woman_girl_boy": "👩\u200d👧\u200d👦",
+ "family_woman_girl_girl": "👩\u200d👧\u200d👧",
+ "family_woman_woman_boy": "👩\u200d👩\u200d👦",
+ "family_woman_woman_boy_boy": "👩\u200d👩\u200d👦\u200d👦",
+ "family_woman_woman_girl": "👩\u200d👩\u200d👧",
+ "family_woman_woman_girl_boy": "👩\u200d👩\u200d👧\u200d👦",
+ "family_woman_woman_girl_girl": "👩\u200d👩\u200d👧\u200d👧",
+ "fast-forward_button": "⏩",
+ "fast_down_button": "⏬",
+ "fast_reverse_button": "⏪",
+ "fast_up_button": "⏫",
+ "fax_machine": "📠",
+ "fearful_face": "😨",
+ "female_sign": "♀",
+ "ferris_wheel": "🎡",
+ "ferry": "⛴",
+ "field_hockey": "🏑",
+ "file_cabinet": "🗄",
+ "file_folder": "📁",
+ "film_frames": "🎞",
+ "film_projector": "📽",
+ "fire": "🔥",
+ "fire_extinguisher": "🧯",
+ "firecracker": "🧨",
+ "fire_engine": "🚒",
+ "fireworks": "🎆",
+ "first_quarter_moon": "🌓",
+ "first_quarter_moon_face": "🌛",
+ "fish": "🐟",
+ "fish_cake_with_swirl": "🍥",
+ "fishing_pole": "🎣",
+ "five-thirty": "🕠",
+ "five_o’clock": "🕔",
+ "flag_in_hole": "⛳",
+ "flamingo": "🦩",
+ "flashlight": "🔦",
+ "flat_shoe": "🥿",
+ "fleur-de-lis": "⚜",
+ "flexed_biceps": "💪",
+ "flexed_biceps_dark_skin_tone": "💪🏿",
+ "flexed_biceps_light_skin_tone": "💪🏻",
+ "flexed_biceps_medium-dark_skin_tone": "💪🏾",
+ "flexed_biceps_medium-light_skin_tone": "💪🏼",
+ "flexed_biceps_medium_skin_tone": "💪🏽",
+ "floppy_disk": "💾",
+ "flower_playing_cards": "🎴",
+ "flushed_face": "😳",
+ "flying_disc": "🥏",
+ "flying_saucer": "🛸",
+ "fog": "🌫",
+ "foggy": "🌁",
+ "folded_hands": "🙏",
+ "folded_hands_dark_skin_tone": "🙏🏿",
+ "folded_hands_light_skin_tone": "🙏🏻",
+ "folded_hands_medium-dark_skin_tone": "🙏🏾",
+ "folded_hands_medium-light_skin_tone": "🙏🏼",
+ "folded_hands_medium_skin_tone": "🙏🏽",
+ "foot": "🦶",
+ "footprints": "👣",
+ "fork_and_knife": "🍴",
+ "fork_and_knife_with_plate": "🍽",
+ "fortune_cookie": "🥠",
+ "fountain": "⛲",
+ "fountain_pen": "🖋",
+ "four-thirty": "🕟",
+ "four_leaf_clover": "🍀",
+ "four_o’clock": "🕓",
+ "fox_face": "🦊",
+ "framed_picture": "🖼",
+ "french_fries": "🍟",
+ "fried_shrimp": "🍤",
+ "frog_face": "🐸",
+ "front-facing_baby_chick": "🐥",
+ "frowning_face": "☹",
+ "frowning_face_with_open_mouth": "😦",
+ "fuel_pump": "⛽",
+ "full_moon": "🌕",
+ "full_moon_face": "🌝",
+ "funeral_urn": "⚱",
+ "game_die": "🎲",
+ "garlic": "🧄",
+ "gear": "⚙",
+ "gem_stone": "💎",
+ "genie": "🧞",
+ "ghost": "👻",
+ "giraffe": "🦒",
+ "girl": "👧",
+ "girl_dark_skin_tone": "👧🏿",
+ "girl_light_skin_tone": "👧🏻",
+ "girl_medium-dark_skin_tone": "👧🏾",
+ "girl_medium-light_skin_tone": "👧🏼",
+ "girl_medium_skin_tone": "👧🏽",
+ "glass_of_milk": "🥛",
+ "glasses": "👓",
+ "globe_showing_americas": "🌎",
+ "globe_showing_asia-australia": "🌏",
+ "globe_showing_europe-africa": "🌍",
+ "globe_with_meridians": "🌐",
+ "gloves": "🧤",
+ "glowing_star": "🌟",
+ "goal_net": "🥅",
+ "goat": "🐐",
+ "goblin": "👺",
+ "goggles": "🥽",
+ "gorilla": "🦍",
+ "graduation_cap": "🎓",
+ "grapes": "🍇",
+ "green_apple": "🍏",
+ "green_book": "📗",
+ "green_circle": "🟢",
+ "green_heart": "💚",
+ "green_salad": "🥗",
+ "green_square": "🟩",
+ "grimacing_face": "😬",
+ "grinning_cat_face": "😺",
+ "grinning_cat_face_with_smiling_eyes": "😸",
+ "grinning_face": "😀",
+ "grinning_face_with_big_eyes": "😃",
+ "grinning_face_with_smiling_eyes": "😄",
+ "grinning_face_with_sweat": "😅",
+ "grinning_squinting_face": "😆",
+ "growing_heart": "💗",
+ "guard": "💂",
+ "guard_dark_skin_tone": "💂🏿",
+ "guard_light_skin_tone": "💂🏻",
+ "guard_medium-dark_skin_tone": "💂🏾",
+ "guard_medium-light_skin_tone": "💂🏼",
+ "guard_medium_skin_tone": "💂🏽",
+ "guide_dog": "🦮",
+ "guitar": "🎸",
+ "hamburger": "🍔",
+ "hammer": "🔨",
+ "hammer_and_pick": "⚒",
+ "hammer_and_wrench": "🛠",
+ "hamster_face": "🐹",
+ "hand_with_fingers_splayed": "🖐",
+ "hand_with_fingers_splayed_dark_skin_tone": "🖐🏿",
+ "hand_with_fingers_splayed_light_skin_tone": "🖐🏻",
+ "hand_with_fingers_splayed_medium-dark_skin_tone": "🖐🏾",
+ "hand_with_fingers_splayed_medium-light_skin_tone": "🖐🏼",
+ "hand_with_fingers_splayed_medium_skin_tone": "🖐🏽",
+ "handbag": "👜",
+ "handshake": "🤝",
+ "hatching_chick": "🐣",
+ "headphone": "🎧",
+ "hear-no-evil_monkey": "🙉",
+ "heart_decoration": "💟",
+ "heart_suit": "♥",
+ "heart_with_arrow": "💘",
+ "heart_with_ribbon": "💝",
+ "heavy_check_mark": "✔",
+ "heavy_division_sign": "➗",
+ "heavy_dollar_sign": "💲",
+ "heavy_heart_exclamation": "❣",
+ "heavy_large_circle": "⭕",
+ "heavy_minus_sign": "➖",
+ "heavy_multiplication_x": "✖",
+ "heavy_plus_sign": "➕",
+ "hedgehog": "🦔",
+ "helicopter": "🚁",
+ "herb": "🌿",
+ "hibiscus": "🌺",
+ "high-heeled_shoe": "👠",
+ "high-speed_train": "🚄",
+ "high_voltage": "⚡",
+ "hiking_boot": "🥾",
+ "hindu_temple": "🛕",
+ "hippopotamus": "🦛",
+ "hole": "🕳",
+ "honey_pot": "🍯",
+ "honeybee": "🐝",
+ "horizontal_traffic_light": "🚥",
+ "horse": "🐴",
+ "horse_face": "🐴",
+ "horse_racing": "🏇",
+ "horse_racing_dark_skin_tone": "🏇🏿",
+ "horse_racing_light_skin_tone": "🏇🏻",
+ "horse_racing_medium-dark_skin_tone": "🏇🏾",
+ "horse_racing_medium-light_skin_tone": "🏇🏼",
+ "horse_racing_medium_skin_tone": "🏇🏽",
+ "hospital": "🏥",
+ "hot_beverage": "☕",
+ "hot_dog": "🌭",
+ "hot_face": "🥵",
+ "hot_pepper": "🌶",
+ "hot_springs": "♨",
+ "hotel": "🏨",
+ "hourglass_done": "⌛",
+ "hourglass_not_done": "⏳",
+ "house": "🏠",
+ "house_with_garden": "🏡",
+ "houses": "🏘",
+ "hugging_face": "🤗",
+ "hundred_points": "💯",
+ "hushed_face": "😯",
+ "ice": "🧊",
+ "ice_cream": "🍨",
+ "ice_hockey": "🏒",
+ "ice_skate": "⛸",
+ "inbox_tray": "📥",
+ "incoming_envelope": "📨",
+ "index_pointing_up": "☝",
+ "index_pointing_up_dark_skin_tone": "☝🏿",
+ "index_pointing_up_light_skin_tone": "☝🏻",
+ "index_pointing_up_medium-dark_skin_tone": "☝🏾",
+ "index_pointing_up_medium-light_skin_tone": "☝🏼",
+ "index_pointing_up_medium_skin_tone": "☝🏽",
+ "infinity": "♾",
+ "information": "ℹ",
+ "input_latin_letters": "🔤",
+ "input_latin_lowercase": "🔡",
+ "input_latin_uppercase": "🔠",
+ "input_numbers": "🔢",
+ "input_symbols": "🔣",
+ "jack-o-lantern": "🎃",
+ "jeans": "👖",
+ "jigsaw": "🧩",
+ "joker": "🃏",
+ "joystick": "🕹",
+ "kaaba": "🕋",
+ "kangaroo": "🦘",
+ "key": "🔑",
+ "keyboard": "⌨",
+ "keycap_#": "#️⃣",
+ "keycap_*": "*️⃣",
+ "keycap_0": "0️⃣",
+ "keycap_1": "1️⃣",
+ "keycap_10": "🔟",
+ "keycap_2": "2️⃣",
+ "keycap_3": "3️⃣",
+ "keycap_4": "4️⃣",
+ "keycap_5": "5️⃣",
+ "keycap_6": "6️⃣",
+ "keycap_7": "7️⃣",
+ "keycap_8": "8️⃣",
+ "keycap_9": "9️⃣",
+ "kick_scooter": "🛴",
+ "kimono": "👘",
+ "kiss": "💋",
+ "kiss_man_man": "👨\u200d❤️\u200d💋\u200d👨",
+ "kiss_mark": "💋",
+ "kiss_woman_man": "👩\u200d❤️\u200d💋\u200d👨",
+ "kiss_woman_woman": "👩\u200d❤️\u200d💋\u200d👩",
+ "kissing_cat_face": "😽",
+ "kissing_face": "😗",
+ "kissing_face_with_closed_eyes": "😚",
+ "kissing_face_with_smiling_eyes": "😙",
+ "kitchen_knife": "🔪",
+ "kite": "🪁",
+ "kiwi_fruit": "🥝",
+ "koala": "🐨",
+ "lab_coat": "🥼",
+ "label": "🏷",
+ "lacrosse": "🥍",
+ "lady_beetle": "🐞",
+ "laptop_computer": "💻",
+ "large_blue_diamond": "🔷",
+ "large_orange_diamond": "🔶",
+ "last_quarter_moon": "🌗",
+ "last_quarter_moon_face": "🌜",
+ "last_track_button": "⏮",
+ "latin_cross": "✝",
+ "leaf_fluttering_in_wind": "🍃",
+ "leafy_green": "🥬",
+ "ledger": "📒",
+ "left-facing_fist": "🤛",
+ "left-facing_fist_dark_skin_tone": "🤛🏿",
+ "left-facing_fist_light_skin_tone": "🤛🏻",
+ "left-facing_fist_medium-dark_skin_tone": "🤛🏾",
+ "left-facing_fist_medium-light_skin_tone": "🤛🏼",
+ "left-facing_fist_medium_skin_tone": "🤛🏽",
+ "left-right_arrow": "↔",
+ "left_arrow": "⬅",
+ "left_arrow_curving_right": "↪",
+ "left_luggage": "🛅",
+ "left_speech_bubble": "🗨",
+ "leg": "🦵",
+ "lemon": "🍋",
+ "leopard": "🐆",
+ "level_slider": "🎚",
+ "light_bulb": "💡",
+ "light_rail": "🚈",
+ "link": "🔗",
+ "linked_paperclips": "🖇",
+ "lion_face": "🦁",
+ "lipstick": "💄",
+ "litter_in_bin_sign": "🚮",
+ "lizard": "🦎",
+ "llama": "🦙",
+ "lobster": "🦞",
+ "locked": "🔒",
+ "locked_with_key": "🔐",
+ "locked_with_pen": "🔏",
+ "locomotive": "🚂",
+ "lollipop": "🍭",
+ "lotion_bottle": "🧴",
+ "loudly_crying_face": "😭",
+ "loudspeaker": "📢",
+ "love-you_gesture": "🤟",
+ "love-you_gesture_dark_skin_tone": "🤟🏿",
+ "love-you_gesture_light_skin_tone": "🤟🏻",
+ "love-you_gesture_medium-dark_skin_tone": "🤟🏾",
+ "love-you_gesture_medium-light_skin_tone": "🤟🏼",
+ "love-you_gesture_medium_skin_tone": "🤟🏽",
+ "love_hotel": "🏩",
+ "love_letter": "💌",
+ "luggage": "🧳",
+ "lying_face": "🤥",
+ "mage": "🧙",
+ "mage_dark_skin_tone": "🧙🏿",
+ "mage_light_skin_tone": "🧙🏻",
+ "mage_medium-dark_skin_tone": "🧙🏾",
+ "mage_medium-light_skin_tone": "🧙🏼",
+ "mage_medium_skin_tone": "🧙🏽",
+ "magnet": "🧲",
+ "magnifying_glass_tilted_left": "🔍",
+ "magnifying_glass_tilted_right": "🔎",
+ "mahjong_red_dragon": "🀄",
+ "male_sign": "♂",
+ "man": "👨",
+ "man_and_woman_holding_hands": "👫",
+ "man_artist": "👨\u200d🎨",
+ "man_artist_dark_skin_tone": "👨🏿\u200d🎨",
+ "man_artist_light_skin_tone": "👨🏻\u200d🎨",
+ "man_artist_medium-dark_skin_tone": "👨🏾\u200d🎨",
+ "man_artist_medium-light_skin_tone": "👨🏼\u200d🎨",
+ "man_artist_medium_skin_tone": "👨🏽\u200d🎨",
+ "man_astronaut": "👨\u200d🚀",
+ "man_astronaut_dark_skin_tone": "👨🏿\u200d🚀",
+ "man_astronaut_light_skin_tone": "👨🏻\u200d🚀",
+ "man_astronaut_medium-dark_skin_tone": "👨🏾\u200d🚀",
+ "man_astronaut_medium-light_skin_tone": "👨🏼\u200d🚀",
+ "man_astronaut_medium_skin_tone": "👨🏽\u200d🚀",
+ "man_biking": "🚴\u200d♂️",
+ "man_biking_dark_skin_tone": "🚴🏿\u200d♂️",
+ "man_biking_light_skin_tone": "🚴🏻\u200d♂️",
+ "man_biking_medium-dark_skin_tone": "🚴🏾\u200d♂️",
+ "man_biking_medium-light_skin_tone": "🚴🏼\u200d♂️",
+ "man_biking_medium_skin_tone": "🚴🏽\u200d♂️",
+ "man_bouncing_ball": "⛹️\u200d♂️",
+ "man_bouncing_ball_dark_skin_tone": "⛹🏿\u200d♂️",
+ "man_bouncing_ball_light_skin_tone": "⛹🏻\u200d♂️",
+ "man_bouncing_ball_medium-dark_skin_tone": "⛹🏾\u200d♂️",
+ "man_bouncing_ball_medium-light_skin_tone": "⛹🏼\u200d♂️",
+ "man_bouncing_ball_medium_skin_tone": "⛹🏽\u200d♂️",
+ "man_bowing": "🙇\u200d♂️",
+ "man_bowing_dark_skin_tone": "🙇🏿\u200d♂️",
+ "man_bowing_light_skin_tone": "🙇🏻\u200d♂️",
+ "man_bowing_medium-dark_skin_tone": "🙇🏾\u200d♂️",
+ "man_bowing_medium-light_skin_tone": "🙇🏼\u200d♂️",
+ "man_bowing_medium_skin_tone": "🙇🏽\u200d♂️",
+ "man_cartwheeling": "🤸\u200d♂️",
+ "man_cartwheeling_dark_skin_tone": "🤸🏿\u200d♂️",
+ "man_cartwheeling_light_skin_tone": "🤸🏻\u200d♂️",
+ "man_cartwheeling_medium-dark_skin_tone": "🤸🏾\u200d♂️",
+ "man_cartwheeling_medium-light_skin_tone": "🤸🏼\u200d♂️",
+ "man_cartwheeling_medium_skin_tone": "🤸🏽\u200d♂️",
+ "man_climbing": "🧗\u200d♂️",
+ "man_climbing_dark_skin_tone": "🧗🏿\u200d♂️",
+ "man_climbing_light_skin_tone": "🧗🏻\u200d♂️",
+ "man_climbing_medium-dark_skin_tone": "🧗🏾\u200d♂️",
+ "man_climbing_medium-light_skin_tone": "🧗🏼\u200d♂️",
+ "man_climbing_medium_skin_tone": "🧗🏽\u200d♂️",
+ "man_construction_worker": "👷\u200d♂️",
+ "man_construction_worker_dark_skin_tone": "👷🏿\u200d♂️",
+ "man_construction_worker_light_skin_tone": "👷🏻\u200d♂️",
+ "man_construction_worker_medium-dark_skin_tone": "👷🏾\u200d♂️",
+ "man_construction_worker_medium-light_skin_tone": "👷🏼\u200d♂️",
+ "man_construction_worker_medium_skin_tone": "👷🏽\u200d♂️",
+ "man_cook": "👨\u200d🍳",
+ "man_cook_dark_skin_tone": "👨🏿\u200d🍳",
+ "man_cook_light_skin_tone": "👨🏻\u200d🍳",
+ "man_cook_medium-dark_skin_tone": "👨🏾\u200d🍳",
+ "man_cook_medium-light_skin_tone": "👨🏼\u200d🍳",
+ "man_cook_medium_skin_tone": "👨🏽\u200d🍳",
+ "man_dancing": "🕺",
+ "man_dancing_dark_skin_tone": "🕺🏿",
+ "man_dancing_light_skin_tone": "🕺🏻",
+ "man_dancing_medium-dark_skin_tone": "🕺🏾",
+ "man_dancing_medium-light_skin_tone": "🕺🏼",
+ "man_dancing_medium_skin_tone": "🕺🏽",
+ "man_dark_skin_tone": "👨🏿",
+ "man_detective": "🕵️\u200d♂️",
+ "man_detective_dark_skin_tone": "🕵🏿\u200d♂️",
+ "man_detective_light_skin_tone": "🕵🏻\u200d♂️",
+ "man_detective_medium-dark_skin_tone": "🕵🏾\u200d♂️",
+ "man_detective_medium-light_skin_tone": "🕵🏼\u200d♂️",
+ "man_detective_medium_skin_tone": "🕵🏽\u200d♂️",
+ "man_elf": "🧝\u200d♂️",
+ "man_elf_dark_skin_tone": "🧝🏿\u200d♂️",
+ "man_elf_light_skin_tone": "🧝🏻\u200d♂️",
+ "man_elf_medium-dark_skin_tone": "🧝🏾\u200d♂️",
+ "man_elf_medium-light_skin_tone": "🧝🏼\u200d♂️",
+ "man_elf_medium_skin_tone": "🧝🏽\u200d♂️",
+ "man_facepalming": "🤦\u200d♂️",
+ "man_facepalming_dark_skin_tone": "🤦🏿\u200d♂️",
+ "man_facepalming_light_skin_tone": "🤦🏻\u200d♂️",
+ "man_facepalming_medium-dark_skin_tone": "🤦🏾\u200d♂️",
+ "man_facepalming_medium-light_skin_tone": "🤦🏼\u200d♂️",
+ "man_facepalming_medium_skin_tone": "🤦🏽\u200d♂️",
+ "man_factory_worker": "👨\u200d🏭",
+ "man_factory_worker_dark_skin_tone": "👨🏿\u200d🏭",
+ "man_factory_worker_light_skin_tone": "👨🏻\u200d🏭",
+ "man_factory_worker_medium-dark_skin_tone": "👨🏾\u200d🏭",
+ "man_factory_worker_medium-light_skin_tone": "👨🏼\u200d🏭",
+ "man_factory_worker_medium_skin_tone": "👨🏽\u200d🏭",
+ "man_fairy": "🧚\u200d♂️",
+ "man_fairy_dark_skin_tone": "🧚🏿\u200d♂️",
+ "man_fairy_light_skin_tone": "🧚🏻\u200d♂️",
+ "man_fairy_medium-dark_skin_tone": "🧚🏾\u200d♂️",
+ "man_fairy_medium-light_skin_tone": "🧚🏼\u200d♂️",
+ "man_fairy_medium_skin_tone": "🧚🏽\u200d♂️",
+ "man_farmer": "👨\u200d🌾",
+ "man_farmer_dark_skin_tone": "👨🏿\u200d🌾",
+ "man_farmer_light_skin_tone": "👨🏻\u200d🌾",
+ "man_farmer_medium-dark_skin_tone": "👨🏾\u200d🌾",
+ "man_farmer_medium-light_skin_tone": "👨🏼\u200d🌾",
+ "man_farmer_medium_skin_tone": "👨🏽\u200d🌾",
+ "man_firefighter": "👨\u200d🚒",
+ "man_firefighter_dark_skin_tone": "👨🏿\u200d🚒",
+ "man_firefighter_light_skin_tone": "👨🏻\u200d🚒",
+ "man_firefighter_medium-dark_skin_tone": "👨🏾\u200d🚒",
+ "man_firefighter_medium-light_skin_tone": "👨🏼\u200d🚒",
+ "man_firefighter_medium_skin_tone": "👨🏽\u200d🚒",
+ "man_frowning": "🙍\u200d♂️",
+ "man_frowning_dark_skin_tone": "🙍🏿\u200d♂️",
+ "man_frowning_light_skin_tone": "🙍🏻\u200d♂️",
+ "man_frowning_medium-dark_skin_tone": "🙍🏾\u200d♂️",
+ "man_frowning_medium-light_skin_tone": "🙍🏼\u200d♂️",
+ "man_frowning_medium_skin_tone": "🙍🏽\u200d♂️",
+ "man_genie": "🧞\u200d♂️",
+ "man_gesturing_no": "🙅\u200d♂️",
+ "man_gesturing_no_dark_skin_tone": "🙅🏿\u200d♂️",
+ "man_gesturing_no_light_skin_tone": "🙅🏻\u200d♂️",
+ "man_gesturing_no_medium-dark_skin_tone": "🙅🏾\u200d♂️",
+ "man_gesturing_no_medium-light_skin_tone": "🙅🏼\u200d♂️",
+ "man_gesturing_no_medium_skin_tone": "🙅🏽\u200d♂️",
+ "man_gesturing_ok": "🙆\u200d♂️",
+ "man_gesturing_ok_dark_skin_tone": "🙆🏿\u200d♂️",
+ "man_gesturing_ok_light_skin_tone": "🙆🏻\u200d♂️",
+ "man_gesturing_ok_medium-dark_skin_tone": "🙆🏾\u200d♂️",
+ "man_gesturing_ok_medium-light_skin_tone": "🙆🏼\u200d♂️",
+ "man_gesturing_ok_medium_skin_tone": "🙆🏽\u200d♂️",
+ "man_getting_haircut": "💇\u200d♂️",
+ "man_getting_haircut_dark_skin_tone": "💇🏿\u200d♂️",
+ "man_getting_haircut_light_skin_tone": "💇🏻\u200d♂️",
+ "man_getting_haircut_medium-dark_skin_tone": "💇🏾\u200d♂️",
+ "man_getting_haircut_medium-light_skin_tone": "💇🏼\u200d♂️",
+ "man_getting_haircut_medium_skin_tone": "💇🏽\u200d♂️",
+ "man_getting_massage": "💆\u200d♂️",
+ "man_getting_massage_dark_skin_tone": "💆🏿\u200d♂️",
+ "man_getting_massage_light_skin_tone": "💆🏻\u200d♂️",
+ "man_getting_massage_medium-dark_skin_tone": "💆🏾\u200d♂️",
+ "man_getting_massage_medium-light_skin_tone": "💆🏼\u200d♂️",
+ "man_getting_massage_medium_skin_tone": "💆🏽\u200d♂️",
+ "man_golfing": "🏌️\u200d♂️",
+ "man_golfing_dark_skin_tone": "🏌🏿\u200d♂️",
+ "man_golfing_light_skin_tone": "🏌🏻\u200d♂️",
+ "man_golfing_medium-dark_skin_tone": "🏌🏾\u200d♂️",
+ "man_golfing_medium-light_skin_tone": "🏌🏼\u200d♂️",
+ "man_golfing_medium_skin_tone": "🏌🏽\u200d♂️",
+ "man_guard": "💂\u200d♂️",
+ "man_guard_dark_skin_tone": "💂🏿\u200d♂️",
+ "man_guard_light_skin_tone": "💂🏻\u200d♂️",
+ "man_guard_medium-dark_skin_tone": "💂🏾\u200d♂️",
+ "man_guard_medium-light_skin_tone": "💂🏼\u200d♂️",
+ "man_guard_medium_skin_tone": "💂🏽\u200d♂️",
+ "man_health_worker": "👨\u200d⚕️",
+ "man_health_worker_dark_skin_tone": "👨🏿\u200d⚕️",
+ "man_health_worker_light_skin_tone": "👨🏻\u200d⚕️",
+ "man_health_worker_medium-dark_skin_tone": "👨🏾\u200d⚕️",
+ "man_health_worker_medium-light_skin_tone": "👨🏼\u200d⚕️",
+ "man_health_worker_medium_skin_tone": "👨🏽\u200d⚕️",
+ "man_in_lotus_position": "🧘\u200d♂️",
+ "man_in_lotus_position_dark_skin_tone": "🧘🏿\u200d♂️",
+ "man_in_lotus_position_light_skin_tone": "🧘🏻\u200d♂️",
+ "man_in_lotus_position_medium-dark_skin_tone": "🧘🏾\u200d♂️",
+ "man_in_lotus_position_medium-light_skin_tone": "🧘🏼\u200d♂️",
+ "man_in_lotus_position_medium_skin_tone": "🧘🏽\u200d♂️",
+ "man_in_manual_wheelchair": "👨\u200d🦽",
+ "man_in_motorized_wheelchair": "👨\u200d🦼",
+ "man_in_steamy_room": "🧖\u200d♂️",
+ "man_in_steamy_room_dark_skin_tone": "🧖🏿\u200d♂️",
+ "man_in_steamy_room_light_skin_tone": "🧖🏻\u200d♂️",
+ "man_in_steamy_room_medium-dark_skin_tone": "🧖🏾\u200d♂️",
+ "man_in_steamy_room_medium-light_skin_tone": "🧖🏼\u200d♂️",
+ "man_in_steamy_room_medium_skin_tone": "🧖🏽\u200d♂️",
+ "man_in_suit_levitating": "🕴",
+ "man_in_suit_levitating_dark_skin_tone": "🕴🏿",
+ "man_in_suit_levitating_light_skin_tone": "🕴🏻",
+ "man_in_suit_levitating_medium-dark_skin_tone": "🕴🏾",
+ "man_in_suit_levitating_medium-light_skin_tone": "🕴🏼",
+ "man_in_suit_levitating_medium_skin_tone": "🕴🏽",
+ "man_in_tuxedo": "🤵",
+ "man_in_tuxedo_dark_skin_tone": "🤵🏿",
+ "man_in_tuxedo_light_skin_tone": "🤵🏻",
+ "man_in_tuxedo_medium-dark_skin_tone": "🤵🏾",
+ "man_in_tuxedo_medium-light_skin_tone": "🤵🏼",
+ "man_in_tuxedo_medium_skin_tone": "🤵🏽",
+ "man_judge": "👨\u200d⚖️",
+ "man_judge_dark_skin_tone": "👨🏿\u200d⚖️",
+ "man_judge_light_skin_tone": "👨🏻\u200d⚖️",
+ "man_judge_medium-dark_skin_tone": "👨🏾\u200d⚖️",
+ "man_judge_medium-light_skin_tone": "👨🏼\u200d⚖️",
+ "man_judge_medium_skin_tone": "👨🏽\u200d⚖️",
+ "man_juggling": "🤹\u200d♂️",
+ "man_juggling_dark_skin_tone": "🤹🏿\u200d♂️",
+ "man_juggling_light_skin_tone": "🤹🏻\u200d♂️",
+ "man_juggling_medium-dark_skin_tone": "🤹🏾\u200d♂️",
+ "man_juggling_medium-light_skin_tone": "🤹🏼\u200d♂️",
+ "man_juggling_medium_skin_tone": "🤹🏽\u200d♂️",
+ "man_lifting_weights": "🏋️\u200d♂️",
+ "man_lifting_weights_dark_skin_tone": "🏋🏿\u200d♂️",
+ "man_lifting_weights_light_skin_tone": "🏋🏻\u200d♂️",
+ "man_lifting_weights_medium-dark_skin_tone": "🏋🏾\u200d♂️",
+ "man_lifting_weights_medium-light_skin_tone": "🏋🏼\u200d♂️",
+ "man_lifting_weights_medium_skin_tone": "🏋🏽\u200d♂️",
+ "man_light_skin_tone": "👨🏻",
+ "man_mage": "🧙\u200d♂️",
+ "man_mage_dark_skin_tone": "🧙🏿\u200d♂️",
+ "man_mage_light_skin_tone": "🧙🏻\u200d♂️",
+ "man_mage_medium-dark_skin_tone": "🧙🏾\u200d♂️",
+ "man_mage_medium-light_skin_tone": "🧙🏼\u200d♂️",
+ "man_mage_medium_skin_tone": "🧙🏽\u200d♂️",
+ "man_mechanic": "👨\u200d🔧",
+ "man_mechanic_dark_skin_tone": "👨🏿\u200d🔧",
+ "man_mechanic_light_skin_tone": "👨🏻\u200d🔧",
+ "man_mechanic_medium-dark_skin_tone": "👨🏾\u200d🔧",
+ "man_mechanic_medium-light_skin_tone": "👨🏼\u200d🔧",
+ "man_mechanic_medium_skin_tone": "👨🏽\u200d🔧",
+ "man_medium-dark_skin_tone": "👨🏾",
+ "man_medium-light_skin_tone": "👨🏼",
+ "man_medium_skin_tone": "👨🏽",
+ "man_mountain_biking": "🚵\u200d♂️",
+ "man_mountain_biking_dark_skin_tone": "🚵🏿\u200d♂️",
+ "man_mountain_biking_light_skin_tone": "🚵🏻\u200d♂️",
+ "man_mountain_biking_medium-dark_skin_tone": "🚵🏾\u200d♂️",
+ "man_mountain_biking_medium-light_skin_tone": "🚵🏼\u200d♂️",
+ "man_mountain_biking_medium_skin_tone": "🚵🏽\u200d♂️",
+ "man_office_worker": "👨\u200d💼",
+ "man_office_worker_dark_skin_tone": "👨🏿\u200d💼",
+ "man_office_worker_light_skin_tone": "👨🏻\u200d💼",
+ "man_office_worker_medium-dark_skin_tone": "👨🏾\u200d💼",
+ "man_office_worker_medium-light_skin_tone": "👨🏼\u200d💼",
+ "man_office_worker_medium_skin_tone": "👨🏽\u200d💼",
+ "man_pilot": "👨\u200d✈️",
+ "man_pilot_dark_skin_tone": "👨🏿\u200d✈️",
+ "man_pilot_light_skin_tone": "👨🏻\u200d✈️",
+ "man_pilot_medium-dark_skin_tone": "👨🏾\u200d✈️",
+ "man_pilot_medium-light_skin_tone": "👨🏼\u200d✈️",
+ "man_pilot_medium_skin_tone": "👨🏽\u200d✈️",
+ "man_playing_handball": "🤾\u200d♂️",
+ "man_playing_handball_dark_skin_tone": "🤾🏿\u200d♂️",
+ "man_playing_handball_light_skin_tone": "🤾🏻\u200d♂️",
+ "man_playing_handball_medium-dark_skin_tone": "🤾🏾\u200d♂️",
+ "man_playing_handball_medium-light_skin_tone": "🤾🏼\u200d♂️",
+ "man_playing_handball_medium_skin_tone": "🤾🏽\u200d♂️",
+ "man_playing_water_polo": "🤽\u200d♂️",
+ "man_playing_water_polo_dark_skin_tone": "🤽🏿\u200d♂️",
+ "man_playing_water_polo_light_skin_tone": "🤽🏻\u200d♂️",
+ "man_playing_water_polo_medium-dark_skin_tone": "🤽🏾\u200d♂️",
+ "man_playing_water_polo_medium-light_skin_tone": "🤽🏼\u200d♂️",
+ "man_playing_water_polo_medium_skin_tone": "🤽🏽\u200d♂️",
+ "man_police_officer": "👮\u200d♂️",
+ "man_police_officer_dark_skin_tone": "👮🏿\u200d♂️",
+ "man_police_officer_light_skin_tone": "👮🏻\u200d♂️",
+ "man_police_officer_medium-dark_skin_tone": "👮🏾\u200d♂️",
+ "man_police_officer_medium-light_skin_tone": "👮🏼\u200d♂️",
+ "man_police_officer_medium_skin_tone": "👮🏽\u200d♂️",
+ "man_pouting": "🙎\u200d♂️",
+ "man_pouting_dark_skin_tone": "🙎🏿\u200d♂️",
+ "man_pouting_light_skin_tone": "🙎🏻\u200d♂️",
+ "man_pouting_medium-dark_skin_tone": "🙎🏾\u200d♂️",
+ "man_pouting_medium-light_skin_tone": "🙎🏼\u200d♂️",
+ "man_pouting_medium_skin_tone": "🙎🏽\u200d♂️",
+ "man_raising_hand": "🙋\u200d♂️",
+ "man_raising_hand_dark_skin_tone": "🙋🏿\u200d♂️",
+ "man_raising_hand_light_skin_tone": "🙋🏻\u200d♂️",
+ "man_raising_hand_medium-dark_skin_tone": "🙋🏾\u200d♂️",
+ "man_raising_hand_medium-light_skin_tone": "🙋🏼\u200d♂️",
+ "man_raising_hand_medium_skin_tone": "🙋🏽\u200d♂️",
+ "man_rowing_boat": "🚣\u200d♂️",
+ "man_rowing_boat_dark_skin_tone": "🚣🏿\u200d♂️",
+ "man_rowing_boat_light_skin_tone": "🚣🏻\u200d♂️",
+ "man_rowing_boat_medium-dark_skin_tone": "🚣🏾\u200d♂️",
+ "man_rowing_boat_medium-light_skin_tone": "🚣🏼\u200d♂️",
+ "man_rowing_boat_medium_skin_tone": "🚣🏽\u200d♂️",
+ "man_running": "🏃\u200d♂️",
+ "man_running_dark_skin_tone": "🏃🏿\u200d♂️",
+ "man_running_light_skin_tone": "🏃🏻\u200d♂️",
+ "man_running_medium-dark_skin_tone": "🏃🏾\u200d♂️",
+ "man_running_medium-light_skin_tone": "🏃🏼\u200d♂️",
+ "man_running_medium_skin_tone": "🏃🏽\u200d♂️",
+ "man_scientist": "👨\u200d🔬",
+ "man_scientist_dark_skin_tone": "👨🏿\u200d🔬",
+ "man_scientist_light_skin_tone": "👨🏻\u200d🔬",
+ "man_scientist_medium-dark_skin_tone": "👨🏾\u200d🔬",
+ "man_scientist_medium-light_skin_tone": "👨🏼\u200d🔬",
+ "man_scientist_medium_skin_tone": "👨🏽\u200d🔬",
+ "man_shrugging": "🤷\u200d♂️",
+ "man_shrugging_dark_skin_tone": "🤷🏿\u200d♂️",
+ "man_shrugging_light_skin_tone": "🤷🏻\u200d♂️",
+ "man_shrugging_medium-dark_skin_tone": "🤷🏾\u200d♂️",
+ "man_shrugging_medium-light_skin_tone": "🤷🏼\u200d♂️",
+ "man_shrugging_medium_skin_tone": "🤷🏽\u200d♂️",
+ "man_singer": "👨\u200d🎤",
+ "man_singer_dark_skin_tone": "👨🏿\u200d🎤",
+ "man_singer_light_skin_tone": "👨🏻\u200d🎤",
+ "man_singer_medium-dark_skin_tone": "👨🏾\u200d🎤",
+ "man_singer_medium-light_skin_tone": "👨🏼\u200d🎤",
+ "man_singer_medium_skin_tone": "👨🏽\u200d🎤",
+ "man_student": "👨\u200d🎓",
+ "man_student_dark_skin_tone": "👨🏿\u200d🎓",
+ "man_student_light_skin_tone": "👨🏻\u200d🎓",
+ "man_student_medium-dark_skin_tone": "👨🏾\u200d🎓",
+ "man_student_medium-light_skin_tone": "👨🏼\u200d🎓",
+ "man_student_medium_skin_tone": "👨🏽\u200d🎓",
+ "man_surfing": "🏄\u200d♂️",
+ "man_surfing_dark_skin_tone": "🏄🏿\u200d♂️",
+ "man_surfing_light_skin_tone": "🏄🏻\u200d♂️",
+ "man_surfing_medium-dark_skin_tone": "🏄🏾\u200d♂️",
+ "man_surfing_medium-light_skin_tone": "🏄🏼\u200d♂️",
+ "man_surfing_medium_skin_tone": "🏄🏽\u200d♂️",
+ "man_swimming": "🏊\u200d♂️",
+ "man_swimming_dark_skin_tone": "🏊🏿\u200d♂️",
+ "man_swimming_light_skin_tone": "🏊🏻\u200d♂️",
+ "man_swimming_medium-dark_skin_tone": "🏊🏾\u200d♂️",
+ "man_swimming_medium-light_skin_tone": "🏊🏼\u200d♂️",
+ "man_swimming_medium_skin_tone": "🏊🏽\u200d♂️",
+ "man_teacher": "👨\u200d🏫",
+ "man_teacher_dark_skin_tone": "👨🏿\u200d🏫",
+ "man_teacher_light_skin_tone": "👨🏻\u200d🏫",
+ "man_teacher_medium-dark_skin_tone": "👨🏾\u200d🏫",
+ "man_teacher_medium-light_skin_tone": "👨🏼\u200d🏫",
+ "man_teacher_medium_skin_tone": "👨🏽\u200d🏫",
+ "man_technologist": "👨\u200d💻",
+ "man_technologist_dark_skin_tone": "👨🏿\u200d💻",
+ "man_technologist_light_skin_tone": "👨🏻\u200d💻",
+ "man_technologist_medium-dark_skin_tone": "👨🏾\u200d💻",
+ "man_technologist_medium-light_skin_tone": "👨🏼\u200d💻",
+ "man_technologist_medium_skin_tone": "👨🏽\u200d💻",
+ "man_tipping_hand": "💁\u200d♂️",
+ "man_tipping_hand_dark_skin_tone": "💁🏿\u200d♂️",
+ "man_tipping_hand_light_skin_tone": "💁🏻\u200d♂️",
+ "man_tipping_hand_medium-dark_skin_tone": "💁🏾\u200d♂️",
+ "man_tipping_hand_medium-light_skin_tone": "💁🏼\u200d♂️",
+ "man_tipping_hand_medium_skin_tone": "💁🏽\u200d♂️",
+ "man_vampire": "🧛\u200d♂️",
+ "man_vampire_dark_skin_tone": "🧛🏿\u200d♂️",
+ "man_vampire_light_skin_tone": "🧛🏻\u200d♂️",
+ "man_vampire_medium-dark_skin_tone": "🧛🏾\u200d♂️",
+ "man_vampire_medium-light_skin_tone": "🧛🏼\u200d♂️",
+ "man_vampire_medium_skin_tone": "🧛🏽\u200d♂️",
+ "man_walking": "🚶\u200d♂️",
+ "man_walking_dark_skin_tone": "🚶🏿\u200d♂️",
+ "man_walking_light_skin_tone": "🚶🏻\u200d♂️",
+ "man_walking_medium-dark_skin_tone": "🚶🏾\u200d♂️",
+ "man_walking_medium-light_skin_tone": "🚶🏼\u200d♂️",
+ "man_walking_medium_skin_tone": "🚶🏽\u200d♂️",
+ "man_wearing_turban": "👳\u200d♂️",
+ "man_wearing_turban_dark_skin_tone": "👳🏿\u200d♂️",
+ "man_wearing_turban_light_skin_tone": "👳🏻\u200d♂️",
+ "man_wearing_turban_medium-dark_skin_tone": "👳🏾\u200d♂️",
+ "man_wearing_turban_medium-light_skin_tone": "👳🏼\u200d♂️",
+ "man_wearing_turban_medium_skin_tone": "👳🏽\u200d♂️",
+ "man_with_probing_cane": "👨\u200d🦯",
+ "man_with_chinese_cap": "👲",
+ "man_with_chinese_cap_dark_skin_tone": "👲🏿",
+ "man_with_chinese_cap_light_skin_tone": "👲🏻",
+ "man_with_chinese_cap_medium-dark_skin_tone": "👲🏾",
+ "man_with_chinese_cap_medium-light_skin_tone": "👲🏼",
+ "man_with_chinese_cap_medium_skin_tone": "👲🏽",
+ "man_zombie": "🧟\u200d♂️",
+ "mango": "🥭",
+ "mantelpiece_clock": "🕰",
+ "manual_wheelchair": "🦽",
+ "man’s_shoe": "👞",
+ "map_of_japan": "🗾",
+ "maple_leaf": "🍁",
+ "martial_arts_uniform": "🥋",
+ "mate": "🧉",
+ "meat_on_bone": "🍖",
+ "mechanical_arm": "🦾",
+ "mechanical_leg": "🦿",
+ "medical_symbol": "⚕",
+ "megaphone": "📣",
+ "melon": "🍈",
+ "memo": "📝",
+ "men_with_bunny_ears": "👯\u200d♂️",
+ "men_wrestling": "🤼\u200d♂️",
+ "menorah": "🕎",
+ "men’s_room": "🚹",
+ "mermaid": "🧜\u200d♀️",
+ "mermaid_dark_skin_tone": "🧜🏿\u200d♀️",
+ "mermaid_light_skin_tone": "🧜🏻\u200d♀️",
+ "mermaid_medium-dark_skin_tone": "🧜🏾\u200d♀️",
+ "mermaid_medium-light_skin_tone": "🧜🏼\u200d♀️",
+ "mermaid_medium_skin_tone": "🧜🏽\u200d♀️",
+ "merman": "🧜\u200d♂️",
+ "merman_dark_skin_tone": "🧜🏿\u200d♂️",
+ "merman_light_skin_tone": "🧜🏻\u200d♂️",
+ "merman_medium-dark_skin_tone": "🧜🏾\u200d♂️",
+ "merman_medium-light_skin_tone": "🧜🏼\u200d♂️",
+ "merman_medium_skin_tone": "🧜🏽\u200d♂️",
+ "merperson": "🧜",
+ "merperson_dark_skin_tone": "🧜🏿",
+ "merperson_light_skin_tone": "🧜🏻",
+ "merperson_medium-dark_skin_tone": "🧜🏾",
+ "merperson_medium-light_skin_tone": "🧜🏼",
+ "merperson_medium_skin_tone": "🧜🏽",
+ "metro": "🚇",
+ "microbe": "🦠",
+ "microphone": "🎤",
+ "microscope": "🔬",
+ "middle_finger": "🖕",
+ "middle_finger_dark_skin_tone": "🖕🏿",
+ "middle_finger_light_skin_tone": "🖕🏻",
+ "middle_finger_medium-dark_skin_tone": "🖕🏾",
+ "middle_finger_medium-light_skin_tone": "🖕🏼",
+ "middle_finger_medium_skin_tone": "🖕🏽",
+ "military_medal": "🎖",
+ "milky_way": "🌌",
+ "minibus": "🚐",
+ "moai": "🗿",
+ "mobile_phone": "📱",
+ "mobile_phone_off": "📴",
+ "mobile_phone_with_arrow": "📲",
+ "money-mouth_face": "🤑",
+ "money_bag": "💰",
+ "money_with_wings": "💸",
+ "monkey": "🐒",
+ "monkey_face": "🐵",
+ "monorail": "🚝",
+ "moon_cake": "🥮",
+ "moon_viewing_ceremony": "🎑",
+ "mosque": "🕌",
+ "mosquito": "🦟",
+ "motor_boat": "🛥",
+ "motor_scooter": "🛵",
+ "motorcycle": "🏍",
+ "motorized_wheelchair": "🦼",
+ "motorway": "🛣",
+ "mount_fuji": "🗻",
+ "mountain": "⛰",
+ "mountain_cableway": "🚠",
+ "mountain_railway": "🚞",
+ "mouse": "🐭",
+ "mouse_face": "🐭",
+ "mouth": "👄",
+ "movie_camera": "🎥",
+ "mushroom": "🍄",
+ "musical_keyboard": "🎹",
+ "musical_note": "🎵",
+ "musical_notes": "🎶",
+ "musical_score": "🎼",
+ "muted_speaker": "🔇",
+ "nail_polish": "💅",
+ "nail_polish_dark_skin_tone": "💅🏿",
+ "nail_polish_light_skin_tone": "💅🏻",
+ "nail_polish_medium-dark_skin_tone": "💅🏾",
+ "nail_polish_medium-light_skin_tone": "💅🏼",
+ "nail_polish_medium_skin_tone": "💅🏽",
+ "name_badge": "📛",
+ "national_park": "🏞",
+ "nauseated_face": "🤢",
+ "nazar_amulet": "🧿",
+ "necktie": "👔",
+ "nerd_face": "🤓",
+ "neutral_face": "😐",
+ "new_moon": "🌑",
+ "new_moon_face": "🌚",
+ "newspaper": "📰",
+ "next_track_button": "⏭",
+ "night_with_stars": "🌃",
+ "nine-thirty": "🕤",
+ "nine_o’clock": "🕘",
+ "no_bicycles": "🚳",
+ "no_entry": "⛔",
+ "no_littering": "🚯",
+ "no_mobile_phones": "📵",
+ "no_one_under_eighteen": "🔞",
+ "no_pedestrians": "🚷",
+ "no_smoking": "🚭",
+ "non-potable_water": "🚱",
+ "nose": "👃",
+ "nose_dark_skin_tone": "👃🏿",
+ "nose_light_skin_tone": "👃🏻",
+ "nose_medium-dark_skin_tone": "👃🏾",
+ "nose_medium-light_skin_tone": "👃🏼",
+ "nose_medium_skin_tone": "👃🏽",
+ "notebook": "📓",
+ "notebook_with_decorative_cover": "📔",
+ "nut_and_bolt": "🔩",
+ "octopus": "🐙",
+ "oden": "🍢",
+ "office_building": "🏢",
+ "ogre": "👹",
+ "oil_drum": "🛢",
+ "old_key": "🗝",
+ "old_man": "👴",
+ "old_man_dark_skin_tone": "👴🏿",
+ "old_man_light_skin_tone": "👴🏻",
+ "old_man_medium-dark_skin_tone": "👴🏾",
+ "old_man_medium-light_skin_tone": "👴🏼",
+ "old_man_medium_skin_tone": "👴🏽",
+ "old_woman": "👵",
+ "old_woman_dark_skin_tone": "👵🏿",
+ "old_woman_light_skin_tone": "👵🏻",
+ "old_woman_medium-dark_skin_tone": "👵🏾",
+ "old_woman_medium-light_skin_tone": "👵🏼",
+ "old_woman_medium_skin_tone": "👵🏽",
+ "older_adult": "🧓",
+ "older_adult_dark_skin_tone": "🧓🏿",
+ "older_adult_light_skin_tone": "🧓🏻",
+ "older_adult_medium-dark_skin_tone": "🧓🏾",
+ "older_adult_medium-light_skin_tone": "🧓🏼",
+ "older_adult_medium_skin_tone": "🧓🏽",
+ "om": "🕉",
+ "oncoming_automobile": "🚘",
+ "oncoming_bus": "🚍",
+ "oncoming_fist": "👊",
+ "oncoming_fist_dark_skin_tone": "👊🏿",
+ "oncoming_fist_light_skin_tone": "👊🏻",
+ "oncoming_fist_medium-dark_skin_tone": "👊🏾",
+ "oncoming_fist_medium-light_skin_tone": "👊🏼",
+ "oncoming_fist_medium_skin_tone": "👊🏽",
+ "oncoming_police_car": "🚔",
+ "oncoming_taxi": "🚖",
+ "one-piece_swimsuit": "🩱",
+ "one-thirty": "🕜",
+ "one_o’clock": "🕐",
+ "onion": "🧅",
+ "open_book": "📖",
+ "open_file_folder": "📂",
+ "open_hands": "👐",
+ "open_hands_dark_skin_tone": "👐🏿",
+ "open_hands_light_skin_tone": "👐🏻",
+ "open_hands_medium-dark_skin_tone": "👐🏾",
+ "open_hands_medium-light_skin_tone": "👐🏼",
+ "open_hands_medium_skin_tone": "👐🏽",
+ "open_mailbox_with_lowered_flag": "📭",
+ "open_mailbox_with_raised_flag": "📬",
+ "optical_disk": "💿",
+ "orange_book": "📙",
+ "orange_circle": "🟠",
+ "orange_heart": "🧡",
+ "orange_square": "🟧",
+ "orangutan": "🦧",
+ "orthodox_cross": "☦",
+ "otter": "🦦",
+ "outbox_tray": "📤",
+ "owl": "🦉",
+ "ox": "🐂",
+ "oyster": "🦪",
+ "package": "📦",
+ "page_facing_up": "📄",
+ "page_with_curl": "📃",
+ "pager": "📟",
+ "paintbrush": "🖌",
+ "palm_tree": "🌴",
+ "palms_up_together": "🤲",
+ "palms_up_together_dark_skin_tone": "🤲🏿",
+ "palms_up_together_light_skin_tone": "🤲🏻",
+ "palms_up_together_medium-dark_skin_tone": "🤲🏾",
+ "palms_up_together_medium-light_skin_tone": "🤲🏼",
+ "palms_up_together_medium_skin_tone": "🤲🏽",
+ "pancakes": "🥞",
+ "panda_face": "🐼",
+ "paperclip": "📎",
+ "parrot": "🦜",
+ "part_alternation_mark": "〽",
+ "party_popper": "🎉",
+ "partying_face": "🥳",
+ "passenger_ship": "🛳",
+ "passport_control": "🛂",
+ "pause_button": "⏸",
+ "paw_prints": "🐾",
+ "peace_symbol": "☮",
+ "peach": "🍑",
+ "peacock": "🦚",
+ "peanuts": "🥜",
+ "pear": "🍐",
+ "pen": "🖊",
+ "pencil": "📝",
+ "penguin": "🐧",
+ "pensive_face": "😔",
+ "people_holding_hands": "🧑\u200d🤝\u200d🧑",
+ "people_with_bunny_ears": "👯",
+ "people_wrestling": "🤼",
+ "performing_arts": "🎭",
+ "persevering_face": "😣",
+ "person_biking": "🚴",
+ "person_biking_dark_skin_tone": "🚴🏿",
+ "person_biking_light_skin_tone": "🚴🏻",
+ "person_biking_medium-dark_skin_tone": "🚴🏾",
+ "person_biking_medium-light_skin_tone": "🚴🏼",
+ "person_biking_medium_skin_tone": "🚴🏽",
+ "person_bouncing_ball": "⛹",
+ "person_bouncing_ball_dark_skin_tone": "⛹🏿",
+ "person_bouncing_ball_light_skin_tone": "⛹🏻",
+ "person_bouncing_ball_medium-dark_skin_tone": "⛹🏾",
+ "person_bouncing_ball_medium-light_skin_tone": "⛹🏼",
+ "person_bouncing_ball_medium_skin_tone": "⛹🏽",
+ "person_bowing": "🙇",
+ "person_bowing_dark_skin_tone": "🙇🏿",
+ "person_bowing_light_skin_tone": "🙇🏻",
+ "person_bowing_medium-dark_skin_tone": "🙇🏾",
+ "person_bowing_medium-light_skin_tone": "🙇🏼",
+ "person_bowing_medium_skin_tone": "🙇🏽",
+ "person_cartwheeling": "🤸",
+ "person_cartwheeling_dark_skin_tone": "🤸🏿",
+ "person_cartwheeling_light_skin_tone": "🤸🏻",
+ "person_cartwheeling_medium-dark_skin_tone": "🤸🏾",
+ "person_cartwheeling_medium-light_skin_tone": "🤸🏼",
+ "person_cartwheeling_medium_skin_tone": "🤸🏽",
+ "person_climbing": "🧗",
+ "person_climbing_dark_skin_tone": "🧗🏿",
+ "person_climbing_light_skin_tone": "🧗🏻",
+ "person_climbing_medium-dark_skin_tone": "🧗🏾",
+ "person_climbing_medium-light_skin_tone": "🧗🏼",
+ "person_climbing_medium_skin_tone": "🧗🏽",
+ "person_facepalming": "🤦",
+ "person_facepalming_dark_skin_tone": "🤦🏿",
+ "person_facepalming_light_skin_tone": "🤦🏻",
+ "person_facepalming_medium-dark_skin_tone": "🤦🏾",
+ "person_facepalming_medium-light_skin_tone": "🤦🏼",
+ "person_facepalming_medium_skin_tone": "🤦🏽",
+ "person_fencing": "🤺",
+ "person_frowning": "🙍",
+ "person_frowning_dark_skin_tone": "🙍🏿",
+ "person_frowning_light_skin_tone": "🙍🏻",
+ "person_frowning_medium-dark_skin_tone": "🙍🏾",
+ "person_frowning_medium-light_skin_tone": "🙍🏼",
+ "person_frowning_medium_skin_tone": "🙍🏽",
+ "person_gesturing_no": "🙅",
+ "person_gesturing_no_dark_skin_tone": "🙅🏿",
+ "person_gesturing_no_light_skin_tone": "🙅🏻",
+ "person_gesturing_no_medium-dark_skin_tone": "🙅🏾",
+ "person_gesturing_no_medium-light_skin_tone": "🙅🏼",
+ "person_gesturing_no_medium_skin_tone": "🙅🏽",
+ "person_gesturing_ok": "🙆",
+ "person_gesturing_ok_dark_skin_tone": "🙆🏿",
+ "person_gesturing_ok_light_skin_tone": "🙆🏻",
+ "person_gesturing_ok_medium-dark_skin_tone": "🙆🏾",
+ "person_gesturing_ok_medium-light_skin_tone": "🙆🏼",
+ "person_gesturing_ok_medium_skin_tone": "🙆🏽",
+ "person_getting_haircut": "💇",
+ "person_getting_haircut_dark_skin_tone": "💇🏿",
+ "person_getting_haircut_light_skin_tone": "💇🏻",
+ "person_getting_haircut_medium-dark_skin_tone": "💇🏾",
+ "person_getting_haircut_medium-light_skin_tone": "💇🏼",
+ "person_getting_haircut_medium_skin_tone": "💇🏽",
+ "person_getting_massage": "💆",
+ "person_getting_massage_dark_skin_tone": "💆🏿",
+ "person_getting_massage_light_skin_tone": "💆🏻",
+ "person_getting_massage_medium-dark_skin_tone": "💆🏾",
+ "person_getting_massage_medium-light_skin_tone": "💆🏼",
+ "person_getting_massage_medium_skin_tone": "💆🏽",
+ "person_golfing": "🏌",
+ "person_golfing_dark_skin_tone": "🏌🏿",
+ "person_golfing_light_skin_tone": "🏌🏻",
+ "person_golfing_medium-dark_skin_tone": "🏌🏾",
+ "person_golfing_medium-light_skin_tone": "🏌🏼",
+ "person_golfing_medium_skin_tone": "🏌🏽",
+ "person_in_bed": "🛌",
+ "person_in_bed_dark_skin_tone": "🛌🏿",
+ "person_in_bed_light_skin_tone": "🛌🏻",
+ "person_in_bed_medium-dark_skin_tone": "🛌🏾",
+ "person_in_bed_medium-light_skin_tone": "🛌🏼",
+ "person_in_bed_medium_skin_tone": "🛌🏽",
+ "person_in_lotus_position": "🧘",
+ "person_in_lotus_position_dark_skin_tone": "🧘🏿",
+ "person_in_lotus_position_light_skin_tone": "🧘🏻",
+ "person_in_lotus_position_medium-dark_skin_tone": "🧘🏾",
+ "person_in_lotus_position_medium-light_skin_tone": "🧘🏼",
+ "person_in_lotus_position_medium_skin_tone": "🧘🏽",
+ "person_in_steamy_room": "🧖",
+ "person_in_steamy_room_dark_skin_tone": "🧖🏿",
+ "person_in_steamy_room_light_skin_tone": "🧖🏻",
+ "person_in_steamy_room_medium-dark_skin_tone": "🧖🏾",
+ "person_in_steamy_room_medium-light_skin_tone": "🧖🏼",
+ "person_in_steamy_room_medium_skin_tone": "🧖🏽",
+ "person_juggling": "🤹",
+ "person_juggling_dark_skin_tone": "🤹🏿",
+ "person_juggling_light_skin_tone": "🤹🏻",
+ "person_juggling_medium-dark_skin_tone": "🤹🏾",
+ "person_juggling_medium-light_skin_tone": "🤹🏼",
+ "person_juggling_medium_skin_tone": "🤹🏽",
+ "person_kneeling": "🧎",
+ "person_lifting_weights": "🏋",
+ "person_lifting_weights_dark_skin_tone": "🏋🏿",
+ "person_lifting_weights_light_skin_tone": "🏋🏻",
+ "person_lifting_weights_medium-dark_skin_tone": "🏋🏾",
+ "person_lifting_weights_medium-light_skin_tone": "🏋🏼",
+ "person_lifting_weights_medium_skin_tone": "🏋🏽",
+ "person_mountain_biking": "🚵",
+ "person_mountain_biking_dark_skin_tone": "🚵🏿",
+ "person_mountain_biking_light_skin_tone": "🚵🏻",
+ "person_mountain_biking_medium-dark_skin_tone": "🚵🏾",
+ "person_mountain_biking_medium-light_skin_tone": "🚵🏼",
+ "person_mountain_biking_medium_skin_tone": "🚵🏽",
+ "person_playing_handball": "🤾",
+ "person_playing_handball_dark_skin_tone": "🤾🏿",
+ "person_playing_handball_light_skin_tone": "🤾🏻",
+ "person_playing_handball_medium-dark_skin_tone": "🤾🏾",
+ "person_playing_handball_medium-light_skin_tone": "🤾🏼",
+ "person_playing_handball_medium_skin_tone": "🤾🏽",
+ "person_playing_water_polo": "🤽",
+ "person_playing_water_polo_dark_skin_tone": "🤽🏿",
+ "person_playing_water_polo_light_skin_tone": "🤽🏻",
+ "person_playing_water_polo_medium-dark_skin_tone": "🤽🏾",
+ "person_playing_water_polo_medium-light_skin_tone": "🤽🏼",
+ "person_playing_water_polo_medium_skin_tone": "🤽🏽",
+ "person_pouting": "🙎",
+ "person_pouting_dark_skin_tone": "🙎🏿",
+ "person_pouting_light_skin_tone": "🙎🏻",
+ "person_pouting_medium-dark_skin_tone": "🙎🏾",
+ "person_pouting_medium-light_skin_tone": "🙎🏼",
+ "person_pouting_medium_skin_tone": "🙎🏽",
+ "person_raising_hand": "🙋",
+ "person_raising_hand_dark_skin_tone": "🙋🏿",
+ "person_raising_hand_light_skin_tone": "🙋🏻",
+ "person_raising_hand_medium-dark_skin_tone": "🙋🏾",
+ "person_raising_hand_medium-light_skin_tone": "🙋🏼",
+ "person_raising_hand_medium_skin_tone": "🙋🏽",
+ "person_rowing_boat": "🚣",
+ "person_rowing_boat_dark_skin_tone": "🚣🏿",
+ "person_rowing_boat_light_skin_tone": "🚣🏻",
+ "person_rowing_boat_medium-dark_skin_tone": "🚣🏾",
+ "person_rowing_boat_medium-light_skin_tone": "🚣🏼",
+ "person_rowing_boat_medium_skin_tone": "🚣🏽",
+ "person_running": "🏃",
+ "person_running_dark_skin_tone": "🏃🏿",
+ "person_running_light_skin_tone": "🏃🏻",
+ "person_running_medium-dark_skin_tone": "🏃🏾",
+ "person_running_medium-light_skin_tone": "🏃🏼",
+ "person_running_medium_skin_tone": "🏃🏽",
+ "person_shrugging": "🤷",
+ "person_shrugging_dark_skin_tone": "🤷🏿",
+ "person_shrugging_light_skin_tone": "🤷🏻",
+ "person_shrugging_medium-dark_skin_tone": "🤷🏾",
+ "person_shrugging_medium-light_skin_tone": "🤷🏼",
+ "person_shrugging_medium_skin_tone": "🤷🏽",
+ "person_standing": "🧍",
+ "person_surfing": "🏄",
+ "person_surfing_dark_skin_tone": "🏄🏿",
+ "person_surfing_light_skin_tone": "🏄🏻",
+ "person_surfing_medium-dark_skin_tone": "🏄🏾",
+ "person_surfing_medium-light_skin_tone": "🏄🏼",
+ "person_surfing_medium_skin_tone": "🏄🏽",
+ "person_swimming": "🏊",
+ "person_swimming_dark_skin_tone": "🏊🏿",
+ "person_swimming_light_skin_tone": "🏊🏻",
+ "person_swimming_medium-dark_skin_tone": "🏊🏾",
+ "person_swimming_medium-light_skin_tone": "🏊🏼",
+ "person_swimming_medium_skin_tone": "🏊🏽",
+ "person_taking_bath": "🛀",
+ "person_taking_bath_dark_skin_tone": "🛀🏿",
+ "person_taking_bath_light_skin_tone": "🛀🏻",
+ "person_taking_bath_medium-dark_skin_tone": "🛀🏾",
+ "person_taking_bath_medium-light_skin_tone": "🛀🏼",
+ "person_taking_bath_medium_skin_tone": "🛀🏽",
+ "person_tipping_hand": "💁",
+ "person_tipping_hand_dark_skin_tone": "💁🏿",
+ "person_tipping_hand_light_skin_tone": "💁🏻",
+ "person_tipping_hand_medium-dark_skin_tone": "💁🏾",
+ "person_tipping_hand_medium-light_skin_tone": "💁🏼",
+ "person_tipping_hand_medium_skin_tone": "💁🏽",
+ "person_walking": "🚶",
+ "person_walking_dark_skin_tone": "🚶🏿",
+ "person_walking_light_skin_tone": "🚶🏻",
+ "person_walking_medium-dark_skin_tone": "🚶🏾",
+ "person_walking_medium-light_skin_tone": "🚶🏼",
+ "person_walking_medium_skin_tone": "🚶🏽",
+ "person_wearing_turban": "👳",
+ "person_wearing_turban_dark_skin_tone": "👳🏿",
+ "person_wearing_turban_light_skin_tone": "👳🏻",
+ "person_wearing_turban_medium-dark_skin_tone": "👳🏾",
+ "person_wearing_turban_medium-light_skin_tone": "👳🏼",
+ "person_wearing_turban_medium_skin_tone": "👳🏽",
+ "petri_dish": "🧫",
+ "pick": "⛏",
+ "pie": "🥧",
+ "pig": "🐷",
+ "pig_face": "🐷",
+ "pig_nose": "🐽",
+ "pile_of_poo": "💩",
+ "pill": "💊",
+ "pinching_hand": "🤏",
+ "pine_decoration": "🎍",
+ "pineapple": "🍍",
+ "ping_pong": "🏓",
+ "pirate_flag": "🏴\u200d☠️",
+ "pistol": "🔫",
+ "pizza": "🍕",
+ "place_of_worship": "🛐",
+ "play_button": "▶",
+ "play_or_pause_button": "⏯",
+ "pleading_face": "🥺",
+ "police_car": "🚓",
+ "police_car_light": "🚨",
+ "police_officer": "👮",
+ "police_officer_dark_skin_tone": "👮🏿",
+ "police_officer_light_skin_tone": "👮🏻",
+ "police_officer_medium-dark_skin_tone": "👮🏾",
+ "police_officer_medium-light_skin_tone": "👮🏼",
+ "police_officer_medium_skin_tone": "👮🏽",
+ "poodle": "🐩",
+ "pool_8_ball": "🎱",
+ "popcorn": "🍿",
+ "post_office": "🏣",
+ "postal_horn": "📯",
+ "postbox": "📮",
+ "pot_of_food": "🍲",
+ "potable_water": "🚰",
+ "potato": "🥔",
+ "poultry_leg": "🍗",
+ "pound_banknote": "💷",
+ "pouting_cat_face": "😾",
+ "pouting_face": "😡",
+ "prayer_beads": "📿",
+ "pregnant_woman": "🤰",
+ "pregnant_woman_dark_skin_tone": "🤰🏿",
+ "pregnant_woman_light_skin_tone": "🤰🏻",
+ "pregnant_woman_medium-dark_skin_tone": "🤰🏾",
+ "pregnant_woman_medium-light_skin_tone": "🤰🏼",
+ "pregnant_woman_medium_skin_tone": "🤰🏽",
+ "pretzel": "🥨",
+ "probing_cane": "🦯",
+ "prince": "🤴",
+ "prince_dark_skin_tone": "🤴🏿",
+ "prince_light_skin_tone": "🤴🏻",
+ "prince_medium-dark_skin_tone": "🤴🏾",
+ "prince_medium-light_skin_tone": "🤴🏼",
+ "prince_medium_skin_tone": "🤴🏽",
+ "princess": "👸",
+ "princess_dark_skin_tone": "👸🏿",
+ "princess_light_skin_tone": "👸🏻",
+ "princess_medium-dark_skin_tone": "👸🏾",
+ "princess_medium-light_skin_tone": "👸🏼",
+ "princess_medium_skin_tone": "👸🏽",
+ "printer": "🖨",
+ "prohibited": "🚫",
+ "purple_circle": "🟣",
+ "purple_heart": "💜",
+ "purple_square": "🟪",
+ "purse": "👛",
+ "pushpin": "📌",
+ "question_mark": "❓",
+ "rabbit": "🐰",
+ "rabbit_face": "🐰",
+ "raccoon": "🦝",
+ "racing_car": "🏎",
+ "radio": "📻",
+ "radio_button": "🔘",
+ "radioactive": "☢",
+ "railway_car": "🚃",
+ "railway_track": "🛤",
+ "rainbow": "🌈",
+ "rainbow_flag": "🏳️\u200d🌈",
+ "raised_back_of_hand": "🤚",
+ "raised_back_of_hand_dark_skin_tone": "🤚🏿",
+ "raised_back_of_hand_light_skin_tone": "🤚🏻",
+ "raised_back_of_hand_medium-dark_skin_tone": "🤚🏾",
+ "raised_back_of_hand_medium-light_skin_tone": "🤚🏼",
+ "raised_back_of_hand_medium_skin_tone": "🤚🏽",
+ "raised_fist": "✊",
+ "raised_fist_dark_skin_tone": "✊🏿",
+ "raised_fist_light_skin_tone": "✊🏻",
+ "raised_fist_medium-dark_skin_tone": "✊🏾",
+ "raised_fist_medium-light_skin_tone": "✊🏼",
+ "raised_fist_medium_skin_tone": "✊🏽",
+ "raised_hand": "✋",
+ "raised_hand_dark_skin_tone": "✋🏿",
+ "raised_hand_light_skin_tone": "✋🏻",
+ "raised_hand_medium-dark_skin_tone": "✋🏾",
+ "raised_hand_medium-light_skin_tone": "✋🏼",
+ "raised_hand_medium_skin_tone": "✋🏽",
+ "raising_hands": "🙌",
+ "raising_hands_dark_skin_tone": "🙌🏿",
+ "raising_hands_light_skin_tone": "🙌🏻",
+ "raising_hands_medium-dark_skin_tone": "🙌🏾",
+ "raising_hands_medium-light_skin_tone": "🙌🏼",
+ "raising_hands_medium_skin_tone": "🙌🏽",
+ "ram": "🐏",
+ "rat": "🐀",
+ "razor": "🪒",
+ "ringed_planet": "🪐",
+ "receipt": "🧾",
+ "record_button": "⏺",
+ "recycling_symbol": "♻",
+ "red_apple": "🍎",
+ "red_circle": "🔴",
+ "red_envelope": "🧧",
+ "red_hair": "🦰",
+ "red-haired_man": "👨\u200d🦰",
+ "red-haired_woman": "👩\u200d🦰",
+ "red_heart": "❤",
+ "red_paper_lantern": "🏮",
+ "red_square": "🟥",
+ "red_triangle_pointed_down": "🔻",
+ "red_triangle_pointed_up": "🔺",
+ "registered": "®",
+ "relieved_face": "😌",
+ "reminder_ribbon": "🎗",
+ "repeat_button": "🔁",
+ "repeat_single_button": "🔂",
+ "rescue_worker’s_helmet": "⛑",
+ "restroom": "🚻",
+ "reverse_button": "◀",
+ "revolving_hearts": "💞",
+ "rhinoceros": "🦏",
+ "ribbon": "🎀",
+ "rice_ball": "🍙",
+ "rice_cracker": "🍘",
+ "right-facing_fist": "🤜",
+ "right-facing_fist_dark_skin_tone": "🤜🏿",
+ "right-facing_fist_light_skin_tone": "🤜🏻",
+ "right-facing_fist_medium-dark_skin_tone": "🤜🏾",
+ "right-facing_fist_medium-light_skin_tone": "🤜🏼",
+ "right-facing_fist_medium_skin_tone": "🤜🏽",
+ "right_anger_bubble": "🗯",
+ "right_arrow": "➡",
+ "right_arrow_curving_down": "⤵",
+ "right_arrow_curving_left": "↩",
+ "right_arrow_curving_up": "⤴",
+ "ring": "💍",
+ "roasted_sweet_potato": "🍠",
+ "robot_face": "🤖",
+ "rocket": "🚀",
+ "roll_of_paper": "🧻",
+ "rolled-up_newspaper": "🗞",
+ "roller_coaster": "🎢",
+ "rolling_on_the_floor_laughing": "🤣",
+ "rooster": "🐓",
+ "rose": "🌹",
+ "rosette": "🏵",
+ "round_pushpin": "📍",
+ "rugby_football": "🏉",
+ "running_shirt": "🎽",
+ "running_shoe": "👟",
+ "sad_but_relieved_face": "😥",
+ "safety_pin": "🧷",
+ "safety_vest": "🦺",
+ "salt": "🧂",
+ "sailboat": "⛵",
+ "sake": "🍶",
+ "sandwich": "🥪",
+ "sari": "🥻",
+ "satellite": "📡",
+ "satellite_antenna": "📡",
+ "sauropod": "🦕",
+ "saxophone": "🎷",
+ "scarf": "🧣",
+ "school": "🏫",
+ "school_backpack": "🎒",
+ "scissors": "✂",
+ "scorpion": "🦂",
+ "scroll": "📜",
+ "seat": "💺",
+ "see-no-evil_monkey": "🙈",
+ "seedling": "🌱",
+ "selfie": "🤳",
+ "selfie_dark_skin_tone": "🤳🏿",
+ "selfie_light_skin_tone": "🤳🏻",
+ "selfie_medium-dark_skin_tone": "🤳🏾",
+ "selfie_medium-light_skin_tone": "🤳🏼",
+ "selfie_medium_skin_tone": "🤳🏽",
+ "service_dog": "🐕\u200d🦺",
+ "seven-thirty": "🕢",
+ "seven_o’clock": "🕖",
+ "shallow_pan_of_food": "🥘",
+ "shamrock": "☘",
+ "shark": "🦈",
+ "shaved_ice": "🍧",
+ "sheaf_of_rice": "🌾",
+ "shield": "🛡",
+ "shinto_shrine": "⛩",
+ "ship": "🚢",
+ "shooting_star": "🌠",
+ "shopping_bags": "🛍",
+ "shopping_cart": "🛒",
+ "shortcake": "🍰",
+ "shorts": "🩳",
+ "shower": "🚿",
+ "shrimp": "🦐",
+ "shuffle_tracks_button": "🔀",
+ "shushing_face": "🤫",
+ "sign_of_the_horns": "🤘",
+ "sign_of_the_horns_dark_skin_tone": "🤘🏿",
+ "sign_of_the_horns_light_skin_tone": "🤘🏻",
+ "sign_of_the_horns_medium-dark_skin_tone": "🤘🏾",
+ "sign_of_the_horns_medium-light_skin_tone": "🤘🏼",
+ "sign_of_the_horns_medium_skin_tone": "🤘🏽",
+ "six-thirty": "🕡",
+ "six_o’clock": "🕕",
+ "skateboard": "🛹",
+ "skier": "⛷",
+ "skis": "🎿",
+ "skull": "💀",
+ "skull_and_crossbones": "☠",
+ "skunk": "🦨",
+ "sled": "🛷",
+ "sleeping_face": "😴",
+ "sleepy_face": "😪",
+ "slightly_frowning_face": "🙁",
+ "slightly_smiling_face": "🙂",
+ "slot_machine": "🎰",
+ "sloth": "🦥",
+ "small_airplane": "🛩",
+ "small_blue_diamond": "🔹",
+ "small_orange_diamond": "🔸",
+ "smiling_cat_face_with_heart-eyes": "😻",
+ "smiling_face": "☺",
+ "smiling_face_with_halo": "😇",
+ "smiling_face_with_3_hearts": "🥰",
+ "smiling_face_with_heart-eyes": "😍",
+ "smiling_face_with_horns": "😈",
+ "smiling_face_with_smiling_eyes": "😊",
+ "smiling_face_with_sunglasses": "😎",
+ "smirking_face": "😏",
+ "snail": "🐌",
+ "snake": "🐍",
+ "sneezing_face": "🤧",
+ "snow-capped_mountain": "🏔",
+ "snowboarder": "🏂",
+ "snowboarder_dark_skin_tone": "🏂🏿",
+ "snowboarder_light_skin_tone": "🏂🏻",
+ "snowboarder_medium-dark_skin_tone": "🏂🏾",
+ "snowboarder_medium-light_skin_tone": "🏂🏼",
+ "snowboarder_medium_skin_tone": "🏂🏽",
+ "snowflake": "❄",
+ "snowman": "☃",
+ "snowman_without_snow": "⛄",
+ "soap": "🧼",
+ "soccer_ball": "⚽",
+ "socks": "🧦",
+ "softball": "🥎",
+ "soft_ice_cream": "🍦",
+ "spade_suit": "♠",
+ "spaghetti": "🍝",
+ "sparkle": "❇",
+ "sparkler": "🎇",
+ "sparkles": "✨",
+ "sparkling_heart": "💖",
+ "speak-no-evil_monkey": "🙊",
+ "speaker_high_volume": "🔊",
+ "speaker_low_volume": "🔈",
+ "speaker_medium_volume": "🔉",
+ "speaking_head": "🗣",
+ "speech_balloon": "💬",
+ "speedboat": "🚤",
+ "spider": "🕷",
+ "spider_web": "🕸",
+ "spiral_calendar": "🗓",
+ "spiral_notepad": "🗒",
+ "spiral_shell": "🐚",
+ "spoon": "🥄",
+ "sponge": "🧽",
+ "sport_utility_vehicle": "🚙",
+ "sports_medal": "🏅",
+ "spouting_whale": "🐳",
+ "squid": "🦑",
+ "squinting_face_with_tongue": "😝",
+ "stadium": "🏟",
+ "star-struck": "🤩",
+ "star_and_crescent": "☪",
+ "star_of_david": "✡",
+ "station": "🚉",
+ "steaming_bowl": "🍜",
+ "stethoscope": "🩺",
+ "stop_button": "⏹",
+ "stop_sign": "🛑",
+ "stopwatch": "⏱",
+ "straight_ruler": "📏",
+ "strawberry": "🍓",
+ "studio_microphone": "🎙",
+ "stuffed_flatbread": "🥙",
+ "sun": "☀",
+ "sun_behind_cloud": "⛅",
+ "sun_behind_large_cloud": "🌥",
+ "sun_behind_rain_cloud": "🌦",
+ "sun_behind_small_cloud": "🌤",
+ "sun_with_face": "🌞",
+ "sunflower": "🌻",
+ "sunglasses": "😎",
+ "sunrise": "🌅",
+ "sunrise_over_mountains": "🌄",
+ "sunset": "🌇",
+ "superhero": "🦸",
+ "supervillain": "🦹",
+ "sushi": "🍣",
+ "suspension_railway": "🚟",
+ "swan": "🦢",
+ "sweat_droplets": "💦",
+ "synagogue": "🕍",
+ "syringe": "💉",
+ "t-shirt": "👕",
+ "taco": "🌮",
+ "takeout_box": "🥡",
+ "tanabata_tree": "🎋",
+ "tangerine": "🍊",
+ "taxi": "🚕",
+ "teacup_without_handle": "🍵",
+ "tear-off_calendar": "📆",
+ "teddy_bear": "🧸",
+ "telephone": "☎",
+ "telephone_receiver": "📞",
+ "telescope": "🔭",
+ "television": "📺",
+ "ten-thirty": "🕥",
+ "ten_o’clock": "🕙",
+ "tennis": "🎾",
+ "tent": "⛺",
+ "test_tube": "🧪",
+ "thermometer": "🌡",
+ "thinking_face": "🤔",
+ "thought_balloon": "💭",
+ "thread": "🧵",
+ "three-thirty": "🕞",
+ "three_o’clock": "🕒",
+ "thumbs_down": "👎",
+ "thumbs_down_dark_skin_tone": "👎🏿",
+ "thumbs_down_light_skin_tone": "👎🏻",
+ "thumbs_down_medium-dark_skin_tone": "👎🏾",
+ "thumbs_down_medium-light_skin_tone": "👎🏼",
+ "thumbs_down_medium_skin_tone": "👎🏽",
+ "thumbs_up": "👍",
+ "thumbs_up_dark_skin_tone": "👍🏿",
+ "thumbs_up_light_skin_tone": "👍🏻",
+ "thumbs_up_medium-dark_skin_tone": "👍🏾",
+ "thumbs_up_medium-light_skin_tone": "👍🏼",
+ "thumbs_up_medium_skin_tone": "👍🏽",
+ "ticket": "🎫",
+ "tiger": "🐯",
+ "tiger_face": "🐯",
+ "timer_clock": "⏲",
+ "tired_face": "😫",
+ "toolbox": "🧰",
+ "toilet": "🚽",
+ "tomato": "🍅",
+ "tongue": "👅",
+ "tooth": "🦷",
+ "top_hat": "🎩",
+ "tornado": "🌪",
+ "trackball": "🖲",
+ "tractor": "🚜",
+ "trade_mark": "™",
+ "train": "🚋",
+ "tram": "🚊",
+ "tram_car": "🚋",
+ "triangular_flag": "🚩",
+ "triangular_ruler": "📐",
+ "trident_emblem": "🔱",
+ "trolleybus": "🚎",
+ "trophy": "🏆",
+ "tropical_drink": "🍹",
+ "tropical_fish": "🐠",
+ "trumpet": "🎺",
+ "tulip": "🌷",
+ "tumbler_glass": "🥃",
+ "turtle": "🐢",
+ "twelve-thirty": "🕧",
+ "twelve_o’clock": "🕛",
+ "two-hump_camel": "🐫",
+ "two-thirty": "🕝",
+ "two_hearts": "💕",
+ "two_men_holding_hands": "👬",
+ "two_o’clock": "🕑",
+ "two_women_holding_hands": "👭",
+ "umbrella": "☂",
+ "umbrella_on_ground": "⛱",
+ "umbrella_with_rain_drops": "☔",
+ "unamused_face": "😒",
+ "unicorn_face": "🦄",
+ "unlocked": "🔓",
+ "up-down_arrow": "↕",
+ "up-left_arrow": "↖",
+ "up-right_arrow": "↗",
+ "up_arrow": "⬆",
+ "upside-down_face": "🙃",
+ "upwards_button": "🔼",
+ "vampire": "🧛",
+ "vampire_dark_skin_tone": "🧛🏿",
+ "vampire_light_skin_tone": "🧛🏻",
+ "vampire_medium-dark_skin_tone": "🧛🏾",
+ "vampire_medium-light_skin_tone": "🧛🏼",
+ "vampire_medium_skin_tone": "🧛🏽",
+ "vertical_traffic_light": "🚦",
+ "vibration_mode": "📳",
+ "victory_hand": "✌",
+ "victory_hand_dark_skin_tone": "✌🏿",
+ "victory_hand_light_skin_tone": "✌🏻",
+ "victory_hand_medium-dark_skin_tone": "✌🏾",
+ "victory_hand_medium-light_skin_tone": "✌🏼",
+ "victory_hand_medium_skin_tone": "✌🏽",
+ "video_camera": "📹",
+ "video_game": "🎮",
+ "videocassette": "📼",
+ "violin": "🎻",
+ "volcano": "🌋",
+ "volleyball": "🏐",
+ "vulcan_salute": "🖖",
+ "vulcan_salute_dark_skin_tone": "🖖🏿",
+ "vulcan_salute_light_skin_tone": "🖖🏻",
+ "vulcan_salute_medium-dark_skin_tone": "🖖🏾",
+ "vulcan_salute_medium-light_skin_tone": "🖖🏼",
+ "vulcan_salute_medium_skin_tone": "🖖🏽",
+ "waffle": "🧇",
+ "waning_crescent_moon": "🌘",
+ "waning_gibbous_moon": "🌖",
+ "warning": "⚠",
+ "wastebasket": "🗑",
+ "watch": "⌚",
+ "water_buffalo": "🐃",
+ "water_closet": "🚾",
+ "water_wave": "🌊",
+ "watermelon": "🍉",
+ "waving_hand": "👋",
+ "waving_hand_dark_skin_tone": "👋🏿",
+ "waving_hand_light_skin_tone": "👋🏻",
+ "waving_hand_medium-dark_skin_tone": "👋🏾",
+ "waving_hand_medium-light_skin_tone": "👋🏼",
+ "waving_hand_medium_skin_tone": "👋🏽",
+ "wavy_dash": "〰",
+ "waxing_crescent_moon": "🌒",
+ "waxing_gibbous_moon": "🌔",
+ "weary_cat_face": "🙀",
+ "weary_face": "😩",
+ "wedding": "💒",
+ "whale": "🐳",
+ "wheel_of_dharma": "☸",
+ "wheelchair_symbol": "♿",
+ "white_circle": "⚪",
+ "white_exclamation_mark": "❕",
+ "white_flag": "🏳",
+ "white_flower": "💮",
+ "white_hair": "🦳",
+ "white-haired_man": "👨\u200d🦳",
+ "white-haired_woman": "👩\u200d🦳",
+ "white_heart": "🤍",
+ "white_heavy_check_mark": "✅",
+ "white_large_square": "⬜",
+ "white_medium-small_square": "◽",
+ "white_medium_square": "◻",
+ "white_medium_star": "⭐",
+ "white_question_mark": "❔",
+ "white_small_square": "▫",
+ "white_square_button": "🔳",
+ "wilted_flower": "🥀",
+ "wind_chime": "🎐",
+ "wind_face": "🌬",
+ "wine_glass": "🍷",
+ "winking_face": "😉",
+ "winking_face_with_tongue": "😜",
+ "wolf_face": "🐺",
+ "woman": "👩",
+ "woman_artist": "👩\u200d🎨",
+ "woman_artist_dark_skin_tone": "👩🏿\u200d🎨",
+ "woman_artist_light_skin_tone": "👩🏻\u200d🎨",
+ "woman_artist_medium-dark_skin_tone": "👩🏾\u200d🎨",
+ "woman_artist_medium-light_skin_tone": "👩🏼\u200d🎨",
+ "woman_artist_medium_skin_tone": "👩🏽\u200d🎨",
+ "woman_astronaut": "👩\u200d🚀",
+ "woman_astronaut_dark_skin_tone": "👩🏿\u200d🚀",
+ "woman_astronaut_light_skin_tone": "👩🏻\u200d🚀",
+ "woman_astronaut_medium-dark_skin_tone": "👩🏾\u200d🚀",
+ "woman_astronaut_medium-light_skin_tone": "👩🏼\u200d🚀",
+ "woman_astronaut_medium_skin_tone": "👩🏽\u200d🚀",
+ "woman_biking": "🚴\u200d♀️",
+ "woman_biking_dark_skin_tone": "🚴🏿\u200d♀️",
+ "woman_biking_light_skin_tone": "🚴🏻\u200d♀️",
+ "woman_biking_medium-dark_skin_tone": "🚴🏾\u200d♀️",
+ "woman_biking_medium-light_skin_tone": "🚴🏼\u200d♀️",
+ "woman_biking_medium_skin_tone": "🚴🏽\u200d♀️",
+ "woman_bouncing_ball": "⛹️\u200d♀️",
+ "woman_bouncing_ball_dark_skin_tone": "⛹🏿\u200d♀️",
+ "woman_bouncing_ball_light_skin_tone": "⛹🏻\u200d♀️",
+ "woman_bouncing_ball_medium-dark_skin_tone": "⛹🏾\u200d♀️",
+ "woman_bouncing_ball_medium-light_skin_tone": "⛹🏼\u200d♀️",
+ "woman_bouncing_ball_medium_skin_tone": "⛹🏽\u200d♀️",
+ "woman_bowing": "🙇\u200d♀️",
+ "woman_bowing_dark_skin_tone": "🙇🏿\u200d♀️",
+ "woman_bowing_light_skin_tone": "🙇🏻\u200d♀️",
+ "woman_bowing_medium-dark_skin_tone": "🙇🏾\u200d♀️",
+ "woman_bowing_medium-light_skin_tone": "🙇🏼\u200d♀️",
+ "woman_bowing_medium_skin_tone": "🙇🏽\u200d♀️",
+ "woman_cartwheeling": "🤸\u200d♀️",
+ "woman_cartwheeling_dark_skin_tone": "🤸🏿\u200d♀️",
+ "woman_cartwheeling_light_skin_tone": "🤸🏻\u200d♀️",
+ "woman_cartwheeling_medium-dark_skin_tone": "🤸🏾\u200d♀️",
+ "woman_cartwheeling_medium-light_skin_tone": "🤸🏼\u200d♀️",
+ "woman_cartwheeling_medium_skin_tone": "🤸🏽\u200d♀️",
+ "woman_climbing": "🧗\u200d♀️",
+ "woman_climbing_dark_skin_tone": "🧗🏿\u200d♀️",
+ "woman_climbing_light_skin_tone": "🧗🏻\u200d♀️",
+ "woman_climbing_medium-dark_skin_tone": "🧗🏾\u200d♀️",
+ "woman_climbing_medium-light_skin_tone": "🧗🏼\u200d♀️",
+ "woman_climbing_medium_skin_tone": "🧗🏽\u200d♀️",
+ "woman_construction_worker": "👷\u200d♀️",
+ "woman_construction_worker_dark_skin_tone": "👷🏿\u200d♀️",
+ "woman_construction_worker_light_skin_tone": "👷🏻\u200d♀️",
+ "woman_construction_worker_medium-dark_skin_tone": "👷🏾\u200d♀️",
+ "woman_construction_worker_medium-light_skin_tone": "👷🏼\u200d♀️",
+ "woman_construction_worker_medium_skin_tone": "👷🏽\u200d♀️",
+ "woman_cook": "👩\u200d🍳",
+ "woman_cook_dark_skin_tone": "👩🏿\u200d🍳",
+ "woman_cook_light_skin_tone": "👩🏻\u200d🍳",
+ "woman_cook_medium-dark_skin_tone": "👩🏾\u200d🍳",
+ "woman_cook_medium-light_skin_tone": "👩🏼\u200d🍳",
+ "woman_cook_medium_skin_tone": "👩🏽\u200d🍳",
+ "woman_dancing": "💃",
+ "woman_dancing_dark_skin_tone": "💃🏿",
+ "woman_dancing_light_skin_tone": "💃🏻",
+ "woman_dancing_medium-dark_skin_tone": "💃🏾",
+ "woman_dancing_medium-light_skin_tone": "💃🏼",
+ "woman_dancing_medium_skin_tone": "💃🏽",
+ "woman_dark_skin_tone": "👩🏿",
+ "woman_detective": "🕵️\u200d♀️",
+ "woman_detective_dark_skin_tone": "🕵🏿\u200d♀️",
+ "woman_detective_light_skin_tone": "🕵🏻\u200d♀️",
+ "woman_detective_medium-dark_skin_tone": "🕵🏾\u200d♀️",
+ "woman_detective_medium-light_skin_tone": "🕵🏼\u200d♀️",
+ "woman_detective_medium_skin_tone": "🕵🏽\u200d♀️",
+ "woman_elf": "🧝\u200d♀️",
+ "woman_elf_dark_skin_tone": "🧝🏿\u200d♀️",
+ "woman_elf_light_skin_tone": "🧝🏻\u200d♀️",
+ "woman_elf_medium-dark_skin_tone": "🧝🏾\u200d♀️",
+ "woman_elf_medium-light_skin_tone": "🧝🏼\u200d♀️",
+ "woman_elf_medium_skin_tone": "🧝🏽\u200d♀️",
+ "woman_facepalming": "🤦\u200d♀️",
+ "woman_facepalming_dark_skin_tone": "🤦🏿\u200d♀️",
+ "woman_facepalming_light_skin_tone": "🤦🏻\u200d♀️",
+ "woman_facepalming_medium-dark_skin_tone": "🤦🏾\u200d♀️",
+ "woman_facepalming_medium-light_skin_tone": "🤦🏼\u200d♀️",
+ "woman_facepalming_medium_skin_tone": "🤦🏽\u200d♀️",
+ "woman_factory_worker": "👩\u200d🏭",
+ "woman_factory_worker_dark_skin_tone": "👩🏿\u200d🏭",
+ "woman_factory_worker_light_skin_tone": "👩🏻\u200d🏭",
+ "woman_factory_worker_medium-dark_skin_tone": "👩🏾\u200d🏭",
+ "woman_factory_worker_medium-light_skin_tone": "👩🏼\u200d🏭",
+ "woman_factory_worker_medium_skin_tone": "👩🏽\u200d🏭",
+ "woman_fairy": "🧚\u200d♀️",
+ "woman_fairy_dark_skin_tone": "🧚🏿\u200d♀️",
+ "woman_fairy_light_skin_tone": "🧚🏻\u200d♀️",
+ "woman_fairy_medium-dark_skin_tone": "🧚🏾\u200d♀️",
+ "woman_fairy_medium-light_skin_tone": "🧚🏼\u200d♀️",
+ "woman_fairy_medium_skin_tone": "🧚🏽\u200d♀️",
+ "woman_farmer": "👩\u200d🌾",
+ "woman_farmer_dark_skin_tone": "👩🏿\u200d🌾",
+ "woman_farmer_light_skin_tone": "👩🏻\u200d🌾",
+ "woman_farmer_medium-dark_skin_tone": "👩🏾\u200d🌾",
+ "woman_farmer_medium-light_skin_tone": "👩🏼\u200d🌾",
+ "woman_farmer_medium_skin_tone": "👩🏽\u200d🌾",
+ "woman_firefighter": "👩\u200d🚒",
+ "woman_firefighter_dark_skin_tone": "👩🏿\u200d🚒",
+ "woman_firefighter_light_skin_tone": "👩🏻\u200d🚒",
+ "woman_firefighter_medium-dark_skin_tone": "👩🏾\u200d🚒",
+ "woman_firefighter_medium-light_skin_tone": "👩🏼\u200d🚒",
+ "woman_firefighter_medium_skin_tone": "👩🏽\u200d🚒",
+ "woman_frowning": "🙍\u200d♀️",
+ "woman_frowning_dark_skin_tone": "🙍🏿\u200d♀️",
+ "woman_frowning_light_skin_tone": "🙍🏻\u200d♀️",
+ "woman_frowning_medium-dark_skin_tone": "🙍🏾\u200d♀️",
+ "woman_frowning_medium-light_skin_tone": "🙍🏼\u200d♀️",
+ "woman_frowning_medium_skin_tone": "🙍🏽\u200d♀️",
+ "woman_genie": "🧞\u200d♀️",
+ "woman_gesturing_no": "🙅\u200d♀️",
+ "woman_gesturing_no_dark_skin_tone": "🙅🏿\u200d♀️",
+ "woman_gesturing_no_light_skin_tone": "🙅🏻\u200d♀️",
+ "woman_gesturing_no_medium-dark_skin_tone": "🙅🏾\u200d♀️",
+ "woman_gesturing_no_medium-light_skin_tone": "🙅🏼\u200d♀️",
+ "woman_gesturing_no_medium_skin_tone": "🙅🏽\u200d♀️",
+ "woman_gesturing_ok": "🙆\u200d♀️",
+ "woman_gesturing_ok_dark_skin_tone": "🙆🏿\u200d♀️",
+ "woman_gesturing_ok_light_skin_tone": "🙆🏻\u200d♀️",
+ "woman_gesturing_ok_medium-dark_skin_tone": "🙆🏾\u200d♀️",
+ "woman_gesturing_ok_medium-light_skin_tone": "🙆🏼\u200d♀️",
+ "woman_gesturing_ok_medium_skin_tone": "🙆🏽\u200d♀️",
+ "woman_getting_haircut": "💇\u200d♀️",
+ "woman_getting_haircut_dark_skin_tone": "💇🏿\u200d♀️",
+ "woman_getting_haircut_light_skin_tone": "💇🏻\u200d♀️",
+ "woman_getting_haircut_medium-dark_skin_tone": "💇🏾\u200d♀️",
+ "woman_getting_haircut_medium-light_skin_tone": "💇🏼\u200d♀️",
+ "woman_getting_haircut_medium_skin_tone": "💇🏽\u200d♀️",
+ "woman_getting_massage": "💆\u200d♀️",
+ "woman_getting_massage_dark_skin_tone": "💆🏿\u200d♀️",
+ "woman_getting_massage_light_skin_tone": "💆🏻\u200d♀️",
+ "woman_getting_massage_medium-dark_skin_tone": "💆🏾\u200d♀️",
+ "woman_getting_massage_medium-light_skin_tone": "💆🏼\u200d♀️",
+ "woman_getting_massage_medium_skin_tone": "💆🏽\u200d♀️",
+ "woman_golfing": "🏌️\u200d♀️",
+ "woman_golfing_dark_skin_tone": "🏌🏿\u200d♀️",
+ "woman_golfing_light_skin_tone": "🏌🏻\u200d♀️",
+ "woman_golfing_medium-dark_skin_tone": "🏌🏾\u200d♀️",
+ "woman_golfing_medium-light_skin_tone": "🏌🏼\u200d♀️",
+ "woman_golfing_medium_skin_tone": "🏌🏽\u200d♀️",
+ "woman_guard": "💂\u200d♀️",
+ "woman_guard_dark_skin_tone": "💂🏿\u200d♀️",
+ "woman_guard_light_skin_tone": "💂🏻\u200d♀️",
+ "woman_guard_medium-dark_skin_tone": "💂🏾\u200d♀️",
+ "woman_guard_medium-light_skin_tone": "💂🏼\u200d♀️",
+ "woman_guard_medium_skin_tone": "💂🏽\u200d♀️",
+ "woman_health_worker": "👩\u200d⚕️",
+ "woman_health_worker_dark_skin_tone": "👩🏿\u200d⚕️",
+ "woman_health_worker_light_skin_tone": "👩🏻\u200d⚕️",
+ "woman_health_worker_medium-dark_skin_tone": "👩🏾\u200d⚕️",
+ "woman_health_worker_medium-light_skin_tone": "👩🏼\u200d⚕️",
+ "woman_health_worker_medium_skin_tone": "👩🏽\u200d⚕️",
+ "woman_in_lotus_position": "🧘\u200d♀️",
+ "woman_in_lotus_position_dark_skin_tone": "🧘🏿\u200d♀️",
+ "woman_in_lotus_position_light_skin_tone": "🧘🏻\u200d♀️",
+ "woman_in_lotus_position_medium-dark_skin_tone": "🧘🏾\u200d♀️",
+ "woman_in_lotus_position_medium-light_skin_tone": "🧘🏼\u200d♀️",
+ "woman_in_lotus_position_medium_skin_tone": "🧘🏽\u200d♀️",
+ "woman_in_manual_wheelchair": "👩\u200d🦽",
+ "woman_in_motorized_wheelchair": "👩\u200d🦼",
+ "woman_in_steamy_room": "🧖\u200d♀️",
+ "woman_in_steamy_room_dark_skin_tone": "🧖🏿\u200d♀️",
+ "woman_in_steamy_room_light_skin_tone": "🧖🏻\u200d♀️",
+ "woman_in_steamy_room_medium-dark_skin_tone": "🧖🏾\u200d♀️",
+ "woman_in_steamy_room_medium-light_skin_tone": "🧖🏼\u200d♀️",
+ "woman_in_steamy_room_medium_skin_tone": "🧖🏽\u200d♀️",
+ "woman_judge": "👩\u200d⚖️",
+ "woman_judge_dark_skin_tone": "👩🏿\u200d⚖️",
+ "woman_judge_light_skin_tone": "👩🏻\u200d⚖️",
+ "woman_judge_medium-dark_skin_tone": "👩🏾\u200d⚖️",
+ "woman_judge_medium-light_skin_tone": "👩🏼\u200d⚖️",
+ "woman_judge_medium_skin_tone": "👩🏽\u200d⚖️",
+ "woman_juggling": "🤹\u200d♀️",
+ "woman_juggling_dark_skin_tone": "🤹🏿\u200d♀️",
+ "woman_juggling_light_skin_tone": "🤹🏻\u200d♀️",
+ "woman_juggling_medium-dark_skin_tone": "🤹🏾\u200d♀️",
+ "woman_juggling_medium-light_skin_tone": "🤹🏼\u200d♀️",
+ "woman_juggling_medium_skin_tone": "🤹🏽\u200d♀️",
+ "woman_lifting_weights": "🏋️\u200d♀️",
+ "woman_lifting_weights_dark_skin_tone": "🏋🏿\u200d♀️",
+ "woman_lifting_weights_light_skin_tone": "🏋🏻\u200d♀️",
+ "woman_lifting_weights_medium-dark_skin_tone": "🏋🏾\u200d♀️",
+ "woman_lifting_weights_medium-light_skin_tone": "🏋🏼\u200d♀️",
+ "woman_lifting_weights_medium_skin_tone": "🏋🏽\u200d♀️",
+ "woman_light_skin_tone": "👩🏻",
+ "woman_mage": "🧙\u200d♀️",
+ "woman_mage_dark_skin_tone": "🧙🏿\u200d♀️",
+ "woman_mage_light_skin_tone": "🧙🏻\u200d♀️",
+ "woman_mage_medium-dark_skin_tone": "🧙🏾\u200d♀️",
+ "woman_mage_medium-light_skin_tone": "🧙🏼\u200d♀️",
+ "woman_mage_medium_skin_tone": "🧙🏽\u200d♀️",
+ "woman_mechanic": "👩\u200d🔧",
+ "woman_mechanic_dark_skin_tone": "👩🏿\u200d🔧",
+ "woman_mechanic_light_skin_tone": "👩🏻\u200d🔧",
+ "woman_mechanic_medium-dark_skin_tone": "👩🏾\u200d🔧",
+ "woman_mechanic_medium-light_skin_tone": "👩🏼\u200d🔧",
+ "woman_mechanic_medium_skin_tone": "👩🏽\u200d🔧",
+ "woman_medium-dark_skin_tone": "👩🏾",
+ "woman_medium-light_skin_tone": "👩🏼",
+ "woman_medium_skin_tone": "👩🏽",
+ "woman_mountain_biking": "🚵\u200d♀️",
+ "woman_mountain_biking_dark_skin_tone": "🚵🏿\u200d♀️",
+ "woman_mountain_biking_light_skin_tone": "🚵🏻\u200d♀️",
+ "woman_mountain_biking_medium-dark_skin_tone": "🚵🏾\u200d♀️",
+ "woman_mountain_biking_medium-light_skin_tone": "🚵🏼\u200d♀️",
+ "woman_mountain_biking_medium_skin_tone": "🚵🏽\u200d♀️",
+ "woman_office_worker": "👩\u200d💼",
+ "woman_office_worker_dark_skin_tone": "👩🏿\u200d💼",
+ "woman_office_worker_light_skin_tone": "👩🏻\u200d💼",
+ "woman_office_worker_medium-dark_skin_tone": "👩🏾\u200d💼",
+ "woman_office_worker_medium-light_skin_tone": "👩🏼\u200d💼",
+ "woman_office_worker_medium_skin_tone": "👩🏽\u200d💼",
+ "woman_pilot": "👩\u200d✈️",
+ "woman_pilot_dark_skin_tone": "👩🏿\u200d✈️",
+ "woman_pilot_light_skin_tone": "👩🏻\u200d✈️",
+ "woman_pilot_medium-dark_skin_tone": "👩🏾\u200d✈️",
+ "woman_pilot_medium-light_skin_tone": "👩🏼\u200d✈️",
+ "woman_pilot_medium_skin_tone": "👩🏽\u200d✈️",
+ "woman_playing_handball": "🤾\u200d♀️",
+ "woman_playing_handball_dark_skin_tone": "🤾🏿\u200d♀️",
+ "woman_playing_handball_light_skin_tone": "🤾🏻\u200d♀️",
+ "woman_playing_handball_medium-dark_skin_tone": "🤾🏾\u200d♀️",
+ "woman_playing_handball_medium-light_skin_tone": "🤾🏼\u200d♀️",
+ "woman_playing_handball_medium_skin_tone": "🤾🏽\u200d♀️",
+ "woman_playing_water_polo": "🤽\u200d♀️",
+ "woman_playing_water_polo_dark_skin_tone": "🤽🏿\u200d♀️",
+ "woman_playing_water_polo_light_skin_tone": "🤽🏻\u200d♀️",
+ "woman_playing_water_polo_medium-dark_skin_tone": "🤽🏾\u200d♀️",
+ "woman_playing_water_polo_medium-light_skin_tone": "🤽🏼\u200d♀️",
+ "woman_playing_water_polo_medium_skin_tone": "🤽🏽\u200d♀️",
+ "woman_police_officer": "👮\u200d♀️",
+ "woman_police_officer_dark_skin_tone": "👮🏿\u200d♀️",
+ "woman_police_officer_light_skin_tone": "👮🏻\u200d♀️",
+ "woman_police_officer_medium-dark_skin_tone": "👮🏾\u200d♀️",
+ "woman_police_officer_medium-light_skin_tone": "👮🏼\u200d♀️",
+ "woman_police_officer_medium_skin_tone": "👮🏽\u200d♀️",
+ "woman_pouting": "🙎\u200d♀️",
+ "woman_pouting_dark_skin_tone": "🙎🏿\u200d♀️",
+ "woman_pouting_light_skin_tone": "🙎🏻\u200d♀️",
+ "woman_pouting_medium-dark_skin_tone": "🙎🏾\u200d♀️",
+ "woman_pouting_medium-light_skin_tone": "🙎🏼\u200d♀️",
+ "woman_pouting_medium_skin_tone": "🙎🏽\u200d♀️",
+ "woman_raising_hand": "🙋\u200d♀️",
+ "woman_raising_hand_dark_skin_tone": "🙋🏿\u200d♀️",
+ "woman_raising_hand_light_skin_tone": "🙋🏻\u200d♀️",
+ "woman_raising_hand_medium-dark_skin_tone": "🙋🏾\u200d♀️",
+ "woman_raising_hand_medium-light_skin_tone": "🙋🏼\u200d♀️",
+ "woman_raising_hand_medium_skin_tone": "🙋🏽\u200d♀️",
+ "woman_rowing_boat": "🚣\u200d♀️",
+ "woman_rowing_boat_dark_skin_tone": "🚣🏿\u200d♀️",
+ "woman_rowing_boat_light_skin_tone": "🚣🏻\u200d♀️",
+ "woman_rowing_boat_medium-dark_skin_tone": "🚣🏾\u200d♀️",
+ "woman_rowing_boat_medium-light_skin_tone": "🚣🏼\u200d♀️",
+ "woman_rowing_boat_medium_skin_tone": "🚣🏽\u200d♀️",
+ "woman_running": "🏃\u200d♀️",
+ "woman_running_dark_skin_tone": "🏃🏿\u200d♀️",
+ "woman_running_light_skin_tone": "🏃🏻\u200d♀️",
+ "woman_running_medium-dark_skin_tone": "🏃🏾\u200d♀️",
+ "woman_running_medium-light_skin_tone": "🏃🏼\u200d♀️",
+ "woman_running_medium_skin_tone": "🏃🏽\u200d♀️",
+ "woman_scientist": "👩\u200d🔬",
+ "woman_scientist_dark_skin_tone": "👩🏿\u200d🔬",
+ "woman_scientist_light_skin_tone": "👩🏻\u200d🔬",
+ "woman_scientist_medium-dark_skin_tone": "👩🏾\u200d🔬",
+ "woman_scientist_medium-light_skin_tone": "👩🏼\u200d🔬",
+ "woman_scientist_medium_skin_tone": "👩🏽\u200d🔬",
+ "woman_shrugging": "🤷\u200d♀️",
+ "woman_shrugging_dark_skin_tone": "🤷🏿\u200d♀️",
+ "woman_shrugging_light_skin_tone": "🤷🏻\u200d♀️",
+ "woman_shrugging_medium-dark_skin_tone": "🤷🏾\u200d♀️",
+ "woman_shrugging_medium-light_skin_tone": "🤷🏼\u200d♀️",
+ "woman_shrugging_medium_skin_tone": "🤷🏽\u200d♀️",
+ "woman_singer": "👩\u200d🎤",
+ "woman_singer_dark_skin_tone": "👩🏿\u200d🎤",
+ "woman_singer_light_skin_tone": "👩🏻\u200d🎤",
+ "woman_singer_medium-dark_skin_tone": "👩🏾\u200d🎤",
+ "woman_singer_medium-light_skin_tone": "👩🏼\u200d🎤",
+ "woman_singer_medium_skin_tone": "👩🏽\u200d🎤",
+ "woman_student": "👩\u200d🎓",
+ "woman_student_dark_skin_tone": "👩🏿\u200d🎓",
+ "woman_student_light_skin_tone": "👩🏻\u200d🎓",
+ "woman_student_medium-dark_skin_tone": "👩🏾\u200d🎓",
+ "woman_student_medium-light_skin_tone": "👩🏼\u200d🎓",
+ "woman_student_medium_skin_tone": "👩🏽\u200d🎓",
+ "woman_surfing": "🏄\u200d♀️",
+ "woman_surfing_dark_skin_tone": "🏄🏿\u200d♀️",
+ "woman_surfing_light_skin_tone": "🏄🏻\u200d♀️",
+ "woman_surfing_medium-dark_skin_tone": "🏄🏾\u200d♀️",
+ "woman_surfing_medium-light_skin_tone": "🏄🏼\u200d♀️",
+ "woman_surfing_medium_skin_tone": "🏄🏽\u200d♀️",
+ "woman_swimming": "🏊\u200d♀️",
+ "woman_swimming_dark_skin_tone": "🏊🏿\u200d♀️",
+ "woman_swimming_light_skin_tone": "🏊🏻\u200d♀️",
+ "woman_swimming_medium-dark_skin_tone": "🏊🏾\u200d♀️",
+ "woman_swimming_medium-light_skin_tone": "🏊🏼\u200d♀️",
+ "woman_swimming_medium_skin_tone": "🏊🏽\u200d♀️",
+ "woman_teacher": "👩\u200d🏫",
+ "woman_teacher_dark_skin_tone": "👩🏿\u200d🏫",
+ "woman_teacher_light_skin_tone": "👩🏻\u200d🏫",
+ "woman_teacher_medium-dark_skin_tone": "👩🏾\u200d🏫",
+ "woman_teacher_medium-light_skin_tone": "👩🏼\u200d🏫",
+ "woman_teacher_medium_skin_tone": "👩🏽\u200d🏫",
+ "woman_technologist": "👩\u200d💻",
+ "woman_technologist_dark_skin_tone": "👩🏿\u200d💻",
+ "woman_technologist_light_skin_tone": "👩🏻\u200d💻",
+ "woman_technologist_medium-dark_skin_tone": "👩🏾\u200d💻",
+ "woman_technologist_medium-light_skin_tone": "👩🏼\u200d💻",
+ "woman_technologist_medium_skin_tone": "👩🏽\u200d💻",
+ "woman_tipping_hand": "💁\u200d♀️",
+ "woman_tipping_hand_dark_skin_tone": "💁🏿\u200d♀️",
+ "woman_tipping_hand_light_skin_tone": "💁🏻\u200d♀️",
+ "woman_tipping_hand_medium-dark_skin_tone": "💁🏾\u200d♀️",
+ "woman_tipping_hand_medium-light_skin_tone": "💁🏼\u200d♀️",
+ "woman_tipping_hand_medium_skin_tone": "💁🏽\u200d♀️",
+ "woman_vampire": "🧛\u200d♀️",
+ "woman_vampire_dark_skin_tone": "🧛🏿\u200d♀️",
+ "woman_vampire_light_skin_tone": "🧛🏻\u200d♀️",
+ "woman_vampire_medium-dark_skin_tone": "🧛🏾\u200d♀️",
+ "woman_vampire_medium-light_skin_tone": "🧛🏼\u200d♀️",
+ "woman_vampire_medium_skin_tone": "🧛🏽\u200d♀️",
+ "woman_walking": "🚶\u200d♀️",
+ "woman_walking_dark_skin_tone": "🚶🏿\u200d♀️",
+ "woman_walking_light_skin_tone": "🚶🏻\u200d♀️",
+ "woman_walking_medium-dark_skin_tone": "🚶🏾\u200d♀️",
+ "woman_walking_medium-light_skin_tone": "🚶🏼\u200d♀️",
+ "woman_walking_medium_skin_tone": "🚶🏽\u200d♀️",
+ "woman_wearing_turban": "👳\u200d♀️",
+ "woman_wearing_turban_dark_skin_tone": "👳🏿\u200d♀️",
+ "woman_wearing_turban_light_skin_tone": "👳🏻\u200d♀️",
+ "woman_wearing_turban_medium-dark_skin_tone": "👳🏾\u200d♀️",
+ "woman_wearing_turban_medium-light_skin_tone": "👳🏼\u200d♀️",
+ "woman_wearing_turban_medium_skin_tone": "👳🏽\u200d♀️",
+ "woman_with_headscarf": "🧕",
+ "woman_with_headscarf_dark_skin_tone": "🧕🏿",
+ "woman_with_headscarf_light_skin_tone": "🧕🏻",
+ "woman_with_headscarf_medium-dark_skin_tone": "🧕🏾",
+ "woman_with_headscarf_medium-light_skin_tone": "🧕🏼",
+ "woman_with_headscarf_medium_skin_tone": "🧕🏽",
+ "woman_with_probing_cane": "👩\u200d🦯",
+ "woman_zombie": "🧟\u200d♀️",
+ "woman’s_boot": "👢",
+ "woman’s_clothes": "👚",
+ "woman’s_hat": "👒",
+ "woman’s_sandal": "👡",
+ "women_with_bunny_ears": "👯\u200d♀️",
+ "women_wrestling": "🤼\u200d♀️",
+ "women’s_room": "🚺",
+ "woozy_face": "🥴",
+ "world_map": "🗺",
+ "worried_face": "😟",
+ "wrapped_gift": "🎁",
+ "wrench": "🔧",
+ "writing_hand": "✍",
+ "writing_hand_dark_skin_tone": "✍🏿",
+ "writing_hand_light_skin_tone": "✍🏻",
+ "writing_hand_medium-dark_skin_tone": "✍🏾",
+ "writing_hand_medium-light_skin_tone": "✍🏼",
+ "writing_hand_medium_skin_tone": "✍🏽",
+ "yarn": "🧶",
+ "yawning_face": "🥱",
+ "yellow_circle": "🟡",
+ "yellow_heart": "💛",
+ "yellow_square": "🟨",
+ "yen_banknote": "💴",
+ "yo-yo": "🪀",
+ "yin_yang": "☯",
+ "zany_face": "🤪",
+ "zebra": "🦓",
+ "zipper-mouth_face": "🤐",
+ "zombie": "🧟",
+ "zzz": "💤",
+ "åland_islands": "🇦🇽",
+ "keycap_asterisk": "*⃣",
+ "keycap_digit_eight": "8⃣",
+ "keycap_digit_five": "5⃣",
+ "keycap_digit_four": "4⃣",
+ "keycap_digit_nine": "9⃣",
+ "keycap_digit_one": "1⃣",
+ "keycap_digit_seven": "7⃣",
+ "keycap_digit_six": "6⃣",
+ "keycap_digit_three": "3⃣",
+ "keycap_digit_two": "2⃣",
+ "keycap_digit_zero": "0⃣",
+ "keycap_number_sign": "#⃣",
+ "light_skin_tone": "🏻",
+ "medium_light_skin_tone": "🏼",
+ "medium_skin_tone": "🏽",
+ "medium_dark_skin_tone": "🏾",
+ "dark_skin_tone": "🏿",
+ "regional_indicator_symbol_letter_a": "🇦",
+ "regional_indicator_symbol_letter_b": "🇧",
+ "regional_indicator_symbol_letter_c": "🇨",
+ "regional_indicator_symbol_letter_d": "🇩",
+ "regional_indicator_symbol_letter_e": "🇪",
+ "regional_indicator_symbol_letter_f": "🇫",
+ "regional_indicator_symbol_letter_g": "🇬",
+ "regional_indicator_symbol_letter_h": "🇭",
+ "regional_indicator_symbol_letter_i": "🇮",
+ "regional_indicator_symbol_letter_j": "🇯",
+ "regional_indicator_symbol_letter_k": "🇰",
+ "regional_indicator_symbol_letter_l": "🇱",
+ "regional_indicator_symbol_letter_m": "🇲",
+ "regional_indicator_symbol_letter_n": "🇳",
+ "regional_indicator_symbol_letter_o": "🇴",
+ "regional_indicator_symbol_letter_p": "🇵",
+ "regional_indicator_symbol_letter_q": "🇶",
+ "regional_indicator_symbol_letter_r": "🇷",
+ "regional_indicator_symbol_letter_s": "🇸",
+ "regional_indicator_symbol_letter_t": "🇹",
+ "regional_indicator_symbol_letter_u": "🇺",
+ "regional_indicator_symbol_letter_v": "🇻",
+ "regional_indicator_symbol_letter_w": "🇼",
+ "regional_indicator_symbol_letter_x": "🇽",
+ "regional_indicator_symbol_letter_y": "🇾",
+ "regional_indicator_symbol_letter_z": "🇿",
+ "airplane_arriving": "🛬",
+ "space_invader": "👾",
+ "football": "🏈",
+ "anger": "💢",
+ "angry": "😠",
+ "anguished": "😧",
+ "signal_strength": "📶",
+ "arrows_counterclockwise": "🔄",
+ "arrow_heading_down": "⤵",
+ "arrow_heading_up": "⤴",
+ "art": "🎨",
+ "astonished": "😲",
+ "athletic_shoe": "👟",
+ "atm": "🏧",
+ "car": "🚗",
+ "red_car": "🚗",
+ "angel": "👼",
+ "back": "🔙",
+ "badminton_racquet_and_shuttlecock": "🏸",
+ "dollar": "💵",
+ "euro": "💶",
+ "pound": "💷",
+ "yen": "💴",
+ "barber": "💈",
+ "bath": "🛀",
+ "bear": "🐻",
+ "heartbeat": "💓",
+ "beer": "🍺",
+ "no_bell": "🔕",
+ "bento": "🍱",
+ "bike": "🚲",
+ "bicyclist": "🚴",
+ "8ball": "🎱",
+ "biohazard_sign": "☣",
+ "birthday": "🎂",
+ "black_circle_for_record": "⏺",
+ "clubs": "♣",
+ "diamonds": "♦",
+ "arrow_double_down": "⏬",
+ "hearts": "♥",
+ "rewind": "⏪",
+ "black_left__pointing_double_triangle_with_vertical_bar": "⏮",
+ "arrow_backward": "◀",
+ "black_medium_small_square": "◾",
+ "question": "❓",
+ "fast_forward": "⏩",
+ "black_right__pointing_double_triangle_with_vertical_bar": "⏭",
+ "arrow_forward": "▶",
+ "black_right__pointing_triangle_with_double_vertical_bar": "⏯",
+ "arrow_right": "➡",
+ "spades": "♠",
+ "black_square_for_stop": "⏹",
+ "sunny": "☀",
+ "phone": "☎",
+ "recycle": "♻",
+ "arrow_double_up": "⏫",
+ "busstop": "🚏",
+ "date": "📅",
+ "flags": "🎏",
+ "cat2": "🐈",
+ "joy_cat": "😹",
+ "smirk_cat": "😼",
+ "chart_with_downwards_trend": "📉",
+ "chart_with_upwards_trend": "📈",
+ "chart": "💹",
+ "mega": "📣",
+ "checkered_flag": "🏁",
+ "accept": "🉑",
+ "ideograph_advantage": "🉐",
+ "congratulations": "㊗",
+ "secret": "㊙",
+ "m": "Ⓜ",
+ "city_sunset": "🌆",
+ "clapper": "🎬",
+ "clap": "👏",
+ "beers": "🍻",
+ "clock830": "🕣",
+ "clock8": "🕗",
+ "clock1130": "🕦",
+ "clock11": "🕚",
+ "clock530": "🕠",
+ "clock5": "🕔",
+ "clock430": "🕟",
+ "clock4": "🕓",
+ "clock930": "🕤",
+ "clock9": "🕘",
+ "clock130": "🕜",
+ "clock1": "🕐",
+ "clock730": "🕢",
+ "clock7": "🕖",
+ "clock630": "🕡",
+ "clock6": "🕕",
+ "clock1030": "🕥",
+ "clock10": "🕙",
+ "clock330": "🕞",
+ "clock3": "🕒",
+ "clock1230": "🕧",
+ "clock12": "🕛",
+ "clock230": "🕝",
+ "clock2": "🕑",
+ "arrows_clockwise": "🔃",
+ "repeat": "🔁",
+ "repeat_one": "🔂",
+ "closed_lock_with_key": "🔐",
+ "mailbox_closed": "📪",
+ "mailbox": "📫",
+ "cloud_with_tornado": "🌪",
+ "cocktail": "🍸",
+ "boom": "💥",
+ "compression": "🗜",
+ "confounded": "😖",
+ "confused": "😕",
+ "rice": "🍚",
+ "cow2": "🐄",
+ "cricket_bat_and_ball": "🏏",
+ "x": "❌",
+ "cry": "😢",
+ "curry": "🍛",
+ "dagger_knife": "🗡",
+ "dancer": "💃",
+ "dark_sunglasses": "🕶",
+ "dash": "💨",
+ "truck": "🚚",
+ "derelict_house_building": "🏚",
+ "diamond_shape_with_a_dot_inside": "💠",
+ "dart": "🎯",
+ "disappointed_relieved": "😥",
+ "disappointed": "😞",
+ "do_not_litter": "🚯",
+ "dog2": "🐕",
+ "flipper": "🐬",
+ "loop": "➿",
+ "bangbang": "‼",
+ "double_vertical_bar": "⏸",
+ "dove_of_peace": "🕊",
+ "small_red_triangle_down": "🔻",
+ "arrow_down_small": "🔽",
+ "arrow_down": "⬇",
+ "dromedary_camel": "🐪",
+ "e__mail": "📧",
+ "corn": "🌽",
+ "ear_of_rice": "🌾",
+ "earth_americas": "🌎",
+ "earth_asia": "🌏",
+ "earth_africa": "🌍",
+ "eight_pointed_black_star": "✴",
+ "eight_spoked_asterisk": "✳",
+ "eject_symbol": "⏏",
+ "bulb": "💡",
+ "emoji_modifier_fitzpatrick_type__1__2": "🏻",
+ "emoji_modifier_fitzpatrick_type__3": "🏼",
+ "emoji_modifier_fitzpatrick_type__4": "🏽",
+ "emoji_modifier_fitzpatrick_type__5": "🏾",
+ "emoji_modifier_fitzpatrick_type__6": "🏿",
+ "end": "🔚",
+ "email": "✉",
+ "european_castle": "🏰",
+ "european_post_office": "🏤",
+ "interrobang": "⁉",
+ "expressionless": "😑",
+ "eyeglasses": "👓",
+ "massage": "💆",
+ "yum": "😋",
+ "scream": "😱",
+ "kissing_heart": "😘",
+ "sweat": "😓",
+ "face_with_head__bandage": "🤕",
+ "triumph": "😤",
+ "mask": "😷",
+ "no_good": "🙅",
+ "ok_woman": "🙆",
+ "open_mouth": "😮",
+ "cold_sweat": "😰",
+ "stuck_out_tongue": "😛",
+ "stuck_out_tongue_closed_eyes": "😝",
+ "stuck_out_tongue_winking_eye": "😜",
+ "joy": "😂",
+ "no_mouth": "😶",
+ "santa": "🎅",
+ "fax": "📠",
+ "fearful": "😨",
+ "field_hockey_stick_and_ball": "🏑",
+ "first_quarter_moon_with_face": "🌛",
+ "fish_cake": "🍥",
+ "fishing_pole_and_fish": "🎣",
+ "facepunch": "👊",
+ "punch": "👊",
+ "flag_for_afghanistan": "🇦🇫",
+ "flag_for_albania": "🇦🇱",
+ "flag_for_algeria": "🇩🇿",
+ "flag_for_american_samoa": "🇦🇸",
+ "flag_for_andorra": "🇦🇩",
+ "flag_for_angola": "🇦🇴",
+ "flag_for_anguilla": "🇦🇮",
+ "flag_for_antarctica": "🇦🇶",
+ "flag_for_antigua_&_barbuda": "🇦🇬",
+ "flag_for_argentina": "🇦🇷",
+ "flag_for_armenia": "🇦🇲",
+ "flag_for_aruba": "🇦🇼",
+ "flag_for_ascension_island": "🇦🇨",
+ "flag_for_australia": "🇦🇺",
+ "flag_for_austria": "🇦🇹",
+ "flag_for_azerbaijan": "🇦🇿",
+ "flag_for_bahamas": "🇧🇸",
+ "flag_for_bahrain": "🇧🇭",
+ "flag_for_bangladesh": "🇧🇩",
+ "flag_for_barbados": "🇧🇧",
+ "flag_for_belarus": "🇧🇾",
+ "flag_for_belgium": "🇧🇪",
+ "flag_for_belize": "🇧🇿",
+ "flag_for_benin": "🇧🇯",
+ "flag_for_bermuda": "🇧🇲",
+ "flag_for_bhutan": "🇧🇹",
+ "flag_for_bolivia": "🇧🇴",
+ "flag_for_bosnia_&_herzegovina": "🇧🇦",
+ "flag_for_botswana": "🇧🇼",
+ "flag_for_bouvet_island": "🇧🇻",
+ "flag_for_brazil": "🇧🇷",
+ "flag_for_british_indian_ocean_territory": "🇮🇴",
+ "flag_for_british_virgin_islands": "🇻🇬",
+ "flag_for_brunei": "🇧🇳",
+ "flag_for_bulgaria": "🇧🇬",
+ "flag_for_burkina_faso": "🇧🇫",
+ "flag_for_burundi": "🇧🇮",
+ "flag_for_cambodia": "🇰🇭",
+ "flag_for_cameroon": "🇨🇲",
+ "flag_for_canada": "🇨🇦",
+ "flag_for_canary_islands": "🇮🇨",
+ "flag_for_cape_verde": "🇨🇻",
+ "flag_for_caribbean_netherlands": "🇧🇶",
+ "flag_for_cayman_islands": "🇰🇾",
+ "flag_for_central_african_republic": "🇨🇫",
+ "flag_for_ceuta_&_melilla": "🇪🇦",
+ "flag_for_chad": "🇹🇩",
+ "flag_for_chile": "🇨🇱",
+ "flag_for_china": "🇨🇳",
+ "flag_for_christmas_island": "🇨🇽",
+ "flag_for_clipperton_island": "🇨🇵",
+ "flag_for_cocos__islands": "🇨🇨",
+ "flag_for_colombia": "🇨🇴",
+ "flag_for_comoros": "🇰🇲",
+ "flag_for_congo____brazzaville": "🇨🇬",
+ "flag_for_congo____kinshasa": "🇨🇩",
+ "flag_for_cook_islands": "🇨🇰",
+ "flag_for_costa_rica": "🇨🇷",
+ "flag_for_croatia": "🇭🇷",
+ "flag_for_cuba": "🇨🇺",
+ "flag_for_curaçao": "🇨🇼",
+ "flag_for_cyprus": "🇨🇾",
+ "flag_for_czech_republic": "🇨🇿",
+ "flag_for_côte_d’ivoire": "🇨🇮",
+ "flag_for_denmark": "🇩🇰",
+ "flag_for_diego_garcia": "🇩🇬",
+ "flag_for_djibouti": "🇩🇯",
+ "flag_for_dominica": "🇩🇲",
+ "flag_for_dominican_republic": "🇩🇴",
+ "flag_for_ecuador": "🇪🇨",
+ "flag_for_egypt": "🇪🇬",
+ "flag_for_el_salvador": "🇸🇻",
+ "flag_for_equatorial_guinea": "🇬🇶",
+ "flag_for_eritrea": "🇪🇷",
+ "flag_for_estonia": "🇪🇪",
+ "flag_for_ethiopia": "🇪🇹",
+ "flag_for_european_union": "🇪🇺",
+ "flag_for_falkland_islands": "🇫🇰",
+ "flag_for_faroe_islands": "🇫🇴",
+ "flag_for_fiji": "🇫🇯",
+ "flag_for_finland": "🇫🇮",
+ "flag_for_france": "🇫🇷",
+ "flag_for_french_guiana": "🇬🇫",
+ "flag_for_french_polynesia": "🇵🇫",
+ "flag_for_french_southern_territories": "🇹🇫",
+ "flag_for_gabon": "🇬🇦",
+ "flag_for_gambia": "🇬🇲",
+ "flag_for_georgia": "🇬🇪",
+ "flag_for_germany": "🇩🇪",
+ "flag_for_ghana": "🇬🇭",
+ "flag_for_gibraltar": "🇬🇮",
+ "flag_for_greece": "🇬🇷",
+ "flag_for_greenland": "🇬🇱",
+ "flag_for_grenada": "🇬🇩",
+ "flag_for_guadeloupe": "🇬🇵",
+ "flag_for_guam": "🇬🇺",
+ "flag_for_guatemala": "🇬🇹",
+ "flag_for_guernsey": "🇬🇬",
+ "flag_for_guinea": "🇬🇳",
+ "flag_for_guinea__bissau": "🇬🇼",
+ "flag_for_guyana": "🇬🇾",
+ "flag_for_haiti": "🇭🇹",
+ "flag_for_heard_&_mcdonald_islands": "🇭🇲",
+ "flag_for_honduras": "🇭🇳",
+ "flag_for_hong_kong": "🇭🇰",
+ "flag_for_hungary": "🇭🇺",
+ "flag_for_iceland": "🇮🇸",
+ "flag_for_india": "🇮🇳",
+ "flag_for_indonesia": "🇮🇩",
+ "flag_for_iran": "🇮🇷",
+ "flag_for_iraq": "🇮🇶",
+ "flag_for_ireland": "🇮🇪",
+ "flag_for_isle_of_man": "🇮🇲",
+ "flag_for_israel": "🇮🇱",
+ "flag_for_italy": "🇮🇹",
+ "flag_for_jamaica": "🇯🇲",
+ "flag_for_japan": "🇯🇵",
+ "flag_for_jersey": "🇯🇪",
+ "flag_for_jordan": "🇯🇴",
+ "flag_for_kazakhstan": "🇰🇿",
+ "flag_for_kenya": "🇰🇪",
+ "flag_for_kiribati": "🇰🇮",
+ "flag_for_kosovo": "🇽🇰",
+ "flag_for_kuwait": "🇰🇼",
+ "flag_for_kyrgyzstan": "🇰🇬",
+ "flag_for_laos": "🇱🇦",
+ "flag_for_latvia": "🇱🇻",
+ "flag_for_lebanon": "🇱🇧",
+ "flag_for_lesotho": "🇱🇸",
+ "flag_for_liberia": "🇱🇷",
+ "flag_for_libya": "🇱🇾",
+ "flag_for_liechtenstein": "🇱🇮",
+ "flag_for_lithuania": "🇱🇹",
+ "flag_for_luxembourg": "🇱🇺",
+ "flag_for_macau": "🇲🇴",
+ "flag_for_macedonia": "🇲🇰",
+ "flag_for_madagascar": "🇲🇬",
+ "flag_for_malawi": "🇲🇼",
+ "flag_for_malaysia": "🇲🇾",
+ "flag_for_maldives": "🇲🇻",
+ "flag_for_mali": "🇲🇱",
+ "flag_for_malta": "🇲🇹",
+ "flag_for_marshall_islands": "🇲🇭",
+ "flag_for_martinique": "🇲🇶",
+ "flag_for_mauritania": "🇲🇷",
+ "flag_for_mauritius": "🇲🇺",
+ "flag_for_mayotte": "🇾🇹",
+ "flag_for_mexico": "🇲🇽",
+ "flag_for_micronesia": "🇫🇲",
+ "flag_for_moldova": "🇲🇩",
+ "flag_for_monaco": "🇲🇨",
+ "flag_for_mongolia": "🇲🇳",
+ "flag_for_montenegro": "🇲🇪",
+ "flag_for_montserrat": "🇲🇸",
+ "flag_for_morocco": "🇲🇦",
+ "flag_for_mozambique": "🇲🇿",
+ "flag_for_myanmar": "🇲🇲",
+ "flag_for_namibia": "🇳🇦",
+ "flag_for_nauru": "🇳🇷",
+ "flag_for_nepal": "🇳🇵",
+ "flag_for_netherlands": "🇳🇱",
+ "flag_for_new_caledonia": "🇳🇨",
+ "flag_for_new_zealand": "🇳🇿",
+ "flag_for_nicaragua": "🇳🇮",
+ "flag_for_niger": "🇳🇪",
+ "flag_for_nigeria": "🇳🇬",
+ "flag_for_niue": "🇳🇺",
+ "flag_for_norfolk_island": "🇳🇫",
+ "flag_for_north_korea": "🇰🇵",
+ "flag_for_northern_mariana_islands": "🇲🇵",
+ "flag_for_norway": "🇳🇴",
+ "flag_for_oman": "🇴🇲",
+ "flag_for_pakistan": "🇵🇰",
+ "flag_for_palau": "🇵🇼",
+ "flag_for_palestinian_territories": "🇵🇸",
+ "flag_for_panama": "🇵🇦",
+ "flag_for_papua_new_guinea": "🇵🇬",
+ "flag_for_paraguay": "🇵🇾",
+ "flag_for_peru": "🇵🇪",
+ "flag_for_philippines": "🇵🇭",
+ "flag_for_pitcairn_islands": "🇵🇳",
+ "flag_for_poland": "🇵🇱",
+ "flag_for_portugal": "🇵🇹",
+ "flag_for_puerto_rico": "🇵🇷",
+ "flag_for_qatar": "🇶🇦",
+ "flag_for_romania": "🇷🇴",
+ "flag_for_russia": "🇷🇺",
+ "flag_for_rwanda": "🇷🇼",
+ "flag_for_réunion": "🇷🇪",
+ "flag_for_samoa": "🇼🇸",
+ "flag_for_san_marino": "🇸🇲",
+ "flag_for_saudi_arabia": "🇸🇦",
+ "flag_for_senegal": "🇸🇳",
+ "flag_for_serbia": "🇷🇸",
+ "flag_for_seychelles": "🇸🇨",
+ "flag_for_sierra_leone": "🇸🇱",
+ "flag_for_singapore": "🇸🇬",
+ "flag_for_sint_maarten": "🇸🇽",
+ "flag_for_slovakia": "🇸🇰",
+ "flag_for_slovenia": "🇸🇮",
+ "flag_for_solomon_islands": "🇸🇧",
+ "flag_for_somalia": "🇸🇴",
+ "flag_for_south_africa": "🇿🇦",
+ "flag_for_south_georgia_&_south_sandwich_islands": "🇬🇸",
+ "flag_for_south_korea": "🇰🇷",
+ "flag_for_south_sudan": "🇸🇸",
+ "flag_for_spain": "🇪🇸",
+ "flag_for_sri_lanka": "🇱🇰",
+ "flag_for_st._barthélemy": "🇧🇱",
+ "flag_for_st._helena": "🇸🇭",
+ "flag_for_st._kitts_&_nevis": "🇰🇳",
+ "flag_for_st._lucia": "🇱🇨",
+ "flag_for_st._martin": "🇲🇫",
+ "flag_for_st._pierre_&_miquelon": "🇵🇲",
+ "flag_for_st._vincent_&_grenadines": "🇻🇨",
+ "flag_for_sudan": "🇸🇩",
+ "flag_for_suriname": "🇸🇷",
+ "flag_for_svalbard_&_jan_mayen": "🇸🇯",
+ "flag_for_swaziland": "🇸🇿",
+ "flag_for_sweden": "🇸🇪",
+ "flag_for_switzerland": "🇨🇭",
+ "flag_for_syria": "🇸🇾",
+ "flag_for_são_tomé_&_príncipe": "🇸🇹",
+ "flag_for_taiwan": "🇹🇼",
+ "flag_for_tajikistan": "🇹🇯",
+ "flag_for_tanzania": "🇹🇿",
+ "flag_for_thailand": "🇹🇭",
+ "flag_for_timor__leste": "🇹🇱",
+ "flag_for_togo": "🇹🇬",
+ "flag_for_tokelau": "🇹🇰",
+ "flag_for_tonga": "🇹🇴",
+ "flag_for_trinidad_&_tobago": "🇹🇹",
+ "flag_for_tristan_da_cunha": "🇹🇦",
+ "flag_for_tunisia": "🇹🇳",
+ "flag_for_turkey": "🇹🇷",
+ "flag_for_turkmenistan": "🇹🇲",
+ "flag_for_turks_&_caicos_islands": "🇹🇨",
+ "flag_for_tuvalu": "🇹🇻",
+ "flag_for_u.s._outlying_islands": "🇺🇲",
+ "flag_for_u.s._virgin_islands": "🇻🇮",
+ "flag_for_uganda": "🇺🇬",
+ "flag_for_ukraine": "🇺🇦",
+ "flag_for_united_arab_emirates": "🇦🇪",
+ "flag_for_united_kingdom": "🇬🇧",
+ "flag_for_united_states": "🇺🇸",
+ "flag_for_uruguay": "🇺🇾",
+ "flag_for_uzbekistan": "🇺🇿",
+ "flag_for_vanuatu": "🇻🇺",
+ "flag_for_vatican_city": "🇻🇦",
+ "flag_for_venezuela": "🇻🇪",
+ "flag_for_vietnam": "🇻🇳",
+ "flag_for_wallis_&_futuna": "🇼🇫",
+ "flag_for_western_sahara": "🇪🇭",
+ "flag_for_yemen": "🇾🇪",
+ "flag_for_zambia": "🇿🇲",
+ "flag_for_zimbabwe": "🇿🇼",
+ "flag_for_åland_islands": "🇦🇽",
+ "golf": "⛳",
+ "fleur__de__lis": "⚜",
+ "muscle": "💪",
+ "flushed": "😳",
+ "frame_with_picture": "🖼",
+ "fries": "🍟",
+ "frog": "🐸",
+ "hatched_chick": "🐥",
+ "frowning": "😦",
+ "fuelpump": "⛽",
+ "full_moon_with_face": "🌝",
+ "gem": "💎",
+ "star2": "🌟",
+ "golfer": "🏌",
+ "mortar_board": "🎓",
+ "grimacing": "😬",
+ "smile_cat": "😸",
+ "grinning": "😀",
+ "grin": "😁",
+ "heartpulse": "💗",
+ "guardsman": "💂",
+ "haircut": "💇",
+ "hamster": "🐹",
+ "raising_hand": "🙋",
+ "headphones": "🎧",
+ "hear_no_evil": "🙉",
+ "cupid": "💘",
+ "gift_heart": "💝",
+ "heart": "❤",
+ "exclamation": "❗",
+ "heavy_exclamation_mark": "❗",
+ "heavy_heart_exclamation_mark_ornament": "❣",
+ "o": "⭕",
+ "helm_symbol": "⎈",
+ "helmet_with_white_cross": "⛑",
+ "high_heel": "👠",
+ "bullettrain_side": "🚄",
+ "bullettrain_front": "🚅",
+ "high_brightness": "🔆",
+ "zap": "⚡",
+ "hocho": "🔪",
+ "knife": "🔪",
+ "bee": "🐝",
+ "traffic_light": "🚥",
+ "racehorse": "🐎",
+ "coffee": "☕",
+ "hotsprings": "♨",
+ "hourglass": "⌛",
+ "hourglass_flowing_sand": "⏳",
+ "house_buildings": "🏘",
+ "100": "💯",
+ "hushed": "😯",
+ "ice_hockey_stick_and_puck": "🏒",
+ "imp": "👿",
+ "information_desk_person": "💁",
+ "information_source": "ℹ",
+ "capital_abcd": "🔠",
+ "abc": "🔤",
+ "abcd": "🔡",
+ "1234": "🔢",
+ "symbols": "🔣",
+ "izakaya_lantern": "🏮",
+ "lantern": "🏮",
+ "jack_o_lantern": "🎃",
+ "dolls": "🎎",
+ "japanese_goblin": "👺",
+ "japanese_ogre": "👹",
+ "beginner": "🔰",
+ "zero": "0️⃣",
+ "one": "1️⃣",
+ "ten": "🔟",
+ "two": "2️⃣",
+ "three": "3️⃣",
+ "four": "4️⃣",
+ "five": "5️⃣",
+ "six": "6️⃣",
+ "seven": "7️⃣",
+ "eight": "8️⃣",
+ "nine": "9️⃣",
+ "couplekiss": "💏",
+ "kissing_cat": "😽",
+ "kissing": "😗",
+ "kissing_closed_eyes": "😚",
+ "kissing_smiling_eyes": "😙",
+ "beetle": "🐞",
+ "large_blue_circle": "🔵",
+ "last_quarter_moon_with_face": "🌜",
+ "leaves": "🍃",
+ "mag": "🔍",
+ "left_right_arrow": "↔",
+ "leftwards_arrow_with_hook": "↩",
+ "arrow_left": "⬅",
+ "lock": "🔒",
+ "lock_with_ink_pen": "🔏",
+ "sob": "😭",
+ "low_brightness": "🔅",
+ "lower_left_ballpoint_pen": "🖊",
+ "lower_left_crayon": "🖍",
+ "lower_left_fountain_pen": "🖋",
+ "lower_left_paintbrush": "🖌",
+ "mahjong": "🀄",
+ "couple": "👫",
+ "man_in_business_suit_levitating": "🕴",
+ "man_with_gua_pi_mao": "👲",
+ "man_with_turban": "👳",
+ "mans_shoe": "👞",
+ "shoe": "👞",
+ "menorah_with_nine_branches": "🕎",
+ "mens": "🚹",
+ "minidisc": "💽",
+ "iphone": "📱",
+ "calling": "📲",
+ "money__mouth_face": "🤑",
+ "moneybag": "💰",
+ "rice_scene": "🎑",
+ "mountain_bicyclist": "🚵",
+ "mouse2": "🐁",
+ "lips": "👄",
+ "moyai": "🗿",
+ "notes": "🎶",
+ "nail_care": "💅",
+ "ab": "🆎",
+ "negative_squared_cross_mark": "❎",
+ "a": "🅰",
+ "b": "🅱",
+ "o2": "🅾",
+ "parking": "🅿",
+ "new_moon_with_face": "🌚",
+ "no_entry_sign": "🚫",
+ "underage": "🔞",
+ "non__potable_water": "🚱",
+ "arrow_upper_right": "↗",
+ "arrow_upper_left": "↖",
+ "office": "🏢",
+ "older_man": "👴",
+ "older_woman": "👵",
+ "om_symbol": "🕉",
+ "on": "🔛",
+ "book": "📖",
+ "unlock": "🔓",
+ "mailbox_with_no_mail": "📭",
+ "mailbox_with_mail": "📬",
+ "cd": "💿",
+ "tada": "🎉",
+ "feet": "🐾",
+ "walking": "🚶",
+ "pencil2": "✏",
+ "pensive": "😔",
+ "persevere": "😣",
+ "bow": "🙇",
+ "raised_hands": "🙌",
+ "person_with_ball": "⛹",
+ "person_with_blond_hair": "👱",
+ "pray": "🙏",
+ "person_with_pouting_face": "🙎",
+ "computer": "💻",
+ "pig2": "🐖",
+ "hankey": "💩",
+ "poop": "💩",
+ "shit": "💩",
+ "bamboo": "🎍",
+ "gun": "🔫",
+ "black_joker": "🃏",
+ "rotating_light": "🚨",
+ "cop": "👮",
+ "stew": "🍲",
+ "pouch": "👝",
+ "pouting_cat": "😾",
+ "rage": "😡",
+ "put_litter_in_its_place": "🚮",
+ "rabbit2": "🐇",
+ "racing_motorcycle": "🏍",
+ "radioactive_sign": "☢",
+ "fist": "✊",
+ "hand": "✋",
+ "raised_hand_with_fingers_splayed": "🖐",
+ "raised_hand_with_part_between_middle_and_ring_fingers": "🖖",
+ "blue_car": "🚙",
+ "apple": "🍎",
+ "relieved": "😌",
+ "reversed_hand_with_middle_finger_extended": "🖕",
+ "mag_right": "🔎",
+ "arrow_right_hook": "↪",
+ "sweet_potato": "🍠",
+ "robot": "🤖",
+ "rolled__up_newspaper": "🗞",
+ "rowboat": "🚣",
+ "runner": "🏃",
+ "running": "🏃",
+ "running_shirt_with_sash": "🎽",
+ "boat": "⛵",
+ "scales": "⚖",
+ "school_satchel": "🎒",
+ "scorpius": "♏",
+ "see_no_evil": "🙈",
+ "sheep": "🐑",
+ "stars": "🌠",
+ "cake": "🍰",
+ "six_pointed_star": "🔯",
+ "ski": "🎿",
+ "sleeping_accommodation": "🛌",
+ "sleeping": "😴",
+ "sleepy": "😪",
+ "sleuth_or_spy": "🕵",
+ "heart_eyes_cat": "😻",
+ "smiley_cat": "😺",
+ "innocent": "😇",
+ "heart_eyes": "😍",
+ "smiling_imp": "😈",
+ "smiley": "😃",
+ "sweat_smile": "😅",
+ "smile": "😄",
+ "laughing": "😆",
+ "satisfied": "😆",
+ "blush": "😊",
+ "smirk": "😏",
+ "smoking": "🚬",
+ "snow_capped_mountain": "🏔",
+ "soccer": "⚽",
+ "icecream": "🍦",
+ "soon": "🔜",
+ "arrow_lower_right": "↘",
+ "arrow_lower_left": "↙",
+ "speak_no_evil": "🙊",
+ "speaker": "🔈",
+ "mute": "🔇",
+ "sound": "🔉",
+ "loud_sound": "🔊",
+ "speaking_head_in_silhouette": "🗣",
+ "spiral_calendar_pad": "🗓",
+ "spiral_note_pad": "🗒",
+ "shell": "🐚",
+ "sweat_drops": "💦",
+ "u5272": "🈹",
+ "u5408": "🈴",
+ "u55b6": "🈺",
+ "u6307": "🈯",
+ "u6708": "🈷",
+ "u6709": "🈶",
+ "u6e80": "🈵",
+ "u7121": "🈚",
+ "u7533": "🈸",
+ "u7981": "🈲",
+ "u7a7a": "🈳",
+ "cl": "🆑",
+ "cool": "🆒",
+ "free": "🆓",
+ "id": "🆔",
+ "koko": "🈁",
+ "sa": "🈂",
+ "new": "🆕",
+ "ng": "🆖",
+ "ok": "🆗",
+ "sos": "🆘",
+ "up": "🆙",
+ "vs": "🆚",
+ "steam_locomotive": "🚂",
+ "ramen": "🍜",
+ "partly_sunny": "⛅",
+ "city_sunrise": "🌇",
+ "surfer": "🏄",
+ "swimmer": "🏊",
+ "shirt": "👕",
+ "tshirt": "👕",
+ "table_tennis_paddle_and_ball": "🏓",
+ "tea": "🍵",
+ "tv": "📺",
+ "three_button_mouse": "🖱",
+ "+1": "👍",
+ "thumbsup": "👍",
+ "__1": "👎",
+ "-1": "👎",
+ "thumbsdown": "👎",
+ "thunder_cloud_and_rain": "⛈",
+ "tiger2": "🐅",
+ "tophat": "🎩",
+ "top": "🔝",
+ "tm": "™",
+ "train2": "🚆",
+ "triangular_flag_on_post": "🚩",
+ "trident": "🔱",
+ "twisted_rightwards_arrows": "🔀",
+ "unamused": "😒",
+ "small_red_triangle": "🔺",
+ "arrow_up_small": "🔼",
+ "arrow_up_down": "↕",
+ "upside__down_face": "🙃",
+ "arrow_up": "⬆",
+ "v": "✌",
+ "vhs": "📼",
+ "wc": "🚾",
+ "ocean": "🌊",
+ "waving_black_flag": "🏴",
+ "wave": "👋",
+ "waving_white_flag": "🏳",
+ "moon": "🌔",
+ "scream_cat": "🙀",
+ "weary": "😩",
+ "weight_lifter": "🏋",
+ "whale2": "🐋",
+ "wheelchair": "♿",
+ "point_down": "👇",
+ "grey_exclamation": "❕",
+ "white_frowning_face": "☹",
+ "white_check_mark": "✅",
+ "point_left": "👈",
+ "white_medium_small_square": "◽",
+ "star": "⭐",
+ "grey_question": "❔",
+ "point_right": "👉",
+ "relaxed": "☺",
+ "white_sun_behind_cloud": "🌥",
+ "white_sun_behind_cloud_with_rain": "🌦",
+ "white_sun_with_small_cloud": "🌤",
+ "point_up_2": "👆",
+ "point_up": "☝",
+ "wind_blowing_face": "🌬",
+ "wink": "😉",
+ "wolf": "🐺",
+ "dancers": "👯",
+ "boot": "👢",
+ "womans_clothes": "👚",
+ "womans_hat": "👒",
+ "sandal": "👡",
+ "womens": "🚺",
+ "worried": "😟",
+ "gift": "🎁",
+ "zipper__mouth_face": "🤐",
+ "regional_indicator_a": "🇦",
+ "regional_indicator_b": "🇧",
+ "regional_indicator_c": "🇨",
+ "regional_indicator_d": "🇩",
+ "regional_indicator_e": "🇪",
+ "regional_indicator_f": "🇫",
+ "regional_indicator_g": "🇬",
+ "regional_indicator_h": "🇭",
+ "regional_indicator_i": "🇮",
+ "regional_indicator_j": "🇯",
+ "regional_indicator_k": "🇰",
+ "regional_indicator_l": "🇱",
+ "regional_indicator_m": "🇲",
+ "regional_indicator_n": "🇳",
+ "regional_indicator_o": "🇴",
+ "regional_indicator_p": "🇵",
+ "regional_indicator_q": "🇶",
+ "regional_indicator_r": "🇷",
+ "regional_indicator_s": "🇸",
+ "regional_indicator_t": "🇹",
+ "regional_indicator_u": "🇺",
+ "regional_indicator_v": "🇻",
+ "regional_indicator_w": "🇼",
+ "regional_indicator_x": "🇽",
+ "regional_indicator_y": "🇾",
+ "regional_indicator_z": "🇿",
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_emoji_replace.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_emoji_replace.py
new file mode 100644
index 000000000..bb2cafa18
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_emoji_replace.py
@@ -0,0 +1,32 @@
+from typing import Callable, Match, Optional
+import re
+
+from ._emoji_codes import EMOJI
+
+
+_ReStringMatch = Match[str] # regex match object
+_ReSubCallable = Callable[[_ReStringMatch], str] # Callable invoked by re.sub
+_EmojiSubMethod = Callable[[_ReSubCallable, str], str] # Sub method of a compiled re
+
+
+def _emoji_replace(
+ text: str,
+ default_variant: Optional[str] = None,
+ _emoji_sub: _EmojiSubMethod = re.compile(r"(:(\S*?)(?:(?:\-)(emoji|text))?:)").sub,
+) -> str:
+ """Replace emoji code in text."""
+ get_emoji = EMOJI.__getitem__
+ variants = {"text": "\uFE0E", "emoji": "\uFE0F"}
+ get_variant = variants.get
+ default_variant_code = variants.get(default_variant, "") if default_variant else ""
+
+ def do_replace(match: Match[str]) -> str:
+ emoji_code, emoji_name, variant = match.groups()
+ try:
+ return get_emoji(emoji_name.lower()) + get_variant(
+ variant, default_variant_code
+ )
+ except KeyError:
+ return emoji_code
+
+ return _emoji_sub(do_replace, text)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_export_format.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_export_format.py
new file mode 100644
index 000000000..e7527e52f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_export_format.py
@@ -0,0 +1,76 @@
+CONSOLE_HTML_FORMAT = """\
+<!DOCTYPE html>
+<html>
+<head>
+<meta charset="UTF-8">
+<style>
+{stylesheet}
+body {{
+ color: {foreground};
+ background-color: {background};
+}}
+</style>
+</head>
+<body>
+ <pre style="font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace"><code style="font-family:inherit">{code}</code></pre>
+</body>
+</html>
+"""
+
+CONSOLE_SVG_FORMAT = """\
+<svg class="rich-terminal" viewBox="0 0 {width} {height}" xmlns="http://www.w3.org/2000/svg">
+ <!-- Generated with Rich https://www.textualize.io -->
+ <style>
+
+ @font-face {{
+ font-family: "Fira Code";
+ src: local("FiraCode-Regular"),
+ url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff2/FiraCode-Regular.woff2") format("woff2"),
+ url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff/FiraCode-Regular.woff") format("woff");
+ font-style: normal;
+ font-weight: 400;
+ }}
+ @font-face {{
+ font-family: "Fira Code";
+ src: local("FiraCode-Bold"),
+ url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff2/FiraCode-Bold.woff2") format("woff2"),
+ url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff/FiraCode-Bold.woff") format("woff");
+ font-style: bold;
+ font-weight: 700;
+ }}
+
+ .{unique_id}-matrix {{
+ font-family: Fira Code, monospace;
+ font-size: {char_height}px;
+ line-height: {line_height}px;
+ font-variant-east-asian: full-width;
+ }}
+
+ .{unique_id}-title {{
+ font-size: 18px;
+ font-weight: bold;
+ font-family: arial;
+ }}
+
+ {styles}
+ </style>
+
+ <defs>
+ <clipPath id="{unique_id}-clip-terminal">
+ <rect x="0" y="0" width="{terminal_width}" height="{terminal_height}" />
+ </clipPath>
+ {lines}
+ </defs>
+
+ {chrome}
+ <g transform="translate({terminal_x}, {terminal_y})" clip-path="url(#{unique_id}-clip-terminal)">
+ {backgrounds}
+ <g class="{unique_id}-matrix">
+ {matrix}
+ </g>
+ </g>
+</svg>
+"""
+
+_SVG_FONT_FAMILY = "Rich Fira Code"
+_SVG_CLASSES_PREFIX = "rich-svg"
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_extension.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_extension.py
new file mode 100644
index 000000000..cbd6da9be
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_extension.py
@@ -0,0 +1,10 @@
+from typing import Any
+
+
+def load_ipython_extension(ip: Any) -> None: # pragma: no cover
+ # prevent circular import
+ from pip._vendor.rich.pretty import install
+ from pip._vendor.rich.traceback import install as tr_install
+
+ install()
+ tr_install()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_fileno.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_fileno.py
new file mode 100644
index 000000000..b17ee6511
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_fileno.py
@@ -0,0 +1,24 @@
+from __future__ import annotations
+
+from typing import IO, Callable
+
+
+def get_fileno(file_like: IO[str]) -> int | None:
+ """Get fileno() from a file, accounting for poorly implemented file-like objects.
+
+ Args:
+ file_like (IO): A file-like object.
+
+ Returns:
+ int | None: The result of fileno if available, or None if operation failed.
+ """
+ fileno: Callable[[], int] | None = getattr(file_like, "fileno", None)
+ if fileno is not None:
+ try:
+ return fileno()
+ except Exception:
+ # `fileno` is documented as potentially raising a OSError
+ # Alas, from the issues, there are so many poorly implemented file-like objects,
+ # that `fileno()` can raise just about anything.
+ return None
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_inspect.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_inspect.py
new file mode 100644
index 000000000..30446ceb3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_inspect.py
@@ -0,0 +1,270 @@
+from __future__ import absolute_import
+
+import inspect
+from inspect import cleandoc, getdoc, getfile, isclass, ismodule, signature
+from typing import Any, Collection, Iterable, Optional, Tuple, Type, Union
+
+from .console import Group, RenderableType
+from .control import escape_control_codes
+from .highlighter import ReprHighlighter
+from .jupyter import JupyterMixin
+from .panel import Panel
+from .pretty import Pretty
+from .table import Table
+from .text import Text, TextType
+
+
+def _first_paragraph(doc: str) -> str:
+ """Get the first paragraph from a docstring."""
+ paragraph, _, _ = doc.partition("\n\n")
+ return paragraph
+
+
+class Inspect(JupyterMixin):
+ """A renderable to inspect any Python Object.
+
+ Args:
+ obj (Any): An object to inspect.
+ title (str, optional): Title to display over inspect result, or None use type. Defaults to None.
+ help (bool, optional): Show full help text rather than just first paragraph. Defaults to False.
+ methods (bool, optional): Enable inspection of callables. Defaults to False.
+ docs (bool, optional): Also render doc strings. Defaults to True.
+ private (bool, optional): Show private attributes (beginning with underscore). Defaults to False.
+ dunder (bool, optional): Show attributes starting with double underscore. Defaults to False.
+ sort (bool, optional): Sort attributes alphabetically. Defaults to True.
+ all (bool, optional): Show all attributes. Defaults to False.
+ value (bool, optional): Pretty print value of object. Defaults to True.
+ """
+
+ def __init__(
+ self,
+ obj: Any,
+ *,
+ title: Optional[TextType] = None,
+ help: bool = False,
+ methods: bool = False,
+ docs: bool = True,
+ private: bool = False,
+ dunder: bool = False,
+ sort: bool = True,
+ all: bool = True,
+ value: bool = True,
+ ) -> None:
+ self.highlighter = ReprHighlighter()
+ self.obj = obj
+ self.title = title or self._make_title(obj)
+ if all:
+ methods = private = dunder = True
+ self.help = help
+ self.methods = methods
+ self.docs = docs or help
+ self.private = private or dunder
+ self.dunder = dunder
+ self.sort = sort
+ self.value = value
+
+ def _make_title(self, obj: Any) -> Text:
+ """Make a default title."""
+ title_str = (
+ str(obj)
+ if (isclass(obj) or callable(obj) or ismodule(obj))
+ else str(type(obj))
+ )
+ title_text = self.highlighter(title_str)
+ return title_text
+
+ def __rich__(self) -> Panel:
+ return Panel.fit(
+ Group(*self._render()),
+ title=self.title,
+ border_style="scope.border",
+ padding=(0, 1),
+ )
+
+ def _get_signature(self, name: str, obj: Any) -> Optional[Text]:
+ """Get a signature for a callable."""
+ try:
+ _signature = str(signature(obj)) + ":"
+ except ValueError:
+ _signature = "(...)"
+ except TypeError:
+ return None
+
+ source_filename: Optional[str] = None
+ try:
+ source_filename = getfile(obj)
+ except (OSError, TypeError):
+ # OSError is raised if obj has no source file, e.g. when defined in REPL.
+ pass
+
+ callable_name = Text(name, style="inspect.callable")
+ if source_filename:
+ callable_name.stylize(f"link file://{source_filename}")
+ signature_text = self.highlighter(_signature)
+
+ qualname = name or getattr(obj, "__qualname__", name)
+
+ # If obj is a module, there may be classes (which are callable) to display
+ if inspect.isclass(obj):
+ prefix = "class"
+ elif inspect.iscoroutinefunction(obj):
+ prefix = "async def"
+ else:
+ prefix = "def"
+
+ qual_signature = Text.assemble(
+ (f"{prefix} ", f"inspect.{prefix.replace(' ', '_')}"),
+ (qualname, "inspect.callable"),
+ signature_text,
+ )
+
+ return qual_signature
+
+ def _render(self) -> Iterable[RenderableType]:
+ """Render object."""
+
+ def sort_items(item: Tuple[str, Any]) -> Tuple[bool, str]:
+ key, (_error, value) = item
+ return (callable(value), key.strip("_").lower())
+
+ def safe_getattr(attr_name: str) -> Tuple[Any, Any]:
+ """Get attribute or any exception."""
+ try:
+ return (None, getattr(obj, attr_name))
+ except Exception as error:
+ return (error, None)
+
+ obj = self.obj
+ keys = dir(obj)
+ total_items = len(keys)
+ if not self.dunder:
+ keys = [key for key in keys if not key.startswith("__")]
+ if not self.private:
+ keys = [key for key in keys if not key.startswith("_")]
+ not_shown_count = total_items - len(keys)
+ items = [(key, safe_getattr(key)) for key in keys]
+ if self.sort:
+ items.sort(key=sort_items)
+
+ items_table = Table.grid(padding=(0, 1), expand=False)
+ items_table.add_column(justify="right")
+ add_row = items_table.add_row
+ highlighter = self.highlighter
+
+ if callable(obj):
+ signature = self._get_signature("", obj)
+ if signature is not None:
+ yield signature
+ yield ""
+
+ if self.docs:
+ _doc = self._get_formatted_doc(obj)
+ if _doc is not None:
+ doc_text = Text(_doc, style="inspect.help")
+ doc_text = highlighter(doc_text)
+ yield doc_text
+ yield ""
+
+ if self.value and not (isclass(obj) or callable(obj) or ismodule(obj)):
+ yield Panel(
+ Pretty(obj, indent_guides=True, max_length=10, max_string=60),
+ border_style="inspect.value.border",
+ )
+ yield ""
+
+ for key, (error, value) in items:
+ key_text = Text.assemble(
+ (
+ key,
+ "inspect.attr.dunder" if key.startswith("__") else "inspect.attr",
+ ),
+ (" =", "inspect.equals"),
+ )
+ if error is not None:
+ warning = key_text.copy()
+ warning.stylize("inspect.error")
+ add_row(warning, highlighter(repr(error)))
+ continue
+
+ if callable(value):
+ if not self.methods:
+ continue
+
+ _signature_text = self._get_signature(key, value)
+ if _signature_text is None:
+ add_row(key_text, Pretty(value, highlighter=highlighter))
+ else:
+ if self.docs:
+ docs = self._get_formatted_doc(value)
+ if docs is not None:
+ _signature_text.append("\n" if "\n" in docs else " ")
+ doc = highlighter(docs)
+ doc.stylize("inspect.doc")
+ _signature_text.append(doc)
+
+ add_row(key_text, _signature_text)
+ else:
+ add_row(key_text, Pretty(value, highlighter=highlighter))
+ if items_table.row_count:
+ yield items_table
+ elif not_shown_count:
+ yield Text.from_markup(
+ f"[b cyan]{not_shown_count}[/][i] attribute(s) not shown.[/i] "
+ f"Run [b][magenta]inspect[/]([not b]inspect[/])[/b] for options."
+ )
+
+ def _get_formatted_doc(self, object_: Any) -> Optional[str]:
+ """
+ Extract the docstring of an object, process it and returns it.
+ The processing consists in cleaning up the doctring's indentation,
+ taking only its 1st paragraph if `self.help` is not True,
+ and escape its control codes.
+
+ Args:
+ object_ (Any): the object to get the docstring from.
+
+ Returns:
+ Optional[str]: the processed docstring, or None if no docstring was found.
+ """
+ docs = getdoc(object_)
+ if docs is None:
+ return None
+ docs = cleandoc(docs).strip()
+ if not self.help:
+ docs = _first_paragraph(docs)
+ return escape_control_codes(docs)
+
+
+def get_object_types_mro(obj: Union[object, Type[Any]]) -> Tuple[type, ...]:
+ """Returns the MRO of an object's class, or of the object itself if it's a class."""
+ if not hasattr(obj, "__mro__"):
+ # N.B. we cannot use `if type(obj) is type` here because it doesn't work with
+ # some types of classes, such as the ones that use abc.ABCMeta.
+ obj = type(obj)
+ return getattr(obj, "__mro__", ())
+
+
+def get_object_types_mro_as_strings(obj: object) -> Collection[str]:
+ """
+ Returns the MRO of an object's class as full qualified names, or of the object itself if it's a class.
+
+ Examples:
+ `object_types_mro_as_strings(JSONDecoder)` will return `['json.decoder.JSONDecoder', 'builtins.object']`
+ """
+ return [
+ f'{getattr(type_, "__module__", "")}.{getattr(type_, "__qualname__", "")}'
+ for type_ in get_object_types_mro(obj)
+ ]
+
+
+def is_object_one_of_types(
+ obj: object, fully_qualified_types_names: Collection[str]
+) -> bool:
+ """
+ Returns `True` if the given object's class (or the object itself, if it's a class) has one of the
+ fully qualified names in its MRO.
+ """
+ for type_name in get_object_types_mro_as_strings(obj):
+ if type_name in fully_qualified_types_names:
+ return True
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_log_render.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_log_render.py
new file mode 100644
index 000000000..fc16c8443
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_log_render.py
@@ -0,0 +1,94 @@
+from datetime import datetime
+from typing import Iterable, List, Optional, TYPE_CHECKING, Union, Callable
+
+
+from .text import Text, TextType
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleRenderable, RenderableType
+ from .table import Table
+
+FormatTimeCallable = Callable[[datetime], Text]
+
+
+class LogRender:
+ def __init__(
+ self,
+ show_time: bool = True,
+ show_level: bool = False,
+ show_path: bool = True,
+ time_format: Union[str, FormatTimeCallable] = "[%x %X]",
+ omit_repeated_times: bool = True,
+ level_width: Optional[int] = 8,
+ ) -> None:
+ self.show_time = show_time
+ self.show_level = show_level
+ self.show_path = show_path
+ self.time_format = time_format
+ self.omit_repeated_times = omit_repeated_times
+ self.level_width = level_width
+ self._last_time: Optional[Text] = None
+
+ def __call__(
+ self,
+ console: "Console",
+ renderables: Iterable["ConsoleRenderable"],
+ log_time: Optional[datetime] = None,
+ time_format: Optional[Union[str, FormatTimeCallable]] = None,
+ level: TextType = "",
+ path: Optional[str] = None,
+ line_no: Optional[int] = None,
+ link_path: Optional[str] = None,
+ ) -> "Table":
+ from .containers import Renderables
+ from .table import Table
+
+ output = Table.grid(padding=(0, 1))
+ output.expand = True
+ if self.show_time:
+ output.add_column(style="log.time")
+ if self.show_level:
+ output.add_column(style="log.level", width=self.level_width)
+ output.add_column(ratio=1, style="log.message", overflow="fold")
+ if self.show_path and path:
+ output.add_column(style="log.path")
+ row: List["RenderableType"] = []
+ if self.show_time:
+ log_time = log_time or console.get_datetime()
+ time_format = time_format or self.time_format
+ if callable(time_format):
+ log_time_display = time_format(log_time)
+ else:
+ log_time_display = Text(log_time.strftime(time_format))
+ if log_time_display == self._last_time and self.omit_repeated_times:
+ row.append(Text(" " * len(log_time_display)))
+ else:
+ row.append(log_time_display)
+ self._last_time = log_time_display
+ if self.show_level:
+ row.append(level)
+
+ row.append(Renderables(renderables))
+ if self.show_path and path:
+ path_text = Text()
+ path_text.append(
+ path, style=f"link file://{link_path}" if link_path else ""
+ )
+ if line_no:
+ path_text.append(":")
+ path_text.append(
+ f"{line_no}",
+ style=f"link file://{link_path}#{line_no}" if link_path else "",
+ )
+ row.append(path_text)
+
+ output.add_row(*row)
+ return output
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.console import Console
+
+ c = Console()
+ c.print("[on blue]Hello", justify="right")
+ c.log("[on blue]hello", justify="right")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_loop.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_loop.py
new file mode 100644
index 000000000..01c6cafbe
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_loop.py
@@ -0,0 +1,43 @@
+from typing import Iterable, Tuple, TypeVar
+
+T = TypeVar("T")
+
+
+def loop_first(values: Iterable[T]) -> Iterable[Tuple[bool, T]]:
+ """Iterate and generate a tuple with a flag for first value."""
+ iter_values = iter(values)
+ try:
+ value = next(iter_values)
+ except StopIteration:
+ return
+ yield True, value
+ for value in iter_values:
+ yield False, value
+
+
+def loop_last(values: Iterable[T]) -> Iterable[Tuple[bool, T]]:
+ """Iterate and generate a tuple with a flag for last value."""
+ iter_values = iter(values)
+ try:
+ previous_value = next(iter_values)
+ except StopIteration:
+ return
+ for value in iter_values:
+ yield False, previous_value
+ previous_value = value
+ yield True, previous_value
+
+
+def loop_first_last(values: Iterable[T]) -> Iterable[Tuple[bool, bool, T]]:
+ """Iterate and generate a tuple with a flag for first and last value."""
+ iter_values = iter(values)
+ try:
+ previous_value = next(iter_values)
+ except StopIteration:
+ return
+ first = True
+ for value in iter_values:
+ yield first, False, previous_value
+ first = False
+ previous_value = value
+ yield first, True, previous_value
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_null_file.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_null_file.py
new file mode 100644
index 000000000..b659673ef
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_null_file.py
@@ -0,0 +1,69 @@
+from types import TracebackType
+from typing import IO, Iterable, Iterator, List, Optional, Type
+
+
+class NullFile(IO[str]):
+ def close(self) -> None:
+ pass
+
+ def isatty(self) -> bool:
+ return False
+
+ def read(self, __n: int = 1) -> str:
+ return ""
+
+ def readable(self) -> bool:
+ return False
+
+ def readline(self, __limit: int = 1) -> str:
+ return ""
+
+ def readlines(self, __hint: int = 1) -> List[str]:
+ return []
+
+ def seek(self, __offset: int, __whence: int = 1) -> int:
+ return 0
+
+ def seekable(self) -> bool:
+ return False
+
+ def tell(self) -> int:
+ return 0
+
+ def truncate(self, __size: Optional[int] = 1) -> int:
+ return 0
+
+ def writable(self) -> bool:
+ return False
+
+ def writelines(self, __lines: Iterable[str]) -> None:
+ pass
+
+ def __next__(self) -> str:
+ return ""
+
+ def __iter__(self) -> Iterator[str]:
+ return iter([""])
+
+ def __enter__(self) -> IO[str]:
+ pass
+
+ def __exit__(
+ self,
+ __t: Optional[Type[BaseException]],
+ __value: Optional[BaseException],
+ __traceback: Optional[TracebackType],
+ ) -> None:
+ pass
+
+ def write(self, text: str) -> int:
+ return 0
+
+ def flush(self) -> None:
+ pass
+
+ def fileno(self) -> int:
+ return -1
+
+
+NULL_FILE = NullFile()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_palettes.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_palettes.py
new file mode 100644
index 000000000..3c748d33e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_palettes.py
@@ -0,0 +1,309 @@
+from .palette import Palette
+
+
+# Taken from https://en.wikipedia.org/wiki/ANSI_escape_code (Windows 10 column)
+WINDOWS_PALETTE = Palette(
+ [
+ (12, 12, 12),
+ (197, 15, 31),
+ (19, 161, 14),
+ (193, 156, 0),
+ (0, 55, 218),
+ (136, 23, 152),
+ (58, 150, 221),
+ (204, 204, 204),
+ (118, 118, 118),
+ (231, 72, 86),
+ (22, 198, 12),
+ (249, 241, 165),
+ (59, 120, 255),
+ (180, 0, 158),
+ (97, 214, 214),
+ (242, 242, 242),
+ ]
+)
+
+# # The standard ansi colors (including bright variants)
+STANDARD_PALETTE = Palette(
+ [
+ (0, 0, 0),
+ (170, 0, 0),
+ (0, 170, 0),
+ (170, 85, 0),
+ (0, 0, 170),
+ (170, 0, 170),
+ (0, 170, 170),
+ (170, 170, 170),
+ (85, 85, 85),
+ (255, 85, 85),
+ (85, 255, 85),
+ (255, 255, 85),
+ (85, 85, 255),
+ (255, 85, 255),
+ (85, 255, 255),
+ (255, 255, 255),
+ ]
+)
+
+
+# The 256 color palette
+EIGHT_BIT_PALETTE = Palette(
+ [
+ (0, 0, 0),
+ (128, 0, 0),
+ (0, 128, 0),
+ (128, 128, 0),
+ (0, 0, 128),
+ (128, 0, 128),
+ (0, 128, 128),
+ (192, 192, 192),
+ (128, 128, 128),
+ (255, 0, 0),
+ (0, 255, 0),
+ (255, 255, 0),
+ (0, 0, 255),
+ (255, 0, 255),
+ (0, 255, 255),
+ (255, 255, 255),
+ (0, 0, 0),
+ (0, 0, 95),
+ (0, 0, 135),
+ (0, 0, 175),
+ (0, 0, 215),
+ (0, 0, 255),
+ (0, 95, 0),
+ (0, 95, 95),
+ (0, 95, 135),
+ (0, 95, 175),
+ (0, 95, 215),
+ (0, 95, 255),
+ (0, 135, 0),
+ (0, 135, 95),
+ (0, 135, 135),
+ (0, 135, 175),
+ (0, 135, 215),
+ (0, 135, 255),
+ (0, 175, 0),
+ (0, 175, 95),
+ (0, 175, 135),
+ (0, 175, 175),
+ (0, 175, 215),
+ (0, 175, 255),
+ (0, 215, 0),
+ (0, 215, 95),
+ (0, 215, 135),
+ (0, 215, 175),
+ (0, 215, 215),
+ (0, 215, 255),
+ (0, 255, 0),
+ (0, 255, 95),
+ (0, 255, 135),
+ (0, 255, 175),
+ (0, 255, 215),
+ (0, 255, 255),
+ (95, 0, 0),
+ (95, 0, 95),
+ (95, 0, 135),
+ (95, 0, 175),
+ (95, 0, 215),
+ (95, 0, 255),
+ (95, 95, 0),
+ (95, 95, 95),
+ (95, 95, 135),
+ (95, 95, 175),
+ (95, 95, 215),
+ (95, 95, 255),
+ (95, 135, 0),
+ (95, 135, 95),
+ (95, 135, 135),
+ (95, 135, 175),
+ (95, 135, 215),
+ (95, 135, 255),
+ (95, 175, 0),
+ (95, 175, 95),
+ (95, 175, 135),
+ (95, 175, 175),
+ (95, 175, 215),
+ (95, 175, 255),
+ (95, 215, 0),
+ (95, 215, 95),
+ (95, 215, 135),
+ (95, 215, 175),
+ (95, 215, 215),
+ (95, 215, 255),
+ (95, 255, 0),
+ (95, 255, 95),
+ (95, 255, 135),
+ (95, 255, 175),
+ (95, 255, 215),
+ (95, 255, 255),
+ (135, 0, 0),
+ (135, 0, 95),
+ (135, 0, 135),
+ (135, 0, 175),
+ (135, 0, 215),
+ (135, 0, 255),
+ (135, 95, 0),
+ (135, 95, 95),
+ (135, 95, 135),
+ (135, 95, 175),
+ (135, 95, 215),
+ (135, 95, 255),
+ (135, 135, 0),
+ (135, 135, 95),
+ (135, 135, 135),
+ (135, 135, 175),
+ (135, 135, 215),
+ (135, 135, 255),
+ (135, 175, 0),
+ (135, 175, 95),
+ (135, 175, 135),
+ (135, 175, 175),
+ (135, 175, 215),
+ (135, 175, 255),
+ (135, 215, 0),
+ (135, 215, 95),
+ (135, 215, 135),
+ (135, 215, 175),
+ (135, 215, 215),
+ (135, 215, 255),
+ (135, 255, 0),
+ (135, 255, 95),
+ (135, 255, 135),
+ (135, 255, 175),
+ (135, 255, 215),
+ (135, 255, 255),
+ (175, 0, 0),
+ (175, 0, 95),
+ (175, 0, 135),
+ (175, 0, 175),
+ (175, 0, 215),
+ (175, 0, 255),
+ (175, 95, 0),
+ (175, 95, 95),
+ (175, 95, 135),
+ (175, 95, 175),
+ (175, 95, 215),
+ (175, 95, 255),
+ (175, 135, 0),
+ (175, 135, 95),
+ (175, 135, 135),
+ (175, 135, 175),
+ (175, 135, 215),
+ (175, 135, 255),
+ (175, 175, 0),
+ (175, 175, 95),
+ (175, 175, 135),
+ (175, 175, 175),
+ (175, 175, 215),
+ (175, 175, 255),
+ (175, 215, 0),
+ (175, 215, 95),
+ (175, 215, 135),
+ (175, 215, 175),
+ (175, 215, 215),
+ (175, 215, 255),
+ (175, 255, 0),
+ (175, 255, 95),
+ (175, 255, 135),
+ (175, 255, 175),
+ (175, 255, 215),
+ (175, 255, 255),
+ (215, 0, 0),
+ (215, 0, 95),
+ (215, 0, 135),
+ (215, 0, 175),
+ (215, 0, 215),
+ (215, 0, 255),
+ (215, 95, 0),
+ (215, 95, 95),
+ (215, 95, 135),
+ (215, 95, 175),
+ (215, 95, 215),
+ (215, 95, 255),
+ (215, 135, 0),
+ (215, 135, 95),
+ (215, 135, 135),
+ (215, 135, 175),
+ (215, 135, 215),
+ (215, 135, 255),
+ (215, 175, 0),
+ (215, 175, 95),
+ (215, 175, 135),
+ (215, 175, 175),
+ (215, 175, 215),
+ (215, 175, 255),
+ (215, 215, 0),
+ (215, 215, 95),
+ (215, 215, 135),
+ (215, 215, 175),
+ (215, 215, 215),
+ (215, 215, 255),
+ (215, 255, 0),
+ (215, 255, 95),
+ (215, 255, 135),
+ (215, 255, 175),
+ (215, 255, 215),
+ (215, 255, 255),
+ (255, 0, 0),
+ (255, 0, 95),
+ (255, 0, 135),
+ (255, 0, 175),
+ (255, 0, 215),
+ (255, 0, 255),
+ (255, 95, 0),
+ (255, 95, 95),
+ (255, 95, 135),
+ (255, 95, 175),
+ (255, 95, 215),
+ (255, 95, 255),
+ (255, 135, 0),
+ (255, 135, 95),
+ (255, 135, 135),
+ (255, 135, 175),
+ (255, 135, 215),
+ (255, 135, 255),
+ (255, 175, 0),
+ (255, 175, 95),
+ (255, 175, 135),
+ (255, 175, 175),
+ (255, 175, 215),
+ (255, 175, 255),
+ (255, 215, 0),
+ (255, 215, 95),
+ (255, 215, 135),
+ (255, 215, 175),
+ (255, 215, 215),
+ (255, 215, 255),
+ (255, 255, 0),
+ (255, 255, 95),
+ (255, 255, 135),
+ (255, 255, 175),
+ (255, 255, 215),
+ (255, 255, 255),
+ (8, 8, 8),
+ (18, 18, 18),
+ (28, 28, 28),
+ (38, 38, 38),
+ (48, 48, 48),
+ (58, 58, 58),
+ (68, 68, 68),
+ (78, 78, 78),
+ (88, 88, 88),
+ (98, 98, 98),
+ (108, 108, 108),
+ (118, 118, 118),
+ (128, 128, 128),
+ (138, 138, 138),
+ (148, 148, 148),
+ (158, 158, 158),
+ (168, 168, 168),
+ (178, 178, 178),
+ (188, 188, 188),
+ (198, 198, 198),
+ (208, 208, 208),
+ (218, 218, 218),
+ (228, 228, 228),
+ (238, 238, 238),
+ ]
+)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_pick.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_pick.py
new file mode 100644
index 000000000..4f6d8b2d7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_pick.py
@@ -0,0 +1,17 @@
+from typing import Optional
+
+
+def pick_bool(*values: Optional[bool]) -> bool:
+ """Pick the first non-none bool or return the last value.
+
+ Args:
+ *values (bool): Any number of boolean or None values.
+
+ Returns:
+ bool: First non-none boolean.
+ """
+ assert values, "1 or more values required"
+ for value in values:
+ if value is not None:
+ return value
+ return bool(value)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_ratio.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_ratio.py
new file mode 100644
index 000000000..95267b0cb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_ratio.py
@@ -0,0 +1,159 @@
+import sys
+from fractions import Fraction
+from math import ceil
+from typing import cast, List, Optional, Sequence
+
+if sys.version_info >= (3, 8):
+ from typing import Protocol
+else:
+ from pip._vendor.typing_extensions import Protocol # pragma: no cover
+
+
+class Edge(Protocol):
+ """Any object that defines an edge (such as Layout)."""
+
+ size: Optional[int] = None
+ ratio: int = 1
+ minimum_size: int = 1
+
+
+def ratio_resolve(total: int, edges: Sequence[Edge]) -> List[int]:
+ """Divide total space to satisfy size, ratio, and minimum_size, constraints.
+
+ The returned list of integers should add up to total in most cases, unless it is
+ impossible to satisfy all the constraints. For instance, if there are two edges
+ with a minimum size of 20 each and `total` is 30 then the returned list will be
+ greater than total. In practice, this would mean that a Layout object would
+ clip the rows that would overflow the screen height.
+
+ Args:
+ total (int): Total number of characters.
+ edges (List[Edge]): Edges within total space.
+
+ Returns:
+ List[int]: Number of characters for each edge.
+ """
+ # Size of edge or None for yet to be determined
+ sizes = [(edge.size or None) for edge in edges]
+
+ _Fraction = Fraction
+
+ # While any edges haven't been calculated
+ while None in sizes:
+ # Get flexible edges and index to map these back on to sizes list
+ flexible_edges = [
+ (index, edge)
+ for index, (size, edge) in enumerate(zip(sizes, edges))
+ if size is None
+ ]
+ # Remaining space in total
+ remaining = total - sum(size or 0 for size in sizes)
+ if remaining <= 0:
+ # No room for flexible edges
+ return [
+ ((edge.minimum_size or 1) if size is None else size)
+ for size, edge in zip(sizes, edges)
+ ]
+ # Calculate number of characters in a ratio portion
+ portion = _Fraction(
+ remaining, sum((edge.ratio or 1) for _, edge in flexible_edges)
+ )
+
+ # If any edges will be less than their minimum, replace size with the minimum
+ for index, edge in flexible_edges:
+ if portion * edge.ratio <= edge.minimum_size:
+ sizes[index] = edge.minimum_size
+ # New fixed size will invalidate calculations, so we need to repeat the process
+ break
+ else:
+ # Distribute flexible space and compensate for rounding error
+ # Since edge sizes can only be integers we need to add the remainder
+ # to the following line
+ remainder = _Fraction(0)
+ for index, edge in flexible_edges:
+ size, remainder = divmod(portion * edge.ratio + remainder, 1)
+ sizes[index] = size
+ break
+ # Sizes now contains integers only
+ return cast(List[int], sizes)
+
+
+def ratio_reduce(
+ total: int, ratios: List[int], maximums: List[int], values: List[int]
+) -> List[int]:
+ """Divide an integer total in to parts based on ratios.
+
+ Args:
+ total (int): The total to divide.
+ ratios (List[int]): A list of integer ratios.
+ maximums (List[int]): List of maximums values for each slot.
+ values (List[int]): List of values
+
+ Returns:
+ List[int]: A list of integers guaranteed to sum to total.
+ """
+ ratios = [ratio if _max else 0 for ratio, _max in zip(ratios, maximums)]
+ total_ratio = sum(ratios)
+ if not total_ratio:
+ return values[:]
+ total_remaining = total
+ result: List[int] = []
+ append = result.append
+ for ratio, maximum, value in zip(ratios, maximums, values):
+ if ratio and total_ratio > 0:
+ distributed = min(maximum, round(ratio * total_remaining / total_ratio))
+ append(value - distributed)
+ total_remaining -= distributed
+ total_ratio -= ratio
+ else:
+ append(value)
+ return result
+
+
+def ratio_distribute(
+ total: int, ratios: List[int], minimums: Optional[List[int]] = None
+) -> List[int]:
+ """Distribute an integer total in to parts based on ratios.
+
+ Args:
+ total (int): The total to divide.
+ ratios (List[int]): A list of integer ratios.
+ minimums (List[int]): List of minimum values for each slot.
+
+ Returns:
+ List[int]: A list of integers guaranteed to sum to total.
+ """
+ if minimums:
+ ratios = [ratio if _min else 0 for ratio, _min in zip(ratios, minimums)]
+ total_ratio = sum(ratios)
+ assert total_ratio > 0, "Sum of ratios must be > 0"
+
+ total_remaining = total
+ distributed_total: List[int] = []
+ append = distributed_total.append
+ if minimums is None:
+ _minimums = [0] * len(ratios)
+ else:
+ _minimums = minimums
+ for ratio, minimum in zip(ratios, _minimums):
+ if total_ratio > 0:
+ distributed = max(minimum, ceil(ratio * total_remaining / total_ratio))
+ else:
+ distributed = total_remaining
+ append(distributed)
+ total_ratio -= ratio
+ total_remaining -= distributed
+ return distributed_total
+
+
+if __name__ == "__main__":
+ from dataclasses import dataclass
+
+ @dataclass
+ class E:
+ size: Optional[int] = None
+ ratio: int = 1
+ minimum_size: int = 1
+
+ resolved = ratio_resolve(110, [E(None, 1, 1), E(None, 1, 1), E(None, 1, 1)])
+ print(sum(resolved))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_spinners.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_spinners.py
new file mode 100644
index 000000000..d0bb1fe75
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_spinners.py
@@ -0,0 +1,482 @@
+"""
+Spinners are from:
+* cli-spinners:
+ MIT License
+ Copyright (c) Sindre Sorhus <sindresorhus@gmail.com> (sindresorhus.com)
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights to
+ use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
+ the Software, and to permit persons to whom the Software is furnished to do so,
+ subject to the following conditions:
+ The above copyright notice and this permission notice shall be included
+ in all copies or substantial portions of the Software.
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
+ INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
+ PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE
+ FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
+ ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
+ IN THE SOFTWARE.
+"""
+
+SPINNERS = {
+ "dots": {
+ "interval": 80,
+ "frames": "⠋⠙⠹⠸⠼⠴⠦⠧⠇⠏",
+ },
+ "dots2": {"interval": 80, "frames": "⣾⣽⣻⢿⡿⣟⣯⣷"},
+ "dots3": {
+ "interval": 80,
+ "frames": "⠋⠙⠚⠞⠖⠦⠴⠲⠳⠓",
+ },
+ "dots4": {
+ "interval": 80,
+ "frames": "⠄⠆⠇⠋⠙⠸⠰⠠⠰⠸⠙⠋⠇⠆",
+ },
+ "dots5": {
+ "interval": 80,
+ "frames": "⠋⠙⠚⠒⠂⠂⠒⠲⠴⠦⠖⠒⠐⠐⠒⠓⠋",
+ },
+ "dots6": {
+ "interval": 80,
+ "frames": "⠁⠉⠙⠚⠒⠂⠂⠒⠲⠴⠤⠄⠄⠤⠴⠲⠒⠂⠂⠒⠚⠙⠉⠁",
+ },
+ "dots7": {
+ "interval": 80,
+ "frames": "⠈⠉⠋⠓⠒⠐⠐⠒⠖⠦⠤⠠⠠⠤⠦⠖⠒⠐⠐⠒⠓⠋⠉⠈",
+ },
+ "dots8": {
+ "interval": 80,
+ "frames": "⠁⠁⠉⠙⠚⠒⠂⠂⠒⠲⠴⠤⠄⠄⠤⠠⠠⠤⠦⠖⠒⠐⠐⠒⠓⠋⠉⠈⠈",
+ },
+ "dots9": {"interval": 80, "frames": "⢹⢺⢼⣸⣇⡧⡗⡏"},
+ "dots10": {"interval": 80, "frames": "⢄⢂⢁⡁⡈⡐⡠"},
+ "dots11": {"interval": 100, "frames": "⠁⠂⠄⡀⢀⠠⠐⠈"},
+ "dots12": {
+ "interval": 80,
+ "frames": [
+ "⢀⠀",
+ "⡀⠀",
+ "⠄⠀",
+ "⢂⠀",
+ "⡂⠀",
+ "⠅⠀",
+ "⢃⠀",
+ "⡃⠀",
+ "⠍⠀",
+ "⢋⠀",
+ "⡋⠀",
+ "⠍⠁",
+ "⢋⠁",
+ "⡋⠁",
+ "⠍⠉",
+ "⠋⠉",
+ "⠋⠉",
+ "⠉⠙",
+ "⠉⠙",
+ "⠉⠩",
+ "⠈⢙",
+ "⠈⡙",
+ "⢈⠩",
+ "⡀⢙",
+ "⠄⡙",
+ "⢂⠩",
+ "⡂⢘",
+ "⠅⡘",
+ "⢃⠨",
+ "⡃⢐",
+ "⠍⡐",
+ "⢋⠠",
+ "⡋⢀",
+ "⠍⡁",
+ "⢋⠁",
+ "⡋⠁",
+ "⠍⠉",
+ "⠋⠉",
+ "⠋⠉",
+ "⠉⠙",
+ "⠉⠙",
+ "⠉⠩",
+ "⠈⢙",
+ "⠈⡙",
+ "⠈⠩",
+ "⠀⢙",
+ "⠀⡙",
+ "⠀⠩",
+ "⠀⢘",
+ "⠀⡘",
+ "⠀⠨",
+ "⠀⢐",
+ "⠀⡐",
+ "⠀⠠",
+ "⠀⢀",
+ "⠀⡀",
+ ],
+ },
+ "dots8Bit": {
+ "interval": 80,
+ "frames": "⠀⠁⠂⠃⠄⠅⠆⠇⡀⡁⡂⡃⡄⡅⡆⡇⠈⠉⠊⠋⠌⠍⠎⠏⡈⡉⡊⡋⡌⡍⡎⡏⠐⠑⠒⠓⠔⠕⠖⠗⡐⡑⡒⡓⡔⡕⡖⡗⠘⠙⠚⠛⠜⠝⠞⠟⡘⡙"
+ "⡚⡛⡜⡝⡞⡟⠠⠡⠢⠣⠤⠥⠦⠧⡠⡡⡢⡣⡤⡥⡦⡧⠨⠩⠪⠫⠬⠭⠮⠯⡨⡩⡪⡫⡬⡭⡮⡯⠰⠱⠲⠳⠴⠵⠶⠷⡰⡱⡲⡳⡴⡵⡶⡷⠸⠹⠺⠻"
+ "⠼⠽⠾⠿⡸⡹⡺⡻⡼⡽⡾⡿⢀⢁⢂⢃⢄⢅⢆⢇⣀⣁⣂⣃⣄⣅⣆⣇⢈⢉⢊⢋⢌⢍⢎⢏⣈⣉⣊⣋⣌⣍⣎⣏⢐⢑⢒⢓⢔⢕⢖⢗⣐⣑⣒⣓⣔⣕"
+ "⣖⣗⢘⢙⢚⢛⢜⢝⢞⢟⣘⣙⣚⣛⣜⣝⣞⣟⢠⢡⢢⢣⢤⢥⢦⢧⣠⣡⣢⣣⣤⣥⣦⣧⢨⢩⢪⢫⢬⢭⢮⢯⣨⣩⣪⣫⣬⣭⣮⣯⢰⢱⢲⢳⢴⢵⢶⢷"
+ "⣰⣱⣲⣳⣴⣵⣶⣷⢸⢹⢺⢻⢼⢽⢾⢿⣸⣹⣺⣻⣼⣽⣾⣿",
+ },
+ "line": {"interval": 130, "frames": ["-", "\\", "|", "/"]},
+ "line2": {"interval": 100, "frames": "⠂-–—–-"},
+ "pipe": {"interval": 100, "frames": "┤┘┴└├┌┬┐"},
+ "simpleDots": {"interval": 400, "frames": [". ", ".. ", "...", " "]},
+ "simpleDotsScrolling": {
+ "interval": 200,
+ "frames": [". ", ".. ", "...", " ..", " .", " "],
+ },
+ "star": {"interval": 70, "frames": "✶✸✹✺✹✷"},
+ "star2": {"interval": 80, "frames": "+x*"},
+ "flip": {
+ "interval": 70,
+ "frames": "___-``'´-___",
+ },
+ "hamburger": {"interval": 100, "frames": "☱☲☴"},
+ "growVertical": {
+ "interval": 120,
+ "frames": "▁▃▄▅▆▇▆▅▄▃",
+ },
+ "growHorizontal": {
+ "interval": 120,
+ "frames": "▏▎▍▌▋▊▉▊▋▌▍▎",
+ },
+ "balloon": {"interval": 140, "frames": " .oO@* "},
+ "balloon2": {"interval": 120, "frames": ".oO°Oo."},
+ "noise": {"interval": 100, "frames": "▓▒░"},
+ "bounce": {"interval": 120, "frames": "⠁⠂⠄⠂"},
+ "boxBounce": {"interval": 120, "frames": "▖▘▝▗"},
+ "boxBounce2": {"interval": 100, "frames": "▌▀▐▄"},
+ "triangle": {"interval": 50, "frames": "◢◣◤◥"},
+ "arc": {"interval": 100, "frames": "◜◠◝◞◡◟"},
+ "circle": {"interval": 120, "frames": "◡⊙◠"},
+ "squareCorners": {"interval": 180, "frames": "◰◳◲◱"},
+ "circleQuarters": {"interval": 120, "frames": "◴◷◶◵"},
+ "circleHalves": {"interval": 50, "frames": "◐◓◑◒"},
+ "squish": {"interval": 100, "frames": "╫╪"},
+ "toggle": {"interval": 250, "frames": "⊶⊷"},
+ "toggle2": {"interval": 80, "frames": "▫▪"},
+ "toggle3": {"interval": 120, "frames": "□■"},
+ "toggle4": {"interval": 100, "frames": "■□▪▫"},
+ "toggle5": {"interval": 100, "frames": "▮▯"},
+ "toggle6": {"interval": 300, "frames": "ဝ၀"},
+ "toggle7": {"interval": 80, "frames": "⦾⦿"},
+ "toggle8": {"interval": 100, "frames": "◍◌"},
+ "toggle9": {"interval": 100, "frames": "◉◎"},
+ "toggle10": {"interval": 100, "frames": "㊂㊀㊁"},
+ "toggle11": {"interval": 50, "frames": "⧇⧆"},
+ "toggle12": {"interval": 120, "frames": "☗☖"},
+ "toggle13": {"interval": 80, "frames": "=*-"},
+ "arrow": {"interval": 100, "frames": "←↖↑↗→↘↓↙"},
+ "arrow2": {
+ "interval": 80,
+ "frames": ["⬆️ ", "↗️ ", "➡️ ", "↘️ ", "⬇️ ", "↙️ ", "⬅️ ", "↖️ "],
+ },
+ "arrow3": {
+ "interval": 120,
+ "frames": ["▹▹▹▹▹", "▸▹▹▹▹", "▹▸▹▹▹", "▹▹▸▹▹", "▹▹▹▸▹", "▹▹▹▹▸"],
+ },
+ "bouncingBar": {
+ "interval": 80,
+ "frames": [
+ "[ ]",
+ "[= ]",
+ "[== ]",
+ "[=== ]",
+ "[ ===]",
+ "[ ==]",
+ "[ =]",
+ "[ ]",
+ "[ =]",
+ "[ ==]",
+ "[ ===]",
+ "[====]",
+ "[=== ]",
+ "[== ]",
+ "[= ]",
+ ],
+ },
+ "bouncingBall": {
+ "interval": 80,
+ "frames": [
+ "( ● )",
+ "( ● )",
+ "( ● )",
+ "( ● )",
+ "( ●)",
+ "( ● )",
+ "( ● )",
+ "( ● )",
+ "( ● )",
+ "(● )",
+ ],
+ },
+ "smiley": {"interval": 200, "frames": ["😄 ", "😝 "]},
+ "monkey": {"interval": 300, "frames": ["🙈 ", "🙈 ", "🙉 ", "🙊 "]},
+ "hearts": {"interval": 100, "frames": ["💛 ", "💙 ", "💜 ", "💚 ", "❤️ "]},
+ "clock": {
+ "interval": 100,
+ "frames": [
+ "🕛 ",
+ "🕐 ",
+ "🕑 ",
+ "🕒 ",
+ "🕓 ",
+ "🕔 ",
+ "🕕 ",
+ "🕖 ",
+ "🕗 ",
+ "🕘 ",
+ "🕙 ",
+ "🕚 ",
+ ],
+ },
+ "earth": {"interval": 180, "frames": ["🌍 ", "🌎 ", "🌏 "]},
+ "material": {
+ "interval": 17,
+ "frames": [
+ "█▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "██▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "███▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "████▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "██████▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "██████▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "███████▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "████████▁▁▁▁▁▁▁▁▁▁▁▁",
+ "█████████▁▁▁▁▁▁▁▁▁▁▁",
+ "█████████▁▁▁▁▁▁▁▁▁▁▁",
+ "██████████▁▁▁▁▁▁▁▁▁▁",
+ "███████████▁▁▁▁▁▁▁▁▁",
+ "█████████████▁▁▁▁▁▁▁",
+ "██████████████▁▁▁▁▁▁",
+ "██████████████▁▁▁▁▁▁",
+ "▁██████████████▁▁▁▁▁",
+ "▁██████████████▁▁▁▁▁",
+ "▁██████████████▁▁▁▁▁",
+ "▁▁██████████████▁▁▁▁",
+ "▁▁▁██████████████▁▁▁",
+ "▁▁▁▁█████████████▁▁▁",
+ "▁▁▁▁██████████████▁▁",
+ "▁▁▁▁██████████████▁▁",
+ "▁▁▁▁▁██████████████▁",
+ "▁▁▁▁▁██████████████▁",
+ "▁▁▁▁▁██████████████▁",
+ "▁▁▁▁▁▁██████████████",
+ "▁▁▁▁▁▁██████████████",
+ "▁▁▁▁▁▁▁█████████████",
+ "▁▁▁▁▁▁▁█████████████",
+ "▁▁▁▁▁▁▁▁████████████",
+ "▁▁▁▁▁▁▁▁████████████",
+ "▁▁▁▁▁▁▁▁▁███████████",
+ "▁▁▁▁▁▁▁▁▁███████████",
+ "▁▁▁▁▁▁▁▁▁▁██████████",
+ "▁▁▁▁▁▁▁▁▁▁██████████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁████████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁███████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁██████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█████",
+ "█▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁████",
+ "██▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁███",
+ "██▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁███",
+ "███▁▁▁▁▁▁▁▁▁▁▁▁▁▁███",
+ "████▁▁▁▁▁▁▁▁▁▁▁▁▁▁██",
+ "█████▁▁▁▁▁▁▁▁▁▁▁▁▁▁█",
+ "█████▁▁▁▁▁▁▁▁▁▁▁▁▁▁█",
+ "██████▁▁▁▁▁▁▁▁▁▁▁▁▁█",
+ "████████▁▁▁▁▁▁▁▁▁▁▁▁",
+ "█████████▁▁▁▁▁▁▁▁▁▁▁",
+ "█████████▁▁▁▁▁▁▁▁▁▁▁",
+ "█████████▁▁▁▁▁▁▁▁▁▁▁",
+ "█████████▁▁▁▁▁▁▁▁▁▁▁",
+ "███████████▁▁▁▁▁▁▁▁▁",
+ "████████████▁▁▁▁▁▁▁▁",
+ "████████████▁▁▁▁▁▁▁▁",
+ "██████████████▁▁▁▁▁▁",
+ "██████████████▁▁▁▁▁▁",
+ "▁██████████████▁▁▁▁▁",
+ "▁██████████████▁▁▁▁▁",
+ "▁▁▁█████████████▁▁▁▁",
+ "▁▁▁▁▁████████████▁▁▁",
+ "▁▁▁▁▁████████████▁▁▁",
+ "▁▁▁▁▁▁███████████▁▁▁",
+ "▁▁▁▁▁▁▁▁█████████▁▁▁",
+ "▁▁▁▁▁▁▁▁█████████▁▁▁",
+ "▁▁▁▁▁▁▁▁▁█████████▁▁",
+ "▁▁▁▁▁▁▁▁▁█████████▁▁",
+ "▁▁▁▁▁▁▁▁▁▁█████████▁",
+ "▁▁▁▁▁▁▁▁▁▁▁████████▁",
+ "▁▁▁▁▁▁▁▁▁▁▁████████▁",
+ "▁▁▁▁▁▁▁▁▁▁▁▁███████▁",
+ "▁▁▁▁▁▁▁▁▁▁▁▁███████▁",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁███████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁███████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁████",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁███",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁███",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁██",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁██",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁██",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ "▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁",
+ ],
+ },
+ "moon": {
+ "interval": 80,
+ "frames": ["🌑 ", "🌒 ", "🌓 ", "🌔 ", "🌕 ", "🌖 ", "🌗 ", "🌘 "],
+ },
+ "runner": {"interval": 140, "frames": ["🚶 ", "🏃 "]},
+ "pong": {
+ "interval": 80,
+ "frames": [
+ "▐⠂ ▌",
+ "▐⠈ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠠ ▌",
+ "▐ ⡀ ▌",
+ "▐ ⠠ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠈ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠠ ▌",
+ "▐ ⡀ ▌",
+ "▐ ⠠ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠈ ▌",
+ "▐ ⠂▌",
+ "▐ ⠠▌",
+ "▐ ⡀▌",
+ "▐ ⠠ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠈ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠠ ▌",
+ "▐ ⡀ ▌",
+ "▐ ⠠ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠈ ▌",
+ "▐ ⠂ ▌",
+ "▐ ⠠ ▌",
+ "▐ ⡀ ▌",
+ "▐⠠ ▌",
+ ],
+ },
+ "shark": {
+ "interval": 120,
+ "frames": [
+ "▐|\\____________▌",
+ "▐_|\\___________▌",
+ "▐__|\\__________▌",
+ "▐___|\\_________▌",
+ "▐____|\\________▌",
+ "▐_____|\\_______▌",
+ "▐______|\\______▌",
+ "▐_______|\\_____▌",
+ "▐________|\\____▌",
+ "▐_________|\\___▌",
+ "▐__________|\\__▌",
+ "▐___________|\\_▌",
+ "▐____________|\\▌",
+ "▐____________/|▌",
+ "▐___________/|_▌",
+ "▐__________/|__▌",
+ "▐_________/|___▌",
+ "▐________/|____▌",
+ "▐_______/|_____▌",
+ "▐______/|______▌",
+ "▐_____/|_______▌",
+ "▐____/|________▌",
+ "▐___/|_________▌",
+ "▐__/|__________▌",
+ "▐_/|___________▌",
+ "▐/|____________▌",
+ ],
+ },
+ "dqpb": {"interval": 100, "frames": "dqpb"},
+ "weather": {
+ "interval": 100,
+ "frames": [
+ "☀️ ",
+ "☀️ ",
+ "☀️ ",
+ "🌤 ",
+ "⛅️ ",
+ "🌥 ",
+ "☁️ ",
+ "🌧 ",
+ "🌨 ",
+ "🌧 ",
+ "🌨 ",
+ "🌧 ",
+ "🌨 ",
+ "⛈ ",
+ "🌨 ",
+ "🌧 ",
+ "🌨 ",
+ "☁️ ",
+ "🌥 ",
+ "⛅️ ",
+ "🌤 ",
+ "☀️ ",
+ "☀️ ",
+ ],
+ },
+ "christmas": {"interval": 400, "frames": "🌲🎄"},
+ "grenade": {
+ "interval": 80,
+ "frames": [
+ "، ",
+ "′ ",
+ " ´ ",
+ " ‾ ",
+ " ⸌",
+ " ⸊",
+ " |",
+ " ⁎",
+ " ⁕",
+ " ෴ ",
+ " ⁓",
+ " ",
+ " ",
+ " ",
+ ],
+ },
+ "point": {"interval": 125, "frames": ["∙∙∙", "●∙∙", "∙●∙", "∙∙●", "∙∙∙"]},
+ "layer": {"interval": 150, "frames": "-=≡"},
+ "betaWave": {
+ "interval": 80,
+ "frames": [
+ "ρββββββ",
+ "βρβββββ",
+ "ββρββββ",
+ "βββρβββ",
+ "ββββρββ",
+ "βββββρβ",
+ "ββββββρ",
+ ],
+ },
+ "aesthetic": {
+ "interval": 80,
+ "frames": [
+ "▰▱▱▱▱▱▱",
+ "▰▰▱▱▱▱▱",
+ "▰▰▰▱▱▱▱",
+ "▰▰▰▰▱▱▱",
+ "▰▰▰▰▰▱▱",
+ "▰▰▰▰▰▰▱",
+ "▰▰▰▰▰▰▰",
+ "▰▱▱▱▱▱▱",
+ ],
+ },
+}
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_stack.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_stack.py
new file mode 100644
index 000000000..194564e76
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_stack.py
@@ -0,0 +1,16 @@
+from typing import List, TypeVar
+
+T = TypeVar("T")
+
+
+class Stack(List[T]):
+ """A small shim over builtin list."""
+
+ @property
+ def top(self) -> T:
+ """Get top of stack."""
+ return self[-1]
+
+ def push(self, item: T) -> None:
+ """Push an item on to the stack (append in stack nomenclature)."""
+ self.append(item)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_timer.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_timer.py
new file mode 100644
index 000000000..a2ca6be03
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_timer.py
@@ -0,0 +1,19 @@
+"""
+Timer context manager, only used in debug.
+
+"""
+
+from time import time
+
+import contextlib
+from typing import Generator
+
+
+@contextlib.contextmanager
+def timer(subject: str = "time") -> Generator[None, None, None]:
+ """print the elapsed time. (only used in debugging)"""
+ start = time()
+ yield
+ elapsed = time() - start
+ elapsed_ms = elapsed * 1000
+ print(f"{subject} elapsed {elapsed_ms:.1f}ms")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_win32_console.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_win32_console.py
new file mode 100644
index 000000000..81b108290
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_win32_console.py
@@ -0,0 +1,662 @@
+"""Light wrapper around the Win32 Console API - this module should only be imported on Windows
+
+The API that this module wraps is documented at https://docs.microsoft.com/en-us/windows/console/console-functions
+"""
+import ctypes
+import sys
+from typing import Any
+
+windll: Any = None
+if sys.platform == "win32":
+ windll = ctypes.LibraryLoader(ctypes.WinDLL)
+else:
+ raise ImportError(f"{__name__} can only be imported on Windows")
+
+import time
+from ctypes import Structure, byref, wintypes
+from typing import IO, NamedTuple, Type, cast
+
+from pip._vendor.rich.color import ColorSystem
+from pip._vendor.rich.style import Style
+
+STDOUT = -11
+ENABLE_VIRTUAL_TERMINAL_PROCESSING = 4
+
+COORD = wintypes._COORD
+
+
+class LegacyWindowsError(Exception):
+ pass
+
+
+class WindowsCoordinates(NamedTuple):
+ """Coordinates in the Windows Console API are (y, x), not (x, y).
+ This class is intended to prevent that confusion.
+ Rows and columns are indexed from 0.
+ This class can be used in place of wintypes._COORD in arguments and argtypes.
+ """
+
+ row: int
+ col: int
+
+ @classmethod
+ def from_param(cls, value: "WindowsCoordinates") -> COORD:
+ """Converts a WindowsCoordinates into a wintypes _COORD structure.
+ This classmethod is internally called by ctypes to perform the conversion.
+
+ Args:
+ value (WindowsCoordinates): The input coordinates to convert.
+
+ Returns:
+ wintypes._COORD: The converted coordinates struct.
+ """
+ return COORD(value.col, value.row)
+
+
+class CONSOLE_SCREEN_BUFFER_INFO(Structure):
+ _fields_ = [
+ ("dwSize", COORD),
+ ("dwCursorPosition", COORD),
+ ("wAttributes", wintypes.WORD),
+ ("srWindow", wintypes.SMALL_RECT),
+ ("dwMaximumWindowSize", COORD),
+ ]
+
+
+class CONSOLE_CURSOR_INFO(ctypes.Structure):
+ _fields_ = [("dwSize", wintypes.DWORD), ("bVisible", wintypes.BOOL)]
+
+
+_GetStdHandle = windll.kernel32.GetStdHandle
+_GetStdHandle.argtypes = [
+ wintypes.DWORD,
+]
+_GetStdHandle.restype = wintypes.HANDLE
+
+
+def GetStdHandle(handle: int = STDOUT) -> wintypes.HANDLE:
+ """Retrieves a handle to the specified standard device (standard input, standard output, or standard error).
+
+ Args:
+ handle (int): Integer identifier for the handle. Defaults to -11 (stdout).
+
+ Returns:
+ wintypes.HANDLE: The handle
+ """
+ return cast(wintypes.HANDLE, _GetStdHandle(handle))
+
+
+_GetConsoleMode = windll.kernel32.GetConsoleMode
+_GetConsoleMode.argtypes = [wintypes.HANDLE, wintypes.LPDWORD]
+_GetConsoleMode.restype = wintypes.BOOL
+
+
+def GetConsoleMode(std_handle: wintypes.HANDLE) -> int:
+ """Retrieves the current input mode of a console's input buffer
+ or the current output mode of a console screen buffer.
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+
+ Raises:
+ LegacyWindowsError: If any error occurs while calling the Windows console API.
+
+ Returns:
+ int: Value representing the current console mode as documented at
+ https://docs.microsoft.com/en-us/windows/console/getconsolemode#parameters
+ """
+
+ console_mode = wintypes.DWORD()
+ success = bool(_GetConsoleMode(std_handle, console_mode))
+ if not success:
+ raise LegacyWindowsError("Unable to get legacy Windows Console Mode")
+ return console_mode.value
+
+
+_FillConsoleOutputCharacterW = windll.kernel32.FillConsoleOutputCharacterW
+_FillConsoleOutputCharacterW.argtypes = [
+ wintypes.HANDLE,
+ ctypes.c_char,
+ wintypes.DWORD,
+ cast(Type[COORD], WindowsCoordinates),
+ ctypes.POINTER(wintypes.DWORD),
+]
+_FillConsoleOutputCharacterW.restype = wintypes.BOOL
+
+
+def FillConsoleOutputCharacter(
+ std_handle: wintypes.HANDLE,
+ char: str,
+ length: int,
+ start: WindowsCoordinates,
+) -> int:
+ """Writes a character to the console screen buffer a specified number of times, beginning at the specified coordinates.
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+ char (str): The character to write. Must be a string of length 1.
+ length (int): The number of times to write the character.
+ start (WindowsCoordinates): The coordinates to start writing at.
+
+ Returns:
+ int: The number of characters written.
+ """
+ character = ctypes.c_char(char.encode())
+ num_characters = wintypes.DWORD(length)
+ num_written = wintypes.DWORD(0)
+ _FillConsoleOutputCharacterW(
+ std_handle,
+ character,
+ num_characters,
+ start,
+ byref(num_written),
+ )
+ return num_written.value
+
+
+_FillConsoleOutputAttribute = windll.kernel32.FillConsoleOutputAttribute
+_FillConsoleOutputAttribute.argtypes = [
+ wintypes.HANDLE,
+ wintypes.WORD,
+ wintypes.DWORD,
+ cast(Type[COORD], WindowsCoordinates),
+ ctypes.POINTER(wintypes.DWORD),
+]
+_FillConsoleOutputAttribute.restype = wintypes.BOOL
+
+
+def FillConsoleOutputAttribute(
+ std_handle: wintypes.HANDLE,
+ attributes: int,
+ length: int,
+ start: WindowsCoordinates,
+) -> int:
+ """Sets the character attributes for a specified number of character cells,
+ beginning at the specified coordinates in a screen buffer.
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+ attributes (int): Integer value representing the foreground and background colours of the cells.
+ length (int): The number of cells to set the output attribute of.
+ start (WindowsCoordinates): The coordinates of the first cell whose attributes are to be set.
+
+ Returns:
+ int: The number of cells whose attributes were actually set.
+ """
+ num_cells = wintypes.DWORD(length)
+ style_attrs = wintypes.WORD(attributes)
+ num_written = wintypes.DWORD(0)
+ _FillConsoleOutputAttribute(
+ std_handle, style_attrs, num_cells, start, byref(num_written)
+ )
+ return num_written.value
+
+
+_SetConsoleTextAttribute = windll.kernel32.SetConsoleTextAttribute
+_SetConsoleTextAttribute.argtypes = [
+ wintypes.HANDLE,
+ wintypes.WORD,
+]
+_SetConsoleTextAttribute.restype = wintypes.BOOL
+
+
+def SetConsoleTextAttribute(
+ std_handle: wintypes.HANDLE, attributes: wintypes.WORD
+) -> bool:
+ """Set the colour attributes for all text written after this function is called.
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+ attributes (int): Integer value representing the foreground and background colours.
+
+
+ Returns:
+ bool: True if the attribute was set successfully, otherwise False.
+ """
+ return bool(_SetConsoleTextAttribute(std_handle, attributes))
+
+
+_GetConsoleScreenBufferInfo = windll.kernel32.GetConsoleScreenBufferInfo
+_GetConsoleScreenBufferInfo.argtypes = [
+ wintypes.HANDLE,
+ ctypes.POINTER(CONSOLE_SCREEN_BUFFER_INFO),
+]
+_GetConsoleScreenBufferInfo.restype = wintypes.BOOL
+
+
+def GetConsoleScreenBufferInfo(
+ std_handle: wintypes.HANDLE,
+) -> CONSOLE_SCREEN_BUFFER_INFO:
+ """Retrieves information about the specified console screen buffer.
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+
+ Returns:
+ CONSOLE_SCREEN_BUFFER_INFO: A CONSOLE_SCREEN_BUFFER_INFO ctype struct contain information about
+ screen size, cursor position, colour attributes, and more."""
+ console_screen_buffer_info = CONSOLE_SCREEN_BUFFER_INFO()
+ _GetConsoleScreenBufferInfo(std_handle, byref(console_screen_buffer_info))
+ return console_screen_buffer_info
+
+
+_SetConsoleCursorPosition = windll.kernel32.SetConsoleCursorPosition
+_SetConsoleCursorPosition.argtypes = [
+ wintypes.HANDLE,
+ cast(Type[COORD], WindowsCoordinates),
+]
+_SetConsoleCursorPosition.restype = wintypes.BOOL
+
+
+def SetConsoleCursorPosition(
+ std_handle: wintypes.HANDLE, coords: WindowsCoordinates
+) -> bool:
+ """Set the position of the cursor in the console screen
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+ coords (WindowsCoordinates): The coordinates to move the cursor to.
+
+ Returns:
+ bool: True if the function succeeds, otherwise False.
+ """
+ return bool(_SetConsoleCursorPosition(std_handle, coords))
+
+
+_GetConsoleCursorInfo = windll.kernel32.GetConsoleCursorInfo
+_GetConsoleCursorInfo.argtypes = [
+ wintypes.HANDLE,
+ ctypes.POINTER(CONSOLE_CURSOR_INFO),
+]
+_GetConsoleCursorInfo.restype = wintypes.BOOL
+
+
+def GetConsoleCursorInfo(
+ std_handle: wintypes.HANDLE, cursor_info: CONSOLE_CURSOR_INFO
+) -> bool:
+ """Get the cursor info - used to get cursor visibility and width
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+ cursor_info (CONSOLE_CURSOR_INFO): CONSOLE_CURSOR_INFO ctype struct that receives information
+ about the console's cursor.
+
+ Returns:
+ bool: True if the function succeeds, otherwise False.
+ """
+ return bool(_GetConsoleCursorInfo(std_handle, byref(cursor_info)))
+
+
+_SetConsoleCursorInfo = windll.kernel32.SetConsoleCursorInfo
+_SetConsoleCursorInfo.argtypes = [
+ wintypes.HANDLE,
+ ctypes.POINTER(CONSOLE_CURSOR_INFO),
+]
+_SetConsoleCursorInfo.restype = wintypes.BOOL
+
+
+def SetConsoleCursorInfo(
+ std_handle: wintypes.HANDLE, cursor_info: CONSOLE_CURSOR_INFO
+) -> bool:
+ """Set the cursor info - used for adjusting cursor visibility and width
+
+ Args:
+ std_handle (wintypes.HANDLE): A handle to the console input buffer or the console screen buffer.
+ cursor_info (CONSOLE_CURSOR_INFO): CONSOLE_CURSOR_INFO ctype struct containing the new cursor info.
+
+ Returns:
+ bool: True if the function succeeds, otherwise False.
+ """
+ return bool(_SetConsoleCursorInfo(std_handle, byref(cursor_info)))
+
+
+_SetConsoleTitle = windll.kernel32.SetConsoleTitleW
+_SetConsoleTitle.argtypes = [wintypes.LPCWSTR]
+_SetConsoleTitle.restype = wintypes.BOOL
+
+
+def SetConsoleTitle(title: str) -> bool:
+ """Sets the title of the current console window
+
+ Args:
+ title (str): The new title of the console window.
+
+ Returns:
+ bool: True if the function succeeds, otherwise False.
+ """
+ return bool(_SetConsoleTitle(title))
+
+
+class LegacyWindowsTerm:
+ """This class allows interaction with the legacy Windows Console API. It should only be used in the context
+ of environments where virtual terminal processing is not available. However, if it is used in a Windows environment,
+ the entire API should work.
+
+ Args:
+ file (IO[str]): The file which the Windows Console API HANDLE is retrieved from, defaults to sys.stdout.
+ """
+
+ BRIGHT_BIT = 8
+
+ # Indices are ANSI color numbers, values are the corresponding Windows Console API color numbers
+ ANSI_TO_WINDOWS = [
+ 0, # black The Windows colours are defined in wincon.h as follows:
+ 4, # red define FOREGROUND_BLUE 0x0001 -- 0000 0001
+ 2, # green define FOREGROUND_GREEN 0x0002 -- 0000 0010
+ 6, # yellow define FOREGROUND_RED 0x0004 -- 0000 0100
+ 1, # blue define FOREGROUND_INTENSITY 0x0008 -- 0000 1000
+ 5, # magenta define BACKGROUND_BLUE 0x0010 -- 0001 0000
+ 3, # cyan define BACKGROUND_GREEN 0x0020 -- 0010 0000
+ 7, # white define BACKGROUND_RED 0x0040 -- 0100 0000
+ 8, # bright black (grey) define BACKGROUND_INTENSITY 0x0080 -- 1000 0000
+ 12, # bright red
+ 10, # bright green
+ 14, # bright yellow
+ 9, # bright blue
+ 13, # bright magenta
+ 11, # bright cyan
+ 15, # bright white
+ ]
+
+ def __init__(self, file: "IO[str]") -> None:
+ handle = GetStdHandle(STDOUT)
+ self._handle = handle
+ default_text = GetConsoleScreenBufferInfo(handle).wAttributes
+ self._default_text = default_text
+
+ self._default_fore = default_text & 7
+ self._default_back = (default_text >> 4) & 7
+ self._default_attrs = self._default_fore | (self._default_back << 4)
+
+ self._file = file
+ self.write = file.write
+ self.flush = file.flush
+
+ @property
+ def cursor_position(self) -> WindowsCoordinates:
+ """Returns the current position of the cursor (0-based)
+
+ Returns:
+ WindowsCoordinates: The current cursor position.
+ """
+ coord: COORD = GetConsoleScreenBufferInfo(self._handle).dwCursorPosition
+ return WindowsCoordinates(row=cast(int, coord.Y), col=cast(int, coord.X))
+
+ @property
+ def screen_size(self) -> WindowsCoordinates:
+ """Returns the current size of the console screen buffer, in character columns and rows
+
+ Returns:
+ WindowsCoordinates: The width and height of the screen as WindowsCoordinates.
+ """
+ screen_size: COORD = GetConsoleScreenBufferInfo(self._handle).dwSize
+ return WindowsCoordinates(
+ row=cast(int, screen_size.Y), col=cast(int, screen_size.X)
+ )
+
+ def write_text(self, text: str) -> None:
+ """Write text directly to the terminal without any modification of styles
+
+ Args:
+ text (str): The text to write to the console
+ """
+ self.write(text)
+ self.flush()
+
+ def write_styled(self, text: str, style: Style) -> None:
+ """Write styled text to the terminal.
+
+ Args:
+ text (str): The text to write
+ style (Style): The style of the text
+ """
+ color = style.color
+ bgcolor = style.bgcolor
+ if style.reverse:
+ color, bgcolor = bgcolor, color
+
+ if color:
+ fore = color.downgrade(ColorSystem.WINDOWS).number
+ fore = fore if fore is not None else 7 # Default to ANSI 7: White
+ if style.bold:
+ fore = fore | self.BRIGHT_BIT
+ if style.dim:
+ fore = fore & ~self.BRIGHT_BIT
+ fore = self.ANSI_TO_WINDOWS[fore]
+ else:
+ fore = self._default_fore
+
+ if bgcolor:
+ back = bgcolor.downgrade(ColorSystem.WINDOWS).number
+ back = back if back is not None else 0 # Default to ANSI 0: Black
+ back = self.ANSI_TO_WINDOWS[back]
+ else:
+ back = self._default_back
+
+ assert fore is not None
+ assert back is not None
+
+ SetConsoleTextAttribute(
+ self._handle, attributes=ctypes.c_ushort(fore | (back << 4))
+ )
+ self.write_text(text)
+ SetConsoleTextAttribute(self._handle, attributes=self._default_text)
+
+ def move_cursor_to(self, new_position: WindowsCoordinates) -> None:
+ """Set the position of the cursor
+
+ Args:
+ new_position (WindowsCoordinates): The WindowsCoordinates representing the new position of the cursor.
+ """
+ if new_position.col < 0 or new_position.row < 0:
+ return
+ SetConsoleCursorPosition(self._handle, coords=new_position)
+
+ def erase_line(self) -> None:
+ """Erase all content on the line the cursor is currently located at"""
+ screen_size = self.screen_size
+ cursor_position = self.cursor_position
+ cells_to_erase = screen_size.col
+ start_coordinates = WindowsCoordinates(row=cursor_position.row, col=0)
+ FillConsoleOutputCharacter(
+ self._handle, " ", length=cells_to_erase, start=start_coordinates
+ )
+ FillConsoleOutputAttribute(
+ self._handle,
+ self._default_attrs,
+ length=cells_to_erase,
+ start=start_coordinates,
+ )
+
+ def erase_end_of_line(self) -> None:
+ """Erase all content from the cursor position to the end of that line"""
+ cursor_position = self.cursor_position
+ cells_to_erase = self.screen_size.col - cursor_position.col
+ FillConsoleOutputCharacter(
+ self._handle, " ", length=cells_to_erase, start=cursor_position
+ )
+ FillConsoleOutputAttribute(
+ self._handle,
+ self._default_attrs,
+ length=cells_to_erase,
+ start=cursor_position,
+ )
+
+ def erase_start_of_line(self) -> None:
+ """Erase all content from the cursor position to the start of that line"""
+ row, col = self.cursor_position
+ start = WindowsCoordinates(row, 0)
+ FillConsoleOutputCharacter(self._handle, " ", length=col, start=start)
+ FillConsoleOutputAttribute(
+ self._handle, self._default_attrs, length=col, start=start
+ )
+
+ def move_cursor_up(self) -> None:
+ """Move the cursor up a single cell"""
+ cursor_position = self.cursor_position
+ SetConsoleCursorPosition(
+ self._handle,
+ coords=WindowsCoordinates(
+ row=cursor_position.row - 1, col=cursor_position.col
+ ),
+ )
+
+ def move_cursor_down(self) -> None:
+ """Move the cursor down a single cell"""
+ cursor_position = self.cursor_position
+ SetConsoleCursorPosition(
+ self._handle,
+ coords=WindowsCoordinates(
+ row=cursor_position.row + 1,
+ col=cursor_position.col,
+ ),
+ )
+
+ def move_cursor_forward(self) -> None:
+ """Move the cursor forward a single cell. Wrap to the next line if required."""
+ row, col = self.cursor_position
+ if col == self.screen_size.col - 1:
+ row += 1
+ col = 0
+ else:
+ col += 1
+ SetConsoleCursorPosition(
+ self._handle, coords=WindowsCoordinates(row=row, col=col)
+ )
+
+ def move_cursor_to_column(self, column: int) -> None:
+ """Move cursor to the column specified by the zero-based column index, staying on the same row
+
+ Args:
+ column (int): The zero-based column index to move the cursor to.
+ """
+ row, _ = self.cursor_position
+ SetConsoleCursorPosition(self._handle, coords=WindowsCoordinates(row, column))
+
+ def move_cursor_backward(self) -> None:
+ """Move the cursor backward a single cell. Wrap to the previous line if required."""
+ row, col = self.cursor_position
+ if col == 0:
+ row -= 1
+ col = self.screen_size.col - 1
+ else:
+ col -= 1
+ SetConsoleCursorPosition(
+ self._handle, coords=WindowsCoordinates(row=row, col=col)
+ )
+
+ def hide_cursor(self) -> None:
+ """Hide the cursor"""
+ current_cursor_size = self._get_cursor_size()
+ invisible_cursor = CONSOLE_CURSOR_INFO(dwSize=current_cursor_size, bVisible=0)
+ SetConsoleCursorInfo(self._handle, cursor_info=invisible_cursor)
+
+ def show_cursor(self) -> None:
+ """Show the cursor"""
+ current_cursor_size = self._get_cursor_size()
+ visible_cursor = CONSOLE_CURSOR_INFO(dwSize=current_cursor_size, bVisible=1)
+ SetConsoleCursorInfo(self._handle, cursor_info=visible_cursor)
+
+ def set_title(self, title: str) -> None:
+ """Set the title of the terminal window
+
+ Args:
+ title (str): The new title of the console window
+ """
+ assert len(title) < 255, "Console title must be less than 255 characters"
+ SetConsoleTitle(title)
+
+ def _get_cursor_size(self) -> int:
+ """Get the percentage of the character cell that is filled by the cursor"""
+ cursor_info = CONSOLE_CURSOR_INFO()
+ GetConsoleCursorInfo(self._handle, cursor_info=cursor_info)
+ return int(cursor_info.dwSize)
+
+
+if __name__ == "__main__":
+ handle = GetStdHandle()
+
+ from pip._vendor.rich.console import Console
+
+ console = Console()
+
+ term = LegacyWindowsTerm(sys.stdout)
+ term.set_title("Win32 Console Examples")
+
+ style = Style(color="black", bgcolor="red")
+
+ heading = Style.parse("black on green")
+
+ # Check colour output
+ console.rule("Checking colour output")
+ console.print("[on red]on red!")
+ console.print("[blue]blue!")
+ console.print("[yellow]yellow!")
+ console.print("[bold yellow]bold yellow!")
+ console.print("[bright_yellow]bright_yellow!")
+ console.print("[dim bright_yellow]dim bright_yellow!")
+ console.print("[italic cyan]italic cyan!")
+ console.print("[bold white on blue]bold white on blue!")
+ console.print("[reverse bold white on blue]reverse bold white on blue!")
+ console.print("[bold black on cyan]bold black on cyan!")
+ console.print("[black on green]black on green!")
+ console.print("[blue on green]blue on green!")
+ console.print("[white on black]white on black!")
+ console.print("[black on white]black on white!")
+ console.print("[#1BB152 on #DA812D]#1BB152 on #DA812D!")
+
+ # Check cursor movement
+ console.rule("Checking cursor movement")
+ console.print()
+ term.move_cursor_backward()
+ term.move_cursor_backward()
+ term.write_text("went back and wrapped to prev line")
+ time.sleep(1)
+ term.move_cursor_up()
+ term.write_text("we go up")
+ time.sleep(1)
+ term.move_cursor_down()
+ term.write_text("and down")
+ time.sleep(1)
+ term.move_cursor_up()
+ term.move_cursor_backward()
+ term.move_cursor_backward()
+ term.write_text("we went up and back 2")
+ time.sleep(1)
+ term.move_cursor_down()
+ term.move_cursor_backward()
+ term.move_cursor_backward()
+ term.write_text("we went down and back 2")
+ time.sleep(1)
+
+ # Check erasing of lines
+ term.hide_cursor()
+ console.print()
+ console.rule("Checking line erasing")
+ console.print("\n...Deleting to the start of the line...")
+ term.write_text("The red arrow shows the cursor location, and direction of erase")
+ time.sleep(1)
+ term.move_cursor_to_column(16)
+ term.write_styled("<", Style.parse("black on red"))
+ term.move_cursor_backward()
+ time.sleep(1)
+ term.erase_start_of_line()
+ time.sleep(1)
+
+ console.print("\n\n...And to the end of the line...")
+ term.write_text("The red arrow shows the cursor location, and direction of erase")
+ time.sleep(1)
+
+ term.move_cursor_to_column(16)
+ term.write_styled(">", Style.parse("black on red"))
+ time.sleep(1)
+ term.erase_end_of_line()
+ time.sleep(1)
+
+ console.print("\n\n...Now the whole line will be erased...")
+ term.write_styled("I'm going to disappear!", style=Style.parse("black on cyan"))
+ time.sleep(1)
+ term.erase_line()
+
+ term.show_cursor()
+ print("\n")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_windows.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_windows.py
new file mode 100644
index 000000000..7520a9f90
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_windows.py
@@ -0,0 +1,71 @@
+import sys
+from dataclasses import dataclass
+
+
+@dataclass
+class WindowsConsoleFeatures:
+ """Windows features available."""
+
+ vt: bool = False
+ """The console supports VT codes."""
+ truecolor: bool = False
+ """The console supports truecolor."""
+
+
+try:
+ import ctypes
+ from ctypes import LibraryLoader
+
+ if sys.platform == "win32":
+ windll = LibraryLoader(ctypes.WinDLL)
+ else:
+ windll = None
+ raise ImportError("Not windows")
+
+ from pip._vendor.rich._win32_console import (
+ ENABLE_VIRTUAL_TERMINAL_PROCESSING,
+ GetConsoleMode,
+ GetStdHandle,
+ LegacyWindowsError,
+ )
+
+except (AttributeError, ImportError, ValueError):
+ # Fallback if we can't load the Windows DLL
+ def get_windows_console_features() -> WindowsConsoleFeatures:
+ features = WindowsConsoleFeatures()
+ return features
+
+else:
+
+ def get_windows_console_features() -> WindowsConsoleFeatures:
+ """Get windows console features.
+
+ Returns:
+ WindowsConsoleFeatures: An instance of WindowsConsoleFeatures.
+ """
+ handle = GetStdHandle()
+ try:
+ console_mode = GetConsoleMode(handle)
+ success = True
+ except LegacyWindowsError:
+ console_mode = 0
+ success = False
+ vt = bool(success and console_mode & ENABLE_VIRTUAL_TERMINAL_PROCESSING)
+ truecolor = False
+ if vt:
+ win_version = sys.getwindowsversion()
+ truecolor = win_version.major > 10 or (
+ win_version.major == 10 and win_version.build >= 15063
+ )
+ features = WindowsConsoleFeatures(vt=vt, truecolor=truecolor)
+ return features
+
+
+if __name__ == "__main__":
+ import platform
+
+ features = get_windows_console_features()
+ from pip._vendor.rich import print
+
+ print(f'platform="{platform.system()}"')
+ print(repr(features))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_windows_renderer.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_windows_renderer.py
new file mode 100644
index 000000000..5ece05649
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_windows_renderer.py
@@ -0,0 +1,56 @@
+from typing import Iterable, Sequence, Tuple, cast
+
+from pip._vendor.rich._win32_console import LegacyWindowsTerm, WindowsCoordinates
+from pip._vendor.rich.segment import ControlCode, ControlType, Segment
+
+
+def legacy_windows_render(buffer: Iterable[Segment], term: LegacyWindowsTerm) -> None:
+ """Makes appropriate Windows Console API calls based on the segments in the buffer.
+
+ Args:
+ buffer (Iterable[Segment]): Iterable of Segments to convert to Win32 API calls.
+ term (LegacyWindowsTerm): Used to call the Windows Console API.
+ """
+ for text, style, control in buffer:
+ if not control:
+ if style:
+ term.write_styled(text, style)
+ else:
+ term.write_text(text)
+ else:
+ control_codes: Sequence[ControlCode] = control
+ for control_code in control_codes:
+ control_type = control_code[0]
+ if control_type == ControlType.CURSOR_MOVE_TO:
+ _, x, y = cast(Tuple[ControlType, int, int], control_code)
+ term.move_cursor_to(WindowsCoordinates(row=y - 1, col=x - 1))
+ elif control_type == ControlType.CARRIAGE_RETURN:
+ term.write_text("\r")
+ elif control_type == ControlType.HOME:
+ term.move_cursor_to(WindowsCoordinates(0, 0))
+ elif control_type == ControlType.CURSOR_UP:
+ term.move_cursor_up()
+ elif control_type == ControlType.CURSOR_DOWN:
+ term.move_cursor_down()
+ elif control_type == ControlType.CURSOR_FORWARD:
+ term.move_cursor_forward()
+ elif control_type == ControlType.CURSOR_BACKWARD:
+ term.move_cursor_backward()
+ elif control_type == ControlType.CURSOR_MOVE_TO_COLUMN:
+ _, column = cast(Tuple[ControlType, int], control_code)
+ term.move_cursor_to_column(column - 1)
+ elif control_type == ControlType.HIDE_CURSOR:
+ term.hide_cursor()
+ elif control_type == ControlType.SHOW_CURSOR:
+ term.show_cursor()
+ elif control_type == ControlType.ERASE_IN_LINE:
+ _, mode = cast(Tuple[ControlType, int], control_code)
+ if mode == 0:
+ term.erase_end_of_line()
+ elif mode == 1:
+ term.erase_start_of_line()
+ elif mode == 2:
+ term.erase_line()
+ elif control_type == ControlType.SET_WINDOW_TITLE:
+ _, title = cast(Tuple[ControlType, str], control_code)
+ term.set_title(title)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_wrap.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_wrap.py
new file mode 100644
index 000000000..2e94ff6f4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/_wrap.py
@@ -0,0 +1,93 @@
+from __future__ import annotations
+
+import re
+from typing import Iterable
+
+from ._loop import loop_last
+from .cells import cell_len, chop_cells
+
+re_word = re.compile(r"\s*\S+\s*")
+
+
+def words(text: str) -> Iterable[tuple[int, int, str]]:
+ """Yields each word from the text as a tuple
+ containing (start_index, end_index, word). A "word" in this context may
+ include the actual word and any whitespace to the right.
+ """
+ position = 0
+ word_match = re_word.match(text, position)
+ while word_match is not None:
+ start, end = word_match.span()
+ word = word_match.group(0)
+ yield start, end, word
+ word_match = re_word.match(text, end)
+
+
+def divide_line(text: str, width: int, fold: bool = True) -> list[int]:
+ """Given a string of text, and a width (measured in cells), return a list
+ of cell offsets which the string should be split at in order for it to fit
+ within the given width.
+
+ Args:
+ text: The text to examine.
+ width: The available cell width.
+ fold: If True, words longer than `width` will be folded onto a new line.
+
+ Returns:
+ A list of indices to break the line at.
+ """
+ break_positions: list[int] = [] # offsets to insert the breaks at
+ append = break_positions.append
+ cell_offset = 0
+ _cell_len = cell_len
+
+ for start, _end, word in words(text):
+ word_length = _cell_len(word.rstrip())
+ remaining_space = width - cell_offset
+ word_fits_remaining_space = remaining_space >= word_length
+
+ if word_fits_remaining_space:
+ # Simplest case - the word fits within the remaining width for this line.
+ cell_offset += _cell_len(word)
+ else:
+ # Not enough space remaining for this word on the current line.
+ if word_length > width:
+ # The word doesn't fit on any line, so we can't simply
+ # place it on the next line...
+ if fold:
+ # Fold the word across multiple lines.
+ folded_word = chop_cells(word, width=width)
+ for last, line in loop_last(folded_word):
+ if start:
+ append(start)
+ if last:
+ cell_offset = _cell_len(line)
+ else:
+ start += len(line)
+ else:
+ # Folding isn't allowed, so crop the word.
+ if start:
+ append(start)
+ cell_offset = _cell_len(word)
+ elif cell_offset and start:
+ # The word doesn't fit within the remaining space on the current
+ # line, but it *can* fit on to the next (empty) line.
+ append(start)
+ cell_offset = _cell_len(word)
+
+ return break_positions
+
+
+if __name__ == "__main__": # pragma: no cover
+ from .console import Console
+
+ console = Console(width=10)
+ console.print("12345 abcdefghijklmnopqrstuvwyxzABCDEFGHIJKLMNOPQRSTUVWXYZ 12345")
+ print(chop_cells("abcdefghijklmnopqrstuvwxyz", 10))
+
+ console = Console(width=20)
+ console.rule()
+ console.print("TextualはPythonの高速アプリケーション開発フレームワークです")
+
+ console.rule()
+ console.print("アプリケーションは1670万色を使用でき")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/abc.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/abc.py
new file mode 100644
index 000000000..e6e498efa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/abc.py
@@ -0,0 +1,33 @@
+from abc import ABC
+
+
+class RichRenderable(ABC):
+ """An abstract base class for Rich renderables.
+
+ Note that there is no need to extend this class, the intended use is to check if an
+ object supports the Rich renderable protocol. For example::
+
+ if isinstance(my_object, RichRenderable):
+ console.print(my_object)
+
+ """
+
+ @classmethod
+ def __subclasshook__(cls, other: type) -> bool:
+ """Check if this class supports the rich render protocol."""
+ return hasattr(other, "__rich_console__") or hasattr(other, "__rich__")
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.text import Text
+
+ t = Text()
+ print(isinstance(Text, RichRenderable))
+ print(isinstance(t, RichRenderable))
+
+ class Foo:
+ pass
+
+ f = Foo()
+ print(isinstance(f, RichRenderable))
+ print(isinstance("", RichRenderable))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/align.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/align.py
new file mode 100644
index 000000000..f7b734fd7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/align.py
@@ -0,0 +1,311 @@
+import sys
+from itertools import chain
+from typing import TYPE_CHECKING, Iterable, Optional
+
+if sys.version_info >= (3, 8):
+ from typing import Literal
+else:
+ from pip._vendor.typing_extensions import Literal # pragma: no cover
+
+from .constrain import Constrain
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .segment import Segment
+from .style import StyleType
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderableType, RenderResult
+
+AlignMethod = Literal["left", "center", "right"]
+VerticalAlignMethod = Literal["top", "middle", "bottom"]
+
+
+class Align(JupyterMixin):
+ """Align a renderable by adding spaces if necessary.
+
+ Args:
+ renderable (RenderableType): A console renderable.
+ align (AlignMethod): One of "left", "center", or "right""
+ style (StyleType, optional): An optional style to apply to the background.
+ vertical (Optional[VerticalAlignMethod], optional): Optional vertical align, one of "top", "middle", or "bottom". Defaults to None.
+ pad (bool, optional): Pad the right with spaces. Defaults to True.
+ width (int, optional): Restrict contents to given width, or None to use default width. Defaults to None.
+ height (int, optional): Set height of align renderable, or None to fit to contents. Defaults to None.
+
+ Raises:
+ ValueError: if ``align`` is not one of the expected values.
+ """
+
+ def __init__(
+ self,
+ renderable: "RenderableType",
+ align: AlignMethod = "left",
+ style: Optional[StyleType] = None,
+ *,
+ vertical: Optional[VerticalAlignMethod] = None,
+ pad: bool = True,
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ ) -> None:
+ if align not in ("left", "center", "right"):
+ raise ValueError(
+ f'invalid value for align, expected "left", "center", or "right" (not {align!r})'
+ )
+ if vertical is not None and vertical not in ("top", "middle", "bottom"):
+ raise ValueError(
+ f'invalid value for vertical, expected "top", "middle", or "bottom" (not {vertical!r})'
+ )
+ self.renderable = renderable
+ self.align = align
+ self.style = style
+ self.vertical = vertical
+ self.pad = pad
+ self.width = width
+ self.height = height
+
+ def __repr__(self) -> str:
+ return f"Align({self.renderable!r}, {self.align!r})"
+
+ @classmethod
+ def left(
+ cls,
+ renderable: "RenderableType",
+ style: Optional[StyleType] = None,
+ *,
+ vertical: Optional[VerticalAlignMethod] = None,
+ pad: bool = True,
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ ) -> "Align":
+ """Align a renderable to the left."""
+ return cls(
+ renderable,
+ "left",
+ style=style,
+ vertical=vertical,
+ pad=pad,
+ width=width,
+ height=height,
+ )
+
+ @classmethod
+ def center(
+ cls,
+ renderable: "RenderableType",
+ style: Optional[StyleType] = None,
+ *,
+ vertical: Optional[VerticalAlignMethod] = None,
+ pad: bool = True,
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ ) -> "Align":
+ """Align a renderable to the center."""
+ return cls(
+ renderable,
+ "center",
+ style=style,
+ vertical=vertical,
+ pad=pad,
+ width=width,
+ height=height,
+ )
+
+ @classmethod
+ def right(
+ cls,
+ renderable: "RenderableType",
+ style: Optional[StyleType] = None,
+ *,
+ vertical: Optional[VerticalAlignMethod] = None,
+ pad: bool = True,
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ ) -> "Align":
+ """Align a renderable to the right."""
+ return cls(
+ renderable,
+ "right",
+ style=style,
+ vertical=vertical,
+ pad=pad,
+ width=width,
+ height=height,
+ )
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ align = self.align
+ width = console.measure(self.renderable, options=options).maximum
+ rendered = console.render(
+ Constrain(
+ self.renderable, width if self.width is None else min(width, self.width)
+ ),
+ options.update(height=None),
+ )
+ lines = list(Segment.split_lines(rendered))
+ width, height = Segment.get_shape(lines)
+ lines = Segment.set_shape(lines, width, height)
+ new_line = Segment.line()
+ excess_space = options.max_width - width
+ style = console.get_style(self.style) if self.style is not None else None
+
+ def generate_segments() -> Iterable[Segment]:
+ if excess_space <= 0:
+ # Exact fit
+ for line in lines:
+ yield from line
+ yield new_line
+
+ elif align == "left":
+ # Pad on the right
+ pad = Segment(" " * excess_space, style) if self.pad else None
+ for line in lines:
+ yield from line
+ if pad:
+ yield pad
+ yield new_line
+
+ elif align == "center":
+ # Pad left and right
+ left = excess_space // 2
+ pad = Segment(" " * left, style)
+ pad_right = (
+ Segment(" " * (excess_space - left), style) if self.pad else None
+ )
+ for line in lines:
+ if left:
+ yield pad
+ yield from line
+ if pad_right:
+ yield pad_right
+ yield new_line
+
+ elif align == "right":
+ # Padding on left
+ pad = Segment(" " * excess_space, style)
+ for line in lines:
+ yield pad
+ yield from line
+ yield new_line
+
+ blank_line = (
+ Segment(f"{' ' * (self.width or options.max_width)}\n", style)
+ if self.pad
+ else Segment("\n")
+ )
+
+ def blank_lines(count: int) -> Iterable[Segment]:
+ if count > 0:
+ for _ in range(count):
+ yield blank_line
+
+ vertical_height = self.height or options.height
+ iter_segments: Iterable[Segment]
+ if self.vertical and vertical_height is not None:
+ if self.vertical == "top":
+ bottom_space = vertical_height - height
+ iter_segments = chain(generate_segments(), blank_lines(bottom_space))
+ elif self.vertical == "middle":
+ top_space = (vertical_height - height) // 2
+ bottom_space = vertical_height - top_space - height
+ iter_segments = chain(
+ blank_lines(top_space),
+ generate_segments(),
+ blank_lines(bottom_space),
+ )
+ else: # self.vertical == "bottom":
+ top_space = vertical_height - height
+ iter_segments = chain(blank_lines(top_space), generate_segments())
+ else:
+ iter_segments = generate_segments()
+ if self.style:
+ style = console.get_style(self.style)
+ iter_segments = Segment.apply_style(iter_segments, style)
+ yield from iter_segments
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Measurement:
+ measurement = Measurement.get(console, options, self.renderable)
+ return measurement
+
+
+class VerticalCenter(JupyterMixin):
+ """Vertically aligns a renderable.
+
+ Warn:
+ This class is deprecated and may be removed in a future version. Use Align class with
+ `vertical="middle"`.
+
+ Args:
+ renderable (RenderableType): A renderable object.
+ """
+
+ def __init__(
+ self,
+ renderable: "RenderableType",
+ style: Optional[StyleType] = None,
+ ) -> None:
+ self.renderable = renderable
+ self.style = style
+
+ def __repr__(self) -> str:
+ return f"VerticalCenter({self.renderable!r})"
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ style = console.get_style(self.style) if self.style is not None else None
+ lines = console.render_lines(
+ self.renderable, options.update(height=None), pad=False
+ )
+ width, _height = Segment.get_shape(lines)
+ new_line = Segment.line()
+ height = options.height or options.size.height
+ top_space = (height - len(lines)) // 2
+ bottom_space = height - top_space - len(lines)
+ blank_line = Segment(f"{' ' * width}", style)
+
+ def blank_lines(count: int) -> Iterable[Segment]:
+ for _ in range(count):
+ yield blank_line
+ yield new_line
+
+ if top_space > 0:
+ yield from blank_lines(top_space)
+ for line in lines:
+ yield from line
+ yield new_line
+ if bottom_space > 0:
+ yield from blank_lines(bottom_space)
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Measurement:
+ measurement = Measurement.get(console, options, self.renderable)
+ return measurement
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.console import Console, Group
+ from pip._vendor.rich.highlighter import ReprHighlighter
+ from pip._vendor.rich.panel import Panel
+
+ highlighter = ReprHighlighter()
+ console = Console()
+
+ panel = Panel(
+ Group(
+ Align.left(highlighter("align='left'")),
+ Align.center(highlighter("align='center'")),
+ Align.right(highlighter("align='right'")),
+ ),
+ width=60,
+ style="on dark_blue",
+ title="Align",
+ )
+
+ console.print(
+ Align.center(panel, vertical="middle", style="on red", height=console.height)
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/ansi.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/ansi.py
new file mode 100644
index 000000000..66365e653
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/ansi.py
@@ -0,0 +1,240 @@
+import re
+import sys
+from contextlib import suppress
+from typing import Iterable, NamedTuple, Optional
+
+from .color import Color
+from .style import Style
+from .text import Text
+
+re_ansi = re.compile(
+ r"""
+(?:\x1b\](.*?)\x1b\\)|
+(?:\x1b([(@-Z\\-_]|\[[0-?]*[ -/]*[@-~]))
+""",
+ re.VERBOSE,
+)
+
+
+class _AnsiToken(NamedTuple):
+ """Result of ansi tokenized string."""
+
+ plain: str = ""
+ sgr: Optional[str] = ""
+ osc: Optional[str] = ""
+
+
+def _ansi_tokenize(ansi_text: str) -> Iterable[_AnsiToken]:
+ """Tokenize a string in to plain text and ANSI codes.
+
+ Args:
+ ansi_text (str): A String containing ANSI codes.
+
+ Yields:
+ AnsiToken: A named tuple of (plain, sgr, osc)
+ """
+
+ position = 0
+ sgr: Optional[str]
+ osc: Optional[str]
+ for match in re_ansi.finditer(ansi_text):
+ start, end = match.span(0)
+ osc, sgr = match.groups()
+ if start > position:
+ yield _AnsiToken(ansi_text[position:start])
+ if sgr:
+ if sgr == "(":
+ position = end + 1
+ continue
+ if sgr.endswith("m"):
+ yield _AnsiToken("", sgr[1:-1], osc)
+ else:
+ yield _AnsiToken("", sgr, osc)
+ position = end
+ if position < len(ansi_text):
+ yield _AnsiToken(ansi_text[position:])
+
+
+SGR_STYLE_MAP = {
+ 1: "bold",
+ 2: "dim",
+ 3: "italic",
+ 4: "underline",
+ 5: "blink",
+ 6: "blink2",
+ 7: "reverse",
+ 8: "conceal",
+ 9: "strike",
+ 21: "underline2",
+ 22: "not dim not bold",
+ 23: "not italic",
+ 24: "not underline",
+ 25: "not blink",
+ 26: "not blink2",
+ 27: "not reverse",
+ 28: "not conceal",
+ 29: "not strike",
+ 30: "color(0)",
+ 31: "color(1)",
+ 32: "color(2)",
+ 33: "color(3)",
+ 34: "color(4)",
+ 35: "color(5)",
+ 36: "color(6)",
+ 37: "color(7)",
+ 39: "default",
+ 40: "on color(0)",
+ 41: "on color(1)",
+ 42: "on color(2)",
+ 43: "on color(3)",
+ 44: "on color(4)",
+ 45: "on color(5)",
+ 46: "on color(6)",
+ 47: "on color(7)",
+ 49: "on default",
+ 51: "frame",
+ 52: "encircle",
+ 53: "overline",
+ 54: "not frame not encircle",
+ 55: "not overline",
+ 90: "color(8)",
+ 91: "color(9)",
+ 92: "color(10)",
+ 93: "color(11)",
+ 94: "color(12)",
+ 95: "color(13)",
+ 96: "color(14)",
+ 97: "color(15)",
+ 100: "on color(8)",
+ 101: "on color(9)",
+ 102: "on color(10)",
+ 103: "on color(11)",
+ 104: "on color(12)",
+ 105: "on color(13)",
+ 106: "on color(14)",
+ 107: "on color(15)",
+}
+
+
+class AnsiDecoder:
+ """Translate ANSI code in to styled Text."""
+
+ def __init__(self) -> None:
+ self.style = Style.null()
+
+ def decode(self, terminal_text: str) -> Iterable[Text]:
+ """Decode ANSI codes in an iterable of lines.
+
+ Args:
+ lines (Iterable[str]): An iterable of lines of terminal output.
+
+ Yields:
+ Text: Marked up Text.
+ """
+ for line in terminal_text.splitlines():
+ yield self.decode_line(line)
+
+ def decode_line(self, line: str) -> Text:
+ """Decode a line containing ansi codes.
+
+ Args:
+ line (str): A line of terminal output.
+
+ Returns:
+ Text: A Text instance marked up according to ansi codes.
+ """
+ from_ansi = Color.from_ansi
+ from_rgb = Color.from_rgb
+ _Style = Style
+ text = Text()
+ append = text.append
+ line = line.rsplit("\r", 1)[-1]
+ for plain_text, sgr, osc in _ansi_tokenize(line):
+ if plain_text:
+ append(plain_text, self.style or None)
+ elif osc is not None:
+ if osc.startswith("8;"):
+ _params, semicolon, link = osc[2:].partition(";")
+ if semicolon:
+ self.style = self.style.update_link(link or None)
+ elif sgr is not None:
+ # Translate in to semi-colon separated codes
+ # Ignore invalid codes, because we want to be lenient
+ codes = [
+ min(255, int(_code) if _code else 0)
+ for _code in sgr.split(";")
+ if _code.isdigit() or _code == ""
+ ]
+ iter_codes = iter(codes)
+ for code in iter_codes:
+ if code == 0:
+ # reset
+ self.style = _Style.null()
+ elif code in SGR_STYLE_MAP:
+ # styles
+ self.style += _Style.parse(SGR_STYLE_MAP[code])
+ elif code == 38:
+ # Foreground
+ with suppress(StopIteration):
+ color_type = next(iter_codes)
+ if color_type == 5:
+ self.style += _Style.from_color(
+ from_ansi(next(iter_codes))
+ )
+ elif color_type == 2:
+ self.style += _Style.from_color(
+ from_rgb(
+ next(iter_codes),
+ next(iter_codes),
+ next(iter_codes),
+ )
+ )
+ elif code == 48:
+ # Background
+ with suppress(StopIteration):
+ color_type = next(iter_codes)
+ if color_type == 5:
+ self.style += _Style.from_color(
+ None, from_ansi(next(iter_codes))
+ )
+ elif color_type == 2:
+ self.style += _Style.from_color(
+ None,
+ from_rgb(
+ next(iter_codes),
+ next(iter_codes),
+ next(iter_codes),
+ ),
+ )
+
+ return text
+
+
+if sys.platform != "win32" and __name__ == "__main__": # pragma: no cover
+ import io
+ import os
+ import pty
+ import sys
+
+ decoder = AnsiDecoder()
+
+ stdout = io.BytesIO()
+
+ def read(fd: int) -> bytes:
+ data = os.read(fd, 1024)
+ stdout.write(data)
+ return data
+
+ pty.spawn(sys.argv[1:], read)
+
+ from .console import Console
+
+ console = Console(record=True)
+
+ stdout_result = stdout.getvalue().decode("utf-8")
+ print(stdout_result)
+
+ for line in decoder.decode(stdout_result):
+ console.print(line)
+
+ console.save_html("stdout.html")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/bar.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/bar.py
new file mode 100644
index 000000000..022284b57
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/bar.py
@@ -0,0 +1,93 @@
+from typing import Optional, Union
+
+from .color import Color
+from .console import Console, ConsoleOptions, RenderResult
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .segment import Segment
+from .style import Style
+
+# There are left-aligned characters for 1/8 to 7/8, but
+# the right-aligned characters exist only for 1/8 and 4/8.
+BEGIN_BLOCK_ELEMENTS = ["█", "█", "█", "▐", "▐", "▐", "▕", "▕"]
+END_BLOCK_ELEMENTS = [" ", "▏", "▎", "▍", "▌", "▋", "▊", "▉"]
+FULL_BLOCK = "█"
+
+
+class Bar(JupyterMixin):
+ """Renders a solid block bar.
+
+ Args:
+ size (float): Value for the end of the bar.
+ begin (float): Begin point (between 0 and size, inclusive).
+ end (float): End point (between 0 and size, inclusive).
+ width (int, optional): Width of the bar, or ``None`` for maximum width. Defaults to None.
+ color (Union[Color, str], optional): Color of the bar. Defaults to "default".
+ bgcolor (Union[Color, str], optional): Color of bar background. Defaults to "default".
+ """
+
+ def __init__(
+ self,
+ size: float,
+ begin: float,
+ end: float,
+ *,
+ width: Optional[int] = None,
+ color: Union[Color, str] = "default",
+ bgcolor: Union[Color, str] = "default",
+ ):
+ self.size = size
+ self.begin = max(begin, 0)
+ self.end = min(end, size)
+ self.width = width
+ self.style = Style(color=color, bgcolor=bgcolor)
+
+ def __repr__(self) -> str:
+ return f"Bar({self.size}, {self.begin}, {self.end})"
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ width = min(
+ self.width if self.width is not None else options.max_width,
+ options.max_width,
+ )
+
+ if self.begin >= self.end:
+ yield Segment(" " * width, self.style)
+ yield Segment.line()
+ return
+
+ prefix_complete_eights = int(width * 8 * self.begin / self.size)
+ prefix_bar_count = prefix_complete_eights // 8
+ prefix_eights_count = prefix_complete_eights % 8
+
+ body_complete_eights = int(width * 8 * self.end / self.size)
+ body_bar_count = body_complete_eights // 8
+ body_eights_count = body_complete_eights % 8
+
+ # When start and end fall into the same cell, we ideally should render
+ # a symbol that's "center-aligned", but there is no good symbol in Unicode.
+ # In this case, we fall back to right-aligned block symbol for simplicity.
+
+ prefix = " " * prefix_bar_count
+ if prefix_eights_count:
+ prefix += BEGIN_BLOCK_ELEMENTS[prefix_eights_count]
+
+ body = FULL_BLOCK * body_bar_count
+ if body_eights_count:
+ body += END_BLOCK_ELEMENTS[body_eights_count]
+
+ suffix = " " * (width - len(body))
+
+ yield Segment(prefix + body[len(prefix) :] + suffix, self.style)
+ yield Segment.line()
+
+ def __rich_measure__(
+ self, console: Console, options: ConsoleOptions
+ ) -> Measurement:
+ return (
+ Measurement(self.width, self.width)
+ if self.width is not None
+ else Measurement(4, options.max_width)
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/box.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/box.py
new file mode 100644
index 000000000..0511a9e48
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/box.py
@@ -0,0 +1,480 @@
+import sys
+from typing import TYPE_CHECKING, Iterable, List
+
+if sys.version_info >= (3, 8):
+ from typing import Literal
+else:
+ from pip._vendor.typing_extensions import Literal # pragma: no cover
+
+
+from ._loop import loop_last
+
+if TYPE_CHECKING:
+ from pip._vendor.rich.console import ConsoleOptions
+
+
+class Box:
+ """Defines characters to render boxes.
+
+ ┌─┬┐ top
+ │ ││ head
+ ├─┼┤ head_row
+ │ ││ mid
+ ├─┼┤ row
+ ├─┼┤ foot_row
+ │ ││ foot
+ └─┴┘ bottom
+
+ Args:
+ box (str): Characters making up box.
+ ascii (bool, optional): True if this box uses ascii characters only. Default is False.
+ """
+
+ def __init__(self, box: str, *, ascii: bool = False) -> None:
+ self._box = box
+ self.ascii = ascii
+ line1, line2, line3, line4, line5, line6, line7, line8 = box.splitlines()
+ # top
+ self.top_left, self.top, self.top_divider, self.top_right = iter(line1)
+ # head
+ self.head_left, _, self.head_vertical, self.head_right = iter(line2)
+ # head_row
+ (
+ self.head_row_left,
+ self.head_row_horizontal,
+ self.head_row_cross,
+ self.head_row_right,
+ ) = iter(line3)
+
+ # mid
+ self.mid_left, _, self.mid_vertical, self.mid_right = iter(line4)
+ # row
+ self.row_left, self.row_horizontal, self.row_cross, self.row_right = iter(line5)
+ # foot_row
+ (
+ self.foot_row_left,
+ self.foot_row_horizontal,
+ self.foot_row_cross,
+ self.foot_row_right,
+ ) = iter(line6)
+ # foot
+ self.foot_left, _, self.foot_vertical, self.foot_right = iter(line7)
+ # bottom
+ self.bottom_left, self.bottom, self.bottom_divider, self.bottom_right = iter(
+ line8
+ )
+
+ def __repr__(self) -> str:
+ return "Box(...)"
+
+ def __str__(self) -> str:
+ return self._box
+
+ def substitute(self, options: "ConsoleOptions", safe: bool = True) -> "Box":
+ """Substitute this box for another if it won't render due to platform issues.
+
+ Args:
+ options (ConsoleOptions): Console options used in rendering.
+ safe (bool, optional): Substitute this for another Box if there are known problems
+ displaying on the platform (currently only relevant on Windows). Default is True.
+
+ Returns:
+ Box: A different Box or the same Box.
+ """
+ box = self
+ if options.legacy_windows and safe:
+ box = LEGACY_WINDOWS_SUBSTITUTIONS.get(box, box)
+ if options.ascii_only and not box.ascii:
+ box = ASCII
+ return box
+
+ def get_plain_headed_box(self) -> "Box":
+ """If this box uses special characters for the borders of the header, then
+ return the equivalent box that does not.
+
+ Returns:
+ Box: The most similar Box that doesn't use header-specific box characters.
+ If the current Box already satisfies this criterion, then it's returned.
+ """
+ return PLAIN_HEADED_SUBSTITUTIONS.get(self, self)
+
+ def get_top(self, widths: Iterable[int]) -> str:
+ """Get the top of a simple box.
+
+ Args:
+ widths (List[int]): Widths of columns.
+
+ Returns:
+ str: A string of box characters.
+ """
+
+ parts: List[str] = []
+ append = parts.append
+ append(self.top_left)
+ for last, width in loop_last(widths):
+ append(self.top * width)
+ if not last:
+ append(self.top_divider)
+ append(self.top_right)
+ return "".join(parts)
+
+ def get_row(
+ self,
+ widths: Iterable[int],
+ level: Literal["head", "row", "foot", "mid"] = "row",
+ edge: bool = True,
+ ) -> str:
+ """Get the top of a simple box.
+
+ Args:
+ width (List[int]): Widths of columns.
+
+ Returns:
+ str: A string of box characters.
+ """
+ if level == "head":
+ left = self.head_row_left
+ horizontal = self.head_row_horizontal
+ cross = self.head_row_cross
+ right = self.head_row_right
+ elif level == "row":
+ left = self.row_left
+ horizontal = self.row_horizontal
+ cross = self.row_cross
+ right = self.row_right
+ elif level == "mid":
+ left = self.mid_left
+ horizontal = " "
+ cross = self.mid_vertical
+ right = self.mid_right
+ elif level == "foot":
+ left = self.foot_row_left
+ horizontal = self.foot_row_horizontal
+ cross = self.foot_row_cross
+ right = self.foot_row_right
+ else:
+ raise ValueError("level must be 'head', 'row' or 'foot'")
+
+ parts: List[str] = []
+ append = parts.append
+ if edge:
+ append(left)
+ for last, width in loop_last(widths):
+ append(horizontal * width)
+ if not last:
+ append(cross)
+ if edge:
+ append(right)
+ return "".join(parts)
+
+ def get_bottom(self, widths: Iterable[int]) -> str:
+ """Get the bottom of a simple box.
+
+ Args:
+ widths (List[int]): Widths of columns.
+
+ Returns:
+ str: A string of box characters.
+ """
+
+ parts: List[str] = []
+ append = parts.append
+ append(self.bottom_left)
+ for last, width in loop_last(widths):
+ append(self.bottom * width)
+ if not last:
+ append(self.bottom_divider)
+ append(self.bottom_right)
+ return "".join(parts)
+
+
+# fmt: off
+ASCII: Box = Box(
+ "+--+\n"
+ "| ||\n"
+ "|-+|\n"
+ "| ||\n"
+ "|-+|\n"
+ "|-+|\n"
+ "| ||\n"
+ "+--+\n",
+ ascii=True,
+)
+
+ASCII2: Box = Box(
+ "+-++\n"
+ "| ||\n"
+ "+-++\n"
+ "| ||\n"
+ "+-++\n"
+ "+-++\n"
+ "| ||\n"
+ "+-++\n",
+ ascii=True,
+)
+
+ASCII_DOUBLE_HEAD: Box = Box(
+ "+-++\n"
+ "| ||\n"
+ "+=++\n"
+ "| ||\n"
+ "+-++\n"
+ "+-++\n"
+ "| ||\n"
+ "+-++\n",
+ ascii=True,
+)
+
+SQUARE: Box = Box(
+ "┌─┬┐\n"
+ "│ ││\n"
+ "├─┼┤\n"
+ "│ ││\n"
+ "├─┼┤\n"
+ "├─┼┤\n"
+ "│ ││\n"
+ "└─┴┘\n"
+)
+
+SQUARE_DOUBLE_HEAD: Box = Box(
+ "┌─┬┐\n"
+ "│ ││\n"
+ "╞═╪╡\n"
+ "│ ││\n"
+ "├─┼┤\n"
+ "├─┼┤\n"
+ "│ ││\n"
+ "└─┴┘\n"
+)
+
+MINIMAL: Box = Box(
+ " ╷ \n"
+ " │ \n"
+ "╶─┼╴\n"
+ " │ \n"
+ "╶─┼╴\n"
+ "╶─┼╴\n"
+ " │ \n"
+ " ╵ \n"
+)
+
+
+MINIMAL_HEAVY_HEAD: Box = Box(
+ " ╷ \n"
+ " │ \n"
+ "╺━┿╸\n"
+ " │ \n"
+ "╶─┼╴\n"
+ "╶─┼╴\n"
+ " │ \n"
+ " ╵ \n"
+)
+
+MINIMAL_DOUBLE_HEAD: Box = Box(
+ " ╷ \n"
+ " │ \n"
+ " ═╪ \n"
+ " │ \n"
+ " ─┼ \n"
+ " ─┼ \n"
+ " │ \n"
+ " ╵ \n"
+)
+
+
+SIMPLE: Box = Box(
+ " \n"
+ " \n"
+ " ── \n"
+ " \n"
+ " \n"
+ " ── \n"
+ " \n"
+ " \n"
+)
+
+SIMPLE_HEAD: Box = Box(
+ " \n"
+ " \n"
+ " ── \n"
+ " \n"
+ " \n"
+ " \n"
+ " \n"
+ " \n"
+)
+
+
+SIMPLE_HEAVY: Box = Box(
+ " \n"
+ " \n"
+ " ━━ \n"
+ " \n"
+ " \n"
+ " ━━ \n"
+ " \n"
+ " \n"
+)
+
+
+HORIZONTALS: Box = Box(
+ " ── \n"
+ " \n"
+ " ── \n"
+ " \n"
+ " ── \n"
+ " ── \n"
+ " \n"
+ " ── \n"
+)
+
+ROUNDED: Box = Box(
+ "╭─┬╮\n"
+ "│ ││\n"
+ "├─┼┤\n"
+ "│ ││\n"
+ "├─┼┤\n"
+ "├─┼┤\n"
+ "│ ││\n"
+ "╰─┴╯\n"
+)
+
+HEAVY: Box = Box(
+ "┏━┳┓\n"
+ "┃ ┃┃\n"
+ "┣━╋┫\n"
+ "┃ ┃┃\n"
+ "┣━╋┫\n"
+ "┣━╋┫\n"
+ "┃ ┃┃\n"
+ "┗━┻┛\n"
+)
+
+HEAVY_EDGE: Box = Box(
+ "┏━┯┓\n"
+ "┃ │┃\n"
+ "┠─┼┨\n"
+ "┃ │┃\n"
+ "┠─┼┨\n"
+ "┠─┼┨\n"
+ "┃ │┃\n"
+ "┗━┷┛\n"
+)
+
+HEAVY_HEAD: Box = Box(
+ "┏━┳┓\n"
+ "┃ ┃┃\n"
+ "┡━╇┩\n"
+ "│ ││\n"
+ "├─┼┤\n"
+ "├─┼┤\n"
+ "│ ││\n"
+ "└─┴┘\n"
+)
+
+DOUBLE: Box = Box(
+ "╔═╦╗\n"
+ "║ ║║\n"
+ "╠═╬╣\n"
+ "║ ║║\n"
+ "╠═╬╣\n"
+ "╠═╬╣\n"
+ "║ ║║\n"
+ "╚═╩╝\n"
+)
+
+DOUBLE_EDGE: Box = Box(
+ "╔═╤╗\n"
+ "║ │║\n"
+ "╟─┼╢\n"
+ "║ │║\n"
+ "╟─┼╢\n"
+ "╟─┼╢\n"
+ "║ │║\n"
+ "╚═╧╝\n"
+)
+
+MARKDOWN: Box = Box(
+ " \n"
+ "| ||\n"
+ "|-||\n"
+ "| ||\n"
+ "|-||\n"
+ "|-||\n"
+ "| ||\n"
+ " \n",
+ ascii=True,
+)
+# fmt: on
+
+# Map Boxes that don't render with raster fonts on to equivalent that do
+LEGACY_WINDOWS_SUBSTITUTIONS = {
+ ROUNDED: SQUARE,
+ MINIMAL_HEAVY_HEAD: MINIMAL,
+ SIMPLE_HEAVY: SIMPLE,
+ HEAVY: SQUARE,
+ HEAVY_EDGE: SQUARE,
+ HEAVY_HEAD: SQUARE,
+}
+
+# Map headed boxes to their headerless equivalents
+PLAIN_HEADED_SUBSTITUTIONS = {
+ HEAVY_HEAD: SQUARE,
+ SQUARE_DOUBLE_HEAD: SQUARE,
+ MINIMAL_DOUBLE_HEAD: MINIMAL,
+ MINIMAL_HEAVY_HEAD: MINIMAL,
+ ASCII_DOUBLE_HEAD: ASCII2,
+}
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.columns import Columns
+ from pip._vendor.rich.panel import Panel
+
+ from . import box as box
+ from .console import Console
+ from .table import Table
+ from .text import Text
+
+ console = Console(record=True)
+
+ BOXES = [
+ "ASCII",
+ "ASCII2",
+ "ASCII_DOUBLE_HEAD",
+ "SQUARE",
+ "SQUARE_DOUBLE_HEAD",
+ "MINIMAL",
+ "MINIMAL_HEAVY_HEAD",
+ "MINIMAL_DOUBLE_HEAD",
+ "SIMPLE",
+ "SIMPLE_HEAD",
+ "SIMPLE_HEAVY",
+ "HORIZONTALS",
+ "ROUNDED",
+ "HEAVY",
+ "HEAVY_EDGE",
+ "HEAVY_HEAD",
+ "DOUBLE",
+ "DOUBLE_EDGE",
+ "MARKDOWN",
+ ]
+
+ console.print(Panel("[bold green]Box Constants", style="green"), justify="center")
+ console.print()
+
+ columns = Columns(expand=True, padding=2)
+ for box_name in sorted(BOXES):
+ table = Table(
+ show_footer=True, style="dim", border_style="not dim", expand=True
+ )
+ table.add_column("Header 1", "Footer 1")
+ table.add_column("Header 2", "Footer 2")
+ table.add_row("Cell", "Cell")
+ table.add_row("Cell", "Cell")
+ table.box = getattr(box, box_name)
+ table.title = Text(f"box.{box_name}", style="magenta")
+ columns.add_renderable(table)
+ console.print(columns)
+
+ # console.save_svg("box.svg")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/cells.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/cells.py
new file mode 100644
index 000000000..f85f928f7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/cells.py
@@ -0,0 +1,167 @@
+from __future__ import annotations
+
+import re
+from functools import lru_cache
+from typing import Callable
+
+from ._cell_widths import CELL_WIDTHS
+
+# Regex to match sequence of the most common character ranges
+_is_single_cell_widths = re.compile("^[\u0020-\u006f\u00a0\u02ff\u0370-\u0482]*$").match
+
+
+@lru_cache(4096)
+def cached_cell_len(text: str) -> int:
+ """Get the number of cells required to display text.
+
+ This method always caches, which may use up a lot of memory. It is recommended to use
+ `cell_len` over this method.
+
+ Args:
+ text (str): Text to display.
+
+ Returns:
+ int: Get the number of cells required to display text.
+ """
+ _get_size = get_character_cell_size
+ total_size = sum(_get_size(character) for character in text)
+ return total_size
+
+
+def cell_len(text: str, _cell_len: Callable[[str], int] = cached_cell_len) -> int:
+ """Get the number of cells required to display text.
+
+ Args:
+ text (str): Text to display.
+
+ Returns:
+ int: Get the number of cells required to display text.
+ """
+ if len(text) < 512:
+ return _cell_len(text)
+ _get_size = get_character_cell_size
+ total_size = sum(_get_size(character) for character in text)
+ return total_size
+
+
+@lru_cache(maxsize=4096)
+def get_character_cell_size(character: str) -> int:
+ """Get the cell size of a character.
+
+ Args:
+ character (str): A single character.
+
+ Returns:
+ int: Number of cells (0, 1 or 2) occupied by that character.
+ """
+ return _get_codepoint_cell_size(ord(character))
+
+
+@lru_cache(maxsize=4096)
+def _get_codepoint_cell_size(codepoint: int) -> int:
+ """Get the cell size of a character.
+
+ Args:
+ codepoint (int): Codepoint of a character.
+
+ Returns:
+ int: Number of cells (0, 1 or 2) occupied by that character.
+ """
+
+ _table = CELL_WIDTHS
+ lower_bound = 0
+ upper_bound = len(_table) - 1
+ index = (lower_bound + upper_bound) // 2
+ while True:
+ start, end, width = _table[index]
+ if codepoint < start:
+ upper_bound = index - 1
+ elif codepoint > end:
+ lower_bound = index + 1
+ else:
+ return 0 if width == -1 else width
+ if upper_bound < lower_bound:
+ break
+ index = (lower_bound + upper_bound) // 2
+ return 1
+
+
+def set_cell_size(text: str, total: int) -> str:
+ """Set the length of a string to fit within given number of cells."""
+
+ if _is_single_cell_widths(text):
+ size = len(text)
+ if size < total:
+ return text + " " * (total - size)
+ return text[:total]
+
+ if total <= 0:
+ return ""
+ cell_size = cell_len(text)
+ if cell_size == total:
+ return text
+ if cell_size < total:
+ return text + " " * (total - cell_size)
+
+ start = 0
+ end = len(text)
+
+ # Binary search until we find the right size
+ while True:
+ pos = (start + end) // 2
+ before = text[: pos + 1]
+ before_len = cell_len(before)
+ if before_len == total + 1 and cell_len(before[-1]) == 2:
+ return before[:-1] + " "
+ if before_len == total:
+ return before
+ if before_len > total:
+ end = pos
+ else:
+ start = pos
+
+
+def chop_cells(
+ text: str,
+ width: int,
+) -> list[str]:
+ """Split text into lines such that each line fits within the available (cell) width.
+
+ Args:
+ text: The text to fold such that it fits in the given width.
+ width: The width available (number of cells).
+
+ Returns:
+ A list of strings such that each string in the list has cell width
+ less than or equal to the available width.
+ """
+ _get_character_cell_size = get_character_cell_size
+ lines: list[list[str]] = [[]]
+
+ append_new_line = lines.append
+ append_to_last_line = lines[-1].append
+
+ total_width = 0
+
+ for character in text:
+ cell_width = _get_character_cell_size(character)
+ char_doesnt_fit = total_width + cell_width > width
+
+ if char_doesnt_fit:
+ append_new_line([character])
+ append_to_last_line = lines[-1].append
+ total_width = cell_width
+ else:
+ append_to_last_line(character)
+ total_width += cell_width
+
+ return ["".join(line) for line in lines]
+
+
+if __name__ == "__main__": # pragma: no cover
+ print(get_character_cell_size("😽"))
+ for line in chop_cells("""这是对亚洲语言支持的测试。面对模棱两可的想法,拒绝猜测的诱惑。""", 8):
+ print(line)
+ for n in range(80, 1, -1):
+ print(set_cell_size("""这是对亚洲语言支持的测试。面对模棱两可的想法,拒绝猜测的诱惑。""", n) + "|")
+ print("x" * n)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/color.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/color.py
new file mode 100644
index 000000000..4270a278d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/color.py
@@ -0,0 +1,621 @@
+import platform
+import re
+from colorsys import rgb_to_hls
+from enum import IntEnum
+from functools import lru_cache
+from typing import TYPE_CHECKING, NamedTuple, Optional, Tuple
+
+from ._palettes import EIGHT_BIT_PALETTE, STANDARD_PALETTE, WINDOWS_PALETTE
+from .color_triplet import ColorTriplet
+from .repr import Result, rich_repr
+from .terminal_theme import DEFAULT_TERMINAL_THEME
+
+if TYPE_CHECKING: # pragma: no cover
+ from .terminal_theme import TerminalTheme
+ from .text import Text
+
+
+WINDOWS = platform.system() == "Windows"
+
+
+class ColorSystem(IntEnum):
+ """One of the 3 color system supported by terminals."""
+
+ STANDARD = 1
+ EIGHT_BIT = 2
+ TRUECOLOR = 3
+ WINDOWS = 4
+
+ def __repr__(self) -> str:
+ return f"ColorSystem.{self.name}"
+
+ def __str__(self) -> str:
+ return repr(self)
+
+
+class ColorType(IntEnum):
+ """Type of color stored in Color class."""
+
+ DEFAULT = 0
+ STANDARD = 1
+ EIGHT_BIT = 2
+ TRUECOLOR = 3
+ WINDOWS = 4
+
+ def __repr__(self) -> str:
+ return f"ColorType.{self.name}"
+
+
+ANSI_COLOR_NAMES = {
+ "black": 0,
+ "red": 1,
+ "green": 2,
+ "yellow": 3,
+ "blue": 4,
+ "magenta": 5,
+ "cyan": 6,
+ "white": 7,
+ "bright_black": 8,
+ "bright_red": 9,
+ "bright_green": 10,
+ "bright_yellow": 11,
+ "bright_blue": 12,
+ "bright_magenta": 13,
+ "bright_cyan": 14,
+ "bright_white": 15,
+ "grey0": 16,
+ "gray0": 16,
+ "navy_blue": 17,
+ "dark_blue": 18,
+ "blue3": 20,
+ "blue1": 21,
+ "dark_green": 22,
+ "deep_sky_blue4": 25,
+ "dodger_blue3": 26,
+ "dodger_blue2": 27,
+ "green4": 28,
+ "spring_green4": 29,
+ "turquoise4": 30,
+ "deep_sky_blue3": 32,
+ "dodger_blue1": 33,
+ "green3": 40,
+ "spring_green3": 41,
+ "dark_cyan": 36,
+ "light_sea_green": 37,
+ "deep_sky_blue2": 38,
+ "deep_sky_blue1": 39,
+ "spring_green2": 47,
+ "cyan3": 43,
+ "dark_turquoise": 44,
+ "turquoise2": 45,
+ "green1": 46,
+ "spring_green1": 48,
+ "medium_spring_green": 49,
+ "cyan2": 50,
+ "cyan1": 51,
+ "dark_red": 88,
+ "deep_pink4": 125,
+ "purple4": 55,
+ "purple3": 56,
+ "blue_violet": 57,
+ "orange4": 94,
+ "grey37": 59,
+ "gray37": 59,
+ "medium_purple4": 60,
+ "slate_blue3": 62,
+ "royal_blue1": 63,
+ "chartreuse4": 64,
+ "dark_sea_green4": 71,
+ "pale_turquoise4": 66,
+ "steel_blue": 67,
+ "steel_blue3": 68,
+ "cornflower_blue": 69,
+ "chartreuse3": 76,
+ "cadet_blue": 73,
+ "sky_blue3": 74,
+ "steel_blue1": 81,
+ "pale_green3": 114,
+ "sea_green3": 78,
+ "aquamarine3": 79,
+ "medium_turquoise": 80,
+ "chartreuse2": 112,
+ "sea_green2": 83,
+ "sea_green1": 85,
+ "aquamarine1": 122,
+ "dark_slate_gray2": 87,
+ "dark_magenta": 91,
+ "dark_violet": 128,
+ "purple": 129,
+ "light_pink4": 95,
+ "plum4": 96,
+ "medium_purple3": 98,
+ "slate_blue1": 99,
+ "yellow4": 106,
+ "wheat4": 101,
+ "grey53": 102,
+ "gray53": 102,
+ "light_slate_grey": 103,
+ "light_slate_gray": 103,
+ "medium_purple": 104,
+ "light_slate_blue": 105,
+ "dark_olive_green3": 149,
+ "dark_sea_green": 108,
+ "light_sky_blue3": 110,
+ "sky_blue2": 111,
+ "dark_sea_green3": 150,
+ "dark_slate_gray3": 116,
+ "sky_blue1": 117,
+ "chartreuse1": 118,
+ "light_green": 120,
+ "pale_green1": 156,
+ "dark_slate_gray1": 123,
+ "red3": 160,
+ "medium_violet_red": 126,
+ "magenta3": 164,
+ "dark_orange3": 166,
+ "indian_red": 167,
+ "hot_pink3": 168,
+ "medium_orchid3": 133,
+ "medium_orchid": 134,
+ "medium_purple2": 140,
+ "dark_goldenrod": 136,
+ "light_salmon3": 173,
+ "rosy_brown": 138,
+ "grey63": 139,
+ "gray63": 139,
+ "medium_purple1": 141,
+ "gold3": 178,
+ "dark_khaki": 143,
+ "navajo_white3": 144,
+ "grey69": 145,
+ "gray69": 145,
+ "light_steel_blue3": 146,
+ "light_steel_blue": 147,
+ "yellow3": 184,
+ "dark_sea_green2": 157,
+ "light_cyan3": 152,
+ "light_sky_blue1": 153,
+ "green_yellow": 154,
+ "dark_olive_green2": 155,
+ "dark_sea_green1": 193,
+ "pale_turquoise1": 159,
+ "deep_pink3": 162,
+ "magenta2": 200,
+ "hot_pink2": 169,
+ "orchid": 170,
+ "medium_orchid1": 207,
+ "orange3": 172,
+ "light_pink3": 174,
+ "pink3": 175,
+ "plum3": 176,
+ "violet": 177,
+ "light_goldenrod3": 179,
+ "tan": 180,
+ "misty_rose3": 181,
+ "thistle3": 182,
+ "plum2": 183,
+ "khaki3": 185,
+ "light_goldenrod2": 222,
+ "light_yellow3": 187,
+ "grey84": 188,
+ "gray84": 188,
+ "light_steel_blue1": 189,
+ "yellow2": 190,
+ "dark_olive_green1": 192,
+ "honeydew2": 194,
+ "light_cyan1": 195,
+ "red1": 196,
+ "deep_pink2": 197,
+ "deep_pink1": 199,
+ "magenta1": 201,
+ "orange_red1": 202,
+ "indian_red1": 204,
+ "hot_pink": 206,
+ "dark_orange": 208,
+ "salmon1": 209,
+ "light_coral": 210,
+ "pale_violet_red1": 211,
+ "orchid2": 212,
+ "orchid1": 213,
+ "orange1": 214,
+ "sandy_brown": 215,
+ "light_salmon1": 216,
+ "light_pink1": 217,
+ "pink1": 218,
+ "plum1": 219,
+ "gold1": 220,
+ "navajo_white1": 223,
+ "misty_rose1": 224,
+ "thistle1": 225,
+ "yellow1": 226,
+ "light_goldenrod1": 227,
+ "khaki1": 228,
+ "wheat1": 229,
+ "cornsilk1": 230,
+ "grey100": 231,
+ "gray100": 231,
+ "grey3": 232,
+ "gray3": 232,
+ "grey7": 233,
+ "gray7": 233,
+ "grey11": 234,
+ "gray11": 234,
+ "grey15": 235,
+ "gray15": 235,
+ "grey19": 236,
+ "gray19": 236,
+ "grey23": 237,
+ "gray23": 237,
+ "grey27": 238,
+ "gray27": 238,
+ "grey30": 239,
+ "gray30": 239,
+ "grey35": 240,
+ "gray35": 240,
+ "grey39": 241,
+ "gray39": 241,
+ "grey42": 242,
+ "gray42": 242,
+ "grey46": 243,
+ "gray46": 243,
+ "grey50": 244,
+ "gray50": 244,
+ "grey54": 245,
+ "gray54": 245,
+ "grey58": 246,
+ "gray58": 246,
+ "grey62": 247,
+ "gray62": 247,
+ "grey66": 248,
+ "gray66": 248,
+ "grey70": 249,
+ "gray70": 249,
+ "grey74": 250,
+ "gray74": 250,
+ "grey78": 251,
+ "gray78": 251,
+ "grey82": 252,
+ "gray82": 252,
+ "grey85": 253,
+ "gray85": 253,
+ "grey89": 254,
+ "gray89": 254,
+ "grey93": 255,
+ "gray93": 255,
+}
+
+
+class ColorParseError(Exception):
+ """The color could not be parsed."""
+
+
+RE_COLOR = re.compile(
+ r"""^
+\#([0-9a-f]{6})$|
+color\(([0-9]{1,3})\)$|
+rgb\(([\d\s,]+)\)$
+""",
+ re.VERBOSE,
+)
+
+
+@rich_repr
+class Color(NamedTuple):
+ """Terminal color definition."""
+
+ name: str
+ """The name of the color (typically the input to Color.parse)."""
+ type: ColorType
+ """The type of the color."""
+ number: Optional[int] = None
+ """The color number, if a standard color, or None."""
+ triplet: Optional[ColorTriplet] = None
+ """A triplet of color components, if an RGB color."""
+
+ def __rich__(self) -> "Text":
+ """Displays the actual color if Rich printed."""
+ from .style import Style
+ from .text import Text
+
+ return Text.assemble(
+ f"<color {self.name!r} ({self.type.name.lower()})",
+ ("⬤", Style(color=self)),
+ " >",
+ )
+
+ def __rich_repr__(self) -> Result:
+ yield self.name
+ yield self.type
+ yield "number", self.number, None
+ yield "triplet", self.triplet, None
+
+ @property
+ def system(self) -> ColorSystem:
+ """Get the native color system for this color."""
+ if self.type == ColorType.DEFAULT:
+ return ColorSystem.STANDARD
+ return ColorSystem(int(self.type))
+
+ @property
+ def is_system_defined(self) -> bool:
+ """Check if the color is ultimately defined by the system."""
+ return self.system not in (ColorSystem.EIGHT_BIT, ColorSystem.TRUECOLOR)
+
+ @property
+ def is_default(self) -> bool:
+ """Check if the color is a default color."""
+ return self.type == ColorType.DEFAULT
+
+ def get_truecolor(
+ self, theme: Optional["TerminalTheme"] = None, foreground: bool = True
+ ) -> ColorTriplet:
+ """Get an equivalent color triplet for this color.
+
+ Args:
+ theme (TerminalTheme, optional): Optional terminal theme, or None to use default. Defaults to None.
+ foreground (bool, optional): True for a foreground color, or False for background. Defaults to True.
+
+ Returns:
+ ColorTriplet: A color triplet containing RGB components.
+ """
+
+ if theme is None:
+ theme = DEFAULT_TERMINAL_THEME
+ if self.type == ColorType.TRUECOLOR:
+ assert self.triplet is not None
+ return self.triplet
+ elif self.type == ColorType.EIGHT_BIT:
+ assert self.number is not None
+ return EIGHT_BIT_PALETTE[self.number]
+ elif self.type == ColorType.STANDARD:
+ assert self.number is not None
+ return theme.ansi_colors[self.number]
+ elif self.type == ColorType.WINDOWS:
+ assert self.number is not None
+ return WINDOWS_PALETTE[self.number]
+ else: # self.type == ColorType.DEFAULT:
+ assert self.number is None
+ return theme.foreground_color if foreground else theme.background_color
+
+ @classmethod
+ def from_ansi(cls, number: int) -> "Color":
+ """Create a Color number from it's 8-bit ansi number.
+
+ Args:
+ number (int): A number between 0-255 inclusive.
+
+ Returns:
+ Color: A new Color instance.
+ """
+ return cls(
+ name=f"color({number})",
+ type=(ColorType.STANDARD if number < 16 else ColorType.EIGHT_BIT),
+ number=number,
+ )
+
+ @classmethod
+ def from_triplet(cls, triplet: "ColorTriplet") -> "Color":
+ """Create a truecolor RGB color from a triplet of values.
+
+ Args:
+ triplet (ColorTriplet): A color triplet containing red, green and blue components.
+
+ Returns:
+ Color: A new color object.
+ """
+ return cls(name=triplet.hex, type=ColorType.TRUECOLOR, triplet=triplet)
+
+ @classmethod
+ def from_rgb(cls, red: float, green: float, blue: float) -> "Color":
+ """Create a truecolor from three color components in the range(0->255).
+
+ Args:
+ red (float): Red component in range 0-255.
+ green (float): Green component in range 0-255.
+ blue (float): Blue component in range 0-255.
+
+ Returns:
+ Color: A new color object.
+ """
+ return cls.from_triplet(ColorTriplet(int(red), int(green), int(blue)))
+
+ @classmethod
+ def default(cls) -> "Color":
+ """Get a Color instance representing the default color.
+
+ Returns:
+ Color: Default color.
+ """
+ return cls(name="default", type=ColorType.DEFAULT)
+
+ @classmethod
+ @lru_cache(maxsize=1024)
+ def parse(cls, color: str) -> "Color":
+ """Parse a color definition."""
+ original_color = color
+ color = color.lower().strip()
+
+ if color == "default":
+ return cls(color, type=ColorType.DEFAULT)
+
+ color_number = ANSI_COLOR_NAMES.get(color)
+ if color_number is not None:
+ return cls(
+ color,
+ type=(ColorType.STANDARD if color_number < 16 else ColorType.EIGHT_BIT),
+ number=color_number,
+ )
+
+ color_match = RE_COLOR.match(color)
+ if color_match is None:
+ raise ColorParseError(f"{original_color!r} is not a valid color")
+
+ color_24, color_8, color_rgb = color_match.groups()
+ if color_24:
+ triplet = ColorTriplet(
+ int(color_24[0:2], 16), int(color_24[2:4], 16), int(color_24[4:6], 16)
+ )
+ return cls(color, ColorType.TRUECOLOR, triplet=triplet)
+
+ elif color_8:
+ number = int(color_8)
+ if number > 255:
+ raise ColorParseError(f"color number must be <= 255 in {color!r}")
+ return cls(
+ color,
+ type=(ColorType.STANDARD if number < 16 else ColorType.EIGHT_BIT),
+ number=number,
+ )
+
+ else: # color_rgb:
+ components = color_rgb.split(",")
+ if len(components) != 3:
+ raise ColorParseError(
+ f"expected three components in {original_color!r}"
+ )
+ red, green, blue = components
+ triplet = ColorTriplet(int(red), int(green), int(blue))
+ if not all(component <= 255 for component in triplet):
+ raise ColorParseError(
+ f"color components must be <= 255 in {original_color!r}"
+ )
+ return cls(color, ColorType.TRUECOLOR, triplet=triplet)
+
+ @lru_cache(maxsize=1024)
+ def get_ansi_codes(self, foreground: bool = True) -> Tuple[str, ...]:
+ """Get the ANSI escape codes for this color."""
+ _type = self.type
+ if _type == ColorType.DEFAULT:
+ return ("39" if foreground else "49",)
+
+ elif _type == ColorType.WINDOWS:
+ number = self.number
+ assert number is not None
+ fore, back = (30, 40) if number < 8 else (82, 92)
+ return (str(fore + number if foreground else back + number),)
+
+ elif _type == ColorType.STANDARD:
+ number = self.number
+ assert number is not None
+ fore, back = (30, 40) if number < 8 else (82, 92)
+ return (str(fore + number if foreground else back + number),)
+
+ elif _type == ColorType.EIGHT_BIT:
+ assert self.number is not None
+ return ("38" if foreground else "48", "5", str(self.number))
+
+ else: # self.standard == ColorStandard.TRUECOLOR:
+ assert self.triplet is not None
+ red, green, blue = self.triplet
+ return ("38" if foreground else "48", "2", str(red), str(green), str(blue))
+
+ @lru_cache(maxsize=1024)
+ def downgrade(self, system: ColorSystem) -> "Color":
+ """Downgrade a color system to a system with fewer colors."""
+
+ if self.type in (ColorType.DEFAULT, system):
+ return self
+ # Convert to 8-bit color from truecolor color
+ if system == ColorSystem.EIGHT_BIT and self.system == ColorSystem.TRUECOLOR:
+ assert self.triplet is not None
+ _h, l, s = rgb_to_hls(*self.triplet.normalized)
+ # If saturation is under 15% assume it is grayscale
+ if s < 0.15:
+ gray = round(l * 25.0)
+ if gray == 0:
+ color_number = 16
+ elif gray == 25:
+ color_number = 231
+ else:
+ color_number = 231 + gray
+ return Color(self.name, ColorType.EIGHT_BIT, number=color_number)
+
+ red, green, blue = self.triplet
+ six_red = red / 95 if red < 95 else 1 + (red - 95) / 40
+ six_green = green / 95 if green < 95 else 1 + (green - 95) / 40
+ six_blue = blue / 95 if blue < 95 else 1 + (blue - 95) / 40
+
+ color_number = (
+ 16 + 36 * round(six_red) + 6 * round(six_green) + round(six_blue)
+ )
+ return Color(self.name, ColorType.EIGHT_BIT, number=color_number)
+
+ # Convert to standard from truecolor or 8-bit
+ elif system == ColorSystem.STANDARD:
+ if self.system == ColorSystem.TRUECOLOR:
+ assert self.triplet is not None
+ triplet = self.triplet
+ else: # self.system == ColorSystem.EIGHT_BIT
+ assert self.number is not None
+ triplet = ColorTriplet(*EIGHT_BIT_PALETTE[self.number])
+
+ color_number = STANDARD_PALETTE.match(triplet)
+ return Color(self.name, ColorType.STANDARD, number=color_number)
+
+ elif system == ColorSystem.WINDOWS:
+ if self.system == ColorSystem.TRUECOLOR:
+ assert self.triplet is not None
+ triplet = self.triplet
+ else: # self.system == ColorSystem.EIGHT_BIT
+ assert self.number is not None
+ if self.number < 16:
+ return Color(self.name, ColorType.WINDOWS, number=self.number)
+ triplet = ColorTriplet(*EIGHT_BIT_PALETTE[self.number])
+
+ color_number = WINDOWS_PALETTE.match(triplet)
+ return Color(self.name, ColorType.WINDOWS, number=color_number)
+
+ return self
+
+
+def parse_rgb_hex(hex_color: str) -> ColorTriplet:
+ """Parse six hex characters in to RGB triplet."""
+ assert len(hex_color) == 6, "must be 6 characters"
+ color = ColorTriplet(
+ int(hex_color[0:2], 16), int(hex_color[2:4], 16), int(hex_color[4:6], 16)
+ )
+ return color
+
+
+def blend_rgb(
+ color1: ColorTriplet, color2: ColorTriplet, cross_fade: float = 0.5
+) -> ColorTriplet:
+ """Blend one RGB color in to another."""
+ r1, g1, b1 = color1
+ r2, g2, b2 = color2
+ new_color = ColorTriplet(
+ int(r1 + (r2 - r1) * cross_fade),
+ int(g1 + (g2 - g1) * cross_fade),
+ int(b1 + (b2 - b1) * cross_fade),
+ )
+ return new_color
+
+
+if __name__ == "__main__": # pragma: no cover
+ from .console import Console
+ from .table import Table
+ from .text import Text
+
+ console = Console()
+
+ table = Table(show_footer=False, show_edge=True)
+ table.add_column("Color", width=10, overflow="ellipsis")
+ table.add_column("Number", justify="right", style="yellow")
+ table.add_column("Name", style="green")
+ table.add_column("Hex", style="blue")
+ table.add_column("RGB", style="magenta")
+
+ colors = sorted((v, k) for k, v in ANSI_COLOR_NAMES.items())
+ for color_number, name in colors:
+ if "grey" in name:
+ continue
+ color_cell = Text(" " * 10, style=f"on {name}")
+ if color_number < 16:
+ table.add_row(color_cell, f"{color_number}", Text(f'"{name}"'))
+ else:
+ color = EIGHT_BIT_PALETTE[color_number] # type: ignore[has-type]
+ table.add_row(
+ color_cell, str(color_number), Text(f'"{name}"'), color.hex, color.rgb
+ )
+
+ console.print(table)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/color_triplet.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/color_triplet.py
new file mode 100644
index 000000000..02cab3282
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/color_triplet.py
@@ -0,0 +1,38 @@
+from typing import NamedTuple, Tuple
+
+
+class ColorTriplet(NamedTuple):
+ """The red, green, and blue components of a color."""
+
+ red: int
+ """Red component in 0 to 255 range."""
+ green: int
+ """Green component in 0 to 255 range."""
+ blue: int
+ """Blue component in 0 to 255 range."""
+
+ @property
+ def hex(self) -> str:
+ """get the color triplet in CSS style."""
+ red, green, blue = self
+ return f"#{red:02x}{green:02x}{blue:02x}"
+
+ @property
+ def rgb(self) -> str:
+ """The color in RGB format.
+
+ Returns:
+ str: An rgb color, e.g. ``"rgb(100,23,255)"``.
+ """
+ red, green, blue = self
+ return f"rgb({red},{green},{blue})"
+
+ @property
+ def normalized(self) -> Tuple[float, float, float]:
+ """Convert components into floats between 0 and 1.
+
+ Returns:
+ Tuple[float, float, float]: A tuple of three normalized colour components.
+ """
+ red, green, blue = self
+ return red / 255.0, green / 255.0, blue / 255.0
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/columns.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/columns.py
new file mode 100644
index 000000000..669a3a707
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/columns.py
@@ -0,0 +1,187 @@
+from collections import defaultdict
+from itertools import chain
+from operator import itemgetter
+from typing import Dict, Iterable, List, Optional, Tuple
+
+from .align import Align, AlignMethod
+from .console import Console, ConsoleOptions, RenderableType, RenderResult
+from .constrain import Constrain
+from .measure import Measurement
+from .padding import Padding, PaddingDimensions
+from .table import Table
+from .text import TextType
+from .jupyter import JupyterMixin
+
+
+class Columns(JupyterMixin):
+ """Display renderables in neat columns.
+
+ Args:
+ renderables (Iterable[RenderableType]): Any number of Rich renderables (including str).
+ width (int, optional): The desired width of the columns, or None to auto detect. Defaults to None.
+ padding (PaddingDimensions, optional): Optional padding around cells. Defaults to (0, 1).
+ expand (bool, optional): Expand columns to full width. Defaults to False.
+ equal (bool, optional): Arrange in to equal sized columns. Defaults to False.
+ column_first (bool, optional): Align items from top to bottom (rather than left to right). Defaults to False.
+ right_to_left (bool, optional): Start column from right hand side. Defaults to False.
+ align (str, optional): Align value ("left", "right", or "center") or None for default. Defaults to None.
+ title (TextType, optional): Optional title for Columns.
+ """
+
+ def __init__(
+ self,
+ renderables: Optional[Iterable[RenderableType]] = None,
+ padding: PaddingDimensions = (0, 1),
+ *,
+ width: Optional[int] = None,
+ expand: bool = False,
+ equal: bool = False,
+ column_first: bool = False,
+ right_to_left: bool = False,
+ align: Optional[AlignMethod] = None,
+ title: Optional[TextType] = None,
+ ) -> None:
+ self.renderables = list(renderables or [])
+ self.width = width
+ self.padding = padding
+ self.expand = expand
+ self.equal = equal
+ self.column_first = column_first
+ self.right_to_left = right_to_left
+ self.align: Optional[AlignMethod] = align
+ self.title = title
+
+ def add_renderable(self, renderable: RenderableType) -> None:
+ """Add a renderable to the columns.
+
+ Args:
+ renderable (RenderableType): Any renderable object.
+ """
+ self.renderables.append(renderable)
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ render_str = console.render_str
+ renderables = [
+ render_str(renderable) if isinstance(renderable, str) else renderable
+ for renderable in self.renderables
+ ]
+ if not renderables:
+ return
+ _top, right, _bottom, left = Padding.unpack(self.padding)
+ width_padding = max(left, right)
+ max_width = options.max_width
+ widths: Dict[int, int] = defaultdict(int)
+ column_count = len(renderables)
+
+ get_measurement = Measurement.get
+ renderable_widths = [
+ get_measurement(console, options, renderable).maximum
+ for renderable in renderables
+ ]
+ if self.equal:
+ renderable_widths = [max(renderable_widths)] * len(renderable_widths)
+
+ def iter_renderables(
+ column_count: int,
+ ) -> Iterable[Tuple[int, Optional[RenderableType]]]:
+ item_count = len(renderables)
+ if self.column_first:
+ width_renderables = list(zip(renderable_widths, renderables))
+
+ column_lengths: List[int] = [item_count // column_count] * column_count
+ for col_no in range(item_count % column_count):
+ column_lengths[col_no] += 1
+
+ row_count = (item_count + column_count - 1) // column_count
+ cells = [[-1] * column_count for _ in range(row_count)]
+ row = col = 0
+ for index in range(item_count):
+ cells[row][col] = index
+ column_lengths[col] -= 1
+ if column_lengths[col]:
+ row += 1
+ else:
+ col += 1
+ row = 0
+ for index in chain.from_iterable(cells):
+ if index == -1:
+ break
+ yield width_renderables[index]
+ else:
+ yield from zip(renderable_widths, renderables)
+ # Pad odd elements with spaces
+ if item_count % column_count:
+ for _ in range(column_count - (item_count % column_count)):
+ yield 0, None
+
+ table = Table.grid(padding=self.padding, collapse_padding=True, pad_edge=False)
+ table.expand = self.expand
+ table.title = self.title
+
+ if self.width is not None:
+ column_count = (max_width) // (self.width + width_padding)
+ for _ in range(column_count):
+ table.add_column(width=self.width)
+ else:
+ while column_count > 1:
+ widths.clear()
+ column_no = 0
+ for renderable_width, _ in iter_renderables(column_count):
+ widths[column_no] = max(widths[column_no], renderable_width)
+ total_width = sum(widths.values()) + width_padding * (
+ len(widths) - 1
+ )
+ if total_width > max_width:
+ column_count = len(widths) - 1
+ break
+ else:
+ column_no = (column_no + 1) % column_count
+ else:
+ break
+
+ get_renderable = itemgetter(1)
+ _renderables = [
+ get_renderable(_renderable)
+ for _renderable in iter_renderables(column_count)
+ ]
+ if self.equal:
+ _renderables = [
+ None
+ if renderable is None
+ else Constrain(renderable, renderable_widths[0])
+ for renderable in _renderables
+ ]
+ if self.align:
+ align = self.align
+ _Align = Align
+ _renderables = [
+ None if renderable is None else _Align(renderable, align)
+ for renderable in _renderables
+ ]
+
+ right_to_left = self.right_to_left
+ add_row = table.add_row
+ for start in range(0, len(_renderables), column_count):
+ row = _renderables[start : start + column_count]
+ if right_to_left:
+ row = row[::-1]
+ add_row(*row)
+ yield table
+
+
+if __name__ == "__main__": # pragma: no cover
+ import os
+
+ console = Console()
+
+ files = [f"{i} {s}" for i, s in enumerate(sorted(os.listdir()))]
+ columns = Columns(files, padding=(0, 1), expand=False, equal=False)
+ console.print(columns)
+ console.rule()
+ columns.column_first = True
+ console.print(columns)
+ columns.right_to_left = True
+ console.rule()
+ console.print(columns)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/console.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/console.py
new file mode 100644
index 000000000..a11c7c137
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/console.py
@@ -0,0 +1,2633 @@
+import inspect
+import os
+import platform
+import sys
+import threading
+import zlib
+from abc import ABC, abstractmethod
+from dataclasses import dataclass, field
+from datetime import datetime
+from functools import wraps
+from getpass import getpass
+from html import escape
+from inspect import isclass
+from itertools import islice
+from math import ceil
+from time import monotonic
+from types import FrameType, ModuleType, TracebackType
+from typing import (
+ IO,
+ TYPE_CHECKING,
+ Any,
+ Callable,
+ Dict,
+ Iterable,
+ List,
+ Mapping,
+ NamedTuple,
+ Optional,
+ TextIO,
+ Tuple,
+ Type,
+ Union,
+ cast,
+)
+
+from pip._vendor.rich._null_file import NULL_FILE
+
+if sys.version_info >= (3, 8):
+ from typing import Literal, Protocol, runtime_checkable
+else:
+ from pip._vendor.typing_extensions import (
+ Literal,
+ Protocol,
+ runtime_checkable,
+ ) # pragma: no cover
+
+from . import errors, themes
+from ._emoji_replace import _emoji_replace
+from ._export_format import CONSOLE_HTML_FORMAT, CONSOLE_SVG_FORMAT
+from ._fileno import get_fileno
+from ._log_render import FormatTimeCallable, LogRender
+from .align import Align, AlignMethod
+from .color import ColorSystem, blend_rgb
+from .control import Control
+from .emoji import EmojiVariant
+from .highlighter import NullHighlighter, ReprHighlighter
+from .markup import render as render_markup
+from .measure import Measurement, measure_renderables
+from .pager import Pager, SystemPager
+from .pretty import Pretty, is_expandable
+from .protocol import rich_cast
+from .region import Region
+from .scope import render_scope
+from .screen import Screen
+from .segment import Segment
+from .style import Style, StyleType
+from .styled import Styled
+from .terminal_theme import DEFAULT_TERMINAL_THEME, SVG_EXPORT_THEME, TerminalTheme
+from .text import Text, TextType
+from .theme import Theme, ThemeStack
+
+if TYPE_CHECKING:
+ from ._windows import WindowsConsoleFeatures
+ from .live import Live
+ from .status import Status
+
+JUPYTER_DEFAULT_COLUMNS = 115
+JUPYTER_DEFAULT_LINES = 100
+WINDOWS = platform.system() == "Windows"
+
+HighlighterType = Callable[[Union[str, "Text"]], "Text"]
+JustifyMethod = Literal["default", "left", "center", "right", "full"]
+OverflowMethod = Literal["fold", "crop", "ellipsis", "ignore"]
+
+
+class NoChange:
+ pass
+
+
+NO_CHANGE = NoChange()
+
+try:
+ _STDIN_FILENO = sys.__stdin__.fileno()
+except Exception:
+ _STDIN_FILENO = 0
+try:
+ _STDOUT_FILENO = sys.__stdout__.fileno()
+except Exception:
+ _STDOUT_FILENO = 1
+try:
+ _STDERR_FILENO = sys.__stderr__.fileno()
+except Exception:
+ _STDERR_FILENO = 2
+
+_STD_STREAMS = (_STDIN_FILENO, _STDOUT_FILENO, _STDERR_FILENO)
+_STD_STREAMS_OUTPUT = (_STDOUT_FILENO, _STDERR_FILENO)
+
+
+_TERM_COLORS = {
+ "kitty": ColorSystem.EIGHT_BIT,
+ "256color": ColorSystem.EIGHT_BIT,
+ "16color": ColorSystem.STANDARD,
+}
+
+
+class ConsoleDimensions(NamedTuple):
+ """Size of the terminal."""
+
+ width: int
+ """The width of the console in 'cells'."""
+ height: int
+ """The height of the console in lines."""
+
+
+@dataclass
+class ConsoleOptions:
+ """Options for __rich_console__ method."""
+
+ size: ConsoleDimensions
+ """Size of console."""
+ legacy_windows: bool
+ """legacy_windows: flag for legacy windows."""
+ min_width: int
+ """Minimum width of renderable."""
+ max_width: int
+ """Maximum width of renderable."""
+ is_terminal: bool
+ """True if the target is a terminal, otherwise False."""
+ encoding: str
+ """Encoding of terminal."""
+ max_height: int
+ """Height of container (starts as terminal)"""
+ justify: Optional[JustifyMethod] = None
+ """Justify value override for renderable."""
+ overflow: Optional[OverflowMethod] = None
+ """Overflow value override for renderable."""
+ no_wrap: Optional[bool] = False
+ """Disable wrapping for text."""
+ highlight: Optional[bool] = None
+ """Highlight override for render_str."""
+ markup: Optional[bool] = None
+ """Enable markup when rendering strings."""
+ height: Optional[int] = None
+
+ @property
+ def ascii_only(self) -> bool:
+ """Check if renderables should use ascii only."""
+ return not self.encoding.startswith("utf")
+
+ def copy(self) -> "ConsoleOptions":
+ """Return a copy of the options.
+
+ Returns:
+ ConsoleOptions: a copy of self.
+ """
+ options: ConsoleOptions = ConsoleOptions.__new__(ConsoleOptions)
+ options.__dict__ = self.__dict__.copy()
+ return options
+
+ def update(
+ self,
+ *,
+ width: Union[int, NoChange] = NO_CHANGE,
+ min_width: Union[int, NoChange] = NO_CHANGE,
+ max_width: Union[int, NoChange] = NO_CHANGE,
+ justify: Union[Optional[JustifyMethod], NoChange] = NO_CHANGE,
+ overflow: Union[Optional[OverflowMethod], NoChange] = NO_CHANGE,
+ no_wrap: Union[Optional[bool], NoChange] = NO_CHANGE,
+ highlight: Union[Optional[bool], NoChange] = NO_CHANGE,
+ markup: Union[Optional[bool], NoChange] = NO_CHANGE,
+ height: Union[Optional[int], NoChange] = NO_CHANGE,
+ ) -> "ConsoleOptions":
+ """Update values, return a copy."""
+ options = self.copy()
+ if not isinstance(width, NoChange):
+ options.min_width = options.max_width = max(0, width)
+ if not isinstance(min_width, NoChange):
+ options.min_width = min_width
+ if not isinstance(max_width, NoChange):
+ options.max_width = max_width
+ if not isinstance(justify, NoChange):
+ options.justify = justify
+ if not isinstance(overflow, NoChange):
+ options.overflow = overflow
+ if not isinstance(no_wrap, NoChange):
+ options.no_wrap = no_wrap
+ if not isinstance(highlight, NoChange):
+ options.highlight = highlight
+ if not isinstance(markup, NoChange):
+ options.markup = markup
+ if not isinstance(height, NoChange):
+ if height is not None:
+ options.max_height = height
+ options.height = None if height is None else max(0, height)
+ return options
+
+ def update_width(self, width: int) -> "ConsoleOptions":
+ """Update just the width, return a copy.
+
+ Args:
+ width (int): New width (sets both min_width and max_width)
+
+ Returns:
+ ~ConsoleOptions: New console options instance.
+ """
+ options = self.copy()
+ options.min_width = options.max_width = max(0, width)
+ return options
+
+ def update_height(self, height: int) -> "ConsoleOptions":
+ """Update the height, and return a copy.
+
+ Args:
+ height (int): New height
+
+ Returns:
+ ~ConsoleOptions: New Console options instance.
+ """
+ options = self.copy()
+ options.max_height = options.height = height
+ return options
+
+ def reset_height(self) -> "ConsoleOptions":
+ """Return a copy of the options with height set to ``None``.
+
+ Returns:
+ ~ConsoleOptions: New console options instance.
+ """
+ options = self.copy()
+ options.height = None
+ return options
+
+ def update_dimensions(self, width: int, height: int) -> "ConsoleOptions":
+ """Update the width and height, and return a copy.
+
+ Args:
+ width (int): New width (sets both min_width and max_width).
+ height (int): New height.
+
+ Returns:
+ ~ConsoleOptions: New console options instance.
+ """
+ options = self.copy()
+ options.min_width = options.max_width = max(0, width)
+ options.height = options.max_height = height
+ return options
+
+
+@runtime_checkable
+class RichCast(Protocol):
+ """An object that may be 'cast' to a console renderable."""
+
+ def __rich__(
+ self,
+ ) -> Union["ConsoleRenderable", "RichCast", str]: # pragma: no cover
+ ...
+
+
+@runtime_checkable
+class ConsoleRenderable(Protocol):
+ """An object that supports the console protocol."""
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult": # pragma: no cover
+ ...
+
+
+# A type that may be rendered by Console.
+RenderableType = Union[ConsoleRenderable, RichCast, str]
+"""A string or any object that may be rendered by Rich."""
+
+# The result of calling a __rich_console__ method.
+RenderResult = Iterable[Union[RenderableType, Segment]]
+
+_null_highlighter = NullHighlighter()
+
+
+class CaptureError(Exception):
+ """An error in the Capture context manager."""
+
+
+class NewLine:
+ """A renderable to generate new line(s)"""
+
+ def __init__(self, count: int = 1) -> None:
+ self.count = count
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Iterable[Segment]:
+ yield Segment("\n" * self.count)
+
+
+class ScreenUpdate:
+ """Render a list of lines at a given offset."""
+
+ def __init__(self, lines: List[List[Segment]], x: int, y: int) -> None:
+ self._lines = lines
+ self.x = x
+ self.y = y
+
+ def __rich_console__(
+ self, console: "Console", options: ConsoleOptions
+ ) -> RenderResult:
+ x = self.x
+ move_to = Control.move_to
+ for offset, line in enumerate(self._lines, self.y):
+ yield move_to(x, offset)
+ yield from line
+
+
+class Capture:
+ """Context manager to capture the result of printing to the console.
+ See :meth:`~rich.console.Console.capture` for how to use.
+
+ Args:
+ console (Console): A console instance to capture output.
+ """
+
+ def __init__(self, console: "Console") -> None:
+ self._console = console
+ self._result: Optional[str] = None
+
+ def __enter__(self) -> "Capture":
+ self._console.begin_capture()
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self._result = self._console.end_capture()
+
+ def get(self) -> str:
+ """Get the result of the capture."""
+ if self._result is None:
+ raise CaptureError(
+ "Capture result is not available until context manager exits."
+ )
+ return self._result
+
+
+class ThemeContext:
+ """A context manager to use a temporary theme. See :meth:`~rich.console.Console.use_theme` for usage."""
+
+ def __init__(self, console: "Console", theme: Theme, inherit: bool = True) -> None:
+ self.console = console
+ self.theme = theme
+ self.inherit = inherit
+
+ def __enter__(self) -> "ThemeContext":
+ self.console.push_theme(self.theme)
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.console.pop_theme()
+
+
+class PagerContext:
+ """A context manager that 'pages' content. See :meth:`~rich.console.Console.pager` for usage."""
+
+ def __init__(
+ self,
+ console: "Console",
+ pager: Optional[Pager] = None,
+ styles: bool = False,
+ links: bool = False,
+ ) -> None:
+ self._console = console
+ self.pager = SystemPager() if pager is None else pager
+ self.styles = styles
+ self.links = links
+
+ def __enter__(self) -> "PagerContext":
+ self._console._enter_buffer()
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ if exc_type is None:
+ with self._console._lock:
+ buffer: List[Segment] = self._console._buffer[:]
+ del self._console._buffer[:]
+ segments: Iterable[Segment] = buffer
+ if not self.styles:
+ segments = Segment.strip_styles(segments)
+ elif not self.links:
+ segments = Segment.strip_links(segments)
+ content = self._console._render_buffer(segments)
+ self.pager.show(content)
+ self._console._exit_buffer()
+
+
+class ScreenContext:
+ """A context manager that enables an alternative screen. See :meth:`~rich.console.Console.screen` for usage."""
+
+ def __init__(
+ self, console: "Console", hide_cursor: bool, style: StyleType = ""
+ ) -> None:
+ self.console = console
+ self.hide_cursor = hide_cursor
+ self.screen = Screen(style=style)
+ self._changed = False
+
+ def update(
+ self, *renderables: RenderableType, style: Optional[StyleType] = None
+ ) -> None:
+ """Update the screen.
+
+ Args:
+ renderable (RenderableType, optional): Optional renderable to replace current renderable,
+ or None for no change. Defaults to None.
+ style: (Style, optional): Replacement style, or None for no change. Defaults to None.
+ """
+ if renderables:
+ self.screen.renderable = (
+ Group(*renderables) if len(renderables) > 1 else renderables[0]
+ )
+ if style is not None:
+ self.screen.style = style
+ self.console.print(self.screen, end="")
+
+ def __enter__(self) -> "ScreenContext":
+ self._changed = self.console.set_alt_screen(True)
+ if self._changed and self.hide_cursor:
+ self.console.show_cursor(False)
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ if self._changed:
+ self.console.set_alt_screen(False)
+ if self.hide_cursor:
+ self.console.show_cursor(True)
+
+
+class Group:
+ """Takes a group of renderables and returns a renderable object that renders the group.
+
+ Args:
+ renderables (Iterable[RenderableType]): An iterable of renderable objects.
+ fit (bool, optional): Fit dimension of group to contents, or fill available space. Defaults to True.
+ """
+
+ def __init__(self, *renderables: "RenderableType", fit: bool = True) -> None:
+ self._renderables = renderables
+ self.fit = fit
+ self._render: Optional[List[RenderableType]] = None
+
+ @property
+ def renderables(self) -> List["RenderableType"]:
+ if self._render is None:
+ self._render = list(self._renderables)
+ return self._render
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ if self.fit:
+ return measure_renderables(console, options, self.renderables)
+ else:
+ return Measurement(options.max_width, options.max_width)
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> RenderResult:
+ yield from self.renderables
+
+
+def group(fit: bool = True) -> Callable[..., Callable[..., Group]]:
+ """A decorator that turns an iterable of renderables in to a group.
+
+ Args:
+ fit (bool, optional): Fit dimension of group to contents, or fill available space. Defaults to True.
+ """
+
+ def decorator(
+ method: Callable[..., Iterable[RenderableType]]
+ ) -> Callable[..., Group]:
+ """Convert a method that returns an iterable of renderables in to a Group."""
+
+ @wraps(method)
+ def _replace(*args: Any, **kwargs: Any) -> Group:
+ renderables = method(*args, **kwargs)
+ return Group(*renderables, fit=fit)
+
+ return _replace
+
+ return decorator
+
+
+def _is_jupyter() -> bool: # pragma: no cover
+ """Check if we're running in a Jupyter notebook."""
+ try:
+ get_ipython # type: ignore[name-defined]
+ except NameError:
+ return False
+ ipython = get_ipython() # type: ignore[name-defined]
+ shell = ipython.__class__.__name__
+ if (
+ "google.colab" in str(ipython.__class__)
+ or os.getenv("DATABRICKS_RUNTIME_VERSION")
+ or shell == "ZMQInteractiveShell"
+ ):
+ return True # Jupyter notebook or qtconsole
+ elif shell == "TerminalInteractiveShell":
+ return False # Terminal running IPython
+ else:
+ return False # Other type (?)
+
+
+COLOR_SYSTEMS = {
+ "standard": ColorSystem.STANDARD,
+ "256": ColorSystem.EIGHT_BIT,
+ "truecolor": ColorSystem.TRUECOLOR,
+ "windows": ColorSystem.WINDOWS,
+}
+
+_COLOR_SYSTEMS_NAMES = {system: name for name, system in COLOR_SYSTEMS.items()}
+
+
+@dataclass
+class ConsoleThreadLocals(threading.local):
+ """Thread local values for Console context."""
+
+ theme_stack: ThemeStack
+ buffer: List[Segment] = field(default_factory=list)
+ buffer_index: int = 0
+
+
+class RenderHook(ABC):
+ """Provides hooks in to the render process."""
+
+ @abstractmethod
+ def process_renderables(
+ self, renderables: List[ConsoleRenderable]
+ ) -> List[ConsoleRenderable]:
+ """Called with a list of objects to render.
+
+ This method can return a new list of renderables, or modify and return the same list.
+
+ Args:
+ renderables (List[ConsoleRenderable]): A number of renderable objects.
+
+ Returns:
+ List[ConsoleRenderable]: A replacement list of renderables.
+ """
+
+
+_windows_console_features: Optional["WindowsConsoleFeatures"] = None
+
+
+def get_windows_console_features() -> "WindowsConsoleFeatures": # pragma: no cover
+ global _windows_console_features
+ if _windows_console_features is not None:
+ return _windows_console_features
+ from ._windows import get_windows_console_features
+
+ _windows_console_features = get_windows_console_features()
+ return _windows_console_features
+
+
+def detect_legacy_windows() -> bool:
+ """Detect legacy Windows."""
+ return WINDOWS and not get_windows_console_features().vt
+
+
+class Console:
+ """A high level console interface.
+
+ Args:
+ color_system (str, optional): The color system supported by your terminal,
+ either ``"standard"``, ``"256"`` or ``"truecolor"``. Leave as ``"auto"`` to autodetect.
+ force_terminal (Optional[bool], optional): Enable/disable terminal control codes, or None to auto-detect terminal. Defaults to None.
+ force_jupyter (Optional[bool], optional): Enable/disable Jupyter rendering, or None to auto-detect Jupyter. Defaults to None.
+ force_interactive (Optional[bool], optional): Enable/disable interactive mode, or None to auto detect. Defaults to None.
+ soft_wrap (Optional[bool], optional): Set soft wrap default on print method. Defaults to False.
+ theme (Theme, optional): An optional style theme object, or ``None`` for default theme.
+ stderr (bool, optional): Use stderr rather than stdout if ``file`` is not specified. Defaults to False.
+ file (IO, optional): A file object where the console should write to. Defaults to stdout.
+ quiet (bool, Optional): Boolean to suppress all output. Defaults to False.
+ width (int, optional): The width of the terminal. Leave as default to auto-detect width.
+ height (int, optional): The height of the terminal. Leave as default to auto-detect height.
+ style (StyleType, optional): Style to apply to all output, or None for no style. Defaults to None.
+ no_color (Optional[bool], optional): Enabled no color mode, or None to auto detect. Defaults to None.
+ tab_size (int, optional): Number of spaces used to replace a tab character. Defaults to 8.
+ record (bool, optional): Boolean to enable recording of terminal output,
+ required to call :meth:`export_html`, :meth:`export_svg`, and :meth:`export_text`. Defaults to False.
+ markup (bool, optional): Boolean to enable :ref:`console_markup`. Defaults to True.
+ emoji (bool, optional): Enable emoji code. Defaults to True.
+ emoji_variant (str, optional): Optional emoji variant, either "text" or "emoji". Defaults to None.
+ highlight (bool, optional): Enable automatic highlighting. Defaults to True.
+ log_time (bool, optional): Boolean to enable logging of time by :meth:`log` methods. Defaults to True.
+ log_path (bool, optional): Boolean to enable the logging of the caller by :meth:`log`. Defaults to True.
+ log_time_format (Union[str, TimeFormatterCallable], optional): If ``log_time`` is enabled, either string for strftime or callable that formats the time. Defaults to "[%X] ".
+ highlighter (HighlighterType, optional): Default highlighter.
+ legacy_windows (bool, optional): Enable legacy Windows mode, or ``None`` to auto detect. Defaults to ``None``.
+ safe_box (bool, optional): Restrict box options that don't render on legacy Windows.
+ get_datetime (Callable[[], datetime], optional): Callable that gets the current time as a datetime.datetime object (used by Console.log),
+ or None for datetime.now.
+ get_time (Callable[[], time], optional): Callable that gets the current time in seconds, default uses time.monotonic.
+ """
+
+ _environ: Mapping[str, str] = os.environ
+
+ def __init__(
+ self,
+ *,
+ color_system: Optional[
+ Literal["auto", "standard", "256", "truecolor", "windows"]
+ ] = "auto",
+ force_terminal: Optional[bool] = None,
+ force_jupyter: Optional[bool] = None,
+ force_interactive: Optional[bool] = None,
+ soft_wrap: bool = False,
+ theme: Optional[Theme] = None,
+ stderr: bool = False,
+ file: Optional[IO[str]] = None,
+ quiet: bool = False,
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ style: Optional[StyleType] = None,
+ no_color: Optional[bool] = None,
+ tab_size: int = 8,
+ record: bool = False,
+ markup: bool = True,
+ emoji: bool = True,
+ emoji_variant: Optional[EmojiVariant] = None,
+ highlight: bool = True,
+ log_time: bool = True,
+ log_path: bool = True,
+ log_time_format: Union[str, FormatTimeCallable] = "[%X]",
+ highlighter: Optional["HighlighterType"] = ReprHighlighter(),
+ legacy_windows: Optional[bool] = None,
+ safe_box: bool = True,
+ get_datetime: Optional[Callable[[], datetime]] = None,
+ get_time: Optional[Callable[[], float]] = None,
+ _environ: Optional[Mapping[str, str]] = None,
+ ):
+ # Copy of os.environ allows us to replace it for testing
+ if _environ is not None:
+ self._environ = _environ
+
+ self.is_jupyter = _is_jupyter() if force_jupyter is None else force_jupyter
+ if self.is_jupyter:
+ if width is None:
+ jupyter_columns = self._environ.get("JUPYTER_COLUMNS")
+ if jupyter_columns is not None and jupyter_columns.isdigit():
+ width = int(jupyter_columns)
+ else:
+ width = JUPYTER_DEFAULT_COLUMNS
+ if height is None:
+ jupyter_lines = self._environ.get("JUPYTER_LINES")
+ if jupyter_lines is not None and jupyter_lines.isdigit():
+ height = int(jupyter_lines)
+ else:
+ height = JUPYTER_DEFAULT_LINES
+
+ self.tab_size = tab_size
+ self.record = record
+ self._markup = markup
+ self._emoji = emoji
+ self._emoji_variant: Optional[EmojiVariant] = emoji_variant
+ self._highlight = highlight
+ self.legacy_windows: bool = (
+ (detect_legacy_windows() and not self.is_jupyter)
+ if legacy_windows is None
+ else legacy_windows
+ )
+
+ if width is None:
+ columns = self._environ.get("COLUMNS")
+ if columns is not None and columns.isdigit():
+ width = int(columns) - self.legacy_windows
+ if height is None:
+ lines = self._environ.get("LINES")
+ if lines is not None and lines.isdigit():
+ height = int(lines)
+
+ self.soft_wrap = soft_wrap
+ self._width = width
+ self._height = height
+
+ self._color_system: Optional[ColorSystem]
+
+ self._force_terminal = None
+ if force_terminal is not None:
+ self._force_terminal = force_terminal
+
+ self._file = file
+ self.quiet = quiet
+ self.stderr = stderr
+
+ if color_system is None:
+ self._color_system = None
+ elif color_system == "auto":
+ self._color_system = self._detect_color_system()
+ else:
+ self._color_system = COLOR_SYSTEMS[color_system]
+
+ self._lock = threading.RLock()
+ self._log_render = LogRender(
+ show_time=log_time,
+ show_path=log_path,
+ time_format=log_time_format,
+ )
+ self.highlighter: HighlighterType = highlighter or _null_highlighter
+ self.safe_box = safe_box
+ self.get_datetime = get_datetime or datetime.now
+ self.get_time = get_time or monotonic
+ self.style = style
+ self.no_color = (
+ no_color if no_color is not None else "NO_COLOR" in self._environ
+ )
+ self.is_interactive = (
+ (self.is_terminal and not self.is_dumb_terminal)
+ if force_interactive is None
+ else force_interactive
+ )
+
+ self._record_buffer_lock = threading.RLock()
+ self._thread_locals = ConsoleThreadLocals(
+ theme_stack=ThemeStack(themes.DEFAULT if theme is None else theme)
+ )
+ self._record_buffer: List[Segment] = []
+ self._render_hooks: List[RenderHook] = []
+ self._live: Optional["Live"] = None
+ self._is_alt_screen = False
+
+ def __repr__(self) -> str:
+ return f"<console width={self.width} {self._color_system!s}>"
+
+ @property
+ def file(self) -> IO[str]:
+ """Get the file object to write to."""
+ file = self._file or (sys.stderr if self.stderr else sys.stdout)
+ file = getattr(file, "rich_proxied_file", file)
+ if file is None:
+ file = NULL_FILE
+ return file
+
+ @file.setter
+ def file(self, new_file: IO[str]) -> None:
+ """Set a new file object."""
+ self._file = new_file
+
+ @property
+ def _buffer(self) -> List[Segment]:
+ """Get a thread local buffer."""
+ return self._thread_locals.buffer
+
+ @property
+ def _buffer_index(self) -> int:
+ """Get a thread local buffer."""
+ return self._thread_locals.buffer_index
+
+ @_buffer_index.setter
+ def _buffer_index(self, value: int) -> None:
+ self._thread_locals.buffer_index = value
+
+ @property
+ def _theme_stack(self) -> ThemeStack:
+ """Get the thread local theme stack."""
+ return self._thread_locals.theme_stack
+
+ def _detect_color_system(self) -> Optional[ColorSystem]:
+ """Detect color system from env vars."""
+ if self.is_jupyter:
+ return ColorSystem.TRUECOLOR
+ if not self.is_terminal or self.is_dumb_terminal:
+ return None
+ if WINDOWS: # pragma: no cover
+ if self.legacy_windows: # pragma: no cover
+ return ColorSystem.WINDOWS
+ windows_console_features = get_windows_console_features()
+ return (
+ ColorSystem.TRUECOLOR
+ if windows_console_features.truecolor
+ else ColorSystem.EIGHT_BIT
+ )
+ else:
+ color_term = self._environ.get("COLORTERM", "").strip().lower()
+ if color_term in ("truecolor", "24bit"):
+ return ColorSystem.TRUECOLOR
+ term = self._environ.get("TERM", "").strip().lower()
+ _term_name, _hyphen, colors = term.rpartition("-")
+ color_system = _TERM_COLORS.get(colors, ColorSystem.STANDARD)
+ return color_system
+
+ def _enter_buffer(self) -> None:
+ """Enter in to a buffer context, and buffer all output."""
+ self._buffer_index += 1
+
+ def _exit_buffer(self) -> None:
+ """Leave buffer context, and render content if required."""
+ self._buffer_index -= 1
+ self._check_buffer()
+
+ def set_live(self, live: "Live") -> None:
+ """Set Live instance. Used by Live context manager.
+
+ Args:
+ live (Live): Live instance using this Console.
+
+ Raises:
+ errors.LiveError: If this Console has a Live context currently active.
+ """
+ with self._lock:
+ if self._live is not None:
+ raise errors.LiveError("Only one live display may be active at once")
+ self._live = live
+
+ def clear_live(self) -> None:
+ """Clear the Live instance."""
+ with self._lock:
+ self._live = None
+
+ def push_render_hook(self, hook: RenderHook) -> None:
+ """Add a new render hook to the stack.
+
+ Args:
+ hook (RenderHook): Render hook instance.
+ """
+ with self._lock:
+ self._render_hooks.append(hook)
+
+ def pop_render_hook(self) -> None:
+ """Pop the last renderhook from the stack."""
+ with self._lock:
+ self._render_hooks.pop()
+
+ def __enter__(self) -> "Console":
+ """Own context manager to enter buffer context."""
+ self._enter_buffer()
+ return self
+
+ def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:
+ """Exit buffer context."""
+ self._exit_buffer()
+
+ def begin_capture(self) -> None:
+ """Begin capturing console output. Call :meth:`end_capture` to exit capture mode and return output."""
+ self._enter_buffer()
+
+ def end_capture(self) -> str:
+ """End capture mode and return captured string.
+
+ Returns:
+ str: Console output.
+ """
+ render_result = self._render_buffer(self._buffer)
+ del self._buffer[:]
+ self._exit_buffer()
+ return render_result
+
+ def push_theme(self, theme: Theme, *, inherit: bool = True) -> None:
+ """Push a new theme on to the top of the stack, replacing the styles from the previous theme.
+ Generally speaking, you should call :meth:`~rich.console.Console.use_theme` to get a context manager, rather
+ than calling this method directly.
+
+ Args:
+ theme (Theme): A theme instance.
+ inherit (bool, optional): Inherit existing styles. Defaults to True.
+ """
+ self._theme_stack.push_theme(theme, inherit=inherit)
+
+ def pop_theme(self) -> None:
+ """Remove theme from top of stack, restoring previous theme."""
+ self._theme_stack.pop_theme()
+
+ def use_theme(self, theme: Theme, *, inherit: bool = True) -> ThemeContext:
+ """Use a different theme for the duration of the context manager.
+
+ Args:
+ theme (Theme): Theme instance to user.
+ inherit (bool, optional): Inherit existing console styles. Defaults to True.
+
+ Returns:
+ ThemeContext: [description]
+ """
+ return ThemeContext(self, theme, inherit)
+
+ @property
+ def color_system(self) -> Optional[str]:
+ """Get color system string.
+
+ Returns:
+ Optional[str]: "standard", "256" or "truecolor".
+ """
+
+ if self._color_system is not None:
+ return _COLOR_SYSTEMS_NAMES[self._color_system]
+ else:
+ return None
+
+ @property
+ def encoding(self) -> str:
+ """Get the encoding of the console file, e.g. ``"utf-8"``.
+
+ Returns:
+ str: A standard encoding string.
+ """
+ return (getattr(self.file, "encoding", "utf-8") or "utf-8").lower()
+
+ @property
+ def is_terminal(self) -> bool:
+ """Check if the console is writing to a terminal.
+
+ Returns:
+ bool: True if the console writing to a device capable of
+ understanding terminal codes, otherwise False.
+ """
+ if self._force_terminal is not None:
+ return self._force_terminal
+
+ if hasattr(sys.stdin, "__module__") and sys.stdin.__module__.startswith(
+ "idlelib"
+ ):
+ # Return False for Idle which claims to be a tty but can't handle ansi codes
+ return False
+
+ if self.is_jupyter:
+ # return False for Jupyter, which may have FORCE_COLOR set
+ return False
+
+ # If FORCE_COLOR env var has any value at all, we assume a terminal.
+ force_color = self._environ.get("FORCE_COLOR")
+ if force_color is not None:
+ self._force_terminal = True
+ return True
+
+ isatty: Optional[Callable[[], bool]] = getattr(self.file, "isatty", None)
+ try:
+ return False if isatty is None else isatty()
+ except ValueError:
+ # in some situation (at the end of a pytest run for example) isatty() can raise
+ # ValueError: I/O operation on closed file
+ # return False because we aren't in a terminal anymore
+ return False
+
+ @property
+ def is_dumb_terminal(self) -> bool:
+ """Detect dumb terminal.
+
+ Returns:
+ bool: True if writing to a dumb terminal, otherwise False.
+
+ """
+ _term = self._environ.get("TERM", "")
+ is_dumb = _term.lower() in ("dumb", "unknown")
+ return self.is_terminal and is_dumb
+
+ @property
+ def options(self) -> ConsoleOptions:
+ """Get default console options."""
+ return ConsoleOptions(
+ max_height=self.size.height,
+ size=self.size,
+ legacy_windows=self.legacy_windows,
+ min_width=1,
+ max_width=self.width,
+ encoding=self.encoding,
+ is_terminal=self.is_terminal,
+ )
+
+ @property
+ def size(self) -> ConsoleDimensions:
+ """Get the size of the console.
+
+ Returns:
+ ConsoleDimensions: A named tuple containing the dimensions.
+ """
+
+ if self._width is not None and self._height is not None:
+ return ConsoleDimensions(self._width - self.legacy_windows, self._height)
+
+ if self.is_dumb_terminal:
+ return ConsoleDimensions(80, 25)
+
+ width: Optional[int] = None
+ height: Optional[int] = None
+
+ if WINDOWS: # pragma: no cover
+ try:
+ width, height = os.get_terminal_size()
+ except (AttributeError, ValueError, OSError): # Probably not a terminal
+ pass
+ else:
+ for file_descriptor in _STD_STREAMS:
+ try:
+ width, height = os.get_terminal_size(file_descriptor)
+ except (AttributeError, ValueError, OSError):
+ pass
+ else:
+ break
+
+ columns = self._environ.get("COLUMNS")
+ if columns is not None and columns.isdigit():
+ width = int(columns)
+ lines = self._environ.get("LINES")
+ if lines is not None and lines.isdigit():
+ height = int(lines)
+
+ # get_terminal_size can report 0, 0 if run from pseudo-terminal
+ width = width or 80
+ height = height or 25
+ return ConsoleDimensions(
+ width - self.legacy_windows if self._width is None else self._width,
+ height if self._height is None else self._height,
+ )
+
+ @size.setter
+ def size(self, new_size: Tuple[int, int]) -> None:
+ """Set a new size for the terminal.
+
+ Args:
+ new_size (Tuple[int, int]): New width and height.
+ """
+ width, height = new_size
+ self._width = width
+ self._height = height
+
+ @property
+ def width(self) -> int:
+ """Get the width of the console.
+
+ Returns:
+ int: The width (in characters) of the console.
+ """
+ return self.size.width
+
+ @width.setter
+ def width(self, width: int) -> None:
+ """Set width.
+
+ Args:
+ width (int): New width.
+ """
+ self._width = width
+
+ @property
+ def height(self) -> int:
+ """Get the height of the console.
+
+ Returns:
+ int: The height (in lines) of the console.
+ """
+ return self.size.height
+
+ @height.setter
+ def height(self, height: int) -> None:
+ """Set height.
+
+ Args:
+ height (int): new height.
+ """
+ self._height = height
+
+ def bell(self) -> None:
+ """Play a 'bell' sound (if supported by the terminal)."""
+ self.control(Control.bell())
+
+ def capture(self) -> Capture:
+ """A context manager to *capture* the result of print() or log() in a string,
+ rather than writing it to the console.
+
+ Example:
+ >>> from rich.console import Console
+ >>> console = Console()
+ >>> with console.capture() as capture:
+ ... console.print("[bold magenta]Hello World[/]")
+ >>> print(capture.get())
+
+ Returns:
+ Capture: Context manager with disables writing to the terminal.
+ """
+ capture = Capture(self)
+ return capture
+
+ def pager(
+ self, pager: Optional[Pager] = None, styles: bool = False, links: bool = False
+ ) -> PagerContext:
+ """A context manager to display anything printed within a "pager". The pager application
+ is defined by the system and will typically support at least pressing a key to scroll.
+
+ Args:
+ pager (Pager, optional): A pager object, or None to use :class:`~rich.pager.SystemPager`. Defaults to None.
+ styles (bool, optional): Show styles in pager. Defaults to False.
+ links (bool, optional): Show links in pager. Defaults to False.
+
+ Example:
+ >>> from rich.console import Console
+ >>> from rich.__main__ import make_test_card
+ >>> console = Console()
+ >>> with console.pager():
+ console.print(make_test_card())
+
+ Returns:
+ PagerContext: A context manager.
+ """
+ return PagerContext(self, pager=pager, styles=styles, links=links)
+
+ def line(self, count: int = 1) -> None:
+ """Write new line(s).
+
+ Args:
+ count (int, optional): Number of new lines. Defaults to 1.
+ """
+
+ assert count >= 0, "count must be >= 0"
+ self.print(NewLine(count))
+
+ def clear(self, home: bool = True) -> None:
+ """Clear the screen.
+
+ Args:
+ home (bool, optional): Also move the cursor to 'home' position. Defaults to True.
+ """
+ if home:
+ self.control(Control.clear(), Control.home())
+ else:
+ self.control(Control.clear())
+
+ def status(
+ self,
+ status: RenderableType,
+ *,
+ spinner: str = "dots",
+ spinner_style: StyleType = "status.spinner",
+ speed: float = 1.0,
+ refresh_per_second: float = 12.5,
+ ) -> "Status":
+ """Display a status and spinner.
+
+ Args:
+ status (RenderableType): A status renderable (str or Text typically).
+ spinner (str, optional): Name of spinner animation (see python -m rich.spinner). Defaults to "dots".
+ spinner_style (StyleType, optional): Style of spinner. Defaults to "status.spinner".
+ speed (float, optional): Speed factor for spinner animation. Defaults to 1.0.
+ refresh_per_second (float, optional): Number of refreshes per second. Defaults to 12.5.
+
+ Returns:
+ Status: A Status object that may be used as a context manager.
+ """
+ from .status import Status
+
+ status_renderable = Status(
+ status,
+ console=self,
+ spinner=spinner,
+ spinner_style=spinner_style,
+ speed=speed,
+ refresh_per_second=refresh_per_second,
+ )
+ return status_renderable
+
+ def show_cursor(self, show: bool = True) -> bool:
+ """Show or hide the cursor.
+
+ Args:
+ show (bool, optional): Set visibility of the cursor.
+ """
+ if self.is_terminal:
+ self.control(Control.show_cursor(show))
+ return True
+ return False
+
+ def set_alt_screen(self, enable: bool = True) -> bool:
+ """Enables alternative screen mode.
+
+ Note, if you enable this mode, you should ensure that is disabled before
+ the application exits. See :meth:`~rich.Console.screen` for a context manager
+ that handles this for you.
+
+ Args:
+ enable (bool, optional): Enable (True) or disable (False) alternate screen. Defaults to True.
+
+ Returns:
+ bool: True if the control codes were written.
+
+ """
+ changed = False
+ if self.is_terminal and not self.legacy_windows:
+ self.control(Control.alt_screen(enable))
+ changed = True
+ self._is_alt_screen = enable
+ return changed
+
+ @property
+ def is_alt_screen(self) -> bool:
+ """Check if the alt screen was enabled.
+
+ Returns:
+ bool: True if the alt screen was enabled, otherwise False.
+ """
+ return self._is_alt_screen
+
+ def set_window_title(self, title: str) -> bool:
+ """Set the title of the console terminal window.
+
+ Warning: There is no means within Rich of "resetting" the window title to its
+ previous value, meaning the title you set will persist even after your application
+ exits.
+
+ ``fish`` shell resets the window title before and after each command by default,
+ negating this issue. Windows Terminal and command prompt will also reset the title for you.
+ Most other shells and terminals, however, do not do this.
+
+ Some terminals may require configuration changes before you can set the title.
+ Some terminals may not support setting the title at all.
+
+ Other software (including the terminal itself, the shell, custom prompts, plugins, etc.)
+ may also set the terminal window title. This could result in whatever value you write
+ using this method being overwritten.
+
+ Args:
+ title (str): The new title of the terminal window.
+
+ Returns:
+ bool: True if the control code to change the terminal title was
+ written, otherwise False. Note that a return value of True
+ does not guarantee that the window title has actually changed,
+ since the feature may be unsupported/disabled in some terminals.
+ """
+ if self.is_terminal:
+ self.control(Control.title(title))
+ return True
+ return False
+
+ def screen(
+ self, hide_cursor: bool = True, style: Optional[StyleType] = None
+ ) -> "ScreenContext":
+ """Context manager to enable and disable 'alternative screen' mode.
+
+ Args:
+ hide_cursor (bool, optional): Also hide the cursor. Defaults to False.
+ style (Style, optional): Optional style for screen. Defaults to None.
+
+ Returns:
+ ~ScreenContext: Context which enables alternate screen on enter, and disables it on exit.
+ """
+ return ScreenContext(self, hide_cursor=hide_cursor, style=style or "")
+
+ def measure(
+ self, renderable: RenderableType, *, options: Optional[ConsoleOptions] = None
+ ) -> Measurement:
+ """Measure a renderable. Returns a :class:`~rich.measure.Measurement` object which contains
+ information regarding the number of characters required to print the renderable.
+
+ Args:
+ renderable (RenderableType): Any renderable or string.
+ options (Optional[ConsoleOptions], optional): Options to use when measuring, or None
+ to use default options. Defaults to None.
+
+ Returns:
+ Measurement: A measurement of the renderable.
+ """
+ measurement = Measurement.get(self, options or self.options, renderable)
+ return measurement
+
+ def render(
+ self, renderable: RenderableType, options: Optional[ConsoleOptions] = None
+ ) -> Iterable[Segment]:
+ """Render an object in to an iterable of `Segment` instances.
+
+ This method contains the logic for rendering objects with the console protocol.
+ You are unlikely to need to use it directly, unless you are extending the library.
+
+ Args:
+ renderable (RenderableType): An object supporting the console protocol, or
+ an object that may be converted to a string.
+ options (ConsoleOptions, optional): An options object, or None to use self.options. Defaults to None.
+
+ Returns:
+ Iterable[Segment]: An iterable of segments that may be rendered.
+ """
+
+ _options = options or self.options
+ if _options.max_width < 1:
+ # No space to render anything. This prevents potential recursion errors.
+ return
+ render_iterable: RenderResult
+
+ renderable = rich_cast(renderable)
+ if hasattr(renderable, "__rich_console__") and not isclass(renderable):
+ render_iterable = renderable.__rich_console__(self, _options) # type: ignore[union-attr]
+ elif isinstance(renderable, str):
+ text_renderable = self.render_str(
+ renderable, highlight=_options.highlight, markup=_options.markup
+ )
+ render_iterable = text_renderable.__rich_console__(self, _options)
+ else:
+ raise errors.NotRenderableError(
+ f"Unable to render {renderable!r}; "
+ "A str, Segment or object with __rich_console__ method is required"
+ )
+
+ try:
+ iter_render = iter(render_iterable)
+ except TypeError:
+ raise errors.NotRenderableError(
+ f"object {render_iterable!r} is not renderable"
+ )
+ _Segment = Segment
+ _options = _options.reset_height()
+ for render_output in iter_render:
+ if isinstance(render_output, _Segment):
+ yield render_output
+ else:
+ yield from self.render(render_output, _options)
+
+ def render_lines(
+ self,
+ renderable: RenderableType,
+ options: Optional[ConsoleOptions] = None,
+ *,
+ style: Optional[Style] = None,
+ pad: bool = True,
+ new_lines: bool = False,
+ ) -> List[List[Segment]]:
+ """Render objects in to a list of lines.
+
+ The output of render_lines is useful when further formatting of rendered console text
+ is required, such as the Panel class which draws a border around any renderable object.
+
+ Args:
+ renderable (RenderableType): Any object renderable in the console.
+ options (Optional[ConsoleOptions], optional): Console options, or None to use self.options. Default to ``None``.
+ style (Style, optional): Optional style to apply to renderables. Defaults to ``None``.
+ pad (bool, optional): Pad lines shorter than render width. Defaults to ``True``.
+ new_lines (bool, optional): Include "\n" characters at end of lines.
+
+ Returns:
+ List[List[Segment]]: A list of lines, where a line is a list of Segment objects.
+ """
+ with self._lock:
+ render_options = options or self.options
+ _rendered = self.render(renderable, render_options)
+ if style:
+ _rendered = Segment.apply_style(_rendered, style)
+
+ render_height = render_options.height
+ if render_height is not None:
+ render_height = max(0, render_height)
+
+ lines = list(
+ islice(
+ Segment.split_and_crop_lines(
+ _rendered,
+ render_options.max_width,
+ include_new_lines=new_lines,
+ pad=pad,
+ style=style,
+ ),
+ None,
+ render_height,
+ )
+ )
+ if render_options.height is not None:
+ extra_lines = render_options.height - len(lines)
+ if extra_lines > 0:
+ pad_line = [
+ [Segment(" " * render_options.max_width, style), Segment("\n")]
+ if new_lines
+ else [Segment(" " * render_options.max_width, style)]
+ ]
+ lines.extend(pad_line * extra_lines)
+
+ return lines
+
+ def render_str(
+ self,
+ text: str,
+ *,
+ style: Union[str, Style] = "",
+ justify: Optional[JustifyMethod] = None,
+ overflow: Optional[OverflowMethod] = None,
+ emoji: Optional[bool] = None,
+ markup: Optional[bool] = None,
+ highlight: Optional[bool] = None,
+ highlighter: Optional[HighlighterType] = None,
+ ) -> "Text":
+ """Convert a string to a Text instance. This is called automatically if
+ you print or log a string.
+
+ Args:
+ text (str): Text to render.
+ style (Union[str, Style], optional): Style to apply to rendered text.
+ justify (str, optional): Justify method: "default", "left", "center", "full", or "right". Defaults to ``None``.
+ overflow (str, optional): Overflow method: "crop", "fold", or "ellipsis". Defaults to ``None``.
+ emoji (Optional[bool], optional): Enable emoji, or ``None`` to use Console default.
+ markup (Optional[bool], optional): Enable markup, or ``None`` to use Console default.
+ highlight (Optional[bool], optional): Enable highlighting, or ``None`` to use Console default.
+ highlighter (HighlighterType, optional): Optional highlighter to apply.
+ Returns:
+ ConsoleRenderable: Renderable object.
+
+ """
+ emoji_enabled = emoji or (emoji is None and self._emoji)
+ markup_enabled = markup or (markup is None and self._markup)
+ highlight_enabled = highlight or (highlight is None and self._highlight)
+
+ if markup_enabled:
+ rich_text = render_markup(
+ text,
+ style=style,
+ emoji=emoji_enabled,
+ emoji_variant=self._emoji_variant,
+ )
+ rich_text.justify = justify
+ rich_text.overflow = overflow
+ else:
+ rich_text = Text(
+ _emoji_replace(text, default_variant=self._emoji_variant)
+ if emoji_enabled
+ else text,
+ justify=justify,
+ overflow=overflow,
+ style=style,
+ )
+
+ _highlighter = (highlighter or self.highlighter) if highlight_enabled else None
+ if _highlighter is not None:
+ highlight_text = _highlighter(str(rich_text))
+ highlight_text.copy_styles(rich_text)
+ return highlight_text
+
+ return rich_text
+
+ def get_style(
+ self, name: Union[str, Style], *, default: Optional[Union[Style, str]] = None
+ ) -> Style:
+ """Get a Style instance by its theme name or parse a definition.
+
+ Args:
+ name (str): The name of a style or a style definition.
+
+ Returns:
+ Style: A Style object.
+
+ Raises:
+ MissingStyle: If no style could be parsed from name.
+
+ """
+ if isinstance(name, Style):
+ return name
+
+ try:
+ style = self._theme_stack.get(name)
+ if style is None:
+ style = Style.parse(name)
+ return style.copy() if style.link else style
+ except errors.StyleSyntaxError as error:
+ if default is not None:
+ return self.get_style(default)
+ raise errors.MissingStyle(
+ f"Failed to get style {name!r}; {error}"
+ ) from None
+
+ def _collect_renderables(
+ self,
+ objects: Iterable[Any],
+ sep: str,
+ end: str,
+ *,
+ justify: Optional[JustifyMethod] = None,
+ emoji: Optional[bool] = None,
+ markup: Optional[bool] = None,
+ highlight: Optional[bool] = None,
+ ) -> List[ConsoleRenderable]:
+ """Combine a number of renderables and text into one renderable.
+
+ Args:
+ objects (Iterable[Any]): Anything that Rich can render.
+ sep (str): String to write between print data.
+ end (str): String to write at end of print data.
+ justify (str, optional): One of "left", "right", "center", or "full". Defaults to ``None``.
+ emoji (Optional[bool], optional): Enable emoji code, or ``None`` to use console default.
+ markup (Optional[bool], optional): Enable markup, or ``None`` to use console default.
+ highlight (Optional[bool], optional): Enable automatic highlighting, or ``None`` to use console default.
+
+ Returns:
+ List[ConsoleRenderable]: A list of things to render.
+ """
+ renderables: List[ConsoleRenderable] = []
+ _append = renderables.append
+ text: List[Text] = []
+ append_text = text.append
+
+ append = _append
+ if justify in ("left", "center", "right"):
+
+ def align_append(renderable: RenderableType) -> None:
+ _append(Align(renderable, cast(AlignMethod, justify)))
+
+ append = align_append
+
+ _highlighter: HighlighterType = _null_highlighter
+ if highlight or (highlight is None and self._highlight):
+ _highlighter = self.highlighter
+
+ def check_text() -> None:
+ if text:
+ sep_text = Text(sep, justify=justify, end=end)
+ append(sep_text.join(text))
+ text.clear()
+
+ for renderable in objects:
+ renderable = rich_cast(renderable)
+ if isinstance(renderable, str):
+ append_text(
+ self.render_str(
+ renderable, emoji=emoji, markup=markup, highlighter=_highlighter
+ )
+ )
+ elif isinstance(renderable, Text):
+ append_text(renderable)
+ elif isinstance(renderable, ConsoleRenderable):
+ check_text()
+ append(renderable)
+ elif is_expandable(renderable):
+ check_text()
+ append(Pretty(renderable, highlighter=_highlighter))
+ else:
+ append_text(_highlighter(str(renderable)))
+
+ check_text()
+
+ if self.style is not None:
+ style = self.get_style(self.style)
+ renderables = [Styled(renderable, style) for renderable in renderables]
+
+ return renderables
+
+ def rule(
+ self,
+ title: TextType = "",
+ *,
+ characters: str = "─",
+ style: Union[str, Style] = "rule.line",
+ align: AlignMethod = "center",
+ ) -> None:
+ """Draw a line with optional centered title.
+
+ Args:
+ title (str, optional): Text to render over the rule. Defaults to "".
+ characters (str, optional): Character(s) to form the line. Defaults to "─".
+ style (str, optional): Style of line. Defaults to "rule.line".
+ align (str, optional): How to align the title, one of "left", "center", or "right". Defaults to "center".
+ """
+ from .rule import Rule
+
+ rule = Rule(title=title, characters=characters, style=style, align=align)
+ self.print(rule)
+
+ def control(self, *control: Control) -> None:
+ """Insert non-printing control codes.
+
+ Args:
+ control_codes (str): Control codes, such as those that may move the cursor.
+ """
+ if not self.is_dumb_terminal:
+ with self:
+ self._buffer.extend(_control.segment for _control in control)
+
+ def out(
+ self,
+ *objects: Any,
+ sep: str = " ",
+ end: str = "\n",
+ style: Optional[Union[str, Style]] = None,
+ highlight: Optional[bool] = None,
+ ) -> None:
+ """Output to the terminal. This is a low-level way of writing to the terminal which unlike
+ :meth:`~rich.console.Console.print` won't pretty print, wrap text, or apply markup, but will
+ optionally apply highlighting and a basic style.
+
+ Args:
+ sep (str, optional): String to write between print data. Defaults to " ".
+ end (str, optional): String to write at end of print data. Defaults to "\\\\n".
+ style (Union[str, Style], optional): A style to apply to output. Defaults to None.
+ highlight (Optional[bool], optional): Enable automatic highlighting, or ``None`` to use
+ console default. Defaults to ``None``.
+ """
+ raw_output: str = sep.join(str(_object) for _object in objects)
+ self.print(
+ raw_output,
+ style=style,
+ highlight=highlight,
+ emoji=False,
+ markup=False,
+ no_wrap=True,
+ overflow="ignore",
+ crop=False,
+ end=end,
+ )
+
+ def print(
+ self,
+ *objects: Any,
+ sep: str = " ",
+ end: str = "\n",
+ style: Optional[Union[str, Style]] = None,
+ justify: Optional[JustifyMethod] = None,
+ overflow: Optional[OverflowMethod] = None,
+ no_wrap: Optional[bool] = None,
+ emoji: Optional[bool] = None,
+ markup: Optional[bool] = None,
+ highlight: Optional[bool] = None,
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ crop: bool = True,
+ soft_wrap: Optional[bool] = None,
+ new_line_start: bool = False,
+ ) -> None:
+ """Print to the console.
+
+ Args:
+ objects (positional args): Objects to log to the terminal.
+ sep (str, optional): String to write between print data. Defaults to " ".
+ end (str, optional): String to write at end of print data. Defaults to "\\\\n".
+ style (Union[str, Style], optional): A style to apply to output. Defaults to None.
+ justify (str, optional): Justify method: "default", "left", "right", "center", or "full". Defaults to ``None``.
+ overflow (str, optional): Overflow method: "ignore", "crop", "fold", or "ellipsis". Defaults to None.
+ no_wrap (Optional[bool], optional): Disable word wrapping. Defaults to None.
+ emoji (Optional[bool], optional): Enable emoji code, or ``None`` to use console default. Defaults to ``None``.
+ markup (Optional[bool], optional): Enable markup, or ``None`` to use console default. Defaults to ``None``.
+ highlight (Optional[bool], optional): Enable automatic highlighting, or ``None`` to use console default. Defaults to ``None``.
+ width (Optional[int], optional): Width of output, or ``None`` to auto-detect. Defaults to ``None``.
+ crop (Optional[bool], optional): Crop output to width of terminal. Defaults to True.
+ soft_wrap (bool, optional): Enable soft wrap mode which disables word wrapping and cropping of text or ``None`` for
+ Console default. Defaults to ``None``.
+ new_line_start (bool, False): Insert a new line at the start if the output contains more than one line. Defaults to ``False``.
+ """
+ if not objects:
+ objects = (NewLine(),)
+
+ if soft_wrap is None:
+ soft_wrap = self.soft_wrap
+ if soft_wrap:
+ if no_wrap is None:
+ no_wrap = True
+ if overflow is None:
+ overflow = "ignore"
+ crop = False
+ render_hooks = self._render_hooks[:]
+ with self:
+ renderables = self._collect_renderables(
+ objects,
+ sep,
+ end,
+ justify=justify,
+ emoji=emoji,
+ markup=markup,
+ highlight=highlight,
+ )
+ for hook in render_hooks:
+ renderables = hook.process_renderables(renderables)
+ render_options = self.options.update(
+ justify=justify,
+ overflow=overflow,
+ width=min(width, self.width) if width is not None else NO_CHANGE,
+ height=height,
+ no_wrap=no_wrap,
+ markup=markup,
+ highlight=highlight,
+ )
+
+ new_segments: List[Segment] = []
+ extend = new_segments.extend
+ render = self.render
+ if style is None:
+ for renderable in renderables:
+ extend(render(renderable, render_options))
+ else:
+ for renderable in renderables:
+ extend(
+ Segment.apply_style(
+ render(renderable, render_options), self.get_style(style)
+ )
+ )
+ if new_line_start:
+ if (
+ len("".join(segment.text for segment in new_segments).splitlines())
+ > 1
+ ):
+ new_segments.insert(0, Segment.line())
+ if crop:
+ buffer_extend = self._buffer.extend
+ for line in Segment.split_and_crop_lines(
+ new_segments, self.width, pad=False
+ ):
+ buffer_extend(line)
+ else:
+ self._buffer.extend(new_segments)
+
+ def print_json(
+ self,
+ json: Optional[str] = None,
+ *,
+ data: Any = None,
+ indent: Union[None, int, str] = 2,
+ highlight: bool = True,
+ skip_keys: bool = False,
+ ensure_ascii: bool = False,
+ check_circular: bool = True,
+ allow_nan: bool = True,
+ default: Optional[Callable[[Any], Any]] = None,
+ sort_keys: bool = False,
+ ) -> None:
+ """Pretty prints JSON. Output will be valid JSON.
+
+ Args:
+ json (Optional[str]): A string containing JSON.
+ data (Any): If json is not supplied, then encode this data.
+ indent (Union[None, int, str], optional): Number of spaces to indent. Defaults to 2.
+ highlight (bool, optional): Enable highlighting of output: Defaults to True.
+ skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.
+ ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.
+ check_circular (bool, optional): Check for circular references. Defaults to True.
+ allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.
+ default (Callable, optional): A callable that converts values that can not be encoded
+ in to something that can be JSON encoded. Defaults to None.
+ sort_keys (bool, optional): Sort dictionary keys. Defaults to False.
+ """
+ from pip._vendor.rich.json import JSON
+
+ if json is None:
+ json_renderable = JSON.from_data(
+ data,
+ indent=indent,
+ highlight=highlight,
+ skip_keys=skip_keys,
+ ensure_ascii=ensure_ascii,
+ check_circular=check_circular,
+ allow_nan=allow_nan,
+ default=default,
+ sort_keys=sort_keys,
+ )
+ else:
+ if not isinstance(json, str):
+ raise TypeError(
+ f"json must be str. Did you mean print_json(data={json!r}) ?"
+ )
+ json_renderable = JSON(
+ json,
+ indent=indent,
+ highlight=highlight,
+ skip_keys=skip_keys,
+ ensure_ascii=ensure_ascii,
+ check_circular=check_circular,
+ allow_nan=allow_nan,
+ default=default,
+ sort_keys=sort_keys,
+ )
+ self.print(json_renderable, soft_wrap=True)
+
+ def update_screen(
+ self,
+ renderable: RenderableType,
+ *,
+ region: Optional[Region] = None,
+ options: Optional[ConsoleOptions] = None,
+ ) -> None:
+ """Update the screen at a given offset.
+
+ Args:
+ renderable (RenderableType): A Rich renderable.
+ region (Region, optional): Region of screen to update, or None for entire screen. Defaults to None.
+ x (int, optional): x offset. Defaults to 0.
+ y (int, optional): y offset. Defaults to 0.
+
+ Raises:
+ errors.NoAltScreen: If the Console isn't in alt screen mode.
+
+ """
+ if not self.is_alt_screen:
+ raise errors.NoAltScreen("Alt screen must be enabled to call update_screen")
+ render_options = options or self.options
+ if region is None:
+ x = y = 0
+ render_options = render_options.update_dimensions(
+ render_options.max_width, render_options.height or self.height
+ )
+ else:
+ x, y, width, height = region
+ render_options = render_options.update_dimensions(width, height)
+
+ lines = self.render_lines(renderable, options=render_options)
+ self.update_screen_lines(lines, x, y)
+
+ def update_screen_lines(
+ self, lines: List[List[Segment]], x: int = 0, y: int = 0
+ ) -> None:
+ """Update lines of the screen at a given offset.
+
+ Args:
+ lines (List[List[Segment]]): Rendered lines (as produced by :meth:`~rich.Console.render_lines`).
+ x (int, optional): x offset (column no). Defaults to 0.
+ y (int, optional): y offset (column no). Defaults to 0.
+
+ Raises:
+ errors.NoAltScreen: If the Console isn't in alt screen mode.
+ """
+ if not self.is_alt_screen:
+ raise errors.NoAltScreen("Alt screen must be enabled to call update_screen")
+ screen_update = ScreenUpdate(lines, x, y)
+ segments = self.render(screen_update)
+ self._buffer.extend(segments)
+ self._check_buffer()
+
+ def print_exception(
+ self,
+ *,
+ width: Optional[int] = 100,
+ extra_lines: int = 3,
+ theme: Optional[str] = None,
+ word_wrap: bool = False,
+ show_locals: bool = False,
+ suppress: Iterable[Union[str, ModuleType]] = (),
+ max_frames: int = 100,
+ ) -> None:
+ """Prints a rich render of the last exception and traceback.
+
+ Args:
+ width (Optional[int], optional): Number of characters used to render code. Defaults to 100.
+ extra_lines (int, optional): Additional lines of code to render. Defaults to 3.
+ theme (str, optional): Override pygments theme used in traceback
+ word_wrap (bool, optional): Enable word wrapping of long lines. Defaults to False.
+ show_locals (bool, optional): Enable display of local variables. Defaults to False.
+ suppress (Iterable[Union[str, ModuleType]]): Optional sequence of modules or paths to exclude from traceback.
+ max_frames (int): Maximum number of frames to show in a traceback, 0 for no maximum. Defaults to 100.
+ """
+ from .traceback import Traceback
+
+ traceback = Traceback(
+ width=width,
+ extra_lines=extra_lines,
+ theme=theme,
+ word_wrap=word_wrap,
+ show_locals=show_locals,
+ suppress=suppress,
+ max_frames=max_frames,
+ )
+ self.print(traceback)
+
+ @staticmethod
+ def _caller_frame_info(
+ offset: int,
+ currentframe: Callable[[], Optional[FrameType]] = inspect.currentframe,
+ ) -> Tuple[str, int, Dict[str, Any]]:
+ """Get caller frame information.
+
+ Args:
+ offset (int): the caller offset within the current frame stack.
+ currentframe (Callable[[], Optional[FrameType]], optional): the callable to use to
+ retrieve the current frame. Defaults to ``inspect.currentframe``.
+
+ Returns:
+ Tuple[str, int, Dict[str, Any]]: A tuple containing the filename, the line number and
+ the dictionary of local variables associated with the caller frame.
+
+ Raises:
+ RuntimeError: If the stack offset is invalid.
+ """
+ # Ignore the frame of this local helper
+ offset += 1
+
+ frame = currentframe()
+ if frame is not None:
+ # Use the faster currentframe where implemented
+ while offset and frame is not None:
+ frame = frame.f_back
+ offset -= 1
+ assert frame is not None
+ return frame.f_code.co_filename, frame.f_lineno, frame.f_locals
+ else:
+ # Fallback to the slower stack
+ frame_info = inspect.stack()[offset]
+ return frame_info.filename, frame_info.lineno, frame_info.frame.f_locals
+
+ def log(
+ self,
+ *objects: Any,
+ sep: str = " ",
+ end: str = "\n",
+ style: Optional[Union[str, Style]] = None,
+ justify: Optional[JustifyMethod] = None,
+ emoji: Optional[bool] = None,
+ markup: Optional[bool] = None,
+ highlight: Optional[bool] = None,
+ log_locals: bool = False,
+ _stack_offset: int = 1,
+ ) -> None:
+ """Log rich content to the terminal.
+
+ Args:
+ objects (positional args): Objects to log to the terminal.
+ sep (str, optional): String to write between print data. Defaults to " ".
+ end (str, optional): String to write at end of print data. Defaults to "\\\\n".
+ style (Union[str, Style], optional): A style to apply to output. Defaults to None.
+ justify (str, optional): One of "left", "right", "center", or "full". Defaults to ``None``.
+ emoji (Optional[bool], optional): Enable emoji code, or ``None`` to use console default. Defaults to None.
+ markup (Optional[bool], optional): Enable markup, or ``None`` to use console default. Defaults to None.
+ highlight (Optional[bool], optional): Enable automatic highlighting, or ``None`` to use console default. Defaults to None.
+ log_locals (bool, optional): Boolean to enable logging of locals where ``log()``
+ was called. Defaults to False.
+ _stack_offset (int, optional): Offset of caller from end of call stack. Defaults to 1.
+ """
+ if not objects:
+ objects = (NewLine(),)
+
+ render_hooks = self._render_hooks[:]
+
+ with self:
+ renderables = self._collect_renderables(
+ objects,
+ sep,
+ end,
+ justify=justify,
+ emoji=emoji,
+ markup=markup,
+ highlight=highlight,
+ )
+ if style is not None:
+ renderables = [Styled(renderable, style) for renderable in renderables]
+
+ filename, line_no, locals = self._caller_frame_info(_stack_offset)
+ link_path = None if filename.startswith("<") else os.path.abspath(filename)
+ path = filename.rpartition(os.sep)[-1]
+ if log_locals:
+ locals_map = {
+ key: value
+ for key, value in locals.items()
+ if not key.startswith("__")
+ }
+ renderables.append(render_scope(locals_map, title="[i]locals"))
+
+ renderables = [
+ self._log_render(
+ self,
+ renderables,
+ log_time=self.get_datetime(),
+ path=path,
+ line_no=line_no,
+ link_path=link_path,
+ )
+ ]
+ for hook in render_hooks:
+ renderables = hook.process_renderables(renderables)
+ new_segments: List[Segment] = []
+ extend = new_segments.extend
+ render = self.render
+ render_options = self.options
+ for renderable in renderables:
+ extend(render(renderable, render_options))
+ buffer_extend = self._buffer.extend
+ for line in Segment.split_and_crop_lines(
+ new_segments, self.width, pad=False
+ ):
+ buffer_extend(line)
+
+ def _check_buffer(self) -> None:
+ """Check if the buffer may be rendered. Render it if it can (e.g. Console.quiet is False)
+ Rendering is supported on Windows, Unix and Jupyter environments. For
+ legacy Windows consoles, the win32 API is called directly.
+ This method will also record what it renders if recording is enabled via Console.record.
+ """
+ if self.quiet:
+ del self._buffer[:]
+ return
+ with self._lock:
+ if self.record:
+ with self._record_buffer_lock:
+ self._record_buffer.extend(self._buffer[:])
+
+ if self._buffer_index == 0:
+ if self.is_jupyter: # pragma: no cover
+ from .jupyter import display
+
+ display(self._buffer, self._render_buffer(self._buffer[:]))
+ del self._buffer[:]
+ else:
+ if WINDOWS:
+ use_legacy_windows_render = False
+ if self.legacy_windows:
+ fileno = get_fileno(self.file)
+ if fileno is not None:
+ use_legacy_windows_render = (
+ fileno in _STD_STREAMS_OUTPUT
+ )
+
+ if use_legacy_windows_render:
+ from pip._vendor.rich._win32_console import LegacyWindowsTerm
+ from pip._vendor.rich._windows_renderer import legacy_windows_render
+
+ buffer = self._buffer[:]
+ if self.no_color and self._color_system:
+ buffer = list(Segment.remove_color(buffer))
+
+ legacy_windows_render(buffer, LegacyWindowsTerm(self.file))
+ else:
+ # Either a non-std stream on legacy Windows, or modern Windows.
+ text = self._render_buffer(self._buffer[:])
+ # https://bugs.python.org/issue37871
+ # https://github.com/python/cpython/issues/82052
+ # We need to avoid writing more than 32Kb in a single write, due to the above bug
+ write = self.file.write
+ # Worse case scenario, every character is 4 bytes of utf-8
+ MAX_WRITE = 32 * 1024 // 4
+ try:
+ if len(text) <= MAX_WRITE:
+ write(text)
+ else:
+ batch: List[str] = []
+ batch_append = batch.append
+ size = 0
+ for line in text.splitlines(True):
+ if size + len(line) > MAX_WRITE and batch:
+ write("".join(batch))
+ batch.clear()
+ size = 0
+ batch_append(line)
+ size += len(line)
+ if batch:
+ write("".join(batch))
+ batch.clear()
+ except UnicodeEncodeError as error:
+ error.reason = f"{error.reason}\n*** You may need to add PYTHONIOENCODING=utf-8 to your environment ***"
+ raise
+ else:
+ text = self._render_buffer(self._buffer[:])
+ try:
+ self.file.write(text)
+ except UnicodeEncodeError as error:
+ error.reason = f"{error.reason}\n*** You may need to add PYTHONIOENCODING=utf-8 to your environment ***"
+ raise
+
+ self.file.flush()
+ del self._buffer[:]
+
+ def _render_buffer(self, buffer: Iterable[Segment]) -> str:
+ """Render buffered output, and clear buffer."""
+ output: List[str] = []
+ append = output.append
+ color_system = self._color_system
+ legacy_windows = self.legacy_windows
+ not_terminal = not self.is_terminal
+ if self.no_color and color_system:
+ buffer = Segment.remove_color(buffer)
+ for text, style, control in buffer:
+ if style:
+ append(
+ style.render(
+ text,
+ color_system=color_system,
+ legacy_windows=legacy_windows,
+ )
+ )
+ elif not (not_terminal and control):
+ append(text)
+
+ rendered = "".join(output)
+ return rendered
+
+ def input(
+ self,
+ prompt: TextType = "",
+ *,
+ markup: bool = True,
+ emoji: bool = True,
+ password: bool = False,
+ stream: Optional[TextIO] = None,
+ ) -> str:
+ """Displays a prompt and waits for input from the user. The prompt may contain color / style.
+
+ It works in the same way as Python's builtin :func:`input` function and provides elaborate line editing and history features if Python's builtin :mod:`readline` module is previously loaded.
+
+ Args:
+ prompt (Union[str, Text]): Text to render in the prompt.
+ markup (bool, optional): Enable console markup (requires a str prompt). Defaults to True.
+ emoji (bool, optional): Enable emoji (requires a str prompt). Defaults to True.
+ password: (bool, optional): Hide typed text. Defaults to False.
+ stream: (TextIO, optional): Optional file to read input from (rather than stdin). Defaults to None.
+
+ Returns:
+ str: Text read from stdin.
+ """
+ if prompt:
+ self.print(prompt, markup=markup, emoji=emoji, end="")
+ if password:
+ result = getpass("", stream=stream)
+ else:
+ if stream:
+ result = stream.readline()
+ else:
+ result = input()
+ return result
+
+ def export_text(self, *, clear: bool = True, styles: bool = False) -> str:
+ """Generate text from console contents (requires record=True argument in constructor).
+
+ Args:
+ clear (bool, optional): Clear record buffer after exporting. Defaults to ``True``.
+ styles (bool, optional): If ``True``, ansi escape codes will be included. ``False`` for plain text.
+ Defaults to ``False``.
+
+ Returns:
+ str: String containing console contents.
+
+ """
+ assert (
+ self.record
+ ), "To export console contents set record=True in the constructor or instance"
+
+ with self._record_buffer_lock:
+ if styles:
+ text = "".join(
+ (style.render(text) if style else text)
+ for text, style, _ in self._record_buffer
+ )
+ else:
+ text = "".join(
+ segment.text
+ for segment in self._record_buffer
+ if not segment.control
+ )
+ if clear:
+ del self._record_buffer[:]
+ return text
+
+ def save_text(self, path: str, *, clear: bool = True, styles: bool = False) -> None:
+ """Generate text from console and save to a given location (requires record=True argument in constructor).
+
+ Args:
+ path (str): Path to write text files.
+ clear (bool, optional): Clear record buffer after exporting. Defaults to ``True``.
+ styles (bool, optional): If ``True``, ansi style codes will be included. ``False`` for plain text.
+ Defaults to ``False``.
+
+ """
+ text = self.export_text(clear=clear, styles=styles)
+ with open(path, "wt", encoding="utf-8") as write_file:
+ write_file.write(text)
+
+ def export_html(
+ self,
+ *,
+ theme: Optional[TerminalTheme] = None,
+ clear: bool = True,
+ code_format: Optional[str] = None,
+ inline_styles: bool = False,
+ ) -> str:
+ """Generate HTML from console contents (requires record=True argument in constructor).
+
+ Args:
+ theme (TerminalTheme, optional): TerminalTheme object containing console colors.
+ clear (bool, optional): Clear record buffer after exporting. Defaults to ``True``.
+ code_format (str, optional): Format string to render HTML. In addition to '{foreground}',
+ '{background}', and '{code}', should contain '{stylesheet}' if inline_styles is ``False``.
+ inline_styles (bool, optional): If ``True`` styles will be inlined in to spans, which makes files
+ larger but easier to cut and paste markup. If ``False``, styles will be embedded in a style tag.
+ Defaults to False.
+
+ Returns:
+ str: String containing console contents as HTML.
+ """
+ assert (
+ self.record
+ ), "To export console contents set record=True in the constructor or instance"
+ fragments: List[str] = []
+ append = fragments.append
+ _theme = theme or DEFAULT_TERMINAL_THEME
+ stylesheet = ""
+
+ render_code_format = CONSOLE_HTML_FORMAT if code_format is None else code_format
+
+ with self._record_buffer_lock:
+ if inline_styles:
+ for text, style, _ in Segment.filter_control(
+ Segment.simplify(self._record_buffer)
+ ):
+ text = escape(text)
+ if style:
+ rule = style.get_html_style(_theme)
+ if style.link:
+ text = f'<a href="{style.link}">{text}</a>'
+ text = f'<span style="{rule}">{text}</span>' if rule else text
+ append(text)
+ else:
+ styles: Dict[str, int] = {}
+ for text, style, _ in Segment.filter_control(
+ Segment.simplify(self._record_buffer)
+ ):
+ text = escape(text)
+ if style:
+ rule = style.get_html_style(_theme)
+ style_number = styles.setdefault(rule, len(styles) + 1)
+ if style.link:
+ text = f'<a class="r{style_number}" href="{style.link}">{text}</a>'
+ else:
+ text = f'<span class="r{style_number}">{text}</span>'
+ append(text)
+ stylesheet_rules: List[str] = []
+ stylesheet_append = stylesheet_rules.append
+ for style_rule, style_number in styles.items():
+ if style_rule:
+ stylesheet_append(f".r{style_number} {{{style_rule}}}")
+ stylesheet = "\n".join(stylesheet_rules)
+
+ rendered_code = render_code_format.format(
+ code="".join(fragments),
+ stylesheet=stylesheet,
+ foreground=_theme.foreground_color.hex,
+ background=_theme.background_color.hex,
+ )
+ if clear:
+ del self._record_buffer[:]
+ return rendered_code
+
+ def save_html(
+ self,
+ path: str,
+ *,
+ theme: Optional[TerminalTheme] = None,
+ clear: bool = True,
+ code_format: str = CONSOLE_HTML_FORMAT,
+ inline_styles: bool = False,
+ ) -> None:
+ """Generate HTML from console contents and write to a file (requires record=True argument in constructor).
+
+ Args:
+ path (str): Path to write html file.
+ theme (TerminalTheme, optional): TerminalTheme object containing console colors.
+ clear (bool, optional): Clear record buffer after exporting. Defaults to ``True``.
+ code_format (str, optional): Format string to render HTML. In addition to '{foreground}',
+ '{background}', and '{code}', should contain '{stylesheet}' if inline_styles is ``False``.
+ inline_styles (bool, optional): If ``True`` styles will be inlined in to spans, which makes files
+ larger but easier to cut and paste markup. If ``False``, styles will be embedded in a style tag.
+ Defaults to False.
+
+ """
+ html = self.export_html(
+ theme=theme,
+ clear=clear,
+ code_format=code_format,
+ inline_styles=inline_styles,
+ )
+ with open(path, "wt", encoding="utf-8") as write_file:
+ write_file.write(html)
+
+ def export_svg(
+ self,
+ *,
+ title: str = "Rich",
+ theme: Optional[TerminalTheme] = None,
+ clear: bool = True,
+ code_format: str = CONSOLE_SVG_FORMAT,
+ font_aspect_ratio: float = 0.61,
+ unique_id: Optional[str] = None,
+ ) -> str:
+ """
+ Generate an SVG from the console contents (requires record=True in Console constructor).
+
+ Args:
+ title (str, optional): The title of the tab in the output image
+ theme (TerminalTheme, optional): The ``TerminalTheme`` object to use to style the terminal
+ clear (bool, optional): Clear record buffer after exporting. Defaults to ``True``
+ code_format (str, optional): Format string used to generate the SVG. Rich will inject a number of variables
+ into the string in order to form the final SVG output. The default template used and the variables
+ injected by Rich can be found by inspecting the ``console.CONSOLE_SVG_FORMAT`` variable.
+ font_aspect_ratio (float, optional): The width to height ratio of the font used in the ``code_format``
+ string. Defaults to 0.61, which is the width to height ratio of Fira Code (the default font).
+ If you aren't specifying a different font inside ``code_format``, you probably don't need this.
+ unique_id (str, optional): unique id that is used as the prefix for various elements (CSS styles, node
+ ids). If not set, this defaults to a computed value based on the recorded content.
+ """
+
+ from pip._vendor.rich.cells import cell_len
+
+ style_cache: Dict[Style, str] = {}
+
+ def get_svg_style(style: Style) -> str:
+ """Convert a Style to CSS rules for SVG."""
+ if style in style_cache:
+ return style_cache[style]
+ css_rules = []
+ color = (
+ _theme.foreground_color
+ if (style.color is None or style.color.is_default)
+ else style.color.get_truecolor(_theme)
+ )
+ bgcolor = (
+ _theme.background_color
+ if (style.bgcolor is None or style.bgcolor.is_default)
+ else style.bgcolor.get_truecolor(_theme)
+ )
+ if style.reverse:
+ color, bgcolor = bgcolor, color
+ if style.dim:
+ color = blend_rgb(color, bgcolor, 0.4)
+ css_rules.append(f"fill: {color.hex}")
+ if style.bold:
+ css_rules.append("font-weight: bold")
+ if style.italic:
+ css_rules.append("font-style: italic;")
+ if style.underline:
+ css_rules.append("text-decoration: underline;")
+ if style.strike:
+ css_rules.append("text-decoration: line-through;")
+
+ css = ";".join(css_rules)
+ style_cache[style] = css
+ return css
+
+ _theme = theme or SVG_EXPORT_THEME
+
+ width = self.width
+ char_height = 20
+ char_width = char_height * font_aspect_ratio
+ line_height = char_height * 1.22
+
+ margin_top = 1
+ margin_right = 1
+ margin_bottom = 1
+ margin_left = 1
+
+ padding_top = 40
+ padding_right = 8
+ padding_bottom = 8
+ padding_left = 8
+
+ padding_width = padding_left + padding_right
+ padding_height = padding_top + padding_bottom
+ margin_width = margin_left + margin_right
+ margin_height = margin_top + margin_bottom
+
+ text_backgrounds: List[str] = []
+ text_group: List[str] = []
+ classes: Dict[str, int] = {}
+ style_no = 1
+
+ def escape_text(text: str) -> str:
+ """HTML escape text and replace spaces with nbsp."""
+ return escape(text).replace(" ", " ")
+
+ def make_tag(
+ name: str, content: Optional[str] = None, **attribs: object
+ ) -> str:
+ """Make a tag from name, content, and attributes."""
+
+ def stringify(value: object) -> str:
+ if isinstance(value, (float)):
+ return format(value, "g")
+ return str(value)
+
+ tag_attribs = " ".join(
+ f'{k.lstrip("_").replace("_", "-")}="{stringify(v)}"'
+ for k, v in attribs.items()
+ )
+ return (
+ f"<{name} {tag_attribs}>{content}</{name}>"
+ if content
+ else f"<{name} {tag_attribs}/>"
+ )
+
+ with self._record_buffer_lock:
+ segments = list(Segment.filter_control(self._record_buffer))
+ if clear:
+ self._record_buffer.clear()
+
+ if unique_id is None:
+ unique_id = "terminal-" + str(
+ zlib.adler32(
+ ("".join(repr(segment) for segment in segments)).encode(
+ "utf-8",
+ "ignore",
+ )
+ + title.encode("utf-8", "ignore")
+ )
+ )
+ y = 0
+ for y, line in enumerate(Segment.split_and_crop_lines(segments, length=width)):
+ x = 0
+ for text, style, _control in line:
+ style = style or Style()
+ rules = get_svg_style(style)
+ if rules not in classes:
+ classes[rules] = style_no
+ style_no += 1
+ class_name = f"r{classes[rules]}"
+
+ if style.reverse:
+ has_background = True
+ background = (
+ _theme.foreground_color.hex
+ if style.color is None
+ else style.color.get_truecolor(_theme).hex
+ )
+ else:
+ bgcolor = style.bgcolor
+ has_background = bgcolor is not None and not bgcolor.is_default
+ background = (
+ _theme.background_color.hex
+ if style.bgcolor is None
+ else style.bgcolor.get_truecolor(_theme).hex
+ )
+
+ text_length = cell_len(text)
+ if has_background:
+ text_backgrounds.append(
+ make_tag(
+ "rect",
+ fill=background,
+ x=x * char_width,
+ y=y * line_height + 1.5,
+ width=char_width * text_length,
+ height=line_height + 0.25,
+ shape_rendering="crispEdges",
+ )
+ )
+
+ if text != " " * len(text):
+ text_group.append(
+ make_tag(
+ "text",
+ escape_text(text),
+ _class=f"{unique_id}-{class_name}",
+ x=x * char_width,
+ y=y * line_height + char_height,
+ textLength=char_width * len(text),
+ clip_path=f"url(#{unique_id}-line-{y})",
+ )
+ )
+ x += cell_len(text)
+
+ line_offsets = [line_no * line_height + 1.5 for line_no in range(y)]
+ lines = "\n".join(
+ f"""<clipPath id="{unique_id}-line-{line_no}">
+ {make_tag("rect", x=0, y=offset, width=char_width * width, height=line_height + 0.25)}
+ </clipPath>"""
+ for line_no, offset in enumerate(line_offsets)
+ )
+
+ styles = "\n".join(
+ f".{unique_id}-r{rule_no} {{ {css} }}" for css, rule_no in classes.items()
+ )
+ backgrounds = "".join(text_backgrounds)
+ matrix = "".join(text_group)
+
+ terminal_width = ceil(width * char_width + padding_width)
+ terminal_height = (y + 1) * line_height + padding_height
+ chrome = make_tag(
+ "rect",
+ fill=_theme.background_color.hex,
+ stroke="rgba(255,255,255,0.35)",
+ stroke_width="1",
+ x=margin_left,
+ y=margin_top,
+ width=terminal_width,
+ height=terminal_height,
+ rx=8,
+ )
+
+ title_color = _theme.foreground_color.hex
+ if title:
+ chrome += make_tag(
+ "text",
+ escape_text(title),
+ _class=f"{unique_id}-title",
+ fill=title_color,
+ text_anchor="middle",
+ x=terminal_width // 2,
+ y=margin_top + char_height + 6,
+ )
+ chrome += f"""
+ <g transform="translate(26,22)">
+ <circle cx="0" cy="0" r="7" fill="#ff5f57"/>
+ <circle cx="22" cy="0" r="7" fill="#febc2e"/>
+ <circle cx="44" cy="0" r="7" fill="#28c840"/>
+ </g>
+ """
+
+ svg = code_format.format(
+ unique_id=unique_id,
+ char_width=char_width,
+ char_height=char_height,
+ line_height=line_height,
+ terminal_width=char_width * width - 1,
+ terminal_height=(y + 1) * line_height - 1,
+ width=terminal_width + margin_width,
+ height=terminal_height + margin_height,
+ terminal_x=margin_left + padding_left,
+ terminal_y=margin_top + padding_top,
+ styles=styles,
+ chrome=chrome,
+ backgrounds=backgrounds,
+ matrix=matrix,
+ lines=lines,
+ )
+ return svg
+
+ def save_svg(
+ self,
+ path: str,
+ *,
+ title: str = "Rich",
+ theme: Optional[TerminalTheme] = None,
+ clear: bool = True,
+ code_format: str = CONSOLE_SVG_FORMAT,
+ font_aspect_ratio: float = 0.61,
+ unique_id: Optional[str] = None,
+ ) -> None:
+ """Generate an SVG file from the console contents (requires record=True in Console constructor).
+
+ Args:
+ path (str): The path to write the SVG to.
+ title (str, optional): The title of the tab in the output image
+ theme (TerminalTheme, optional): The ``TerminalTheme`` object to use to style the terminal
+ clear (bool, optional): Clear record buffer after exporting. Defaults to ``True``
+ code_format (str, optional): Format string used to generate the SVG. Rich will inject a number of variables
+ into the string in order to form the final SVG output. The default template used and the variables
+ injected by Rich can be found by inspecting the ``console.CONSOLE_SVG_FORMAT`` variable.
+ font_aspect_ratio (float, optional): The width to height ratio of the font used in the ``code_format``
+ string. Defaults to 0.61, which is the width to height ratio of Fira Code (the default font).
+ If you aren't specifying a different font inside ``code_format``, you probably don't need this.
+ unique_id (str, optional): unique id that is used as the prefix for various elements (CSS styles, node
+ ids). If not set, this defaults to a computed value based on the recorded content.
+ """
+ svg = self.export_svg(
+ title=title,
+ theme=theme,
+ clear=clear,
+ code_format=code_format,
+ font_aspect_ratio=font_aspect_ratio,
+ unique_id=unique_id,
+ )
+ with open(path, "wt", encoding="utf-8") as write_file:
+ write_file.write(svg)
+
+
+def _svg_hash(svg_main_code: str) -> str:
+ """Returns a unique hash for the given SVG main code.
+
+ Args:
+ svg_main_code (str): The content we're going to inject in the SVG envelope.
+
+ Returns:
+ str: a hash of the given content
+ """
+ return str(zlib.adler32(svg_main_code.encode()))
+
+
+if __name__ == "__main__": # pragma: no cover
+ console = Console(record=True)
+
+ console.log(
+ "JSONRPC [i]request[/i]",
+ 5,
+ 1.3,
+ True,
+ False,
+ None,
+ {
+ "jsonrpc": "2.0",
+ "method": "subtract",
+ "params": {"minuend": 42, "subtrahend": 23},
+ "id": 3,
+ },
+ )
+
+ console.log("Hello, World!", "{'a': 1}", repr(console))
+
+ console.print(
+ {
+ "name": None,
+ "empty": [],
+ "quiz": {
+ "sport": {
+ "answered": True,
+ "q1": {
+ "question": "Which one is correct team name in NBA?",
+ "options": [
+ "New York Bulls",
+ "Los Angeles Kings",
+ "Golden State Warriors",
+ "Huston Rocket",
+ ],
+ "answer": "Huston Rocket",
+ },
+ },
+ "maths": {
+ "answered": False,
+ "q1": {
+ "question": "5 + 7 = ?",
+ "options": [10, 11, 12, 13],
+ "answer": 12,
+ },
+ "q2": {
+ "question": "12 - 8 = ?",
+ "options": [1, 2, 3, 4],
+ "answer": 4,
+ },
+ },
+ },
+ }
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/constrain.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/constrain.py
new file mode 100644
index 000000000..65fdf5634
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/constrain.py
@@ -0,0 +1,37 @@
+from typing import Optional, TYPE_CHECKING
+
+from .jupyter import JupyterMixin
+from .measure import Measurement
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderableType, RenderResult
+
+
+class Constrain(JupyterMixin):
+ """Constrain the width of a renderable to a given number of characters.
+
+ Args:
+ renderable (RenderableType): A renderable object.
+ width (int, optional): The maximum width (in characters) to render. Defaults to 80.
+ """
+
+ def __init__(self, renderable: "RenderableType", width: Optional[int] = 80) -> None:
+ self.renderable = renderable
+ self.width = width
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ if self.width is None:
+ yield self.renderable
+ else:
+ child_options = options.update_width(min(self.width, options.max_width))
+ yield from console.render(self.renderable, child_options)
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ if self.width is not None:
+ options = options.update_width(self.width)
+ measurement = Measurement.get(console, options, self.renderable)
+ return measurement
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/containers.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/containers.py
new file mode 100644
index 000000000..901ff8ba6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/containers.py
@@ -0,0 +1,167 @@
+from itertools import zip_longest
+from typing import (
+ TYPE_CHECKING,
+ Iterable,
+ Iterator,
+ List,
+ Optional,
+ TypeVar,
+ Union,
+ overload,
+)
+
+if TYPE_CHECKING:
+ from .console import (
+ Console,
+ ConsoleOptions,
+ JustifyMethod,
+ OverflowMethod,
+ RenderResult,
+ RenderableType,
+ )
+ from .text import Text
+
+from .cells import cell_len
+from .measure import Measurement
+
+T = TypeVar("T")
+
+
+class Renderables:
+ """A list subclass which renders its contents to the console."""
+
+ def __init__(
+ self, renderables: Optional[Iterable["RenderableType"]] = None
+ ) -> None:
+ self._renderables: List["RenderableType"] = (
+ list(renderables) if renderables is not None else []
+ )
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ """Console render method to insert line-breaks."""
+ yield from self._renderables
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ dimensions = [
+ Measurement.get(console, options, renderable)
+ for renderable in self._renderables
+ ]
+ if not dimensions:
+ return Measurement(1, 1)
+ _min = max(dimension.minimum for dimension in dimensions)
+ _max = max(dimension.maximum for dimension in dimensions)
+ return Measurement(_min, _max)
+
+ def append(self, renderable: "RenderableType") -> None:
+ self._renderables.append(renderable)
+
+ def __iter__(self) -> Iterable["RenderableType"]:
+ return iter(self._renderables)
+
+
+class Lines:
+ """A list subclass which can render to the console."""
+
+ def __init__(self, lines: Iterable["Text"] = ()) -> None:
+ self._lines: List["Text"] = list(lines)
+
+ def __repr__(self) -> str:
+ return f"Lines({self._lines!r})"
+
+ def __iter__(self) -> Iterator["Text"]:
+ return iter(self._lines)
+
+ @overload
+ def __getitem__(self, index: int) -> "Text":
+ ...
+
+ @overload
+ def __getitem__(self, index: slice) -> List["Text"]:
+ ...
+
+ def __getitem__(self, index: Union[slice, int]) -> Union["Text", List["Text"]]:
+ return self._lines[index]
+
+ def __setitem__(self, index: int, value: "Text") -> "Lines":
+ self._lines[index] = value
+ return self
+
+ def __len__(self) -> int:
+ return self._lines.__len__()
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ """Console render method to insert line-breaks."""
+ yield from self._lines
+
+ def append(self, line: "Text") -> None:
+ self._lines.append(line)
+
+ def extend(self, lines: Iterable["Text"]) -> None:
+ self._lines.extend(lines)
+
+ def pop(self, index: int = -1) -> "Text":
+ return self._lines.pop(index)
+
+ def justify(
+ self,
+ console: "Console",
+ width: int,
+ justify: "JustifyMethod" = "left",
+ overflow: "OverflowMethod" = "fold",
+ ) -> None:
+ """Justify and overflow text to a given width.
+
+ Args:
+ console (Console): Console instance.
+ width (int): Number of cells available per line.
+ justify (str, optional): Default justify method for text: "left", "center", "full" or "right". Defaults to "left".
+ overflow (str, optional): Default overflow for text: "crop", "fold", or "ellipsis". Defaults to "fold".
+
+ """
+ from .text import Text
+
+ if justify == "left":
+ for line in self._lines:
+ line.truncate(width, overflow=overflow, pad=True)
+ elif justify == "center":
+ for line in self._lines:
+ line.rstrip()
+ line.truncate(width, overflow=overflow)
+ line.pad_left((width - cell_len(line.plain)) // 2)
+ line.pad_right(width - cell_len(line.plain))
+ elif justify == "right":
+ for line in self._lines:
+ line.rstrip()
+ line.truncate(width, overflow=overflow)
+ line.pad_left(width - cell_len(line.plain))
+ elif justify == "full":
+ for line_index, line in enumerate(self._lines):
+ if line_index == len(self._lines) - 1:
+ break
+ words = line.split(" ")
+ words_size = sum(cell_len(word.plain) for word in words)
+ num_spaces = len(words) - 1
+ spaces = [1 for _ in range(num_spaces)]
+ index = 0
+ if spaces:
+ while words_size + num_spaces < width:
+ spaces[len(spaces) - index - 1] += 1
+ num_spaces += 1
+ index = (index + 1) % len(spaces)
+ tokens: List[Text] = []
+ for index, (word, next_word) in enumerate(
+ zip_longest(words, words[1:])
+ ):
+ tokens.append(word)
+ if index < len(spaces):
+ style = word.get_style_at_offset(console, -1)
+ next_style = next_word.get_style_at_offset(console, 0)
+ space_style = style if style == next_style else line.style
+ tokens.append(Text(" " * spaces[index], style=space_style))
+ self[line_index] = Text("").join(tokens)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/control.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/control.py
new file mode 100644
index 000000000..88fcb9295
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/control.py
@@ -0,0 +1,225 @@
+import sys
+import time
+from typing import TYPE_CHECKING, Callable, Dict, Iterable, List, Union
+
+if sys.version_info >= (3, 8):
+ from typing import Final
+else:
+ from pip._vendor.typing_extensions import Final # pragma: no cover
+
+from .segment import ControlCode, ControlType, Segment
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderResult
+
+STRIP_CONTROL_CODES: Final = [
+ 7, # Bell
+ 8, # Backspace
+ 11, # Vertical tab
+ 12, # Form feed
+ 13, # Carriage return
+]
+_CONTROL_STRIP_TRANSLATE: Final = {
+ _codepoint: None for _codepoint in STRIP_CONTROL_CODES
+}
+
+CONTROL_ESCAPE: Final = {
+ 7: "\\a",
+ 8: "\\b",
+ 11: "\\v",
+ 12: "\\f",
+ 13: "\\r",
+}
+
+CONTROL_CODES_FORMAT: Dict[int, Callable[..., str]] = {
+ ControlType.BELL: lambda: "\x07",
+ ControlType.CARRIAGE_RETURN: lambda: "\r",
+ ControlType.HOME: lambda: "\x1b[H",
+ ControlType.CLEAR: lambda: "\x1b[2J",
+ ControlType.ENABLE_ALT_SCREEN: lambda: "\x1b[?1049h",
+ ControlType.DISABLE_ALT_SCREEN: lambda: "\x1b[?1049l",
+ ControlType.SHOW_CURSOR: lambda: "\x1b[?25h",
+ ControlType.HIDE_CURSOR: lambda: "\x1b[?25l",
+ ControlType.CURSOR_UP: lambda param: f"\x1b[{param}A",
+ ControlType.CURSOR_DOWN: lambda param: f"\x1b[{param}B",
+ ControlType.CURSOR_FORWARD: lambda param: f"\x1b[{param}C",
+ ControlType.CURSOR_BACKWARD: lambda param: f"\x1b[{param}D",
+ ControlType.CURSOR_MOVE_TO_COLUMN: lambda param: f"\x1b[{param+1}G",
+ ControlType.ERASE_IN_LINE: lambda param: f"\x1b[{param}K",
+ ControlType.CURSOR_MOVE_TO: lambda x, y: f"\x1b[{y+1};{x+1}H",
+ ControlType.SET_WINDOW_TITLE: lambda title: f"\x1b]0;{title}\x07",
+}
+
+
+class Control:
+ """A renderable that inserts a control code (non printable but may move cursor).
+
+ Args:
+ *codes (str): Positional arguments are either a :class:`~rich.segment.ControlType` enum or a
+ tuple of ControlType and an integer parameter
+ """
+
+ __slots__ = ["segment"]
+
+ def __init__(self, *codes: Union[ControlType, ControlCode]) -> None:
+ control_codes: List[ControlCode] = [
+ (code,) if isinstance(code, ControlType) else code for code in codes
+ ]
+ _format_map = CONTROL_CODES_FORMAT
+ rendered_codes = "".join(
+ _format_map[code](*parameters) for code, *parameters in control_codes
+ )
+ self.segment = Segment(rendered_codes, None, control_codes)
+
+ @classmethod
+ def bell(cls) -> "Control":
+ """Ring the 'bell'."""
+ return cls(ControlType.BELL)
+
+ @classmethod
+ def home(cls) -> "Control":
+ """Move cursor to 'home' position."""
+ return cls(ControlType.HOME)
+
+ @classmethod
+ def move(cls, x: int = 0, y: int = 0) -> "Control":
+ """Move cursor relative to current position.
+
+ Args:
+ x (int): X offset.
+ y (int): Y offset.
+
+ Returns:
+ ~Control: Control object.
+
+ """
+
+ def get_codes() -> Iterable[ControlCode]:
+ control = ControlType
+ if x:
+ yield (
+ control.CURSOR_FORWARD if x > 0 else control.CURSOR_BACKWARD,
+ abs(x),
+ )
+ if y:
+ yield (
+ control.CURSOR_DOWN if y > 0 else control.CURSOR_UP,
+ abs(y),
+ )
+
+ control = cls(*get_codes())
+ return control
+
+ @classmethod
+ def move_to_column(cls, x: int, y: int = 0) -> "Control":
+ """Move to the given column, optionally add offset to row.
+
+ Returns:
+ x (int): absolute x (column)
+ y (int): optional y offset (row)
+
+ Returns:
+ ~Control: Control object.
+ """
+
+ return (
+ cls(
+ (ControlType.CURSOR_MOVE_TO_COLUMN, x),
+ (
+ ControlType.CURSOR_DOWN if y > 0 else ControlType.CURSOR_UP,
+ abs(y),
+ ),
+ )
+ if y
+ else cls((ControlType.CURSOR_MOVE_TO_COLUMN, x))
+ )
+
+ @classmethod
+ def move_to(cls, x: int, y: int) -> "Control":
+ """Move cursor to absolute position.
+
+ Args:
+ x (int): x offset (column)
+ y (int): y offset (row)
+
+ Returns:
+ ~Control: Control object.
+ """
+ return cls((ControlType.CURSOR_MOVE_TO, x, y))
+
+ @classmethod
+ def clear(cls) -> "Control":
+ """Clear the screen."""
+ return cls(ControlType.CLEAR)
+
+ @classmethod
+ def show_cursor(cls, show: bool) -> "Control":
+ """Show or hide the cursor."""
+ return cls(ControlType.SHOW_CURSOR if show else ControlType.HIDE_CURSOR)
+
+ @classmethod
+ def alt_screen(cls, enable: bool) -> "Control":
+ """Enable or disable alt screen."""
+ if enable:
+ return cls(ControlType.ENABLE_ALT_SCREEN, ControlType.HOME)
+ else:
+ return cls(ControlType.DISABLE_ALT_SCREEN)
+
+ @classmethod
+ def title(cls, title: str) -> "Control":
+ """Set the terminal window title
+
+ Args:
+ title (str): The new terminal window title
+ """
+ return cls((ControlType.SET_WINDOW_TITLE, title))
+
+ def __str__(self) -> str:
+ return self.segment.text
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ if self.segment.text:
+ yield self.segment
+
+
+def strip_control_codes(
+ text: str, _translate_table: Dict[int, None] = _CONTROL_STRIP_TRANSLATE
+) -> str:
+ """Remove control codes from text.
+
+ Args:
+ text (str): A string possibly contain control codes.
+
+ Returns:
+ str: String with control codes removed.
+ """
+ return text.translate(_translate_table)
+
+
+def escape_control_codes(
+ text: str,
+ _translate_table: Dict[int, str] = CONTROL_ESCAPE,
+) -> str:
+ """Replace control codes with their "escaped" equivalent in the given text.
+ (e.g. "\b" becomes "\\b")
+
+ Args:
+ text (str): A string possibly containing control codes.
+
+ Returns:
+ str: String with control codes replaced with their escaped version.
+ """
+ return text.translate(_translate_table)
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.console import Console
+
+ console = Console()
+ console.print("Look at the title of your terminal window ^")
+ # console.print(Control((ControlType.SET_WINDOW_TITLE, "Hello, world!")))
+ for i in range(10):
+ console.set_window_title("🚀 Loading" + "." * i)
+ time.sleep(0.5)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/default_styles.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/default_styles.py
new file mode 100644
index 000000000..dca37193a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/default_styles.py
@@ -0,0 +1,190 @@
+from typing import Dict
+
+from .style import Style
+
+DEFAULT_STYLES: Dict[str, Style] = {
+ "none": Style.null(),
+ "reset": Style(
+ color="default",
+ bgcolor="default",
+ dim=False,
+ bold=False,
+ italic=False,
+ underline=False,
+ blink=False,
+ blink2=False,
+ reverse=False,
+ conceal=False,
+ strike=False,
+ ),
+ "dim": Style(dim=True),
+ "bright": Style(dim=False),
+ "bold": Style(bold=True),
+ "strong": Style(bold=True),
+ "code": Style(reverse=True, bold=True),
+ "italic": Style(italic=True),
+ "emphasize": Style(italic=True),
+ "underline": Style(underline=True),
+ "blink": Style(blink=True),
+ "blink2": Style(blink2=True),
+ "reverse": Style(reverse=True),
+ "strike": Style(strike=True),
+ "black": Style(color="black"),
+ "red": Style(color="red"),
+ "green": Style(color="green"),
+ "yellow": Style(color="yellow"),
+ "magenta": Style(color="magenta"),
+ "cyan": Style(color="cyan"),
+ "white": Style(color="white"),
+ "inspect.attr": Style(color="yellow", italic=True),
+ "inspect.attr.dunder": Style(color="yellow", italic=True, dim=True),
+ "inspect.callable": Style(bold=True, color="red"),
+ "inspect.async_def": Style(italic=True, color="bright_cyan"),
+ "inspect.def": Style(italic=True, color="bright_cyan"),
+ "inspect.class": Style(italic=True, color="bright_cyan"),
+ "inspect.error": Style(bold=True, color="red"),
+ "inspect.equals": Style(),
+ "inspect.help": Style(color="cyan"),
+ "inspect.doc": Style(dim=True),
+ "inspect.value.border": Style(color="green"),
+ "live.ellipsis": Style(bold=True, color="red"),
+ "layout.tree.row": Style(dim=False, color="red"),
+ "layout.tree.column": Style(dim=False, color="blue"),
+ "logging.keyword": Style(bold=True, color="yellow"),
+ "logging.level.notset": Style(dim=True),
+ "logging.level.debug": Style(color="green"),
+ "logging.level.info": Style(color="blue"),
+ "logging.level.warning": Style(color="red"),
+ "logging.level.error": Style(color="red", bold=True),
+ "logging.level.critical": Style(color="red", bold=True, reverse=True),
+ "log.level": Style.null(),
+ "log.time": Style(color="cyan", dim=True),
+ "log.message": Style.null(),
+ "log.path": Style(dim=True),
+ "repr.ellipsis": Style(color="yellow"),
+ "repr.indent": Style(color="green", dim=True),
+ "repr.error": Style(color="red", bold=True),
+ "repr.str": Style(color="green", italic=False, bold=False),
+ "repr.brace": Style(bold=True),
+ "repr.comma": Style(bold=True),
+ "repr.ipv4": Style(bold=True, color="bright_green"),
+ "repr.ipv6": Style(bold=True, color="bright_green"),
+ "repr.eui48": Style(bold=True, color="bright_green"),
+ "repr.eui64": Style(bold=True, color="bright_green"),
+ "repr.tag_start": Style(bold=True),
+ "repr.tag_name": Style(color="bright_magenta", bold=True),
+ "repr.tag_contents": Style(color="default"),
+ "repr.tag_end": Style(bold=True),
+ "repr.attrib_name": Style(color="yellow", italic=False),
+ "repr.attrib_equal": Style(bold=True),
+ "repr.attrib_value": Style(color="magenta", italic=False),
+ "repr.number": Style(color="cyan", bold=True, italic=False),
+ "repr.number_complex": Style(color="cyan", bold=True, italic=False), # same
+ "repr.bool_true": Style(color="bright_green", italic=True),
+ "repr.bool_false": Style(color="bright_red", italic=True),
+ "repr.none": Style(color="magenta", italic=True),
+ "repr.url": Style(underline=True, color="bright_blue", italic=False, bold=False),
+ "repr.uuid": Style(color="bright_yellow", bold=False),
+ "repr.call": Style(color="magenta", bold=True),
+ "repr.path": Style(color="magenta"),
+ "repr.filename": Style(color="bright_magenta"),
+ "rule.line": Style(color="bright_green"),
+ "rule.text": Style.null(),
+ "json.brace": Style(bold=True),
+ "json.bool_true": Style(color="bright_green", italic=True),
+ "json.bool_false": Style(color="bright_red", italic=True),
+ "json.null": Style(color="magenta", italic=True),
+ "json.number": Style(color="cyan", bold=True, italic=False),
+ "json.str": Style(color="green", italic=False, bold=False),
+ "json.key": Style(color="blue", bold=True),
+ "prompt": Style.null(),
+ "prompt.choices": Style(color="magenta", bold=True),
+ "prompt.default": Style(color="cyan", bold=True),
+ "prompt.invalid": Style(color="red"),
+ "prompt.invalid.choice": Style(color="red"),
+ "pretty": Style.null(),
+ "scope.border": Style(color="blue"),
+ "scope.key": Style(color="yellow", italic=True),
+ "scope.key.special": Style(color="yellow", italic=True, dim=True),
+ "scope.equals": Style(color="red"),
+ "table.header": Style(bold=True),
+ "table.footer": Style(bold=True),
+ "table.cell": Style.null(),
+ "table.title": Style(italic=True),
+ "table.caption": Style(italic=True, dim=True),
+ "traceback.error": Style(color="red", italic=True),
+ "traceback.border.syntax_error": Style(color="bright_red"),
+ "traceback.border": Style(color="red"),
+ "traceback.text": Style.null(),
+ "traceback.title": Style(color="red", bold=True),
+ "traceback.exc_type": Style(color="bright_red", bold=True),
+ "traceback.exc_value": Style.null(),
+ "traceback.offset": Style(color="bright_red", bold=True),
+ "bar.back": Style(color="grey23"),
+ "bar.complete": Style(color="rgb(249,38,114)"),
+ "bar.finished": Style(color="rgb(114,156,31)"),
+ "bar.pulse": Style(color="rgb(249,38,114)"),
+ "progress.description": Style.null(),
+ "progress.filesize": Style(color="green"),
+ "progress.filesize.total": Style(color="green"),
+ "progress.download": Style(color="green"),
+ "progress.elapsed": Style(color="yellow"),
+ "progress.percentage": Style(color="magenta"),
+ "progress.remaining": Style(color="cyan"),
+ "progress.data.speed": Style(color="red"),
+ "progress.spinner": Style(color="green"),
+ "status.spinner": Style(color="green"),
+ "tree": Style(),
+ "tree.line": Style(),
+ "markdown.paragraph": Style(),
+ "markdown.text": Style(),
+ "markdown.em": Style(italic=True),
+ "markdown.emph": Style(italic=True), # For commonmark backwards compatibility
+ "markdown.strong": Style(bold=True),
+ "markdown.code": Style(bold=True, color="cyan", bgcolor="black"),
+ "markdown.code_block": Style(color="cyan", bgcolor="black"),
+ "markdown.block_quote": Style(color="magenta"),
+ "markdown.list": Style(color="cyan"),
+ "markdown.item": Style(),
+ "markdown.item.bullet": Style(color="yellow", bold=True),
+ "markdown.item.number": Style(color="yellow", bold=True),
+ "markdown.hr": Style(color="yellow"),
+ "markdown.h1.border": Style(),
+ "markdown.h1": Style(bold=True),
+ "markdown.h2": Style(bold=True, underline=True),
+ "markdown.h3": Style(bold=True),
+ "markdown.h4": Style(bold=True, dim=True),
+ "markdown.h5": Style(underline=True),
+ "markdown.h6": Style(italic=True),
+ "markdown.h7": Style(italic=True, dim=True),
+ "markdown.link": Style(color="bright_blue"),
+ "markdown.link_url": Style(color="blue", underline=True),
+ "markdown.s": Style(strike=True),
+ "iso8601.date": Style(color="blue"),
+ "iso8601.time": Style(color="magenta"),
+ "iso8601.timezone": Style(color="yellow"),
+}
+
+
+if __name__ == "__main__": # pragma: no cover
+ import argparse
+ import io
+
+ from pip._vendor.rich.console import Console
+ from pip._vendor.rich.table import Table
+ from pip._vendor.rich.text import Text
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--html", action="store_true", help="Export as HTML table")
+ args = parser.parse_args()
+ html: bool = args.html
+ console = Console(record=True, width=70, file=io.StringIO()) if html else Console()
+
+ table = Table("Name", "Styling")
+
+ for style_name, style in DEFAULT_STYLES.items():
+ table.add_row(Text(style_name, style=style), str(style))
+
+ console.print(table)
+ if html:
+ print(console.export_html(inline_styles=True))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/diagnose.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/diagnose.py
new file mode 100644
index 000000000..ad3618389
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/diagnose.py
@@ -0,0 +1,37 @@
+import os
+import platform
+
+from pip._vendor.rich import inspect
+from pip._vendor.rich.console import Console, get_windows_console_features
+from pip._vendor.rich.panel import Panel
+from pip._vendor.rich.pretty import Pretty
+
+
+def report() -> None: # pragma: no cover
+ """Print a report to the terminal with debugging information"""
+ console = Console()
+ inspect(console)
+ features = get_windows_console_features()
+ inspect(features)
+
+ env_names = (
+ "TERM",
+ "COLORTERM",
+ "CLICOLOR",
+ "NO_COLOR",
+ "TERM_PROGRAM",
+ "COLUMNS",
+ "LINES",
+ "JUPYTER_COLUMNS",
+ "JUPYTER_LINES",
+ "JPY_PARENT_PID",
+ "VSCODE_VERBOSE_LOGGING",
+ )
+ env = {name: os.getenv(name) for name in env_names}
+ console.print(Panel.fit((Pretty(env)), title="[b]Environment Variables"))
+
+ console.print(f'platform="{platform.system()}"')
+
+
+if __name__ == "__main__": # pragma: no cover
+ report()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/emoji.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/emoji.py
new file mode 100644
index 000000000..791f0465d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/emoji.py
@@ -0,0 +1,96 @@
+import sys
+from typing import TYPE_CHECKING, Optional, Union
+
+from .jupyter import JupyterMixin
+from .segment import Segment
+from .style import Style
+from ._emoji_codes import EMOJI
+from ._emoji_replace import _emoji_replace
+
+if sys.version_info >= (3, 8):
+ from typing import Literal
+else:
+ from pip._vendor.typing_extensions import Literal # pragma: no cover
+
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderResult
+
+
+EmojiVariant = Literal["emoji", "text"]
+
+
+class NoEmoji(Exception):
+ """No emoji by that name."""
+
+
+class Emoji(JupyterMixin):
+ __slots__ = ["name", "style", "_char", "variant"]
+
+ VARIANTS = {"text": "\uFE0E", "emoji": "\uFE0F"}
+
+ def __init__(
+ self,
+ name: str,
+ style: Union[str, Style] = "none",
+ variant: Optional[EmojiVariant] = None,
+ ) -> None:
+ """A single emoji character.
+
+ Args:
+ name (str): Name of emoji.
+ style (Union[str, Style], optional): Optional style. Defaults to None.
+
+ Raises:
+ NoEmoji: If the emoji doesn't exist.
+ """
+ self.name = name
+ self.style = style
+ self.variant = variant
+ try:
+ self._char = EMOJI[name]
+ except KeyError:
+ raise NoEmoji(f"No emoji called {name!r}")
+ if variant is not None:
+ self._char += self.VARIANTS.get(variant, "")
+
+ @classmethod
+ def replace(cls, text: str) -> str:
+ """Replace emoji markup with corresponding unicode characters.
+
+ Args:
+ text (str): A string with emojis codes, e.g. "Hello :smiley:!"
+
+ Returns:
+ str: A string with emoji codes replaces with actual emoji.
+ """
+ return _emoji_replace(text)
+
+ def __repr__(self) -> str:
+ return f"<emoji {self.name!r}>"
+
+ def __str__(self) -> str:
+ return self._char
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ yield Segment(self._char, console.get_style(self.style))
+
+
+if __name__ == "__main__": # pragma: no cover
+ import sys
+
+ from pip._vendor.rich.columns import Columns
+ from pip._vendor.rich.console import Console
+
+ console = Console(record=True)
+
+ columns = Columns(
+ (f":{name}: {name}" for name in sorted(EMOJI.keys()) if "\u200D" not in name),
+ column_first=True,
+ )
+
+ console.print(columns)
+ if len(sys.argv) > 1:
+ console.save_html(sys.argv[1])
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/errors.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/errors.py
new file mode 100644
index 000000000..0bcbe53ef
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/errors.py
@@ -0,0 +1,34 @@
+class ConsoleError(Exception):
+ """An error in console operation."""
+
+
+class StyleError(Exception):
+ """An error in styles."""
+
+
+class StyleSyntaxError(ConsoleError):
+ """Style was badly formatted."""
+
+
+class MissingStyle(StyleError):
+ """No such style."""
+
+
+class StyleStackError(ConsoleError):
+ """Style stack is invalid."""
+
+
+class NotRenderableError(ConsoleError):
+ """Object is not renderable."""
+
+
+class MarkupError(ConsoleError):
+ """Markup was badly formatted."""
+
+
+class LiveError(ConsoleError):
+ """Error related to Live display."""
+
+
+class NoAltScreen(ConsoleError):
+ """Alt screen mode was required."""
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/file_proxy.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/file_proxy.py
new file mode 100644
index 000000000..4b0b0da6c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/file_proxy.py
@@ -0,0 +1,57 @@
+import io
+from typing import IO, TYPE_CHECKING, Any, List
+
+from .ansi import AnsiDecoder
+from .text import Text
+
+if TYPE_CHECKING:
+ from .console import Console
+
+
+class FileProxy(io.TextIOBase):
+ """Wraps a file (e.g. sys.stdout) and redirects writes to a console."""
+
+ def __init__(self, console: "Console", file: IO[str]) -> None:
+ self.__console = console
+ self.__file = file
+ self.__buffer: List[str] = []
+ self.__ansi_decoder = AnsiDecoder()
+
+ @property
+ def rich_proxied_file(self) -> IO[str]:
+ """Get proxied file."""
+ return self.__file
+
+ def __getattr__(self, name: str) -> Any:
+ return getattr(self.__file, name)
+
+ def write(self, text: str) -> int:
+ if not isinstance(text, str):
+ raise TypeError(f"write() argument must be str, not {type(text).__name__}")
+ buffer = self.__buffer
+ lines: List[str] = []
+ while text:
+ line, new_line, text = text.partition("\n")
+ if new_line:
+ lines.append("".join(buffer) + line)
+ buffer.clear()
+ else:
+ buffer.append(line)
+ break
+ if lines:
+ console = self.__console
+ with console:
+ output = Text("\n").join(
+ self.__ansi_decoder.decode_line(line) for line in lines
+ )
+ console.print(output)
+ return len(text)
+
+ def flush(self) -> None:
+ output = "".join(self.__buffer)
+ if output:
+ self.__console.print(output)
+ del self.__buffer[:]
+
+ def fileno(self) -> int:
+ return self.__file.fileno()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/filesize.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/filesize.py
new file mode 100644
index 000000000..99f118e20
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/filesize.py
@@ -0,0 +1,89 @@
+# coding: utf-8
+"""Functions for reporting filesizes. Borrowed from https://github.com/PyFilesystem/pyfilesystem2
+
+The functions declared in this module should cover the different
+use cases needed to generate a string representation of a file size
+using several different units. Since there are many standards regarding
+file size units, three different functions have been implemented.
+
+See Also:
+ * `Wikipedia: Binary prefix <https://en.wikipedia.org/wiki/Binary_prefix>`_
+
+"""
+
+__all__ = ["decimal"]
+
+from typing import Iterable, List, Optional, Tuple
+
+
+def _to_str(
+ size: int,
+ suffixes: Iterable[str],
+ base: int,
+ *,
+ precision: Optional[int] = 1,
+ separator: Optional[str] = " ",
+) -> str:
+ if size == 1:
+ return "1 byte"
+ elif size < base:
+ return "{:,} bytes".format(size)
+
+ for i, suffix in enumerate(suffixes, 2): # noqa: B007
+ unit = base**i
+ if size < unit:
+ break
+ return "{:,.{precision}f}{separator}{}".format(
+ (base * size / unit),
+ suffix,
+ precision=precision,
+ separator=separator,
+ )
+
+
+def pick_unit_and_suffix(size: int, suffixes: List[str], base: int) -> Tuple[int, str]:
+ """Pick a suffix and base for the given size."""
+ for i, suffix in enumerate(suffixes):
+ unit = base**i
+ if size < unit * base:
+ break
+ return unit, suffix
+
+
+def decimal(
+ size: int,
+ *,
+ precision: Optional[int] = 1,
+ separator: Optional[str] = " ",
+) -> str:
+ """Convert a filesize in to a string (powers of 1000, SI prefixes).
+
+ In this convention, ``1000 B = 1 kB``.
+
+ This is typically the format used to advertise the storage
+ capacity of USB flash drives and the like (*256 MB* meaning
+ actually a storage capacity of more than *256 000 000 B*),
+ or used by **Mac OS X** since v10.6 to report file sizes.
+
+ Arguments:
+ int (size): A file size.
+ int (precision): The number of decimal places to include (default = 1).
+ str (separator): The string to separate the value from the units (default = " ").
+
+ Returns:
+ `str`: A string containing a abbreviated file size and units.
+
+ Example:
+ >>> filesize.decimal(30000)
+ '30.0 kB'
+ >>> filesize.decimal(30000, precision=2, separator="")
+ '30.00kB'
+
+ """
+ return _to_str(
+ size,
+ ("kB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB"),
+ 1000,
+ precision=precision,
+ separator=separator,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/highlighter.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/highlighter.py
new file mode 100644
index 000000000..27714b25b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/highlighter.py
@@ -0,0 +1,232 @@
+import re
+from abc import ABC, abstractmethod
+from typing import List, Union
+
+from .text import Span, Text
+
+
+def _combine_regex(*regexes: str) -> str:
+ """Combine a number of regexes in to a single regex.
+
+ Returns:
+ str: New regex with all regexes ORed together.
+ """
+ return "|".join(regexes)
+
+
+class Highlighter(ABC):
+ """Abstract base class for highlighters."""
+
+ def __call__(self, text: Union[str, Text]) -> Text:
+ """Highlight a str or Text instance.
+
+ Args:
+ text (Union[str, ~Text]): Text to highlight.
+
+ Raises:
+ TypeError: If not called with text or str.
+
+ Returns:
+ Text: A test instance with highlighting applied.
+ """
+ if isinstance(text, str):
+ highlight_text = Text(text)
+ elif isinstance(text, Text):
+ highlight_text = text.copy()
+ else:
+ raise TypeError(f"str or Text instance required, not {text!r}")
+ self.highlight(highlight_text)
+ return highlight_text
+
+ @abstractmethod
+ def highlight(self, text: Text) -> None:
+ """Apply highlighting in place to text.
+
+ Args:
+ text (~Text): A text object highlight.
+ """
+
+
+class NullHighlighter(Highlighter):
+ """A highlighter object that doesn't highlight.
+
+ May be used to disable highlighting entirely.
+
+ """
+
+ def highlight(self, text: Text) -> None:
+ """Nothing to do"""
+
+
+class RegexHighlighter(Highlighter):
+ """Applies highlighting from a list of regular expressions."""
+
+ highlights: List[str] = []
+ base_style: str = ""
+
+ def highlight(self, text: Text) -> None:
+ """Highlight :class:`rich.text.Text` using regular expressions.
+
+ Args:
+ text (~Text): Text to highlighted.
+
+ """
+
+ highlight_regex = text.highlight_regex
+ for re_highlight in self.highlights:
+ highlight_regex(re_highlight, style_prefix=self.base_style)
+
+
+class ReprHighlighter(RegexHighlighter):
+ """Highlights the text typically produced from ``__repr__`` methods."""
+
+ base_style = "repr."
+ highlights = [
+ r"(?P<tag_start><)(?P<tag_name>[-\w.:|]*)(?P<tag_contents>[\w\W]*)(?P<tag_end>>)",
+ r'(?P<attrib_name>[\w_]{1,50})=(?P<attrib_value>"?[\w_]+"?)?',
+ r"(?P<brace>[][{}()])",
+ _combine_regex(
+ r"(?P<ipv4>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})",
+ r"(?P<ipv6>([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})",
+ r"(?P<eui64>(?:[0-9A-Fa-f]{1,2}-){7}[0-9A-Fa-f]{1,2}|(?:[0-9A-Fa-f]{1,2}:){7}[0-9A-Fa-f]{1,2}|(?:[0-9A-Fa-f]{4}\.){3}[0-9A-Fa-f]{4})",
+ r"(?P<eui48>(?:[0-9A-Fa-f]{1,2}-){5}[0-9A-Fa-f]{1,2}|(?:[0-9A-Fa-f]{1,2}:){5}[0-9A-Fa-f]{1,2}|(?:[0-9A-Fa-f]{4}\.){2}[0-9A-Fa-f]{4})",
+ r"(?P<uuid>[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12})",
+ r"(?P<call>[\w.]*?)\(",
+ r"\b(?P<bool_true>True)\b|\b(?P<bool_false>False)\b|\b(?P<none>None)\b",
+ r"(?P<ellipsis>\.\.\.)",
+ r"(?P<number_complex>(?<!\w)(?:\-?[0-9]+\.?[0-9]*(?:e[-+]?\d+?)?)(?:[-+](?:[0-9]+\.?[0-9]*(?:e[-+]?\d+)?))?j)",
+ r"(?P<number>(?<!\w)\-?[0-9]+\.?[0-9]*(e[-+]?\d+?)?\b|0x[0-9a-fA-F]*)",
+ r"(?P<path>\B(/[-\w._+]+)*\/)(?P<filename>[-\w._+]*)?",
+ r"(?<![\\\w])(?P<str>b?'''.*?(?<!\\)'''|b?'.*?(?<!\\)'|b?\"\"\".*?(?<!\\)\"\"\"|b?\".*?(?<!\\)\")",
+ r"(?P<url>(file|https|http|ws|wss)://[-0-9a-zA-Z$_+!`(),.?/;:&=%#~]*)",
+ ),
+ ]
+
+
+class JSONHighlighter(RegexHighlighter):
+ """Highlights JSON"""
+
+ # Captures the start and end of JSON strings, handling escaped quotes
+ JSON_STR = r"(?<![\\\w])(?P<str>b?\".*?(?<!\\)\")"
+ JSON_WHITESPACE = {" ", "\n", "\r", "\t"}
+
+ base_style = "json."
+ highlights = [
+ _combine_regex(
+ r"(?P<brace>[\{\[\(\)\]\}])",
+ r"\b(?P<bool_true>true)\b|\b(?P<bool_false>false)\b|\b(?P<null>null)\b",
+ r"(?P<number>(?<!\w)\-?[0-9]+\.?[0-9]*(e[\-\+]?\d+?)?\b|0x[0-9a-fA-F]*)",
+ JSON_STR,
+ ),
+ ]
+
+ def highlight(self, text: Text) -> None:
+ super().highlight(text)
+
+ # Additional work to handle highlighting JSON keys
+ plain = text.plain
+ append = text.spans.append
+ whitespace = self.JSON_WHITESPACE
+ for match in re.finditer(self.JSON_STR, plain):
+ start, end = match.span()
+ cursor = end
+ while cursor < len(plain):
+ char = plain[cursor]
+ cursor += 1
+ if char == ":":
+ append(Span(start, end, "json.key"))
+ elif char in whitespace:
+ continue
+ break
+
+
+class ISO8601Highlighter(RegexHighlighter):
+ """Highlights the ISO8601 date time strings.
+ Regex reference: https://www.oreilly.com/library/view/regular-expressions-cookbook/9781449327453/ch04s07.html
+ """
+
+ base_style = "iso8601."
+ highlights = [
+ #
+ # Dates
+ #
+ # Calendar month (e.g. 2008-08). The hyphen is required
+ r"^(?P<year>[0-9]{4})-(?P<month>1[0-2]|0[1-9])$",
+ # Calendar date w/o hyphens (e.g. 20080830)
+ r"^(?P<date>(?P<year>[0-9]{4})(?P<month>1[0-2]|0[1-9])(?P<day>3[01]|0[1-9]|[12][0-9]))$",
+ # Ordinal date (e.g. 2008-243). The hyphen is optional
+ r"^(?P<date>(?P<year>[0-9]{4})-?(?P<day>36[0-6]|3[0-5][0-9]|[12][0-9]{2}|0[1-9][0-9]|00[1-9]))$",
+ #
+ # Weeks
+ #
+ # Week of the year (e.g., 2008-W35). The hyphen is optional
+ r"^(?P<date>(?P<year>[0-9]{4})-?W(?P<week>5[0-3]|[1-4][0-9]|0[1-9]))$",
+ # Week date (e.g., 2008-W35-6). The hyphens are optional
+ r"^(?P<date>(?P<year>[0-9]{4})-?W(?P<week>5[0-3]|[1-4][0-9]|0[1-9])-?(?P<day>[1-7]))$",
+ #
+ # Times
+ #
+ # Hours and minutes (e.g., 17:21). The colon is optional
+ r"^(?P<time>(?P<hour>2[0-3]|[01][0-9]):?(?P<minute>[0-5][0-9]))$",
+ # Hours, minutes, and seconds w/o colons (e.g., 172159)
+ r"^(?P<time>(?P<hour>2[0-3]|[01][0-9])(?P<minute>[0-5][0-9])(?P<second>[0-5][0-9]))$",
+ # Time zone designator (e.g., Z, +07 or +07:00). The colons and the minutes are optional
+ r"^(?P<timezone>(Z|[+-](?:2[0-3]|[01][0-9])(?::?(?:[0-5][0-9]))?))$",
+ # Hours, minutes, and seconds with time zone designator (e.g., 17:21:59+07:00).
+ # All the colons are optional. The minutes in the time zone designator are also optional
+ r"^(?P<time>(?P<hour>2[0-3]|[01][0-9])(?P<minute>[0-5][0-9])(?P<second>[0-5][0-9]))(?P<timezone>Z|[+-](?:2[0-3]|[01][0-9])(?::?(?:[0-5][0-9]))?)$",
+ #
+ # Date and Time
+ #
+ # Calendar date with hours, minutes, and seconds (e.g., 2008-08-30 17:21:59 or 20080830 172159).
+ # A space is required between the date and the time. The hyphens and colons are optional.
+ # This regex matches dates and times that specify some hyphens or colons but omit others.
+ # This does not follow ISO 8601
+ r"^(?P<date>(?P<year>[0-9]{4})(?P<hyphen>-)?(?P<month>1[0-2]|0[1-9])(?(hyphen)-)(?P<day>3[01]|0[1-9]|[12][0-9])) (?P<time>(?P<hour>2[0-3]|[01][0-9])(?(hyphen):)(?P<minute>[0-5][0-9])(?(hyphen):)(?P<second>[0-5][0-9]))$",
+ #
+ # XML Schema dates and times
+ #
+ # Date, with optional time zone (e.g., 2008-08-30 or 2008-08-30+07:00).
+ # Hyphens are required. This is the XML Schema 'date' type
+ r"^(?P<date>(?P<year>-?(?:[1-9][0-9]*)?[0-9]{4})-(?P<month>1[0-2]|0[1-9])-(?P<day>3[01]|0[1-9]|[12][0-9]))(?P<timezone>Z|[+-](?:2[0-3]|[01][0-9]):[0-5][0-9])?$",
+ # Time, with optional fractional seconds and time zone (e.g., 01:45:36 or 01:45:36.123+07:00).
+ # There is no limit on the number of digits for the fractional seconds. This is the XML Schema 'time' type
+ r"^(?P<time>(?P<hour>2[0-3]|[01][0-9]):(?P<minute>[0-5][0-9]):(?P<second>[0-5][0-9])(?P<frac>\.[0-9]+)?)(?P<timezone>Z|[+-](?:2[0-3]|[01][0-9]):[0-5][0-9])?$",
+ # Date and time, with optional fractional seconds and time zone (e.g., 2008-08-30T01:45:36 or 2008-08-30T01:45:36.123Z).
+ # This is the XML Schema 'dateTime' type
+ r"^(?P<date>(?P<year>-?(?:[1-9][0-9]*)?[0-9]{4})-(?P<month>1[0-2]|0[1-9])-(?P<day>3[01]|0[1-9]|[12][0-9]))T(?P<time>(?P<hour>2[0-3]|[01][0-9]):(?P<minute>[0-5][0-9]):(?P<second>[0-5][0-9])(?P<ms>\.[0-9]+)?)(?P<timezone>Z|[+-](?:2[0-3]|[01][0-9]):[0-5][0-9])?$",
+ ]
+
+
+if __name__ == "__main__": # pragma: no cover
+ from .console import Console
+
+ console = Console()
+ console.print("[bold green]hello world![/bold green]")
+ console.print("'[bold green]hello world![/bold green]'")
+
+ console.print(" /foo")
+ console.print("/foo/")
+ console.print("/foo/bar")
+ console.print("foo/bar/baz")
+
+ console.print("/foo/bar/baz?foo=bar+egg&egg=baz")
+ console.print("/foo/bar/baz/")
+ console.print("/foo/bar/baz/egg")
+ console.print("/foo/bar/baz/egg.py")
+ console.print("/foo/bar/baz/egg.py word")
+ console.print(" /foo/bar/baz/egg.py word")
+ console.print("foo /foo/bar/baz/egg.py word")
+ console.print("foo /foo/bar/ba._++z/egg+.py word")
+ console.print("https://example.org?foo=bar#header")
+
+ console.print(1234567.34)
+ console.print(1 / 2)
+ console.print(-1 / 123123123123)
+
+ console.print(
+ "127.0.1.1 bar 192.168.1.4 2001:0db8:85a3:0000:0000:8a2e:0370:7334 foo"
+ )
+ import json
+
+ console.print_json(json.dumps(obj={"name": "apple", "count": 1}), indent=None)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/json.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/json.py
new file mode 100644
index 000000000..4087c79bb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/json.py
@@ -0,0 +1,139 @@
+from pathlib import Path
+from json import loads, dumps
+from typing import Any, Callable, Optional, Union
+
+from .text import Text
+from .highlighter import JSONHighlighter, NullHighlighter
+
+
+class JSON:
+ """A renderable which pretty prints JSON.
+
+ Args:
+ json (str): JSON encoded data.
+ indent (Union[None, int, str], optional): Number of characters to indent by. Defaults to 2.
+ highlight (bool, optional): Enable highlighting. Defaults to True.
+ skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.
+ ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.
+ check_circular (bool, optional): Check for circular references. Defaults to True.
+ allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.
+ default (Callable, optional): A callable that converts values that can not be encoded
+ in to something that can be JSON encoded. Defaults to None.
+ sort_keys (bool, optional): Sort dictionary keys. Defaults to False.
+ """
+
+ def __init__(
+ self,
+ json: str,
+ indent: Union[None, int, str] = 2,
+ highlight: bool = True,
+ skip_keys: bool = False,
+ ensure_ascii: bool = False,
+ check_circular: bool = True,
+ allow_nan: bool = True,
+ default: Optional[Callable[[Any], Any]] = None,
+ sort_keys: bool = False,
+ ) -> None:
+ data = loads(json)
+ json = dumps(
+ data,
+ indent=indent,
+ skipkeys=skip_keys,
+ ensure_ascii=ensure_ascii,
+ check_circular=check_circular,
+ allow_nan=allow_nan,
+ default=default,
+ sort_keys=sort_keys,
+ )
+ highlighter = JSONHighlighter() if highlight else NullHighlighter()
+ self.text = highlighter(json)
+ self.text.no_wrap = True
+ self.text.overflow = None
+
+ @classmethod
+ def from_data(
+ cls,
+ data: Any,
+ indent: Union[None, int, str] = 2,
+ highlight: bool = True,
+ skip_keys: bool = False,
+ ensure_ascii: bool = False,
+ check_circular: bool = True,
+ allow_nan: bool = True,
+ default: Optional[Callable[[Any], Any]] = None,
+ sort_keys: bool = False,
+ ) -> "JSON":
+ """Encodes a JSON object from arbitrary data.
+
+ Args:
+ data (Any): An object that may be encoded in to JSON
+ indent (Union[None, int, str], optional): Number of characters to indent by. Defaults to 2.
+ highlight (bool, optional): Enable highlighting. Defaults to True.
+ default (Callable, optional): Optional callable which will be called for objects that cannot be serialized. Defaults to None.
+ skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.
+ ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.
+ check_circular (bool, optional): Check for circular references. Defaults to True.
+ allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.
+ default (Callable, optional): A callable that converts values that can not be encoded
+ in to something that can be JSON encoded. Defaults to None.
+ sort_keys (bool, optional): Sort dictionary keys. Defaults to False.
+
+ Returns:
+ JSON: New JSON object from the given data.
+ """
+ json_instance: "JSON" = cls.__new__(cls)
+ json = dumps(
+ data,
+ indent=indent,
+ skipkeys=skip_keys,
+ ensure_ascii=ensure_ascii,
+ check_circular=check_circular,
+ allow_nan=allow_nan,
+ default=default,
+ sort_keys=sort_keys,
+ )
+ highlighter = JSONHighlighter() if highlight else NullHighlighter()
+ json_instance.text = highlighter(json)
+ json_instance.text.no_wrap = True
+ json_instance.text.overflow = None
+ return json_instance
+
+ def __rich__(self) -> Text:
+ return self.text
+
+
+if __name__ == "__main__":
+ import argparse
+ import sys
+
+ parser = argparse.ArgumentParser(description="Pretty print json")
+ parser.add_argument(
+ "path",
+ metavar="PATH",
+ help="path to file, or - for stdin",
+ )
+ parser.add_argument(
+ "-i",
+ "--indent",
+ metavar="SPACES",
+ type=int,
+ help="Number of spaces in an indent",
+ default=2,
+ )
+ args = parser.parse_args()
+
+ from pip._vendor.rich.console import Console
+
+ console = Console()
+ error_console = Console(stderr=True)
+
+ try:
+ if args.path == "-":
+ json_data = sys.stdin.read()
+ else:
+ json_data = Path(args.path).read_text()
+ except Exception as error:
+ error_console.print(f"Unable to read {args.path!r}; {error}")
+ sys.exit(-1)
+
+ console.print(JSON(json_data, indent=args.indent), soft_wrap=True)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/jupyter.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/jupyter.py
new file mode 100644
index 000000000..22f4d716a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/jupyter.py
@@ -0,0 +1,101 @@
+from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Sequence
+
+if TYPE_CHECKING:
+ from pip._vendor.rich.console import ConsoleRenderable
+
+from . import get_console
+from .segment import Segment
+from .terminal_theme import DEFAULT_TERMINAL_THEME
+
+if TYPE_CHECKING:
+ from pip._vendor.rich.console import ConsoleRenderable
+
+JUPYTER_HTML_FORMAT = """\
+<pre style="white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace">{code}</pre>
+"""
+
+
+class JupyterRenderable:
+ """A shim to write html to Jupyter notebook."""
+
+ def __init__(self, html: str, text: str) -> None:
+ self.html = html
+ self.text = text
+
+ def _repr_mimebundle_(
+ self, include: Sequence[str], exclude: Sequence[str], **kwargs: Any
+ ) -> Dict[str, str]:
+ data = {"text/plain": self.text, "text/html": self.html}
+ if include:
+ data = {k: v for (k, v) in data.items() if k in include}
+ if exclude:
+ data = {k: v for (k, v) in data.items() if k not in exclude}
+ return data
+
+
+class JupyterMixin:
+ """Add to an Rich renderable to make it render in Jupyter notebook."""
+
+ __slots__ = ()
+
+ def _repr_mimebundle_(
+ self: "ConsoleRenderable",
+ include: Sequence[str],
+ exclude: Sequence[str],
+ **kwargs: Any,
+ ) -> Dict[str, str]:
+ console = get_console()
+ segments = list(console.render(self, console.options))
+ html = _render_segments(segments)
+ text = console._render_buffer(segments)
+ data = {"text/plain": text, "text/html": html}
+ if include:
+ data = {k: v for (k, v) in data.items() if k in include}
+ if exclude:
+ data = {k: v for (k, v) in data.items() if k not in exclude}
+ return data
+
+
+def _render_segments(segments: Iterable[Segment]) -> str:
+ def escape(text: str) -> str:
+ """Escape html."""
+ return text.replace("&", "&").replace("<", "<").replace(">", ">")
+
+ fragments: List[str] = []
+ append_fragment = fragments.append
+ theme = DEFAULT_TERMINAL_THEME
+ for text, style, control in Segment.simplify(segments):
+ if control:
+ continue
+ text = escape(text)
+ if style:
+ rule = style.get_html_style(theme)
+ text = f'<span style="{rule}">{text}</span>' if rule else text
+ if style.link:
+ text = f'<a href="{style.link}" target="_blank">{text}</a>'
+ append_fragment(text)
+
+ code = "".join(fragments)
+ html = JUPYTER_HTML_FORMAT.format(code=code)
+
+ return html
+
+
+def display(segments: Iterable[Segment], text: str) -> None:
+ """Render segments to Jupyter."""
+ html = _render_segments(segments)
+ jupyter_renderable = JupyterRenderable(html, text)
+ try:
+ from IPython.display import display as ipython_display
+
+ ipython_display(jupyter_renderable)
+ except ModuleNotFoundError:
+ # Handle the case where the Console has force_jupyter=True,
+ # but IPython is not installed.
+ pass
+
+
+def print(*args: Any, **kwargs: Any) -> None:
+ """Proxy for Console print."""
+ console = get_console()
+ return console.print(*args, **kwargs)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/layout.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/layout.py
new file mode 100644
index 000000000..a6f1a31b2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/layout.py
@@ -0,0 +1,442 @@
+from abc import ABC, abstractmethod
+from itertools import islice
+from operator import itemgetter
+from threading import RLock
+from typing import (
+ TYPE_CHECKING,
+ Dict,
+ Iterable,
+ List,
+ NamedTuple,
+ Optional,
+ Sequence,
+ Tuple,
+ Union,
+)
+
+from ._ratio import ratio_resolve
+from .align import Align
+from .console import Console, ConsoleOptions, RenderableType, RenderResult
+from .highlighter import ReprHighlighter
+from .panel import Panel
+from .pretty import Pretty
+from .region import Region
+from .repr import Result, rich_repr
+from .segment import Segment
+from .style import StyleType
+
+if TYPE_CHECKING:
+ from pip._vendor.rich.tree import Tree
+
+
+class LayoutRender(NamedTuple):
+ """An individual layout render."""
+
+ region: Region
+ render: List[List[Segment]]
+
+
+RegionMap = Dict["Layout", Region]
+RenderMap = Dict["Layout", LayoutRender]
+
+
+class LayoutError(Exception):
+ """Layout related error."""
+
+
+class NoSplitter(LayoutError):
+ """Requested splitter does not exist."""
+
+
+class _Placeholder:
+ """An internal renderable used as a Layout placeholder."""
+
+ highlighter = ReprHighlighter()
+
+ def __init__(self, layout: "Layout", style: StyleType = "") -> None:
+ self.layout = layout
+ self.style = style
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ width = options.max_width
+ height = options.height or options.size.height
+ layout = self.layout
+ title = (
+ f"{layout.name!r} ({width} x {height})"
+ if layout.name
+ else f"({width} x {height})"
+ )
+ yield Panel(
+ Align.center(Pretty(layout), vertical="middle"),
+ style=self.style,
+ title=self.highlighter(title),
+ border_style="blue",
+ height=height,
+ )
+
+
+class Splitter(ABC):
+ """Base class for a splitter."""
+
+ name: str = ""
+
+ @abstractmethod
+ def get_tree_icon(self) -> str:
+ """Get the icon (emoji) used in layout.tree"""
+
+ @abstractmethod
+ def divide(
+ self, children: Sequence["Layout"], region: Region
+ ) -> Iterable[Tuple["Layout", Region]]:
+ """Divide a region amongst several child layouts.
+
+ Args:
+ children (Sequence(Layout)): A number of child layouts.
+ region (Region): A rectangular region to divide.
+ """
+
+
+class RowSplitter(Splitter):
+ """Split a layout region in to rows."""
+
+ name = "row"
+
+ def get_tree_icon(self) -> str:
+ return "[layout.tree.row]⬌"
+
+ def divide(
+ self, children: Sequence["Layout"], region: Region
+ ) -> Iterable[Tuple["Layout", Region]]:
+ x, y, width, height = region
+ render_widths = ratio_resolve(width, children)
+ offset = 0
+ _Region = Region
+ for child, child_width in zip(children, render_widths):
+ yield child, _Region(x + offset, y, child_width, height)
+ offset += child_width
+
+
+class ColumnSplitter(Splitter):
+ """Split a layout region in to columns."""
+
+ name = "column"
+
+ def get_tree_icon(self) -> str:
+ return "[layout.tree.column]⬍"
+
+ def divide(
+ self, children: Sequence["Layout"], region: Region
+ ) -> Iterable[Tuple["Layout", Region]]:
+ x, y, width, height = region
+ render_heights = ratio_resolve(height, children)
+ offset = 0
+ _Region = Region
+ for child, child_height in zip(children, render_heights):
+ yield child, _Region(x, y + offset, width, child_height)
+ offset += child_height
+
+
+@rich_repr
+class Layout:
+ """A renderable to divide a fixed height in to rows or columns.
+
+ Args:
+ renderable (RenderableType, optional): Renderable content, or None for placeholder. Defaults to None.
+ name (str, optional): Optional identifier for Layout. Defaults to None.
+ size (int, optional): Optional fixed size of layout. Defaults to None.
+ minimum_size (int, optional): Minimum size of layout. Defaults to 1.
+ ratio (int, optional): Optional ratio for flexible layout. Defaults to 1.
+ visible (bool, optional): Visibility of layout. Defaults to True.
+ """
+
+ splitters = {"row": RowSplitter, "column": ColumnSplitter}
+
+ def __init__(
+ self,
+ renderable: Optional[RenderableType] = None,
+ *,
+ name: Optional[str] = None,
+ size: Optional[int] = None,
+ minimum_size: int = 1,
+ ratio: int = 1,
+ visible: bool = True,
+ ) -> None:
+ self._renderable = renderable or _Placeholder(self)
+ self.size = size
+ self.minimum_size = minimum_size
+ self.ratio = ratio
+ self.name = name
+ self.visible = visible
+ self.splitter: Splitter = self.splitters["column"]()
+ self._children: List[Layout] = []
+ self._render_map: RenderMap = {}
+ self._lock = RLock()
+
+ def __rich_repr__(self) -> Result:
+ yield "name", self.name, None
+ yield "size", self.size, None
+ yield "minimum_size", self.minimum_size, 1
+ yield "ratio", self.ratio, 1
+
+ @property
+ def renderable(self) -> RenderableType:
+ """Layout renderable."""
+ return self if self._children else self._renderable
+
+ @property
+ def children(self) -> List["Layout"]:
+ """Gets (visible) layout children."""
+ return [child for child in self._children if child.visible]
+
+ @property
+ def map(self) -> RenderMap:
+ """Get a map of the last render."""
+ return self._render_map
+
+ def get(self, name: str) -> Optional["Layout"]:
+ """Get a named layout, or None if it doesn't exist.
+
+ Args:
+ name (str): Name of layout.
+
+ Returns:
+ Optional[Layout]: Layout instance or None if no layout was found.
+ """
+ if self.name == name:
+ return self
+ else:
+ for child in self._children:
+ named_layout = child.get(name)
+ if named_layout is not None:
+ return named_layout
+ return None
+
+ def __getitem__(self, name: str) -> "Layout":
+ layout = self.get(name)
+ if layout is None:
+ raise KeyError(f"No layout with name {name!r}")
+ return layout
+
+ @property
+ def tree(self) -> "Tree":
+ """Get a tree renderable to show layout structure."""
+ from pip._vendor.rich.styled import Styled
+ from pip._vendor.rich.table import Table
+ from pip._vendor.rich.tree import Tree
+
+ def summary(layout: "Layout") -> Table:
+ icon = layout.splitter.get_tree_icon()
+
+ table = Table.grid(padding=(0, 1, 0, 0))
+
+ text: RenderableType = (
+ Pretty(layout) if layout.visible else Styled(Pretty(layout), "dim")
+ )
+ table.add_row(icon, text)
+ _summary = table
+ return _summary
+
+ layout = self
+ tree = Tree(
+ summary(layout),
+ guide_style=f"layout.tree.{layout.splitter.name}",
+ highlight=True,
+ )
+
+ def recurse(tree: "Tree", layout: "Layout") -> None:
+ for child in layout._children:
+ recurse(
+ tree.add(
+ summary(child),
+ guide_style=f"layout.tree.{child.splitter.name}",
+ ),
+ child,
+ )
+
+ recurse(tree, self)
+ return tree
+
+ def split(
+ self,
+ *layouts: Union["Layout", RenderableType],
+ splitter: Union[Splitter, str] = "column",
+ ) -> None:
+ """Split the layout in to multiple sub-layouts.
+
+ Args:
+ *layouts (Layout): Positional arguments should be (sub) Layout instances.
+ splitter (Union[Splitter, str]): Splitter instance or name of splitter.
+ """
+ _layouts = [
+ layout if isinstance(layout, Layout) else Layout(layout)
+ for layout in layouts
+ ]
+ try:
+ self.splitter = (
+ splitter
+ if isinstance(splitter, Splitter)
+ else self.splitters[splitter]()
+ )
+ except KeyError:
+ raise NoSplitter(f"No splitter called {splitter!r}")
+ self._children[:] = _layouts
+
+ def add_split(self, *layouts: Union["Layout", RenderableType]) -> None:
+ """Add a new layout(s) to existing split.
+
+ Args:
+ *layouts (Union[Layout, RenderableType]): Positional arguments should be renderables or (sub) Layout instances.
+
+ """
+ _layouts = (
+ layout if isinstance(layout, Layout) else Layout(layout)
+ for layout in layouts
+ )
+ self._children.extend(_layouts)
+
+ def split_row(self, *layouts: Union["Layout", RenderableType]) -> None:
+ """Split the layout in to a row (layouts side by side).
+
+ Args:
+ *layouts (Layout): Positional arguments should be (sub) Layout instances.
+ """
+ self.split(*layouts, splitter="row")
+
+ def split_column(self, *layouts: Union["Layout", RenderableType]) -> None:
+ """Split the layout in to a column (layouts stacked on top of each other).
+
+ Args:
+ *layouts (Layout): Positional arguments should be (sub) Layout instances.
+ """
+ self.split(*layouts, splitter="column")
+
+ def unsplit(self) -> None:
+ """Reset splits to initial state."""
+ del self._children[:]
+
+ def update(self, renderable: RenderableType) -> None:
+ """Update renderable.
+
+ Args:
+ renderable (RenderableType): New renderable object.
+ """
+ with self._lock:
+ self._renderable = renderable
+
+ def refresh_screen(self, console: "Console", layout_name: str) -> None:
+ """Refresh a sub-layout.
+
+ Args:
+ console (Console): Console instance where Layout is to be rendered.
+ layout_name (str): Name of layout.
+ """
+ with self._lock:
+ layout = self[layout_name]
+ region, _lines = self._render_map[layout]
+ (x, y, width, height) = region
+ lines = console.render_lines(
+ layout, console.options.update_dimensions(width, height)
+ )
+ self._render_map[layout] = LayoutRender(region, lines)
+ console.update_screen_lines(lines, x, y)
+
+ def _make_region_map(self, width: int, height: int) -> RegionMap:
+ """Create a dict that maps layout on to Region."""
+ stack: List[Tuple[Layout, Region]] = [(self, Region(0, 0, width, height))]
+ push = stack.append
+ pop = stack.pop
+ layout_regions: List[Tuple[Layout, Region]] = []
+ append_layout_region = layout_regions.append
+ while stack:
+ append_layout_region(pop())
+ layout, region = layout_regions[-1]
+ children = layout.children
+ if children:
+ for child_and_region in layout.splitter.divide(children, region):
+ push(child_and_region)
+
+ region_map = {
+ layout: region
+ for layout, region in sorted(layout_regions, key=itemgetter(1))
+ }
+ return region_map
+
+ def render(self, console: Console, options: ConsoleOptions) -> RenderMap:
+ """Render the sub_layouts.
+
+ Args:
+ console (Console): Console instance.
+ options (ConsoleOptions): Console options.
+
+ Returns:
+ RenderMap: A dict that maps Layout on to a tuple of Region, lines
+ """
+ render_width = options.max_width
+ render_height = options.height or console.height
+ region_map = self._make_region_map(render_width, render_height)
+ layout_regions = [
+ (layout, region)
+ for layout, region in region_map.items()
+ if not layout.children
+ ]
+ render_map: Dict["Layout", "LayoutRender"] = {}
+ render_lines = console.render_lines
+ update_dimensions = options.update_dimensions
+
+ for layout, region in layout_regions:
+ lines = render_lines(
+ layout.renderable, update_dimensions(region.width, region.height)
+ )
+ render_map[layout] = LayoutRender(region, lines)
+ return render_map
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ with self._lock:
+ width = options.max_width or console.width
+ height = options.height or console.height
+ render_map = self.render(console, options.update_dimensions(width, height))
+ self._render_map = render_map
+ layout_lines: List[List[Segment]] = [[] for _ in range(height)]
+ _islice = islice
+ for region, lines in render_map.values():
+ _x, y, _layout_width, layout_height = region
+ for row, line in zip(
+ _islice(layout_lines, y, y + layout_height), lines
+ ):
+ row.extend(line)
+
+ new_line = Segment.line()
+ for layout_row in layout_lines:
+ yield from layout_row
+ yield new_line
+
+
+if __name__ == "__main__":
+ from pip._vendor.rich.console import Console
+
+ console = Console()
+ layout = Layout()
+
+ layout.split_column(
+ Layout(name="header", size=3),
+ Layout(ratio=1, name="main"),
+ Layout(size=10, name="footer"),
+ )
+
+ layout["main"].split_row(Layout(name="side"), Layout(name="body", ratio=2))
+
+ layout["body"].split_row(Layout(name="content", ratio=2), Layout(name="s2"))
+
+ layout["s2"].split_column(
+ Layout(name="top"), Layout(name="middle"), Layout(name="bottom")
+ )
+
+ layout["side"].split_column(Layout(layout.tree, name="left1"), Layout(name="left2"))
+
+ layout["content"].update("foo")
+
+ console.print(layout)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/live.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/live.py
new file mode 100644
index 000000000..f0529a781
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/live.py
@@ -0,0 +1,375 @@
+import sys
+from threading import Event, RLock, Thread
+from types import TracebackType
+from typing import IO, Any, Callable, List, Optional, TextIO, Type, cast
+
+from . import get_console
+from .console import Console, ConsoleRenderable, RenderableType, RenderHook
+from .control import Control
+from .file_proxy import FileProxy
+from .jupyter import JupyterMixin
+from .live_render import LiveRender, VerticalOverflowMethod
+from .screen import Screen
+from .text import Text
+
+
+class _RefreshThread(Thread):
+ """A thread that calls refresh() at regular intervals."""
+
+ def __init__(self, live: "Live", refresh_per_second: float) -> None:
+ self.live = live
+ self.refresh_per_second = refresh_per_second
+ self.done = Event()
+ super().__init__(daemon=True)
+
+ def stop(self) -> None:
+ self.done.set()
+
+ def run(self) -> None:
+ while not self.done.wait(1 / self.refresh_per_second):
+ with self.live._lock:
+ if not self.done.is_set():
+ self.live.refresh()
+
+
+class Live(JupyterMixin, RenderHook):
+ """Renders an auto-updating live display of any given renderable.
+
+ Args:
+ renderable (RenderableType, optional): The renderable to live display. Defaults to displaying nothing.
+ console (Console, optional): Optional Console instance. Default will an internal Console instance writing to stdout.
+ screen (bool, optional): Enable alternate screen mode. Defaults to False.
+ auto_refresh (bool, optional): Enable auto refresh. If disabled, you will need to call `refresh()` or `update()` with refresh flag. Defaults to True
+ refresh_per_second (float, optional): Number of times per second to refresh the live display. Defaults to 4.
+ transient (bool, optional): Clear the renderable on exit (has no effect when screen=True). Defaults to False.
+ redirect_stdout (bool, optional): Enable redirection of stdout, so ``print`` may be used. Defaults to True.
+ redirect_stderr (bool, optional): Enable redirection of stderr. Defaults to True.
+ vertical_overflow (VerticalOverflowMethod, optional): How to handle renderable when it is too tall for the console. Defaults to "ellipsis".
+ get_renderable (Callable[[], RenderableType], optional): Optional callable to get renderable. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ renderable: Optional[RenderableType] = None,
+ *,
+ console: Optional[Console] = None,
+ screen: bool = False,
+ auto_refresh: bool = True,
+ refresh_per_second: float = 4,
+ transient: bool = False,
+ redirect_stdout: bool = True,
+ redirect_stderr: bool = True,
+ vertical_overflow: VerticalOverflowMethod = "ellipsis",
+ get_renderable: Optional[Callable[[], RenderableType]] = None,
+ ) -> None:
+ assert refresh_per_second > 0, "refresh_per_second must be > 0"
+ self._renderable = renderable
+ self.console = console if console is not None else get_console()
+ self._screen = screen
+ self._alt_screen = False
+
+ self._redirect_stdout = redirect_stdout
+ self._redirect_stderr = redirect_stderr
+ self._restore_stdout: Optional[IO[str]] = None
+ self._restore_stderr: Optional[IO[str]] = None
+
+ self._lock = RLock()
+ self.ipy_widget: Optional[Any] = None
+ self.auto_refresh = auto_refresh
+ self._started: bool = False
+ self.transient = True if screen else transient
+
+ self._refresh_thread: Optional[_RefreshThread] = None
+ self.refresh_per_second = refresh_per_second
+
+ self.vertical_overflow = vertical_overflow
+ self._get_renderable = get_renderable
+ self._live_render = LiveRender(
+ self.get_renderable(), vertical_overflow=vertical_overflow
+ )
+
+ @property
+ def is_started(self) -> bool:
+ """Check if live display has been started."""
+ return self._started
+
+ def get_renderable(self) -> RenderableType:
+ renderable = (
+ self._get_renderable()
+ if self._get_renderable is not None
+ else self._renderable
+ )
+ return renderable or ""
+
+ def start(self, refresh: bool = False) -> None:
+ """Start live rendering display.
+
+ Args:
+ refresh (bool, optional): Also refresh. Defaults to False.
+ """
+ with self._lock:
+ if self._started:
+ return
+ self.console.set_live(self)
+ self._started = True
+ if self._screen:
+ self._alt_screen = self.console.set_alt_screen(True)
+ self.console.show_cursor(False)
+ self._enable_redirect_io()
+ self.console.push_render_hook(self)
+ if refresh:
+ try:
+ self.refresh()
+ except Exception:
+ # If refresh fails, we want to stop the redirection of sys.stderr,
+ # so the error stacktrace is properly displayed in the terminal.
+ # (or, if the code that calls Rich captures the exception and wants to display something,
+ # let this be displayed in the terminal).
+ self.stop()
+ raise
+ if self.auto_refresh:
+ self._refresh_thread = _RefreshThread(self, self.refresh_per_second)
+ self._refresh_thread.start()
+
+ def stop(self) -> None:
+ """Stop live rendering display."""
+ with self._lock:
+ if not self._started:
+ return
+ self.console.clear_live()
+ self._started = False
+
+ if self.auto_refresh and self._refresh_thread is not None:
+ self._refresh_thread.stop()
+ self._refresh_thread = None
+ # allow it to fully render on the last even if overflow
+ self.vertical_overflow = "visible"
+ with self.console:
+ try:
+ if not self._alt_screen and not self.console.is_jupyter:
+ self.refresh()
+ finally:
+ self._disable_redirect_io()
+ self.console.pop_render_hook()
+ if not self._alt_screen and self.console.is_terminal:
+ self.console.line()
+ self.console.show_cursor(True)
+ if self._alt_screen:
+ self.console.set_alt_screen(False)
+
+ if self.transient and not self._alt_screen:
+ self.console.control(self._live_render.restore_cursor())
+ if self.ipy_widget is not None and self.transient:
+ self.ipy_widget.close() # pragma: no cover
+
+ def __enter__(self) -> "Live":
+ self.start(refresh=self._renderable is not None)
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.stop()
+
+ def _enable_redirect_io(self) -> None:
+ """Enable redirecting of stdout / stderr."""
+ if self.console.is_terminal or self.console.is_jupyter:
+ if self._redirect_stdout and not isinstance(sys.stdout, FileProxy):
+ self._restore_stdout = sys.stdout
+ sys.stdout = cast("TextIO", FileProxy(self.console, sys.stdout))
+ if self._redirect_stderr and not isinstance(sys.stderr, FileProxy):
+ self._restore_stderr = sys.stderr
+ sys.stderr = cast("TextIO", FileProxy(self.console, sys.stderr))
+
+ def _disable_redirect_io(self) -> None:
+ """Disable redirecting of stdout / stderr."""
+ if self._restore_stdout:
+ sys.stdout = cast("TextIO", self._restore_stdout)
+ self._restore_stdout = None
+ if self._restore_stderr:
+ sys.stderr = cast("TextIO", self._restore_stderr)
+ self._restore_stderr = None
+
+ @property
+ def renderable(self) -> RenderableType:
+ """Get the renderable that is being displayed
+
+ Returns:
+ RenderableType: Displayed renderable.
+ """
+ renderable = self.get_renderable()
+ return Screen(renderable) if self._alt_screen else renderable
+
+ def update(self, renderable: RenderableType, *, refresh: bool = False) -> None:
+ """Update the renderable that is being displayed
+
+ Args:
+ renderable (RenderableType): New renderable to use.
+ refresh (bool, optional): Refresh the display. Defaults to False.
+ """
+ if isinstance(renderable, str):
+ renderable = self.console.render_str(renderable)
+ with self._lock:
+ self._renderable = renderable
+ if refresh:
+ self.refresh()
+
+ def refresh(self) -> None:
+ """Update the display of the Live Render."""
+ with self._lock:
+ self._live_render.set_renderable(self.renderable)
+ if self.console.is_jupyter: # pragma: no cover
+ try:
+ from IPython.display import display
+ from ipywidgets import Output
+ except ImportError:
+ import warnings
+
+ warnings.warn('install "ipywidgets" for Jupyter support')
+ else:
+ if self.ipy_widget is None:
+ self.ipy_widget = Output()
+ display(self.ipy_widget)
+
+ with self.ipy_widget:
+ self.ipy_widget.clear_output(wait=True)
+ self.console.print(self._live_render.renderable)
+ elif self.console.is_terminal and not self.console.is_dumb_terminal:
+ with self.console:
+ self.console.print(Control())
+ elif (
+ not self._started and not self.transient
+ ): # if it is finished allow files or dumb-terminals to see final result
+ with self.console:
+ self.console.print(Control())
+
+ def process_renderables(
+ self, renderables: List[ConsoleRenderable]
+ ) -> List[ConsoleRenderable]:
+ """Process renderables to restore cursor and display progress."""
+ self._live_render.vertical_overflow = self.vertical_overflow
+ if self.console.is_interactive:
+ # lock needs acquiring as user can modify live_render renderable at any time unlike in Progress.
+ with self._lock:
+ reset = (
+ Control.home()
+ if self._alt_screen
+ else self._live_render.position_cursor()
+ )
+ renderables = [reset, *renderables, self._live_render]
+ elif (
+ not self._started and not self.transient
+ ): # if it is finished render the final output for files or dumb_terminals
+ renderables = [*renderables, self._live_render]
+
+ return renderables
+
+
+if __name__ == "__main__": # pragma: no cover
+ import random
+ import time
+ from itertools import cycle
+ from typing import Dict, List, Tuple
+
+ from .align import Align
+ from .console import Console
+ from .live import Live as Live
+ from .panel import Panel
+ from .rule import Rule
+ from .syntax import Syntax
+ from .table import Table
+
+ console = Console()
+
+ syntax = Syntax(
+ '''def loop_last(values: Iterable[T]) -> Iterable[Tuple[bool, T]]:
+ """Iterate and generate a tuple with a flag for last value."""
+ iter_values = iter(values)
+ try:
+ previous_value = next(iter_values)
+ except StopIteration:
+ return
+ for value in iter_values:
+ yield False, previous_value
+ previous_value = value
+ yield True, previous_value''',
+ "python",
+ line_numbers=True,
+ )
+
+ table = Table("foo", "bar", "baz")
+ table.add_row("1", "2", "3")
+
+ progress_renderables = [
+ "You can make the terminal shorter and taller to see the live table hide"
+ "Text may be printed while the progress bars are rendering.",
+ Panel("In fact, [i]any[/i] renderable will work"),
+ "Such as [magenta]tables[/]...",
+ table,
+ "Pretty printed structures...",
+ {"type": "example", "text": "Pretty printed"},
+ "Syntax...",
+ syntax,
+ Rule("Give it a try!"),
+ ]
+
+ examples = cycle(progress_renderables)
+
+ exchanges = [
+ "SGD",
+ "MYR",
+ "EUR",
+ "USD",
+ "AUD",
+ "JPY",
+ "CNH",
+ "HKD",
+ "CAD",
+ "INR",
+ "DKK",
+ "GBP",
+ "RUB",
+ "NZD",
+ "MXN",
+ "IDR",
+ "TWD",
+ "THB",
+ "VND",
+ ]
+ with Live(console=console) as live_table:
+ exchange_rate_dict: Dict[Tuple[str, str], float] = {}
+
+ for index in range(100):
+ select_exchange = exchanges[index % len(exchanges)]
+
+ for exchange in exchanges:
+ if exchange == select_exchange:
+ continue
+ time.sleep(0.4)
+ if random.randint(0, 10) < 1:
+ console.log(next(examples))
+ exchange_rate_dict[(select_exchange, exchange)] = 200 / (
+ (random.random() * 320) + 1
+ )
+ if len(exchange_rate_dict) > len(exchanges) - 1:
+ exchange_rate_dict.pop(list(exchange_rate_dict.keys())[0])
+ table = Table(title="Exchange Rates")
+
+ table.add_column("Source Currency")
+ table.add_column("Destination Currency")
+ table.add_column("Exchange Rate")
+
+ for (source, dest), exchange_rate in exchange_rate_dict.items():
+ table.add_row(
+ source,
+ dest,
+ Text(
+ f"{exchange_rate:.4f}",
+ style="red" if exchange_rate < 1.0 else "green",
+ ),
+ )
+
+ live_table.update(Align.center(table))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/live_render.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/live_render.py
new file mode 100644
index 000000000..e20745df6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/live_render.py
@@ -0,0 +1,112 @@
+import sys
+from typing import Optional, Tuple
+
+if sys.version_info >= (3, 8):
+ from typing import Literal
+else:
+ from pip._vendor.typing_extensions import Literal # pragma: no cover
+
+
+from ._loop import loop_last
+from .console import Console, ConsoleOptions, RenderableType, RenderResult
+from .control import Control
+from .segment import ControlType, Segment
+from .style import StyleType
+from .text import Text
+
+VerticalOverflowMethod = Literal["crop", "ellipsis", "visible"]
+
+
+class LiveRender:
+ """Creates a renderable that may be updated.
+
+ Args:
+ renderable (RenderableType): Any renderable object.
+ style (StyleType, optional): An optional style to apply to the renderable. Defaults to "".
+ """
+
+ def __init__(
+ self,
+ renderable: RenderableType,
+ style: StyleType = "",
+ vertical_overflow: VerticalOverflowMethod = "ellipsis",
+ ) -> None:
+ self.renderable = renderable
+ self.style = style
+ self.vertical_overflow = vertical_overflow
+ self._shape: Optional[Tuple[int, int]] = None
+
+ def set_renderable(self, renderable: RenderableType) -> None:
+ """Set a new renderable.
+
+ Args:
+ renderable (RenderableType): Any renderable object, including str.
+ """
+ self.renderable = renderable
+
+ def position_cursor(self) -> Control:
+ """Get control codes to move cursor to beginning of live render.
+
+ Returns:
+ Control: A control instance that may be printed.
+ """
+ if self._shape is not None:
+ _, height = self._shape
+ return Control(
+ ControlType.CARRIAGE_RETURN,
+ (ControlType.ERASE_IN_LINE, 2),
+ *(
+ (
+ (ControlType.CURSOR_UP, 1),
+ (ControlType.ERASE_IN_LINE, 2),
+ )
+ * (height - 1)
+ )
+ )
+ return Control()
+
+ def restore_cursor(self) -> Control:
+ """Get control codes to clear the render and restore the cursor to its previous position.
+
+ Returns:
+ Control: A Control instance that may be printed.
+ """
+ if self._shape is not None:
+ _, height = self._shape
+ return Control(
+ ControlType.CARRIAGE_RETURN,
+ *((ControlType.CURSOR_UP, 1), (ControlType.ERASE_IN_LINE, 2)) * height
+ )
+ return Control()
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ renderable = self.renderable
+ style = console.get_style(self.style)
+ lines = console.render_lines(renderable, options, style=style, pad=False)
+ shape = Segment.get_shape(lines)
+
+ _, height = shape
+ if height > options.size.height:
+ if self.vertical_overflow == "crop":
+ lines = lines[: options.size.height]
+ shape = Segment.get_shape(lines)
+ elif self.vertical_overflow == "ellipsis":
+ lines = lines[: (options.size.height - 1)]
+ overflow_text = Text(
+ "...",
+ overflow="crop",
+ justify="center",
+ end="",
+ style="live.ellipsis",
+ )
+ lines.append(list(console.render(overflow_text)))
+ shape = Segment.get_shape(lines)
+ self._shape = shape
+
+ new_line = Segment.line()
+ for last, line in loop_last(lines):
+ yield from line
+ if not last:
+ yield new_line
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/logging.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/logging.py
new file mode 100644
index 000000000..91368dda7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/logging.py
@@ -0,0 +1,289 @@
+import logging
+from datetime import datetime
+from logging import Handler, LogRecord
+from pathlib import Path
+from types import ModuleType
+from typing import ClassVar, Iterable, List, Optional, Type, Union
+
+from pip._vendor.rich._null_file import NullFile
+
+from . import get_console
+from ._log_render import FormatTimeCallable, LogRender
+from .console import Console, ConsoleRenderable
+from .highlighter import Highlighter, ReprHighlighter
+from .text import Text
+from .traceback import Traceback
+
+
+class RichHandler(Handler):
+ """A logging handler that renders output with Rich. The time / level / message and file are displayed in columns.
+ The level is color coded, and the message is syntax highlighted.
+
+ Note:
+ Be careful when enabling console markup in log messages if you have configured logging for libraries not
+ under your control. If a dependency writes messages containing square brackets, it may not produce the intended output.
+
+ Args:
+ level (Union[int, str], optional): Log level. Defaults to logging.NOTSET.
+ console (:class:`~rich.console.Console`, optional): Optional console instance to write logs.
+ Default will use a global console instance writing to stdout.
+ show_time (bool, optional): Show a column for the time. Defaults to True.
+ omit_repeated_times (bool, optional): Omit repetition of the same time. Defaults to True.
+ show_level (bool, optional): Show a column for the level. Defaults to True.
+ show_path (bool, optional): Show the path to the original log call. Defaults to True.
+ enable_link_path (bool, optional): Enable terminal link of path column to file. Defaults to True.
+ highlighter (Highlighter, optional): Highlighter to style log messages, or None to use ReprHighlighter. Defaults to None.
+ markup (bool, optional): Enable console markup in log messages. Defaults to False.
+ rich_tracebacks (bool, optional): Enable rich tracebacks with syntax highlighting and formatting. Defaults to False.
+ tracebacks_width (Optional[int], optional): Number of characters used to render tracebacks, or None for full width. Defaults to None.
+ tracebacks_extra_lines (int, optional): Additional lines of code to render tracebacks, or None for full width. Defaults to None.
+ tracebacks_theme (str, optional): Override pygments theme used in traceback.
+ tracebacks_word_wrap (bool, optional): Enable word wrapping of long tracebacks lines. Defaults to True.
+ tracebacks_show_locals (bool, optional): Enable display of locals in tracebacks. Defaults to False.
+ tracebacks_suppress (Sequence[Union[str, ModuleType]]): Optional sequence of modules or paths to exclude from traceback.
+ locals_max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to 10.
+ locals_max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to 80.
+ log_time_format (Union[str, TimeFormatterCallable], optional): If ``log_time`` is enabled, either string for strftime or callable that formats the time. Defaults to "[%x %X] ".
+ keywords (List[str], optional): List of words to highlight instead of ``RichHandler.KEYWORDS``.
+ """
+
+ KEYWORDS: ClassVar[Optional[List[str]]] = [
+ "GET",
+ "POST",
+ "HEAD",
+ "PUT",
+ "DELETE",
+ "OPTIONS",
+ "TRACE",
+ "PATCH",
+ ]
+ HIGHLIGHTER_CLASS: ClassVar[Type[Highlighter]] = ReprHighlighter
+
+ def __init__(
+ self,
+ level: Union[int, str] = logging.NOTSET,
+ console: Optional[Console] = None,
+ *,
+ show_time: bool = True,
+ omit_repeated_times: bool = True,
+ show_level: bool = True,
+ show_path: bool = True,
+ enable_link_path: bool = True,
+ highlighter: Optional[Highlighter] = None,
+ markup: bool = False,
+ rich_tracebacks: bool = False,
+ tracebacks_width: Optional[int] = None,
+ tracebacks_extra_lines: int = 3,
+ tracebacks_theme: Optional[str] = None,
+ tracebacks_word_wrap: bool = True,
+ tracebacks_show_locals: bool = False,
+ tracebacks_suppress: Iterable[Union[str, ModuleType]] = (),
+ locals_max_length: int = 10,
+ locals_max_string: int = 80,
+ log_time_format: Union[str, FormatTimeCallable] = "[%x %X]",
+ keywords: Optional[List[str]] = None,
+ ) -> None:
+ super().__init__(level=level)
+ self.console = console or get_console()
+ self.highlighter = highlighter or self.HIGHLIGHTER_CLASS()
+ self._log_render = LogRender(
+ show_time=show_time,
+ show_level=show_level,
+ show_path=show_path,
+ time_format=log_time_format,
+ omit_repeated_times=omit_repeated_times,
+ level_width=None,
+ )
+ self.enable_link_path = enable_link_path
+ self.markup = markup
+ self.rich_tracebacks = rich_tracebacks
+ self.tracebacks_width = tracebacks_width
+ self.tracebacks_extra_lines = tracebacks_extra_lines
+ self.tracebacks_theme = tracebacks_theme
+ self.tracebacks_word_wrap = tracebacks_word_wrap
+ self.tracebacks_show_locals = tracebacks_show_locals
+ self.tracebacks_suppress = tracebacks_suppress
+ self.locals_max_length = locals_max_length
+ self.locals_max_string = locals_max_string
+ self.keywords = keywords
+
+ def get_level_text(self, record: LogRecord) -> Text:
+ """Get the level name from the record.
+
+ Args:
+ record (LogRecord): LogRecord instance.
+
+ Returns:
+ Text: A tuple of the style and level name.
+ """
+ level_name = record.levelname
+ level_text = Text.styled(
+ level_name.ljust(8), f"logging.level.{level_name.lower()}"
+ )
+ return level_text
+
+ def emit(self, record: LogRecord) -> None:
+ """Invoked by logging."""
+ message = self.format(record)
+ traceback = None
+ if (
+ self.rich_tracebacks
+ and record.exc_info
+ and record.exc_info != (None, None, None)
+ ):
+ exc_type, exc_value, exc_traceback = record.exc_info
+ assert exc_type is not None
+ assert exc_value is not None
+ traceback = Traceback.from_exception(
+ exc_type,
+ exc_value,
+ exc_traceback,
+ width=self.tracebacks_width,
+ extra_lines=self.tracebacks_extra_lines,
+ theme=self.tracebacks_theme,
+ word_wrap=self.tracebacks_word_wrap,
+ show_locals=self.tracebacks_show_locals,
+ locals_max_length=self.locals_max_length,
+ locals_max_string=self.locals_max_string,
+ suppress=self.tracebacks_suppress,
+ )
+ message = record.getMessage()
+ if self.formatter:
+ record.message = record.getMessage()
+ formatter = self.formatter
+ if hasattr(formatter, "usesTime") and formatter.usesTime():
+ record.asctime = formatter.formatTime(record, formatter.datefmt)
+ message = formatter.formatMessage(record)
+
+ message_renderable = self.render_message(record, message)
+ log_renderable = self.render(
+ record=record, traceback=traceback, message_renderable=message_renderable
+ )
+ if isinstance(self.console.file, NullFile):
+ # Handles pythonw, where stdout/stderr are null, and we return NullFile
+ # instance from Console.file. In this case, we still want to make a log record
+ # even though we won't be writing anything to a file.
+ self.handleError(record)
+ else:
+ try:
+ self.console.print(log_renderable)
+ except Exception:
+ self.handleError(record)
+
+ def render_message(self, record: LogRecord, message: str) -> "ConsoleRenderable":
+ """Render message text in to Text.
+
+ Args:
+ record (LogRecord): logging Record.
+ message (str): String containing log message.
+
+ Returns:
+ ConsoleRenderable: Renderable to display log message.
+ """
+ use_markup = getattr(record, "markup", self.markup)
+ message_text = Text.from_markup(message) if use_markup else Text(message)
+
+ highlighter = getattr(record, "highlighter", self.highlighter)
+ if highlighter:
+ message_text = highlighter(message_text)
+
+ if self.keywords is None:
+ self.keywords = self.KEYWORDS
+
+ if self.keywords:
+ message_text.highlight_words(self.keywords, "logging.keyword")
+
+ return message_text
+
+ def render(
+ self,
+ *,
+ record: LogRecord,
+ traceback: Optional[Traceback],
+ message_renderable: "ConsoleRenderable",
+ ) -> "ConsoleRenderable":
+ """Render log for display.
+
+ Args:
+ record (LogRecord): logging Record.
+ traceback (Optional[Traceback]): Traceback instance or None for no Traceback.
+ message_renderable (ConsoleRenderable): Renderable (typically Text) containing log message contents.
+
+ Returns:
+ ConsoleRenderable: Renderable to display log.
+ """
+ path = Path(record.pathname).name
+ level = self.get_level_text(record)
+ time_format = None if self.formatter is None else self.formatter.datefmt
+ log_time = datetime.fromtimestamp(record.created)
+
+ log_renderable = self._log_render(
+ self.console,
+ [message_renderable] if not traceback else [message_renderable, traceback],
+ log_time=log_time,
+ time_format=time_format,
+ level=level,
+ path=path,
+ line_no=record.lineno,
+ link_path=record.pathname if self.enable_link_path else None,
+ )
+ return log_renderable
+
+
+if __name__ == "__main__": # pragma: no cover
+ from time import sleep
+
+ FORMAT = "%(message)s"
+ # FORMAT = "%(asctime)-15s - %(levelname)s - %(message)s"
+ logging.basicConfig(
+ level="NOTSET",
+ format=FORMAT,
+ datefmt="[%X]",
+ handlers=[RichHandler(rich_tracebacks=True, tracebacks_show_locals=True)],
+ )
+ log = logging.getLogger("rich")
+
+ log.info("Server starting...")
+ log.info("Listening on http://127.0.0.1:8080")
+ sleep(1)
+
+ log.info("GET /index.html 200 1298")
+ log.info("GET /imgs/backgrounds/back1.jpg 200 54386")
+ log.info("GET /css/styles.css 200 54386")
+ log.warning("GET /favicon.ico 404 242")
+ sleep(1)
+
+ log.debug(
+ "JSONRPC request\n--> %r\n<-- %r",
+ {
+ "version": "1.1",
+ "method": "confirmFruitPurchase",
+ "params": [["apple", "orange", "mangoes", "pomelo"], 1.123],
+ "id": "194521489",
+ },
+ {"version": "1.1", "result": True, "error": None, "id": "194521489"},
+ )
+ log.debug(
+ "Loading configuration file /adasd/asdasd/qeqwe/qwrqwrqwr/sdgsdgsdg/werwerwer/dfgerert/ertertert/ertetert/werwerwer"
+ )
+ log.error("Unable to find 'pomelo' in database!")
+ log.info("POST /jsonrpc/ 200 65532")
+ log.info("POST /admin/ 401 42234")
+ log.warning("password was rejected for admin site.")
+
+ def divide() -> None:
+ number = 1
+ divisor = 0
+ foos = ["foo"] * 100
+ log.debug("in divide")
+ try:
+ number / divisor
+ except:
+ log.exception("An error of some kind occurred!")
+
+ divide()
+ sleep(1)
+ log.critical("Out of memory!")
+ log.info("Server exited with code=-1")
+ log.info("[bold]EXITING...[/bold]", extra=dict(markup=True))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/markup.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/markup.py
new file mode 100644
index 000000000..f6171878f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/markup.py
@@ -0,0 +1,251 @@
+import re
+from ast import literal_eval
+from operator import attrgetter
+from typing import Callable, Iterable, List, Match, NamedTuple, Optional, Tuple, Union
+
+from ._emoji_replace import _emoji_replace
+from .emoji import EmojiVariant
+from .errors import MarkupError
+from .style import Style
+from .text import Span, Text
+
+RE_TAGS = re.compile(
+ r"""((\\*)\[([a-z#/@][^[]*?)])""",
+ re.VERBOSE,
+)
+
+RE_HANDLER = re.compile(r"^([\w.]*?)(\(.*?\))?$")
+
+
+class Tag(NamedTuple):
+ """A tag in console markup."""
+
+ name: str
+ """The tag name. e.g. 'bold'."""
+ parameters: Optional[str]
+ """Any additional parameters after the name."""
+
+ def __str__(self) -> str:
+ return (
+ self.name if self.parameters is None else f"{self.name} {self.parameters}"
+ )
+
+ @property
+ def markup(self) -> str:
+ """Get the string representation of this tag."""
+ return (
+ f"[{self.name}]"
+ if self.parameters is None
+ else f"[{self.name}={self.parameters}]"
+ )
+
+
+_ReStringMatch = Match[str] # regex match object
+_ReSubCallable = Callable[[_ReStringMatch], str] # Callable invoked by re.sub
+_EscapeSubMethod = Callable[[_ReSubCallable, str], str] # Sub method of a compiled re
+
+
+def escape(
+ markup: str,
+ _escape: _EscapeSubMethod = re.compile(r"(\\*)(\[[a-z#/@][^[]*?])").sub,
+) -> str:
+ """Escapes text so that it won't be interpreted as markup.
+
+ Args:
+ markup (str): Content to be inserted in to markup.
+
+ Returns:
+ str: Markup with square brackets escaped.
+ """
+
+ def escape_backslashes(match: Match[str]) -> str:
+ """Called by re.sub replace matches."""
+ backslashes, text = match.groups()
+ return f"{backslashes}{backslashes}\\{text}"
+
+ markup = _escape(escape_backslashes, markup)
+ if markup.endswith("\\") and not markup.endswith("\\\\"):
+ return markup + "\\"
+
+ return markup
+
+
+def _parse(markup: str) -> Iterable[Tuple[int, Optional[str], Optional[Tag]]]:
+ """Parse markup in to an iterable of tuples of (position, text, tag).
+
+ Args:
+ markup (str): A string containing console markup
+
+ """
+ position = 0
+ _divmod = divmod
+ _Tag = Tag
+ for match in RE_TAGS.finditer(markup):
+ full_text, escapes, tag_text = match.groups()
+ start, end = match.span()
+ if start > position:
+ yield start, markup[position:start], None
+ if escapes:
+ backslashes, escaped = _divmod(len(escapes), 2)
+ if backslashes:
+ # Literal backslashes
+ yield start, "\\" * backslashes, None
+ start += backslashes * 2
+ if escaped:
+ # Escape of tag
+ yield start, full_text[len(escapes) :], None
+ position = end
+ continue
+ text, equals, parameters = tag_text.partition("=")
+ yield start, None, _Tag(text, parameters if equals else None)
+ position = end
+ if position < len(markup):
+ yield position, markup[position:], None
+
+
+def render(
+ markup: str,
+ style: Union[str, Style] = "",
+ emoji: bool = True,
+ emoji_variant: Optional[EmojiVariant] = None,
+) -> Text:
+ """Render console markup in to a Text instance.
+
+ Args:
+ markup (str): A string containing console markup.
+ style: (Union[str, Style]): The style to use.
+ emoji (bool, optional): Also render emoji code. Defaults to True.
+ emoji_variant (str, optional): Optional emoji variant, either "text" or "emoji". Defaults to None.
+
+
+ Raises:
+ MarkupError: If there is a syntax error in the markup.
+
+ Returns:
+ Text: A test instance.
+ """
+ emoji_replace = _emoji_replace
+ if "[" not in markup:
+ return Text(
+ emoji_replace(markup, default_variant=emoji_variant) if emoji else markup,
+ style=style,
+ )
+ text = Text(style=style)
+ append = text.append
+ normalize = Style.normalize
+
+ style_stack: List[Tuple[int, Tag]] = []
+ pop = style_stack.pop
+
+ spans: List[Span] = []
+ append_span = spans.append
+
+ _Span = Span
+ _Tag = Tag
+
+ def pop_style(style_name: str) -> Tuple[int, Tag]:
+ """Pop tag matching given style name."""
+ for index, (_, tag) in enumerate(reversed(style_stack), 1):
+ if tag.name == style_name:
+ return pop(-index)
+ raise KeyError(style_name)
+
+ for position, plain_text, tag in _parse(markup):
+ if plain_text is not None:
+ # Handle open brace escapes, where the brace is not part of a tag.
+ plain_text = plain_text.replace("\\[", "[")
+ append(emoji_replace(plain_text) if emoji else plain_text)
+ elif tag is not None:
+ if tag.name.startswith("/"): # Closing tag
+ style_name = tag.name[1:].strip()
+
+ if style_name: # explicit close
+ style_name = normalize(style_name)
+ try:
+ start, open_tag = pop_style(style_name)
+ except KeyError:
+ raise MarkupError(
+ f"closing tag '{tag.markup}' at position {position} doesn't match any open tag"
+ ) from None
+ else: # implicit close
+ try:
+ start, open_tag = pop()
+ except IndexError:
+ raise MarkupError(
+ f"closing tag '[/]' at position {position} has nothing to close"
+ ) from None
+
+ if open_tag.name.startswith("@"):
+ if open_tag.parameters:
+ handler_name = ""
+ parameters = open_tag.parameters.strip()
+ handler_match = RE_HANDLER.match(parameters)
+ if handler_match is not None:
+ handler_name, match_parameters = handler_match.groups()
+ parameters = (
+ "()" if match_parameters is None else match_parameters
+ )
+
+ try:
+ meta_params = literal_eval(parameters)
+ except SyntaxError as error:
+ raise MarkupError(
+ f"error parsing {parameters!r} in {open_tag.parameters!r}; {error.msg}"
+ )
+ except Exception as error:
+ raise MarkupError(
+ f"error parsing {open_tag.parameters!r}; {error}"
+ ) from None
+
+ if handler_name:
+ meta_params = (
+ handler_name,
+ meta_params
+ if isinstance(meta_params, tuple)
+ else (meta_params,),
+ )
+
+ else:
+ meta_params = ()
+
+ append_span(
+ _Span(
+ start, len(text), Style(meta={open_tag.name: meta_params})
+ )
+ )
+ else:
+ append_span(_Span(start, len(text), str(open_tag)))
+
+ else: # Opening tag
+ normalized_tag = _Tag(normalize(tag.name), tag.parameters)
+ style_stack.append((len(text), normalized_tag))
+
+ text_length = len(text)
+ while style_stack:
+ start, tag = style_stack.pop()
+ style = str(tag)
+ if style:
+ append_span(_Span(start, text_length, style))
+
+ text.spans = sorted(spans[::-1], key=attrgetter("start"))
+ return text
+
+
+if __name__ == "__main__": # pragma: no cover
+ MARKUP = [
+ "[red]Hello World[/red]",
+ "[magenta]Hello [b]World[/b]",
+ "[bold]Bold[italic] bold and italic [/bold]italic[/italic]",
+ "Click [link=https://www.willmcgugan.com]here[/link] to visit my Blog",
+ ":warning-emoji: [bold red blink] DANGER![/]",
+ ]
+
+ from pip._vendor.rich import print
+ from pip._vendor.rich.table import Table
+
+ grid = Table("Markup", "Result", padding=(0, 1))
+
+ for markup in MARKUP:
+ grid.add_row(Text(markup), markup)
+
+ print(grid)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/measure.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/measure.py
new file mode 100644
index 000000000..a508ffa80
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/measure.py
@@ -0,0 +1,151 @@
+from operator import itemgetter
+from typing import TYPE_CHECKING, Callable, NamedTuple, Optional, Sequence
+
+from . import errors
+from .protocol import is_renderable, rich_cast
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderableType
+
+
+class Measurement(NamedTuple):
+ """Stores the minimum and maximum widths (in characters) required to render an object."""
+
+ minimum: int
+ """Minimum number of cells required to render."""
+ maximum: int
+ """Maximum number of cells required to render."""
+
+ @property
+ def span(self) -> int:
+ """Get difference between maximum and minimum."""
+ return self.maximum - self.minimum
+
+ def normalize(self) -> "Measurement":
+ """Get measurement that ensures that minimum <= maximum and minimum >= 0
+
+ Returns:
+ Measurement: A normalized measurement.
+ """
+ minimum, maximum = self
+ minimum = min(max(0, minimum), maximum)
+ return Measurement(max(0, minimum), max(0, max(minimum, maximum)))
+
+ def with_maximum(self, width: int) -> "Measurement":
+ """Get a RenderableWith where the widths are <= width.
+
+ Args:
+ width (int): Maximum desired width.
+
+ Returns:
+ Measurement: New Measurement object.
+ """
+ minimum, maximum = self
+ return Measurement(min(minimum, width), min(maximum, width))
+
+ def with_minimum(self, width: int) -> "Measurement":
+ """Get a RenderableWith where the widths are >= width.
+
+ Args:
+ width (int): Minimum desired width.
+
+ Returns:
+ Measurement: New Measurement object.
+ """
+ minimum, maximum = self
+ width = max(0, width)
+ return Measurement(max(minimum, width), max(maximum, width))
+
+ def clamp(
+ self, min_width: Optional[int] = None, max_width: Optional[int] = None
+ ) -> "Measurement":
+ """Clamp a measurement within the specified range.
+
+ Args:
+ min_width (int): Minimum desired width, or ``None`` for no minimum. Defaults to None.
+ max_width (int): Maximum desired width, or ``None`` for no maximum. Defaults to None.
+
+ Returns:
+ Measurement: New Measurement object.
+ """
+ measurement = self
+ if min_width is not None:
+ measurement = measurement.with_minimum(min_width)
+ if max_width is not None:
+ measurement = measurement.with_maximum(max_width)
+ return measurement
+
+ @classmethod
+ def get(
+ cls, console: "Console", options: "ConsoleOptions", renderable: "RenderableType"
+ ) -> "Measurement":
+ """Get a measurement for a renderable.
+
+ Args:
+ console (~rich.console.Console): Console instance.
+ options (~rich.console.ConsoleOptions): Console options.
+ renderable (RenderableType): An object that may be rendered with Rich.
+
+ Raises:
+ errors.NotRenderableError: If the object is not renderable.
+
+ Returns:
+ Measurement: Measurement object containing range of character widths required to render the object.
+ """
+ _max_width = options.max_width
+ if _max_width < 1:
+ return Measurement(0, 0)
+ if isinstance(renderable, str):
+ renderable = console.render_str(
+ renderable, markup=options.markup, highlight=False
+ )
+ renderable = rich_cast(renderable)
+ if is_renderable(renderable):
+ get_console_width: Optional[
+ Callable[["Console", "ConsoleOptions"], "Measurement"]
+ ] = getattr(renderable, "__rich_measure__", None)
+ if get_console_width is not None:
+ render_width = (
+ get_console_width(console, options)
+ .normalize()
+ .with_maximum(_max_width)
+ )
+ if render_width.maximum < 1:
+ return Measurement(0, 0)
+ return render_width.normalize()
+ else:
+ return Measurement(0, _max_width)
+ else:
+ raise errors.NotRenderableError(
+ f"Unable to get render width for {renderable!r}; "
+ "a str, Segment, or object with __rich_console__ method is required"
+ )
+
+
+def measure_renderables(
+ console: "Console",
+ options: "ConsoleOptions",
+ renderables: Sequence["RenderableType"],
+) -> "Measurement":
+ """Get a measurement that would fit a number of renderables.
+
+ Args:
+ console (~rich.console.Console): Console instance.
+ options (~rich.console.ConsoleOptions): Console options.
+ renderables (Iterable[RenderableType]): One or more renderable objects.
+
+ Returns:
+ Measurement: Measurement object containing range of character widths required to
+ contain all given renderables.
+ """
+ if not renderables:
+ return Measurement(0, 0)
+ get_measurement = Measurement.get
+ measurements = [
+ get_measurement(console, options, renderable) for renderable in renderables
+ ]
+ measured_width = Measurement(
+ max(measurements, key=itemgetter(0)).minimum,
+ max(measurements, key=itemgetter(1)).maximum,
+ )
+ return measured_width
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/padding.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/padding.py
new file mode 100644
index 000000000..1b2204f59
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/padding.py
@@ -0,0 +1,141 @@
+from typing import cast, List, Optional, Tuple, TYPE_CHECKING, Union
+
+if TYPE_CHECKING:
+ from .console import (
+ Console,
+ ConsoleOptions,
+ RenderableType,
+ RenderResult,
+ )
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .style import Style
+from .segment import Segment
+
+
+PaddingDimensions = Union[int, Tuple[int], Tuple[int, int], Tuple[int, int, int, int]]
+
+
+class Padding(JupyterMixin):
+ """Draw space around content.
+
+ Example:
+ >>> print(Padding("Hello", (2, 4), style="on blue"))
+
+ Args:
+ renderable (RenderableType): String or other renderable.
+ pad (Union[int, Tuple[int]]): Padding for top, right, bottom, and left borders.
+ May be specified with 1, 2, or 4 integers (CSS style).
+ style (Union[str, Style], optional): Style for padding characters. Defaults to "none".
+ expand (bool, optional): Expand padding to fit available width. Defaults to True.
+ """
+
+ def __init__(
+ self,
+ renderable: "RenderableType",
+ pad: "PaddingDimensions" = (0, 0, 0, 0),
+ *,
+ style: Union[str, Style] = "none",
+ expand: bool = True,
+ ):
+ self.renderable = renderable
+ self.top, self.right, self.bottom, self.left = self.unpack(pad)
+ self.style = style
+ self.expand = expand
+
+ @classmethod
+ def indent(cls, renderable: "RenderableType", level: int) -> "Padding":
+ """Make padding instance to render an indent.
+
+ Args:
+ renderable (RenderableType): String or other renderable.
+ level (int): Number of characters to indent.
+
+ Returns:
+ Padding: A Padding instance.
+ """
+
+ return Padding(renderable, pad=(0, 0, 0, level), expand=False)
+
+ @staticmethod
+ def unpack(pad: "PaddingDimensions") -> Tuple[int, int, int, int]:
+ """Unpack padding specified in CSS style."""
+ if isinstance(pad, int):
+ return (pad, pad, pad, pad)
+ if len(pad) == 1:
+ _pad = pad[0]
+ return (_pad, _pad, _pad, _pad)
+ if len(pad) == 2:
+ pad_top, pad_right = cast(Tuple[int, int], pad)
+ return (pad_top, pad_right, pad_top, pad_right)
+ if len(pad) == 4:
+ top, right, bottom, left = cast(Tuple[int, int, int, int], pad)
+ return (top, right, bottom, left)
+ raise ValueError(f"1, 2 or 4 integers required for padding; {len(pad)} given")
+
+ def __repr__(self) -> str:
+ return f"Padding({self.renderable!r}, ({self.top},{self.right},{self.bottom},{self.left}))"
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ style = console.get_style(self.style)
+ if self.expand:
+ width = options.max_width
+ else:
+ width = min(
+ Measurement.get(console, options, self.renderable).maximum
+ + self.left
+ + self.right,
+ options.max_width,
+ )
+ render_options = options.update_width(width - self.left - self.right)
+ if render_options.height is not None:
+ render_options = render_options.update_height(
+ height=render_options.height - self.top - self.bottom
+ )
+ lines = console.render_lines(
+ self.renderable, render_options, style=style, pad=True
+ )
+ _Segment = Segment
+
+ left = _Segment(" " * self.left, style) if self.left else None
+ right = (
+ [_Segment(f'{" " * self.right}', style), _Segment.line()]
+ if self.right
+ else [_Segment.line()]
+ )
+ blank_line: Optional[List[Segment]] = None
+ if self.top:
+ blank_line = [_Segment(f'{" " * width}\n', style)]
+ yield from blank_line * self.top
+ if left:
+ for line in lines:
+ yield left
+ yield from line
+ yield from right
+ else:
+ for line in lines:
+ yield from line
+ yield from right
+ if self.bottom:
+ blank_line = blank_line or [_Segment(f'{" " * width}\n', style)]
+ yield from blank_line * self.bottom
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ max_width = options.max_width
+ extra_width = self.left + self.right
+ if max_width - extra_width < 1:
+ return Measurement(max_width, max_width)
+ measure_min, measure_max = Measurement.get(console, options, self.renderable)
+ measurement = Measurement(measure_min + extra_width, measure_max + extra_width)
+ measurement = measurement.with_maximum(max_width)
+ return measurement
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich import print
+
+ print(Padding("Hello, World", (2, 4), style="on blue"))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/pager.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/pager.py
new file mode 100644
index 000000000..a3f7aa62a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/pager.py
@@ -0,0 +1,34 @@
+from abc import ABC, abstractmethod
+from typing import Any
+
+
+class Pager(ABC):
+ """Base class for a pager."""
+
+ @abstractmethod
+ def show(self, content: str) -> None:
+ """Show content in pager.
+
+ Args:
+ content (str): Content to be displayed.
+ """
+
+
+class SystemPager(Pager):
+ """Uses the pager installed on the system."""
+
+ def _pager(self, content: str) -> Any: # pragma: no cover
+ return __import__("pydoc").pager(content)
+
+ def show(self, content: str) -> None:
+ """Use the same pager used by pydoc."""
+ self._pager(content)
+
+
+if __name__ == "__main__": # pragma: no cover
+ from .__main__ import make_test_card
+ from .console import Console
+
+ console = Console()
+ with console.pager(styles=True):
+ console.print(make_test_card())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/palette.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/palette.py
new file mode 100644
index 000000000..fa0c4dd40
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/palette.py
@@ -0,0 +1,100 @@
+from math import sqrt
+from functools import lru_cache
+from typing import Sequence, Tuple, TYPE_CHECKING
+
+from .color_triplet import ColorTriplet
+
+if TYPE_CHECKING:
+ from pip._vendor.rich.table import Table
+
+
+class Palette:
+ """A palette of available colors."""
+
+ def __init__(self, colors: Sequence[Tuple[int, int, int]]):
+ self._colors = colors
+
+ def __getitem__(self, number: int) -> ColorTriplet:
+ return ColorTriplet(*self._colors[number])
+
+ def __rich__(self) -> "Table":
+ from pip._vendor.rich.color import Color
+ from pip._vendor.rich.style import Style
+ from pip._vendor.rich.text import Text
+ from pip._vendor.rich.table import Table
+
+ table = Table(
+ "index",
+ "RGB",
+ "Color",
+ title="Palette",
+ caption=f"{len(self._colors)} colors",
+ highlight=True,
+ caption_justify="right",
+ )
+ for index, color in enumerate(self._colors):
+ table.add_row(
+ str(index),
+ repr(color),
+ Text(" " * 16, style=Style(bgcolor=Color.from_rgb(*color))),
+ )
+ return table
+
+ # This is somewhat inefficient and needs caching
+ @lru_cache(maxsize=1024)
+ def match(self, color: Tuple[int, int, int]) -> int:
+ """Find a color from a palette that most closely matches a given color.
+
+ Args:
+ color (Tuple[int, int, int]): RGB components in range 0 > 255.
+
+ Returns:
+ int: Index of closes matching color.
+ """
+ red1, green1, blue1 = color
+ _sqrt = sqrt
+ get_color = self._colors.__getitem__
+
+ def get_color_distance(index: int) -> float:
+ """Get the distance to a color."""
+ red2, green2, blue2 = get_color(index)
+ red_mean = (red1 + red2) // 2
+ red = red1 - red2
+ green = green1 - green2
+ blue = blue1 - blue2
+ return _sqrt(
+ (((512 + red_mean) * red * red) >> 8)
+ + 4 * green * green
+ + (((767 - red_mean) * blue * blue) >> 8)
+ )
+
+ min_index = min(range(len(self._colors)), key=get_color_distance)
+ return min_index
+
+
+if __name__ == "__main__": # pragma: no cover
+ import colorsys
+ from typing import Iterable
+ from pip._vendor.rich.color import Color
+ from pip._vendor.rich.console import Console, ConsoleOptions
+ from pip._vendor.rich.segment import Segment
+ from pip._vendor.rich.style import Style
+
+ class ColorBox:
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> Iterable[Segment]:
+ height = console.size.height - 3
+ for y in range(0, height):
+ for x in range(options.max_width):
+ h = x / options.max_width
+ l = y / (height + 1)
+ r1, g1, b1 = colorsys.hls_to_rgb(h, l, 1.0)
+ r2, g2, b2 = colorsys.hls_to_rgb(h, l + (1 / height / 2), 1.0)
+ bgcolor = Color.from_rgb(r1 * 255, g1 * 255, b1 * 255)
+ color = Color.from_rgb(r2 * 255, g2 * 255, b2 * 255)
+ yield Segment("▄", Style(color=color, bgcolor=bgcolor))
+ yield Segment.line()
+
+ console = Console()
+ console.print(ColorBox())
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/panel.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/panel.py
new file mode 100644
index 000000000..95f4c84cf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/panel.py
@@ -0,0 +1,312 @@
+from typing import TYPE_CHECKING, Optional
+
+from .align import AlignMethod
+from .box import ROUNDED, Box
+from .cells import cell_len
+from .jupyter import JupyterMixin
+from .measure import Measurement, measure_renderables
+from .padding import Padding, PaddingDimensions
+from .segment import Segment
+from .style import Style, StyleType
+from .text import Text, TextType
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderableType, RenderResult
+
+
+class Panel(JupyterMixin):
+ """A console renderable that draws a border around its contents.
+
+ Example:
+ >>> console.print(Panel("Hello, World!"))
+
+ Args:
+ renderable (RenderableType): A console renderable object.
+ box (Box, optional): A Box instance that defines the look of the border (see :ref:`appendix_box`.
+ Defaults to box.ROUNDED.
+ safe_box (bool, optional): Disable box characters that don't display on windows legacy terminal with *raster* fonts. Defaults to True.
+ expand (bool, optional): If True the panel will stretch to fill the console
+ width, otherwise it will be sized to fit the contents. Defaults to True.
+ style (str, optional): The style of the panel (border and contents). Defaults to "none".
+ border_style (str, optional): The style of the border. Defaults to "none".
+ width (Optional[int], optional): Optional width of panel. Defaults to None to auto-detect.
+ height (Optional[int], optional): Optional height of panel. Defaults to None to auto-detect.
+ padding (Optional[PaddingDimensions]): Optional padding around renderable. Defaults to 0.
+ highlight (bool, optional): Enable automatic highlighting of panel title (if str). Defaults to False.
+ """
+
+ def __init__(
+ self,
+ renderable: "RenderableType",
+ box: Box = ROUNDED,
+ *,
+ title: Optional[TextType] = None,
+ title_align: AlignMethod = "center",
+ subtitle: Optional[TextType] = None,
+ subtitle_align: AlignMethod = "center",
+ safe_box: Optional[bool] = None,
+ expand: bool = True,
+ style: StyleType = "none",
+ border_style: StyleType = "none",
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ padding: PaddingDimensions = (0, 1),
+ highlight: bool = False,
+ ) -> None:
+ self.renderable = renderable
+ self.box = box
+ self.title = title
+ self.title_align: AlignMethod = title_align
+ self.subtitle = subtitle
+ self.subtitle_align = subtitle_align
+ self.safe_box = safe_box
+ self.expand = expand
+ self.style = style
+ self.border_style = border_style
+ self.width = width
+ self.height = height
+ self.padding = padding
+ self.highlight = highlight
+
+ @classmethod
+ def fit(
+ cls,
+ renderable: "RenderableType",
+ box: Box = ROUNDED,
+ *,
+ title: Optional[TextType] = None,
+ title_align: AlignMethod = "center",
+ subtitle: Optional[TextType] = None,
+ subtitle_align: AlignMethod = "center",
+ safe_box: Optional[bool] = None,
+ style: StyleType = "none",
+ border_style: StyleType = "none",
+ width: Optional[int] = None,
+ height: Optional[int] = None,
+ padding: PaddingDimensions = (0, 1),
+ highlight: bool = False,
+ ) -> "Panel":
+ """An alternative constructor that sets expand=False."""
+ return cls(
+ renderable,
+ box,
+ title=title,
+ title_align=title_align,
+ subtitle=subtitle,
+ subtitle_align=subtitle_align,
+ safe_box=safe_box,
+ style=style,
+ border_style=border_style,
+ width=width,
+ height=height,
+ padding=padding,
+ highlight=highlight,
+ expand=False,
+ )
+
+ @property
+ def _title(self) -> Optional[Text]:
+ if self.title:
+ title_text = (
+ Text.from_markup(self.title)
+ if isinstance(self.title, str)
+ else self.title.copy()
+ )
+ title_text.end = ""
+ title_text.plain = title_text.plain.replace("\n", " ")
+ title_text.no_wrap = True
+ title_text.expand_tabs()
+ title_text.pad(1)
+ return title_text
+ return None
+
+ @property
+ def _subtitle(self) -> Optional[Text]:
+ if self.subtitle:
+ subtitle_text = (
+ Text.from_markup(self.subtitle)
+ if isinstance(self.subtitle, str)
+ else self.subtitle.copy()
+ )
+ subtitle_text.end = ""
+ subtitle_text.plain = subtitle_text.plain.replace("\n", " ")
+ subtitle_text.no_wrap = True
+ subtitle_text.expand_tabs()
+ subtitle_text.pad(1)
+ return subtitle_text
+ return None
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ _padding = Padding.unpack(self.padding)
+ renderable = (
+ Padding(self.renderable, _padding) if any(_padding) else self.renderable
+ )
+ style = console.get_style(self.style)
+ border_style = style + console.get_style(self.border_style)
+ width = (
+ options.max_width
+ if self.width is None
+ else min(options.max_width, self.width)
+ )
+
+ safe_box: bool = console.safe_box if self.safe_box is None else self.safe_box
+ box = self.box.substitute(options, safe=safe_box)
+
+ def align_text(
+ text: Text, width: int, align: str, character: str, style: Style
+ ) -> Text:
+ """Gets new aligned text.
+
+ Args:
+ text (Text): Title or subtitle text.
+ width (int): Desired width.
+ align (str): Alignment.
+ character (str): Character for alignment.
+ style (Style): Border style
+
+ Returns:
+ Text: New text instance
+ """
+ text = text.copy()
+ text.truncate(width)
+ excess_space = width - cell_len(text.plain)
+ if excess_space:
+ if align == "left":
+ return Text.assemble(
+ text,
+ (character * excess_space, style),
+ no_wrap=True,
+ end="",
+ )
+ elif align == "center":
+ left = excess_space // 2
+ return Text.assemble(
+ (character * left, style),
+ text,
+ (character * (excess_space - left), style),
+ no_wrap=True,
+ end="",
+ )
+ else:
+ return Text.assemble(
+ (character * excess_space, style),
+ text,
+ no_wrap=True,
+ end="",
+ )
+ return text
+
+ title_text = self._title
+ if title_text is not None:
+ title_text.stylize_before(border_style)
+
+ child_width = (
+ width - 2
+ if self.expand
+ else console.measure(
+ renderable, options=options.update_width(width - 2)
+ ).maximum
+ )
+ child_height = self.height or options.height or None
+ if child_height:
+ child_height -= 2
+ if title_text is not None:
+ child_width = min(
+ options.max_width - 2, max(child_width, title_text.cell_len + 2)
+ )
+
+ width = child_width + 2
+ child_options = options.update(
+ width=child_width, height=child_height, highlight=self.highlight
+ )
+ lines = console.render_lines(renderable, child_options, style=style)
+
+ line_start = Segment(box.mid_left, border_style)
+ line_end = Segment(f"{box.mid_right}", border_style)
+ new_line = Segment.line()
+ if title_text is None or width <= 4:
+ yield Segment(box.get_top([width - 2]), border_style)
+ else:
+ title_text = align_text(
+ title_text,
+ width - 4,
+ self.title_align,
+ box.top,
+ border_style,
+ )
+ yield Segment(box.top_left + box.top, border_style)
+ yield from console.render(title_text, child_options.update_width(width - 4))
+ yield Segment(box.top + box.top_right, border_style)
+
+ yield new_line
+ for line in lines:
+ yield line_start
+ yield from line
+ yield line_end
+ yield new_line
+
+ subtitle_text = self._subtitle
+ if subtitle_text is not None:
+ subtitle_text.stylize_before(border_style)
+
+ if subtitle_text is None or width <= 4:
+ yield Segment(box.get_bottom([width - 2]), border_style)
+ else:
+ subtitle_text = align_text(
+ subtitle_text,
+ width - 4,
+ self.subtitle_align,
+ box.bottom,
+ border_style,
+ )
+ yield Segment(box.bottom_left + box.bottom, border_style)
+ yield from console.render(
+ subtitle_text, child_options.update_width(width - 4)
+ )
+ yield Segment(box.bottom + box.bottom_right, border_style)
+
+ yield new_line
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ _title = self._title
+ _, right, _, left = Padding.unpack(self.padding)
+ padding = left + right
+ renderables = [self.renderable, _title] if _title else [self.renderable]
+
+ if self.width is None:
+ width = (
+ measure_renderables(
+ console,
+ options.update_width(options.max_width - padding - 2),
+ renderables,
+ ).maximum
+ + padding
+ + 2
+ )
+ else:
+ width = self.width
+ return Measurement(width, width)
+
+
+if __name__ == "__main__": # pragma: no cover
+ from .console import Console
+
+ c = Console()
+
+ from .box import DOUBLE, ROUNDED
+ from .padding import Padding
+
+ p = Panel(
+ "Hello, World!",
+ title="rich.Panel",
+ style="white on blue",
+ box=DOUBLE,
+ padding=1,
+ )
+
+ c.print()
+ c.print(p)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/pretty.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/pretty.py
new file mode 100644
index 000000000..9b9e3ba90
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/pretty.py
@@ -0,0 +1,995 @@
+import builtins
+import collections
+import dataclasses
+import inspect
+import os
+import sys
+from array import array
+from collections import Counter, UserDict, UserList, defaultdict, deque
+from dataclasses import dataclass, fields, is_dataclass
+from inspect import isclass
+from itertools import islice
+from types import MappingProxyType
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Callable,
+ DefaultDict,
+ Dict,
+ Iterable,
+ List,
+ Optional,
+ Sequence,
+ Set,
+ Tuple,
+ Union,
+)
+
+from pip._vendor.rich.repr import RichReprResult
+
+try:
+ import attr as _attr_module
+
+ _has_attrs = hasattr(_attr_module, "ib")
+except ImportError: # pragma: no cover
+ _has_attrs = False
+
+from . import get_console
+from ._loop import loop_last
+from ._pick import pick_bool
+from .abc import RichRenderable
+from .cells import cell_len
+from .highlighter import ReprHighlighter
+from .jupyter import JupyterMixin, JupyterRenderable
+from .measure import Measurement
+from .text import Text
+
+if TYPE_CHECKING:
+ from .console import (
+ Console,
+ ConsoleOptions,
+ HighlighterType,
+ JustifyMethod,
+ OverflowMethod,
+ RenderResult,
+ )
+
+
+def _is_attr_object(obj: Any) -> bool:
+ """Check if an object was created with attrs module."""
+ return _has_attrs and _attr_module.has(type(obj))
+
+
+def _get_attr_fields(obj: Any) -> Sequence["_attr_module.Attribute[Any]"]:
+ """Get fields for an attrs object."""
+ return _attr_module.fields(type(obj)) if _has_attrs else []
+
+
+def _is_dataclass_repr(obj: object) -> bool:
+ """Check if an instance of a dataclass contains the default repr.
+
+ Args:
+ obj (object): A dataclass instance.
+
+ Returns:
+ bool: True if the default repr is used, False if there is a custom repr.
+ """
+ # Digging in to a lot of internals here
+ # Catching all exceptions in case something is missing on a non CPython implementation
+ try:
+ return obj.__repr__.__code__.co_filename == dataclasses.__file__
+ except Exception: # pragma: no coverage
+ return False
+
+
+_dummy_namedtuple = collections.namedtuple("_dummy_namedtuple", [])
+
+
+def _has_default_namedtuple_repr(obj: object) -> bool:
+ """Check if an instance of namedtuple contains the default repr
+
+ Args:
+ obj (object): A namedtuple
+
+ Returns:
+ bool: True if the default repr is used, False if there's a custom repr.
+ """
+ obj_file = None
+ try:
+ obj_file = inspect.getfile(obj.__repr__)
+ except (OSError, TypeError):
+ # OSError handles case where object is defined in __main__ scope, e.g. REPL - no filename available.
+ # TypeError trapped defensively, in case of object without filename slips through.
+ pass
+ default_repr_file = inspect.getfile(_dummy_namedtuple.__repr__)
+ return obj_file == default_repr_file
+
+
+def _ipy_display_hook(
+ value: Any,
+ console: Optional["Console"] = None,
+ overflow: "OverflowMethod" = "ignore",
+ crop: bool = False,
+ indent_guides: bool = False,
+ max_length: Optional[int] = None,
+ max_string: Optional[int] = None,
+ max_depth: Optional[int] = None,
+ expand_all: bool = False,
+) -> Union[str, None]:
+ # needed here to prevent circular import:
+ from .console import ConsoleRenderable
+
+ # always skip rich generated jupyter renderables or None values
+ if _safe_isinstance(value, JupyterRenderable) or value is None:
+ return None
+
+ console = console or get_console()
+
+ with console.capture() as capture:
+ # certain renderables should start on a new line
+ if _safe_isinstance(value, ConsoleRenderable):
+ console.line()
+ console.print(
+ value
+ if _safe_isinstance(value, RichRenderable)
+ else Pretty(
+ value,
+ overflow=overflow,
+ indent_guides=indent_guides,
+ max_length=max_length,
+ max_string=max_string,
+ max_depth=max_depth,
+ expand_all=expand_all,
+ margin=12,
+ ),
+ crop=crop,
+ new_line_start=True,
+ end="",
+ )
+ # strip trailing newline, not usually part of a text repr
+ # I'm not sure if this should be prevented at a lower level
+ return capture.get().rstrip("\n")
+
+
+def _safe_isinstance(
+ obj: object, class_or_tuple: Union[type, Tuple[type, ...]]
+) -> bool:
+ """isinstance can fail in rare cases, for example types with no __class__"""
+ try:
+ return isinstance(obj, class_or_tuple)
+ except Exception:
+ return False
+
+
+def install(
+ console: Optional["Console"] = None,
+ overflow: "OverflowMethod" = "ignore",
+ crop: bool = False,
+ indent_guides: bool = False,
+ max_length: Optional[int] = None,
+ max_string: Optional[int] = None,
+ max_depth: Optional[int] = None,
+ expand_all: bool = False,
+) -> None:
+ """Install automatic pretty printing in the Python REPL.
+
+ Args:
+ console (Console, optional): Console instance or ``None`` to use global console. Defaults to None.
+ overflow (Optional[OverflowMethod], optional): Overflow method. Defaults to "ignore".
+ crop (Optional[bool], optional): Enable cropping of long lines. Defaults to False.
+ indent_guides (bool, optional): Enable indentation guides. Defaults to False.
+ max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to None.
+ max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to None.
+ max_depth (int, optional): Maximum depth of nested data structures, or None for no maximum. Defaults to None.
+ expand_all (bool, optional): Expand all containers. Defaults to False.
+ max_frames (int): Maximum number of frames to show in a traceback, 0 for no maximum. Defaults to 100.
+ """
+ from pip._vendor.rich import get_console
+
+ console = console or get_console()
+ assert console is not None
+
+ def display_hook(value: Any) -> None:
+ """Replacement sys.displayhook which prettifies objects with Rich."""
+ if value is not None:
+ assert console is not None
+ builtins._ = None # type: ignore[attr-defined]
+ console.print(
+ value
+ if _safe_isinstance(value, RichRenderable)
+ else Pretty(
+ value,
+ overflow=overflow,
+ indent_guides=indent_guides,
+ max_length=max_length,
+ max_string=max_string,
+ max_depth=max_depth,
+ expand_all=expand_all,
+ ),
+ crop=crop,
+ )
+ builtins._ = value # type: ignore[attr-defined]
+
+ try:
+ ip = get_ipython() # type: ignore[name-defined]
+ except NameError:
+ sys.displayhook = display_hook
+ else:
+ from IPython.core.formatters import BaseFormatter
+
+ class RichFormatter(BaseFormatter): # type: ignore[misc]
+ pprint: bool = True
+
+ def __call__(self, value: Any) -> Any:
+ if self.pprint:
+ return _ipy_display_hook(
+ value,
+ console=get_console(),
+ overflow=overflow,
+ indent_guides=indent_guides,
+ max_length=max_length,
+ max_string=max_string,
+ max_depth=max_depth,
+ expand_all=expand_all,
+ )
+ else:
+ return repr(value)
+
+ # replace plain text formatter with rich formatter
+ rich_formatter = RichFormatter()
+ ip.display_formatter.formatters["text/plain"] = rich_formatter
+
+
+class Pretty(JupyterMixin):
+ """A rich renderable that pretty prints an object.
+
+ Args:
+ _object (Any): An object to pretty print.
+ highlighter (HighlighterType, optional): Highlighter object to apply to result, or None for ReprHighlighter. Defaults to None.
+ indent_size (int, optional): Number of spaces in indent. Defaults to 4.
+ justify (JustifyMethod, optional): Justify method, or None for default. Defaults to None.
+ overflow (OverflowMethod, optional): Overflow method, or None for default. Defaults to None.
+ no_wrap (Optional[bool], optional): Disable word wrapping. Defaults to False.
+ indent_guides (bool, optional): Enable indentation guides. Defaults to False.
+ max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to None.
+ max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to None.
+ max_depth (int, optional): Maximum depth of nested data structures, or None for no maximum. Defaults to None.
+ expand_all (bool, optional): Expand all containers. Defaults to False.
+ margin (int, optional): Subtrace a margin from width to force containers to expand earlier. Defaults to 0.
+ insert_line (bool, optional): Insert a new line if the output has multiple new lines. Defaults to False.
+ """
+
+ def __init__(
+ self,
+ _object: Any,
+ highlighter: Optional["HighlighterType"] = None,
+ *,
+ indent_size: int = 4,
+ justify: Optional["JustifyMethod"] = None,
+ overflow: Optional["OverflowMethod"] = None,
+ no_wrap: Optional[bool] = False,
+ indent_guides: bool = False,
+ max_length: Optional[int] = None,
+ max_string: Optional[int] = None,
+ max_depth: Optional[int] = None,
+ expand_all: bool = False,
+ margin: int = 0,
+ insert_line: bool = False,
+ ) -> None:
+ self._object = _object
+ self.highlighter = highlighter or ReprHighlighter()
+ self.indent_size = indent_size
+ self.justify: Optional["JustifyMethod"] = justify
+ self.overflow: Optional["OverflowMethod"] = overflow
+ self.no_wrap = no_wrap
+ self.indent_guides = indent_guides
+ self.max_length = max_length
+ self.max_string = max_string
+ self.max_depth = max_depth
+ self.expand_all = expand_all
+ self.margin = margin
+ self.insert_line = insert_line
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ pretty_str = pretty_repr(
+ self._object,
+ max_width=options.max_width - self.margin,
+ indent_size=self.indent_size,
+ max_length=self.max_length,
+ max_string=self.max_string,
+ max_depth=self.max_depth,
+ expand_all=self.expand_all,
+ )
+ pretty_text = Text.from_ansi(
+ pretty_str,
+ justify=self.justify or options.justify,
+ overflow=self.overflow or options.overflow,
+ no_wrap=pick_bool(self.no_wrap, options.no_wrap),
+ style="pretty",
+ )
+ pretty_text = (
+ self.highlighter(pretty_text)
+ if pretty_text
+ else Text(
+ f"{type(self._object)}.__repr__ returned empty string",
+ style="dim italic",
+ )
+ )
+ if self.indent_guides and not options.ascii_only:
+ pretty_text = pretty_text.with_indent_guides(
+ self.indent_size, style="repr.indent"
+ )
+ if self.insert_line and "\n" in pretty_text:
+ yield ""
+ yield pretty_text
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ pretty_str = pretty_repr(
+ self._object,
+ max_width=options.max_width,
+ indent_size=self.indent_size,
+ max_length=self.max_length,
+ max_string=self.max_string,
+ max_depth=self.max_depth,
+ expand_all=self.expand_all,
+ )
+ text_width = (
+ max(cell_len(line) for line in pretty_str.splitlines()) if pretty_str else 0
+ )
+ return Measurement(text_width, text_width)
+
+
+def _get_braces_for_defaultdict(_object: DefaultDict[Any, Any]) -> Tuple[str, str, str]:
+ return (
+ f"defaultdict({_object.default_factory!r}, {{",
+ "})",
+ f"defaultdict({_object.default_factory!r}, {{}})",
+ )
+
+
+def _get_braces_for_array(_object: "array[Any]") -> Tuple[str, str, str]:
+ return (f"array({_object.typecode!r}, [", "])", f"array({_object.typecode!r})")
+
+
+_BRACES: Dict[type, Callable[[Any], Tuple[str, str, str]]] = {
+ os._Environ: lambda _object: ("environ({", "})", "environ({})"),
+ array: _get_braces_for_array,
+ defaultdict: _get_braces_for_defaultdict,
+ Counter: lambda _object: ("Counter({", "})", "Counter()"),
+ deque: lambda _object: ("deque([", "])", "deque()"),
+ dict: lambda _object: ("{", "}", "{}"),
+ UserDict: lambda _object: ("{", "}", "{}"),
+ frozenset: lambda _object: ("frozenset({", "})", "frozenset()"),
+ list: lambda _object: ("[", "]", "[]"),
+ UserList: lambda _object: ("[", "]", "[]"),
+ set: lambda _object: ("{", "}", "set()"),
+ tuple: lambda _object: ("(", ")", "()"),
+ MappingProxyType: lambda _object: ("mappingproxy({", "})", "mappingproxy({})"),
+}
+_CONTAINERS = tuple(_BRACES.keys())
+_MAPPING_CONTAINERS = (dict, os._Environ, MappingProxyType, UserDict)
+
+
+def is_expandable(obj: Any) -> bool:
+ """Check if an object may be expanded by pretty print."""
+ return (
+ _safe_isinstance(obj, _CONTAINERS)
+ or (is_dataclass(obj))
+ or (hasattr(obj, "__rich_repr__"))
+ or _is_attr_object(obj)
+ ) and not isclass(obj)
+
+
+@dataclass
+class Node:
+ """A node in a repr tree. May be atomic or a container."""
+
+ key_repr: str = ""
+ value_repr: str = ""
+ open_brace: str = ""
+ close_brace: str = ""
+ empty: str = ""
+ last: bool = False
+ is_tuple: bool = False
+ is_namedtuple: bool = False
+ children: Optional[List["Node"]] = None
+ key_separator: str = ": "
+ separator: str = ", "
+
+ def iter_tokens(self) -> Iterable[str]:
+ """Generate tokens for this node."""
+ if self.key_repr:
+ yield self.key_repr
+ yield self.key_separator
+ if self.value_repr:
+ yield self.value_repr
+ elif self.children is not None:
+ if self.children:
+ yield self.open_brace
+ if self.is_tuple and not self.is_namedtuple and len(self.children) == 1:
+ yield from self.children[0].iter_tokens()
+ yield ","
+ else:
+ for child in self.children:
+ yield from child.iter_tokens()
+ if not child.last:
+ yield self.separator
+ yield self.close_brace
+ else:
+ yield self.empty
+
+ def check_length(self, start_length: int, max_length: int) -> bool:
+ """Check the length fits within a limit.
+
+ Args:
+ start_length (int): Starting length of the line (indent, prefix, suffix).
+ max_length (int): Maximum length.
+
+ Returns:
+ bool: True if the node can be rendered within max length, otherwise False.
+ """
+ total_length = start_length
+ for token in self.iter_tokens():
+ total_length += cell_len(token)
+ if total_length > max_length:
+ return False
+ return True
+
+ def __str__(self) -> str:
+ repr_text = "".join(self.iter_tokens())
+ return repr_text
+
+ def render(
+ self, max_width: int = 80, indent_size: int = 4, expand_all: bool = False
+ ) -> str:
+ """Render the node to a pretty repr.
+
+ Args:
+ max_width (int, optional): Maximum width of the repr. Defaults to 80.
+ indent_size (int, optional): Size of indents. Defaults to 4.
+ expand_all (bool, optional): Expand all levels. Defaults to False.
+
+ Returns:
+ str: A repr string of the original object.
+ """
+ lines = [_Line(node=self, is_root=True)]
+ line_no = 0
+ while line_no < len(lines):
+ line = lines[line_no]
+ if line.expandable and not line.expanded:
+ if expand_all or not line.check_length(max_width):
+ lines[line_no : line_no + 1] = line.expand(indent_size)
+ line_no += 1
+
+ repr_str = "\n".join(str(line) for line in lines)
+ return repr_str
+
+
+@dataclass
+class _Line:
+ """A line in repr output."""
+
+ parent: Optional["_Line"] = None
+ is_root: bool = False
+ node: Optional[Node] = None
+ text: str = ""
+ suffix: str = ""
+ whitespace: str = ""
+ expanded: bool = False
+ last: bool = False
+
+ @property
+ def expandable(self) -> bool:
+ """Check if the line may be expanded."""
+ return bool(self.node is not None and self.node.children)
+
+ def check_length(self, max_length: int) -> bool:
+ """Check this line fits within a given number of cells."""
+ start_length = (
+ len(self.whitespace) + cell_len(self.text) + cell_len(self.suffix)
+ )
+ assert self.node is not None
+ return self.node.check_length(start_length, max_length)
+
+ def expand(self, indent_size: int) -> Iterable["_Line"]:
+ """Expand this line by adding children on their own line."""
+ node = self.node
+ assert node is not None
+ whitespace = self.whitespace
+ assert node.children
+ if node.key_repr:
+ new_line = yield _Line(
+ text=f"{node.key_repr}{node.key_separator}{node.open_brace}",
+ whitespace=whitespace,
+ )
+ else:
+ new_line = yield _Line(text=node.open_brace, whitespace=whitespace)
+ child_whitespace = self.whitespace + " " * indent_size
+ tuple_of_one = node.is_tuple and len(node.children) == 1
+ for last, child in loop_last(node.children):
+ separator = "," if tuple_of_one else node.separator
+ line = _Line(
+ parent=new_line,
+ node=child,
+ whitespace=child_whitespace,
+ suffix=separator,
+ last=last and not tuple_of_one,
+ )
+ yield line
+
+ yield _Line(
+ text=node.close_brace,
+ whitespace=whitespace,
+ suffix=self.suffix,
+ last=self.last,
+ )
+
+ def __str__(self) -> str:
+ if self.last:
+ return f"{self.whitespace}{self.text}{self.node or ''}"
+ else:
+ return (
+ f"{self.whitespace}{self.text}{self.node or ''}{self.suffix.rstrip()}"
+ )
+
+
+def _is_namedtuple(obj: Any) -> bool:
+ """Checks if an object is most likely a namedtuple. It is possible
+ to craft an object that passes this check and isn't a namedtuple, but
+ there is only a minuscule chance of this happening unintentionally.
+
+ Args:
+ obj (Any): The object to test
+
+ Returns:
+ bool: True if the object is a namedtuple. False otherwise.
+ """
+ try:
+ fields = getattr(obj, "_fields", None)
+ except Exception:
+ # Being very defensive - if we cannot get the attr then its not a namedtuple
+ return False
+ return isinstance(obj, tuple) and isinstance(fields, tuple)
+
+
+def traverse(
+ _object: Any,
+ max_length: Optional[int] = None,
+ max_string: Optional[int] = None,
+ max_depth: Optional[int] = None,
+) -> Node:
+ """Traverse object and generate a tree.
+
+ Args:
+ _object (Any): Object to be traversed.
+ max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to None.
+ max_string (int, optional): Maximum length of string before truncating, or None to disable truncating.
+ Defaults to None.
+ max_depth (int, optional): Maximum depth of data structures, or None for no maximum.
+ Defaults to None.
+
+ Returns:
+ Node: The root of a tree structure which can be used to render a pretty repr.
+ """
+
+ def to_repr(obj: Any) -> str:
+ """Get repr string for an object, but catch errors."""
+ if (
+ max_string is not None
+ and _safe_isinstance(obj, (bytes, str))
+ and len(obj) > max_string
+ ):
+ truncated = len(obj) - max_string
+ obj_repr = f"{obj[:max_string]!r}+{truncated}"
+ else:
+ try:
+ obj_repr = repr(obj)
+ except Exception as error:
+ obj_repr = f"<repr-error {str(error)!r}>"
+ return obj_repr
+
+ visited_ids: Set[int] = set()
+ push_visited = visited_ids.add
+ pop_visited = visited_ids.remove
+
+ def _traverse(obj: Any, root: bool = False, depth: int = 0) -> Node:
+ """Walk the object depth first."""
+
+ obj_id = id(obj)
+ if obj_id in visited_ids:
+ # Recursion detected
+ return Node(value_repr="...")
+
+ obj_type = type(obj)
+ children: List[Node]
+ reached_max_depth = max_depth is not None and depth >= max_depth
+
+ def iter_rich_args(rich_args: Any) -> Iterable[Union[Any, Tuple[str, Any]]]:
+ for arg in rich_args:
+ if _safe_isinstance(arg, tuple):
+ if len(arg) == 3:
+ key, child, default = arg
+ if default == child:
+ continue
+ yield key, child
+ elif len(arg) == 2:
+ key, child = arg
+ yield key, child
+ elif len(arg) == 1:
+ yield arg[0]
+ else:
+ yield arg
+
+ try:
+ fake_attributes = hasattr(
+ obj, "awehoi234_wdfjwljet234_234wdfoijsdfmmnxpi492"
+ )
+ except Exception:
+ fake_attributes = False
+
+ rich_repr_result: Optional[RichReprResult] = None
+ if not fake_attributes:
+ try:
+ if hasattr(obj, "__rich_repr__") and not isclass(obj):
+ rich_repr_result = obj.__rich_repr__()
+ except Exception:
+ pass
+
+ if rich_repr_result is not None:
+ push_visited(obj_id)
+ angular = getattr(obj.__rich_repr__, "angular", False)
+ args = list(iter_rich_args(rich_repr_result))
+ class_name = obj.__class__.__name__
+
+ if args:
+ children = []
+ append = children.append
+
+ if reached_max_depth:
+ if angular:
+ node = Node(value_repr=f"<{class_name}...>")
+ else:
+ node = Node(value_repr=f"{class_name}(...)")
+ else:
+ if angular:
+ node = Node(
+ open_brace=f"<{class_name} ",
+ close_brace=">",
+ children=children,
+ last=root,
+ separator=" ",
+ )
+ else:
+ node = Node(
+ open_brace=f"{class_name}(",
+ close_brace=")",
+ children=children,
+ last=root,
+ )
+ for last, arg in loop_last(args):
+ if _safe_isinstance(arg, tuple):
+ key, child = arg
+ child_node = _traverse(child, depth=depth + 1)
+ child_node.last = last
+ child_node.key_repr = key
+ child_node.key_separator = "="
+ append(child_node)
+ else:
+ child_node = _traverse(arg, depth=depth + 1)
+ child_node.last = last
+ append(child_node)
+ else:
+ node = Node(
+ value_repr=f"<{class_name}>" if angular else f"{class_name}()",
+ children=[],
+ last=root,
+ )
+ pop_visited(obj_id)
+ elif _is_attr_object(obj) and not fake_attributes:
+ push_visited(obj_id)
+ children = []
+ append = children.append
+
+ attr_fields = _get_attr_fields(obj)
+ if attr_fields:
+ if reached_max_depth:
+ node = Node(value_repr=f"{obj.__class__.__name__}(...)")
+ else:
+ node = Node(
+ open_brace=f"{obj.__class__.__name__}(",
+ close_brace=")",
+ children=children,
+ last=root,
+ )
+
+ def iter_attrs() -> (
+ Iterable[Tuple[str, Any, Optional[Callable[[Any], str]]]]
+ ):
+ """Iterate over attr fields and values."""
+ for attr in attr_fields:
+ if attr.repr:
+ try:
+ value = getattr(obj, attr.name)
+ except Exception as error:
+ # Can happen, albeit rarely
+ yield (attr.name, error, None)
+ else:
+ yield (
+ attr.name,
+ value,
+ attr.repr if callable(attr.repr) else None,
+ )
+
+ for last, (name, value, repr_callable) in loop_last(iter_attrs()):
+ if repr_callable:
+ child_node = Node(value_repr=str(repr_callable(value)))
+ else:
+ child_node = _traverse(value, depth=depth + 1)
+ child_node.last = last
+ child_node.key_repr = name
+ child_node.key_separator = "="
+ append(child_node)
+ else:
+ node = Node(
+ value_repr=f"{obj.__class__.__name__}()", children=[], last=root
+ )
+ pop_visited(obj_id)
+ elif (
+ is_dataclass(obj)
+ and not _safe_isinstance(obj, type)
+ and not fake_attributes
+ and _is_dataclass_repr(obj)
+ ):
+ push_visited(obj_id)
+ children = []
+ append = children.append
+ if reached_max_depth:
+ node = Node(value_repr=f"{obj.__class__.__name__}(...)")
+ else:
+ node = Node(
+ open_brace=f"{obj.__class__.__name__}(",
+ close_brace=")",
+ children=children,
+ last=root,
+ empty=f"{obj.__class__.__name__}()",
+ )
+
+ for last, field in loop_last(
+ field for field in fields(obj) if field.repr
+ ):
+ child_node = _traverse(getattr(obj, field.name), depth=depth + 1)
+ child_node.key_repr = field.name
+ child_node.last = last
+ child_node.key_separator = "="
+ append(child_node)
+
+ pop_visited(obj_id)
+ elif _is_namedtuple(obj) and _has_default_namedtuple_repr(obj):
+ push_visited(obj_id)
+ class_name = obj.__class__.__name__
+ if reached_max_depth:
+ # If we've reached the max depth, we still show the class name, but not its contents
+ node = Node(
+ value_repr=f"{class_name}(...)",
+ )
+ else:
+ children = []
+ append = children.append
+ node = Node(
+ open_brace=f"{class_name}(",
+ close_brace=")",
+ children=children,
+ empty=f"{class_name}()",
+ )
+ for last, (key, value) in loop_last(obj._asdict().items()):
+ child_node = _traverse(value, depth=depth + 1)
+ child_node.key_repr = key
+ child_node.last = last
+ child_node.key_separator = "="
+ append(child_node)
+ pop_visited(obj_id)
+ elif _safe_isinstance(obj, _CONTAINERS):
+ for container_type in _CONTAINERS:
+ if _safe_isinstance(obj, container_type):
+ obj_type = container_type
+ break
+
+ push_visited(obj_id)
+
+ open_brace, close_brace, empty = _BRACES[obj_type](obj)
+
+ if reached_max_depth:
+ node = Node(value_repr=f"{open_brace}...{close_brace}")
+ elif obj_type.__repr__ != type(obj).__repr__:
+ node = Node(value_repr=to_repr(obj), last=root)
+ elif obj:
+ children = []
+ node = Node(
+ open_brace=open_brace,
+ close_brace=close_brace,
+ children=children,
+ last=root,
+ )
+ append = children.append
+ num_items = len(obj)
+ last_item_index = num_items - 1
+
+ if _safe_isinstance(obj, _MAPPING_CONTAINERS):
+ iter_items = iter(obj.items())
+ if max_length is not None:
+ iter_items = islice(iter_items, max_length)
+ for index, (key, child) in enumerate(iter_items):
+ child_node = _traverse(child, depth=depth + 1)
+ child_node.key_repr = to_repr(key)
+ child_node.last = index == last_item_index
+ append(child_node)
+ else:
+ iter_values = iter(obj)
+ if max_length is not None:
+ iter_values = islice(iter_values, max_length)
+ for index, child in enumerate(iter_values):
+ child_node = _traverse(child, depth=depth + 1)
+ child_node.last = index == last_item_index
+ append(child_node)
+ if max_length is not None and num_items > max_length:
+ append(Node(value_repr=f"... +{num_items - max_length}", last=True))
+ else:
+ node = Node(empty=empty, children=[], last=root)
+
+ pop_visited(obj_id)
+ else:
+ node = Node(value_repr=to_repr(obj), last=root)
+ node.is_tuple = _safe_isinstance(obj, tuple)
+ node.is_namedtuple = _is_namedtuple(obj)
+ return node
+
+ node = _traverse(_object, root=True)
+ return node
+
+
+def pretty_repr(
+ _object: Any,
+ *,
+ max_width: int = 80,
+ indent_size: int = 4,
+ max_length: Optional[int] = None,
+ max_string: Optional[int] = None,
+ max_depth: Optional[int] = None,
+ expand_all: bool = False,
+) -> str:
+ """Prettify repr string by expanding on to new lines to fit within a given width.
+
+ Args:
+ _object (Any): Object to repr.
+ max_width (int, optional): Desired maximum width of repr string. Defaults to 80.
+ indent_size (int, optional): Number of spaces to indent. Defaults to 4.
+ max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to None.
+ max_string (int, optional): Maximum length of string before truncating, or None to disable truncating.
+ Defaults to None.
+ max_depth (int, optional): Maximum depth of nested data structure, or None for no depth.
+ Defaults to None.
+ expand_all (bool, optional): Expand all containers regardless of available width. Defaults to False.
+
+ Returns:
+ str: A possibly multi-line representation of the object.
+ """
+
+ if _safe_isinstance(_object, Node):
+ node = _object
+ else:
+ node = traverse(
+ _object, max_length=max_length, max_string=max_string, max_depth=max_depth
+ )
+ repr_str: str = node.render(
+ max_width=max_width, indent_size=indent_size, expand_all=expand_all
+ )
+ return repr_str
+
+
+def pprint(
+ _object: Any,
+ *,
+ console: Optional["Console"] = None,
+ indent_guides: bool = True,
+ max_length: Optional[int] = None,
+ max_string: Optional[int] = None,
+ max_depth: Optional[int] = None,
+ expand_all: bool = False,
+) -> None:
+ """A convenience function for pretty printing.
+
+ Args:
+ _object (Any): Object to pretty print.
+ console (Console, optional): Console instance, or None to use default. Defaults to None.
+ max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to None.
+ max_string (int, optional): Maximum length of strings before truncating, or None to disable. Defaults to None.
+ max_depth (int, optional): Maximum depth for nested data structures, or None for unlimited depth. Defaults to None.
+ indent_guides (bool, optional): Enable indentation guides. Defaults to True.
+ expand_all (bool, optional): Expand all containers. Defaults to False.
+ """
+ _console = get_console() if console is None else console
+ _console.print(
+ Pretty(
+ _object,
+ max_length=max_length,
+ max_string=max_string,
+ max_depth=max_depth,
+ indent_guides=indent_guides,
+ expand_all=expand_all,
+ overflow="ignore",
+ ),
+ soft_wrap=True,
+ )
+
+
+if __name__ == "__main__": # pragma: no cover
+
+ class BrokenRepr:
+ def __repr__(self) -> str:
+ 1 / 0
+ return "this will fail"
+
+ from typing import NamedTuple
+
+ class StockKeepingUnit(NamedTuple):
+ name: str
+ description: str
+ price: float
+ category: str
+ reviews: List[str]
+
+ d = defaultdict(int)
+ d["foo"] = 5
+ data = {
+ "foo": [
+ 1,
+ "Hello World!",
+ 100.123,
+ 323.232,
+ 432324.0,
+ {5, 6, 7, (1, 2, 3, 4), 8},
+ ],
+ "bar": frozenset({1, 2, 3}),
+ "defaultdict": defaultdict(
+ list, {"crumble": ["apple", "rhubarb", "butter", "sugar", "flour"]}
+ ),
+ "counter": Counter(
+ [
+ "apple",
+ "orange",
+ "pear",
+ "kumquat",
+ "kumquat",
+ "durian" * 100,
+ ]
+ ),
+ "atomic": (False, True, None),
+ "namedtuple": StockKeepingUnit(
+ "Sparkling British Spring Water",
+ "Carbonated spring water",
+ 0.9,
+ "water",
+ ["its amazing!", "its terrible!"],
+ ),
+ "Broken": BrokenRepr(),
+ }
+ data["foo"].append(data) # type: ignore[attr-defined]
+
+ from pip._vendor.rich import print
+
+ print(Pretty(data, indent_guides=True, max_string=20))
+
+ class Thing:
+ def __repr__(self) -> str:
+ return "Hello\x1b[38;5;239m World!"
+
+ print(Pretty(Thing()))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/progress.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/progress.py
new file mode 100644
index 000000000..2420c24e6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/progress.py
@@ -0,0 +1,1699 @@
+import io
+import sys
+import typing
+import warnings
+from abc import ABC, abstractmethod
+from collections import deque
+from dataclasses import dataclass, field
+from datetime import timedelta
+from io import RawIOBase, UnsupportedOperation
+from math import ceil
+from mmap import mmap
+from operator import length_hint
+from os import PathLike, stat
+from threading import Event, RLock, Thread
+from types import TracebackType
+from typing import (
+ Any,
+ BinaryIO,
+ Callable,
+ ContextManager,
+ Deque,
+ Dict,
+ Generic,
+ Iterable,
+ List,
+ NamedTuple,
+ NewType,
+ Optional,
+ Sequence,
+ TextIO,
+ Tuple,
+ Type,
+ TypeVar,
+ Union,
+)
+
+if sys.version_info >= (3, 8):
+ from typing import Literal
+else:
+ from pip._vendor.typing_extensions import Literal # pragma: no cover
+
+from . import filesize, get_console
+from .console import Console, Group, JustifyMethod, RenderableType
+from .highlighter import Highlighter
+from .jupyter import JupyterMixin
+from .live import Live
+from .progress_bar import ProgressBar
+from .spinner import Spinner
+from .style import StyleType
+from .table import Column, Table
+from .text import Text, TextType
+
+TaskID = NewType("TaskID", int)
+
+ProgressType = TypeVar("ProgressType")
+
+GetTimeCallable = Callable[[], float]
+
+
+_I = typing.TypeVar("_I", TextIO, BinaryIO)
+
+
+class _TrackThread(Thread):
+ """A thread to periodically update progress."""
+
+ def __init__(self, progress: "Progress", task_id: "TaskID", update_period: float):
+ self.progress = progress
+ self.task_id = task_id
+ self.update_period = update_period
+ self.done = Event()
+
+ self.completed = 0
+ super().__init__()
+
+ def run(self) -> None:
+ task_id = self.task_id
+ advance = self.progress.advance
+ update_period = self.update_period
+ last_completed = 0
+ wait = self.done.wait
+ while not wait(update_period):
+ completed = self.completed
+ if last_completed != completed:
+ advance(task_id, completed - last_completed)
+ last_completed = completed
+
+ self.progress.update(self.task_id, completed=self.completed, refresh=True)
+
+ def __enter__(self) -> "_TrackThread":
+ self.start()
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.done.set()
+ self.join()
+
+
+def track(
+ sequence: Union[Sequence[ProgressType], Iterable[ProgressType]],
+ description: str = "Working...",
+ total: Optional[float] = None,
+ auto_refresh: bool = True,
+ console: Optional[Console] = None,
+ transient: bool = False,
+ get_time: Optional[Callable[[], float]] = None,
+ refresh_per_second: float = 10,
+ style: StyleType = "bar.back",
+ complete_style: StyleType = "bar.complete",
+ finished_style: StyleType = "bar.finished",
+ pulse_style: StyleType = "bar.pulse",
+ update_period: float = 0.1,
+ disable: bool = False,
+ show_speed: bool = True,
+) -> Iterable[ProgressType]:
+ """Track progress by iterating over a sequence.
+
+ Args:
+ sequence (Iterable[ProgressType]): A sequence (must support "len") you wish to iterate over.
+ description (str, optional): Description of task show next to progress bar. Defaults to "Working".
+ total: (float, optional): Total number of steps. Default is len(sequence).
+ auto_refresh (bool, optional): Automatic refresh, disable to force a refresh after each iteration. Default is True.
+ transient: (bool, optional): Clear the progress on exit. Defaults to False.
+ console (Console, optional): Console to write to. Default creates internal Console instance.
+ refresh_per_second (float): Number of times per second to refresh the progress information. Defaults to 10.
+ style (StyleType, optional): Style for the bar background. Defaults to "bar.back".
+ complete_style (StyleType, optional): Style for the completed bar. Defaults to "bar.complete".
+ finished_style (StyleType, optional): Style for a finished bar. Defaults to "bar.finished".
+ pulse_style (StyleType, optional): Style for pulsing bars. Defaults to "bar.pulse".
+ update_period (float, optional): Minimum time (in seconds) between calls to update(). Defaults to 0.1.
+ disable (bool, optional): Disable display of progress.
+ show_speed (bool, optional): Show speed if total isn't known. Defaults to True.
+ Returns:
+ Iterable[ProgressType]: An iterable of the values in the sequence.
+
+ """
+
+ columns: List["ProgressColumn"] = (
+ [TextColumn("[progress.description]{task.description}")] if description else []
+ )
+ columns.extend(
+ (
+ BarColumn(
+ style=style,
+ complete_style=complete_style,
+ finished_style=finished_style,
+ pulse_style=pulse_style,
+ ),
+ TaskProgressColumn(show_speed=show_speed),
+ TimeRemainingColumn(elapsed_when_finished=True),
+ )
+ )
+ progress = Progress(
+ *columns,
+ auto_refresh=auto_refresh,
+ console=console,
+ transient=transient,
+ get_time=get_time,
+ refresh_per_second=refresh_per_second or 10,
+ disable=disable,
+ )
+
+ with progress:
+ yield from progress.track(
+ sequence, total=total, description=description, update_period=update_period
+ )
+
+
+class _Reader(RawIOBase, BinaryIO):
+ """A reader that tracks progress while it's being read from."""
+
+ def __init__(
+ self,
+ handle: BinaryIO,
+ progress: "Progress",
+ task: TaskID,
+ close_handle: bool = True,
+ ) -> None:
+ self.handle = handle
+ self.progress = progress
+ self.task = task
+ self.close_handle = close_handle
+ self._closed = False
+
+ def __enter__(self) -> "_Reader":
+ self.handle.__enter__()
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.close()
+
+ def __iter__(self) -> BinaryIO:
+ return self
+
+ def __next__(self) -> bytes:
+ line = next(self.handle)
+ self.progress.advance(self.task, advance=len(line))
+ return line
+
+ @property
+ def closed(self) -> bool:
+ return self._closed
+
+ def fileno(self) -> int:
+ return self.handle.fileno()
+
+ def isatty(self) -> bool:
+ return self.handle.isatty()
+
+ @property
+ def mode(self) -> str:
+ return self.handle.mode
+
+ @property
+ def name(self) -> str:
+ return self.handle.name
+
+ def readable(self) -> bool:
+ return self.handle.readable()
+
+ def seekable(self) -> bool:
+ return self.handle.seekable()
+
+ def writable(self) -> bool:
+ return False
+
+ def read(self, size: int = -1) -> bytes:
+ block = self.handle.read(size)
+ self.progress.advance(self.task, advance=len(block))
+ return block
+
+ def readinto(self, b: Union[bytearray, memoryview, mmap]): # type: ignore[no-untyped-def, override]
+ n = self.handle.readinto(b) # type: ignore[attr-defined]
+ self.progress.advance(self.task, advance=n)
+ return n
+
+ def readline(self, size: int = -1) -> bytes: # type: ignore[override]
+ line = self.handle.readline(size)
+ self.progress.advance(self.task, advance=len(line))
+ return line
+
+ def readlines(self, hint: int = -1) -> List[bytes]:
+ lines = self.handle.readlines(hint)
+ self.progress.advance(self.task, advance=sum(map(len, lines)))
+ return lines
+
+ def close(self) -> None:
+ if self.close_handle:
+ self.handle.close()
+ self._closed = True
+
+ def seek(self, offset: int, whence: int = 0) -> int:
+ pos = self.handle.seek(offset, whence)
+ self.progress.update(self.task, completed=pos)
+ return pos
+
+ def tell(self) -> int:
+ return self.handle.tell()
+
+ def write(self, s: Any) -> int:
+ raise UnsupportedOperation("write")
+
+
+class _ReadContext(ContextManager[_I], Generic[_I]):
+ """A utility class to handle a context for both a reader and a progress."""
+
+ def __init__(self, progress: "Progress", reader: _I) -> None:
+ self.progress = progress
+ self.reader: _I = reader
+
+ def __enter__(self) -> _I:
+ self.progress.start()
+ return self.reader.__enter__()
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.progress.stop()
+ self.reader.__exit__(exc_type, exc_val, exc_tb)
+
+
+def wrap_file(
+ file: BinaryIO,
+ total: int,
+ *,
+ description: str = "Reading...",
+ auto_refresh: bool = True,
+ console: Optional[Console] = None,
+ transient: bool = False,
+ get_time: Optional[Callable[[], float]] = None,
+ refresh_per_second: float = 10,
+ style: StyleType = "bar.back",
+ complete_style: StyleType = "bar.complete",
+ finished_style: StyleType = "bar.finished",
+ pulse_style: StyleType = "bar.pulse",
+ disable: bool = False,
+) -> ContextManager[BinaryIO]:
+ """Read bytes from a file while tracking progress.
+
+ Args:
+ file (Union[str, PathLike[str], BinaryIO]): The path to the file to read, or a file-like object in binary mode.
+ total (int): Total number of bytes to read.
+ description (str, optional): Description of task show next to progress bar. Defaults to "Reading".
+ auto_refresh (bool, optional): Automatic refresh, disable to force a refresh after each iteration. Default is True.
+ transient: (bool, optional): Clear the progress on exit. Defaults to False.
+ console (Console, optional): Console to write to. Default creates internal Console instance.
+ refresh_per_second (float): Number of times per second to refresh the progress information. Defaults to 10.
+ style (StyleType, optional): Style for the bar background. Defaults to "bar.back".
+ complete_style (StyleType, optional): Style for the completed bar. Defaults to "bar.complete".
+ finished_style (StyleType, optional): Style for a finished bar. Defaults to "bar.finished".
+ pulse_style (StyleType, optional): Style for pulsing bars. Defaults to "bar.pulse".
+ disable (bool, optional): Disable display of progress.
+ Returns:
+ ContextManager[BinaryIO]: A context manager yielding a progress reader.
+
+ """
+
+ columns: List["ProgressColumn"] = (
+ [TextColumn("[progress.description]{task.description}")] if description else []
+ )
+ columns.extend(
+ (
+ BarColumn(
+ style=style,
+ complete_style=complete_style,
+ finished_style=finished_style,
+ pulse_style=pulse_style,
+ ),
+ DownloadColumn(),
+ TimeRemainingColumn(),
+ )
+ )
+ progress = Progress(
+ *columns,
+ auto_refresh=auto_refresh,
+ console=console,
+ transient=transient,
+ get_time=get_time,
+ refresh_per_second=refresh_per_second or 10,
+ disable=disable,
+ )
+
+ reader = progress.wrap_file(file, total=total, description=description)
+ return _ReadContext(progress, reader)
+
+
+@typing.overload
+def open(
+ file: Union[str, "PathLike[str]", bytes],
+ mode: Union[Literal["rt"], Literal["r"]],
+ buffering: int = -1,
+ encoding: Optional[str] = None,
+ errors: Optional[str] = None,
+ newline: Optional[str] = None,
+ *,
+ total: Optional[int] = None,
+ description: str = "Reading...",
+ auto_refresh: bool = True,
+ console: Optional[Console] = None,
+ transient: bool = False,
+ get_time: Optional[Callable[[], float]] = None,
+ refresh_per_second: float = 10,
+ style: StyleType = "bar.back",
+ complete_style: StyleType = "bar.complete",
+ finished_style: StyleType = "bar.finished",
+ pulse_style: StyleType = "bar.pulse",
+ disable: bool = False,
+) -> ContextManager[TextIO]:
+ pass
+
+
+@typing.overload
+def open(
+ file: Union[str, "PathLike[str]", bytes],
+ mode: Literal["rb"],
+ buffering: int = -1,
+ encoding: Optional[str] = None,
+ errors: Optional[str] = None,
+ newline: Optional[str] = None,
+ *,
+ total: Optional[int] = None,
+ description: str = "Reading...",
+ auto_refresh: bool = True,
+ console: Optional[Console] = None,
+ transient: bool = False,
+ get_time: Optional[Callable[[], float]] = None,
+ refresh_per_second: float = 10,
+ style: StyleType = "bar.back",
+ complete_style: StyleType = "bar.complete",
+ finished_style: StyleType = "bar.finished",
+ pulse_style: StyleType = "bar.pulse",
+ disable: bool = False,
+) -> ContextManager[BinaryIO]:
+ pass
+
+
+def open(
+ file: Union[str, "PathLike[str]", bytes],
+ mode: Union[Literal["rb"], Literal["rt"], Literal["r"]] = "r",
+ buffering: int = -1,
+ encoding: Optional[str] = None,
+ errors: Optional[str] = None,
+ newline: Optional[str] = None,
+ *,
+ total: Optional[int] = None,
+ description: str = "Reading...",
+ auto_refresh: bool = True,
+ console: Optional[Console] = None,
+ transient: bool = False,
+ get_time: Optional[Callable[[], float]] = None,
+ refresh_per_second: float = 10,
+ style: StyleType = "bar.back",
+ complete_style: StyleType = "bar.complete",
+ finished_style: StyleType = "bar.finished",
+ pulse_style: StyleType = "bar.pulse",
+ disable: bool = False,
+) -> Union[ContextManager[BinaryIO], ContextManager[TextIO]]:
+ """Read bytes from a file while tracking progress.
+
+ Args:
+ path (Union[str, PathLike[str], BinaryIO]): The path to the file to read, or a file-like object in binary mode.
+ mode (str): The mode to use to open the file. Only supports "r", "rb" or "rt".
+ buffering (int): The buffering strategy to use, see :func:`io.open`.
+ encoding (str, optional): The encoding to use when reading in text mode, see :func:`io.open`.
+ errors (str, optional): The error handling strategy for decoding errors, see :func:`io.open`.
+ newline (str, optional): The strategy for handling newlines in text mode, see :func:`io.open`
+ total: (int, optional): Total number of bytes to read. Must be provided if reading from a file handle. Default for a path is os.stat(file).st_size.
+ description (str, optional): Description of task show next to progress bar. Defaults to "Reading".
+ auto_refresh (bool, optional): Automatic refresh, disable to force a refresh after each iteration. Default is True.
+ transient: (bool, optional): Clear the progress on exit. Defaults to False.
+ console (Console, optional): Console to write to. Default creates internal Console instance.
+ refresh_per_second (float): Number of times per second to refresh the progress information. Defaults to 10.
+ style (StyleType, optional): Style for the bar background. Defaults to "bar.back".
+ complete_style (StyleType, optional): Style for the completed bar. Defaults to "bar.complete".
+ finished_style (StyleType, optional): Style for a finished bar. Defaults to "bar.finished".
+ pulse_style (StyleType, optional): Style for pulsing bars. Defaults to "bar.pulse".
+ disable (bool, optional): Disable display of progress.
+ encoding (str, optional): The encoding to use when reading in text mode.
+
+ Returns:
+ ContextManager[BinaryIO]: A context manager yielding a progress reader.
+
+ """
+
+ columns: List["ProgressColumn"] = (
+ [TextColumn("[progress.description]{task.description}")] if description else []
+ )
+ columns.extend(
+ (
+ BarColumn(
+ style=style,
+ complete_style=complete_style,
+ finished_style=finished_style,
+ pulse_style=pulse_style,
+ ),
+ DownloadColumn(),
+ TimeRemainingColumn(),
+ )
+ )
+ progress = Progress(
+ *columns,
+ auto_refresh=auto_refresh,
+ console=console,
+ transient=transient,
+ get_time=get_time,
+ refresh_per_second=refresh_per_second or 10,
+ disable=disable,
+ )
+
+ reader = progress.open(
+ file,
+ mode=mode,
+ buffering=buffering,
+ encoding=encoding,
+ errors=errors,
+ newline=newline,
+ total=total,
+ description=description,
+ )
+ return _ReadContext(progress, reader) # type: ignore[return-value, type-var]
+
+
+class ProgressColumn(ABC):
+ """Base class for a widget to use in progress display."""
+
+ max_refresh: Optional[float] = None
+
+ def __init__(self, table_column: Optional[Column] = None) -> None:
+ self._table_column = table_column
+ self._renderable_cache: Dict[TaskID, Tuple[float, RenderableType]] = {}
+ self._update_time: Optional[float] = None
+
+ def get_table_column(self) -> Column:
+ """Get a table column, used to build tasks table."""
+ return self._table_column or Column()
+
+ def __call__(self, task: "Task") -> RenderableType:
+ """Called by the Progress object to return a renderable for the given task.
+
+ Args:
+ task (Task): An object containing information regarding the task.
+
+ Returns:
+ RenderableType: Anything renderable (including str).
+ """
+ current_time = task.get_time()
+ if self.max_refresh is not None and not task.completed:
+ try:
+ timestamp, renderable = self._renderable_cache[task.id]
+ except KeyError:
+ pass
+ else:
+ if timestamp + self.max_refresh > current_time:
+ return renderable
+
+ renderable = self.render(task)
+ self._renderable_cache[task.id] = (current_time, renderable)
+ return renderable
+
+ @abstractmethod
+ def render(self, task: "Task") -> RenderableType:
+ """Should return a renderable object."""
+
+
+class RenderableColumn(ProgressColumn):
+ """A column to insert an arbitrary column.
+
+ Args:
+ renderable (RenderableType, optional): Any renderable. Defaults to empty string.
+ """
+
+ def __init__(
+ self, renderable: RenderableType = "", *, table_column: Optional[Column] = None
+ ):
+ self.renderable = renderable
+ super().__init__(table_column=table_column)
+
+ def render(self, task: "Task") -> RenderableType:
+ return self.renderable
+
+
+class SpinnerColumn(ProgressColumn):
+ """A column with a 'spinner' animation.
+
+ Args:
+ spinner_name (str, optional): Name of spinner animation. Defaults to "dots".
+ style (StyleType, optional): Style of spinner. Defaults to "progress.spinner".
+ speed (float, optional): Speed factor of spinner. Defaults to 1.0.
+ finished_text (TextType, optional): Text used when task is finished. Defaults to " ".
+ """
+
+ def __init__(
+ self,
+ spinner_name: str = "dots",
+ style: Optional[StyleType] = "progress.spinner",
+ speed: float = 1.0,
+ finished_text: TextType = " ",
+ table_column: Optional[Column] = None,
+ ):
+ self.spinner = Spinner(spinner_name, style=style, speed=speed)
+ self.finished_text = (
+ Text.from_markup(finished_text)
+ if isinstance(finished_text, str)
+ else finished_text
+ )
+ super().__init__(table_column=table_column)
+
+ def set_spinner(
+ self,
+ spinner_name: str,
+ spinner_style: Optional[StyleType] = "progress.spinner",
+ speed: float = 1.0,
+ ) -> None:
+ """Set a new spinner.
+
+ Args:
+ spinner_name (str): Spinner name, see python -m rich.spinner.
+ spinner_style (Optional[StyleType], optional): Spinner style. Defaults to "progress.spinner".
+ speed (float, optional): Speed factor of spinner. Defaults to 1.0.
+ """
+ self.spinner = Spinner(spinner_name, style=spinner_style, speed=speed)
+
+ def render(self, task: "Task") -> RenderableType:
+ text = (
+ self.finished_text
+ if task.finished
+ else self.spinner.render(task.get_time())
+ )
+ return text
+
+
+class TextColumn(ProgressColumn):
+ """A column containing text."""
+
+ def __init__(
+ self,
+ text_format: str,
+ style: StyleType = "none",
+ justify: JustifyMethod = "left",
+ markup: bool = True,
+ highlighter: Optional[Highlighter] = None,
+ table_column: Optional[Column] = None,
+ ) -> None:
+ self.text_format = text_format
+ self.justify: JustifyMethod = justify
+ self.style = style
+ self.markup = markup
+ self.highlighter = highlighter
+ super().__init__(table_column=table_column or Column(no_wrap=True))
+
+ def render(self, task: "Task") -> Text:
+ _text = self.text_format.format(task=task)
+ if self.markup:
+ text = Text.from_markup(_text, style=self.style, justify=self.justify)
+ else:
+ text = Text(_text, style=self.style, justify=self.justify)
+ if self.highlighter:
+ self.highlighter.highlight(text)
+ return text
+
+
+class BarColumn(ProgressColumn):
+ """Renders a visual progress bar.
+
+ Args:
+ bar_width (Optional[int], optional): Width of bar or None for full width. Defaults to 40.
+ style (StyleType, optional): Style for the bar background. Defaults to "bar.back".
+ complete_style (StyleType, optional): Style for the completed bar. Defaults to "bar.complete".
+ finished_style (StyleType, optional): Style for a finished bar. Defaults to "bar.finished".
+ pulse_style (StyleType, optional): Style for pulsing bars. Defaults to "bar.pulse".
+ """
+
+ def __init__(
+ self,
+ bar_width: Optional[int] = 40,
+ style: StyleType = "bar.back",
+ complete_style: StyleType = "bar.complete",
+ finished_style: StyleType = "bar.finished",
+ pulse_style: StyleType = "bar.pulse",
+ table_column: Optional[Column] = None,
+ ) -> None:
+ self.bar_width = bar_width
+ self.style = style
+ self.complete_style = complete_style
+ self.finished_style = finished_style
+ self.pulse_style = pulse_style
+ super().__init__(table_column=table_column)
+
+ def render(self, task: "Task") -> ProgressBar:
+ """Gets a progress bar widget for a task."""
+ return ProgressBar(
+ total=max(0, task.total) if task.total is not None else None,
+ completed=max(0, task.completed),
+ width=None if self.bar_width is None else max(1, self.bar_width),
+ pulse=not task.started,
+ animation_time=task.get_time(),
+ style=self.style,
+ complete_style=self.complete_style,
+ finished_style=self.finished_style,
+ pulse_style=self.pulse_style,
+ )
+
+
+class TimeElapsedColumn(ProgressColumn):
+ """Renders time elapsed."""
+
+ def render(self, task: "Task") -> Text:
+ """Show time elapsed."""
+ elapsed = task.finished_time if task.finished else task.elapsed
+ if elapsed is None:
+ return Text("-:--:--", style="progress.elapsed")
+ delta = timedelta(seconds=max(0, int(elapsed)))
+ return Text(str(delta), style="progress.elapsed")
+
+
+class TaskProgressColumn(TextColumn):
+ """Show task progress as a percentage.
+
+ Args:
+ text_format (str, optional): Format for percentage display. Defaults to "[progress.percentage]{task.percentage:>3.0f}%".
+ text_format_no_percentage (str, optional): Format if percentage is unknown. Defaults to "".
+ style (StyleType, optional): Style of output. Defaults to "none".
+ justify (JustifyMethod, optional): Text justification. Defaults to "left".
+ markup (bool, optional): Enable markup. Defaults to True.
+ highlighter (Optional[Highlighter], optional): Highlighter to apply to output. Defaults to None.
+ table_column (Optional[Column], optional): Table Column to use. Defaults to None.
+ show_speed (bool, optional): Show speed if total is unknown. Defaults to False.
+ """
+
+ def __init__(
+ self,
+ text_format: str = "[progress.percentage]{task.percentage:>3.0f}%",
+ text_format_no_percentage: str = "",
+ style: StyleType = "none",
+ justify: JustifyMethod = "left",
+ markup: bool = True,
+ highlighter: Optional[Highlighter] = None,
+ table_column: Optional[Column] = None,
+ show_speed: bool = False,
+ ) -> None:
+ self.text_format_no_percentage = text_format_no_percentage
+ self.show_speed = show_speed
+ super().__init__(
+ text_format=text_format,
+ style=style,
+ justify=justify,
+ markup=markup,
+ highlighter=highlighter,
+ table_column=table_column,
+ )
+
+ @classmethod
+ def render_speed(cls, speed: Optional[float]) -> Text:
+ """Render the speed in iterations per second.
+
+ Args:
+ task (Task): A Task object.
+
+ Returns:
+ Text: Text object containing the task speed.
+ """
+ if speed is None:
+ return Text("", style="progress.percentage")
+ unit, suffix = filesize.pick_unit_and_suffix(
+ int(speed),
+ ["", "×10³", "×10⁶", "×10⁹", "×10¹²"],
+ 1000,
+ )
+ data_speed = speed / unit
+ return Text(f"{data_speed:.1f}{suffix} it/s", style="progress.percentage")
+
+ def render(self, task: "Task") -> Text:
+ if task.total is None and self.show_speed:
+ return self.render_speed(task.finished_speed or task.speed)
+ text_format = (
+ self.text_format_no_percentage if task.total is None else self.text_format
+ )
+ _text = text_format.format(task=task)
+ if self.markup:
+ text = Text.from_markup(_text, style=self.style, justify=self.justify)
+ else:
+ text = Text(_text, style=self.style, justify=self.justify)
+ if self.highlighter:
+ self.highlighter.highlight(text)
+ return text
+
+
+class TimeRemainingColumn(ProgressColumn):
+ """Renders estimated time remaining.
+
+ Args:
+ compact (bool, optional): Render MM:SS when time remaining is less than an hour. Defaults to False.
+ elapsed_when_finished (bool, optional): Render time elapsed when the task is finished. Defaults to False.
+ """
+
+ # Only refresh twice a second to prevent jitter
+ max_refresh = 0.5
+
+ def __init__(
+ self,
+ compact: bool = False,
+ elapsed_when_finished: bool = False,
+ table_column: Optional[Column] = None,
+ ):
+ self.compact = compact
+ self.elapsed_when_finished = elapsed_when_finished
+ super().__init__(table_column=table_column)
+
+ def render(self, task: "Task") -> Text:
+ """Show time remaining."""
+ if self.elapsed_when_finished and task.finished:
+ task_time = task.finished_time
+ style = "progress.elapsed"
+ else:
+ task_time = task.time_remaining
+ style = "progress.remaining"
+
+ if task.total is None:
+ return Text("", style=style)
+
+ if task_time is None:
+ return Text("--:--" if self.compact else "-:--:--", style=style)
+
+ # Based on https://github.com/tqdm/tqdm/blob/master/tqdm/std.py
+ minutes, seconds = divmod(int(task_time), 60)
+ hours, minutes = divmod(minutes, 60)
+
+ if self.compact and not hours:
+ formatted = f"{minutes:02d}:{seconds:02d}"
+ else:
+ formatted = f"{hours:d}:{minutes:02d}:{seconds:02d}"
+
+ return Text(formatted, style=style)
+
+
+class FileSizeColumn(ProgressColumn):
+ """Renders completed filesize."""
+
+ def render(self, task: "Task") -> Text:
+ """Show data completed."""
+ data_size = filesize.decimal(int(task.completed))
+ return Text(data_size, style="progress.filesize")
+
+
+class TotalFileSizeColumn(ProgressColumn):
+ """Renders total filesize."""
+
+ def render(self, task: "Task") -> Text:
+ """Show data completed."""
+ data_size = filesize.decimal(int(task.total)) if task.total is not None else ""
+ return Text(data_size, style="progress.filesize.total")
+
+
+class MofNCompleteColumn(ProgressColumn):
+ """Renders completed count/total, e.g. ' 10/1000'.
+
+ Best for bounded tasks with int quantities.
+
+ Space pads the completed count so that progress length does not change as task progresses
+ past powers of 10.
+
+ Args:
+ separator (str, optional): Text to separate completed and total values. Defaults to "/".
+ """
+
+ def __init__(self, separator: str = "/", table_column: Optional[Column] = None):
+ self.separator = separator
+ super().__init__(table_column=table_column)
+
+ def render(self, task: "Task") -> Text:
+ """Show completed/total."""
+ completed = int(task.completed)
+ total = int(task.total) if task.total is not None else "?"
+ total_width = len(str(total))
+ return Text(
+ f"{completed:{total_width}d}{self.separator}{total}",
+ style="progress.download",
+ )
+
+
+class DownloadColumn(ProgressColumn):
+ """Renders file size downloaded and total, e.g. '0.5/2.3 GB'.
+
+ Args:
+ binary_units (bool, optional): Use binary units, KiB, MiB etc. Defaults to False.
+ """
+
+ def __init__(
+ self, binary_units: bool = False, table_column: Optional[Column] = None
+ ) -> None:
+ self.binary_units = binary_units
+ super().__init__(table_column=table_column)
+
+ def render(self, task: "Task") -> Text:
+ """Calculate common unit for completed and total."""
+ completed = int(task.completed)
+
+ unit_and_suffix_calculation_base = (
+ int(task.total) if task.total is not None else completed
+ )
+ if self.binary_units:
+ unit, suffix = filesize.pick_unit_and_suffix(
+ unit_and_suffix_calculation_base,
+ ["bytes", "KiB", "MiB", "GiB", "TiB", "PiB", "EiB", "ZiB", "YiB"],
+ 1024,
+ )
+ else:
+ unit, suffix = filesize.pick_unit_and_suffix(
+ unit_and_suffix_calculation_base,
+ ["bytes", "kB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB"],
+ 1000,
+ )
+ precision = 0 if unit == 1 else 1
+
+ completed_ratio = completed / unit
+ completed_str = f"{completed_ratio:,.{precision}f}"
+
+ if task.total is not None:
+ total = int(task.total)
+ total_ratio = total / unit
+ total_str = f"{total_ratio:,.{precision}f}"
+ else:
+ total_str = "?"
+
+ download_status = f"{completed_str}/{total_str} {suffix}"
+ download_text = Text(download_status, style="progress.download")
+ return download_text
+
+
+class TransferSpeedColumn(ProgressColumn):
+ """Renders human readable transfer speed."""
+
+ def render(self, task: "Task") -> Text:
+ """Show data transfer speed."""
+ speed = task.finished_speed or task.speed
+ if speed is None:
+ return Text("?", style="progress.data.speed")
+ data_speed = filesize.decimal(int(speed))
+ return Text(f"{data_speed}/s", style="progress.data.speed")
+
+
+class ProgressSample(NamedTuple):
+ """Sample of progress for a given time."""
+
+ timestamp: float
+ """Timestamp of sample."""
+ completed: float
+ """Number of steps completed."""
+
+
+@dataclass
+class Task:
+ """Information regarding a progress task.
+
+ This object should be considered read-only outside of the :class:`~Progress` class.
+
+ """
+
+ id: TaskID
+ """Task ID associated with this task (used in Progress methods)."""
+
+ description: str
+ """str: Description of the task."""
+
+ total: Optional[float]
+ """Optional[float]: Total number of steps in this task."""
+
+ completed: float
+ """float: Number of steps completed"""
+
+ _get_time: GetTimeCallable
+ """Callable to get the current time."""
+
+ finished_time: Optional[float] = None
+ """float: Time task was finished."""
+
+ visible: bool = True
+ """bool: Indicates if this task is visible in the progress display."""
+
+ fields: Dict[str, Any] = field(default_factory=dict)
+ """dict: Arbitrary fields passed in via Progress.update."""
+
+ start_time: Optional[float] = field(default=None, init=False, repr=False)
+ """Optional[float]: Time this task was started, or None if not started."""
+
+ stop_time: Optional[float] = field(default=None, init=False, repr=False)
+ """Optional[float]: Time this task was stopped, or None if not stopped."""
+
+ finished_speed: Optional[float] = None
+ """Optional[float]: The last speed for a finished task."""
+
+ _progress: Deque[ProgressSample] = field(
+ default_factory=lambda: deque(maxlen=1000), init=False, repr=False
+ )
+
+ _lock: RLock = field(repr=False, default_factory=RLock)
+ """Thread lock."""
+
+ def get_time(self) -> float:
+ """float: Get the current time, in seconds."""
+ return self._get_time()
+
+ @property
+ def started(self) -> bool:
+ """bool: Check if the task as started."""
+ return self.start_time is not None
+
+ @property
+ def remaining(self) -> Optional[float]:
+ """Optional[float]: Get the number of steps remaining, if a non-None total was set."""
+ if self.total is None:
+ return None
+ return self.total - self.completed
+
+ @property
+ def elapsed(self) -> Optional[float]:
+ """Optional[float]: Time elapsed since task was started, or ``None`` if the task hasn't started."""
+ if self.start_time is None:
+ return None
+ if self.stop_time is not None:
+ return self.stop_time - self.start_time
+ return self.get_time() - self.start_time
+
+ @property
+ def finished(self) -> bool:
+ """Check if the task has finished."""
+ return self.finished_time is not None
+
+ @property
+ def percentage(self) -> float:
+ """float: Get progress of task as a percentage. If a None total was set, returns 0"""
+ if not self.total:
+ return 0.0
+ completed = (self.completed / self.total) * 100.0
+ completed = min(100.0, max(0.0, completed))
+ return completed
+
+ @property
+ def speed(self) -> Optional[float]:
+ """Optional[float]: Get the estimated speed in steps per second."""
+ if self.start_time is None:
+ return None
+ with self._lock:
+ progress = self._progress
+ if not progress:
+ return None
+ total_time = progress[-1].timestamp - progress[0].timestamp
+ if total_time == 0:
+ return None
+ iter_progress = iter(progress)
+ next(iter_progress)
+ total_completed = sum(sample.completed for sample in iter_progress)
+ speed = total_completed / total_time
+ return speed
+
+ @property
+ def time_remaining(self) -> Optional[float]:
+ """Optional[float]: Get estimated time to completion, or ``None`` if no data."""
+ if self.finished:
+ return 0.0
+ speed = self.speed
+ if not speed:
+ return None
+ remaining = self.remaining
+ if remaining is None:
+ return None
+ estimate = ceil(remaining / speed)
+ return estimate
+
+ def _reset(self) -> None:
+ """Reset progress."""
+ self._progress.clear()
+ self.finished_time = None
+ self.finished_speed = None
+
+
+class Progress(JupyterMixin):
+ """Renders an auto-updating progress bar(s).
+
+ Args:
+ console (Console, optional): Optional Console instance. Default will an internal Console instance writing to stdout.
+ auto_refresh (bool, optional): Enable auto refresh. If disabled, you will need to call `refresh()`.
+ refresh_per_second (Optional[float], optional): Number of times per second to refresh the progress information or None to use default (10). Defaults to None.
+ speed_estimate_period: (float, optional): Period (in seconds) used to calculate the speed estimate. Defaults to 30.
+ transient: (bool, optional): Clear the progress on exit. Defaults to False.
+ redirect_stdout: (bool, optional): Enable redirection of stdout, so ``print`` may be used. Defaults to True.
+ redirect_stderr: (bool, optional): Enable redirection of stderr. Defaults to True.
+ get_time: (Callable, optional): A callable that gets the current time, or None to use Console.get_time. Defaults to None.
+ disable (bool, optional): Disable progress display. Defaults to False
+ expand (bool, optional): Expand tasks table to fit width. Defaults to False.
+ """
+
+ def __init__(
+ self,
+ *columns: Union[str, ProgressColumn],
+ console: Optional[Console] = None,
+ auto_refresh: bool = True,
+ refresh_per_second: float = 10,
+ speed_estimate_period: float = 30.0,
+ transient: bool = False,
+ redirect_stdout: bool = True,
+ redirect_stderr: bool = True,
+ get_time: Optional[GetTimeCallable] = None,
+ disable: bool = False,
+ expand: bool = False,
+ ) -> None:
+ assert refresh_per_second > 0, "refresh_per_second must be > 0"
+ self._lock = RLock()
+ self.columns = columns or self.get_default_columns()
+ self.speed_estimate_period = speed_estimate_period
+
+ self.disable = disable
+ self.expand = expand
+ self._tasks: Dict[TaskID, Task] = {}
+ self._task_index: TaskID = TaskID(0)
+ self.live = Live(
+ console=console or get_console(),
+ auto_refresh=auto_refresh,
+ refresh_per_second=refresh_per_second,
+ transient=transient,
+ redirect_stdout=redirect_stdout,
+ redirect_stderr=redirect_stderr,
+ get_renderable=self.get_renderable,
+ )
+ self.get_time = get_time or self.console.get_time
+ self.print = self.console.print
+ self.log = self.console.log
+
+ @classmethod
+ def get_default_columns(cls) -> Tuple[ProgressColumn, ...]:
+ """Get the default columns used for a new Progress instance:
+ - a text column for the description (TextColumn)
+ - the bar itself (BarColumn)
+ - a text column showing completion percentage (TextColumn)
+ - an estimated-time-remaining column (TimeRemainingColumn)
+ If the Progress instance is created without passing a columns argument,
+ the default columns defined here will be used.
+
+ You can also create a Progress instance using custom columns before
+ and/or after the defaults, as in this example:
+
+ progress = Progress(
+ SpinnerColumn(),
+ *Progress.get_default_columns(),
+ "Elapsed:",
+ TimeElapsedColumn(),
+ )
+
+ This code shows the creation of a Progress display, containing
+ a spinner to the left, the default columns, and a labeled elapsed
+ time column.
+ """
+ return (
+ TextColumn("[progress.description]{task.description}"),
+ BarColumn(),
+ TaskProgressColumn(),
+ TimeRemainingColumn(),
+ )
+
+ @property
+ def console(self) -> Console:
+ return self.live.console
+
+ @property
+ def tasks(self) -> List[Task]:
+ """Get a list of Task instances."""
+ with self._lock:
+ return list(self._tasks.values())
+
+ @property
+ def task_ids(self) -> List[TaskID]:
+ """A list of task IDs."""
+ with self._lock:
+ return list(self._tasks.keys())
+
+ @property
+ def finished(self) -> bool:
+ """Check if all tasks have been completed."""
+ with self._lock:
+ if not self._tasks:
+ return True
+ return all(task.finished for task in self._tasks.values())
+
+ def start(self) -> None:
+ """Start the progress display."""
+ if not self.disable:
+ self.live.start(refresh=True)
+
+ def stop(self) -> None:
+ """Stop the progress display."""
+ self.live.stop()
+ if not self.console.is_interactive:
+ self.console.print()
+
+ def __enter__(self) -> "Progress":
+ self.start()
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.stop()
+
+ def track(
+ self,
+ sequence: Union[Iterable[ProgressType], Sequence[ProgressType]],
+ total: Optional[float] = None,
+ task_id: Optional[TaskID] = None,
+ description: str = "Working...",
+ update_period: float = 0.1,
+ ) -> Iterable[ProgressType]:
+ """Track progress by iterating over a sequence.
+
+ Args:
+ sequence (Sequence[ProgressType]): A sequence of values you want to iterate over and track progress.
+ total: (float, optional): Total number of steps. Default is len(sequence).
+ task_id: (TaskID): Task to track. Default is new task.
+ description: (str, optional): Description of task, if new task is created.
+ update_period (float, optional): Minimum time (in seconds) between calls to update(). Defaults to 0.1.
+
+ Returns:
+ Iterable[ProgressType]: An iterable of values taken from the provided sequence.
+ """
+ if total is None:
+ total = float(length_hint(sequence)) or None
+
+ if task_id is None:
+ task_id = self.add_task(description, total=total)
+ else:
+ self.update(task_id, total=total)
+
+ if self.live.auto_refresh:
+ with _TrackThread(self, task_id, update_period) as track_thread:
+ for value in sequence:
+ yield value
+ track_thread.completed += 1
+ else:
+ advance = self.advance
+ refresh = self.refresh
+ for value in sequence:
+ yield value
+ advance(task_id, 1)
+ refresh()
+
+ def wrap_file(
+ self,
+ file: BinaryIO,
+ total: Optional[int] = None,
+ *,
+ task_id: Optional[TaskID] = None,
+ description: str = "Reading...",
+ ) -> BinaryIO:
+ """Track progress file reading from a binary file.
+
+ Args:
+ file (BinaryIO): A file-like object opened in binary mode.
+ total (int, optional): Total number of bytes to read. This must be provided unless a task with a total is also given.
+ task_id (TaskID): Task to track. Default is new task.
+ description (str, optional): Description of task, if new task is created.
+
+ Returns:
+ BinaryIO: A readable file-like object in binary mode.
+
+ Raises:
+ ValueError: When no total value can be extracted from the arguments or the task.
+ """
+ # attempt to recover the total from the task
+ total_bytes: Optional[float] = None
+ if total is not None:
+ total_bytes = total
+ elif task_id is not None:
+ with self._lock:
+ total_bytes = self._tasks[task_id].total
+ if total_bytes is None:
+ raise ValueError(
+ f"unable to get the total number of bytes, please specify 'total'"
+ )
+
+ # update total of task or create new task
+ if task_id is None:
+ task_id = self.add_task(description, total=total_bytes)
+ else:
+ self.update(task_id, total=total_bytes)
+
+ return _Reader(file, self, task_id, close_handle=False)
+
+ @typing.overload
+ def open(
+ self,
+ file: Union[str, "PathLike[str]", bytes],
+ mode: Literal["rb"],
+ buffering: int = -1,
+ encoding: Optional[str] = None,
+ errors: Optional[str] = None,
+ newline: Optional[str] = None,
+ *,
+ total: Optional[int] = None,
+ task_id: Optional[TaskID] = None,
+ description: str = "Reading...",
+ ) -> BinaryIO:
+ pass
+
+ @typing.overload
+ def open(
+ self,
+ file: Union[str, "PathLike[str]", bytes],
+ mode: Union[Literal["r"], Literal["rt"]],
+ buffering: int = -1,
+ encoding: Optional[str] = None,
+ errors: Optional[str] = None,
+ newline: Optional[str] = None,
+ *,
+ total: Optional[int] = None,
+ task_id: Optional[TaskID] = None,
+ description: str = "Reading...",
+ ) -> TextIO:
+ pass
+
+ def open(
+ self,
+ file: Union[str, "PathLike[str]", bytes],
+ mode: Union[Literal["rb"], Literal["rt"], Literal["r"]] = "r",
+ buffering: int = -1,
+ encoding: Optional[str] = None,
+ errors: Optional[str] = None,
+ newline: Optional[str] = None,
+ *,
+ total: Optional[int] = None,
+ task_id: Optional[TaskID] = None,
+ description: str = "Reading...",
+ ) -> Union[BinaryIO, TextIO]:
+ """Track progress while reading from a binary file.
+
+ Args:
+ path (Union[str, PathLike[str]]): The path to the file to read.
+ mode (str): The mode to use to open the file. Only supports "r", "rb" or "rt".
+ buffering (int): The buffering strategy to use, see :func:`io.open`.
+ encoding (str, optional): The encoding to use when reading in text mode, see :func:`io.open`.
+ errors (str, optional): The error handling strategy for decoding errors, see :func:`io.open`.
+ newline (str, optional): The strategy for handling newlines in text mode, see :func:`io.open`.
+ total (int, optional): Total number of bytes to read. If none given, os.stat(path).st_size is used.
+ task_id (TaskID): Task to track. Default is new task.
+ description (str, optional): Description of task, if new task is created.
+
+ Returns:
+ BinaryIO: A readable file-like object in binary mode.
+
+ Raises:
+ ValueError: When an invalid mode is given.
+ """
+ # normalize the mode (always rb, rt)
+ _mode = "".join(sorted(mode, reverse=False))
+ if _mode not in ("br", "rt", "r"):
+ raise ValueError("invalid mode {!r}".format(mode))
+
+ # patch buffering to provide the same behaviour as the builtin `open`
+ line_buffering = buffering == 1
+ if _mode == "br" and buffering == 1:
+ warnings.warn(
+ "line buffering (buffering=1) isn't supported in binary mode, the default buffer size will be used",
+ RuntimeWarning,
+ )
+ buffering = -1
+ elif _mode in ("rt", "r"):
+ if buffering == 0:
+ raise ValueError("can't have unbuffered text I/O")
+ elif buffering == 1:
+ buffering = -1
+
+ # attempt to get the total with `os.stat`
+ if total is None:
+ total = stat(file).st_size
+
+ # update total of task or create new task
+ if task_id is None:
+ task_id = self.add_task(description, total=total)
+ else:
+ self.update(task_id, total=total)
+
+ # open the file in binary mode,
+ handle = io.open(file, "rb", buffering=buffering)
+ reader = _Reader(handle, self, task_id, close_handle=True)
+
+ # wrap the reader in a `TextIOWrapper` if text mode
+ if mode in ("r", "rt"):
+ return io.TextIOWrapper(
+ reader,
+ encoding=encoding,
+ errors=errors,
+ newline=newline,
+ line_buffering=line_buffering,
+ )
+
+ return reader
+
+ def start_task(self, task_id: TaskID) -> None:
+ """Start a task.
+
+ Starts a task (used when calculating elapsed time). You may need to call this manually,
+ if you called ``add_task`` with ``start=False``.
+
+ Args:
+ task_id (TaskID): ID of task.
+ """
+ with self._lock:
+ task = self._tasks[task_id]
+ if task.start_time is None:
+ task.start_time = self.get_time()
+
+ def stop_task(self, task_id: TaskID) -> None:
+ """Stop a task.
+
+ This will freeze the elapsed time on the task.
+
+ Args:
+ task_id (TaskID): ID of task.
+ """
+ with self._lock:
+ task = self._tasks[task_id]
+ current_time = self.get_time()
+ if task.start_time is None:
+ task.start_time = current_time
+ task.stop_time = current_time
+
+ def update(
+ self,
+ task_id: TaskID,
+ *,
+ total: Optional[float] = None,
+ completed: Optional[float] = None,
+ advance: Optional[float] = None,
+ description: Optional[str] = None,
+ visible: Optional[bool] = None,
+ refresh: bool = False,
+ **fields: Any,
+ ) -> None:
+ """Update information associated with a task.
+
+ Args:
+ task_id (TaskID): Task id (returned by add_task).
+ total (float, optional): Updates task.total if not None.
+ completed (float, optional): Updates task.completed if not None.
+ advance (float, optional): Add a value to task.completed if not None.
+ description (str, optional): Change task description if not None.
+ visible (bool, optional): Set visible flag if not None.
+ refresh (bool): Force a refresh of progress information. Default is False.
+ **fields (Any): Additional data fields required for rendering.
+ """
+ with self._lock:
+ task = self._tasks[task_id]
+ completed_start = task.completed
+
+ if total is not None and total != task.total:
+ task.total = total
+ task._reset()
+ if advance is not None:
+ task.completed += advance
+ if completed is not None:
+ task.completed = completed
+ if description is not None:
+ task.description = description
+ if visible is not None:
+ task.visible = visible
+ task.fields.update(fields)
+ update_completed = task.completed - completed_start
+
+ current_time = self.get_time()
+ old_sample_time = current_time - self.speed_estimate_period
+ _progress = task._progress
+
+ popleft = _progress.popleft
+ while _progress and _progress[0].timestamp < old_sample_time:
+ popleft()
+ if update_completed > 0:
+ _progress.append(ProgressSample(current_time, update_completed))
+ if (
+ task.total is not None
+ and task.completed >= task.total
+ and task.finished_time is None
+ ):
+ task.finished_time = task.elapsed
+
+ if refresh:
+ self.refresh()
+
+ def reset(
+ self,
+ task_id: TaskID,
+ *,
+ start: bool = True,
+ total: Optional[float] = None,
+ completed: int = 0,
+ visible: Optional[bool] = None,
+ description: Optional[str] = None,
+ **fields: Any,
+ ) -> None:
+ """Reset a task so completed is 0 and the clock is reset.
+
+ Args:
+ task_id (TaskID): ID of task.
+ start (bool, optional): Start the task after reset. Defaults to True.
+ total (float, optional): New total steps in task, or None to use current total. Defaults to None.
+ completed (int, optional): Number of steps completed. Defaults to 0.
+ visible (bool, optional): Enable display of the task. Defaults to True.
+ description (str, optional): Change task description if not None. Defaults to None.
+ **fields (str): Additional data fields required for rendering.
+ """
+ current_time = self.get_time()
+ with self._lock:
+ task = self._tasks[task_id]
+ task._reset()
+ task.start_time = current_time if start else None
+ if total is not None:
+ task.total = total
+ task.completed = completed
+ if visible is not None:
+ task.visible = visible
+ if fields:
+ task.fields = fields
+ if description is not None:
+ task.description = description
+ task.finished_time = None
+ self.refresh()
+
+ def advance(self, task_id: TaskID, advance: float = 1) -> None:
+ """Advance task by a number of steps.
+
+ Args:
+ task_id (TaskID): ID of task.
+ advance (float): Number of steps to advance. Default is 1.
+ """
+ current_time = self.get_time()
+ with self._lock:
+ task = self._tasks[task_id]
+ completed_start = task.completed
+ task.completed += advance
+ update_completed = task.completed - completed_start
+ old_sample_time = current_time - self.speed_estimate_period
+ _progress = task._progress
+
+ popleft = _progress.popleft
+ while _progress and _progress[0].timestamp < old_sample_time:
+ popleft()
+ while len(_progress) > 1000:
+ popleft()
+ _progress.append(ProgressSample(current_time, update_completed))
+ if (
+ task.total is not None
+ and task.completed >= task.total
+ and task.finished_time is None
+ ):
+ task.finished_time = task.elapsed
+ task.finished_speed = task.speed
+
+ def refresh(self) -> None:
+ """Refresh (render) the progress information."""
+ if not self.disable and self.live.is_started:
+ self.live.refresh()
+
+ def get_renderable(self) -> RenderableType:
+ """Get a renderable for the progress display."""
+ renderable = Group(*self.get_renderables())
+ return renderable
+
+ def get_renderables(self) -> Iterable[RenderableType]:
+ """Get a number of renderables for the progress display."""
+ table = self.make_tasks_table(self.tasks)
+ yield table
+
+ def make_tasks_table(self, tasks: Iterable[Task]) -> Table:
+ """Get a table to render the Progress display.
+
+ Args:
+ tasks (Iterable[Task]): An iterable of Task instances, one per row of the table.
+
+ Returns:
+ Table: A table instance.
+ """
+ table_columns = (
+ (
+ Column(no_wrap=True)
+ if isinstance(_column, str)
+ else _column.get_table_column().copy()
+ )
+ for _column in self.columns
+ )
+ table = Table.grid(*table_columns, padding=(0, 1), expand=self.expand)
+
+ for task in tasks:
+ if task.visible:
+ table.add_row(
+ *(
+ (
+ column.format(task=task)
+ if isinstance(column, str)
+ else column(task)
+ )
+ for column in self.columns
+ )
+ )
+ return table
+
+ def __rich__(self) -> RenderableType:
+ """Makes the Progress class itself renderable."""
+ with self._lock:
+ return self.get_renderable()
+
+ def add_task(
+ self,
+ description: str,
+ start: bool = True,
+ total: Optional[float] = 100.0,
+ completed: int = 0,
+ visible: bool = True,
+ **fields: Any,
+ ) -> TaskID:
+ """Add a new 'task' to the Progress display.
+
+ Args:
+ description (str): A description of the task.
+ start (bool, optional): Start the task immediately (to calculate elapsed time). If set to False,
+ you will need to call `start` manually. Defaults to True.
+ total (float, optional): Number of total steps in the progress if known.
+ Set to None to render a pulsing animation. Defaults to 100.
+ completed (int, optional): Number of steps completed so far. Defaults to 0.
+ visible (bool, optional): Enable display of the task. Defaults to True.
+ **fields (str): Additional data fields required for rendering.
+
+ Returns:
+ TaskID: An ID you can use when calling `update`.
+ """
+ with self._lock:
+ task = Task(
+ self._task_index,
+ description,
+ total,
+ completed,
+ visible=visible,
+ fields=fields,
+ _get_time=self.get_time,
+ _lock=self._lock,
+ )
+ self._tasks[self._task_index] = task
+ if start:
+ self.start_task(self._task_index)
+ new_task_index = self._task_index
+ self._task_index = TaskID(int(self._task_index) + 1)
+ self.refresh()
+ return new_task_index
+
+ def remove_task(self, task_id: TaskID) -> None:
+ """Delete a task if it exists.
+
+ Args:
+ task_id (TaskID): A task ID.
+
+ """
+ with self._lock:
+ del self._tasks[task_id]
+
+
+if __name__ == "__main__": # pragma: no coverage
+ import random
+ import time
+
+ from .panel import Panel
+ from .rule import Rule
+ from .syntax import Syntax
+ from .table import Table
+
+ syntax = Syntax(
+ '''def loop_last(values: Iterable[T]) -> Iterable[Tuple[bool, T]]:
+ """Iterate and generate a tuple with a flag for last value."""
+ iter_values = iter(values)
+ try:
+ previous_value = next(iter_values)
+ except StopIteration:
+ return
+ for value in iter_values:
+ yield False, previous_value
+ previous_value = value
+ yield True, previous_value''',
+ "python",
+ line_numbers=True,
+ )
+
+ table = Table("foo", "bar", "baz")
+ table.add_row("1", "2", "3")
+
+ progress_renderables = [
+ "Text may be printed while the progress bars are rendering.",
+ Panel("In fact, [i]any[/i] renderable will work"),
+ "Such as [magenta]tables[/]...",
+ table,
+ "Pretty printed structures...",
+ {"type": "example", "text": "Pretty printed"},
+ "Syntax...",
+ syntax,
+ Rule("Give it a try!"),
+ ]
+
+ from itertools import cycle
+
+ examples = cycle(progress_renderables)
+
+ console = Console(record=True)
+
+ with Progress(
+ SpinnerColumn(),
+ *Progress.get_default_columns(),
+ TimeElapsedColumn(),
+ console=console,
+ transient=False,
+ ) as progress:
+ task1 = progress.add_task("[red]Downloading", total=1000)
+ task2 = progress.add_task("[green]Processing", total=1000)
+ task3 = progress.add_task("[yellow]Thinking", total=None)
+
+ while not progress.finished:
+ progress.update(task1, advance=0.5)
+ progress.update(task2, advance=0.3)
+ time.sleep(0.01)
+ if random.randint(0, 100) < 1:
+ progress.log(next(examples))
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/progress_bar.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/progress_bar.py
new file mode 100644
index 000000000..a2bf32614
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/progress_bar.py
@@ -0,0 +1,223 @@
+import math
+from functools import lru_cache
+from time import monotonic
+from typing import Iterable, List, Optional
+
+from .color import Color, blend_rgb
+from .color_triplet import ColorTriplet
+from .console import Console, ConsoleOptions, RenderResult
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .segment import Segment
+from .style import Style, StyleType
+
+# Number of characters before 'pulse' animation repeats
+PULSE_SIZE = 20
+
+
+class ProgressBar(JupyterMixin):
+ """Renders a (progress) bar. Used by rich.progress.
+
+ Args:
+ total (float, optional): Number of steps in the bar. Defaults to 100. Set to None to render a pulsing animation.
+ completed (float, optional): Number of steps completed. Defaults to 0.
+ width (int, optional): Width of the bar, or ``None`` for maximum width. Defaults to None.
+ pulse (bool, optional): Enable pulse effect. Defaults to False. Will pulse if a None total was passed.
+ style (StyleType, optional): Style for the bar background. Defaults to "bar.back".
+ complete_style (StyleType, optional): Style for the completed bar. Defaults to "bar.complete".
+ finished_style (StyleType, optional): Style for a finished bar. Defaults to "bar.finished".
+ pulse_style (StyleType, optional): Style for pulsing bars. Defaults to "bar.pulse".
+ animation_time (Optional[float], optional): Time in seconds to use for animation, or None to use system time.
+ """
+
+ def __init__(
+ self,
+ total: Optional[float] = 100.0,
+ completed: float = 0,
+ width: Optional[int] = None,
+ pulse: bool = False,
+ style: StyleType = "bar.back",
+ complete_style: StyleType = "bar.complete",
+ finished_style: StyleType = "bar.finished",
+ pulse_style: StyleType = "bar.pulse",
+ animation_time: Optional[float] = None,
+ ):
+ self.total = total
+ self.completed = completed
+ self.width = width
+ self.pulse = pulse
+ self.style = style
+ self.complete_style = complete_style
+ self.finished_style = finished_style
+ self.pulse_style = pulse_style
+ self.animation_time = animation_time
+
+ self._pulse_segments: Optional[List[Segment]] = None
+
+ def __repr__(self) -> str:
+ return f"<Bar {self.completed!r} of {self.total!r}>"
+
+ @property
+ def percentage_completed(self) -> Optional[float]:
+ """Calculate percentage complete."""
+ if self.total is None:
+ return None
+ completed = (self.completed / self.total) * 100.0
+ completed = min(100, max(0.0, completed))
+ return completed
+
+ @lru_cache(maxsize=16)
+ def _get_pulse_segments(
+ self,
+ fore_style: Style,
+ back_style: Style,
+ color_system: str,
+ no_color: bool,
+ ascii: bool = False,
+ ) -> List[Segment]:
+ """Get a list of segments to render a pulse animation.
+
+ Returns:
+ List[Segment]: A list of segments, one segment per character.
+ """
+ bar = "-" if ascii else "━"
+ segments: List[Segment] = []
+ if color_system not in ("standard", "eight_bit", "truecolor") or no_color:
+ segments += [Segment(bar, fore_style)] * (PULSE_SIZE // 2)
+ segments += [Segment(" " if no_color else bar, back_style)] * (
+ PULSE_SIZE - (PULSE_SIZE // 2)
+ )
+ return segments
+
+ append = segments.append
+ fore_color = (
+ fore_style.color.get_truecolor()
+ if fore_style.color
+ else ColorTriplet(255, 0, 255)
+ )
+ back_color = (
+ back_style.color.get_truecolor()
+ if back_style.color
+ else ColorTriplet(0, 0, 0)
+ )
+ cos = math.cos
+ pi = math.pi
+ _Segment = Segment
+ _Style = Style
+ from_triplet = Color.from_triplet
+
+ for index in range(PULSE_SIZE):
+ position = index / PULSE_SIZE
+ fade = 0.5 + cos((position * pi * 2)) / 2.0
+ color = blend_rgb(fore_color, back_color, cross_fade=fade)
+ append(_Segment(bar, _Style(color=from_triplet(color))))
+ return segments
+
+ def update(self, completed: float, total: Optional[float] = None) -> None:
+ """Update progress with new values.
+
+ Args:
+ completed (float): Number of steps completed.
+ total (float, optional): Total number of steps, or ``None`` to not change. Defaults to None.
+ """
+ self.completed = completed
+ self.total = total if total is not None else self.total
+
+ def _render_pulse(
+ self, console: Console, width: int, ascii: bool = False
+ ) -> Iterable[Segment]:
+ """Renders the pulse animation.
+
+ Args:
+ console (Console): Console instance.
+ width (int): Width in characters of pulse animation.
+
+ Returns:
+ RenderResult: [description]
+
+ Yields:
+ Iterator[Segment]: Segments to render pulse
+ """
+ fore_style = console.get_style(self.pulse_style, default="white")
+ back_style = console.get_style(self.style, default="black")
+
+ pulse_segments = self._get_pulse_segments(
+ fore_style, back_style, console.color_system, console.no_color, ascii=ascii
+ )
+ segment_count = len(pulse_segments)
+ current_time = (
+ monotonic() if self.animation_time is None else self.animation_time
+ )
+ segments = pulse_segments * (int(width / segment_count) + 2)
+ offset = int(-current_time * 15) % segment_count
+ segments = segments[offset : offset + width]
+ yield from segments
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ width = min(self.width or options.max_width, options.max_width)
+ ascii = options.legacy_windows or options.ascii_only
+ should_pulse = self.pulse or self.total is None
+ if should_pulse:
+ yield from self._render_pulse(console, width, ascii=ascii)
+ return
+
+ completed: Optional[float] = (
+ min(self.total, max(0, self.completed)) if self.total is not None else None
+ )
+
+ bar = "-" if ascii else "━"
+ half_bar_right = " " if ascii else "╸"
+ half_bar_left = " " if ascii else "╺"
+ complete_halves = (
+ int(width * 2 * completed / self.total)
+ if self.total and completed is not None
+ else width * 2
+ )
+ bar_count = complete_halves // 2
+ half_bar_count = complete_halves % 2
+ style = console.get_style(self.style)
+ is_finished = self.total is None or self.completed >= self.total
+ complete_style = console.get_style(
+ self.finished_style if is_finished else self.complete_style
+ )
+ _Segment = Segment
+ if bar_count:
+ yield _Segment(bar * bar_count, complete_style)
+ if half_bar_count:
+ yield _Segment(half_bar_right * half_bar_count, complete_style)
+
+ if not console.no_color:
+ remaining_bars = width - bar_count - half_bar_count
+ if remaining_bars and console.color_system is not None:
+ if not half_bar_count and bar_count:
+ yield _Segment(half_bar_left, style)
+ remaining_bars -= 1
+ if remaining_bars:
+ yield _Segment(bar * remaining_bars, style)
+
+ def __rich_measure__(
+ self, console: Console, options: ConsoleOptions
+ ) -> Measurement:
+ return (
+ Measurement(self.width, self.width)
+ if self.width is not None
+ else Measurement(4, options.max_width)
+ )
+
+
+if __name__ == "__main__": # pragma: no cover
+ console = Console()
+ bar = ProgressBar(width=50, total=100)
+
+ import time
+
+ console.show_cursor(False)
+ for n in range(0, 101, 1):
+ bar.update(n)
+ console.print(bar)
+ console.file.write("\r")
+ time.sleep(0.05)
+ console.show_cursor(True)
+ console.print()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/prompt.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/prompt.py
new file mode 100644
index 000000000..75ff04816
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/prompt.py
@@ -0,0 +1,375 @@
+from typing import Any, Generic, List, Optional, TextIO, TypeVar, Union, overload
+
+from . import get_console
+from .console import Console
+from .text import Text, TextType
+
+PromptType = TypeVar("PromptType")
+DefaultType = TypeVar("DefaultType")
+
+
+class PromptError(Exception):
+ """Exception base class for prompt related errors."""
+
+
+class InvalidResponse(PromptError):
+ """Exception to indicate a response was invalid. Raise this within process_response() to indicate an error
+ and provide an error message.
+
+ Args:
+ message (Union[str, Text]): Error message.
+ """
+
+ def __init__(self, message: TextType) -> None:
+ self.message = message
+
+ def __rich__(self) -> TextType:
+ return self.message
+
+
+class PromptBase(Generic[PromptType]):
+ """Ask the user for input until a valid response is received. This is the base class, see one of
+ the concrete classes for examples.
+
+ Args:
+ prompt (TextType, optional): Prompt text. Defaults to "".
+ console (Console, optional): A Console instance or None to use global console. Defaults to None.
+ password (bool, optional): Enable password input. Defaults to False.
+ choices (List[str], optional): A list of valid choices. Defaults to None.
+ show_default (bool, optional): Show default in prompt. Defaults to True.
+ show_choices (bool, optional): Show choices in prompt. Defaults to True.
+ """
+
+ response_type: type = str
+
+ validate_error_message = "[prompt.invalid]Please enter a valid value"
+ illegal_choice_message = (
+ "[prompt.invalid.choice]Please select one of the available options"
+ )
+ prompt_suffix = ": "
+
+ choices: Optional[List[str]] = None
+
+ def __init__(
+ self,
+ prompt: TextType = "",
+ *,
+ console: Optional[Console] = None,
+ password: bool = False,
+ choices: Optional[List[str]] = None,
+ show_default: bool = True,
+ show_choices: bool = True,
+ ) -> None:
+ self.console = console or get_console()
+ self.prompt = (
+ Text.from_markup(prompt, style="prompt")
+ if isinstance(prompt, str)
+ else prompt
+ )
+ self.password = password
+ if choices is not None:
+ self.choices = choices
+ self.show_default = show_default
+ self.show_choices = show_choices
+
+ @classmethod
+ @overload
+ def ask(
+ cls,
+ prompt: TextType = "",
+ *,
+ console: Optional[Console] = None,
+ password: bool = False,
+ choices: Optional[List[str]] = None,
+ show_default: bool = True,
+ show_choices: bool = True,
+ default: DefaultType,
+ stream: Optional[TextIO] = None,
+ ) -> Union[DefaultType, PromptType]:
+ ...
+
+ @classmethod
+ @overload
+ def ask(
+ cls,
+ prompt: TextType = "",
+ *,
+ console: Optional[Console] = None,
+ password: bool = False,
+ choices: Optional[List[str]] = None,
+ show_default: bool = True,
+ show_choices: bool = True,
+ stream: Optional[TextIO] = None,
+ ) -> PromptType:
+ ...
+
+ @classmethod
+ def ask(
+ cls,
+ prompt: TextType = "",
+ *,
+ console: Optional[Console] = None,
+ password: bool = False,
+ choices: Optional[List[str]] = None,
+ show_default: bool = True,
+ show_choices: bool = True,
+ default: Any = ...,
+ stream: Optional[TextIO] = None,
+ ) -> Any:
+ """Shortcut to construct and run a prompt loop and return the result.
+
+ Example:
+ >>> filename = Prompt.ask("Enter a filename")
+
+ Args:
+ prompt (TextType, optional): Prompt text. Defaults to "".
+ console (Console, optional): A Console instance or None to use global console. Defaults to None.
+ password (bool, optional): Enable password input. Defaults to False.
+ choices (List[str], optional): A list of valid choices. Defaults to None.
+ show_default (bool, optional): Show default in prompt. Defaults to True.
+ show_choices (bool, optional): Show choices in prompt. Defaults to True.
+ stream (TextIO, optional): Optional text file open for reading to get input. Defaults to None.
+ """
+ _prompt = cls(
+ prompt,
+ console=console,
+ password=password,
+ choices=choices,
+ show_default=show_default,
+ show_choices=show_choices,
+ )
+ return _prompt(default=default, stream=stream)
+
+ def render_default(self, default: DefaultType) -> Text:
+ """Turn the supplied default in to a Text instance.
+
+ Args:
+ default (DefaultType): Default value.
+
+ Returns:
+ Text: Text containing rendering of default value.
+ """
+ return Text(f"({default})", "prompt.default")
+
+ def make_prompt(self, default: DefaultType) -> Text:
+ """Make prompt text.
+
+ Args:
+ default (DefaultType): Default value.
+
+ Returns:
+ Text: Text to display in prompt.
+ """
+ prompt = self.prompt.copy()
+ prompt.end = ""
+
+ if self.show_choices and self.choices:
+ _choices = "/".join(self.choices)
+ choices = f"[{_choices}]"
+ prompt.append(" ")
+ prompt.append(choices, "prompt.choices")
+
+ if (
+ default != ...
+ and self.show_default
+ and isinstance(default, (str, self.response_type))
+ ):
+ prompt.append(" ")
+ _default = self.render_default(default)
+ prompt.append(_default)
+
+ prompt.append(self.prompt_suffix)
+
+ return prompt
+
+ @classmethod
+ def get_input(
+ cls,
+ console: Console,
+ prompt: TextType,
+ password: bool,
+ stream: Optional[TextIO] = None,
+ ) -> str:
+ """Get input from user.
+
+ Args:
+ console (Console): Console instance.
+ prompt (TextType): Prompt text.
+ password (bool): Enable password entry.
+
+ Returns:
+ str: String from user.
+ """
+ return console.input(prompt, password=password, stream=stream)
+
+ def check_choice(self, value: str) -> bool:
+ """Check value is in the list of valid choices.
+
+ Args:
+ value (str): Value entered by user.
+
+ Returns:
+ bool: True if choice was valid, otherwise False.
+ """
+ assert self.choices is not None
+ return value.strip() in self.choices
+
+ def process_response(self, value: str) -> PromptType:
+ """Process response from user, convert to prompt type.
+
+ Args:
+ value (str): String typed by user.
+
+ Raises:
+ InvalidResponse: If ``value`` is invalid.
+
+ Returns:
+ PromptType: The value to be returned from ask method.
+ """
+ value = value.strip()
+ try:
+ return_value: PromptType = self.response_type(value)
+ except ValueError:
+ raise InvalidResponse(self.validate_error_message)
+
+ if self.choices is not None and not self.check_choice(value):
+ raise InvalidResponse(self.illegal_choice_message)
+
+ return return_value
+
+ def on_validate_error(self, value: str, error: InvalidResponse) -> None:
+ """Called to handle validation error.
+
+ Args:
+ value (str): String entered by user.
+ error (InvalidResponse): Exception instance the initiated the error.
+ """
+ self.console.print(error)
+
+ def pre_prompt(self) -> None:
+ """Hook to display something before the prompt."""
+
+ @overload
+ def __call__(self, *, stream: Optional[TextIO] = None) -> PromptType:
+ ...
+
+ @overload
+ def __call__(
+ self, *, default: DefaultType, stream: Optional[TextIO] = None
+ ) -> Union[PromptType, DefaultType]:
+ ...
+
+ def __call__(self, *, default: Any = ..., stream: Optional[TextIO] = None) -> Any:
+ """Run the prompt loop.
+
+ Args:
+ default (Any, optional): Optional default value.
+
+ Returns:
+ PromptType: Processed value.
+ """
+ while True:
+ self.pre_prompt()
+ prompt = self.make_prompt(default)
+ value = self.get_input(self.console, prompt, self.password, stream=stream)
+ if value == "" and default != ...:
+ return default
+ try:
+ return_value = self.process_response(value)
+ except InvalidResponse as error:
+ self.on_validate_error(value, error)
+ continue
+ else:
+ return return_value
+
+
+class Prompt(PromptBase[str]):
+ """A prompt that returns a str.
+
+ Example:
+ >>> name = Prompt.ask("Enter your name")
+
+
+ """
+
+ response_type = str
+
+
+class IntPrompt(PromptBase[int]):
+ """A prompt that returns an integer.
+
+ Example:
+ >>> burrito_count = IntPrompt.ask("How many burritos do you want to order")
+
+ """
+
+ response_type = int
+ validate_error_message = "[prompt.invalid]Please enter a valid integer number"
+
+
+class FloatPrompt(PromptBase[float]):
+ """A prompt that returns a float.
+
+ Example:
+ >>> temperature = FloatPrompt.ask("Enter desired temperature")
+
+ """
+
+ response_type = float
+ validate_error_message = "[prompt.invalid]Please enter a number"
+
+
+class Confirm(PromptBase[bool]):
+ """A yes / no confirmation prompt.
+
+ Example:
+ >>> if Confirm.ask("Continue"):
+ run_job()
+
+ """
+
+ response_type = bool
+ validate_error_message = "[prompt.invalid]Please enter Y or N"
+ choices: List[str] = ["y", "n"]
+
+ def render_default(self, default: DefaultType) -> Text:
+ """Render the default as (y) or (n) rather than True/False."""
+ yes, no = self.choices
+ return Text(f"({yes})" if default else f"({no})", style="prompt.default")
+
+ def process_response(self, value: str) -> bool:
+ """Convert choices to a bool."""
+ value = value.strip().lower()
+ if value not in self.choices:
+ raise InvalidResponse(self.validate_error_message)
+ return value == self.choices[0]
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich import print
+
+ if Confirm.ask("Run [i]prompt[/i] tests?", default=True):
+ while True:
+ result = IntPrompt.ask(
+ ":rocket: Enter a number between [b]1[/b] and [b]10[/b]", default=5
+ )
+ if result >= 1 and result <= 10:
+ break
+ print(":pile_of_poo: [prompt.invalid]Number must be between 1 and 10")
+ print(f"number={result}")
+
+ while True:
+ password = Prompt.ask(
+ "Please enter a password [cyan](must be at least 5 characters)",
+ password=True,
+ )
+ if len(password) >= 5:
+ break
+ print("[prompt.invalid]password too short")
+ print(f"password={password!r}")
+
+ fruit = Prompt.ask("Enter a fruit", choices=["apple", "orange", "pear"])
+ print(f"fruit={fruit!r}")
+
+ else:
+ print("[b]OK :loudly_crying_face:")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/protocol.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/protocol.py
new file mode 100644
index 000000000..12ab23713
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/protocol.py
@@ -0,0 +1,42 @@
+from typing import Any, cast, Set, TYPE_CHECKING
+from inspect import isclass
+
+if TYPE_CHECKING:
+ from pip._vendor.rich.console import RenderableType
+
+_GIBBERISH = """aihwerij235234ljsdnp34ksodfipwoe234234jlskjdf"""
+
+
+def is_renderable(check_object: Any) -> bool:
+ """Check if an object may be rendered by Rich."""
+ return (
+ isinstance(check_object, str)
+ or hasattr(check_object, "__rich__")
+ or hasattr(check_object, "__rich_console__")
+ )
+
+
+def rich_cast(renderable: object) -> "RenderableType":
+ """Cast an object to a renderable by calling __rich__ if present.
+
+ Args:
+ renderable (object): A potentially renderable object
+
+ Returns:
+ object: The result of recursively calling __rich__.
+ """
+ from pip._vendor.rich.console import RenderableType
+
+ rich_visited_set: Set[type] = set() # Prevent potential infinite loop
+ while hasattr(renderable, "__rich__") and not isclass(renderable):
+ # Detect object which claim to have all the attributes
+ if hasattr(renderable, _GIBBERISH):
+ return repr(renderable)
+ cast_method = getattr(renderable, "__rich__")
+ renderable = cast_method()
+ renderable_type = type(renderable)
+ if renderable_type in rich_visited_set:
+ break
+ rich_visited_set.add(renderable_type)
+
+ return cast(RenderableType, renderable)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/region.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/region.py
new file mode 100644
index 000000000..75b3631c3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/region.py
@@ -0,0 +1,10 @@
+from typing import NamedTuple
+
+
+class Region(NamedTuple):
+ """Defines a rectangular region of the screen."""
+
+ x: int
+ y: int
+ width: int
+ height: int
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/repr.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/repr.py
new file mode 100644
index 000000000..10efc427c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/repr.py
@@ -0,0 +1,149 @@
+import inspect
+from functools import partial
+from typing import (
+ Any,
+ Callable,
+ Iterable,
+ List,
+ Optional,
+ Tuple,
+ Type,
+ TypeVar,
+ Union,
+ overload,
+)
+
+T = TypeVar("T")
+
+
+Result = Iterable[Union[Any, Tuple[Any], Tuple[str, Any], Tuple[str, Any, Any]]]
+RichReprResult = Result
+
+
+class ReprError(Exception):
+ """An error occurred when attempting to build a repr."""
+
+
+@overload
+def auto(cls: Optional[Type[T]]) -> Type[T]:
+ ...
+
+
+@overload
+def auto(*, angular: bool = False) -> Callable[[Type[T]], Type[T]]:
+ ...
+
+
+def auto(
+ cls: Optional[Type[T]] = None, *, angular: Optional[bool] = None
+) -> Union[Type[T], Callable[[Type[T]], Type[T]]]:
+ """Class decorator to create __repr__ from __rich_repr__"""
+
+ def do_replace(cls: Type[T], angular: Optional[bool] = None) -> Type[T]:
+ def auto_repr(self: T) -> str:
+ """Create repr string from __rich_repr__"""
+ repr_str: List[str] = []
+ append = repr_str.append
+
+ angular: bool = getattr(self.__rich_repr__, "angular", False) # type: ignore[attr-defined]
+ for arg in self.__rich_repr__(): # type: ignore[attr-defined]
+ if isinstance(arg, tuple):
+ if len(arg) == 1:
+ append(repr(arg[0]))
+ else:
+ key, value, *default = arg
+ if key is None:
+ append(repr(value))
+ else:
+ if default and default[0] == value:
+ continue
+ append(f"{key}={value!r}")
+ else:
+ append(repr(arg))
+ if angular:
+ return f"<{self.__class__.__name__} {' '.join(repr_str)}>"
+ else:
+ return f"{self.__class__.__name__}({', '.join(repr_str)})"
+
+ def auto_rich_repr(self: Type[T]) -> Result:
+ """Auto generate __rich_rep__ from signature of __init__"""
+ try:
+ signature = inspect.signature(self.__init__)
+ for name, param in signature.parameters.items():
+ if param.kind == param.POSITIONAL_ONLY:
+ yield getattr(self, name)
+ elif param.kind in (
+ param.POSITIONAL_OR_KEYWORD,
+ param.KEYWORD_ONLY,
+ ):
+ if param.default is param.empty:
+ yield getattr(self, param.name)
+ else:
+ yield param.name, getattr(self, param.name), param.default
+ except Exception as error:
+ raise ReprError(
+ f"Failed to auto generate __rich_repr__; {error}"
+ ) from None
+
+ if not hasattr(cls, "__rich_repr__"):
+ auto_rich_repr.__doc__ = "Build a rich repr"
+ cls.__rich_repr__ = auto_rich_repr # type: ignore[attr-defined]
+
+ auto_repr.__doc__ = "Return repr(self)"
+ cls.__repr__ = auto_repr # type: ignore[assignment]
+ if angular is not None:
+ cls.__rich_repr__.angular = angular # type: ignore[attr-defined]
+ return cls
+
+ if cls is None:
+ return partial(do_replace, angular=angular)
+ else:
+ return do_replace(cls, angular=angular)
+
+
+@overload
+def rich_repr(cls: Optional[Type[T]]) -> Type[T]:
+ ...
+
+
+@overload
+def rich_repr(*, angular: bool = False) -> Callable[[Type[T]], Type[T]]:
+ ...
+
+
+def rich_repr(
+ cls: Optional[Type[T]] = None, *, angular: bool = False
+) -> Union[Type[T], Callable[[Type[T]], Type[T]]]:
+ if cls is None:
+ return auto(angular=angular)
+ else:
+ return auto(cls)
+
+
+if __name__ == "__main__":
+
+ @auto
+ class Foo:
+ def __rich_repr__(self) -> Result:
+ yield "foo"
+ yield "bar", {"shopping": ["eggs", "ham", "pineapple"]}
+ yield "buy", "hand sanitizer"
+
+ foo = Foo()
+ from pip._vendor.rich.console import Console
+
+ console = Console()
+
+ console.rule("Standard repr")
+ console.print(foo)
+
+ console.print(foo, width=60)
+ console.print(foo, width=30)
+
+ console.rule("Angular repr")
+ Foo.__rich_repr__.angular = True # type: ignore[attr-defined]
+
+ console.print(foo)
+
+ console.print(foo, width=60)
+ console.print(foo, width=30)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/rule.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/rule.py
new file mode 100644
index 000000000..fd00ce6e4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/rule.py
@@ -0,0 +1,130 @@
+from typing import Union
+
+from .align import AlignMethod
+from .cells import cell_len, set_cell_size
+from .console import Console, ConsoleOptions, RenderResult
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .style import Style
+from .text import Text
+
+
+class Rule(JupyterMixin):
+ """A console renderable to draw a horizontal rule (line).
+
+ Args:
+ title (Union[str, Text], optional): Text to render in the rule. Defaults to "".
+ characters (str, optional): Character(s) used to draw the line. Defaults to "─".
+ style (StyleType, optional): Style of Rule. Defaults to "rule.line".
+ end (str, optional): Character at end of Rule. defaults to "\\\\n"
+ align (str, optional): How to align the title, one of "left", "center", or "right". Defaults to "center".
+ """
+
+ def __init__(
+ self,
+ title: Union[str, Text] = "",
+ *,
+ characters: str = "─",
+ style: Union[str, Style] = "rule.line",
+ end: str = "\n",
+ align: AlignMethod = "center",
+ ) -> None:
+ if cell_len(characters) < 1:
+ raise ValueError(
+ "'characters' argument must have a cell width of at least 1"
+ )
+ if align not in ("left", "center", "right"):
+ raise ValueError(
+ f'invalid value for align, expected "left", "center", "right" (not {align!r})'
+ )
+ self.title = title
+ self.characters = characters
+ self.style = style
+ self.end = end
+ self.align = align
+
+ def __repr__(self) -> str:
+ return f"Rule({self.title!r}, {self.characters!r})"
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ width = options.max_width
+
+ characters = (
+ "-"
+ if (options.ascii_only and not self.characters.isascii())
+ else self.characters
+ )
+
+ chars_len = cell_len(characters)
+ if not self.title:
+ yield self._rule_line(chars_len, width)
+ return
+
+ if isinstance(self.title, Text):
+ title_text = self.title
+ else:
+ title_text = console.render_str(self.title, style="rule.text")
+
+ title_text.plain = title_text.plain.replace("\n", " ")
+ title_text.expand_tabs()
+
+ required_space = 4 if self.align == "center" else 2
+ truncate_width = max(0, width - required_space)
+ if not truncate_width:
+ yield self._rule_line(chars_len, width)
+ return
+
+ rule_text = Text(end=self.end)
+ if self.align == "center":
+ title_text.truncate(truncate_width, overflow="ellipsis")
+ side_width = (width - cell_len(title_text.plain)) // 2
+ left = Text(characters * (side_width // chars_len + 1))
+ left.truncate(side_width - 1)
+ right_length = width - cell_len(left.plain) - cell_len(title_text.plain)
+ right = Text(characters * (side_width // chars_len + 1))
+ right.truncate(right_length)
+ rule_text.append(left.plain + " ", self.style)
+ rule_text.append(title_text)
+ rule_text.append(" " + right.plain, self.style)
+ elif self.align == "left":
+ title_text.truncate(truncate_width, overflow="ellipsis")
+ rule_text.append(title_text)
+ rule_text.append(" ")
+ rule_text.append(characters * (width - rule_text.cell_len), self.style)
+ elif self.align == "right":
+ title_text.truncate(truncate_width, overflow="ellipsis")
+ rule_text.append(characters * (width - title_text.cell_len - 1), self.style)
+ rule_text.append(" ")
+ rule_text.append(title_text)
+
+ rule_text.plain = set_cell_size(rule_text.plain, width)
+ yield rule_text
+
+ def _rule_line(self, chars_len: int, width: int) -> Text:
+ rule_text = Text(self.characters * ((width // chars_len) + 1), self.style)
+ rule_text.truncate(width)
+ rule_text.plain = set_cell_size(rule_text.plain, width)
+ return rule_text
+
+ def __rich_measure__(
+ self, console: Console, options: ConsoleOptions
+ ) -> Measurement:
+ return Measurement(1, 1)
+
+
+if __name__ == "__main__": # pragma: no cover
+ import sys
+
+ from pip._vendor.rich.console import Console
+
+ try:
+ text = sys.argv[1]
+ except IndexError:
+ text = "Hello, World"
+ console = Console()
+ console.print(Rule(title=text))
+
+ console = Console()
+ console.print(Rule("foo"), width=4)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/scope.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/scope.py
new file mode 100644
index 000000000..c9d134cc3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/scope.py
@@ -0,0 +1,86 @@
+from collections.abc import Mapping
+from typing import TYPE_CHECKING, Any, Optional, Tuple
+
+from .highlighter import ReprHighlighter
+from .panel import Panel
+from .pretty import Pretty
+from .table import Table
+from .text import Text, TextType
+
+if TYPE_CHECKING:
+ from .console import ConsoleRenderable
+
+
+def render_scope(
+ scope: "Mapping[str, Any]",
+ *,
+ title: Optional[TextType] = None,
+ sort_keys: bool = True,
+ indent_guides: bool = False,
+ max_length: Optional[int] = None,
+ max_string: Optional[int] = None,
+) -> "ConsoleRenderable":
+ """Render python variables in a given scope.
+
+ Args:
+ scope (Mapping): A mapping containing variable names and values.
+ title (str, optional): Optional title. Defaults to None.
+ sort_keys (bool, optional): Enable sorting of items. Defaults to True.
+ indent_guides (bool, optional): Enable indentation guides. Defaults to False.
+ max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to None.
+ max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to None.
+
+ Returns:
+ ConsoleRenderable: A renderable object.
+ """
+ highlighter = ReprHighlighter()
+ items_table = Table.grid(padding=(0, 1), expand=False)
+ items_table.add_column(justify="right")
+
+ def sort_items(item: Tuple[str, Any]) -> Tuple[bool, str]:
+ """Sort special variables first, then alphabetically."""
+ key, _ = item
+ return (not key.startswith("__"), key.lower())
+
+ items = sorted(scope.items(), key=sort_items) if sort_keys else scope.items()
+ for key, value in items:
+ key_text = Text.assemble(
+ (key, "scope.key.special" if key.startswith("__") else "scope.key"),
+ (" =", "scope.equals"),
+ )
+ items_table.add_row(
+ key_text,
+ Pretty(
+ value,
+ highlighter=highlighter,
+ indent_guides=indent_guides,
+ max_length=max_length,
+ max_string=max_string,
+ ),
+ )
+ return Panel.fit(
+ items_table,
+ title=title,
+ border_style="scope.border",
+ padding=(0, 1),
+ )
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich import print
+
+ print()
+
+ def test(foo: float, bar: float) -> None:
+ list_of_things = [1, 2, 3, None, 4, True, False, "Hello World"]
+ dict_of_things = {
+ "version": "1.1",
+ "method": "confirmFruitPurchase",
+ "params": [["apple", "orange", "mangoes", "pomelo"], 1.123],
+ "id": "194521489",
+ }
+ print(render_scope(locals(), title="[i]locals", sort_keys=False))
+
+ test(20.3423, 3.1427)
+ print()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/screen.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/screen.py
new file mode 100644
index 000000000..7f416e1e7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/screen.py
@@ -0,0 +1,54 @@
+from typing import Optional, TYPE_CHECKING
+
+from .segment import Segment
+from .style import StyleType
+from ._loop import loop_last
+
+
+if TYPE_CHECKING:
+ from .console import (
+ Console,
+ ConsoleOptions,
+ RenderResult,
+ RenderableType,
+ Group,
+ )
+
+
+class Screen:
+ """A renderable that fills the terminal screen and crops excess.
+
+ Args:
+ renderable (RenderableType): Child renderable.
+ style (StyleType, optional): Optional background style. Defaults to None.
+ """
+
+ renderable: "RenderableType"
+
+ def __init__(
+ self,
+ *renderables: "RenderableType",
+ style: Optional[StyleType] = None,
+ application_mode: bool = False,
+ ) -> None:
+ from pip._vendor.rich.console import Group
+
+ self.renderable = Group(*renderables)
+ self.style = style
+ self.application_mode = application_mode
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ width, height = options.size
+ style = console.get_style(self.style) if self.style else None
+ render_options = options.update(width=width, height=height)
+ lines = console.render_lines(
+ self.renderable or "", render_options, style=style, pad=True
+ )
+ lines = Segment.set_shape(lines, width, height, style=style)
+ new_line = Segment("\n\r") if self.application_mode else Segment.line()
+ for last, line in loop_last(lines):
+ yield from line
+ if not last:
+ yield new_line
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/segment.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/segment.py
new file mode 100644
index 000000000..93edbbdeb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/segment.py
@@ -0,0 +1,738 @@
+from enum import IntEnum
+from functools import lru_cache
+from itertools import filterfalse
+from logging import getLogger
+from operator import attrgetter
+from typing import (
+ TYPE_CHECKING,
+ Dict,
+ Iterable,
+ List,
+ NamedTuple,
+ Optional,
+ Sequence,
+ Tuple,
+ Type,
+ Union,
+)
+
+from .cells import (
+ _is_single_cell_widths,
+ cached_cell_len,
+ cell_len,
+ get_character_cell_size,
+ set_cell_size,
+)
+from .repr import Result, rich_repr
+from .style import Style
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderResult
+
+log = getLogger("rich")
+
+
+class ControlType(IntEnum):
+ """Non-printable control codes which typically translate to ANSI codes."""
+
+ BELL = 1
+ CARRIAGE_RETURN = 2
+ HOME = 3
+ CLEAR = 4
+ SHOW_CURSOR = 5
+ HIDE_CURSOR = 6
+ ENABLE_ALT_SCREEN = 7
+ DISABLE_ALT_SCREEN = 8
+ CURSOR_UP = 9
+ CURSOR_DOWN = 10
+ CURSOR_FORWARD = 11
+ CURSOR_BACKWARD = 12
+ CURSOR_MOVE_TO_COLUMN = 13
+ CURSOR_MOVE_TO = 14
+ ERASE_IN_LINE = 15
+ SET_WINDOW_TITLE = 16
+
+
+ControlCode = Union[
+ Tuple[ControlType],
+ Tuple[ControlType, Union[int, str]],
+ Tuple[ControlType, int, int],
+]
+
+
+@rich_repr()
+class Segment(NamedTuple):
+ """A piece of text with associated style. Segments are produced by the Console render process and
+ are ultimately converted in to strings to be written to the terminal.
+
+ Args:
+ text (str): A piece of text.
+ style (:class:`~rich.style.Style`, optional): An optional style to apply to the text.
+ control (Tuple[ControlCode], optional): Optional sequence of control codes.
+
+ Attributes:
+ cell_length (int): The cell length of this Segment.
+ """
+
+ text: str
+ style: Optional[Style] = None
+ control: Optional[Sequence[ControlCode]] = None
+
+ @property
+ def cell_length(self) -> int:
+ """The number of terminal cells required to display self.text.
+
+ Returns:
+ int: A number of cells.
+ """
+ text, _style, control = self
+ return 0 if control else cell_len(text)
+
+ def __rich_repr__(self) -> Result:
+ yield self.text
+ if self.control is None:
+ if self.style is not None:
+ yield self.style
+ else:
+ yield self.style
+ yield self.control
+
+ def __bool__(self) -> bool:
+ """Check if the segment contains text."""
+ return bool(self.text)
+
+ @property
+ def is_control(self) -> bool:
+ """Check if the segment contains control codes."""
+ return self.control is not None
+
+ @classmethod
+ @lru_cache(1024 * 16)
+ def _split_cells(cls, segment: "Segment", cut: int) -> Tuple["Segment", "Segment"]:
+ text, style, control = segment
+ _Segment = Segment
+
+ cell_length = segment.cell_length
+ if cut >= cell_length:
+ return segment, _Segment("", style, control)
+
+ cell_size = get_character_cell_size
+
+ pos = int((cut / cell_length) * (len(text) - 1))
+
+ before = text[:pos]
+ cell_pos = cell_len(before)
+ if cell_pos == cut:
+ return (
+ _Segment(before, style, control),
+ _Segment(text[pos:], style, control),
+ )
+ while pos < len(text):
+ char = text[pos]
+ pos += 1
+ cell_pos += cell_size(char)
+ before = text[:pos]
+ if cell_pos == cut:
+ return (
+ _Segment(before, style, control),
+ _Segment(text[pos:], style, control),
+ )
+ if cell_pos > cut:
+ return (
+ _Segment(before[: pos - 1] + " ", style, control),
+ _Segment(" " + text[pos:], style, control),
+ )
+
+ raise AssertionError("Will never reach here")
+
+ def split_cells(self, cut: int) -> Tuple["Segment", "Segment"]:
+ """Split segment in to two segments at the specified column.
+
+ If the cut point falls in the middle of a 2-cell wide character then it is replaced
+ by two spaces, to preserve the display width of the parent segment.
+
+ Returns:
+ Tuple[Segment, Segment]: Two segments.
+ """
+ text, style, control = self
+
+ if _is_single_cell_widths(text):
+ # Fast path with all 1 cell characters
+ if cut >= len(text):
+ return self, Segment("", style, control)
+ return (
+ Segment(text[:cut], style, control),
+ Segment(text[cut:], style, control),
+ )
+
+ return self._split_cells(self, cut)
+
+ @classmethod
+ def line(cls) -> "Segment":
+ """Make a new line segment."""
+ return cls("\n")
+
+ @classmethod
+ def apply_style(
+ cls,
+ segments: Iterable["Segment"],
+ style: Optional[Style] = None,
+ post_style: Optional[Style] = None,
+ ) -> Iterable["Segment"]:
+ """Apply style(s) to an iterable of segments.
+
+ Returns an iterable of segments where the style is replaced by ``style + segment.style + post_style``.
+
+ Args:
+ segments (Iterable[Segment]): Segments to process.
+ style (Style, optional): Base style. Defaults to None.
+ post_style (Style, optional): Style to apply on top of segment style. Defaults to None.
+
+ Returns:
+ Iterable[Segments]: A new iterable of segments (possibly the same iterable).
+ """
+ result_segments = segments
+ if style:
+ apply = style.__add__
+ result_segments = (
+ cls(text, None if control else apply(_style), control)
+ for text, _style, control in result_segments
+ )
+ if post_style:
+ result_segments = (
+ cls(
+ text,
+ (
+ None
+ if control
+ else (_style + post_style if _style else post_style)
+ ),
+ control,
+ )
+ for text, _style, control in result_segments
+ )
+ return result_segments
+
+ @classmethod
+ def filter_control(
+ cls, segments: Iterable["Segment"], is_control: bool = False
+ ) -> Iterable["Segment"]:
+ """Filter segments by ``is_control`` attribute.
+
+ Args:
+ segments (Iterable[Segment]): An iterable of Segment instances.
+ is_control (bool, optional): is_control flag to match in search.
+
+ Returns:
+ Iterable[Segment]: And iterable of Segment instances.
+
+ """
+ if is_control:
+ return filter(attrgetter("control"), segments)
+ else:
+ return filterfalse(attrgetter("control"), segments)
+
+ @classmethod
+ def split_lines(cls, segments: Iterable["Segment"]) -> Iterable[List["Segment"]]:
+ """Split a sequence of segments in to a list of lines.
+
+ Args:
+ segments (Iterable[Segment]): Segments potentially containing line feeds.
+
+ Yields:
+ Iterable[List[Segment]]: Iterable of segment lists, one per line.
+ """
+ line: List[Segment] = []
+ append = line.append
+
+ for segment in segments:
+ if "\n" in segment.text and not segment.control:
+ text, style, _ = segment
+ while text:
+ _text, new_line, text = text.partition("\n")
+ if _text:
+ append(cls(_text, style))
+ if new_line:
+ yield line
+ line = []
+ append = line.append
+ else:
+ append(segment)
+ if line:
+ yield line
+
+ @classmethod
+ def split_and_crop_lines(
+ cls,
+ segments: Iterable["Segment"],
+ length: int,
+ style: Optional[Style] = None,
+ pad: bool = True,
+ include_new_lines: bool = True,
+ ) -> Iterable[List["Segment"]]:
+ """Split segments in to lines, and crop lines greater than a given length.
+
+ Args:
+ segments (Iterable[Segment]): An iterable of segments, probably
+ generated from console.render.
+ length (int): Desired line length.
+ style (Style, optional): Style to use for any padding.
+ pad (bool): Enable padding of lines that are less than `length`.
+
+ Returns:
+ Iterable[List[Segment]]: An iterable of lines of segments.
+ """
+ line: List[Segment] = []
+ append = line.append
+
+ adjust_line_length = cls.adjust_line_length
+ new_line_segment = cls("\n")
+
+ for segment in segments:
+ if "\n" in segment.text and not segment.control:
+ text, segment_style, _ = segment
+ while text:
+ _text, new_line, text = text.partition("\n")
+ if _text:
+ append(cls(_text, segment_style))
+ if new_line:
+ cropped_line = adjust_line_length(
+ line, length, style=style, pad=pad
+ )
+ if include_new_lines:
+ cropped_line.append(new_line_segment)
+ yield cropped_line
+ line.clear()
+ else:
+ append(segment)
+ if line:
+ yield adjust_line_length(line, length, style=style, pad=pad)
+
+ @classmethod
+ def adjust_line_length(
+ cls,
+ line: List["Segment"],
+ length: int,
+ style: Optional[Style] = None,
+ pad: bool = True,
+ ) -> List["Segment"]:
+ """Adjust a line to a given width (cropping or padding as required).
+
+ Args:
+ segments (Iterable[Segment]): A list of segments in a single line.
+ length (int): The desired width of the line.
+ style (Style, optional): The style of padding if used (space on the end). Defaults to None.
+ pad (bool, optional): Pad lines with spaces if they are shorter than `length`. Defaults to True.
+
+ Returns:
+ List[Segment]: A line of segments with the desired length.
+ """
+ line_length = sum(segment.cell_length for segment in line)
+ new_line: List[Segment]
+
+ if line_length < length:
+ if pad:
+ new_line = line + [cls(" " * (length - line_length), style)]
+ else:
+ new_line = line[:]
+ elif line_length > length:
+ new_line = []
+ append = new_line.append
+ line_length = 0
+ for segment in line:
+ segment_length = segment.cell_length
+ if line_length + segment_length < length or segment.control:
+ append(segment)
+ line_length += segment_length
+ else:
+ text, segment_style, _ = segment
+ text = set_cell_size(text, length - line_length)
+ append(cls(text, segment_style))
+ break
+ else:
+ new_line = line[:]
+ return new_line
+
+ @classmethod
+ def get_line_length(cls, line: List["Segment"]) -> int:
+ """Get the length of list of segments.
+
+ Args:
+ line (List[Segment]): A line encoded as a list of Segments (assumes no '\\\\n' characters),
+
+ Returns:
+ int: The length of the line.
+ """
+ _cell_len = cell_len
+ return sum(_cell_len(text) for text, style, control in line if not control)
+
+ @classmethod
+ def get_shape(cls, lines: List[List["Segment"]]) -> Tuple[int, int]:
+ """Get the shape (enclosing rectangle) of a list of lines.
+
+ Args:
+ lines (List[List[Segment]]): A list of lines (no '\\\\n' characters).
+
+ Returns:
+ Tuple[int, int]: Width and height in characters.
+ """
+ get_line_length = cls.get_line_length
+ max_width = max(get_line_length(line) for line in lines) if lines else 0
+ return (max_width, len(lines))
+
+ @classmethod
+ def set_shape(
+ cls,
+ lines: List[List["Segment"]],
+ width: int,
+ height: Optional[int] = None,
+ style: Optional[Style] = None,
+ new_lines: bool = False,
+ ) -> List[List["Segment"]]:
+ """Set the shape of a list of lines (enclosing rectangle).
+
+ Args:
+ lines (List[List[Segment]]): A list of lines.
+ width (int): Desired width.
+ height (int, optional): Desired height or None for no change.
+ style (Style, optional): Style of any padding added.
+ new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
+
+ Returns:
+ List[List[Segment]]: New list of lines.
+ """
+ _height = height or len(lines)
+
+ blank = (
+ [cls(" " * width + "\n", style)] if new_lines else [cls(" " * width, style)]
+ )
+
+ adjust_line_length = cls.adjust_line_length
+ shaped_lines = lines[:_height]
+ shaped_lines[:] = [
+ adjust_line_length(line, width, style=style) for line in lines
+ ]
+ if len(shaped_lines) < _height:
+ shaped_lines.extend([blank] * (_height - len(shaped_lines)))
+ return shaped_lines
+
+ @classmethod
+ def align_top(
+ cls: Type["Segment"],
+ lines: List[List["Segment"]],
+ width: int,
+ height: int,
+ style: Style,
+ new_lines: bool = False,
+ ) -> List[List["Segment"]]:
+ """Aligns lines to top (adds extra lines to bottom as required).
+
+ Args:
+ lines (List[List[Segment]]): A list of lines.
+ width (int): Desired width.
+ height (int, optional): Desired height or None for no change.
+ style (Style): Style of any padding added.
+ new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
+
+ Returns:
+ List[List[Segment]]: New list of lines.
+ """
+ extra_lines = height - len(lines)
+ if not extra_lines:
+ return lines[:]
+ lines = lines[:height]
+ blank = cls(" " * width + "\n", style) if new_lines else cls(" " * width, style)
+ lines = lines + [[blank]] * extra_lines
+ return lines
+
+ @classmethod
+ def align_bottom(
+ cls: Type["Segment"],
+ lines: List[List["Segment"]],
+ width: int,
+ height: int,
+ style: Style,
+ new_lines: bool = False,
+ ) -> List[List["Segment"]]:
+ """Aligns render to bottom (adds extra lines above as required).
+
+ Args:
+ lines (List[List[Segment]]): A list of lines.
+ width (int): Desired width.
+ height (int, optional): Desired height or None for no change.
+ style (Style): Style of any padding added. Defaults to None.
+ new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
+
+ Returns:
+ List[List[Segment]]: New list of lines.
+ """
+ extra_lines = height - len(lines)
+ if not extra_lines:
+ return lines[:]
+ lines = lines[:height]
+ blank = cls(" " * width + "\n", style) if new_lines else cls(" " * width, style)
+ lines = [[blank]] * extra_lines + lines
+ return lines
+
+ @classmethod
+ def align_middle(
+ cls: Type["Segment"],
+ lines: List[List["Segment"]],
+ width: int,
+ height: int,
+ style: Style,
+ new_lines: bool = False,
+ ) -> List[List["Segment"]]:
+ """Aligns lines to middle (adds extra lines to above and below as required).
+
+ Args:
+ lines (List[List[Segment]]): A list of lines.
+ width (int): Desired width.
+ height (int, optional): Desired height or None for no change.
+ style (Style): Style of any padding added.
+ new_lines (bool, optional): Padded lines should include "\n". Defaults to False.
+
+ Returns:
+ List[List[Segment]]: New list of lines.
+ """
+ extra_lines = height - len(lines)
+ if not extra_lines:
+ return lines[:]
+ lines = lines[:height]
+ blank = cls(" " * width + "\n", style) if new_lines else cls(" " * width, style)
+ top_lines = extra_lines // 2
+ bottom_lines = extra_lines - top_lines
+ lines = [[blank]] * top_lines + lines + [[blank]] * bottom_lines
+ return lines
+
+ @classmethod
+ def simplify(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
+ """Simplify an iterable of segments by combining contiguous segments with the same style.
+
+ Args:
+ segments (Iterable[Segment]): An iterable of segments.
+
+ Returns:
+ Iterable[Segment]: A possibly smaller iterable of segments that will render the same way.
+ """
+ iter_segments = iter(segments)
+ try:
+ last_segment = next(iter_segments)
+ except StopIteration:
+ return
+
+ _Segment = Segment
+ for segment in iter_segments:
+ if last_segment.style == segment.style and not segment.control:
+ last_segment = _Segment(
+ last_segment.text + segment.text, last_segment.style
+ )
+ else:
+ yield last_segment
+ last_segment = segment
+ yield last_segment
+
+ @classmethod
+ def strip_links(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
+ """Remove all links from an iterable of styles.
+
+ Args:
+ segments (Iterable[Segment]): An iterable segments.
+
+ Yields:
+ Segment: Segments with link removed.
+ """
+ for segment in segments:
+ if segment.control or segment.style is None:
+ yield segment
+ else:
+ text, style, _control = segment
+ yield cls(text, style.update_link(None) if style else None)
+
+ @classmethod
+ def strip_styles(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
+ """Remove all styles from an iterable of segments.
+
+ Args:
+ segments (Iterable[Segment]): An iterable segments.
+
+ Yields:
+ Segment: Segments with styles replace with None
+ """
+ for text, _style, control in segments:
+ yield cls(text, None, control)
+
+ @classmethod
+ def remove_color(cls, segments: Iterable["Segment"]) -> Iterable["Segment"]:
+ """Remove all color from an iterable of segments.
+
+ Args:
+ segments (Iterable[Segment]): An iterable segments.
+
+ Yields:
+ Segment: Segments with colorless style.
+ """
+
+ cache: Dict[Style, Style] = {}
+ for text, style, control in segments:
+ if style:
+ colorless_style = cache.get(style)
+ if colorless_style is None:
+ colorless_style = style.without_color
+ cache[style] = colorless_style
+ yield cls(text, colorless_style, control)
+ else:
+ yield cls(text, None, control)
+
+ @classmethod
+ def divide(
+ cls, segments: Iterable["Segment"], cuts: Iterable[int]
+ ) -> Iterable[List["Segment"]]:
+ """Divides an iterable of segments in to portions.
+
+ Args:
+ cuts (Iterable[int]): Cell positions where to divide.
+
+ Yields:
+ [Iterable[List[Segment]]]: An iterable of Segments in List.
+ """
+ split_segments: List["Segment"] = []
+ add_segment = split_segments.append
+
+ iter_cuts = iter(cuts)
+
+ while True:
+ cut = next(iter_cuts, -1)
+ if cut == -1:
+ return []
+ if cut != 0:
+ break
+ yield []
+ pos = 0
+
+ segments_clear = split_segments.clear
+ segments_copy = split_segments.copy
+
+ _cell_len = cached_cell_len
+ for segment in segments:
+ text, _style, control = segment
+ while text:
+ end_pos = pos if control else pos + _cell_len(text)
+ if end_pos < cut:
+ add_segment(segment)
+ pos = end_pos
+ break
+
+ if end_pos == cut:
+ add_segment(segment)
+ yield segments_copy()
+ segments_clear()
+ pos = end_pos
+
+ cut = next(iter_cuts, -1)
+ if cut == -1:
+ if split_segments:
+ yield segments_copy()
+ return
+
+ break
+
+ else:
+ before, segment = segment.split_cells(cut - pos)
+ text, _style, control = segment
+ add_segment(before)
+ yield segments_copy()
+ segments_clear()
+ pos = cut
+
+ cut = next(iter_cuts, -1)
+ if cut == -1:
+ if split_segments:
+ yield segments_copy()
+ return
+
+ yield segments_copy()
+
+
+class Segments:
+ """A simple renderable to render an iterable of segments. This class may be useful if
+ you want to print segments outside of a __rich_console__ method.
+
+ Args:
+ segments (Iterable[Segment]): An iterable of segments.
+ new_lines (bool, optional): Add new lines between segments. Defaults to False.
+ """
+
+ def __init__(self, segments: Iterable[Segment], new_lines: bool = False) -> None:
+ self.segments = list(segments)
+ self.new_lines = new_lines
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ if self.new_lines:
+ line = Segment.line()
+ for segment in self.segments:
+ yield segment
+ yield line
+ else:
+ yield from self.segments
+
+
+class SegmentLines:
+ def __init__(self, lines: Iterable[List[Segment]], new_lines: bool = False) -> None:
+ """A simple renderable containing a number of lines of segments. May be used as an intermediate
+ in rendering process.
+
+ Args:
+ lines (Iterable[List[Segment]]): Lists of segments forming lines.
+ new_lines (bool, optional): Insert new lines after each line. Defaults to False.
+ """
+ self.lines = list(lines)
+ self.new_lines = new_lines
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ if self.new_lines:
+ new_line = Segment.line()
+ for line in self.lines:
+ yield from line
+ yield new_line
+ else:
+ for line in self.lines:
+ yield from line
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.console import Console
+ from pip._vendor.rich.syntax import Syntax
+ from pip._vendor.rich.text import Text
+
+ code = """from rich.console import Console
+console = Console()
+text = Text.from_markup("Hello, [bold magenta]World[/]!")
+console.print(text)"""
+
+ text = Text.from_markup("Hello, [bold magenta]World[/]!")
+
+ console = Console()
+
+ console.rule("rich.Segment")
+ console.print(
+ "A Segment is the last step in the Rich render process before generating text with ANSI codes."
+ )
+ console.print("\nConsider the following code:\n")
+ console.print(Syntax(code, "python", line_numbers=True))
+ console.print()
+ console.print(
+ "When you call [b]print()[/b], Rich [i]renders[/i] the object in to the following:\n"
+ )
+ fragments = list(console.render(text))
+ console.print(fragments)
+ console.print()
+ console.print("The Segments are then processed to produce the following output:\n")
+ console.print(text)
+ console.print(
+ "\nYou will only need to know this if you are implementing your own Rich renderables."
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/spinner.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/spinner.py
new file mode 100644
index 000000000..91ea630e1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/spinner.py
@@ -0,0 +1,137 @@
+from typing import cast, List, Optional, TYPE_CHECKING, Union
+
+from ._spinners import SPINNERS
+from .measure import Measurement
+from .table import Table
+from .text import Text
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderResult, RenderableType
+ from .style import StyleType
+
+
+class Spinner:
+ """A spinner animation.
+
+ Args:
+ name (str): Name of spinner (run python -m rich.spinner).
+ text (RenderableType, optional): A renderable to display at the right of the spinner (str or Text typically). Defaults to "".
+ style (StyleType, optional): Style for spinner animation. Defaults to None.
+ speed (float, optional): Speed factor for animation. Defaults to 1.0.
+
+ Raises:
+ KeyError: If name isn't one of the supported spinner animations.
+ """
+
+ def __init__(
+ self,
+ name: str,
+ text: "RenderableType" = "",
+ *,
+ style: Optional["StyleType"] = None,
+ speed: float = 1.0,
+ ) -> None:
+ try:
+ spinner = SPINNERS[name]
+ except KeyError:
+ raise KeyError(f"no spinner called {name!r}")
+ self.text: "Union[RenderableType, Text]" = (
+ Text.from_markup(text) if isinstance(text, str) else text
+ )
+ self.frames = cast(List[str], spinner["frames"])[:]
+ self.interval = cast(float, spinner["interval"])
+ self.start_time: Optional[float] = None
+ self.style = style
+ self.speed = speed
+ self.frame_no_offset: float = 0.0
+ self._update_speed = 0.0
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ yield self.render(console.get_time())
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Measurement:
+ text = self.render(0)
+ return Measurement.get(console, options, text)
+
+ def render(self, time: float) -> "RenderableType":
+ """Render the spinner for a given time.
+
+ Args:
+ time (float): Time in seconds.
+
+ Returns:
+ RenderableType: A renderable containing animation frame.
+ """
+ if self.start_time is None:
+ self.start_time = time
+
+ frame_no = ((time - self.start_time) * self.speed) / (
+ self.interval / 1000.0
+ ) + self.frame_no_offset
+ frame = Text(
+ self.frames[int(frame_no) % len(self.frames)], style=self.style or ""
+ )
+
+ if self._update_speed:
+ self.frame_no_offset = frame_no
+ self.start_time = time
+ self.speed = self._update_speed
+ self._update_speed = 0.0
+
+ if not self.text:
+ return frame
+ elif isinstance(self.text, (str, Text)):
+ return Text.assemble(frame, " ", self.text)
+ else:
+ table = Table.grid(padding=1)
+ table.add_row(frame, self.text)
+ return table
+
+ def update(
+ self,
+ *,
+ text: "RenderableType" = "",
+ style: Optional["StyleType"] = None,
+ speed: Optional[float] = None,
+ ) -> None:
+ """Updates attributes of a spinner after it has been started.
+
+ Args:
+ text (RenderableType, optional): A renderable to display at the right of the spinner (str or Text typically). Defaults to "".
+ style (StyleType, optional): Style for spinner animation. Defaults to None.
+ speed (float, optional): Speed factor for animation. Defaults to None.
+ """
+ if text:
+ self.text = Text.from_markup(text) if isinstance(text, str) else text
+ if style:
+ self.style = style
+ if speed:
+ self._update_speed = speed
+
+
+if __name__ == "__main__": # pragma: no cover
+ from time import sleep
+
+ from .columns import Columns
+ from .panel import Panel
+ from .live import Live
+
+ all_spinners = Columns(
+ [
+ Spinner(spinner_name, text=Text(repr(spinner_name), style="green"))
+ for spinner_name in sorted(SPINNERS.keys())
+ ],
+ column_first=True,
+ expand=True,
+ )
+
+ with Live(
+ Panel(all_spinners, title="Spinners", border_style="blue"),
+ refresh_per_second=20,
+ ) as live:
+ while True:
+ sleep(0.1)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/status.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/status.py
new file mode 100644
index 000000000..65744838e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/status.py
@@ -0,0 +1,131 @@
+from types import TracebackType
+from typing import Optional, Type
+
+from .console import Console, RenderableType
+from .jupyter import JupyterMixin
+from .live import Live
+from .spinner import Spinner
+from .style import StyleType
+
+
+class Status(JupyterMixin):
+ """Displays a status indicator with a 'spinner' animation.
+
+ Args:
+ status (RenderableType): A status renderable (str or Text typically).
+ console (Console, optional): Console instance to use, or None for global console. Defaults to None.
+ spinner (str, optional): Name of spinner animation (see python -m rich.spinner). Defaults to "dots".
+ spinner_style (StyleType, optional): Style of spinner. Defaults to "status.spinner".
+ speed (float, optional): Speed factor for spinner animation. Defaults to 1.0.
+ refresh_per_second (float, optional): Number of refreshes per second. Defaults to 12.5.
+ """
+
+ def __init__(
+ self,
+ status: RenderableType,
+ *,
+ console: Optional[Console] = None,
+ spinner: str = "dots",
+ spinner_style: StyleType = "status.spinner",
+ speed: float = 1.0,
+ refresh_per_second: float = 12.5,
+ ):
+ self.status = status
+ self.spinner_style = spinner_style
+ self.speed = speed
+ self._spinner = Spinner(spinner, text=status, style=spinner_style, speed=speed)
+ self._live = Live(
+ self.renderable,
+ console=console,
+ refresh_per_second=refresh_per_second,
+ transient=True,
+ )
+
+ @property
+ def renderable(self) -> Spinner:
+ return self._spinner
+
+ @property
+ def console(self) -> "Console":
+ """Get the Console used by the Status objects."""
+ return self._live.console
+
+ def update(
+ self,
+ status: Optional[RenderableType] = None,
+ *,
+ spinner: Optional[str] = None,
+ spinner_style: Optional[StyleType] = None,
+ speed: Optional[float] = None,
+ ) -> None:
+ """Update status.
+
+ Args:
+ status (Optional[RenderableType], optional): New status renderable or None for no change. Defaults to None.
+ spinner (Optional[str], optional): New spinner or None for no change. Defaults to None.
+ spinner_style (Optional[StyleType], optional): New spinner style or None for no change. Defaults to None.
+ speed (Optional[float], optional): Speed factor for spinner animation or None for no change. Defaults to None.
+ """
+ if status is not None:
+ self.status = status
+ if spinner_style is not None:
+ self.spinner_style = spinner_style
+ if speed is not None:
+ self.speed = speed
+ if spinner is not None:
+ self._spinner = Spinner(
+ spinner, text=self.status, style=self.spinner_style, speed=self.speed
+ )
+ self._live.update(self.renderable, refresh=True)
+ else:
+ self._spinner.update(
+ text=self.status, style=self.spinner_style, speed=self.speed
+ )
+
+ def start(self) -> None:
+ """Start the status animation."""
+ self._live.start()
+
+ def stop(self) -> None:
+ """Stop the spinner animation."""
+ self._live.stop()
+
+ def __rich__(self) -> RenderableType:
+ return self.renderable
+
+ def __enter__(self) -> "Status":
+ self.start()
+ return self
+
+ def __exit__(
+ self,
+ exc_type: Optional[Type[BaseException]],
+ exc_val: Optional[BaseException],
+ exc_tb: Optional[TracebackType],
+ ) -> None:
+ self.stop()
+
+
+if __name__ == "__main__": # pragma: no cover
+ from time import sleep
+
+ from .console import Console
+
+ console = Console()
+ with console.status("[magenta]Covid detector booting up") as status:
+ sleep(3)
+ console.log("Importing advanced AI")
+ sleep(3)
+ console.log("Advanced Covid AI Ready")
+ sleep(3)
+ status.update(status="[bold blue] Scanning for Covid", spinner="earth")
+ sleep(3)
+ console.log("Found 10,000,000,000 copies of Covid32.exe")
+ sleep(3)
+ status.update(
+ status="[bold red]Moving Covid32.exe to Trash",
+ spinner="bouncingBall",
+ spinner_style="yellow",
+ )
+ sleep(5)
+ console.print("[bold green]Covid deleted successfully")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/style.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/style.py
new file mode 100644
index 000000000..313c88949
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/style.py
@@ -0,0 +1,796 @@
+import sys
+from functools import lru_cache
+from marshal import dumps, loads
+from random import randint
+from typing import Any, Dict, Iterable, List, Optional, Type, Union, cast
+
+from . import errors
+from .color import Color, ColorParseError, ColorSystem, blend_rgb
+from .repr import Result, rich_repr
+from .terminal_theme import DEFAULT_TERMINAL_THEME, TerminalTheme
+
+# Style instances and style definitions are often interchangeable
+StyleType = Union[str, "Style"]
+
+
+class _Bit:
+ """A descriptor to get/set a style attribute bit."""
+
+ __slots__ = ["bit"]
+
+ def __init__(self, bit_no: int) -> None:
+ self.bit = 1 << bit_no
+
+ def __get__(self, obj: "Style", objtype: Type["Style"]) -> Optional[bool]:
+ if obj._set_attributes & self.bit:
+ return obj._attributes & self.bit != 0
+ return None
+
+
+@rich_repr
+class Style:
+ """A terminal style.
+
+ A terminal style consists of a color (`color`), a background color (`bgcolor`), and a number of attributes, such
+ as bold, italic etc. The attributes have 3 states: they can either be on
+ (``True``), off (``False``), or not set (``None``).
+
+ Args:
+ color (Union[Color, str], optional): Color of terminal text. Defaults to None.
+ bgcolor (Union[Color, str], optional): Color of terminal background. Defaults to None.
+ bold (bool, optional): Enable bold text. Defaults to None.
+ dim (bool, optional): Enable dim text. Defaults to None.
+ italic (bool, optional): Enable italic text. Defaults to None.
+ underline (bool, optional): Enable underlined text. Defaults to None.
+ blink (bool, optional): Enabled blinking text. Defaults to None.
+ blink2 (bool, optional): Enable fast blinking text. Defaults to None.
+ reverse (bool, optional): Enabled reverse text. Defaults to None.
+ conceal (bool, optional): Enable concealed text. Defaults to None.
+ strike (bool, optional): Enable strikethrough text. Defaults to None.
+ underline2 (bool, optional): Enable doubly underlined text. Defaults to None.
+ frame (bool, optional): Enable framed text. Defaults to None.
+ encircle (bool, optional): Enable encircled text. Defaults to None.
+ overline (bool, optional): Enable overlined text. Defaults to None.
+ link (str, link): Link URL. Defaults to None.
+
+ """
+
+ _color: Optional[Color]
+ _bgcolor: Optional[Color]
+ _attributes: int
+ _set_attributes: int
+ _hash: Optional[int]
+ _null: bool
+ _meta: Optional[bytes]
+
+ __slots__ = [
+ "_color",
+ "_bgcolor",
+ "_attributes",
+ "_set_attributes",
+ "_link",
+ "_link_id",
+ "_ansi",
+ "_style_definition",
+ "_hash",
+ "_null",
+ "_meta",
+ ]
+
+ # maps bits on to SGR parameter
+ _style_map = {
+ 0: "1",
+ 1: "2",
+ 2: "3",
+ 3: "4",
+ 4: "5",
+ 5: "6",
+ 6: "7",
+ 7: "8",
+ 8: "9",
+ 9: "21",
+ 10: "51",
+ 11: "52",
+ 12: "53",
+ }
+
+ STYLE_ATTRIBUTES = {
+ "dim": "dim",
+ "d": "dim",
+ "bold": "bold",
+ "b": "bold",
+ "italic": "italic",
+ "i": "italic",
+ "underline": "underline",
+ "u": "underline",
+ "blink": "blink",
+ "blink2": "blink2",
+ "reverse": "reverse",
+ "r": "reverse",
+ "conceal": "conceal",
+ "c": "conceal",
+ "strike": "strike",
+ "s": "strike",
+ "underline2": "underline2",
+ "uu": "underline2",
+ "frame": "frame",
+ "encircle": "encircle",
+ "overline": "overline",
+ "o": "overline",
+ }
+
+ def __init__(
+ self,
+ *,
+ color: Optional[Union[Color, str]] = None,
+ bgcolor: Optional[Union[Color, str]] = None,
+ bold: Optional[bool] = None,
+ dim: Optional[bool] = None,
+ italic: Optional[bool] = None,
+ underline: Optional[bool] = None,
+ blink: Optional[bool] = None,
+ blink2: Optional[bool] = None,
+ reverse: Optional[bool] = None,
+ conceal: Optional[bool] = None,
+ strike: Optional[bool] = None,
+ underline2: Optional[bool] = None,
+ frame: Optional[bool] = None,
+ encircle: Optional[bool] = None,
+ overline: Optional[bool] = None,
+ link: Optional[str] = None,
+ meta: Optional[Dict[str, Any]] = None,
+ ):
+ self._ansi: Optional[str] = None
+ self._style_definition: Optional[str] = None
+
+ def _make_color(color: Union[Color, str]) -> Color:
+ return color if isinstance(color, Color) else Color.parse(color)
+
+ self._color = None if color is None else _make_color(color)
+ self._bgcolor = None if bgcolor is None else _make_color(bgcolor)
+ self._set_attributes = sum(
+ (
+ bold is not None,
+ dim is not None and 2,
+ italic is not None and 4,
+ underline is not None and 8,
+ blink is not None and 16,
+ blink2 is not None and 32,
+ reverse is not None and 64,
+ conceal is not None and 128,
+ strike is not None and 256,
+ underline2 is not None and 512,
+ frame is not None and 1024,
+ encircle is not None and 2048,
+ overline is not None and 4096,
+ )
+ )
+ self._attributes = (
+ sum(
+ (
+ bold and 1 or 0,
+ dim and 2 or 0,
+ italic and 4 or 0,
+ underline and 8 or 0,
+ blink and 16 or 0,
+ blink2 and 32 or 0,
+ reverse and 64 or 0,
+ conceal and 128 or 0,
+ strike and 256 or 0,
+ underline2 and 512 or 0,
+ frame and 1024 or 0,
+ encircle and 2048 or 0,
+ overline and 4096 or 0,
+ )
+ )
+ if self._set_attributes
+ else 0
+ )
+
+ self._link = link
+ self._meta = None if meta is None else dumps(meta)
+ self._link_id = (
+ f"{randint(0, 999999)}{hash(self._meta)}" if (link or meta) else ""
+ )
+ self._hash: Optional[int] = None
+ self._null = not (self._set_attributes or color or bgcolor or link or meta)
+
+ @classmethod
+ def null(cls) -> "Style":
+ """Create an 'null' style, equivalent to Style(), but more performant."""
+ return NULL_STYLE
+
+ @classmethod
+ def from_color(
+ cls, color: Optional[Color] = None, bgcolor: Optional[Color] = None
+ ) -> "Style":
+ """Create a new style with colors and no attributes.
+
+ Returns:
+ color (Optional[Color]): A (foreground) color, or None for no color. Defaults to None.
+ bgcolor (Optional[Color]): A (background) color, or None for no color. Defaults to None.
+ """
+ style: Style = cls.__new__(Style)
+ style._ansi = None
+ style._style_definition = None
+ style._color = color
+ style._bgcolor = bgcolor
+ style._set_attributes = 0
+ style._attributes = 0
+ style._link = None
+ style._link_id = ""
+ style._meta = None
+ style._null = not (color or bgcolor)
+ style._hash = None
+ return style
+
+ @classmethod
+ def from_meta(cls, meta: Optional[Dict[str, Any]]) -> "Style":
+ """Create a new style with meta data.
+
+ Returns:
+ meta (Optional[Dict[str, Any]]): A dictionary of meta data. Defaults to None.
+ """
+ style: Style = cls.__new__(Style)
+ style._ansi = None
+ style._style_definition = None
+ style._color = None
+ style._bgcolor = None
+ style._set_attributes = 0
+ style._attributes = 0
+ style._link = None
+ style._meta = dumps(meta)
+ style._link_id = f"{randint(0, 999999)}{hash(style._meta)}"
+ style._hash = None
+ style._null = not (meta)
+ return style
+
+ @classmethod
+ def on(cls, meta: Optional[Dict[str, Any]] = None, **handlers: Any) -> "Style":
+ """Create a blank style with meta information.
+
+ Example:
+ style = Style.on(click=self.on_click)
+
+ Args:
+ meta (Optional[Dict[str, Any]], optional): An optional dict of meta information.
+ **handlers (Any): Keyword arguments are translated in to handlers.
+
+ Returns:
+ Style: A Style with meta information attached.
+ """
+ meta = {} if meta is None else meta
+ meta.update({f"@{key}": value for key, value in handlers.items()})
+ return cls.from_meta(meta)
+
+ bold = _Bit(0)
+ dim = _Bit(1)
+ italic = _Bit(2)
+ underline = _Bit(3)
+ blink = _Bit(4)
+ blink2 = _Bit(5)
+ reverse = _Bit(6)
+ conceal = _Bit(7)
+ strike = _Bit(8)
+ underline2 = _Bit(9)
+ frame = _Bit(10)
+ encircle = _Bit(11)
+ overline = _Bit(12)
+
+ @property
+ def link_id(self) -> str:
+ """Get a link id, used in ansi code for links."""
+ return self._link_id
+
+ def __str__(self) -> str:
+ """Re-generate style definition from attributes."""
+ if self._style_definition is None:
+ attributes: List[str] = []
+ append = attributes.append
+ bits = self._set_attributes
+ if bits & 0b0000000001111:
+ if bits & 1:
+ append("bold" if self.bold else "not bold")
+ if bits & (1 << 1):
+ append("dim" if self.dim else "not dim")
+ if bits & (1 << 2):
+ append("italic" if self.italic else "not italic")
+ if bits & (1 << 3):
+ append("underline" if self.underline else "not underline")
+ if bits & 0b0000111110000:
+ if bits & (1 << 4):
+ append("blink" if self.blink else "not blink")
+ if bits & (1 << 5):
+ append("blink2" if self.blink2 else "not blink2")
+ if bits & (1 << 6):
+ append("reverse" if self.reverse else "not reverse")
+ if bits & (1 << 7):
+ append("conceal" if self.conceal else "not conceal")
+ if bits & (1 << 8):
+ append("strike" if self.strike else "not strike")
+ if bits & 0b1111000000000:
+ if bits & (1 << 9):
+ append("underline2" if self.underline2 else "not underline2")
+ if bits & (1 << 10):
+ append("frame" if self.frame else "not frame")
+ if bits & (1 << 11):
+ append("encircle" if self.encircle else "not encircle")
+ if bits & (1 << 12):
+ append("overline" if self.overline else "not overline")
+ if self._color is not None:
+ append(self._color.name)
+ if self._bgcolor is not None:
+ append("on")
+ append(self._bgcolor.name)
+ if self._link:
+ append("link")
+ append(self._link)
+ self._style_definition = " ".join(attributes) or "none"
+ return self._style_definition
+
+ def __bool__(self) -> bool:
+ """A Style is false if it has no attributes, colors, or links."""
+ return not self._null
+
+ def _make_ansi_codes(self, color_system: ColorSystem) -> str:
+ """Generate ANSI codes for this style.
+
+ Args:
+ color_system (ColorSystem): Color system.
+
+ Returns:
+ str: String containing codes.
+ """
+
+ if self._ansi is None:
+ sgr: List[str] = []
+ append = sgr.append
+ _style_map = self._style_map
+ attributes = self._attributes & self._set_attributes
+ if attributes:
+ if attributes & 1:
+ append(_style_map[0])
+ if attributes & 2:
+ append(_style_map[1])
+ if attributes & 4:
+ append(_style_map[2])
+ if attributes & 8:
+ append(_style_map[3])
+ if attributes & 0b0000111110000:
+ for bit in range(4, 9):
+ if attributes & (1 << bit):
+ append(_style_map[bit])
+ if attributes & 0b1111000000000:
+ for bit in range(9, 13):
+ if attributes & (1 << bit):
+ append(_style_map[bit])
+ if self._color is not None:
+ sgr.extend(self._color.downgrade(color_system).get_ansi_codes())
+ if self._bgcolor is not None:
+ sgr.extend(
+ self._bgcolor.downgrade(color_system).get_ansi_codes(
+ foreground=False
+ )
+ )
+ self._ansi = ";".join(sgr)
+ return self._ansi
+
+ @classmethod
+ @lru_cache(maxsize=1024)
+ def normalize(cls, style: str) -> str:
+ """Normalize a style definition so that styles with the same effect have the same string
+ representation.
+
+ Args:
+ style (str): A style definition.
+
+ Returns:
+ str: Normal form of style definition.
+ """
+ try:
+ return str(cls.parse(style))
+ except errors.StyleSyntaxError:
+ return style.strip().lower()
+
+ @classmethod
+ def pick_first(cls, *values: Optional[StyleType]) -> StyleType:
+ """Pick first non-None style."""
+ for value in values:
+ if value is not None:
+ return value
+ raise ValueError("expected at least one non-None style")
+
+ def __rich_repr__(self) -> Result:
+ yield "color", self.color, None
+ yield "bgcolor", self.bgcolor, None
+ yield "bold", self.bold, None,
+ yield "dim", self.dim, None,
+ yield "italic", self.italic, None
+ yield "underline", self.underline, None,
+ yield "blink", self.blink, None
+ yield "blink2", self.blink2, None
+ yield "reverse", self.reverse, None
+ yield "conceal", self.conceal, None
+ yield "strike", self.strike, None
+ yield "underline2", self.underline2, None
+ yield "frame", self.frame, None
+ yield "encircle", self.encircle, None
+ yield "link", self.link, None
+ if self._meta:
+ yield "meta", self.meta
+
+ def __eq__(self, other: Any) -> bool:
+ if not isinstance(other, Style):
+ return NotImplemented
+ return self.__hash__() == other.__hash__()
+
+ def __ne__(self, other: Any) -> bool:
+ if not isinstance(other, Style):
+ return NotImplemented
+ return self.__hash__() != other.__hash__()
+
+ def __hash__(self) -> int:
+ if self._hash is not None:
+ return self._hash
+ self._hash = hash(
+ (
+ self._color,
+ self._bgcolor,
+ self._attributes,
+ self._set_attributes,
+ self._link,
+ self._meta,
+ )
+ )
+ return self._hash
+
+ @property
+ def color(self) -> Optional[Color]:
+ """The foreground color or None if it is not set."""
+ return self._color
+
+ @property
+ def bgcolor(self) -> Optional[Color]:
+ """The background color or None if it is not set."""
+ return self._bgcolor
+
+ @property
+ def link(self) -> Optional[str]:
+ """Link text, if set."""
+ return self._link
+
+ @property
+ def transparent_background(self) -> bool:
+ """Check if the style specified a transparent background."""
+ return self.bgcolor is None or self.bgcolor.is_default
+
+ @property
+ def background_style(self) -> "Style":
+ """A Style with background only."""
+ return Style(bgcolor=self.bgcolor)
+
+ @property
+ def meta(self) -> Dict[str, Any]:
+ """Get meta information (can not be changed after construction)."""
+ return {} if self._meta is None else cast(Dict[str, Any], loads(self._meta))
+
+ @property
+ def without_color(self) -> "Style":
+ """Get a copy of the style with color removed."""
+ if self._null:
+ return NULL_STYLE
+ style: Style = self.__new__(Style)
+ style._ansi = None
+ style._style_definition = None
+ style._color = None
+ style._bgcolor = None
+ style._attributes = self._attributes
+ style._set_attributes = self._set_attributes
+ style._link = self._link
+ style._link_id = f"{randint(0, 999999)}" if self._link else ""
+ style._null = False
+ style._meta = None
+ style._hash = None
+ return style
+
+ @classmethod
+ @lru_cache(maxsize=4096)
+ def parse(cls, style_definition: str) -> "Style":
+ """Parse a style definition.
+
+ Args:
+ style_definition (str): A string containing a style.
+
+ Raises:
+ errors.StyleSyntaxError: If the style definition syntax is invalid.
+
+ Returns:
+ `Style`: A Style instance.
+ """
+ if style_definition.strip() == "none" or not style_definition:
+ return cls.null()
+
+ STYLE_ATTRIBUTES = cls.STYLE_ATTRIBUTES
+ color: Optional[str] = None
+ bgcolor: Optional[str] = None
+ attributes: Dict[str, Optional[Any]] = {}
+ link: Optional[str] = None
+
+ words = iter(style_definition.split())
+ for original_word in words:
+ word = original_word.lower()
+ if word == "on":
+ word = next(words, "")
+ if not word:
+ raise errors.StyleSyntaxError("color expected after 'on'")
+ try:
+ Color.parse(word) is None
+ except ColorParseError as error:
+ raise errors.StyleSyntaxError(
+ f"unable to parse {word!r} as background color; {error}"
+ ) from None
+ bgcolor = word
+
+ elif word == "not":
+ word = next(words, "")
+ attribute = STYLE_ATTRIBUTES.get(word)
+ if attribute is None:
+ raise errors.StyleSyntaxError(
+ f"expected style attribute after 'not', found {word!r}"
+ )
+ attributes[attribute] = False
+
+ elif word == "link":
+ word = next(words, "")
+ if not word:
+ raise errors.StyleSyntaxError("URL expected after 'link'")
+ link = word
+
+ elif word in STYLE_ATTRIBUTES:
+ attributes[STYLE_ATTRIBUTES[word]] = True
+
+ else:
+ try:
+ Color.parse(word)
+ except ColorParseError as error:
+ raise errors.StyleSyntaxError(
+ f"unable to parse {word!r} as color; {error}"
+ ) from None
+ color = word
+ style = Style(color=color, bgcolor=bgcolor, link=link, **attributes)
+ return style
+
+ @lru_cache(maxsize=1024)
+ def get_html_style(self, theme: Optional[TerminalTheme] = None) -> str:
+ """Get a CSS style rule."""
+ theme = theme or DEFAULT_TERMINAL_THEME
+ css: List[str] = []
+ append = css.append
+
+ color = self.color
+ bgcolor = self.bgcolor
+ if self.reverse:
+ color, bgcolor = bgcolor, color
+ if self.dim:
+ foreground_color = (
+ theme.foreground_color if color is None else color.get_truecolor(theme)
+ )
+ color = Color.from_triplet(
+ blend_rgb(foreground_color, theme.background_color, 0.5)
+ )
+ if color is not None:
+ theme_color = color.get_truecolor(theme)
+ append(f"color: {theme_color.hex}")
+ append(f"text-decoration-color: {theme_color.hex}")
+ if bgcolor is not None:
+ theme_color = bgcolor.get_truecolor(theme, foreground=False)
+ append(f"background-color: {theme_color.hex}")
+ if self.bold:
+ append("font-weight: bold")
+ if self.italic:
+ append("font-style: italic")
+ if self.underline:
+ append("text-decoration: underline")
+ if self.strike:
+ append("text-decoration: line-through")
+ if self.overline:
+ append("text-decoration: overline")
+ return "; ".join(css)
+
+ @classmethod
+ def combine(cls, styles: Iterable["Style"]) -> "Style":
+ """Combine styles and get result.
+
+ Args:
+ styles (Iterable[Style]): Styles to combine.
+
+ Returns:
+ Style: A new style instance.
+ """
+ iter_styles = iter(styles)
+ return sum(iter_styles, next(iter_styles))
+
+ @classmethod
+ def chain(cls, *styles: "Style") -> "Style":
+ """Combine styles from positional argument in to a single style.
+
+ Args:
+ *styles (Iterable[Style]): Styles to combine.
+
+ Returns:
+ Style: A new style instance.
+ """
+ iter_styles = iter(styles)
+ return sum(iter_styles, next(iter_styles))
+
+ def copy(self) -> "Style":
+ """Get a copy of this style.
+
+ Returns:
+ Style: A new Style instance with identical attributes.
+ """
+ if self._null:
+ return NULL_STYLE
+ style: Style = self.__new__(Style)
+ style._ansi = self._ansi
+ style._style_definition = self._style_definition
+ style._color = self._color
+ style._bgcolor = self._bgcolor
+ style._attributes = self._attributes
+ style._set_attributes = self._set_attributes
+ style._link = self._link
+ style._link_id = f"{randint(0, 999999)}" if self._link else ""
+ style._hash = self._hash
+ style._null = False
+ style._meta = self._meta
+ return style
+
+ @lru_cache(maxsize=128)
+ def clear_meta_and_links(self) -> "Style":
+ """Get a copy of this style with link and meta information removed.
+
+ Returns:
+ Style: New style object.
+ """
+ if self._null:
+ return NULL_STYLE
+ style: Style = self.__new__(Style)
+ style._ansi = self._ansi
+ style._style_definition = self._style_definition
+ style._color = self._color
+ style._bgcolor = self._bgcolor
+ style._attributes = self._attributes
+ style._set_attributes = self._set_attributes
+ style._link = None
+ style._link_id = ""
+ style._hash = self._hash
+ style._null = False
+ style._meta = None
+ return style
+
+ def update_link(self, link: Optional[str] = None) -> "Style":
+ """Get a copy with a different value for link.
+
+ Args:
+ link (str, optional): New value for link. Defaults to None.
+
+ Returns:
+ Style: A new Style instance.
+ """
+ style: Style = self.__new__(Style)
+ style._ansi = self._ansi
+ style._style_definition = self._style_definition
+ style._color = self._color
+ style._bgcolor = self._bgcolor
+ style._attributes = self._attributes
+ style._set_attributes = self._set_attributes
+ style._link = link
+ style._link_id = f"{randint(0, 999999)}" if link else ""
+ style._hash = None
+ style._null = False
+ style._meta = self._meta
+ return style
+
+ def render(
+ self,
+ text: str = "",
+ *,
+ color_system: Optional[ColorSystem] = ColorSystem.TRUECOLOR,
+ legacy_windows: bool = False,
+ ) -> str:
+ """Render the ANSI codes for the style.
+
+ Args:
+ text (str, optional): A string to style. Defaults to "".
+ color_system (Optional[ColorSystem], optional): Color system to render to. Defaults to ColorSystem.TRUECOLOR.
+
+ Returns:
+ str: A string containing ANSI style codes.
+ """
+ if not text or color_system is None:
+ return text
+ attrs = self._ansi or self._make_ansi_codes(color_system)
+ rendered = f"\x1b[{attrs}m{text}\x1b[0m" if attrs else text
+ if self._link and not legacy_windows:
+ rendered = (
+ f"\x1b]8;id={self._link_id};{self._link}\x1b\\{rendered}\x1b]8;;\x1b\\"
+ )
+ return rendered
+
+ def test(self, text: Optional[str] = None) -> None:
+ """Write text with style directly to terminal.
+
+ This method is for testing purposes only.
+
+ Args:
+ text (Optional[str], optional): Text to style or None for style name.
+
+ """
+ text = text or str(self)
+ sys.stdout.write(f"{self.render(text)}\n")
+
+ @lru_cache(maxsize=1024)
+ def _add(self, style: Optional["Style"]) -> "Style":
+ if style is None or style._null:
+ return self
+ if self._null:
+ return style
+ new_style: Style = self.__new__(Style)
+ new_style._ansi = None
+ new_style._style_definition = None
+ new_style._color = style._color or self._color
+ new_style._bgcolor = style._bgcolor or self._bgcolor
+ new_style._attributes = (self._attributes & ~style._set_attributes) | (
+ style._attributes & style._set_attributes
+ )
+ new_style._set_attributes = self._set_attributes | style._set_attributes
+ new_style._link = style._link or self._link
+ new_style._link_id = style._link_id or self._link_id
+ new_style._null = style._null
+ if self._meta and style._meta:
+ new_style._meta = dumps({**self.meta, **style.meta})
+ else:
+ new_style._meta = self._meta or style._meta
+ new_style._hash = None
+ return new_style
+
+ def __add__(self, style: Optional["Style"]) -> "Style":
+ combined_style = self._add(style)
+ return combined_style.copy() if combined_style.link else combined_style
+
+
+NULL_STYLE = Style()
+
+
+class StyleStack:
+ """A stack of styles."""
+
+ __slots__ = ["_stack"]
+
+ def __init__(self, default_style: "Style") -> None:
+ self._stack: List[Style] = [default_style]
+
+ def __repr__(self) -> str:
+ return f"<stylestack {self._stack!r}>"
+
+ @property
+ def current(self) -> Style:
+ """Get the Style at the top of the stack."""
+ return self._stack[-1]
+
+ def push(self, style: Style) -> None:
+ """Push a new style on to the stack.
+
+ Args:
+ style (Style): New style to combine with current style.
+ """
+ self._stack.append(self._stack[-1] + style)
+
+ def pop(self) -> Style:
+ """Pop last style and discard.
+
+ Returns:
+ Style: New current style (also available as stack.current)
+ """
+ self._stack.pop()
+ return self._stack[-1]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/styled.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/styled.py
new file mode 100644
index 000000000..91cd0db31
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/styled.py
@@ -0,0 +1,42 @@
+from typing import TYPE_CHECKING
+
+from .measure import Measurement
+from .segment import Segment
+from .style import StyleType
+
+if TYPE_CHECKING:
+ from .console import Console, ConsoleOptions, RenderResult, RenderableType
+
+
+class Styled:
+ """Apply a style to a renderable.
+
+ Args:
+ renderable (RenderableType): Any renderable.
+ style (StyleType): A style to apply across the entire renderable.
+ """
+
+ def __init__(self, renderable: "RenderableType", style: "StyleType") -> None:
+ self.renderable = renderable
+ self.style = style
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ style = console.get_style(self.style)
+ rendered_segments = console.render(self.renderable, options)
+ segments = Segment.apply_style(rendered_segments, style)
+ return segments
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Measurement:
+ return Measurement.get(console, options, self.renderable)
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich import print
+ from pip._vendor.rich.panel import Panel
+
+ panel = Styled(Panel("hello"), "on blue")
+ print(panel)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/syntax.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/syntax.py
new file mode 100644
index 000000000..c26fd8784
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/syntax.py
@@ -0,0 +1,958 @@
+import os.path
+import platform
+import re
+import sys
+import textwrap
+from abc import ABC, abstractmethod
+from pathlib import Path
+from typing import (
+ Any,
+ Dict,
+ Iterable,
+ List,
+ NamedTuple,
+ Optional,
+ Sequence,
+ Set,
+ Tuple,
+ Type,
+ Union,
+)
+
+from pip._vendor.pygments.lexer import Lexer
+from pip._vendor.pygments.lexers import get_lexer_by_name, guess_lexer_for_filename
+from pip._vendor.pygments.style import Style as PygmentsStyle
+from pip._vendor.pygments.styles import get_style_by_name
+from pip._vendor.pygments.token import (
+ Comment,
+ Error,
+ Generic,
+ Keyword,
+ Name,
+ Number,
+ Operator,
+ String,
+ Token,
+ Whitespace,
+)
+from pip._vendor.pygments.util import ClassNotFound
+
+from pip._vendor.rich.containers import Lines
+from pip._vendor.rich.padding import Padding, PaddingDimensions
+
+from ._loop import loop_first
+from .cells import cell_len
+from .color import Color, blend_rgb
+from .console import Console, ConsoleOptions, JustifyMethod, RenderResult
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .segment import Segment, Segments
+from .style import Style, StyleType
+from .text import Text
+
+TokenType = Tuple[str, ...]
+
+WINDOWS = platform.system() == "Windows"
+DEFAULT_THEME = "monokai"
+
+# The following styles are based on https://github.com/pygments/pygments/blob/master/pygments/formatters/terminal.py
+# A few modifications were made
+
+ANSI_LIGHT: Dict[TokenType, Style] = {
+ Token: Style(),
+ Whitespace: Style(color="white"),
+ Comment: Style(dim=True),
+ Comment.Preproc: Style(color="cyan"),
+ Keyword: Style(color="blue"),
+ Keyword.Type: Style(color="cyan"),
+ Operator.Word: Style(color="magenta"),
+ Name.Builtin: Style(color="cyan"),
+ Name.Function: Style(color="green"),
+ Name.Namespace: Style(color="cyan", underline=True),
+ Name.Class: Style(color="green", underline=True),
+ Name.Exception: Style(color="cyan"),
+ Name.Decorator: Style(color="magenta", bold=True),
+ Name.Variable: Style(color="red"),
+ Name.Constant: Style(color="red"),
+ Name.Attribute: Style(color="cyan"),
+ Name.Tag: Style(color="bright_blue"),
+ String: Style(color="yellow"),
+ Number: Style(color="blue"),
+ Generic.Deleted: Style(color="bright_red"),
+ Generic.Inserted: Style(color="green"),
+ Generic.Heading: Style(bold=True),
+ Generic.Subheading: Style(color="magenta", bold=True),
+ Generic.Prompt: Style(bold=True),
+ Generic.Error: Style(color="bright_red"),
+ Error: Style(color="red", underline=True),
+}
+
+ANSI_DARK: Dict[TokenType, Style] = {
+ Token: Style(),
+ Whitespace: Style(color="bright_black"),
+ Comment: Style(dim=True),
+ Comment.Preproc: Style(color="bright_cyan"),
+ Keyword: Style(color="bright_blue"),
+ Keyword.Type: Style(color="bright_cyan"),
+ Operator.Word: Style(color="bright_magenta"),
+ Name.Builtin: Style(color="bright_cyan"),
+ Name.Function: Style(color="bright_green"),
+ Name.Namespace: Style(color="bright_cyan", underline=True),
+ Name.Class: Style(color="bright_green", underline=True),
+ Name.Exception: Style(color="bright_cyan"),
+ Name.Decorator: Style(color="bright_magenta", bold=True),
+ Name.Variable: Style(color="bright_red"),
+ Name.Constant: Style(color="bright_red"),
+ Name.Attribute: Style(color="bright_cyan"),
+ Name.Tag: Style(color="bright_blue"),
+ String: Style(color="yellow"),
+ Number: Style(color="bright_blue"),
+ Generic.Deleted: Style(color="bright_red"),
+ Generic.Inserted: Style(color="bright_green"),
+ Generic.Heading: Style(bold=True),
+ Generic.Subheading: Style(color="bright_magenta", bold=True),
+ Generic.Prompt: Style(bold=True),
+ Generic.Error: Style(color="bright_red"),
+ Error: Style(color="red", underline=True),
+}
+
+RICH_SYNTAX_THEMES = {"ansi_light": ANSI_LIGHT, "ansi_dark": ANSI_DARK}
+NUMBERS_COLUMN_DEFAULT_PADDING = 2
+
+
+class SyntaxTheme(ABC):
+ """Base class for a syntax theme."""
+
+ @abstractmethod
+ def get_style_for_token(self, token_type: TokenType) -> Style:
+ """Get a style for a given Pygments token."""
+ raise NotImplementedError # pragma: no cover
+
+ @abstractmethod
+ def get_background_style(self) -> Style:
+ """Get the background color."""
+ raise NotImplementedError # pragma: no cover
+
+
+class PygmentsSyntaxTheme(SyntaxTheme):
+ """Syntax theme that delegates to Pygments theme."""
+
+ def __init__(self, theme: Union[str, Type[PygmentsStyle]]) -> None:
+ self._style_cache: Dict[TokenType, Style] = {}
+ if isinstance(theme, str):
+ try:
+ self._pygments_style_class = get_style_by_name(theme)
+ except ClassNotFound:
+ self._pygments_style_class = get_style_by_name("default")
+ else:
+ self._pygments_style_class = theme
+
+ self._background_color = self._pygments_style_class.background_color
+ self._background_style = Style(bgcolor=self._background_color)
+
+ def get_style_for_token(self, token_type: TokenType) -> Style:
+ """Get a style from a Pygments class."""
+ try:
+ return self._style_cache[token_type]
+ except KeyError:
+ try:
+ pygments_style = self._pygments_style_class.style_for_token(token_type)
+ except KeyError:
+ style = Style.null()
+ else:
+ color = pygments_style["color"]
+ bgcolor = pygments_style["bgcolor"]
+ style = Style(
+ color="#" + color if color else "#000000",
+ bgcolor="#" + bgcolor if bgcolor else self._background_color,
+ bold=pygments_style["bold"],
+ italic=pygments_style["italic"],
+ underline=pygments_style["underline"],
+ )
+ self._style_cache[token_type] = style
+ return style
+
+ def get_background_style(self) -> Style:
+ return self._background_style
+
+
+class ANSISyntaxTheme(SyntaxTheme):
+ """Syntax theme to use standard colors."""
+
+ def __init__(self, style_map: Dict[TokenType, Style]) -> None:
+ self.style_map = style_map
+ self._missing_style = Style.null()
+ self._background_style = Style.null()
+ self._style_cache: Dict[TokenType, Style] = {}
+
+ def get_style_for_token(self, token_type: TokenType) -> Style:
+ """Look up style in the style map."""
+ try:
+ return self._style_cache[token_type]
+ except KeyError:
+ # Styles form a hierarchy
+ # We need to go from most to least specific
+ # e.g. ("foo", "bar", "baz") to ("foo", "bar") to ("foo",)
+ get_style = self.style_map.get
+ token = tuple(token_type)
+ style = self._missing_style
+ while token:
+ _style = get_style(token)
+ if _style is not None:
+ style = _style
+ break
+ token = token[:-1]
+ self._style_cache[token_type] = style
+ return style
+
+ def get_background_style(self) -> Style:
+ return self._background_style
+
+
+SyntaxPosition = Tuple[int, int]
+
+
+class _SyntaxHighlightRange(NamedTuple):
+ """
+ A range to highlight in a Syntax object.
+ `start` and `end` are 2-integers tuples, where the first integer is the line number
+ (starting from 1) and the second integer is the column index (starting from 0).
+ """
+
+ style: StyleType
+ start: SyntaxPosition
+ end: SyntaxPosition
+
+
+class Syntax(JupyterMixin):
+ """Construct a Syntax object to render syntax highlighted code.
+
+ Args:
+ code (str): Code to highlight.
+ lexer (Lexer | str): Lexer to use (see https://pygments.org/docs/lexers/)
+ theme (str, optional): Color theme, aka Pygments style (see https://pygments.org/docs/styles/#getting-a-list-of-available-styles). Defaults to "monokai".
+ dedent (bool, optional): Enable stripping of initial whitespace. Defaults to False.
+ line_numbers (bool, optional): Enable rendering of line numbers. Defaults to False.
+ start_line (int, optional): Starting number for line numbers. Defaults to 1.
+ line_range (Tuple[int | None, int | None], optional): If given should be a tuple of the start and end line to render.
+ A value of None in the tuple indicates the range is open in that direction.
+ highlight_lines (Set[int]): A set of line numbers to highlight.
+ code_width: Width of code to render (not including line numbers), or ``None`` to use all available width.
+ tab_size (int, optional): Size of tabs. Defaults to 4.
+ word_wrap (bool, optional): Enable word wrapping.
+ background_color (str, optional): Optional background color, or None to use theme color. Defaults to None.
+ indent_guides (bool, optional): Show indent guides. Defaults to False.
+ padding (PaddingDimensions): Padding to apply around the syntax. Defaults to 0 (no padding).
+ """
+
+ _pygments_style_class: Type[PygmentsStyle]
+ _theme: SyntaxTheme
+
+ @classmethod
+ def get_theme(cls, name: Union[str, SyntaxTheme]) -> SyntaxTheme:
+ """Get a syntax theme instance."""
+ if isinstance(name, SyntaxTheme):
+ return name
+ theme: SyntaxTheme
+ if name in RICH_SYNTAX_THEMES:
+ theme = ANSISyntaxTheme(RICH_SYNTAX_THEMES[name])
+ else:
+ theme = PygmentsSyntaxTheme(name)
+ return theme
+
+ def __init__(
+ self,
+ code: str,
+ lexer: Union[Lexer, str],
+ *,
+ theme: Union[str, SyntaxTheme] = DEFAULT_THEME,
+ dedent: bool = False,
+ line_numbers: bool = False,
+ start_line: int = 1,
+ line_range: Optional[Tuple[Optional[int], Optional[int]]] = None,
+ highlight_lines: Optional[Set[int]] = None,
+ code_width: Optional[int] = None,
+ tab_size: int = 4,
+ word_wrap: bool = False,
+ background_color: Optional[str] = None,
+ indent_guides: bool = False,
+ padding: PaddingDimensions = 0,
+ ) -> None:
+ self.code = code
+ self._lexer = lexer
+ self.dedent = dedent
+ self.line_numbers = line_numbers
+ self.start_line = start_line
+ self.line_range = line_range
+ self.highlight_lines = highlight_lines or set()
+ self.code_width = code_width
+ self.tab_size = tab_size
+ self.word_wrap = word_wrap
+ self.background_color = background_color
+ self.background_style = (
+ Style(bgcolor=background_color) if background_color else Style()
+ )
+ self.indent_guides = indent_guides
+ self.padding = padding
+
+ self._theme = self.get_theme(theme)
+ self._stylized_ranges: List[_SyntaxHighlightRange] = []
+
+ @classmethod
+ def from_path(
+ cls,
+ path: str,
+ encoding: str = "utf-8",
+ lexer: Optional[Union[Lexer, str]] = None,
+ theme: Union[str, SyntaxTheme] = DEFAULT_THEME,
+ dedent: bool = False,
+ line_numbers: bool = False,
+ line_range: Optional[Tuple[int, int]] = None,
+ start_line: int = 1,
+ highlight_lines: Optional[Set[int]] = None,
+ code_width: Optional[int] = None,
+ tab_size: int = 4,
+ word_wrap: bool = False,
+ background_color: Optional[str] = None,
+ indent_guides: bool = False,
+ padding: PaddingDimensions = 0,
+ ) -> "Syntax":
+ """Construct a Syntax object from a file.
+
+ Args:
+ path (str): Path to file to highlight.
+ encoding (str): Encoding of file.
+ lexer (str | Lexer, optional): Lexer to use. If None, lexer will be auto-detected from path/file content.
+ theme (str, optional): Color theme, aka Pygments style (see https://pygments.org/docs/styles/#getting-a-list-of-available-styles). Defaults to "emacs".
+ dedent (bool, optional): Enable stripping of initial whitespace. Defaults to True.
+ line_numbers (bool, optional): Enable rendering of line numbers. Defaults to False.
+ start_line (int, optional): Starting number for line numbers. Defaults to 1.
+ line_range (Tuple[int, int], optional): If given should be a tuple of the start and end line to render.
+ highlight_lines (Set[int]): A set of line numbers to highlight.
+ code_width: Width of code to render (not including line numbers), or ``None`` to use all available width.
+ tab_size (int, optional): Size of tabs. Defaults to 4.
+ word_wrap (bool, optional): Enable word wrapping of code.
+ background_color (str, optional): Optional background color, or None to use theme color. Defaults to None.
+ indent_guides (bool, optional): Show indent guides. Defaults to False.
+ padding (PaddingDimensions): Padding to apply around the syntax. Defaults to 0 (no padding).
+
+ Returns:
+ [Syntax]: A Syntax object that may be printed to the console
+ """
+ code = Path(path).read_text(encoding=encoding)
+
+ if not lexer:
+ lexer = cls.guess_lexer(path, code=code)
+
+ return cls(
+ code,
+ lexer,
+ theme=theme,
+ dedent=dedent,
+ line_numbers=line_numbers,
+ line_range=line_range,
+ start_line=start_line,
+ highlight_lines=highlight_lines,
+ code_width=code_width,
+ tab_size=tab_size,
+ word_wrap=word_wrap,
+ background_color=background_color,
+ indent_guides=indent_guides,
+ padding=padding,
+ )
+
+ @classmethod
+ def guess_lexer(cls, path: str, code: Optional[str] = None) -> str:
+ """Guess the alias of the Pygments lexer to use based on a path and an optional string of code.
+ If code is supplied, it will use a combination of the code and the filename to determine the
+ best lexer to use. For example, if the file is ``index.html`` and the file contains Django
+ templating syntax, then "html+django" will be returned. If the file is ``index.html``, and no
+ templating language is used, the "html" lexer will be used. If no string of code
+ is supplied, the lexer will be chosen based on the file extension..
+
+ Args:
+ path (AnyStr): The path to the file containing the code you wish to know the lexer for.
+ code (str, optional): Optional string of code that will be used as a fallback if no lexer
+ is found for the supplied path.
+
+ Returns:
+ str: The name of the Pygments lexer that best matches the supplied path/code.
+ """
+ lexer: Optional[Lexer] = None
+ lexer_name = "default"
+ if code:
+ try:
+ lexer = guess_lexer_for_filename(path, code)
+ except ClassNotFound:
+ pass
+
+ if not lexer:
+ try:
+ _, ext = os.path.splitext(path)
+ if ext:
+ extension = ext.lstrip(".").lower()
+ lexer = get_lexer_by_name(extension)
+ except ClassNotFound:
+ pass
+
+ if lexer:
+ if lexer.aliases:
+ lexer_name = lexer.aliases[0]
+ else:
+ lexer_name = lexer.name
+
+ return lexer_name
+
+ def _get_base_style(self) -> Style:
+ """Get the base style."""
+ default_style = self._theme.get_background_style() + self.background_style
+ return default_style
+
+ def _get_token_color(self, token_type: TokenType) -> Optional[Color]:
+ """Get a color (if any) for the given token.
+
+ Args:
+ token_type (TokenType): A token type tuple from Pygments.
+
+ Returns:
+ Optional[Color]: Color from theme, or None for no color.
+ """
+ style = self._theme.get_style_for_token(token_type)
+ return style.color
+
+ @property
+ def lexer(self) -> Optional[Lexer]:
+ """The lexer for this syntax, or None if no lexer was found.
+
+ Tries to find the lexer by name if a string was passed to the constructor.
+ """
+
+ if isinstance(self._lexer, Lexer):
+ return self._lexer
+ try:
+ return get_lexer_by_name(
+ self._lexer,
+ stripnl=False,
+ ensurenl=True,
+ tabsize=self.tab_size,
+ )
+ except ClassNotFound:
+ return None
+
+ @property
+ def default_lexer(self) -> Lexer:
+ """A Pygments Lexer to use if one is not specified or invalid."""
+ return get_lexer_by_name(
+ "text",
+ stripnl=False,
+ ensurenl=True,
+ tabsize=self.tab_size,
+ )
+
+ def highlight(
+ self,
+ code: str,
+ line_range: Optional[Tuple[Optional[int], Optional[int]]] = None,
+ ) -> Text:
+ """Highlight code and return a Text instance.
+
+ Args:
+ code (str): Code to highlight.
+ line_range(Tuple[int, int], optional): Optional line range to highlight.
+
+ Returns:
+ Text: A text instance containing highlighted syntax.
+ """
+
+ base_style = self._get_base_style()
+ justify: JustifyMethod = (
+ "default" if base_style.transparent_background else "left"
+ )
+
+ text = Text(
+ justify=justify,
+ style=base_style,
+ tab_size=self.tab_size,
+ no_wrap=not self.word_wrap,
+ )
+ _get_theme_style = self._theme.get_style_for_token
+
+ lexer = self.lexer or self.default_lexer
+
+ if lexer is None:
+ text.append(code)
+ else:
+ if line_range:
+ # More complicated path to only stylize a portion of the code
+ # This speeds up further operations as there are less spans to process
+ line_start, line_end = line_range
+
+ def line_tokenize() -> Iterable[Tuple[Any, str]]:
+ """Split tokens to one per line."""
+ assert lexer # required to make MyPy happy - we know lexer is not None at this point
+
+ for token_type, token in lexer.get_tokens(code):
+ while token:
+ line_token, new_line, token = token.partition("\n")
+ yield token_type, line_token + new_line
+
+ def tokens_to_spans() -> Iterable[Tuple[str, Optional[Style]]]:
+ """Convert tokens to spans."""
+ tokens = iter(line_tokenize())
+ line_no = 0
+ _line_start = line_start - 1 if line_start else 0
+
+ # Skip over tokens until line start
+ while line_no < _line_start:
+ try:
+ _token_type, token = next(tokens)
+ except StopIteration:
+ break
+ yield (token, None)
+ if token.endswith("\n"):
+ line_no += 1
+ # Generate spans until line end
+ for token_type, token in tokens:
+ yield (token, _get_theme_style(token_type))
+ if token.endswith("\n"):
+ line_no += 1
+ if line_end and line_no >= line_end:
+ break
+
+ text.append_tokens(tokens_to_spans())
+
+ else:
+ text.append_tokens(
+ (token, _get_theme_style(token_type))
+ for token_type, token in lexer.get_tokens(code)
+ )
+ if self.background_color is not None:
+ text.stylize(f"on {self.background_color}")
+
+ if self._stylized_ranges:
+ self._apply_stylized_ranges(text)
+
+ return text
+
+ def stylize_range(
+ self, style: StyleType, start: SyntaxPosition, end: SyntaxPosition
+ ) -> None:
+ """
+ Adds a custom style on a part of the code, that will be applied to the syntax display when it's rendered.
+ Line numbers are 1-based, while column indexes are 0-based.
+
+ Args:
+ style (StyleType): The style to apply.
+ start (Tuple[int, int]): The start of the range, in the form `[line number, column index]`.
+ end (Tuple[int, int]): The end of the range, in the form `[line number, column index]`.
+ """
+ self._stylized_ranges.append(_SyntaxHighlightRange(style, start, end))
+
+ def _get_line_numbers_color(self, blend: float = 0.3) -> Color:
+ background_style = self._theme.get_background_style() + self.background_style
+ background_color = background_style.bgcolor
+ if background_color is None or background_color.is_system_defined:
+ return Color.default()
+ foreground_color = self._get_token_color(Token.Text)
+ if foreground_color is None or foreground_color.is_system_defined:
+ return foreground_color or Color.default()
+ new_color = blend_rgb(
+ background_color.get_truecolor(),
+ foreground_color.get_truecolor(),
+ cross_fade=blend,
+ )
+ return Color.from_triplet(new_color)
+
+ @property
+ def _numbers_column_width(self) -> int:
+ """Get the number of characters used to render the numbers column."""
+ column_width = 0
+ if self.line_numbers:
+ column_width = (
+ len(str(self.start_line + self.code.count("\n")))
+ + NUMBERS_COLUMN_DEFAULT_PADDING
+ )
+ return column_width
+
+ def _get_number_styles(self, console: Console) -> Tuple[Style, Style, Style]:
+ """Get background, number, and highlight styles for line numbers."""
+ background_style = self._get_base_style()
+ if background_style.transparent_background:
+ return Style.null(), Style(dim=True), Style.null()
+ if console.color_system in ("256", "truecolor"):
+ number_style = Style.chain(
+ background_style,
+ self._theme.get_style_for_token(Token.Text),
+ Style(color=self._get_line_numbers_color()),
+ self.background_style,
+ )
+ highlight_number_style = Style.chain(
+ background_style,
+ self._theme.get_style_for_token(Token.Text),
+ Style(bold=True, color=self._get_line_numbers_color(0.9)),
+ self.background_style,
+ )
+ else:
+ number_style = background_style + Style(dim=True)
+ highlight_number_style = background_style + Style(dim=False)
+ return background_style, number_style, highlight_number_style
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ _, right, _, left = Padding.unpack(self.padding)
+ padding = left + right
+ if self.code_width is not None:
+ width = self.code_width + self._numbers_column_width + padding + 1
+ return Measurement(self._numbers_column_width, width)
+ lines = self.code.splitlines()
+ width = (
+ self._numbers_column_width
+ + padding
+ + (max(cell_len(line) for line in lines) if lines else 0)
+ )
+ if self.line_numbers:
+ width += 1
+ return Measurement(self._numbers_column_width, width)
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ segments = Segments(self._get_syntax(console, options))
+ if self.padding:
+ yield Padding(
+ segments, style=self._theme.get_background_style(), pad=self.padding
+ )
+ else:
+ yield segments
+
+ def _get_syntax(
+ self,
+ console: Console,
+ options: ConsoleOptions,
+ ) -> Iterable[Segment]:
+ """
+ Get the Segments for the Syntax object, excluding any vertical/horizontal padding
+ """
+ transparent_background = self._get_base_style().transparent_background
+ code_width = (
+ (
+ (options.max_width - self._numbers_column_width - 1)
+ if self.line_numbers
+ else options.max_width
+ )
+ if self.code_width is None
+ else self.code_width
+ )
+
+ ends_on_nl, processed_code = self._process_code(self.code)
+ text = self.highlight(processed_code, self.line_range)
+
+ if not self.line_numbers and not self.word_wrap and not self.line_range:
+ if not ends_on_nl:
+ text.remove_suffix("\n")
+ # Simple case of just rendering text
+ style = (
+ self._get_base_style()
+ + self._theme.get_style_for_token(Comment)
+ + Style(dim=True)
+ + self.background_style
+ )
+ if self.indent_guides and not options.ascii_only:
+ text = text.with_indent_guides(self.tab_size, style=style)
+ text.overflow = "crop"
+ if style.transparent_background:
+ yield from console.render(
+ text, options=options.update(width=code_width)
+ )
+ else:
+ syntax_lines = console.render_lines(
+ text,
+ options.update(width=code_width, height=None, justify="left"),
+ style=self.background_style,
+ pad=True,
+ new_lines=True,
+ )
+ for syntax_line in syntax_lines:
+ yield from syntax_line
+ return
+
+ start_line, end_line = self.line_range or (None, None)
+ line_offset = 0
+ if start_line:
+ line_offset = max(0, start_line - 1)
+ lines: Union[List[Text], Lines] = text.split("\n", allow_blank=ends_on_nl)
+ if self.line_range:
+ if line_offset > len(lines):
+ return
+ lines = lines[line_offset:end_line]
+
+ if self.indent_guides and not options.ascii_only:
+ style = (
+ self._get_base_style()
+ + self._theme.get_style_for_token(Comment)
+ + Style(dim=True)
+ + self.background_style
+ )
+ lines = (
+ Text("\n")
+ .join(lines)
+ .with_indent_guides(self.tab_size, style=style + Style(italic=False))
+ .split("\n", allow_blank=True)
+ )
+
+ numbers_column_width = self._numbers_column_width
+ render_options = options.update(width=code_width)
+
+ highlight_line = self.highlight_lines.__contains__
+ _Segment = Segment
+ new_line = _Segment("\n")
+
+ line_pointer = "> " if options.legacy_windows else "❱ "
+
+ (
+ background_style,
+ number_style,
+ highlight_number_style,
+ ) = self._get_number_styles(console)
+
+ for line_no, line in enumerate(lines, self.start_line + line_offset):
+ if self.word_wrap:
+ wrapped_lines = console.render_lines(
+ line,
+ render_options.update(height=None, justify="left"),
+ style=background_style,
+ pad=not transparent_background,
+ )
+ else:
+ segments = list(line.render(console, end=""))
+ if options.no_wrap:
+ wrapped_lines = [segments]
+ else:
+ wrapped_lines = [
+ _Segment.adjust_line_length(
+ segments,
+ render_options.max_width,
+ style=background_style,
+ pad=not transparent_background,
+ )
+ ]
+
+ if self.line_numbers:
+ wrapped_line_left_pad = _Segment(
+ " " * numbers_column_width + " ", background_style
+ )
+ for first, wrapped_line in loop_first(wrapped_lines):
+ if first:
+ line_column = str(line_no).rjust(numbers_column_width - 2) + " "
+ if highlight_line(line_no):
+ yield _Segment(line_pointer, Style(color="red"))
+ yield _Segment(line_column, highlight_number_style)
+ else:
+ yield _Segment(" ", highlight_number_style)
+ yield _Segment(line_column, number_style)
+ else:
+ yield wrapped_line_left_pad
+ yield from wrapped_line
+ yield new_line
+ else:
+ for wrapped_line in wrapped_lines:
+ yield from wrapped_line
+ yield new_line
+
+ def _apply_stylized_ranges(self, text: Text) -> None:
+ """
+ Apply stylized ranges to a text instance,
+ using the given code to determine the right portion to apply the style to.
+
+ Args:
+ text (Text): Text instance to apply the style to.
+ """
+ code = text.plain
+ newlines_offsets = [
+ # Let's add outer boundaries at each side of the list:
+ 0,
+ # N.B. using "\n" here is much faster than using metacharacters such as "^" or "\Z":
+ *[
+ match.start() + 1
+ for match in re.finditer("\n", code, flags=re.MULTILINE)
+ ],
+ len(code) + 1,
+ ]
+
+ for stylized_range in self._stylized_ranges:
+ start = _get_code_index_for_syntax_position(
+ newlines_offsets, stylized_range.start
+ )
+ end = _get_code_index_for_syntax_position(
+ newlines_offsets, stylized_range.end
+ )
+ if start is not None and end is not None:
+ text.stylize(stylized_range.style, start, end)
+
+ def _process_code(self, code: str) -> Tuple[bool, str]:
+ """
+ Applies various processing to a raw code string
+ (normalises it so it always ends with a line return, dedents it if necessary, etc.)
+
+ Args:
+ code (str): The raw code string to process
+
+ Returns:
+ Tuple[bool, str]: the boolean indicates whether the raw code ends with a line return,
+ while the string is the processed code.
+ """
+ ends_on_nl = code.endswith("\n")
+ processed_code = code if ends_on_nl else code + "\n"
+ processed_code = (
+ textwrap.dedent(processed_code) if self.dedent else processed_code
+ )
+ processed_code = processed_code.expandtabs(self.tab_size)
+ return ends_on_nl, processed_code
+
+
+def _get_code_index_for_syntax_position(
+ newlines_offsets: Sequence[int], position: SyntaxPosition
+) -> Optional[int]:
+ """
+ Returns the index of the code string for the given positions.
+
+ Args:
+ newlines_offsets (Sequence[int]): The offset of each newline character found in the code snippet.
+ position (SyntaxPosition): The position to search for.
+
+ Returns:
+ Optional[int]: The index of the code string for this position, or `None`
+ if the given position's line number is out of range (if it's the column that is out of range
+ we silently clamp its value so that it reaches the end of the line)
+ """
+ lines_count = len(newlines_offsets)
+
+ line_number, column_index = position
+ if line_number > lines_count or len(newlines_offsets) < (line_number + 1):
+ return None # `line_number` is out of range
+ line_index = line_number - 1
+ line_length = newlines_offsets[line_index + 1] - newlines_offsets[line_index] - 1
+ # If `column_index` is out of range: let's silently clamp it:
+ column_index = min(line_length, column_index)
+ return newlines_offsets[line_index] + column_index
+
+
+if __name__ == "__main__": # pragma: no cover
+ import argparse
+ import sys
+
+ parser = argparse.ArgumentParser(
+ description="Render syntax to the console with Rich"
+ )
+ parser.add_argument(
+ "path",
+ metavar="PATH",
+ help="path to file, or - for stdin",
+ )
+ parser.add_argument(
+ "-c",
+ "--force-color",
+ dest="force_color",
+ action="store_true",
+ default=None,
+ help="force color for non-terminals",
+ )
+ parser.add_argument(
+ "-i",
+ "--indent-guides",
+ dest="indent_guides",
+ action="store_true",
+ default=False,
+ help="display indent guides",
+ )
+ parser.add_argument(
+ "-l",
+ "--line-numbers",
+ dest="line_numbers",
+ action="store_true",
+ help="render line numbers",
+ )
+ parser.add_argument(
+ "-w",
+ "--width",
+ type=int,
+ dest="width",
+ default=None,
+ help="width of output (default will auto-detect)",
+ )
+ parser.add_argument(
+ "-r",
+ "--wrap",
+ dest="word_wrap",
+ action="store_true",
+ default=False,
+ help="word wrap long lines",
+ )
+ parser.add_argument(
+ "-s",
+ "--soft-wrap",
+ action="store_true",
+ dest="soft_wrap",
+ default=False,
+ help="enable soft wrapping mode",
+ )
+ parser.add_argument(
+ "-t", "--theme", dest="theme", default="monokai", help="pygments theme"
+ )
+ parser.add_argument(
+ "-b",
+ "--background-color",
+ dest="background_color",
+ default=None,
+ help="Override background color",
+ )
+ parser.add_argument(
+ "-x",
+ "--lexer",
+ default=None,
+ dest="lexer_name",
+ help="Lexer name",
+ )
+ parser.add_argument(
+ "-p", "--padding", type=int, default=0, dest="padding", help="Padding"
+ )
+ parser.add_argument(
+ "--highlight-line",
+ type=int,
+ default=None,
+ dest="highlight_line",
+ help="The line number (not index!) to highlight",
+ )
+ args = parser.parse_args()
+
+ from pip._vendor.rich.console import Console
+
+ console = Console(force_terminal=args.force_color, width=args.width)
+
+ if args.path == "-":
+ code = sys.stdin.read()
+ syntax = Syntax(
+ code=code,
+ lexer=args.lexer_name,
+ line_numbers=args.line_numbers,
+ word_wrap=args.word_wrap,
+ theme=args.theme,
+ background_color=args.background_color,
+ indent_guides=args.indent_guides,
+ padding=args.padding,
+ highlight_lines={args.highlight_line},
+ )
+ else:
+ syntax = Syntax.from_path(
+ args.path,
+ lexer=args.lexer_name,
+ line_numbers=args.line_numbers,
+ word_wrap=args.word_wrap,
+ theme=args.theme,
+ background_color=args.background_color,
+ indent_guides=args.indent_guides,
+ padding=args.padding,
+ highlight_lines={args.highlight_line},
+ )
+ console.print(syntax, soft_wrap=args.soft_wrap)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/table.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/table.py
new file mode 100644
index 000000000..43c718ebf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/table.py
@@ -0,0 +1,1000 @@
+from dataclasses import dataclass, field, replace
+from typing import (
+ TYPE_CHECKING,
+ Dict,
+ Iterable,
+ List,
+ NamedTuple,
+ Optional,
+ Sequence,
+ Tuple,
+ Union,
+)
+
+from . import box, errors
+from ._loop import loop_first_last, loop_last
+from ._pick import pick_bool
+from ._ratio import ratio_distribute, ratio_reduce
+from .align import VerticalAlignMethod
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .padding import Padding, PaddingDimensions
+from .protocol import is_renderable
+from .segment import Segment
+from .style import Style, StyleType
+from .text import Text, TextType
+
+if TYPE_CHECKING:
+ from .console import (
+ Console,
+ ConsoleOptions,
+ JustifyMethod,
+ OverflowMethod,
+ RenderableType,
+ RenderResult,
+ )
+
+
+@dataclass
+class Column:
+ """Defines a column within a ~Table.
+
+ Args:
+ title (Union[str, Text], optional): The title of the table rendered at the top. Defaults to None.
+ caption (Union[str, Text], optional): The table caption rendered below. Defaults to None.
+ width (int, optional): The width in characters of the table, or ``None`` to automatically fit. Defaults to None.
+ min_width (Optional[int], optional): The minimum width of the table, or ``None`` for no minimum. Defaults to None.
+ box (box.Box, optional): One of the constants in box.py used to draw the edges (see :ref:`appendix_box`), or ``None`` for no box lines. Defaults to box.HEAVY_HEAD.
+ safe_box (Optional[bool], optional): Disable box characters that don't display on windows legacy terminal with *raster* fonts. Defaults to True.
+ padding (PaddingDimensions, optional): Padding for cells (top, right, bottom, left). Defaults to (0, 1).
+ collapse_padding (bool, optional): Enable collapsing of padding around cells. Defaults to False.
+ pad_edge (bool, optional): Enable padding of edge cells. Defaults to True.
+ expand (bool, optional): Expand the table to fit the available space if ``True``, otherwise the table width will be auto-calculated. Defaults to False.
+ show_header (bool, optional): Show a header row. Defaults to True.
+ show_footer (bool, optional): Show a footer row. Defaults to False.
+ show_edge (bool, optional): Draw a box around the outside of the table. Defaults to True.
+ show_lines (bool, optional): Draw lines between every row. Defaults to False.
+ leading (bool, optional): Number of blank lines between rows (precludes ``show_lines``). Defaults to 0.
+ style (Union[str, Style], optional): Default style for the table. Defaults to "none".
+ row_styles (List[Union, str], optional): Optional list of row styles, if more than one style is given then the styles will alternate. Defaults to None.
+ header_style (Union[str, Style], optional): Style of the header. Defaults to "table.header".
+ footer_style (Union[str, Style], optional): Style of the footer. Defaults to "table.footer".
+ border_style (Union[str, Style], optional): Style of the border. Defaults to None.
+ title_style (Union[str, Style], optional): Style of the title. Defaults to None.
+ caption_style (Union[str, Style], optional): Style of the caption. Defaults to None.
+ title_justify (str, optional): Justify method for title. Defaults to "center".
+ caption_justify (str, optional): Justify method for caption. Defaults to "center".
+ highlight (bool, optional): Highlight cell contents (if str). Defaults to False.
+ """
+
+ header: "RenderableType" = ""
+ """RenderableType: Renderable for the header (typically a string)"""
+
+ footer: "RenderableType" = ""
+ """RenderableType: Renderable for the footer (typically a string)"""
+
+ header_style: StyleType = ""
+ """StyleType: The style of the header."""
+
+ footer_style: StyleType = ""
+ """StyleType: The style of the footer."""
+
+ style: StyleType = ""
+ """StyleType: The style of the column."""
+
+ justify: "JustifyMethod" = "left"
+ """str: How to justify text within the column ("left", "center", "right", or "full")"""
+
+ vertical: "VerticalAlignMethod" = "top"
+ """str: How to vertically align content ("top", "middle", or "bottom")"""
+
+ overflow: "OverflowMethod" = "ellipsis"
+ """str: Overflow method."""
+
+ width: Optional[int] = None
+ """Optional[int]: Width of the column, or ``None`` (default) to auto calculate width."""
+
+ min_width: Optional[int] = None
+ """Optional[int]: Minimum width of column, or ``None`` for no minimum. Defaults to None."""
+
+ max_width: Optional[int] = None
+ """Optional[int]: Maximum width of column, or ``None`` for no maximum. Defaults to None."""
+
+ ratio: Optional[int] = None
+ """Optional[int]: Ratio to use when calculating column width, or ``None`` (default) to adapt to column contents."""
+
+ no_wrap: bool = False
+ """bool: Prevent wrapping of text within the column. Defaults to ``False``."""
+
+ _index: int = 0
+ """Index of column."""
+
+ _cells: List["RenderableType"] = field(default_factory=list)
+
+ def copy(self) -> "Column":
+ """Return a copy of this Column."""
+ return replace(self, _cells=[])
+
+ @property
+ def cells(self) -> Iterable["RenderableType"]:
+ """Get all cells in the column, not including header."""
+ yield from self._cells
+
+ @property
+ def flexible(self) -> bool:
+ """Check if this column is flexible."""
+ return self.ratio is not None
+
+
+@dataclass
+class Row:
+ """Information regarding a row."""
+
+ style: Optional[StyleType] = None
+ """Style to apply to row."""
+
+ end_section: bool = False
+ """Indicated end of section, which will force a line beneath the row."""
+
+
+class _Cell(NamedTuple):
+ """A single cell in a table."""
+
+ style: StyleType
+ """Style to apply to cell."""
+ renderable: "RenderableType"
+ """Cell renderable."""
+ vertical: VerticalAlignMethod
+ """Cell vertical alignment."""
+
+
+class Table(JupyterMixin):
+ """A console renderable to draw a table.
+
+ Args:
+ *headers (Union[Column, str]): Column headers, either as a string, or :class:`~rich.table.Column` instance.
+ title (Union[str, Text], optional): The title of the table rendered at the top. Defaults to None.
+ caption (Union[str, Text], optional): The table caption rendered below. Defaults to None.
+ width (int, optional): The width in characters of the table, or ``None`` to automatically fit. Defaults to None.
+ min_width (Optional[int], optional): The minimum width of the table, or ``None`` for no minimum. Defaults to None.
+ box (box.Box, optional): One of the constants in box.py used to draw the edges (see :ref:`appendix_box`), or ``None`` for no box lines. Defaults to box.HEAVY_HEAD.
+ safe_box (Optional[bool], optional): Disable box characters that don't display on windows legacy terminal with *raster* fonts. Defaults to True.
+ padding (PaddingDimensions, optional): Padding for cells (top, right, bottom, left). Defaults to (0, 1).
+ collapse_padding (bool, optional): Enable collapsing of padding around cells. Defaults to False.
+ pad_edge (bool, optional): Enable padding of edge cells. Defaults to True.
+ expand (bool, optional): Expand the table to fit the available space if ``True``, otherwise the table width will be auto-calculated. Defaults to False.
+ show_header (bool, optional): Show a header row. Defaults to True.
+ show_footer (bool, optional): Show a footer row. Defaults to False.
+ show_edge (bool, optional): Draw a box around the outside of the table. Defaults to True.
+ show_lines (bool, optional): Draw lines between every row. Defaults to False.
+ leading (bool, optional): Number of blank lines between rows (precludes ``show_lines``). Defaults to 0.
+ style (Union[str, Style], optional): Default style for the table. Defaults to "none".
+ row_styles (List[Union, str], optional): Optional list of row styles, if more than one style is given then the styles will alternate. Defaults to None.
+ header_style (Union[str, Style], optional): Style of the header. Defaults to "table.header".
+ footer_style (Union[str, Style], optional): Style of the footer. Defaults to "table.footer".
+ border_style (Union[str, Style], optional): Style of the border. Defaults to None.
+ title_style (Union[str, Style], optional): Style of the title. Defaults to None.
+ caption_style (Union[str, Style], optional): Style of the caption. Defaults to None.
+ title_justify (str, optional): Justify method for title. Defaults to "center".
+ caption_justify (str, optional): Justify method for caption. Defaults to "center".
+ highlight (bool, optional): Highlight cell contents (if str). Defaults to False.
+ """
+
+ columns: List[Column]
+ rows: List[Row]
+
+ def __init__(
+ self,
+ *headers: Union[Column, str],
+ title: Optional[TextType] = None,
+ caption: Optional[TextType] = None,
+ width: Optional[int] = None,
+ min_width: Optional[int] = None,
+ box: Optional[box.Box] = box.HEAVY_HEAD,
+ safe_box: Optional[bool] = None,
+ padding: PaddingDimensions = (0, 1),
+ collapse_padding: bool = False,
+ pad_edge: bool = True,
+ expand: bool = False,
+ show_header: bool = True,
+ show_footer: bool = False,
+ show_edge: bool = True,
+ show_lines: bool = False,
+ leading: int = 0,
+ style: StyleType = "none",
+ row_styles: Optional[Iterable[StyleType]] = None,
+ header_style: Optional[StyleType] = "table.header",
+ footer_style: Optional[StyleType] = "table.footer",
+ border_style: Optional[StyleType] = None,
+ title_style: Optional[StyleType] = None,
+ caption_style: Optional[StyleType] = None,
+ title_justify: "JustifyMethod" = "center",
+ caption_justify: "JustifyMethod" = "center",
+ highlight: bool = False,
+ ) -> None:
+ self.columns: List[Column] = []
+ self.rows: List[Row] = []
+ self.title = title
+ self.caption = caption
+ self.width = width
+ self.min_width = min_width
+ self.box = box
+ self.safe_box = safe_box
+ self._padding = Padding.unpack(padding)
+ self.pad_edge = pad_edge
+ self._expand = expand
+ self.show_header = show_header
+ self.show_footer = show_footer
+ self.show_edge = show_edge
+ self.show_lines = show_lines
+ self.leading = leading
+ self.collapse_padding = collapse_padding
+ self.style = style
+ self.header_style = header_style or ""
+ self.footer_style = footer_style or ""
+ self.border_style = border_style
+ self.title_style = title_style
+ self.caption_style = caption_style
+ self.title_justify: "JustifyMethod" = title_justify
+ self.caption_justify: "JustifyMethod" = caption_justify
+ self.highlight = highlight
+ self.row_styles: Sequence[StyleType] = list(row_styles or [])
+ append_column = self.columns.append
+ for header in headers:
+ if isinstance(header, str):
+ self.add_column(header=header)
+ else:
+ header._index = len(self.columns)
+ append_column(header)
+
+ @classmethod
+ def grid(
+ cls,
+ *headers: Union[Column, str],
+ padding: PaddingDimensions = 0,
+ collapse_padding: bool = True,
+ pad_edge: bool = False,
+ expand: bool = False,
+ ) -> "Table":
+ """Get a table with no lines, headers, or footer.
+
+ Args:
+ *headers (Union[Column, str]): Column headers, either as a string, or :class:`~rich.table.Column` instance.
+ padding (PaddingDimensions, optional): Get padding around cells. Defaults to 0.
+ collapse_padding (bool, optional): Enable collapsing of padding around cells. Defaults to True.
+ pad_edge (bool, optional): Enable padding around edges of table. Defaults to False.
+ expand (bool, optional): Expand the table to fit the available space if ``True``, otherwise the table width will be auto-calculated. Defaults to False.
+
+ Returns:
+ Table: A table instance.
+ """
+ return cls(
+ *headers,
+ box=None,
+ padding=padding,
+ collapse_padding=collapse_padding,
+ show_header=False,
+ show_footer=False,
+ show_edge=False,
+ pad_edge=pad_edge,
+ expand=expand,
+ )
+
+ @property
+ def expand(self) -> bool:
+ """Setting a non-None self.width implies expand."""
+ return self._expand or self.width is not None
+
+ @expand.setter
+ def expand(self, expand: bool) -> None:
+ """Set expand."""
+ self._expand = expand
+
+ @property
+ def _extra_width(self) -> int:
+ """Get extra width to add to cell content."""
+ width = 0
+ if self.box and self.show_edge:
+ width += 2
+ if self.box:
+ width += len(self.columns) - 1
+ return width
+
+ @property
+ def row_count(self) -> int:
+ """Get the current number of rows."""
+ return len(self.rows)
+
+ def get_row_style(self, console: "Console", index: int) -> StyleType:
+ """Get the current row style."""
+ style = Style.null()
+ if self.row_styles:
+ style += console.get_style(self.row_styles[index % len(self.row_styles)])
+ row_style = self.rows[index].style
+ if row_style is not None:
+ style += console.get_style(row_style)
+ return style
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Measurement:
+ max_width = options.max_width
+ if self.width is not None:
+ max_width = self.width
+ if max_width < 0:
+ return Measurement(0, 0)
+
+ extra_width = self._extra_width
+ max_width = sum(
+ self._calculate_column_widths(
+ console, options.update_width(max_width - extra_width)
+ )
+ )
+ _measure_column = self._measure_column
+
+ measurements = [
+ _measure_column(console, options.update_width(max_width), column)
+ for column in self.columns
+ ]
+ minimum_width = (
+ sum(measurement.minimum for measurement in measurements) + extra_width
+ )
+ maximum_width = (
+ sum(measurement.maximum for measurement in measurements) + extra_width
+ if (self.width is None)
+ else self.width
+ )
+ measurement = Measurement(minimum_width, maximum_width)
+ measurement = measurement.clamp(self.min_width)
+ return measurement
+
+ @property
+ def padding(self) -> Tuple[int, int, int, int]:
+ """Get cell padding."""
+ return self._padding
+
+ @padding.setter
+ def padding(self, padding: PaddingDimensions) -> "Table":
+ """Set cell padding."""
+ self._padding = Padding.unpack(padding)
+ return self
+
+ def add_column(
+ self,
+ header: "RenderableType" = "",
+ footer: "RenderableType" = "",
+ *,
+ header_style: Optional[StyleType] = None,
+ footer_style: Optional[StyleType] = None,
+ style: Optional[StyleType] = None,
+ justify: "JustifyMethod" = "left",
+ vertical: "VerticalAlignMethod" = "top",
+ overflow: "OverflowMethod" = "ellipsis",
+ width: Optional[int] = None,
+ min_width: Optional[int] = None,
+ max_width: Optional[int] = None,
+ ratio: Optional[int] = None,
+ no_wrap: bool = False,
+ ) -> None:
+ """Add a column to the table.
+
+ Args:
+ header (RenderableType, optional): Text or renderable for the header.
+ Defaults to "".
+ footer (RenderableType, optional): Text or renderable for the footer.
+ Defaults to "".
+ header_style (Union[str, Style], optional): Style for the header, or None for default. Defaults to None.
+ footer_style (Union[str, Style], optional): Style for the footer, or None for default. Defaults to None.
+ style (Union[str, Style], optional): Style for the column cells, or None for default. Defaults to None.
+ justify (JustifyMethod, optional): Alignment for cells. Defaults to "left".
+ vertical (VerticalAlignMethod, optional): Vertical alignment, one of "top", "middle", or "bottom". Defaults to "top".
+ overflow (OverflowMethod): Overflow method: "crop", "fold", "ellipsis". Defaults to "ellipsis".
+ width (int, optional): Desired width of column in characters, or None to fit to contents. Defaults to None.
+ min_width (Optional[int], optional): Minimum width of column, or ``None`` for no minimum. Defaults to None.
+ max_width (Optional[int], optional): Maximum width of column, or ``None`` for no maximum. Defaults to None.
+ ratio (int, optional): Flexible ratio for the column (requires ``Table.expand`` or ``Table.width``). Defaults to None.
+ no_wrap (bool, optional): Set to ``True`` to disable wrapping of this column.
+ """
+
+ column = Column(
+ _index=len(self.columns),
+ header=header,
+ footer=footer,
+ header_style=header_style or "",
+ footer_style=footer_style or "",
+ style=style or "",
+ justify=justify,
+ vertical=vertical,
+ overflow=overflow,
+ width=width,
+ min_width=min_width,
+ max_width=max_width,
+ ratio=ratio,
+ no_wrap=no_wrap,
+ )
+ self.columns.append(column)
+
+ def add_row(
+ self,
+ *renderables: Optional["RenderableType"],
+ style: Optional[StyleType] = None,
+ end_section: bool = False,
+ ) -> None:
+ """Add a row of renderables.
+
+ Args:
+ *renderables (None or renderable): Each cell in a row must be a renderable object (including str),
+ or ``None`` for a blank cell.
+ style (StyleType, optional): An optional style to apply to the entire row. Defaults to None.
+ end_section (bool, optional): End a section and draw a line. Defaults to False.
+
+ Raises:
+ errors.NotRenderableError: If you add something that can't be rendered.
+ """
+
+ def add_cell(column: Column, renderable: "RenderableType") -> None:
+ column._cells.append(renderable)
+
+ cell_renderables: List[Optional["RenderableType"]] = list(renderables)
+
+ columns = self.columns
+ if len(cell_renderables) < len(columns):
+ cell_renderables = [
+ *cell_renderables,
+ *[None] * (len(columns) - len(cell_renderables)),
+ ]
+ for index, renderable in enumerate(cell_renderables):
+ if index == len(columns):
+ column = Column(_index=index)
+ for _ in self.rows:
+ add_cell(column, Text(""))
+ self.columns.append(column)
+ else:
+ column = columns[index]
+ if renderable is None:
+ add_cell(column, "")
+ elif is_renderable(renderable):
+ add_cell(column, renderable)
+ else:
+ raise errors.NotRenderableError(
+ f"unable to render {type(renderable).__name__}; a string or other renderable object is required"
+ )
+ self.rows.append(Row(style=style, end_section=end_section))
+
+ def add_section(self) -> None:
+ """Add a new section (draw a line after current row)."""
+
+ if self.rows:
+ self.rows[-1].end_section = True
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ if not self.columns:
+ yield Segment("\n")
+ return
+
+ max_width = options.max_width
+ if self.width is not None:
+ max_width = self.width
+
+ extra_width = self._extra_width
+ widths = self._calculate_column_widths(
+ console, options.update_width(max_width - extra_width)
+ )
+ table_width = sum(widths) + extra_width
+
+ render_options = options.update(
+ width=table_width, highlight=self.highlight, height=None
+ )
+
+ def render_annotation(
+ text: TextType, style: StyleType, justify: "JustifyMethod" = "center"
+ ) -> "RenderResult":
+ render_text = (
+ console.render_str(text, style=style, highlight=False)
+ if isinstance(text, str)
+ else text
+ )
+ return console.render(
+ render_text, options=render_options.update(justify=justify)
+ )
+
+ if self.title:
+ yield from render_annotation(
+ self.title,
+ style=Style.pick_first(self.title_style, "table.title"),
+ justify=self.title_justify,
+ )
+ yield from self._render(console, render_options, widths)
+ if self.caption:
+ yield from render_annotation(
+ self.caption,
+ style=Style.pick_first(self.caption_style, "table.caption"),
+ justify=self.caption_justify,
+ )
+
+ def _calculate_column_widths(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> List[int]:
+ """Calculate the widths of each column, including padding, not including borders."""
+ max_width = options.max_width
+ columns = self.columns
+ width_ranges = [
+ self._measure_column(console, options, column) for column in columns
+ ]
+ widths = [_range.maximum or 1 for _range in width_ranges]
+ get_padding_width = self._get_padding_width
+ extra_width = self._extra_width
+ if self.expand:
+ ratios = [col.ratio or 0 for col in columns if col.flexible]
+ if any(ratios):
+ fixed_widths = [
+ 0 if column.flexible else _range.maximum
+ for _range, column in zip(width_ranges, columns)
+ ]
+ flex_minimum = [
+ (column.width or 1) + get_padding_width(column._index)
+ for column in columns
+ if column.flexible
+ ]
+ flexible_width = max_width - sum(fixed_widths)
+ flex_widths = ratio_distribute(flexible_width, ratios, flex_minimum)
+ iter_flex_widths = iter(flex_widths)
+ for index, column in enumerate(columns):
+ if column.flexible:
+ widths[index] = fixed_widths[index] + next(iter_flex_widths)
+ table_width = sum(widths)
+
+ if table_width > max_width:
+ widths = self._collapse_widths(
+ widths,
+ [(column.width is None and not column.no_wrap) for column in columns],
+ max_width,
+ )
+ table_width = sum(widths)
+ # last resort, reduce columns evenly
+ if table_width > max_width:
+ excess_width = table_width - max_width
+ widths = ratio_reduce(excess_width, [1] * len(widths), widths, widths)
+ table_width = sum(widths)
+
+ width_ranges = [
+ self._measure_column(console, options.update_width(width), column)
+ for width, column in zip(widths, columns)
+ ]
+ widths = [_range.maximum or 0 for _range in width_ranges]
+
+ if (table_width < max_width and self.expand) or (
+ self.min_width is not None and table_width < (self.min_width - extra_width)
+ ):
+ _max_width = (
+ max_width
+ if self.min_width is None
+ else min(self.min_width - extra_width, max_width)
+ )
+ pad_widths = ratio_distribute(_max_width - table_width, widths)
+ widths = [_width + pad for _width, pad in zip(widths, pad_widths)]
+
+ return widths
+
+ @classmethod
+ def _collapse_widths(
+ cls, widths: List[int], wrapable: List[bool], max_width: int
+ ) -> List[int]:
+ """Reduce widths so that the total is under max_width.
+
+ Args:
+ widths (List[int]): List of widths.
+ wrapable (List[bool]): List of booleans that indicate if a column may shrink.
+ max_width (int): Maximum width to reduce to.
+
+ Returns:
+ List[int]: A new list of widths.
+ """
+ total_width = sum(widths)
+ excess_width = total_width - max_width
+ if any(wrapable):
+ while total_width and excess_width > 0:
+ max_column = max(
+ width for width, allow_wrap in zip(widths, wrapable) if allow_wrap
+ )
+ second_max_column = max(
+ width if allow_wrap and width != max_column else 0
+ for width, allow_wrap in zip(widths, wrapable)
+ )
+ column_difference = max_column - second_max_column
+ ratios = [
+ (1 if (width == max_column and allow_wrap) else 0)
+ for width, allow_wrap in zip(widths, wrapable)
+ ]
+ if not any(ratios) or not column_difference:
+ break
+ max_reduce = [min(excess_width, column_difference)] * len(widths)
+ widths = ratio_reduce(excess_width, ratios, max_reduce, widths)
+
+ total_width = sum(widths)
+ excess_width = total_width - max_width
+ return widths
+
+ def _get_cells(
+ self, console: "Console", column_index: int, column: Column
+ ) -> Iterable[_Cell]:
+ """Get all the cells with padding and optional header."""
+
+ collapse_padding = self.collapse_padding
+ pad_edge = self.pad_edge
+ padding = self.padding
+ any_padding = any(padding)
+
+ first_column = column_index == 0
+ last_column = column_index == len(self.columns) - 1
+
+ _padding_cache: Dict[Tuple[bool, bool], Tuple[int, int, int, int]] = {}
+
+ def get_padding(first_row: bool, last_row: bool) -> Tuple[int, int, int, int]:
+ cached = _padding_cache.get((first_row, last_row))
+ if cached:
+ return cached
+ top, right, bottom, left = padding
+
+ if collapse_padding:
+ if not first_column:
+ left = max(0, left - right)
+ if not last_row:
+ bottom = max(0, top - bottom)
+
+ if not pad_edge:
+ if first_column:
+ left = 0
+ if last_column:
+ right = 0
+ if first_row:
+ top = 0
+ if last_row:
+ bottom = 0
+ _padding = (top, right, bottom, left)
+ _padding_cache[(first_row, last_row)] = _padding
+ return _padding
+
+ raw_cells: List[Tuple[StyleType, "RenderableType"]] = []
+ _append = raw_cells.append
+ get_style = console.get_style
+ if self.show_header:
+ header_style = get_style(self.header_style or "") + get_style(
+ column.header_style
+ )
+ _append((header_style, column.header))
+ cell_style = get_style(column.style or "")
+ for cell in column.cells:
+ _append((cell_style, cell))
+ if self.show_footer:
+ footer_style = get_style(self.footer_style or "") + get_style(
+ column.footer_style
+ )
+ _append((footer_style, column.footer))
+
+ if any_padding:
+ _Padding = Padding
+ for first, last, (style, renderable) in loop_first_last(raw_cells):
+ yield _Cell(
+ style,
+ _Padding(renderable, get_padding(first, last)),
+ getattr(renderable, "vertical", None) or column.vertical,
+ )
+ else:
+ for style, renderable in raw_cells:
+ yield _Cell(
+ style,
+ renderable,
+ getattr(renderable, "vertical", None) or column.vertical,
+ )
+
+ def _get_padding_width(self, column_index: int) -> int:
+ """Get extra width from padding."""
+ _, pad_right, _, pad_left = self.padding
+ if self.collapse_padding:
+ if column_index > 0:
+ pad_left = max(0, pad_left - pad_right)
+ return pad_left + pad_right
+
+ def _measure_column(
+ self,
+ console: "Console",
+ options: "ConsoleOptions",
+ column: Column,
+ ) -> Measurement:
+ """Get the minimum and maximum width of the column."""
+
+ max_width = options.max_width
+ if max_width < 1:
+ return Measurement(0, 0)
+
+ padding_width = self._get_padding_width(column._index)
+
+ if column.width is not None:
+ # Fixed width column
+ return Measurement(
+ column.width + padding_width, column.width + padding_width
+ ).with_maximum(max_width)
+ # Flexible column, we need to measure contents
+ min_widths: List[int] = []
+ max_widths: List[int] = []
+ append_min = min_widths.append
+ append_max = max_widths.append
+ get_render_width = Measurement.get
+ for cell in self._get_cells(console, column._index, column):
+ _min, _max = get_render_width(console, options, cell.renderable)
+ append_min(_min)
+ append_max(_max)
+
+ measurement = Measurement(
+ max(min_widths) if min_widths else 1,
+ max(max_widths) if max_widths else max_width,
+ ).with_maximum(max_width)
+ measurement = measurement.clamp(
+ None if column.min_width is None else column.min_width + padding_width,
+ None if column.max_width is None else column.max_width + padding_width,
+ )
+ return measurement
+
+ def _render(
+ self, console: "Console", options: "ConsoleOptions", widths: List[int]
+ ) -> "RenderResult":
+ table_style = console.get_style(self.style or "")
+
+ border_style = table_style + console.get_style(self.border_style or "")
+ _column_cells = (
+ self._get_cells(console, column_index, column)
+ for column_index, column in enumerate(self.columns)
+ )
+ row_cells: List[Tuple[_Cell, ...]] = list(zip(*_column_cells))
+ _box = (
+ self.box.substitute(
+ options, safe=pick_bool(self.safe_box, console.safe_box)
+ )
+ if self.box
+ else None
+ )
+ _box = _box.get_plain_headed_box() if _box and not self.show_header else _box
+
+ new_line = Segment.line()
+
+ columns = self.columns
+ show_header = self.show_header
+ show_footer = self.show_footer
+ show_edge = self.show_edge
+ show_lines = self.show_lines
+ leading = self.leading
+
+ _Segment = Segment
+ if _box:
+ box_segments = [
+ (
+ _Segment(_box.head_left, border_style),
+ _Segment(_box.head_right, border_style),
+ _Segment(_box.head_vertical, border_style),
+ ),
+ (
+ _Segment(_box.foot_left, border_style),
+ _Segment(_box.foot_right, border_style),
+ _Segment(_box.foot_vertical, border_style),
+ ),
+ (
+ _Segment(_box.mid_left, border_style),
+ _Segment(_box.mid_right, border_style),
+ _Segment(_box.mid_vertical, border_style),
+ ),
+ ]
+ if show_edge:
+ yield _Segment(_box.get_top(widths), border_style)
+ yield new_line
+ else:
+ box_segments = []
+
+ get_row_style = self.get_row_style
+ get_style = console.get_style
+
+ for index, (first, last, row_cell) in enumerate(loop_first_last(row_cells)):
+ header_row = first and show_header
+ footer_row = last and show_footer
+ row = (
+ self.rows[index - show_header]
+ if (not header_row and not footer_row)
+ else None
+ )
+ max_height = 1
+ cells: List[List[List[Segment]]] = []
+ if header_row or footer_row:
+ row_style = Style.null()
+ else:
+ row_style = get_style(
+ get_row_style(console, index - 1 if show_header else index)
+ )
+ for width, cell, column in zip(widths, row_cell, columns):
+ render_options = options.update(
+ width=width,
+ justify=column.justify,
+ no_wrap=column.no_wrap,
+ overflow=column.overflow,
+ height=None,
+ )
+ lines = console.render_lines(
+ cell.renderable,
+ render_options,
+ style=get_style(cell.style) + row_style,
+ )
+ max_height = max(max_height, len(lines))
+ cells.append(lines)
+
+ row_height = max(len(cell) for cell in cells)
+
+ def align_cell(
+ cell: List[List[Segment]],
+ vertical: "VerticalAlignMethod",
+ width: int,
+ style: Style,
+ ) -> List[List[Segment]]:
+ if header_row:
+ vertical = "bottom"
+ elif footer_row:
+ vertical = "top"
+
+ if vertical == "top":
+ return _Segment.align_top(cell, width, row_height, style)
+ elif vertical == "middle":
+ return _Segment.align_middle(cell, width, row_height, style)
+ return _Segment.align_bottom(cell, width, row_height, style)
+
+ cells[:] = [
+ _Segment.set_shape(
+ align_cell(
+ cell,
+ _cell.vertical,
+ width,
+ get_style(_cell.style) + row_style,
+ ),
+ width,
+ max_height,
+ )
+ for width, _cell, cell, column in zip(widths, row_cell, cells, columns)
+ ]
+
+ if _box:
+ if last and show_footer:
+ yield _Segment(
+ _box.get_row(widths, "foot", edge=show_edge), border_style
+ )
+ yield new_line
+ left, right, _divider = box_segments[0 if first else (2 if last else 1)]
+
+ # If the column divider is whitespace also style it with the row background
+ divider = (
+ _divider
+ if _divider.text.strip()
+ else _Segment(
+ _divider.text, row_style.background_style + _divider.style
+ )
+ )
+ for line_no in range(max_height):
+ if show_edge:
+ yield left
+ for last_cell, rendered_cell in loop_last(cells):
+ yield from rendered_cell[line_no]
+ if not last_cell:
+ yield divider
+ if show_edge:
+ yield right
+ yield new_line
+ else:
+ for line_no in range(max_height):
+ for rendered_cell in cells:
+ yield from rendered_cell[line_no]
+ yield new_line
+ if _box and first and show_header:
+ yield _Segment(
+ _box.get_row(widths, "head", edge=show_edge), border_style
+ )
+ yield new_line
+ end_section = row and row.end_section
+ if _box and (show_lines or leading or end_section):
+ if (
+ not last
+ and not (show_footer and index >= len(row_cells) - 2)
+ and not (show_header and header_row)
+ ):
+ if leading:
+ yield _Segment(
+ _box.get_row(widths, "mid", edge=show_edge) * leading,
+ border_style,
+ )
+ else:
+ yield _Segment(
+ _box.get_row(widths, "row", edge=show_edge), border_style
+ )
+ yield new_line
+
+ if _box and show_edge:
+ yield _Segment(_box.get_bottom(widths), border_style)
+ yield new_line
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.console import Console
+ from pip._vendor.rich.highlighter import ReprHighlighter
+ from pip._vendor.rich.table import Table as Table
+
+ from ._timer import timer
+
+ with timer("Table render"):
+ table = Table(
+ title="Star Wars Movies",
+ caption="Rich example table",
+ caption_justify="right",
+ )
+
+ table.add_column(
+ "Released", header_style="bright_cyan", style="cyan", no_wrap=True
+ )
+ table.add_column("Title", style="magenta")
+ table.add_column("Box Office", justify="right", style="green")
+
+ table.add_row(
+ "Dec 20, 2019",
+ "Star Wars: The Rise of Skywalker",
+ "$952,110,690",
+ )
+ table.add_row("May 25, 2018", "Solo: A Star Wars Story", "$393,151,347")
+ table.add_row(
+ "Dec 15, 2017",
+ "Star Wars Ep. V111: The Last Jedi",
+ "$1,332,539,889",
+ style="on black",
+ end_section=True,
+ )
+ table.add_row(
+ "Dec 16, 2016",
+ "Rogue One: A Star Wars Story",
+ "$1,332,439,889",
+ )
+
+ def header(text: str) -> None:
+ console.print()
+ console.rule(highlight(text))
+ console.print()
+
+ console = Console()
+ highlight = ReprHighlighter()
+ header("Example Table")
+ console.print(table, justify="center")
+
+ table.expand = True
+ header("expand=True")
+ console.print(table)
+
+ table.width = 50
+ header("width=50")
+
+ console.print(table, justify="center")
+
+ table.width = None
+ table.expand = False
+ table.row_styles = ["dim", "none"]
+ header("row_styles=['dim', 'none']")
+
+ console.print(table, justify="center")
+
+ table.width = None
+ table.expand = False
+ table.row_styles = ["dim", "none"]
+ table.leading = 1
+ header("leading=1, row_styles=['dim', 'none']")
+ console.print(table, justify="center")
+
+ table.width = None
+ table.expand = False
+ table.row_styles = ["dim", "none"]
+ table.show_lines = True
+ table.leading = 0
+ header("show_lines=True, row_styles=['dim', 'none']")
+ console.print(table, justify="center")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/terminal_theme.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/terminal_theme.py
new file mode 100644
index 000000000..565e9d960
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/terminal_theme.py
@@ -0,0 +1,153 @@
+from typing import List, Optional, Tuple
+
+from .color_triplet import ColorTriplet
+from .palette import Palette
+
+_ColorTuple = Tuple[int, int, int]
+
+
+class TerminalTheme:
+ """A color theme used when exporting console content.
+
+ Args:
+ background (Tuple[int, int, int]): The background color.
+ foreground (Tuple[int, int, int]): The foreground (text) color.
+ normal (List[Tuple[int, int, int]]): A list of 8 normal intensity colors.
+ bright (List[Tuple[int, int, int]], optional): A list of 8 bright colors, or None
+ to repeat normal intensity. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ background: _ColorTuple,
+ foreground: _ColorTuple,
+ normal: List[_ColorTuple],
+ bright: Optional[List[_ColorTuple]] = None,
+ ) -> None:
+ self.background_color = ColorTriplet(*background)
+ self.foreground_color = ColorTriplet(*foreground)
+ self.ansi_colors = Palette(normal + (bright or normal))
+
+
+DEFAULT_TERMINAL_THEME = TerminalTheme(
+ (255, 255, 255),
+ (0, 0, 0),
+ [
+ (0, 0, 0),
+ (128, 0, 0),
+ (0, 128, 0),
+ (128, 128, 0),
+ (0, 0, 128),
+ (128, 0, 128),
+ (0, 128, 128),
+ (192, 192, 192),
+ ],
+ [
+ (128, 128, 128),
+ (255, 0, 0),
+ (0, 255, 0),
+ (255, 255, 0),
+ (0, 0, 255),
+ (255, 0, 255),
+ (0, 255, 255),
+ (255, 255, 255),
+ ],
+)
+
+MONOKAI = TerminalTheme(
+ (12, 12, 12),
+ (217, 217, 217),
+ [
+ (26, 26, 26),
+ (244, 0, 95),
+ (152, 224, 36),
+ (253, 151, 31),
+ (157, 101, 255),
+ (244, 0, 95),
+ (88, 209, 235),
+ (196, 197, 181),
+ (98, 94, 76),
+ ],
+ [
+ (244, 0, 95),
+ (152, 224, 36),
+ (224, 213, 97),
+ (157, 101, 255),
+ (244, 0, 95),
+ (88, 209, 235),
+ (246, 246, 239),
+ ],
+)
+DIMMED_MONOKAI = TerminalTheme(
+ (25, 25, 25),
+ (185, 188, 186),
+ [
+ (58, 61, 67),
+ (190, 63, 72),
+ (135, 154, 59),
+ (197, 166, 53),
+ (79, 118, 161),
+ (133, 92, 141),
+ (87, 143, 164),
+ (185, 188, 186),
+ (136, 137, 135),
+ ],
+ [
+ (251, 0, 31),
+ (15, 114, 47),
+ (196, 112, 51),
+ (24, 109, 227),
+ (251, 0, 103),
+ (46, 112, 109),
+ (253, 255, 185),
+ ],
+)
+NIGHT_OWLISH = TerminalTheme(
+ (255, 255, 255),
+ (64, 63, 83),
+ [
+ (1, 22, 39),
+ (211, 66, 62),
+ (42, 162, 152),
+ (218, 170, 1),
+ (72, 118, 214),
+ (64, 63, 83),
+ (8, 145, 106),
+ (122, 129, 129),
+ (122, 129, 129),
+ ],
+ [
+ (247, 110, 110),
+ (73, 208, 197),
+ (218, 194, 107),
+ (92, 167, 228),
+ (105, 112, 152),
+ (0, 201, 144),
+ (152, 159, 177),
+ ],
+)
+
+SVG_EXPORT_THEME = TerminalTheme(
+ (41, 41, 41),
+ (197, 200, 198),
+ [
+ (75, 78, 85),
+ (204, 85, 90),
+ (152, 168, 75),
+ (208, 179, 68),
+ (96, 138, 177),
+ (152, 114, 159),
+ (104, 160, 179),
+ (197, 200, 198),
+ (154, 155, 153),
+ ],
+ [
+ (255, 38, 39),
+ (0, 130, 61),
+ (208, 132, 66),
+ (25, 132, 233),
+ (255, 44, 122),
+ (57, 130, 128),
+ (253, 253, 197),
+ ],
+)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/text.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/text.py
new file mode 100644
index 000000000..209aa9434
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/text.py
@@ -0,0 +1,1357 @@
+import re
+from functools import partial, reduce
+from math import gcd
+from operator import itemgetter
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Callable,
+ Dict,
+ Iterable,
+ List,
+ NamedTuple,
+ Optional,
+ Tuple,
+ Union,
+)
+
+from ._loop import loop_last
+from ._pick import pick_bool
+from ._wrap import divide_line
+from .align import AlignMethod
+from .cells import cell_len, set_cell_size
+from .containers import Lines
+from .control import strip_control_codes
+from .emoji import EmojiVariant
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .segment import Segment
+from .style import Style, StyleType
+
+if TYPE_CHECKING: # pragma: no cover
+ from .console import Console, ConsoleOptions, JustifyMethod, OverflowMethod
+
+DEFAULT_JUSTIFY: "JustifyMethod" = "default"
+DEFAULT_OVERFLOW: "OverflowMethod" = "fold"
+
+
+_re_whitespace = re.compile(r"\s+$")
+
+TextType = Union[str, "Text"]
+"""A plain string or a :class:`Text` instance."""
+
+GetStyleCallable = Callable[[str], Optional[StyleType]]
+
+
+class Span(NamedTuple):
+ """A marked up region in some text."""
+
+ start: int
+ """Span start index."""
+ end: int
+ """Span end index."""
+ style: Union[str, Style]
+ """Style associated with the span."""
+
+ def __repr__(self) -> str:
+ return f"Span({self.start}, {self.end}, {self.style!r})"
+
+ def __bool__(self) -> bool:
+ return self.end > self.start
+
+ def split(self, offset: int) -> Tuple["Span", Optional["Span"]]:
+ """Split a span in to 2 from a given offset."""
+
+ if offset < self.start:
+ return self, None
+ if offset >= self.end:
+ return self, None
+
+ start, end, style = self
+ span1 = Span(start, min(end, offset), style)
+ span2 = Span(span1.end, end, style)
+ return span1, span2
+
+ def move(self, offset: int) -> "Span":
+ """Move start and end by a given offset.
+
+ Args:
+ offset (int): Number of characters to add to start and end.
+
+ Returns:
+ TextSpan: A new TextSpan with adjusted position.
+ """
+ start, end, style = self
+ return Span(start + offset, end + offset, style)
+
+ def right_crop(self, offset: int) -> "Span":
+ """Crop the span at the given offset.
+
+ Args:
+ offset (int): A value between start and end.
+
+ Returns:
+ Span: A new (possibly smaller) span.
+ """
+ start, end, style = self
+ if offset >= end:
+ return self
+ return Span(start, min(offset, end), style)
+
+ def extend(self, cells: int) -> "Span":
+ """Extend the span by the given number of cells.
+
+ Args:
+ cells (int): Additional space to add to end of span.
+
+ Returns:
+ Span: A span.
+ """
+ if cells:
+ start, end, style = self
+ return Span(start, end + cells, style)
+ else:
+ return self
+
+
+class Text(JupyterMixin):
+ """Text with color / style.
+
+ Args:
+ text (str, optional): Default unstyled text. Defaults to "".
+ style (Union[str, Style], optional): Base style for text. Defaults to "".
+ justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
+ overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
+ no_wrap (bool, optional): Disable text wrapping, or None for default. Defaults to None.
+ end (str, optional): Character to end text with. Defaults to "\\\\n".
+ tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to None.
+ spans (List[Span], optional). A list of predefined style spans. Defaults to None.
+ """
+
+ __slots__ = [
+ "_text",
+ "style",
+ "justify",
+ "overflow",
+ "no_wrap",
+ "end",
+ "tab_size",
+ "_spans",
+ "_length",
+ ]
+
+ def __init__(
+ self,
+ text: str = "",
+ style: Union[str, Style] = "",
+ *,
+ justify: Optional["JustifyMethod"] = None,
+ overflow: Optional["OverflowMethod"] = None,
+ no_wrap: Optional[bool] = None,
+ end: str = "\n",
+ tab_size: Optional[int] = None,
+ spans: Optional[List[Span]] = None,
+ ) -> None:
+ sanitized_text = strip_control_codes(text)
+ self._text = [sanitized_text]
+ self.style = style
+ self.justify: Optional["JustifyMethod"] = justify
+ self.overflow: Optional["OverflowMethod"] = overflow
+ self.no_wrap = no_wrap
+ self.end = end
+ self.tab_size = tab_size
+ self._spans: List[Span] = spans or []
+ self._length: int = len(sanitized_text)
+
+ def __len__(self) -> int:
+ return self._length
+
+ def __bool__(self) -> bool:
+ return bool(self._length)
+
+ def __str__(self) -> str:
+ return self.plain
+
+ def __repr__(self) -> str:
+ return f"<text {self.plain!r} {self._spans!r}>"
+
+ def __add__(self, other: Any) -> "Text":
+ if isinstance(other, (str, Text)):
+ result = self.copy()
+ result.append(other)
+ return result
+ return NotImplemented
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, Text):
+ return NotImplemented
+ return self.plain == other.plain and self._spans == other._spans
+
+ def __contains__(self, other: object) -> bool:
+ if isinstance(other, str):
+ return other in self.plain
+ elif isinstance(other, Text):
+ return other.plain in self.plain
+ return False
+
+ def __getitem__(self, slice: Union[int, slice]) -> "Text":
+ def get_text_at(offset: int) -> "Text":
+ _Span = Span
+ text = Text(
+ self.plain[offset],
+ spans=[
+ _Span(0, 1, style)
+ for start, end, style in self._spans
+ if end > offset >= start
+ ],
+ end="",
+ )
+ return text
+
+ if isinstance(slice, int):
+ return get_text_at(slice)
+ else:
+ start, stop, step = slice.indices(len(self.plain))
+ if step == 1:
+ lines = self.divide([start, stop])
+ return lines[1]
+ else:
+ # This would be a bit of work to implement efficiently
+ # For now, its not required
+ raise TypeError("slices with step!=1 are not supported")
+
+ @property
+ def cell_len(self) -> int:
+ """Get the number of cells required to render this text."""
+ return cell_len(self.plain)
+
+ @property
+ def markup(self) -> str:
+ """Get console markup to render this Text.
+
+ Returns:
+ str: A string potentially creating markup tags.
+ """
+ from .markup import escape
+
+ output: List[str] = []
+
+ plain = self.plain
+ markup_spans = [
+ (0, False, self.style),
+ *((span.start, False, span.style) for span in self._spans),
+ *((span.end, True, span.style) for span in self._spans),
+ (len(plain), True, self.style),
+ ]
+ markup_spans.sort(key=itemgetter(0, 1))
+ position = 0
+ append = output.append
+ for offset, closing, style in markup_spans:
+ if offset > position:
+ append(escape(plain[position:offset]))
+ position = offset
+ if style:
+ append(f"[/{style}]" if closing else f"[{style}]")
+ markup = "".join(output)
+ return markup
+
+ @classmethod
+ def from_markup(
+ cls,
+ text: str,
+ *,
+ style: Union[str, Style] = "",
+ emoji: bool = True,
+ emoji_variant: Optional[EmojiVariant] = None,
+ justify: Optional["JustifyMethod"] = None,
+ overflow: Optional["OverflowMethod"] = None,
+ end: str = "\n",
+ ) -> "Text":
+ """Create Text instance from markup.
+
+ Args:
+ text (str): A string containing console markup.
+ style (Union[str, Style], optional): Base style for text. Defaults to "".
+ emoji (bool, optional): Also render emoji code. Defaults to True.
+ emoji_variant (str, optional): Optional emoji variant, either "text" or "emoji". Defaults to None.
+ justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
+ overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
+ end (str, optional): Character to end text with. Defaults to "\\\\n".
+
+ Returns:
+ Text: A Text instance with markup rendered.
+ """
+ from .markup import render
+
+ rendered_text = render(text, style, emoji=emoji, emoji_variant=emoji_variant)
+ rendered_text.justify = justify
+ rendered_text.overflow = overflow
+ rendered_text.end = end
+ return rendered_text
+
+ @classmethod
+ def from_ansi(
+ cls,
+ text: str,
+ *,
+ style: Union[str, Style] = "",
+ justify: Optional["JustifyMethod"] = None,
+ overflow: Optional["OverflowMethod"] = None,
+ no_wrap: Optional[bool] = None,
+ end: str = "\n",
+ tab_size: Optional[int] = 8,
+ ) -> "Text":
+ """Create a Text object from a string containing ANSI escape codes.
+
+ Args:
+ text (str): A string containing escape codes.
+ style (Union[str, Style], optional): Base style for text. Defaults to "".
+ justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
+ overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
+ no_wrap (bool, optional): Disable text wrapping, or None for default. Defaults to None.
+ end (str, optional): Character to end text with. Defaults to "\\\\n".
+ tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to None.
+ """
+ from .ansi import AnsiDecoder
+
+ joiner = Text(
+ "\n",
+ justify=justify,
+ overflow=overflow,
+ no_wrap=no_wrap,
+ end=end,
+ tab_size=tab_size,
+ style=style,
+ )
+ decoder = AnsiDecoder()
+ result = joiner.join(line for line in decoder.decode(text))
+ return result
+
+ @classmethod
+ def styled(
+ cls,
+ text: str,
+ style: StyleType = "",
+ *,
+ justify: Optional["JustifyMethod"] = None,
+ overflow: Optional["OverflowMethod"] = None,
+ ) -> "Text":
+ """Construct a Text instance with a pre-applied styled. A style applied in this way won't be used
+ to pad the text when it is justified.
+
+ Args:
+ text (str): A string containing console markup.
+ style (Union[str, Style]): Style to apply to the text. Defaults to "".
+ justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
+ overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
+
+ Returns:
+ Text: A text instance with a style applied to the entire string.
+ """
+ styled_text = cls(text, justify=justify, overflow=overflow)
+ styled_text.stylize(style)
+ return styled_text
+
+ @classmethod
+ def assemble(
+ cls,
+ *parts: Union[str, "Text", Tuple[str, StyleType]],
+ style: Union[str, Style] = "",
+ justify: Optional["JustifyMethod"] = None,
+ overflow: Optional["OverflowMethod"] = None,
+ no_wrap: Optional[bool] = None,
+ end: str = "\n",
+ tab_size: int = 8,
+ meta: Optional[Dict[str, Any]] = None,
+ ) -> "Text":
+ """Construct a text instance by combining a sequence of strings with optional styles.
+ The positional arguments should be either strings, or a tuple of string + style.
+
+ Args:
+ style (Union[str, Style], optional): Base style for text. Defaults to "".
+ justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
+ overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
+ no_wrap (bool, optional): Disable text wrapping, or None for default. Defaults to None.
+ end (str, optional): Character to end text with. Defaults to "\\\\n".
+ tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to None.
+ meta (Dict[str, Any], optional). Meta data to apply to text, or None for no meta data. Default to None
+
+ Returns:
+ Text: A new text instance.
+ """
+ text = cls(
+ style=style,
+ justify=justify,
+ overflow=overflow,
+ no_wrap=no_wrap,
+ end=end,
+ tab_size=tab_size,
+ )
+ append = text.append
+ _Text = Text
+ for part in parts:
+ if isinstance(part, (_Text, str)):
+ append(part)
+ else:
+ append(*part)
+ if meta:
+ text.apply_meta(meta)
+ return text
+
+ @property
+ def plain(self) -> str:
+ """Get the text as a single string."""
+ if len(self._text) != 1:
+ self._text[:] = ["".join(self._text)]
+ return self._text[0]
+
+ @plain.setter
+ def plain(self, new_text: str) -> None:
+ """Set the text to a new value."""
+ if new_text != self.plain:
+ sanitized_text = strip_control_codes(new_text)
+ self._text[:] = [sanitized_text]
+ old_length = self._length
+ self._length = len(sanitized_text)
+ if old_length > self._length:
+ self._trim_spans()
+
+ @property
+ def spans(self) -> List[Span]:
+ """Get a reference to the internal list of spans."""
+ return self._spans
+
+ @spans.setter
+ def spans(self, spans: List[Span]) -> None:
+ """Set spans."""
+ self._spans = spans[:]
+
+ def blank_copy(self, plain: str = "") -> "Text":
+ """Return a new Text instance with copied metadata (but not the string or spans)."""
+ copy_self = Text(
+ plain,
+ style=self.style,
+ justify=self.justify,
+ overflow=self.overflow,
+ no_wrap=self.no_wrap,
+ end=self.end,
+ tab_size=self.tab_size,
+ )
+ return copy_self
+
+ def copy(self) -> "Text":
+ """Return a copy of this instance."""
+ copy_self = Text(
+ self.plain,
+ style=self.style,
+ justify=self.justify,
+ overflow=self.overflow,
+ no_wrap=self.no_wrap,
+ end=self.end,
+ tab_size=self.tab_size,
+ )
+ copy_self._spans[:] = self._spans
+ return copy_self
+
+ def stylize(
+ self,
+ style: Union[str, Style],
+ start: int = 0,
+ end: Optional[int] = None,
+ ) -> None:
+ """Apply a style to the text, or a portion of the text.
+
+ Args:
+ style (Union[str, Style]): Style instance or style definition to apply.
+ start (int): Start offset (negative indexing is supported). Defaults to 0.
+ end (Optional[int], optional): End offset (negative indexing is supported), or None for end of text. Defaults to None.
+ """
+ if style:
+ length = len(self)
+ if start < 0:
+ start = length + start
+ if end is None:
+ end = length
+ if end < 0:
+ end = length + end
+ if start >= length or end <= start:
+ # Span not in text or not valid
+ return
+ self._spans.append(Span(start, min(length, end), style))
+
+ def stylize_before(
+ self,
+ style: Union[str, Style],
+ start: int = 0,
+ end: Optional[int] = None,
+ ) -> None:
+ """Apply a style to the text, or a portion of the text. Styles will be applied before other styles already present.
+
+ Args:
+ style (Union[str, Style]): Style instance or style definition to apply.
+ start (int): Start offset (negative indexing is supported). Defaults to 0.
+ end (Optional[int], optional): End offset (negative indexing is supported), or None for end of text. Defaults to None.
+ """
+ if style:
+ length = len(self)
+ if start < 0:
+ start = length + start
+ if end is None:
+ end = length
+ if end < 0:
+ end = length + end
+ if start >= length or end <= start:
+ # Span not in text or not valid
+ return
+ self._spans.insert(0, Span(start, min(length, end), style))
+
+ def apply_meta(
+ self, meta: Dict[str, Any], start: int = 0, end: Optional[int] = None
+ ) -> None:
+ """Apply metadata to the text, or a portion of the text.
+
+ Args:
+ meta (Dict[str, Any]): A dict of meta information.
+ start (int): Start offset (negative indexing is supported). Defaults to 0.
+ end (Optional[int], optional): End offset (negative indexing is supported), or None for end of text. Defaults to None.
+
+ """
+ style = Style.from_meta(meta)
+ self.stylize(style, start=start, end=end)
+
+ def on(self, meta: Optional[Dict[str, Any]] = None, **handlers: Any) -> "Text":
+ """Apply event handlers (used by Textual project).
+
+ Example:
+ >>> from rich.text import Text
+ >>> text = Text("hello world")
+ >>> text.on(click="view.toggle('world')")
+
+ Args:
+ meta (Dict[str, Any]): Mapping of meta information.
+ **handlers: Keyword args are prefixed with "@" to defined handlers.
+
+ Returns:
+ Text: Self is returned to method may be chained.
+ """
+ meta = {} if meta is None else meta
+ meta.update({f"@{key}": value for key, value in handlers.items()})
+ self.stylize(Style.from_meta(meta))
+ return self
+
+ def remove_suffix(self, suffix: str) -> None:
+ """Remove a suffix if it exists.
+
+ Args:
+ suffix (str): Suffix to remove.
+ """
+ if self.plain.endswith(suffix):
+ self.right_crop(len(suffix))
+
+ def get_style_at_offset(self, console: "Console", offset: int) -> Style:
+ """Get the style of a character at give offset.
+
+ Args:
+ console (~Console): Console where text will be rendered.
+ offset (int): Offset in to text (negative indexing supported)
+
+ Returns:
+ Style: A Style instance.
+ """
+ # TODO: This is a little inefficient, it is only used by full justify
+ if offset < 0:
+ offset = len(self) + offset
+ get_style = console.get_style
+ style = get_style(self.style).copy()
+ for start, end, span_style in self._spans:
+ if end > offset >= start:
+ style += get_style(span_style, default="")
+ return style
+
+ def extend_style(self, spaces: int) -> None:
+ """Extend the Text given number of spaces where the spaces have the same style as the last character.
+
+ Args:
+ spaces (int): Number of spaces to add to the Text.
+ """
+ if spaces <= 0:
+ return
+ spans = self.spans
+ new_spaces = " " * spaces
+ if spans:
+ end_offset = len(self)
+ self._spans[:] = [
+ span.extend(spaces) if span.end >= end_offset else span
+ for span in spans
+ ]
+ self._text.append(new_spaces)
+ self._length += spaces
+ else:
+ self.plain += new_spaces
+
+ def highlight_regex(
+ self,
+ re_highlight: str,
+ style: Optional[Union[GetStyleCallable, StyleType]] = None,
+ *,
+ style_prefix: str = "",
+ ) -> int:
+ """Highlight text with a regular expression, where group names are
+ translated to styles.
+
+ Args:
+ re_highlight (str): A regular expression.
+ style (Union[GetStyleCallable, StyleType]): Optional style to apply to whole match, or a callable
+ which accepts the matched text and returns a style. Defaults to None.
+ style_prefix (str, optional): Optional prefix to add to style group names.
+
+ Returns:
+ int: Number of regex matches
+ """
+ count = 0
+ append_span = self._spans.append
+ _Span = Span
+ plain = self.plain
+ for match in re.finditer(re_highlight, plain):
+ get_span = match.span
+ if style:
+ start, end = get_span()
+ match_style = style(plain[start:end]) if callable(style) else style
+ if match_style is not None and end > start:
+ append_span(_Span(start, end, match_style))
+
+ count += 1
+ for name in match.groupdict().keys():
+ start, end = get_span(name)
+ if start != -1 and end > start:
+ append_span(_Span(start, end, f"{style_prefix}{name}"))
+ return count
+
+ def highlight_words(
+ self,
+ words: Iterable[str],
+ style: Union[str, Style],
+ *,
+ case_sensitive: bool = True,
+ ) -> int:
+ """Highlight words with a style.
+
+ Args:
+ words (Iterable[str]): Words to highlight.
+ style (Union[str, Style]): Style to apply.
+ case_sensitive (bool, optional): Enable case sensitive matching. Defaults to True.
+
+ Returns:
+ int: Number of words highlighted.
+ """
+ re_words = "|".join(re.escape(word) for word in words)
+ add_span = self._spans.append
+ count = 0
+ _Span = Span
+ for match in re.finditer(
+ re_words, self.plain, flags=0 if case_sensitive else re.IGNORECASE
+ ):
+ start, end = match.span(0)
+ add_span(_Span(start, end, style))
+ count += 1
+ return count
+
+ def rstrip(self) -> None:
+ """Strip whitespace from end of text."""
+ self.plain = self.plain.rstrip()
+
+ def rstrip_end(self, size: int) -> None:
+ """Remove whitespace beyond a certain width at the end of the text.
+
+ Args:
+ size (int): The desired size of the text.
+ """
+ text_length = len(self)
+ if text_length > size:
+ excess = text_length - size
+ whitespace_match = _re_whitespace.search(self.plain)
+ if whitespace_match is not None:
+ whitespace_count = len(whitespace_match.group(0))
+ self.right_crop(min(whitespace_count, excess))
+
+ def set_length(self, new_length: int) -> None:
+ """Set new length of the text, clipping or padding is required."""
+ length = len(self)
+ if length != new_length:
+ if length < new_length:
+ self.pad_right(new_length - length)
+ else:
+ self.right_crop(length - new_length)
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Iterable[Segment]:
+ tab_size: int = console.tab_size if self.tab_size is None else self.tab_size
+ justify = self.justify or options.justify or DEFAULT_JUSTIFY
+
+ overflow = self.overflow or options.overflow or DEFAULT_OVERFLOW
+
+ lines = self.wrap(
+ console,
+ options.max_width,
+ justify=justify,
+ overflow=overflow,
+ tab_size=tab_size or 8,
+ no_wrap=pick_bool(self.no_wrap, options.no_wrap, False),
+ )
+ all_lines = Text("\n").join(lines)
+ yield from all_lines.render(console, end=self.end)
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> Measurement:
+ text = self.plain
+ lines = text.splitlines()
+ max_text_width = max(cell_len(line) for line in lines) if lines else 0
+ words = text.split()
+ min_text_width = (
+ max(cell_len(word) for word in words) if words else max_text_width
+ )
+ return Measurement(min_text_width, max_text_width)
+
+ def render(self, console: "Console", end: str = "") -> Iterable["Segment"]:
+ """Render the text as Segments.
+
+ Args:
+ console (Console): Console instance.
+ end (Optional[str], optional): Optional end character.
+
+ Returns:
+ Iterable[Segment]: Result of render that may be written to the console.
+ """
+ _Segment = Segment
+ text = self.plain
+ if not self._spans:
+ yield Segment(text)
+ if end:
+ yield _Segment(end)
+ return
+ get_style = partial(console.get_style, default=Style.null())
+
+ enumerated_spans = list(enumerate(self._spans, 1))
+ style_map = {index: get_style(span.style) for index, span in enumerated_spans}
+ style_map[0] = get_style(self.style)
+
+ spans = [
+ (0, False, 0),
+ *((span.start, False, index) for index, span in enumerated_spans),
+ *((span.end, True, index) for index, span in enumerated_spans),
+ (len(text), True, 0),
+ ]
+ spans.sort(key=itemgetter(0, 1))
+
+ stack: List[int] = []
+ stack_append = stack.append
+ stack_pop = stack.remove
+
+ style_cache: Dict[Tuple[Style, ...], Style] = {}
+ style_cache_get = style_cache.get
+ combine = Style.combine
+
+ def get_current_style() -> Style:
+ """Construct current style from stack."""
+ styles = tuple(style_map[_style_id] for _style_id in sorted(stack))
+ cached_style = style_cache_get(styles)
+ if cached_style is not None:
+ return cached_style
+ current_style = combine(styles)
+ style_cache[styles] = current_style
+ return current_style
+
+ for (offset, leaving, style_id), (next_offset, _, _) in zip(spans, spans[1:]):
+ if leaving:
+ stack_pop(style_id)
+ else:
+ stack_append(style_id)
+ if next_offset > offset:
+ yield _Segment(text[offset:next_offset], get_current_style())
+ if end:
+ yield _Segment(end)
+
+ def join(self, lines: Iterable["Text"]) -> "Text":
+ """Join text together with this instance as the separator.
+
+ Args:
+ lines (Iterable[Text]): An iterable of Text instances to join.
+
+ Returns:
+ Text: A new text instance containing join text.
+ """
+
+ new_text = self.blank_copy()
+
+ def iter_text() -> Iterable["Text"]:
+ if self.plain:
+ for last, line in loop_last(lines):
+ yield line
+ if not last:
+ yield self
+ else:
+ yield from lines
+
+ extend_text = new_text._text.extend
+ append_span = new_text._spans.append
+ extend_spans = new_text._spans.extend
+ offset = 0
+ _Span = Span
+
+ for text in iter_text():
+ extend_text(text._text)
+ if text.style:
+ append_span(_Span(offset, offset + len(text), text.style))
+ extend_spans(
+ _Span(offset + start, offset + end, style)
+ for start, end, style in text._spans
+ )
+ offset += len(text)
+ new_text._length = offset
+ return new_text
+
+ def expand_tabs(self, tab_size: Optional[int] = None) -> None:
+ """Converts tabs to spaces.
+
+ Args:
+ tab_size (int, optional): Size of tabs. Defaults to 8.
+
+ """
+ if "\t" not in self.plain:
+ return
+ if tab_size is None:
+ tab_size = self.tab_size
+ if tab_size is None:
+ tab_size = 8
+
+ new_text: List[Text] = []
+ append = new_text.append
+
+ for line in self.split("\n", include_separator=True):
+ if "\t" not in line.plain:
+ append(line)
+ else:
+ cell_position = 0
+ parts = line.split("\t", include_separator=True)
+ for part in parts:
+ if part.plain.endswith("\t"):
+ part._text[-1] = part._text[-1][:-1] + " "
+ cell_position += part.cell_len
+ tab_remainder = cell_position % tab_size
+ if tab_remainder:
+ spaces = tab_size - tab_remainder
+ part.extend_style(spaces)
+ cell_position += spaces
+ else:
+ cell_position += part.cell_len
+ append(part)
+
+ result = Text("").join(new_text)
+
+ self._text = [result.plain]
+ self._length = len(self.plain)
+ self._spans[:] = result._spans
+
+ def truncate(
+ self,
+ max_width: int,
+ *,
+ overflow: Optional["OverflowMethod"] = None,
+ pad: bool = False,
+ ) -> None:
+ """Truncate text if it is longer that a given width.
+
+ Args:
+ max_width (int): Maximum number of characters in text.
+ overflow (str, optional): Overflow method: "crop", "fold", or "ellipsis". Defaults to None, to use self.overflow.
+ pad (bool, optional): Pad with spaces if the length is less than max_width. Defaults to False.
+ """
+ _overflow = overflow or self.overflow or DEFAULT_OVERFLOW
+ if _overflow != "ignore":
+ length = cell_len(self.plain)
+ if length > max_width:
+ if _overflow == "ellipsis":
+ self.plain = set_cell_size(self.plain, max_width - 1) + "…"
+ else:
+ self.plain = set_cell_size(self.plain, max_width)
+ if pad and length < max_width:
+ spaces = max_width - length
+ self._text = [f"{self.plain}{' ' * spaces}"]
+ self._length = len(self.plain)
+
+ def _trim_spans(self) -> None:
+ """Remove or modify any spans that are over the end of the text."""
+ max_offset = len(self.plain)
+ _Span = Span
+ self._spans[:] = [
+ (
+ span
+ if span.end < max_offset
+ else _Span(span.start, min(max_offset, span.end), span.style)
+ )
+ for span in self._spans
+ if span.start < max_offset
+ ]
+
+ def pad(self, count: int, character: str = " ") -> None:
+ """Pad left and right with a given number of characters.
+
+ Args:
+ count (int): Width of padding.
+ character (str): The character to pad with. Must be a string of length 1.
+ """
+ assert len(character) == 1, "Character must be a string of length 1"
+ if count:
+ pad_characters = character * count
+ self.plain = f"{pad_characters}{self.plain}{pad_characters}"
+ _Span = Span
+ self._spans[:] = [
+ _Span(start + count, end + count, style)
+ for start, end, style in self._spans
+ ]
+
+ def pad_left(self, count: int, character: str = " ") -> None:
+ """Pad the left with a given character.
+
+ Args:
+ count (int): Number of characters to pad.
+ character (str, optional): Character to pad with. Defaults to " ".
+ """
+ assert len(character) == 1, "Character must be a string of length 1"
+ if count:
+ self.plain = f"{character * count}{self.plain}"
+ _Span = Span
+ self._spans[:] = [
+ _Span(start + count, end + count, style)
+ for start, end, style in self._spans
+ ]
+
+ def pad_right(self, count: int, character: str = " ") -> None:
+ """Pad the right with a given character.
+
+ Args:
+ count (int): Number of characters to pad.
+ character (str, optional): Character to pad with. Defaults to " ".
+ """
+ assert len(character) == 1, "Character must be a string of length 1"
+ if count:
+ self.plain = f"{self.plain}{character * count}"
+
+ def align(self, align: AlignMethod, width: int, character: str = " ") -> None:
+ """Align text to a given width.
+
+ Args:
+ align (AlignMethod): One of "left", "center", or "right".
+ width (int): Desired width.
+ character (str, optional): Character to pad with. Defaults to " ".
+ """
+ self.truncate(width)
+ excess_space = width - cell_len(self.plain)
+ if excess_space:
+ if align == "left":
+ self.pad_right(excess_space, character)
+ elif align == "center":
+ left = excess_space // 2
+ self.pad_left(left, character)
+ self.pad_right(excess_space - left, character)
+ else:
+ self.pad_left(excess_space, character)
+
+ def append(
+ self, text: Union["Text", str], style: Optional[Union[str, "Style"]] = None
+ ) -> "Text":
+ """Add text with an optional style.
+
+ Args:
+ text (Union[Text, str]): A str or Text to append.
+ style (str, optional): A style name. Defaults to None.
+
+ Returns:
+ Text: Returns self for chaining.
+ """
+
+ if not isinstance(text, (str, Text)):
+ raise TypeError("Only str or Text can be appended to Text")
+
+ if len(text):
+ if isinstance(text, str):
+ sanitized_text = strip_control_codes(text)
+ self._text.append(sanitized_text)
+ offset = len(self)
+ text_length = len(sanitized_text)
+ if style:
+ self._spans.append(Span(offset, offset + text_length, style))
+ self._length += text_length
+ elif isinstance(text, Text):
+ _Span = Span
+ if style is not None:
+ raise ValueError(
+ "style must not be set when appending Text instance"
+ )
+ text_length = self._length
+ if text.style:
+ self._spans.append(
+ _Span(text_length, text_length + len(text), text.style)
+ )
+ self._text.append(text.plain)
+ self._spans.extend(
+ _Span(start + text_length, end + text_length, style)
+ for start, end, style in text._spans
+ )
+ self._length += len(text)
+ return self
+
+ def append_text(self, text: "Text") -> "Text":
+ """Append another Text instance. This method is more performant that Text.append, but
+ only works for Text.
+
+ Args:
+ text (Text): The Text instance to append to this instance.
+
+ Returns:
+ Text: Returns self for chaining.
+ """
+ _Span = Span
+ text_length = self._length
+ if text.style:
+ self._spans.append(_Span(text_length, text_length + len(text), text.style))
+ self._text.append(text.plain)
+ self._spans.extend(
+ _Span(start + text_length, end + text_length, style)
+ for start, end, style in text._spans
+ )
+ self._length += len(text)
+ return self
+
+ def append_tokens(
+ self, tokens: Iterable[Tuple[str, Optional[StyleType]]]
+ ) -> "Text":
+ """Append iterable of str and style. Style may be a Style instance or a str style definition.
+
+ Args:
+ tokens (Iterable[Tuple[str, Optional[StyleType]]]): An iterable of tuples containing str content and style.
+
+ Returns:
+ Text: Returns self for chaining.
+ """
+ append_text = self._text.append
+ append_span = self._spans.append
+ _Span = Span
+ offset = len(self)
+ for content, style in tokens:
+ append_text(content)
+ if style:
+ append_span(_Span(offset, offset + len(content), style))
+ offset += len(content)
+ self._length = offset
+ return self
+
+ def copy_styles(self, text: "Text") -> None:
+ """Copy styles from another Text instance.
+
+ Args:
+ text (Text): A Text instance to copy styles from, must be the same length.
+ """
+ self._spans.extend(text._spans)
+
+ def split(
+ self,
+ separator: str = "\n",
+ *,
+ include_separator: bool = False,
+ allow_blank: bool = False,
+ ) -> Lines:
+ """Split rich text in to lines, preserving styles.
+
+ Args:
+ separator (str, optional): String to split on. Defaults to "\\\\n".
+ include_separator (bool, optional): Include the separator in the lines. Defaults to False.
+ allow_blank (bool, optional): Return a blank line if the text ends with a separator. Defaults to False.
+
+ Returns:
+ List[RichText]: A list of rich text, one per line of the original.
+ """
+ assert separator, "separator must not be empty"
+
+ text = self.plain
+ if separator not in text:
+ return Lines([self.copy()])
+
+ if include_separator:
+ lines = self.divide(
+ match.end() for match in re.finditer(re.escape(separator), text)
+ )
+ else:
+
+ def flatten_spans() -> Iterable[int]:
+ for match in re.finditer(re.escape(separator), text):
+ start, end = match.span()
+ yield start
+ yield end
+
+ lines = Lines(
+ line for line in self.divide(flatten_spans()) if line.plain != separator
+ )
+
+ if not allow_blank and text.endswith(separator):
+ lines.pop()
+
+ return lines
+
+ def divide(self, offsets: Iterable[int]) -> Lines:
+ """Divide text in to a number of lines at given offsets.
+
+ Args:
+ offsets (Iterable[int]): Offsets used to divide text.
+
+ Returns:
+ Lines: New RichText instances between offsets.
+ """
+ _offsets = list(offsets)
+
+ if not _offsets:
+ return Lines([self.copy()])
+
+ text = self.plain
+ text_length = len(text)
+ divide_offsets = [0, *_offsets, text_length]
+ line_ranges = list(zip(divide_offsets, divide_offsets[1:]))
+
+ style = self.style
+ justify = self.justify
+ overflow = self.overflow
+ _Text = Text
+ new_lines = Lines(
+ _Text(
+ text[start:end],
+ style=style,
+ justify=justify,
+ overflow=overflow,
+ )
+ for start, end in line_ranges
+ )
+ if not self._spans:
+ return new_lines
+
+ _line_appends = [line._spans.append for line in new_lines._lines]
+ line_count = len(line_ranges)
+ _Span = Span
+
+ for span_start, span_end, style in self._spans:
+ lower_bound = 0
+ upper_bound = line_count
+ start_line_no = (lower_bound + upper_bound) // 2
+
+ while True:
+ line_start, line_end = line_ranges[start_line_no]
+ if span_start < line_start:
+ upper_bound = start_line_no - 1
+ elif span_start > line_end:
+ lower_bound = start_line_no + 1
+ else:
+ break
+ start_line_no = (lower_bound + upper_bound) // 2
+
+ if span_end < line_end:
+ end_line_no = start_line_no
+ else:
+ end_line_no = lower_bound = start_line_no
+ upper_bound = line_count
+
+ while True:
+ line_start, line_end = line_ranges[end_line_no]
+ if span_end < line_start:
+ upper_bound = end_line_no - 1
+ elif span_end > line_end:
+ lower_bound = end_line_no + 1
+ else:
+ break
+ end_line_no = (lower_bound + upper_bound) // 2
+
+ for line_no in range(start_line_no, end_line_no + 1):
+ line_start, line_end = line_ranges[line_no]
+ new_start = max(0, span_start - line_start)
+ new_end = min(span_end - line_start, line_end - line_start)
+ if new_end > new_start:
+ _line_appends[line_no](_Span(new_start, new_end, style))
+
+ return new_lines
+
+ def right_crop(self, amount: int = 1) -> None:
+ """Remove a number of characters from the end of the text."""
+ max_offset = len(self.plain) - amount
+ _Span = Span
+ self._spans[:] = [
+ (
+ span
+ if span.end < max_offset
+ else _Span(span.start, min(max_offset, span.end), span.style)
+ )
+ for span in self._spans
+ if span.start < max_offset
+ ]
+ self._text = [self.plain[:-amount]]
+ self._length -= amount
+
+ def wrap(
+ self,
+ console: "Console",
+ width: int,
+ *,
+ justify: Optional["JustifyMethod"] = None,
+ overflow: Optional["OverflowMethod"] = None,
+ tab_size: int = 8,
+ no_wrap: Optional[bool] = None,
+ ) -> Lines:
+ """Word wrap the text.
+
+ Args:
+ console (Console): Console instance.
+ width (int): Number of cells available per line.
+ justify (str, optional): Justify method: "default", "left", "center", "full", "right". Defaults to "default".
+ overflow (str, optional): Overflow method: "crop", "fold", or "ellipsis". Defaults to None.
+ tab_size (int, optional): Default tab size. Defaults to 8.
+ no_wrap (bool, optional): Disable wrapping, Defaults to False.
+
+ Returns:
+ Lines: Number of lines.
+ """
+ wrap_justify = justify or self.justify or DEFAULT_JUSTIFY
+ wrap_overflow = overflow or self.overflow or DEFAULT_OVERFLOW
+
+ no_wrap = pick_bool(no_wrap, self.no_wrap, False) or overflow == "ignore"
+
+ lines = Lines()
+ for line in self.split(allow_blank=True):
+ if "\t" in line:
+ line.expand_tabs(tab_size)
+ if no_wrap:
+ new_lines = Lines([line])
+ else:
+ offsets = divide_line(str(line), width, fold=wrap_overflow == "fold")
+ new_lines = line.divide(offsets)
+ for line in new_lines:
+ line.rstrip_end(width)
+ if wrap_justify:
+ new_lines.justify(
+ console, width, justify=wrap_justify, overflow=wrap_overflow
+ )
+ for line in new_lines:
+ line.truncate(width, overflow=wrap_overflow)
+ lines.extend(new_lines)
+ return lines
+
+ def fit(self, width: int) -> Lines:
+ """Fit the text in to given width by chopping in to lines.
+
+ Args:
+ width (int): Maximum characters in a line.
+
+ Returns:
+ Lines: Lines container.
+ """
+ lines: Lines = Lines()
+ append = lines.append
+ for line in self.split():
+ line.set_length(width)
+ append(line)
+ return lines
+
+ def detect_indentation(self) -> int:
+ """Auto-detect indentation of code.
+
+ Returns:
+ int: Number of spaces used to indent code.
+ """
+
+ _indentations = {
+ len(match.group(1))
+ for match in re.finditer(r"^( *)(.*)$", self.plain, flags=re.MULTILINE)
+ }
+
+ try:
+ indentation = (
+ reduce(gcd, [indent for indent in _indentations if not indent % 2]) or 1
+ )
+ except TypeError:
+ indentation = 1
+
+ return indentation
+
+ def with_indent_guides(
+ self,
+ indent_size: Optional[int] = None,
+ *,
+ character: str = "│",
+ style: StyleType = "dim green",
+ ) -> "Text":
+ """Adds indent guide lines to text.
+
+ Args:
+ indent_size (Optional[int]): Size of indentation, or None to auto detect. Defaults to None.
+ character (str, optional): Character to use for indentation. Defaults to "│".
+ style (Union[Style, str], optional): Style of indent guides.
+
+ Returns:
+ Text: New text with indentation guides.
+ """
+
+ _indent_size = self.detect_indentation() if indent_size is None else indent_size
+
+ text = self.copy()
+ text.expand_tabs()
+ indent_line = f"{character}{' ' * (_indent_size - 1)}"
+
+ re_indent = re.compile(r"^( *)(.*)$")
+ new_lines: List[Text] = []
+ add_line = new_lines.append
+ blank_lines = 0
+ for line in text.split(allow_blank=True):
+ match = re_indent.match(line.plain)
+ if not match or not match.group(2):
+ blank_lines += 1
+ continue
+ indent = match.group(1)
+ full_indents, remaining_space = divmod(len(indent), _indent_size)
+ new_indent = f"{indent_line * full_indents}{' ' * remaining_space}"
+ line.plain = new_indent + line.plain[len(new_indent) :]
+ line.stylize(style, 0, len(new_indent))
+ if blank_lines:
+ new_lines.extend([Text(new_indent, style=style)] * blank_lines)
+ blank_lines = 0
+ add_line(line)
+ if blank_lines:
+ new_lines.extend([Text("", style=style)] * blank_lines)
+
+ new_text = text.blank_copy("\n").join(new_lines)
+ return new_text
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.console import Console
+
+ text = Text(
+ """\nLorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n"""
+ )
+ text.highlight_words(["Lorem"], "bold")
+ text.highlight_words(["ipsum"], "italic")
+
+ console = Console()
+
+ console.rule("justify='left'")
+ console.print(text, style="red")
+ console.print()
+
+ console.rule("justify='center'")
+ console.print(text, style="green", justify="center")
+ console.print()
+
+ console.rule("justify='right'")
+ console.print(text, style="blue", justify="right")
+ console.print()
+
+ console.rule("justify='full'")
+ console.print(text, style="magenta", justify="full")
+ console.print()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/theme.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/theme.py
new file mode 100644
index 000000000..471dfb2f9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/theme.py
@@ -0,0 +1,115 @@
+import configparser
+from typing import Dict, List, IO, Mapping, Optional
+
+from .default_styles import DEFAULT_STYLES
+from .style import Style, StyleType
+
+
+class Theme:
+ """A container for style information, used by :class:`~rich.console.Console`.
+
+ Args:
+ styles (Dict[str, Style], optional): A mapping of style names on to styles. Defaults to None for a theme with no styles.
+ inherit (bool, optional): Inherit default styles. Defaults to True.
+ """
+
+ styles: Dict[str, Style]
+
+ def __init__(
+ self, styles: Optional[Mapping[str, StyleType]] = None, inherit: bool = True
+ ):
+ self.styles = DEFAULT_STYLES.copy() if inherit else {}
+ if styles is not None:
+ self.styles.update(
+ {
+ name: style if isinstance(style, Style) else Style.parse(style)
+ for name, style in styles.items()
+ }
+ )
+
+ @property
+ def config(self) -> str:
+ """Get contents of a config file for this theme."""
+ config = "[styles]\n" + "\n".join(
+ f"{name} = {style}" for name, style in sorted(self.styles.items())
+ )
+ return config
+
+ @classmethod
+ def from_file(
+ cls, config_file: IO[str], source: Optional[str] = None, inherit: bool = True
+ ) -> "Theme":
+ """Load a theme from a text mode file.
+
+ Args:
+ config_file (IO[str]): An open conf file.
+ source (str, optional): The filename of the open file. Defaults to None.
+ inherit (bool, optional): Inherit default styles. Defaults to True.
+
+ Returns:
+ Theme: A New theme instance.
+ """
+ config = configparser.ConfigParser()
+ config.read_file(config_file, source=source)
+ styles = {name: Style.parse(value) for name, value in config.items("styles")}
+ theme = Theme(styles, inherit=inherit)
+ return theme
+
+ @classmethod
+ def read(
+ cls, path: str, inherit: bool = True, encoding: Optional[str] = None
+ ) -> "Theme":
+ """Read a theme from a path.
+
+ Args:
+ path (str): Path to a config file readable by Python configparser module.
+ inherit (bool, optional): Inherit default styles. Defaults to True.
+ encoding (str, optional): Encoding of the config file. Defaults to None.
+
+ Returns:
+ Theme: A new theme instance.
+ """
+ with open(path, "rt", encoding=encoding) as config_file:
+ return cls.from_file(config_file, source=path, inherit=inherit)
+
+
+class ThemeStackError(Exception):
+ """Base exception for errors related to the theme stack."""
+
+
+class ThemeStack:
+ """A stack of themes.
+
+ Args:
+ theme (Theme): A theme instance
+ """
+
+ def __init__(self, theme: Theme) -> None:
+ self._entries: List[Dict[str, Style]] = [theme.styles]
+ self.get = self._entries[-1].get
+
+ def push_theme(self, theme: Theme, inherit: bool = True) -> None:
+ """Push a theme on the top of the stack.
+
+ Args:
+ theme (Theme): A Theme instance.
+ inherit (boolean, optional): Inherit styles from current top of stack.
+ """
+ styles: Dict[str, Style]
+ styles = (
+ {**self._entries[-1], **theme.styles} if inherit else theme.styles.copy()
+ )
+ self._entries.append(styles)
+ self.get = self._entries[-1].get
+
+ def pop_theme(self) -> None:
+ """Pop (and discard) the top-most theme."""
+ if len(self._entries) == 1:
+ raise ThemeStackError("Unable to pop base theme")
+ self._entries.pop()
+ self.get = self._entries[-1].get
+
+
+if __name__ == "__main__": # pragma: no cover
+ theme = Theme()
+ print(theme.config)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/themes.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/themes.py
new file mode 100644
index 000000000..bf6db104a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/themes.py
@@ -0,0 +1,5 @@
+from .default_styles import DEFAULT_STYLES
+from .theme import Theme
+
+
+DEFAULT = Theme(DEFAULT_STYLES)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/traceback.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/traceback.py
new file mode 100644
index 000000000..f223ad44b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/traceback.py
@@ -0,0 +1,753 @@
+from __future__ import absolute_import
+
+import linecache
+import os
+import platform
+import sys
+from dataclasses import dataclass, field
+from traceback import walk_tb
+from types import ModuleType, TracebackType
+from typing import (
+ Any,
+ Callable,
+ Dict,
+ Iterable,
+ List,
+ Optional,
+ Sequence,
+ Tuple,
+ Type,
+ Union,
+)
+
+from pip._vendor.pygments.lexers import guess_lexer_for_filename
+from pip._vendor.pygments.token import Comment, Keyword, Name, Number, Operator, String
+from pip._vendor.pygments.token import Text as TextToken
+from pip._vendor.pygments.token import Token
+from pip._vendor.pygments.util import ClassNotFound
+
+from . import pretty
+from ._loop import loop_last
+from .columns import Columns
+from .console import Console, ConsoleOptions, ConsoleRenderable, RenderResult, group
+from .constrain import Constrain
+from .highlighter import RegexHighlighter, ReprHighlighter
+from .panel import Panel
+from .scope import render_scope
+from .style import Style
+from .syntax import Syntax
+from .text import Text
+from .theme import Theme
+
+WINDOWS = platform.system() == "Windows"
+
+LOCALS_MAX_LENGTH = 10
+LOCALS_MAX_STRING = 80
+
+
+def install(
+ *,
+ console: Optional[Console] = None,
+ width: Optional[int] = 100,
+ extra_lines: int = 3,
+ theme: Optional[str] = None,
+ word_wrap: bool = False,
+ show_locals: bool = False,
+ locals_max_length: int = LOCALS_MAX_LENGTH,
+ locals_max_string: int = LOCALS_MAX_STRING,
+ locals_hide_dunder: bool = True,
+ locals_hide_sunder: Optional[bool] = None,
+ indent_guides: bool = True,
+ suppress: Iterable[Union[str, ModuleType]] = (),
+ max_frames: int = 100,
+) -> Callable[[Type[BaseException], BaseException, Optional[TracebackType]], Any]:
+ """Install a rich traceback handler.
+
+ Once installed, any tracebacks will be printed with syntax highlighting and rich formatting.
+
+
+ Args:
+ console (Optional[Console], optional): Console to write exception to. Default uses internal Console instance.
+ width (Optional[int], optional): Width (in characters) of traceback. Defaults to 100.
+ extra_lines (int, optional): Extra lines of code. Defaults to 3.
+ theme (Optional[str], optional): Pygments theme to use in traceback. Defaults to ``None`` which will pick
+ a theme appropriate for the platform.
+ word_wrap (bool, optional): Enable word wrapping of long lines. Defaults to False.
+ show_locals (bool, optional): Enable display of local variables. Defaults to False.
+ locals_max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to 10.
+ locals_max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to 80.
+ locals_hide_dunder (bool, optional): Hide locals prefixed with double underscore. Defaults to True.
+ locals_hide_sunder (bool, optional): Hide locals prefixed with single underscore. Defaults to False.
+ indent_guides (bool, optional): Enable indent guides in code and locals. Defaults to True.
+ suppress (Sequence[Union[str, ModuleType]]): Optional sequence of modules or paths to exclude from traceback.
+
+ Returns:
+ Callable: The previous exception handler that was replaced.
+
+ """
+ traceback_console = Console(stderr=True) if console is None else console
+
+ locals_hide_sunder = (
+ True
+ if (traceback_console.is_jupyter and locals_hide_sunder is None)
+ else locals_hide_sunder
+ )
+
+ def excepthook(
+ type_: Type[BaseException],
+ value: BaseException,
+ traceback: Optional[TracebackType],
+ ) -> None:
+ traceback_console.print(
+ Traceback.from_exception(
+ type_,
+ value,
+ traceback,
+ width=width,
+ extra_lines=extra_lines,
+ theme=theme,
+ word_wrap=word_wrap,
+ show_locals=show_locals,
+ locals_max_length=locals_max_length,
+ locals_max_string=locals_max_string,
+ locals_hide_dunder=locals_hide_dunder,
+ locals_hide_sunder=bool(locals_hide_sunder),
+ indent_guides=indent_guides,
+ suppress=suppress,
+ max_frames=max_frames,
+ )
+ )
+
+ def ipy_excepthook_closure(ip: Any) -> None: # pragma: no cover
+ tb_data = {} # store information about showtraceback call
+ default_showtraceback = ip.showtraceback # keep reference of default traceback
+
+ def ipy_show_traceback(*args: Any, **kwargs: Any) -> None:
+ """wrap the default ip.showtraceback to store info for ip._showtraceback"""
+ nonlocal tb_data
+ tb_data = kwargs
+ default_showtraceback(*args, **kwargs)
+
+ def ipy_display_traceback(
+ *args: Any, is_syntax: bool = False, **kwargs: Any
+ ) -> None:
+ """Internally called traceback from ip._showtraceback"""
+ nonlocal tb_data
+ exc_tuple = ip._get_exc_info()
+
+ # do not display trace on syntax error
+ tb: Optional[TracebackType] = None if is_syntax else exc_tuple[2]
+
+ # determine correct tb_offset
+ compiled = tb_data.get("running_compiled_code", False)
+ tb_offset = tb_data.get("tb_offset", 1 if compiled else 0)
+ # remove ipython internal frames from trace with tb_offset
+ for _ in range(tb_offset):
+ if tb is None:
+ break
+ tb = tb.tb_next
+
+ excepthook(exc_tuple[0], exc_tuple[1], tb)
+ tb_data = {} # clear data upon usage
+
+ # replace _showtraceback instead of showtraceback to allow ipython features such as debugging to work
+ # this is also what the ipython docs recommends to modify when subclassing InteractiveShell
+ ip._showtraceback = ipy_display_traceback
+ # add wrapper to capture tb_data
+ ip.showtraceback = ipy_show_traceback
+ ip.showsyntaxerror = lambda *args, **kwargs: ipy_display_traceback(
+ *args, is_syntax=True, **kwargs
+ )
+
+ try: # pragma: no cover
+ # if within ipython, use customized traceback
+ ip = get_ipython() # type: ignore[name-defined]
+ ipy_excepthook_closure(ip)
+ return sys.excepthook
+ except Exception:
+ # otherwise use default system hook
+ old_excepthook = sys.excepthook
+ sys.excepthook = excepthook
+ return old_excepthook
+
+
+@dataclass
+class Frame:
+ filename: str
+ lineno: int
+ name: str
+ line: str = ""
+ locals: Optional[Dict[str, pretty.Node]] = None
+
+
+@dataclass
+class _SyntaxError:
+ offset: int
+ filename: str
+ line: str
+ lineno: int
+ msg: str
+
+
+@dataclass
+class Stack:
+ exc_type: str
+ exc_value: str
+ syntax_error: Optional[_SyntaxError] = None
+ is_cause: bool = False
+ frames: List[Frame] = field(default_factory=list)
+
+
+@dataclass
+class Trace:
+ stacks: List[Stack]
+
+
+class PathHighlighter(RegexHighlighter):
+ highlights = [r"(?P<dim>.*/)(?P<bold>.+)"]
+
+
+class Traceback:
+ """A Console renderable that renders a traceback.
+
+ Args:
+ trace (Trace, optional): A `Trace` object produced from `extract`. Defaults to None, which uses
+ the last exception.
+ width (Optional[int], optional): Number of characters used to traceback. Defaults to 100.
+ extra_lines (int, optional): Additional lines of code to render. Defaults to 3.
+ theme (str, optional): Override pygments theme used in traceback.
+ word_wrap (bool, optional): Enable word wrapping of long lines. Defaults to False.
+ show_locals (bool, optional): Enable display of local variables. Defaults to False.
+ indent_guides (bool, optional): Enable indent guides in code and locals. Defaults to True.
+ locals_max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to 10.
+ locals_max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to 80.
+ locals_hide_dunder (bool, optional): Hide locals prefixed with double underscore. Defaults to True.
+ locals_hide_sunder (bool, optional): Hide locals prefixed with single underscore. Defaults to False.
+ suppress (Sequence[Union[str, ModuleType]]): Optional sequence of modules or paths to exclude from traceback.
+ max_frames (int): Maximum number of frames to show in a traceback, 0 for no maximum. Defaults to 100.
+
+ """
+
+ LEXERS = {
+ "": "text",
+ ".py": "python",
+ ".pxd": "cython",
+ ".pyx": "cython",
+ ".pxi": "pyrex",
+ }
+
+ def __init__(
+ self,
+ trace: Optional[Trace] = None,
+ *,
+ width: Optional[int] = 100,
+ extra_lines: int = 3,
+ theme: Optional[str] = None,
+ word_wrap: bool = False,
+ show_locals: bool = False,
+ locals_max_length: int = LOCALS_MAX_LENGTH,
+ locals_max_string: int = LOCALS_MAX_STRING,
+ locals_hide_dunder: bool = True,
+ locals_hide_sunder: bool = False,
+ indent_guides: bool = True,
+ suppress: Iterable[Union[str, ModuleType]] = (),
+ max_frames: int = 100,
+ ):
+ if trace is None:
+ exc_type, exc_value, traceback = sys.exc_info()
+ if exc_type is None or exc_value is None or traceback is None:
+ raise ValueError(
+ "Value for 'trace' required if not called in except: block"
+ )
+ trace = self.extract(
+ exc_type, exc_value, traceback, show_locals=show_locals
+ )
+ self.trace = trace
+ self.width = width
+ self.extra_lines = extra_lines
+ self.theme = Syntax.get_theme(theme or "ansi_dark")
+ self.word_wrap = word_wrap
+ self.show_locals = show_locals
+ self.indent_guides = indent_guides
+ self.locals_max_length = locals_max_length
+ self.locals_max_string = locals_max_string
+ self.locals_hide_dunder = locals_hide_dunder
+ self.locals_hide_sunder = locals_hide_sunder
+
+ self.suppress: Sequence[str] = []
+ for suppress_entity in suppress:
+ if not isinstance(suppress_entity, str):
+ assert (
+ suppress_entity.__file__ is not None
+ ), f"{suppress_entity!r} must be a module with '__file__' attribute"
+ path = os.path.dirname(suppress_entity.__file__)
+ else:
+ path = suppress_entity
+ path = os.path.normpath(os.path.abspath(path))
+ self.suppress.append(path)
+ self.max_frames = max(4, max_frames) if max_frames > 0 else 0
+
+ @classmethod
+ def from_exception(
+ cls,
+ exc_type: Type[Any],
+ exc_value: BaseException,
+ traceback: Optional[TracebackType],
+ *,
+ width: Optional[int] = 100,
+ extra_lines: int = 3,
+ theme: Optional[str] = None,
+ word_wrap: bool = False,
+ show_locals: bool = False,
+ locals_max_length: int = LOCALS_MAX_LENGTH,
+ locals_max_string: int = LOCALS_MAX_STRING,
+ locals_hide_dunder: bool = True,
+ locals_hide_sunder: bool = False,
+ indent_guides: bool = True,
+ suppress: Iterable[Union[str, ModuleType]] = (),
+ max_frames: int = 100,
+ ) -> "Traceback":
+ """Create a traceback from exception info
+
+ Args:
+ exc_type (Type[BaseException]): Exception type.
+ exc_value (BaseException): Exception value.
+ traceback (TracebackType): Python Traceback object.
+ width (Optional[int], optional): Number of characters used to traceback. Defaults to 100.
+ extra_lines (int, optional): Additional lines of code to render. Defaults to 3.
+ theme (str, optional): Override pygments theme used in traceback.
+ word_wrap (bool, optional): Enable word wrapping of long lines. Defaults to False.
+ show_locals (bool, optional): Enable display of local variables. Defaults to False.
+ indent_guides (bool, optional): Enable indent guides in code and locals. Defaults to True.
+ locals_max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to 10.
+ locals_max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to 80.
+ locals_hide_dunder (bool, optional): Hide locals prefixed with double underscore. Defaults to True.
+ locals_hide_sunder (bool, optional): Hide locals prefixed with single underscore. Defaults to False.
+ suppress (Iterable[Union[str, ModuleType]]): Optional sequence of modules or paths to exclude from traceback.
+ max_frames (int): Maximum number of frames to show in a traceback, 0 for no maximum. Defaults to 100.
+
+ Returns:
+ Traceback: A Traceback instance that may be printed.
+ """
+ rich_traceback = cls.extract(
+ exc_type,
+ exc_value,
+ traceback,
+ show_locals=show_locals,
+ locals_max_length=locals_max_length,
+ locals_max_string=locals_max_string,
+ locals_hide_dunder=locals_hide_dunder,
+ locals_hide_sunder=locals_hide_sunder,
+ )
+
+ return cls(
+ rich_traceback,
+ width=width,
+ extra_lines=extra_lines,
+ theme=theme,
+ word_wrap=word_wrap,
+ show_locals=show_locals,
+ indent_guides=indent_guides,
+ locals_max_length=locals_max_length,
+ locals_max_string=locals_max_string,
+ locals_hide_dunder=locals_hide_dunder,
+ locals_hide_sunder=locals_hide_sunder,
+ suppress=suppress,
+ max_frames=max_frames,
+ )
+
+ @classmethod
+ def extract(
+ cls,
+ exc_type: Type[BaseException],
+ exc_value: BaseException,
+ traceback: Optional[TracebackType],
+ *,
+ show_locals: bool = False,
+ locals_max_length: int = LOCALS_MAX_LENGTH,
+ locals_max_string: int = LOCALS_MAX_STRING,
+ locals_hide_dunder: bool = True,
+ locals_hide_sunder: bool = False,
+ ) -> Trace:
+ """Extract traceback information.
+
+ Args:
+ exc_type (Type[BaseException]): Exception type.
+ exc_value (BaseException): Exception value.
+ traceback (TracebackType): Python Traceback object.
+ show_locals (bool, optional): Enable display of local variables. Defaults to False.
+ locals_max_length (int, optional): Maximum length of containers before abbreviating, or None for no abbreviation.
+ Defaults to 10.
+ locals_max_string (int, optional): Maximum length of string before truncating, or None to disable. Defaults to 80.
+ locals_hide_dunder (bool, optional): Hide locals prefixed with double underscore. Defaults to True.
+ locals_hide_sunder (bool, optional): Hide locals prefixed with single underscore. Defaults to False.
+
+ Returns:
+ Trace: A Trace instance which you can use to construct a `Traceback`.
+ """
+
+ stacks: List[Stack] = []
+ is_cause = False
+
+ from pip._vendor.rich import _IMPORT_CWD
+
+ def safe_str(_object: Any) -> str:
+ """Don't allow exceptions from __str__ to propagate."""
+ try:
+ return str(_object)
+ except Exception:
+ return "<exception str() failed>"
+
+ while True:
+ stack = Stack(
+ exc_type=safe_str(exc_type.__name__),
+ exc_value=safe_str(exc_value),
+ is_cause=is_cause,
+ )
+
+ if isinstance(exc_value, SyntaxError):
+ stack.syntax_error = _SyntaxError(
+ offset=exc_value.offset or 0,
+ filename=exc_value.filename or "?",
+ lineno=exc_value.lineno or 0,
+ line=exc_value.text or "",
+ msg=exc_value.msg,
+ )
+
+ stacks.append(stack)
+ append = stack.frames.append
+
+ def get_locals(
+ iter_locals: Iterable[Tuple[str, object]]
+ ) -> Iterable[Tuple[str, object]]:
+ """Extract locals from an iterator of key pairs."""
+ if not (locals_hide_dunder or locals_hide_sunder):
+ yield from iter_locals
+ return
+ for key, value in iter_locals:
+ if locals_hide_dunder and key.startswith("__"):
+ continue
+ if locals_hide_sunder and key.startswith("_"):
+ continue
+ yield key, value
+
+ for frame_summary, line_no in walk_tb(traceback):
+ filename = frame_summary.f_code.co_filename
+ if filename and not filename.startswith("<"):
+ if not os.path.isabs(filename):
+ filename = os.path.join(_IMPORT_CWD, filename)
+ if frame_summary.f_locals.get("_rich_traceback_omit", False):
+ continue
+
+ frame = Frame(
+ filename=filename or "?",
+ lineno=line_no,
+ name=frame_summary.f_code.co_name,
+ locals={
+ key: pretty.traverse(
+ value,
+ max_length=locals_max_length,
+ max_string=locals_max_string,
+ )
+ for key, value in get_locals(frame_summary.f_locals.items())
+ }
+ if show_locals
+ else None,
+ )
+ append(frame)
+ if frame_summary.f_locals.get("_rich_traceback_guard", False):
+ del stack.frames[:]
+
+ cause = getattr(exc_value, "__cause__", None)
+ if cause:
+ exc_type = cause.__class__
+ exc_value = cause
+ # __traceback__ can be None, e.g. for exceptions raised by the
+ # 'multiprocessing' module
+ traceback = cause.__traceback__
+ is_cause = True
+ continue
+
+ cause = exc_value.__context__
+ if cause and not getattr(exc_value, "__suppress_context__", False):
+ exc_type = cause.__class__
+ exc_value = cause
+ traceback = cause.__traceback__
+ is_cause = False
+ continue
+ # No cover, code is reached but coverage doesn't recognize it.
+ break # pragma: no cover
+
+ trace = Trace(stacks=stacks)
+ return trace
+
+ def __rich_console__(
+ self, console: Console, options: ConsoleOptions
+ ) -> RenderResult:
+ theme = self.theme
+ background_style = theme.get_background_style()
+ token_style = theme.get_style_for_token
+
+ traceback_theme = Theme(
+ {
+ "pretty": token_style(TextToken),
+ "pygments.text": token_style(Token),
+ "pygments.string": token_style(String),
+ "pygments.function": token_style(Name.Function),
+ "pygments.number": token_style(Number),
+ "repr.indent": token_style(Comment) + Style(dim=True),
+ "repr.str": token_style(String),
+ "repr.brace": token_style(TextToken) + Style(bold=True),
+ "repr.number": token_style(Number),
+ "repr.bool_true": token_style(Keyword.Constant),
+ "repr.bool_false": token_style(Keyword.Constant),
+ "repr.none": token_style(Keyword.Constant),
+ "scope.border": token_style(String.Delimiter),
+ "scope.equals": token_style(Operator),
+ "scope.key": token_style(Name),
+ "scope.key.special": token_style(Name.Constant) + Style(dim=True),
+ },
+ inherit=False,
+ )
+
+ highlighter = ReprHighlighter()
+ for last, stack in loop_last(reversed(self.trace.stacks)):
+ if stack.frames:
+ stack_renderable: ConsoleRenderable = Panel(
+ self._render_stack(stack),
+ title="[traceback.title]Traceback [dim](most recent call last)",
+ style=background_style,
+ border_style="traceback.border",
+ expand=True,
+ padding=(0, 1),
+ )
+ stack_renderable = Constrain(stack_renderable, self.width)
+ with console.use_theme(traceback_theme):
+ yield stack_renderable
+ if stack.syntax_error is not None:
+ with console.use_theme(traceback_theme):
+ yield Constrain(
+ Panel(
+ self._render_syntax_error(stack.syntax_error),
+ style=background_style,
+ border_style="traceback.border.syntax_error",
+ expand=True,
+ padding=(0, 1),
+ width=self.width,
+ ),
+ self.width,
+ )
+ yield Text.assemble(
+ (f"{stack.exc_type}: ", "traceback.exc_type"),
+ highlighter(stack.syntax_error.msg),
+ )
+ elif stack.exc_value:
+ yield Text.assemble(
+ (f"{stack.exc_type}: ", "traceback.exc_type"),
+ highlighter(stack.exc_value),
+ )
+ else:
+ yield Text.assemble((f"{stack.exc_type}", "traceback.exc_type"))
+
+ if not last:
+ if stack.is_cause:
+ yield Text.from_markup(
+ "\n[i]The above exception was the direct cause of the following exception:\n",
+ )
+ else:
+ yield Text.from_markup(
+ "\n[i]During handling of the above exception, another exception occurred:\n",
+ )
+
+ @group()
+ def _render_syntax_error(self, syntax_error: _SyntaxError) -> RenderResult:
+ highlighter = ReprHighlighter()
+ path_highlighter = PathHighlighter()
+ if syntax_error.filename != "<stdin>":
+ if os.path.exists(syntax_error.filename):
+ text = Text.assemble(
+ (f" {syntax_error.filename}", "pygments.string"),
+ (":", "pygments.text"),
+ (str(syntax_error.lineno), "pygments.number"),
+ style="pygments.text",
+ )
+ yield path_highlighter(text)
+ syntax_error_text = highlighter(syntax_error.line.rstrip())
+ syntax_error_text.no_wrap = True
+ offset = min(syntax_error.offset - 1, len(syntax_error_text))
+ syntax_error_text.stylize("bold underline", offset, offset)
+ syntax_error_text += Text.from_markup(
+ "\n" + " " * offset + "[traceback.offset]▲[/]",
+ style="pygments.text",
+ )
+ yield syntax_error_text
+
+ @classmethod
+ def _guess_lexer(cls, filename: str, code: str) -> str:
+ ext = os.path.splitext(filename)[-1]
+ if not ext:
+ # No extension, look at first line to see if it is a hashbang
+ # Note, this is an educated guess and not a guarantee
+ # If it fails, the only downside is that the code is highlighted strangely
+ new_line_index = code.index("\n")
+ first_line = code[:new_line_index] if new_line_index != -1 else code
+ if first_line.startswith("#!") and "python" in first_line.lower():
+ return "python"
+ try:
+ return cls.LEXERS.get(ext) or guess_lexer_for_filename(filename, code).name
+ except ClassNotFound:
+ return "text"
+
+ @group()
+ def _render_stack(self, stack: Stack) -> RenderResult:
+ path_highlighter = PathHighlighter()
+ theme = self.theme
+
+ def read_code(filename: str) -> str:
+ """Read files, and cache results on filename.
+
+ Args:
+ filename (str): Filename to read
+
+ Returns:
+ str: Contents of file
+ """
+ return "".join(linecache.getlines(filename))
+
+ def render_locals(frame: Frame) -> Iterable[ConsoleRenderable]:
+ if frame.locals:
+ yield render_scope(
+ frame.locals,
+ title="locals",
+ indent_guides=self.indent_guides,
+ max_length=self.locals_max_length,
+ max_string=self.locals_max_string,
+ )
+
+ exclude_frames: Optional[range] = None
+ if self.max_frames != 0:
+ exclude_frames = range(
+ self.max_frames // 2,
+ len(stack.frames) - self.max_frames // 2,
+ )
+
+ excluded = False
+ for frame_index, frame in enumerate(stack.frames):
+ if exclude_frames and frame_index in exclude_frames:
+ excluded = True
+ continue
+
+ if excluded:
+ assert exclude_frames is not None
+ yield Text(
+ f"\n... {len(exclude_frames)} frames hidden ...",
+ justify="center",
+ style="traceback.error",
+ )
+ excluded = False
+
+ first = frame_index == 0
+ frame_filename = frame.filename
+ suppressed = any(frame_filename.startswith(path) for path in self.suppress)
+
+ if os.path.exists(frame.filename):
+ text = Text.assemble(
+ path_highlighter(Text(frame.filename, style="pygments.string")),
+ (":", "pygments.text"),
+ (str(frame.lineno), "pygments.number"),
+ " in ",
+ (frame.name, "pygments.function"),
+ style="pygments.text",
+ )
+ else:
+ text = Text.assemble(
+ "in ",
+ (frame.name, "pygments.function"),
+ (":", "pygments.text"),
+ (str(frame.lineno), "pygments.number"),
+ style="pygments.text",
+ )
+ if not frame.filename.startswith("<") and not first:
+ yield ""
+ yield text
+ if frame.filename.startswith("<"):
+ yield from render_locals(frame)
+ continue
+ if not suppressed:
+ try:
+ code = read_code(frame.filename)
+ if not code:
+ # code may be an empty string if the file doesn't exist, OR
+ # if the traceback filename is generated dynamically
+ continue
+ lexer_name = self._guess_lexer(frame.filename, code)
+ syntax = Syntax(
+ code,
+ lexer_name,
+ theme=theme,
+ line_numbers=True,
+ line_range=(
+ frame.lineno - self.extra_lines,
+ frame.lineno + self.extra_lines,
+ ),
+ highlight_lines={frame.lineno},
+ word_wrap=self.word_wrap,
+ code_width=88,
+ indent_guides=self.indent_guides,
+ dedent=False,
+ )
+ yield ""
+ except Exception as error:
+ yield Text.assemble(
+ (f"\n{error}", "traceback.error"),
+ )
+ else:
+ yield (
+ Columns(
+ [
+ syntax,
+ *render_locals(frame),
+ ],
+ padding=1,
+ )
+ if frame.locals
+ else syntax
+ )
+
+
+if __name__ == "__main__": # pragma: no cover
+ from .console import Console
+
+ console = Console()
+ import sys
+
+ def bar(a: Any) -> None: # 这是对亚洲语言支持的测试。面对模棱两可的想法,拒绝猜测的诱惑
+ one = 1
+ print(one / a)
+
+ def foo(a: Any) -> None:
+ _rich_traceback_guard = True
+ zed = {
+ "characters": {
+ "Paul Atreides",
+ "Vladimir Harkonnen",
+ "Thufir Hawat",
+ "Duncan Idaho",
+ },
+ "atomic_types": (None, False, True),
+ }
+ bar(a)
+
+ def error() -> None:
+ try:
+ try:
+ foo(0)
+ except:
+ slfkjsldkfj # type: ignore[name-defined]
+ except:
+ console.print_exception(show_locals=True)
+
+ error()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/rich/tree.py b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/tree.py
new file mode 100644
index 000000000..64bc75d22
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/rich/tree.py
@@ -0,0 +1,249 @@
+from typing import Iterator, List, Optional, Tuple
+
+from ._loop import loop_first, loop_last
+from .console import Console, ConsoleOptions, RenderableType, RenderResult
+from .jupyter import JupyterMixin
+from .measure import Measurement
+from .segment import Segment
+from .style import Style, StyleStack, StyleType
+from .styled import Styled
+
+
+class Tree(JupyterMixin):
+ """A renderable for a tree structure.
+
+ Args:
+ label (RenderableType): The renderable or str for the tree label.
+ style (StyleType, optional): Style of this tree. Defaults to "tree".
+ guide_style (StyleType, optional): Style of the guide lines. Defaults to "tree.line".
+ expanded (bool, optional): Also display children. Defaults to True.
+ highlight (bool, optional): Highlight renderable (if str). Defaults to False.
+ """
+
+ def __init__(
+ self,
+ label: RenderableType,
+ *,
+ style: StyleType = "tree",
+ guide_style: StyleType = "tree.line",
+ expanded: bool = True,
+ highlight: bool = False,
+ hide_root: bool = False,
+ ) -> None:
+ self.label = label
+ self.style = style
+ self.guide_style = guide_style
+ self.children: List[Tree] = []
+ self.expanded = expanded
+ self.highlight = highlight
+ self.hide_root = hide_root
+
+ def add(
+ self,
+ label: RenderableType,
+ *,
+ style: Optional[StyleType] = None,
+ guide_style: Optional[StyleType] = None,
+ expanded: bool = True,
+ highlight: Optional[bool] = False,
+ ) -> "Tree":
+ """Add a child tree.
+
+ Args:
+ label (RenderableType): The renderable or str for the tree label.
+ style (StyleType, optional): Style of this tree. Defaults to "tree".
+ guide_style (StyleType, optional): Style of the guide lines. Defaults to "tree.line".
+ expanded (bool, optional): Also display children. Defaults to True.
+ highlight (Optional[bool], optional): Highlight renderable (if str). Defaults to False.
+
+ Returns:
+ Tree: A new child Tree, which may be further modified.
+ """
+ node = Tree(
+ label,
+ style=self.style if style is None else style,
+ guide_style=self.guide_style if guide_style is None else guide_style,
+ expanded=expanded,
+ highlight=self.highlight if highlight is None else highlight,
+ )
+ self.children.append(node)
+ return node
+
+ def __rich_console__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "RenderResult":
+ stack: List[Iterator[Tuple[bool, Tree]]] = []
+ pop = stack.pop
+ push = stack.append
+ new_line = Segment.line()
+
+ get_style = console.get_style
+ null_style = Style.null()
+ guide_style = get_style(self.guide_style, default="") or null_style
+ SPACE, CONTINUE, FORK, END = range(4)
+
+ ASCII_GUIDES = (" ", "| ", "+-- ", "`-- ")
+ TREE_GUIDES = [
+ (" ", "│ ", "├── ", "└── "),
+ (" ", "┃ ", "┣━━ ", "┗━━ "),
+ (" ", "║ ", "╠══ ", "╚══ "),
+ ]
+ _Segment = Segment
+
+ def make_guide(index: int, style: Style) -> Segment:
+ """Make a Segment for a level of the guide lines."""
+ if options.ascii_only:
+ line = ASCII_GUIDES[index]
+ else:
+ guide = 1 if style.bold else (2 if style.underline2 else 0)
+ line = TREE_GUIDES[0 if options.legacy_windows else guide][index]
+ return _Segment(line, style)
+
+ levels: List[Segment] = [make_guide(CONTINUE, guide_style)]
+ push(iter(loop_last([self])))
+
+ guide_style_stack = StyleStack(get_style(self.guide_style))
+ style_stack = StyleStack(get_style(self.style))
+ remove_guide_styles = Style(bold=False, underline2=False)
+
+ depth = 0
+
+ while stack:
+ stack_node = pop()
+ try:
+ last, node = next(stack_node)
+ except StopIteration:
+ levels.pop()
+ if levels:
+ guide_style = levels[-1].style or null_style
+ levels[-1] = make_guide(FORK, guide_style)
+ guide_style_stack.pop()
+ style_stack.pop()
+ continue
+ push(stack_node)
+ if last:
+ levels[-1] = make_guide(END, levels[-1].style or null_style)
+
+ guide_style = guide_style_stack.current + get_style(node.guide_style)
+ style = style_stack.current + get_style(node.style)
+ prefix = levels[(2 if self.hide_root else 1) :]
+ renderable_lines = console.render_lines(
+ Styled(node.label, style),
+ options.update(
+ width=options.max_width
+ - sum(level.cell_length for level in prefix),
+ highlight=self.highlight,
+ height=None,
+ ),
+ pad=options.justify is not None,
+ )
+
+ if not (depth == 0 and self.hide_root):
+ for first, line in loop_first(renderable_lines):
+ if prefix:
+ yield from _Segment.apply_style(
+ prefix,
+ style.background_style,
+ post_style=remove_guide_styles,
+ )
+ yield from line
+ yield new_line
+ if first and prefix:
+ prefix[-1] = make_guide(
+ SPACE if last else CONTINUE, prefix[-1].style or null_style
+ )
+
+ if node.expanded and node.children:
+ levels[-1] = make_guide(
+ SPACE if last else CONTINUE, levels[-1].style or null_style
+ )
+ levels.append(
+ make_guide(END if len(node.children) == 1 else FORK, guide_style)
+ )
+ style_stack.push(get_style(node.style))
+ guide_style_stack.push(get_style(node.guide_style))
+ push(iter(loop_last(node.children)))
+ depth += 1
+
+ def __rich_measure__(
+ self, console: "Console", options: "ConsoleOptions"
+ ) -> "Measurement":
+ stack: List[Iterator[Tree]] = [iter([self])]
+ pop = stack.pop
+ push = stack.append
+ minimum = 0
+ maximum = 0
+ measure = Measurement.get
+ level = 0
+ while stack:
+ iter_tree = pop()
+ try:
+ tree = next(iter_tree)
+ except StopIteration:
+ level -= 1
+ continue
+ push(iter_tree)
+ min_measure, max_measure = measure(console, options, tree.label)
+ indent = level * 4
+ minimum = max(min_measure + indent, minimum)
+ maximum = max(max_measure + indent, maximum)
+ if tree.expanded and tree.children:
+ push(iter(tree.children))
+ level += 1
+ return Measurement(minimum, maximum)
+
+
+if __name__ == "__main__": # pragma: no cover
+ from pip._vendor.rich.console import Group
+ from pip._vendor.rich.markdown import Markdown
+ from pip._vendor.rich.panel import Panel
+ from pip._vendor.rich.syntax import Syntax
+ from pip._vendor.rich.table import Table
+
+ table = Table(row_styles=["", "dim"])
+
+ table.add_column("Released", style="cyan", no_wrap=True)
+ table.add_column("Title", style="magenta")
+ table.add_column("Box Office", justify="right", style="green")
+
+ table.add_row("Dec 20, 2019", "Star Wars: The Rise of Skywalker", "$952,110,690")
+ table.add_row("May 25, 2018", "Solo: A Star Wars Story", "$393,151,347")
+ table.add_row("Dec 15, 2017", "Star Wars Ep. V111: The Last Jedi", "$1,332,539,889")
+ table.add_row("Dec 16, 2016", "Rogue One: A Star Wars Story", "$1,332,439,889")
+
+ code = """\
+class Segment(NamedTuple):
+ text: str = ""
+ style: Optional[Style] = None
+ is_control: bool = False
+"""
+ syntax = Syntax(code, "python", theme="monokai", line_numbers=True)
+
+ markdown = Markdown(
+ """\
+### example.md
+> Hello, World!
+>
+> Markdown _all_ the things
+"""
+ )
+
+ root = Tree("🌲 [b green]Rich Tree", highlight=True, hide_root=True)
+
+ node = root.add(":file_folder: Renderables", guide_style="red")
+ simple_node = node.add(":file_folder: [bold yellow]Atomic", guide_style="uu green")
+ simple_node.add(Group("📄 Syntax", syntax))
+ simple_node.add(Group("📄 Markdown", Panel(markdown, border_style="green")))
+
+ containers_node = node.add(
+ ":file_folder: [bold magenta]Containers", guide_style="bold magenta"
+ )
+ containers_node.expanded = True
+ panel = Panel.fit("Just a panel", border_style="red")
+ containers_node.add(Group("📄 Panels", panel))
+
+ containers_node.add(Group("📄 [b magenta]Table", table))
+
+ console = Console()
+
+ console.print(root)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/__init__.py
new file mode 100644
index 000000000..4c6ec97ec
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/__init__.py
@@ -0,0 +1,11 @@
+# SPDX-License-Identifier: MIT
+# SPDX-FileCopyrightText: 2021 Taneli Hukkinen
+# Licensed to PSF under a Contributor Agreement.
+
+__all__ = ("loads", "load", "TOMLDecodeError")
+__version__ = "2.0.1" # DO NOT EDIT THIS LINE MANUALLY. LET bump2version UTILITY DO IT
+
+from ._parser import TOMLDecodeError, load, loads
+
+# Pretend this exception was created here.
+TOMLDecodeError.__module__ = __name__
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_parser.py b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_parser.py
new file mode 100644
index 000000000..f1bb0aa19
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_parser.py
@@ -0,0 +1,691 @@
+# SPDX-License-Identifier: MIT
+# SPDX-FileCopyrightText: 2021 Taneli Hukkinen
+# Licensed to PSF under a Contributor Agreement.
+
+from __future__ import annotations
+
+from collections.abc import Iterable
+import string
+from types import MappingProxyType
+from typing import Any, BinaryIO, NamedTuple
+
+from ._re import (
+ RE_DATETIME,
+ RE_LOCALTIME,
+ RE_NUMBER,
+ match_to_datetime,
+ match_to_localtime,
+ match_to_number,
+)
+from ._types import Key, ParseFloat, Pos
+
+ASCII_CTRL = frozenset(chr(i) for i in range(32)) | frozenset(chr(127))
+
+# Neither of these sets include quotation mark or backslash. They are
+# currently handled as separate cases in the parser functions.
+ILLEGAL_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t")
+ILLEGAL_MULTILINE_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t\n")
+
+ILLEGAL_LITERAL_STR_CHARS = ILLEGAL_BASIC_STR_CHARS
+ILLEGAL_MULTILINE_LITERAL_STR_CHARS = ILLEGAL_MULTILINE_BASIC_STR_CHARS
+
+ILLEGAL_COMMENT_CHARS = ILLEGAL_BASIC_STR_CHARS
+
+TOML_WS = frozenset(" \t")
+TOML_WS_AND_NEWLINE = TOML_WS | frozenset("\n")
+BARE_KEY_CHARS = frozenset(string.ascii_letters + string.digits + "-_")
+KEY_INITIAL_CHARS = BARE_KEY_CHARS | frozenset("\"'")
+HEXDIGIT_CHARS = frozenset(string.hexdigits)
+
+BASIC_STR_ESCAPE_REPLACEMENTS = MappingProxyType(
+ {
+ "\\b": "\u0008", # backspace
+ "\\t": "\u0009", # tab
+ "\\n": "\u000A", # linefeed
+ "\\f": "\u000C", # form feed
+ "\\r": "\u000D", # carriage return
+ '\\"': "\u0022", # quote
+ "\\\\": "\u005C", # backslash
+ }
+)
+
+
+class TOMLDecodeError(ValueError):
+ """An error raised if a document is not valid TOML."""
+
+
+def load(__fp: BinaryIO, *, parse_float: ParseFloat = float) -> dict[str, Any]:
+ """Parse TOML from a binary file object."""
+ b = __fp.read()
+ try:
+ s = b.decode()
+ except AttributeError:
+ raise TypeError(
+ "File must be opened in binary mode, e.g. use `open('foo.toml', 'rb')`"
+ ) from None
+ return loads(s, parse_float=parse_float)
+
+
+def loads(__s: str, *, parse_float: ParseFloat = float) -> dict[str, Any]: # noqa: C901
+ """Parse TOML from a string."""
+
+ # The spec allows converting "\r\n" to "\n", even in string
+ # literals. Let's do so to simplify parsing.
+ src = __s.replace("\r\n", "\n")
+ pos = 0
+ out = Output(NestedDict(), Flags())
+ header: Key = ()
+ parse_float = make_safe_parse_float(parse_float)
+
+ # Parse one statement at a time
+ # (typically means one line in TOML source)
+ while True:
+ # 1. Skip line leading whitespace
+ pos = skip_chars(src, pos, TOML_WS)
+
+ # 2. Parse rules. Expect one of the following:
+ # - end of file
+ # - end of line
+ # - comment
+ # - key/value pair
+ # - append dict to list (and move to its namespace)
+ # - create dict (and move to its namespace)
+ # Skip trailing whitespace when applicable.
+ try:
+ char = src[pos]
+ except IndexError:
+ break
+ if char == "\n":
+ pos += 1
+ continue
+ if char in KEY_INITIAL_CHARS:
+ pos = key_value_rule(src, pos, out, header, parse_float)
+ pos = skip_chars(src, pos, TOML_WS)
+ elif char == "[":
+ try:
+ second_char: str | None = src[pos + 1]
+ except IndexError:
+ second_char = None
+ out.flags.finalize_pending()
+ if second_char == "[":
+ pos, header = create_list_rule(src, pos, out)
+ else:
+ pos, header = create_dict_rule(src, pos, out)
+ pos = skip_chars(src, pos, TOML_WS)
+ elif char != "#":
+ raise suffixed_err(src, pos, "Invalid statement")
+
+ # 3. Skip comment
+ pos = skip_comment(src, pos)
+
+ # 4. Expect end of line or end of file
+ try:
+ char = src[pos]
+ except IndexError:
+ break
+ if char != "\n":
+ raise suffixed_err(
+ src, pos, "Expected newline or end of document after a statement"
+ )
+ pos += 1
+
+ return out.data.dict
+
+
+class Flags:
+ """Flags that map to parsed keys/namespaces."""
+
+ # Marks an immutable namespace (inline array or inline table).
+ FROZEN = 0
+ # Marks a nest that has been explicitly created and can no longer
+ # be opened using the "[table]" syntax.
+ EXPLICIT_NEST = 1
+
+ def __init__(self) -> None:
+ self._flags: dict[str, dict] = {}
+ self._pending_flags: set[tuple[Key, int]] = set()
+
+ def add_pending(self, key: Key, flag: int) -> None:
+ self._pending_flags.add((key, flag))
+
+ def finalize_pending(self) -> None:
+ for key, flag in self._pending_flags:
+ self.set(key, flag, recursive=False)
+ self._pending_flags.clear()
+
+ def unset_all(self, key: Key) -> None:
+ cont = self._flags
+ for k in key[:-1]:
+ if k not in cont:
+ return
+ cont = cont[k]["nested"]
+ cont.pop(key[-1], None)
+
+ def set(self, key: Key, flag: int, *, recursive: bool) -> None: # noqa: A003
+ cont = self._flags
+ key_parent, key_stem = key[:-1], key[-1]
+ for k in key_parent:
+ if k not in cont:
+ cont[k] = {"flags": set(), "recursive_flags": set(), "nested": {}}
+ cont = cont[k]["nested"]
+ if key_stem not in cont:
+ cont[key_stem] = {"flags": set(), "recursive_flags": set(), "nested": {}}
+ cont[key_stem]["recursive_flags" if recursive else "flags"].add(flag)
+
+ def is_(self, key: Key, flag: int) -> bool:
+ if not key:
+ return False # document root has no flags
+ cont = self._flags
+ for k in key[:-1]:
+ if k not in cont:
+ return False
+ inner_cont = cont[k]
+ if flag in inner_cont["recursive_flags"]:
+ return True
+ cont = inner_cont["nested"]
+ key_stem = key[-1]
+ if key_stem in cont:
+ cont = cont[key_stem]
+ return flag in cont["flags"] or flag in cont["recursive_flags"]
+ return False
+
+
+class NestedDict:
+ def __init__(self) -> None:
+ # The parsed content of the TOML document
+ self.dict: dict[str, Any] = {}
+
+ def get_or_create_nest(
+ self,
+ key: Key,
+ *,
+ access_lists: bool = True,
+ ) -> dict:
+ cont: Any = self.dict
+ for k in key:
+ if k not in cont:
+ cont[k] = {}
+ cont = cont[k]
+ if access_lists and isinstance(cont, list):
+ cont = cont[-1]
+ if not isinstance(cont, dict):
+ raise KeyError("There is no nest behind this key")
+ return cont
+
+ def append_nest_to_list(self, key: Key) -> None:
+ cont = self.get_or_create_nest(key[:-1])
+ last_key = key[-1]
+ if last_key in cont:
+ list_ = cont[last_key]
+ if not isinstance(list_, list):
+ raise KeyError("An object other than list found behind this key")
+ list_.append({})
+ else:
+ cont[last_key] = [{}]
+
+
+class Output(NamedTuple):
+ data: NestedDict
+ flags: Flags
+
+
+def skip_chars(src: str, pos: Pos, chars: Iterable[str]) -> Pos:
+ try:
+ while src[pos] in chars:
+ pos += 1
+ except IndexError:
+ pass
+ return pos
+
+
+def skip_until(
+ src: str,
+ pos: Pos,
+ expect: str,
+ *,
+ error_on: frozenset[str],
+ error_on_eof: bool,
+) -> Pos:
+ try:
+ new_pos = src.index(expect, pos)
+ except ValueError:
+ new_pos = len(src)
+ if error_on_eof:
+ raise suffixed_err(src, new_pos, f"Expected {expect!r}") from None
+
+ if not error_on.isdisjoint(src[pos:new_pos]):
+ while src[pos] not in error_on:
+ pos += 1
+ raise suffixed_err(src, pos, f"Found invalid character {src[pos]!r}")
+ return new_pos
+
+
+def skip_comment(src: str, pos: Pos) -> Pos:
+ try:
+ char: str | None = src[pos]
+ except IndexError:
+ char = None
+ if char == "#":
+ return skip_until(
+ src, pos + 1, "\n", error_on=ILLEGAL_COMMENT_CHARS, error_on_eof=False
+ )
+ return pos
+
+
+def skip_comments_and_array_ws(src: str, pos: Pos) -> Pos:
+ while True:
+ pos_before_skip = pos
+ pos = skip_chars(src, pos, TOML_WS_AND_NEWLINE)
+ pos = skip_comment(src, pos)
+ if pos == pos_before_skip:
+ return pos
+
+
+def create_dict_rule(src: str, pos: Pos, out: Output) -> tuple[Pos, Key]:
+ pos += 1 # Skip "["
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, key = parse_key(src, pos)
+
+ if out.flags.is_(key, Flags.EXPLICIT_NEST) or out.flags.is_(key, Flags.FROZEN):
+ raise suffixed_err(src, pos, f"Cannot declare {key} twice")
+ out.flags.set(key, Flags.EXPLICIT_NEST, recursive=False)
+ try:
+ out.data.get_or_create_nest(key)
+ except KeyError:
+ raise suffixed_err(src, pos, "Cannot overwrite a value") from None
+
+ if not src.startswith("]", pos):
+ raise suffixed_err(src, pos, "Expected ']' at the end of a table declaration")
+ return pos + 1, key
+
+
+def create_list_rule(src: str, pos: Pos, out: Output) -> tuple[Pos, Key]:
+ pos += 2 # Skip "[["
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, key = parse_key(src, pos)
+
+ if out.flags.is_(key, Flags.FROZEN):
+ raise suffixed_err(src, pos, f"Cannot mutate immutable namespace {key}")
+ # Free the namespace now that it points to another empty list item...
+ out.flags.unset_all(key)
+ # ...but this key precisely is still prohibited from table declaration
+ out.flags.set(key, Flags.EXPLICIT_NEST, recursive=False)
+ try:
+ out.data.append_nest_to_list(key)
+ except KeyError:
+ raise suffixed_err(src, pos, "Cannot overwrite a value") from None
+
+ if not src.startswith("]]", pos):
+ raise suffixed_err(src, pos, "Expected ']]' at the end of an array declaration")
+ return pos + 2, key
+
+
+def key_value_rule(
+ src: str, pos: Pos, out: Output, header: Key, parse_float: ParseFloat
+) -> Pos:
+ pos, key, value = parse_key_value_pair(src, pos, parse_float)
+ key_parent, key_stem = key[:-1], key[-1]
+ abs_key_parent = header + key_parent
+
+ relative_path_cont_keys = (header + key[:i] for i in range(1, len(key)))
+ for cont_key in relative_path_cont_keys:
+ # Check that dotted key syntax does not redefine an existing table
+ if out.flags.is_(cont_key, Flags.EXPLICIT_NEST):
+ raise suffixed_err(src, pos, f"Cannot redefine namespace {cont_key}")
+ # Containers in the relative path can't be opened with the table syntax or
+ # dotted key/value syntax in following table sections.
+ out.flags.add_pending(cont_key, Flags.EXPLICIT_NEST)
+
+ if out.flags.is_(abs_key_parent, Flags.FROZEN):
+ raise suffixed_err(
+ src, pos, f"Cannot mutate immutable namespace {abs_key_parent}"
+ )
+
+ try:
+ nest = out.data.get_or_create_nest(abs_key_parent)
+ except KeyError:
+ raise suffixed_err(src, pos, "Cannot overwrite a value") from None
+ if key_stem in nest:
+ raise suffixed_err(src, pos, "Cannot overwrite a value")
+ # Mark inline table and array namespaces recursively immutable
+ if isinstance(value, (dict, list)):
+ out.flags.set(header + key, Flags.FROZEN, recursive=True)
+ nest[key_stem] = value
+ return pos
+
+
+def parse_key_value_pair(
+ src: str, pos: Pos, parse_float: ParseFloat
+) -> tuple[Pos, Key, Any]:
+ pos, key = parse_key(src, pos)
+ try:
+ char: str | None = src[pos]
+ except IndexError:
+ char = None
+ if char != "=":
+ raise suffixed_err(src, pos, "Expected '=' after a key in a key/value pair")
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, value = parse_value(src, pos, parse_float)
+ return pos, key, value
+
+
+def parse_key(src: str, pos: Pos) -> tuple[Pos, Key]:
+ pos, key_part = parse_key_part(src, pos)
+ key: Key = (key_part,)
+ pos = skip_chars(src, pos, TOML_WS)
+ while True:
+ try:
+ char: str | None = src[pos]
+ except IndexError:
+ char = None
+ if char != ".":
+ return pos, key
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS)
+ pos, key_part = parse_key_part(src, pos)
+ key += (key_part,)
+ pos = skip_chars(src, pos, TOML_WS)
+
+
+def parse_key_part(src: str, pos: Pos) -> tuple[Pos, str]:
+ try:
+ char: str | None = src[pos]
+ except IndexError:
+ char = None
+ if char in BARE_KEY_CHARS:
+ start_pos = pos
+ pos = skip_chars(src, pos, BARE_KEY_CHARS)
+ return pos, src[start_pos:pos]
+ if char == "'":
+ return parse_literal_str(src, pos)
+ if char == '"':
+ return parse_one_line_basic_str(src, pos)
+ raise suffixed_err(src, pos, "Invalid initial character for a key part")
+
+
+def parse_one_line_basic_str(src: str, pos: Pos) -> tuple[Pos, str]:
+ pos += 1
+ return parse_basic_str(src, pos, multiline=False)
+
+
+def parse_array(src: str, pos: Pos, parse_float: ParseFloat) -> tuple[Pos, list]:
+ pos += 1
+ array: list = []
+
+ pos = skip_comments_and_array_ws(src, pos)
+ if src.startswith("]", pos):
+ return pos + 1, array
+ while True:
+ pos, val = parse_value(src, pos, parse_float)
+ array.append(val)
+ pos = skip_comments_and_array_ws(src, pos)
+
+ c = src[pos : pos + 1]
+ if c == "]":
+ return pos + 1, array
+ if c != ",":
+ raise suffixed_err(src, pos, "Unclosed array")
+ pos += 1
+
+ pos = skip_comments_and_array_ws(src, pos)
+ if src.startswith("]", pos):
+ return pos + 1, array
+
+
+def parse_inline_table(src: str, pos: Pos, parse_float: ParseFloat) -> tuple[Pos, dict]:
+ pos += 1
+ nested_dict = NestedDict()
+ flags = Flags()
+
+ pos = skip_chars(src, pos, TOML_WS)
+ if src.startswith("}", pos):
+ return pos + 1, nested_dict.dict
+ while True:
+ pos, key, value = parse_key_value_pair(src, pos, parse_float)
+ key_parent, key_stem = key[:-1], key[-1]
+ if flags.is_(key, Flags.FROZEN):
+ raise suffixed_err(src, pos, f"Cannot mutate immutable namespace {key}")
+ try:
+ nest = nested_dict.get_or_create_nest(key_parent, access_lists=False)
+ except KeyError:
+ raise suffixed_err(src, pos, "Cannot overwrite a value") from None
+ if key_stem in nest:
+ raise suffixed_err(src, pos, f"Duplicate inline table key {key_stem!r}")
+ nest[key_stem] = value
+ pos = skip_chars(src, pos, TOML_WS)
+ c = src[pos : pos + 1]
+ if c == "}":
+ return pos + 1, nested_dict.dict
+ if c != ",":
+ raise suffixed_err(src, pos, "Unclosed inline table")
+ if isinstance(value, (dict, list)):
+ flags.set(key, Flags.FROZEN, recursive=True)
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS)
+
+
+def parse_basic_str_escape(
+ src: str, pos: Pos, *, multiline: bool = False
+) -> tuple[Pos, str]:
+ escape_id = src[pos : pos + 2]
+ pos += 2
+ if multiline and escape_id in {"\\ ", "\\\t", "\\\n"}:
+ # Skip whitespace until next non-whitespace character or end of
+ # the doc. Error if non-whitespace is found before newline.
+ if escape_id != "\\\n":
+ pos = skip_chars(src, pos, TOML_WS)
+ try:
+ char = src[pos]
+ except IndexError:
+ return pos, ""
+ if char != "\n":
+ raise suffixed_err(src, pos, "Unescaped '\\' in a string")
+ pos += 1
+ pos = skip_chars(src, pos, TOML_WS_AND_NEWLINE)
+ return pos, ""
+ if escape_id == "\\u":
+ return parse_hex_char(src, pos, 4)
+ if escape_id == "\\U":
+ return parse_hex_char(src, pos, 8)
+ try:
+ return pos, BASIC_STR_ESCAPE_REPLACEMENTS[escape_id]
+ except KeyError:
+ raise suffixed_err(src, pos, "Unescaped '\\' in a string") from None
+
+
+def parse_basic_str_escape_multiline(src: str, pos: Pos) -> tuple[Pos, str]:
+ return parse_basic_str_escape(src, pos, multiline=True)
+
+
+def parse_hex_char(src: str, pos: Pos, hex_len: int) -> tuple[Pos, str]:
+ hex_str = src[pos : pos + hex_len]
+ if len(hex_str) != hex_len or not HEXDIGIT_CHARS.issuperset(hex_str):
+ raise suffixed_err(src, pos, "Invalid hex value")
+ pos += hex_len
+ hex_int = int(hex_str, 16)
+ if not is_unicode_scalar_value(hex_int):
+ raise suffixed_err(src, pos, "Escaped character is not a Unicode scalar value")
+ return pos, chr(hex_int)
+
+
+def parse_literal_str(src: str, pos: Pos) -> tuple[Pos, str]:
+ pos += 1 # Skip starting apostrophe
+ start_pos = pos
+ pos = skip_until(
+ src, pos, "'", error_on=ILLEGAL_LITERAL_STR_CHARS, error_on_eof=True
+ )
+ return pos + 1, src[start_pos:pos] # Skip ending apostrophe
+
+
+def parse_multiline_str(src: str, pos: Pos, *, literal: bool) -> tuple[Pos, str]:
+ pos += 3
+ if src.startswith("\n", pos):
+ pos += 1
+
+ if literal:
+ delim = "'"
+ end_pos = skip_until(
+ src,
+ pos,
+ "'''",
+ error_on=ILLEGAL_MULTILINE_LITERAL_STR_CHARS,
+ error_on_eof=True,
+ )
+ result = src[pos:end_pos]
+ pos = end_pos + 3
+ else:
+ delim = '"'
+ pos, result = parse_basic_str(src, pos, multiline=True)
+
+ # Add at maximum two extra apostrophes/quotes if the end sequence
+ # is 4 or 5 chars long instead of just 3.
+ if not src.startswith(delim, pos):
+ return pos, result
+ pos += 1
+ if not src.startswith(delim, pos):
+ return pos, result + delim
+ pos += 1
+ return pos, result + (delim * 2)
+
+
+def parse_basic_str(src: str, pos: Pos, *, multiline: bool) -> tuple[Pos, str]:
+ if multiline:
+ error_on = ILLEGAL_MULTILINE_BASIC_STR_CHARS
+ parse_escapes = parse_basic_str_escape_multiline
+ else:
+ error_on = ILLEGAL_BASIC_STR_CHARS
+ parse_escapes = parse_basic_str_escape
+ result = ""
+ start_pos = pos
+ while True:
+ try:
+ char = src[pos]
+ except IndexError:
+ raise suffixed_err(src, pos, "Unterminated string") from None
+ if char == '"':
+ if not multiline:
+ return pos + 1, result + src[start_pos:pos]
+ if src.startswith('"""', pos):
+ return pos + 3, result + src[start_pos:pos]
+ pos += 1
+ continue
+ if char == "\\":
+ result += src[start_pos:pos]
+ pos, parsed_escape = parse_escapes(src, pos)
+ result += parsed_escape
+ start_pos = pos
+ continue
+ if char in error_on:
+ raise suffixed_err(src, pos, f"Illegal character {char!r}")
+ pos += 1
+
+
+def parse_value( # noqa: C901
+ src: str, pos: Pos, parse_float: ParseFloat
+) -> tuple[Pos, Any]:
+ try:
+ char: str | None = src[pos]
+ except IndexError:
+ char = None
+
+ # IMPORTANT: order conditions based on speed of checking and likelihood
+
+ # Basic strings
+ if char == '"':
+ if src.startswith('"""', pos):
+ return parse_multiline_str(src, pos, literal=False)
+ return parse_one_line_basic_str(src, pos)
+
+ # Literal strings
+ if char == "'":
+ if src.startswith("'''", pos):
+ return parse_multiline_str(src, pos, literal=True)
+ return parse_literal_str(src, pos)
+
+ # Booleans
+ if char == "t":
+ if src.startswith("true", pos):
+ return pos + 4, True
+ if char == "f":
+ if src.startswith("false", pos):
+ return pos + 5, False
+
+ # Arrays
+ if char == "[":
+ return parse_array(src, pos, parse_float)
+
+ # Inline tables
+ if char == "{":
+ return parse_inline_table(src, pos, parse_float)
+
+ # Dates and times
+ datetime_match = RE_DATETIME.match(src, pos)
+ if datetime_match:
+ try:
+ datetime_obj = match_to_datetime(datetime_match)
+ except ValueError as e:
+ raise suffixed_err(src, pos, "Invalid date or datetime") from e
+ return datetime_match.end(), datetime_obj
+ localtime_match = RE_LOCALTIME.match(src, pos)
+ if localtime_match:
+ return localtime_match.end(), match_to_localtime(localtime_match)
+
+ # Integers and "normal" floats.
+ # The regex will greedily match any type starting with a decimal
+ # char, so needs to be located after handling of dates and times.
+ number_match = RE_NUMBER.match(src, pos)
+ if number_match:
+ return number_match.end(), match_to_number(number_match, parse_float)
+
+ # Special floats
+ first_three = src[pos : pos + 3]
+ if first_three in {"inf", "nan"}:
+ return pos + 3, parse_float(first_three)
+ first_four = src[pos : pos + 4]
+ if first_four in {"-inf", "+inf", "-nan", "+nan"}:
+ return pos + 4, parse_float(first_four)
+
+ raise suffixed_err(src, pos, "Invalid value")
+
+
+def suffixed_err(src: str, pos: Pos, msg: str) -> TOMLDecodeError:
+ """Return a `TOMLDecodeError` where error message is suffixed with
+ coordinates in source."""
+
+ def coord_repr(src: str, pos: Pos) -> str:
+ if pos >= len(src):
+ return "end of document"
+ line = src.count("\n", 0, pos) + 1
+ if line == 1:
+ column = pos + 1
+ else:
+ column = pos - src.rindex("\n", 0, pos)
+ return f"line {line}, column {column}"
+
+ return TOMLDecodeError(f"{msg} (at {coord_repr(src, pos)})")
+
+
+def is_unicode_scalar_value(codepoint: int) -> bool:
+ return (0 <= codepoint <= 55295) or (57344 <= codepoint <= 1114111)
+
+
+def make_safe_parse_float(parse_float: ParseFloat) -> ParseFloat:
+ """A decorator to make `parse_float` safe.
+
+ `parse_float` must not return dicts or lists, because these types
+ would be mixed with parsed TOML tables and arrays, thus confusing
+ the parser. The returned decorated callable raises `ValueError`
+ instead of returning illegal types.
+ """
+ # The default `float` callable never returns illegal types. Optimize it.
+ if parse_float is float: # type: ignore[comparison-overlap]
+ return float
+
+ def safe_parse_float(float_str: str) -> Any:
+ float_value = parse_float(float_str)
+ if isinstance(float_value, (dict, list)):
+ raise ValueError("parse_float must not return dicts or lists")
+ return float_value
+
+ return safe_parse_float
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_re.py b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_re.py
new file mode 100644
index 000000000..994bb7493
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_re.py
@@ -0,0 +1,107 @@
+# SPDX-License-Identifier: MIT
+# SPDX-FileCopyrightText: 2021 Taneli Hukkinen
+# Licensed to PSF under a Contributor Agreement.
+
+from __future__ import annotations
+
+from datetime import date, datetime, time, timedelta, timezone, tzinfo
+from functools import lru_cache
+import re
+from typing import Any
+
+from ._types import ParseFloat
+
+# E.g.
+# - 00:32:00.999999
+# - 00:32:00
+_TIME_RE_STR = r"([01][0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9])(?:\.([0-9]{1,6})[0-9]*)?"
+
+RE_NUMBER = re.compile(
+ r"""
+0
+(?:
+ x[0-9A-Fa-f](?:_?[0-9A-Fa-f])* # hex
+ |
+ b[01](?:_?[01])* # bin
+ |
+ o[0-7](?:_?[0-7])* # oct
+)
+|
+[+-]?(?:0|[1-9](?:_?[0-9])*) # dec, integer part
+(?P<floatpart>
+ (?:\.[0-9](?:_?[0-9])*)? # optional fractional part
+ (?:[eE][+-]?[0-9](?:_?[0-9])*)? # optional exponent part
+)
+""",
+ flags=re.VERBOSE,
+)
+RE_LOCALTIME = re.compile(_TIME_RE_STR)
+RE_DATETIME = re.compile(
+ rf"""
+([0-9]{{4}})-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01]) # date, e.g. 1988-10-27
+(?:
+ [Tt ]
+ {_TIME_RE_STR}
+ (?:([Zz])|([+-])([01][0-9]|2[0-3]):([0-5][0-9]))? # optional time offset
+)?
+""",
+ flags=re.VERBOSE,
+)
+
+
+def match_to_datetime(match: re.Match) -> datetime | date:
+ """Convert a `RE_DATETIME` match to `datetime.datetime` or `datetime.date`.
+
+ Raises ValueError if the match does not correspond to a valid date
+ or datetime.
+ """
+ (
+ year_str,
+ month_str,
+ day_str,
+ hour_str,
+ minute_str,
+ sec_str,
+ micros_str,
+ zulu_time,
+ offset_sign_str,
+ offset_hour_str,
+ offset_minute_str,
+ ) = match.groups()
+ year, month, day = int(year_str), int(month_str), int(day_str)
+ if hour_str is None:
+ return date(year, month, day)
+ hour, minute, sec = int(hour_str), int(minute_str), int(sec_str)
+ micros = int(micros_str.ljust(6, "0")) if micros_str else 0
+ if offset_sign_str:
+ tz: tzinfo | None = cached_tz(
+ offset_hour_str, offset_minute_str, offset_sign_str
+ )
+ elif zulu_time:
+ tz = timezone.utc
+ else: # local date-time
+ tz = None
+ return datetime(year, month, day, hour, minute, sec, micros, tzinfo=tz)
+
+
+@lru_cache(maxsize=None)
+def cached_tz(hour_str: str, minute_str: str, sign_str: str) -> timezone:
+ sign = 1 if sign_str == "+" else -1
+ return timezone(
+ timedelta(
+ hours=sign * int(hour_str),
+ minutes=sign * int(minute_str),
+ )
+ )
+
+
+def match_to_localtime(match: re.Match) -> time:
+ hour_str, minute_str, sec_str, micros_str = match.groups()
+ micros = int(micros_str.ljust(6, "0")) if micros_str else 0
+ return time(int(hour_str), int(minute_str), int(sec_str), micros)
+
+
+def match_to_number(match: re.Match, parse_float: ParseFloat) -> Any:
+ if match.group("floatpart"):
+ return parse_float(match.group())
+ return int(match.group(), 0)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_types.py b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_types.py
new file mode 100644
index 000000000..d949412e0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/_types.py
@@ -0,0 +1,10 @@
+# SPDX-License-Identifier: MIT
+# SPDX-FileCopyrightText: 2021 Taneli Hukkinen
+# Licensed to PSF under a Contributor Agreement.
+
+from typing import Any, Callable, Tuple
+
+# Type annotations
+ParseFloat = Callable[[str], Any]
+Key = Tuple[str, ...]
+Pos = int
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/py.typed
new file mode 100644
index 000000000..7632ecf77
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/tomli/py.typed
@@ -0,0 +1 @@
+# Marker file for PEP 561
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/__init__.py
new file mode 100644
index 000000000..e468bf8ce
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/__init__.py
@@ -0,0 +1,36 @@
+"""Verify certificates using native system trust stores"""
+
+import sys as _sys
+
+if _sys.version_info < (3, 10):
+ raise ImportError("truststore requires Python 3.10 or later")
+
+# Detect Python runtimes which don't implement SSLObject.get_unverified_chain() API
+# This API only became public in Python 3.13 but was available in CPython and PyPy since 3.10.
+if _sys.version_info < (3, 13):
+ try:
+ import ssl as _ssl
+ except ImportError:
+ raise ImportError("truststore requires the 'ssl' module")
+ else:
+ _sslmem = _ssl.MemoryBIO()
+ _sslobj = _ssl.create_default_context().wrap_bio(
+ _sslmem,
+ _sslmem,
+ )
+ try:
+ while not hasattr(_sslobj, "get_unverified_chain"):
+ _sslobj = _sslobj._sslobj # type: ignore[attr-defined]
+ except AttributeError:
+ raise ImportError(
+ "truststore requires peer certificate chain APIs to be available"
+ ) from None
+
+ del _ssl, _sslobj, _sslmem # noqa: F821
+
+from ._api import SSLContext, extract_from_ssl, inject_into_ssl # noqa: E402
+
+del _api, _sys # type: ignore[name-defined] # noqa: F821
+
+__all__ = ["SSLContext", "inject_into_ssl", "extract_from_ssl"]
+__version__ = "0.10.0"
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_api.py b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_api.py
new file mode 100644
index 000000000..aeb023af7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_api.py
@@ -0,0 +1,316 @@
+import os
+import platform
+import socket
+import ssl
+import sys
+import typing
+
+import _ssl # type: ignore[import-not-found]
+
+from ._ssl_constants import (
+ _original_SSLContext,
+ _original_super_SSLContext,
+ _truststore_SSLContext_dunder_class,
+ _truststore_SSLContext_super_class,
+)
+
+if platform.system() == "Windows":
+ from ._windows import _configure_context, _verify_peercerts_impl
+elif platform.system() == "Darwin":
+ from ._macos import _configure_context, _verify_peercerts_impl
+else:
+ from ._openssl import _configure_context, _verify_peercerts_impl
+
+if typing.TYPE_CHECKING:
+ from pip._vendor.typing_extensions import Buffer
+
+# From typeshed/stdlib/ssl.pyi
+_StrOrBytesPath: typing.TypeAlias = str | bytes | os.PathLike[str] | os.PathLike[bytes]
+_PasswordType: typing.TypeAlias = str | bytes | typing.Callable[[], str | bytes]
+
+
+def inject_into_ssl() -> None:
+ """Injects the :class:`truststore.SSLContext` into the ``ssl``
+ module by replacing :class:`ssl.SSLContext`.
+ """
+ setattr(ssl, "SSLContext", SSLContext)
+ # urllib3 holds on to its own reference of ssl.SSLContext
+ # so we need to replace that reference too.
+ try:
+ import pip._vendor.urllib3.util.ssl_ as urllib3_ssl
+
+ setattr(urllib3_ssl, "SSLContext", SSLContext)
+ except ImportError:
+ pass
+
+
+def extract_from_ssl() -> None:
+ """Restores the :class:`ssl.SSLContext` class to its original state"""
+ setattr(ssl, "SSLContext", _original_SSLContext)
+ try:
+ import pip._vendor.urllib3.util.ssl_ as urllib3_ssl
+
+ urllib3_ssl.SSLContext = _original_SSLContext # type: ignore[assignment]
+ except ImportError:
+ pass
+
+
+class SSLContext(_truststore_SSLContext_super_class): # type: ignore[misc]
+ """SSLContext API that uses system certificates on all platforms"""
+
+ @property # type: ignore[misc]
+ def __class__(self) -> type:
+ # Dirty hack to get around isinstance() checks
+ # for ssl.SSLContext instances in aiohttp/trustme
+ # when using non-CPython implementations.
+ return _truststore_SSLContext_dunder_class or SSLContext
+
+ def __init__(self, protocol: int = None) -> None: # type: ignore[assignment]
+ self._ctx = _original_SSLContext(protocol)
+
+ class TruststoreSSLObject(ssl.SSLObject):
+ # This object exists because wrap_bio() doesn't
+ # immediately do the handshake so we need to do
+ # certificate verifications after SSLObject.do_handshake()
+
+ def do_handshake(self) -> None:
+ ret = super().do_handshake()
+ _verify_peercerts(self, server_hostname=self.server_hostname)
+ return ret
+
+ self._ctx.sslobject_class = TruststoreSSLObject
+
+ def wrap_socket(
+ self,
+ sock: socket.socket,
+ server_side: bool = False,
+ do_handshake_on_connect: bool = True,
+ suppress_ragged_eofs: bool = True,
+ server_hostname: str | None = None,
+ session: ssl.SSLSession | None = None,
+ ) -> ssl.SSLSocket:
+ # Use a context manager here because the
+ # inner SSLContext holds on to our state
+ # but also does the actual handshake.
+ with _configure_context(self._ctx):
+ ssl_sock = self._ctx.wrap_socket(
+ sock,
+ server_side=server_side,
+ server_hostname=server_hostname,
+ do_handshake_on_connect=do_handshake_on_connect,
+ suppress_ragged_eofs=suppress_ragged_eofs,
+ session=session,
+ )
+ try:
+ _verify_peercerts(ssl_sock, server_hostname=server_hostname)
+ except Exception:
+ ssl_sock.close()
+ raise
+ return ssl_sock
+
+ def wrap_bio(
+ self,
+ incoming: ssl.MemoryBIO,
+ outgoing: ssl.MemoryBIO,
+ server_side: bool = False,
+ server_hostname: str | None = None,
+ session: ssl.SSLSession | None = None,
+ ) -> ssl.SSLObject:
+ with _configure_context(self._ctx):
+ ssl_obj = self._ctx.wrap_bio(
+ incoming,
+ outgoing,
+ server_hostname=server_hostname,
+ server_side=server_side,
+ session=session,
+ )
+ return ssl_obj
+
+ def load_verify_locations(
+ self,
+ cafile: str | bytes | os.PathLike[str] | os.PathLike[bytes] | None = None,
+ capath: str | bytes | os.PathLike[str] | os.PathLike[bytes] | None = None,
+ cadata: typing.Union[str, "Buffer", None] = None,
+ ) -> None:
+ return self._ctx.load_verify_locations(
+ cafile=cafile, capath=capath, cadata=cadata
+ )
+
+ def load_cert_chain(
+ self,
+ certfile: _StrOrBytesPath,
+ keyfile: _StrOrBytesPath | None = None,
+ password: _PasswordType | None = None,
+ ) -> None:
+ return self._ctx.load_cert_chain(
+ certfile=certfile, keyfile=keyfile, password=password
+ )
+
+ def load_default_certs(
+ self, purpose: ssl.Purpose = ssl.Purpose.SERVER_AUTH
+ ) -> None:
+ return self._ctx.load_default_certs(purpose)
+
+ def set_alpn_protocols(self, alpn_protocols: typing.Iterable[str]) -> None:
+ return self._ctx.set_alpn_protocols(alpn_protocols)
+
+ def set_npn_protocols(self, npn_protocols: typing.Iterable[str]) -> None:
+ return self._ctx.set_npn_protocols(npn_protocols)
+
+ def set_ciphers(self, __cipherlist: str) -> None:
+ return self._ctx.set_ciphers(__cipherlist)
+
+ def get_ciphers(self) -> typing.Any:
+ return self._ctx.get_ciphers()
+
+ def session_stats(self) -> dict[str, int]:
+ return self._ctx.session_stats()
+
+ def cert_store_stats(self) -> dict[str, int]:
+ raise NotImplementedError()
+
+ def set_default_verify_paths(self) -> None:
+ self._ctx.set_default_verify_paths()
+
+ @typing.overload
+ def get_ca_certs(
+ self, binary_form: typing.Literal[False] = ...
+ ) -> list[typing.Any]: ...
+
+ @typing.overload
+ def get_ca_certs(self, binary_form: typing.Literal[True] = ...) -> list[bytes]: ...
+
+ @typing.overload
+ def get_ca_certs(self, binary_form: bool = ...) -> typing.Any: ...
+
+ def get_ca_certs(self, binary_form: bool = False) -> list[typing.Any] | list[bytes]:
+ raise NotImplementedError()
+
+ @property
+ def check_hostname(self) -> bool:
+ return self._ctx.check_hostname
+
+ @check_hostname.setter
+ def check_hostname(self, value: bool) -> None:
+ self._ctx.check_hostname = value
+
+ @property
+ def hostname_checks_common_name(self) -> bool:
+ return self._ctx.hostname_checks_common_name
+
+ @hostname_checks_common_name.setter
+ def hostname_checks_common_name(self, value: bool) -> None:
+ self._ctx.hostname_checks_common_name = value
+
+ @property
+ def keylog_filename(self) -> str:
+ return self._ctx.keylog_filename
+
+ @keylog_filename.setter
+ def keylog_filename(self, value: str) -> None:
+ self._ctx.keylog_filename = value
+
+ @property
+ def maximum_version(self) -> ssl.TLSVersion:
+ return self._ctx.maximum_version
+
+ @maximum_version.setter
+ def maximum_version(self, value: ssl.TLSVersion) -> None:
+ _original_super_SSLContext.maximum_version.__set__( # type: ignore[attr-defined]
+ self._ctx, value
+ )
+
+ @property
+ def minimum_version(self) -> ssl.TLSVersion:
+ return self._ctx.minimum_version
+
+ @minimum_version.setter
+ def minimum_version(self, value: ssl.TLSVersion) -> None:
+ _original_super_SSLContext.minimum_version.__set__( # type: ignore[attr-defined]
+ self._ctx, value
+ )
+
+ @property
+ def options(self) -> ssl.Options:
+ return self._ctx.options
+
+ @options.setter
+ def options(self, value: ssl.Options) -> None:
+ _original_super_SSLContext.options.__set__( # type: ignore[attr-defined]
+ self._ctx, value
+ )
+
+ @property
+ def post_handshake_auth(self) -> bool:
+ return self._ctx.post_handshake_auth
+
+ @post_handshake_auth.setter
+ def post_handshake_auth(self, value: bool) -> None:
+ self._ctx.post_handshake_auth = value
+
+ @property
+ def protocol(self) -> ssl._SSLMethod:
+ return self._ctx.protocol
+
+ @property
+ def security_level(self) -> int:
+ return self._ctx.security_level
+
+ @property
+ def verify_flags(self) -> ssl.VerifyFlags:
+ return self._ctx.verify_flags
+
+ @verify_flags.setter
+ def verify_flags(self, value: ssl.VerifyFlags) -> None:
+ _original_super_SSLContext.verify_flags.__set__( # type: ignore[attr-defined]
+ self._ctx, value
+ )
+
+ @property
+ def verify_mode(self) -> ssl.VerifyMode:
+ return self._ctx.verify_mode
+
+ @verify_mode.setter
+ def verify_mode(self, value: ssl.VerifyMode) -> None:
+ _original_super_SSLContext.verify_mode.__set__( # type: ignore[attr-defined]
+ self._ctx, value
+ )
+
+
+# Python 3.13+ makes get_unverified_chain() a public API that only returns DER
+# encoded certificates. We detect whether we need to call public_bytes() for 3.10->3.12
+# Pre-3.13 returned None instead of an empty list from get_unverified_chain()
+if sys.version_info >= (3, 13):
+
+ def _get_unverified_chain_bytes(sslobj: ssl.SSLObject) -> list[bytes]:
+ unverified_chain = sslobj.get_unverified_chain() or () # type: ignore[attr-defined]
+ return [
+ cert if isinstance(cert, bytes) else cert.public_bytes(_ssl.ENCODING_DER)
+ for cert in unverified_chain
+ ]
+
+else:
+
+ def _get_unverified_chain_bytes(sslobj: ssl.SSLObject) -> list[bytes]:
+ unverified_chain = sslobj.get_unverified_chain() or () # type: ignore[attr-defined]
+ return [cert.public_bytes(_ssl.ENCODING_DER) for cert in unverified_chain]
+
+
+def _verify_peercerts(
+ sock_or_sslobj: ssl.SSLSocket | ssl.SSLObject, server_hostname: str | None
+) -> None:
+ """
+ Verifies the peer certificates from an SSLSocket or SSLObject
+ against the certificates in the OS trust store.
+ """
+ sslobj: ssl.SSLObject = sock_or_sslobj # type: ignore[assignment]
+ try:
+ while not hasattr(sslobj, "get_unverified_chain"):
+ sslobj = sslobj._sslobj # type: ignore[attr-defined]
+ except AttributeError:
+ pass
+
+ cert_bytes = _get_unverified_chain_bytes(sslobj)
+ _verify_peercerts_impl(
+ sock_or_sslobj.context, cert_bytes, server_hostname=server_hostname
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_macos.py b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_macos.py
new file mode 100644
index 000000000..345030772
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_macos.py
@@ -0,0 +1,571 @@
+import contextlib
+import ctypes
+import platform
+import ssl
+import typing
+from ctypes import (
+ CDLL,
+ POINTER,
+ c_bool,
+ c_char_p,
+ c_int32,
+ c_long,
+ c_uint32,
+ c_ulong,
+ c_void_p,
+)
+from ctypes.util import find_library
+
+from ._ssl_constants import _set_ssl_context_verify_mode
+
+_mac_version = platform.mac_ver()[0]
+_mac_version_info = tuple(map(int, _mac_version.split(".")))
+if _mac_version_info < (10, 8):
+ raise ImportError(
+ f"Only OS X 10.8 and newer are supported, not {_mac_version_info[0]}.{_mac_version_info[1]}"
+ )
+
+_is_macos_version_10_14_or_later = _mac_version_info >= (10, 14)
+
+
+def _load_cdll(name: str, macos10_16_path: str) -> CDLL:
+ """Loads a CDLL by name, falling back to known path on 10.16+"""
+ try:
+ # Big Sur is technically 11 but we use 10.16 due to the Big Sur
+ # beta being labeled as 10.16.
+ path: str | None
+ if _mac_version_info >= (10, 16):
+ path = macos10_16_path
+ else:
+ path = find_library(name)
+ if not path:
+ raise OSError # Caught and reraised as 'ImportError'
+ return CDLL(path, use_errno=True)
+ except OSError:
+ raise ImportError(f"The library {name} failed to load") from None
+
+
+Security = _load_cdll(
+ "Security", "/System/Library/Frameworks/Security.framework/Security"
+)
+CoreFoundation = _load_cdll(
+ "CoreFoundation",
+ "/System/Library/Frameworks/CoreFoundation.framework/CoreFoundation",
+)
+
+Boolean = c_bool
+CFIndex = c_long
+CFStringEncoding = c_uint32
+CFData = c_void_p
+CFString = c_void_p
+CFArray = c_void_p
+CFMutableArray = c_void_p
+CFError = c_void_p
+CFType = c_void_p
+CFTypeID = c_ulong
+CFTypeRef = POINTER(CFType)
+CFAllocatorRef = c_void_p
+
+OSStatus = c_int32
+
+CFErrorRef = POINTER(CFError)
+CFDataRef = POINTER(CFData)
+CFStringRef = POINTER(CFString)
+CFArrayRef = POINTER(CFArray)
+CFMutableArrayRef = POINTER(CFMutableArray)
+CFArrayCallBacks = c_void_p
+CFOptionFlags = c_uint32
+
+SecCertificateRef = POINTER(c_void_p)
+SecPolicyRef = POINTER(c_void_p)
+SecTrustRef = POINTER(c_void_p)
+SecTrustResultType = c_uint32
+SecTrustOptionFlags = c_uint32
+
+try:
+ Security.SecCertificateCreateWithData.argtypes = [CFAllocatorRef, CFDataRef]
+ Security.SecCertificateCreateWithData.restype = SecCertificateRef
+
+ Security.SecCertificateCopyData.argtypes = [SecCertificateRef]
+ Security.SecCertificateCopyData.restype = CFDataRef
+
+ Security.SecCopyErrorMessageString.argtypes = [OSStatus, c_void_p]
+ Security.SecCopyErrorMessageString.restype = CFStringRef
+
+ Security.SecTrustSetAnchorCertificates.argtypes = [SecTrustRef, CFArrayRef]
+ Security.SecTrustSetAnchorCertificates.restype = OSStatus
+
+ Security.SecTrustSetAnchorCertificatesOnly.argtypes = [SecTrustRef, Boolean]
+ Security.SecTrustSetAnchorCertificatesOnly.restype = OSStatus
+
+ Security.SecPolicyCreateRevocation.argtypes = [CFOptionFlags]
+ Security.SecPolicyCreateRevocation.restype = SecPolicyRef
+
+ Security.SecPolicyCreateSSL.argtypes = [Boolean, CFStringRef]
+ Security.SecPolicyCreateSSL.restype = SecPolicyRef
+
+ Security.SecTrustCreateWithCertificates.argtypes = [
+ CFTypeRef,
+ CFTypeRef,
+ POINTER(SecTrustRef),
+ ]
+ Security.SecTrustCreateWithCertificates.restype = OSStatus
+
+ Security.SecTrustGetTrustResult.argtypes = [
+ SecTrustRef,
+ POINTER(SecTrustResultType),
+ ]
+ Security.SecTrustGetTrustResult.restype = OSStatus
+
+ Security.SecTrustEvaluate.argtypes = [
+ SecTrustRef,
+ POINTER(SecTrustResultType),
+ ]
+ Security.SecTrustEvaluate.restype = OSStatus
+
+ Security.SecTrustRef = SecTrustRef # type: ignore[attr-defined]
+ Security.SecTrustResultType = SecTrustResultType # type: ignore[attr-defined]
+ Security.OSStatus = OSStatus # type: ignore[attr-defined]
+
+ kSecRevocationUseAnyAvailableMethod = 3
+ kSecRevocationRequirePositiveResponse = 8
+
+ CoreFoundation.CFRelease.argtypes = [CFTypeRef]
+ CoreFoundation.CFRelease.restype = None
+
+ CoreFoundation.CFGetTypeID.argtypes = [CFTypeRef]
+ CoreFoundation.CFGetTypeID.restype = CFTypeID
+
+ CoreFoundation.CFStringCreateWithCString.argtypes = [
+ CFAllocatorRef,
+ c_char_p,
+ CFStringEncoding,
+ ]
+ CoreFoundation.CFStringCreateWithCString.restype = CFStringRef
+
+ CoreFoundation.CFStringGetCStringPtr.argtypes = [CFStringRef, CFStringEncoding]
+ CoreFoundation.CFStringGetCStringPtr.restype = c_char_p
+
+ CoreFoundation.CFStringGetCString.argtypes = [
+ CFStringRef,
+ c_char_p,
+ CFIndex,
+ CFStringEncoding,
+ ]
+ CoreFoundation.CFStringGetCString.restype = c_bool
+
+ CoreFoundation.CFDataCreate.argtypes = [CFAllocatorRef, c_char_p, CFIndex]
+ CoreFoundation.CFDataCreate.restype = CFDataRef
+
+ CoreFoundation.CFDataGetLength.argtypes = [CFDataRef]
+ CoreFoundation.CFDataGetLength.restype = CFIndex
+
+ CoreFoundation.CFDataGetBytePtr.argtypes = [CFDataRef]
+ CoreFoundation.CFDataGetBytePtr.restype = c_void_p
+
+ CoreFoundation.CFArrayCreate.argtypes = [
+ CFAllocatorRef,
+ POINTER(CFTypeRef),
+ CFIndex,
+ CFArrayCallBacks,
+ ]
+ CoreFoundation.CFArrayCreate.restype = CFArrayRef
+
+ CoreFoundation.CFArrayCreateMutable.argtypes = [
+ CFAllocatorRef,
+ CFIndex,
+ CFArrayCallBacks,
+ ]
+ CoreFoundation.CFArrayCreateMutable.restype = CFMutableArrayRef
+
+ CoreFoundation.CFArrayAppendValue.argtypes = [CFMutableArrayRef, c_void_p]
+ CoreFoundation.CFArrayAppendValue.restype = None
+
+ CoreFoundation.CFArrayGetCount.argtypes = [CFArrayRef]
+ CoreFoundation.CFArrayGetCount.restype = CFIndex
+
+ CoreFoundation.CFArrayGetValueAtIndex.argtypes = [CFArrayRef, CFIndex]
+ CoreFoundation.CFArrayGetValueAtIndex.restype = c_void_p
+
+ CoreFoundation.CFErrorGetCode.argtypes = [CFErrorRef]
+ CoreFoundation.CFErrorGetCode.restype = CFIndex
+
+ CoreFoundation.CFErrorCopyDescription.argtypes = [CFErrorRef]
+ CoreFoundation.CFErrorCopyDescription.restype = CFStringRef
+
+ CoreFoundation.kCFAllocatorDefault = CFAllocatorRef.in_dll( # type: ignore[attr-defined]
+ CoreFoundation, "kCFAllocatorDefault"
+ )
+ CoreFoundation.kCFTypeArrayCallBacks = c_void_p.in_dll( # type: ignore[attr-defined]
+ CoreFoundation, "kCFTypeArrayCallBacks"
+ )
+
+ CoreFoundation.CFTypeRef = CFTypeRef # type: ignore[attr-defined]
+ CoreFoundation.CFArrayRef = CFArrayRef # type: ignore[attr-defined]
+ CoreFoundation.CFStringRef = CFStringRef # type: ignore[attr-defined]
+ CoreFoundation.CFErrorRef = CFErrorRef # type: ignore[attr-defined]
+
+except AttributeError as e:
+ raise ImportError(f"Error initializing ctypes: {e}") from None
+
+# SecTrustEvaluateWithError is macOS 10.14+
+if _is_macos_version_10_14_or_later:
+ try:
+ Security.SecTrustEvaluateWithError.argtypes = [
+ SecTrustRef,
+ POINTER(CFErrorRef),
+ ]
+ Security.SecTrustEvaluateWithError.restype = c_bool
+ except AttributeError as e:
+ raise ImportError(f"Error initializing ctypes: {e}") from None
+
+
+def _handle_osstatus(result: OSStatus, _: typing.Any, args: typing.Any) -> typing.Any:
+ """
+ Raises an error if the OSStatus value is non-zero.
+ """
+ if int(result) == 0:
+ return args
+
+ # Returns a CFString which we need to transform
+ # into a UTF-8 Python string.
+ error_message_cfstring = None
+ try:
+ error_message_cfstring = Security.SecCopyErrorMessageString(result, None)
+
+ # First step is convert the CFString into a C string pointer.
+ # We try the fast no-copy way first.
+ error_message_cfstring_c_void_p = ctypes.cast(
+ error_message_cfstring, ctypes.POINTER(ctypes.c_void_p)
+ )
+ message = CoreFoundation.CFStringGetCStringPtr(
+ error_message_cfstring_c_void_p, CFConst.kCFStringEncodingUTF8
+ )
+
+ # Quoting the Apple dev docs:
+ #
+ # "A pointer to a C string or NULL if the internal
+ # storage of theString does not allow this to be
+ # returned efficiently."
+ #
+ # So we need to get our hands dirty.
+ if message is None:
+ buffer = ctypes.create_string_buffer(1024)
+ result = CoreFoundation.CFStringGetCString(
+ error_message_cfstring_c_void_p,
+ buffer,
+ 1024,
+ CFConst.kCFStringEncodingUTF8,
+ )
+ if not result:
+ raise OSError("Error copying C string from CFStringRef")
+ message = buffer.value
+
+ finally:
+ if error_message_cfstring is not None:
+ CoreFoundation.CFRelease(error_message_cfstring)
+
+ # If no message can be found for this status we come
+ # up with a generic one that forwards the status code.
+ if message is None or message == "":
+ message = f"SecureTransport operation returned a non-zero OSStatus: {result}"
+
+ raise ssl.SSLError(message)
+
+
+Security.SecTrustCreateWithCertificates.errcheck = _handle_osstatus # type: ignore[assignment]
+Security.SecTrustSetAnchorCertificates.errcheck = _handle_osstatus # type: ignore[assignment]
+Security.SecTrustSetAnchorCertificatesOnly.errcheck = _handle_osstatus # type: ignore[assignment]
+Security.SecTrustGetTrustResult.errcheck = _handle_osstatus # type: ignore[assignment]
+Security.SecTrustEvaluate.errcheck = _handle_osstatus # type: ignore[assignment]
+
+
+class CFConst:
+ """CoreFoundation constants"""
+
+ kCFStringEncodingUTF8 = CFStringEncoding(0x08000100)
+
+ errSecIncompleteCertRevocationCheck = -67635
+ errSecHostNameMismatch = -67602
+ errSecCertificateExpired = -67818
+ errSecNotTrusted = -67843
+
+
+def _bytes_to_cf_data_ref(value: bytes) -> CFDataRef: # type: ignore[valid-type]
+ return CoreFoundation.CFDataCreate( # type: ignore[no-any-return]
+ CoreFoundation.kCFAllocatorDefault, value, len(value)
+ )
+
+
+def _bytes_to_cf_string(value: bytes) -> CFString:
+ """
+ Given a Python binary data, create a CFString.
+ The string must be CFReleased by the caller.
+ """
+ c_str = ctypes.c_char_p(value)
+ cf_str = CoreFoundation.CFStringCreateWithCString(
+ CoreFoundation.kCFAllocatorDefault,
+ c_str,
+ CFConst.kCFStringEncodingUTF8,
+ )
+ return cf_str # type: ignore[no-any-return]
+
+
+def _cf_string_ref_to_str(cf_string_ref: CFStringRef) -> str | None: # type: ignore[valid-type]
+ """
+ Creates a Unicode string from a CFString object. Used entirely for error
+ reporting.
+ Yes, it annoys me quite a lot that this function is this complex.
+ """
+
+ string = CoreFoundation.CFStringGetCStringPtr(
+ cf_string_ref, CFConst.kCFStringEncodingUTF8
+ )
+ if string is None:
+ buffer = ctypes.create_string_buffer(1024)
+ result = CoreFoundation.CFStringGetCString(
+ cf_string_ref, buffer, 1024, CFConst.kCFStringEncodingUTF8
+ )
+ if not result:
+ raise OSError("Error copying C string from CFStringRef")
+ string = buffer.value
+ if string is not None:
+ string = string.decode("utf-8")
+ return string # type: ignore[no-any-return]
+
+
+def _der_certs_to_cf_cert_array(certs: list[bytes]) -> CFMutableArrayRef: # type: ignore[valid-type]
+ """Builds a CFArray of SecCertificateRefs from a list of DER-encoded certificates.
+ Responsibility of the caller to call CoreFoundation.CFRelease on the CFArray.
+ """
+ cf_array = CoreFoundation.CFArrayCreateMutable(
+ CoreFoundation.kCFAllocatorDefault,
+ 0,
+ ctypes.byref(CoreFoundation.kCFTypeArrayCallBacks),
+ )
+ if not cf_array:
+ raise MemoryError("Unable to allocate memory!")
+
+ for cert_data in certs:
+ cf_data = None
+ sec_cert_ref = None
+ try:
+ cf_data = _bytes_to_cf_data_ref(cert_data)
+ sec_cert_ref = Security.SecCertificateCreateWithData(
+ CoreFoundation.kCFAllocatorDefault, cf_data
+ )
+ CoreFoundation.CFArrayAppendValue(cf_array, sec_cert_ref)
+ finally:
+ if cf_data:
+ CoreFoundation.CFRelease(cf_data)
+ if sec_cert_ref:
+ CoreFoundation.CFRelease(sec_cert_ref)
+
+ return cf_array # type: ignore[no-any-return]
+
+
+@contextlib.contextmanager
+def _configure_context(ctx: ssl.SSLContext) -> typing.Iterator[None]:
+ check_hostname = ctx.check_hostname
+ verify_mode = ctx.verify_mode
+ ctx.check_hostname = False
+ _set_ssl_context_verify_mode(ctx, ssl.CERT_NONE)
+ try:
+ yield
+ finally:
+ ctx.check_hostname = check_hostname
+ _set_ssl_context_verify_mode(ctx, verify_mode)
+
+
+def _verify_peercerts_impl(
+ ssl_context: ssl.SSLContext,
+ cert_chain: list[bytes],
+ server_hostname: str | None = None,
+) -> None:
+ certs = None
+ policies = None
+ trust = None
+ try:
+ # Only set a hostname on the policy if we're verifying the hostname
+ # on the leaf certificate.
+ if server_hostname is not None and ssl_context.check_hostname:
+ cf_str_hostname = None
+ try:
+ cf_str_hostname = _bytes_to_cf_string(server_hostname.encode("ascii"))
+ ssl_policy = Security.SecPolicyCreateSSL(True, cf_str_hostname)
+ finally:
+ if cf_str_hostname:
+ CoreFoundation.CFRelease(cf_str_hostname)
+ else:
+ ssl_policy = Security.SecPolicyCreateSSL(True, None)
+
+ policies = ssl_policy
+ if ssl_context.verify_flags & ssl.VERIFY_CRL_CHECK_CHAIN:
+ # Add explicit policy requiring positive revocation checks
+ policies = CoreFoundation.CFArrayCreateMutable(
+ CoreFoundation.kCFAllocatorDefault,
+ 0,
+ ctypes.byref(CoreFoundation.kCFTypeArrayCallBacks),
+ )
+ CoreFoundation.CFArrayAppendValue(policies, ssl_policy)
+ CoreFoundation.CFRelease(ssl_policy)
+ revocation_policy = Security.SecPolicyCreateRevocation(
+ kSecRevocationUseAnyAvailableMethod
+ | kSecRevocationRequirePositiveResponse
+ )
+ CoreFoundation.CFArrayAppendValue(policies, revocation_policy)
+ CoreFoundation.CFRelease(revocation_policy)
+ elif ssl_context.verify_flags & ssl.VERIFY_CRL_CHECK_LEAF:
+ raise NotImplementedError("VERIFY_CRL_CHECK_LEAF not implemented for macOS")
+
+ certs = None
+ try:
+ certs = _der_certs_to_cf_cert_array(cert_chain)
+
+ # Now that we have certificates loaded and a SecPolicy
+ # we can finally create a SecTrust object!
+ trust = Security.SecTrustRef()
+ Security.SecTrustCreateWithCertificates(
+ certs, policies, ctypes.byref(trust)
+ )
+
+ finally:
+ # The certs are now being held by SecTrust so we can
+ # release our handles for the array.
+ if certs:
+ CoreFoundation.CFRelease(certs)
+
+ # If there are additional trust anchors to load we need to transform
+ # the list of DER-encoded certificates into a CFArray.
+ ctx_ca_certs_der: list[bytes] | None = ssl_context.get_ca_certs(
+ binary_form=True
+ )
+ if ctx_ca_certs_der:
+ ctx_ca_certs = None
+ try:
+ ctx_ca_certs = _der_certs_to_cf_cert_array(ctx_ca_certs_der)
+ Security.SecTrustSetAnchorCertificates(trust, ctx_ca_certs)
+ finally:
+ if ctx_ca_certs:
+ CoreFoundation.CFRelease(ctx_ca_certs)
+
+ # We always want system certificates.
+ Security.SecTrustSetAnchorCertificatesOnly(trust, False)
+
+ # macOS 10.13 and earlier don't support SecTrustEvaluateWithError()
+ # so we use SecTrustEvaluate() which means we need to construct error
+ # messages ourselves.
+ if _is_macos_version_10_14_or_later:
+ _verify_peercerts_impl_macos_10_14(ssl_context, trust)
+ else:
+ _verify_peercerts_impl_macos_10_13(ssl_context, trust)
+ finally:
+ if policies:
+ CoreFoundation.CFRelease(policies)
+ if trust:
+ CoreFoundation.CFRelease(trust)
+
+
+def _verify_peercerts_impl_macos_10_13(
+ ssl_context: ssl.SSLContext, sec_trust_ref: typing.Any
+) -> None:
+ """Verify using 'SecTrustEvaluate' API for macOS 10.13 and earlier.
+ macOS 10.14 added the 'SecTrustEvaluateWithError' API.
+ """
+ sec_trust_result_type = Security.SecTrustResultType()
+ Security.SecTrustEvaluate(sec_trust_ref, ctypes.byref(sec_trust_result_type))
+
+ try:
+ sec_trust_result_type_as_int = int(sec_trust_result_type.value)
+ except (ValueError, TypeError):
+ sec_trust_result_type_as_int = -1
+
+ # Apple doesn't document these values in their own API docs.
+ # See: https://github.com/xybp888/iOS-SDKs/blob/master/iPhoneOS13.0.sdk/System/Library/Frameworks/Security.framework/Headers/SecTrust.h#L84
+ if (
+ ssl_context.verify_mode == ssl.CERT_REQUIRED
+ and sec_trust_result_type_as_int not in (1, 4)
+ ):
+ # Note that we're not able to ignore only hostname errors
+ # for macOS 10.13 and earlier, so check_hostname=False will
+ # still return an error.
+ sec_trust_result_type_to_message = {
+ 0: "Invalid trust result type",
+ # 1: "Trust evaluation succeeded",
+ 2: "User confirmation required",
+ 3: "User specified that certificate is not trusted",
+ # 4: "Trust result is unspecified",
+ 5: "Recoverable trust failure occurred",
+ 6: "Fatal trust failure occurred",
+ 7: "Other error occurred, certificate may be revoked",
+ }
+ error_message = sec_trust_result_type_to_message.get(
+ sec_trust_result_type_as_int,
+ f"Unknown trust result: {sec_trust_result_type_as_int}",
+ )
+
+ err = ssl.SSLCertVerificationError(error_message)
+ err.verify_message = error_message
+ err.verify_code = sec_trust_result_type_as_int
+ raise err
+
+
+def _verify_peercerts_impl_macos_10_14(
+ ssl_context: ssl.SSLContext, sec_trust_ref: typing.Any
+) -> None:
+ """Verify using 'SecTrustEvaluateWithError' API for macOS 10.14+."""
+ cf_error = CoreFoundation.CFErrorRef()
+ sec_trust_eval_result = Security.SecTrustEvaluateWithError(
+ sec_trust_ref, ctypes.byref(cf_error)
+ )
+ # sec_trust_eval_result is a bool (0 or 1)
+ # where 1 means that the certs are trusted.
+ if sec_trust_eval_result == 1:
+ is_trusted = True
+ elif sec_trust_eval_result == 0:
+ is_trusted = False
+ else:
+ raise ssl.SSLError(
+ f"Unknown result from Security.SecTrustEvaluateWithError: {sec_trust_eval_result!r}"
+ )
+
+ cf_error_code = 0
+ if not is_trusted:
+ cf_error_code = CoreFoundation.CFErrorGetCode(cf_error)
+
+ # If the error is a known failure that we're
+ # explicitly okay with from SSLContext configuration
+ # we can set is_trusted accordingly.
+ if ssl_context.verify_mode != ssl.CERT_REQUIRED and (
+ cf_error_code == CFConst.errSecNotTrusted
+ or cf_error_code == CFConst.errSecCertificateExpired
+ ):
+ is_trusted = True
+
+ # If we're still not trusted then we start to
+ # construct and raise the SSLCertVerificationError.
+ if not is_trusted:
+ cf_error_string_ref = None
+ try:
+ cf_error_string_ref = CoreFoundation.CFErrorCopyDescription(cf_error)
+
+ # Can this ever return 'None' if there's a CFError?
+ cf_error_message = (
+ _cf_string_ref_to_str(cf_error_string_ref)
+ or "Certificate verification failed"
+ )
+
+ # TODO: Not sure if we need the SecTrustResultType for anything?
+ # We only care whether or not it's a success or failure for now.
+ sec_trust_result_type = Security.SecTrustResultType()
+ Security.SecTrustGetTrustResult(
+ sec_trust_ref, ctypes.byref(sec_trust_result_type)
+ )
+
+ err = ssl.SSLCertVerificationError(cf_error_message)
+ err.verify_message = cf_error_message
+ err.verify_code = cf_error_code
+ raise err
+ finally:
+ if cf_error_string_ref:
+ CoreFoundation.CFRelease(cf_error_string_ref)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_openssl.py b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_openssl.py
new file mode 100644
index 000000000..9951cf75c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_openssl.py
@@ -0,0 +1,66 @@
+import contextlib
+import os
+import re
+import ssl
+import typing
+
+# candidates based on https://github.com/tiran/certifi-system-store by Christian Heimes
+_CA_FILE_CANDIDATES = [
+ # Alpine, Arch, Fedora 34+, OpenWRT, RHEL 9+, BSD
+ "/etc/ssl/cert.pem",
+ # Fedora <= 34, RHEL <= 9, CentOS <= 9
+ "/etc/pki/tls/cert.pem",
+ # Debian, Ubuntu (requires ca-certificates)
+ "/etc/ssl/certs/ca-certificates.crt",
+ # SUSE
+ "/etc/ssl/ca-bundle.pem",
+]
+
+_HASHED_CERT_FILENAME_RE = re.compile(r"^[0-9a-fA-F]{8}\.[0-9]$")
+
+
+@contextlib.contextmanager
+def _configure_context(ctx: ssl.SSLContext) -> typing.Iterator[None]:
+ # First, check whether the default locations from OpenSSL
+ # seem like they will give us a usable set of CA certs.
+ # ssl.get_default_verify_paths already takes care of:
+ # - getting cafile from either the SSL_CERT_FILE env var
+ # or the path configured when OpenSSL was compiled,
+ # and verifying that that path exists
+ # - getting capath from either the SSL_CERT_DIR env var
+ # or the path configured when OpenSSL was compiled,
+ # and verifying that that path exists
+ # In addition we'll check whether capath appears to contain certs.
+ defaults = ssl.get_default_verify_paths()
+ if defaults.cafile or (defaults.capath and _capath_contains_certs(defaults.capath)):
+ ctx.set_default_verify_paths()
+ else:
+ # cafile from OpenSSL doesn't exist
+ # and capath from OpenSSL doesn't contain certs.
+ # Let's search other common locations instead.
+ for cafile in _CA_FILE_CANDIDATES:
+ if os.path.isfile(cafile):
+ ctx.load_verify_locations(cafile=cafile)
+ break
+
+ yield
+
+
+def _capath_contains_certs(capath: str) -> bool:
+ """Check whether capath exists and contains certs in the expected format."""
+ if not os.path.isdir(capath):
+ return False
+ for name in os.listdir(capath):
+ if _HASHED_CERT_FILENAME_RE.match(name):
+ return True
+ return False
+
+
+def _verify_peercerts_impl(
+ ssl_context: ssl.SSLContext,
+ cert_chain: list[bytes],
+ server_hostname: str | None = None,
+) -> None:
+ # This is a no-op because we've enabled SSLContext's built-in
+ # verification via verify_mode=CERT_REQUIRED, and don't need to repeat it.
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_ssl_constants.py b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_ssl_constants.py
new file mode 100644
index 000000000..b1ee7a3cb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_ssl_constants.py
@@ -0,0 +1,31 @@
+import ssl
+import sys
+import typing
+
+# Hold on to the original class so we can create it consistently
+# even if we inject our own SSLContext into the ssl module.
+_original_SSLContext = ssl.SSLContext
+_original_super_SSLContext = super(_original_SSLContext, _original_SSLContext)
+
+# CPython is known to be good, but non-CPython implementations
+# may implement SSLContext differently so to be safe we don't
+# subclass the SSLContext.
+
+# This is returned by truststore.SSLContext.__class__()
+_truststore_SSLContext_dunder_class: typing.Optional[type]
+
+# This value is the superclass of truststore.SSLContext.
+_truststore_SSLContext_super_class: type
+
+if sys.implementation.name == "cpython":
+ _truststore_SSLContext_super_class = _original_SSLContext
+ _truststore_SSLContext_dunder_class = None
+else:
+ _truststore_SSLContext_super_class = object
+ _truststore_SSLContext_dunder_class = _original_SSLContext
+
+
+def _set_ssl_context_verify_mode(
+ ssl_context: ssl.SSLContext, verify_mode: ssl.VerifyMode
+) -> None:
+ _original_super_SSLContext.verify_mode.__set__(ssl_context, verify_mode) # type: ignore[attr-defined]
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_windows.py b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_windows.py
new file mode 100644
index 000000000..a9bf9abdf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/_windows.py
@@ -0,0 +1,567 @@
+import contextlib
+import ssl
+import typing
+from ctypes import WinDLL # type: ignore
+from ctypes import WinError # type: ignore
+from ctypes import (
+ POINTER,
+ Structure,
+ c_char_p,
+ c_ulong,
+ c_void_p,
+ c_wchar_p,
+ cast,
+ create_unicode_buffer,
+ pointer,
+ sizeof,
+)
+from ctypes.wintypes import (
+ BOOL,
+ DWORD,
+ HANDLE,
+ LONG,
+ LPCSTR,
+ LPCVOID,
+ LPCWSTR,
+ LPFILETIME,
+ LPSTR,
+ LPWSTR,
+)
+from typing import TYPE_CHECKING, Any
+
+from ._ssl_constants import _set_ssl_context_verify_mode
+
+HCERTCHAINENGINE = HANDLE
+HCERTSTORE = HANDLE
+HCRYPTPROV_LEGACY = HANDLE
+
+
+class CERT_CONTEXT(Structure):
+ _fields_ = (
+ ("dwCertEncodingType", DWORD),
+ ("pbCertEncoded", c_void_p),
+ ("cbCertEncoded", DWORD),
+ ("pCertInfo", c_void_p),
+ ("hCertStore", HCERTSTORE),
+ )
+
+
+PCERT_CONTEXT = POINTER(CERT_CONTEXT)
+PCCERT_CONTEXT = POINTER(PCERT_CONTEXT)
+
+
+class CERT_ENHKEY_USAGE(Structure):
+ _fields_ = (
+ ("cUsageIdentifier", DWORD),
+ ("rgpszUsageIdentifier", POINTER(LPSTR)),
+ )
+
+
+PCERT_ENHKEY_USAGE = POINTER(CERT_ENHKEY_USAGE)
+
+
+class CERT_USAGE_MATCH(Structure):
+ _fields_ = (
+ ("dwType", DWORD),
+ ("Usage", CERT_ENHKEY_USAGE),
+ )
+
+
+class CERT_CHAIN_PARA(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("RequestedUsage", CERT_USAGE_MATCH),
+ ("RequestedIssuancePolicy", CERT_USAGE_MATCH),
+ ("dwUrlRetrievalTimeout", DWORD),
+ ("fCheckRevocationFreshnessTime", BOOL),
+ ("dwRevocationFreshnessTime", DWORD),
+ ("pftCacheResync", LPFILETIME),
+ ("pStrongSignPara", c_void_p),
+ ("dwStrongSignFlags", DWORD),
+ )
+
+
+if TYPE_CHECKING:
+ PCERT_CHAIN_PARA = pointer[CERT_CHAIN_PARA] # type: ignore[misc]
+else:
+ PCERT_CHAIN_PARA = POINTER(CERT_CHAIN_PARA)
+
+
+class CERT_TRUST_STATUS(Structure):
+ _fields_ = (
+ ("dwErrorStatus", DWORD),
+ ("dwInfoStatus", DWORD),
+ )
+
+
+class CERT_CHAIN_ELEMENT(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("pCertContext", PCERT_CONTEXT),
+ ("TrustStatus", CERT_TRUST_STATUS),
+ ("pRevocationInfo", c_void_p),
+ ("pIssuanceUsage", PCERT_ENHKEY_USAGE),
+ ("pApplicationUsage", PCERT_ENHKEY_USAGE),
+ ("pwszExtendedErrorInfo", LPCWSTR),
+ )
+
+
+PCERT_CHAIN_ELEMENT = POINTER(CERT_CHAIN_ELEMENT)
+
+
+class CERT_SIMPLE_CHAIN(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("TrustStatus", CERT_TRUST_STATUS),
+ ("cElement", DWORD),
+ ("rgpElement", POINTER(PCERT_CHAIN_ELEMENT)),
+ ("pTrustListInfo", c_void_p),
+ ("fHasRevocationFreshnessTime", BOOL),
+ ("dwRevocationFreshnessTime", DWORD),
+ )
+
+
+PCERT_SIMPLE_CHAIN = POINTER(CERT_SIMPLE_CHAIN)
+
+
+class CERT_CHAIN_CONTEXT(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("TrustStatus", CERT_TRUST_STATUS),
+ ("cChain", DWORD),
+ ("rgpChain", POINTER(PCERT_SIMPLE_CHAIN)),
+ ("cLowerQualityChainContext", DWORD),
+ ("rgpLowerQualityChainContext", c_void_p),
+ ("fHasRevocationFreshnessTime", BOOL),
+ ("dwRevocationFreshnessTime", DWORD),
+ )
+
+
+PCERT_CHAIN_CONTEXT = POINTER(CERT_CHAIN_CONTEXT)
+PCCERT_CHAIN_CONTEXT = POINTER(PCERT_CHAIN_CONTEXT)
+
+
+class SSL_EXTRA_CERT_CHAIN_POLICY_PARA(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("dwAuthType", DWORD),
+ ("fdwChecks", DWORD),
+ ("pwszServerName", LPCWSTR),
+ )
+
+
+class CERT_CHAIN_POLICY_PARA(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("dwFlags", DWORD),
+ ("pvExtraPolicyPara", c_void_p),
+ )
+
+
+PCERT_CHAIN_POLICY_PARA = POINTER(CERT_CHAIN_POLICY_PARA)
+
+
+class CERT_CHAIN_POLICY_STATUS(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("dwError", DWORD),
+ ("lChainIndex", LONG),
+ ("lElementIndex", LONG),
+ ("pvExtraPolicyStatus", c_void_p),
+ )
+
+
+PCERT_CHAIN_POLICY_STATUS = POINTER(CERT_CHAIN_POLICY_STATUS)
+
+
+class CERT_CHAIN_ENGINE_CONFIG(Structure):
+ _fields_ = (
+ ("cbSize", DWORD),
+ ("hRestrictedRoot", HCERTSTORE),
+ ("hRestrictedTrust", HCERTSTORE),
+ ("hRestrictedOther", HCERTSTORE),
+ ("cAdditionalStore", DWORD),
+ ("rghAdditionalStore", c_void_p),
+ ("dwFlags", DWORD),
+ ("dwUrlRetrievalTimeout", DWORD),
+ ("MaximumCachedCertificates", DWORD),
+ ("CycleDetectionModulus", DWORD),
+ ("hExclusiveRoot", HCERTSTORE),
+ ("hExclusiveTrustedPeople", HCERTSTORE),
+ ("dwExclusiveFlags", DWORD),
+ )
+
+
+PCERT_CHAIN_ENGINE_CONFIG = POINTER(CERT_CHAIN_ENGINE_CONFIG)
+PHCERTCHAINENGINE = POINTER(HCERTCHAINENGINE)
+
+X509_ASN_ENCODING = 0x00000001
+PKCS_7_ASN_ENCODING = 0x00010000
+CERT_STORE_PROV_MEMORY = b"Memory"
+CERT_STORE_ADD_USE_EXISTING = 2
+USAGE_MATCH_TYPE_OR = 1
+OID_PKIX_KP_SERVER_AUTH = c_char_p(b"1.3.6.1.5.5.7.3.1")
+CERT_CHAIN_REVOCATION_CHECK_END_CERT = 0x10000000
+CERT_CHAIN_REVOCATION_CHECK_CHAIN = 0x20000000
+CERT_CHAIN_POLICY_IGNORE_ALL_NOT_TIME_VALID_FLAGS = 0x00000007
+CERT_CHAIN_POLICY_IGNORE_INVALID_BASIC_CONSTRAINTS_FLAG = 0x00000008
+CERT_CHAIN_POLICY_ALLOW_UNKNOWN_CA_FLAG = 0x00000010
+CERT_CHAIN_POLICY_IGNORE_INVALID_NAME_FLAG = 0x00000040
+CERT_CHAIN_POLICY_IGNORE_WRONG_USAGE_FLAG = 0x00000020
+CERT_CHAIN_POLICY_IGNORE_INVALID_POLICY_FLAG = 0x00000080
+CERT_CHAIN_POLICY_IGNORE_ALL_REV_UNKNOWN_FLAGS = 0x00000F00
+CERT_CHAIN_POLICY_ALLOW_TESTROOT_FLAG = 0x00008000
+CERT_CHAIN_POLICY_TRUST_TESTROOT_FLAG = 0x00004000
+SECURITY_FLAG_IGNORE_CERT_CN_INVALID = 0x00001000
+AUTHTYPE_SERVER = 2
+CERT_CHAIN_POLICY_SSL = 4
+FORMAT_MESSAGE_FROM_SYSTEM = 0x00001000
+FORMAT_MESSAGE_IGNORE_INSERTS = 0x00000200
+
+# Flags to set for SSLContext.verify_mode=CERT_NONE
+CERT_CHAIN_POLICY_VERIFY_MODE_NONE_FLAGS = (
+ CERT_CHAIN_POLICY_IGNORE_ALL_NOT_TIME_VALID_FLAGS
+ | CERT_CHAIN_POLICY_IGNORE_INVALID_BASIC_CONSTRAINTS_FLAG
+ | CERT_CHAIN_POLICY_ALLOW_UNKNOWN_CA_FLAG
+ | CERT_CHAIN_POLICY_IGNORE_INVALID_NAME_FLAG
+ | CERT_CHAIN_POLICY_IGNORE_WRONG_USAGE_FLAG
+ | CERT_CHAIN_POLICY_IGNORE_INVALID_POLICY_FLAG
+ | CERT_CHAIN_POLICY_IGNORE_ALL_REV_UNKNOWN_FLAGS
+ | CERT_CHAIN_POLICY_ALLOW_TESTROOT_FLAG
+ | CERT_CHAIN_POLICY_TRUST_TESTROOT_FLAG
+)
+
+wincrypt = WinDLL("crypt32.dll")
+kernel32 = WinDLL("kernel32.dll")
+
+
+def _handle_win_error(result: bool, _: Any, args: Any) -> Any:
+ if not result:
+ # Note, actually raises OSError after calling GetLastError and FormatMessage
+ raise WinError()
+ return args
+
+
+CertCreateCertificateChainEngine = wincrypt.CertCreateCertificateChainEngine
+CertCreateCertificateChainEngine.argtypes = (
+ PCERT_CHAIN_ENGINE_CONFIG,
+ PHCERTCHAINENGINE,
+)
+CertCreateCertificateChainEngine.errcheck = _handle_win_error
+
+CertOpenStore = wincrypt.CertOpenStore
+CertOpenStore.argtypes = (LPCSTR, DWORD, HCRYPTPROV_LEGACY, DWORD, c_void_p)
+CertOpenStore.restype = HCERTSTORE
+CertOpenStore.errcheck = _handle_win_error
+
+CertAddEncodedCertificateToStore = wincrypt.CertAddEncodedCertificateToStore
+CertAddEncodedCertificateToStore.argtypes = (
+ HCERTSTORE,
+ DWORD,
+ c_char_p,
+ DWORD,
+ DWORD,
+ PCCERT_CONTEXT,
+)
+CertAddEncodedCertificateToStore.restype = BOOL
+
+CertCreateCertificateContext = wincrypt.CertCreateCertificateContext
+CertCreateCertificateContext.argtypes = (DWORD, c_char_p, DWORD)
+CertCreateCertificateContext.restype = PCERT_CONTEXT
+CertCreateCertificateContext.errcheck = _handle_win_error
+
+CertGetCertificateChain = wincrypt.CertGetCertificateChain
+CertGetCertificateChain.argtypes = (
+ HCERTCHAINENGINE,
+ PCERT_CONTEXT,
+ LPFILETIME,
+ HCERTSTORE,
+ PCERT_CHAIN_PARA,
+ DWORD,
+ c_void_p,
+ PCCERT_CHAIN_CONTEXT,
+)
+CertGetCertificateChain.restype = BOOL
+CertGetCertificateChain.errcheck = _handle_win_error
+
+CertVerifyCertificateChainPolicy = wincrypt.CertVerifyCertificateChainPolicy
+CertVerifyCertificateChainPolicy.argtypes = (
+ c_ulong,
+ PCERT_CHAIN_CONTEXT,
+ PCERT_CHAIN_POLICY_PARA,
+ PCERT_CHAIN_POLICY_STATUS,
+)
+CertVerifyCertificateChainPolicy.restype = BOOL
+
+CertCloseStore = wincrypt.CertCloseStore
+CertCloseStore.argtypes = (HCERTSTORE, DWORD)
+CertCloseStore.restype = BOOL
+CertCloseStore.errcheck = _handle_win_error
+
+CertFreeCertificateChain = wincrypt.CertFreeCertificateChain
+CertFreeCertificateChain.argtypes = (PCERT_CHAIN_CONTEXT,)
+
+CertFreeCertificateContext = wincrypt.CertFreeCertificateContext
+CertFreeCertificateContext.argtypes = (PCERT_CONTEXT,)
+
+CertFreeCertificateChainEngine = wincrypt.CertFreeCertificateChainEngine
+CertFreeCertificateChainEngine.argtypes = (HCERTCHAINENGINE,)
+
+FormatMessageW = kernel32.FormatMessageW
+FormatMessageW.argtypes = (
+ DWORD,
+ LPCVOID,
+ DWORD,
+ DWORD,
+ LPWSTR,
+ DWORD,
+ c_void_p,
+)
+FormatMessageW.restype = DWORD
+
+
+def _verify_peercerts_impl(
+ ssl_context: ssl.SSLContext,
+ cert_chain: list[bytes],
+ server_hostname: str | None = None,
+) -> None:
+ """Verify the cert_chain from the server using Windows APIs."""
+
+ # If the peer didn't send any certificates then
+ # we can't do verification. Raise an error.
+ if not cert_chain:
+ raise ssl.SSLCertVerificationError("Peer sent no certificates to verify")
+
+ pCertContext = None
+ hIntermediateCertStore = CertOpenStore(CERT_STORE_PROV_MEMORY, 0, None, 0, None)
+ try:
+ # Add intermediate certs to an in-memory cert store
+ for cert_bytes in cert_chain[1:]:
+ CertAddEncodedCertificateToStore(
+ hIntermediateCertStore,
+ X509_ASN_ENCODING | PKCS_7_ASN_ENCODING,
+ cert_bytes,
+ len(cert_bytes),
+ CERT_STORE_ADD_USE_EXISTING,
+ None,
+ )
+
+ # Cert context for leaf cert
+ leaf_cert = cert_chain[0]
+ pCertContext = CertCreateCertificateContext(
+ X509_ASN_ENCODING | PKCS_7_ASN_ENCODING, leaf_cert, len(leaf_cert)
+ )
+
+ # Chain params to match certs for serverAuth extended usage
+ cert_enhkey_usage = CERT_ENHKEY_USAGE()
+ cert_enhkey_usage.cUsageIdentifier = 1
+ cert_enhkey_usage.rgpszUsageIdentifier = (c_char_p * 1)(OID_PKIX_KP_SERVER_AUTH)
+ cert_usage_match = CERT_USAGE_MATCH()
+ cert_usage_match.Usage = cert_enhkey_usage
+ chain_params = CERT_CHAIN_PARA()
+ chain_params.RequestedUsage = cert_usage_match
+ chain_params.cbSize = sizeof(chain_params)
+ pChainPara = pointer(chain_params)
+
+ if ssl_context.verify_flags & ssl.VERIFY_CRL_CHECK_CHAIN:
+ chain_flags = CERT_CHAIN_REVOCATION_CHECK_CHAIN
+ elif ssl_context.verify_flags & ssl.VERIFY_CRL_CHECK_LEAF:
+ chain_flags = CERT_CHAIN_REVOCATION_CHECK_END_CERT
+ else:
+ chain_flags = 0
+
+ try:
+ # First attempt to verify using the default Windows system trust roots
+ # (default chain engine).
+ _get_and_verify_cert_chain(
+ ssl_context,
+ None,
+ hIntermediateCertStore,
+ pCertContext,
+ pChainPara,
+ server_hostname,
+ chain_flags=chain_flags,
+ )
+ except ssl.SSLCertVerificationError as e:
+ # If that fails but custom CA certs have been added
+ # to the SSLContext using load_verify_locations,
+ # try verifying using a custom chain engine
+ # that trusts the custom CA certs.
+ custom_ca_certs: list[bytes] | None = ssl_context.get_ca_certs(
+ binary_form=True
+ )
+ if custom_ca_certs:
+ try:
+ _verify_using_custom_ca_certs(
+ ssl_context,
+ custom_ca_certs,
+ hIntermediateCertStore,
+ pCertContext,
+ pChainPara,
+ server_hostname,
+ chain_flags=chain_flags,
+ )
+ # Raise the original error, not the new error.
+ except ssl.SSLCertVerificationError:
+ raise e from None
+ else:
+ raise
+ finally:
+ CertCloseStore(hIntermediateCertStore, 0)
+ if pCertContext:
+ CertFreeCertificateContext(pCertContext)
+
+
+def _get_and_verify_cert_chain(
+ ssl_context: ssl.SSLContext,
+ hChainEngine: HCERTCHAINENGINE | None,
+ hIntermediateCertStore: HCERTSTORE,
+ pPeerCertContext: c_void_p,
+ pChainPara: PCERT_CHAIN_PARA, # type: ignore[valid-type]
+ server_hostname: str | None,
+ chain_flags: int,
+) -> None:
+ ppChainContext = None
+ try:
+ # Get cert chain
+ ppChainContext = pointer(PCERT_CHAIN_CONTEXT())
+ CertGetCertificateChain(
+ hChainEngine, # chain engine
+ pPeerCertContext, # leaf cert context
+ None, # current system time
+ hIntermediateCertStore, # additional in-memory cert store
+ pChainPara, # chain-building parameters
+ chain_flags,
+ None, # reserved
+ ppChainContext, # the resulting chain context
+ )
+ pChainContext = ppChainContext.contents
+
+ # Verify cert chain
+ ssl_extra_cert_chain_policy_para = SSL_EXTRA_CERT_CHAIN_POLICY_PARA()
+ ssl_extra_cert_chain_policy_para.cbSize = sizeof(
+ ssl_extra_cert_chain_policy_para
+ )
+ ssl_extra_cert_chain_policy_para.dwAuthType = AUTHTYPE_SERVER
+ ssl_extra_cert_chain_policy_para.fdwChecks = 0
+ if ssl_context.check_hostname is False:
+ ssl_extra_cert_chain_policy_para.fdwChecks = (
+ SECURITY_FLAG_IGNORE_CERT_CN_INVALID
+ )
+ if server_hostname:
+ ssl_extra_cert_chain_policy_para.pwszServerName = c_wchar_p(server_hostname)
+
+ chain_policy = CERT_CHAIN_POLICY_PARA()
+ chain_policy.pvExtraPolicyPara = cast(
+ pointer(ssl_extra_cert_chain_policy_para), c_void_p
+ )
+ if ssl_context.verify_mode == ssl.CERT_NONE:
+ chain_policy.dwFlags |= CERT_CHAIN_POLICY_VERIFY_MODE_NONE_FLAGS
+ chain_policy.cbSize = sizeof(chain_policy)
+
+ pPolicyPara = pointer(chain_policy)
+ policy_status = CERT_CHAIN_POLICY_STATUS()
+ policy_status.cbSize = sizeof(policy_status)
+ pPolicyStatus = pointer(policy_status)
+ CertVerifyCertificateChainPolicy(
+ CERT_CHAIN_POLICY_SSL,
+ pChainContext,
+ pPolicyPara,
+ pPolicyStatus,
+ )
+
+ # Check status
+ error_code = policy_status.dwError
+ if error_code:
+ # Try getting a human readable message for an error code.
+ error_message_buf = create_unicode_buffer(1024)
+ error_message_chars = FormatMessageW(
+ FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_IGNORE_INSERTS,
+ None,
+ error_code,
+ 0,
+ error_message_buf,
+ sizeof(error_message_buf),
+ None,
+ )
+
+ # See if we received a message for the error,
+ # otherwise we use a generic error with the
+ # error code and hope that it's search-able.
+ if error_message_chars <= 0:
+ error_message = f"Certificate chain policy error {error_code:#x} [{policy_status.lElementIndex}]"
+ else:
+ error_message = error_message_buf.value.strip()
+
+ err = ssl.SSLCertVerificationError(error_message)
+ err.verify_message = error_message
+ err.verify_code = error_code
+ raise err from None
+ finally:
+ if ppChainContext:
+ CertFreeCertificateChain(ppChainContext.contents)
+
+
+def _verify_using_custom_ca_certs(
+ ssl_context: ssl.SSLContext,
+ custom_ca_certs: list[bytes],
+ hIntermediateCertStore: HCERTSTORE,
+ pPeerCertContext: c_void_p,
+ pChainPara: PCERT_CHAIN_PARA, # type: ignore[valid-type]
+ server_hostname: str | None,
+ chain_flags: int,
+) -> None:
+ hChainEngine = None
+ hRootCertStore = CertOpenStore(CERT_STORE_PROV_MEMORY, 0, None, 0, None)
+ try:
+ # Add custom CA certs to an in-memory cert store
+ for cert_bytes in custom_ca_certs:
+ CertAddEncodedCertificateToStore(
+ hRootCertStore,
+ X509_ASN_ENCODING | PKCS_7_ASN_ENCODING,
+ cert_bytes,
+ len(cert_bytes),
+ CERT_STORE_ADD_USE_EXISTING,
+ None,
+ )
+
+ # Create a custom cert chain engine which exclusively trusts
+ # certs from our hRootCertStore
+ cert_chain_engine_config = CERT_CHAIN_ENGINE_CONFIG()
+ cert_chain_engine_config.cbSize = sizeof(cert_chain_engine_config)
+ cert_chain_engine_config.hExclusiveRoot = hRootCertStore
+ pConfig = pointer(cert_chain_engine_config)
+ phChainEngine = pointer(HCERTCHAINENGINE())
+ CertCreateCertificateChainEngine(
+ pConfig,
+ phChainEngine,
+ )
+ hChainEngine = phChainEngine.contents
+
+ # Get and verify a cert chain using the custom chain engine
+ _get_and_verify_cert_chain(
+ ssl_context,
+ hChainEngine,
+ hIntermediateCertStore,
+ pPeerCertContext,
+ pChainPara,
+ server_hostname,
+ chain_flags,
+ )
+ finally:
+ if hChainEngine:
+ CertFreeCertificateChainEngine(hChainEngine)
+ CertCloseStore(hRootCertStore, 0)
+
+
+@contextlib.contextmanager
+def _configure_context(ctx: ssl.SSLContext) -> typing.Iterator[None]:
+ check_hostname = ctx.check_hostname
+ verify_mode = ctx.verify_mode
+ ctx.check_hostname = False
+ _set_ssl_context_verify_mode(ctx, ssl.CERT_NONE)
+ try:
+ yield
+ finally:
+ ctx.check_hostname = check_hostname
+ _set_ssl_context_verify_mode(ctx, verify_mode)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/py.typed b/solutions/.venv/Lib/site-packages/pip/_vendor/truststore/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/typing_extensions.py b/solutions/.venv/Lib/site-packages/pip/_vendor/typing_extensions.py
new file mode 100644
index 000000000..e429384e7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/typing_extensions.py
@@ -0,0 +1,3641 @@
+import abc
+import collections
+import collections.abc
+import contextlib
+import functools
+import inspect
+import operator
+import sys
+import types as _types
+import typing
+import warnings
+
+__all__ = [
+ # Super-special typing primitives.
+ 'Any',
+ 'ClassVar',
+ 'Concatenate',
+ 'Final',
+ 'LiteralString',
+ 'ParamSpec',
+ 'ParamSpecArgs',
+ 'ParamSpecKwargs',
+ 'Self',
+ 'Type',
+ 'TypeVar',
+ 'TypeVarTuple',
+ 'Unpack',
+
+ # ABCs (from collections.abc).
+ 'Awaitable',
+ 'AsyncIterator',
+ 'AsyncIterable',
+ 'Coroutine',
+ 'AsyncGenerator',
+ 'AsyncContextManager',
+ 'Buffer',
+ 'ChainMap',
+
+ # Concrete collection types.
+ 'ContextManager',
+ 'Counter',
+ 'Deque',
+ 'DefaultDict',
+ 'NamedTuple',
+ 'OrderedDict',
+ 'TypedDict',
+
+ # Structural checks, a.k.a. protocols.
+ 'SupportsAbs',
+ 'SupportsBytes',
+ 'SupportsComplex',
+ 'SupportsFloat',
+ 'SupportsIndex',
+ 'SupportsInt',
+ 'SupportsRound',
+
+ # One-off things.
+ 'Annotated',
+ 'assert_never',
+ 'assert_type',
+ 'clear_overloads',
+ 'dataclass_transform',
+ 'deprecated',
+ 'Doc',
+ 'get_overloads',
+ 'final',
+ 'get_args',
+ 'get_origin',
+ 'get_original_bases',
+ 'get_protocol_members',
+ 'get_type_hints',
+ 'IntVar',
+ 'is_protocol',
+ 'is_typeddict',
+ 'Literal',
+ 'NewType',
+ 'overload',
+ 'override',
+ 'Protocol',
+ 'reveal_type',
+ 'runtime',
+ 'runtime_checkable',
+ 'Text',
+ 'TypeAlias',
+ 'TypeAliasType',
+ 'TypeGuard',
+ 'TypeIs',
+ 'TYPE_CHECKING',
+ 'Never',
+ 'NoReturn',
+ 'ReadOnly',
+ 'Required',
+ 'NotRequired',
+
+ # Pure aliases, have always been in typing
+ 'AbstractSet',
+ 'AnyStr',
+ 'BinaryIO',
+ 'Callable',
+ 'Collection',
+ 'Container',
+ 'Dict',
+ 'ForwardRef',
+ 'FrozenSet',
+ 'Generator',
+ 'Generic',
+ 'Hashable',
+ 'IO',
+ 'ItemsView',
+ 'Iterable',
+ 'Iterator',
+ 'KeysView',
+ 'List',
+ 'Mapping',
+ 'MappingView',
+ 'Match',
+ 'MutableMapping',
+ 'MutableSequence',
+ 'MutableSet',
+ 'NoDefault',
+ 'Optional',
+ 'Pattern',
+ 'Reversible',
+ 'Sequence',
+ 'Set',
+ 'Sized',
+ 'TextIO',
+ 'Tuple',
+ 'Union',
+ 'ValuesView',
+ 'cast',
+ 'no_type_check',
+ 'no_type_check_decorator',
+]
+
+# for backward compatibility
+PEP_560 = True
+GenericMeta = type
+_PEP_696_IMPLEMENTED = sys.version_info >= (3, 13, 0, "beta")
+
+# The functions below are modified copies of typing internal helpers.
+# They are needed by _ProtocolMeta and they provide support for PEP 646.
+
+
+class _Sentinel:
+ def __repr__(self):
+ return "<sentinel>"
+
+
+_marker = _Sentinel()
+
+
+if sys.version_info >= (3, 10):
+ def _should_collect_from_parameters(t):
+ return isinstance(
+ t, (typing._GenericAlias, _types.GenericAlias, _types.UnionType)
+ )
+elif sys.version_info >= (3, 9):
+ def _should_collect_from_parameters(t):
+ return isinstance(t, (typing._GenericAlias, _types.GenericAlias))
+else:
+ def _should_collect_from_parameters(t):
+ return isinstance(t, typing._GenericAlias) and not t._special
+
+
+NoReturn = typing.NoReturn
+
+# Some unconstrained type variables. These are used by the container types.
+# (These are not for export.)
+T = typing.TypeVar('T') # Any type.
+KT = typing.TypeVar('KT') # Key type.
+VT = typing.TypeVar('VT') # Value type.
+T_co = typing.TypeVar('T_co', covariant=True) # Any type covariant containers.
+T_contra = typing.TypeVar('T_contra', contravariant=True) # Ditto contravariant.
+
+
+if sys.version_info >= (3, 11):
+ from typing import Any
+else:
+
+ class _AnyMeta(type):
+ def __instancecheck__(self, obj):
+ if self is Any:
+ raise TypeError("typing_extensions.Any cannot be used with isinstance()")
+ return super().__instancecheck__(obj)
+
+ def __repr__(self):
+ if self is Any:
+ return "typing_extensions.Any"
+ return super().__repr__()
+
+ class Any(metaclass=_AnyMeta):
+ """Special type indicating an unconstrained type.
+ - Any is compatible with every type.
+ - Any assumed to have all methods.
+ - All values assumed to be instances of Any.
+ Note that all the above statements are true from the point of view of
+ static type checkers. At runtime, Any should not be used with instance
+ checks.
+ """
+ def __new__(cls, *args, **kwargs):
+ if cls is Any:
+ raise TypeError("Any cannot be instantiated")
+ return super().__new__(cls, *args, **kwargs)
+
+
+ClassVar = typing.ClassVar
+
+
+class _ExtensionsSpecialForm(typing._SpecialForm, _root=True):
+ def __repr__(self):
+ return 'typing_extensions.' + self._name
+
+
+Final = typing.Final
+
+if sys.version_info >= (3, 11):
+ final = typing.final
+else:
+ # @final exists in 3.8+, but we backport it for all versions
+ # before 3.11 to keep support for the __final__ attribute.
+ # See https://bugs.python.org/issue46342
+ def final(f):
+ """This decorator can be used to indicate to type checkers that
+ the decorated method cannot be overridden, and decorated class
+ cannot be subclassed. For example:
+
+ class Base:
+ @final
+ def done(self) -> None:
+ ...
+ class Sub(Base):
+ def done(self) -> None: # Error reported by type checker
+ ...
+ @final
+ class Leaf:
+ ...
+ class Other(Leaf): # Error reported by type checker
+ ...
+
+ There is no runtime checking of these properties. The decorator
+ sets the ``__final__`` attribute to ``True`` on the decorated object
+ to allow runtime introspection.
+ """
+ try:
+ f.__final__ = True
+ except (AttributeError, TypeError):
+ # Skip the attribute silently if it is not writable.
+ # AttributeError happens if the object has __slots__ or a
+ # read-only property, TypeError if it's a builtin class.
+ pass
+ return f
+
+
+def IntVar(name):
+ return typing.TypeVar(name)
+
+
+# A Literal bug was fixed in 3.11.0, 3.10.1 and 3.9.8
+if sys.version_info >= (3, 10, 1):
+ Literal = typing.Literal
+else:
+ def _flatten_literal_params(parameters):
+ """An internal helper for Literal creation: flatten Literals among parameters"""
+ params = []
+ for p in parameters:
+ if isinstance(p, _LiteralGenericAlias):
+ params.extend(p.__args__)
+ else:
+ params.append(p)
+ return tuple(params)
+
+ def _value_and_type_iter(params):
+ for p in params:
+ yield p, type(p)
+
+ class _LiteralGenericAlias(typing._GenericAlias, _root=True):
+ def __eq__(self, other):
+ if not isinstance(other, _LiteralGenericAlias):
+ return NotImplemented
+ these_args_deduped = set(_value_and_type_iter(self.__args__))
+ other_args_deduped = set(_value_and_type_iter(other.__args__))
+ return these_args_deduped == other_args_deduped
+
+ def __hash__(self):
+ return hash(frozenset(_value_and_type_iter(self.__args__)))
+
+ class _LiteralForm(_ExtensionsSpecialForm, _root=True):
+ def __init__(self, doc: str):
+ self._name = 'Literal'
+ self._doc = self.__doc__ = doc
+
+ def __getitem__(self, parameters):
+ if not isinstance(parameters, tuple):
+ parameters = (parameters,)
+
+ parameters = _flatten_literal_params(parameters)
+
+ val_type_pairs = list(_value_and_type_iter(parameters))
+ try:
+ deduped_pairs = set(val_type_pairs)
+ except TypeError:
+ # unhashable parameters
+ pass
+ else:
+ # similar logic to typing._deduplicate on Python 3.9+
+ if len(deduped_pairs) < len(val_type_pairs):
+ new_parameters = []
+ for pair in val_type_pairs:
+ if pair in deduped_pairs:
+ new_parameters.append(pair[0])
+ deduped_pairs.remove(pair)
+ assert not deduped_pairs, deduped_pairs
+ parameters = tuple(new_parameters)
+
+ return _LiteralGenericAlias(self, parameters)
+
+ Literal = _LiteralForm(doc="""\
+ A type that can be used to indicate to type checkers
+ that the corresponding value has a value literally equivalent
+ to the provided parameter. For example:
+
+ var: Literal[4] = 4
+
+ The type checker understands that 'var' is literally equal to
+ the value 4 and no other value.
+
+ Literal[...] cannot be subclassed. There is no runtime
+ checking verifying that the parameter is actually a value
+ instead of a type.""")
+
+
+_overload_dummy = typing._overload_dummy
+
+
+if hasattr(typing, "get_overloads"): # 3.11+
+ overload = typing.overload
+ get_overloads = typing.get_overloads
+ clear_overloads = typing.clear_overloads
+else:
+ # {module: {qualname: {firstlineno: func}}}
+ _overload_registry = collections.defaultdict(
+ functools.partial(collections.defaultdict, dict)
+ )
+
+ def overload(func):
+ """Decorator for overloaded functions/methods.
+
+ In a stub file, place two or more stub definitions for the same
+ function in a row, each decorated with @overload. For example:
+
+ @overload
+ def utf8(value: None) -> None: ...
+ @overload
+ def utf8(value: bytes) -> bytes: ...
+ @overload
+ def utf8(value: str) -> bytes: ...
+
+ In a non-stub file (i.e. a regular .py file), do the same but
+ follow it with an implementation. The implementation should *not*
+ be decorated with @overload. For example:
+
+ @overload
+ def utf8(value: None) -> None: ...
+ @overload
+ def utf8(value: bytes) -> bytes: ...
+ @overload
+ def utf8(value: str) -> bytes: ...
+ def utf8(value):
+ # implementation goes here
+
+ The overloads for a function can be retrieved at runtime using the
+ get_overloads() function.
+ """
+ # classmethod and staticmethod
+ f = getattr(func, "__func__", func)
+ try:
+ _overload_registry[f.__module__][f.__qualname__][
+ f.__code__.co_firstlineno
+ ] = func
+ except AttributeError:
+ # Not a normal function; ignore.
+ pass
+ return _overload_dummy
+
+ def get_overloads(func):
+ """Return all defined overloads for *func* as a sequence."""
+ # classmethod and staticmethod
+ f = getattr(func, "__func__", func)
+ if f.__module__ not in _overload_registry:
+ return []
+ mod_dict = _overload_registry[f.__module__]
+ if f.__qualname__ not in mod_dict:
+ return []
+ return list(mod_dict[f.__qualname__].values())
+
+ def clear_overloads():
+ """Clear all overloads in the registry."""
+ _overload_registry.clear()
+
+
+# This is not a real generic class. Don't use outside annotations.
+Type = typing.Type
+
+# Various ABCs mimicking those in collections.abc.
+# A few are simply re-exported for completeness.
+Awaitable = typing.Awaitable
+Coroutine = typing.Coroutine
+AsyncIterable = typing.AsyncIterable
+AsyncIterator = typing.AsyncIterator
+Deque = typing.Deque
+DefaultDict = typing.DefaultDict
+OrderedDict = typing.OrderedDict
+Counter = typing.Counter
+ChainMap = typing.ChainMap
+Text = typing.Text
+TYPE_CHECKING = typing.TYPE_CHECKING
+
+
+if sys.version_info >= (3, 13, 0, "beta"):
+ from typing import AsyncContextManager, AsyncGenerator, ContextManager, Generator
+else:
+ def _is_dunder(attr):
+ return attr.startswith('__') and attr.endswith('__')
+
+ # Python <3.9 doesn't have typing._SpecialGenericAlias
+ _special_generic_alias_base = getattr(
+ typing, "_SpecialGenericAlias", typing._GenericAlias
+ )
+
+ class _SpecialGenericAlias(_special_generic_alias_base, _root=True):
+ def __init__(self, origin, nparams, *, inst=True, name=None, defaults=()):
+ if _special_generic_alias_base is typing._GenericAlias:
+ # Python <3.9
+ self.__origin__ = origin
+ self._nparams = nparams
+ super().__init__(origin, nparams, special=True, inst=inst, name=name)
+ else:
+ # Python >= 3.9
+ super().__init__(origin, nparams, inst=inst, name=name)
+ self._defaults = defaults
+
+ def __setattr__(self, attr, val):
+ allowed_attrs = {'_name', '_inst', '_nparams', '_defaults'}
+ if _special_generic_alias_base is typing._GenericAlias:
+ # Python <3.9
+ allowed_attrs.add("__origin__")
+ if _is_dunder(attr) or attr in allowed_attrs:
+ object.__setattr__(self, attr, val)
+ else:
+ setattr(self.__origin__, attr, val)
+
+ @typing._tp_cache
+ def __getitem__(self, params):
+ if not isinstance(params, tuple):
+ params = (params,)
+ msg = "Parameters to generic types must be types."
+ params = tuple(typing._type_check(p, msg) for p in params)
+ if (
+ self._defaults
+ and len(params) < self._nparams
+ and len(params) + len(self._defaults) >= self._nparams
+ ):
+ params = (*params, *self._defaults[len(params) - self._nparams:])
+ actual_len = len(params)
+
+ if actual_len != self._nparams:
+ if self._defaults:
+ expected = f"at least {self._nparams - len(self._defaults)}"
+ else:
+ expected = str(self._nparams)
+ if not self._nparams:
+ raise TypeError(f"{self} is not a generic class")
+ raise TypeError(
+ f"Too {'many' if actual_len > self._nparams else 'few'}"
+ f" arguments for {self};"
+ f" actual {actual_len}, expected {expected}"
+ )
+ return self.copy_with(params)
+
+ _NoneType = type(None)
+ Generator = _SpecialGenericAlias(
+ collections.abc.Generator, 3, defaults=(_NoneType, _NoneType)
+ )
+ AsyncGenerator = _SpecialGenericAlias(
+ collections.abc.AsyncGenerator, 2, defaults=(_NoneType,)
+ )
+ ContextManager = _SpecialGenericAlias(
+ contextlib.AbstractContextManager,
+ 2,
+ name="ContextManager",
+ defaults=(typing.Optional[bool],)
+ )
+ AsyncContextManager = _SpecialGenericAlias(
+ contextlib.AbstractAsyncContextManager,
+ 2,
+ name="AsyncContextManager",
+ defaults=(typing.Optional[bool],)
+ )
+
+
+_PROTO_ALLOWLIST = {
+ 'collections.abc': [
+ 'Callable', 'Awaitable', 'Iterable', 'Iterator', 'AsyncIterable',
+ 'Hashable', 'Sized', 'Container', 'Collection', 'Reversible', 'Buffer',
+ ],
+ 'contextlib': ['AbstractContextManager', 'AbstractAsyncContextManager'],
+ 'typing_extensions': ['Buffer'],
+}
+
+
+_EXCLUDED_ATTRS = frozenset(typing.EXCLUDED_ATTRIBUTES) | {
+ "__match_args__", "__protocol_attrs__", "__non_callable_proto_members__",
+ "__final__",
+}
+
+
+def _get_protocol_attrs(cls):
+ attrs = set()
+ for base in cls.__mro__[:-1]: # without object
+ if base.__name__ in {'Protocol', 'Generic'}:
+ continue
+ annotations = getattr(base, '__annotations__', {})
+ for attr in (*base.__dict__, *annotations):
+ if (not attr.startswith('_abc_') and attr not in _EXCLUDED_ATTRS):
+ attrs.add(attr)
+ return attrs
+
+
+def _caller(depth=2):
+ try:
+ return sys._getframe(depth).f_globals.get('__name__', '__main__')
+ except (AttributeError, ValueError): # For platforms without _getframe()
+ return None
+
+
+# `__match_args__` attribute was removed from protocol members in 3.13,
+# we want to backport this change to older Python versions.
+if sys.version_info >= (3, 13):
+ Protocol = typing.Protocol
+else:
+ def _allow_reckless_class_checks(depth=3):
+ """Allow instance and class checks for special stdlib modules.
+ The abc and functools modules indiscriminately call isinstance() and
+ issubclass() on the whole MRO of a user class, which may contain protocols.
+ """
+ return _caller(depth) in {'abc', 'functools', None}
+
+ def _no_init(self, *args, **kwargs):
+ if type(self)._is_protocol:
+ raise TypeError('Protocols cannot be instantiated')
+
+ def _type_check_issubclass_arg_1(arg):
+ """Raise TypeError if `arg` is not an instance of `type`
+ in `issubclass(arg, <protocol>)`.
+
+ In most cases, this is verified by type.__subclasscheck__.
+ Checking it again unnecessarily would slow down issubclass() checks,
+ so, we don't perform this check unless we absolutely have to.
+
+ For various error paths, however,
+ we want to ensure that *this* error message is shown to the user
+ where relevant, rather than a typing.py-specific error message.
+ """
+ if not isinstance(arg, type):
+ # Same error message as for issubclass(1, int).
+ raise TypeError('issubclass() arg 1 must be a class')
+
+ # Inheriting from typing._ProtocolMeta isn't actually desirable,
+ # but is necessary to allow typing.Protocol and typing_extensions.Protocol
+ # to mix without getting TypeErrors about "metaclass conflict"
+ class _ProtocolMeta(type(typing.Protocol)):
+ # This metaclass is somewhat unfortunate,
+ # but is necessary for several reasons...
+ #
+ # NOTE: DO NOT call super() in any methods in this class
+ # That would call the methods on typing._ProtocolMeta on Python 3.8-3.11
+ # and those are slow
+ def __new__(mcls, name, bases, namespace, **kwargs):
+ if name == "Protocol" and len(bases) < 2:
+ pass
+ elif {Protocol, typing.Protocol} & set(bases):
+ for base in bases:
+ if not (
+ base in {object, typing.Generic, Protocol, typing.Protocol}
+ or base.__name__ in _PROTO_ALLOWLIST.get(base.__module__, [])
+ or is_protocol(base)
+ ):
+ raise TypeError(
+ f"Protocols can only inherit from other protocols, "
+ f"got {base!r}"
+ )
+ return abc.ABCMeta.__new__(mcls, name, bases, namespace, **kwargs)
+
+ def __init__(cls, *args, **kwargs):
+ abc.ABCMeta.__init__(cls, *args, **kwargs)
+ if getattr(cls, "_is_protocol", False):
+ cls.__protocol_attrs__ = _get_protocol_attrs(cls)
+
+ def __subclasscheck__(cls, other):
+ if cls is Protocol:
+ return type.__subclasscheck__(cls, other)
+ if (
+ getattr(cls, '_is_protocol', False)
+ and not _allow_reckless_class_checks()
+ ):
+ if not getattr(cls, '_is_runtime_protocol', False):
+ _type_check_issubclass_arg_1(other)
+ raise TypeError(
+ "Instance and class checks can only be used with "
+ "@runtime_checkable protocols"
+ )
+ if (
+ # this attribute is set by @runtime_checkable:
+ cls.__non_callable_proto_members__
+ and cls.__dict__.get("__subclasshook__") is _proto_hook
+ ):
+ _type_check_issubclass_arg_1(other)
+ non_method_attrs = sorted(cls.__non_callable_proto_members__)
+ raise TypeError(
+ "Protocols with non-method members don't support issubclass()."
+ f" Non-method members: {str(non_method_attrs)[1:-1]}."
+ )
+ return abc.ABCMeta.__subclasscheck__(cls, other)
+
+ def __instancecheck__(cls, instance):
+ # We need this method for situations where attributes are
+ # assigned in __init__.
+ if cls is Protocol:
+ return type.__instancecheck__(cls, instance)
+ if not getattr(cls, "_is_protocol", False):
+ # i.e., it's a concrete subclass of a protocol
+ return abc.ABCMeta.__instancecheck__(cls, instance)
+
+ if (
+ not getattr(cls, '_is_runtime_protocol', False) and
+ not _allow_reckless_class_checks()
+ ):
+ raise TypeError("Instance and class checks can only be used with"
+ " @runtime_checkable protocols")
+
+ if abc.ABCMeta.__instancecheck__(cls, instance):
+ return True
+
+ for attr in cls.__protocol_attrs__:
+ try:
+ val = inspect.getattr_static(instance, attr)
+ except AttributeError:
+ break
+ # this attribute is set by @runtime_checkable:
+ if val is None and attr not in cls.__non_callable_proto_members__:
+ break
+ else:
+ return True
+
+ return False
+
+ def __eq__(cls, other):
+ # Hack so that typing.Generic.__class_getitem__
+ # treats typing_extensions.Protocol
+ # as equivalent to typing.Protocol
+ if abc.ABCMeta.__eq__(cls, other) is True:
+ return True
+ return cls is Protocol and other is typing.Protocol
+
+ # This has to be defined, or the abc-module cache
+ # complains about classes with this metaclass being unhashable,
+ # if we define only __eq__!
+ def __hash__(cls) -> int:
+ return type.__hash__(cls)
+
+ @classmethod
+ def _proto_hook(cls, other):
+ if not cls.__dict__.get('_is_protocol', False):
+ return NotImplemented
+
+ for attr in cls.__protocol_attrs__:
+ for base in other.__mro__:
+ # Check if the members appears in the class dictionary...
+ if attr in base.__dict__:
+ if base.__dict__[attr] is None:
+ return NotImplemented
+ break
+
+ # ...or in annotations, if it is a sub-protocol.
+ annotations = getattr(base, '__annotations__', {})
+ if (
+ isinstance(annotations, collections.abc.Mapping)
+ and attr in annotations
+ and is_protocol(other)
+ ):
+ break
+ else:
+ return NotImplemented
+ return True
+
+ class Protocol(typing.Generic, metaclass=_ProtocolMeta):
+ __doc__ = typing.Protocol.__doc__
+ __slots__ = ()
+ _is_protocol = True
+ _is_runtime_protocol = False
+
+ def __init_subclass__(cls, *args, **kwargs):
+ super().__init_subclass__(*args, **kwargs)
+
+ # Determine if this is a protocol or a concrete subclass.
+ if not cls.__dict__.get('_is_protocol', False):
+ cls._is_protocol = any(b is Protocol for b in cls.__bases__)
+
+ # Set (or override) the protocol subclass hook.
+ if '__subclasshook__' not in cls.__dict__:
+ cls.__subclasshook__ = _proto_hook
+
+ # Prohibit instantiation for protocol classes
+ if cls._is_protocol and cls.__init__ is Protocol.__init__:
+ cls.__init__ = _no_init
+
+
+if sys.version_info >= (3, 13):
+ runtime_checkable = typing.runtime_checkable
+else:
+ def runtime_checkable(cls):
+ """Mark a protocol class as a runtime protocol.
+
+ Such protocol can be used with isinstance() and issubclass().
+ Raise TypeError if applied to a non-protocol class.
+ This allows a simple-minded structural check very similar to
+ one trick ponies in collections.abc such as Iterable.
+
+ For example::
+
+ @runtime_checkable
+ class Closable(Protocol):
+ def close(self): ...
+
+ assert isinstance(open('/some/file'), Closable)
+
+ Warning: this will check only the presence of the required methods,
+ not their type signatures!
+ """
+ if not issubclass(cls, typing.Generic) or not getattr(cls, '_is_protocol', False):
+ raise TypeError(f'@runtime_checkable can be only applied to protocol classes,'
+ f' got {cls!r}')
+ cls._is_runtime_protocol = True
+
+ # typing.Protocol classes on <=3.11 break if we execute this block,
+ # because typing.Protocol classes on <=3.11 don't have a
+ # `__protocol_attrs__` attribute, and this block relies on the
+ # `__protocol_attrs__` attribute. Meanwhile, typing.Protocol classes on 3.12.2+
+ # break if we *don't* execute this block, because *they* assume that all
+ # protocol classes have a `__non_callable_proto_members__` attribute
+ # (which this block sets)
+ if isinstance(cls, _ProtocolMeta) or sys.version_info >= (3, 12, 2):
+ # PEP 544 prohibits using issubclass()
+ # with protocols that have non-method members.
+ # See gh-113320 for why we compute this attribute here,
+ # rather than in `_ProtocolMeta.__init__`
+ cls.__non_callable_proto_members__ = set()
+ for attr in cls.__protocol_attrs__:
+ try:
+ is_callable = callable(getattr(cls, attr, None))
+ except Exception as e:
+ raise TypeError(
+ f"Failed to determine whether protocol member {attr!r} "
+ "is a method member"
+ ) from e
+ else:
+ if not is_callable:
+ cls.__non_callable_proto_members__.add(attr)
+
+ return cls
+
+
+# The "runtime" alias exists for backwards compatibility.
+runtime = runtime_checkable
+
+
+# Our version of runtime-checkable protocols is faster on Python 3.8-3.11
+if sys.version_info >= (3, 12):
+ SupportsInt = typing.SupportsInt
+ SupportsFloat = typing.SupportsFloat
+ SupportsComplex = typing.SupportsComplex
+ SupportsBytes = typing.SupportsBytes
+ SupportsIndex = typing.SupportsIndex
+ SupportsAbs = typing.SupportsAbs
+ SupportsRound = typing.SupportsRound
+else:
+ @runtime_checkable
+ class SupportsInt(Protocol):
+ """An ABC with one abstract method __int__."""
+ __slots__ = ()
+
+ @abc.abstractmethod
+ def __int__(self) -> int:
+ pass
+
+ @runtime_checkable
+ class SupportsFloat(Protocol):
+ """An ABC with one abstract method __float__."""
+ __slots__ = ()
+
+ @abc.abstractmethod
+ def __float__(self) -> float:
+ pass
+
+ @runtime_checkable
+ class SupportsComplex(Protocol):
+ """An ABC with one abstract method __complex__."""
+ __slots__ = ()
+
+ @abc.abstractmethod
+ def __complex__(self) -> complex:
+ pass
+
+ @runtime_checkable
+ class SupportsBytes(Protocol):
+ """An ABC with one abstract method __bytes__."""
+ __slots__ = ()
+
+ @abc.abstractmethod
+ def __bytes__(self) -> bytes:
+ pass
+
+ @runtime_checkable
+ class SupportsIndex(Protocol):
+ __slots__ = ()
+
+ @abc.abstractmethod
+ def __index__(self) -> int:
+ pass
+
+ @runtime_checkable
+ class SupportsAbs(Protocol[T_co]):
+ """
+ An ABC with one abstract method __abs__ that is covariant in its return type.
+ """
+ __slots__ = ()
+
+ @abc.abstractmethod
+ def __abs__(self) -> T_co:
+ pass
+
+ @runtime_checkable
+ class SupportsRound(Protocol[T_co]):
+ """
+ An ABC with one abstract method __round__ that is covariant in its return type.
+ """
+ __slots__ = ()
+
+ @abc.abstractmethod
+ def __round__(self, ndigits: int = 0) -> T_co:
+ pass
+
+
+def _ensure_subclassable(mro_entries):
+ def inner(func):
+ if sys.implementation.name == "pypy" and sys.version_info < (3, 9):
+ cls_dict = {
+ "__call__": staticmethod(func),
+ "__mro_entries__": staticmethod(mro_entries)
+ }
+ t = type(func.__name__, (), cls_dict)
+ return functools.update_wrapper(t(), func)
+ else:
+ func.__mro_entries__ = mro_entries
+ return func
+ return inner
+
+
+# Update this to something like >=3.13.0b1 if and when
+# PEP 728 is implemented in CPython
+_PEP_728_IMPLEMENTED = False
+
+if _PEP_728_IMPLEMENTED:
+ # The standard library TypedDict in Python 3.8 does not store runtime information
+ # about which (if any) keys are optional. See https://bugs.python.org/issue38834
+ # The standard library TypedDict in Python 3.9.0/1 does not honour the "total"
+ # keyword with old-style TypedDict(). See https://bugs.python.org/issue42059
+ # The standard library TypedDict below Python 3.11 does not store runtime
+ # information about optional and required keys when using Required or NotRequired.
+ # Generic TypedDicts are also impossible using typing.TypedDict on Python <3.11.
+ # Aaaand on 3.12 we add __orig_bases__ to TypedDict
+ # to enable better runtime introspection.
+ # On 3.13 we deprecate some odd ways of creating TypedDicts.
+ # Also on 3.13, PEP 705 adds the ReadOnly[] qualifier.
+ # PEP 728 (still pending) makes more changes.
+ TypedDict = typing.TypedDict
+ _TypedDictMeta = typing._TypedDictMeta
+ is_typeddict = typing.is_typeddict
+else:
+ # 3.10.0 and later
+ _TAKES_MODULE = "module" in inspect.signature(typing._type_check).parameters
+
+ def _get_typeddict_qualifiers(annotation_type):
+ while True:
+ annotation_origin = get_origin(annotation_type)
+ if annotation_origin is Annotated:
+ annotation_args = get_args(annotation_type)
+ if annotation_args:
+ annotation_type = annotation_args[0]
+ else:
+ break
+ elif annotation_origin is Required:
+ yield Required
+ annotation_type, = get_args(annotation_type)
+ elif annotation_origin is NotRequired:
+ yield NotRequired
+ annotation_type, = get_args(annotation_type)
+ elif annotation_origin is ReadOnly:
+ yield ReadOnly
+ annotation_type, = get_args(annotation_type)
+ else:
+ break
+
+ class _TypedDictMeta(type):
+ def __new__(cls, name, bases, ns, *, total=True, closed=False):
+ """Create new typed dict class object.
+
+ This method is called when TypedDict is subclassed,
+ or when TypedDict is instantiated. This way
+ TypedDict supports all three syntax forms described in its docstring.
+ Subclasses and instances of TypedDict return actual dictionaries.
+ """
+ for base in bases:
+ if type(base) is not _TypedDictMeta and base is not typing.Generic:
+ raise TypeError('cannot inherit from both a TypedDict type '
+ 'and a non-TypedDict base class')
+
+ if any(issubclass(b, typing.Generic) for b in bases):
+ generic_base = (typing.Generic,)
+ else:
+ generic_base = ()
+
+ # typing.py generally doesn't let you inherit from plain Generic, unless
+ # the name of the class happens to be "Protocol"
+ tp_dict = type.__new__(_TypedDictMeta, "Protocol", (*generic_base, dict), ns)
+ tp_dict.__name__ = name
+ if tp_dict.__qualname__ == "Protocol":
+ tp_dict.__qualname__ = name
+
+ if not hasattr(tp_dict, '__orig_bases__'):
+ tp_dict.__orig_bases__ = bases
+
+ annotations = {}
+ if "__annotations__" in ns:
+ own_annotations = ns["__annotations__"]
+ elif "__annotate__" in ns:
+ # TODO: Use inspect.VALUE here, and make the annotations lazily evaluated
+ own_annotations = ns["__annotate__"](1)
+ else:
+ own_annotations = {}
+ msg = "TypedDict('Name', {f0: t0, f1: t1, ...}); each t must be a type"
+ if _TAKES_MODULE:
+ own_annotations = {
+ n: typing._type_check(tp, msg, module=tp_dict.__module__)
+ for n, tp in own_annotations.items()
+ }
+ else:
+ own_annotations = {
+ n: typing._type_check(tp, msg)
+ for n, tp in own_annotations.items()
+ }
+ required_keys = set()
+ optional_keys = set()
+ readonly_keys = set()
+ mutable_keys = set()
+ extra_items_type = None
+
+ for base in bases:
+ base_dict = base.__dict__
+
+ annotations.update(base_dict.get('__annotations__', {}))
+ required_keys.update(base_dict.get('__required_keys__', ()))
+ optional_keys.update(base_dict.get('__optional_keys__', ()))
+ readonly_keys.update(base_dict.get('__readonly_keys__', ()))
+ mutable_keys.update(base_dict.get('__mutable_keys__', ()))
+ base_extra_items_type = base_dict.get('__extra_items__', None)
+ if base_extra_items_type is not None:
+ extra_items_type = base_extra_items_type
+
+ if closed and extra_items_type is None:
+ extra_items_type = Never
+ if closed and "__extra_items__" in own_annotations:
+ annotation_type = own_annotations.pop("__extra_items__")
+ qualifiers = set(_get_typeddict_qualifiers(annotation_type))
+ if Required in qualifiers:
+ raise TypeError(
+ "Special key __extra_items__ does not support "
+ "Required"
+ )
+ if NotRequired in qualifiers:
+ raise TypeError(
+ "Special key __extra_items__ does not support "
+ "NotRequired"
+ )
+ extra_items_type = annotation_type
+
+ annotations.update(own_annotations)
+ for annotation_key, annotation_type in own_annotations.items():
+ qualifiers = set(_get_typeddict_qualifiers(annotation_type))
+
+ if Required in qualifiers:
+ required_keys.add(annotation_key)
+ elif NotRequired in qualifiers:
+ optional_keys.add(annotation_key)
+ elif total:
+ required_keys.add(annotation_key)
+ else:
+ optional_keys.add(annotation_key)
+ if ReadOnly in qualifiers:
+ mutable_keys.discard(annotation_key)
+ readonly_keys.add(annotation_key)
+ else:
+ mutable_keys.add(annotation_key)
+ readonly_keys.discard(annotation_key)
+
+ tp_dict.__annotations__ = annotations
+ tp_dict.__required_keys__ = frozenset(required_keys)
+ tp_dict.__optional_keys__ = frozenset(optional_keys)
+ tp_dict.__readonly_keys__ = frozenset(readonly_keys)
+ tp_dict.__mutable_keys__ = frozenset(mutable_keys)
+ if not hasattr(tp_dict, '__total__'):
+ tp_dict.__total__ = total
+ tp_dict.__closed__ = closed
+ tp_dict.__extra_items__ = extra_items_type
+ return tp_dict
+
+ __call__ = dict # static method
+
+ def __subclasscheck__(cls, other):
+ # Typed dicts are only for static structural subtyping.
+ raise TypeError('TypedDict does not support instance and class checks')
+
+ __instancecheck__ = __subclasscheck__
+
+ _TypedDict = type.__new__(_TypedDictMeta, 'TypedDict', (), {})
+
+ @_ensure_subclassable(lambda bases: (_TypedDict,))
+ def TypedDict(typename, fields=_marker, /, *, total=True, closed=False, **kwargs):
+ """A simple typed namespace. At runtime it is equivalent to a plain dict.
+
+ TypedDict creates a dictionary type such that a type checker will expect all
+ instances to have a certain set of keys, where each key is
+ associated with a value of a consistent type. This expectation
+ is not checked at runtime.
+
+ Usage::
+
+ class Point2D(TypedDict):
+ x: int
+ y: int
+ label: str
+
+ a: Point2D = {'x': 1, 'y': 2, 'label': 'good'} # OK
+ b: Point2D = {'z': 3, 'label': 'bad'} # Fails type check
+
+ assert Point2D(x=1, y=2, label='first') == dict(x=1, y=2, label='first')
+
+ The type info can be accessed via the Point2D.__annotations__ dict, and
+ the Point2D.__required_keys__ and Point2D.__optional_keys__ frozensets.
+ TypedDict supports an additional equivalent form::
+
+ Point2D = TypedDict('Point2D', {'x': int, 'y': int, 'label': str})
+
+ By default, all keys must be present in a TypedDict. It is possible
+ to override this by specifying totality::
+
+ class Point2D(TypedDict, total=False):
+ x: int
+ y: int
+
+ This means that a Point2D TypedDict can have any of the keys omitted. A type
+ checker is only expected to support a literal False or True as the value of
+ the total argument. True is the default, and makes all items defined in the
+ class body be required.
+
+ The Required and NotRequired special forms can also be used to mark
+ individual keys as being required or not required::
+
+ class Point2D(TypedDict):
+ x: int # the "x" key must always be present (Required is the default)
+ y: NotRequired[int] # the "y" key can be omitted
+
+ See PEP 655 for more details on Required and NotRequired.
+ """
+ if fields is _marker or fields is None:
+ if fields is _marker:
+ deprecated_thing = "Failing to pass a value for the 'fields' parameter"
+ else:
+ deprecated_thing = "Passing `None` as the 'fields' parameter"
+
+ example = f"`{typename} = TypedDict({typename!r}, {{}})`"
+ deprecation_msg = (
+ f"{deprecated_thing} is deprecated and will be disallowed in "
+ "Python 3.15. To create a TypedDict class with 0 fields "
+ "using the functional syntax, pass an empty dictionary, e.g. "
+ ) + example + "."
+ warnings.warn(deprecation_msg, DeprecationWarning, stacklevel=2)
+ if closed is not False and closed is not True:
+ kwargs["closed"] = closed
+ closed = False
+ fields = kwargs
+ elif kwargs:
+ raise TypeError("TypedDict takes either a dict or keyword arguments,"
+ " but not both")
+ if kwargs:
+ if sys.version_info >= (3, 13):
+ raise TypeError("TypedDict takes no keyword arguments")
+ warnings.warn(
+ "The kwargs-based syntax for TypedDict definitions is deprecated "
+ "in Python 3.11, will be removed in Python 3.13, and may not be "
+ "understood by third-party type checkers.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+
+ ns = {'__annotations__': dict(fields)}
+ module = _caller()
+ if module is not None:
+ # Setting correct module is necessary to make typed dict classes pickleable.
+ ns['__module__'] = module
+
+ td = _TypedDictMeta(typename, (), ns, total=total, closed=closed)
+ td.__orig_bases__ = (TypedDict,)
+ return td
+
+ if hasattr(typing, "_TypedDictMeta"):
+ _TYPEDDICT_TYPES = (typing._TypedDictMeta, _TypedDictMeta)
+ else:
+ _TYPEDDICT_TYPES = (_TypedDictMeta,)
+
+ def is_typeddict(tp):
+ """Check if an annotation is a TypedDict class
+
+ For example::
+ class Film(TypedDict):
+ title: str
+ year: int
+
+ is_typeddict(Film) # => True
+ is_typeddict(Union[list, str]) # => False
+ """
+ # On 3.8, this would otherwise return True
+ if hasattr(typing, "TypedDict") and tp is typing.TypedDict:
+ return False
+ return isinstance(tp, _TYPEDDICT_TYPES)
+
+
+if hasattr(typing, "assert_type"):
+ assert_type = typing.assert_type
+
+else:
+ def assert_type(val, typ, /):
+ """Assert (to the type checker) that the value is of the given type.
+
+ When the type checker encounters a call to assert_type(), it
+ emits an error if the value is not of the specified type::
+
+ def greet(name: str) -> None:
+ assert_type(name, str) # ok
+ assert_type(name, int) # type checker error
+
+ At runtime this returns the first argument unchanged and otherwise
+ does nothing.
+ """
+ return val
+
+
+if hasattr(typing, "ReadOnly"): # 3.13+
+ get_type_hints = typing.get_type_hints
+else: # <=3.13
+ # replaces _strip_annotations()
+ def _strip_extras(t):
+ """Strips Annotated, Required and NotRequired from a given type."""
+ if isinstance(t, _AnnotatedAlias):
+ return _strip_extras(t.__origin__)
+ if hasattr(t, "__origin__") and t.__origin__ in (Required, NotRequired, ReadOnly):
+ return _strip_extras(t.__args__[0])
+ if isinstance(t, typing._GenericAlias):
+ stripped_args = tuple(_strip_extras(a) for a in t.__args__)
+ if stripped_args == t.__args__:
+ return t
+ return t.copy_with(stripped_args)
+ if hasattr(_types, "GenericAlias") and isinstance(t, _types.GenericAlias):
+ stripped_args = tuple(_strip_extras(a) for a in t.__args__)
+ if stripped_args == t.__args__:
+ return t
+ return _types.GenericAlias(t.__origin__, stripped_args)
+ if hasattr(_types, "UnionType") and isinstance(t, _types.UnionType):
+ stripped_args = tuple(_strip_extras(a) for a in t.__args__)
+ if stripped_args == t.__args__:
+ return t
+ return functools.reduce(operator.or_, stripped_args)
+
+ return t
+
+ def get_type_hints(obj, globalns=None, localns=None, include_extras=False):
+ """Return type hints for an object.
+
+ This is often the same as obj.__annotations__, but it handles
+ forward references encoded as string literals, adds Optional[t] if a
+ default value equal to None is set and recursively replaces all
+ 'Annotated[T, ...]', 'Required[T]' or 'NotRequired[T]' with 'T'
+ (unless 'include_extras=True').
+
+ The argument may be a module, class, method, or function. The annotations
+ are returned as a dictionary. For classes, annotations include also
+ inherited members.
+
+ TypeError is raised if the argument is not of a type that can contain
+ annotations, and an empty dictionary is returned if no annotations are
+ present.
+
+ BEWARE -- the behavior of globalns and localns is counterintuitive
+ (unless you are familiar with how eval() and exec() work). The
+ search order is locals first, then globals.
+
+ - If no dict arguments are passed, an attempt is made to use the
+ globals from obj (or the respective module's globals for classes),
+ and these are also used as the locals. If the object does not appear
+ to have globals, an empty dictionary is used.
+
+ - If one dict argument is passed, it is used for both globals and
+ locals.
+
+ - If two dict arguments are passed, they specify globals and
+ locals, respectively.
+ """
+ if hasattr(typing, "Annotated"): # 3.9+
+ hint = typing.get_type_hints(
+ obj, globalns=globalns, localns=localns, include_extras=True
+ )
+ else: # 3.8
+ hint = typing.get_type_hints(obj, globalns=globalns, localns=localns)
+ if include_extras:
+ return hint
+ return {k: _strip_extras(t) for k, t in hint.items()}
+
+
+# Python 3.9+ has PEP 593 (Annotated)
+if hasattr(typing, 'Annotated'):
+ Annotated = typing.Annotated
+ # Not exported and not a public API, but needed for get_origin() and get_args()
+ # to work.
+ _AnnotatedAlias = typing._AnnotatedAlias
+# 3.8
+else:
+ class _AnnotatedAlias(typing._GenericAlias, _root=True):
+ """Runtime representation of an annotated type.
+
+ At its core 'Annotated[t, dec1, dec2, ...]' is an alias for the type 't'
+ with extra annotations. The alias behaves like a normal typing alias,
+ instantiating is the same as instantiating the underlying type, binding
+ it to types is also the same.
+ """
+ def __init__(self, origin, metadata):
+ if isinstance(origin, _AnnotatedAlias):
+ metadata = origin.__metadata__ + metadata
+ origin = origin.__origin__
+ super().__init__(origin, origin)
+ self.__metadata__ = metadata
+
+ def copy_with(self, params):
+ assert len(params) == 1
+ new_type = params[0]
+ return _AnnotatedAlias(new_type, self.__metadata__)
+
+ def __repr__(self):
+ return (f"typing_extensions.Annotated[{typing._type_repr(self.__origin__)}, "
+ f"{', '.join(repr(a) for a in self.__metadata__)}]")
+
+ def __reduce__(self):
+ return operator.getitem, (
+ Annotated, (self.__origin__, *self.__metadata__)
+ )
+
+ def __eq__(self, other):
+ if not isinstance(other, _AnnotatedAlias):
+ return NotImplemented
+ if self.__origin__ != other.__origin__:
+ return False
+ return self.__metadata__ == other.__metadata__
+
+ def __hash__(self):
+ return hash((self.__origin__, self.__metadata__))
+
+ class Annotated:
+ """Add context specific metadata to a type.
+
+ Example: Annotated[int, runtime_check.Unsigned] indicates to the
+ hypothetical runtime_check module that this type is an unsigned int.
+ Every other consumer of this type can ignore this metadata and treat
+ this type as int.
+
+ The first argument to Annotated must be a valid type (and will be in
+ the __origin__ field), the remaining arguments are kept as a tuple in
+ the __extra__ field.
+
+ Details:
+
+ - It's an error to call `Annotated` with less than two arguments.
+ - Nested Annotated are flattened::
+
+ Annotated[Annotated[T, Ann1, Ann2], Ann3] == Annotated[T, Ann1, Ann2, Ann3]
+
+ - Instantiating an annotated type is equivalent to instantiating the
+ underlying type::
+
+ Annotated[C, Ann1](5) == C(5)
+
+ - Annotated can be used as a generic type alias::
+
+ Optimized = Annotated[T, runtime.Optimize()]
+ Optimized[int] == Annotated[int, runtime.Optimize()]
+
+ OptimizedList = Annotated[List[T], runtime.Optimize()]
+ OptimizedList[int] == Annotated[List[int], runtime.Optimize()]
+ """
+
+ __slots__ = ()
+
+ def __new__(cls, *args, **kwargs):
+ raise TypeError("Type Annotated cannot be instantiated.")
+
+ @typing._tp_cache
+ def __class_getitem__(cls, params):
+ if not isinstance(params, tuple) or len(params) < 2:
+ raise TypeError("Annotated[...] should be used "
+ "with at least two arguments (a type and an "
+ "annotation).")
+ allowed_special_forms = (ClassVar, Final)
+ if get_origin(params[0]) in allowed_special_forms:
+ origin = params[0]
+ else:
+ msg = "Annotated[t, ...]: t must be a type."
+ origin = typing._type_check(params[0], msg)
+ metadata = tuple(params[1:])
+ return _AnnotatedAlias(origin, metadata)
+
+ def __init_subclass__(cls, *args, **kwargs):
+ raise TypeError(
+ f"Cannot subclass {cls.__module__}.Annotated"
+ )
+
+# Python 3.8 has get_origin() and get_args() but those implementations aren't
+# Annotated-aware, so we can't use those. Python 3.9's versions don't support
+# ParamSpecArgs and ParamSpecKwargs, so only Python 3.10's versions will do.
+if sys.version_info[:2] >= (3, 10):
+ get_origin = typing.get_origin
+ get_args = typing.get_args
+# 3.8-3.9
+else:
+ try:
+ # 3.9+
+ from typing import _BaseGenericAlias
+ except ImportError:
+ _BaseGenericAlias = typing._GenericAlias
+ try:
+ # 3.9+
+ from typing import GenericAlias as _typing_GenericAlias
+ except ImportError:
+ _typing_GenericAlias = typing._GenericAlias
+
+ def get_origin(tp):
+ """Get the unsubscripted version of a type.
+
+ This supports generic types, Callable, Tuple, Union, Literal, Final, ClassVar
+ and Annotated. Return None for unsupported types. Examples::
+
+ get_origin(Literal[42]) is Literal
+ get_origin(int) is None
+ get_origin(ClassVar[int]) is ClassVar
+ get_origin(Generic) is Generic
+ get_origin(Generic[T]) is Generic
+ get_origin(Union[T, int]) is Union
+ get_origin(List[Tuple[T, T]][int]) == list
+ get_origin(P.args) is P
+ """
+ if isinstance(tp, _AnnotatedAlias):
+ return Annotated
+ if isinstance(tp, (typing._GenericAlias, _typing_GenericAlias, _BaseGenericAlias,
+ ParamSpecArgs, ParamSpecKwargs)):
+ return tp.__origin__
+ if tp is typing.Generic:
+ return typing.Generic
+ return None
+
+ def get_args(tp):
+ """Get type arguments with all substitutions performed.
+
+ For unions, basic simplifications used by Union constructor are performed.
+ Examples::
+ get_args(Dict[str, int]) == (str, int)
+ get_args(int) == ()
+ get_args(Union[int, Union[T, int], str][int]) == (int, str)
+ get_args(Union[int, Tuple[T, int]][str]) == (int, Tuple[str, int])
+ get_args(Callable[[], T][int]) == ([], int)
+ """
+ if isinstance(tp, _AnnotatedAlias):
+ return (tp.__origin__, *tp.__metadata__)
+ if isinstance(tp, (typing._GenericAlias, _typing_GenericAlias)):
+ if getattr(tp, "_special", False):
+ return ()
+ res = tp.__args__
+ if get_origin(tp) is collections.abc.Callable and res[0] is not Ellipsis:
+ res = (list(res[:-1]), res[-1])
+ return res
+ return ()
+
+
+# 3.10+
+if hasattr(typing, 'TypeAlias'):
+ TypeAlias = typing.TypeAlias
+# 3.9
+elif sys.version_info[:2] >= (3, 9):
+ @_ExtensionsSpecialForm
+ def TypeAlias(self, parameters):
+ """Special marker indicating that an assignment should
+ be recognized as a proper type alias definition by type
+ checkers.
+
+ For example::
+
+ Predicate: TypeAlias = Callable[..., bool]
+
+ It's invalid when used anywhere except as in the example above.
+ """
+ raise TypeError(f"{self} is not subscriptable")
+# 3.8
+else:
+ TypeAlias = _ExtensionsSpecialForm(
+ 'TypeAlias',
+ doc="""Special marker indicating that an assignment should
+ be recognized as a proper type alias definition by type
+ checkers.
+
+ For example::
+
+ Predicate: TypeAlias = Callable[..., bool]
+
+ It's invalid when used anywhere except as in the example
+ above."""
+ )
+
+
+if hasattr(typing, "NoDefault"):
+ NoDefault = typing.NoDefault
+else:
+ class NoDefaultTypeMeta(type):
+ def __setattr__(cls, attr, value):
+ # TypeError is consistent with the behavior of NoneType
+ raise TypeError(
+ f"cannot set {attr!r} attribute of immutable type {cls.__name__!r}"
+ )
+
+ class NoDefaultType(metaclass=NoDefaultTypeMeta):
+ """The type of the NoDefault singleton."""
+
+ __slots__ = ()
+
+ def __new__(cls):
+ return globals().get("NoDefault") or object.__new__(cls)
+
+ def __repr__(self):
+ return "typing_extensions.NoDefault"
+
+ def __reduce__(self):
+ return "NoDefault"
+
+ NoDefault = NoDefaultType()
+ del NoDefaultType, NoDefaultTypeMeta
+
+
+def _set_default(type_param, default):
+ type_param.has_default = lambda: default is not NoDefault
+ type_param.__default__ = default
+
+
+def _set_module(typevarlike):
+ # for pickling:
+ def_mod = _caller(depth=3)
+ if def_mod != 'typing_extensions':
+ typevarlike.__module__ = def_mod
+
+
+class _DefaultMixin:
+ """Mixin for TypeVarLike defaults."""
+
+ __slots__ = ()
+ __init__ = _set_default
+
+
+# Classes using this metaclass must provide a _backported_typevarlike ClassVar
+class _TypeVarLikeMeta(type):
+ def __instancecheck__(cls, __instance: Any) -> bool:
+ return isinstance(__instance, cls._backported_typevarlike)
+
+
+if _PEP_696_IMPLEMENTED:
+ from typing import TypeVar
+else:
+ # Add default and infer_variance parameters from PEP 696 and 695
+ class TypeVar(metaclass=_TypeVarLikeMeta):
+ """Type variable."""
+
+ _backported_typevarlike = typing.TypeVar
+
+ def __new__(cls, name, *constraints, bound=None,
+ covariant=False, contravariant=False,
+ default=NoDefault, infer_variance=False):
+ if hasattr(typing, "TypeAliasType"):
+ # PEP 695 implemented (3.12+), can pass infer_variance to typing.TypeVar
+ typevar = typing.TypeVar(name, *constraints, bound=bound,
+ covariant=covariant, contravariant=contravariant,
+ infer_variance=infer_variance)
+ else:
+ typevar = typing.TypeVar(name, *constraints, bound=bound,
+ covariant=covariant, contravariant=contravariant)
+ if infer_variance and (covariant or contravariant):
+ raise ValueError("Variance cannot be specified with infer_variance.")
+ typevar.__infer_variance__ = infer_variance
+
+ _set_default(typevar, default)
+ _set_module(typevar)
+
+ def _tvar_prepare_subst(alias, args):
+ if (
+ typevar.has_default()
+ and alias.__parameters__.index(typevar) == len(args)
+ ):
+ args += (typevar.__default__,)
+ return args
+
+ typevar.__typing_prepare_subst__ = _tvar_prepare_subst
+ return typevar
+
+ def __init_subclass__(cls) -> None:
+ raise TypeError(f"type '{__name__}.TypeVar' is not an acceptable base type")
+
+
+# Python 3.10+ has PEP 612
+if hasattr(typing, 'ParamSpecArgs'):
+ ParamSpecArgs = typing.ParamSpecArgs
+ ParamSpecKwargs = typing.ParamSpecKwargs
+# 3.8-3.9
+else:
+ class _Immutable:
+ """Mixin to indicate that object should not be copied."""
+ __slots__ = ()
+
+ def __copy__(self):
+ return self
+
+ def __deepcopy__(self, memo):
+ return self
+
+ class ParamSpecArgs(_Immutable):
+ """The args for a ParamSpec object.
+
+ Given a ParamSpec object P, P.args is an instance of ParamSpecArgs.
+
+ ParamSpecArgs objects have a reference back to their ParamSpec:
+
+ P.args.__origin__ is P
+
+ This type is meant for runtime introspection and has no special meaning to
+ static type checkers.
+ """
+ def __init__(self, origin):
+ self.__origin__ = origin
+
+ def __repr__(self):
+ return f"{self.__origin__.__name__}.args"
+
+ def __eq__(self, other):
+ if not isinstance(other, ParamSpecArgs):
+ return NotImplemented
+ return self.__origin__ == other.__origin__
+
+ class ParamSpecKwargs(_Immutable):
+ """The kwargs for a ParamSpec object.
+
+ Given a ParamSpec object P, P.kwargs is an instance of ParamSpecKwargs.
+
+ ParamSpecKwargs objects have a reference back to their ParamSpec:
+
+ P.kwargs.__origin__ is P
+
+ This type is meant for runtime introspection and has no special meaning to
+ static type checkers.
+ """
+ def __init__(self, origin):
+ self.__origin__ = origin
+
+ def __repr__(self):
+ return f"{self.__origin__.__name__}.kwargs"
+
+ def __eq__(self, other):
+ if not isinstance(other, ParamSpecKwargs):
+ return NotImplemented
+ return self.__origin__ == other.__origin__
+
+
+if _PEP_696_IMPLEMENTED:
+ from typing import ParamSpec
+
+# 3.10+
+elif hasattr(typing, 'ParamSpec'):
+
+ # Add default parameter - PEP 696
+ class ParamSpec(metaclass=_TypeVarLikeMeta):
+ """Parameter specification."""
+
+ _backported_typevarlike = typing.ParamSpec
+
+ def __new__(cls, name, *, bound=None,
+ covariant=False, contravariant=False,
+ infer_variance=False, default=NoDefault):
+ if hasattr(typing, "TypeAliasType"):
+ # PEP 695 implemented, can pass infer_variance to typing.TypeVar
+ paramspec = typing.ParamSpec(name, bound=bound,
+ covariant=covariant,
+ contravariant=contravariant,
+ infer_variance=infer_variance)
+ else:
+ paramspec = typing.ParamSpec(name, bound=bound,
+ covariant=covariant,
+ contravariant=contravariant)
+ paramspec.__infer_variance__ = infer_variance
+
+ _set_default(paramspec, default)
+ _set_module(paramspec)
+
+ def _paramspec_prepare_subst(alias, args):
+ params = alias.__parameters__
+ i = params.index(paramspec)
+ if i == len(args) and paramspec.has_default():
+ args = [*args, paramspec.__default__]
+ if i >= len(args):
+ raise TypeError(f"Too few arguments for {alias}")
+ # Special case where Z[[int, str, bool]] == Z[int, str, bool] in PEP 612.
+ if len(params) == 1 and not typing._is_param_expr(args[0]):
+ assert i == 0
+ args = (args,)
+ # Convert lists to tuples to help other libraries cache the results.
+ elif isinstance(args[i], list):
+ args = (*args[:i], tuple(args[i]), *args[i + 1:])
+ return args
+
+ paramspec.__typing_prepare_subst__ = _paramspec_prepare_subst
+ return paramspec
+
+ def __init_subclass__(cls) -> None:
+ raise TypeError(f"type '{__name__}.ParamSpec' is not an acceptable base type")
+
+# 3.8-3.9
+else:
+
+ # Inherits from list as a workaround for Callable checks in Python < 3.9.2.
+ class ParamSpec(list, _DefaultMixin):
+ """Parameter specification variable.
+
+ Usage::
+
+ P = ParamSpec('P')
+
+ Parameter specification variables exist primarily for the benefit of static
+ type checkers. They are used to forward the parameter types of one
+ callable to another callable, a pattern commonly found in higher order
+ functions and decorators. They are only valid when used in ``Concatenate``,
+ or s the first argument to ``Callable``. In Python 3.10 and higher,
+ they are also supported in user-defined Generics at runtime.
+ See class Generic for more information on generic types. An
+ example for annotating a decorator::
+
+ T = TypeVar('T')
+ P = ParamSpec('P')
+
+ def add_logging(f: Callable[P, T]) -> Callable[P, T]:
+ '''A type-safe decorator to add logging to a function.'''
+ def inner(*args: P.args, **kwargs: P.kwargs) -> T:
+ logging.info(f'{f.__name__} was called')
+ return f(*args, **kwargs)
+ return inner
+
+ @add_logging
+ def add_two(x: float, y: float) -> float:
+ '''Add two numbers together.'''
+ return x + y
+
+ Parameter specification variables defined with covariant=True or
+ contravariant=True can be used to declare covariant or contravariant
+ generic types. These keyword arguments are valid, but their actual semantics
+ are yet to be decided. See PEP 612 for details.
+
+ Parameter specification variables can be introspected. e.g.:
+
+ P.__name__ == 'T'
+ P.__bound__ == None
+ P.__covariant__ == False
+ P.__contravariant__ == False
+
+ Note that only parameter specification variables defined in global scope can
+ be pickled.
+ """
+
+ # Trick Generic __parameters__.
+ __class__ = typing.TypeVar
+
+ @property
+ def args(self):
+ return ParamSpecArgs(self)
+
+ @property
+ def kwargs(self):
+ return ParamSpecKwargs(self)
+
+ def __init__(self, name, *, bound=None, covariant=False, contravariant=False,
+ infer_variance=False, default=NoDefault):
+ list.__init__(self, [self])
+ self.__name__ = name
+ self.__covariant__ = bool(covariant)
+ self.__contravariant__ = bool(contravariant)
+ self.__infer_variance__ = bool(infer_variance)
+ if bound:
+ self.__bound__ = typing._type_check(bound, 'Bound must be a type.')
+ else:
+ self.__bound__ = None
+ _DefaultMixin.__init__(self, default)
+
+ # for pickling:
+ def_mod = _caller()
+ if def_mod != 'typing_extensions':
+ self.__module__ = def_mod
+
+ def __repr__(self):
+ if self.__infer_variance__:
+ prefix = ''
+ elif self.__covariant__:
+ prefix = '+'
+ elif self.__contravariant__:
+ prefix = '-'
+ else:
+ prefix = '~'
+ return prefix + self.__name__
+
+ def __hash__(self):
+ return object.__hash__(self)
+
+ def __eq__(self, other):
+ return self is other
+
+ def __reduce__(self):
+ return self.__name__
+
+ # Hack to get typing._type_check to pass.
+ def __call__(self, *args, **kwargs):
+ pass
+
+
+# 3.8-3.9
+if not hasattr(typing, 'Concatenate'):
+ # Inherits from list as a workaround for Callable checks in Python < 3.9.2.
+ class _ConcatenateGenericAlias(list):
+
+ # Trick Generic into looking into this for __parameters__.
+ __class__ = typing._GenericAlias
+
+ # Flag in 3.8.
+ _special = False
+
+ def __init__(self, origin, args):
+ super().__init__(args)
+ self.__origin__ = origin
+ self.__args__ = args
+
+ def __repr__(self):
+ _type_repr = typing._type_repr
+ return (f'{_type_repr(self.__origin__)}'
+ f'[{", ".join(_type_repr(arg) for arg in self.__args__)}]')
+
+ def __hash__(self):
+ return hash((self.__origin__, self.__args__))
+
+ # Hack to get typing._type_check to pass in Generic.
+ def __call__(self, *args, **kwargs):
+ pass
+
+ @property
+ def __parameters__(self):
+ return tuple(
+ tp for tp in self.__args__ if isinstance(tp, (typing.TypeVar, ParamSpec))
+ )
+
+
+# 3.8-3.9
+@typing._tp_cache
+def _concatenate_getitem(self, parameters):
+ if parameters == ():
+ raise TypeError("Cannot take a Concatenate of no types.")
+ if not isinstance(parameters, tuple):
+ parameters = (parameters,)
+ if not isinstance(parameters[-1], ParamSpec):
+ raise TypeError("The last parameter to Concatenate should be a "
+ "ParamSpec variable.")
+ msg = "Concatenate[arg, ...]: each arg must be a type."
+ parameters = tuple(typing._type_check(p, msg) for p in parameters)
+ return _ConcatenateGenericAlias(self, parameters)
+
+
+# 3.10+
+if hasattr(typing, 'Concatenate'):
+ Concatenate = typing.Concatenate
+ _ConcatenateGenericAlias = typing._ConcatenateGenericAlias
+# 3.9
+elif sys.version_info[:2] >= (3, 9):
+ @_ExtensionsSpecialForm
+ def Concatenate(self, parameters):
+ """Used in conjunction with ``ParamSpec`` and ``Callable`` to represent a
+ higher order function which adds, removes or transforms parameters of a
+ callable.
+
+ For example::
+
+ Callable[Concatenate[int, P], int]
+
+ See PEP 612 for detailed information.
+ """
+ return _concatenate_getitem(self, parameters)
+# 3.8
+else:
+ class _ConcatenateForm(_ExtensionsSpecialForm, _root=True):
+ def __getitem__(self, parameters):
+ return _concatenate_getitem(self, parameters)
+
+ Concatenate = _ConcatenateForm(
+ 'Concatenate',
+ doc="""Used in conjunction with ``ParamSpec`` and ``Callable`` to represent a
+ higher order function which adds, removes or transforms parameters of a
+ callable.
+
+ For example::
+
+ Callable[Concatenate[int, P], int]
+
+ See PEP 612 for detailed information.
+ """)
+
+# 3.10+
+if hasattr(typing, 'TypeGuard'):
+ TypeGuard = typing.TypeGuard
+# 3.9
+elif sys.version_info[:2] >= (3, 9):
+ @_ExtensionsSpecialForm
+ def TypeGuard(self, parameters):
+ """Special typing form used to annotate the return type of a user-defined
+ type guard function. ``TypeGuard`` only accepts a single type argument.
+ At runtime, functions marked this way should return a boolean.
+
+ ``TypeGuard`` aims to benefit *type narrowing* -- a technique used by static
+ type checkers to determine a more precise type of an expression within a
+ program's code flow. Usually type narrowing is done by analyzing
+ conditional code flow and applying the narrowing to a block of code. The
+ conditional expression here is sometimes referred to as a "type guard".
+
+ Sometimes it would be convenient to use a user-defined boolean function
+ as a type guard. Such a function should use ``TypeGuard[...]`` as its
+ return type to alert static type checkers to this intention.
+
+ Using ``-> TypeGuard`` tells the static type checker that for a given
+ function:
+
+ 1. The return value is a boolean.
+ 2. If the return value is ``True``, the type of its argument
+ is the type inside ``TypeGuard``.
+
+ For example::
+
+ def is_str(val: Union[str, float]):
+ # "isinstance" type guard
+ if isinstance(val, str):
+ # Type of ``val`` is narrowed to ``str``
+ ...
+ else:
+ # Else, type of ``val`` is narrowed to ``float``.
+ ...
+
+ Strict type narrowing is not enforced -- ``TypeB`` need not be a narrower
+ form of ``TypeA`` (it can even be a wider form) and this may lead to
+ type-unsafe results. The main reason is to allow for things like
+ narrowing ``List[object]`` to ``List[str]`` even though the latter is not
+ a subtype of the former, since ``List`` is invariant. The responsibility of
+ writing type-safe type guards is left to the user.
+
+ ``TypeGuard`` also works with type variables. For more information, see
+ PEP 647 (User-Defined Type Guards).
+ """
+ item = typing._type_check(parameters, f'{self} accepts only a single type.')
+ return typing._GenericAlias(self, (item,))
+# 3.8
+else:
+ class _TypeGuardForm(_ExtensionsSpecialForm, _root=True):
+ def __getitem__(self, parameters):
+ item = typing._type_check(parameters,
+ f'{self._name} accepts only a single type')
+ return typing._GenericAlias(self, (item,))
+
+ TypeGuard = _TypeGuardForm(
+ 'TypeGuard',
+ doc="""Special typing form used to annotate the return type of a user-defined
+ type guard function. ``TypeGuard`` only accepts a single type argument.
+ At runtime, functions marked this way should return a boolean.
+
+ ``TypeGuard`` aims to benefit *type narrowing* -- a technique used by static
+ type checkers to determine a more precise type of an expression within a
+ program's code flow. Usually type narrowing is done by analyzing
+ conditional code flow and applying the narrowing to a block of code. The
+ conditional expression here is sometimes referred to as a "type guard".
+
+ Sometimes it would be convenient to use a user-defined boolean function
+ as a type guard. Such a function should use ``TypeGuard[...]`` as its
+ return type to alert static type checkers to this intention.
+
+ Using ``-> TypeGuard`` tells the static type checker that for a given
+ function:
+
+ 1. The return value is a boolean.
+ 2. If the return value is ``True``, the type of its argument
+ is the type inside ``TypeGuard``.
+
+ For example::
+
+ def is_str(val: Union[str, float]):
+ # "isinstance" type guard
+ if isinstance(val, str):
+ # Type of ``val`` is narrowed to ``str``
+ ...
+ else:
+ # Else, type of ``val`` is narrowed to ``float``.
+ ...
+
+ Strict type narrowing is not enforced -- ``TypeB`` need not be a narrower
+ form of ``TypeA`` (it can even be a wider form) and this may lead to
+ type-unsafe results. The main reason is to allow for things like
+ narrowing ``List[object]`` to ``List[str]`` even though the latter is not
+ a subtype of the former, since ``List`` is invariant. The responsibility of
+ writing type-safe type guards is left to the user.
+
+ ``TypeGuard`` also works with type variables. For more information, see
+ PEP 647 (User-Defined Type Guards).
+ """)
+
+# 3.13+
+if hasattr(typing, 'TypeIs'):
+ TypeIs = typing.TypeIs
+# 3.9
+elif sys.version_info[:2] >= (3, 9):
+ @_ExtensionsSpecialForm
+ def TypeIs(self, parameters):
+ """Special typing form used to annotate the return type of a user-defined
+ type narrower function. ``TypeIs`` only accepts a single type argument.
+ At runtime, functions marked this way should return a boolean.
+
+ ``TypeIs`` aims to benefit *type narrowing* -- a technique used by static
+ type checkers to determine a more precise type of an expression within a
+ program's code flow. Usually type narrowing is done by analyzing
+ conditional code flow and applying the narrowing to a block of code. The
+ conditional expression here is sometimes referred to as a "type guard".
+
+ Sometimes it would be convenient to use a user-defined boolean function
+ as a type guard. Such a function should use ``TypeIs[...]`` as its
+ return type to alert static type checkers to this intention.
+
+ Using ``-> TypeIs`` tells the static type checker that for a given
+ function:
+
+ 1. The return value is a boolean.
+ 2. If the return value is ``True``, the type of its argument
+ is the intersection of the type inside ``TypeGuard`` and the argument's
+ previously known type.
+
+ For example::
+
+ def is_awaitable(val: object) -> TypeIs[Awaitable[Any]]:
+ return hasattr(val, '__await__')
+
+ def f(val: Union[int, Awaitable[int]]) -> int:
+ if is_awaitable(val):
+ assert_type(val, Awaitable[int])
+ else:
+ assert_type(val, int)
+
+ ``TypeIs`` also works with type variables. For more information, see
+ PEP 742 (Narrowing types with TypeIs).
+ """
+ item = typing._type_check(parameters, f'{self} accepts only a single type.')
+ return typing._GenericAlias(self, (item,))
+# 3.8
+else:
+ class _TypeIsForm(_ExtensionsSpecialForm, _root=True):
+ def __getitem__(self, parameters):
+ item = typing._type_check(parameters,
+ f'{self._name} accepts only a single type')
+ return typing._GenericAlias(self, (item,))
+
+ TypeIs = _TypeIsForm(
+ 'TypeIs',
+ doc="""Special typing form used to annotate the return type of a user-defined
+ type narrower function. ``TypeIs`` only accepts a single type argument.
+ At runtime, functions marked this way should return a boolean.
+
+ ``TypeIs`` aims to benefit *type narrowing* -- a technique used by static
+ type checkers to determine a more precise type of an expression within a
+ program's code flow. Usually type narrowing is done by analyzing
+ conditional code flow and applying the narrowing to a block of code. The
+ conditional expression here is sometimes referred to as a "type guard".
+
+ Sometimes it would be convenient to use a user-defined boolean function
+ as a type guard. Such a function should use ``TypeIs[...]`` as its
+ return type to alert static type checkers to this intention.
+
+ Using ``-> TypeIs`` tells the static type checker that for a given
+ function:
+
+ 1. The return value is a boolean.
+ 2. If the return value is ``True``, the type of its argument
+ is the intersection of the type inside ``TypeGuard`` and the argument's
+ previously known type.
+
+ For example::
+
+ def is_awaitable(val: object) -> TypeIs[Awaitable[Any]]:
+ return hasattr(val, '__await__')
+
+ def f(val: Union[int, Awaitable[int]]) -> int:
+ if is_awaitable(val):
+ assert_type(val, Awaitable[int])
+ else:
+ assert_type(val, int)
+
+ ``TypeIs`` also works with type variables. For more information, see
+ PEP 742 (Narrowing types with TypeIs).
+ """)
+
+
+# Vendored from cpython typing._SpecialFrom
+class _SpecialForm(typing._Final, _root=True):
+ __slots__ = ('_name', '__doc__', '_getitem')
+
+ def __init__(self, getitem):
+ self._getitem = getitem
+ self._name = getitem.__name__
+ self.__doc__ = getitem.__doc__
+
+ def __getattr__(self, item):
+ if item in {'__name__', '__qualname__'}:
+ return self._name
+
+ raise AttributeError(item)
+
+ def __mro_entries__(self, bases):
+ raise TypeError(f"Cannot subclass {self!r}")
+
+ def __repr__(self):
+ return f'typing_extensions.{self._name}'
+
+ def __reduce__(self):
+ return self._name
+
+ def __call__(self, *args, **kwds):
+ raise TypeError(f"Cannot instantiate {self!r}")
+
+ def __or__(self, other):
+ return typing.Union[self, other]
+
+ def __ror__(self, other):
+ return typing.Union[other, self]
+
+ def __instancecheck__(self, obj):
+ raise TypeError(f"{self} cannot be used with isinstance()")
+
+ def __subclasscheck__(self, cls):
+ raise TypeError(f"{self} cannot be used with issubclass()")
+
+ @typing._tp_cache
+ def __getitem__(self, parameters):
+ return self._getitem(self, parameters)
+
+
+if hasattr(typing, "LiteralString"): # 3.11+
+ LiteralString = typing.LiteralString
+else:
+ @_SpecialForm
+ def LiteralString(self, params):
+ """Represents an arbitrary literal string.
+
+ Example::
+
+ from pip._vendor.typing_extensions import LiteralString
+
+ def query(sql: LiteralString) -> ...:
+ ...
+
+ query("SELECT * FROM table") # ok
+ query(f"SELECT * FROM {input()}") # not ok
+
+ See PEP 675 for details.
+
+ """
+ raise TypeError(f"{self} is not subscriptable")
+
+
+if hasattr(typing, "Self"): # 3.11+
+ Self = typing.Self
+else:
+ @_SpecialForm
+ def Self(self, params):
+ """Used to spell the type of "self" in classes.
+
+ Example::
+
+ from typing import Self
+
+ class ReturnsSelf:
+ def parse(self, data: bytes) -> Self:
+ ...
+ return self
+
+ """
+
+ raise TypeError(f"{self} is not subscriptable")
+
+
+if hasattr(typing, "Never"): # 3.11+
+ Never = typing.Never
+else:
+ @_SpecialForm
+ def Never(self, params):
+ """The bottom type, a type that has no members.
+
+ This can be used to define a function that should never be
+ called, or a function that never returns::
+
+ from pip._vendor.typing_extensions import Never
+
+ def never_call_me(arg: Never) -> None:
+ pass
+
+ def int_or_str(arg: int | str) -> None:
+ never_call_me(arg) # type checker error
+ match arg:
+ case int():
+ print("It's an int")
+ case str():
+ print("It's a str")
+ case _:
+ never_call_me(arg) # ok, arg is of type Never
+
+ """
+
+ raise TypeError(f"{self} is not subscriptable")
+
+
+if hasattr(typing, 'Required'): # 3.11+
+ Required = typing.Required
+ NotRequired = typing.NotRequired
+elif sys.version_info[:2] >= (3, 9): # 3.9-3.10
+ @_ExtensionsSpecialForm
+ def Required(self, parameters):
+ """A special typing construct to mark a key of a total=False TypedDict
+ as required. For example:
+
+ class Movie(TypedDict, total=False):
+ title: Required[str]
+ year: int
+
+ m = Movie(
+ title='The Matrix', # typechecker error if key is omitted
+ year=1999,
+ )
+
+ There is no runtime checking that a required key is actually provided
+ when instantiating a related TypedDict.
+ """
+ item = typing._type_check(parameters, f'{self._name} accepts only a single type.')
+ return typing._GenericAlias(self, (item,))
+
+ @_ExtensionsSpecialForm
+ def NotRequired(self, parameters):
+ """A special typing construct to mark a key of a TypedDict as
+ potentially missing. For example:
+
+ class Movie(TypedDict):
+ title: str
+ year: NotRequired[int]
+
+ m = Movie(
+ title='The Matrix', # typechecker error if key is omitted
+ year=1999,
+ )
+ """
+ item = typing._type_check(parameters, f'{self._name} accepts only a single type.')
+ return typing._GenericAlias(self, (item,))
+
+else: # 3.8
+ class _RequiredForm(_ExtensionsSpecialForm, _root=True):
+ def __getitem__(self, parameters):
+ item = typing._type_check(parameters,
+ f'{self._name} accepts only a single type.')
+ return typing._GenericAlias(self, (item,))
+
+ Required = _RequiredForm(
+ 'Required',
+ doc="""A special typing construct to mark a key of a total=False TypedDict
+ as required. For example:
+
+ class Movie(TypedDict, total=False):
+ title: Required[str]
+ year: int
+
+ m = Movie(
+ title='The Matrix', # typechecker error if key is omitted
+ year=1999,
+ )
+
+ There is no runtime checking that a required key is actually provided
+ when instantiating a related TypedDict.
+ """)
+ NotRequired = _RequiredForm(
+ 'NotRequired',
+ doc="""A special typing construct to mark a key of a TypedDict as
+ potentially missing. For example:
+
+ class Movie(TypedDict):
+ title: str
+ year: NotRequired[int]
+
+ m = Movie(
+ title='The Matrix', # typechecker error if key is omitted
+ year=1999,
+ )
+ """)
+
+
+if hasattr(typing, 'ReadOnly'):
+ ReadOnly = typing.ReadOnly
+elif sys.version_info[:2] >= (3, 9): # 3.9-3.12
+ @_ExtensionsSpecialForm
+ def ReadOnly(self, parameters):
+ """A special typing construct to mark an item of a TypedDict as read-only.
+
+ For example:
+
+ class Movie(TypedDict):
+ title: ReadOnly[str]
+ year: int
+
+ def mutate_movie(m: Movie) -> None:
+ m["year"] = 1992 # allowed
+ m["title"] = "The Matrix" # typechecker error
+
+ There is no runtime checking for this property.
+ """
+ item = typing._type_check(parameters, f'{self._name} accepts only a single type.')
+ return typing._GenericAlias(self, (item,))
+
+else: # 3.8
+ class _ReadOnlyForm(_ExtensionsSpecialForm, _root=True):
+ def __getitem__(self, parameters):
+ item = typing._type_check(parameters,
+ f'{self._name} accepts only a single type.')
+ return typing._GenericAlias(self, (item,))
+
+ ReadOnly = _ReadOnlyForm(
+ 'ReadOnly',
+ doc="""A special typing construct to mark a key of a TypedDict as read-only.
+
+ For example:
+
+ class Movie(TypedDict):
+ title: ReadOnly[str]
+ year: int
+
+ def mutate_movie(m: Movie) -> None:
+ m["year"] = 1992 # allowed
+ m["title"] = "The Matrix" # typechecker error
+
+ There is no runtime checking for this propery.
+ """)
+
+
+_UNPACK_DOC = """\
+Type unpack operator.
+
+The type unpack operator takes the child types from some container type,
+such as `tuple[int, str]` or a `TypeVarTuple`, and 'pulls them out'. For
+example:
+
+ # For some generic class `Foo`:
+ Foo[Unpack[tuple[int, str]]] # Equivalent to Foo[int, str]
+
+ Ts = TypeVarTuple('Ts')
+ # Specifies that `Bar` is generic in an arbitrary number of types.
+ # (Think of `Ts` as a tuple of an arbitrary number of individual
+ # `TypeVar`s, which the `Unpack` is 'pulling out' directly into the
+ # `Generic[]`.)
+ class Bar(Generic[Unpack[Ts]]): ...
+ Bar[int] # Valid
+ Bar[int, str] # Also valid
+
+From Python 3.11, this can also be done using the `*` operator:
+
+ Foo[*tuple[int, str]]
+ class Bar(Generic[*Ts]): ...
+
+The operator can also be used along with a `TypedDict` to annotate
+`**kwargs` in a function signature. For instance:
+
+ class Movie(TypedDict):
+ name: str
+ year: int
+
+ # This function expects two keyword arguments - *name* of type `str` and
+ # *year* of type `int`.
+ def foo(**kwargs: Unpack[Movie]): ...
+
+Note that there is only some runtime checking of this operator. Not
+everything the runtime allows may be accepted by static type checkers.
+
+For more information, see PEP 646 and PEP 692.
+"""
+
+
+if sys.version_info >= (3, 12): # PEP 692 changed the repr of Unpack[]
+ Unpack = typing.Unpack
+
+ def _is_unpack(obj):
+ return get_origin(obj) is Unpack
+
+elif sys.version_info[:2] >= (3, 9): # 3.9+
+ class _UnpackSpecialForm(_ExtensionsSpecialForm, _root=True):
+ def __init__(self, getitem):
+ super().__init__(getitem)
+ self.__doc__ = _UNPACK_DOC
+
+ class _UnpackAlias(typing._GenericAlias, _root=True):
+ __class__ = typing.TypeVar
+
+ @property
+ def __typing_unpacked_tuple_args__(self):
+ assert self.__origin__ is Unpack
+ assert len(self.__args__) == 1
+ arg, = self.__args__
+ if isinstance(arg, (typing._GenericAlias, _types.GenericAlias)):
+ if arg.__origin__ is not tuple:
+ raise TypeError("Unpack[...] must be used with a tuple type")
+ return arg.__args__
+ return None
+
+ @_UnpackSpecialForm
+ def Unpack(self, parameters):
+ item = typing._type_check(parameters, f'{self._name} accepts only a single type.')
+ return _UnpackAlias(self, (item,))
+
+ def _is_unpack(obj):
+ return isinstance(obj, _UnpackAlias)
+
+else: # 3.8
+ class _UnpackAlias(typing._GenericAlias, _root=True):
+ __class__ = typing.TypeVar
+
+ class _UnpackForm(_ExtensionsSpecialForm, _root=True):
+ def __getitem__(self, parameters):
+ item = typing._type_check(parameters,
+ f'{self._name} accepts only a single type.')
+ return _UnpackAlias(self, (item,))
+
+ Unpack = _UnpackForm('Unpack', doc=_UNPACK_DOC)
+
+ def _is_unpack(obj):
+ return isinstance(obj, _UnpackAlias)
+
+
+if _PEP_696_IMPLEMENTED:
+ from typing import TypeVarTuple
+
+elif hasattr(typing, "TypeVarTuple"): # 3.11+
+
+ def _unpack_args(*args):
+ newargs = []
+ for arg in args:
+ subargs = getattr(arg, '__typing_unpacked_tuple_args__', None)
+ if subargs is not None and not (subargs and subargs[-1] is ...):
+ newargs.extend(subargs)
+ else:
+ newargs.append(arg)
+ return newargs
+
+ # Add default parameter - PEP 696
+ class TypeVarTuple(metaclass=_TypeVarLikeMeta):
+ """Type variable tuple."""
+
+ _backported_typevarlike = typing.TypeVarTuple
+
+ def __new__(cls, name, *, default=NoDefault):
+ tvt = typing.TypeVarTuple(name)
+ _set_default(tvt, default)
+ _set_module(tvt)
+
+ def _typevartuple_prepare_subst(alias, args):
+ params = alias.__parameters__
+ typevartuple_index = params.index(tvt)
+ for param in params[typevartuple_index + 1:]:
+ if isinstance(param, TypeVarTuple):
+ raise TypeError(
+ f"More than one TypeVarTuple parameter in {alias}"
+ )
+
+ alen = len(args)
+ plen = len(params)
+ left = typevartuple_index
+ right = plen - typevartuple_index - 1
+ var_tuple_index = None
+ fillarg = None
+ for k, arg in enumerate(args):
+ if not isinstance(arg, type):
+ subargs = getattr(arg, '__typing_unpacked_tuple_args__', None)
+ if subargs and len(subargs) == 2 and subargs[-1] is ...:
+ if var_tuple_index is not None:
+ raise TypeError(
+ "More than one unpacked "
+ "arbitrary-length tuple argument"
+ )
+ var_tuple_index = k
+ fillarg = subargs[0]
+ if var_tuple_index is not None:
+ left = min(left, var_tuple_index)
+ right = min(right, alen - var_tuple_index - 1)
+ elif left + right > alen:
+ raise TypeError(f"Too few arguments for {alias};"
+ f" actual {alen}, expected at least {plen - 1}")
+ if left == alen - right and tvt.has_default():
+ replacement = _unpack_args(tvt.__default__)
+ else:
+ replacement = args[left: alen - right]
+
+ return (
+ *args[:left],
+ *([fillarg] * (typevartuple_index - left)),
+ replacement,
+ *([fillarg] * (plen - right - left - typevartuple_index - 1)),
+ *args[alen - right:],
+ )
+
+ tvt.__typing_prepare_subst__ = _typevartuple_prepare_subst
+ return tvt
+
+ def __init_subclass__(self, *args, **kwds):
+ raise TypeError("Cannot subclass special typing classes")
+
+else: # <=3.10
+ class TypeVarTuple(_DefaultMixin):
+ """Type variable tuple.
+
+ Usage::
+
+ Ts = TypeVarTuple('Ts')
+
+ In the same way that a normal type variable is a stand-in for a single
+ type such as ``int``, a type variable *tuple* is a stand-in for a *tuple*
+ type such as ``Tuple[int, str]``.
+
+ Type variable tuples can be used in ``Generic`` declarations.
+ Consider the following example::
+
+ class Array(Generic[*Ts]): ...
+
+ The ``Ts`` type variable tuple here behaves like ``tuple[T1, T2]``,
+ where ``T1`` and ``T2`` are type variables. To use these type variables
+ as type parameters of ``Array``, we must *unpack* the type variable tuple using
+ the star operator: ``*Ts``. The signature of ``Array`` then behaves
+ as if we had simply written ``class Array(Generic[T1, T2]): ...``.
+ In contrast to ``Generic[T1, T2]``, however, ``Generic[*Shape]`` allows
+ us to parameterise the class with an *arbitrary* number of type parameters.
+
+ Type variable tuples can be used anywhere a normal ``TypeVar`` can.
+ This includes class definitions, as shown above, as well as function
+ signatures and variable annotations::
+
+ class Array(Generic[*Ts]):
+
+ def __init__(self, shape: Tuple[*Ts]):
+ self._shape: Tuple[*Ts] = shape
+
+ def get_shape(self) -> Tuple[*Ts]:
+ return self._shape
+
+ shape = (Height(480), Width(640))
+ x: Array[Height, Width] = Array(shape)
+ y = abs(x) # Inferred type is Array[Height, Width]
+ z = x + x # ... is Array[Height, Width]
+ x.get_shape() # ... is tuple[Height, Width]
+
+ """
+
+ # Trick Generic __parameters__.
+ __class__ = typing.TypeVar
+
+ def __iter__(self):
+ yield self.__unpacked__
+
+ def __init__(self, name, *, default=NoDefault):
+ self.__name__ = name
+ _DefaultMixin.__init__(self, default)
+
+ # for pickling:
+ def_mod = _caller()
+ if def_mod != 'typing_extensions':
+ self.__module__ = def_mod
+
+ self.__unpacked__ = Unpack[self]
+
+ def __repr__(self):
+ return self.__name__
+
+ def __hash__(self):
+ return object.__hash__(self)
+
+ def __eq__(self, other):
+ return self is other
+
+ def __reduce__(self):
+ return self.__name__
+
+ def __init_subclass__(self, *args, **kwds):
+ if '_root' not in kwds:
+ raise TypeError("Cannot subclass special typing classes")
+
+
+if hasattr(typing, "reveal_type"): # 3.11+
+ reveal_type = typing.reveal_type
+else: # <=3.10
+ def reveal_type(obj: T, /) -> T:
+ """Reveal the inferred type of a variable.
+
+ When a static type checker encounters a call to ``reveal_type()``,
+ it will emit the inferred type of the argument::
+
+ x: int = 1
+ reveal_type(x)
+
+ Running a static type checker (e.g., ``mypy``) on this example
+ will produce output similar to 'Revealed type is "builtins.int"'.
+
+ At runtime, the function prints the runtime type of the
+ argument and returns it unchanged.
+
+ """
+ print(f"Runtime type is {type(obj).__name__!r}", file=sys.stderr)
+ return obj
+
+
+if hasattr(typing, "_ASSERT_NEVER_REPR_MAX_LENGTH"): # 3.11+
+ _ASSERT_NEVER_REPR_MAX_LENGTH = typing._ASSERT_NEVER_REPR_MAX_LENGTH
+else: # <=3.10
+ _ASSERT_NEVER_REPR_MAX_LENGTH = 100
+
+
+if hasattr(typing, "assert_never"): # 3.11+
+ assert_never = typing.assert_never
+else: # <=3.10
+ def assert_never(arg: Never, /) -> Never:
+ """Assert to the type checker that a line of code is unreachable.
+
+ Example::
+
+ def int_or_str(arg: int | str) -> None:
+ match arg:
+ case int():
+ print("It's an int")
+ case str():
+ print("It's a str")
+ case _:
+ assert_never(arg)
+
+ If a type checker finds that a call to assert_never() is
+ reachable, it will emit an error.
+
+ At runtime, this throws an exception when called.
+
+ """
+ value = repr(arg)
+ if len(value) > _ASSERT_NEVER_REPR_MAX_LENGTH:
+ value = value[:_ASSERT_NEVER_REPR_MAX_LENGTH] + '...'
+ raise AssertionError(f"Expected code to be unreachable, but got: {value}")
+
+
+if sys.version_info >= (3, 12): # 3.12+
+ # dataclass_transform exists in 3.11 but lacks the frozen_default parameter
+ dataclass_transform = typing.dataclass_transform
+else: # <=3.11
+ def dataclass_transform(
+ *,
+ eq_default: bool = True,
+ order_default: bool = False,
+ kw_only_default: bool = False,
+ frozen_default: bool = False,
+ field_specifiers: typing.Tuple[
+ typing.Union[typing.Type[typing.Any], typing.Callable[..., typing.Any]],
+ ...
+ ] = (),
+ **kwargs: typing.Any,
+ ) -> typing.Callable[[T], T]:
+ """Decorator that marks a function, class, or metaclass as providing
+ dataclass-like behavior.
+
+ Example:
+
+ from pip._vendor.typing_extensions import dataclass_transform
+
+ _T = TypeVar("_T")
+
+ # Used on a decorator function
+ @dataclass_transform()
+ def create_model(cls: type[_T]) -> type[_T]:
+ ...
+ return cls
+
+ @create_model
+ class CustomerModel:
+ id: int
+ name: str
+
+ # Used on a base class
+ @dataclass_transform()
+ class ModelBase: ...
+
+ class CustomerModel(ModelBase):
+ id: int
+ name: str
+
+ # Used on a metaclass
+ @dataclass_transform()
+ class ModelMeta(type): ...
+
+ class ModelBase(metaclass=ModelMeta): ...
+
+ class CustomerModel(ModelBase):
+ id: int
+ name: str
+
+ Each of the ``CustomerModel`` classes defined in this example will now
+ behave similarly to a dataclass created with the ``@dataclasses.dataclass``
+ decorator. For example, the type checker will synthesize an ``__init__``
+ method.
+
+ The arguments to this decorator can be used to customize this behavior:
+ - ``eq_default`` indicates whether the ``eq`` parameter is assumed to be
+ True or False if it is omitted by the caller.
+ - ``order_default`` indicates whether the ``order`` parameter is
+ assumed to be True or False if it is omitted by the caller.
+ - ``kw_only_default`` indicates whether the ``kw_only`` parameter is
+ assumed to be True or False if it is omitted by the caller.
+ - ``frozen_default`` indicates whether the ``frozen`` parameter is
+ assumed to be True or False if it is omitted by the caller.
+ - ``field_specifiers`` specifies a static list of supported classes
+ or functions that describe fields, similar to ``dataclasses.field()``.
+
+ At runtime, this decorator records its arguments in the
+ ``__dataclass_transform__`` attribute on the decorated object.
+
+ See PEP 681 for details.
+
+ """
+ def decorator(cls_or_fn):
+ cls_or_fn.__dataclass_transform__ = {
+ "eq_default": eq_default,
+ "order_default": order_default,
+ "kw_only_default": kw_only_default,
+ "frozen_default": frozen_default,
+ "field_specifiers": field_specifiers,
+ "kwargs": kwargs,
+ }
+ return cls_or_fn
+ return decorator
+
+
+if hasattr(typing, "override"): # 3.12+
+ override = typing.override
+else: # <=3.11
+ _F = typing.TypeVar("_F", bound=typing.Callable[..., typing.Any])
+
+ def override(arg: _F, /) -> _F:
+ """Indicate that a method is intended to override a method in a base class.
+
+ Usage:
+
+ class Base:
+ def method(self) -> None:
+ pass
+
+ class Child(Base):
+ @override
+ def method(self) -> None:
+ super().method()
+
+ When this decorator is applied to a method, the type checker will
+ validate that it overrides a method with the same name on a base class.
+ This helps prevent bugs that may occur when a base class is changed
+ without an equivalent change to a child class.
+
+ There is no runtime checking of these properties. The decorator
+ sets the ``__override__`` attribute to ``True`` on the decorated object
+ to allow runtime introspection.
+
+ See PEP 698 for details.
+
+ """
+ try:
+ arg.__override__ = True
+ except (AttributeError, TypeError):
+ # Skip the attribute silently if it is not writable.
+ # AttributeError happens if the object has __slots__ or a
+ # read-only property, TypeError if it's a builtin class.
+ pass
+ return arg
+
+
+if hasattr(warnings, "deprecated"):
+ deprecated = warnings.deprecated
+else:
+ _T = typing.TypeVar("_T")
+
+ class deprecated:
+ """Indicate that a class, function or overload is deprecated.
+
+ When this decorator is applied to an object, the type checker
+ will generate a diagnostic on usage of the deprecated object.
+
+ Usage:
+
+ @deprecated("Use B instead")
+ class A:
+ pass
+
+ @deprecated("Use g instead")
+ def f():
+ pass
+
+ @overload
+ @deprecated("int support is deprecated")
+ def g(x: int) -> int: ...
+ @overload
+ def g(x: str) -> int: ...
+
+ The warning specified by *category* will be emitted at runtime
+ on use of deprecated objects. For functions, that happens on calls;
+ for classes, on instantiation and on creation of subclasses.
+ If the *category* is ``None``, no warning is emitted at runtime.
+ The *stacklevel* determines where the
+ warning is emitted. If it is ``1`` (the default), the warning
+ is emitted at the direct caller of the deprecated object; if it
+ is higher, it is emitted further up the stack.
+ Static type checker behavior is not affected by the *category*
+ and *stacklevel* arguments.
+
+ The deprecation message passed to the decorator is saved in the
+ ``__deprecated__`` attribute on the decorated object.
+ If applied to an overload, the decorator
+ must be after the ``@overload`` decorator for the attribute to
+ exist on the overload as returned by ``get_overloads()``.
+
+ See PEP 702 for details.
+
+ """
+ def __init__(
+ self,
+ message: str,
+ /,
+ *,
+ category: typing.Optional[typing.Type[Warning]] = DeprecationWarning,
+ stacklevel: int = 1,
+ ) -> None:
+ if not isinstance(message, str):
+ raise TypeError(
+ "Expected an object of type str for 'message', not "
+ f"{type(message).__name__!r}"
+ )
+ self.message = message
+ self.category = category
+ self.stacklevel = stacklevel
+
+ def __call__(self, arg: _T, /) -> _T:
+ # Make sure the inner functions created below don't
+ # retain a reference to self.
+ msg = self.message
+ category = self.category
+ stacklevel = self.stacklevel
+ if category is None:
+ arg.__deprecated__ = msg
+ return arg
+ elif isinstance(arg, type):
+ import functools
+ from types import MethodType
+
+ original_new = arg.__new__
+
+ @functools.wraps(original_new)
+ def __new__(cls, *args, **kwargs):
+ if cls is arg:
+ warnings.warn(msg, category=category, stacklevel=stacklevel + 1)
+ if original_new is not object.__new__:
+ return original_new(cls, *args, **kwargs)
+ # Mirrors a similar check in object.__new__.
+ elif cls.__init__ is object.__init__ and (args or kwargs):
+ raise TypeError(f"{cls.__name__}() takes no arguments")
+ else:
+ return original_new(cls)
+
+ arg.__new__ = staticmethod(__new__)
+
+ original_init_subclass = arg.__init_subclass__
+ # We need slightly different behavior if __init_subclass__
+ # is a bound method (likely if it was implemented in Python)
+ if isinstance(original_init_subclass, MethodType):
+ original_init_subclass = original_init_subclass.__func__
+
+ @functools.wraps(original_init_subclass)
+ def __init_subclass__(*args, **kwargs):
+ warnings.warn(msg, category=category, stacklevel=stacklevel + 1)
+ return original_init_subclass(*args, **kwargs)
+
+ arg.__init_subclass__ = classmethod(__init_subclass__)
+ # Or otherwise, which likely means it's a builtin such as
+ # object's implementation of __init_subclass__.
+ else:
+ @functools.wraps(original_init_subclass)
+ def __init_subclass__(*args, **kwargs):
+ warnings.warn(msg, category=category, stacklevel=stacklevel + 1)
+ return original_init_subclass(*args, **kwargs)
+
+ arg.__init_subclass__ = __init_subclass__
+
+ arg.__deprecated__ = __new__.__deprecated__ = msg
+ __init_subclass__.__deprecated__ = msg
+ return arg
+ elif callable(arg):
+ import functools
+
+ @functools.wraps(arg)
+ def wrapper(*args, **kwargs):
+ warnings.warn(msg, category=category, stacklevel=stacklevel + 1)
+ return arg(*args, **kwargs)
+
+ arg.__deprecated__ = wrapper.__deprecated__ = msg
+ return wrapper
+ else:
+ raise TypeError(
+ "@deprecated decorator with non-None category must be applied to "
+ f"a class or callable, not {arg!r}"
+ )
+
+
+# We have to do some monkey patching to deal with the dual nature of
+# Unpack/TypeVarTuple:
+# - We want Unpack to be a kind of TypeVar so it gets accepted in
+# Generic[Unpack[Ts]]
+# - We want it to *not* be treated as a TypeVar for the purposes of
+# counting generic parameters, so that when we subscript a generic,
+# the runtime doesn't try to substitute the Unpack with the subscripted type.
+if not hasattr(typing, "TypeVarTuple"):
+ def _check_generic(cls, parameters, elen=_marker):
+ """Check correct count for parameters of a generic cls (internal helper).
+
+ This gives a nice error message in case of count mismatch.
+ """
+ if not elen:
+ raise TypeError(f"{cls} is not a generic class")
+ if elen is _marker:
+ if not hasattr(cls, "__parameters__") or not cls.__parameters__:
+ raise TypeError(f"{cls} is not a generic class")
+ elen = len(cls.__parameters__)
+ alen = len(parameters)
+ if alen != elen:
+ expect_val = elen
+ if hasattr(cls, "__parameters__"):
+ parameters = [p for p in cls.__parameters__ if not _is_unpack(p)]
+ num_tv_tuples = sum(isinstance(p, TypeVarTuple) for p in parameters)
+ if (num_tv_tuples > 0) and (alen >= elen - num_tv_tuples):
+ return
+
+ # deal with TypeVarLike defaults
+ # required TypeVarLikes cannot appear after a defaulted one.
+ if alen < elen:
+ # since we validate TypeVarLike default in _collect_type_vars
+ # or _collect_parameters we can safely check parameters[alen]
+ if (
+ getattr(parameters[alen], '__default__', NoDefault)
+ is not NoDefault
+ ):
+ return
+
+ num_default_tv = sum(getattr(p, '__default__', NoDefault)
+ is not NoDefault for p in parameters)
+
+ elen -= num_default_tv
+
+ expect_val = f"at least {elen}"
+
+ things = "arguments" if sys.version_info >= (3, 10) else "parameters"
+ raise TypeError(f"Too {'many' if alen > elen else 'few'} {things}"
+ f" for {cls}; actual {alen}, expected {expect_val}")
+else:
+ # Python 3.11+
+
+ def _check_generic(cls, parameters, elen):
+ """Check correct count for parameters of a generic cls (internal helper).
+
+ This gives a nice error message in case of count mismatch.
+ """
+ if not elen:
+ raise TypeError(f"{cls} is not a generic class")
+ alen = len(parameters)
+ if alen != elen:
+ expect_val = elen
+ if hasattr(cls, "__parameters__"):
+ parameters = [p for p in cls.__parameters__ if not _is_unpack(p)]
+
+ # deal with TypeVarLike defaults
+ # required TypeVarLikes cannot appear after a defaulted one.
+ if alen < elen:
+ # since we validate TypeVarLike default in _collect_type_vars
+ # or _collect_parameters we can safely check parameters[alen]
+ if (
+ getattr(parameters[alen], '__default__', NoDefault)
+ is not NoDefault
+ ):
+ return
+
+ num_default_tv = sum(getattr(p, '__default__', NoDefault)
+ is not NoDefault for p in parameters)
+
+ elen -= num_default_tv
+
+ expect_val = f"at least {elen}"
+
+ raise TypeError(f"Too {'many' if alen > elen else 'few'} arguments"
+ f" for {cls}; actual {alen}, expected {expect_val}")
+
+if not _PEP_696_IMPLEMENTED:
+ typing._check_generic = _check_generic
+
+
+def _has_generic_or_protocol_as_origin() -> bool:
+ try:
+ frame = sys._getframe(2)
+ # - Catch AttributeError: not all Python implementations have sys._getframe()
+ # - Catch ValueError: maybe we're called from an unexpected module
+ # and the call stack isn't deep enough
+ except (AttributeError, ValueError):
+ return False # err on the side of leniency
+ else:
+ # If we somehow get invoked from outside typing.py,
+ # also err on the side of leniency
+ if frame.f_globals.get("__name__") != "typing":
+ return False
+ origin = frame.f_locals.get("origin")
+ # Cannot use "in" because origin may be an object with a buggy __eq__ that
+ # throws an error.
+ return origin is typing.Generic or origin is Protocol or origin is typing.Protocol
+
+
+_TYPEVARTUPLE_TYPES = {TypeVarTuple, getattr(typing, "TypeVarTuple", None)}
+
+
+def _is_unpacked_typevartuple(x) -> bool:
+ if get_origin(x) is not Unpack:
+ return False
+ args = get_args(x)
+ return (
+ bool(args)
+ and len(args) == 1
+ and type(args[0]) in _TYPEVARTUPLE_TYPES
+ )
+
+
+# Python 3.11+ _collect_type_vars was renamed to _collect_parameters
+if hasattr(typing, '_collect_type_vars'):
+ def _collect_type_vars(types, typevar_types=None):
+ """Collect all type variable contained in types in order of
+ first appearance (lexicographic order). For example::
+
+ _collect_type_vars((T, List[S, T])) == (T, S)
+ """
+ if typevar_types is None:
+ typevar_types = typing.TypeVar
+ tvars = []
+
+ # A required TypeVarLike cannot appear after a TypeVarLike with a default
+ # if it was a direct call to `Generic[]` or `Protocol[]`
+ enforce_default_ordering = _has_generic_or_protocol_as_origin()
+ default_encountered = False
+
+ # Also, a TypeVarLike with a default cannot appear after a TypeVarTuple
+ type_var_tuple_encountered = False
+
+ for t in types:
+ if _is_unpacked_typevartuple(t):
+ type_var_tuple_encountered = True
+ elif isinstance(t, typevar_types) and t not in tvars:
+ if enforce_default_ordering:
+ has_default = getattr(t, '__default__', NoDefault) is not NoDefault
+ if has_default:
+ if type_var_tuple_encountered:
+ raise TypeError('Type parameter with a default'
+ ' follows TypeVarTuple')
+ default_encountered = True
+ elif default_encountered:
+ raise TypeError(f'Type parameter {t!r} without a default'
+ ' follows type parameter with a default')
+
+ tvars.append(t)
+ if _should_collect_from_parameters(t):
+ tvars.extend([t for t in t.__parameters__ if t not in tvars])
+ return tuple(tvars)
+
+ typing._collect_type_vars = _collect_type_vars
+else:
+ def _collect_parameters(args):
+ """Collect all type variables and parameter specifications in args
+ in order of first appearance (lexicographic order).
+
+ For example::
+
+ assert _collect_parameters((T, Callable[P, T])) == (T, P)
+ """
+ parameters = []
+
+ # A required TypeVarLike cannot appear after a TypeVarLike with default
+ # if it was a direct call to `Generic[]` or `Protocol[]`
+ enforce_default_ordering = _has_generic_or_protocol_as_origin()
+ default_encountered = False
+
+ # Also, a TypeVarLike with a default cannot appear after a TypeVarTuple
+ type_var_tuple_encountered = False
+
+ for t in args:
+ if isinstance(t, type):
+ # We don't want __parameters__ descriptor of a bare Python class.
+ pass
+ elif isinstance(t, tuple):
+ # `t` might be a tuple, when `ParamSpec` is substituted with
+ # `[T, int]`, or `[int, *Ts]`, etc.
+ for x in t:
+ for collected in _collect_parameters([x]):
+ if collected not in parameters:
+ parameters.append(collected)
+ elif hasattr(t, '__typing_subst__'):
+ if t not in parameters:
+ if enforce_default_ordering:
+ has_default = (
+ getattr(t, '__default__', NoDefault) is not NoDefault
+ )
+
+ if type_var_tuple_encountered and has_default:
+ raise TypeError('Type parameter with a default'
+ ' follows TypeVarTuple')
+
+ if has_default:
+ default_encountered = True
+ elif default_encountered:
+ raise TypeError(f'Type parameter {t!r} without a default'
+ ' follows type parameter with a default')
+
+ parameters.append(t)
+ else:
+ if _is_unpacked_typevartuple(t):
+ type_var_tuple_encountered = True
+ for x in getattr(t, '__parameters__', ()):
+ if x not in parameters:
+ parameters.append(x)
+
+ return tuple(parameters)
+
+ if not _PEP_696_IMPLEMENTED:
+ typing._collect_parameters = _collect_parameters
+
+# Backport typing.NamedTuple as it exists in Python 3.13.
+# In 3.11, the ability to define generic `NamedTuple`s was supported.
+# This was explicitly disallowed in 3.9-3.10, and only half-worked in <=3.8.
+# On 3.12, we added __orig_bases__ to call-based NamedTuples
+# On 3.13, we deprecated kwargs-based NamedTuples
+if sys.version_info >= (3, 13):
+ NamedTuple = typing.NamedTuple
+else:
+ def _make_nmtuple(name, types, module, defaults=()):
+ fields = [n for n, t in types]
+ annotations = {n: typing._type_check(t, f"field {n} annotation must be a type")
+ for n, t in types}
+ nm_tpl = collections.namedtuple(name, fields,
+ defaults=defaults, module=module)
+ nm_tpl.__annotations__ = nm_tpl.__new__.__annotations__ = annotations
+ # The `_field_types` attribute was removed in 3.9;
+ # in earlier versions, it is the same as the `__annotations__` attribute
+ if sys.version_info < (3, 9):
+ nm_tpl._field_types = annotations
+ return nm_tpl
+
+ _prohibited_namedtuple_fields = typing._prohibited
+ _special_namedtuple_fields = frozenset({'__module__', '__name__', '__annotations__'})
+
+ class _NamedTupleMeta(type):
+ def __new__(cls, typename, bases, ns):
+ assert _NamedTuple in bases
+ for base in bases:
+ if base is not _NamedTuple and base is not typing.Generic:
+ raise TypeError(
+ 'can only inherit from a NamedTuple type and Generic')
+ bases = tuple(tuple if base is _NamedTuple else base for base in bases)
+ if "__annotations__" in ns:
+ types = ns["__annotations__"]
+ elif "__annotate__" in ns:
+ # TODO: Use inspect.VALUE here, and make the annotations lazily evaluated
+ types = ns["__annotate__"](1)
+ else:
+ types = {}
+ default_names = []
+ for field_name in types:
+ if field_name in ns:
+ default_names.append(field_name)
+ elif default_names:
+ raise TypeError(f"Non-default namedtuple field {field_name} "
+ f"cannot follow default field"
+ f"{'s' if len(default_names) > 1 else ''} "
+ f"{', '.join(default_names)}")
+ nm_tpl = _make_nmtuple(
+ typename, types.items(),
+ defaults=[ns[n] for n in default_names],
+ module=ns['__module__']
+ )
+ nm_tpl.__bases__ = bases
+ if typing.Generic in bases:
+ if hasattr(typing, '_generic_class_getitem'): # 3.12+
+ nm_tpl.__class_getitem__ = classmethod(typing._generic_class_getitem)
+ else:
+ class_getitem = typing.Generic.__class_getitem__.__func__
+ nm_tpl.__class_getitem__ = classmethod(class_getitem)
+ # update from user namespace without overriding special namedtuple attributes
+ for key, val in ns.items():
+ if key in _prohibited_namedtuple_fields:
+ raise AttributeError("Cannot overwrite NamedTuple attribute " + key)
+ elif key not in _special_namedtuple_fields:
+ if key not in nm_tpl._fields:
+ setattr(nm_tpl, key, ns[key])
+ try:
+ set_name = type(val).__set_name__
+ except AttributeError:
+ pass
+ else:
+ try:
+ set_name(val, nm_tpl, key)
+ except BaseException as e:
+ msg = (
+ f"Error calling __set_name__ on {type(val).__name__!r} "
+ f"instance {key!r} in {typename!r}"
+ )
+ # BaseException.add_note() existed on py311,
+ # but the __set_name__ machinery didn't start
+ # using add_note() until py312.
+ # Making sure exceptions are raised in the same way
+ # as in "normal" classes seems most important here.
+ if sys.version_info >= (3, 12):
+ e.add_note(msg)
+ raise
+ else:
+ raise RuntimeError(msg) from e
+
+ if typing.Generic in bases:
+ nm_tpl.__init_subclass__()
+ return nm_tpl
+
+ _NamedTuple = type.__new__(_NamedTupleMeta, 'NamedTuple', (), {})
+
+ def _namedtuple_mro_entries(bases):
+ assert NamedTuple in bases
+ return (_NamedTuple,)
+
+ @_ensure_subclassable(_namedtuple_mro_entries)
+ def NamedTuple(typename, fields=_marker, /, **kwargs):
+ """Typed version of namedtuple.
+
+ Usage::
+
+ class Employee(NamedTuple):
+ name: str
+ id: int
+
+ This is equivalent to::
+
+ Employee = collections.namedtuple('Employee', ['name', 'id'])
+
+ The resulting class has an extra __annotations__ attribute, giving a
+ dict that maps field names to types. (The field names are also in
+ the _fields attribute, which is part of the namedtuple API.)
+ An alternative equivalent functional syntax is also accepted::
+
+ Employee = NamedTuple('Employee', [('name', str), ('id', int)])
+ """
+ if fields is _marker:
+ if kwargs:
+ deprecated_thing = "Creating NamedTuple classes using keyword arguments"
+ deprecation_msg = (
+ "{name} is deprecated and will be disallowed in Python {remove}. "
+ "Use the class-based or functional syntax instead."
+ )
+ else:
+ deprecated_thing = "Failing to pass a value for the 'fields' parameter"
+ example = f"`{typename} = NamedTuple({typename!r}, [])`"
+ deprecation_msg = (
+ "{name} is deprecated and will be disallowed in Python {remove}. "
+ "To create a NamedTuple class with 0 fields "
+ "using the functional syntax, "
+ "pass an empty list, e.g. "
+ ) + example + "."
+ elif fields is None:
+ if kwargs:
+ raise TypeError(
+ "Cannot pass `None` as the 'fields' parameter "
+ "and also specify fields using keyword arguments"
+ )
+ else:
+ deprecated_thing = "Passing `None` as the 'fields' parameter"
+ example = f"`{typename} = NamedTuple({typename!r}, [])`"
+ deprecation_msg = (
+ "{name} is deprecated and will be disallowed in Python {remove}. "
+ "To create a NamedTuple class with 0 fields "
+ "using the functional syntax, "
+ "pass an empty list, e.g. "
+ ) + example + "."
+ elif kwargs:
+ raise TypeError("Either list of fields or keywords"
+ " can be provided to NamedTuple, not both")
+ if fields is _marker or fields is None:
+ warnings.warn(
+ deprecation_msg.format(name=deprecated_thing, remove="3.15"),
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ fields = kwargs.items()
+ nt = _make_nmtuple(typename, fields, module=_caller())
+ nt.__orig_bases__ = (NamedTuple,)
+ return nt
+
+
+if hasattr(collections.abc, "Buffer"):
+ Buffer = collections.abc.Buffer
+else:
+ class Buffer(abc.ABC): # noqa: B024
+ """Base class for classes that implement the buffer protocol.
+
+ The buffer protocol allows Python objects to expose a low-level
+ memory buffer interface. Before Python 3.12, it is not possible
+ to implement the buffer protocol in pure Python code, or even
+ to check whether a class implements the buffer protocol. In
+ Python 3.12 and higher, the ``__buffer__`` method allows access
+ to the buffer protocol from Python code, and the
+ ``collections.abc.Buffer`` ABC allows checking whether a class
+ implements the buffer protocol.
+
+ To indicate support for the buffer protocol in earlier versions,
+ inherit from this ABC, either in a stub file or at runtime,
+ or use ABC registration. This ABC provides no methods, because
+ there is no Python-accessible methods shared by pre-3.12 buffer
+ classes. It is useful primarily for static checks.
+
+ """
+
+ # As a courtesy, register the most common stdlib buffer classes.
+ Buffer.register(memoryview)
+ Buffer.register(bytearray)
+ Buffer.register(bytes)
+
+
+# Backport of types.get_original_bases, available on 3.12+ in CPython
+if hasattr(_types, "get_original_bases"):
+ get_original_bases = _types.get_original_bases
+else:
+ def get_original_bases(cls, /):
+ """Return the class's "original" bases prior to modification by `__mro_entries__`.
+
+ Examples::
+
+ from typing import TypeVar, Generic
+ from pip._vendor.typing_extensions import NamedTuple, TypedDict
+
+ T = TypeVar("T")
+ class Foo(Generic[T]): ...
+ class Bar(Foo[int], float): ...
+ class Baz(list[str]): ...
+ Eggs = NamedTuple("Eggs", [("a", int), ("b", str)])
+ Spam = TypedDict("Spam", {"a": int, "b": str})
+
+ assert get_original_bases(Bar) == (Foo[int], float)
+ assert get_original_bases(Baz) == (list[str],)
+ assert get_original_bases(Eggs) == (NamedTuple,)
+ assert get_original_bases(Spam) == (TypedDict,)
+ assert get_original_bases(int) == (object,)
+ """
+ try:
+ return cls.__dict__.get("__orig_bases__", cls.__bases__)
+ except AttributeError:
+ raise TypeError(
+ f'Expected an instance of type, not {type(cls).__name__!r}'
+ ) from None
+
+
+# NewType is a class on Python 3.10+, making it pickleable
+# The error message for subclassing instances of NewType was improved on 3.11+
+if sys.version_info >= (3, 11):
+ NewType = typing.NewType
+else:
+ class NewType:
+ """NewType creates simple unique types with almost zero
+ runtime overhead. NewType(name, tp) is considered a subtype of tp
+ by static type checkers. At runtime, NewType(name, tp) returns
+ a dummy callable that simply returns its argument. Usage::
+ UserId = NewType('UserId', int)
+ def name_by_id(user_id: UserId) -> str:
+ ...
+ UserId('user') # Fails type check
+ name_by_id(42) # Fails type check
+ name_by_id(UserId(42)) # OK
+ num = UserId(5) + 1 # type: int
+ """
+
+ def __call__(self, obj, /):
+ return obj
+
+ def __init__(self, name, tp):
+ self.__qualname__ = name
+ if '.' in name:
+ name = name.rpartition('.')[-1]
+ self.__name__ = name
+ self.__supertype__ = tp
+ def_mod = _caller()
+ if def_mod != 'typing_extensions':
+ self.__module__ = def_mod
+
+ def __mro_entries__(self, bases):
+ # We defined __mro_entries__ to get a better error message
+ # if a user attempts to subclass a NewType instance. bpo-46170
+ supercls_name = self.__name__
+
+ class Dummy:
+ def __init_subclass__(cls):
+ subcls_name = cls.__name__
+ raise TypeError(
+ f"Cannot subclass an instance of NewType. "
+ f"Perhaps you were looking for: "
+ f"`{subcls_name} = NewType({subcls_name!r}, {supercls_name})`"
+ )
+
+ return (Dummy,)
+
+ def __repr__(self):
+ return f'{self.__module__}.{self.__qualname__}'
+
+ def __reduce__(self):
+ return self.__qualname__
+
+ if sys.version_info >= (3, 10):
+ # PEP 604 methods
+ # It doesn't make sense to have these methods on Python <3.10
+
+ def __or__(self, other):
+ return typing.Union[self, other]
+
+ def __ror__(self, other):
+ return typing.Union[other, self]
+
+
+if hasattr(typing, "TypeAliasType"):
+ TypeAliasType = typing.TypeAliasType
+else:
+ def _is_unionable(obj):
+ """Corresponds to is_unionable() in unionobject.c in CPython."""
+ return obj is None or isinstance(obj, (
+ type,
+ _types.GenericAlias,
+ _types.UnionType,
+ TypeAliasType,
+ ))
+
+ class TypeAliasType:
+ """Create named, parameterized type aliases.
+
+ This provides a backport of the new `type` statement in Python 3.12:
+
+ type ListOrSet[T] = list[T] | set[T]
+
+ is equivalent to:
+
+ T = TypeVar("T")
+ ListOrSet = TypeAliasType("ListOrSet", list[T] | set[T], type_params=(T,))
+
+ The name ListOrSet can then be used as an alias for the type it refers to.
+
+ The type_params argument should contain all the type parameters used
+ in the value of the type alias. If the alias is not generic, this
+ argument is omitted.
+
+ Static type checkers should only support type aliases declared using
+ TypeAliasType that follow these rules:
+
+ - The first argument (the name) must be a string literal.
+ - The TypeAliasType instance must be immediately assigned to a variable
+ of the same name. (For example, 'X = TypeAliasType("Y", int)' is invalid,
+ as is 'X, Y = TypeAliasType("X", int), TypeAliasType("Y", int)').
+
+ """
+
+ def __init__(self, name: str, value, *, type_params=()):
+ if not isinstance(name, str):
+ raise TypeError("TypeAliasType name must be a string")
+ self.__value__ = value
+ self.__type_params__ = type_params
+
+ parameters = []
+ for type_param in type_params:
+ if isinstance(type_param, TypeVarTuple):
+ parameters.extend(type_param)
+ else:
+ parameters.append(type_param)
+ self.__parameters__ = tuple(parameters)
+ def_mod = _caller()
+ if def_mod != 'typing_extensions':
+ self.__module__ = def_mod
+ # Setting this attribute closes the TypeAliasType from further modification
+ self.__name__ = name
+
+ def __setattr__(self, name: str, value: object, /) -> None:
+ if hasattr(self, "__name__"):
+ self._raise_attribute_error(name)
+ super().__setattr__(name, value)
+
+ def __delattr__(self, name: str, /) -> Never:
+ self._raise_attribute_error(name)
+
+ def _raise_attribute_error(self, name: str) -> Never:
+ # Match the Python 3.12 error messages exactly
+ if name == "__name__":
+ raise AttributeError("readonly attribute")
+ elif name in {"__value__", "__type_params__", "__parameters__", "__module__"}:
+ raise AttributeError(
+ f"attribute '{name}' of 'typing.TypeAliasType' objects "
+ "is not writable"
+ )
+ else:
+ raise AttributeError(
+ f"'typing.TypeAliasType' object has no attribute '{name}'"
+ )
+
+ def __repr__(self) -> str:
+ return self.__name__
+
+ def __getitem__(self, parameters):
+ if not isinstance(parameters, tuple):
+ parameters = (parameters,)
+ parameters = [
+ typing._type_check(
+ item, f'Subscripting {self.__name__} requires a type.'
+ )
+ for item in parameters
+ ]
+ return typing._GenericAlias(self, tuple(parameters))
+
+ def __reduce__(self):
+ return self.__name__
+
+ def __init_subclass__(cls, *args, **kwargs):
+ raise TypeError(
+ "type 'typing_extensions.TypeAliasType' is not an acceptable base type"
+ )
+
+ # The presence of this method convinces typing._type_check
+ # that TypeAliasTypes are types.
+ def __call__(self):
+ raise TypeError("Type alias is not callable")
+
+ if sys.version_info >= (3, 10):
+ def __or__(self, right):
+ # For forward compatibility with 3.12, reject Unions
+ # that are not accepted by the built-in Union.
+ if not _is_unionable(right):
+ return NotImplemented
+ return typing.Union[self, right]
+
+ def __ror__(self, left):
+ if not _is_unionable(left):
+ return NotImplemented
+ return typing.Union[left, self]
+
+
+if hasattr(typing, "is_protocol"):
+ is_protocol = typing.is_protocol
+ get_protocol_members = typing.get_protocol_members
+else:
+ def is_protocol(tp: type, /) -> bool:
+ """Return True if the given type is a Protocol.
+
+ Example::
+
+ >>> from typing_extensions import Protocol, is_protocol
+ >>> class P(Protocol):
+ ... def a(self) -> str: ...
+ ... b: int
+ >>> is_protocol(P)
+ True
+ >>> is_protocol(int)
+ False
+ """
+ return (
+ isinstance(tp, type)
+ and getattr(tp, '_is_protocol', False)
+ and tp is not Protocol
+ and tp is not typing.Protocol
+ )
+
+ def get_protocol_members(tp: type, /) -> typing.FrozenSet[str]:
+ """Return the set of members defined in a Protocol.
+
+ Example::
+
+ >>> from typing_extensions import Protocol, get_protocol_members
+ >>> class P(Protocol):
+ ... def a(self) -> str: ...
+ ... b: int
+ >>> get_protocol_members(P)
+ frozenset({'a', 'b'})
+
+ Raise a TypeError for arguments that are not Protocols.
+ """
+ if not is_protocol(tp):
+ raise TypeError(f'{tp!r} is not a Protocol')
+ if hasattr(tp, '__protocol_attrs__'):
+ return frozenset(tp.__protocol_attrs__)
+ return frozenset(_get_protocol_attrs(tp))
+
+
+if hasattr(typing, "Doc"):
+ Doc = typing.Doc
+else:
+ class Doc:
+ """Define the documentation of a type annotation using ``Annotated``, to be
+ used in class attributes, function and method parameters, return values,
+ and variables.
+
+ The value should be a positional-only string literal to allow static tools
+ like editors and documentation generators to use it.
+
+ This complements docstrings.
+
+ The string value passed is available in the attribute ``documentation``.
+
+ Example::
+
+ >>> from typing_extensions import Annotated, Doc
+ >>> def hi(to: Annotated[str, Doc("Who to say hi to")]) -> None: ...
+ """
+ def __init__(self, documentation: str, /) -> None:
+ self.documentation = documentation
+
+ def __repr__(self) -> str:
+ return f"Doc({self.documentation!r})"
+
+ def __hash__(self) -> int:
+ return hash(self.documentation)
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, Doc):
+ return NotImplemented
+ return self.documentation == other.documentation
+
+
+_CapsuleType = getattr(_types, "CapsuleType", None)
+
+if _CapsuleType is None:
+ try:
+ import _socket
+ except ImportError:
+ pass
+ else:
+ _CAPI = getattr(_socket, "CAPI", None)
+ if _CAPI is not None:
+ _CapsuleType = type(_CAPI)
+
+if _CapsuleType is not None:
+ CapsuleType = _CapsuleType
+ __all__.append("CapsuleType")
+
+
+# Aliases for items that have always been in typing.
+# Explicitly assign these (rather than using `from typing import *` at the top),
+# so that we get a CI error if one of these is deleted from typing.py
+# in a future version of Python
+AbstractSet = typing.AbstractSet
+AnyStr = typing.AnyStr
+BinaryIO = typing.BinaryIO
+Callable = typing.Callable
+Collection = typing.Collection
+Container = typing.Container
+Dict = typing.Dict
+ForwardRef = typing.ForwardRef
+FrozenSet = typing.FrozenSet
+Generic = typing.Generic
+Hashable = typing.Hashable
+IO = typing.IO
+ItemsView = typing.ItemsView
+Iterable = typing.Iterable
+Iterator = typing.Iterator
+KeysView = typing.KeysView
+List = typing.List
+Mapping = typing.Mapping
+MappingView = typing.MappingView
+Match = typing.Match
+MutableMapping = typing.MutableMapping
+MutableSequence = typing.MutableSequence
+MutableSet = typing.MutableSet
+Optional = typing.Optional
+Pattern = typing.Pattern
+Reversible = typing.Reversible
+Sequence = typing.Sequence
+Set = typing.Set
+Sized = typing.Sized
+TextIO = typing.TextIO
+Tuple = typing.Tuple
+Union = typing.Union
+ValuesView = typing.ValuesView
+cast = typing.cast
+no_type_check = typing.no_type_check
+no_type_check_decorator = typing.no_type_check_decorator
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/__init__.py
new file mode 100644
index 000000000..c6fa38212
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/__init__.py
@@ -0,0 +1,102 @@
+"""
+Python HTTP library with thread-safe connection pooling, file post support, user friendly, and more
+"""
+from __future__ import absolute_import
+
+# Set default logging handler to avoid "No handler found" warnings.
+import logging
+import warnings
+from logging import NullHandler
+
+from . import exceptions
+from ._version import __version__
+from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, connection_from_url
+from .filepost import encode_multipart_formdata
+from .poolmanager import PoolManager, ProxyManager, proxy_from_url
+from .response import HTTPResponse
+from .util.request import make_headers
+from .util.retry import Retry
+from .util.timeout import Timeout
+from .util.url import get_host
+
+# === NOTE TO REPACKAGERS AND VENDORS ===
+# Please delete this block, this logic is only
+# for urllib3 being distributed via PyPI.
+# See: https://github.com/urllib3/urllib3/issues/2680
+try:
+ import urllib3_secure_extra # type: ignore # noqa: F401
+except ImportError:
+ pass
+else:
+ warnings.warn(
+ "'urllib3[secure]' extra is deprecated and will be removed "
+ "in a future release of urllib3 2.x. Read more in this issue: "
+ "https://github.com/urllib3/urllib3/issues/2680",
+ category=DeprecationWarning,
+ stacklevel=2,
+ )
+
+__author__ = "Andrey Petrov (andrey.petrov@shazow.net)"
+__license__ = "MIT"
+__version__ = __version__
+
+__all__ = (
+ "HTTPConnectionPool",
+ "HTTPSConnectionPool",
+ "PoolManager",
+ "ProxyManager",
+ "HTTPResponse",
+ "Retry",
+ "Timeout",
+ "add_stderr_logger",
+ "connection_from_url",
+ "disable_warnings",
+ "encode_multipart_formdata",
+ "get_host",
+ "make_headers",
+ "proxy_from_url",
+)
+
+logging.getLogger(__name__).addHandler(NullHandler())
+
+
+def add_stderr_logger(level=logging.DEBUG):
+ """
+ Helper for quickly adding a StreamHandler to the logger. Useful for
+ debugging.
+
+ Returns the handler after adding it.
+ """
+ # This method needs to be in this __init__.py to get the __name__ correct
+ # even if urllib3 is vendored within another package.
+ logger = logging.getLogger(__name__)
+ handler = logging.StreamHandler()
+ handler.setFormatter(logging.Formatter("%(asctime)s %(levelname)s %(message)s"))
+ logger.addHandler(handler)
+ logger.setLevel(level)
+ logger.debug("Added a stderr logging handler to logger: %s", __name__)
+ return handler
+
+
+# ... Clean up.
+del NullHandler
+
+
+# All warning filters *must* be appended unless you're really certain that they
+# shouldn't be: otherwise, it's very hard for users to use most Python
+# mechanisms to silence them.
+# SecurityWarning's always go off by default.
+warnings.simplefilter("always", exceptions.SecurityWarning, append=True)
+# SubjectAltNameWarning's should go off once per host
+warnings.simplefilter("default", exceptions.SubjectAltNameWarning, append=True)
+# InsecurePlatformWarning's don't vary between requests, so we keep it default.
+warnings.simplefilter("default", exceptions.InsecurePlatformWarning, append=True)
+# SNIMissingWarnings should go off only once.
+warnings.simplefilter("default", exceptions.SNIMissingWarning, append=True)
+
+
+def disable_warnings(category=exceptions.HTTPWarning):
+ """
+ Helper for quickly disabling all urllib3 warnings.
+ """
+ warnings.simplefilter("ignore", category)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/_collections.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/_collections.py
new file mode 100644
index 000000000..bceb8451f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/_collections.py
@@ -0,0 +1,355 @@
+from __future__ import absolute_import
+
+try:
+ from collections.abc import Mapping, MutableMapping
+except ImportError:
+ from collections import Mapping, MutableMapping
+try:
+ from threading import RLock
+except ImportError: # Platform-specific: No threads available
+
+ class RLock:
+ def __enter__(self):
+ pass
+
+ def __exit__(self, exc_type, exc_value, traceback):
+ pass
+
+
+from collections import OrderedDict
+
+from .exceptions import InvalidHeader
+from .packages import six
+from .packages.six import iterkeys, itervalues
+
+__all__ = ["RecentlyUsedContainer", "HTTPHeaderDict"]
+
+
+_Null = object()
+
+
+class RecentlyUsedContainer(MutableMapping):
+ """
+ Provides a thread-safe dict-like container which maintains up to
+ ``maxsize`` keys while throwing away the least-recently-used keys beyond
+ ``maxsize``.
+
+ :param maxsize:
+ Maximum number of recent elements to retain.
+
+ :param dispose_func:
+ Every time an item is evicted from the container,
+ ``dispose_func(value)`` is called. Callback which will get called
+ """
+
+ ContainerCls = OrderedDict
+
+ def __init__(self, maxsize=10, dispose_func=None):
+ self._maxsize = maxsize
+ self.dispose_func = dispose_func
+
+ self._container = self.ContainerCls()
+ self.lock = RLock()
+
+ def __getitem__(self, key):
+ # Re-insert the item, moving it to the end of the eviction line.
+ with self.lock:
+ item = self._container.pop(key)
+ self._container[key] = item
+ return item
+
+ def __setitem__(self, key, value):
+ evicted_value = _Null
+ with self.lock:
+ # Possibly evict the existing value of 'key'
+ evicted_value = self._container.get(key, _Null)
+ self._container[key] = value
+
+ # If we didn't evict an existing value, we might have to evict the
+ # least recently used item from the beginning of the container.
+ if len(self._container) > self._maxsize:
+ _key, evicted_value = self._container.popitem(last=False)
+
+ if self.dispose_func and evicted_value is not _Null:
+ self.dispose_func(evicted_value)
+
+ def __delitem__(self, key):
+ with self.lock:
+ value = self._container.pop(key)
+
+ if self.dispose_func:
+ self.dispose_func(value)
+
+ def __len__(self):
+ with self.lock:
+ return len(self._container)
+
+ def __iter__(self):
+ raise NotImplementedError(
+ "Iteration over this class is unlikely to be threadsafe."
+ )
+
+ def clear(self):
+ with self.lock:
+ # Copy pointers to all values, then wipe the mapping
+ values = list(itervalues(self._container))
+ self._container.clear()
+
+ if self.dispose_func:
+ for value in values:
+ self.dispose_func(value)
+
+ def keys(self):
+ with self.lock:
+ return list(iterkeys(self._container))
+
+
+class HTTPHeaderDict(MutableMapping):
+ """
+ :param headers:
+ An iterable of field-value pairs. Must not contain multiple field names
+ when compared case-insensitively.
+
+ :param kwargs:
+ Additional field-value pairs to pass in to ``dict.update``.
+
+ A ``dict`` like container for storing HTTP Headers.
+
+ Field names are stored and compared case-insensitively in compliance with
+ RFC 7230. Iteration provides the first case-sensitive key seen for each
+ case-insensitive pair.
+
+ Using ``__setitem__`` syntax overwrites fields that compare equal
+ case-insensitively in order to maintain ``dict``'s api. For fields that
+ compare equal, instead create a new ``HTTPHeaderDict`` and use ``.add``
+ in a loop.
+
+ If multiple fields that are equal case-insensitively are passed to the
+ constructor or ``.update``, the behavior is undefined and some will be
+ lost.
+
+ >>> headers = HTTPHeaderDict()
+ >>> headers.add('Set-Cookie', 'foo=bar')
+ >>> headers.add('set-cookie', 'baz=quxx')
+ >>> headers['content-length'] = '7'
+ >>> headers['SET-cookie']
+ 'foo=bar, baz=quxx'
+ >>> headers['Content-Length']
+ '7'
+ """
+
+ def __init__(self, headers=None, **kwargs):
+ super(HTTPHeaderDict, self).__init__()
+ self._container = OrderedDict()
+ if headers is not None:
+ if isinstance(headers, HTTPHeaderDict):
+ self._copy_from(headers)
+ else:
+ self.extend(headers)
+ if kwargs:
+ self.extend(kwargs)
+
+ def __setitem__(self, key, val):
+ self._container[key.lower()] = [key, val]
+ return self._container[key.lower()]
+
+ def __getitem__(self, key):
+ val = self._container[key.lower()]
+ return ", ".join(val[1:])
+
+ def __delitem__(self, key):
+ del self._container[key.lower()]
+
+ def __contains__(self, key):
+ return key.lower() in self._container
+
+ def __eq__(self, other):
+ if not isinstance(other, Mapping) and not hasattr(other, "keys"):
+ return False
+ if not isinstance(other, type(self)):
+ other = type(self)(other)
+ return dict((k.lower(), v) for k, v in self.itermerged()) == dict(
+ (k.lower(), v) for k, v in other.itermerged()
+ )
+
+ def __ne__(self, other):
+ return not self.__eq__(other)
+
+ if six.PY2: # Python 2
+ iterkeys = MutableMapping.iterkeys
+ itervalues = MutableMapping.itervalues
+
+ __marker = object()
+
+ def __len__(self):
+ return len(self._container)
+
+ def __iter__(self):
+ # Only provide the originally cased names
+ for vals in self._container.values():
+ yield vals[0]
+
+ def pop(self, key, default=__marker):
+ """D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
+ If key is not found, d is returned if given, otherwise KeyError is raised.
+ """
+ # Using the MutableMapping function directly fails due to the private marker.
+ # Using ordinary dict.pop would expose the internal structures.
+ # So let's reinvent the wheel.
+ try:
+ value = self[key]
+ except KeyError:
+ if default is self.__marker:
+ raise
+ return default
+ else:
+ del self[key]
+ return value
+
+ def discard(self, key):
+ try:
+ del self[key]
+ except KeyError:
+ pass
+
+ def add(self, key, val):
+ """Adds a (name, value) pair, doesn't overwrite the value if it already
+ exists.
+
+ >>> headers = HTTPHeaderDict(foo='bar')
+ >>> headers.add('Foo', 'baz')
+ >>> headers['foo']
+ 'bar, baz'
+ """
+ key_lower = key.lower()
+ new_vals = [key, val]
+ # Keep the common case aka no item present as fast as possible
+ vals = self._container.setdefault(key_lower, new_vals)
+ if new_vals is not vals:
+ vals.append(val)
+
+ def extend(self, *args, **kwargs):
+ """Generic import function for any type of header-like object.
+ Adapted version of MutableMapping.update in order to insert items
+ with self.add instead of self.__setitem__
+ """
+ if len(args) > 1:
+ raise TypeError(
+ "extend() takes at most 1 positional "
+ "arguments ({0} given)".format(len(args))
+ )
+ other = args[0] if len(args) >= 1 else ()
+
+ if isinstance(other, HTTPHeaderDict):
+ for key, val in other.iteritems():
+ self.add(key, val)
+ elif isinstance(other, Mapping):
+ for key in other:
+ self.add(key, other[key])
+ elif hasattr(other, "keys"):
+ for key in other.keys():
+ self.add(key, other[key])
+ else:
+ for key, value in other:
+ self.add(key, value)
+
+ for key, value in kwargs.items():
+ self.add(key, value)
+
+ def getlist(self, key, default=__marker):
+ """Returns a list of all the values for the named field. Returns an
+ empty list if the key doesn't exist."""
+ try:
+ vals = self._container[key.lower()]
+ except KeyError:
+ if default is self.__marker:
+ return []
+ return default
+ else:
+ return vals[1:]
+
+ def _prepare_for_method_change(self):
+ """
+ Remove content-specific header fields before changing the request
+ method to GET or HEAD according to RFC 9110, Section 15.4.
+ """
+ content_specific_headers = [
+ "Content-Encoding",
+ "Content-Language",
+ "Content-Location",
+ "Content-Type",
+ "Content-Length",
+ "Digest",
+ "Last-Modified",
+ ]
+ for header in content_specific_headers:
+ self.discard(header)
+ return self
+
+ # Backwards compatibility for httplib
+ getheaders = getlist
+ getallmatchingheaders = getlist
+ iget = getlist
+
+ # Backwards compatibility for http.cookiejar
+ get_all = getlist
+
+ def __repr__(self):
+ return "%s(%s)" % (type(self).__name__, dict(self.itermerged()))
+
+ def _copy_from(self, other):
+ for key in other:
+ val = other.getlist(key)
+ if isinstance(val, list):
+ # Don't need to convert tuples
+ val = list(val)
+ self._container[key.lower()] = [key] + val
+
+ def copy(self):
+ clone = type(self)()
+ clone._copy_from(self)
+ return clone
+
+ def iteritems(self):
+ """Iterate over all header lines, including duplicate ones."""
+ for key in self:
+ vals = self._container[key.lower()]
+ for val in vals[1:]:
+ yield vals[0], val
+
+ def itermerged(self):
+ """Iterate over all headers, merging duplicate ones together."""
+ for key in self:
+ val = self._container[key.lower()]
+ yield val[0], ", ".join(val[1:])
+
+ def items(self):
+ return list(self.iteritems())
+
+ @classmethod
+ def from_httplib(cls, message): # Python 2
+ """Read headers from a Python 2 httplib message object."""
+ # python2.7 does not expose a proper API for exporting multiheaders
+ # efficiently. This function re-reads raw lines from the message
+ # object and extracts the multiheaders properly.
+ obs_fold_continued_leaders = (" ", "\t")
+ headers = []
+
+ for line in message.headers:
+ if line.startswith(obs_fold_continued_leaders):
+ if not headers:
+ # We received a header line that starts with OWS as described
+ # in RFC-7230 S3.2.4. This indicates a multiline header, but
+ # there exists no previous header to which we can attach it.
+ raise InvalidHeader(
+ "Header continuation with no previous header: %s" % line
+ )
+ else:
+ key, value = headers[-1]
+ headers[-1] = (key, value + " " + line.strip())
+ continue
+
+ key, value = line.split(":", 1)
+ headers.append((key, value.strip()))
+
+ return cls(headers)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/_version.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/_version.py
new file mode 100644
index 000000000..d49df2a0c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/_version.py
@@ -0,0 +1,2 @@
+# This file is protected via CODEOWNERS
+__version__ = "1.26.20"
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/connection.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/connection.py
new file mode 100644
index 000000000..de35b63d6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/connection.py
@@ -0,0 +1,572 @@
+from __future__ import absolute_import
+
+import datetime
+import logging
+import os
+import re
+import socket
+import warnings
+from socket import error as SocketError
+from socket import timeout as SocketTimeout
+
+from .packages import six
+from .packages.six.moves.http_client import HTTPConnection as _HTTPConnection
+from .packages.six.moves.http_client import HTTPException # noqa: F401
+from .util.proxy import create_proxy_ssl_context
+
+try: # Compiled with SSL?
+ import ssl
+
+ BaseSSLError = ssl.SSLError
+except (ImportError, AttributeError): # Platform-specific: No SSL.
+ ssl = None
+
+ class BaseSSLError(BaseException):
+ pass
+
+
+try:
+ # Python 3: not a no-op, we're adding this to the namespace so it can be imported.
+ ConnectionError = ConnectionError
+except NameError:
+ # Python 2
+ class ConnectionError(Exception):
+ pass
+
+
+try: # Python 3:
+ # Not a no-op, we're adding this to the namespace so it can be imported.
+ BrokenPipeError = BrokenPipeError
+except NameError: # Python 2:
+
+ class BrokenPipeError(Exception):
+ pass
+
+
+from ._collections import HTTPHeaderDict # noqa (historical, removed in v2)
+from ._version import __version__
+from .exceptions import (
+ ConnectTimeoutError,
+ NewConnectionError,
+ SubjectAltNameWarning,
+ SystemTimeWarning,
+)
+from .util import SKIP_HEADER, SKIPPABLE_HEADERS, connection
+from .util.ssl_ import (
+ assert_fingerprint,
+ create_urllib3_context,
+ is_ipaddress,
+ resolve_cert_reqs,
+ resolve_ssl_version,
+ ssl_wrap_socket,
+)
+from .util.ssl_match_hostname import CertificateError, match_hostname
+
+log = logging.getLogger(__name__)
+
+port_by_scheme = {"http": 80, "https": 443}
+
+# When it comes time to update this value as a part of regular maintenance
+# (ie test_recent_date is failing) update it to ~6 months before the current date.
+RECENT_DATE = datetime.date(2024, 1, 1)
+
+_CONTAINS_CONTROL_CHAR_RE = re.compile(r"[^-!#$%&'*+.^_`|~0-9a-zA-Z]")
+
+
+class HTTPConnection(_HTTPConnection, object):
+ """
+ Based on :class:`http.client.HTTPConnection` but provides an extra constructor
+ backwards-compatibility layer between older and newer Pythons.
+
+ Additional keyword parameters are used to configure attributes of the connection.
+ Accepted parameters include:
+
+ - ``strict``: See the documentation on :class:`urllib3.connectionpool.HTTPConnectionPool`
+ - ``source_address``: Set the source address for the current connection.
+ - ``socket_options``: Set specific options on the underlying socket. If not specified, then
+ defaults are loaded from ``HTTPConnection.default_socket_options`` which includes disabling
+ Nagle's algorithm (sets TCP_NODELAY to 1) unless the connection is behind a proxy.
+
+ For example, if you wish to enable TCP Keep Alive in addition to the defaults,
+ you might pass:
+
+ .. code-block:: python
+
+ HTTPConnection.default_socket_options + [
+ (socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1),
+ ]
+
+ Or you may want to disable the defaults by passing an empty list (e.g., ``[]``).
+ """
+
+ default_port = port_by_scheme["http"]
+
+ #: Disable Nagle's algorithm by default.
+ #: ``[(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)]``
+ default_socket_options = [(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)]
+
+ #: Whether this connection verifies the host's certificate.
+ is_verified = False
+
+ #: Whether this proxy connection (if used) verifies the proxy host's
+ #: certificate.
+ proxy_is_verified = None
+
+ def __init__(self, *args, **kw):
+ if not six.PY2:
+ kw.pop("strict", None)
+
+ # Pre-set source_address.
+ self.source_address = kw.get("source_address")
+
+ #: The socket options provided by the user. If no options are
+ #: provided, we use the default options.
+ self.socket_options = kw.pop("socket_options", self.default_socket_options)
+
+ # Proxy options provided by the user.
+ self.proxy = kw.pop("proxy", None)
+ self.proxy_config = kw.pop("proxy_config", None)
+
+ _HTTPConnection.__init__(self, *args, **kw)
+
+ @property
+ def host(self):
+ """
+ Getter method to remove any trailing dots that indicate the hostname is an FQDN.
+
+ In general, SSL certificates don't include the trailing dot indicating a
+ fully-qualified domain name, and thus, they don't validate properly when
+ checked against a domain name that includes the dot. In addition, some
+ servers may not expect to receive the trailing dot when provided.
+
+ However, the hostname with trailing dot is critical to DNS resolution; doing a
+ lookup with the trailing dot will properly only resolve the appropriate FQDN,
+ whereas a lookup without a trailing dot will search the system's search domain
+ list. Thus, it's important to keep the original host around for use only in
+ those cases where it's appropriate (i.e., when doing DNS lookup to establish the
+ actual TCP connection across which we're going to send HTTP requests).
+ """
+ return self._dns_host.rstrip(".")
+
+ @host.setter
+ def host(self, value):
+ """
+ Setter for the `host` property.
+
+ We assume that only urllib3 uses the _dns_host attribute; httplib itself
+ only uses `host`, and it seems reasonable that other libraries follow suit.
+ """
+ self._dns_host = value
+
+ def _new_conn(self):
+ """Establish a socket connection and set nodelay settings on it.
+
+ :return: New socket connection.
+ """
+ extra_kw = {}
+ if self.source_address:
+ extra_kw["source_address"] = self.source_address
+
+ if self.socket_options:
+ extra_kw["socket_options"] = self.socket_options
+
+ try:
+ conn = connection.create_connection(
+ (self._dns_host, self.port), self.timeout, **extra_kw
+ )
+
+ except SocketTimeout:
+ raise ConnectTimeoutError(
+ self,
+ "Connection to %s timed out. (connect timeout=%s)"
+ % (self.host, self.timeout),
+ )
+
+ except SocketError as e:
+ raise NewConnectionError(
+ self, "Failed to establish a new connection: %s" % e
+ )
+
+ return conn
+
+ def _is_using_tunnel(self):
+ # Google App Engine's httplib does not define _tunnel_host
+ return getattr(self, "_tunnel_host", None)
+
+ def _prepare_conn(self, conn):
+ self.sock = conn
+ if self._is_using_tunnel():
+ # TODO: Fix tunnel so it doesn't depend on self.sock state.
+ self._tunnel()
+ # Mark this connection as not reusable
+ self.auto_open = 0
+
+ def connect(self):
+ conn = self._new_conn()
+ self._prepare_conn(conn)
+
+ def putrequest(self, method, url, *args, **kwargs):
+ """ """
+ # Empty docstring because the indentation of CPython's implementation
+ # is broken but we don't want this method in our documentation.
+ match = _CONTAINS_CONTROL_CHAR_RE.search(method)
+ if match:
+ raise ValueError(
+ "Method cannot contain non-token characters %r (found at least %r)"
+ % (method, match.group())
+ )
+
+ return _HTTPConnection.putrequest(self, method, url, *args, **kwargs)
+
+ def putheader(self, header, *values):
+ """ """
+ if not any(isinstance(v, str) and v == SKIP_HEADER for v in values):
+ _HTTPConnection.putheader(self, header, *values)
+ elif six.ensure_str(header.lower()) not in SKIPPABLE_HEADERS:
+ raise ValueError(
+ "urllib3.util.SKIP_HEADER only supports '%s'"
+ % ("', '".join(map(str.title, sorted(SKIPPABLE_HEADERS))),)
+ )
+
+ def request(self, method, url, body=None, headers=None):
+ # Update the inner socket's timeout value to send the request.
+ # This only triggers if the connection is re-used.
+ if getattr(self, "sock", None) is not None:
+ self.sock.settimeout(self.timeout)
+
+ if headers is None:
+ headers = {}
+ else:
+ # Avoid modifying the headers passed into .request()
+ headers = headers.copy()
+ if "user-agent" not in (six.ensure_str(k.lower()) for k in headers):
+ headers["User-Agent"] = _get_default_user_agent()
+ super(HTTPConnection, self).request(method, url, body=body, headers=headers)
+
+ def request_chunked(self, method, url, body=None, headers=None):
+ """
+ Alternative to the common request method, which sends the
+ body with chunked encoding and not as one block
+ """
+ headers = headers or {}
+ header_keys = set([six.ensure_str(k.lower()) for k in headers])
+ skip_accept_encoding = "accept-encoding" in header_keys
+ skip_host = "host" in header_keys
+ self.putrequest(
+ method, url, skip_accept_encoding=skip_accept_encoding, skip_host=skip_host
+ )
+ if "user-agent" not in header_keys:
+ self.putheader("User-Agent", _get_default_user_agent())
+ for header, value in headers.items():
+ self.putheader(header, value)
+ if "transfer-encoding" not in header_keys:
+ self.putheader("Transfer-Encoding", "chunked")
+ self.endheaders()
+
+ if body is not None:
+ stringish_types = six.string_types + (bytes,)
+ if isinstance(body, stringish_types):
+ body = (body,)
+ for chunk in body:
+ if not chunk:
+ continue
+ if not isinstance(chunk, bytes):
+ chunk = chunk.encode("utf8")
+ len_str = hex(len(chunk))[2:]
+ to_send = bytearray(len_str.encode())
+ to_send += b"\r\n"
+ to_send += chunk
+ to_send += b"\r\n"
+ self.send(to_send)
+
+ # After the if clause, to always have a closed body
+ self.send(b"0\r\n\r\n")
+
+
+class HTTPSConnection(HTTPConnection):
+ """
+ Many of the parameters to this constructor are passed to the underlying SSL
+ socket by means of :py:func:`urllib3.util.ssl_wrap_socket`.
+ """
+
+ default_port = port_by_scheme["https"]
+
+ cert_reqs = None
+ ca_certs = None
+ ca_cert_dir = None
+ ca_cert_data = None
+ ssl_version = None
+ assert_fingerprint = None
+ tls_in_tls_required = False
+
+ def __init__(
+ self,
+ host,
+ port=None,
+ key_file=None,
+ cert_file=None,
+ key_password=None,
+ strict=None,
+ timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
+ ssl_context=None,
+ server_hostname=None,
+ **kw
+ ):
+
+ HTTPConnection.__init__(self, host, port, strict=strict, timeout=timeout, **kw)
+
+ self.key_file = key_file
+ self.cert_file = cert_file
+ self.key_password = key_password
+ self.ssl_context = ssl_context
+ self.server_hostname = server_hostname
+
+ # Required property for Google AppEngine 1.9.0 which otherwise causes
+ # HTTPS requests to go out as HTTP. (See Issue #356)
+ self._protocol = "https"
+
+ def set_cert(
+ self,
+ key_file=None,
+ cert_file=None,
+ cert_reqs=None,
+ key_password=None,
+ ca_certs=None,
+ assert_hostname=None,
+ assert_fingerprint=None,
+ ca_cert_dir=None,
+ ca_cert_data=None,
+ ):
+ """
+ This method should only be called once, before the connection is used.
+ """
+ # If cert_reqs is not provided we'll assume CERT_REQUIRED unless we also
+ # have an SSLContext object in which case we'll use its verify_mode.
+ if cert_reqs is None:
+ if self.ssl_context is not None:
+ cert_reqs = self.ssl_context.verify_mode
+ else:
+ cert_reqs = resolve_cert_reqs(None)
+
+ self.key_file = key_file
+ self.cert_file = cert_file
+ self.cert_reqs = cert_reqs
+ self.key_password = key_password
+ self.assert_hostname = assert_hostname
+ self.assert_fingerprint = assert_fingerprint
+ self.ca_certs = ca_certs and os.path.expanduser(ca_certs)
+ self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)
+ self.ca_cert_data = ca_cert_data
+
+ def connect(self):
+ # Add certificate verification
+ self.sock = conn = self._new_conn()
+ hostname = self.host
+ tls_in_tls = False
+
+ if self._is_using_tunnel():
+ if self.tls_in_tls_required:
+ self.sock = conn = self._connect_tls_proxy(hostname, conn)
+ tls_in_tls = True
+
+ # Calls self._set_hostport(), so self.host is
+ # self._tunnel_host below.
+ self._tunnel()
+ # Mark this connection as not reusable
+ self.auto_open = 0
+
+ # Override the host with the one we're requesting data from.
+ hostname = self._tunnel_host
+
+ server_hostname = hostname
+ if self.server_hostname is not None:
+ server_hostname = self.server_hostname
+
+ is_time_off = datetime.date.today() < RECENT_DATE
+ if is_time_off:
+ warnings.warn(
+ (
+ "System time is way off (before {0}). This will probably "
+ "lead to SSL verification errors"
+ ).format(RECENT_DATE),
+ SystemTimeWarning,
+ )
+
+ # Wrap socket using verification with the root certs in
+ # trusted_root_certs
+ default_ssl_context = False
+ if self.ssl_context is None:
+ default_ssl_context = True
+ self.ssl_context = create_urllib3_context(
+ ssl_version=resolve_ssl_version(self.ssl_version),
+ cert_reqs=resolve_cert_reqs(self.cert_reqs),
+ )
+
+ context = self.ssl_context
+ context.verify_mode = resolve_cert_reqs(self.cert_reqs)
+
+ # Try to load OS default certs if none are given.
+ # Works well on Windows (requires Python3.4+)
+ if (
+ not self.ca_certs
+ and not self.ca_cert_dir
+ and not self.ca_cert_data
+ and default_ssl_context
+ and hasattr(context, "load_default_certs")
+ ):
+ context.load_default_certs()
+
+ self.sock = ssl_wrap_socket(
+ sock=conn,
+ keyfile=self.key_file,
+ certfile=self.cert_file,
+ key_password=self.key_password,
+ ca_certs=self.ca_certs,
+ ca_cert_dir=self.ca_cert_dir,
+ ca_cert_data=self.ca_cert_data,
+ server_hostname=server_hostname,
+ ssl_context=context,
+ tls_in_tls=tls_in_tls,
+ )
+
+ # If we're using all defaults and the connection
+ # is TLSv1 or TLSv1.1 we throw a DeprecationWarning
+ # for the host.
+ if (
+ default_ssl_context
+ and self.ssl_version is None
+ and hasattr(self.sock, "version")
+ and self.sock.version() in {"TLSv1", "TLSv1.1"}
+ ): # Defensive:
+ warnings.warn(
+ "Negotiating TLSv1/TLSv1.1 by default is deprecated "
+ "and will be disabled in urllib3 v2.0.0. Connecting to "
+ "'%s' with '%s' can be enabled by explicitly opting-in "
+ "with 'ssl_version'" % (self.host, self.sock.version()),
+ DeprecationWarning,
+ )
+
+ if self.assert_fingerprint:
+ assert_fingerprint(
+ self.sock.getpeercert(binary_form=True), self.assert_fingerprint
+ )
+ elif (
+ context.verify_mode != ssl.CERT_NONE
+ and not getattr(context, "check_hostname", False)
+ and self.assert_hostname is not False
+ ):
+ # While urllib3 attempts to always turn off hostname matching from
+ # the TLS library, this cannot always be done. So we check whether
+ # the TLS Library still thinks it's matching hostnames.
+ cert = self.sock.getpeercert()
+ if not cert.get("subjectAltName", ()):
+ warnings.warn(
+ (
+ "Certificate for {0} has no `subjectAltName`, falling back to check for a "
+ "`commonName` for now. This feature is being removed by major browsers and "
+ "deprecated by RFC 2818. (See https://github.com/urllib3/urllib3/issues/497 "
+ "for details.)".format(hostname)
+ ),
+ SubjectAltNameWarning,
+ )
+ _match_hostname(cert, self.assert_hostname or server_hostname)
+
+ self.is_verified = (
+ context.verify_mode == ssl.CERT_REQUIRED
+ or self.assert_fingerprint is not None
+ )
+
+ def _connect_tls_proxy(self, hostname, conn):
+ """
+ Establish a TLS connection to the proxy using the provided SSL context.
+ """
+ proxy_config = self.proxy_config
+ ssl_context = proxy_config.ssl_context
+ if ssl_context:
+ # If the user provided a proxy context, we assume CA and client
+ # certificates have already been set
+ return ssl_wrap_socket(
+ sock=conn,
+ server_hostname=hostname,
+ ssl_context=ssl_context,
+ )
+
+ ssl_context = create_proxy_ssl_context(
+ self.ssl_version,
+ self.cert_reqs,
+ self.ca_certs,
+ self.ca_cert_dir,
+ self.ca_cert_data,
+ )
+
+ # If no cert was provided, use only the default options for server
+ # certificate validation
+ socket = ssl_wrap_socket(
+ sock=conn,
+ ca_certs=self.ca_certs,
+ ca_cert_dir=self.ca_cert_dir,
+ ca_cert_data=self.ca_cert_data,
+ server_hostname=hostname,
+ ssl_context=ssl_context,
+ )
+
+ if ssl_context.verify_mode != ssl.CERT_NONE and not getattr(
+ ssl_context, "check_hostname", False
+ ):
+ # While urllib3 attempts to always turn off hostname matching from
+ # the TLS library, this cannot always be done. So we check whether
+ # the TLS Library still thinks it's matching hostnames.
+ cert = socket.getpeercert()
+ if not cert.get("subjectAltName", ()):
+ warnings.warn(
+ (
+ "Certificate for {0} has no `subjectAltName`, falling back to check for a "
+ "`commonName` for now. This feature is being removed by major browsers and "
+ "deprecated by RFC 2818. (See https://github.com/urllib3/urllib3/issues/497 "
+ "for details.)".format(hostname)
+ ),
+ SubjectAltNameWarning,
+ )
+ _match_hostname(cert, hostname)
+
+ self.proxy_is_verified = ssl_context.verify_mode == ssl.CERT_REQUIRED
+ return socket
+
+
+def _match_hostname(cert, asserted_hostname):
+ # Our upstream implementation of ssl.match_hostname()
+ # only applies this normalization to IP addresses so it doesn't
+ # match DNS SANs so we do the same thing!
+ stripped_hostname = asserted_hostname.strip("u[]")
+ if is_ipaddress(stripped_hostname):
+ asserted_hostname = stripped_hostname
+
+ try:
+ match_hostname(cert, asserted_hostname)
+ except CertificateError as e:
+ log.warning(
+ "Certificate did not match expected hostname: %s. Certificate: %s",
+ asserted_hostname,
+ cert,
+ )
+ # Add cert to exception and reraise so client code can inspect
+ # the cert when catching the exception, if they want to
+ e._peer_cert = cert
+ raise
+
+
+def _get_default_user_agent():
+ return "python-urllib3/%s" % __version__
+
+
+class DummyConnection(object):
+ """Used to detect a failed ConnectionCls import."""
+
+ pass
+
+
+if not ssl:
+ HTTPSConnection = DummyConnection # noqa: F811
+
+
+VerifiedHTTPSConnection = HTTPSConnection
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/connectionpool.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/connectionpool.py
new file mode 100644
index 000000000..0872ed770
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/connectionpool.py
@@ -0,0 +1,1140 @@
+from __future__ import absolute_import
+
+import errno
+import logging
+import re
+import socket
+import sys
+import warnings
+from socket import error as SocketError
+from socket import timeout as SocketTimeout
+
+from ._collections import HTTPHeaderDict
+from .connection import (
+ BaseSSLError,
+ BrokenPipeError,
+ DummyConnection,
+ HTTPConnection,
+ HTTPException,
+ HTTPSConnection,
+ VerifiedHTTPSConnection,
+ port_by_scheme,
+)
+from .exceptions import (
+ ClosedPoolError,
+ EmptyPoolError,
+ HeaderParsingError,
+ HostChangedError,
+ InsecureRequestWarning,
+ LocationValueError,
+ MaxRetryError,
+ NewConnectionError,
+ ProtocolError,
+ ProxyError,
+ ReadTimeoutError,
+ SSLError,
+ TimeoutError,
+)
+from .packages import six
+from .packages.six.moves import queue
+from .request import RequestMethods
+from .response import HTTPResponse
+from .util.connection import is_connection_dropped
+from .util.proxy import connection_requires_http_tunnel
+from .util.queue import LifoQueue
+from .util.request import set_file_position
+from .util.response import assert_header_parsing
+from .util.retry import Retry
+from .util.ssl_match_hostname import CertificateError
+from .util.timeout import Timeout
+from .util.url import Url, _encode_target
+from .util.url import _normalize_host as normalize_host
+from .util.url import get_host, parse_url
+
+try: # Platform-specific: Python 3
+ import weakref
+
+ weakref_finalize = weakref.finalize
+except AttributeError: # Platform-specific: Python 2
+ from .packages.backports.weakref_finalize import weakref_finalize
+
+xrange = six.moves.xrange
+
+log = logging.getLogger(__name__)
+
+_Default = object()
+
+
+# Pool objects
+class ConnectionPool(object):
+ """
+ Base class for all connection pools, such as
+ :class:`.HTTPConnectionPool` and :class:`.HTTPSConnectionPool`.
+
+ .. note::
+ ConnectionPool.urlopen() does not normalize or percent-encode target URIs
+ which is useful if your target server doesn't support percent-encoded
+ target URIs.
+ """
+
+ scheme = None
+ QueueCls = LifoQueue
+
+ def __init__(self, host, port=None):
+ if not host:
+ raise LocationValueError("No host specified.")
+
+ self.host = _normalize_host(host, scheme=self.scheme)
+ self._proxy_host = host.lower()
+ self.port = port
+
+ def __str__(self):
+ return "%s(host=%r, port=%r)" % (type(self).__name__, self.host, self.port)
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.close()
+ # Return False to re-raise any potential exceptions
+ return False
+
+ def close(self):
+ """
+ Close all pooled connections and disable the pool.
+ """
+ pass
+
+
+# This is taken from http://hg.python.org/cpython/file/7aaba721ebc0/Lib/socket.py#l252
+_blocking_errnos = {errno.EAGAIN, errno.EWOULDBLOCK}
+
+
+class HTTPConnectionPool(ConnectionPool, RequestMethods):
+ """
+ Thread-safe connection pool for one host.
+
+ :param host:
+ Host used for this HTTP Connection (e.g. "localhost"), passed into
+ :class:`http.client.HTTPConnection`.
+
+ :param port:
+ Port used for this HTTP Connection (None is equivalent to 80), passed
+ into :class:`http.client.HTTPConnection`.
+
+ :param strict:
+ Causes BadStatusLine to be raised if the status line can't be parsed
+ as a valid HTTP/1.0 or 1.1 status line, passed into
+ :class:`http.client.HTTPConnection`.
+
+ .. note::
+ Only works in Python 2. This parameter is ignored in Python 3.
+
+ :param timeout:
+ Socket timeout in seconds for each individual connection. This can
+ be a float or integer, which sets the timeout for the HTTP request,
+ or an instance of :class:`urllib3.util.Timeout` which gives you more
+ fine-grained control over request timeouts. After the constructor has
+ been parsed, this is always a `urllib3.util.Timeout` object.
+
+ :param maxsize:
+ Number of connections to save that can be reused. More than 1 is useful
+ in multithreaded situations. If ``block`` is set to False, more
+ connections will be created but they will not be saved once they've
+ been used.
+
+ :param block:
+ If set to True, no more than ``maxsize`` connections will be used at
+ a time. When no free connections are available, the call will block
+ until a connection has been released. This is a useful side effect for
+ particular multithreaded situations where one does not want to use more
+ than maxsize connections per host to prevent flooding.
+
+ :param headers:
+ Headers to include with all requests, unless other headers are given
+ explicitly.
+
+ :param retries:
+ Retry configuration to use by default with requests in this pool.
+
+ :param _proxy:
+ Parsed proxy URL, should not be used directly, instead, see
+ :class:`urllib3.ProxyManager`
+
+ :param _proxy_headers:
+ A dictionary with proxy headers, should not be used directly,
+ instead, see :class:`urllib3.ProxyManager`
+
+ :param \\**conn_kw:
+ Additional parameters are used to create fresh :class:`urllib3.connection.HTTPConnection`,
+ :class:`urllib3.connection.HTTPSConnection` instances.
+ """
+
+ scheme = "http"
+ ConnectionCls = HTTPConnection
+ ResponseCls = HTTPResponse
+
+ def __init__(
+ self,
+ host,
+ port=None,
+ strict=False,
+ timeout=Timeout.DEFAULT_TIMEOUT,
+ maxsize=1,
+ block=False,
+ headers=None,
+ retries=None,
+ _proxy=None,
+ _proxy_headers=None,
+ _proxy_config=None,
+ **conn_kw
+ ):
+ ConnectionPool.__init__(self, host, port)
+ RequestMethods.__init__(self, headers)
+
+ self.strict = strict
+
+ if not isinstance(timeout, Timeout):
+ timeout = Timeout.from_float(timeout)
+
+ if retries is None:
+ retries = Retry.DEFAULT
+
+ self.timeout = timeout
+ self.retries = retries
+
+ self.pool = self.QueueCls(maxsize)
+ self.block = block
+
+ self.proxy = _proxy
+ self.proxy_headers = _proxy_headers or {}
+ self.proxy_config = _proxy_config
+
+ # Fill the queue up so that doing get() on it will block properly
+ for _ in xrange(maxsize):
+ self.pool.put(None)
+
+ # These are mostly for testing and debugging purposes.
+ self.num_connections = 0
+ self.num_requests = 0
+ self.conn_kw = conn_kw
+
+ if self.proxy:
+ # Enable Nagle's algorithm for proxies, to avoid packet fragmentation.
+ # We cannot know if the user has added default socket options, so we cannot replace the
+ # list.
+ self.conn_kw.setdefault("socket_options", [])
+
+ self.conn_kw["proxy"] = self.proxy
+ self.conn_kw["proxy_config"] = self.proxy_config
+
+ # Do not pass 'self' as callback to 'finalize'.
+ # Then the 'finalize' would keep an endless living (leak) to self.
+ # By just passing a reference to the pool allows the garbage collector
+ # to free self if nobody else has a reference to it.
+ pool = self.pool
+
+ # Close all the HTTPConnections in the pool before the
+ # HTTPConnectionPool object is garbage collected.
+ weakref_finalize(self, _close_pool_connections, pool)
+
+ def _new_conn(self):
+ """
+ Return a fresh :class:`HTTPConnection`.
+ """
+ self.num_connections += 1
+ log.debug(
+ "Starting new HTTP connection (%d): %s:%s",
+ self.num_connections,
+ self.host,
+ self.port or "80",
+ )
+
+ conn = self.ConnectionCls(
+ host=self.host,
+ port=self.port,
+ timeout=self.timeout.connect_timeout,
+ strict=self.strict,
+ **self.conn_kw
+ )
+ return conn
+
+ def _get_conn(self, timeout=None):
+ """
+ Get a connection. Will return a pooled connection if one is available.
+
+ If no connections are available and :prop:`.block` is ``False``, then a
+ fresh connection is returned.
+
+ :param timeout:
+ Seconds to wait before giving up and raising
+ :class:`urllib3.exceptions.EmptyPoolError` if the pool is empty and
+ :prop:`.block` is ``True``.
+ """
+ conn = None
+ try:
+ conn = self.pool.get(block=self.block, timeout=timeout)
+
+ except AttributeError: # self.pool is None
+ raise ClosedPoolError(self, "Pool is closed.")
+
+ except queue.Empty:
+ if self.block:
+ raise EmptyPoolError(
+ self,
+ "Pool reached maximum size and no more connections are allowed.",
+ )
+ pass # Oh well, we'll create a new connection then
+
+ # If this is a persistent connection, check if it got disconnected
+ if conn and is_connection_dropped(conn):
+ log.debug("Resetting dropped connection: %s", self.host)
+ conn.close()
+ if getattr(conn, "auto_open", 1) == 0:
+ # This is a proxied connection that has been mutated by
+ # http.client._tunnel() and cannot be reused (since it would
+ # attempt to bypass the proxy)
+ conn = None
+
+ return conn or self._new_conn()
+
+ def _put_conn(self, conn):
+ """
+ Put a connection back into the pool.
+
+ :param conn:
+ Connection object for the current host and port as returned by
+ :meth:`._new_conn` or :meth:`._get_conn`.
+
+ If the pool is already full, the connection is closed and discarded
+ because we exceeded maxsize. If connections are discarded frequently,
+ then maxsize should be increased.
+
+ If the pool is closed, then the connection will be closed and discarded.
+ """
+ try:
+ self.pool.put(conn, block=False)
+ return # Everything is dandy, done.
+ except AttributeError:
+ # self.pool is None.
+ pass
+ except queue.Full:
+ # This should never happen if self.block == True
+ log.warning(
+ "Connection pool is full, discarding connection: %s. Connection pool size: %s",
+ self.host,
+ self.pool.qsize(),
+ )
+ # Connection never got put back into the pool, close it.
+ if conn:
+ conn.close()
+
+ def _validate_conn(self, conn):
+ """
+ Called right before a request is made, after the socket is created.
+ """
+ pass
+
+ def _prepare_proxy(self, conn):
+ # Nothing to do for HTTP connections.
+ pass
+
+ def _get_timeout(self, timeout):
+ """Helper that always returns a :class:`urllib3.util.Timeout`"""
+ if timeout is _Default:
+ return self.timeout.clone()
+
+ if isinstance(timeout, Timeout):
+ return timeout.clone()
+ else:
+ # User passed us an int/float. This is for backwards compatibility,
+ # can be removed later
+ return Timeout.from_float(timeout)
+
+ def _raise_timeout(self, err, url, timeout_value):
+ """Is the error actually a timeout? Will raise a ReadTimeout or pass"""
+
+ if isinstance(err, SocketTimeout):
+ raise ReadTimeoutError(
+ self, url, "Read timed out. (read timeout=%s)" % timeout_value
+ )
+
+ # See the above comment about EAGAIN in Python 3. In Python 2 we have
+ # to specifically catch it and throw the timeout error
+ if hasattr(err, "errno") and err.errno in _blocking_errnos:
+ raise ReadTimeoutError(
+ self, url, "Read timed out. (read timeout=%s)" % timeout_value
+ )
+
+ # Catch possible read timeouts thrown as SSL errors. If not the
+ # case, rethrow the original. We need to do this because of:
+ # http://bugs.python.org/issue10272
+ if "timed out" in str(err) or "did not complete (read)" in str(
+ err
+ ): # Python < 2.7.4
+ raise ReadTimeoutError(
+ self, url, "Read timed out. (read timeout=%s)" % timeout_value
+ )
+
+ def _make_request(
+ self, conn, method, url, timeout=_Default, chunked=False, **httplib_request_kw
+ ):
+ """
+ Perform a request on a given urllib connection object taken from our
+ pool.
+
+ :param conn:
+ a connection from one of our connection pools
+
+ :param timeout:
+ Socket timeout in seconds for the request. This can be a
+ float or integer, which will set the same timeout value for
+ the socket connect and the socket read, or an instance of
+ :class:`urllib3.util.Timeout`, which gives you more fine-grained
+ control over your timeouts.
+ """
+ self.num_requests += 1
+
+ timeout_obj = self._get_timeout(timeout)
+ timeout_obj.start_connect()
+ conn.timeout = Timeout.resolve_default_timeout(timeout_obj.connect_timeout)
+
+ # Trigger any extra validation we need to do.
+ try:
+ self._validate_conn(conn)
+ except (SocketTimeout, BaseSSLError) as e:
+ # Py2 raises this as a BaseSSLError, Py3 raises it as socket timeout.
+ self._raise_timeout(err=e, url=url, timeout_value=conn.timeout)
+ raise
+
+ # conn.request() calls http.client.*.request, not the method in
+ # urllib3.request. It also calls makefile (recv) on the socket.
+ try:
+ if chunked:
+ conn.request_chunked(method, url, **httplib_request_kw)
+ else:
+ conn.request(method, url, **httplib_request_kw)
+
+ # We are swallowing BrokenPipeError (errno.EPIPE) since the server is
+ # legitimately able to close the connection after sending a valid response.
+ # With this behaviour, the received response is still readable.
+ except BrokenPipeError:
+ # Python 3
+ pass
+ except IOError as e:
+ # Python 2 and macOS/Linux
+ # EPIPE and ESHUTDOWN are BrokenPipeError on Python 2, and EPROTOTYPE/ECONNRESET are needed on macOS
+ # https://erickt.github.io/blog/2014/11/19/adventures-in-debugging-a-potential-osx-kernel-bug/
+ if e.errno not in {
+ errno.EPIPE,
+ errno.ESHUTDOWN,
+ errno.EPROTOTYPE,
+ errno.ECONNRESET,
+ }:
+ raise
+
+ # Reset the timeout for the recv() on the socket
+ read_timeout = timeout_obj.read_timeout
+
+ # App Engine doesn't have a sock attr
+ if getattr(conn, "sock", None):
+ # In Python 3 socket.py will catch EAGAIN and return None when you
+ # try and read into the file pointer created by http.client, which
+ # instead raises a BadStatusLine exception. Instead of catching
+ # the exception and assuming all BadStatusLine exceptions are read
+ # timeouts, check for a zero timeout before making the request.
+ if read_timeout == 0:
+ raise ReadTimeoutError(
+ self, url, "Read timed out. (read timeout=%s)" % read_timeout
+ )
+ if read_timeout is Timeout.DEFAULT_TIMEOUT:
+ conn.sock.settimeout(socket.getdefaulttimeout())
+ else: # None or a value
+ conn.sock.settimeout(read_timeout)
+
+ # Receive the response from the server
+ try:
+ try:
+ # Python 2.7, use buffering of HTTP responses
+ httplib_response = conn.getresponse(buffering=True)
+ except TypeError:
+ # Python 3
+ try:
+ httplib_response = conn.getresponse()
+ except BaseException as e:
+ # Remove the TypeError from the exception chain in
+ # Python 3 (including for exceptions like SystemExit).
+ # Otherwise it looks like a bug in the code.
+ six.raise_from(e, None)
+ except (SocketTimeout, BaseSSLError, SocketError) as e:
+ self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
+ raise
+
+ # AppEngine doesn't have a version attr.
+ http_version = getattr(conn, "_http_vsn_str", "HTTP/?")
+ log.debug(
+ '%s://%s:%s "%s %s %s" %s %s',
+ self.scheme,
+ self.host,
+ self.port,
+ method,
+ url,
+ http_version,
+ httplib_response.status,
+ httplib_response.length,
+ )
+
+ try:
+ assert_header_parsing(httplib_response.msg)
+ except (HeaderParsingError, TypeError) as hpe: # Platform-specific: Python 3
+ log.warning(
+ "Failed to parse headers (url=%s): %s",
+ self._absolute_url(url),
+ hpe,
+ exc_info=True,
+ )
+
+ return httplib_response
+
+ def _absolute_url(self, path):
+ return Url(scheme=self.scheme, host=self.host, port=self.port, path=path).url
+
+ def close(self):
+ """
+ Close all pooled connections and disable the pool.
+ """
+ if self.pool is None:
+ return
+ # Disable access to the pool
+ old_pool, self.pool = self.pool, None
+
+ # Close all the HTTPConnections in the pool.
+ _close_pool_connections(old_pool)
+
+ def is_same_host(self, url):
+ """
+ Check if the given ``url`` is a member of the same host as this
+ connection pool.
+ """
+ if url.startswith("/"):
+ return True
+
+ # TODO: Add optional support for socket.gethostbyname checking.
+ scheme, host, port = get_host(url)
+ if host is not None:
+ host = _normalize_host(host, scheme=scheme)
+
+ # Use explicit default port for comparison when none is given
+ if self.port and not port:
+ port = port_by_scheme.get(scheme)
+ elif not self.port and port == port_by_scheme.get(scheme):
+ port = None
+
+ return (scheme, host, port) == (self.scheme, self.host, self.port)
+
+ def urlopen(
+ self,
+ method,
+ url,
+ body=None,
+ headers=None,
+ retries=None,
+ redirect=True,
+ assert_same_host=True,
+ timeout=_Default,
+ pool_timeout=None,
+ release_conn=None,
+ chunked=False,
+ body_pos=None,
+ **response_kw
+ ):
+ """
+ Get a connection from the pool and perform an HTTP request. This is the
+ lowest level call for making a request, so you'll need to specify all
+ the raw details.
+
+ .. note::
+
+ More commonly, it's appropriate to use a convenience method provided
+ by :class:`.RequestMethods`, such as :meth:`request`.
+
+ .. note::
+
+ `release_conn` will only behave as expected if
+ `preload_content=False` because we want to make
+ `preload_content=False` the default behaviour someday soon without
+ breaking backwards compatibility.
+
+ :param method:
+ HTTP request method (such as GET, POST, PUT, etc.)
+
+ :param url:
+ The URL to perform the request on.
+
+ :param body:
+ Data to send in the request body, either :class:`str`, :class:`bytes`,
+ an iterable of :class:`str`/:class:`bytes`, or a file-like object.
+
+ :param headers:
+ Dictionary of custom headers to send, such as User-Agent,
+ If-None-Match, etc. If None, pool headers are used. If provided,
+ these headers completely replace any pool-specific headers.
+
+ :param retries:
+ Configure the number of retries to allow before raising a
+ :class:`~urllib3.exceptions.MaxRetryError` exception.
+
+ Pass ``None`` to retry until you receive a response. Pass a
+ :class:`~urllib3.util.retry.Retry` object for fine-grained control
+ over different types of retries.
+ Pass an integer number to retry connection errors that many times,
+ but no other types of errors. Pass zero to never retry.
+
+ If ``False``, then retries are disabled and any exception is raised
+ immediately. Also, instead of raising a MaxRetryError on redirects,
+ the redirect response will be returned.
+
+ :type retries: :class:`~urllib3.util.retry.Retry`, False, or an int.
+
+ :param redirect:
+ If True, automatically handle redirects (status codes 301, 302,
+ 303, 307, 308). Each redirect counts as a retry. Disabling retries
+ will disable redirect, too.
+
+ :param assert_same_host:
+ If ``True``, will make sure that the host of the pool requests is
+ consistent else will raise HostChangedError. When ``False``, you can
+ use the pool on an HTTP proxy and request foreign hosts.
+
+ :param timeout:
+ If specified, overrides the default timeout for this one
+ request. It may be a float (in seconds) or an instance of
+ :class:`urllib3.util.Timeout`.
+
+ :param pool_timeout:
+ If set and the pool is set to block=True, then this method will
+ block for ``pool_timeout`` seconds and raise EmptyPoolError if no
+ connection is available within the time period.
+
+ :param release_conn:
+ If False, then the urlopen call will not release the connection
+ back into the pool once a response is received (but will release if
+ you read the entire contents of the response such as when
+ `preload_content=True`). This is useful if you're not preloading
+ the response's content immediately. You will need to call
+ ``r.release_conn()`` on the response ``r`` to return the connection
+ back into the pool. If None, it takes the value of
+ ``response_kw.get('preload_content', True)``.
+
+ :param chunked:
+ If True, urllib3 will send the body using chunked transfer
+ encoding. Otherwise, urllib3 will send the body using the standard
+ content-length form. Defaults to False.
+
+ :param int body_pos:
+ Position to seek to in file-like body in the event of a retry or
+ redirect. Typically this won't need to be set because urllib3 will
+ auto-populate the value when needed.
+
+ :param \\**response_kw:
+ Additional parameters are passed to
+ :meth:`urllib3.response.HTTPResponse.from_httplib`
+ """
+
+ parsed_url = parse_url(url)
+ destination_scheme = parsed_url.scheme
+
+ if headers is None:
+ headers = self.headers
+
+ if not isinstance(retries, Retry):
+ retries = Retry.from_int(retries, redirect=redirect, default=self.retries)
+
+ if release_conn is None:
+ release_conn = response_kw.get("preload_content", True)
+
+ # Check host
+ if assert_same_host and not self.is_same_host(url):
+ raise HostChangedError(self, url, retries)
+
+ # Ensure that the URL we're connecting to is properly encoded
+ if url.startswith("/"):
+ url = six.ensure_str(_encode_target(url))
+ else:
+ url = six.ensure_str(parsed_url.url)
+
+ conn = None
+
+ # Track whether `conn` needs to be released before
+ # returning/raising/recursing. Update this variable if necessary, and
+ # leave `release_conn` constant throughout the function. That way, if
+ # the function recurses, the original value of `release_conn` will be
+ # passed down into the recursive call, and its value will be respected.
+ #
+ # See issue #651 [1] for details.
+ #
+ # [1] <https://github.com/urllib3/urllib3/issues/651>
+ release_this_conn = release_conn
+
+ http_tunnel_required = connection_requires_http_tunnel(
+ self.proxy, self.proxy_config, destination_scheme
+ )
+
+ # Merge the proxy headers. Only done when not using HTTP CONNECT. We
+ # have to copy the headers dict so we can safely change it without those
+ # changes being reflected in anyone else's copy.
+ if not http_tunnel_required:
+ headers = headers.copy()
+ headers.update(self.proxy_headers)
+
+ # Must keep the exception bound to a separate variable or else Python 3
+ # complains about UnboundLocalError.
+ err = None
+
+ # Keep track of whether we cleanly exited the except block. This
+ # ensures we do proper cleanup in finally.
+ clean_exit = False
+
+ # Rewind body position, if needed. Record current position
+ # for future rewinds in the event of a redirect/retry.
+ body_pos = set_file_position(body, body_pos)
+
+ try:
+ # Request a connection from the queue.
+ timeout_obj = self._get_timeout(timeout)
+ conn = self._get_conn(timeout=pool_timeout)
+
+ conn.timeout = timeout_obj.connect_timeout
+
+ is_new_proxy_conn = self.proxy is not None and not getattr(
+ conn, "sock", None
+ )
+ if is_new_proxy_conn and http_tunnel_required:
+ self._prepare_proxy(conn)
+
+ # Make the request on the httplib connection object.
+ httplib_response = self._make_request(
+ conn,
+ method,
+ url,
+ timeout=timeout_obj,
+ body=body,
+ headers=headers,
+ chunked=chunked,
+ )
+
+ # If we're going to release the connection in ``finally:``, then
+ # the response doesn't need to know about the connection. Otherwise
+ # it will also try to release it and we'll have a double-release
+ # mess.
+ response_conn = conn if not release_conn else None
+
+ # Pass method to Response for length checking
+ response_kw["request_method"] = method
+
+ # Import httplib's response into our own wrapper object
+ response = self.ResponseCls.from_httplib(
+ httplib_response,
+ pool=self,
+ connection=response_conn,
+ retries=retries,
+ **response_kw
+ )
+
+ # Everything went great!
+ clean_exit = True
+
+ except EmptyPoolError:
+ # Didn't get a connection from the pool, no need to clean up
+ clean_exit = True
+ release_this_conn = False
+ raise
+
+ except (
+ TimeoutError,
+ HTTPException,
+ SocketError,
+ ProtocolError,
+ BaseSSLError,
+ SSLError,
+ CertificateError,
+ ) as e:
+ # Discard the connection for these exceptions. It will be
+ # replaced during the next _get_conn() call.
+ clean_exit = False
+
+ def _is_ssl_error_message_from_http_proxy(ssl_error):
+ # We're trying to detect the message 'WRONG_VERSION_NUMBER' but
+ # SSLErrors are kinda all over the place when it comes to the message,
+ # so we try to cover our bases here!
+ message = " ".join(re.split("[^a-z]", str(ssl_error).lower()))
+ return (
+ "wrong version number" in message
+ or "unknown protocol" in message
+ or "record layer failure" in message
+ )
+
+ # Try to detect a common user error with proxies which is to
+ # set an HTTP proxy to be HTTPS when it should be 'http://'
+ # (ie {'http': 'http://proxy', 'https': 'https://proxy'})
+ # Instead we add a nice error message and point to a URL.
+ if (
+ isinstance(e, BaseSSLError)
+ and self.proxy
+ and _is_ssl_error_message_from_http_proxy(e)
+ and conn.proxy
+ and conn.proxy.scheme == "https"
+ ):
+ e = ProxyError(
+ "Your proxy appears to only use HTTP and not HTTPS, "
+ "try changing your proxy URL to be HTTP. See: "
+ "https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html"
+ "#https-proxy-error-http-proxy",
+ SSLError(e),
+ )
+ elif isinstance(e, (BaseSSLError, CertificateError)):
+ e = SSLError(e)
+ elif isinstance(e, (SocketError, NewConnectionError)) and self.proxy:
+ e = ProxyError("Cannot connect to proxy.", e)
+ elif isinstance(e, (SocketError, HTTPException)):
+ e = ProtocolError("Connection aborted.", e)
+
+ retries = retries.increment(
+ method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
+ )
+ retries.sleep()
+
+ # Keep track of the error for the retry warning.
+ err = e
+
+ finally:
+ if not clean_exit:
+ # We hit some kind of exception, handled or otherwise. We need
+ # to throw the connection away unless explicitly told not to.
+ # Close the connection, set the variable to None, and make sure
+ # we put the None back in the pool to avoid leaking it.
+ conn = conn and conn.close()
+ release_this_conn = True
+
+ if release_this_conn:
+ # Put the connection back to be reused. If the connection is
+ # expired then it will be None, which will get replaced with a
+ # fresh connection during _get_conn.
+ self._put_conn(conn)
+
+ if not conn:
+ # Try again
+ log.warning(
+ "Retrying (%r) after connection broken by '%r': %s", retries, err, url
+ )
+ return self.urlopen(
+ method,
+ url,
+ body,
+ headers,
+ retries,
+ redirect,
+ assert_same_host,
+ timeout=timeout,
+ pool_timeout=pool_timeout,
+ release_conn=release_conn,
+ chunked=chunked,
+ body_pos=body_pos,
+ **response_kw
+ )
+
+ # Handle redirect?
+ redirect_location = redirect and response.get_redirect_location()
+ if redirect_location:
+ if response.status == 303:
+ # Change the method according to RFC 9110, Section 15.4.4.
+ method = "GET"
+ # And lose the body not to transfer anything sensitive.
+ body = None
+ headers = HTTPHeaderDict(headers)._prepare_for_method_change()
+
+ try:
+ retries = retries.increment(method, url, response=response, _pool=self)
+ except MaxRetryError:
+ if retries.raise_on_redirect:
+ response.drain_conn()
+ raise
+ return response
+
+ response.drain_conn()
+ retries.sleep_for_retry(response)
+ log.debug("Redirecting %s -> %s", url, redirect_location)
+ return self.urlopen(
+ method,
+ redirect_location,
+ body,
+ headers,
+ retries=retries,
+ redirect=redirect,
+ assert_same_host=assert_same_host,
+ timeout=timeout,
+ pool_timeout=pool_timeout,
+ release_conn=release_conn,
+ chunked=chunked,
+ body_pos=body_pos,
+ **response_kw
+ )
+
+ # Check if we should retry the HTTP response.
+ has_retry_after = bool(response.headers.get("Retry-After"))
+ if retries.is_retry(method, response.status, has_retry_after):
+ try:
+ retries = retries.increment(method, url, response=response, _pool=self)
+ except MaxRetryError:
+ if retries.raise_on_status:
+ response.drain_conn()
+ raise
+ return response
+
+ response.drain_conn()
+ retries.sleep(response)
+ log.debug("Retry: %s", url)
+ return self.urlopen(
+ method,
+ url,
+ body,
+ headers,
+ retries=retries,
+ redirect=redirect,
+ assert_same_host=assert_same_host,
+ timeout=timeout,
+ pool_timeout=pool_timeout,
+ release_conn=release_conn,
+ chunked=chunked,
+ body_pos=body_pos,
+ **response_kw
+ )
+
+ return response
+
+
+class HTTPSConnectionPool(HTTPConnectionPool):
+ """
+ Same as :class:`.HTTPConnectionPool`, but HTTPS.
+
+ :class:`.HTTPSConnection` uses one of ``assert_fingerprint``,
+ ``assert_hostname`` and ``host`` in this order to verify connections.
+ If ``assert_hostname`` is False, no verification is done.
+
+ The ``key_file``, ``cert_file``, ``cert_reqs``, ``ca_certs``,
+ ``ca_cert_dir``, ``ssl_version``, ``key_password`` are only used if :mod:`ssl`
+ is available and are fed into :meth:`urllib3.util.ssl_wrap_socket` to upgrade
+ the connection socket into an SSL socket.
+ """
+
+ scheme = "https"
+ ConnectionCls = HTTPSConnection
+
+ def __init__(
+ self,
+ host,
+ port=None,
+ strict=False,
+ timeout=Timeout.DEFAULT_TIMEOUT,
+ maxsize=1,
+ block=False,
+ headers=None,
+ retries=None,
+ _proxy=None,
+ _proxy_headers=None,
+ key_file=None,
+ cert_file=None,
+ cert_reqs=None,
+ key_password=None,
+ ca_certs=None,
+ ssl_version=None,
+ assert_hostname=None,
+ assert_fingerprint=None,
+ ca_cert_dir=None,
+ **conn_kw
+ ):
+
+ HTTPConnectionPool.__init__(
+ self,
+ host,
+ port,
+ strict,
+ timeout,
+ maxsize,
+ block,
+ headers,
+ retries,
+ _proxy,
+ _proxy_headers,
+ **conn_kw
+ )
+
+ self.key_file = key_file
+ self.cert_file = cert_file
+ self.cert_reqs = cert_reqs
+ self.key_password = key_password
+ self.ca_certs = ca_certs
+ self.ca_cert_dir = ca_cert_dir
+ self.ssl_version = ssl_version
+ self.assert_hostname = assert_hostname
+ self.assert_fingerprint = assert_fingerprint
+
+ def _prepare_conn(self, conn):
+ """
+ Prepare the ``connection`` for :meth:`urllib3.util.ssl_wrap_socket`
+ and establish the tunnel if proxy is used.
+ """
+
+ if isinstance(conn, VerifiedHTTPSConnection):
+ conn.set_cert(
+ key_file=self.key_file,
+ key_password=self.key_password,
+ cert_file=self.cert_file,
+ cert_reqs=self.cert_reqs,
+ ca_certs=self.ca_certs,
+ ca_cert_dir=self.ca_cert_dir,
+ assert_hostname=self.assert_hostname,
+ assert_fingerprint=self.assert_fingerprint,
+ )
+ conn.ssl_version = self.ssl_version
+ return conn
+
+ def _prepare_proxy(self, conn):
+ """
+ Establishes a tunnel connection through HTTP CONNECT.
+
+ Tunnel connection is established early because otherwise httplib would
+ improperly set Host: header to proxy's IP:port.
+ """
+
+ conn.set_tunnel(self._proxy_host, self.port, self.proxy_headers)
+
+ if self.proxy.scheme == "https":
+ conn.tls_in_tls_required = True
+
+ conn.connect()
+
+ def _new_conn(self):
+ """
+ Return a fresh :class:`http.client.HTTPSConnection`.
+ """
+ self.num_connections += 1
+ log.debug(
+ "Starting new HTTPS connection (%d): %s:%s",
+ self.num_connections,
+ self.host,
+ self.port or "443",
+ )
+
+ if not self.ConnectionCls or self.ConnectionCls is DummyConnection:
+ raise SSLError(
+ "Can't connect to HTTPS URL because the SSL module is not available."
+ )
+
+ actual_host = self.host
+ actual_port = self.port
+ if self.proxy is not None:
+ actual_host = self.proxy.host
+ actual_port = self.proxy.port
+
+ conn = self.ConnectionCls(
+ host=actual_host,
+ port=actual_port,
+ timeout=self.timeout.connect_timeout,
+ strict=self.strict,
+ cert_file=self.cert_file,
+ key_file=self.key_file,
+ key_password=self.key_password,
+ **self.conn_kw
+ )
+
+ return self._prepare_conn(conn)
+
+ def _validate_conn(self, conn):
+ """
+ Called right before a request is made, after the socket is created.
+ """
+ super(HTTPSConnectionPool, self)._validate_conn(conn)
+
+ # Force connect early to allow us to validate the connection.
+ if not getattr(conn, "sock", None): # AppEngine might not have `.sock`
+ conn.connect()
+
+ if not conn.is_verified:
+ warnings.warn(
+ (
+ "Unverified HTTPS request is being made to host '%s'. "
+ "Adding certificate verification is strongly advised. See: "
+ "https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html"
+ "#ssl-warnings" % conn.host
+ ),
+ InsecureRequestWarning,
+ )
+
+ if getattr(conn, "proxy_is_verified", None) is False:
+ warnings.warn(
+ (
+ "Unverified HTTPS connection done to an HTTPS proxy. "
+ "Adding certificate verification is strongly advised. See: "
+ "https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html"
+ "#ssl-warnings"
+ ),
+ InsecureRequestWarning,
+ )
+
+
+def connection_from_url(url, **kw):
+ """
+ Given a url, return an :class:`.ConnectionPool` instance of its host.
+
+ This is a shortcut for not having to parse out the scheme, host, and port
+ of the url before creating an :class:`.ConnectionPool` instance.
+
+ :param url:
+ Absolute URL string that must include the scheme. Port is optional.
+
+ :param \\**kw:
+ Passes additional parameters to the constructor of the appropriate
+ :class:`.ConnectionPool`. Useful for specifying things like
+ timeout, maxsize, headers, etc.
+
+ Example::
+
+ >>> conn = connection_from_url('http://google.com/')
+ >>> r = conn.request('GET', '/')
+ """
+ scheme, host, port = get_host(url)
+ port = port or port_by_scheme.get(scheme, 80)
+ if scheme == "https":
+ return HTTPSConnectionPool(host, port=port, **kw)
+ else:
+ return HTTPConnectionPool(host, port=port, **kw)
+
+
+def _normalize_host(host, scheme):
+ """
+ Normalize hosts for comparisons and use with sockets.
+ """
+
+ host = normalize_host(host, scheme)
+
+ # httplib doesn't like it when we include brackets in IPv6 addresses
+ # Specifically, if we include brackets but also pass the port then
+ # httplib crazily doubles up the square brackets on the Host header.
+ # Instead, we need to make sure we never pass ``None`` as the port.
+ # However, for backward compatibility reasons we can't actually
+ # *assert* that. See http://bugs.python.org/issue28539
+ if host.startswith("[") and host.endswith("]"):
+ host = host[1:-1]
+ return host
+
+
+def _close_pool_connections(pool):
+ """Drains a queue of connections and closes each one."""
+ try:
+ while True:
+ conn = pool.get(block=False)
+ if conn:
+ conn.close()
+ except queue.Empty:
+ pass # Done.
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_appengine_environ.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_appengine_environ.py
new file mode 100644
index 000000000..8765b907d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_appengine_environ.py
@@ -0,0 +1,36 @@
+"""
+This module provides means to detect the App Engine environment.
+"""
+
+import os
+
+
+def is_appengine():
+ return is_local_appengine() or is_prod_appengine()
+
+
+def is_appengine_sandbox():
+ """Reports if the app is running in the first generation sandbox.
+
+ The second generation runtimes are technically still in a sandbox, but it
+ is much less restrictive, so generally you shouldn't need to check for it.
+ see https://cloud.google.com/appengine/docs/standard/runtimes
+ """
+ return is_appengine() and os.environ["APPENGINE_RUNTIME"] == "python27"
+
+
+def is_local_appengine():
+ return "APPENGINE_RUNTIME" in os.environ and os.environ.get(
+ "SERVER_SOFTWARE", ""
+ ).startswith("Development/")
+
+
+def is_prod_appengine():
+ return "APPENGINE_RUNTIME" in os.environ and os.environ.get(
+ "SERVER_SOFTWARE", ""
+ ).startswith("Google App Engine/")
+
+
+def is_prod_appengine_mvms():
+ """Deprecated."""
+ return False
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/bindings.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/bindings.py
new file mode 100644
index 000000000..264d564db
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/bindings.py
@@ -0,0 +1,519 @@
+"""
+This module uses ctypes to bind a whole bunch of functions and constants from
+SecureTransport. The goal here is to provide the low-level API to
+SecureTransport. These are essentially the C-level functions and constants, and
+they're pretty gross to work with.
+
+This code is a bastardised version of the code found in Will Bond's oscrypto
+library. An enormous debt is owed to him for blazing this trail for us. For
+that reason, this code should be considered to be covered both by urllib3's
+license and by oscrypto's:
+
+ Copyright (c) 2015-2016 Will Bond <will@wbond.net>
+
+ Permission is hereby granted, free of charge, to any person obtaining a
+ copy of this software and associated documentation files (the "Software"),
+ to deal in the Software without restriction, including without limitation
+ the rights to use, copy, modify, merge, publish, distribute, sublicense,
+ and/or sell copies of the Software, and to permit persons to whom the
+ Software is furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
+ FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
+ DEALINGS IN THE SOFTWARE.
+"""
+from __future__ import absolute_import
+
+import platform
+from ctypes import (
+ CDLL,
+ CFUNCTYPE,
+ POINTER,
+ c_bool,
+ c_byte,
+ c_char_p,
+ c_int32,
+ c_long,
+ c_size_t,
+ c_uint32,
+ c_ulong,
+ c_void_p,
+)
+from ctypes.util import find_library
+
+from ...packages.six import raise_from
+
+if platform.system() != "Darwin":
+ raise ImportError("Only macOS is supported")
+
+version = platform.mac_ver()[0]
+version_info = tuple(map(int, version.split(".")))
+if version_info < (10, 8):
+ raise OSError(
+ "Only OS X 10.8 and newer are supported, not %s.%s"
+ % (version_info[0], version_info[1])
+ )
+
+
+def load_cdll(name, macos10_16_path):
+ """Loads a CDLL by name, falling back to known path on 10.16+"""
+ try:
+ # Big Sur is technically 11 but we use 10.16 due to the Big Sur
+ # beta being labeled as 10.16.
+ if version_info >= (10, 16):
+ path = macos10_16_path
+ else:
+ path = find_library(name)
+ if not path:
+ raise OSError # Caught and reraised as 'ImportError'
+ return CDLL(path, use_errno=True)
+ except OSError:
+ raise_from(ImportError("The library %s failed to load" % name), None)
+
+
+Security = load_cdll(
+ "Security", "/System/Library/Frameworks/Security.framework/Security"
+)
+CoreFoundation = load_cdll(
+ "CoreFoundation",
+ "/System/Library/Frameworks/CoreFoundation.framework/CoreFoundation",
+)
+
+
+Boolean = c_bool
+CFIndex = c_long
+CFStringEncoding = c_uint32
+CFData = c_void_p
+CFString = c_void_p
+CFArray = c_void_p
+CFMutableArray = c_void_p
+CFDictionary = c_void_p
+CFError = c_void_p
+CFType = c_void_p
+CFTypeID = c_ulong
+
+CFTypeRef = POINTER(CFType)
+CFAllocatorRef = c_void_p
+
+OSStatus = c_int32
+
+CFDataRef = POINTER(CFData)
+CFStringRef = POINTER(CFString)
+CFArrayRef = POINTER(CFArray)
+CFMutableArrayRef = POINTER(CFMutableArray)
+CFDictionaryRef = POINTER(CFDictionary)
+CFArrayCallBacks = c_void_p
+CFDictionaryKeyCallBacks = c_void_p
+CFDictionaryValueCallBacks = c_void_p
+
+SecCertificateRef = POINTER(c_void_p)
+SecExternalFormat = c_uint32
+SecExternalItemType = c_uint32
+SecIdentityRef = POINTER(c_void_p)
+SecItemImportExportFlags = c_uint32
+SecItemImportExportKeyParameters = c_void_p
+SecKeychainRef = POINTER(c_void_p)
+SSLProtocol = c_uint32
+SSLCipherSuite = c_uint32
+SSLContextRef = POINTER(c_void_p)
+SecTrustRef = POINTER(c_void_p)
+SSLConnectionRef = c_uint32
+SecTrustResultType = c_uint32
+SecTrustOptionFlags = c_uint32
+SSLProtocolSide = c_uint32
+SSLConnectionType = c_uint32
+SSLSessionOption = c_uint32
+
+
+try:
+ Security.SecItemImport.argtypes = [
+ CFDataRef,
+ CFStringRef,
+ POINTER(SecExternalFormat),
+ POINTER(SecExternalItemType),
+ SecItemImportExportFlags,
+ POINTER(SecItemImportExportKeyParameters),
+ SecKeychainRef,
+ POINTER(CFArrayRef),
+ ]
+ Security.SecItemImport.restype = OSStatus
+
+ Security.SecCertificateGetTypeID.argtypes = []
+ Security.SecCertificateGetTypeID.restype = CFTypeID
+
+ Security.SecIdentityGetTypeID.argtypes = []
+ Security.SecIdentityGetTypeID.restype = CFTypeID
+
+ Security.SecKeyGetTypeID.argtypes = []
+ Security.SecKeyGetTypeID.restype = CFTypeID
+
+ Security.SecCertificateCreateWithData.argtypes = [CFAllocatorRef, CFDataRef]
+ Security.SecCertificateCreateWithData.restype = SecCertificateRef
+
+ Security.SecCertificateCopyData.argtypes = [SecCertificateRef]
+ Security.SecCertificateCopyData.restype = CFDataRef
+
+ Security.SecCopyErrorMessageString.argtypes = [OSStatus, c_void_p]
+ Security.SecCopyErrorMessageString.restype = CFStringRef
+
+ Security.SecIdentityCreateWithCertificate.argtypes = [
+ CFTypeRef,
+ SecCertificateRef,
+ POINTER(SecIdentityRef),
+ ]
+ Security.SecIdentityCreateWithCertificate.restype = OSStatus
+
+ Security.SecKeychainCreate.argtypes = [
+ c_char_p,
+ c_uint32,
+ c_void_p,
+ Boolean,
+ c_void_p,
+ POINTER(SecKeychainRef),
+ ]
+ Security.SecKeychainCreate.restype = OSStatus
+
+ Security.SecKeychainDelete.argtypes = [SecKeychainRef]
+ Security.SecKeychainDelete.restype = OSStatus
+
+ Security.SecPKCS12Import.argtypes = [
+ CFDataRef,
+ CFDictionaryRef,
+ POINTER(CFArrayRef),
+ ]
+ Security.SecPKCS12Import.restype = OSStatus
+
+ SSLReadFunc = CFUNCTYPE(OSStatus, SSLConnectionRef, c_void_p, POINTER(c_size_t))
+ SSLWriteFunc = CFUNCTYPE(
+ OSStatus, SSLConnectionRef, POINTER(c_byte), POINTER(c_size_t)
+ )
+
+ Security.SSLSetIOFuncs.argtypes = [SSLContextRef, SSLReadFunc, SSLWriteFunc]
+ Security.SSLSetIOFuncs.restype = OSStatus
+
+ Security.SSLSetPeerID.argtypes = [SSLContextRef, c_char_p, c_size_t]
+ Security.SSLSetPeerID.restype = OSStatus
+
+ Security.SSLSetCertificate.argtypes = [SSLContextRef, CFArrayRef]
+ Security.SSLSetCertificate.restype = OSStatus
+
+ Security.SSLSetCertificateAuthorities.argtypes = [SSLContextRef, CFTypeRef, Boolean]
+ Security.SSLSetCertificateAuthorities.restype = OSStatus
+
+ Security.SSLSetConnection.argtypes = [SSLContextRef, SSLConnectionRef]
+ Security.SSLSetConnection.restype = OSStatus
+
+ Security.SSLSetPeerDomainName.argtypes = [SSLContextRef, c_char_p, c_size_t]
+ Security.SSLSetPeerDomainName.restype = OSStatus
+
+ Security.SSLHandshake.argtypes = [SSLContextRef]
+ Security.SSLHandshake.restype = OSStatus
+
+ Security.SSLRead.argtypes = [SSLContextRef, c_char_p, c_size_t, POINTER(c_size_t)]
+ Security.SSLRead.restype = OSStatus
+
+ Security.SSLWrite.argtypes = [SSLContextRef, c_char_p, c_size_t, POINTER(c_size_t)]
+ Security.SSLWrite.restype = OSStatus
+
+ Security.SSLClose.argtypes = [SSLContextRef]
+ Security.SSLClose.restype = OSStatus
+
+ Security.SSLGetNumberSupportedCiphers.argtypes = [SSLContextRef, POINTER(c_size_t)]
+ Security.SSLGetNumberSupportedCiphers.restype = OSStatus
+
+ Security.SSLGetSupportedCiphers.argtypes = [
+ SSLContextRef,
+ POINTER(SSLCipherSuite),
+ POINTER(c_size_t),
+ ]
+ Security.SSLGetSupportedCiphers.restype = OSStatus
+
+ Security.SSLSetEnabledCiphers.argtypes = [
+ SSLContextRef,
+ POINTER(SSLCipherSuite),
+ c_size_t,
+ ]
+ Security.SSLSetEnabledCiphers.restype = OSStatus
+
+ Security.SSLGetNumberEnabledCiphers.argtype = [SSLContextRef, POINTER(c_size_t)]
+ Security.SSLGetNumberEnabledCiphers.restype = OSStatus
+
+ Security.SSLGetEnabledCiphers.argtypes = [
+ SSLContextRef,
+ POINTER(SSLCipherSuite),
+ POINTER(c_size_t),
+ ]
+ Security.SSLGetEnabledCiphers.restype = OSStatus
+
+ Security.SSLGetNegotiatedCipher.argtypes = [SSLContextRef, POINTER(SSLCipherSuite)]
+ Security.SSLGetNegotiatedCipher.restype = OSStatus
+
+ Security.SSLGetNegotiatedProtocolVersion.argtypes = [
+ SSLContextRef,
+ POINTER(SSLProtocol),
+ ]
+ Security.SSLGetNegotiatedProtocolVersion.restype = OSStatus
+
+ Security.SSLCopyPeerTrust.argtypes = [SSLContextRef, POINTER(SecTrustRef)]
+ Security.SSLCopyPeerTrust.restype = OSStatus
+
+ Security.SecTrustSetAnchorCertificates.argtypes = [SecTrustRef, CFArrayRef]
+ Security.SecTrustSetAnchorCertificates.restype = OSStatus
+
+ Security.SecTrustSetAnchorCertificatesOnly.argstypes = [SecTrustRef, Boolean]
+ Security.SecTrustSetAnchorCertificatesOnly.restype = OSStatus
+
+ Security.SecTrustEvaluate.argtypes = [SecTrustRef, POINTER(SecTrustResultType)]
+ Security.SecTrustEvaluate.restype = OSStatus
+
+ Security.SecTrustGetCertificateCount.argtypes = [SecTrustRef]
+ Security.SecTrustGetCertificateCount.restype = CFIndex
+
+ Security.SecTrustGetCertificateAtIndex.argtypes = [SecTrustRef, CFIndex]
+ Security.SecTrustGetCertificateAtIndex.restype = SecCertificateRef
+
+ Security.SSLCreateContext.argtypes = [
+ CFAllocatorRef,
+ SSLProtocolSide,
+ SSLConnectionType,
+ ]
+ Security.SSLCreateContext.restype = SSLContextRef
+
+ Security.SSLSetSessionOption.argtypes = [SSLContextRef, SSLSessionOption, Boolean]
+ Security.SSLSetSessionOption.restype = OSStatus
+
+ Security.SSLSetProtocolVersionMin.argtypes = [SSLContextRef, SSLProtocol]
+ Security.SSLSetProtocolVersionMin.restype = OSStatus
+
+ Security.SSLSetProtocolVersionMax.argtypes = [SSLContextRef, SSLProtocol]
+ Security.SSLSetProtocolVersionMax.restype = OSStatus
+
+ try:
+ Security.SSLSetALPNProtocols.argtypes = [SSLContextRef, CFArrayRef]
+ Security.SSLSetALPNProtocols.restype = OSStatus
+ except AttributeError:
+ # Supported only in 10.12+
+ pass
+
+ Security.SecCopyErrorMessageString.argtypes = [OSStatus, c_void_p]
+ Security.SecCopyErrorMessageString.restype = CFStringRef
+
+ Security.SSLReadFunc = SSLReadFunc
+ Security.SSLWriteFunc = SSLWriteFunc
+ Security.SSLContextRef = SSLContextRef
+ Security.SSLProtocol = SSLProtocol
+ Security.SSLCipherSuite = SSLCipherSuite
+ Security.SecIdentityRef = SecIdentityRef
+ Security.SecKeychainRef = SecKeychainRef
+ Security.SecTrustRef = SecTrustRef
+ Security.SecTrustResultType = SecTrustResultType
+ Security.SecExternalFormat = SecExternalFormat
+ Security.OSStatus = OSStatus
+
+ Security.kSecImportExportPassphrase = CFStringRef.in_dll(
+ Security, "kSecImportExportPassphrase"
+ )
+ Security.kSecImportItemIdentity = CFStringRef.in_dll(
+ Security, "kSecImportItemIdentity"
+ )
+
+ # CoreFoundation time!
+ CoreFoundation.CFRetain.argtypes = [CFTypeRef]
+ CoreFoundation.CFRetain.restype = CFTypeRef
+
+ CoreFoundation.CFRelease.argtypes = [CFTypeRef]
+ CoreFoundation.CFRelease.restype = None
+
+ CoreFoundation.CFGetTypeID.argtypes = [CFTypeRef]
+ CoreFoundation.CFGetTypeID.restype = CFTypeID
+
+ CoreFoundation.CFStringCreateWithCString.argtypes = [
+ CFAllocatorRef,
+ c_char_p,
+ CFStringEncoding,
+ ]
+ CoreFoundation.CFStringCreateWithCString.restype = CFStringRef
+
+ CoreFoundation.CFStringGetCStringPtr.argtypes = [CFStringRef, CFStringEncoding]
+ CoreFoundation.CFStringGetCStringPtr.restype = c_char_p
+
+ CoreFoundation.CFStringGetCString.argtypes = [
+ CFStringRef,
+ c_char_p,
+ CFIndex,
+ CFStringEncoding,
+ ]
+ CoreFoundation.CFStringGetCString.restype = c_bool
+
+ CoreFoundation.CFDataCreate.argtypes = [CFAllocatorRef, c_char_p, CFIndex]
+ CoreFoundation.CFDataCreate.restype = CFDataRef
+
+ CoreFoundation.CFDataGetLength.argtypes = [CFDataRef]
+ CoreFoundation.CFDataGetLength.restype = CFIndex
+
+ CoreFoundation.CFDataGetBytePtr.argtypes = [CFDataRef]
+ CoreFoundation.CFDataGetBytePtr.restype = c_void_p
+
+ CoreFoundation.CFDictionaryCreate.argtypes = [
+ CFAllocatorRef,
+ POINTER(CFTypeRef),
+ POINTER(CFTypeRef),
+ CFIndex,
+ CFDictionaryKeyCallBacks,
+ CFDictionaryValueCallBacks,
+ ]
+ CoreFoundation.CFDictionaryCreate.restype = CFDictionaryRef
+
+ CoreFoundation.CFDictionaryGetValue.argtypes = [CFDictionaryRef, CFTypeRef]
+ CoreFoundation.CFDictionaryGetValue.restype = CFTypeRef
+
+ CoreFoundation.CFArrayCreate.argtypes = [
+ CFAllocatorRef,
+ POINTER(CFTypeRef),
+ CFIndex,
+ CFArrayCallBacks,
+ ]
+ CoreFoundation.CFArrayCreate.restype = CFArrayRef
+
+ CoreFoundation.CFArrayCreateMutable.argtypes = [
+ CFAllocatorRef,
+ CFIndex,
+ CFArrayCallBacks,
+ ]
+ CoreFoundation.CFArrayCreateMutable.restype = CFMutableArrayRef
+
+ CoreFoundation.CFArrayAppendValue.argtypes = [CFMutableArrayRef, c_void_p]
+ CoreFoundation.CFArrayAppendValue.restype = None
+
+ CoreFoundation.CFArrayGetCount.argtypes = [CFArrayRef]
+ CoreFoundation.CFArrayGetCount.restype = CFIndex
+
+ CoreFoundation.CFArrayGetValueAtIndex.argtypes = [CFArrayRef, CFIndex]
+ CoreFoundation.CFArrayGetValueAtIndex.restype = c_void_p
+
+ CoreFoundation.kCFAllocatorDefault = CFAllocatorRef.in_dll(
+ CoreFoundation, "kCFAllocatorDefault"
+ )
+ CoreFoundation.kCFTypeArrayCallBacks = c_void_p.in_dll(
+ CoreFoundation, "kCFTypeArrayCallBacks"
+ )
+ CoreFoundation.kCFTypeDictionaryKeyCallBacks = c_void_p.in_dll(
+ CoreFoundation, "kCFTypeDictionaryKeyCallBacks"
+ )
+ CoreFoundation.kCFTypeDictionaryValueCallBacks = c_void_p.in_dll(
+ CoreFoundation, "kCFTypeDictionaryValueCallBacks"
+ )
+
+ CoreFoundation.CFTypeRef = CFTypeRef
+ CoreFoundation.CFArrayRef = CFArrayRef
+ CoreFoundation.CFStringRef = CFStringRef
+ CoreFoundation.CFDictionaryRef = CFDictionaryRef
+
+except (AttributeError):
+ raise ImportError("Error initializing ctypes")
+
+
+class CFConst(object):
+ """
+ A class object that acts as essentially a namespace for CoreFoundation
+ constants.
+ """
+
+ kCFStringEncodingUTF8 = CFStringEncoding(0x08000100)
+
+
+class SecurityConst(object):
+ """
+ A class object that acts as essentially a namespace for Security constants.
+ """
+
+ kSSLSessionOptionBreakOnServerAuth = 0
+
+ kSSLProtocol2 = 1
+ kSSLProtocol3 = 2
+ kTLSProtocol1 = 4
+ kTLSProtocol11 = 7
+ kTLSProtocol12 = 8
+ # SecureTransport does not support TLS 1.3 even if there's a constant for it
+ kTLSProtocol13 = 10
+ kTLSProtocolMaxSupported = 999
+
+ kSSLClientSide = 1
+ kSSLStreamType = 0
+
+ kSecFormatPEMSequence = 10
+
+ kSecTrustResultInvalid = 0
+ kSecTrustResultProceed = 1
+ # This gap is present on purpose: this was kSecTrustResultConfirm, which
+ # is deprecated.
+ kSecTrustResultDeny = 3
+ kSecTrustResultUnspecified = 4
+ kSecTrustResultRecoverableTrustFailure = 5
+ kSecTrustResultFatalTrustFailure = 6
+ kSecTrustResultOtherError = 7
+
+ errSSLProtocol = -9800
+ errSSLWouldBlock = -9803
+ errSSLClosedGraceful = -9805
+ errSSLClosedNoNotify = -9816
+ errSSLClosedAbort = -9806
+
+ errSSLXCertChainInvalid = -9807
+ errSSLCrypto = -9809
+ errSSLInternal = -9810
+ errSSLCertExpired = -9814
+ errSSLCertNotYetValid = -9815
+ errSSLUnknownRootCert = -9812
+ errSSLNoRootCert = -9813
+ errSSLHostNameMismatch = -9843
+ errSSLPeerHandshakeFail = -9824
+ errSSLPeerUserCancelled = -9839
+ errSSLWeakPeerEphemeralDHKey = -9850
+ errSSLServerAuthCompleted = -9841
+ errSSLRecordOverflow = -9847
+
+ errSecVerifyFailed = -67808
+ errSecNoTrustSettings = -25263
+ errSecItemNotFound = -25300
+ errSecInvalidTrustSettings = -25262
+
+ # Cipher suites. We only pick the ones our default cipher string allows.
+ # Source: https://developer.apple.com/documentation/security/1550981-ssl_cipher_suite_values
+ TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 = 0xC02C
+ TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 = 0xC030
+ TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 = 0xC02B
+ TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 = 0xC02F
+ TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256 = 0xCCA9
+ TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256 = 0xCCA8
+ TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 = 0x009F
+ TLS_DHE_RSA_WITH_AES_128_GCM_SHA256 = 0x009E
+ TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384 = 0xC024
+ TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384 = 0xC028
+ TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA = 0xC00A
+ TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA = 0xC014
+ TLS_DHE_RSA_WITH_AES_256_CBC_SHA256 = 0x006B
+ TLS_DHE_RSA_WITH_AES_256_CBC_SHA = 0x0039
+ TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256 = 0xC023
+ TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256 = 0xC027
+ TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA = 0xC009
+ TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA = 0xC013
+ TLS_DHE_RSA_WITH_AES_128_CBC_SHA256 = 0x0067
+ TLS_DHE_RSA_WITH_AES_128_CBC_SHA = 0x0033
+ TLS_RSA_WITH_AES_256_GCM_SHA384 = 0x009D
+ TLS_RSA_WITH_AES_128_GCM_SHA256 = 0x009C
+ TLS_RSA_WITH_AES_256_CBC_SHA256 = 0x003D
+ TLS_RSA_WITH_AES_128_CBC_SHA256 = 0x003C
+ TLS_RSA_WITH_AES_256_CBC_SHA = 0x0035
+ TLS_RSA_WITH_AES_128_CBC_SHA = 0x002F
+ TLS_AES_128_GCM_SHA256 = 0x1301
+ TLS_AES_256_GCM_SHA384 = 0x1302
+ TLS_AES_128_CCM_8_SHA256 = 0x1305
+ TLS_AES_128_CCM_SHA256 = 0x1304
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/low_level.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/low_level.py
new file mode 100644
index 000000000..fa0b245d2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/_securetransport/low_level.py
@@ -0,0 +1,397 @@
+"""
+Low-level helpers for the SecureTransport bindings.
+
+These are Python functions that are not directly related to the high-level APIs
+but are necessary to get them to work. They include a whole bunch of low-level
+CoreFoundation messing about and memory management. The concerns in this module
+are almost entirely about trying to avoid memory leaks and providing
+appropriate and useful assistance to the higher-level code.
+"""
+import base64
+import ctypes
+import itertools
+import os
+import re
+import ssl
+import struct
+import tempfile
+
+from .bindings import CFConst, CoreFoundation, Security
+
+# This regular expression is used to grab PEM data out of a PEM bundle.
+_PEM_CERTS_RE = re.compile(
+ b"-----BEGIN CERTIFICATE-----\n(.*?)\n-----END CERTIFICATE-----", re.DOTALL
+)
+
+
+def _cf_data_from_bytes(bytestring):
+ """
+ Given a bytestring, create a CFData object from it. This CFData object must
+ be CFReleased by the caller.
+ """
+ return CoreFoundation.CFDataCreate(
+ CoreFoundation.kCFAllocatorDefault, bytestring, len(bytestring)
+ )
+
+
+def _cf_dictionary_from_tuples(tuples):
+ """
+ Given a list of Python tuples, create an associated CFDictionary.
+ """
+ dictionary_size = len(tuples)
+
+ # We need to get the dictionary keys and values out in the same order.
+ keys = (t[0] for t in tuples)
+ values = (t[1] for t in tuples)
+ cf_keys = (CoreFoundation.CFTypeRef * dictionary_size)(*keys)
+ cf_values = (CoreFoundation.CFTypeRef * dictionary_size)(*values)
+
+ return CoreFoundation.CFDictionaryCreate(
+ CoreFoundation.kCFAllocatorDefault,
+ cf_keys,
+ cf_values,
+ dictionary_size,
+ CoreFoundation.kCFTypeDictionaryKeyCallBacks,
+ CoreFoundation.kCFTypeDictionaryValueCallBacks,
+ )
+
+
+def _cfstr(py_bstr):
+ """
+ Given a Python binary data, create a CFString.
+ The string must be CFReleased by the caller.
+ """
+ c_str = ctypes.c_char_p(py_bstr)
+ cf_str = CoreFoundation.CFStringCreateWithCString(
+ CoreFoundation.kCFAllocatorDefault,
+ c_str,
+ CFConst.kCFStringEncodingUTF8,
+ )
+ return cf_str
+
+
+def _create_cfstring_array(lst):
+ """
+ Given a list of Python binary data, create an associated CFMutableArray.
+ The array must be CFReleased by the caller.
+
+ Raises an ssl.SSLError on failure.
+ """
+ cf_arr = None
+ try:
+ cf_arr = CoreFoundation.CFArrayCreateMutable(
+ CoreFoundation.kCFAllocatorDefault,
+ 0,
+ ctypes.byref(CoreFoundation.kCFTypeArrayCallBacks),
+ )
+ if not cf_arr:
+ raise MemoryError("Unable to allocate memory!")
+ for item in lst:
+ cf_str = _cfstr(item)
+ if not cf_str:
+ raise MemoryError("Unable to allocate memory!")
+ try:
+ CoreFoundation.CFArrayAppendValue(cf_arr, cf_str)
+ finally:
+ CoreFoundation.CFRelease(cf_str)
+ except BaseException as e:
+ if cf_arr:
+ CoreFoundation.CFRelease(cf_arr)
+ raise ssl.SSLError("Unable to allocate array: %s" % (e,))
+ return cf_arr
+
+
+def _cf_string_to_unicode(value):
+ """
+ Creates a Unicode string from a CFString object. Used entirely for error
+ reporting.
+
+ Yes, it annoys me quite a lot that this function is this complex.
+ """
+ value_as_void_p = ctypes.cast(value, ctypes.POINTER(ctypes.c_void_p))
+
+ string = CoreFoundation.CFStringGetCStringPtr(
+ value_as_void_p, CFConst.kCFStringEncodingUTF8
+ )
+ if string is None:
+ buffer = ctypes.create_string_buffer(1024)
+ result = CoreFoundation.CFStringGetCString(
+ value_as_void_p, buffer, 1024, CFConst.kCFStringEncodingUTF8
+ )
+ if not result:
+ raise OSError("Error copying C string from CFStringRef")
+ string = buffer.value
+ if string is not None:
+ string = string.decode("utf-8")
+ return string
+
+
+def _assert_no_error(error, exception_class=None):
+ """
+ Checks the return code and throws an exception if there is an error to
+ report
+ """
+ if error == 0:
+ return
+
+ cf_error_string = Security.SecCopyErrorMessageString(error, None)
+ output = _cf_string_to_unicode(cf_error_string)
+ CoreFoundation.CFRelease(cf_error_string)
+
+ if output is None or output == u"":
+ output = u"OSStatus %s" % error
+
+ if exception_class is None:
+ exception_class = ssl.SSLError
+
+ raise exception_class(output)
+
+
+def _cert_array_from_pem(pem_bundle):
+ """
+ Given a bundle of certs in PEM format, turns them into a CFArray of certs
+ that can be used to validate a cert chain.
+ """
+ # Normalize the PEM bundle's line endings.
+ pem_bundle = pem_bundle.replace(b"\r\n", b"\n")
+
+ der_certs = [
+ base64.b64decode(match.group(1)) for match in _PEM_CERTS_RE.finditer(pem_bundle)
+ ]
+ if not der_certs:
+ raise ssl.SSLError("No root certificates specified")
+
+ cert_array = CoreFoundation.CFArrayCreateMutable(
+ CoreFoundation.kCFAllocatorDefault,
+ 0,
+ ctypes.byref(CoreFoundation.kCFTypeArrayCallBacks),
+ )
+ if not cert_array:
+ raise ssl.SSLError("Unable to allocate memory!")
+
+ try:
+ for der_bytes in der_certs:
+ certdata = _cf_data_from_bytes(der_bytes)
+ if not certdata:
+ raise ssl.SSLError("Unable to allocate memory!")
+ cert = Security.SecCertificateCreateWithData(
+ CoreFoundation.kCFAllocatorDefault, certdata
+ )
+ CoreFoundation.CFRelease(certdata)
+ if not cert:
+ raise ssl.SSLError("Unable to build cert object!")
+
+ CoreFoundation.CFArrayAppendValue(cert_array, cert)
+ CoreFoundation.CFRelease(cert)
+ except Exception:
+ # We need to free the array before the exception bubbles further.
+ # We only want to do that if an error occurs: otherwise, the caller
+ # should free.
+ CoreFoundation.CFRelease(cert_array)
+ raise
+
+ return cert_array
+
+
+def _is_cert(item):
+ """
+ Returns True if a given CFTypeRef is a certificate.
+ """
+ expected = Security.SecCertificateGetTypeID()
+ return CoreFoundation.CFGetTypeID(item) == expected
+
+
+def _is_identity(item):
+ """
+ Returns True if a given CFTypeRef is an identity.
+ """
+ expected = Security.SecIdentityGetTypeID()
+ return CoreFoundation.CFGetTypeID(item) == expected
+
+
+def _temporary_keychain():
+ """
+ This function creates a temporary Mac keychain that we can use to work with
+ credentials. This keychain uses a one-time password and a temporary file to
+ store the data. We expect to have one keychain per socket. The returned
+ SecKeychainRef must be freed by the caller, including calling
+ SecKeychainDelete.
+
+ Returns a tuple of the SecKeychainRef and the path to the temporary
+ directory that contains it.
+ """
+ # Unfortunately, SecKeychainCreate requires a path to a keychain. This
+ # means we cannot use mkstemp to use a generic temporary file. Instead,
+ # we're going to create a temporary directory and a filename to use there.
+ # This filename will be 8 random bytes expanded into base64. We also need
+ # some random bytes to password-protect the keychain we're creating, so we
+ # ask for 40 random bytes.
+ random_bytes = os.urandom(40)
+ filename = base64.b16encode(random_bytes[:8]).decode("utf-8")
+ password = base64.b16encode(random_bytes[8:]) # Must be valid UTF-8
+ tempdirectory = tempfile.mkdtemp()
+
+ keychain_path = os.path.join(tempdirectory, filename).encode("utf-8")
+
+ # We now want to create the keychain itself.
+ keychain = Security.SecKeychainRef()
+ status = Security.SecKeychainCreate(
+ keychain_path, len(password), password, False, None, ctypes.byref(keychain)
+ )
+ _assert_no_error(status)
+
+ # Having created the keychain, we want to pass it off to the caller.
+ return keychain, tempdirectory
+
+
+def _load_items_from_file(keychain, path):
+ """
+ Given a single file, loads all the trust objects from it into arrays and
+ the keychain.
+ Returns a tuple of lists: the first list is a list of identities, the
+ second a list of certs.
+ """
+ certificates = []
+ identities = []
+ result_array = None
+
+ with open(path, "rb") as f:
+ raw_filedata = f.read()
+
+ try:
+ filedata = CoreFoundation.CFDataCreate(
+ CoreFoundation.kCFAllocatorDefault, raw_filedata, len(raw_filedata)
+ )
+ result_array = CoreFoundation.CFArrayRef()
+ result = Security.SecItemImport(
+ filedata, # cert data
+ None, # Filename, leaving it out for now
+ None, # What the type of the file is, we don't care
+ None, # what's in the file, we don't care
+ 0, # import flags
+ None, # key params, can include passphrase in the future
+ keychain, # The keychain to insert into
+ ctypes.byref(result_array), # Results
+ )
+ _assert_no_error(result)
+
+ # A CFArray is not very useful to us as an intermediary
+ # representation, so we are going to extract the objects we want
+ # and then free the array. We don't need to keep hold of keys: the
+ # keychain already has them!
+ result_count = CoreFoundation.CFArrayGetCount(result_array)
+ for index in range(result_count):
+ item = CoreFoundation.CFArrayGetValueAtIndex(result_array, index)
+ item = ctypes.cast(item, CoreFoundation.CFTypeRef)
+
+ if _is_cert(item):
+ CoreFoundation.CFRetain(item)
+ certificates.append(item)
+ elif _is_identity(item):
+ CoreFoundation.CFRetain(item)
+ identities.append(item)
+ finally:
+ if result_array:
+ CoreFoundation.CFRelease(result_array)
+
+ CoreFoundation.CFRelease(filedata)
+
+ return (identities, certificates)
+
+
+def _load_client_cert_chain(keychain, *paths):
+ """
+ Load certificates and maybe keys from a number of files. Has the end goal
+ of returning a CFArray containing one SecIdentityRef, and then zero or more
+ SecCertificateRef objects, suitable for use as a client certificate trust
+ chain.
+ """
+ # Ok, the strategy.
+ #
+ # This relies on knowing that macOS will not give you a SecIdentityRef
+ # unless you have imported a key into a keychain. This is a somewhat
+ # artificial limitation of macOS (for example, it doesn't necessarily
+ # affect iOS), but there is nothing inside Security.framework that lets you
+ # get a SecIdentityRef without having a key in a keychain.
+ #
+ # So the policy here is we take all the files and iterate them in order.
+ # Each one will use SecItemImport to have one or more objects loaded from
+ # it. We will also point at a keychain that macOS can use to work with the
+ # private key.
+ #
+ # Once we have all the objects, we'll check what we actually have. If we
+ # already have a SecIdentityRef in hand, fab: we'll use that. Otherwise,
+ # we'll take the first certificate (which we assume to be our leaf) and
+ # ask the keychain to give us a SecIdentityRef with that cert's associated
+ # key.
+ #
+ # We'll then return a CFArray containing the trust chain: one
+ # SecIdentityRef and then zero-or-more SecCertificateRef objects. The
+ # responsibility for freeing this CFArray will be with the caller. This
+ # CFArray must remain alive for the entire connection, so in practice it
+ # will be stored with a single SSLSocket, along with the reference to the
+ # keychain.
+ certificates = []
+ identities = []
+
+ # Filter out bad paths.
+ paths = (path for path in paths if path)
+
+ try:
+ for file_path in paths:
+ new_identities, new_certs = _load_items_from_file(keychain, file_path)
+ identities.extend(new_identities)
+ certificates.extend(new_certs)
+
+ # Ok, we have everything. The question is: do we have an identity? If
+ # not, we want to grab one from the first cert we have.
+ if not identities:
+ new_identity = Security.SecIdentityRef()
+ status = Security.SecIdentityCreateWithCertificate(
+ keychain, certificates[0], ctypes.byref(new_identity)
+ )
+ _assert_no_error(status)
+ identities.append(new_identity)
+
+ # We now want to release the original certificate, as we no longer
+ # need it.
+ CoreFoundation.CFRelease(certificates.pop(0))
+
+ # We now need to build a new CFArray that holds the trust chain.
+ trust_chain = CoreFoundation.CFArrayCreateMutable(
+ CoreFoundation.kCFAllocatorDefault,
+ 0,
+ ctypes.byref(CoreFoundation.kCFTypeArrayCallBacks),
+ )
+ for item in itertools.chain(identities, certificates):
+ # ArrayAppendValue does a CFRetain on the item. That's fine,
+ # because the finally block will release our other refs to them.
+ CoreFoundation.CFArrayAppendValue(trust_chain, item)
+
+ return trust_chain
+ finally:
+ for obj in itertools.chain(identities, certificates):
+ CoreFoundation.CFRelease(obj)
+
+
+TLS_PROTOCOL_VERSIONS = {
+ "SSLv2": (0, 2),
+ "SSLv3": (3, 0),
+ "TLSv1": (3, 1),
+ "TLSv1.1": (3, 2),
+ "TLSv1.2": (3, 3),
+}
+
+
+def _build_tls_unknown_ca_alert(version):
+ """
+ Builds a TLS alert record for an unknown CA.
+ """
+ ver_maj, ver_min = TLS_PROTOCOL_VERSIONS[version]
+ severity_fatal = 0x02
+ description_unknown_ca = 0x30
+ msg = struct.pack(">BB", severity_fatal, description_unknown_ca)
+ msg_len = len(msg)
+ record_type_alert = 0x15
+ record = struct.pack(">BBBH", record_type_alert, ver_maj, ver_min, msg_len) + msg
+ return record
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/appengine.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/appengine.py
new file mode 100644
index 000000000..1717ee22c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/appengine.py
@@ -0,0 +1,314 @@
+"""
+This module provides a pool manager that uses Google App Engine's
+`URLFetch Service <https://cloud.google.com/appengine/docs/python/urlfetch>`_.
+
+Example usage::
+
+ from pip._vendor.urllib3 import PoolManager
+ from pip._vendor.urllib3.contrib.appengine import AppEngineManager, is_appengine_sandbox
+
+ if is_appengine_sandbox():
+ # AppEngineManager uses AppEngine's URLFetch API behind the scenes
+ http = AppEngineManager()
+ else:
+ # PoolManager uses a socket-level API behind the scenes
+ http = PoolManager()
+
+ r = http.request('GET', 'https://google.com/')
+
+There are `limitations <https://cloud.google.com/appengine/docs/python/\
+urlfetch/#Python_Quotas_and_limits>`_ to the URLFetch service and it may not be
+the best choice for your application. There are three options for using
+urllib3 on Google App Engine:
+
+1. You can use :class:`AppEngineManager` with URLFetch. URLFetch is
+ cost-effective in many circumstances as long as your usage is within the
+ limitations.
+2. You can use a normal :class:`~urllib3.PoolManager` by enabling sockets.
+ Sockets also have `limitations and restrictions
+ <https://cloud.google.com/appengine/docs/python/sockets/\
+ #limitations-and-restrictions>`_ and have a lower free quota than URLFetch.
+ To use sockets, be sure to specify the following in your ``app.yaml``::
+
+ env_variables:
+ GAE_USE_SOCKETS_HTTPLIB : 'true'
+
+3. If you are using `App Engine Flexible
+<https://cloud.google.com/appengine/docs/flexible/>`_, you can use the standard
+:class:`PoolManager` without any configuration or special environment variables.
+"""
+
+from __future__ import absolute_import
+
+import io
+import logging
+import warnings
+
+from ..exceptions import (
+ HTTPError,
+ HTTPWarning,
+ MaxRetryError,
+ ProtocolError,
+ SSLError,
+ TimeoutError,
+)
+from ..packages.six.moves.urllib.parse import urljoin
+from ..request import RequestMethods
+from ..response import HTTPResponse
+from ..util.retry import Retry
+from ..util.timeout import Timeout
+from . import _appengine_environ
+
+try:
+ from google.appengine.api import urlfetch
+except ImportError:
+ urlfetch = None
+
+
+log = logging.getLogger(__name__)
+
+
+class AppEnginePlatformWarning(HTTPWarning):
+ pass
+
+
+class AppEnginePlatformError(HTTPError):
+ pass
+
+
+class AppEngineManager(RequestMethods):
+ """
+ Connection manager for Google App Engine sandbox applications.
+
+ This manager uses the URLFetch service directly instead of using the
+ emulated httplib, and is subject to URLFetch limitations as described in
+ the App Engine documentation `here
+ <https://cloud.google.com/appengine/docs/python/urlfetch>`_.
+
+ Notably it will raise an :class:`AppEnginePlatformError` if:
+ * URLFetch is not available.
+ * If you attempt to use this on App Engine Flexible, as full socket
+ support is available.
+ * If a request size is more than 10 megabytes.
+ * If a response size is more than 32 megabytes.
+ * If you use an unsupported request method such as OPTIONS.
+
+ Beyond those cases, it will raise normal urllib3 errors.
+ """
+
+ def __init__(
+ self,
+ headers=None,
+ retries=None,
+ validate_certificate=True,
+ urlfetch_retries=True,
+ ):
+ if not urlfetch:
+ raise AppEnginePlatformError(
+ "URLFetch is not available in this environment."
+ )
+
+ warnings.warn(
+ "urllib3 is using URLFetch on Google App Engine sandbox instead "
+ "of sockets. To use sockets directly instead of URLFetch see "
+ "https://urllib3.readthedocs.io/en/1.26.x/reference/urllib3.contrib.html.",
+ AppEnginePlatformWarning,
+ )
+
+ RequestMethods.__init__(self, headers)
+ self.validate_certificate = validate_certificate
+ self.urlfetch_retries = urlfetch_retries
+
+ self.retries = retries or Retry.DEFAULT
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ # Return False to re-raise any potential exceptions
+ return False
+
+ def urlopen(
+ self,
+ method,
+ url,
+ body=None,
+ headers=None,
+ retries=None,
+ redirect=True,
+ timeout=Timeout.DEFAULT_TIMEOUT,
+ **response_kw
+ ):
+
+ retries = self._get_retries(retries, redirect)
+
+ try:
+ follow_redirects = redirect and retries.redirect != 0 and retries.total
+ response = urlfetch.fetch(
+ url,
+ payload=body,
+ method=method,
+ headers=headers or {},
+ allow_truncated=False,
+ follow_redirects=self.urlfetch_retries and follow_redirects,
+ deadline=self._get_absolute_timeout(timeout),
+ validate_certificate=self.validate_certificate,
+ )
+ except urlfetch.DeadlineExceededError as e:
+ raise TimeoutError(self, e)
+
+ except urlfetch.InvalidURLError as e:
+ if "too large" in str(e):
+ raise AppEnginePlatformError(
+ "URLFetch request too large, URLFetch only "
+ "supports requests up to 10mb in size.",
+ e,
+ )
+ raise ProtocolError(e)
+
+ except urlfetch.DownloadError as e:
+ if "Too many redirects" in str(e):
+ raise MaxRetryError(self, url, reason=e)
+ raise ProtocolError(e)
+
+ except urlfetch.ResponseTooLargeError as e:
+ raise AppEnginePlatformError(
+ "URLFetch response too large, URLFetch only supports"
+ "responses up to 32mb in size.",
+ e,
+ )
+
+ except urlfetch.SSLCertificateError as e:
+ raise SSLError(e)
+
+ except urlfetch.InvalidMethodError as e:
+ raise AppEnginePlatformError(
+ "URLFetch does not support method: %s" % method, e
+ )
+
+ http_response = self._urlfetch_response_to_http_response(
+ response, retries=retries, **response_kw
+ )
+
+ # Handle redirect?
+ redirect_location = redirect and http_response.get_redirect_location()
+ if redirect_location:
+ # Check for redirect response
+ if self.urlfetch_retries and retries.raise_on_redirect:
+ raise MaxRetryError(self, url, "too many redirects")
+ else:
+ if http_response.status == 303:
+ method = "GET"
+
+ try:
+ retries = retries.increment(
+ method, url, response=http_response, _pool=self
+ )
+ except MaxRetryError:
+ if retries.raise_on_redirect:
+ raise MaxRetryError(self, url, "too many redirects")
+ return http_response
+
+ retries.sleep_for_retry(http_response)
+ log.debug("Redirecting %s -> %s", url, redirect_location)
+ redirect_url = urljoin(url, redirect_location)
+ return self.urlopen(
+ method,
+ redirect_url,
+ body,
+ headers,
+ retries=retries,
+ redirect=redirect,
+ timeout=timeout,
+ **response_kw
+ )
+
+ # Check if we should retry the HTTP response.
+ has_retry_after = bool(http_response.headers.get("Retry-After"))
+ if retries.is_retry(method, http_response.status, has_retry_after):
+ retries = retries.increment(method, url, response=http_response, _pool=self)
+ log.debug("Retry: %s", url)
+ retries.sleep(http_response)
+ return self.urlopen(
+ method,
+ url,
+ body=body,
+ headers=headers,
+ retries=retries,
+ redirect=redirect,
+ timeout=timeout,
+ **response_kw
+ )
+
+ return http_response
+
+ def _urlfetch_response_to_http_response(self, urlfetch_resp, **response_kw):
+
+ if is_prod_appengine():
+ # Production GAE handles deflate encoding automatically, but does
+ # not remove the encoding header.
+ content_encoding = urlfetch_resp.headers.get("content-encoding")
+
+ if content_encoding == "deflate":
+ del urlfetch_resp.headers["content-encoding"]
+
+ transfer_encoding = urlfetch_resp.headers.get("transfer-encoding")
+ # We have a full response's content,
+ # so let's make sure we don't report ourselves as chunked data.
+ if transfer_encoding == "chunked":
+ encodings = transfer_encoding.split(",")
+ encodings.remove("chunked")
+ urlfetch_resp.headers["transfer-encoding"] = ",".join(encodings)
+
+ original_response = HTTPResponse(
+ # In order for decoding to work, we must present the content as
+ # a file-like object.
+ body=io.BytesIO(urlfetch_resp.content),
+ msg=urlfetch_resp.header_msg,
+ headers=urlfetch_resp.headers,
+ status=urlfetch_resp.status_code,
+ **response_kw
+ )
+
+ return HTTPResponse(
+ body=io.BytesIO(urlfetch_resp.content),
+ headers=urlfetch_resp.headers,
+ status=urlfetch_resp.status_code,
+ original_response=original_response,
+ **response_kw
+ )
+
+ def _get_absolute_timeout(self, timeout):
+ if timeout is Timeout.DEFAULT_TIMEOUT:
+ return None # Defer to URLFetch's default.
+ if isinstance(timeout, Timeout):
+ if timeout._read is not None or timeout._connect is not None:
+ warnings.warn(
+ "URLFetch does not support granular timeout settings, "
+ "reverting to total or default URLFetch timeout.",
+ AppEnginePlatformWarning,
+ )
+ return timeout.total
+ return timeout
+
+ def _get_retries(self, retries, redirect):
+ if not isinstance(retries, Retry):
+ retries = Retry.from_int(retries, redirect=redirect, default=self.retries)
+
+ if retries.connect or retries.read or retries.redirect:
+ warnings.warn(
+ "URLFetch only supports total retries and does not "
+ "recognize connect, read, or redirect retry parameters.",
+ AppEnginePlatformWarning,
+ )
+
+ return retries
+
+
+# Alias methods from _appengine_environ to maintain public API interface.
+
+is_appengine = _appengine_environ.is_appengine
+is_appengine_sandbox = _appengine_environ.is_appengine_sandbox
+is_local_appengine = _appengine_environ.is_local_appengine
+is_prod_appengine = _appengine_environ.is_prod_appengine
+is_prod_appengine_mvms = _appengine_environ.is_prod_appengine_mvms
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/ntlmpool.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/ntlmpool.py
new file mode 100644
index 000000000..471665754
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/ntlmpool.py
@@ -0,0 +1,130 @@
+"""
+NTLM authenticating pool, contributed by erikcederstran
+
+Issue #10, see: http://code.google.com/p/urllib3/issues/detail?id=10
+"""
+from __future__ import absolute_import
+
+import warnings
+from logging import getLogger
+
+from ntlm import ntlm
+
+from .. import HTTPSConnectionPool
+from ..packages.six.moves.http_client import HTTPSConnection
+
+warnings.warn(
+ "The 'urllib3.contrib.ntlmpool' module is deprecated and will be removed "
+ "in urllib3 v2.0 release, urllib3 is not able to support it properly due "
+ "to reasons listed in issue: https://github.com/urllib3/urllib3/issues/2282. "
+ "If you are a user of this module please comment in the mentioned issue.",
+ DeprecationWarning,
+)
+
+log = getLogger(__name__)
+
+
+class NTLMConnectionPool(HTTPSConnectionPool):
+ """
+ Implements an NTLM authentication version of an urllib3 connection pool
+ """
+
+ scheme = "https"
+
+ def __init__(self, user, pw, authurl, *args, **kwargs):
+ """
+ authurl is a random URL on the server that is protected by NTLM.
+ user is the Windows user, probably in the DOMAIN\\username format.
+ pw is the password for the user.
+ """
+ super(NTLMConnectionPool, self).__init__(*args, **kwargs)
+ self.authurl = authurl
+ self.rawuser = user
+ user_parts = user.split("\\", 1)
+ self.domain = user_parts[0].upper()
+ self.user = user_parts[1]
+ self.pw = pw
+
+ def _new_conn(self):
+ # Performs the NTLM handshake that secures the connection. The socket
+ # must be kept open while requests are performed.
+ self.num_connections += 1
+ log.debug(
+ "Starting NTLM HTTPS connection no. %d: https://%s%s",
+ self.num_connections,
+ self.host,
+ self.authurl,
+ )
+
+ headers = {"Connection": "Keep-Alive"}
+ req_header = "Authorization"
+ resp_header = "www-authenticate"
+
+ conn = HTTPSConnection(host=self.host, port=self.port)
+
+ # Send negotiation message
+ headers[req_header] = "NTLM %s" % ntlm.create_NTLM_NEGOTIATE_MESSAGE(
+ self.rawuser
+ )
+ log.debug("Request headers: %s", headers)
+ conn.request("GET", self.authurl, None, headers)
+ res = conn.getresponse()
+ reshdr = dict(res.headers)
+ log.debug("Response status: %s %s", res.status, res.reason)
+ log.debug("Response headers: %s", reshdr)
+ log.debug("Response data: %s [...]", res.read(100))
+
+ # Remove the reference to the socket, so that it can not be closed by
+ # the response object (we want to keep the socket open)
+ res.fp = None
+
+ # Server should respond with a challenge message
+ auth_header_values = reshdr[resp_header].split(", ")
+ auth_header_value = None
+ for s in auth_header_values:
+ if s[:5] == "NTLM ":
+ auth_header_value = s[5:]
+ if auth_header_value is None:
+ raise Exception(
+ "Unexpected %s response header: %s" % (resp_header, reshdr[resp_header])
+ )
+
+ # Send authentication message
+ ServerChallenge, NegotiateFlags = ntlm.parse_NTLM_CHALLENGE_MESSAGE(
+ auth_header_value
+ )
+ auth_msg = ntlm.create_NTLM_AUTHENTICATE_MESSAGE(
+ ServerChallenge, self.user, self.domain, self.pw, NegotiateFlags
+ )
+ headers[req_header] = "NTLM %s" % auth_msg
+ log.debug("Request headers: %s", headers)
+ conn.request("GET", self.authurl, None, headers)
+ res = conn.getresponse()
+ log.debug("Response status: %s %s", res.status, res.reason)
+ log.debug("Response headers: %s", dict(res.headers))
+ log.debug("Response data: %s [...]", res.read()[:100])
+ if res.status != 200:
+ if res.status == 401:
+ raise Exception("Server rejected request: wrong username or password")
+ raise Exception("Wrong server response: %s %s" % (res.status, res.reason))
+
+ res.fp = None
+ log.debug("Connection established")
+ return conn
+
+ def urlopen(
+ self,
+ method,
+ url,
+ body=None,
+ headers=None,
+ retries=3,
+ redirect=True,
+ assert_same_host=True,
+ ):
+ if headers is None:
+ headers = {}
+ headers["Connection"] = "Keep-Alive"
+ return super(NTLMConnectionPool, self).urlopen(
+ method, url, body, headers, retries, redirect, assert_same_host
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/pyopenssl.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/pyopenssl.py
new file mode 100644
index 000000000..19e4aa97c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/pyopenssl.py
@@ -0,0 +1,518 @@
+"""
+TLS with SNI_-support for Python 2. Follow these instructions if you would
+like to verify TLS certificates in Python 2. Note, the default libraries do
+*not* do certificate checking; you need to do additional work to validate
+certificates yourself.
+
+This needs the following packages installed:
+
+* `pyOpenSSL`_ (tested with 16.0.0)
+* `cryptography`_ (minimum 1.3.4, from pyopenssl)
+* `idna`_ (minimum 2.0, from cryptography)
+
+However, pyopenssl depends on cryptography, which depends on idna, so while we
+use all three directly here we end up having relatively few packages required.
+
+You can install them with the following command:
+
+.. code-block:: bash
+
+ $ python -m pip install pyopenssl cryptography idna
+
+To activate certificate checking, call
+:func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code
+before you begin making HTTP requests. This can be done in a ``sitecustomize``
+module, or at any other time before your application begins using ``urllib3``,
+like this:
+
+.. code-block:: python
+
+ try:
+ import pip._vendor.urllib3.contrib.pyopenssl as pyopenssl
+ pyopenssl.inject_into_urllib3()
+ except ImportError:
+ pass
+
+Now you can use :mod:`urllib3` as you normally would, and it will support SNI
+when the required modules are installed.
+
+Activating this module also has the positive side effect of disabling SSL/TLS
+compression in Python 2 (see `CRIME attack`_).
+
+.. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication
+.. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)
+.. _pyopenssl: https://www.pyopenssl.org
+.. _cryptography: https://cryptography.io
+.. _idna: https://github.com/kjd/idna
+"""
+from __future__ import absolute_import
+
+import OpenSSL.crypto
+import OpenSSL.SSL
+from cryptography import x509
+from cryptography.hazmat.backends.openssl import backend as openssl_backend
+
+try:
+ from cryptography.x509 import UnsupportedExtension
+except ImportError:
+ # UnsupportedExtension is gone in cryptography >= 2.1.0
+ class UnsupportedExtension(Exception):
+ pass
+
+
+from io import BytesIO
+from socket import error as SocketError
+from socket import timeout
+
+try: # Platform-specific: Python 2
+ from socket import _fileobject
+except ImportError: # Platform-specific: Python 3
+ _fileobject = None
+ from ..packages.backports.makefile import backport_makefile
+
+import logging
+import ssl
+import sys
+import warnings
+
+from .. import util
+from ..packages import six
+from ..util.ssl_ import PROTOCOL_TLS_CLIENT
+
+warnings.warn(
+ "'urllib3.contrib.pyopenssl' module is deprecated and will be removed "
+ "in a future release of urllib3 2.x. Read more in this issue: "
+ "https://github.com/urllib3/urllib3/issues/2680",
+ category=DeprecationWarning,
+ stacklevel=2,
+)
+
+__all__ = ["inject_into_urllib3", "extract_from_urllib3"]
+
+# SNI always works.
+HAS_SNI = True
+
+# Map from urllib3 to PyOpenSSL compatible parameter-values.
+_openssl_versions = {
+ util.PROTOCOL_TLS: OpenSSL.SSL.SSLv23_METHOD,
+ PROTOCOL_TLS_CLIENT: OpenSSL.SSL.SSLv23_METHOD,
+ ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,
+}
+
+if hasattr(ssl, "PROTOCOL_SSLv3") and hasattr(OpenSSL.SSL, "SSLv3_METHOD"):
+ _openssl_versions[ssl.PROTOCOL_SSLv3] = OpenSSL.SSL.SSLv3_METHOD
+
+if hasattr(ssl, "PROTOCOL_TLSv1_1") and hasattr(OpenSSL.SSL, "TLSv1_1_METHOD"):
+ _openssl_versions[ssl.PROTOCOL_TLSv1_1] = OpenSSL.SSL.TLSv1_1_METHOD
+
+if hasattr(ssl, "PROTOCOL_TLSv1_2") and hasattr(OpenSSL.SSL, "TLSv1_2_METHOD"):
+ _openssl_versions[ssl.PROTOCOL_TLSv1_2] = OpenSSL.SSL.TLSv1_2_METHOD
+
+
+_stdlib_to_openssl_verify = {
+ ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,
+ ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,
+ ssl.CERT_REQUIRED: OpenSSL.SSL.VERIFY_PEER
+ + OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,
+}
+_openssl_to_stdlib_verify = dict((v, k) for k, v in _stdlib_to_openssl_verify.items())
+
+# OpenSSL will only write 16K at a time
+SSL_WRITE_BLOCKSIZE = 16384
+
+orig_util_HAS_SNI = util.HAS_SNI
+orig_util_SSLContext = util.ssl_.SSLContext
+
+
+log = logging.getLogger(__name__)
+
+
+def inject_into_urllib3():
+ "Monkey-patch urllib3 with PyOpenSSL-backed SSL-support."
+
+ _validate_dependencies_met()
+
+ util.SSLContext = PyOpenSSLContext
+ util.ssl_.SSLContext = PyOpenSSLContext
+ util.HAS_SNI = HAS_SNI
+ util.ssl_.HAS_SNI = HAS_SNI
+ util.IS_PYOPENSSL = True
+ util.ssl_.IS_PYOPENSSL = True
+
+
+def extract_from_urllib3():
+ "Undo monkey-patching by :func:`inject_into_urllib3`."
+
+ util.SSLContext = orig_util_SSLContext
+ util.ssl_.SSLContext = orig_util_SSLContext
+ util.HAS_SNI = orig_util_HAS_SNI
+ util.ssl_.HAS_SNI = orig_util_HAS_SNI
+ util.IS_PYOPENSSL = False
+ util.ssl_.IS_PYOPENSSL = False
+
+
+def _validate_dependencies_met():
+ """
+ Verifies that PyOpenSSL's package-level dependencies have been met.
+ Throws `ImportError` if they are not met.
+ """
+ # Method added in `cryptography==1.1`; not available in older versions
+ from cryptography.x509.extensions import Extensions
+
+ if getattr(Extensions, "get_extension_for_class", None) is None:
+ raise ImportError(
+ "'cryptography' module missing required functionality. "
+ "Try upgrading to v1.3.4 or newer."
+ )
+
+ # pyOpenSSL 0.14 and above use cryptography for OpenSSL bindings. The _x509
+ # attribute is only present on those versions.
+ from OpenSSL.crypto import X509
+
+ x509 = X509()
+ if getattr(x509, "_x509", None) is None:
+ raise ImportError(
+ "'pyOpenSSL' module missing required functionality. "
+ "Try upgrading to v0.14 or newer."
+ )
+
+
+def _dnsname_to_stdlib(name):
+ """
+ Converts a dNSName SubjectAlternativeName field to the form used by the
+ standard library on the given Python version.
+
+ Cryptography produces a dNSName as a unicode string that was idna-decoded
+ from ASCII bytes. We need to idna-encode that string to get it back, and
+ then on Python 3 we also need to convert to unicode via UTF-8 (the stdlib
+ uses PyUnicode_FromStringAndSize on it, which decodes via UTF-8).
+
+ If the name cannot be idna-encoded then we return None signalling that
+ the name given should be skipped.
+ """
+
+ def idna_encode(name):
+ """
+ Borrowed wholesale from the Python Cryptography Project. It turns out
+ that we can't just safely call `idna.encode`: it can explode for
+ wildcard names. This avoids that problem.
+ """
+ from pip._vendor import idna
+
+ try:
+ for prefix in [u"*.", u"."]:
+ if name.startswith(prefix):
+ name = name[len(prefix) :]
+ return prefix.encode("ascii") + idna.encode(name)
+ return idna.encode(name)
+ except idna.core.IDNAError:
+ return None
+
+ # Don't send IPv6 addresses through the IDNA encoder.
+ if ":" in name:
+ return name
+
+ name = idna_encode(name)
+ if name is None:
+ return None
+ elif sys.version_info >= (3, 0):
+ name = name.decode("utf-8")
+ return name
+
+
+def get_subj_alt_name(peer_cert):
+ """
+ Given an PyOpenSSL certificate, provides all the subject alternative names.
+ """
+ # Pass the cert to cryptography, which has much better APIs for this.
+ if hasattr(peer_cert, "to_cryptography"):
+ cert = peer_cert.to_cryptography()
+ else:
+ der = OpenSSL.crypto.dump_certificate(OpenSSL.crypto.FILETYPE_ASN1, peer_cert)
+ cert = x509.load_der_x509_certificate(der, openssl_backend)
+
+ # We want to find the SAN extension. Ask Cryptography to locate it (it's
+ # faster than looping in Python)
+ try:
+ ext = cert.extensions.get_extension_for_class(x509.SubjectAlternativeName).value
+ except x509.ExtensionNotFound:
+ # No such extension, return the empty list.
+ return []
+ except (
+ x509.DuplicateExtension,
+ UnsupportedExtension,
+ x509.UnsupportedGeneralNameType,
+ UnicodeError,
+ ) as e:
+ # A problem has been found with the quality of the certificate. Assume
+ # no SAN field is present.
+ log.warning(
+ "A problem was encountered with the certificate that prevented "
+ "urllib3 from finding the SubjectAlternativeName field. This can "
+ "affect certificate validation. The error was %s",
+ e,
+ )
+ return []
+
+ # We want to return dNSName and iPAddress fields. We need to cast the IPs
+ # back to strings because the match_hostname function wants them as
+ # strings.
+ # Sadly the DNS names need to be idna encoded and then, on Python 3, UTF-8
+ # decoded. This is pretty frustrating, but that's what the standard library
+ # does with certificates, and so we need to attempt to do the same.
+ # We also want to skip over names which cannot be idna encoded.
+ names = [
+ ("DNS", name)
+ for name in map(_dnsname_to_stdlib, ext.get_values_for_type(x509.DNSName))
+ if name is not None
+ ]
+ names.extend(
+ ("IP Address", str(name)) for name in ext.get_values_for_type(x509.IPAddress)
+ )
+
+ return names
+
+
+class WrappedSocket(object):
+ """API-compatibility wrapper for Python OpenSSL's Connection-class.
+
+ Note: _makefile_refs, _drop() and _reuse() are needed for the garbage
+ collector of pypy.
+ """
+
+ def __init__(self, connection, socket, suppress_ragged_eofs=True):
+ self.connection = connection
+ self.socket = socket
+ self.suppress_ragged_eofs = suppress_ragged_eofs
+ self._makefile_refs = 0
+ self._closed = False
+
+ def fileno(self):
+ return self.socket.fileno()
+
+ # Copy-pasted from Python 3.5 source code
+ def _decref_socketios(self):
+ if self._makefile_refs > 0:
+ self._makefile_refs -= 1
+ if self._closed:
+ self.close()
+
+ def recv(self, *args, **kwargs):
+ try:
+ data = self.connection.recv(*args, **kwargs)
+ except OpenSSL.SSL.SysCallError as e:
+ if self.suppress_ragged_eofs and e.args == (-1, "Unexpected EOF"):
+ return b""
+ else:
+ raise SocketError(str(e))
+ except OpenSSL.SSL.ZeroReturnError:
+ if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:
+ return b""
+ else:
+ raise
+ except OpenSSL.SSL.WantReadError:
+ if not util.wait_for_read(self.socket, self.socket.gettimeout()):
+ raise timeout("The read operation timed out")
+ else:
+ return self.recv(*args, **kwargs)
+
+ # TLS 1.3 post-handshake authentication
+ except OpenSSL.SSL.Error as e:
+ raise ssl.SSLError("read error: %r" % e)
+ else:
+ return data
+
+ def recv_into(self, *args, **kwargs):
+ try:
+ return self.connection.recv_into(*args, **kwargs)
+ except OpenSSL.SSL.SysCallError as e:
+ if self.suppress_ragged_eofs and e.args == (-1, "Unexpected EOF"):
+ return 0
+ else:
+ raise SocketError(str(e))
+ except OpenSSL.SSL.ZeroReturnError:
+ if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:
+ return 0
+ else:
+ raise
+ except OpenSSL.SSL.WantReadError:
+ if not util.wait_for_read(self.socket, self.socket.gettimeout()):
+ raise timeout("The read operation timed out")
+ else:
+ return self.recv_into(*args, **kwargs)
+
+ # TLS 1.3 post-handshake authentication
+ except OpenSSL.SSL.Error as e:
+ raise ssl.SSLError("read error: %r" % e)
+
+ def settimeout(self, timeout):
+ return self.socket.settimeout(timeout)
+
+ def _send_until_done(self, data):
+ while True:
+ try:
+ return self.connection.send(data)
+ except OpenSSL.SSL.WantWriteError:
+ if not util.wait_for_write(self.socket, self.socket.gettimeout()):
+ raise timeout()
+ continue
+ except OpenSSL.SSL.SysCallError as e:
+ raise SocketError(str(e))
+
+ def sendall(self, data):
+ total_sent = 0
+ while total_sent < len(data):
+ sent = self._send_until_done(
+ data[total_sent : total_sent + SSL_WRITE_BLOCKSIZE]
+ )
+ total_sent += sent
+
+ def shutdown(self):
+ # FIXME rethrow compatible exceptions should we ever use this
+ self.connection.shutdown()
+
+ def close(self):
+ if self._makefile_refs < 1:
+ try:
+ self._closed = True
+ return self.connection.close()
+ except OpenSSL.SSL.Error:
+ return
+ else:
+ self._makefile_refs -= 1
+
+ def getpeercert(self, binary_form=False):
+ x509 = self.connection.get_peer_certificate()
+
+ if not x509:
+ return x509
+
+ if binary_form:
+ return OpenSSL.crypto.dump_certificate(OpenSSL.crypto.FILETYPE_ASN1, x509)
+
+ return {
+ "subject": ((("commonName", x509.get_subject().CN),),),
+ "subjectAltName": get_subj_alt_name(x509),
+ }
+
+ def version(self):
+ return self.connection.get_protocol_version_name()
+
+ def _reuse(self):
+ self._makefile_refs += 1
+
+ def _drop(self):
+ if self._makefile_refs < 1:
+ self.close()
+ else:
+ self._makefile_refs -= 1
+
+
+if _fileobject: # Platform-specific: Python 2
+
+ def makefile(self, mode, bufsize=-1):
+ self._makefile_refs += 1
+ return _fileobject(self, mode, bufsize, close=True)
+
+else: # Platform-specific: Python 3
+ makefile = backport_makefile
+
+WrappedSocket.makefile = makefile
+
+
+class PyOpenSSLContext(object):
+ """
+ I am a wrapper class for the PyOpenSSL ``Context`` object. I am responsible
+ for translating the interface of the standard library ``SSLContext`` object
+ to calls into PyOpenSSL.
+ """
+
+ def __init__(self, protocol):
+ self.protocol = _openssl_versions[protocol]
+ self._ctx = OpenSSL.SSL.Context(self.protocol)
+ self._options = 0
+ self.check_hostname = False
+
+ @property
+ def options(self):
+ return self._options
+
+ @options.setter
+ def options(self, value):
+ self._options = value
+ self._ctx.set_options(value)
+
+ @property
+ def verify_mode(self):
+ return _openssl_to_stdlib_verify[self._ctx.get_verify_mode()]
+
+ @verify_mode.setter
+ def verify_mode(self, value):
+ self._ctx.set_verify(_stdlib_to_openssl_verify[value], _verify_callback)
+
+ def set_default_verify_paths(self):
+ self._ctx.set_default_verify_paths()
+
+ def set_ciphers(self, ciphers):
+ if isinstance(ciphers, six.text_type):
+ ciphers = ciphers.encode("utf-8")
+ self._ctx.set_cipher_list(ciphers)
+
+ def load_verify_locations(self, cafile=None, capath=None, cadata=None):
+ if cafile is not None:
+ cafile = cafile.encode("utf-8")
+ if capath is not None:
+ capath = capath.encode("utf-8")
+ try:
+ self._ctx.load_verify_locations(cafile, capath)
+ if cadata is not None:
+ self._ctx.load_verify_locations(BytesIO(cadata))
+ except OpenSSL.SSL.Error as e:
+ raise ssl.SSLError("unable to load trusted certificates: %r" % e)
+
+ def load_cert_chain(self, certfile, keyfile=None, password=None):
+ self._ctx.use_certificate_chain_file(certfile)
+ if password is not None:
+ if not isinstance(password, six.binary_type):
+ password = password.encode("utf-8")
+ self._ctx.set_passwd_cb(lambda *_: password)
+ self._ctx.use_privatekey_file(keyfile or certfile)
+
+ def set_alpn_protocols(self, protocols):
+ protocols = [six.ensure_binary(p) for p in protocols]
+ return self._ctx.set_alpn_protos(protocols)
+
+ def wrap_socket(
+ self,
+ sock,
+ server_side=False,
+ do_handshake_on_connect=True,
+ suppress_ragged_eofs=True,
+ server_hostname=None,
+ ):
+ cnx = OpenSSL.SSL.Connection(self._ctx, sock)
+
+ if isinstance(server_hostname, six.text_type): # Platform-specific: Python 3
+ server_hostname = server_hostname.encode("utf-8")
+
+ if server_hostname is not None:
+ cnx.set_tlsext_host_name(server_hostname)
+
+ cnx.set_connect_state()
+
+ while True:
+ try:
+ cnx.do_handshake()
+ except OpenSSL.SSL.WantReadError:
+ if not util.wait_for_read(sock, sock.gettimeout()):
+ raise timeout("select timed out")
+ continue
+ except OpenSSL.SSL.Error as e:
+ raise ssl.SSLError("bad handshake: %r" % e)
+ break
+
+ return WrappedSocket(cnx, sock)
+
+
+def _verify_callback(cnx, x509, err_no, err_depth, return_code):
+ return err_no == 0
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/securetransport.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/securetransport.py
new file mode 100644
index 000000000..722ee4e12
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/securetransport.py
@@ -0,0 +1,920 @@
+"""
+SecureTranport support for urllib3 via ctypes.
+
+This makes platform-native TLS available to urllib3 users on macOS without the
+use of a compiler. This is an important feature because the Python Package
+Index is moving to become a TLSv1.2-or-higher server, and the default OpenSSL
+that ships with macOS is not capable of doing TLSv1.2. The only way to resolve
+this is to give macOS users an alternative solution to the problem, and that
+solution is to use SecureTransport.
+
+We use ctypes here because this solution must not require a compiler. That's
+because pip is not allowed to require a compiler either.
+
+This is not intended to be a seriously long-term solution to this problem.
+The hope is that PEP 543 will eventually solve this issue for us, at which
+point we can retire this contrib module. But in the short term, we need to
+solve the impending tire fire that is Python on Mac without this kind of
+contrib module. So...here we are.
+
+To use this module, simply import and inject it::
+
+ import pip._vendor.urllib3.contrib.securetransport as securetransport
+ securetransport.inject_into_urllib3()
+
+Happy TLSing!
+
+This code is a bastardised version of the code found in Will Bond's oscrypto
+library. An enormous debt is owed to him for blazing this trail for us. For
+that reason, this code should be considered to be covered both by urllib3's
+license and by oscrypto's:
+
+.. code-block::
+
+ Copyright (c) 2015-2016 Will Bond <will@wbond.net>
+
+ Permission is hereby granted, free of charge, to any person obtaining a
+ copy of this software and associated documentation files (the "Software"),
+ to deal in the Software without restriction, including without limitation
+ the rights to use, copy, modify, merge, publish, distribute, sublicense,
+ and/or sell copies of the Software, and to permit persons to whom the
+ Software is furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
+ FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
+ DEALINGS IN THE SOFTWARE.
+"""
+from __future__ import absolute_import
+
+import contextlib
+import ctypes
+import errno
+import os.path
+import shutil
+import socket
+import ssl
+import struct
+import threading
+import weakref
+
+from .. import util
+from ..packages import six
+from ..util.ssl_ import PROTOCOL_TLS_CLIENT
+from ._securetransport.bindings import CoreFoundation, Security, SecurityConst
+from ._securetransport.low_level import (
+ _assert_no_error,
+ _build_tls_unknown_ca_alert,
+ _cert_array_from_pem,
+ _create_cfstring_array,
+ _load_client_cert_chain,
+ _temporary_keychain,
+)
+
+try: # Platform-specific: Python 2
+ from socket import _fileobject
+except ImportError: # Platform-specific: Python 3
+ _fileobject = None
+ from ..packages.backports.makefile import backport_makefile
+
+__all__ = ["inject_into_urllib3", "extract_from_urllib3"]
+
+# SNI always works
+HAS_SNI = True
+
+orig_util_HAS_SNI = util.HAS_SNI
+orig_util_SSLContext = util.ssl_.SSLContext
+
+# This dictionary is used by the read callback to obtain a handle to the
+# calling wrapped socket. This is a pretty silly approach, but for now it'll
+# do. I feel like I should be able to smuggle a handle to the wrapped socket
+# directly in the SSLConnectionRef, but for now this approach will work I
+# guess.
+#
+# We need to lock around this structure for inserts, but we don't do it for
+# reads/writes in the callbacks. The reasoning here goes as follows:
+#
+# 1. It is not possible to call into the callbacks before the dictionary is
+# populated, so once in the callback the id must be in the dictionary.
+# 2. The callbacks don't mutate the dictionary, they only read from it, and
+# so cannot conflict with any of the insertions.
+#
+# This is good: if we had to lock in the callbacks we'd drastically slow down
+# the performance of this code.
+_connection_refs = weakref.WeakValueDictionary()
+_connection_ref_lock = threading.Lock()
+
+# Limit writes to 16kB. This is OpenSSL's limit, but we'll cargo-cult it over
+# for no better reason than we need *a* limit, and this one is right there.
+SSL_WRITE_BLOCKSIZE = 16384
+
+# This is our equivalent of util.ssl_.DEFAULT_CIPHERS, but expanded out to
+# individual cipher suites. We need to do this because this is how
+# SecureTransport wants them.
+CIPHER_SUITES = [
+ SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,
+ SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,
+ SecurityConst.TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,
+ SecurityConst.TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,
+ SecurityConst.TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256,
+ SecurityConst.TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256,
+ SecurityConst.TLS_DHE_RSA_WITH_AES_256_GCM_SHA384,
+ SecurityConst.TLS_DHE_RSA_WITH_AES_128_GCM_SHA256,
+ SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384,
+ SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA,
+ SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256,
+ SecurityConst.TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA,
+ SecurityConst.TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384,
+ SecurityConst.TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA,
+ SecurityConst.TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256,
+ SecurityConst.TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,
+ SecurityConst.TLS_DHE_RSA_WITH_AES_256_CBC_SHA256,
+ SecurityConst.TLS_DHE_RSA_WITH_AES_256_CBC_SHA,
+ SecurityConst.TLS_DHE_RSA_WITH_AES_128_CBC_SHA256,
+ SecurityConst.TLS_DHE_RSA_WITH_AES_128_CBC_SHA,
+ SecurityConst.TLS_AES_256_GCM_SHA384,
+ SecurityConst.TLS_AES_128_GCM_SHA256,
+ SecurityConst.TLS_RSA_WITH_AES_256_GCM_SHA384,
+ SecurityConst.TLS_RSA_WITH_AES_128_GCM_SHA256,
+ SecurityConst.TLS_AES_128_CCM_8_SHA256,
+ SecurityConst.TLS_AES_128_CCM_SHA256,
+ SecurityConst.TLS_RSA_WITH_AES_256_CBC_SHA256,
+ SecurityConst.TLS_RSA_WITH_AES_128_CBC_SHA256,
+ SecurityConst.TLS_RSA_WITH_AES_256_CBC_SHA,
+ SecurityConst.TLS_RSA_WITH_AES_128_CBC_SHA,
+]
+
+# Basically this is simple: for PROTOCOL_SSLv23 we turn it into a low of
+# TLSv1 and a high of TLSv1.2. For everything else, we pin to that version.
+# TLSv1 to 1.2 are supported on macOS 10.8+
+_protocol_to_min_max = {
+ util.PROTOCOL_TLS: (SecurityConst.kTLSProtocol1, SecurityConst.kTLSProtocol12),
+ PROTOCOL_TLS_CLIENT: (SecurityConst.kTLSProtocol1, SecurityConst.kTLSProtocol12),
+}
+
+if hasattr(ssl, "PROTOCOL_SSLv2"):
+ _protocol_to_min_max[ssl.PROTOCOL_SSLv2] = (
+ SecurityConst.kSSLProtocol2,
+ SecurityConst.kSSLProtocol2,
+ )
+if hasattr(ssl, "PROTOCOL_SSLv3"):
+ _protocol_to_min_max[ssl.PROTOCOL_SSLv3] = (
+ SecurityConst.kSSLProtocol3,
+ SecurityConst.kSSLProtocol3,
+ )
+if hasattr(ssl, "PROTOCOL_TLSv1"):
+ _protocol_to_min_max[ssl.PROTOCOL_TLSv1] = (
+ SecurityConst.kTLSProtocol1,
+ SecurityConst.kTLSProtocol1,
+ )
+if hasattr(ssl, "PROTOCOL_TLSv1_1"):
+ _protocol_to_min_max[ssl.PROTOCOL_TLSv1_1] = (
+ SecurityConst.kTLSProtocol11,
+ SecurityConst.kTLSProtocol11,
+ )
+if hasattr(ssl, "PROTOCOL_TLSv1_2"):
+ _protocol_to_min_max[ssl.PROTOCOL_TLSv1_2] = (
+ SecurityConst.kTLSProtocol12,
+ SecurityConst.kTLSProtocol12,
+ )
+
+
+def inject_into_urllib3():
+ """
+ Monkey-patch urllib3 with SecureTransport-backed SSL-support.
+ """
+ util.SSLContext = SecureTransportContext
+ util.ssl_.SSLContext = SecureTransportContext
+ util.HAS_SNI = HAS_SNI
+ util.ssl_.HAS_SNI = HAS_SNI
+ util.IS_SECURETRANSPORT = True
+ util.ssl_.IS_SECURETRANSPORT = True
+
+
+def extract_from_urllib3():
+ """
+ Undo monkey-patching by :func:`inject_into_urllib3`.
+ """
+ util.SSLContext = orig_util_SSLContext
+ util.ssl_.SSLContext = orig_util_SSLContext
+ util.HAS_SNI = orig_util_HAS_SNI
+ util.ssl_.HAS_SNI = orig_util_HAS_SNI
+ util.IS_SECURETRANSPORT = False
+ util.ssl_.IS_SECURETRANSPORT = False
+
+
+def _read_callback(connection_id, data_buffer, data_length_pointer):
+ """
+ SecureTransport read callback. This is called by ST to request that data
+ be returned from the socket.
+ """
+ wrapped_socket = None
+ try:
+ wrapped_socket = _connection_refs.get(connection_id)
+ if wrapped_socket is None:
+ return SecurityConst.errSSLInternal
+ base_socket = wrapped_socket.socket
+
+ requested_length = data_length_pointer[0]
+
+ timeout = wrapped_socket.gettimeout()
+ error = None
+ read_count = 0
+
+ try:
+ while read_count < requested_length:
+ if timeout is None or timeout >= 0:
+ if not util.wait_for_read(base_socket, timeout):
+ raise socket.error(errno.EAGAIN, "timed out")
+
+ remaining = requested_length - read_count
+ buffer = (ctypes.c_char * remaining).from_address(
+ data_buffer + read_count
+ )
+ chunk_size = base_socket.recv_into(buffer, remaining)
+ read_count += chunk_size
+ if not chunk_size:
+ if not read_count:
+ return SecurityConst.errSSLClosedGraceful
+ break
+ except (socket.error) as e:
+ error = e.errno
+
+ if error is not None and error != errno.EAGAIN:
+ data_length_pointer[0] = read_count
+ if error == errno.ECONNRESET or error == errno.EPIPE:
+ return SecurityConst.errSSLClosedAbort
+ raise
+
+ data_length_pointer[0] = read_count
+
+ if read_count != requested_length:
+ return SecurityConst.errSSLWouldBlock
+
+ return 0
+ except Exception as e:
+ if wrapped_socket is not None:
+ wrapped_socket._exception = e
+ return SecurityConst.errSSLInternal
+
+
+def _write_callback(connection_id, data_buffer, data_length_pointer):
+ """
+ SecureTransport write callback. This is called by ST to request that data
+ actually be sent on the network.
+ """
+ wrapped_socket = None
+ try:
+ wrapped_socket = _connection_refs.get(connection_id)
+ if wrapped_socket is None:
+ return SecurityConst.errSSLInternal
+ base_socket = wrapped_socket.socket
+
+ bytes_to_write = data_length_pointer[0]
+ data = ctypes.string_at(data_buffer, bytes_to_write)
+
+ timeout = wrapped_socket.gettimeout()
+ error = None
+ sent = 0
+
+ try:
+ while sent < bytes_to_write:
+ if timeout is None or timeout >= 0:
+ if not util.wait_for_write(base_socket, timeout):
+ raise socket.error(errno.EAGAIN, "timed out")
+ chunk_sent = base_socket.send(data)
+ sent += chunk_sent
+
+ # This has some needless copying here, but I'm not sure there's
+ # much value in optimising this data path.
+ data = data[chunk_sent:]
+ except (socket.error) as e:
+ error = e.errno
+
+ if error is not None and error != errno.EAGAIN:
+ data_length_pointer[0] = sent
+ if error == errno.ECONNRESET or error == errno.EPIPE:
+ return SecurityConst.errSSLClosedAbort
+ raise
+
+ data_length_pointer[0] = sent
+
+ if sent != bytes_to_write:
+ return SecurityConst.errSSLWouldBlock
+
+ return 0
+ except Exception as e:
+ if wrapped_socket is not None:
+ wrapped_socket._exception = e
+ return SecurityConst.errSSLInternal
+
+
+# We need to keep these two objects references alive: if they get GC'd while
+# in use then SecureTransport could attempt to call a function that is in freed
+# memory. That would be...uh...bad. Yeah, that's the word. Bad.
+_read_callback_pointer = Security.SSLReadFunc(_read_callback)
+_write_callback_pointer = Security.SSLWriteFunc(_write_callback)
+
+
+class WrappedSocket(object):
+ """
+ API-compatibility wrapper for Python's OpenSSL wrapped socket object.
+
+ Note: _makefile_refs, _drop(), and _reuse() are needed for the garbage
+ collector of PyPy.
+ """
+
+ def __init__(self, socket):
+ self.socket = socket
+ self.context = None
+ self._makefile_refs = 0
+ self._closed = False
+ self._exception = None
+ self._keychain = None
+ self._keychain_dir = None
+ self._client_cert_chain = None
+
+ # We save off the previously-configured timeout and then set it to
+ # zero. This is done because we use select and friends to handle the
+ # timeouts, but if we leave the timeout set on the lower socket then
+ # Python will "kindly" call select on that socket again for us. Avoid
+ # that by forcing the timeout to zero.
+ self._timeout = self.socket.gettimeout()
+ self.socket.settimeout(0)
+
+ @contextlib.contextmanager
+ def _raise_on_error(self):
+ """
+ A context manager that can be used to wrap calls that do I/O from
+ SecureTransport. If any of the I/O callbacks hit an exception, this
+ context manager will correctly propagate the exception after the fact.
+ This avoids silently swallowing those exceptions.
+
+ It also correctly forces the socket closed.
+ """
+ self._exception = None
+
+ # We explicitly don't catch around this yield because in the unlikely
+ # event that an exception was hit in the block we don't want to swallow
+ # it.
+ yield
+ if self._exception is not None:
+ exception, self._exception = self._exception, None
+ self.close()
+ raise exception
+
+ def _set_ciphers(self):
+ """
+ Sets up the allowed ciphers. By default this matches the set in
+ util.ssl_.DEFAULT_CIPHERS, at least as supported by macOS. This is done
+ custom and doesn't allow changing at this time, mostly because parsing
+ OpenSSL cipher strings is going to be a freaking nightmare.
+ """
+ ciphers = (Security.SSLCipherSuite * len(CIPHER_SUITES))(*CIPHER_SUITES)
+ result = Security.SSLSetEnabledCiphers(
+ self.context, ciphers, len(CIPHER_SUITES)
+ )
+ _assert_no_error(result)
+
+ def _set_alpn_protocols(self, protocols):
+ """
+ Sets up the ALPN protocols on the context.
+ """
+ if not protocols:
+ return
+ protocols_arr = _create_cfstring_array(protocols)
+ try:
+ result = Security.SSLSetALPNProtocols(self.context, protocols_arr)
+ _assert_no_error(result)
+ finally:
+ CoreFoundation.CFRelease(protocols_arr)
+
+ def _custom_validate(self, verify, trust_bundle):
+ """
+ Called when we have set custom validation. We do this in two cases:
+ first, when cert validation is entirely disabled; and second, when
+ using a custom trust DB.
+ Raises an SSLError if the connection is not trusted.
+ """
+ # If we disabled cert validation, just say: cool.
+ if not verify:
+ return
+
+ successes = (
+ SecurityConst.kSecTrustResultUnspecified,
+ SecurityConst.kSecTrustResultProceed,
+ )
+ try:
+ trust_result = self._evaluate_trust(trust_bundle)
+ if trust_result in successes:
+ return
+ reason = "error code: %d" % (trust_result,)
+ except Exception as e:
+ # Do not trust on error
+ reason = "exception: %r" % (e,)
+
+ # SecureTransport does not send an alert nor shuts down the connection.
+ rec = _build_tls_unknown_ca_alert(self.version())
+ self.socket.sendall(rec)
+ # close the connection immediately
+ # l_onoff = 1, activate linger
+ # l_linger = 0, linger for 0 seoncds
+ opts = struct.pack("ii", 1, 0)
+ self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_LINGER, opts)
+ self.close()
+ raise ssl.SSLError("certificate verify failed, %s" % reason)
+
+ def _evaluate_trust(self, trust_bundle):
+ # We want data in memory, so load it up.
+ if os.path.isfile(trust_bundle):
+ with open(trust_bundle, "rb") as f:
+ trust_bundle = f.read()
+
+ cert_array = None
+ trust = Security.SecTrustRef()
+
+ try:
+ # Get a CFArray that contains the certs we want.
+ cert_array = _cert_array_from_pem(trust_bundle)
+
+ # Ok, now the hard part. We want to get the SecTrustRef that ST has
+ # created for this connection, shove our CAs into it, tell ST to
+ # ignore everything else it knows, and then ask if it can build a
+ # chain. This is a buuuunch of code.
+ result = Security.SSLCopyPeerTrust(self.context, ctypes.byref(trust))
+ _assert_no_error(result)
+ if not trust:
+ raise ssl.SSLError("Failed to copy trust reference")
+
+ result = Security.SecTrustSetAnchorCertificates(trust, cert_array)
+ _assert_no_error(result)
+
+ result = Security.SecTrustSetAnchorCertificatesOnly(trust, True)
+ _assert_no_error(result)
+
+ trust_result = Security.SecTrustResultType()
+ result = Security.SecTrustEvaluate(trust, ctypes.byref(trust_result))
+ _assert_no_error(result)
+ finally:
+ if trust:
+ CoreFoundation.CFRelease(trust)
+
+ if cert_array is not None:
+ CoreFoundation.CFRelease(cert_array)
+
+ return trust_result.value
+
+ def handshake(
+ self,
+ server_hostname,
+ verify,
+ trust_bundle,
+ min_version,
+ max_version,
+ client_cert,
+ client_key,
+ client_key_passphrase,
+ alpn_protocols,
+ ):
+ """
+ Actually performs the TLS handshake. This is run automatically by
+ wrapped socket, and shouldn't be needed in user code.
+ """
+ # First, we do the initial bits of connection setup. We need to create
+ # a context, set its I/O funcs, and set the connection reference.
+ self.context = Security.SSLCreateContext(
+ None, SecurityConst.kSSLClientSide, SecurityConst.kSSLStreamType
+ )
+ result = Security.SSLSetIOFuncs(
+ self.context, _read_callback_pointer, _write_callback_pointer
+ )
+ _assert_no_error(result)
+
+ # Here we need to compute the handle to use. We do this by taking the
+ # id of self modulo 2**31 - 1. If this is already in the dictionary, we
+ # just keep incrementing by one until we find a free space.
+ with _connection_ref_lock:
+ handle = id(self) % 2147483647
+ while handle in _connection_refs:
+ handle = (handle + 1) % 2147483647
+ _connection_refs[handle] = self
+
+ result = Security.SSLSetConnection(self.context, handle)
+ _assert_no_error(result)
+
+ # If we have a server hostname, we should set that too.
+ if server_hostname:
+ if not isinstance(server_hostname, bytes):
+ server_hostname = server_hostname.encode("utf-8")
+
+ result = Security.SSLSetPeerDomainName(
+ self.context, server_hostname, len(server_hostname)
+ )
+ _assert_no_error(result)
+
+ # Setup the ciphers.
+ self._set_ciphers()
+
+ # Setup the ALPN protocols.
+ self._set_alpn_protocols(alpn_protocols)
+
+ # Set the minimum and maximum TLS versions.
+ result = Security.SSLSetProtocolVersionMin(self.context, min_version)
+ _assert_no_error(result)
+
+ result = Security.SSLSetProtocolVersionMax(self.context, max_version)
+ _assert_no_error(result)
+
+ # If there's a trust DB, we need to use it. We do that by telling
+ # SecureTransport to break on server auth. We also do that if we don't
+ # want to validate the certs at all: we just won't actually do any
+ # authing in that case.
+ if not verify or trust_bundle is not None:
+ result = Security.SSLSetSessionOption(
+ self.context, SecurityConst.kSSLSessionOptionBreakOnServerAuth, True
+ )
+ _assert_no_error(result)
+
+ # If there's a client cert, we need to use it.
+ if client_cert:
+ self._keychain, self._keychain_dir = _temporary_keychain()
+ self._client_cert_chain = _load_client_cert_chain(
+ self._keychain, client_cert, client_key
+ )
+ result = Security.SSLSetCertificate(self.context, self._client_cert_chain)
+ _assert_no_error(result)
+
+ while True:
+ with self._raise_on_error():
+ result = Security.SSLHandshake(self.context)
+
+ if result == SecurityConst.errSSLWouldBlock:
+ raise socket.timeout("handshake timed out")
+ elif result == SecurityConst.errSSLServerAuthCompleted:
+ self._custom_validate(verify, trust_bundle)
+ continue
+ else:
+ _assert_no_error(result)
+ break
+
+ def fileno(self):
+ return self.socket.fileno()
+
+ # Copy-pasted from Python 3.5 source code
+ def _decref_socketios(self):
+ if self._makefile_refs > 0:
+ self._makefile_refs -= 1
+ if self._closed:
+ self.close()
+
+ def recv(self, bufsiz):
+ buffer = ctypes.create_string_buffer(bufsiz)
+ bytes_read = self.recv_into(buffer, bufsiz)
+ data = buffer[:bytes_read]
+ return data
+
+ def recv_into(self, buffer, nbytes=None):
+ # Read short on EOF.
+ if self._closed:
+ return 0
+
+ if nbytes is None:
+ nbytes = len(buffer)
+
+ buffer = (ctypes.c_char * nbytes).from_buffer(buffer)
+ processed_bytes = ctypes.c_size_t(0)
+
+ with self._raise_on_error():
+ result = Security.SSLRead(
+ self.context, buffer, nbytes, ctypes.byref(processed_bytes)
+ )
+
+ # There are some result codes that we want to treat as "not always
+ # errors". Specifically, those are errSSLWouldBlock,
+ # errSSLClosedGraceful, and errSSLClosedNoNotify.
+ if result == SecurityConst.errSSLWouldBlock:
+ # If we didn't process any bytes, then this was just a time out.
+ # However, we can get errSSLWouldBlock in situations when we *did*
+ # read some data, and in those cases we should just read "short"
+ # and return.
+ if processed_bytes.value == 0:
+ # Timed out, no data read.
+ raise socket.timeout("recv timed out")
+ elif result in (
+ SecurityConst.errSSLClosedGraceful,
+ SecurityConst.errSSLClosedNoNotify,
+ ):
+ # The remote peer has closed this connection. We should do so as
+ # well. Note that we don't actually return here because in
+ # principle this could actually be fired along with return data.
+ # It's unlikely though.
+ self.close()
+ else:
+ _assert_no_error(result)
+
+ # Ok, we read and probably succeeded. We should return whatever data
+ # was actually read.
+ return processed_bytes.value
+
+ def settimeout(self, timeout):
+ self._timeout = timeout
+
+ def gettimeout(self):
+ return self._timeout
+
+ def send(self, data):
+ processed_bytes = ctypes.c_size_t(0)
+
+ with self._raise_on_error():
+ result = Security.SSLWrite(
+ self.context, data, len(data), ctypes.byref(processed_bytes)
+ )
+
+ if result == SecurityConst.errSSLWouldBlock and processed_bytes.value == 0:
+ # Timed out
+ raise socket.timeout("send timed out")
+ else:
+ _assert_no_error(result)
+
+ # We sent, and probably succeeded. Tell them how much we sent.
+ return processed_bytes.value
+
+ def sendall(self, data):
+ total_sent = 0
+ while total_sent < len(data):
+ sent = self.send(data[total_sent : total_sent + SSL_WRITE_BLOCKSIZE])
+ total_sent += sent
+
+ def shutdown(self):
+ with self._raise_on_error():
+ Security.SSLClose(self.context)
+
+ def close(self):
+ # TODO: should I do clean shutdown here? Do I have to?
+ if self._makefile_refs < 1:
+ self._closed = True
+ if self.context:
+ CoreFoundation.CFRelease(self.context)
+ self.context = None
+ if self._client_cert_chain:
+ CoreFoundation.CFRelease(self._client_cert_chain)
+ self._client_cert_chain = None
+ if self._keychain:
+ Security.SecKeychainDelete(self._keychain)
+ CoreFoundation.CFRelease(self._keychain)
+ shutil.rmtree(self._keychain_dir)
+ self._keychain = self._keychain_dir = None
+ return self.socket.close()
+ else:
+ self._makefile_refs -= 1
+
+ def getpeercert(self, binary_form=False):
+ # Urgh, annoying.
+ #
+ # Here's how we do this:
+ #
+ # 1. Call SSLCopyPeerTrust to get hold of the trust object for this
+ # connection.
+ # 2. Call SecTrustGetCertificateAtIndex for index 0 to get the leaf.
+ # 3. To get the CN, call SecCertificateCopyCommonName and process that
+ # string so that it's of the appropriate type.
+ # 4. To get the SAN, we need to do something a bit more complex:
+ # a. Call SecCertificateCopyValues to get the data, requesting
+ # kSecOIDSubjectAltName.
+ # b. Mess about with this dictionary to try to get the SANs out.
+ #
+ # This is gross. Really gross. It's going to be a few hundred LoC extra
+ # just to repeat something that SecureTransport can *already do*. So my
+ # operating assumption at this time is that what we want to do is
+ # instead to just flag to urllib3 that it shouldn't do its own hostname
+ # validation when using SecureTransport.
+ if not binary_form:
+ raise ValueError("SecureTransport only supports dumping binary certs")
+ trust = Security.SecTrustRef()
+ certdata = None
+ der_bytes = None
+
+ try:
+ # Grab the trust store.
+ result = Security.SSLCopyPeerTrust(self.context, ctypes.byref(trust))
+ _assert_no_error(result)
+ if not trust:
+ # Probably we haven't done the handshake yet. No biggie.
+ return None
+
+ cert_count = Security.SecTrustGetCertificateCount(trust)
+ if not cert_count:
+ # Also a case that might happen if we haven't handshaked.
+ # Handshook? Handshaken?
+ return None
+
+ leaf = Security.SecTrustGetCertificateAtIndex(trust, 0)
+ assert leaf
+
+ # Ok, now we want the DER bytes.
+ certdata = Security.SecCertificateCopyData(leaf)
+ assert certdata
+
+ data_length = CoreFoundation.CFDataGetLength(certdata)
+ data_buffer = CoreFoundation.CFDataGetBytePtr(certdata)
+ der_bytes = ctypes.string_at(data_buffer, data_length)
+ finally:
+ if certdata:
+ CoreFoundation.CFRelease(certdata)
+ if trust:
+ CoreFoundation.CFRelease(trust)
+
+ return der_bytes
+
+ def version(self):
+ protocol = Security.SSLProtocol()
+ result = Security.SSLGetNegotiatedProtocolVersion(
+ self.context, ctypes.byref(protocol)
+ )
+ _assert_no_error(result)
+ if protocol.value == SecurityConst.kTLSProtocol13:
+ raise ssl.SSLError("SecureTransport does not support TLS 1.3")
+ elif protocol.value == SecurityConst.kTLSProtocol12:
+ return "TLSv1.2"
+ elif protocol.value == SecurityConst.kTLSProtocol11:
+ return "TLSv1.1"
+ elif protocol.value == SecurityConst.kTLSProtocol1:
+ return "TLSv1"
+ elif protocol.value == SecurityConst.kSSLProtocol3:
+ return "SSLv3"
+ elif protocol.value == SecurityConst.kSSLProtocol2:
+ return "SSLv2"
+ else:
+ raise ssl.SSLError("Unknown TLS version: %r" % protocol)
+
+ def _reuse(self):
+ self._makefile_refs += 1
+
+ def _drop(self):
+ if self._makefile_refs < 1:
+ self.close()
+ else:
+ self._makefile_refs -= 1
+
+
+if _fileobject: # Platform-specific: Python 2
+
+ def makefile(self, mode, bufsize=-1):
+ self._makefile_refs += 1
+ return _fileobject(self, mode, bufsize, close=True)
+
+else: # Platform-specific: Python 3
+
+ def makefile(self, mode="r", buffering=None, *args, **kwargs):
+ # We disable buffering with SecureTransport because it conflicts with
+ # the buffering that ST does internally (see issue #1153 for more).
+ buffering = 0
+ return backport_makefile(self, mode, buffering, *args, **kwargs)
+
+
+WrappedSocket.makefile = makefile
+
+
+class SecureTransportContext(object):
+ """
+ I am a wrapper class for the SecureTransport library, to translate the
+ interface of the standard library ``SSLContext`` object to calls into
+ SecureTransport.
+ """
+
+ def __init__(self, protocol):
+ self._min_version, self._max_version = _protocol_to_min_max[protocol]
+ self._options = 0
+ self._verify = False
+ self._trust_bundle = None
+ self._client_cert = None
+ self._client_key = None
+ self._client_key_passphrase = None
+ self._alpn_protocols = None
+
+ @property
+ def check_hostname(self):
+ """
+ SecureTransport cannot have its hostname checking disabled. For more,
+ see the comment on getpeercert() in this file.
+ """
+ return True
+
+ @check_hostname.setter
+ def check_hostname(self, value):
+ """
+ SecureTransport cannot have its hostname checking disabled. For more,
+ see the comment on getpeercert() in this file.
+ """
+ pass
+
+ @property
+ def options(self):
+ # TODO: Well, crap.
+ #
+ # So this is the bit of the code that is the most likely to cause us
+ # trouble. Essentially we need to enumerate all of the SSL options that
+ # users might want to use and try to see if we can sensibly translate
+ # them, or whether we should just ignore them.
+ return self._options
+
+ @options.setter
+ def options(self, value):
+ # TODO: Update in line with above.
+ self._options = value
+
+ @property
+ def verify_mode(self):
+ return ssl.CERT_REQUIRED if self._verify else ssl.CERT_NONE
+
+ @verify_mode.setter
+ def verify_mode(self, value):
+ self._verify = True if value == ssl.CERT_REQUIRED else False
+
+ def set_default_verify_paths(self):
+ # So, this has to do something a bit weird. Specifically, what it does
+ # is nothing.
+ #
+ # This means that, if we had previously had load_verify_locations
+ # called, this does not undo that. We need to do that because it turns
+ # out that the rest of the urllib3 code will attempt to load the
+ # default verify paths if it hasn't been told about any paths, even if
+ # the context itself was sometime earlier. We resolve that by just
+ # ignoring it.
+ pass
+
+ def load_default_certs(self):
+ return self.set_default_verify_paths()
+
+ def set_ciphers(self, ciphers):
+ # For now, we just require the default cipher string.
+ if ciphers != util.ssl_.DEFAULT_CIPHERS:
+ raise ValueError("SecureTransport doesn't support custom cipher strings")
+
+ def load_verify_locations(self, cafile=None, capath=None, cadata=None):
+ # OK, we only really support cadata and cafile.
+ if capath is not None:
+ raise ValueError("SecureTransport does not support cert directories")
+
+ # Raise if cafile does not exist.
+ if cafile is not None:
+ with open(cafile):
+ pass
+
+ self._trust_bundle = cafile or cadata
+
+ def load_cert_chain(self, certfile, keyfile=None, password=None):
+ self._client_cert = certfile
+ self._client_key = keyfile
+ self._client_cert_passphrase = password
+
+ def set_alpn_protocols(self, protocols):
+ """
+ Sets the ALPN protocols that will later be set on the context.
+
+ Raises a NotImplementedError if ALPN is not supported.
+ """
+ if not hasattr(Security, "SSLSetALPNProtocols"):
+ raise NotImplementedError(
+ "SecureTransport supports ALPN only in macOS 10.12+"
+ )
+ self._alpn_protocols = [six.ensure_binary(p) for p in protocols]
+
+ def wrap_socket(
+ self,
+ sock,
+ server_side=False,
+ do_handshake_on_connect=True,
+ suppress_ragged_eofs=True,
+ server_hostname=None,
+ ):
+ # So, what do we do here? Firstly, we assert some properties. This is a
+ # stripped down shim, so there is some functionality we don't support.
+ # See PEP 543 for the real deal.
+ assert not server_side
+ assert do_handshake_on_connect
+ assert suppress_ragged_eofs
+
+ # Ok, we're good to go. Now we want to create the wrapped socket object
+ # and store it in the appropriate place.
+ wrapped_socket = WrappedSocket(sock)
+
+ # Now we can handshake
+ wrapped_socket.handshake(
+ server_hostname,
+ self._verify,
+ self._trust_bundle,
+ self._min_version,
+ self._max_version,
+ self._client_cert,
+ self._client_key,
+ self._client_key_passphrase,
+ self._alpn_protocols,
+ )
+ return wrapped_socket
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/socks.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/socks.py
new file mode 100644
index 000000000..c326e80dd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/contrib/socks.py
@@ -0,0 +1,216 @@
+# -*- coding: utf-8 -*-
+"""
+This module contains provisional support for SOCKS proxies from within
+urllib3. This module supports SOCKS4, SOCKS4A (an extension of SOCKS4), and
+SOCKS5. To enable its functionality, either install PySocks or install this
+module with the ``socks`` extra.
+
+The SOCKS implementation supports the full range of urllib3 features. It also
+supports the following SOCKS features:
+
+- SOCKS4A (``proxy_url='socks4a://...``)
+- SOCKS4 (``proxy_url='socks4://...``)
+- SOCKS5 with remote DNS (``proxy_url='socks5h://...``)
+- SOCKS5 with local DNS (``proxy_url='socks5://...``)
+- Usernames and passwords for the SOCKS proxy
+
+.. note::
+ It is recommended to use ``socks5h://`` or ``socks4a://`` schemes in
+ your ``proxy_url`` to ensure that DNS resolution is done from the remote
+ server instead of client-side when connecting to a domain name.
+
+SOCKS4 supports IPv4 and domain names with the SOCKS4A extension. SOCKS5
+supports IPv4, IPv6, and domain names.
+
+When connecting to a SOCKS4 proxy the ``username`` portion of the ``proxy_url``
+will be sent as the ``userid`` section of the SOCKS request:
+
+.. code-block:: python
+
+ proxy_url="socks4a://<userid>@proxy-host"
+
+When connecting to a SOCKS5 proxy the ``username`` and ``password`` portion
+of the ``proxy_url`` will be sent as the username/password to authenticate
+with the proxy:
+
+.. code-block:: python
+
+ proxy_url="socks5h://<username>:<password>@proxy-host"
+
+"""
+from __future__ import absolute_import
+
+try:
+ import socks
+except ImportError:
+ import warnings
+
+ from ..exceptions import DependencyWarning
+
+ warnings.warn(
+ (
+ "SOCKS support in urllib3 requires the installation of optional "
+ "dependencies: specifically, PySocks. For more information, see "
+ "https://urllib3.readthedocs.io/en/1.26.x/contrib.html#socks-proxies"
+ ),
+ DependencyWarning,
+ )
+ raise
+
+from socket import error as SocketError
+from socket import timeout as SocketTimeout
+
+from ..connection import HTTPConnection, HTTPSConnection
+from ..connectionpool import HTTPConnectionPool, HTTPSConnectionPool
+from ..exceptions import ConnectTimeoutError, NewConnectionError
+from ..poolmanager import PoolManager
+from ..util.url import parse_url
+
+try:
+ import ssl
+except ImportError:
+ ssl = None
+
+
+class SOCKSConnection(HTTPConnection):
+ """
+ A plain-text HTTP connection that connects via a SOCKS proxy.
+ """
+
+ def __init__(self, *args, **kwargs):
+ self._socks_options = kwargs.pop("_socks_options")
+ super(SOCKSConnection, self).__init__(*args, **kwargs)
+
+ def _new_conn(self):
+ """
+ Establish a new connection via the SOCKS proxy.
+ """
+ extra_kw = {}
+ if self.source_address:
+ extra_kw["source_address"] = self.source_address
+
+ if self.socket_options:
+ extra_kw["socket_options"] = self.socket_options
+
+ try:
+ conn = socks.create_connection(
+ (self.host, self.port),
+ proxy_type=self._socks_options["socks_version"],
+ proxy_addr=self._socks_options["proxy_host"],
+ proxy_port=self._socks_options["proxy_port"],
+ proxy_username=self._socks_options["username"],
+ proxy_password=self._socks_options["password"],
+ proxy_rdns=self._socks_options["rdns"],
+ timeout=self.timeout,
+ **extra_kw
+ )
+
+ except SocketTimeout:
+ raise ConnectTimeoutError(
+ self,
+ "Connection to %s timed out. (connect timeout=%s)"
+ % (self.host, self.timeout),
+ )
+
+ except socks.ProxyError as e:
+ # This is fragile as hell, but it seems to be the only way to raise
+ # useful errors here.
+ if e.socket_err:
+ error = e.socket_err
+ if isinstance(error, SocketTimeout):
+ raise ConnectTimeoutError(
+ self,
+ "Connection to %s timed out. (connect timeout=%s)"
+ % (self.host, self.timeout),
+ )
+ else:
+ raise NewConnectionError(
+ self, "Failed to establish a new connection: %s" % error
+ )
+ else:
+ raise NewConnectionError(
+ self, "Failed to establish a new connection: %s" % e
+ )
+
+ except SocketError as e: # Defensive: PySocks should catch all these.
+ raise NewConnectionError(
+ self, "Failed to establish a new connection: %s" % e
+ )
+
+ return conn
+
+
+# We don't need to duplicate the Verified/Unverified distinction from
+# urllib3/connection.py here because the HTTPSConnection will already have been
+# correctly set to either the Verified or Unverified form by that module. This
+# means the SOCKSHTTPSConnection will automatically be the correct type.
+class SOCKSHTTPSConnection(SOCKSConnection, HTTPSConnection):
+ pass
+
+
+class SOCKSHTTPConnectionPool(HTTPConnectionPool):
+ ConnectionCls = SOCKSConnection
+
+
+class SOCKSHTTPSConnectionPool(HTTPSConnectionPool):
+ ConnectionCls = SOCKSHTTPSConnection
+
+
+class SOCKSProxyManager(PoolManager):
+ """
+ A version of the urllib3 ProxyManager that routes connections via the
+ defined SOCKS proxy.
+ """
+
+ pool_classes_by_scheme = {
+ "http": SOCKSHTTPConnectionPool,
+ "https": SOCKSHTTPSConnectionPool,
+ }
+
+ def __init__(
+ self,
+ proxy_url,
+ username=None,
+ password=None,
+ num_pools=10,
+ headers=None,
+ **connection_pool_kw
+ ):
+ parsed = parse_url(proxy_url)
+
+ if username is None and password is None and parsed.auth is not None:
+ split = parsed.auth.split(":")
+ if len(split) == 2:
+ username, password = split
+ if parsed.scheme == "socks5":
+ socks_version = socks.PROXY_TYPE_SOCKS5
+ rdns = False
+ elif parsed.scheme == "socks5h":
+ socks_version = socks.PROXY_TYPE_SOCKS5
+ rdns = True
+ elif parsed.scheme == "socks4":
+ socks_version = socks.PROXY_TYPE_SOCKS4
+ rdns = False
+ elif parsed.scheme == "socks4a":
+ socks_version = socks.PROXY_TYPE_SOCKS4
+ rdns = True
+ else:
+ raise ValueError("Unable to determine SOCKS version from %s" % proxy_url)
+
+ self.proxy_url = proxy_url
+
+ socks_options = {
+ "socks_version": socks_version,
+ "proxy_host": parsed.host,
+ "proxy_port": parsed.port,
+ "username": username,
+ "password": password,
+ "rdns": rdns,
+ }
+ connection_pool_kw["_socks_options"] = socks_options
+
+ super(SOCKSProxyManager, self).__init__(
+ num_pools, headers, **connection_pool_kw
+ )
+
+ self.pool_classes_by_scheme = SOCKSProxyManager.pool_classes_by_scheme
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/exceptions.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/exceptions.py
new file mode 100644
index 000000000..cba6f3f56
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/exceptions.py
@@ -0,0 +1,323 @@
+from __future__ import absolute_import
+
+from .packages.six.moves.http_client import IncompleteRead as httplib_IncompleteRead
+
+# Base Exceptions
+
+
+class HTTPError(Exception):
+ """Base exception used by this module."""
+
+ pass
+
+
+class HTTPWarning(Warning):
+ """Base warning used by this module."""
+
+ pass
+
+
+class PoolError(HTTPError):
+ """Base exception for errors caused within a pool."""
+
+ def __init__(self, pool, message):
+ self.pool = pool
+ HTTPError.__init__(self, "%s: %s" % (pool, message))
+
+ def __reduce__(self):
+ # For pickling purposes.
+ return self.__class__, (None, None)
+
+
+class RequestError(PoolError):
+ """Base exception for PoolErrors that have associated URLs."""
+
+ def __init__(self, pool, url, message):
+ self.url = url
+ PoolError.__init__(self, pool, message)
+
+ def __reduce__(self):
+ # For pickling purposes.
+ return self.__class__, (None, self.url, None)
+
+
+class SSLError(HTTPError):
+ """Raised when SSL certificate fails in an HTTPS connection."""
+
+ pass
+
+
+class ProxyError(HTTPError):
+ """Raised when the connection to a proxy fails."""
+
+ def __init__(self, message, error, *args):
+ super(ProxyError, self).__init__(message, error, *args)
+ self.original_error = error
+
+
+class DecodeError(HTTPError):
+ """Raised when automatic decoding based on Content-Type fails."""
+
+ pass
+
+
+class ProtocolError(HTTPError):
+ """Raised when something unexpected happens mid-request/response."""
+
+ pass
+
+
+#: Renamed to ProtocolError but aliased for backwards compatibility.
+ConnectionError = ProtocolError
+
+
+# Leaf Exceptions
+
+
+class MaxRetryError(RequestError):
+ """Raised when the maximum number of retries is exceeded.
+
+ :param pool: The connection pool
+ :type pool: :class:`~urllib3.connectionpool.HTTPConnectionPool`
+ :param string url: The requested Url
+ :param exceptions.Exception reason: The underlying error
+
+ """
+
+ def __init__(self, pool, url, reason=None):
+ self.reason = reason
+
+ message = "Max retries exceeded with url: %s (Caused by %r)" % (url, reason)
+
+ RequestError.__init__(self, pool, url, message)
+
+
+class HostChangedError(RequestError):
+ """Raised when an existing pool gets a request for a foreign host."""
+
+ def __init__(self, pool, url, retries=3):
+ message = "Tried to open a foreign host with url: %s" % url
+ RequestError.__init__(self, pool, url, message)
+ self.retries = retries
+
+
+class TimeoutStateError(HTTPError):
+ """Raised when passing an invalid state to a timeout"""
+
+ pass
+
+
+class TimeoutError(HTTPError):
+ """Raised when a socket timeout error occurs.
+
+ Catching this error will catch both :exc:`ReadTimeoutErrors
+ <ReadTimeoutError>` and :exc:`ConnectTimeoutErrors <ConnectTimeoutError>`.
+ """
+
+ pass
+
+
+class ReadTimeoutError(TimeoutError, RequestError):
+ """Raised when a socket timeout occurs while receiving data from a server"""
+
+ pass
+
+
+# This timeout error does not have a URL attached and needs to inherit from the
+# base HTTPError
+class ConnectTimeoutError(TimeoutError):
+ """Raised when a socket timeout occurs while connecting to a server"""
+
+ pass
+
+
+class NewConnectionError(ConnectTimeoutError, PoolError):
+ """Raised when we fail to establish a new connection. Usually ECONNREFUSED."""
+
+ pass
+
+
+class EmptyPoolError(PoolError):
+ """Raised when a pool runs out of connections and no more are allowed."""
+
+ pass
+
+
+class ClosedPoolError(PoolError):
+ """Raised when a request enters a pool after the pool has been closed."""
+
+ pass
+
+
+class LocationValueError(ValueError, HTTPError):
+ """Raised when there is something wrong with a given URL input."""
+
+ pass
+
+
+class LocationParseError(LocationValueError):
+ """Raised when get_host or similar fails to parse the URL input."""
+
+ def __init__(self, location):
+ message = "Failed to parse: %s" % location
+ HTTPError.__init__(self, message)
+
+ self.location = location
+
+
+class URLSchemeUnknown(LocationValueError):
+ """Raised when a URL input has an unsupported scheme."""
+
+ def __init__(self, scheme):
+ message = "Not supported URL scheme %s" % scheme
+ super(URLSchemeUnknown, self).__init__(message)
+
+ self.scheme = scheme
+
+
+class ResponseError(HTTPError):
+ """Used as a container for an error reason supplied in a MaxRetryError."""
+
+ GENERIC_ERROR = "too many error responses"
+ SPECIFIC_ERROR = "too many {status_code} error responses"
+
+
+class SecurityWarning(HTTPWarning):
+ """Warned when performing security reducing actions"""
+
+ pass
+
+
+class SubjectAltNameWarning(SecurityWarning):
+ """Warned when connecting to a host with a certificate missing a SAN."""
+
+ pass
+
+
+class InsecureRequestWarning(SecurityWarning):
+ """Warned when making an unverified HTTPS request."""
+
+ pass
+
+
+class SystemTimeWarning(SecurityWarning):
+ """Warned when system time is suspected to be wrong"""
+
+ pass
+
+
+class InsecurePlatformWarning(SecurityWarning):
+ """Warned when certain TLS/SSL configuration is not available on a platform."""
+
+ pass
+
+
+class SNIMissingWarning(HTTPWarning):
+ """Warned when making a HTTPS request without SNI available."""
+
+ pass
+
+
+class DependencyWarning(HTTPWarning):
+ """
+ Warned when an attempt is made to import a module with missing optional
+ dependencies.
+ """
+
+ pass
+
+
+class ResponseNotChunked(ProtocolError, ValueError):
+ """Response needs to be chunked in order to read it as chunks."""
+
+ pass
+
+
+class BodyNotHttplibCompatible(HTTPError):
+ """
+ Body should be :class:`http.client.HTTPResponse` like
+ (have an fp attribute which returns raw chunks) for read_chunked().
+ """
+
+ pass
+
+
+class IncompleteRead(HTTPError, httplib_IncompleteRead):
+ """
+ Response length doesn't match expected Content-Length
+
+ Subclass of :class:`http.client.IncompleteRead` to allow int value
+ for ``partial`` to avoid creating large objects on streamed reads.
+ """
+
+ def __init__(self, partial, expected):
+ super(IncompleteRead, self).__init__(partial, expected)
+
+ def __repr__(self):
+ return "IncompleteRead(%i bytes read, %i more expected)" % (
+ self.partial,
+ self.expected,
+ )
+
+
+class InvalidChunkLength(HTTPError, httplib_IncompleteRead):
+ """Invalid chunk length in a chunked response."""
+
+ def __init__(self, response, length):
+ super(InvalidChunkLength, self).__init__(
+ response.tell(), response.length_remaining
+ )
+ self.response = response
+ self.length = length
+
+ def __repr__(self):
+ return "InvalidChunkLength(got length %r, %i bytes read)" % (
+ self.length,
+ self.partial,
+ )
+
+
+class InvalidHeader(HTTPError):
+ """The header provided was somehow invalid."""
+
+ pass
+
+
+class ProxySchemeUnknown(AssertionError, URLSchemeUnknown):
+ """ProxyManager does not support the supplied scheme"""
+
+ # TODO(t-8ch): Stop inheriting from AssertionError in v2.0.
+
+ def __init__(self, scheme):
+ # 'localhost' is here because our URL parser parses
+ # localhost:8080 -> scheme=localhost, remove if we fix this.
+ if scheme == "localhost":
+ scheme = None
+ if scheme is None:
+ message = "Proxy URL had no scheme, should start with http:// or https://"
+ else:
+ message = (
+ "Proxy URL had unsupported scheme %s, should use http:// or https://"
+ % scheme
+ )
+ super(ProxySchemeUnknown, self).__init__(message)
+
+
+class ProxySchemeUnsupported(ValueError):
+ """Fetching HTTPS resources through HTTPS proxies is unsupported"""
+
+ pass
+
+
+class HeaderParsingError(HTTPError):
+ """Raised by assert_header_parsing, but we convert it to a log.warning statement."""
+
+ def __init__(self, defects, unparsed_data):
+ message = "%s, unparsed data: %r" % (defects or "Unknown", unparsed_data)
+ super(HeaderParsingError, self).__init__(message)
+
+
+class UnrewindableBodyError(HTTPError):
+ """urllib3 encountered an error when trying to rewind a body"""
+
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/fields.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/fields.py
new file mode 100644
index 000000000..9d630f491
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/fields.py
@@ -0,0 +1,274 @@
+from __future__ import absolute_import
+
+import email.utils
+import mimetypes
+import re
+
+from .packages import six
+
+
+def guess_content_type(filename, default="application/octet-stream"):
+ """
+ Guess the "Content-Type" of a file.
+
+ :param filename:
+ The filename to guess the "Content-Type" of using :mod:`mimetypes`.
+ :param default:
+ If no "Content-Type" can be guessed, default to `default`.
+ """
+ if filename:
+ return mimetypes.guess_type(filename)[0] or default
+ return default
+
+
+def format_header_param_rfc2231(name, value):
+ """
+ Helper function to format and quote a single header parameter using the
+ strategy defined in RFC 2231.
+
+ Particularly useful for header parameters which might contain
+ non-ASCII values, like file names. This follows
+ `RFC 2388 Section 4.4 <https://tools.ietf.org/html/rfc2388#section-4.4>`_.
+
+ :param name:
+ The name of the parameter, a string expected to be ASCII only.
+ :param value:
+ The value of the parameter, provided as ``bytes`` or `str``.
+ :ret:
+ An RFC-2231-formatted unicode string.
+ """
+ if isinstance(value, six.binary_type):
+ value = value.decode("utf-8")
+
+ if not any(ch in value for ch in '"\\\r\n'):
+ result = u'%s="%s"' % (name, value)
+ try:
+ result.encode("ascii")
+ except (UnicodeEncodeError, UnicodeDecodeError):
+ pass
+ else:
+ return result
+
+ if six.PY2: # Python 2:
+ value = value.encode("utf-8")
+
+ # encode_rfc2231 accepts an encoded string and returns an ascii-encoded
+ # string in Python 2 but accepts and returns unicode strings in Python 3
+ value = email.utils.encode_rfc2231(value, "utf-8")
+ value = "%s*=%s" % (name, value)
+
+ if six.PY2: # Python 2:
+ value = value.decode("utf-8")
+
+ return value
+
+
+_HTML5_REPLACEMENTS = {
+ u"\u0022": u"%22",
+ # Replace "\" with "\\".
+ u"\u005C": u"\u005C\u005C",
+}
+
+# All control characters from 0x00 to 0x1F *except* 0x1B.
+_HTML5_REPLACEMENTS.update(
+ {
+ six.unichr(cc): u"%{:02X}".format(cc)
+ for cc in range(0x00, 0x1F + 1)
+ if cc not in (0x1B,)
+ }
+)
+
+
+def _replace_multiple(value, needles_and_replacements):
+ def replacer(match):
+ return needles_and_replacements[match.group(0)]
+
+ pattern = re.compile(
+ r"|".join([re.escape(needle) for needle in needles_and_replacements.keys()])
+ )
+
+ result = pattern.sub(replacer, value)
+
+ return result
+
+
+def format_header_param_html5(name, value):
+ """
+ Helper function to format and quote a single header parameter using the
+ HTML5 strategy.
+
+ Particularly useful for header parameters which might contain
+ non-ASCII values, like file names. This follows the `HTML5 Working Draft
+ Section 4.10.22.7`_ and matches the behavior of curl and modern browsers.
+
+ .. _HTML5 Working Draft Section 4.10.22.7:
+ https://w3c.github.io/html/sec-forms.html#multipart-form-data
+
+ :param name:
+ The name of the parameter, a string expected to be ASCII only.
+ :param value:
+ The value of the parameter, provided as ``bytes`` or `str``.
+ :ret:
+ A unicode string, stripped of troublesome characters.
+ """
+ if isinstance(value, six.binary_type):
+ value = value.decode("utf-8")
+
+ value = _replace_multiple(value, _HTML5_REPLACEMENTS)
+
+ return u'%s="%s"' % (name, value)
+
+
+# For backwards-compatibility.
+format_header_param = format_header_param_html5
+
+
+class RequestField(object):
+ """
+ A data container for request body parameters.
+
+ :param name:
+ The name of this request field. Must be unicode.
+ :param data:
+ The data/value body.
+ :param filename:
+ An optional filename of the request field. Must be unicode.
+ :param headers:
+ An optional dict-like object of headers to initially use for the field.
+ :param header_formatter:
+ An optional callable that is used to encode and format the headers. By
+ default, this is :func:`format_header_param_html5`.
+ """
+
+ def __init__(
+ self,
+ name,
+ data,
+ filename=None,
+ headers=None,
+ header_formatter=format_header_param_html5,
+ ):
+ self._name = name
+ self._filename = filename
+ self.data = data
+ self.headers = {}
+ if headers:
+ self.headers = dict(headers)
+ self.header_formatter = header_formatter
+
+ @classmethod
+ def from_tuples(cls, fieldname, value, header_formatter=format_header_param_html5):
+ """
+ A :class:`~urllib3.fields.RequestField` factory from old-style tuple parameters.
+
+ Supports constructing :class:`~urllib3.fields.RequestField` from
+ parameter of key/value strings AND key/filetuple. A filetuple is a
+ (filename, data, MIME type) tuple where the MIME type is optional.
+ For example::
+
+ 'foo': 'bar',
+ 'fakefile': ('foofile.txt', 'contents of foofile'),
+ 'realfile': ('barfile.txt', open('realfile').read()),
+ 'typedfile': ('bazfile.bin', open('bazfile').read(), 'image/jpeg'),
+ 'nonamefile': 'contents of nonamefile field',
+
+ Field names and filenames must be unicode.
+ """
+ if isinstance(value, tuple):
+ if len(value) == 3:
+ filename, data, content_type = value
+ else:
+ filename, data = value
+ content_type = guess_content_type(filename)
+ else:
+ filename = None
+ content_type = None
+ data = value
+
+ request_param = cls(
+ fieldname, data, filename=filename, header_formatter=header_formatter
+ )
+ request_param.make_multipart(content_type=content_type)
+
+ return request_param
+
+ def _render_part(self, name, value):
+ """
+ Overridable helper function to format a single header parameter. By
+ default, this calls ``self.header_formatter``.
+
+ :param name:
+ The name of the parameter, a string expected to be ASCII only.
+ :param value:
+ The value of the parameter, provided as a unicode string.
+ """
+
+ return self.header_formatter(name, value)
+
+ def _render_parts(self, header_parts):
+ """
+ Helper function to format and quote a single header.
+
+ Useful for single headers that are composed of multiple items. E.g.,
+ 'Content-Disposition' fields.
+
+ :param header_parts:
+ A sequence of (k, v) tuples or a :class:`dict` of (k, v) to format
+ as `k1="v1"; k2="v2"; ...`.
+ """
+ parts = []
+ iterable = header_parts
+ if isinstance(header_parts, dict):
+ iterable = header_parts.items()
+
+ for name, value in iterable:
+ if value is not None:
+ parts.append(self._render_part(name, value))
+
+ return u"; ".join(parts)
+
+ def render_headers(self):
+ """
+ Renders the headers for this request field.
+ """
+ lines = []
+
+ sort_keys = ["Content-Disposition", "Content-Type", "Content-Location"]
+ for sort_key in sort_keys:
+ if self.headers.get(sort_key, False):
+ lines.append(u"%s: %s" % (sort_key, self.headers[sort_key]))
+
+ for header_name, header_value in self.headers.items():
+ if header_name not in sort_keys:
+ if header_value:
+ lines.append(u"%s: %s" % (header_name, header_value))
+
+ lines.append(u"\r\n")
+ return u"\r\n".join(lines)
+
+ def make_multipart(
+ self, content_disposition=None, content_type=None, content_location=None
+ ):
+ """
+ Makes this request field into a multipart request field.
+
+ This method overrides "Content-Disposition", "Content-Type" and
+ "Content-Location" headers to the request parameter.
+
+ :param content_type:
+ The 'Content-Type' of the request body.
+ :param content_location:
+ The 'Content-Location' of the request body.
+
+ """
+ self.headers["Content-Disposition"] = content_disposition or u"form-data"
+ self.headers["Content-Disposition"] += u"; ".join(
+ [
+ u"",
+ self._render_parts(
+ ((u"name", self._name), (u"filename", self._filename))
+ ),
+ ]
+ )
+ self.headers["Content-Type"] = content_type
+ self.headers["Content-Location"] = content_location
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/filepost.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/filepost.py
new file mode 100644
index 000000000..36c9252c6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/filepost.py
@@ -0,0 +1,98 @@
+from __future__ import absolute_import
+
+import binascii
+import codecs
+import os
+from io import BytesIO
+
+from .fields import RequestField
+from .packages import six
+from .packages.six import b
+
+writer = codecs.lookup("utf-8")[3]
+
+
+def choose_boundary():
+ """
+ Our embarrassingly-simple replacement for mimetools.choose_boundary.
+ """
+ boundary = binascii.hexlify(os.urandom(16))
+ if not six.PY2:
+ boundary = boundary.decode("ascii")
+ return boundary
+
+
+def iter_field_objects(fields):
+ """
+ Iterate over fields.
+
+ Supports list of (k, v) tuples and dicts, and lists of
+ :class:`~urllib3.fields.RequestField`.
+
+ """
+ if isinstance(fields, dict):
+ i = six.iteritems(fields)
+ else:
+ i = iter(fields)
+
+ for field in i:
+ if isinstance(field, RequestField):
+ yield field
+ else:
+ yield RequestField.from_tuples(*field)
+
+
+def iter_fields(fields):
+ """
+ .. deprecated:: 1.6
+
+ Iterate over fields.
+
+ The addition of :class:`~urllib3.fields.RequestField` makes this function
+ obsolete. Instead, use :func:`iter_field_objects`, which returns
+ :class:`~urllib3.fields.RequestField` objects.
+
+ Supports list of (k, v) tuples and dicts.
+ """
+ if isinstance(fields, dict):
+ return ((k, v) for k, v in six.iteritems(fields))
+
+ return ((k, v) for k, v in fields)
+
+
+def encode_multipart_formdata(fields, boundary=None):
+ """
+ Encode a dictionary of ``fields`` using the multipart/form-data MIME format.
+
+ :param fields:
+ Dictionary of fields or list of (key, :class:`~urllib3.fields.RequestField`).
+
+ :param boundary:
+ If not specified, then a random boundary will be generated using
+ :func:`urllib3.filepost.choose_boundary`.
+ """
+ body = BytesIO()
+ if boundary is None:
+ boundary = choose_boundary()
+
+ for field in iter_field_objects(fields):
+ body.write(b("--%s\r\n" % (boundary)))
+
+ writer(body).write(field.render_headers())
+ data = field.data
+
+ if isinstance(data, int):
+ data = str(data) # Backwards compatibility
+
+ if isinstance(data, six.text_type):
+ writer(body).write(data)
+ else:
+ body.write(data)
+
+ body.write(b"\r\n")
+
+ body.write(b("--%s--\r\n" % (boundary)))
+
+ content_type = str("multipart/form-data; boundary=%s" % boundary)
+
+ return body.getvalue(), content_type
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py
new file mode 100644
index 000000000..b8fb2154b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py
@@ -0,0 +1,51 @@
+# -*- coding: utf-8 -*-
+"""
+backports.makefile
+~~~~~~~~~~~~~~~~~~
+
+Backports the Python 3 ``socket.makefile`` method for use with anything that
+wants to create a "fake" socket object.
+"""
+import io
+from socket import SocketIO
+
+
+def backport_makefile(
+ self, mode="r", buffering=None, encoding=None, errors=None, newline=None
+):
+ """
+ Backport of ``socket.makefile`` from Python 3.5.
+ """
+ if not set(mode) <= {"r", "w", "b"}:
+ raise ValueError("invalid mode %r (only r, w, b allowed)" % (mode,))
+ writing = "w" in mode
+ reading = "r" in mode or not writing
+ assert reading or writing
+ binary = "b" in mode
+ rawmode = ""
+ if reading:
+ rawmode += "r"
+ if writing:
+ rawmode += "w"
+ raw = SocketIO(self, rawmode)
+ self._makefile_refs += 1
+ if buffering is None:
+ buffering = -1
+ if buffering < 0:
+ buffering = io.DEFAULT_BUFFER_SIZE
+ if buffering == 0:
+ if not binary:
+ raise ValueError("unbuffered streams must be binary")
+ return raw
+ if reading and writing:
+ buffer = io.BufferedRWPair(raw, raw, buffering)
+ elif reading:
+ buffer = io.BufferedReader(raw, buffering)
+ else:
+ assert writing
+ buffer = io.BufferedWriter(raw, buffering)
+ if binary:
+ return buffer
+ text = io.TextIOWrapper(buffer, encoding, errors, newline)
+ text.mode = mode
+ return text
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/weakref_finalize.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/weakref_finalize.py
new file mode 100644
index 000000000..a2f2966e5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/backports/weakref_finalize.py
@@ -0,0 +1,155 @@
+# -*- coding: utf-8 -*-
+"""
+backports.weakref_finalize
+~~~~~~~~~~~~~~~~~~
+
+Backports the Python 3 ``weakref.finalize`` method.
+"""
+from __future__ import absolute_import
+
+import itertools
+import sys
+from weakref import ref
+
+__all__ = ["weakref_finalize"]
+
+
+class weakref_finalize(object):
+ """Class for finalization of weakrefable objects
+ finalize(obj, func, *args, **kwargs) returns a callable finalizer
+ object which will be called when obj is garbage collected. The
+ first time the finalizer is called it evaluates func(*arg, **kwargs)
+ and returns the result. After this the finalizer is dead, and
+ calling it just returns None.
+ When the program exits any remaining finalizers for which the
+ atexit attribute is true will be run in reverse order of creation.
+ By default atexit is true.
+ """
+
+ # Finalizer objects don't have any state of their own. They are
+ # just used as keys to lookup _Info objects in the registry. This
+ # ensures that they cannot be part of a ref-cycle.
+
+ __slots__ = ()
+ _registry = {}
+ _shutdown = False
+ _index_iter = itertools.count()
+ _dirty = False
+ _registered_with_atexit = False
+
+ class _Info(object):
+ __slots__ = ("weakref", "func", "args", "kwargs", "atexit", "index")
+
+ def __init__(self, obj, func, *args, **kwargs):
+ if not self._registered_with_atexit:
+ # We may register the exit function more than once because
+ # of a thread race, but that is harmless
+ import atexit
+
+ atexit.register(self._exitfunc)
+ weakref_finalize._registered_with_atexit = True
+ info = self._Info()
+ info.weakref = ref(obj, self)
+ info.func = func
+ info.args = args
+ info.kwargs = kwargs or None
+ info.atexit = True
+ info.index = next(self._index_iter)
+ self._registry[self] = info
+ weakref_finalize._dirty = True
+
+ def __call__(self, _=None):
+ """If alive then mark as dead and return func(*args, **kwargs);
+ otherwise return None"""
+ info = self._registry.pop(self, None)
+ if info and not self._shutdown:
+ return info.func(*info.args, **(info.kwargs or {}))
+
+ def detach(self):
+ """If alive then mark as dead and return (obj, func, args, kwargs);
+ otherwise return None"""
+ info = self._registry.get(self)
+ obj = info and info.weakref()
+ if obj is not None and self._registry.pop(self, None):
+ return (obj, info.func, info.args, info.kwargs or {})
+
+ def peek(self):
+ """If alive then return (obj, func, args, kwargs);
+ otherwise return None"""
+ info = self._registry.get(self)
+ obj = info and info.weakref()
+ if obj is not None:
+ return (obj, info.func, info.args, info.kwargs or {})
+
+ @property
+ def alive(self):
+ """Whether finalizer is alive"""
+ return self in self._registry
+
+ @property
+ def atexit(self):
+ """Whether finalizer should be called at exit"""
+ info = self._registry.get(self)
+ return bool(info) and info.atexit
+
+ @atexit.setter
+ def atexit(self, value):
+ info = self._registry.get(self)
+ if info:
+ info.atexit = bool(value)
+
+ def __repr__(self):
+ info = self._registry.get(self)
+ obj = info and info.weakref()
+ if obj is None:
+ return "<%s object at %#x; dead>" % (type(self).__name__, id(self))
+ else:
+ return "<%s object at %#x; for %r at %#x>" % (
+ type(self).__name__,
+ id(self),
+ type(obj).__name__,
+ id(obj),
+ )
+
+ @classmethod
+ def _select_for_exit(cls):
+ # Return live finalizers marked for exit, oldest first
+ L = [(f, i) for (f, i) in cls._registry.items() if i.atexit]
+ L.sort(key=lambda item: item[1].index)
+ return [f for (f, i) in L]
+
+ @classmethod
+ def _exitfunc(cls):
+ # At shutdown invoke finalizers for which atexit is true.
+ # This is called once all other non-daemonic threads have been
+ # joined.
+ reenable_gc = False
+ try:
+ if cls._registry:
+ import gc
+
+ if gc.isenabled():
+ reenable_gc = True
+ gc.disable()
+ pending = None
+ while True:
+ if pending is None or weakref_finalize._dirty:
+ pending = cls._select_for_exit()
+ weakref_finalize._dirty = False
+ if not pending:
+ break
+ f = pending.pop()
+ try:
+ # gc is disabled, so (assuming no daemonic
+ # threads) the following is the only line in
+ # this function which might trigger creation
+ # of a new finalizer
+ f()
+ except Exception:
+ sys.excepthook(*sys.exc_info())
+ assert f not in cls._registry
+ finally:
+ # prevent any more finalizers from executing during shutdown
+ weakref_finalize._shutdown = True
+ if reenable_gc:
+ gc.enable()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/six.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/six.py
new file mode 100644
index 000000000..f099a3dcd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/packages/six.py
@@ -0,0 +1,1076 @@
+# Copyright (c) 2010-2020 Benjamin Peterson
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+"""Utilities for writing code that runs on Python 2 and 3"""
+
+from __future__ import absolute_import
+
+import functools
+import itertools
+import operator
+import sys
+import types
+
+__author__ = "Benjamin Peterson <benjamin@python.org>"
+__version__ = "1.16.0"
+
+
+# Useful for very coarse version differentiation.
+PY2 = sys.version_info[0] == 2
+PY3 = sys.version_info[0] == 3
+PY34 = sys.version_info[0:2] >= (3, 4)
+
+if PY3:
+ string_types = (str,)
+ integer_types = (int,)
+ class_types = (type,)
+ text_type = str
+ binary_type = bytes
+
+ MAXSIZE = sys.maxsize
+else:
+ string_types = (basestring,)
+ integer_types = (int, long)
+ class_types = (type, types.ClassType)
+ text_type = unicode
+ binary_type = str
+
+ if sys.platform.startswith("java"):
+ # Jython always uses 32 bits.
+ MAXSIZE = int((1 << 31) - 1)
+ else:
+ # It's possible to have sizeof(long) != sizeof(Py_ssize_t).
+ class X(object):
+ def __len__(self):
+ return 1 << 31
+
+ try:
+ len(X())
+ except OverflowError:
+ # 32-bit
+ MAXSIZE = int((1 << 31) - 1)
+ else:
+ # 64-bit
+ MAXSIZE = int((1 << 63) - 1)
+ del X
+
+if PY34:
+ from importlib.util import spec_from_loader
+else:
+ spec_from_loader = None
+
+
+def _add_doc(func, doc):
+ """Add documentation to a function."""
+ func.__doc__ = doc
+
+
+def _import_module(name):
+ """Import module, returning the module after the last dot."""
+ __import__(name)
+ return sys.modules[name]
+
+
+class _LazyDescr(object):
+ def __init__(self, name):
+ self.name = name
+
+ def __get__(self, obj, tp):
+ result = self._resolve()
+ setattr(obj, self.name, result) # Invokes __set__.
+ try:
+ # This is a bit ugly, but it avoids running this again by
+ # removing this descriptor.
+ delattr(obj.__class__, self.name)
+ except AttributeError:
+ pass
+ return result
+
+
+class MovedModule(_LazyDescr):
+ def __init__(self, name, old, new=None):
+ super(MovedModule, self).__init__(name)
+ if PY3:
+ if new is None:
+ new = name
+ self.mod = new
+ else:
+ self.mod = old
+
+ def _resolve(self):
+ return _import_module(self.mod)
+
+ def __getattr__(self, attr):
+ _module = self._resolve()
+ value = getattr(_module, attr)
+ setattr(self, attr, value)
+ return value
+
+
+class _LazyModule(types.ModuleType):
+ def __init__(self, name):
+ super(_LazyModule, self).__init__(name)
+ self.__doc__ = self.__class__.__doc__
+
+ def __dir__(self):
+ attrs = ["__doc__", "__name__"]
+ attrs += [attr.name for attr in self._moved_attributes]
+ return attrs
+
+ # Subclasses should override this
+ _moved_attributes = []
+
+
+class MovedAttribute(_LazyDescr):
+ def __init__(self, name, old_mod, new_mod, old_attr=None, new_attr=None):
+ super(MovedAttribute, self).__init__(name)
+ if PY3:
+ if new_mod is None:
+ new_mod = name
+ self.mod = new_mod
+ if new_attr is None:
+ if old_attr is None:
+ new_attr = name
+ else:
+ new_attr = old_attr
+ self.attr = new_attr
+ else:
+ self.mod = old_mod
+ if old_attr is None:
+ old_attr = name
+ self.attr = old_attr
+
+ def _resolve(self):
+ module = _import_module(self.mod)
+ return getattr(module, self.attr)
+
+
+class _SixMetaPathImporter(object):
+
+ """
+ A meta path importer to import six.moves and its submodules.
+
+ This class implements a PEP302 finder and loader. It should be compatible
+ with Python 2.5 and all existing versions of Python3
+ """
+
+ def __init__(self, six_module_name):
+ self.name = six_module_name
+ self.known_modules = {}
+
+ def _add_module(self, mod, *fullnames):
+ for fullname in fullnames:
+ self.known_modules[self.name + "." + fullname] = mod
+
+ def _get_module(self, fullname):
+ return self.known_modules[self.name + "." + fullname]
+
+ def find_module(self, fullname, path=None):
+ if fullname in self.known_modules:
+ return self
+ return None
+
+ def find_spec(self, fullname, path, target=None):
+ if fullname in self.known_modules:
+ return spec_from_loader(fullname, self)
+ return None
+
+ def __get_module(self, fullname):
+ try:
+ return self.known_modules[fullname]
+ except KeyError:
+ raise ImportError("This loader does not know module " + fullname)
+
+ def load_module(self, fullname):
+ try:
+ # in case of a reload
+ return sys.modules[fullname]
+ except KeyError:
+ pass
+ mod = self.__get_module(fullname)
+ if isinstance(mod, MovedModule):
+ mod = mod._resolve()
+ else:
+ mod.__loader__ = self
+ sys.modules[fullname] = mod
+ return mod
+
+ def is_package(self, fullname):
+ """
+ Return true, if the named module is a package.
+
+ We need this method to get correct spec objects with
+ Python 3.4 (see PEP451)
+ """
+ return hasattr(self.__get_module(fullname), "__path__")
+
+ def get_code(self, fullname):
+ """Return None
+
+ Required, if is_package is implemented"""
+ self.__get_module(fullname) # eventually raises ImportError
+ return None
+
+ get_source = get_code # same as get_code
+
+ def create_module(self, spec):
+ return self.load_module(spec.name)
+
+ def exec_module(self, module):
+ pass
+
+
+_importer = _SixMetaPathImporter(__name__)
+
+
+class _MovedItems(_LazyModule):
+
+ """Lazy loading of moved objects"""
+
+ __path__ = [] # mark as package
+
+
+_moved_attributes = [
+ MovedAttribute("cStringIO", "cStringIO", "io", "StringIO"),
+ MovedAttribute("filter", "itertools", "builtins", "ifilter", "filter"),
+ MovedAttribute(
+ "filterfalse", "itertools", "itertools", "ifilterfalse", "filterfalse"
+ ),
+ MovedAttribute("input", "__builtin__", "builtins", "raw_input", "input"),
+ MovedAttribute("intern", "__builtin__", "sys"),
+ MovedAttribute("map", "itertools", "builtins", "imap", "map"),
+ MovedAttribute("getcwd", "os", "os", "getcwdu", "getcwd"),
+ MovedAttribute("getcwdb", "os", "os", "getcwd", "getcwdb"),
+ MovedAttribute("getoutput", "commands", "subprocess"),
+ MovedAttribute("range", "__builtin__", "builtins", "xrange", "range"),
+ MovedAttribute(
+ "reload_module", "__builtin__", "importlib" if PY34 else "imp", "reload"
+ ),
+ MovedAttribute("reduce", "__builtin__", "functools"),
+ MovedAttribute("shlex_quote", "pipes", "shlex", "quote"),
+ MovedAttribute("StringIO", "StringIO", "io"),
+ MovedAttribute("UserDict", "UserDict", "collections"),
+ MovedAttribute("UserList", "UserList", "collections"),
+ MovedAttribute("UserString", "UserString", "collections"),
+ MovedAttribute("xrange", "__builtin__", "builtins", "xrange", "range"),
+ MovedAttribute("zip", "itertools", "builtins", "izip", "zip"),
+ MovedAttribute(
+ "zip_longest", "itertools", "itertools", "izip_longest", "zip_longest"
+ ),
+ MovedModule("builtins", "__builtin__"),
+ MovedModule("configparser", "ConfigParser"),
+ MovedModule(
+ "collections_abc",
+ "collections",
+ "collections.abc" if sys.version_info >= (3, 3) else "collections",
+ ),
+ MovedModule("copyreg", "copy_reg"),
+ MovedModule("dbm_gnu", "gdbm", "dbm.gnu"),
+ MovedModule("dbm_ndbm", "dbm", "dbm.ndbm"),
+ MovedModule(
+ "_dummy_thread",
+ "dummy_thread",
+ "_dummy_thread" if sys.version_info < (3, 9) else "_thread",
+ ),
+ MovedModule("http_cookiejar", "cookielib", "http.cookiejar"),
+ MovedModule("http_cookies", "Cookie", "http.cookies"),
+ MovedModule("html_entities", "htmlentitydefs", "html.entities"),
+ MovedModule("html_parser", "HTMLParser", "html.parser"),
+ MovedModule("http_client", "httplib", "http.client"),
+ MovedModule("email_mime_base", "email.MIMEBase", "email.mime.base"),
+ MovedModule("email_mime_image", "email.MIMEImage", "email.mime.image"),
+ MovedModule("email_mime_multipart", "email.MIMEMultipart", "email.mime.multipart"),
+ MovedModule(
+ "email_mime_nonmultipart", "email.MIMENonMultipart", "email.mime.nonmultipart"
+ ),
+ MovedModule("email_mime_text", "email.MIMEText", "email.mime.text"),
+ MovedModule("BaseHTTPServer", "BaseHTTPServer", "http.server"),
+ MovedModule("CGIHTTPServer", "CGIHTTPServer", "http.server"),
+ MovedModule("SimpleHTTPServer", "SimpleHTTPServer", "http.server"),
+ MovedModule("cPickle", "cPickle", "pickle"),
+ MovedModule("queue", "Queue"),
+ MovedModule("reprlib", "repr"),
+ MovedModule("socketserver", "SocketServer"),
+ MovedModule("_thread", "thread", "_thread"),
+ MovedModule("tkinter", "Tkinter"),
+ MovedModule("tkinter_dialog", "Dialog", "tkinter.dialog"),
+ MovedModule("tkinter_filedialog", "FileDialog", "tkinter.filedialog"),
+ MovedModule("tkinter_scrolledtext", "ScrolledText", "tkinter.scrolledtext"),
+ MovedModule("tkinter_simpledialog", "SimpleDialog", "tkinter.simpledialog"),
+ MovedModule("tkinter_tix", "Tix", "tkinter.tix"),
+ MovedModule("tkinter_ttk", "ttk", "tkinter.ttk"),
+ MovedModule("tkinter_constants", "Tkconstants", "tkinter.constants"),
+ MovedModule("tkinter_dnd", "Tkdnd", "tkinter.dnd"),
+ MovedModule("tkinter_colorchooser", "tkColorChooser", "tkinter.colorchooser"),
+ MovedModule("tkinter_commondialog", "tkCommonDialog", "tkinter.commondialog"),
+ MovedModule("tkinter_tkfiledialog", "tkFileDialog", "tkinter.filedialog"),
+ MovedModule("tkinter_font", "tkFont", "tkinter.font"),
+ MovedModule("tkinter_messagebox", "tkMessageBox", "tkinter.messagebox"),
+ MovedModule("tkinter_tksimpledialog", "tkSimpleDialog", "tkinter.simpledialog"),
+ MovedModule("urllib_parse", __name__ + ".moves.urllib_parse", "urllib.parse"),
+ MovedModule("urllib_error", __name__ + ".moves.urllib_error", "urllib.error"),
+ MovedModule("urllib", __name__ + ".moves.urllib", __name__ + ".moves.urllib"),
+ MovedModule("urllib_robotparser", "robotparser", "urllib.robotparser"),
+ MovedModule("xmlrpc_client", "xmlrpclib", "xmlrpc.client"),
+ MovedModule("xmlrpc_server", "SimpleXMLRPCServer", "xmlrpc.server"),
+]
+# Add windows specific modules.
+if sys.platform == "win32":
+ _moved_attributes += [
+ MovedModule("winreg", "_winreg"),
+ ]
+
+for attr in _moved_attributes:
+ setattr(_MovedItems, attr.name, attr)
+ if isinstance(attr, MovedModule):
+ _importer._add_module(attr, "moves." + attr.name)
+del attr
+
+_MovedItems._moved_attributes = _moved_attributes
+
+moves = _MovedItems(__name__ + ".moves")
+_importer._add_module(moves, "moves")
+
+
+class Module_six_moves_urllib_parse(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_parse"""
+
+
+_urllib_parse_moved_attributes = [
+ MovedAttribute("ParseResult", "urlparse", "urllib.parse"),
+ MovedAttribute("SplitResult", "urlparse", "urllib.parse"),
+ MovedAttribute("parse_qs", "urlparse", "urllib.parse"),
+ MovedAttribute("parse_qsl", "urlparse", "urllib.parse"),
+ MovedAttribute("urldefrag", "urlparse", "urllib.parse"),
+ MovedAttribute("urljoin", "urlparse", "urllib.parse"),
+ MovedAttribute("urlparse", "urlparse", "urllib.parse"),
+ MovedAttribute("urlsplit", "urlparse", "urllib.parse"),
+ MovedAttribute("urlunparse", "urlparse", "urllib.parse"),
+ MovedAttribute("urlunsplit", "urlparse", "urllib.parse"),
+ MovedAttribute("quote", "urllib", "urllib.parse"),
+ MovedAttribute("quote_plus", "urllib", "urllib.parse"),
+ MovedAttribute("unquote", "urllib", "urllib.parse"),
+ MovedAttribute("unquote_plus", "urllib", "urllib.parse"),
+ MovedAttribute(
+ "unquote_to_bytes", "urllib", "urllib.parse", "unquote", "unquote_to_bytes"
+ ),
+ MovedAttribute("urlencode", "urllib", "urllib.parse"),
+ MovedAttribute("splitquery", "urllib", "urllib.parse"),
+ MovedAttribute("splittag", "urllib", "urllib.parse"),
+ MovedAttribute("splituser", "urllib", "urllib.parse"),
+ MovedAttribute("splitvalue", "urllib", "urllib.parse"),
+ MovedAttribute("uses_fragment", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_netloc", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_params", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_query", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_relative", "urlparse", "urllib.parse"),
+]
+for attr in _urllib_parse_moved_attributes:
+ setattr(Module_six_moves_urllib_parse, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_parse._moved_attributes = _urllib_parse_moved_attributes
+
+_importer._add_module(
+ Module_six_moves_urllib_parse(__name__ + ".moves.urllib_parse"),
+ "moves.urllib_parse",
+ "moves.urllib.parse",
+)
+
+
+class Module_six_moves_urllib_error(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_error"""
+
+
+_urllib_error_moved_attributes = [
+ MovedAttribute("URLError", "urllib2", "urllib.error"),
+ MovedAttribute("HTTPError", "urllib2", "urllib.error"),
+ MovedAttribute("ContentTooShortError", "urllib", "urllib.error"),
+]
+for attr in _urllib_error_moved_attributes:
+ setattr(Module_six_moves_urllib_error, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_error._moved_attributes = _urllib_error_moved_attributes
+
+_importer._add_module(
+ Module_six_moves_urllib_error(__name__ + ".moves.urllib.error"),
+ "moves.urllib_error",
+ "moves.urllib.error",
+)
+
+
+class Module_six_moves_urllib_request(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_request"""
+
+
+_urllib_request_moved_attributes = [
+ MovedAttribute("urlopen", "urllib2", "urllib.request"),
+ MovedAttribute("install_opener", "urllib2", "urllib.request"),
+ MovedAttribute("build_opener", "urllib2", "urllib.request"),
+ MovedAttribute("pathname2url", "urllib", "urllib.request"),
+ MovedAttribute("url2pathname", "urllib", "urllib.request"),
+ MovedAttribute("getproxies", "urllib", "urllib.request"),
+ MovedAttribute("Request", "urllib2", "urllib.request"),
+ MovedAttribute("OpenerDirector", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPDefaultErrorHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPRedirectHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPCookieProcessor", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyHandler", "urllib2", "urllib.request"),
+ MovedAttribute("BaseHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPPasswordMgr", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPPasswordMgrWithDefaultRealm", "urllib2", "urllib.request"),
+ MovedAttribute("AbstractBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("AbstractDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPSHandler", "urllib2", "urllib.request"),
+ MovedAttribute("FileHandler", "urllib2", "urllib.request"),
+ MovedAttribute("FTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("CacheFTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("UnknownHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPErrorProcessor", "urllib2", "urllib.request"),
+ MovedAttribute("urlretrieve", "urllib", "urllib.request"),
+ MovedAttribute("urlcleanup", "urllib", "urllib.request"),
+ MovedAttribute("URLopener", "urllib", "urllib.request"),
+ MovedAttribute("FancyURLopener", "urllib", "urllib.request"),
+ MovedAttribute("proxy_bypass", "urllib", "urllib.request"),
+ MovedAttribute("parse_http_list", "urllib2", "urllib.request"),
+ MovedAttribute("parse_keqv_list", "urllib2", "urllib.request"),
+]
+for attr in _urllib_request_moved_attributes:
+ setattr(Module_six_moves_urllib_request, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_request._moved_attributes = _urllib_request_moved_attributes
+
+_importer._add_module(
+ Module_six_moves_urllib_request(__name__ + ".moves.urllib.request"),
+ "moves.urllib_request",
+ "moves.urllib.request",
+)
+
+
+class Module_six_moves_urllib_response(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_response"""
+
+
+_urllib_response_moved_attributes = [
+ MovedAttribute("addbase", "urllib", "urllib.response"),
+ MovedAttribute("addclosehook", "urllib", "urllib.response"),
+ MovedAttribute("addinfo", "urllib", "urllib.response"),
+ MovedAttribute("addinfourl", "urllib", "urllib.response"),
+]
+for attr in _urllib_response_moved_attributes:
+ setattr(Module_six_moves_urllib_response, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_response._moved_attributes = _urllib_response_moved_attributes
+
+_importer._add_module(
+ Module_six_moves_urllib_response(__name__ + ".moves.urllib.response"),
+ "moves.urllib_response",
+ "moves.urllib.response",
+)
+
+
+class Module_six_moves_urllib_robotparser(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_robotparser"""
+
+
+_urllib_robotparser_moved_attributes = [
+ MovedAttribute("RobotFileParser", "robotparser", "urllib.robotparser"),
+]
+for attr in _urllib_robotparser_moved_attributes:
+ setattr(Module_six_moves_urllib_robotparser, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_robotparser._moved_attributes = (
+ _urllib_robotparser_moved_attributes
+)
+
+_importer._add_module(
+ Module_six_moves_urllib_robotparser(__name__ + ".moves.urllib.robotparser"),
+ "moves.urllib_robotparser",
+ "moves.urllib.robotparser",
+)
+
+
+class Module_six_moves_urllib(types.ModuleType):
+
+ """Create a six.moves.urllib namespace that resembles the Python 3 namespace"""
+
+ __path__ = [] # mark as package
+ parse = _importer._get_module("moves.urllib_parse")
+ error = _importer._get_module("moves.urllib_error")
+ request = _importer._get_module("moves.urllib_request")
+ response = _importer._get_module("moves.urllib_response")
+ robotparser = _importer._get_module("moves.urllib_robotparser")
+
+ def __dir__(self):
+ return ["parse", "error", "request", "response", "robotparser"]
+
+
+_importer._add_module(
+ Module_six_moves_urllib(__name__ + ".moves.urllib"), "moves.urllib"
+)
+
+
+def add_move(move):
+ """Add an item to six.moves."""
+ setattr(_MovedItems, move.name, move)
+
+
+def remove_move(name):
+ """Remove item from six.moves."""
+ try:
+ delattr(_MovedItems, name)
+ except AttributeError:
+ try:
+ del moves.__dict__[name]
+ except KeyError:
+ raise AttributeError("no such move, %r" % (name,))
+
+
+if PY3:
+ _meth_func = "__func__"
+ _meth_self = "__self__"
+
+ _func_closure = "__closure__"
+ _func_code = "__code__"
+ _func_defaults = "__defaults__"
+ _func_globals = "__globals__"
+else:
+ _meth_func = "im_func"
+ _meth_self = "im_self"
+
+ _func_closure = "func_closure"
+ _func_code = "func_code"
+ _func_defaults = "func_defaults"
+ _func_globals = "func_globals"
+
+
+try:
+ advance_iterator = next
+except NameError:
+
+ def advance_iterator(it):
+ return it.next()
+
+
+next = advance_iterator
+
+
+try:
+ callable = callable
+except NameError:
+
+ def callable(obj):
+ return any("__call__" in klass.__dict__ for klass in type(obj).__mro__)
+
+
+if PY3:
+
+ def get_unbound_function(unbound):
+ return unbound
+
+ create_bound_method = types.MethodType
+
+ def create_unbound_method(func, cls):
+ return func
+
+ Iterator = object
+else:
+
+ def get_unbound_function(unbound):
+ return unbound.im_func
+
+ def create_bound_method(func, obj):
+ return types.MethodType(func, obj, obj.__class__)
+
+ def create_unbound_method(func, cls):
+ return types.MethodType(func, None, cls)
+
+ class Iterator(object):
+ def next(self):
+ return type(self).__next__(self)
+
+ callable = callable
+_add_doc(
+ get_unbound_function, """Get the function out of a possibly unbound function"""
+)
+
+
+get_method_function = operator.attrgetter(_meth_func)
+get_method_self = operator.attrgetter(_meth_self)
+get_function_closure = operator.attrgetter(_func_closure)
+get_function_code = operator.attrgetter(_func_code)
+get_function_defaults = operator.attrgetter(_func_defaults)
+get_function_globals = operator.attrgetter(_func_globals)
+
+
+if PY3:
+
+ def iterkeys(d, **kw):
+ return iter(d.keys(**kw))
+
+ def itervalues(d, **kw):
+ return iter(d.values(**kw))
+
+ def iteritems(d, **kw):
+ return iter(d.items(**kw))
+
+ def iterlists(d, **kw):
+ return iter(d.lists(**kw))
+
+ viewkeys = operator.methodcaller("keys")
+
+ viewvalues = operator.methodcaller("values")
+
+ viewitems = operator.methodcaller("items")
+else:
+
+ def iterkeys(d, **kw):
+ return d.iterkeys(**kw)
+
+ def itervalues(d, **kw):
+ return d.itervalues(**kw)
+
+ def iteritems(d, **kw):
+ return d.iteritems(**kw)
+
+ def iterlists(d, **kw):
+ return d.iterlists(**kw)
+
+ viewkeys = operator.methodcaller("viewkeys")
+
+ viewvalues = operator.methodcaller("viewvalues")
+
+ viewitems = operator.methodcaller("viewitems")
+
+_add_doc(iterkeys, "Return an iterator over the keys of a dictionary.")
+_add_doc(itervalues, "Return an iterator over the values of a dictionary.")
+_add_doc(iteritems, "Return an iterator over the (key, value) pairs of a dictionary.")
+_add_doc(
+ iterlists, "Return an iterator over the (key, [values]) pairs of a dictionary."
+)
+
+
+if PY3:
+
+ def b(s):
+ return s.encode("latin-1")
+
+ def u(s):
+ return s
+
+ unichr = chr
+ import struct
+
+ int2byte = struct.Struct(">B").pack
+ del struct
+ byte2int = operator.itemgetter(0)
+ indexbytes = operator.getitem
+ iterbytes = iter
+ import io
+
+ StringIO = io.StringIO
+ BytesIO = io.BytesIO
+ del io
+ _assertCountEqual = "assertCountEqual"
+ if sys.version_info[1] <= 1:
+ _assertRaisesRegex = "assertRaisesRegexp"
+ _assertRegex = "assertRegexpMatches"
+ _assertNotRegex = "assertNotRegexpMatches"
+ else:
+ _assertRaisesRegex = "assertRaisesRegex"
+ _assertRegex = "assertRegex"
+ _assertNotRegex = "assertNotRegex"
+else:
+
+ def b(s):
+ return s
+
+ # Workaround for standalone backslash
+
+ def u(s):
+ return unicode(s.replace(r"\\", r"\\\\"), "unicode_escape")
+
+ unichr = unichr
+ int2byte = chr
+
+ def byte2int(bs):
+ return ord(bs[0])
+
+ def indexbytes(buf, i):
+ return ord(buf[i])
+
+ iterbytes = functools.partial(itertools.imap, ord)
+ import StringIO
+
+ StringIO = BytesIO = StringIO.StringIO
+ _assertCountEqual = "assertItemsEqual"
+ _assertRaisesRegex = "assertRaisesRegexp"
+ _assertRegex = "assertRegexpMatches"
+ _assertNotRegex = "assertNotRegexpMatches"
+_add_doc(b, """Byte literal""")
+_add_doc(u, """Text literal""")
+
+
+def assertCountEqual(self, *args, **kwargs):
+ return getattr(self, _assertCountEqual)(*args, **kwargs)
+
+
+def assertRaisesRegex(self, *args, **kwargs):
+ return getattr(self, _assertRaisesRegex)(*args, **kwargs)
+
+
+def assertRegex(self, *args, **kwargs):
+ return getattr(self, _assertRegex)(*args, **kwargs)
+
+
+def assertNotRegex(self, *args, **kwargs):
+ return getattr(self, _assertNotRegex)(*args, **kwargs)
+
+
+if PY3:
+ exec_ = getattr(moves.builtins, "exec")
+
+ def reraise(tp, value, tb=None):
+ try:
+ if value is None:
+ value = tp()
+ if value.__traceback__ is not tb:
+ raise value.with_traceback(tb)
+ raise value
+ finally:
+ value = None
+ tb = None
+
+else:
+
+ def exec_(_code_, _globs_=None, _locs_=None):
+ """Execute code in a namespace."""
+ if _globs_ is None:
+ frame = sys._getframe(1)
+ _globs_ = frame.f_globals
+ if _locs_ is None:
+ _locs_ = frame.f_locals
+ del frame
+ elif _locs_ is None:
+ _locs_ = _globs_
+ exec ("""exec _code_ in _globs_, _locs_""")
+
+ exec_(
+ """def reraise(tp, value, tb=None):
+ try:
+ raise tp, value, tb
+ finally:
+ tb = None
+"""
+ )
+
+
+if sys.version_info[:2] > (3,):
+ exec_(
+ """def raise_from(value, from_value):
+ try:
+ raise value from from_value
+ finally:
+ value = None
+"""
+ )
+else:
+
+ def raise_from(value, from_value):
+ raise value
+
+
+print_ = getattr(moves.builtins, "print", None)
+if print_ is None:
+
+ def print_(*args, **kwargs):
+ """The new-style print function for Python 2.4 and 2.5."""
+ fp = kwargs.pop("file", sys.stdout)
+ if fp is None:
+ return
+
+ def write(data):
+ if not isinstance(data, basestring):
+ data = str(data)
+ # If the file has an encoding, encode unicode with it.
+ if (
+ isinstance(fp, file)
+ and isinstance(data, unicode)
+ and fp.encoding is not None
+ ):
+ errors = getattr(fp, "errors", None)
+ if errors is None:
+ errors = "strict"
+ data = data.encode(fp.encoding, errors)
+ fp.write(data)
+
+ want_unicode = False
+ sep = kwargs.pop("sep", None)
+ if sep is not None:
+ if isinstance(sep, unicode):
+ want_unicode = True
+ elif not isinstance(sep, str):
+ raise TypeError("sep must be None or a string")
+ end = kwargs.pop("end", None)
+ if end is not None:
+ if isinstance(end, unicode):
+ want_unicode = True
+ elif not isinstance(end, str):
+ raise TypeError("end must be None or a string")
+ if kwargs:
+ raise TypeError("invalid keyword arguments to print()")
+ if not want_unicode:
+ for arg in args:
+ if isinstance(arg, unicode):
+ want_unicode = True
+ break
+ if want_unicode:
+ newline = unicode("\n")
+ space = unicode(" ")
+ else:
+ newline = "\n"
+ space = " "
+ if sep is None:
+ sep = space
+ if end is None:
+ end = newline
+ for i, arg in enumerate(args):
+ if i:
+ write(sep)
+ write(arg)
+ write(end)
+
+
+if sys.version_info[:2] < (3, 3):
+ _print = print_
+
+ def print_(*args, **kwargs):
+ fp = kwargs.get("file", sys.stdout)
+ flush = kwargs.pop("flush", False)
+ _print(*args, **kwargs)
+ if flush and fp is not None:
+ fp.flush()
+
+
+_add_doc(reraise, """Reraise an exception.""")
+
+if sys.version_info[0:2] < (3, 4):
+ # This does exactly the same what the :func:`py3:functools.update_wrapper`
+ # function does on Python versions after 3.2. It sets the ``__wrapped__``
+ # attribute on ``wrapper`` object and it doesn't raise an error if any of
+ # the attributes mentioned in ``assigned`` and ``updated`` are missing on
+ # ``wrapped`` object.
+ def _update_wrapper(
+ wrapper,
+ wrapped,
+ assigned=functools.WRAPPER_ASSIGNMENTS,
+ updated=functools.WRAPPER_UPDATES,
+ ):
+ for attr in assigned:
+ try:
+ value = getattr(wrapped, attr)
+ except AttributeError:
+ continue
+ else:
+ setattr(wrapper, attr, value)
+ for attr in updated:
+ getattr(wrapper, attr).update(getattr(wrapped, attr, {}))
+ wrapper.__wrapped__ = wrapped
+ return wrapper
+
+ _update_wrapper.__doc__ = functools.update_wrapper.__doc__
+
+ def wraps(
+ wrapped,
+ assigned=functools.WRAPPER_ASSIGNMENTS,
+ updated=functools.WRAPPER_UPDATES,
+ ):
+ return functools.partial(
+ _update_wrapper, wrapped=wrapped, assigned=assigned, updated=updated
+ )
+
+ wraps.__doc__ = functools.wraps.__doc__
+
+else:
+ wraps = functools.wraps
+
+
+def with_metaclass(meta, *bases):
+ """Create a base class with a metaclass."""
+ # This requires a bit of explanation: the basic idea is to make a dummy
+ # metaclass for one level of class instantiation that replaces itself with
+ # the actual metaclass.
+ class metaclass(type):
+ def __new__(cls, name, this_bases, d):
+ if sys.version_info[:2] >= (3, 7):
+ # This version introduced PEP 560 that requires a bit
+ # of extra care (we mimic what is done by __build_class__).
+ resolved_bases = types.resolve_bases(bases)
+ if resolved_bases is not bases:
+ d["__orig_bases__"] = bases
+ else:
+ resolved_bases = bases
+ return meta(name, resolved_bases, d)
+
+ @classmethod
+ def __prepare__(cls, name, this_bases):
+ return meta.__prepare__(name, bases)
+
+ return type.__new__(metaclass, "temporary_class", (), {})
+
+
+def add_metaclass(metaclass):
+ """Class decorator for creating a class with a metaclass."""
+
+ def wrapper(cls):
+ orig_vars = cls.__dict__.copy()
+ slots = orig_vars.get("__slots__")
+ if slots is not None:
+ if isinstance(slots, str):
+ slots = [slots]
+ for slots_var in slots:
+ orig_vars.pop(slots_var)
+ orig_vars.pop("__dict__", None)
+ orig_vars.pop("__weakref__", None)
+ if hasattr(cls, "__qualname__"):
+ orig_vars["__qualname__"] = cls.__qualname__
+ return metaclass(cls.__name__, cls.__bases__, orig_vars)
+
+ return wrapper
+
+
+def ensure_binary(s, encoding="utf-8", errors="strict"):
+ """Coerce **s** to six.binary_type.
+
+ For Python 2:
+ - `unicode` -> encoded to `str`
+ - `str` -> `str`
+
+ For Python 3:
+ - `str` -> encoded to `bytes`
+ - `bytes` -> `bytes`
+ """
+ if isinstance(s, binary_type):
+ return s
+ if isinstance(s, text_type):
+ return s.encode(encoding, errors)
+ raise TypeError("not expecting type '%s'" % type(s))
+
+
+def ensure_str(s, encoding="utf-8", errors="strict"):
+ """Coerce *s* to `str`.
+
+ For Python 2:
+ - `unicode` -> encoded to `str`
+ - `str` -> `str`
+
+ For Python 3:
+ - `str` -> `str`
+ - `bytes` -> decoded to `str`
+ """
+ # Optimization: Fast return for the common case.
+ if type(s) is str:
+ return s
+ if PY2 and isinstance(s, text_type):
+ return s.encode(encoding, errors)
+ elif PY3 and isinstance(s, binary_type):
+ return s.decode(encoding, errors)
+ elif not isinstance(s, (text_type, binary_type)):
+ raise TypeError("not expecting type '%s'" % type(s))
+ return s
+
+
+def ensure_text(s, encoding="utf-8", errors="strict"):
+ """Coerce *s* to six.text_type.
+
+ For Python 2:
+ - `unicode` -> `unicode`
+ - `str` -> `unicode`
+
+ For Python 3:
+ - `str` -> `str`
+ - `bytes` -> decoded to `str`
+ """
+ if isinstance(s, binary_type):
+ return s.decode(encoding, errors)
+ elif isinstance(s, text_type):
+ return s
+ else:
+ raise TypeError("not expecting type '%s'" % type(s))
+
+
+def python_2_unicode_compatible(klass):
+ """
+ A class decorator that defines __unicode__ and __str__ methods under Python 2.
+ Under Python 3 it does nothing.
+
+ To support Python 2 and 3 with a single code base, define a __str__ method
+ returning text and apply this decorator to the class.
+ """
+ if PY2:
+ if "__str__" not in klass.__dict__:
+ raise ValueError(
+ "@python_2_unicode_compatible cannot be applied "
+ "to %s because it doesn't define __str__()." % klass.__name__
+ )
+ klass.__unicode__ = klass.__str__
+ klass.__str__ = lambda self: self.__unicode__().encode("utf-8")
+ return klass
+
+
+# Complete the moves implementation.
+# This code is at the end of this module to speed up module loading.
+# Turn this module into a package.
+__path__ = [] # required for PEP 302 and PEP 451
+__package__ = __name__ # see PEP 366 @ReservedAssignment
+if globals().get("__spec__") is not None:
+ __spec__.submodule_search_locations = [] # PEP 451 @UndefinedVariable
+# Remove other six meta path importers, since they cause problems. This can
+# happen if six is removed from sys.modules and then reloaded. (Setuptools does
+# this for some reason.)
+if sys.meta_path:
+ for i, importer in enumerate(sys.meta_path):
+ # Here's some real nastiness: Another "instance" of the six module might
+ # be floating around. Therefore, we can't use isinstance() to check for
+ # the six meta path importer, since the other six instance will have
+ # inserted an importer with different class.
+ if (
+ type(importer).__name__ == "_SixMetaPathImporter"
+ and importer.name == __name__
+ ):
+ del sys.meta_path[i]
+ break
+ del i, importer
+# Finally, add the importer to the meta path import hook.
+sys.meta_path.append(_importer)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/poolmanager.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/poolmanager.py
new file mode 100644
index 000000000..fb51bf7d9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/poolmanager.py
@@ -0,0 +1,540 @@
+from __future__ import absolute_import
+
+import collections
+import functools
+import logging
+
+from ._collections import HTTPHeaderDict, RecentlyUsedContainer
+from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, port_by_scheme
+from .exceptions import (
+ LocationValueError,
+ MaxRetryError,
+ ProxySchemeUnknown,
+ ProxySchemeUnsupported,
+ URLSchemeUnknown,
+)
+from .packages import six
+from .packages.six.moves.urllib.parse import urljoin
+from .request import RequestMethods
+from .util.proxy import connection_requires_http_tunnel
+from .util.retry import Retry
+from .util.url import parse_url
+
+__all__ = ["PoolManager", "ProxyManager", "proxy_from_url"]
+
+
+log = logging.getLogger(__name__)
+
+SSL_KEYWORDS = (
+ "key_file",
+ "cert_file",
+ "cert_reqs",
+ "ca_certs",
+ "ssl_version",
+ "ca_cert_dir",
+ "ssl_context",
+ "key_password",
+ "server_hostname",
+)
+
+# All known keyword arguments that could be provided to the pool manager, its
+# pools, or the underlying connections. This is used to construct a pool key.
+_key_fields = (
+ "key_scheme", # str
+ "key_host", # str
+ "key_port", # int
+ "key_timeout", # int or float or Timeout
+ "key_retries", # int or Retry
+ "key_strict", # bool
+ "key_block", # bool
+ "key_source_address", # str
+ "key_key_file", # str
+ "key_key_password", # str
+ "key_cert_file", # str
+ "key_cert_reqs", # str
+ "key_ca_certs", # str
+ "key_ssl_version", # str
+ "key_ca_cert_dir", # str
+ "key_ssl_context", # instance of ssl.SSLContext or urllib3.util.ssl_.SSLContext
+ "key_maxsize", # int
+ "key_headers", # dict
+ "key__proxy", # parsed proxy url
+ "key__proxy_headers", # dict
+ "key__proxy_config", # class
+ "key_socket_options", # list of (level (int), optname (int), value (int or str)) tuples
+ "key__socks_options", # dict
+ "key_assert_hostname", # bool or string
+ "key_assert_fingerprint", # str
+ "key_server_hostname", # str
+)
+
+#: The namedtuple class used to construct keys for the connection pool.
+#: All custom key schemes should include the fields in this key at a minimum.
+PoolKey = collections.namedtuple("PoolKey", _key_fields)
+
+_proxy_config_fields = ("ssl_context", "use_forwarding_for_https")
+ProxyConfig = collections.namedtuple("ProxyConfig", _proxy_config_fields)
+
+
+def _default_key_normalizer(key_class, request_context):
+ """
+ Create a pool key out of a request context dictionary.
+
+ According to RFC 3986, both the scheme and host are case-insensitive.
+ Therefore, this function normalizes both before constructing the pool
+ key for an HTTPS request. If you wish to change this behaviour, provide
+ alternate callables to ``key_fn_by_scheme``.
+
+ :param key_class:
+ The class to use when constructing the key. This should be a namedtuple
+ with the ``scheme`` and ``host`` keys at a minimum.
+ :type key_class: namedtuple
+ :param request_context:
+ A dictionary-like object that contain the context for a request.
+ :type request_context: dict
+
+ :return: A namedtuple that can be used as a connection pool key.
+ :rtype: PoolKey
+ """
+ # Since we mutate the dictionary, make a copy first
+ context = request_context.copy()
+ context["scheme"] = context["scheme"].lower()
+ context["host"] = context["host"].lower()
+
+ # These are both dictionaries and need to be transformed into frozensets
+ for key in ("headers", "_proxy_headers", "_socks_options"):
+ if key in context and context[key] is not None:
+ context[key] = frozenset(context[key].items())
+
+ # The socket_options key may be a list and needs to be transformed into a
+ # tuple.
+ socket_opts = context.get("socket_options")
+ if socket_opts is not None:
+ context["socket_options"] = tuple(socket_opts)
+
+ # Map the kwargs to the names in the namedtuple - this is necessary since
+ # namedtuples can't have fields starting with '_'.
+ for key in list(context.keys()):
+ context["key_" + key] = context.pop(key)
+
+ # Default to ``None`` for keys missing from the context
+ for field in key_class._fields:
+ if field not in context:
+ context[field] = None
+
+ return key_class(**context)
+
+
+#: A dictionary that maps a scheme to a callable that creates a pool key.
+#: This can be used to alter the way pool keys are constructed, if desired.
+#: Each PoolManager makes a copy of this dictionary so they can be configured
+#: globally here, or individually on the instance.
+key_fn_by_scheme = {
+ "http": functools.partial(_default_key_normalizer, PoolKey),
+ "https": functools.partial(_default_key_normalizer, PoolKey),
+}
+
+pool_classes_by_scheme = {"http": HTTPConnectionPool, "https": HTTPSConnectionPool}
+
+
+class PoolManager(RequestMethods):
+ """
+ Allows for arbitrary requests while transparently keeping track of
+ necessary connection pools for you.
+
+ :param num_pools:
+ Number of connection pools to cache before discarding the least
+ recently used pool.
+
+ :param headers:
+ Headers to include with all requests, unless other headers are given
+ explicitly.
+
+ :param \\**connection_pool_kw:
+ Additional parameters are used to create fresh
+ :class:`urllib3.connectionpool.ConnectionPool` instances.
+
+ Example::
+
+ >>> manager = PoolManager(num_pools=2)
+ >>> r = manager.request('GET', 'http://google.com/')
+ >>> r = manager.request('GET', 'http://google.com/mail')
+ >>> r = manager.request('GET', 'http://yahoo.com/')
+ >>> len(manager.pools)
+ 2
+
+ """
+
+ proxy = None
+ proxy_config = None
+
+ def __init__(self, num_pools=10, headers=None, **connection_pool_kw):
+ RequestMethods.__init__(self, headers)
+ self.connection_pool_kw = connection_pool_kw
+ self.pools = RecentlyUsedContainer(num_pools)
+
+ # Locally set the pool classes and keys so other PoolManagers can
+ # override them.
+ self.pool_classes_by_scheme = pool_classes_by_scheme
+ self.key_fn_by_scheme = key_fn_by_scheme.copy()
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.clear()
+ # Return False to re-raise any potential exceptions
+ return False
+
+ def _new_pool(self, scheme, host, port, request_context=None):
+ """
+ Create a new :class:`urllib3.connectionpool.ConnectionPool` based on host, port, scheme, and
+ any additional pool keyword arguments.
+
+ If ``request_context`` is provided, it is provided as keyword arguments
+ to the pool class used. This method is used to actually create the
+ connection pools handed out by :meth:`connection_from_url` and
+ companion methods. It is intended to be overridden for customization.
+ """
+ pool_cls = self.pool_classes_by_scheme[scheme]
+ if request_context is None:
+ request_context = self.connection_pool_kw.copy()
+
+ # Although the context has everything necessary to create the pool,
+ # this function has historically only used the scheme, host, and port
+ # in the positional args. When an API change is acceptable these can
+ # be removed.
+ for key in ("scheme", "host", "port"):
+ request_context.pop(key, None)
+
+ if scheme == "http":
+ for kw in SSL_KEYWORDS:
+ request_context.pop(kw, None)
+
+ return pool_cls(host, port, **request_context)
+
+ def clear(self):
+ """
+ Empty our store of pools and direct them all to close.
+
+ This will not affect in-flight connections, but they will not be
+ re-used after completion.
+ """
+ self.pools.clear()
+
+ def connection_from_host(self, host, port=None, scheme="http", pool_kwargs=None):
+ """
+ Get a :class:`urllib3.connectionpool.ConnectionPool` based on the host, port, and scheme.
+
+ If ``port`` isn't given, it will be derived from the ``scheme`` using
+ ``urllib3.connectionpool.port_by_scheme``. If ``pool_kwargs`` is
+ provided, it is merged with the instance's ``connection_pool_kw``
+ variable and used to create the new connection pool, if one is
+ needed.
+ """
+
+ if not host:
+ raise LocationValueError("No host specified.")
+
+ request_context = self._merge_pool_kwargs(pool_kwargs)
+ request_context["scheme"] = scheme or "http"
+ if not port:
+ port = port_by_scheme.get(request_context["scheme"].lower(), 80)
+ request_context["port"] = port
+ request_context["host"] = host
+
+ return self.connection_from_context(request_context)
+
+ def connection_from_context(self, request_context):
+ """
+ Get a :class:`urllib3.connectionpool.ConnectionPool` based on the request context.
+
+ ``request_context`` must at least contain the ``scheme`` key and its
+ value must be a key in ``key_fn_by_scheme`` instance variable.
+ """
+ scheme = request_context["scheme"].lower()
+ pool_key_constructor = self.key_fn_by_scheme.get(scheme)
+ if not pool_key_constructor:
+ raise URLSchemeUnknown(scheme)
+ pool_key = pool_key_constructor(request_context)
+
+ return self.connection_from_pool_key(pool_key, request_context=request_context)
+
+ def connection_from_pool_key(self, pool_key, request_context=None):
+ """
+ Get a :class:`urllib3.connectionpool.ConnectionPool` based on the provided pool key.
+
+ ``pool_key`` should be a namedtuple that only contains immutable
+ objects. At a minimum it must have the ``scheme``, ``host``, and
+ ``port`` fields.
+ """
+ with self.pools.lock:
+ # If the scheme, host, or port doesn't match existing open
+ # connections, open a new ConnectionPool.
+ pool = self.pools.get(pool_key)
+ if pool:
+ return pool
+
+ # Make a fresh ConnectionPool of the desired type
+ scheme = request_context["scheme"]
+ host = request_context["host"]
+ port = request_context["port"]
+ pool = self._new_pool(scheme, host, port, request_context=request_context)
+ self.pools[pool_key] = pool
+
+ return pool
+
+ def connection_from_url(self, url, pool_kwargs=None):
+ """
+ Similar to :func:`urllib3.connectionpool.connection_from_url`.
+
+ If ``pool_kwargs`` is not provided and a new pool needs to be
+ constructed, ``self.connection_pool_kw`` is used to initialize
+ the :class:`urllib3.connectionpool.ConnectionPool`. If ``pool_kwargs``
+ is provided, it is used instead. Note that if a new pool does not
+ need to be created for the request, the provided ``pool_kwargs`` are
+ not used.
+ """
+ u = parse_url(url)
+ return self.connection_from_host(
+ u.host, port=u.port, scheme=u.scheme, pool_kwargs=pool_kwargs
+ )
+
+ def _merge_pool_kwargs(self, override):
+ """
+ Merge a dictionary of override values for self.connection_pool_kw.
+
+ This does not modify self.connection_pool_kw and returns a new dict.
+ Any keys in the override dictionary with a value of ``None`` are
+ removed from the merged dictionary.
+ """
+ base_pool_kwargs = self.connection_pool_kw.copy()
+ if override:
+ for key, value in override.items():
+ if value is None:
+ try:
+ del base_pool_kwargs[key]
+ except KeyError:
+ pass
+ else:
+ base_pool_kwargs[key] = value
+ return base_pool_kwargs
+
+ def _proxy_requires_url_absolute_form(self, parsed_url):
+ """
+ Indicates if the proxy requires the complete destination URL in the
+ request. Normally this is only needed when not using an HTTP CONNECT
+ tunnel.
+ """
+ if self.proxy is None:
+ return False
+
+ return not connection_requires_http_tunnel(
+ self.proxy, self.proxy_config, parsed_url.scheme
+ )
+
+ def _validate_proxy_scheme_url_selection(self, url_scheme):
+ """
+ Validates that were not attempting to do TLS in TLS connections on
+ Python2 or with unsupported SSL implementations.
+ """
+ if self.proxy is None or url_scheme != "https":
+ return
+
+ if self.proxy.scheme != "https":
+ return
+
+ if six.PY2 and not self.proxy_config.use_forwarding_for_https:
+ raise ProxySchemeUnsupported(
+ "Contacting HTTPS destinations through HTTPS proxies "
+ "'via CONNECT tunnels' is not supported in Python 2"
+ )
+
+ def urlopen(self, method, url, redirect=True, **kw):
+ """
+ Same as :meth:`urllib3.HTTPConnectionPool.urlopen`
+ with custom cross-host redirect logic and only sends the request-uri
+ portion of the ``url``.
+
+ The given ``url`` parameter must be absolute, such that an appropriate
+ :class:`urllib3.connectionpool.ConnectionPool` can be chosen for it.
+ """
+ u = parse_url(url)
+ self._validate_proxy_scheme_url_selection(u.scheme)
+
+ conn = self.connection_from_host(u.host, port=u.port, scheme=u.scheme)
+
+ kw["assert_same_host"] = False
+ kw["redirect"] = False
+
+ if "headers" not in kw:
+ kw["headers"] = self.headers.copy()
+
+ if self._proxy_requires_url_absolute_form(u):
+ response = conn.urlopen(method, url, **kw)
+ else:
+ response = conn.urlopen(method, u.request_uri, **kw)
+
+ redirect_location = redirect and response.get_redirect_location()
+ if not redirect_location:
+ return response
+
+ # Support relative URLs for redirecting.
+ redirect_location = urljoin(url, redirect_location)
+
+ if response.status == 303:
+ # Change the method according to RFC 9110, Section 15.4.4.
+ method = "GET"
+ # And lose the body not to transfer anything sensitive.
+ kw["body"] = None
+ kw["headers"] = HTTPHeaderDict(kw["headers"])._prepare_for_method_change()
+
+ retries = kw.get("retries")
+ if not isinstance(retries, Retry):
+ retries = Retry.from_int(retries, redirect=redirect)
+
+ # Strip headers marked as unsafe to forward to the redirected location.
+ # Check remove_headers_on_redirect to avoid a potential network call within
+ # conn.is_same_host() which may use socket.gethostbyname() in the future.
+ if retries.remove_headers_on_redirect and not conn.is_same_host(
+ redirect_location
+ ):
+ headers = list(six.iterkeys(kw["headers"]))
+ for header in headers:
+ if header.lower() in retries.remove_headers_on_redirect:
+ kw["headers"].pop(header, None)
+
+ try:
+ retries = retries.increment(method, url, response=response, _pool=conn)
+ except MaxRetryError:
+ if retries.raise_on_redirect:
+ response.drain_conn()
+ raise
+ return response
+
+ kw["retries"] = retries
+ kw["redirect"] = redirect
+
+ log.info("Redirecting %s -> %s", url, redirect_location)
+
+ response.drain_conn()
+ return self.urlopen(method, redirect_location, **kw)
+
+
+class ProxyManager(PoolManager):
+ """
+ Behaves just like :class:`PoolManager`, but sends all requests through
+ the defined proxy, using the CONNECT method for HTTPS URLs.
+
+ :param proxy_url:
+ The URL of the proxy to be used.
+
+ :param proxy_headers:
+ A dictionary containing headers that will be sent to the proxy. In case
+ of HTTP they are being sent with each request, while in the
+ HTTPS/CONNECT case they are sent only once. Could be used for proxy
+ authentication.
+
+ :param proxy_ssl_context:
+ The proxy SSL context is used to establish the TLS connection to the
+ proxy when using HTTPS proxies.
+
+ :param use_forwarding_for_https:
+ (Defaults to False) If set to True will forward requests to the HTTPS
+ proxy to be made on behalf of the client instead of creating a TLS
+ tunnel via the CONNECT method. **Enabling this flag means that request
+ and response headers and content will be visible from the HTTPS proxy**
+ whereas tunneling keeps request and response headers and content
+ private. IP address, target hostname, SNI, and port are always visible
+ to an HTTPS proxy even when this flag is disabled.
+
+ Example:
+ >>> proxy = urllib3.ProxyManager('http://localhost:3128/')
+ >>> r1 = proxy.request('GET', 'http://google.com/')
+ >>> r2 = proxy.request('GET', 'http://httpbin.org/')
+ >>> len(proxy.pools)
+ 1
+ >>> r3 = proxy.request('GET', 'https://httpbin.org/')
+ >>> r4 = proxy.request('GET', 'https://twitter.com/')
+ >>> len(proxy.pools)
+ 3
+
+ """
+
+ def __init__(
+ self,
+ proxy_url,
+ num_pools=10,
+ headers=None,
+ proxy_headers=None,
+ proxy_ssl_context=None,
+ use_forwarding_for_https=False,
+ **connection_pool_kw
+ ):
+
+ if isinstance(proxy_url, HTTPConnectionPool):
+ proxy_url = "%s://%s:%i" % (
+ proxy_url.scheme,
+ proxy_url.host,
+ proxy_url.port,
+ )
+ proxy = parse_url(proxy_url)
+
+ if proxy.scheme not in ("http", "https"):
+ raise ProxySchemeUnknown(proxy.scheme)
+
+ if not proxy.port:
+ port = port_by_scheme.get(proxy.scheme, 80)
+ proxy = proxy._replace(port=port)
+
+ self.proxy = proxy
+ self.proxy_headers = proxy_headers or {}
+ self.proxy_ssl_context = proxy_ssl_context
+ self.proxy_config = ProxyConfig(proxy_ssl_context, use_forwarding_for_https)
+
+ connection_pool_kw["_proxy"] = self.proxy
+ connection_pool_kw["_proxy_headers"] = self.proxy_headers
+ connection_pool_kw["_proxy_config"] = self.proxy_config
+
+ super(ProxyManager, self).__init__(num_pools, headers, **connection_pool_kw)
+
+ def connection_from_host(self, host, port=None, scheme="http", pool_kwargs=None):
+ if scheme == "https":
+ return super(ProxyManager, self).connection_from_host(
+ host, port, scheme, pool_kwargs=pool_kwargs
+ )
+
+ return super(ProxyManager, self).connection_from_host(
+ self.proxy.host, self.proxy.port, self.proxy.scheme, pool_kwargs=pool_kwargs
+ )
+
+ def _set_proxy_headers(self, url, headers=None):
+ """
+ Sets headers needed by proxies: specifically, the Accept and Host
+ headers. Only sets headers not provided by the user.
+ """
+ headers_ = {"Accept": "*/*"}
+
+ netloc = parse_url(url).netloc
+ if netloc:
+ headers_["Host"] = netloc
+
+ if headers:
+ headers_.update(headers)
+ return headers_
+
+ def urlopen(self, method, url, redirect=True, **kw):
+ "Same as HTTP(S)ConnectionPool.urlopen, ``url`` must be absolute."
+ u = parse_url(url)
+ if not connection_requires_http_tunnel(self.proxy, self.proxy_config, u.scheme):
+ # For connections using HTTP CONNECT, httplib sets the necessary
+ # headers on the CONNECT to the proxy. If we're not using CONNECT,
+ # we'll definitely need to set 'Host' at the very least.
+ headers = kw.get("headers", self.headers)
+ kw["headers"] = self._set_proxy_headers(url, headers)
+
+ return super(ProxyManager, self).urlopen(method, url, redirect=redirect, **kw)
+
+
+def proxy_from_url(url, **kw):
+ return ProxyManager(proxy_url=url, **kw)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/request.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/request.py
new file mode 100644
index 000000000..3b4cf9992
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/request.py
@@ -0,0 +1,191 @@
+from __future__ import absolute_import
+
+import sys
+
+from .filepost import encode_multipart_formdata
+from .packages import six
+from .packages.six.moves.urllib.parse import urlencode
+
+__all__ = ["RequestMethods"]
+
+
+class RequestMethods(object):
+ """
+ Convenience mixin for classes who implement a :meth:`urlopen` method, such
+ as :class:`urllib3.HTTPConnectionPool` and
+ :class:`urllib3.PoolManager`.
+
+ Provides behavior for making common types of HTTP request methods and
+ decides which type of request field encoding to use.
+
+ Specifically,
+
+ :meth:`.request_encode_url` is for sending requests whose fields are
+ encoded in the URL (such as GET, HEAD, DELETE).
+
+ :meth:`.request_encode_body` is for sending requests whose fields are
+ encoded in the *body* of the request using multipart or www-form-urlencoded
+ (such as for POST, PUT, PATCH).
+
+ :meth:`.request` is for making any kind of request, it will look up the
+ appropriate encoding format and use one of the above two methods to make
+ the request.
+
+ Initializer parameters:
+
+ :param headers:
+ Headers to include with all requests, unless other headers are given
+ explicitly.
+ """
+
+ _encode_url_methods = {"DELETE", "GET", "HEAD", "OPTIONS"}
+
+ def __init__(self, headers=None):
+ self.headers = headers or {}
+
+ def urlopen(
+ self,
+ method,
+ url,
+ body=None,
+ headers=None,
+ encode_multipart=True,
+ multipart_boundary=None,
+ **kw
+ ): # Abstract
+ raise NotImplementedError(
+ "Classes extending RequestMethods must implement "
+ "their own ``urlopen`` method."
+ )
+
+ def request(self, method, url, fields=None, headers=None, **urlopen_kw):
+ """
+ Make a request using :meth:`urlopen` with the appropriate encoding of
+ ``fields`` based on the ``method`` used.
+
+ This is a convenience method that requires the least amount of manual
+ effort. It can be used in most situations, while still having the
+ option to drop down to more specific methods when necessary, such as
+ :meth:`request_encode_url`, :meth:`request_encode_body`,
+ or even the lowest level :meth:`urlopen`.
+ """
+ method = method.upper()
+
+ urlopen_kw["request_url"] = url
+
+ if method in self._encode_url_methods:
+ return self.request_encode_url(
+ method, url, fields=fields, headers=headers, **urlopen_kw
+ )
+ else:
+ return self.request_encode_body(
+ method, url, fields=fields, headers=headers, **urlopen_kw
+ )
+
+ def request_encode_url(self, method, url, fields=None, headers=None, **urlopen_kw):
+ """
+ Make a request using :meth:`urlopen` with the ``fields`` encoded in
+ the url. This is useful for request methods like GET, HEAD, DELETE, etc.
+ """
+ if headers is None:
+ headers = self.headers
+
+ extra_kw = {"headers": headers}
+ extra_kw.update(urlopen_kw)
+
+ if fields:
+ url += "?" + urlencode(fields)
+
+ return self.urlopen(method, url, **extra_kw)
+
+ def request_encode_body(
+ self,
+ method,
+ url,
+ fields=None,
+ headers=None,
+ encode_multipart=True,
+ multipart_boundary=None,
+ **urlopen_kw
+ ):
+ """
+ Make a request using :meth:`urlopen` with the ``fields`` encoded in
+ the body. This is useful for request methods like POST, PUT, PATCH, etc.
+
+ When ``encode_multipart=True`` (default), then
+ :func:`urllib3.encode_multipart_formdata` is used to encode
+ the payload with the appropriate content type. Otherwise
+ :func:`urllib.parse.urlencode` is used with the
+ 'application/x-www-form-urlencoded' content type.
+
+ Multipart encoding must be used when posting files, and it's reasonably
+ safe to use it in other times too. However, it may break request
+ signing, such as with OAuth.
+
+ Supports an optional ``fields`` parameter of key/value strings AND
+ key/filetuple. A filetuple is a (filename, data, MIME type) tuple where
+ the MIME type is optional. For example::
+
+ fields = {
+ 'foo': 'bar',
+ 'fakefile': ('foofile.txt', 'contents of foofile'),
+ 'realfile': ('barfile.txt', open('realfile').read()),
+ 'typedfile': ('bazfile.bin', open('bazfile').read(),
+ 'image/jpeg'),
+ 'nonamefile': 'contents of nonamefile field',
+ }
+
+ When uploading a file, providing a filename (the first parameter of the
+ tuple) is optional but recommended to best mimic behavior of browsers.
+
+ Note that if ``headers`` are supplied, the 'Content-Type' header will
+ be overwritten because it depends on the dynamic random boundary string
+ which is used to compose the body of the request. The random boundary
+ string can be explicitly set with the ``multipart_boundary`` parameter.
+ """
+ if headers is None:
+ headers = self.headers
+
+ extra_kw = {"headers": {}}
+
+ if fields:
+ if "body" in urlopen_kw:
+ raise TypeError(
+ "request got values for both 'fields' and 'body', can only specify one."
+ )
+
+ if encode_multipart:
+ body, content_type = encode_multipart_formdata(
+ fields, boundary=multipart_boundary
+ )
+ else:
+ body, content_type = (
+ urlencode(fields),
+ "application/x-www-form-urlencoded",
+ )
+
+ extra_kw["body"] = body
+ extra_kw["headers"] = {"Content-Type": content_type}
+
+ extra_kw["headers"].update(headers)
+ extra_kw.update(urlopen_kw)
+
+ return self.urlopen(method, url, **extra_kw)
+
+
+if not six.PY2:
+
+ class RequestModule(sys.modules[__name__].__class__):
+ def __call__(self, *args, **kwargs):
+ """
+ If user tries to call this module directly urllib3 v2.x style raise an error to the user
+ suggesting they may need urllib3 v2
+ """
+ raise TypeError(
+ "'module' object is not callable\n"
+ "urllib3.request() method is not supported in this release, "
+ "upgrade to urllib3 v2 to use it\n"
+ "see https://urllib3.readthedocs.io/en/stable/v2-migration-guide.html"
+ )
+
+ sys.modules[__name__].__class__ = RequestModule
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/response.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/response.py
new file mode 100644
index 000000000..8909f8454
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/response.py
@@ -0,0 +1,879 @@
+from __future__ import absolute_import
+
+import io
+import logging
+import sys
+import warnings
+import zlib
+from contextlib import contextmanager
+from socket import error as SocketError
+from socket import timeout as SocketTimeout
+
+brotli = None
+
+from . import util
+from ._collections import HTTPHeaderDict
+from .connection import BaseSSLError, HTTPException
+from .exceptions import (
+ BodyNotHttplibCompatible,
+ DecodeError,
+ HTTPError,
+ IncompleteRead,
+ InvalidChunkLength,
+ InvalidHeader,
+ ProtocolError,
+ ReadTimeoutError,
+ ResponseNotChunked,
+ SSLError,
+)
+from .packages import six
+from .util.response import is_fp_closed, is_response_to_head
+
+log = logging.getLogger(__name__)
+
+
+class DeflateDecoder(object):
+ def __init__(self):
+ self._first_try = True
+ self._data = b""
+ self._obj = zlib.decompressobj()
+
+ def __getattr__(self, name):
+ return getattr(self._obj, name)
+
+ def decompress(self, data):
+ if not data:
+ return data
+
+ if not self._first_try:
+ return self._obj.decompress(data)
+
+ self._data += data
+ try:
+ decompressed = self._obj.decompress(data)
+ if decompressed:
+ self._first_try = False
+ self._data = None
+ return decompressed
+ except zlib.error:
+ self._first_try = False
+ self._obj = zlib.decompressobj(-zlib.MAX_WBITS)
+ try:
+ return self.decompress(self._data)
+ finally:
+ self._data = None
+
+
+class GzipDecoderState(object):
+
+ FIRST_MEMBER = 0
+ OTHER_MEMBERS = 1
+ SWALLOW_DATA = 2
+
+
+class GzipDecoder(object):
+ def __init__(self):
+ self._obj = zlib.decompressobj(16 + zlib.MAX_WBITS)
+ self._state = GzipDecoderState.FIRST_MEMBER
+
+ def __getattr__(self, name):
+ return getattr(self._obj, name)
+
+ def decompress(self, data):
+ ret = bytearray()
+ if self._state == GzipDecoderState.SWALLOW_DATA or not data:
+ return bytes(ret)
+ while True:
+ try:
+ ret += self._obj.decompress(data)
+ except zlib.error:
+ previous_state = self._state
+ # Ignore data after the first error
+ self._state = GzipDecoderState.SWALLOW_DATA
+ if previous_state == GzipDecoderState.OTHER_MEMBERS:
+ # Allow trailing garbage acceptable in other gzip clients
+ return bytes(ret)
+ raise
+ data = self._obj.unused_data
+ if not data:
+ return bytes(ret)
+ self._state = GzipDecoderState.OTHER_MEMBERS
+ self._obj = zlib.decompressobj(16 + zlib.MAX_WBITS)
+
+
+if brotli is not None:
+
+ class BrotliDecoder(object):
+ # Supports both 'brotlipy' and 'Brotli' packages
+ # since they share an import name. The top branches
+ # are for 'brotlipy' and bottom branches for 'Brotli'
+ def __init__(self):
+ self._obj = brotli.Decompressor()
+ if hasattr(self._obj, "decompress"):
+ self.decompress = self._obj.decompress
+ else:
+ self.decompress = self._obj.process
+
+ def flush(self):
+ if hasattr(self._obj, "flush"):
+ return self._obj.flush()
+ return b""
+
+
+class MultiDecoder(object):
+ """
+ From RFC7231:
+ If one or more encodings have been applied to a representation, the
+ sender that applied the encodings MUST generate a Content-Encoding
+ header field that lists the content codings in the order in which
+ they were applied.
+ """
+
+ def __init__(self, modes):
+ self._decoders = [_get_decoder(m.strip()) for m in modes.split(",")]
+
+ def flush(self):
+ return self._decoders[0].flush()
+
+ def decompress(self, data):
+ for d in reversed(self._decoders):
+ data = d.decompress(data)
+ return data
+
+
+def _get_decoder(mode):
+ if "," in mode:
+ return MultiDecoder(mode)
+
+ if mode == "gzip":
+ return GzipDecoder()
+
+ if brotli is not None and mode == "br":
+ return BrotliDecoder()
+
+ return DeflateDecoder()
+
+
+class HTTPResponse(io.IOBase):
+ """
+ HTTP Response container.
+
+ Backwards-compatible with :class:`http.client.HTTPResponse` but the response ``body`` is
+ loaded and decoded on-demand when the ``data`` property is accessed. This
+ class is also compatible with the Python standard library's :mod:`io`
+ module, and can hence be treated as a readable object in the context of that
+ framework.
+
+ Extra parameters for behaviour not present in :class:`http.client.HTTPResponse`:
+
+ :param preload_content:
+ If True, the response's body will be preloaded during construction.
+
+ :param decode_content:
+ If True, will attempt to decode the body based on the
+ 'content-encoding' header.
+
+ :param original_response:
+ When this HTTPResponse wrapper is generated from an :class:`http.client.HTTPResponse`
+ object, it's convenient to include the original for debug purposes. It's
+ otherwise unused.
+
+ :param retries:
+ The retries contains the last :class:`~urllib3.util.retry.Retry` that
+ was used during the request.
+
+ :param enforce_content_length:
+ Enforce content length checking. Body returned by server must match
+ value of Content-Length header, if present. Otherwise, raise error.
+ """
+
+ CONTENT_DECODERS = ["gzip", "deflate"]
+ if brotli is not None:
+ CONTENT_DECODERS += ["br"]
+ REDIRECT_STATUSES = [301, 302, 303, 307, 308]
+
+ def __init__(
+ self,
+ body="",
+ headers=None,
+ status=0,
+ version=0,
+ reason=None,
+ strict=0,
+ preload_content=True,
+ decode_content=True,
+ original_response=None,
+ pool=None,
+ connection=None,
+ msg=None,
+ retries=None,
+ enforce_content_length=False,
+ request_method=None,
+ request_url=None,
+ auto_close=True,
+ ):
+
+ if isinstance(headers, HTTPHeaderDict):
+ self.headers = headers
+ else:
+ self.headers = HTTPHeaderDict(headers)
+ self.status = status
+ self.version = version
+ self.reason = reason
+ self.strict = strict
+ self.decode_content = decode_content
+ self.retries = retries
+ self.enforce_content_length = enforce_content_length
+ self.auto_close = auto_close
+
+ self._decoder = None
+ self._body = None
+ self._fp = None
+ self._original_response = original_response
+ self._fp_bytes_read = 0
+ self.msg = msg
+ self._request_url = request_url
+
+ if body and isinstance(body, (six.string_types, bytes)):
+ self._body = body
+
+ self._pool = pool
+ self._connection = connection
+
+ if hasattr(body, "read"):
+ self._fp = body
+
+ # Are we using the chunked-style of transfer encoding?
+ self.chunked = False
+ self.chunk_left = None
+ tr_enc = self.headers.get("transfer-encoding", "").lower()
+ # Don't incur the penalty of creating a list and then discarding it
+ encodings = (enc.strip() for enc in tr_enc.split(","))
+ if "chunked" in encodings:
+ self.chunked = True
+
+ # Determine length of response
+ self.length_remaining = self._init_length(request_method)
+
+ # If requested, preload the body.
+ if preload_content and not self._body:
+ self._body = self.read(decode_content=decode_content)
+
+ def get_redirect_location(self):
+ """
+ Should we redirect and where to?
+
+ :returns: Truthy redirect location string if we got a redirect status
+ code and valid location. ``None`` if redirect status and no
+ location. ``False`` if not a redirect status code.
+ """
+ if self.status in self.REDIRECT_STATUSES:
+ return self.headers.get("location")
+
+ return False
+
+ def release_conn(self):
+ if not self._pool or not self._connection:
+ return
+
+ self._pool._put_conn(self._connection)
+ self._connection = None
+
+ def drain_conn(self):
+ """
+ Read and discard any remaining HTTP response data in the response connection.
+
+ Unread data in the HTTPResponse connection blocks the connection from being released back to the pool.
+ """
+ try:
+ self.read()
+ except (HTTPError, SocketError, BaseSSLError, HTTPException):
+ pass
+
+ @property
+ def data(self):
+ # For backwards-compat with earlier urllib3 0.4 and earlier.
+ if self._body:
+ return self._body
+
+ if self._fp:
+ return self.read(cache_content=True)
+
+ @property
+ def connection(self):
+ return self._connection
+
+ def isclosed(self):
+ return is_fp_closed(self._fp)
+
+ def tell(self):
+ """
+ Obtain the number of bytes pulled over the wire so far. May differ from
+ the amount of content returned by :meth:``urllib3.response.HTTPResponse.read``
+ if bytes are encoded on the wire (e.g, compressed).
+ """
+ return self._fp_bytes_read
+
+ def _init_length(self, request_method):
+ """
+ Set initial length value for Response content if available.
+ """
+ length = self.headers.get("content-length")
+
+ if length is not None:
+ if self.chunked:
+ # This Response will fail with an IncompleteRead if it can't be
+ # received as chunked. This method falls back to attempt reading
+ # the response before raising an exception.
+ log.warning(
+ "Received response with both Content-Length and "
+ "Transfer-Encoding set. This is expressly forbidden "
+ "by RFC 7230 sec 3.3.2. Ignoring Content-Length and "
+ "attempting to process response as Transfer-Encoding: "
+ "chunked."
+ )
+ return None
+
+ try:
+ # RFC 7230 section 3.3.2 specifies multiple content lengths can
+ # be sent in a single Content-Length header
+ # (e.g. Content-Length: 42, 42). This line ensures the values
+ # are all valid ints and that as long as the `set` length is 1,
+ # all values are the same. Otherwise, the header is invalid.
+ lengths = set([int(val) for val in length.split(",")])
+ if len(lengths) > 1:
+ raise InvalidHeader(
+ "Content-Length contained multiple "
+ "unmatching values (%s)" % length
+ )
+ length = lengths.pop()
+ except ValueError:
+ length = None
+ else:
+ if length < 0:
+ length = None
+
+ # Convert status to int for comparison
+ # In some cases, httplib returns a status of "_UNKNOWN"
+ try:
+ status = int(self.status)
+ except ValueError:
+ status = 0
+
+ # Check for responses that shouldn't include a body
+ if status in (204, 304) or 100 <= status < 200 or request_method == "HEAD":
+ length = 0
+
+ return length
+
+ def _init_decoder(self):
+ """
+ Set-up the _decoder attribute if necessary.
+ """
+ # Note: content-encoding value should be case-insensitive, per RFC 7230
+ # Section 3.2
+ content_encoding = self.headers.get("content-encoding", "").lower()
+ if self._decoder is None:
+ if content_encoding in self.CONTENT_DECODERS:
+ self._decoder = _get_decoder(content_encoding)
+ elif "," in content_encoding:
+ encodings = [
+ e.strip()
+ for e in content_encoding.split(",")
+ if e.strip() in self.CONTENT_DECODERS
+ ]
+ if len(encodings):
+ self._decoder = _get_decoder(content_encoding)
+
+ DECODER_ERROR_CLASSES = (IOError, zlib.error)
+ if brotli is not None:
+ DECODER_ERROR_CLASSES += (brotli.error,)
+
+ def _decode(self, data, decode_content, flush_decoder):
+ """
+ Decode the data passed in and potentially flush the decoder.
+ """
+ if not decode_content:
+ return data
+
+ try:
+ if self._decoder:
+ data = self._decoder.decompress(data)
+ except self.DECODER_ERROR_CLASSES as e:
+ content_encoding = self.headers.get("content-encoding", "").lower()
+ raise DecodeError(
+ "Received response with content-encoding: %s, but "
+ "failed to decode it." % content_encoding,
+ e,
+ )
+ if flush_decoder:
+ data += self._flush_decoder()
+
+ return data
+
+ def _flush_decoder(self):
+ """
+ Flushes the decoder. Should only be called if the decoder is actually
+ being used.
+ """
+ if self._decoder:
+ buf = self._decoder.decompress(b"")
+ return buf + self._decoder.flush()
+
+ return b""
+
+ @contextmanager
+ def _error_catcher(self):
+ """
+ Catch low-level python exceptions, instead re-raising urllib3
+ variants, so that low-level exceptions are not leaked in the
+ high-level api.
+
+ On exit, release the connection back to the pool.
+ """
+ clean_exit = False
+
+ try:
+ try:
+ yield
+
+ except SocketTimeout:
+ # FIXME: Ideally we'd like to include the url in the ReadTimeoutError but
+ # there is yet no clean way to get at it from this context.
+ raise ReadTimeoutError(self._pool, None, "Read timed out.")
+
+ except BaseSSLError as e:
+ # FIXME: Is there a better way to differentiate between SSLErrors?
+ if "read operation timed out" not in str(e):
+ # SSL errors related to framing/MAC get wrapped and reraised here
+ raise SSLError(e)
+
+ raise ReadTimeoutError(self._pool, None, "Read timed out.")
+
+ except (HTTPException, SocketError) as e:
+ # This includes IncompleteRead.
+ raise ProtocolError("Connection broken: %r" % e, e)
+
+ # If no exception is thrown, we should avoid cleaning up
+ # unnecessarily.
+ clean_exit = True
+ finally:
+ # If we didn't terminate cleanly, we need to throw away our
+ # connection.
+ if not clean_exit:
+ # The response may not be closed but we're not going to use it
+ # anymore so close it now to ensure that the connection is
+ # released back to the pool.
+ if self._original_response:
+ self._original_response.close()
+
+ # Closing the response may not actually be sufficient to close
+ # everything, so if we have a hold of the connection close that
+ # too.
+ if self._connection:
+ self._connection.close()
+
+ # If we hold the original response but it's closed now, we should
+ # return the connection back to the pool.
+ if self._original_response and self._original_response.isclosed():
+ self.release_conn()
+
+ def _fp_read(self, amt):
+ """
+ Read a response with the thought that reading the number of bytes
+ larger than can fit in a 32-bit int at a time via SSL in some
+ known cases leads to an overflow error that has to be prevented
+ if `amt` or `self.length_remaining` indicate that a problem may
+ happen.
+
+ The known cases:
+ * 3.8 <= CPython < 3.9.7 because of a bug
+ https://github.com/urllib3/urllib3/issues/2513#issuecomment-1152559900.
+ * urllib3 injected with pyOpenSSL-backed SSL-support.
+ * CPython < 3.10 only when `amt` does not fit 32-bit int.
+ """
+ assert self._fp
+ c_int_max = 2 ** 31 - 1
+ if (
+ (
+ (amt and amt > c_int_max)
+ or (self.length_remaining and self.length_remaining > c_int_max)
+ )
+ and not util.IS_SECURETRANSPORT
+ and (util.IS_PYOPENSSL or sys.version_info < (3, 10))
+ ):
+ buffer = io.BytesIO()
+ # Besides `max_chunk_amt` being a maximum chunk size, it
+ # affects memory overhead of reading a response by this
+ # method in CPython.
+ # `c_int_max` equal to 2 GiB - 1 byte is the actual maximum
+ # chunk size that does not lead to an overflow error, but
+ # 256 MiB is a compromise.
+ max_chunk_amt = 2 ** 28
+ while amt is None or amt != 0:
+ if amt is not None:
+ chunk_amt = min(amt, max_chunk_amt)
+ amt -= chunk_amt
+ else:
+ chunk_amt = max_chunk_amt
+ data = self._fp.read(chunk_amt)
+ if not data:
+ break
+ buffer.write(data)
+ del data # to reduce peak memory usage by `max_chunk_amt`.
+ return buffer.getvalue()
+ else:
+ # StringIO doesn't like amt=None
+ return self._fp.read(amt) if amt is not None else self._fp.read()
+
+ def read(self, amt=None, decode_content=None, cache_content=False):
+ """
+ Similar to :meth:`http.client.HTTPResponse.read`, but with two additional
+ parameters: ``decode_content`` and ``cache_content``.
+
+ :param amt:
+ How much of the content to read. If specified, caching is skipped
+ because it doesn't make sense to cache partial content as the full
+ response.
+
+ :param decode_content:
+ If True, will attempt to decode the body based on the
+ 'content-encoding' header.
+
+ :param cache_content:
+ If True, will save the returned data such that the same result is
+ returned despite of the state of the underlying file object. This
+ is useful if you want the ``.data`` property to continue working
+ after having ``.read()`` the file object. (Overridden if ``amt`` is
+ set.)
+ """
+ self._init_decoder()
+ if decode_content is None:
+ decode_content = self.decode_content
+
+ if self._fp is None:
+ return
+
+ flush_decoder = False
+ fp_closed = getattr(self._fp, "closed", False)
+
+ with self._error_catcher():
+ data = self._fp_read(amt) if not fp_closed else b""
+ if amt is None:
+ flush_decoder = True
+ else:
+ cache_content = False
+ if (
+ amt != 0 and not data
+ ): # Platform-specific: Buggy versions of Python.
+ # Close the connection when no data is returned
+ #
+ # This is redundant to what httplib/http.client _should_
+ # already do. However, versions of python released before
+ # December 15, 2012 (http://bugs.python.org/issue16298) do
+ # not properly close the connection in all cases. There is
+ # no harm in redundantly calling close.
+ self._fp.close()
+ flush_decoder = True
+ if self.enforce_content_length and self.length_remaining not in (
+ 0,
+ None,
+ ):
+ # This is an edge case that httplib failed to cover due
+ # to concerns of backward compatibility. We're
+ # addressing it here to make sure IncompleteRead is
+ # raised during streaming, so all calls with incorrect
+ # Content-Length are caught.
+ raise IncompleteRead(self._fp_bytes_read, self.length_remaining)
+
+ if data:
+ self._fp_bytes_read += len(data)
+ if self.length_remaining is not None:
+ self.length_remaining -= len(data)
+
+ data = self._decode(data, decode_content, flush_decoder)
+
+ if cache_content:
+ self._body = data
+
+ return data
+
+ def stream(self, amt=2 ** 16, decode_content=None):
+ """
+ A generator wrapper for the read() method. A call will block until
+ ``amt`` bytes have been read from the connection or until the
+ connection is closed.
+
+ :param amt:
+ How much of the content to read. The generator will return up to
+ much data per iteration, but may return less. This is particularly
+ likely when using compressed data. However, the empty string will
+ never be returned.
+
+ :param decode_content:
+ If True, will attempt to decode the body based on the
+ 'content-encoding' header.
+ """
+ if self.chunked and self.supports_chunked_reads():
+ for line in self.read_chunked(amt, decode_content=decode_content):
+ yield line
+ else:
+ while not is_fp_closed(self._fp):
+ data = self.read(amt=amt, decode_content=decode_content)
+
+ if data:
+ yield data
+
+ @classmethod
+ def from_httplib(ResponseCls, r, **response_kw):
+ """
+ Given an :class:`http.client.HTTPResponse` instance ``r``, return a
+ corresponding :class:`urllib3.response.HTTPResponse` object.
+
+ Remaining parameters are passed to the HTTPResponse constructor, along
+ with ``original_response=r``.
+ """
+ headers = r.msg
+
+ if not isinstance(headers, HTTPHeaderDict):
+ if six.PY2:
+ # Python 2.7
+ headers = HTTPHeaderDict.from_httplib(headers)
+ else:
+ headers = HTTPHeaderDict(headers.items())
+
+ # HTTPResponse objects in Python 3 don't have a .strict attribute
+ strict = getattr(r, "strict", 0)
+ resp = ResponseCls(
+ body=r,
+ headers=headers,
+ status=r.status,
+ version=r.version,
+ reason=r.reason,
+ strict=strict,
+ original_response=r,
+ **response_kw
+ )
+ return resp
+
+ # Backwards-compatibility methods for http.client.HTTPResponse
+ def getheaders(self):
+ warnings.warn(
+ "HTTPResponse.getheaders() is deprecated and will be removed "
+ "in urllib3 v2.1.0. Instead access HTTPResponse.headers directly.",
+ category=DeprecationWarning,
+ stacklevel=2,
+ )
+ return self.headers
+
+ def getheader(self, name, default=None):
+ warnings.warn(
+ "HTTPResponse.getheader() is deprecated and will be removed "
+ "in urllib3 v2.1.0. Instead use HTTPResponse.headers.get(name, default).",
+ category=DeprecationWarning,
+ stacklevel=2,
+ )
+ return self.headers.get(name, default)
+
+ # Backwards compatibility for http.cookiejar
+ def info(self):
+ return self.headers
+
+ # Overrides from io.IOBase
+ def close(self):
+ if not self.closed:
+ self._fp.close()
+
+ if self._connection:
+ self._connection.close()
+
+ if not self.auto_close:
+ io.IOBase.close(self)
+
+ @property
+ def closed(self):
+ if not self.auto_close:
+ return io.IOBase.closed.__get__(self)
+ elif self._fp is None:
+ return True
+ elif hasattr(self._fp, "isclosed"):
+ return self._fp.isclosed()
+ elif hasattr(self._fp, "closed"):
+ return self._fp.closed
+ else:
+ return True
+
+ def fileno(self):
+ if self._fp is None:
+ raise IOError("HTTPResponse has no file to get a fileno from")
+ elif hasattr(self._fp, "fileno"):
+ return self._fp.fileno()
+ else:
+ raise IOError(
+ "The file-like object this HTTPResponse is wrapped "
+ "around has no file descriptor"
+ )
+
+ def flush(self):
+ if (
+ self._fp is not None
+ and hasattr(self._fp, "flush")
+ and not getattr(self._fp, "closed", False)
+ ):
+ return self._fp.flush()
+
+ def readable(self):
+ # This method is required for `io` module compatibility.
+ return True
+
+ def readinto(self, b):
+ # This method is required for `io` module compatibility.
+ temp = self.read(len(b))
+ if len(temp) == 0:
+ return 0
+ else:
+ b[: len(temp)] = temp
+ return len(temp)
+
+ def supports_chunked_reads(self):
+ """
+ Checks if the underlying file-like object looks like a
+ :class:`http.client.HTTPResponse` object. We do this by testing for
+ the fp attribute. If it is present we assume it returns raw chunks as
+ processed by read_chunked().
+ """
+ return hasattr(self._fp, "fp")
+
+ def _update_chunk_length(self):
+ # First, we'll figure out length of a chunk and then
+ # we'll try to read it from socket.
+ if self.chunk_left is not None:
+ return
+ line = self._fp.fp.readline()
+ line = line.split(b";", 1)[0]
+ try:
+ self.chunk_left = int(line, 16)
+ except ValueError:
+ # Invalid chunked protocol response, abort.
+ self.close()
+ raise InvalidChunkLength(self, line)
+
+ def _handle_chunk(self, amt):
+ returned_chunk = None
+ if amt is None:
+ chunk = self._fp._safe_read(self.chunk_left)
+ returned_chunk = chunk
+ self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
+ self.chunk_left = None
+ elif amt < self.chunk_left:
+ value = self._fp._safe_read(amt)
+ self.chunk_left = self.chunk_left - amt
+ returned_chunk = value
+ elif amt == self.chunk_left:
+ value = self._fp._safe_read(amt)
+ self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
+ self.chunk_left = None
+ returned_chunk = value
+ else: # amt > self.chunk_left
+ returned_chunk = self._fp._safe_read(self.chunk_left)
+ self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
+ self.chunk_left = None
+ return returned_chunk
+
+ def read_chunked(self, amt=None, decode_content=None):
+ """
+ Similar to :meth:`HTTPResponse.read`, but with an additional
+ parameter: ``decode_content``.
+
+ :param amt:
+ How much of the content to read. If specified, caching is skipped
+ because it doesn't make sense to cache partial content as the full
+ response.
+
+ :param decode_content:
+ If True, will attempt to decode the body based on the
+ 'content-encoding' header.
+ """
+ self._init_decoder()
+ # FIXME: Rewrite this method and make it a class with a better structured logic.
+ if not self.chunked:
+ raise ResponseNotChunked(
+ "Response is not chunked. "
+ "Header 'transfer-encoding: chunked' is missing."
+ )
+ if not self.supports_chunked_reads():
+ raise BodyNotHttplibCompatible(
+ "Body should be http.client.HTTPResponse like. "
+ "It should have have an fp attribute which returns raw chunks."
+ )
+
+ with self._error_catcher():
+ # Don't bother reading the body of a HEAD request.
+ if self._original_response and is_response_to_head(self._original_response):
+ self._original_response.close()
+ return
+
+ # If a response is already read and closed
+ # then return immediately.
+ if self._fp.fp is None:
+ return
+
+ while True:
+ self._update_chunk_length()
+ if self.chunk_left == 0:
+ break
+ chunk = self._handle_chunk(amt)
+ decoded = self._decode(
+ chunk, decode_content=decode_content, flush_decoder=False
+ )
+ if decoded:
+ yield decoded
+
+ if decode_content:
+ # On CPython and PyPy, we should never need to flush the
+ # decoder. However, on Jython we *might* need to, so
+ # lets defensively do it anyway.
+ decoded = self._flush_decoder()
+ if decoded: # Platform-specific: Jython.
+ yield decoded
+
+ # Chunk content ends with \r\n: discard it.
+ while True:
+ line = self._fp.fp.readline()
+ if not line:
+ # Some sites may not end with '\r\n'.
+ break
+ if line == b"\r\n":
+ break
+
+ # We read everything; close the "file".
+ if self._original_response:
+ self._original_response.close()
+
+ def geturl(self):
+ """
+ Returns the URL that was the source of this response.
+ If the request that generated this response redirected, this method
+ will return the final redirect location.
+ """
+ if self.retries is not None and len(self.retries.history):
+ return self.retries.history[-1].redirect_location
+ else:
+ return self._request_url
+
+ def __iter__(self):
+ buffer = []
+ for chunk in self.stream(decode_content=True):
+ if b"\n" in chunk:
+ chunk = chunk.split(b"\n")
+ yield b"".join(buffer) + chunk[0] + b"\n"
+ for x in chunk[1:-1]:
+ yield x + b"\n"
+ if chunk[-1]:
+ buffer = [chunk[-1]]
+ else:
+ buffer = []
+ else:
+ buffer.append(chunk)
+ if buffer:
+ yield b"".join(buffer)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/__init__.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/__init__.py
new file mode 100644
index 000000000..4547fc522
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/__init__.py
@@ -0,0 +1,49 @@
+from __future__ import absolute_import
+
+# For backwards compatibility, provide imports that used to be here.
+from .connection import is_connection_dropped
+from .request import SKIP_HEADER, SKIPPABLE_HEADERS, make_headers
+from .response import is_fp_closed
+from .retry import Retry
+from .ssl_ import (
+ ALPN_PROTOCOLS,
+ HAS_SNI,
+ IS_PYOPENSSL,
+ IS_SECURETRANSPORT,
+ PROTOCOL_TLS,
+ SSLContext,
+ assert_fingerprint,
+ resolve_cert_reqs,
+ resolve_ssl_version,
+ ssl_wrap_socket,
+)
+from .timeout import Timeout, current_time
+from .url import Url, get_host, parse_url, split_first
+from .wait import wait_for_read, wait_for_write
+
+__all__ = (
+ "HAS_SNI",
+ "IS_PYOPENSSL",
+ "IS_SECURETRANSPORT",
+ "SSLContext",
+ "PROTOCOL_TLS",
+ "ALPN_PROTOCOLS",
+ "Retry",
+ "Timeout",
+ "Url",
+ "assert_fingerprint",
+ "current_time",
+ "is_connection_dropped",
+ "is_fp_closed",
+ "get_host",
+ "parse_url",
+ "make_headers",
+ "resolve_cert_reqs",
+ "resolve_ssl_version",
+ "split_first",
+ "ssl_wrap_socket",
+ "wait_for_read",
+ "wait_for_write",
+ "SKIP_HEADER",
+ "SKIPPABLE_HEADERS",
+)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/connection.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/connection.py
new file mode 100644
index 000000000..6af1138f2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/connection.py
@@ -0,0 +1,149 @@
+from __future__ import absolute_import
+
+import socket
+
+from ..contrib import _appengine_environ
+from ..exceptions import LocationParseError
+from ..packages import six
+from .wait import NoWayToWaitForSocketError, wait_for_read
+
+
+def is_connection_dropped(conn): # Platform-specific
+ """
+ Returns True if the connection is dropped and should be closed.
+
+ :param conn:
+ :class:`http.client.HTTPConnection` object.
+
+ Note: For platforms like AppEngine, this will always return ``False`` to
+ let the platform handle connection recycling transparently for us.
+ """
+ sock = getattr(conn, "sock", False)
+ if sock is False: # Platform-specific: AppEngine
+ return False
+ if sock is None: # Connection already closed (such as by httplib).
+ return True
+ try:
+ # Returns True if readable, which here means it's been dropped
+ return wait_for_read(sock, timeout=0.0)
+ except NoWayToWaitForSocketError: # Platform-specific: AppEngine
+ return False
+
+
+# This function is copied from socket.py in the Python 2.7 standard
+# library test suite. Added to its signature is only `socket_options`.
+# One additional modification is that we avoid binding to IPv6 servers
+# discovered in DNS if the system doesn't have IPv6 functionality.
+def create_connection(
+ address,
+ timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
+ source_address=None,
+ socket_options=None,
+):
+ """Connect to *address* and return the socket object.
+
+ Convenience function. Connect to *address* (a 2-tuple ``(host,
+ port)``) and return the socket object. Passing the optional
+ *timeout* parameter will set the timeout on the socket instance
+ before attempting to connect. If no *timeout* is supplied, the
+ global default timeout setting returned by :func:`socket.getdefaulttimeout`
+ is used. If *source_address* is set it must be a tuple of (host, port)
+ for the socket to bind as a source address before making the connection.
+ An host of '' or port 0 tells the OS to use the default.
+ """
+
+ host, port = address
+ if host.startswith("["):
+ host = host.strip("[]")
+ err = None
+
+ # Using the value from allowed_gai_family() in the context of getaddrinfo lets
+ # us select whether to work with IPv4 DNS records, IPv6 records, or both.
+ # The original create_connection function always returns all records.
+ family = allowed_gai_family()
+
+ try:
+ host.encode("idna")
+ except UnicodeError:
+ return six.raise_from(
+ LocationParseError(u"'%s', label empty or too long" % host), None
+ )
+
+ for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
+ af, socktype, proto, canonname, sa = res
+ sock = None
+ try:
+ sock = socket.socket(af, socktype, proto)
+
+ # If provided, set socket level options before connecting.
+ _set_socket_options(sock, socket_options)
+
+ if timeout is not socket._GLOBAL_DEFAULT_TIMEOUT:
+ sock.settimeout(timeout)
+ if source_address:
+ sock.bind(source_address)
+ sock.connect(sa)
+ return sock
+
+ except socket.error as e:
+ err = e
+ if sock is not None:
+ sock.close()
+ sock = None
+
+ if err is not None:
+ raise err
+
+ raise socket.error("getaddrinfo returns an empty list")
+
+
+def _set_socket_options(sock, options):
+ if options is None:
+ return
+
+ for opt in options:
+ sock.setsockopt(*opt)
+
+
+def allowed_gai_family():
+ """This function is designed to work in the context of
+ getaddrinfo, where family=socket.AF_UNSPEC is the default and
+ will perform a DNS search for both IPv6 and IPv4 records."""
+
+ family = socket.AF_INET
+ if HAS_IPV6:
+ family = socket.AF_UNSPEC
+ return family
+
+
+def _has_ipv6(host):
+ """Returns True if the system can bind an IPv6 address."""
+ sock = None
+ has_ipv6 = False
+
+ # App Engine doesn't support IPV6 sockets and actually has a quota on the
+ # number of sockets that can be used, so just early out here instead of
+ # creating a socket needlessly.
+ # See https://github.com/urllib3/urllib3/issues/1446
+ if _appengine_environ.is_appengine_sandbox():
+ return False
+
+ if socket.has_ipv6:
+ # has_ipv6 returns true if cPython was compiled with IPv6 support.
+ # It does not tell us if the system has IPv6 support enabled. To
+ # determine that we must bind to an IPv6 address.
+ # https://github.com/urllib3/urllib3/pull/611
+ # https://bugs.python.org/issue658327
+ try:
+ sock = socket.socket(socket.AF_INET6)
+ sock.bind((host, 0))
+ has_ipv6 = True
+ except Exception:
+ pass
+
+ if sock:
+ sock.close()
+ return has_ipv6
+
+
+HAS_IPV6 = _has_ipv6("::1")
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/proxy.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/proxy.py
new file mode 100644
index 000000000..2199cc7b7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/proxy.py
@@ -0,0 +1,57 @@
+from .ssl_ import create_urllib3_context, resolve_cert_reqs, resolve_ssl_version
+
+
+def connection_requires_http_tunnel(
+ proxy_url=None, proxy_config=None, destination_scheme=None
+):
+ """
+ Returns True if the connection requires an HTTP CONNECT through the proxy.
+
+ :param URL proxy_url:
+ URL of the proxy.
+ :param ProxyConfig proxy_config:
+ Proxy configuration from poolmanager.py
+ :param str destination_scheme:
+ The scheme of the destination. (i.e https, http, etc)
+ """
+ # If we're not using a proxy, no way to use a tunnel.
+ if proxy_url is None:
+ return False
+
+ # HTTP destinations never require tunneling, we always forward.
+ if destination_scheme == "http":
+ return False
+
+ # Support for forwarding with HTTPS proxies and HTTPS destinations.
+ if (
+ proxy_url.scheme == "https"
+ and proxy_config
+ and proxy_config.use_forwarding_for_https
+ ):
+ return False
+
+ # Otherwise always use a tunnel.
+ return True
+
+
+def create_proxy_ssl_context(
+ ssl_version, cert_reqs, ca_certs=None, ca_cert_dir=None, ca_cert_data=None
+):
+ """
+ Generates a default proxy ssl context if one hasn't been provided by the
+ user.
+ """
+ ssl_context = create_urllib3_context(
+ ssl_version=resolve_ssl_version(ssl_version),
+ cert_reqs=resolve_cert_reqs(cert_reqs),
+ )
+
+ if (
+ not ca_certs
+ and not ca_cert_dir
+ and not ca_cert_data
+ and hasattr(ssl_context, "load_default_certs")
+ ):
+ ssl_context.load_default_certs()
+
+ return ssl_context
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/queue.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/queue.py
new file mode 100644
index 000000000..41784104e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/queue.py
@@ -0,0 +1,22 @@
+import collections
+
+from ..packages import six
+from ..packages.six.moves import queue
+
+if six.PY2:
+ # Queue is imported for side effects on MS Windows. See issue #229.
+ import Queue as _unused_module_Queue # noqa: F401
+
+
+class LifoQueue(queue.Queue):
+ def _init(self, _):
+ self.queue = collections.deque()
+
+ def _qsize(self, len=len):
+ return len(self.queue)
+
+ def _put(self, item):
+ self.queue.append(item)
+
+ def _get(self):
+ return self.queue.pop()
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/request.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/request.py
new file mode 100644
index 000000000..330766ef4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/request.py
@@ -0,0 +1,137 @@
+from __future__ import absolute_import
+
+from base64 import b64encode
+
+from ..exceptions import UnrewindableBodyError
+from ..packages.six import b, integer_types
+
+# Pass as a value within ``headers`` to skip
+# emitting some HTTP headers that are added automatically.
+# The only headers that are supported are ``Accept-Encoding``,
+# ``Host``, and ``User-Agent``.
+SKIP_HEADER = "@@@SKIP_HEADER@@@"
+SKIPPABLE_HEADERS = frozenset(["accept-encoding", "host", "user-agent"])
+
+ACCEPT_ENCODING = "gzip,deflate"
+
+_FAILEDTELL = object()
+
+
+def make_headers(
+ keep_alive=None,
+ accept_encoding=None,
+ user_agent=None,
+ basic_auth=None,
+ proxy_basic_auth=None,
+ disable_cache=None,
+):
+ """
+ Shortcuts for generating request headers.
+
+ :param keep_alive:
+ If ``True``, adds 'connection: keep-alive' header.
+
+ :param accept_encoding:
+ Can be a boolean, list, or string.
+ ``True`` translates to 'gzip,deflate'.
+ List will get joined by comma.
+ String will be used as provided.
+
+ :param user_agent:
+ String representing the user-agent you want, such as
+ "python-urllib3/0.6"
+
+ :param basic_auth:
+ Colon-separated username:password string for 'authorization: basic ...'
+ auth header.
+
+ :param proxy_basic_auth:
+ Colon-separated username:password string for 'proxy-authorization: basic ...'
+ auth header.
+
+ :param disable_cache:
+ If ``True``, adds 'cache-control: no-cache' header.
+
+ Example::
+
+ >>> make_headers(keep_alive=True, user_agent="Batman/1.0")
+ {'connection': 'keep-alive', 'user-agent': 'Batman/1.0'}
+ >>> make_headers(accept_encoding=True)
+ {'accept-encoding': 'gzip,deflate'}
+ """
+ headers = {}
+ if accept_encoding:
+ if isinstance(accept_encoding, str):
+ pass
+ elif isinstance(accept_encoding, list):
+ accept_encoding = ",".join(accept_encoding)
+ else:
+ accept_encoding = ACCEPT_ENCODING
+ headers["accept-encoding"] = accept_encoding
+
+ if user_agent:
+ headers["user-agent"] = user_agent
+
+ if keep_alive:
+ headers["connection"] = "keep-alive"
+
+ if basic_auth:
+ headers["authorization"] = "Basic " + b64encode(b(basic_auth)).decode("utf-8")
+
+ if proxy_basic_auth:
+ headers["proxy-authorization"] = "Basic " + b64encode(
+ b(proxy_basic_auth)
+ ).decode("utf-8")
+
+ if disable_cache:
+ headers["cache-control"] = "no-cache"
+
+ return headers
+
+
+def set_file_position(body, pos):
+ """
+ If a position is provided, move file to that point.
+ Otherwise, we'll attempt to record a position for future use.
+ """
+ if pos is not None:
+ rewind_body(body, pos)
+ elif getattr(body, "tell", None) is not None:
+ try:
+ pos = body.tell()
+ except (IOError, OSError):
+ # This differentiates from None, allowing us to catch
+ # a failed `tell()` later when trying to rewind the body.
+ pos = _FAILEDTELL
+
+ return pos
+
+
+def rewind_body(body, body_pos):
+ """
+ Attempt to rewind body to a certain position.
+ Primarily used for request redirects and retries.
+
+ :param body:
+ File-like object that supports seek.
+
+ :param int pos:
+ Position to seek to in file.
+ """
+ body_seek = getattr(body, "seek", None)
+ if body_seek is not None and isinstance(body_pos, integer_types):
+ try:
+ body_seek(body_pos)
+ except (IOError, OSError):
+ raise UnrewindableBodyError(
+ "An error occurred when rewinding request body for redirect/retry."
+ )
+ elif body_pos is _FAILEDTELL:
+ raise UnrewindableBodyError(
+ "Unable to record file position for rewinding "
+ "request body during a redirect/retry."
+ )
+ else:
+ raise ValueError(
+ "body_pos must be of type integer, instead it was %s." % type(body_pos)
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/response.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/response.py
new file mode 100644
index 000000000..5ea609cce
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/response.py
@@ -0,0 +1,107 @@
+from __future__ import absolute_import
+
+from email.errors import MultipartInvariantViolationDefect, StartBoundaryNotFoundDefect
+
+from ..exceptions import HeaderParsingError
+from ..packages.six.moves import http_client as httplib
+
+
+def is_fp_closed(obj):
+ """
+ Checks whether a given file-like object is closed.
+
+ :param obj:
+ The file-like object to check.
+ """
+
+ try:
+ # Check `isclosed()` first, in case Python3 doesn't set `closed`.
+ # GH Issue #928
+ return obj.isclosed()
+ except AttributeError:
+ pass
+
+ try:
+ # Check via the official file-like-object way.
+ return obj.closed
+ except AttributeError:
+ pass
+
+ try:
+ # Check if the object is a container for another file-like object that
+ # gets released on exhaustion (e.g. HTTPResponse).
+ return obj.fp is None
+ except AttributeError:
+ pass
+
+ raise ValueError("Unable to determine whether fp is closed.")
+
+
+def assert_header_parsing(headers):
+ """
+ Asserts whether all headers have been successfully parsed.
+ Extracts encountered errors from the result of parsing headers.
+
+ Only works on Python 3.
+
+ :param http.client.HTTPMessage headers: Headers to verify.
+
+ :raises urllib3.exceptions.HeaderParsingError:
+ If parsing errors are found.
+ """
+
+ # This will fail silently if we pass in the wrong kind of parameter.
+ # To make debugging easier add an explicit check.
+ if not isinstance(headers, httplib.HTTPMessage):
+ raise TypeError("expected httplib.Message, got {0}.".format(type(headers)))
+
+ defects = getattr(headers, "defects", None)
+ get_payload = getattr(headers, "get_payload", None)
+
+ unparsed_data = None
+ if get_payload:
+ # get_payload is actually email.message.Message.get_payload;
+ # we're only interested in the result if it's not a multipart message
+ if not headers.is_multipart():
+ payload = get_payload()
+
+ if isinstance(payload, (bytes, str)):
+ unparsed_data = payload
+ if defects:
+ # httplib is assuming a response body is available
+ # when parsing headers even when httplib only sends
+ # header data to parse_headers() This results in
+ # defects on multipart responses in particular.
+ # See: https://github.com/urllib3/urllib3/issues/800
+
+ # So we ignore the following defects:
+ # - StartBoundaryNotFoundDefect:
+ # The claimed start boundary was never found.
+ # - MultipartInvariantViolationDefect:
+ # A message claimed to be a multipart but no subparts were found.
+ defects = [
+ defect
+ for defect in defects
+ if not isinstance(
+ defect, (StartBoundaryNotFoundDefect, MultipartInvariantViolationDefect)
+ )
+ ]
+
+ if defects or unparsed_data:
+ raise HeaderParsingError(defects=defects, unparsed_data=unparsed_data)
+
+
+def is_response_to_head(response):
+ """
+ Checks whether the request of a response has been a HEAD-request.
+ Handles the quirks of AppEngine.
+
+ :param http.client.HTTPResponse response:
+ Response to check if the originating request
+ used 'HEAD' as a method.
+ """
+ # FIXME: Can we do this somehow without accessing private httplib _method?
+ method = response._method
+ if isinstance(method, int): # Platform-specific: Appengine
+ return method == 3
+ return method.upper() == "HEAD"
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/retry.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/retry.py
new file mode 100644
index 000000000..9a1e90d0b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/retry.py
@@ -0,0 +1,622 @@
+from __future__ import absolute_import
+
+import email
+import logging
+import re
+import time
+import warnings
+from collections import namedtuple
+from itertools import takewhile
+
+from ..exceptions import (
+ ConnectTimeoutError,
+ InvalidHeader,
+ MaxRetryError,
+ ProtocolError,
+ ProxyError,
+ ReadTimeoutError,
+ ResponseError,
+)
+from ..packages import six
+
+log = logging.getLogger(__name__)
+
+
+# Data structure for representing the metadata of requests that result in a retry.
+RequestHistory = namedtuple(
+ "RequestHistory", ["method", "url", "error", "status", "redirect_location"]
+)
+
+
+# TODO: In v2 we can remove this sentinel and metaclass with deprecated options.
+_Default = object()
+
+
+class _RetryMeta(type):
+ @property
+ def DEFAULT_METHOD_WHITELIST(cls):
+ warnings.warn(
+ "Using 'Retry.DEFAULT_METHOD_WHITELIST' is deprecated and "
+ "will be removed in v2.0. Use 'Retry.DEFAULT_ALLOWED_METHODS' instead",
+ DeprecationWarning,
+ )
+ return cls.DEFAULT_ALLOWED_METHODS
+
+ @DEFAULT_METHOD_WHITELIST.setter
+ def DEFAULT_METHOD_WHITELIST(cls, value):
+ warnings.warn(
+ "Using 'Retry.DEFAULT_METHOD_WHITELIST' is deprecated and "
+ "will be removed in v2.0. Use 'Retry.DEFAULT_ALLOWED_METHODS' instead",
+ DeprecationWarning,
+ )
+ cls.DEFAULT_ALLOWED_METHODS = value
+
+ @property
+ def DEFAULT_REDIRECT_HEADERS_BLACKLIST(cls):
+ warnings.warn(
+ "Using 'Retry.DEFAULT_REDIRECT_HEADERS_BLACKLIST' is deprecated and "
+ "will be removed in v2.0. Use 'Retry.DEFAULT_REMOVE_HEADERS_ON_REDIRECT' instead",
+ DeprecationWarning,
+ )
+ return cls.DEFAULT_REMOVE_HEADERS_ON_REDIRECT
+
+ @DEFAULT_REDIRECT_HEADERS_BLACKLIST.setter
+ def DEFAULT_REDIRECT_HEADERS_BLACKLIST(cls, value):
+ warnings.warn(
+ "Using 'Retry.DEFAULT_REDIRECT_HEADERS_BLACKLIST' is deprecated and "
+ "will be removed in v2.0. Use 'Retry.DEFAULT_REMOVE_HEADERS_ON_REDIRECT' instead",
+ DeprecationWarning,
+ )
+ cls.DEFAULT_REMOVE_HEADERS_ON_REDIRECT = value
+
+ @property
+ def BACKOFF_MAX(cls):
+ warnings.warn(
+ "Using 'Retry.BACKOFF_MAX' is deprecated and "
+ "will be removed in v2.0. Use 'Retry.DEFAULT_BACKOFF_MAX' instead",
+ DeprecationWarning,
+ )
+ return cls.DEFAULT_BACKOFF_MAX
+
+ @BACKOFF_MAX.setter
+ def BACKOFF_MAX(cls, value):
+ warnings.warn(
+ "Using 'Retry.BACKOFF_MAX' is deprecated and "
+ "will be removed in v2.0. Use 'Retry.DEFAULT_BACKOFF_MAX' instead",
+ DeprecationWarning,
+ )
+ cls.DEFAULT_BACKOFF_MAX = value
+
+
+@six.add_metaclass(_RetryMeta)
+class Retry(object):
+ """Retry configuration.
+
+ Each retry attempt will create a new Retry object with updated values, so
+ they can be safely reused.
+
+ Retries can be defined as a default for a pool::
+
+ retries = Retry(connect=5, read=2, redirect=5)
+ http = PoolManager(retries=retries)
+ response = http.request('GET', 'http://example.com/')
+
+ Or per-request (which overrides the default for the pool)::
+
+ response = http.request('GET', 'http://example.com/', retries=Retry(10))
+
+ Retries can be disabled by passing ``False``::
+
+ response = http.request('GET', 'http://example.com/', retries=False)
+
+ Errors will be wrapped in :class:`~urllib3.exceptions.MaxRetryError` unless
+ retries are disabled, in which case the causing exception will be raised.
+
+ :param int total:
+ Total number of retries to allow. Takes precedence over other counts.
+
+ Set to ``None`` to remove this constraint and fall back on other
+ counts.
+
+ Set to ``0`` to fail on the first retry.
+
+ Set to ``False`` to disable and imply ``raise_on_redirect=False``.
+
+ :param int connect:
+ How many connection-related errors to retry on.
+
+ These are errors raised before the request is sent to the remote server,
+ which we assume has not triggered the server to process the request.
+
+ Set to ``0`` to fail on the first retry of this type.
+
+ :param int read:
+ How many times to retry on read errors.
+
+ These errors are raised after the request was sent to the server, so the
+ request may have side-effects.
+
+ Set to ``0`` to fail on the first retry of this type.
+
+ :param int redirect:
+ How many redirects to perform. Limit this to avoid infinite redirect
+ loops.
+
+ A redirect is a HTTP response with a status code 301, 302, 303, 307 or
+ 308.
+
+ Set to ``0`` to fail on the first retry of this type.
+
+ Set to ``False`` to disable and imply ``raise_on_redirect=False``.
+
+ :param int status:
+ How many times to retry on bad status codes.
+
+ These are retries made on responses, where status code matches
+ ``status_forcelist``.
+
+ Set to ``0`` to fail on the first retry of this type.
+
+ :param int other:
+ How many times to retry on other errors.
+
+ Other errors are errors that are not connect, read, redirect or status errors.
+ These errors might be raised after the request was sent to the server, so the
+ request might have side-effects.
+
+ Set to ``0`` to fail on the first retry of this type.
+
+ If ``total`` is not set, it's a good idea to set this to 0 to account
+ for unexpected edge cases and avoid infinite retry loops.
+
+ :param iterable allowed_methods:
+ Set of uppercased HTTP method verbs that we should retry on.
+
+ By default, we only retry on methods which are considered to be
+ idempotent (multiple requests with the same parameters end with the
+ same state). See :attr:`Retry.DEFAULT_ALLOWED_METHODS`.
+
+ Set to a ``False`` value to retry on any verb.
+
+ .. warning::
+
+ Previously this parameter was named ``method_whitelist``, that
+ usage is deprecated in v1.26.0 and will be removed in v2.0.
+
+ :param iterable status_forcelist:
+ A set of integer HTTP status codes that we should force a retry on.
+ A retry is initiated if the request method is in ``allowed_methods``
+ and the response status code is in ``status_forcelist``.
+
+ By default, this is disabled with ``None``.
+
+ :param float backoff_factor:
+ A backoff factor to apply between attempts after the second try
+ (most errors are resolved immediately by a second try without a
+ delay). urllib3 will sleep for::
+
+ {backoff factor} * (2 ** ({number of total retries} - 1))
+
+ seconds. If the backoff_factor is 0.1, then :func:`.sleep` will sleep
+ for [0.0s, 0.2s, 0.4s, ...] between retries. It will never be longer
+ than :attr:`Retry.DEFAULT_BACKOFF_MAX`.
+
+ By default, backoff is disabled (set to 0).
+
+ :param bool raise_on_redirect: Whether, if the number of redirects is
+ exhausted, to raise a MaxRetryError, or to return a response with a
+ response code in the 3xx range.
+
+ :param bool raise_on_status: Similar meaning to ``raise_on_redirect``:
+ whether we should raise an exception, or return a response,
+ if status falls in ``status_forcelist`` range and retries have
+ been exhausted.
+
+ :param tuple history: The history of the request encountered during
+ each call to :meth:`~Retry.increment`. The list is in the order
+ the requests occurred. Each list item is of class :class:`RequestHistory`.
+
+ :param bool respect_retry_after_header:
+ Whether to respect Retry-After header on status codes defined as
+ :attr:`Retry.RETRY_AFTER_STATUS_CODES` or not.
+
+ :param iterable remove_headers_on_redirect:
+ Sequence of headers to remove from the request when a response
+ indicating a redirect is returned before firing off the redirected
+ request.
+ """
+
+ #: Default methods to be used for ``allowed_methods``
+ DEFAULT_ALLOWED_METHODS = frozenset(
+ ["HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE"]
+ )
+
+ #: Default status codes to be used for ``status_forcelist``
+ RETRY_AFTER_STATUS_CODES = frozenset([413, 429, 503])
+
+ #: Default headers to be used for ``remove_headers_on_redirect``
+ DEFAULT_REMOVE_HEADERS_ON_REDIRECT = frozenset(
+ ["Cookie", "Authorization", "Proxy-Authorization"]
+ )
+
+ #: Maximum backoff time.
+ DEFAULT_BACKOFF_MAX = 120
+
+ def __init__(
+ self,
+ total=10,
+ connect=None,
+ read=None,
+ redirect=None,
+ status=None,
+ other=None,
+ allowed_methods=_Default,
+ status_forcelist=None,
+ backoff_factor=0,
+ raise_on_redirect=True,
+ raise_on_status=True,
+ history=None,
+ respect_retry_after_header=True,
+ remove_headers_on_redirect=_Default,
+ # TODO: Deprecated, remove in v2.0
+ method_whitelist=_Default,
+ ):
+
+ if method_whitelist is not _Default:
+ if allowed_methods is not _Default:
+ raise ValueError(
+ "Using both 'allowed_methods' and "
+ "'method_whitelist' together is not allowed. "
+ "Instead only use 'allowed_methods'"
+ )
+ warnings.warn(
+ "Using 'method_whitelist' with Retry is deprecated and "
+ "will be removed in v2.0. Use 'allowed_methods' instead",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ allowed_methods = method_whitelist
+ if allowed_methods is _Default:
+ allowed_methods = self.DEFAULT_ALLOWED_METHODS
+ if remove_headers_on_redirect is _Default:
+ remove_headers_on_redirect = self.DEFAULT_REMOVE_HEADERS_ON_REDIRECT
+
+ self.total = total
+ self.connect = connect
+ self.read = read
+ self.status = status
+ self.other = other
+
+ if redirect is False or total is False:
+ redirect = 0
+ raise_on_redirect = False
+
+ self.redirect = redirect
+ self.status_forcelist = status_forcelist or set()
+ self.allowed_methods = allowed_methods
+ self.backoff_factor = backoff_factor
+ self.raise_on_redirect = raise_on_redirect
+ self.raise_on_status = raise_on_status
+ self.history = history or tuple()
+ self.respect_retry_after_header = respect_retry_after_header
+ self.remove_headers_on_redirect = frozenset(
+ [h.lower() for h in remove_headers_on_redirect]
+ )
+
+ def new(self, **kw):
+ params = dict(
+ total=self.total,
+ connect=self.connect,
+ read=self.read,
+ redirect=self.redirect,
+ status=self.status,
+ other=self.other,
+ status_forcelist=self.status_forcelist,
+ backoff_factor=self.backoff_factor,
+ raise_on_redirect=self.raise_on_redirect,
+ raise_on_status=self.raise_on_status,
+ history=self.history,
+ remove_headers_on_redirect=self.remove_headers_on_redirect,
+ respect_retry_after_header=self.respect_retry_after_header,
+ )
+
+ # TODO: If already given in **kw we use what's given to us
+ # If not given we need to figure out what to pass. We decide
+ # based on whether our class has the 'method_whitelist' property
+ # and if so we pass the deprecated 'method_whitelist' otherwise
+ # we use 'allowed_methods'. Remove in v2.0
+ if "method_whitelist" not in kw and "allowed_methods" not in kw:
+ if "method_whitelist" in self.__dict__:
+ warnings.warn(
+ "Using 'method_whitelist' with Retry is deprecated and "
+ "will be removed in v2.0. Use 'allowed_methods' instead",
+ DeprecationWarning,
+ )
+ params["method_whitelist"] = self.allowed_methods
+ else:
+ params["allowed_methods"] = self.allowed_methods
+
+ params.update(kw)
+ return type(self)(**params)
+
+ @classmethod
+ def from_int(cls, retries, redirect=True, default=None):
+ """Backwards-compatibility for the old retries format."""
+ if retries is None:
+ retries = default if default is not None else cls.DEFAULT
+
+ if isinstance(retries, Retry):
+ return retries
+
+ redirect = bool(redirect) and None
+ new_retries = cls(retries, redirect=redirect)
+ log.debug("Converted retries value: %r -> %r", retries, new_retries)
+ return new_retries
+
+ def get_backoff_time(self):
+ """Formula for computing the current backoff
+
+ :rtype: float
+ """
+ # We want to consider only the last consecutive errors sequence (Ignore redirects).
+ consecutive_errors_len = len(
+ list(
+ takewhile(lambda x: x.redirect_location is None, reversed(self.history))
+ )
+ )
+ if consecutive_errors_len <= 1:
+ return 0
+
+ backoff_value = self.backoff_factor * (2 ** (consecutive_errors_len - 1))
+ return min(self.DEFAULT_BACKOFF_MAX, backoff_value)
+
+ def parse_retry_after(self, retry_after):
+ # Whitespace: https://tools.ietf.org/html/rfc7230#section-3.2.4
+ if re.match(r"^\s*[0-9]+\s*$", retry_after):
+ seconds = int(retry_after)
+ else:
+ retry_date_tuple = email.utils.parsedate_tz(retry_after)
+ if retry_date_tuple is None:
+ raise InvalidHeader("Invalid Retry-After header: %s" % retry_after)
+ if retry_date_tuple[9] is None: # Python 2
+ # Assume UTC if no timezone was specified
+ # On Python2.7, parsedate_tz returns None for a timezone offset
+ # instead of 0 if no timezone is given, where mktime_tz treats
+ # a None timezone offset as local time.
+ retry_date_tuple = retry_date_tuple[:9] + (0,) + retry_date_tuple[10:]
+
+ retry_date = email.utils.mktime_tz(retry_date_tuple)
+ seconds = retry_date - time.time()
+
+ if seconds < 0:
+ seconds = 0
+
+ return seconds
+
+ def get_retry_after(self, response):
+ """Get the value of Retry-After in seconds."""
+
+ retry_after = response.headers.get("Retry-After")
+
+ if retry_after is None:
+ return None
+
+ return self.parse_retry_after(retry_after)
+
+ def sleep_for_retry(self, response=None):
+ retry_after = self.get_retry_after(response)
+ if retry_after:
+ time.sleep(retry_after)
+ return True
+
+ return False
+
+ def _sleep_backoff(self):
+ backoff = self.get_backoff_time()
+ if backoff <= 0:
+ return
+ time.sleep(backoff)
+
+ def sleep(self, response=None):
+ """Sleep between retry attempts.
+
+ This method will respect a server's ``Retry-After`` response header
+ and sleep the duration of the time requested. If that is not present, it
+ will use an exponential backoff. By default, the backoff factor is 0 and
+ this method will return immediately.
+ """
+
+ if self.respect_retry_after_header and response:
+ slept = self.sleep_for_retry(response)
+ if slept:
+ return
+
+ self._sleep_backoff()
+
+ def _is_connection_error(self, err):
+ """Errors when we're fairly sure that the server did not receive the
+ request, so it should be safe to retry.
+ """
+ if isinstance(err, ProxyError):
+ err = err.original_error
+ return isinstance(err, ConnectTimeoutError)
+
+ def _is_read_error(self, err):
+ """Errors that occur after the request has been started, so we should
+ assume that the server began processing it.
+ """
+ return isinstance(err, (ReadTimeoutError, ProtocolError))
+
+ def _is_method_retryable(self, method):
+ """Checks if a given HTTP method should be retried upon, depending if
+ it is included in the allowed_methods
+ """
+ # TODO: For now favor if the Retry implementation sets its own method_whitelist
+ # property outside of our constructor to avoid breaking custom implementations.
+ if "method_whitelist" in self.__dict__:
+ warnings.warn(
+ "Using 'method_whitelist' with Retry is deprecated and "
+ "will be removed in v2.0. Use 'allowed_methods' instead",
+ DeprecationWarning,
+ )
+ allowed_methods = self.method_whitelist
+ else:
+ allowed_methods = self.allowed_methods
+
+ if allowed_methods and method.upper() not in allowed_methods:
+ return False
+ return True
+
+ def is_retry(self, method, status_code, has_retry_after=False):
+ """Is this method/status code retryable? (Based on allowlists and control
+ variables such as the number of total retries to allow, whether to
+ respect the Retry-After header, whether this header is present, and
+ whether the returned status code is on the list of status codes to
+ be retried upon on the presence of the aforementioned header)
+ """
+ if not self._is_method_retryable(method):
+ return False
+
+ if self.status_forcelist and status_code in self.status_forcelist:
+ return True
+
+ return (
+ self.total
+ and self.respect_retry_after_header
+ and has_retry_after
+ and (status_code in self.RETRY_AFTER_STATUS_CODES)
+ )
+
+ def is_exhausted(self):
+ """Are we out of retries?"""
+ retry_counts = (
+ self.total,
+ self.connect,
+ self.read,
+ self.redirect,
+ self.status,
+ self.other,
+ )
+ retry_counts = list(filter(None, retry_counts))
+ if not retry_counts:
+ return False
+
+ return min(retry_counts) < 0
+
+ def increment(
+ self,
+ method=None,
+ url=None,
+ response=None,
+ error=None,
+ _pool=None,
+ _stacktrace=None,
+ ):
+ """Return a new Retry object with incremented retry counters.
+
+ :param response: A response object, or None, if the server did not
+ return a response.
+ :type response: :class:`~urllib3.response.HTTPResponse`
+ :param Exception error: An error encountered during the request, or
+ None if the response was received successfully.
+
+ :return: A new ``Retry`` object.
+ """
+ if self.total is False and error:
+ # Disabled, indicate to re-raise the error.
+ raise six.reraise(type(error), error, _stacktrace)
+
+ total = self.total
+ if total is not None:
+ total -= 1
+
+ connect = self.connect
+ read = self.read
+ redirect = self.redirect
+ status_count = self.status
+ other = self.other
+ cause = "unknown"
+ status = None
+ redirect_location = None
+
+ if error and self._is_connection_error(error):
+ # Connect retry?
+ if connect is False:
+ raise six.reraise(type(error), error, _stacktrace)
+ elif connect is not None:
+ connect -= 1
+
+ elif error and self._is_read_error(error):
+ # Read retry?
+ if read is False or not self._is_method_retryable(method):
+ raise six.reraise(type(error), error, _stacktrace)
+ elif read is not None:
+ read -= 1
+
+ elif error:
+ # Other retry?
+ if other is not None:
+ other -= 1
+
+ elif response and response.get_redirect_location():
+ # Redirect retry?
+ if redirect is not None:
+ redirect -= 1
+ cause = "too many redirects"
+ redirect_location = response.get_redirect_location()
+ status = response.status
+
+ else:
+ # Incrementing because of a server error like a 500 in
+ # status_forcelist and the given method is in the allowed_methods
+ cause = ResponseError.GENERIC_ERROR
+ if response and response.status:
+ if status_count is not None:
+ status_count -= 1
+ cause = ResponseError.SPECIFIC_ERROR.format(status_code=response.status)
+ status = response.status
+
+ history = self.history + (
+ RequestHistory(method, url, error, status, redirect_location),
+ )
+
+ new_retry = self.new(
+ total=total,
+ connect=connect,
+ read=read,
+ redirect=redirect,
+ status=status_count,
+ other=other,
+ history=history,
+ )
+
+ if new_retry.is_exhausted():
+ raise MaxRetryError(_pool, url, error or ResponseError(cause))
+
+ log.debug("Incremented Retry for (url='%s'): %r", url, new_retry)
+
+ return new_retry
+
+ def __repr__(self):
+ return (
+ "{cls.__name__}(total={self.total}, connect={self.connect}, "
+ "read={self.read}, redirect={self.redirect}, status={self.status})"
+ ).format(cls=type(self), self=self)
+
+ def __getattr__(self, item):
+ if item == "method_whitelist":
+ # TODO: Remove this deprecated alias in v2.0
+ warnings.warn(
+ "Using 'method_whitelist' with Retry is deprecated and "
+ "will be removed in v2.0. Use 'allowed_methods' instead",
+ DeprecationWarning,
+ )
+ return self.allowed_methods
+ try:
+ return getattr(super(Retry, self), item)
+ except AttributeError:
+ return getattr(Retry, item)
+
+
+# For backwards compatibility (equivalent to pre-v1.9):
+Retry.DEFAULT = Retry(3)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssl_.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssl_.py
new file mode 100644
index 000000000..0a6a0e06a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssl_.py
@@ -0,0 +1,504 @@
+from __future__ import absolute_import
+
+import hashlib
+import hmac
+import os
+import sys
+import warnings
+from binascii import hexlify, unhexlify
+
+from ..exceptions import (
+ InsecurePlatformWarning,
+ ProxySchemeUnsupported,
+ SNIMissingWarning,
+ SSLError,
+)
+from ..packages import six
+from .url import BRACELESS_IPV6_ADDRZ_RE, IPV4_RE
+
+SSLContext = None
+SSLTransport = None
+HAS_SNI = False
+IS_PYOPENSSL = False
+IS_SECURETRANSPORT = False
+ALPN_PROTOCOLS = ["http/1.1"]
+
+# Maps the length of a digest to a possible hash function producing this digest
+HASHFUNC_MAP = {
+ length: getattr(hashlib, algorithm, None)
+ for length, algorithm in ((32, "md5"), (40, "sha1"), (64, "sha256"))
+}
+
+
+def _const_compare_digest_backport(a, b):
+ """
+ Compare two digests of equal length in constant time.
+
+ The digests must be of type str/bytes.
+ Returns True if the digests match, and False otherwise.
+ """
+ result = abs(len(a) - len(b))
+ for left, right in zip(bytearray(a), bytearray(b)):
+ result |= left ^ right
+ return result == 0
+
+
+_const_compare_digest = getattr(hmac, "compare_digest", _const_compare_digest_backport)
+
+try: # Test for SSL features
+ import ssl
+ from ssl import CERT_REQUIRED, wrap_socket
+except ImportError:
+ pass
+
+try:
+ from ssl import HAS_SNI # Has SNI?
+except ImportError:
+ pass
+
+try:
+ from .ssltransport import SSLTransport
+except ImportError:
+ pass
+
+
+try: # Platform-specific: Python 3.6
+ from ssl import PROTOCOL_TLS
+
+ PROTOCOL_SSLv23 = PROTOCOL_TLS
+except ImportError:
+ try:
+ from ssl import PROTOCOL_SSLv23 as PROTOCOL_TLS
+
+ PROTOCOL_SSLv23 = PROTOCOL_TLS
+ except ImportError:
+ PROTOCOL_SSLv23 = PROTOCOL_TLS = 2
+
+try:
+ from ssl import PROTOCOL_TLS_CLIENT
+except ImportError:
+ PROTOCOL_TLS_CLIENT = PROTOCOL_TLS
+
+
+try:
+ from ssl import OP_NO_COMPRESSION, OP_NO_SSLv2, OP_NO_SSLv3
+except ImportError:
+ OP_NO_SSLv2, OP_NO_SSLv3 = 0x1000000, 0x2000000
+ OP_NO_COMPRESSION = 0x20000
+
+
+try: # OP_NO_TICKET was added in Python 3.6
+ from ssl import OP_NO_TICKET
+except ImportError:
+ OP_NO_TICKET = 0x4000
+
+
+# A secure default.
+# Sources for more information on TLS ciphers:
+#
+# - https://wiki.mozilla.org/Security/Server_Side_TLS
+# - https://www.ssllabs.com/projects/best-practices/index.html
+# - https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/
+#
+# The general intent is:
+# - prefer cipher suites that offer perfect forward secrecy (DHE/ECDHE),
+# - prefer ECDHE over DHE for better performance,
+# - prefer any AES-GCM and ChaCha20 over any AES-CBC for better performance and
+# security,
+# - prefer AES-GCM over ChaCha20 because hardware-accelerated AES is common,
+# - disable NULL authentication, MD5 MACs, DSS, and other
+# insecure ciphers for security reasons.
+# - NOTE: TLS 1.3 cipher suites are managed through a different interface
+# not exposed by CPython (yet!) and are enabled by default if they're available.
+DEFAULT_CIPHERS = ":".join(
+ [
+ "ECDHE+AESGCM",
+ "ECDHE+CHACHA20",
+ "DHE+AESGCM",
+ "DHE+CHACHA20",
+ "ECDH+AESGCM",
+ "DH+AESGCM",
+ "ECDH+AES",
+ "DH+AES",
+ "RSA+AESGCM",
+ "RSA+AES",
+ "!aNULL",
+ "!eNULL",
+ "!MD5",
+ "!DSS",
+ ]
+)
+
+try:
+ from ssl import SSLContext # Modern SSL?
+except ImportError:
+
+ class SSLContext(object): # Platform-specific: Python 2
+ def __init__(self, protocol_version):
+ self.protocol = protocol_version
+ # Use default values from a real SSLContext
+ self.check_hostname = False
+ self.verify_mode = ssl.CERT_NONE
+ self.ca_certs = None
+ self.options = 0
+ self.certfile = None
+ self.keyfile = None
+ self.ciphers = None
+
+ def load_cert_chain(self, certfile, keyfile):
+ self.certfile = certfile
+ self.keyfile = keyfile
+
+ def load_verify_locations(self, cafile=None, capath=None, cadata=None):
+ self.ca_certs = cafile
+
+ if capath is not None:
+ raise SSLError("CA directories not supported in older Pythons")
+
+ if cadata is not None:
+ raise SSLError("CA data not supported in older Pythons")
+
+ def set_ciphers(self, cipher_suite):
+ self.ciphers = cipher_suite
+
+ def wrap_socket(self, socket, server_hostname=None, server_side=False):
+ warnings.warn(
+ "A true SSLContext object is not available. This prevents "
+ "urllib3 from configuring SSL appropriately and may cause "
+ "certain SSL connections to fail. You can upgrade to a newer "
+ "version of Python to solve this. For more information, see "
+ "https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html"
+ "#ssl-warnings",
+ InsecurePlatformWarning,
+ )
+ kwargs = {
+ "keyfile": self.keyfile,
+ "certfile": self.certfile,
+ "ca_certs": self.ca_certs,
+ "cert_reqs": self.verify_mode,
+ "ssl_version": self.protocol,
+ "server_side": server_side,
+ }
+ return wrap_socket(socket, ciphers=self.ciphers, **kwargs)
+
+
+def assert_fingerprint(cert, fingerprint):
+ """
+ Checks if given fingerprint matches the supplied certificate.
+
+ :param cert:
+ Certificate as bytes object.
+ :param fingerprint:
+ Fingerprint as string of hexdigits, can be interspersed by colons.
+ """
+
+ fingerprint = fingerprint.replace(":", "").lower()
+ digest_length = len(fingerprint)
+ if digest_length not in HASHFUNC_MAP:
+ raise SSLError("Fingerprint of invalid length: {0}".format(fingerprint))
+ hashfunc = HASHFUNC_MAP.get(digest_length)
+ if hashfunc is None:
+ raise SSLError(
+ "Hash function implementation unavailable for fingerprint length: {0}".format(
+ digest_length
+ )
+ )
+
+ # We need encode() here for py32; works on py2 and p33.
+ fingerprint_bytes = unhexlify(fingerprint.encode())
+
+ cert_digest = hashfunc(cert).digest()
+
+ if not _const_compare_digest(cert_digest, fingerprint_bytes):
+ raise SSLError(
+ 'Fingerprints did not match. Expected "{0}", got "{1}".'.format(
+ fingerprint, hexlify(cert_digest)
+ )
+ )
+
+
+def resolve_cert_reqs(candidate):
+ """
+ Resolves the argument to a numeric constant, which can be passed to
+ the wrap_socket function/method from the ssl module.
+ Defaults to :data:`ssl.CERT_REQUIRED`.
+ If given a string it is assumed to be the name of the constant in the
+ :mod:`ssl` module or its abbreviation.
+ (So you can specify `REQUIRED` instead of `CERT_REQUIRED`.
+ If it's neither `None` nor a string we assume it is already the numeric
+ constant which can directly be passed to wrap_socket.
+ """
+ if candidate is None:
+ return CERT_REQUIRED
+
+ if isinstance(candidate, str):
+ res = getattr(ssl, candidate, None)
+ if res is None:
+ res = getattr(ssl, "CERT_" + candidate)
+ return res
+
+ return candidate
+
+
+def resolve_ssl_version(candidate):
+ """
+ like resolve_cert_reqs
+ """
+ if candidate is None:
+ return PROTOCOL_TLS
+
+ if isinstance(candidate, str):
+ res = getattr(ssl, candidate, None)
+ if res is None:
+ res = getattr(ssl, "PROTOCOL_" + candidate)
+ return res
+
+ return candidate
+
+
+def create_urllib3_context(
+ ssl_version=None, cert_reqs=None, options=None, ciphers=None
+):
+ """All arguments have the same meaning as ``ssl_wrap_socket``.
+
+ By default, this function does a lot of the same work that
+ ``ssl.create_default_context`` does on Python 3.4+. It:
+
+ - Disables SSLv2, SSLv3, and compression
+ - Sets a restricted set of server ciphers
+
+ If you wish to enable SSLv3, you can do::
+
+ from pip._vendor.urllib3.util import ssl_
+ context = ssl_.create_urllib3_context()
+ context.options &= ~ssl_.OP_NO_SSLv3
+
+ You can do the same to enable compression (substituting ``COMPRESSION``
+ for ``SSLv3`` in the last line above).
+
+ :param ssl_version:
+ The desired protocol version to use. This will default to
+ PROTOCOL_SSLv23 which will negotiate the highest protocol that both
+ the server and your installation of OpenSSL support.
+ :param cert_reqs:
+ Whether to require the certificate verification. This defaults to
+ ``ssl.CERT_REQUIRED``.
+ :param options:
+ Specific OpenSSL options. These default to ``ssl.OP_NO_SSLv2``,
+ ``ssl.OP_NO_SSLv3``, ``ssl.OP_NO_COMPRESSION``, and ``ssl.OP_NO_TICKET``.
+ :param ciphers:
+ Which cipher suites to allow the server to select.
+ :returns:
+ Constructed SSLContext object with specified options
+ :rtype: SSLContext
+ """
+ # PROTOCOL_TLS is deprecated in Python 3.10
+ if not ssl_version or ssl_version == PROTOCOL_TLS:
+ ssl_version = PROTOCOL_TLS_CLIENT
+
+ context = SSLContext(ssl_version)
+
+ context.set_ciphers(ciphers or DEFAULT_CIPHERS)
+
+ # Setting the default here, as we may have no ssl module on import
+ cert_reqs = ssl.CERT_REQUIRED if cert_reqs is None else cert_reqs
+
+ if options is None:
+ options = 0
+ # SSLv2 is easily broken and is considered harmful and dangerous
+ options |= OP_NO_SSLv2
+ # SSLv3 has several problems and is now dangerous
+ options |= OP_NO_SSLv3
+ # Disable compression to prevent CRIME attacks for OpenSSL 1.0+
+ # (issue #309)
+ options |= OP_NO_COMPRESSION
+ # TLSv1.2 only. Unless set explicitly, do not request tickets.
+ # This may save some bandwidth on wire, and although the ticket is encrypted,
+ # there is a risk associated with it being on wire,
+ # if the server is not rotating its ticketing keys properly.
+ options |= OP_NO_TICKET
+
+ context.options |= options
+
+ # Enable post-handshake authentication for TLS 1.3, see GH #1634. PHA is
+ # necessary for conditional client cert authentication with TLS 1.3.
+ # The attribute is None for OpenSSL <= 1.1.0 or does not exist in older
+ # versions of Python. We only enable on Python 3.7.4+ or if certificate
+ # verification is enabled to work around Python issue #37428
+ # See: https://bugs.python.org/issue37428
+ if (cert_reqs == ssl.CERT_REQUIRED or sys.version_info >= (3, 7, 4)) and getattr(
+ context, "post_handshake_auth", None
+ ) is not None:
+ context.post_handshake_auth = True
+
+ def disable_check_hostname():
+ if (
+ getattr(context, "check_hostname", None) is not None
+ ): # Platform-specific: Python 3.2
+ # We do our own verification, including fingerprints and alternative
+ # hostnames. So disable it here
+ context.check_hostname = False
+
+ # The order of the below lines setting verify_mode and check_hostname
+ # matter due to safe-guards SSLContext has to prevent an SSLContext with
+ # check_hostname=True, verify_mode=NONE/OPTIONAL. This is made even more
+ # complex because we don't know whether PROTOCOL_TLS_CLIENT will be used
+ # or not so we don't know the initial state of the freshly created SSLContext.
+ if cert_reqs == ssl.CERT_REQUIRED:
+ context.verify_mode = cert_reqs
+ disable_check_hostname()
+ else:
+ disable_check_hostname()
+ context.verify_mode = cert_reqs
+
+ # Enable logging of TLS session keys via defacto standard environment variable
+ # 'SSLKEYLOGFILE', if the feature is available (Python 3.8+). Skip empty values.
+ if hasattr(context, "keylog_filename"):
+ sslkeylogfile = os.environ.get("SSLKEYLOGFILE")
+ if sslkeylogfile:
+ context.keylog_filename = sslkeylogfile
+
+ return context
+
+
+def ssl_wrap_socket(
+ sock,
+ keyfile=None,
+ certfile=None,
+ cert_reqs=None,
+ ca_certs=None,
+ server_hostname=None,
+ ssl_version=None,
+ ciphers=None,
+ ssl_context=None,
+ ca_cert_dir=None,
+ key_password=None,
+ ca_cert_data=None,
+ tls_in_tls=False,
+):
+ """
+ All arguments except for server_hostname, ssl_context, and ca_cert_dir have
+ the same meaning as they do when using :func:`ssl.wrap_socket`.
+
+ :param server_hostname:
+ When SNI is supported, the expected hostname of the certificate
+ :param ssl_context:
+ A pre-made :class:`SSLContext` object. If none is provided, one will
+ be created using :func:`create_urllib3_context`.
+ :param ciphers:
+ A string of ciphers we wish the client to support.
+ :param ca_cert_dir:
+ A directory containing CA certificates in multiple separate files, as
+ supported by OpenSSL's -CApath flag or the capath argument to
+ SSLContext.load_verify_locations().
+ :param key_password:
+ Optional password if the keyfile is encrypted.
+ :param ca_cert_data:
+ Optional string containing CA certificates in PEM format suitable for
+ passing as the cadata parameter to SSLContext.load_verify_locations()
+ :param tls_in_tls:
+ Use SSLTransport to wrap the existing socket.
+ """
+ context = ssl_context
+ if context is None:
+ # Note: This branch of code and all the variables in it are no longer
+ # used by urllib3 itself. We should consider deprecating and removing
+ # this code.
+ context = create_urllib3_context(ssl_version, cert_reqs, ciphers=ciphers)
+
+ if ca_certs or ca_cert_dir or ca_cert_data:
+ try:
+ context.load_verify_locations(ca_certs, ca_cert_dir, ca_cert_data)
+ except (IOError, OSError) as e:
+ raise SSLError(e)
+
+ elif ssl_context is None and hasattr(context, "load_default_certs"):
+ # try to load OS default certs; works well on Windows (require Python3.4+)
+ context.load_default_certs()
+
+ # Attempt to detect if we get the goofy behavior of the
+ # keyfile being encrypted and OpenSSL asking for the
+ # passphrase via the terminal and instead error out.
+ if keyfile and key_password is None and _is_key_file_encrypted(keyfile):
+ raise SSLError("Client private key is encrypted, password is required")
+
+ if certfile:
+ if key_password is None:
+ context.load_cert_chain(certfile, keyfile)
+ else:
+ context.load_cert_chain(certfile, keyfile, key_password)
+
+ try:
+ if hasattr(context, "set_alpn_protocols"):
+ context.set_alpn_protocols(ALPN_PROTOCOLS)
+ except NotImplementedError: # Defensive: in CI, we always have set_alpn_protocols
+ pass
+
+ # If we detect server_hostname is an IP address then the SNI
+ # extension should not be used according to RFC3546 Section 3.1
+ use_sni_hostname = server_hostname and not is_ipaddress(server_hostname)
+ # SecureTransport uses server_hostname in certificate verification.
+ send_sni = (use_sni_hostname and HAS_SNI) or (
+ IS_SECURETRANSPORT and server_hostname
+ )
+ # Do not warn the user if server_hostname is an invalid SNI hostname.
+ if not HAS_SNI and use_sni_hostname:
+ warnings.warn(
+ "An HTTPS request has been made, but the SNI (Server Name "
+ "Indication) extension to TLS is not available on this platform. "
+ "This may cause the server to present an incorrect TLS "
+ "certificate, which can cause validation failures. You can upgrade to "
+ "a newer version of Python to solve this. For more information, see "
+ "https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html"
+ "#ssl-warnings",
+ SNIMissingWarning,
+ )
+
+ if send_sni:
+ ssl_sock = _ssl_wrap_socket_impl(
+ sock, context, tls_in_tls, server_hostname=server_hostname
+ )
+ else:
+ ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls)
+ return ssl_sock
+
+
+def is_ipaddress(hostname):
+ """Detects whether the hostname given is an IPv4 or IPv6 address.
+ Also detects IPv6 addresses with Zone IDs.
+
+ :param str hostname: Hostname to examine.
+ :return: True if the hostname is an IP address, False otherwise.
+ """
+ if not six.PY2 and isinstance(hostname, bytes):
+ # IDN A-label bytes are ASCII compatible.
+ hostname = hostname.decode("ascii")
+ return bool(IPV4_RE.match(hostname) or BRACELESS_IPV6_ADDRZ_RE.match(hostname))
+
+
+def _is_key_file_encrypted(key_file):
+ """Detects if a key file is encrypted or not."""
+ with open(key_file, "r") as f:
+ for line in f:
+ # Look for Proc-Type: 4,ENCRYPTED
+ if "ENCRYPTED" in line:
+ return True
+
+ return False
+
+
+def _ssl_wrap_socket_impl(sock, ssl_context, tls_in_tls, server_hostname=None):
+ if tls_in_tls:
+ if not SSLTransport:
+ # Import error, ssl is not available.
+ raise ProxySchemeUnsupported(
+ "TLS in TLS requires support for the 'ssl' module"
+ )
+
+ SSLTransport._validate_ssl_context_for_tls_in_tls(ssl_context)
+ return SSLTransport(sock, ssl_context, server_hostname)
+
+ if server_hostname:
+ return ssl_context.wrap_socket(sock, server_hostname=server_hostname)
+ else:
+ return ssl_context.wrap_socket(sock)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssl_match_hostname.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssl_match_hostname.py
new file mode 100644
index 000000000..1dd950c48
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssl_match_hostname.py
@@ -0,0 +1,159 @@
+"""The match_hostname() function from Python 3.3.3, essential when using SSL."""
+
+# Note: This file is under the PSF license as the code comes from the python
+# stdlib. http://docs.python.org/3/license.html
+
+import re
+import sys
+
+# ipaddress has been backported to 2.6+ in pypi. If it is installed on the
+# system, use it to handle IPAddress ServerAltnames (this was added in
+# python-3.5) otherwise only do DNS matching. This allows
+# util.ssl_match_hostname to continue to be used in Python 2.7.
+try:
+ import ipaddress
+except ImportError:
+ ipaddress = None
+
+__version__ = "3.5.0.1"
+
+
+class CertificateError(ValueError):
+ pass
+
+
+def _dnsname_match(dn, hostname, max_wildcards=1):
+ """Matching according to RFC 6125, section 6.4.3
+
+ http://tools.ietf.org/html/rfc6125#section-6.4.3
+ """
+ pats = []
+ if not dn:
+ return False
+
+ # Ported from python3-syntax:
+ # leftmost, *remainder = dn.split(r'.')
+ parts = dn.split(r".")
+ leftmost = parts[0]
+ remainder = parts[1:]
+
+ wildcards = leftmost.count("*")
+ if wildcards > max_wildcards:
+ # Issue #17980: avoid denials of service by refusing more
+ # than one wildcard per fragment. A survey of established
+ # policy among SSL implementations showed it to be a
+ # reasonable choice.
+ raise CertificateError(
+ "too many wildcards in certificate DNS name: " + repr(dn)
+ )
+
+ # speed up common case w/o wildcards
+ if not wildcards:
+ return dn.lower() == hostname.lower()
+
+ # RFC 6125, section 6.4.3, subitem 1.
+ # The client SHOULD NOT attempt to match a presented identifier in which
+ # the wildcard character comprises a label other than the left-most label.
+ if leftmost == "*":
+ # When '*' is a fragment by itself, it matches a non-empty dotless
+ # fragment.
+ pats.append("[^.]+")
+ elif leftmost.startswith("xn--") or hostname.startswith("xn--"):
+ # RFC 6125, section 6.4.3, subitem 3.
+ # The client SHOULD NOT attempt to match a presented identifier
+ # where the wildcard character is embedded within an A-label or
+ # U-label of an internationalized domain name.
+ pats.append(re.escape(leftmost))
+ else:
+ # Otherwise, '*' matches any dotless string, e.g. www*
+ pats.append(re.escape(leftmost).replace(r"\*", "[^.]*"))
+
+ # add the remaining fragments, ignore any wildcards
+ for frag in remainder:
+ pats.append(re.escape(frag))
+
+ pat = re.compile(r"\A" + r"\.".join(pats) + r"\Z", re.IGNORECASE)
+ return pat.match(hostname)
+
+
+def _to_unicode(obj):
+ if isinstance(obj, str) and sys.version_info < (3,):
+ # ignored flake8 # F821 to support python 2.7 function
+ obj = unicode(obj, encoding="ascii", errors="strict") # noqa: F821
+ return obj
+
+
+def _ipaddress_match(ipname, host_ip):
+ """Exact matching of IP addresses.
+
+ RFC 6125 explicitly doesn't define an algorithm for this
+ (section 1.7.2 - "Out of Scope").
+ """
+ # OpenSSL may add a trailing newline to a subjectAltName's IP address
+ # Divergence from upstream: ipaddress can't handle byte str
+ ip = ipaddress.ip_address(_to_unicode(ipname).rstrip())
+ return ip == host_ip
+
+
+def match_hostname(cert, hostname):
+ """Verify that *cert* (in decoded format as returned by
+ SSLSocket.getpeercert()) matches the *hostname*. RFC 2818 and RFC 6125
+ rules are followed, but IP addresses are not accepted for *hostname*.
+
+ CertificateError is raised on failure. On success, the function
+ returns nothing.
+ """
+ if not cert:
+ raise ValueError(
+ "empty or no certificate, match_hostname needs a "
+ "SSL socket or SSL context with either "
+ "CERT_OPTIONAL or CERT_REQUIRED"
+ )
+ try:
+ # Divergence from upstream: ipaddress can't handle byte str
+ host_ip = ipaddress.ip_address(_to_unicode(hostname))
+ except (UnicodeError, ValueError):
+ # ValueError: Not an IP address (common case)
+ # UnicodeError: Divergence from upstream: Have to deal with ipaddress not taking
+ # byte strings. addresses should be all ascii, so we consider it not
+ # an ipaddress in this case
+ host_ip = None
+ except AttributeError:
+ # Divergence from upstream: Make ipaddress library optional
+ if ipaddress is None:
+ host_ip = None
+ else: # Defensive
+ raise
+ dnsnames = []
+ san = cert.get("subjectAltName", ())
+ for key, value in san:
+ if key == "DNS":
+ if host_ip is None and _dnsname_match(value, hostname):
+ return
+ dnsnames.append(value)
+ elif key == "IP Address":
+ if host_ip is not None and _ipaddress_match(value, host_ip):
+ return
+ dnsnames.append(value)
+ if not dnsnames:
+ # The subject is only checked when there is no dNSName entry
+ # in subjectAltName
+ for sub in cert.get("subject", ()):
+ for key, value in sub:
+ # XXX according to RFC 2818, the most specific Common Name
+ # must be used.
+ if key == "commonName":
+ if _dnsname_match(value, hostname):
+ return
+ dnsnames.append(value)
+ if len(dnsnames) > 1:
+ raise CertificateError(
+ "hostname %r "
+ "doesn't match either of %s" % (hostname, ", ".join(map(repr, dnsnames)))
+ )
+ elif len(dnsnames) == 1:
+ raise CertificateError("hostname %r doesn't match %r" % (hostname, dnsnames[0]))
+ else:
+ raise CertificateError(
+ "no appropriate commonName or subjectAltName fields were found"
+ )
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssltransport.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssltransport.py
new file mode 100644
index 000000000..4a7105d17
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/ssltransport.py
@@ -0,0 +1,221 @@
+import io
+import socket
+import ssl
+
+from ..exceptions import ProxySchemeUnsupported
+from ..packages import six
+
+SSL_BLOCKSIZE = 16384
+
+
+class SSLTransport:
+ """
+ The SSLTransport wraps an existing socket and establishes an SSL connection.
+
+ Contrary to Python's implementation of SSLSocket, it allows you to chain
+ multiple TLS connections together. It's particularly useful if you need to
+ implement TLS within TLS.
+
+ The class supports most of the socket API operations.
+ """
+
+ @staticmethod
+ def _validate_ssl_context_for_tls_in_tls(ssl_context):
+ """
+ Raises a ProxySchemeUnsupported if the provided ssl_context can't be used
+ for TLS in TLS.
+
+ The only requirement is that the ssl_context provides the 'wrap_bio'
+ methods.
+ """
+
+ if not hasattr(ssl_context, "wrap_bio"):
+ if six.PY2:
+ raise ProxySchemeUnsupported(
+ "TLS in TLS requires SSLContext.wrap_bio() which isn't "
+ "supported on Python 2"
+ )
+ else:
+ raise ProxySchemeUnsupported(
+ "TLS in TLS requires SSLContext.wrap_bio() which isn't "
+ "available on non-native SSLContext"
+ )
+
+ def __init__(
+ self, socket, ssl_context, server_hostname=None, suppress_ragged_eofs=True
+ ):
+ """
+ Create an SSLTransport around socket using the provided ssl_context.
+ """
+ self.incoming = ssl.MemoryBIO()
+ self.outgoing = ssl.MemoryBIO()
+
+ self.suppress_ragged_eofs = suppress_ragged_eofs
+ self.socket = socket
+
+ self.sslobj = ssl_context.wrap_bio(
+ self.incoming, self.outgoing, server_hostname=server_hostname
+ )
+
+ # Perform initial handshake.
+ self._ssl_io_loop(self.sslobj.do_handshake)
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, *_):
+ self.close()
+
+ def fileno(self):
+ return self.socket.fileno()
+
+ def read(self, len=1024, buffer=None):
+ return self._wrap_ssl_read(len, buffer)
+
+ def recv(self, len=1024, flags=0):
+ if flags != 0:
+ raise ValueError("non-zero flags not allowed in calls to recv")
+ return self._wrap_ssl_read(len)
+
+ def recv_into(self, buffer, nbytes=None, flags=0):
+ if flags != 0:
+ raise ValueError("non-zero flags not allowed in calls to recv_into")
+ if buffer and (nbytes is None):
+ nbytes = len(buffer)
+ elif nbytes is None:
+ nbytes = 1024
+ return self.read(nbytes, buffer)
+
+ def sendall(self, data, flags=0):
+ if flags != 0:
+ raise ValueError("non-zero flags not allowed in calls to sendall")
+ count = 0
+ with memoryview(data) as view, view.cast("B") as byte_view:
+ amount = len(byte_view)
+ while count < amount:
+ v = self.send(byte_view[count:])
+ count += v
+
+ def send(self, data, flags=0):
+ if flags != 0:
+ raise ValueError("non-zero flags not allowed in calls to send")
+ response = self._ssl_io_loop(self.sslobj.write, data)
+ return response
+
+ def makefile(
+ self, mode="r", buffering=None, encoding=None, errors=None, newline=None
+ ):
+ """
+ Python's httpclient uses makefile and buffered io when reading HTTP
+ messages and we need to support it.
+
+ This is unfortunately a copy and paste of socket.py makefile with small
+ changes to point to the socket directly.
+ """
+ if not set(mode) <= {"r", "w", "b"}:
+ raise ValueError("invalid mode %r (only r, w, b allowed)" % (mode,))
+
+ writing = "w" in mode
+ reading = "r" in mode or not writing
+ assert reading or writing
+ binary = "b" in mode
+ rawmode = ""
+ if reading:
+ rawmode += "r"
+ if writing:
+ rawmode += "w"
+ raw = socket.SocketIO(self, rawmode)
+ self.socket._io_refs += 1
+ if buffering is None:
+ buffering = -1
+ if buffering < 0:
+ buffering = io.DEFAULT_BUFFER_SIZE
+ if buffering == 0:
+ if not binary:
+ raise ValueError("unbuffered streams must be binary")
+ return raw
+ if reading and writing:
+ buffer = io.BufferedRWPair(raw, raw, buffering)
+ elif reading:
+ buffer = io.BufferedReader(raw, buffering)
+ else:
+ assert writing
+ buffer = io.BufferedWriter(raw, buffering)
+ if binary:
+ return buffer
+ text = io.TextIOWrapper(buffer, encoding, errors, newline)
+ text.mode = mode
+ return text
+
+ def unwrap(self):
+ self._ssl_io_loop(self.sslobj.unwrap)
+
+ def close(self):
+ self.socket.close()
+
+ def getpeercert(self, binary_form=False):
+ return self.sslobj.getpeercert(binary_form)
+
+ def version(self):
+ return self.sslobj.version()
+
+ def cipher(self):
+ return self.sslobj.cipher()
+
+ def selected_alpn_protocol(self):
+ return self.sslobj.selected_alpn_protocol()
+
+ def selected_npn_protocol(self):
+ return self.sslobj.selected_npn_protocol()
+
+ def shared_ciphers(self):
+ return self.sslobj.shared_ciphers()
+
+ def compression(self):
+ return self.sslobj.compression()
+
+ def settimeout(self, value):
+ self.socket.settimeout(value)
+
+ def gettimeout(self):
+ return self.socket.gettimeout()
+
+ def _decref_socketios(self):
+ self.socket._decref_socketios()
+
+ def _wrap_ssl_read(self, len, buffer=None):
+ try:
+ return self._ssl_io_loop(self.sslobj.read, len, buffer)
+ except ssl.SSLError as e:
+ if e.errno == ssl.SSL_ERROR_EOF and self.suppress_ragged_eofs:
+ return 0 # eof, return 0.
+ else:
+ raise
+
+ def _ssl_io_loop(self, func, *args):
+ """Performs an I/O loop between incoming/outgoing and the socket."""
+ should_loop = True
+ ret = None
+
+ while should_loop:
+ errno = None
+ try:
+ ret = func(*args)
+ except ssl.SSLError as e:
+ if e.errno not in (ssl.SSL_ERROR_WANT_READ, ssl.SSL_ERROR_WANT_WRITE):
+ # WANT_READ, and WANT_WRITE are expected, others are not.
+ raise e
+ errno = e.errno
+
+ buf = self.outgoing.read()
+ self.socket.sendall(buf)
+
+ if errno is None:
+ should_loop = False
+ elif errno == ssl.SSL_ERROR_WANT_READ:
+ buf = self.socket.recv(SSL_BLOCKSIZE)
+ if buf:
+ self.incoming.write(buf)
+ else:
+ self.incoming.write_eof()
+ return ret
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/timeout.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/timeout.py
new file mode 100644
index 000000000..78e18a627
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/timeout.py
@@ -0,0 +1,271 @@
+from __future__ import absolute_import
+
+import time
+
+# The default socket timeout, used by httplib to indicate that no timeout was; specified by the user
+from socket import _GLOBAL_DEFAULT_TIMEOUT, getdefaulttimeout
+
+from ..exceptions import TimeoutStateError
+
+# A sentinel value to indicate that no timeout was specified by the user in
+# urllib3
+_Default = object()
+
+
+# Use time.monotonic if available.
+current_time = getattr(time, "monotonic", time.time)
+
+
+class Timeout(object):
+ """Timeout configuration.
+
+ Timeouts can be defined as a default for a pool:
+
+ .. code-block:: python
+
+ timeout = Timeout(connect=2.0, read=7.0)
+ http = PoolManager(timeout=timeout)
+ response = http.request('GET', 'http://example.com/')
+
+ Or per-request (which overrides the default for the pool):
+
+ .. code-block:: python
+
+ response = http.request('GET', 'http://example.com/', timeout=Timeout(10))
+
+ Timeouts can be disabled by setting all the parameters to ``None``:
+
+ .. code-block:: python
+
+ no_timeout = Timeout(connect=None, read=None)
+ response = http.request('GET', 'http://example.com/, timeout=no_timeout)
+
+
+ :param total:
+ This combines the connect and read timeouts into one; the read timeout
+ will be set to the time leftover from the connect attempt. In the
+ event that both a connect timeout and a total are specified, or a read
+ timeout and a total are specified, the shorter timeout will be applied.
+
+ Defaults to None.
+
+ :type total: int, float, or None
+
+ :param connect:
+ The maximum amount of time (in seconds) to wait for a connection
+ attempt to a server to succeed. Omitting the parameter will default the
+ connect timeout to the system default, probably `the global default
+ timeout in socket.py
+ <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.
+ None will set an infinite timeout for connection attempts.
+
+ :type connect: int, float, or None
+
+ :param read:
+ The maximum amount of time (in seconds) to wait between consecutive
+ read operations for a response from the server. Omitting the parameter
+ will default the read timeout to the system default, probably `the
+ global default timeout in socket.py
+ <http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.
+ None will set an infinite timeout.
+
+ :type read: int, float, or None
+
+ .. note::
+
+ Many factors can affect the total amount of time for urllib3 to return
+ an HTTP response.
+
+ For example, Python's DNS resolver does not obey the timeout specified
+ on the socket. Other factors that can affect total request time include
+ high CPU load, high swap, the program running at a low priority level,
+ or other behaviors.
+
+ In addition, the read and total timeouts only measure the time between
+ read operations on the socket connecting the client and the server,
+ not the total amount of time for the request to return a complete
+ response. For most requests, the timeout is raised because the server
+ has not sent the first byte in the specified time. This is not always
+ the case; if a server streams one byte every fifteen seconds, a timeout
+ of 20 seconds will not trigger, even though the request will take
+ several minutes to complete.
+
+ If your goal is to cut off any request after a set amount of wall clock
+ time, consider having a second "watcher" thread to cut off a slow
+ request.
+ """
+
+ #: A sentinel object representing the default timeout value
+ DEFAULT_TIMEOUT = _GLOBAL_DEFAULT_TIMEOUT
+
+ def __init__(self, total=None, connect=_Default, read=_Default):
+ self._connect = self._validate_timeout(connect, "connect")
+ self._read = self._validate_timeout(read, "read")
+ self.total = self._validate_timeout(total, "total")
+ self._start_connect = None
+
+ def __repr__(self):
+ return "%s(connect=%r, read=%r, total=%r)" % (
+ type(self).__name__,
+ self._connect,
+ self._read,
+ self.total,
+ )
+
+ # __str__ provided for backwards compatibility
+ __str__ = __repr__
+
+ @classmethod
+ def resolve_default_timeout(cls, timeout):
+ return getdefaulttimeout() if timeout is cls.DEFAULT_TIMEOUT else timeout
+
+ @classmethod
+ def _validate_timeout(cls, value, name):
+ """Check that a timeout attribute is valid.
+
+ :param value: The timeout value to validate
+ :param name: The name of the timeout attribute to validate. This is
+ used to specify in error messages.
+ :return: The validated and casted version of the given value.
+ :raises ValueError: If it is a numeric value less than or equal to
+ zero, or the type is not an integer, float, or None.
+ """
+ if value is _Default:
+ return cls.DEFAULT_TIMEOUT
+
+ if value is None or value is cls.DEFAULT_TIMEOUT:
+ return value
+
+ if isinstance(value, bool):
+ raise ValueError(
+ "Timeout cannot be a boolean value. It must "
+ "be an int, float or None."
+ )
+ try:
+ float(value)
+ except (TypeError, ValueError):
+ raise ValueError(
+ "Timeout value %s was %s, but it must be an "
+ "int, float or None." % (name, value)
+ )
+
+ try:
+ if value <= 0:
+ raise ValueError(
+ "Attempted to set %s timeout to %s, but the "
+ "timeout cannot be set to a value less "
+ "than or equal to 0." % (name, value)
+ )
+ except TypeError:
+ # Python 3
+ raise ValueError(
+ "Timeout value %s was %s, but it must be an "
+ "int, float or None." % (name, value)
+ )
+
+ return value
+
+ @classmethod
+ def from_float(cls, timeout):
+ """Create a new Timeout from a legacy timeout value.
+
+ The timeout value used by httplib.py sets the same timeout on the
+ connect(), and recv() socket requests. This creates a :class:`Timeout`
+ object that sets the individual timeouts to the ``timeout`` value
+ passed to this function.
+
+ :param timeout: The legacy timeout value.
+ :type timeout: integer, float, sentinel default object, or None
+ :return: Timeout object
+ :rtype: :class:`Timeout`
+ """
+ return Timeout(read=timeout, connect=timeout)
+
+ def clone(self):
+ """Create a copy of the timeout object
+
+ Timeout properties are stored per-pool but each request needs a fresh
+ Timeout object to ensure each one has its own start/stop configured.
+
+ :return: a copy of the timeout object
+ :rtype: :class:`Timeout`
+ """
+ # We can't use copy.deepcopy because that will also create a new object
+ # for _GLOBAL_DEFAULT_TIMEOUT, which socket.py uses as a sentinel to
+ # detect the user default.
+ return Timeout(connect=self._connect, read=self._read, total=self.total)
+
+ def start_connect(self):
+ """Start the timeout clock, used during a connect() attempt
+
+ :raises urllib3.exceptions.TimeoutStateError: if you attempt
+ to start a timer that has been started already.
+ """
+ if self._start_connect is not None:
+ raise TimeoutStateError("Timeout timer has already been started.")
+ self._start_connect = current_time()
+ return self._start_connect
+
+ def get_connect_duration(self):
+ """Gets the time elapsed since the call to :meth:`start_connect`.
+
+ :return: Elapsed time in seconds.
+ :rtype: float
+ :raises urllib3.exceptions.TimeoutStateError: if you attempt
+ to get duration for a timer that hasn't been started.
+ """
+ if self._start_connect is None:
+ raise TimeoutStateError(
+ "Can't get connect duration for timer that has not started."
+ )
+ return current_time() - self._start_connect
+
+ @property
+ def connect_timeout(self):
+ """Get the value to use when setting a connection timeout.
+
+ This will be a positive float or integer, the value None
+ (never timeout), or the default system timeout.
+
+ :return: Connect timeout.
+ :rtype: int, float, :attr:`Timeout.DEFAULT_TIMEOUT` or None
+ """
+ if self.total is None:
+ return self._connect
+
+ if self._connect is None or self._connect is self.DEFAULT_TIMEOUT:
+ return self.total
+
+ return min(self._connect, self.total)
+
+ @property
+ def read_timeout(self):
+ """Get the value for the read timeout.
+
+ This assumes some time has elapsed in the connection timeout and
+ computes the read timeout appropriately.
+
+ If self.total is set, the read timeout is dependent on the amount of
+ time taken by the connect timeout. If the connection time has not been
+ established, a :exc:`~urllib3.exceptions.TimeoutStateError` will be
+ raised.
+
+ :return: Value to use for the read timeout.
+ :rtype: int, float, :attr:`Timeout.DEFAULT_TIMEOUT` or None
+ :raises urllib3.exceptions.TimeoutStateError: If :meth:`start_connect`
+ has not yet been called on this object.
+ """
+ if (
+ self.total is not None
+ and self.total is not self.DEFAULT_TIMEOUT
+ and self._read is not None
+ and self._read is not self.DEFAULT_TIMEOUT
+ ):
+ # In case the connect timeout has not yet been established.
+ if self._start_connect is None:
+ return self._read
+ return max(0, min(self.total - self.get_connect_duration(), self._read))
+ elif self.total is not None and self.total is not self.DEFAULT_TIMEOUT:
+ return max(0, self.total - self.get_connect_duration())
+ else:
+ return self._read
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/url.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/url.py
new file mode 100644
index 000000000..a960b2f3c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/url.py
@@ -0,0 +1,435 @@
+from __future__ import absolute_import
+
+import re
+from collections import namedtuple
+
+from ..exceptions import LocationParseError
+from ..packages import six
+
+url_attrs = ["scheme", "auth", "host", "port", "path", "query", "fragment"]
+
+# We only want to normalize urls with an HTTP(S) scheme.
+# urllib3 infers URLs without a scheme (None) to be http.
+NORMALIZABLE_SCHEMES = ("http", "https", None)
+
+# Almost all of these patterns were derived from the
+# 'rfc3986' module: https://github.com/python-hyper/rfc3986
+PERCENT_RE = re.compile(r"%[a-fA-F0-9]{2}")
+SCHEME_RE = re.compile(r"^(?:[a-zA-Z][a-zA-Z0-9+-]*:|/)")
+URI_RE = re.compile(
+ r"^(?:([a-zA-Z][a-zA-Z0-9+.-]*):)?"
+ r"(?://([^\\/?#]*))?"
+ r"([^?#]*)"
+ r"(?:\?([^#]*))?"
+ r"(?:#(.*))?$",
+ re.UNICODE | re.DOTALL,
+)
+
+IPV4_PAT = r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}"
+HEX_PAT = "[0-9A-Fa-f]{1,4}"
+LS32_PAT = "(?:{hex}:{hex}|{ipv4})".format(hex=HEX_PAT, ipv4=IPV4_PAT)
+_subs = {"hex": HEX_PAT, "ls32": LS32_PAT}
+_variations = [
+ # 6( h16 ":" ) ls32
+ "(?:%(hex)s:){6}%(ls32)s",
+ # "::" 5( h16 ":" ) ls32
+ "::(?:%(hex)s:){5}%(ls32)s",
+ # [ h16 ] "::" 4( h16 ":" ) ls32
+ "(?:%(hex)s)?::(?:%(hex)s:){4}%(ls32)s",
+ # [ *1( h16 ":" ) h16 ] "::" 3( h16 ":" ) ls32
+ "(?:(?:%(hex)s:)?%(hex)s)?::(?:%(hex)s:){3}%(ls32)s",
+ # [ *2( h16 ":" ) h16 ] "::" 2( h16 ":" ) ls32
+ "(?:(?:%(hex)s:){0,2}%(hex)s)?::(?:%(hex)s:){2}%(ls32)s",
+ # [ *3( h16 ":" ) h16 ] "::" h16 ":" ls32
+ "(?:(?:%(hex)s:){0,3}%(hex)s)?::%(hex)s:%(ls32)s",
+ # [ *4( h16 ":" ) h16 ] "::" ls32
+ "(?:(?:%(hex)s:){0,4}%(hex)s)?::%(ls32)s",
+ # [ *5( h16 ":" ) h16 ] "::" h16
+ "(?:(?:%(hex)s:){0,5}%(hex)s)?::%(hex)s",
+ # [ *6( h16 ":" ) h16 ] "::"
+ "(?:(?:%(hex)s:){0,6}%(hex)s)?::",
+]
+
+UNRESERVED_PAT = r"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789._\-~"
+IPV6_PAT = "(?:" + "|".join([x % _subs for x in _variations]) + ")"
+ZONE_ID_PAT = "(?:%25|%)(?:[" + UNRESERVED_PAT + "]|%[a-fA-F0-9]{2})+"
+IPV6_ADDRZ_PAT = r"\[" + IPV6_PAT + r"(?:" + ZONE_ID_PAT + r")?\]"
+REG_NAME_PAT = r"(?:[^\[\]%:/?#]|%[a-fA-F0-9]{2})*"
+TARGET_RE = re.compile(r"^(/[^?#]*)(?:\?([^#]*))?(?:#.*)?$")
+
+IPV4_RE = re.compile("^" + IPV4_PAT + "$")
+IPV6_RE = re.compile("^" + IPV6_PAT + "$")
+IPV6_ADDRZ_RE = re.compile("^" + IPV6_ADDRZ_PAT + "$")
+BRACELESS_IPV6_ADDRZ_RE = re.compile("^" + IPV6_ADDRZ_PAT[2:-2] + "$")
+ZONE_ID_RE = re.compile("(" + ZONE_ID_PAT + r")\]$")
+
+_HOST_PORT_PAT = ("^(%s|%s|%s)(?::0*?(|0|[1-9][0-9]{0,4}))?$") % (
+ REG_NAME_PAT,
+ IPV4_PAT,
+ IPV6_ADDRZ_PAT,
+)
+_HOST_PORT_RE = re.compile(_HOST_PORT_PAT, re.UNICODE | re.DOTALL)
+
+UNRESERVED_CHARS = set(
+ "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789._-~"
+)
+SUB_DELIM_CHARS = set("!$&'()*+,;=")
+USERINFO_CHARS = UNRESERVED_CHARS | SUB_DELIM_CHARS | {":"}
+PATH_CHARS = USERINFO_CHARS | {"@", "/"}
+QUERY_CHARS = FRAGMENT_CHARS = PATH_CHARS | {"?"}
+
+
+class Url(namedtuple("Url", url_attrs)):
+ """
+ Data structure for representing an HTTP URL. Used as a return value for
+ :func:`parse_url`. Both the scheme and host are normalized as they are
+ both case-insensitive according to RFC 3986.
+ """
+
+ __slots__ = ()
+
+ def __new__(
+ cls,
+ scheme=None,
+ auth=None,
+ host=None,
+ port=None,
+ path=None,
+ query=None,
+ fragment=None,
+ ):
+ if path and not path.startswith("/"):
+ path = "/" + path
+ if scheme is not None:
+ scheme = scheme.lower()
+ return super(Url, cls).__new__(
+ cls, scheme, auth, host, port, path, query, fragment
+ )
+
+ @property
+ def hostname(self):
+ """For backwards-compatibility with urlparse. We're nice like that."""
+ return self.host
+
+ @property
+ def request_uri(self):
+ """Absolute path including the query string."""
+ uri = self.path or "/"
+
+ if self.query is not None:
+ uri += "?" + self.query
+
+ return uri
+
+ @property
+ def netloc(self):
+ """Network location including host and port"""
+ if self.port:
+ return "%s:%d" % (self.host, self.port)
+ return self.host
+
+ @property
+ def url(self):
+ """
+ Convert self into a url
+
+ This function should more or less round-trip with :func:`.parse_url`. The
+ returned url may not be exactly the same as the url inputted to
+ :func:`.parse_url`, but it should be equivalent by the RFC (e.g., urls
+ with a blank port will have : removed).
+
+ Example: ::
+
+ >>> U = parse_url('http://google.com/mail/')
+ >>> U.url
+ 'http://google.com/mail/'
+ >>> Url('http', 'username:password', 'host.com', 80,
+ ... '/path', 'query', 'fragment').url
+ 'http://username:password@host.com:80/path?query#fragment'
+ """
+ scheme, auth, host, port, path, query, fragment = self
+ url = u""
+
+ # We use "is not None" we want things to happen with empty strings (or 0 port)
+ if scheme is not None:
+ url += scheme + u"://"
+ if auth is not None:
+ url += auth + u"@"
+ if host is not None:
+ url += host
+ if port is not None:
+ url += u":" + str(port)
+ if path is not None:
+ url += path
+ if query is not None:
+ url += u"?" + query
+ if fragment is not None:
+ url += u"#" + fragment
+
+ return url
+
+ def __str__(self):
+ return self.url
+
+
+def split_first(s, delims):
+ """
+ .. deprecated:: 1.25
+
+ Given a string and an iterable of delimiters, split on the first found
+ delimiter. Return two split parts and the matched delimiter.
+
+ If not found, then the first part is the full input string.
+
+ Example::
+
+ >>> split_first('foo/bar?baz', '?/=')
+ ('foo', 'bar?baz', '/')
+ >>> split_first('foo/bar?baz', '123')
+ ('foo/bar?baz', '', None)
+
+ Scales linearly with number of delims. Not ideal for large number of delims.
+ """
+ min_idx = None
+ min_delim = None
+ for d in delims:
+ idx = s.find(d)
+ if idx < 0:
+ continue
+
+ if min_idx is None or idx < min_idx:
+ min_idx = idx
+ min_delim = d
+
+ if min_idx is None or min_idx < 0:
+ return s, "", None
+
+ return s[:min_idx], s[min_idx + 1 :], min_delim
+
+
+def _encode_invalid_chars(component, allowed_chars, encoding="utf-8"):
+ """Percent-encodes a URI component without reapplying
+ onto an already percent-encoded component.
+ """
+ if component is None:
+ return component
+
+ component = six.ensure_text(component)
+
+ # Normalize existing percent-encoded bytes.
+ # Try to see if the component we're encoding is already percent-encoded
+ # so we can skip all '%' characters but still encode all others.
+ component, percent_encodings = PERCENT_RE.subn(
+ lambda match: match.group(0).upper(), component
+ )
+
+ uri_bytes = component.encode("utf-8", "surrogatepass")
+ is_percent_encoded = percent_encodings == uri_bytes.count(b"%")
+ encoded_component = bytearray()
+
+ for i in range(0, len(uri_bytes)):
+ # Will return a single character bytestring on both Python 2 & 3
+ byte = uri_bytes[i : i + 1]
+ byte_ord = ord(byte)
+ if (is_percent_encoded and byte == b"%") or (
+ byte_ord < 128 and byte.decode() in allowed_chars
+ ):
+ encoded_component += byte
+ continue
+ encoded_component.extend(b"%" + (hex(byte_ord)[2:].encode().zfill(2).upper()))
+
+ return encoded_component.decode(encoding)
+
+
+def _remove_path_dot_segments(path):
+ # See http://tools.ietf.org/html/rfc3986#section-5.2.4 for pseudo-code
+ segments = path.split("/") # Turn the path into a list of segments
+ output = [] # Initialize the variable to use to store output
+
+ for segment in segments:
+ # '.' is the current directory, so ignore it, it is superfluous
+ if segment == ".":
+ continue
+ # Anything other than '..', should be appended to the output
+ elif segment != "..":
+ output.append(segment)
+ # In this case segment == '..', if we can, we should pop the last
+ # element
+ elif output:
+ output.pop()
+
+ # If the path starts with '/' and the output is empty or the first string
+ # is non-empty
+ if path.startswith("/") and (not output or output[0]):
+ output.insert(0, "")
+
+ # If the path starts with '/.' or '/..' ensure we add one more empty
+ # string to add a trailing '/'
+ if path.endswith(("/.", "/..")):
+ output.append("")
+
+ return "/".join(output)
+
+
+def _normalize_host(host, scheme):
+ if host:
+ if isinstance(host, six.binary_type):
+ host = six.ensure_str(host)
+
+ if scheme in NORMALIZABLE_SCHEMES:
+ is_ipv6 = IPV6_ADDRZ_RE.match(host)
+ if is_ipv6:
+ # IPv6 hosts of the form 'a::b%zone' are encoded in a URL as
+ # such per RFC 6874: 'a::b%25zone'. Unquote the ZoneID
+ # separator as necessary to return a valid RFC 4007 scoped IP.
+ match = ZONE_ID_RE.search(host)
+ if match:
+ start, end = match.span(1)
+ zone_id = host[start:end]
+
+ if zone_id.startswith("%25") and zone_id != "%25":
+ zone_id = zone_id[3:]
+ else:
+ zone_id = zone_id[1:]
+ zone_id = "%" + _encode_invalid_chars(zone_id, UNRESERVED_CHARS)
+ return host[:start].lower() + zone_id + host[end:]
+ else:
+ return host.lower()
+ elif not IPV4_RE.match(host):
+ return six.ensure_str(
+ b".".join([_idna_encode(label) for label in host.split(".")])
+ )
+ return host
+
+
+def _idna_encode(name):
+ if name and any(ord(x) >= 128 for x in name):
+ try:
+ from pip._vendor import idna
+ except ImportError:
+ six.raise_from(
+ LocationParseError("Unable to parse URL without the 'idna' module"),
+ None,
+ )
+ try:
+ return idna.encode(name.lower(), strict=True, std3_rules=True)
+ except idna.IDNAError:
+ six.raise_from(
+ LocationParseError(u"Name '%s' is not a valid IDNA label" % name), None
+ )
+ return name.lower().encode("ascii")
+
+
+def _encode_target(target):
+ """Percent-encodes a request target so that there are no invalid characters"""
+ path, query = TARGET_RE.match(target).groups()
+ target = _encode_invalid_chars(path, PATH_CHARS)
+ query = _encode_invalid_chars(query, QUERY_CHARS)
+ if query is not None:
+ target += "?" + query
+ return target
+
+
+def parse_url(url):
+ """
+ Given a url, return a parsed :class:`.Url` namedtuple. Best-effort is
+ performed to parse incomplete urls. Fields not provided will be None.
+ This parser is RFC 3986 and RFC 6874 compliant.
+
+ The parser logic and helper functions are based heavily on
+ work done in the ``rfc3986`` module.
+
+ :param str url: URL to parse into a :class:`.Url` namedtuple.
+
+ Partly backwards-compatible with :mod:`urlparse`.
+
+ Example::
+
+ >>> parse_url('http://google.com/mail/')
+ Url(scheme='http', host='google.com', port=None, path='/mail/', ...)
+ >>> parse_url('google.com:80')
+ Url(scheme=None, host='google.com', port=80, path=None, ...)
+ >>> parse_url('/foo?bar')
+ Url(scheme=None, host=None, port=None, path='/foo', query='bar', ...)
+ """
+ if not url:
+ # Empty
+ return Url()
+
+ source_url = url
+ if not SCHEME_RE.search(url):
+ url = "//" + url
+
+ try:
+ scheme, authority, path, query, fragment = URI_RE.match(url).groups()
+ normalize_uri = scheme is None or scheme.lower() in NORMALIZABLE_SCHEMES
+
+ if scheme:
+ scheme = scheme.lower()
+
+ if authority:
+ auth, _, host_port = authority.rpartition("@")
+ auth = auth or None
+ host, port = _HOST_PORT_RE.match(host_port).groups()
+ if auth and normalize_uri:
+ auth = _encode_invalid_chars(auth, USERINFO_CHARS)
+ if port == "":
+ port = None
+ else:
+ auth, host, port = None, None, None
+
+ if port is not None:
+ port = int(port)
+ if not (0 <= port <= 65535):
+ raise LocationParseError(url)
+
+ host = _normalize_host(host, scheme)
+
+ if normalize_uri and path:
+ path = _remove_path_dot_segments(path)
+ path = _encode_invalid_chars(path, PATH_CHARS)
+ if normalize_uri and query:
+ query = _encode_invalid_chars(query, QUERY_CHARS)
+ if normalize_uri and fragment:
+ fragment = _encode_invalid_chars(fragment, FRAGMENT_CHARS)
+
+ except (ValueError, AttributeError):
+ return six.raise_from(LocationParseError(source_url), None)
+
+ # For the sake of backwards compatibility we put empty
+ # string values for path if there are any defined values
+ # beyond the path in the URL.
+ # TODO: Remove this when we break backwards compatibility.
+ if not path:
+ if query is not None or fragment is not None:
+ path = ""
+ else:
+ path = None
+
+ # Ensure that each part of the URL is a `str` for
+ # backwards compatibility.
+ if isinstance(url, six.text_type):
+ ensure_func = six.ensure_text
+ else:
+ ensure_func = six.ensure_str
+
+ def ensure_type(x):
+ return x if x is None else ensure_func(x)
+
+ return Url(
+ scheme=ensure_type(scheme),
+ auth=ensure_type(auth),
+ host=ensure_type(host),
+ port=port,
+ path=ensure_type(path),
+ query=ensure_type(query),
+ fragment=ensure_type(fragment),
+ )
+
+
+def get_host(url):
+ """
+ Deprecated. Use :func:`parse_url` instead.
+ """
+ p = parse_url(url)
+ return p.scheme or "http", p.hostname, p.port
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/wait.py b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/wait.py
new file mode 100644
index 000000000..21b4590b3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/urllib3/util/wait.py
@@ -0,0 +1,152 @@
+import errno
+import select
+import sys
+from functools import partial
+
+try:
+ from time import monotonic
+except ImportError:
+ from time import time as monotonic
+
+__all__ = ["NoWayToWaitForSocketError", "wait_for_read", "wait_for_write"]
+
+
+class NoWayToWaitForSocketError(Exception):
+ pass
+
+
+# How should we wait on sockets?
+#
+# There are two types of APIs you can use for waiting on sockets: the fancy
+# modern stateful APIs like epoll/kqueue, and the older stateless APIs like
+# select/poll. The stateful APIs are more efficient when you have a lots of
+# sockets to keep track of, because you can set them up once and then use them
+# lots of times. But we only ever want to wait on a single socket at a time
+# and don't want to keep track of state, so the stateless APIs are actually
+# more efficient. So we want to use select() or poll().
+#
+# Now, how do we choose between select() and poll()? On traditional Unixes,
+# select() has a strange calling convention that makes it slow, or fail
+# altogether, for high-numbered file descriptors. The point of poll() is to fix
+# that, so on Unixes, we prefer poll().
+#
+# On Windows, there is no poll() (or at least Python doesn't provide a wrapper
+# for it), but that's OK, because on Windows, select() doesn't have this
+# strange calling convention; plain select() works fine.
+#
+# So: on Windows we use select(), and everywhere else we use poll(). We also
+# fall back to select() in case poll() is somehow broken or missing.
+
+if sys.version_info >= (3, 5):
+ # Modern Python, that retries syscalls by default
+ def _retry_on_intr(fn, timeout):
+ return fn(timeout)
+
+else:
+ # Old and broken Pythons.
+ def _retry_on_intr(fn, timeout):
+ if timeout is None:
+ deadline = float("inf")
+ else:
+ deadline = monotonic() + timeout
+
+ while True:
+ try:
+ return fn(timeout)
+ # OSError for 3 <= pyver < 3.5, select.error for pyver <= 2.7
+ except (OSError, select.error) as e:
+ # 'e.args[0]' incantation works for both OSError and select.error
+ if e.args[0] != errno.EINTR:
+ raise
+ else:
+ timeout = deadline - monotonic()
+ if timeout < 0:
+ timeout = 0
+ if timeout == float("inf"):
+ timeout = None
+ continue
+
+
+def select_wait_for_socket(sock, read=False, write=False, timeout=None):
+ if not read and not write:
+ raise RuntimeError("must specify at least one of read=True, write=True")
+ rcheck = []
+ wcheck = []
+ if read:
+ rcheck.append(sock)
+ if write:
+ wcheck.append(sock)
+ # When doing a non-blocking connect, most systems signal success by
+ # marking the socket writable. Windows, though, signals success by marked
+ # it as "exceptional". We paper over the difference by checking the write
+ # sockets for both conditions. (The stdlib selectors module does the same
+ # thing.)
+ fn = partial(select.select, rcheck, wcheck, wcheck)
+ rready, wready, xready = _retry_on_intr(fn, timeout)
+ return bool(rready or wready or xready)
+
+
+def poll_wait_for_socket(sock, read=False, write=False, timeout=None):
+ if not read and not write:
+ raise RuntimeError("must specify at least one of read=True, write=True")
+ mask = 0
+ if read:
+ mask |= select.POLLIN
+ if write:
+ mask |= select.POLLOUT
+ poll_obj = select.poll()
+ poll_obj.register(sock, mask)
+
+ # For some reason, poll() takes timeout in milliseconds
+ def do_poll(t):
+ if t is not None:
+ t *= 1000
+ return poll_obj.poll(t)
+
+ return bool(_retry_on_intr(do_poll, timeout))
+
+
+def null_wait_for_socket(*args, **kwargs):
+ raise NoWayToWaitForSocketError("no select-equivalent available")
+
+
+def _have_working_poll():
+ # Apparently some systems have a select.poll that fails as soon as you try
+ # to use it, either due to strange configuration or broken monkeypatching
+ # from libraries like eventlet/greenlet.
+ try:
+ poll_obj = select.poll()
+ _retry_on_intr(poll_obj.poll, 0)
+ except (AttributeError, OSError):
+ return False
+ else:
+ return True
+
+
+def wait_for_socket(*args, **kwargs):
+ # We delay choosing which implementation to use until the first time we're
+ # called. We could do it at import time, but then we might make the wrong
+ # decision if someone goes wild with monkeypatching select.poll after
+ # we're imported.
+ global wait_for_socket
+ if _have_working_poll():
+ wait_for_socket = poll_wait_for_socket
+ elif hasattr(select, "select"):
+ wait_for_socket = select_wait_for_socket
+ else: # Platform-specific: Appengine.
+ wait_for_socket = null_wait_for_socket
+ return wait_for_socket(*args, **kwargs)
+
+
+def wait_for_read(sock, timeout=None):
+ """Waits for reading to be available on a given socket.
+ Returns True if the socket is readable, or False if the timeout expired.
+ """
+ return wait_for_socket(sock, read=True, timeout=timeout)
+
+
+def wait_for_write(sock, timeout=None):
+ """Waits for writing to be available on a given socket.
+ Returns True if the socket is readable, or False if the timeout expired.
+ """
+ return wait_for_socket(sock, write=True, timeout=timeout)
diff --git a/solutions/.venv/Lib/site-packages/pip/_vendor/vendor.txt b/solutions/.venv/Lib/site-packages/pip/_vendor/vendor.txt
new file mode 100644
index 000000000..2ba053a6e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/_vendor/vendor.txt
@@ -0,0 +1,18 @@
+CacheControl==0.14.0
+distlib==0.3.9
+distro==1.9.0
+msgpack==1.0.8
+packaging==24.1
+platformdirs==4.2.2
+pyproject-hooks==1.0.0
+requests==2.32.3
+ certifi==2024.8.30
+ idna==3.7
+ urllib3==1.26.20
+rich==13.7.1
+ pygments==2.18.0
+ typing_extensions==4.12.2
+resolvelib==1.0.1
+setuptools==70.3.0
+tomli==2.0.1
+truststore==0.10.0
diff --git a/solutions/.venv/Lib/site-packages/pip/py.typed b/solutions/.venv/Lib/site-packages/pip/py.typed
new file mode 100644
index 000000000..493b53e4e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pip/py.typed
@@ -0,0 +1,4 @@
+pip is a command line program. While it is implemented in Python, and so is
+available for import, you must not use pip's internal APIs in this way. Typing
+information is provided as a convenience only and is not a guarantee. Expect
+unannounced changes to the API and types in releases.
diff --git a/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/METADATA b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/METADATA
new file mode 100644
index 000000000..91c59c9a2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/METADATA
@@ -0,0 +1,327 @@
+Metadata-Version: 2.3
+Name: platformdirs
+Version: 4.3.6
+Summary: A small Python package for determining appropriate platform-specific dirs, e.g. a `user data dir`.
+Project-URL: Changelog, https://github.com/tox-dev/platformdirs/releases
+Project-URL: Documentation, https://platformdirs.readthedocs.io
+Project-URL: Homepage, https://github.com/tox-dev/platformdirs
+Project-URL: Source, https://github.com/tox-dev/platformdirs
+Project-URL: Tracker, https://github.com/tox-dev/platformdirs/issues
+Maintainer-email: Bernát Gábor <gaborjbernat@gmail.com>, Julian Berman <Julian@GrayVines.com>, Ofek Lev <oss@ofek.dev>, Ronny Pfannschmidt <opensource@ronnypfannschmidt.de>
+License-Expression: MIT
+License-File: LICENSE
+Keywords: appdirs,application,cache,directory,log,user
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Classifier: Programming Language :: Python :: 3.13
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Software Development :: Libraries :: Python Modules
+Requires-Python: >=3.8
+Provides-Extra: docs
+Requires-Dist: furo>=2024.8.6; extra == 'docs'
+Requires-Dist: proselint>=0.14; extra == 'docs'
+Requires-Dist: sphinx-autodoc-typehints>=2.4; extra == 'docs'
+Requires-Dist: sphinx>=8.0.2; extra == 'docs'
+Provides-Extra: test
+Requires-Dist: appdirs==1.4.4; extra == 'test'
+Requires-Dist: covdefaults>=2.3; extra == 'test'
+Requires-Dist: pytest-cov>=5; extra == 'test'
+Requires-Dist: pytest-mock>=3.14; extra == 'test'
+Requires-Dist: pytest>=8.3.2; extra == 'test'
+Provides-Extra: type
+Requires-Dist: mypy>=1.11.2; extra == 'type'
+Description-Content-Type: text/x-rst
+
+The problem
+===========
+
+.. image:: https://badge.fury.io/py/platformdirs.svg
+ :target: https://badge.fury.io/py/platformdirs
+.. image:: https://img.shields.io/pypi/pyversions/platformdirs.svg
+ :target: https://pypi.python.org/pypi/platformdirs/
+.. image:: https://github.com/tox-dev/platformdirs/actions/workflows/check.yaml/badge.svg
+ :target: https://github.com/platformdirs/platformdirs/actions
+.. image:: https://static.pepy.tech/badge/platformdirs/month
+ :target: https://pepy.tech/project/platformdirs
+
+When writing desktop application, finding the right location to store user data
+and configuration varies per platform. Even for single-platform apps, there
+may by plenty of nuances in figuring out the right location.
+
+For example, if running on macOS, you should use::
+
+ ~/Library/Application Support/<AppName>
+
+If on Windows (at least English Win) that should be::
+
+ C:\Documents and Settings\<User>\Application Data\Local Settings\<AppAuthor>\<AppName>
+
+or possibly::
+
+ C:\Documents and Settings\<User>\Application Data\<AppAuthor>\<AppName>
+
+for `roaming profiles <https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-vista/cc766489(v=ws.10)>`_ but that is another story.
+
+On Linux (and other Unices), according to the `XDG Basedir Spec`_, it should be::
+
+ ~/.local/share/<AppName>
+
+.. _XDG Basedir Spec: https://specifications.freedesktop.org/basedir-spec/basedir-spec-latest.html
+
+``platformdirs`` to the rescue
+==============================
+
+This kind of thing is what the ``platformdirs`` package is for.
+``platformdirs`` will help you choose an appropriate:
+
+- user data dir (``user_data_dir``)
+- user config dir (``user_config_dir``)
+- user cache dir (``user_cache_dir``)
+- site data dir (``site_data_dir``)
+- site config dir (``site_config_dir``)
+- user log dir (``user_log_dir``)
+- user documents dir (``user_documents_dir``)
+- user downloads dir (``user_downloads_dir``)
+- user pictures dir (``user_pictures_dir``)
+- user videos dir (``user_videos_dir``)
+- user music dir (``user_music_dir``)
+- user desktop dir (``user_desktop_dir``)
+- user runtime dir (``user_runtime_dir``)
+
+And also:
+
+- Is slightly opinionated on the directory names used. Look for "OPINION" in
+ documentation and code for when an opinion is being applied.
+
+Example output
+==============
+
+On macOS:
+
+.. code-block:: pycon
+
+ >>> from platformdirs import *
+ >>> appname = "SuperApp"
+ >>> appauthor = "Acme"
+ >>> user_data_dir(appname, appauthor)
+ '/Users/trentm/Library/Application Support/SuperApp'
+ >>> site_data_dir(appname, appauthor)
+ '/Library/Application Support/SuperApp'
+ >>> user_cache_dir(appname, appauthor)
+ '/Users/trentm/Library/Caches/SuperApp'
+ >>> user_log_dir(appname, appauthor)
+ '/Users/trentm/Library/Logs/SuperApp'
+ >>> user_documents_dir()
+ '/Users/trentm/Documents'
+ >>> user_downloads_dir()
+ '/Users/trentm/Downloads'
+ >>> user_pictures_dir()
+ '/Users/trentm/Pictures'
+ >>> user_videos_dir()
+ '/Users/trentm/Movies'
+ >>> user_music_dir()
+ '/Users/trentm/Music'
+ >>> user_desktop_dir()
+ '/Users/trentm/Desktop'
+ >>> user_runtime_dir(appname, appauthor)
+ '/Users/trentm/Library/Caches/TemporaryItems/SuperApp'
+
+On Windows:
+
+.. code-block:: pycon
+
+ >>> from platformdirs import *
+ >>> appname = "SuperApp"
+ >>> appauthor = "Acme"
+ >>> user_data_dir(appname, appauthor)
+ 'C:\\Users\\trentm\\AppData\\Local\\Acme\\SuperApp'
+ >>> user_data_dir(appname, appauthor, roaming=True)
+ 'C:\\Users\\trentm\\AppData\\Roaming\\Acme\\SuperApp'
+ >>> user_cache_dir(appname, appauthor)
+ 'C:\\Users\\trentm\\AppData\\Local\\Acme\\SuperApp\\Cache'
+ >>> user_log_dir(appname, appauthor)
+ 'C:\\Users\\trentm\\AppData\\Local\\Acme\\SuperApp\\Logs'
+ >>> user_documents_dir()
+ 'C:\\Users\\trentm\\Documents'
+ >>> user_downloads_dir()
+ 'C:\\Users\\trentm\\Downloads'
+ >>> user_pictures_dir()
+ 'C:\\Users\\trentm\\Pictures'
+ >>> user_videos_dir()
+ 'C:\\Users\\trentm\\Videos'
+ >>> user_music_dir()
+ 'C:\\Users\\trentm\\Music'
+ >>> user_desktop_dir()
+ 'C:\\Users\\trentm\\Desktop'
+ >>> user_runtime_dir(appname, appauthor)
+ 'C:\\Users\\trentm\\AppData\\Local\\Temp\\Acme\\SuperApp'
+
+On Linux:
+
+.. code-block:: pycon
+
+ >>> from platformdirs import *
+ >>> appname = "SuperApp"
+ >>> appauthor = "Acme"
+ >>> user_data_dir(appname, appauthor)
+ '/home/trentm/.local/share/SuperApp'
+ >>> site_data_dir(appname, appauthor)
+ '/usr/local/share/SuperApp'
+ >>> site_data_dir(appname, appauthor, multipath=True)
+ '/usr/local/share/SuperApp:/usr/share/SuperApp'
+ >>> user_cache_dir(appname, appauthor)
+ '/home/trentm/.cache/SuperApp'
+ >>> user_log_dir(appname, appauthor)
+ '/home/trentm/.local/state/SuperApp/log'
+ >>> user_config_dir(appname)
+ '/home/trentm/.config/SuperApp'
+ >>> user_documents_dir()
+ '/home/trentm/Documents'
+ >>> user_downloads_dir()
+ '/home/trentm/Downloads'
+ >>> user_pictures_dir()
+ '/home/trentm/Pictures'
+ >>> user_videos_dir()
+ '/home/trentm/Videos'
+ >>> user_music_dir()
+ '/home/trentm/Music'
+ >>> user_desktop_dir()
+ '/home/trentm/Desktop'
+ >>> user_runtime_dir(appname, appauthor)
+ '/run/user/{os.getuid()}/SuperApp'
+ >>> site_config_dir(appname)
+ '/etc/xdg/SuperApp'
+ >>> os.environ["XDG_CONFIG_DIRS"] = "/etc:/usr/local/etc"
+ >>> site_config_dir(appname, multipath=True)
+ '/etc/SuperApp:/usr/local/etc/SuperApp'
+
+On Android::
+
+ >>> from platformdirs import *
+ >>> appname = "SuperApp"
+ >>> appauthor = "Acme"
+ >>> user_data_dir(appname, appauthor)
+ '/data/data/com.myApp/files/SuperApp'
+ >>> user_cache_dir(appname, appauthor)
+ '/data/data/com.myApp/cache/SuperApp'
+ >>> user_log_dir(appname, appauthor)
+ '/data/data/com.myApp/cache/SuperApp/log'
+ >>> user_config_dir(appname)
+ '/data/data/com.myApp/shared_prefs/SuperApp'
+ >>> user_documents_dir()
+ '/storage/emulated/0/Documents'
+ >>> user_downloads_dir()
+ '/storage/emulated/0/Downloads'
+ >>> user_pictures_dir()
+ '/storage/emulated/0/Pictures'
+ >>> user_videos_dir()
+ '/storage/emulated/0/DCIM/Camera'
+ >>> user_music_dir()
+ '/storage/emulated/0/Music'
+ >>> user_desktop_dir()
+ '/storage/emulated/0/Desktop'
+ >>> user_runtime_dir(appname, appauthor)
+ '/data/data/com.myApp/cache/SuperApp/tmp'
+
+Note: Some android apps like Termux and Pydroid are used as shells. These
+apps are used by the end user to emulate Linux environment. Presence of
+``SHELL`` environment variable is used by Platformdirs to differentiate
+between general android apps and android apps used as shells. Shell android
+apps also support ``XDG_*`` environment variables.
+
+
+``PlatformDirs`` for convenience
+================================
+
+.. code-block:: pycon
+
+ >>> from platformdirs import PlatformDirs
+ >>> dirs = PlatformDirs("SuperApp", "Acme")
+ >>> dirs.user_data_dir
+ '/Users/trentm/Library/Application Support/SuperApp'
+ >>> dirs.site_data_dir
+ '/Library/Application Support/SuperApp'
+ >>> dirs.user_cache_dir
+ '/Users/trentm/Library/Caches/SuperApp'
+ >>> dirs.user_log_dir
+ '/Users/trentm/Library/Logs/SuperApp'
+ >>> dirs.user_documents_dir
+ '/Users/trentm/Documents'
+ >>> dirs.user_downloads_dir
+ '/Users/trentm/Downloads'
+ >>> dirs.user_pictures_dir
+ '/Users/trentm/Pictures'
+ >>> dirs.user_videos_dir
+ '/Users/trentm/Movies'
+ >>> dirs.user_music_dir
+ '/Users/trentm/Music'
+ >>> dirs.user_desktop_dir
+ '/Users/trentm/Desktop'
+ >>> dirs.user_runtime_dir
+ '/Users/trentm/Library/Caches/TemporaryItems/SuperApp'
+
+Per-version isolation
+=====================
+
+If you have multiple versions of your app in use that you want to be
+able to run side-by-side, then you may want version-isolation for these
+dirs::
+
+ >>> from platformdirs import PlatformDirs
+ >>> dirs = PlatformDirs("SuperApp", "Acme", version="1.0")
+ >>> dirs.user_data_dir
+ '/Users/trentm/Library/Application Support/SuperApp/1.0'
+ >>> dirs.site_data_dir
+ '/Library/Application Support/SuperApp/1.0'
+ >>> dirs.user_cache_dir
+ '/Users/trentm/Library/Caches/SuperApp/1.0'
+ >>> dirs.user_log_dir
+ '/Users/trentm/Library/Logs/SuperApp/1.0'
+ >>> dirs.user_documents_dir
+ '/Users/trentm/Documents'
+ >>> dirs.user_downloads_dir
+ '/Users/trentm/Downloads'
+ >>> dirs.user_pictures_dir
+ '/Users/trentm/Pictures'
+ >>> dirs.user_videos_dir
+ '/Users/trentm/Movies'
+ >>> dirs.user_music_dir
+ '/Users/trentm/Music'
+ >>> dirs.user_desktop_dir
+ '/Users/trentm/Desktop'
+ >>> dirs.user_runtime_dir
+ '/Users/trentm/Library/Caches/TemporaryItems/SuperApp/1.0'
+
+Be wary of using this for configuration files though; you'll need to handle
+migrating configuration files manually.
+
+Why this Fork?
+==============
+
+This repository is a friendly fork of the wonderful work started by
+`ActiveState <https://github.com/ActiveState/appdirs>`_ who created
+``appdirs``, this package's ancestor.
+
+Maintaining an open source project is no easy task, particularly
+from within an organization, and the Python community is indebted
+to ``appdirs`` (and to Trent Mick and Jeff Rouse in particular) for
+creating an incredibly useful simple module, as evidenced by the wide
+number of users it has attracted over the years.
+
+Nonetheless, given the number of long-standing open issues
+and pull requests, and no clear path towards `ensuring
+that maintenance of the package would continue or grow
+<https://github.com/ActiveState/appdirs/issues/79>`_, this fork was
+created.
+
+Contributions are most welcome.
diff --git a/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/RECORD b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/RECORD
new file mode 100644
index 000000000..0ff1fc7c5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/RECORD
@@ -0,0 +1,22 @@
+platformdirs-4.3.6.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+platformdirs-4.3.6.dist-info/METADATA,sha256=085GgRFo5U1nc9NR8e6unEWKxUjDMsgSHDyaCETsCQ4,11868
+platformdirs-4.3.6.dist-info/RECORD,,
+platformdirs-4.3.6.dist-info/WHEEL,sha256=1yFddiXMmvYK7QYTqtRNtX66WJ0Mz8PYEiEUoOUUxRY,87
+platformdirs-4.3.6.dist-info/licenses/LICENSE,sha256=KeD9YukphQ6G6yjD_czwzv30-pSHkBHP-z0NS-1tTbY,1089
+platformdirs/__init__.py,sha256=mVCfMmBM4q24lq6336V3VJncdxaOegI4qQSmQCjkR5E,22284
+platformdirs/__main__.py,sha256=HnsUQHpiBaiTxwcmwVw-nFaPdVNZtQIdi1eWDtI-MzI,1493
+platformdirs/__pycache__/__init__.cpython-312.pyc,,
+platformdirs/__pycache__/__main__.cpython-312.pyc,,
+platformdirs/__pycache__/android.cpython-312.pyc,,
+platformdirs/__pycache__/api.cpython-312.pyc,,
+platformdirs/__pycache__/macos.cpython-312.pyc,,
+platformdirs/__pycache__/unix.cpython-312.pyc,,
+platformdirs/__pycache__/version.cpython-312.pyc,,
+platformdirs/__pycache__/windows.cpython-312.pyc,,
+platformdirs/android.py,sha256=kV5oL3V3DZ6WZKu9yFiQupv18yp_jlSV2ChH1TmPcds,9007
+platformdirs/api.py,sha256=2dfUDNbEXeDhDKarqtR5NY7oUikUZ4RZhs3ozstmhBQ,9246
+platformdirs/macos.py,sha256=UlbyFZ8Rzu3xndCqQEHrfsYTeHwYdFap1Ioz-yxveT4,6154
+platformdirs/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+platformdirs/unix.py,sha256=uRPJWRyQEtv7yOSvU94rUmsblo5XKDLA1SzFg55kbK0,10393
+platformdirs/version.py,sha256=oH4KgTfK4AklbTYVcV_yynvJ9JLI3pyvDVay0hRsLCs,411
+platformdirs/windows.py,sha256=IFpiohUBwxPtCzlyKwNtxyW4Jk8haa6W8o59mfrDXVo,10125
diff --git a/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/WHEEL
new file mode 100644
index 000000000..cdd68a497
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/WHEEL
@@ -0,0 +1,4 @@
+Wheel-Version: 1.0
+Generator: hatchling 1.25.0
+Root-Is-Purelib: true
+Tag: py3-none-any
diff --git a/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/licenses/LICENSE b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/licenses/LICENSE
new file mode 100644
index 000000000..f35fed919
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs-4.3.6.dist-info/licenses/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2010-202x The platformdirs developers
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/__init__.py b/solutions/.venv/Lib/site-packages/platformdirs/__init__.py
new file mode 100644
index 000000000..afe8351d2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/__init__.py
@@ -0,0 +1,631 @@
+"""
+Utilities for determining application-specific dirs.
+
+See <https://github.com/platformdirs/platformdirs> for details and usage.
+
+"""
+
+from __future__ import annotations
+
+import os
+import sys
+from typing import TYPE_CHECKING
+
+from .api import PlatformDirsABC
+from .version import __version__
+from .version import __version_tuple__ as __version_info__
+
+if TYPE_CHECKING:
+ from pathlib import Path
+ from typing import Literal
+
+if sys.platform == "win32":
+ from platformdirs.windows import Windows as _Result
+elif sys.platform == "darwin":
+ from platformdirs.macos import MacOS as _Result
+else:
+ from platformdirs.unix import Unix as _Result
+
+
+def _set_platform_dir_class() -> type[PlatformDirsABC]:
+ if os.getenv("ANDROID_DATA") == "/data" and os.getenv("ANDROID_ROOT") == "/system":
+ if os.getenv("SHELL") or os.getenv("PREFIX"):
+ return _Result
+
+ from platformdirs.android import _android_folder # noqa: PLC0415
+
+ if _android_folder() is not None:
+ from platformdirs.android import Android # noqa: PLC0415
+
+ return Android # return to avoid redefinition of a result
+
+ return _Result
+
+
+if TYPE_CHECKING:
+ # Work around mypy issue: https://github.com/python/mypy/issues/10962
+ PlatformDirs = _Result
+else:
+ PlatformDirs = _set_platform_dir_class() #: Currently active platform
+AppDirs = PlatformDirs #: Backwards compatibility with appdirs
+
+
+def user_data_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_data_dir
+
+
+def site_data_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `roaming <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data directory shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_data_dir
+
+
+def user_config_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_config_dir
+
+
+def site_config_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `roaming <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config directory shared by the users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_config_dir
+
+
+def user_cache_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_cache_dir
+
+
+def site_cache_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_cache_dir
+
+
+def user_state_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: state directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_state_dir
+
+
+def user_log_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: log directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_log_dir
+
+
+def user_documents_dir() -> str:
+ """:returns: documents directory tied to the user"""
+ return PlatformDirs().user_documents_dir
+
+
+def user_downloads_dir() -> str:
+ """:returns: downloads directory tied to the user"""
+ return PlatformDirs().user_downloads_dir
+
+
+def user_pictures_dir() -> str:
+ """:returns: pictures directory tied to the user"""
+ return PlatformDirs().user_pictures_dir
+
+
+def user_videos_dir() -> str:
+ """:returns: videos directory tied to the user"""
+ return PlatformDirs().user_videos_dir
+
+
+def user_music_dir() -> str:
+ """:returns: music directory tied to the user"""
+ return PlatformDirs().user_music_dir
+
+
+def user_desktop_dir() -> str:
+ """:returns: desktop directory tied to the user"""
+ return PlatformDirs().user_desktop_dir
+
+
+def user_runtime_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_runtime_dir
+
+
+def site_runtime_dir(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> str:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime directory shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_runtime_dir
+
+
+def user_data_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_data_path
+
+
+def site_data_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `multipath <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: data path shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_data_path
+
+
+def user_config_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_config_path
+
+
+def site_config_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ multipath: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param multipath: See `roaming <platformdirs.api.PlatformDirsABC.multipath>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: config path shared by the users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ multipath=multipath,
+ ensure_exists=ensure_exists,
+ ).site_config_path
+
+
+def site_cache_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache directory tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_cache_path
+
+
+def user_cache_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: cache path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_cache_path
+
+
+def user_state_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param roaming: See `roaming <platformdirs.api.PlatformDirsABC.roaming>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: state path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ roaming=roaming,
+ ensure_exists=ensure_exists,
+ ).user_state_path
+
+
+def user_log_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `roaming <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: log path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_log_path
+
+
+def user_documents_path() -> Path:
+ """:returns: documents a path tied to the user"""
+ return PlatformDirs().user_documents_path
+
+
+def user_downloads_path() -> Path:
+ """:returns: downloads path tied to the user"""
+ return PlatformDirs().user_downloads_path
+
+
+def user_pictures_path() -> Path:
+ """:returns: pictures path tied to the user"""
+ return PlatformDirs().user_pictures_path
+
+
+def user_videos_path() -> Path:
+ """:returns: videos path tied to the user"""
+ return PlatformDirs().user_videos_path
+
+
+def user_music_path() -> Path:
+ """:returns: music path tied to the user"""
+ return PlatformDirs().user_music_path
+
+
+def user_desktop_path() -> Path:
+ """:returns: desktop path tied to the user"""
+ return PlatformDirs().user_desktop_path
+
+
+def user_runtime_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime path tied to the user
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).user_runtime_path
+
+
+def site_runtime_path(
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+) -> Path:
+ """
+ :param appname: See `appname <platformdirs.api.PlatformDirsABC.appname>`.
+ :param appauthor: See `appauthor <platformdirs.api.PlatformDirsABC.appauthor>`.
+ :param version: See `version <platformdirs.api.PlatformDirsABC.version>`.
+ :param opinion: See `opinion <platformdirs.api.PlatformDirsABC.opinion>`.
+ :param ensure_exists: See `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+ :returns: runtime path shared by users
+ """
+ return PlatformDirs(
+ appname=appname,
+ appauthor=appauthor,
+ version=version,
+ opinion=opinion,
+ ensure_exists=ensure_exists,
+ ).site_runtime_path
+
+
+__all__ = [
+ "AppDirs",
+ "PlatformDirs",
+ "PlatformDirsABC",
+ "__version__",
+ "__version_info__",
+ "site_cache_dir",
+ "site_cache_path",
+ "site_config_dir",
+ "site_config_path",
+ "site_data_dir",
+ "site_data_path",
+ "site_runtime_dir",
+ "site_runtime_path",
+ "user_cache_dir",
+ "user_cache_path",
+ "user_config_dir",
+ "user_config_path",
+ "user_data_dir",
+ "user_data_path",
+ "user_desktop_dir",
+ "user_desktop_path",
+ "user_documents_dir",
+ "user_documents_path",
+ "user_downloads_dir",
+ "user_downloads_path",
+ "user_log_dir",
+ "user_log_path",
+ "user_music_dir",
+ "user_music_path",
+ "user_pictures_dir",
+ "user_pictures_path",
+ "user_runtime_dir",
+ "user_runtime_path",
+ "user_state_dir",
+ "user_state_path",
+ "user_videos_dir",
+ "user_videos_path",
+]
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/__main__.py b/solutions/.venv/Lib/site-packages/platformdirs/__main__.py
new file mode 100644
index 000000000..922c52135
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/__main__.py
@@ -0,0 +1,55 @@
+"""Main entry point."""
+
+from __future__ import annotations
+
+from platformdirs import PlatformDirs, __version__
+
+PROPS = (
+ "user_data_dir",
+ "user_config_dir",
+ "user_cache_dir",
+ "user_state_dir",
+ "user_log_dir",
+ "user_documents_dir",
+ "user_downloads_dir",
+ "user_pictures_dir",
+ "user_videos_dir",
+ "user_music_dir",
+ "user_runtime_dir",
+ "site_data_dir",
+ "site_config_dir",
+ "site_cache_dir",
+ "site_runtime_dir",
+)
+
+
+def main() -> None:
+ """Run the main entry point."""
+ app_name = "MyApp"
+ app_author = "MyCompany"
+
+ print(f"-- platformdirs {__version__} --") # noqa: T201
+
+ print("-- app dirs (with optional 'version')") # noqa: T201
+ dirs = PlatformDirs(app_name, app_author, version="1.0")
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+ print("\n-- app dirs (without optional 'version')") # noqa: T201
+ dirs = PlatformDirs(app_name, app_author)
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+ print("\n-- app dirs (without optional 'appauthor')") # noqa: T201
+ dirs = PlatformDirs(app_name)
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+ print("\n-- app dirs (with disabled 'appauthor')") # noqa: T201
+ dirs = PlatformDirs(app_name, appauthor=False)
+ for prop in PROPS:
+ print(f"{prop}: {getattr(dirs, prop)}") # noqa: T201
+
+
+if __name__ == "__main__":
+ main()
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/android.py b/solutions/.venv/Lib/site-packages/platformdirs/android.py
new file mode 100644
index 000000000..7004a8524
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/android.py
@@ -0,0 +1,249 @@
+"""Android."""
+
+from __future__ import annotations
+
+import os
+import re
+import sys
+from functools import lru_cache
+from typing import TYPE_CHECKING, cast
+
+from .api import PlatformDirsABC
+
+
+class Android(PlatformDirsABC):
+ """
+ Follows the guidance `from here <https://android.stackexchange.com/a/216132>`_.
+
+ Makes use of the `appname <platformdirs.api.PlatformDirsABC.appname>`, `version
+ <platformdirs.api.PlatformDirsABC.version>`, `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """:return: data directory tied to the user, e.g. ``/data/user/<userid>/<packagename>/files/<AppName>``"""
+ return self._append_app_name_and_version(cast(str, _android_folder()), "files")
+
+ @property
+ def site_data_dir(self) -> str:
+ """:return: data directory shared by users, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_config_dir(self) -> str:
+ """
+ :return: config directory tied to the user, e.g. \
+ ``/data/user/<userid>/<packagename>/shared_prefs/<AppName>``
+ """
+ return self._append_app_name_and_version(cast(str, _android_folder()), "shared_prefs")
+
+ @property
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users, same as `user_config_dir`"""
+ return self.user_config_dir
+
+ @property
+ def user_cache_dir(self) -> str:
+ """:return: cache directory tied to the user, e.g.,``/data/user/<userid>/<packagename>/cache/<AppName>``"""
+ return self._append_app_name_and_version(cast(str, _android_folder()), "cache")
+
+ @property
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users, same as `user_cache_dir`"""
+ return self.user_cache_dir
+
+ @property
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_log_dir(self) -> str:
+ """
+ :return: log directory tied to the user, same as `user_cache_dir` if not opinionated else ``log`` in it,
+ e.g. ``/data/user/<userid>/<packagename>/cache/<AppName>/log``
+ """
+ path = self.user_cache_dir
+ if self.opinion:
+ path = os.path.join(path, "log") # noqa: PTH118
+ return path
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user e.g. ``/storage/emulated/0/Documents``"""
+ return _android_documents_folder()
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user e.g. ``/storage/emulated/0/Downloads``"""
+ return _android_downloads_folder()
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user e.g. ``/storage/emulated/0/Pictures``"""
+ return _android_pictures_folder()
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user e.g. ``/storage/emulated/0/DCIM/Camera``"""
+ return _android_videos_folder()
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user e.g. ``/storage/emulated/0/Music``"""
+ return _android_music_folder()
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user e.g. ``/storage/emulated/0/Desktop``"""
+ return "/storage/emulated/0/Desktop"
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """
+ :return: runtime directory tied to the user, same as `user_cache_dir` if not opinionated else ``tmp`` in it,
+ e.g. ``/data/user/<userid>/<packagename>/cache/<AppName>/tmp``
+ """
+ path = self.user_cache_dir
+ if self.opinion:
+ path = os.path.join(path, "tmp") # noqa: PTH118
+ return path
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users, same as `user_runtime_dir`"""
+ return self.user_runtime_dir
+
+
+@lru_cache(maxsize=1)
+def _android_folder() -> str | None: # noqa: C901
+ """:return: base folder for the Android OS or None if it cannot be found"""
+ result: str | None = None
+ # type checker isn't happy with our "import android", just don't do this when type checking see
+ # https://stackoverflow.com/a/61394121
+ if not TYPE_CHECKING:
+ try:
+ # First try to get a path to android app using python4android (if available)...
+ from android import mActivity # noqa: PLC0415
+
+ context = cast("android.content.Context", mActivity.getApplicationContext()) # noqa: F821
+ result = context.getFilesDir().getParentFile().getAbsolutePath()
+ except Exception: # noqa: BLE001
+ result = None
+ if result is None:
+ try:
+ # ...and fall back to using plain pyjnius, if python4android isn't available or doesn't deliver any useful
+ # result...
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ result = context.getFilesDir().getParentFile().getAbsolutePath()
+ except Exception: # noqa: BLE001
+ result = None
+ if result is None:
+ # and if that fails, too, find an android folder looking at path on the sys.path
+ # warning: only works for apps installed under /data, not adopted storage etc.
+ pattern = re.compile(r"/data/(data|user/\d+)/(.+)/files")
+ for path in sys.path:
+ if pattern.match(path):
+ result = path.split("/files")[0]
+ break
+ else:
+ result = None
+ if result is None:
+ # one last try: find an android folder looking at path on the sys.path taking adopted storage paths into
+ # account
+ pattern = re.compile(r"/mnt/expand/[a-fA-F0-9-]{36}/(data|user/\d+)/(.+)/files")
+ for path in sys.path:
+ if pattern.match(path):
+ result = path.split("/files")[0]
+ break
+ else:
+ result = None
+ return result
+
+
+@lru_cache(maxsize=1)
+def _android_documents_folder() -> str:
+ """:return: documents folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ documents_dir: str = context.getExternalFilesDir(environment.DIRECTORY_DOCUMENTS).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ documents_dir = "/storage/emulated/0/Documents"
+
+ return documents_dir
+
+
+@lru_cache(maxsize=1)
+def _android_downloads_folder() -> str:
+ """:return: downloads folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ downloads_dir: str = context.getExternalFilesDir(environment.DIRECTORY_DOWNLOADS).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ downloads_dir = "/storage/emulated/0/Downloads"
+
+ return downloads_dir
+
+
+@lru_cache(maxsize=1)
+def _android_pictures_folder() -> str:
+ """:return: pictures folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ pictures_dir: str = context.getExternalFilesDir(environment.DIRECTORY_PICTURES).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ pictures_dir = "/storage/emulated/0/Pictures"
+
+ return pictures_dir
+
+
+@lru_cache(maxsize=1)
+def _android_videos_folder() -> str:
+ """:return: videos folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ videos_dir: str = context.getExternalFilesDir(environment.DIRECTORY_DCIM).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ videos_dir = "/storage/emulated/0/DCIM/Camera"
+
+ return videos_dir
+
+
+@lru_cache(maxsize=1)
+def _android_music_folder() -> str:
+ """:return: music folder for the Android OS"""
+ # Get directories with pyjnius
+ try:
+ from jnius import autoclass # noqa: PLC0415
+
+ context = autoclass("android.content.Context")
+ environment = autoclass("android.os.Environment")
+ music_dir: str = context.getExternalFilesDir(environment.DIRECTORY_MUSIC).getAbsolutePath()
+ except Exception: # noqa: BLE001
+ music_dir = "/storage/emulated/0/Music"
+
+ return music_dir
+
+
+__all__ = [
+ "Android",
+]
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/api.py b/solutions/.venv/Lib/site-packages/platformdirs/api.py
new file mode 100644
index 000000000..18d660e4f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/api.py
@@ -0,0 +1,298 @@
+"""Base API."""
+
+from __future__ import annotations
+
+import os
+from abc import ABC, abstractmethod
+from pathlib import Path
+from typing import TYPE_CHECKING
+
+if TYPE_CHECKING:
+ from typing import Iterator, Literal
+
+
+class PlatformDirsABC(ABC): # noqa: PLR0904
+ """Abstract base class for platform directories."""
+
+ def __init__( # noqa: PLR0913, PLR0917
+ self,
+ appname: str | None = None,
+ appauthor: str | None | Literal[False] = None,
+ version: str | None = None,
+ roaming: bool = False, # noqa: FBT001, FBT002
+ multipath: bool = False, # noqa: FBT001, FBT002
+ opinion: bool = True, # noqa: FBT001, FBT002
+ ensure_exists: bool = False, # noqa: FBT001, FBT002
+ ) -> None:
+ """
+ Create a new platform directory.
+
+ :param appname: See `appname`.
+ :param appauthor: See `appauthor`.
+ :param version: See `version`.
+ :param roaming: See `roaming`.
+ :param multipath: See `multipath`.
+ :param opinion: See `opinion`.
+ :param ensure_exists: See `ensure_exists`.
+
+ """
+ self.appname = appname #: The name of application.
+ self.appauthor = appauthor
+ """
+ The name of the app author or distributing body for this application.
+
+ Typically, it is the owning company name. Defaults to `appname`. You may pass ``False`` to disable it.
+
+ """
+ self.version = version
+ """
+ An optional version path element to append to the path.
+
+ You might want to use this if you want multiple versions of your app to be able to run independently. If used,
+ this would typically be ``<major>.<minor>``.
+
+ """
+ self.roaming = roaming
+ """
+ Whether to use the roaming appdata directory on Windows.
+
+ That means that for users on a Windows network setup for roaming profiles, this user data will be synced on
+ login (see
+ `here <https://technet.microsoft.com/en-us/library/cc766489(WS.10).aspx>`_).
+
+ """
+ self.multipath = multipath
+ """
+ An optional parameter which indicates that the entire list of data dirs should be returned.
+
+ By default, the first item would only be returned.
+
+ """
+ self.opinion = opinion #: A flag to indicating to use opinionated values.
+ self.ensure_exists = ensure_exists
+ """
+ Optionally create the directory (and any missing parents) upon access if it does not exist.
+
+ By default, no directories are created.
+
+ """
+
+ def _append_app_name_and_version(self, *base: str) -> str:
+ params = list(base[1:])
+ if self.appname:
+ params.append(self.appname)
+ if self.version:
+ params.append(self.version)
+ path = os.path.join(base[0], *params) # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ def _optionally_create_directory(self, path: str) -> None:
+ if self.ensure_exists:
+ Path(path).mkdir(parents=True, exist_ok=True)
+
+ def _first_item_as_path_if_multipath(self, directory: str) -> Path:
+ if self.multipath:
+ # If multipath is True, the first path is returned.
+ directory = directory.split(os.pathsep)[0]
+ return Path(directory)
+
+ @property
+ @abstractmethod
+ def user_data_dir(self) -> str:
+ """:return: data directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_data_dir(self) -> str:
+ """:return: data directory shared by users"""
+
+ @property
+ @abstractmethod
+ def user_config_dir(self) -> str:
+ """:return: config directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users"""
+
+ @property
+ @abstractmethod
+ def user_cache_dir(self) -> str:
+ """:return: cache directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users"""
+
+ @property
+ @abstractmethod
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def user_runtime_dir(self) -> str:
+ """:return: runtime directory tied to the user"""
+
+ @property
+ @abstractmethod
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users"""
+
+ @property
+ def user_data_path(self) -> Path:
+ """:return: data path tied to the user"""
+ return Path(self.user_data_dir)
+
+ @property
+ def site_data_path(self) -> Path:
+ """:return: data path shared by users"""
+ return Path(self.site_data_dir)
+
+ @property
+ def user_config_path(self) -> Path:
+ """:return: config path tied to the user"""
+ return Path(self.user_config_dir)
+
+ @property
+ def site_config_path(self) -> Path:
+ """:return: config path shared by the users"""
+ return Path(self.site_config_dir)
+
+ @property
+ def user_cache_path(self) -> Path:
+ """:return: cache path tied to the user"""
+ return Path(self.user_cache_dir)
+
+ @property
+ def site_cache_path(self) -> Path:
+ """:return: cache path shared by users"""
+ return Path(self.site_cache_dir)
+
+ @property
+ def user_state_path(self) -> Path:
+ """:return: state path tied to the user"""
+ return Path(self.user_state_dir)
+
+ @property
+ def user_log_path(self) -> Path:
+ """:return: log path tied to the user"""
+ return Path(self.user_log_dir)
+
+ @property
+ def user_documents_path(self) -> Path:
+ """:return: documents a path tied to the user"""
+ return Path(self.user_documents_dir)
+
+ @property
+ def user_downloads_path(self) -> Path:
+ """:return: downloads path tied to the user"""
+ return Path(self.user_downloads_dir)
+
+ @property
+ def user_pictures_path(self) -> Path:
+ """:return: pictures path tied to the user"""
+ return Path(self.user_pictures_dir)
+
+ @property
+ def user_videos_path(self) -> Path:
+ """:return: videos path tied to the user"""
+ return Path(self.user_videos_dir)
+
+ @property
+ def user_music_path(self) -> Path:
+ """:return: music path tied to the user"""
+ return Path(self.user_music_dir)
+
+ @property
+ def user_desktop_path(self) -> Path:
+ """:return: desktop path tied to the user"""
+ return Path(self.user_desktop_dir)
+
+ @property
+ def user_runtime_path(self) -> Path:
+ """:return: runtime path tied to the user"""
+ return Path(self.user_runtime_dir)
+
+ @property
+ def site_runtime_path(self) -> Path:
+ """:return: runtime path shared by users"""
+ return Path(self.site_runtime_dir)
+
+ def iter_config_dirs(self) -> Iterator[str]:
+ """:yield: all user and site configuration directories."""
+ yield self.user_config_dir
+ yield self.site_config_dir
+
+ def iter_data_dirs(self) -> Iterator[str]:
+ """:yield: all user and site data directories."""
+ yield self.user_data_dir
+ yield self.site_data_dir
+
+ def iter_cache_dirs(self) -> Iterator[str]:
+ """:yield: all user and site cache directories."""
+ yield self.user_cache_dir
+ yield self.site_cache_dir
+
+ def iter_runtime_dirs(self) -> Iterator[str]:
+ """:yield: all user and site runtime directories."""
+ yield self.user_runtime_dir
+ yield self.site_runtime_dir
+
+ def iter_config_paths(self) -> Iterator[Path]:
+ """:yield: all user and site configuration paths."""
+ for path in self.iter_config_dirs():
+ yield Path(path)
+
+ def iter_data_paths(self) -> Iterator[Path]:
+ """:yield: all user and site data paths."""
+ for path in self.iter_data_dirs():
+ yield Path(path)
+
+ def iter_cache_paths(self) -> Iterator[Path]:
+ """:yield: all user and site cache paths."""
+ for path in self.iter_cache_dirs():
+ yield Path(path)
+
+ def iter_runtime_paths(self) -> Iterator[Path]:
+ """:yield: all user and site runtime paths."""
+ for path in self.iter_runtime_dirs():
+ yield Path(path)
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/macos.py b/solutions/.venv/Lib/site-packages/platformdirs/macos.py
new file mode 100644
index 000000000..e4b0391ab
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/macos.py
@@ -0,0 +1,144 @@
+"""macOS."""
+
+from __future__ import annotations
+
+import os.path
+import sys
+from typing import TYPE_CHECKING
+
+from .api import PlatformDirsABC
+
+if TYPE_CHECKING:
+ from pathlib import Path
+
+
+class MacOS(PlatformDirsABC):
+ """
+ Platform directories for the macOS operating system.
+
+ Follows the guidance from
+ `Apple documentation <https://developer.apple.com/library/archive/documentation/FileManagement/Conceptual/FileSystemProgrammingGuide/MacOSXDirectories/MacOSXDirectories.html>`_.
+ Makes use of the `appname <platformdirs.api.PlatformDirsABC.appname>`,
+ `version <platformdirs.api.PlatformDirsABC.version>`,
+ `ensure_exists <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """:return: data directory tied to the user, e.g. ``~/Library/Application Support/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Application Support")) # noqa: PTH111
+
+ @property
+ def site_data_dir(self) -> str:
+ """
+ :return: data directory shared by users, e.g. ``/Library/Application Support/$appname/$version``.
+ If we're using a Python binary managed by `Homebrew <https://brew.sh>`_, the directory
+ will be under the Homebrew prefix, e.g. ``/opt/homebrew/share/$appname/$version``.
+ If `multipath <platformdirs.api.PlatformDirsABC.multipath>` is enabled, and we're in Homebrew,
+ the response is a multi-path string separated by ":", e.g.
+ ``/opt/homebrew/share/$appname/$version:/Library/Application Support/$appname/$version``
+ """
+ is_homebrew = sys.prefix.startswith("/opt/homebrew")
+ path_list = [self._append_app_name_and_version("/opt/homebrew/share")] if is_homebrew else []
+ path_list.append(self._append_app_name_and_version("/Library/Application Support"))
+ if self.multipath:
+ return os.pathsep.join(path_list)
+ return path_list[0]
+
+ @property
+ def site_data_path(self) -> Path:
+ """:return: data path shared by users. Only return the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_data_dir)
+
+ @property
+ def user_config_dir(self) -> str:
+ """:return: config directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users, same as `site_data_dir`"""
+ return self.site_data_dir
+
+ @property
+ def user_cache_dir(self) -> str:
+ """:return: cache directory tied to the user, e.g. ``~/Library/Caches/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Caches")) # noqa: PTH111
+
+ @property
+ def site_cache_dir(self) -> str:
+ """
+ :return: cache directory shared by users, e.g. ``/Library/Caches/$appname/$version``.
+ If we're using a Python binary managed by `Homebrew <https://brew.sh>`_, the directory
+ will be under the Homebrew prefix, e.g. ``/opt/homebrew/var/cache/$appname/$version``.
+ If `multipath <platformdirs.api.PlatformDirsABC.multipath>` is enabled, and we're in Homebrew,
+ the response is a multi-path string separated by ":", e.g.
+ ``/opt/homebrew/var/cache/$appname/$version:/Library/Caches/$appname/$version``
+ """
+ is_homebrew = sys.prefix.startswith("/opt/homebrew")
+ path_list = [self._append_app_name_and_version("/opt/homebrew/var/cache")] if is_homebrew else []
+ path_list.append(self._append_app_name_and_version("/Library/Caches"))
+ if self.multipath:
+ return os.pathsep.join(path_list)
+ return path_list[0]
+
+ @property
+ def site_cache_path(self) -> Path:
+ """:return: cache path shared by users. Only return the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_cache_dir)
+
+ @property
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user, e.g. ``~/Library/Logs/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Logs")) # noqa: PTH111
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user, e.g. ``~/Documents``"""
+ return os.path.expanduser("~/Documents") # noqa: PTH111
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user, e.g. ``~/Downloads``"""
+ return os.path.expanduser("~/Downloads") # noqa: PTH111
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user, e.g. ``~/Pictures``"""
+ return os.path.expanduser("~/Pictures") # noqa: PTH111
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user, e.g. ``~/Movies``"""
+ return os.path.expanduser("~/Movies") # noqa: PTH111
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user, e.g. ``~/Music``"""
+ return os.path.expanduser("~/Music") # noqa: PTH111
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user, e.g. ``~/Desktop``"""
+ return os.path.expanduser("~/Desktop") # noqa: PTH111
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """:return: runtime directory tied to the user, e.g. ``~/Library/Caches/TemporaryItems/$appname/$version``"""
+ return self._append_app_name_and_version(os.path.expanduser("~/Library/Caches/TemporaryItems")) # noqa: PTH111
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users, same as `user_runtime_dir`"""
+ return self.user_runtime_dir
+
+
+__all__ = [
+ "MacOS",
+]
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/py.typed b/solutions/.venv/Lib/site-packages/platformdirs/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/unix.py b/solutions/.venv/Lib/site-packages/platformdirs/unix.py
new file mode 100644
index 000000000..f1942e92e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/unix.py
@@ -0,0 +1,269 @@
+"""Unix."""
+
+from __future__ import annotations
+
+import os
+import sys
+from configparser import ConfigParser
+from pathlib import Path
+from typing import Iterator, NoReturn
+
+from .api import PlatformDirsABC
+
+if sys.platform == "win32":
+
+ def getuid() -> NoReturn:
+ msg = "should only be used on Unix"
+ raise RuntimeError(msg)
+
+else:
+ from os import getuid
+
+
+class Unix(PlatformDirsABC): # noqa: PLR0904
+ """
+ On Unix/Linux, we follow the `XDG Basedir Spec <https://specifications.freedesktop.org/basedir-spec/basedir-spec-
+ latest.html>`_.
+
+ The spec allows overriding directories with environment variables. The examples shown are the default values,
+ alongside the name of the environment variable that overrides them. Makes use of the `appname
+ <platformdirs.api.PlatformDirsABC.appname>`, `version <platformdirs.api.PlatformDirsABC.version>`, `multipath
+ <platformdirs.api.PlatformDirsABC.multipath>`, `opinion <platformdirs.api.PlatformDirsABC.opinion>`, `ensure_exists
+ <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """
+ :return: data directory tied to the user, e.g. ``~/.local/share/$appname/$version`` or
+ ``$XDG_DATA_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_DATA_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.local/share") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def _site_data_dirs(self) -> list[str]:
+ path = os.environ.get("XDG_DATA_DIRS", "")
+ if not path.strip():
+ path = f"/usr/local/share{os.pathsep}/usr/share"
+ return [self._append_app_name_and_version(p) for p in path.split(os.pathsep)]
+
+ @property
+ def site_data_dir(self) -> str:
+ """
+ :return: data directories shared by users (if `multipath <platformdirs.api.PlatformDirsABC.multipath>` is
+ enabled and ``XDG_DATA_DIRS`` is set and a multi path the response is also a multi path separated by the
+ OS path separator), e.g. ``/usr/local/share/$appname/$version`` or ``/usr/share/$appname/$version``
+ """
+ # XDG default for $XDG_DATA_DIRS; only first, if multipath is False
+ dirs = self._site_data_dirs
+ if not self.multipath:
+ return dirs[0]
+ return os.pathsep.join(dirs)
+
+ @property
+ def user_config_dir(self) -> str:
+ """
+ :return: config directory tied to the user, e.g. ``~/.config/$appname/$version`` or
+ ``$XDG_CONFIG_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_CONFIG_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.config") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def _site_config_dirs(self) -> list[str]:
+ path = os.environ.get("XDG_CONFIG_DIRS", "")
+ if not path.strip():
+ path = "/etc/xdg"
+ return [self._append_app_name_and_version(p) for p in path.split(os.pathsep)]
+
+ @property
+ def site_config_dir(self) -> str:
+ """
+ :return: config directories shared by users (if `multipath <platformdirs.api.PlatformDirsABC.multipath>`
+ is enabled and ``XDG_CONFIG_DIRS`` is set and a multi path the response is also a multi path separated by
+ the OS path separator), e.g. ``/etc/xdg/$appname/$version``
+ """
+ # XDG default for $XDG_CONFIG_DIRS only first, if multipath is False
+ dirs = self._site_config_dirs
+ if not self.multipath:
+ return dirs[0]
+ return os.pathsep.join(dirs)
+
+ @property
+ def user_cache_dir(self) -> str:
+ """
+ :return: cache directory tied to the user, e.g. ``~/.cache/$appname/$version`` or
+ ``~/$XDG_CACHE_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_CACHE_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.cache") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users, e.g. ``/var/cache/$appname/$version``"""
+ return self._append_app_name_and_version("/var/cache")
+
+ @property
+ def user_state_dir(self) -> str:
+ """
+ :return: state directory tied to the user, e.g. ``~/.local/state/$appname/$version`` or
+ ``$XDG_STATE_HOME/$appname/$version``
+ """
+ path = os.environ.get("XDG_STATE_HOME", "")
+ if not path.strip():
+ path = os.path.expanduser("~/.local/state") # noqa: PTH111
+ return self._append_app_name_and_version(path)
+
+ @property
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user, same as `user_state_dir` if not opinionated else ``log`` in it"""
+ path = self.user_state_dir
+ if self.opinion:
+ path = os.path.join(path, "log") # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user, e.g. ``~/Documents``"""
+ return _get_user_media_dir("XDG_DOCUMENTS_DIR", "~/Documents")
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user, e.g. ``~/Downloads``"""
+ return _get_user_media_dir("XDG_DOWNLOAD_DIR", "~/Downloads")
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user, e.g. ``~/Pictures``"""
+ return _get_user_media_dir("XDG_PICTURES_DIR", "~/Pictures")
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user, e.g. ``~/Videos``"""
+ return _get_user_media_dir("XDG_VIDEOS_DIR", "~/Videos")
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user, e.g. ``~/Music``"""
+ return _get_user_media_dir("XDG_MUSIC_DIR", "~/Music")
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user, e.g. ``~/Desktop``"""
+ return _get_user_media_dir("XDG_DESKTOP_DIR", "~/Desktop")
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """
+ :return: runtime directory tied to the user, e.g. ``/run/user/$(id -u)/$appname/$version`` or
+ ``$XDG_RUNTIME_DIR/$appname/$version``.
+
+ For FreeBSD/OpenBSD/NetBSD, it would return ``/var/run/user/$(id -u)/$appname/$version`` if
+ exists, otherwise ``/tmp/runtime-$(id -u)/$appname/$version``, if``$XDG_RUNTIME_DIR``
+ is not set.
+ """
+ path = os.environ.get("XDG_RUNTIME_DIR", "")
+ if not path.strip():
+ if sys.platform.startswith(("freebsd", "openbsd", "netbsd")):
+ path = f"/var/run/user/{getuid()}"
+ if not Path(path).exists():
+ path = f"/tmp/runtime-{getuid()}" # noqa: S108
+ else:
+ path = f"/run/user/{getuid()}"
+ return self._append_app_name_and_version(path)
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """
+ :return: runtime directory shared by users, e.g. ``/run/$appname/$version`` or \
+ ``$XDG_RUNTIME_DIR/$appname/$version``.
+
+ Note that this behaves almost exactly like `user_runtime_dir` if ``$XDG_RUNTIME_DIR`` is set, but will
+ fall back to paths associated to the root user instead of a regular logged-in user if it's not set.
+
+ If you wish to ensure that a logged-in root user path is returned e.g. ``/run/user/0``, use `user_runtime_dir`
+ instead.
+
+ For FreeBSD/OpenBSD/NetBSD, it would return ``/var/run/$appname/$version`` if ``$XDG_RUNTIME_DIR`` is not set.
+ """
+ path = os.environ.get("XDG_RUNTIME_DIR", "")
+ if not path.strip():
+ if sys.platform.startswith(("freebsd", "openbsd", "netbsd")):
+ path = "/var/run"
+ else:
+ path = "/run"
+ return self._append_app_name_and_version(path)
+
+ @property
+ def site_data_path(self) -> Path:
+ """:return: data path shared by users. Only return the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_data_dir)
+
+ @property
+ def site_config_path(self) -> Path:
+ """:return: config path shared by the users, returns the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_config_dir)
+
+ @property
+ def site_cache_path(self) -> Path:
+ """:return: cache path shared by users. Only return the first item, even if ``multipath`` is set to ``True``"""
+ return self._first_item_as_path_if_multipath(self.site_cache_dir)
+
+ def iter_config_dirs(self) -> Iterator[str]:
+ """:yield: all user and site configuration directories."""
+ yield self.user_config_dir
+ yield from self._site_config_dirs
+
+ def iter_data_dirs(self) -> Iterator[str]:
+ """:yield: all user and site data directories."""
+ yield self.user_data_dir
+ yield from self._site_data_dirs
+
+
+def _get_user_media_dir(env_var: str, fallback_tilde_path: str) -> str:
+ media_dir = _get_user_dirs_folder(env_var)
+ if media_dir is None:
+ media_dir = os.environ.get(env_var, "").strip()
+ if not media_dir:
+ media_dir = os.path.expanduser(fallback_tilde_path) # noqa: PTH111
+
+ return media_dir
+
+
+def _get_user_dirs_folder(key: str) -> str | None:
+ """
+ Return directory from user-dirs.dirs config file.
+
+ See https://freedesktop.org/wiki/Software/xdg-user-dirs/.
+
+ """
+ user_dirs_config_path = Path(Unix().user_config_dir) / "user-dirs.dirs"
+ if user_dirs_config_path.exists():
+ parser = ConfigParser()
+
+ with user_dirs_config_path.open() as stream:
+ # Add fake section header, so ConfigParser doesn't complain
+ parser.read_string(f"[top]\n{stream.read()}")
+
+ if key not in parser["top"]:
+ return None
+
+ path = parser["top"][key].strip('"')
+ # Handle relative home paths
+ return path.replace("$HOME", os.path.expanduser("~")) # noqa: PTH111
+
+ return None
+
+
+__all__ = [
+ "Unix",
+]
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/version.py b/solutions/.venv/Lib/site-packages/platformdirs/version.py
new file mode 100644
index 000000000..afb49243e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/version.py
@@ -0,0 +1,16 @@
+# file generated by setuptools_scm
+# don't change, don't track in version control
+TYPE_CHECKING = False
+if TYPE_CHECKING:
+ from typing import Tuple, Union
+ VERSION_TUPLE = Tuple[Union[int, str], ...]
+else:
+ VERSION_TUPLE = object
+
+version: str
+__version__: str
+__version_tuple__: VERSION_TUPLE
+version_tuple: VERSION_TUPLE
+
+__version__ = version = '4.3.6'
+__version_tuple__ = version_tuple = (4, 3, 6)
diff --git a/solutions/.venv/Lib/site-packages/platformdirs/windows.py b/solutions/.venv/Lib/site-packages/platformdirs/windows.py
new file mode 100644
index 000000000..d7bc96091
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/platformdirs/windows.py
@@ -0,0 +1,272 @@
+"""Windows."""
+
+from __future__ import annotations
+
+import os
+import sys
+from functools import lru_cache
+from typing import TYPE_CHECKING
+
+from .api import PlatformDirsABC
+
+if TYPE_CHECKING:
+ from collections.abc import Callable
+
+
+class Windows(PlatformDirsABC):
+ """
+ `MSDN on where to store app data files <https://learn.microsoft.com/en-us/windows/win32/shell/knownfolderid>`_.
+
+ Makes use of the `appname <platformdirs.api.PlatformDirsABC.appname>`, `appauthor
+ <platformdirs.api.PlatformDirsABC.appauthor>`, `version <platformdirs.api.PlatformDirsABC.version>`, `roaming
+ <platformdirs.api.PlatformDirsABC.roaming>`, `opinion <platformdirs.api.PlatformDirsABC.opinion>`, `ensure_exists
+ <platformdirs.api.PlatformDirsABC.ensure_exists>`.
+
+ """
+
+ @property
+ def user_data_dir(self) -> str:
+ """
+ :return: data directory tied to the user, e.g.
+ ``%USERPROFILE%\\AppData\\Local\\$appauthor\\$appname`` (not roaming) or
+ ``%USERPROFILE%\\AppData\\Roaming\\$appauthor\\$appname`` (roaming)
+ """
+ const = "CSIDL_APPDATA" if self.roaming else "CSIDL_LOCAL_APPDATA"
+ path = os.path.normpath(get_win_folder(const))
+ return self._append_parts(path)
+
+ def _append_parts(self, path: str, *, opinion_value: str | None = None) -> str:
+ params = []
+ if self.appname:
+ if self.appauthor is not False:
+ author = self.appauthor or self.appname
+ params.append(author)
+ params.append(self.appname)
+ if opinion_value is not None and self.opinion:
+ params.append(opinion_value)
+ if self.version:
+ params.append(self.version)
+ path = os.path.join(path, *params) # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ @property
+ def site_data_dir(self) -> str:
+ """:return: data directory shared by users, e.g. ``C:\\ProgramData\\$appauthor\\$appname``"""
+ path = os.path.normpath(get_win_folder("CSIDL_COMMON_APPDATA"))
+ return self._append_parts(path)
+
+ @property
+ def user_config_dir(self) -> str:
+ """:return: config directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def site_config_dir(self) -> str:
+ """:return: config directory shared by the users, same as `site_data_dir`"""
+ return self.site_data_dir
+
+ @property
+ def user_cache_dir(self) -> str:
+ """
+ :return: cache directory tied to the user (if opinionated with ``Cache`` folder within ``$appname``) e.g.
+ ``%USERPROFILE%\\AppData\\Local\\$appauthor\\$appname\\Cache\\$version``
+ """
+ path = os.path.normpath(get_win_folder("CSIDL_LOCAL_APPDATA"))
+ return self._append_parts(path, opinion_value="Cache")
+
+ @property
+ def site_cache_dir(self) -> str:
+ """:return: cache directory shared by users, e.g. ``C:\\ProgramData\\$appauthor\\$appname\\Cache\\$version``"""
+ path = os.path.normpath(get_win_folder("CSIDL_COMMON_APPDATA"))
+ return self._append_parts(path, opinion_value="Cache")
+
+ @property
+ def user_state_dir(self) -> str:
+ """:return: state directory tied to the user, same as `user_data_dir`"""
+ return self.user_data_dir
+
+ @property
+ def user_log_dir(self) -> str:
+ """:return: log directory tied to the user, same as `user_data_dir` if not opinionated else ``Logs`` in it"""
+ path = self.user_data_dir
+ if self.opinion:
+ path = os.path.join(path, "Logs") # noqa: PTH118
+ self._optionally_create_directory(path)
+ return path
+
+ @property
+ def user_documents_dir(self) -> str:
+ """:return: documents directory tied to the user e.g. ``%USERPROFILE%\\Documents``"""
+ return os.path.normpath(get_win_folder("CSIDL_PERSONAL"))
+
+ @property
+ def user_downloads_dir(self) -> str:
+ """:return: downloads directory tied to the user e.g. ``%USERPROFILE%\\Downloads``"""
+ return os.path.normpath(get_win_folder("CSIDL_DOWNLOADS"))
+
+ @property
+ def user_pictures_dir(self) -> str:
+ """:return: pictures directory tied to the user e.g. ``%USERPROFILE%\\Pictures``"""
+ return os.path.normpath(get_win_folder("CSIDL_MYPICTURES"))
+
+ @property
+ def user_videos_dir(self) -> str:
+ """:return: videos directory tied to the user e.g. ``%USERPROFILE%\\Videos``"""
+ return os.path.normpath(get_win_folder("CSIDL_MYVIDEO"))
+
+ @property
+ def user_music_dir(self) -> str:
+ """:return: music directory tied to the user e.g. ``%USERPROFILE%\\Music``"""
+ return os.path.normpath(get_win_folder("CSIDL_MYMUSIC"))
+
+ @property
+ def user_desktop_dir(self) -> str:
+ """:return: desktop directory tied to the user, e.g. ``%USERPROFILE%\\Desktop``"""
+ return os.path.normpath(get_win_folder("CSIDL_DESKTOPDIRECTORY"))
+
+ @property
+ def user_runtime_dir(self) -> str:
+ """
+ :return: runtime directory tied to the user, e.g.
+ ``%USERPROFILE%\\AppData\\Local\\Temp\\$appauthor\\$appname``
+ """
+ path = os.path.normpath(os.path.join(get_win_folder("CSIDL_LOCAL_APPDATA"), "Temp")) # noqa: PTH118
+ return self._append_parts(path)
+
+ @property
+ def site_runtime_dir(self) -> str:
+ """:return: runtime directory shared by users, same as `user_runtime_dir`"""
+ return self.user_runtime_dir
+
+
+def get_win_folder_from_env_vars(csidl_name: str) -> str:
+ """Get folder from environment variables."""
+ result = get_win_folder_if_csidl_name_not_env_var(csidl_name)
+ if result is not None:
+ return result
+
+ env_var_name = {
+ "CSIDL_APPDATA": "APPDATA",
+ "CSIDL_COMMON_APPDATA": "ALLUSERSPROFILE",
+ "CSIDL_LOCAL_APPDATA": "LOCALAPPDATA",
+ }.get(csidl_name)
+ if env_var_name is None:
+ msg = f"Unknown CSIDL name: {csidl_name}"
+ raise ValueError(msg)
+ result = os.environ.get(env_var_name)
+ if result is None:
+ msg = f"Unset environment variable: {env_var_name}"
+ raise ValueError(msg)
+ return result
+
+
+def get_win_folder_if_csidl_name_not_env_var(csidl_name: str) -> str | None:
+ """Get a folder for a CSIDL name that does not exist as an environment variable."""
+ if csidl_name == "CSIDL_PERSONAL":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Documents") # noqa: PTH118
+
+ if csidl_name == "CSIDL_DOWNLOADS":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Downloads") # noqa: PTH118
+
+ if csidl_name == "CSIDL_MYPICTURES":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Pictures") # noqa: PTH118
+
+ if csidl_name == "CSIDL_MYVIDEO":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Videos") # noqa: PTH118
+
+ if csidl_name == "CSIDL_MYMUSIC":
+ return os.path.join(os.path.normpath(os.environ["USERPROFILE"]), "Music") # noqa: PTH118
+ return None
+
+
+def get_win_folder_from_registry(csidl_name: str) -> str:
+ """
+ Get folder from the registry.
+
+ This is a fallback technique at best. I'm not sure if using the registry for these guarantees us the correct answer
+ for all CSIDL_* names.
+
+ """
+ shell_folder_name = {
+ "CSIDL_APPDATA": "AppData",
+ "CSIDL_COMMON_APPDATA": "Common AppData",
+ "CSIDL_LOCAL_APPDATA": "Local AppData",
+ "CSIDL_PERSONAL": "Personal",
+ "CSIDL_DOWNLOADS": "{374DE290-123F-4565-9164-39C4925E467B}",
+ "CSIDL_MYPICTURES": "My Pictures",
+ "CSIDL_MYVIDEO": "My Video",
+ "CSIDL_MYMUSIC": "My Music",
+ }.get(csidl_name)
+ if shell_folder_name is None:
+ msg = f"Unknown CSIDL name: {csidl_name}"
+ raise ValueError(msg)
+ if sys.platform != "win32": # only needed for mypy type checker to know that this code runs only on Windows
+ raise NotImplementedError
+ import winreg # noqa: PLC0415
+
+ key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r"Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders")
+ directory, _ = winreg.QueryValueEx(key, shell_folder_name)
+ return str(directory)
+
+
+def get_win_folder_via_ctypes(csidl_name: str) -> str:
+ """Get folder with ctypes."""
+ # There is no 'CSIDL_DOWNLOADS'.
+ # Use 'CSIDL_PROFILE' (40) and append the default folder 'Downloads' instead.
+ # https://learn.microsoft.com/en-us/windows/win32/shell/knownfolderid
+
+ import ctypes # noqa: PLC0415
+
+ csidl_const = {
+ "CSIDL_APPDATA": 26,
+ "CSIDL_COMMON_APPDATA": 35,
+ "CSIDL_LOCAL_APPDATA": 28,
+ "CSIDL_PERSONAL": 5,
+ "CSIDL_MYPICTURES": 39,
+ "CSIDL_MYVIDEO": 14,
+ "CSIDL_MYMUSIC": 13,
+ "CSIDL_DOWNLOADS": 40,
+ "CSIDL_DESKTOPDIRECTORY": 16,
+ }.get(csidl_name)
+ if csidl_const is None:
+ msg = f"Unknown CSIDL name: {csidl_name}"
+ raise ValueError(msg)
+
+ buf = ctypes.create_unicode_buffer(1024)
+ windll = getattr(ctypes, "windll") # noqa: B009 # using getattr to avoid false positive with mypy type checker
+ windll.shell32.SHGetFolderPathW(None, csidl_const, None, 0, buf)
+
+ # Downgrade to short path name if it has high-bit chars.
+ if any(ord(c) > 255 for c in buf): # noqa: PLR2004
+ buf2 = ctypes.create_unicode_buffer(1024)
+ if windll.kernel32.GetShortPathNameW(buf.value, buf2, 1024):
+ buf = buf2
+
+ if csidl_name == "CSIDL_DOWNLOADS":
+ return os.path.join(buf.value, "Downloads") # noqa: PTH118
+
+ return buf.value
+
+
+def _pick_get_win_folder() -> Callable[[str], str]:
+ try:
+ import ctypes # noqa: PLC0415
+ except ImportError:
+ pass
+ else:
+ if hasattr(ctypes, "windll"):
+ return get_win_folder_via_ctypes
+ try:
+ import winreg # noqa: PLC0415, F401
+ except ImportError:
+ return get_win_folder_from_env_vars
+ else:
+ return get_win_folder_from_registry
+
+
+get_win_folder = lru_cache(maxsize=None)(_pick_get_win_folder())
+
+__all__ = [
+ "Windows",
+]
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/CONTRIBUTORS.txt b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/CONTRIBUTORS.txt
new file mode 100644
index 000000000..4e238428e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/CONTRIBUTORS.txt
@@ -0,0 +1,670 @@
+# This file is autocompleted by 'contributors-txt',
+# using the configuration in 'script/.contributors_aliases.json'.
+# Do not add new persons manually and only add information without
+# using '-' as the line first character.
+# Please verify that your change are stable if you modify manually.
+
+Ex-maintainers
+--------------
+- Claudiu Popa <pcmanticore@gmail.com>
+- Sylvain Thénault <thenault@gmail.com> : main author / maintainer
+- Torsten Marek <shlomme@gmail.com>
+
+
+Maintainers
+-----------
+- Pierre Sassoulas <pierre.sassoulas@gmail.com>
+- Daniël van Noord <13665637+DanielNoord@users.noreply.github.com>
+- Jacob Walls <jacobtylerwalls@gmail.com>
+- Marc Mueller <30130371+cdce8p@users.noreply.github.com>
+- Hippo91 <guillaume.peillex@gmail.com>
+- Mark Byrne <31762852+mbyrnepr2@users.noreply.github.com>
+- Andreas Finkler <3929834+DudeNr33@users.noreply.github.com>
+- Matus Valo <matusvalo@users.noreply.github.com>
+- Dani Alcala <112832187+clavedeluna@users.noreply.github.com>
+- Łukasz Rogalski <rogalski.91@gmail.com>
+- Ashley Whetter <ashley@awhetter.co.uk>
+- Nick Drozd <nicholasdrozd@gmail.com>: performance improvements to astroid
+- Bryce Guinta <bryce.paul.guinta@gmail.com>
+- Yu Shao, Pang <36848472+yushao2@users.noreply.github.com>
+- Dimitri Prybysh <dmand@yandex.ru>
+ * multiple-imports, not-iterable, not-a-mapping, various patches.
+- Roy Williams <roy.williams.iii@gmail.com> (Lyft)
+ * added check for implementing __eq__ without implementing __hash__,
+ * Added Python 3 check for accessing Exception.message.
+ * Added Python 3 check for calling encode/decode with invalid codecs.
+ * Added Python 3 check for accessing sys.maxint.
+ * Added Python 3 check for bad import statements.
+ * Added Python 3 check for accessing deprecated methods on the 'string' module,
+ various patches.
+- Florian Bruhin <me@the-compiler.org>
+- Arianna Yang <areveny@protonmail.com>
+
+
+Contributors
+------------
+
+We would not be here without folks that contributed patches, pull requests,
+issues and their time to pylint. We're incredibly grateful to all of these
+contributors:
+
+- Emile Anclin <emile.anclin@logilab.fr> (Logilab): python 3 support
+- Michal Nowikowski <godfryd@gmail.com>:
+ * wrong-spelling-in-comment
+ * wrong-spelling-in-docstring
+ * parallel execution on multiple CPUs
+- Julthep Nandakwang <julthep@nandakwang.com>
+- Bruno Daniel <bruno.daniel@blue-yonder.com>: check_docs extension.
+- Sushobhit <31987769+sushobhit27@users.noreply.github.com> (sushobhit27)
+ * Added new check 'comparison-with-itself'.
+ * Added new check 'useless-import-alias'.
+ * Added support of annotations in missing-type-doc and missing-return-type-doc.
+ * Added new check 'comparison-with-callable'.
+ * Removed six package dependency.
+ * Added new check 'chained-comparison'.
+ * Added new check 'useless-object-inheritance'.
+- Brett Cannon <brett@python.org>:
+ * Port source code to be Python 2/3 compatible
+ * Python 3 checker
+- Laura Médioni <laura.medioni@logilab.fr> (Logilab, on behalf of the CNES):
+ * misplaced-comparison-constant
+ * no-classmethod-decorator
+ * no-staticmethod-decorator
+ * too-many-nested-blocks,
+ * too-many-boolean-expressions
+ * unneeded-not
+ * wrong-import-order
+ * ungrouped-imports,
+ * wrong-import-position
+ * redefined-variable-type
+- Harutaka Kawamura <hkawamura0130@gmail.com>
+- Alexandre Fayolle <alexandre.fayolle@logilab.fr> (Logilab): TkInter gui, documentation, debian support
+- Ville Skyttä <ville.skytta@iki.fi>
+- Julien Cristau <julien.cristau@logilab.fr> (Logilab): python 3 support
+- Adrien Di Mascio <Adrien.DiMascio@logilab.fr>
+- Moisés López <moylop260@vauxoo.com> (Vauxoo):
+ * Support for deprecated-modules in modules not installed,
+ * Refactor wrong-import-order to integrate it with `isort` library
+ * Add check too-complex with mccabe for cyclomatic complexity
+ * Refactor wrong-import-position to skip try-import and nested cases
+ * Add consider-merging-isinstance, superfluous-else-return
+ * Fix consider-using-ternary for 'True and True and True or True' case
+ * Add bad-docstring-quotes and docstring-first-line-empty
+ * Add missing-timeout
+- Frank Harrison <frank@doublethefish.com> (doublethefish)
+- Pierre-Yves David <pierre-yves.david@logilab.fr>
+- David Shea <dshea@redhat.com>: invalid sequence and slice index
+- Gunung P. Wibisono <55311527+gunungpw@users.noreply.github.com>
+- Derek Gustafson <degustaf@gmail.com>
+- Cezar Elnazli <cezar.elnazli2@gmail.com>: deprecated-method
+- Joseph Young <80432516+jpy-git@users.noreply.github.com> (jpy-git)
+- Tim Martin <tim@asymptotic.co.uk>
+- Ollie <46904826+ollie-iterators@users.noreply.github.com>
+- Zen Lee <53538590+zenlyj@users.noreply.github.com>
+- Tushar Sadhwani <tushar.sadhwani000@gmail.com> (tusharsadhwani)
+- Nicolas Chauvat <nicolas.chauvat@logilab.fr>
+- orSolocate <38433858+orSolocate@users.noreply.github.com>
+- Radu Ciorba <radu@devrandom.ro>: not-context-manager and confusing-with-statement warnings.
+- Holger Peters <email@holger-peters.de>
+- Cosmin Poieană <cmin@ropython.org>: unichr-builtin and improvements to bad-open-mode.
+- Yilei "Dolee" Yang <yileiyang@google.com>
+- Steven Myint <hg@stevenmyint.com>: duplicate-except.
+- Peter Kolbus <peter.kolbus@gmail.com> (Garmin)
+- Luigi Bertaco Cristofolini <lucristofolini@gmail.com> (luigibertaco)
+- Glenn Matthews <glenn@e-dad.net>:
+ * autogenerated documentation for optional extensions,
+ * bug fixes and enhancements for docparams (née check_docs) extension
+- crazybolillo <antonio@zoftko.com>
+- Vlad Temian <vladtemian@gmail.com>: redundant-unittest-assert and the JSON reporter.
+- Julien Jehannet <julien.jehannet@logilab.fr>
+- Boris Feld <lothiraldan@gmail.com>
+- Anthony Sottile <asottile@umich.edu>
+- Robert Hofer <hofrob@protonmail.com>
+- Pedro Algarvio <pedro@algarvio.me> (s0undt3ch)
+- Julien Palard <julien@palard.fr>
+- David Liu <david@cs.toronto.edu> (david-yz-liu)
+- Dan Goldsmith <djgoldsmith@googlemail.com>: support for msg-template in HTML reporter.
+- Buck Evan <buck.2019@gmail.com>
+- Mariatta Wijaya <Mariatta@users.noreply.github.com>
+ * Added new check `logging-fstring-interpolation`
+ * Documentation typo fixes
+- Jakub Wilk <jwilk@jwilk.net>
+- Hugo van Kemenade <hugovk@users.noreply.github.com>
+- Eli Fine <ejfine@gmail.com> (eli88fine): Fixed false positive duplicate code warning for lines with symbols only
+- Andrew Haigh <nelfin@gmail.com> (nelfin)
+- Émile Crater <emile@crater.logilab.fr>
+- Pavel Roskin <proski@gnu.org>
+- David Gilman <davidgilman1@gmail.com>
+- へーさん <hira9603859504@gmail.com>
+- Thomas Hisch <t.hisch@gmail.com>
+- Marianna Polatoglou <mpolatoglou@bloomberg.net>: minor contribution for wildcard import check
+- Manuel Vázquez Acosta <mva.led@gmail.com>
+- Luis Escobar <lescobar@vauxoo.com> (Vauxoo): Add bad-docstring-quotes and docstring-first-line-empty
+- Lucas Cimon <lucas.cimon@gmail.com>
+- Konstantina Saketou <56515303+ksaketou@users.noreply.github.com>
+- Konstantin <Github@pheanex.de>
+- Jim Robertson <jrobertson98atx@gmail.com>
+- Ethan Leba <ethanleba5@gmail.com>
+- Enji Cooper <yaneurabeya@gmail.com>
+- Drum Ogilvie <me@daogilvie.com>
+- David Lindquist <dlindquist@google.com>: logging-format-interpolation warning.
+- Daniel Harding <dharding@gmail.com>
+- Anthony Truchet <anthony.truchet@logilab.fr>
+- Alexander Todorov <atodorov@otb.bg>:
+ * added new error conditions to 'bad-super-call',
+ * Added new check for incorrect len(SEQUENCE) usage,
+ * Added new extension for comparison against empty string constants,
+ * Added new extension which detects comparing integers to zero,
+ * Added new useless-return checker,
+ * Added new try-except-raise checker
+- theirix <theirix@gmail.com>
+- correctmost <134317971+correctmost@users.noreply.github.com>
+- Téo Bouvard <teobouvard@gmail.com>
+- Stavros Ntentos <133706+stdedos@users.noreply.github.com>
+- Nicolas Boulenguez <nicolas@debian.org>
+- Mihai Balint <balint.mihai@gmail.com>
+- Mark Bell <mark00bell@googlemail.com>
+- Levi Gruspe <mail.levig@gmail.com>
+- Jakub Kuczys <me@jacken.men>
+- Hornwitser <github@hornwitser.no>: fix import graph
+- Fureigh <rhys.fureigh@gsa.gov>
+- David Douard <david.douard@sdfa3.org>
+- Daniel Balparda <balparda@google.com> (Google): GPyLint maintainer (Google's pylint variant)
+- Bastien Vallet <bastien.vallet@gmail.com> (Djailla)
+- Aru Sahni <arusahni@gmail.com>: Git ignoring, regex-based ignores
+- Andreas Freimuth <andreas.freimuth@united-bits.de>: fix indentation checking with tabs
+- Alexandru Coman <fcoman@bitdefender.com>
+- jpkotta <jpkotta@gmail.com>
+- Thomas Grainger <tagrain@gmail.com>
+- Takahide Nojima <nozzy123nozzy@gmail.com>
+- Taewon D. Kim <kimt33@mcmaster.ca>
+- Sneaky Pete <sneakypete81@gmail.com>
+- Sergey B Kirpichev <skirpichev@gmail.com>
+- Sandro Tosi <sandro.tosi@gmail.com>: Debian packaging
+- Rogdham <contact@rogdham.net>
+- Rene Zhang <rz99@cornell.edu>
+- Paul Lichtenberger <paul.lichtenberger.rgbg@gmail.com>
+- Or Bahari <or.ba402@gmail.com>
+- Mr. Senko <atodorov@mrsenko.com>
+- Mike Frysinger <vapier@gmail.com>
+- Martin von Gagern <gagern@google.com> (Google): Added 'raising-format-tuple' warning.
+- Martin Vielsmaier <martin@vielsmaier.net>
+- Martin Pool <mbp@google.com> (Google):
+ * warnings for anomalous backslashes
+ * symbolic names for messages (like 'unused')
+ * etc.
+- Martin Bašti <MartinBasti@users.noreply.github.com>
+ * Added new check for shallow copy of os.environ
+ * Added new check for useless `with threading.Lock():` statement
+- Marcus Näslund <naslundx@gmail.com> (naslundx)
+- Marco Pernigotti <7657251+mpernigo@users.noreply.github.com>
+- Marco Forte <fortemarco.irl@gmail.com>
+- James Addison <55152140+jayaddison@users.noreply.github.com>
+- Ionel Maries Cristian <contact@ionelmc.ro>
+- Gergely Kalmár <gergely.kalmar@logikal.jp>
+- Damien Baty <damien.baty@polyconseil.fr>
+- Benjamin Drung <benjamin.drung@profitbricks.com>: contributing Debian Developer
+- Anubhav <35621759+anubh-v@users.noreply.github.com>
+- Antonio Quarta <sgheppy88@gmail.com>
+- Andrew J. Simmons <anjsimmo@gmail.com>
+- Alexey Pelykh <alexey.pelykh@gmail.com>
+- wtracy <afishionado@gmail.com>
+- jessebrennan <jesse@jesse.computer>
+- chohner <mail@chohner.com>
+- aatle <168398276+aatle@users.noreply.github.com>
+- Tiago Honorato <61059243+tiagohonorato@users.noreply.github.com>
+- Steven M. Vascellaro <svascellaro@gmail.com>
+- Robin Tweedie <70587124+robin-wayve@users.noreply.github.com>
+- Roberto Leinardi <leinardi@gmail.com>: PyCharm plugin maintainer
+- Ricardo Gemignani <ricardo.gemignani@gmail.com>
+- Pieter Engelbrecht <pengelbrecht@rems2.com>
+- Philipp Albrecht <flying-sheep@web.de> (pylbrecht)
+- Nicolas Dickreuter <dickreuter@gmail.com>
+- Nick Bastin <nick.bastin@gmail.com>
+- Nathaniel Manista <nathaniel@google.com>: suspicious lambda checking
+- Maksym Humetskyi <Humetsky@gmail.com> (mhumetskyi)
+ * Fixed ignored empty functions by similarities checker with "ignore-signatures" option enabled
+ * Ignore function decorators signatures as well by similarities checker with "ignore-signatures" option enabled
+ * Ignore class methods and nested functions signatures as well by similarities checker with "ignore-signatures" option enabled
+- Kylian <development@goudcode.nl>
+- Konstantin Manna <Konstantin@Manna.uno>
+- Kai Mueller <15907922+kasium@users.noreply.github.com>
+- Joshua Cannon <joshdcannon@gmail.com>
+- John Leach <jfleach@jfleach.com>
+- James Morgensen <james.morgensen@gmail.com>: ignored-modules option applies to import errors.
+- Jaehoon Hwang <jaehoonhwang@users.noreply.github.com> (jaehoonhwang)
+- Huw Jones <huw@huwcbjones.co.uk>
+- Gideon <87426140+GideonBear@users.noreply.github.com>
+- Ganden Schaffner <gschaffner@pm.me>
+- Frost Ming <frostming@tencent.com>
+- Federico Bond <federicobond@gmail.com>
+- Erik Wright <erik.wright@shopify.com>
+- Erik Eriksson <molobrakos@users.noreply.github.com>: Added overlapping-except error check.
+- Daniel Mouritzen <dmrtzn@gmail.com>
+- Dan Hemberger <846186+hemberger@users.noreply.github.com>
+- Chris Rebert <code@rebertia.com>: unidiomatic-typecheck.
+- Aurelien Campeas <aurelien.campeas@logilab.fr>
+- Alvaro Frias <alvarofriasgaray@gmail.com>
+- Alexander Pervakov <frost.nzcr4@jagmort.com>
+- Alain Leufroy <alain.leufroy@logilab.fr>
+- Adam Williamson <awilliam@redhat.com>
+- xmo-odoo <xmo-odoo@users.noreply.github.com>
+- tbennett0 <tbennett0@users.noreply.github.com>
+- omarandlorraine <64254276+omarandlorraine@users.noreply.github.com>
+- craig-sh <craig-sh@users.noreply.github.com>
+- bernie gray <bfgray3@users.noreply.github.com>
+- azinneck0485 <123660683+azinneck0485@users.noreply.github.com>
+- Wes Turner <westurner@google.com> (Google): added new check 'inconsistent-quotes'
+- Tyler Thieding <tyler@thieding.com>
+- Tobias Hernstig <30827238+thernstig@users.noreply.github.com>
+- Sviatoslav Sydorenko <wk@sydorenko.org.ua>
+- Smixi <sismixx@hotmail.fr>
+- Simu Toni <simutoni@gmail.com>
+- Sergei Lebedev <185856+superbobry@users.noreply.github.com>
+- Scott Worley <scottworley@scottworley.com>
+- Saugat Pachhai <suagatchhetri@outlook.com>
+- Samuel FORESTIER <HorlogeSkynet@users.noreply.github.com>
+- Rémi Cardona <remi.cardona@polyconseil.fr>
+- Ryan Ozawa <ryan.ozawa21@gmail.com>
+- Roger Sheu <78449574+rogersheu@users.noreply.github.com>
+- Raphael Gaschignard <raphael@makeleaps.com>
+- Ram Rachum <ram@rachum.com> (cool-RR)
+- Radostin Stoyanov <rst0git@users.noreply.github.com>
+- Peter Bittner <django@bittner.it>
+- Paul Renvoisé <PaulRenvoise@users.noreply.github.com>
+- PHeanEX <github@pheanex.de>
+- Omega Weapon <OmegaPhil+hg@gmail.com>
+- Nikolai Kristiansen <nikolaik@gmail.com>
+- Nick Pesce <nickpesce22@gmail.com>
+- Nathan Marrow <nmarrow@google.com>
+- Mikhail Fesenko <m.fesenko@corp.vk.com>
+- Matthew Suozzo <msuozzo@google.com>
+- Matthew Beckers <17108752+mattlbeck@users.noreply.github.com> (mattlbeck)
+- Mark Roman Miller <mtmiller@users.noreply.github.com>: fix inline defs in too-many-statements
+- MalanB <malan.kmu@gmail.com>
+- Mads Kiilerich <mads@kiilerich.com>
+- Maarten ter Huurne <maarten@treewalker.org>
+- Lefteris Karapetsas <lefteris@refu.co>
+- LCD 47 <lcd047@gmail.com>
+- Jérome Perrin <perrinjerome@gmail.com>
+- Justin Li <justinnhli@gmail.com>
+- John Kirkham <jakirkham@gmail.com>
+- Jens H. Nielsen <Jens.Nielsen@microsoft.com>
+- Jake Lishman <jake.lishman@ibm.com>
+- Ioana Tagirta <ioana.tagirta@gmail.com>: fix bad thread instantiation check
+- Ikraduya Edian <ikraduya@gmail.com>: Added new checks 'consider-using-generator' and 'use-a-generator'.
+- Hugues Bruant <hugues.bruant@affirm.com>
+- Hashem Nasarat <Hnasar@users.noreply.github.com>
+- Harut <yes@harutune.name>
+- Grygorii Iermolenko <gyermolenko@gmail.com>
+- Grizzly Nyo <grizzly.nyo@gmail.com>
+- Gabriel R. Sezefredo <g@briel.dev>: Fixed "exception-escape" false positive with generators
+- Filipe Brandenburger <filbranden@google.com>
+- Fantix King <fantix@uchicago.edu> (UChicago)
+- Eric McDonald <221418+emcd@users.noreply.github.com>
+- Elias Dorneles <eliasdorneles@gmail.com>: minor adjust to config defaults and docs
+- Elazrod56 <thomas.lf5629@gmail.com>
+- Derek Harland <derek.harland@finq.co.nz>
+- David Pursehouse <david.pursehouse@gmail.com>
+- Dave Bunten <dave.bunten@cuanschutz.edu>
+- Daniel Miller <millerdev@gmail.com>
+- Christoph Blessing <33834216+cblessing24@users.noreply.github.com>
+- Chris Murray <chris@chrismurray.scot>
+- Chris Lamb <chris@chris-lamb.co.uk>
+- Charles Hebert <charles.hebert@logilab.fr>
+- Carli Freudenberg <carli.freudenberg@energymeteo.de> (CarliJoy)
+ * Fixed issue 5281, added Unicode checker
+ * Improve non-ascii-name checker
+- Bruce Dawson <randomascii@users.noreply.github.com>
+- Brian Shaginaw <brian.shaginaw@warbyparker.com>: prevent error on exception check for functions
+- Benny Mueller <benny.mueller91@gmail.com>
+- Ben James <benjames1999@hotmail.co.uk>
+- Ben Green <benhgreen@icloud.com>
+- Batuhan Taskaya <batuhanosmantaskaya@gmail.com>
+- Alexander Kapshuna <kapsh@kap.sh>
+- Akhil Kamat <akhil.kamat@gmail.com>
+- Adam Parkin <pzelnip@users.noreply.github.com>
+- 谭九鼎 <109224573@qq.com>
+- Łukasz Sznuk <ls@rdprojekt.pl>
+- zasca <gorstav@gmail.com>
+- y2kbugger <y2kbugger@users.noreply.github.com>
+- vinnyrose <vinnyrose@users.noreply.github.com>
+- ttenhoeve-aa <ttenhoeve@appannie.com>
+- thinwybk <florian.k@mailbox.org>
+- syutbai <syutbai@gmail.com>
+- sur.la.route <17788706+christopherpickering@users.noreply.github.com>
+- sdet_liang <liangway@users.noreply.github.com>
+- paschich <millen@gridium.com>
+- oittaa <8972248+oittaa@users.noreply.github.com>
+- nyabkun <75878387+nyabkun@users.noreply.github.com>
+- moxian <aleftmail@inbox.ru>
+- mar-chi-pan <mar.polatoglou@gmail.com>
+- lrjball <50599110+lrjball@users.noreply.github.com>
+- laike9m <laike9m@users.noreply.github.com>
+- kyoto7250 <50972773+kyoto7250@users.noreply.github.com>
+- kriek <sylvain.ackermann@gmail.com>
+- kdestin <101366538+kdestin@users.noreply.github.com>
+- jaydesl <35102795+jaydesl@users.noreply.github.com>
+- jab <jab@users.noreply.github.com>
+- gracejiang16 <70730457+gracejiang16@users.noreply.github.com>
+- glmdgrielson <32415403+glmdgrielson@users.noreply.github.com>
+- glegoux <gilles.legoux@gmail.com>
+- gaurikholkar <f2013002@goa.bits-pilani.ac.in>
+- flyingbot91 <flyingbot91@gmx.com>
+- fly <fly@users.noreply.github.com>
+- fahhem <fahhem>
+- fadedDexofan <fadedDexofan@gmail.com>
+- epenet <6771947+epenet@users.noreply.github.com>
+- danields <danields761@gmail.com>
+- cosven <cosven@users.noreply.github.com>
+- cordis-dev <darius@adroiti.com>
+- cherryblossom <31467609+cherryblossom000@users.noreply.github.com>
+- bluesheeptoken <louis.fruleux1@gmail.com>
+- anatoly techtonik <techtonik@gmail.com>
+- akirchhoff-modular <github-work@kirchhoff.digital>
+- agutole <toldo_carp@hotmail.com>
+- Zeckie <49095968+Zeckie@users.noreply.github.com>
+- Zeb Nicholls <zebedee.nicholls@climate-energy-college.org>
+ * Made W9011 compatible with 'of' syntax in return types
+- Yuval Langer <yuvallanger@mail.tau.ac.il>
+- Yury Gribov <tetra2005@gmail.com>
+- Yuri Bochkarev <baltazar.bz@gmail.com>: Added epytext support to docparams extension.
+- Youngsoo Sung <ysung@bepro11.com>
+- Yory <39745367+yory8@users.noreply.github.com>
+- Yoichi Nakayama <yoichi.nakayama@gmail.com>
+- Yeting Li <liyt@ios.ac.cn> (yetingli)
+- Yannack <yannack@users.noreply.github.com>
+- Yann Dirson <ydirson@free.fr>
+- Yang Yang <y4n9squared@gmail.com>
+- Xi Shen <davidshen84@gmail.com>
+- Winston H <56998716+winstxnhdw@users.noreply.github.com>
+- Will Shanks <wsha@posteo.net>
+- Viorel Știrbu <viorels@gmail.com>: intern-builtin warning.
+- VictorT <victor.taix@gmail.com>
+- Victor Jiajunsu <16359131+jiajunsu@users.noreply.github.com>
+- ViRuSTriNiTy <cradle-of-mail@gmx.de>
+- Val Lorentz <progval+github@progval.net>
+- Ulrich Eckhardt <UlrichEckhardt@users.noreply.github.com>
+- Udi Fuchs <udifuchs@gmail.com>
+- Trevor Bekolay <tbekolay@gmail.com>
+ * Added --list-msgs-enabled command
+- Tomer Chachamu <tomer.chachamu@gmail.com>: simplifiable-if-expression
+- Tomasz Michalski <tomasz.michalski@rtbhouse.com>
+- Tomasz Magulski <tomasz@magullab.io>
+- Tom <tsarantis@proton.me>
+- Tim Hatch <tim@timhatch.com>
+- Tim Gates <tim.gates@iress.com>
+- Tianyu Chen <124018391+UTsweetyfish@users.noreply.github.com>
+- Théo Battrel <theo.util@protonmail.ch>
+- Thomas Benhamou <thomas@lightricks.com>
+- Theodore Ni <3806110+tjni@users.noreply.github.com>
+- Tanvi Moharir <74228962+tanvimoharir@users.noreply.github.com>: Fix for invalid toml config
+- T.Rzepka <Tobias.Rzepka@gmail.com>
+- Svetoslav Neykov <svet@hyperscience.com>
+- SubaruArai <78188579+SubaruArai@users.noreply.github.com>
+- Stéphane Wirtel <stephane@wirtel.be>: nonlocal-without-binding
+- Stephen Longofono <8992396+SLongofono@users.noreply.github.com>
+- Stephane Odul <1504511+sodul@users.noreply.github.com>
+- Stanislav Levin <slev@altlinux.org>
+- Sorin Sbarnea <ssbarnea@redhat.com>
+- Slavfox <slavfoxman@gmail.com>
+- Skip Montanaro <skip@pobox.com>
+- Sigurd Spieckermann <2206639+sisp@users.noreply.github.com>
+- Shiv Venkatasubrahmanyam <shvenkat@users.noreply.github.com>
+- Sebastian Müller <mueller.seb@posteo.de>
+- Sayyed Faisal Ali <80758388+C0DE-SLAYER@users.noreply.github.com>
+- Sasha Bagan <pnlbagan@gmail.com>
+- Sardorbek Imomaliev <sardorbek.imomaliev@gmail.com>
+- Santiago Castro <bryant@montevideo.com.uy>
+- Samuel Freilich <sfreilich@google.com> (sfreilich)
+- Sam Vermeiren <88253337+PaaEl@users.noreply.github.com>
+- Ryan McGuire <ryan@enigmacurry.com>
+- Ry4an Brase <ry4an-hg@ry4an.org>
+- Ruro <ruro.ruro@ya.ru>
+- Roshan Shetty <roshan.shetty2816@gmail.com>
+- Roman Ivanov <me@roivanov.com>
+- Robert Schweizer <robert_schweizer@gmx.de>
+- Reverb Chu <reverbc@users.noreply.github.com>
+- Renat Galimov <renat2017@gmail.com>
+- Rebecca Turner <rbt@sent.as> (9999years)
+- Randall Leeds <randall@bleeds.info>
+- Ramon Saraiva <ramonsaraiva@gmail.com>
+- Ramiro Leal-Cavazos <ramiroleal050@gmail.com> (ramiro050): Fixed bug preventing pylint from working with Emacs tramp
+- RSTdefg <34202999+RSTdefg@users.noreply.github.com>
+- R. N. West <98110034+rnwst@users.noreply.github.com>
+- Qwiddle13 <32040075+Qwiddle13@users.noreply.github.com>
+- Quentin Young <qlyoung@users.noreply.github.com>
+- Prajwal Borkar <sunnyborkar7777@gmail.com>
+- Petr Pulc <petrpulc@gmail.com>: require whitespace around annotations
+- Peter Dawyndt <Peter.Dawyndt@UGent.be>
+- Peter Dave Hello <hsu@peterdavehello.org>
+- Peter Aronoff <peter@aronoff.org>
+- Paul Cochrane <paul@liekut.de>
+- Patrik <patrik.mrx@gmail.com>
+- Pascal Corpet <pcorpet@users.noreply.github.com>
+- Pablo Galindo Salgado <Pablogsal@gmail.com>
+ * Fix false positive 'Non-iterable value' with async comprehensions.
+- Osher De Paz <odepaz@redhat.com>
+- Oisín Moran <OisinMoran@users.noreply.github.com>
+- Obscuron <Abscuron@gmail.com>
+- Noam Yorav-Raphael <noamraph@gmail.com>
+- Noah-Agnel <138210920+Noah-Agnel@users.noreply.github.com>
+- Nir Soffer <nirsof@gmail.com>
+- Niko Wenselowski <niko@nerdno.de>
+- Nikita Sobolev <mail@sobolevn.me>
+- Nick Smith <clickthisnick@users.noreply.github.com>
+- Neowizard <Neowizard@users.noreply.github.com>
+- Ned Batchelder <ned@nedbatchelder.com>
+- Natalie Serebryakova <natalie.serebryakova@Natalies-MacBook-Pro.local>
+- Naglis Jonaitis <827324+naglis@users.noreply.github.com>
+- Moody <mooodyhunter@outlook.com>
+- Mitchell Young <mitchelly@gmail.com>: minor adjustment to docparams
+- Mitar <mitar.github@tnode.com>
+- Ming Lyu <CareF.Lm@gmail.com>
+- Mikhail f. Shiryaev <mr.felixoid@gmail.com>
+- Mike Fiedler <miketheman@gmail.com> (miketheman)
+- Mike Bryant <leachim@leachim.info>
+- Mike Bernard <mdbernard@pm.me>
+- Michka Popoff <michkapopoff@gmail.com>
+- Michal Vasilek <michal@vasilek.cz>
+- Michael Scott Cuthbert <cuthbert@mit.edu>
+- Michael Kefeder <oss@multiwave.ch>
+- Michael K <michael-k@users.noreply.github.com>
+- Michael Hudson-Doyle <michael.hudson@canonical.com>
+- Michael Giuffrida <mgiuffrida@users.noreply.github.com>
+- Melvin Hazeleger <31448155+melvio@users.noreply.github.com>
+- Meltem Kenis <meltem.kenis@plentific.com>
+- Mehdi Drissi <mdrissi@hmc.edu>
+- Matěj Grabovský <mgrabovs@redhat.com>
+- Matthijs Blom <19817960+MatthijsBlom@users.noreply.github.com>
+- Matej Spiller Muys <matej.spiller-muys@bitstamp.net>
+- Matej Marušák <marusak.matej@gmail.com>
+- Markus Siebenhaar <41283549+siehar@users.noreply.github.com>
+- Marco Edward Gorelli <marcogorelli@protonmail.com>: Documented Jupyter integration
+- Marcin Kurczewski <rr-@sakuya.pl> (rr-)
+- Maik Röder <maikroeder@gmail.com>
+- Lumír 'Frenzy' Balhar <frenzy.madness@gmail.com>
+- Ludovic Aubry <ludal@logilab.fr>
+- Louis Sautier <sautier.louis@gmail.com>
+- Lorena Buciu <46202743+lorena-b@users.noreply.github.com>
+- Logan Miller <14319179+komodo472@users.noreply.github.com>
+- Kári Tristan Helgason <kthelgason@gmail.com>
+- Kurian Benoy <70306694+kurianbenoy-aot@users.noreply.github.com>
+- Krzysztof Czapla <k.czapla68@gmail.com>
+- Kraig Brockschmidt <kraigbr@msn.com>
+- Kound <norman.freudenberg@posteo.de>
+- KotlinIsland <65446343+KotlinIsland@users.noreply.github.com>
+- Kosarchuk Sergey <sergeykosarchuk@gmail.com>
+- Konrad Weihmann <46938494+priv-kweihmann@users.noreply.github.com>
+- Kian Meng, Ang <kianmeng.ang@gmail.com>
+- Kevin Phillips <thefriendlycoder@gmail.com>
+- Kevin Jing Qiu <kevin.jing.qiu@gmail.com>
+- Kenneth Schackart <schackartk1@gmail.com>
+- Kayran Schmidt <59456929+yumasheta@users.noreply.github.com>
+- Karthik Nadig <kanadig@microsoft.com>
+- Jürgen Hermann <jh@web.de>
+- Josselin Feist <josselin@trailofbits.com>
+- Jonathan Kotta <KottaJonathan@JohnDeere.com>
+- John Paraskevopoulos <io.paraskev@gmail.com>: add 'differing-param-doc' and 'differing-type-doc'
+- John McGehee <jmcgehee@altera.com>
+- John Gabriele <jgabriele@fastmail.fm>
+- John Belmonte <john@neggie.net>
+- Joffrey Mander <joffrey.mander+pro@gmail.com>
+- Jochen Preusche <iilei@users.noreply.github.com>
+- Jeroen Seegers <jeroenseegers@users.noreply.github.com>:
+ * Fixed `toml` dependency issue
+- Jeremy Fleischman <jeremyfleischman@gmail.com>
+- Jason Owen <jason.a.owen@gmail.com>
+- Jason Lau <github.com@dotkr.nl>
+- Jared Garst <cultofjared@gmail.com>
+- Jared Deckard <jared.deckard@gmail.com>
+- Janne Rönkkö <jannero@users.noreply.github.com>
+- Jamie Scott <jamie@jami.org.uk>
+- James Sinclair <james@nurfherder.com>
+- James M. Allen <james.m.allen@gmail.com>
+- James Lingard <jchl@aristanetworks.com>
+- James Broadhead <jamesbroadhead@gmail.com>
+- Jakub Kulík <Kulikjak@gmail.com>
+- Jakob Normark <jakobnormark@gmail.com>
+- Jacques Kvam <jwkvam@gmail.com>
+- Jace Browning <jacebrowning@gmail.com>: updated default report format with clickable paths
+- JT Olds <jtolds@xnet5.com>
+- Iggy Eom <iggy.eom@sendbird.com>
+- Hayden Richards <62866982+SupImDos@users.noreply.github.com>
+ * Fixed "no-self-use" for async methods
+ * Fixed "docparams" extension for async functions and methods
+- Harshil <37377066+harshil21@users.noreply.github.com>
+- Harry <harrymcwinters@gmail.com>
+- Grégoire <96051754+gregoire-mullvad@users.noreply.github.com>
+- Grant Welch <gwelch925+github@gmail.com>
+- Giuseppe Valente <gvalente@arista.com>
+- Gary Tyler McLeod <mail@garytyler.com>
+- Felix von Drigalski <FvDrigalski@gmail.com>
+- Fabrice Douchant <Fabrice.Douchant@logilab.fr>
+- Fabio Natali <me@fabionatali.com>
+- Fabian Damken <fdamken+github@frisp.org>
+- Eric Froemling <ericfroemling@gmail.com>
+- Emmanuel Chaudron <manu.chaud@hotmail.fr>
+- Elizabeth Bott <52465744+elizabethbott@users.noreply.github.com>
+- Ekin Dursun <ekindursun@gmail.com>
+- Eisuke Kawashima <e-kwsm@users.noreply.github.com>
+- Edward K. Ream <edreamleo@gmail.com>
+- Edgemaster <grand.edgemaster@gmail.com>
+- Eddie Darling <eddie.darling@genapsys.com>
+- Drew Risinger <drewrisinger@users.noreply.github.com>
+- Dr. Nick <das-intensity@users.noreply.github.com>
+- Don Jayamanne <don.jayamanne@yahoo.com>
+- Dmytro Kyrychuk <dmytro.kyrychuck@gmail.com>
+- Dionisio E Alonso <baco@users.noreply.github.com>
+- DetachHead <57028336+DetachHead@users.noreply.github.com>
+- Dennis Keck <26092524+fellhorn@users.noreply.github.com>
+- Denis Laxalde <denis.laxalde@logilab.fr>
+- David Lawson <dmrlawson@gmail.com>
+- David Cain <davidjosephcain@gmail.com>
+- Danny Hermes <daniel.j.hermes@gmail.com>
+- Daniele Procida <daniele@vurt.org>
+- Daniela Plascencia <daplascen@gmail.com>
+- Daniel Werner <daniel.werner@scalableminds.com>
+- Daniel Wang <danielwang405@gmail.com>
+- Daniel R. Neal <dan.r.neal@gmail.com> (danrneal)
+- Daniel Draper <Germandrummer92@users.noreply.github.com>
+- Daniel Dorani <ddandd@gmail.com> (doranid)
+- Daniel Brookman <53625739+dbrookman@users.noreply.github.com>
+- Dan Garrette <dhgarrette@gmail.com>
+- Damien Nozay <damien.nozay@gmail.com>
+- Cubicpath <Cubicpath@protonmail.com>
+- Craig Citro <craigcitro@gmail.com>
+- Cosmo <cosmo@cosmo.red>
+- Clément Schreiner <clement@mux.me>
+- Clément Pit-Claudel <cpitclaudel@users.noreply.github.com>
+- Christopher Zurcher <zurcher@users.noreply.github.com>
+- Christian Clauss <cclauss@me.com>
+- Carl Crowder <bitbucket@carlcrowder.com>: don't evaluate the value of arguments for 'dangerous-default-value'
+- Carey Metcalfe <carey@cmetcalfe.ca>: demoted `try-except-raise` from error to warning
+- Cameron Olechowski <camsterole@users.noreply.github.com>
+- Calin Don <calin.don@gmail.com>
+- Caio Carrara <ccarrara@redhat.com>
+- C.A.M. Gerlach <WIDEnetServices@gmail.com>
+- Bruno P. Kinoshita <kinow@users.noreply.github.com>
+- Brice Chardin <brice.chardin@gmail.com>
+- Brian C. Lane <bcl@redhat.com>
+- Brandon W Maister <quodlibetor@gmail.com>
+- BioGeek <jeroen.vangoey@gmail.com>
+- Benjamin Graham <benwilliamgraham@gmail.com>
+- Benedikt Morbach <benedikt.morbach@googlemail.com>
+- Ben Greiner <code@bnavigator.de>
+- Barak Shoshany <baraksh@gmail.com>
+- Banjamin Freeman <befreeman@users.noreply.github.com>
+- Avram Lubkin <avylove@rockhopper.net>
+- Athos Ribeiro <athoscr@fedoraproject.org>: Fixed dict-keys-not-iterating false positive for inverse containment checks
+- Arun Persaud <arun@nubati.net>
+- Arthur Lutz <arthur.lutz@logilab.fr>
+- Antonio Ossa <aaossa@uc.cl>
+- Antonio Gámiz Delgado <73933988+antoniogamizbadger@users.noreply.github.com>
+- Anthony VEREZ <anthony.verez.external@cassidian.com>
+- Anthony Tan <tanant@users.noreply.github.com>
+- Anthony Foglia <afoglia@users.noreply.github.com> (Google): Added simple string slots check.
+- Anentropic <ego@anentropic.com>
+- Andy Young <a7young@ucsd.edu>
+- Andy Palmer <25123779+ninezerozeronine@users.noreply.github.com>
+- Andrzej Klajnert <github@aklajnert.pl>
+- Andrew Howe <howeaj@users.noreply.github.com>
+- Andres Perez Hortal <andresperezcba@gmail.com>
+- Andre Hora <andrehora@users.noreply.github.com>
+- Aman Salwan <121633121+AmanSal1@users.noreply.github.com>
+- Alok Singh <8325708+alok@users.noreply.github.com>
+- Allan Chandler <95424144+allanc65@users.noreply.github.com> (allanc65)
+ * Fixed issue 5452, false positive missing-param-doc for multi-line Google-style params
+- Alex Waygood <alex.waygood@gmail.com>
+- Alex Mor <5476113+nashcontrol@users.noreply.github.com>
+- Alex Jurkiewicz <alex@jurkiewi.cz>
+- Alex Hearn <alex.d.hearn@gmail.com>
+- Alex Fortin <alex.antoine.fortin@gmail.com>
+- Aleksander Mamla <alek.mamla@gmail.com>
+- Alan Evangelista <alanoe@linux.vnet.ibm.com>
+- Alan Chan <achan961117@gmail.com>
+- Aivar Annamaa <aivarannamaa@users.noreply.github.com>
+- Aidan Haase <44787650+haasea@users.noreply.github.com>
+- Ahirnish Pareek <ahirnish@gmail.com>: 'keyword-arg-before-var-arg' check
+- Agustin Marquez <agusdmb@gmail.com>
+- Adrian Chirieac <chirieacam@gmail.com>
+- Aditya Gupta <adityagupta1089@users.noreply.github.com> (adityagupta1089)
+ * Added ignore_signatures to duplicate checker
+- Adam Tuft <73994535+adamtuft@users.noreply.github.com>
+- Adam Dangoor <adamdangoor@gmail.com>
+- 243f6a88 85a308d3 <33170174+243f6a8885a308d313198a2e037@users.noreply.github.com>
+
+
+Co-Author
+---------
+The following persons were credited manually but did not commit themselves
+under this name, or we did not manage to find their commits in the history.
+
+- Agustin Toledo
+- Amaury Forgeot d'Arc: check names imported from a module exists in the module
+- Anthony Tan
+- Axel Muller
+- Benjamin Niemann: allow block level enabling/disabling of messages
+- Bernard Nauwelaerts
+- Bill Wendling
+- Brian van den Broek: windows installation documentation
+- Craig Henriques
+- D. Alphus (Alphadelta14)
+- Daniil Kharkov
+- Eero Vuojolahti
+- Fabio Zadrozny
+- Gauthier Sebaux
+- James DesLauriers
+- manderj
+- Mirko Friedenhagen
+- Nicholas Smith
+- Nuzula H. Yudaka (Nuzhuka)
+- Pek Chhan
+- Peter Hammond
+- Pierre Rouleau
+- Richard Goodman: simplifiable-if-expression (with Tomer Chachamu)
+- Sebastian Ulrich
+- Takashi Hirashima
+- Thomas Snowden: fix missing-docstring for inner functions
+- Wolfgang Grafen
+- Yannick Brehon
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/LICENSE b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/LICENSE
new file mode 100644
index 000000000..8c4c849e2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/LICENSE
@@ -0,0 +1,340 @@
+ GNU GENERAL PUBLIC LICENSE
+ Version 2, June 1991
+
+ Copyright (C) 1989, 1991 Free Software Foundation, Inc.
+ 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
+ Everyone is permitted to copy and distribute verbatim copies
+ of this license document, but changing it is not allowed.
+
+ Preamble
+
+ The licenses for most software are designed to take away your
+freedom to share and change it. By contrast, the GNU General Public
+License is intended to guarantee your freedom to share and change free
+software--to make sure the software is free for all its users. This
+General Public License applies to most of the Free Software
+Foundation's software and to any other program whose authors commit to
+using it. (Some other Free Software Foundation software is covered by
+the GNU Library General Public License instead.) You can apply it to
+your programs, too.
+
+ When we speak of free software, we are referring to freedom, not
+price. Our General Public Licenses are designed to make sure that you
+have the freedom to distribute copies of free software (and charge for
+this service if you wish), that you receive source code or can get it
+if you want it, that you can change the software or use pieces of it
+in new free programs; and that you know you can do these things.
+
+ To protect your rights, we need to make restrictions that forbid
+anyone to deny you these rights or to ask you to surrender the rights.
+These restrictions translate to certain responsibilities for you if you
+distribute copies of the software, or if you modify it.
+
+ For example, if you distribute copies of such a program, whether
+gratis or for a fee, you must give the recipients all the rights that
+you have. You must make sure that they, too, receive or can get the
+source code. And you must show them these terms so they know their
+rights.
+
+ We protect your rights with two steps: (1) copyright the software, and
+(2) offer you this license which gives you legal permission to copy,
+distribute and/or modify the software.
+
+ Also, for each author's protection and ours, we want to make certain
+that everyone understands that there is no warranty for this free
+software. If the software is modified by someone else and passed on, we
+want its recipients to know that what they have is not the original, so
+that any problems introduced by others will not reflect on the original
+authors' reputations.
+
+ Finally, any free program is threatened constantly by software
+patents. We wish to avoid the danger that redistributors of a free
+program will individually obtain patent licenses, in effect making the
+program proprietary. To prevent this, we have made it clear that any
+patent must be licensed for everyone's free use or not licensed at all.
+
+ The precise terms and conditions for copying, distribution and
+modification follow.
+
+ GNU GENERAL PUBLIC LICENSE
+ TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
+
+ 0. This License applies to any program or other work which contains
+a notice placed by the copyright holder saying it may be distributed
+under the terms of this General Public License. The "Program", below,
+refers to any such program or work, and a "work based on the Program"
+means either the Program or any derivative work under copyright law:
+that is to say, a work containing the Program or a portion of it,
+either verbatim or with modifications and/or translated into another
+language. (Hereinafter, translation is included without limitation in
+the term "modification".) Each licensee is addressed as "you".
+
+Activities other than copying, distribution and modification are not
+covered by this License; they are outside its scope. The act of
+running the Program is not restricted, and the output from the Program
+is covered only if its contents constitute a work based on the
+Program (independent of having been made by running the Program).
+Whether that is true depends on what the Program does.
+
+ 1. You may copy and distribute verbatim copies of the Program's
+source code as you receive it, in any medium, provided that you
+conspicuously and appropriately publish on each copy an appropriate
+copyright notice and disclaimer of warranty; keep intact all the
+notices that refer to this License and to the absence of any warranty;
+and give any other recipients of the Program a copy of this License
+along with the Program.
+
+You may charge a fee for the physical act of transferring a copy, and
+you may at your option offer warranty protection in exchange for a fee.
+
+ 2. You may modify your copy or copies of the Program or any portion
+of it, thus forming a work based on the Program, and copy and
+distribute such modifications or work under the terms of Section 1
+above, provided that you also meet all of these conditions:
+
+ a) You must cause the modified files to carry prominent notices
+ stating that you changed the files and the date of any change.
+
+ b) You must cause any work that you distribute or publish, that in
+ whole or in part contains or is derived from the Program or any
+ part thereof, to be licensed as a whole at no charge to all third
+ parties under the terms of this License.
+
+ c) If the modified program normally reads commands interactively
+ when run, you must cause it, when started running for such
+ interactive use in the most ordinary way, to print or display an
+ announcement including an appropriate copyright notice and a
+ notice that there is no warranty (or else, saying that you provide
+ a warranty) and that users may redistribute the program under
+ these conditions, and telling the user how to view a copy of this
+ License. (Exception: if the Program itself is interactive but
+ does not normally print such an announcement, your work based on
+ the Program is not required to print an announcement.)
+
+These requirements apply to the modified work as a whole. If
+identifiable sections of that work are not derived from the Program,
+and can be reasonably considered independent and separate works in
+themselves, then this License, and its terms, do not apply to those
+sections when you distribute them as separate works. But when you
+distribute the same sections as part of a whole which is a work based
+on the Program, the distribution of the whole must be on the terms of
+this License, whose permissions for other licensees extend to the
+entire whole, and thus to each and every part regardless of who wrote it.
+
+Thus, it is not the intent of this section to claim rights or contest
+your rights to work written entirely by you; rather, the intent is to
+exercise the right to control the distribution of derivative or
+collective works based on the Program.
+
+In addition, mere aggregation of another work not based on the Program
+with the Program (or with a work based on the Program) on a volume of
+a storage or distribution medium does not bring the other work under
+the scope of this License.
+
+ 3. You may copy and distribute the Program (or a work based on it,
+under Section 2) in object code or executable form under the terms of
+Sections 1 and 2 above provided that you also do one of the following:
+
+ a) Accompany it with the complete corresponding machine-readable
+ source code, which must be distributed under the terms of Sections
+ 1 and 2 above on a medium customarily used for software interchange; or,
+
+ b) Accompany it with a written offer, valid for at least three
+ years, to give any third party, for a charge no more than your
+ cost of physically performing source distribution, a complete
+ machine-readable copy of the corresponding source code, to be
+ distributed under the terms of Sections 1 and 2 above on a medium
+ customarily used for software interchange; or,
+
+ c) Accompany it with the information you received as to the offer
+ to distribute corresponding source code. (This alternative is
+ allowed only for noncommercial distribution and only if you
+ received the program in object code or executable form with such
+ an offer, in accord with Subsection b above.)
+
+The source code for a work means the preferred form of the work for
+making modifications to it. For an executable work, complete source
+code means all the source code for all modules it contains, plus any
+associated interface definition files, plus the scripts used to
+control compilation and installation of the executable. However, as a
+special exception, the source code distributed need not include
+anything that is normally distributed (in either source or binary
+form) with the major components (compiler, kernel, and so on) of the
+operating system on which the executable runs, unless that component
+itself accompanies the executable.
+
+If distribution of executable or object code is made by offering
+access to copy from a designated place, then offering equivalent
+access to copy the source code from the same place counts as
+distribution of the source code, even though third parties are not
+compelled to copy the source along with the object code.
+
+ 4. You may not copy, modify, sublicense, or distribute the Program
+except as expressly provided under this License. Any attempt
+otherwise to copy, modify, sublicense or distribute the Program is
+void, and will automatically terminate your rights under this License.
+However, parties who have received copies, or rights, from you under
+this License will not have their licenses terminated so long as such
+parties remain in full compliance.
+
+ 5. You are not required to accept this License, since you have not
+signed it. However, nothing else grants you permission to modify or
+distribute the Program or its derivative works. These actions are
+prohibited by law if you do not accept this License. Therefore, by
+modifying or distributing the Program (or any work based on the
+Program), you indicate your acceptance of this License to do so, and
+all its terms and conditions for copying, distributing or modifying
+the Program or works based on it.
+
+ 6. Each time you redistribute the Program (or any work based on the
+Program), the recipient automatically receives a license from the
+original licensor to copy, distribute or modify the Program subject to
+these terms and conditions. You may not impose any further
+restrictions on the recipients' exercise of the rights granted herein.
+You are not responsible for enforcing compliance by third parties to
+this License.
+
+ 7. If, as a consequence of a court judgment or allegation of patent
+infringement or for any other reason (not limited to patent issues),
+conditions are imposed on you (whether by court order, agreement or
+otherwise) that contradict the conditions of this License, they do not
+excuse you from the conditions of this License. If you cannot
+distribute so as to satisfy simultaneously your obligations under this
+License and any other pertinent obligations, then as a consequence you
+may not distribute the Program at all. For example, if a patent
+license would not permit royalty-free redistribution of the Program by
+all those who receive copies directly or indirectly through you, then
+the only way you could satisfy both it and this License would be to
+refrain entirely from distribution of the Program.
+
+If any portion of this section is held invalid or unenforceable under
+any particular circumstance, the balance of the section is intended to
+apply and the section as a whole is intended to apply in other
+circumstances.
+
+It is not the purpose of this section to induce you to infringe any
+patents or other property right claims or to contest validity of any
+such claims; this section has the sole purpose of protecting the
+integrity of the free software distribution system, which is
+implemented by public license practices. Many people have made
+generous contributions to the wide range of software distributed
+through that system in reliance on consistent application of that
+system; it is up to the author/donor to decide if he or she is willing
+to distribute software through any other system and a licensee cannot
+impose that choice.
+
+This section is intended to make thoroughly clear what is believed to
+be a consequence of the rest of this License.
+
+ 8. If the distribution and/or use of the Program is restricted in
+certain countries either by patents or by copyrighted interfaces, the
+original copyright holder who places the Program under this License
+may add an explicit geographical distribution limitation excluding
+those countries, so that distribution is permitted only in or among
+countries not thus excluded. In such case, this License incorporates
+the limitation as if written in the body of this License.
+
+ 9. The Free Software Foundation may publish revised and/or new versions
+of the General Public License from time to time. Such new versions will
+be similar in spirit to the present version, but may differ in detail to
+address new problems or concerns.
+
+Each version is given a distinguishing version number. If the Program
+specifies a version number of this License which applies to it and "any
+later version", you have the option of following the terms and conditions
+either of that version or of any later version published by the Free
+Software Foundation. If the Program does not specify a version number of
+this License, you may choose any version ever published by the Free Software
+Foundation.
+
+ 10. If you wish to incorporate parts of the Program into other free
+programs whose distribution conditions are different, write to the author
+to ask for permission. For software which is copyrighted by the Free
+Software Foundation, write to the Free Software Foundation; we sometimes
+make exceptions for this. Our decision will be guided by the two goals
+of preserving the free status of all derivatives of our free software and
+of promoting the sharing and reuse of software generally.
+
+ NO WARRANTY
+
+ 11. BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY
+FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN
+OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES
+PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED
+OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF
+MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS
+TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE
+PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING,
+REPAIR OR CORRECTION.
+
+ 12. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
+WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR
+REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES,
+INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING
+OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED
+TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY
+YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER
+PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE
+POSSIBILITY OF SUCH DAMAGES.
+
+ END OF TERMS AND CONDITIONS
+
+ How to Apply These Terms to Your New Programs
+
+ If you develop a new program, and you want it to be of the greatest
+possible use to the public, the best way to achieve this is to make it
+free software which everyone can redistribute and change under these terms.
+
+ To do so, attach the following notices to the program. It is safest
+to attach them to the start of each source file to most effectively
+convey the exclusion of warranty; and each file should have at least
+the "copyright" line and a pointer to where the full notice is found.
+
+ <one line to give the program's name and a brief idea of what it does.>
+ Copyright (C) <year> <name of author>
+
+ This program is free software; you can redistribute it and/or modify
+ it under the terms of the GNU General Public License as published by
+ the Free Software Foundation; either version 2 of the License, or
+ (at your option) any later version.
+
+ This program is distributed in the hope that it will be useful,
+ but WITHOUT ANY WARRANTY; without even the implied warranty of
+ MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ GNU General Public License for more details.
+
+ You should have received a copy of the GNU General Public License
+ along with this program; if not, write to the Free Software
+ Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
+
+
+Also add information on how to contact you by electronic and paper mail.
+
+If the program is interactive, make it output a short notice like this
+when it starts in an interactive mode:
+
+ Gnomovision version 69, Copyright (C) year name of author
+ Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
+ This is free software, and you are welcome to redistribute it
+ under certain conditions; type `show c' for details.
+
+The hypothetical commands `show w' and `show c' should show the appropriate
+parts of the General Public License. Of course, the commands you use may
+be called something other than `show w' and `show c'; they could even be
+mouse-clicks or menu items--whatever suits your program.
+
+You should also get your employer (if you work as a programmer) or your
+school, if any, to sign a "copyright disclaimer" for the program, if
+necessary. Here is a sample; alter the names:
+
+ Yoyodyne, Inc., hereby disclaims all copyright interest in the program
+ `Gnomovision' (which makes passes at compilers) written by James Hacker.
+
+ <signature of Ty Coon>, 1 April 1989
+ Ty Coon, President of Vice
+
+This General Public License does not permit incorporating your program into
+proprietary programs. If your program is a subroutine library, you may
+consider it more useful to permit linking proprietary applications with the
+library. If this is what you want to do, use the GNU Library General
+Public License instead of this License.
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/METADATA b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/METADATA
new file mode 100644
index 000000000..3db3c8df8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/METADATA
@@ -0,0 +1,278 @@
+Metadata-Version: 2.1
+Name: pylint
+Version: 3.3.3
+Summary: python code static checker
+Author-email: Python Code Quality Authority <code-quality@python.org>
+License: GPL-2.0-or-later
+Project-URL: Docs: User Guide, https://pylint.readthedocs.io/en/latest/
+Project-URL: Source Code, https://github.com/pylint-dev/pylint
+Project-URL: homepage, https://github.com/pylint-dev/pylint
+Project-URL: What's New, https://pylint.readthedocs.io/en/latest/whatsnew/3/
+Project-URL: Bug Tracker, https://github.com/pylint-dev/pylint/issues
+Project-URL: Discord Server, https://discord.com/invite/Egy6P8AMB5
+Project-URL: Docs: Contributor Guide, https://pylint.readthedocs.io/en/latest/development_guide/contributor_guide/index.html
+Keywords: static code analysis,linter,python,lint
+Classifier: Development Status :: 6 - Mature
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: GNU General Public License v2 (GPLv2)
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Classifier: Programming Language :: Python :: 3.13
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Software Development :: Debuggers
+Classifier: Topic :: Software Development :: Quality Assurance
+Classifier: Topic :: Software Development :: Testing
+Classifier: Typing :: Typed
+Requires-Python: >=3.9.0
+Description-Content-Type: text/x-rst
+License-File: LICENSE
+License-File: CONTRIBUTORS.txt
+Requires-Dist: dill>=0.2; python_version < "3.11"
+Requires-Dist: dill>=0.3.6; python_version >= "3.11"
+Requires-Dist: dill>=0.3.7; python_version >= "3.12"
+Requires-Dist: platformdirs>=2.2.0
+Requires-Dist: astroid<=3.4.0-dev0,>=3.3.8
+Requires-Dist: isort!=5.13.0,<6,>=4.2.5
+Requires-Dist: mccabe<0.8,>=0.6
+Requires-Dist: tomli>=1.1.0; python_version < "3.11"
+Requires-Dist: tomlkit>=0.10.1
+Requires-Dist: colorama>=0.4.5; sys_platform == "win32"
+Requires-Dist: typing-extensions>=3.10.0; python_version < "3.10"
+Provides-Extra: testutils
+Requires-Dist: gitpython>3; extra == "testutils"
+Provides-Extra: spelling
+Requires-Dist: pyenchant~=3.2; extra == "spelling"
+
+`Pylint`_
+=========
+
+.. _`Pylint`: https://pylint.readthedocs.io/
+
+.. This is used inside the doc to recover the start of the introduction
+
+.. image:: https://github.com/pylint-dev/pylint/actions/workflows/tests.yaml/badge.svg?branch=main
+ :target: https://github.com/pylint-dev/pylint/actions
+
+.. image:: https://codecov.io/gh/pylint-dev/pylint/branch/main/graph/badge.svg?token=ZETEzayrfk
+ :target: https://codecov.io/gh/pylint-dev/pylint
+
+.. image:: https://img.shields.io/pypi/v/pylint.svg
+ :alt: PyPI Package version
+ :target: https://pypi.python.org/pypi/pylint
+
+.. image:: https://readthedocs.org/projects/pylint/badge/?version=latest
+ :target: https://pylint.readthedocs.io/en/latest/?badge=latest
+ :alt: Documentation Status
+
+.. image:: https://img.shields.io/badge/code%20style-black-000000.svg
+ :target: https://github.com/ambv/black
+
+.. image:: https://img.shields.io/badge/linting-pylint-yellowgreen
+ :target: https://github.com/pylint-dev/pylint
+
+.. image:: https://results.pre-commit.ci/badge/github/pylint-dev/pylint/main.svg
+ :target: https://results.pre-commit.ci/latest/github/pylint-dev/pylint/main
+ :alt: pre-commit.ci status
+
+.. image:: https://bestpractices.coreinfrastructure.org/projects/6328/badge
+ :target: https://bestpractices.coreinfrastructure.org/projects/6328
+ :alt: CII Best Practices
+
+.. image:: https://img.shields.io/ossf-scorecard/github.com/PyCQA/pylint?label=openssf%20scorecard&style=flat
+ :target: https://api.securityscorecards.dev/projects/github.com/PyCQA/pylint
+ :alt: OpenSSF Scorecard
+
+.. image:: https://img.shields.io/discord/825463413634891776.svg
+ :target: https://discord.gg/qYxpadCgkx
+ :alt: Discord
+
+What is Pylint?
+---------------
+
+Pylint is a `static code analyser`_ for Python 2 or 3. The latest version supports Python
+3.9.0 and above.
+
+.. _`static code analyser`: https://en.wikipedia.org/wiki/Static_code_analysis
+
+Pylint analyses your code without actually running it. It checks for errors, enforces a
+coding standard, looks for `code smells`_, and can make suggestions about how the code
+could be refactored.
+
+.. _`code smells`: https://martinfowler.com/bliki/CodeSmell.html
+
+Install
+-------
+
+.. This is used inside the doc to recover the start of the short text for installation
+
+For command line use, pylint is installed with::
+
+ pip install pylint
+
+Or if you want to also check spelling with ``enchant`` (you might need to
+`install the enchant C library <https://pyenchant.github.io/pyenchant/install.html#installing-the-enchant-c-library>`_):
+
+.. code-block:: sh
+
+ pip install pylint[spelling]
+
+It can also be integrated in most editors or IDEs. More information can be found
+`in the documentation`_.
+
+.. _in the documentation: https://pylint.readthedocs.io/en/latest/user_guide/installation/index.html
+
+.. This is used inside the doc to recover the end of the short text for installation
+
+What differentiates Pylint?
+---------------------------
+
+Pylint is not trusting your typing and is inferring the actual values of nodes (for a
+start because there was no typing when pylint started off) using its internal code
+representation (astroid). If your code is ``import logging as argparse``, Pylint
+can check and know that ``argparse.error(...)`` is in fact a logging call and not an
+argparse call. This makes pylint slower, but it also lets pylint find more issues if
+your code is not fully typed.
+
+ [inference] is the killer feature that keeps us using [pylint] in our project despite how painfully slow it is.
+ - `Realist pylint user`_, 2022
+
+.. _`Realist pylint user`: https://github.com/charliermarsh/ruff/issues/970#issuecomment-1381067064
+
+pylint, not afraid of being a little slower than it already is, is also a lot more thorough than other linters.
+There are more checks, including some opinionated ones that are deactivated by default
+but can be enabled using configuration.
+
+How to use pylint
+-----------------
+
+Pylint isn't smarter than you: it may warn you about things that you have
+conscientiously done or check for some things that you don't care about.
+During adoption, especially in a legacy project where pylint was never enforced,
+it's best to start with the ``--errors-only`` flag, then disable
+convention and refactor messages with ``--disable=C,R`` and progressively
+re-evaluate and re-enable messages as your priorities evolve.
+
+Pylint is highly configurable and permits to write plugins in order to add your
+own checks (for example, for internal libraries or an internal rule). Pylint also has an
+ecosystem of existing plugins for popular frameworks and third-party libraries.
+
+.. note::
+
+ Pylint supports the Python standard library out of the box. Third-party
+ libraries are not always supported, so a plugin might be needed. A good place
+ to start is ``PyPI`` which often returns a plugin by searching for
+ ``pylint <library>``. `pylint-pydantic`_, `pylint-django`_ and
+ `pylint-sonarjson`_ are examples of such plugins. More information about plugins
+ and how to load them can be found at `plugins`_.
+
+.. _`plugins`: https://pylint.readthedocs.io/en/latest/development_guide/how_tos/plugins.html#plugins
+.. _`pylint-pydantic`: https://pypi.org/project/pylint-pydantic
+.. _`pylint-django`: https://github.com/pylint-dev/pylint-django
+.. _`pylint-sonarjson`: https://github.com/cnescatlab/pylint-sonarjson-catlab
+
+Advised linters alongside pylint
+--------------------------------
+
+Projects that you might want to use alongside pylint include ruff_ (**really** fast,
+with builtin auto-fix and a large number of checks taken from popular linters, but
+implemented in ``rust``) or flake8_ (a framework to implement your own checks in python using ``ast`` directly),
+mypy_, pyright_ / pylance or pyre_ (typing checks), bandit_ (security oriented checks), black_ and
+isort_ (auto-formatting), autoflake_ (automated removal of unused imports or variables), pyupgrade_
+(automated upgrade to newer python syntax) and pydocstringformatter_ (automated pep257).
+
+.. _ruff: https://github.com/astral-sh/ruff
+.. _flake8: https://github.com/PyCQA/flake8
+.. _bandit: https://github.com/PyCQA/bandit
+.. _mypy: https://github.com/python/mypy
+.. _pyright: https://github.com/microsoft/pyright
+.. _pyre: https://github.com/facebook/pyre-check
+.. _black: https://github.com/psf/black
+.. _autoflake: https://github.com/myint/autoflake
+.. _pyupgrade: https://github.com/asottile/pyupgrade
+.. _pydocstringformatter: https://github.com/DanielNoord/pydocstringformatter
+.. _isort: https://pycqa.github.io/isort/
+
+Additional tools included in pylint
+-----------------------------------
+
+Pylint ships with two additional tools:
+
+- pyreverse_ (standalone tool that generates package and class diagrams.)
+- symilar_ (duplicate code finder that is also integrated in pylint)
+
+.. _pyreverse: https://pylint.readthedocs.io/en/latest/pyreverse.html
+.. _symilar: https://pylint.readthedocs.io/en/latest/symilar.html
+
+
+.. This is used inside the doc to recover the end of the introduction
+
+Contributing
+------------
+
+.. This is used inside the doc to recover the start of the short text for contribution
+
+We welcome all forms of contributions such as updates for documentation, new code, checking issues for duplicates or telling us
+that we can close them, confirming that issues still exist, `creating issues because
+you found a bug or want a feature`_, etc. Everything is much appreciated!
+
+Please follow the `code of conduct`_ and check `the Contributor Guides`_ if you want to
+make a code contribution.
+
+.. _creating issues because you found a bug or want a feature: https://pylint.readthedocs.io/en/latest/contact.html#bug-reports-feedback
+.. _code of conduct: https://github.com/pylint-dev/pylint/blob/main/CODE_OF_CONDUCT.md
+.. _the Contributor Guides: https://pylint.readthedocs.io/en/latest/development_guide/contribute.html
+
+.. This is used inside the doc to recover the end of the short text for contribution
+
+Show your usage
+-----------------
+
+You can place this badge in your README to let others know your project uses pylint.
+
+ .. image:: https://img.shields.io/badge/linting-pylint-yellowgreen
+ :target: https://github.com/pylint-dev/pylint
+
+Learn how to add a badge to your documentation in `the badge documentation`_.
+
+.. _the badge documentation: https://pylint.readthedocs.io/en/latest/user_guide/installation/badge.html
+
+License
+-------
+
+pylint is, with a few exceptions listed below, `GPLv2 <https://github.com/pylint-dev/pylint/blob/main/LICENSE>`_.
+
+The icon files are licensed under the `CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0/>`_ license:
+
+- `doc/logo.png <https://raw.githubusercontent.com/pylint-dev/pylint/main/doc/logo.png>`_
+- `doc/logo.svg <https://raw.githubusercontent.com/pylint-dev/pylint/main/doc/logo.svg>`_
+
+Support
+-------
+
+Please check `the contact information`_.
+
+.. _`the contact information`: https://pylint.readthedocs.io/en/latest/contact.html
+
+.. |tideliftlogo| image:: https://raw.githubusercontent.com/pylint-dev/pylint/main/doc/media/Tidelift_Logos_RGB_Tidelift_Shorthand_On-White.png
+ :width: 200
+ :alt: Tidelift
+
+.. list-table::
+ :widths: 10 100
+
+ * - |tideliftlogo|
+ - Professional support for pylint is available as part of the `Tidelift
+ Subscription`_. Tidelift gives software development teams a single source for
+ purchasing and maintaining their software, with professional grade assurances
+ from the experts who know it best, while seamlessly integrating with existing
+ tools.
+
+.. _Tidelift Subscription: https://tidelift.com/subscription/pkg/pypi-pylint?utm_source=pypi-pylint&utm_medium=referral&utm_campaign=readme
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/RECORD b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/RECORD
new file mode 100644
index 000000000..ba290016e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/RECORD
@@ -0,0 +1,365 @@
+../../Scripts/pylint-config.exe,sha256=dEE4PHbzeDQ--ibOEJhAtXCyj4t_BRcqVKlZcYae2zA,108467
+../../Scripts/pylint.exe,sha256=dZwRUwlPt7PjtBku0NRwChJ0qCZPXBVI6eiqBUVZhwU,108451
+../../Scripts/pyreverse.exe,sha256=_x1SqHHAqhdQRdOl0PBxVurmPzMMwXwQBk5CXXHkHbY,108457
+../../Scripts/symilar.exe,sha256=28aNks3nM49DIYaulO7iAxCRaSSjlaiHqyAbeejRtqM,108453
+pylint-3.3.3.dist-info/CONTRIBUTORS.txt,sha256=o22pkVfAKjlCgsRksUNg6v4VNkIGpf2tPx4XdW2rL04,31714
+pylint-3.3.3.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+pylint-3.3.3.dist-info/LICENSE,sha256=-XsUCA3ouEkNYOs9Yg68QZlD4HeUZtHdDV1vaP4ZXc0,17984
+pylint-3.3.3.dist-info/METADATA,sha256=yJLPuLL4Htb80hivMICryTSlPBFXZkmbB-JtW21tQeE,12208
+pylint-3.3.3.dist-info/RECORD,,
+pylint-3.3.3.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pylint-3.3.3.dist-info/WHEEL,sha256=PZUExdf71Ui_so67QXpySuHtCi3-J3wvF4ORK6k_S8U,91
+pylint-3.3.3.dist-info/entry_points.txt,sha256=0wBRzcsPs1QNE1gWMZ5yepPnOat1elSm-EwS_0ngOY4,149
+pylint-3.3.3.dist-info/top_level.txt,sha256=j6Z9i__pIuaiCka6Ul9YIy6yI5aw5QbCtldLvZlMksE,7
+pylint/__init__.py,sha256=zeR49LwZkyKzr1mFBytkIV8bQt43pCyJkuT9P3HqwOo,3771
+pylint/__main__.py,sha256=dd_IH1XzarvFnYJeY2QqhYpNAcPSHX6nbA4p8JJdwwo,315
+pylint/__pkginfo__.py,sha256=vaau5ZJz3ybgMno9HjpJTPjfIdlSDpMMVDmMwJDquD0,1359
+pylint/__pycache__/__init__.cpython-312.pyc,,
+pylint/__pycache__/__main__.cpython-312.pyc,,
+pylint/__pycache__/__pkginfo__.cpython-312.pyc,,
+pylint/__pycache__/constants.cpython-312.pyc,,
+pylint/__pycache__/exceptions.cpython-312.pyc,,
+pylint/__pycache__/graph.cpython-312.pyc,,
+pylint/__pycache__/interfaces.cpython-312.pyc,,
+pylint/__pycache__/typing.cpython-312.pyc,,
+pylint/checkers/__init__.py,sha256=555_38K_w0Bq5dTxN2Hi1KIl1o_hhGe9z33e8j0hHow,4235
+pylint/checkers/__pycache__/__init__.cpython-312.pyc,,
+pylint/checkers/__pycache__/async.cpython-312.pyc,,
+pylint/checkers/__pycache__/bad_chained_comparison.cpython-312.pyc,,
+pylint/checkers/__pycache__/base_checker.cpython-312.pyc,,
+pylint/checkers/__pycache__/dataclass_checker.cpython-312.pyc,,
+pylint/checkers/__pycache__/deprecated.cpython-312.pyc,,
+pylint/checkers/__pycache__/design_analysis.cpython-312.pyc,,
+pylint/checkers/__pycache__/dunder_methods.cpython-312.pyc,,
+pylint/checkers/__pycache__/ellipsis_checker.cpython-312.pyc,,
+pylint/checkers/__pycache__/exceptions.cpython-312.pyc,,
+pylint/checkers/__pycache__/format.cpython-312.pyc,,
+pylint/checkers/__pycache__/imports.cpython-312.pyc,,
+pylint/checkers/__pycache__/lambda_expressions.cpython-312.pyc,,
+pylint/checkers/__pycache__/logging.cpython-312.pyc,,
+pylint/checkers/__pycache__/method_args.cpython-312.pyc,,
+pylint/checkers/__pycache__/misc.cpython-312.pyc,,
+pylint/checkers/__pycache__/modified_iterating_checker.cpython-312.pyc,,
+pylint/checkers/__pycache__/nested_min_max.cpython-312.pyc,,
+pylint/checkers/__pycache__/newstyle.cpython-312.pyc,,
+pylint/checkers/__pycache__/non_ascii_names.cpython-312.pyc,,
+pylint/checkers/__pycache__/raw_metrics.cpython-312.pyc,,
+pylint/checkers/__pycache__/spelling.cpython-312.pyc,,
+pylint/checkers/__pycache__/stdlib.cpython-312.pyc,,
+pylint/checkers/__pycache__/strings.cpython-312.pyc,,
+pylint/checkers/__pycache__/symilar.cpython-312.pyc,,
+pylint/checkers/__pycache__/threading_checker.cpython-312.pyc,,
+pylint/checkers/__pycache__/typecheck.cpython-312.pyc,,
+pylint/checkers/__pycache__/unicode.cpython-312.pyc,,
+pylint/checkers/__pycache__/unsupported_version.cpython-312.pyc,,
+pylint/checkers/__pycache__/utils.cpython-312.pyc,,
+pylint/checkers/__pycache__/variables.cpython-312.pyc,,
+pylint/checkers/async.py,sha256=n3FBf05RWdcY6lYtStj8xwqW6N0U-4h2f5JUiUz6dqw,3933
+pylint/checkers/bad_chained_comparison.py,sha256=3kximBOnJoj41mP0fOrZr-OVNI2-ki-e7fBcfTDnrOg,2238
+pylint/checkers/base/__init__.py,sha256=RJ4UJ9bbC9gg2MFVlNsiAqzKk60PBxqQZdcJJuxGPvg,1697
+pylint/checkers/base/__pycache__/__init__.cpython-312.pyc,,
+pylint/checkers/base/__pycache__/basic_checker.cpython-312.pyc,,
+pylint/checkers/base/__pycache__/basic_error_checker.cpython-312.pyc,,
+pylint/checkers/base/__pycache__/comparison_checker.cpython-312.pyc,,
+pylint/checkers/base/__pycache__/docstring_checker.cpython-312.pyc,,
+pylint/checkers/base/__pycache__/function_checker.cpython-312.pyc,,
+pylint/checkers/base/__pycache__/pass_checker.cpython-312.pyc,,
+pylint/checkers/base/basic_checker.py,sha256=r9Kp2-pm4iRkYSZbf41ng96PO-JZANPuwm1alDv1W_Y,40429
+pylint/checkers/base/basic_error_checker.py,sha256=vosAHp6uV1nLyY1bzIOumkA9l-U-iDtHRFTDCeixeLg,22281
+pylint/checkers/base/comparison_checker.py,sha256=UvuOjC_LEo_JYNdToVHG3lWzKRtJlMF5xMEnNwM2GvU,13873
+pylint/checkers/base/docstring_checker.py,sha256=bpUwHiqbuIKeKJckNLuLzrdNOnDbd3u-ctiZ4ELu7ss,7786
+pylint/checkers/base/function_checker.py,sha256=tJZq0G7PtAMO5JXjwJCEHCUUjAEpqPtGLYg_W3v3eAU,5866
+pylint/checkers/base/name_checker/__init__.py,sha256=_mfnrh798AJSsAoMGUP7fWhXi-N94c-9HWtwGttiSAk,699
+pylint/checkers/base/name_checker/__pycache__/__init__.cpython-312.pyc,,
+pylint/checkers/base/name_checker/__pycache__/checker.cpython-312.pyc,,
+pylint/checkers/base/name_checker/__pycache__/naming_style.cpython-312.pyc,,
+pylint/checkers/base/name_checker/checker.py,sha256=Afw-F56DKHpQieE9UDKwMe7Zyz4MYWFjVXL9vekHuMc,27947
+pylint/checkers/base/name_checker/naming_style.py,sha256=eu3FgDjIjqdBU75UkzxLMbJ-Qm4j-RwAPddqR8yK8dk,5867
+pylint/checkers/base/pass_checker.py,sha256=IrTskPQkMYvAQKSoixfY_zKrlDyJMMBh-cC1Wa4E608,1041
+pylint/checkers/base_checker.py,sha256=1Td7YGKxVGjezvomvVpNIvAT04z7GELGKrnEym0gm4g,9221
+pylint/checkers/classes/__init__.py,sha256=V2WMlI77SPVkD1KaSBAaRTx2PgC51rYKOzse8VOw2-8,654
+pylint/checkers/classes/__pycache__/__init__.cpython-312.pyc,,
+pylint/checkers/classes/__pycache__/class_checker.cpython-312.pyc,,
+pylint/checkers/classes/__pycache__/special_methods_checker.cpython-312.pyc,,
+pylint/checkers/classes/class_checker.py,sha256=83_8jXNrnbaM5JFUq9GnnTpikPYLFvtnTfBOZxWj_yM,94788
+pylint/checkers/classes/special_methods_checker.py,sha256=xtKuRwoqnOdNkBHFMNtCg9mjiFcbBehfhDETpmyX79Q,15125
+pylint/checkers/dataclass_checker.py,sha256=bHuPEYNm167wb5aTNpUstaBL10gKGjK7NjaDVyu8KHY,4503
+pylint/checkers/deprecated.py,sha256=QKqQhD7I2d6HkEkbGGnG2kDQGjUoAwnY_jQ6fIInB8k,11125
+pylint/checkers/design_analysis.py,sha256=kN6vfb8nF72wQ88pWZFLd4NlXj5CPkxQWAxTDuXRejk,24588
+pylint/checkers/dunder_methods.py,sha256=o2UVtwR_ZeNwhSP7bOYPBBIvodGfZ4mqKVL6H5JJS4Y,3908
+pylint/checkers/ellipsis_checker.py,sha256=Qw7l0vN_26OTOpH3yNOTgHQYRRCGF_sUb5enzbbJXpU,2024
+pylint/checkers/exceptions.py,sha256=eIkJ5B7lLWW54RaN4AZdUUmzpqFQt7x4cRr9Ki41plI,26337
+pylint/checkers/format.py,sha256=uVqA1Mb4ygYXWEBpn_00_Xx9s5F_PbK_J_MoPwOikKU,27912
+pylint/checkers/imports.py,sha256=5-1B-Mz0pL4uytlbDmeyN2LVzOvxO7K2BLvENmOgTw8,49032
+pylint/checkers/lambda_expressions.py,sha256=u-CM_tdvU08WzqjIrH_-7Z34_sdIeEVk0b_0bzQQMDg,3472
+pylint/checkers/logging.py,sha256=n5_SYkSDMOvfo9p0t4YgGTpZSHTGpWsb31m5GIHPapk,16420
+pylint/checkers/method_args.py,sha256=88dKdFAvs4w5EbX1FhmeuOBWiWEotGsYPBtDtgEzP18,4764
+pylint/checkers/misc.py,sha256=W7I-iL3OcDXX_eAl0Kz-G3rB22Kkfu2dFcfHfU_GWfE,5035
+pylint/checkers/modified_iterating_checker.py,sha256=brkj89jGLe0TH5RBPjQvAk2t3HE2YZfpZU5OnoI-SnY,7750
+pylint/checkers/nested_min_max.py,sha256=mINYcJQ4WCIKHDIQSUg3weG9wMfExxYN1m3pbLo_uNI,5583
+pylint/checkers/newstyle.py,sha256=ngMjgsCeXSdmDIq9xEacX7WJW-UX9N5ku88REPru9jg,4200
+pylint/checkers/non_ascii_names.py,sha256=etExQME84KCxMkygAitrJ1Epv3oohg2VoID3_nYWaSo,7155
+pylint/checkers/raw_metrics.py,sha256=DHgLXip6X15Dqef862JugIvICr4edGiEXm-9XwEUC1I,3797
+pylint/checkers/refactoring/__init__.py,sha256=g8LJprDaWRc6QEVtmz9HvQhGsS6rnwMPe9QxrrMKE7E,1124
+pylint/checkers/refactoring/__pycache__/__init__.cpython-312.pyc,,
+pylint/checkers/refactoring/__pycache__/implicit_booleaness_checker.cpython-312.pyc,,
+pylint/checkers/refactoring/__pycache__/not_checker.cpython-312.pyc,,
+pylint/checkers/refactoring/__pycache__/recommendation_checker.cpython-312.pyc,,
+pylint/checkers/refactoring/__pycache__/refactoring_checker.cpython-312.pyc,,
+pylint/checkers/refactoring/implicit_booleaness_checker.py,sha256=7k1FvjSGFPNCz_nKnVPb5C1eUAv-Y0b1xQwxuSIDvG0,14008
+pylint/checkers/refactoring/not_checker.py,sha256=vvVEcw2TFzoV3UJdFp2vFdfDgu1q8V80-D4RsX3APwU,2976
+pylint/checkers/refactoring/recommendation_checker.py,sha256=eKeboaJ7_WHrWxCe9Gjs5_C0A_hoqvNh3JyGMMHefNM,18864
+pylint/checkers/refactoring/refactoring_checker.py,sha256=6G0bFSYBtvmcJsCrRXg5ZX2dVm8q0jyN-dZhAMsxXbk,102563
+pylint/checkers/spelling.py,sha256=K9ksOhLAiX27J2YwNjiPv2M-0XTSh2myl4ssD9StuYQ,16454
+pylint/checkers/stdlib.py,sha256=D11QqU8aDk4JKPI-7i_yAR5Ik7xv44SVpFFFnuM13Vc,36609
+pylint/checkers/strings.py,sha256=chVCgazdASNSR5YQ1q9vnf5NTat_EeCzGr05QDrtRag,44785
+pylint/checkers/symilar.py,sha256=6Hq68t3Lqh3mUgVThpSwai4TEZGIlAhfL0ss-hVymGY,33948
+pylint/checkers/threading_checker.py,sha256=H_fy_ySghjCd-wfG4pPMhS9eF6X9593wtDDV7nGo018,1951
+pylint/checkers/typecheck.py,sha256=r00BEKSuDbdLPbxN-WCKBQj7827aNmiEMnFXWw1VN_c,90489
+pylint/checkers/unicode.py,sha256=Dyuo26TZGPYrbrBQ_7ddfPCTDlLMiJcV36lfuMnEgJs,18474
+pylint/checkers/unsupported_version.py,sha256=gWzlJXbJ4CM7TsjmygzWh5LnX7AVXoz0v7NeyDfdIhE,7745
+pylint/checkers/utils.py,sha256=rc5vGe9qQkIMXr20gLG8uEr2ed7corqSalWT5blnakM,79825
+pylint/checkers/variables.py,sha256=ri5sXiL46FcdOZu83ra5G1RTOLckukXbcYTklZTmwYE,136950
+pylint/config/__init__.py,sha256=Pq5uSrT_lQQe68zth16TBbe_EpzKUci3nKXxzZAFE20,387
+pylint/config/__pycache__/__init__.cpython-312.pyc,,
+pylint/config/__pycache__/_breaking_changes.cpython-312.pyc,,
+pylint/config/__pycache__/argument.cpython-312.pyc,,
+pylint/config/__pycache__/arguments_manager.cpython-312.pyc,,
+pylint/config/__pycache__/arguments_provider.cpython-312.pyc,,
+pylint/config/__pycache__/callback_actions.cpython-312.pyc,,
+pylint/config/__pycache__/config_file_parser.cpython-312.pyc,,
+pylint/config/__pycache__/config_initialization.cpython-312.pyc,,
+pylint/config/__pycache__/deprecation_actions.cpython-312.pyc,,
+pylint/config/__pycache__/exceptions.cpython-312.pyc,,
+pylint/config/__pycache__/find_default_config_files.cpython-312.pyc,,
+pylint/config/__pycache__/help_formatter.cpython-312.pyc,,
+pylint/config/__pycache__/utils.cpython-312.pyc,,
+pylint/config/_breaking_changes.py,sha256=SL-iSXK-HUXzJHHIQkJ8vOw30F6o8MbW-L6puNRqQIk,3651
+pylint/config/_pylint_config/__init__.py,sha256=B9J0yKzTWcEqJreLhgFmq0J4lGfz4Fg_GFNASCYO814,571
+pylint/config/_pylint_config/__pycache__/__init__.cpython-312.pyc,,
+pylint/config/_pylint_config/__pycache__/generate_command.cpython-312.pyc,,
+pylint/config/_pylint_config/__pycache__/help_message.cpython-312.pyc,,
+pylint/config/_pylint_config/__pycache__/main.cpython-312.pyc,,
+pylint/config/_pylint_config/__pycache__/setup.cpython-312.pyc,,
+pylint/config/_pylint_config/__pycache__/utils.cpython-312.pyc,,
+pylint/config/_pylint_config/generate_command.py,sha256=kvUxyyvZNxKWVbmaxnYcX5Auv4pPra5bhaExDuSr_fM,1718
+pylint/config/_pylint_config/help_message.py,sha256=fLjKdnNZbRindEpGMRux7wTpdBwX3WLIE48om-5VYlE,2007
+pylint/config/_pylint_config/main.py,sha256=taUrBKRaS_N256KQPgvu9ElHLkSWStL5_aL4hfgDwCA,855
+pylint/config/_pylint_config/setup.py,sha256=imOS5tT_5mcmB0IclU1H1LqQZ6qCwskFyZh6Vi6l7-U,1613
+pylint/config/_pylint_config/utils.py,sha256=-O3GmZ341hzeKZNxr0qpsOPjwwrHnaSfumahXpM_0JA,3662
+pylint/config/argument.py,sha256=XHSSmneI4nMnVI5mkHZjzxajRocgoHMNAqkJe4Ck6tE,14858
+pylint/config/arguments_manager.py,sha256=-ZmX_Y_RqYI_QcnqeXbtz-Y5M0ldSO60qidw4xkezlQ,15083
+pylint/config/arguments_provider.py,sha256=EG2Hw8zwbk4QvXCeqBGOYLWNL9xHf_DK8yBeYmdmd7M,2392
+pylint/config/callback_actions.py,sha256=fGPnUppIJR9MM0bEWwcp8RxcsFOaNUcFmt8y7oQ9L8c,13391
+pylint/config/config_file_parser.py,sha256=RhOf_peHAzFDpcahsOsEoIagdNeY8j7c6E8wEKk9fj8,4513
+pylint/config/config_initialization.py,sha256=v7aAbPESbB7c1WL-zM9WCi5jRb0gZvLO6FRD-PtGEc8,7368
+pylint/config/deprecation_actions.py,sha256=LAxHHR6kF0k82rCSTb_BOZT2wOSR027IzMzcS7mb4Yg,2983
+pylint/config/exceptions.py,sha256=GLd4fUNrbIky8ZgQrbOgGWLxXhcs3wlZtOvXjRLVap4,826
+pylint/config/find_default_config_files.py,sha256=WyuViPtEuTpl9ZV3fgbUgCe_qQ1q9oL3x323ZmXQKEY,4634
+pylint/config/help_formatter.py,sha256=Gd4ZYCVFu5VgnIlBLHTm3elByo0-UXNo1lQLJm3JuGo,2583
+pylint/config/utils.py,sha256=VjuKef8rQiWoHkarX3Ir8kB1lW5oP3a02emBXZj601A,8774
+pylint/constants.py,sha256=0_Ko5rJ2tRl0-DeDqIU5BidluzimR5MnV-Dy0iDE_8Y,8695
+pylint/exceptions.py,sha256=Ysrp0ddkUlebm2n4lWH8tYyqWdOImyyvdliMlGGbMgo,1726
+pylint/extensions/__init__.py,sha256=QNagpSKuKHwFXh3jUpvZGtFP27OT0NSec_vXfUS-cuk,585
+pylint/extensions/__pycache__/__init__.cpython-312.pyc,,
+pylint/extensions/__pycache__/_check_docs_utils.cpython-312.pyc,,
+pylint/extensions/__pycache__/bad_builtin.cpython-312.pyc,,
+pylint/extensions/__pycache__/broad_try_clause.cpython-312.pyc,,
+pylint/extensions/__pycache__/check_elif.cpython-312.pyc,,
+pylint/extensions/__pycache__/code_style.cpython-312.pyc,,
+pylint/extensions/__pycache__/comparison_placement.cpython-312.pyc,,
+pylint/extensions/__pycache__/confusing_elif.cpython-312.pyc,,
+pylint/extensions/__pycache__/consider_refactoring_into_while_condition.cpython-312.pyc,,
+pylint/extensions/__pycache__/consider_ternary_expression.cpython-312.pyc,,
+pylint/extensions/__pycache__/dict_init_mutate.cpython-312.pyc,,
+pylint/extensions/__pycache__/docparams.cpython-312.pyc,,
+pylint/extensions/__pycache__/docstyle.cpython-312.pyc,,
+pylint/extensions/__pycache__/dunder.cpython-312.pyc,,
+pylint/extensions/__pycache__/empty_comment.cpython-312.pyc,,
+pylint/extensions/__pycache__/eq_without_hash.cpython-312.pyc,,
+pylint/extensions/__pycache__/for_any_all.cpython-312.pyc,,
+pylint/extensions/__pycache__/magic_value.cpython-312.pyc,,
+pylint/extensions/__pycache__/mccabe.cpython-312.pyc,,
+pylint/extensions/__pycache__/no_self_use.cpython-312.pyc,,
+pylint/extensions/__pycache__/overlapping_exceptions.cpython-312.pyc,,
+pylint/extensions/__pycache__/private_import.cpython-312.pyc,,
+pylint/extensions/__pycache__/redefined_loop_name.cpython-312.pyc,,
+pylint/extensions/__pycache__/redefined_variable_type.cpython-312.pyc,,
+pylint/extensions/__pycache__/set_membership.cpython-312.pyc,,
+pylint/extensions/__pycache__/typing.cpython-312.pyc,,
+pylint/extensions/__pycache__/while_used.cpython-312.pyc,,
+pylint/extensions/_check_docs_utils.py,sha256=764frFLbEKr0jkoslVKgB2iIjGyp6ClqFWcEmKTUyZw,29753
+pylint/extensions/bad_builtin.py,sha256=vyKS9BQ3yElI58n-MHz8oB3_lCMqp-FmedHH_49mJug,2268
+pylint/extensions/broad_try_clause.py,sha256=56N3eMlJ_1cfHA9ek5LpkbIOhnoFk0aC6R8W7S0Pt3c,2268
+pylint/extensions/check_elif.py,sha256=XduStUiTNc4SOSlMmZyD5EPfknZNPfL2_eENK0YX4JY,2149
+pylint/extensions/code_style.py,sha256=Y8-L5jSZ-yFT3jGA4NRLC3sjnhGCUyAg9bS3D6tyORY,13675
+pylint/extensions/comparison_placement.py,sha256=UTYXBM4jXsOV5VrCqRbP62kYdztGaCjQ42fNsGtqtVM,2362
+pylint/extensions/confusing_elif.py,sha256=ab3tf81CQnRmdxyGU40Fb4pM2On4jsI4YfYlpv6id5k,2049
+pylint/extensions/consider_refactoring_into_while_condition.py,sha256=zDHMZNztIVAxYJtVGiC4rSILNKqiVUseO2V0Lt_UZbw,3322
+pylint/extensions/consider_ternary_expression.py,sha256=PFeB7tKJAdcg5u6xXT0NuclZ6lAs93MBCxstnETyVnI,1708
+pylint/extensions/dict_init_mutate.py,sha256=x7yxEQ--0WgKmAc-zfZ4JeihIMxWiUPLHkNK9jZObso,2121
+pylint/extensions/docparams.py,sha256=rzw46aCtbiDcyJe7nyYRTaXKxnDvcTUyBKN6QkSAjBM,25716
+pylint/extensions/docstyle.py,sha256=wh5S31An6fYB6ZJu3RAhGuHTdMbgO6SrfxWiU4449Bo,2953
+pylint/extensions/dunder.py,sha256=sQzJmiqaIR3V202MLgS39MbKcv369cF-vyFl5X4Xufg,2378
+pylint/extensions/empty_comment.py,sha256=B_NXCNYu_7EJmIrdENpt9ffuQGOnzRqy5TB7KmgZmsY,1963
+pylint/extensions/eq_without_hash.py,sha256=EghMfVWHCJGr-gqY26Qbzw6Do3XuyMkbgn7kTRfhcH8,1470
+pylint/extensions/for_any_all.py,sha256=IBK2YXH3JBD0Wlaq7Ru5XrVKXJB9mvdghXnmEshnFFs,5835
+pylint/extensions/magic_value.py,sha256=_eSTknhC7ZX4ZQWDrPTVnK8mJgHaooo4rN0StuS5CF0,4260
+pylint/extensions/mccabe.py,sha256=jUnJzRF8lPtSwxC6BdSDYkFAZg8DPgTrd3MWr05noPg,6916
+pylint/extensions/no_self_use.py,sha256=VLbtcdhS1icQ-F6voF0J0O-R8wjH4W8U3ZZKmAL3IdM,3710
+pylint/extensions/overlapping_exceptions.py,sha256=c7QpsZtTUR8bjD7n8LUUFxwokQaHYRAB4Zck_Vy09R0,3338
+pylint/extensions/private_import.py,sha256=LcxN9p75dqP0pW6Ms1vP4U1vFFBuAgNbE8AzvLyx5Rg,11247
+pylint/extensions/redefined_loop_name.py,sha256=QvIVd8gD-8FpbnBT4VLXN6h1vszPgb9rJVLVgtcRGFw,3230
+pylint/extensions/redefined_variable_type.py,sha256=ga8WIDw57G6qWiWIY4SV5kzrDlK1RQ3BtkAJRoNxqZI,4105
+pylint/extensions/set_membership.py,sha256=GKnGo_kRnF462QJL15VcRBo-3Ml_HJTG0r8brQXFS-c,1806
+pylint/extensions/typing.py,sha256=PsnhWNAoZP4Uf4C9yvqdYSUkUz91xxmMVCDnwxzqFFE,21907
+pylint/extensions/while_used.py,sha256=IZKtKqTAsbqenOp_Gik4_iEL9dHPSdYbe3MPD8IJLq8,1103
+pylint/graph.py,sha256=4FEA-tZrOXtw1NZWH4xJvvLPAZasSU3mt5q6pg6MTuM,7122
+pylint/interfaces.py,sha256=dWPnVcu1Y1vjG1mjSRG8xzfVC1kiuQZYRrzPGUnfOZw,1191
+pylint/lint/__init__.py,sha256=a9HOO4cHC7XCxGr8QaF3jg8gK5f90G4mj1FqF3ZofJY,1394
+pylint/lint/__pycache__/__init__.cpython-312.pyc,,
+pylint/lint/__pycache__/base_options.cpython-312.pyc,,
+pylint/lint/__pycache__/caching.cpython-312.pyc,,
+pylint/lint/__pycache__/expand_modules.cpython-312.pyc,,
+pylint/lint/__pycache__/message_state_handler.cpython-312.pyc,,
+pylint/lint/__pycache__/parallel.cpython-312.pyc,,
+pylint/lint/__pycache__/pylinter.cpython-312.pyc,,
+pylint/lint/__pycache__/report_functions.cpython-312.pyc,,
+pylint/lint/__pycache__/run.cpython-312.pyc,,
+pylint/lint/__pycache__/utils.cpython-312.pyc,,
+pylint/lint/base_options.py,sha256=3KrzPmu2RQ_j_Xgm8h99RYyMOreYX0680zGMNCS4yU8,21931
+pylint/lint/caching.py,sha256=mdNDPZBwYWJw17e7_1QvAE_l827KnJfxAL6CfSoJ2xw,2424
+pylint/lint/expand_modules.py,sha256=fKSmqwukrA2Iutzdk96KQ8OBKx917A4OL2JaPHJ0ViU,6757
+pylint/lint/message_state_handler.py,sha256=gvZ4-z-O_fUR5K7drWqhpI5SG2MMFC9SHgJVRBL3orM,17954
+pylint/lint/parallel.py,sha256=bchzKK-yKYXkGo2s-hfm_zL9Nx_vJG4DpX71Mq_QbUU,6425
+pylint/lint/pylinter.py,sha256=ExZeMifIpcrWFyk_uCo1Lv64s95dvuA2oUoSaowli2o,50544
+pylint/lint/report_functions.py,sha256=wV9e_PO0WRF9SAlSJzFFJJpJQ3FP-mykvkvehhPmyA0,3078
+pylint/lint/run.py,sha256=sVwu8nsTxs7YIsXFCrKPojfNUJloMama76JcPdPea8w,9062
+pylint/lint/utils.py,sha256=r4u1nbT1budbfzL-Y-IGIaEKqUrNPo_wzrzj6TZGbOg,3357
+pylint/message/__init__.py,sha256=83tEoCsTjG15vPoEnVW99qg5Lpy1Ee14kwjrX_PK-eQ,632
+pylint/message/__pycache__/__init__.cpython-312.pyc,,
+pylint/message/__pycache__/_deleted_message_ids.cpython-312.pyc,,
+pylint/message/__pycache__/message.cpython-312.pyc,,
+pylint/message/__pycache__/message_definition.cpython-312.pyc,,
+pylint/message/__pycache__/message_definition_store.cpython-312.pyc,,
+pylint/message/__pycache__/message_id_store.cpython-312.pyc,,
+pylint/message/_deleted_message_ids.py,sha256=6xtPh55G_rOwh319gl8a2iNMZPkWzFwujnzQZVlYttY,7578
+pylint/message/message.py,sha256=Qndr3rNqYW5KxEfqRV5wEXO47NVGvElkFH1n2Cc6BL0,2165
+pylint/message/message_definition.py,sha256=Uzbvffv6fuFkxkBHBTZHN3DkSgwIqZTIt5dZUrAiTOg,5013
+pylint/message/message_definition_store.py,sha256=b7uFTDz9nj8KMms2BffjiWZtWJbD6BcymazX2DkRq5M,5083
+pylint/message/message_id_store.py,sha256=Yx5wc3wUXKYUdvPZTGKGWBni7vwzwKYAq0HshU5GeWQ,6456
+pylint/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+pylint/pyreverse/__init__.py,sha256=eHl5rdin7-cPqgefwZteuF89noKc-nhavpyH1Y6ppyk,284
+pylint/pyreverse/__pycache__/__init__.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/diadefslib.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/diagrams.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/dot_printer.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/inspector.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/main.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/mermaidjs_printer.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/plantuml_printer.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/printer.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/printer_factory.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/utils.cpython-312.pyc,,
+pylint/pyreverse/__pycache__/writer.cpython-312.pyc,,
+pylint/pyreverse/diadefslib.py,sha256=Ml1grReMhjuAKJSKwGUgkDmpx76GxjetvO5Avy0pTjA,8872
+pylint/pyreverse/diagrams.py,sha256=DOup9Uh64HvWHt6RLVe84n6q7XhYgScRe3Dgd1mk0tM,11578
+pylint/pyreverse/dot_printer.py,sha256=255cbKCKbC5UY29ORT5oc48XGYaWo-4iprRWcVDOlz0,6513
+pylint/pyreverse/inspector.py,sha256=uuno1TZU4lXpQf_gCxGosCOdF1wZiKhObUNMsPLL-IU,13503
+pylint/pyreverse/main.py,sha256=wfCAq_rfteTkrId0bDuIEv8dDYiCadpnX9O3_lwyPLw,9640
+pylint/pyreverse/mermaidjs_printer.py,sha256=1rx-nRoV5UC5gZ3sKMXzFUsQWJ8wL_dXXIbGNA_9bnk,3441
+pylint/pyreverse/plantuml_printer.py,sha256=Ddy3rWNzaQHeYg9kJgZLl06bdrgLdXc6bWLY0NchM-E,3541
+pylint/pyreverse/printer.py,sha256=qLT8qr5X7FmCZOIKVmY8VSB4r018k6aWDzgh5esJ4W8,3726
+pylint/pyreverse/printer_factory.py,sha256=YOzS71r89gBWtuJdb35AuQNXqacHTNkppBIFNleDHCY,835
+pylint/pyreverse/utils.py,sha256=L8W664pHMch7tgfaaXMyoicNMcaBJ-E0UTVuEQtg2iA,8411
+pylint/pyreverse/writer.py,sha256=eMRY0RQss5zaegEMCDA57GSPZV8oCKt_W89I9oWTL2s,7579
+pylint/reporters/__init__.py,sha256=_c0wc7kqK3hZSlExp_7tpW4G7xBOh8wx9n1DQ6tfdBw,1072
+pylint/reporters/__pycache__/__init__.cpython-312.pyc,,
+pylint/reporters/__pycache__/base_reporter.cpython-312.pyc,,
+pylint/reporters/__pycache__/collecting_reporter.cpython-312.pyc,,
+pylint/reporters/__pycache__/json_reporter.cpython-312.pyc,,
+pylint/reporters/__pycache__/multi_reporter.cpython-312.pyc,,
+pylint/reporters/__pycache__/reports_handler_mix_in.cpython-312.pyc,,
+pylint/reporters/__pycache__/text.cpython-312.pyc,,
+pylint/reporters/base_reporter.py,sha256=Lq9UmTV6Ic4BlnksegVoP2BhS4Plzi7VvdRVe6g7j4Q,2788
+pylint/reporters/collecting_reporter.py,sha256=46dS4dzm2HBe9Lcr5AuQl1kx2OLa83YVpoorqGX5Nig,735
+pylint/reporters/json_reporter.py,sha256=LHL_87JYeYwW9_V3iNvq07dBjZEFRadbrhgbG9_ACbE,6421
+pylint/reporters/multi_reporter.py,sha256=tIceA90VF49orK3RtxBjLEi-VNwK9H-1zwEAbEpgoHI,3771
+pylint/reporters/reports_handler_mix_in.py,sha256=QPThQi4t7RkiQsZlFQfwXG2c1_Fgghan12ADB1HfEpg,3069
+pylint/reporters/text.py,sha256=vsZv8t-lbskrWrvvz7f0VPVuQfDtcNqtXu6BV14cZR0,9606
+pylint/reporters/ureports/__init__.py,sha256=nLdCdbJuOW6AfeCVl5BZ90ZV_Ms1EOeMcg_xP8C-JqA,320
+pylint/reporters/ureports/__pycache__/__init__.cpython-312.pyc,,
+pylint/reporters/ureports/__pycache__/base_writer.cpython-312.pyc,,
+pylint/reporters/ureports/__pycache__/nodes.cpython-312.pyc,,
+pylint/reporters/ureports/__pycache__/text_writer.cpython-312.pyc,,
+pylint/reporters/ureports/base_writer.py,sha256=WcGtCmHJjlp3YT-KRFHLQ6w1KkrVQeQeITfXvrb5WYo,3440
+pylint/reporters/ureports/nodes.py,sha256=VvOWfrGIqmrIsUID7DbELpMGkaTktcupFkxmdPy4EEk,5255
+pylint/reporters/ureports/text_writer.py,sha256=4qsrpWU7vr8whu0xbZtgRXzZo7KSaQF-5mZHp8VnEUQ,3616
+pylint/testutils/__init__.py,sha256=Sx8j8fvAJDwokpmLgvPv2gsNQeNVjtws-ow_aHNNcYM,1319
+pylint/testutils/__pycache__/__init__.cpython-312.pyc,,
+pylint/testutils/__pycache__/_run.cpython-312.pyc,,
+pylint/testutils/__pycache__/checker_test_case.cpython-312.pyc,,
+pylint/testutils/__pycache__/configuration_test.cpython-312.pyc,,
+pylint/testutils/__pycache__/constants.cpython-312.pyc,,
+pylint/testutils/__pycache__/decorator.cpython-312.pyc,,
+pylint/testutils/__pycache__/get_test_info.cpython-312.pyc,,
+pylint/testutils/__pycache__/global_test_linter.cpython-312.pyc,,
+pylint/testutils/__pycache__/lint_module_test.cpython-312.pyc,,
+pylint/testutils/__pycache__/output_line.cpython-312.pyc,,
+pylint/testutils/__pycache__/pyreverse.cpython-312.pyc,,
+pylint/testutils/__pycache__/reporter_for_tests.cpython-312.pyc,,
+pylint/testutils/__pycache__/tokenize_str.cpython-312.pyc,,
+pylint/testutils/__pycache__/unittest_linter.cpython-312.pyc,,
+pylint/testutils/__pycache__/utils.cpython-312.pyc,,
+pylint/testutils/_primer/__init__.py,sha256=91E7QjazQohtvZzpbH7_vKedMIswZ4Y4q7meXtHF-Gk,389
+pylint/testutils/_primer/__pycache__/__init__.cpython-312.pyc,,
+pylint/testutils/_primer/__pycache__/package_to_lint.cpython-312.pyc,,
+pylint/testutils/_primer/__pycache__/primer.cpython-312.pyc,,
+pylint/testutils/_primer/__pycache__/primer_command.cpython-312.pyc,,
+pylint/testutils/_primer/__pycache__/primer_compare_command.cpython-312.pyc,,
+pylint/testutils/_primer/__pycache__/primer_prepare_command.cpython-312.pyc,,
+pylint/testutils/_primer/__pycache__/primer_run_command.cpython-312.pyc,,
+pylint/testutils/_primer/package_to_lint.py,sha256=IjSGIPEMqmeUpBKwdOtnrIS9IHqPN3B49DesOVMWA4Y,5102
+pylint/testutils/_primer/primer.py,sha256=txjjMeYhi6T4rQ3SDOQtlFkEcjZ_1JSgnaREP_tJyn0,4685
+pylint/testutils/_primer/primer_command.py,sha256=ow1w5XXtPvEm56fgA5SnwTgeBfejZv2zcipBS_foGqc,999
+pylint/testutils/_primer/primer_compare_command.py,sha256=dHV04WOMAUN1FQ5cZDIDoMXBkPDTisqhf6VQ9nkw-H0,6989
+pylint/testutils/_primer/primer_prepare_command.py,sha256=2crSGDxfhBEltEc2NH7Rgw_ujw-excceHfEGWSAzjCk,2040
+pylint/testutils/_primer/primer_run_command.py,sha256=AZKyb9w5d3NhWOUUMk5FviJvecqAUKCFVhSBCaHYj3Q,4520
+pylint/testutils/_run.py,sha256=lukrQmA9nD5iEuQ-hVOVgMMXHQu99NCw8FOh1RJF35Y,1430
+pylint/testutils/checker_test_case.py,sha256=jnTFL-m7ueC7BmHymsXnZ7R5cKtVsMpMRgQ4I0a6qbk,3325
+pylint/testutils/configuration_test.py,sha256=4nbzk1AnEz80u324ZE7SY_FswkWcdXXkhiH_MFkPv0U,5416
+pylint/testutils/constants.py,sha256=qopINEz7apQA9y2Z88R5Lrd0gYUQEKs4QihB8S3QMUk,1159
+pylint/testutils/decorator.py,sha256=1s06oWObolRBPbwXcYd2fgmHhyBObYuaJTr7RX7kG9k,1262
+pylint/testutils/functional/__init__.py,sha256=qtLKMZBs6eM63Vg8LwUt-eXkEmI2e6S1kY5mz-wBKGA,800
+pylint/testutils/functional/__pycache__/__init__.cpython-312.pyc,,
+pylint/testutils/functional/__pycache__/find_functional_tests.cpython-312.pyc,,
+pylint/testutils/functional/__pycache__/lint_module_output_update.cpython-312.pyc,,
+pylint/testutils/functional/__pycache__/test_file.cpython-312.pyc,,
+pylint/testutils/functional/find_functional_tests.py,sha256=mbJN1Mi-okaX4mkGAMNqtanMHiE39ZpGV0E9vcWLRg4,5196
+pylint/testutils/functional/lint_module_output_update.py,sha256=THmSoS4jZpq-4dHDraL5rAWU0CFFcBr7sduKLjRZ18I,1518
+pylint/testutils/functional/test_file.py,sha256=4KV6nhZsk9c-O2izK1NbkZb38nGzxEnD_q2L5e1mwM0,3717
+pylint/testutils/get_test_info.py,sha256=wxPeK4mMELPV6FhOav8y5RJY3xwerB55a5NM_2-hjFI,2137
+pylint/testutils/global_test_linter.py,sha256=AAfD8FrniXJW_yPtm79FVCMjEYcJEYMj7V-V_xZamSA,695
+pylint/testutils/lint_module_test.py,sha256=rNZP4W10LVidbIM-D4fBhfIZezG_Q0G7iBpirxHeSVI,12538
+pylint/testutils/output_line.py,sha256=nKvWm8tnqy7nN0arPgFF5GlDnXtkmmQz1IZ_S4Xt7Rc,3994
+pylint/testutils/pyreverse.py,sha256=S9eRgwW2J6wFdIsvXsPc32a7kb9aA9_1wBPePFgUI2s,4254
+pylint/testutils/reporter_for_tests.py,sha256=59f73wUKi9-gXSpLT1UyCUnjC0MbAl5lDrVnN6nvVYk,2321
+pylint/testutils/testing_pylintrc,sha256=Y2Tex2VkUOP6dbE8pWQQRcWsTkue8J27y-nBpiAGPLU,264
+pylint/testutils/tokenize_str.py,sha256=TBA3SPx1kQX87AVJkYxCEG_UPID4zD3zIz_Qa6-OyuE,457
+pylint/testutils/unittest_linter.py,sha256=mtO59-zFLN0RoyJeVXByJ9UM9jENNdfJCSZuylhHOq0,2692
+pylint/testutils/utils.py,sha256=-k2ZsWgu5gABhmUvAOERG3L5nT-ShD3fjRZNbfbtWh0,3107
+pylint/typing.py,sha256=Ka_pOqviqGc3e-hpTU7z-LBQQ-hn0JhNuSM1_KTitwE,3146
+pylint/utils/__init__.py,sha256=0_OOONhVwISAO4bEMgC5AA1bjkg2hIVJwOlITfUwb64,1338
+pylint/utils/__pycache__/__init__.cpython-312.pyc,,
+pylint/utils/__pycache__/ast_walker.cpython-312.pyc,,
+pylint/utils/__pycache__/docs.cpython-312.pyc,,
+pylint/utils/__pycache__/file_state.cpython-312.pyc,,
+pylint/utils/__pycache__/linterstats.cpython-312.pyc,,
+pylint/utils/__pycache__/pragma_parser.cpython-312.pyc,,
+pylint/utils/__pycache__/utils.cpython-312.pyc,,
+pylint/utils/ast_walker.py,sha256=blguZYCwdmk20z22B0mZmw4FxJxzB5RX2M_jPhOfJIY,3959
+pylint/utils/docs.py,sha256=pxGJ1bV9-2y8gR53rPEprwvTu5lGSo_VLW7Dha74X6o,3406
+pylint/utils/file_state.py,sha256=orrjTq59eGm9IGpasxuab7hrxwaqebuhS5UCwlX7Hes,9628
+pylint/utils/linterstats.py,sha256=2u9dAz0V-7x-GzhmiroQkgQ764d8WxaMrPC7RShX_Xg,12466
+pylint/utils/pragma_parser.py,sha256=VeSO93CgYtq7BpjI0qjbq2vZMPYv_6U41xx9O1A_CWk,5052
+pylint/utils/utils.py,sha256=35O9T-AQg0_Jhec3yvp8Hw337plbtaQ1Ftm41vtP8UY,12333
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/REQUESTED b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/REQUESTED
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/WHEEL
new file mode 100644
index 000000000..ae527e7d6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/WHEEL
@@ -0,0 +1,5 @@
+Wheel-Version: 1.0
+Generator: setuptools (75.6.0)
+Root-Is-Purelib: true
+Tag: py3-none-any
+
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/entry_points.txt b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/entry_points.txt
new file mode 100644
index 000000000..09401fa81
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/entry_points.txt
@@ -0,0 +1,5 @@
+[console_scripts]
+pylint = pylint:run_pylint
+pylint-config = pylint:_run_pylint_config
+pyreverse = pylint:run_pyreverse
+symilar = pylint:run_symilar
diff --git a/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/top_level.txt b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/top_level.txt
new file mode 100644
index 000000000..7fb0ea150
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint-3.3.3.dist-info/top_level.txt
@@ -0,0 +1 @@
+pylint
diff --git a/solutions/.venv/Lib/site-packages/pylint/__init__.py b/solutions/.venv/Lib/site-packages/pylint/__init__.py
new file mode 100644
index 000000000..74bde8a39
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/__init__.py
@@ -0,0 +1,119 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+__all__ = [
+ "__version__",
+ "version",
+ "modify_sys_path",
+ "run_pylint",
+ "run_symilar",
+ "run_pyreverse",
+]
+
+import os
+import sys
+from collections.abc import Sequence
+from typing import NoReturn
+
+from pylint.__pkginfo__ import __version__
+
+# pylint: disable=import-outside-toplevel
+
+
+def run_pylint(argv: Sequence[str] | None = None) -> None:
+ """Run pylint.
+
+ argv can be a sequence of strings normally supplied as arguments on the command line
+ """
+ from pylint.lint import Run as PylintRun
+
+ try:
+ PylintRun(argv or sys.argv[1:])
+ except KeyboardInterrupt:
+ sys.exit(1)
+
+
+def _run_pylint_config(argv: Sequence[str] | None = None) -> None:
+ """Run pylint-config.
+
+ argv can be a sequence of strings normally supplied as arguments on the command line
+ """
+ from pylint.lint.run import _PylintConfigRun
+
+ _PylintConfigRun(argv or sys.argv[1:])
+
+
+def run_pyreverse(argv: Sequence[str] | None = None) -> NoReturn:
+ """Run pyreverse.
+
+ argv can be a sequence of strings normally supplied as arguments on the command line
+ """
+ from pylint.pyreverse.main import Run as PyreverseRun
+
+ PyreverseRun(argv or sys.argv[1:])
+
+
+def run_symilar(argv: Sequence[str] | None = None) -> NoReturn:
+ """Run symilar.
+
+ argv can be a sequence of strings normally supplied as arguments on the command line
+ """
+ from pylint.checkers.symilar import Run as SymilarRun
+
+ SymilarRun(argv or sys.argv[1:])
+
+
+def modify_sys_path() -> None:
+ """Modify sys path for execution as Python module.
+
+ Strip out the current working directory from sys.path.
+ Having the working directory in `sys.path` means that `pylint` might
+ inadvertently import user code from modules having the same name as
+ stdlib or pylint's own modules.
+ CPython issue: https://bugs.python.org/issue33053
+
+ - Remove the first entry. This will always be either "" or the working directory
+ - Remove the working directory from the second and third entries
+ if PYTHONPATH includes a ":" at the beginning or the end.
+ https://github.com/pylint-dev/pylint/issues/3636
+ Don't remove it if PYTHONPATH contains the cwd or '.' as the entry will
+ only be added once.
+ - Don't remove the working directory from the rest. It will be included
+ if pylint is installed in an editable configuration (as the last item).
+ https://github.com/pylint-dev/pylint/issues/4161
+ """
+ cwd = os.getcwd()
+ if sys.path[0] in ("", ".", cwd):
+ sys.path.pop(0)
+ env_pythonpath = os.environ.get("PYTHONPATH", "")
+ if env_pythonpath.startswith(":") and env_pythonpath not in (f":{cwd}", ":."):
+ sys.path.pop(0)
+ elif env_pythonpath.endswith(":") and env_pythonpath not in (f"{cwd}:", ".:"):
+ sys.path.pop(1)
+
+
+def _catch_valueerror(unraisable: sys.UnraisableHookArgs) -> None: # pragma: no cover
+ """Overwrite sys.unraisablehook to catch incorrect ValueError.
+
+ Python 3.12 introduced changes that sometimes cause astroid to emit ValueErrors
+ with 'generator already executing'. Fixed in Python 3.12.3 and 3.13.
+
+ https://github.com/pylint-dev/pylint/issues/9138
+ """
+ if (
+ isinstance(unraisable.exc_value, ValueError)
+ and unraisable.exc_value.args[0] == "generator already executing"
+ ):
+ return
+
+ sys.__unraisablehook__(unraisable)
+
+
+if (3, 12, 0) <= sys.version_info[:3] < (3, 12, 3):
+ sys.unraisablehook = _catch_valueerror
+
+
+version = __version__
diff --git a/solutions/.venv/Lib/site-packages/pylint/__main__.py b/solutions/.venv/Lib/site-packages/pylint/__main__.py
new file mode 100644
index 000000000..448ac55b6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/__main__.py
@@ -0,0 +1,10 @@
+#!/usr/bin/env python
+
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+import pylint
+
+pylint.modify_sys_path()
+pylint.run_pylint()
diff --git a/solutions/.venv/Lib/site-packages/pylint/__pkginfo__.py b/solutions/.venv/Lib/site-packages/pylint/__pkginfo__.py
new file mode 100644
index 000000000..625eeee1b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/__pkginfo__.py
@@ -0,0 +1,43 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""This module exists for compatibility reasons.
+
+It's updated via tbump, do not modify.
+"""
+
+from __future__ import annotations
+
+__version__ = "3.3.3"
+
+
+def get_numversion_from_version(v: str) -> tuple[int, int, int]:
+ """Kept for compatibility reason.
+
+ See https://github.com/pylint-dev/pylint/issues/4399
+ https://github.com/pylint-dev/pylint/issues/4420,
+ """
+ version = v.replace("pylint-", "")
+ result_version = []
+ for number in version.split(".")[0:3]:
+ try:
+ result_version.append(int(number))
+ except ValueError:
+ current_number = ""
+ for char in number:
+ if char.isdigit():
+ current_number += char
+ else:
+ break
+ try:
+ result_version.append(int(current_number))
+ except ValueError:
+ result_version.append(0)
+ while len(result_version) != 3:
+ result_version.append(0)
+
+ return tuple(result_version) # type: ignore[return-value] # mypy can't infer the length
+
+
+numversion = get_numversion_from_version(__version__)
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/__init__.py b/solutions/.venv/Lib/site-packages/pylint/checkers/__init__.py
new file mode 100644
index 000000000..9f65eb6e1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/__init__.py
@@ -0,0 +1,140 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Utilities methods and classes for checkers.
+
+Base id of standard checkers (used in msg and report ids):
+01: base
+02: classes
+03: format
+04: import
+05: misc
+06: variables
+07: exceptions
+08: similar
+09: design_analysis
+10: newstyle
+11: typecheck
+12: logging
+13: string_format
+14: string_constant
+15: stdlib
+16: python3 (This one was deleted but needs to be reserved for consistency with old messages)
+17: refactoring
+.
+.
+.
+24: non-ascii-names
+25: unicode
+26: unsupported_version
+27: private-import
+28-50: not yet used: reserved for future internal checkers.
+This file is not updated. Use
+ script/get_unused_message_id_category.py
+to get the next free checker id.
+
+51-99: perhaps used: reserved for external checkers
+
+The raw_metrics checker has no number associated since it doesn't emit any
+messages nor reports. XXX not true, emit a 07 report !
+"""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING, Literal
+
+from pylint.checkers.base_checker import (
+ BaseChecker,
+ BaseRawFileChecker,
+ BaseTokenChecker,
+)
+from pylint.checkers.deprecated import DeprecatedMixin
+from pylint.utils import LinterStats, diff_string, register_plugins
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def table_lines_from_stats(
+ stats: LinterStats,
+ old_stats: LinterStats | None,
+ stat_type: Literal["duplicated_lines", "message_types"],
+) -> list[str]:
+ """Get values listed in <columns> from <stats> and <old_stats>,
+ and return a formatted list of values.
+
+ The return value is designed to be given to a ureport.Table object
+ """
+ lines: list[str] = []
+ if stat_type == "duplicated_lines":
+ new: list[tuple[str, int | float]] = [
+ ("nb_duplicated_lines", stats.duplicated_lines["nb_duplicated_lines"]),
+ (
+ "percent_duplicated_lines",
+ stats.duplicated_lines["percent_duplicated_lines"],
+ ),
+ ]
+ if old_stats:
+ old: list[tuple[str, str | int | float]] = [
+ (
+ "nb_duplicated_lines",
+ old_stats.duplicated_lines["nb_duplicated_lines"],
+ ),
+ (
+ "percent_duplicated_lines",
+ old_stats.duplicated_lines["percent_duplicated_lines"],
+ ),
+ ]
+ else:
+ old = [("nb_duplicated_lines", "NC"), ("percent_duplicated_lines", "NC")]
+ elif stat_type == "message_types":
+ new = [
+ ("convention", stats.convention),
+ ("refactor", stats.refactor),
+ ("warning", stats.warning),
+ ("error", stats.error),
+ ]
+ if old_stats:
+ old = [
+ ("convention", old_stats.convention),
+ ("refactor", old_stats.refactor),
+ ("warning", old_stats.warning),
+ ("error", old_stats.error),
+ ]
+ else:
+ old = [
+ ("convention", "NC"),
+ ("refactor", "NC"),
+ ("warning", "NC"),
+ ("error", "NC"),
+ ]
+
+ # pylint: disable=possibly-used-before-assignment
+ for index, value in enumerate(new):
+ new_value = value[1]
+ old_value = old[index][1]
+ diff_str = (
+ diff_string(old_value, new_value)
+ if isinstance(old_value, float)
+ else old_value
+ )
+ new_str = f"{new_value:.3f}" if isinstance(new_value, float) else str(new_value)
+ old_str = f"{old_value:.3f}" if isinstance(old_value, float) else str(old_value)
+ lines.extend((value[0].replace("_", " "), new_str, old_str, diff_str)) # type: ignore[arg-type]
+ return lines
+
+
+def initialize(linter: PyLinter) -> None:
+ """Initialize linter with checkers in this package."""
+ register_plugins(linter, __path__[0])
+
+
+__all__ = [
+ "BaseChecker",
+ "BaseTokenChecker",
+ "BaseRawFileChecker",
+ "initialize",
+ "DeprecatedMixin",
+ "register_plugins",
+]
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/async.py b/solutions/.venv/Lib/site-packages/pylint/checkers/async.py
new file mode 100644
index 000000000..a8ee77302
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/async.py
@@ -0,0 +1,96 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checker for anything related to the async protocol (PEP 492)."""
+
+from __future__ import annotations
+
+import sys
+from typing import TYPE_CHECKING
+
+import astroid
+from astroid import nodes, util
+
+from pylint import checkers
+from pylint.checkers import utils as checker_utils
+from pylint.checkers.utils import decorated_with
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class AsyncChecker(checkers.BaseChecker):
+ name = "async"
+ msgs = {
+ "E1700": (
+ "Yield inside async function",
+ "yield-inside-async-function",
+ "Used when an `yield` or `yield from` statement is "
+ "found inside an async function.",
+ {"minversion": (3, 5)},
+ ),
+ "E1701": (
+ "Async context manager '%s' doesn't implement __aenter__ and __aexit__.",
+ "not-async-context-manager",
+ "Used when an async context manager is used with an object "
+ "that does not implement the async context management protocol.",
+ {"minversion": (3, 5)},
+ ),
+ }
+
+ def open(self) -> None:
+ self._mixin_class_rgx = self.linter.config.mixin_class_rgx
+ self._async_generators = ["contextlib.asynccontextmanager"]
+
+ @checker_utils.only_required_for_messages("yield-inside-async-function")
+ def visit_asyncfunctiondef(self, node: nodes.AsyncFunctionDef) -> None:
+ for child in node.nodes_of_class(nodes.Yield):
+ if child.scope() is node and (
+ sys.version_info[:2] == (3, 5) or isinstance(child, nodes.YieldFrom)
+ ):
+ self.add_message("yield-inside-async-function", node=child)
+
+ @checker_utils.only_required_for_messages("not-async-context-manager")
+ def visit_asyncwith(self, node: nodes.AsyncWith) -> None:
+ for ctx_mgr, _ in node.items:
+ inferred = checker_utils.safe_infer(ctx_mgr)
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ continue
+
+ if isinstance(inferred, nodes.AsyncFunctionDef):
+ # Check if we are dealing with a function decorated
+ # with contextlib.asynccontextmanager.
+ if decorated_with(inferred, self._async_generators):
+ continue
+ elif isinstance(inferred, astroid.bases.AsyncGenerator):
+ # Check if we are dealing with a function decorated
+ # with contextlib.asynccontextmanager.
+ if decorated_with(inferred.parent, self._async_generators):
+ continue
+ else:
+ try:
+ inferred.getattr("__aenter__")
+ inferred.getattr("__aexit__")
+ except astroid.exceptions.NotFoundError:
+ if isinstance(inferred, astroid.Instance):
+ # If we do not know the bases of this class,
+ # just skip it.
+ if not checker_utils.has_known_bases(inferred):
+ continue
+ # Ignore mixin classes if they match the rgx option.
+ if (
+ "not-async-context-manager"
+ in self.linter.config.ignored_checks_for_mixins
+ and self._mixin_class_rgx.match(inferred.name)
+ ):
+ continue
+ else:
+ continue
+ self.add_message(
+ "not-async-context-manager", node=node, args=(inferred.name,)
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(AsyncChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/bad_chained_comparison.py b/solutions/.venv/Lib/site-packages/pylint/checkers/bad_chained_comparison.py
new file mode 100644
index 000000000..2e1912160
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/bad_chained_comparison.py
@@ -0,0 +1,60 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+COMPARISON_OP = frozenset(("<", "<=", ">", ">=", "!=", "=="))
+IDENTITY_OP = frozenset(("is", "is not"))
+MEMBERSHIP_OP = frozenset(("in", "not in"))
+
+
+class BadChainedComparisonChecker(BaseChecker):
+ """Checks for unintentional usage of chained comparison."""
+
+ name = "bad-chained-comparison"
+ msgs = {
+ "W3601": (
+ "Suspicious %s-part chained comparison using semantically incompatible operators (%s)",
+ "bad-chained-comparison",
+ "Used when there is a chained comparison where one expression is part "
+ "of two comparisons that belong to different semantic groups "
+ '("<" does not mean the same thing as "is", chaining them in '
+ '"0 < x is None" is probably a mistake).',
+ )
+ }
+
+ def _has_diff_semantic_groups(self, operators: list[str]) -> bool:
+ # Check if comparison operators are in the same semantic group
+ for semantic_group in (COMPARISON_OP, IDENTITY_OP, MEMBERSHIP_OP):
+ if operators[0] in semantic_group:
+ group = semantic_group
+ return not all(o in group for o in operators)
+
+ def visit_compare(self, node: nodes.Compare) -> None:
+ operators = sorted({op[0] for op in node.ops})
+ if self._has_diff_semantic_groups(operators):
+ num_parts = f"{len(node.ops)}"
+ incompatibles = (
+ ", ".join(f"'{o}'" for o in operators[:-1]) + f" and '{operators[-1]}'"
+ )
+ self.add_message(
+ "bad-chained-comparison",
+ node=node,
+ args=(num_parts, incompatibles),
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(BadChainedComparisonChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/__init__.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/__init__.py
new file mode 100644
index 000000000..a3e6071c4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/__init__.py
@@ -0,0 +1,50 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+# pylint: disable=duplicate-code # This is similar to the __init__ of .name_checker
+
+from __future__ import annotations
+
+__all__ = [
+ "NameChecker",
+ "NamingStyle",
+ "KNOWN_NAME_TYPES_WITH_STYLE",
+ "SnakeCaseStyle",
+ "CamelCaseStyle",
+ "UpperCaseStyle",
+ "PascalCaseStyle",
+ "AnyStyle",
+]
+
+from typing import TYPE_CHECKING
+
+from pylint.checkers.base.basic_checker import BasicChecker
+from pylint.checkers.base.basic_error_checker import BasicErrorChecker
+from pylint.checkers.base.comparison_checker import ComparisonChecker
+from pylint.checkers.base.docstring_checker import DocStringChecker
+from pylint.checkers.base.function_checker import FunctionChecker
+from pylint.checkers.base.name_checker import (
+ KNOWN_NAME_TYPES_WITH_STYLE,
+ AnyStyle,
+ CamelCaseStyle,
+ NamingStyle,
+ PascalCaseStyle,
+ SnakeCaseStyle,
+ UpperCaseStyle,
+)
+from pylint.checkers.base.name_checker.checker import NameChecker
+from pylint.checkers.base.pass_checker import PassChecker
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(BasicErrorChecker(linter))
+ linter.register_checker(BasicChecker(linter))
+ linter.register_checker(NameChecker(linter))
+ linter.register_checker(DocStringChecker(linter))
+ linter.register_checker(PassChecker(linter))
+ linter.register_checker(ComparisonChecker(linter))
+ linter.register_checker(FunctionChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/basic_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/basic_checker.py
new file mode 100644
index 000000000..bd3190528
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/basic_checker.py
@@ -0,0 +1,971 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Basic checker for Python code."""
+
+from __future__ import annotations
+
+import collections
+import itertools
+from collections.abc import Iterator
+from typing import TYPE_CHECKING, Literal, cast
+
+import astroid
+from astroid import nodes, objects, util
+
+from pylint import utils as lint_utils
+from pylint.checkers import BaseChecker, utils
+from pylint.interfaces import HIGH, INFERENCE, Confidence
+from pylint.reporters.ureports import nodes as reporter_nodes
+from pylint.utils import LinterStats
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+class _BasicChecker(BaseChecker):
+ """Permits separating multiple checks with the same checker name into
+ classes/file.
+ """
+
+ name = "basic"
+
+
+REVERSED_PROTOCOL_METHOD = "__reversed__"
+SEQUENCE_PROTOCOL_METHODS = ("__getitem__", "__len__")
+REVERSED_METHODS = (SEQUENCE_PROTOCOL_METHODS, (REVERSED_PROTOCOL_METHOD,))
+# A mapping from qname -> symbol, to be used when generating messages
+# about dangerous default values as arguments
+DEFAULT_ARGUMENT_SYMBOLS = dict(
+ zip(
+ [".".join(["builtins", x]) for x in ("set", "dict", "list")],
+ ["set()", "{}", "[]"],
+ ),
+ **{
+ x: f"{x}()"
+ for x in (
+ "collections.deque",
+ "collections.ChainMap",
+ "collections.Counter",
+ "collections.OrderedDict",
+ "collections.defaultdict",
+ "collections.UserDict",
+ "collections.UserList",
+ )
+ },
+)
+
+
+def report_by_type_stats(
+ sect: reporter_nodes.Section,
+ stats: LinterStats,
+ old_stats: LinterStats | None,
+) -> None:
+ """Make a report of.
+
+ * percentage of different types documented
+ * percentage of different types with a bad name
+ """
+ # percentage of different types documented and/or with a bad name
+ nice_stats: dict[str, dict[str, str]] = {}
+ for node_type in ("module", "class", "method", "function"):
+ node_type = cast(Literal["function", "class", "method", "module"], node_type)
+ total = stats.get_node_count(node_type)
+ nice_stats[node_type] = {}
+ if total != 0:
+ undocumented_node = stats.get_undocumented(node_type)
+ documented = total - undocumented_node
+ percent = (documented * 100.0) / total
+ nice_stats[node_type]["percent_documented"] = f"{percent:.2f}"
+ badname_node = stats.get_bad_names(node_type)
+ percent = (badname_node * 100.0) / total
+ nice_stats[node_type]["percent_badname"] = f"{percent:.2f}"
+ lines = ["type", "number", "old number", "difference", "%documented", "%badname"]
+ for node_type in ("module", "class", "method", "function"):
+ node_type = cast(Literal["function", "class", "method", "module"], node_type)
+ new = stats.get_node_count(node_type)
+ old = old_stats.get_node_count(node_type) if old_stats else None
+ diff_str = lint_utils.diff_string(old, new) if old else None
+ lines += [
+ node_type,
+ str(new),
+ str(old) if old else "NC",
+ diff_str if diff_str else "NC",
+ nice_stats[node_type].get("percent_documented", "0"),
+ nice_stats[node_type].get("percent_badname", "0"),
+ ]
+ sect.append(reporter_nodes.Table(children=lines, cols=6, rheaders=1))
+
+
+# pylint: disable-next = too-many-public-methods
+class BasicChecker(_BasicChecker):
+ """Basic checker.
+
+ Checks for :
+ * doc strings
+ * number of arguments, local variables, branches, returns and statements in
+ functions, methods
+ * required module attributes
+ * dangerous default values as arguments
+ * redefinition of function / method / class
+ * uses of the global statement
+ """
+
+ name = "basic"
+ msgs = {
+ "W0101": (
+ "Unreachable code",
+ "unreachable",
+ 'Used when there is some code behind a "return" or "raise" '
+ "statement, which will never be accessed.",
+ ),
+ "W0102": (
+ "Dangerous default value %s as argument",
+ "dangerous-default-value",
+ "Used when a mutable value as list or dictionary is detected in "
+ "a default value for an argument.",
+ ),
+ "W0104": (
+ "Statement seems to have no effect",
+ "pointless-statement",
+ "Used when a statement doesn't have (or at least seems to) any effect.",
+ ),
+ "W0105": (
+ "String statement has no effect",
+ "pointless-string-statement",
+ "Used when a string is used as a statement (which of course "
+ "has no effect). This is a particular case of W0104 with its "
+ "own message so you can easily disable it if you're using "
+ "those strings as documentation, instead of comments.",
+ ),
+ "W0106": (
+ 'Expression "%s" is assigned to nothing',
+ "expression-not-assigned",
+ "Used when an expression that is not a function call is assigned "
+ "to nothing. Probably something else was intended.",
+ ),
+ "W0108": (
+ "Lambda may not be necessary",
+ "unnecessary-lambda",
+ "Used when the body of a lambda expression is a function call "
+ "on the same argument list as the lambda itself; such lambda "
+ "expressions are in all but a few cases replaceable with the "
+ "function being called in the body of the lambda.",
+ ),
+ "W0109": (
+ "Duplicate key %r in dictionary",
+ "duplicate-key",
+ "Used when a dictionary expression binds the same key multiple times.",
+ ),
+ "W0122": (
+ "Use of exec",
+ "exec-used",
+ "Raised when the 'exec' statement is used. It's dangerous to use this "
+ "function for a user input, and it's also slower than actual code in "
+ "general. This doesn't mean you should never use it, but you should "
+ "consider alternatives first and restrict the functions available.",
+ ),
+ "W0123": (
+ "Use of eval",
+ "eval-used",
+ 'Used when you use the "eval" function, to discourage its '
+ "usage. Consider using `ast.literal_eval` for safely evaluating "
+ "strings containing Python expressions "
+ "from untrusted sources.",
+ ),
+ "W0150": (
+ "%s statement in finally block may swallow exception",
+ "lost-exception",
+ "Used when a break or a return statement is found inside the "
+ "finally clause of a try...finally block: the exceptions raised "
+ "in the try clause will be silently swallowed instead of being "
+ "re-raised.",
+ ),
+ "W0199": (
+ "Assert called on a populated tuple. Did you mean 'assert x,y'?",
+ "assert-on-tuple",
+ "A call of assert on a tuple will always evaluate to true if "
+ "the tuple is not empty, and will always evaluate to false if "
+ "it is.",
+ ),
+ "W0124": (
+ 'Following "as" with another context manager looks like a tuple.',
+ "confusing-with-statement",
+ "Emitted when a `with` statement component returns multiple values "
+ "and uses name binding with `as` only for a part of those values, "
+ "as in with ctx() as a, b. This can be misleading, since it's not "
+ "clear if the context manager returns a tuple or if the node without "
+ "a name binding is another context manager.",
+ ),
+ "W0125": (
+ "Using a conditional statement with a constant value",
+ "using-constant-test",
+ "Emitted when a conditional statement (If or ternary if) "
+ "uses a constant value for its test. This might not be what "
+ "the user intended to do.",
+ ),
+ "W0126": (
+ "Using a conditional statement with potentially wrong function or method call due to "
+ "missing parentheses",
+ "missing-parentheses-for-call-in-test",
+ "Emitted when a conditional statement (If or ternary if) "
+ "seems to wrongly call a function due to missing parentheses",
+ ),
+ "W0127": (
+ "Assigning the same variable %r to itself",
+ "self-assigning-variable",
+ "Emitted when we detect that a variable is assigned to itself",
+ ),
+ "W0128": (
+ "Redeclared variable %r in assignment",
+ "redeclared-assigned-name",
+ "Emitted when we detect that a variable was redeclared in the same assignment.",
+ ),
+ "E0111": (
+ "The first reversed() argument is not a sequence",
+ "bad-reversed-sequence",
+ "Used when the first argument to reversed() builtin "
+ "isn't a sequence (does not implement __reversed__, "
+ "nor __getitem__ and __len__",
+ ),
+ "E0119": (
+ "format function is not called on str",
+ "misplaced-format-function",
+ "Emitted when format function is not called on str object. "
+ 'e.g doing print("value: {}").format(123) instead of '
+ 'print("value: {}".format(123)). This might not be what the user '
+ "intended to do.",
+ ),
+ "W0129": (
+ "Assert statement has a string literal as its first argument. The assert will %s fail.",
+ "assert-on-string-literal",
+ "Used when an assert statement has a string literal as its first argument, which will "
+ "cause the assert to always pass.",
+ ),
+ "W0130": (
+ "Duplicate value %r in set",
+ "duplicate-value",
+ "This message is emitted when a set contains the same value two or more times.",
+ ),
+ "W0131": (
+ "Named expression used without context",
+ "named-expr-without-context",
+ "Emitted if named expression is used to do a regular assignment "
+ "outside a context like if, for, while, or a comprehension.",
+ ),
+ "W0133": (
+ "Exception statement has no effect",
+ "pointless-exception-statement",
+ "Used when an exception is created without being assigned, raised or returned "
+ "for subsequent use elsewhere.",
+ ),
+ "W0134": (
+ "'return' shadowed by the 'finally' clause.",
+ "return-in-finally",
+ "Emitted when a 'return' statement is found in a 'finally' block. This will overwrite "
+ "the return value of a function and should be avoided.",
+ ),
+ }
+
+ reports = (("RP0101", "Statistics by type", report_by_type_stats),)
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._trys: list[nodes.Try]
+
+ def open(self) -> None:
+ """Initialize visit variables and statistics."""
+ py_version = self.linter.config.py_version
+ self._py38_plus = py_version >= (3, 8)
+ self._trys = []
+ self.linter.stats.reset_node_count()
+
+ @utils.only_required_for_messages(
+ "using-constant-test", "missing-parentheses-for-call-in-test"
+ )
+ def visit_if(self, node: nodes.If) -> None:
+ self._check_using_constant_test(node, node.test)
+
+ @utils.only_required_for_messages(
+ "using-constant-test", "missing-parentheses-for-call-in-test"
+ )
+ def visit_ifexp(self, node: nodes.IfExp) -> None:
+ self._check_using_constant_test(node, node.test)
+
+ @utils.only_required_for_messages(
+ "using-constant-test", "missing-parentheses-for-call-in-test"
+ )
+ def visit_comprehension(self, node: nodes.Comprehension) -> None:
+ if node.ifs:
+ for if_test in node.ifs:
+ self._check_using_constant_test(node, if_test)
+
+ def _check_using_constant_test(
+ self,
+ node: nodes.If | nodes.IfExp | nodes.Comprehension,
+ test: nodes.NodeNG | None,
+ ) -> None:
+ const_nodes = (
+ nodes.Module,
+ nodes.GeneratorExp,
+ nodes.Lambda,
+ nodes.FunctionDef,
+ nodes.ClassDef,
+ astroid.bases.Generator,
+ astroid.UnboundMethod,
+ astroid.BoundMethod,
+ nodes.Module,
+ )
+ structs = (nodes.Dict, nodes.Tuple, nodes.Set, nodes.List)
+
+ # These nodes are excepted, since they are not constant
+ # values, requiring a computation to happen.
+ except_nodes = (
+ nodes.Call,
+ nodes.BinOp,
+ nodes.BoolOp,
+ nodes.UnaryOp,
+ nodes.Subscript,
+ )
+ inferred = None
+ emit = isinstance(test, (nodes.Const, *structs, *const_nodes))
+ maybe_generator_call = None
+ if not isinstance(test, except_nodes):
+ inferred = utils.safe_infer(test)
+ if isinstance(inferred, util.UninferableBase) and isinstance(
+ test, nodes.Name
+ ):
+ emit, maybe_generator_call = BasicChecker._name_holds_generator(test)
+
+ # Emit if calling a function that only returns GeneratorExp (always tests True)
+ elif isinstance(test, nodes.Call):
+ maybe_generator_call = test
+ if maybe_generator_call:
+ inferred_call = utils.safe_infer(maybe_generator_call.func)
+ if isinstance(inferred_call, nodes.FunctionDef):
+ # Can't use all(x) or not any(not x) for this condition, because it
+ # will return True for empty generators, which is not what we want.
+ all_returns_were_generator = None
+ for return_node in inferred_call._get_return_nodes_skip_functions():
+ if not isinstance(return_node.value, nodes.GeneratorExp):
+ all_returns_were_generator = False
+ break
+ all_returns_were_generator = True
+ if all_returns_were_generator:
+ self.add_message(
+ "using-constant-test", node=node, confidence=INFERENCE
+ )
+ return
+
+ if emit:
+ self.add_message("using-constant-test", node=test, confidence=INFERENCE)
+ elif isinstance(inferred, const_nodes):
+ # If the constant node is a FunctionDef or Lambda then
+ # it may be an illicit function call due to missing parentheses
+ call_inferred = None
+ try:
+ # Just forcing the generator to infer all elements.
+ # astroid.exceptions.InferenceError are false positives
+ # see https://github.com/pylint-dev/pylint/pull/8185
+ if isinstance(inferred, nodes.FunctionDef):
+ call_inferred = list(inferred.infer_call_result(node))
+ elif isinstance(inferred, nodes.Lambda):
+ call_inferred = list(inferred.infer_call_result(node))
+ except astroid.InferenceError:
+ call_inferred = None
+ if call_inferred:
+ self.add_message(
+ "missing-parentheses-for-call-in-test",
+ node=test,
+ confidence=INFERENCE,
+ )
+ self.add_message("using-constant-test", node=test, confidence=INFERENCE)
+
+ @staticmethod
+ def _name_holds_generator(test: nodes.Name) -> tuple[bool, nodes.Call | None]:
+ """Return whether `test` tests a name certain to hold a generator, or optionally
+ a call that should be then tested to see if *it* returns only generators.
+ """
+ assert isinstance(test, nodes.Name)
+ emit = False
+ maybe_generator_call = None
+ lookup_result = test.frame().lookup(test.name)
+ if not lookup_result:
+ return emit, maybe_generator_call
+ maybe_generator_assigned = (
+ isinstance(assign_name.parent.value, nodes.GeneratorExp)
+ for assign_name in lookup_result[1]
+ if isinstance(assign_name.parent, nodes.Assign)
+ )
+ first_item = next(maybe_generator_assigned, None)
+ if first_item is not None:
+ # Emit if this variable is certain to hold a generator
+ if all(itertools.chain((first_item,), maybe_generator_assigned)):
+ emit = True
+ # If this variable holds the result of a call, save it for next test
+ elif (
+ len(lookup_result[1]) == 1
+ and isinstance(lookup_result[1][0].parent, nodes.Assign)
+ and isinstance(lookup_result[1][0].parent.value, nodes.Call)
+ ):
+ maybe_generator_call = lookup_result[1][0].parent.value
+ return emit, maybe_generator_call
+
+ def visit_module(self, _: nodes.Module) -> None:
+ """Check module name, docstring and required arguments."""
+ self.linter.stats.node_count["module"] += 1
+
+ def visit_classdef(self, _: nodes.ClassDef) -> None:
+ """Check module name, docstring and redefinition
+ increment branch counter.
+ """
+ self.linter.stats.node_count["klass"] += 1
+
+ @utils.only_required_for_messages(
+ "pointless-statement",
+ "pointless-exception-statement",
+ "pointless-string-statement",
+ "expression-not-assigned",
+ "named-expr-without-context",
+ )
+ def visit_expr(self, node: nodes.Expr) -> None:
+ """Check for various kind of statements without effect."""
+ expr = node.value
+ if isinstance(expr, nodes.Const) and isinstance(expr.value, str):
+ # treat string statement in a separated message
+ # Handle PEP-257 attribute docstrings.
+ # An attribute docstring is defined as being a string right after
+ # an assignment at the module level, class level or __init__ level.
+ scope = expr.scope()
+ if isinstance(scope, (nodes.ClassDef, nodes.Module, nodes.FunctionDef)):
+ if isinstance(scope, nodes.FunctionDef) and scope.name != "__init__":
+ pass
+ else:
+ sibling = expr.previous_sibling()
+ if (
+ sibling is not None
+ and sibling.scope() is scope
+ and isinstance(
+ sibling, (nodes.Assign, nodes.AnnAssign, nodes.TypeAlias)
+ )
+ ):
+ return
+ self.add_message("pointless-string-statement", node=node)
+ return
+
+ # Warn W0133 for exceptions that are used as statements
+ if isinstance(expr, nodes.Call):
+ name = ""
+ if isinstance(expr.func, nodes.Name):
+ name = expr.func.name
+ elif isinstance(expr.func, nodes.Attribute):
+ name = expr.func.attrname
+
+ # Heuristic: only run inference for names that begin with an uppercase char
+ # This reduces W0133's coverage, but retains acceptable runtime performance
+ # For more details, see: https://github.com/pylint-dev/pylint/issues/8073
+ inferred = utils.safe_infer(expr) if name[:1].isupper() else None
+ if isinstance(inferred, objects.ExceptionInstance):
+ self.add_message(
+ "pointless-exception-statement", node=node, confidence=INFERENCE
+ )
+ return
+
+ # Ignore if this is :
+ # * the unique child of a try/except body
+ # * a yield statement
+ # * an ellipsis (which can be used on Python 3 instead of pass)
+ # warn W0106 if we have any underlying function call (we can't predict
+ # side effects), else pointless-statement
+ if (
+ isinstance(expr, (nodes.Yield, nodes.Await))
+ or (
+ isinstance(node.parent, (nodes.Try, nodes.TryStar))
+ and node.parent.body == [node]
+ )
+ or (isinstance(expr, nodes.Const) and expr.value is Ellipsis)
+ ):
+ return
+ if isinstance(expr, nodes.NamedExpr):
+ self.add_message("named-expr-without-context", node=node, confidence=HIGH)
+ elif any(expr.nodes_of_class(nodes.Call)):
+ self.add_message(
+ "expression-not-assigned", node=node, args=expr.as_string()
+ )
+ else:
+ self.add_message("pointless-statement", node=node)
+
+ @staticmethod
+ def _filter_vararg(
+ node: nodes.Lambda, call_args: list[nodes.NodeNG]
+ ) -> Iterator[nodes.NodeNG]:
+ # Return the arguments for the given call which are
+ # not passed as vararg.
+ for arg in call_args:
+ if isinstance(arg, nodes.Starred):
+ if (
+ isinstance(arg.value, nodes.Name)
+ and arg.value.name != node.args.vararg
+ ):
+ yield arg
+ else:
+ yield arg
+
+ @staticmethod
+ def _has_variadic_argument(
+ args: list[nodes.Starred | nodes.Keyword], variadic_name: str
+ ) -> bool:
+ return not args or any(
+ isinstance(a.value, nodes.Name)
+ and a.value.name != variadic_name
+ or not isinstance(a.value, nodes.Name)
+ for a in args
+ )
+
+ @utils.only_required_for_messages("unnecessary-lambda")
+ def visit_lambda(self, node: nodes.Lambda) -> None:
+ """Check whether the lambda is suspicious."""
+ # if the body of the lambda is a call expression with the same
+ # argument list as the lambda itself, then the lambda is
+ # possibly unnecessary and at least suspicious.
+ if node.args.defaults:
+ # If the arguments of the lambda include defaults, then a
+ # judgment cannot be made because there is no way to check
+ # that the defaults defined by the lambda are the same as
+ # the defaults defined by the function called in the body
+ # of the lambda.
+ return
+ call = node.body
+ if not isinstance(call, nodes.Call):
+ # The body of the lambda must be a function call expression
+ # for the lambda to be unnecessary.
+ return
+ if isinstance(node.body.func, nodes.Attribute) and isinstance(
+ node.body.func.expr, nodes.Call
+ ):
+ # Chained call, the intermediate call might
+ # return something else (but we don't check that, yet).
+ return
+
+ ordinary_args = list(node.args.args)
+ new_call_args = list(self._filter_vararg(node, call.args))
+ if node.args.kwarg:
+ if self._has_variadic_argument(call.keywords, node.args.kwarg):
+ return
+ elif call.keywords:
+ return
+
+ if node.args.vararg:
+ if self._has_variadic_argument(call.starargs, node.args.vararg):
+ return
+ elif call.starargs:
+ return
+
+ # The "ordinary" arguments must be in a correspondence such that:
+ # ordinary_args[i].name == call.args[i].name.
+ if len(ordinary_args) != len(new_call_args):
+ return
+ for arg, passed_arg in zip(ordinary_args, new_call_args):
+ if not isinstance(passed_arg, nodes.Name):
+ return
+ if arg.name != passed_arg.name:
+ return
+
+ # The lambda is necessary if it uses its parameter in the function it is
+ # calling in the lambda's body
+ # e.g. lambda foo: (func1 if foo else func2)(foo)
+ for name in call.func.nodes_of_class(nodes.Name):
+ if name.lookup(name.name)[0] is node:
+ return
+
+ self.add_message("unnecessary-lambda", line=node.fromlineno, node=node)
+
+ @utils.only_required_for_messages("dangerous-default-value")
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Check function name, docstring, arguments, redefinition,
+ variable names, max locals.
+ """
+ if node.is_method():
+ self.linter.stats.node_count["method"] += 1
+ else:
+ self.linter.stats.node_count["function"] += 1
+ self._check_dangerous_default(node)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_dangerous_default(self, node: nodes.FunctionDef) -> None:
+ """Check for dangerous default values as arguments."""
+
+ def is_iterable(internal_node: nodes.NodeNG) -> bool:
+ return isinstance(internal_node, (nodes.List, nodes.Set, nodes.Dict))
+
+ defaults = (node.args.defaults or []) + (node.args.kw_defaults or [])
+ for default in defaults:
+ if not default:
+ continue
+ try:
+ value = next(default.infer())
+ except astroid.InferenceError:
+ continue
+
+ if (
+ isinstance(value, astroid.Instance)
+ and value.qname() in DEFAULT_ARGUMENT_SYMBOLS
+ ):
+ if value is default:
+ msg = DEFAULT_ARGUMENT_SYMBOLS[value.qname()]
+ elif isinstance(value, astroid.Instance) or is_iterable(value):
+ # We are here in the following situation(s):
+ # * a dict/set/list/tuple call which wasn't inferred
+ # to a syntax node ({}, () etc.). This can happen
+ # when the arguments are invalid or unknown to
+ # the inference.
+ # * a variable from somewhere else, which turns out to be a list
+ # or a dict.
+ if is_iterable(default):
+ msg = value.pytype()
+ elif isinstance(default, nodes.Call):
+ msg = f"{value.name}() ({value.qname()})"
+ else:
+ msg = f"{default.as_string()} ({value.qname()})"
+ else:
+ # this argument is a name
+ msg = f"{default.as_string()} ({DEFAULT_ARGUMENT_SYMBOLS[value.qname()]})"
+ self.add_message("dangerous-default-value", node=node, args=(msg,))
+
+ @utils.only_required_for_messages("unreachable", "lost-exception")
+ def visit_return(self, node: nodes.Return) -> None:
+ """Return node visitor.
+
+ 1 - check if the node has a right sibling (if so, that's some
+ unreachable code)
+ 2 - check if the node is inside the 'finally' clause of a 'try...finally'
+ block
+ """
+ self._check_unreachable(node)
+ # Is it inside final body of a try...finally block ?
+ self._check_not_in_finally(node, "return", (nodes.FunctionDef,))
+
+ @utils.only_required_for_messages("unreachable")
+ def visit_continue(self, node: nodes.Continue) -> None:
+ """Check is the node has a right sibling (if so, that's some unreachable
+ code).
+ """
+ self._check_unreachable(node)
+
+ @utils.only_required_for_messages("unreachable", "lost-exception")
+ def visit_break(self, node: nodes.Break) -> None:
+ """Break node visitor.
+
+ 1 - check if the node has a right sibling (if so, that's some
+ unreachable code)
+ 2 - check if the node is inside the 'finally' clause of a 'try...finally'
+ block
+ """
+ # 1 - Is it right sibling ?
+ self._check_unreachable(node)
+ # 2 - Is it inside final body of a try...finally block ?
+ self._check_not_in_finally(node, "break", (nodes.For, nodes.While))
+
+ @utils.only_required_for_messages("unreachable")
+ def visit_raise(self, node: nodes.Raise) -> None:
+ """Check if the node has a right sibling (if so, that's some unreachable
+ code).
+ """
+ self._check_unreachable(node)
+
+ def _check_misplaced_format_function(self, call_node: nodes.Call) -> None:
+ if not isinstance(call_node.func, nodes.Attribute):
+ return
+ if call_node.func.attrname != "format":
+ return
+
+ expr = utils.safe_infer(call_node.func.expr)
+ if isinstance(expr, util.UninferableBase):
+ return
+ if not expr:
+ # we are doubtful on inferred type of node, so here just check if format
+ # was called on print()
+ call_expr = call_node.func.expr
+ if not isinstance(call_expr, nodes.Call):
+ return
+ if (
+ isinstance(call_expr.func, nodes.Name)
+ and call_expr.func.name == "print"
+ ):
+ self.add_message("misplaced-format-function", node=call_node)
+
+ @utils.only_required_for_messages(
+ "eval-used",
+ "exec-used",
+ "bad-reversed-sequence",
+ "misplaced-format-function",
+ "unreachable",
+ )
+ def visit_call(self, node: nodes.Call) -> None:
+ """Visit a Call node."""
+ if utils.is_terminating_func(node):
+ self._check_unreachable(node, confidence=INFERENCE)
+ self._check_misplaced_format_function(node)
+ if isinstance(node.func, nodes.Name):
+ name = node.func.name
+ # ignore the name if it's not a builtin (i.e. not defined in the
+ # locals nor globals scope)
+ if not (name in node.frame() or name in node.root()):
+ if name == "exec":
+ self.add_message("exec-used", node=node)
+ elif name == "reversed":
+ self._check_reversed(node)
+ elif name == "eval":
+ self.add_message("eval-used", node=node)
+
+ @utils.only_required_for_messages("assert-on-tuple", "assert-on-string-literal")
+ def visit_assert(self, node: nodes.Assert) -> None:
+ """Check whether assert is used on a tuple or string literal."""
+ if isinstance(node.test, nodes.Tuple) and len(node.test.elts) > 0:
+ self.add_message("assert-on-tuple", node=node, confidence=HIGH)
+
+ if isinstance(node.test, nodes.Const) and isinstance(node.test.value, str):
+ if node.test.value:
+ when = "never"
+ else:
+ when = "always"
+ self.add_message("assert-on-string-literal", node=node, args=(when,))
+
+ @utils.only_required_for_messages("duplicate-key")
+ def visit_dict(self, node: nodes.Dict) -> None:
+ """Check duplicate key in dictionary."""
+ keys = set()
+ for k, _ in node.items:
+ if isinstance(k, nodes.Const):
+ key = k.value
+ elif isinstance(k, nodes.Attribute):
+ key = k.as_string()
+ else:
+ continue
+ if key in keys:
+ self.add_message("duplicate-key", node=node, args=key)
+ keys.add(key)
+
+ @utils.only_required_for_messages("duplicate-value")
+ def visit_set(self, node: nodes.Set) -> None:
+ """Check duplicate value in set."""
+ values = set()
+ for v in node.elts:
+ if isinstance(v, nodes.Const):
+ value = v.value
+ else:
+ continue
+ if value in values:
+ self.add_message(
+ "duplicate-value", node=node, args=value, confidence=HIGH
+ )
+ values.add(value)
+
+ def visit_try(self, node: nodes.Try) -> None:
+ """Update try block flag."""
+ self._trys.append(node)
+
+ for final_node in node.finalbody:
+ for return_node in final_node.nodes_of_class(nodes.Return):
+ self.add_message("return-in-finally", node=return_node, confidence=HIGH)
+
+ def leave_try(self, _: nodes.Try) -> None:
+ """Update try block flag."""
+ self._trys.pop()
+
+ def _check_unreachable(
+ self,
+ node: nodes.Return | nodes.Continue | nodes.Break | nodes.Raise | nodes.Call,
+ confidence: Confidence = HIGH,
+ ) -> None:
+ """Check unreachable code."""
+ unreachable_statement = node.next_sibling()
+ if unreachable_statement is not None:
+ if (
+ isinstance(node, nodes.Return)
+ and isinstance(unreachable_statement, nodes.Expr)
+ and isinstance(unreachable_statement.value, nodes.Yield)
+ ):
+ # Don't add 'unreachable' for empty generators.
+ # Only add warning if 'yield' is followed by another node.
+ unreachable_statement = unreachable_statement.next_sibling()
+ if unreachable_statement is None:
+ return
+ self.add_message(
+ "unreachable", node=unreachable_statement, confidence=confidence
+ )
+
+ def _check_not_in_finally(
+ self,
+ node: nodes.Break | nodes.Return,
+ node_name: str,
+ breaker_classes: tuple[nodes.NodeNG, ...] = (),
+ ) -> None:
+ """Check that a node is not inside a 'finally' clause of a
+ 'try...finally' statement.
+
+ If we find a parent which type is in breaker_classes before
+ a 'try...finally' block we skip the whole check.
+ """
+ # if self._trys is empty, we're not an in try block
+ if not self._trys:
+ return
+ # the node could be a grand-grand...-child of the 'try...finally'
+ _parent = node.parent
+ _node = node
+ while _parent and not isinstance(_parent, breaker_classes):
+ if hasattr(_parent, "finalbody") and _node in _parent.finalbody:
+ self.add_message("lost-exception", node=node, args=node_name)
+ return
+ _node = _parent
+ _parent = _node.parent
+
+ def _check_reversed(self, node: nodes.Call) -> None:
+ """Check that the argument to `reversed` is a sequence."""
+ try:
+ argument = utils.safe_infer(utils.get_argument_from_call(node, position=0))
+ except utils.NoSuchArgumentError:
+ pass
+ else:
+ if isinstance(argument, util.UninferableBase):
+ return
+ if argument is None:
+ # Nothing was inferred.
+ # Try to see if we have iter().
+ if isinstance(node.args[0], nodes.Call):
+ try:
+ func = next(node.args[0].func.infer())
+ except astroid.InferenceError:
+ return
+ if getattr(
+ func, "name", None
+ ) == "iter" and utils.is_builtin_object(func):
+ self.add_message("bad-reversed-sequence", node=node)
+ return
+
+ if isinstance(argument, (nodes.List, nodes.Tuple)):
+ return
+
+ # dicts are reversible, but only from Python 3.8 onward. Prior to
+ # that, any class based on dict must explicitly provide a
+ # __reversed__ method
+ if not self._py38_plus and isinstance(argument, astroid.Instance):
+ if any(
+ ancestor.name == "dict" and utils.is_builtin_object(ancestor)
+ for ancestor in itertools.chain(
+ (argument._proxied,), argument._proxied.ancestors()
+ )
+ ):
+ try:
+ argument.locals[REVERSED_PROTOCOL_METHOD]
+ except KeyError:
+ self.add_message("bad-reversed-sequence", node=node)
+ return
+
+ if hasattr(argument, "getattr"):
+ # everything else is not a proper sequence for reversed()
+ for methods in REVERSED_METHODS:
+ for meth in methods:
+ try:
+ argument.getattr(meth)
+ except astroid.NotFoundError:
+ break
+ else:
+ break
+ else:
+ self.add_message("bad-reversed-sequence", node=node)
+ else:
+ self.add_message("bad-reversed-sequence", node=node)
+
+ @utils.only_required_for_messages("confusing-with-statement")
+ def visit_with(self, node: nodes.With) -> None:
+ # a "with" statement with multiple managers corresponds
+ # to one AST "With" node with multiple items
+ pairs = node.items
+ if pairs:
+ for prev_pair, pair in zip(pairs, pairs[1:]):
+ if isinstance(prev_pair[1], nodes.AssignName) and (
+ pair[1] is None and not isinstance(pair[0], nodes.Call)
+ ):
+ # Don't emit a message if the second is a function call
+ # there's no way that can be mistaken for a name assignment.
+ # If the line number doesn't match
+ # we assume it's a nested "with".
+ self.add_message("confusing-with-statement", node=node)
+
+ def _check_self_assigning_variable(self, node: nodes.Assign) -> None:
+ # Detect assigning to the same variable.
+
+ scope = node.scope()
+ scope_locals = scope.locals
+
+ rhs_names = []
+ targets = node.targets
+ if isinstance(targets[0], nodes.Tuple):
+ if len(targets) != 1:
+ # A complex assignment, so bail out early.
+ return
+ targets = targets[0].elts
+ if len(targets) == 1:
+ # Unpacking a variable into the same name.
+ return
+
+ if isinstance(node.value, nodes.Name):
+ if len(targets) != 1:
+ return
+ rhs_names = [node.value]
+ elif isinstance(node.value, nodes.Tuple):
+ rhs_count = len(node.value.elts)
+ if len(targets) != rhs_count or rhs_count == 1:
+ return
+ rhs_names = node.value.elts
+
+ for target, lhs_name in zip(targets, rhs_names):
+ if not isinstance(lhs_name, nodes.Name):
+ continue
+ if not isinstance(target, nodes.AssignName):
+ continue
+ # Check that the scope is different from a class level, which is usually
+ # a pattern to expose module level attributes as class level ones.
+ if isinstance(scope, nodes.ClassDef) and target.name in scope_locals:
+ continue
+ if target.name == lhs_name.name:
+ self.add_message(
+ "self-assigning-variable", args=(target.name,), node=target
+ )
+
+ def _check_redeclared_assign_name(self, targets: list[nodes.NodeNG | None]) -> None:
+ dummy_variables_rgx = self.linter.config.dummy_variables_rgx
+
+ for target in targets:
+ if not isinstance(target, nodes.Tuple):
+ continue
+
+ found_names = []
+ for element in target.elts:
+ if isinstance(element, nodes.Tuple):
+ self._check_redeclared_assign_name([element])
+ elif isinstance(element, nodes.AssignName) and element.name != "_":
+ if dummy_variables_rgx and dummy_variables_rgx.match(element.name):
+ return
+ found_names.append(element.name)
+
+ names = collections.Counter(found_names)
+ for name, count in names.most_common():
+ if count > 1:
+ self.add_message(
+ "redeclared-assigned-name", args=(name,), node=target
+ )
+
+ @utils.only_required_for_messages(
+ "self-assigning-variable", "redeclared-assigned-name"
+ )
+ def visit_assign(self, node: nodes.Assign) -> None:
+ self._check_self_assigning_variable(node)
+ self._check_redeclared_assign_name(node.targets)
+
+ @utils.only_required_for_messages("redeclared-assigned-name")
+ def visit_for(self, node: nodes.For) -> None:
+ self._check_redeclared_assign_name([node.target])
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/basic_error_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/basic_error_checker.py
new file mode 100644
index 000000000..d6e10f31d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/basic_error_checker.py
@@ -0,0 +1,578 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Basic Error checker from the basic checker."""
+
+from __future__ import annotations
+
+import itertools
+
+import astroid
+from astroid import nodes
+from astroid.typing import InferenceResult
+
+from pylint.checkers import utils
+from pylint.checkers.base.basic_checker import _BasicChecker
+from pylint.checkers.utils import infer_all
+from pylint.interfaces import HIGH
+
+ABC_METACLASSES = {"_py_abc.ABCMeta", "abc.ABCMeta"} # Python 3.7+,
+# List of methods which can be redefined
+REDEFINABLE_METHODS = frozenset(("__module__",))
+TYPING_FORWARD_REF_QNAME = "typing.ForwardRef"
+
+
+def _get_break_loop_node(break_node: nodes.Break) -> nodes.For | nodes.While | None:
+ """Returns the loop node that holds the break node in arguments.
+
+ Args:
+ break_node (astroid.Break): the break node of interest.
+
+ Returns:
+ astroid.For or astroid.While: the loop node holding the break node.
+ """
+ loop_nodes = (nodes.For, nodes.While)
+ parent = break_node.parent
+ while not isinstance(parent, loop_nodes) or break_node in getattr(
+ parent, "orelse", []
+ ):
+ break_node = parent
+ parent = parent.parent
+ if parent is None:
+ break
+ return parent
+
+
+def _loop_exits_early(loop: nodes.For | nodes.While) -> bool:
+ """Returns true if a loop may end with a break statement.
+
+ Args:
+ loop (astroid.For, astroid.While): the loop node inspected.
+
+ Returns:
+ bool: True if the loop may end with a break statement, False otherwise.
+ """
+ loop_nodes = (nodes.For, nodes.While)
+ definition_nodes = (nodes.FunctionDef, nodes.ClassDef)
+ inner_loop_nodes: list[nodes.For | nodes.While] = [
+ _node
+ for _node in loop.nodes_of_class(loop_nodes, skip_klass=definition_nodes)
+ if _node != loop
+ ]
+ return any(
+ _node
+ for _node in loop.nodes_of_class(nodes.Break, skip_klass=definition_nodes)
+ if _get_break_loop_node(_node) not in inner_loop_nodes
+ )
+
+
+def _has_abstract_methods(node: nodes.ClassDef) -> bool:
+ """Determine if the given `node` has abstract methods.
+
+ The methods should be made abstract by decorating them
+ with `abc` decorators.
+ """
+ return len(utils.unimplemented_abstract_methods(node)) > 0
+
+
+def redefined_by_decorator(node: nodes.FunctionDef) -> bool:
+ """Return True if the object is a method redefined via decorator.
+
+ For example:
+ @property
+ def x(self): return self._x
+ @x.setter
+ def x(self, value): self._x = value
+ """
+ if node.decorators:
+ for decorator in node.decorators.nodes:
+ if (
+ isinstance(decorator, nodes.Attribute)
+ and getattr(decorator.expr, "name", None) == node.name
+ ):
+ return True
+ return False
+
+
+class BasicErrorChecker(_BasicChecker):
+ msgs = {
+ "E0100": (
+ "__init__ method is a generator",
+ "init-is-generator",
+ "Used when the special class method __init__ is turned into a "
+ "generator by a yield in its body.",
+ ),
+ "E0101": (
+ "Explicit return in __init__",
+ "return-in-init",
+ "Used when the special class method __init__ has an explicit "
+ "return value.",
+ ),
+ "E0102": (
+ "%s already defined line %s",
+ "function-redefined",
+ "Used when a function / class / method is redefined.",
+ ),
+ "E0103": (
+ "%r not properly in loop",
+ "not-in-loop",
+ "Used when break or continue keywords are used outside a loop.",
+ ),
+ "E0104": (
+ "Return outside function",
+ "return-outside-function",
+ 'Used when a "return" statement is found outside a function or method.',
+ ),
+ "E0105": (
+ "Yield outside function",
+ "yield-outside-function",
+ 'Used when a "yield" statement is found outside a function or method.',
+ ),
+ "E0106": (
+ "Return with argument inside generator",
+ "return-arg-in-generator",
+ 'Used when a "return" statement with an argument is found '
+ 'in a generator function or method (e.g. with some "yield" statements).',
+ {"maxversion": (3, 3)},
+ ),
+ "E0107": (
+ "Use of the non-existent %s operator",
+ "nonexistent-operator",
+ "Used when you attempt to use the C-style pre-increment or "
+ "pre-decrement operator -- and ++, which doesn't exist in Python.",
+ ),
+ "E0108": (
+ "Duplicate argument name %r in function definition",
+ "duplicate-argument-name",
+ "Duplicate argument names in function definitions are syntax errors.",
+ ),
+ "E0110": (
+ "Abstract class %r with abstract methods instantiated",
+ "abstract-class-instantiated",
+ "Used when an abstract class with `abc.ABCMeta` as metaclass "
+ "has abstract methods and is instantiated.",
+ ),
+ "W0120": (
+ "Else clause on loop without a break statement, remove the else and"
+ " de-indent all the code inside it",
+ "useless-else-on-loop",
+ "Loops should only have an else clause if they can exit early "
+ "with a break statement, otherwise the statements under else "
+ "should be on the same scope as the loop itself.",
+ ),
+ "E0112": (
+ "More than one starred expression in assignment",
+ "too-many-star-expressions",
+ "Emitted when there are more than one starred "
+ "expressions (`*x`) in an assignment. This is a SyntaxError.",
+ ),
+ "E0113": (
+ "Starred assignment target must be in a list or tuple",
+ "invalid-star-assignment-target",
+ "Emitted when a star expression is used as a starred assignment target.",
+ ),
+ "E0114": (
+ "Can use starred expression only in assignment target",
+ "star-needs-assignment-target",
+ "Emitted when a star expression is not used in an assignment target.",
+ ),
+ "E0115": (
+ "Name %r is nonlocal and global",
+ "nonlocal-and-global",
+ "Emitted when a name is both nonlocal and global.",
+ ),
+ "E0116": (
+ "'continue' not supported inside 'finally' clause",
+ "continue-in-finally",
+ "Emitted when the `continue` keyword is found "
+ "inside a finally clause, which is a SyntaxError.",
+ ),
+ "E0117": (
+ "nonlocal name %s found without binding",
+ "nonlocal-without-binding",
+ "Emitted when a nonlocal variable does not have an attached "
+ "name somewhere in the parent scopes",
+ ),
+ "E0118": (
+ "Name %r is used prior to global declaration",
+ "used-prior-global-declaration",
+ "Emitted when a name is used prior a global declaration, "
+ "which results in an error since Python 3.6.",
+ {"minversion": (3, 6)},
+ ),
+ }
+
+ def open(self) -> None:
+ py_version = self.linter.config.py_version
+ self._py38_plus = py_version >= (3, 8)
+
+ @utils.only_required_for_messages("function-redefined")
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ self._check_redefinition("class", node)
+
+ def _too_many_starred_for_tuple(self, assign_tuple: nodes.Tuple) -> bool:
+ starred_count = 0
+ for elem in assign_tuple.itered():
+ if isinstance(elem, nodes.Tuple):
+ return self._too_many_starred_for_tuple(elem)
+ if isinstance(elem, nodes.Starred):
+ starred_count += 1
+ return starred_count > 1
+
+ @utils.only_required_for_messages(
+ "too-many-star-expressions", "invalid-star-assignment-target"
+ )
+ def visit_assign(self, node: nodes.Assign) -> None:
+ # Check *a, *b = ...
+ assign_target = node.targets[0]
+ # Check *a = b
+ if isinstance(node.targets[0], nodes.Starred):
+ self.add_message("invalid-star-assignment-target", node=node)
+
+ if not isinstance(assign_target, nodes.Tuple):
+ return
+ if self._too_many_starred_for_tuple(assign_target):
+ self.add_message("too-many-star-expressions", node=node)
+
+ @utils.only_required_for_messages("star-needs-assignment-target")
+ def visit_starred(self, node: nodes.Starred) -> None:
+ """Check that a Starred expression is used in an assignment target."""
+ if isinstance(node.parent, nodes.Call):
+ # f(*args) is converted to Call(args=[Starred]), so ignore
+ # them for this check.
+ return
+ if isinstance(node.parent, (nodes.List, nodes.Tuple, nodes.Set, nodes.Dict)):
+ # PEP 448 unpacking.
+ return
+
+ stmt = node.statement()
+ if not isinstance(stmt, nodes.Assign):
+ return
+
+ if stmt.value is node or stmt.value.parent_of(node):
+ self.add_message("star-needs-assignment-target", node=node)
+
+ @utils.only_required_for_messages(
+ "init-is-generator",
+ "return-in-init",
+ "function-redefined",
+ "return-arg-in-generator",
+ "duplicate-argument-name",
+ "nonlocal-and-global",
+ "used-prior-global-declaration",
+ )
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ self._check_nonlocal_and_global(node)
+ self._check_name_used_prior_global(node)
+ if not redefined_by_decorator(
+ node
+ ) and not utils.is_registered_in_singledispatch_function(node):
+ self._check_redefinition(node.is_method() and "method" or "function", node)
+ # checks for max returns, branch, return in __init__
+ returns = node.nodes_of_class(
+ nodes.Return, skip_klass=(nodes.FunctionDef, nodes.ClassDef)
+ )
+ if node.is_method() and node.name == "__init__":
+ if node.is_generator():
+ self.add_message("init-is-generator", node=node)
+ else:
+ values = [r.value for r in returns]
+ # Are we returning anything but None from constructors
+ if any(v for v in values if not utils.is_none(v)):
+ self.add_message("return-in-init", node=node)
+ # Check for duplicate names by clustering args with same name for detailed report
+ arg_clusters = {}
+ for arg in node.args.arguments:
+ if arg.name in arg_clusters:
+ self.add_message(
+ "duplicate-argument-name",
+ node=arg,
+ args=(arg.name,),
+ confidence=HIGH,
+ )
+ else:
+ arg_clusters[arg.name] = arg
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_name_used_prior_global(self, node: nodes.FunctionDef) -> None:
+ scope_globals = {
+ name: child
+ for child in node.nodes_of_class(nodes.Global)
+ for name in child.names
+ if child.scope() is node
+ }
+
+ if not scope_globals:
+ return
+
+ for node_name in node.nodes_of_class(nodes.Name):
+ if node_name.scope() is not node:
+ continue
+
+ name = node_name.name
+ corresponding_global = scope_globals.get(name)
+ if not corresponding_global:
+ continue
+
+ global_lineno = corresponding_global.fromlineno
+ if global_lineno and global_lineno > node_name.fromlineno:
+ self.add_message(
+ "used-prior-global-declaration", node=node_name, args=(name,)
+ )
+
+ def _check_nonlocal_and_global(self, node: nodes.FunctionDef) -> None:
+ """Check that a name is both nonlocal and global."""
+
+ def same_scope(current: nodes.Global | nodes.Nonlocal) -> bool:
+ return current.scope() is node
+
+ from_iter = itertools.chain.from_iterable
+ nonlocals = set(
+ from_iter(
+ child.names
+ for child in node.nodes_of_class(nodes.Nonlocal)
+ if same_scope(child)
+ )
+ )
+
+ if not nonlocals:
+ return
+
+ global_vars = set(
+ from_iter(
+ child.names
+ for child in node.nodes_of_class(nodes.Global)
+ if same_scope(child)
+ )
+ )
+ for name in nonlocals.intersection(global_vars):
+ self.add_message("nonlocal-and-global", args=(name,), node=node)
+
+ @utils.only_required_for_messages("return-outside-function")
+ def visit_return(self, node: nodes.Return) -> None:
+ if not isinstance(node.frame(), nodes.FunctionDef):
+ self.add_message("return-outside-function", node=node)
+
+ @utils.only_required_for_messages("yield-outside-function")
+ def visit_yield(self, node: nodes.Yield) -> None:
+ self._check_yield_outside_func(node)
+
+ @utils.only_required_for_messages("yield-outside-function")
+ def visit_yieldfrom(self, node: nodes.YieldFrom) -> None:
+ self._check_yield_outside_func(node)
+
+ @utils.only_required_for_messages("not-in-loop", "continue-in-finally")
+ def visit_continue(self, node: nodes.Continue) -> None:
+ self._check_in_loop(node, "continue")
+
+ @utils.only_required_for_messages("not-in-loop")
+ def visit_break(self, node: nodes.Break) -> None:
+ self._check_in_loop(node, "break")
+
+ @utils.only_required_for_messages("useless-else-on-loop")
+ def visit_for(self, node: nodes.For) -> None:
+ self._check_else_on_loop(node)
+
+ @utils.only_required_for_messages("useless-else-on-loop")
+ def visit_while(self, node: nodes.While) -> None:
+ self._check_else_on_loop(node)
+
+ @utils.only_required_for_messages("nonexistent-operator")
+ def visit_unaryop(self, node: nodes.UnaryOp) -> None:
+ """Check use of the non-existent ++ and -- operators."""
+ if (
+ (node.op in "+-")
+ and isinstance(node.operand, nodes.UnaryOp)
+ and (node.operand.op == node.op)
+ and (node.col_offset + 1 == node.operand.col_offset)
+ ):
+ self.add_message("nonexistent-operator", node=node, args=node.op * 2)
+
+ def _check_nonlocal_without_binding(self, node: nodes.Nonlocal, name: str) -> None:
+ current_scope = node.scope()
+ while current_scope.parent is not None:
+ if not isinstance(current_scope, (nodes.ClassDef, nodes.FunctionDef)):
+ self.add_message("nonlocal-without-binding", args=(name,), node=node)
+ return
+
+ # Search for `name` in the parent scope if:
+ # `current_scope` is the same scope in which the `nonlocal` name is declared
+ # or `name` is not in `current_scope.locals`.
+ if current_scope is node.scope() or name not in current_scope.locals:
+ current_scope = current_scope.parent.scope()
+ continue
+
+ # Okay, found it.
+ return
+
+ if not isinstance(current_scope, nodes.FunctionDef):
+ self.add_message(
+ "nonlocal-without-binding", args=(name,), node=node, confidence=HIGH
+ )
+
+ @utils.only_required_for_messages("nonlocal-without-binding")
+ def visit_nonlocal(self, node: nodes.Nonlocal) -> None:
+ for name in node.names:
+ self._check_nonlocal_without_binding(node, name)
+
+ @utils.only_required_for_messages("abstract-class-instantiated")
+ def visit_call(self, node: nodes.Call) -> None:
+ """Check instantiating abstract class with
+ abc.ABCMeta as metaclass.
+ """
+ for inferred in infer_all(node.func):
+ self._check_inferred_class_is_abstract(inferred, node)
+
+ def _check_inferred_class_is_abstract(
+ self, inferred: InferenceResult, node: nodes.Call
+ ) -> None:
+ if not isinstance(inferred, nodes.ClassDef):
+ return
+
+ klass = utils.node_frame_class(node)
+ if klass is inferred:
+ # Don't emit the warning if the class is instantiated
+ # in its own body or if the call is not an instance
+ # creation. If the class is instantiated into its own
+ # body, we're expecting that it knows what it is doing.
+ return
+
+ # __init__ was called
+ abstract_methods = _has_abstract_methods(inferred)
+
+ if not abstract_methods:
+ return
+
+ metaclass = inferred.metaclass()
+
+ if metaclass is None:
+ # Python 3.4 has `abc.ABC`, which won't be detected
+ # by ClassNode.metaclass()
+ for ancestor in inferred.ancestors():
+ if ancestor.qname() == "abc.ABC":
+ self.add_message(
+ "abstract-class-instantiated", args=(inferred.name,), node=node
+ )
+ break
+
+ return
+
+ if metaclass.qname() in ABC_METACLASSES:
+ self.add_message(
+ "abstract-class-instantiated", args=(inferred.name,), node=node
+ )
+
+ def _check_yield_outside_func(self, node: nodes.Yield) -> None:
+ if not isinstance(node.frame(), (nodes.FunctionDef, nodes.Lambda)):
+ self.add_message("yield-outside-function", node=node)
+
+ def _check_else_on_loop(self, node: nodes.For | nodes.While) -> None:
+ """Check that any loop with an else clause has a break statement."""
+ if node.orelse and not _loop_exits_early(node):
+ self.add_message(
+ "useless-else-on-loop",
+ node=node,
+ # This is not optimal, but the line previous
+ # to the first statement in the else clause
+ # will usually be the one that contains the else:.
+ line=node.orelse[0].lineno - 1,
+ )
+
+ def _check_in_loop(
+ self, node: nodes.Continue | nodes.Break, node_name: str
+ ) -> None:
+ """Check that a node is inside a for or while loop."""
+ for parent in node.node_ancestors():
+ if isinstance(parent, (nodes.For, nodes.While)):
+ if node not in parent.orelse:
+ return
+
+ if isinstance(parent, (nodes.ClassDef, nodes.FunctionDef)):
+ break
+ if (
+ isinstance(parent, nodes.Try)
+ and node in parent.finalbody
+ and isinstance(node, nodes.Continue)
+ and not self._py38_plus
+ ):
+ self.add_message("continue-in-finally", node=node)
+
+ self.add_message("not-in-loop", node=node, args=node_name)
+
+ def _check_redefinition(
+ self, redeftype: str, node: nodes.Call | nodes.FunctionDef
+ ) -> None:
+ """Check for redefinition of a function / method / class name."""
+ parent_frame = node.parent.frame()
+
+ # Ignore function stubs created for type information
+ redefinitions = [
+ i
+ for i in parent_frame.locals[node.name]
+ if not (isinstance(i.parent, nodes.AnnAssign) and i.parent.simple)
+ ]
+ defined_self = next(
+ (local for local in redefinitions if not utils.is_overload_stub(local)),
+ node,
+ )
+ if defined_self is not node and not astroid.are_exclusive(node, defined_self):
+ # Additional checks for methods which are not considered
+ # redefined, since they are already part of the base API.
+ if (
+ isinstance(parent_frame, nodes.ClassDef)
+ and node.name in REDEFINABLE_METHODS
+ ):
+ return
+
+ # Skip typing.overload() functions.
+ if utils.is_overload_stub(node):
+ return
+
+ # Exempt functions redefined on a condition.
+ if isinstance(node.parent, nodes.If):
+ # Exempt "if not <func>" cases
+ if (
+ isinstance(node.parent.test, nodes.UnaryOp)
+ and node.parent.test.op == "not"
+ and isinstance(node.parent.test.operand, nodes.Name)
+ and node.parent.test.operand.name == node.name
+ ):
+ return
+
+ # Exempt "if <func> is not None" cases
+ # pylint: disable=too-many-boolean-expressions
+ if (
+ isinstance(node.parent.test, nodes.Compare)
+ and isinstance(node.parent.test.left, nodes.Name)
+ and node.parent.test.left.name == node.name
+ and node.parent.test.ops[0][0] == "is"
+ and isinstance(node.parent.test.ops[0][1], nodes.Const)
+ and node.parent.test.ops[0][1].value is None
+ ):
+ return
+
+ # Check if we have forward references for this node.
+ try:
+ redefinition_index = redefinitions.index(node)
+ except ValueError:
+ pass
+ else:
+ for redefinition in redefinitions[:redefinition_index]:
+ inferred = utils.safe_infer(redefinition)
+ if (
+ inferred
+ and isinstance(inferred, astroid.Instance)
+ and inferred.qname() == TYPING_FORWARD_REF_QNAME
+ ):
+ return
+
+ dummy_variables_rgx = self.linter.config.dummy_variables_rgx
+ if dummy_variables_rgx and dummy_variables_rgx.match(node.name):
+ return
+ self.add_message(
+ "function-redefined",
+ node=node,
+ args=(redeftype, defined_self.fromlineno),
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/comparison_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/comparison_checker.py
new file mode 100644
index 000000000..6fb053e2e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/comparison_checker.py
@@ -0,0 +1,353 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Comparison checker from the basic checker."""
+
+import astroid
+from astroid import nodes
+
+from pylint.checkers import utils
+from pylint.checkers.base.basic_checker import _BasicChecker
+from pylint.interfaces import HIGH
+
+LITERAL_NODE_TYPES = (nodes.Const, nodes.Dict, nodes.List, nodes.Set)
+COMPARISON_OPERATORS = frozenset(("==", "!=", "<", ">", "<=", ">="))
+TYPECHECK_COMPARISON_OPERATORS = frozenset(("is", "is not", "==", "!="))
+TYPE_QNAME = "builtins.type"
+
+
+def _is_one_arg_pos_call(call: nodes.NodeNG) -> bool:
+ """Is this a call with exactly 1 positional argument ?"""
+ return isinstance(call, nodes.Call) and len(call.args) == 1 and not call.keywords
+
+
+class ComparisonChecker(_BasicChecker):
+ """Checks for comparisons.
+
+ - singleton comparison: 'expr == True', 'expr == False' and 'expr == None'
+ - yoda condition: 'const "comp" right' where comp can be '==', '!=', '<',
+ '<=', '>' or '>=', and right can be a variable, an attribute, a method or
+ a function
+ """
+
+ msgs = {
+ "C0121": (
+ "Comparison %s should be %s",
+ "singleton-comparison",
+ "Used when an expression is compared to singleton "
+ "values like True, False or None.",
+ ),
+ "C0123": (
+ "Use isinstance() rather than type() for a typecheck.",
+ "unidiomatic-typecheck",
+ "The idiomatic way to perform an explicit typecheck in "
+ "Python is to use isinstance(x, Y) rather than "
+ "type(x) == Y, type(x) is Y. Though there are unusual "
+ "situations where these give different results.",
+ {"old_names": [("W0154", "old-unidiomatic-typecheck")]},
+ ),
+ "R0123": (
+ "In '%s', use '%s' when comparing constant literals not '%s' ('%s')",
+ "literal-comparison",
+ "Used when comparing an object to a literal, which is usually "
+ "what you do not want to do, since you can compare to a different "
+ "literal than what was expected altogether.",
+ ),
+ "R0124": (
+ "Redundant comparison - %s",
+ "comparison-with-itself",
+ "Used when something is compared against itself.",
+ ),
+ "R0133": (
+ "Comparison between constants: '%s %s %s' has a constant value",
+ "comparison-of-constants",
+ "When two literals are compared with each other the result is a constant. "
+ "Using the constant directly is both easier to read and more performant. "
+ "Initializing 'True' and 'False' this way is not required since Python 2.3.",
+ ),
+ "W0143": (
+ "Comparing against a callable, did you omit the parenthesis?",
+ "comparison-with-callable",
+ "This message is emitted when pylint detects that a comparison with a "
+ "callable was made, which might suggest that some parenthesis were omitted, "
+ "resulting in potential unwanted behaviour.",
+ ),
+ "W0177": (
+ "Comparison %s should be %s",
+ "nan-comparison",
+ "Used when an expression is compared to NaN "
+ "values like numpy.NaN and float('nan').",
+ ),
+ }
+
+ def _check_singleton_comparison(
+ self,
+ left_value: nodes.NodeNG,
+ right_value: nodes.NodeNG,
+ root_node: nodes.Compare,
+ checking_for_absence: bool = False,
+ ) -> None:
+ """Check if == or != is being used to compare a singleton value."""
+ if utils.is_singleton_const(left_value):
+ singleton, other_value = left_value.value, right_value
+ elif utils.is_singleton_const(right_value):
+ singleton, other_value = right_value.value, left_value
+ else:
+ return
+
+ singleton_comparison_example = {False: "'{} is {}'", True: "'{} is not {}'"}
+
+ # True/False singletons have a special-cased message in case the user is
+ # mistakenly using == or != to check for truthiness
+ if singleton in {True, False}:
+ suggestion_template = (
+ "{} if checking for the singleton value {}, or {} if testing for {}"
+ )
+ truthiness_example = {False: "not {}", True: "{}"}
+ truthiness_phrase = {True: "truthiness", False: "falsiness"}
+
+ # Looks for comparisons like x == True or x != False
+ checking_truthiness = singleton is not checking_for_absence
+
+ suggestion = suggestion_template.format(
+ singleton_comparison_example[checking_for_absence].format(
+ left_value.as_string(), right_value.as_string()
+ ),
+ singleton,
+ (
+ "'bool({})'"
+ if not utils.is_test_condition(root_node) and checking_truthiness
+ else "'{}'"
+ ).format(
+ truthiness_example[checking_truthiness].format(
+ other_value.as_string()
+ )
+ ),
+ truthiness_phrase[checking_truthiness],
+ )
+ else:
+ suggestion = singleton_comparison_example[checking_for_absence].format(
+ left_value.as_string(), right_value.as_string()
+ )
+ self.add_message(
+ "singleton-comparison",
+ node=root_node,
+ args=(f"'{root_node.as_string()}'", suggestion),
+ )
+
+ def _check_nan_comparison(
+ self,
+ left_value: nodes.NodeNG,
+ right_value: nodes.NodeNG,
+ root_node: nodes.Compare,
+ checking_for_absence: bool = False,
+ ) -> None:
+ def _is_float_nan(node: nodes.NodeNG) -> bool:
+ try:
+ if isinstance(node, nodes.Call) and len(node.args) == 1:
+ if (
+ node.args[0].value.lower() == "nan"
+ and node.inferred()[0].pytype() == "builtins.float"
+ ):
+ return True
+ return False
+ except AttributeError:
+ return False
+
+ def _is_numpy_nan(node: nodes.NodeNG) -> bool:
+ if isinstance(node, nodes.Attribute) and node.attrname == "NaN":
+ if isinstance(node.expr, nodes.Name):
+ return node.expr.name in {"numpy", "nmp", "np"}
+ return False
+
+ def _is_nan(node: nodes.NodeNG) -> bool:
+ return _is_float_nan(node) or _is_numpy_nan(node)
+
+ nan_left = _is_nan(left_value)
+ if not nan_left and not _is_nan(right_value):
+ return
+
+ absence_text = ""
+ if checking_for_absence:
+ absence_text = "not "
+ if nan_left:
+ suggestion = f"'{absence_text}math.isnan({right_value.as_string()})'"
+ else:
+ suggestion = f"'{absence_text}math.isnan({left_value.as_string()})'"
+ self.add_message(
+ "nan-comparison",
+ node=root_node,
+ args=(f"'{root_node.as_string()}'", suggestion),
+ )
+
+ def _check_literal_comparison(
+ self, literal: nodes.NodeNG, node: nodes.Compare
+ ) -> None:
+ """Check if we compare to a literal, which is usually what we do not want to do."""
+ is_other_literal = isinstance(literal, (nodes.List, nodes.Dict, nodes.Set))
+ is_const = False
+ if isinstance(literal, nodes.Const):
+ if isinstance(literal.value, bool) or literal.value is None:
+ # Not interested in these values.
+ return
+ is_const = isinstance(literal.value, (bytes, str, int, float))
+
+ if is_const or is_other_literal:
+ incorrect_node_str = node.as_string()
+ if "is not" in incorrect_node_str:
+ equal_or_not_equal = "!="
+ is_or_is_not = "is not"
+ else:
+ equal_or_not_equal = "=="
+ is_or_is_not = "is"
+ fixed_node_str = incorrect_node_str.replace(
+ is_or_is_not, equal_or_not_equal
+ )
+ self.add_message(
+ "literal-comparison",
+ args=(
+ incorrect_node_str,
+ equal_or_not_equal,
+ is_or_is_not,
+ fixed_node_str,
+ ),
+ node=node,
+ confidence=HIGH,
+ )
+
+ def _check_logical_tautology(self, node: nodes.Compare) -> None:
+ """Check if identifier is compared against itself.
+
+ :param node: Compare node
+ :Example:
+ val = 786
+ if val == val: # [comparison-with-itself]
+ pass
+ """
+ left_operand = node.left
+ right_operand = node.ops[0][1]
+ operator = node.ops[0][0]
+ if isinstance(left_operand, nodes.Const) and isinstance(
+ right_operand, nodes.Const
+ ):
+ left_operand = left_operand.value
+ right_operand = right_operand.value
+ elif isinstance(left_operand, nodes.Name) and isinstance(
+ right_operand, nodes.Name
+ ):
+ left_operand = left_operand.name
+ right_operand = right_operand.name
+
+ if left_operand == right_operand:
+ suggestion = f"{left_operand} {operator} {right_operand}"
+ self.add_message("comparison-with-itself", node=node, args=(suggestion,))
+
+ def _check_constants_comparison(self, node: nodes.Compare) -> None:
+ """When two constants are being compared it is always a logical tautology."""
+ left_operand = node.left
+ if not isinstance(left_operand, nodes.Const):
+ return
+
+ right_operand = node.ops[0][1]
+ if not isinstance(right_operand, nodes.Const):
+ return
+
+ operator = node.ops[0][0]
+ self.add_message(
+ "comparison-of-constants",
+ node=node,
+ args=(left_operand.value, operator, right_operand.value),
+ confidence=HIGH,
+ )
+
+ def _check_callable_comparison(self, node: nodes.Compare) -> None:
+ operator = node.ops[0][0]
+ if operator not in COMPARISON_OPERATORS:
+ return
+
+ bare_callables = (nodes.FunctionDef, astroid.BoundMethod)
+ left_operand, right_operand = node.left, node.ops[0][1]
+ # this message should be emitted only when there is comparison of bare callable
+ # with non bare callable.
+ number_of_bare_callables = 0
+ for operand in left_operand, right_operand:
+ inferred = utils.safe_infer(operand)
+ # Ignore callables that raise, as well as typing constants
+ # implemented as functions (that raise via their decorator)
+ if (
+ isinstance(inferred, bare_callables)
+ and "typing._SpecialForm" not in inferred.decoratornames()
+ and not any(isinstance(x, nodes.Raise) for x in inferred.body)
+ ):
+ number_of_bare_callables += 1
+ if number_of_bare_callables == 1:
+ self.add_message("comparison-with-callable", node=node)
+
+ @utils.only_required_for_messages(
+ "singleton-comparison",
+ "unidiomatic-typecheck",
+ "literal-comparison",
+ "comparison-with-itself",
+ "comparison-of-constants",
+ "comparison-with-callable",
+ "nan-comparison",
+ )
+ def visit_compare(self, node: nodes.Compare) -> None:
+ self._check_callable_comparison(node)
+ self._check_logical_tautology(node)
+ self._check_unidiomatic_typecheck(node)
+ self._check_constants_comparison(node)
+ # NOTE: this checker only works with binary comparisons like 'x == 42'
+ # but not 'x == y == 42'
+ if len(node.ops) != 1:
+ return
+
+ left = node.left
+ operator, right = node.ops[0]
+
+ if operator in {"==", "!="}:
+ self._check_singleton_comparison(
+ left, right, node, checking_for_absence=operator == "!="
+ )
+
+ if operator in {"==", "!=", "is", "is not"}:
+ self._check_nan_comparison(
+ left, right, node, checking_for_absence=operator in {"!=", "is not"}
+ )
+ if operator in {"is", "is not"}:
+ self._check_literal_comparison(right, node)
+
+ def _check_unidiomatic_typecheck(self, node: nodes.Compare) -> None:
+ operator, right = node.ops[0]
+ if operator in TYPECHECK_COMPARISON_OPERATORS:
+ left = node.left
+ if _is_one_arg_pos_call(left):
+ self._check_type_x_is_y(node, left, operator, right)
+
+ def _check_type_x_is_y(
+ self,
+ node: nodes.Compare,
+ left: nodes.NodeNG,
+ operator: str,
+ right: nodes.NodeNG,
+ ) -> None:
+ """Check for expressions like type(x) == Y."""
+ left_func = utils.safe_infer(left.func)
+ if not (
+ isinstance(left_func, nodes.ClassDef) and left_func.qname() == TYPE_QNAME
+ ):
+ return
+
+ if operator in {"is", "is not"} and _is_one_arg_pos_call(right):
+ right_func = utils.safe_infer(right.func)
+ if (
+ isinstance(right_func, nodes.ClassDef)
+ and right_func.qname() == TYPE_QNAME
+ ):
+ # type(x) == type(a)
+ right_arg = utils.safe_infer(right.args[0])
+ if not isinstance(right_arg, LITERAL_NODE_TYPES):
+ # not e.g. type(x) == type([])
+ return
+ self.add_message("unidiomatic-typecheck", node=node)
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/docstring_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/docstring_checker.py
new file mode 100644
index 000000000..aecfd9b06
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/docstring_checker.py
@@ -0,0 +1,208 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Docstring checker from the basic checker."""
+
+from __future__ import annotations
+
+import re
+from typing import Literal
+
+import astroid
+from astroid import nodes
+
+from pylint import interfaces
+from pylint.checkers import utils
+from pylint.checkers.base.basic_checker import _BasicChecker
+from pylint.checkers.utils import (
+ is_overload_stub,
+ is_property_deleter,
+ is_property_setter,
+)
+
+# do not require a doc string on private/system methods
+NO_REQUIRED_DOC_RGX = re.compile("^_")
+
+
+def _infer_dunder_doc_attribute(
+ node: nodes.Module | nodes.ClassDef | nodes.FunctionDef,
+) -> str | None:
+ # Try to see if we have a `__doc__` attribute.
+ try:
+ docstring = node["__doc__"]
+ except KeyError:
+ return None
+
+ docstring = utils.safe_infer(docstring)
+ if not docstring:
+ return None
+ if not isinstance(docstring, nodes.Const):
+ return None
+ return str(docstring.value)
+
+
+class DocStringChecker(_BasicChecker):
+ msgs = {
+ "C0112": (
+ "Empty %s docstring",
+ "empty-docstring",
+ "Used when a module, function, class or method has an empty "
+ "docstring (it would be too easy ;).",
+ {"old_names": [("W0132", "old-empty-docstring")]},
+ ),
+ "C0114": (
+ "Missing module docstring",
+ "missing-module-docstring",
+ "Used when a module has no docstring. "
+ "Empty modules do not require a docstring.",
+ {"old_names": [("C0111", "missing-docstring")]},
+ ),
+ "C0115": (
+ "Missing class docstring",
+ "missing-class-docstring",
+ "Used when a class has no docstring. "
+ "Even an empty class must have a docstring.",
+ {"old_names": [("C0111", "missing-docstring")]},
+ ),
+ "C0116": (
+ "Missing function or method docstring",
+ "missing-function-docstring",
+ "Used when a function or method has no docstring. "
+ "Some special methods like __init__ do not require a "
+ "docstring.",
+ {"old_names": [("C0111", "missing-docstring")]},
+ ),
+ }
+ options = (
+ (
+ "no-docstring-rgx",
+ {
+ "default": NO_REQUIRED_DOC_RGX,
+ "type": "regexp",
+ "metavar": "<regexp>",
+ "help": "Regular expression which should only match "
+ "function or class names that do not require a "
+ "docstring.",
+ },
+ ),
+ (
+ "docstring-min-length",
+ {
+ "default": -1,
+ "type": "int",
+ "metavar": "<int>",
+ "help": (
+ "Minimum line length for functions/classes that"
+ " require docstrings, shorter ones are exempt."
+ ),
+ },
+ ),
+ )
+
+ def open(self) -> None:
+ self.linter.stats.reset_undocumented()
+
+ @utils.only_required_for_messages("missing-module-docstring", "empty-docstring")
+ def visit_module(self, node: nodes.Module) -> None:
+ self._check_docstring("module", node)
+
+ @utils.only_required_for_messages("missing-class-docstring", "empty-docstring")
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ if self.linter.config.no_docstring_rgx.match(node.name) is None:
+ self._check_docstring("class", node)
+
+ @utils.only_required_for_messages("missing-function-docstring", "empty-docstring")
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ if self.linter.config.no_docstring_rgx.match(node.name) is None:
+ ftype = "method" if node.is_method() else "function"
+ if (
+ is_property_setter(node)
+ or is_property_deleter(node)
+ or is_overload_stub(node)
+ ):
+ return
+
+ if isinstance(node.parent.frame(), nodes.ClassDef):
+ overridden = False
+ confidence = (
+ interfaces.INFERENCE
+ if utils.has_known_bases(node.parent.frame())
+ else interfaces.INFERENCE_FAILURE
+ )
+ # check if node is from a method overridden by its ancestor
+ for ancestor in node.parent.frame().ancestors():
+ if ancestor.qname() == "builtins.object":
+ continue
+ if node.name in ancestor and isinstance(
+ ancestor[node.name], nodes.FunctionDef
+ ):
+ overridden = True
+ break
+ self._check_docstring(
+ ftype, node, report_missing=not overridden, confidence=confidence # type: ignore[arg-type]
+ )
+ elif isinstance(node.parent.frame(), nodes.Module):
+ self._check_docstring(ftype, node) # type: ignore[arg-type]
+ else:
+ return
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_docstring(
+ self,
+ node_type: Literal["class", "function", "method", "module"],
+ node: nodes.Module | nodes.ClassDef | nodes.FunctionDef,
+ report_missing: bool = True,
+ confidence: interfaces.Confidence = interfaces.HIGH,
+ ) -> None:
+ """Check if the node has a non-empty docstring."""
+ docstring = node.doc_node.value if node.doc_node else None
+ if docstring is None:
+ docstring = _infer_dunder_doc_attribute(node)
+
+ if docstring is None:
+ if not report_missing:
+ return
+ lines = utils.get_node_last_lineno(node) - node.lineno
+
+ if node_type == "module" and not lines:
+ # If the module does not have a body, there's no reason
+ # to require a docstring.
+ return
+ max_lines = self.linter.config.docstring_min_length
+
+ if node_type != "module" and max_lines > -1 and lines < max_lines:
+ return
+ if node_type == "class":
+ self.linter.stats.undocumented["klass"] += 1
+ else:
+ self.linter.stats.undocumented[node_type] += 1
+ if (
+ node.body
+ and isinstance(node.body[0], nodes.Expr)
+ and isinstance(node.body[0].value, nodes.Call)
+ ):
+ # Most likely a string with a format call. Let's see.
+ func = utils.safe_infer(node.body[0].value.func)
+ if isinstance(func, astroid.BoundMethod) and isinstance(
+ func.bound, astroid.Instance
+ ):
+ # Strings.
+ if func.bound.name in {"str", "unicode", "bytes"}:
+ return
+ if node_type == "module":
+ message = "missing-module-docstring"
+ elif node_type == "class":
+ message = "missing-class-docstring"
+ else:
+ message = "missing-function-docstring"
+ self.add_message(message, node=node, confidence=confidence)
+ elif not docstring.strip():
+ if node_type == "class":
+ self.linter.stats.undocumented["klass"] += 1
+ else:
+ self.linter.stats.undocumented[node_type] += 1
+ self.add_message(
+ "empty-docstring", node=node, args=(node_type,), confidence=confidence
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/function_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/function_checker.py
new file mode 100644
index 000000000..2826b40b4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/function_checker.py
@@ -0,0 +1,149 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Function checker for Python code."""
+
+from __future__ import annotations
+
+from itertools import chain
+
+from astroid import nodes
+
+from pylint.checkers import utils
+from pylint.checkers.base.basic_checker import _BasicChecker
+
+
+class FunctionChecker(_BasicChecker):
+ """Check if a function definition handles possible side effects."""
+
+ msgs = {
+ "W0135": (
+ "The context used in function %r will not be exited.",
+ "contextmanager-generator-missing-cleanup",
+ "Used when a contextmanager is used inside a generator function"
+ " and the cleanup is not handled.",
+ )
+ }
+
+ @utils.only_required_for_messages("contextmanager-generator-missing-cleanup")
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ self._check_contextmanager_generator_missing_cleanup(node)
+
+ @utils.only_required_for_messages("contextmanager-generator-missing-cleanup")
+ def visit_asyncfunctiondef(self, node: nodes.AsyncFunctionDef) -> None:
+ self._check_contextmanager_generator_missing_cleanup(node)
+
+ def _check_contextmanager_generator_missing_cleanup(
+ self, node: nodes.FunctionDef
+ ) -> None:
+ """Check a FunctionDef to find if it is a generator
+ that uses a contextmanager internally.
+
+ If it is, check if the contextmanager is properly cleaned up. Otherwise, add message.
+
+ :param node: FunctionDef node to check
+ :type node: nodes.FunctionDef
+ """
+ # if function does not use a Yield statement, it can't be a generator
+ with_nodes = list(node.nodes_of_class(nodes.With))
+ if not with_nodes:
+ return
+ # check for Yield inside the With statement
+ yield_nodes = list(
+ chain.from_iterable(
+ with_node.nodes_of_class(nodes.Yield) for with_node in with_nodes
+ )
+ )
+ if not yield_nodes:
+ return
+
+ # infer the call that yields a value, and check if it is a contextmanager
+ for with_node in with_nodes:
+ for call, held in with_node.items:
+ if held is None:
+ # if we discard the value, then we can skip checking it
+ continue
+
+ # safe infer is a generator
+ inferred_node = getattr(utils.safe_infer(call), "parent", None)
+ if not isinstance(inferred_node, nodes.FunctionDef):
+ continue
+ if self._node_fails_contextmanager_cleanup(inferred_node, yield_nodes):
+ self.add_message(
+ "contextmanager-generator-missing-cleanup",
+ node=with_node,
+ args=(node.name,),
+ )
+
+ @staticmethod
+ def _node_fails_contextmanager_cleanup(
+ node: nodes.FunctionDef, yield_nodes: list[nodes.Yield]
+ ) -> bool:
+ """Check if a node fails contextmanager cleanup.
+
+ Current checks for a contextmanager:
+ - only if the context manager yields a non-constant value
+ - only if the context manager lacks a finally, or does not catch GeneratorExit
+ - only if some statement follows the yield, some manually cleanup happens
+
+ :param node: Node to check
+ :type node: nodes.FunctionDef
+ :return: True if fails, False otherwise
+ :param yield_nodes: List of Yield nodes in the function body
+ :type yield_nodes: list[nodes.Yield]
+ :rtype: bool
+ """
+
+ def check_handles_generator_exceptions(try_node: nodes.Try) -> bool:
+ # needs to handle either GeneratorExit, Exception, or bare except
+ for handler in try_node.handlers:
+ if handler.type is None:
+ # handles all exceptions (bare except)
+ return True
+ inferred = utils.safe_infer(handler.type)
+ if inferred and inferred.qname() in {
+ "builtins.GeneratorExit",
+ "builtins.Exception",
+ }:
+ return True
+ return False
+
+ # if context manager yields a non-constant value, then continue checking
+ if any(
+ yield_node.value is None or isinstance(yield_node.value, nodes.Const)
+ for yield_node in yield_nodes
+ ):
+ return False
+
+ # Check if yield expression is last statement
+ yield_nodes = list(node.nodes_of_class(nodes.Yield))
+ if len(yield_nodes) == 1:
+ n = yield_nodes[0].parent
+ while n is not node:
+ if n.next_sibling() is not None:
+ break
+ n = n.parent
+ else:
+ # No next statement found
+ return False
+
+ # if function body has multiple Try, filter down to the ones that have a yield node
+ try_with_yield_nodes = [
+ try_node
+ for try_node in node.nodes_of_class(nodes.Try)
+ if any(try_node.nodes_of_class(nodes.Yield))
+ ]
+ if not try_with_yield_nodes:
+ # no try blocks at all, so checks after this line do not apply
+ return True
+ # if the contextmanager has a finally block, then it is fine
+ if all(try_node.finalbody for try_node in try_with_yield_nodes):
+ return False
+ # if the contextmanager catches GeneratorExit, then it is fine
+ if all(
+ check_handles_generator_exceptions(try_node)
+ for try_node in try_with_yield_nodes
+ ):
+ return False
+ return True
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/__init__.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/__init__.py
new file mode 100644
index 000000000..dec4335f5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/__init__.py
@@ -0,0 +1,25 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+__all__ = [
+ "NameChecker",
+ "NamingStyle",
+ "KNOWN_NAME_TYPES_WITH_STYLE",
+ "SnakeCaseStyle",
+ "CamelCaseStyle",
+ "UpperCaseStyle",
+ "PascalCaseStyle",
+ "AnyStyle",
+]
+
+from pylint.checkers.base.name_checker.checker import NameChecker
+from pylint.checkers.base.name_checker.naming_style import (
+ KNOWN_NAME_TYPES_WITH_STYLE,
+ AnyStyle,
+ CamelCaseStyle,
+ NamingStyle,
+ PascalCaseStyle,
+ SnakeCaseStyle,
+ UpperCaseStyle,
+)
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/checker.py
new file mode 100644
index 000000000..1d8589a57
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/checker.py
@@ -0,0 +1,716 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Basic checker for Python code."""
+
+from __future__ import annotations
+
+import argparse
+import collections
+import itertools
+import re
+import sys
+from collections.abc import Iterable
+from enum import Enum, auto
+from re import Pattern
+from typing import TYPE_CHECKING
+
+import astroid
+from astroid import nodes
+
+from pylint import constants, interfaces
+from pylint.checkers import utils
+from pylint.checkers.base.basic_checker import _BasicChecker
+from pylint.checkers.base.name_checker.naming_style import (
+ KNOWN_NAME_TYPES,
+ KNOWN_NAME_TYPES_WITH_STYLE,
+ NAMING_STYLES,
+ _create_naming_options,
+)
+from pylint.checkers.utils import is_property_deleter, is_property_setter
+from pylint.typing import Options
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+_BadNamesTuple = tuple[nodes.NodeNG, str, str, interfaces.Confidence]
+
+# Default patterns for name types that do not have styles
+DEFAULT_PATTERNS = {
+ "typevar": re.compile(
+ r"^_{0,2}(?!T[A-Z])(?:[A-Z]+|(?:[A-Z]+[a-z]+)+T?(?<!Type))(?:_co(?:ntra)?)?$"
+ ),
+ "typealias": re.compile(
+ r"^_{0,2}(?!T[A-Z]|Type)[A-Z]+[a-z0-9]+(?:[A-Z][a-z0-9]+)*$"
+ ),
+}
+
+BUILTIN_PROPERTY = "builtins.property"
+TYPE_VAR_QNAME = frozenset(
+ (
+ "typing.TypeVar",
+ "typing_extensions.TypeVar",
+ )
+)
+
+
+class TypeVarVariance(Enum):
+ invariant = auto()
+ covariant = auto()
+ contravariant = auto()
+ double_variant = auto()
+ inferred = auto()
+
+
+def _get_properties(config: argparse.Namespace) -> tuple[set[str], set[str]]:
+ """Returns a tuple of property classes and names.
+
+ Property classes are fully qualified, such as 'abc.abstractproperty' and
+ property names are the actual names, such as 'abstract_property'.
+ """
+ property_classes = {BUILTIN_PROPERTY}
+ property_names: set[str] = set() # Not returning 'property', it has its own check.
+ if config is not None:
+ property_classes.update(config.property_classes)
+ property_names.update(
+ prop.rsplit(".", 1)[-1] for prop in config.property_classes
+ )
+ return property_classes, property_names
+
+
+def _redefines_import(node: nodes.AssignName) -> bool:
+ """Detect that the given node (AssignName) is inside an
+ exception handler and redefines an import from the tryexcept body.
+
+ Returns True if the node redefines an import, False otherwise.
+ """
+ current = node
+ while current and not isinstance(current.parent, nodes.ExceptHandler):
+ current = current.parent
+ if not current or not utils.error_of_type(current.parent, ImportError):
+ return False
+ try_block = current.parent.parent
+ for import_node in try_block.nodes_of_class((nodes.ImportFrom, nodes.Import)):
+ for name, alias in import_node.names:
+ if alias:
+ if alias == node.name:
+ return True
+ elif name == node.name:
+ return True
+ return False
+
+
+def _determine_function_name_type(
+ node: nodes.FunctionDef, config: argparse.Namespace
+) -> str:
+ """Determine the name type whose regex the function's name should match.
+
+ :param node: A function node.
+ :param config: Configuration from which to pull additional property classes.
+
+ :returns: One of ('function', 'method', 'attr')
+ """
+ property_classes, property_names = _get_properties(config)
+ if not node.is_method():
+ return "function"
+
+ if is_property_setter(node) or is_property_deleter(node):
+ # If the function is decorated using the prop_method.{setter,getter}
+ # form, treat it like an attribute as well.
+ return "attr"
+
+ decorators = node.decorators.nodes if node.decorators else []
+ for decorator in decorators:
+ # If the function is a property (decorated with @property
+ # or @abc.abstractproperty), the name type is 'attr'.
+ if isinstance(decorator, nodes.Name) or (
+ isinstance(decorator, nodes.Attribute)
+ and decorator.attrname in property_names
+ ):
+ inferred = utils.safe_infer(decorator)
+ if (
+ inferred
+ and hasattr(inferred, "qname")
+ and inferred.qname() in property_classes
+ ):
+ return "attr"
+ return "method"
+
+
+# Name categories that are always consistent with all naming conventions.
+EXEMPT_NAME_CATEGORIES = {"exempt", "ignore"}
+
+
+def _is_multi_naming_match(
+ match: re.Match[str] | None, node_type: str, confidence: interfaces.Confidence
+) -> bool:
+ return (
+ match is not None
+ and match.lastgroup is not None
+ and match.lastgroup not in EXEMPT_NAME_CATEGORIES
+ and (node_type != "method" or confidence != interfaces.INFERENCE_FAILURE)
+ )
+
+
+class NameChecker(_BasicChecker):
+ msgs = {
+ "C0103": (
+ '%s name "%s" doesn\'t conform to %s',
+ "invalid-name",
+ "Used when the name doesn't conform to naming rules "
+ "associated to its type (constant, variable, class...).",
+ ),
+ "C0104": (
+ 'Disallowed name "%s"',
+ "disallowed-name",
+ "Used when the name matches bad-names or bad-names-rgxs- (unauthorized names).",
+ {
+ "old_names": [
+ ("C0102", "blacklisted-name"),
+ ]
+ },
+ ),
+ "C0105": (
+ "Type variable name does not reflect variance%s",
+ "typevar-name-incorrect-variance",
+ "Emitted when a TypeVar name doesn't reflect its type variance. "
+ "According to PEP8, it is recommended to add suffixes '_co' and "
+ "'_contra' to the variables used to declare covariant or "
+ "contravariant behaviour respectively. Invariant (default) variables "
+ "do not require a suffix. The message is also emitted when invariant "
+ "variables do have a suffix.",
+ ),
+ "C0131": (
+ "TypeVar cannot be both covariant and contravariant",
+ "typevar-double-variance",
+ 'Emitted when both the "covariant" and "contravariant" '
+ 'keyword arguments are set to "True" in a TypeVar.',
+ ),
+ "C0132": (
+ 'TypeVar name "%s" does not match assigned variable name "%s"',
+ "typevar-name-mismatch",
+ "Emitted when a TypeVar is assigned to a variable "
+ "that does not match its name argument.",
+ ),
+ }
+
+ _options: Options = (
+ (
+ "good-names",
+ {
+ "default": ("i", "j", "k", "ex", "Run", "_"),
+ "type": "csv",
+ "metavar": "<names>",
+ "help": "Good variable names which should always be accepted,"
+ " separated by a comma.",
+ },
+ ),
+ (
+ "good-names-rgxs",
+ {
+ "default": "",
+ "type": "regexp_csv",
+ "metavar": "<names>",
+ "help": "Good variable names regexes, separated by a comma. If names match any regex,"
+ " they will always be accepted",
+ },
+ ),
+ (
+ "bad-names",
+ {
+ "default": ("foo", "bar", "baz", "toto", "tutu", "tata"),
+ "type": "csv",
+ "metavar": "<names>",
+ "help": "Bad variable names which should always be refused, "
+ "separated by a comma.",
+ },
+ ),
+ (
+ "bad-names-rgxs",
+ {
+ "default": "",
+ "type": "regexp_csv",
+ "metavar": "<names>",
+ "help": "Bad variable names regexes, separated by a comma. If names match any regex,"
+ " they will always be refused",
+ },
+ ),
+ (
+ "name-group",
+ {
+ "default": (),
+ "type": "csv",
+ "metavar": "<name1:name2>",
+ "help": (
+ "Colon-delimited sets of names that determine each"
+ " other's naming style when the name regexes"
+ " allow several styles."
+ ),
+ },
+ ),
+ (
+ "include-naming-hint",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Include a hint for the correct naming format with invalid-name.",
+ },
+ ),
+ (
+ "property-classes",
+ {
+ "default": ("abc.abstractproperty",),
+ "type": "csv",
+ "metavar": "<decorator names>",
+ "help": "List of decorators that produce properties, such as "
+ "abc.abstractproperty. Add to this list to register "
+ "other decorators that produce valid properties. "
+ "These decorators are taken in consideration only for invalid-name.",
+ },
+ ),
+ )
+ options: Options = _options + _create_naming_options()
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._name_group: dict[str, str] = {}
+ self._bad_names: dict[str, dict[str, list[_BadNamesTuple]]] = {}
+ self._name_regexps: dict[str, re.Pattern[str]] = {}
+ self._name_hints: dict[str, str] = {}
+ self._good_names_rgxs_compiled: list[re.Pattern[str]] = []
+ self._bad_names_rgxs_compiled: list[re.Pattern[str]] = []
+
+ def open(self) -> None:
+ self.linter.stats.reset_bad_names()
+ for group in self.linter.config.name_group:
+ for name_type in group.split(":"):
+ self._name_group[name_type] = f"group_{group}"
+
+ regexps, hints = self._create_naming_rules()
+ self._name_regexps = regexps
+ self._name_hints = hints
+ self._good_names_rgxs_compiled = [
+ re.compile(rgxp) for rgxp in self.linter.config.good_names_rgxs
+ ]
+ self._bad_names_rgxs_compiled = [
+ re.compile(rgxp) for rgxp in self.linter.config.bad_names_rgxs
+ ]
+
+ def _create_naming_rules(self) -> tuple[dict[str, Pattern[str]], dict[str, str]]:
+ regexps: dict[str, Pattern[str]] = {}
+ hints: dict[str, str] = {}
+
+ for name_type in KNOWN_NAME_TYPES:
+ if name_type in KNOWN_NAME_TYPES_WITH_STYLE:
+ naming_style_name = getattr(
+ self.linter.config, f"{name_type}_naming_style"
+ )
+ regexps[name_type] = NAMING_STYLES[naming_style_name].get_regex(
+ name_type
+ )
+ else:
+ naming_style_name = "predefined"
+ regexps[name_type] = DEFAULT_PATTERNS[name_type]
+
+ custom_regex_setting_name = f"{name_type}_rgx"
+ custom_regex = getattr(self.linter.config, custom_regex_setting_name, None)
+ if custom_regex is not None:
+ regexps[name_type] = custom_regex
+
+ if custom_regex is not None:
+ hints[name_type] = f"{custom_regex.pattern!r} pattern"
+ else:
+ hints[name_type] = f"{naming_style_name} naming style"
+
+ return regexps, hints
+
+ @utils.only_required_for_messages("disallowed-name", "invalid-name")
+ def visit_module(self, node: nodes.Module) -> None:
+ self._check_name("module", node.name.split(".")[-1], node)
+ self._bad_names = {}
+
+ def leave_module(self, _: nodes.Module) -> None:
+ for all_groups in self._bad_names.values():
+ if len(all_groups) < 2:
+ continue
+ groups: collections.defaultdict[int, list[list[_BadNamesTuple]]] = (
+ collections.defaultdict(list)
+ )
+ min_warnings = sys.maxsize
+ prevalent_group, _ = max(all_groups.items(), key=lambda item: len(item[1]))
+ for group in all_groups.values():
+ groups[len(group)].append(group)
+ min_warnings = min(len(group), min_warnings)
+ if len(groups[min_warnings]) > 1:
+ by_line = sorted(
+ groups[min_warnings],
+ key=lambda group: min(
+ warning[0].lineno
+ for warning in group
+ if warning[0].lineno is not None
+ ),
+ )
+ warnings: Iterable[_BadNamesTuple] = itertools.chain(*by_line[1:])
+ else:
+ warnings = groups[min_warnings][0]
+ for args in warnings:
+ self._raise_name_warning(prevalent_group, *args)
+
+ @utils.only_required_for_messages("disallowed-name", "invalid-name")
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ self._check_name("class", node.name, node)
+ for attr, anodes in node.instance_attrs.items():
+ if not any(node.instance_attr_ancestors(attr)):
+ self._check_name("attr", attr, anodes[0])
+
+ @utils.only_required_for_messages("disallowed-name", "invalid-name")
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ # Do not emit any warnings if the method is just an implementation
+ # of a base class method.
+ confidence = interfaces.HIGH
+ if node.is_method():
+ if utils.overrides_a_method(node.parent.frame(), node.name):
+ return
+ confidence = (
+ interfaces.INFERENCE
+ if utils.has_known_bases(node.parent.frame())
+ else interfaces.INFERENCE_FAILURE
+ )
+
+ self._check_name(
+ _determine_function_name_type(node, config=self.linter.config),
+ node.name,
+ node,
+ confidence,
+ )
+ # Check argument names
+ args = node.args.args
+ if args is not None:
+ self._recursive_check_names(args)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ @utils.only_required_for_messages(
+ "disallowed-name",
+ "invalid-name",
+ "typevar-name-incorrect-variance",
+ "typevar-double-variance",
+ "typevar-name-mismatch",
+ )
+ def visit_assignname( # pylint: disable=too-many-branches
+ self, node: nodes.AssignName
+ ) -> None:
+ """Check module level assigned names."""
+ frame = node.frame()
+ assign_type = node.assign_type()
+
+ # Check names defined in comprehensions
+ if isinstance(assign_type, nodes.Comprehension):
+ self._check_name("inlinevar", node.name, node)
+
+ elif isinstance(assign_type, nodes.TypeVar):
+ self._check_name("typevar", node.name, node)
+
+ elif isinstance(assign_type, nodes.TypeAlias):
+ self._check_name("typealias", node.name, node)
+
+ # Check names defined in module scope
+ elif isinstance(frame, nodes.Module):
+ # Check names defined in Assign nodes
+ if isinstance(assign_type, nodes.Assign):
+ inferred_assign_type = utils.safe_infer(assign_type.value)
+
+ # Check TypeVar's and TypeAliases assigned alone or in tuple assignment
+ if isinstance(node.parent, nodes.Assign):
+ if self._assigns_typevar(assign_type.value):
+ self._check_name("typevar", assign_type.targets[0].name, node)
+ return
+ if self._assigns_typealias(assign_type.value):
+ self._check_name("typealias", assign_type.targets[0].name, node)
+ return
+
+ if (
+ isinstance(node.parent, nodes.Tuple)
+ and isinstance(assign_type.value, nodes.Tuple)
+ # protect against unbalanced tuple unpacking
+ and node.parent.elts.index(node) < len(assign_type.value.elts)
+ ):
+ assigner = assign_type.value.elts[node.parent.elts.index(node)]
+ if self._assigns_typevar(assigner):
+ self._check_name(
+ "typevar",
+ assign_type.targets[0]
+ .elts[node.parent.elts.index(node)]
+ .name,
+ node,
+ )
+ return
+ if self._assigns_typealias(assigner):
+ self._check_name(
+ "typealias",
+ assign_type.targets[0]
+ .elts[node.parent.elts.index(node)]
+ .name,
+ node,
+ )
+ return
+
+ # Check classes (TypeVar's are classes so they need to be excluded first)
+ elif isinstance(inferred_assign_type, nodes.ClassDef):
+ self._check_name("class", node.name, node)
+
+ # Don't emit if the name redefines an import in an ImportError except handler.
+ elif not _redefines_import(node) and isinstance(
+ inferred_assign_type, nodes.Const
+ ):
+ self._check_name("const", node.name, node)
+ else:
+ self._check_name(
+ "variable", node.name, node, disallowed_check_only=True
+ )
+
+ # Check names defined in AnnAssign nodes
+ elif isinstance(assign_type, nodes.AnnAssign):
+ if utils.is_assign_name_annotated_with(node, "Final"):
+ self._check_name("const", node.name, node)
+ elif self._assigns_typealias(assign_type.annotation):
+ self._check_name("typealias", node.name, node)
+
+ # Check names defined in function scopes
+ elif isinstance(frame, nodes.FunctionDef):
+ # global introduced variable aren't in the function locals
+ if node.name in frame and node.name not in frame.argnames():
+ if not _redefines_import(node):
+ if isinstance(
+ assign_type, nodes.AnnAssign
+ ) and self._assigns_typealias(assign_type.annotation):
+ self._check_name("typealias", node.name, node)
+ else:
+ self._check_name("variable", node.name, node)
+
+ # Check names defined in class scopes
+ elif isinstance(frame, nodes.ClassDef) and not any(
+ frame.local_attr_ancestors(node.name)
+ ):
+ if utils.is_enum_member(node) or utils.is_assign_name_annotated_with(
+ node, "Final"
+ ):
+ self._check_name("class_const", node.name, node)
+ else:
+ self._check_name("class_attribute", node.name, node)
+
+ def _recursive_check_names(self, args: list[nodes.AssignName]) -> None:
+ """Check names in a possibly recursive list <arg>."""
+ for arg in args:
+ self._check_name("argument", arg.name, arg)
+
+ def _find_name_group(self, node_type: str) -> str:
+ return self._name_group.get(node_type, node_type)
+
+ def _raise_name_warning(
+ self,
+ prevalent_group: str | None,
+ node: nodes.NodeNG,
+ node_type: str,
+ name: str,
+ confidence: interfaces.Confidence,
+ warning: str = "invalid-name",
+ ) -> None:
+ type_label = constants.HUMAN_READABLE_TYPES[node_type]
+ hint = self._name_hints[node_type]
+ if prevalent_group:
+ # This happens in the multi naming match case. The expected
+ # prevalent group needs to be spelled out to make the message
+ # correct.
+ hint = f"the `{prevalent_group}` group in the {hint}"
+ if self.linter.config.include_naming_hint:
+ hint += f" ({self._name_regexps[node_type].pattern!r} pattern)"
+ args = (
+ (type_label.capitalize(), name, hint)
+ if warning == "invalid-name"
+ else (type_label.capitalize(), name)
+ )
+
+ self.add_message(warning, node=node, args=args, confidence=confidence)
+ self.linter.stats.increase_bad_name(node_type, 1)
+
+ def _name_allowed_by_regex(self, name: str) -> bool:
+ return name in self.linter.config.good_names or any(
+ pattern.match(name) for pattern in self._good_names_rgxs_compiled
+ )
+
+ def _name_disallowed_by_regex(self, name: str) -> bool:
+ return name in self.linter.config.bad_names or any(
+ pattern.match(name) for pattern in self._bad_names_rgxs_compiled
+ )
+
+ def _check_name(
+ self,
+ node_type: str,
+ name: str,
+ node: nodes.NodeNG,
+ confidence: interfaces.Confidence = interfaces.HIGH,
+ disallowed_check_only: bool = False,
+ ) -> None:
+ """Check for a name using the type's regexp."""
+
+ def _should_exempt_from_invalid_name(node: nodes.NodeNG) -> bool:
+ if node_type == "variable":
+ inferred = utils.safe_infer(node)
+ if isinstance(inferred, nodes.ClassDef):
+ return True
+ return False
+
+ if self._name_allowed_by_regex(name=name):
+ return
+ if self._name_disallowed_by_regex(name=name):
+ self.linter.stats.increase_bad_name(node_type, 1)
+ self.add_message(
+ "disallowed-name", node=node, args=name, confidence=interfaces.HIGH
+ )
+ return
+ regexp = self._name_regexps[node_type]
+ match = regexp.match(name)
+
+ if _is_multi_naming_match(match, node_type, confidence):
+ name_group = self._find_name_group(node_type)
+ bad_name_group = self._bad_names.setdefault(name_group, {})
+ # Ignored because this is checked by the if statement
+ warnings = bad_name_group.setdefault(match.lastgroup, []) # type: ignore[union-attr, arg-type]
+ warnings.append((node, node_type, name, confidence))
+
+ if (
+ match is None
+ and not disallowed_check_only
+ and not _should_exempt_from_invalid_name(node)
+ ):
+ self._raise_name_warning(None, node, node_type, name, confidence)
+
+ # Check TypeVar names for variance suffixes
+ if node_type == "typevar":
+ self._check_typevar(name, node)
+
+ @staticmethod
+ def _assigns_typevar(node: nodes.NodeNG | None) -> bool:
+ """Check if a node is assigning a TypeVar."""
+ if isinstance(node, astroid.Call):
+ inferred = utils.safe_infer(node.func)
+ if (
+ isinstance(inferred, astroid.ClassDef)
+ and inferred.qname() in TYPE_VAR_QNAME
+ ):
+ return True
+ return False
+
+ @staticmethod
+ def _assigns_typealias(node: nodes.NodeNG | None) -> bool:
+ """Check if a node is assigning a TypeAlias."""
+ inferred = utils.safe_infer(node)
+ if isinstance(inferred, nodes.ClassDef):
+ qname = inferred.qname()
+ if qname == "typing.TypeAlias":
+ return True
+ if qname == ".Union":
+ # Union is a special case because it can be used as a type alias
+ # or as a type annotation. We only want to check the former.
+ assert node is not None
+ return not isinstance(node.parent, nodes.AnnAssign)
+ elif isinstance(inferred, nodes.FunctionDef):
+ # TODO: when py3.12 is minimum, remove this condition
+ # TypeAlias became a class in python 3.12
+ if inferred.qname() == "typing.TypeAlias":
+ return True
+ return False
+
+ def _check_typevar(self, name: str, node: nodes.AssignName) -> None:
+ """Check for TypeVar lint violations."""
+ variance: TypeVarVariance = TypeVarVariance.invariant
+ if isinstance(node.parent, nodes.Assign):
+ keywords = node.assign_type().value.keywords
+ args = node.assign_type().value.args
+ elif isinstance(node.parent, nodes.Tuple):
+ keywords = (
+ node.assign_type().value.elts[node.parent.elts.index(node)].keywords
+ )
+ args = node.assign_type().value.elts[node.parent.elts.index(node)].args
+ else: # PEP 695 generic type nodes
+ keywords = ()
+ args = ()
+ variance = TypeVarVariance.inferred
+
+ name_arg = None
+ for kw in keywords:
+ if variance == TypeVarVariance.double_variant:
+ pass
+ elif kw.arg == "covariant" and kw.value.value:
+ variance = (
+ TypeVarVariance.covariant
+ if variance != TypeVarVariance.contravariant
+ else TypeVarVariance.double_variant
+ )
+ elif kw.arg == "contravariant" and kw.value.value:
+ variance = (
+ TypeVarVariance.contravariant
+ if variance != TypeVarVariance.covariant
+ else TypeVarVariance.double_variant
+ )
+
+ if kw.arg == "name" and isinstance(kw.value, nodes.Const):
+ name_arg = kw.value.value
+
+ if name_arg is None and args and isinstance(args[0], nodes.Const):
+ name_arg = args[0].value
+
+ if variance == TypeVarVariance.inferred:
+ # Ignore variance check for PEP 695 type parameters.
+ # The variance is inferred by the type checker.
+ # Adding _co or _contra suffix can help to reason about TypeVar.
+ pass
+ elif variance == TypeVarVariance.double_variant:
+ self.add_message(
+ "typevar-double-variance",
+ node=node,
+ confidence=interfaces.INFERENCE,
+ )
+ self.add_message(
+ "typevar-name-incorrect-variance",
+ node=node,
+ args=("",),
+ confidence=interfaces.INFERENCE,
+ )
+ elif variance == TypeVarVariance.covariant and not name.endswith("_co"):
+ suggest_name = f"{re.sub('_contra$', '', name)}_co"
+ self.add_message(
+ "typevar-name-incorrect-variance",
+ node=node,
+ args=(f'. "{name}" is covariant, use "{suggest_name}" instead'),
+ confidence=interfaces.INFERENCE,
+ )
+ elif variance == TypeVarVariance.contravariant and not name.endswith("_contra"):
+ suggest_name = f"{re.sub('_co$', '', name)}_contra"
+ self.add_message(
+ "typevar-name-incorrect-variance",
+ node=node,
+ args=(f'. "{name}" is contravariant, use "{suggest_name}" instead'),
+ confidence=interfaces.INFERENCE,
+ )
+ elif variance == TypeVarVariance.invariant and (
+ name.endswith(("_co", "_contra"))
+ ):
+ suggest_name = re.sub("_contra$|_co$", "", name)
+ self.add_message(
+ "typevar-name-incorrect-variance",
+ node=node,
+ args=(f'. "{name}" is invariant, use "{suggest_name}" instead'),
+ confidence=interfaces.INFERENCE,
+ )
+
+ if name_arg is not None and name_arg != name:
+ self.add_message(
+ "typevar-name-mismatch",
+ node=node,
+ args=(name_arg, name),
+ confidence=interfaces.INFERENCE,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/naming_style.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/naming_style.py
new file mode 100644
index 000000000..0198ae7d1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/name_checker/naming_style.py
@@ -0,0 +1,185 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import re
+from re import Pattern
+
+from pylint import constants
+from pylint.typing import OptionDict, Options
+
+
+class NamingStyle:
+ """Class to register all accepted forms of a single naming style.
+
+ It may seem counter-intuitive that single naming style has multiple "accepted"
+ forms of regular expressions, but we need to special-case stuff like dunder
+ names in method names.
+ """
+
+ ANY: Pattern[str] = re.compile(".*")
+ CLASS_NAME_RGX: Pattern[str] = ANY
+ MOD_NAME_RGX: Pattern[str] = ANY
+ CONST_NAME_RGX: Pattern[str] = ANY
+ COMP_VAR_RGX: Pattern[str] = ANY
+ DEFAULT_NAME_RGX: Pattern[str] = ANY
+ CLASS_ATTRIBUTE_RGX: Pattern[str] = ANY
+
+ @classmethod
+ def get_regex(cls, name_type: str) -> Pattern[str]:
+ return {
+ "module": cls.MOD_NAME_RGX,
+ "const": cls.CONST_NAME_RGX,
+ "class": cls.CLASS_NAME_RGX,
+ "function": cls.DEFAULT_NAME_RGX,
+ "method": cls.DEFAULT_NAME_RGX,
+ "attr": cls.DEFAULT_NAME_RGX,
+ "argument": cls.DEFAULT_NAME_RGX,
+ "variable": cls.DEFAULT_NAME_RGX,
+ "class_attribute": cls.CLASS_ATTRIBUTE_RGX,
+ "class_const": cls.CONST_NAME_RGX,
+ "inlinevar": cls.COMP_VAR_RGX,
+ }[name_type]
+
+
+class SnakeCaseStyle(NamingStyle):
+ """Regex rules for snake_case naming style."""
+
+ CLASS_NAME_RGX = re.compile(r"[^\W\dA-Z][^\WA-Z]*$")
+ MOD_NAME_RGX = re.compile(r"[^\W\dA-Z][^\WA-Z]*$")
+ CONST_NAME_RGX = re.compile(r"([^\W\dA-Z][^\WA-Z]*|__.*__)$")
+ COMP_VAR_RGX = CLASS_NAME_RGX
+ DEFAULT_NAME_RGX = re.compile(
+ r"([^\W\dA-Z][^\WA-Z]*|_[^\WA-Z]*|__[^\WA-Z\d_][^\WA-Z]+__)$"
+ )
+ CLASS_ATTRIBUTE_RGX = re.compile(r"([^\W\dA-Z][^\WA-Z]*|__.*__)$")
+
+
+class CamelCaseStyle(NamingStyle):
+ """Regex rules for camelCase naming style."""
+
+ CLASS_NAME_RGX = re.compile(r"[^\W\dA-Z][^\W_]*$")
+ MOD_NAME_RGX = re.compile(r"[^\W\dA-Z][^\W_]*$")
+ CONST_NAME_RGX = re.compile(r"([^\W\dA-Z][^\W_]*|__.*__)$")
+ COMP_VAR_RGX = MOD_NAME_RGX
+ DEFAULT_NAME_RGX = re.compile(r"([^\W\dA-Z][^\W_]*|__[^\W\dA-Z_]\w+__)$")
+ CLASS_ATTRIBUTE_RGX = re.compile(r"([^\W\dA-Z][^\W_]*|__.*__)$")
+
+
+class PascalCaseStyle(NamingStyle):
+ """Regex rules for PascalCase naming style."""
+
+ CLASS_NAME_RGX = re.compile(r"[^\W\da-z][^\W_]*$")
+ MOD_NAME_RGX = CLASS_NAME_RGX
+ CONST_NAME_RGX = re.compile(r"([^\W\da-z][^\W_]*|__.*__)$")
+ COMP_VAR_RGX = CLASS_NAME_RGX
+ DEFAULT_NAME_RGX = re.compile(r"([^\W\da-z][^\W_]*|__[^\W\dA-Z_]\w+__)$")
+ CLASS_ATTRIBUTE_RGX = re.compile(r"[^\W\da-z][^\W_]*$")
+
+
+class UpperCaseStyle(NamingStyle):
+ """Regex rules for UPPER_CASE naming style."""
+
+ CLASS_NAME_RGX = re.compile(r"[^\W\da-z][^\Wa-z]*$")
+ MOD_NAME_RGX = CLASS_NAME_RGX
+ CONST_NAME_RGX = re.compile(r"([^\W\da-z][^\Wa-z]*|__.*__)$")
+ COMP_VAR_RGX = CLASS_NAME_RGX
+ DEFAULT_NAME_RGX = re.compile(r"([^\W\da-z][^\Wa-z]*|__[^\W\dA-Z_]\w+__)$")
+ CLASS_ATTRIBUTE_RGX = re.compile(r"[^\W\da-z][^\Wa-z]*$")
+
+
+class AnyStyle(NamingStyle):
+ pass
+
+
+NAMING_STYLES = {
+ "snake_case": SnakeCaseStyle,
+ "camelCase": CamelCaseStyle,
+ "PascalCase": PascalCaseStyle,
+ "UPPER_CASE": UpperCaseStyle,
+ "any": AnyStyle,
+}
+
+# Name types that have a style option
+KNOWN_NAME_TYPES_WITH_STYLE = {
+ "module",
+ "const",
+ "class",
+ "function",
+ "method",
+ "attr",
+ "argument",
+ "variable",
+ "class_attribute",
+ "class_const",
+ "inlinevar",
+}
+
+
+DEFAULT_NAMING_STYLES = {
+ "module": "snake_case",
+ "const": "UPPER_CASE",
+ "class": "PascalCase",
+ "function": "snake_case",
+ "method": "snake_case",
+ "attr": "snake_case",
+ "argument": "snake_case",
+ "variable": "snake_case",
+ "class_attribute": "any",
+ "class_const": "UPPER_CASE",
+ "inlinevar": "any",
+}
+
+
+# Name types that have a 'rgx' option
+KNOWN_NAME_TYPES = {
+ *KNOWN_NAME_TYPES_WITH_STYLE,
+ "typevar",
+ "typealias",
+}
+
+
+def _create_naming_options() -> Options:
+ name_options: list[tuple[str, OptionDict]] = []
+ for name_type in sorted(KNOWN_NAME_TYPES):
+ human_readable_name = constants.HUMAN_READABLE_TYPES[name_type]
+ name_type_hyphened = name_type.replace("_", "-")
+
+ help_msg = f"Regular expression matching correct {human_readable_name} names. "
+ if name_type in KNOWN_NAME_TYPES_WITH_STYLE:
+ help_msg += f"Overrides {name_type_hyphened}-naming-style. "
+ help_msg += (
+ f"If left empty, {human_readable_name} names will be checked "
+ "with the set naming style."
+ )
+
+ # Add style option for names that support it
+ if name_type in KNOWN_NAME_TYPES_WITH_STYLE:
+ default_style = DEFAULT_NAMING_STYLES[name_type]
+ name_options.append(
+ (
+ f"{name_type_hyphened}-naming-style",
+ {
+ "default": default_style,
+ "type": "choice",
+ "choices": list(NAMING_STYLES.keys()),
+ "metavar": "<style>",
+ "help": f"Naming style matching correct {human_readable_name} names.",
+ },
+ )
+ )
+
+ name_options.append(
+ (
+ f"{name_type_hyphened}-rgx",
+ {
+ "default": None,
+ "type": "regexp",
+ "metavar": "<regexp>",
+ "help": help_msg,
+ },
+ )
+ )
+ return tuple(name_options)
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base/pass_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base/pass_checker.py
new file mode 100644
index 000000000..19952ca4f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base/pass_checker.py
@@ -0,0 +1,29 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from astroid import nodes
+
+from pylint.checkers import utils
+from pylint.checkers.base.basic_checker import _BasicChecker
+
+
+class PassChecker(_BasicChecker):
+ """Check if the pass statement is really necessary."""
+
+ msgs = {
+ "W0107": (
+ "Unnecessary pass statement",
+ "unnecessary-pass",
+ 'Used when a "pass" statement can be removed without affecting '
+ "the behaviour of the code.",
+ )
+ }
+
+ @utils.only_required_for_messages("unnecessary-pass")
+ def visit_pass(self, node: nodes.Pass) -> None:
+ if len(node.parent.child_sequence(node)) > 1 or (
+ isinstance(node.parent, (nodes.ClassDef, nodes.FunctionDef))
+ and node.parent.doc_node
+ ):
+ self.add_message("unnecessary-pass", node=node)
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/base_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/base_checker.py
new file mode 100644
index 000000000..6d577e0bd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/base_checker.py
@@ -0,0 +1,248 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import abc
+import functools
+from collections.abc import Iterable, Sequence
+from inspect import cleandoc
+from tokenize import TokenInfo
+from typing import TYPE_CHECKING, Any
+
+from astroid import nodes
+
+from pylint.config.arguments_provider import _ArgumentsProvider
+from pylint.constants import _MSG_ORDER, MAIN_CHECKER_NAME, WarningScope
+from pylint.exceptions import InvalidMessageError
+from pylint.interfaces import Confidence
+from pylint.message.message_definition import MessageDefinition
+from pylint.typing import (
+ ExtraMessageOptions,
+ MessageDefinitionTuple,
+ OptionDict,
+ Options,
+ ReportsCallable,
+)
+from pylint.utils import get_rst_section, get_rst_title
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+@functools.total_ordering
+class BaseChecker(_ArgumentsProvider):
+ # checker name (you may reuse an existing one)
+ name: str = ""
+ # ordered list of options to control the checker behaviour
+ options: Options = ()
+ # messages issued by this checker
+ msgs: dict[str, MessageDefinitionTuple] = {}
+ # reports issued by this checker
+ reports: tuple[tuple[str, str, ReportsCallable], ...] = ()
+ # mark this checker as enabled or not.
+ enabled: bool = True
+
+ def __init__(self, linter: PyLinter) -> None:
+ """Checker instances should have the linter as argument."""
+ if self.name is not None:
+ self.name = self.name.lower()
+ self.linter = linter
+ _ArgumentsProvider.__init__(self, linter)
+
+ def __gt__(self, other: Any) -> bool:
+ """Permits sorting checkers for stable doc and tests.
+
+ The main checker is always the first one, then builtin checkers in alphabetical
+ order, then extension checkers in alphabetical order.
+ """
+ if not isinstance(other, BaseChecker):
+ return False
+ if self.name == MAIN_CHECKER_NAME:
+ return False
+ if other.name == MAIN_CHECKER_NAME:
+ return True
+ self_is_builtin = type(self).__module__.startswith("pylint.checkers")
+ if self_is_builtin ^ type(other).__module__.startswith("pylint.checkers"):
+ return not self_is_builtin
+ return self.name > other.name
+
+ def __eq__(self, other: object) -> bool:
+ """Permit to assert Checkers are equal."""
+ if not isinstance(other, BaseChecker):
+ return False
+ return f"{self.name}{self.msgs}" == f"{other.name}{other.msgs}"
+
+ def __hash__(self) -> int:
+ """Make Checker hashable."""
+ return hash(f"{self.name}{self.msgs}")
+
+ def __repr__(self) -> str:
+ status = "Checker" if self.enabled else "Disabled checker"
+ msgs = "', '".join(self.msgs.keys())
+ return f"{status} '{self.name}' (responsible for '{msgs}')"
+
+ def __str__(self) -> str:
+ """This might be incomplete because multiple classes inheriting BaseChecker
+ can have the same name.
+
+ See: MessageHandlerMixIn.get_full_documentation()
+ """
+ return self.get_full_documentation(
+ msgs=self.msgs, options=self._options_and_values(), reports=self.reports
+ )
+
+ def get_full_documentation(
+ self,
+ msgs: dict[str, MessageDefinitionTuple],
+ options: Iterable[tuple[str, OptionDict, Any]],
+ reports: Sequence[tuple[str, str, ReportsCallable]],
+ doc: str | None = None,
+ module: str | None = None,
+ show_options: bool = True,
+ ) -> str:
+ result = ""
+ checker_title = f"{self.name.replace('_', ' ').title()} checker"
+ if module:
+ # Provide anchor to link against
+ result += f".. _{module}:\n\n"
+ result += f"{get_rst_title(checker_title, '~')}\n"
+ if module:
+ result += f"This checker is provided by ``{module}``.\n"
+ result += f"Verbatim name of the checker is ``{self.name}``.\n\n"
+ if doc:
+ # Provide anchor to link against
+ result += get_rst_title(f"{checker_title} Documentation", "^")
+ result += f"{cleandoc(doc)}\n\n"
+ # options might be an empty generator and not be False when cast to boolean
+ options_list = list(options)
+ if options_list:
+ if show_options:
+ result += get_rst_title(f"{checker_title} Options", "^")
+ result += f"{get_rst_section(None, options_list)}\n"
+ else:
+ result += f"See also :ref:`{self.name} checker's options' documentation <{self.name}-options>`\n\n"
+ if msgs:
+ result += get_rst_title(f"{checker_title} Messages", "^")
+ for msgid, msg in sorted(
+ msgs.items(), key=lambda kv: (_MSG_ORDER.index(kv[0][0]), kv[1])
+ ):
+ msg_def = self.create_message_definition_from_tuple(msgid, msg)
+ result += f"{msg_def.format_help(checkerref=False)}\n"
+ result += "\n"
+ if reports:
+ result += get_rst_title(f"{checker_title} Reports", "^")
+ for report in reports:
+ result += f":{report[0]}: {report[1]}\n"
+ result += "\n"
+ result += "\n"
+ return result
+
+ def add_message(
+ self,
+ msgid: str,
+ line: int | None = None,
+ node: nodes.NodeNG | None = None,
+ args: Any = None,
+ confidence: Confidence | None = None,
+ col_offset: int | None = None,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ self.linter.add_message(
+ msgid, line, node, args, confidence, col_offset, end_lineno, end_col_offset
+ )
+
+ def check_consistency(self) -> None:
+ """Check the consistency of msgid.
+
+ msg ids for a checker should be a string of len 4, where the two first
+ characters are the checker id and the two last the msg id in this
+ checker.
+
+ :raises InvalidMessageError: If the checker id in the messages are not
+ always the same.
+ """
+ checker_id = None
+ existing_ids = []
+ for message in self.messages:
+ # Id's for shared messages such as the 'deprecated-*' messages
+ # can be inconsistent with their checker id.
+ if message.shared:
+ continue
+ if checker_id is not None and checker_id != message.msgid[1:3]:
+ error_msg = "Inconsistent checker part in message id "
+ error_msg += f"'{message.msgid}' (expected 'x{checker_id}xx' "
+ error_msg += f"because we already had {existing_ids})."
+ raise InvalidMessageError(error_msg)
+ checker_id = message.msgid[1:3]
+ existing_ids.append(message.msgid)
+
+ def create_message_definition_from_tuple(
+ self, msgid: str, msg_tuple: MessageDefinitionTuple
+ ) -> MessageDefinition:
+ if isinstance(self, (BaseTokenChecker, BaseRawFileChecker)):
+ default_scope = WarningScope.LINE
+ else:
+ default_scope = WarningScope.NODE
+ options: ExtraMessageOptions = {}
+ if len(msg_tuple) == 4:
+ (msg, symbol, descr, msg_options) = msg_tuple
+ options = ExtraMessageOptions(**msg_options)
+ elif len(msg_tuple) == 3:
+ (msg, symbol, descr) = msg_tuple
+ else:
+ error_msg = """Messages should have a msgid, a symbol and a description. Something like this :
+
+"W1234": (
+ "message",
+ "message-symbol",
+ "Message description with detail.",
+ ...
+),
+"""
+ raise InvalidMessageError(error_msg)
+ options.setdefault("scope", default_scope)
+ return MessageDefinition(self, msgid, msg, descr, symbol, **options)
+
+ @property
+ def messages(self) -> list[MessageDefinition]:
+ return [
+ self.create_message_definition_from_tuple(msgid, msg_tuple)
+ for msgid, msg_tuple in sorted(self.msgs.items())
+ ]
+
+ def open(self) -> None:
+ """Called before visiting project (i.e. set of modules)."""
+
+ def close(self) -> None:
+ """Called after visiting project (i.e set of modules)."""
+
+ def get_map_data(self) -> Any:
+ return None
+
+ # pylint: disable-next=unused-argument
+ def reduce_map_data(self, linter: PyLinter, data: list[Any]) -> None:
+ return None
+
+
+class BaseTokenChecker(BaseChecker):
+ """Base class for checkers that want to have access to the token stream."""
+
+ @abc.abstractmethod
+ def process_tokens(self, tokens: list[TokenInfo]) -> None:
+ """Should be overridden by subclasses."""
+ raise NotImplementedError()
+
+
+class BaseRawFileChecker(BaseChecker):
+ """Base class for checkers which need to parse the raw file."""
+
+ @abc.abstractmethod
+ def process_module(self, node: nodes.Module) -> None:
+ """Process a module.
+
+ The module's content is accessible via ``astroid.stream``
+ """
+ raise NotImplementedError()
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/classes/__init__.py b/solutions/.venv/Lib/site-packages/pylint/checkers/classes/__init__.py
new file mode 100644
index 000000000..422fae2ee
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/classes/__init__.py
@@ -0,0 +1,18 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from pylint.checkers.classes.class_checker import ClassChecker
+from pylint.checkers.classes.special_methods_checker import SpecialMethodsChecker
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ClassChecker(linter))
+ linter.register_checker(SpecialMethodsChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/classes/class_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/classes/class_checker.py
new file mode 100644
index 000000000..0caeeadcd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/classes/class_checker.py
@@ -0,0 +1,2450 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Classes checker for Python code."""
+
+from __future__ import annotations
+
+from collections import defaultdict
+from collections.abc import Callable, Sequence
+from functools import cached_property
+from itertools import chain, zip_longest
+from re import Pattern
+from typing import TYPE_CHECKING, Any, NamedTuple, Union
+
+import astroid
+from astroid import bases, nodes, util
+from astroid.nodes import LocalsDictNodeNG
+from astroid.typing import SuccessfulInferenceResult
+
+from pylint.checkers import BaseChecker, utils
+from pylint.checkers.utils import (
+ PYMETHODS,
+ class_is_abstract,
+ decorated_with,
+ decorated_with_property,
+ get_outer_class,
+ has_known_bases,
+ is_attr_private,
+ is_attr_protected,
+ is_builtin_object,
+ is_comprehension,
+ is_iterable,
+ is_property_setter,
+ is_property_setter_or_deleter,
+ node_frame_class,
+ only_required_for_messages,
+ safe_infer,
+ unimplemented_abstract_methods,
+ uninferable_final_decorators,
+)
+from pylint.interfaces import HIGH, INFERENCE
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+_AccessNodes = Union[nodes.Attribute, nodes.AssignAttr]
+
+INVALID_BASE_CLASSES = {"bool", "range", "slice", "memoryview"}
+ALLOWED_PROPERTIES = {"bultins.property", "functools.cached_property"}
+BUILTIN_DECORATORS = {"builtins.property", "builtins.classmethod"}
+ASTROID_TYPE_COMPARATORS = {
+ nodes.Const: lambda a, b: a.value == b.value,
+ nodes.ClassDef: lambda a, b: a.qname == b.qname,
+ nodes.Tuple: lambda a, b: a.elts == b.elts,
+ nodes.List: lambda a, b: a.elts == b.elts,
+ nodes.Dict: lambda a, b: a.items == b.items,
+ nodes.Name: lambda a, b: set(a.infer()) == set(b.infer()),
+}
+
+# Dealing with useless override detection, with regard
+# to parameters vs arguments
+
+
+class _CallSignature(NamedTuple):
+ args: list[str | None]
+ kws: dict[str | None, str | None]
+ starred_args: list[str]
+ starred_kws: list[str]
+
+
+class _ParameterSignature(NamedTuple):
+ args: list[str]
+ kwonlyargs: list[str]
+ varargs: str
+ kwargs: str
+
+
+def _signature_from_call(call: nodes.Call) -> _CallSignature:
+ kws = {}
+ args = []
+ starred_kws = []
+ starred_args = []
+ for keyword in call.keywords or []:
+ arg, value = keyword.arg, keyword.value
+ if arg is None and isinstance(value, nodes.Name):
+ # Starred node, and we are interested only in names,
+ # otherwise some transformation might occur for the parameter.
+ starred_kws.append(value.name)
+ elif isinstance(value, nodes.Name):
+ kws[arg] = value.name
+ else:
+ kws[arg] = None
+
+ for arg in call.args:
+ if isinstance(arg, nodes.Starred) and isinstance(arg.value, nodes.Name):
+ # Positional variadic and a name, otherwise some transformation
+ # might have occurred.
+ starred_args.append(arg.value.name)
+ elif isinstance(arg, nodes.Name):
+ args.append(arg.name)
+ else:
+ args.append(None)
+
+ return _CallSignature(args, kws, starred_args, starred_kws)
+
+
+def _signature_from_arguments(arguments: nodes.Arguments) -> _ParameterSignature:
+ kwarg = arguments.kwarg
+ vararg = arguments.vararg
+ args = [
+ arg.name
+ for arg in chain(arguments.posonlyargs, arguments.args)
+ if arg.name != "self"
+ ]
+ kwonlyargs = [arg.name for arg in arguments.kwonlyargs]
+ return _ParameterSignature(args, kwonlyargs, vararg, kwarg)
+
+
+def _definition_equivalent_to_call(
+ definition: _ParameterSignature, call: _CallSignature
+) -> bool:
+ """Check if a definition signature is equivalent to a call."""
+ if definition.kwargs:
+ if definition.kwargs not in call.starred_kws:
+ return False
+ elif call.starred_kws:
+ return False
+ if definition.varargs:
+ if definition.varargs not in call.starred_args:
+ return False
+ elif call.starred_args:
+ return False
+ if any(kw not in call.kws for kw in definition.kwonlyargs):
+ return False
+ if definition.args != call.args:
+ return False
+
+ # No extra kwargs in call.
+ return all(kw in call.args or kw in definition.kwonlyargs for kw in call.kws)
+
+
+def _is_trivial_super_delegation(function: nodes.FunctionDef) -> bool:
+ """Check whether a function definition is a method consisting only of a
+ call to the same function on the superclass.
+ """
+ if (
+ not function.is_method()
+ # Adding decorators to a function changes behavior and
+ # constitutes a non-trivial change.
+ or function.decorators
+ ):
+ return False
+
+ body = function.body
+ if len(body) != 1:
+ # Multiple statements, which means this overridden method
+ # could do multiple things we are not aware of.
+ return False
+
+ statement = body[0]
+ if not isinstance(statement, (nodes.Expr, nodes.Return)):
+ # Doing something else than what we are interested in.
+ return False
+
+ call = statement.value
+ if (
+ not isinstance(call, nodes.Call)
+ # Not a super() attribute access.
+ or not isinstance(call.func, nodes.Attribute)
+ ):
+ return False
+
+ # Anything other than a super call is non-trivial.
+ super_call = safe_infer(call.func.expr)
+ if not isinstance(super_call, astroid.objects.Super):
+ return False
+
+ # The name should be the same.
+ if call.func.attrname != function.name:
+ return False
+
+ # Should be a super call with the MRO pointer being the
+ # current class and the type being the current instance.
+ current_scope = function.parent.scope()
+ if (
+ super_call.mro_pointer != current_scope
+ or not isinstance(super_call.type, astroid.Instance)
+ or super_call.type.name != current_scope.name
+ ):
+ return False
+
+ return True
+
+
+# Deal with parameters overriding in two methods.
+
+
+def _positional_parameters(method: nodes.FunctionDef) -> list[nodes.AssignName]:
+ positional = method.args.args
+ if method.is_bound() and method.type in {"classmethod", "method"}:
+ positional = positional[1:]
+ return positional # type: ignore[no-any-return]
+
+
+class _DefaultMissing:
+ """Sentinel value for missing arg default, use _DEFAULT_MISSING."""
+
+
+_DEFAULT_MISSING = _DefaultMissing()
+
+
+def _has_different_parameters_default_value(
+ original: nodes.Arguments, overridden: nodes.Arguments
+) -> bool:
+ """Check if original and overridden methods arguments have different default values.
+
+ Return True if one of the overridden arguments has a default
+ value different from the default value of the original argument
+ If one of the method doesn't have argument (.args is None)
+ return False
+ """
+ if original.args is None or overridden.args is None:
+ return False
+
+ for param in chain(original.args, original.kwonlyargs):
+ try:
+ original_default = original.default_value(param.name)
+ except astroid.exceptions.NoDefault:
+ original_default = _DEFAULT_MISSING
+ try:
+ overridden_default = overridden.default_value(param.name)
+ if original_default is _DEFAULT_MISSING:
+ # Only the original has a default.
+ return True
+ except astroid.exceptions.NoDefault:
+ if original_default is _DEFAULT_MISSING:
+ # Both have a default, no difference
+ continue
+ # Only the override has a default.
+ return True
+
+ original_type = type(original_default)
+ if not isinstance(overridden_default, original_type):
+ # Two args with same name but different types
+ return True
+ is_same_fn: Callable[[Any, Any], bool] | None = ASTROID_TYPE_COMPARATORS.get(
+ original_type
+ )
+ if is_same_fn is None:
+ # If the default value comparison is unhandled, assume the value is different
+ return True
+ if not is_same_fn(original_default, overridden_default):
+ # Two args with same type but different values
+ return True
+ return False
+
+
+def _has_different_parameters(
+ original: list[nodes.AssignName],
+ overridden: list[nodes.AssignName],
+ dummy_parameter_regex: Pattern[str],
+) -> list[str]:
+ result: list[str] = []
+ zipped = zip_longest(original, overridden)
+ for original_param, overridden_param in zipped:
+ if not overridden_param:
+ return ["Number of parameters "]
+
+ if not original_param:
+ try:
+ overridden_param.parent.default_value(overridden_param.name)
+ continue
+ except astroid.NoDefault:
+ return ["Number of parameters "]
+
+ # check for the arguments' name
+ names = [param.name for param in (original_param, overridden_param)]
+ if any(dummy_parameter_regex.match(name) for name in names):
+ continue
+ if original_param.name != overridden_param.name:
+ result.append(
+ f"Parameter '{original_param.name}' has been renamed "
+ f"to '{overridden_param.name}' in"
+ )
+
+ return result
+
+
+def _has_different_keyword_only_parameters(
+ original: list[nodes.AssignName],
+ overridden: list[nodes.AssignName],
+) -> list[str]:
+ """Determine if the two methods have different keyword only parameters."""
+ original_names = [i.name for i in original]
+ overridden_names = [i.name for i in overridden]
+
+ if any(name not in overridden_names for name in original_names):
+ return ["Number of parameters "]
+
+ for name in overridden_names:
+ if name in original_names:
+ continue
+
+ try:
+ overridden[0].parent.default_value(name)
+ except astroid.NoDefault:
+ return ["Number of parameters "]
+
+ return []
+
+
+def _different_parameters(
+ original: nodes.FunctionDef,
+ overridden: nodes.FunctionDef,
+ dummy_parameter_regex: Pattern[str],
+) -> list[str]:
+ """Determine if the two methods have different parameters.
+
+ They are considered to have different parameters if:
+
+ * they have different positional parameters, including different names
+
+ * one of the methods is having variadics, while the other is not
+
+ * they have different keyword only parameters.
+ """
+ output_messages = []
+ original_parameters = _positional_parameters(original)
+ overridden_parameters = _positional_parameters(overridden)
+
+ # Copy kwonlyargs list so that we don't affect later function linting
+ original_kwonlyargs = original.args.kwonlyargs
+
+ # Allow positional/keyword variadic in overridden to match against any
+ # positional/keyword argument in original.
+ # Keep any arguments that are found separately in overridden to satisfy
+ # later tests
+ if overridden.args.vararg:
+ overridden_names = [v.name for v in overridden_parameters]
+ original_parameters = [
+ v for v in original_parameters if v.name in overridden_names
+ ]
+
+ if overridden.args.kwarg:
+ overridden_names = [v.name for v in overridden.args.kwonlyargs]
+ original_kwonlyargs = [
+ v for v in original.args.kwonlyargs if v.name in overridden_names
+ ]
+
+ different_positional = _has_different_parameters(
+ original_parameters, overridden_parameters, dummy_parameter_regex
+ )
+ different_kwonly = _has_different_keyword_only_parameters(
+ original_kwonlyargs, overridden.args.kwonlyargs
+ )
+ if different_kwonly and different_positional:
+ if "Number " in different_positional[0] and "Number " in different_kwonly[0]:
+ output_messages.append("Number of parameters ")
+ output_messages += different_positional[1:]
+ output_messages += different_kwonly[1:]
+ else:
+ output_messages += different_positional
+ output_messages += different_kwonly
+ else:
+ if different_positional:
+ output_messages += different_positional
+ if different_kwonly:
+ output_messages += different_kwonly
+
+ # Arguments will only violate LSP if there are variadics in the original
+ # that are then removed from the overridden
+ kwarg_lost = original.args.kwarg and not overridden.args.kwarg
+ vararg_lost = original.args.vararg and not overridden.args.vararg
+
+ if kwarg_lost or vararg_lost:
+ output_messages += ["Variadics removed in"]
+
+ if original.name in PYMETHODS:
+ # Ignore the difference for special methods. If the parameter
+ # numbers are different, then that is going to be caught by
+ # unexpected-special-method-signature.
+ # If the names are different, it doesn't matter, since they can't
+ # be used as keyword arguments anyway.
+ output_messages.clear()
+
+ return output_messages
+
+
+def _is_invalid_base_class(cls: nodes.ClassDef) -> bool:
+ return cls.name in INVALID_BASE_CLASSES and is_builtin_object(cls)
+
+
+def _has_data_descriptor(cls: nodes.ClassDef, attr: str) -> bool:
+ attributes = cls.getattr(attr)
+ for attribute in attributes:
+ try:
+ for inferred in attribute.infer():
+ if isinstance(inferred, astroid.Instance):
+ try:
+ inferred.getattr("__get__")
+ inferred.getattr("__set__")
+ except astroid.NotFoundError:
+ continue
+ else:
+ return True
+ except astroid.InferenceError:
+ # Can't infer, avoid emitting a false positive in this case.
+ return True
+ return False
+
+
+def _called_in_methods(
+ func: LocalsDictNodeNG,
+ klass: nodes.ClassDef,
+ methods: Sequence[str],
+) -> bool:
+ """Check if the func was called in any of the given methods,
+ belonging to the *klass*.
+
+ Returns True if so, False otherwise.
+ """
+ if not isinstance(func, nodes.FunctionDef):
+ return False
+ for method in methods:
+ try:
+ inferred = klass.getattr(method)
+ except astroid.NotFoundError:
+ continue
+ for infer_method in inferred:
+ for call in infer_method.nodes_of_class(nodes.Call):
+ try:
+ bound = next(call.func.infer())
+ except (astroid.InferenceError, StopIteration):
+ continue
+ if not isinstance(bound, astroid.BoundMethod):
+ continue
+ func_obj = bound._proxied
+ if isinstance(func_obj, astroid.UnboundMethod):
+ func_obj = func_obj._proxied
+ if func_obj.name == func.name:
+ return True
+ return False
+
+
+def _is_attribute_property(name: str, klass: nodes.ClassDef) -> bool:
+ """Check if the given attribute *name* is a property in the given *klass*.
+
+ It will look for `property` calls or for functions
+ with the given name, decorated by `property` or `property`
+ subclasses.
+ Returns ``True`` if the name is a property in the given klass,
+ ``False`` otherwise.
+ """
+ try:
+ attributes = klass.getattr(name)
+ except astroid.NotFoundError:
+ return False
+ property_name = "builtins.property"
+ for attr in attributes:
+ if isinstance(attr, util.UninferableBase):
+ continue
+ try:
+ inferred = next(attr.infer())
+ except astroid.InferenceError:
+ continue
+ if isinstance(inferred, nodes.FunctionDef) and decorated_with_property(
+ inferred
+ ):
+ return True
+ if inferred.pytype() != property_name:
+ continue
+
+ cls = node_frame_class(inferred)
+ if cls == klass.declared_metaclass():
+ continue
+ return True
+ return False
+
+
+def _has_same_layout_slots(
+ slots: list[nodes.Const | None], assigned_value: nodes.Name
+) -> bool:
+ inferred = next(assigned_value.infer())
+ if isinstance(inferred, nodes.ClassDef):
+ other_slots = inferred.slots()
+ if all(
+ first_slot and second_slot and first_slot.value == second_slot.value
+ for (first_slot, second_slot) in zip_longest(slots, other_slots)
+ ):
+ return True
+ return False
+
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "F0202": (
+ "Unable to check methods signature (%s / %s)",
+ "method-check-failed",
+ "Used when Pylint has been unable to check methods signature "
+ "compatibility for an unexpected reason. Please report this kind "
+ "if you don't make sense of it.",
+ ),
+ "E0202": (
+ "An attribute defined in %s line %s hides this method",
+ "method-hidden",
+ "Used when a class defines a method which is hidden by an "
+ "instance attribute from an ancestor class or set by some "
+ "client code.",
+ ),
+ "E0203": (
+ "Access to member %r before its definition line %s",
+ "access-member-before-definition",
+ "Used when an instance member is accessed before it's actually assigned.",
+ ),
+ "W0201": (
+ "Attribute %r defined outside __init__",
+ "attribute-defined-outside-init",
+ "Used when an instance attribute is defined outside the __init__ method.",
+ ),
+ "W0212": (
+ "Access to a protected member %s of a client class", # E0214
+ "protected-access",
+ "Used when a protected member (i.e. class member with a name "
+ "beginning with an underscore) is accessed outside the class or a "
+ "descendant of the class where it's defined.",
+ ),
+ "W0213": (
+ "Flag member %(overlap)s shares bit positions with %(sources)s",
+ "implicit-flag-alias",
+ "Used when multiple integer values declared within an enum.IntFlag "
+ "class share a common bit position.",
+ ),
+ "E0211": (
+ "Method %r has no argument",
+ "no-method-argument",
+ "Used when a method which should have the bound instance as "
+ "first argument has no argument defined.",
+ ),
+ "E0213": (
+ 'Method %r should have "self" as first argument',
+ "no-self-argument",
+ 'Used when a method has an attribute different the "self" as '
+ "first argument. This is considered as an error since this is "
+ "a so common convention that you shouldn't break it!",
+ ),
+ "C0202": (
+ "Class method %s should have %s as first argument",
+ "bad-classmethod-argument",
+ "Used when a class method has a first argument named differently "
+ "than the value specified in valid-classmethod-first-arg option "
+ '(default to "cls"), recommended to easily differentiate them '
+ "from regular instance methods.",
+ ),
+ "C0203": (
+ "Metaclass method %s should have %s as first argument",
+ "bad-mcs-method-argument",
+ "Used when a metaclass method has a first argument named "
+ "differently than the value specified in valid-classmethod-first"
+ '-arg option (default to "cls"), recommended to easily '
+ "differentiate them from regular instance methods.",
+ ),
+ "C0204": (
+ "Metaclass class method %s should have %s as first argument",
+ "bad-mcs-classmethod-argument",
+ "Used when a metaclass class method has a first argument named "
+ "differently than the value specified in valid-metaclass-"
+ 'classmethod-first-arg option (default to "mcs"), recommended to '
+ "easily differentiate them from regular instance methods.",
+ ),
+ "W0211": (
+ "Static method with %r as first argument",
+ "bad-staticmethod-argument",
+ 'Used when a static method has "self" or a value specified in '
+ "valid-classmethod-first-arg option or "
+ "valid-metaclass-classmethod-first-arg option as first argument.",
+ ),
+ "W0221": (
+ "%s %s %r method",
+ "arguments-differ",
+ "Used when a method has a different number of arguments than in "
+ "the implemented interface or in an overridden method. Extra arguments "
+ "with default values are ignored.",
+ ),
+ "W0222": (
+ "Signature differs from %s %r method",
+ "signature-differs",
+ "Used when a method signature is different than in the "
+ "implemented interface or in an overridden method.",
+ ),
+ "W0223": (
+ "Method %r is abstract in class %r but is not overridden in child class %r",
+ "abstract-method",
+ "Used when an abstract method (i.e. raise NotImplementedError) is "
+ "not overridden in concrete class.",
+ ),
+ "W0231": (
+ "__init__ method from base class %r is not called",
+ "super-init-not-called",
+ "Used when an ancestor class method has an __init__ method "
+ "which is not called by a derived class.",
+ ),
+ "W0233": (
+ "__init__ method from a non direct base class %r is called",
+ "non-parent-init-called",
+ "Used when an __init__ method is called on a class which is not "
+ "in the direct ancestors for the analysed class.",
+ ),
+ "W0246": (
+ "Useless parent or super() delegation in method %r",
+ "useless-parent-delegation",
+ "Used whenever we can detect that an overridden method is useless, "
+ "relying on parent or super() delegation to do the same thing as another method "
+ "from the MRO.",
+ {"old_names": [("W0235", "useless-super-delegation")]},
+ ),
+ "W0236": (
+ "Method %r was expected to be %r, found it instead as %r",
+ "invalid-overridden-method",
+ "Used when we detect that a method was overridden in a way "
+ "that does not match its base class "
+ "which could result in potential bugs at runtime.",
+ ),
+ "W0237": (
+ "%s %s %r method",
+ "arguments-renamed",
+ "Used when a method parameter has a different name than in "
+ "the implemented interface or in an overridden method.",
+ ),
+ "W0238": (
+ "Unused private member `%s.%s`",
+ "unused-private-member",
+ "Emitted when a private member of a class is defined but not used.",
+ ),
+ "W0239": (
+ "Method %r overrides a method decorated with typing.final which is defined in class %r",
+ "overridden-final-method",
+ "Used when a method decorated with typing.final has been overridden.",
+ ),
+ "W0240": (
+ "Class %r is a subclass of a class decorated with typing.final: %r",
+ "subclassed-final-class",
+ "Used when a class decorated with typing.final has been subclassed.",
+ ),
+ "W0244": (
+ "Redefined slots %r in subclass",
+ "redefined-slots-in-subclass",
+ "Used when a slot is re-defined in a subclass.",
+ ),
+ "W0245": (
+ "Super call without brackets",
+ "super-without-brackets",
+ "Used when a call to super does not have brackets and thus is not an actual "
+ "call and does not work as expected.",
+ ),
+ "E0236": (
+ "Invalid object %r in __slots__, must contain only non empty strings",
+ "invalid-slots-object",
+ "Used when an invalid (non-string) object occurs in __slots__.",
+ ),
+ "E0237": (
+ "Assigning to attribute %r not defined in class slots",
+ "assigning-non-slot",
+ "Used when assigning to an attribute not defined in the class slots.",
+ ),
+ "E0238": (
+ "Invalid __slots__ object",
+ "invalid-slots",
+ "Used when an invalid __slots__ is found in class. "
+ "Only a string, an iterable or a sequence is permitted.",
+ ),
+ "E0239": (
+ "Inheriting %r, which is not a class.",
+ "inherit-non-class",
+ "Used when a class inherits from something which is not a class.",
+ ),
+ "E0240": (
+ "Inconsistent method resolution order for class %r",
+ "inconsistent-mro",
+ "Used when a class has an inconsistent method resolution order.",
+ ),
+ "E0241": (
+ "Duplicate bases for class %r",
+ "duplicate-bases",
+ "Duplicate use of base classes in derived classes raise TypeErrors.",
+ ),
+ "E0242": (
+ "Value %r in slots conflicts with class variable",
+ "class-variable-slots-conflict",
+ "Used when a value in __slots__ conflicts with a class variable, property or method.",
+ ),
+ "E0243": (
+ "Invalid assignment to '__class__'. Should be a class definition but got a '%s'",
+ "invalid-class-object",
+ "Used when an invalid object is assigned to a __class__ property. "
+ "Only a class is permitted.",
+ ),
+ "E0244": (
+ 'Extending inherited Enum class "%s"',
+ "invalid-enum-extension",
+ "Used when a class tries to extend an inherited Enum class. "
+ "Doing so will raise a TypeError at runtime.",
+ ),
+ "E0245": (
+ "No such name %r in __slots__",
+ "declare-non-slot",
+ "Raised when a type annotation on a class is absent from the list of names in __slots__, "
+ "and __slots__ does not contain a __dict__ entry.",
+ ),
+ "R0202": (
+ "Consider using a decorator instead of calling classmethod",
+ "no-classmethod-decorator",
+ "Used when a class method is defined without using the decorator syntax.",
+ ),
+ "R0203": (
+ "Consider using a decorator instead of calling staticmethod",
+ "no-staticmethod-decorator",
+ "Used when a static method is defined without using the decorator syntax.",
+ ),
+ "C0205": (
+ "Class __slots__ should be a non-string iterable",
+ "single-string-used-for-slots",
+ "Used when a class __slots__ is a simple string, rather than an iterable.",
+ ),
+ "R0205": (
+ "Class %r inherits from object, can be safely removed from bases in python3",
+ "useless-object-inheritance",
+ "Used when a class inherit from object, which under python3 is implicit, "
+ "hence can be safely removed from bases.",
+ ),
+ "R0206": (
+ "Cannot have defined parameters for properties",
+ "property-with-parameters",
+ "Used when we detect that a property also has parameters, which are useless, "
+ "given that properties cannot be called with additional arguments.",
+ ),
+}
+
+
+def _scope_default() -> defaultdict[str, list[_AccessNodes]]:
+ # It's impossible to nest defaultdicts so we must use a function
+ return defaultdict(list)
+
+
+class ScopeAccessMap:
+ """Store the accessed variables per scope."""
+
+ def __init__(self) -> None:
+ self._scopes: defaultdict[
+ nodes.ClassDef, defaultdict[str, list[_AccessNodes]]
+ ] = defaultdict(_scope_default)
+
+ def set_accessed(self, node: _AccessNodes) -> None:
+ """Set the given node as accessed."""
+ frame = node_frame_class(node)
+ if frame is None:
+ # The node does not live in a class.
+ return
+ self._scopes[frame][node.attrname].append(node)
+
+ def accessed(self, scope: nodes.ClassDef) -> dict[str, list[_AccessNodes]]:
+ """Get the accessed variables for the given scope."""
+ return self._scopes.get(scope, {})
+
+
+class ClassChecker(BaseChecker):
+ """Checker for class nodes.
+
+ Checks for :
+ * methods without self as first argument
+ * overridden methods signature
+ * access only to existent members via self
+ * attributes not defined in the __init__ method
+ * unreachable code
+ """
+
+ # configuration section name
+ name = "classes"
+ # messages
+ msgs = MSGS
+ # configuration options
+ options = (
+ (
+ "defining-attr-methods",
+ {
+ "default": (
+ "__init__",
+ "__new__",
+ "setUp",
+ "asyncSetUp",
+ "__post_init__",
+ ),
+ "type": "csv",
+ "metavar": "<method names>",
+ "help": "List of method names used to declare (i.e. assign) \
+instance attributes.",
+ },
+ ),
+ (
+ "valid-classmethod-first-arg",
+ {
+ "default": ("cls",),
+ "type": "csv",
+ "metavar": "<argument names>",
+ "help": "List of valid names for the first argument in \
+a class method.",
+ },
+ ),
+ (
+ "valid-metaclass-classmethod-first-arg",
+ {
+ "default": ("mcs",),
+ "type": "csv",
+ "metavar": "<argument names>",
+ "help": "List of valid names for the first argument in \
+a metaclass class method.",
+ },
+ ),
+ (
+ "exclude-protected",
+ {
+ "default": (
+ # namedtuple public API.
+ "_asdict",
+ "_fields",
+ "_replace",
+ "_source",
+ "_make",
+ "os._exit",
+ ),
+ "type": "csv",
+ "metavar": "<protected access exclusions>",
+ "help": (
+ "List of member names, which should be excluded "
+ "from the protected access warning."
+ ),
+ },
+ ),
+ (
+ "check-protected-access-in-special-methods",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Warn about protected attribute access inside special methods",
+ },
+ ),
+ )
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._accessed = ScopeAccessMap()
+ self._first_attrs: list[str | None] = []
+
+ def open(self) -> None:
+ self._mixin_class_rgx = self.linter.config.mixin_class_rgx
+ py_version = self.linter.config.py_version
+ self._py38_plus = py_version >= (3, 8)
+
+ @cached_property
+ def _dummy_rgx(self) -> Pattern[str]:
+ return self.linter.config.dummy_variables_rgx # type: ignore[no-any-return]
+
+ @only_required_for_messages(
+ "abstract-method",
+ "invalid-slots",
+ "single-string-used-for-slots",
+ "invalid-slots-object",
+ "class-variable-slots-conflict",
+ "inherit-non-class",
+ "useless-object-inheritance",
+ "inconsistent-mro",
+ "duplicate-bases",
+ "redefined-slots-in-subclass",
+ "invalid-enum-extension",
+ "subclassed-final-class",
+ "implicit-flag-alias",
+ "declare-non-slot",
+ )
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ """Init visit variable _accessed."""
+ self._check_bases_classes(node)
+ self._check_slots(node)
+ self._check_proper_bases(node)
+ self._check_typing_final(node)
+ self._check_consistent_mro(node)
+ self._check_declare_non_slot(node)
+
+ def _check_declare_non_slot(self, node: nodes.ClassDef) -> None:
+ if not self._has_valid_slots(node):
+ return
+
+ slot_names = self._get_classdef_slots_names(node)
+
+ # Stop if empty __slots__ in the class body, this likely indicates that
+ # this class takes part in multiple inheritance with other slotted classes.
+ if not slot_names:
+ return
+
+ # Stop if we find __dict__, since this means attributes can be set
+ # dynamically
+ if "__dict__" in slot_names:
+ return
+
+ for base in node.bases:
+ ancestor = safe_infer(base)
+ if not isinstance(ancestor, nodes.ClassDef):
+ continue
+ # if any base doesn't have __slots__, attributes can be set dynamically, so stop
+ if not self._has_valid_slots(ancestor):
+ return
+ for slot_name in self._get_classdef_slots_names(ancestor):
+ if slot_name == "__dict__":
+ return
+ slot_names.append(slot_name)
+
+ # Every class in bases has __slots__, our __slots__ is non-empty and there is no __dict__
+
+ for child in node.body:
+ if isinstance(child, nodes.AnnAssign):
+ if child.value is not None:
+ continue
+ if isinstance(child.target, nodes.AssignName):
+ if child.target.name not in slot_names:
+ self.add_message(
+ "declare-non-slot",
+ args=child.target.name,
+ node=child.target,
+ confidence=INFERENCE,
+ )
+
+ def _check_consistent_mro(self, node: nodes.ClassDef) -> None:
+ """Detect that a class has a consistent mro or duplicate bases."""
+ try:
+ node.mro()
+ except astroid.InconsistentMroError:
+ self.add_message("inconsistent-mro", args=node.name, node=node)
+ except astroid.DuplicateBasesError:
+ self.add_message("duplicate-bases", args=node.name, node=node)
+
+ def _check_enum_base(self, node: nodes.ClassDef, ancestor: nodes.ClassDef) -> None:
+ members = ancestor.getattr("__members__")
+ if members and isinstance(members[0], nodes.Dict) and members[0].items:
+ for _, name_node in members[0].items:
+ # Exempt type annotations without value assignments
+ if all(
+ isinstance(item.parent, nodes.AnnAssign)
+ and item.parent.value is None
+ for item in ancestor.getattr(name_node.name)
+ ):
+ continue
+ self.add_message(
+ "invalid-enum-extension",
+ args=ancestor.name,
+ node=node,
+ confidence=INFERENCE,
+ )
+ break
+
+ if ancestor.is_subtype_of("enum.IntFlag"):
+ # Collect integer flag assignments present on the class
+ assignments = defaultdict(list)
+ for assign_name in node.nodes_of_class(nodes.AssignName):
+ if isinstance(assign_name.parent, nodes.Assign):
+ value = getattr(assign_name.parent.value, "value", None)
+ if isinstance(value, int):
+ assignments[value].append(assign_name)
+
+ # For each bit position, collect all the flags that set the bit
+ bit_flags = defaultdict(set)
+ for flag in assignments:
+ flag_bits = (i for i, c in enumerate(reversed(bin(flag))) if c == "1")
+ for bit in flag_bits:
+ bit_flags[bit].add(flag)
+
+ # Collect the minimum, unique values that each flag overlaps with
+ overlaps = defaultdict(list)
+ for flags in bit_flags.values():
+ source, *conflicts = sorted(flags)
+ for conflict in conflicts:
+ overlaps[conflict].append(source)
+
+ # Report the overlapping values
+ for overlap in overlaps:
+ for assignment_node in assignments[overlap]:
+ self.add_message(
+ "implicit-flag-alias",
+ node=assignment_node,
+ args={
+ "overlap": f"<{node.name}.{assignment_node.name}: {overlap}>",
+ "sources": ", ".join(
+ f"<{node.name}.{assignments[source][0].name}: {source}> "
+ f"({overlap} & {source} = {overlap & source})"
+ for source in overlaps[overlap]
+ ),
+ },
+ confidence=INFERENCE,
+ )
+
+ def _check_proper_bases(self, node: nodes.ClassDef) -> None:
+ """Detect that a class inherits something which is not
+ a class or a type.
+ """
+ for base in node.bases:
+ ancestor = safe_infer(base)
+ if not ancestor:
+ continue
+ if isinstance(ancestor, astroid.Instance) and (
+ ancestor.is_subtype_of("builtins.type")
+ or ancestor.is_subtype_of(".Protocol")
+ ):
+ continue
+
+ if not isinstance(ancestor, nodes.ClassDef) or _is_invalid_base_class(
+ ancestor
+ ):
+ self.add_message("inherit-non-class", args=base.as_string(), node=node)
+
+ if isinstance(ancestor, nodes.ClassDef) and ancestor.is_subtype_of(
+ "enum.Enum"
+ ):
+ self._check_enum_base(node, ancestor)
+
+ if ancestor.name == object.__name__:
+ self.add_message(
+ "useless-object-inheritance", args=node.name, node=node
+ )
+
+ def _check_typing_final(self, node: nodes.ClassDef) -> None:
+ """Detect that a class does not subclass a class decorated with
+ `typing.final`.
+ """
+ if not self._py38_plus:
+ return
+ for base in node.bases:
+ ancestor = safe_infer(base)
+ if not ancestor:
+ continue
+
+ if isinstance(ancestor, nodes.ClassDef) and (
+ decorated_with(ancestor, ["typing.final"])
+ or uninferable_final_decorators(ancestor.decorators)
+ ):
+ self.add_message(
+ "subclassed-final-class",
+ args=(node.name, ancestor.name),
+ node=node,
+ )
+
+ @only_required_for_messages(
+ "unused-private-member",
+ "attribute-defined-outside-init",
+ "access-member-before-definition",
+ )
+ def leave_classdef(self, node: nodes.ClassDef) -> None:
+ """Checker for Class nodes.
+
+ check that instance attributes are defined in __init__ and check
+ access to existent members
+ """
+ self._check_unused_private_functions(node)
+ self._check_unused_private_variables(node)
+ self._check_unused_private_attributes(node)
+ self._check_attribute_defined_outside_init(node)
+
+ def _check_unused_private_functions(self, node: nodes.ClassDef) -> None:
+ for function_def in node.nodes_of_class(nodes.FunctionDef):
+ if not is_attr_private(function_def.name):
+ continue
+ parent_scope = function_def.parent.scope()
+ if isinstance(parent_scope, nodes.FunctionDef):
+ # Handle nested functions
+ if function_def.name in (
+ n.name for n in parent_scope.nodes_of_class(nodes.Name)
+ ):
+ continue
+ for child in node.nodes_of_class((nodes.Name, nodes.Attribute)):
+ # Check for cases where the functions are used as a variable instead of as a
+ # method call
+ if isinstance(child, nodes.Name) and child.name == function_def.name:
+ break
+ if isinstance(child, nodes.Attribute):
+ # Ignore recursive calls
+ if (
+ child.attrname != function_def.name
+ or child.scope() == function_def
+ ):
+ continue
+
+ # Check self.__attrname, cls.__attrname, node_name.__attrname
+ if isinstance(child.expr, nodes.Name) and child.expr.name in {
+ "self",
+ "cls",
+ node.name,
+ }:
+ break
+
+ # Check type(self).__attrname
+ if isinstance(child.expr, nodes.Call):
+ inferred = safe_infer(child.expr)
+ if (
+ isinstance(inferred, nodes.ClassDef)
+ and inferred.name == node.name
+ ):
+ break
+ else:
+ name_stack = []
+ curr = parent_scope
+ # Generate proper names for nested functions
+ while curr != node:
+ name_stack.append(curr.name)
+ curr = curr.parent.scope()
+
+ outer_level_names = f"{'.'.join(reversed(name_stack))}"
+ function_repr = f"{outer_level_names}.{function_def.name}({function_def.args.as_string()})"
+ self.add_message(
+ "unused-private-member",
+ node=function_def,
+ args=(node.name, function_repr.lstrip(".")),
+ )
+
+ def _check_unused_private_variables(self, node: nodes.ClassDef) -> None:
+ """Check if private variables are never used within a class."""
+ for assign_name in node.nodes_of_class(nodes.AssignName):
+ if isinstance(assign_name.parent, nodes.Arguments):
+ continue # Ignore function arguments
+ if not is_attr_private(assign_name.name):
+ continue
+ for child in node.nodes_of_class((nodes.Name, nodes.Attribute)):
+ if isinstance(child, nodes.Name) and child.name == assign_name.name:
+ break
+ if isinstance(child, nodes.Attribute):
+ if not isinstance(child.expr, nodes.Name):
+ break
+ if child.attrname == assign_name.name and child.expr.name in (
+ "self",
+ "cls",
+ node.name,
+ ):
+ break
+ else:
+ args = (node.name, assign_name.name)
+ self.add_message("unused-private-member", node=assign_name, args=args)
+
+ def _check_unused_private_attributes(self, node: nodes.ClassDef) -> None:
+ for assign_attr in node.nodes_of_class(nodes.AssignAttr):
+ if not is_attr_private(assign_attr.attrname) or not isinstance(
+ assign_attr.expr, nodes.Name
+ ):
+ continue
+
+ # Logic for checking false positive when using __new__,
+ # Get the returned object names of the __new__ magic function
+ # Then check if the attribute was consumed in other instance methods
+ acceptable_obj_names: list[str] = ["self"]
+ scope = assign_attr.scope()
+ if isinstance(scope, nodes.FunctionDef) and scope.name == "__new__":
+ acceptable_obj_names.extend(
+ [
+ return_node.value.name
+ for return_node in scope.nodes_of_class(nodes.Return)
+ if isinstance(return_node.value, nodes.Name)
+ ]
+ )
+
+ for attribute in node.nodes_of_class(nodes.Attribute):
+ if attribute.attrname != assign_attr.attrname:
+ continue
+
+ if not isinstance(attribute.expr, nodes.Name):
+ continue
+
+ if assign_attr.expr.name in {
+ "cls",
+ node.name,
+ } and attribute.expr.name in {"cls", "self", node.name}:
+ # If assigned to cls or class name, can be accessed by cls/self/class name
+ break
+
+ if (
+ assign_attr.expr.name in acceptable_obj_names
+ and attribute.expr.name == "self"
+ ):
+ # If assigned to self.attrib, can only be accessed by self
+ # Or if __new__ was used, the returned object names are acceptable
+ break
+
+ if assign_attr.expr.name == attribute.expr.name == node.name:
+ # Recognise attributes which are accessed via the class name
+ break
+
+ else:
+ args = (node.name, assign_attr.attrname)
+ self.add_message("unused-private-member", node=assign_attr, args=args)
+
+ def _check_attribute_defined_outside_init(self, cnode: nodes.ClassDef) -> None:
+ # check access to existent members on non metaclass classes
+ if (
+ "attribute-defined-outside-init"
+ in self.linter.config.ignored_checks_for_mixins
+ and self._mixin_class_rgx.match(cnode.name)
+ ):
+ # We are in a mixin class. No need to try to figure out if
+ # something is missing, since it is most likely that it will
+ # miss.
+ return
+
+ accessed = self._accessed.accessed(cnode)
+ if cnode.type != "metaclass":
+ self._check_accessed_members(cnode, accessed)
+ # checks attributes are defined in an allowed method such as __init__
+ if not self.linter.is_message_enabled("attribute-defined-outside-init"):
+ return
+ defining_methods = self.linter.config.defining_attr_methods
+ current_module = cnode.root()
+ for attr, nodes_lst in cnode.instance_attrs.items():
+ # Exclude `__dict__` as it is already defined.
+ if attr == "__dict__":
+ continue
+
+ # Skip nodes which are not in the current module and it may screw up
+ # the output, while it's not worth it
+ nodes_lst = [
+ n
+ for n in nodes_lst
+ if not isinstance(n.statement(), (nodes.Delete, nodes.AugAssign))
+ and n.root() is current_module
+ ]
+ if not nodes_lst:
+ continue # error detected by typechecking
+
+ # Check if any method attr is defined in is a defining method
+ # or if we have the attribute defined in a setter.
+ frames = (node.frame() for node in nodes_lst)
+ if any(
+ frame.name in defining_methods or is_property_setter(frame)
+ for frame in frames
+ ):
+ continue
+
+ # check attribute is defined in a parent's __init__
+ for parent in cnode.instance_attr_ancestors(attr):
+ attr_defined = False
+ # check if any parent method attr is defined in is a defining method
+ for node in parent.instance_attrs[attr]:
+ if node.frame().name in defining_methods:
+ attr_defined = True
+ if attr_defined:
+ # we're done :)
+ break
+ else:
+ # check attribute is defined as a class attribute
+ try:
+ cnode.local_attr(attr)
+ except astroid.NotFoundError:
+ for node in nodes_lst:
+ if node.frame().name not in defining_methods:
+ # If the attribute was set by a call in any
+ # of the defining methods, then don't emit
+ # the warning.
+ if _called_in_methods(
+ node.frame(), cnode, defining_methods
+ ):
+ continue
+ self.add_message(
+ "attribute-defined-outside-init", args=attr, node=node
+ )
+
+ # pylint: disable = too-many-branches
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Check method arguments, overriding."""
+ # ignore actual functions
+ if not node.is_method():
+ return
+
+ self._check_useless_super_delegation(node)
+ self._check_property_with_parameters(node)
+
+ # 'is_method()' is called and makes sure that this is a 'nodes.ClassDef'
+ klass: nodes.ClassDef = node.parent.frame()
+ # check first argument is self if this is actually a method
+ self._check_first_arg_for_type(node, klass.type == "metaclass")
+ if node.name == "__init__":
+ self._check_init(node, klass)
+ return
+ # check signature if the method overloads inherited method
+ for overridden in klass.local_attr_ancestors(node.name):
+ # get astroid for the searched method
+ try:
+ parent_function = overridden[node.name]
+ except KeyError:
+ # we have found the method but it's not in the local
+ # dictionary.
+ # This may happen with astroid build from living objects
+ continue
+ if not isinstance(parent_function, nodes.FunctionDef):
+ continue
+ self._check_signature(node, parent_function, klass)
+ self._check_invalid_overridden_method(node, parent_function)
+ break
+
+ if node.decorators:
+ for decorator in node.decorators.nodes:
+ if isinstance(decorator, nodes.Attribute) and decorator.attrname in {
+ "getter",
+ "setter",
+ "deleter",
+ }:
+ # attribute affectation will call this method, not hiding it
+ return
+ if isinstance(decorator, nodes.Name):
+ if decorator.name in ALLOWED_PROPERTIES:
+ # attribute affectation will either call a setter or raise
+ # an attribute error, anyway not hiding the function
+ return
+
+ if isinstance(decorator, nodes.Attribute):
+ if self._check_functools_or_not(decorator):
+ return
+
+ # Infer the decorator and see if it returns something useful
+ inferred = safe_infer(decorator)
+ if not inferred:
+ return
+ if isinstance(inferred, nodes.FunctionDef):
+ # Okay, it's a decorator, let's see what it can infer.
+ try:
+ inferred = next(inferred.infer_call_result(inferred))
+ except astroid.InferenceError:
+ return
+ try:
+ if (
+ isinstance(inferred, (astroid.Instance, nodes.ClassDef))
+ and inferred.getattr("__get__")
+ and inferred.getattr("__set__")
+ ):
+ return
+ except astroid.AttributeInferenceError:
+ pass
+
+ # check if the method is hidden by an attribute
+ # pylint: disable = too-many-try-statements
+ try:
+ overridden = klass.instance_attr(node.name)[0]
+ overridden_frame = overridden.frame()
+ if (
+ isinstance(overridden_frame, nodes.FunctionDef)
+ and overridden_frame.type == "method"
+ ):
+ overridden_frame = overridden_frame.parent.frame()
+ if not (
+ isinstance(overridden_frame, nodes.ClassDef)
+ and klass.is_subtype_of(overridden_frame.qname())
+ ):
+ return
+
+ # If a subclass defined the method then it's not our fault.
+ for ancestor in klass.ancestors():
+ if node.name in ancestor.instance_attrs and is_attr_private(node.name):
+ return
+ for obj in ancestor.lookup(node.name)[1]:
+ if isinstance(obj, nodes.FunctionDef):
+ return
+ args = (overridden.root().name, overridden.fromlineno)
+ self.add_message("method-hidden", args=args, node=node)
+ except astroid.NotFoundError:
+ pass
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_useless_super_delegation(self, function: nodes.FunctionDef) -> None:
+ """Check if the given function node is an useless method override.
+
+ We consider it *useless* if it uses the super() builtin, but having
+ nothing additional whatsoever than not implementing the method at all.
+ If the method uses super() to delegate an operation to the rest of the MRO,
+ and if the method called is the same as the current one, the arguments
+ passed to super() are the same as the parameters that were passed to
+ this method, then the method could be removed altogether, by letting
+ other implementation to take precedence.
+ """
+ if not _is_trivial_super_delegation(function):
+ return
+
+ call: nodes.Call = function.body[0].value
+
+ # Classes that override __eq__ should also override
+ # __hash__, even a trivial override is meaningful
+ if function.name == "__hash__":
+ for other_method in function.parent.mymethods():
+ if other_method.name == "__eq__":
+ return
+
+ # Check values of default args
+ klass = function.parent.frame()
+ meth_node = None
+ for overridden in klass.local_attr_ancestors(function.name):
+ # get astroid for the searched method
+ try:
+ meth_node = overridden[function.name]
+ except KeyError:
+ # we have found the method but it's not in the local
+ # dictionary.
+ # This may happen with astroid build from living objects
+ continue
+ if (
+ not isinstance(meth_node, nodes.FunctionDef)
+ # If the method have an ancestor which is not a
+ # function then it is legitimate to redefine it
+ or _has_different_parameters_default_value(
+ meth_node.args, function.args
+ )
+ # arguments to builtins such as Exception.__init__() cannot be inspected
+ or (meth_node.args.args is None and function.argnames() != ["self"])
+ ):
+ return
+ break
+
+ # Detect if the parameters are the same as the call's arguments.
+ params = _signature_from_arguments(function.args)
+ args = _signature_from_call(call)
+
+ if meth_node is not None:
+ # Detect if the super method uses varargs and the function doesn't or makes some of those explicit
+ if meth_node.args.vararg and (
+ not function.args.vararg
+ or len(function.args.args) > len(meth_node.args.args)
+ ):
+ return
+
+ def form_annotations(arguments: nodes.Arguments) -> list[str]:
+ annotations = chain(
+ (arguments.posonlyargs_annotations or []), arguments.annotations
+ )
+ return [ann.as_string() for ann in annotations if ann is not None]
+
+ called_annotations = form_annotations(function.args)
+ overridden_annotations = form_annotations(meth_node.args)
+ if called_annotations and overridden_annotations:
+ if called_annotations != overridden_annotations:
+ return
+
+ if (
+ function.returns is not None
+ and meth_node.returns is not None
+ and meth_node.returns.as_string() != function.returns.as_string()
+ ):
+ # Override adds typing information to the return type
+ return
+
+ if _definition_equivalent_to_call(params, args):
+ self.add_message(
+ "useless-parent-delegation",
+ node=function,
+ args=(function.name,),
+ confidence=INFERENCE,
+ )
+
+ def _check_property_with_parameters(self, node: nodes.FunctionDef) -> None:
+ if (
+ len(node.args.arguments) > 1
+ and decorated_with_property(node)
+ and not is_property_setter(node)
+ ):
+ self.add_message("property-with-parameters", node=node, confidence=HIGH)
+
+ def _check_invalid_overridden_method(
+ self,
+ function_node: nodes.FunctionDef,
+ parent_function_node: nodes.FunctionDef,
+ ) -> None:
+ parent_is_property = decorated_with_property(
+ parent_function_node
+ ) or is_property_setter_or_deleter(parent_function_node)
+ current_is_property = decorated_with_property(
+ function_node
+ ) or is_property_setter_or_deleter(function_node)
+ if parent_is_property and not current_is_property:
+ self.add_message(
+ "invalid-overridden-method",
+ args=(function_node.name, "property", function_node.type),
+ node=function_node,
+ )
+ elif not parent_is_property and current_is_property:
+ self.add_message(
+ "invalid-overridden-method",
+ args=(function_node.name, "method", "property"),
+ node=function_node,
+ )
+
+ parent_is_async = isinstance(parent_function_node, nodes.AsyncFunctionDef)
+ current_is_async = isinstance(function_node, nodes.AsyncFunctionDef)
+
+ if parent_is_async and not current_is_async:
+ self.add_message(
+ "invalid-overridden-method",
+ args=(function_node.name, "async", "non-async"),
+ node=function_node,
+ )
+
+ elif not parent_is_async and current_is_async:
+ self.add_message(
+ "invalid-overridden-method",
+ args=(function_node.name, "non-async", "async"),
+ node=function_node,
+ )
+ if (
+ decorated_with(parent_function_node, ["typing.final"])
+ or uninferable_final_decorators(parent_function_node.decorators)
+ ) and self._py38_plus:
+ self.add_message(
+ "overridden-final-method",
+ args=(function_node.name, parent_function_node.parent.frame().name),
+ node=function_node,
+ )
+
+ def _check_functools_or_not(self, decorator: nodes.Attribute) -> bool:
+ if decorator.attrname != "cached_property":
+ return False
+
+ if not isinstance(decorator.expr, nodes.Name):
+ return False
+
+ _, import_nodes = decorator.expr.lookup(decorator.expr.name)
+
+ if not import_nodes:
+ return False
+ import_node = import_nodes[0]
+
+ if not isinstance(import_node, (astroid.Import, astroid.ImportFrom)):
+ return False
+
+ return "functools" in dict(import_node.names)
+
+ def _has_valid_slots(self, node: nodes.ClassDef) -> bool:
+ if "__slots__" not in node.locals:
+ return False
+
+ try:
+ inferred_slots = tuple(node.ilookup("__slots__"))
+ except astroid.InferenceError:
+ return False
+ for slots in inferred_slots:
+ # check if __slots__ is a valid type
+ if isinstance(slots, util.UninferableBase):
+ return False
+ if not is_iterable(slots) and not is_comprehension(slots):
+ return False
+ if isinstance(slots, nodes.Const):
+ return False
+ if not hasattr(slots, "itered"):
+ # we can't obtain the values, maybe a .deque?
+ return False
+
+ return True
+
+ def _check_slots(self, node: nodes.ClassDef) -> None:
+ if "__slots__" not in node.locals:
+ return
+
+ try:
+ inferred_slots = tuple(node.ilookup("__slots__"))
+ except astroid.InferenceError:
+ return
+ for slots in inferred_slots:
+ # check if __slots__ is a valid type
+ if isinstance(slots, util.UninferableBase):
+ continue
+ if not is_iterable(slots) and not is_comprehension(slots):
+ self.add_message("invalid-slots", node=node)
+ continue
+
+ if isinstance(slots, nodes.Const):
+ # a string, ignore the following checks
+ self.add_message("single-string-used-for-slots", node=node)
+ continue
+ if not hasattr(slots, "itered"):
+ # we can't obtain the values, maybe a .deque?
+ continue
+
+ if isinstance(slots, nodes.Dict):
+ values = [item[0] for item in slots.items]
+ else:
+ values = slots.itered()
+ if isinstance(values, util.UninferableBase):
+ continue
+ for elt in values:
+ try:
+ self._check_slots_elt(elt, node)
+ except astroid.InferenceError:
+ continue
+ self._check_redefined_slots(node, slots, values)
+
+ def _get_classdef_slots_names(self, node: nodes.ClassDef) -> list[str]:
+
+ slots_names: list[str] = []
+ try:
+ inferred_slots = tuple(node.ilookup("__slots__"))
+ except astroid.InferenceError: # pragma: no cover
+ return slots_names
+ for slots in inferred_slots:
+ if isinstance(slots, nodes.Dict):
+ values = [item[0] for item in slots.items]
+ else:
+ values = slots.itered()
+ slots_names.extend(self._get_slots_names(values))
+
+ return slots_names
+
+ def _get_slots_names(self, slots_list: list[nodes.NodeNG]) -> list[str]:
+ slots_names: list[str] = []
+ for slot in slots_list:
+ if isinstance(slot, nodes.Const):
+ slots_names.append(slot.value)
+ else:
+ inferred_slot = safe_infer(slot)
+ inferred_slot_value = getattr(inferred_slot, "value", None)
+ if isinstance(inferred_slot_value, str):
+ slots_names.append(inferred_slot_value)
+ return slots_names
+
+ def _check_redefined_slots(
+ self,
+ node: nodes.ClassDef,
+ slots_node: nodes.NodeNG,
+ slots_list: list[nodes.NodeNG],
+ ) -> None:
+ """Check if `node` redefines a slot which is defined in an ancestor class."""
+ slots_names: list[str] = self._get_slots_names(slots_list)
+
+ # Slots of all parent classes
+ ancestors_slots_names = {
+ slot.value
+ for ancestor in node.local_attr_ancestors("__slots__")
+ for slot in ancestor.slots() or []
+ }
+
+ # Slots which are common to `node` and its parent classes
+ redefined_slots = ancestors_slots_names.intersection(slots_names)
+
+ if redefined_slots:
+ self.add_message(
+ "redefined-slots-in-subclass",
+ args=([name for name in slots_names if name in redefined_slots],),
+ node=slots_node,
+ )
+
+ def _check_slots_elt(
+ self, elt: SuccessfulInferenceResult, node: nodes.ClassDef
+ ) -> None:
+ for inferred in elt.infer():
+ if isinstance(inferred, util.UninferableBase):
+ continue
+ if not isinstance(inferred, nodes.Const) or not isinstance(
+ inferred.value, str
+ ):
+ self.add_message(
+ "invalid-slots-object",
+ args=elt.as_string(),
+ node=elt,
+ confidence=INFERENCE,
+ )
+ continue
+ if not inferred.value:
+ self.add_message(
+ "invalid-slots-object",
+ args=elt.as_string(),
+ node=elt,
+ confidence=INFERENCE,
+ )
+
+ # Check if we have a conflict with a class variable.
+ class_variable = node.locals.get(inferred.value)
+ if class_variable:
+ # Skip annotated assignments which don't conflict at all with slots.
+ if len(class_variable) == 1:
+ parent = class_variable[0].parent
+ if isinstance(parent, nodes.AnnAssign) and parent.value is None:
+ return
+ self.add_message(
+ "class-variable-slots-conflict", args=(inferred.value,), node=elt
+ )
+
+ def leave_functiondef(self, node: nodes.FunctionDef) -> None:
+ """On method node, check if this method couldn't be a function.
+
+ ignore class, static and abstract methods, initializer,
+ methods overridden from a parent class.
+ """
+ if node.is_method():
+ if node.args.args is not None:
+ self._first_attrs.pop()
+
+ leave_asyncfunctiondef = leave_functiondef
+
+ def visit_attribute(self, node: nodes.Attribute) -> None:
+ """Check if the getattr is an access to a class member
+ if so, register it.
+
+ Also check for access to protected
+ class member from outside its class (but ignore __special__
+ methods)
+ """
+ self._check_super_without_brackets(node)
+
+ # Check self
+ if self._uses_mandatory_method_param(node):
+ self._accessed.set_accessed(node)
+ return
+ if not self.linter.is_message_enabled("protected-access"):
+ return
+
+ self._check_protected_attribute_access(node)
+
+ def _check_super_without_brackets(self, node: nodes.Attribute) -> None:
+ """Check if there is a function call on a super call without brackets."""
+ # Check if attribute call is in frame definition in class definition
+ frame = node.frame()
+ if not isinstance(frame, nodes.FunctionDef):
+ return
+ if not isinstance(frame.parent.frame(), nodes.ClassDef):
+ return
+ if not isinstance(node.parent, nodes.Call):
+ return
+ if not isinstance(node.expr, nodes.Name):
+ return
+ if node.expr.name == "super":
+ self.add_message("super-without-brackets", node=node.expr, confidence=HIGH)
+
+ @only_required_for_messages(
+ "assigning-non-slot", "invalid-class-object", "access-member-before-definition"
+ )
+ def visit_assignattr(self, node: nodes.AssignAttr) -> None:
+ if isinstance(
+ node.assign_type(), nodes.AugAssign
+ ) and self._uses_mandatory_method_param(node):
+ self._accessed.set_accessed(node)
+ self._check_in_slots(node)
+ self._check_invalid_class_object(node)
+
+ def _check_invalid_class_object(self, node: nodes.AssignAttr) -> None:
+ if not node.attrname == "__class__":
+ return
+ if isinstance(node.parent, nodes.Tuple):
+ class_index = -1
+ for i, elt in enumerate(node.parent.elts):
+ if hasattr(elt, "attrname") and elt.attrname == "__class__":
+ class_index = i
+ if class_index == -1:
+ # This should not happen because we checked that the node name
+ # is '__class__' earlier, but let's not be too confident here
+ return # pragma: no cover
+ inferred = safe_infer(node.parent.parent.value.elts[class_index])
+ else:
+ inferred = safe_infer(node.parent.value)
+ if (
+ isinstance(inferred, (nodes.ClassDef, util.UninferableBase))
+ or inferred is None
+ ):
+ # If is uninferable, we allow it to prevent false positives
+ return
+ self.add_message(
+ "invalid-class-object",
+ node=node,
+ args=inferred.__class__.__name__,
+ confidence=INFERENCE,
+ )
+
+ def _check_in_slots(self, node: nodes.AssignAttr) -> None:
+ """Check that the given AssignAttr node
+ is defined in the class slots.
+ """
+ inferred = safe_infer(node.expr)
+ if not isinstance(inferred, astroid.Instance):
+ return
+
+ klass = inferred._proxied
+ if not has_known_bases(klass):
+ return
+ if "__slots__" not in klass.locals:
+ return
+ # If `__setattr__` is defined on the class, then we can't reason about
+ # what will happen when assigning to an attribute.
+ if any(
+ base.locals.get("__setattr__")
+ for base in klass.mro()
+ if base.qname() != "builtins.object"
+ ):
+ return
+
+ # If 'typing.Generic' is a base of bases of klass, the cached version
+ # of 'slots()' might have been evaluated incorrectly, thus deleted cache entry.
+ if any(base.qname() == "typing.Generic" for base in klass.mro()):
+ cache = getattr(klass, "__cache", None)
+ if cache and cache.get(klass.slots) is not None:
+ del cache[klass.slots]
+
+ slots = klass.slots()
+ if slots is None:
+ return
+ # If any ancestor doesn't use slots, the slots
+ # defined for this class are superfluous.
+ if any(
+ "__slots__" not in ancestor.locals
+ and ancestor.name not in ("Generic", "object")
+ for ancestor in klass.ancestors()
+ ):
+ return
+
+ if not any(slot.value == node.attrname for slot in slots):
+ # If we have a '__dict__' in slots, then
+ # assigning any name is valid.
+ if not any(slot.value == "__dict__" for slot in slots):
+ if _is_attribute_property(node.attrname, klass):
+ # Properties circumvent the slots mechanism,
+ # so we should not emit a warning for them.
+ return
+ if node.attrname != "__class__" and utils.is_class_attr(
+ node.attrname, klass
+ ):
+ return
+ if node.attrname in klass.locals:
+ for local_name in klass.locals.get(node.attrname):
+ statement = local_name.statement()
+ if (
+ isinstance(statement, nodes.AnnAssign)
+ and not statement.value
+ ):
+ return
+ if _has_data_descriptor(klass, node.attrname):
+ # Descriptors circumvent the slots mechanism as well.
+ return
+ if node.attrname == "__class__" and _has_same_layout_slots(
+ slots, node.parent.value
+ ):
+ return
+ self.add_message(
+ "assigning-non-slot",
+ args=(node.attrname,),
+ node=node,
+ confidence=INFERENCE,
+ )
+
+ @only_required_for_messages(
+ "protected-access", "no-classmethod-decorator", "no-staticmethod-decorator"
+ )
+ def visit_assign(self, assign_node: nodes.Assign) -> None:
+ self._check_classmethod_declaration(assign_node)
+ node = assign_node.targets[0]
+ if not isinstance(node, nodes.AssignAttr):
+ return
+
+ if self._uses_mandatory_method_param(node):
+ return
+ self._check_protected_attribute_access(node)
+
+ def _check_classmethod_declaration(self, node: nodes.Assign) -> None:
+ """Checks for uses of classmethod() or staticmethod().
+
+ When a @classmethod or @staticmethod decorator should be used instead.
+ A message will be emitted only if the assignment is at a class scope
+ and only if the classmethod's argument belongs to the class where it
+ is defined.
+ `node` is an assign node.
+ """
+ if not isinstance(node.value, nodes.Call):
+ return
+
+ # check the function called is "classmethod" or "staticmethod"
+ func = node.value.func
+ if not isinstance(func, nodes.Name) or func.name not in (
+ "classmethod",
+ "staticmethod",
+ ):
+ return
+
+ msg = (
+ "no-classmethod-decorator"
+ if func.name == "classmethod"
+ else "no-staticmethod-decorator"
+ )
+ # assignment must be at a class scope
+ parent_class = node.scope()
+ if not isinstance(parent_class, nodes.ClassDef):
+ return
+
+ # Check if the arg passed to classmethod is a class member
+ classmeth_arg = node.value.args[0]
+ if not isinstance(classmeth_arg, nodes.Name):
+ return
+
+ method_name = classmeth_arg.name
+ if any(method_name == member.name for member in parent_class.mymethods()):
+ self.add_message(msg, node=node.targets[0])
+
+ def _check_protected_attribute_access(
+ self, node: nodes.Attribute | nodes.AssignAttr
+ ) -> None:
+ """Given an attribute access node (set or get), check if attribute
+ access is legitimate.
+
+ Call _check_first_attr with node before calling
+ this method. Valid cases are:
+ * self._attr in a method or cls._attr in a classmethod. Checked by
+ _check_first_attr.
+ * Klass._attr inside "Klass" class.
+ * Klass2._attr inside "Klass" class when Klass2 is a base class of
+ Klass.
+ """
+ attrname = node.attrname
+
+ if (
+ not is_attr_protected(attrname)
+ or attrname in self.linter.config.exclude_protected
+ ):
+ return
+
+ # Typing annotations in function definitions can include protected members
+ if utils.is_node_in_type_annotation_context(node):
+ return
+
+ # Return if `attrname` is defined at the module-level or as a class attribute
+ # and is listed in `exclude-protected`.
+ inferred = safe_infer(node.expr)
+ if (
+ inferred
+ and isinstance(inferred, (nodes.ClassDef, nodes.Module))
+ and f"{inferred.name}.{attrname}" in self.linter.config.exclude_protected
+ ):
+ return
+
+ klass = node_frame_class(node)
+ if klass is None:
+ # We are not in a class, no remaining valid case
+ self.add_message("protected-access", node=node, args=attrname)
+ return
+
+ # In classes, check we are not getting a parent method
+ # through the class object or through super
+
+ # If the expression begins with a call to super, that's ok.
+ if (
+ isinstance(node.expr, nodes.Call)
+ and isinstance(node.expr.func, nodes.Name)
+ and node.expr.func.name == "super"
+ ):
+ return
+
+ # If the expression begins with a call to type(self), that's ok.
+ if self._is_type_self_call(node.expr):
+ return
+
+ # Check if we are inside the scope of a class or nested inner class
+ inside_klass = True
+ outer_klass = klass
+ callee = node.expr.as_string()
+ parents_callee = callee.split(".")
+ parents_callee.reverse()
+ for callee in parents_callee:
+ if not outer_klass or callee != outer_klass.name:
+ inside_klass = False
+ break
+
+ # Move up one level within the nested classes
+ outer_klass = get_outer_class(outer_klass)
+
+ # We are in a class, one remaining valid cases, Klass._attr inside
+ # Klass
+ if not (inside_klass or callee in klass.basenames):
+ # Detect property assignments in the body of the class.
+ # This is acceptable:
+ #
+ # class A:
+ # b = property(lambda: self._b)
+
+ stmt = node.parent.statement()
+ if (
+ isinstance(stmt, nodes.Assign)
+ and len(stmt.targets) == 1
+ and isinstance(stmt.targets[0], nodes.AssignName)
+ ):
+ name = stmt.targets[0].name
+ if _is_attribute_property(name, klass):
+ return
+
+ if (
+ self._is_classmethod(node.frame())
+ and self._is_inferred_instance(node.expr, klass)
+ and self._is_class_or_instance_attribute(attrname, klass)
+ ):
+ return
+
+ licit_protected_member = not attrname.startswith("__")
+ if (
+ not self.linter.config.check_protected_access_in_special_methods
+ and licit_protected_member
+ and self._is_called_inside_special_method(node)
+ ):
+ return
+
+ self.add_message("protected-access", node=node, args=attrname)
+
+ @staticmethod
+ def _is_called_inside_special_method(node: nodes.NodeNG) -> bool:
+ """Returns true if the node is located inside a special (aka dunder) method."""
+ frame_name = node.frame().name
+ return frame_name and frame_name in PYMETHODS
+
+ def _is_type_self_call(self, expr: nodes.NodeNG) -> bool:
+ return (
+ isinstance(expr, nodes.Call)
+ and isinstance(expr.func, nodes.Name)
+ and expr.func.name == "type"
+ and len(expr.args) == 1
+ and self._is_mandatory_method_param(expr.args[0])
+ )
+
+ @staticmethod
+ def _is_classmethod(func: LocalsDictNodeNG) -> bool:
+ """Check if the given *func* node is a class method."""
+ return isinstance(func, nodes.FunctionDef) and (
+ func.type == "classmethod" or func.name == "__class_getitem__"
+ )
+
+ @staticmethod
+ def _is_inferred_instance(expr: nodes.NodeNG, klass: nodes.ClassDef) -> bool:
+ """Check if the inferred value of the given *expr* is an instance of
+ *klass*.
+ """
+ inferred = safe_infer(expr)
+ if not isinstance(inferred, astroid.Instance):
+ return False
+ return inferred._proxied is klass
+
+ @staticmethod
+ def _is_class_or_instance_attribute(name: str, klass: nodes.ClassDef) -> bool:
+ """Check if the given attribute *name* is a class or instance member of the
+ given *klass*.
+
+ Returns ``True`` if the name is a property in the given klass,
+ ``False`` otherwise.
+ """
+ if utils.is_class_attr(name, klass):
+ return True
+
+ try:
+ klass.instance_attr(name)
+ return True
+ except astroid.NotFoundError:
+ return False
+
+ def _check_accessed_members(
+ self, node: nodes.ClassDef, accessed: dict[str, list[_AccessNodes]]
+ ) -> None:
+ """Check that accessed members are defined."""
+ excs = ("AttributeError", "Exception", "BaseException")
+ for attr, nodes_lst in accessed.items():
+ try:
+ # is it a class attribute ?
+ node.local_attr(attr)
+ # yes, stop here
+ continue
+ except astroid.NotFoundError:
+ pass
+ # is it an instance attribute of a parent class ?
+ try:
+ next(node.instance_attr_ancestors(attr))
+ # yes, stop here
+ continue
+ except StopIteration:
+ pass
+ # is it an instance attribute ?
+ try:
+ defstmts = node.instance_attr(attr)
+ except astroid.NotFoundError:
+ pass
+ else:
+ # filter out augment assignment nodes
+ defstmts = [stmt for stmt in defstmts if stmt not in nodes_lst]
+ if not defstmts:
+ # only augment assignment for this node, no-member should be
+ # triggered by the typecheck checker
+ continue
+ # filter defstmts to only pick the first one when there are
+ # several assignments in the same scope
+ scope = defstmts[0].scope()
+ defstmts = [
+ stmt
+ for i, stmt in enumerate(defstmts)
+ if i == 0 or stmt.scope() is not scope
+ ]
+ # if there are still more than one, don't attempt to be smarter
+ # than we can be
+ if len(defstmts) == 1:
+ defstmt = defstmts[0]
+ # check that if the node is accessed in the same method as
+ # it's defined, it's accessed after the initial assignment
+ frame = defstmt.frame()
+ lno = defstmt.fromlineno
+ for _node in nodes_lst:
+ if (
+ _node.frame() is frame
+ and _node.fromlineno < lno
+ and not astroid.are_exclusive(
+ _node.statement(), defstmt, excs
+ )
+ ):
+ self.add_message(
+ "access-member-before-definition",
+ node=_node,
+ args=(attr, lno),
+ )
+
+ def _check_first_arg_for_type(
+ self, node: nodes.FunctionDef, metaclass: bool
+ ) -> None:
+ """Check the name of first argument, expect:.
+
+ * 'self' for a regular method
+ * 'cls' for a class method or a metaclass regular method (actually
+ valid-classmethod-first-arg value)
+ * 'mcs' for a metaclass class method (actually
+ valid-metaclass-classmethod-first-arg)
+ * not one of the above for a static method
+ """
+ # don't care about functions with unknown argument (builtins)
+ if node.args.args is None:
+ return
+ if node.args.posonlyargs:
+ first_arg = node.args.posonlyargs[0].name
+ elif node.args.args:
+ first_arg = node.argnames()[0]
+ else:
+ first_arg = None
+ self._first_attrs.append(first_arg)
+ first = self._first_attrs[-1]
+ # static method
+ if node.type == "staticmethod":
+ if (
+ first_arg == "self"
+ or first_arg in self.linter.config.valid_classmethod_first_arg
+ or first_arg in self.linter.config.valid_metaclass_classmethod_first_arg
+ ):
+ self.add_message("bad-staticmethod-argument", args=first, node=node)
+ return
+ self._first_attrs[-1] = None
+ elif "builtins.staticmethod" in node.decoratornames():
+ # Check if there is a decorator which is not named `staticmethod`
+ # but is assigned to one.
+ return
+ # class / regular method with no args
+ elif not (
+ node.args.args
+ or node.args.posonlyargs
+ or node.args.vararg
+ or node.args.kwarg
+ ):
+ self.add_message("no-method-argument", node=node, args=node.name)
+ # metaclass
+ elif metaclass:
+ # metaclass __new__ or classmethod
+ if node.type == "classmethod":
+ self._check_first_arg_config(
+ first,
+ self.linter.config.valid_metaclass_classmethod_first_arg,
+ node,
+ "bad-mcs-classmethod-argument",
+ node.name,
+ )
+ # metaclass regular method
+ else:
+ self._check_first_arg_config(
+ first,
+ self.linter.config.valid_classmethod_first_arg,
+ node,
+ "bad-mcs-method-argument",
+ node.name,
+ )
+ # regular class with class method
+ elif node.type == "classmethod" or node.name == "__class_getitem__":
+ self._check_first_arg_config(
+ first,
+ self.linter.config.valid_classmethod_first_arg,
+ node,
+ "bad-classmethod-argument",
+ node.name,
+ )
+ # regular class with regular method without self as argument
+ elif first != "self":
+ self.add_message("no-self-argument", node=node, args=node.name)
+
+ def _check_first_arg_config(
+ self,
+ first: str | None,
+ config: Sequence[str],
+ node: nodes.FunctionDef,
+ message: str,
+ method_name: str,
+ ) -> None:
+ if first not in config:
+ if len(config) == 1:
+ valid = repr(config[0])
+ else:
+ valid = ", ".join(repr(v) for v in config[:-1])
+ valid = f"{valid} or {config[-1]!r}"
+ self.add_message(message, args=(method_name, valid), node=node)
+
+ def _check_bases_classes(self, node: nodes.ClassDef) -> None:
+ """Check that the given class node implements abstract methods from
+ base classes.
+ """
+
+ def is_abstract(method: nodes.FunctionDef) -> bool:
+ return method.is_abstract(pass_is_abstract=False) # type: ignore[no-any-return]
+
+ # check if this class abstract
+ if class_is_abstract(node):
+ return
+
+ methods = sorted(
+ unimplemented_abstract_methods(node, is_abstract).items(),
+ key=lambda item: item[0],
+ )
+ for name, method in methods:
+ owner = method.parent.frame()
+ if owner is node:
+ continue
+ # owner is not this class, it must be a parent class
+ # check that the ancestor's method is not abstract
+ if name in node.locals:
+ # it is redefined as an attribute or with a descriptor
+ continue
+
+ self.add_message(
+ "abstract-method",
+ node=node,
+ args=(name, owner.name, node.name),
+ confidence=INFERENCE,
+ )
+
+ def _check_init(self, node: nodes.FunctionDef, klass_node: nodes.ClassDef) -> None:
+ """Check that the __init__ method call super or ancestors'__init__
+ method (unless it is used for type hinting with `typing.overload`).
+ """
+ if not self.linter.is_message_enabled(
+ "super-init-not-called"
+ ) and not self.linter.is_message_enabled("non-parent-init-called"):
+ return
+ to_call = _ancestors_to_call(klass_node)
+ not_called_yet = dict(to_call)
+ parents_with_called_inits: set[bases.UnboundMethod] = set()
+ for stmt in node.nodes_of_class(nodes.Call):
+ expr = stmt.func
+ if not isinstance(expr, nodes.Attribute) or expr.attrname != "__init__":
+ continue
+ # skip the test if using super
+ if (
+ isinstance(expr.expr, nodes.Call)
+ and isinstance(expr.expr.func, nodes.Name)
+ and expr.expr.func.name == "super"
+ ):
+ return
+ # pylint: disable = too-many-try-statements
+ try:
+ for klass in expr.expr.infer():
+ if isinstance(klass, util.UninferableBase):
+ continue
+ # The inferred klass can be super(), which was
+ # assigned to a variable and the `__init__`
+ # was called later.
+ #
+ # base = super()
+ # base.__init__(...)
+
+ if (
+ isinstance(klass, astroid.Instance)
+ and isinstance(klass._proxied, nodes.ClassDef)
+ and is_builtin_object(klass._proxied)
+ and klass._proxied.name == "super"
+ ):
+ return
+ if isinstance(klass, astroid.objects.Super):
+ return
+ try:
+ method = not_called_yet.pop(klass)
+ # Record that the class' init has been called
+ parents_with_called_inits.add(node_frame_class(method))
+ except KeyError:
+ if klass not in klass_node.ancestors(recurs=False):
+ self.add_message(
+ "non-parent-init-called", node=expr, args=klass.name
+ )
+ except astroid.InferenceError:
+ continue
+ for klass, method in not_called_yet.items():
+ # Check if the init of the class that defines this init has already
+ # been called.
+ if node_frame_class(method) in parents_with_called_inits:
+ return
+
+ if utils.is_protocol_class(klass):
+ return
+
+ if decorated_with(node, ["typing.overload"]):
+ continue
+ self.add_message(
+ "super-init-not-called",
+ args=klass.name,
+ node=node,
+ confidence=INFERENCE,
+ )
+
+ def _check_signature(
+ self,
+ method1: nodes.FunctionDef,
+ refmethod: nodes.FunctionDef,
+ cls: nodes.ClassDef,
+ ) -> None:
+ """Check that the signature of the two given methods match."""
+ if not (
+ isinstance(method1, nodes.FunctionDef)
+ and isinstance(refmethod, nodes.FunctionDef)
+ ):
+ self.add_message(
+ "method-check-failed", args=(method1, refmethod), node=method1
+ )
+ return
+
+ instance = cls.instantiate_class()
+ method1 = astroid.scoped_nodes.function_to_method(method1, instance)
+ refmethod = astroid.scoped_nodes.function_to_method(refmethod, instance)
+
+ # Don't care about functions with unknown argument (builtins).
+ if method1.args.args is None or refmethod.args.args is None:
+ return
+
+ # Ignore private to class methods.
+ if is_attr_private(method1.name):
+ return
+ # Ignore setters, they have an implicit extra argument,
+ # which shouldn't be taken in consideration.
+ if is_property_setter(method1):
+ return
+
+ arg_differ_output = _different_parameters(
+ refmethod, method1, dummy_parameter_regex=self._dummy_rgx
+ )
+
+ class_type = "overriding"
+
+ if len(arg_differ_output) > 0:
+ for msg in arg_differ_output:
+ if "Number" in msg:
+ total_args_method1 = len(method1.args.args)
+ if method1.args.vararg:
+ total_args_method1 += 1
+ if method1.args.kwarg:
+ total_args_method1 += 1
+ if method1.args.kwonlyargs:
+ total_args_method1 += len(method1.args.kwonlyargs)
+ total_args_refmethod = len(refmethod.args.args)
+ if refmethod.args.vararg:
+ total_args_refmethod += 1
+ if refmethod.args.kwarg:
+ total_args_refmethod += 1
+ if refmethod.args.kwonlyargs:
+ total_args_refmethod += len(refmethod.args.kwonlyargs)
+ error_type = "arguments-differ"
+ msg_args = (
+ msg
+ + f"was {total_args_refmethod} in '{refmethod.parent.frame().name}.{refmethod.name}' and "
+ f"is now {total_args_method1} in",
+ class_type,
+ f"{method1.parent.frame().name}.{method1.name}",
+ )
+ elif "renamed" in msg:
+ error_type = "arguments-renamed"
+ msg_args = (
+ msg,
+ class_type,
+ f"{method1.parent.frame().name}.{method1.name}",
+ )
+ else:
+ error_type = "arguments-differ"
+ msg_args = (
+ msg,
+ class_type,
+ f"{method1.parent.frame().name}.{method1.name}",
+ )
+ self.add_message(error_type, args=msg_args, node=method1)
+ elif (
+ len(method1.args.defaults) < len(refmethod.args.defaults)
+ and not method1.args.vararg
+ ):
+ class_type = "overridden"
+ self.add_message(
+ "signature-differs", args=(class_type, method1.name), node=method1
+ )
+
+ def _uses_mandatory_method_param(
+ self, node: nodes.Attribute | nodes.Assign | nodes.AssignAttr
+ ) -> bool:
+ """Check that attribute lookup name use first attribute variable name.
+
+ Name is `self` for method, `cls` for classmethod and `mcs` for metaclass.
+ """
+ return self._is_mandatory_method_param(node.expr)
+
+ def _is_mandatory_method_param(self, node: nodes.NodeNG) -> bool:
+ """Check if nodes.Name corresponds to first attribute variable name.
+
+ Name is `self` for method, `cls` for classmethod and `mcs` for metaclass.
+ Static methods return False.
+ """
+ if self._first_attrs:
+ first_attr = self._first_attrs[-1]
+ else:
+ # It's possible the function was already unregistered.
+ closest_func = utils.get_node_first_ancestor_of_type(
+ node, nodes.FunctionDef
+ )
+ if closest_func is None:
+ return False
+ if not closest_func.is_bound():
+ return False
+ if not closest_func.args.args:
+ return False
+ first_attr = closest_func.args.args[0].name
+ return isinstance(node, nodes.Name) and node.name == first_attr
+
+
+def _ancestors_to_call(
+ klass_node: nodes.ClassDef, method_name: str = "__init__"
+) -> dict[nodes.ClassDef, bases.UnboundMethod]:
+ """Return a dictionary where keys are the list of base classes providing
+ the queried method, and so that should/may be called from the method node.
+ """
+ to_call: dict[nodes.ClassDef, bases.UnboundMethod] = {}
+ for base_node in klass_node.ancestors(recurs=False):
+ try:
+ init_node = next(base_node.igetattr(method_name))
+ if not isinstance(init_node, astroid.UnboundMethod):
+ continue
+ if init_node.is_abstract():
+ continue
+ to_call[base_node] = init_node
+ except astroid.InferenceError:
+ continue
+ return to_call
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/classes/special_methods_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/classes/special_methods_checker.py
new file mode 100644
index 000000000..025f28562
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/classes/special_methods_checker.py
@@ -0,0 +1,403 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Special methods checker and helper function's module."""
+
+from __future__ import annotations
+
+from collections.abc import Callable
+
+import astroid
+from astroid import bases, nodes, util
+from astroid.context import InferenceContext
+from astroid.typing import InferenceResult
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import (
+ PYMETHODS,
+ SPECIAL_METHODS_PARAMS,
+ decorated_with,
+ is_function_body_ellipsis,
+ only_required_for_messages,
+ safe_infer,
+)
+from pylint.lint.pylinter import PyLinter
+
+NEXT_METHOD = "__next__"
+
+
+def _safe_infer_call_result(
+ node: nodes.FunctionDef,
+ caller: nodes.FunctionDef,
+ context: InferenceContext | None = None,
+) -> InferenceResult | None:
+ """Safely infer the return value of a function.
+
+ Returns None if inference failed or if there is some ambiguity (more than
+ one node has been inferred). Otherwise, returns inferred value.
+ """
+ try:
+ inferit = node.infer_call_result(caller, context=context)
+ value = next(inferit)
+ except astroid.InferenceError:
+ return None # inference failed
+ except StopIteration:
+ return None # no values inferred
+ try:
+ next(inferit)
+ return None # there is ambiguity on the inferred node
+ except astroid.InferenceError:
+ return None # there is some kind of ambiguity
+ except StopIteration:
+ return value
+
+
+class SpecialMethodsChecker(BaseChecker):
+ """Checker which verifies that special methods
+ are implemented correctly.
+ """
+
+ name = "classes"
+ msgs = {
+ "E0301": (
+ "__iter__ returns non-iterator",
+ "non-iterator-returned",
+ "Used when an __iter__ method returns something which is not an "
+ f"iterable (i.e. has no `{NEXT_METHOD}` method)",
+ {
+ "old_names": [
+ ("W0234", "old-non-iterator-returned-1"),
+ ("E0234", "old-non-iterator-returned-2"),
+ ]
+ },
+ ),
+ "E0302": (
+ "The special method %r expects %s param(s), %d %s given",
+ "unexpected-special-method-signature",
+ "Emitted when a special method was defined with an "
+ "invalid number of parameters. If it has too few or "
+ "too many, it might not work at all.",
+ {"old_names": [("E0235", "bad-context-manager")]},
+ ),
+ "E0303": (
+ "__len__ does not return non-negative integer",
+ "invalid-length-returned",
+ "Used when a __len__ method returns something which is not a "
+ "non-negative integer",
+ ),
+ "E0304": (
+ "__bool__ does not return bool",
+ "invalid-bool-returned",
+ "Used when a __bool__ method returns something which is not a bool",
+ ),
+ "E0305": (
+ "__index__ does not return int",
+ "invalid-index-returned",
+ "Used when an __index__ method returns something which is not "
+ "an integer",
+ ),
+ "E0306": (
+ "__repr__ does not return str",
+ "invalid-repr-returned",
+ "Used when a __repr__ method returns something which is not a string",
+ ),
+ "E0307": (
+ "__str__ does not return str",
+ "invalid-str-returned",
+ "Used when a __str__ method returns something which is not a string",
+ ),
+ "E0308": (
+ "__bytes__ does not return bytes",
+ "invalid-bytes-returned",
+ "Used when a __bytes__ method returns something which is not bytes",
+ ),
+ "E0309": (
+ "__hash__ does not return int",
+ "invalid-hash-returned",
+ "Used when a __hash__ method returns something which is not an integer",
+ ),
+ "E0310": (
+ "__length_hint__ does not return non-negative integer",
+ "invalid-length-hint-returned",
+ "Used when a __length_hint__ method returns something which is not a "
+ "non-negative integer",
+ ),
+ "E0311": (
+ "__format__ does not return str",
+ "invalid-format-returned",
+ "Used when a __format__ method returns something which is not a string",
+ ),
+ "E0312": (
+ "__getnewargs__ does not return a tuple",
+ "invalid-getnewargs-returned",
+ "Used when a __getnewargs__ method returns something which is not "
+ "a tuple",
+ ),
+ "E0313": (
+ "__getnewargs_ex__ does not return a tuple containing (tuple, dict)",
+ "invalid-getnewargs-ex-returned",
+ "Used when a __getnewargs_ex__ method returns something which is not "
+ "of the form tuple(tuple, dict)",
+ ),
+ }
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._protocol_map: dict[
+ str, Callable[[nodes.FunctionDef, InferenceResult], None]
+ ] = {
+ "__iter__": self._check_iter,
+ "__len__": self._check_len,
+ "__bool__": self._check_bool,
+ "__index__": self._check_index,
+ "__repr__": self._check_repr,
+ "__str__": self._check_str,
+ "__bytes__": self._check_bytes,
+ "__hash__": self._check_hash,
+ "__length_hint__": self._check_length_hint,
+ "__format__": self._check_format,
+ "__getnewargs__": self._check_getnewargs,
+ "__getnewargs_ex__": self._check_getnewargs_ex,
+ }
+
+ @only_required_for_messages(
+ "unexpected-special-method-signature",
+ "non-iterator-returned",
+ "invalid-length-returned",
+ "invalid-bool-returned",
+ "invalid-index-returned",
+ "invalid-repr-returned",
+ "invalid-str-returned",
+ "invalid-bytes-returned",
+ "invalid-hash-returned",
+ "invalid-length-hint-returned",
+ "invalid-format-returned",
+ "invalid-getnewargs-returned",
+ "invalid-getnewargs-ex-returned",
+ )
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ if not node.is_method():
+ return
+
+ inferred = _safe_infer_call_result(node, node)
+ # Only want to check types that we are able to infer
+ if (
+ inferred
+ and node.name in self._protocol_map
+ and not is_function_body_ellipsis(node)
+ ):
+ self._protocol_map[node.name](node, inferred)
+
+ if node.name in PYMETHODS:
+ self._check_unexpected_method_signature(node)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_unexpected_method_signature(self, node: nodes.FunctionDef) -> None:
+ expected_params = SPECIAL_METHODS_PARAMS[node.name]
+
+ if expected_params is None:
+ # This can support a variable number of parameters.
+ return
+ if not node.args.args and not node.args.vararg:
+ # Method has no parameter, will be caught
+ # by no-method-argument.
+ return
+
+ if decorated_with(node, ["builtins.staticmethod"]):
+ # We expect to not take in consideration self.
+ all_args = node.args.args
+ else:
+ all_args = node.args.args[1:]
+ mandatory = len(all_args) - len(node.args.defaults)
+ optional = len(node.args.defaults)
+ current_params = mandatory + optional
+
+ emit = False # If we don't know we choose a false negative
+ if isinstance(expected_params, tuple):
+ # The expected number of parameters can be any value from this
+ # tuple, although the user should implement the method
+ # to take all of them in consideration.
+ emit = mandatory not in expected_params
+ # mypy thinks that expected_params has type tuple[int, int] | int | None
+ # But at this point it must be 'tuple[int, int]' because of the type check
+ expected_params = f"between {expected_params[0]} or {expected_params[1]}" # type: ignore[assignment]
+ else:
+ # If the number of mandatory parameters doesn't
+ # suffice, the expected parameters for this
+ # function will be deduced from the optional
+ # parameters.
+ rest = expected_params - mandatory
+ if rest == 0:
+ emit = False
+ elif rest < 0:
+ emit = True
+ elif rest > 0:
+ emit = not ((optional - rest) >= 0 or node.args.vararg)
+
+ if emit:
+ verb = "was" if current_params <= 1 else "were"
+ self.add_message(
+ "unexpected-special-method-signature",
+ args=(node.name, expected_params, current_params, verb),
+ node=node,
+ )
+
+ @staticmethod
+ def _is_wrapped_type(node: InferenceResult, type_: str) -> bool:
+ return (
+ isinstance(node, bases.Instance)
+ and node.name == type_
+ and not isinstance(node, nodes.Const)
+ )
+
+ @staticmethod
+ def _is_int(node: InferenceResult) -> bool:
+ if SpecialMethodsChecker._is_wrapped_type(node, "int"):
+ return True
+
+ return isinstance(node, nodes.Const) and isinstance(node.value, int)
+
+ @staticmethod
+ def _is_str(node: InferenceResult) -> bool:
+ if SpecialMethodsChecker._is_wrapped_type(node, "str"):
+ return True
+
+ return isinstance(node, nodes.Const) and isinstance(node.value, str)
+
+ @staticmethod
+ def _is_bool(node: InferenceResult) -> bool:
+ if SpecialMethodsChecker._is_wrapped_type(node, "bool"):
+ return True
+
+ return isinstance(node, nodes.Const) and isinstance(node.value, bool)
+
+ @staticmethod
+ def _is_bytes(node: InferenceResult) -> bool:
+ if SpecialMethodsChecker._is_wrapped_type(node, "bytes"):
+ return True
+
+ return isinstance(node, nodes.Const) and isinstance(node.value, bytes)
+
+ @staticmethod
+ def _is_tuple(node: InferenceResult) -> bool:
+ if SpecialMethodsChecker._is_wrapped_type(node, "tuple"):
+ return True
+
+ return isinstance(node, nodes.Const) and isinstance(node.value, tuple)
+
+ @staticmethod
+ def _is_dict(node: InferenceResult) -> bool:
+ if SpecialMethodsChecker._is_wrapped_type(node, "dict"):
+ return True
+
+ return isinstance(node, nodes.Const) and isinstance(node.value, dict)
+
+ @staticmethod
+ def _is_iterator(node: InferenceResult) -> bool:
+ if isinstance(node, bases.Generator):
+ # Generators can be iterated.
+ return True
+ if isinstance(node, nodes.ComprehensionScope):
+ # Comprehensions can be iterated.
+ return True
+
+ if isinstance(node, bases.Instance):
+ try:
+ node.local_attr(NEXT_METHOD)
+ return True
+ except astroid.NotFoundError:
+ pass
+ elif isinstance(node, nodes.ClassDef):
+ metaclass = node.metaclass()
+ if metaclass and isinstance(metaclass, nodes.ClassDef):
+ try:
+ metaclass.local_attr(NEXT_METHOD)
+ return True
+ except astroid.NotFoundError:
+ pass
+ return False
+
+ def _check_iter(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_iterator(inferred):
+ self.add_message("non-iterator-returned", node=node)
+
+ def _check_len(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_int(inferred):
+ self.add_message("invalid-length-returned", node=node)
+ elif isinstance(inferred, nodes.Const) and inferred.value < 0:
+ self.add_message("invalid-length-returned", node=node)
+
+ def _check_bool(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_bool(inferred):
+ self.add_message("invalid-bool-returned", node=node)
+
+ def _check_index(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_int(inferred):
+ self.add_message("invalid-index-returned", node=node)
+
+ def _check_repr(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_str(inferred):
+ self.add_message("invalid-repr-returned", node=node)
+
+ def _check_str(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_str(inferred):
+ self.add_message("invalid-str-returned", node=node)
+
+ def _check_bytes(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_bytes(inferred):
+ self.add_message("invalid-bytes-returned", node=node)
+
+ def _check_hash(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_int(inferred):
+ self.add_message("invalid-hash-returned", node=node)
+
+ def _check_length_hint(
+ self, node: nodes.FunctionDef, inferred: InferenceResult
+ ) -> None:
+ if not self._is_int(inferred):
+ self.add_message("invalid-length-hint-returned", node=node)
+ elif isinstance(inferred, nodes.Const) and inferred.value < 0:
+ self.add_message("invalid-length-hint-returned", node=node)
+
+ def _check_format(self, node: nodes.FunctionDef, inferred: InferenceResult) -> None:
+ if not self._is_str(inferred):
+ self.add_message("invalid-format-returned", node=node)
+
+ def _check_getnewargs(
+ self, node: nodes.FunctionDef, inferred: InferenceResult
+ ) -> None:
+ if not self._is_tuple(inferred):
+ self.add_message("invalid-getnewargs-returned", node=node)
+
+ def _check_getnewargs_ex(
+ self, node: nodes.FunctionDef, inferred: InferenceResult
+ ) -> None:
+ if not self._is_tuple(inferred):
+ self.add_message("invalid-getnewargs-ex-returned", node=node)
+ return
+
+ if not isinstance(inferred, nodes.Tuple):
+ # If it's not an astroid.Tuple we can't analyze it further
+ return
+
+ found_error = False
+
+ if len(inferred.elts) != 2:
+ found_error = True
+ else:
+ for arg, check in (
+ (inferred.elts[0], self._is_tuple),
+ (inferred.elts[1], self._is_dict),
+ ):
+ if isinstance(arg, nodes.Call):
+ arg = safe_infer(arg)
+
+ if arg and not isinstance(arg, util.UninferableBase):
+ if not check(arg):
+ found_error = True
+ break
+
+ if found_error:
+ self.add_message("invalid-getnewargs-ex-returned", node=node)
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/dataclass_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/dataclass_checker.py
new file mode 100644
index 000000000..60b1b23cd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/dataclass_checker.py
@@ -0,0 +1,129 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Dataclass checkers for Python code."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+from astroid.brain.brain_dataclasses import DATACLASS_MODULES
+
+from pylint.checkers import BaseChecker, utils
+from pylint.interfaces import INFERENCE
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def _is_dataclasses_module(node: nodes.Module) -> bool:
+ """Utility function to check if node is from dataclasses_module."""
+ return node.name in DATACLASS_MODULES
+
+
+def _check_name_or_attrname_eq_to(
+ node: nodes.Name | nodes.Attribute, check_with: str
+) -> bool:
+ """Utility function to check either a Name/Attribute node's name/attrname with a
+ given string.
+ """
+ if isinstance(node, nodes.Name):
+ return str(node.name) == check_with
+ return str(node.attrname) == check_with
+
+
+class DataclassChecker(BaseChecker):
+ """Checker that detects invalid or problematic usage in dataclasses.
+
+ Checks for
+ * invalid-field-call
+ """
+
+ name = "dataclass"
+ msgs = {
+ "E3701": (
+ "Invalid usage of field(), %s",
+ "invalid-field-call",
+ "The dataclasses.field() specifier should only be used as the value of "
+ "an assignment within a dataclass, or within the make_dataclass() function.",
+ ),
+ }
+
+ @utils.only_required_for_messages("invalid-field-call")
+ def visit_call(self, node: nodes.Call) -> None:
+ self._check_invalid_field_call(node)
+
+ def _check_invalid_field_call(self, node: nodes.Call) -> None:
+ """Checks for correct usage of the dataclasses.field() specifier in
+ dataclasses or within the make_dataclass() function.
+
+ Emits message
+ when field() is detected to be used outside a class decorated with
+ @dataclass decorator and outside make_dataclass() function, or when it
+ is used improperly within a dataclass.
+ """
+ if not isinstance(node.func, (nodes.Name, nodes.Attribute)):
+ return
+ if not _check_name_or_attrname_eq_to(node.func, "field"):
+ return
+ inferred_func = utils.safe_infer(node.func)
+ if not (
+ isinstance(inferred_func, nodes.FunctionDef)
+ and _is_dataclasses_module(inferred_func.root())
+ ):
+ return
+ scope_node = node.parent
+ while scope_node and not isinstance(scope_node, (nodes.ClassDef, nodes.Call)):
+ scope_node = scope_node.parent
+
+ if isinstance(scope_node, nodes.Call):
+ self._check_invalid_field_call_within_call(node, scope_node)
+ return
+
+ if not scope_node or not scope_node.is_dataclass:
+ self.add_message(
+ "invalid-field-call",
+ node=node,
+ args=(
+ "it should be used within a dataclass or the make_dataclass() function.",
+ ),
+ confidence=INFERENCE,
+ )
+ return
+
+ if not (isinstance(node.parent, nodes.AnnAssign) and node == node.parent.value):
+ self.add_message(
+ "invalid-field-call",
+ node=node,
+ args=("it should be the value of an assignment within a dataclass.",),
+ confidence=INFERENCE,
+ )
+
+ def _check_invalid_field_call_within_call(
+ self, node: nodes.Call, scope_node: nodes.Call
+ ) -> None:
+ """Checks for special case where calling field is valid as an argument of the
+ make_dataclass() function.
+ """
+ inferred_func = utils.safe_infer(scope_node.func)
+ if (
+ isinstance(scope_node.func, (nodes.Name, nodes.AssignName))
+ and scope_node.func.name == "make_dataclass"
+ and isinstance(inferred_func, nodes.FunctionDef)
+ and _is_dataclasses_module(inferred_func.root())
+ ):
+ return
+ self.add_message(
+ "invalid-field-call",
+ node=node,
+ args=(
+ "it should be used within a dataclass or the make_dataclass() function.",
+ ),
+ confidence=INFERENCE,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(DataclassChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/deprecated.py b/solutions/.venv/Lib/site-packages/pylint/checkers/deprecated.py
new file mode 100644
index 000000000..028dc13f3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/deprecated.py
@@ -0,0 +1,287 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checker mixin for deprecated functionality."""
+
+from __future__ import annotations
+
+from collections.abc import Container, Iterable
+from itertools import chain
+
+import astroid
+from astroid import nodes
+from astroid.bases import Instance
+
+from pylint.checkers import utils
+from pylint.checkers.base_checker import BaseChecker
+from pylint.checkers.utils import get_import_name, infer_all, safe_infer
+from pylint.interfaces import INFERENCE
+from pylint.typing import MessageDefinitionTuple
+
+ACCEPTABLE_NODES = (
+ astroid.BoundMethod,
+ astroid.UnboundMethod,
+ nodes.FunctionDef,
+ nodes.ClassDef,
+ astroid.Attribute,
+)
+
+
+class DeprecatedMixin(BaseChecker):
+ """A mixin implementing logic for checking deprecated symbols.
+
+ A class implementing mixin must define "deprecated-method" Message.
+ """
+
+ DEPRECATED_ATTRIBUTE_MESSAGE: dict[str, MessageDefinitionTuple] = {
+ "W4906": (
+ "Using deprecated attribute %r",
+ "deprecated-attribute",
+ "The attribute is marked as deprecated and will be removed in the future.",
+ {"shared": True},
+ ),
+ }
+
+ DEPRECATED_MODULE_MESSAGE: dict[str, MessageDefinitionTuple] = {
+ "W4901": (
+ "Deprecated module %r",
+ "deprecated-module",
+ "A module marked as deprecated is imported.",
+ {"old_names": [("W0402", "old-deprecated-module")], "shared": True},
+ ),
+ }
+
+ DEPRECATED_METHOD_MESSAGE: dict[str, MessageDefinitionTuple] = {
+ "W4902": (
+ "Using deprecated method %s()",
+ "deprecated-method",
+ "The method is marked as deprecated and will be removed in the future.",
+ {"old_names": [("W1505", "old-deprecated-method")], "shared": True},
+ ),
+ }
+
+ DEPRECATED_ARGUMENT_MESSAGE: dict[str, MessageDefinitionTuple] = {
+ "W4903": (
+ "Using deprecated argument %s of method %s()",
+ "deprecated-argument",
+ "The argument is marked as deprecated and will be removed in the future.",
+ {"old_names": [("W1511", "old-deprecated-argument")], "shared": True},
+ ),
+ }
+
+ DEPRECATED_CLASS_MESSAGE: dict[str, MessageDefinitionTuple] = {
+ "W4904": (
+ "Using deprecated class %s of module %s",
+ "deprecated-class",
+ "The class is marked as deprecated and will be removed in the future.",
+ {"old_names": [("W1512", "old-deprecated-class")], "shared": True},
+ ),
+ }
+
+ DEPRECATED_DECORATOR_MESSAGE: dict[str, MessageDefinitionTuple] = {
+ "W4905": (
+ "Using deprecated decorator %s()",
+ "deprecated-decorator",
+ "The decorator is marked as deprecated and will be removed in the future.",
+ {"old_names": [("W1513", "old-deprecated-decorator")], "shared": True},
+ ),
+ }
+
+ @utils.only_required_for_messages("deprecated-attribute")
+ def visit_attribute(self, node: astroid.Attribute) -> None:
+ """Called when an `astroid.Attribute` node is visited."""
+ self.check_deprecated_attribute(node)
+
+ @utils.only_required_for_messages(
+ "deprecated-method",
+ "deprecated-argument",
+ "deprecated-class",
+ )
+ def visit_call(self, node: nodes.Call) -> None:
+ """Called when a :class:`nodes.Call` node is visited."""
+ self.check_deprecated_class_in_call(node)
+ for inferred in infer_all(node.func):
+ # Calling entry point for deprecation check logic.
+ self.check_deprecated_method(node, inferred)
+
+ @utils.only_required_for_messages(
+ "deprecated-module",
+ "deprecated-class",
+ )
+ def visit_import(self, node: nodes.Import) -> None:
+ """Triggered when an import statement is seen."""
+ for name in (name for name, _ in node.names):
+ self.check_deprecated_module(node, name)
+ if "." in name:
+ # Checking deprecation for import module with class
+ mod_name, class_name = name.split(".", 1)
+ self.check_deprecated_class(node, mod_name, (class_name,))
+
+ def deprecated_decorators(self) -> Iterable[str]:
+ """Callback returning the deprecated decorators.
+
+ Returns:
+ collections.abc.Container of deprecated decorator names.
+ """
+ return ()
+
+ @utils.only_required_for_messages("deprecated-decorator")
+ def visit_decorators(self, node: nodes.Decorators) -> None:
+ """Triggered when a decorator statement is seen."""
+ children = list(node.get_children())
+ if not children:
+ return
+ if isinstance(children[0], nodes.Call):
+ inf = safe_infer(children[0].func)
+ else:
+ inf = safe_infer(children[0])
+ qname = inf.qname() if inf else None
+ if qname in self.deprecated_decorators():
+ self.add_message("deprecated-decorator", node=node, args=qname)
+
+ @utils.only_required_for_messages(
+ "deprecated-module",
+ "deprecated-class",
+ )
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ """Triggered when a from statement is seen."""
+ basename = node.modname
+ basename = get_import_name(node, basename)
+ self.check_deprecated_module(node, basename)
+ class_names = (name for name, _ in node.names)
+ self.check_deprecated_class(node, basename, class_names)
+
+ def deprecated_methods(self) -> Container[str]:
+ """Callback returning the deprecated methods/functions.
+
+ Returns:
+ collections.abc.Container of deprecated function/method names.
+ """
+ return ()
+
+ def deprecated_arguments(self, method: str) -> Iterable[tuple[int | None, str]]:
+ """Callback returning the deprecated arguments of method/function.
+
+ Args:
+ method (str): name of function/method checked for deprecated arguments
+
+ Returns:
+ collections.abc.Iterable in form:
+ ((POSITION1, PARAM1), (POSITION2: PARAM2) ...)
+ where
+ * POSITIONX - position of deprecated argument PARAMX in function definition.
+ If argument is keyword-only, POSITIONX should be None.
+ * PARAMX - name of the deprecated argument.
+ E.g. suppose function:
+
+ .. code-block:: python
+ def bar(arg1, arg2, arg3, arg4, arg5='spam')
+
+ with deprecated arguments `arg2` and `arg4`. `deprecated_arguments` should return:
+
+ .. code-block:: python
+ ((1, 'arg2'), (3, 'arg4'))
+ """
+ # pylint: disable=unused-argument
+ return ()
+
+ def deprecated_modules(self) -> Iterable[str]:
+ """Callback returning the deprecated modules.
+
+ Returns:
+ collections.abc.Container of deprecated module names.
+ """
+ return ()
+
+ def deprecated_classes(self, module: str) -> Iterable[str]:
+ """Callback returning the deprecated classes of module.
+
+ Args:
+ module (str): name of module checked for deprecated classes
+
+ Returns:
+ collections.abc.Container of deprecated class names.
+ """
+ # pylint: disable=unused-argument
+ return ()
+
+ def deprecated_attributes(self) -> Iterable[str]:
+ """Callback returning the deprecated attributes."""
+ return ()
+
+ def check_deprecated_attribute(self, node: astroid.Attribute) -> None:
+ """Checks if the attribute is deprecated."""
+ inferred_expr = safe_infer(node.expr)
+ if not isinstance(inferred_expr, (nodes.ClassDef, Instance, nodes.Module)):
+ return
+ attribute_qname = ".".join((inferred_expr.qname(), node.attrname))
+ for deprecated_name in self.deprecated_attributes():
+ if attribute_qname == deprecated_name:
+ self.add_message(
+ "deprecated-attribute",
+ node=node,
+ args=(attribute_qname,),
+ confidence=INFERENCE,
+ )
+
+ def check_deprecated_module(self, node: nodes.Import, mod_path: str | None) -> None:
+ """Checks if the module is deprecated."""
+ for mod_name in self.deprecated_modules():
+ if mod_path == mod_name or mod_path and mod_path.startswith(mod_name + "."):
+ self.add_message("deprecated-module", node=node, args=mod_path)
+
+ def check_deprecated_method(self, node: nodes.Call, inferred: nodes.NodeNG) -> None:
+ """Executes the checker for the given node.
+
+ This method should be called from the checker implementing this mixin.
+ """
+ # Reject nodes which aren't of interest to us.
+ if not isinstance(inferred, ACCEPTABLE_NODES):
+ return
+
+ if isinstance(node.func, nodes.Attribute):
+ func_name = node.func.attrname
+ elif isinstance(node.func, nodes.Name):
+ func_name = node.func.name
+ else:
+ # Not interested in other nodes.
+ return
+
+ qnames = {inferred.qname(), func_name}
+ if any(name in self.deprecated_methods() for name in qnames):
+ self.add_message("deprecated-method", node=node, args=(func_name,))
+ return
+ num_of_args = len(node.args)
+ kwargs = {kw.arg for kw in node.keywords} if node.keywords else {}
+ deprecated_arguments = (self.deprecated_arguments(qn) for qn in qnames)
+ for position, arg_name in chain(*deprecated_arguments):
+ if arg_name in kwargs:
+ # function was called with deprecated argument as keyword argument
+ self.add_message(
+ "deprecated-argument", node=node, args=(arg_name, func_name)
+ )
+ elif position is not None and position < num_of_args:
+ # function was called with deprecated argument as positional argument
+ self.add_message(
+ "deprecated-argument", node=node, args=(arg_name, func_name)
+ )
+
+ def check_deprecated_class(
+ self, node: nodes.NodeNG, mod_name: str, class_names: Iterable[str]
+ ) -> None:
+ """Checks if the class is deprecated."""
+ for class_name in class_names:
+ if class_name in self.deprecated_classes(mod_name):
+ self.add_message(
+ "deprecated-class", node=node, args=(class_name, mod_name)
+ )
+
+ def check_deprecated_class_in_call(self, node: nodes.Call) -> None:
+ """Checks if call the deprecated class."""
+ if isinstance(node.func, nodes.Attribute) and isinstance(
+ node.func.expr, nodes.Name
+ ):
+ mod_name = node.func.expr.name
+ class_name = node.func.attrname
+ self.check_deprecated_class(node, mod_name, (class_name,))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/design_analysis.py b/solutions/.venv/Lib/site-packages/pylint/checkers/design_analysis.py
new file mode 100644
index 000000000..5c1adbc88
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/design_analysis.py
@@ -0,0 +1,702 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for signs of poor design."""
+
+from __future__ import annotations
+
+import re
+from collections import defaultdict
+from collections.abc import Iterator
+from typing import TYPE_CHECKING
+
+import astroid
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import is_enum, only_required_for_messages
+from pylint.interfaces import HIGH
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+MSGS: dict[str, MessageDefinitionTuple] = (
+ { # pylint: disable=consider-using-namedtuple-or-dataclass
+ "R0901": (
+ "Too many ancestors (%s/%s)",
+ "too-many-ancestors",
+ "Used when class has too many parent classes, try to reduce "
+ "this to get a simpler (and so easier to use) class.",
+ ),
+ "R0902": (
+ "Too many instance attributes (%s/%s)",
+ "too-many-instance-attributes",
+ "Used when class has too many instance attributes, try to reduce "
+ "this to get a simpler (and so easier to use) class.",
+ ),
+ "R0903": (
+ "Too few public methods (%s/%s)",
+ "too-few-public-methods",
+ "Used when class has too few public methods, so be sure it's "
+ "really worth it.",
+ ),
+ "R0904": (
+ "Too many public methods (%s/%s)",
+ "too-many-public-methods",
+ "Used when class has too many public methods, try to reduce "
+ "this to get a simpler (and so easier to use) class.",
+ ),
+ "R0911": (
+ "Too many return statements (%s/%s)",
+ "too-many-return-statements",
+ "Used when a function or method has too many return statement, "
+ "making it hard to follow.",
+ ),
+ "R0912": (
+ "Too many branches (%s/%s)",
+ "too-many-branches",
+ "Used when a function or method has too many branches, "
+ "making it hard to follow.",
+ ),
+ "R0913": (
+ "Too many arguments (%s/%s)",
+ "too-many-arguments",
+ "Used when a function or method takes too many arguments.",
+ ),
+ "R0914": (
+ "Too many local variables (%s/%s)",
+ "too-many-locals",
+ "Used when a function or method has too many local variables.",
+ ),
+ "R0915": (
+ "Too many statements (%s/%s)",
+ "too-many-statements",
+ "Used when a function or method has too many statements. You "
+ "should then split it in smaller functions / methods.",
+ ),
+ "R0916": (
+ "Too many boolean expressions in if statement (%s/%s)",
+ "too-many-boolean-expressions",
+ "Used when an if statement contains too many boolean expressions.",
+ ),
+ "R0917": (
+ "Too many positional arguments (%s/%s)",
+ "too-many-positional-arguments",
+ "Used when a function has too many positional arguments.",
+ ),
+ }
+)
+SPECIAL_OBJ = re.compile("^_{2}[a-z]+_{2}$")
+DATACLASSES_DECORATORS = frozenset({"dataclass", "attrs"})
+DATACLASS_IMPORT = "dataclasses"
+ATTRS_DECORATORS = frozenset({"define", "frozen"})
+ATTRS_IMPORT = "attrs"
+TYPING_NAMEDTUPLE = "typing.NamedTuple"
+TYPING_TYPEDDICT = "typing.TypedDict"
+TYPING_EXTENSIONS_TYPEDDICT = "typing_extensions.TypedDict"
+
+# Set of stdlib classes to ignore when calculating number of ancestors
+STDLIB_CLASSES_IGNORE_ANCESTOR = frozenset(
+ (
+ "builtins.object",
+ "builtins.tuple",
+ "builtins.dict",
+ "builtins.list",
+ "builtins.set",
+ "bulitins.frozenset",
+ "collections.ChainMap",
+ "collections.Counter",
+ "collections.OrderedDict",
+ "collections.UserDict",
+ "collections.UserList",
+ "collections.UserString",
+ "collections.defaultdict",
+ "collections.deque",
+ "collections.namedtuple",
+ "_collections_abc.Awaitable",
+ "_collections_abc.Coroutine",
+ "_collections_abc.AsyncIterable",
+ "_collections_abc.AsyncIterator",
+ "_collections_abc.AsyncGenerator",
+ "_collections_abc.Hashable",
+ "_collections_abc.Iterable",
+ "_collections_abc.Iterator",
+ "_collections_abc.Generator",
+ "_collections_abc.Reversible",
+ "_collections_abc.Sized",
+ "_collections_abc.Container",
+ "_collections_abc.Collection",
+ "_collections_abc.Set",
+ "_collections_abc.MutableSet",
+ "_collections_abc.Mapping",
+ "_collections_abc.MutableMapping",
+ "_collections_abc.MappingView",
+ "_collections_abc.KeysView",
+ "_collections_abc.ItemsView",
+ "_collections_abc.ValuesView",
+ "_collections_abc.Sequence",
+ "_collections_abc.MutableSequence",
+ "_collections_abc.ByteString",
+ "typing.Tuple",
+ "typing.List",
+ "typing.Dict",
+ "typing.Set",
+ "typing.FrozenSet",
+ "typing.Deque",
+ "typing.DefaultDict",
+ "typing.OrderedDict",
+ "typing.Counter",
+ "typing.ChainMap",
+ "typing.Awaitable",
+ "typing.Coroutine",
+ "typing.AsyncIterable",
+ "typing.AsyncIterator",
+ "typing.AsyncGenerator",
+ "typing.Iterable",
+ "typing.Iterator",
+ "typing.Generator",
+ "typing.Reversible",
+ "typing.Container",
+ "typing.Collection",
+ "typing.AbstractSet",
+ "typing.MutableSet",
+ "typing.Mapping",
+ "typing.MutableMapping",
+ "typing.Sequence",
+ "typing.MutableSequence",
+ "typing.ByteString",
+ "typing.MappingView",
+ "typing.KeysView",
+ "typing.ItemsView",
+ "typing.ValuesView",
+ "typing.ContextManager",
+ "typing.AsyncContextManager",
+ "typing.Hashable",
+ "typing.Sized",
+ TYPING_NAMEDTUPLE,
+ TYPING_TYPEDDICT,
+ TYPING_EXTENSIONS_TYPEDDICT,
+ )
+)
+
+
+def _is_exempt_from_public_methods(node: astroid.ClassDef) -> bool:
+ """Check if a class is exempt from too-few-public-methods."""
+ # If it's a typing.Namedtuple, typing.TypedDict or an Enum
+ for ancestor in node.ancestors():
+ if is_enum(ancestor):
+ return True
+ if ancestor.qname() in (
+ TYPING_NAMEDTUPLE,
+ TYPING_TYPEDDICT,
+ TYPING_EXTENSIONS_TYPEDDICT,
+ ):
+ return True
+
+ # Or if it's a dataclass
+ if not node.decorators:
+ return False
+
+ root_locals = set(node.root().locals)
+ for decorator in node.decorators.nodes:
+ if isinstance(decorator, astroid.Call):
+ decorator = decorator.func
+ if not isinstance(decorator, (astroid.Name, astroid.Attribute)):
+ continue
+ if isinstance(decorator, astroid.Name):
+ name = decorator.name
+ else:
+ name = decorator.attrname
+ if name in DATACLASSES_DECORATORS and (
+ root_locals.intersection(DATACLASSES_DECORATORS)
+ or DATACLASS_IMPORT in root_locals
+ ):
+ return True
+ if name in ATTRS_DECORATORS and (
+ root_locals.intersection(ATTRS_DECORATORS) or ATTRS_IMPORT in root_locals
+ ):
+ return True
+ return False
+
+
+def _count_boolean_expressions(bool_op: nodes.BoolOp) -> int:
+ """Counts the number of boolean expressions in BoolOp `bool_op` (recursive).
+
+ example: a and (b or c or (d and e)) ==> 5 boolean expressions
+ """
+ nb_bool_expr = 0
+ for bool_expr in bool_op.get_children():
+ if isinstance(bool_expr, astroid.BoolOp):
+ nb_bool_expr += _count_boolean_expressions(bool_expr)
+ else:
+ nb_bool_expr += 1
+ return nb_bool_expr
+
+
+def _count_methods_in_class(node: nodes.ClassDef) -> int:
+ all_methods = sum(1 for method in node.methods() if not method.name.startswith("_"))
+ # Special methods count towards the number of public methods,
+ # but don't count towards there being too many methods.
+ for method in node.mymethods():
+ if SPECIAL_OBJ.search(method.name) and method.name != "__init__":
+ all_methods += 1
+ return all_methods
+
+
+def _get_parents_iter(
+ node: nodes.ClassDef, ignored_parents: frozenset[str]
+) -> Iterator[nodes.ClassDef]:
+ r"""Get parents of ``node``, excluding ancestors of ``ignored_parents``.
+
+ If we have the following inheritance diagram:
+
+ F
+ /
+ D E
+ \/
+ B C
+ \/
+ A # class A(B, C): ...
+
+ And ``ignored_parents`` is ``{"E"}``, then this function will return
+ ``{A, B, C, D}`` -- both ``E`` and its ancestors are excluded.
+ """
+ parents: set[nodes.ClassDef] = set()
+ to_explore = list(node.ancestors(recurs=False))
+ while to_explore:
+ parent = to_explore.pop()
+ if parent.qname() in ignored_parents:
+ continue
+ if parent not in parents:
+ # This guard might appear to be performing the same function as
+ # adding the resolved parents to a set to eliminate duplicates
+ # (legitimate due to diamond inheritance patterns), but its
+ # additional purpose is to prevent cycles (not normally possible,
+ # but potential due to inference) and thus guarantee termination
+ # of the while-loop
+ yield parent
+ parents.add(parent)
+ to_explore.extend(parent.ancestors(recurs=False))
+
+
+def _get_parents(
+ node: nodes.ClassDef, ignored_parents: frozenset[str]
+) -> set[nodes.ClassDef]:
+ return set(_get_parents_iter(node, ignored_parents))
+
+
+class MisdesignChecker(BaseChecker):
+ """Checker of potential misdesigns.
+
+ Checks for sign of poor/misdesign:
+ * number of methods, attributes, local variables...
+ * size, complexity of functions, methods
+ """
+
+ # configuration section name
+ name = "design"
+ # messages
+ msgs = MSGS
+ # configuration options
+ options = (
+ (
+ "max-args",
+ {
+ "default": 5,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of arguments for function / method.",
+ },
+ ),
+ (
+ "max-positional-arguments",
+ {
+ "default": 5,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of positional arguments for function / method.",
+ },
+ ),
+ (
+ "max-locals",
+ {
+ "default": 15,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of locals for function / method body.",
+ },
+ ),
+ (
+ "max-returns",
+ {
+ "default": 6,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of return / yield for function / "
+ "method body.",
+ },
+ ),
+ (
+ "max-branches",
+ {
+ "default": 12,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of branch for function / method body.",
+ },
+ ),
+ (
+ "max-statements",
+ {
+ "default": 50,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of statements in function / method body.",
+ },
+ ),
+ (
+ "max-parents",
+ {
+ "default": 7,
+ "type": "int",
+ "metavar": "<num>",
+ "help": "Maximum number of parents for a class (see R0901).",
+ },
+ ),
+ (
+ "ignored-parents",
+ {
+ "default": (),
+ "type": "csv",
+ "metavar": "<comma separated list of class names>",
+ "help": "List of qualified class names to ignore when counting class parents (see R0901)",
+ },
+ ),
+ (
+ "max-attributes",
+ {
+ "default": 7,
+ "type": "int",
+ "metavar": "<num>",
+ "help": "Maximum number of attributes for a class \
+(see R0902).",
+ },
+ ),
+ (
+ "min-public-methods",
+ {
+ "default": 2,
+ "type": "int",
+ "metavar": "<num>",
+ "help": "Minimum number of public methods for a class \
+(see R0903).",
+ },
+ ),
+ (
+ "max-public-methods",
+ {
+ "default": 20,
+ "type": "int",
+ "metavar": "<num>",
+ "help": "Maximum number of public methods for a class \
+(see R0904).",
+ },
+ ),
+ (
+ "max-bool-expr",
+ {
+ "default": 5,
+ "type": "int",
+ "metavar": "<num>",
+ "help": "Maximum number of boolean expressions in an if "
+ "statement (see R0916).",
+ },
+ ),
+ (
+ "exclude-too-few-public-methods",
+ {
+ "default": [],
+ "type": "regexp_csv",
+ "metavar": "<pattern>[,<pattern>...]",
+ "help": "List of regular expressions of class ancestor names "
+ "to ignore when counting public methods (see R0903)",
+ },
+ ),
+ )
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._returns: list[int]
+ self._branches: defaultdict[nodes.LocalsDictNodeNG, int]
+ self._stmts: list[int]
+
+ def open(self) -> None:
+ """Initialize visit variables."""
+ self.linter.stats.reset_node_count()
+ self._returns = []
+ self._branches = defaultdict(int)
+ self._stmts = []
+ self._exclude_too_few_public_methods = (
+ self.linter.config.exclude_too_few_public_methods
+ )
+
+ def _inc_all_stmts(self, amount: int) -> None:
+ for i, _ in enumerate(self._stmts):
+ self._stmts[i] += amount
+
+ @only_required_for_messages(
+ "too-many-ancestors",
+ "too-many-instance-attributes",
+ "too-few-public-methods",
+ "too-many-public-methods",
+ )
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ """Check size of inheritance hierarchy and number of instance attributes."""
+ parents = _get_parents(
+ node,
+ STDLIB_CLASSES_IGNORE_ANCESTOR.union(self.linter.config.ignored_parents),
+ )
+ nb_parents = len(parents)
+ if nb_parents > self.linter.config.max_parents:
+ self.add_message(
+ "too-many-ancestors",
+ node=node,
+ args=(nb_parents, self.linter.config.max_parents),
+ )
+
+ # Something at inference time is modifying instance_attrs to add
+ # properties from parent classes. Given how much we cache inference
+ # results, mutating instance_attrs can become a real mess. Filter
+ # them out here until the root cause is solved.
+ # https://github.com/pylint-dev/astroid/issues/2273
+ root = node.root()
+ filtered_attrs = [
+ k for (k, v) in node.instance_attrs.items() if v[0].root() is root
+ ]
+ if len(filtered_attrs) > self.linter.config.max_attributes:
+ self.add_message(
+ "too-many-instance-attributes",
+ node=node,
+ args=(len(filtered_attrs), self.linter.config.max_attributes),
+ )
+
+ @only_required_for_messages("too-few-public-methods", "too-many-public-methods")
+ def leave_classdef(self, node: nodes.ClassDef) -> None:
+ """Check number of public methods."""
+ my_methods = sum(
+ 1 for method in node.mymethods() if not method.name.startswith("_")
+ )
+
+ # Does the class contain less than n public methods ?
+ # This checks only the methods defined in the current class,
+ # since the user might not have control over the classes
+ # from the ancestors. It avoids some false positives
+ # for classes such as unittest.TestCase, which provides
+ # a lot of assert methods. It doesn't make sense to warn
+ # when the user subclasses TestCase to add his own tests.
+ if my_methods > self.linter.config.max_public_methods:
+ self.add_message(
+ "too-many-public-methods",
+ node=node,
+ args=(my_methods, self.linter.config.max_public_methods),
+ )
+
+ # Stop here if the class is excluded via configuration.
+ if node.type == "class" and self._exclude_too_few_public_methods:
+ for ancestor in node.ancestors():
+ if any(
+ pattern.match(ancestor.qname())
+ for pattern in self._exclude_too_few_public_methods
+ ):
+ return
+
+ # Stop here for exception, metaclass, interface classes and other
+ # classes for which we don't need to count the methods.
+ if node.type != "class" or _is_exempt_from_public_methods(node):
+ return
+
+ # Does the class contain more than n public methods ?
+ # This checks all the methods defined by ancestors and
+ # by the current class.
+ all_methods = _count_methods_in_class(node)
+ if all_methods < self.linter.config.min_public_methods:
+ self.add_message(
+ "too-few-public-methods",
+ node=node,
+ args=(all_methods, self.linter.config.min_public_methods),
+ )
+
+ @only_required_for_messages(
+ "too-many-return-statements",
+ "too-many-branches",
+ "too-many-arguments",
+ "too-many-locals",
+ "too-many-positional-arguments",
+ "too-many-statements",
+ "keyword-arg-before-vararg",
+ )
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Check function name, docstring, arguments, redefinition,
+ variable names, max locals.
+ """
+ # init branch and returns counters
+ self._returns.append(0)
+ # check number of arguments
+ args = node.args.args + node.args.posonlyargs + node.args.kwonlyargs
+ pos_args = node.args.args + node.args.posonlyargs
+ ignored_argument_names = self.linter.config.ignored_argument_names
+ if args is not None:
+ ignored_args_num = 0
+ if ignored_argument_names:
+ ignored_pos_args_num = sum(
+ 1 for arg in pos_args if ignored_argument_names.match(arg.name)
+ )
+ ignored_kwonly_args_num = sum(
+ 1
+ for arg in node.args.kwonlyargs
+ if ignored_argument_names.match(arg.name)
+ )
+ ignored_args_num = ignored_pos_args_num + ignored_kwonly_args_num
+
+ argnum = len(args) - ignored_args_num
+ if argnum > self.linter.config.max_args:
+ self.add_message(
+ "too-many-arguments",
+ node=node,
+ args=(len(args), self.linter.config.max_args),
+ )
+ pos_args_count = (
+ len(args) - len(node.args.kwonlyargs) - ignored_pos_args_num
+ )
+ if pos_args_count > self.linter.config.max_positional_arguments:
+ self.add_message(
+ "too-many-positional-arguments",
+ node=node,
+ args=(pos_args_count, self.linter.config.max_positional_arguments),
+ confidence=HIGH,
+ )
+ else:
+ ignored_args_num = 0
+ # check number of local variables
+ locnum = len(node.locals) - ignored_args_num
+
+ # decrement number of local variables if '_' is one of them
+ if "_" in node.locals:
+ locnum -= 1
+
+ if locnum > self.linter.config.max_locals:
+ self.add_message(
+ "too-many-locals",
+ node=node,
+ args=(locnum, self.linter.config.max_locals),
+ )
+ # init new statements counter
+ self._stmts.append(1)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ @only_required_for_messages(
+ "too-many-return-statements",
+ "too-many-branches",
+ "too-many-arguments",
+ "too-many-locals",
+ "too-many-statements",
+ )
+ def leave_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Most of the work is done here on close:
+ checks for max returns, branch, return in __init__.
+ """
+ returns = self._returns.pop()
+ if returns > self.linter.config.max_returns:
+ self.add_message(
+ "too-many-return-statements",
+ node=node,
+ args=(returns, self.linter.config.max_returns),
+ )
+ branches = self._branches[node]
+ if branches > self.linter.config.max_branches:
+ self.add_message(
+ "too-many-branches",
+ node=node,
+ args=(branches, self.linter.config.max_branches),
+ )
+ # check number of statements
+ stmts = self._stmts.pop()
+ if stmts > self.linter.config.max_statements:
+ self.add_message(
+ "too-many-statements",
+ node=node,
+ args=(stmts, self.linter.config.max_statements),
+ )
+
+ leave_asyncfunctiondef = leave_functiondef
+
+ def visit_return(self, _: nodes.Return) -> None:
+ """Count number of returns."""
+ if not self._returns:
+ return # return outside function, reported by the base checker
+ self._returns[-1] += 1
+
+ def visit_default(self, node: nodes.NodeNG) -> None:
+ """Default visit method -> increments the statements counter if
+ necessary.
+ """
+ if node.is_statement:
+ self._inc_all_stmts(1)
+
+ def visit_try(self, node: nodes.Try) -> None:
+ """Increments the branches counter."""
+ branches = len(node.handlers)
+ if node.orelse:
+ branches += 1
+ if node.finalbody:
+ branches += 1
+ self._inc_branch(node, branches)
+ self._inc_all_stmts(branches)
+
+ @only_required_for_messages("too-many-boolean-expressions", "too-many-branches")
+ def visit_if(self, node: nodes.If) -> None:
+ """Increments the branches counter and checks boolean expressions."""
+ self._check_boolean_expressions(node)
+ branches = 1
+ # don't double count If nodes coming from some 'elif'
+ if node.orelse and (
+ len(node.orelse) > 1 or not isinstance(node.orelse[0], astroid.If)
+ ):
+ branches += 1
+ self._inc_branch(node, branches)
+ self._inc_all_stmts(branches)
+
+ def _check_boolean_expressions(self, node: nodes.If) -> None:
+ """Go through "if" node `node` and count its boolean expressions
+ if the 'if' node test is a BoolOp node.
+ """
+ condition = node.test
+ if not isinstance(condition, astroid.BoolOp):
+ return
+ nb_bool_expr = _count_boolean_expressions(condition)
+ if nb_bool_expr > self.linter.config.max_bool_expr:
+ self.add_message(
+ "too-many-boolean-expressions",
+ node=condition,
+ args=(nb_bool_expr, self.linter.config.max_bool_expr),
+ )
+
+ def visit_while(self, node: nodes.While) -> None:
+ """Increments the branches counter."""
+ branches = 1
+ if node.orelse:
+ branches += 1
+ self._inc_branch(node, branches)
+
+ visit_for = visit_while
+
+ def _inc_branch(self, node: nodes.NodeNG, branchesnum: int = 1) -> None:
+ """Increments the branches counter."""
+ self._branches[node.scope()] += branchesnum
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(MisdesignChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/dunder_methods.py b/solutions/.venv/Lib/site-packages/pylint/checkers/dunder_methods.py
new file mode 100644
index 000000000..4bd89c2a1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/dunder_methods.py
@@ -0,0 +1,103 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import Instance, nodes
+from astroid.util import UninferableBase
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import safe_infer
+from pylint.constants import DUNDER_METHODS, UNNECESSARY_DUNDER_CALL_LAMBDA_EXCEPTIONS
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class DunderCallChecker(BaseChecker):
+ """Check for unnecessary dunder method calls.
+
+ Docs: https://docs.python.org/3/reference/datamodel.html#basic-customization
+ We exclude names in list pylint.constants.EXTRA_DUNDER_METHODS such as
+ __index__ (see https://github.com/pylint-dev/pylint/issues/6795)
+ since these either have no alternative method of being called or
+ have a genuine use case for being called manually.
+
+ Additionally, we exclude classes that are not instantiated since these
+ might be used to access the dunder methods of a base class of an instance.
+ We also exclude dunder method calls on super() since
+ these can't be written in an alternative manner.
+ """
+
+ name = "unnecessary-dunder-call"
+ msgs = {
+ "C2801": (
+ "Unnecessarily calls dunder method %s. %s.",
+ "unnecessary-dunder-call",
+ "Used when a dunder method is manually called instead "
+ "of using the corresponding function/method/operator.",
+ ),
+ }
+ options = ()
+
+ def open(self) -> None:
+ self._dunder_methods: dict[str, str] = {}
+ for since_vers, dunder_methods in DUNDER_METHODS.items():
+ if since_vers <= self.linter.config.py_version:
+ self._dunder_methods.update(dunder_methods)
+
+ @staticmethod
+ def within_dunder_or_lambda_def(node: nodes.NodeNG) -> bool:
+ """Check if dunder method call is within a dunder method definition."""
+ parent = node.parent
+ while parent is not None:
+ if (
+ isinstance(parent, nodes.FunctionDef)
+ and parent.name.startswith("__")
+ and parent.name.endswith("__")
+ or DunderCallChecker.is_lambda_rule_exception(parent, node)
+ ):
+ return True
+ parent = parent.parent
+ return False
+
+ @staticmethod
+ def is_lambda_rule_exception(ancestor: nodes.NodeNG, node: nodes.NodeNG) -> bool:
+ return (
+ isinstance(ancestor, nodes.Lambda)
+ and node.func.attrname in UNNECESSARY_DUNDER_CALL_LAMBDA_EXCEPTIONS
+ )
+
+ def visit_call(self, node: nodes.Call) -> None:
+ """Check if method being called is an unnecessary dunder method."""
+ if (
+ isinstance(node.func, nodes.Attribute)
+ and node.func.attrname in self._dunder_methods
+ and not self.within_dunder_or_lambda_def(node)
+ and not (
+ isinstance(node.func.expr, nodes.Call)
+ and isinstance(node.func.expr.func, nodes.Name)
+ and node.func.expr.func.name == "super"
+ )
+ ):
+ inf_expr = safe_infer(node.func.expr)
+ if not (
+ inf_expr is None or isinstance(inf_expr, (Instance, UninferableBase))
+ ):
+ # Skip dunder calls to non instantiated classes.
+ return
+
+ self.add_message(
+ "unnecessary-dunder-call",
+ node=node,
+ args=(node.func.attrname, self._dunder_methods[node.func.attrname]),
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(DunderCallChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/ellipsis_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/ellipsis_checker.py
new file mode 100644
index 000000000..4e7e3bd35
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/ellipsis_checker.py
@@ -0,0 +1,58 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Ellipsis checker for Python code."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class EllipsisChecker(BaseChecker):
+ name = "unnecessary_ellipsis"
+ msgs = {
+ "W2301": (
+ "Unnecessary ellipsis constant",
+ "unnecessary-ellipsis",
+ "Used when the ellipsis constant is encountered and can be avoided. "
+ "A line of code consisting of an ellipsis is unnecessary if "
+ "there is a docstring on the preceding line or if there is a "
+ "statement in the same scope.",
+ )
+ }
+
+ @only_required_for_messages("unnecessary-ellipsis")
+ def visit_const(self, node: nodes.Const) -> None:
+ """Check if the ellipsis constant is used unnecessarily.
+
+ Emits a warning when:
+ - A line consisting of an ellipsis is preceded by a docstring.
+ - A statement exists in the same scope as the ellipsis.
+ For example: A function consisting of an ellipsis followed by a
+ return statement on the next line.
+ """
+ if (
+ node.pytype() == "builtins.Ellipsis"
+ and isinstance(node.parent, nodes.Expr)
+ and (
+ (
+ isinstance(node.parent.parent, (nodes.ClassDef, nodes.FunctionDef))
+ and node.parent.parent.doc_node
+ )
+ or len(node.parent.parent.body) > 1
+ )
+ ):
+ self.add_message("unnecessary-ellipsis", node=node)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(EllipsisChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/exceptions.py b/solutions/.venv/Lib/site-packages/pylint/checkers/exceptions.py
new file mode 100644
index 000000000..3834f260b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/exceptions.py
@@ -0,0 +1,654 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checks for various exception related errors."""
+
+from __future__ import annotations
+
+import builtins
+import inspect
+from collections.abc import Generator
+from typing import TYPE_CHECKING, Any
+
+import astroid
+from astroid import nodes, objects, util
+from astroid.context import InferenceContext
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.interfaces import HIGH, INFERENCE
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def _builtin_exceptions() -> set[str]:
+ def predicate(obj: Any) -> bool:
+ return isinstance(obj, type) and issubclass(obj, BaseException)
+
+ members = inspect.getmembers(builtins, predicate)
+ return {exc.__name__ for (_, exc) in members}
+
+
+def _annotated_unpack_infer(
+ stmt: nodes.NodeNG, context: InferenceContext | None = None
+) -> Generator[tuple[nodes.NodeNG, SuccessfulInferenceResult]]:
+ """Recursively generate nodes inferred by the given statement.
+
+ If the inferred value is a list or a tuple, recurse on the elements.
+ Returns an iterator which yields tuples in the format
+ ('original node', 'inferred node').
+ """
+ if isinstance(stmt, (nodes.List, nodes.Tuple)):
+ for elt in stmt.elts:
+ inferred = utils.safe_infer(elt)
+ if inferred and not isinstance(inferred, util.UninferableBase):
+ yield elt, inferred
+ return
+ for inferred in stmt.infer(context):
+ if isinstance(inferred, util.UninferableBase):
+ continue
+ yield stmt, inferred
+
+
+def _is_raising(body: list[nodes.NodeNG]) -> bool:
+ """Return whether the given statement node raises an exception."""
+ return any(isinstance(node, nodes.Raise) for node in body)
+
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "E0701": (
+ "Bad except clauses order (%s)",
+ "bad-except-order",
+ "Used when except clauses are not in the correct order (from the "
+ "more specific to the more generic). If you don't fix the order, "
+ "some exceptions may not be caught by the most specific handler.",
+ ),
+ "E0702": (
+ "Raising %s while only classes or instances are allowed",
+ "raising-bad-type",
+ "Used when something which is neither a class nor an instance "
+ "is raised (i.e. a `TypeError` will be raised).",
+ ),
+ "E0704": (
+ "The raise statement is not inside an except clause",
+ "misplaced-bare-raise",
+ "Used when a bare raise is not used inside an except clause. "
+ "This generates an error, since there are no active exceptions "
+ "to be reraised. An exception to this rule is represented by "
+ "a bare raise inside a finally clause, which might work, as long "
+ "as an exception is raised inside the try block, but it is "
+ "nevertheless a code smell that must not be relied upon.",
+ ),
+ "E0705": (
+ "Exception cause set to something which is not an exception, nor None",
+ "bad-exception-cause",
+ 'Used when using the syntax "raise ... from ...", '
+ "where the exception cause is not an exception, "
+ "nor None.",
+ {"old_names": [("E0703", "bad-exception-context")]},
+ ),
+ "E0710": (
+ "Raising a class which doesn't inherit from BaseException",
+ "raising-non-exception",
+ "Used when a class which doesn't inherit from BaseException is raised.",
+ ),
+ "E0711": (
+ "NotImplemented raised - should raise NotImplementedError",
+ "notimplemented-raised",
+ "Used when NotImplemented is raised instead of NotImplementedError",
+ ),
+ "E0712": (
+ "Catching an exception which doesn't inherit from Exception: %s",
+ "catching-non-exception",
+ "Used when a class which doesn't inherit from "
+ "Exception is used as an exception in an except clause.",
+ ),
+ "W0702": (
+ "No exception type(s) specified",
+ "bare-except",
+ "A bare ``except:`` clause will catch ``SystemExit`` and "
+ "``KeyboardInterrupt`` exceptions, making it harder to interrupt a program "
+ "with ``Control-C``, and can disguise other problems. If you want to catch "
+ "all exceptions that signal program errors, use ``except Exception:`` (bare "
+ "except is equivalent to ``except BaseException:``).",
+ ),
+ "W0718": (
+ "Catching too general exception %s",
+ "broad-exception-caught",
+ "If you use a naked ``except Exception:`` clause, you might end up catching "
+ "exceptions other than the ones you expect to catch. This can hide bugs or "
+ "make it harder to debug programs when unrelated errors are hidden.",
+ {"old_names": [("W0703", "broad-except")]},
+ ),
+ "W0705": (
+ "Catching previously caught exception type %s",
+ "duplicate-except",
+ "Used when an except catches a type that was already caught by "
+ "a previous handler.",
+ ),
+ "W0706": (
+ "The except handler raises immediately",
+ "try-except-raise",
+ "Used when an except handler uses raise as its first or only "
+ "operator. This is useless because it raises back the exception "
+ "immediately. Remove the raise operator or the entire "
+ "try-except-raise block!",
+ ),
+ "W0707": (
+ "Consider explicitly re-raising using %s'%s from %s'",
+ "raise-missing-from",
+ "Python's exception chaining shows the traceback of the current exception, "
+ "but also of the original exception. When you raise a new exception after "
+ "another exception was caught it's likely that the second exception is a "
+ "friendly re-wrapping of the first exception. In such cases `raise from` "
+ "provides a better link between the two tracebacks in the final error.",
+ ),
+ "W0711": (
+ 'Exception to catch is the result of a binary "%s" operation',
+ "binary-op-exception",
+ "Used when the exception to catch is of the form "
+ '"except A or B:". If intending to catch multiple, '
+ 'rewrite as "except (A, B):"',
+ ),
+ "W0715": (
+ "Exception arguments suggest string formatting might be intended",
+ "raising-format-tuple",
+ "Used when passing multiple arguments to an exception "
+ "constructor, the first of them a string literal containing what "
+ "appears to be placeholders intended for formatting",
+ ),
+ "W0716": (
+ "Invalid exception operation. %s",
+ "wrong-exception-operation",
+ "Used when an operation is done against an exception, but the operation "
+ "is not valid for the exception in question. Usually emitted when having "
+ "binary operations between exceptions in except handlers.",
+ ),
+ "W0719": (
+ "Raising too general exception: %s",
+ "broad-exception-raised",
+ "Raising exceptions that are too generic force you to catch exceptions "
+ "generically too. It will force you to use a naked ``except Exception:`` "
+ "clause. You might then end up catching exceptions other than the ones "
+ "you expect to catch. This can hide bugs or make it harder to debug programs "
+ "when unrelated errors are hidden.",
+ ),
+}
+
+
+class BaseVisitor:
+ """Base class for visitors defined in this module."""
+
+ def __init__(self, checker: ExceptionsChecker, node: nodes.Raise) -> None:
+ self._checker = checker
+ self._node = node
+
+ def visit(self, node: SuccessfulInferenceResult) -> None:
+ name = node.__class__.__name__.lower()
+ dispatch_meth = getattr(self, "visit_" + name, None)
+ if dispatch_meth:
+ dispatch_meth(node)
+ else:
+ self.visit_default(node)
+
+ def visit_default(self, _: nodes.NodeNG) -> None:
+ """Default implementation for all the nodes."""
+
+
+class ExceptionRaiseRefVisitor(BaseVisitor):
+ """Visit references (anything that is not an AST leaf)."""
+
+ def visit_name(self, node: nodes.Name) -> None:
+ if node.name == "NotImplemented":
+ self._checker.add_message(
+ "notimplemented-raised", node=self._node, confidence=HIGH
+ )
+ return
+ try:
+ exceptions = [
+ c
+ for _, c in _annotated_unpack_infer(node)
+ if isinstance(c, nodes.ClassDef)
+ ]
+ except astroid.InferenceError:
+ return
+
+ for exception in exceptions:
+ if self._checker._is_overgeneral_exception(exception):
+ self._checker.add_message(
+ "broad-exception-raised",
+ args=exception.name,
+ node=self._node,
+ confidence=INFERENCE,
+ )
+
+ def visit_call(self, node: nodes.Call) -> None:
+ if isinstance(node.func, nodes.Name):
+ self.visit_name(node.func)
+ if (
+ len(node.args) > 1
+ and isinstance(node.args[0], nodes.Const)
+ and isinstance(node.args[0].value, str)
+ ):
+ msg = node.args[0].value
+ if "%" in msg or ("{" in msg and "}" in msg):
+ self._checker.add_message(
+ "raising-format-tuple", node=self._node, confidence=HIGH
+ )
+
+
+class ExceptionRaiseLeafVisitor(BaseVisitor):
+ """Visitor for handling leaf kinds of a raise value."""
+
+ def visit_const(self, node: nodes.Const) -> None:
+ self._checker.add_message(
+ "raising-bad-type",
+ node=self._node,
+ args=node.value.__class__.__name__,
+ confidence=INFERENCE,
+ )
+
+ def visit_instance(self, instance: objects.ExceptionInstance) -> None:
+ cls = instance._proxied
+ self.visit_classdef(cls)
+
+ # Exception instances have a particular class type
+ visit_exceptioninstance = visit_instance
+
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ if not utils.inherit_from_std_ex(node) and utils.has_known_bases(node):
+ self._checker.add_message(
+ "raising-non-exception",
+ node=self._node,
+ confidence=INFERENCE,
+ )
+
+ def visit_tuple(self, _: nodes.Tuple) -> None:
+ self._checker.add_message(
+ "raising-bad-type",
+ node=self._node,
+ args="tuple",
+ confidence=INFERENCE,
+ )
+
+ def visit_default(self, node: nodes.NodeNG) -> None:
+ name = getattr(node, "name", node.__class__.__name__)
+ self._checker.add_message(
+ "raising-bad-type",
+ node=self._node,
+ args=name,
+ confidence=INFERENCE,
+ )
+
+
+class ExceptionsChecker(checkers.BaseChecker):
+ """Exception related checks."""
+
+ name = "exceptions"
+ msgs = MSGS
+ options = (
+ (
+ "overgeneral-exceptions",
+ {
+ "default": ("builtins.BaseException", "builtins.Exception"),
+ "type": "csv",
+ "metavar": "<comma-separated class names>",
+ "help": "Exceptions that will emit a warning when caught.",
+ },
+ ),
+ )
+
+ def open(self) -> None:
+ self._builtin_exceptions = _builtin_exceptions()
+ super().open()
+
+ @utils.only_required_for_messages(
+ "misplaced-bare-raise",
+ "raising-bad-type",
+ "raising-non-exception",
+ "notimplemented-raised",
+ "bad-exception-cause",
+ "raising-format-tuple",
+ "raise-missing-from",
+ "broad-exception-raised",
+ )
+ def visit_raise(self, node: nodes.Raise) -> None:
+ if node.exc is None:
+ self._check_misplaced_bare_raise(node)
+ return
+
+ if node.cause is None:
+ self._check_raise_missing_from(node)
+ else:
+ self._check_bad_exception_cause(node)
+
+ expr = node.exc
+ ExceptionRaiseRefVisitor(self, node).visit(expr)
+
+ inferred = utils.safe_infer(expr)
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ return
+ ExceptionRaiseLeafVisitor(self, node).visit(inferred)
+
+ def _check_misplaced_bare_raise(self, node: nodes.Raise) -> None:
+ # Filter out if it's present in __exit__.
+ scope = node.scope()
+ if (
+ isinstance(scope, nodes.FunctionDef)
+ and scope.is_method()
+ and scope.name == "__exit__"
+ ):
+ return
+
+ current = node
+ # Stop when a new scope is generated or when the raise
+ # statement is found inside a Try.
+ ignores = (nodes.ExceptHandler, nodes.FunctionDef)
+ while current and not isinstance(current.parent, ignores):
+ current = current.parent
+
+ expected = (nodes.ExceptHandler,)
+ if not current or not isinstance(current.parent, expected):
+ self.add_message("misplaced-bare-raise", node=node, confidence=HIGH)
+
+ def _check_bad_exception_cause(self, node: nodes.Raise) -> None:
+ """Verify that the exception cause is properly set.
+
+ An exception cause can be only `None` or an exception.
+ """
+ cause = utils.safe_infer(node.cause)
+ if cause is None or isinstance(cause, util.UninferableBase):
+ return
+
+ if isinstance(cause, nodes.Const):
+ if cause.value is not None:
+ self.add_message("bad-exception-cause", node=node, confidence=INFERENCE)
+ elif not isinstance(cause, nodes.ClassDef) and not utils.inherit_from_std_ex(
+ cause
+ ):
+ self.add_message("bad-exception-cause", node=node, confidence=INFERENCE)
+
+ def _check_raise_missing_from(self, node: nodes.Raise) -> None:
+ if node.exc is None:
+ # This is a plain `raise`, raising the previously-caught exception. No need for a
+ # cause.
+ return
+ # We'd like to check whether we're inside an `except` clause:
+ containing_except_node = utils.find_except_wrapper_node_in_scope(node)
+ if not containing_except_node:
+ return
+ # We found a surrounding `except`! We're almost done proving there's a
+ # `raise-missing-from` here. The only thing we need to protect against is that maybe
+ # the `raise` is raising the exception that was caught, possibly with some shenanigans
+ # like `exc.with_traceback(whatever)`. We won't analyze these, we'll just assume
+ # there's a violation on two simple cases: `raise SomeException(whatever)` and `raise
+ # SomeException`.
+ if containing_except_node.name is None:
+ # The `except` doesn't have an `as exception:` part, meaning there's no way that
+ # the `raise` is raising the same exception.
+ class_of_old_error = "Exception"
+ if isinstance(containing_except_node.type, (nodes.Name, nodes.Tuple)):
+ # 'except ZeroDivisionError' or 'except (ZeroDivisionError, ValueError)'
+ class_of_old_error = containing_except_node.type.as_string()
+ self.add_message(
+ "raise-missing-from",
+ node=node,
+ args=(
+ f"'except {class_of_old_error} as exc' and ",
+ node.as_string(),
+ "exc",
+ ),
+ confidence=HIGH,
+ )
+ elif (
+ isinstance(node.exc, nodes.Call)
+ and isinstance(node.exc.func, nodes.Name)
+ or isinstance(node.exc, nodes.Name)
+ and node.exc.name != containing_except_node.name.name
+ ):
+ # We have a `raise SomeException(whatever)` or a `raise SomeException`
+ self.add_message(
+ "raise-missing-from",
+ node=node,
+ args=("", node.as_string(), containing_except_node.name.name),
+ confidence=HIGH,
+ )
+
+ def _check_catching_non_exception(
+ self,
+ handler: nodes.ExceptHandler,
+ exc: SuccessfulInferenceResult,
+ part: nodes.NodeNG,
+ ) -> None:
+ if isinstance(exc, nodes.Tuple):
+ # Check if it is a tuple of exceptions.
+ inferred = [utils.safe_infer(elt) for elt in exc.elts]
+ if any(isinstance(node, util.UninferableBase) for node in inferred):
+ # Don't emit if we don't know every component.
+ return
+ if all(
+ node
+ and (utils.inherit_from_std_ex(node) or not utils.has_known_bases(node))
+ for node in inferred
+ ):
+ return
+
+ if not isinstance(exc, nodes.ClassDef):
+ # Don't emit the warning if the inferred stmt
+ # is None, but the exception handler is something else,
+ # maybe it was redefined.
+ if isinstance(exc, nodes.Const) and exc.value is None:
+ if (
+ isinstance(handler.type, nodes.Const) and handler.type.value is None
+ ) or handler.type.parent_of(exc):
+ # If the exception handler catches None or
+ # the exception component, which is None, is
+ # defined by the entire exception handler, then
+ # emit a warning.
+ self.add_message(
+ "catching-non-exception",
+ node=handler.type,
+ args=(part.as_string(),),
+ )
+ else:
+ self.add_message(
+ "catching-non-exception",
+ node=handler.type,
+ args=(part.as_string(),),
+ )
+ return
+
+ if (
+ not utils.inherit_from_std_ex(exc)
+ and exc.name not in self._builtin_exceptions
+ ):
+ if utils.has_known_bases(exc):
+ self.add_message(
+ "catching-non-exception", node=handler.type, args=(exc.name,)
+ )
+
+ def _check_try_except_raise(self, node: nodes.Try) -> None:
+ def gather_exceptions_from_handler(
+ handler: nodes.ExceptHandler,
+ ) -> list[InferenceResult] | None:
+ exceptions: list[InferenceResult] = []
+ if handler.type:
+ exceptions_in_handler = utils.safe_infer(handler.type)
+ if isinstance(exceptions_in_handler, nodes.Tuple):
+ exceptions = list(
+ {
+ exception
+ for exception in exceptions_in_handler.elts
+ if isinstance(exception, (nodes.Name, nodes.Attribute))
+ }
+ )
+ elif exceptions_in_handler:
+ exceptions = [exceptions_in_handler]
+ else:
+ # Break when we cannot infer anything reliably.
+ return None
+ return exceptions
+
+ bare_raise = False
+ handler_having_bare_raise = None
+ exceptions_in_bare_handler: list[InferenceResult] | None = []
+ for handler in node.handlers:
+ if bare_raise:
+ # check that subsequent handler is not parent of handler which had bare raise.
+ # since utils.safe_infer can fail for bare except, check it before.
+ # also break early if bare except is followed by bare except.
+
+ excs_in_current_handler = gather_exceptions_from_handler(handler)
+ if not excs_in_current_handler:
+ break
+ if exceptions_in_bare_handler is None:
+ # It can be `None` when the inference failed
+ break
+ for exc_in_current_handler in excs_in_current_handler:
+ inferred_current = utils.safe_infer(exc_in_current_handler)
+ if any(
+ utils.is_subclass_of(utils.safe_infer(e), inferred_current)
+ for e in exceptions_in_bare_handler
+ ):
+ bare_raise = False
+ break
+
+ # `raise` as the first operator inside the except handler
+ if _is_raising([handler.body[0]]):
+ # flags when there is a bare raise
+ if handler.body[0].exc is None:
+ bare_raise = True
+ handler_having_bare_raise = handler
+ exceptions_in_bare_handler = gather_exceptions_from_handler(handler)
+ else:
+ if bare_raise:
+ self.add_message("try-except-raise", node=handler_having_bare_raise)
+
+ @utils.only_required_for_messages("wrong-exception-operation")
+ def visit_binop(self, node: nodes.BinOp) -> None:
+ if isinstance(node.parent, nodes.ExceptHandler):
+ both_sides_tuple_or_uninferable = isinstance(
+ utils.safe_infer(node.left), (nodes.Tuple, util.UninferableBase)
+ ) and isinstance(
+ utils.safe_infer(node.right), (nodes.Tuple, util.UninferableBase)
+ )
+ # Tuple concatenation allowed
+ if both_sides_tuple_or_uninferable:
+ if node.op == "+":
+ return
+ suggestion = f"Did you mean '({node.left.as_string()} + {node.right.as_string()})' instead?"
+ # except (V | A)
+ else:
+ suggestion = f"Did you mean '({node.left.as_string()}, {node.right.as_string()})' instead?"
+ self.add_message("wrong-exception-operation", node=node, args=(suggestion,))
+
+ @utils.only_required_for_messages("wrong-exception-operation")
+ def visit_compare(self, node: nodes.Compare) -> None:
+ if isinstance(node.parent, nodes.ExceptHandler):
+ # except (V < A)
+ suggestion = (
+ f"Did you mean '({node.left.as_string()}, "
+ f"{', '.join(o.as_string() for _, o in node.ops)})' instead?"
+ )
+ self.add_message("wrong-exception-operation", node=node, args=(suggestion,))
+
+ @utils.only_required_for_messages(
+ "bare-except",
+ "broad-exception-caught",
+ "try-except-raise",
+ "binary-op-exception",
+ "bad-except-order",
+ "catching-non-exception",
+ "duplicate-except",
+ )
+ def visit_trystar(self, node: nodes.TryStar) -> None:
+ """Check for empty except*."""
+ self.visit_try(node)
+
+ def visit_try(self, node: nodes.Try) -> None:
+ """Check for empty except."""
+ self._check_try_except_raise(node)
+ exceptions_classes: list[Any] = []
+ nb_handlers = len(node.handlers)
+ for index, handler in enumerate(node.handlers):
+ if handler.type is None:
+ if not _is_raising(handler.body):
+ self.add_message("bare-except", node=handler, confidence=HIGH)
+
+ # check if an "except:" is followed by some other
+ # except
+ if index < (nb_handlers - 1):
+ msg = "empty except clause should always appear last"
+ self.add_message(
+ "bad-except-order", node=node, args=msg, confidence=HIGH
+ )
+
+ elif isinstance(handler.type, nodes.BoolOp):
+ self.add_message(
+ "binary-op-exception",
+ node=handler,
+ args=handler.type.op,
+ confidence=HIGH,
+ )
+ else:
+ try:
+ exceptions = list(_annotated_unpack_infer(handler.type))
+ except astroid.InferenceError:
+ continue
+
+ for part, exception in exceptions:
+ if isinstance(
+ exception, astroid.Instance
+ ) and utils.inherit_from_std_ex(exception):
+ exception = exception._proxied
+
+ self._check_catching_non_exception(handler, exception, part)
+
+ if not isinstance(exception, nodes.ClassDef):
+ continue
+
+ exc_ancestors = [
+ anc
+ for anc in exception.ancestors()
+ if isinstance(anc, nodes.ClassDef)
+ ]
+
+ for previous_exc in exceptions_classes:
+ if previous_exc in exc_ancestors:
+ msg = f"{previous_exc.name} is an ancestor class of {exception.name}"
+ self.add_message(
+ "bad-except-order",
+ node=handler.type,
+ args=msg,
+ confidence=INFERENCE,
+ )
+ if self._is_overgeneral_exception(exception) and not _is_raising(
+ handler.body
+ ):
+ self.add_message(
+ "broad-exception-caught",
+ args=exception.name,
+ node=handler.type,
+ confidence=INFERENCE,
+ )
+
+ if exception in exceptions_classes:
+ self.add_message(
+ "duplicate-except",
+ args=exception.name,
+ node=handler.type,
+ confidence=INFERENCE,
+ )
+
+ exceptions_classes += [exc for _, exc in exceptions]
+
+ def _is_overgeneral_exception(self, exception: nodes.ClassDef) -> bool:
+ return exception.qname() in self.linter.config.overgeneral_exceptions
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ExceptionsChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/format.py b/solutions/.venv/Lib/site-packages/pylint/checkers/format.py
new file mode 100644
index 000000000..12fa93016
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/format.py
@@ -0,0 +1,731 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Python code format's checker.
+
+By default, try to follow Guido's style guide :
+
+https://www.python.org/doc/essays/styleguide/
+
+Some parts of the process_token method is based from The Tab Nanny std module.
+"""
+
+from __future__ import annotations
+
+import tokenize
+from functools import reduce
+from re import Match
+from typing import TYPE_CHECKING, Literal
+
+from astroid import nodes
+
+from pylint.checkers import BaseRawFileChecker, BaseTokenChecker
+from pylint.checkers.utils import only_required_for_messages
+from pylint.constants import WarningScope
+from pylint.interfaces import HIGH
+from pylint.typing import MessageDefinitionTuple
+from pylint.utils.pragma_parser import OPTION_PO, PragmaParserError, parse_pragma
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+_KEYWORD_TOKENS = {
+ "assert",
+ "del",
+ "elif",
+ "except",
+ "for",
+ "if",
+ "in",
+ "not",
+ "raise",
+ "return",
+ "while",
+ "yield",
+ "with",
+ "=",
+ ":=",
+}
+_JUNK_TOKENS = {tokenize.COMMENT, tokenize.NL}
+
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "C0301": (
+ "Line too long (%s/%s)",
+ "line-too-long",
+ "Used when a line is longer than a given number of characters.",
+ ),
+ "C0302": (
+ "Too many lines in module (%s/%s)", # was W0302
+ "too-many-lines",
+ "Used when a module has too many lines, reducing its readability.",
+ ),
+ "C0303": (
+ "Trailing whitespace",
+ "trailing-whitespace",
+ "Used when there is whitespace between the end of a line and the newline.",
+ ),
+ "C0304": (
+ "Final newline missing",
+ "missing-final-newline",
+ "Used when the last line in a file is missing a newline.",
+ ),
+ "C0305": (
+ "Trailing newlines",
+ "trailing-newlines",
+ "Used when there are trailing blank lines in a file.",
+ ),
+ "W0311": (
+ "Bad indentation. Found %s %s, expected %s",
+ "bad-indentation",
+ "Used when an unexpected number of indentation's tabulations or "
+ "spaces has been found.",
+ ),
+ "W0301": (
+ "Unnecessary semicolon", # was W0106
+ "unnecessary-semicolon",
+ 'Used when a statement is ended by a semi-colon (";"), which '
+ "isn't necessary (that's python, not C ;).",
+ ),
+ "C0321": (
+ "More than one statement on a single line",
+ "multiple-statements",
+ "Used when more than on statement are found on the same line.",
+ {"scope": WarningScope.NODE},
+ ),
+ "C0325": (
+ "Unnecessary parens after %r keyword",
+ "superfluous-parens",
+ "Used when a single item in parentheses follows an if, for, or "
+ "other keyword.",
+ ),
+ "C0327": (
+ "Mixed line endings LF and CRLF",
+ "mixed-line-endings",
+ "Used when there are mixed (LF and CRLF) newline signs in a file.",
+ ),
+ "C0328": (
+ "Unexpected line ending format. There is '%s' while it should be '%s'.",
+ "unexpected-line-ending-format",
+ "Used when there is different newline than expected.",
+ ),
+}
+
+
+def _last_token_on_line_is(tokens: TokenWrapper, line_end: int, token: str) -> bool:
+ return (
+ line_end > 0
+ and tokens.token(line_end - 1) == token
+ or line_end > 1
+ and tokens.token(line_end - 2) == token
+ and tokens.type(line_end - 1) == tokenize.COMMENT
+ )
+
+
+class TokenWrapper:
+ """A wrapper for readable access to token information."""
+
+ def __init__(self, tokens: list[tokenize.TokenInfo]) -> None:
+ self._tokens = tokens
+
+ def token(self, idx: int) -> str:
+ return self._tokens[idx][1]
+
+ def type(self, idx: int) -> int:
+ return self._tokens[idx][0]
+
+ def start_line(self, idx: int) -> int:
+ return self._tokens[idx][2][0]
+
+ def start_col(self, idx: int) -> int:
+ return self._tokens[idx][2][1]
+
+ def line(self, idx: int) -> str:
+ return self._tokens[idx][4]
+
+
+class FormatChecker(BaseTokenChecker, BaseRawFileChecker):
+ """Formatting checker.
+
+ Checks for :
+ * unauthorized constructions
+ * strict indentation
+ * line length
+ """
+
+ # configuration section name
+ name = "format"
+ # messages
+ msgs = MSGS
+ # configuration options
+ # for available dict keys/values see the optik parser 'add_option' method
+ options = (
+ (
+ "max-line-length",
+ {
+ "default": 100,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of characters on a single line.",
+ },
+ ),
+ (
+ "ignore-long-lines",
+ {
+ "type": "regexp",
+ "metavar": "<regexp>",
+ "default": r"^\s*(# )?<?https?://\S+>?$",
+ "help": (
+ "Regexp for a line that is allowed to be longer than the limit."
+ ),
+ },
+ ),
+ (
+ "single-line-if-stmt",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": (
+ "Allow the body of an if to be on the same "
+ "line as the test if there is no else."
+ ),
+ },
+ ),
+ (
+ "single-line-class-stmt",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": (
+ "Allow the body of a class to be on the same "
+ "line as the declaration if body contains "
+ "single statement."
+ ),
+ },
+ ),
+ (
+ "max-module-lines",
+ {
+ "default": 1000,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of lines in a module.",
+ },
+ ),
+ (
+ "indent-string",
+ {
+ "default": " ",
+ "type": "non_empty_string",
+ "metavar": "<string>",
+ "help": "String used as indentation unit. This is usually "
+ '" " (4 spaces) or "\\t" (1 tab).',
+ },
+ ),
+ (
+ "indent-after-paren",
+ {
+ "type": "int",
+ "metavar": "<int>",
+ "default": 4,
+ "help": "Number of spaces of indent required inside a hanging "
+ "or continued line.",
+ },
+ ),
+ (
+ "expected-line-ending-format",
+ {
+ "type": "choice",
+ "metavar": "<empty or LF or CRLF>",
+ "default": "",
+ "choices": ["", "LF", "CRLF"],
+ "help": (
+ "Expected format of line ending, "
+ "e.g. empty (any line ending), LF or CRLF."
+ ),
+ },
+ ),
+ )
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._lines: dict[int, str] = {}
+ self._visited_lines: dict[int, Literal[1, 2]] = {}
+
+ def new_line(self, tokens: TokenWrapper, line_end: int, line_start: int) -> None:
+ """A new line has been encountered, process it if necessary."""
+ if _last_token_on_line_is(tokens, line_end, ";"):
+ self.add_message("unnecessary-semicolon", line=tokens.start_line(line_end))
+
+ line_num = tokens.start_line(line_start)
+ line = tokens.line(line_start)
+ if tokens.type(line_start) not in _JUNK_TOKENS:
+ self._lines[line_num] = line.split("\n")[0]
+ self.check_lines(tokens, line_start, line, line_num)
+
+ def process_module(self, node: nodes.Module) -> None:
+ pass
+
+ # pylint: disable-next = too-many-return-statements, too-many-branches
+ def _check_keyword_parentheses(
+ self, tokens: list[tokenize.TokenInfo], start: int
+ ) -> None:
+ """Check that there are not unnecessary parentheses after a keyword.
+
+ Parens are unnecessary if there is exactly one balanced outer pair on a
+ line and contains no commas (i.e. is not a tuple).
+
+ Args:
+ tokens: The entire list of Tokens.
+ start: The position of the keyword in the token list.
+ """
+ # If the next token is not a paren, we're fine.
+ if tokens[start + 1].string != "(":
+ return
+ if (
+ tokens[start].string == "not"
+ and start > 0
+ and tokens[start - 1].string == "is"
+ ):
+ # If this is part of an `is not` expression, we have a binary operator
+ # so the parentheses are not necessarily redundant.
+ return
+ found_and_or = False
+ contains_walrus_operator = False
+ walrus_operator_depth = 0
+ contains_double_parens = 0
+ depth = 0
+ keyword_token = str(tokens[start].string)
+ line_num = tokens[start].start[0]
+ for i in range(start, len(tokens) - 1):
+ token = tokens[i]
+
+ # If we hit a newline, then assume any parens were for continuation.
+ if token.type == tokenize.NL:
+ return
+ # Since the walrus operator doesn't exist below python3.8, the tokenizer
+ # generates independent tokens
+ if (
+ token.string == ":=" # <-- python3.8+ path
+ or token.string + tokens[i + 1].string == ":="
+ ):
+ contains_walrus_operator = True
+ walrus_operator_depth = depth
+ if token.string == "(":
+ depth += 1
+ if tokens[i + 1].string == "(":
+ contains_double_parens = 1
+ elif token.string == ")":
+ depth -= 1
+ if depth:
+ if contains_double_parens and tokens[i + 1].string == ")":
+ # For walrus operators in `if (not)` conditions and comprehensions
+ if keyword_token in {"in", "if", "not"}:
+ continue
+ return
+ contains_double_parens -= 1
+ continue
+ # ')' can't happen after if (foo), since it would be a syntax error.
+ if tokens[i + 1].string in {":", ")", "]", "}", "in"} or tokens[
+ i + 1
+ ].type in {tokenize.NEWLINE, tokenize.ENDMARKER, tokenize.COMMENT}:
+ if contains_walrus_operator and walrus_operator_depth - 1 == depth:
+ return
+ # The empty tuple () is always accepted.
+ if i == start + 2:
+ return
+ if found_and_or:
+ return
+ if keyword_token == "in":
+ # This special case was added in https://github.com/pylint-dev/pylint/pull/4948
+ # but it could be removed in the future. Avoid churn for now.
+ return
+ self.add_message(
+ "superfluous-parens", line=line_num, args=keyword_token
+ )
+ return
+ elif depth == 1:
+ # This is a tuple, which is always acceptable.
+ if token[1] == ",":
+ return
+ # 'and' and 'or' are the only boolean operators with lower precedence
+ # than 'not', so parens are only required when they are found.
+ if token[1] in {"and", "or"}:
+ found_and_or = True
+ # A yield inside an expression must always be in parentheses,
+ # quit early without error.
+ elif token[1] == "yield":
+ return
+ # A generator expression always has a 'for' token in it, and
+ # the 'for' token is only legal inside parens when it is in a
+ # generator expression. The parens are necessary here, so bail
+ # without an error.
+ elif token[1] == "for":
+ return
+ # A generator expression can have an 'else' token in it.
+ # We check the rest of the tokens to see if any problems occur after
+ # the 'else'.
+ elif token[1] == "else":
+ if "(" in (i.string for i in tokens[i:]):
+ self._check_keyword_parentheses(tokens[i:], 0)
+ return
+
+ def process_tokens(self, tokens: list[tokenize.TokenInfo]) -> None:
+ """Process tokens and search for:
+
+ - too long lines (i.e. longer than <max_chars>)
+ - optionally bad construct (if given, bad_construct must be a compiled
+ regular expression).
+ """
+ indents = [0]
+ check_equal = False
+ line_num = 0
+ self._lines = {}
+ self._visited_lines = {}
+ self._last_line_ending: str | None = None
+ last_blank_line_num = 0
+ for idx, (tok_type, string, start, _, line) in enumerate(tokens):
+ if start[0] != line_num:
+ line_num = start[0]
+ # A tokenizer oddity: if an indented line contains a multi-line
+ # docstring, the line member of the INDENT token does not contain
+ # the full line; therefore we check the next token on the line.
+ if tok_type == tokenize.INDENT:
+ self.new_line(TokenWrapper(tokens), idx - 1, idx + 1)
+ else:
+ self.new_line(TokenWrapper(tokens), idx - 1, idx)
+
+ if tok_type == tokenize.NEWLINE:
+ # a program statement, or ENDMARKER, will eventually follow,
+ # after some (possibly empty) run of tokens of the form
+ # (NL | COMMENT)* (INDENT | DEDENT+)?
+ # If an INDENT appears, setting check_equal is wrong, and will
+ # be undone when we see the INDENT.
+ check_equal = True
+ self._check_line_ending(string, line_num)
+ elif tok_type == tokenize.INDENT:
+ check_equal = False
+ self.check_indent_level(string, indents[-1] + 1, line_num)
+ indents.append(indents[-1] + 1)
+ elif tok_type == tokenize.DEDENT:
+ # there's nothing we need to check here! what's important is
+ # that when the run of DEDENTs ends, the indentation of the
+ # program statement (or ENDMARKER) that triggered the run is
+ # equal to what's left at the top of the indents stack
+ check_equal = True
+ if len(indents) > 1:
+ del indents[-1]
+ elif tok_type == tokenize.NL:
+ if not line.strip("\r\n"):
+ last_blank_line_num = line_num
+ elif tok_type not in (tokenize.COMMENT, tokenize.ENCODING):
+ # This is the first concrete token following a NEWLINE, so it
+ # must be the first token of the next program statement, or an
+ # ENDMARKER; the "line" argument exposes the leading white-space
+ # for this statement; in the case of ENDMARKER, line is an empty
+ # string, so will properly match the empty string with which the
+ # "indents" stack was seeded
+ if check_equal:
+ check_equal = False
+ self.check_indent_level(line, indents[-1], line_num)
+
+ if tok_type == tokenize.NUMBER and string.endswith("l"):
+ self.add_message("lowercase-l-suffix", line=line_num)
+
+ if string in _KEYWORD_TOKENS:
+ self._check_keyword_parentheses(tokens, idx)
+
+ line_num -= 1 # to be ok with "wc -l"
+ if line_num > self.linter.config.max_module_lines:
+ # Get the line where the too-many-lines (or its message id)
+ # was disabled or default to 1.
+ message_definition = self.linter.msgs_store.get_message_definitions(
+ "too-many-lines"
+ )[0]
+ names = (message_definition.msgid, "too-many-lines")
+ lineno = next(
+ filter(None, (self.linter._pragma_lineno.get(name) for name in names)),
+ 1,
+ )
+ self.add_message(
+ "too-many-lines",
+ args=(line_num, self.linter.config.max_module_lines),
+ line=lineno,
+ )
+
+ # See if there are any trailing lines. Do not complain about empty
+ # files like __init__.py markers.
+ if line_num == last_blank_line_num and line_num > 0:
+ self.add_message("trailing-newlines", line=line_num)
+
+ def _check_line_ending(self, line_ending: str, line_num: int) -> None:
+ # check if line endings are mixed
+ if self._last_line_ending is not None:
+ # line_ending == "" indicates a synthetic newline added at
+ # the end of a file that does not, in fact, end with a
+ # newline.
+ if line_ending and line_ending != self._last_line_ending:
+ self.add_message("mixed-line-endings", line=line_num)
+
+ self._last_line_ending = line_ending
+
+ # check if line ending is as expected
+ expected = self.linter.config.expected_line_ending_format
+ if expected:
+ # reduce multiple \n\n\n\n to one \n
+ line_ending = reduce(lambda x, y: x + y if x != y else x, line_ending, "")
+ line_ending = "LF" if line_ending == "\n" else "CRLF"
+ if line_ending != expected:
+ self.add_message(
+ "unexpected-line-ending-format",
+ args=(line_ending, expected),
+ line=line_num,
+ )
+
+ @only_required_for_messages("multiple-statements")
+ def visit_default(self, node: nodes.NodeNG) -> None:
+ """Check the node line number and check it if not yet done."""
+ if not node.is_statement:
+ return
+ if not node.root().pure_python:
+ return
+ prev_sibl = node.previous_sibling()
+ if prev_sibl is not None:
+ prev_line = prev_sibl.fromlineno
+ elif isinstance(
+ node.parent, nodes.Try
+ ) and self._is_first_node_in_else_finally_body(node, node.parent):
+ prev_line = self._infer_else_finally_line_number(node, node.parent)
+ elif isinstance(node.parent, nodes.Module):
+ prev_line = 0
+ else:
+ prev_line = node.parent.statement().fromlineno
+ line = node.fromlineno
+ assert line, node
+ if prev_line == line and self._visited_lines.get(line) != 2:
+ self._check_multi_statement_line(node, line)
+ return
+ if line in self._visited_lines:
+ return
+ try:
+ tolineno = node.blockstart_tolineno
+ except AttributeError:
+ tolineno = node.tolineno
+ assert tolineno, node
+ lines: list[str] = []
+ for line in range(line, tolineno + 1): # noqa: B020
+ self._visited_lines[line] = 1
+ try:
+ lines.append(self._lines[line].rstrip())
+ except KeyError:
+ lines.append("")
+
+ def _is_first_node_in_else_finally_body(
+ self, node: nodes.NodeNG, parent: nodes.Try
+ ) -> bool:
+ if parent.orelse and node == parent.orelse[0]:
+ return True
+ if parent.finalbody and node == parent.finalbody[0]:
+ return True
+ return False
+
+ def _infer_else_finally_line_number(
+ self, node: nodes.NodeNG, parent: nodes.Try
+ ) -> int:
+ last_line_of_prev_block = 0
+ if node in parent.finalbody and parent.orelse:
+ last_line_of_prev_block = parent.orelse[-1].tolineno
+ elif parent.handlers and parent.handlers[-1].body:
+ last_line_of_prev_block = parent.handlers[-1].body[-1].tolineno
+ elif parent.body:
+ last_line_of_prev_block = parent.body[-1].tolineno
+
+ return last_line_of_prev_block + 1 if last_line_of_prev_block else 0
+
+ def _check_multi_statement_line(self, node: nodes.NodeNG, line: int) -> None:
+ """Check for lines containing multiple statements."""
+ if isinstance(node, nodes.With):
+ # Do not warn about multiple nested context managers in with statements.
+ return
+ if (
+ isinstance(node.parent, nodes.If)
+ and not node.parent.orelse
+ and self.linter.config.single_line_if_stmt
+ ):
+ return
+ if (
+ isinstance(node.parent, nodes.ClassDef)
+ and len(node.parent.body) == 1
+ and self.linter.config.single_line_class_stmt
+ ):
+ return
+
+ # Functions stubs and class with ``Ellipsis`` as body are exempted.
+ if (
+ isinstance(node, nodes.Expr)
+ and isinstance(node.parent, (nodes.FunctionDef, nodes.ClassDef))
+ and isinstance(node.value, nodes.Const)
+ and node.value.value is Ellipsis
+ ):
+ return
+
+ self.add_message("multiple-statements", node=node, confidence=HIGH)
+ self._visited_lines[line] = 2
+
+ def check_trailing_whitespace_ending(self, line: str, i: int) -> None:
+ """Check that there is no trailing white-space."""
+ # exclude \f (formfeed) from the rstrip
+ stripped_line = line.rstrip("\t\n\r\v ")
+ if line[len(stripped_line) :] not in ("\n", "\r\n"):
+ self.add_message(
+ "trailing-whitespace",
+ line=i,
+ col_offset=len(stripped_line),
+ confidence=HIGH,
+ )
+
+ def check_line_length(self, line: str, i: int, checker_off: bool) -> None:
+ """Check that the line length is less than the authorized value."""
+ max_chars = self.linter.config.max_line_length
+ ignore_long_line = self.linter.config.ignore_long_lines
+ line = line.rstrip()
+ if len(line) > max_chars and not ignore_long_line.search(line):
+ if checker_off:
+ self.linter.add_ignored_message("line-too-long", i)
+ else:
+ self.add_message("line-too-long", line=i, args=(len(line), max_chars))
+
+ @staticmethod
+ def remove_pylint_option_from_lines(options_pattern_obj: Match[str]) -> str:
+ """Remove the `# pylint ...` pattern from lines."""
+ lines = options_pattern_obj.string
+ purged_lines = (
+ lines[: options_pattern_obj.start(1)].rstrip()
+ + lines[options_pattern_obj.end(1) :]
+ )
+ return purged_lines
+
+ @staticmethod
+ def is_line_length_check_activated(pylint_pattern_match_object: Match[str]) -> bool:
+ """Return True if the line length check is activated."""
+ try:
+ for pragma in parse_pragma(pylint_pattern_match_object.group(2)):
+ if pragma.action == "disable" and "line-too-long" in pragma.messages:
+ return False
+ except PragmaParserError:
+ # Printing useful information dealing with this error is done in the lint package
+ pass
+ return True
+
+ @staticmethod
+ def specific_splitlines(lines: str) -> list[str]:
+ """Split lines according to universal newlines except those in a specific
+ sets.
+ """
+ unsplit_ends = {
+ "\x0b", # synonym of \v
+ "\x0c", # synonym of \f
+ "\x1c",
+ "\x1d",
+ "\x1e",
+ "\x85",
+ "\u2028",
+ "\u2029",
+ }
+ res: list[str] = []
+ buffer = ""
+ for atomic_line in lines.splitlines(True):
+ if atomic_line[-1] not in unsplit_ends:
+ res.append(buffer + atomic_line)
+ buffer = ""
+ else:
+ buffer += atomic_line
+ return res
+
+ def check_lines(
+ self, tokens: TokenWrapper, line_start: int, lines: str, lineno: int
+ ) -> None:
+ """Check given lines for potential messages.
+
+ Check if lines have:
+ - a final newline
+ - no trailing white-space
+ - less than a maximum number of characters
+ """
+ # we're first going to do a rough check whether any lines in this set
+ # go over the line limit. If none of them do, then we don't need to
+ # parse out the pylint options later on and can just assume that these
+ # lines are clean
+
+ # we'll also handle the line ending check here to avoid double-iteration
+ # unless the line lengths are suspect
+
+ max_chars = self.linter.config.max_line_length
+
+ split_lines = self.specific_splitlines(lines)
+
+ for offset, line in enumerate(split_lines):
+ if not line.endswith("\n"):
+ self.add_message("missing-final-newline", line=lineno + offset)
+ continue
+ # We don't test for trailing whitespaces in strings
+ # See https://github.com/pylint-dev/pylint/issues/6936
+ # and https://github.com/pylint-dev/pylint/issues/3822
+ if tokens.type(line_start) != tokenize.STRING:
+ self.check_trailing_whitespace_ending(line, lineno + offset)
+
+ # This check is purposefully simple and doesn't rstrip since this is running
+ # on every line you're checking it's advantageous to avoid doing a lot of work
+ potential_line_length_warning = any(
+ len(line) > max_chars for line in split_lines
+ )
+
+ # if there were no lines passing the max_chars config, we don't bother
+ # running the full line check (as we've met an even more strict condition)
+ if not potential_line_length_warning:
+ return
+
+ # Line length check may be deactivated through `pylint: disable` comment
+ mobj = OPTION_PO.search(lines)
+ checker_off = False
+ if mobj:
+ if not self.is_line_length_check_activated(mobj):
+ checker_off = True
+ # The 'pylint: disable whatever' should not be taken into account for line length count
+ lines = self.remove_pylint_option_from_lines(mobj)
+
+ # here we re-run specific_splitlines since we have filtered out pylint options above
+ for offset, line in enumerate(self.specific_splitlines(lines)):
+ self.check_line_length(line, lineno + offset, checker_off)
+
+ def check_indent_level(self, string: str, expected: int, line_num: int) -> None:
+ """Return the indent level of the string."""
+ indent = self.linter.config.indent_string
+ if indent == "\\t": # \t is not interpreted in the configuration file
+ indent = "\t"
+ level = 0
+ unit_size = len(indent)
+ while string[:unit_size] == indent:
+ string = string[unit_size:]
+ level += 1
+ suppl = ""
+ while string and string[0] in " \t":
+ suppl += string[0]
+ string = string[1:]
+ if level != expected or suppl:
+ i_type = "spaces"
+ if indent[0] == "\t":
+ i_type = "tabs"
+ self.add_message(
+ "bad-indentation",
+ line=line_num,
+ args=(level * unit_size + len(suppl), i_type, expected * unit_size),
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(FormatChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/imports.py b/solutions/.venv/Lib/site-packages/pylint/checkers/imports.py
new file mode 100644
index 000000000..2fa212cd7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/imports.py
@@ -0,0 +1,1263 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Imports checkers for Python code."""
+
+from __future__ import annotations
+
+import collections
+import copy
+import os
+import sys
+from collections import defaultdict
+from collections.abc import ItemsView, Sequence
+from functools import cached_property
+from typing import TYPE_CHECKING, Any, Union
+
+import astroid
+from astroid import nodes
+from astroid.nodes._base_nodes import ImportNode
+
+from pylint.checkers import BaseChecker, DeprecatedMixin
+from pylint.checkers.utils import (
+ get_import_name,
+ in_type_checking_block,
+ is_from_fallback_block,
+ is_module_ignored,
+ is_sys_guard,
+ node_ignores_exception,
+)
+from pylint.constants import MAX_NUMBER_OF_IMPORT_SHOWN
+from pylint.exceptions import EmptyReportError
+from pylint.graph import DotBackend, get_cycles
+from pylint.interfaces import HIGH
+from pylint.reporters.ureports.nodes import Paragraph, Section, VerbatimText
+from pylint.typing import MessageDefinitionTuple
+from pylint.utils import IsortDriver
+from pylint.utils.linterstats import LinterStats
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+# The dictionary with Any should actually be a _ImportTree again
+# but mypy doesn't support recursive types yet
+_ImportTree = dict[str, Union[list[dict[str, Any]], list[str]]]
+
+DEPRECATED_MODULES = {
+ (0, 0, 0): {"tkinter.tix", "fpectl"},
+ (3, 2, 0): {"optparse"},
+ (3, 3, 0): {"xml.etree.cElementTree"},
+ (3, 4, 0): {"imp"},
+ (3, 5, 0): {"formatter"},
+ (3, 6, 0): {"asynchat", "asyncore", "smtpd"},
+ (3, 7, 0): {"macpath"},
+ (3, 9, 0): {"lib2to3", "parser", "symbol", "binhex"},
+ (3, 10, 0): {"distutils", "typing.io", "typing.re"},
+ (3, 11, 0): {
+ "aifc",
+ "audioop",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "crypt",
+ "imghdr",
+ "msilib",
+ "mailcap",
+ "nis",
+ "nntplib",
+ "ossaudiodev",
+ "pipes",
+ "sndhdr",
+ "spwd",
+ "sunau",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "telnetlib",
+ "uu",
+ "xdrlib",
+ },
+ (3, 13, 0): {"getopt"},
+}
+
+
+def _get_first_import(
+ node: ImportNode,
+ context: nodes.LocalsDictNodeNG,
+ name: str,
+ base: str | None,
+ level: int | None,
+ alias: str | None,
+) -> tuple[nodes.Import | nodes.ImportFrom | None, str | None]:
+ """Return the node where [base.]<name> is imported or None if not found."""
+ fullname = f"{base}.{name}" if base else name
+
+ first = None
+ found = False
+ msg = "reimported"
+
+ for first in context.body:
+ if first is node:
+ continue
+ if first.scope() is node.scope() and first.fromlineno > node.fromlineno:
+ continue
+ if isinstance(first, nodes.Import):
+ if any(fullname == iname[0] for iname in first.names):
+ found = True
+ break
+ for imported_name, imported_alias in first.names:
+ if not imported_alias and imported_name == alias:
+ found = True
+ msg = "shadowed-import"
+ break
+ if found:
+ break
+ elif isinstance(first, nodes.ImportFrom):
+ if level == first.level:
+ for imported_name, imported_alias in first.names:
+ if fullname == f"{first.modname}.{imported_name}":
+ found = True
+ break
+ if (
+ name != "*"
+ and name == imported_name
+ and not (alias or imported_alias)
+ ):
+ found = True
+ break
+ if not imported_alias and imported_name == alias:
+ found = True
+ msg = "shadowed-import"
+ break
+ if found:
+ break
+ if found and not astroid.are_exclusive(first, node):
+ return first, msg
+ return None, None
+
+
+def _ignore_import_failure(
+ node: ImportNode,
+ modname: str,
+ ignored_modules: Sequence[str],
+) -> bool:
+ if is_module_ignored(modname, ignored_modules):
+ return True
+
+ # Ignore import failure if part of guarded import block
+ # I.e. `sys.version_info` or `typing.TYPE_CHECKING`
+ if in_type_checking_block(node):
+ return True
+ if isinstance(node.parent, nodes.If) and is_sys_guard(node.parent):
+ return True
+
+ return node_ignores_exception(node, ImportError)
+
+
+# utilities to represents import dependencies as tree and dot graph ###########
+
+
+def _make_tree_defs(mod_files_list: ItemsView[str, set[str]]) -> _ImportTree:
+ """Get a list of 2-uple (module, list_of_files_which_import_this_module),
+ it will return a dictionary to represent this as a tree.
+ """
+ tree_defs: _ImportTree = {}
+ for mod, files in mod_files_list:
+ node: list[_ImportTree | list[str]] = [tree_defs, []]
+ for prefix in mod.split("."):
+ assert isinstance(node[0], dict)
+ node = node[0].setdefault(prefix, ({}, [])) # type: ignore[arg-type,assignment]
+ assert isinstance(node[1], list)
+ node[1].extend(files)
+ return tree_defs
+
+
+def _repr_tree_defs(data: _ImportTree, indent_str: str | None = None) -> str:
+ """Return a string which represents imports as a tree."""
+ lines = []
+ nodes_items = data.items()
+ for i, (mod, (sub, files)) in enumerate(sorted(nodes_items, key=lambda x: x[0])):
+ files_list = "" if not files else f"({','.join(sorted(files))})"
+ if indent_str is None:
+ lines.append(f"{mod} {files_list}")
+ sub_indent_str = " "
+ else:
+ lines.append(rf"{indent_str}\-{mod} {files_list}")
+ if i == len(nodes_items) - 1:
+ sub_indent_str = f"{indent_str} "
+ else:
+ sub_indent_str = f"{indent_str}| "
+ if sub and isinstance(sub, dict):
+ lines.append(_repr_tree_defs(sub, sub_indent_str))
+ return "\n".join(lines)
+
+
+def _dependencies_graph(filename: str, dep_info: dict[str, set[str]]) -> str:
+ """Write dependencies as a dot (graphviz) file."""
+ done = {}
+ printer = DotBackend(os.path.splitext(os.path.basename(filename))[0], rankdir="LR")
+ printer.emit('URL="." node[shape="box"]')
+ for modname, dependencies in sorted(dep_info.items()):
+ sorted_dependencies = sorted(dependencies)
+ done[modname] = 1
+ printer.emit_node(modname)
+ for depmodname in sorted_dependencies:
+ if depmodname not in done:
+ done[depmodname] = 1
+ printer.emit_node(depmodname)
+ for depmodname, dependencies in sorted(dep_info.items()):
+ for modname in sorted(dependencies):
+ printer.emit_edge(modname, depmodname)
+ return printer.generate(filename)
+
+
+def _make_graph(
+ filename: str, dep_info: dict[str, set[str]], sect: Section, gtype: str
+) -> None:
+ """Generate a dependencies graph and add some information about it in the
+ report's section.
+ """
+ outputfile = _dependencies_graph(filename, dep_info)
+ sect.append(Paragraph((f"{gtype}imports graph has been written to {outputfile}",)))
+
+
+# the import checker itself ###################################################
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "E0401": (
+ "Unable to import %s",
+ "import-error",
+ "Used when pylint has been unable to import a module.",
+ {"old_names": [("F0401", "old-import-error")]},
+ ),
+ "E0402": (
+ "Attempted relative import beyond top-level package",
+ "relative-beyond-top-level",
+ "Used when a relative import tries to access too many levels "
+ "in the current package.",
+ ),
+ "R0401": (
+ "Cyclic import (%s)",
+ "cyclic-import",
+ "Used when a cyclic import between two or more modules is detected.",
+ ),
+ "R0402": (
+ "Use 'from %s import %s' instead",
+ "consider-using-from-import",
+ "Emitted when a submodule of a package is imported and "
+ "aliased with the same name, "
+ "e.g., instead of ``import concurrent.futures as futures`` use "
+ "``from concurrent import futures``.",
+ ),
+ "W0401": (
+ "Wildcard import %s",
+ "wildcard-import",
+ "Used when `from module import *` is detected.",
+ ),
+ "W0404": (
+ "Reimport %r (imported line %s)",
+ "reimported",
+ "Used when a module is imported more than once.",
+ ),
+ "W0406": (
+ "Module import itself",
+ "import-self",
+ "Used when a module is importing itself.",
+ ),
+ "W0407": (
+ "Prefer importing %r instead of %r",
+ "preferred-module",
+ "Used when a module imported has a preferred replacement module.",
+ ),
+ "W0410": (
+ "__future__ import is not the first non docstring statement",
+ "misplaced-future",
+ "Python 2.5 and greater require __future__ import to be the "
+ "first non docstring statement in the module.",
+ ),
+ "C0410": (
+ "Multiple imports on one line (%s)",
+ "multiple-imports",
+ "Used when import statement importing multiple modules is detected.",
+ ),
+ "C0411": (
+ "%s should be placed before %s",
+ "wrong-import-order",
+ "Used when PEP8 import order is not respected (standard imports "
+ "first, then third-party libraries, then local imports).",
+ ),
+ "C0412": (
+ "Imports from package %s are not grouped",
+ "ungrouped-imports",
+ "Used when imports are not grouped by packages.",
+ ),
+ "C0413": (
+ 'Import "%s" should be placed at the top of the module',
+ "wrong-import-position",
+ "Used when code and imports are mixed.",
+ ),
+ "C0414": (
+ "Import alias does not rename original package",
+ "useless-import-alias",
+ "Used when an import alias is same as original package, "
+ "e.g., using import numpy as numpy instead of import numpy as np.",
+ ),
+ "C0415": (
+ "Import outside toplevel (%s)",
+ "import-outside-toplevel",
+ "Used when an import statement is used anywhere other than the module "
+ "toplevel. Move this import to the top of the file.",
+ ),
+ "W0416": (
+ "Shadowed %r (imported line %s)",
+ "shadowed-import",
+ "Used when a module is aliased with a name that shadows another import.",
+ ),
+}
+
+
+DEFAULT_STANDARD_LIBRARY = ()
+DEFAULT_KNOWN_THIRD_PARTY = ("enchant",)
+DEFAULT_PREFERRED_MODULES = ()
+
+
+class ImportsChecker(DeprecatedMixin, BaseChecker):
+ """BaseChecker for import statements.
+
+ Checks for
+ * external modules dependencies
+ * relative / wildcard imports
+ * cyclic imports
+ * uses of deprecated modules
+ * uses of modules instead of preferred modules
+ """
+
+ name = "imports"
+ msgs = {**DeprecatedMixin.DEPRECATED_MODULE_MESSAGE, **MSGS}
+ default_deprecated_modules = ()
+
+ options = (
+ (
+ "deprecated-modules",
+ {
+ "default": default_deprecated_modules,
+ "type": "csv",
+ "metavar": "<modules>",
+ "help": "Deprecated modules which should not be used,"
+ " separated by a comma.",
+ },
+ ),
+ (
+ "preferred-modules",
+ {
+ "default": DEFAULT_PREFERRED_MODULES,
+ "type": "csv",
+ "metavar": "<module:preferred-module>",
+ "help": "Couples of modules and preferred modules,"
+ " separated by a comma.",
+ },
+ ),
+ (
+ "import-graph",
+ {
+ "default": "",
+ "type": "path",
+ "metavar": "<file.gv>",
+ "help": "Output a graph (.gv or any supported image format) of"
+ " all (i.e. internal and external) dependencies to the given file"
+ " (report RP0402 must not be disabled).",
+ },
+ ),
+ (
+ "ext-import-graph",
+ {
+ "default": "",
+ "type": "path",
+ "metavar": "<file.gv>",
+ "help": "Output a graph (.gv or any supported image format)"
+ " of external dependencies to the given file"
+ " (report RP0402 must not be disabled).",
+ },
+ ),
+ (
+ "int-import-graph",
+ {
+ "default": "",
+ "type": "path",
+ "metavar": "<file.gv>",
+ "help": "Output a graph (.gv or any supported image format)"
+ " of internal dependencies to the given file"
+ " (report RP0402 must not be disabled).",
+ },
+ ),
+ (
+ "known-standard-library",
+ {
+ "default": DEFAULT_STANDARD_LIBRARY,
+ "type": "csv",
+ "metavar": "<modules>",
+ "help": "Force import order to recognize a module as part of "
+ "the standard compatibility libraries.",
+ },
+ ),
+ (
+ "known-third-party",
+ {
+ "default": DEFAULT_KNOWN_THIRD_PARTY,
+ "type": "csv",
+ "metavar": "<modules>",
+ "help": "Force import order to recognize a module as part of "
+ "a third party library.",
+ },
+ ),
+ (
+ "allow-any-import-level",
+ {
+ "default": (),
+ "type": "csv",
+ "metavar": "<modules>",
+ "help": (
+ "List of modules that can be imported at any level, not just "
+ "the top level one."
+ ),
+ },
+ ),
+ (
+ "allow-wildcard-with-all",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Allow wildcard imports from modules that define __all__.",
+ },
+ ),
+ (
+ "allow-reexport-from-package",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Allow explicit reexports by alias from a package __init__.",
+ },
+ ),
+ )
+
+ def __init__(self, linter: PyLinter) -> None:
+ BaseChecker.__init__(self, linter)
+ self.import_graph: defaultdict[str, set[str]] = defaultdict(set)
+ self._imports_stack: list[tuple[ImportNode, str]] = []
+ self._first_non_import_node = None
+ self._module_pkg: dict[Any, Any] = (
+ {}
+ ) # mapping of modules to the pkg they belong in
+ self._allow_any_import_level: set[Any] = set()
+ self.reports = (
+ ("RP0401", "External dependencies", self._report_external_dependencies),
+ ("RP0402", "Modules dependencies graph", self._report_dependencies_graph),
+ )
+ self._excluded_edges: defaultdict[str, set[str]] = defaultdict(set)
+
+ def open(self) -> None:
+ """Called before visiting project (i.e set of modules)."""
+ self.linter.stats.dependencies = {}
+ self.linter.stats = self.linter.stats
+ self.import_graph = defaultdict(set)
+ self._module_pkg = {} # mapping of modules to the pkg they belong in
+ self._current_module_package = False
+ self._ignored_modules: Sequence[str] = self.linter.config.ignored_modules
+ # Build a mapping {'module': 'preferred-module'}
+ self.preferred_modules = dict(
+ module.split(":")
+ for module in self.linter.config.preferred_modules
+ if ":" in module
+ )
+ self._allow_any_import_level = set(self.linter.config.allow_any_import_level)
+ self._allow_reexport_package = self.linter.config.allow_reexport_from_package
+
+ def _import_graph_without_ignored_edges(self) -> defaultdict[str, set[str]]:
+ filtered_graph = copy.deepcopy(self.import_graph)
+ for node in filtered_graph:
+ filtered_graph[node].difference_update(self._excluded_edges[node])
+ return filtered_graph
+
+ def close(self) -> None:
+ """Called before visiting project (i.e set of modules)."""
+ if self.linter.is_message_enabled("cyclic-import"):
+ graph = self._import_graph_without_ignored_edges()
+ vertices = list(graph)
+ for cycle in get_cycles(graph, vertices=vertices):
+ self.add_message("cyclic-import", args=" -> ".join(cycle))
+
+ def get_map_data(
+ self,
+ ) -> tuple[defaultdict[str, set[str]], defaultdict[str, set[str]]]:
+ if self.linter.is_message_enabled("cyclic-import"):
+ return (self.import_graph, self._excluded_edges)
+ return (defaultdict(set), defaultdict(set))
+
+ def reduce_map_data(
+ self,
+ linter: PyLinter,
+ data: list[tuple[defaultdict[str, set[str]], defaultdict[str, set[str]]]],
+ ) -> None:
+ if self.linter.is_message_enabled("cyclic-import"):
+ self.import_graph = defaultdict(set)
+ self._excluded_edges = defaultdict(set)
+ for to_update in data:
+ graph, excluded_edges = to_update
+ self.import_graph.update(graph)
+ self._excluded_edges.update(excluded_edges)
+
+ self.close()
+
+ def deprecated_modules(self) -> set[str]:
+ """Callback returning the deprecated modules."""
+ # First get the modules the user indicated
+ all_deprecated_modules = set(self.linter.config.deprecated_modules)
+ # Now get the hard-coded ones from the stdlib
+ for since_vers, mod_set in DEPRECATED_MODULES.items():
+ if since_vers <= sys.version_info:
+ all_deprecated_modules = all_deprecated_modules.union(mod_set)
+ return all_deprecated_modules
+
+ def visit_module(self, node: nodes.Module) -> None:
+ """Store if current module is a package, i.e. an __init__ file."""
+ self._current_module_package = node.package
+
+ def visit_import(self, node: nodes.Import) -> None:
+ """Triggered when an import statement is seen."""
+ self._check_reimport(node)
+ self._check_import_as_rename(node)
+ self._check_toplevel(node)
+
+ names = [name for name, _ in node.names]
+ if len(names) >= 2:
+ self.add_message("multiple-imports", args=", ".join(names), node=node)
+
+ for name in names:
+ self.check_deprecated_module(node, name)
+ self._check_preferred_module(node, name)
+ imported_module = self._get_imported_module(node, name)
+ if isinstance(node.parent, nodes.Module):
+ # Allow imports nested
+ self._check_position(node)
+ if isinstance(node.scope(), nodes.Module):
+ self._record_import(node, imported_module)
+
+ if imported_module is None:
+ continue
+
+ self._add_imported_module(node, imported_module.name)
+
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ """Triggered when a from statement is seen."""
+ basename = node.modname
+ imported_module = self._get_imported_module(node, basename)
+ absolute_name = get_import_name(node, basename)
+
+ self._check_import_as_rename(node)
+ self._check_misplaced_future(node)
+ self.check_deprecated_module(node, absolute_name)
+ self._check_preferred_module(node, basename)
+ self._check_wildcard_imports(node, imported_module)
+ self._check_same_line_imports(node)
+ self._check_reimport(node, basename=basename, level=node.level)
+ self._check_toplevel(node)
+
+ if isinstance(node.parent, nodes.Module):
+ # Allow imports nested
+ self._check_position(node)
+ if isinstance(node.scope(), nodes.Module):
+ self._record_import(node, imported_module)
+ if imported_module is None:
+ return
+ for name, _ in node.names:
+ if name != "*":
+ self._add_imported_module(node, f"{imported_module.name}.{name}")
+ else:
+ self._add_imported_module(node, imported_module.name)
+
+ def leave_module(self, node: nodes.Module) -> None:
+ # Check imports are grouped by category (standard, 3rd party, local)
+ std_imports, ext_imports, loc_imports = self._check_imports_order(node)
+
+ # Check that imports are grouped by package within a given category
+ met_import: set[str] = set() # set for 'import x' style
+ met_from: set[str] = set() # set for 'from x import y' style
+ current_package = None
+ for import_node, import_name in std_imports + ext_imports + loc_imports:
+ met = met_from if isinstance(import_node, nodes.ImportFrom) else met_import
+ package, _, _ = import_name.partition(".")
+ if (
+ current_package
+ and current_package != package
+ and package in met
+ and not in_type_checking_block(import_node)
+ and not (
+ isinstance(import_node.parent, nodes.If)
+ and is_sys_guard(import_node.parent)
+ )
+ ):
+ self.add_message("ungrouped-imports", node=import_node, args=package)
+ current_package = package
+ if not self.linter.is_message_enabled(
+ "ungrouped-imports", import_node.fromlineno
+ ):
+ continue
+ met.add(package)
+
+ self._imports_stack = []
+ self._first_non_import_node = None
+
+ def compute_first_non_import_node(
+ self,
+ node: (
+ nodes.If
+ | nodes.Expr
+ | nodes.Comprehension
+ | nodes.IfExp
+ | nodes.Assign
+ | nodes.AssignAttr
+ | nodes.Try
+ ),
+ ) -> None:
+ # if the node does not contain an import instruction, and if it is the
+ # first node of the module, keep a track of it (all the import positions
+ # of the module will be compared to the position of this first
+ # instruction)
+ if self._first_non_import_node:
+ return
+ if not isinstance(node.parent, nodes.Module):
+ return
+ if isinstance(node, nodes.Try) and any(
+ node.nodes_of_class((nodes.Import, nodes.ImportFrom))
+ ):
+ return
+ if isinstance(node, nodes.Assign):
+ # Add compatibility for module level dunder names
+ # https://www.python.org/dev/peps/pep-0008/#module-level-dunder-names
+ valid_targets = [
+ isinstance(target, nodes.AssignName)
+ and target.name.startswith("__")
+ and target.name.endswith("__")
+ for target in node.targets
+ ]
+ if all(valid_targets):
+ return
+ self._first_non_import_node = node
+
+ visit_try = visit_assignattr = visit_assign = visit_ifexp = visit_comprehension = (
+ visit_expr
+ ) = visit_if = compute_first_non_import_node
+
+ def visit_functiondef(
+ self, node: nodes.FunctionDef | nodes.While | nodes.For | nodes.ClassDef
+ ) -> None:
+ # If it is the first non import instruction of the module, record it.
+ if self._first_non_import_node:
+ return
+
+ # Check if the node belongs to an `If` or a `Try` block. If they
+ # contain imports, skip recording this node.
+ if not isinstance(node.parent.scope(), nodes.Module):
+ return
+
+ root = node
+ while not isinstance(root.parent, nodes.Module):
+ root = root.parent
+
+ if isinstance(root, (nodes.If, nodes.Try)):
+ if any(root.nodes_of_class((nodes.Import, nodes.ImportFrom))):
+ return
+
+ self._first_non_import_node = node
+
+ visit_classdef = visit_for = visit_while = visit_functiondef
+
+ def _check_misplaced_future(self, node: nodes.ImportFrom) -> None:
+ basename = node.modname
+ if basename == "__future__":
+ # check if this is the first non-docstring statement in the module
+ prev = node.previous_sibling()
+ if prev:
+ # consecutive future statements are possible
+ if not (
+ isinstance(prev, nodes.ImportFrom) and prev.modname == "__future__"
+ ):
+ self.add_message("misplaced-future", node=node)
+
+ def _check_same_line_imports(self, node: nodes.ImportFrom) -> None:
+ # Detect duplicate imports on the same line.
+ names = (name for name, _ in node.names)
+ counter = collections.Counter(names)
+ for name, count in counter.items():
+ if count > 1:
+ self.add_message("reimported", node=node, args=(name, node.fromlineno))
+
+ def _check_position(self, node: ImportNode) -> None:
+ """Check `node` import or importfrom node position is correct.
+
+ Send a message if `node` comes before another instruction
+ """
+ # if a first non-import instruction has already been encountered,
+ # it means the import comes after it and therefore is not well placed
+ if self._first_non_import_node:
+ if self.linter.is_message_enabled(
+ "wrong-import-position", self._first_non_import_node.fromlineno
+ ):
+ self.add_message(
+ "wrong-import-position", node=node, args=node.as_string()
+ )
+ else:
+ self.linter.add_ignored_message(
+ "wrong-import-position", node.fromlineno, node
+ )
+
+ def _record_import(
+ self,
+ node: ImportNode,
+ importedmodnode: nodes.Module | None,
+ ) -> None:
+ """Record the package `node` imports from."""
+ if isinstance(node, nodes.ImportFrom):
+ importedname = node.modname
+ else:
+ importedname = importedmodnode.name if importedmodnode else None
+ if not importedname:
+ importedname = node.names[0][0].split(".")[0]
+
+ if isinstance(node, nodes.ImportFrom) and (node.level or 0) >= 1:
+ # We need the importedname with first point to detect local package
+ # Example of node:
+ # 'from .my_package1 import MyClass1'
+ # the output should be '.my_package1' instead of 'my_package1'
+ # Example of node:
+ # 'from . import my_package2'
+ # the output should be '.my_package2' instead of '{pyfile}'
+ importedname = "." + importedname
+
+ self._imports_stack.append((node, importedname))
+
+ @staticmethod
+ def _is_fallback_import(
+ node: ImportNode, imports: list[tuple[ImportNode, str]]
+ ) -> bool:
+ imports = [import_node for (import_node, _) in imports]
+ return any(astroid.are_exclusive(import_node, node) for import_node in imports)
+
+ # pylint: disable = too-many-statements
+ def _check_imports_order(self, _module_node: nodes.Module) -> tuple[
+ list[tuple[ImportNode, str]],
+ list[tuple[ImportNode, str]],
+ list[tuple[ImportNode, str]],
+ ]:
+ """Checks imports of module `node` are grouped by category.
+
+ Imports must follow this order: standard, 3rd party, local
+ """
+ std_imports: list[tuple[ImportNode, str]] = []
+ third_party_imports: list[tuple[ImportNode, str]] = []
+ first_party_imports: list[tuple[ImportNode, str]] = []
+ # need of a list that holds third or first party ordered import
+ external_imports: list[tuple[ImportNode, str]] = []
+ local_imports: list[tuple[ImportNode, str]] = []
+ third_party_not_ignored: list[tuple[ImportNode, str]] = []
+ first_party_not_ignored: list[tuple[ImportNode, str]] = []
+ local_not_ignored: list[tuple[ImportNode, str]] = []
+ isort_driver = IsortDriver(self.linter.config)
+ for node, modname in self._imports_stack:
+ if modname.startswith("."):
+ package = "." + modname.split(".")[1]
+ else:
+ package = modname.split(".")[0]
+ nested = not isinstance(node.parent, nodes.Module)
+ ignore_for_import_order = not self.linter.is_message_enabled(
+ "wrong-import-order", node.fromlineno
+ )
+ import_category = isort_driver.place_module(package)
+ node_and_package_import = (node, package)
+
+ if import_category in {"FUTURE", "STDLIB"}:
+ std_imports.append(node_and_package_import)
+ wrong_import = (
+ third_party_not_ignored
+ or first_party_not_ignored
+ or local_not_ignored
+ )
+ if self._is_fallback_import(node, wrong_import):
+ continue
+ if wrong_import and not nested:
+ self.add_message(
+ "wrong-import-order",
+ node=node,
+ args=( ## TODO - this isn't right for multiple on the same line...
+ f'standard import "{self._get_full_import_name((node, package))}"',
+ self._get_out_of_order_string(
+ third_party_not_ignored,
+ first_party_not_ignored,
+ local_not_ignored,
+ ),
+ ),
+ )
+ elif import_category == "THIRDPARTY":
+ third_party_imports.append(node_and_package_import)
+ external_imports.append(node_and_package_import)
+ if not nested:
+ if not ignore_for_import_order:
+ third_party_not_ignored.append(node_and_package_import)
+ else:
+ self.linter.add_ignored_message(
+ "wrong-import-order", node.fromlineno, node
+ )
+ wrong_import = first_party_not_ignored or local_not_ignored
+ if wrong_import and not nested:
+ self.add_message(
+ "wrong-import-order",
+ node=node,
+ args=(
+ f'third party import "{self._get_full_import_name((node, package))}"',
+ self._get_out_of_order_string(
+ None, first_party_not_ignored, local_not_ignored
+ ),
+ ),
+ )
+ elif import_category == "FIRSTPARTY":
+ first_party_imports.append(node_and_package_import)
+ external_imports.append(node_and_package_import)
+ if not nested:
+ if not ignore_for_import_order:
+ first_party_not_ignored.append(node_and_package_import)
+ else:
+ self.linter.add_ignored_message(
+ "wrong-import-order", node.fromlineno, node
+ )
+ wrong_import = local_not_ignored
+ if wrong_import and not nested:
+ self.add_message(
+ "wrong-import-order",
+ node=node,
+ args=(
+ f'first party import "{self._get_full_import_name((node, package))}"',
+ self._get_out_of_order_string(
+ None, None, local_not_ignored
+ ),
+ ),
+ )
+ elif import_category == "LOCALFOLDER":
+ local_imports.append((node, package))
+ if not nested:
+ if not ignore_for_import_order:
+ local_not_ignored.append((node, package))
+ else:
+ self.linter.add_ignored_message(
+ "wrong-import-order", node.fromlineno, node
+ )
+ return std_imports, external_imports, local_imports
+
+ def _get_out_of_order_string(
+ self,
+ third_party_imports: list[tuple[ImportNode, str]] | None,
+ first_party_imports: list[tuple[ImportNode, str]] | None,
+ local_imports: list[tuple[ImportNode, str]] | None,
+ ) -> str:
+ # construct the string listing out of order imports used in the message
+ # for wrong-import-order
+ if third_party_imports:
+ plural = "s" if len(third_party_imports) > 1 else ""
+ if len(third_party_imports) > MAX_NUMBER_OF_IMPORT_SHOWN:
+ imports_list = (
+ ", ".join(
+ [
+ f'"{self._get_full_import_name(tpi)}"'
+ for tpi in third_party_imports[
+ : int(MAX_NUMBER_OF_IMPORT_SHOWN // 2)
+ ]
+ ]
+ )
+ + " (...) "
+ + ", ".join(
+ [
+ f'"{self._get_full_import_name(tpi)}"'
+ for tpi in third_party_imports[
+ int(-MAX_NUMBER_OF_IMPORT_SHOWN // 2) :
+ ]
+ ]
+ )
+ )
+ else:
+ imports_list = ", ".join(
+ [
+ f'"{self._get_full_import_name(tpi)}"'
+ for tpi in third_party_imports
+ ]
+ )
+ third_party = f"third party import{plural} {imports_list}"
+ else:
+ third_party = ""
+
+ if first_party_imports:
+ plural = "s" if len(first_party_imports) > 1 else ""
+ if len(first_party_imports) > MAX_NUMBER_OF_IMPORT_SHOWN:
+ imports_list = (
+ ", ".join(
+ [
+ f'"{self._get_full_import_name(tpi)}"'
+ for tpi in first_party_imports[
+ : int(MAX_NUMBER_OF_IMPORT_SHOWN // 2)
+ ]
+ ]
+ )
+ + " (...) "
+ + ", ".join(
+ [
+ f'"{self._get_full_import_name(tpi)}"'
+ for tpi in first_party_imports[
+ int(-MAX_NUMBER_OF_IMPORT_SHOWN // 2) :
+ ]
+ ]
+ )
+ )
+ else:
+ imports_list = ", ".join(
+ [
+ f'"{self._get_full_import_name(fpi)}"'
+ for fpi in first_party_imports
+ ]
+ )
+ first_party = f"first party import{plural} {imports_list}"
+ else:
+ first_party = ""
+
+ if local_imports:
+ plural = "s" if len(local_imports) > 1 else ""
+ if len(local_imports) > MAX_NUMBER_OF_IMPORT_SHOWN:
+ imports_list = (
+ ", ".join(
+ [
+ f'"{self._get_full_import_name(tpi)}"'
+ for tpi in local_imports[
+ : int(MAX_NUMBER_OF_IMPORT_SHOWN // 2)
+ ]
+ ]
+ )
+ + " (...) "
+ + ", ".join(
+ [
+ f'"{self._get_full_import_name(tpi)}"'
+ for tpi in local_imports[
+ int(-MAX_NUMBER_OF_IMPORT_SHOWN // 2) :
+ ]
+ ]
+ )
+ )
+ else:
+ imports_list = ", ".join(
+ [f'"{self._get_full_import_name(li)}"' for li in local_imports]
+ )
+ local = f"local import{plural} {imports_list}"
+ else:
+ local = ""
+
+ delimiter_third_party = (
+ (
+ ", "
+ if (first_party and local)
+ else (" and " if (first_party or local) else "")
+ )
+ if third_party
+ else ""
+ )
+ delimiter_first_party1 = (
+ (", " if (third_party and local) else " ") if first_party else ""
+ )
+ delimiter_first_party2 = ("and " if local else "") if first_party else ""
+ delimiter_first_party = f"{delimiter_first_party1}{delimiter_first_party2}"
+ msg = (
+ f"{third_party}{delimiter_third_party}"
+ f"{first_party}{delimiter_first_party}"
+ f'{local if local else ""}'
+ )
+
+ return msg
+
+ def _get_full_import_name(self, importNode: ImportNode) -> str:
+ # construct a more descriptive name of the import
+ # for: import X, this returns X
+ # for: import X.Y this returns X.Y
+ # for: from X import Y, this returns X.Y
+
+ try:
+ # this will only succeed for ImportFrom nodes, which in themselves
+ # contain the information needed to reconstruct the package
+ return f"{importNode[0].modname}.{importNode[0].names[0][0]}"
+ except AttributeError:
+ # in all other cases, the import will either be X or X.Y
+ node: str = importNode[0].names[0][0]
+ package: str = importNode[1]
+
+ if node.split(".")[0] == package:
+ # this is sufficient with one import per line, since package = X
+ # and node = X.Y or X
+ return node
+
+ # when there is a node that contains multiple imports, the "current"
+ # import being analyzed is specified by package (node is the first
+ # import on the line and therefore != package in this case)
+ return package
+
+ def _get_imported_module(
+ self, importnode: ImportNode, modname: str
+ ) -> nodes.Module | None:
+ try:
+ return importnode.do_import_module(modname)
+ except astroid.TooManyLevelsError:
+ if _ignore_import_failure(importnode, modname, self._ignored_modules):
+ return None
+ self.add_message("relative-beyond-top-level", node=importnode)
+ except astroid.AstroidSyntaxError as exc:
+ message = f"Cannot import {modname!r} due to '{exc.error}'"
+ self.add_message(
+ "syntax-error", line=importnode.lineno, args=message, confidence=HIGH
+ )
+
+ except astroid.AstroidBuildingError:
+ if not self.linter.is_message_enabled("import-error"):
+ return None
+ if _ignore_import_failure(importnode, modname, self._ignored_modules):
+ return None
+ if (
+ not self.linter.config.analyse_fallback_blocks
+ and is_from_fallback_block(importnode)
+ ):
+ return None
+
+ dotted_modname = get_import_name(importnode, modname)
+ self.add_message("import-error", args=repr(dotted_modname), node=importnode)
+ except Exception as e: # pragma: no cover
+ raise astroid.AstroidError from e
+ return None
+
+ def _add_imported_module(self, node: ImportNode, importedmodname: str) -> None:
+ """Notify an imported module, used to analyze dependencies."""
+ module_file = node.root().file
+ context_name = node.root().name
+ base = os.path.splitext(os.path.basename(module_file))[0]
+
+ try:
+ if isinstance(node, nodes.ImportFrom) and node.level:
+ importedmodname = astroid.modutils.get_module_part(
+ importedmodname, module_file
+ )
+ else:
+ importedmodname = astroid.modutils.get_module_part(importedmodname)
+ except ImportError:
+ pass
+
+ if context_name == importedmodname:
+ self.add_message("import-self", node=node)
+
+ elif not astroid.modutils.is_stdlib_module(importedmodname):
+ # if this is not a package __init__ module
+ if base != "__init__" and context_name not in self._module_pkg:
+ # record the module's parent, or the module itself if this is
+ # a top level module, as the package it belongs to
+ self._module_pkg[context_name] = context_name.rsplit(".", 1)[0]
+
+ # handle dependencies
+ dependencies_stat: dict[str, set[str]] = self.linter.stats.dependencies
+ importedmodnames = dependencies_stat.setdefault(importedmodname, set())
+ if context_name not in importedmodnames:
+ importedmodnames.add(context_name)
+
+ # update import graph
+ self.import_graph[context_name].add(importedmodname)
+ if not self.linter.is_message_enabled(
+ "cyclic-import", line=node.lineno
+ ) or in_type_checking_block(node):
+ self._excluded_edges[context_name].add(importedmodname)
+
+ def _check_preferred_module(self, node: ImportNode, mod_path: str) -> None:
+ """Check if the module has a preferred replacement."""
+ mod_compare = [mod_path]
+ # build a comparison list of possible names using importfrom
+ if isinstance(node, astroid.nodes.node_classes.ImportFrom):
+ mod_compare = [f"{node.modname}.{name[0]}" for name in node.names]
+
+ # find whether there are matches with the import vs preferred_modules keys
+ matches = [
+ k
+ for k in self.preferred_modules
+ for mod in mod_compare
+ # exact match
+ if k == mod
+ # checks for base module matches
+ or k in mod.split(".")[0]
+ ]
+
+ # if we have matches, add message
+ if matches:
+ self.add_message(
+ "preferred-module",
+ node=node,
+ args=(self.preferred_modules[matches[0]], matches[0]),
+ )
+
+ def _check_import_as_rename(self, node: ImportNode) -> None:
+ names = node.names
+ for name in names:
+ if not all(name):
+ return
+
+ splitted_packages = name[0].rsplit(".", maxsplit=1)
+ import_name = splitted_packages[-1]
+ aliased_name = name[1]
+ if import_name != aliased_name:
+ continue
+
+ if len(splitted_packages) == 1 and (
+ self._allow_reexport_package is False
+ or self._current_module_package is False
+ ):
+ self.add_message("useless-import-alias", node=node, confidence=HIGH)
+ elif len(splitted_packages) == 2:
+ self.add_message(
+ "consider-using-from-import",
+ node=node,
+ args=(splitted_packages[0], import_name),
+ )
+
+ def _check_reimport(
+ self,
+ node: ImportNode,
+ basename: str | None = None,
+ level: int | None = None,
+ ) -> None:
+ """Check if a module with the same name is already imported or aliased."""
+ if not self.linter.is_message_enabled(
+ "reimported"
+ ) and not self.linter.is_message_enabled("shadowed-import"):
+ return
+
+ frame = node.frame()
+ root = node.root()
+ contexts = [(frame, level)]
+ if root is not frame:
+ contexts.append((root, None))
+
+ for known_context, known_level in contexts:
+ for name, alias in node.names:
+ first, msg = _get_first_import(
+ node, known_context, name, basename, known_level, alias
+ )
+ if first is not None and msg is not None:
+ name = name if msg == "reimported" else alias
+ self.add_message(
+ msg, node=node, args=(name, first.fromlineno), confidence=HIGH
+ )
+
+ def _report_external_dependencies(
+ self, sect: Section, _: LinterStats, _dummy: LinterStats | None
+ ) -> None:
+ """Return a verbatim layout for displaying dependencies."""
+ dep_info = _make_tree_defs(self._external_dependencies_info.items())
+ if not dep_info:
+ raise EmptyReportError()
+ tree_str = _repr_tree_defs(dep_info)
+ sect.append(VerbatimText(tree_str))
+
+ def _report_dependencies_graph(
+ self, sect: Section, _: LinterStats, _dummy: LinterStats | None
+ ) -> None:
+ """Write dependencies as a dot (graphviz) file."""
+ dep_info = self.linter.stats.dependencies
+ if not dep_info or not (
+ self.linter.config.import_graph
+ or self.linter.config.ext_import_graph
+ or self.linter.config.int_import_graph
+ ):
+ raise EmptyReportError()
+ filename = self.linter.config.import_graph
+ if filename:
+ _make_graph(filename, dep_info, sect, "")
+ filename = self.linter.config.ext_import_graph
+ if filename:
+ _make_graph(filename, self._external_dependencies_info, sect, "external ")
+ filename = self.linter.config.int_import_graph
+ if filename:
+ _make_graph(filename, self._internal_dependencies_info, sect, "internal ")
+
+ def _filter_dependencies_graph(self, internal: bool) -> defaultdict[str, set[str]]:
+ """Build the internal or the external dependency graph."""
+ graph: defaultdict[str, set[str]] = defaultdict(set)
+ for importee, importers in self.linter.stats.dependencies.items():
+ for importer in importers:
+ package = self._module_pkg.get(importer, importer)
+ is_inside = importee.startswith(package)
+ if is_inside and internal or not is_inside and not internal:
+ graph[importee].add(importer)
+ return graph
+
+ @cached_property
+ def _external_dependencies_info(self) -> defaultdict[str, set[str]]:
+ """Return cached external dependencies information or build and
+ cache them.
+ """
+ return self._filter_dependencies_graph(internal=False)
+
+ @cached_property
+ def _internal_dependencies_info(self) -> defaultdict[str, set[str]]:
+ """Return cached internal dependencies information or build and
+ cache them.
+ """
+ return self._filter_dependencies_graph(internal=True)
+
+ def _check_wildcard_imports(
+ self, node: nodes.ImportFrom, imported_module: nodes.Module | None
+ ) -> None:
+ if node.root().package:
+ # Skip the check if in __init__.py issue #2026
+ return
+
+ wildcard_import_is_allowed = self._wildcard_import_is_allowed(imported_module)
+ for name, _ in node.names:
+ if name == "*" and not wildcard_import_is_allowed:
+ self.add_message("wildcard-import", args=node.modname, node=node)
+
+ def _wildcard_import_is_allowed(self, imported_module: nodes.Module | None) -> bool:
+ return (
+ self.linter.config.allow_wildcard_with_all
+ and imported_module is not None
+ and "__all__" in imported_module.locals
+ )
+
+ def _check_toplevel(self, node: ImportNode) -> None:
+ """Check whether the import is made outside the module toplevel."""
+ # If the scope of the import is a module, then obviously it is
+ # not outside the module toplevel.
+ if isinstance(node.scope(), nodes.Module):
+ return
+
+ module_names = [
+ (
+ f"{node.modname}.{name[0]}"
+ if isinstance(node, nodes.ImportFrom)
+ else name[0]
+ )
+ for name in node.names
+ ]
+
+ # Get the full names of all the imports that are only allowed at the module level
+ scoped_imports = [
+ name for name in module_names if name not in self._allow_any_import_level
+ ]
+
+ if scoped_imports:
+ self.add_message(
+ "import-outside-toplevel", args=", ".join(scoped_imports), node=node
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ImportsChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/lambda_expressions.py b/solutions/.venv/Lib/site-packages/pylint/checkers/lambda_expressions.py
new file mode 100644
index 000000000..18c03060d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/lambda_expressions.py
@@ -0,0 +1,93 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from itertools import zip_longest
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class LambdaExpressionChecker(BaseChecker):
+ """Check for unnecessary usage of lambda expressions."""
+
+ name = "lambda-expressions"
+ msgs = {
+ "C3001": (
+ "Lambda expression assigned to a variable. "
+ 'Define a function using the "def" keyword instead.',
+ "unnecessary-lambda-assignment",
+ "Used when a lambda expression is assigned to variable "
+ 'rather than defining a standard function with the "def" keyword.',
+ ),
+ "C3002": (
+ "Lambda expression called directly. Execute the expression inline instead.",
+ "unnecessary-direct-lambda-call",
+ "Used when a lambda expression is directly called "
+ "rather than executing its contents inline.",
+ ),
+ }
+ options = ()
+
+ def visit_assign(self, node: nodes.Assign) -> None:
+ """Check if lambda expression is assigned to a variable."""
+ if isinstance(node.targets[0], nodes.AssignName) and isinstance(
+ node.value, nodes.Lambda
+ ):
+ self.add_message(
+ "unnecessary-lambda-assignment",
+ node=node.value,
+ confidence=HIGH,
+ )
+ elif isinstance(node.targets[0], nodes.Tuple) and isinstance(
+ node.value, (nodes.Tuple, nodes.List)
+ ):
+ # Iterate over tuple unpacking assignment elements and
+ # see if any lambdas are assigned to a variable.
+ # N.B. We may encounter W0632 (unbalanced-tuple-unpacking)
+ # and still need to flag the lambdas that are being assigned.
+ for lhs_elem, rhs_elem in zip_longest(
+ node.targets[0].elts, node.value.elts
+ ):
+ if lhs_elem is None or rhs_elem is None:
+ # unbalanced tuple unpacking. stop checking.
+ break
+ if isinstance(lhs_elem, nodes.AssignName) and isinstance(
+ rhs_elem, nodes.Lambda
+ ):
+ self.add_message(
+ "unnecessary-lambda-assignment",
+ node=rhs_elem,
+ confidence=HIGH,
+ )
+
+ def visit_namedexpr(self, node: nodes.NamedExpr) -> None:
+ if isinstance(node.target, nodes.AssignName) and isinstance(
+ node.value, nodes.Lambda
+ ):
+ self.add_message(
+ "unnecessary-lambda-assignment",
+ node=node.value,
+ confidence=HIGH,
+ )
+
+ def visit_call(self, node: nodes.Call) -> None:
+ """Check if lambda expression is called directly."""
+ if isinstance(node.func, nodes.Lambda):
+ self.add_message(
+ "unnecessary-direct-lambda-call",
+ node=node,
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(LambdaExpressionChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/logging.py b/solutions/.venv/Lib/site-packages/pylint/checkers/logging.py
new file mode 100644
index 000000000..d057c78ec
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/logging.py
@@ -0,0 +1,423 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checker for use of Python logging."""
+
+from __future__ import annotations
+
+import string
+from typing import TYPE_CHECKING, Literal
+
+import astroid
+from astroid import bases, nodes
+from astroid.typing import InferenceResult
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.checkers.utils import infer_all
+from pylint.interfaces import HIGH
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+MSGS: dict[str, MessageDefinitionTuple] = (
+ { # pylint: disable=consider-using-namedtuple-or-dataclass
+ "W1201": (
+ "Use %s formatting in logging functions",
+ "logging-not-lazy",
+ "Used when a logging statement has a call form of "
+ '"logging.<logging method>(format_string % (format_args...))". '
+ "Use another type of string formatting instead. "
+ "You can use % formatting but leave interpolation to "
+ "the logging function by passing the parameters as arguments. "
+ "If logging-fstring-interpolation is disabled then "
+ "you can use fstring formatting. "
+ "If logging-format-interpolation is disabled then "
+ "you can use str.format.",
+ ),
+ "W1202": (
+ "Use %s formatting in logging functions",
+ "logging-format-interpolation",
+ "Used when a logging statement has a call form of "
+ '"logging.<logging method>(format_string.format(format_args...))". '
+ "Use another type of string formatting instead. "
+ "You can use % formatting but leave interpolation to "
+ "the logging function by passing the parameters as arguments. "
+ "If logging-fstring-interpolation is disabled then "
+ "you can use fstring formatting. "
+ "If logging-not-lazy is disabled then "
+ "you can use % formatting as normal.",
+ ),
+ "W1203": (
+ "Use %s formatting in logging functions",
+ "logging-fstring-interpolation",
+ "Used when a logging statement has a call form of "
+ '"logging.<logging method>(f"...")".'
+ "Use another type of string formatting instead. "
+ "You can use % formatting but leave interpolation to "
+ "the logging function by passing the parameters as arguments. "
+ "If logging-format-interpolation is disabled then "
+ "you can use str.format. "
+ "If logging-not-lazy is disabled then "
+ "you can use % formatting as normal.",
+ ),
+ "E1200": (
+ "Unsupported logging format character %r (%#02x) at index %d",
+ "logging-unsupported-format",
+ "Used when an unsupported format character is used in a logging "
+ "statement format string.",
+ ),
+ "E1201": (
+ "Logging format string ends in middle of conversion specifier",
+ "logging-format-truncated",
+ "Used when a logging statement format string terminates before "
+ "the end of a conversion specifier.",
+ ),
+ "E1205": (
+ "Too many arguments for logging format string",
+ "logging-too-many-args",
+ "Used when a logging format string is given too many arguments.",
+ ),
+ "E1206": (
+ "Not enough arguments for logging format string",
+ "logging-too-few-args",
+ "Used when a logging format string is given too few arguments.",
+ ),
+ }
+)
+
+
+CHECKED_CONVENIENCE_FUNCTIONS = {
+ "critical",
+ "debug",
+ "error",
+ "exception",
+ "fatal",
+ "info",
+ "warn",
+ "warning",
+}
+
+MOST_COMMON_FORMATTING = frozenset(["%s", "%d", "%f", "%r"])
+
+
+def is_method_call(
+ func: bases.BoundMethod, types: tuple[str, ...] = (), methods: tuple[str, ...] = ()
+) -> bool:
+ """Determines if a BoundMethod node represents a method call.
+
+ Args:
+ func: The BoundMethod AST node to check.
+ types: Optional sequence of caller type names to restrict check.
+ methods: Optional sequence of method names to restrict check.
+
+ Returns:
+ true if the node represents a method call for the given type and
+ method names, False otherwise.
+ """
+ return (
+ isinstance(func, astroid.BoundMethod)
+ and isinstance(func.bound, astroid.Instance)
+ and (func.bound.name in types if types else True)
+ and (func.name in methods if methods else True)
+ )
+
+
+class LoggingChecker(checkers.BaseChecker):
+ """Checks use of the logging module."""
+
+ name = "logging"
+ msgs = MSGS
+
+ options = (
+ (
+ "logging-modules",
+ {
+ "default": ("logging",),
+ "type": "csv",
+ "metavar": "<comma separated list>",
+ "help": "Logging modules to check that the string format "
+ "arguments are in logging function parameter format.",
+ },
+ ),
+ (
+ "logging-format-style",
+ {
+ "default": "old",
+ "type": "choice",
+ "metavar": "<old (%) or new ({)>",
+ "choices": ["old", "new"],
+ "help": "The type of string formatting that logging methods do. "
+ "`old` means using % formatting, `new` is for `{}` formatting.",
+ },
+ ),
+ )
+
+ def visit_module(self, _: nodes.Module) -> None:
+ """Clears any state left in this checker from last module checked."""
+ # The code being checked can just as easily "import logging as foo",
+ # so it is necessary to process the imports and store in this field
+ # what name the logging module is actually given.
+ self._logging_names: set[str] = set()
+ logging_mods = self.linter.config.logging_modules
+
+ self._format_style = self.linter.config.logging_format_style
+
+ self._logging_modules = set(logging_mods)
+ self._from_imports = {}
+ for logging_mod in logging_mods:
+ parts = logging_mod.rsplit(".", 1)
+ if len(parts) > 1:
+ self._from_imports[parts[0]] = parts[1]
+
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ """Checks to see if a module uses a non-Python logging module."""
+ try:
+ logging_name = self._from_imports[node.modname]
+ for module, as_name in node.names:
+ if module == logging_name:
+ self._logging_names.add(as_name or module)
+ except KeyError:
+ pass
+
+ def visit_import(self, node: nodes.Import) -> None:
+ """Checks to see if this module uses Python's built-in logging."""
+ for module, as_name in node.names:
+ if module in self._logging_modules:
+ self._logging_names.add(as_name or module)
+
+ def visit_call(self, node: nodes.Call) -> None:
+ """Checks calls to logging methods."""
+
+ def is_logging_name() -> bool:
+ return (
+ isinstance(node.func, nodes.Attribute)
+ and isinstance(node.func.expr, nodes.Name)
+ and node.func.expr.name in self._logging_names
+ )
+
+ def is_logger_class() -> tuple[bool, str | None]:
+ for inferred in infer_all(node.func):
+ if isinstance(inferred, astroid.BoundMethod):
+ parent = inferred._proxied.parent
+ if isinstance(parent, nodes.ClassDef) and (
+ parent.qname() == "logging.Logger"
+ or any(
+ ancestor.qname() == "logging.Logger"
+ for ancestor in parent.ancestors()
+ )
+ ):
+ return True, inferred._proxied.name
+ return False, None
+
+ if is_logging_name():
+ name = node.func.attrname
+ else:
+ result, name = is_logger_class()
+ if not result:
+ return
+ self._check_log_method(node, name)
+
+ def _check_log_method(self, node: nodes.Call, name: str) -> None:
+ """Checks calls to logging.log(level, format, *format_args)."""
+ if name == "log":
+ if node.starargs or node.kwargs or len(node.args) < 2:
+ # Either a malformed call, star args, or double-star args. Beyond
+ # the scope of this checker.
+ return
+ format_pos: Literal[0, 1] = 1
+ elif name in CHECKED_CONVENIENCE_FUNCTIONS:
+ if node.starargs or node.kwargs or not node.args:
+ # Either no args, star args, or double-star args. Beyond the
+ # scope of this checker.
+ return
+ format_pos = 0
+ else:
+ return
+
+ format_arg = node.args[format_pos]
+ if isinstance(format_arg, nodes.BinOp):
+ binop = format_arg
+ emit = binop.op == "%"
+ if binop.op == "+" and not self._is_node_explicit_str_concatenation(binop):
+ total_number_of_strings = sum(
+ 1
+ for operand in (binop.left, binop.right)
+ if self._is_operand_literal_str(utils.safe_infer(operand))
+ )
+ emit = total_number_of_strings > 0
+ if emit:
+ self.add_message(
+ "logging-not-lazy",
+ node=node,
+ args=(self._helper_string(node),),
+ )
+ elif isinstance(format_arg, nodes.Call):
+ self._check_call_func(format_arg)
+ elif isinstance(format_arg, nodes.Const):
+ self._check_format_string(node, format_pos)
+ elif isinstance(format_arg, nodes.JoinedStr):
+ if str_formatting_in_f_string(format_arg):
+ return
+ self.add_message(
+ "logging-fstring-interpolation",
+ node=node,
+ args=(self._helper_string(node),),
+ )
+
+ def _helper_string(self, node: nodes.Call) -> str:
+ """Create a string that lists the valid types of formatting for this node."""
+ valid_types = ["lazy %"]
+
+ if not self.linter.is_message_enabled(
+ "logging-fstring-formatting", node.fromlineno
+ ):
+ valid_types.append("fstring")
+ if not self.linter.is_message_enabled(
+ "logging-format-interpolation", node.fromlineno
+ ):
+ valid_types.append(".format()")
+ if not self.linter.is_message_enabled("logging-not-lazy", node.fromlineno):
+ valid_types.append("%")
+
+ return " or ".join(valid_types)
+
+ @staticmethod
+ def _is_operand_literal_str(operand: InferenceResult | None) -> bool:
+ """Return True if the operand in argument is a literal string."""
+ return isinstance(operand, nodes.Const) and operand.name == "str"
+
+ @staticmethod
+ def _is_node_explicit_str_concatenation(node: nodes.NodeNG) -> bool:
+ """Return True if the node represents an explicitly concatenated string."""
+ if not isinstance(node, nodes.BinOp):
+ return False
+ return (
+ LoggingChecker._is_operand_literal_str(node.left)
+ or LoggingChecker._is_node_explicit_str_concatenation(node.left)
+ ) and (
+ LoggingChecker._is_operand_literal_str(node.right)
+ or LoggingChecker._is_node_explicit_str_concatenation(node.right)
+ )
+
+ def _check_call_func(self, node: nodes.Call) -> None:
+ """Checks that function call is not format_string.format()."""
+ func = utils.safe_infer(node.func)
+ types = ("str", "unicode")
+ methods = ("format",)
+ if (
+ isinstance(func, astroid.BoundMethod)
+ and is_method_call(func, types, methods)
+ and not is_complex_format_str(func.bound)
+ ):
+ self.add_message(
+ "logging-format-interpolation",
+ node=node,
+ args=(self._helper_string(node),),
+ )
+
+ def _check_format_string(self, node: nodes.Call, format_arg: Literal[0, 1]) -> None:
+ """Checks that format string tokens match the supplied arguments.
+
+ Args:
+ node: AST node to be checked.
+ format_arg: Index of the format string in the node arguments.
+ """
+ num_args = _count_supplied_tokens(node.args[format_arg + 1 :])
+ if not num_args:
+ # If no args were supplied the string is not interpolated and can contain
+ # formatting characters - it's used verbatim. Don't check any further.
+ return
+
+ format_string = node.args[format_arg].value
+ required_num_args = 0
+ if isinstance(format_string, bytes):
+ format_string = format_string.decode()
+ if isinstance(format_string, str):
+ try:
+ if self._format_style == "old":
+ keyword_args, required_num_args, _, _ = utils.parse_format_string(
+ format_string
+ )
+ if keyword_args:
+ # Keyword checking on logging strings is complicated by
+ # special keywords - out of scope.
+ return
+ elif self._format_style == "new":
+ (
+ keyword_arguments,
+ implicit_pos_args,
+ explicit_pos_args,
+ ) = utils.parse_format_method_string(format_string)
+
+ keyword_args_cnt = len(
+ {k for k, _ in keyword_arguments if not isinstance(k, int)}
+ )
+ required_num_args = (
+ keyword_args_cnt + implicit_pos_args + explicit_pos_args
+ )
+ except utils.UnsupportedFormatCharacter as ex:
+ char = format_string[ex.index]
+ self.add_message(
+ "logging-unsupported-format",
+ node=node,
+ args=(char, ord(char), ex.index),
+ )
+ return
+ except utils.IncompleteFormatString:
+ self.add_message("logging-format-truncated", node=node)
+ return
+ if num_args > required_num_args:
+ self.add_message("logging-too-many-args", node=node, confidence=HIGH)
+ elif num_args < required_num_args:
+ self.add_message("logging-too-few-args", node=node)
+
+
+def is_complex_format_str(node: nodes.NodeNG) -> bool:
+ """Return whether the node represents a string with complex formatting specs."""
+ inferred = utils.safe_infer(node)
+ if inferred is None or not (
+ isinstance(inferred, nodes.Const) and isinstance(inferred.value, str)
+ ):
+ return True
+ try:
+ parsed = list(string.Formatter().parse(inferred.value))
+ except ValueError:
+ # This format string is invalid
+ return False
+ return any(format_spec for (_, _, format_spec, _) in parsed)
+
+
+def _count_supplied_tokens(args: list[nodes.NodeNG]) -> int:
+ """Counts the number of tokens in an args list.
+
+ The Python log functions allow for special keyword arguments: func,
+ exc_info and extra. To handle these cases correctly, we only count
+ arguments that aren't keywords.
+
+ Args:
+ args: AST nodes that are arguments for a log format string.
+
+ Returns:
+ Number of AST nodes that aren't keywords.
+ """
+ return sum(1 for arg in args if not isinstance(arg, nodes.Keyword))
+
+
+def str_formatting_in_f_string(node: nodes.JoinedStr) -> bool:
+ """Determine whether the node represents an f-string with string formatting.
+
+ For example: `f'Hello %s'`
+ """
+ # Check "%" presence first for performance.
+ return any(
+ "%" in val.value and any(x in val.value for x in MOST_COMMON_FORMATTING)
+ for val in node.values
+ if isinstance(val, nodes.Const)
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(LoggingChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/method_args.py b/solutions/.venv/Lib/site-packages/pylint/checkers/method_args.py
new file mode 100644
index 000000000..565309d28
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/method_args.py
@@ -0,0 +1,129 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Variables checkers for Python code."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+import astroid
+from astroid import arguments, bases, nodes
+
+from pylint.checkers import BaseChecker, utils
+from pylint.interfaces import INFERENCE
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class MethodArgsChecker(BaseChecker):
+ """BaseChecker for method_args.
+
+ Checks for
+ * missing-timeout
+ * positional-only-arguments-expected
+ """
+
+ name = "method_args"
+ msgs = {
+ "W3101": (
+ "Missing timeout argument for method '%s' can cause your program to hang indefinitely",
+ "missing-timeout",
+ "Used when a method needs a 'timeout' parameter in order to avoid waiting "
+ "for a long time. If no timeout is specified explicitly the default value "
+ "is used. For example for 'requests' the program will never time out "
+ "(i.e. hang indefinitely).",
+ ),
+ "E3102": (
+ "`%s()` got some positional-only arguments passed as keyword arguments: %s",
+ "positional-only-arguments-expected",
+ "Emitted when positional-only arguments have been passed as keyword arguments. "
+ "Remove the keywords for the affected arguments in the function call.",
+ ),
+ }
+ options = (
+ (
+ "timeout-methods",
+ {
+ "default": (
+ "requests.api.delete",
+ "requests.api.get",
+ "requests.api.head",
+ "requests.api.options",
+ "requests.api.patch",
+ "requests.api.post",
+ "requests.api.put",
+ "requests.api.request",
+ ),
+ "type": "csv",
+ "metavar": "<comma separated list>",
+ "help": "List of qualified names (i.e., library.method) which require a timeout parameter "
+ "e.g. 'requests.api.get,requests.api.post'",
+ },
+ ),
+ )
+
+ @utils.only_required_for_messages(
+ "missing-timeout", "positional-only-arguments-expected"
+ )
+ def visit_call(self, node: nodes.Call) -> None:
+ self._check_missing_timeout(node)
+ self._check_positional_only_arguments_expected(node)
+
+ def _check_missing_timeout(self, node: nodes.Call) -> None:
+ """Check if the call needs a timeout parameter based on package.func_name
+ configured in config.timeout_methods.
+
+ Package uses inferred node in order to know the package imported.
+ """
+ inferred = utils.safe_infer(node.func)
+ call_site = arguments.CallSite.from_call(node)
+ if (
+ inferred
+ and not call_site.has_invalid_keywords()
+ and isinstance(
+ inferred, (nodes.FunctionDef, nodes.ClassDef, bases.UnboundMethod)
+ )
+ and inferred.qname() in self.linter.config.timeout_methods
+ ):
+ keyword_arguments = [keyword.arg for keyword in node.keywords]
+ keyword_arguments.extend(call_site.keyword_arguments)
+ if "timeout" not in keyword_arguments:
+ self.add_message(
+ "missing-timeout",
+ node=node,
+ args=(node.func.as_string(),),
+ confidence=INFERENCE,
+ )
+
+ def _check_positional_only_arguments_expected(self, node: nodes.Call) -> None:
+ """Check if positional only arguments have been passed as keyword arguments by
+ inspecting its method definition.
+ """
+ inferred_func = utils.safe_infer(node.func)
+ while isinstance(inferred_func, (astroid.BoundMethod, astroid.UnboundMethod)):
+ inferred_func = inferred_func._proxied
+ if not (
+ isinstance(inferred_func, (nodes.FunctionDef))
+ and inferred_func.args.posonlyargs
+ ):
+ return
+ if inferred_func.args.kwarg:
+ return
+ pos_args = [a.name for a in inferred_func.args.posonlyargs]
+ kws = [k.arg for k in node.keywords if k.arg in pos_args]
+ if not kws:
+ return
+
+ self.add_message(
+ "positional-only-arguments-expected",
+ node=node,
+ args=(node.func.as_string(), ", ".join(f"'{k}'" for k in kws)),
+ confidence=INFERENCE,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(MethodArgsChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/misc.py b/solutions/.venv/Lib/site-packages/pylint/checkers/misc.py
new file mode 100644
index 000000000..78c21d0c5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/misc.py
@@ -0,0 +1,150 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check source code is ascii only or has an encoding declaration (PEP 263)."""
+
+from __future__ import annotations
+
+import re
+import tokenize
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseRawFileChecker, BaseTokenChecker
+from pylint.typing import ManagedMessage
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class ByIdManagedMessagesChecker(BaseRawFileChecker):
+ """Checks for messages that are enabled or disabled by id instead of symbol."""
+
+ name = "miscellaneous"
+ msgs = {
+ "I0023": (
+ "%s",
+ "use-symbolic-message-instead",
+ "Used when a message is enabled or disabled by id.",
+ {"default_enabled": False},
+ )
+ }
+ options = ()
+
+ def _clear_by_id_managed_msgs(self) -> None:
+ self.linter._by_id_managed_msgs.clear()
+
+ def _get_by_id_managed_msgs(self) -> list[ManagedMessage]:
+ return self.linter._by_id_managed_msgs
+
+ def process_module(self, node: nodes.Module) -> None:
+ """Inspect the source file to find messages activated or deactivated by id."""
+ managed_msgs = self._get_by_id_managed_msgs()
+ for mod_name, msgid, symbol, lineno, is_disabled in managed_msgs:
+ if mod_name == node.name:
+ verb = "disable" if is_disabled else "enable"
+ txt = f"'{msgid}' is cryptic: use '# pylint: {verb}={symbol}' instead"
+ self.add_message("use-symbolic-message-instead", line=lineno, args=txt)
+ self._clear_by_id_managed_msgs()
+
+
+class EncodingChecker(BaseTokenChecker, BaseRawFileChecker):
+ """BaseChecker for encoding issues.
+
+ Checks for:
+ * warning notes in the code like FIXME, XXX
+ * encoding issues.
+ """
+
+ # configuration section name
+ name = "miscellaneous"
+ msgs = {
+ "W0511": (
+ "%s",
+ "fixme",
+ "Used when a warning note as FIXME or XXX is detected.",
+ )
+ }
+
+ options = (
+ (
+ "notes",
+ {
+ "type": "csv",
+ "metavar": "<comma separated values>",
+ "default": ("FIXME", "XXX", "TODO"),
+ "help": (
+ "List of note tags to take in consideration, "
+ "separated by a comma."
+ ),
+ },
+ ),
+ (
+ "notes-rgx",
+ {
+ "type": "string",
+ "metavar": "<regexp>",
+ "help": "Regular expression of note tags to take in consideration.",
+ "default": "",
+ },
+ ),
+ )
+
+ def open(self) -> None:
+ super().open()
+
+ notes = "|".join(re.escape(note) for note in self.linter.config.notes)
+ if self.linter.config.notes_rgx:
+ regex_string = rf"#\s*({notes}|{self.linter.config.notes_rgx})(?=(:|\s|\Z))"
+ else:
+ regex_string = rf"#\s*({notes})(?=(:|\s|\Z))"
+
+ self._fixme_pattern = re.compile(regex_string, re.I)
+
+ def _check_encoding(
+ self, lineno: int, line: bytes, file_encoding: str
+ ) -> str | None:
+ try:
+ return line.decode(file_encoding)
+ except UnicodeDecodeError:
+ pass
+ except LookupError:
+ if (
+ line.startswith(b"#")
+ and "coding" in str(line)
+ and file_encoding in str(line)
+ ):
+ msg = f"Cannot decode using encoding '{file_encoding}', bad encoding"
+ self.add_message("syntax-error", line=lineno, args=msg)
+ return None
+
+ def process_module(self, node: nodes.Module) -> None:
+ """Inspect the source file to find encoding problem."""
+ encoding = node.file_encoding if node.file_encoding else "ascii"
+
+ with node.stream() as stream:
+ for lineno, line in enumerate(stream):
+ self._check_encoding(lineno + 1, line, encoding)
+
+ def process_tokens(self, tokens: list[tokenize.TokenInfo]) -> None:
+ """Inspect the source to find fixme problems."""
+ if not self.linter.config.notes:
+ return
+ for token_info in tokens:
+ if token_info.type != tokenize.COMMENT:
+ continue
+ comment_text = token_info.string[1:].lstrip() # trim '#' and white-spaces
+ if self._fixme_pattern.search("#" + comment_text.lower()):
+ self.add_message(
+ "fixme",
+ col_offset=token_info.start[1] + 1,
+ args=comment_text,
+ line=token_info.start[0],
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(EncodingChecker(linter))
+ linter.register_checker(ByIdManagedMessagesChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/modified_iterating_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/modified_iterating_checker.py
new file mode 100644
index 000000000..be8d967ab
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/modified_iterating_checker.py
@@ -0,0 +1,200 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint import checkers, interfaces
+from pylint.checkers import utils
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+_LIST_MODIFIER_METHODS = {"append", "remove"}
+_SET_MODIFIER_METHODS = {"add", "clear", "discard", "pop", "remove"}
+
+
+class ModifiedIterationChecker(checkers.BaseChecker):
+ """Checks for modified iterators in for loops iterations.
+
+ Currently supports `for` loops for Sets, Dictionaries and Lists.
+ """
+
+ name = "modified_iteration"
+
+ msgs = {
+ "W4701": (
+ "Iterated list '%s' is being modified inside for loop body, consider iterating through a copy of it "
+ "instead.",
+ "modified-iterating-list",
+ "Emitted when items are added or removed to a list being iterated through. "
+ "Doing so can result in unexpected behaviour, that is why it is preferred to use a copy of the list.",
+ ),
+ "E4702": (
+ "Iterated dict '%s' is being modified inside for loop body, iterate through a copy of it instead.",
+ "modified-iterating-dict",
+ "Emitted when items are added or removed to a dict being iterated through. "
+ "Doing so raises a RuntimeError.",
+ ),
+ "E4703": (
+ "Iterated set '%s' is being modified inside for loop body, iterate through a copy of it instead.",
+ "modified-iterating-set",
+ "Emitted when items are added or removed to a set being iterated through. "
+ "Doing so raises a RuntimeError.",
+ ),
+ }
+
+ options = ()
+
+ @utils.only_required_for_messages(
+ "modified-iterating-list", "modified-iterating-dict", "modified-iterating-set"
+ )
+ def visit_for(self, node: nodes.For) -> None:
+ iter_obj = node.iter
+ for body_node in node.body:
+ self._modified_iterating_check_on_node_and_children(body_node, iter_obj)
+
+ def _modified_iterating_check_on_node_and_children(
+ self, body_node: nodes.NodeNG, iter_obj: nodes.NodeNG
+ ) -> None:
+ """See if node or any of its children raises modified iterating messages."""
+ self._modified_iterating_check(body_node, iter_obj)
+ for child in body_node.get_children():
+ self._modified_iterating_check_on_node_and_children(child, iter_obj)
+
+ def _modified_iterating_check(
+ self, node: nodes.NodeNG, iter_obj: nodes.NodeNG
+ ) -> None:
+ msg_id = None
+ if isinstance(node, nodes.Delete) and any(
+ self._deleted_iteration_target_cond(t, iter_obj) for t in node.targets
+ ):
+ inferred = utils.safe_infer(iter_obj)
+ if isinstance(inferred, nodes.List):
+ msg_id = "modified-iterating-list"
+ elif isinstance(inferred, nodes.Dict):
+ msg_id = "modified-iterating-dict"
+ elif isinstance(inferred, nodes.Set):
+ msg_id = "modified-iterating-set"
+ elif not isinstance(iter_obj, (nodes.Name, nodes.Attribute)):
+ pass
+ elif self._modified_iterating_list_cond(node, iter_obj):
+ msg_id = "modified-iterating-list"
+ elif self._modified_iterating_dict_cond(node, iter_obj):
+ msg_id = "modified-iterating-dict"
+ elif self._modified_iterating_set_cond(node, iter_obj):
+ msg_id = "modified-iterating-set"
+ if msg_id:
+ self.add_message(
+ msg_id,
+ node=node,
+ args=(iter_obj.repr_name(),),
+ confidence=interfaces.INFERENCE,
+ )
+
+ @staticmethod
+ def _is_node_expr_that_calls_attribute_name(node: nodes.NodeNG) -> bool:
+ return (
+ isinstance(node, nodes.Expr)
+ and isinstance(node.value, nodes.Call)
+ and isinstance(node.value.func, nodes.Attribute)
+ and isinstance(node.value.func.expr, nodes.Name)
+ )
+
+ @staticmethod
+ def _common_cond_list_set(
+ node: nodes.Expr,
+ iter_obj: nodes.Name | nodes.Attribute,
+ infer_val: nodes.List | nodes.Set,
+ ) -> bool:
+ iter_obj_name = (
+ iter_obj.attrname
+ if isinstance(iter_obj, nodes.Attribute)
+ else iter_obj.name
+ )
+ return (infer_val == utils.safe_infer(iter_obj)) and ( # type: ignore[no-any-return]
+ node.value.func.expr.name == iter_obj_name
+ )
+
+ @staticmethod
+ def _is_node_assigns_subscript_name(node: nodes.NodeNG) -> bool:
+ return isinstance(node, nodes.Assign) and (
+ isinstance(node.targets[0], nodes.Subscript)
+ and (isinstance(node.targets[0].value, nodes.Name))
+ )
+
+ def _modified_iterating_list_cond(
+ self, node: nodes.NodeNG, iter_obj: nodes.Name | nodes.Attribute
+ ) -> bool:
+ if not self._is_node_expr_that_calls_attribute_name(node):
+ return False
+ infer_val = utils.safe_infer(node.value.func.expr)
+ if not isinstance(infer_val, nodes.List):
+ return False
+ return (
+ self._common_cond_list_set(node, iter_obj, infer_val)
+ and node.value.func.attrname in _LIST_MODIFIER_METHODS
+ )
+
+ def _modified_iterating_dict_cond(
+ self, node: nodes.NodeNG, iter_obj: nodes.Name | nodes.Attribute
+ ) -> bool:
+ if not self._is_node_assigns_subscript_name(node):
+ return False
+ # Do not emit when merely updating the same key being iterated
+ if (
+ isinstance(iter_obj, nodes.Name)
+ and iter_obj.name == node.targets[0].value.name
+ and isinstance(iter_obj.parent.target, nodes.AssignName)
+ and isinstance(node.targets[0].slice, nodes.Name)
+ and iter_obj.parent.target.name == node.targets[0].slice.name
+ ):
+ return False
+ infer_val = utils.safe_infer(node.targets[0].value)
+ if not isinstance(infer_val, nodes.Dict):
+ return False
+ if infer_val != utils.safe_infer(iter_obj):
+ return False
+ if isinstance(iter_obj, nodes.Attribute):
+ iter_obj_name = iter_obj.attrname
+ else:
+ iter_obj_name = iter_obj.name
+ return node.targets[0].value.name == iter_obj_name # type: ignore[no-any-return]
+
+ def _modified_iterating_set_cond(
+ self, node: nodes.NodeNG, iter_obj: nodes.Name | nodes.Attribute
+ ) -> bool:
+ if not self._is_node_expr_that_calls_attribute_name(node):
+ return False
+ infer_val = utils.safe_infer(node.value.func.expr)
+ if not isinstance(infer_val, nodes.Set):
+ return False
+ return (
+ self._common_cond_list_set(node, iter_obj, infer_val)
+ and node.value.func.attrname in _SET_MODIFIER_METHODS
+ )
+
+ def _deleted_iteration_target_cond(
+ self, node: nodes.DelName, iter_obj: nodes.NodeNG
+ ) -> bool:
+ if not isinstance(node, nodes.DelName):
+ return False
+ if not isinstance(iter_obj.parent, nodes.For):
+ return False
+ if not isinstance(
+ iter_obj.parent.target, (nodes.AssignName, nodes.BaseContainer)
+ ):
+ return False
+ return any(
+ t == node.name
+ for t in utils.find_assigned_names_recursive(iter_obj.parent.target)
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ModifiedIterationChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/nested_min_max.py b/solutions/.venv/Lib/site-packages/pylint/checkers/nested_min_max.py
new file mode 100644
index 000000000..2a3e05459
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/nested_min_max.py
@@ -0,0 +1,167 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for use of nested min/max functions."""
+
+from __future__ import annotations
+
+import copy
+from typing import TYPE_CHECKING
+
+from astroid import nodes, objects
+from astroid.const import Context
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages, safe_infer
+from pylint.interfaces import INFERENCE
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+DICT_TYPES = (
+ objects.DictValues,
+ objects.DictKeys,
+ objects.DictItems,
+ nodes.node_classes.Dict,
+)
+
+
+class NestedMinMaxChecker(BaseChecker):
+ """Multiple nested min/max calls on the same line will raise multiple messages.
+
+ This behaviour is intended as it would slow down the checker to check
+ for nested call with minimal benefits.
+ """
+
+ FUNC_NAMES = ("builtins.min", "builtins.max")
+
+ name = "nested_min_max"
+ msgs = {
+ "W3301": (
+ "Do not use nested call of '%s'; it's possible to do '%s' instead",
+ "nested-min-max",
+ "Nested calls ``min(1, min(2, 3))`` can be rewritten as ``min(1, 2, 3)``.",
+ )
+ }
+
+ @classmethod
+ def is_min_max_call(cls, node: nodes.NodeNG) -> bool:
+ if not isinstance(node, nodes.Call):
+ return False
+
+ inferred = safe_infer(node.func)
+ return (
+ isinstance(inferred, nodes.FunctionDef)
+ and inferred.qname() in cls.FUNC_NAMES
+ )
+
+ @classmethod
+ def get_redundant_calls(cls, node: nodes.Call) -> list[nodes.Call]:
+ return [
+ arg
+ for arg in node.args
+ if (
+ cls.is_min_max_call(arg)
+ and arg.func.name == node.func.name
+ # Nesting is useful for finding the maximum in a matrix.
+ # Allow: max(max([[1, 2, 3], [4, 5, 6]]))
+ # Meaning, redundant call only if parent max call has more than 1 arg.
+ and len(arg.parent.args) > 1
+ )
+ ]
+
+ @only_required_for_messages("nested-min-max")
+ def visit_call(self, node: nodes.Call) -> None:
+ if not self.is_min_max_call(node):
+ return
+
+ redundant_calls = self.get_redundant_calls(node)
+ if not redundant_calls:
+ return
+
+ fixed_node = copy.copy(node)
+ while len(redundant_calls) > 0:
+ for i, arg in enumerate(fixed_node.args):
+ # Exclude any calls with generator expressions as there is no
+ # clear better suggestion for them.
+ if isinstance(arg, nodes.Call) and any(
+ isinstance(a, nodes.GeneratorExp) for a in arg.args
+ ):
+ return
+
+ if arg in redundant_calls:
+ fixed_node.args = (
+ fixed_node.args[:i] + arg.args + fixed_node.args[i + 1 :]
+ )
+ break
+
+ redundant_calls = self.get_redundant_calls(fixed_node)
+
+ for idx, arg in enumerate(fixed_node.args):
+ if not isinstance(arg, nodes.Const):
+ if self._is_splattable_expression(arg):
+ splat_node = nodes.Starred(
+ ctx=Context.Load,
+ lineno=arg.lineno,
+ col_offset=0,
+ parent=nodes.NodeNG(
+ lineno=None,
+ col_offset=None,
+ end_lineno=None,
+ end_col_offset=None,
+ parent=None,
+ ),
+ end_lineno=0,
+ end_col_offset=0,
+ )
+ splat_node.value = arg
+ fixed_node.args = (
+ fixed_node.args[:idx]
+ + [splat_node]
+ + fixed_node.args[idx + 1 : idx]
+ )
+
+ self.add_message(
+ "nested-min-max",
+ node=node,
+ args=(node.func.name, fixed_node.as_string()),
+ confidence=INFERENCE,
+ )
+
+ def _is_splattable_expression(self, arg: nodes.NodeNG) -> bool:
+ """Returns true if expression under min/max could be converted to splat
+ expression.
+ """
+ # Support sequence addition (operator __add__)
+ if isinstance(arg, nodes.BinOp) and arg.op == "+":
+ return self._is_splattable_expression(
+ arg.left
+ ) and self._is_splattable_expression(arg.right)
+ # Support dict merge (operator __or__)
+ if isinstance(arg, nodes.BinOp) and arg.op == "|":
+ return self._is_splattable_expression(
+ arg.left
+ ) and self._is_splattable_expression(arg.right)
+
+ inferred = safe_infer(arg)
+ if inferred and inferred.pytype() in {"builtins.list", "builtins.tuple"}:
+ return True
+ if isinstance(
+ inferred or arg,
+ (
+ nodes.List,
+ nodes.Tuple,
+ nodes.Set,
+ nodes.ListComp,
+ nodes.DictComp,
+ *DICT_TYPES,
+ ),
+ ):
+ return True
+
+ return False
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(NestedMinMaxChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/newstyle.py b/solutions/.venv/Lib/site-packages/pylint/checkers/newstyle.py
new file mode 100644
index 000000000..920c8cc41
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/newstyle.py
@@ -0,0 +1,121 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for new / old style related problems."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+import astroid
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import node_frame_class, only_required_for_messages
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "E1003": (
+ "Bad first argument %r given to super()",
+ "bad-super-call",
+ "Used when another argument than the current class is given as "
+ "first argument of the super builtin.",
+ )
+}
+
+
+class NewStyleConflictChecker(BaseChecker):
+ """Checks for usage of new style capabilities on old style classes and
+ other new/old styles conflicts problems.
+
+ * use of property, __slots__, super
+ * "super" usage
+ """
+
+ # configuration section name
+ name = "newstyle"
+ # messages
+ msgs = MSGS
+ # configuration options
+ options = ()
+
+ @only_required_for_messages("bad-super-call")
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Check use of super."""
+ # ignore actual functions or method within a new style class
+ if not node.is_method():
+ return
+ klass = node.parent.frame()
+ for stmt in node.nodes_of_class(nodes.Call):
+ if node_frame_class(stmt) != node_frame_class(node):
+ # Don't look down in other scopes.
+ continue
+
+ expr = stmt.func
+ if not isinstance(expr, nodes.Attribute):
+ continue
+
+ call = expr.expr
+ # skip the test if using super
+ if not (
+ isinstance(call, nodes.Call)
+ and isinstance(call.func, nodes.Name)
+ and call.func.name == "super"
+ ):
+ continue
+
+ # super first arg should not be the class
+ if not call.args:
+ continue
+
+ # calling super(type(self), self) can lead to recursion loop
+ # in derived classes
+ arg0 = call.args[0]
+ if (
+ isinstance(arg0, nodes.Call)
+ and isinstance(arg0.func, nodes.Name)
+ and arg0.func.name == "type"
+ ):
+ self.add_message("bad-super-call", node=call, args=("type",))
+ continue
+
+ # calling super(self.__class__, self) can lead to recursion loop
+ # in derived classes
+ if (
+ len(call.args) >= 2
+ and isinstance(call.args[1], nodes.Name)
+ and call.args[1].name == "self"
+ and isinstance(arg0, nodes.Attribute)
+ and arg0.attrname == "__class__"
+ ):
+ self.add_message("bad-super-call", node=call, args=("self.__class__",))
+ continue
+
+ try:
+ supcls = call.args and next(call.args[0].infer(), None)
+ except astroid.InferenceError:
+ continue
+
+ # If the supcls is in the ancestors of klass super can be used to skip
+ # a step in the mro() and get a method from a higher parent
+ if klass is not supcls and all(i != supcls for i in klass.ancestors()):
+ name = None
+ # if supcls is not Uninferable, then supcls was inferred
+ # and use its name. Otherwise, try to look
+ # for call.args[0].name
+ if supcls:
+ name = supcls.name
+ elif call.args and hasattr(call.args[0], "name"):
+ name = call.args[0].name
+ if name:
+ self.add_message("bad-super-call", node=call, args=(name,))
+
+ visit_asyncfunctiondef = visit_functiondef
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(NewStyleConflictChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/non_ascii_names.py b/solutions/.venv/Lib/site-packages/pylint/checkers/non_ascii_names.py
new file mode 100644
index 000000000..693d8529f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/non_ascii_names.py
@@ -0,0 +1,174 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""All alphanumeric unicode character are allowed in Python but due
+to similarities in how they look they can be confused.
+
+See: https://peps.python.org/pep-0672/#confusing-features
+
+The following checkers are intended to make users are aware of these issues.
+"""
+
+from __future__ import annotations
+
+from astroid import nodes
+
+from pylint import constants, interfaces, lint
+from pylint.checkers import base_checker, utils
+
+NON_ASCII_HELP = (
+ "Used when the name contains at least one non-ASCII unicode character. "
+ "See https://peps.python.org/pep-0672/#confusing-features"
+ " for a background why this could be bad. \n"
+ "If your programming guideline defines that you are programming in "
+ "English, then there should be no need for non ASCII characters in "
+ "Python Names. If not you can simply disable this check."
+)
+
+
+class NonAsciiNameChecker(base_checker.BaseChecker):
+ """A strict name checker only allowing ASCII.
+
+ Note: This check only checks Names, so it ignores the content of
+ docstrings and comments!
+ """
+
+ msgs = {
+ "C2401": (
+ '%s name "%s" contains a non-ASCII character, consider renaming it.',
+ "non-ascii-name",
+ NON_ASCII_HELP,
+ {"old_names": [("C0144", "old-non-ascii-name")]},
+ ),
+ # First %s will always be "file"
+ "W2402": (
+ '%s name "%s" contains a non-ASCII character.',
+ "non-ascii-file-name",
+ (
+ # Some = PyCharm at the time of writing didn't display the non_ascii_name_loł
+ # files. That's also why this is a warning and not only a convention!
+ "Under python 3.5, PEP 3131 allows non-ascii identifiers, but not non-ascii file names."
+ "Since Python 3.5, even though Python supports UTF-8 files, some editors or tools "
+ "don't."
+ ),
+ ),
+ # First %s will always be "module"
+ "C2403": (
+ '%s name "%s" contains a non-ASCII character, use an ASCII-only alias for import.',
+ "non-ascii-module-import",
+ NON_ASCII_HELP,
+ ),
+ }
+
+ name = "NonASCII-Checker"
+
+ def _check_name(self, node_type: str, name: str | None, node: nodes.NodeNG) -> None:
+ """Check whether a name is using non-ASCII characters."""
+ if name is None:
+ # For some nodes i.e. *kwargs from a dict, the name will be empty
+ return
+
+ if not str(name).isascii():
+ type_label = constants.HUMAN_READABLE_TYPES[node_type]
+ args = (type_label.capitalize(), name)
+
+ msg = "non-ascii-name"
+
+ # Some node types have customized messages
+ if node_type == "file":
+ msg = "non-ascii-file-name"
+ elif node_type == "module":
+ msg = "non-ascii-module-import"
+
+ self.add_message(msg, node=node, args=args, confidence=interfaces.HIGH)
+
+ @utils.only_required_for_messages("non-ascii-name", "non-ascii-file-name")
+ def visit_module(self, node: nodes.Module) -> None:
+ self._check_name("file", node.name.split(".")[-1], node)
+
+ @utils.only_required_for_messages("non-ascii-name")
+ def visit_functiondef(
+ self, node: nodes.FunctionDef | nodes.AsyncFunctionDef
+ ) -> None:
+ self._check_name("function", node.name, node)
+
+ # Check argument names
+ arguments = node.args
+
+ # Check position only arguments
+ if arguments.posonlyargs:
+ for pos_only_arg in arguments.posonlyargs:
+ self._check_name("argument", pos_only_arg.name, pos_only_arg)
+
+ # Check "normal" arguments
+ if arguments.args:
+ for arg in arguments.args:
+ self._check_name("argument", arg.name, arg)
+
+ # Check key word only arguments
+ if arguments.kwonlyargs:
+ for kwarg in arguments.kwonlyargs:
+ self._check_name("argument", kwarg.name, kwarg)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ @utils.only_required_for_messages("non-ascii-name")
+ def visit_global(self, node: nodes.Global) -> None:
+ for name in node.names:
+ self._check_name("const", name, node)
+
+ @utils.only_required_for_messages("non-ascii-name")
+ def visit_assignname(self, node: nodes.AssignName) -> None:
+ """Check module level assigned names."""
+ # The NameChecker from which this Checker originates knows a lot of different
+ # versions of variables, i.e. constants, inline variables etc.
+ # To simplify we use only `variable` here, as we don't need to apply different
+ # rules to different types of variables.
+ frame = node.frame()
+
+ if isinstance(frame, nodes.FunctionDef):
+ if node.parent in frame.body:
+ # Only perform the check if the assignment was done in within the body
+ # of the function (and not the function parameter definition
+ # (will be handled in visit_functiondef)
+ # or within a decorator (handled in visit_call)
+ self._check_name("variable", node.name, node)
+ elif isinstance(frame, nodes.ClassDef):
+ self._check_name("attr", node.name, node)
+ else:
+ # Possibilities here:
+ # - isinstance(node.assign_type(), nodes.Comprehension) == inlinevar
+ # - isinstance(frame, nodes.Module) == variable (constant?)
+ # - some other kind of assignment missed but still most likely a variable
+ self._check_name("variable", node.name, node)
+
+ @utils.only_required_for_messages("non-ascii-name")
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ self._check_name("class", node.name, node)
+ for attr, anodes in node.instance_attrs.items():
+ if not any(node.instance_attr_ancestors(attr)):
+ self._check_name("attr", attr, anodes[0])
+
+ def _check_module_import(self, node: nodes.ImportFrom | nodes.Import) -> None:
+ for module_name, alias in node.names:
+ name = alias or module_name
+ self._check_name("module", name, node)
+
+ @utils.only_required_for_messages("non-ascii-name", "non-ascii-module-import")
+ def visit_import(self, node: nodes.Import) -> None:
+ self._check_module_import(node)
+
+ @utils.only_required_for_messages("non-ascii-name", "non-ascii-module-import")
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ self._check_module_import(node)
+
+ @utils.only_required_for_messages("non-ascii-name")
+ def visit_call(self, node: nodes.Call) -> None:
+ """Check if the used keyword args are correct."""
+ for keyword in node.keywords:
+ self._check_name("argument", keyword.arg, keyword)
+
+
+def register(linter: lint.PyLinter) -> None:
+ linter.register_checker(NonAsciiNameChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/raw_metrics.py b/solutions/.venv/Lib/site-packages/pylint/checkers/raw_metrics.py
new file mode 100644
index 000000000..ef4535345
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/raw_metrics.py
@@ -0,0 +1,110 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import tokenize
+from typing import TYPE_CHECKING, Any, Literal, cast
+
+from pylint.checkers import BaseTokenChecker
+from pylint.reporters.ureports.nodes import Paragraph, Section, Table, Text
+from pylint.utils import LinterStats, diff_string
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def report_raw_stats(
+ sect: Section,
+ stats: LinterStats,
+ old_stats: LinterStats | None,
+) -> None:
+ """Calculate percentage of code / doc / comment / empty."""
+ total_lines = stats.code_type_count["total"]
+ sect.insert(0, Paragraph([Text(f"{total_lines} lines have been analyzed\n")]))
+ lines = ["type", "number", "%", "previous", "difference"]
+ for node_type in ("code", "docstring", "comment", "empty"):
+ node_type = cast(Literal["code", "docstring", "comment", "empty"], node_type)
+ total = stats.code_type_count[node_type]
+ percent = float(total * 100) / total_lines if total_lines else None
+ old = old_stats.code_type_count[node_type] if old_stats else None
+ diff_str = diff_string(old, total) if old else None
+ lines += [
+ node_type,
+ str(total),
+ f"{percent:.2f}" if percent is not None else "NC",
+ str(old) if old else "NC",
+ diff_str if diff_str else "NC",
+ ]
+ sect.append(Table(children=lines, cols=5, rheaders=1))
+
+
+class RawMetricsChecker(BaseTokenChecker):
+ """Checker that provides raw metrics instead of checking anything.
+
+ Provides:
+ * total number of lines
+ * total number of code lines
+ * total number of docstring lines
+ * total number of comments lines
+ * total number of empty lines
+ """
+
+ # configuration section name
+ name = "metrics"
+ # configuration options
+ options = ()
+ # messages
+ msgs: Any = {}
+ # reports
+ reports = (("RP0701", "Raw metrics", report_raw_stats),)
+
+ def open(self) -> None:
+ """Init statistics."""
+ self.linter.stats.reset_code_count()
+
+ def process_tokens(self, tokens: list[tokenize.TokenInfo]) -> None:
+ """Update stats."""
+ i = 0
+ tokens = list(tokens)
+ while i < len(tokens):
+ i, lines_number, line_type = get_type(tokens, i)
+ self.linter.stats.code_type_count["total"] += lines_number
+ self.linter.stats.code_type_count[line_type] += lines_number
+
+
+JUNK = (tokenize.NL, tokenize.INDENT, tokenize.NEWLINE, tokenize.ENDMARKER)
+
+
+def get_type(
+ tokens: list[tokenize.TokenInfo], start_index: int
+) -> tuple[int, int, Literal["code", "docstring", "comment", "empty"]]:
+ """Return the line type : docstring, comment, code, empty."""
+ i = start_index
+ start = tokens[i][2]
+ pos = start
+ line_type = None
+ while i < len(tokens) and tokens[i][2][0] == start[0]:
+ tok_type = tokens[i][0]
+ pos = tokens[i][3]
+ if line_type is None:
+ if tok_type == tokenize.STRING:
+ line_type = "docstring"
+ elif tok_type == tokenize.COMMENT:
+ line_type = "comment"
+ elif tok_type in JUNK:
+ pass
+ else:
+ line_type = "code"
+ i += 1
+ if line_type is None:
+ line_type = "empty"
+ elif i < len(tokens) and tokens[i][0] == tokenize.NEWLINE:
+ i += 1
+ # Mypy fails to infer the literal of line_type
+ return i, pos[0] - start[0] + 1, line_type # type: ignore[return-value]
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(RawMetricsChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/__init__.py b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/__init__.py
new file mode 100644
index 000000000..785ce3f96
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/__init__.py
@@ -0,0 +1,33 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Looks for code which can be refactored."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from pylint.checkers.refactoring.implicit_booleaness_checker import (
+ ImplicitBooleanessChecker,
+)
+from pylint.checkers.refactoring.not_checker import NotChecker
+from pylint.checkers.refactoring.recommendation_checker import RecommendationChecker
+from pylint.checkers.refactoring.refactoring_checker import RefactoringChecker
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+__all__ = [
+ "ImplicitBooleanessChecker",
+ "NotChecker",
+ "RecommendationChecker",
+ "RefactoringChecker",
+]
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(RefactoringChecker(linter))
+ linter.register_checker(NotChecker(linter))
+ linter.register_checker(RecommendationChecker(linter))
+ linter.register_checker(ImplicitBooleanessChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/implicit_booleaness_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/implicit_booleaness_checker.py
new file mode 100644
index 000000000..7522faeb1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/implicit_booleaness_checker.py
@@ -0,0 +1,334 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import itertools
+
+import astroid
+from astroid import bases, nodes, util
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.interfaces import HIGH, INFERENCE
+
+
+def _is_constant_zero(node: str | nodes.NodeNG) -> bool:
+ # We have to check that node.value is not False because node.value == 0 is True
+ # when node.value is False
+ return (
+ isinstance(node, astroid.Const) and node.value == 0 and node.value is not False
+ )
+
+
+class ImplicitBooleanessChecker(checkers.BaseChecker):
+ """Checks for incorrect usage of comparisons or len() inside conditions.
+
+ Incorrect usage of len()
+ Pep8 states:
+ For sequences, (strings, lists, tuples), use the fact that empty sequences are false.
+
+ Yes: if not seq:
+ if seq:
+
+ No: if len(seq):
+ if not len(seq):
+
+ Problems detected:
+ * if len(sequence):
+ * if not len(sequence):
+ * elif len(sequence):
+ * elif not len(sequence):
+ * while len(sequence):
+ * while not len(sequence):
+ * assert len(sequence):
+ * assert not len(sequence):
+ * bool(len(sequence))
+
+ Incorrect usage of empty literal sequences; (), [], {},
+
+ For empty sequences, (dicts, lists, tuples), use the fact that empty sequences are false.
+
+ Yes: if variable:
+ if not variable
+
+ No: if variable == empty_literal:
+ if variable != empty_literal:
+
+ Problems detected:
+ * comparison such as variable == empty_literal:
+ * comparison such as variable != empty_literal:
+ """
+
+ name = "refactoring"
+ msgs = {
+ "C1802": (
+ "Do not use `len(SEQUENCE)` without comparison to determine if a sequence is empty",
+ "use-implicit-booleaness-not-len",
+ "Empty sequences are considered false in a boolean context. You can either"
+ " remove the call to 'len' (``if not x``) or compare the length against a"
+ " scalar (``if len(x) > 1``).",
+ {"old_names": [("C1801", "len-as-condition")]},
+ ),
+ "C1803": (
+ '"%s" can be simplified to "%s", if it is strictly a sequence, as an empty %s is falsey',
+ "use-implicit-booleaness-not-comparison",
+ "Empty sequences are considered false in a boolean context. Following this"
+ " check blindly in weakly typed code base can create hard to debug issues."
+ " If the value can be something else that is falsey but not a sequence (for"
+ " example ``None``, an empty string, or ``0``) the code will not be "
+ "equivalent.",
+ ),
+ "C1804": (
+ '"%s" can be simplified to "%s", if it is strictly a string, as an empty string is falsey',
+ "use-implicit-booleaness-not-comparison-to-string",
+ "Empty string are considered false in a boolean context. Following this"
+ " check blindly in weakly typed code base can create hard to debug issues."
+ " If the value can be something else that is falsey but not a string (for"
+ " example ``None``, an empty sequence, or ``0``) the code will not be "
+ "equivalent.",
+ {
+ "default_enabled": False,
+ "old_names": [("C1901", "compare-to-empty-string")],
+ },
+ ),
+ "C1805": (
+ '"%s" can be simplified to "%s", if it is strictly an int, as 0 is falsey',
+ "use-implicit-booleaness-not-comparison-to-zero",
+ "0 is considered false in a boolean context. Following this"
+ " check blindly in weakly typed code base can create hard to debug issues."
+ " If the value can be something else that is falsey but not an int (for"
+ " example ``None``, an empty string, or an empty sequence) the code will not be "
+ "equivalent.",
+ {"default_enabled": False, "old_names": [("C2001", "compare-to-zero")]},
+ ),
+ }
+
+ options = ()
+ _operators = {"!=", "==", "is not", "is"}
+
+ @utils.only_required_for_messages("use-implicit-booleaness-not-len")
+ def visit_call(self, node: nodes.Call) -> None:
+ # a len(S) call is used inside a test condition
+ # could be if, while, assert or if expression statement
+ # e.g. `if len(S):`
+ if not utils.is_call_of_name(node, "len"):
+ return
+ # the len() call could also be nested together with other
+ # boolean operations, e.g. `if z or len(x):`
+ parent = node.parent
+ while isinstance(parent, nodes.BoolOp):
+ parent = parent.parent
+ # we're finally out of any nested boolean operations so check if
+ # this len() call is part of a test condition
+ if not utils.is_test_condition(node, parent):
+ return
+ len_arg = node.args[0]
+ if isinstance(len_arg, (nodes.ListComp, nodes.SetComp, nodes.DictComp)):
+ # The node is a comprehension as in len([x for x in ...])
+ self.add_message(
+ "use-implicit-booleaness-not-len",
+ node=node,
+ confidence=HIGH,
+ )
+ return
+ try:
+ instance = next(len_arg.infer())
+ except astroid.InferenceError:
+ # Probably undefined-variable, abort check
+ return
+ mother_classes = self.base_names_of_instance(instance)
+ affected_by_pep8 = any(
+ t in mother_classes for t in ("str", "tuple", "list", "set")
+ )
+ if "range" in mother_classes or (
+ affected_by_pep8 and not self.instance_has_bool(instance)
+ ):
+ self.add_message(
+ "use-implicit-booleaness-not-len",
+ node=node,
+ confidence=INFERENCE,
+ )
+
+ @staticmethod
+ def instance_has_bool(class_def: nodes.ClassDef) -> bool:
+ try:
+ class_def.getattr("__bool__")
+ return True
+ except astroid.AttributeInferenceError:
+ ...
+ return False
+
+ @utils.only_required_for_messages("use-implicit-booleaness-not-len")
+ def visit_unaryop(self, node: nodes.UnaryOp) -> None:
+ """`not len(S)` must become `not S` regardless if the parent block is a test
+ condition or something else (boolean expression) e.g. `if not len(S):`.
+ """
+ if (
+ isinstance(node, nodes.UnaryOp)
+ and node.op == "not"
+ and utils.is_call_of_name(node.operand, "len")
+ ):
+ self.add_message(
+ "use-implicit-booleaness-not-len", node=node, confidence=HIGH
+ )
+
+ @utils.only_required_for_messages(
+ "use-implicit-booleaness-not-comparison",
+ "use-implicit-booleaness-not-comparison-to-string",
+ "use-implicit-booleaness-not-comparison-to-zero",
+ )
+ def visit_compare(self, node: nodes.Compare) -> None:
+ if self.linter.is_message_enabled("use-implicit-booleaness-not-comparison"):
+ self._check_use_implicit_booleaness_not_comparison(node)
+ if self.linter.is_message_enabled(
+ "use-implicit-booleaness-not-comparison-to-zero"
+ ) or self.linter.is_message_enabled(
+ "use-implicit-booleaness-not-comparison-to-str"
+ ):
+ self._check_compare_to_str_or_zero(node)
+
+ def _check_compare_to_str_or_zero(self, node: nodes.Compare) -> None:
+ # note: astroid.Compare has the left most operand in node.left
+ # while the rest are a list of tuples in node.ops
+ # the format of the tuple is ('compare operator sign', node)
+ # here we squash everything into `ops` to make it easier for processing later
+ ops: list[tuple[str, nodes.NodeNG]] = [("", node.left), *node.ops]
+ iter_ops = iter(ops)
+ all_ops = list(itertools.chain(*iter_ops))
+ for ops_idx in range(len(all_ops) - 2):
+ op_2 = all_ops[ops_idx + 1]
+ if op_2 not in self._operators:
+ continue
+ op_1 = all_ops[ops_idx]
+ op_3 = all_ops[ops_idx + 2]
+ if self.linter.is_message_enabled(
+ "use-implicit-booleaness-not-comparison-to-zero"
+ ):
+ op = None
+ # 0 ?? X
+ if _is_constant_zero(op_1):
+ op = op_3
+ # X ?? 0
+ elif _is_constant_zero(op_3):
+ op = op_1
+ if op is not None:
+ original = f"{op_1.as_string()} {op_2} {op_3.as_string()}"
+ suggestion = (
+ op.as_string()
+ if op_2 in {"!=", "is not"}
+ else f"not {op.as_string()}"
+ )
+ self.add_message(
+ "use-implicit-booleaness-not-comparison-to-zero",
+ args=(original, suggestion),
+ node=node,
+ confidence=HIGH,
+ )
+ if self.linter.is_message_enabled(
+ "use-implicit-booleaness-not-comparison-to-str"
+ ):
+ node_name = None
+ # x ?? ""
+ if utils.is_empty_str_literal(op_1):
+ node_name = op_3.as_string()
+ # '' ?? X
+ elif utils.is_empty_str_literal(op_3):
+ node_name = op_1.as_string()
+ if node_name is not None:
+ suggestion = (
+ f"not {node_name}" if op_2 in {"==", "is"} else node_name
+ )
+ self.add_message(
+ "use-implicit-booleaness-not-comparison-to-string",
+ args=(node.as_string(), suggestion),
+ node=node,
+ confidence=HIGH,
+ )
+
+ def _check_use_implicit_booleaness_not_comparison(
+ self, node: nodes.Compare
+ ) -> None:
+ """Check for left side and right side of the node for empty literals."""
+ is_left_empty_literal = utils.is_base_container(
+ node.left
+ ) or utils.is_empty_dict_literal(node.left)
+
+ # Check both left-hand side and right-hand side for literals
+ for operator, comparator in node.ops:
+ is_right_empty_literal = utils.is_base_container(
+ comparator
+ ) or utils.is_empty_dict_literal(comparator)
+ # Using Exclusive OR (XOR) to compare between two side.
+ # If two sides are both literal, it should be different error.
+ if is_right_empty_literal ^ is_left_empty_literal:
+ # set target_node to opposite side of literal
+ target_node = node.left if is_right_empty_literal else comparator
+ literal_node = comparator if is_right_empty_literal else node.left
+ # Infer node to check
+ target_instance = utils.safe_infer(target_node)
+ if target_instance is None:
+ continue
+ mother_classes = self.base_names_of_instance(target_instance)
+ is_base_comprehension_type = any(
+ t in mother_classes for t in ("tuple", "list", "dict", "set")
+ )
+
+ # Only time we bypass check is when target_node is not inherited by
+ # collection literals and have its own __bool__ implementation.
+ if not is_base_comprehension_type and self.instance_has_bool(
+ target_instance
+ ):
+ continue
+
+ # No need to check for operator when visiting compare node
+ if operator in {"==", "!=", ">=", ">", "<=", "<"}:
+ self.add_message(
+ "use-implicit-booleaness-not-comparison",
+ args=self._implicit_booleaness_message_args(
+ literal_node, operator, target_node
+ ),
+ node=node,
+ confidence=HIGH,
+ )
+
+ def _get_node_description(self, node: nodes.NodeNG) -> str:
+ return {
+ nodes.List: "list",
+ nodes.Tuple: "tuple",
+ nodes.Dict: "dict",
+ nodes.Const: "str",
+ }.get(type(node), "iterable")
+
+ def _implicit_booleaness_message_args(
+ self, literal_node: nodes.NodeNG, operator: str, target_node: nodes.NodeNG
+ ) -> tuple[str, str, str]:
+ """Helper to get the right message for "use-implicit-booleaness-not-comparison"."""
+ description = self._get_node_description(literal_node)
+ collection_literal = {
+ "list": "[]",
+ "tuple": "()",
+ "dict": "{}",
+ }.get(description, "iterable")
+ instance_name = "x"
+ if isinstance(target_node, nodes.Call) and target_node.func:
+ instance_name = f"{target_node.func.as_string()}(...)"
+ elif isinstance(target_node, (nodes.Attribute, nodes.Name)):
+ instance_name = target_node.as_string()
+ original_comparison = f"{instance_name} {operator} {collection_literal}"
+ suggestion = f"{instance_name}" if operator == "!=" else f"not {instance_name}"
+ return original_comparison, suggestion, description
+
+ @staticmethod
+ def base_names_of_instance(
+ node: util.UninferableBase | bases.Instance,
+ ) -> list[str]:
+ """Return all names inherited by a class instance or those returned by a
+ function.
+
+ The inherited names include 'object'.
+ """
+ if isinstance(node, bases.Instance):
+ return [node.name] + [x.name for x in node.ancestors()]
+ return []
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/not_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/not_checker.py
new file mode 100644
index 000000000..c46b477b5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/not_checker.py
@@ -0,0 +1,84 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+import astroid
+from astroid import nodes
+
+from pylint import checkers
+from pylint.checkers import utils
+
+
+class NotChecker(checkers.BaseChecker):
+ """Checks for too many not in comparison expressions.
+
+ - "not not" should trigger a warning
+ - "not" followed by a comparison should trigger a warning
+ """
+
+ msgs = {
+ "C0117": (
+ 'Consider changing "%s" to "%s"',
+ "unnecessary-negation",
+ "Used when a boolean expression contains an unneeded negation, "
+ "e.g. when two negation operators cancel each other out.",
+ {"old_names": [("C0113", "unneeded-not")]},
+ )
+ }
+ name = "refactoring"
+ reverse_op = {
+ "<": ">=",
+ "<=": ">",
+ ">": "<=",
+ ">=": "<",
+ "==": "!=",
+ "!=": "==",
+ "in": "not in",
+ "is": "is not",
+ }
+ # sets are not ordered, so for example "not set(LEFT_VALS) <= set(RIGHT_VALS)" is
+ # not equivalent to "set(LEFT_VALS) > set(RIGHT_VALS)"
+ skipped_nodes = (nodes.Set,)
+ # 'builtins' py3, '__builtin__' py2
+ skipped_classnames = [f"builtins.{qname}" for qname in ("set", "frozenset")]
+
+ @utils.only_required_for_messages("unnecessary-negation")
+ def visit_unaryop(self, node: nodes.UnaryOp) -> None:
+ if node.op != "not":
+ return
+ operand = node.operand
+
+ if isinstance(operand, nodes.UnaryOp) and operand.op == "not":
+ self.add_message(
+ "unnecessary-negation",
+ node=node,
+ args=(node.as_string(), operand.operand.as_string()),
+ )
+ elif isinstance(operand, nodes.Compare):
+ left = operand.left
+ # ignore multiple comparisons
+ if len(operand.ops) > 1:
+ return
+ operator, right = operand.ops[0]
+ if operator not in self.reverse_op:
+ return
+ # Ignore __ne__ as function of __eq__
+ frame = node.frame()
+ if frame.name == "__ne__" and operator == "==":
+ return
+ for _type in (utils.node_type(left), utils.node_type(right)):
+ if not _type:
+ return
+ if isinstance(_type, self.skipped_nodes):
+ return
+ if (
+ isinstance(_type, astroid.Instance)
+ and _type.qname() in self.skipped_classnames
+ ):
+ return
+ suggestion = (
+ f"{left.as_string()} {self.reverse_op[operator]} {right.as_string()}"
+ )
+ self.add_message(
+ "unnecessary-negation", node=node, args=(node.as_string(), suggestion)
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/recommendation_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/recommendation_checker.py
new file mode 100644
index 000000000..c5b19e1a5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/recommendation_checker.py
@@ -0,0 +1,454 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import astroid
+from astroid import nodes
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.interfaces import HIGH, INFERENCE
+
+
+class RecommendationChecker(checkers.BaseChecker):
+ name = "refactoring"
+ msgs = {
+ "C0200": (
+ "Consider using enumerate instead of iterating with range and len",
+ "consider-using-enumerate",
+ "Emitted when code that iterates with range and len is "
+ "encountered. Such code can be simplified by using the "
+ "enumerate builtin.",
+ ),
+ "C0201": (
+ "Consider iterating the dictionary directly instead of calling .keys()",
+ "consider-iterating-dictionary",
+ "Emitted when the keys of a dictionary are iterated through the ``.keys()`` "
+ "method or when ``.keys()`` is used for a membership check. "
+ "It is enough to iterate through the dictionary itself, "
+ "``for key in dictionary``. For membership checks, "
+ "``if key in dictionary`` is faster.",
+ ),
+ "C0206": (
+ "Consider iterating with .items()",
+ "consider-using-dict-items",
+ "Emitted when iterating over the keys of a dictionary and accessing the "
+ "value by index lookup. "
+ "Both the key and value can be accessed by iterating using the .items() "
+ "method of the dictionary instead.",
+ ),
+ "C0207": (
+ "Use %s instead",
+ "use-maxsplit-arg",
+ "Emitted when accessing only the first or last element of str.split(). "
+ "The first and last element can be accessed by using "
+ "str.split(sep, maxsplit=1)[0] or str.rsplit(sep, maxsplit=1)[-1] "
+ "instead.",
+ ),
+ "C0208": (
+ "Use a sequence type when iterating over values",
+ "use-sequence-for-iteration",
+ "When iterating over values, sequence types (e.g., ``lists``, ``tuples``, ``ranges``) "
+ "are more efficient than ``sets``.",
+ ),
+ "C0209": (
+ "Formatting a regular string which could be an f-string",
+ "consider-using-f-string",
+ "Used when we detect a string that is being formatted with format() or % "
+ "which could potentially be an f-string. The use of f-strings is preferred. "
+ "Requires Python 3.6 and ``py-version >= 3.6``.",
+ ),
+ }
+
+ def open(self) -> None:
+ py_version = self.linter.config.py_version
+ self._py36_plus = py_version >= (3, 6)
+
+ @staticmethod
+ def _is_builtin(node: nodes.NodeNG, function: str) -> bool:
+ inferred = utils.safe_infer(node)
+ if not inferred:
+ return False
+ return utils.is_builtin_object(inferred) and inferred.name == function
+
+ @utils.only_required_for_messages(
+ "consider-iterating-dictionary", "use-maxsplit-arg"
+ )
+ def visit_call(self, node: nodes.Call) -> None:
+ self._check_consider_iterating_dictionary(node)
+ self._check_use_maxsplit_arg(node)
+
+ def _check_consider_iterating_dictionary(self, node: nodes.Call) -> None:
+ if not isinstance(node.func, nodes.Attribute):
+ return
+ if node.func.attrname != "keys":
+ return
+
+ if isinstance(node.parent, nodes.BinOp) and node.parent.op in {"&", "|", "^"}:
+ return
+
+ comp_ancestor = utils.get_node_first_ancestor_of_type(node, nodes.Compare)
+ if (
+ isinstance(node.parent, (nodes.For, nodes.Comprehension))
+ or comp_ancestor
+ and any(
+ op
+ for op, comparator in comp_ancestor.ops
+ if op in {"in", "not in"}
+ and (comparator in node.node_ancestors() or comparator is node)
+ )
+ ):
+ inferred = utils.safe_infer(node.func)
+ if not isinstance(inferred, astroid.BoundMethod) or not isinstance(
+ inferred.bound, nodes.Dict
+ ):
+ return
+ self.add_message(
+ "consider-iterating-dictionary", node=node, confidence=INFERENCE
+ )
+
+ def _check_use_maxsplit_arg(self, node: nodes.Call) -> None:
+ """Add message when accessing first or last elements of a str.split() or
+ str.rsplit().
+ """
+ # Check if call is split() or rsplit()
+ if not (
+ isinstance(node.func, nodes.Attribute)
+ and node.func.attrname in {"split", "rsplit"}
+ and isinstance(utils.safe_infer(node.func), astroid.BoundMethod)
+ ):
+ return
+ inferred_expr = utils.safe_infer(node.func.expr)
+ if isinstance(inferred_expr, astroid.Instance) and any(
+ inferred_expr.nodes_of_class(nodes.ClassDef)
+ ):
+ return
+
+ confidence = HIGH
+ try:
+ sep = utils.get_argument_from_call(node, 0, "sep")
+ except utils.NoSuchArgumentError:
+ sep = utils.infer_kwarg_from_call(node, keyword="sep")
+ confidence = INFERENCE
+ if not sep:
+ return
+
+ try:
+ # Ignore if maxsplit arg has been set
+ utils.get_argument_from_call(node, 1, "maxsplit")
+ return
+ except utils.NoSuchArgumentError:
+ if utils.infer_kwarg_from_call(node, keyword="maxsplit"):
+ return
+
+ if isinstance(node.parent, nodes.Subscript):
+ try:
+ subscript_value = utils.get_subscript_const_value(node.parent).value
+ except utils.InferredTypeError:
+ return
+
+ # Check for cases where variable (Name) subscripts may be mutated within a loop
+ if isinstance(node.parent.slice, nodes.Name):
+ # Check if loop present within the scope of the node
+ scope = node.scope()
+ for loop_node in scope.nodes_of_class((nodes.For, nodes.While)):
+ if not loop_node.parent_of(node):
+ continue
+
+ # Check if var is mutated within loop (Assign/AugAssign)
+ for assignment_node in loop_node.nodes_of_class(nodes.AugAssign):
+ if node.parent.slice.name == assignment_node.target.name:
+ return
+ for assignment_node in loop_node.nodes_of_class(nodes.Assign):
+ if node.parent.slice.name in [
+ n.name for n in assignment_node.targets
+ ]:
+ return
+
+ if subscript_value in (-1, 0):
+ fn_name = node.func.attrname
+ new_fn = "rsplit" if subscript_value == -1 else "split"
+ new_name = (
+ node.func.as_string().rsplit(fn_name, maxsplit=1)[0]
+ + new_fn
+ + f"({sep.as_string()}, maxsplit=1)[{subscript_value}]"
+ )
+ self.add_message(
+ "use-maxsplit-arg",
+ node=node,
+ args=(new_name,),
+ confidence=confidence,
+ )
+
+ @utils.only_required_for_messages(
+ "consider-using-enumerate",
+ "consider-using-dict-items",
+ "use-sequence-for-iteration",
+ )
+ def visit_for(self, node: nodes.For) -> None:
+ self._check_consider_using_enumerate(node)
+ self._check_consider_using_dict_items(node)
+ self._check_use_sequence_for_iteration(node)
+
+ def _check_consider_using_enumerate(self, node: nodes.For) -> None:
+ """Emit a convention whenever range and len are used for indexing."""
+ # Verify that we have a `range([start], len(...), [stop])` call and
+ # that the object which is iterated is used as a subscript in the
+ # body of the for.
+
+ # Is it a proper range call?
+ if not isinstance(node.iter, nodes.Call):
+ return
+ if not self._is_builtin(node.iter.func, "range"):
+ return
+ if not node.iter.args:
+ return
+ is_constant_zero = (
+ isinstance(node.iter.args[0], nodes.Const) and node.iter.args[0].value == 0
+ )
+ if len(node.iter.args) == 2 and not is_constant_zero:
+ return
+ if len(node.iter.args) > 2:
+ return
+
+ # Is it a proper len call?
+ if not isinstance(node.iter.args[-1], nodes.Call):
+ return
+ second_func = node.iter.args[-1].func
+ if not self._is_builtin(second_func, "len"):
+ return
+ len_args = node.iter.args[-1].args
+ if not len_args or len(len_args) != 1:
+ return
+ iterating_object = len_args[0]
+ if isinstance(iterating_object, nodes.Name):
+ expected_subscript_val_type = nodes.Name
+ elif isinstance(iterating_object, nodes.Attribute):
+ expected_subscript_val_type = nodes.Attribute
+ else:
+ return
+ # If we're defining __iter__ on self, enumerate won't work
+ scope = node.scope()
+ if (
+ isinstance(iterating_object, nodes.Name)
+ and iterating_object.name == "self"
+ and scope.name == "__iter__"
+ ):
+ return
+
+ # Verify that the body of the for loop uses a subscript
+ # with the object that was iterated. This uses some heuristics
+ # in order to make sure that the same object is used in the
+ # for body.
+ for child in node.body:
+ for subscript in child.nodes_of_class(nodes.Subscript):
+ if not isinstance(subscript.value, expected_subscript_val_type):
+ continue
+
+ value = subscript.slice
+ if not isinstance(value, nodes.Name):
+ continue
+ if subscript.value.scope() != node.scope():
+ # Ignore this subscript if it's not in the same
+ # scope. This means that in the body of the for
+ # loop, another scope was created, where the same
+ # name for the iterating object was used.
+ continue
+ if value.name == node.target.name and (
+ isinstance(subscript.value, nodes.Name)
+ and iterating_object.name == subscript.value.name
+ or isinstance(subscript.value, nodes.Attribute)
+ and iterating_object.attrname == subscript.value.attrname
+ ):
+ self.add_message("consider-using-enumerate", node=node)
+ return
+
+ def _check_consider_using_dict_items(self, node: nodes.For) -> None:
+ """Add message when accessing dict values by index lookup."""
+ # Verify that we have a .keys() call and
+ # that the object which is iterated is used as a subscript in the
+ # body of the for.
+
+ iterating_object_name = utils.get_iterating_dictionary_name(node)
+ if iterating_object_name is None:
+ return
+
+ # Verify that the body of the for loop uses a subscript
+ # with the object that was iterated. This uses some heuristics
+ # in order to make sure that the same object is used in the
+ # for body.
+ for child in node.body:
+ for subscript in child.nodes_of_class(nodes.Subscript):
+ if not isinstance(subscript.value, (nodes.Name, nodes.Attribute)):
+ continue
+
+ value = subscript.slice
+ if (
+ not isinstance(value, nodes.Name)
+ or value.name != node.target.name
+ or iterating_object_name != subscript.value.as_string()
+ ):
+ continue
+ last_definition_lineno = value.lookup(value.name)[1][-1].lineno
+ if last_definition_lineno > node.lineno:
+ # Ignore this subscript if it has been redefined after
+ # the for loop. This checks for the line number using .lookup()
+ # to get the line number where the iterating object was last
+ # defined and compare that to the for loop's line number
+ continue
+ if (
+ isinstance(subscript.parent, nodes.Assign)
+ and subscript in subscript.parent.targets
+ or isinstance(subscript.parent, nodes.AugAssign)
+ and subscript == subscript.parent.target
+ ):
+ # Ignore this subscript if it is the target of an assignment
+ # Early termination as dict index lookup is necessary
+ return
+ if isinstance(subscript.parent, nodes.Delete):
+ # Ignore this subscript if the index is used to delete a
+ # dictionary item.
+ return
+
+ self.add_message("consider-using-dict-items", node=node)
+ return
+
+ @utils.only_required_for_messages(
+ "consider-using-dict-items",
+ "use-sequence-for-iteration",
+ )
+ def visit_comprehension(self, node: nodes.Comprehension) -> None:
+ self._check_consider_using_dict_items_comprehension(node)
+ self._check_use_sequence_for_iteration(node)
+
+ def _check_consider_using_dict_items_comprehension(
+ self, node: nodes.Comprehension
+ ) -> None:
+ """Add message when accessing dict values by index lookup."""
+ iterating_object_name = utils.get_iterating_dictionary_name(node)
+ if iterating_object_name is None:
+ return
+
+ for child in node.parent.get_children():
+ for subscript in child.nodes_of_class(nodes.Subscript):
+ if not isinstance(subscript.value, (nodes.Name, nodes.Attribute)):
+ continue
+
+ value = subscript.slice
+ if (
+ not isinstance(value, nodes.Name)
+ or value.name != node.target.name
+ or iterating_object_name != subscript.value.as_string()
+ ):
+ continue
+
+ self.add_message("consider-using-dict-items", node=node)
+ return
+
+ def _check_use_sequence_for_iteration(
+ self, node: nodes.For | nodes.Comprehension
+ ) -> None:
+ """Check if code iterates over an in-place defined set.
+
+ Sets using `*` are not considered in-place.
+ """
+ if isinstance(node.iter, nodes.Set) and not any(
+ utils.has_starred_node_recursive(node)
+ ):
+ self.add_message(
+ "use-sequence-for-iteration", node=node.iter, confidence=HIGH
+ )
+
+ @utils.only_required_for_messages("consider-using-f-string")
+ def visit_const(self, node: nodes.Const) -> None:
+ if self._py36_plus:
+ # f-strings require Python 3.6
+ if node.pytype() == "builtins.str" and not isinstance(
+ node.parent, nodes.JoinedStr
+ ):
+ self._detect_replacable_format_call(node)
+
+ def _detect_replacable_format_call(self, node: nodes.Const) -> None:
+ """Check whether a string is used in a call to format() or '%' and whether it
+ can be replaced by an f-string.
+ """
+ if (
+ isinstance(node.parent, nodes.Attribute)
+ and node.parent.attrname == "format"
+ ):
+ # Don't warn on referencing / assigning .format without calling it
+ if not isinstance(node.parent.parent, nodes.Call):
+ return
+
+ if node.parent.parent.args:
+ for arg in node.parent.parent.args:
+ # If star expressions with more than 1 element are being used
+ if isinstance(arg, nodes.Starred):
+ inferred = utils.safe_infer(arg.value)
+ if (
+ isinstance(inferred, astroid.List)
+ and len(inferred.elts) > 1
+ ):
+ return
+ # Backslashes can't be in f-string expressions
+ if "\\" in arg.as_string():
+ return
+
+ elif node.parent.parent.keywords:
+ keyword_args = [
+ i[0] for i in utils.parse_format_method_string(node.value)[0]
+ ]
+ for keyword in node.parent.parent.keywords:
+ # If keyword is used multiple times
+ if keyword_args.count(keyword.arg) > 1:
+ return
+
+ keyword = utils.safe_infer(keyword.value)
+
+ # If lists of more than one element are being unpacked
+ if isinstance(keyword, nodes.Dict):
+ if len(keyword.items) > 1 and len(keyword_args) > 1:
+ return
+
+ # If all tests pass, then raise message
+ self.add_message(
+ "consider-using-f-string",
+ node=node,
+ line=node.lineno,
+ col_offset=node.col_offset,
+ )
+
+ elif isinstance(node.parent, nodes.BinOp) and node.parent.op == "%":
+ # Backslashes can't be in f-string expressions
+ if "\\" in node.parent.right.as_string():
+ return
+
+ # If % applied to another type than str, it's modulo and can't be replaced by formatting
+ if not hasattr(node.parent.left, "value") or not isinstance(
+ node.parent.left.value, str
+ ):
+ return
+
+ # Brackets can be inconvenient in f-string expressions
+ if "{" in node.parent.left.value or "}" in node.parent.left.value:
+ return
+
+ inferred_right = utils.safe_infer(node.parent.right)
+
+ # If dicts or lists of length > 1 are used
+ if isinstance(inferred_right, nodes.Dict):
+ if len(inferred_right.items) > 1:
+ return
+ elif isinstance(inferred_right, nodes.List):
+ if len(inferred_right.elts) > 1:
+ return
+
+ # If all tests pass, then raise message
+ self.add_message(
+ "consider-using-f-string",
+ node=node,
+ line=node.lineno,
+ col_offset=node.col_offset,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/refactoring_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/refactoring_checker.py
new file mode 100644
index 000000000..c67c8dd23
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/refactoring/refactoring_checker.py
@@ -0,0 +1,2469 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import collections
+import copy
+import itertools
+import tokenize
+from collections.abc import Iterator
+from functools import cached_property, reduce
+from re import Pattern
+from typing import TYPE_CHECKING, Any, NamedTuple, Union, cast
+
+import astroid
+from astroid import bases, nodes
+from astroid.util import UninferableBase
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.checkers.base.basic_error_checker import _loop_exits_early
+from pylint.checkers.utils import node_frame_class
+from pylint.interfaces import HIGH, INFERENCE, Confidence
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+NodesWithNestedBlocks = Union[nodes.Try, nodes.While, nodes.For, nodes.If]
+
+KNOWN_INFINITE_ITERATORS = {"itertools.count", "itertools.cycle"}
+BUILTIN_EXIT_FUNCS = frozenset(("quit", "exit"))
+CALLS_THAT_COULD_BE_REPLACED_BY_WITH = frozenset(
+ (
+ "threading.lock.acquire",
+ "threading._RLock.acquire",
+ "threading.Semaphore.acquire",
+ "multiprocessing.managers.BaseManager.start",
+ "multiprocessing.managers.SyncManager.start",
+ )
+)
+CALLS_RETURNING_CONTEXT_MANAGERS = frozenset(
+ (
+ "_io.open", # regular 'open()' call
+ "pathlib.Path.open",
+ "pathlib._local.Path.open", # Python 3.13
+ "codecs.open",
+ "urllib.request.urlopen",
+ "tempfile.NamedTemporaryFile",
+ "tempfile.SpooledTemporaryFile",
+ "tempfile.TemporaryDirectory",
+ "tempfile.TemporaryFile",
+ "zipfile.ZipFile",
+ "zipfile.PyZipFile",
+ "zipfile.ZipFile.open",
+ "zipfile.PyZipFile.open",
+ "tarfile.TarFile",
+ "tarfile.TarFile.open",
+ "multiprocessing.context.BaseContext.Pool",
+ "subprocess.Popen",
+ )
+)
+
+
+def _if_statement_is_always_returning(
+ if_node: nodes.If, returning_node_class: nodes.NodeNG
+) -> bool:
+ return any(isinstance(node, returning_node_class) for node in if_node.body)
+
+
+def _except_statement_is_always_returning(
+ node: nodes.Try, returning_node_class: nodes.NodeNG
+) -> bool:
+ """Detect if all except statements return."""
+ return all(
+ any(isinstance(child, returning_node_class) for child in handler.body)
+ for handler in node.handlers
+ )
+
+
+def _is_trailing_comma(tokens: list[tokenize.TokenInfo], index: int) -> bool:
+ """Check if the given token is a trailing comma.
+
+ :param tokens: Sequence of modules tokens
+ :type tokens: list[tokenize.TokenInfo]
+ :param int index: Index of token under check in tokens
+ :returns: True if the token is a comma which trails an expression
+ :rtype: bool
+ """
+ token = tokens[index]
+ if token.exact_type != tokenize.COMMA:
+ return False
+ # Must have remaining tokens on the same line such as NEWLINE
+ left_tokens = itertools.islice(tokens, index + 1, None)
+
+ more_tokens_on_line = False
+ for remaining_token in left_tokens:
+ if remaining_token.start[0] == token.start[0]:
+ more_tokens_on_line = True
+ # If one of the remaining same line tokens is not NEWLINE or COMMENT
+ # the comma is not trailing.
+ if remaining_token.type not in (tokenize.NEWLINE, tokenize.COMMENT):
+ return False
+
+ if not more_tokens_on_line:
+ return False
+
+ def get_curline_index_start() -> int:
+ """Get the index denoting the start of the current line."""
+ for subindex, token in enumerate(reversed(tokens[:index])):
+ # See Lib/tokenize.py and Lib/token.py in cpython for more info
+ if token.type == tokenize.NEWLINE:
+ return index - subindex
+ return 0
+
+ curline_start = get_curline_index_start()
+ expected_tokens = {"return", "yield"}
+ return any(
+ "=" in prevtoken.string or prevtoken.string in expected_tokens
+ for prevtoken in tokens[curline_start:index]
+ )
+
+
+def _is_inside_context_manager(node: nodes.Call) -> bool:
+ frame = node.frame()
+ if not isinstance(
+ frame, (nodes.FunctionDef, astroid.BoundMethod, astroid.UnboundMethod)
+ ):
+ return False
+ return frame.name == "__enter__" or utils.decorated_with(
+ frame, "contextlib.contextmanager"
+ )
+
+
+def _is_a_return_statement(node: nodes.Call) -> bool:
+ frame = node.frame()
+ for parent in node.node_ancestors():
+ if parent is frame:
+ break
+ if isinstance(parent, nodes.Return):
+ return True
+ return False
+
+
+def _is_part_of_with_items(node: nodes.Call) -> bool:
+ """Checks if one of the node's parents is a ``nodes.With`` node and that the node
+ itself is located somewhere under its ``items``.
+ """
+ frame = node.frame()
+ current = node
+ while current != frame:
+ if isinstance(current, nodes.With):
+ items_start = current.items[0][0].lineno
+ items_end = current.items[-1][0].tolineno
+ return items_start <= node.lineno <= items_end # type: ignore[no-any-return]
+ current = current.parent
+ return False
+
+
+def _will_be_released_automatically(node: nodes.Call) -> bool:
+ """Checks if a call that could be used in a ``with`` statement is used in an
+ alternative construct which would ensure that its __exit__ method is called.
+ """
+ callables_taking_care_of_exit = frozenset(
+ (
+ "contextlib._BaseExitStack.enter_context",
+ "contextlib.ExitStack.enter_context", # necessary for Python 3.6 compatibility
+ )
+ )
+ if not isinstance(node.parent, nodes.Call):
+ return False
+ func = utils.safe_infer(node.parent.func)
+ if not func:
+ return False
+ return func.qname() in callables_taking_care_of_exit
+
+
+def _is_part_of_assignment_target(node: nodes.NodeNG) -> bool:
+ """Check whether use of a variable is happening as part of the left-hand
+ side of an assignment.
+
+ This requires recursive checking, because destructuring assignment can have
+ arbitrarily nested tuples and lists to unpack.
+ """
+ if isinstance(node.parent, nodes.Assign):
+ return node in node.parent.targets
+
+ if isinstance(node.parent, nodes.AugAssign):
+ return node == node.parent.target # type: ignore[no-any-return]
+
+ if isinstance(node.parent, (nodes.Tuple, nodes.List)):
+ return _is_part_of_assignment_target(node.parent)
+
+ return False
+
+
+class ConsiderUsingWithStack(NamedTuple):
+ """Stack for objects that may potentially trigger a R1732 message
+ if they are not used in a ``with`` block later on.
+ """
+
+ module_scope: dict[str, nodes.NodeNG] = {}
+ class_scope: dict[str, nodes.NodeNG] = {}
+ function_scope: dict[str, nodes.NodeNG] = {}
+
+ def __iter__(self) -> Iterator[dict[str, nodes.NodeNG]]:
+ yield from (self.function_scope, self.class_scope, self.module_scope)
+
+ def get_stack_for_frame(
+ self, frame: nodes.FunctionDef | nodes.ClassDef | nodes.Module
+ ) -> dict[str, nodes.NodeNG]:
+ """Get the stack corresponding to the scope of the given frame."""
+ if isinstance(frame, nodes.FunctionDef):
+ return self.function_scope
+ if isinstance(frame, nodes.ClassDef):
+ return self.class_scope
+ return self.module_scope
+
+ def clear_all(self) -> None:
+ """Convenience method to clear all stacks."""
+ for stack in self:
+ stack.clear()
+
+
+class RefactoringChecker(checkers.BaseTokenChecker):
+ """Looks for code which can be refactored.
+
+ This checker also mixes the astroid and the token approaches
+ in order to create knowledge about whether an "else if" node
+ is a true "else if" node, or an "elif" node.
+ """
+
+ name = "refactoring"
+
+ msgs = {
+ "R1701": (
+ "Consider merging these isinstance calls to isinstance(%s, (%s))",
+ "consider-merging-isinstance",
+ "Used when multiple consecutive isinstance calls can be merged into one.",
+ ),
+ "R1706": (
+ "Consider using ternary (%s)",
+ "consider-using-ternary",
+ "Used when one of known pre-python 2.5 ternary syntax is used.",
+ ),
+ "R1709": (
+ "Boolean expression may be simplified to %s",
+ "simplify-boolean-expression",
+ "Emitted when redundant pre-python 2.5 ternary syntax is used.",
+ ),
+ "R1726": (
+ 'Boolean condition "%s" may be simplified to "%s"',
+ "simplifiable-condition",
+ "Emitted when a boolean condition is able to be simplified.",
+ ),
+ "R1727": (
+ "Boolean condition '%s' will always evaluate to '%s'",
+ "condition-evals-to-constant",
+ "Emitted when a boolean condition can be simplified to a constant value.",
+ ),
+ "R1702": (
+ "Too many nested blocks (%s/%s)",
+ "too-many-nested-blocks",
+ "Used when a function or a method has too many nested "
+ "blocks. This makes the code less understandable and "
+ "maintainable.",
+ {"old_names": [("R0101", "old-too-many-nested-blocks")]},
+ ),
+ "R1703": (
+ "The if statement can be replaced with %s",
+ "simplifiable-if-statement",
+ "Used when an if statement can be replaced with 'bool(test)'.",
+ {"old_names": [("R0102", "old-simplifiable-if-statement")]},
+ ),
+ "R1704": (
+ "Redefining argument with the local name %r",
+ "redefined-argument-from-local",
+ "Used when a local name is redefining an argument, which might "
+ "suggest a potential error. This is taken in account only for "
+ "a handful of name binding operations, such as for iteration, "
+ "with statement assignment and exception handler assignment.",
+ ),
+ "R1705": (
+ 'Unnecessary "%s" after "return", %s',
+ "no-else-return",
+ "Used in order to highlight an unnecessary block of "
+ "code following an if containing a return statement. "
+ "As such, it will warn when it encounters an else "
+ "following a chain of ifs, all of them containing a "
+ "return statement.",
+ ),
+ "R1707": (
+ "Disallow trailing comma tuple",
+ "trailing-comma-tuple",
+ "In Python, a tuple is actually created by the comma symbol, "
+ "not by the parentheses. Unfortunately, one can actually create a "
+ "tuple by misplacing a trailing comma, which can lead to potential "
+ "weird bugs in your code. You should always use parentheses "
+ "explicitly for creating a tuple.",
+ ),
+ "R1708": (
+ "Do not raise StopIteration in generator, use return statement instead",
+ "stop-iteration-return",
+ "According to PEP479, the raise of StopIteration to end the loop of "
+ "a generator may lead to hard to find bugs. This PEP specify that "
+ "raise StopIteration has to be replaced by a simple return statement",
+ ),
+ "R1710": (
+ "Either all return statements in a function should return an expression, "
+ "or none of them should.",
+ "inconsistent-return-statements",
+ "According to PEP8, if any return statement returns an expression, "
+ "any return statements where no value is returned should explicitly "
+ "state this as return None, and an explicit return statement "
+ "should be present at the end of the function (if reachable)",
+ ),
+ "R1711": (
+ "Useless return at end of function or method",
+ "useless-return",
+ 'Emitted when a single "return" or "return None" statement is found '
+ "at the end of function or method definition. This statement can safely be "
+ "removed because Python will implicitly return None",
+ ),
+ "R1712": (
+ "Consider using tuple unpacking for swapping variables",
+ "consider-swap-variables",
+ "You do not have to use a temporary variable in order to "
+ 'swap variables. Using "tuple unpacking" to directly swap '
+ "variables makes the intention more clear.",
+ ),
+ "R1713": (
+ "Consider using str.join(sequence) for concatenating "
+ "strings from an iterable",
+ "consider-using-join",
+ "Using str.join(sequence) is faster, uses less memory "
+ "and increases readability compared to for-loop iteration.",
+ ),
+ "R1714": (
+ "Consider merging these comparisons with 'in' by using '%s %sin (%s)'."
+ " Use a set instead if elements are hashable.",
+ "consider-using-in",
+ "To check if a variable is equal to one of many values, "
+ 'combine the values into a set or tuple and check if the variable is contained "in" it '
+ "instead of checking for equality against each of the values. "
+ "This is faster and less verbose.",
+ ),
+ "R1715": (
+ "Consider using dict.get for getting values from a dict "
+ "if a key is present or a default if not",
+ "consider-using-get",
+ "Using the builtin dict.get for getting a value from a dictionary "
+ "if a key is present or a default if not, is simpler and considered "
+ "more idiomatic, although sometimes a bit slower",
+ ),
+ "R1716": (
+ "Simplify chained comparison between the operands",
+ "chained-comparison",
+ "This message is emitted when pylint encounters boolean operation like "
+ '"a < b and b < c", suggesting instead to refactor it to "a < b < c"',
+ ),
+ "R1717": (
+ "Consider using a dictionary comprehension",
+ "consider-using-dict-comprehension",
+ "Emitted when we detect the creation of a dictionary "
+ "using the dict() callable and a transient list. "
+ "Although there is nothing syntactically wrong with this code, "
+ "it is hard to read and can be simplified to a dict comprehension. "
+ "Also it is faster since you don't need to create another "
+ "transient list",
+ ),
+ "R1718": (
+ "Consider using a set comprehension",
+ "consider-using-set-comprehension",
+ "Although there is nothing syntactically wrong with this code, "
+ "it is hard to read and can be simplified to a set comprehension. "
+ "Also it is faster since you don't need to create another "
+ "transient list",
+ ),
+ "R1719": (
+ "The if expression can be replaced with %s",
+ "simplifiable-if-expression",
+ "Used when an if expression can be replaced with 'bool(test)' "
+ "or simply 'test' if the boolean cast is implicit.",
+ ),
+ "R1720": (
+ 'Unnecessary "%s" after "raise", %s',
+ "no-else-raise",
+ "Used in order to highlight an unnecessary block of "
+ "code following an if containing a raise statement. "
+ "As such, it will warn when it encounters an else "
+ "following a chain of ifs, all of them containing a "
+ "raise statement.",
+ ),
+ "R1721": (
+ "Unnecessary use of a comprehension, use %s instead.",
+ "unnecessary-comprehension",
+ "Instead of using an identity comprehension, "
+ "consider using the list, dict or set constructor. "
+ "It is faster and simpler.",
+ ),
+ "R1722": (
+ "Consider using 'sys.exit' instead",
+ "consider-using-sys-exit",
+ "Contrary to 'exit()' or 'quit()', 'sys.exit' does not rely on the "
+ "site module being available (as the 'sys' module is always available).",
+ ),
+ "R1723": (
+ 'Unnecessary "%s" after "break", %s',
+ "no-else-break",
+ "Used in order to highlight an unnecessary block of "
+ "code following an if containing a break statement. "
+ "As such, it will warn when it encounters an else "
+ "following a chain of ifs, all of them containing a "
+ "break statement.",
+ ),
+ "R1724": (
+ 'Unnecessary "%s" after "continue", %s',
+ "no-else-continue",
+ "Used in order to highlight an unnecessary block of "
+ "code following an if containing a continue statement. "
+ "As such, it will warn when it encounters an else "
+ "following a chain of ifs, all of them containing a "
+ "continue statement.",
+ ),
+ "R1725": (
+ "Consider using Python 3 style super() without arguments",
+ "super-with-arguments",
+ "Emitted when calling the super() builtin with the current class "
+ "and instance. On Python 3 these arguments are the default and they can be omitted.",
+ ),
+ "R1728": (
+ "Consider using a generator instead '%s(%s)'",
+ "consider-using-generator",
+ "If your container can be large using "
+ "a generator will bring better performance.",
+ ),
+ "R1729": (
+ "Use a generator instead '%s(%s)'",
+ "use-a-generator",
+ "Comprehension inside of 'any', 'all', 'max', 'min' or 'sum' is unnecessary. "
+ "A generator would be sufficient and faster.",
+ ),
+ "R1730": (
+ "Consider using '%s' instead of unnecessary if block",
+ "consider-using-min-builtin",
+ "Using the min builtin instead of a conditional improves readability and conciseness.",
+ ),
+ "R1731": (
+ "Consider using '%s' instead of unnecessary if block",
+ "consider-using-max-builtin",
+ "Using the max builtin instead of a conditional improves readability and conciseness.",
+ ),
+ "R1732": (
+ "Consider using 'with' for resource-allocating operations",
+ "consider-using-with",
+ "Emitted if a resource-allocating assignment or call may be replaced by a 'with' block. "
+ "By using 'with' the release of the allocated resources is ensured even in the case "
+ "of an exception.",
+ ),
+ "R1733": (
+ "Unnecessary dictionary index lookup, use '%s' instead",
+ "unnecessary-dict-index-lookup",
+ "Emitted when iterating over the dictionary items (key-item pairs) and accessing the "
+ "value by index lookup. "
+ "The value can be accessed directly instead.",
+ ),
+ "R1734": (
+ "Consider using [] instead of list()",
+ "use-list-literal",
+ "Emitted when using list() to create an empty list instead of the literal []. "
+ "The literal is faster as it avoids an additional function call.",
+ ),
+ "R1735": (
+ "Consider using '%s' instead of a call to 'dict'.",
+ "use-dict-literal",
+ "Emitted when using dict() to create a dictionary instead of a literal '{ ... }'. "
+ "The literal is faster as it avoids an additional function call.",
+ ),
+ "R1736": (
+ "Unnecessary list index lookup, use '%s' instead",
+ "unnecessary-list-index-lookup",
+ "Emitted when iterating over an enumeration and accessing the "
+ "value by index lookup. "
+ "The value can be accessed directly instead.",
+ ),
+ "R1737": (
+ "Use 'yield from' directly instead of yielding each element one by one",
+ "use-yield-from",
+ "Yielding directly from the iterator is faster and arguably cleaner code than yielding each element "
+ "one by one in the loop.",
+ ),
+ }
+ options = (
+ (
+ "max-nested-blocks",
+ {
+ "default": 5,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of nested blocks for function / method body",
+ },
+ ),
+ (
+ "never-returning-functions",
+ {
+ "default": ("sys.exit", "argparse.parse_error"),
+ "type": "csv",
+ "metavar": "<members names>",
+ "help": "Complete name of functions that never returns. When checking "
+ "for inconsistent-return-statements if a never returning function is "
+ "called then it will be considered as an explicit return statement "
+ "and no message will be printed.",
+ },
+ ),
+ (
+ "suggest-join-with-non-empty-separator",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": (
+ "Let 'consider-using-join' be raised when the separator to "
+ "join on would be non-empty (resulting in expected fixes "
+ 'of the type: ``"- " + "\n- ".join(items)``)'
+ ),
+ },
+ ),
+ )
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._return_nodes: dict[str, list[nodes.Return]] = {}
+ self._consider_using_with_stack = ConsiderUsingWithStack()
+ self._init()
+ self._never_returning_functions: set[str] = set()
+ self._suggest_join_with_non_empty_separator: bool = False
+
+ def _init(self) -> None:
+ self._nested_blocks: list[NodesWithNestedBlocks] = []
+ self._elifs: list[tuple[int, int]] = []
+ self._reported_swap_nodes: set[nodes.NodeNG] = set()
+ self._can_simplify_bool_op: bool = False
+ self._consider_using_with_stack.clear_all()
+
+ def open(self) -> None:
+ # do this in open since config not fully initialized in __init__
+ self._never_returning_functions = set(
+ self.linter.config.never_returning_functions
+ )
+ self._suggest_join_with_non_empty_separator = (
+ self.linter.config.suggest_join_with_non_empty_separator
+ )
+
+ @cached_property
+ def _dummy_rgx(self) -> Pattern[str]:
+ return self.linter.config.dummy_variables_rgx # type: ignore[no-any-return]
+
+ @staticmethod
+ def _is_bool_const(node: nodes.Return | nodes.Assign) -> bool:
+ return isinstance(node.value, nodes.Const) and isinstance(
+ node.value.value, bool
+ )
+
+ def _is_actual_elif(self, node: nodes.If | nodes.Try) -> bool:
+ """Check if the given node is an actual elif.
+
+ This is a problem we're having with the builtin ast module,
+ which splits `elif` branches into a separate if statement.
+ Unfortunately we need to know the exact type in certain
+ cases.
+ """
+ if isinstance(node.parent, nodes.If):
+ orelse = node.parent.orelse
+ # current if node must directly follow an "else"
+ if orelse and orelse == [node]:
+ if (node.lineno, node.col_offset) in self._elifs:
+ return True
+ return False
+
+ def _check_simplifiable_if(self, node: nodes.If) -> None:
+ """Check if the given if node can be simplified.
+
+ The if statement can be reduced to a boolean expression
+ in some cases. For instance, if there are two branches
+ and both of them return a boolean value that depends on
+ the result of the statement's test, then this can be reduced
+ to `bool(test)` without losing any functionality.
+ """
+ if self._is_actual_elif(node):
+ # Not interested in if statements with multiple branches.
+ return
+ if len(node.orelse) != 1 or len(node.body) != 1:
+ return
+
+ # Check if both branches can be reduced.
+ first_branch = node.body[0]
+ else_branch = node.orelse[0]
+ if isinstance(first_branch, nodes.Return):
+ if not isinstance(else_branch, nodes.Return):
+ return
+ first_branch_is_bool = self._is_bool_const(first_branch)
+ else_branch_is_bool = self._is_bool_const(else_branch)
+ reduced_to = "'return bool(test)'"
+ elif isinstance(first_branch, nodes.Assign):
+ if not isinstance(else_branch, nodes.Assign):
+ return
+
+ # Check if we assign to the same value
+ first_branch_targets = [
+ target.name
+ for target in first_branch.targets
+ if isinstance(target, nodes.AssignName)
+ ]
+ else_branch_targets = [
+ target.name
+ for target in else_branch.targets
+ if isinstance(target, nodes.AssignName)
+ ]
+ if not first_branch_targets or not else_branch_targets:
+ return
+ if sorted(first_branch_targets) != sorted(else_branch_targets):
+ return
+
+ first_branch_is_bool = self._is_bool_const(first_branch)
+ else_branch_is_bool = self._is_bool_const(else_branch)
+ reduced_to = "'var = bool(test)'"
+ else:
+ return
+
+ if not first_branch_is_bool or not else_branch_is_bool:
+ return
+ if not first_branch.value.value:
+ # This is a case that can't be easily simplified and
+ # if it can be simplified, it will usually result in a
+ # code that's harder to understand and comprehend.
+ # Let's take for instance `arg and arg <= 3`. This could theoretically be
+ # reduced to `not arg or arg > 3`, but the net result is that now the
+ # condition is harder to understand, because it requires understanding of
+ # an extra clause:
+ # * first, there is the negation of truthness with `not arg`
+ # * the second clause is `arg > 3`, which occurs when arg has a
+ # a truth value, but it implies that `arg > 3` is equivalent
+ # with `arg and arg > 3`, which means that the user must
+ # think about this assumption when evaluating `arg > 3`.
+ # The original form is easier to grasp.
+ return
+
+ self.add_message("simplifiable-if-statement", node=node, args=(reduced_to,))
+
+ def process_tokens(self, tokens: list[tokenize.TokenInfo]) -> None:
+ # Optimization flag because '_is_trailing_comma' is costly
+ trailing_comma_tuple_enabled_for_file = self.linter.is_message_enabled(
+ "trailing-comma-tuple"
+ )
+ trailing_comma_tuple_enabled_once: bool = trailing_comma_tuple_enabled_for_file
+ # Process tokens and look for 'if' or 'elif'
+ for index, token in enumerate(tokens):
+ token_string = token[1]
+ if (
+ not trailing_comma_tuple_enabled_once
+ and token_string.startswith("#")
+ # We have at least 1 '#' (one char) at the start of the token
+ and "pylint:" in token_string[1:]
+ # We have at least '#' 'pylint' ( + ':') (8 chars) at the start of the token
+ and "enable" in token_string[8:]
+ # We have at least '#', 'pylint', ( + ':'), 'enable' (+ '=') (15 chars) at
+ # the start of the token
+ and any(
+ c in token_string[15:] for c in ("trailing-comma-tuple", "R1707")
+ )
+ ):
+ # Way to not have to check if "trailing-comma-tuple" is enabled or
+ # disabled on each line: Any enable for it during tokenization and
+ # we'll start using the costly '_is_trailing_comma' to check if we
+ # need to raise the message. We still won't raise if it's disabled
+ # again due to the usual generic message control handling later.
+ trailing_comma_tuple_enabled_once = True
+ if token_string == "elif":
+ # AST exists by the time process_tokens is called, so
+ # it's safe to assume tokens[index+1] exists.
+ # tokens[index+1][2] is the elif's position as
+ # reported by CPython and PyPy,
+ # token[2] is the actual position and also is
+ # reported by IronPython.
+ self._elifs.extend([token[2], tokens[index + 1][2]])
+ elif (
+ trailing_comma_tuple_enabled_for_file
+ or trailing_comma_tuple_enabled_once
+ ) and _is_trailing_comma(tokens, index):
+ # If "trailing-comma-tuple" is enabled globally we always check _is_trailing_comma
+ # it might be for nothing if there's a local disable, or if the message control is
+ # not enabling 'trailing-comma-tuple', but the alternative is having to check if
+ # it's enabled for a line each line (just to avoid calling '_is_trailing_comma').
+ self.add_message(
+ "trailing-comma-tuple", line=token.start[0], confidence=HIGH
+ )
+
+ @utils.only_required_for_messages("consider-using-with")
+ def leave_module(self, _: nodes.Module) -> None:
+ # check for context managers that have been created but not used
+ self._emit_consider_using_with_if_needed(
+ self._consider_using_with_stack.module_scope
+ )
+ self._init()
+
+ @utils.only_required_for_messages("too-many-nested-blocks", "no-else-return")
+ def visit_try(self, node: nodes.Try) -> None:
+ self._check_nested_blocks(node)
+
+ self._check_superfluous_else_return(node)
+ self._check_superfluous_else_raise(node)
+
+ visit_while = visit_try
+
+ def _check_redefined_argument_from_local(self, name_node: nodes.AssignName) -> None:
+ if self._dummy_rgx and self._dummy_rgx.match(name_node.name):
+ return
+ if not name_node.lineno:
+ # Unknown position, maybe it is a manually built AST?
+ return
+
+ scope = name_node.scope()
+ if not isinstance(scope, nodes.FunctionDef):
+ return
+
+ for defined_argument in scope.args.nodes_of_class(
+ nodes.AssignName, skip_klass=(nodes.Lambda,)
+ ):
+ if defined_argument.name == name_node.name:
+ self.add_message(
+ "redefined-argument-from-local",
+ node=name_node,
+ args=(name_node.name,),
+ )
+
+ @utils.only_required_for_messages(
+ "redefined-argument-from-local",
+ "too-many-nested-blocks",
+ "unnecessary-dict-index-lookup",
+ "unnecessary-list-index-lookup",
+ )
+ def visit_for(self, node: nodes.For) -> None:
+ self._check_nested_blocks(node)
+ self._check_unnecessary_dict_index_lookup(node)
+ self._check_unnecessary_list_index_lookup(node)
+
+ for name in node.target.nodes_of_class(nodes.AssignName):
+ self._check_redefined_argument_from_local(name)
+
+ @utils.only_required_for_messages("redefined-argument-from-local")
+ def visit_excepthandler(self, node: nodes.ExceptHandler) -> None:
+ if node.name and isinstance(node.name, nodes.AssignName):
+ self._check_redefined_argument_from_local(node.name)
+
+ @utils.only_required_for_messages(
+ "redefined-argument-from-local", "consider-using-with"
+ )
+ def visit_with(self, node: nodes.With) -> None:
+ for var, names in node.items:
+ if isinstance(var, nodes.Name):
+ for stack in self._consider_using_with_stack:
+ # We don't need to restrict the stacks we search to the current scope and
+ # outer scopes, as e.g. the function_scope stack will be empty when we
+ # check a ``with`` on the class level.
+ if var.name in stack:
+ del stack[var.name]
+ break
+ if not names:
+ continue
+ for name in names.nodes_of_class(nodes.AssignName):
+ self._check_redefined_argument_from_local(name)
+
+ def _check_superfluous_else(
+ self,
+ node: nodes.If | nodes.Try,
+ msg_id: str,
+ returning_node_class: nodes.NodeNG,
+ ) -> None:
+ if isinstance(node, nodes.Try) and node.finalbody:
+ # Not interested in try/except/else/finally statements.
+ return
+
+ if not node.orelse:
+ # Not interested in if/try statements without else.
+ return
+
+ if self._is_actual_elif(node):
+ # Not interested in elif nodes; only if
+ return
+
+ if (
+ isinstance(node, nodes.If)
+ and _if_statement_is_always_returning(node, returning_node_class)
+ ) or (
+ isinstance(node, nodes.Try)
+ and not node.finalbody
+ and _except_statement_is_always_returning(node, returning_node_class)
+ ):
+ orelse = node.orelse[0]
+ if (orelse.lineno, orelse.col_offset) in self._elifs:
+ args = ("elif", 'remove the leading "el" from "elif"')
+ else:
+ args = ("else", 'remove the "else" and de-indent the code inside it')
+ self.add_message(msg_id, node=node, args=args, confidence=HIGH)
+
+ def _check_superfluous_else_return(self, node: nodes.If) -> None:
+ return self._check_superfluous_else(
+ node, msg_id="no-else-return", returning_node_class=nodes.Return
+ )
+
+ def _check_superfluous_else_raise(self, node: nodes.If) -> None:
+ return self._check_superfluous_else(
+ node, msg_id="no-else-raise", returning_node_class=nodes.Raise
+ )
+
+ def _check_superfluous_else_break(self, node: nodes.If) -> None:
+ return self._check_superfluous_else(
+ node, msg_id="no-else-break", returning_node_class=nodes.Break
+ )
+
+ def _check_superfluous_else_continue(self, node: nodes.If) -> None:
+ return self._check_superfluous_else(
+ node, msg_id="no-else-continue", returning_node_class=nodes.Continue
+ )
+
+ @staticmethod
+ def _type_and_name_are_equal(node_a: Any, node_b: Any) -> bool:
+ if isinstance(node_a, nodes.Name) and isinstance(node_b, nodes.Name):
+ return node_a.name == node_b.name # type: ignore[no-any-return]
+ if isinstance(node_a, nodes.AssignName) and isinstance(
+ node_b, nodes.AssignName
+ ):
+ return node_a.name == node_b.name # type: ignore[no-any-return]
+ if isinstance(node_a, nodes.Const) and isinstance(node_b, nodes.Const):
+ return node_a.value == node_b.value # type: ignore[no-any-return]
+ return False
+
+ def _is_dict_get_block(self, node: nodes.If) -> bool:
+ # "if <compare node>"
+ if not isinstance(node.test, nodes.Compare):
+ return False
+
+ # Does not have a single statement in the guard's body
+ if len(node.body) != 1:
+ return False
+
+ # Look for a single variable assignment on the LHS and a subscript on RHS
+ stmt = node.body[0]
+ if not (
+ isinstance(stmt, nodes.Assign)
+ and len(node.body[0].targets) == 1
+ and isinstance(node.body[0].targets[0], nodes.AssignName)
+ and isinstance(stmt.value, nodes.Subscript)
+ ):
+ return False
+
+ # The subscript's slice needs to be the same as the test variable.
+ slice_value = stmt.value.slice
+ if not (
+ self._type_and_name_are_equal(stmt.value.value, node.test.ops[0][1])
+ and self._type_and_name_are_equal(slice_value, node.test.left)
+ ):
+ return False
+
+ # The object needs to be a dictionary instance
+ return isinstance(utils.safe_infer(node.test.ops[0][1]), nodes.Dict)
+
+ def _check_consider_get(self, node: nodes.If) -> None:
+ if_block_ok = self._is_dict_get_block(node)
+ if if_block_ok and not node.orelse:
+ self.add_message("consider-using-get", node=node)
+ elif (
+ if_block_ok
+ and len(node.orelse) == 1
+ and isinstance(node.orelse[0], nodes.Assign)
+ and self._type_and_name_are_equal(
+ node.orelse[0].targets[0], node.body[0].targets[0]
+ )
+ and len(node.orelse[0].targets) == 1
+ ):
+ self.add_message("consider-using-get", node=node)
+
+ @utils.only_required_for_messages(
+ "too-many-nested-blocks",
+ "simplifiable-if-statement",
+ "no-else-return",
+ "no-else-raise",
+ "no-else-break",
+ "no-else-continue",
+ "consider-using-get",
+ "consider-using-min-builtin",
+ "consider-using-max-builtin",
+ )
+ def visit_if(self, node: nodes.If) -> None:
+ self._check_simplifiable_if(node)
+ self._check_nested_blocks(node)
+ self._check_superfluous_else_return(node)
+ self._check_superfluous_else_raise(node)
+ self._check_superfluous_else_break(node)
+ self._check_superfluous_else_continue(node)
+ self._check_consider_get(node)
+ self._check_consider_using_min_max_builtin(node)
+
+ def _check_consider_using_min_max_builtin(self, node: nodes.If) -> None:
+ """Check if the given if node can be refactored as a min/max python builtin."""
+ # This function is written expecting a test condition of form:
+ # if a < b: # [consider-using-max-builtin]
+ # a = b
+ # if a > b: # [consider-using-min-builtin]
+ # a = b
+ if self._is_actual_elif(node) or node.orelse:
+ # Not interested in if statements with multiple branches.
+ return
+
+ if len(node.body) != 1:
+ return
+
+ def get_node_name(node: nodes.NodeNG) -> str:
+ """Obtain simplest representation of a node as a string."""
+ if isinstance(node, nodes.Name):
+ return node.name # type: ignore[no-any-return]
+ if isinstance(node, nodes.Const):
+ return str(node.value)
+ # this is a catch-all for nodes that are not of type Name or Const
+ # extremely helpful for Call or BinOp
+ return node.as_string() # type: ignore[no-any-return]
+
+ body = node.body[0]
+ # Check if condition can be reduced.
+ if not hasattr(body, "targets") or len(body.targets) != 1:
+ return
+
+ target = body.targets[0]
+ if not (
+ isinstance(node.test, nodes.Compare)
+ and not isinstance(target, nodes.Subscript)
+ and not isinstance(node.test.left, nodes.Subscript)
+ and isinstance(body, nodes.Assign)
+ ):
+ return
+ # Assign body line has one requirement and that is the assign target
+ # is of type name or attribute. Attribute referring to NamedTuple.x perse.
+ # So we have to check that target is of these types
+
+ if not (hasattr(target, "name") or hasattr(target, "attrname")):
+ return
+
+ target_assignation = get_node_name(target)
+
+ if len(node.test.ops) > 1:
+ return
+ operator, right_statement = node.test.ops[0]
+
+ body_value = get_node_name(body.value)
+ left_operand = get_node_name(node.test.left)
+ right_statement_value = get_node_name(right_statement)
+
+ if left_operand == target_assignation:
+ # statement is in expected form
+ pass
+ elif right_statement_value == target_assignation:
+ # statement is in reverse form
+ operator = utils.get_inverse_comparator(operator)
+ else:
+ return
+
+ if body_value not in (right_statement_value, left_operand):
+ return
+
+ if operator in {"<", "<="}:
+ reduced_to = (
+ f"{target_assignation} = max({target_assignation}, {body_value})"
+ )
+ self.add_message(
+ "consider-using-max-builtin", node=node, args=(reduced_to,)
+ )
+ elif operator in {">", ">="}:
+ reduced_to = (
+ f"{target_assignation} = min({target_assignation}, {body_value})"
+ )
+ self.add_message(
+ "consider-using-min-builtin", node=node, args=(reduced_to,)
+ )
+
+ @utils.only_required_for_messages("simplifiable-if-expression")
+ def visit_ifexp(self, node: nodes.IfExp) -> None:
+ self._check_simplifiable_ifexp(node)
+
+ def _check_simplifiable_ifexp(self, node: nodes.IfExp) -> None:
+ if not isinstance(node.body, nodes.Const) or not isinstance(
+ node.orelse, nodes.Const
+ ):
+ return
+
+ if not isinstance(node.body.value, bool) or not isinstance(
+ node.orelse.value, bool
+ ):
+ return
+
+ if isinstance(node.test, nodes.Compare):
+ test_reduced_to = "test"
+ else:
+ test_reduced_to = "bool(test)"
+
+ if (node.body.value, node.orelse.value) == (True, False):
+ reduced_to = f"'{test_reduced_to}'"
+ elif (node.body.value, node.orelse.value) == (False, True):
+ reduced_to = "'not test'"
+ else:
+ return
+
+ self.add_message("simplifiable-if-expression", node=node, args=(reduced_to,))
+
+ @utils.only_required_for_messages(
+ "too-many-nested-blocks",
+ "inconsistent-return-statements",
+ "useless-return",
+ "consider-using-with",
+ )
+ def leave_functiondef(self, node: nodes.FunctionDef) -> None:
+ # check left-over nested blocks stack
+ self._emit_nested_blocks_message_if_needed(self._nested_blocks)
+ # new scope = reinitialize the stack of nested blocks
+ self._nested_blocks = []
+ # check consistent return statements
+ self._check_consistent_returns(node)
+ # check for single return or return None at the end
+ self._check_return_at_the_end(node)
+ self._return_nodes[node.name] = []
+ # check for context managers that have been created but not used
+ self._emit_consider_using_with_if_needed(
+ self._consider_using_with_stack.function_scope
+ )
+ self._consider_using_with_stack.function_scope.clear()
+
+ @utils.only_required_for_messages("consider-using-with")
+ def leave_classdef(self, _: nodes.ClassDef) -> None:
+ # check for context managers that have been created but not used
+ self._emit_consider_using_with_if_needed(
+ self._consider_using_with_stack.class_scope
+ )
+ self._consider_using_with_stack.class_scope.clear()
+
+ @utils.only_required_for_messages("stop-iteration-return")
+ def visit_raise(self, node: nodes.Raise) -> None:
+ self._check_stop_iteration_inside_generator(node)
+
+ def _check_stop_iteration_inside_generator(self, node: nodes.Raise) -> None:
+ """Check if an exception of type StopIteration is raised inside a generator."""
+ frame = node.frame()
+ if not isinstance(frame, nodes.FunctionDef) or not frame.is_generator():
+ return
+ if utils.node_ignores_exception(node, StopIteration):
+ return
+ if not node.exc:
+ return
+ exc = utils.safe_infer(node.exc)
+ if not exc or not isinstance(exc, (bases.Instance, nodes.ClassDef)):
+ return
+ if self._check_exception_inherit_from_stopiteration(exc):
+ self.add_message("stop-iteration-return", node=node, confidence=INFERENCE)
+
+ @staticmethod
+ def _check_exception_inherit_from_stopiteration(
+ exc: nodes.ClassDef | bases.Instance,
+ ) -> bool:
+ """Return True if the exception node in argument inherit from StopIteration."""
+ stopiteration_qname = f"{utils.EXCEPTIONS_MODULE}.StopIteration"
+ return any(_class.qname() == stopiteration_qname for _class in exc.mro())
+
+ def _check_consider_using_comprehension_constructor(self, node: nodes.Call) -> None:
+ if (
+ isinstance(node.func, nodes.Name)
+ and node.args
+ and isinstance(node.args[0], nodes.ListComp)
+ ):
+ if node.func.name == "dict":
+ element = node.args[0].elt
+ if isinstance(element, nodes.Call):
+ return
+
+ # If we have an `IfExp` here where both the key AND value
+ # are different, then don't raise the issue. See #5588
+ if (
+ isinstance(element, nodes.IfExp)
+ and isinstance(element.body, (nodes.Tuple, nodes.List))
+ and len(element.body.elts) == 2
+ and isinstance(element.orelse, (nodes.Tuple, nodes.List))
+ and len(element.orelse.elts) == 2
+ ):
+ key1, value1 = element.body.elts
+ key2, value2 = element.orelse.elts
+ if (
+ key1.as_string() != key2.as_string()
+ and value1.as_string() != value2.as_string()
+ ):
+ return
+
+ message_name = "consider-using-dict-comprehension"
+ self.add_message(message_name, node=node)
+ elif node.func.name == "set":
+ message_name = "consider-using-set-comprehension"
+ self.add_message(message_name, node=node)
+
+ def _check_consider_using_generator(self, node: nodes.Call) -> None:
+ # 'any', 'all', definitely should use generator, while 'list', 'tuple',
+ # 'sum', 'max', and 'min' need to be considered first
+ # See https://github.com/pylint-dev/pylint/pull/3309#discussion_r576683109
+ # https://github.com/pylint-dev/pylint/pull/6595#issuecomment-1125704244
+ # and https://peps.python.org/pep-0289/
+ checked_call = ["any", "all", "sum", "max", "min", "list", "tuple"]
+ if (
+ isinstance(node, nodes.Call)
+ and node.func
+ and isinstance(node.func, nodes.Name)
+ and node.func.name in checked_call
+ ):
+ # functions in checked_calls take exactly one positional argument
+ # check whether the argument is list comprehension
+ if len(node.args) == 1 and isinstance(node.args[0], nodes.ListComp):
+ # remove square brackets '[]'
+ inside_comp = node.args[0].as_string()[1:-1]
+ if node.keywords:
+ inside_comp = f"({inside_comp})"
+ inside_comp += ", "
+ inside_comp += ", ".join(kw.as_string() for kw in node.keywords)
+ call_name = node.func.name
+ if call_name in {"any", "all"}:
+ self.add_message(
+ "use-a-generator",
+ node=node,
+ args=(call_name, inside_comp),
+ )
+ else:
+ self.add_message(
+ "consider-using-generator",
+ node=node,
+ args=(call_name, inside_comp),
+ )
+
+ @utils.only_required_for_messages(
+ "stop-iteration-return",
+ "consider-using-dict-comprehension",
+ "consider-using-set-comprehension",
+ "consider-using-sys-exit",
+ "super-with-arguments",
+ "consider-using-generator",
+ "consider-using-with",
+ "use-list-literal",
+ "use-dict-literal",
+ "use-a-generator",
+ )
+ def visit_call(self, node: nodes.Call) -> None:
+ self._check_raising_stopiteration_in_generator_next_call(node)
+ self._check_consider_using_comprehension_constructor(node)
+ self._check_quit_exit_call(node)
+ self._check_super_with_arguments(node)
+ self._check_consider_using_generator(node)
+ self._check_consider_using_with(node)
+ self._check_use_list_literal(node)
+ self._check_use_dict_literal(node)
+
+ @utils.only_required_for_messages("use-yield-from")
+ def visit_yield(self, node: nodes.Yield) -> None:
+ if not isinstance(node.value, nodes.Name):
+ return
+
+ loop_node = node.parent.parent
+ if (
+ not isinstance(loop_node, nodes.For)
+ or isinstance(loop_node, nodes.AsyncFor)
+ or len(loop_node.body) != 1
+ # Avoid a false positive if the return value from `yield` is used,
+ # (such as via Assign, AugAssign, etc).
+ or not isinstance(node.parent, nodes.Expr)
+ ):
+ return
+
+ if loop_node.target.name != node.value.name:
+ return
+
+ if isinstance(node.frame(), nodes.AsyncFunctionDef):
+ return
+
+ self.add_message("use-yield-from", node=loop_node, confidence=HIGH)
+
+ @staticmethod
+ def _has_exit_in_scope(scope: nodes.LocalsDictNodeNG) -> bool:
+ exit_func = scope.locals.get("exit")
+ return bool(
+ exit_func and isinstance(exit_func[0], (nodes.ImportFrom, nodes.Import))
+ )
+
+ def _check_quit_exit_call(self, node: nodes.Call) -> None:
+ if isinstance(node.func, nodes.Name) and node.func.name in BUILTIN_EXIT_FUNCS:
+ # If we have `exit` imported from `sys` in the current or global scope,
+ # exempt this instance.
+ local_scope = node.scope()
+ if self._has_exit_in_scope(local_scope) or self._has_exit_in_scope(
+ node.root()
+ ):
+ return
+ self.add_message("consider-using-sys-exit", node=node, confidence=HIGH)
+
+ def _check_super_with_arguments(self, node: nodes.Call) -> None:
+ if not isinstance(node.func, nodes.Name) or node.func.name != "super":
+ return
+
+ if (
+ len(node.args) != 2
+ or not all(isinstance(arg, nodes.Name) for arg in node.args)
+ or node.args[1].name != "self"
+ or (frame_class := node_frame_class(node)) is None
+ or node.args[0].name != frame_class.name
+ ):
+ return
+
+ self.add_message("super-with-arguments", node=node)
+
+ def _check_raising_stopiteration_in_generator_next_call(
+ self, node: nodes.Call
+ ) -> None:
+ """Check if a StopIteration exception is raised by the call to next function.
+
+ If the next value has a default value, then do not add message.
+
+ :param node: Check to see if this Call node is a next function
+ :type node: :class:`nodes.Call`
+ """
+
+ def _looks_like_infinite_iterator(param: nodes.NodeNG) -> bool:
+ inferred = utils.safe_infer(param)
+ if isinstance(inferred, bases.Instance):
+ return inferred.qname() in KNOWN_INFINITE_ITERATORS
+ return False
+
+ if isinstance(node.func, nodes.Attribute):
+ # A next() method, which is now what we want.
+ return
+
+ if len(node.args) == 0:
+ # handle case when builtin.next is called without args.
+ # see https://github.com/pylint-dev/pylint/issues/7828
+ return
+
+ inferred = utils.safe_infer(node.func)
+
+ if (
+ isinstance(inferred, nodes.FunctionDef)
+ and inferred.qname() == "builtins.next"
+ ):
+ frame = node.frame()
+ # The next builtin can only have up to two
+ # positional arguments and no keyword arguments
+ has_sentinel_value = len(node.args) > 1
+ if (
+ isinstance(frame, nodes.FunctionDef)
+ and frame.is_generator()
+ and not has_sentinel_value
+ and not utils.node_ignores_exception(node, StopIteration)
+ and not _looks_like_infinite_iterator(node.args[0])
+ ):
+ self.add_message(
+ "stop-iteration-return", node=node, confidence=INFERENCE
+ )
+
+ def _check_nested_blocks(
+ self,
+ node: NodesWithNestedBlocks,
+ ) -> None:
+ """Update and check the number of nested blocks."""
+ # only check block levels inside functions or methods
+ if not isinstance(node.scope(), nodes.FunctionDef):
+ return
+ # messages are triggered on leaving the nested block. Here we save the
+ # stack in case the current node isn't nested in the previous one
+ nested_blocks = self._nested_blocks[:]
+ if node.parent == node.scope():
+ self._nested_blocks = [node]
+ else:
+ # go through ancestors from the most nested to the less
+ for ancestor_node in reversed(self._nested_blocks):
+ if ancestor_node == node.parent:
+ break
+ self._nested_blocks.pop()
+ # if the node is an elif, this should not be another nesting level
+ if isinstance(node, nodes.If) and self._is_actual_elif(node):
+ if self._nested_blocks:
+ self._nested_blocks.pop()
+ self._nested_blocks.append(node)
+
+ # send message only once per group of nested blocks
+ if len(nested_blocks) > len(self._nested_blocks):
+ self._emit_nested_blocks_message_if_needed(nested_blocks)
+
+ def _emit_nested_blocks_message_if_needed(
+ self, nested_blocks: list[NodesWithNestedBlocks]
+ ) -> None:
+ if len(nested_blocks) > self.linter.config.max_nested_blocks:
+ self.add_message(
+ "too-many-nested-blocks",
+ node=nested_blocks[0],
+ args=(len(nested_blocks), self.linter.config.max_nested_blocks),
+ )
+
+ def _emit_consider_using_with_if_needed(
+ self, stack: dict[str, nodes.NodeNG]
+ ) -> None:
+ for node in stack.values():
+ self.add_message("consider-using-with", node=node)
+
+ @staticmethod
+ def _duplicated_isinstance_types(node: nodes.BoolOp) -> dict[str, set[str]]:
+ """Get the duplicated types from the underlying isinstance calls.
+
+ :param nodes.BoolOp node: Node which should contain a bunch of isinstance calls.
+ :returns: Dictionary of the comparison objects from the isinstance calls,
+ to duplicate values from consecutive calls.
+ :rtype: dict
+ """
+ duplicated_objects: set[str] = set()
+ all_types: collections.defaultdict[str, set[str]] = collections.defaultdict(set)
+
+ for call in node.values:
+ if not isinstance(call, nodes.Call) or len(call.args) != 2:
+ continue
+
+ inferred = utils.safe_infer(call.func)
+ if not inferred or not utils.is_builtin_object(inferred):
+ continue
+
+ if inferred.name != "isinstance":
+ continue
+
+ isinstance_object = call.args[0].as_string()
+ isinstance_types = call.args[1]
+
+ if isinstance_object in all_types:
+ duplicated_objects.add(isinstance_object)
+
+ if isinstance(isinstance_types, nodes.Tuple):
+ elems = [
+ class_type.as_string() for class_type in isinstance_types.itered()
+ ]
+ else:
+ elems = [isinstance_types.as_string()]
+ all_types[isinstance_object].update(elems)
+
+ # Remove all keys which not duplicated
+ return {
+ key: value for key, value in all_types.items() if key in duplicated_objects
+ }
+
+ def _check_consider_merging_isinstance(self, node: nodes.BoolOp) -> None:
+ """Check isinstance calls which can be merged together."""
+ if node.op != "or":
+ return
+
+ first_args = self._duplicated_isinstance_types(node)
+ for duplicated_name, class_names in first_args.items():
+ names = sorted(name for name in class_names)
+ self.add_message(
+ "consider-merging-isinstance",
+ node=node,
+ args=(duplicated_name, ", ".join(names)),
+ )
+
+ def _check_consider_using_in(self, node: nodes.BoolOp) -> None:
+ allowed_ops = {"or": "==", "and": "!="}
+
+ if node.op not in allowed_ops or len(node.values) < 2:
+ return
+
+ for value in node.values:
+ if (
+ not isinstance(value, nodes.Compare)
+ or len(value.ops) != 1
+ or value.ops[0][0] not in allowed_ops[node.op]
+ ):
+ return
+ for comparable in value.left, value.ops[0][1]:
+ if isinstance(comparable, nodes.Call):
+ return
+
+ # Gather variables and values from comparisons
+ variables, values = [], []
+ for value in node.values:
+ variable_set = set()
+ for comparable in value.left, value.ops[0][1]:
+ if isinstance(comparable, (nodes.Name, nodes.Attribute)):
+ variable_set.add(comparable.as_string())
+ values.append(comparable.as_string())
+ variables.append(variable_set)
+
+ # Look for (common-)variables that occur in all comparisons
+ common_variables = reduce(lambda a, b: a.intersection(b), variables)
+
+ if not common_variables:
+ return
+
+ # Gather information for the suggestion
+ common_variable = sorted(list(common_variables))[0]
+ values = list(collections.OrderedDict.fromkeys(values))
+ values.remove(common_variable)
+ values_string = ", ".join(values) if len(values) != 1 else values[0] + ","
+ maybe_not = "" if node.op == "or" else "not "
+ self.add_message(
+ "consider-using-in",
+ node=node,
+ args=(common_variable, maybe_not, values_string),
+ confidence=HIGH,
+ )
+
+ def _check_chained_comparison(self, node: nodes.BoolOp) -> None:
+ """Check if there is any chained comparison in the expression.
+
+ Add a refactoring message if a boolOp contains comparison like a < b and b < c,
+ which can be chained as a < b < c.
+
+ Care is taken to avoid simplifying a < b < c and b < d.
+ """
+ if node.op != "and" or len(node.values) < 2:
+ return
+
+ def _find_lower_upper_bounds(
+ comparison_node: nodes.Compare,
+ uses: collections.defaultdict[str, dict[str, set[nodes.Compare]]],
+ ) -> None:
+ left_operand = comparison_node.left
+ for operator, right_operand in comparison_node.ops:
+ for operand in (left_operand, right_operand):
+ value = None
+ if isinstance(operand, nodes.Name):
+ value = operand.name
+ elif isinstance(operand, nodes.Const):
+ value = operand.value
+
+ if value is None:
+ continue
+
+ if operator in {"<", "<="}:
+ if operand is left_operand:
+ uses[value]["lower_bound"].add(comparison_node)
+ elif operand is right_operand:
+ uses[value]["upper_bound"].add(comparison_node)
+ elif operator in {">", ">="}:
+ if operand is left_operand:
+ uses[value]["upper_bound"].add(comparison_node)
+ elif operand is right_operand:
+ uses[value]["lower_bound"].add(comparison_node)
+ left_operand = right_operand
+
+ uses: collections.defaultdict[str, dict[str, set[nodes.Compare]]] = (
+ collections.defaultdict(
+ lambda: {"lower_bound": set(), "upper_bound": set()}
+ )
+ )
+ for comparison_node in node.values:
+ if isinstance(comparison_node, nodes.Compare):
+ _find_lower_upper_bounds(comparison_node, uses)
+
+ for bounds in uses.values():
+ num_shared = len(bounds["lower_bound"].intersection(bounds["upper_bound"]))
+ num_lower_bounds = len(bounds["lower_bound"])
+ num_upper_bounds = len(bounds["upper_bound"])
+ if num_shared < num_lower_bounds and num_shared < num_upper_bounds:
+ self.add_message("chained-comparison", node=node)
+ break
+
+ @staticmethod
+ def _apply_boolean_simplification_rules(
+ operator: str, values: list[nodes.NodeNG]
+ ) -> list[nodes.NodeNG]:
+ """Removes irrelevant values or returns short-circuiting values.
+
+ This function applies the following two rules:
+ 1) an OR expression with True in it will always be true, and the
+ reverse for AND
+
+ 2) False values in OR expressions are only relevant if all values are
+ false, and the reverse for AND
+ """
+ simplified_values: list[nodes.NodeNG] = []
+
+ for subnode in values:
+ inferred_bool = None
+ if not next(subnode.nodes_of_class(nodes.Name), False):
+ inferred = utils.safe_infer(subnode)
+ if inferred:
+ inferred_bool = inferred.bool_value()
+
+ if not isinstance(inferred_bool, bool):
+ simplified_values.append(subnode)
+ elif (operator == "or") == inferred_bool:
+ return [subnode]
+
+ return simplified_values or [nodes.Const(operator == "and")]
+
+ def _simplify_boolean_operation(self, bool_op: nodes.BoolOp) -> nodes.BoolOp:
+ """Attempts to simplify a boolean operation.
+
+ Recursively applies simplification on the operator terms,
+ and keeps track of whether reductions have been made.
+ """
+ children = list(bool_op.get_children())
+ intermediate = [
+ (
+ self._simplify_boolean_operation(child)
+ if isinstance(child, nodes.BoolOp)
+ else child
+ )
+ for child in children
+ ]
+ result = self._apply_boolean_simplification_rules(bool_op.op, intermediate)
+ if len(result) < len(children):
+ self._can_simplify_bool_op = True
+ if len(result) == 1:
+ return result[0]
+ simplified_bool_op = copy.copy(bool_op)
+ simplified_bool_op.postinit(result)
+ return simplified_bool_op
+
+ def _check_simplifiable_condition(self, node: nodes.BoolOp) -> None:
+ """Check if a boolean condition can be simplified.
+
+ Variables will not be simplified, even if the value can be inferred,
+ and expressions like '3 + 4' will remain expanded.
+ """
+ if not utils.is_test_condition(node):
+ return
+
+ self._can_simplify_bool_op = False
+ simplified_expr = self._simplify_boolean_operation(node)
+
+ if not self._can_simplify_bool_op:
+ return
+
+ if not next(simplified_expr.nodes_of_class(nodes.Name), False):
+ self.add_message(
+ "condition-evals-to-constant",
+ node=node,
+ args=(node.as_string(), simplified_expr.as_string()),
+ )
+ else:
+ self.add_message(
+ "simplifiable-condition",
+ node=node,
+ args=(node.as_string(), simplified_expr.as_string()),
+ )
+
+ @utils.only_required_for_messages(
+ "consider-merging-isinstance",
+ "consider-using-in",
+ "chained-comparison",
+ "simplifiable-condition",
+ "condition-evals-to-constant",
+ )
+ def visit_boolop(self, node: nodes.BoolOp) -> None:
+ self._check_consider_merging_isinstance(node)
+ self._check_consider_using_in(node)
+ self._check_chained_comparison(node)
+ self._check_simplifiable_condition(node)
+
+ @staticmethod
+ def _is_simple_assignment(node: nodes.NodeNG | None) -> bool:
+ return (
+ isinstance(node, nodes.Assign)
+ and len(node.targets) == 1
+ and isinstance(node.targets[0], nodes.AssignName)
+ and isinstance(node.value, nodes.Name)
+ )
+
+ def _check_swap_variables(self, node: nodes.Return | nodes.Assign) -> None:
+ if not node.next_sibling() or not node.next_sibling().next_sibling():
+ return
+ assignments = [node, node.next_sibling(), node.next_sibling().next_sibling()]
+ if not all(self._is_simple_assignment(node) for node in assignments):
+ return
+ if any(node in self._reported_swap_nodes for node in assignments):
+ return
+ left = [node.targets[0].name for node in assignments]
+ right = [node.value.name for node in assignments]
+ if left[0] == right[-1] and left[1:] == right[:-1]:
+ self._reported_swap_nodes.update(assignments)
+ message = "consider-swap-variables"
+ self.add_message(message, node=node)
+
+ @utils.only_required_for_messages(
+ "simplify-boolean-expression",
+ "consider-using-ternary",
+ "consider-swap-variables",
+ "consider-using-with",
+ )
+ def visit_assign(self, node: nodes.Assign) -> None:
+ self._append_context_managers_to_stack(node)
+ self.visit_return(node) # remaining checks are identical as for return nodes
+
+ @utils.only_required_for_messages(
+ "simplify-boolean-expression",
+ "consider-using-ternary",
+ "consider-swap-variables",
+ )
+ def visit_return(self, node: nodes.Return | nodes.Assign) -> None:
+ self._check_swap_variables(node)
+ if self._is_and_or_ternary(node.value):
+ cond, truth_value, false_value = self._and_or_ternary_arguments(node.value)
+ else:
+ return
+
+ if all(
+ isinstance(value, nodes.Compare) for value in (truth_value, false_value)
+ ):
+ return
+
+ inferred_truth_value = utils.safe_infer(truth_value, compare_constants=True)
+ if inferred_truth_value is None or isinstance(
+ inferred_truth_value, UninferableBase
+ ):
+ return
+ truth_boolean_value = inferred_truth_value.bool_value()
+
+ if truth_boolean_value is False:
+ message = "simplify-boolean-expression"
+ suggestion = false_value.as_string()
+ else:
+ message = "consider-using-ternary"
+ suggestion = f"{truth_value.as_string()} if {cond.as_string()} else {false_value.as_string()}"
+ self.add_message(message, node=node, args=(suggestion,), confidence=INFERENCE)
+
+ def _append_context_managers_to_stack(self, node: nodes.Assign) -> None:
+ if _is_inside_context_manager(node):
+ # if we are inside a context manager itself, we assume that it will handle
+ # the resource management itself.
+ return
+ if isinstance(node.targets[0], (nodes.Tuple, nodes.List, nodes.Set)):
+ assignees = node.targets[0].elts
+ value = utils.safe_infer(node.value)
+ if value is None or not hasattr(value, "elts"):
+ # We cannot deduce what values are assigned, so we have to skip this
+ return
+ values = value.elts
+ else:
+ assignees = [node.targets[0]]
+ values = [node.value]
+ if any(isinstance(n, UninferableBase) for n in (assignees, values)):
+ return
+ for assignee, value in zip(assignees, values):
+ if not isinstance(value, nodes.Call):
+ continue
+ inferred = utils.safe_infer(value.func)
+ if (
+ not inferred
+ or inferred.qname() not in CALLS_RETURNING_CONTEXT_MANAGERS
+ or not isinstance(assignee, (nodes.AssignName, nodes.AssignAttr))
+ ):
+ continue
+ stack = self._consider_using_with_stack.get_stack_for_frame(node.frame())
+ varname = (
+ assignee.name
+ if isinstance(assignee, nodes.AssignName)
+ else assignee.attrname
+ )
+ if varname in stack:
+ existing_node = stack[varname]
+ if astroid.are_exclusive(node, existing_node):
+ # only one of the two assignments can be executed at runtime, thus it is fine
+ stack[varname] = value
+ continue
+ # variable was redefined before it was used in a ``with`` block
+ self.add_message(
+ "consider-using-with",
+ node=existing_node,
+ )
+ stack[varname] = value
+
+ def _check_consider_using_with(self, node: nodes.Call) -> None:
+ if _is_inside_context_manager(node) or _is_a_return_statement(node):
+ # If we are inside a context manager itself, we assume that it will handle the
+ # resource management itself.
+ # If the node is a child of a return, we assume that the caller knows he is getting
+ # a context manager he should use properly (i.e. in a ``with``).
+ return
+ if (
+ node
+ in self._consider_using_with_stack.get_stack_for_frame(
+ node.frame()
+ ).values()
+ ):
+ # the result of this call was already assigned to a variable and will be
+ # checked when leaving the scope.
+ return
+ inferred = utils.safe_infer(node.func)
+ if not inferred or not isinstance(
+ inferred, (nodes.FunctionDef, nodes.ClassDef, bases.BoundMethod)
+ ):
+ return
+ could_be_used_in_with = (
+ # things like ``lock.acquire()``
+ inferred.qname() in CALLS_THAT_COULD_BE_REPLACED_BY_WITH
+ or (
+ # things like ``open("foo")`` which are not already inside a ``with`` statement
+ inferred.qname() in CALLS_RETURNING_CONTEXT_MANAGERS
+ and not _is_part_of_with_items(node)
+ )
+ )
+ if could_be_used_in_with and not _will_be_released_automatically(node):
+ self.add_message("consider-using-with", node=node)
+
+ def _check_use_list_literal(self, node: nodes.Call) -> None:
+ """Check if empty list is created by using the literal []."""
+ if node.as_string() == "list()":
+ inferred = utils.safe_infer(node.func)
+ if isinstance(inferred, nodes.ClassDef) and not node.args:
+ if inferred.qname() == "builtins.list":
+ self.add_message("use-list-literal", node=node)
+
+ def _check_use_dict_literal(self, node: nodes.Call) -> None:
+ """Check if dict is created by using the literal {}."""
+ if not isinstance(node.func, astroid.Name) or node.func.name != "dict":
+ return
+ inferred = utils.safe_infer(node.func)
+ if (
+ isinstance(inferred, nodes.ClassDef)
+ and inferred.qname() == "builtins.dict"
+ and not node.args
+ ):
+ self.add_message(
+ "use-dict-literal",
+ args=(self._dict_literal_suggestion(node),),
+ node=node,
+ confidence=INFERENCE,
+ )
+
+ @staticmethod
+ def _dict_literal_suggestion(node: nodes.Call) -> str:
+ """Return a suggestion of reasonable length."""
+ elements: list[str] = []
+ for keyword in node.keywords:
+ if len(", ".join(elements)) >= 64:
+ break
+ if keyword not in node.kwargs:
+ elements.append(f'"{keyword.arg}": {keyword.value.as_string()}')
+ for keyword in node.kwargs:
+ if len(", ".join(elements)) >= 64:
+ break
+ elements.append(f"**{keyword.value.as_string()}")
+ suggestion = ", ".join(elements)
+ return f"{{{suggestion}{', ... ' if len(suggestion) > 64 else ''}}}"
+
+ def _name_to_concatenate(self, node: nodes.NodeNG) -> str | None:
+ """Try to extract the name used in a concatenation loop."""
+ if isinstance(node, nodes.Name):
+ return cast("str | None", node.name)
+ if not isinstance(node, nodes.JoinedStr):
+ return None
+
+ values = [
+ value for value in node.values if isinstance(value, nodes.FormattedValue)
+ ]
+ if len(values) != 1 or not isinstance(values[0].value, nodes.Name):
+ return None
+ # If there are more values in joined string than formatted values,
+ # they are probably separators.
+ # Allow them only if the option `suggest-join-with-non-empty-separator` is set
+ with_separators = len(node.values) > len(values)
+ if with_separators and not self._suggest_join_with_non_empty_separator:
+ return None
+ return cast("str | None", values[0].value.name)
+
+ def _check_consider_using_join(self, aug_assign: nodes.AugAssign) -> None:
+ """We start with the augmented assignment and work our way upwards.
+
+ Names of variables for nodes if match successful:
+ result = '' # assign
+ for number in ['1', '2', '3'] # for_loop
+ result += number # aug_assign
+ """
+ for_loop = aug_assign.parent
+ if not isinstance(for_loop, nodes.For) or len(for_loop.body) > 1:
+ return
+ assign = for_loop.previous_sibling()
+ if not isinstance(assign, nodes.Assign):
+ return
+ result_assign_names = {
+ target.name
+ for target in assign.targets
+ if isinstance(target, nodes.AssignName)
+ }
+
+ is_concat_loop = (
+ aug_assign.op == "+="
+ and isinstance(aug_assign.target, nodes.AssignName)
+ and len(for_loop.body) == 1
+ and aug_assign.target.name in result_assign_names
+ and isinstance(assign.value, nodes.Const)
+ and isinstance(assign.value.value, str)
+ and self._name_to_concatenate(aug_assign.value) == for_loop.target.name
+ )
+ if is_concat_loop:
+ self.add_message("consider-using-join", node=aug_assign)
+
+ @utils.only_required_for_messages("consider-using-join")
+ def visit_augassign(self, node: nodes.AugAssign) -> None:
+ self._check_consider_using_join(node)
+
+ @utils.only_required_for_messages(
+ "unnecessary-comprehension",
+ "unnecessary-dict-index-lookup",
+ "unnecessary-list-index-lookup",
+ )
+ def visit_comprehension(self, node: nodes.Comprehension) -> None:
+ self._check_unnecessary_comprehension(node)
+ self._check_unnecessary_dict_index_lookup(node)
+ self._check_unnecessary_list_index_lookup(node)
+
+ def _check_unnecessary_comprehension(self, node: nodes.Comprehension) -> None:
+ if (
+ isinstance(node.parent, nodes.GeneratorExp)
+ or len(node.ifs) != 0
+ or len(node.parent.generators) != 1
+ or node.is_async
+ ):
+ return
+
+ if (
+ isinstance(node.parent, nodes.DictComp)
+ and isinstance(node.parent.key, nodes.Name)
+ and isinstance(node.parent.value, nodes.Name)
+ and isinstance(node.target, nodes.Tuple)
+ and all(isinstance(elt, nodes.AssignName) for elt in node.target.elts)
+ ):
+ expr_list = [node.parent.key.name, node.parent.value.name]
+ target_list = [elt.name for elt in node.target.elts]
+
+ elif isinstance(node.parent, (nodes.ListComp, nodes.SetComp)):
+ expr = node.parent.elt
+ if isinstance(expr, nodes.Name):
+ expr_list = expr.name
+ elif isinstance(expr, nodes.Tuple):
+ if any(not isinstance(elt, nodes.Name) for elt in expr.elts):
+ return
+ expr_list = [elt.name for elt in expr.elts]
+ else:
+ expr_list = []
+ target = node.parent.generators[0].target
+ target_list = (
+ target.name
+ if isinstance(target, nodes.AssignName)
+ else (
+ [
+ elt.name
+ for elt in target.elts
+ if isinstance(elt, nodes.AssignName)
+ ]
+ if isinstance(target, nodes.Tuple)
+ else []
+ )
+ )
+ else:
+ return
+ if expr_list == target_list and expr_list:
+ args: tuple[str] | None = None
+ inferred = utils.safe_infer(node.iter)
+ if isinstance(node.parent, nodes.DictComp) and isinstance(
+ inferred, astroid.objects.DictItems
+ ):
+ args = (f"dict({node.iter.func.expr.as_string()})",)
+ elif isinstance(node.parent, nodes.ListComp) and isinstance(
+ inferred, nodes.List
+ ):
+ args = (f"list({node.iter.as_string()})",)
+ elif isinstance(node.parent, nodes.SetComp) and isinstance(
+ inferred, nodes.Set
+ ):
+ args = (f"set({node.iter.as_string()})",)
+ if args:
+ self.add_message(
+ "unnecessary-comprehension", node=node.parent, args=args
+ )
+ return
+
+ if isinstance(node.parent, nodes.DictComp):
+ func = "dict"
+ elif isinstance(node.parent, nodes.ListComp):
+ func = "list"
+ elif isinstance(node.parent, nodes.SetComp):
+ func = "set"
+ else:
+ return
+
+ self.add_message(
+ "unnecessary-comprehension",
+ node=node.parent,
+ args=(f"{func}({node.iter.as_string()})",),
+ )
+
+ @staticmethod
+ def _is_and_or_ternary(node: nodes.NodeNG | None) -> bool:
+ """Returns true if node is 'condition and true_value or false_value' form.
+
+ All of: condition, true_value and false_value should not be a complex boolean expression
+ """
+ return (
+ isinstance(node, nodes.BoolOp)
+ and node.op == "or"
+ and len(node.values) == 2
+ and isinstance(node.values[0], nodes.BoolOp)
+ and not isinstance(node.values[1], nodes.BoolOp)
+ and node.values[0].op == "and"
+ and not isinstance(node.values[0].values[1], nodes.BoolOp)
+ and len(node.values[0].values) == 2
+ )
+
+ @staticmethod
+ def _and_or_ternary_arguments(
+ node: nodes.BoolOp,
+ ) -> tuple[nodes.NodeNG, nodes.NodeNG, nodes.NodeNG]:
+ false_value = node.values[1]
+ condition, true_value = node.values[0].values
+ return condition, true_value, false_value
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ self._return_nodes[node.name] = list(
+ node.nodes_of_class(nodes.Return, skip_klass=nodes.FunctionDef)
+ )
+
+ def _check_consistent_returns(self, node: nodes.FunctionDef) -> None:
+ """Check that all return statements inside a function are consistent.
+
+ Return statements are consistent if:
+ - all returns are explicit and if there is no implicit return;
+ - all returns are empty and if there is, possibly, an implicit return.
+
+ Args:
+ node (nodes.FunctionDef): the function holding the return statements.
+ """
+ # explicit return statements are those with a not None value
+ explicit_returns = [
+ _node for _node in self._return_nodes[node.name] if _node.value is not None
+ ]
+ if not explicit_returns:
+ return
+ if len(explicit_returns) == len(
+ self._return_nodes[node.name]
+ ) and self._is_node_return_ended(node):
+ return
+ self.add_message("inconsistent-return-statements", node=node)
+
+ def _is_if_node_return_ended(self, node: nodes.If) -> bool:
+ """Check if the If node ends with an explicit return statement.
+
+ Args:
+ node (nodes.If): If node to be checked.
+
+ Returns:
+ bool: True if the node ends with an explicit statement, False otherwise.
+ """
+ # Do not check if inner function definition are return ended.
+ is_if_returning = any(
+ self._is_node_return_ended(_ifn)
+ for _ifn in node.body
+ if not isinstance(_ifn, nodes.FunctionDef)
+ )
+ if not node.orelse:
+ # If there is not orelse part then the if statement is returning if :
+ # - there is at least one return statement in its siblings;
+ # - the if body is itself returning.
+ if not self._has_return_in_siblings(node):
+ return False
+ return is_if_returning
+ # If there is an orelse part then both if body and orelse part should return.
+ is_orelse_returning = any(
+ self._is_node_return_ended(_ore)
+ for _ore in node.orelse
+ if not isinstance(_ore, nodes.FunctionDef)
+ )
+ return is_if_returning and is_orelse_returning
+
+ def _is_raise_node_return_ended(self, node: nodes.Raise) -> bool:
+ """Check if the Raise node ends with an explicit return statement.
+
+ Args:
+ node (nodes.Raise): Raise node to be checked.
+
+ Returns:
+ bool: True if the node ends with an explicit statement, False otherwise.
+ """
+ # a Raise statement doesn't need to end with a return statement
+ # but if the exception raised is handled, then the handler has to
+ # ends with a return statement
+ if not node.exc:
+ # Ignore bare raises
+ return True
+ if not utils.is_node_inside_try_except(node):
+ # If the raise statement is not inside a try/except statement
+ # then the exception is raised and cannot be caught. No need
+ # to infer it.
+ return True
+ exc = utils.safe_infer(node.exc)
+ if (
+ exc is None
+ or isinstance(exc, UninferableBase)
+ or not hasattr(exc, "pytype")
+ ):
+ return False
+ exc_name = exc.pytype().split(".")[-1]
+ handlers = utils.get_exception_handlers(node, exc_name)
+ handlers = list(handlers) if handlers is not None else []
+ if handlers:
+ # among all the handlers handling the exception at least one
+ # must end with a return statement
+ return any(self._is_node_return_ended(_handler) for _handler in handlers)
+ # if no handlers handle the exception then it's ok
+ return True
+
+ def _is_node_return_ended(self, node: nodes.NodeNG) -> bool:
+ """Check if the node ends with an explicit return statement.
+
+ Args:
+ node (nodes.NodeNG): node to be checked.
+
+ Returns:
+ bool: True if the node ends with an explicit statement, False otherwise.
+ """
+ # Recursion base case
+ if isinstance(node, nodes.Return):
+ return True
+ if isinstance(node, nodes.Call):
+ return any(
+ (
+ isinstance(maybe_func, (nodes.FunctionDef, bases.BoundMethod))
+ and self._is_function_def_never_returning(maybe_func)
+ )
+ for maybe_func in utils.infer_all(node.func)
+ )
+ if isinstance(node, nodes.While):
+ # A while-loop is considered return-ended if it has a
+ # truthy test and no break statements
+ return (node.test.bool_value() and not _loop_exits_early(node)) or any(
+ self._is_node_return_ended(child) for child in node.orelse
+ )
+ if isinstance(node, nodes.Raise):
+ return self._is_raise_node_return_ended(node)
+ if isinstance(node, nodes.If):
+ return self._is_if_node_return_ended(node)
+ if isinstance(node, nodes.Try):
+ handlers = {
+ _child
+ for _child in node.get_children()
+ if isinstance(_child, nodes.ExceptHandler)
+ }
+ all_but_handler = set(node.get_children()) - handlers
+ return any(
+ self._is_node_return_ended(_child) for _child in all_but_handler
+ ) and all(self._is_node_return_ended(_child) for _child in handlers)
+ if (
+ isinstance(node, nodes.Assert)
+ and isinstance(node.test, nodes.Const)
+ and not node.test.value
+ ):
+ # consider assert False as a return node
+ return True
+ # recurses on the children of the node
+ return any(self._is_node_return_ended(_child) for _child in node.get_children())
+
+ @staticmethod
+ def _has_return_in_siblings(node: nodes.NodeNG) -> bool:
+ """Returns True if there is at least one return in the node's siblings."""
+ next_sibling = node.next_sibling()
+ while next_sibling:
+ if isinstance(next_sibling, nodes.Return):
+ return True
+ next_sibling = next_sibling.next_sibling()
+ return False
+
+ def _is_function_def_never_returning(
+ self, node: nodes.FunctionDef | astroid.BoundMethod
+ ) -> bool:
+ """Return True if the function never returns, False otherwise.
+
+ Args:
+ node (nodes.FunctionDef or astroid.BoundMethod): function definition node to be analyzed.
+
+ Returns:
+ bool: True if the function never returns, False otherwise.
+ """
+ try:
+ if node.qname() in self._never_returning_functions:
+ return True
+ except (TypeError, AttributeError):
+ pass
+
+ try:
+ returns: nodes.NodeNG | None = node.returns
+ except AttributeError:
+ return False # the BoundMethod proxy may be a lambda without a returns
+
+ return (
+ isinstance(returns, nodes.Attribute)
+ and returns.attrname in {"NoReturn", "Never"}
+ or isinstance(returns, nodes.Name)
+ and returns.name in {"NoReturn", "Never"}
+ )
+
+ def _check_return_at_the_end(self, node: nodes.FunctionDef) -> None:
+ """Check for presence of a *single* return statement at the end of a
+ function.
+
+ "return" or "return None" are useless because None is the
+ default return type if they are missing.
+
+ NOTE: produces a message only if there is a single return statement
+ in the function body. Otherwise _check_consistent_returns() is called!
+ Per its implementation and PEP8 we can have a "return None" at the end
+ of the function body if there are other return statements before that!
+ """
+ if len(self._return_nodes[node.name]) != 1:
+ return
+ if not node.body:
+ return
+
+ last = node.body[-1]
+ if isinstance(last, nodes.Return) and len(node.body) == 1:
+ return
+
+ while isinstance(last, (nodes.If, nodes.Try, nodes.ExceptHandler)):
+ last = last.last_child()
+
+ if isinstance(last, nodes.Return):
+ # e.g. "return"
+ if last.value is None:
+ self.add_message("useless-return", node=node)
+ # return None"
+ elif isinstance(last.value, nodes.Const) and (last.value.value is None):
+ self.add_message("useless-return", node=node)
+
+ def _check_unnecessary_dict_index_lookup(
+ self, node: nodes.For | nodes.Comprehension
+ ) -> None:
+ """Add message when accessing dict values by index lookup."""
+ # Verify that we have an .items() call and
+ # that the object which is iterated is used as a subscript in the
+ # body of the for.
+ # Is it a proper items call?
+ if (
+ isinstance(node.iter, nodes.Call)
+ and isinstance(node.iter.func, nodes.Attribute)
+ and node.iter.func.attrname == "items"
+ ):
+ inferred = utils.safe_infer(node.iter.func)
+ if not isinstance(inferred, astroid.BoundMethod):
+ return
+ iterating_object_name = node.iter.func.expr.as_string()
+
+ # Store potential violations. These will only be reported if we don't
+ # discover any writes to the collection during the loop.
+ messages = []
+
+ # Verify that the body of the for loop uses a subscript
+ # with the object that was iterated. This uses some heuristics
+ # in order to make sure that the same object is used in the
+ # for body.
+
+ children = (
+ node.body
+ if isinstance(node, nodes.For)
+ else list(node.parent.get_children())
+ )
+
+ # Check if there are any for / while loops within the loop in question;
+ # If so, we will be more conservative about reporting errors as we
+ # can't yet do proper control flow analysis to be sure when
+ # reassignment will affect us
+ nested_loops = itertools.chain.from_iterable(
+ child.nodes_of_class((nodes.For, nodes.While)) for child in children
+ )
+ has_nested_loops = next(nested_loops, None) is not None
+
+ for child in children:
+ for subscript in child.nodes_of_class(nodes.Subscript):
+ if not isinstance(subscript.value, (nodes.Name, nodes.Attribute)):
+ continue
+
+ value = subscript.slice
+
+ if isinstance(node, nodes.For) and _is_part_of_assignment_target(
+ subscript
+ ):
+ # Ignore this subscript if it is the target of an assignment
+ # Early termination; after reassignment dict index lookup will be necessary
+ return
+
+ if isinstance(subscript.parent, nodes.Delete):
+ # Ignore this subscript if it's used with the delete keyword
+ return
+
+ # Case where .items is assigned to k,v (i.e., for k, v in d.items())
+ if isinstance(value, nodes.Name):
+ if (
+ not isinstance(node.target, nodes.Tuple)
+ # Ignore 1-tuples: for k, in d.items()
+ or len(node.target.elts) < 2
+ or value.name != node.target.elts[0].name
+ or iterating_object_name != subscript.value.as_string()
+ ):
+ continue
+
+ if (
+ isinstance(node, nodes.For)
+ and value.lookup(value.name)[1][-1].lineno > node.lineno
+ ):
+ # Ignore this subscript if it has been redefined after
+ # the for loop. This checks for the line number using .lookup()
+ # to get the line number where the iterating object was last
+ # defined and compare that to the for loop's line number
+ continue
+
+ if has_nested_loops:
+ messages.append(
+ {
+ "node": subscript,
+ "variable": node.target.elts[1].as_string(),
+ }
+ )
+ else:
+ self.add_message(
+ "unnecessary-dict-index-lookup",
+ node=subscript,
+ args=(node.target.elts[1].as_string(),),
+ )
+
+ # Case where .items is assigned to single var (i.e., for item in d.items())
+ elif isinstance(value, nodes.Subscript):
+ if (
+ not isinstance(node.target, nodes.AssignName)
+ or not isinstance(value.value, nodes.Name)
+ or node.target.name != value.value.name
+ or iterating_object_name != subscript.value.as_string()
+ ):
+ continue
+
+ if (
+ isinstance(node, nodes.For)
+ and value.value.lookup(value.value.name)[1][-1].lineno
+ > node.lineno
+ ):
+ # Ignore this subscript if it has been redefined after
+ # the for loop. This checks for the line number using .lookup()
+ # to get the line number where the iterating object was last
+ # defined and compare that to the for loop's line number
+ continue
+
+ # check if subscripted by 0 (key)
+ inferred = utils.safe_infer(value.slice)
+ if not isinstance(inferred, nodes.Const) or inferred.value != 0:
+ continue
+
+ if has_nested_loops:
+ messages.append(
+ {
+ "node": subscript,
+ "variable": "1".join(
+ value.as_string().rsplit("0", maxsplit=1)
+ ),
+ }
+ )
+ else:
+ self.add_message(
+ "unnecessary-dict-index-lookup",
+ node=subscript,
+ args=(
+ "1".join(value.as_string().rsplit("0", maxsplit=1)),
+ ),
+ )
+
+ for message in messages:
+ self.add_message(
+ "unnecessary-dict-index-lookup",
+ node=message["node"],
+ args=(message["variable"],),
+ )
+
+ def _check_unnecessary_list_index_lookup(
+ self, node: nodes.For | nodes.Comprehension
+ ) -> None:
+ if (
+ not isinstance(node.iter, nodes.Call)
+ or not isinstance(node.iter.func, nodes.Name)
+ or not node.iter.func.name == "enumerate"
+ ):
+ return
+
+ preliminary_confidence = HIGH
+ try:
+ iterable_arg = utils.get_argument_from_call(
+ node.iter, position=0, keyword="iterable"
+ )
+ except utils.NoSuchArgumentError:
+ iterable_arg = utils.infer_kwarg_from_call(node.iter, keyword="iterable")
+ preliminary_confidence = INFERENCE
+
+ if not isinstance(iterable_arg, nodes.Name):
+ return
+
+ if not isinstance(node.target, nodes.Tuple) or len(node.target.elts) < 2:
+ # enumerate() result is being assigned without destructuring
+ return
+
+ if not isinstance(node.target.elts[1], nodes.AssignName):
+ # The value is not being assigned to a single variable, e.g. being
+ # destructured, so we can't necessarily use it.
+ return
+
+ has_start_arg, confidence = self._enumerate_with_start(node)
+ if has_start_arg:
+ # enumerate is being called with start arg/kwarg so resulting index lookup
+ # is not redundant, hence we should not report an error.
+ return
+
+ # Preserve preliminary_confidence if it was INFERENCE
+ confidence = (
+ preliminary_confidence
+ if preliminary_confidence == INFERENCE
+ else confidence
+ )
+
+ iterating_object_name = iterable_arg.name
+ value_variable = node.target.elts[1]
+
+ # Store potential violations. These will only be reported if we don't
+ # discover any writes to the collection during the loop.
+ bad_nodes = []
+
+ children = (
+ node.body
+ if isinstance(node, nodes.For)
+ else list(node.parent.get_children())
+ )
+
+ # Check if there are any for / while loops within the loop in question;
+ # If so, we will be more conservative about reporting errors as we
+ # can't yet do proper control flow analysis to be sure when
+ # reassignment will affect us
+ nested_loops = itertools.chain.from_iterable(
+ child.nodes_of_class((nodes.For, nodes.While)) for child in children
+ )
+ has_nested_loops = next(nested_loops, None) is not None
+
+ # Check if there are any if statements within the loop in question;
+ # If so, we will be more conservative about reporting errors as we
+ # can't yet do proper control flow analysis to be sure when
+ # reassignment will affect us
+ if_statements = itertools.chain.from_iterable(
+ child.nodes_of_class(nodes.If) for child in children
+ )
+ has_if_statements = next(if_statements, None) is not None
+
+ for child in children:
+ for subscript in child.nodes_of_class(nodes.Subscript):
+ if isinstance(node, nodes.For) and _is_part_of_assignment_target(
+ subscript
+ ):
+ # Ignore this subscript if it is the target of an assignment
+ # Early termination; after reassignment index lookup will be necessary
+ return
+
+ if isinstance(subscript.parent, nodes.Delete):
+ # Ignore this subscript if it's used with the delete keyword
+ return
+
+ index = subscript.slice
+ if isinstance(index, nodes.Name):
+ if (
+ index.name != node.target.elts[0].name
+ or iterating_object_name != subscript.value.as_string()
+ ):
+ continue
+
+ if (
+ isinstance(node, nodes.For)
+ and index.lookup(index.name)[1][-1].lineno > node.lineno
+ ):
+ # Ignore this subscript if it has been redefined after
+ # the for loop.
+ continue
+
+ if (
+ isinstance(node, nodes.For)
+ and index.lookup(value_variable.name)[1][-1].lineno
+ > node.lineno
+ ):
+ # The variable holding the value from iteration has been
+ # reassigned on a later line, so it can't be used.
+ continue
+
+ if has_nested_loops:
+ # Have found a likely issue, but since there are nested
+ # loops we don't want to report this unless we get to the
+ # end of the loop without updating the collection
+ bad_nodes.append(subscript)
+ elif has_if_statements:
+ continue
+ else:
+ self.add_message(
+ "unnecessary-list-index-lookup",
+ node=subscript,
+ args=(node.target.elts[1].name,),
+ confidence=confidence,
+ )
+
+ for subscript in bad_nodes:
+ self.add_message(
+ "unnecessary-list-index-lookup",
+ node=subscript,
+ args=(node.target.elts[1].name,),
+ confidence=confidence,
+ )
+
+ def _enumerate_with_start(
+ self, node: nodes.For | nodes.Comprehension
+ ) -> tuple[bool, Confidence]:
+ """Check presence of `start` kwarg or second argument to enumerate.
+
+ For example:
+
+ `enumerate([1,2,3], start=1)`
+ `enumerate([1,2,3], 1)`
+
+ If `start` is assigned to `0`, the default value, this is equivalent to
+ not calling `enumerate` with start.
+ """
+ confidence = HIGH
+
+ if len(node.iter.args) > 1:
+ # We assume the second argument to `enumerate` is the `start` int arg.
+ # It's a reasonable assumption for now as it's the only possible argument:
+ # https://docs.python.org/3/library/functions.html#enumerate
+ start_arg = node.iter.args[1]
+ start_val, confidence = self._get_start_value(start_arg)
+ if start_val is None:
+ return False, confidence
+ return not start_val == 0, confidence
+
+ for keyword in node.iter.keywords:
+ if keyword.arg == "start":
+ start_val, confidence = self._get_start_value(keyword.value)
+ if start_val is None:
+ return False, confidence
+ return not start_val == 0, confidence
+
+ return False, confidence
+
+ def _get_start_value(self, node: nodes.NodeNG) -> tuple[int | None, Confidence]:
+ if (
+ isinstance(node, (nodes.Name, nodes.Call, nodes.Attribute))
+ or isinstance(node, nodes.UnaryOp)
+ and isinstance(node.operand, (nodes.Attribute, nodes.Name))
+ ):
+ inferred = utils.safe_infer(node)
+ # inferred can be an astroid.base.Instance as in 'enumerate(x, int(y))' or
+ # not correctly inferred (None)
+ start_val = inferred.value if isinstance(inferred, nodes.Const) else None
+ return start_val, INFERENCE
+ if isinstance(node, nodes.UnaryOp):
+ return node.operand.value, HIGH
+ if isinstance(node, nodes.Const):
+ return node.value, HIGH
+ return None, HIGH
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/spelling.py b/solutions/.venv/Lib/site-packages/pylint/checkers/spelling.py
new file mode 100644
index 000000000..27d1c7ce0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/spelling.py
@@ -0,0 +1,474 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checker for spelling errors in comments and docstrings."""
+
+from __future__ import annotations
+
+import re
+import tokenize
+from re import Pattern
+from typing import TYPE_CHECKING, Any, Literal
+
+from astroid import nodes
+
+from pylint.checkers import BaseTokenChecker
+from pylint.checkers.utils import only_required_for_messages
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+try:
+ import enchant
+ from enchant.tokenize import (
+ Chunker,
+ EmailFilter,
+ Filter,
+ URLFilter,
+ WikiWordFilter,
+ get_tokenizer,
+ )
+
+ PYENCHANT_AVAILABLE = True
+except ImportError: # pragma: no cover
+ enchant = None
+ PYENCHANT_AVAILABLE = False
+
+ class EmailFilter: # type: ignore[no-redef]
+ ...
+
+ class URLFilter: # type: ignore[no-redef]
+ ...
+
+ class WikiWordFilter: # type: ignore[no-redef]
+ ...
+
+ class Filter: # type: ignore[no-redef]
+ def _skip(self, word: str) -> bool:
+ raise NotImplementedError
+
+ class Chunker: # type: ignore[no-redef]
+ pass
+
+ def get_tokenizer(
+ tag: str | None = None, # pylint: disable=unused-argument
+ chunkers: list[Chunker] | None = None, # pylint: disable=unused-argument
+ filters: list[Filter] | None = None, # pylint: disable=unused-argument
+ ) -> Filter:
+ return Filter()
+
+
+def _get_enchant_dicts() -> list[tuple[Any, enchant.ProviderDesc]]:
+ # Broker().list_dicts() is not typed in enchant, but it does return tuples
+ return enchant.Broker().list_dicts() if PYENCHANT_AVAILABLE else [] # type: ignore[no-any-return]
+
+
+def _get_enchant_dict_choices(
+ inner_enchant_dicts: list[tuple[Any, enchant.ProviderDesc]]
+) -> list[str]:
+ return [""] + [d[0] for d in inner_enchant_dicts]
+
+
+def _get_enchant_dict_help(
+ inner_enchant_dicts: list[tuple[Any, enchant.ProviderDesc]],
+ pyenchant_available: bool,
+) -> str:
+ if inner_enchant_dicts:
+ dict_as_str = [f"{d[0]} ({d[1].name})" for d in inner_enchant_dicts]
+ enchant_help = f"Available dictionaries: {', '.join(dict_as_str)}"
+ else:
+ enchant_help = "No available dictionaries : You need to install "
+ if not pyenchant_available:
+ enchant_help += "both the python package and "
+ enchant_help += "the system dependency for enchant to work"
+ return f"Spelling dictionary name. {enchant_help}."
+
+
+enchant_dicts = _get_enchant_dicts()
+
+
+class WordsWithDigitsFilter(Filter): # type: ignore[misc]
+ """Skips words with digits."""
+
+ def _skip(self, word: str) -> bool:
+ return any(char.isdigit() for char in word)
+
+
+class WordsWithUnderscores(Filter): # type: ignore[misc]
+ """Skips words with underscores.
+
+ They are probably function parameter names.
+ """
+
+ def _skip(self, word: str) -> bool:
+ return "_" in word
+
+
+class RegExFilter(Filter): # type: ignore[misc]
+ """Parent class for filters using regular expressions.
+
+ This filter skips any words the match the expression
+ assigned to the class attribute ``_pattern``.
+ """
+
+ _pattern: Pattern[str]
+
+ def _skip(self, word: str) -> bool:
+ return bool(self._pattern.match(word))
+
+
+class CamelCasedWord(RegExFilter):
+ r"""Filter skipping over camelCasedWords.
+ This filter skips any words matching the following regular expression:
+
+ ^([a-z]\w+[A-Z]+\w+)
+
+ That is, any words that are camelCasedWords.
+ """
+
+ _pattern = re.compile(r"^([a-z]+(\d|[A-Z])(?:\w+)?)")
+
+
+class SphinxDirectives(RegExFilter):
+ r"""Filter skipping over Sphinx Directives.
+ This filter skips any words matching the following regular expression:
+
+ ^(:([a-z]+)){1,2}:`([^`]+)(`)?
+
+ That is, for example, :class:`BaseQuery`
+ """
+
+ # The final ` in the pattern is optional because enchant strips it out
+ _pattern = re.compile(r"^(:([a-z]+)){1,2}:`([^`]+)(`)?")
+
+
+class ForwardSlashChunker(Chunker): # type: ignore[misc]
+ """This chunker allows splitting words like 'before/after' into 'before' and
+ 'after'.
+ """
+
+ _text: str
+
+ def next(self) -> tuple[str, int]:
+ while True:
+ if not self._text:
+ raise StopIteration()
+ if "/" not in self._text:
+ text = self._text
+ self._offset = 0
+ self._text = ""
+ return text, 0
+ pre_text, post_text = self._text.split("/", 1)
+ self._text = post_text
+ self._offset = 0
+ if (
+ not pre_text
+ or not post_text
+ or not pre_text[-1].isalpha()
+ or not post_text[0].isalpha()
+ ):
+ self._text = ""
+ self._offset = 0
+ return f"{pre_text}/{post_text}", 0
+ return pre_text, 0
+
+ def _next(self) -> tuple[str, Literal[0]]:
+ while True:
+ if "/" not in self._text:
+ return self._text, 0
+ pre_text, post_text = self._text.split("/", 1)
+ if not pre_text or not post_text:
+ break
+ if not pre_text[-1].isalpha() or not post_text[0].isalpha():
+ raise StopIteration()
+ self._text = pre_text + " " + post_text
+ raise StopIteration()
+
+
+CODE_FLANKED_IN_BACKTICK_REGEX = re.compile(r"(\s|^)(`{1,2})([^`]+)(\2)([^`]|$)")
+
+
+def _strip_code_flanked_in_backticks(line: str) -> str:
+ """Alter line so code flanked in back-ticks is ignored.
+
+ Pyenchant automatically strips back-ticks when parsing tokens,
+ so this cannot be done at the individual filter level.
+ """
+
+ def replace_code_but_leave_surrounding_characters(match_obj: re.Match[str]) -> str:
+ return match_obj.group(1) + match_obj.group(5)
+
+ return CODE_FLANKED_IN_BACKTICK_REGEX.sub(
+ replace_code_but_leave_surrounding_characters, line
+ )
+
+
+class SpellingChecker(BaseTokenChecker):
+ """Check spelling in comments and docstrings."""
+
+ name = "spelling"
+ msgs = {
+ "C0401": (
+ "Wrong spelling of a word '%s' in a comment:\n%s\n"
+ "%s\nDid you mean: '%s'?",
+ "wrong-spelling-in-comment",
+ "Used when a word in comment is not spelled correctly.",
+ ),
+ "C0402": (
+ "Wrong spelling of a word '%s' in a docstring:\n%s\n"
+ "%s\nDid you mean: '%s'?",
+ "wrong-spelling-in-docstring",
+ "Used when a word in docstring is not spelled correctly.",
+ ),
+ "C0403": (
+ "Invalid characters %r in a docstring",
+ "invalid-characters-in-docstring",
+ "Used when a word in docstring cannot be checked by enchant.",
+ ),
+ }
+ options = (
+ (
+ "spelling-dict",
+ {
+ "default": "",
+ "type": "choice",
+ "metavar": "<dict name>",
+ "choices": _get_enchant_dict_choices(enchant_dicts),
+ "help": _get_enchant_dict_help(enchant_dicts, PYENCHANT_AVAILABLE),
+ },
+ ),
+ (
+ "spelling-ignore-words",
+ {
+ "default": "",
+ "type": "string",
+ "metavar": "<comma separated words>",
+ "help": "List of comma separated words that should not be checked.",
+ },
+ ),
+ (
+ "spelling-private-dict-file",
+ {
+ "default": "",
+ "type": "path",
+ "metavar": "<path to file>",
+ "help": "A path to a file that contains the private "
+ "dictionary; one word per line.",
+ },
+ ),
+ (
+ "spelling-store-unknown-words",
+ {
+ "default": "n",
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Tells whether to store unknown words to the "
+ "private dictionary (see the "
+ "--spelling-private-dict-file option) instead of "
+ "raising a message.",
+ },
+ ),
+ (
+ "max-spelling-suggestions",
+ {
+ "default": 4,
+ "type": "int",
+ "metavar": "N",
+ "help": "Limits count of emitted suggestions for spelling mistakes.",
+ },
+ ),
+ (
+ "spelling-ignore-comment-directives",
+ {
+ "default": "fmt: on,fmt: off,noqa:,noqa,nosec,isort:skip,mypy:",
+ "type": "string",
+ "metavar": "<comma separated words>",
+ "help": "List of comma separated words that should be considered "
+ "directives if they appear at the beginning of a comment "
+ "and should not be checked.",
+ },
+ ),
+ )
+
+ def open(self) -> None:
+ self.initialized = False
+ if not PYENCHANT_AVAILABLE:
+ return
+ dict_name = self.linter.config.spelling_dict
+ if not dict_name:
+ return
+
+ self.ignore_list = [
+ w.strip() for w in self.linter.config.spelling_ignore_words.split(",")
+ ]
+ # "param" appears in docstring in param description and
+ # "pylint" appears in comments in pylint pragmas.
+ self.ignore_list.extend(["param", "pylint"])
+
+ self.ignore_comment_directive_list = [
+ w.strip()
+ for w in self.linter.config.spelling_ignore_comment_directives.split(",")
+ ]
+
+ if self.linter.config.spelling_private_dict_file:
+ self.spelling_dict = enchant.DictWithPWL(
+ dict_name, self.linter.config.spelling_private_dict_file
+ )
+ else:
+ self.spelling_dict = enchant.Dict(dict_name)
+
+ if self.linter.config.spelling_store_unknown_words:
+ self.unknown_words: set[str] = set()
+
+ self.tokenizer = get_tokenizer(
+ dict_name,
+ chunkers=[ForwardSlashChunker],
+ filters=[
+ EmailFilter,
+ URLFilter,
+ WikiWordFilter,
+ WordsWithDigitsFilter,
+ WordsWithUnderscores,
+ CamelCasedWord,
+ SphinxDirectives,
+ ],
+ )
+ self.initialized = True
+
+ # pylint: disable = too-many-statements
+ def _check_spelling(self, msgid: str, line: str, line_num: int) -> None:
+ original_line = line
+ try:
+ # The mypy warning is caught by the except statement
+ initial_space = re.search(r"^\s+", line).regs[0][1] # type: ignore[union-attr]
+ except (IndexError, AttributeError):
+ initial_space = 0
+ if line.strip().startswith("#") and "docstring" not in msgid:
+ line = line.strip()[1:]
+ # A ``Filter`` cannot determine if the directive is at the beginning of a line,
+ # nor determine if a colon is present or not (``pyenchant`` strips trailing colons).
+ # So implementing this here.
+ for iter_directive in self.ignore_comment_directive_list:
+ if line.startswith(" " + iter_directive):
+ line = line[(len(iter_directive) + 1) :]
+ break
+ starts_with_comment = True
+ else:
+ starts_with_comment = False
+
+ line = _strip_code_flanked_in_backticks(line)
+
+ for word, word_start_at in self.tokenizer(line.strip()):
+ word_start_at += initial_space
+ lower_cased_word = word.casefold()
+
+ # Skip words from ignore list.
+ if word in self.ignore_list or lower_cased_word in self.ignore_list:
+ continue
+
+ # Strip starting u' from unicode literals and r' from raw strings.
+ if word.startswith(("u'", 'u"', "r'", 'r"')) and len(word) > 2:
+ word = word[2:]
+ lower_cased_word = lower_cased_word[2:]
+
+ # If it is a known word, then continue.
+ try:
+ if self.spelling_dict.check(lower_cased_word):
+ # The lower cased version of word passed spell checking
+ continue
+
+ # If we reached this far, it means there was a spelling mistake.
+ # Let's retry with the original work because 'unicode' is a
+ # spelling mistake but 'Unicode' is not
+ if self.spelling_dict.check(word):
+ continue
+ except enchant.errors.Error:
+ self.add_message(
+ "invalid-characters-in-docstring", line=line_num, args=(word,)
+ )
+ continue
+
+ # Store word to private dict or raise a message.
+ if self.linter.config.spelling_store_unknown_words:
+ if lower_cased_word not in self.unknown_words:
+ with open(
+ self.linter.config.spelling_private_dict_file,
+ "a",
+ encoding="utf-8",
+ ) as f:
+ f.write(f"{lower_cased_word}\n")
+ self.unknown_words.add(lower_cased_word)
+ else:
+ # Present up to N suggestions.
+ suggestions = self.spelling_dict.suggest(word)
+ del suggestions[self.linter.config.max_spelling_suggestions :]
+ line_segment = line[word_start_at:]
+ match = re.search(rf"(\W|^)({word})(\W|$)", line_segment)
+ if match:
+ # Start position of second group in regex.
+ col = match.regs[2][0]
+ else:
+ col = line_segment.index(word)
+ col += word_start_at
+ if starts_with_comment:
+ col += 1
+ indicator = (" " * col) + ("^" * len(word))
+ all_suggestion = "' or '".join(suggestions)
+ args = (word, original_line, indicator, f"'{all_suggestion}'")
+ self.add_message(msgid, line=line_num, args=args)
+
+ def process_tokens(self, tokens: list[tokenize.TokenInfo]) -> None:
+ if not self.initialized:
+ return
+
+ # Process tokens and look for comments.
+ for tok_type, token, (start_row, _), _, _ in tokens:
+ if tok_type == tokenize.COMMENT:
+ if start_row == 1 and token.startswith("#!/"):
+ # Skip shebang lines
+ continue
+ if token.startswith("# pylint:"):
+ # Skip pylint enable/disable comments
+ continue
+ if token.startswith("# type: "):
+ # Skip python 2 type comments and mypy type ignore comments
+ # mypy do not support additional text in type comments
+ continue
+ self._check_spelling("wrong-spelling-in-comment", token, start_row)
+
+ @only_required_for_messages("wrong-spelling-in-docstring")
+ def visit_module(self, node: nodes.Module) -> None:
+ self._check_docstring(node)
+
+ @only_required_for_messages("wrong-spelling-in-docstring")
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ self._check_docstring(node)
+
+ @only_required_for_messages("wrong-spelling-in-docstring")
+ def visit_functiondef(
+ self, node: nodes.FunctionDef | nodes.AsyncFunctionDef
+ ) -> None:
+ self._check_docstring(node)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_docstring(
+ self,
+ node: (
+ nodes.FunctionDef | nodes.AsyncFunctionDef | nodes.ClassDef | nodes.Module
+ ),
+ ) -> None:
+ """Check if the node has any spelling errors."""
+ if not self.initialized:
+ return
+ if not node.doc_node:
+ return
+ start_line = node.lineno + 1
+ # Go through lines of docstring
+ for idx, line in enumerate(node.doc_node.value.splitlines()):
+ self._check_spelling("wrong-spelling-in-docstring", line, start_line + idx)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(SpellingChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/stdlib.py b/solutions/.venv/Lib/site-packages/pylint/checkers/stdlib.py
new file mode 100644
index 000000000..9225cd4d2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/stdlib.py
@@ -0,0 +1,975 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checkers for various standard library functions."""
+
+from __future__ import annotations
+
+import sys
+from collections.abc import Iterable
+from typing import TYPE_CHECKING, Any
+
+import astroid
+from astroid import nodes, util
+from astroid.typing import InferenceResult
+
+from pylint import interfaces
+from pylint.checkers import BaseChecker, DeprecatedMixin, utils
+from pylint.interfaces import HIGH, INFERENCE
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+DeprecationDict = dict[tuple[int, int, int], set[str]]
+
+OPEN_FILES_MODE = ("open", "file")
+OPEN_FILES_FUNCS = (*OPEN_FILES_MODE, "read_text", "write_text")
+UNITTEST_CASE = "unittest.case"
+THREADING_THREAD = "threading.Thread"
+COPY_COPY = "copy.copy"
+OS_ENVIRON = "os._Environ"
+ENV_GETTERS = ("os.getenv",)
+SUBPROCESS_POPEN = "subprocess.Popen"
+SUBPROCESS_RUN = "subprocess.run"
+OPEN_MODULE = {"_io", "pathlib", "pathlib._local"}
+PATHLIB_MODULE = {"pathlib", "pathlib._local"}
+DEBUG_BREAKPOINTS = ("builtins.breakpoint", "sys.breakpointhook", "pdb.set_trace")
+LRU_CACHE = {
+ "functools.lru_cache", # Inferred for @lru_cache
+ "functools._lru_cache_wrapper.wrapper", # Inferred for @lru_cache() on >= Python 3.8
+ "functools.lru_cache.decorating_function", # Inferred for @lru_cache() on <= Python 3.7
+}
+NON_INSTANCE_METHODS = {"builtins.staticmethod", "builtins.classmethod"}
+
+
+# For modules, see ImportsChecker
+
+DEPRECATED_ARGUMENTS: dict[
+ tuple[int, int, int], dict[str, tuple[tuple[int | None, str], ...]]
+] = {
+ (0, 0, 0): {
+ "int": ((None, "x"),),
+ "bool": ((None, "x"),),
+ "float": ((None, "x"),),
+ },
+ (3, 5, 0): {
+ "importlib._bootstrap_external.cache_from_source": ((1, "debug_override"),),
+ },
+ (3, 8, 0): {
+ "asyncio.tasks.sleep": ((None, "loop"),),
+ "asyncio.tasks.gather": ((None, "loop"),),
+ "asyncio.tasks.shield": ((None, "loop"),),
+ "asyncio.tasks.wait_for": ((None, "loop"),),
+ "asyncio.tasks.wait": ((None, "loop"),),
+ "asyncio.tasks.as_completed": ((None, "loop"),),
+ "asyncio.subprocess.create_subprocess_exec": ((None, "loop"),),
+ "asyncio.subprocess.create_subprocess_shell": ((4, "loop"),),
+ "gettext.translation": ((5, "codeset"),),
+ "gettext.install": ((2, "codeset"),),
+ "functools.partialmethod": ((None, "func"),),
+ "weakref.finalize": ((None, "func"), (None, "obj")),
+ "profile.Profile.runcall": ((None, "func"),),
+ "cProfile.Profile.runcall": ((None, "func"),),
+ "bdb.Bdb.runcall": ((None, "func"),),
+ "trace.Trace.runfunc": ((None, "func"),),
+ "curses.wrapper": ((None, "func"),),
+ "unittest.case.TestCase.addCleanup": ((None, "function"),),
+ "concurrent.futures.thread.ThreadPoolExecutor.submit": ((None, "fn"),),
+ "concurrent.futures.process.ProcessPoolExecutor.submit": ((None, "fn"),),
+ "contextlib._BaseExitStack.callback": ((None, "callback"),),
+ "contextlib.AsyncExitStack.push_async_callback": ((None, "callback"),),
+ "multiprocessing.managers.Server.create": ((None, "c"), (None, "typeid")),
+ "multiprocessing.managers.SharedMemoryServer.create": (
+ (None, "c"),
+ (None, "typeid"),
+ ),
+ },
+ (3, 9, 0): {"random.Random.shuffle": ((1, "random"),)},
+ (3, 12, 0): {
+ "argparse.BooleanOptionalAction": ((3, "type"), (4, "choices"), (7, "metavar")),
+ "coroutine.throw": ((1, "value"), (2, "traceback")),
+ "email.utils.localtime": ((1, "isdst"),),
+ "shutil.rmtree": ((2, "onerror"),),
+ },
+ (3, 13, 0): {
+ "dis.get_instructions": ((2, "show_caches"),),
+ },
+}
+
+DEPRECATED_DECORATORS: DeprecationDict = {
+ (3, 8, 0): {"asyncio.coroutine"},
+ (3, 3, 0): {
+ "abc.abstractclassmethod",
+ "abc.abstractstaticmethod",
+ "abc.abstractproperty",
+ },
+ (3, 4, 0): {"importlib.util.module_for_loader"},
+ (3, 13, 0): {"typing.no_type_check_decorator"},
+}
+
+
+DEPRECATED_METHODS: dict[int, DeprecationDict] = {
+ 0: {
+ (0, 0, 0): {
+ "cgi.parse_qs",
+ "cgi.parse_qsl",
+ "ctypes.c_buffer",
+ "distutils.command.register.register.check_metadata",
+ "distutils.command.sdist.sdist.check_metadata",
+ "tkinter.Misc.tk_menuBar",
+ "tkinter.Menu.tk_bindForTraversal",
+ }
+ },
+ 2: {
+ (2, 6, 0): {
+ "commands.getstatus",
+ "os.popen2",
+ "os.popen3",
+ "os.popen4",
+ "macostools.touched",
+ },
+ (2, 7, 0): {
+ "unittest.case.TestCase.assertEquals",
+ "unittest.case.TestCase.assertNotEquals",
+ "unittest.case.TestCase.assertAlmostEquals",
+ "unittest.case.TestCase.assertNotAlmostEquals",
+ "unittest.case.TestCase.assert_",
+ "xml.etree.ElementTree.Element.getchildren",
+ "xml.etree.ElementTree.Element.getiterator",
+ "xml.etree.ElementTree.XMLParser.getiterator",
+ "xml.etree.ElementTree.XMLParser.doctype",
+ },
+ },
+ 3: {
+ (3, 0, 0): {
+ "inspect.getargspec",
+ "failUnlessEqual",
+ "assertEquals",
+ "failIfEqual",
+ "assertNotEquals",
+ "failUnlessAlmostEqual",
+ "assertAlmostEquals",
+ "failIfAlmostEqual",
+ "assertNotAlmostEquals",
+ "failUnless",
+ "assert_",
+ "failUnlessRaises",
+ "failIf",
+ "assertRaisesRegexp",
+ "assertRegexpMatches",
+ "assertNotRegexpMatches",
+ },
+ (3, 1, 0): {
+ "base64.encodestring",
+ "base64.decodestring",
+ "ntpath.splitunc",
+ "os.path.splitunc",
+ "os.stat_float_times",
+ "turtle.RawTurtle.settiltangle",
+ },
+ (3, 2, 0): {
+ "cgi.escape",
+ "configparser.RawConfigParser.readfp",
+ "xml.etree.ElementTree.Element.getchildren",
+ "xml.etree.ElementTree.Element.getiterator",
+ "xml.etree.ElementTree.XMLParser.getiterator",
+ "xml.etree.ElementTree.XMLParser.doctype",
+ },
+ (3, 3, 0): {
+ "inspect.getmoduleinfo",
+ "logging.warn",
+ "logging.Logger.warn",
+ "logging.LoggerAdapter.warn",
+ "nntplib._NNTPBase.xpath",
+ "platform.popen",
+ "sqlite3.OptimizedUnicode",
+ "time.clock",
+ },
+ (3, 4, 0): {
+ "importlib.find_loader",
+ "importlib.abc.Loader.load_module",
+ "importlib.abc.Loader.module_repr",
+ "importlib.abc.PathEntryFinder.find_loader",
+ "importlib.abc.PathEntryFinder.find_module",
+ "plistlib.readPlist",
+ "plistlib.writePlist",
+ "plistlib.readPlistFromBytes",
+ "plistlib.writePlistToBytes",
+ },
+ (3, 4, 4): {"asyncio.tasks.async"},
+ (3, 5, 0): {
+ "fractions.gcd",
+ "inspect.formatargspec",
+ "inspect.getcallargs",
+ "platform.linux_distribution",
+ "platform.dist",
+ },
+ (3, 6, 0): {
+ "importlib._bootstrap_external.FileLoader.load_module",
+ "_ssl.RAND_pseudo_bytes",
+ },
+ (3, 7, 0): {
+ "sys.set_coroutine_wrapper",
+ "sys.get_coroutine_wrapper",
+ "aifc.openfp",
+ "threading.Thread.isAlive",
+ "asyncio.Task.current_task",
+ "asyncio.Task.all_task",
+ "locale.format",
+ "ssl.wrap_socket",
+ "ssl.match_hostname",
+ "sunau.openfp",
+ "wave.openfp",
+ },
+ (3, 8, 0): {
+ "gettext.lgettext",
+ "gettext.ldgettext",
+ "gettext.lngettext",
+ "gettext.ldngettext",
+ "gettext.bind_textdomain_codeset",
+ "gettext.NullTranslations.output_charset",
+ "gettext.NullTranslations.set_output_charset",
+ "threading.Thread.isAlive",
+ },
+ (3, 9, 0): {
+ "binascii.b2a_hqx",
+ "binascii.a2b_hqx",
+ "binascii.rlecode_hqx",
+ "binascii.rledecode_hqx",
+ "importlib.resources.contents",
+ "importlib.resources.is_resource",
+ "importlib.resources.open_binary",
+ "importlib.resources.open_text",
+ "importlib.resources.path",
+ "importlib.resources.read_binary",
+ "importlib.resources.read_text",
+ },
+ (3, 10, 0): {
+ "_sqlite3.enable_shared_cache",
+ "importlib.abc.Finder.find_module",
+ "pathlib.Path.link_to",
+ "zipimport.zipimporter.load_module",
+ "zipimport.zipimporter.find_module",
+ "zipimport.zipimporter.find_loader",
+ "threading.currentThread",
+ "threading.activeCount",
+ "threading.Condition.notifyAll",
+ "threading.Event.isSet",
+ "threading.Thread.setName",
+ "threading.Thread.getName",
+ "threading.Thread.isDaemon",
+ "threading.Thread.setDaemon",
+ "cgi.log",
+ },
+ (3, 11, 0): {
+ "locale.getdefaultlocale",
+ "locale.resetlocale",
+ "re.template",
+ "unittest.findTestCases",
+ "unittest.makeSuite",
+ "unittest.getTestCaseNames",
+ "unittest.TestLoader.loadTestsFromModule",
+ "unittest.TestLoader.loadTestsFromTestCase",
+ "unittest.TestLoader.getTestCaseNames",
+ "unittest.TestProgram.usageExit",
+ },
+ (3, 12, 0): {
+ "asyncio.get_child_watcher",
+ "asyncio.set_child_watcher",
+ "asyncio.AbstractEventLoopPolicy.get_child_watcher",
+ "asyncio.AbstractEventLoopPolicy.set_child_watcher",
+ "builtins.bool.__invert__",
+ "datetime.datetime.utcfromtimestamp",
+ "datetime.datetime.utcnow",
+ "pkgutil.find_loader",
+ "pkgutil.get_loader",
+ "pty.master_open",
+ "pty.slave_open",
+ "xml.etree.ElementTree.Element.__bool__",
+ },
+ (3, 13, 0): {
+ "ctypes.SetPointerType",
+ "pathlib.PurePath.is_reserved",
+ "platform.java_ver",
+ "pydoc.is_package",
+ "sys._enablelegacywindowsfsencoding",
+ "wave.Wave_read.getmark",
+ "wave.Wave_read.getmarkers",
+ "wave.Wave_read.setmark",
+ "wave.Wave_write.getmark",
+ "wave.Wave_write.getmarkers",
+ "wave.Wave_write.setmark",
+ },
+ },
+}
+
+
+DEPRECATED_CLASSES: dict[tuple[int, int, int], dict[str, set[str]]] = {
+ (3, 2, 0): {
+ "configparser": {
+ "LegacyInterpolation",
+ "SafeConfigParser",
+ },
+ },
+ (3, 3, 0): {
+ "importlib.abc": {
+ "Finder",
+ },
+ "pkgutil": {
+ "ImpImporter",
+ "ImpLoader",
+ },
+ "collections": {
+ "Awaitable",
+ "Coroutine",
+ "AsyncIterable",
+ "AsyncIterator",
+ "AsyncGenerator",
+ "Hashable",
+ "Iterable",
+ "Iterator",
+ "Generator",
+ "Reversible",
+ "Sized",
+ "Container",
+ "Callable",
+ "Collection",
+ "Set",
+ "MutableSet",
+ "Mapping",
+ "MutableMapping",
+ "MappingView",
+ "KeysView",
+ "ItemsView",
+ "ValuesView",
+ "Sequence",
+ "MutableSequence",
+ "ByteString",
+ },
+ },
+ (3, 9, 0): {
+ "smtpd": {
+ "MailmanProxy",
+ }
+ },
+ (3, 11, 0): {
+ "typing": {
+ "Text",
+ },
+ "urllib.parse": {
+ "Quoter",
+ },
+ "webbrowser": {
+ "MacOSX",
+ },
+ },
+ (3, 12, 0): {
+ "ast": {
+ "Bytes",
+ "Ellipsis",
+ "NameConstant",
+ "Num",
+ "Str",
+ },
+ "asyncio": {
+ "AbstractChildWatcher",
+ "MultiLoopChildWatcher",
+ "FastChildWatcher",
+ "SafeChildWatcher",
+ },
+ "collections.abc": {
+ "ByteString",
+ },
+ "importlib.abc": {
+ "ResourceReader",
+ "Traversable",
+ "TraversableResources",
+ },
+ "typing": {
+ "ByteString",
+ "Hashable",
+ "Sized",
+ },
+ },
+ (3, 13, 0): {
+ "glob": {
+ "glob.glob0",
+ "glob.glob1",
+ },
+ "http.server": {
+ "CGIHTTPRequestHandler",
+ },
+ },
+}
+
+
+DEPRECATED_ATTRIBUTES: DeprecationDict = {
+ (3, 2, 0): {
+ "configparser.ParsingError.filename",
+ },
+ (3, 12, 0): {
+ "calendar.January",
+ "calendar.February",
+ "sqlite3.version",
+ "sqlite3.version_info",
+ "sys.last_traceback",
+ "sys.last_type",
+ "sys.last_value",
+ },
+ (3, 13, 0): {
+ "dis.HAVE_ARGUMENT",
+ "tarfile.TarFile.tarfile",
+ "traceback.TracebackException.exc_type",
+ "typing.AnyStr",
+ },
+}
+
+
+def _check_mode_str(mode: Any) -> bool:
+ # check type
+ if not isinstance(mode, str):
+ return False
+ # check syntax
+ modes = set(mode)
+ _mode = "rwatb+Ux"
+ creating = "x" in modes
+ if modes - set(_mode) or len(mode) > len(modes):
+ return False
+ # check logic
+ reading = "r" in modes
+ writing = "w" in modes
+ appending = "a" in modes
+ text = "t" in modes
+ binary = "b" in modes
+ if "U" in modes:
+ if writing or appending or creating:
+ return False
+ reading = True
+ if text and binary:
+ return False
+ total = reading + writing + appending + creating
+ if total > 1:
+ return False
+ if not (reading or writing or appending or creating):
+ return False
+ return True
+
+
+class StdlibChecker(DeprecatedMixin, BaseChecker):
+ name = "stdlib"
+
+ msgs: dict[str, MessageDefinitionTuple] = {
+ **DeprecatedMixin.DEPRECATED_METHOD_MESSAGE,
+ **DeprecatedMixin.DEPRECATED_ARGUMENT_MESSAGE,
+ **DeprecatedMixin.DEPRECATED_CLASS_MESSAGE,
+ **DeprecatedMixin.DEPRECATED_DECORATOR_MESSAGE,
+ **DeprecatedMixin.DEPRECATED_ATTRIBUTE_MESSAGE,
+ "W1501": (
+ '"%s" is not a valid mode for open.',
+ "bad-open-mode",
+ "Python supports: r, w, a[, x] modes with b, +, "
+ "and U (only with r) options. "
+ "See https://docs.python.org/3/library/functions.html#open",
+ ),
+ "W1502": (
+ "Using datetime.time in a boolean context.",
+ "boolean-datetime",
+ "Using datetime.time in a boolean context can hide "
+ "subtle bugs when the time they represent matches "
+ "midnight UTC. This behaviour was fixed in Python 3.5. "
+ "See https://bugs.python.org/issue13936 for reference.",
+ {"maxversion": (3, 5)},
+ ),
+ "W1503": (
+ "Redundant use of %s with constant value %r",
+ "redundant-unittest-assert",
+ "The first argument of assertTrue and assertFalse is "
+ "a condition. If a constant is passed as parameter, that "
+ "condition will be always true. In this case a warning "
+ "should be emitted.",
+ ),
+ "W1506": (
+ "threading.Thread needs the target function",
+ "bad-thread-instantiation",
+ "The warning is emitted when a threading.Thread class "
+ "is instantiated without the target function being passed as a kwarg or as a second argument. "
+ "By default, the first parameter is the group param, not the target param.",
+ ),
+ "W1507": (
+ "Using copy.copy(os.environ). Use os.environ.copy() instead.",
+ "shallow-copy-environ",
+ "os.environ is not a dict object but proxy object, so "
+ "shallow copy has still effects on original object. "
+ "See https://bugs.python.org/issue15373 for reference.",
+ ),
+ "E1507": (
+ "%s does not support %s type argument",
+ "invalid-envvar-value",
+ "Env manipulation functions support only string type arguments. "
+ "See https://docs.python.org/3/library/os.html#os.getenv.",
+ ),
+ "E1519": (
+ "singledispatch decorator should not be used with methods, "
+ "use singledispatchmethod instead.",
+ "singledispatch-method",
+ "singledispatch should decorate functions and not class/instance methods. "
+ "Use singledispatchmethod for those cases.",
+ ),
+ "E1520": (
+ "singledispatchmethod decorator should not be used with functions, "
+ "use singledispatch instead.",
+ "singledispatchmethod-function",
+ "singledispatchmethod should decorate class/instance methods and not functions. "
+ "Use singledispatch for those cases.",
+ ),
+ "W1508": (
+ "%s default type is %s. Expected str or None.",
+ "invalid-envvar-default",
+ "Env manipulation functions return None or str values. "
+ "Supplying anything different as a default may cause bugs. "
+ "See https://docs.python.org/3/library/os.html#os.getenv.",
+ ),
+ "W1509": (
+ "Using preexec_fn keyword which may be unsafe in the presence "
+ "of threads",
+ "subprocess-popen-preexec-fn",
+ "The preexec_fn parameter is not safe to use in the presence "
+ "of threads in your application. The child process could "
+ "deadlock before exec is called. If you must use it, keep it "
+ "trivial! Minimize the number of libraries you call into. "
+ "See https://docs.python.org/3/library/subprocess.html#popen-constructor",
+ ),
+ "W1510": (
+ "'subprocess.run' used without explicitly defining the value for 'check'.",
+ "subprocess-run-check",
+ "The ``check`` keyword is set to False by default. It means the process "
+ "launched by ``subprocess.run`` can exit with a non-zero exit code and "
+ "fail silently. It's better to set it explicitly to make clear what the "
+ "error-handling behavior is.",
+ ),
+ "W1514": (
+ "Using open without explicitly specifying an encoding",
+ "unspecified-encoding",
+ "It is better to specify an encoding when opening documents. "
+ "Using the system default implicitly can create problems on other operating systems. "
+ "See https://peps.python.org/pep-0597/",
+ ),
+ "W1515": (
+ "Leaving functions creating breakpoints in production code is not recommended",
+ "forgotten-debug-statement",
+ "Calls to breakpoint(), sys.breakpointhook() and pdb.set_trace() should be removed "
+ "from code that is not actively being debugged.",
+ ),
+ "W1518": (
+ "'lru_cache(maxsize=None)' or 'cache' will keep all method args alive indefinitely, including 'self'",
+ "method-cache-max-size-none",
+ "By decorating a method with lru_cache or cache the 'self' argument will be linked to "
+ "the function and therefore never garbage collected. Unless your instance "
+ "will never need to be garbage collected (singleton) it is recommended to refactor "
+ "code to avoid this pattern or add a maxsize to the cache. "
+ "The default value for maxsize is 128.",
+ {
+ "old_names": [
+ ("W1516", "lru-cache-decorating-method"),
+ ("W1517", "cache-max-size-none"),
+ ]
+ },
+ ),
+ }
+
+ def __init__(self, linter: PyLinter) -> None:
+ BaseChecker.__init__(self, linter)
+ self._deprecated_methods: set[str] = set()
+ self._deprecated_arguments: dict[str, tuple[tuple[int | None, str], ...]] = {}
+ self._deprecated_classes: dict[str, set[str]] = {}
+ self._deprecated_decorators: set[str] = set()
+ self._deprecated_attributes: set[str] = set()
+
+ for since_vers, func_list in DEPRECATED_METHODS[sys.version_info[0]].items():
+ if since_vers <= sys.version_info:
+ self._deprecated_methods.update(func_list)
+ for since_vers, args_list in DEPRECATED_ARGUMENTS.items():
+ if since_vers <= sys.version_info:
+ self._deprecated_arguments.update(args_list)
+ for since_vers, class_list in DEPRECATED_CLASSES.items():
+ if since_vers <= sys.version_info:
+ self._deprecated_classes.update(class_list)
+ for since_vers, decorator_list in DEPRECATED_DECORATORS.items():
+ if since_vers <= sys.version_info:
+ self._deprecated_decorators.update(decorator_list)
+ for since_vers, attribute_list in DEPRECATED_ATTRIBUTES.items():
+ if since_vers <= sys.version_info:
+ self._deprecated_attributes.update(attribute_list)
+ # Modules are checked by the ImportsChecker, because the list is
+ # synced with the config argument deprecated-modules
+
+ def _check_bad_thread_instantiation(self, node: nodes.Call) -> None:
+ func_kwargs = {key.arg for key in node.keywords}
+ if "target" in func_kwargs:
+ return
+
+ if len(node.args) < 2 and (not node.kwargs or "target" not in func_kwargs):
+ self.add_message(
+ "bad-thread-instantiation", node=node, confidence=interfaces.HIGH
+ )
+
+ def _check_for_preexec_fn_in_popen(self, node: nodes.Call) -> None:
+ if node.keywords:
+ for keyword in node.keywords:
+ if keyword.arg == "preexec_fn":
+ self.add_message("subprocess-popen-preexec-fn", node=node)
+
+ def _check_for_check_kw_in_run(self, node: nodes.Call) -> None:
+ kwargs = {keyword.arg for keyword in (node.keywords or ())}
+ if "check" not in kwargs:
+ self.add_message("subprocess-run-check", node=node, confidence=INFERENCE)
+
+ def _check_shallow_copy_environ(self, node: nodes.Call) -> None:
+ confidence = HIGH
+ try:
+ arg = utils.get_argument_from_call(node, position=0, keyword="x")
+ except utils.NoSuchArgumentError:
+ arg = utils.infer_kwarg_from_call(node, keyword="x")
+ if not arg:
+ return
+ confidence = INFERENCE
+ try:
+ inferred_args = arg.inferred()
+ except astroid.InferenceError:
+ return
+ for inferred in inferred_args:
+ if inferred.qname() == OS_ENVIRON:
+ self.add_message(
+ "shallow-copy-environ", node=node, confidence=confidence
+ )
+ break
+
+ @utils.only_required_for_messages(
+ "bad-open-mode",
+ "redundant-unittest-assert",
+ "deprecated-method",
+ "deprecated-argument",
+ "bad-thread-instantiation",
+ "shallow-copy-environ",
+ "invalid-envvar-value",
+ "invalid-envvar-default",
+ "subprocess-popen-preexec-fn",
+ "subprocess-run-check",
+ "deprecated-class",
+ "unspecified-encoding",
+ "forgotten-debug-statement",
+ )
+ def visit_call(self, node: nodes.Call) -> None:
+ """Visit a Call node."""
+ self.check_deprecated_class_in_call(node)
+ for inferred in utils.infer_all(node.func):
+ if isinstance(inferred, util.UninferableBase):
+ continue
+ if inferred.root().name in OPEN_MODULE:
+ open_func_name: str | None = None
+ if isinstance(node.func, nodes.Name):
+ open_func_name = node.func.name
+ if isinstance(node.func, nodes.Attribute):
+ open_func_name = node.func.attrname
+ if open_func_name in OPEN_FILES_FUNCS:
+ self._check_open_call(node, inferred.root().name, open_func_name)
+ elif inferred.root().name == UNITTEST_CASE:
+ self._check_redundant_assert(node, inferred)
+ elif isinstance(inferred, nodes.ClassDef):
+ if inferred.qname() == THREADING_THREAD:
+ self._check_bad_thread_instantiation(node)
+ elif inferred.qname() == SUBPROCESS_POPEN:
+ self._check_for_preexec_fn_in_popen(node)
+ elif isinstance(inferred, nodes.FunctionDef):
+ name = inferred.qname()
+ if name == COPY_COPY:
+ self._check_shallow_copy_environ(node)
+ elif name in ENV_GETTERS:
+ self._check_env_function(node, inferred)
+ elif name == SUBPROCESS_RUN:
+ self._check_for_check_kw_in_run(node)
+ elif name in DEBUG_BREAKPOINTS:
+ self.add_message("forgotten-debug-statement", node=node)
+ self.check_deprecated_method(node, inferred)
+
+ @utils.only_required_for_messages("boolean-datetime")
+ def visit_unaryop(self, node: nodes.UnaryOp) -> None:
+ if node.op == "not":
+ self._check_datetime(node.operand)
+
+ @utils.only_required_for_messages("boolean-datetime")
+ def visit_if(self, node: nodes.If) -> None:
+ self._check_datetime(node.test)
+
+ @utils.only_required_for_messages("boolean-datetime")
+ def visit_ifexp(self, node: nodes.IfExp) -> None:
+ self._check_datetime(node.test)
+
+ @utils.only_required_for_messages("boolean-datetime")
+ def visit_boolop(self, node: nodes.BoolOp) -> None:
+ for value in node.values:
+ self._check_datetime(value)
+
+ @utils.only_required_for_messages(
+ "method-cache-max-size-none",
+ "singledispatch-method",
+ "singledispatchmethod-function",
+ )
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ if node.decorators:
+ if isinstance(node.parent, nodes.ClassDef):
+ self._check_lru_cache_decorators(node)
+ self._check_dispatch_decorators(node)
+
+ def _check_lru_cache_decorators(self, node: nodes.FunctionDef) -> None:
+ """Check if instance methods are decorated with functools.lru_cache."""
+ if any(utils.is_enum(ancestor) for ancestor in node.parent.ancestors()):
+ # method of class inheriting from Enum is exempt from this check.
+ return
+
+ lru_cache_nodes: list[nodes.NodeNG] = []
+ for d_node in node.decorators.nodes:
+ # pylint: disable = too-many-try-statements
+ try:
+ for infered_node in d_node.infer():
+ q_name = infered_node.qname()
+ if q_name in NON_INSTANCE_METHODS:
+ return
+
+ # Check if there is a maxsize argument set to None in the call
+ if q_name in LRU_CACHE and isinstance(d_node, nodes.Call):
+ try:
+ arg = utils.get_argument_from_call(
+ d_node, position=0, keyword="maxsize"
+ )
+ except utils.NoSuchArgumentError:
+ arg = utils.infer_kwarg_from_call(d_node, "maxsize")
+
+ if not isinstance(arg, nodes.Const) or arg.value is not None:
+ break
+
+ lru_cache_nodes.append(d_node)
+ break
+
+ if q_name == "functools.cache":
+ lru_cache_nodes.append(d_node)
+ break
+ except astroid.InferenceError:
+ pass
+ for lru_cache_node in lru_cache_nodes:
+ self.add_message(
+ "method-cache-max-size-none",
+ node=lru_cache_node,
+ confidence=interfaces.INFERENCE,
+ )
+
+ def _check_dispatch_decorators(self, node: nodes.FunctionDef) -> None:
+ decorators_map: dict[str, tuple[nodes.NodeNG, interfaces.Confidence]] = {}
+
+ for decorator in node.decorators.nodes:
+ if isinstance(decorator, nodes.Name) and decorator.name:
+ decorators_map[decorator.name] = (decorator, interfaces.HIGH)
+ elif utils.is_registered_in_singledispatch_function(node):
+ decorators_map["singledispatch"] = (decorator, interfaces.INFERENCE)
+ elif utils.is_registered_in_singledispatchmethod_function(node):
+ decorators_map["singledispatchmethod"] = (
+ decorator,
+ interfaces.INFERENCE,
+ )
+
+ if node.is_method():
+ if "singledispatch" in decorators_map:
+ self.add_message(
+ "singledispatch-method",
+ node=decorators_map["singledispatch"][0],
+ confidence=decorators_map["singledispatch"][1],
+ )
+ elif "singledispatchmethod" in decorators_map:
+ self.add_message(
+ "singledispatchmethod-function",
+ node=decorators_map["singledispatchmethod"][0],
+ confidence=decorators_map["singledispatchmethod"][1],
+ )
+
+ def _check_redundant_assert(self, node: nodes.Call, infer: InferenceResult) -> None:
+ if (
+ isinstance(infer, astroid.BoundMethod)
+ and node.args
+ and isinstance(node.args[0], nodes.Const)
+ and infer.name in {"assertTrue", "assertFalse"}
+ ):
+ self.add_message(
+ "redundant-unittest-assert",
+ args=(infer.name, node.args[0].value),
+ node=node,
+ )
+
+ def _check_datetime(self, node: nodes.NodeNG) -> None:
+ """Check that a datetime was inferred, if so, emit boolean-datetime warning."""
+ try:
+ inferred = next(node.infer())
+ except astroid.InferenceError:
+ return
+ if isinstance(inferred, astroid.Instance) and inferred.qname() in {
+ "_pydatetime.time",
+ "datetime.time",
+ }:
+ self.add_message("boolean-datetime", node=node)
+
+ def _check_open_call(
+ self, node: nodes.Call, open_module: str, func_name: str
+ ) -> None:
+ """Various checks for an open call."""
+ mode_arg = None
+ confidence = HIGH
+ try:
+ if open_module == "_io":
+ mode_arg = utils.get_argument_from_call(
+ node, position=1, keyword="mode"
+ )
+ elif open_module in PATHLIB_MODULE:
+ mode_arg = utils.get_argument_from_call(
+ node, position=0, keyword="mode"
+ )
+ except utils.NoSuchArgumentError:
+ mode_arg = utils.infer_kwarg_from_call(node, keyword="mode")
+ if mode_arg:
+ confidence = INFERENCE
+
+ if mode_arg:
+ mode_arg = utils.safe_infer(mode_arg)
+ if (
+ func_name in OPEN_FILES_MODE
+ and isinstance(mode_arg, nodes.Const)
+ and not _check_mode_str(mode_arg.value)
+ ):
+ self.add_message(
+ "bad-open-mode",
+ node=node,
+ args=mode_arg.value or str(mode_arg.value),
+ confidence=confidence,
+ )
+
+ if (
+ not mode_arg
+ or isinstance(mode_arg, nodes.Const)
+ and (not mode_arg.value or "b" not in str(mode_arg.value))
+ ):
+ confidence = HIGH
+ try:
+ if open_module in PATHLIB_MODULE:
+ if node.func.attrname == "read_text":
+ encoding_arg = utils.get_argument_from_call(
+ node, position=0, keyword="encoding"
+ )
+ elif node.func.attrname == "write_text":
+ encoding_arg = utils.get_argument_from_call(
+ node, position=1, keyword="encoding"
+ )
+ else:
+ encoding_arg = utils.get_argument_from_call(
+ node, position=2, keyword="encoding"
+ )
+ else:
+ encoding_arg = utils.get_argument_from_call(
+ node, position=3, keyword="encoding"
+ )
+ except utils.NoSuchArgumentError:
+ encoding_arg = utils.infer_kwarg_from_call(node, keyword="encoding")
+ if encoding_arg:
+ confidence = INFERENCE
+ else:
+ self.add_message(
+ "unspecified-encoding", node=node, confidence=confidence
+ )
+
+ if encoding_arg:
+ encoding_arg = utils.safe_infer(encoding_arg)
+
+ if isinstance(encoding_arg, nodes.Const) and encoding_arg.value is None:
+ self.add_message(
+ "unspecified-encoding", node=node, confidence=confidence
+ )
+
+ def _check_env_function(self, node: nodes.Call, infer: nodes.FunctionDef) -> None:
+ env_name_kwarg = "key"
+ env_value_kwarg = "default"
+ if node.keywords:
+ kwargs = {keyword.arg: keyword.value for keyword in node.keywords}
+ else:
+ kwargs = None
+ if node.args:
+ env_name_arg = node.args[0]
+ elif kwargs and env_name_kwarg in kwargs:
+ env_name_arg = kwargs[env_name_kwarg]
+ else:
+ env_name_arg = None
+
+ if env_name_arg:
+ self._check_invalid_envvar_value(
+ node=node,
+ message="invalid-envvar-value",
+ call_arg=utils.safe_infer(env_name_arg),
+ infer=infer,
+ allow_none=False,
+ )
+
+ if len(node.args) == 2:
+ env_value_arg = node.args[1]
+ elif kwargs and env_value_kwarg in kwargs:
+ env_value_arg = kwargs[env_value_kwarg]
+ else:
+ env_value_arg = None
+
+ if env_value_arg:
+ self._check_invalid_envvar_value(
+ node=node,
+ infer=infer,
+ message="invalid-envvar-default",
+ call_arg=utils.safe_infer(env_value_arg),
+ allow_none=True,
+ )
+
+ def _check_invalid_envvar_value(
+ self,
+ node: nodes.Call,
+ infer: nodes.FunctionDef,
+ message: str,
+ call_arg: InferenceResult | None,
+ allow_none: bool,
+ ) -> None:
+ if call_arg is None or isinstance(call_arg, util.UninferableBase):
+ return
+
+ name = infer.qname()
+ if isinstance(call_arg, nodes.Const):
+ emit = False
+ if call_arg.value is None:
+ emit = not allow_none
+ elif not isinstance(call_arg.value, str):
+ emit = True
+ if emit:
+ self.add_message(message, node=node, args=(name, call_arg.pytype()))
+ else:
+ self.add_message(message, node=node, args=(name, call_arg.pytype()))
+
+ def deprecated_methods(self) -> set[str]:
+ return self._deprecated_methods
+
+ def deprecated_arguments(self, method: str) -> tuple[tuple[int | None, str], ...]:
+ return self._deprecated_arguments.get(method, ())
+
+ def deprecated_classes(self, module: str) -> Iterable[str]:
+ return self._deprecated_classes.get(module, ())
+
+ def deprecated_decorators(self) -> Iterable[str]:
+ return self._deprecated_decorators
+
+ def deprecated_attributes(self) -> Iterable[str]:
+ return self._deprecated_attributes
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(StdlibChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/strings.py b/solutions/.venv/Lib/site-packages/pylint/checkers/strings.py
new file mode 100644
index 000000000..90493fa00
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/strings.py
@@ -0,0 +1,1099 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checker for string formatting operations."""
+
+from __future__ import annotations
+
+import collections
+import re
+import sys
+import tokenize
+from collections import Counter
+from collections.abc import Iterable, Sequence
+from typing import TYPE_CHECKING, Literal
+
+import astroid
+from astroid import bases, nodes, util
+from astroid.typing import SuccessfulInferenceResult
+
+from pylint.checkers import BaseChecker, BaseRawFileChecker, BaseTokenChecker, utils
+from pylint.checkers.utils import only_required_for_messages
+from pylint.interfaces import HIGH
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+_AST_NODE_STR_TYPES = ("__builtin__.unicode", "__builtin__.str", "builtins.str")
+# Prefixes for both strings and bytes literals per
+# https://docs.python.org/3/reference/lexical_analysis.html#string-and-bytes-literals
+_PREFIXES = {
+ "r",
+ "u",
+ "R",
+ "U",
+ "f",
+ "F",
+ "fr",
+ "Fr",
+ "fR",
+ "FR",
+ "rf",
+ "rF",
+ "Rf",
+ "RF",
+ "b",
+ "B",
+ "br",
+ "Br",
+ "bR",
+ "BR",
+ "rb",
+ "rB",
+ "Rb",
+ "RB",
+}
+_PAREN_IGNORE_TOKEN_TYPES = (
+ tokenize.NEWLINE,
+ tokenize.NL,
+ tokenize.COMMENT,
+)
+SINGLE_QUOTED_REGEX = re.compile(f"({'|'.join(_PREFIXES)})?'''")
+DOUBLE_QUOTED_REGEX = re.compile(f"({'|'.join(_PREFIXES)})?\"\"\"")
+QUOTE_DELIMITER_REGEX = re.compile(f"({'|'.join(_PREFIXES)})?(\"|')", re.DOTALL)
+
+MSGS: dict[str, MessageDefinitionTuple] = (
+ { # pylint: disable=consider-using-namedtuple-or-dataclass
+ "E1300": (
+ "Unsupported format character %r (%#02x) at index %d",
+ "bad-format-character",
+ "Used when an unsupported format character is used in a format string.",
+ ),
+ "E1301": (
+ "Format string ends in middle of conversion specifier",
+ "truncated-format-string",
+ "Used when a format string terminates before the end of a "
+ "conversion specifier.",
+ ),
+ "E1302": (
+ "Mixing named and unnamed conversion specifiers in format string",
+ "mixed-format-string",
+ "Used when a format string contains both named (e.g. '%(foo)d') "
+ "and unnamed (e.g. '%d') conversion specifiers. This is also "
+ "used when a named conversion specifier contains * for the "
+ "minimum field width and/or precision.",
+ ),
+ "E1303": (
+ "Expected mapping for format string, not %s",
+ "format-needs-mapping",
+ "Used when a format string that uses named conversion specifiers "
+ "is used with an argument that is not a mapping.",
+ ),
+ "W1300": (
+ "Format string dictionary key should be a string, not %s",
+ "bad-format-string-key",
+ "Used when a format string that uses named conversion specifiers "
+ "is used with a dictionary whose keys are not all strings.",
+ ),
+ "W1301": (
+ "Unused key %r in format string dictionary",
+ "unused-format-string-key",
+ "Used when a format string that uses named conversion specifiers "
+ "is used with a dictionary that contains keys not required by the "
+ "format string.",
+ ),
+ "E1304": (
+ "Missing key %r in format string dictionary",
+ "missing-format-string-key",
+ "Used when a format string that uses named conversion specifiers "
+ "is used with a dictionary that doesn't contain all the keys "
+ "required by the format string.",
+ ),
+ "E1305": (
+ "Too many arguments for format string",
+ "too-many-format-args",
+ "Used when a format string that uses unnamed conversion "
+ "specifiers is given too many arguments.",
+ ),
+ "E1306": (
+ "Not enough arguments for format string",
+ "too-few-format-args",
+ "Used when a format string that uses unnamed conversion "
+ "specifiers is given too few arguments",
+ ),
+ "E1307": (
+ "Argument %r does not match format type %r",
+ "bad-string-format-type",
+ "Used when a type required by format string "
+ "is not suitable for actual argument type",
+ ),
+ "E1310": (
+ "Suspicious argument in %s.%s call",
+ "bad-str-strip-call",
+ "The argument to a str.{l,r,}strip call contains a duplicate character,",
+ ),
+ "W1302": (
+ "Invalid format string",
+ "bad-format-string",
+ "Used when a PEP 3101 format string is invalid.",
+ ),
+ "W1303": (
+ "Missing keyword argument %r for format string",
+ "missing-format-argument-key",
+ "Used when a PEP 3101 format string that uses named fields "
+ "doesn't receive one or more required keywords.",
+ ),
+ "W1304": (
+ "Unused format argument %r",
+ "unused-format-string-argument",
+ "Used when a PEP 3101 format string that uses named "
+ "fields is used with an argument that "
+ "is not required by the format string.",
+ ),
+ "W1305": (
+ "Format string contains both automatic field numbering "
+ "and manual field specification",
+ "format-combined-specification",
+ "Used when a PEP 3101 format string contains both automatic "
+ "field numbering (e.g. '{}') and manual field "
+ "specification (e.g. '{0}').",
+ ),
+ "W1306": (
+ "Missing format attribute %r in format specifier %r",
+ "missing-format-attribute",
+ "Used when a PEP 3101 format string uses an "
+ "attribute specifier ({0.length}), but the argument "
+ "passed for formatting doesn't have that attribute.",
+ ),
+ "W1307": (
+ "Using invalid lookup key %r in format specifier %r",
+ "invalid-format-index",
+ "Used when a PEP 3101 format string uses a lookup specifier "
+ "({a[1]}), but the argument passed for formatting "
+ "doesn't contain or doesn't have that key as an attribute.",
+ ),
+ "W1308": (
+ "Duplicate string formatting argument %r, consider passing as named argument",
+ "duplicate-string-formatting-argument",
+ "Used when we detect that a string formatting is "
+ "repeating an argument instead of using named string arguments",
+ ),
+ "W1309": (
+ "Using an f-string that does not have any interpolated variables",
+ "f-string-without-interpolation",
+ "Used when we detect an f-string that does not use any interpolation variables, "
+ "in which case it can be either a normal string or a bug in the code.",
+ ),
+ "W1310": (
+ "Using formatting for a string that does not have any interpolated variables",
+ "format-string-without-interpolation",
+ "Used when we detect a string that does not have any interpolation variables, "
+ "in which case it can be either a normal string without formatting or a bug in the code.",
+ ),
+ }
+)
+
+OTHER_NODES = (
+ nodes.Const,
+ nodes.List,
+ nodes.Lambda,
+ nodes.FunctionDef,
+ nodes.ListComp,
+ nodes.SetComp,
+ nodes.GeneratorExp,
+)
+
+
+def get_access_path(key: str | Literal[0], parts: list[tuple[bool, str]]) -> str:
+ """Given a list of format specifiers, returns
+ the final access path (e.g. a.b.c[0][1]).
+ """
+ path = []
+ for is_attribute, specifier in parts:
+ if is_attribute:
+ path.append(f".{specifier}")
+ else:
+ path.append(f"[{specifier!r}]")
+ return str(key) + "".join(path)
+
+
+def arg_matches_format_type(
+ arg_type: SuccessfulInferenceResult, format_type: str
+) -> bool:
+ if format_type in "sr":
+ # All types can be printed with %s and %r
+ return True
+ if isinstance(arg_type, astroid.Instance):
+ arg_type = arg_type.pytype()
+ if arg_type == "builtins.str":
+ return format_type == "c"
+ if arg_type == "builtins.float":
+ return format_type in "deEfFgGn%"
+ if arg_type == "builtins.int":
+ # Integers allow all types
+ return True
+ return False
+ return True
+
+
+class StringFormatChecker(BaseChecker):
+ """Checks string formatting operations to ensure that the format string
+ is valid and the arguments match the format string.
+ """
+
+ name = "string"
+ msgs = MSGS
+
+ # pylint: disable = too-many-branches, too-many-locals, too-many-statements
+ @only_required_for_messages(
+ "bad-format-character",
+ "truncated-format-string",
+ "mixed-format-string",
+ "bad-format-string-key",
+ "missing-format-string-key",
+ "unused-format-string-key",
+ "bad-string-format-type",
+ "format-needs-mapping",
+ "too-many-format-args",
+ "too-few-format-args",
+ "format-string-without-interpolation",
+ )
+ def visit_binop(self, node: nodes.BinOp) -> None:
+ if node.op != "%":
+ return
+ left = node.left
+ args = node.right
+
+ if not (isinstance(left, nodes.Const) and isinstance(left.value, str)):
+ return
+ format_string = left.value
+ try:
+ (
+ required_keys,
+ required_num_args,
+ required_key_types,
+ required_arg_types,
+ ) = utils.parse_format_string(format_string)
+ except utils.UnsupportedFormatCharacter as exc:
+ formatted = format_string[exc.index]
+ self.add_message(
+ "bad-format-character",
+ node=node,
+ args=(formatted, ord(formatted), exc.index),
+ )
+ return
+ except utils.IncompleteFormatString:
+ self.add_message("truncated-format-string", node=node)
+ return
+ if not required_keys and not required_num_args:
+ self.add_message("format-string-without-interpolation", node=node)
+ return
+ if required_keys and required_num_args:
+ # The format string uses both named and unnamed format
+ # specifiers.
+ self.add_message("mixed-format-string", node=node)
+ elif required_keys:
+ # The format string uses only named format specifiers.
+ # Check that the RHS of the % operator is a mapping object
+ # that contains precisely the set of keys required by the
+ # format string.
+ if isinstance(args, nodes.Dict):
+ keys = set()
+ unknown_keys = False
+ for k, _ in args.items:
+ if isinstance(k, nodes.Const):
+ key = k.value
+ if isinstance(key, str):
+ keys.add(key)
+ else:
+ self.add_message(
+ "bad-format-string-key", node=node, args=key
+ )
+ else:
+ # One of the keys was something other than a
+ # constant. Since we can't tell what it is,
+ # suppress checks for missing keys in the
+ # dictionary.
+ unknown_keys = True
+ if not unknown_keys:
+ for key in required_keys:
+ if key not in keys:
+ self.add_message(
+ "missing-format-string-key", node=node, args=key
+ )
+ for key in keys:
+ if key not in required_keys:
+ self.add_message(
+ "unused-format-string-key", node=node, args=key
+ )
+ for key, arg in args.items:
+ if not isinstance(key, nodes.Const):
+ continue
+ format_type = required_key_types.get(key.value, None)
+ arg_type = utils.safe_infer(arg)
+ if (
+ format_type is not None
+ and arg_type
+ and not isinstance(arg_type, util.UninferableBase)
+ and not arg_matches_format_type(arg_type, format_type)
+ ):
+ self.add_message(
+ "bad-string-format-type",
+ node=node,
+ args=(arg_type.pytype(), format_type),
+ )
+ elif isinstance(args, (OTHER_NODES, nodes.Tuple)):
+ type_name = type(args).__name__
+ self.add_message("format-needs-mapping", node=node, args=type_name)
+ # else:
+ # The RHS of the format specifier is a name or
+ # expression. It may be a mapping object, so
+ # there's nothing we can check.
+ else:
+ # The format string uses only unnamed format specifiers.
+ # Check that the number of arguments passed to the RHS of
+ # the % operator matches the number required by the format
+ # string.
+ args_elts = []
+ if isinstance(args, nodes.Tuple):
+ rhs_tuple = utils.safe_infer(args)
+ num_args = None
+ if isinstance(rhs_tuple, nodes.BaseContainer):
+ args_elts = rhs_tuple.elts
+ num_args = len(args_elts)
+ elif isinstance(args, (OTHER_NODES, (nodes.Dict, nodes.DictComp))):
+ args_elts = [args]
+ num_args = 1
+ elif isinstance(args, nodes.Name):
+ inferred = utils.safe_infer(args)
+ if isinstance(inferred, nodes.Tuple):
+ # The variable is a tuple, so we need to get the elements
+ # from it for further inspection
+ args_elts = inferred.elts
+ num_args = len(args_elts)
+ elif isinstance(inferred, nodes.Const):
+ args_elts = [inferred]
+ num_args = 1
+ else:
+ num_args = None
+ else:
+ # The RHS of the format specifier is an expression.
+ # It could be a tuple of unknown size, so
+ # there's nothing we can check.
+ num_args = None
+ if num_args is not None:
+ if num_args > required_num_args:
+ self.add_message("too-many-format-args", node=node)
+ elif num_args < required_num_args:
+ self.add_message("too-few-format-args", node=node)
+ for arg, format_type in zip(args_elts, required_arg_types):
+ if not arg:
+ continue
+ arg_type = utils.safe_infer(arg)
+ if (
+ arg_type
+ and not isinstance(arg_type, util.UninferableBase)
+ and not arg_matches_format_type(arg_type, format_type)
+ ):
+ self.add_message(
+ "bad-string-format-type",
+ node=node,
+ args=(arg_type.pytype(), format_type),
+ )
+
+ @only_required_for_messages("f-string-without-interpolation")
+ def visit_joinedstr(self, node: nodes.JoinedStr) -> None:
+ self._check_interpolation(node)
+
+ def _check_interpolation(self, node: nodes.JoinedStr) -> None:
+ if isinstance(node.parent, nodes.FormattedValue):
+ return
+ for value in node.values:
+ if isinstance(value, nodes.FormattedValue):
+ return
+ self.add_message("f-string-without-interpolation", node=node)
+
+ def visit_call(self, node: nodes.Call) -> None:
+ func = utils.safe_infer(node.func)
+ if (
+ isinstance(func, astroid.BoundMethod)
+ and isinstance(func.bound, astroid.Instance)
+ and func.bound.name in {"str", "unicode", "bytes"}
+ ):
+ if func.name in {"strip", "lstrip", "rstrip"} and node.args:
+ arg = utils.safe_infer(node.args[0])
+ if not isinstance(arg, nodes.Const) or not isinstance(arg.value, str):
+ return
+ if len(arg.value) != len(set(arg.value)):
+ self.add_message(
+ "bad-str-strip-call",
+ node=node,
+ args=(func.bound.name, func.name),
+ )
+ elif func.name == "format":
+ self._check_new_format(node, func)
+
+ def _detect_vacuous_formatting(
+ self, node: nodes.Call, positional_arguments: list[SuccessfulInferenceResult]
+ ) -> None:
+ counter = collections.Counter(
+ arg.name for arg in positional_arguments if isinstance(arg, nodes.Name)
+ )
+ for name, count in counter.items():
+ if count == 1:
+ continue
+ self.add_message(
+ "duplicate-string-formatting-argument", node=node, args=(name,)
+ )
+
+ def _check_new_format(self, node: nodes.Call, func: bases.BoundMethod) -> None:
+ """Check the new string formatting."""
+ # Skip format nodes which don't have an explicit string on the
+ # left side of the format operation.
+ # We do this because our inference engine can't properly handle
+ # redefinition of the original string.
+ # Note that there may not be any left side at all, if the format method
+ # has been assigned to another variable. See issue 351. For example:
+ #
+ # fmt = 'some string {}'.format
+ # fmt('arg')
+ if isinstance(node.func, nodes.Attribute) and not isinstance(
+ node.func.expr, nodes.Const
+ ):
+ return
+ if node.starargs or node.kwargs:
+ return
+ try:
+ strnode = next(func.bound.infer())
+ except astroid.InferenceError:
+ return
+ if not (isinstance(strnode, nodes.Const) and isinstance(strnode.value, str)):
+ return
+ try:
+ call_site = astroid.arguments.CallSite.from_call(node)
+ except astroid.InferenceError:
+ return
+
+ try:
+ fields, num_args, manual_pos = utils.parse_format_method_string(
+ strnode.value
+ )
+ except utils.IncompleteFormatString:
+ self.add_message("bad-format-string", node=node)
+ return
+
+ positional_arguments = call_site.positional_arguments
+ named_arguments = call_site.keyword_arguments
+ named_fields = {field[0] for field in fields if isinstance(field[0], str)}
+ if num_args and manual_pos:
+ self.add_message("format-combined-specification", node=node)
+ return
+
+ check_args = False
+ # Consider "{[0]} {[1]}" as num_args.
+ num_args += sum(1 for field in named_fields if not field)
+ if named_fields:
+ for field in named_fields:
+ if field and field not in named_arguments:
+ self.add_message(
+ "missing-format-argument-key", node=node, args=(field,)
+ )
+ for field in named_arguments:
+ if field not in named_fields:
+ self.add_message(
+ "unused-format-string-argument", node=node, args=(field,)
+ )
+ # num_args can be 0 if manual_pos is not.
+ num_args = num_args or manual_pos
+ if positional_arguments or num_args:
+ empty = not all(field for field in named_fields)
+ if named_arguments or empty:
+ # Verify the required number of positional arguments
+ # only if the .format got at least one keyword argument.
+ # This means that the format strings accepts both
+ # positional and named fields and we should warn
+ # when one of them is missing or is extra.
+ check_args = True
+ else:
+ check_args = True
+ if check_args:
+ # num_args can be 0 if manual_pos is not.
+ num_args = num_args or manual_pos
+ if not num_args:
+ self.add_message("format-string-without-interpolation", node=node)
+ return
+ if len(positional_arguments) > num_args:
+ self.add_message("too-many-format-args", node=node)
+ elif len(positional_arguments) < num_args:
+ self.add_message("too-few-format-args", node=node)
+
+ self._detect_vacuous_formatting(node, positional_arguments)
+ self._check_new_format_specifiers(node, fields, named_arguments)
+
+ # pylint: disable = too-many-statements
+ def _check_new_format_specifiers(
+ self,
+ node: nodes.Call,
+ fields: list[tuple[str, list[tuple[bool, str]]]],
+ named: dict[str, SuccessfulInferenceResult],
+ ) -> None:
+ """Check attribute and index access in the format
+ string ("{0.a}" and "{0[a]}").
+ """
+ key: Literal[0] | str
+ for key, specifiers in fields:
+ # Obtain the argument. If it can't be obtained
+ # or inferred, skip this check.
+ if not key:
+ # {[0]} will have an unnamed argument, defaulting
+ # to 0. It will not be present in `named`, so use the value
+ # 0 for it.
+ key = 0
+ if isinstance(key, int):
+ try:
+ argname = utils.get_argument_from_call(node, key)
+ except utils.NoSuchArgumentError:
+ continue
+ else:
+ if key not in named:
+ continue
+ argname = named[key]
+ if argname is None or isinstance(argname, util.UninferableBase):
+ continue
+ try:
+ argument = utils.safe_infer(argname)
+ except astroid.InferenceError:
+ continue
+ if not specifiers or not argument:
+ # No need to check this key if it doesn't
+ # use attribute / item access
+ continue
+ if argument.parent and isinstance(argument.parent, nodes.Arguments):
+ # Ignore any object coming from an argument,
+ # because we can't infer its value properly.
+ continue
+ previous = argument
+ parsed: list[tuple[bool, str]] = []
+ for is_attribute, specifier in specifiers:
+ if isinstance(previous, util.UninferableBase):
+ break
+ parsed.append((is_attribute, specifier))
+ if is_attribute:
+ try:
+ previous = previous.getattr(specifier)[0]
+ except astroid.NotFoundError:
+ if (
+ hasattr(previous, "has_dynamic_getattr")
+ and previous.has_dynamic_getattr()
+ ):
+ # Don't warn if the object has a custom __getattr__
+ break
+ path = get_access_path(key, parsed)
+ self.add_message(
+ "missing-format-attribute",
+ args=(specifier, path),
+ node=node,
+ )
+ break
+ else:
+ warn_error = False
+ if hasattr(previous, "getitem"):
+ try:
+ previous = previous.getitem(nodes.Const(specifier))
+ except (
+ astroid.AstroidIndexError,
+ astroid.AstroidTypeError,
+ astroid.AttributeInferenceError,
+ ):
+ warn_error = True
+ except astroid.InferenceError:
+ break
+ if isinstance(previous, util.UninferableBase):
+ break
+ else:
+ try:
+ # Lookup __getitem__ in the current node,
+ # but skip further checks, because we can't
+ # retrieve the looked object
+ previous.getattr("__getitem__")
+ break
+ except astroid.NotFoundError:
+ warn_error = True
+ if warn_error:
+ path = get_access_path(key, parsed)
+ self.add_message(
+ "invalid-format-index", args=(specifier, path), node=node
+ )
+ break
+
+ try:
+ previous = next(previous.infer())
+ except astroid.InferenceError:
+ # can't check further if we can't infer it
+ break
+
+
+class StringConstantChecker(BaseTokenChecker, BaseRawFileChecker):
+ """Check string literals."""
+
+ name = "string"
+ msgs = {
+ "W1401": (
+ "Anomalous backslash in string: '%s'. "
+ "String constant might be missing an r prefix.",
+ "anomalous-backslash-in-string",
+ "Used when a backslash is in a literal string but not as an escape.",
+ ),
+ "W1402": (
+ "Anomalous Unicode escape in byte string: '%s'. "
+ "String constant might be missing an r or u prefix.",
+ "anomalous-unicode-escape-in-string",
+ "Used when an escape like \\u is encountered in a byte "
+ "string where it has no effect.",
+ ),
+ "W1404": (
+ "Implicit string concatenation found in %s",
+ "implicit-str-concat",
+ "String literals are implicitly concatenated in a "
+ "literal iterable definition : "
+ "maybe a comma is missing ?",
+ {"old_names": [("W1403", "implicit-str-concat-in-sequence")]},
+ ),
+ "W1405": (
+ "Quote delimiter %s is inconsistent with the rest of the file",
+ "inconsistent-quotes",
+ "Quote delimiters are not used consistently throughout a module "
+ "(with allowances made for avoiding unnecessary escaping).",
+ ),
+ "W1406": (
+ "The u prefix for strings is no longer necessary in Python >=3.0",
+ "redundant-u-string-prefix",
+ "Used when we detect a string with a u prefix. These prefixes were necessary "
+ "in Python 2 to indicate a string was Unicode, but since Python 3.0 strings "
+ "are Unicode by default.",
+ ),
+ }
+ options = (
+ (
+ "check-str-concat-over-line-jumps",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "This flag controls whether the "
+ "implicit-str-concat should generate a warning "
+ "on implicit string concatenation in sequences defined over "
+ "several lines.",
+ },
+ ),
+ (
+ "check-quote-consistency",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "This flag controls whether inconsistent-quotes generates a "
+ "warning when the character used as a quote delimiter is used "
+ "inconsistently within a module.",
+ },
+ ),
+ )
+
+ # Characters that have a special meaning after a backslash in either
+ # Unicode or byte strings.
+ ESCAPE_CHARACTERS = "abfnrtvx\n\r\t\\'\"01234567"
+
+ # Characters that have a special meaning after a backslash but only in
+ # Unicode strings.
+ UNICODE_ESCAPE_CHARACTERS = "uUN"
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self.string_tokens: dict[
+ tuple[int, int], tuple[str, tokenize.TokenInfo | None]
+ ] = {}
+ """Token position -> (token value, next token)."""
+ self._parenthesized_string_tokens: dict[tuple[int, int], bool] = {}
+
+ def process_module(self, node: nodes.Module) -> None:
+ self._unicode_literals = "unicode_literals" in node.future_imports
+
+ def process_tokens(self, tokens: list[tokenize.TokenInfo]) -> None:
+ encoding = "ascii"
+ for i, (token_type, token, start, _, line) in enumerate(tokens):
+ if token_type == tokenize.ENCODING:
+ # this is always the first token processed
+ encoding = token
+ elif token_type == tokenize.STRING:
+ # 'token' is the whole un-parsed token; we can look at the start
+ # of it to see whether it's a raw or unicode string etc.
+ self.process_string_token(token, start[0], start[1])
+ # We figure the next token, ignoring comments & newlines:
+ j = i + 1
+ while j < len(tokens) and tokens[j].type in (
+ tokenize.NEWLINE,
+ tokenize.NL,
+ tokenize.COMMENT,
+ ):
+ j += 1
+ next_token = tokens[j] if j < len(tokens) else None
+ if encoding != "ascii":
+ # We convert `tokenize` character count into a byte count,
+ # to match with astroid `.col_offset`
+ start = (start[0], len(line[: start[1]].encode(encoding)))
+ self.string_tokens[start] = (str_eval(token), next_token)
+ is_parenthesized = self._is_initial_string_token(
+ i, tokens
+ ) and self._is_parenthesized(i, tokens)
+ self._parenthesized_string_tokens[start] = is_parenthesized
+
+ if self.linter.config.check_quote_consistency:
+ self.check_for_consistent_string_delimiters(tokens)
+
+ def _is_initial_string_token(
+ self, index: int, tokens: Sequence[tokenize.TokenInfo]
+ ) -> bool:
+ # Must NOT be preceded by a string literal
+ prev_token = self._find_prev_token(index, tokens)
+ if prev_token and prev_token.type == tokenize.STRING:
+ return False
+ # Must be followed by a string literal token.
+ next_token = self._find_next_token(index, tokens)
+ return bool(next_token and next_token.type == tokenize.STRING)
+
+ def _is_parenthesized(self, index: int, tokens: list[tokenize.TokenInfo]) -> bool:
+ prev_token = self._find_prev_token(
+ index, tokens, ignore=(*_PAREN_IGNORE_TOKEN_TYPES, tokenize.STRING)
+ )
+ if not prev_token or prev_token.type != tokenize.OP or prev_token[1] != "(":
+ return False
+ next_token = self._find_next_token(
+ index, tokens, ignore=(*_PAREN_IGNORE_TOKEN_TYPES, tokenize.STRING)
+ )
+ return bool(
+ next_token and next_token.type == tokenize.OP and next_token[1] == ")"
+ )
+
+ def _find_prev_token(
+ self,
+ index: int,
+ tokens: Sequence[tokenize.TokenInfo],
+ *,
+ ignore: tuple[int, ...] = _PAREN_IGNORE_TOKEN_TYPES,
+ ) -> tokenize.TokenInfo | None:
+ i = index - 1
+ while i >= 0 and tokens[i].type in ignore:
+ i -= 1
+ return tokens[i] if i >= 0 else None
+
+ def _find_next_token(
+ self,
+ index: int,
+ tokens: Sequence[tokenize.TokenInfo],
+ *,
+ ignore: tuple[int, ...] = _PAREN_IGNORE_TOKEN_TYPES,
+ ) -> tokenize.TokenInfo | None:
+ i = index + 1
+ while i < len(tokens) and tokens[i].type in ignore:
+ i += 1
+ return tokens[i] if i < len(tokens) else None
+
+ @only_required_for_messages("implicit-str-concat")
+ def visit_call(self, node: nodes.Call) -> None:
+ self.check_for_concatenated_strings(node.args, "call")
+
+ @only_required_for_messages("implicit-str-concat")
+ def visit_list(self, node: nodes.List) -> None:
+ self.check_for_concatenated_strings(node.elts, "list")
+
+ @only_required_for_messages("implicit-str-concat")
+ def visit_set(self, node: nodes.Set) -> None:
+ self.check_for_concatenated_strings(node.elts, "set")
+
+ @only_required_for_messages("implicit-str-concat")
+ def visit_tuple(self, node: nodes.Tuple) -> None:
+ self.check_for_concatenated_strings(node.elts, "tuple")
+
+ def visit_assign(self, node: nodes.Assign) -> None:
+ if isinstance(node.value, nodes.Const) and isinstance(node.value.value, str):
+ self.check_for_concatenated_strings([node.value], "assignment")
+
+ def check_for_consistent_string_delimiters(
+ self, tokens: Iterable[tokenize.TokenInfo]
+ ) -> None:
+ """Adds a message for each string using inconsistent quote delimiters.
+
+ Quote delimiters are used inconsistently if " and ' are mixed in a module's
+ shortstrings without having done so to avoid escaping an internal quote
+ character.
+
+ Args:
+ tokens: The tokens to be checked against for consistent usage.
+ """
+ string_delimiters: Counter[str] = collections.Counter()
+
+ inside_fstring = False # whether token is inside f-string (since 3.12)
+ target_py312 = self.linter.config.py_version >= (3, 12)
+
+ # First, figure out which quote character predominates in the module
+ for tok_type, token, _, _, _ in tokens:
+ if sys.version_info[:2] >= (3, 12):
+ # pylint: disable=no-member,useless-suppression
+ if tok_type == tokenize.FSTRING_START:
+ inside_fstring = True
+ elif tok_type == tokenize.FSTRING_END:
+ inside_fstring = False
+
+ if inside_fstring and not target_py312:
+ # skip analysis of f-string contents
+ continue
+
+ if tok_type == tokenize.STRING and _is_quote_delimiter_chosen_freely(token):
+ string_delimiters[_get_quote_delimiter(token)] += 1
+
+ if len(string_delimiters) > 1:
+ # Ties are broken arbitrarily
+ most_common_delimiter = string_delimiters.most_common(1)[0][0]
+ for tok_type, token, start, _, _ in tokens:
+ if tok_type != tokenize.STRING:
+ continue
+ quote_delimiter = _get_quote_delimiter(token)
+ if (
+ _is_quote_delimiter_chosen_freely(token)
+ and quote_delimiter != most_common_delimiter
+ ):
+ self.add_message(
+ "inconsistent-quotes", line=start[0], args=(quote_delimiter,)
+ )
+
+ def check_for_concatenated_strings(
+ self, elements: Sequence[nodes.NodeNG], iterable_type: str
+ ) -> None:
+ for elt in elements:
+ if not (
+ isinstance(elt, nodes.Const) and elt.pytype() in _AST_NODE_STR_TYPES
+ ):
+ continue
+ if elt.col_offset < 0:
+ # This can happen in case of escaped newlines
+ continue
+ token_index = (elt.lineno, elt.col_offset)
+ if token_index not in self.string_tokens:
+ # This may happen with Latin1 encoding
+ # cf. https://github.com/pylint-dev/pylint/issues/2610
+ continue
+ matching_token, next_token = self.string_tokens[token_index]
+ # We detect string concatenation: the AST Const is the
+ # combination of 2 string tokens
+ if (
+ matching_token != elt.value
+ and next_token is not None
+ and next_token.type == tokenize.STRING
+ ):
+ if next_token.start[0] == elt.lineno or (
+ self.linter.config.check_str_concat_over_line_jumps
+ # Allow implicitly concatenated strings in parens.
+ # See https://github.com/pylint-dev/pylint/issues/8552.
+ and not self._parenthesized_string_tokens.get(
+ (elt.lineno, elt.col_offset)
+ )
+ ):
+ self.add_message(
+ "implicit-str-concat",
+ line=elt.lineno,
+ args=(iterable_type,),
+ confidence=HIGH,
+ )
+
+ def process_string_token(self, token: str, start_row: int, start_col: int) -> None:
+ quote_char = None
+ for _index, char in enumerate(token):
+ if char in "'\"":
+ quote_char = char
+ break
+ if quote_char is None:
+ return
+ # pylint: disable=undefined-loop-variable
+ prefix = token[:_index].lower() # markers like u, b, r.
+ after_prefix = token[_index:]
+ # pylint: enable=undefined-loop-variable
+ # Chop off quotes
+ quote_length = (
+ 3 if after_prefix[:3] == after_prefix[-3:] == 3 * quote_char else 1
+ )
+ string_body = after_prefix[quote_length:-quote_length]
+ # No special checks on raw strings at the moment.
+ if "r" not in prefix:
+ self.process_non_raw_string_token(
+ prefix,
+ string_body,
+ start_row,
+ start_col + len(prefix) + quote_length,
+ )
+
+ def process_non_raw_string_token(
+ self, prefix: str, string_body: str, start_row: int, string_start_col: int
+ ) -> None:
+ """Check for bad escapes in a non-raw string.
+
+ prefix: lowercase string of string prefix markers ('ur').
+ string_body: the un-parsed body of the string, not including the quote
+ marks.
+ start_row: line number in the source.
+ string_start_col: col number of the string start in the source.
+ """
+ # Walk through the string; if we see a backslash then escape the next
+ # character, and skip over it. If we see a non-escaped character,
+ # alert, and continue.
+ #
+ # Accept a backslash when it escapes a backslash, or a quote, or
+ # end-of-line, or one of the letters that introduce a special escape
+ # sequence <https://docs.python.org/reference/lexical_analysis.html>
+ #
+ index = 0
+ while True:
+ index = string_body.find("\\", index)
+ if index == -1:
+ break
+ # There must be a next character; having a backslash at the end
+ # of the string would be a SyntaxError.
+ next_char = string_body[index + 1]
+ match = string_body[index : index + 2]
+ # The column offset will vary depending on whether the string token
+ # is broken across lines. Calculate relative to the nearest line
+ # break or relative to the start of the token's line.
+ last_newline = string_body.rfind("\n", 0, index)
+ if last_newline == -1:
+ line = start_row
+ col_offset = index + string_start_col
+ else:
+ line = start_row + string_body.count("\n", 0, index)
+ col_offset = index - last_newline - 1
+ if next_char in self.UNICODE_ESCAPE_CHARACTERS:
+ if "u" in prefix:
+ pass
+ elif "b" not in prefix:
+ pass # unicode by default
+ else:
+ self.add_message(
+ "anomalous-unicode-escape-in-string",
+ line=line,
+ args=(match,),
+ col_offset=col_offset,
+ )
+ elif next_char not in self.ESCAPE_CHARACTERS:
+ self.add_message(
+ "anomalous-backslash-in-string",
+ line=line,
+ args=(match,),
+ col_offset=col_offset,
+ )
+ # Whether it was a valid escape or not, backslash followed by
+ # another character can always be consumed whole: the second
+ # character can never be the start of a new backslash escape.
+ index += 2
+
+ @only_required_for_messages("redundant-u-string-prefix")
+ def visit_const(self, node: nodes.Const) -> None:
+ if node.pytype() == "builtins.str" and not isinstance(
+ node.parent, nodes.JoinedStr
+ ):
+ self._detect_u_string_prefix(node)
+
+ def _detect_u_string_prefix(self, node: nodes.Const) -> None:
+ """Check whether strings include a 'u' prefix like u'String'."""
+ if node.kind == "u":
+ self.add_message(
+ "redundant-u-string-prefix",
+ line=node.lineno,
+ col_offset=node.col_offset,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(StringFormatChecker(linter))
+ linter.register_checker(StringConstantChecker(linter))
+
+
+def str_eval(token: str) -> str:
+ """Mostly replicate `ast.literal_eval(token)` manually to avoid any performance hit.
+
+ This supports f-strings, contrary to `ast.literal_eval`.
+ We have to support all string literal notations:
+ https://docs.python.org/3/reference/lexical_analysis.html#string-and-bytes-literals
+ """
+ if token[0:2].lower() in {"fr", "rf"}:
+ token = token[2:]
+ elif token[0].lower() in {"r", "u", "f"}:
+ token = token[1:]
+ if token[0:3] in {'"""', "'''"}:
+ return token[3:-3]
+ return token[1:-1]
+
+
+def _is_long_string(string_token: str) -> bool:
+ """Is this string token a "longstring" (is it triple-quoted)?
+
+ Long strings are triple-quoted as defined in
+ https://docs.python.org/3/reference/lexical_analysis.html#string-and-bytes-literals
+
+ This function only checks characters up through the open quotes. Because it's meant
+ to be applied only to tokens that represent string literals, it doesn't bother to
+ check for close-quotes (demonstrating that the literal is a well-formed string).
+
+ Args:
+ string_token: The string token to be parsed.
+
+ Returns:
+ A boolean representing whether this token matches a longstring
+ regex.
+ """
+ return bool(
+ SINGLE_QUOTED_REGEX.match(string_token)
+ or DOUBLE_QUOTED_REGEX.match(string_token)
+ )
+
+
+def _get_quote_delimiter(string_token: str) -> str:
+ """Returns the quote character used to delimit this token string.
+
+ This function checks whether the token is a well-formed string.
+
+ Args:
+ string_token: The token to be parsed.
+
+ Returns:
+ A string containing solely the first quote delimiter character in the
+ given string.
+
+ Raises:
+ ValueError: No quote delimiter characters are present.
+ """
+ match = QUOTE_DELIMITER_REGEX.match(string_token)
+ if not match:
+ raise ValueError(f"string token {string_token} is not a well-formed string")
+ return match.group(2)
+
+
+def _is_quote_delimiter_chosen_freely(string_token: str) -> bool:
+ """Was there a non-awkward option for the quote delimiter?
+
+ Args:
+ string_token: The quoted string whose delimiters are to be checked.
+
+ Returns:
+ Whether there was a choice in this token's quote character that would
+ not have involved backslash-escaping an interior quote character. Long
+ strings are excepted from this analysis under the assumption that their
+ quote characters are set by policy.
+ """
+ quote_delimiter = _get_quote_delimiter(string_token)
+ unchosen_delimiter = '"' if quote_delimiter == "'" else "'"
+ return bool(
+ quote_delimiter
+ and not _is_long_string(string_token)
+ and unchosen_delimiter not in str_eval(string_token)
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/symilar.py b/solutions/.venv/Lib/site-packages/pylint/checkers/symilar.py
new file mode 100644
index 000000000..1e82633e6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/symilar.py
@@ -0,0 +1,934 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""A similarities / code duplication command line tool and pylint checker.
+
+The algorithm is based on comparing the hash value of n successive lines of a file.
+First the files are read and any line that doesn't fulfill requirement are removed
+(comments, docstrings...)
+
+Those stripped lines are stored in the LineSet class which gives access to them.
+Then each index of the stripped lines collection is associated with the hash of n
+successive entries of the stripped lines starting at the current index (n is the
+minimum common lines option).
+
+The common hashes between both linesets are then looked for. If there are matches, then
+the match indices in both linesets are stored and associated with the corresponding
+couples (start line number/end line number) in both files.
+
+This association is then post-processed to handle the case of successive matches. For
+example if the minimum common lines setting is set to four, then the hashes are
+computed with four lines. If one of match indices couple (12, 34) is the
+successor of another one (11, 33) then it means that there are in fact five lines which
+are common.
+
+Once post-processed the values of association table are the result looked for, i.e.
+start and end lines numbers of common lines in both files.
+"""
+
+from __future__ import annotations
+
+import argparse
+import copy
+import functools
+import itertools
+import operator
+import re
+import sys
+import warnings
+from collections import defaultdict
+from collections.abc import Callable, Generator, Iterable, Sequence
+from io import BufferedIOBase, BufferedReader, BytesIO
+from itertools import chain
+from typing import TYPE_CHECKING, NamedTuple, NewType, NoReturn, TextIO, Union
+
+import astroid
+from astroid import nodes
+
+from pylint.checkers import BaseChecker, BaseRawFileChecker, table_lines_from_stats
+from pylint.reporters.ureports.nodes import Section, Table
+from pylint.typing import MessageDefinitionTuple, Options
+from pylint.utils import LinterStats, decoding_stream
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+DEFAULT_MIN_SIMILARITY_LINE = 4
+
+REGEX_FOR_LINES_WITH_CONTENT = re.compile(r".*\w+")
+
+# Index defines a location in a LineSet stripped lines collection
+Index = NewType("Index", int)
+
+# LineNumber defines a location in a LinesSet real lines collection (the whole file lines)
+LineNumber = NewType("LineNumber", int)
+
+
+# LineSpecifs holds characteristics of a line in a file
+class LineSpecifs(NamedTuple):
+ line_number: LineNumber
+ text: str
+
+
+# Links LinesChunk object to the starting indices (in lineset's stripped lines)
+# of the different chunk of lines that are used to compute the hash
+HashToIndex_T = dict["LinesChunk", list[Index]]
+
+# Links index in the lineset's stripped lines to the real lines in the file
+IndexToLines_T = dict[Index, "SuccessiveLinesLimits"]
+
+# The types the streams read by pylint can take. Originating from astroid.nodes.Module.stream() and open()
+STREAM_TYPES = Union[TextIO, BufferedReader, BytesIO]
+
+
+class CplSuccessiveLinesLimits:
+ """Holds a SuccessiveLinesLimits object for each checked file and counts the number
+ of common lines between both stripped lines collections extracted from both files.
+ """
+
+ __slots__ = ("first_file", "second_file", "effective_cmn_lines_nb")
+
+ def __init__(
+ self,
+ first_file: SuccessiveLinesLimits,
+ second_file: SuccessiveLinesLimits,
+ effective_cmn_lines_nb: int,
+ ) -> None:
+ self.first_file = first_file
+ self.second_file = second_file
+ self.effective_cmn_lines_nb = effective_cmn_lines_nb
+
+
+# Links the indices to the starting line in both lineset's stripped lines to
+# the start and end lines in both files
+CplIndexToCplLines_T = dict["LineSetStartCouple", CplSuccessiveLinesLimits]
+
+
+class LinesChunk:
+ """The LinesChunk object computes and stores the hash of some consecutive stripped
+ lines of a lineset.
+ """
+
+ __slots__ = ("_fileid", "_index", "_hash")
+
+ def __init__(self, fileid: str, num_line: int, *lines: Iterable[str]) -> None:
+ self._fileid: str = fileid
+ """The name of the file from which the LinesChunk object is generated."""
+
+ self._index: Index = Index(num_line)
+ """The index in the stripped lines that is the starting of consecutive
+ lines.
+ """
+
+ self._hash: int = sum(hash(lin) for lin in lines)
+ """The hash of some consecutive lines."""
+
+ def __eq__(self, o: object) -> bool:
+ if not isinstance(o, LinesChunk):
+ return NotImplemented
+ return self._hash == o._hash
+
+ def __hash__(self) -> int:
+ return self._hash
+
+ def __repr__(self) -> str:
+ return (
+ f"<LinesChunk object for file {self._fileid} ({self._index}, {self._hash})>"
+ )
+
+ def __str__(self) -> str:
+ return (
+ f"LinesChunk object for file {self._fileid}, starting at line {self._index} \n"
+ f"Hash is {self._hash}"
+ )
+
+
+class SuccessiveLinesLimits:
+ """A class to handle the numbering of begin and end of successive lines.
+
+ :note: Only the end line number can be updated.
+ """
+
+ __slots__ = ("_start", "_end")
+
+ def __init__(self, start: LineNumber, end: LineNumber) -> None:
+ self._start: LineNumber = start
+ self._end: LineNumber = end
+
+ @property
+ def start(self) -> LineNumber:
+ return self._start
+
+ @property
+ def end(self) -> LineNumber:
+ return self._end
+
+ @end.setter
+ def end(self, value: LineNumber) -> None:
+ self._end = value
+
+ def __repr__(self) -> str:
+ return f"<SuccessiveLinesLimits <{self._start};{self._end}>>"
+
+
+class LineSetStartCouple(NamedTuple):
+ """Indices in both linesets that mark the beginning of successive lines."""
+
+ fst_lineset_index: Index
+ snd_lineset_index: Index
+
+ def __repr__(self) -> str:
+ return (
+ f"<LineSetStartCouple <{self.fst_lineset_index};{self.snd_lineset_index}>>"
+ )
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, LineSetStartCouple):
+ return NotImplemented
+ return (
+ self.fst_lineset_index == other.fst_lineset_index
+ and self.snd_lineset_index == other.snd_lineset_index
+ )
+
+ def __hash__(self) -> int:
+ return hash(self.fst_lineset_index) + hash(self.snd_lineset_index)
+
+ def increment(self, value: Index) -> LineSetStartCouple:
+ return LineSetStartCouple(
+ Index(self.fst_lineset_index + value),
+ Index(self.snd_lineset_index + value),
+ )
+
+
+LinesChunkLimits_T = tuple["LineSet", LineNumber, LineNumber]
+
+
+def hash_lineset(
+ lineset: LineSet, min_common_lines: int = DEFAULT_MIN_SIMILARITY_LINE
+) -> tuple[HashToIndex_T, IndexToLines_T]:
+ """Return two dicts.
+
+ The first associates the hash of successive stripped lines of a lineset
+ to the indices of the starting lines.
+ The second dict, associates the index of the starting line in the lineset's stripped lines to the
+ couple [start, end] lines number in the corresponding file.
+
+ :param lineset: lineset object (i.e the lines in a file)
+ :param min_common_lines: number of successive lines that are used to compute the hash
+ :return: a dict linking hashes to corresponding start index and a dict that links this
+ index to the start and end lines in the file
+ """
+ hash2index = defaultdict(list)
+ index2lines = {}
+ # Comments, docstring and other specific patterns maybe excluded -> call to stripped_lines
+ # to get only what is desired
+ lines = tuple(x.text for x in lineset.stripped_lines)
+ # Need different iterators on same lines but each one is shifted 1 from the precedent
+ shifted_lines = [iter(lines[i:]) for i in range(min_common_lines)]
+
+ for i, *succ_lines in enumerate(zip(*shifted_lines)):
+ start_linenumber = LineNumber(lineset.stripped_lines[i].line_number)
+ try:
+ end_linenumber = lineset.stripped_lines[i + min_common_lines].line_number
+ except IndexError:
+ end_linenumber = LineNumber(lineset.stripped_lines[-1].line_number + 1)
+
+ index = Index(i)
+ index2lines[index] = SuccessiveLinesLimits(
+ start=start_linenumber, end=end_linenumber
+ )
+
+ l_c = LinesChunk(lineset.name, index, *succ_lines)
+ hash2index[l_c].append(index)
+
+ return hash2index, index2lines
+
+
+def remove_successive(all_couples: CplIndexToCplLines_T) -> None:
+ """Removes all successive entries in the dictionary in argument.
+
+ :param all_couples: collection that has to be cleaned up from successive entries.
+ The keys are couples of indices that mark the beginning of common entries
+ in both linesets. The values have two parts. The first one is the couple
+ of starting and ending line numbers of common successive lines in the first file.
+ The second part is the same for the second file.
+
+ For example consider the following dict:
+
+ >>> all_couples
+ {(11, 34): ([5, 9], [27, 31]),
+ (23, 79): ([15, 19], [45, 49]),
+ (12, 35): ([6, 10], [28, 32])}
+
+ There are two successive keys (11, 34) and (12, 35).
+ It means there are two consecutive similar chunks of lines in both files.
+ Thus remove last entry and update the last line numbers in the first entry
+
+ >>> remove_successive(all_couples)
+ >>> all_couples
+ {(11, 34): ([5, 10], [27, 32]),
+ (23, 79): ([15, 19], [45, 49])}
+ """
+ couple: LineSetStartCouple
+ for couple in tuple(all_couples.keys()):
+ to_remove = []
+ test = couple.increment(Index(1))
+ while test in all_couples:
+ all_couples[couple].first_file.end = all_couples[test].first_file.end
+ all_couples[couple].second_file.end = all_couples[test].second_file.end
+ all_couples[couple].effective_cmn_lines_nb += 1
+ to_remove.append(test)
+ test = test.increment(Index(1))
+
+ for target in to_remove:
+ try:
+ all_couples.pop(target)
+ except KeyError:
+ pass
+
+
+def filter_noncode_lines(
+ ls_1: LineSet,
+ stindex_1: Index,
+ ls_2: LineSet,
+ stindex_2: Index,
+ common_lines_nb: int,
+) -> int:
+ """Return the effective number of common lines between lineset1
+ and lineset2 filtered from non code lines.
+
+ That is to say the number of common successive stripped
+ lines except those that do not contain code (for example
+ a line with only an ending parenthesis)
+
+ :param ls_1: first lineset
+ :param stindex_1: first lineset starting index
+ :param ls_2: second lineset
+ :param stindex_2: second lineset starting index
+ :param common_lines_nb: number of common successive stripped lines before being filtered from non code lines
+ :return: the number of common successive stripped lines that contain code
+ """
+ stripped_l1 = [
+ lspecif.text
+ for lspecif in ls_1.stripped_lines[stindex_1 : stindex_1 + common_lines_nb]
+ if REGEX_FOR_LINES_WITH_CONTENT.match(lspecif.text)
+ ]
+ stripped_l2 = [
+ lspecif.text
+ for lspecif in ls_2.stripped_lines[stindex_2 : stindex_2 + common_lines_nb]
+ if REGEX_FOR_LINES_WITH_CONTENT.match(lspecif.text)
+ ]
+ return sum(sline_1 == sline_2 for sline_1, sline_2 in zip(stripped_l1, stripped_l2))
+
+
+class Commonality(NamedTuple):
+ cmn_lines_nb: int
+ fst_lset: LineSet
+ fst_file_start: LineNumber
+ fst_file_end: LineNumber
+ snd_lset: LineSet
+ snd_file_start: LineNumber
+ snd_file_end: LineNumber
+
+
+class Symilar:
+ """Finds copy-pasted lines of code in a project."""
+
+ def __init__(
+ self,
+ min_lines: int = DEFAULT_MIN_SIMILARITY_LINE,
+ ignore_comments: bool = False,
+ ignore_docstrings: bool = False,
+ ignore_imports: bool = False,
+ ignore_signatures: bool = False,
+ ) -> None:
+ # If we run in pylint mode we link the namespace objects
+ if isinstance(self, BaseChecker):
+ self.namespace = self.linter.config
+ else:
+ self.namespace = argparse.Namespace()
+
+ self.namespace.min_similarity_lines = min_lines
+ self.namespace.ignore_comments = ignore_comments
+ self.namespace.ignore_docstrings = ignore_docstrings
+ self.namespace.ignore_imports = ignore_imports
+ self.namespace.ignore_signatures = ignore_signatures
+ self.linesets: list[LineSet] = []
+
+ def append_stream(
+ self, streamid: str, stream: STREAM_TYPES, encoding: str | None = None
+ ) -> None:
+ """Append a file to search for similarities."""
+ if isinstance(stream, BufferedIOBase):
+ if encoding is None:
+ raise ValueError
+ readlines = decoding_stream(stream, encoding).readlines
+ else:
+ # hint parameter is incorrectly typed as non-optional
+ readlines = stream.readlines # type: ignore[assignment]
+
+ try:
+ lines = readlines()
+ except UnicodeDecodeError:
+ lines = []
+
+ self.linesets.append(
+ LineSet(
+ streamid,
+ lines,
+ self.namespace.ignore_comments,
+ self.namespace.ignore_docstrings,
+ self.namespace.ignore_imports,
+ self.namespace.ignore_signatures,
+ line_enabled_callback=(
+ self.linter._is_one_message_enabled
+ if hasattr(self, "linter")
+ else None
+ ),
+ )
+ )
+
+ def run(self) -> None:
+ """Start looking for similarities and display results on stdout."""
+ if self.namespace.min_similarity_lines == 0:
+ return
+ self._display_sims(self._compute_sims())
+
+ def _compute_sims(self) -> list[tuple[int, set[LinesChunkLimits_T]]]:
+ """Compute similarities in appended files."""
+ no_duplicates: dict[int, list[set[LinesChunkLimits_T]]] = defaultdict(list)
+
+ for commonality in self._iter_sims():
+ num = commonality.cmn_lines_nb
+ lineset1 = commonality.fst_lset
+ start_line_1 = commonality.fst_file_start
+ end_line_1 = commonality.fst_file_end
+ lineset2 = commonality.snd_lset
+ start_line_2 = commonality.snd_file_start
+ end_line_2 = commonality.snd_file_end
+
+ duplicate = no_duplicates[num]
+ couples: set[LinesChunkLimits_T]
+ for couples in duplicate:
+ if (lineset1, start_line_1, end_line_1) in couples or (
+ lineset2,
+ start_line_2,
+ end_line_2,
+ ) in couples:
+ break
+ else:
+ duplicate.append(
+ {
+ (lineset1, start_line_1, end_line_1),
+ (lineset2, start_line_2, end_line_2),
+ }
+ )
+ sims: list[tuple[int, set[LinesChunkLimits_T]]] = []
+ ensembles: list[set[LinesChunkLimits_T]]
+ for num, ensembles in no_duplicates.items():
+ cpls: set[LinesChunkLimits_T]
+ for cpls in ensembles:
+ sims.append((num, cpls))
+ sims.sort()
+ sims.reverse()
+ return sims
+
+ def _display_sims(
+ self, similarities: list[tuple[int, set[LinesChunkLimits_T]]]
+ ) -> None:
+ """Display computed similarities on stdout."""
+ report = self._get_similarity_report(similarities)
+ print(report)
+
+ def _get_similarity_report(
+ self, similarities: list[tuple[int, set[LinesChunkLimits_T]]]
+ ) -> str:
+ """Create a report from similarities."""
+ report: str = ""
+ duplicated_line_number: int = 0
+ for number, couples in similarities:
+ report += f"\n{number} similar lines in {len(couples)} files\n"
+ couples_l = sorted(couples)
+ line_set = start_line = end_line = None
+ for line_set, start_line, end_line in couples_l:
+ report += f"=={line_set.name}:[{start_line}:{end_line}]\n"
+ if line_set:
+ for line in line_set._real_lines[start_line:end_line]:
+ report += f" {line.rstrip()}\n" if line.rstrip() else "\n"
+ duplicated_line_number += number * (len(couples_l) - 1)
+ total_line_number: int = sum(len(lineset) for lineset in self.linesets)
+ report += (
+ f"TOTAL lines={total_line_number} "
+ f"duplicates={duplicated_line_number} "
+ f"percent={duplicated_line_number * 100.0 / total_line_number:.2f}\n"
+ )
+ return report
+
+ # pylint: disable = too-many-locals
+ def _find_common(
+ self, lineset1: LineSet, lineset2: LineSet
+ ) -> Generator[Commonality]:
+ """Find similarities in the two given linesets.
+
+ This the core of the algorithm. The idea is to compute the hashes of a
+ minimal number of successive lines of each lineset and then compare the
+ hashes. Every match of such comparison is stored in a dict that links the
+ couple of starting indices in both linesets to the couple of corresponding
+ starting and ending lines in both files.
+
+ Last regroups all successive couples in a bigger one. It allows to take into
+ account common chunk of lines that have more than the minimal number of
+ successive lines required.
+ """
+ hash_to_index_1: HashToIndex_T
+ hash_to_index_2: HashToIndex_T
+ index_to_lines_1: IndexToLines_T
+ index_to_lines_2: IndexToLines_T
+ hash_to_index_1, index_to_lines_1 = hash_lineset(
+ lineset1, self.namespace.min_similarity_lines
+ )
+ hash_to_index_2, index_to_lines_2 = hash_lineset(
+ lineset2, self.namespace.min_similarity_lines
+ )
+
+ hash_1: frozenset[LinesChunk] = frozenset(hash_to_index_1.keys())
+ hash_2: frozenset[LinesChunk] = frozenset(hash_to_index_2.keys())
+
+ common_hashes: Iterable[LinesChunk] = sorted(
+ hash_1 & hash_2, key=lambda m: hash_to_index_1[m][0]
+ )
+
+ # all_couples is a dict that links the couple of indices in both linesets that mark the beginning of
+ # successive common lines, to the corresponding starting and ending number lines in both files
+ all_couples: CplIndexToCplLines_T = {}
+
+ for c_hash in sorted(common_hashes, key=operator.attrgetter("_index")):
+ for indices_in_linesets in itertools.product(
+ hash_to_index_1[c_hash], hash_to_index_2[c_hash]
+ ):
+ index_1 = indices_in_linesets[0]
+ index_2 = indices_in_linesets[1]
+ all_couples[LineSetStartCouple(index_1, index_2)] = (
+ CplSuccessiveLinesLimits(
+ copy.copy(index_to_lines_1[index_1]),
+ copy.copy(index_to_lines_2[index_2]),
+ effective_cmn_lines_nb=self.namespace.min_similarity_lines,
+ )
+ )
+
+ remove_successive(all_couples)
+
+ for cml_stripped_l, cmn_l in all_couples.items():
+ start_index_1 = cml_stripped_l.fst_lineset_index
+ start_index_2 = cml_stripped_l.snd_lineset_index
+ nb_common_lines = cmn_l.effective_cmn_lines_nb
+
+ com = Commonality(
+ cmn_lines_nb=nb_common_lines,
+ fst_lset=lineset1,
+ fst_file_start=cmn_l.first_file.start,
+ fst_file_end=cmn_l.first_file.end,
+ snd_lset=lineset2,
+ snd_file_start=cmn_l.second_file.start,
+ snd_file_end=cmn_l.second_file.end,
+ )
+
+ eff_cmn_nb = filter_noncode_lines(
+ lineset1, start_index_1, lineset2, start_index_2, nb_common_lines
+ )
+
+ if eff_cmn_nb > self.namespace.min_similarity_lines:
+ yield com
+
+ def _iter_sims(self) -> Generator[Commonality]:
+ """Iterate on similarities among all files, by making a Cartesian
+ product.
+ """
+ for idx, lineset in enumerate(self.linesets[:-1]):
+ for lineset2 in self.linesets[idx + 1 :]:
+ yield from self._find_common(lineset, lineset2)
+
+ def get_map_data(self) -> list[LineSet]:
+ """Returns the data we can use for a map/reduce process.
+
+ In this case we are returning this instance's Linesets, that is all file
+ information that will later be used for vectorisation.
+ """
+ return self.linesets
+
+ def combine_mapreduce_data(self, linesets_collection: list[list[LineSet]]) -> None:
+ """Reduces and recombines data into a format that we can report on.
+
+ The partner function of get_map_data()
+ """
+ self.linesets = [line for lineset in linesets_collection for line in lineset]
+
+
+def stripped_lines(
+ lines: Iterable[str],
+ ignore_comments: bool,
+ ignore_docstrings: bool,
+ ignore_imports: bool,
+ ignore_signatures: bool,
+ line_enabled_callback: Callable[[str, int], bool] | None = None,
+) -> list[LineSpecifs]:
+ """Return tuples of line/line number/line type with leading/trailing white-space and
+ any ignored code features removed.
+
+ :param lines: a collection of lines
+ :param ignore_comments: if true, any comment in the lines collection is removed from the result
+ :param ignore_docstrings: if true, any line that is a docstring is removed from the result
+ :param ignore_imports: if true, any line that is an import is removed from the result
+ :param ignore_signatures: if true, any line that is part of a function signature is removed from the result
+ :param line_enabled_callback: If called with "R0801" and a line number, a return value of False will disregard
+ the line
+ :return: the collection of line/line number/line type tuples
+ """
+ ignore_lines: set[int] = set()
+ if ignore_imports or ignore_signatures:
+ tree = astroid.parse("".join(lines))
+ if ignore_imports:
+ ignore_lines.update(
+ chain.from_iterable(
+ range(node.lineno, (node.end_lineno or node.lineno) + 1)
+ for node in tree.nodes_of_class((nodes.Import, nodes.ImportFrom))
+ )
+ )
+ if ignore_signatures:
+
+ def _get_functions(
+ functions: list[nodes.NodeNG], tree: nodes.NodeNG
+ ) -> list[nodes.NodeNG]:
+ """Recursively get all functions including nested in the classes from
+ the.
+
+ tree.
+ """
+ for node in tree.body:
+ if isinstance(node, (nodes.FunctionDef, nodes.AsyncFunctionDef)):
+ functions.append(node)
+
+ if isinstance(
+ node,
+ (nodes.ClassDef, nodes.FunctionDef, nodes.AsyncFunctionDef),
+ ):
+ _get_functions(functions, node)
+
+ return functions
+
+ functions = _get_functions([], tree)
+ ignore_lines.update(
+ chain.from_iterable(
+ range(
+ func.lineno,
+ func.body[0].lineno if func.body else func.tolineno + 1,
+ )
+ for func in functions
+ )
+ )
+
+ strippedlines = []
+ docstring = None
+ for lineno, line in enumerate(lines, start=1):
+ if line_enabled_callback is not None and not line_enabled_callback(
+ "R0801", lineno
+ ):
+ continue
+ line = line.strip()
+ if ignore_docstrings:
+ if not docstring:
+ if line.startswith(('"""', "'''")):
+ docstring = line[:3]
+ line = line[3:]
+ elif line.startswith(('r"""', "r'''")):
+ docstring = line[1:4]
+ line = line[4:]
+ if docstring:
+ if line.endswith(docstring):
+ docstring = None
+ line = ""
+ if ignore_comments:
+ line = line.split("#", 1)[0].strip()
+ if lineno in ignore_lines:
+ line = ""
+ if line:
+ strippedlines.append(
+ LineSpecifs(text=line, line_number=LineNumber(lineno - 1))
+ )
+ return strippedlines
+
+
+@functools.total_ordering
+class LineSet:
+ """Holds and indexes all the lines of a single source file.
+
+ Allows for correspondence between real lines of the source file and stripped ones, which
+ are the real ones from which undesired patterns have been removed.
+ """
+
+ def __init__(
+ self,
+ name: str,
+ lines: list[str],
+ ignore_comments: bool = False,
+ ignore_docstrings: bool = False,
+ ignore_imports: bool = False,
+ ignore_signatures: bool = False,
+ line_enabled_callback: Callable[[str, int], bool] | None = None,
+ ) -> None:
+ self.name = name
+ self._real_lines = lines
+ self._stripped_lines = stripped_lines(
+ lines,
+ ignore_comments,
+ ignore_docstrings,
+ ignore_imports,
+ ignore_signatures,
+ line_enabled_callback=line_enabled_callback,
+ )
+
+ def __str__(self) -> str:
+ return f"<Lineset for {self.name}>"
+
+ def __len__(self) -> int:
+ return len(self._real_lines)
+
+ def __getitem__(self, index: int) -> LineSpecifs:
+ return self._stripped_lines[index]
+
+ def __lt__(self, other: LineSet) -> bool:
+ return self.name < other.name
+
+ def __hash__(self) -> int:
+ return id(self)
+
+ def __eq__(self, other: object) -> bool:
+ if not isinstance(other, LineSet):
+ return False
+ return self.__dict__ == other.__dict__
+
+ @property
+ def stripped_lines(self) -> list[LineSpecifs]:
+ return self._stripped_lines
+
+ @property
+ def real_lines(self) -> list[str]:
+ return self._real_lines
+
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "R0801": (
+ "Similar lines in %s files\n%s",
+ "duplicate-code",
+ "Indicates that a set of similar lines has been detected "
+ "among multiple file. This usually means that the code should "
+ "be refactored to avoid this duplication.",
+ )
+}
+
+
+def report_similarities(
+ sect: Section,
+ stats: LinterStats,
+ old_stats: LinterStats | None,
+) -> None:
+ """Make a layout with some stats about duplication."""
+ lines = ["", "now", "previous", "difference"]
+ lines += table_lines_from_stats(stats, old_stats, "duplicated_lines")
+ sect.append(Table(children=lines, cols=4, rheaders=1, cheaders=1))
+
+
+# wrapper to get a pylint checker from the similar class
+class SimilaritiesChecker(BaseRawFileChecker, Symilar):
+ """Checks for similarities and duplicated code.
+
+ This computation may be memory / CPU intensive, so you
+ should disable it if you experience some problems.
+ """
+
+ name = "similarities"
+ msgs = MSGS
+ MIN_SIMILARITY_HELP = "Minimum lines number of a similarity."
+ IGNORE_COMMENTS_HELP = "Comments are removed from the similarity computation"
+ IGNORE_DOCSTRINGS_HELP = "Docstrings are removed from the similarity computation"
+ IGNORE_IMPORTS_HELP = "Imports are removed from the similarity computation"
+ IGNORE_SIGNATURES_HELP = "Signatures are removed from the similarity computation"
+ # for available dict keys/values see the option parser 'add_option' method
+ options: Options = (
+ (
+ "min-similarity-lines",
+ {
+ "default": DEFAULT_MIN_SIMILARITY_LINE,
+ "type": "int",
+ "metavar": "<int>",
+ "help": MIN_SIMILARITY_HELP,
+ },
+ ),
+ (
+ "ignore-comments",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": IGNORE_COMMENTS_HELP,
+ },
+ ),
+ (
+ "ignore-docstrings",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": IGNORE_DOCSTRINGS_HELP,
+ },
+ ),
+ (
+ "ignore-imports",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": IGNORE_IMPORTS_HELP,
+ },
+ ),
+ (
+ "ignore-signatures",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": IGNORE_SIGNATURES_HELP,
+ },
+ ),
+ )
+ reports = (("RP0801", "Duplication", report_similarities),)
+
+ def __init__(self, linter: PyLinter) -> None:
+ BaseRawFileChecker.__init__(self, linter)
+ Symilar.__init__(
+ self,
+ min_lines=self.linter.config.min_similarity_lines,
+ ignore_comments=self.linter.config.ignore_comments,
+ ignore_docstrings=self.linter.config.ignore_docstrings,
+ ignore_imports=self.linter.config.ignore_imports,
+ ignore_signatures=self.linter.config.ignore_signatures,
+ )
+
+ def open(self) -> None:
+ """Init the checkers: reset linesets and statistics information."""
+ self.linesets = []
+ self.linter.stats.reset_duplicated_lines()
+
+ def process_module(self, node: nodes.Module) -> None:
+ """Process a module.
+
+ the module's content is accessible via the stream object
+
+ stream must implement the readlines method
+ """
+ if self.linter.current_name is None:
+ # TODO: 4.0 Fix current_name
+ warnings.warn(
+ (
+ "In pylint 3.0 the current_name attribute of the linter object should be a string. "
+ "If unknown it should be initialized as an empty string."
+ ),
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ with node.stream() as stream:
+ self.append_stream(self.linter.current_name, stream, node.file_encoding)
+
+ def close(self) -> None:
+ """Compute and display similarities on closing (i.e. end of parsing)."""
+ total = sum(len(lineset) for lineset in self.linesets)
+ duplicated = 0
+ stats = self.linter.stats
+ for num, couples in self._compute_sims():
+ msg = []
+ lineset = start_line = end_line = None
+ for lineset, start_line, end_line in couples:
+ msg.append(f"=={lineset.name}:[{start_line}:{end_line}]")
+ msg.sort()
+
+ if lineset:
+ for line in lineset.real_lines[start_line:end_line]:
+ msg.append(line.rstrip())
+
+ self.add_message("R0801", args=(len(couples), "\n".join(msg)))
+ duplicated += num * (len(couples) - 1)
+ stats.nb_duplicated_lines += int(duplicated)
+ stats.percent_duplicated_lines += float(total and duplicated * 100.0 / total)
+
+ def get_map_data(self) -> list[LineSet]:
+ """Passthru override."""
+ return Symilar.get_map_data(self)
+
+ def reduce_map_data(self, linter: PyLinter, data: list[list[LineSet]]) -> None:
+ """Reduces and recombines data into a format that we can report on.
+
+ The partner function of get_map_data()
+
+ Calls self.close() to actually calculate and report duplicate code.
+ """
+ Symilar.combine_mapreduce_data(self, linesets_collection=data)
+ self.close()
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(SimilaritiesChecker(linter))
+
+
+def Run(argv: Sequence[str] | None = None) -> NoReturn:
+ """Standalone command line access point."""
+ parser = argparse.ArgumentParser(
+ prog="symilar", description="Finds copy pasted blocks in a set of files."
+ )
+ parser.add_argument("files", nargs="+")
+ parser.add_argument(
+ "-d",
+ "--duplicates",
+ type=int,
+ default=DEFAULT_MIN_SIMILARITY_LINE,
+ help=SimilaritiesChecker.MIN_SIMILARITY_HELP,
+ )
+ parser.add_argument(
+ "-i",
+ "--ignore-comments",
+ action="store_true",
+ help=SimilaritiesChecker.IGNORE_COMMENTS_HELP,
+ )
+ parser.add_argument(
+ "--ignore-docstrings",
+ action="store_true",
+ help=SimilaritiesChecker.IGNORE_DOCSTRINGS_HELP,
+ )
+ parser.add_argument(
+ "--ignore-imports",
+ action="store_true",
+ help=SimilaritiesChecker.IGNORE_IMPORTS_HELP,
+ )
+ parser.add_argument(
+ "--ignore-signatures",
+ action="store_true",
+ help=SimilaritiesChecker.IGNORE_SIGNATURES_HELP,
+ )
+ parsed_args = parser.parse_args(args=argv)
+ similar_runner = Symilar(
+ min_lines=parsed_args.duplicates,
+ ignore_comments=parsed_args.ignore_comments,
+ ignore_docstrings=parsed_args.ignore_docstrings,
+ ignore_imports=parsed_args.ignore_imports,
+ ignore_signatures=parsed_args.ignore_signatures,
+ )
+ for filename in parsed_args.files:
+ with open(filename, encoding="utf-8") as stream:
+ similar_runner.append_stream(filename, stream)
+ similar_runner.run()
+ # the sys exit must be kept because of the unit tests that rely on it
+ sys.exit(0)
+
+
+if __name__ == "__main__":
+ Run()
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/threading_checker.py b/solutions/.venv/Lib/site-packages/pylint/checkers/threading_checker.py
new file mode 100644
index 000000000..b289d6707
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/threading_checker.py
@@ -0,0 +1,59 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages, safe_infer
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class ThreadingChecker(BaseChecker):
+ """Checks for threading module.
+
+ - useless with lock - locking used in wrong way that has no effect (with threading.Lock():)
+ """
+
+ name = "threading"
+
+ LOCKS = frozenset(
+ (
+ "threading.Lock",
+ "threading.RLock",
+ "threading.Condition",
+ "threading.Semaphore",
+ "threading.BoundedSemaphore",
+ )
+ )
+
+ msgs = {
+ "W2101": (
+ "'%s()' directly created in 'with' has no effect",
+ "useless-with-lock",
+ "Used when a new lock instance is created by using with statement "
+ "which has no effect. Instead, an existing instance should be used to acquire lock.",
+ ),
+ }
+
+ @only_required_for_messages("useless-with-lock")
+ def visit_with(self, node: nodes.With) -> None:
+ context_managers = (c for c, _ in node.items if isinstance(c, nodes.Call))
+ for context_manager in context_managers:
+ if isinstance(context_manager, nodes.Call):
+ infered_function = safe_infer(context_manager.func)
+ if infered_function is None:
+ continue
+ qname = infered_function.qname()
+ if qname in self.LOCKS:
+ self.add_message("useless-with-lock", node=node, args=qname)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ThreadingChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/typecheck.py b/solutions/.venv/Lib/site-packages/pylint/checkers/typecheck.py
new file mode 100644
index 000000000..bc7ddfc2a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/typecheck.py
@@ -0,0 +1,2339 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Try to find more bugs in the code using astroid inference capabilities."""
+
+from __future__ import annotations
+
+import heapq
+import itertools
+import operator
+import re
+import shlex
+import sys
+from collections.abc import Callable, Iterable
+from functools import cached_property, singledispatch
+from re import Pattern
+from typing import TYPE_CHECKING, Any, Literal, Union
+
+import astroid
+import astroid.exceptions
+import astroid.helpers
+from astroid import arguments, bases, nodes, util
+from astroid.nodes import _base_nodes
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+from pylint.checkers import BaseChecker, utils
+from pylint.checkers.utils import (
+ decorated_with,
+ decorated_with_property,
+ has_known_bases,
+ is_builtin_object,
+ is_comprehension,
+ is_hashable,
+ is_inside_abstract_class,
+ is_iterable,
+ is_mapping,
+ is_module_ignored,
+ is_node_in_type_annotation_context,
+ is_none,
+ is_overload_stub,
+ is_postponed_evaluation_enabled,
+ is_super,
+ node_ignores_exception,
+ only_required_for_messages,
+ safe_infer,
+ supports_delitem,
+ supports_getitem,
+ supports_membership_test,
+ supports_setitem,
+)
+from pylint.constants import PY310_PLUS
+from pylint.interfaces import HIGH, INFERENCE
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+CallableObjects = Union[
+ bases.BoundMethod,
+ bases.UnboundMethod,
+ nodes.FunctionDef,
+ nodes.Lambda,
+ nodes.ClassDef,
+]
+
+STR_FORMAT = {"builtins.str.format"}
+ASYNCIO_COROUTINE = "asyncio.coroutines.coroutine"
+BUILTIN_TUPLE = "builtins.tuple"
+TYPE_ANNOTATION_NODES_TYPES = (
+ nodes.AnnAssign,
+ nodes.Arguments,
+ nodes.FunctionDef,
+)
+BUILTINS_IMPLICIT_RETURN_NONE = {
+ "builtins.dict": {"clear", "update"},
+ "builtins.list": {
+ "append",
+ "clear",
+ "extend",
+ "insert",
+ "remove",
+ "reverse",
+ "sort",
+ },
+ "builtins.set": {
+ "add",
+ "clear",
+ "difference_update",
+ "discard",
+ "intersection_update",
+ "remove",
+ "symmetric_difference_update",
+ "update",
+ },
+}
+
+
+class VERSION_COMPATIBLE_OVERLOAD:
+ pass
+
+
+VERSION_COMPATIBLE_OVERLOAD_SENTINEL = VERSION_COMPATIBLE_OVERLOAD()
+
+
+def _is_owner_ignored(
+ owner: SuccessfulInferenceResult,
+ attrname: str | None,
+ ignored_classes: Iterable[str],
+ ignored_modules: Iterable[str],
+) -> bool:
+ """Check if the given owner should be ignored.
+
+ This will verify if the owner's module is in *ignored_modules*
+ or the owner's module fully qualified name is in *ignored_modules*
+ or if the *ignored_modules* contains a pattern which catches
+ the fully qualified name of the module.
+
+ Also, similar checks are done for the owner itself, if its name
+ matches any name from the *ignored_classes* or if its qualified
+ name can be found in *ignored_classes*.
+ """
+ if is_module_ignored(owner.root().qname(), ignored_modules):
+ return True
+
+ # Match against ignored classes.
+ ignored_classes = set(ignored_classes)
+ qname = owner.qname() if hasattr(owner, "qname") else ""
+ return any(ignore in (attrname, qname) for ignore in ignored_classes)
+
+
+@singledispatch
+def _node_names(node: SuccessfulInferenceResult) -> Iterable[str]:
+ if not hasattr(node, "locals"):
+ return []
+ return node.locals.keys() # type: ignore[no-any-return]
+
+
+@_node_names.register(nodes.ClassDef)
+@_node_names.register(astroid.Instance)
+def _(node: nodes.ClassDef | bases.Instance) -> Iterable[str]:
+ values = itertools.chain(node.instance_attrs.keys(), node.locals.keys())
+
+ try:
+ mro = node.mro()[1:]
+ except (NotImplementedError, TypeError, astroid.MroError):
+ mro = node.ancestors()
+
+ other_values = [value for cls in mro for value in _node_names(cls)]
+ return itertools.chain(values, other_values)
+
+
+def _string_distance(seq1: str, seq2: str) -> int:
+ seq2_length = len(seq2)
+
+ row = [*list(range(1, seq2_length + 1)), 0]
+ for seq1_index, seq1_char in enumerate(seq1):
+ last_row = row
+ row = [0] * seq2_length + [seq1_index + 1]
+
+ for seq2_index, seq2_char in enumerate(seq2):
+ row[seq2_index] = min(
+ last_row[seq2_index] + 1,
+ row[seq2_index - 1] + 1,
+ last_row[seq2_index - 1] + (seq1_char != seq2_char),
+ )
+
+ return row[seq2_length - 1]
+
+
+def _similar_names(
+ owner: SuccessfulInferenceResult,
+ attrname: str | None,
+ distance_threshold: int,
+ max_choices: int,
+) -> list[str]:
+ """Given an owner and a name, try to find similar names.
+
+ The similar names are searched given a distance metric and only
+ a given number of choices will be returned.
+ """
+ possible_names: list[tuple[str, int]] = []
+ names = _node_names(owner)
+
+ for name in names:
+ if name == attrname:
+ continue
+
+ distance = _string_distance(attrname or "", name)
+ if distance <= distance_threshold:
+ possible_names.append((name, distance))
+
+ # Now get back the values with a minimum, up to the given
+ # limit or choices.
+ picked = [
+ name
+ for (name, _) in heapq.nsmallest(
+ max_choices, possible_names, key=operator.itemgetter(1)
+ )
+ ]
+ return sorted(picked)
+
+
+def _missing_member_hint(
+ owner: SuccessfulInferenceResult,
+ attrname: str | None,
+ distance_threshold: int,
+ max_choices: int,
+) -> str:
+ names = _similar_names(owner, attrname, distance_threshold, max_choices)
+ if not names:
+ # No similar name.
+ return ""
+
+ names = [repr(name) for name in names]
+ if len(names) == 1:
+ names_hint = ", ".join(names)
+ else:
+ names_hint = f"one of {', '.join(names[:-1])} or {names[-1]}"
+
+ return f"; maybe {names_hint}?"
+
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "E1101": (
+ "%s %r has no %r member%s",
+ "no-member",
+ "Used when a variable is accessed for a nonexistent member.",
+ {"old_names": [("E1103", "maybe-no-member")]},
+ ),
+ "I1101": (
+ "%s %r has no %r member%s, but source is unavailable. Consider "
+ "adding this module to extension-pkg-allow-list if you want "
+ "to perform analysis based on run-time introspection of living objects.",
+ "c-extension-no-member",
+ "Used when a variable is accessed for non-existent member of C "
+ "extension. Due to unavailability of source static analysis is impossible, "
+ "but it may be performed by introspecting living objects in run-time.",
+ ),
+ "E1102": (
+ "%s is not callable",
+ "not-callable",
+ "Used when an object being called has been inferred to a non "
+ "callable object.",
+ ),
+ "E1111": (
+ "Assigning result of a function call, where the function has no return",
+ "assignment-from-no-return",
+ "Used when an assignment is done on a function call but the "
+ "inferred function doesn't return anything.",
+ ),
+ "E1120": (
+ "No value for argument %s in %s call",
+ "no-value-for-parameter",
+ "Used when a function call passes too few arguments.",
+ ),
+ "E1121": (
+ "Too many positional arguments for %s call",
+ "too-many-function-args",
+ "Used when a function call passes too many positional arguments.",
+ ),
+ "E1123": (
+ "Unexpected keyword argument %r in %s call",
+ "unexpected-keyword-arg",
+ "Used when a function call passes a keyword argument that "
+ "doesn't correspond to one of the function's parameter names.",
+ ),
+ "E1124": (
+ "Argument %r passed by position and keyword in %s call",
+ "redundant-keyword-arg",
+ "Used when a function call would result in assigning multiple "
+ "values to a function parameter, one value from a positional "
+ "argument and one from a keyword argument.",
+ ),
+ "E1125": (
+ "Missing mandatory keyword argument %r in %s call",
+ "missing-kwoa",
+ (
+ "Used when a function call does not pass a mandatory"
+ " keyword-only argument."
+ ),
+ ),
+ "E1126": (
+ "Sequence index is not an int, slice, or instance with __index__",
+ "invalid-sequence-index",
+ "Used when a sequence type is indexed with an invalid type. "
+ "Valid types are ints, slices, and objects with an __index__ "
+ "method.",
+ ),
+ "E1127": (
+ "Slice index is not an int, None, or instance with __index__",
+ "invalid-slice-index",
+ "Used when a slice index is not an integer, None, or an object "
+ "with an __index__ method.",
+ ),
+ "E1128": (
+ "Assigning result of a function call, where the function returns None",
+ "assignment-from-none",
+ "Used when an assignment is done on a function call but the "
+ "inferred function returns nothing but None.",
+ {"old_names": [("W1111", "old-assignment-from-none")]},
+ ),
+ "E1129": (
+ "Context manager '%s' doesn't implement __enter__ and __exit__.",
+ "not-context-manager",
+ "Used when an instance in a with statement doesn't implement "
+ "the context manager protocol(__enter__/__exit__).",
+ ),
+ "E1130": (
+ "%s",
+ "invalid-unary-operand-type",
+ "Emitted when a unary operand is used on an object which does not "
+ "support this type of operation.",
+ ),
+ "E1131": (
+ "%s",
+ "unsupported-binary-operation",
+ "Emitted when a binary arithmetic operation between two "
+ "operands is not supported.",
+ ),
+ "E1132": (
+ "Got multiple values for keyword argument %r in function call",
+ "repeated-keyword",
+ "Emitted when a function call got multiple values for a keyword.",
+ ),
+ "E1135": (
+ "Value '%s' doesn't support membership test",
+ "unsupported-membership-test",
+ "Emitted when an instance in membership test expression doesn't "
+ "implement membership protocol (__contains__/__iter__/__getitem__).",
+ ),
+ "E1136": (
+ "Value '%s' is unsubscriptable",
+ "unsubscriptable-object",
+ "Emitted when a subscripted value doesn't support subscription "
+ "(i.e. doesn't define __getitem__ method or __class_getitem__ for a class).",
+ ),
+ "E1137": (
+ "%r does not support item assignment",
+ "unsupported-assignment-operation",
+ "Emitted when an object does not support item assignment "
+ "(i.e. doesn't define __setitem__ method).",
+ ),
+ "E1138": (
+ "%r does not support item deletion",
+ "unsupported-delete-operation",
+ "Emitted when an object does not support item deletion "
+ "(i.e. doesn't define __delitem__ method).",
+ ),
+ "E1139": (
+ "Invalid metaclass %r used",
+ "invalid-metaclass",
+ "Emitted whenever we can detect that a class is using, "
+ "as a metaclass, something which might be invalid for using as "
+ "a metaclass.",
+ ),
+ "E1141": (
+ "Unpacking a dictionary in iteration without calling .items()",
+ "dict-iter-missing-items",
+ "Emitted when trying to iterate through a dict without calling .items()",
+ ),
+ "E1142": (
+ "'await' should be used within an async function",
+ "await-outside-async",
+ "Emitted when await is used outside an async function.",
+ ),
+ "E1143": (
+ "'%s' is unhashable and can't be used as a %s in a %s",
+ "unhashable-member",
+ "Emitted when a dict key or set member is not hashable "
+ "(i.e. doesn't define __hash__ method).",
+ {"old_names": [("E1140", "unhashable-dict-key")]},
+ ),
+ "E1144": (
+ "Slice step cannot be 0",
+ "invalid-slice-step",
+ "Used when a slice step is 0 and the object doesn't implement "
+ "a custom __getitem__ method.",
+ ),
+ "W1113": (
+ "Keyword argument before variable positional arguments list "
+ "in the definition of %s function",
+ "keyword-arg-before-vararg",
+ "When defining a keyword argument before variable positional arguments, one can "
+ "end up in having multiple values passed for the aforementioned parameter in "
+ "case the method is called with keyword arguments.",
+ ),
+ "W1114": (
+ "Positional arguments appear to be out of order",
+ "arguments-out-of-order",
+ "Emitted when the caller's argument names fully match the parameter "
+ "names in the function signature but do not have the same order.",
+ ),
+ "W1115": (
+ "Non-string value assigned to __name__",
+ "non-str-assignment-to-dunder-name",
+ "Emitted when a non-string value is assigned to __name__",
+ ),
+ "W1116": (
+ "Second argument of isinstance is not a type",
+ "isinstance-second-argument-not-valid-type",
+ "Emitted when the second argument of an isinstance call is not a type.",
+ ),
+ "W1117": (
+ "%r will be included in %r since a positional-only parameter with this name already exists",
+ "kwarg-superseded-by-positional-arg",
+ "Emitted when a function is called with a keyword argument that has the "
+ "same name as a positional-only parameter and the function contains a "
+ "keyword variadic parameter dict.",
+ ),
+}
+
+# builtin sequence types in Python 2 and 3.
+SEQUENCE_TYPES = {
+ "str",
+ "unicode",
+ "list",
+ "tuple",
+ "bytearray",
+ "xrange",
+ "range",
+ "bytes",
+ "memoryview",
+}
+
+
+def _emit_no_member(
+ node: nodes.Attribute | nodes.AssignAttr | nodes.DelAttr,
+ owner: InferenceResult,
+ owner_name: str | None,
+ mixin_class_rgx: Pattern[str],
+ ignored_mixins: bool = True,
+ ignored_none: bool = True,
+) -> bool:
+ """Try to see if no-member should be emitted for the given owner.
+
+ The following cases are ignored:
+
+ * the owner is a function and it has decorators.
+ * the owner is an instance and it has __getattr__, __getattribute__ implemented
+ * the module is explicitly ignored from no-member checks
+ * the owner is a class and the name can be found in its metaclass.
+ * The access node is protected by an except handler, which handles
+ AttributeError, Exception or bare except.
+ * The node is guarded behind and `IF` or `IFExp` node
+ """
+ # pylint: disable = too-many-return-statements, too-many-branches
+ if node_ignores_exception(node, AttributeError):
+ return False
+ if ignored_none and isinstance(owner, nodes.Const) and owner.value is None:
+ return False
+ if is_super(owner) or getattr(owner, "type", None) == "metaclass":
+ return False
+ if owner_name and ignored_mixins and mixin_class_rgx.match(owner_name):
+ return False
+ if isinstance(owner, nodes.FunctionDef) and (
+ owner.decorators or owner.is_abstract()
+ ):
+ return False
+ if isinstance(owner, (astroid.Instance, nodes.ClassDef)):
+ # Issue #2565: Don't ignore enums, as they have a `__getattr__` but it's not
+ # invoked at this point.
+ try:
+ metaclass = owner.metaclass()
+ except astroid.MroError:
+ pass
+ else:
+ # Renamed in Python 3.10 to `EnumType`
+ if metaclass and metaclass.qname() in {"enum.EnumMeta", "enum.EnumType"}:
+ return not _enum_has_attribute(owner, node)
+ if owner.has_dynamic_getattr():
+ return False
+ if not has_known_bases(owner):
+ return False
+
+ # Exclude typed annotations, since these might actually exist
+ # at some point during the runtime of the program.
+ if utils.is_attribute_typed_annotation(owner, node.attrname):
+ return False
+ if isinstance(owner, astroid.objects.Super):
+ # Verify if we are dealing with an invalid Super object.
+ # If it is invalid, then there's no point in checking that
+ # it has the required attribute. Also, don't fail if the
+ # MRO is invalid.
+ try:
+ owner.super_mro()
+ except (astroid.MroError, astroid.SuperError):
+ return False
+ if not all(has_known_bases(base) for base in owner.type.mro()):
+ return False
+ if isinstance(owner, nodes.Module):
+ try:
+ owner.getattr("__getattr__")
+ return False
+ except astroid.NotFoundError:
+ pass
+ if owner_name and node.attrname.startswith("_" + owner_name):
+ # Test if an attribute has been mangled ('private' attribute)
+ unmangled_name = node.attrname.split("_" + owner_name)[-1]
+ try:
+ if owner.getattr(unmangled_name, context=None) is not None:
+ return False
+ except astroid.NotFoundError:
+ return True
+
+ # Don't emit no-member if guarded behind `IF` or `IFExp`
+ # * Walk up recursively until if statement is found.
+ # * Check if condition can be inferred as `Const`,
+ # would evaluate as `False`,
+ # and whether the node is part of the `body`.
+ # * Continue checking until scope of node is reached.
+ scope: nodes.NodeNG = node.scope()
+ node_origin: nodes.NodeNG = node
+ parent: nodes.NodeNG = node.parent
+ while parent != scope:
+ if isinstance(parent, (nodes.If, nodes.IfExp)):
+ inferred = safe_infer(parent.test)
+ if ( # pylint: disable=too-many-boolean-expressions
+ isinstance(inferred, nodes.Const)
+ and inferred.bool_value() is False
+ and (
+ isinstance(parent, nodes.If)
+ and node_origin in parent.body
+ or isinstance(parent, nodes.IfExp)
+ and node_origin == parent.body
+ )
+ ):
+ return False
+ node_origin, parent = parent, parent.parent
+
+ return True
+
+
+def _get_all_attribute_assignments(
+ node: nodes.FunctionDef, name: str | None = None
+) -> set[str]:
+ attributes: set[str] = set()
+ for child in node.nodes_of_class((nodes.Assign, nodes.AnnAssign)):
+ targets = []
+ if isinstance(child, nodes.Assign):
+ targets = child.targets
+ elif isinstance(child, nodes.AnnAssign):
+ targets = [child.target]
+ for assign_target in targets:
+ if isinstance(assign_target, nodes.Tuple):
+ targets.extend(assign_target.elts)
+ continue
+ if (
+ isinstance(assign_target, nodes.AssignAttr)
+ and isinstance(assign_target.expr, nodes.Name)
+ and (name is None or assign_target.expr.name == name)
+ ):
+ attributes.add(assign_target.attrname)
+ return attributes
+
+
+def _enum_has_attribute(
+ owner: astroid.Instance | nodes.ClassDef, node: nodes.Attribute
+) -> bool:
+ if isinstance(owner, astroid.Instance):
+ enum_def = next(
+ (b.parent for b in owner.bases if isinstance(b.parent, nodes.ClassDef)),
+ None,
+ )
+
+ if enum_def is None:
+ # We don't inherit from anything, so try to find the parent
+ # class definition and roll with that
+ enum_def = node
+ while enum_def is not None and not isinstance(enum_def, nodes.ClassDef):
+ enum_def = enum_def.parent
+
+ # If this blows, something is clearly wrong
+ assert enum_def is not None, "enum_def unexpectedly None"
+ else:
+ enum_def = owner
+
+ # Find __new__ and __init__
+ dunder_new = next((m for m in enum_def.methods() if m.name == "__new__"), None)
+ dunder_init = next((m for m in enum_def.methods() if m.name == "__init__"), None)
+
+ enum_attributes: set[str] = set()
+
+ # Find attributes defined in __new__
+ if dunder_new:
+ # Get the object returned in __new__
+ returned_obj_name = next(
+ (c.value for c in dunder_new.get_children() if isinstance(c, nodes.Return)),
+ None,
+ )
+ if isinstance(returned_obj_name, nodes.Name):
+ # Find all attribute assignments to the returned object
+ enum_attributes |= _get_all_attribute_assignments(
+ dunder_new, returned_obj_name.name
+ )
+
+ # Find attributes defined in __init__
+ if dunder_init and dunder_init.body and dunder_init.args:
+ # Grab the name referring to `self` from the function def
+ enum_attributes |= _get_all_attribute_assignments(
+ dunder_init, dunder_init.args.arguments[0].name
+ )
+
+ return node.attrname in enum_attributes
+
+
+def _determine_callable(
+ callable_obj: nodes.NodeNG,
+) -> tuple[CallableObjects, int, str]:
+ # TODO: The typing of the second return variable is actually Literal[0,1]
+ # We need typing on astroid.NodeNG.implicit_parameters for this
+ # TODO: The typing of the third return variable can be narrowed to a Literal
+ # We need typing on astroid.NodeNG.type for this
+
+ # Ordering is important, since BoundMethod is a subclass of UnboundMethod,
+ # and Function inherits Lambda.
+ parameters = 0
+ if hasattr(callable_obj, "implicit_parameters"):
+ parameters = callable_obj.implicit_parameters()
+ if isinstance(callable_obj, bases.BoundMethod):
+ # Bound methods have an extra implicit 'self' argument.
+ return callable_obj, parameters, callable_obj.type
+ if isinstance(callable_obj, bases.UnboundMethod):
+ return callable_obj, parameters, "unbound method"
+ if isinstance(callable_obj, nodes.FunctionDef):
+ return callable_obj, parameters, callable_obj.type
+ if isinstance(callable_obj, nodes.Lambda):
+ return callable_obj, parameters, "lambda"
+ if isinstance(callable_obj, nodes.ClassDef):
+ # Class instantiation, lookup __new__ instead.
+ # If we only find object.__new__, we can safely check __init__
+ # instead. If __new__ belongs to builtins, then we look
+ # again for __init__ in the locals, since we won't have
+ # argument information for the builtin __new__ function.
+ try:
+ # Use the last definition of __new__.
+ new = callable_obj.local_attr("__new__")[-1]
+ except astroid.NotFoundError:
+ new = None
+
+ from_object = new and new.parent.scope().name == "object"
+ from_builtins = new and new.root().name in sys.builtin_module_names
+
+ if not new or from_object or from_builtins:
+ try:
+ # Use the last definition of __init__.
+ callable_obj = callable_obj.local_attr("__init__")[-1]
+ except astroid.NotFoundError as e:
+ raise ValueError from e
+ else:
+ callable_obj = new
+
+ if not isinstance(callable_obj, nodes.FunctionDef):
+ raise ValueError
+ # both have an extra implicit 'cls'/'self' argument.
+ return callable_obj, parameters, "constructor"
+
+ raise ValueError
+
+
+def _has_parent_of_type(
+ node: nodes.Call,
+ node_type: nodes.Keyword | nodes.Starred,
+ statement: _base_nodes.Statement,
+) -> bool:
+ """Check if the given node has a parent of the given type."""
+ parent = node.parent
+ while not isinstance(parent, node_type) and statement.parent_of(parent):
+ parent = parent.parent
+ return isinstance(parent, node_type)
+
+
+def _no_context_variadic_keywords(node: nodes.Call, scope: nodes.Lambda) -> bool:
+ statement = node.statement()
+ variadics = []
+
+ if (
+ isinstance(scope, nodes.Lambda)
+ and not isinstance(scope, nodes.FunctionDef)
+ or isinstance(statement, nodes.With)
+ ):
+ variadics = list(node.keywords or []) + node.kwargs
+ elif isinstance(statement, (nodes.Return, nodes.Expr, nodes.Assign)) and isinstance(
+ statement.value, nodes.Call
+ ):
+ call = statement.value
+ variadics = list(call.keywords or []) + call.kwargs
+
+ return _no_context_variadic(node, scope.args.kwarg, nodes.Keyword, variadics)
+
+
+def _no_context_variadic_positional(node: nodes.Call, scope: nodes.Lambda) -> bool:
+ variadics = node.starargs + node.kwargs
+ return _no_context_variadic(node, scope.args.vararg, nodes.Starred, variadics)
+
+
+def _no_context_variadic(
+ node: nodes.Call,
+ variadic_name: str | None,
+ variadic_type: nodes.Keyword | nodes.Starred,
+ variadics: list[nodes.Keyword | nodes.Starred],
+) -> bool:
+ """Verify if the given call node has variadic nodes without context.
+
+ This is a workaround for handling cases of nested call functions
+ which don't have the specific call context at hand.
+ Variadic arguments (variable positional arguments and variable
+ keyword arguments) are inferred, inherently wrong, by astroid
+ as a Tuple, respectively a Dict with empty elements.
+ This can lead pylint to believe that a function call receives
+ too few arguments.
+ """
+ scope = node.scope()
+ is_in_lambda_scope = not isinstance(scope, nodes.FunctionDef) and isinstance(
+ scope, nodes.Lambda
+ )
+ statement = node.statement()
+ for name in statement.nodes_of_class(nodes.Name):
+ if name.name != variadic_name:
+ continue
+
+ inferred = safe_infer(name)
+ if isinstance(inferred, (nodes.List, nodes.Tuple)):
+ length = len(inferred.elts)
+ elif isinstance(inferred, nodes.Dict):
+ length = len(inferred.items)
+ else:
+ continue
+
+ if is_in_lambda_scope and isinstance(inferred.parent, nodes.Arguments):
+ # The statement of the variadic will be the assignment itself,
+ # so we need to go the lambda instead
+ inferred_statement = inferred.parent.parent
+ else:
+ inferred_statement = inferred.statement()
+
+ if not length and isinstance(
+ inferred_statement, (nodes.Lambda, nodes.FunctionDef)
+ ):
+ is_in_starred_context = _has_parent_of_type(node, variadic_type, statement)
+ used_as_starred_argument = any(
+ variadic.value == name or variadic.value.parent_of(name)
+ for variadic in variadics
+ )
+ if is_in_starred_context or used_as_starred_argument:
+ return True
+ return False
+
+
+def _is_invalid_metaclass(metaclass: nodes.ClassDef) -> bool:
+ try:
+ mro = metaclass.mro()
+ except (astroid.DuplicateBasesError, astroid.InconsistentMroError):
+ return True
+ return not any(is_builtin_object(cls) and cls.name == "type" for cls in mro)
+
+
+def _infer_from_metaclass_constructor(
+ cls: nodes.ClassDef, func: nodes.FunctionDef
+) -> InferenceResult | None:
+ """Try to infer what the given *func* constructor is building.
+
+ :param astroid.FunctionDef func:
+ A metaclass constructor. Metaclass definitions can be
+ functions, which should accept three arguments, the name of
+ the class, the bases of the class and the attributes.
+ The function could return anything, but usually it should
+ be a proper metaclass.
+ :param astroid.ClassDef cls:
+ The class for which the *func* parameter should generate
+ a metaclass.
+ :returns:
+ The class generated by the function or None,
+ if we couldn't infer it.
+ :rtype: astroid.ClassDef
+ """
+ context = astroid.context.InferenceContext()
+
+ class_bases = nodes.List()
+ class_bases.postinit(elts=cls.bases)
+
+ attrs = nodes.Dict(
+ lineno=0, col_offset=0, parent=None, end_lineno=0, end_col_offset=0
+ )
+ local_names = [(name, values[-1]) for name, values in cls.locals.items()]
+ attrs.postinit(local_names)
+
+ builder_args = nodes.Tuple()
+ builder_args.postinit([cls.name, class_bases, attrs])
+
+ context.callcontext = astroid.context.CallContext(builder_args)
+ try:
+ inferred = next(func.infer_call_result(func, context), None)
+ except astroid.InferenceError:
+ return None
+ return inferred or None
+
+
+def _is_c_extension(module_node: InferenceResult) -> bool:
+ return (
+ isinstance(module_node, nodes.Module)
+ and not astroid.modutils.is_stdlib_module(module_node.name)
+ and not module_node.fully_defined()
+ )
+
+
+def _is_invalid_isinstance_type(arg: nodes.NodeNG) -> bool:
+ # Return True if we are sure that arg is not a type
+ if PY310_PLUS and isinstance(arg, nodes.BinOp) and arg.op == "|":
+ return any(
+ _is_invalid_isinstance_type(elt) and not is_none(elt)
+ for elt in (arg.left, arg.right)
+ )
+ inferred = utils.safe_infer(arg)
+ if not inferred:
+ # Cannot infer it so skip it.
+ return False
+ if isinstance(inferred, nodes.Tuple):
+ return any(_is_invalid_isinstance_type(elt) for elt in inferred.elts)
+ if isinstance(inferred, nodes.ClassDef):
+ return False
+ if isinstance(inferred, astroid.Instance) and inferred.qname() == BUILTIN_TUPLE:
+ return False
+ if PY310_PLUS and isinstance(inferred, bases.UnionType):
+ return any(
+ _is_invalid_isinstance_type(elt) and not is_none(elt)
+ for elt in (inferred.left, inferred.right)
+ )
+ return True
+
+
+class TypeChecker(BaseChecker):
+ """Try to find bugs in the code using type inference."""
+
+ # configuration section name
+ name = "typecheck"
+ # messages
+ msgs = MSGS
+ # configuration options
+ options = (
+ (
+ "ignore-on-opaque-inference",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "This flag controls whether pylint should warn about "
+ "no-member and similar checks whenever an opaque object "
+ "is returned when inferring. The inference can return "
+ "multiple potential results while evaluating a Python object, "
+ "but some branches might not be evaluated, which results in "
+ "partial inference. In that case, it might be useful to still emit "
+ "no-member and other checks for the rest of the inferred objects.",
+ },
+ ),
+ (
+ "mixin-class-rgx",
+ {
+ "default": ".*[Mm]ixin",
+ "type": "regexp",
+ "metavar": "<regexp>",
+ "help": "Regex pattern to define which classes are considered mixins.",
+ },
+ ),
+ (
+ "ignore-mixin-members",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Tells whether missing members accessed in mixin "
+ "class should be ignored. A class is considered mixin if its name matches "
+ "the mixin-class-rgx option.",
+ "kwargs": {"new_names": ["ignore-checks-for-mixin"]},
+ },
+ ),
+ (
+ "ignored-checks-for-mixins",
+ {
+ "default": [
+ "no-member",
+ "not-async-context-manager",
+ "not-context-manager",
+ "attribute-defined-outside-init",
+ ],
+ "type": "csv",
+ "metavar": "<list of messages names>",
+ "help": "List of symbolic message names to ignore for Mixin members.",
+ },
+ ),
+ (
+ "ignore-none",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Tells whether to warn about missing members when the owner "
+ "of the attribute is inferred to be None.",
+ },
+ ),
+ # the defaults here are *stdlib* names that (almost) always
+ # lead to false positives, since their idiomatic use is
+ # 'too dynamic' for pylint to grok.
+ (
+ "ignored-classes",
+ {
+ "default": (
+ "optparse.Values",
+ "thread._local",
+ "_thread._local",
+ "argparse.Namespace",
+ ),
+ "type": "csv",
+ "metavar": "<members names>",
+ "help": "List of class names for which member attributes "
+ "should not be checked (useful for classes with "
+ "dynamically set attributes). This supports "
+ "the use of qualified names.",
+ },
+ ),
+ (
+ "generated-members",
+ {
+ "default": (),
+ "type": "string",
+ "metavar": "<members names>",
+ "help": "List of members which are set dynamically and \
+missed by pylint inference system, and so shouldn't trigger E1101 when \
+accessed. Python regular expressions are accepted.",
+ },
+ ),
+ (
+ "contextmanager-decorators",
+ {
+ "default": ["contextlib.contextmanager"],
+ "type": "csv",
+ "metavar": "<decorator names>",
+ "help": "List of decorators that produce context managers, "
+ "such as contextlib.contextmanager. Add to this list "
+ "to register other decorators that produce valid "
+ "context managers.",
+ },
+ ),
+ (
+ "missing-member-hint-distance",
+ {
+ "default": 1,
+ "type": "int",
+ "metavar": "<member hint edit distance>",
+ "help": "The minimum edit distance a name should have in order "
+ "to be considered a similar match for a missing member name.",
+ },
+ ),
+ (
+ "missing-member-max-choices",
+ {
+ "default": 1,
+ "type": "int",
+ "metavar": "<member hint max choices>",
+ "help": "The total number of similar names that should be taken in "
+ "consideration when showing a hint for a missing member.",
+ },
+ ),
+ (
+ "missing-member-hint",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<missing member hint>",
+ "help": "Show a hint with possible names when a member name was not "
+ "found. The aspect of finding the hint is based on edit distance.",
+ },
+ ),
+ (
+ "signature-mutators",
+ {
+ "default": [],
+ "type": "csv",
+ "metavar": "<decorator names>",
+ "help": "List of decorators that change the signature of "
+ "a decorated function.",
+ },
+ ),
+ )
+
+ def open(self) -> None:
+ py_version = self.linter.config.py_version
+ self._py310_plus = py_version >= (3, 10)
+ self._mixin_class_rgx = self.linter.config.mixin_class_rgx
+
+ @cached_property
+ def _suggestion_mode(self) -> bool:
+ return self.linter.config.suggestion_mode # type: ignore[no-any-return]
+
+ @cached_property
+ def _compiled_generated_members(self) -> tuple[Pattern[str], ...]:
+ # do this lazily since config not fully initialized in __init__
+ # generated_members may contain regular expressions
+ # (surrounded by quote `"` and followed by a comma `,`)
+ # REQUEST,aq_parent,"[a-zA-Z]+_set{1,2}"' =>
+ # ('REQUEST', 'aq_parent', '[a-zA-Z]+_set{1,2}')
+ generated_members = self.linter.config.generated_members
+ if isinstance(generated_members, str):
+ gen = shlex.shlex(generated_members)
+ gen.whitespace += ","
+ gen.wordchars += r"[]-+\.*?()|"
+ generated_members = tuple(tok.strip('"') for tok in gen)
+ return tuple(re.compile(exp) for exp in generated_members)
+
+ @only_required_for_messages("keyword-arg-before-vararg")
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ # check for keyword arg before varargs.
+
+ if node.args.vararg and node.args.defaults:
+ # When `positional-only` parameters are present then only
+ # `positional-or-keyword` parameters are checked. I.e:
+ # >>> def name(pos_only_params, /, pos_or_keyword_params, *args): ...
+ if node.args.posonlyargs and not node.args.args:
+ return
+ self.add_message("keyword-arg-before-vararg", node=node, args=(node.name))
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ @only_required_for_messages("invalid-metaclass")
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ def _metaclass_name(metaclass: InferenceResult) -> str | None:
+ # pylint: disable=unidiomatic-typecheck
+ if isinstance(metaclass, (nodes.ClassDef, nodes.FunctionDef)):
+ return metaclass.name # type: ignore[no-any-return]
+ if type(metaclass) is bases.Instance:
+ # Really do mean type, not isinstance, since subclasses of bases.Instance
+ # like Const or Dict should use metaclass.as_string below.
+ return str(metaclass)
+ return metaclass.as_string() # type: ignore[no-any-return]
+
+ metaclass = node.declared_metaclass()
+ if not metaclass:
+ return
+
+ if isinstance(metaclass, nodes.FunctionDef):
+ # Try to infer the result.
+ metaclass = _infer_from_metaclass_constructor(node, metaclass)
+ if not metaclass:
+ # Don't do anything if we cannot infer the result.
+ return
+
+ if isinstance(metaclass, nodes.ClassDef):
+ if _is_invalid_metaclass(metaclass):
+ self.add_message(
+ "invalid-metaclass", node=node, args=(_metaclass_name(metaclass),)
+ )
+ else:
+ self.add_message(
+ "invalid-metaclass", node=node, args=(_metaclass_name(metaclass),)
+ )
+
+ def visit_assignattr(self, node: nodes.AssignAttr) -> None:
+ if isinstance(node.assign_type(), nodes.AugAssign):
+ self.visit_attribute(node)
+
+ def visit_delattr(self, node: nodes.DelAttr) -> None:
+ self.visit_attribute(node)
+
+ # pylint: disable = too-many-branches, too-many-statements
+ @only_required_for_messages("no-member", "c-extension-no-member")
+ def visit_attribute(
+ self, node: nodes.Attribute | nodes.AssignAttr | nodes.DelAttr
+ ) -> None:
+ """Check that the accessed attribute exists.
+
+ to avoid too much false positives for now, we'll consider the code as
+ correct if a single of the inferred nodes has the accessed attribute.
+
+ function/method, super call and metaclasses are ignored
+ """
+ if any(
+ pattern.match(name)
+ for name in (node.attrname, node.as_string())
+ for pattern in self._compiled_generated_members
+ ):
+ return
+
+ if is_postponed_evaluation_enabled(node) and is_node_in_type_annotation_context(
+ node
+ ):
+ return
+
+ try:
+ inferred = list(node.expr.infer())
+ except astroid.InferenceError:
+ return
+
+ # list of (node, nodename) which are missing the attribute
+ missingattr: set[tuple[SuccessfulInferenceResult, str | None]] = set()
+
+ non_opaque_inference_results: list[SuccessfulInferenceResult] = [
+ owner
+ for owner in inferred
+ if not isinstance(owner, (nodes.Unknown, util.UninferableBase))
+ ]
+ if (
+ len(non_opaque_inference_results) != len(inferred)
+ and self.linter.config.ignore_on_opaque_inference
+ ):
+ # There is an ambiguity in the inference. Since we can't
+ # make sure that we won't emit a false positive, we just stop
+ # whenever the inference returns an opaque inference object.
+ return
+ for owner in non_opaque_inference_results:
+ name = getattr(owner, "name", None)
+ if _is_owner_ignored(
+ owner,
+ name,
+ self.linter.config.ignored_classes,
+ self.linter.config.ignored_modules,
+ ):
+ continue
+
+ qualname = f"{owner.pytype()}.{node.attrname}"
+ if any(
+ pattern.match(qualname) for pattern in self._compiled_generated_members
+ ):
+ return
+
+ try:
+ attr_nodes = owner.getattr(node.attrname)
+ except AttributeError:
+ continue
+ except astroid.DuplicateBasesError:
+ continue
+ except astroid.NotFoundError:
+ # Avoid false positive in case a decorator supplies member.
+ if (
+ isinstance(owner, (astroid.FunctionDef, astroid.BoundMethod))
+ and owner.decorators
+ ):
+ continue
+ # This can't be moved before the actual .getattr call,
+ # because there can be more values inferred and we are
+ # stopping after the first one which has the attribute in question.
+ # The problem is that if the first one has the attribute,
+ # but we continue to the next values which doesn't have the
+ # attribute, then we'll have a false positive.
+ # So call this only after the call has been made.
+ if not _emit_no_member(
+ node,
+ owner,
+ name,
+ self._mixin_class_rgx,
+ ignored_mixins=(
+ "no-member" in self.linter.config.ignored_checks_for_mixins
+ ),
+ ignored_none=self.linter.config.ignore_none,
+ ):
+ continue
+ missingattr.add((owner, name))
+ continue
+ else:
+ for attr_node in attr_nodes:
+ attr_parent = attr_node.parent
+ # Skip augmented assignments
+ try:
+ if isinstance(attr_node.statement(), nodes.AugAssign) or (
+ isinstance(attr_parent, nodes.Assign)
+ and utils.is_augmented_assign(attr_parent)[0]
+ ):
+ continue
+ except astroid.exceptions.StatementMissing:
+ break
+ # Skip self-referencing assignments
+ if attr_parent is node.parent:
+ continue
+ break
+ else:
+ missingattr.add((owner, name))
+ continue
+ # stop on the first found
+ break
+ else:
+ # we have not found any node with the attributes, display the
+ # message for inferred nodes
+ done = set()
+ for owner, name in missingattr:
+ if isinstance(owner, astroid.Instance):
+ actual = owner._proxied
+ else:
+ actual = owner
+ if actual in done:
+ continue
+ done.add(actual)
+
+ msg, hint = self._get_nomember_msgid_hint(node, owner)
+ self.add_message(
+ msg,
+ node=node,
+ args=(owner.display_type(), name, node.attrname, hint),
+ confidence=INFERENCE,
+ )
+
+ def _get_nomember_msgid_hint(
+ self,
+ node: nodes.Attribute | nodes.AssignAttr | nodes.DelAttr,
+ owner: SuccessfulInferenceResult,
+ ) -> tuple[Literal["c-extension-no-member", "no-member"], str]:
+ suggestions_are_possible = self._suggestion_mode and isinstance(
+ owner, nodes.Module
+ )
+ if suggestions_are_possible and _is_c_extension(owner):
+ msg = "c-extension-no-member"
+ hint = ""
+ else:
+ msg = "no-member"
+ if self.linter.config.missing_member_hint:
+ hint = _missing_member_hint(
+ owner,
+ node.attrname,
+ self.linter.config.missing_member_hint_distance,
+ self.linter.config.missing_member_max_choices,
+ )
+ else:
+ hint = ""
+ return msg, hint # type: ignore[return-value]
+
+ @only_required_for_messages(
+ "assignment-from-no-return",
+ "assignment-from-none",
+ "non-str-assignment-to-dunder-name",
+ )
+ def visit_assign(self, node: nodes.Assign) -> None:
+ """Process assignments in the AST."""
+ self._check_assignment_from_function_call(node)
+ self._check_dundername_is_string(node)
+
+ def _check_assignment_from_function_call(self, node: nodes.Assign) -> None:
+ """When assigning to a function call, check that the function returns a valid
+ value.
+ """
+ if not isinstance(node.value, nodes.Call):
+ return
+
+ function_node = safe_infer(node.value.func)
+ funcs = (nodes.FunctionDef, astroid.UnboundMethod, astroid.BoundMethod)
+ if not isinstance(function_node, funcs):
+ return
+
+ # Unwrap to get the actual function node object
+ if isinstance(function_node, astroid.BoundMethod) and isinstance(
+ function_node._proxied, astroid.UnboundMethod
+ ):
+ function_node = function_node._proxied._proxied
+
+ # Make sure that it's a valid function that we can analyze.
+ # Ordered from less expensive to more expensive checks.
+ if (
+ not function_node.is_function
+ or function_node.decorators
+ or self._is_ignored_function(function_node)
+ ):
+ return
+
+ # Handle builtins such as list.sort() or dict.update()
+ if self._is_builtin_no_return(node):
+ self.add_message(
+ "assignment-from-no-return", node=node, confidence=INFERENCE
+ )
+ return
+
+ if not function_node.root().fully_defined():
+ return
+
+ return_nodes = list(
+ function_node.nodes_of_class(nodes.Return, skip_klass=nodes.FunctionDef)
+ )
+ if not return_nodes:
+ self.add_message("assignment-from-no-return", node=node)
+ else:
+ for ret_node in return_nodes:
+ if not (
+ isinstance(ret_node.value, nodes.Const)
+ and ret_node.value.value is None
+ or ret_node.value is None
+ ):
+ break
+ else:
+ self.add_message("assignment-from-none", node=node)
+
+ @staticmethod
+ def _is_ignored_function(
+ function_node: nodes.FunctionDef | bases.UnboundMethod,
+ ) -> bool:
+ return (
+ isinstance(function_node, nodes.AsyncFunctionDef)
+ or utils.is_error(function_node)
+ or function_node.is_generator()
+ or function_node.is_abstract(pass_is_abstract=False)
+ )
+
+ @staticmethod
+ def _is_builtin_no_return(node: nodes.Assign) -> bool:
+ return (
+ isinstance(node.value, nodes.Call)
+ and isinstance(node.value.func, nodes.Attribute)
+ and bool(inferred := utils.safe_infer(node.value.func.expr))
+ and isinstance(inferred, bases.Instance)
+ and node.value.func.attrname
+ in BUILTINS_IMPLICIT_RETURN_NONE.get(inferred.pytype(), ())
+ )
+
+ def _check_dundername_is_string(self, node: nodes.Assign) -> None:
+ """Check a string is assigned to self.__name__."""
+ # Check the left-hand side of the assignment is <something>.__name__
+ lhs = node.targets[0]
+ if not isinstance(lhs, nodes.AssignAttr):
+ return
+ if not lhs.attrname == "__name__":
+ return
+
+ # If the right-hand side is not a string
+ rhs = node.value
+ if isinstance(rhs, nodes.Const) and isinstance(rhs.value, str):
+ return
+ inferred = utils.safe_infer(rhs)
+ if not inferred:
+ return
+ if not (isinstance(inferred, nodes.Const) and isinstance(inferred.value, str)):
+ # Add the message
+ self.add_message("non-str-assignment-to-dunder-name", node=node)
+
+ def _check_uninferable_call(self, node: nodes.Call) -> None:
+ """Check that the given uninferable Call node does not
+ call an actual function.
+ """
+ if not isinstance(node.func, nodes.Attribute):
+ return
+
+ # Look for properties. First, obtain
+ # the lhs of the Attribute node and search the attribute
+ # there. If that attribute is a property or a subclass of properties,
+ # then most likely it's not callable.
+
+ expr = node.func.expr
+ klass = safe_infer(expr)
+ if not isinstance(klass, astroid.Instance):
+ return
+
+ try:
+ attrs = klass._proxied.getattr(node.func.attrname)
+ except astroid.NotFoundError:
+ return
+
+ for attr in attrs:
+ if not isinstance(attr, nodes.FunctionDef):
+ continue
+
+ # Decorated, see if it is decorated with a property.
+ # Also, check the returns and see if they are callable.
+ if decorated_with_property(attr):
+ try:
+ call_results = list(attr.infer_call_result(node))
+ except astroid.InferenceError:
+ continue
+
+ if all(
+ isinstance(return_node, util.UninferableBase)
+ for return_node in call_results
+ ):
+ # We were unable to infer return values of the call, skipping
+ continue
+
+ if any(return_node.callable() for return_node in call_results):
+ # Only raise this issue if *all* the inferred values are not callable
+ continue
+
+ self.add_message("not-callable", node=node, args=node.func.as_string())
+
+ def _check_argument_order(
+ self,
+ node: nodes.Call,
+ call_site: arguments.CallSite,
+ called: CallableObjects,
+ called_param_names: list[str | None],
+ ) -> None:
+ """Match the supplied argument names against the function parameters.
+
+ Warn if some argument names are not in the same order as they are in
+ the function signature.
+ """
+ # Check for called function being an object instance function
+ # If so, ignore the initial 'self' argument in the signature
+ try:
+ is_classdef = isinstance(called.parent, nodes.ClassDef)
+ if is_classdef and called_param_names[0] == "self":
+ called_param_names = called_param_names[1:]
+ except IndexError:
+ return
+
+ try:
+ # extract argument names, if they have names
+ calling_parg_names = [p.name for p in call_site.positional_arguments]
+
+ # Additionally, get names of keyword arguments to use in a full match
+ # against parameters
+ calling_kwarg_names = [
+ arg.name for arg in call_site.keyword_arguments.values()
+ ]
+ except AttributeError:
+ # the type of arg does not provide a `.name`. In this case we
+ # stop checking for out-of-order arguments because it is only relevant
+ # for named variables.
+ return
+
+ # Don't check for ordering if there is an unmatched arg or param
+ arg_set = set(calling_parg_names) | set(calling_kwarg_names)
+ param_set = set(called_param_names)
+ if arg_set != param_set:
+ return
+
+ # Warn based on the equality of argument ordering
+ if calling_parg_names != called_param_names[: len(calling_parg_names)]:
+ self.add_message("arguments-out-of-order", node=node, args=())
+
+ def _check_isinstance_args(self, node: nodes.Call, callable_name: str) -> None:
+ if len(node.args) > 2:
+ # for when isinstance called with too many args
+ self.add_message(
+ "too-many-function-args",
+ node=node,
+ args=(callable_name,),
+ confidence=HIGH,
+ )
+ elif len(node.args) < 2:
+ # NOTE: Hard-coding the parameters for `isinstance` is fragile,
+ # but as noted elsewhere, built-in functions do not provide
+ # argument info, making this necessary for now.
+ parameters = ("'_obj'", "'__class_or_tuple'")
+ for parameter in parameters[len(node.args) :]:
+ self.add_message(
+ "no-value-for-parameter",
+ node=node,
+ args=(parameter, callable_name),
+ confidence=HIGH,
+ )
+ return
+
+ second_arg = node.args[1]
+ if _is_invalid_isinstance_type(second_arg):
+ self.add_message(
+ "isinstance-second-argument-not-valid-type",
+ node=node,
+ confidence=INFERENCE,
+ )
+
+ # pylint: disable = too-many-branches, too-many-locals, too-many-statements
+ def visit_call(self, node: nodes.Call) -> None:
+ """Check that called functions/methods are inferred to callable objects,
+ and that passed arguments match the parameters in the inferred function.
+ """
+ called = safe_infer(node.func, compare_constructors=True)
+
+ self._check_not_callable(node, called)
+
+ try:
+ called, implicit_args, callable_name = _determine_callable(called)
+ except ValueError:
+ # Any error occurred during determining the function type, most of
+ # those errors are handled by different warnings.
+ return
+
+ if called.args.args is None:
+ if called.name == "isinstance":
+ # Verify whether second argument of isinstance is a valid type
+ self._check_isinstance_args(node, callable_name)
+ # Built-in functions have no argument information.
+ return
+
+ if len(called.argnames()) != len(set(called.argnames())):
+ # Duplicate parameter name (see duplicate-argument). We can't really
+ # make sense of the function call in this case, so just return.
+ return
+
+ # Build the set of keyword arguments, checking for duplicate keywords,
+ # and count the positional arguments.
+ call_site = astroid.arguments.CallSite.from_call(node)
+
+ # Warn about duplicated keyword arguments, such as `f=24, **{'f': 24}`
+ for keyword in call_site.duplicated_keywords:
+ self.add_message("repeated-keyword", node=node, args=(keyword,))
+
+ if call_site.has_invalid_arguments() or call_site.has_invalid_keywords():
+ # Can't make sense of this.
+ return
+
+ # Has the function signature changed in ways we cannot reliably detect?
+ if hasattr(called, "decorators") and decorated_with(
+ called, self.linter.config.signature_mutators
+ ):
+ return
+
+ num_positional_args = len(call_site.positional_arguments)
+ keyword_args = list(call_site.keyword_arguments.keys())
+ overload_function = is_overload_stub(called)
+
+ # Determine if we don't have a context for our call and we use variadics.
+ node_scope = node.scope()
+ if isinstance(node_scope, (nodes.Lambda, nodes.FunctionDef)):
+ has_no_context_positional_variadic = _no_context_variadic_positional(
+ node, node_scope
+ )
+ has_no_context_keywords_variadic = _no_context_variadic_keywords(
+ node, node_scope
+ )
+ else:
+ has_no_context_positional_variadic = has_no_context_keywords_variadic = (
+ False
+ )
+
+ # These are coming from the functools.partial implementation in astroid
+ already_filled_positionals = getattr(called, "filled_positionals", 0)
+ already_filled_keywords = getattr(called, "filled_keywords", {})
+
+ keyword_args += list(already_filled_keywords)
+ num_positional_args += implicit_args + already_filled_positionals
+
+ # Decrement `num_positional_args` by 1 when a function call is assigned to a class attribute
+ # inside the class where the function is defined.
+ # This avoids emitting `too-many-function-args` since `num_positional_args`
+ # includes an implicit `self` argument which is not present in `called.args`.
+ if (
+ isinstance(node.frame(), nodes.ClassDef)
+ and isinstance(called, nodes.FunctionDef)
+ and called in node.frame().body
+ and num_positional_args > 0
+ and "builtins.staticmethod" not in called.decoratornames()
+ ):
+ num_positional_args -= 1
+
+ # Analyze the list of formal parameters.
+ args = list(itertools.chain(called.args.posonlyargs or (), called.args.args))
+ num_mandatory_parameters = len(args) - len(called.args.defaults)
+ parameters: list[tuple[tuple[str | None, nodes.NodeNG | None], bool]] = []
+ parameter_name_to_index = {}
+ for i, arg in enumerate(args):
+ name = arg.name
+ parameter_name_to_index[name] = i
+ if i >= num_mandatory_parameters:
+ defval = called.args.defaults[i - num_mandatory_parameters]
+ else:
+ defval = None
+ parameters.append(((name, defval), False))
+
+ kwparams = {}
+ for i, arg in enumerate(called.args.kwonlyargs):
+ if isinstance(arg, nodes.Keyword):
+ name = arg.arg
+ else:
+ assert isinstance(arg, nodes.AssignName)
+ name = arg.name
+ kwparams[name] = [called.args.kw_defaults[i], False]
+
+ self._check_argument_order(
+ node, call_site, called, [p[0][0] for p in parameters]
+ )
+
+ # 1. Match the positional arguments.
+ for i in range(num_positional_args):
+ if i < len(parameters):
+ parameters[i] = (parameters[i][0], True)
+ elif called.args.vararg is not None:
+ # The remaining positional arguments get assigned to the *args
+ # parameter.
+ break
+ elif not overload_function:
+ # Too many positional arguments.
+ self.add_message(
+ "too-many-function-args",
+ node=node,
+ args=(callable_name,),
+ )
+ break
+
+ # 2. Match the keyword arguments.
+ for keyword in keyword_args:
+ # Skip if `keyword` is the same name as a positional-only parameter
+ # and a `**kwargs` parameter exists.
+ if called.args.kwarg and keyword in [
+ arg.name for arg in called.args.posonlyargs
+ ]:
+ self.add_message(
+ "kwarg-superseded-by-positional-arg",
+ node=node,
+ args=(keyword, f"**{called.args.kwarg}"),
+ confidence=HIGH,
+ )
+ continue
+ if keyword in parameter_name_to_index:
+ i = parameter_name_to_index[keyword]
+ if parameters[i][1]:
+ # Duplicate definition of function parameter.
+
+ # Might be too hard-coded, but this can actually
+ # happen when using str.format and `self` is passed
+ # by keyword argument, as in `.format(self=self)`.
+ # It's perfectly valid to so, so we're just skipping
+ # it if that's the case.
+ if not (keyword == "self" and called.qname() in STR_FORMAT):
+ self.add_message(
+ "redundant-keyword-arg",
+ node=node,
+ args=(keyword, callable_name),
+ )
+ else:
+ parameters[i] = (parameters[i][0], True)
+ elif keyword in kwparams:
+ if kwparams[keyword][1]:
+ # Duplicate definition of function parameter.
+ self.add_message(
+ "redundant-keyword-arg",
+ node=node,
+ args=(keyword, callable_name),
+ )
+ else:
+ kwparams[keyword][1] = True
+ elif called.args.kwarg is not None:
+ # The keyword argument gets assigned to the **kwargs parameter.
+ pass
+ elif isinstance(
+ called, nodes.FunctionDef
+ ) and self._keyword_argument_is_in_all_decorator_returns(called, keyword):
+ pass
+ elif not overload_function:
+ # Unexpected keyword argument.
+ self.add_message(
+ "unexpected-keyword-arg", node=node, args=(keyword, callable_name)
+ )
+
+ # 3. Match the **kwargs, if any.
+ if node.kwargs:
+ for i, [(name, _defval), _assigned] in enumerate(parameters):
+ # Assume that *kwargs provides values for all remaining
+ # unassigned named parameters.
+ if name is not None:
+ parameters[i] = (parameters[i][0], True)
+ else:
+ # **kwargs can't assign to tuples.
+ pass
+
+ # Check that any parameters without a default have been assigned
+ # values.
+ for [(name, defval), assigned] in parameters:
+ if (defval is None) and not assigned:
+ display_name = "<tuple>" if name is None else repr(name)
+ if not has_no_context_positional_variadic and not overload_function:
+ self.add_message(
+ "no-value-for-parameter",
+ node=node,
+ args=(display_name, callable_name),
+ )
+
+ for name, val in kwparams.items():
+ defval, assigned = val
+ if (
+ defval is None
+ and not assigned
+ and not has_no_context_keywords_variadic
+ and not overload_function
+ ):
+ self.add_message(
+ "missing-kwoa",
+ node=node,
+ args=(name, callable_name),
+ confidence=INFERENCE,
+ )
+
+ @staticmethod
+ def _keyword_argument_is_in_all_decorator_returns(
+ func: nodes.FunctionDef, keyword: str
+ ) -> bool:
+ """Check if the keyword argument exists in all signatures of the
+ return values of all decorators of the function.
+ """
+ if not func.decorators:
+ return False
+
+ for decorator in func.decorators.nodes:
+ inferred = safe_infer(decorator)
+
+ # If we can't infer the decorator we assume it satisfies consumes
+ # the keyword, so we don't raise false positives
+ if not inferred:
+ return True
+
+ # We only check arguments of function decorators
+ if not isinstance(inferred, nodes.FunctionDef):
+ return False
+
+ for return_value in inferred.infer_call_result(caller=None):
+ # infer_call_result() returns nodes.Const.None for None return values
+ # so this also catches non-returning decorators
+ if not isinstance(return_value, nodes.FunctionDef):
+ return False
+
+ # If the return value uses a kwarg the keyword will be consumed
+ if return_value.args.kwarg:
+ continue
+
+ # Check if the keyword is another type of argument
+ if return_value.args.is_argument(keyword):
+ continue
+
+ return False
+
+ return True
+
+ def _check_invalid_sequence_index(self, subscript: nodes.Subscript) -> None:
+ # Look for index operations where the parent is a sequence type.
+ # If the types can be determined, only allow indices to be int,
+ # slice or instances with __index__.
+ parent_type = safe_infer(subscript.value)
+ if not isinstance(
+ parent_type, (nodes.ClassDef, astroid.Instance)
+ ) or not has_known_bases(parent_type):
+ return None
+
+ # Determine what method on the parent this index will use
+ # The parent of this node will be a Subscript, and the parent of that
+ # node determines if the Subscript is a get, set, or delete operation.
+ if subscript.ctx is astroid.Context.Store:
+ methodname = "__setitem__"
+ elif subscript.ctx is astroid.Context.Del:
+ methodname = "__delitem__"
+ else:
+ methodname = "__getitem__"
+
+ # Check if this instance's __getitem__, __setitem__, or __delitem__, as
+ # appropriate to the statement, is implemented in a builtin sequence
+ # type. This way we catch subclasses of sequence types but skip classes
+ # that override __getitem__ and which may allow non-integer indices.
+ try:
+ methods = astroid.interpreter.dunder_lookup.lookup(parent_type, methodname)
+ if isinstance(methods, util.UninferableBase):
+ return None
+ itemmethod = methods[0]
+ except (
+ astroid.AttributeInferenceError,
+ IndexError,
+ ):
+ return None
+ if (
+ not isinstance(itemmethod, nodes.FunctionDef)
+ or itemmethod.root().name != "builtins"
+ or not itemmethod.parent
+ or itemmethod.parent.frame().name not in SEQUENCE_TYPES
+ ):
+ return None
+
+ index_type = safe_infer(subscript.slice)
+ if index_type is None or isinstance(index_type, util.UninferableBase):
+ return None
+ # Constants must be of type int
+ if isinstance(index_type, nodes.Const):
+ if isinstance(index_type.value, int):
+ return None
+ # Instance values must be int, slice, or have an __index__ method
+ elif isinstance(index_type, astroid.Instance):
+ if index_type.pytype() in {"builtins.int", "builtins.slice"}:
+ return None
+ try:
+ index_type.getattr("__index__")
+ return None
+ except astroid.NotFoundError:
+ pass
+ elif isinstance(index_type, nodes.Slice):
+ # A slice can be present
+ # here after inferring the index node, which could
+ # be a `slice(...)` call for instance.
+ return self._check_invalid_slice_index(index_type)
+
+ # Anything else is an error
+ self.add_message("invalid-sequence-index", node=subscript)
+ return None
+
+ def _check_not_callable(
+ self, node: nodes.Call, inferred_call: nodes.NodeNG | None
+ ) -> None:
+ """Checks to see if the not-callable message should be emitted.
+
+ Only functions, generators and objects defining __call__ are "callable"
+ We ignore instances of descriptors since astroid cannot properly handle them yet
+ """
+ # Handle uninferable calls
+ if not inferred_call or inferred_call.callable():
+ self._check_uninferable_call(node)
+ return
+
+ if not isinstance(inferred_call, astroid.Instance):
+ self.add_message("not-callable", node=node, args=node.func.as_string())
+ return
+
+ # Don't emit if we can't make sure this object is callable.
+ if not has_known_bases(inferred_call):
+ return
+
+ if inferred_call.parent and isinstance(inferred_call.scope(), nodes.ClassDef):
+ # Ignore descriptor instances
+ if "__get__" in inferred_call.locals:
+ return
+ # NamedTuple instances are callable
+ if inferred_call.qname() == "typing.NamedTuple":
+ return
+
+ self.add_message("not-callable", node=node, args=node.func.as_string())
+
+ def _check_invalid_slice_index(self, node: nodes.Slice) -> None:
+ # Check the type of each part of the slice
+ invalid_slices_nodes: list[nodes.NodeNG] = []
+ for index in (node.lower, node.upper, node.step):
+ if index is None:
+ continue
+
+ index_type = safe_infer(index)
+ if index_type is None or isinstance(index_type, util.UninferableBase):
+ continue
+
+ # Constants must be of type int or None
+ if isinstance(index_type, nodes.Const):
+ if isinstance(index_type.value, (int, type(None))):
+ continue
+ # Instance values must be of type int, None or an object
+ # with __index__
+ elif isinstance(index_type, astroid.Instance):
+ if index_type.pytype() in {"builtins.int", "builtins.NoneType"}:
+ continue
+
+ try:
+ index_type.getattr("__index__")
+ return
+ except astroid.NotFoundError:
+ pass
+ invalid_slices_nodes.append(index)
+
+ invalid_slice_step = (
+ node.step and isinstance(node.step, nodes.Const) and node.step.value == 0
+ )
+
+ if not (invalid_slices_nodes or invalid_slice_step):
+ return
+
+ # Anything else is an error, unless the object that is indexed
+ # is a custom object, which knows how to handle this kind of slices
+ parent = node.parent
+ if isinstance(parent, nodes.Subscript):
+ inferred = safe_infer(parent.value)
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ # Don't know what this is
+ return
+ known_objects = (
+ nodes.List,
+ nodes.Dict,
+ nodes.Tuple,
+ astroid.objects.FrozenSet,
+ nodes.Set,
+ )
+ if not (
+ isinstance(inferred, known_objects)
+ or isinstance(inferred, nodes.Const)
+ and inferred.pytype() in {"builtins.str", "builtins.bytes"}
+ or isinstance(inferred, astroid.bases.Instance)
+ and inferred.pytype() == "builtins.range"
+ ):
+ # Might be an instance that knows how to handle this slice object
+ return
+ for snode in invalid_slices_nodes:
+ self.add_message("invalid-slice-index", node=snode)
+ if invalid_slice_step:
+ self.add_message("invalid-slice-step", node=node.step, confidence=HIGH)
+
+ @only_required_for_messages("not-context-manager")
+ def visit_with(self, node: nodes.With) -> None:
+ for ctx_mgr, _ in node.items:
+ context = astroid.context.InferenceContext()
+ inferred = safe_infer(ctx_mgr, context=context)
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ continue
+
+ if isinstance(inferred, astroid.bases.Generator):
+ # Check if we are dealing with a function decorated
+ # with contextlib.contextmanager.
+ if decorated_with(
+ inferred.parent, self.linter.config.contextmanager_decorators
+ ):
+ continue
+ # If the parent of the generator is not the context manager itself,
+ # that means that it could have been returned from another
+ # function which was the real context manager.
+ # The following approach is more of a hack rather than a real
+ # solution: walk all the inferred statements for the
+ # given *ctx_mgr* and if you find one function scope
+ # which is decorated, consider it to be the real
+ # manager and give up, otherwise emit not-context-manager.
+ # See the test file for not_context_manager for a couple
+ # of self explaining tests.
+
+ # Retrieve node from all previously visited nodes in the
+ # inference history
+ for inferred_path, _ in context.path:
+ if not inferred_path:
+ continue
+ if isinstance(inferred_path, nodes.Call):
+ scope = safe_infer(inferred_path.func)
+ else:
+ scope = inferred_path.scope()
+ if not isinstance(scope, nodes.FunctionDef):
+ continue
+ if decorated_with(
+ scope, self.linter.config.contextmanager_decorators
+ ):
+ break
+ else:
+ self.add_message(
+ "not-context-manager", node=node, args=(inferred.name,)
+ )
+ else:
+ try:
+ inferred.getattr("__enter__")
+ inferred.getattr("__exit__")
+ except astroid.NotFoundError:
+ if isinstance(inferred, astroid.Instance):
+ # If we do not know the bases of this class,
+ # just skip it.
+ if not has_known_bases(inferred):
+ continue
+ # Just ignore mixin classes.
+ if (
+ "not-context-manager"
+ in self.linter.config.ignored_checks_for_mixins
+ ):
+ if inferred.name[-5:].lower() == "mixin":
+ continue
+
+ self.add_message(
+ "not-context-manager", node=node, args=(inferred.name,)
+ )
+
+ @only_required_for_messages("invalid-unary-operand-type")
+ def visit_unaryop(self, node: nodes.UnaryOp) -> None:
+ """Detect TypeErrors for unary operands."""
+ for error in node.type_errors():
+ # Let the error customize its output.
+ self.add_message("invalid-unary-operand-type", args=str(error), node=node)
+
+ @only_required_for_messages("unsupported-binary-operation")
+ def visit_binop(self, node: nodes.BinOp) -> None:
+ if node.op == "|":
+ self._detect_unsupported_alternative_union_syntax(node)
+
+ def _detect_unsupported_alternative_union_syntax(self, node: nodes.BinOp) -> None:
+ """Detect if unsupported alternative Union syntax (PEP 604) was used."""
+ if self._py310_plus: # 310+ supports the new syntax
+ return
+
+ if isinstance(
+ node.parent, TYPE_ANNOTATION_NODES_TYPES
+ ) and not is_postponed_evaluation_enabled(node):
+ # Use in type annotations only allowed if
+ # postponed evaluation is enabled.
+ self._check_unsupported_alternative_union_syntax(node)
+
+ if isinstance(
+ node.parent,
+ (
+ nodes.Assign,
+ nodes.Call,
+ nodes.Keyword,
+ nodes.Dict,
+ nodes.Tuple,
+ nodes.Set,
+ nodes.List,
+ nodes.BinOp,
+ ),
+ ):
+ # Check other contexts the syntax might appear, but are invalid.
+ # Make sure to filter context if postponed evaluation is enabled
+ # and parent is allowed node type.
+ allowed_nested_syntax = False
+ if is_postponed_evaluation_enabled(node):
+ parent_node = node.parent
+ while True:
+ if isinstance(parent_node, TYPE_ANNOTATION_NODES_TYPES):
+ allowed_nested_syntax = True
+ break
+ parent_node = parent_node.parent
+ if isinstance(parent_node, nodes.Module):
+ break
+ if not allowed_nested_syntax:
+ self._check_unsupported_alternative_union_syntax(node)
+
+ def _includes_version_compatible_overload(self, attrs: list[nodes.NodeNG]) -> bool:
+ """Check if a set of overloads of an operator includes one that
+ can be relied upon for our configured Python version.
+
+ If we are running under a Python 3.10+ runtime but configured for
+ pre-3.10 compatibility then Astroid will have inferred the
+ existence of __or__ / __ror__ on builtins.type, but these aren't
+ available in the configured version of Python.
+ """
+ is_py310_builtin = all(
+ isinstance(attr, (nodes.FunctionDef, astroid.BoundMethod))
+ and attr.parent.qname() == "builtins.type"
+ for attr in attrs
+ )
+ return not is_py310_builtin or self._py310_plus
+
+ def _recursive_search_for_classdef_type(
+ self, node: nodes.ClassDef, operation: Literal["__or__", "__ror__"]
+ ) -> bool | VERSION_COMPATIBLE_OVERLOAD:
+ if not isinstance(node, nodes.ClassDef):
+ return False
+ try:
+ attrs = node.getattr(operation)
+ except astroid.NotFoundError:
+ return True
+ if self._includes_version_compatible_overload(attrs):
+ return VERSION_COMPATIBLE_OVERLOAD_SENTINEL
+ return True
+
+ def _check_unsupported_alternative_union_syntax(self, node: nodes.BinOp) -> None:
+ """Check if left or right node is of type `type`.
+
+ If either is, and doesn't support an or operator via a metaclass,
+ infer that this is a mistaken attempt to use alternative union
+ syntax when not supported.
+ """
+ msg = "unsupported operand type(s) for |"
+ left_obj = astroid.helpers.object_type(node.left)
+ right_obj = astroid.helpers.object_type(node.right)
+ left_is_type = self._recursive_search_for_classdef_type(left_obj, "__or__")
+ if left_is_type is VERSION_COMPATIBLE_OVERLOAD_SENTINEL:
+ return
+ right_is_type = self._recursive_search_for_classdef_type(right_obj, "__ror__")
+ if right_is_type is VERSION_COMPATIBLE_OVERLOAD_SENTINEL:
+ return
+
+ if left_is_type or right_is_type:
+ self.add_message(
+ "unsupported-binary-operation",
+ args=msg,
+ node=node,
+ confidence=INFERENCE,
+ )
+
+ # TODO: This check was disabled (by adding the leading underscore)
+ # due to false positives several years ago - can we re-enable it?
+ # https://github.com/pylint-dev/pylint/issues/6359
+ @only_required_for_messages("unsupported-binary-operation")
+ def _visit_binop(self, node: nodes.BinOp) -> None:
+ """Detect TypeErrors for binary arithmetic operands."""
+ self._check_binop_errors(node)
+
+ # TODO: This check was disabled (by adding the leading underscore)
+ # due to false positives several years ago - can we re-enable it?
+ # https://github.com/pylint-dev/pylint/issues/6359
+ @only_required_for_messages("unsupported-binary-operation")
+ def _visit_augassign(self, node: nodes.AugAssign) -> None:
+ """Detect TypeErrors for augmented binary arithmetic operands."""
+ self._check_binop_errors(node)
+
+ def _check_binop_errors(self, node: nodes.BinOp | nodes.AugAssign) -> None:
+ for error in node.type_errors():
+ # Let the error customize its output.
+ if any(
+ isinstance(obj, nodes.ClassDef) and not has_known_bases(obj)
+ for obj in (error.left_type, error.right_type)
+ ):
+ continue
+ self.add_message("unsupported-binary-operation", args=str(error), node=node)
+
+ def _check_membership_test(self, node: nodes.NodeNG) -> None:
+ if is_inside_abstract_class(node):
+ return
+ if is_comprehension(node):
+ return
+ inferred = safe_infer(node)
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ return
+ if not supports_membership_test(inferred):
+ self.add_message(
+ "unsupported-membership-test", args=node.as_string(), node=node
+ )
+
+ @only_required_for_messages("unsupported-membership-test")
+ def visit_compare(self, node: nodes.Compare) -> None:
+ if len(node.ops) != 1:
+ return
+
+ op, right = node.ops[0]
+ if op in {"in", "not in"}:
+ self._check_membership_test(right)
+
+ @only_required_for_messages("unhashable-member")
+ def visit_dict(self, node: nodes.Dict) -> None:
+ for k, _ in node.items:
+ if not is_hashable(k):
+ self.add_message(
+ "unhashable-member",
+ node=k,
+ args=(k.as_string(), "key", "dict"),
+ confidence=INFERENCE,
+ )
+
+ @only_required_for_messages("unhashable-member")
+ def visit_set(self, node: nodes.Set) -> None:
+ for element in node.elts:
+ if not is_hashable(element):
+ self.add_message(
+ "unhashable-member",
+ node=element,
+ args=(element.as_string(), "member", "set"),
+ confidence=INFERENCE,
+ )
+
+ @only_required_for_messages(
+ "unsubscriptable-object",
+ "unsupported-assignment-operation",
+ "unsupported-delete-operation",
+ "unhashable-member",
+ "invalid-sequence-index",
+ "invalid-slice-index",
+ "invalid-slice-step",
+ )
+ def visit_subscript(self, node: nodes.Subscript) -> None:
+ self._check_invalid_sequence_index(node)
+
+ supported_protocol: Callable[[Any, Any], bool] | None = None
+ if isinstance(node.value, (nodes.ListComp, nodes.DictComp)):
+ return
+
+ if isinstance(node.value, nodes.Dict):
+ # Assert dict key is hashable
+ if not is_hashable(node.slice):
+ self.add_message(
+ "unhashable-member",
+ node=node.value,
+ args=(node.slice.as_string(), "key", "dict"),
+ confidence=INFERENCE,
+ )
+
+ if node.ctx == astroid.Context.Load:
+ supported_protocol = supports_getitem
+ msg = "unsubscriptable-object"
+ elif node.ctx == astroid.Context.Store:
+ supported_protocol = supports_setitem
+ msg = "unsupported-assignment-operation"
+ elif node.ctx == astroid.Context.Del:
+ supported_protocol = supports_delitem
+ msg = "unsupported-delete-operation"
+
+ if isinstance(node.value, nodes.SetComp):
+ # pylint: disable-next=possibly-used-before-assignment
+ self.add_message(msg, args=node.value.as_string(), node=node.value)
+ return
+
+ if is_inside_abstract_class(node):
+ return
+
+ inferred = safe_infer(node.value)
+
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ return
+
+ if getattr(inferred, "decorators", None):
+ first_decorator = astroid.util.safe_infer(inferred.decorators.nodes[0])
+ if isinstance(first_decorator, nodes.ClassDef):
+ inferred = first_decorator.instantiate_class()
+ else:
+ return # It would be better to handle function
+ # decorators, but let's start slow.
+
+ if (
+ supported_protocol
+ and not supported_protocol(inferred, node)
+ and not utils.in_type_checking_block(node)
+ ):
+ self.add_message(msg, args=node.value.as_string(), node=node.value)
+
+ @only_required_for_messages("dict-items-missing-iter")
+ def visit_for(self, node: nodes.For) -> None:
+ if not isinstance(node.target, nodes.Tuple):
+ # target is not a tuple
+ return
+ if not len(node.target.elts) == 2:
+ # target is not a tuple of two elements
+ return
+
+ iterable = node.iter
+ if not isinstance(iterable, nodes.Name):
+ # it's not a bare variable
+ return
+
+ inferred = safe_infer(iterable)
+ if not inferred:
+ return
+ if not isinstance(inferred, nodes.Dict):
+ # the iterable is not a dict
+ return
+
+ if all(isinstance(i[0], nodes.Tuple) for i in inferred.items):
+ # if all keys are tuples
+ return
+
+ self.add_message("dict-iter-missing-items", node=node)
+
+ @only_required_for_messages("await-outside-async")
+ def visit_await(self, node: nodes.Await) -> None:
+ self._check_await_outside_coroutine(node)
+
+ def _check_await_outside_coroutine(self, node: nodes.Await) -> None:
+ node_scope = node.scope()
+ while not isinstance(node_scope, nodes.Module):
+ if isinstance(node_scope, nodes.AsyncFunctionDef):
+ return
+ if isinstance(node_scope, (nodes.FunctionDef, nodes.Lambda)):
+ break
+ node_scope = node_scope.parent.scope()
+ self.add_message("await-outside-async", node=node)
+
+
+class IterableChecker(BaseChecker):
+ """Checks for non-iterables used in an iterable context.
+
+ Contexts include:
+ - for-statement
+ - starargs in function call
+ - `yield from`-statement
+ - list, dict and set comprehensions
+ - generator expressions
+ Also checks for non-mappings in function call kwargs.
+ """
+
+ name = "typecheck"
+
+ msgs = {
+ "E1133": (
+ "Non-iterable value %s is used in an iterating context",
+ "not-an-iterable",
+ "Used when a non-iterable value is used in place where "
+ "iterable is expected",
+ ),
+ "E1134": (
+ "Non-mapping value %s is used in a mapping context",
+ "not-a-mapping",
+ "Used when a non-mapping value is used in place where "
+ "mapping is expected",
+ ),
+ }
+
+ @staticmethod
+ def _is_asyncio_coroutine(node: nodes.NodeNG) -> bool:
+ if not isinstance(node, nodes.Call):
+ return False
+
+ inferred_func = safe_infer(node.func)
+ if not isinstance(inferred_func, nodes.FunctionDef):
+ return False
+ if not inferred_func.decorators:
+ return False
+ for decorator in inferred_func.decorators.nodes:
+ inferred_decorator = safe_infer(decorator)
+ if not isinstance(inferred_decorator, nodes.FunctionDef):
+ continue
+ if inferred_decorator.qname() != ASYNCIO_COROUTINE:
+ continue
+ return True
+ return False
+
+ def _check_iterable(self, node: nodes.NodeNG, check_async: bool = False) -> None:
+ if is_inside_abstract_class(node):
+ return
+ inferred = safe_infer(node)
+ if not inferred or is_comprehension(inferred):
+ return
+ if not is_iterable(inferred, check_async=check_async):
+ self.add_message("not-an-iterable", args=node.as_string(), node=node)
+
+ def _check_mapping(self, node: nodes.NodeNG) -> None:
+ if is_inside_abstract_class(node):
+ return
+ if isinstance(node, nodes.DictComp):
+ return
+ inferred = safe_infer(node)
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ return
+ if not is_mapping(inferred):
+ self.add_message("not-a-mapping", args=node.as_string(), node=node)
+
+ @only_required_for_messages("not-an-iterable")
+ def visit_for(self, node: nodes.For) -> None:
+ self._check_iterable(node.iter)
+
+ @only_required_for_messages("not-an-iterable")
+ def visit_asyncfor(self, node: nodes.AsyncFor) -> None:
+ self._check_iterable(node.iter, check_async=True)
+
+ @only_required_for_messages("not-an-iterable")
+ def visit_yieldfrom(self, node: nodes.YieldFrom) -> None:
+ if self._is_asyncio_coroutine(node.value):
+ return
+ self._check_iterable(node.value)
+
+ @only_required_for_messages("not-an-iterable", "not-a-mapping")
+ def visit_call(self, node: nodes.Call) -> None:
+ for stararg in node.starargs:
+ self._check_iterable(stararg.value)
+ for kwarg in node.kwargs:
+ self._check_mapping(kwarg.value)
+
+ @only_required_for_messages("not-an-iterable")
+ def visit_listcomp(self, node: nodes.ListComp) -> None:
+ for gen in node.generators:
+ self._check_iterable(gen.iter, check_async=gen.is_async)
+
+ @only_required_for_messages("not-an-iterable")
+ def visit_dictcomp(self, node: nodes.DictComp) -> None:
+ for gen in node.generators:
+ self._check_iterable(gen.iter, check_async=gen.is_async)
+
+ @only_required_for_messages("not-an-iterable")
+ def visit_setcomp(self, node: nodes.SetComp) -> None:
+ for gen in node.generators:
+ self._check_iterable(gen.iter, check_async=gen.is_async)
+
+ @only_required_for_messages("not-an-iterable")
+ def visit_generatorexp(self, node: nodes.GeneratorExp) -> None:
+ for gen in node.generators:
+ self._check_iterable(gen.iter, check_async=gen.is_async)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(TypeChecker(linter))
+ linter.register_checker(IterableChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/unicode.py b/solutions/.venv/Lib/site-packages/pylint/checkers/unicode.py
new file mode 100644
index 000000000..c90ace971
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/unicode.py
@@ -0,0 +1,537 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Unicode and some other ASCII characters can be used to create programs that run
+much different compared to what a human reader would expect from them.
+
+PEP 672 lists some examples.
+See: https://www.python.org/dev/peps/pep-0672/
+
+The following checkers are intended to make users are aware of these issues.
+"""
+
+from __future__ import annotations
+
+import codecs
+import contextlib
+import io
+import re
+from collections import OrderedDict
+from collections.abc import Iterable
+from functools import lru_cache
+from tokenize import detect_encoding
+from typing import NamedTuple, TypeVar
+
+from astroid import nodes
+
+import pylint.interfaces
+import pylint.lint
+from pylint import checkers
+
+_StrLike = TypeVar("_StrLike", str, bytes)
+
+# Based on:
+# https://golangexample.com/go-linter-which-checks-for-dangerous-unicode-character-sequences/
+# We use '\u' because it doesn't require a map lookup and is therefore faster
+BIDI_UNICODE = [
+ "\u202A", # \N{LEFT-TO-RIGHT EMBEDDING}
+ "\u202B", # \N{RIGHT-TO-LEFT EMBEDDING}
+ "\u202C", # \N{POP DIRECTIONAL FORMATTING}
+ "\u202D", # \N{LEFT-TO-RIGHT OVERRIDE}
+ "\u202E", # \N{RIGHT-TO-LEFT OVERRIDE}
+ "\u2066", # \N{LEFT-TO-RIGHT ISOLATE}
+ "\u2067", # \N{RIGHT-TO-LEFT ISOLATE}
+ "\u2068", # \N{FIRST STRONG ISOLATE}
+ "\u2069", # \N{POP DIRECTIONAL ISOLATE}
+ # The following was part of PEP 672:
+ # https://www.python.org/dev/peps/pep-0672/
+ # so the list above might not be complete
+ "\u200F", # \n{RIGHT-TO-LEFT MARK}
+ # We don't use
+ # "\u200E" # \n{LEFT-TO-RIGHT MARK}
+ # as this is the default for latin files and can't be used
+ # to hide code
+]
+
+
+class _BadChar(NamedTuple):
+ """Representation of an ASCII char considered bad."""
+
+ name: str
+ unescaped: str
+ escaped: str
+ code: str
+ help_text: str
+
+ def description(self) -> str:
+ """Used for the detailed error message description."""
+ return (
+ f"Invalid unescaped character {self.name}, "
+ f'use "{self.escaped}" instead.'
+ )
+
+ def human_code(self) -> str:
+ """Used to generate the human readable error message."""
+ return f"invalid-character-{self.name}"
+
+
+# Based on https://www.python.org/dev/peps/pep-0672/
+BAD_CHARS = [
+ _BadChar(
+ "backspace",
+ "\b",
+ "\\b",
+ "E2510",
+ (
+ "Moves the cursor back, so the character after it will overwrite the "
+ "character before."
+ ),
+ ),
+ _BadChar(
+ "carriage-return",
+ "\r",
+ "\\r",
+ "E2511",
+ (
+ "Moves the cursor to the start of line, subsequent characters overwrite "
+ "the start of the line."
+ ),
+ ),
+ _BadChar(
+ "sub",
+ "\x1A",
+ "\\x1A",
+ "E2512",
+ (
+ 'Ctrl+Z "End of text" on Windows. Some programs (such as type) ignore '
+ "the rest of the file after it."
+ ),
+ ),
+ _BadChar(
+ "esc",
+ "\x1B",
+ "\\x1B",
+ "E2513",
+ (
+ "Commonly initiates escape codes which allow arbitrary control "
+ "of the terminal."
+ ),
+ ),
+ _BadChar(
+ "nul",
+ "\0",
+ "\\0",
+ "E2514",
+ "Mostly end of input for python.",
+ ),
+ _BadChar(
+ # Zero Width with Space. At the time of writing not accepted by Python.
+ # But used in Trojan Source Examples, so still included and tested for.
+ "zero-width-space",
+ "\u200B", # \n{ZERO WIDTH SPACE}
+ "\\u200B",
+ "E2515",
+ "Invisible space character could hide real code execution.",
+ ),
+]
+BAD_ASCII_SEARCH_DICT = {char.unescaped: char for char in BAD_CHARS}
+
+
+def _line_length(line: _StrLike, codec: str) -> int:
+ """Get the length of a string like line as displayed in an editor."""
+ if isinstance(line, bytes):
+ decoded = _remove_bom(line, codec).decode(codec, "replace")
+ else:
+ decoded = line
+
+ stripped = decoded.rstrip("\n")
+
+ if stripped != decoded:
+ stripped = stripped.rstrip("\r")
+
+ return len(stripped)
+
+
+def _map_positions_to_result(
+ line: _StrLike,
+ search_dict: dict[_StrLike, _BadChar],
+ new_line: _StrLike,
+ byte_str_length: int = 1,
+) -> dict[int, _BadChar]:
+ """Get all occurrences of search dict keys within line.
+
+ Ignores Windows end of line and can handle bytes as well as string.
+ Also takes care of encodings for which the length of an encoded code point does not
+ default to 8 Bit.
+ """
+ result: dict[int, _BadChar] = {}
+
+ for search_for, char in search_dict.items():
+ if search_for not in line:
+ continue
+
+ # Special Handling for Windows '\r\n'
+ if char.unescaped == "\r" and line.endswith(new_line):
+ ignore_pos = len(line) - 2 * byte_str_length
+ else:
+ ignore_pos = None
+
+ start = 0
+ pos = line.find(search_for, start)
+ while pos > 0:
+ if pos != ignore_pos:
+ # Calculate the column
+ col = int(pos / byte_str_length)
+ result[col] = char
+ start = pos + 1
+ pos = line.find(search_for, start)
+
+ return result
+
+
+UNICODE_BOMS = {
+ "utf-8": codecs.BOM_UTF8,
+ "utf-16": codecs.BOM_UTF16,
+ "utf-32": codecs.BOM_UTF32,
+ "utf-16le": codecs.BOM_UTF16_LE,
+ "utf-16be": codecs.BOM_UTF16_BE,
+ "utf-32le": codecs.BOM_UTF32_LE,
+ "utf-32be": codecs.BOM_UTF32_BE,
+}
+BOM_SORTED_TO_CODEC = OrderedDict(
+ # Sorted by length of BOM of each codec
+ (UNICODE_BOMS[codec], codec)
+ for codec in ("utf-32le", "utf-32be", "utf-8", "utf-16le", "utf-16be")
+)
+
+UTF_NAME_REGEX_COMPILED = re.compile(
+ "utf[ -]?(8|16|32)[ -]?(le|be|)?(sig)?", flags=re.IGNORECASE
+)
+
+
+def _normalize_codec_name(codec: str) -> str:
+ """Make sure the codec name is always given as defined in the BOM dict."""
+ return UTF_NAME_REGEX_COMPILED.sub(r"utf-\1\2", codec).lower()
+
+
+def _remove_bom(encoded: bytes, encoding: str) -> bytes:
+ """Remove the bom if given from a line."""
+ if encoding not in UNICODE_BOMS:
+ return encoded
+ bom = UNICODE_BOMS[encoding]
+ if encoded.startswith(bom):
+ return encoded[len(bom) :]
+ return encoded
+
+
+def _encode_without_bom(string: str, encoding: str) -> bytes:
+ """Encode a string but remove the BOM."""
+ return _remove_bom(string.encode(encoding), encoding)
+
+
+def _byte_to_str_length(codec: str) -> int:
+ """Return how many byte are usually(!) a character point."""
+ if codec.startswith("utf-32"):
+ return 4
+ if codec.startswith("utf-16"):
+ return 2
+
+ return 1
+
+
+@lru_cache(maxsize=1000)
+def _cached_encode_search(string: str, encoding: str) -> bytes:
+ """A cached version of encode used for search pattern."""
+ return _encode_without_bom(string, encoding)
+
+
+def _fix_utf16_32_line_stream(steam: Iterable[bytes], codec: str) -> Iterable[bytes]:
+ r"""Handle line ending for UTF16 and UTF32 correctly.
+
+ Currently, Python simply strips the required zeros after \n after the
+ line ending. Leading to lines that can't be decoded properly
+ """
+ if not codec.startswith("utf-16") and not codec.startswith("utf-32"):
+ yield from steam
+ else:
+ # First we get all the bytes in memory
+ content = b"".join(line for line in steam)
+
+ new_line = _cached_encode_search("\n", codec)
+
+ # Now we split the line by the real new line in the correct encoding
+ # we can't use split as it would strip the \n that we need
+ start = 0
+ while True:
+ pos = content.find(new_line, start)
+ if pos >= 0:
+ yield content[start : pos + len(new_line)]
+ else:
+ # Yield the rest and finish
+ if content[start:]:
+ yield content[start:]
+ break
+
+ start = pos + len(new_line)
+
+
+def extract_codec_from_bom(first_line: bytes) -> str:
+ """Try to extract the codec (unicode only) by checking for the BOM.
+
+ For details about BOM see https://unicode.org/faq/utf_bom.html#BOM
+
+ Args:
+ first_line: the first line of a file
+
+ Returns:
+ a codec name
+
+ Raises:
+ ValueError: if no codec was found
+ """
+ for bom, codec in BOM_SORTED_TO_CODEC.items():
+ if first_line.startswith(bom):
+ return codec
+
+ raise ValueError("No BOM found. Could not detect Unicode codec.")
+
+
+class UnicodeChecker(checkers.BaseRawFileChecker):
+ """Check characters that could be used to hide bad code to humans.
+
+ This includes:
+
+ - Bidirectional Unicode (see https://trojansource.codes/)
+
+ - Bad ASCII characters (see PEP672)
+
+ If a programmer requires to use such a character they should use the escaped
+ version, that is also much easier to read and does not depend on the editor used.
+
+ The Checker also includes a check that UTF-16 and UTF-32 are not used to encode
+ Python files.
+
+ At the time of writing Python supported only UTF-8. See
+ https://stackoverflow.com/questions/69897842/ and https://bugs.python.org/issue1503789
+ for background.
+ """
+
+ name = "unicode_checker"
+
+ msgs = {
+ "E2501": (
+ # This error will be only displayed to users once Python Supports
+ # UTF-16/UTF-32 (if at all)
+ "UTF-16 and UTF-32 aren't backward compatible. Use UTF-8 instead",
+ "invalid-unicode-codec",
+ (
+ "For compatibility use UTF-8 instead of UTF-16/UTF-32. "
+ "See also https://bugs.python.org/issue1503789 for a history "
+ "of this issue. And "
+ "https://softwareengineering.stackexchange.com/questions/102205/ "
+ "for some possible problems when using UTF-16 for instance."
+ ),
+ ),
+ "E2502": (
+ (
+ "Contains control characters that can permit obfuscated code "
+ "executed differently than displayed"
+ ),
+ "bidirectional-unicode",
+ (
+ "bidirectional unicode are typically not displayed characters required "
+ "to display right-to-left (RTL) script "
+ "(i.e. Chinese, Japanese, Arabic, Hebrew, ...) correctly. "
+ "So can you trust this code? "
+ "Are you sure it displayed correctly in all editors? "
+ "If you did not write it or your language is not RTL,"
+ " remove the special characters, as they could be used to trick you into "
+ "executing code, "
+ "that does something else than what it looks like.\n"
+ "More Information:\n"
+ "https://en.wikipedia.org/wiki/Bidirectional_text\n"
+ "https://trojansource.codes/"
+ ),
+ ),
+ "C2503": (
+ "PEP8 recommends UTF-8 as encoding for Python files",
+ "bad-file-encoding",
+ (
+ "PEP8 recommends UTF-8 default encoding for Python files. See "
+ "https://peps.python.org/pep-0008/#source-file-encoding"
+ ),
+ ),
+ **{
+ bad_char.code: (
+ bad_char.description(),
+ bad_char.human_code(),
+ bad_char.help_text,
+ )
+ for bad_char in BAD_CHARS
+ },
+ }
+
+ @staticmethod
+ def _is_invalid_codec(codec: str) -> bool:
+ return codec.startswith(("utf-16", "utf-32"))
+
+ @staticmethod
+ def _is_unicode(codec: str) -> bool:
+ return codec.startswith("utf")
+
+ @classmethod
+ def _find_line_matches(cls, line: bytes, codec: str) -> dict[int, _BadChar]:
+ """Find all matches of BAD_CHARS within line.
+
+ Args:
+ line: the input
+ codec: that will be used to convert line/or search string into
+
+ Return:
+ A dictionary with the column offset and the BadASCIIChar
+ """
+ # We try to decode in Unicode to get the correct column offset
+ # if we would use bytes, it could be off because UTF-8 has no fixed length
+ try:
+ line_search = line.decode(codec, errors="strict")
+ search_dict = BAD_ASCII_SEARCH_DICT
+ return _map_positions_to_result(line_search, search_dict, "\n")
+ except UnicodeDecodeError:
+ # If we can't decode properly, we simply use bytes, even so the column offsets
+ # might be wrong a bit, but it is still better then nothing
+ line_search_byte = line
+ search_dict_byte: dict[bytes, _BadChar] = {}
+ for char in BAD_CHARS:
+ # Some characters might not exist in all encodings
+ with contextlib.suppress(UnicodeDecodeError):
+ search_dict_byte[_cached_encode_search(char.unescaped, codec)] = (
+ char
+ )
+
+ return _map_positions_to_result(
+ line_search_byte,
+ search_dict_byte,
+ _cached_encode_search("\n", codec),
+ byte_str_length=_byte_to_str_length(codec),
+ )
+
+ @staticmethod
+ def _determine_codec(stream: io.BytesIO) -> tuple[str, int]:
+ """Determine the codec from the given stream.
+
+ first tries https://www.python.org/dev/peps/pep-0263/
+ and if this fails also checks for BOMs of UTF-16 and UTF-32
+ to be future-proof.
+
+ Args:
+ stream: The byte stream to analyse
+
+ Returns: A tuple consisting of:
+ - normalized codec name
+ - the line in which the codec was found
+
+ Raises:
+ SyntaxError: if failing to detect codec
+ """
+ try:
+ # First try to detect encoding with PEP 263
+ # Doesn't work with UTF-16/32 at the time of writing
+ # see https://bugs.python.org/issue1503789
+ codec, lines = detect_encoding(stream.readline)
+
+ # lines are empty if UTF-8 BOM is found
+ codec_definition_line = len(lines) or 1
+ except SyntaxError as e:
+ # Codec could not be detected by Python, we try manually to check for
+ # UTF 16/32 BOMs, which aren't supported by Python at the time of writing.
+ # This is only included to be future save and handle these codecs as well
+ stream.seek(0)
+ try:
+ codec = extract_codec_from_bom(stream.readline())
+ codec_definition_line = 1
+ except ValueError as ve:
+ # Failed to detect codec, so the syntax error originated not from
+ # UTF16/32 codec usage. So simply raise the error again.
+ raise e from ve
+
+ return _normalize_codec_name(codec), codec_definition_line
+
+ def _check_codec(self, codec: str, codec_definition_line: int) -> None:
+ """Check validity of the codec."""
+ if codec != "utf-8":
+ msg = "bad-file-encoding"
+ if self._is_invalid_codec(codec):
+ msg = "invalid-unicode-codec"
+ self.add_message(
+ msg,
+ # Currently Nodes will lead to crashes of pylint
+ # node=node,
+ line=codec_definition_line,
+ end_lineno=codec_definition_line,
+ confidence=pylint.interfaces.HIGH,
+ col_offset=None,
+ end_col_offset=None,
+ )
+
+ def _check_invalid_chars(self, line: bytes, lineno: int, codec: str) -> None:
+ """Look for chars considered bad."""
+ matches = self._find_line_matches(line, codec)
+ for col, char in matches.items():
+ self.add_message(
+ char.human_code(),
+ # Currently Nodes will lead to crashes of pylint
+ # node=node,
+ line=lineno,
+ end_lineno=lineno,
+ confidence=pylint.interfaces.HIGH,
+ col_offset=col + 1,
+ end_col_offset=col + len(char.unescaped) + 1,
+ )
+
+ def _check_bidi_chars(self, line: bytes, lineno: int, codec: str) -> None:
+ """Look for Bidirectional Unicode, if we use unicode."""
+ if not self._is_unicode(codec):
+ return
+ for dangerous in BIDI_UNICODE:
+ if _cached_encode_search(dangerous, codec) in line:
+ # Note that we don't add a col_offset on purpose:
+ # Using these unicode characters it depends on the editor
+ # how it displays the location of characters in the line.
+ # So we mark the complete line.
+ self.add_message(
+ "bidirectional-unicode",
+ # Currently Nodes will lead to crashes of pylint
+ # node=node,
+ line=lineno,
+ end_lineno=lineno,
+ # We mark the complete line, as bidi controls make it hard
+ # to determine the correct cursor position within an editor
+ col_offset=0,
+ end_col_offset=_line_length(line, codec),
+ confidence=pylint.interfaces.HIGH,
+ )
+ # We look for bidirectional unicode only once per line
+ # as we mark the complete line anyway
+ break
+
+ def process_module(self, node: nodes.Module) -> None:
+ """Perform the actual check by checking module stream."""
+ with node.stream() as stream:
+ codec, codec_line = self._determine_codec(stream)
+ self._check_codec(codec, codec_line)
+
+ stream.seek(0)
+
+ # Check for invalid content (controls/chars)
+ for lineno, line in enumerate(
+ _fix_utf16_32_line_stream(stream, codec), start=1
+ ):
+ if lineno == 1:
+ line = _remove_bom(line, codec)
+ self._check_bidi_chars(line, lineno, codec)
+ self._check_invalid_chars(line, lineno, codec)
+
+
+def register(linter: pylint.lint.PyLinter) -> None:
+ linter.register_checker(UnicodeChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/unsupported_version.py b/solutions/.venv/Lib/site-packages/pylint/checkers/unsupported_version.py
new file mode 100644
index 000000000..53b5f63fb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/unsupported_version.py
@@ -0,0 +1,196 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checker for features used that are not supported by all python versions
+indicated by the py-version setting.
+"""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import (
+ only_required_for_messages,
+ safe_infer,
+ uninferable_final_decorators,
+)
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class UnsupportedVersionChecker(BaseChecker):
+ """Checker for features that are not supported by all python versions
+ indicated by the py-version setting.
+ """
+
+ name = "unsupported_version"
+ msgs = {
+ "W2601": (
+ "F-strings are not supported by all versions included in the py-version setting",
+ "using-f-string-in-unsupported-version",
+ "Used when the py-version set by the user is lower than 3.6 and pylint encounters "
+ "an f-string.",
+ ),
+ "W2602": (
+ "typing.final is not supported by all versions included in the py-version setting",
+ "using-final-decorator-in-unsupported-version",
+ "Used when the py-version set by the user is lower than 3.8 and pylint encounters "
+ "a ``typing.final`` decorator.",
+ ),
+ "W2603": (
+ "Exception groups are not supported by all versions included in the py-version setting",
+ "using-exception-groups-in-unsupported-version",
+ "Used when the py-version set by the user is lower than 3.11 and pylint encounters "
+ "``except*`` or `ExceptionGroup``.",
+ ),
+ "W2604": (
+ "Generic type syntax (PEP 695) is not supported by all versions included in the py-version setting",
+ "using-generic-type-syntax-in-unsupported-version",
+ "Used when the py-version set by the user is lower than 3.12 and pylint encounters "
+ "generic type syntax.",
+ ),
+ "W2605": (
+ "Assignment expression is not supported by all versions included in the py-version setting",
+ "using-assignment-expression-in-unsupported-version",
+ "Used when the py-version set by the user is lower than 3.8 and pylint encounters "
+ "an assignment expression (walrus) operator.",
+ ),
+ "W2606": (
+ "Positional-only arguments are not supported by all versions included in the py-version setting",
+ "using-positional-only-args-in-unsupported-version",
+ "Used when the py-version set by the user is lower than 3.8 and pylint encounters "
+ "positional-only arguments.",
+ ),
+ }
+
+ def open(self) -> None:
+ """Initialize visit variables and statistics."""
+ py_version = self.linter.config.py_version
+ self._py36_plus = py_version >= (3, 6)
+ self._py38_plus = py_version >= (3, 8)
+ self._py311_plus = py_version >= (3, 11)
+ self._py312_plus = py_version >= (3, 12)
+
+ @only_required_for_messages("using-f-string-in-unsupported-version")
+ def visit_joinedstr(self, node: nodes.JoinedStr) -> None:
+ """Check f-strings."""
+ if not self._py36_plus:
+ self.add_message(
+ "using-f-string-in-unsupported-version", node=node, confidence=HIGH
+ )
+
+ @only_required_for_messages("using-assignment-expression-in-unsupported-version")
+ def visit_namedexpr(self, node: nodes.JoinedStr) -> None:
+ if not self._py38_plus:
+ self.add_message(
+ "using-assignment-expression-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-positional-only-args-in-unsupported-version")
+ def visit_arguments(self, node: nodes.Arguments) -> None:
+ if not self._py38_plus and node.posonlyargs:
+ self.add_message(
+ "using-positional-only-args-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-final-decorator-in-unsupported-version")
+ def visit_decorators(self, node: nodes.Decorators) -> None:
+ """Check decorators."""
+ self._check_typing_final(node)
+
+ def _check_typing_final(self, node: nodes.Decorators) -> None:
+ """Add a message when the `typing.final` decorator is used and the
+ py-version is lower than 3.8.
+ """
+ if self._py38_plus:
+ return
+
+ decorators = []
+ for decorator in node.get_children():
+ inferred = safe_infer(decorator)
+ if inferred and inferred.qname() == "typing.final":
+ decorators.append(decorator)
+
+ for decorator in decorators or uninferable_final_decorators(node):
+ self.add_message(
+ "using-final-decorator-in-unsupported-version",
+ node=decorator,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-exception-groups-in-unsupported-version")
+ def visit_trystar(self, node: nodes.TryStar) -> None:
+ if not self._py311_plus:
+ self.add_message(
+ "using-exception-groups-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-exception-groups-in-unsupported-version")
+ def visit_excepthandler(self, node: nodes.ExceptHandler) -> None:
+ if (
+ not self._py311_plus
+ and isinstance(node.type, nodes.Name)
+ and node.type.name == "ExceptionGroup"
+ ):
+ self.add_message(
+ "using-exception-groups-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-exception-groups-in-unsupported-version")
+ def visit_raise(self, node: nodes.Raise) -> None:
+ if (
+ not self._py311_plus
+ and isinstance(node.exc, nodes.Call)
+ and isinstance(node.exc.func, nodes.Name)
+ and node.exc.func.name == "ExceptionGroup"
+ ):
+ self.add_message(
+ "using-exception-groups-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-generic-type-syntax-in-unsupported-version")
+ def visit_typealias(self, node: nodes.TypeAlias) -> None:
+ if not self._py312_plus:
+ self.add_message(
+ "using-generic-type-syntax-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-generic-type-syntax-in-unsupported-version")
+ def visit_typevar(self, node: nodes.TypeVar) -> None:
+ if not self._py312_plus:
+ self.add_message(
+ "using-generic-type-syntax-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+ @only_required_for_messages("using-generic-type-syntax-in-unsupported-version")
+ def visit_typevartuple(self, node: nodes.TypeVarTuple) -> None:
+ if not self._py312_plus:
+ self.add_message(
+ "using-generic-type-syntax-in-unsupported-version",
+ node=node,
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(UnsupportedVersionChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/utils.py b/solutions/.venv/Lib/site-packages/pylint/checkers/utils.py
new file mode 100644
index 000000000..bfc4bc61d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/utils.py
@@ -0,0 +1,2341 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Some functions that may be useful for various checkers."""
+
+from __future__ import annotations
+
+import _string
+import builtins
+import fnmatch
+import itertools
+import numbers
+import re
+import string
+from collections.abc import Callable, Iterable, Iterator
+from functools import lru_cache, partial
+from re import Match
+from typing import TYPE_CHECKING, Any, TypeVar
+
+import astroid.objects
+from astroid import TooManyLevelsError, nodes, util
+from astroid.context import InferenceContext
+from astroid.exceptions import AstroidError
+from astroid.nodes._base_nodes import ImportNode, Statement
+from astroid.typing import InferenceResult, SuccessfulInferenceResult
+
+from pylint.constants import TYPING_NEVER, TYPING_NORETURN
+
+if TYPE_CHECKING:
+ from functools import _lru_cache_wrapper
+
+ from pylint.checkers import BaseChecker
+
+_NodeT = TypeVar("_NodeT", bound=nodes.NodeNG)
+_CheckerT = TypeVar("_CheckerT", bound="BaseChecker")
+AstCallbackMethod = Callable[[_CheckerT, _NodeT], None]
+
+COMP_NODE_TYPES = (
+ nodes.ListComp,
+ nodes.SetComp,
+ nodes.DictComp,
+ nodes.GeneratorExp,
+)
+EXCEPTIONS_MODULE = "builtins"
+ABC_MODULES = {"abc", "_py_abc"}
+ABC_METHODS = {
+ "abc.abstractproperty",
+ "abc.abstractmethod",
+ "abc.abstractclassmethod",
+ "abc.abstractstaticmethod",
+}
+TYPING_PROTOCOLS = frozenset(
+ {"typing.Protocol", "typing_extensions.Protocol", ".Protocol"}
+)
+COMMUTATIVE_OPERATORS = frozenset({"*", "+", "^", "&", "|"})
+ITER_METHOD = "__iter__"
+AITER_METHOD = "__aiter__"
+NEXT_METHOD = "__next__"
+GETITEM_METHOD = "__getitem__"
+CLASS_GETITEM_METHOD = "__class_getitem__"
+SETITEM_METHOD = "__setitem__"
+DELITEM_METHOD = "__delitem__"
+CONTAINS_METHOD = "__contains__"
+KEYS_METHOD = "keys"
+
+# Dictionary which maps the number of expected parameters a
+# special method can have to a set of special methods.
+# The following keys are used to denote the parameters restrictions:
+#
+# * None: variable number of parameters
+# * number: exactly that number of parameters
+# * tuple: these are the odd ones. Basically it means that the function
+# can work with any number of arguments from that tuple,
+# although it's best to implement it in order to accept
+# all of them.
+_SPECIAL_METHODS_PARAMS = {
+ None: ("__new__", "__init__", "__call__", "__init_subclass__"),
+ 0: (
+ "__del__",
+ "__repr__",
+ "__str__",
+ "__bytes__",
+ "__hash__",
+ "__bool__",
+ "__dir__",
+ "__len__",
+ "__length_hint__",
+ "__iter__",
+ "__reversed__",
+ "__neg__",
+ "__pos__",
+ "__abs__",
+ "__invert__",
+ "__complex__",
+ "__int__",
+ "__float__",
+ "__index__",
+ "__trunc__",
+ "__floor__",
+ "__ceil__",
+ "__enter__",
+ "__aenter__",
+ "__getnewargs_ex__",
+ "__getnewargs__",
+ "__getstate__",
+ "__reduce__",
+ "__copy__",
+ "__unicode__",
+ "__nonzero__",
+ "__await__",
+ "__aiter__",
+ "__anext__",
+ "__fspath__",
+ "__subclasses__",
+ ),
+ 1: (
+ "__format__",
+ "__lt__",
+ "__le__",
+ "__eq__",
+ "__ne__",
+ "__gt__",
+ "__ge__",
+ "__getattr__",
+ "__getattribute__",
+ "__delattr__",
+ "__delete__",
+ "__instancecheck__",
+ "__subclasscheck__",
+ "__getitem__",
+ "__missing__",
+ "__delitem__",
+ "__contains__",
+ "__add__",
+ "__sub__",
+ "__mul__",
+ "__truediv__",
+ "__floordiv__",
+ "__rfloordiv__",
+ "__mod__",
+ "__divmod__",
+ "__lshift__",
+ "__rshift__",
+ "__and__",
+ "__xor__",
+ "__or__",
+ "__radd__",
+ "__rsub__",
+ "__rmul__",
+ "__rtruediv__",
+ "__rmod__",
+ "__rdivmod__",
+ "__rpow__",
+ "__rlshift__",
+ "__rrshift__",
+ "__rand__",
+ "__rxor__",
+ "__ror__",
+ "__iadd__",
+ "__isub__",
+ "__imul__",
+ "__itruediv__",
+ "__ifloordiv__",
+ "__imod__",
+ "__ilshift__",
+ "__irshift__",
+ "__iand__",
+ "__ixor__",
+ "__ior__",
+ "__ipow__",
+ "__setstate__",
+ "__reduce_ex__",
+ "__deepcopy__",
+ "__cmp__",
+ "__matmul__",
+ "__rmatmul__",
+ "__imatmul__",
+ "__div__",
+ ),
+ 2: ("__setattr__", "__get__", "__set__", "__setitem__", "__set_name__"),
+ 3: ("__exit__", "__aexit__"),
+ (0, 1): ("__round__",),
+ (1, 2): ("__pow__",),
+}
+
+SPECIAL_METHODS_PARAMS = {
+ name: params
+ for params, methods in _SPECIAL_METHODS_PARAMS.items()
+ for name in methods
+}
+PYMETHODS = set(SPECIAL_METHODS_PARAMS)
+
+SUBSCRIPTABLE_CLASSES_PEP585 = frozenset(
+ (
+ "builtins.tuple",
+ "builtins.list",
+ "builtins.dict",
+ "builtins.set",
+ "builtins.frozenset",
+ "builtins.type",
+ "collections.deque",
+ "collections.defaultdict",
+ "collections.OrderedDict",
+ "collections.Counter",
+ "collections.ChainMap",
+ "_collections_abc.Awaitable",
+ "_collections_abc.Coroutine",
+ "_collections_abc.AsyncIterable",
+ "_collections_abc.AsyncIterator",
+ "_collections_abc.AsyncGenerator",
+ "_collections_abc.Iterable",
+ "_collections_abc.Iterator",
+ "_collections_abc.Generator",
+ "_collections_abc.Reversible",
+ "_collections_abc.Container",
+ "_collections_abc.Collection",
+ "_collections_abc.Callable",
+ "_collections_abc.Set",
+ "_collections_abc.MutableSet",
+ "_collections_abc.Mapping",
+ "_collections_abc.MutableMapping",
+ "_collections_abc.Sequence",
+ "_collections_abc.MutableSequence",
+ "_collections_abc.ByteString",
+ "_collections_abc.MappingView",
+ "_collections_abc.KeysView",
+ "_collections_abc.ItemsView",
+ "_collections_abc.ValuesView",
+ "contextlib.AbstractContextManager",
+ "contextlib.AbstractAsyncContextManager",
+ "re.Pattern",
+ "re.Match",
+ )
+)
+
+SINGLETON_VALUES = {True, False, None}
+
+TERMINATING_FUNCS_QNAMES = frozenset(
+ {"_sitebuiltins.Quitter", "sys.exit", "posix._exit", "nt._exit"}
+)
+
+
+class NoSuchArgumentError(Exception):
+ pass
+
+
+class InferredTypeError(Exception):
+ pass
+
+
+def get_all_elements(
+ node: nodes.NodeNG,
+) -> Iterable[nodes.NodeNG]:
+ """Recursively returns all atoms in nested lists and tuples."""
+ if isinstance(node, (nodes.Tuple, nodes.List)):
+ for child in node.elts:
+ yield from get_all_elements(child)
+ else:
+ yield node
+
+
+def is_super(node: nodes.NodeNG) -> bool:
+ """Return True if the node is referencing the "super" builtin function."""
+ if getattr(node, "name", None) == "super" and node.root().name == "builtins":
+ return True
+ return False
+
+
+def is_error(node: nodes.FunctionDef) -> bool:
+ """Return true if the given function node only raises an exception."""
+ return len(node.body) == 1 and isinstance(node.body[0], nodes.Raise)
+
+
+builtins = builtins.__dict__.copy() # type: ignore[assignment]
+SPECIAL_BUILTINS = ("__builtins__",) # '__path__', '__file__')
+
+
+def is_builtin_object(node: nodes.NodeNG) -> bool:
+ """Returns True if the given node is an object from the __builtin__ module."""
+ return node and node.root().name == "builtins" # type: ignore[no-any-return]
+
+
+def is_builtin(name: str) -> bool:
+ """Return true if <name> could be considered as a builtin defined by python."""
+ return name in builtins or name in SPECIAL_BUILTINS # type: ignore[operator]
+
+
+def is_defined_in_scope(
+ var_node: nodes.NodeNG,
+ varname: str,
+ scope: nodes.NodeNG,
+) -> bool:
+ return defnode_in_scope(var_node, varname, scope) is not None
+
+
+# pylint: disable = too-many-branches
+def defnode_in_scope(
+ var_node: nodes.NodeNG,
+ varname: str,
+ scope: nodes.NodeNG,
+) -> nodes.NodeNG | None:
+ if isinstance(scope, nodes.If):
+ for node in scope.body:
+ if isinstance(node, nodes.Nonlocal) and varname in node.names:
+ return node
+ if isinstance(node, nodes.Assign):
+ for target in node.targets:
+ if isinstance(target, nodes.AssignName) and target.name == varname:
+ return target
+ elif isinstance(scope, (COMP_NODE_TYPES, nodes.For)):
+ for ass_node in scope.nodes_of_class(nodes.AssignName):
+ if ass_node.name == varname:
+ return ass_node
+ elif isinstance(scope, nodes.With):
+ for expr, ids in scope.items:
+ if expr.parent_of(var_node):
+ break
+ if ids and isinstance(ids, nodes.AssignName) and ids.name == varname:
+ return ids
+ elif isinstance(scope, (nodes.Lambda, nodes.FunctionDef)):
+ if scope.args.is_argument(varname):
+ # If the name is found inside a default value
+ # of a function, then let the search continue
+ # in the parent's tree.
+ if scope.args.parent_of(var_node):
+ try:
+ scope.args.default_value(varname)
+ scope = scope.parent
+ defnode = defnode_in_scope(var_node, varname, scope)
+ except astroid.NoDefault:
+ pass
+ else:
+ return defnode
+ return scope
+ if getattr(scope, "name", None) == varname:
+ return scope
+ elif isinstance(scope, nodes.ExceptHandler):
+ if isinstance(scope.name, nodes.AssignName):
+ ass_node = scope.name
+ if ass_node.name == varname:
+ return ass_node
+ return None
+
+
+def is_defined_before(var_node: nodes.Name) -> bool:
+ """Check if the given variable node is defined before.
+
+ Verify that the variable node is defined by a parent node
+ (e.g. if or with) earlier than `var_node`, or is defined by a
+ (list, set, dict, or generator comprehension, lambda)
+ or in a previous sibling node on the same line
+ (statement_defining ; statement_using).
+ """
+ varname = var_node.name
+ for parent in var_node.node_ancestors():
+ defnode = defnode_in_scope(var_node, varname, parent)
+ if defnode is None:
+ continue
+ defnode_scope = defnode.scope()
+ if isinstance(
+ defnode_scope, (*COMP_NODE_TYPES, nodes.Lambda, nodes.FunctionDef)
+ ):
+ # Avoid the case where var_node_scope is a nested function
+ if isinstance(defnode_scope, nodes.FunctionDef):
+ var_node_scope = var_node.scope()
+ if var_node_scope is not defnode_scope and isinstance(
+ var_node_scope, nodes.FunctionDef
+ ):
+ return False
+ return True
+ if defnode.lineno < var_node.lineno:
+ return True
+ # `defnode` and `var_node` on the same line
+ for defnode_anc in defnode.node_ancestors():
+ if defnode_anc.lineno != var_node.lineno:
+ continue
+ if isinstance(
+ defnode_anc,
+ (
+ nodes.For,
+ nodes.While,
+ nodes.With,
+ nodes.Try,
+ nodes.ExceptHandler,
+ ),
+ ):
+ return True
+ # possibly multiple statements on the same line using semicolon separator
+ stmt = var_node.statement()
+ _node = stmt.previous_sibling()
+ lineno = stmt.fromlineno
+ while _node and _node.fromlineno == lineno:
+ for assign_node in _node.nodes_of_class(nodes.AssignName):
+ if assign_node.name == varname:
+ return True
+ for imp_node in _node.nodes_of_class((nodes.ImportFrom, nodes.Import)):
+ if varname in [name[1] or name[0] for name in imp_node.names]:
+ return True
+ _node = _node.previous_sibling()
+ return False
+
+
+def is_default_argument(node: nodes.NodeNG, scope: nodes.NodeNG | None = None) -> bool:
+ """Return true if the given Name node is used in function or lambda
+ default argument's value.
+ """
+ if not scope:
+ scope = node.scope()
+ if isinstance(scope, (nodes.FunctionDef, nodes.Lambda)):
+ all_defaults = itertools.chain(
+ scope.args.defaults, (d for d in scope.args.kw_defaults if d is not None)
+ )
+ return any(
+ default_name_node is node
+ for default_node in all_defaults
+ for default_name_node in default_node.nodes_of_class(nodes.Name)
+ )
+
+ return False
+
+
+def is_func_decorator(node: nodes.NodeNG) -> bool:
+ """Return true if the name is used in function decorator."""
+ for parent in node.node_ancestors():
+ if isinstance(parent, nodes.Decorators):
+ return True
+ if parent.is_statement or isinstance(
+ parent,
+ (
+ nodes.Lambda,
+ nodes.ComprehensionScope,
+ nodes.ListComp,
+ ),
+ ):
+ break
+ return False
+
+
+def is_ancestor_name(frame: nodes.ClassDef, node: nodes.NodeNG) -> bool:
+ """Return whether `frame` is an astroid.Class node with `node` in the
+ subtree of its bases attribute.
+ """
+ if not isinstance(frame, nodes.ClassDef):
+ return False
+ return any(node in base.nodes_of_class(nodes.Name) for base in frame.bases)
+
+
+def is_being_called(node: nodes.NodeNG) -> bool:
+ """Return True if node is the function being called in a Call node."""
+ return isinstance(node.parent, nodes.Call) and node.parent.func is node
+
+
+def assign_parent(node: nodes.NodeNG) -> nodes.NodeNG:
+ """Return the higher parent which is not an AssignName, Tuple or List node."""
+ while node and isinstance(node, (nodes.AssignName, nodes.Tuple, nodes.List)):
+ node = node.parent
+ return node
+
+
+def overrides_a_method(class_node: nodes.ClassDef, name: str) -> bool:
+ """Return True if <name> is a method overridden from an ancestor
+ which is not the base object class.
+ """
+ for ancestor in class_node.ancestors():
+ if ancestor.name == "object":
+ continue
+ if name in ancestor and isinstance(ancestor[name], nodes.FunctionDef):
+ return True
+ return False
+
+
+def only_required_for_messages(
+ *messages: str,
+) -> Callable[
+ [AstCallbackMethod[_CheckerT, _NodeT]], AstCallbackMethod[_CheckerT, _NodeT]
+]:
+ """Decorator to store messages that are handled by a checker method as an
+ attribute of the function object.
+
+ This information is used by ``ASTWalker`` to decide whether to call the decorated
+ method or not. If none of the messages is enabled, the method will be skipped.
+ Therefore, the list of messages must be well maintained at all times!
+ This decorator only has an effect on ``visit_*`` and ``leave_*`` methods
+ of a class inheriting from ``BaseChecker``.
+ """
+
+ def store_messages(
+ func: AstCallbackMethod[_CheckerT, _NodeT]
+ ) -> AstCallbackMethod[_CheckerT, _NodeT]:
+ func.checks_msgs = messages # type: ignore[attr-defined]
+ return func
+
+ return store_messages
+
+
+class IncompleteFormatString(Exception):
+ """A format string ended in the middle of a format specifier."""
+
+
+class UnsupportedFormatCharacter(Exception):
+ """A format character in a format string is not one of the supported
+ format characters.
+ """
+
+ def __init__(self, index: int) -> None:
+ super().__init__(index)
+ self.index = index
+
+
+def parse_format_string(
+ format_string: str,
+) -> tuple[set[str], int, dict[str, str], list[str]]:
+ """Parses a format string, returning a tuple (keys, num_args).
+
+ Where 'keys' is the set of mapping keys in the format string, and 'num_args' is the number
+ of arguments required by the format string. Raises IncompleteFormatString or
+ UnsupportedFormatCharacter if a parse error occurs.
+ """
+ keys = set()
+ key_types = {}
+ pos_types = []
+ num_args = 0
+
+ def next_char(i: int) -> tuple[int, str]:
+ i += 1
+ if i == len(format_string):
+ raise IncompleteFormatString
+ return (i, format_string[i])
+
+ i = 0
+ while i < len(format_string):
+ char = format_string[i]
+ if char == "%":
+ i, char = next_char(i)
+ # Parse the mapping key (optional).
+ key = None
+ if char == "(":
+ depth = 1
+ i, char = next_char(i)
+ key_start = i
+ while depth != 0:
+ if char == "(":
+ depth += 1
+ elif char == ")":
+ depth -= 1
+ i, char = next_char(i)
+ key_end = i - 1
+ key = format_string[key_start:key_end]
+
+ # Parse the conversion flags (optional).
+ while char in "#0- +":
+ i, char = next_char(i)
+ # Parse the minimum field width (optional).
+ if char == "*":
+ num_args += 1
+ i, char = next_char(i)
+ else:
+ while char in string.digits:
+ i, char = next_char(i)
+ # Parse the precision (optional).
+ if char == ".":
+ i, char = next_char(i)
+ if char == "*":
+ num_args += 1
+ i, char = next_char(i)
+ else:
+ while char in string.digits:
+ i, char = next_char(i)
+ # Parse the length modifier (optional).
+ if char in "hlL":
+ i, char = next_char(i)
+ # Parse the conversion type (mandatory).
+ flags = "diouxXeEfFgGcrs%a"
+ if char not in flags:
+ raise UnsupportedFormatCharacter(i)
+ if key:
+ keys.add(key)
+ key_types[key] = char
+ elif char != "%":
+ num_args += 1
+ pos_types.append(char)
+ i += 1
+ return keys, num_args, key_types, pos_types
+
+
+def split_format_field_names(
+ format_string: str,
+) -> tuple[str, Iterable[tuple[bool, str]]]:
+ try:
+ return _string.formatter_field_name_split(format_string) # type: ignore[no-any-return]
+ except ValueError as e:
+ raise IncompleteFormatString() from e
+
+
+def collect_string_fields(format_string: str) -> Iterable[str | None]:
+ """Given a format string, return an iterator
+ of all the valid format fields.
+
+ It handles nested fields as well.
+ """
+ formatter = string.Formatter()
+ # pylint: disable = too-many-try-statements
+ try:
+ parseiterator = formatter.parse(format_string)
+ for result in parseiterator:
+ if all(item is None for item in result[1:]):
+ # not a replacement format
+ continue
+ name = result[1]
+ nested = result[2]
+ yield name
+ if nested:
+ yield from collect_string_fields(nested)
+ except ValueError as exc:
+ # Probably the format string is invalid.
+ if exc.args[0].startswith("cannot switch from manual"):
+ # On Jython, parsing a string with both manual
+ # and automatic positions will fail with a ValueError,
+ # while on CPython it will simply return the fields,
+ # the validation being done in the interpreter (?).
+ # We're just returning two mixed fields in order
+ # to trigger the format-combined-specification check.
+ yield ""
+ yield "1"
+ return
+ raise IncompleteFormatString(format_string) from exc
+
+
+def parse_format_method_string(
+ format_string: str,
+) -> tuple[list[tuple[str, list[tuple[bool, str]]]], int, int]:
+ """Parses a PEP 3101 format string, returning a tuple of
+ (keyword_arguments, implicit_pos_args_cnt, explicit_pos_args).
+
+ keyword_arguments is the set of mapping keys in the format string, implicit_pos_args_cnt
+ is the number of arguments required by the format string and
+ explicit_pos_args is the number of arguments passed with the position.
+ """
+ keyword_arguments = []
+ implicit_pos_args_cnt = 0
+ explicit_pos_args = set()
+ for name in collect_string_fields(format_string):
+ if name and str(name).isdigit():
+ explicit_pos_args.add(str(name))
+ elif name:
+ keyname, fielditerator = split_format_field_names(name)
+ if isinstance(keyname, numbers.Number):
+ explicit_pos_args.add(str(keyname))
+ try:
+ keyword_arguments.append((keyname, list(fielditerator)))
+ except ValueError as e:
+ raise IncompleteFormatString() from e
+ else:
+ implicit_pos_args_cnt += 1
+ return keyword_arguments, implicit_pos_args_cnt, len(explicit_pos_args)
+
+
+def is_attr_protected(attrname: str) -> bool:
+ """Return True if attribute name is protected (start with _ and some other
+ details), False otherwise.
+ """
+ return (
+ attrname[0] == "_"
+ and attrname != "_"
+ and not (attrname.startswith("__") and attrname.endswith("__"))
+ )
+
+
+def node_frame_class(node: nodes.NodeNG) -> nodes.ClassDef | None:
+ """Return the class that is wrapping the given node.
+
+ The function returns a class for a method node (or a staticmethod or a
+ classmethod), otherwise it returns `None`.
+ """
+ klass = node.frame()
+ nodes_to_check = (
+ nodes.NodeNG,
+ astroid.UnboundMethod,
+ astroid.BaseInstance,
+ )
+ while (
+ klass
+ and isinstance(klass, nodes_to_check)
+ and not isinstance(klass, nodes.ClassDef)
+ ):
+ if klass.parent is None:
+ return None
+
+ klass = klass.parent.frame()
+
+ return klass
+
+
+def get_outer_class(class_node: astroid.ClassDef) -> astroid.ClassDef | None:
+ """Return the class that is the outer class of given (nested) class_node."""
+ parent_klass = class_node.parent.frame()
+
+ return parent_klass if isinstance(parent_klass, astroid.ClassDef) else None
+
+
+def is_attr_private(attrname: str) -> Match[str] | None:
+ """Check that attribute name is private (at least two leading underscores,
+ at most one trailing underscore).
+ """
+ regex = re.compile("^_{2,10}.*[^_]+_?$")
+ return regex.match(attrname)
+
+
+def get_argument_from_call(
+ call_node: nodes.Call, position: int | None = None, keyword: str | None = None
+) -> nodes.Name:
+ """Returns the specified argument from a function call.
+
+ :param nodes.Call call_node: Node representing a function call to check.
+ :param int position: position of the argument.
+ :param str keyword: the keyword of the argument.
+
+ :returns: The node representing the argument, None if the argument is not found.
+ :rtype: nodes.Name
+ :raises ValueError: if both position and keyword are None.
+ :raises NoSuchArgumentError: if no argument at the provided position or with
+ the provided keyword.
+ """
+ if position is None and keyword is None:
+ raise ValueError("Must specify at least one of: position or keyword.")
+ if position is not None:
+ try:
+ return call_node.args[position]
+ except IndexError:
+ pass
+ if keyword and call_node.keywords:
+ for arg in call_node.keywords:
+ if arg.arg == keyword:
+ return arg.value
+
+ raise NoSuchArgumentError
+
+
+def infer_kwarg_from_call(call_node: nodes.Call, keyword: str) -> nodes.Name | None:
+ """Returns the specified argument from a function's kwargs.
+
+ :param nodes.Call call_node: Node representing a function call to check.
+ :param str keyword: Name of the argument to be extracted.
+
+ :returns: The node representing the argument, None if the argument is not found.
+ :rtype: nodes.Name
+ """
+ for arg in call_node.kwargs:
+ inferred = safe_infer(arg.value)
+ if isinstance(inferred, nodes.Dict):
+ for item in inferred.items:
+ if item[0].value == keyword:
+ return item[1]
+
+ return None
+
+
+def inherit_from_std_ex(node: nodes.NodeNG | astroid.Instance) -> bool:
+ """Return whether the given class node is subclass of
+ exceptions.Exception.
+ """
+ ancestors = node.ancestors() if hasattr(node, "ancestors") else []
+ return any(
+ ancestor.name in {"Exception", "BaseException"}
+ and ancestor.root().name == EXCEPTIONS_MODULE
+ for ancestor in itertools.chain([node], ancestors)
+ )
+
+
+def error_of_type(
+ handler: nodes.ExceptHandler,
+ error_type: str | type[Exception] | tuple[str | type[Exception], ...],
+) -> bool:
+ """Check if the given exception handler catches
+ the given error_type.
+
+ The *handler* parameter is a node, representing an ExceptHandler node.
+ The *error_type* can be an exception, such as AttributeError,
+ the name of an exception, or it can be a tuple of errors.
+ The function will return True if the handler catches any of the
+ given errors.
+ """
+
+ def stringify_error(error: str | type[Exception]) -> str:
+ if not isinstance(error, str):
+ return error.__name__
+ return error
+
+ if not isinstance(error_type, tuple):
+ error_type = (error_type,)
+ expected_errors = {stringify_error(error) for error in error_type}
+ if not handler.type:
+ return False
+ return handler.catch(expected_errors) # type: ignore[no-any-return]
+
+
+def decorated_with_property(node: nodes.FunctionDef) -> bool:
+ """Detect if the given function node is decorated with a property."""
+ if not node.decorators:
+ return False
+ for decorator in node.decorators.nodes:
+ try:
+ if _is_property_decorator(decorator):
+ return True
+ except astroid.InferenceError:
+ pass
+ return False
+
+
+def _is_property_kind(node: nodes.NodeNG, *kinds: str) -> bool:
+ if not isinstance(node, (astroid.UnboundMethod, nodes.FunctionDef)):
+ return False
+ if node.decorators:
+ for decorator in node.decorators.nodes:
+ if isinstance(decorator, nodes.Attribute) and decorator.attrname in kinds:
+ return True
+ return False
+
+
+def is_property_setter(node: nodes.NodeNG) -> bool:
+ """Check if the given node is a property setter."""
+ return _is_property_kind(node, "setter")
+
+
+def is_property_deleter(node: nodes.NodeNG) -> bool:
+ """Check if the given node is a property deleter."""
+ return _is_property_kind(node, "deleter")
+
+
+def is_property_setter_or_deleter(node: nodes.NodeNG) -> bool:
+ """Check if the given node is either a property setter or a deleter."""
+ return _is_property_kind(node, "setter", "deleter")
+
+
+def _is_property_decorator(decorator: nodes.Name) -> bool:
+ for inferred in decorator.infer():
+ if isinstance(inferred, nodes.ClassDef):
+ if inferred.qname() in {"builtins.property", "functools.cached_property"}:
+ return True
+ for ancestor in inferred.ancestors():
+ if ancestor.name == "property" and ancestor.root().name == "builtins":
+ return True
+ elif isinstance(inferred, nodes.FunctionDef):
+ # If decorator is function, check if it has exactly one return
+ # and the return is itself a function decorated with property
+ returns: list[nodes.Return] = list(
+ inferred._get_return_nodes_skip_functions()
+ )
+ if len(returns) == 1 and isinstance(
+ returns[0].value, (nodes.Name, nodes.Attribute)
+ ):
+ inferred = safe_infer(returns[0].value)
+ if (
+ inferred
+ and isinstance(inferred, astroid.objects.Property)
+ and isinstance(inferred.function, nodes.FunctionDef)
+ ):
+ return decorated_with_property(inferred.function)
+ return False
+
+
+def decorated_with(
+ func: (
+ nodes.ClassDef | nodes.FunctionDef | astroid.BoundMethod | astroid.UnboundMethod
+ ),
+ qnames: Iterable[str],
+) -> bool:
+ """Determine if the `func` node has a decorator with the qualified name `qname`."""
+ decorators = func.decorators.nodes if func.decorators else []
+ for decorator_node in decorators:
+ if isinstance(decorator_node, nodes.Call):
+ # We only want to infer the function name
+ decorator_node = decorator_node.func
+ try:
+ if any(
+ i.name in qnames or i.qname() in qnames
+ for i in decorator_node.infer()
+ if i is not None and not isinstance(i, util.UninferableBase)
+ ):
+ return True
+ except astroid.InferenceError:
+ continue
+ return False
+
+
+def uninferable_final_decorators(
+ node: nodes.Decorators,
+) -> list[nodes.Attribute | nodes.Name | None]:
+ """Return a list of uninferable `typing.final` decorators in `node`.
+
+ This function is used to determine if the `typing.final` decorator is used
+ with an unsupported Python version; the decorator cannot be inferred when
+ using a Python version lower than 3.8.
+ """
+ decorators = []
+ for decorator in getattr(node, "nodes", []):
+ import_nodes: tuple[nodes.Import | nodes.ImportFrom] | None = None
+
+ # Get the `Import` node. The decorator is of the form: @module.name
+ if isinstance(decorator, nodes.Attribute):
+ inferred = safe_infer(decorator.expr)
+ if isinstance(inferred, nodes.Module) and inferred.qname() == "typing":
+ _, import_nodes = decorator.expr.lookup(decorator.expr.name)
+
+ # Get the `ImportFrom` node. The decorator is of the form: @name
+ elif isinstance(decorator, nodes.Name):
+ _, import_nodes = decorator.lookup(decorator.name)
+
+ # The `final` decorator is expected to be found in the
+ # import_nodes. Continue if we don't find any `Import` or `ImportFrom`
+ # nodes for this decorator.
+ if not import_nodes:
+ continue
+ import_node = import_nodes[0]
+
+ if not isinstance(import_node, (astroid.Import, astroid.ImportFrom)):
+ continue
+
+ import_names = dict(import_node.names)
+
+ # Check if the import is of the form: `from typing import final`
+ is_from_import = ("final" in import_names) and import_node.modname == "typing"
+
+ # Check if the import is of the form: `import typing`
+ is_import = ("typing" in import_names) and getattr(
+ decorator, "attrname", None
+ ) == "final"
+
+ if is_from_import or is_import:
+ inferred = safe_infer(decorator)
+ if inferred is None or isinstance(inferred, util.UninferableBase):
+ decorators.append(decorator)
+ return decorators
+
+
+@lru_cache(maxsize=1024)
+def unimplemented_abstract_methods(
+ node: nodes.ClassDef, is_abstract_cb: nodes.FunctionDef | None = None
+) -> dict[str, nodes.FunctionDef]:
+ """Get the unimplemented abstract methods for the given *node*.
+
+ A method can be considered abstract if the callback *is_abstract_cb*
+ returns a ``True`` value. The check defaults to verifying that
+ a method is decorated with abstract methods.
+ It will return a dictionary of abstract method
+ names and their inferred objects.
+ """
+ if is_abstract_cb is None:
+ is_abstract_cb = partial(decorated_with, qnames=ABC_METHODS)
+ visited: dict[str, nodes.FunctionDef] = {}
+ try:
+ mro = reversed(node.mro())
+ except astroid.ResolveError:
+ # Probably inconsistent hierarchy, don't try to figure this out here.
+ return {}
+ for ancestor in mro:
+ for obj in ancestor.values():
+ inferred = obj
+ if isinstance(obj, nodes.AssignName):
+ inferred = safe_infer(obj)
+ if not inferred:
+ # Might be an abstract function,
+ # but since we don't have enough information
+ # in order to take this decision, we're taking
+ # the *safe* decision instead.
+ if obj.name in visited:
+ del visited[obj.name]
+ continue
+ if not isinstance(inferred, nodes.FunctionDef):
+ if obj.name in visited:
+ del visited[obj.name]
+ if isinstance(inferred, nodes.FunctionDef):
+ # It's critical to use the original name,
+ # since after inferring, an object can be something
+ # else than expected, as in the case of the
+ # following assignment.
+ #
+ # class A:
+ # def keys(self): pass
+ # __iter__ = keys
+ abstract = is_abstract_cb(inferred)
+ if abstract:
+ visited[obj.name] = inferred
+ elif not abstract and obj.name in visited:
+ del visited[obj.name]
+ return visited
+
+
+def find_try_except_wrapper_node(
+ node: nodes.NodeNG,
+) -> nodes.ExceptHandler | nodes.Try | None:
+ """Return the ExceptHandler or the Try node in which the node is."""
+ current = node
+ ignores = (nodes.ExceptHandler, nodes.Try)
+ while current and not isinstance(current.parent, ignores):
+ current = current.parent
+
+ if current and isinstance(current.parent, ignores):
+ return current.parent
+ return None
+
+
+def find_except_wrapper_node_in_scope(
+ node: nodes.NodeNG,
+) -> nodes.ExceptHandler | None:
+ """Return the ExceptHandler in which the node is, without going out of scope."""
+ for current in node.node_ancestors():
+ if isinstance(current, astroid.scoped_nodes.LocalsDictNodeNG):
+ # If we're inside a function/class definition, we don't want to keep checking
+ # higher ancestors for `except` clauses, because if these exist, it means our
+ # function/class was defined in an `except` clause, rather than the current code
+ # actually running in an `except` clause.
+ return None
+ if isinstance(current, nodes.ExceptHandler):
+ return current
+ return None
+
+
+def is_from_fallback_block(node: nodes.NodeNG) -> bool:
+ """Check if the given node is from a fallback import block."""
+ context = find_try_except_wrapper_node(node)
+ if not context:
+ return False
+
+ if isinstance(context, nodes.ExceptHandler):
+ other_body = context.parent.body
+ handlers = context.parent.handlers
+ else:
+ other_body = itertools.chain.from_iterable(
+ handler.body for handler in context.handlers
+ )
+ handlers = context.handlers
+
+ has_fallback_imports = any(
+ isinstance(import_node, (nodes.ImportFrom, nodes.Import))
+ for import_node in other_body
+ )
+ ignores_import_error = _except_handlers_ignores_exceptions(
+ handlers, (ImportError, ModuleNotFoundError)
+ )
+ return ignores_import_error or has_fallback_imports
+
+
+def _except_handlers_ignores_exceptions(
+ handlers: nodes.ExceptHandler,
+ exceptions: tuple[type[ImportError], type[ModuleNotFoundError]],
+) -> bool:
+ func = partial(error_of_type, error_type=exceptions)
+ return any(func(handler) for handler in handlers)
+
+
+def get_exception_handlers(
+ node: nodes.NodeNG, exception: type[Exception] | str = Exception
+) -> list[nodes.ExceptHandler] | None:
+ """Return the collections of handlers handling the exception in arguments.
+
+ Args:
+ node (nodes.NodeNG): A node that is potentially wrapped in a try except.
+ exception (builtin.Exception or str): exception or name of the exception.
+
+ Returns:
+ list: the collection of handlers that are handling the exception or None.
+ """
+ context = find_try_except_wrapper_node(node)
+ if isinstance(context, nodes.Try):
+ return [
+ handler for handler in context.handlers if error_of_type(handler, exception)
+ ]
+ return []
+
+
+def get_contextlib_with_statements(node: nodes.NodeNG) -> Iterator[nodes.With]:
+ """Get all contextlib.with statements in the ancestors of the given node."""
+ for with_node in node.node_ancestors():
+ if isinstance(with_node, nodes.With):
+ yield with_node
+
+
+def _suppresses_exception(
+ call: nodes.Call, exception: type[Exception] | str = Exception
+) -> bool:
+ """Check if the given node suppresses the given exception."""
+ if not isinstance(exception, str):
+ exception = exception.__name__
+ for arg in call.args:
+ inferred = safe_infer(arg)
+ if isinstance(inferred, nodes.ClassDef):
+ if inferred.name == exception:
+ return True
+ elif isinstance(inferred, nodes.Tuple):
+ for elt in inferred.elts:
+ inferred_elt = safe_infer(elt)
+ if (
+ isinstance(inferred_elt, nodes.ClassDef)
+ and inferred_elt.name == exception
+ ):
+ return True
+ return False
+
+
+def get_contextlib_suppressors(
+ node: nodes.NodeNG, exception: type[Exception] | str = Exception
+) -> Iterator[nodes.With]:
+ """Return the contextlib suppressors handling the exception.
+
+ Args:
+ node (nodes.NodeNG): A node that is potentially wrapped in a contextlib.suppress.
+ exception (builtin.Exception): exception or name of the exception.
+
+ Yields:
+ nodes.With: A with node that is suppressing the exception.
+ """
+ for with_node in get_contextlib_with_statements(node):
+ for item, _ in with_node.items:
+ if isinstance(item, nodes.Call):
+ inferred = safe_infer(item.func)
+ if (
+ isinstance(inferred, nodes.ClassDef)
+ and inferred.qname() == "contextlib.suppress"
+ ):
+ if _suppresses_exception(item, exception):
+ yield with_node
+
+
+def is_node_inside_try_except(node: nodes.Raise) -> bool:
+ """Check if the node is directly under a Try/Except statement
+ (but not under an ExceptHandler!).
+
+ Args:
+ node (nodes.Raise): the node raising the exception.
+
+ Returns:
+ bool: True if the node is inside a try/except statement, False otherwise.
+ """
+ context = find_try_except_wrapper_node(node)
+ return isinstance(context, nodes.Try)
+
+
+def node_ignores_exception(
+ node: nodes.NodeNG, exception: type[Exception] | str = Exception
+) -> bool:
+ """Check if the node is in a Try which handles the given exception.
+
+ If the exception is not given, the function is going to look for bare
+ excepts.
+ """
+ managing_handlers = get_exception_handlers(node, exception)
+ if managing_handlers:
+ return True
+ return any(get_contextlib_suppressors(node, exception))
+
+
+@lru_cache(maxsize=1024)
+def class_is_abstract(node: nodes.ClassDef) -> bool:
+ """Return true if the given class node should be considered as an abstract
+ class.
+ """
+ # Protocol classes are considered "abstract"
+ if is_protocol_class(node):
+ return True
+
+ # Only check for explicit metaclass=ABCMeta on this specific class
+ meta = node.declared_metaclass()
+ if meta is not None:
+ if meta.name == "ABCMeta" and meta.root().name in ABC_MODULES:
+ return True
+
+ for ancestor in node.ancestors():
+ if ancestor.name == "ABC" and ancestor.root().name in ABC_MODULES:
+ # abc.ABC inheritance
+ return True
+
+ for method in node.methods():
+ if method.parent.frame() is node:
+ if method.is_abstract(pass_is_abstract=False):
+ return True
+ return False
+
+
+def _supports_protocol_method(value: nodes.NodeNG, attr: str) -> bool:
+ try:
+ attributes = value.getattr(attr)
+ except astroid.NotFoundError:
+ return False
+
+ first = attributes[0]
+
+ # Return False if a constant is assigned
+ if isinstance(first, nodes.AssignName):
+ this_assign_parent = get_node_first_ancestor_of_type(
+ first, (nodes.Assign, nodes.NamedExpr)
+ )
+ if this_assign_parent is None: # pragma: no cover
+ # Cannot imagine this being None, but return True to avoid false positives
+ return True
+ if isinstance(this_assign_parent.value, nodes.BaseContainer):
+ if all(isinstance(n, nodes.Const) for n in this_assign_parent.value.elts):
+ return False
+ if isinstance(this_assign_parent.value, nodes.Const):
+ return False
+ return True
+
+
+def is_comprehension(node: nodes.NodeNG) -> bool:
+ comprehensions = (
+ nodes.ListComp,
+ nodes.SetComp,
+ nodes.DictComp,
+ nodes.GeneratorExp,
+ )
+ return isinstance(node, comprehensions)
+
+
+def _supports_mapping_protocol(value: nodes.NodeNG) -> bool:
+ return _supports_protocol_method(
+ value, GETITEM_METHOD
+ ) and _supports_protocol_method(value, KEYS_METHOD)
+
+
+def _supports_membership_test_protocol(value: nodes.NodeNG) -> bool:
+ return _supports_protocol_method(value, CONTAINS_METHOD)
+
+
+def _supports_iteration_protocol(value: nodes.NodeNG) -> bool:
+ return _supports_protocol_method(value, ITER_METHOD) or _supports_protocol_method(
+ value, GETITEM_METHOD
+ )
+
+
+def _supports_async_iteration_protocol(value: nodes.NodeNG) -> bool:
+ return _supports_protocol_method(value, AITER_METHOD)
+
+
+def _supports_getitem_protocol(value: nodes.NodeNG) -> bool:
+ return _supports_protocol_method(value, GETITEM_METHOD)
+
+
+def _supports_setitem_protocol(value: nodes.NodeNG) -> bool:
+ return _supports_protocol_method(value, SETITEM_METHOD)
+
+
+def _supports_delitem_protocol(value: nodes.NodeNG) -> bool:
+ return _supports_protocol_method(value, DELITEM_METHOD)
+
+
+def _is_abstract_class_name(name: str) -> bool:
+ lname = name.lower()
+ is_mixin = lname.endswith("mixin")
+ is_abstract = lname.startswith("abstract")
+ is_base = lname.startswith("base") or lname.endswith("base")
+ return is_mixin or is_abstract or is_base
+
+
+def is_inside_abstract_class(node: nodes.NodeNG) -> bool:
+ while node is not None:
+ if isinstance(node, nodes.ClassDef):
+ if class_is_abstract(node):
+ return True
+ name = getattr(node, "name", None)
+ if name is not None and _is_abstract_class_name(name):
+ return True
+ node = node.parent
+ return False
+
+
+def _supports_protocol(
+ value: nodes.NodeNG, protocol_callback: Callable[[nodes.NodeNG], bool]
+) -> bool:
+ if isinstance(value, nodes.ClassDef):
+ if not has_known_bases(value):
+ return True
+ # classobj can only be iterable if it has an iterable metaclass
+ meta = value.metaclass()
+ if meta is not None:
+ if protocol_callback(meta):
+ return True
+ if isinstance(value, astroid.BaseInstance):
+ if not has_known_bases(value):
+ return True
+ if value.has_dynamic_getattr():
+ return True
+ if protocol_callback(value):
+ return True
+
+ if isinstance(value, nodes.ComprehensionScope):
+ return True
+
+ if (
+ isinstance(value, astroid.bases.Proxy)
+ and isinstance(value._proxied, astroid.BaseInstance)
+ and has_known_bases(value._proxied)
+ ):
+ value = value._proxied
+ return protocol_callback(value)
+
+ return False
+
+
+def is_iterable(value: nodes.NodeNG, check_async: bool = False) -> bool:
+ if check_async:
+ protocol_check = _supports_async_iteration_protocol
+ else:
+ protocol_check = _supports_iteration_protocol
+ return _supports_protocol(value, protocol_check)
+
+
+def is_mapping(value: nodes.NodeNG) -> bool:
+ return _supports_protocol(value, _supports_mapping_protocol)
+
+
+def supports_membership_test(value: nodes.NodeNG) -> bool:
+ supported = _supports_protocol(value, _supports_membership_test_protocol)
+ return supported or is_iterable(value)
+
+
+def supports_getitem(value: nodes.NodeNG, node: nodes.NodeNG) -> bool:
+ if isinstance(value, nodes.ClassDef):
+ if _supports_protocol_method(value, CLASS_GETITEM_METHOD):
+ return True
+ if is_postponed_evaluation_enabled(node) and is_node_in_type_annotation_context(
+ node
+ ):
+ return True
+ return _supports_protocol(value, _supports_getitem_protocol)
+
+
+def supports_setitem(value: nodes.NodeNG, _: nodes.NodeNG) -> bool:
+ return _supports_protocol(value, _supports_setitem_protocol)
+
+
+def supports_delitem(value: nodes.NodeNG, _: nodes.NodeNG) -> bool:
+ return _supports_protocol(value, _supports_delitem_protocol)
+
+
+def _get_python_type_of_node(node: nodes.NodeNG) -> str | None:
+ pytype: Callable[[], str] | None = getattr(node, "pytype", None)
+ if callable(pytype):
+ return pytype()
+ return None
+
+
+@lru_cache(maxsize=1024)
+def safe_infer(
+ node: nodes.NodeNG,
+ context: InferenceContext | None = None,
+ *,
+ compare_constants: bool = False,
+ compare_constructors: bool = False,
+) -> InferenceResult | None:
+ """Return the inferred value for the given node.
+
+ Return None if inference failed or if there is some ambiguity (more than
+ one node has been inferred of different types).
+
+ If compare_constants is True and if multiple constants are inferred,
+ unequal inferred values are also considered ambiguous and return None.
+
+ If compare_constructors is True and if multiple classes are inferred,
+ constructors with different signatures are held ambiguous and return None.
+ """
+ inferred_types: set[str | None] = set()
+ try:
+ infer_gen = node.infer(context=context)
+ value = next(infer_gen)
+ except astroid.InferenceError:
+ return None
+ except Exception as e: # pragma: no cover
+ raise AstroidError from e
+
+ if not isinstance(value, util.UninferableBase):
+ inferred_types.add(_get_python_type_of_node(value))
+
+ # pylint: disable = too-many-try-statements
+ try:
+ for inferred in infer_gen:
+ inferred_type = _get_python_type_of_node(inferred)
+ if inferred_type not in inferred_types:
+ return None # If there is ambiguity on the inferred node.
+ if (
+ compare_constants
+ and isinstance(inferred, nodes.Const)
+ and isinstance(value, nodes.Const)
+ and inferred.value != value.value
+ ):
+ return None
+ if (
+ isinstance(inferred, nodes.FunctionDef)
+ and isinstance(value, nodes.FunctionDef)
+ and function_arguments_are_ambiguous(inferred, value)
+ ):
+ return None
+ if (
+ compare_constructors
+ and isinstance(inferred, nodes.ClassDef)
+ and isinstance(value, nodes.ClassDef)
+ and class_constructors_are_ambiguous(inferred, value)
+ ):
+ return None
+ except astroid.InferenceError:
+ return None # There is some kind of ambiguity
+ except StopIteration:
+ return value
+ except Exception as e: # pragma: no cover
+ raise AstroidError from e
+ return value if len(inferred_types) <= 1 else None
+
+
+@lru_cache(maxsize=512)
+def infer_all(
+ node: nodes.NodeNG, context: InferenceContext | None = None
+) -> list[InferenceResult]:
+ try:
+ return list(node.infer(context=context))
+ except astroid.InferenceError:
+ return []
+ except Exception as e: # pragma: no cover
+ raise AstroidError from e
+
+
+def function_arguments_are_ambiguous(
+ func1: nodes.FunctionDef, func2: nodes.FunctionDef
+) -> bool:
+ if func1.argnames() != func2.argnames():
+ return True
+ # Check ambiguity among function default values
+ pairs_of_defaults = [
+ (func1.args.defaults, func2.args.defaults),
+ (func1.args.kw_defaults, func2.args.kw_defaults),
+ ]
+ for zippable_default in pairs_of_defaults:
+ if None in zippable_default:
+ continue
+ if len(zippable_default[0]) != len(zippable_default[1]):
+ return True
+ for default1, default2 in zip(*zippable_default):
+ if isinstance(default1, nodes.Const) and isinstance(default2, nodes.Const):
+ if default1.value != default2.value:
+ return True
+ elif isinstance(default1, nodes.Name) and isinstance(default2, nodes.Name):
+ if default1.name != default2.name:
+ return True
+ else:
+ return True
+ return False
+
+
+def class_constructors_are_ambiguous(
+ class1: nodes.ClassDef, class2: nodes.ClassDef
+) -> bool:
+ try:
+ constructor1 = class1.local_attr("__init__")[0]
+ constructor2 = class2.local_attr("__init__")[0]
+ except astroid.NotFoundError:
+ return False
+ if not isinstance(constructor1, nodes.FunctionDef):
+ return False
+ if not isinstance(constructor2, nodes.FunctionDef):
+ return False
+ return function_arguments_are_ambiguous(constructor1, constructor2)
+
+
+def has_known_bases(
+ klass: nodes.ClassDef, context: InferenceContext | None = None
+) -> bool:
+ """Return true if all base classes of a class could be inferred."""
+ try:
+ return klass._all_bases_known # type: ignore[no-any-return]
+ except AttributeError:
+ pass
+ for base in klass.bases:
+ result = safe_infer(base, context=context)
+ if (
+ not isinstance(result, nodes.ClassDef)
+ or result is klass
+ or not has_known_bases(result, context=context)
+ ):
+ klass._all_bases_known = False
+ return False
+ klass._all_bases_known = True
+ return True
+
+
+def is_none(node: nodes.NodeNG) -> bool:
+ return (
+ node is None
+ or (isinstance(node, nodes.Const) and node.value is None)
+ or (isinstance(node, nodes.Name) and node.name == "None")
+ )
+
+
+def node_type(node: nodes.NodeNG) -> SuccessfulInferenceResult | None:
+ """Return the inferred type for `node`.
+
+ If there is more than one possible type, or if inferred type is Uninferable or None,
+ return None
+ """
+ # check there is only one possible type for the assign node. Else we
+ # don't handle it for now
+ types: set[SuccessfulInferenceResult] = set()
+ try:
+ for var_type in node.infer():
+ if isinstance(var_type, util.UninferableBase) or is_none(var_type):
+ continue
+ types.add(var_type)
+ if len(types) > 1:
+ return None
+ except astroid.InferenceError:
+ return None
+ return types.pop() if types else None
+
+
+def is_registered_in_singledispatch_function(node: nodes.FunctionDef) -> bool:
+ """Check if the given function node is a singledispatch function."""
+ singledispatch_qnames = (
+ "functools.singledispatch",
+ "singledispatch.singledispatch",
+ )
+
+ if not isinstance(node, nodes.FunctionDef):
+ return False
+
+ decorators = node.decorators.nodes if node.decorators else []
+ for decorator in decorators:
+ # func.register are function calls or register attributes
+ # when the function is annotated with types
+ if isinstance(decorator, nodes.Call):
+ func = decorator.func
+ elif isinstance(decorator, nodes.Attribute):
+ func = decorator
+ else:
+ continue
+
+ if not isinstance(func, nodes.Attribute) or func.attrname != "register":
+ continue
+
+ try:
+ func_def = next(func.expr.infer())
+ except astroid.InferenceError:
+ continue
+
+ if isinstance(func_def, nodes.FunctionDef):
+ return decorated_with(func_def, singledispatch_qnames)
+
+ return False
+
+
+def find_inferred_fn_from_register(node: nodes.NodeNG) -> nodes.FunctionDef | None:
+ # func.register are function calls or register attributes
+ # when the function is annotated with types
+ if isinstance(node, nodes.Call):
+ func = node.func
+ elif isinstance(node, nodes.Attribute):
+ func = node
+ else:
+ return None
+
+ if not isinstance(func, nodes.Attribute) or func.attrname != "register":
+ return None
+
+ func_def = safe_infer(func.expr)
+ if not isinstance(func_def, nodes.FunctionDef):
+ return None
+
+ return func_def
+
+
+def is_registered_in_singledispatchmethod_function(node: nodes.FunctionDef) -> bool:
+ """Check if the given function node is a singledispatchmethod function."""
+ singledispatchmethod_qnames = (
+ "functools.singledispatchmethod",
+ "singledispatch.singledispatchmethod",
+ )
+
+ decorators = node.decorators.nodes if node.decorators else []
+ for decorator in decorators:
+ func_def = find_inferred_fn_from_register(decorator)
+ if func_def:
+ return decorated_with(func_def, singledispatchmethod_qnames)
+
+ return False
+
+
+def get_node_last_lineno(node: nodes.NodeNG) -> int:
+ """Get the last lineno of the given node.
+
+ For a simple statement this will just be node.lineno,
+ but for a node that has child statements (e.g. a method) this will be the lineno of the last
+ child statement recursively.
+ """
+ # 'finalbody' is always the last clause in a try statement, if present
+ if getattr(node, "finalbody", False):
+ return get_node_last_lineno(node.finalbody[-1])
+ # For if, while, and for statements 'orelse' is always the last clause.
+ # For try statements 'orelse' is the last in the absence of a 'finalbody'
+ if getattr(node, "orelse", False):
+ return get_node_last_lineno(node.orelse[-1])
+ # try statements have the 'handlers' last if there is no 'orelse' or 'finalbody'
+ if getattr(node, "handlers", False):
+ return get_node_last_lineno(node.handlers[-1])
+ # All compound statements have a 'body'
+ if getattr(node, "body", False):
+ return get_node_last_lineno(node.body[-1])
+ # Not a compound statement
+ return node.lineno # type: ignore[no-any-return]
+
+
+def is_postponed_evaluation_enabled(node: nodes.NodeNG) -> bool:
+ """Check if the postponed evaluation of annotations is enabled."""
+ module = node.root()
+ return "annotations" in module.future_imports
+
+
+def is_node_in_type_annotation_context(node: nodes.NodeNG) -> bool:
+ """Check if node is in type annotation context.
+
+ Check for 'AnnAssign', function 'Arguments',
+ or part of function return type annotation.
+ """
+ # pylint: disable=too-many-boolean-expressions
+ current_node, parent_node = node, node.parent
+ while True:
+ if (
+ isinstance(parent_node, nodes.AnnAssign)
+ and parent_node.annotation == current_node
+ or isinstance(parent_node, nodes.Arguments)
+ and current_node
+ in (
+ *parent_node.annotations,
+ *parent_node.posonlyargs_annotations,
+ *parent_node.kwonlyargs_annotations,
+ parent_node.varargannotation,
+ parent_node.kwargannotation,
+ )
+ or isinstance(parent_node, nodes.FunctionDef)
+ and parent_node.returns == current_node
+ ):
+ return True
+ current_node, parent_node = parent_node, parent_node.parent
+ if isinstance(parent_node, nodes.Module):
+ return False
+
+
+def is_subclass_of(child: nodes.ClassDef, parent: nodes.ClassDef) -> bool:
+ """Check if first node is a subclass of second node.
+
+ :param child: Node to check for subclass.
+ :param parent: Node to check for superclass.
+ :returns: True if child is derived from parent. False otherwise.
+ """
+ if not all(isinstance(node, nodes.ClassDef) for node in (child, parent)):
+ return False
+
+ for ancestor in child.ancestors():
+ try:
+ if astroid.helpers.is_subtype(ancestor, parent):
+ return True
+ except astroid.exceptions._NonDeducibleTypeHierarchy:
+ continue
+ return False
+
+
+@lru_cache(maxsize=1024)
+def is_overload_stub(node: nodes.NodeNG) -> bool:
+ """Check if a node is a function stub decorated with typing.overload.
+
+ :param node: Node to check.
+ :returns: True if node is an overload function stub. False otherwise.
+ """
+ decorators = getattr(node, "decorators", None)
+ return bool(decorators and decorated_with(node, ["typing.overload", "overload"]))
+
+
+def is_protocol_class(cls: nodes.NodeNG) -> bool:
+ """Check if the given node represents a protocol class.
+
+ :param cls: The node to check
+ :returns: True if the node is or inherits from typing.Protocol directly, false otherwise.
+ """
+ if not isinstance(cls, nodes.ClassDef):
+ return False
+
+ # Return if klass is protocol
+ if cls.qname() in TYPING_PROTOCOLS:
+ return True
+
+ for base in cls.bases:
+ try:
+ for inf_base in base.infer():
+ if inf_base.qname() in TYPING_PROTOCOLS:
+ return True
+ except astroid.InferenceError:
+ continue
+ return False
+
+
+def is_call_of_name(node: nodes.NodeNG, name: str) -> bool:
+ """Checks if node is a function call with the given name."""
+ return (
+ isinstance(node, nodes.Call)
+ and isinstance(node.func, nodes.Name)
+ and node.func.name == name
+ )
+
+
+def is_test_condition(
+ node: nodes.NodeNG,
+ parent: nodes.NodeNG | None = None,
+) -> bool:
+ """Returns true if the given node is being tested for truthiness."""
+ parent = parent or node.parent
+ if isinstance(parent, (nodes.While, nodes.If, nodes.IfExp, nodes.Assert)):
+ return node is parent.test or parent.test.parent_of(node)
+ if isinstance(parent, nodes.Comprehension):
+ return node in parent.ifs
+ return is_call_of_name(parent, "bool") and parent.parent_of(node)
+
+
+def is_classdef_type(node: nodes.ClassDef) -> bool:
+ """Test if ClassDef node is Type."""
+ if node.name == "type":
+ return True
+ return any(isinstance(b, nodes.Name) and b.name == "type" for b in node.bases)
+
+
+def is_attribute_typed_annotation(
+ node: nodes.ClassDef | astroid.Instance, attr_name: str
+) -> bool:
+ """Test if attribute is typed annotation in current node
+ or any base nodes.
+ """
+ attribute = node.locals.get(attr_name, [None])[0]
+ if (
+ attribute
+ and isinstance(attribute, nodes.AssignName)
+ and isinstance(attribute.parent, nodes.AnnAssign)
+ ):
+ return True
+ for base in node.bases:
+ inferred = safe_infer(base)
+ if (
+ inferred
+ and isinstance(inferred, nodes.ClassDef)
+ and is_attribute_typed_annotation(inferred, attr_name)
+ ):
+ return True
+ return False
+
+
+def is_enum(node: nodes.ClassDef) -> bool:
+ return node.name == "Enum" and node.root().name == "enum" # type: ignore[no-any-return]
+
+
+def is_assign_name_annotated_with(node: nodes.AssignName, typing_name: str) -> bool:
+ """Test if AssignName node has `typing_name` annotation.
+
+ Especially useful to check for `typing._SpecialForm` instances
+ like: `Union`, `Optional`, `Literal`, `ClassVar`, `Final`.
+ """
+ if not isinstance(node.parent, nodes.AnnAssign):
+ return False
+ annotation = node.parent.annotation
+ if isinstance(annotation, nodes.Subscript):
+ annotation = annotation.value
+ if (
+ isinstance(annotation, nodes.Name)
+ and annotation.name == typing_name
+ or isinstance(annotation, nodes.Attribute)
+ and annotation.attrname == typing_name
+ ):
+ return True
+ return False
+
+
+def get_iterating_dictionary_name(node: nodes.For | nodes.Comprehension) -> str | None:
+ """Get the name of the dictionary which keys are being iterated over on
+ a ``nodes.For`` or ``nodes.Comprehension`` node.
+
+ If the iterating object is not either the keys method of a dictionary
+ or a dictionary itself, this returns None.
+ """
+ # Is it a proper keys call?
+ if (
+ isinstance(node.iter, nodes.Call)
+ and isinstance(node.iter.func, nodes.Attribute)
+ and node.iter.func.attrname == "keys"
+ ):
+ inferred = safe_infer(node.iter.func)
+ if not isinstance(inferred, astroid.BoundMethod):
+ return None
+ return node.iter.as_string().rpartition(".keys")[0] # type: ignore[no-any-return]
+
+ # Is it a dictionary?
+ if isinstance(node.iter, (nodes.Name, nodes.Attribute)):
+ inferred = safe_infer(node.iter)
+ if not isinstance(inferred, nodes.Dict):
+ return None
+ return node.iter.as_string() # type: ignore[no-any-return]
+
+ return None
+
+
+def get_subscript_const_value(node: nodes.Subscript) -> nodes.Const:
+ """Returns the value 'subscript.slice' of a Subscript node.
+
+ :param node: Subscript Node to extract value from
+ :returns: Const Node containing subscript value
+ :raises InferredTypeError: if the subscript node cannot be inferred as a Const
+ """
+ inferred = safe_infer(node.slice)
+ if not isinstance(inferred, nodes.Const):
+ raise InferredTypeError("Subscript.slice cannot be inferred as a nodes.Const")
+
+ return inferred
+
+
+def get_import_name(importnode: ImportNode, modname: str | None) -> str | None:
+ """Get a prepared module name from the given import node.
+
+ In the case of relative imports, this will return the
+ absolute qualified module name, which might be useful
+ for debugging. Otherwise, the initial module name
+ is returned unchanged.
+
+ :param importnode: node representing import statement.
+ :param modname: module name from import statement.
+ :returns: absolute qualified module name of the module
+ used in import.
+ """
+ if isinstance(importnode, nodes.ImportFrom) and importnode.level:
+ root = importnode.root()
+ if isinstance(root, nodes.Module):
+ try:
+ return root.relative_to_absolute_name( # type: ignore[no-any-return]
+ modname, level=importnode.level
+ )
+ except TooManyLevelsError:
+ return modname
+ return modname
+
+
+def is_sys_guard(node: nodes.If) -> bool:
+ """Return True if IF stmt is a sys.version_info guard.
+
+ >>> import sys
+ >>> from typing import Literal
+ """
+ if isinstance(node.test, nodes.Compare):
+ value = node.test.left
+ if isinstance(value, nodes.Subscript):
+ value = value.value
+ if (
+ isinstance(value, nodes.Attribute)
+ and value.as_string() == "sys.version_info"
+ ):
+ return True
+ elif isinstance(node.test, nodes.Attribute) and node.test.as_string() in {
+ "six.PY2",
+ "six.PY3",
+ }:
+ return True
+ return False
+
+
+def is_reassigned_after_current(node: nodes.NodeNG, varname: str) -> bool:
+ """Check if the given variable name is reassigned in the same scope after the
+ current node.
+ """
+ return any(
+ a.name == varname and a.lineno > node.lineno
+ for a in node.scope().nodes_of_class(
+ (nodes.AssignName, nodes.ClassDef, nodes.FunctionDef)
+ )
+ )
+
+
+def is_deleted_after_current(node: nodes.NodeNG, varname: str) -> bool:
+ """Check if the given variable name is deleted in the same scope after the current
+ node.
+ """
+ return any(
+ getattr(target, "name", None) == varname and target.lineno > node.lineno
+ for del_node in node.scope().nodes_of_class(nodes.Delete)
+ for target in del_node.targets
+ )
+
+
+def is_function_body_ellipsis(node: nodes.FunctionDef) -> bool:
+ """Checks whether a function body only consists of a single Ellipsis."""
+ return (
+ len(node.body) == 1
+ and isinstance(node.body[0], nodes.Expr)
+ and isinstance(node.body[0].value, nodes.Const)
+ and node.body[0].value.value == Ellipsis
+ )
+
+
+def is_base_container(node: nodes.NodeNG | None) -> bool:
+ return isinstance(node, nodes.BaseContainer) and not node.elts
+
+
+def is_empty_dict_literal(node: nodes.NodeNG | None) -> bool:
+ return isinstance(node, nodes.Dict) and not node.items
+
+
+def is_empty_str_literal(node: nodes.NodeNG | None) -> bool:
+ return (
+ isinstance(node, nodes.Const) and isinstance(node.value, str) and not node.value
+ )
+
+
+def returns_bool(node: nodes.NodeNG) -> bool:
+ """Returns true if a node is a nodes.Return that returns a constant boolean."""
+ return (
+ isinstance(node, nodes.Return)
+ and isinstance(node.value, nodes.Const)
+ and isinstance(node.value.value, bool)
+ )
+
+
+def assigned_bool(node: nodes.NodeNG) -> bool:
+ """Returns true if a node is a nodes.Assign that returns a constant boolean."""
+ return (
+ isinstance(node, nodes.Assign)
+ and isinstance(node.value, nodes.Const)
+ and isinstance(node.value.value, bool)
+ )
+
+
+def get_node_first_ancestor_of_type(
+ node: nodes.NodeNG, ancestor_type: type[_NodeT] | tuple[type[_NodeT], ...]
+) -> _NodeT | None:
+ """Return the first parent node that is any of the provided types (or None)."""
+ for ancestor in node.node_ancestors():
+ if isinstance(ancestor, ancestor_type):
+ return ancestor # type: ignore[no-any-return]
+ return None
+
+
+def get_node_first_ancestor_of_type_and_its_child(
+ node: nodes.NodeNG, ancestor_type: type[_NodeT] | tuple[type[_NodeT], ...]
+) -> tuple[None, None] | tuple[_NodeT, nodes.NodeNG]:
+ """Modified version of get_node_first_ancestor_of_type to also return the
+ descendant visited directly before reaching the sought ancestor.
+
+ Useful for extracting whether a statement is guarded by a try, except, or finally
+ when searching for a Try ancestor.
+ """
+ child = node
+ for ancestor in node.node_ancestors():
+ if isinstance(ancestor, ancestor_type):
+ return (ancestor, child)
+ child = ancestor
+ return None, None
+
+
+def in_type_checking_block(node: nodes.NodeNG) -> bool:
+ """Check if a node is guarded by a TYPE_CHECKING guard."""
+ for ancestor in node.node_ancestors():
+ if not isinstance(ancestor, nodes.If):
+ continue
+ if isinstance(ancestor.test, nodes.Name):
+ if ancestor.test.name != "TYPE_CHECKING":
+ continue
+ lookup_result = ancestor.test.lookup(ancestor.test.name)[1]
+ if not lookup_result:
+ return False
+ maybe_import_from = lookup_result[0]
+ if (
+ isinstance(maybe_import_from, nodes.ImportFrom)
+ and maybe_import_from.modname == "typing"
+ ):
+ return True
+ inferred = safe_infer(ancestor.test)
+ if isinstance(inferred, nodes.Const) and inferred.value is False:
+ return True
+ elif isinstance(ancestor.test, nodes.Attribute):
+ if ancestor.test.attrname != "TYPE_CHECKING":
+ continue
+ inferred_module = safe_infer(ancestor.test.expr)
+ if (
+ isinstance(inferred_module, nodes.Module)
+ and inferred_module.name == "typing"
+ ):
+ return True
+
+ return False
+
+
+def is_typing_member(node: nodes.NodeNG, names_to_check: tuple[str, ...]) -> bool:
+ """Check if `node` is a member of the `typing` module and has one of the names from
+ `names_to_check`.
+ """
+ if isinstance(node, nodes.Name):
+ try:
+ import_from = node.lookup(node.name)[1][0]
+ except IndexError:
+ return False
+
+ if isinstance(import_from, nodes.ImportFrom):
+ return (
+ import_from.modname == "typing"
+ and import_from.real_name(node.name) in names_to_check
+ )
+ elif isinstance(node, nodes.Attribute):
+ inferred_module = safe_infer(node.expr)
+ return (
+ isinstance(inferred_module, nodes.Module)
+ and inferred_module.name == "typing"
+ and node.attrname in names_to_check
+ )
+ return False
+
+
+@lru_cache
+def in_for_else_branch(parent: nodes.NodeNG, stmt: Statement) -> bool:
+ """Returns True if stmt is inside the else branch for a parent For stmt."""
+ return isinstance(parent, nodes.For) and any(
+ else_stmt.parent_of(stmt) or else_stmt == stmt for else_stmt in parent.orelse
+ )
+
+
+def find_assigned_names_recursive(
+ target: nodes.AssignName | nodes.BaseContainer,
+) -> Iterator[str]:
+ """Yield the names of assignment targets, accounting for nested ones."""
+ if isinstance(target, nodes.AssignName):
+ if target.name is not None:
+ yield target.name
+ elif isinstance(target, nodes.BaseContainer):
+ for elt in target.elts:
+ yield from find_assigned_names_recursive(elt)
+
+
+def has_starred_node_recursive(
+ node: nodes.For | nodes.Comprehension | nodes.Set,
+) -> Iterator[bool]:
+ """Yield ``True`` if a Starred node is found recursively."""
+ if isinstance(node, nodes.Starred):
+ yield True
+ elif isinstance(node, nodes.Set):
+ for elt in node.elts:
+ yield from has_starred_node_recursive(elt)
+ elif isinstance(node, (nodes.For, nodes.Comprehension)):
+ for elt in node.iter.elts:
+ yield from has_starred_node_recursive(elt)
+
+
+def is_hashable(node: nodes.NodeNG) -> bool:
+ """Return whether any inferred value of `node` is hashable.
+
+ When finding ambiguity, return True.
+ """
+ # pylint: disable = too-many-try-statements
+ try:
+ for inferred in node.infer():
+ if isinstance(inferred, (nodes.ClassDef, util.UninferableBase)):
+ return True
+ if not hasattr(inferred, "igetattr"):
+ return True
+ hash_fn = next(inferred.igetattr("__hash__"))
+ if hash_fn.parent is inferred:
+ return True
+ if getattr(hash_fn, "value", True) is not None:
+ return True
+ return False
+ except astroid.InferenceError:
+ return True
+
+
+def subscript_chain_is_equal(left: nodes.Subscript, right: nodes.Subscript) -> bool:
+ while isinstance(left, nodes.Subscript) and isinstance(right, nodes.Subscript):
+ try:
+ if (
+ get_subscript_const_value(left).value
+ != get_subscript_const_value(right).value
+ ):
+ return False
+
+ left = left.value
+ right = right.value
+ except InferredTypeError:
+ return False
+
+ return left.as_string() == right.as_string() # type: ignore[no-any-return]
+
+
+def _is_target_name_in_binop_side(
+ target: nodes.AssignName | nodes.AssignAttr, side: nodes.NodeNG | None
+) -> bool:
+ """Determine whether the target name-like node is referenced in the side node."""
+ if isinstance(side, nodes.Name):
+ if isinstance(target, nodes.AssignName):
+ return target.name == side.name # type: ignore[no-any-return]
+ return False
+ if isinstance(side, nodes.Attribute) and isinstance(target, nodes.AssignAttr):
+ return target.as_string() == side.as_string() # type: ignore[no-any-return]
+ if isinstance(side, nodes.Subscript) and isinstance(target, nodes.Subscript):
+ return subscript_chain_is_equal(target, side)
+
+ return False
+
+
+def is_augmented_assign(node: nodes.Assign) -> tuple[bool, str]:
+ """Determine if the node is assigning itself (with modifications) to itself.
+
+ For example: x = 1 + x
+ """
+ if not isinstance(node.value, nodes.BinOp):
+ return False, ""
+
+ binop = node.value
+ target = node.targets[0]
+
+ if not isinstance(target, (nodes.AssignName, nodes.AssignAttr, nodes.Subscript)):
+ return False, ""
+
+ # We don't want to catch x = "1" + x or x = "%s" % x
+ if isinstance(binop.left, nodes.Const) and isinstance(
+ binop.left.value, (str, bytes)
+ ):
+ return False, ""
+
+ # This could probably be improved but for now we disregard all assignments from calls
+ if isinstance(binop.left, nodes.Call) or isinstance(binop.right, nodes.Call):
+ return False, ""
+
+ if _is_target_name_in_binop_side(target, binop.left):
+ return True, binop.op
+ if (
+ # Unless an operator is commutative, we should not raise (i.e. x = 3/x)
+ binop.op in COMMUTATIVE_OPERATORS
+ and _is_target_name_in_binop_side(target, binop.right)
+ ):
+ inferred_left = safe_infer(binop.left)
+ if isinstance(inferred_left, nodes.Const) and isinstance(
+ inferred_left.value, int
+ ):
+ return True, binop.op
+ return False, ""
+ return False, ""
+
+
+def _qualified_name_parts(qualified_module_name: str) -> list[str]:
+ """Split the names of the given module into subparts.
+
+ For example,
+ _qualified_name_parts('pylint.checkers.ImportsChecker')
+ returns
+ ['pylint', 'pylint.checkers', 'pylint.checkers.ImportsChecker']
+ """
+ names = qualified_module_name.split(".")
+ return [".".join(names[0 : i + 1]) for i in range(len(names))]
+
+
+def is_module_ignored(
+ qualified_module_name: str, ignored_modules: Iterable[str]
+) -> bool:
+ ignored_modules = set(ignored_modules)
+ for current_module in _qualified_name_parts(qualified_module_name):
+ # Try to match the module name directly
+ if current_module in ignored_modules:
+ return True
+ for ignore in ignored_modules:
+ # Try to see if the ignores pattern match against the module name.
+ if fnmatch.fnmatch(current_module, ignore):
+ return True
+ return False
+
+
+def is_singleton_const(node: nodes.NodeNG) -> bool:
+ return isinstance(node, nodes.Const) and any(
+ node.value is value for value in SINGLETON_VALUES
+ )
+
+
+def is_terminating_func(node: nodes.Call) -> bool:
+ """Detect call to exit(), quit(), os._exit(), sys.exit(), or
+ functions annotated with `typing.NoReturn` or `typing.Never`.
+ """
+ if (
+ not isinstance(node.func, nodes.Attribute)
+ and not (isinstance(node.func, nodes.Name))
+ or isinstance(node.parent, nodes.Lambda)
+ ):
+ return False
+
+ try:
+ for inferred in node.func.infer():
+ if (
+ hasattr(inferred, "qname")
+ and inferred.qname() in TERMINATING_FUNCS_QNAMES
+ ):
+ return True
+ # Unwrap to get the actual function node object
+ if isinstance(inferred, astroid.BoundMethod) and isinstance(
+ inferred._proxied, astroid.UnboundMethod
+ ):
+ inferred = inferred._proxied._proxied
+ if ( # pylint: disable=too-many-boolean-expressions
+ isinstance(inferred, nodes.FunctionDef)
+ and (
+ not isinstance(inferred, nodes.AsyncFunctionDef)
+ or isinstance(node.parent, nodes.Await)
+ )
+ and isinstance(inferred.returns, nodes.Name)
+ and (inferred_func := safe_infer(inferred.returns))
+ and hasattr(inferred_func, "qname")
+ and inferred_func.qname()
+ in (
+ *TYPING_NEVER,
+ *TYPING_NORETURN,
+ # In Python 3.7 - 3.8, NoReturn is alias of '_SpecialForm'
+ # "typing._SpecialForm",
+ # But 'typing.Any' also inherits _SpecialForm
+ # See #9751
+ )
+ ):
+ return True
+ except (StopIteration, astroid.InferenceError):
+ pass
+
+ return False
+
+
+def is_class_attr(name: str, klass: nodes.ClassDef) -> bool:
+ try:
+ klass.getattr(name)
+ return True
+ except astroid.NotFoundError:
+ return False
+
+
+def get_inverse_comparator(op: str) -> str:
+ """Returns the inverse comparator given a comparator.
+
+ E.g. when given "==", returns "!="
+
+ :param str op: the comparator to look up.
+
+ :returns: The inverse of the comparator in string format
+ :raises KeyError: if input is not recognized as a comparator
+ """
+ return {
+ "==": "!=",
+ "!=": "==",
+ "<": ">=",
+ ">": "<=",
+ "<=": ">",
+ ">=": "<",
+ "in": "not in",
+ "not in": "in",
+ "is": "is not",
+ "is not": "is",
+ }[op]
+
+
+def not_condition_as_string(
+ test_node: nodes.Compare | nodes.Name | nodes.UnaryOp | nodes.BoolOp | nodes.BinOp,
+) -> str:
+ msg = f"not {test_node.as_string()}"
+ if isinstance(test_node, nodes.UnaryOp):
+ msg = test_node.operand.as_string()
+ elif isinstance(test_node, nodes.BoolOp):
+ msg = f"not ({test_node.as_string()})"
+ elif isinstance(test_node, nodes.Compare):
+ lhs = test_node.left
+ ops, rhs = test_node.ops[0]
+ lower_priority_expressions = (
+ nodes.Lambda,
+ nodes.UnaryOp,
+ nodes.BoolOp,
+ nodes.IfExp,
+ nodes.NamedExpr,
+ )
+ lhs = (
+ f"({lhs.as_string()})"
+ if isinstance(lhs, lower_priority_expressions)
+ else lhs.as_string()
+ )
+ rhs = (
+ f"({rhs.as_string()})"
+ if isinstance(rhs, lower_priority_expressions)
+ else rhs.as_string()
+ )
+ msg = f"{lhs} {get_inverse_comparator(ops)} {rhs}"
+ return msg
+
+
+@lru_cache(maxsize=1000)
+def overridden_method(
+ klass: nodes.LocalsDictNodeNG, name: str | None
+) -> nodes.FunctionDef | None:
+ """Get overridden method if any."""
+ try:
+ parent = next(klass.local_attr_ancestors(name))
+ except (StopIteration, KeyError):
+ return None
+ try:
+ meth_node = parent[name]
+ except KeyError: # pragma: no cover
+ # We have found an ancestor defining <name> but it's not in the local
+ # dictionary. This may happen with astroid built from living objects.
+ return None
+ if isinstance(meth_node, nodes.FunctionDef):
+ return meth_node
+ return None # pragma: no cover
+
+
+def clear_lru_caches() -> None:
+ """Clear caches holding references to AST nodes."""
+ caches_holding_node_references: list[_lru_cache_wrapper[Any]] = [
+ class_is_abstract,
+ in_for_else_branch,
+ infer_all,
+ is_overload_stub,
+ overridden_method,
+ unimplemented_abstract_methods,
+ safe_infer,
+ ]
+ for lru in caches_holding_node_references:
+ lru.cache_clear()
+
+
+def is_enum_member(node: nodes.AssignName) -> bool:
+ """Return `True` if `node` is an Enum member (is an item of the
+ `__members__` container).
+ """
+ frame = node.frame()
+ if (
+ not isinstance(frame, nodes.ClassDef)
+ or not frame.is_subtype_of("enum.Enum")
+ or frame.root().qname() == "enum"
+ ):
+ return False
+
+ members = frame.locals.get("__members__")
+ # A dataclass is one known case for when `members` can be `None`
+ if members is None:
+ return False
+ return node.name in [name_obj.name for value, name_obj in members[0].items]
diff --git a/solutions/.venv/Lib/site-packages/pylint/checkers/variables.py b/solutions/.venv/Lib/site-packages/pylint/checkers/variables.py
new file mode 100644
index 000000000..35d6d7ce0
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/checkers/variables.py
@@ -0,0 +1,3441 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Variables checkers for Python code."""
+
+from __future__ import annotations
+
+import collections
+import copy
+import itertools
+import math
+import os
+import re
+from collections import defaultdict
+from collections.abc import Generator, Iterable, Iterator
+from enum import Enum
+from functools import cached_property
+from typing import TYPE_CHECKING, Any, NamedTuple
+
+import astroid
+import astroid.exceptions
+from astroid import bases, extract_node, nodes, util
+from astroid.nodes import _base_nodes
+from astroid.typing import InferenceResult
+
+from pylint.checkers import BaseChecker, utils
+from pylint.checkers.utils import (
+ in_type_checking_block,
+ is_module_ignored,
+ is_postponed_evaluation_enabled,
+ is_sys_guard,
+ overridden_method,
+)
+from pylint.constants import TYPING_NEVER, TYPING_NORETURN
+from pylint.interfaces import CONTROL_FLOW, HIGH, INFERENCE, INFERENCE_FAILURE
+from pylint.typing import MessageDefinitionTuple
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+SPECIAL_OBJ = re.compile("^_{2}[a-z]+_{2}$")
+FUTURE = "__future__"
+# regexp for ignored argument name
+IGNORED_ARGUMENT_NAMES = re.compile("_.*|^ignored_|^unused_")
+# In Python 3.7 abc has a Python implementation which is preferred
+# by astroid. Unfortunately this also messes up our explicit checks
+# for `abc`
+METACLASS_NAME_TRANSFORMS = {"_py_abc": "abc"}
+BUILTIN_RANGE = "builtins.range"
+TYPING_MODULE = "typing"
+TYPING_NAMES = frozenset(
+ {
+ "Any",
+ "Callable",
+ "ClassVar",
+ "Generic",
+ "Optional",
+ "Tuple",
+ "Type",
+ "TypeVar",
+ "Union",
+ "AbstractSet",
+ "ByteString",
+ "Container",
+ "ContextManager",
+ "Hashable",
+ "ItemsView",
+ "Iterable",
+ "Iterator",
+ "KeysView",
+ "Mapping",
+ "MappingView",
+ "MutableMapping",
+ "MutableSequence",
+ "MutableSet",
+ "Sequence",
+ "Sized",
+ "ValuesView",
+ "Awaitable",
+ "AsyncIterator",
+ "AsyncIterable",
+ "Coroutine",
+ "Collection",
+ "AsyncGenerator",
+ "AsyncContextManager",
+ "Reversible",
+ "SupportsAbs",
+ "SupportsBytes",
+ "SupportsComplex",
+ "SupportsFloat",
+ "SupportsInt",
+ "SupportsRound",
+ "Counter",
+ "Deque",
+ "Dict",
+ "DefaultDict",
+ "List",
+ "Set",
+ "FrozenSet",
+ "NamedTuple",
+ "Generator",
+ "AnyStr",
+ "Text",
+ "Pattern",
+ "BinaryIO",
+ }
+)
+
+DICT_TYPES = (
+ astroid.objects.DictValues,
+ astroid.objects.DictKeys,
+ astroid.objects.DictItems,
+ astroid.nodes.node_classes.Dict,
+)
+
+NODES_WITH_VALUE_ATTR = (
+ nodes.Assign,
+ nodes.AnnAssign,
+ nodes.AugAssign,
+ nodes.Expr,
+ nodes.Return,
+ nodes.Match,
+ nodes.TypeAlias,
+)
+
+
+class VariableVisitConsumerAction(Enum):
+ """Reported by _check_consumer() and its sub-methods to determine the
+ subsequent action to take in _undefined_and_used_before_checker().
+
+ Continue -> continue loop to next consumer
+ Return -> return and thereby break the loop
+ """
+
+ CONTINUE = 0
+ RETURN = 1
+
+
+def _is_from_future_import(stmt: nodes.ImportFrom, name: str) -> bool | None:
+ """Check if the name is a future import from another module."""
+ try:
+ module = stmt.do_import_module(stmt.modname)
+ except astroid.AstroidBuildingError:
+ return None
+
+ for local_node in module.locals.get(name, []):
+ if isinstance(local_node, nodes.ImportFrom) and local_node.modname == FUTURE:
+ return True
+ return None
+
+
+def _get_unpacking_extra_info(node: nodes.Assign, inferred: InferenceResult) -> str:
+ """Return extra information to add to the message for unpacking-non-sequence
+ and unbalanced-tuple/dict-unpacking errors.
+ """
+ more = ""
+ if isinstance(inferred, DICT_TYPES):
+ if isinstance(node, nodes.Assign):
+ more = node.value.as_string()
+ elif isinstance(node, nodes.For):
+ more = node.iter.as_string()
+ return more
+
+ inferred_module = inferred.root().name
+ if node.root().name == inferred_module:
+ if node.lineno == inferred.lineno:
+ more = f"'{inferred.as_string()}'"
+ elif inferred.lineno:
+ more = f"defined at line {inferred.lineno}"
+ elif inferred.lineno:
+ more = f"defined at line {inferred.lineno} of {inferred_module}"
+ return more
+
+
+def _detect_global_scope(
+ node: nodes.Name, frame: nodes.LocalsDictNodeNG, defframe: nodes.LocalsDictNodeNG
+) -> bool:
+ """Detect that the given frames share a global scope.
+
+ Two frames share a global scope when neither
+ of them are hidden under a function scope, as well
+ as any parent scope of them, until the root scope.
+ In this case, depending from something defined later on
+ will only work if guarded by a nested function definition.
+
+ Example:
+ class A:
+ # B has the same global scope as `C`, leading to a NameError.
+ # Return True to indicate a shared scope.
+ class B(C): ...
+ class C: ...
+
+ Whereas this does not lead to a NameError:
+ class A:
+ def guard():
+ # Return False to indicate no scope sharing.
+ class B(C): ...
+ class C: ...
+ """
+ def_scope = scope = None
+ if frame and frame.parent:
+ scope = frame.parent.scope()
+ if defframe and defframe.parent:
+ def_scope = defframe.parent.scope()
+ if (
+ isinstance(frame, nodes.ClassDef)
+ and scope is not def_scope
+ and scope is utils.get_node_first_ancestor_of_type(node, nodes.FunctionDef)
+ ):
+ # If the current node's scope is a class nested under a function,
+ # and the def_scope is something else, then they aren't shared.
+ return False
+ if isinstance(frame, nodes.FunctionDef):
+ # If the parent of the current node is a
+ # function, then it can be under its scope (defined in); or
+ # the `->` part of annotations. The same goes
+ # for annotations of function arguments, they'll have
+ # their parent the Arguments node.
+ if frame.parent_of(defframe):
+ return node.lineno < defframe.lineno # type: ignore[no-any-return]
+ if not isinstance(node.parent, (nodes.FunctionDef, nodes.Arguments)):
+ return False
+
+ break_scopes = []
+ for current_scope in (scope or frame, def_scope):
+ # Look for parent scopes. If there is anything different
+ # than a module or a class scope, then the frames don't
+ # share a global scope.
+ parent_scope = current_scope
+ while parent_scope:
+ if not isinstance(parent_scope, (nodes.ClassDef, nodes.Module)):
+ break_scopes.append(parent_scope)
+ break
+ if parent_scope.parent:
+ parent_scope = parent_scope.parent.scope()
+ else:
+ break
+ if len(set(break_scopes)) > 1:
+ # Store different scopes than expected.
+ # If the stored scopes are, in fact, the very same, then it means
+ # that the two frames (frame and defframe) share the same scope,
+ # and we could apply our lineno analysis over them.
+ # For instance, this works when they are inside a function, the node
+ # that uses a definition and the definition itself.
+ return False
+ # At this point, we are certain that frame and defframe share a scope
+ # and the definition of the first depends on the second.
+ return frame.lineno < defframe.lineno # type: ignore[no-any-return]
+
+
+def _infer_name_module(node: nodes.Import, name: str) -> Generator[InferenceResult]:
+ context = astroid.context.InferenceContext()
+ context.lookupname = name
+ return node.infer(context, asname=False) # type: ignore[no-any-return]
+
+
+def _fix_dot_imports(
+ not_consumed: dict[str, list[nodes.NodeNG]]
+) -> list[tuple[str, _base_nodes.ImportNode]]:
+ """Try to fix imports with multiple dots, by returning a dictionary
+ with the import names expanded.
+
+ The function unflattens root imports,
+ like 'xml' (when we have both 'xml.etree' and 'xml.sax'), to 'xml.etree'
+ and 'xml.sax' respectively.
+ """
+ names: dict[str, _base_nodes.ImportNode] = {}
+ for name, stmts in not_consumed.items():
+ if any(
+ isinstance(stmt, nodes.AssignName)
+ and isinstance(stmt.assign_type(), nodes.AugAssign)
+ for stmt in stmts
+ ):
+ continue
+ for stmt in stmts:
+ if not isinstance(stmt, (nodes.ImportFrom, nodes.Import)):
+ continue
+ for imports in stmt.names:
+ second_name = None
+ import_module_name = imports[0]
+ if import_module_name == "*":
+ # In case of wildcard imports,
+ # pick the name from inside the imported module.
+ second_name = name
+ else:
+ name_matches_dotted_import = False
+ if (
+ import_module_name.startswith(name)
+ and import_module_name.find(".") > -1
+ ):
+ name_matches_dotted_import = True
+
+ if name_matches_dotted_import or name in imports:
+ # Most likely something like 'xml.etree',
+ # which will appear in the .locals as 'xml'.
+ # Only pick the name if it wasn't consumed.
+ second_name = import_module_name
+ if second_name and second_name not in names:
+ names[second_name] = stmt
+ return sorted(names.items(), key=lambda a: a[1].fromlineno)
+
+
+def _find_frame_imports(name: str, frame: nodes.LocalsDictNodeNG) -> bool:
+ """Detect imports in the frame, with the required *name*.
+
+ Such imports can be considered assignments if they are not globals.
+ Returns True if an import for the given name was found.
+ """
+ if name in _flattened_scope_names(frame.nodes_of_class(nodes.Global)):
+ return False
+
+ imports = frame.nodes_of_class((nodes.Import, nodes.ImportFrom))
+ for import_node in imports:
+ for import_name, import_alias in import_node.names:
+ # If the import uses an alias, check only that.
+ # Otherwise, check only the import name.
+ if import_alias:
+ if import_alias == name:
+ return True
+ elif import_name and import_name == name:
+ return True
+ return False
+
+
+def _import_name_is_global(
+ stmt: nodes.Global | _base_nodes.ImportNode, global_names: set[str]
+) -> bool:
+ for import_name, import_alias in stmt.names:
+ # If the import uses an alias, check only that.
+ # Otherwise, check only the import name.
+ if import_alias:
+ if import_alias in global_names:
+ return True
+ elif import_name in global_names:
+ return True
+ return False
+
+
+def _flattened_scope_names(
+ iterator: Iterator[nodes.Global | nodes.Nonlocal],
+) -> set[str]:
+ values = (set(stmt.names) for stmt in iterator)
+ return set(itertools.chain.from_iterable(values))
+
+
+def _assigned_locally(name_node: nodes.Name) -> bool:
+ """Checks if name_node has corresponding assign statement in same scope."""
+ name_node_scope = name_node.scope()
+ assign_stmts = name_node_scope.nodes_of_class(nodes.AssignName)
+ return any(a.name == name_node.name for a in assign_stmts) or _find_frame_imports(
+ name_node.name, name_node_scope
+ )
+
+
+def _has_locals_call_after_node(stmt: nodes.NodeNG, scope: nodes.FunctionDef) -> bool:
+ skip_nodes = (
+ nodes.FunctionDef,
+ nodes.ClassDef,
+ nodes.Import,
+ nodes.ImportFrom,
+ )
+ for call in scope.nodes_of_class(nodes.Call, skip_klass=skip_nodes):
+ inferred = utils.safe_infer(call.func)
+ if (
+ utils.is_builtin_object(inferred)
+ and getattr(inferred, "name", None) == "locals"
+ ):
+ if stmt.lineno < call.lineno:
+ return True
+ return False
+
+
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "E0601": (
+ "Using variable %r before assignment",
+ "used-before-assignment",
+ "Emitted when a local variable is accessed before its assignment took place. "
+ "Assignments in try blocks are assumed not to have occurred when evaluating "
+ "associated except/finally blocks. Assignments in except blocks are assumed "
+ "not to have occurred when evaluating statements outside the block, except "
+ "when the associated try block contains a return statement.",
+ ),
+ "E0602": (
+ "Undefined variable %r",
+ "undefined-variable",
+ "Used when an undefined variable is accessed.",
+ ),
+ "E0603": (
+ "Undefined variable name %r in __all__",
+ "undefined-all-variable",
+ "Used when an undefined variable name is referenced in __all__.",
+ ),
+ "E0604": (
+ "Invalid object %r in __all__, must contain only strings",
+ "invalid-all-object",
+ "Used when an invalid (non-string) object occurs in __all__.",
+ ),
+ "E0605": (
+ "Invalid format for __all__, must be tuple or list",
+ "invalid-all-format",
+ "Used when __all__ has an invalid format.",
+ ),
+ "E0606": (
+ "Possibly using variable %r before assignment",
+ "possibly-used-before-assignment",
+ "Emitted when a local variable is accessed before its assignment took place "
+ "in both branches of an if/else switch.",
+ ),
+ "E0611": (
+ "No name %r in module %r",
+ "no-name-in-module",
+ "Used when a name cannot be found in a module.",
+ ),
+ "W0601": (
+ "Global variable %r undefined at the module level",
+ "global-variable-undefined",
+ 'Used when a variable is defined through the "global" statement '
+ "but the variable is not defined in the module scope.",
+ ),
+ "W0602": (
+ "Using global for %r but no assignment is done",
+ "global-variable-not-assigned",
+ "When a variable defined in the global scope is modified in an inner scope, "
+ "the 'global' keyword is required in the inner scope only if there is an "
+ "assignment operation done in the inner scope.",
+ ),
+ "W0603": (
+ "Using the global statement", # W0121
+ "global-statement",
+ 'Used when you use the "global" statement to update a global '
+ "variable. Pylint discourages its usage. That doesn't mean you cannot "
+ "use it!",
+ ),
+ "W0604": (
+ "Using the global statement at the module level", # W0103
+ "global-at-module-level",
+ 'Used when you use the "global" statement at the module level '
+ "since it has no effect.",
+ ),
+ "W0611": (
+ "Unused %s",
+ "unused-import",
+ "Used when an imported module or variable is not used.",
+ ),
+ "W0612": (
+ "Unused variable %r",
+ "unused-variable",
+ "Used when a variable is defined but not used.",
+ ),
+ "W0613": (
+ "Unused argument %r",
+ "unused-argument",
+ "Used when a function or method argument is not used.",
+ ),
+ "W0614": (
+ "Unused import(s) %s from wildcard import of %s",
+ "unused-wildcard-import",
+ "Used when an imported module or variable is not used from a "
+ "`'from X import *'` style import.",
+ ),
+ "W0621": (
+ "Redefining name %r from outer scope (line %s)",
+ "redefined-outer-name",
+ "Used when a variable's name hides a name defined in an outer scope or except handler.",
+ ),
+ "W0622": (
+ "Redefining built-in %r",
+ "redefined-builtin",
+ "Used when a variable or function override a built-in.",
+ ),
+ "W0631": (
+ "Using possibly undefined loop variable %r",
+ "undefined-loop-variable",
+ "Used when a loop variable (i.e. defined by a for loop or "
+ "a list comprehension or a generator expression) is used outside "
+ "the loop.",
+ ),
+ "W0632": (
+ "Possible unbalanced tuple unpacking with sequence %s: left side has %d "
+ "label%s, right side has %d value%s",
+ "unbalanced-tuple-unpacking",
+ "Used when there is an unbalanced tuple unpacking in assignment",
+ {"old_names": [("E0632", "old-unbalanced-tuple-unpacking")]},
+ ),
+ "E0633": (
+ "Attempting to unpack a non-sequence%s",
+ "unpacking-non-sequence",
+ "Used when something which is not a sequence is used in an unpack assignment",
+ {"old_names": [("W0633", "old-unpacking-non-sequence")]},
+ ),
+ "W0640": (
+ "Cell variable %s defined in loop",
+ "cell-var-from-loop",
+ "A variable used in a closure is defined in a loop. "
+ "This will result in all closures using the same value for "
+ "the closed-over variable.",
+ ),
+ "W0641": (
+ "Possibly unused variable %r",
+ "possibly-unused-variable",
+ "Used when a variable is defined but might not be used. "
+ "The possibility comes from the fact that locals() might be used, "
+ "which could consume or not the said variable",
+ ),
+ "W0642": (
+ "Invalid assignment to %s in method",
+ "self-cls-assignment",
+ "Invalid assignment to self or cls in instance or class method "
+ "respectively.",
+ ),
+ "E0643": (
+ "Invalid index for iterable length",
+ "potential-index-error",
+ "Emitted when an index used on an iterable goes beyond the length of that "
+ "iterable.",
+ ),
+ "W0644": (
+ "Possible unbalanced dict unpacking with %s: "
+ "left side has %d label%s, right side has %d value%s",
+ "unbalanced-dict-unpacking",
+ "Used when there is an unbalanced dict unpacking in assignment or for loop",
+ ),
+}
+
+
+class ScopeConsumer(NamedTuple):
+ """Store nodes and their consumption states."""
+
+ to_consume: dict[str, list[nodes.NodeNG]]
+ consumed: dict[str, list[nodes.NodeNG]]
+ consumed_uncertain: defaultdict[str, list[nodes.NodeNG]]
+ scope_type: str
+
+
+class NamesConsumer:
+ """A simple class to handle consumed, to consume and scope type info of node locals."""
+
+ def __init__(self, node: nodes.NodeNG, scope_type: str) -> None:
+ self._atomic = ScopeConsumer(
+ copy.copy(node.locals), {}, collections.defaultdict(list), scope_type
+ )
+ self.node = node
+ self.names_under_always_false_test: set[str] = set()
+ self.names_defined_under_one_branch_only: set[str] = set()
+
+ def __repr__(self) -> str:
+ _to_consumes = [f"{k}->{v}" for k, v in self._atomic.to_consume.items()]
+ _consumed = [f"{k}->{v}" for k, v in self._atomic.consumed.items()]
+ _consumed_uncertain = [
+ f"{k}->{v}" for k, v in self._atomic.consumed_uncertain.items()
+ ]
+ to_consumes = ", ".join(_to_consumes)
+ consumed = ", ".join(_consumed)
+ consumed_uncertain = ", ".join(_consumed_uncertain)
+ return f"""
+to_consume : {to_consumes}
+consumed : {consumed}
+consumed_uncertain: {consumed_uncertain}
+scope_type : {self._atomic.scope_type}
+"""
+
+ def __iter__(self) -> Iterator[Any]:
+ return iter(self._atomic)
+
+ @property
+ def to_consume(self) -> dict[str, list[nodes.NodeNG]]:
+ return self._atomic.to_consume
+
+ @property
+ def consumed(self) -> dict[str, list[nodes.NodeNG]]:
+ return self._atomic.consumed
+
+ @property
+ def consumed_uncertain(self) -> defaultdict[str, list[nodes.NodeNG]]:
+ """Retrieves nodes filtered out by get_next_to_consume() that may not
+ have executed.
+
+ These include nodes such as statements in except blocks, or statements
+ in try blocks (when evaluating their corresponding except and finally
+ blocks). Checkers that want to treat the statements as executed
+ (e.g. for unused-variable) may need to add them back.
+ """
+ return self._atomic.consumed_uncertain
+
+ @property
+ def scope_type(self) -> str:
+ return self._atomic.scope_type
+
+ def mark_as_consumed(self, name: str, consumed_nodes: list[nodes.NodeNG]) -> None:
+ """Mark the given nodes as consumed for the name.
+
+ If all of the nodes for the name were consumed, delete the name from
+ the to_consume dictionary
+ """
+ unconsumed = [n for n in self.to_consume[name] if n not in set(consumed_nodes)]
+ self.consumed[name] = consumed_nodes
+
+ if unconsumed:
+ self.to_consume[name] = unconsumed
+ else:
+ del self.to_consume[name]
+
+ def get_next_to_consume(self, node: nodes.Name) -> list[nodes.NodeNG] | None:
+ """Return a list of the nodes that define `node` from this scope.
+
+ If it is uncertain whether a node will be consumed, such as for statements in
+ except blocks, add it to self.consumed_uncertain instead of returning it.
+ Return None to indicate a special case that needs to be handled by the caller.
+ """
+ name = node.name
+ parent_node = node.parent
+ found_nodes = self.to_consume.get(name)
+ node_statement = node.statement()
+ if (
+ found_nodes
+ and isinstance(parent_node, nodes.Assign)
+ and parent_node == found_nodes[0].parent
+ ):
+ lhs = found_nodes[0].parent.targets[0]
+ if (
+ isinstance(lhs, nodes.AssignName) and lhs.name == name
+ ): # this name is defined in this very statement
+ found_nodes = None
+
+ if (
+ found_nodes
+ and isinstance(parent_node, nodes.For)
+ and parent_node.iter == node
+ and parent_node.target in found_nodes
+ ):
+ found_nodes = None
+
+ # Before filtering, check that this node's name is not a nonlocal
+ if any(
+ isinstance(child, nodes.Nonlocal) and node.name in child.names
+ for child in node.frame().get_children()
+ ):
+ return found_nodes
+
+ # And no comprehension is under the node's frame
+ if VariablesChecker._comprehension_between_frame_and_node(node):
+ return found_nodes
+
+ # Filter out assignments in ExceptHandlers that node is not contained in
+ if found_nodes:
+ found_nodes = [
+ n
+ for n in found_nodes
+ if not isinstance(n.statement(), nodes.ExceptHandler)
+ or n.statement().parent_of(node)
+ ]
+
+ # Filter out assignments guarded by always false conditions
+ if found_nodes:
+ uncertain_nodes = self._uncertain_nodes_if_tests(found_nodes, node)
+ self.consumed_uncertain[node.name] += uncertain_nodes
+ uncertain_nodes_set = set(uncertain_nodes)
+ found_nodes = [n for n in found_nodes if n not in uncertain_nodes_set]
+
+ # Filter out assignments in an Except clause that the node is not
+ # contained in, assuming they may fail
+ if found_nodes:
+ uncertain_nodes = self._uncertain_nodes_in_except_blocks(
+ found_nodes, node, node_statement
+ )
+ self.consumed_uncertain[node.name] += uncertain_nodes
+ uncertain_nodes_set = set(uncertain_nodes)
+ found_nodes = [n for n in found_nodes if n not in uncertain_nodes_set]
+
+ # If this node is in a Finally block of a Try/Finally,
+ # filter out assignments in the try portion, assuming they may fail
+ if found_nodes:
+ uncertain_nodes = (
+ self._uncertain_nodes_in_try_blocks_when_evaluating_finally_blocks(
+ found_nodes, node_statement, name
+ )
+ )
+ self.consumed_uncertain[node.name] += uncertain_nodes
+ uncertain_nodes_set = set(uncertain_nodes)
+ found_nodes = [n for n in found_nodes if n not in uncertain_nodes_set]
+
+ # If this node is in an ExceptHandler,
+ # filter out assignments in the try portion, assuming they may fail
+ if found_nodes:
+ uncertain_nodes = (
+ self._uncertain_nodes_in_try_blocks_when_evaluating_except_blocks(
+ found_nodes, node_statement
+ )
+ )
+ self.consumed_uncertain[node.name] += uncertain_nodes
+ uncertain_nodes_set = set(uncertain_nodes)
+ found_nodes = [n for n in found_nodes if n not in uncertain_nodes_set]
+
+ return found_nodes
+
+ def _inferred_to_define_name_raise_or_return(
+ self, name: str, node: nodes.NodeNG
+ ) -> bool:
+ """Return True if there is a path under this `if_node`
+ that is inferred to define `name`, raise, or return.
+ """
+ # Handle try and with
+ if isinstance(node, nodes.Try):
+ # Allow either a path through try/else/finally OR a path through ALL except handlers
+ try_except_node = node
+ if node.finalbody:
+ try_except_node = next(
+ (child for child in node.nodes_of_class(nodes.Try)),
+ None,
+ )
+ handlers = try_except_node.handlers if try_except_node else []
+ return NamesConsumer._defines_name_raises_or_returns_recursive(
+ name, node
+ ) or all(
+ NamesConsumer._defines_name_raises_or_returns_recursive(name, handler)
+ for handler in handlers
+ )
+
+ if isinstance(node, (nodes.With, nodes.For, nodes.While)):
+ return NamesConsumer._defines_name_raises_or_returns_recursive(name, node)
+
+ if not isinstance(node, nodes.If):
+ return False
+
+ # Be permissive if there is a break or a continue
+ if any(node.nodes_of_class(nodes.Break, nodes.Continue)):
+ return True
+
+ # Is there an assignment in this node itself, e.g. in named expression?
+ if NamesConsumer._defines_name_raises_or_returns(name, node):
+ return True
+
+ test = node.test.value if isinstance(node.test, nodes.NamedExpr) else node.test
+ all_inferred = utils.infer_all(test)
+ only_search_if = False
+ only_search_else = True
+
+ for inferred in all_inferred:
+ if not isinstance(inferred, nodes.Const):
+ only_search_else = False
+ continue
+ val = inferred.value
+ only_search_if = only_search_if or (val != NotImplemented and val)
+ only_search_else = only_search_else and not val
+
+ # Only search else branch when test condition is inferred to be false
+ if all_inferred and only_search_else:
+ self.names_under_always_false_test.add(name)
+ return self._branch_handles_name(name, node.orelse)
+ # Search both if and else branches
+ if_branch_handles = self._branch_handles_name(name, node.body)
+ else_branch_handles = self._branch_handles_name(name, node.orelse)
+ if if_branch_handles ^ else_branch_handles:
+ self.names_defined_under_one_branch_only.add(name)
+ elif name in self.names_defined_under_one_branch_only:
+ self.names_defined_under_one_branch_only.remove(name)
+ return if_branch_handles and else_branch_handles
+
+ def _branch_handles_name(self, name: str, body: Iterable[nodes.NodeNG]) -> bool:
+ return any(
+ NamesConsumer._defines_name_raises_or_returns(name, if_body_stmt)
+ or isinstance(
+ if_body_stmt,
+ (
+ nodes.If,
+ nodes.Try,
+ nodes.With,
+ nodes.For,
+ nodes.While,
+ ),
+ )
+ and self._inferred_to_define_name_raise_or_return(name, if_body_stmt)
+ for if_body_stmt in body
+ )
+
+ def _uncertain_nodes_if_tests(
+ self, found_nodes: list[nodes.NodeNG], node: nodes.NodeNG
+ ) -> list[nodes.NodeNG]:
+ """Identify nodes of uncertain execution because they are defined under if
+ tests.
+
+ Don't identify a node if there is a path that is inferred to
+ define the name, raise, or return (e.g. any executed if/elif/else branch).
+ """
+ uncertain_nodes = []
+ for other_node in found_nodes:
+ if isinstance(other_node, nodes.AssignName):
+ name = other_node.name
+ elif isinstance(other_node, (nodes.Import, nodes.ImportFrom)):
+ name = node.name
+ else:
+ continue
+
+ all_if = [
+ n
+ for n in other_node.node_ancestors()
+ if isinstance(n, nodes.If) and not n.parent_of(node)
+ ]
+ if not all_if:
+ continue
+
+ closest_if = all_if[0]
+ if (
+ isinstance(node, nodes.AssignName)
+ and node.frame() is not closest_if.frame()
+ ):
+ continue
+ if closest_if.parent_of(node):
+ continue
+
+ outer_if = all_if[-1]
+ if NamesConsumer._node_guarded_by_same_test(node, outer_if):
+ continue
+
+ # Name defined in the if/else control flow
+ if self._inferred_to_define_name_raise_or_return(name, outer_if):
+ continue
+
+ uncertain_nodes.append(other_node)
+
+ return uncertain_nodes
+
+ @staticmethod
+ def _node_guarded_by_same_test(node: nodes.NodeNG, other_if: nodes.If) -> bool:
+ """Identify if `node` is guarded by an equivalent test as `other_if`.
+
+ Two tests are equivalent if their string representations are identical
+ or if their inferred values consist only of constants and those constants
+ are identical, and the if test guarding `node` is not a Name.
+ """
+ other_if_test_as_string = other_if.test.as_string()
+ other_if_test_all_inferred = utils.infer_all(other_if.test)
+ for ancestor in node.node_ancestors():
+ if not isinstance(ancestor, nodes.If):
+ continue
+ if ancestor.test.as_string() == other_if_test_as_string:
+ return True
+ if isinstance(ancestor.test, nodes.Name):
+ continue
+ all_inferred = utils.infer_all(ancestor.test)
+ if len(all_inferred) == len(other_if_test_all_inferred):
+ if any(
+ not isinstance(test, nodes.Const)
+ for test in (*all_inferred, *other_if_test_all_inferred)
+ ):
+ continue
+ if {test.value for test in all_inferred} != {
+ test.value for test in other_if_test_all_inferred
+ }:
+ continue
+ return True
+
+ return False
+
+ @staticmethod
+ def _uncertain_nodes_in_except_blocks(
+ found_nodes: list[nodes.NodeNG],
+ node: nodes.NodeNG,
+ node_statement: _base_nodes.Statement,
+ ) -> list[nodes.NodeNG]:
+ """Return any nodes in ``found_nodes`` that should be treated as uncertain
+ because they are in an except block.
+ """
+ uncertain_nodes = []
+ for other_node in found_nodes:
+ other_node_statement = other_node.statement()
+ # Only testing for statements in the except block of Try
+ closest_except_handler = utils.get_node_first_ancestor_of_type(
+ other_node_statement, nodes.ExceptHandler
+ )
+ if not closest_except_handler:
+ continue
+ # If the other node is in the same scope as this node, assume it executes
+ if closest_except_handler.parent_of(node):
+ continue
+ closest_try_except: nodes.Try = closest_except_handler.parent
+ # If the try or else blocks return, assume the except blocks execute.
+ try_block_returns = any(
+ isinstance(try_statement, nodes.Return)
+ for try_statement in closest_try_except.body
+ )
+ else_block_returns = any(
+ isinstance(else_statement, nodes.Return)
+ for else_statement in closest_try_except.orelse
+ )
+ else_block_exits = any(
+ isinstance(else_statement, nodes.Expr)
+ and isinstance(else_statement.value, nodes.Call)
+ and utils.is_terminating_func(else_statement.value)
+ for else_statement in closest_try_except.orelse
+ )
+ else_block_continues = any(
+ isinstance(else_statement, nodes.Continue)
+ for else_statement in closest_try_except.orelse
+ )
+ if (
+ else_block_continues
+ and isinstance(node_statement.parent, (nodes.For, nodes.While))
+ and closest_try_except.parent.parent_of(node_statement)
+ ):
+ continue
+
+ if try_block_returns or else_block_returns or else_block_exits:
+ # Exception: if this node is in the final block of the other_node_statement,
+ # it will execute before returning. Assume the except statements are uncertain.
+ if (
+ isinstance(node_statement.parent, nodes.Try)
+ and node_statement in node_statement.parent.finalbody
+ and closest_try_except.parent.parent_of(node_statement)
+ ):
+ uncertain_nodes.append(other_node)
+ # Or the node_statement is in the else block of the relevant Try
+ elif (
+ isinstance(node_statement.parent, nodes.Try)
+ and node_statement in node_statement.parent.orelse
+ and closest_try_except.parent.parent_of(node_statement)
+ ):
+ uncertain_nodes.append(other_node)
+ # Assume the except blocks execute, so long as each handler
+ # defines the name, raises, or returns.
+ elif all(
+ NamesConsumer._defines_name_raises_or_returns_recursive(
+ node.name, handler
+ )
+ for handler in closest_try_except.handlers
+ ):
+ continue
+
+ if NamesConsumer._check_loop_finishes_via_except(node, closest_try_except):
+ continue
+
+ # Passed all tests for uncertain execution
+ uncertain_nodes.append(other_node)
+ return uncertain_nodes
+
+ @staticmethod
+ def _defines_name_raises_or_returns(name: str, node: nodes.NodeNG) -> bool:
+ if isinstance(node, (nodes.Raise, nodes.Assert, nodes.Return, nodes.Continue)):
+ return True
+ if isinstance(node, nodes.Expr) and isinstance(node.value, nodes.Call):
+ if utils.is_terminating_func(node.value):
+ return True
+ if (
+ isinstance(node.value.func, nodes.Name)
+ and node.value.func.name == "assert_never"
+ ):
+ return True
+ if (
+ isinstance(node, nodes.AnnAssign)
+ and node.value
+ and isinstance(node.target, nodes.AssignName)
+ and node.target.name == name
+ ):
+ return True
+ if isinstance(node, nodes.Assign):
+ for target in node.targets:
+ for elt in utils.get_all_elements(target):
+ if isinstance(elt, nodes.Starred):
+ elt = elt.value
+ if isinstance(elt, nodes.AssignName) and elt.name == name:
+ return True
+ if isinstance(node, nodes.If):
+ if any(
+ child_named_expr.target.name == name
+ for child_named_expr in node.nodes_of_class(nodes.NamedExpr)
+ ):
+ return True
+ if isinstance(node, (nodes.Import, nodes.ImportFrom)) and any(
+ (node_name[1] and node_name[1] == name) or (node_name[0] == name)
+ for node_name in node.names
+ ):
+ return True
+ if isinstance(node, nodes.With) and any(
+ isinstance(item[1], nodes.AssignName) and item[1].name == name
+ for item in node.items
+ ):
+ return True
+ if isinstance(node, (nodes.ClassDef, nodes.FunctionDef)) and node.name == name:
+ return True
+ if (
+ isinstance(node, nodes.ExceptHandler)
+ and node.name
+ and node.name.name == name
+ ):
+ return True
+ return False
+
+ @staticmethod
+ def _defines_name_raises_or_returns_recursive(
+ name: str, node: nodes.NodeNG
+ ) -> bool:
+ """Return True if some child of `node` defines the name `name`,
+ raises, or returns.
+ """
+ for stmt in node.get_children():
+ if NamesConsumer._defines_name_raises_or_returns(name, stmt):
+ return True
+ if isinstance(stmt, (nodes.If, nodes.With)):
+ if any(
+ NamesConsumer._defines_name_raises_or_returns(name, nested_stmt)
+ for nested_stmt in stmt.get_children()
+ ):
+ return True
+ if (
+ isinstance(stmt, nodes.Try)
+ and not stmt.finalbody
+ and NamesConsumer._defines_name_raises_or_returns_recursive(name, stmt)
+ ):
+ return True
+ return False
+
+ @staticmethod
+ def _check_loop_finishes_via_except(
+ node: nodes.NodeNG, other_node_try_except: nodes.Try
+ ) -> bool:
+ """Check for a specific control flow scenario.
+
+ Described in https://github.com/pylint-dev/pylint/issues/5683.
+
+ A scenario where the only non-break exit from a loop consists of the very
+ except handler we are examining, such that code in the `else` branch of
+ the loop can depend on it being assigned.
+
+ Example:
+ for _ in range(3):
+ try:
+ do_something()
+ except:
+ name = 1 <-- only non-break exit from loop
+ else:
+ break
+ else:
+ print(name)
+ """
+ if not other_node_try_except.orelse:
+ return False
+ closest_loop: None | (nodes.For | nodes.While) = (
+ utils.get_node_first_ancestor_of_type(node, (nodes.For, nodes.While))
+ )
+ if closest_loop is None:
+ return False
+ if not any(
+ else_statement is node or else_statement.parent_of(node)
+ for else_statement in closest_loop.orelse
+ ):
+ # `node` not guarded by `else`
+ return False
+ for inner_else_statement in other_node_try_except.orelse:
+ if isinstance(inner_else_statement, nodes.Break):
+ break_stmt = inner_else_statement
+ break
+ else:
+ # No break statement
+ return False
+
+ def _try_in_loop_body(
+ other_node_try_except: nodes.Try, loop: nodes.For | nodes.While
+ ) -> bool:
+ """Return True if `other_node_try_except` is a descendant of `loop`."""
+ return any(
+ loop_body_statement is other_node_try_except
+ or loop_body_statement.parent_of(other_node_try_except)
+ for loop_body_statement in loop.body
+ )
+
+ if not _try_in_loop_body(other_node_try_except, closest_loop):
+ for ancestor in closest_loop.node_ancestors():
+ if isinstance(ancestor, (nodes.For, nodes.While)):
+ if _try_in_loop_body(other_node_try_except, ancestor):
+ break
+ else:
+ # `other_node_try_except` didn't have a shared ancestor loop
+ return False
+
+ for loop_stmt in closest_loop.body:
+ if NamesConsumer._recursive_search_for_continue_before_break(
+ loop_stmt, break_stmt
+ ):
+ break
+ else:
+ # No continue found, so we arrived at our special case!
+ return True
+ return False
+
+ @staticmethod
+ def _recursive_search_for_continue_before_break(
+ stmt: _base_nodes.Statement, break_stmt: nodes.Break
+ ) -> bool:
+ """Return True if any Continue node can be found in descendants of `stmt`
+ before encountering `break_stmt`, ignoring any nested loops.
+ """
+ if stmt is break_stmt:
+ return False
+ if isinstance(stmt, nodes.Continue):
+ return True
+ for child in stmt.get_children():
+ if isinstance(stmt, (nodes.For, nodes.While)):
+ continue
+ if NamesConsumer._recursive_search_for_continue_before_break(
+ child, break_stmt
+ ):
+ return True
+ return False
+
+ @staticmethod
+ def _uncertain_nodes_in_try_blocks_when_evaluating_except_blocks(
+ found_nodes: list[nodes.NodeNG], node_statement: _base_nodes.Statement
+ ) -> list[nodes.NodeNG]:
+ """Return any nodes in ``found_nodes`` that should be treated as uncertain.
+
+ Nodes are uncertain when they are in a try block and the ``node_statement``
+ being evaluated is in one of its except handlers.
+ """
+ uncertain_nodes: list[nodes.NodeNG] = []
+ closest_except_handler = utils.get_node_first_ancestor_of_type(
+ node_statement, nodes.ExceptHandler
+ )
+ if closest_except_handler is None:
+ return uncertain_nodes
+ for other_node in found_nodes:
+ other_node_statement = other_node.statement()
+ # If the other statement is the except handler guarding `node`, it executes
+ if other_node_statement is closest_except_handler:
+ continue
+ # Ensure other_node is in a try block
+ (
+ other_node_try_ancestor,
+ other_node_try_ancestor_visited_child,
+ ) = utils.get_node_first_ancestor_of_type_and_its_child(
+ other_node_statement, nodes.Try
+ )
+ if other_node_try_ancestor is None:
+ continue
+ if (
+ other_node_try_ancestor_visited_child
+ not in other_node_try_ancestor.body
+ ):
+ continue
+ # Make sure nesting is correct -- there should be at least one
+ # except handler that is a sibling attached to the try ancestor,
+ # or is an ancestor of the try ancestor.
+ if not any(
+ closest_except_handler in other_node_try_ancestor.handlers
+ or other_node_try_ancestor_except_handler
+ in closest_except_handler.node_ancestors()
+ for other_node_try_ancestor_except_handler in other_node_try_ancestor.handlers
+ ):
+ continue
+ # Passed all tests for uncertain execution
+ uncertain_nodes.append(other_node)
+ return uncertain_nodes
+
+ @staticmethod
+ def _uncertain_nodes_in_try_blocks_when_evaluating_finally_blocks(
+ found_nodes: list[nodes.NodeNG],
+ node_statement: _base_nodes.Statement,
+ name: str,
+ ) -> list[nodes.NodeNG]:
+ uncertain_nodes: list[nodes.NodeNG] = []
+ (
+ closest_try_finally_ancestor,
+ child_of_closest_try_finally_ancestor,
+ ) = utils.get_node_first_ancestor_of_type_and_its_child(
+ node_statement, nodes.Try
+ )
+ if closest_try_finally_ancestor is None:
+ return uncertain_nodes
+ if (
+ child_of_closest_try_finally_ancestor
+ not in closest_try_finally_ancestor.finalbody
+ ):
+ return uncertain_nodes
+ for other_node in found_nodes:
+ other_node_statement = other_node.statement()
+ (
+ other_node_try_finally_ancestor,
+ child_of_other_node_try_finally_ancestor,
+ ) = utils.get_node_first_ancestor_of_type_and_its_child(
+ other_node_statement, nodes.Try
+ )
+ if other_node_try_finally_ancestor is None:
+ continue
+ # other_node needs to descend from the try of a try/finally.
+ if (
+ child_of_other_node_try_finally_ancestor
+ not in other_node_try_finally_ancestor.body
+ ):
+ continue
+ # If the two try/finally ancestors are not the same, then
+ # node_statement's closest try/finally ancestor needs to be in
+ # the final body of other_node's try/finally ancestor, or
+ # descend from one of the statements in that final body.
+ if (
+ other_node_try_finally_ancestor is not closest_try_finally_ancestor
+ and not any(
+ other_node_final_statement is closest_try_finally_ancestor
+ or other_node_final_statement.parent_of(
+ closest_try_finally_ancestor
+ )
+ for other_node_final_statement in other_node_try_finally_ancestor.finalbody
+ )
+ ):
+ continue
+ # Is the name defined in all exception clauses?
+ if other_node_try_finally_ancestor.handlers and all(
+ NamesConsumer._defines_name_raises_or_returns_recursive(name, handler)
+ for handler in other_node_try_finally_ancestor.handlers
+ ):
+ continue
+ # Passed all tests for uncertain execution
+ uncertain_nodes.append(other_node)
+ return uncertain_nodes
+
+
+# pylint: disable=too-many-public-methods
+class VariablesChecker(BaseChecker):
+ """BaseChecker for variables.
+
+ Checks for
+ * unused variables / imports
+ * undefined variables
+ * redefinition of variable from builtins or from an outer scope or except handler
+ * use of variable before assignment
+ * __all__ consistency
+ * self/cls assignment
+ """
+
+ name = "variables"
+ msgs = MSGS
+ options = (
+ (
+ "init-import",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Tells whether we should check for unused import in "
+ "__init__ files.",
+ },
+ ),
+ (
+ "dummy-variables-rgx",
+ {
+ "default": "_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_",
+ "type": "regexp",
+ "metavar": "<regexp>",
+ "help": "A regular expression matching the name of dummy "
+ "variables (i.e. expected to not be used).",
+ },
+ ),
+ (
+ "additional-builtins",
+ {
+ "default": (),
+ "type": "csv",
+ "metavar": "<comma separated list>",
+ "help": "List of additional names supposed to be defined in "
+ "builtins. Remember that you should avoid defining new builtins "
+ "when possible.",
+ },
+ ),
+ (
+ "callbacks",
+ {
+ "default": ("cb_", "_cb"),
+ "type": "csv",
+ "metavar": "<callbacks>",
+ "help": "List of strings which can identify a callback "
+ "function by name. A callback name must start or "
+ "end with one of those strings.",
+ },
+ ),
+ (
+ "redefining-builtins-modules",
+ {
+ "default": (
+ "six.moves",
+ "past.builtins",
+ "future.builtins",
+ "builtins",
+ "io",
+ ),
+ "type": "csv",
+ "metavar": "<comma separated list>",
+ "help": "List of qualified module names which can have objects "
+ "that can redefine builtins.",
+ },
+ ),
+ (
+ "ignored-argument-names",
+ {
+ "default": IGNORED_ARGUMENT_NAMES,
+ "type": "regexp",
+ "metavar": "<regexp>",
+ "help": "Argument names that match this expression will be ignored.",
+ },
+ ),
+ (
+ "allow-global-unused-variables",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Tells whether unused global variables should be treated as a violation.",
+ },
+ ),
+ (
+ "allowed-redefined-builtins",
+ {
+ "default": (),
+ "type": "csv",
+ "metavar": "<comma separated list>",
+ "help": "List of names allowed to shadow builtins",
+ },
+ ),
+ )
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._to_consume: list[NamesConsumer] = []
+ self._type_annotation_names: list[str] = []
+ self._except_handler_names_queue: list[
+ tuple[nodes.ExceptHandler, nodes.AssignName]
+ ] = []
+ """This is a queue, last in first out."""
+ self._evaluated_type_checking_scopes: dict[
+ str, list[nodes.LocalsDictNodeNG]
+ ] = {}
+ self._postponed_evaluation_enabled = False
+
+ @utils.only_required_for_messages(
+ "unbalanced-dict-unpacking",
+ )
+ def visit_for(self, node: nodes.For) -> None:
+ if not isinstance(node.target, nodes.Tuple):
+ return
+
+ targets = node.target.elts
+
+ inferred = utils.safe_infer(node.iter)
+ if not isinstance(inferred, DICT_TYPES):
+ return
+
+ values = self._nodes_to_unpack(inferred)
+ if not values:
+ # no dict items returned
+ return
+
+ if isinstance(inferred, astroid.objects.DictItems):
+ # dict.items() is a bit special because values will be a tuple
+ # So as long as there are always 2 targets and values each are
+ # a tuple with two items, this will unpack correctly.
+ # Example: `for key, val in {1: 2, 3: 4}.items()`
+ if len(targets) == 2 and all(len(x.elts) == 2 for x in values):
+ return
+
+ # Starred nodes indicate ambiguous unpacking
+ # if `dict.items()` is used so we won't flag them.
+ if any(isinstance(target, nodes.Starred) for target in targets):
+ return
+
+ if isinstance(inferred, nodes.Dict):
+ if isinstance(node.iter, nodes.Name):
+ # If this a case of 'dict-items-missing-iter', we don't want to
+ # report it as an 'unbalanced-dict-unpacking' as well
+ # TODO (performance), merging both checks would streamline this
+ if len(targets) == 2:
+ return
+
+ else:
+ is_starred_targets = any(
+ isinstance(target, nodes.Starred) for target in targets
+ )
+ for value in values:
+ value_length = self._get_value_length(value)
+ is_valid_star_unpack = is_starred_targets and value_length >= len(
+ targets
+ )
+ if len(targets) != value_length and not is_valid_star_unpack:
+ details = _get_unpacking_extra_info(node, inferred)
+ self._report_unbalanced_unpacking(
+ node, inferred, targets, value_length, details
+ )
+ break
+
+ def leave_for(self, node: nodes.For) -> None:
+ self._store_type_annotation_names(node)
+
+ def visit_module(self, node: nodes.Module) -> None:
+ """Visit module : update consumption analysis variable
+ checks globals doesn't overrides builtins.
+ """
+ self._to_consume = [NamesConsumer(node, "module")]
+ self._postponed_evaluation_enabled = is_postponed_evaluation_enabled(node)
+
+ for name, stmts in node.locals.items():
+ if utils.is_builtin(name):
+ if self._should_ignore_redefined_builtin(stmts[0]) or name == "__doc__":
+ continue
+ self.add_message("redefined-builtin", args=name, node=stmts[0])
+
+ @utils.only_required_for_messages(
+ "unused-import",
+ "unused-wildcard-import",
+ "redefined-builtin",
+ "undefined-all-variable",
+ "invalid-all-object",
+ "invalid-all-format",
+ "unused-variable",
+ "undefined-variable",
+ )
+ def leave_module(self, node: nodes.Module) -> None:
+ """Leave module: check globals."""
+ assert len(self._to_consume) == 1
+
+ self._check_metaclasses(node)
+ not_consumed = self._to_consume.pop().to_consume
+ # attempt to check for __all__ if defined
+ if "__all__" in node.locals:
+ self._check_all(node, not_consumed)
+
+ # check for unused globals
+ self._check_globals(not_consumed)
+
+ # don't check unused imports in __init__ files
+ if not self.linter.config.init_import and node.package:
+ return
+
+ self._check_imports(not_consumed)
+ self._type_annotation_names = []
+
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ """Visit class: update consumption analysis variable."""
+ self._to_consume.append(NamesConsumer(node, "class"))
+
+ def leave_classdef(self, node: nodes.ClassDef) -> None:
+ """Leave class: update consumption analysis variable."""
+ # Check for hidden ancestor names
+ # e.g. "six" in: Class X(six.with_metaclass(ABCMeta, object)):
+ for name_node in node.nodes_of_class(nodes.Name):
+ if (
+ isinstance(name_node.parent, nodes.Call)
+ and isinstance(name_node.parent.func, nodes.Attribute)
+ and isinstance(name_node.parent.func.expr, nodes.Name)
+ ):
+ hidden_name_node = name_node.parent.func.expr
+ for consumer in self._to_consume:
+ if hidden_name_node.name in consumer.to_consume:
+ consumer.mark_as_consumed(
+ hidden_name_node.name,
+ consumer.to_consume[hidden_name_node.name],
+ )
+ break
+ self._to_consume.pop()
+
+ def visit_lambda(self, node: nodes.Lambda) -> None:
+ """Visit lambda: update consumption analysis variable."""
+ self._to_consume.append(NamesConsumer(node, "lambda"))
+
+ def leave_lambda(self, _: nodes.Lambda) -> None:
+ """Leave lambda: update consumption analysis variable."""
+ # do not check for not used locals here
+ self._to_consume.pop()
+
+ def visit_generatorexp(self, node: nodes.GeneratorExp) -> None:
+ """Visit genexpr: update consumption analysis variable."""
+ self._to_consume.append(NamesConsumer(node, "comprehension"))
+
+ def leave_generatorexp(self, _: nodes.GeneratorExp) -> None:
+ """Leave genexpr: update consumption analysis variable."""
+ # do not check for not used locals here
+ self._to_consume.pop()
+
+ def visit_dictcomp(self, node: nodes.DictComp) -> None:
+ """Visit dictcomp: update consumption analysis variable."""
+ self._to_consume.append(NamesConsumer(node, "comprehension"))
+
+ def leave_dictcomp(self, _: nodes.DictComp) -> None:
+ """Leave dictcomp: update consumption analysis variable."""
+ # do not check for not used locals here
+ self._to_consume.pop()
+
+ def visit_setcomp(self, node: nodes.SetComp) -> None:
+ """Visit setcomp: update consumption analysis variable."""
+ self._to_consume.append(NamesConsumer(node, "comprehension"))
+
+ def leave_setcomp(self, _: nodes.SetComp) -> None:
+ """Leave setcomp: update consumption analysis variable."""
+ # do not check for not used locals here
+ self._to_consume.pop()
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Visit function: update consumption analysis variable and check locals."""
+ self._to_consume.append(NamesConsumer(node, "function"))
+ if not (
+ self.linter.is_message_enabled("redefined-outer-name")
+ or self.linter.is_message_enabled("redefined-builtin")
+ ):
+ return
+ globs = node.root().globals
+ for name, stmt in node.items():
+ if name in globs and not isinstance(stmt, nodes.Global):
+ definition = globs[name][0]
+ if (
+ isinstance(definition, nodes.ImportFrom)
+ and definition.modname == FUTURE
+ ):
+ # It is a __future__ directive, not a symbol.
+ continue
+
+ # Do not take in account redefined names for the purpose
+ # of type checking.:
+ if any(
+ in_type_checking_block(definition) for definition in globs[name]
+ ):
+ continue
+
+ # Suppress emitting the message if the outer name is in the
+ # scope of an exception assignment.
+ # For example: the `e` in `except ValueError as e`
+ global_node = globs[name][0]
+ if isinstance(global_node, nodes.AssignName) and isinstance(
+ global_node.parent, nodes.ExceptHandler
+ ):
+ continue
+
+ line = definition.fromlineno
+ if not self._is_name_ignored(stmt, name):
+ self.add_message(
+ "redefined-outer-name", args=(name, line), node=stmt
+ )
+
+ elif (
+ utils.is_builtin(name)
+ and not self._allowed_redefined_builtin(name)
+ and not self._should_ignore_redefined_builtin(stmt)
+ ):
+ # do not print Redefining builtin for additional builtins
+ self.add_message("redefined-builtin", args=name, node=stmt)
+
+ def leave_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Leave function: check function's locals are consumed."""
+ self._check_metaclasses(node)
+
+ if node.type_comment_returns:
+ self._store_type_annotation_node(node.type_comment_returns)
+ if node.type_comment_args:
+ for argument_annotation in node.type_comment_args:
+ self._store_type_annotation_node(argument_annotation)
+
+ not_consumed = self._to_consume.pop().to_consume
+ if not (
+ self.linter.is_message_enabled("unused-variable")
+ or self.linter.is_message_enabled("possibly-unused-variable")
+ or self.linter.is_message_enabled("unused-argument")
+ ):
+ return
+
+ # Don't check arguments of function which are only raising an exception.
+ if utils.is_error(node):
+ return
+
+ # Don't check arguments of abstract methods or within an interface.
+ is_method = node.is_method()
+ if is_method and node.is_abstract():
+ return
+
+ global_names = _flattened_scope_names(node.nodes_of_class(nodes.Global))
+ nonlocal_names = _flattened_scope_names(node.nodes_of_class(nodes.Nonlocal))
+ comprehension_target_names: set[str] = set()
+
+ for comprehension_scope in node.nodes_of_class(nodes.ComprehensionScope):
+ for generator in comprehension_scope.generators:
+ for name in utils.find_assigned_names_recursive(generator.target):
+ comprehension_target_names.add(name)
+
+ for name, stmts in not_consumed.items():
+ self._check_is_unused(
+ name,
+ node,
+ stmts[0],
+ global_names,
+ nonlocal_names,
+ comprehension_target_names,
+ )
+
+ visit_asyncfunctiondef = visit_functiondef
+ leave_asyncfunctiondef = leave_functiondef
+
+ @utils.only_required_for_messages(
+ "global-variable-undefined",
+ "global-variable-not-assigned",
+ "global-statement",
+ "global-at-module-level",
+ "redefined-builtin",
+ )
+ def visit_global(self, node: nodes.Global) -> None:
+ """Check names imported exists in the global scope."""
+ frame = node.frame()
+ if isinstance(frame, nodes.Module):
+ self.add_message("global-at-module-level", node=node, confidence=HIGH)
+ return
+
+ module = frame.root()
+ default_message = True
+ locals_ = node.scope().locals
+ for name in node.names:
+ try:
+ assign_nodes = module.getattr(name)
+ except astroid.NotFoundError:
+ # unassigned global, skip
+ assign_nodes = []
+
+ not_defined_locally_by_import = not any(
+ isinstance(local, (nodes.Import, nodes.ImportFrom))
+ for local in locals_.get(name, ())
+ )
+ if (
+ not utils.is_reassigned_after_current(node, name)
+ and not utils.is_deleted_after_current(node, name)
+ and not_defined_locally_by_import
+ ):
+ self.add_message(
+ "global-variable-not-assigned",
+ args=name,
+ node=node,
+ confidence=HIGH,
+ )
+ default_message = False
+ continue
+
+ for anode in assign_nodes:
+ if (
+ isinstance(anode, nodes.AssignName)
+ and anode.name in module.special_attributes
+ ):
+ self.add_message("redefined-builtin", args=name, node=node)
+ break
+ if anode.frame() is module:
+ # module level assignment
+ break
+ if (
+ isinstance(anode, (nodes.ClassDef, nodes.FunctionDef))
+ and anode.parent is module
+ ):
+ # module level function assignment
+ break
+ else:
+ if not_defined_locally_by_import:
+ # global undefined at the module scope
+ self.add_message(
+ "global-variable-undefined",
+ args=name,
+ node=node,
+ confidence=HIGH,
+ )
+ default_message = False
+
+ if default_message:
+ self.add_message("global-statement", node=node, confidence=HIGH)
+
+ def visit_assignname(self, node: nodes.AssignName) -> None:
+ if isinstance(node.assign_type(), nodes.AugAssign):
+ self.visit_name(node)
+
+ def visit_delname(self, node: nodes.DelName) -> None:
+ self.visit_name(node)
+
+ def visit_name(self, node: nodes.Name | nodes.AssignName | nodes.DelName) -> None:
+ """Don't add the 'utils.only_required_for_messages' decorator here!
+
+ It's important that all 'Name' nodes are visited, otherwise the
+ 'NamesConsumers' won't be correct.
+ """
+ stmt = node.statement()
+ if stmt.fromlineno is None:
+ # name node from an astroid built from live code, skip
+ assert not stmt.root().file.endswith(".py")
+ return
+
+ self._undefined_and_used_before_checker(node, stmt)
+ self._loopvar_name(node)
+
+ @utils.only_required_for_messages("redefined-outer-name")
+ def visit_excepthandler(self, node: nodes.ExceptHandler) -> None:
+ if not node.name or not isinstance(node.name, nodes.AssignName):
+ return
+
+ for outer_except, outer_except_assign_name in self._except_handler_names_queue:
+ if node.name.name == outer_except_assign_name.name:
+ self.add_message(
+ "redefined-outer-name",
+ args=(outer_except_assign_name.name, outer_except.fromlineno),
+ node=node,
+ )
+ break
+
+ self._except_handler_names_queue.append((node, node.name))
+
+ @utils.only_required_for_messages("redefined-outer-name")
+ def leave_excepthandler(self, node: nodes.ExceptHandler) -> None:
+ if not node.name or not isinstance(node.name, nodes.AssignName):
+ return
+ self._except_handler_names_queue.pop()
+
+ def _undefined_and_used_before_checker(
+ self, node: nodes.Name, stmt: nodes.NodeNG
+ ) -> None:
+ frame = stmt.scope()
+ start_index = len(self._to_consume) - 1
+
+ # iterates through parent scopes, from the inner to the outer
+ base_scope_type = self._to_consume[start_index].scope_type
+
+ for i in range(start_index, -1, -1):
+ current_consumer = self._to_consume[i]
+
+ # Certain nodes shouldn't be checked as they get checked another time
+ if self._should_node_be_skipped(node, current_consumer, i == start_index):
+ continue
+
+ action, nodes_to_consume = self._check_consumer(
+ node, stmt, frame, current_consumer, base_scope_type
+ )
+ if nodes_to_consume:
+ # Any nodes added to consumed_uncertain by get_next_to_consume()
+ # should be added back so that they are marked as used.
+ # They will have already had a chance to emit used-before-assignment.
+ # We check here instead of before every single return in _check_consumer()
+ nodes_to_consume += current_consumer.consumed_uncertain[node.name]
+ current_consumer.mark_as_consumed(node.name, nodes_to_consume)
+ if action is VariableVisitConsumerAction.CONTINUE:
+ continue
+ if action is VariableVisitConsumerAction.RETURN:
+ return
+
+ # we have not found the name, if it isn't a builtin, that's an
+ # undefined name !
+ if not (
+ node.name in nodes.Module.scope_attrs
+ or utils.is_builtin(node.name)
+ or node.name in self.linter.config.additional_builtins
+ or (
+ node.name == "__class__"
+ and any(
+ i.is_method()
+ for i in node.node_ancestors()
+ if isinstance(i, nodes.FunctionDef)
+ )
+ )
+ ) and not utils.node_ignores_exception(node, NameError):
+ self.add_message("undefined-variable", args=node.name, node=node)
+
+ def _should_node_be_skipped(
+ self, node: nodes.Name, consumer: NamesConsumer, is_start_index: bool
+ ) -> bool:
+ """Tests a consumer and node for various conditions in which the node shouldn't
+ be checked for the undefined-variable and used-before-assignment checks.
+ """
+ if consumer.scope_type == "class":
+ # The list of base classes in the class definition is not part
+ # of the class body.
+ # If the current scope is a class scope but it's not the inner
+ # scope, ignore it. This prevents to access this scope instead of
+ # the globals one in function members when there are some common
+ # names.
+ if utils.is_ancestor_name(consumer.node, node) or (
+ not is_start_index and self._ignore_class_scope(node)
+ ):
+ if any(
+ node.name == param.name.name for param in consumer.node.type_params
+ ):
+ return False
+
+ return True
+
+ # Ignore inner class scope for keywords in class definition
+ if isinstance(node.parent, nodes.Keyword) and isinstance(
+ node.parent.parent, nodes.ClassDef
+ ):
+ return True
+
+ elif consumer.scope_type == "function" and self._defined_in_function_definition(
+ node, consumer.node
+ ):
+ if any(node.name == param.name.name for param in consumer.node.type_params):
+ return False
+
+ # If the name node is used as a function default argument's value or as
+ # a decorator, then start from the parent frame of the function instead
+ # of the function frame - and thus open an inner class scope
+ return True
+
+ elif consumer.scope_type == "lambda" and utils.is_default_argument(
+ node, consumer.node
+ ):
+ return True
+
+ return False
+
+ # pylint: disable = too-many-return-statements, too-many-branches
+ def _check_consumer(
+ self,
+ node: nodes.Name,
+ stmt: nodes.NodeNG,
+ frame: nodes.LocalsDictNodeNG,
+ current_consumer: NamesConsumer,
+ base_scope_type: str,
+ ) -> tuple[VariableVisitConsumerAction, list[nodes.NodeNG] | None]:
+ """Checks a consumer for conditions that should trigger messages."""
+ # If the name has already been consumed, only check it's not a loop
+ # variable used outside the loop.
+ if node.name in current_consumer.consumed:
+ # Avoid the case where there are homonyms inside function scope and
+ # comprehension current scope (avoid bug #1731)
+ if utils.is_func_decorator(current_consumer.node) or not isinstance(
+ node, nodes.ComprehensionScope
+ ):
+ self._check_late_binding_closure(node)
+ return (VariableVisitConsumerAction.RETURN, None)
+
+ found_nodes = current_consumer.get_next_to_consume(node)
+ if found_nodes is None:
+ return (VariableVisitConsumerAction.CONTINUE, None)
+ if not found_nodes:
+ self._report_unfound_name_definition(node, current_consumer)
+ # Mark for consumption any nodes added to consumed_uncertain by
+ # get_next_to_consume() because they might not have executed.
+ nodes_to_consume = current_consumer.consumed_uncertain[node.name]
+ nodes_to_consume = self._filter_type_checking_import_from_consumption(
+ node, nodes_to_consume
+ )
+ return (
+ VariableVisitConsumerAction.RETURN,
+ nodes_to_consume,
+ )
+
+ self._check_late_binding_closure(node)
+
+ defnode = utils.assign_parent(found_nodes[0])
+ defstmt = defnode.statement()
+ defframe = defstmt.frame()
+
+ # The class reuses itself in the class scope.
+ is_recursive_klass: bool = (
+ frame is defframe
+ and defframe.parent_of(node)
+ and isinstance(defframe, nodes.ClassDef)
+ and node.name == defframe.name
+ )
+
+ if (
+ is_recursive_klass
+ and utils.get_node_first_ancestor_of_type(node, nodes.Lambda)
+ and (
+ not utils.is_default_argument(node)
+ or node.scope().parent.scope() is not defframe
+ )
+ ):
+ # Self-referential class references are fine in lambda's --
+ # As long as they are not part of the default argument directly
+ # under the scope of the parent self-referring class.
+ # Example of valid default argument:
+ # class MyName3:
+ # myattr = 1
+ # mylambda3 = lambda: lambda a=MyName3: a
+ # Example of invalid default argument:
+ # class MyName4:
+ # myattr = 1
+ # mylambda4 = lambda a=MyName4: lambda: a
+
+ # If the above conditional is True,
+ # there is no possibility of undefined-variable
+ # Also do not consume class name
+ # (since consuming blocks subsequent checks)
+ # -- quit
+ return (VariableVisitConsumerAction.RETURN, None)
+
+ (
+ maybe_before_assign,
+ annotation_return,
+ use_outer_definition,
+ ) = self._is_variable_violation(
+ node,
+ defnode,
+ stmt,
+ defstmt,
+ frame,
+ defframe,
+ base_scope_type,
+ is_recursive_klass,
+ )
+
+ if use_outer_definition:
+ return (VariableVisitConsumerAction.CONTINUE, None)
+
+ if (
+ maybe_before_assign
+ and not utils.is_defined_before(node)
+ and not astroid.are_exclusive(stmt, defstmt, ("NameError",))
+ ):
+ # Used and defined in the same place, e.g `x += 1` and `del x`
+ defined_by_stmt = defstmt is stmt and isinstance(
+ node, (nodes.DelName, nodes.AssignName)
+ )
+ if (
+ is_recursive_klass
+ or defined_by_stmt
+ or annotation_return
+ or isinstance(defstmt, nodes.Delete)
+ ):
+ if not utils.node_ignores_exception(node, NameError):
+ # Handle postponed evaluation of annotations
+ if not (
+ self._postponed_evaluation_enabled
+ and isinstance(
+ stmt,
+ (
+ nodes.AnnAssign,
+ nodes.FunctionDef,
+ nodes.Arguments,
+ ),
+ )
+ and node.name in node.root().locals
+ ):
+ if defined_by_stmt:
+ return (VariableVisitConsumerAction.CONTINUE, [node])
+ return (VariableVisitConsumerAction.CONTINUE, None)
+
+ elif base_scope_type != "lambda":
+ # E0601 may *not* occurs in lambda scope.
+
+ # Skip postponed evaluation of annotations
+ # and unevaluated annotations inside a function body
+ if not (
+ self._postponed_evaluation_enabled
+ and isinstance(stmt, (nodes.AnnAssign, nodes.FunctionDef))
+ ) and not (
+ isinstance(stmt, nodes.AnnAssign)
+ and utils.get_node_first_ancestor_of_type(stmt, nodes.FunctionDef)
+ ):
+ self.add_message(
+ "used-before-assignment",
+ args=node.name,
+ node=node,
+ confidence=HIGH,
+ )
+ return (VariableVisitConsumerAction.RETURN, found_nodes)
+
+ elif base_scope_type == "lambda":
+ # E0601 can occur in class-level scope in lambdas, as in
+ # the following example:
+ # class A:
+ # x = lambda attr: f + attr
+ # f = 42
+ # We check lineno because doing the following is fine:
+ # class A:
+ # x = 42
+ # y = lambda attr: x + attr
+ if (
+ isinstance(frame, nodes.ClassDef)
+ and node.name in frame.locals
+ and stmt.fromlineno <= defstmt.fromlineno
+ ):
+ self.add_message(
+ "used-before-assignment",
+ args=node.name,
+ node=node,
+ confidence=HIGH,
+ )
+
+ elif not self._is_builtin(node.name) and self._is_only_type_assignment(
+ node, defstmt
+ ):
+ if node.scope().locals.get(node.name):
+ self.add_message(
+ "used-before-assignment", args=node.name, node=node, confidence=HIGH
+ )
+ else:
+ self.add_message(
+ "undefined-variable", args=node.name, node=node, confidence=HIGH
+ )
+ return (VariableVisitConsumerAction.RETURN, found_nodes)
+
+ elif (
+ isinstance(defstmt, nodes.ClassDef) and defnode not in defframe.type_params
+ ):
+ return self._is_first_level_self_reference(node, defstmt, found_nodes)
+
+ elif isinstance(defnode, nodes.NamedExpr):
+ if isinstance(defnode.parent, nodes.IfExp):
+ if self._is_never_evaluated(defnode, defnode.parent):
+ self.add_message(
+ "undefined-variable",
+ args=node.name,
+ node=node,
+ confidence=INFERENCE,
+ )
+ return (VariableVisitConsumerAction.RETURN, found_nodes)
+
+ return (VariableVisitConsumerAction.RETURN, found_nodes)
+
+ def _report_unfound_name_definition(
+ self, node: nodes.NodeNG, current_consumer: NamesConsumer
+ ) -> None:
+ """Reports used-before-assignment when all name definition nodes
+ get filtered out by NamesConsumer.
+ """
+ if (
+ self._postponed_evaluation_enabled
+ and utils.is_node_in_type_annotation_context(node)
+ ):
+ return
+ if self._is_builtin(node.name):
+ return
+ if self._is_variable_annotation_in_function(node):
+ return
+ if (
+ node.name in self._evaluated_type_checking_scopes
+ and node.scope() in self._evaluated_type_checking_scopes[node.name]
+ ):
+ return
+
+ confidence = HIGH
+ if node.name in current_consumer.names_under_always_false_test:
+ confidence = INFERENCE
+ elif node.name in current_consumer.consumed_uncertain:
+ confidence = CONTROL_FLOW
+
+ if node.name in current_consumer.names_defined_under_one_branch_only:
+ msg = "possibly-used-before-assignment"
+ else:
+ msg = "used-before-assignment"
+
+ self.add_message(
+ msg,
+ args=node.name,
+ node=node,
+ confidence=confidence,
+ )
+
+ def _filter_type_checking_import_from_consumption(
+ self, node: nodes.NodeNG, nodes_to_consume: list[nodes.NodeNG]
+ ) -> list[nodes.NodeNG]:
+ """Do not consume type-checking import node as used-before-assignment
+ may invoke in different scopes.
+ """
+ type_checking_import = next(
+ (
+ n
+ for n in nodes_to_consume
+ if isinstance(n, (nodes.Import, nodes.ImportFrom))
+ and in_type_checking_block(n)
+ ),
+ None,
+ )
+ # If used-before-assignment reported for usage of type checking import
+ # keep track of its scope
+ if type_checking_import and not self._is_variable_annotation_in_function(node):
+ self._evaluated_type_checking_scopes.setdefault(node.name, []).append(
+ node.scope()
+ )
+ nodes_to_consume = [n for n in nodes_to_consume if n != type_checking_import]
+ return nodes_to_consume
+
+ @utils.only_required_for_messages("no-name-in-module")
+ def visit_import(self, node: nodes.Import) -> None:
+ """Check modules attribute accesses."""
+ if not self._analyse_fallback_blocks and utils.is_from_fallback_block(node):
+ # No need to verify this, since ImportError is already
+ # handled by the client code.
+ return
+ # Don't verify import if part of guarded import block
+ if in_type_checking_block(node):
+ return
+ if isinstance(node.parent, nodes.If) and is_sys_guard(node.parent):
+ return
+
+ for name, _ in node.names:
+ parts = name.split(".")
+ try:
+ module = next(_infer_name_module(node, parts[0]))
+ except astroid.ResolveError:
+ continue
+ if not isinstance(module, nodes.Module):
+ continue
+ self._check_module_attrs(node, module, parts[1:])
+
+ @utils.only_required_for_messages("no-name-in-module")
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ """Check modules attribute accesses."""
+ if not self._analyse_fallback_blocks and utils.is_from_fallback_block(node):
+ # No need to verify this, since ImportError is already
+ # handled by the client code.
+ return
+ # Don't verify import if part of guarded import block
+ # I.e. `sys.version_info` or `typing.TYPE_CHECKING`
+ if in_type_checking_block(node):
+ return
+ if isinstance(node.parent, nodes.If) and is_sys_guard(node.parent):
+ return
+
+ name_parts = node.modname.split(".")
+ try:
+ module = node.do_import_module(name_parts[0])
+ except astroid.AstroidBuildingError:
+ return
+ module = self._check_module_attrs(node, module, name_parts[1:])
+ if not module:
+ return
+ for name, _ in node.names:
+ if name == "*":
+ continue
+ self._check_module_attrs(node, module, name.split("."))
+
+ @utils.only_required_for_messages(
+ "unbalanced-tuple-unpacking",
+ "unpacking-non-sequence",
+ "self-cls-assignment",
+ "unbalanced_dict_unpacking",
+ )
+ def visit_assign(self, node: nodes.Assign) -> None:
+ """Check unbalanced tuple unpacking for assignments and unpacking
+ non-sequences as well as in case self/cls get assigned.
+ """
+ self._check_self_cls_assign(node)
+ if not isinstance(node.targets[0], (nodes.Tuple, nodes.List)):
+ return
+
+ targets = node.targets[0].itered()
+
+ # Check if we have starred nodes.
+ if any(isinstance(target, nodes.Starred) for target in targets):
+ return
+
+ try:
+ inferred = utils.safe_infer(node.value)
+ if inferred is not None:
+ self._check_unpacking(inferred, node, targets)
+ except astroid.InferenceError:
+ return
+
+ # listcomp have now also their scope
+ def visit_listcomp(self, node: nodes.ListComp) -> None:
+ """Visit listcomp: update consumption analysis variable."""
+ self._to_consume.append(NamesConsumer(node, "comprehension"))
+
+ def leave_listcomp(self, _: nodes.ListComp) -> None:
+ """Leave listcomp: update consumption analysis variable."""
+ # do not check for not used locals here
+ self._to_consume.pop()
+
+ def leave_assign(self, node: nodes.Assign) -> None:
+ self._store_type_annotation_names(node)
+
+ def leave_with(self, node: nodes.With) -> None:
+ self._store_type_annotation_names(node)
+
+ def visit_arguments(self, node: nodes.Arguments) -> None:
+ for annotation in node.type_comment_args:
+ self._store_type_annotation_node(annotation)
+
+ # Relying on other checker's options, which might not have been initialized yet.
+ @cached_property
+ def _analyse_fallback_blocks(self) -> bool:
+ return bool(self.linter.config.analyse_fallback_blocks)
+
+ @cached_property
+ def _ignored_modules(self) -> Iterable[str]:
+ return self.linter.config.ignored_modules # type: ignore[no-any-return]
+
+ @cached_property
+ def _allow_global_unused_variables(self) -> bool:
+ return bool(self.linter.config.allow_global_unused_variables)
+
+ @staticmethod
+ def _defined_in_function_definition(
+ node: nodes.NodeNG, frame: nodes.NodeNG
+ ) -> bool:
+ in_annotation_or_default_or_decorator = False
+ if isinstance(frame, nodes.FunctionDef) and node.statement() is frame:
+ in_annotation_or_default_or_decorator = (
+ (
+ node in frame.args.annotations
+ or node in frame.args.posonlyargs_annotations
+ or node in frame.args.kwonlyargs_annotations
+ or node is frame.args.varargannotation
+ or node is frame.args.kwargannotation
+ )
+ or frame.args.parent_of(node)
+ or (frame.decorators and frame.decorators.parent_of(node))
+ or (
+ frame.returns
+ and (node is frame.returns or frame.returns.parent_of(node))
+ )
+ )
+ return in_annotation_or_default_or_decorator
+
+ @staticmethod
+ def _in_lambda_or_comprehension_body(
+ node: nodes.NodeNG, frame: nodes.NodeNG
+ ) -> bool:
+ """Return True if node within a lambda/comprehension body (or similar) and thus
+ should not have access to class attributes in frame.
+ """
+ child = node
+ parent = node.parent
+ while parent is not None:
+ if parent is frame:
+ return False
+ if isinstance(parent, nodes.Lambda) and child is not parent.args:
+ # Body of lambda should not have access to class attributes.
+ return True
+ if isinstance(parent, nodes.Comprehension) and child is not parent.iter:
+ # Only iter of list/set/dict/generator comprehension should have access.
+ return True
+ if isinstance(parent, nodes.ComprehensionScope) and not (
+ parent.generators and child is parent.generators[0]
+ ):
+ # Body of list/set/dict/generator comprehension should not have access to class attributes.
+ # Furthermore, only the first generator (if multiple) in comprehension should have access.
+ return True
+ child = parent
+ parent = parent.parent
+ return False
+
+ @staticmethod
+ def _is_variable_violation(
+ node: nodes.Name,
+ defnode: nodes.NodeNG,
+ stmt: _base_nodes.Statement,
+ defstmt: _base_nodes.Statement,
+ frame: nodes.LocalsDictNodeNG, # scope of statement of node
+ defframe: nodes.LocalsDictNodeNG,
+ base_scope_type: str,
+ is_recursive_klass: bool,
+ ) -> tuple[bool, bool, bool]:
+ maybe_before_assign = True
+ annotation_return = False
+ use_outer_definition = False
+ if frame is not defframe:
+ maybe_before_assign = _detect_global_scope(node, frame, defframe)
+ elif defframe.parent is None:
+ # we are at the module level, check the name is not
+ # defined in builtins
+ if (
+ node.name in defframe.scope_attrs
+ or astroid.builtin_lookup(node.name)[1]
+ ):
+ maybe_before_assign = False
+ else:
+ # we are in a local scope, check the name is not
+ # defined in global or builtin scope
+ # skip this lookup if name is assigned later in function scope/lambda
+ # Note: the node.frame() is not the same as the `frame` argument which is
+ # equivalent to frame.statement().scope()
+ forbid_lookup = (
+ isinstance(frame, nodes.FunctionDef)
+ or isinstance(node.frame(), nodes.Lambda)
+ ) and _assigned_locally(node)
+ if not forbid_lookup and defframe.root().lookup(node.name)[1]:
+ maybe_before_assign = False
+ use_outer_definition = stmt == defstmt and not isinstance(
+ defnode, nodes.Comprehension
+ )
+ # check if we have a nonlocal
+ elif node.name in defframe.locals:
+ maybe_before_assign = not any(
+ isinstance(child, nodes.Nonlocal) and node.name in child.names
+ for child in defframe.get_children()
+ )
+
+ if (
+ base_scope_type == "lambda"
+ and isinstance(frame, nodes.ClassDef)
+ and node.name in frame.locals
+ ):
+ # This rule verifies that if the definition node of the
+ # checked name is an Arguments node and if the name
+ # is used a default value in the arguments defaults
+ # and the actual definition of the variable label
+ # is happening before the Arguments definition.
+ #
+ # bar = None
+ # foo = lambda bar=bar: bar
+ #
+ # In this case, maybe_before_assign should be False, otherwise
+ # it should be True.
+ maybe_before_assign = not (
+ isinstance(defnode, nodes.Arguments)
+ and node in defnode.defaults
+ and frame.locals[node.name][0].fromlineno < defstmt.fromlineno
+ )
+ elif isinstance(defframe, nodes.ClassDef) and isinstance(
+ frame, nodes.FunctionDef
+ ):
+ # Special rule for function return annotations,
+ # using a name defined earlier in the class containing the function.
+ if node is frame.returns and defframe.parent_of(frame.returns):
+ annotation_return = True
+ if frame.returns.name in defframe.locals:
+ definition = defframe.locals[node.name][0]
+ if definition.lineno is None or definition.lineno < frame.lineno:
+ # Detect class assignments with a name defined earlier in the
+ # class. In this case, no warning should be raised.
+ maybe_before_assign = False
+ else:
+ maybe_before_assign = True
+ else:
+ maybe_before_assign = True
+ if isinstance(node.parent, nodes.Arguments):
+ maybe_before_assign = stmt.fromlineno <= defstmt.fromlineno
+ elif is_recursive_klass:
+ maybe_before_assign = True
+ else:
+ maybe_before_assign = (
+ maybe_before_assign and stmt.fromlineno <= defstmt.fromlineno
+ )
+ if maybe_before_assign and stmt.fromlineno == defstmt.fromlineno:
+ if (
+ isinstance(defframe, nodes.FunctionDef)
+ and frame is defframe
+ and defframe.parent_of(node)
+ and (
+ defnode in defframe.type_params
+ # Single statement function, with the statement on the
+ # same line as the function definition
+ or stmt is not defstmt
+ )
+ ):
+ maybe_before_assign = False
+ elif (
+ isinstance(defstmt, NODES_WITH_VALUE_ATTR)
+ and VariablesChecker._maybe_used_and_assigned_at_once(defstmt)
+ and frame is defframe
+ and defframe.parent_of(node)
+ and stmt is defstmt
+ ):
+ # Single statement if, with assignment expression on same
+ # line as assignment
+ # x = b if (b := True) else False
+ maybe_before_assign = False
+ elif (
+ isinstance( # pylint: disable=too-many-boolean-expressions
+ defnode, nodes.NamedExpr
+ )
+ and frame is defframe
+ and defframe.parent_of(stmt)
+ and stmt is defstmt
+ and (
+ (
+ defnode.lineno == node.lineno
+ and defnode.col_offset < node.col_offset
+ )
+ or (defnode.lineno < node.lineno)
+ )
+ ):
+ # Relation of a name to the same name in a named expression
+ # Could be used before assignment if self-referencing:
+ # (b := b)
+ # Otherwise, safe if used after assignment:
+ # (b := 2) and b
+ maybe_before_assign = defnode.value is node or any(
+ anc is defnode.value for anc in node.node_ancestors()
+ )
+ elif (
+ isinstance(defframe, nodes.ClassDef)
+ and defnode in defframe.type_params
+ ):
+ # Generic on parent class:
+ # class Child[_T](Parent[_T])
+ maybe_before_assign = False
+
+ return maybe_before_assign, annotation_return, use_outer_definition
+
+ @staticmethod
+ def _maybe_used_and_assigned_at_once(defstmt: _base_nodes.Statement) -> bool:
+ """Check if `defstmt` has the potential to use and assign a name in the
+ same statement.
+ """
+ if isinstance(defstmt, nodes.Match):
+ return any(case.guard for case in defstmt.cases)
+ if isinstance(defstmt, nodes.IfExp):
+ return True
+ if isinstance(defstmt, nodes.TypeAlias):
+ return True
+ if isinstance(defstmt.value, nodes.BaseContainer):
+ return any(
+ VariablesChecker._maybe_used_and_assigned_at_once(elt)
+ for elt in defstmt.value.elts
+ if isinstance(elt, (*NODES_WITH_VALUE_ATTR, nodes.IfExp, nodes.Match))
+ )
+ value = defstmt.value
+ if isinstance(value, nodes.IfExp):
+ return True
+ if isinstance(value, nodes.Lambda) and isinstance(value.body, nodes.IfExp):
+ return True
+ if isinstance(value, nodes.Dict) and any(
+ isinstance(item[0], nodes.IfExp) or isinstance(item[1], nodes.IfExp)
+ for item in value.items
+ ):
+ return True
+ if not isinstance(value, nodes.Call):
+ return False
+ return any(
+ any(isinstance(kwarg.value, nodes.IfExp) for kwarg in call.keywords)
+ or any(isinstance(arg, nodes.IfExp) for arg in call.args)
+ or (
+ isinstance(call.func, nodes.Attribute)
+ and isinstance(call.func.expr, nodes.IfExp)
+ )
+ for call in value.nodes_of_class(klass=nodes.Call)
+ )
+
+ def _is_builtin(self, name: str) -> bool:
+ return name in self.linter.config.additional_builtins or utils.is_builtin(name)
+
+ @staticmethod
+ def _is_only_type_assignment(
+ node: nodes.Name, defstmt: _base_nodes.Statement
+ ) -> bool:
+ """Check if variable only gets assigned a type and never a value."""
+ if not isinstance(defstmt, nodes.AnnAssign) or defstmt.value:
+ return False
+
+ defstmt_frame = defstmt.frame()
+ node_frame = node.frame()
+
+ parent = node
+ while parent is not defstmt_frame.parent:
+ parent_scope = parent.scope()
+
+ # Find out if any nonlocals receive values in nested functions
+ for inner_func in parent_scope.nodes_of_class(nodes.FunctionDef):
+ if inner_func is parent_scope:
+ continue
+ if any(
+ node.name in nl.names
+ for nl in inner_func.nodes_of_class(nodes.Nonlocal)
+ ) and any(
+ node.name == an.name
+ for an in inner_func.nodes_of_class(nodes.AssignName)
+ ):
+ return False
+
+ local_refs = parent_scope.locals.get(node.name, [])
+ for ref_node in local_refs:
+ # If local ref is in the same frame as our node, but on a later lineno
+ # we don't actually care about this local ref.
+ # Local refs are ordered, so we break.
+ # print(var)
+ # var = 1 # <- irrelevant
+ if defstmt_frame == node_frame and ref_node.lineno > node.lineno:
+ break
+
+ # If the parent of the local reference is anything but an AnnAssign
+ # Or if the AnnAssign adds a value the variable will now have a value
+ # var = 1 # OR
+ # var: int = 1
+ if (
+ not isinstance(ref_node.parent, nodes.AnnAssign)
+ or ref_node.parent.value
+ ) and not (
+ # EXCEPTION: will not have a value if a self-referencing named expression
+ # var: int
+ # if (var := var * var) <-- "var" still undefined
+ isinstance(ref_node.parent, nodes.NamedExpr)
+ and any(
+ anc is ref_node.parent.value for anc in node.node_ancestors()
+ )
+ ):
+ return False
+ parent = parent_scope.parent
+ return True
+
+ @staticmethod
+ def _is_first_level_self_reference(
+ node: nodes.Name, defstmt: nodes.ClassDef, found_nodes: list[nodes.NodeNG]
+ ) -> tuple[VariableVisitConsumerAction, list[nodes.NodeNG] | None]:
+ """Check if a first level method's annotation or default values
+ refers to its own class, and return a consumer action.
+ """
+ if node.frame().parent == defstmt and node.statement() == node.frame():
+ # Check if used as type annotation
+ # Break if postponed evaluation is enabled
+ if utils.is_node_in_type_annotation_context(node):
+ if not utils.is_postponed_evaluation_enabled(node):
+ return (VariableVisitConsumerAction.CONTINUE, None)
+ return (VariableVisitConsumerAction.RETURN, None)
+ # Check if used as default value by calling the class
+ if isinstance(node.parent, nodes.Call) and isinstance(
+ node.parent.parent, nodes.Arguments
+ ):
+ return (VariableVisitConsumerAction.CONTINUE, None)
+ return (VariableVisitConsumerAction.RETURN, found_nodes)
+
+ @staticmethod
+ def _is_never_evaluated(
+ defnode: nodes.NamedExpr, defnode_parent: nodes.IfExp
+ ) -> bool:
+ """Check if a NamedExpr is inside a side of if ... else that never
+ gets evaluated.
+ """
+ inferred_test = utils.safe_infer(defnode_parent.test)
+ if isinstance(inferred_test, nodes.Const):
+ if inferred_test.value is True and defnode == defnode_parent.orelse:
+ return True
+ if inferred_test.value is False and defnode == defnode_parent.body:
+ return True
+ return False
+
+ @staticmethod
+ def _is_variable_annotation_in_function(node: nodes.NodeNG) -> bool:
+ is_annotation = utils.get_node_first_ancestor_of_type(node, nodes.AnnAssign)
+ return (
+ is_annotation
+ and utils.get_node_first_ancestor_of_type( # type: ignore[return-value]
+ is_annotation, nodes.FunctionDef
+ )
+ )
+
+ def _ignore_class_scope(self, node: nodes.NodeNG) -> bool:
+ """Return True if the node is in a local class scope, as an assignment.
+
+ Detect if we are in a local class scope, as an assignment.
+ For example, the following is fair game.
+
+ class A:
+ b = 1
+ c = lambda b=b: b * b
+
+ class B:
+ tp = 1
+ def func(self, arg: tp):
+ ...
+ class C:
+ tp = 2
+ def func(self, arg=tp):
+ ...
+ class C:
+ class Tp:
+ pass
+ class D(Tp):
+ ...
+ """
+ name = node.name
+ frame = node.statement().scope()
+ in_annotation_or_default_or_decorator = self._defined_in_function_definition(
+ node, frame
+ )
+ in_ancestor_list = utils.is_ancestor_name(frame, node)
+ if in_annotation_or_default_or_decorator or in_ancestor_list:
+ frame_locals = frame.parent.scope().locals
+ else:
+ frame_locals = frame.locals
+ return not (
+ (isinstance(frame, nodes.ClassDef) or in_annotation_or_default_or_decorator)
+ and not self._in_lambda_or_comprehension_body(node, frame)
+ and name in frame_locals
+ )
+
+ # pylint: disable-next=too-many-branches,too-many-statements
+ def _loopvar_name(self, node: astroid.Name) -> None:
+ # filter variables according to node's scope
+ astmts = [s for s in node.lookup(node.name)[1] if hasattr(s, "assign_type")]
+ # If this variable usage exists inside a function definition
+ # that exists in the same loop,
+ # the usage is safe because the function will not be defined either if
+ # the variable is not defined.
+ scope = node.scope()
+ if isinstance(scope, (nodes.Lambda, nodes.FunctionDef)) and any(
+ asmt.scope().parent_of(scope) for asmt in astmts
+ ):
+ return
+ # Filter variables according to their respective scope. Test parent
+ # and statement to avoid #74747. This is not a total fix, which would
+ # introduce a mechanism similar to special attribute lookup in
+ # modules. Also, in order to get correct inference in this case, the
+ # scope lookup rules would need to be changed to return the initial
+ # assignment (which does not exist in code per se) as well as any later
+ # modifications.
+ if (
+ not astmts # pylint: disable=too-many-boolean-expressions
+ or (
+ astmts[0].parent == astmts[0].root()
+ and astmts[0].parent.parent_of(node)
+ )
+ or (
+ astmts[0].is_statement
+ or not isinstance(astmts[0].parent, nodes.Module)
+ and astmts[0].statement().parent_of(node)
+ )
+ ):
+ _astmts = []
+ else:
+ _astmts = astmts[:1]
+ for i, stmt in enumerate(astmts[1:]):
+ try:
+ astmt_statement = astmts[i].statement()
+ except astroid.exceptions.ParentMissingError:
+ continue
+ if astmt_statement.parent_of(stmt) and not utils.in_for_else_branch(
+ astmt_statement, stmt
+ ):
+ continue
+ _astmts.append(stmt)
+ astmts = _astmts
+ if len(astmts) != 1:
+ return
+
+ assign = astmts[0].assign_type()
+ if not (
+ isinstance(assign, (nodes.For, nodes.Comprehension, nodes.GeneratorExp))
+ and assign.statement() is not node.statement()
+ ):
+ return
+
+ if not isinstance(assign, nodes.For):
+ self.add_message("undefined-loop-variable", args=node.name, node=node)
+ return
+ for else_stmt in assign.orelse:
+ if isinstance(
+ else_stmt, (nodes.Return, nodes.Raise, nodes.Break, nodes.Continue)
+ ):
+ return
+ # TODO: 4.0: Consider using utils.is_terminating_func
+ # after merging it with RefactoringChecker._is_function_def_never_returning
+ if isinstance(else_stmt, nodes.Expr) and isinstance(
+ else_stmt.value, nodes.Call
+ ):
+ inferred_func = utils.safe_infer(else_stmt.value.func)
+ if (
+ isinstance(inferred_func, nodes.FunctionDef)
+ and inferred_func.returns
+ ):
+ inferred_return = utils.safe_infer(inferred_func.returns)
+ if isinstance(
+ inferred_return, nodes.FunctionDef
+ ) and inferred_return.qname() in {
+ *TYPING_NORETURN,
+ *TYPING_NEVER,
+ "typing._SpecialForm",
+ }:
+ return
+ # typing_extensions.NoReturn returns a _SpecialForm
+ if (
+ isinstance(inferred_return, bases.Instance)
+ and inferred_return.qname() == "typing._SpecialForm"
+ ):
+ return
+
+ maybe_walrus = utils.get_node_first_ancestor_of_type(node, nodes.NamedExpr)
+ if maybe_walrus:
+ maybe_comprehension = utils.get_node_first_ancestor_of_type(
+ maybe_walrus, nodes.Comprehension
+ )
+ if maybe_comprehension:
+ comprehension_scope = utils.get_node_first_ancestor_of_type(
+ maybe_comprehension, nodes.ComprehensionScope
+ )
+ if comprehension_scope is None:
+ # Should not be possible.
+ pass
+ elif (
+ comprehension_scope.parent.scope() is scope
+ and node.name in comprehension_scope.locals
+ ):
+ return
+
+ # For functions we can do more by inferring the length of the itered object
+ try:
+ inferred = next(assign.iter.infer())
+ # Prefer the target of enumerate() rather than the enumerate object itself
+ if (
+ isinstance(inferred, astroid.Instance)
+ and inferred.qname() == "builtins.enumerate"
+ ):
+ likely_call = assign.iter
+ if isinstance(assign.iter, nodes.IfExp):
+ likely_call = assign.iter.body
+ if isinstance(likely_call, nodes.Call) and likely_call.args:
+ inferred = next(likely_call.args[0].infer())
+ except astroid.InferenceError:
+ self.add_message("undefined-loop-variable", args=node.name, node=node)
+ else:
+ if (
+ isinstance(inferred, astroid.Instance)
+ and inferred.qname() == BUILTIN_RANGE
+ ):
+ # Consider range() objects safe, even if they might not yield any results.
+ return
+
+ # Consider sequences.
+ sequences = (
+ nodes.List,
+ nodes.Tuple,
+ nodes.Dict,
+ nodes.Set,
+ astroid.objects.FrozenSet,
+ )
+ if not isinstance(inferred, sequences):
+ self.add_message("undefined-loop-variable", args=node.name, node=node)
+ return
+
+ elements = getattr(inferred, "elts", getattr(inferred, "items", []))
+ if not elements:
+ self.add_message("undefined-loop-variable", args=node.name, node=node)
+
+ # pylint: disable = too-many-branches
+ def _check_is_unused(
+ self,
+ name: str,
+ node: nodes.FunctionDef,
+ stmt: nodes.NodeNG,
+ global_names: set[str],
+ nonlocal_names: Iterable[str],
+ comprehension_target_names: Iterable[str],
+ ) -> None:
+ # Ignore some special names specified by user configuration.
+ if self._is_name_ignored(stmt, name):
+ return
+ # Ignore names that were added dynamically to the Function scope
+ if (
+ isinstance(node, nodes.FunctionDef)
+ and name == "__class__"
+ and len(node.locals["__class__"]) == 1
+ and isinstance(node.locals["__class__"][0], nodes.ClassDef)
+ ):
+ return
+
+ # Ignore names imported by the global statement.
+ if isinstance(stmt, (nodes.Global, nodes.Import, nodes.ImportFrom)):
+ # Detect imports, assigned to global statements.
+ if global_names and _import_name_is_global(stmt, global_names):
+ return
+
+ # Ignore names in comprehension targets
+ if name in comprehension_target_names:
+ return
+
+ # Ignore names in string literal type annotation.
+ if name in self._type_annotation_names:
+ return
+
+ argnames = node.argnames()
+ # Care about functions with unknown argument (builtins)
+ if name in argnames:
+ if node.name == "__new__":
+ is_init_def = False
+ # Look for the `__init__` method in all the methods of the same class.
+ for n in node.parent.get_children():
+ is_init_def = hasattr(n, "name") and (n.name == "__init__")
+ if is_init_def:
+ break
+ # Ignore unused arguments check for `__new__` if `__init__` is defined.
+ if is_init_def:
+ return
+ self._check_unused_arguments(name, node, stmt, argnames, nonlocal_names)
+ else:
+ if stmt.parent and isinstance(
+ stmt.parent, (nodes.Assign, nodes.AnnAssign, nodes.Tuple, nodes.For)
+ ):
+ if name in nonlocal_names:
+ return
+
+ qname = asname = None
+ if isinstance(stmt, (nodes.Import, nodes.ImportFrom)):
+ # Need the complete name, which we don't have in .locals.
+ if len(stmt.names) > 1:
+ import_names = next(
+ (names for names in stmt.names if name in names), None
+ )
+ else:
+ import_names = stmt.names[0]
+ if import_names:
+ qname, asname = import_names
+ name = asname or qname
+
+ if _has_locals_call_after_node(stmt, node.scope()):
+ message_name = "possibly-unused-variable"
+ else:
+ if isinstance(stmt, nodes.Import):
+ if asname is not None:
+ msg = f"{qname} imported as {asname}"
+ else:
+ msg = f"import {name}"
+ self.add_message("unused-import", args=msg, node=stmt)
+ return
+ if isinstance(stmt, nodes.ImportFrom):
+ if asname is not None:
+ msg = f"{qname} imported from {stmt.modname} as {asname}"
+ else:
+ msg = f"{name} imported from {stmt.modname}"
+ self.add_message("unused-import", args=msg, node=stmt)
+ return
+ message_name = "unused-variable"
+
+ if isinstance(stmt, nodes.FunctionDef) and stmt.decorators:
+ return
+
+ # Don't check function stubs created only for type information
+ if utils.is_overload_stub(node):
+ return
+
+ # Special case for exception variable
+ if isinstance(stmt.parent, nodes.ExceptHandler) and any(
+ n.name == name for n in stmt.parent.nodes_of_class(nodes.Name)
+ ):
+ return
+
+ self.add_message(message_name, args=name, node=stmt)
+
+ def _is_name_ignored(
+ self, stmt: nodes.NodeNG, name: str
+ ) -> re.Pattern[str] | re.Match[str] | None:
+ authorized_rgx = self.linter.config.dummy_variables_rgx
+ if (
+ isinstance(stmt, nodes.AssignName)
+ and isinstance(stmt.parent, nodes.Arguments)
+ or isinstance(stmt, nodes.Arguments)
+ ):
+ regex: re.Pattern[str] = self.linter.config.ignored_argument_names
+ else:
+ regex = authorized_rgx
+ # See https://stackoverflow.com/a/47007761/2519059 to
+ # understand what this function return. Please do NOT use
+ # this elsewhere, this is confusing for no benefit
+ return regex and regex.match(name)
+
+ def _check_unused_arguments(
+ self,
+ name: str,
+ node: nodes.FunctionDef,
+ stmt: nodes.NodeNG,
+ argnames: list[str],
+ nonlocal_names: Iterable[str],
+ ) -> None:
+ is_method = node.is_method()
+ klass = node.parent.frame()
+ if is_method and isinstance(klass, nodes.ClassDef):
+ confidence = (
+ INFERENCE if utils.has_known_bases(klass) else INFERENCE_FAILURE
+ )
+ else:
+ confidence = HIGH
+
+ if is_method:
+ # Don't warn for the first argument of a (non static) method
+ if node.type != "staticmethod" and name == argnames[0]:
+ return
+ # Don't warn for argument of an overridden method
+ overridden = overridden_method(klass, node.name)
+ if overridden is not None and name in overridden.argnames():
+ return
+ if node.name in utils.PYMETHODS and node.name not in (
+ "__init__",
+ "__new__",
+ ):
+ return
+ # Don't check callback arguments
+ if any(
+ node.name.startswith(cb) or node.name.endswith(cb)
+ for cb in self.linter.config.callbacks
+ ):
+ return
+ # Don't check arguments of singledispatch.register function.
+ if utils.is_registered_in_singledispatch_function(node):
+ return
+
+ # Don't check function stubs created only for type information
+ if utils.is_overload_stub(node):
+ return
+
+ # Don't check protocol classes
+ if utils.is_protocol_class(klass):
+ return
+
+ if name in nonlocal_names:
+ return
+
+ self.add_message("unused-argument", args=name, node=stmt, confidence=confidence)
+
+ def _check_late_binding_closure(self, node: nodes.Name) -> None:
+ """Check whether node is a cell var that is assigned within a containing loop.
+
+ Special cases where we don't care about the error:
+ 1. When the node's function is immediately called, e.g. (lambda: i)()
+ 2. When the node's function is returned from within the loop, e.g. return lambda: i
+ """
+ if not self.linter.is_message_enabled("cell-var-from-loop"):
+ return
+
+ node_scope = node.frame()
+
+ # If node appears in a default argument expression,
+ # look at the next enclosing frame instead
+ if utils.is_default_argument(node, node_scope):
+ node_scope = node_scope.parent.frame()
+
+ # Check if node is a cell var
+ if (
+ not isinstance(node_scope, (nodes.Lambda, nodes.FunctionDef))
+ or node.name in node_scope.locals
+ ):
+ return
+
+ assign_scope, stmts = node.lookup(node.name)
+ if not stmts or not assign_scope.parent_of(node_scope):
+ return
+
+ if utils.is_comprehension(assign_scope):
+ self.add_message("cell-var-from-loop", node=node, args=node.name)
+ else:
+ # Look for an enclosing For loop.
+ # Currently, we only consider the first assignment
+ assignment_node = stmts[0]
+
+ maybe_for = assignment_node
+ while maybe_for and not isinstance(maybe_for, nodes.For):
+ if maybe_for is assign_scope:
+ break
+ maybe_for = maybe_for.parent
+ else:
+ if (
+ maybe_for
+ and maybe_for.parent_of(node_scope)
+ and not utils.is_being_called(node_scope)
+ and node_scope.parent
+ and not isinstance(node_scope.statement(), nodes.Return)
+ ):
+ self.add_message("cell-var-from-loop", node=node, args=node.name)
+
+ def _should_ignore_redefined_builtin(self, stmt: nodes.NodeNG) -> bool:
+ if not isinstance(stmt, nodes.ImportFrom):
+ return False
+ return stmt.modname in self.linter.config.redefining_builtins_modules
+
+ def _allowed_redefined_builtin(self, name: str) -> bool:
+ return name in self.linter.config.allowed_redefined_builtins
+
+ @staticmethod
+ def _comprehension_between_frame_and_node(node: nodes.Name) -> bool:
+ """Return True if a ComprehensionScope intervenes between `node` and its
+ frame.
+ """
+ closest_comprehension_scope = utils.get_node_first_ancestor_of_type(
+ node, nodes.ComprehensionScope
+ )
+ return closest_comprehension_scope is not None and node.frame().parent_of(
+ closest_comprehension_scope
+ )
+
+ def _store_type_annotation_node(self, type_annotation: nodes.NodeNG) -> None:
+ """Given a type annotation, store all the name nodes it refers to."""
+ if isinstance(type_annotation, nodes.Name):
+ self._type_annotation_names.append(type_annotation.name)
+ return
+
+ if isinstance(type_annotation, nodes.Attribute):
+ self._store_type_annotation_node(type_annotation.expr)
+ return
+
+ if not isinstance(type_annotation, nodes.Subscript):
+ return
+
+ if (
+ isinstance(type_annotation.value, nodes.Attribute)
+ and isinstance(type_annotation.value.expr, nodes.Name)
+ and type_annotation.value.expr.name == TYPING_MODULE
+ ):
+ self._type_annotation_names.append(TYPING_MODULE)
+ return
+
+ self._type_annotation_names.extend(
+ annotation.name for annotation in type_annotation.nodes_of_class(nodes.Name)
+ )
+
+ def _store_type_annotation_names(
+ self, node: nodes.For | nodes.Assign | nodes.With
+ ) -> None:
+ type_annotation = node.type_annotation
+ if not type_annotation:
+ return
+ self._store_type_annotation_node(node.type_annotation)
+
+ def _check_self_cls_assign(self, node: nodes.Assign) -> None:
+ """Check that self/cls don't get assigned."""
+ assign_names: set[str | None] = set()
+ for target in node.targets:
+ if isinstance(target, nodes.AssignName):
+ assign_names.add(target.name)
+ elif isinstance(target, nodes.Tuple):
+ assign_names.update(
+ elt.name for elt in target.elts if isinstance(elt, nodes.AssignName)
+ )
+ scope = node.scope()
+ nonlocals_with_same_name = node.scope().parent and any(
+ child for child in scope.body if isinstance(child, nodes.Nonlocal)
+ )
+ if nonlocals_with_same_name:
+ scope = node.scope().parent.scope()
+
+ if not (
+ isinstance(scope, nodes.FunctionDef)
+ and scope.is_method()
+ and "builtins.staticmethod" not in scope.decoratornames()
+ ):
+ return
+ argument_names = scope.argnames()
+ if not argument_names:
+ return
+ self_cls_name = argument_names[0]
+ if self_cls_name in assign_names:
+ self.add_message("self-cls-assignment", node=node, args=(self_cls_name,))
+
+ def _check_unpacking(
+ self, inferred: InferenceResult, node: nodes.Assign, targets: list[nodes.NodeNG]
+ ) -> None:
+ """Check for unbalanced tuple unpacking
+ and unpacking non sequences.
+ """
+ if utils.is_inside_abstract_class(node):
+ return
+ if utils.is_comprehension(node):
+ return
+ if isinstance(inferred, util.UninferableBase):
+ return
+ if (
+ isinstance(inferred.parent, nodes.Arguments)
+ and isinstance(node.value, nodes.Name)
+ and node.value.name == inferred.parent.vararg
+ ):
+ # Variable-length argument, we can't determine the length.
+ return
+
+ # Attempt to check unpacking is properly balanced
+ values = self._nodes_to_unpack(inferred)
+ details = _get_unpacking_extra_info(node, inferred)
+
+ if values is not None:
+ if len(targets) != len(values):
+ self._report_unbalanced_unpacking(
+ node, inferred, targets, len(values), details
+ )
+ # attempt to check unpacking may be possible (i.e. RHS is iterable)
+ elif not utils.is_iterable(inferred):
+ self._report_unpacking_non_sequence(node, details)
+
+ @staticmethod
+ def _get_value_length(value_node: nodes.NodeNG) -> int:
+ value_subnodes = VariablesChecker._nodes_to_unpack(value_node)
+ if value_subnodes is not None:
+ return len(value_subnodes)
+ if isinstance(value_node, nodes.Const) and isinstance(
+ value_node.value, (str, bytes)
+ ):
+ return len(value_node.value)
+ if isinstance(value_node, nodes.Subscript):
+ step = value_node.slice.step or 1
+ splice_range = value_node.slice.upper.value - value_node.slice.lower.value
+ splice_length = int(math.ceil(splice_range / step))
+ return splice_length
+ return 1
+
+ @staticmethod
+ def _nodes_to_unpack(node: nodes.NodeNG) -> list[nodes.NodeNG] | None:
+ """Return the list of values of the `Assign` node."""
+ if isinstance(node, (nodes.Tuple, nodes.List, nodes.Set, *DICT_TYPES)):
+ return node.itered() # type: ignore[no-any-return]
+ if isinstance(node, astroid.Instance) and any(
+ ancestor.qname() == "typing.NamedTuple" for ancestor in node.ancestors()
+ ):
+ return [i for i in node.values() if isinstance(i, nodes.AssignName)]
+ return None
+
+ def _report_unbalanced_unpacking(
+ self,
+ node: nodes.NodeNG,
+ inferred: InferenceResult,
+ targets: list[nodes.NodeNG],
+ values_count: int,
+ details: str,
+ ) -> None:
+ args = (
+ details,
+ len(targets),
+ "" if len(targets) == 1 else "s",
+ values_count,
+ "" if values_count == 1 else "s",
+ )
+
+ symbol = (
+ "unbalanced-dict-unpacking"
+ if isinstance(inferred, DICT_TYPES)
+ else "unbalanced-tuple-unpacking"
+ )
+ self.add_message(symbol, node=node, args=args, confidence=INFERENCE)
+
+ def _report_unpacking_non_sequence(self, node: nodes.NodeNG, details: str) -> None:
+ if details and not details.startswith(" "):
+ details = f" {details}"
+ self.add_message("unpacking-non-sequence", node=node, args=details)
+
+ def _check_module_attrs(
+ self,
+ node: _base_nodes.ImportNode,
+ module: nodes.Module,
+ module_names: list[str],
+ ) -> nodes.Module | None:
+ """Check that module_names (list of string) are accessible through the
+ given module, if the latest access name corresponds to a module, return it.
+ """
+ while module_names:
+ name = module_names.pop(0)
+ if name == "__dict__":
+ module = None
+ break
+ try:
+ module = module.getattr(name)[0]
+ if not isinstance(module, nodes.Module):
+ module = next(module.infer())
+ if not isinstance(module, nodes.Module):
+ return None
+ except astroid.NotFoundError:
+ # Unable to import `name` from `module`. Since `name` may itself be a
+ # module, we first check if it matches the ignored modules.
+ if is_module_ignored(f"{module.qname()}.{name}", self._ignored_modules):
+ return None
+ self.add_message(
+ "no-name-in-module", args=(name, module.name), node=node
+ )
+ return None
+ except astroid.InferenceError:
+ return None
+ if module_names:
+ modname = module.name if module else "__dict__"
+ self.add_message(
+ "no-name-in-module", node=node, args=(".".join(module_names), modname)
+ )
+ return None
+ if isinstance(module, nodes.Module):
+ return module
+ return None
+
+ def _check_all(
+ self, node: nodes.Module, not_consumed: dict[str, list[nodes.NodeNG]]
+ ) -> None:
+ try:
+ assigned = next(node.igetattr("__all__"))
+ except astroid.InferenceError:
+ return
+ if isinstance(assigned, util.UninferableBase):
+ return
+ if assigned.pytype() not in {"builtins.list", "builtins.tuple"}:
+ line, col = assigned.tolineno, assigned.col_offset
+ self.add_message("invalid-all-format", line=line, col_offset=col, node=node)
+ return
+ for elt in getattr(assigned, "elts", ()):
+ try:
+ elt_name = next(elt.infer())
+ except astroid.InferenceError:
+ continue
+ if isinstance(elt_name, util.UninferableBase):
+ continue
+ if not elt_name.parent:
+ continue
+
+ if not isinstance(elt_name, nodes.Const) or not isinstance(
+ elt_name.value, str
+ ):
+ self.add_message("invalid-all-object", args=elt.as_string(), node=elt)
+ continue
+
+ elt_name = elt_name.value
+ # If elt is in not_consumed, remove it from not_consumed
+ if elt_name in not_consumed:
+ del not_consumed[elt_name]
+ continue
+
+ if elt_name not in node.locals:
+ if not node.package:
+ self.add_message(
+ "undefined-all-variable", args=(elt_name,), node=elt
+ )
+ else:
+ basename = os.path.splitext(node.file)[0]
+ if os.path.basename(basename) == "__init__":
+ name = node.name + "." + elt_name
+ try:
+ astroid.modutils.file_from_modpath(name.split("."))
+ except ImportError:
+ self.add_message(
+ "undefined-all-variable", args=(elt_name,), node=elt
+ )
+ except SyntaxError:
+ # don't yield a syntax-error warning,
+ # because it will be later yielded
+ # when the file will be checked
+ pass
+
+ def _check_globals(self, not_consumed: dict[str, nodes.NodeNG]) -> None:
+ if self._allow_global_unused_variables:
+ return
+ for name, node_lst in not_consumed.items():
+ for node in node_lst:
+ if in_type_checking_block(node):
+ continue
+ self.add_message("unused-variable", args=(name,), node=node)
+
+ # pylint: disable = too-many-branches
+ def _check_imports(self, not_consumed: dict[str, list[nodes.NodeNG]]) -> None:
+ local_names = _fix_dot_imports(not_consumed)
+ checked = set()
+ unused_wildcard_imports: defaultdict[
+ tuple[str, nodes.ImportFrom], list[str]
+ ] = collections.defaultdict(list)
+ for name, stmt in local_names:
+ for imports in stmt.names:
+ real_name = imported_name = imports[0]
+ if imported_name == "*":
+ real_name = name
+ as_name = imports[1]
+ if real_name in checked:
+ continue
+ if name not in (real_name, as_name):
+ continue
+ checked.add(real_name)
+
+ is_type_annotation_import = (
+ imported_name in self._type_annotation_names
+ or as_name in self._type_annotation_names
+ )
+
+ is_dummy_import = (
+ as_name
+ and self.linter.config.dummy_variables_rgx
+ and self.linter.config.dummy_variables_rgx.match(as_name)
+ )
+
+ if isinstance(stmt, nodes.Import) or (
+ isinstance(stmt, nodes.ImportFrom) and not stmt.modname
+ ):
+ if isinstance(stmt, nodes.ImportFrom) and SPECIAL_OBJ.search(
+ imported_name
+ ):
+ # Filter special objects (__doc__, __all__) etc.,
+ # because they can be imported for exporting.
+ continue
+
+ if is_type_annotation_import or is_dummy_import:
+ # Most likely a typing import if it wasn't used so far.
+ # Also filter dummy variables.
+ continue
+
+ if as_name is None:
+ msg = f"import {imported_name}"
+ else:
+ msg = f"{imported_name} imported as {as_name}"
+ if not in_type_checking_block(stmt):
+ self.add_message("unused-import", args=msg, node=stmt)
+ elif isinstance(stmt, nodes.ImportFrom) and stmt.modname != FUTURE:
+ if SPECIAL_OBJ.search(imported_name):
+ # Filter special objects (__doc__, __all__) etc.,
+ # because they can be imported for exporting.
+ continue
+
+ if _is_from_future_import(stmt, name):
+ # Check if the name is in fact loaded from a
+ # __future__ import in another module.
+ continue
+
+ if is_type_annotation_import or is_dummy_import:
+ # Most likely a typing import if it wasn't used so far.
+ # Also filter dummy variables.
+ continue
+
+ if imported_name == "*":
+ unused_wildcard_imports[(stmt.modname, stmt)].append(name)
+ else:
+ if as_name is None:
+ msg = f"{imported_name} imported from {stmt.modname}"
+ else:
+ msg = f"{imported_name} imported from {stmt.modname} as {as_name}"
+ if not in_type_checking_block(stmt):
+ self.add_message("unused-import", args=msg, node=stmt)
+
+ # Construct string for unused-wildcard-import message
+ for module, unused_list in unused_wildcard_imports.items():
+ if len(unused_list) == 1:
+ arg_string = unused_list[0]
+ else:
+ arg_string = (
+ f"{', '.join(i for i in unused_list[:-1])} and {unused_list[-1]}"
+ )
+ self.add_message(
+ "unused-wildcard-import", args=(arg_string, module[0]), node=module[1]
+ )
+ del self._to_consume
+
+ def _check_metaclasses(self, node: nodes.Module | nodes.FunctionDef) -> None:
+ """Update consumption analysis for metaclasses."""
+ consumed: list[tuple[dict[str, list[nodes.NodeNG]], str]] = []
+
+ for child_node in node.get_children():
+ if isinstance(child_node, nodes.ClassDef):
+ consumed.extend(self._check_classdef_metaclasses(child_node, node))
+
+ # Pop the consumed items, in order to avoid having
+ # unused-import and unused-variable false positives
+ for scope_locals, name in consumed:
+ scope_locals.pop(name, None)
+
+ def _check_classdef_metaclasses(
+ self, klass: nodes.ClassDef, parent_node: nodes.Module | nodes.FunctionDef
+ ) -> list[tuple[dict[str, list[nodes.NodeNG]], str]]:
+ if not klass._metaclass:
+ # Skip if this class doesn't use explicitly a metaclass, but inherits it from ancestors
+ return []
+
+ consumed: list[tuple[dict[str, list[nodes.NodeNG]], str]] = []
+ metaclass = klass.metaclass()
+ name = ""
+ if isinstance(klass._metaclass, nodes.Name):
+ name = klass._metaclass.name
+ elif isinstance(klass._metaclass, nodes.Attribute) and klass._metaclass.expr:
+ attr = klass._metaclass.expr
+ while not isinstance(attr, nodes.Name):
+ attr = attr.expr
+ name = attr.name
+ elif isinstance(klass._metaclass, nodes.Call) and isinstance(
+ klass._metaclass.func, nodes.Name
+ ):
+ name = klass._metaclass.func.name
+ elif metaclass:
+ name = metaclass.root().name
+
+ found = False
+ name = METACLASS_NAME_TRANSFORMS.get(name, name)
+ if name:
+ # check enclosing scopes starting from most local
+ for scope_locals, _, _, _ in self._to_consume[::-1]:
+ found_nodes = scope_locals.get(name, [])
+ for found_node in found_nodes:
+ if found_node.lineno <= klass.lineno:
+ consumed.append((scope_locals, name))
+ found = True
+ break
+ # Check parent scope
+ nodes_in_parent_scope = parent_node.locals.get(name, [])
+ for found_node_parent in nodes_in_parent_scope:
+ if found_node_parent.lineno <= klass.lineno:
+ found = True
+ break
+ if (
+ not found
+ and not metaclass
+ and not (
+ name in nodes.Module.scope_attrs
+ or utils.is_builtin(name)
+ or name in self.linter.config.additional_builtins
+ )
+ ):
+ self.add_message("undefined-variable", node=klass, args=(name,))
+
+ return consumed
+
+ def visit_subscript(self, node: nodes.Subscript) -> None:
+ inferred_slice = utils.safe_infer(node.slice)
+
+ self._check_potential_index_error(node, inferred_slice)
+
+ def _inferred_iterable_length(self, iterable: nodes.Tuple | nodes.List) -> int:
+ length = 0
+ for elt in iterable.elts:
+ if not isinstance(elt, nodes.Starred):
+ length += 1
+ continue
+ unpacked = utils.safe_infer(elt.value)
+ if isinstance(unpacked, nodes.BaseContainer):
+ length += len(unpacked.elts)
+ else:
+ length += 1
+ return length
+
+ def _check_potential_index_error(
+ self, node: nodes.Subscript, inferred_slice: nodes.NodeNG | None
+ ) -> None:
+ """Check for the potential-index-error message."""
+ # Currently we only check simple slices of a single integer
+ if not isinstance(inferred_slice, nodes.Const) or not isinstance(
+ inferred_slice.value, int
+ ):
+ return
+
+ # If the node.value is a Tuple or List without inference it is defined in place
+ if isinstance(node.value, (nodes.Tuple, nodes.List)):
+ # Add 1 because iterables are 0-indexed
+ if self._inferred_iterable_length(node.value) < inferred_slice.value + 1:
+ self.add_message(
+ "potential-index-error", node=node, confidence=INFERENCE
+ )
+ return
+
+ @utils.only_required_for_messages(
+ "unused-import",
+ "unused-variable",
+ )
+ def visit_const(self, node: nodes.Const) -> None:
+ """Take note of names that appear inside string literal type annotations
+ unless the string is a parameter to `typing.Literal` or `typing.Annotation`.
+ """
+ if node.pytype() != "builtins.str":
+ return
+ if not utils.is_node_in_type_annotation_context(node):
+ return
+
+ # Check if parent's or grandparent's first child is typing.Literal
+ parent = node.parent
+ if isinstance(parent, nodes.Tuple):
+ parent = parent.parent
+ if isinstance(parent, nodes.Subscript):
+ origin = next(parent.get_children(), None)
+ if origin is not None and utils.is_typing_member(
+ origin, ("Annotated", "Literal")
+ ):
+ return
+
+ try:
+ annotation = extract_node(node.value)
+ self._store_type_annotation_node(annotation)
+ except ValueError:
+ # e.g. node.value is white space
+ pass
+ except astroid.AstroidSyntaxError:
+ # e.g. "?" or ":" in typing.Literal["?", ":"]
+ pass
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(VariablesChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/__init__.py b/solutions/.venv/Lib/site-packages/pylint/config/__init__.py
new file mode 100644
index 000000000..5dbda321c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/__init__.py
@@ -0,0 +1,9 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+__all__ = ["find_default_config_files"]
+
+from pylint.config.find_default_config_files import find_default_config_files
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/_breaking_changes.py b/solutions/.venv/Lib/site-packages/pylint/config/_breaking_changes.py
new file mode 100644
index 000000000..943f708aa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/_breaking_changes.py
@@ -0,0 +1,97 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""List the breaking changes in configuration files and their solutions."""
+
+from __future__ import annotations
+
+import enum
+from typing import NamedTuple
+
+
+class BreakingChange(enum.Enum):
+ MESSAGE_MADE_DISABLED_BY_DEFAULT = "{symbol} ({msgid}) was disabled by default"
+ MESSAGE_MADE_ENABLED_BY_DEFAULT = "{symbol} ({msgid}) was enabled by default"
+ MESSAGE_MOVED_TO_EXTENSION = "{symbol} ({msgid}) was moved to {extension}"
+ EXTENSION_REMOVED = "{extension} was removed"
+ # This kind of upgrade is non-breaking but if we want to automatically upgrade it,
+ # then we should use the message store and old_names values instead of duplicating
+ # MESSAGE_RENAMED= "{symbol} ({msgid}) was renamed"
+
+
+class Condition(enum.Enum):
+ MESSAGE_IS_ENABLED = "{symbol} ({msgid}) is enabled"
+ MESSAGE_IS_NOT_ENABLED = "{symbol} ({msgid}) is not enabled"
+ MESSAGE_IS_DISABLED = "{symbol} ({msgid}) is disabled"
+ MESSAGE_IS_NOT_DISABLED = "{symbol} ({msgid}) is not disabled"
+ EXTENSION_IS_LOADED = "{extension} is loaded"
+ EXTENSION_IS_NOT_LOADED = "{extension} is not loaded"
+
+
+class Information(NamedTuple):
+ msgid_or_symbol: str
+ extension: str | None
+
+
+class Solution(enum.Enum):
+ ADD_EXTENSION = "Add {extension} in 'load-plugins' option"
+ REMOVE_EXTENSION = "Remove {extension} from the 'load-plugins' option"
+ ENABLE_MESSAGE_EXPLICITLY = (
+ "{symbol} ({msgid}) should be added in the 'enable' option"
+ )
+ ENABLE_MESSAGE_IMPLICITLY = (
+ "{symbol} ({msgid}) should be removed from the 'disable' option"
+ )
+ DISABLE_MESSAGE_EXPLICITLY = (
+ "{symbol} ({msgid}) should be added in the 'disable' option"
+ )
+ DISABLE_MESSAGE_IMPLICITLY = (
+ "{symbol} ({msgid}) should be removed from the 'enable' option"
+ )
+
+
+ConditionsToBeAffected = list[Condition]
+# A solution to a breaking change might imply multiple actions
+MultipleActionSolution = list[Solution]
+# Sometimes there's multiple solutions and the user needs to choose
+Solutions = list[MultipleActionSolution]
+BreakingChangeWithSolution = tuple[
+ BreakingChange, Information, ConditionsToBeAffected, Solutions
+]
+
+NO_SELF_USE = Information(
+ msgid_or_symbol="no-self-use", extension="pylint.extensions.no_self_use"
+)
+COMPARE_TO_ZERO = Information(
+ msgid_or_symbol="compare-to-zero", extension="pylint.extensions.comparetozero"
+)
+COMPARE_TO_EMPTY_STRING = Information(
+ msgid_or_symbol="compare-to-empty-string",
+ extension="pylint.extensions.emptystring",
+)
+
+CONFIGURATION_BREAKING_CHANGES: dict[str, list[BreakingChangeWithSolution]] = {
+ "2.14.0": [
+ (
+ BreakingChange.MESSAGE_MOVED_TO_EXTENSION,
+ NO_SELF_USE,
+ [Condition.MESSAGE_IS_ENABLED, Condition.EXTENSION_IS_NOT_LOADED],
+ [[Solution.ADD_EXTENSION], [Solution.DISABLE_MESSAGE_IMPLICITLY]],
+ ),
+ ],
+ "3.0.0": [
+ (
+ BreakingChange.EXTENSION_REMOVED,
+ COMPARE_TO_ZERO,
+ [Condition.MESSAGE_IS_NOT_DISABLED, Condition.EXTENSION_IS_LOADED],
+ [[Solution.REMOVE_EXTENSION, Solution.ENABLE_MESSAGE_EXPLICITLY]],
+ ),
+ (
+ BreakingChange.EXTENSION_REMOVED,
+ COMPARE_TO_EMPTY_STRING,
+ [Condition.MESSAGE_IS_NOT_DISABLED, Condition.EXTENSION_IS_LOADED],
+ [[Solution.REMOVE_EXTENSION, Solution.ENABLE_MESSAGE_EXPLICITLY]],
+ ),
+ ],
+}
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/__init__.py b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/__init__.py
new file mode 100644
index 000000000..8d36bd88b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/__init__.py
@@ -0,0 +1,13 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Everything related to the 'pylint-config' command.
+
+Everything in this module is private.
+"""
+
+from pylint.config._pylint_config.main import _handle_pylint_config_commands
+from pylint.config._pylint_config.setup import _register_generate_config_options
+
+__all__ = ("_handle_pylint_config_commands", "_register_generate_config_options")
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/generate_command.py b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/generate_command.py
new file mode 100644
index 000000000..d1b73c99b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/generate_command.py
@@ -0,0 +1,49 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Everything related to the 'pylint-config generate' command."""
+
+
+from __future__ import annotations
+
+from io import StringIO
+from typing import TYPE_CHECKING
+
+from pylint.config._pylint_config import utils
+from pylint.config._pylint_config.help_message import get_subparser_help
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+def generate_interactive_config(linter: PyLinter) -> None:
+ print("Starting interactive pylint configuration generation")
+
+ format_type = utils.get_and_validate_format()
+ minimal = format_type == "toml" and utils.get_minimal_setting()
+ to_file, output_file_name = utils.get_and_validate_output_file()
+
+ if format_type == "toml":
+ config_string = linter._generate_config_file(minimal=minimal)
+ else:
+ output_stream = StringIO()
+ linter._generate_config(stream=output_stream, skipsections=("Commands",))
+ config_string = output_stream.getvalue()
+
+ if to_file:
+ with open(output_file_name, "w", encoding="utf-8") as f:
+ print(config_string, file=f)
+ print(f"Wrote configuration file to {output_file_name.resolve()}")
+ else:
+ print(config_string)
+
+
+def handle_generate_command(linter: PyLinter) -> int:
+ """Handle 'pylint-config generate'."""
+ # Interactively generate a pylint configuration
+ if linter.config.interactive:
+ generate_interactive_config(linter)
+ return 0
+ print(get_subparser_help(linter, "generate"))
+ return 32
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/help_message.py b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/help_message.py
new file mode 100644
index 000000000..7ba947429
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/help_message.py
@@ -0,0 +1,59 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Everything related to the 'pylint-config -h' command and subcommands."""
+
+
+from __future__ import annotations
+
+import argparse
+from typing import TYPE_CHECKING
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+def get_subparser_help(linter: PyLinter, command: str) -> str:
+ """Get the help message for one of the subcommands."""
+ # Make sure subparsers are initialized properly
+ assert linter._arg_parser._subparsers
+ subparser_action = linter._arg_parser._subparsers._group_actions[0]
+ assert isinstance(subparser_action, argparse._SubParsersAction)
+
+ for name, subparser in subparser_action.choices.items():
+ assert isinstance(subparser, argparse.ArgumentParser)
+ if name == command:
+ # Remove last character which is an extra new line
+ return subparser.format_help()[:-1]
+ return "" # pragma: no cover
+
+
+def get_help(parser: argparse.ArgumentParser) -> str:
+ """Get the help message for the main 'pylint-config' command.
+
+ Taken from argparse.ArgumentParser.format_help.
+ """
+ formatter = parser._get_formatter()
+
+ # usage
+ formatter.add_usage(
+ parser.usage, parser._actions, parser._mutually_exclusive_groups
+ )
+
+ # description
+ formatter.add_text(parser.description)
+
+ # positionals, optionals and user-defined groups
+ for action_group in parser._action_groups:
+ if action_group.title == "Subcommands":
+ formatter.start_section(action_group.title)
+ formatter.add_text(action_group.description)
+ formatter.add_arguments(action_group._group_actions)
+ formatter.end_section()
+
+ # epilog
+ formatter.add_text(parser.epilog)
+
+ # determine help from format above
+ return formatter.format_help()
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/main.py b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/main.py
new file mode 100644
index 000000000..e562da2ef
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/main.py
@@ -0,0 +1,25 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Everything related to the 'pylint-config' command."""
+
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from pylint.config._pylint_config.generate_command import handle_generate_command
+from pylint.config._pylint_config.help_message import get_help
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+def _handle_pylint_config_commands(linter: PyLinter) -> int:
+ """Handle whichever command is passed to 'pylint-config'."""
+ if linter.config.config_subcommand == "generate":
+ return handle_generate_command(linter)
+
+ print(get_help(linter._arg_parser))
+ return 32
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/setup.py b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/setup.py
new file mode 100644
index 000000000..211f9bc6d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/setup.py
@@ -0,0 +1,49 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Everything related to the setup of the 'pylint-config' command."""
+
+
+from __future__ import annotations
+
+import argparse
+from collections.abc import Sequence
+from typing import Any
+
+from pylint.config._pylint_config.help_message import get_help
+from pylint.config.callback_actions import _AccessParserAction
+
+
+class _HelpAction(_AccessParserAction):
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--help",
+ ) -> None:
+ get_help(self.parser)
+
+
+def _register_generate_config_options(parser: argparse.ArgumentParser) -> None:
+ """Registers the necessary arguments on the parser."""
+ parser.prog = "pylint-config"
+ # Overwrite the help command
+ parser.add_argument(
+ "-h",
+ "--help",
+ action=_HelpAction,
+ default=argparse.SUPPRESS,
+ help="show this help message and exit",
+ parser=parser,
+ )
+
+ # We use subparsers to create various subcommands under 'pylint-config'
+ subparsers = parser.add_subparsers(dest="config_subcommand", title="Subcommands")
+
+ # Add the generate command
+ generate_parser = subparsers.add_parser(
+ "generate", help="Generate a pylint configuration"
+ )
+ generate_parser.add_argument("--interactive", action="store_true")
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/utils.py b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/utils.py
new file mode 100644
index 000000000..f9185e8b1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/_pylint_config/utils.py
@@ -0,0 +1,115 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Utils for the 'pylint-config' command."""
+
+from __future__ import annotations
+
+import sys
+from collections.abc import Callable
+from pathlib import Path
+from typing import Literal, TypeVar
+
+if sys.version_info >= (3, 10):
+ from typing import ParamSpec
+else:
+ from typing_extensions import ParamSpec
+
+_P = ParamSpec("_P")
+_ReturnValueT = TypeVar("_ReturnValueT", bool, str)
+
+SUPPORTED_FORMATS = {"t", "toml", "i", "ini"}
+YES_NO_ANSWERS = {"y", "yes", "n", "no"}
+
+
+class InvalidUserInput(Exception):
+ """Raised whenever a user input is invalid."""
+
+ def __init__(self, valid_input: str, input_value: str, *args: object) -> None:
+ self.valid = valid_input
+ self.input = input_value
+ super().__init__(*args)
+
+
+def should_retry_after_invalid_input(
+ func: Callable[_P, _ReturnValueT]
+) -> Callable[_P, _ReturnValueT]:
+ """Decorator that handles InvalidUserInput exceptions and retries."""
+
+ def inner_function(*args: _P.args, **kwargs: _P.kwargs) -> _ReturnValueT:
+ called_once = False
+ while True:
+ try:
+ return func(*args, **kwargs)
+ except InvalidUserInput as exc:
+ if called_once and exc.input == "exit()":
+ print("Stopping 'pylint-config'.")
+ sys.exit()
+ print(f"Answer should be one of {exc.valid}.")
+ print("Type 'exit()' if you want to exit the program.")
+ called_once = True
+
+ return inner_function
+
+
+@should_retry_after_invalid_input
+def get_and_validate_format() -> Literal["toml", "ini"]:
+ """Make sure that the output format is either .toml or .ini."""
+ # pylint: disable-next=bad-builtin
+ format_type = input(
+ "Please choose the format of configuration, (T)oml or (I)ni (.cfg): "
+ ).lower()
+
+ if format_type not in SUPPORTED_FORMATS:
+ raise InvalidUserInput(", ".join(sorted(SUPPORTED_FORMATS)), format_type)
+
+ if format_type.startswith("t"):
+ return "toml"
+ return "ini"
+
+
+@should_retry_after_invalid_input
+def validate_yes_no(question: str, default: Literal["yes", "no"] | None) -> bool:
+ """Validate that a yes or no answer is correct."""
+ question = f"{question} (y)es or (n)o "
+ if default:
+ question += f" (default={default}) "
+ # pylint: disable-next=bad-builtin
+ answer = input(question).lower()
+
+ if not answer and default:
+ answer = default
+
+ if answer not in YES_NO_ANSWERS:
+ raise InvalidUserInput(", ".join(sorted(YES_NO_ANSWERS)), answer)
+
+ return answer.startswith("y")
+
+
+def get_minimal_setting() -> bool:
+ """Ask the user if they want to use the minimal setting."""
+ return validate_yes_no(
+ "Do you want a minimal configuration without comments or default values?", "no"
+ )
+
+
+def get_and_validate_output_file() -> tuple[bool, Path]:
+ """Make sure that the output file is correct."""
+ to_file = validate_yes_no("Do you want to write the output to a file?", "no")
+
+ if not to_file:
+ return False, Path()
+
+ # pylint: disable-next=bad-builtin
+ file_name = Path(input("What should the file be called: "))
+ if file_name.exists():
+ overwrite = validate_yes_no(
+ f"{file_name} already exists. Are you sure you want to overwrite?", "no"
+ )
+
+ if not overwrite:
+ return False, file_name
+ return True, file_name
+
+ return True, file_name
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/argument.py b/solutions/.venv/Lib/site-packages/pylint/config/argument.py
new file mode 100644
index 000000000..a515a942b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/argument.py
@@ -0,0 +1,503 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Definition of an Argument class and transformers for various argument types.
+
+An Argument instance represents a pylint option to be handled by an argparse.ArgumentParser
+"""
+
+from __future__ import annotations
+
+import argparse
+import os
+import pathlib
+import re
+from collections.abc import Callable, Sequence
+from glob import glob
+from re import Pattern
+from typing import Any, Literal, Union
+
+from pylint import interfaces
+from pylint import utils as pylint_utils
+from pylint.config.callback_actions import _CallbackAction
+from pylint.config.deprecation_actions import _NewNamesAction, _OldNamesAction
+
+_ArgumentTypes = Union[
+ str,
+ int,
+ float,
+ bool,
+ Pattern[str],
+ Sequence[str],
+ Sequence[Pattern[str]],
+ tuple[int, ...],
+]
+"""List of possible argument types."""
+
+
+def _confidence_transformer(value: str) -> Sequence[str]:
+ """Transforms a comma separated string of confidence values."""
+ if not value:
+ return interfaces.CONFIDENCE_LEVEL_NAMES
+ values = pylint_utils._check_csv(value)
+ for confidence in values:
+ if confidence not in interfaces.CONFIDENCE_LEVEL_NAMES:
+ raise argparse.ArgumentTypeError(
+ f"{value} should be in {*interfaces.CONFIDENCE_LEVEL_NAMES,}"
+ )
+ return values
+
+
+def _csv_transformer(value: str) -> Sequence[str]:
+ """Transforms a comma separated string."""
+ return pylint_utils._check_csv(value)
+
+
+YES_VALUES = {"y", "yes", "true"}
+NO_VALUES = {"n", "no", "false"}
+
+
+def _yn_transformer(value: str) -> bool:
+ """Transforms a yes/no or stringified bool into a bool."""
+ value = value.lower()
+ if value in YES_VALUES:
+ return True
+ if value in NO_VALUES:
+ return False
+ raise argparse.ArgumentTypeError(
+ None, f"Invalid yn value '{value}', should be in {*YES_VALUES, *NO_VALUES}"
+ )
+
+
+def _non_empty_string_transformer(value: str) -> str:
+ """Check that a string is not empty and remove quotes."""
+ if not value:
+ raise argparse.ArgumentTypeError("Option cannot be an empty string.")
+ return pylint_utils._unquote(value)
+
+
+def _path_transformer(value: str) -> str:
+ """Expand user and variables in a path."""
+ return os.path.expandvars(os.path.expanduser(value))
+
+
+def _glob_paths_csv_transformer(value: str) -> Sequence[str]:
+ """Transforms a comma separated list of paths while expanding user and
+ variables and glob patterns.
+ """
+ paths: list[str] = []
+ for path in _csv_transformer(value):
+ paths.extend(glob(_path_transformer(path), recursive=True))
+ return paths
+
+
+def _py_version_transformer(value: str) -> tuple[int, ...]:
+ """Transforms a version string into a version tuple."""
+ try:
+ version = tuple(int(val) for val in value.replace(",", ".").split("."))
+ except ValueError:
+ raise argparse.ArgumentTypeError(
+ f"{value} has an invalid format, should be a version string. E.g., '3.8'"
+ ) from None
+ return version
+
+
+def _regex_transformer(value: str) -> Pattern[str]:
+ """Prevents 're.error' from propagating and crash pylint."""
+ try:
+ return re.compile(value)
+ except re.error as e:
+ msg = f"Error in provided regular expression: {value} beginning at index {e.pos}: {e.msg}"
+ raise argparse.ArgumentTypeError(msg) from e
+
+
+def _regexp_csv_transfomer(value: str) -> Sequence[Pattern[str]]:
+ """Transforms a comma separated list of regular expressions."""
+ patterns: list[Pattern[str]] = []
+ for pattern in pylint_utils._check_regexp_csv(value):
+ patterns.append(_regex_transformer(pattern))
+ return patterns
+
+
+def _regexp_paths_csv_transfomer(value: str) -> Sequence[Pattern[str]]:
+ """Transforms a comma separated list of regular expressions paths."""
+ patterns: list[Pattern[str]] = []
+ for pattern in _csv_transformer(value):
+ patterns.append(
+ _regex_transformer(
+ str(pathlib.PureWindowsPath(pattern)).replace("\\", "\\\\")
+ + "|"
+ + pathlib.PureWindowsPath(pattern).as_posix()
+ )
+ )
+ return patterns
+
+
+_TYPE_TRANSFORMERS: dict[str, Callable[[str], _ArgumentTypes]] = {
+ "choice": str,
+ "csv": _csv_transformer,
+ "float": float,
+ "int": int,
+ "confidence": _confidence_transformer,
+ "non_empty_string": _non_empty_string_transformer,
+ "path": _path_transformer,
+ "glob_paths_csv": _glob_paths_csv_transformer,
+ "py_version": _py_version_transformer,
+ "regexp": _regex_transformer,
+ "regexp_csv": _regexp_csv_transfomer,
+ "regexp_paths_csv": _regexp_paths_csv_transfomer,
+ "string": pylint_utils._unquote,
+ "yn": _yn_transformer,
+}
+"""Type transformers for all argument types.
+
+A transformer should accept a string and return one of the supported
+Argument types. It will only be called when parsing 1) command-line,
+2) configuration files and 3) a string default value.
+Non-string default values are assumed to be of the correct type.
+"""
+
+
+class _Argument:
+ """Class representing an argument to be parsed by an argparse.ArgumentsParser.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ arg_help: str,
+ hide_help: bool,
+ section: str | None,
+ ) -> None:
+ self.flags = flags
+ """The name of the argument."""
+
+ self.hide_help = hide_help
+ """Whether to hide this argument in the help message."""
+
+ # argparse uses % formatting on help strings, so a % needs to be escaped
+ self.help = arg_help.replace("%", "%%")
+ """The description of the argument."""
+
+ if hide_help:
+ self.help = argparse.SUPPRESS
+
+ self.section = section
+ """The section to add this argument to."""
+
+
+class _BaseStoreArgument(_Argument):
+ """Base class for store arguments to be parsed by an argparse.ArgumentsParser.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ action: str,
+ default: _ArgumentTypes,
+ arg_help: str,
+ hide_help: bool,
+ section: str | None,
+ ) -> None:
+ super().__init__(
+ flags=flags, arg_help=arg_help, hide_help=hide_help, section=section
+ )
+
+ self.action = action
+ """The action to perform with the argument."""
+
+ self.default = default
+ """The default value of the argument."""
+
+
+class _StoreArgument(_BaseStoreArgument):
+ """Class representing a store argument to be parsed by an argparse.ArgumentsParser.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ # pylint: disable-next=too-many-arguments
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ action: str,
+ default: _ArgumentTypes,
+ arg_type: str,
+ choices: list[str] | None,
+ arg_help: str,
+ metavar: str,
+ hide_help: bool,
+ section: str | None,
+ ) -> None:
+ super().__init__(
+ flags=flags,
+ action=action,
+ default=default,
+ arg_help=arg_help,
+ hide_help=hide_help,
+ section=section,
+ )
+
+ self.type = _TYPE_TRANSFORMERS[arg_type]
+ """A transformer function that returns a transformed type of the argument."""
+
+ self.choices = choices
+ """A list of possible choices for the argument.
+
+ None if there are no restrictions.
+ """
+
+ self.metavar = metavar
+ """The metavar of the argument.
+
+ See:
+ https://docs.python.org/3/library/argparse.html#metavar
+ """
+
+
+class _StoreTrueArgument(_BaseStoreArgument):
+ """Class representing a 'store_true' argument to be parsed by an
+ argparse.ArgumentsParser.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ # pylint: disable-next=useless-parent-delegation # We narrow down the type of action
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ action: Literal["store_true"],
+ default: _ArgumentTypes,
+ arg_help: str,
+ hide_help: bool,
+ section: str | None,
+ ) -> None:
+ super().__init__(
+ flags=flags,
+ action=action,
+ default=default,
+ arg_help=arg_help,
+ hide_help=hide_help,
+ section=section,
+ )
+
+
+class _DeprecationArgument(_Argument):
+ """Store arguments while also handling deprecation warnings for old and new names.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ # pylint: disable-next=too-many-arguments
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ action: type[argparse.Action],
+ default: _ArgumentTypes,
+ arg_type: str,
+ choices: list[str] | None,
+ arg_help: str,
+ metavar: str,
+ hide_help: bool,
+ section: str | None,
+ ) -> None:
+ super().__init__(
+ flags=flags, arg_help=arg_help, hide_help=hide_help, section=section
+ )
+
+ self.action = action
+ """The action to perform with the argument."""
+
+ self.default = default
+ """The default value of the argument."""
+
+ self.type = _TYPE_TRANSFORMERS[arg_type]
+ """A transformer function that returns a transformed type of the argument."""
+
+ self.choices = choices
+ """A list of possible choices for the argument.
+
+ None if there are no restrictions.
+ """
+
+ self.metavar = metavar
+ """The metavar of the argument.
+
+ See:
+ https://docs.python.org/3/library/argparse.html#metavar
+ """
+
+
+class _ExtendArgument(_DeprecationArgument):
+ """Class for extend arguments to be parsed by an argparse.ArgumentsParser.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ # pylint: disable-next=too-many-arguments
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ action: Literal["extend"],
+ default: _ArgumentTypes,
+ arg_type: str,
+ metavar: str,
+ arg_help: str,
+ hide_help: bool,
+ section: str | None,
+ choices: list[str] | None,
+ dest: str | None,
+ ) -> None:
+ action_class = argparse._ExtendAction
+
+ self.dest = dest
+ """The destination of the argument."""
+
+ super().__init__(
+ flags=flags,
+ action=action_class,
+ default=default,
+ arg_type=arg_type,
+ choices=choices,
+ arg_help=arg_help,
+ metavar=metavar,
+ hide_help=hide_help,
+ section=section,
+ )
+
+
+class _StoreOldNamesArgument(_DeprecationArgument):
+ """Store arguments while also handling old names.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ # pylint: disable-next=too-many-arguments
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ default: _ArgumentTypes,
+ arg_type: str,
+ choices: list[str] | None,
+ arg_help: str,
+ metavar: str,
+ hide_help: bool,
+ kwargs: dict[str, Any],
+ section: str | None,
+ ) -> None:
+ super().__init__(
+ flags=flags,
+ action=_OldNamesAction,
+ default=default,
+ arg_type=arg_type,
+ choices=choices,
+ arg_help=arg_help,
+ metavar=metavar,
+ hide_help=hide_help,
+ section=section,
+ )
+
+ self.kwargs = kwargs
+ """Any additional arguments passed to the action."""
+
+
+class _StoreNewNamesArgument(_DeprecationArgument):
+ """Store arguments while also emitting deprecation warnings.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ # pylint: disable-next=too-many-arguments
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ default: _ArgumentTypes,
+ arg_type: str,
+ choices: list[str] | None,
+ arg_help: str,
+ metavar: str,
+ hide_help: bool,
+ kwargs: dict[str, Any],
+ section: str | None,
+ ) -> None:
+ super().__init__(
+ flags=flags,
+ action=_NewNamesAction,
+ default=default,
+ arg_type=arg_type,
+ choices=choices,
+ arg_help=arg_help,
+ metavar=metavar,
+ hide_help=hide_help,
+ section=section,
+ )
+
+ self.kwargs = kwargs
+ """Any additional arguments passed to the action."""
+
+
+class _CallableArgument(_Argument):
+ """Class representing an callable argument to be parsed by an
+ argparse.ArgumentsParser.
+
+ This is based on the parameters passed to argparse.ArgumentsParser.add_message.
+ See:
+ https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser.add_argument
+ """
+
+ def __init__(
+ self,
+ *,
+ flags: list[str],
+ action: type[_CallbackAction],
+ arg_help: str,
+ kwargs: dict[str, Any],
+ hide_help: bool,
+ section: str | None,
+ metavar: str,
+ ) -> None:
+ super().__init__(
+ flags=flags, arg_help=arg_help, hide_help=hide_help, section=section
+ )
+
+ self.action = action
+ """The action to perform with the argument."""
+
+ self.kwargs = kwargs
+ """Any additional arguments passed to the action."""
+
+ self.metavar = metavar
+ """The metavar of the argument.
+
+ See:
+ https://docs.python.org/3/library/argparse.html#metavar
+ """
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/arguments_manager.py b/solutions/.venv/Lib/site-packages/pylint/config/arguments_manager.py
new file mode 100644
index 000000000..aca8f5f87
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/arguments_manager.py
@@ -0,0 +1,402 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Arguments manager class used to handle command-line arguments and options."""
+
+from __future__ import annotations
+
+import argparse
+import re
+import sys
+import textwrap
+import warnings
+from collections.abc import Sequence
+from typing import TYPE_CHECKING, Any, TextIO
+
+import tomlkit
+
+from pylint import utils
+from pylint.config.argument import (
+ _Argument,
+ _CallableArgument,
+ _ExtendArgument,
+ _StoreArgument,
+ _StoreNewNamesArgument,
+ _StoreOldNamesArgument,
+ _StoreTrueArgument,
+)
+from pylint.config.exceptions import (
+ UnrecognizedArgumentAction,
+ _UnrecognizedOptionError,
+)
+from pylint.config.help_formatter import _HelpFormatter
+from pylint.config.utils import _convert_option_to_argument, _parse_rich_type_value
+from pylint.constants import MAIN_CHECKER_NAME
+from pylint.typing import DirectoryNamespaceDict, OptionDict
+
+if sys.version_info >= (3, 11):
+ import tomllib
+else:
+ import tomli as tomllib
+
+
+if TYPE_CHECKING:
+ from pylint.config.arguments_provider import _ArgumentsProvider
+
+
+class _ArgumentsManager:
+ """Arguments manager class used to handle command-line arguments and options."""
+
+ def __init__(
+ self, prog: str, usage: str | None = None, description: str | None = None
+ ) -> None:
+ self._config = argparse.Namespace()
+ """Namespace for all options."""
+
+ self._base_config = self._config
+ """Fall back Namespace object created during initialization.
+
+ This is necessary for the per-directory configuration support. Whenever we
+ fail to match a file with a directory we fall back to the Namespace object
+ created during initialization.
+ """
+
+ self._arg_parser = argparse.ArgumentParser(
+ prog=prog,
+ usage=usage or "%(prog)s [options]",
+ description=description,
+ formatter_class=_HelpFormatter,
+ # Needed to let 'pylint-config' overwrite the -h command
+ conflict_handler="resolve",
+ )
+ """The command line argument parser."""
+
+ self._argument_groups_dict: dict[str, argparse._ArgumentGroup] = {}
+ """Dictionary of all the argument groups."""
+
+ self._option_dicts: dict[str, OptionDict] = {}
+ """All option dictionaries that have been registered."""
+
+ self._directory_namespaces: DirectoryNamespaceDict = {}
+ """Mapping of directories and their respective namespace objects."""
+
+ @property
+ def config(self) -> argparse.Namespace:
+ """Namespace for all options."""
+ return self._config
+
+ @config.setter
+ def config(self, value: argparse.Namespace) -> None:
+ self._config = value
+
+ def _register_options_provider(self, provider: _ArgumentsProvider) -> None:
+ """Register an options provider and load its defaults."""
+ for opt, optdict in provider.options:
+ self._option_dicts[opt] = optdict
+ argument = _convert_option_to_argument(opt, optdict)
+ section = argument.section or provider.name.capitalize()
+
+ section_desc = provider.option_groups_descs.get(section, None)
+
+ # We exclude main since its docstring comes from PyLinter
+ if provider.name != MAIN_CHECKER_NAME and provider.__doc__:
+ section_desc = provider.__doc__.split("\n\n")[0]
+
+ self._add_arguments_to_parser(section, section_desc, argument)
+
+ self._load_default_argument_values()
+
+ def _add_arguments_to_parser(
+ self, section: str, section_desc: str | None, argument: _Argument
+ ) -> None:
+ """Add an argument to the correct argument section/group."""
+ try:
+ section_group = self._argument_groups_dict[section]
+ except KeyError:
+ if section_desc:
+ section_group = self._arg_parser.add_argument_group(
+ section, section_desc
+ )
+ else:
+ section_group = self._arg_parser.add_argument_group(title=section)
+ self._argument_groups_dict[section] = section_group
+ self._add_parser_option(section_group, argument)
+
+ @staticmethod
+ def _add_parser_option(
+ section_group: argparse._ArgumentGroup, argument: _Argument
+ ) -> None:
+ """Add an argument."""
+ if isinstance(argument, _StoreArgument):
+ section_group.add_argument(
+ *argument.flags,
+ action=argument.action,
+ default=argument.default,
+ type=argument.type, # type: ignore[arg-type] # incorrect typing in typeshed
+ help=argument.help,
+ metavar=argument.metavar,
+ choices=argument.choices,
+ )
+ elif isinstance(argument, _StoreOldNamesArgument):
+ section_group.add_argument(
+ *argument.flags,
+ **argument.kwargs,
+ action=argument.action,
+ default=argument.default,
+ type=argument.type, # type: ignore[arg-type] # incorrect typing in typeshed
+ help=argument.help,
+ metavar=argument.metavar,
+ choices=argument.choices,
+ )
+ # We add the old name as hidden option to make its default value get loaded when
+ # argparse initializes all options from the checker
+ assert argument.kwargs["old_names"]
+ for old_name in argument.kwargs["old_names"]:
+ section_group.add_argument(
+ f"--{old_name}",
+ action="store",
+ default=argument.default,
+ type=argument.type, # type: ignore[arg-type] # incorrect typing in typeshed
+ help=argparse.SUPPRESS,
+ metavar=argument.metavar,
+ choices=argument.choices,
+ )
+ elif isinstance(argument, _StoreNewNamesArgument):
+ section_group.add_argument(
+ *argument.flags,
+ **argument.kwargs,
+ action=argument.action,
+ default=argument.default,
+ type=argument.type, # type: ignore[arg-type] # incorrect typing in typeshed
+ help=argument.help,
+ metavar=argument.metavar,
+ choices=argument.choices,
+ )
+ elif isinstance(argument, _StoreTrueArgument):
+ section_group.add_argument(
+ *argument.flags,
+ action=argument.action,
+ default=argument.default,
+ help=argument.help,
+ )
+ elif isinstance(argument, _CallableArgument):
+ section_group.add_argument(
+ *argument.flags,
+ **argument.kwargs,
+ action=argument.action,
+ help=argument.help,
+ metavar=argument.metavar,
+ )
+ elif isinstance(argument, _ExtendArgument):
+ section_group.add_argument(
+ *argument.flags,
+ action=argument.action,
+ default=argument.default,
+ type=argument.type, # type: ignore[arg-type] # incorrect typing in typeshed
+ help=argument.help,
+ metavar=argument.metavar,
+ choices=argument.choices,
+ dest=argument.dest,
+ )
+ else:
+ raise UnrecognizedArgumentAction
+
+ def _load_default_argument_values(self) -> None:
+ """Loads the default values of all registered options."""
+ self.config = self._arg_parser.parse_args([], self.config)
+
+ def _parse_configuration_file(self, arguments: list[str]) -> None:
+ """Parse the arguments found in a configuration file into the namespace."""
+ try:
+ self.config, parsed_args = self._arg_parser.parse_known_args(
+ arguments, self.config
+ )
+ except SystemExit:
+ sys.exit(32)
+ unrecognized_options: list[str] = []
+ for opt in parsed_args:
+ if opt.startswith("--"):
+ unrecognized_options.append(opt[2:])
+ if unrecognized_options:
+ raise _UnrecognizedOptionError(options=unrecognized_options)
+
+ def _parse_command_line_configuration(
+ self, arguments: Sequence[str] | None = None
+ ) -> list[str]:
+ """Parse the arguments found on the command line into the namespace."""
+ arguments = sys.argv[1:] if arguments is None else arguments
+
+ self.config, parsed_args = self._arg_parser.parse_known_args(
+ arguments, self.config
+ )
+
+ return parsed_args
+
+ def _generate_config(
+ self, stream: TextIO | None = None, skipsections: tuple[str, ...] = ()
+ ) -> None:
+ """Write a configuration file according to the current configuration
+ into the given stream or stdout.
+ """
+ options_by_section = {}
+ sections = []
+ for group in sorted(
+ self._arg_parser._action_groups,
+ key=lambda x: (x.title != "Main", x.title),
+ ):
+ group_name = group.title
+ assert group_name
+ if group_name in skipsections:
+ continue
+
+ options = []
+ option_actions = [
+ i
+ for i in group._group_actions
+ if not isinstance(i, argparse._SubParsersAction)
+ ]
+ for opt in sorted(option_actions, key=lambda x: x.option_strings[0][2:]):
+ if "--help" in opt.option_strings:
+ continue
+
+ optname = opt.option_strings[0][2:]
+
+ try:
+ optdict = self._option_dicts[optname]
+ except KeyError:
+ continue
+
+ options.append(
+ (
+ optname,
+ optdict,
+ getattr(self.config, optname.replace("-", "_")),
+ )
+ )
+
+ options = [
+ (n, d, v) for (n, d, v) in options if not d.get("deprecated")
+ ]
+
+ if options:
+ sections.append(group_name)
+ options_by_section[group_name] = options
+ stream = stream or sys.stdout
+ printed = False
+ for section in sections:
+ if printed:
+ print("\n", file=stream)
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=DeprecationWarning)
+ utils.format_section(
+ stream, section.upper(), sorted(options_by_section[section])
+ )
+ printed = True
+
+ def help(self) -> str:
+ """Return the usage string based on the available options."""
+ return self._arg_parser.format_help()
+
+ def _generate_config_file(self, *, minimal: bool = False) -> str:
+ """Write a configuration file according to the current configuration into
+ stdout.
+ """
+ toml_doc = tomlkit.document()
+ tool_table = tomlkit.table(is_super_table=True)
+ toml_doc.add(tomlkit.key("tool"), tool_table)
+
+ pylint_tool_table = tomlkit.table(is_super_table=True)
+ tool_table.add(tomlkit.key("pylint"), pylint_tool_table)
+
+ for group in sorted(
+ self._arg_parser._action_groups,
+ key=lambda x: (x.title != "Main", x.title),
+ ):
+ # Skip the options section with the --help option
+ if group.title in {"options", "optional arguments", "Commands"}:
+ continue
+
+ # Skip sections without options such as "positional arguments"
+ if not group._group_actions:
+ continue
+
+ group_table = tomlkit.table()
+ option_actions = [
+ i
+ for i in group._group_actions
+ if not isinstance(i, argparse._SubParsersAction)
+ ]
+ for action in sorted(option_actions, key=lambda x: x.option_strings[0][2:]):
+ optname = action.option_strings[0][2:]
+
+ # We skip old name options that don't have their own optdict
+ try:
+ optdict = self._option_dicts[optname]
+ except KeyError:
+ continue
+
+ if optdict.get("hide_from_config_file"):
+ continue
+
+ # Add help comment
+ if not minimal:
+ help_msg = optdict.get("help", "")
+ assert isinstance(help_msg, str)
+ help_text = textwrap.wrap(help_msg, width=79)
+ for line in help_text:
+ group_table.add(tomlkit.comment(line))
+
+ # Get current value of option
+ value = getattr(self.config, optname.replace("-", "_"))
+
+ # Create a comment if the option has no value
+ if not value:
+ if not minimal:
+ group_table.add(tomlkit.comment(f"{optname} ="))
+ group_table.add(tomlkit.nl())
+ continue
+
+ # Skip deprecated options
+ if "kwargs" in optdict:
+ assert isinstance(optdict["kwargs"], dict)
+ if "new_names" in optdict["kwargs"]:
+ continue
+
+ # Tomlkit doesn't support regular expressions
+ if isinstance(value, re.Pattern):
+ value = value.pattern
+ elif isinstance(value, (list, tuple)) and isinstance(
+ value[0], re.Pattern
+ ):
+ value = [i.pattern for i in value]
+
+ # Handle tuples that should be strings
+ if optdict.get("type") == "py_version":
+ value = ".".join(str(i) for i in value)
+
+ # Check if it is default value if we are in minimal mode
+ if minimal and value == optdict.get("default"):
+ continue
+
+ # Add to table
+ group_table.add(optname, value)
+ group_table.add(tomlkit.nl())
+
+ assert group.title
+ if group_table:
+ pylint_tool_table.add(group.title.lower(), group_table)
+
+ toml_string = tomlkit.dumps(toml_doc)
+
+ # Make sure the string we produce is valid toml and can be parsed
+ tomllib.loads(toml_string)
+
+ return str(toml_string)
+
+ def set_option(self, optname: str, value: Any) -> None:
+ """Set an option on the namespace object."""
+ self.config = self._arg_parser.parse_known_args(
+ [f"--{optname.replace('_', '-')}", _parse_rich_type_value(value)],
+ self.config,
+ )[0]
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/arguments_provider.py b/solutions/.venv/Lib/site-packages/pylint/config/arguments_provider.py
new file mode 100644
index 000000000..7f75718ca
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/arguments_provider.py
@@ -0,0 +1,65 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Arguments provider class used to expose options."""
+
+from __future__ import annotations
+
+from collections.abc import Iterator
+from typing import Any
+
+from pylint.config.arguments_manager import _ArgumentsManager
+from pylint.typing import OptionDict, Options
+
+
+class _ArgumentsProvider:
+ """Base class for classes that provide arguments."""
+
+ name: str
+ """Name of the provider."""
+
+ options: Options = ()
+ """Options provided by this provider."""
+
+ option_groups_descs: dict[str, str] = {}
+ """Option groups of this provider and their descriptions."""
+
+ def __init__(self, arguments_manager: _ArgumentsManager) -> None:
+ self._arguments_manager = arguments_manager
+ """The manager that will parse and register any options provided."""
+
+ self._arguments_manager._register_options_provider(self)
+
+ def _option_value(self, opt: str) -> Any:
+ """Get the current value for the given option."""
+ return getattr(self._arguments_manager.config, opt.replace("-", "_"), None)
+
+ def _options_by_section(
+ self,
+ ) -> Iterator[
+ tuple[str, list[tuple[str, OptionDict, Any]]]
+ | tuple[None, dict[str, list[tuple[str, OptionDict, Any]]]]
+ ]:
+ """Return an iterator on options grouped by section.
+
+ (section, [list of (optname, optdict, optvalue)])
+ """
+ sections: dict[str, list[tuple[str, OptionDict, Any]]] = {}
+ for optname, optdict in self.options:
+ sections.setdefault(optdict.get("group"), []).append( # type: ignore[arg-type]
+ (optname, optdict, self._option_value(optname))
+ )
+ if None in sections:
+ yield None, sections.pop(None) # type: ignore[call-overload]
+ for section, options in sorted(sections.items()):
+ yield section.upper(), options
+
+ def _options_and_values(
+ self, options: Options | None = None
+ ) -> Iterator[tuple[str, OptionDict, Any]]:
+ """DEPRECATED."""
+ if options is None:
+ options = self.options
+ for optname, optdict in options:
+ yield optname, optdict, self._option_value(optname)
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/callback_actions.py b/solutions/.venv/Lib/site-packages/pylint/config/callback_actions.py
new file mode 100644
index 000000000..bf2decd3c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/callback_actions.py
@@ -0,0 +1,468 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+# pylint: disable=too-many-arguments, redefined-builtin, duplicate-code
+
+"""Callback actions for various options."""
+
+from __future__ import annotations
+
+import abc
+import argparse
+import sys
+from collections.abc import Callable, Sequence
+from pathlib import Path
+from typing import TYPE_CHECKING, Any
+
+from pylint import exceptions, extensions, interfaces, utils
+
+if TYPE_CHECKING:
+ from pylint.config.help_formatter import _HelpFormatter
+ from pylint.lint import PyLinter
+ from pylint.lint.run import Run
+
+
+class _CallbackAction(argparse.Action):
+ """Custom callback action."""
+
+ @abc.abstractmethod
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = None,
+ ) -> None:
+ raise NotImplementedError # pragma: no cover
+
+
+class _DoNothingAction(_CallbackAction):
+ """Action that just passes.
+
+ This action is used to allow pre-processing of certain options
+ without erroring when they are then processed again by argparse.
+ """
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = None,
+ ) -> None:
+ return None
+
+
+class _AccessRunObjectAction(_CallbackAction):
+ """Action that has access to the Run object."""
+
+ def __init__(
+ self,
+ option_strings: Sequence[str],
+ dest: str,
+ nargs: None = None,
+ const: None = None,
+ default: None = None,
+ type: None = None,
+ choices: None = None,
+ required: bool = False,
+ help: str = "",
+ metavar: str = "",
+ **kwargs: Run,
+ ) -> None:
+ self.run = kwargs["Run"]
+
+ super().__init__(
+ option_strings,
+ dest,
+ 0,
+ const,
+ default,
+ type,
+ choices,
+ required,
+ help,
+ metavar,
+ )
+
+ @abc.abstractmethod
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = None,
+ ) -> None:
+ raise NotImplementedError # pragma: no cover
+
+
+class _MessageHelpAction(_CallbackAction):
+ """Display the help message of a message."""
+
+ def __init__(
+ self,
+ option_strings: Sequence[str],
+ dest: str,
+ nargs: None = None,
+ const: None = None,
+ default: None = None,
+ type: None = None,
+ choices: None = None,
+ required: bool = False,
+ help: str = "",
+ metavar: str = "",
+ **kwargs: Run,
+ ) -> None:
+ self.run = kwargs["Run"]
+ super().__init__(
+ option_strings,
+ dest,
+ "+",
+ const,
+ default,
+ type,
+ choices,
+ required,
+ help,
+ metavar,
+ )
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[str] | None,
+ option_string: str | None = "--help-msg",
+ ) -> None:
+ assert isinstance(values, (list, tuple))
+ values_to_print: list[str] = []
+ for msg in values:
+ assert isinstance(msg, str)
+ values_to_print += utils._check_csv(msg)
+ self.run.linter.msgs_store.help_message(values_to_print)
+ sys.exit(0)
+
+
+class _ListMessagesAction(_AccessRunObjectAction):
+ """Display all available messages."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--list-enabled",
+ ) -> None:
+ self.run.linter.msgs_store.list_messages()
+ sys.exit(0)
+
+
+class _ListMessagesEnabledAction(_AccessRunObjectAction):
+ """Display all enabled messages."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--list-msgs-enabled",
+ ) -> None:
+ self.run.linter.list_messages_enabled()
+ sys.exit(0)
+
+
+class _ListCheckGroupsAction(_AccessRunObjectAction):
+ """Display all the check groups that pylint knows about."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--list-groups",
+ ) -> None:
+ for check in self.run.linter.get_checker_names():
+ print(check)
+ sys.exit(0)
+
+
+class _ListConfidenceLevelsAction(_AccessRunObjectAction):
+ """Display all the confidence levels that pylint knows about."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--list-conf-levels",
+ ) -> None:
+ for level in interfaces.CONFIDENCE_LEVELS:
+ print(f"%-18s: {level}")
+ sys.exit(0)
+
+
+class _ListExtensionsAction(_AccessRunObjectAction):
+ """Display all extensions under pylint.extensions."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--list-extensions",
+ ) -> None:
+ for filename in Path(extensions.__file__).parent.iterdir():
+ if filename.suffix == ".py" and not filename.stem.startswith("_"):
+ extension_name, _, _ = filename.stem.partition(".")
+ print(f"pylint.extensions.{extension_name}")
+ sys.exit(0)
+
+
+class _FullDocumentationAction(_AccessRunObjectAction):
+ """Display the full documentation."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--full-documentation",
+ ) -> None:
+ utils.print_full_documentation(self.run.linter)
+ sys.exit(0)
+
+
+class _GenerateRCFileAction(_AccessRunObjectAction):
+ """Generate a pylintrc file."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--generate-rcfile",
+ ) -> None:
+ # TODO: 4.x: Deprecate this after the auto-upgrade functionality of
+ # pylint-config is sufficient.
+ self.run.linter._generate_config(skipsections=("Commands",))
+ sys.exit(0)
+
+
+class _GenerateConfigFileAction(_AccessRunObjectAction):
+ """Generate a .toml format configuration file."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--generate-toml-config",
+ ) -> None:
+ print(self.run.linter._generate_config_file())
+ sys.exit(0)
+
+
+class _ErrorsOnlyModeAction(_AccessRunObjectAction):
+ """Turn on errors-only mode.
+
+ Error mode:
+ * disable all but error messages
+ * disable the 'miscellaneous' checker which can be safely deactivated in
+ debug
+ * disable reports
+ * do not save execution information
+ """
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--errors-only",
+ ) -> None:
+ self.run.linter._error_mode = True
+
+
+class _LongHelpAction(_AccessRunObjectAction):
+ """Display the long help message."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--long-help",
+ ) -> None:
+ formatter: _HelpFormatter = self.run.linter._arg_parser._get_formatter() # type: ignore[assignment]
+
+ # Add extra info as epilog to the help message
+ self.run.linter._arg_parser.epilog = formatter.get_long_description()
+ print(self.run.linter.help())
+
+ sys.exit(0)
+
+
+class _AccessLinterObjectAction(_CallbackAction):
+ """Action that has access to the Linter object."""
+
+ def __init__(
+ self,
+ option_strings: Sequence[str],
+ dest: str,
+ nargs: None = None,
+ const: None = None,
+ default: None = None,
+ type: None = None,
+ choices: None = None,
+ required: bool = False,
+ help: str = "",
+ metavar: str = "",
+ **kwargs: PyLinter,
+ ) -> None:
+ self.linter = kwargs["linter"]
+
+ super().__init__(
+ option_strings,
+ dest,
+ 1,
+ const,
+ default,
+ type,
+ choices,
+ required,
+ help,
+ metavar,
+ )
+
+ @abc.abstractmethod
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = None,
+ ) -> None:
+ raise NotImplementedError # pragma: no cover
+
+
+class _XableAction(_AccessLinterObjectAction):
+ """Callback action for enabling or disabling a message."""
+
+ def _call(
+ self,
+ xabling_function: Callable[[str], None],
+ values: str | Sequence[Any] | None,
+ option_string: str | None,
+ ) -> None:
+ assert isinstance(values, (tuple, list))
+ for msgid in utils._check_csv(values[0]):
+ try:
+ xabling_function(msgid)
+ except (
+ exceptions.DeletedMessageError,
+ exceptions.MessageBecameExtensionError,
+ ) as e:
+ self.linter._stashed_messages[
+ (self.linter.current_name, "useless-option-value")
+ ].append((option_string, str(e)))
+ except exceptions.UnknownMessageError:
+ self.linter._stashed_messages[
+ (self.linter.current_name, "unknown-option-value")
+ ].append((option_string, msgid))
+
+ @abc.abstractmethod
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--disable",
+ ) -> None:
+ raise NotImplementedError # pragma: no cover
+
+
+class _DisableAction(_XableAction):
+ """Callback action for disabling a message."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--disable",
+ ) -> None:
+ self._call(self.linter.disable, values, option_string)
+
+
+class _EnableAction(_XableAction):
+ """Callback action for enabling a message."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--enable",
+ ) -> None:
+ self._call(self.linter.enable, values, option_string)
+
+
+class _OutputFormatAction(_AccessLinterObjectAction):
+ """Callback action for setting the output format."""
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = "--enable",
+ ) -> None:
+ assert isinstance(values, (tuple, list))
+ assert isinstance(
+ values[0], str
+ ), "'output-format' should be a comma separated string of reporters"
+ self.linter._load_reporters(values[0])
+
+
+class _AccessParserAction(_CallbackAction):
+ """Action that has access to the ArgumentParser object."""
+
+ def __init__(
+ self,
+ option_strings: Sequence[str],
+ dest: str,
+ nargs: None = None,
+ const: None = None,
+ default: None = None,
+ type: None = None,
+ choices: None = None,
+ required: bool = False,
+ help: str = "",
+ metavar: str = "",
+ **kwargs: argparse.ArgumentParser,
+ ) -> None:
+ self.parser = kwargs["parser"]
+
+ super().__init__(
+ option_strings,
+ dest,
+ 0,
+ const,
+ default,
+ type,
+ choices,
+ required,
+ help,
+ metavar,
+ )
+
+ @abc.abstractmethod
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = None,
+ ) -> None:
+ raise NotImplementedError # pragma: no cover
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/config_file_parser.py b/solutions/.venv/Lib/site-packages/pylint/config/config_file_parser.py
new file mode 100644
index 000000000..4ceed28d6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/config_file_parser.py
@@ -0,0 +1,129 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Configuration file parser class."""
+
+from __future__ import annotations
+
+import configparser
+import os
+import sys
+from pathlib import Path
+from typing import TYPE_CHECKING
+
+from pylint.config.utils import _parse_rich_type_value
+
+if sys.version_info >= (3, 11):
+ import tomllib
+else:
+ import tomli as tomllib
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+PylintConfigFileData = tuple[dict[str, str], list[str]]
+
+
+class _RawConfParser:
+ """Class to parse various formats of configuration files."""
+
+ @staticmethod
+ def parse_ini_file(file_path: Path) -> PylintConfigFileData:
+ """Parse and handle errors of an ini configuration file.
+
+ Raises ``configparser.Error``.
+ """
+ parser = configparser.ConfigParser(inline_comment_prefixes=("#", ";"))
+ # Use this encoding in order to strip the BOM marker, if any.
+ with open(file_path, encoding="utf_8_sig") as fp:
+ parser.read_file(fp)
+
+ config_content: dict[str, str] = {}
+ options: list[str] = []
+ ini_file_with_sections = _RawConfParser._ini_file_with_sections(file_path)
+ for section in parser.sections():
+ if ini_file_with_sections and not section.startswith("pylint"):
+ continue
+ for option, value in parser[section].items():
+ config_content[option] = value
+ options += [f"--{option}", value]
+ return config_content, options
+
+ @staticmethod
+ def _ini_file_with_sections(file_path: Path) -> bool:
+ """Return whether the file uses sections."""
+ if "setup.cfg" in file_path.parts:
+ return True
+ if "tox.ini" in file_path.parts:
+ return True
+ return False
+
+ @staticmethod
+ def parse_toml_file(file_path: Path) -> PylintConfigFileData:
+ """Parse and handle errors of a toml configuration file.
+
+ Raises ``tomllib.TOMLDecodeError``.
+ """
+ with open(file_path, mode="rb") as fp:
+ content = tomllib.load(fp)
+ try:
+ sections_values = content["tool"]["pylint"]
+ except KeyError:
+ return {}, []
+
+ config_content: dict[str, str] = {}
+ options: list[str] = []
+ for opt, values in sections_values.items():
+ if isinstance(values, dict):
+ for config, value in values.items():
+ value = _parse_rich_type_value(value)
+ config_content[config] = value
+ options += [f"--{config}", value]
+ else:
+ values = _parse_rich_type_value(values)
+ config_content[opt] = values
+ options += [f"--{opt}", values]
+ return config_content, options
+
+ @staticmethod
+ def parse_config_file(
+ file_path: Path | None, verbose: bool
+ ) -> PylintConfigFileData:
+ """Parse a config file and return str-str pairs.
+
+ Raises ``tomllib.TOMLDecodeError``, ``configparser.Error``.
+ """
+ if file_path is None:
+ if verbose:
+ print(
+ "No config file found, using default configuration", file=sys.stderr
+ )
+ return {}, []
+
+ file_path = Path(os.path.expandvars(file_path)).expanduser()
+ if not file_path.exists():
+ raise OSError(f"The config file {file_path} doesn't exist!")
+
+ if verbose:
+ print(f"Using config file {file_path}", file=sys.stderr)
+
+ if file_path.suffix == ".toml":
+ return _RawConfParser.parse_toml_file(file_path)
+ return _RawConfParser.parse_ini_file(file_path)
+
+
+class _ConfigurationFileParser:
+ """Class to parse various formats of configuration files."""
+
+ def __init__(self, verbose: bool, linter: PyLinter) -> None:
+ self.verbose_mode = verbose
+ self.linter = linter
+
+ def parse_config_file(self, file_path: Path | None) -> PylintConfigFileData:
+ """Parse a config file and return str-str pairs."""
+ try:
+ return _RawConfParser.parse_config_file(file_path, self.verbose_mode)
+ except (configparser.Error, tomllib.TOMLDecodeError) as e:
+ self.linter.add_message("config-parse-error", line=0, args=str(e))
+ return {}, []
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/config_initialization.py b/solutions/.venv/Lib/site-packages/pylint/config/config_initialization.py
new file mode 100644
index 000000000..9656ea564
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/config_initialization.py
@@ -0,0 +1,202 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import sys
+import warnings
+from glob import glob
+from itertools import chain
+from pathlib import Path
+from typing import TYPE_CHECKING
+
+from pylint import reporters
+from pylint.config.config_file_parser import _ConfigurationFileParser
+from pylint.config.exceptions import (
+ ArgumentPreprocessingError,
+ _UnrecognizedOptionError,
+)
+from pylint.utils import utils
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def _config_initialization(
+ linter: PyLinter,
+ args_list: list[str],
+ reporter: reporters.BaseReporter | reporters.MultiReporter | None = None,
+ config_file: None | str | Path = None,
+ verbose_mode: bool = False,
+) -> list[str]:
+ """Parse all available options, read config files and command line arguments and
+ set options accordingly.
+ """
+ config_file = Path(config_file) if config_file else None
+
+ # Set the current module to the configuration file
+ # to allow raising messages on the configuration file.
+ linter.set_current_module(str(config_file) if config_file else "")
+
+ # Read the configuration file
+ config_file_parser = _ConfigurationFileParser(verbose_mode, linter)
+ try:
+ config_data, config_args = config_file_parser.parse_config_file(
+ file_path=config_file
+ )
+ except OSError as ex:
+ print(ex, file=sys.stderr)
+ sys.exit(32)
+
+ # Order --enable=all or --disable=all to come first.
+ config_args = _order_all_first(config_args, joined=False)
+
+ # Run init hook, if present, before loading plugins
+ if "init-hook" in config_data:
+ exec(utils._unquote(config_data["init-hook"])) # pylint: disable=exec-used
+
+ # Load plugins if specified in the config file
+ if "load-plugins" in config_data:
+ linter.load_plugin_modules(utils._splitstrip(config_data["load-plugins"]))
+
+ unrecognized_options_message = None
+ # First we parse any options from a configuration file
+ try:
+ linter._parse_configuration_file(config_args)
+ except _UnrecognizedOptionError as exc:
+ unrecognized_options_message = ", ".join(exc.options)
+
+ # Then, if a custom reporter is provided as argument, it may be overridden
+ # by file parameters, so we re-set it here. We do this before command line
+ # parsing, so it's still overridable by command line options
+ if reporter:
+ linter.set_reporter(reporter)
+
+ # Set the current module to the command line
+ # to allow raising messages on it
+ linter.set_current_module("Command line")
+
+ # Now we parse any options from the command line, so they can override
+ # the configuration file
+ args_list = _order_all_first(args_list, joined=True)
+ parsed_args_list = linter._parse_command_line_configuration(args_list)
+
+ # Remove the positional arguments separator from the list of arguments if it exists
+ try:
+ parsed_args_list.remove("--")
+ except ValueError:
+ pass
+
+ # Check if there are any options that we do not recognize
+ unrecognized_options: list[str] = []
+ for opt in parsed_args_list:
+ if opt.startswith("--"):
+ unrecognized_options.append(opt[2:])
+ elif opt.startswith("-"):
+ unrecognized_options.append(opt[1:])
+ if unrecognized_options:
+ msg = ", ".join(unrecognized_options)
+ try:
+ linter._arg_parser.error(f"Unrecognized option found: {msg}")
+ except SystemExit:
+ sys.exit(32)
+
+ # Now that config file and command line options have been loaded
+ # with all disables, it is safe to emit messages
+ if unrecognized_options_message is not None:
+ linter.set_current_module(str(config_file) if config_file else "")
+ linter.add_message(
+ "unrecognized-option", args=unrecognized_options_message, line=0
+ )
+
+ # TODO: Change this to be checked only when upgrading the configuration
+ for exc_name in linter.config.overgeneral_exceptions:
+ if "." not in exc_name:
+ warnings.warn_explicit(
+ f"'{exc_name}' is not a proper value for the 'overgeneral-exceptions' option. "
+ f"Use fully qualified name (maybe 'builtins.{exc_name}' ?) instead. "
+ "This will cease to be checked at runtime when the configuration "
+ "upgrader is released.",
+ category=UserWarning,
+ filename="pylint: Command line or configuration file",
+ lineno=1,
+ module="pylint",
+ )
+
+ linter._emit_stashed_messages()
+
+ # Set the current module to configuration as we don't know where
+ # the --load-plugins key is coming from
+ linter.set_current_module("Command line or configuration file")
+
+ # We have loaded configuration from config file and command line. Now, we can
+ # load plugin specific configuration.
+ linter.load_plugin_configuration()
+
+ # Now that plugins are loaded, get list of all fail_on messages, and
+ # enable them
+ linter.enable_fail_on_messages()
+
+ linter._parse_error_mode()
+
+ # Link the base Namespace object on the current directory
+ linter._directory_namespaces[Path().resolve()] = (linter.config, {})
+
+ # parsed_args_list should now only be a list of inputs to lint.
+ # All other options have been removed from the list.
+ return list(
+ chain.from_iterable(
+ # NOTE: 'or [arg]' is needed in the case the input file or directory does
+ # not exist and 'glob(arg)' cannot find anything. Without this we would
+ # not be able to output the fatal import error for this module later on,
+ # as it would get silently ignored.
+ glob(arg, recursive=True) or [arg]
+ for arg in parsed_args_list
+ )
+ )
+
+
+def _order_all_first(config_args: list[str], *, joined: bool) -> list[str]:
+ """Reorder config_args such that --enable=all or --disable=all comes first.
+
+ Raise if both are given.
+
+ If joined is True, expect args in the form '--enable=all,for-any-all'.
+ If joined is False, expect args in the form '--enable', 'all,for-any-all'.
+ """
+ indexes_to_prepend = []
+ all_action = ""
+
+ for i, arg in enumerate(config_args):
+ if joined and arg.startswith(("--enable=", "--disable=")):
+ value = arg.split("=")[1]
+ elif arg in {"--enable", "--disable"}:
+ value = config_args[i + 1]
+ else:
+ continue
+
+ if "all" not in (msg.strip() for msg in value.split(",")):
+ continue
+
+ arg = arg.split("=")[0]
+ if all_action and (arg != all_action):
+ raise ArgumentPreprocessingError(
+ "--enable=all and --disable=all are incompatible."
+ )
+ all_action = arg
+
+ indexes_to_prepend.append(i)
+ if not joined:
+ indexes_to_prepend.append(i + 1)
+
+ returned_args = []
+ for i in indexes_to_prepend:
+ returned_args.append(config_args[i])
+
+ for i, arg in enumerate(config_args):
+ if i in indexes_to_prepend:
+ continue
+ returned_args.append(arg)
+
+ return returned_args
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/deprecation_actions.py b/solutions/.venv/Lib/site-packages/pylint/config/deprecation_actions.py
new file mode 100644
index 000000000..85a77cc78
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/deprecation_actions.py
@@ -0,0 +1,108 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+# pylint: disable=too-many-arguments, redefined-builtin
+
+"""Deprecated option actions."""
+
+from __future__ import annotations
+
+import argparse
+import warnings
+from collections.abc import Sequence
+from typing import Any
+
+
+class _OldNamesAction(argparse._StoreAction):
+ """Store action that also sets the value to old names."""
+
+ def __init__(
+ self,
+ option_strings: Sequence[str],
+ dest: str,
+ nargs: None = None,
+ const: None = None,
+ default: None = None,
+ type: None = None,
+ choices: None = None,
+ required: bool = False,
+ help: str = "",
+ metavar: str = "",
+ old_names: list[str] | None = None,
+ ) -> None:
+ assert old_names
+ self.old_names = old_names
+ super().__init__(
+ option_strings,
+ dest,
+ 1,
+ const,
+ default,
+ type,
+ choices,
+ required,
+ help,
+ metavar,
+ )
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = None,
+ ) -> None:
+ assert isinstance(values, list)
+ setattr(namespace, self.dest, values[0])
+ for old_name in self.old_names:
+ setattr(namespace, old_name, values[0])
+
+
+class _NewNamesAction(argparse._StoreAction):
+ """Store action that also emits a deprecation warning about a new name."""
+
+ def __init__(
+ self,
+ option_strings: Sequence[str],
+ dest: str,
+ nargs: None = None,
+ const: None = None,
+ default: None = None,
+ type: None = None,
+ choices: None = None,
+ required: bool = False,
+ help: str = "",
+ metavar: str = "",
+ new_names: list[str] | None = None,
+ ) -> None:
+ assert new_names
+ self.new_names = new_names
+ super().__init__(
+ option_strings,
+ dest,
+ 1,
+ const,
+ default,
+ type,
+ choices,
+ required,
+ help,
+ metavar,
+ )
+
+ def __call__(
+ self,
+ parser: argparse.ArgumentParser,
+ namespace: argparse.Namespace,
+ values: str | Sequence[Any] | None,
+ option_string: str | None = None,
+ ) -> None:
+ assert isinstance(values, list)
+ setattr(namespace, self.dest, values[0])
+ warnings.warn(
+ f"{self.option_strings[0]} has been deprecated. Please look into "
+ f"using any of the following options: {', '.join(self.new_names)}.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/exceptions.py b/solutions/.venv/Lib/site-packages/pylint/config/exceptions.py
new file mode 100644
index 000000000..982e3f494
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/exceptions.py
@@ -0,0 +1,25 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+
+class UnrecognizedArgumentAction(Exception):
+ """Raised if an ArgumentManager instance tries to add an argument for which the
+ action is not recognized.
+ """
+
+
+class _UnrecognizedOptionError(Exception):
+ """Raised if an ArgumentManager instance tries to parse an option that is
+ unknown.
+ """
+
+ def __init__(self, options: list[str], *args: object) -> None:
+ self.options = options
+ super().__init__(*args)
+
+
+class ArgumentPreprocessingError(Exception):
+ """Raised if an error occurs during argument pre-processing."""
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/find_default_config_files.py b/solutions/.venv/Lib/site-packages/pylint/config/find_default_config_files.py
new file mode 100644
index 000000000..7e53e7720
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/find_default_config_files.py
@@ -0,0 +1,150 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import configparser
+import os
+import sys
+from collections.abc import Iterator
+from pathlib import Path
+
+if sys.version_info >= (3, 11):
+ import tomllib
+else:
+ import tomli as tomllib
+
+RC_NAMES = (
+ Path("pylintrc"),
+ Path("pylintrc.toml"),
+ Path(".pylintrc"),
+ Path(".pylintrc.toml"),
+)
+PYPROJECT_NAME = Path("pyproject.toml")
+CONFIG_NAMES = (*RC_NAMES, PYPROJECT_NAME, Path("setup.cfg"), Path("tox.ini"))
+
+
+def _find_pyproject() -> Path:
+ """Search for file pyproject.toml in the parent directories recursively.
+
+ It resolves symlinks, so if there is any symlink up in the tree, it does not respect them
+ """
+ current_dir = Path.cwd().resolve()
+ is_root = False
+ while not is_root:
+ if (current_dir / PYPROJECT_NAME).is_file():
+ return current_dir / PYPROJECT_NAME
+ is_root = (
+ current_dir == current_dir.parent
+ or (current_dir / ".git").is_dir()
+ or (current_dir / ".hg").is_dir()
+ )
+ current_dir = current_dir.parent
+
+ return current_dir
+
+
+def _toml_has_config(path: Path | str) -> bool:
+ with open(path, mode="rb") as toml_handle:
+ try:
+ content = tomllib.load(toml_handle)
+ except tomllib.TOMLDecodeError as error:
+ print(f"Failed to load '{path}': {error}")
+ return False
+ return "pylint" in content.get("tool", [])
+
+
+def _cfg_or_ini_has_config(path: Path | str) -> bool:
+ parser = configparser.ConfigParser()
+ try:
+ parser.read(path, encoding="utf-8")
+ except configparser.Error:
+ return False
+ return any(
+ section == "pylint" or section.startswith("pylint.")
+ for section in parser.sections()
+ )
+
+
+def _yield_default_files() -> Iterator[Path]:
+ """Iterate over the default config file names and see if they exist."""
+ for config_name in CONFIG_NAMES:
+ try:
+ if config_name.is_file():
+ if config_name.suffix == ".toml" and not _toml_has_config(config_name):
+ continue
+ if config_name.suffix in {
+ ".cfg",
+ ".ini",
+ } and not _cfg_or_ini_has_config(config_name):
+ continue
+
+ yield config_name.resolve()
+ except OSError:
+ pass
+
+
+def _find_project_config() -> Iterator[Path]:
+ """Traverse up the directory tree to find a config file.
+
+ Stop if no '__init__' is found and thus we are no longer in a package.
+ """
+ if Path("__init__.py").is_file():
+ curdir = Path(os.getcwd()).resolve()
+ while (curdir / "__init__.py").is_file():
+ curdir = curdir.parent
+ for rc_name in RC_NAMES:
+ rc_path = curdir / rc_name
+ if rc_path.is_file():
+ yield rc_path.resolve()
+
+
+def _find_config_in_home_or_environment() -> Iterator[Path]:
+ """Find a config file in the specified environment var or the home directory."""
+ if "PYLINTRC" in os.environ and Path(os.environ["PYLINTRC"]).exists():
+ if Path(os.environ["PYLINTRC"]).is_file():
+ yield Path(os.environ["PYLINTRC"]).resolve()
+ else:
+ try:
+ user_home = Path.home()
+ except RuntimeError:
+ # If the home directory does not exist a RuntimeError will be raised
+ user_home = None
+
+ if user_home is not None and str(user_home) not in ("~", "/root"):
+ home_rc = user_home / ".pylintrc"
+ if home_rc.is_file():
+ yield home_rc.resolve()
+
+ home_rc = user_home / ".config" / "pylintrc"
+ if home_rc.is_file():
+ yield home_rc.resolve()
+
+
+def find_default_config_files() -> Iterator[Path]:
+ """Find all possible config files."""
+ yield from _yield_default_files()
+
+ try:
+ yield from _find_project_config()
+ except OSError:
+ pass
+
+ try:
+ parent_pyproject = _find_pyproject()
+ if parent_pyproject.is_file() and _toml_has_config(parent_pyproject):
+ yield parent_pyproject.resolve()
+ except OSError:
+ pass
+
+ try:
+ yield from _find_config_in_home_or_environment()
+ except OSError:
+ pass
+
+ try:
+ if os.path.isfile("/etc/pylintrc"):
+ yield Path("/etc/pylintrc").resolve()
+ except OSError:
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/help_formatter.py b/solutions/.venv/Lib/site-packages/pylint/config/help_formatter.py
new file mode 100644
index 000000000..78d43d178
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/help_formatter.py
@@ -0,0 +1,64 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import argparse
+
+from pylint.config.callback_actions import _CallbackAction
+from pylint.constants import DEFAULT_PYLINT_HOME
+
+
+class _HelpFormatter(argparse.RawDescriptionHelpFormatter):
+ """Formatter for the help message emitted by argparse."""
+
+ def _get_help_string(self, action: argparse.Action) -> str | None:
+ """Copied from argparse.ArgumentDefaultsHelpFormatter."""
+ assert action.help
+ help_string = action.help
+
+ # CallbackActions don't have a default
+ if isinstance(action, _CallbackAction):
+ return help_string
+
+ if "%(default)" not in help_string:
+ if action.default is not argparse.SUPPRESS:
+ defaulting_nargs = [argparse.OPTIONAL, argparse.ZERO_OR_MORE]
+ if action.option_strings or action.nargs in defaulting_nargs:
+ help_string += " (default: %(default)s)"
+ return help_string
+
+ @staticmethod
+ def get_long_description() -> str:
+ return f"""
+Environment variables:
+ The following environment variables are used:
+ * PYLINTHOME Path to the directory where persistent data for the run will
+ be stored. If not found, it defaults to '{DEFAULT_PYLINT_HOME}'.
+ * PYLINTRC Path to the configuration file. See the documentation for the method used
+ to search for configuration file.
+
+Output:
+ Using the default text output, the message format is :
+
+ MESSAGE_TYPE: LINE_NUM:[OBJECT:] MESSAGE
+
+ There are 5 kind of message types :
+ * (I) info, for informational messages
+ * (C) convention, for programming standard violation
+ * (R) refactor, for bad code smell
+ * (W) warning, for python specific problems
+ * (E) error, for probable bugs in the code
+ * (F) fatal, if an error occurred which prevented pylint from doing further processing.
+
+Output status code:
+ Pylint should leave with following bitwise status codes:
+ * 0 if everything went fine
+ * 1 if a fatal message was issued
+ * 2 if an error message was issued
+ * 4 if a warning message was issued
+ * 8 if a refactor message was issued
+ * 16 if a convention message was issued
+ * 32 on usage error
+"""
diff --git a/solutions/.venv/Lib/site-packages/pylint/config/utils.py b/solutions/.venv/Lib/site-packages/pylint/config/utils.py
new file mode 100644
index 000000000..91e4ff86f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/config/utils.py
@@ -0,0 +1,259 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Utils for arguments/options parsing and handling."""
+
+from __future__ import annotations
+
+import re
+from collections.abc import Callable, Sequence
+from pathlib import Path
+from typing import TYPE_CHECKING, Any
+
+from pylint import extensions, utils
+from pylint.config.argument import (
+ _CallableArgument,
+ _ExtendArgument,
+ _StoreArgument,
+ _StoreNewNamesArgument,
+ _StoreOldNamesArgument,
+ _StoreTrueArgument,
+)
+from pylint.config.callback_actions import _CallbackAction
+from pylint.config.exceptions import ArgumentPreprocessingError
+
+if TYPE_CHECKING:
+ from pylint.lint.run import Run
+
+
+def _convert_option_to_argument(
+ opt: str, optdict: dict[str, Any]
+) -> (
+ _StoreArgument
+ | _StoreTrueArgument
+ | _CallableArgument
+ | _StoreOldNamesArgument
+ | _StoreNewNamesArgument
+ | _ExtendArgument
+):
+ """Convert an optdict to an Argument class instance."""
+ # Get the long and short flags
+ flags = [f"--{opt}"]
+ if "short" in optdict:
+ flags += [f"-{optdict['short']}"]
+
+ # Get the action type
+ action = optdict.get("action", "store")
+
+ if action == "store_true":
+ return _StoreTrueArgument(
+ flags=flags,
+ action=action,
+ default=optdict.get("default", True),
+ arg_help=optdict.get("help", ""),
+ hide_help=optdict.get("hide", False),
+ section=optdict.get("group", None),
+ )
+ if not isinstance(action, str) and issubclass(action, _CallbackAction):
+ return _CallableArgument(
+ flags=flags,
+ action=action,
+ arg_help=optdict.get("help", ""),
+ kwargs=optdict.get("kwargs", {}),
+ hide_help=optdict.get("hide", False),
+ section=optdict.get("group", None),
+ metavar=optdict.get("metavar", None),
+ )
+
+ default = optdict["default"]
+
+ if action == "extend":
+ return _ExtendArgument(
+ flags=flags,
+ action=action,
+ default=[] if default is None else default,
+ arg_type=optdict["type"],
+ choices=optdict.get("choices", None),
+ arg_help=optdict.get("help", ""),
+ metavar=optdict.get("metavar", ""),
+ hide_help=optdict.get("hide", False),
+ section=optdict.get("group", None),
+ dest=optdict.get("dest", None),
+ )
+ if "kwargs" in optdict:
+ if "old_names" in optdict["kwargs"]:
+ return _StoreOldNamesArgument(
+ flags=flags,
+ default=default,
+ arg_type=optdict["type"],
+ choices=optdict.get("choices", None),
+ arg_help=optdict.get("help", ""),
+ metavar=optdict.get("metavar", ""),
+ hide_help=optdict.get("hide", False),
+ kwargs=optdict.get("kwargs", {}),
+ section=optdict.get("group", None),
+ )
+ if "new_names" in optdict["kwargs"]:
+ return _StoreNewNamesArgument(
+ flags=flags,
+ default=default,
+ arg_type=optdict["type"],
+ choices=optdict.get("choices", None),
+ arg_help=optdict.get("help", ""),
+ metavar=optdict.get("metavar", ""),
+ hide_help=optdict.get("hide", False),
+ kwargs=optdict.get("kwargs", {}),
+ section=optdict.get("group", None),
+ )
+ if "dest" in optdict:
+ return _StoreOldNamesArgument(
+ flags=flags,
+ default=default,
+ arg_type=optdict["type"],
+ choices=optdict.get("choices", None),
+ arg_help=optdict.get("help", ""),
+ metavar=optdict.get("metavar", ""),
+ hide_help=optdict.get("hide", False),
+ kwargs={"old_names": [optdict["dest"]]},
+ section=optdict.get("group", None),
+ )
+ return _StoreArgument(
+ flags=flags,
+ action=action,
+ default=default,
+ arg_type=optdict["type"],
+ choices=optdict.get("choices", None),
+ arg_help=optdict.get("help", ""),
+ metavar=optdict.get("metavar", ""),
+ hide_help=optdict.get("hide", False),
+ section=optdict.get("group", None),
+ )
+
+
+def _parse_rich_type_value(value: Any) -> str:
+ """Parse rich (toml) types into strings."""
+ if isinstance(value, (list, tuple)):
+ return ",".join(_parse_rich_type_value(i) for i in value)
+ if isinstance(value, re.Pattern):
+ return str(value.pattern)
+ if isinstance(value, dict):
+ return ",".join(f"{k}:{v}" for k, v in value.items())
+ return str(value)
+
+
+# pylint: disable-next=unused-argument
+def _init_hook(run: Run, value: str | None) -> None:
+ """Execute arbitrary code from the init_hook.
+
+ This can be used to set the 'sys.path' for example.
+ """
+ assert value is not None
+ exec(value) # pylint: disable=exec-used
+
+
+def _set_rcfile(run: Run, value: str | None) -> None:
+ """Set the rcfile."""
+ assert value is not None
+ run._rcfile = value
+
+
+def _set_output(run: Run, value: str | None) -> None:
+ """Set the output."""
+ assert value is not None
+ run._output = value
+
+
+def _add_plugins(run: Run, value: str | None) -> None:
+ """Add plugins to the list of loadable plugins."""
+ assert value is not None
+ run._plugins.extend(utils._splitstrip(value))
+
+
+def _set_verbose_mode(run: Run, value: str | None) -> None:
+ assert value is None
+ run.verbose = True
+
+
+def _enable_all_extensions(run: Run, value: str | None) -> None:
+ """Enable all extensions."""
+ assert value is None
+ for filename in Path(extensions.__file__).parent.iterdir():
+ if filename.suffix == ".py" and not filename.stem.startswith("_"):
+ extension_name = f"pylint.extensions.{filename.stem}"
+ if extension_name not in run._plugins:
+ run._plugins.append(extension_name)
+
+
+PREPROCESSABLE_OPTIONS: dict[
+ str, tuple[bool, Callable[[Run, str | None], None], int]
+] = { # pylint: disable=consider-using-namedtuple-or-dataclass
+ # pylint: disable=useless-suppression, wrong-spelling-in-comment
+ # Argparse by default allows abbreviations. It behaves differently
+ # if you turn this off, so we also turn it on. We mimic this
+ # by allowing some abbreviations or incorrect spelling here.
+ # The integer at the end of the tuple indicates how many letters
+ # should match, include the '-'. 0 indicates a full match.
+ #
+ # Clashes with --init-(import)
+ "--init-hook": (True, _init_hook, 8),
+ # Clashes with --r(ecursive)
+ "--rcfile": (True, _set_rcfile, 4),
+ # Clashes with --output(-format)
+ "--output": (True, _set_output, 0),
+ # Clashes with --lo(ng-help)
+ "--load-plugins": (True, _add_plugins, 5),
+ # Clashes with --v(ariable-rgx)
+ "--verbose": (False, _set_verbose_mode, 4),
+ "-v": (False, _set_verbose_mode, 2),
+ # Clashes with --enable
+ "--enable-all-extensions": (False, _enable_all_extensions, 9),
+}
+# pylint: enable=wrong-spelling-in-comment
+
+
+def _preprocess_options(run: Run, args: Sequence[str]) -> list[str]:
+ """Pre-process options before full config parsing has started."""
+ processed_args: list[str] = []
+
+ i = 0
+ while i < len(args):
+ argument = args[i]
+ if not argument.startswith("-"):
+ processed_args.append(argument)
+ i += 1
+ continue
+
+ try:
+ option, value = argument.split("=", 1)
+ except ValueError:
+ option, value = argument, None
+
+ matched_option = None
+ for option_name, data in PREPROCESSABLE_OPTIONS.items():
+ to_match = data[2]
+ if to_match == 0:
+ if option == option_name:
+ matched_option = option_name
+ elif option.startswith(option_name[:to_match]):
+ matched_option = option_name
+
+ if matched_option is None:
+ processed_args.append(argument)
+ i += 1
+ continue
+
+ takearg, cb, _ = PREPROCESSABLE_OPTIONS[matched_option]
+
+ if takearg and value is None:
+ i += 1
+ if i >= len(args) or args[i].startswith("-"):
+ raise ArgumentPreprocessingError(f"Option {option} expects a value")
+ value = args[i]
+ elif not takearg and value is not None:
+ raise ArgumentPreprocessingError(f"Option {option} doesn't expect a value")
+
+ cb(run, value)
+ i += 1
+
+ return processed_args
diff --git a/solutions/.venv/Lib/site-packages/pylint/constants.py b/solutions/.venv/Lib/site-packages/pylint/constants.py
new file mode 100644
index 000000000..0ba20162a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/constants.py
@@ -0,0 +1,277 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import os
+import platform
+import sys
+
+import astroid
+import platformdirs
+
+from pylint.__pkginfo__ import __version__
+from pylint.typing import MessageTypesFullName
+
+PY310_PLUS = sys.version_info[:2] >= (3, 10)
+PY311_PLUS = sys.version_info[:2] >= (3, 11)
+PY312_PLUS = sys.version_info[:2] >= (3, 12)
+
+IS_PYPY = platform.python_implementation() == "PyPy"
+
+PY_EXTS = (".py", ".pyc", ".pyo", ".pyw", ".so", ".dll")
+
+MSG_STATE_CONFIDENCE = 2
+_MSG_ORDER = "EWRCIF"
+MSG_STATE_SCOPE_CONFIG = 0
+MSG_STATE_SCOPE_MODULE = 1
+
+# The line/node distinction does not apply to fatal errors and reports.
+_SCOPE_EXEMPT = "FR"
+
+MSG_TYPES: dict[str, MessageTypesFullName] = {
+ "I": "info",
+ "C": "convention",
+ "R": "refactor",
+ "W": "warning",
+ "E": "error",
+ "F": "fatal",
+}
+MSG_TYPES_LONG: dict[str, str] = {v: k for k, v in MSG_TYPES.items()}
+
+MSG_TYPES_STATUS = {"I": 0, "C": 16, "R": 8, "W": 4, "E": 2, "F": 1}
+
+# You probably don't want to change the MAIN_CHECKER_NAME
+# This would affect rcfile generation and retro-compatibility
+# on all project using [MAIN] in their rcfile.
+MAIN_CHECKER_NAME = "main"
+
+DEFAULT_PYLINT_HOME = platformdirs.user_cache_dir("pylint")
+
+DEFAULT_IGNORE_LIST = ("CVS",)
+
+
+class WarningScope:
+ LINE = "line-based-msg"
+ NODE = "node-based-msg"
+
+
+full_version = f"""pylint {__version__}
+astroid {astroid.__version__}
+Python {sys.version}"""
+
+HUMAN_READABLE_TYPES = {
+ "file": "file",
+ "module": "module",
+ "const": "constant",
+ "class": "class",
+ "function": "function",
+ "method": "method",
+ "attr": "attribute",
+ "argument": "argument",
+ "variable": "variable",
+ "class_attribute": "class attribute",
+ "class_const": "class constant",
+ "inlinevar": "inline iteration",
+ "typevar": "type variable",
+ "typealias": "type alias",
+}
+
+# ignore some messages when emitting useless-suppression:
+# - cyclic-import: can show false positives due to incomplete context
+# - deprecated-{module, argument, class, method, decorator}:
+# can cause false positives for multi-interpreter projects
+# when linting with an interpreter on a lower python version
+INCOMPATIBLE_WITH_USELESS_SUPPRESSION = frozenset(
+ [
+ "R0401", # cyclic-import
+ "W0402", # deprecated-module
+ "W1505", # deprecated-method
+ "W1511", # deprecated-argument
+ "W1512", # deprecated-class
+ "W1513", # deprecated-decorator
+ "R0801", # duplicate-code
+ ]
+)
+
+
+def _get_pylint_home() -> str:
+ """Return the pylint home."""
+ if "PYLINTHOME" in os.environ:
+ return os.environ["PYLINTHOME"]
+ return DEFAULT_PYLINT_HOME
+
+
+PYLINT_HOME = _get_pylint_home()
+
+TYPING_NORETURN = frozenset(
+ (
+ "typing.NoReturn",
+ "typing_extensions.NoReturn",
+ )
+)
+TYPING_NEVER = frozenset(
+ (
+ "typing.Never",
+ "typing_extensions.Never",
+ )
+)
+
+DUNDER_METHODS: dict[tuple[int, int], dict[str, str]] = {
+ (0, 0): {
+ "__init__": "Instantiate class directly",
+ "__del__": "Use del keyword",
+ "__repr__": "Use repr built-in function",
+ "__str__": "Use str built-in function",
+ "__bytes__": "Use bytes built-in function",
+ "__format__": "Use format built-in function, format string method, or f-string",
+ "__lt__": "Use < operator",
+ "__le__": "Use <= operator",
+ "__eq__": "Use == operator",
+ "__ne__": "Use != operator",
+ "__gt__": "Use > operator",
+ "__ge__": "Use >= operator",
+ "__hash__": "Use hash built-in function",
+ "__bool__": "Use bool built-in function",
+ "__getattr__": "Access attribute directly or use getattr built-in function",
+ "__getattribute__": "Access attribute directly or use getattr built-in function",
+ "__setattr__": "Set attribute directly or use setattr built-in function",
+ "__delattr__": "Use del keyword",
+ "__dir__": "Use dir built-in function",
+ "__get__": "Use get method",
+ "__set__": "Use set method",
+ "__delete__": "Use del keyword",
+ "__instancecheck__": "Use isinstance built-in function",
+ "__subclasscheck__": "Use issubclass built-in function",
+ "__call__": "Invoke instance directly",
+ "__len__": "Use len built-in function",
+ "__length_hint__": "Use length_hint method",
+ "__getitem__": "Access item via subscript",
+ "__setitem__": "Set item via subscript",
+ "__delitem__": "Use del keyword",
+ "__iter__": "Use iter built-in function",
+ "__next__": "Use next built-in function",
+ "__reversed__": "Use reversed built-in function",
+ "__contains__": "Use in keyword",
+ "__add__": "Use + operator",
+ "__sub__": "Use - operator",
+ "__mul__": "Use * operator",
+ "__matmul__": "Use @ operator",
+ "__truediv__": "Use / operator",
+ "__floordiv__": "Use // operator",
+ "__mod__": "Use % operator",
+ "__divmod__": "Use divmod built-in function",
+ "__pow__": "Use ** operator or pow built-in function",
+ "__lshift__": "Use << operator",
+ "__rshift__": "Use >> operator",
+ "__and__": "Use & operator",
+ "__xor__": "Use ^ operator",
+ "__or__": "Use | operator",
+ "__radd__": "Use + operator",
+ "__rsub__": "Use - operator",
+ "__rmul__": "Use * operator",
+ "__rmatmul__": "Use @ operator",
+ "__rtruediv__": "Use / operator",
+ "__rfloordiv__": "Use // operator",
+ "__rmod__": "Use % operator",
+ "__rdivmod__": "Use divmod built-in function",
+ "__rpow__": "Use ** operator or pow built-in function",
+ "__rlshift__": "Use << operator",
+ "__rrshift__": "Use >> operator",
+ "__rand__": "Use & operator",
+ "__rxor__": "Use ^ operator",
+ "__ror__": "Use | operator",
+ "__iadd__": "Use += operator",
+ "__isub__": "Use -= operator",
+ "__imul__": "Use *= operator",
+ "__imatmul__": "Use @= operator",
+ "__itruediv__": "Use /= operator",
+ "__ifloordiv__": "Use //= operator",
+ "__imod__": "Use %= operator",
+ "__ipow__": "Use **= operator",
+ "__ilshift__": "Use <<= operator",
+ "__irshift__": "Use >>= operator",
+ "__iand__": "Use &= operator",
+ "__ixor__": "Use ^= operator",
+ "__ior__": "Use |= operator",
+ "__neg__": "Multiply by -1 instead",
+ "__pos__": "Multiply by +1 instead",
+ "__abs__": "Use abs built-in function",
+ "__invert__": "Use ~ operator",
+ "__complex__": "Use complex built-in function",
+ "__int__": "Use int built-in function",
+ "__float__": "Use float built-in function",
+ "__round__": "Use round built-in function",
+ "__trunc__": "Use math.trunc function",
+ "__floor__": "Use math.floor function",
+ "__ceil__": "Use math.ceil function",
+ "__enter__": "Invoke context manager directly",
+ "__aenter__": "Invoke context manager directly",
+ "__copy__": "Use copy.copy function",
+ "__deepcopy__": "Use copy.deepcopy function",
+ "__fspath__": "Use os.fspath function instead",
+ },
+ (3, 10): {
+ "__aiter__": "Use aiter built-in function",
+ "__anext__": "Use anext built-in function",
+ },
+}
+
+EXTRA_DUNDER_METHODS = [
+ "__new__",
+ "__subclasses__",
+ "__init_subclass__",
+ "__set_name__",
+ "__class_getitem__",
+ "__missing__",
+ "__exit__",
+ "__await__",
+ "__aexit__",
+ "__getnewargs_ex__",
+ "__getnewargs__",
+ "__getstate__",
+ "__index__",
+ "__setstate__",
+ "__reduce__",
+ "__reduce_ex__",
+ "__post_init__", # part of `dataclasses` module
+]
+
+DUNDER_PROPERTIES = [
+ "__class__",
+ "__dict__",
+ "__doc__",
+ "__format__",
+ "__module__",
+ "__sizeof__",
+ "__subclasshook__",
+ "__weakref__",
+]
+
+# C2801 rule exceptions as their corresponding function/method/operator
+# is not valid python syntax in a lambda definition
+UNNECESSARY_DUNDER_CALL_LAMBDA_EXCEPTIONS = [
+ "__init__",
+ "__del__",
+ "__delattr__",
+ "__set__",
+ "__delete__",
+ "__setitem__",
+ "__delitem__",
+ "__iadd__",
+ "__isub__",
+ "__imul__",
+ "__imatmul__",
+ "__itruediv__",
+ "__ifloordiv__",
+ "__imod__",
+ "__ipow__",
+ "__ilshift__",
+ "__irshift__",
+ "__iand__",
+ "__ixor__",
+ "__ior__",
+]
+
+MAX_NUMBER_OF_IMPORT_SHOWN = 6
diff --git a/solutions/.venv/Lib/site-packages/pylint/exceptions.py b/solutions/.venv/Lib/site-packages/pylint/exceptions.py
new file mode 100644
index 000000000..2bfbfa8cc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/exceptions.py
@@ -0,0 +1,53 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Exception classes raised by various operations within pylint."""
+
+
+class InvalidMessageError(Exception):
+ """Raised when a message creation, registration or addition is rejected."""
+
+
+class UnknownMessageError(Exception):
+ """Raised when an unregistered message id is encountered."""
+
+
+class DeletedMessageError(UnknownMessageError):
+ """Raised when a message id or symbol that was deleted from pylint is
+ encountered.
+ """
+
+ def __init__(self, msgid_or_symbol: str, removal_explanation: str):
+ super().__init__(
+ f"'{msgid_or_symbol}' was removed from pylint, see {removal_explanation}."
+ )
+
+
+class MessageBecameExtensionError(UnknownMessageError):
+ """Raised when a message id or symbol that was moved to an optional
+ extension is encountered.
+ """
+
+ def __init__(self, msgid_or_symbol: str, moved_explanation: str):
+ super().__init__(
+ f"'{msgid_or_symbol}' was moved to an optional extension, see {moved_explanation}."
+ )
+
+
+class EmptyReportError(Exception):
+ """Raised when a report is empty and so should not be displayed."""
+
+
+class InvalidReporterError(Exception):
+ """Raised when selected reporter is invalid (e.g. not found)."""
+
+
+class InvalidArgsError(ValueError):
+ """Raised when passed arguments are invalid, e.g., have the wrong length."""
+
+
+class NoLineSuppliedError(Exception):
+ """Raised when trying to disable a message on a next line without supplying a line
+ number.
+ """
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/__init__.py b/solutions/.venv/Lib/site-packages/pylint/extensions/__init__.py
new file mode 100644
index 000000000..e9e2b0d1b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/__init__.py
@@ -0,0 +1,20 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from pylint.utils import register_plugins
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def initialize(linter: PyLinter) -> None:
+ """Initialize linter with checkers in the extensions' directory."""
+ register_plugins(linter, __path__[0])
+
+
+__all__ = ["initialize"]
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/_check_docs_utils.py b/solutions/.venv/Lib/site-packages/pylint/extensions/_check_docs_utils.py
new file mode 100644
index 000000000..9b4b3e0db
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/_check_docs_utils.py
@@ -0,0 +1,946 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Utility methods for docstring checking."""
+
+from __future__ import annotations
+
+import itertools
+import re
+from collections.abc import Iterable
+
+import astroid
+from astroid import nodes
+from astroid.util import UninferableBase
+
+from pylint.checkers import utils
+
+
+def space_indentation(s: str) -> int:
+ """The number of leading spaces in a string.
+
+ :param str s: input string
+
+ :rtype: int
+ :return: number of leading spaces
+ """
+ return len(s) - len(s.lstrip(" "))
+
+
+def get_setters_property_name(node: nodes.FunctionDef) -> str | None:
+ """Get the name of the property that the given node is a setter for.
+
+ :param node: The node to get the property name for.
+ :type node: str
+
+ :rtype: str or None
+ :returns: The name of the property that the node is a setter for,
+ or None if one could not be found.
+ """
+ decorators = node.decorators.nodes if node.decorators else []
+ for decorator in decorators:
+ if (
+ isinstance(decorator, nodes.Attribute)
+ and decorator.attrname == "setter"
+ and isinstance(decorator.expr, nodes.Name)
+ ):
+ return decorator.expr.name # type: ignore[no-any-return]
+ return None
+
+
+def get_setters_property(node: nodes.FunctionDef) -> nodes.FunctionDef | None:
+ """Get the property node for the given setter node.
+
+ :param node: The node to get the property for.
+ :type node: nodes.FunctionDef
+
+ :rtype: nodes.FunctionDef or None
+ :returns: The node relating to the property of the given setter node,
+ or None if one could not be found.
+ """
+ property_ = None
+
+ property_name = get_setters_property_name(node)
+ class_node = utils.node_frame_class(node)
+ if property_name and class_node:
+ class_attrs: list[nodes.FunctionDef] = class_node.getattr(node.name)
+ for attr in class_attrs:
+ if utils.decorated_with_property(attr):
+ property_ = attr
+ break
+
+ return property_
+
+
+def returns_something(return_node: nodes.Return) -> bool:
+ """Check if a return node returns a value other than None.
+
+ :param return_node: The return node to check.
+ :type return_node: astroid.Return
+
+ :rtype: bool
+ :return: True if the return node returns a value other than None,
+ False otherwise.
+ """
+ returns = return_node.value
+
+ if returns is None:
+ return False
+
+ return not (isinstance(returns, nodes.Const) and returns.value is None)
+
+
+def _get_raise_target(node: nodes.NodeNG) -> nodes.NodeNG | UninferableBase | None:
+ if isinstance(node.exc, nodes.Call):
+ func = node.exc.func
+ if isinstance(func, (nodes.Name, nodes.Attribute)):
+ return utils.safe_infer(func)
+ return None
+
+
+def _split_multiple_exc_types(target: str) -> list[str]:
+ delimiters = r"(\s*,(?:\s*or\s)?\s*|\s+or\s+)"
+ return re.split(delimiters, target)
+
+
+def possible_exc_types(node: nodes.NodeNG) -> set[nodes.ClassDef]:
+ """Gets all the possible raised exception types for the given raise node.
+
+ .. note::
+
+ Caught exception types are ignored.
+
+ :param node: The raise node to find exception types for.
+
+ :returns: A list of exception types possibly raised by :param:`node`.
+ """
+ exceptions = []
+ if isinstance(node.exc, nodes.Name):
+ inferred = utils.safe_infer(node.exc)
+ if inferred:
+ exceptions = [inferred]
+ elif node.exc is None:
+ handler = node.parent
+ while handler and not isinstance(handler, nodes.ExceptHandler):
+ handler = handler.parent
+
+ if handler and handler.type:
+ try:
+ for exception in astroid.unpack_infer(handler.type):
+ if not isinstance(exception, UninferableBase):
+ exceptions.append(exception)
+ except astroid.InferenceError:
+ pass
+ else:
+ target = _get_raise_target(node)
+ if isinstance(target, nodes.ClassDef):
+ exceptions = [target]
+ elif isinstance(target, nodes.FunctionDef):
+ for ret in target.nodes_of_class(nodes.Return):
+ if ret.value is None:
+ continue
+ if ret.frame() != target:
+ # return from inner function - ignore it
+ continue
+
+ val = utils.safe_infer(ret.value)
+ if val and utils.inherit_from_std_ex(val):
+ if isinstance(val, nodes.ClassDef):
+ exceptions.append(val)
+ elif isinstance(val, astroid.Instance):
+ exceptions.append(val.getattr("__class__")[0])
+
+ try:
+ return {
+ exc
+ for exc in exceptions
+ if not utils.node_ignores_exception(node, exc.name)
+ }
+ except astroid.InferenceError:
+ return set()
+
+
+def _is_ellipsis(node: nodes.NodeNG) -> bool:
+ return isinstance(node, nodes.Const) and node.value == Ellipsis
+
+
+def _merge_annotations(
+ annotations: Iterable[nodes.NodeNG], comment_annotations: Iterable[nodes.NodeNG]
+) -> Iterable[nodes.NodeNG | None]:
+ for ann, comment_ann in itertools.zip_longest(annotations, comment_annotations):
+ if ann and not _is_ellipsis(ann):
+ yield ann
+ elif comment_ann and not _is_ellipsis(comment_ann):
+ yield comment_ann
+ else:
+ yield None
+
+
+def _annotations_list(args_node: nodes.Arguments) -> list[nodes.NodeNG]:
+ """Get a merged list of annotations.
+
+ The annotations can come from:
+
+ * Real type annotations.
+ * A type comment on the function.
+ * A type common on the individual argument.
+
+ :param args_node: The node to get the annotations for.
+ :returns: The annotations.
+ """
+ plain_annotations = args_node.annotations or ()
+ func_comment_annotations = args_node.parent.type_comment_args or ()
+ comment_annotations = args_node.type_comment_posonlyargs
+ comment_annotations += args_node.type_comment_args or []
+ comment_annotations += args_node.type_comment_kwonlyargs
+ return list(
+ _merge_annotations(
+ plain_annotations,
+ _merge_annotations(func_comment_annotations, comment_annotations),
+ )
+ )
+
+
+def args_with_annotation(args_node: nodes.Arguments) -> set[str]:
+ result = set()
+ annotations = _annotations_list(args_node)
+ annotation_offset = 0
+
+ if args_node.posonlyargs:
+ posonlyargs_annotations = args_node.posonlyargs_annotations
+ if not any(args_node.posonlyargs_annotations):
+ num_args = len(args_node.posonlyargs)
+ posonlyargs_annotations = annotations[
+ annotation_offset : annotation_offset + num_args
+ ]
+ annotation_offset += num_args
+
+ for arg, annotation in zip(args_node.posonlyargs, posonlyargs_annotations):
+ if annotation:
+ result.add(arg.name)
+
+ if args_node.args:
+ num_args = len(args_node.args)
+ for arg, annotation in zip(
+ args_node.args,
+ annotations[annotation_offset : annotation_offset + num_args],
+ ):
+ if annotation:
+ result.add(arg.name)
+
+ annotation_offset += num_args
+
+ if args_node.vararg:
+ if args_node.varargannotation:
+ result.add(args_node.vararg)
+ elif len(annotations) > annotation_offset and annotations[annotation_offset]:
+ result.add(args_node.vararg)
+ annotation_offset += 1
+
+ if args_node.kwonlyargs:
+ kwonlyargs_annotations = args_node.kwonlyargs_annotations
+ if not any(args_node.kwonlyargs_annotations):
+ num_args = len(args_node.kwonlyargs)
+ kwonlyargs_annotations = annotations[
+ annotation_offset : annotation_offset + num_args
+ ]
+ annotation_offset += num_args
+
+ for arg, annotation in zip(args_node.kwonlyargs, kwonlyargs_annotations):
+ if annotation:
+ result.add(arg.name)
+
+ if args_node.kwarg:
+ if args_node.kwargannotation:
+ result.add(args_node.kwarg)
+ elif len(annotations) > annotation_offset and annotations[annotation_offset]:
+ result.add(args_node.kwarg)
+ annotation_offset += 1
+
+ return result
+
+
+def docstringify(
+ docstring: nodes.Const | None, default_type: str = "default"
+) -> Docstring:
+ best_match = (0, DOCSTRING_TYPES.get(default_type, Docstring)(docstring))
+ for docstring_type in (
+ SphinxDocstring,
+ EpytextDocstring,
+ GoogleDocstring,
+ NumpyDocstring,
+ ):
+ instance = docstring_type(docstring)
+ matching_sections = instance.matching_sections()
+ if matching_sections > best_match[0]:
+ best_match = (matching_sections, instance)
+
+ return best_match[1]
+
+
+class Docstring:
+ re_for_parameters_see = re.compile(
+ r"""
+ For\s+the\s+(other)?\s*parameters\s*,\s+see
+ """,
+ re.X | re.S,
+ )
+
+ supports_yields: bool = False
+ """True if the docstring supports a "yield" section.
+
+ False if the docstring uses the returns section to document generators.
+ """
+
+ # These methods are designed to be overridden
+ def __init__(self, doc: nodes.Const | None) -> None:
+ docstring: str = doc.value if doc else ""
+ self.doc = docstring.expandtabs()
+
+ def __repr__(self) -> str:
+ return f"<{self.__class__.__name__}:'''{self.doc}'''>"
+
+ def matching_sections(self) -> int:
+ """Returns the number of matching docstring sections."""
+ return 0
+
+ def exceptions(self) -> set[str]:
+ return set()
+
+ def has_params(self) -> bool:
+ return False
+
+ def has_returns(self) -> bool:
+ return False
+
+ def has_rtype(self) -> bool:
+ return False
+
+ def has_property_returns(self) -> bool:
+ return False
+
+ def has_property_type(self) -> bool:
+ return False
+
+ def has_yields(self) -> bool:
+ return False
+
+ def has_yields_type(self) -> bool:
+ return False
+
+ def match_param_docs(self) -> tuple[set[str], set[str]]:
+ return set(), set()
+
+ def params_documented_elsewhere(self) -> bool:
+ return self.re_for_parameters_see.search(self.doc) is not None
+
+
+class SphinxDocstring(Docstring):
+ re_type = r"""
+ [~!.]? # Optional link style prefix
+ \w(?:\w|\.[^\.])* # Valid python name
+ """
+
+ re_simple_container_type = rf"""
+ {re_type} # a container type
+ [\(\[] [^\n\s]+ [\)\]] # with the contents of the container
+ """
+
+ re_multiple_simple_type = rf"""
+ (?:{re_simple_container_type}|{re_type})
+ (?:(?:\s+(?:of|or)\s+|\s*,\s*|\s+\|\s+)(?:{re_simple_container_type}|{re_type}))*
+ """
+
+ re_xref = rf"""
+ (?::\w+:)? # optional tag
+ `{re_type}` # what to reference
+ """
+
+ re_param_raw = rf"""
+ : # initial colon
+ (?: # Sphinx keywords
+ param|parameter|
+ arg|argument|
+ key|keyword
+ )
+ \s+ # whitespace
+
+ (?: # optional type declaration
+ ({re_type}|{re_simple_container_type})
+ \s+
+ )?
+
+ ((\\\*{{0,2}}\w+)|(\w+)) # Parameter name with potential asterisks
+ \s* # whitespace
+ : # final colon
+ """
+ re_param_in_docstring = re.compile(re_param_raw, re.X | re.S)
+
+ re_type_raw = rf"""
+ :type # Sphinx keyword
+ \s+ # whitespace
+ ({re_multiple_simple_type}) # Parameter name
+ \s* # whitespace
+ : # final colon
+ """
+ re_type_in_docstring = re.compile(re_type_raw, re.X | re.S)
+
+ re_property_type_raw = rf"""
+ :type: # Sphinx keyword
+ \s+ # whitespace
+ {re_multiple_simple_type} # type declaration
+ """
+ re_property_type_in_docstring = re.compile(re_property_type_raw, re.X | re.S)
+
+ re_raise_raw = rf"""
+ : # initial colon
+ (?: # Sphinx keyword
+ raises?|
+ except|exception
+ )
+ \s+ # whitespace
+ ({re_multiple_simple_type}) # exception type
+ \s* # whitespace
+ : # final colon
+ """
+ re_raise_in_docstring = re.compile(re_raise_raw, re.X | re.S)
+
+ re_rtype_in_docstring = re.compile(r":rtype:")
+
+ re_returns_in_docstring = re.compile(r":returns?:")
+
+ supports_yields = False
+
+ def matching_sections(self) -> int:
+ """Returns the number of matching docstring sections."""
+ return sum(
+ bool(i)
+ for i in (
+ self.re_param_in_docstring.search(self.doc),
+ self.re_raise_in_docstring.search(self.doc),
+ self.re_rtype_in_docstring.search(self.doc),
+ self.re_returns_in_docstring.search(self.doc),
+ self.re_property_type_in_docstring.search(self.doc),
+ )
+ )
+
+ def exceptions(self) -> set[str]:
+ types: set[str] = set()
+
+ for match in re.finditer(self.re_raise_in_docstring, self.doc):
+ raise_type = match.group(1)
+ types.update(_split_multiple_exc_types(raise_type))
+
+ return types
+
+ def has_params(self) -> bool:
+ if not self.doc:
+ return False
+
+ return self.re_param_in_docstring.search(self.doc) is not None
+
+ def has_returns(self) -> bool:
+ if not self.doc:
+ return False
+
+ return bool(self.re_returns_in_docstring.search(self.doc))
+
+ def has_rtype(self) -> bool:
+ if not self.doc:
+ return False
+
+ return bool(self.re_rtype_in_docstring.search(self.doc))
+
+ def has_property_returns(self) -> bool:
+ if not self.doc:
+ return False
+
+ # The summary line is the return doc,
+ # so the first line must not be a known directive.
+ return not self.doc.lstrip().startswith(":")
+
+ def has_property_type(self) -> bool:
+ if not self.doc:
+ return False
+
+ return bool(self.re_property_type_in_docstring.search(self.doc))
+
+ def match_param_docs(self) -> tuple[set[str], set[str]]:
+ params_with_doc = set()
+ params_with_type = set()
+
+ for match in re.finditer(self.re_param_in_docstring, self.doc):
+ name = match.group(2)
+ # Remove escape characters necessary for asterisks
+ name = name.replace("\\", "")
+ params_with_doc.add(name)
+ param_type = match.group(1)
+ if param_type is not None:
+ params_with_type.add(name)
+
+ params_with_type.update(re.findall(self.re_type_in_docstring, self.doc))
+ return params_with_doc, params_with_type
+
+
+class EpytextDocstring(SphinxDocstring):
+ """Epytext is similar to Sphinx.
+
+ See the docs:
+ http://epydoc.sourceforge.net/epytext.html
+ http://epydoc.sourceforge.net/fields.html#fields
+
+ It's used in PyCharm:
+ https://www.jetbrains.com/help/pycharm/2016.1/creating-documentation-comments.html#d848203e314
+ https://www.jetbrains.com/help/pycharm/2016.1/using-docstrings-to-specify-types.html
+ """
+
+ re_param_in_docstring = re.compile(
+ SphinxDocstring.re_param_raw.replace(":", "@", 1), re.X | re.S
+ )
+
+ re_type_in_docstring = re.compile(
+ SphinxDocstring.re_type_raw.replace(":", "@", 1), re.X | re.S
+ )
+
+ re_property_type_in_docstring = re.compile(
+ SphinxDocstring.re_property_type_raw.replace(":", "@", 1), re.X | re.S
+ )
+
+ re_raise_in_docstring = re.compile(
+ SphinxDocstring.re_raise_raw.replace(":", "@", 1), re.X | re.S
+ )
+
+ re_rtype_in_docstring = re.compile(
+ r"""
+ @ # initial "at" symbol
+ (?: # Epytext keyword
+ rtype|returntype
+ )
+ : # final colon
+ """,
+ re.X | re.S,
+ )
+
+ re_returns_in_docstring = re.compile(r"@returns?:")
+
+ def has_property_returns(self) -> bool:
+ if not self.doc:
+ return False
+
+ # If this is a property docstring, the summary is the return doc.
+ if self.has_property_type():
+ # The summary line is the return doc,
+ # so the first line must not be a known directive.
+ return not self.doc.lstrip().startswith("@")
+
+ return False
+
+
+class GoogleDocstring(Docstring):
+ re_type = SphinxDocstring.re_type
+
+ re_xref = SphinxDocstring.re_xref
+
+ re_container_type = rf"""
+ (?:{re_type}|{re_xref}) # a container type
+ [\(\[] [^\n]+ [\)\]] # with the contents of the container
+ """
+
+ re_multiple_type = rf"""
+ (?:{re_container_type}|{re_type}|{re_xref})
+ (?:(?:\s+(?:of|or)\s+|\s*,\s*|\s+\|\s+)(?:{re_container_type}|{re_type}|{re_xref}))*
+ """
+
+ _re_section_template = r"""
+ ^([ ]*) {0} \s*: \s*$ # Google parameter header
+ ( .* ) # section
+ """
+
+ re_param_section = re.compile(
+ _re_section_template.format(r"(?:Args|Arguments|Parameters)"),
+ re.X | re.S | re.M,
+ )
+
+ re_keyword_param_section = re.compile(
+ _re_section_template.format(r"Keyword\s(?:Args|Arguments|Parameters)"),
+ re.X | re.S | re.M,
+ )
+
+ re_param_line = re.compile(
+ rf"""
+ \s* ((?:\\?\*{{0,2}})?[\w\\]+) # identifier potentially with asterisks or escaped `\`
+ \s* ( [(]
+ {re_multiple_type}
+ (?:,\s+optional)?
+ [)] )? \s* : # optional type declaration
+ \s* (.*) # beginning of optional description
+ """,
+ re.X | re.S | re.M,
+ )
+
+ re_raise_section = re.compile(
+ _re_section_template.format(r"Raises"), re.X | re.S | re.M
+ )
+
+ re_raise_line = re.compile(
+ rf"""
+ \s* ({re_multiple_type}) \s* : # identifier
+ \s* (.*) # beginning of optional description
+ """,
+ re.X | re.S | re.M,
+ )
+
+ re_returns_section = re.compile(
+ _re_section_template.format(r"Returns?"), re.X | re.S | re.M
+ )
+
+ re_returns_line = re.compile(
+ rf"""
+ \s* ({re_multiple_type}:)? # identifier
+ \s* (.*) # beginning of description
+ """,
+ re.X | re.S | re.M,
+ )
+
+ re_property_returns_line = re.compile(
+ rf"""
+ ^{re_multiple_type}: # identifier
+ \s* (.*) # Summary line / description
+ """,
+ re.X | re.S | re.M,
+ )
+
+ re_yields_section = re.compile(
+ _re_section_template.format(r"Yields?"), re.X | re.S | re.M
+ )
+
+ re_yields_line = re_returns_line
+
+ supports_yields = True
+
+ def matching_sections(self) -> int:
+ """Returns the number of matching docstring sections."""
+ return sum(
+ bool(i)
+ for i in (
+ self.re_param_section.search(self.doc),
+ self.re_raise_section.search(self.doc),
+ self.re_returns_section.search(self.doc),
+ self.re_yields_section.search(self.doc),
+ self.re_property_returns_line.search(self._first_line()),
+ )
+ )
+
+ def has_params(self) -> bool:
+ if not self.doc:
+ return False
+
+ return self.re_param_section.search(self.doc) is not None
+
+ def has_returns(self) -> bool:
+ if not self.doc:
+ return False
+
+ entries = self._parse_section(self.re_returns_section)
+ for entry in entries:
+ match = self.re_returns_line.match(entry)
+ if not match:
+ continue
+
+ return_desc = match.group(2)
+ if return_desc:
+ return True
+
+ return False
+
+ def has_rtype(self) -> bool:
+ if not self.doc:
+ return False
+
+ entries = self._parse_section(self.re_returns_section)
+ for entry in entries:
+ match = self.re_returns_line.match(entry)
+ if not match:
+ continue
+
+ return_type = match.group(1)
+ if return_type:
+ return True
+
+ return False
+
+ def has_property_returns(self) -> bool:
+ # The summary line is the return doc,
+ # so the first line must not be a known directive.
+ first_line = self._first_line()
+ return not bool(
+ self.re_param_section.search(first_line)
+ or self.re_raise_section.search(first_line)
+ or self.re_returns_section.search(first_line)
+ or self.re_yields_section.search(first_line)
+ )
+
+ def has_property_type(self) -> bool:
+ if not self.doc:
+ return False
+
+ return bool(self.re_property_returns_line.match(self._first_line()))
+
+ def has_yields(self) -> bool:
+ if not self.doc:
+ return False
+
+ entries = self._parse_section(self.re_yields_section)
+ for entry in entries:
+ match = self.re_yields_line.match(entry)
+ if not match:
+ continue
+
+ yield_desc = match.group(2)
+ if yield_desc:
+ return True
+
+ return False
+
+ def has_yields_type(self) -> bool:
+ if not self.doc:
+ return False
+
+ entries = self._parse_section(self.re_yields_section)
+ for entry in entries:
+ match = self.re_yields_line.match(entry)
+ if not match:
+ continue
+
+ yield_type = match.group(1)
+ if yield_type:
+ return True
+
+ return False
+
+ def exceptions(self) -> set[str]:
+ types: set[str] = set()
+
+ entries = self._parse_section(self.re_raise_section)
+ for entry in entries:
+ match = self.re_raise_line.match(entry)
+ if not match:
+ continue
+
+ exc_type = match.group(1)
+ exc_desc = match.group(2)
+ if exc_desc:
+ types.update(_split_multiple_exc_types(exc_type))
+
+ return types
+
+ def match_param_docs(self) -> tuple[set[str], set[str]]:
+ params_with_doc: set[str] = set()
+ params_with_type: set[str] = set()
+
+ entries = self._parse_section(self.re_param_section)
+ entries.extend(self._parse_section(self.re_keyword_param_section))
+ for entry in entries:
+ match = self.re_param_line.match(entry)
+ if not match:
+ continue
+
+ param_name = match.group(1)
+ # Remove escape characters necessary for asterisks
+ param_name = param_name.replace("\\", "")
+
+ param_type = match.group(2)
+ param_desc = match.group(3)
+
+ if param_type:
+ params_with_type.add(param_name)
+
+ if param_desc:
+ params_with_doc.add(param_name)
+
+ return params_with_doc, params_with_type
+
+ def _first_line(self) -> str:
+ return self.doc.lstrip().split("\n", 1)[0]
+
+ @staticmethod
+ def min_section_indent(section_match: re.Match[str]) -> int:
+ return len(section_match.group(1)) + 1
+
+ @staticmethod
+ def _is_section_header(_: str) -> bool:
+ # Google parsing does not need to detect section headers,
+ # because it works off of indentation level only
+ return False
+
+ def _parse_section(self, section_re: re.Pattern[str]) -> list[str]:
+ section_match = section_re.search(self.doc)
+ if section_match is None:
+ return []
+
+ min_indentation = self.min_section_indent(section_match)
+
+ entries: list[str] = []
+ entry: list[str] = []
+ is_first = True
+ for line in section_match.group(2).splitlines():
+ if not line.strip():
+ continue
+ indentation = space_indentation(line)
+ if indentation < min_indentation:
+ break
+
+ # The first line after the header defines the minimum
+ # indentation.
+ if is_first:
+ min_indentation = indentation
+ is_first = False
+
+ if indentation == min_indentation:
+ if self._is_section_header(line):
+ break
+ # Lines with minimum indentation must contain the beginning
+ # of a new parameter documentation.
+ if entry:
+ entries.append("\n".join(entry))
+ entry = []
+
+ entry.append(line)
+
+ if entry:
+ entries.append("\n".join(entry))
+
+ return entries
+
+
+class NumpyDocstring(GoogleDocstring):
+ _re_section_template = r"""
+ ^([ ]*) {0} \s*?$ # Numpy parameters header
+ \s* [-=]+ \s*?$ # underline
+ ( .* ) # section
+ """
+
+ re_param_section = re.compile(
+ _re_section_template.format(r"(?:Args|Arguments|Parameters)"),
+ re.X | re.S | re.M,
+ )
+
+ re_default_value = r"""((['"]\w+\s*['"])|(\d+)|(True)|(False)|(None))"""
+
+ re_param_line = re.compile(
+ rf"""
+ \s* (?P<param_name>\*{{0,2}}\w+)(\s?(:|\n)) # identifier with potential asterisks
+ \s*
+ (?P<param_type>
+ (
+ ({GoogleDocstring.re_multiple_type}) # default type declaration
+ (,\s+optional)? # optional 'optional' indication
+ )?
+ (
+ {{({re_default_value},?\s*)+}} # set of default values
+ )?
+ (?:$|\n)
+ )?
+ (
+ \s* (?P<param_desc>.*) # optional description
+ )?
+ """,
+ re.X | re.S,
+ )
+
+ re_raise_section = re.compile(
+ _re_section_template.format(r"Raises"), re.X | re.S | re.M
+ )
+
+ re_raise_line = re.compile(
+ rf"""
+ \s* ({GoogleDocstring.re_type})$ # type declaration
+ \s* (.*) # optional description
+ """,
+ re.X | re.S | re.M,
+ )
+
+ re_returns_section = re.compile(
+ _re_section_template.format(r"Returns?"), re.X | re.S | re.M
+ )
+
+ re_returns_line = re.compile(
+ rf"""
+ \s* (?:\w+\s+:\s+)? # optional name
+ ({GoogleDocstring.re_multiple_type})$ # type declaration
+ \s* (.*) # optional description
+ """,
+ re.X | re.S | re.M,
+ )
+
+ re_yields_section = re.compile(
+ _re_section_template.format(r"Yields?"), re.X | re.S | re.M
+ )
+
+ re_yields_line = re_returns_line
+
+ supports_yields = True
+
+ def match_param_docs(self) -> tuple[set[str], set[str]]:
+ """Matches parameter documentation section to parameter documentation rules."""
+ params_with_doc = set()
+ params_with_type = set()
+
+ entries = self._parse_section(self.re_param_section)
+ entries.extend(self._parse_section(self.re_keyword_param_section))
+ for entry in entries:
+ match = self.re_param_line.match(entry)
+ if not match:
+ continue
+
+ # check if parameter has description only
+ re_only_desc = re.match(r"\s*(\*{0,2}\w+)\s*:?\n\s*\w*$", entry)
+ if re_only_desc:
+ param_name = match.group("param_name")
+ param_desc = match.group("param_type")
+ param_type = None
+ else:
+ param_name = match.group("param_name")
+ param_type = match.group("param_type")
+ param_desc = match.group("param_desc")
+ # The re_param_line pattern needs to match multi-line which removes the ability
+ # to match a single line description like 'arg : a number type.'
+ # We are not trying to determine whether 'a number type' is correct typing
+ # but we do accept it as typing as it is in the place where typing
+ # should be
+ if param_type is None and re.match(r"\s*(\*{0,2}\w+)\s*:.+$", entry):
+ param_type = param_desc
+ # If the description is "" but we have a type description
+ # we consider the description to be the type
+ if not param_desc and param_type:
+ param_desc = param_type
+
+ if param_type:
+ params_with_type.add(param_name)
+
+ if param_desc:
+ params_with_doc.add(param_name)
+
+ return params_with_doc, params_with_type
+
+ @staticmethod
+ def min_section_indent(section_match: re.Match[str]) -> int:
+ return len(section_match.group(1))
+
+ @staticmethod
+ def _is_section_header(line: str) -> bool:
+ return bool(re.match(r"\s*-+$", line))
+
+
+DOCSTRING_TYPES = {
+ "sphinx": SphinxDocstring,
+ "epytext": EpytextDocstring,
+ "google": GoogleDocstring,
+ "numpy": NumpyDocstring,
+ "default": Docstring,
+}
+"""A map of the name of the docstring type to its class.
+
+:type: dict(str, type)
+"""
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/bad_builtin.py b/solutions/.venv/Lib/site-packages/pylint/extensions/bad_builtin.py
new file mode 100644
index 000000000..79cc5d9f4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/bad_builtin.py
@@ -0,0 +1,65 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checker for deprecated builtins."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+BAD_FUNCTIONS = ["map", "filter"]
+# Some hints regarding the use of bad builtins.
+LIST_COMP_MSG = "Using a list comprehension can be clearer."
+BUILTIN_HINTS = {"map": LIST_COMP_MSG, "filter": LIST_COMP_MSG}
+
+
+class BadBuiltinChecker(BaseChecker):
+ name = "deprecated_builtins"
+ msgs = {
+ "W0141": (
+ "Used builtin function %s",
+ "bad-builtin",
+ "Used when a disallowed builtin function is used (see the "
+ "bad-function option). Usual disallowed functions are the ones "
+ "like map, or filter , where Python offers now some cleaner "
+ "alternative like list comprehension.",
+ )
+ }
+
+ options = (
+ (
+ "bad-functions",
+ {
+ "default": BAD_FUNCTIONS,
+ "type": "csv",
+ "metavar": "<builtin function names>",
+ "help": "List of builtins function names that should not be "
+ "used, separated by a comma",
+ },
+ ),
+ )
+
+ @only_required_for_messages("bad-builtin")
+ def visit_call(self, node: nodes.Call) -> None:
+ if isinstance(node.func, nodes.Name):
+ name = node.func.name
+ # ignore the name if it's not a builtin (i.e. not defined in the
+ # locals nor globals scope)
+ if not (name in node.frame() or name in node.root()):
+ if name in self.linter.config.bad_functions:
+ hint = BUILTIN_HINTS.get(name)
+ args = f"{name!r}. {hint}" if hint else repr(name)
+ self.add_message("bad-builtin", node=node, args=args)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(BadBuiltinChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/broad_try_clause.py b/solutions/.venv/Lib/site-packages/pylint/extensions/broad_try_clause.py
new file mode 100644
index 000000000..90168909a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/broad_try_clause.py
@@ -0,0 +1,73 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Looks for try/except statements with too much code in the try clause."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint import checkers
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class BroadTryClauseChecker(checkers.BaseChecker):
+ """Checks for try clauses with too many lines.
+
+ According to PEP 8, ``try`` clauses shall contain the absolute minimum
+ amount of code. This checker enforces a maximum number of statements within
+ ``try`` clauses.
+ """
+
+ # configuration section name
+ name = "broad_try_clause"
+ msgs = {
+ "W0717": (
+ "%s",
+ "too-many-try-statements",
+ "Try clause contains too many statements.",
+ )
+ }
+
+ options = (
+ (
+ "max-try-statements",
+ {
+ "default": 1,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "Maximum number of statements allowed in a try clause",
+ },
+ ),
+ )
+
+ def _count_statements(
+ self, node: nodes.For | nodes.If | nodes.Try | nodes.While | nodes.With
+ ) -> int:
+ statement_count = len(node.body)
+
+ for body_node in node.body:
+ if isinstance(body_node, (nodes.For, nodes.If, nodes.While, nodes.With)):
+ statement_count += self._count_statements(body_node)
+
+ return statement_count
+
+ def visit_try(self, node: nodes.Try) -> None:
+ try_clause_statements = self._count_statements(node)
+ if try_clause_statements > self.linter.config.max_try_statements:
+ msg = (
+ f"try clause contains {try_clause_statements} statements, expected at"
+ f" most {self.linter.config.max_try_statements}"
+ )
+ self.add_message(
+ "too-many-try-statements", node.lineno, node=node, args=msg
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(BroadTryClauseChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/check_elif.py b/solutions/.venv/Lib/site-packages/pylint/extensions/check_elif.py
new file mode 100644
index 000000000..de20ed8ec
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/check_elif.py
@@ -0,0 +1,64 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import tokenize
+from tokenize import TokenInfo
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseTokenChecker
+from pylint.checkers.utils import only_required_for_messages
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class ElseifUsedChecker(BaseTokenChecker):
+ """Checks for use of "else if" when an "elif" could be used."""
+
+ name = "else_if_used"
+ msgs = {
+ "R5501": (
+ 'Consider using "elif" instead of "else" then "if" to remove one indentation level',
+ "else-if-used",
+ "Used when an else statement is immediately followed by "
+ "an if statement and does not contain statements that "
+ "would be unrelated to it.",
+ )
+ }
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._init()
+
+ def _init(self) -> None:
+ self._elifs: dict[tokenize._Position, str] = {}
+
+ def process_tokens(self, tokens: list[TokenInfo]) -> None:
+ """Process tokens and look for 'if' or 'elif'."""
+ self._elifs = {
+ begin: token for _, token, begin, _, _ in tokens if token in {"elif", "if"}
+ }
+
+ def leave_module(self, _: nodes.Module) -> None:
+ self._init()
+
+ @only_required_for_messages("else-if-used")
+ def visit_if(self, node: nodes.If) -> None:
+ """Current if node must directly follow an 'else'."""
+ if (
+ isinstance(node.parent, nodes.If)
+ and node.parent.orelse == [node]
+ and (node.lineno, node.col_offset) in self._elifs
+ and self._elifs[(node.lineno, node.col_offset)] == "if"
+ ):
+ self.add_message("else-if-used", node=node, confidence=HIGH)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ElseifUsedChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/code_style.py b/solutions/.venv/Lib/site-packages/pylint/extensions/code_style.py
new file mode 100644
index 000000000..00d539500
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/code_style.py
@@ -0,0 +1,350 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import sys
+from typing import TYPE_CHECKING, cast
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker, utils
+from pylint.checkers.utils import only_required_for_messages, safe_infer
+from pylint.interfaces import INFERENCE
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+if sys.version_info >= (3, 10):
+ from typing import TypeGuard
+else:
+ from typing_extensions import TypeGuard
+
+
+class CodeStyleChecker(BaseChecker):
+ """Checkers that can improve code consistency.
+
+ As such they don't necessarily provide a performance benefit and
+ are often times opinionated.
+
+ Before adding another checker here, consider this:
+ 1. Does the checker provide a clear benefit,
+ i.e. detect a common issue or improve performance
+ => it should probably be part of the core checker classes
+ 2. Is it something that would improve code consistency,
+ maybe because it's slightly better with regard to performance
+ and therefore preferred => this is the right place
+ 3. Everything else should go into another extension
+ """
+
+ name = "code_style"
+ msgs = {
+ "R6101": (
+ "Consider using namedtuple or dataclass for dictionary values",
+ "consider-using-namedtuple-or-dataclass",
+ "Emitted when dictionary values can be replaced by namedtuples or dataclass instances.",
+ ),
+ "R6102": (
+ "Consider using an in-place tuple instead of list",
+ "consider-using-tuple",
+ "Only for style consistency! "
+ "Emitted where an in-place defined ``list`` can be replaced by a ``tuple``. "
+ "Due to optimizations by CPython, there is no performance benefit from it.",
+ ),
+ "R6103": (
+ "Use '%s' instead",
+ "consider-using-assignment-expr",
+ "Emitted when an if assignment is directly followed by an if statement and "
+ "both can be combined by using an assignment expression ``:=``. "
+ "Requires Python 3.8 and ``py-version >= 3.8``.",
+ ),
+ "R6104": (
+ "Use '%s' to do an augmented assign directly",
+ "consider-using-augmented-assign",
+ "Emitted when an assignment is referring to the object that it is assigning "
+ "to. This can be changed to be an augmented assign.\n"
+ "Disabled by default!",
+ {
+ "default_enabled": False,
+ },
+ ),
+ "R6105": (
+ "Prefer 'typing.NamedTuple' over 'collections.namedtuple'",
+ "prefer-typing-namedtuple",
+ "'typing.NamedTuple' uses the well-known 'class' keyword "
+ "with type-hints for readability (it's also faster as it avoids "
+ "an internal exec call).\n"
+ "Disabled by default!",
+ {
+ "default_enabled": False,
+ },
+ ),
+ }
+ options = (
+ (
+ "max-line-length-suggestions",
+ {
+ "type": "int",
+ "default": 0,
+ "metavar": "<int>",
+ "help": (
+ "Max line length for which to sill emit suggestions. "
+ "Used to prevent optional suggestions which would get split "
+ "by a code formatter (e.g., black). "
+ "Will default to the setting for ``max-line-length``."
+ ),
+ },
+ ),
+ )
+
+ def open(self) -> None:
+ py_version = self.linter.config.py_version
+ self._py36_plus = py_version >= (3, 6)
+ self._py38_plus = py_version >= (3, 8)
+ self._max_length: int = (
+ self.linter.config.max_line_length_suggestions
+ or self.linter.config.max_line_length
+ )
+
+ @only_required_for_messages("prefer-typing-namedtuple")
+ def visit_call(self, node: nodes.Call) -> None:
+ if self._py36_plus:
+ called = safe_infer(node.func)
+ if called and called.qname() == "collections.namedtuple":
+ self.add_message(
+ "prefer-typing-namedtuple", node=node, confidence=INFERENCE
+ )
+
+ @only_required_for_messages("consider-using-namedtuple-or-dataclass")
+ def visit_dict(self, node: nodes.Dict) -> None:
+ self._check_dict_consider_namedtuple_dataclass(node)
+
+ @only_required_for_messages("consider-using-tuple")
+ def visit_for(self, node: nodes.For) -> None:
+ if isinstance(node.iter, nodes.List):
+ self.add_message("consider-using-tuple", node=node.iter)
+
+ @only_required_for_messages("consider-using-tuple")
+ def visit_comprehension(self, node: nodes.Comprehension) -> None:
+ if isinstance(node.iter, nodes.List):
+ self.add_message("consider-using-tuple", node=node.iter)
+
+ @only_required_for_messages("consider-using-assignment-expr")
+ def visit_if(self, node: nodes.If) -> None:
+ if self._py38_plus:
+ self._check_consider_using_assignment_expr(node)
+
+ def _check_dict_consider_namedtuple_dataclass(self, node: nodes.Dict) -> None:
+ """Check if dictionary values can be replaced by Namedtuple or Dataclass."""
+ if not (
+ isinstance(node.parent, (nodes.Assign, nodes.AnnAssign))
+ and isinstance(node.parent.parent, nodes.Module)
+ or isinstance(node.parent, nodes.AnnAssign)
+ and isinstance(node.parent.target, nodes.AssignName)
+ and utils.is_assign_name_annotated_with(node.parent.target, "Final")
+ ):
+ # If dict is not part of an 'Assign' or 'AnnAssign' node in
+ # a module context OR 'AnnAssign' with 'Final' annotation, skip check.
+ return
+
+ # All dict_values are itself dict nodes
+ if len(node.items) > 1 and all(
+ isinstance(dict_value, nodes.Dict) for _, dict_value in node.items
+ ):
+ KeyTupleT = tuple[type[nodes.NodeNG], str]
+
+ # Makes sure all keys are 'Const' string nodes
+ keys_checked: set[KeyTupleT] = set()
+ for _, dict_value in node.items:
+ dict_value = cast(nodes.Dict, dict_value)
+ for key, _ in dict_value.items:
+ key_tuple = (type(key), key.as_string())
+ if key_tuple in keys_checked:
+ continue
+ inferred = safe_infer(key)
+ if not (
+ isinstance(inferred, nodes.Const)
+ and inferred.pytype() == "builtins.str"
+ ):
+ return
+ keys_checked.add(key_tuple)
+
+ # Makes sure all subdicts have at least 1 common key
+ key_tuples: list[tuple[KeyTupleT, ...]] = []
+ for _, dict_value in node.items:
+ dict_value = cast(nodes.Dict, dict_value)
+ key_tuples.append(
+ tuple((type(key), key.as_string()) for key, _ in dict_value.items)
+ )
+ keys_intersection: set[KeyTupleT] = set(key_tuples[0])
+ for sub_key_tuples in key_tuples[1:]:
+ keys_intersection.intersection_update(sub_key_tuples)
+ if not keys_intersection:
+ return
+
+ self.add_message("consider-using-namedtuple-or-dataclass", node=node)
+ return
+
+ # All dict_values are itself either list or tuple nodes
+ if len(node.items) > 1 and all(
+ isinstance(dict_value, (nodes.List, nodes.Tuple))
+ for _, dict_value in node.items
+ ):
+ # Make sure all sublists have the same length > 0
+ list_length = len(node.items[0][1].elts)
+ if list_length == 0:
+ return
+ for _, dict_value in node.items[1:]:
+ if len(dict_value.elts) != list_length:
+ return
+
+ # Make sure at least one list entry isn't a dict
+ for _, dict_value in node.items:
+ if all(isinstance(entry, nodes.Dict) for entry in dict_value.elts):
+ return
+
+ self.add_message("consider-using-namedtuple-or-dataclass", node=node)
+ return
+
+ def _check_consider_using_assignment_expr(self, node: nodes.If) -> None:
+ """Check if an assignment expression (walrus operator) can be used.
+
+ For example if an assignment is directly followed by an if statement:
+ >>> x = 2
+ >>> if x:
+ >>> ...
+
+ Can be replaced by:
+ >>> if (x := 2):
+ >>> ...
+
+ Note: Assignment expressions were added in Python 3.8
+ """
+ # Check if `node.test` contains a `Name` node
+ node_name: nodes.Name | None = None
+ if isinstance(node.test, nodes.Name):
+ node_name = node.test
+ elif (
+ isinstance(node.test, nodes.UnaryOp)
+ and node.test.op == "not"
+ and isinstance(node.test.operand, nodes.Name)
+ ):
+ node_name = node.test.operand
+ elif (
+ isinstance(node.test, nodes.Compare)
+ and isinstance(node.test.left, nodes.Name)
+ and len(node.test.ops) == 1
+ ):
+ node_name = node.test.left
+ else:
+ return
+
+ # Make sure the previous node is an assignment to the same name
+ # used in `node.test`. Furthermore, ignore if assignment spans multiple lines.
+ prev_sibling = node.previous_sibling()
+ if CodeStyleChecker._check_prev_sibling_to_if_stmt(
+ prev_sibling, node_name.name
+ ):
+ # Check if match statement would be a better fit.
+ # I.e. multiple ifs that test the same name.
+ if CodeStyleChecker._check_ignore_assignment_expr_suggestion(
+ node, node_name.name
+ ):
+ return
+
+ # Build suggestion string. Check length of suggestion
+ # does not exceed max-line-length-suggestions
+ test_str = node.test.as_string().replace(
+ node_name.name,
+ f"({node_name.name} := {prev_sibling.value.as_string()})",
+ 1,
+ )
+ suggestion = f"if {test_str}:"
+ if (
+ node.col_offset is not None
+ and len(suggestion) + node.col_offset > self._max_length
+ or len(suggestion) > self._max_length
+ ):
+ return
+
+ self.add_message(
+ "consider-using-assignment-expr",
+ node=node_name,
+ args=(suggestion,),
+ )
+
+ @staticmethod
+ def _check_prev_sibling_to_if_stmt(
+ prev_sibling: nodes.NodeNG | None, name: str | None
+ ) -> TypeGuard[nodes.Assign | nodes.AnnAssign]:
+ """Check if previous sibling is an assignment with the same name.
+
+ Ignore statements which span multiple lines.
+ """
+ if prev_sibling is None or prev_sibling.tolineno - prev_sibling.fromlineno != 0:
+ return False
+
+ if (
+ isinstance(prev_sibling, nodes.Assign)
+ and len(prev_sibling.targets) == 1
+ and isinstance(prev_sibling.targets[0], nodes.AssignName)
+ and prev_sibling.targets[0].name == name
+ ):
+ return True
+ if (
+ isinstance(prev_sibling, nodes.AnnAssign)
+ and isinstance(prev_sibling.target, nodes.AssignName)
+ and prev_sibling.target.name == name
+ ):
+ return True
+ return False
+
+ @staticmethod
+ def _check_ignore_assignment_expr_suggestion(
+ node: nodes.If, name: str | None
+ ) -> bool:
+ """Return True if suggestion for assignment expr should be ignored.
+
+ E.g., in cases where a match statement would be a better fit
+ (multiple conditions).
+ """
+ if isinstance(node.test, nodes.Compare):
+ next_if_node: nodes.If | None = None
+ next_sibling = node.next_sibling()
+ if len(node.orelse) == 1 and isinstance(node.orelse[0], nodes.If):
+ # elif block
+ next_if_node = node.orelse[0]
+ elif isinstance(next_sibling, nodes.If):
+ # separate if block
+ next_if_node = next_sibling
+
+ if ( # pylint: disable=too-many-boolean-expressions
+ next_if_node is not None
+ and (
+ isinstance(next_if_node.test, nodes.Compare)
+ and isinstance(next_if_node.test.left, nodes.Name)
+ and next_if_node.test.left.name == name
+ or isinstance(next_if_node.test, nodes.Name)
+ and next_if_node.test.name == name
+ )
+ ):
+ return True
+ return False
+
+ @only_required_for_messages("consider-using-augmented-assign")
+ def visit_assign(self, node: nodes.Assign) -> None:
+ is_aug, op = utils.is_augmented_assign(node)
+ if is_aug:
+ self.add_message(
+ "consider-using-augmented-assign",
+ args=f"{op}=",
+ node=node,
+ line=node.lineno,
+ col_offset=node.col_offset,
+ confidence=INFERENCE,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(CodeStyleChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/comparison_placement.py b/solutions/.venv/Lib/site-packages/pylint/extensions/comparison_placement.py
new file mode 100644
index 000000000..f7ecceae3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/comparison_placement.py
@@ -0,0 +1,69 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checks for yoda comparisons (variable before constant)
+See https://en.wikipedia.org/wiki/Yoda_conditions.
+"""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker, utils
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+REVERSED_COMPS = {"<": ">", "<=": ">=", ">": "<", ">=": "<="}
+COMPARISON_OPERATORS = frozenset(("==", "!=", "<", ">", "<=", ">="))
+
+
+class MisplacedComparisonConstantChecker(BaseChecker):
+ """Checks the placement of constants in comparisons."""
+
+ # configuration section name
+ name = "comparison-placement"
+ msgs = {
+ "C2201": (
+ "Comparison should be %s",
+ "misplaced-comparison-constant",
+ "Used when the constant is placed on the left side "
+ "of a comparison. It is usually clearer in intent to "
+ "place it in the right hand side of the comparison.",
+ {"old_names": [("C0122", "old-misplaced-comparison-constant")]},
+ )
+ }
+
+ options = ()
+
+ def _check_misplaced_constant(
+ self,
+ node: nodes.Compare,
+ left: nodes.NodeNG,
+ right: nodes.NodeNG,
+ operator: str,
+ ) -> None:
+ if isinstance(right, nodes.Const):
+ return
+ operator = REVERSED_COMPS.get(operator, operator)
+ suggestion = f"{right.as_string()} {operator} {left.value!r}"
+ self.add_message("misplaced-comparison-constant", node=node, args=(suggestion,))
+
+ @utils.only_required_for_messages("misplaced-comparison-constant")
+ def visit_compare(self, node: nodes.Compare) -> None:
+ # NOTE: this checker only works with binary comparisons like 'x == 42'
+ # but not 'x == y == 42'
+ if len(node.ops) != 1:
+ return
+
+ left = node.left
+ operator, right = node.ops[0]
+ if operator in COMPARISON_OPERATORS and isinstance(left, nodes.Const):
+ self._check_misplaced_constant(node, left, right, operator)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(MisplacedComparisonConstantChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/confusing_elif.py b/solutions/.venv/Lib/site-packages/pylint/extensions/confusing_elif.py
new file mode 100644
index 000000000..287547eaa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/confusing_elif.py
@@ -0,0 +1,55 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class ConfusingConsecutiveElifChecker(BaseChecker):
+ """Checks if "elif" is used right after an indented block that finishes with "if" or
+ "elif" itself.
+ """
+
+ name = "confusing_elif"
+ msgs = {
+ "R5601": (
+ "Consecutive elif with differing indentation level, consider creating a function to separate the inner"
+ " elif",
+ "confusing-consecutive-elif",
+ "Used when an elif statement follows right after an indented block which itself ends with if or elif. "
+ "It may not be obvious if the elif statement was willingly or mistakenly unindented. "
+ "Extracting the indented if statement into a separate function might avoid confusion and prevent "
+ "errors.",
+ )
+ }
+
+ @only_required_for_messages("confusing-consecutive-elif")
+ def visit_if(self, node: nodes.If) -> None:
+ body_ends_with_if = isinstance(
+ node.body[-1], nodes.If
+ ) and self._has_no_else_clause(node.body[-1])
+ if node.has_elif_block() and body_ends_with_if:
+ self.add_message("confusing-consecutive-elif", node=node.orelse[0])
+
+ @staticmethod
+ def _has_no_else_clause(node: nodes.If) -> bool:
+ orelse = node.orelse
+ while orelse and isinstance(orelse[0], nodes.If):
+ orelse = orelse[0].orelse
+ if not orelse or isinstance(orelse[0], nodes.If):
+ return True
+ return False
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ConfusingConsecutiveElifChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/consider_refactoring_into_while_condition.py b/solutions/.venv/Lib/site-packages/pylint/extensions/consider_refactoring_into_while_condition.py
new file mode 100644
index 000000000..b7e905e8a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/consider_refactoring_into_while_condition.py
@@ -0,0 +1,93 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Looks for try/except statements with too much code in the try clause."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class ConsiderRefactorIntoWhileConditionChecker(checkers.BaseChecker):
+ """Checks for instances where while loops are implemented with a constant condition
+ which.
+
+ always evaluates to truthy and the first statement(s) is/are if statements which, when
+ evaluated.
+
+ to True, breaks out of the loop.
+
+ The if statement(s) can be refactored into the while loop.
+ """
+
+ name = "consider_refactoring_into_while"
+ msgs = {
+ "R3501": (
+ "Consider using 'while %s' instead of 'while %s:' an 'if', and a 'break'",
+ "consider-refactoring-into-while-condition",
+ "Emitted when `while True:` loop is used and the first statement is a break condition. "
+ "The ``if / break`` construct can be removed if the check is inverted and moved to "
+ "the ``while`` statement.",
+ ),
+ }
+
+ @utils.only_required_for_messages("consider-refactoring-into-while-condition")
+ def visit_while(self, node: nodes.While) -> None:
+ self._check_breaking_after_while_true(node)
+
+ def _check_breaking_after_while_true(self, node: nodes.While) -> None:
+ """Check that any loop with an ``if`` clause has a break statement."""
+ if not isinstance(node.test, nodes.Const) or not node.test.bool_value():
+ return
+ pri_candidates: list[nodes.If] = []
+ for n in node.body:
+ if not isinstance(n, nodes.If):
+ break
+ pri_candidates.append(n)
+ candidates = []
+ tainted = False
+ for c in pri_candidates:
+ if tainted or not isinstance(c.body[0], nodes.Break):
+ break
+ candidates.append(c)
+ orelse = c.orelse
+ while orelse:
+ orelse_node = orelse[0]
+ if not isinstance(orelse_node, nodes.If):
+ tainted = True
+ else:
+ candidates.append(orelse_node)
+ if not isinstance(orelse_node, nodes.If):
+ break
+ orelse = orelse_node.orelse
+
+ candidates = [n for n in candidates if isinstance(n.body[0], nodes.Break)]
+ msg = " and ".join(
+ [f"({utils.not_condition_as_string(c.test)})" for c in candidates]
+ )
+ if len(candidates) == 1:
+ msg = utils.not_condition_as_string(candidates[0].test)
+ if not msg:
+ return
+
+ self.add_message(
+ "consider-refactoring-into-while-condition",
+ node=node,
+ line=node.lineno,
+ args=(msg, node.test.as_string()),
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ConsiderRefactorIntoWhileConditionChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/consider_ternary_expression.py b/solutions/.venv/Lib/site-packages/pylint/extensions/consider_ternary_expression.py
new file mode 100644
index 000000000..83046ce38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/consider_ternary_expression.py
@@ -0,0 +1,56 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for if / assign blocks that can be rewritten with if-expressions."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class ConsiderTernaryExpressionChecker(BaseChecker):
+ name = "consider_ternary_expression"
+ msgs = {
+ "W0160": (
+ "Consider rewriting as a ternary expression",
+ "consider-ternary-expression",
+ "Multiple assign statements spread across if/else blocks can be "
+ "rewritten with a single assignment and ternary expression",
+ )
+ }
+
+ def visit_if(self, node: nodes.If) -> None:
+ if isinstance(node.parent, nodes.If):
+ return
+
+ if len(node.body) != 1 or len(node.orelse) != 1:
+ return
+
+ bst = node.body[0]
+ ost = node.orelse[0]
+
+ if not isinstance(bst, nodes.Assign) or not isinstance(ost, nodes.Assign):
+ return
+
+ for bname, oname in zip(bst.targets, ost.targets):
+ if not isinstance(bname, nodes.AssignName) or not isinstance(
+ oname, nodes.AssignName
+ ):
+ return
+
+ if bname.name != oname.name:
+ return
+
+ self.add_message("consider-ternary-expression", node=node)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ConsiderTernaryExpressionChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/dict_init_mutate.py b/solutions/.venv/Lib/site-packages/pylint/extensions/dict_init_mutate.py
new file mode 100644
index 000000000..4977e234b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/dict_init_mutate.py
@@ -0,0 +1,66 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for use of dictionary mutation after initialization."""
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+class DictInitMutateChecker(BaseChecker):
+ name = "dict-init-mutate"
+ msgs = {
+ "C3401": (
+ "Declare all known key/values when initializing the dictionary.",
+ "dict-init-mutate",
+ "Dictionaries can be initialized with a single statement "
+ "using dictionary literal syntax.",
+ )
+ }
+
+ @only_required_for_messages("dict-init-mutate")
+ def visit_assign(self, node: nodes.Assign) -> None:
+ """
+ Detect dictionary mutation immediately after initialization.
+
+ At this time, detecting nested mutation is not supported.
+ """
+ if not isinstance(node.value, nodes.Dict):
+ return
+
+ dict_name = node.targets[0]
+ if len(node.targets) != 1 or not isinstance(dict_name, nodes.AssignName):
+ return
+
+ first_sibling = node.next_sibling()
+ if (
+ not first_sibling
+ or not isinstance(first_sibling, nodes.Assign)
+ or len(first_sibling.targets) != 1
+ ):
+ return
+
+ sibling_target = first_sibling.targets[0]
+ if not isinstance(sibling_target, nodes.Subscript):
+ return
+
+ sibling_name = sibling_target.value
+ if not isinstance(sibling_name, nodes.Name):
+ return
+
+ if sibling_name.name == dict_name.name:
+ self.add_message("dict-init-mutate", node=node, confidence=HIGH)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(DictInitMutateChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/docparams.py b/solutions/.venv/Lib/site-packages/pylint/extensions/docparams.py
new file mode 100644
index 000000000..b19560b7f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/docparams.py
@@ -0,0 +1,676 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Pylint plugin for checking in Sphinx, Google, or Numpy style docstrings."""
+
+from __future__ import annotations
+
+import re
+from typing import TYPE_CHECKING
+
+import astroid
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers import utils as checker_utils
+from pylint.extensions import _check_docs_utils as utils
+from pylint.extensions._check_docs_utils import Docstring
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class DocstringParameterChecker(BaseChecker):
+ """Checker for Sphinx, Google, or Numpy style docstrings.
+
+ * Check that all function, method and constructor parameters are mentioned
+ in the params and types part of the docstring. Constructor parameters
+ can be documented in either the class docstring or ``__init__`` docstring,
+ but not both.
+ * Check that there are no naming inconsistencies between the signature and
+ the documentation, i.e. also report documented parameters that are missing
+ in the signature. This is important to find cases where parameters are
+ renamed only in the code, not in the documentation.
+ * Check that all explicitly raised exceptions in a function are documented
+ in the function docstring. Caught exceptions are ignored.
+
+ Activate this checker by adding the line::
+
+ load-plugins=pylint.extensions.docparams
+
+ to the ``MAIN`` section of your ``.pylintrc``.
+ """
+
+ name = "parameter_documentation"
+ msgs = {
+ "W9005": (
+ '"%s" has constructor parameters documented in class and __init__',
+ "multiple-constructor-doc",
+ "Please remove parameter declarations in the class or constructor.",
+ ),
+ "W9006": (
+ '"%s" not documented as being raised',
+ "missing-raises-doc",
+ "Please document exceptions for all raised exception types.",
+ ),
+ "W9008": (
+ "Redundant returns documentation",
+ "redundant-returns-doc",
+ "Please remove the return/rtype documentation from this method.",
+ ),
+ "W9010": (
+ "Redundant yields documentation",
+ "redundant-yields-doc",
+ "Please remove the yields documentation from this method.",
+ ),
+ "W9011": (
+ "Missing return documentation",
+ "missing-return-doc",
+ "Please add documentation about what this method returns.",
+ {"old_names": [("W9007", "old-missing-returns-doc")]},
+ ),
+ "W9012": (
+ "Missing return type documentation",
+ "missing-return-type-doc",
+ "Please document the type returned by this method.",
+ # we can't use the same old_name for two different warnings
+ # {'old_names': [('W9007', 'missing-returns-doc')]},
+ ),
+ "W9013": (
+ "Missing yield documentation",
+ "missing-yield-doc",
+ "Please add documentation about what this generator yields.",
+ {"old_names": [("W9009", "old-missing-yields-doc")]},
+ ),
+ "W9014": (
+ "Missing yield type documentation",
+ "missing-yield-type-doc",
+ "Please document the type yielded by this method.",
+ # we can't use the same old_name for two different warnings
+ # {'old_names': [('W9009', 'missing-yields-doc')]},
+ ),
+ "W9015": (
+ '"%s" missing in parameter documentation',
+ "missing-param-doc",
+ "Please add parameter declarations for all parameters.",
+ {"old_names": [("W9003", "old-missing-param-doc")]},
+ ),
+ "W9016": (
+ '"%s" missing in parameter type documentation',
+ "missing-type-doc",
+ "Please add parameter type declarations for all parameters.",
+ {"old_names": [("W9004", "old-missing-type-doc")]},
+ ),
+ "W9017": (
+ '"%s" differing in parameter documentation',
+ "differing-param-doc",
+ "Please check parameter names in declarations.",
+ ),
+ "W9018": (
+ '"%s" differing in parameter type documentation',
+ "differing-type-doc",
+ "Please check parameter names in type declarations.",
+ ),
+ "W9019": (
+ '"%s" useless ignored parameter documentation',
+ "useless-param-doc",
+ "Please remove the ignored parameter documentation.",
+ ),
+ "W9020": (
+ '"%s" useless ignored parameter type documentation',
+ "useless-type-doc",
+ "Please remove the ignored parameter type documentation.",
+ ),
+ "W9021": (
+ 'Missing any documentation in "%s"',
+ "missing-any-param-doc",
+ "Please add parameter and/or type documentation.",
+ ),
+ }
+
+ options = (
+ (
+ "accept-no-param-doc",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Whether to accept totally missing parameter "
+ "documentation in the docstring of a function that has "
+ "parameters.",
+ },
+ ),
+ (
+ "accept-no-raise-doc",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Whether to accept totally missing raises "
+ "documentation in the docstring of a function that "
+ "raises an exception.",
+ },
+ ),
+ (
+ "accept-no-return-doc",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Whether to accept totally missing return "
+ "documentation in the docstring of a function that "
+ "returns a statement.",
+ },
+ ),
+ (
+ "accept-no-yields-doc",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Whether to accept totally missing yields "
+ "documentation in the docstring of a generator.",
+ },
+ ),
+ (
+ "default-docstring-type",
+ {
+ "type": "choice",
+ "default": "default",
+ "metavar": "<docstring type>",
+ "choices": list(utils.DOCSTRING_TYPES),
+ "help": "If the docstring type cannot be guessed "
+ "the specified docstring type will be used.",
+ },
+ ),
+ )
+
+ constructor_names = {"__init__", "__new__"}
+ not_needed_param_in_docstring = {"self", "cls"}
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Called for function and method definitions (def).
+
+ :param node: Node for a function or method definition in the AST
+ :type node: :class:`astroid.scoped_nodes.Function`
+ """
+ if checker_utils.is_overload_stub(node):
+ return
+
+ node_doc = utils.docstringify(
+ node.doc_node, self.linter.config.default_docstring_type
+ )
+
+ # skip functions that match the 'no-docstring-rgx' config option
+ no_docstring_rgx = self.linter.config.no_docstring_rgx
+ if no_docstring_rgx and re.match(no_docstring_rgx, node.name):
+ return
+
+ # skip functions smaller than 'docstring-min-length'
+ lines = checker_utils.get_node_last_lineno(node) - node.lineno
+ max_lines = self.linter.config.docstring_min_length
+ if max_lines > -1 and lines < max_lines:
+ return
+
+ self.check_functiondef_params(node, node_doc)
+ self.check_functiondef_returns(node, node_doc)
+ self.check_functiondef_yields(node, node_doc)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def check_functiondef_params(
+ self, node: nodes.FunctionDef, node_doc: Docstring
+ ) -> None:
+ node_allow_no_param = None
+ if node.name in self.constructor_names:
+ class_node = checker_utils.node_frame_class(node)
+ if class_node is not None:
+ class_doc = utils.docstringify(
+ class_node.doc_node, self.linter.config.default_docstring_type
+ )
+ self.check_single_constructor_params(class_doc, node_doc, class_node)
+
+ # __init__ or class docstrings can have no parameters documented
+ # as long as the other documents them.
+ node_allow_no_param = (
+ class_doc.has_params()
+ or class_doc.params_documented_elsewhere()
+ or None
+ )
+ class_allow_no_param = (
+ node_doc.has_params()
+ or node_doc.params_documented_elsewhere()
+ or None
+ )
+
+ self.check_arguments_in_docstring(
+ class_doc, node.args, class_node, class_allow_no_param
+ )
+
+ self.check_arguments_in_docstring(
+ node_doc, node.args, node, node_allow_no_param
+ )
+
+ def check_functiondef_returns(
+ self, node: nodes.FunctionDef, node_doc: Docstring
+ ) -> None:
+ if (not node_doc.supports_yields and node.is_generator()) or node.is_abstract():
+ return
+
+ return_nodes = node.nodes_of_class(astroid.Return)
+ if (node_doc.has_returns() or node_doc.has_rtype()) and not any(
+ utils.returns_something(ret_node) for ret_node in return_nodes
+ ):
+ self.add_message("redundant-returns-doc", node=node, confidence=HIGH)
+
+ def check_functiondef_yields(
+ self, node: nodes.FunctionDef, node_doc: Docstring
+ ) -> None:
+ if not node_doc.supports_yields or node.is_abstract():
+ return
+
+ if (
+ node_doc.has_yields() or node_doc.has_yields_type()
+ ) and not node.is_generator():
+ self.add_message("redundant-yields-doc", node=node)
+
+ def visit_raise(self, node: nodes.Raise) -> None:
+ func_node = node.frame()
+ if not isinstance(func_node, astroid.FunctionDef):
+ return
+
+ # skip functions that match the 'no-docstring-rgx' config option
+ no_docstring_rgx = self.linter.config.no_docstring_rgx
+ if no_docstring_rgx and re.match(no_docstring_rgx, func_node.name):
+ return
+
+ expected_excs = utils.possible_exc_types(node)
+
+ if not expected_excs:
+ return
+
+ if not func_node.doc_node:
+ # If this is a property setter,
+ # the property should have the docstring instead.
+ property_ = utils.get_setters_property(func_node)
+ if property_:
+ func_node = property_
+
+ doc = utils.docstringify(
+ func_node.doc_node, self.linter.config.default_docstring_type
+ )
+
+ if self.linter.config.accept_no_raise_doc and not doc.exceptions():
+ return
+
+ if not doc.matching_sections():
+ if doc.doc:
+ missing = {exc.name for exc in expected_excs}
+ self._add_raise_message(missing, func_node)
+ return
+
+ found_excs_full_names = doc.exceptions()
+
+ # Extract just the class name, e.g. "error" from "re.error"
+ found_excs_class_names = {exc.split(".")[-1] for exc in found_excs_full_names}
+
+ missing_excs = set()
+ for expected in expected_excs:
+ for found_exc in found_excs_class_names:
+ if found_exc == expected.name:
+ break
+ if found_exc == "error" and expected.name == "PatternError":
+ # Python 3.13: re.error aliases re.PatternError
+ break
+ if any(found_exc == ancestor.name for ancestor in expected.ancestors()):
+ break
+ else:
+ missing_excs.add(expected.name)
+
+ self._add_raise_message(missing_excs, func_node)
+
+ def visit_return(self, node: nodes.Return) -> None:
+ if not utils.returns_something(node):
+ return
+
+ if self.linter.config.accept_no_return_doc:
+ return
+
+ func_node: astroid.FunctionDef = node.frame()
+
+ # skip functions that match the 'no-docstring-rgx' config option
+ no_docstring_rgx = self.linter.config.no_docstring_rgx
+ if no_docstring_rgx and re.match(no_docstring_rgx, func_node.name):
+ return
+
+ doc = utils.docstringify(
+ func_node.doc_node, self.linter.config.default_docstring_type
+ )
+
+ is_property = checker_utils.decorated_with_property(func_node)
+
+ if not (doc.has_returns() or (doc.has_property_returns() and is_property)):
+ self.add_message("missing-return-doc", node=func_node, confidence=HIGH)
+
+ if func_node.returns or func_node.type_comment_returns:
+ return
+
+ if not (doc.has_rtype() or (doc.has_property_type() and is_property)):
+ self.add_message("missing-return-type-doc", node=func_node, confidence=HIGH)
+
+ def visit_yield(self, node: nodes.Yield | nodes.YieldFrom) -> None:
+ if self.linter.config.accept_no_yields_doc:
+ return
+
+ func_node: astroid.FunctionDef = node.frame()
+
+ # skip functions that match the 'no-docstring-rgx' config option
+ no_docstring_rgx = self.linter.config.no_docstring_rgx
+ if no_docstring_rgx and re.match(no_docstring_rgx, func_node.name):
+ return
+
+ doc = utils.docstringify(
+ func_node.doc_node, self.linter.config.default_docstring_type
+ )
+
+ if doc.supports_yields:
+ doc_has_yields = doc.has_yields()
+ doc_has_yields_type = doc.has_yields_type()
+ else:
+ doc_has_yields = doc.has_returns()
+ doc_has_yields_type = doc.has_rtype()
+
+ if not doc_has_yields:
+ self.add_message("missing-yield-doc", node=func_node, confidence=HIGH)
+
+ if not (
+ doc_has_yields_type or func_node.returns or func_node.type_comment_returns
+ ):
+ self.add_message("missing-yield-type-doc", node=func_node, confidence=HIGH)
+
+ visit_yieldfrom = visit_yield
+
+ def _compare_missing_args(
+ self,
+ found_argument_names: set[str],
+ message_id: str,
+ not_needed_names: set[str],
+ expected_argument_names: set[str],
+ warning_node: nodes.NodeNG,
+ ) -> None:
+ """Compare the found argument names with the expected ones and
+ generate a message if there are arguments missing.
+
+ :param found_argument_names: argument names found in the docstring
+
+ :param message_id: pylint message id
+
+ :param not_needed_names: names that may be omitted
+
+ :param expected_argument_names: Expected argument names
+
+ :param warning_node: The node to be analyzed
+ """
+ potential_missing_argument_names = (
+ expected_argument_names - found_argument_names
+ ) - not_needed_names
+
+ # Handle variadic and keyword args without asterisks
+ missing_argument_names = set()
+ for name in potential_missing_argument_names:
+ if name.replace("*", "") in found_argument_names:
+ continue
+ missing_argument_names.add(name)
+
+ if missing_argument_names:
+ self.add_message(
+ message_id,
+ args=(", ".join(sorted(missing_argument_names)),),
+ node=warning_node,
+ confidence=HIGH,
+ )
+
+ def _compare_different_args(
+ self,
+ found_argument_names: set[str],
+ message_id: str,
+ not_needed_names: set[str],
+ expected_argument_names: set[str],
+ warning_node: nodes.NodeNG,
+ ) -> None:
+ """Compare the found argument names with the expected ones and
+ generate a message if there are extra arguments found.
+
+ :param found_argument_names: argument names found in the docstring
+
+ :param message_id: pylint message id
+
+ :param not_needed_names: names that may be omitted
+
+ :param expected_argument_names: Expected argument names
+
+ :param warning_node: The node to be analyzed
+ """
+ # Handle variadic and keyword args without asterisks
+ modified_expected_argument_names: set[str] = set()
+ for name in expected_argument_names:
+ if name.replace("*", "") in found_argument_names:
+ modified_expected_argument_names.add(name.replace("*", ""))
+ else:
+ modified_expected_argument_names.add(name)
+
+ differing_argument_names = (
+ (modified_expected_argument_names ^ found_argument_names)
+ - not_needed_names
+ - expected_argument_names
+ )
+
+ if differing_argument_names:
+ self.add_message(
+ message_id,
+ args=(", ".join(sorted(differing_argument_names)),),
+ node=warning_node,
+ confidence=HIGH,
+ )
+
+ def _compare_ignored_args( # pylint: disable=useless-param-doc
+ self,
+ found_argument_names: set[str],
+ message_id: str,
+ ignored_argument_names: set[str],
+ warning_node: nodes.NodeNG,
+ ) -> None:
+ """Compare the found argument names with the ignored ones and
+ generate a message if there are ignored arguments found.
+
+ :param found_argument_names: argument names found in the docstring
+ :param message_id: pylint message id
+ :param ignored_argument_names: Expected argument names
+ :param warning_node: The node to be analyzed
+ """
+ existing_ignored_argument_names = ignored_argument_names & found_argument_names
+
+ if existing_ignored_argument_names:
+ self.add_message(
+ message_id,
+ args=(", ".join(sorted(existing_ignored_argument_names)),),
+ node=warning_node,
+ confidence=HIGH,
+ )
+
+ def check_arguments_in_docstring(
+ self,
+ doc: Docstring,
+ arguments_node: astroid.Arguments,
+ warning_node: astroid.NodeNG,
+ accept_no_param_doc: bool | None = None,
+ ) -> None:
+ """Check that all parameters are consistent with the parameters mentioned
+ in the parameter documentation (e.g. the Sphinx tags 'param' and 'type').
+
+ * Undocumented parameters except 'self' are noticed.
+ * Undocumented parameter types except for 'self' and the ``*<args>``
+ and ``**<kwargs>`` parameters are noticed.
+ * Parameters mentioned in the parameter documentation that don't or no
+ longer exist in the function parameter list are noticed.
+ * If the text "For the parameters, see" or "For the other parameters,
+ see" (ignoring additional white-space) is mentioned in the docstring,
+ missing parameter documentation is tolerated.
+ * If there's no Sphinx style, Google style or NumPy style parameter
+ documentation at all, i.e. ``:param`` is never mentioned etc., the
+ checker assumes that the parameters are documented in another format
+ and the absence is tolerated.
+
+ :param doc: Docstring for the function, method or class.
+ :type doc: :class:`Docstring`
+
+ :param arguments_node: Arguments node for the function, method or
+ class constructor.
+ :type arguments_node: :class:`astroid.scoped_nodes.Arguments`
+
+ :param warning_node: The node to assign the warnings to
+ :type warning_node: :class:`astroid.scoped_nodes.Node`
+
+ :param accept_no_param_doc: Whether to allow no parameters to be
+ documented. If None then this value is read from the configuration.
+ :type accept_no_param_doc: bool or None
+ """
+ # Tolerate missing param or type declarations if there is a link to
+ # another method carrying the same name.
+ if not doc.doc:
+ return
+
+ if accept_no_param_doc is None:
+ accept_no_param_doc = self.linter.config.accept_no_param_doc
+ tolerate_missing_params = doc.params_documented_elsewhere()
+
+ # Collect the function arguments.
+ expected_argument_names = {arg.name for arg in arguments_node.args}
+ expected_argument_names.update(
+ a.name for a in arguments_node.posonlyargs + arguments_node.kwonlyargs
+ )
+ not_needed_type_in_docstring = self.not_needed_param_in_docstring.copy()
+
+ expected_but_ignored_argument_names = set()
+ ignored_argument_names = self.linter.config.ignored_argument_names
+ if ignored_argument_names:
+ expected_but_ignored_argument_names = {
+ arg
+ for arg in expected_argument_names
+ if ignored_argument_names.match(arg)
+ }
+
+ if arguments_node.vararg is not None:
+ expected_argument_names.add(f"*{arguments_node.vararg}")
+ not_needed_type_in_docstring.add(f"*{arguments_node.vararg}")
+ if arguments_node.kwarg is not None:
+ expected_argument_names.add(f"**{arguments_node.kwarg}")
+ not_needed_type_in_docstring.add(f"**{arguments_node.kwarg}")
+ params_with_doc, params_with_type = doc.match_param_docs()
+ # Tolerate no parameter documentation at all.
+ if not params_with_doc and not params_with_type and accept_no_param_doc:
+ tolerate_missing_params = True
+
+ # This is before the update of params_with_type because this must check only
+ # the type documented in a docstring, not the one using pep484
+ # See #4117 and #4593
+ self._compare_ignored_args(
+ params_with_type,
+ "useless-type-doc",
+ expected_but_ignored_argument_names,
+ warning_node,
+ )
+ params_with_type |= utils.args_with_annotation(arguments_node)
+
+ if not tolerate_missing_params:
+ missing_param_doc = (expected_argument_names - params_with_doc) - (
+ self.not_needed_param_in_docstring | expected_but_ignored_argument_names
+ )
+ missing_type_doc = (expected_argument_names - params_with_type) - (
+ not_needed_type_in_docstring | expected_but_ignored_argument_names
+ )
+ if (
+ missing_param_doc == expected_argument_names == missing_type_doc
+ and len(expected_argument_names) != 0
+ ):
+ self.add_message(
+ "missing-any-param-doc",
+ args=(warning_node.name,),
+ node=warning_node,
+ confidence=HIGH,
+ )
+ else:
+ self._compare_missing_args(
+ params_with_doc,
+ "missing-param-doc",
+ self.not_needed_param_in_docstring
+ | expected_but_ignored_argument_names,
+ expected_argument_names,
+ warning_node,
+ )
+ self._compare_missing_args(
+ params_with_type,
+ "missing-type-doc",
+ not_needed_type_in_docstring | expected_but_ignored_argument_names,
+ expected_argument_names,
+ warning_node,
+ )
+
+ self._compare_different_args(
+ params_with_doc,
+ "differing-param-doc",
+ self.not_needed_param_in_docstring,
+ expected_argument_names,
+ warning_node,
+ )
+ self._compare_different_args(
+ params_with_type,
+ "differing-type-doc",
+ not_needed_type_in_docstring,
+ expected_argument_names,
+ warning_node,
+ )
+ self._compare_ignored_args(
+ params_with_doc,
+ "useless-param-doc",
+ expected_but_ignored_argument_names,
+ warning_node,
+ )
+
+ def check_single_constructor_params(
+ self, class_doc: Docstring, init_doc: Docstring, class_node: nodes.ClassDef
+ ) -> None:
+ if class_doc.has_params() and init_doc.has_params():
+ self.add_message(
+ "multiple-constructor-doc",
+ args=(class_node.name,),
+ node=class_node,
+ confidence=HIGH,
+ )
+
+ def _add_raise_message(
+ self, missing_exceptions: set[str], node: nodes.FunctionDef
+ ) -> None:
+ """Adds a message on :param:`node` for the missing exception type.
+
+ :param missing_exceptions: A list of missing exception types.
+ :param node: The node to show the message on.
+ """
+ if node.is_abstract():
+ try:
+ missing_exceptions.remove("NotImplementedError")
+ except KeyError:
+ pass
+ if missing_exceptions:
+ self.add_message(
+ "missing-raises-doc",
+ args=(", ".join(sorted(missing_exceptions)),),
+ node=node,
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(DocstringParameterChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/docstyle.py b/solutions/.venv/Lib/site-packages/pylint/extensions/docstyle.py
new file mode 100644
index 000000000..c54ab93b2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/docstyle.py
@@ -0,0 +1,89 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import linecache
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint import checkers
+from pylint.checkers.utils import only_required_for_messages
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class DocStringStyleChecker(checkers.BaseChecker):
+ """Checks format of docstrings based on PEP 0257."""
+
+ name = "docstyle"
+
+ msgs = {
+ "C0198": (
+ 'Bad docstring quotes in %s, expected """, given %s',
+ "bad-docstring-quotes",
+ "Used when a docstring does not have triple double quotes.",
+ ),
+ "C0199": (
+ "First line empty in %s docstring",
+ "docstring-first-line-empty",
+ "Used when a blank line is found at the beginning of a docstring.",
+ ),
+ }
+
+ @only_required_for_messages("docstring-first-line-empty", "bad-docstring-quotes")
+ def visit_module(self, node: nodes.Module) -> None:
+ self._check_docstring("module", node)
+
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ self._check_docstring("class", node)
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ ftype = "method" if node.is_method() else "function"
+ self._check_docstring(ftype, node)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_docstring(
+ self, node_type: str, node: nodes.Module | nodes.ClassDef | nodes.FunctionDef
+ ) -> None:
+ docstring = node.doc_node.value if node.doc_node else None
+ if docstring and docstring[0] == "\n":
+ self.add_message(
+ "docstring-first-line-empty",
+ node=node,
+ args=(node_type,),
+ confidence=HIGH,
+ )
+
+ # Use "linecache", instead of node.as_string(), because the latter
+ # looses the original form of the docstrings.
+
+ if docstring:
+ lineno = node.fromlineno + 1
+ line = linecache.getline(node.root().file, lineno).lstrip()
+ if line and line.find('"""') == 0:
+ return
+ if line and "'''" in line:
+ quotes = "'''"
+ elif line and line[0] == '"':
+ quotes = '"'
+ elif line and line[0] == "'":
+ quotes = "'"
+ else:
+ quotes = ""
+ if quotes:
+ self.add_message(
+ "bad-docstring-quotes",
+ node=node,
+ args=(node_type, quotes),
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(DocStringStyleChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/dunder.py b/solutions/.venv/Lib/site-packages/pylint/extensions/dunder.py
new file mode 100644
index 000000000..1683f8147
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/dunder.py
@@ -0,0 +1,76 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.constants import DUNDER_METHODS, DUNDER_PROPERTIES, EXTRA_DUNDER_METHODS
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class DunderChecker(BaseChecker):
+ """Checks related to dunder methods."""
+
+ name = "dunder"
+ msgs = {
+ "W3201": (
+ "Bad or misspelled dunder method name %s.",
+ "bad-dunder-name",
+ "Used when a dunder method is misspelled or defined with a name "
+ "not within the predefined list of dunder names.",
+ ),
+ }
+ options = (
+ (
+ "good-dunder-names",
+ {
+ "default": [],
+ "type": "csv",
+ "metavar": "<comma-separated names>",
+ "help": "Good dunder names which should always be accepted.",
+ },
+ ),
+ )
+
+ def open(self) -> None:
+ self._dunder_methods = (
+ EXTRA_DUNDER_METHODS
+ + DUNDER_PROPERTIES
+ + self.linter.config.good_dunder_names
+ )
+ for since_vers, dunder_methods in DUNDER_METHODS.items():
+ if since_vers <= self.linter.config.py_version:
+ self._dunder_methods.extend(list(dunder_methods.keys()))
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Check if known dunder method is misspelled or dunder name is not one
+ of the pre-defined names.
+ """
+ # ignore module-level functions
+ if not node.is_method():
+ return
+
+ # Detect something that could be a bad dunder method
+ if (
+ node.name.startswith("_")
+ and node.name.endswith("_")
+ and node.name not in self._dunder_methods
+ ):
+ self.add_message(
+ "bad-dunder-name",
+ node=node,
+ args=(node.name),
+ confidence=HIGH,
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(DunderChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/empty_comment.py b/solutions/.venv/Lib/site-packages/pylint/extensions/empty_comment.py
new file mode 100644
index 000000000..7f54322ae
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/empty_comment.py
@@ -0,0 +1,63 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseRawFileChecker
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+def is_line_commented(line: bytes) -> bool:
+ """Checks if a `# symbol that is not part of a string was found in line."""
+ comment_idx = line.find(b"#")
+ if comment_idx == -1:
+ return False
+ if comment_part_of_string(line, comment_idx):
+ return is_line_commented(line[:comment_idx] + line[comment_idx + 1 :])
+ return True
+
+
+def comment_part_of_string(line: bytes, comment_idx: int) -> bool:
+ """Checks if the symbol at comment_idx is part of a string."""
+ if (
+ line[:comment_idx].count(b"'") % 2 == 1
+ and line[comment_idx:].count(b"'") % 2 == 1
+ ) or (
+ line[:comment_idx].count(b'"') % 2 == 1
+ and line[comment_idx:].count(b'"') % 2 == 1
+ ):
+ return True
+ return False
+
+
+class CommentChecker(BaseRawFileChecker):
+ name = "empty-comment"
+ msgs = {
+ "R2044": (
+ "Line with empty comment",
+ "empty-comment",
+ (
+ "Used when a # symbol appears on a line not followed by an actual comment"
+ ),
+ )
+ }
+ options = ()
+
+ def process_module(self, node: nodes.Module) -> None:
+ with node.stream() as stream:
+ for line_num, line in enumerate(stream):
+ line = line.rstrip()
+ if line.endswith(b"#"):
+ if not is_line_commented(line[:-1]):
+ self.add_message("empty-comment", line=line_num + 1)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(CommentChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/eq_without_hash.py b/solutions/.venv/Lib/site-packages/pylint/extensions/eq_without_hash.py
new file mode 100644
index 000000000..5f39dfa3e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/eq_without_hash.py
@@ -0,0 +1,39 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""This is the remnant of the python3 checker.
+
+It was removed because the transition from python 2 to python3 is
+behind us, but some checks are still useful in python3 after all.
+See https://github.com/pylint-dev/pylint/issues/5025
+"""
+
+from astroid import nodes
+
+from pylint import checkers, interfaces
+from pylint.checkers import utils
+from pylint.lint import PyLinter
+
+
+class EqWithoutHash(checkers.BaseChecker):
+ name = "eq-without-hash"
+
+ msgs = {
+ "W1641": (
+ "Implementing __eq__ without also implementing __hash__",
+ "eq-without-hash",
+ "Used when a class implements __eq__ but not __hash__. Objects get "
+ "None as their default __hash__ implementation if they also implement __eq__.",
+ ),
+ }
+
+ @utils.only_required_for_messages("eq-without-hash")
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ locals_and_methods = set(node.locals).union(x.name for x in node.mymethods())
+ if "__eq__" in locals_and_methods and "__hash__" not in locals_and_methods:
+ self.add_message("eq-without-hash", node=node, confidence=interfaces.HIGH)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(EqWithoutHash(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/for_any_all.py b/solutions/.venv/Lib/site-packages/pylint/extensions/for_any_all.py
new file mode 100644
index 000000000..2369a595d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/for_any_all.py
@@ -0,0 +1,162 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for use of for loops that only check for a condition."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import (
+ assigned_bool,
+ only_required_for_messages,
+ returns_bool,
+)
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+class ConsiderUsingAnyOrAllChecker(BaseChecker):
+ name = "consider-using-any-or-all"
+ msgs = {
+ "C0501": (
+ "`for` loop could be `%s`",
+ "consider-using-any-or-all",
+ "A for loop that checks for a condition and return a bool can be replaced with any or all.",
+ )
+ }
+
+ @only_required_for_messages("consider-using-any-or-all")
+ def visit_for(self, node: nodes.For) -> None:
+ if len(node.body) != 1: # Only If node with no Else
+ return
+ if not isinstance(node.body[0], nodes.If):
+ return
+
+ if_children = list(node.body[0].get_children())
+ if any(isinstance(child, nodes.If) for child in if_children):
+ # an if node within the if-children indicates an elif clause,
+ # suggesting complex logic.
+ return
+
+ node_after_loop = node.next_sibling()
+
+ if self._assigned_reassigned_returned(node, if_children, node_after_loop):
+ final_return_bool = node_after_loop.value.name
+ suggested_string = self._build_suggested_string(node, final_return_bool)
+ self.add_message(
+ "consider-using-any-or-all",
+ node=node,
+ args=suggested_string,
+ confidence=HIGH,
+ )
+ return
+
+ if self._if_statement_returns_bool(if_children, node_after_loop):
+ final_return_bool = node_after_loop.value.value
+ suggested_string = self._build_suggested_string(node, final_return_bool)
+ self.add_message(
+ "consider-using-any-or-all",
+ node=node,
+ args=suggested_string,
+ confidence=HIGH,
+ )
+ return
+
+ @staticmethod
+ def _if_statement_returns_bool(
+ if_children: list[nodes.NodeNG], node_after_loop: nodes.NodeNG
+ ) -> bool:
+ """Detect for-loop, if-statement, return pattern:
+
+ Ex:
+ def any_uneven(items):
+ for item in items:
+ if not item % 2 == 0:
+ return True
+ return False
+ """
+ if not len(if_children) == 2:
+ # The If node has only a comparison and return
+ return False
+ if not returns_bool(if_children[1]):
+ return False
+
+ # Check for terminating boolean return right after the loop
+ return returns_bool(node_after_loop)
+
+ @staticmethod
+ def _assigned_reassigned_returned(
+ node: nodes.For, if_children: list[nodes.NodeNG], node_after_loop: nodes.NodeNG
+ ) -> bool:
+ """Detect boolean-assign, for-loop, re-assign, return pattern:
+
+ Ex:
+ def check_lines(lines, max_chars):
+ long_line = False
+ for line in lines:
+ if len(line) > max_chars:
+ long_line = True
+ # no elif / else statement
+ return long_line
+ """
+ node_before_loop = node.previous_sibling()
+
+ if not assigned_bool(node_before_loop):
+ # node before loop isn't assigning to boolean
+ return False
+
+ assign_children = [x for x in if_children if isinstance(x, nodes.Assign)]
+ if not assign_children:
+ # if-nodes inside loop aren't assignments
+ return False
+
+ # We only care for the first assign node of the if-children. Otherwise it breaks the pattern.
+ first_target = assign_children[0].targets[0]
+ target_before_loop = node_before_loop.targets[0]
+
+ if not (
+ isinstance(first_target, nodes.AssignName)
+ and isinstance(target_before_loop, nodes.AssignName)
+ ):
+ return False
+
+ node_before_loop_name = node_before_loop.targets[0].name
+ return (
+ first_target.name == node_before_loop_name
+ and isinstance(node_after_loop, nodes.Return)
+ and isinstance(node_after_loop.value, nodes.Name)
+ and node_after_loop.value.name == node_before_loop_name
+ )
+
+ @staticmethod
+ def _build_suggested_string(node: nodes.For, final_return_bool: bool) -> str:
+ """When a nodes.For node can be rewritten as an any/all statement, return a
+ suggestion for that statement.
+
+ 'final_return_bool' is the boolean literal returned after the for loop if all
+ conditions fail.
+ """
+ loop_var = node.target.as_string()
+ loop_iter = node.iter.as_string()
+ test_node = next(node.body[0].get_children())
+
+ if isinstance(test_node, nodes.UnaryOp) and test_node.op == "not":
+ # The condition is negated. Advance the node to the operand and modify the suggestion
+ test_node = test_node.operand
+ suggested_function = "all" if final_return_bool else "not all"
+ else:
+ suggested_function = "not any" if final_return_bool else "any"
+
+ test = test_node.as_string()
+ return f"{suggested_function}({test} for {loop_var} in {loop_iter})"
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(ConsiderUsingAnyOrAllChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/magic_value.py b/solutions/.venv/Lib/site-packages/pylint/extensions/magic_value.py
new file mode 100644
index 000000000..fd18476ae
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/magic_value.py
@@ -0,0 +1,119 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Checks for magic values instead of literals."""
+
+from __future__ import annotations
+
+from re import match as regex_match
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker, utils
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class MagicValueChecker(BaseChecker):
+ """Checks for constants in comparisons."""
+
+ name = "magic-value"
+ msgs = {
+ "R2004": (
+ "Consider using a named constant or an enum instead of '%s'.",
+ "magic-value-comparison",
+ "Using named constants instead of magic values helps improve readability and maintainability of your"
+ " code, try to avoid them in comparisons.",
+ )
+ }
+
+ options = (
+ (
+ "valid-magic-values",
+ {
+ "default": (0, -1, 1, "", "__main__"),
+ "type": "csv",
+ "metavar": "<argument names>",
+ "help": "List of valid magic values that `magic-value-compare` will not detect. "
+ "Supports integers, floats, negative numbers, for empty string enter ``''``,"
+ " for backslash values just use one backslash e.g \\n.",
+ },
+ ),
+ )
+
+ def __init__(self, linter: PyLinter) -> None:
+ """Initialize checker instance."""
+ super().__init__(linter=linter)
+ self.valid_magic_vals: tuple[float | str, ...] = ()
+
+ def open(self) -> None:
+ # Extra manipulation is needed in case of using external configuration like an rcfile
+ if self._magic_vals_ext_configured():
+ self.valid_magic_vals = tuple(
+ self._parse_rcfile_magic_numbers(value)
+ for value in self.linter.config.valid_magic_values
+ )
+ else:
+ self.valid_magic_vals = self.linter.config.valid_magic_values
+
+ def _magic_vals_ext_configured(self) -> bool:
+ return not isinstance(self.linter.config.valid_magic_values, tuple)
+
+ def _check_constants_comparison(self, node: nodes.Compare) -> None:
+ """
+ Magic values in any side of the comparison should be avoided,
+ Detects comparisons that `comparison-of-constants` core checker cannot detect.
+ """
+ const_operands = []
+ LEFT_OPERAND = 0
+ RIGHT_OPERAND = 1
+
+ left_operand = node.left
+ const_operands.append(isinstance(left_operand, nodes.Const))
+
+ right_operand = node.ops[0][1]
+ const_operands.append(isinstance(right_operand, nodes.Const))
+
+ if all(const_operands):
+ # `comparison-of-constants` avoided
+ return
+
+ operand_value = None
+ if const_operands[LEFT_OPERAND] and self._is_magic_value(left_operand):
+ operand_value = left_operand.as_string()
+ elif const_operands[RIGHT_OPERAND] and self._is_magic_value(right_operand):
+ operand_value = right_operand.as_string()
+ if operand_value is not None:
+ self.add_message(
+ "magic-value-comparison",
+ node=node,
+ args=(operand_value),
+ confidence=HIGH,
+ )
+
+ def _is_magic_value(self, node: nodes.Const) -> bool:
+ return (not utils.is_singleton_const(node)) and (
+ node.value not in (self.valid_magic_vals)
+ )
+
+ @staticmethod
+ def _parse_rcfile_magic_numbers(parsed_val: str) -> float | str:
+ parsed_val = parsed_val.encode().decode("unicode_escape")
+
+ if parsed_val.startswith("'") and parsed_val.endswith("'"):
+ return parsed_val[1:-1]
+
+ is_number = regex_match(r"[-+]?\d+(\.0*)?$", parsed_val)
+ return float(parsed_val) if is_number else parsed_val
+
+ @utils.only_required_for_messages("magic-comparison")
+ def visit_compare(self, node: nodes.Compare) -> None:
+ self._check_constants_comparison(node)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(MagicValueChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/mccabe.py b/solutions/.venv/Lib/site-packages/pylint/extensions/mccabe.py
new file mode 100644
index 000000000..9489f24d6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/mccabe.py
@@ -0,0 +1,212 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Module to add McCabe checker class for pylint."""
+
+from __future__ import annotations
+
+from collections.abc import Sequence
+from typing import TYPE_CHECKING, Any, TypeVar, Union
+
+from astroid import nodes
+from mccabe import PathGraph as Mccabe_PathGraph
+from mccabe import PathGraphingAstVisitor as Mccabe_PathGraphingAstVisitor
+
+from pylint import checkers
+from pylint.checkers.utils import only_required_for_messages
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+_StatementNodes = Union[
+ nodes.Assert,
+ nodes.Assign,
+ nodes.AugAssign,
+ nodes.Delete,
+ nodes.Raise,
+ nodes.Yield,
+ nodes.Import,
+ nodes.Call,
+ nodes.Subscript,
+ nodes.Pass,
+ nodes.Continue,
+ nodes.Break,
+ nodes.Global,
+ nodes.Return,
+ nodes.Expr,
+ nodes.Await,
+]
+
+_SubGraphNodes = Union[nodes.If, nodes.Try, nodes.For, nodes.While]
+_AppendableNodeT = TypeVar(
+ "_AppendableNodeT", bound=Union[_StatementNodes, nodes.While, nodes.FunctionDef]
+)
+
+
+class PathGraph(Mccabe_PathGraph): # type: ignore[misc]
+ def __init__(self, node: _SubGraphNodes | nodes.FunctionDef):
+ super().__init__(name="", entity="", lineno=1)
+ self.root = node
+
+
+class PathGraphingAstVisitor(Mccabe_PathGraphingAstVisitor): # type: ignore[misc]
+ def __init__(self) -> None:
+ super().__init__()
+ self._bottom_counter = 0
+ self.graph: PathGraph | None = None
+
+ def default(self, node: nodes.NodeNG, *args: Any) -> None:
+ for child in node.get_children():
+ self.dispatch(child, *args)
+
+ def dispatch(self, node: nodes.NodeNG, *args: Any) -> Any:
+ self.node = node
+ klass = node.__class__
+ meth = self._cache.get(klass)
+ if meth is None:
+ class_name = klass.__name__
+ meth = getattr(self.visitor, "visit" + class_name, self.default)
+ self._cache[klass] = meth
+ return meth(node, *args)
+
+ def visitFunctionDef(self, node: nodes.FunctionDef) -> None:
+ if self.graph is not None:
+ # closure
+ pathnode = self._append_node(node)
+ self.tail = pathnode
+ self.dispatch_list(node.body)
+ bottom = f"{self._bottom_counter}"
+ self._bottom_counter += 1
+ self.graph.connect(self.tail, bottom)
+ self.graph.connect(node, bottom)
+ self.tail = bottom
+ else:
+ self.graph = PathGraph(node)
+ self.tail = node
+ self.dispatch_list(node.body)
+ self.graphs[f"{self.classname}{node.name}"] = self.graph
+ self.reset()
+
+ visitAsyncFunctionDef = visitFunctionDef
+
+ def visitSimpleStatement(self, node: _StatementNodes) -> None:
+ self._append_node(node)
+
+ visitAssert = visitAssign = visitAugAssign = visitDelete = visitRaise = (
+ visitYield
+ ) = visitImport = visitCall = visitSubscript = visitPass = visitContinue = (
+ visitBreak
+ ) = visitGlobal = visitReturn = visitExpr = visitAwait = visitSimpleStatement
+
+ def visitWith(self, node: nodes.With) -> None:
+ self._append_node(node)
+ self.dispatch_list(node.body)
+
+ visitAsyncWith = visitWith
+
+ def _append_node(self, node: _AppendableNodeT) -> _AppendableNodeT | None:
+ if not self.tail or not self.graph:
+ return None
+ self.graph.connect(self.tail, node)
+ self.tail = node
+ return node
+
+ def _subgraph(
+ self,
+ node: _SubGraphNodes,
+ name: str,
+ extra_blocks: Sequence[nodes.ExceptHandler] = (),
+ ) -> None:
+ """Create the subgraphs representing any `if` and `for` statements."""
+ if self.graph is None:
+ # global loop
+ self.graph = PathGraph(node)
+ self._subgraph_parse(node, node, extra_blocks)
+ self.graphs[f"{self.classname}{name}"] = self.graph
+ self.reset()
+ else:
+ self._append_node(node)
+ self._subgraph_parse(node, node, extra_blocks)
+
+ def _subgraph_parse(
+ self,
+ node: _SubGraphNodes,
+ pathnode: _SubGraphNodes,
+ extra_blocks: Sequence[nodes.ExceptHandler],
+ ) -> None:
+ """Parse the body and any `else` block of `if` and `for` statements."""
+ loose_ends = []
+ self.tail = node
+ self.dispatch_list(node.body)
+ loose_ends.append(self.tail)
+ for extra in extra_blocks:
+ self.tail = node
+ self.dispatch_list(extra.body)
+ loose_ends.append(self.tail)
+ if node.orelse:
+ self.tail = node
+ self.dispatch_list(node.orelse)
+ loose_ends.append(self.tail)
+ else:
+ loose_ends.append(node)
+ if node and self.graph:
+ bottom = f"{self._bottom_counter}"
+ self._bottom_counter += 1
+ for end in loose_ends:
+ self.graph.connect(end, bottom)
+ self.tail = bottom
+
+
+class McCabeMethodChecker(checkers.BaseChecker):
+ """Checks McCabe complexity cyclomatic threshold in methods and functions
+ to validate a too complex code.
+ """
+
+ name = "design"
+
+ msgs = {
+ "R1260": (
+ "%s is too complex. The McCabe rating is %d",
+ "too-complex",
+ "Used when a method or function is too complex based on "
+ "McCabe Complexity Cyclomatic",
+ )
+ }
+ options = (
+ (
+ "max-complexity",
+ {
+ "default": 10,
+ "type": "int",
+ "metavar": "<int>",
+ "help": "McCabe complexity cyclomatic threshold",
+ },
+ ),
+ )
+
+ @only_required_for_messages("too-complex")
+ def visit_module(self, node: nodes.Module) -> None:
+ """Visit an astroid.Module node to check too complex rating and
+ add message if is greater than max_complexity stored from options.
+ """
+ visitor = PathGraphingAstVisitor()
+ for child in node.body:
+ visitor.preorder(child, visitor)
+ for graph in visitor.graphs.values():
+ complexity = graph.complexity()
+ node = graph.root
+ if hasattr(node, "name"):
+ node_name = f"'{node.name}'"
+ else:
+ node_name = f"This '{node.__class__.__name__.lower()}'"
+ if complexity <= self.linter.config.max_complexity:
+ continue
+ self.add_message(
+ "too-complex", node=node, confidence=HIGH, args=(node_name, complexity)
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(McCabeMethodChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/no_self_use.py b/solutions/.venv/Lib/site-packages/pylint/extensions/no_self_use.py
new file mode 100644
index 000000000..28a6620a8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/no_self_use.py
@@ -0,0 +1,111 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import (
+ PYMETHODS,
+ decorated_with_property,
+ is_overload_stub,
+ is_protocol_class,
+ overrides_a_method,
+)
+from pylint.interfaces import INFERENCE
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+class NoSelfUseChecker(BaseChecker):
+ name = "no_self_use"
+ msgs = {
+ "R6301": (
+ "Method could be a function",
+ "no-self-use",
+ "Used when a method doesn't use its bound instance, and so could "
+ "be written as a function.",
+ {"old_names": [("R0201", "old-no-self-use")]},
+ ),
+ }
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._first_attrs: list[str | None] = []
+ self._meth_could_be_func: bool | None = None
+
+ def visit_name(self, node: nodes.Name) -> None:
+ """Check if the name handle an access to a class member
+ if so, register it.
+ """
+ if self._first_attrs and (
+ node.name == self._first_attrs[-1] or not self._first_attrs[-1]
+ ):
+ self._meth_could_be_func = False
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ if not node.is_method():
+ return
+ self._meth_could_be_func = True
+ self._check_first_arg_for_type(node)
+
+ visit_asyncfunctiondef = visit_functiondef
+
+ def _check_first_arg_for_type(self, node: nodes.FunctionDef) -> None:
+ """Check the name of first argument."""
+ # pylint: disable=duplicate-code
+ if node.args.posonlyargs:
+ first_arg = node.args.posonlyargs[0].name
+ elif node.args.args:
+ first_arg = node.argnames()[0]
+ else:
+ first_arg = None
+ self._first_attrs.append(first_arg)
+ # static method
+ if node.type == "staticmethod":
+ self._first_attrs[-1] = None
+
+ def leave_functiondef(self, node: nodes.FunctionDef) -> None:
+ """On method node, check if this method couldn't be a function.
+
+ ignore class, static and abstract methods, initializer,
+ methods overridden from a parent class.
+ """
+ if node.is_method():
+ first = self._first_attrs.pop()
+ if first is None:
+ return
+ class_node = node.parent.frame()
+ if (
+ self._meth_could_be_func
+ and node.type == "method"
+ and node.name not in PYMETHODS
+ and not (
+ node.is_abstract()
+ or overrides_a_method(class_node, node.name)
+ or decorated_with_property(node)
+ or _has_bare_super_call(node)
+ or is_protocol_class(class_node)
+ or is_overload_stub(node)
+ )
+ ):
+ self.add_message("no-self-use", node=node, confidence=INFERENCE)
+
+ leave_asyncfunctiondef = leave_functiondef
+
+
+def _has_bare_super_call(fundef_node: nodes.FunctionDef) -> bool:
+ for call in fundef_node.nodes_of_class(nodes.Call):
+ func = call.func
+ if isinstance(func, nodes.Name) and func.name == "super" and not call.args:
+ return True
+ return False
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(NoSelfUseChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/overlapping_exceptions.py b/solutions/.venv/Lib/site-packages/pylint/extensions/overlapping_exceptions.py
new file mode 100644
index 000000000..8d35e4ce3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/overlapping_exceptions.py
@@ -0,0 +1,90 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Looks for overlapping exceptions."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING, Any
+
+import astroid
+from astroid import nodes, util
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.checkers.exceptions import _annotated_unpack_infer
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class OverlappingExceptionsChecker(checkers.BaseChecker):
+ """Checks for two or more exceptions in the same exception handler
+ clause that are identical or parts of the same inheritance hierarchy.
+
+ (i.e. overlapping).
+ """
+
+ name = "overlap-except"
+ msgs = {
+ "W0714": (
+ "Overlapping exceptions (%s)",
+ "overlapping-except",
+ "Used when exceptions in handler overlap or are identical",
+ )
+ }
+ options = ()
+
+ @utils.only_required_for_messages("overlapping-except")
+ def visit_try(self, node: nodes.Try) -> None:
+ """Check for empty except."""
+ for handler in node.handlers:
+ if handler.type is None:
+ continue
+ if isinstance(handler.type, astroid.BoolOp):
+ continue
+ try:
+ excs = list(_annotated_unpack_infer(handler.type))
+ except astroid.InferenceError:
+ continue
+
+ handled_in_clause: list[tuple[Any, Any]] = []
+ for part, exc in excs:
+ if isinstance(exc, util.UninferableBase):
+ continue
+ if isinstance(exc, astroid.Instance) and utils.inherit_from_std_ex(exc):
+ exc = exc._proxied
+
+ if not isinstance(exc, astroid.ClassDef):
+ continue
+
+ exc_ancestors = [
+ anc for anc in exc.ancestors() if isinstance(anc, astroid.ClassDef)
+ ]
+
+ for prev_part, prev_exc in handled_in_clause:
+ prev_exc_ancestors = [
+ anc
+ for anc in prev_exc.ancestors()
+ if isinstance(anc, astroid.ClassDef)
+ ]
+ if exc == prev_exc:
+ self.add_message(
+ "overlapping-except",
+ node=handler.type,
+ args=f"{prev_part.as_string()} and {part.as_string()} are the same",
+ )
+ elif prev_exc in exc_ancestors or exc in prev_exc_ancestors:
+ ancestor = part if exc in prev_exc_ancestors else prev_part
+ descendant = part if prev_exc in exc_ancestors else prev_part
+ self.add_message(
+ "overlapping-except",
+ node=handler.type,
+ args=f"{ancestor.as_string()} is an ancestor class of {descendant.as_string()}",
+ )
+ handled_in_clause += [(part, exc)]
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(OverlappingExceptionsChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/private_import.py b/solutions/.venv/Lib/site-packages/pylint/extensions/private_import.py
new file mode 100644
index 000000000..962bfe1f1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/private_import.py
@@ -0,0 +1,264 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for imports on private external modules and names."""
+
+from __future__ import annotations
+
+from pathlib import Path
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker, utils
+from pylint.interfaces import HIGH
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+class PrivateImportChecker(BaseChecker):
+ name = "import-private-name"
+ msgs = {
+ "C2701": (
+ "Imported private %s (%s)",
+ "import-private-name",
+ "Used when a private module or object prefixed with _ is imported. "
+ "PEP8 guidance on Naming Conventions states that public attributes with "
+ "leading underscores should be considered private.",
+ ),
+ }
+
+ def __init__(self, linter: PyLinter) -> None:
+ BaseChecker.__init__(self, linter)
+
+ # A mapping of private names used as a type annotation to whether it is an acceptable import
+ self.all_used_type_annotations: dict[str, bool] = {}
+ self.populated_annotations = False
+
+ @utils.only_required_for_messages("import-private-name")
+ def visit_import(self, node: nodes.Import) -> None:
+ if utils.in_type_checking_block(node):
+ return
+ names = [name[0] for name in node.names]
+ private_names = self._get_private_imports(names)
+ private_names = self._get_type_annotation_names(node, private_names)
+ if private_names:
+ imported_identifier = "modules" if len(private_names) > 1 else "module"
+ private_name_string = ", ".join(private_names)
+ self.add_message(
+ "import-private-name",
+ node=node,
+ args=(imported_identifier, private_name_string),
+ confidence=HIGH,
+ )
+
+ @utils.only_required_for_messages("import-private-name")
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ if utils.in_type_checking_block(node):
+ return
+ # Only check imported names if the module is external
+ if self.same_root_dir(node, node.modname):
+ return
+
+ names = [n[0] for n in node.names]
+
+ # Check the imported objects first. If they are all valid type annotations,
+ # the package can be private
+ private_names = self._get_type_annotation_names(node, names)
+ if not private_names:
+ return
+
+ # There are invalid imported objects, so check the name of the package
+ private_module_imports = self._get_private_imports([node.modname])
+ private_module_imports = self._get_type_annotation_names(
+ node, private_module_imports
+ )
+ if private_module_imports:
+ self.add_message(
+ "import-private-name",
+ node=node,
+ args=("module", private_module_imports[0]),
+ confidence=HIGH,
+ )
+ return # Do not emit messages on the objects if the package is private
+
+ private_names = self._get_private_imports(private_names)
+
+ if private_names:
+ imported_identifier = "objects" if len(private_names) > 1 else "object"
+ private_name_string = ", ".join(private_names)
+ self.add_message(
+ "import-private-name",
+ node=node,
+ args=(imported_identifier, private_name_string),
+ confidence=HIGH,
+ )
+
+ def _get_private_imports(self, names: list[str]) -> list[str]:
+ """Returns the private names from input names by a simple string check."""
+ return [name for name in names if self._name_is_private(name)]
+
+ @staticmethod
+ def _name_is_private(name: str) -> bool:
+ """Returns true if the name exists, starts with `_`, and if len(name) > 4
+ it is not a dunder, i.e. it does not begin and end with two underscores.
+ """
+ return (
+ bool(name)
+ and name[0] == "_"
+ and (len(name) <= 4 or name[1] != "_" or name[-2:] != "__")
+ )
+
+ def _get_type_annotation_names(
+ self, node: nodes.Import | nodes.ImportFrom, names: list[str]
+ ) -> list[str]:
+ """Removes from names any names that are used as type annotations with no other
+ illegal usages.
+ """
+ if names and not self.populated_annotations:
+ self._populate_type_annotations(node.root(), self.all_used_type_annotations)
+ self.populated_annotations = True
+
+ return [
+ n
+ for n in names
+ if n not in self.all_used_type_annotations
+ or (
+ n in self.all_used_type_annotations
+ and not self.all_used_type_annotations[n]
+ )
+ ]
+
+ def _populate_type_annotations(
+ self, node: nodes.LocalsDictNodeNG, all_used_type_annotations: dict[str, bool]
+ ) -> None:
+ """Adds to `all_used_type_annotations` all names ever used as a type annotation
+ in the node's (nested) scopes and whether they are only used as annotation.
+ """
+ for name in node.locals:
+ # If we find a private type annotation, make sure we do not mask illegal usages
+ private_name = None
+ # All the assignments using this variable that we might have to check for
+ # illegal usages later
+ name_assignments = []
+ for usage_node in node.locals[name]:
+ if isinstance(usage_node, nodes.AssignName) and isinstance(
+ usage_node.parent, (nodes.AnnAssign, nodes.Assign)
+ ):
+ assign_parent = usage_node.parent
+ if isinstance(assign_parent, nodes.AnnAssign):
+ name_assignments.append(assign_parent)
+ private_name = self._populate_type_annotations_annotation(
+ usage_node.parent.annotation, all_used_type_annotations
+ )
+ elif isinstance(assign_parent, nodes.Assign):
+ name_assignments.append(assign_parent)
+
+ if isinstance(usage_node, nodes.FunctionDef):
+ self._populate_type_annotations_function(
+ usage_node, all_used_type_annotations
+ )
+ if isinstance(usage_node, nodes.LocalsDictNodeNG):
+ self._populate_type_annotations(
+ usage_node, all_used_type_annotations
+ )
+ if private_name is not None:
+ # Found a new private annotation, make sure we are not accessing it elsewhere
+ all_used_type_annotations[private_name] = (
+ self._assignments_call_private_name(name_assignments, private_name)
+ )
+
+ def _populate_type_annotations_function(
+ self, node: nodes.FunctionDef, all_used_type_annotations: dict[str, bool]
+ ) -> None:
+ """Adds all names used as type annotation in the arguments and return type of
+ the function node into the dict `all_used_type_annotations`.
+ """
+ if node.args and node.args.annotations:
+ for annotation in node.args.annotations:
+ self._populate_type_annotations_annotation(
+ annotation, all_used_type_annotations
+ )
+ if node.returns:
+ self._populate_type_annotations_annotation(
+ node.returns, all_used_type_annotations
+ )
+
+ def _populate_type_annotations_annotation(
+ self,
+ node: nodes.Attribute | nodes.Subscript | nodes.Name | None,
+ all_used_type_annotations: dict[str, bool],
+ ) -> str | None:
+ """Handles the possibility of an annotation either being a Name, i.e. just type,
+ or a Subscript e.g. `Optional[type]` or an Attribute, e.g. `pylint.lint.linter`.
+ """
+ if isinstance(node, nodes.Name) and node.name not in all_used_type_annotations:
+ all_used_type_annotations[node.name] = True
+ return node.name # type: ignore[no-any-return]
+ if isinstance(node, nodes.Subscript): # e.g. Optional[List[str]]
+ # slice is the next nested type
+ self._populate_type_annotations_annotation(
+ node.slice, all_used_type_annotations
+ )
+ # value is the current type name: could be a Name or Attribute
+ return self._populate_type_annotations_annotation(
+ node.value, all_used_type_annotations
+ )
+ if isinstance(node, nodes.Attribute):
+ # An attribute is a type like `pylint.lint.pylinter`. node.expr is the next level
+ # up, could be another attribute
+ return self._populate_type_annotations_annotation(
+ node.expr, all_used_type_annotations
+ )
+ return None
+
+ @staticmethod
+ def _assignments_call_private_name(
+ assignments: list[nodes.AnnAssign | nodes.Assign], private_name: str
+ ) -> bool:
+ """Returns True if no assignments involve accessing `private_name`."""
+ if all(not assignment.value for assignment in assignments):
+ # Variable annotated but unassigned is not allowed because there may be
+ # possible illegal access elsewhere
+ return False
+ for assignment in assignments:
+ current_attribute = None
+ if isinstance(assignment.value, nodes.Call):
+ current_attribute = assignment.value.func
+ elif isinstance(assignment.value, nodes.Attribute):
+ current_attribute = assignment.value
+ elif isinstance(assignment.value, nodes.Name):
+ current_attribute = assignment.value.name
+ if not current_attribute:
+ continue
+ while isinstance(current_attribute, (nodes.Attribute, nodes.Call)):
+ if isinstance(current_attribute, nodes.Call):
+ current_attribute = current_attribute.func
+ if not isinstance(current_attribute, nodes.Name):
+ current_attribute = current_attribute.expr
+ if (
+ isinstance(current_attribute, nodes.Name)
+ and current_attribute.name == private_name
+ ):
+ return False
+ return True
+
+ @staticmethod
+ def same_root_dir(
+ node: nodes.Import | nodes.ImportFrom, import_mod_name: str
+ ) -> bool:
+ """Does the node's file's path contain the base name of `import_mod_name`?"""
+ if not import_mod_name: # from . import ...
+ return True
+ if node.level: # from .foo import ..., from ..bar import ...
+ return True
+
+ base_import_package = import_mod_name.split(".")[0]
+
+ return base_import_package in Path(node.root().file).parent.parts
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(PrivateImportChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/redefined_loop_name.py b/solutions/.venv/Lib/site-packages/pylint/extensions/redefined_loop_name.py
new file mode 100644
index 000000000..d03b80be3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/redefined_loop_name.py
@@ -0,0 +1,88 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Optional checker to warn when loop variables are overwritten in the loop's body."""
+
+from __future__ import annotations
+
+from astroid import nodes
+
+from pylint import checkers
+from pylint.checkers import utils
+from pylint.interfaces import HIGH
+from pylint.lint import PyLinter
+
+
+class RedefinedLoopNameChecker(checkers.BaseChecker):
+ name = "redefined-loop-name"
+
+ msgs = {
+ "W2901": (
+ "Redefining %r from loop (line %s)",
+ "redefined-loop-name",
+ "Used when a loop variable is overwritten in the loop body.",
+ ),
+ }
+
+ def __init__(self, linter: PyLinter) -> None:
+ super().__init__(linter)
+ self._loop_variables: list[
+ tuple[nodes.For, list[str], nodes.LocalsDictNodeNG]
+ ] = []
+
+ @utils.only_required_for_messages("redefined-loop-name")
+ def visit_assignname(self, node: nodes.AssignName) -> None:
+ assign_type = node.assign_type()
+ if not isinstance(assign_type, (nodes.Assign, nodes.AugAssign)):
+ return
+ node_scope = node.scope()
+ for outer_for, outer_variables, outer_for_scope in self._loop_variables:
+ if node_scope is not outer_for_scope:
+ continue
+ if node.name in outer_variables and not utils.in_for_else_branch(
+ outer_for, node
+ ):
+ self.add_message(
+ "redefined-loop-name",
+ args=(node.name, outer_for.fromlineno),
+ node=node,
+ confidence=HIGH,
+ )
+ break
+
+ @utils.only_required_for_messages("redefined-loop-name")
+ def visit_for(self, node: nodes.For) -> None:
+ assigned_to = [a.name for a in node.target.nodes_of_class(nodes.AssignName)]
+ # Only check variables that are used
+ assigned_to = [
+ var
+ for var in assigned_to
+ if not self.linter.config.dummy_variables_rgx.match(var)
+ ]
+
+ node_scope = node.scope()
+ for variable in assigned_to:
+ for outer_for, outer_variables, outer_for_scope in self._loop_variables:
+ if node_scope is not outer_for_scope:
+ continue
+ if variable in outer_variables and not utils.in_for_else_branch(
+ outer_for, node
+ ):
+ self.add_message(
+ "redefined-loop-name",
+ args=(variable, outer_for.fromlineno),
+ node=node,
+ confidence=HIGH,
+ )
+ break
+
+ self._loop_variables.append((node, assigned_to, node.scope()))
+
+ @utils.only_required_for_messages("redefined-loop-name")
+ def leave_for(self, node: nodes.For) -> None: # pylint: disable=unused-argument
+ self._loop_variables.pop()
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(RedefinedLoopNameChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/redefined_variable_type.py b/solutions/.venv/Lib/site-packages/pylint/extensions/redefined_variable_type.py
new file mode 100644
index 000000000..ba5af3136
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/redefined_variable_type.py
@@ -0,0 +1,108 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import is_none, node_type, only_required_for_messages
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class MultipleTypesChecker(BaseChecker):
+ """Checks for variable type redefinition (NoneType excepted).
+
+ At a function, method, class or module scope
+
+ This rule could be improved:
+
+ - Currently, if an attribute is set to different types in 2 methods of a
+ same class, it won't be detected (see functional test)
+ - One could improve the support for inference on assignment with tuples,
+ ifexpr, etc. Also, it would be great to have support for inference on
+ str.split()
+ """
+
+ name = "multiple_types"
+ msgs = {
+ "R0204": (
+ "Redefinition of %s type from %s to %s",
+ "redefined-variable-type",
+ "Used when the type of a variable changes inside a "
+ "method or a function.",
+ )
+ }
+
+ def visit_classdef(self, _: nodes.ClassDef) -> None:
+ self._assigns.append({})
+
+ @only_required_for_messages("redefined-variable-type")
+ def leave_classdef(self, _: nodes.ClassDef) -> None:
+ self._check_and_add_messages()
+
+ visit_functiondef = visit_asyncfunctiondef = visit_classdef
+ leave_functiondef = leave_asyncfunctiondef = leave_module = leave_classdef
+
+ def visit_module(self, _: nodes.Module) -> None:
+ self._assigns: list[dict[str, list[tuple[nodes.Assign, str]]]] = [{}]
+
+ def _check_and_add_messages(self) -> None:
+ assigns = self._assigns.pop()
+ for name, args in assigns.items():
+ if len(args) <= 1:
+ continue
+ orig_node, orig_type = args[0]
+ # Check if there is a type in the following nodes that would be
+ # different from orig_type.
+ for redef_node, redef_type in args[1:]:
+ if redef_type == orig_type:
+ continue
+ # if a variable is defined to several types in an if node,
+ # this is not actually redefining.
+ orig_parent = orig_node.parent
+ redef_parent = redef_node.parent
+ if isinstance(orig_parent, nodes.If):
+ if orig_parent == redef_parent:
+ if (
+ redef_node in orig_parent.orelse
+ and orig_node not in orig_parent.orelse
+ ):
+ orig_node, orig_type = redef_node, redef_type
+ continue
+ elif isinstance(
+ redef_parent, nodes.If
+ ) and redef_parent in orig_parent.nodes_of_class(nodes.If):
+ orig_node, orig_type = redef_node, redef_type
+ continue
+ orig_type = orig_type.replace("builtins.", "")
+ redef_type = redef_type.replace("builtins.", "")
+ self.add_message(
+ "redefined-variable-type",
+ node=redef_node,
+ args=(name, orig_type, redef_type),
+ )
+ break
+
+ def visit_assign(self, node: nodes.Assign) -> None:
+ # we don't handle multiple assignment nor slice assignment
+ target = node.targets[0]
+ if isinstance(target, (nodes.Tuple, nodes.Subscript)):
+ return
+ # ignore NoneType
+ if is_none(node):
+ return
+ _type = node_type(node.value)
+ if _type:
+ self._assigns[-1].setdefault(target.as_string(), []).append(
+ (node, _type.pytype())
+ )
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(MultipleTypesChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/set_membership.py b/solutions/.venv/Lib/site-packages/pylint/extensions/set_membership.py
new file mode 100644
index 000000000..b72f5aa18
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/set_membership.py
@@ -0,0 +1,52 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class SetMembershipChecker(BaseChecker):
+ name = "set_membership"
+ msgs = {
+ "R6201": (
+ "Consider using set for membership test",
+ "use-set-for-membership",
+ "Membership tests are more efficient when performed on "
+ "a lookup optimized datatype like ``sets``.",
+ ),
+ }
+
+ def __init__(self, linter: PyLinter) -> None:
+ """Initialize checker instance."""
+ super().__init__(linter=linter)
+
+ @only_required_for_messages("use-set-for-membership")
+ def visit_compare(self, node: nodes.Compare) -> None:
+ for op, comparator in node.ops:
+ if op == "in":
+ self._check_in_comparison(comparator)
+
+ def _check_in_comparison(self, comparator: nodes.NodeNG) -> None:
+ """Checks for membership comparisons with in-place container objects."""
+ if not isinstance(comparator, nodes.BaseContainer) or isinstance(
+ comparator, nodes.Set
+ ):
+ return
+
+ # Heuristic - We need to be sure all items in set are hashable
+ if all(isinstance(item, nodes.Const) for item in comparator.elts):
+ self.add_message("use-set-for-membership", node=comparator)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(SetMembershipChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/typing.py b/solutions/.venv/Lib/site-packages/pylint/extensions/typing.py
new file mode 100644
index 000000000..f9ef83bab
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/typing.py
@@ -0,0 +1,539 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING, NamedTuple
+
+import astroid.bases
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import (
+ in_type_checking_block,
+ is_node_in_type_annotation_context,
+ is_postponed_evaluation_enabled,
+ only_required_for_messages,
+ safe_infer,
+)
+from pylint.constants import TYPING_NORETURN
+from pylint.interfaces import HIGH, INFERENCE
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class TypingAlias(NamedTuple):
+ name: str
+ name_collision: bool
+
+
+DEPRECATED_TYPING_ALIASES: dict[str, TypingAlias] = {
+ "typing.Tuple": TypingAlias("tuple", False),
+ "typing.List": TypingAlias("list", False),
+ "typing.Dict": TypingAlias("dict", False),
+ "typing.Set": TypingAlias("set", False),
+ "typing.FrozenSet": TypingAlias("frozenset", False),
+ "typing.Type": TypingAlias("type", False),
+ "typing.Deque": TypingAlias("collections.deque", True),
+ "typing.DefaultDict": TypingAlias("collections.defaultdict", True),
+ "typing.OrderedDict": TypingAlias("collections.OrderedDict", True),
+ "typing.Counter": TypingAlias("collections.Counter", True),
+ "typing.ChainMap": TypingAlias("collections.ChainMap", True),
+ "typing.Awaitable": TypingAlias("collections.abc.Awaitable", True),
+ "typing.Coroutine": TypingAlias("collections.abc.Coroutine", True),
+ "typing.AsyncIterable": TypingAlias("collections.abc.AsyncIterable", True),
+ "typing.AsyncIterator": TypingAlias("collections.abc.AsyncIterator", True),
+ "typing.AsyncGenerator": TypingAlias("collections.abc.AsyncGenerator", True),
+ "typing.Iterable": TypingAlias("collections.abc.Iterable", True),
+ "typing.Iterator": TypingAlias("collections.abc.Iterator", True),
+ "typing.Generator": TypingAlias("collections.abc.Generator", True),
+ "typing.Reversible": TypingAlias("collections.abc.Reversible", True),
+ "typing.Container": TypingAlias("collections.abc.Container", True),
+ "typing.Collection": TypingAlias("collections.abc.Collection", True),
+ "typing.Callable": TypingAlias("collections.abc.Callable", True),
+ "typing.AbstractSet": TypingAlias("collections.abc.Set", False),
+ "typing.MutableSet": TypingAlias("collections.abc.MutableSet", True),
+ "typing.Mapping": TypingAlias("collections.abc.Mapping", True),
+ "typing.MutableMapping": TypingAlias("collections.abc.MutableMapping", True),
+ "typing.Sequence": TypingAlias("collections.abc.Sequence", True),
+ "typing.MutableSequence": TypingAlias("collections.abc.MutableSequence", True),
+ "typing.ByteString": TypingAlias("collections.abc.ByteString", True),
+ "typing.MappingView": TypingAlias("collections.abc.MappingView", True),
+ "typing.KeysView": TypingAlias("collections.abc.KeysView", True),
+ "typing.ItemsView": TypingAlias("collections.abc.ItemsView", True),
+ "typing.ValuesView": TypingAlias("collections.abc.ValuesView", True),
+ "typing.ContextManager": TypingAlias("contextlib.AbstractContextManager", False),
+ "typing.AsyncContextManager": TypingAlias(
+ "contextlib.AbstractAsyncContextManager", False
+ ),
+ "typing.Pattern": TypingAlias("re.Pattern", True),
+ "typing.Match": TypingAlias("re.Match", True),
+ "typing.Hashable": TypingAlias("collections.abc.Hashable", True),
+ "typing.Sized": TypingAlias("collections.abc.Sized", True),
+}
+
+ALIAS_NAMES = frozenset(key.split(".")[1] for key in DEPRECATED_TYPING_ALIASES)
+UNION_NAMES = ("Optional", "Union")
+
+
+class DeprecatedTypingAliasMsg(NamedTuple):
+ node: nodes.Name | nodes.Attribute
+ qname: str
+ alias: str
+ parent_subscript: bool = False
+
+
+# pylint: disable-next=too-many-instance-attributes
+class TypingChecker(BaseChecker):
+ """Find issue specifically related to type annotations."""
+
+ name = "typing"
+ msgs = {
+ "W6001": (
+ "'%s' is deprecated, use '%s' instead",
+ "deprecated-typing-alias",
+ "Emitted when a deprecated typing alias is used.",
+ ),
+ "R6002": (
+ "'%s' will be deprecated with PY39, consider using '%s' instead%s",
+ "consider-using-alias",
+ "Only emitted if 'runtime-typing=no' and a deprecated "
+ "typing alias is used in a type annotation context in "
+ "Python 3.7 or 3.8.",
+ ),
+ "R6003": (
+ "Consider using alternative Union syntax instead of '%s'%s",
+ "consider-alternative-union-syntax",
+ "Emitted when 'typing.Union' or 'typing.Optional' is used "
+ "instead of the alternative Union syntax 'int | None'.",
+ ),
+ "E6004": (
+ "'NoReturn' inside compound types is broken in 3.7.0 / 3.7.1",
+ "broken-noreturn",
+ "``typing.NoReturn`` inside compound types is broken in "
+ "Python 3.7.0 and 3.7.1. If not dependent on runtime introspection, "
+ "use string annotation instead. E.g. "
+ "``Callable[..., 'NoReturn']``. https://bugs.python.org/issue34921",
+ ),
+ "E6005": (
+ "'collections.abc.Callable' inside Optional and Union is broken in "
+ "3.9.0 / 3.9.1 (use 'typing.Callable' instead)",
+ "broken-collections-callable",
+ "``collections.abc.Callable`` inside Optional and Union is broken in "
+ "Python 3.9.0 and 3.9.1. Use ``typing.Callable`` for these cases instead. "
+ "https://bugs.python.org/issue42965",
+ ),
+ "R6006": (
+ "Type `%s` is used more than once in union type annotation. Remove redundant typehints.",
+ "redundant-typehint-argument",
+ "Duplicated type arguments will be skipped by `mypy` tool, therefore should be "
+ "removed to avoid confusion.",
+ ),
+ "R6007": (
+ "Type `%s` has unnecessary default type args. Change it to `%s`.",
+ "unnecessary-default-type-args",
+ "Emitted when types have default type args which can be omitted. "
+ "Mainly used for `typing.Generator` and `typing.AsyncGenerator`.",
+ ),
+ }
+ options = (
+ (
+ "runtime-typing",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": (
+ "Set to ``no`` if the app / library does **NOT** need to "
+ "support runtime introspection of type annotations. "
+ "If you use type annotations **exclusively** for type checking "
+ "of an application, you're probably fine. For libraries, "
+ "evaluate if some users want to access the type hints "
+ "at runtime first, e.g., through ``typing.get_type_hints``. "
+ "Applies to Python versions 3.7 - 3.9"
+ ),
+ },
+ ),
+ )
+
+ _should_check_typing_alias: bool
+ """The use of type aliases (PEP 585) requires Python 3.9
+ or Python 3.7+ with postponed evaluation.
+ """
+
+ _should_check_alternative_union_syntax: bool
+ """The use of alternative union syntax (PEP 604) requires Python 3.10
+ or Python 3.7+ with postponed evaluation.
+ """
+
+ def __init__(self, linter: PyLinter) -> None:
+ """Initialize checker instance."""
+ super().__init__(linter=linter)
+ self._found_broken_callable_location: bool = False
+ self._alias_name_collisions: set[str] = set()
+ self._deprecated_typing_alias_msgs: list[DeprecatedTypingAliasMsg] = []
+ self._consider_using_alias_msgs: list[DeprecatedTypingAliasMsg] = []
+
+ def open(self) -> None:
+ py_version = self.linter.config.py_version
+ self._py37_plus = py_version >= (3, 7)
+ self._py39_plus = py_version >= (3, 9)
+ self._py310_plus = py_version >= (3, 10)
+ self._py313_plus = py_version >= (3, 13)
+
+ self._should_check_typing_alias = self._py39_plus or (
+ self._py37_plus and self.linter.config.runtime_typing is False
+ )
+ self._should_check_alternative_union_syntax = self._py310_plus or (
+ self._py37_plus and self.linter.config.runtime_typing is False
+ )
+
+ self._should_check_noreturn = py_version < (3, 7, 2)
+ self._should_check_callable = py_version < (3, 9, 2)
+
+ def _msg_postponed_eval_hint(self, node: nodes.NodeNG) -> str:
+ """Message hint if postponed evaluation isn't enabled."""
+ if self._py310_plus or "annotations" in node.root().future_imports:
+ return ""
+ return ". Add 'from __future__ import annotations' as well"
+
+ @only_required_for_messages(
+ "deprecated-typing-alias",
+ "consider-using-alias",
+ "consider-alternative-union-syntax",
+ "broken-noreturn",
+ "broken-collections-callable",
+ )
+ def visit_name(self, node: nodes.Name) -> None:
+ if self._should_check_typing_alias and node.name in ALIAS_NAMES:
+ self._check_for_typing_alias(node)
+ if self._should_check_alternative_union_syntax and node.name in UNION_NAMES:
+ self._check_for_alternative_union_syntax(node, node.name)
+ if self._should_check_noreturn and node.name == "NoReturn":
+ self._check_broken_noreturn(node)
+ if self._should_check_callable and node.name == "Callable":
+ self._check_broken_callable(node)
+
+ @only_required_for_messages(
+ "deprecated-typing-alias",
+ "consider-using-alias",
+ "consider-alternative-union-syntax",
+ "broken-noreturn",
+ "broken-collections-callable",
+ )
+ def visit_attribute(self, node: nodes.Attribute) -> None:
+ if self._should_check_typing_alias and node.attrname in ALIAS_NAMES:
+ self._check_for_typing_alias(node)
+ if self._should_check_alternative_union_syntax and node.attrname in UNION_NAMES:
+ self._check_for_alternative_union_syntax(node, node.attrname)
+ if self._should_check_noreturn and node.attrname == "NoReturn":
+ self._check_broken_noreturn(node)
+ if self._should_check_callable and node.attrname == "Callable":
+ self._check_broken_callable(node)
+
+ @only_required_for_messages("redundant-typehint-argument")
+ def visit_annassign(self, node: nodes.AnnAssign) -> None:
+ annotation = node.annotation
+ if self._is_deprecated_union_annotation(annotation, "Optional"):
+ if self._is_optional_none_annotation(annotation):
+ self.add_message(
+ "redundant-typehint-argument",
+ node=annotation,
+ args="None",
+ confidence=HIGH,
+ )
+ return
+ if self._is_deprecated_union_annotation(annotation, "Union") and isinstance(
+ annotation.slice, nodes.Tuple
+ ):
+ types = annotation.slice.elts
+ elif self._is_binop_union_annotation(annotation):
+ types = self._parse_binops_typehints(annotation)
+ else:
+ return
+
+ self._check_union_types(types, node)
+
+ @only_required_for_messages("unnecessary-default-type-args")
+ def visit_subscript(self, node: nodes.Subscript) -> None:
+ inferred = safe_infer(node.value)
+ if ( # pylint: disable=too-many-boolean-expressions
+ isinstance(inferred, nodes.ClassDef)
+ and (
+ inferred.qname() in {"typing.Generator", "typing.AsyncGenerator"}
+ and self._py313_plus
+ or inferred.qname()
+ in {"_collections_abc.Generator", "_collections_abc.AsyncGenerator"}
+ )
+ and isinstance(node.slice, nodes.Tuple)
+ and all(
+ (isinstance(el, nodes.Const) and el.value is None)
+ for el in node.slice.elts[1:]
+ )
+ ):
+ suggested_str = (
+ f"{node.value.as_string()}[{node.slice.elts[0].as_string()}]"
+ )
+ self.add_message(
+ "unnecessary-default-type-args",
+ args=(node.as_string(), suggested_str),
+ node=node,
+ confidence=HIGH,
+ )
+
+ @staticmethod
+ def _is_deprecated_union_annotation(
+ annotation: nodes.NodeNG, union_name: str
+ ) -> bool:
+ return (
+ isinstance(annotation, nodes.Subscript)
+ and isinstance(annotation.value, nodes.Name)
+ and annotation.value.name == union_name
+ )
+
+ def _is_binop_union_annotation(self, annotation: nodes.NodeNG) -> bool:
+ return self._should_check_alternative_union_syntax and isinstance(
+ annotation, nodes.BinOp
+ )
+
+ @staticmethod
+ def _is_optional_none_annotation(annotation: nodes.Subscript) -> bool:
+ return (
+ isinstance(annotation.slice, nodes.Const) and annotation.slice.value is None
+ )
+
+ def _parse_binops_typehints(
+ self, binop_node: nodes.BinOp, typehints_list: list[nodes.NodeNG] | None = None
+ ) -> list[nodes.NodeNG]:
+ typehints_list = typehints_list or []
+ if isinstance(binop_node.left, nodes.BinOp):
+ typehints_list.extend(
+ self._parse_binops_typehints(binop_node.left, typehints_list)
+ )
+ else:
+ typehints_list.append(binop_node.left)
+ typehints_list.append(binop_node.right)
+ return typehints_list
+
+ def _check_union_types(
+ self, types: list[nodes.NodeNG], annotation: nodes.NodeNG
+ ) -> None:
+ types_set = set()
+ for typehint in types:
+ typehint_str = typehint.as_string()
+ if typehint_str in types_set:
+ self.add_message(
+ "redundant-typehint-argument",
+ node=annotation,
+ args=(typehint_str),
+ confidence=HIGH,
+ )
+ else:
+ types_set.add(typehint_str)
+
+ def _check_for_alternative_union_syntax(
+ self,
+ node: nodes.Name | nodes.Attribute,
+ name: str,
+ ) -> None:
+ """Check if alternative union syntax could be used.
+
+ Requires
+ - Python 3.10
+ - OR: Python 3.7+ with postponed evaluation in
+ a type annotation context
+ """
+ inferred = safe_infer(node)
+ if not (
+ isinstance(inferred, nodes.FunctionDef)
+ and inferred.qname() in {"typing.Optional", "typing.Union"}
+ or isinstance(inferred, astroid.bases.Instance)
+ and inferred.qname() == "typing._SpecialForm"
+ ):
+ return
+ if not (self._py310_plus or is_node_in_type_annotation_context(node)):
+ return
+ self.add_message(
+ "consider-alternative-union-syntax",
+ node=node,
+ args=(name, self._msg_postponed_eval_hint(node)),
+ confidence=INFERENCE,
+ )
+
+ def _check_for_typing_alias(
+ self,
+ node: nodes.Name | nodes.Attribute,
+ ) -> None:
+ """Check if typing alias is deprecated or could be replaced.
+
+ Requires
+ - Python 3.9
+ - OR: Python 3.7+ with postponed evaluation in
+ a type annotation context
+
+ For Python 3.7+: Only emit message if change doesn't create
+ any name collisions, only ever used in a type annotation
+ context, and can safely be replaced.
+ """
+ inferred = safe_infer(node)
+ if not isinstance(inferred, nodes.ClassDef):
+ return
+ alias = DEPRECATED_TYPING_ALIASES.get(inferred.qname(), None)
+ if alias is None:
+ return
+
+ if self._py39_plus:
+ if inferred.qname() == "typing.Callable" and self._broken_callable_location(
+ node
+ ):
+ self._found_broken_callable_location = True
+ self._deprecated_typing_alias_msgs.append(
+ DeprecatedTypingAliasMsg(
+ node,
+ inferred.qname(),
+ alias.name,
+ )
+ )
+ return
+
+ # For PY37+, check for type annotation context first
+ if not is_node_in_type_annotation_context(node) and isinstance(
+ node.parent, nodes.Subscript
+ ):
+ if alias.name_collision is True:
+ self._alias_name_collisions.add(inferred.qname())
+ return
+ self._consider_using_alias_msgs.append(
+ DeprecatedTypingAliasMsg(
+ node,
+ inferred.qname(),
+ alias.name,
+ isinstance(node.parent, nodes.Subscript),
+ )
+ )
+
+ @only_required_for_messages("consider-using-alias", "deprecated-typing-alias")
+ def leave_module(self, node: nodes.Module) -> None:
+ """After parsing of module is complete, add messages for
+ 'consider-using-alias' check.
+
+ Make sure results are safe to recommend / collision free.
+ """
+ if self._py39_plus:
+ for msg in self._deprecated_typing_alias_msgs:
+ if (
+ self._found_broken_callable_location
+ and msg.qname == "typing.Callable"
+ ):
+ continue
+ self.add_message(
+ "deprecated-typing-alias",
+ node=msg.node,
+ args=(msg.qname, msg.alias),
+ confidence=INFERENCE,
+ )
+
+ elif self._py37_plus:
+ msg_future_import = self._msg_postponed_eval_hint(node)
+ for msg in self._consider_using_alias_msgs:
+ if msg.qname in self._alias_name_collisions:
+ continue
+ self.add_message(
+ "consider-using-alias",
+ node=msg.node,
+ args=(
+ msg.qname,
+ msg.alias,
+ msg_future_import if msg.parent_subscript else "",
+ ),
+ confidence=INFERENCE,
+ )
+
+ # Clear all module cache variables
+ self._found_broken_callable_location = False
+ self._deprecated_typing_alias_msgs.clear()
+ self._alias_name_collisions.clear()
+ self._consider_using_alias_msgs.clear()
+
+ def _check_broken_noreturn(self, node: nodes.Name | nodes.Attribute) -> None:
+ """Check for 'NoReturn' inside compound types."""
+ if not isinstance(node.parent, nodes.BaseContainer):
+ # NoReturn not part of a Union or Callable type
+ return
+
+ if (
+ in_type_checking_block(node)
+ or is_postponed_evaluation_enabled(node)
+ and is_node_in_type_annotation_context(node)
+ ):
+ return
+
+ for inferred in node.infer():
+ # To deal with typing_extensions, don't use safe_infer
+ if (
+ isinstance(inferred, (nodes.FunctionDef, nodes.ClassDef))
+ and inferred.qname() in TYPING_NORETURN
+ # In Python 3.7 - 3.8, NoReturn is alias of '_SpecialForm'
+ or isinstance(inferred, astroid.bases.BaseInstance)
+ and isinstance(inferred._proxied, nodes.ClassDef)
+ and inferred._proxied.qname() == "typing._SpecialForm"
+ ):
+ self.add_message("broken-noreturn", node=node, confidence=INFERENCE)
+ break
+
+ def _check_broken_callable(self, node: nodes.Name | nodes.Attribute) -> None:
+ """Check for 'collections.abc.Callable' inside Optional and Union."""
+ inferred = safe_infer(node)
+ if not (
+ isinstance(inferred, nodes.ClassDef)
+ and inferred.qname() == "_collections_abc.Callable"
+ and self._broken_callable_location(node)
+ ):
+ return
+
+ self.add_message("broken-collections-callable", node=node, confidence=INFERENCE)
+
+ def _broken_callable_location(self, node: nodes.Name | nodes.Attribute) -> bool:
+ """Check if node would be a broken location for collections.abc.Callable."""
+ if (
+ in_type_checking_block(node)
+ or is_postponed_evaluation_enabled(node)
+ and is_node_in_type_annotation_context(node)
+ ):
+ return False
+
+ # Check first Callable arg is a list of arguments -> Callable[[int], None]
+ if not (
+ isinstance(node.parent, nodes.Subscript)
+ and isinstance(node.parent.slice, nodes.Tuple)
+ and len(node.parent.slice.elts) == 2
+ and isinstance(node.parent.slice.elts[0], nodes.List)
+ ):
+ return False
+
+ # Check nested inside Optional or Union
+ parent_subscript = node.parent.parent
+ if isinstance(parent_subscript, nodes.BaseContainer):
+ parent_subscript = parent_subscript.parent
+ if not (
+ isinstance(parent_subscript, nodes.Subscript)
+ and isinstance(parent_subscript.value, (nodes.Name, nodes.Attribute))
+ ):
+ return False
+
+ inferred_parent = safe_infer(parent_subscript.value)
+ if not (
+ isinstance(inferred_parent, nodes.FunctionDef)
+ and inferred_parent.qname() in {"typing.Optional", "typing.Union"}
+ or isinstance(inferred_parent, astroid.bases.Instance)
+ and inferred_parent.qname() == "typing._SpecialForm"
+ ):
+ return False
+
+ return True
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(TypingChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/extensions/while_used.py b/solutions/.venv/Lib/site-packages/pylint/extensions/while_used.py
new file mode 100644
index 000000000..da1f9d59c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/extensions/while_used.py
@@ -0,0 +1,37 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Check for use of while loops."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.checkers import BaseChecker
+from pylint.checkers.utils import only_required_for_messages
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+
+class WhileChecker(BaseChecker):
+ name = "while_used"
+ msgs = {
+ "W0149": (
+ "Used `while` loop",
+ "while-used",
+ "Unbounded `while` loops can often be rewritten as bounded `for` loops. "
+ "Exceptions can be made for cases such as event loops, listeners, etc.",
+ )
+ }
+
+ @only_required_for_messages("while-used")
+ def visit_while(self, node: nodes.While) -> None:
+ self.add_message("while-used", node=node)
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_checker(WhileChecker(linter))
diff --git a/solutions/.venv/Lib/site-packages/pylint/graph.py b/solutions/.venv/Lib/site-packages/pylint/graph.py
new file mode 100644
index 000000000..4112fadfa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/graph.py
@@ -0,0 +1,212 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Graph manipulation utilities.
+
+(dot generation adapted from pypy/translator/tool/make_dot.py)
+"""
+
+from __future__ import annotations
+
+import codecs
+import os
+import shutil
+import subprocess
+import tempfile
+from collections.abc import Sequence
+from typing import Any
+
+
+def target_info_from_filename(filename: str) -> tuple[str, str, str]:
+ """Transforms /some/path/foo.png into ('/some/path', 'foo.png', 'png')."""
+ basename = os.path.basename(filename)
+ storedir = os.path.dirname(os.path.abspath(filename))
+ target = os.path.splitext(filename)[-1][1:]
+ return storedir, basename, target
+
+
+class DotBackend:
+ """Dot File back-end."""
+
+ def __init__(
+ self,
+ graphname: str,
+ rankdir: str | None = None,
+ size: Any = None,
+ ratio: Any = None,
+ charset: str = "utf-8",
+ renderer: str = "dot",
+ additional_param: dict[str, Any] | None = None,
+ ) -> None:
+ if additional_param is None:
+ additional_param = {}
+ self.graphname = graphname
+ self.renderer = renderer
+ self.lines: list[str] = []
+ self._source: str | None = None
+ self.emit(f"digraph {normalize_node_id(graphname)} {{")
+ if rankdir:
+ self.emit(f"rankdir={rankdir}")
+ if ratio:
+ self.emit(f"ratio={ratio}")
+ if size:
+ self.emit(f'size="{size}"')
+ if charset:
+ assert charset.lower() in {
+ "utf-8",
+ "iso-8859-1",
+ "latin1",
+ }, f"unsupported charset {charset}"
+ self.emit(f'charset="{charset}"')
+ for param in additional_param.items():
+ self.emit("=".join(param))
+
+ def get_source(self) -> str:
+ """Returns self._source."""
+ if self._source is None:
+ self.emit("}\n")
+ self._source = "\n".join(self.lines)
+ del self.lines
+ return self._source
+
+ source = property(get_source)
+
+ def generate(
+ self, outputfile: str | None = None, mapfile: str | None = None
+ ) -> str:
+ """Generates a graph file.
+
+ :param str outputfile: filename and path [defaults to graphname.png]
+ :param str mapfile: filename and path
+
+ :rtype: str
+ :return: a path to the generated file
+ :raises RuntimeError: if the executable for rendering was not found
+ """
+ # pylint: disable=duplicate-code
+ graphviz_extensions = ("dot", "gv")
+ name = self.graphname
+ if outputfile is None:
+ target = "png"
+ pdot, dot_sourcepath = tempfile.mkstemp(".gv", name)
+ ppng, outputfile = tempfile.mkstemp(".png", name)
+ os.close(pdot)
+ os.close(ppng)
+ else:
+ _, _, target = target_info_from_filename(outputfile)
+ if not target:
+ target = "png"
+ outputfile = outputfile + "." + target
+ if target not in graphviz_extensions:
+ pdot, dot_sourcepath = tempfile.mkstemp(".gv", name)
+ os.close(pdot)
+ else:
+ dot_sourcepath = outputfile
+ with codecs.open(dot_sourcepath, "w", encoding="utf8") as file:
+ file.write(self.source)
+ if target not in graphviz_extensions:
+ if shutil.which(self.renderer) is None:
+ raise RuntimeError(
+ f"Cannot generate `{outputfile}` because '{self.renderer}' "
+ "executable not found. Install graphviz, or specify a `.gv` "
+ "outputfile to produce the DOT source code."
+ )
+ if mapfile:
+ subprocess.run(
+ [
+ self.renderer,
+ "-Tcmapx",
+ "-o",
+ mapfile,
+ "-T",
+ target,
+ dot_sourcepath,
+ "-o",
+ outputfile,
+ ],
+ check=True,
+ )
+ else:
+ subprocess.run(
+ [self.renderer, "-T", target, dot_sourcepath, "-o", outputfile],
+ check=True,
+ )
+ os.unlink(dot_sourcepath)
+ return outputfile
+
+ def emit(self, line: str) -> None:
+ """Adds <line> to final output."""
+ self.lines.append(line)
+
+ def emit_edge(self, name1: str, name2: str, **props: Any) -> None:
+ """Emit an edge from <name1> to <name2>.
+
+ For edge properties: see https://www.graphviz.org/doc/info/attrs.html
+ """
+ attrs = [f'{prop}="{value}"' for prop, value in props.items()]
+ n_from, n_to = normalize_node_id(name1), normalize_node_id(name2)
+ self.emit(f"{n_from} -> {n_to} [{', '.join(sorted(attrs))}];")
+
+ def emit_node(self, name: str, **props: Any) -> None:
+ """Emit a node with given properties.
+
+ For node properties: see https://www.graphviz.org/doc/info/attrs.html
+ """
+ attrs = [f'{prop}="{value}"' for prop, value in props.items()]
+ self.emit(f"{normalize_node_id(name)} [{', '.join(sorted(attrs))}];")
+
+
+def normalize_node_id(nid: str) -> str:
+ """Returns a suitable DOT node id for `nid`."""
+ return f'"{nid}"'
+
+
+def get_cycles(
+ graph_dict: dict[str, set[str]], vertices: list[str] | None = None
+) -> Sequence[list[str]]:
+ """Return a list of detected cycles based on an ordered graph (i.e. keys are
+ vertices and values are lists of destination vertices representing edges).
+ """
+ if not graph_dict:
+ return ()
+ result: list[list[str]] = []
+ if vertices is None:
+ vertices = list(graph_dict.keys())
+ for vertice in vertices:
+ _get_cycles(graph_dict, [], set(), result, vertice)
+ return result
+
+
+def _get_cycles(
+ graph_dict: dict[str, set[str]],
+ path: list[str],
+ visited: set[str],
+ result: list[list[str]],
+ vertice: str,
+) -> None:
+ """Recursive function doing the real work for get_cycles."""
+ if vertice in path:
+ cycle = [vertice]
+ for node in path[::-1]:
+ if node == vertice:
+ break
+ cycle.insert(0, node)
+ # make a canonical representation
+ start_from = min(cycle)
+ index = cycle.index(start_from)
+ cycle = cycle[index:] + cycle[0:index]
+ # append it to result if not already in
+ if cycle not in result:
+ result.append(cycle)
+ return
+ path.append(vertice)
+ try:
+ for node in graph_dict[vertice]:
+ # don't check already visited nodes again
+ if node not in visited:
+ _get_cycles(graph_dict, path, visited, result, node)
+ visited.add(node)
+ except KeyError:
+ pass
+ path.pop()
diff --git a/solutions/.venv/Lib/site-packages/pylint/interfaces.py b/solutions/.venv/Lib/site-packages/pylint/interfaces.py
new file mode 100644
index 000000000..c47e297b4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/interfaces.py
@@ -0,0 +1,38 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import NamedTuple
+
+__all__ = (
+ "HIGH",
+ "CONTROL_FLOW",
+ "INFERENCE",
+ "INFERENCE_FAILURE",
+ "UNDEFINED",
+ "CONFIDENCE_LEVELS",
+ "CONFIDENCE_LEVEL_NAMES",
+)
+
+
+class Confidence(NamedTuple):
+ name: str
+ description: str
+
+
+# Warning Certainties
+HIGH = Confidence("HIGH", "Warning that is not based on inference result.")
+CONTROL_FLOW = Confidence(
+ "CONTROL_FLOW", "Warning based on assumptions about control flow."
+)
+INFERENCE = Confidence("INFERENCE", "Warning based on inference result.")
+INFERENCE_FAILURE = Confidence(
+ "INFERENCE_FAILURE", "Warning based on inference with failures."
+)
+UNDEFINED = Confidence("UNDEFINED", "Warning without any associated confidence level.")
+
+CONFIDENCE_LEVELS = [HIGH, CONTROL_FLOW, INFERENCE, INFERENCE_FAILURE, UNDEFINED]
+CONFIDENCE_LEVEL_NAMES = [i.name for i in CONFIDENCE_LEVELS]
+CONFIDENCE_MAP = {i.name: i for i in CONFIDENCE_LEVELS}
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/__init__.py b/solutions/.venv/Lib/site-packages/pylint/lint/__init__.py
new file mode 100644
index 000000000..1c0c6d9f5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/__init__.py
@@ -0,0 +1,48 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Pylint [options] modules_or_packages.
+
+Check that module(s) satisfy a coding standard (and more !).
+
+pylint --help
+
+Display this help message and exit.
+
+pylint --help-msg <msg-id>[,<msg-id>]
+
+Display help messages about given message identifiers and exit.
+"""
+import sys
+
+from pylint.config.exceptions import ArgumentPreprocessingError
+from pylint.lint.caching import load_results, save_results
+from pylint.lint.expand_modules import discover_package_path
+from pylint.lint.parallel import check_parallel
+from pylint.lint.pylinter import PyLinter
+from pylint.lint.report_functions import (
+ report_messages_by_module_stats,
+ report_messages_stats,
+ report_total_messages_stats,
+)
+from pylint.lint.run import Run
+from pylint.lint.utils import _augment_sys_path, augmented_sys_path
+
+__all__ = [
+ "check_parallel",
+ "PyLinter",
+ "report_messages_by_module_stats",
+ "report_messages_stats",
+ "report_total_messages_stats",
+ "Run",
+ "ArgumentPreprocessingError",
+ "_augment_sys_path",
+ "augmented_sys_path",
+ "discover_package_path",
+ "save_results",
+ "load_results",
+]
+
+if __name__ == "__main__":
+ Run(sys.argv[1:])
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/base_options.py b/solutions/.venv/Lib/site-packages/pylint/lint/base_options.py
new file mode 100644
index 000000000..59a811d9c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/base_options.py
@@ -0,0 +1,608 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Functions that creates the basic options for the Run and PyLinter classes."""
+
+from __future__ import annotations
+
+import re
+import sys
+from typing import TYPE_CHECKING
+
+from pylint import constants, interfaces
+from pylint.config.callback_actions import (
+ _DisableAction,
+ _DoNothingAction,
+ _EnableAction,
+ _ErrorsOnlyModeAction,
+ _FullDocumentationAction,
+ _GenerateConfigFileAction,
+ _GenerateRCFileAction,
+ _ListCheckGroupsAction,
+ _ListConfidenceLevelsAction,
+ _ListExtensionsAction,
+ _ListMessagesAction,
+ _ListMessagesEnabledAction,
+ _LongHelpAction,
+ _MessageHelpAction,
+ _OutputFormatAction,
+)
+from pylint.typing import Options
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter, Run
+
+
+def _make_linter_options(linter: PyLinter) -> Options:
+ """Return the options used in a PyLinter class."""
+ return (
+ (
+ "ignore",
+ {
+ "type": "csv",
+ "metavar": "<file>[,<file>...]",
+ "dest": "black_list",
+ "kwargs": {"old_names": ["black_list"]},
+ "default": constants.DEFAULT_IGNORE_LIST,
+ "help": "Files or directories to be skipped. "
+ "They should be base names, not paths.",
+ },
+ ),
+ (
+ "ignore-patterns",
+ {
+ "type": "regexp_csv",
+ "metavar": "<pattern>[,<pattern>...]",
+ "dest": "black_list_re",
+ "default": (re.compile(r"^\.#"),),
+ "help": "Files or directories matching the regular expression patterns are"
+ " skipped. The regex matches against base names, not paths. The default value "
+ "ignores Emacs file locks",
+ },
+ ),
+ (
+ "ignore-paths",
+ {
+ "type": "regexp_paths_csv",
+ "metavar": "<pattern>[,<pattern>...]",
+ "default": [],
+ "help": "Add files or directories matching the regular expressions patterns to the "
+ "ignore-list. The regex matches against paths and can be in "
+ "Posix or Windows format. Because '\\\\' represents the directory delimiter "
+ "on Windows systems, it can't be used as an escape character.",
+ },
+ ),
+ (
+ "persistent",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Pickle collected data for later comparisons.",
+ },
+ ),
+ (
+ "load-plugins",
+ {
+ "type": "csv",
+ "metavar": "<modules>",
+ "default": (),
+ "help": "List of plugins (as comma separated values of "
+ "python module names) to load, usually to register "
+ "additional checkers.",
+ },
+ ),
+ (
+ "output-format",
+ {
+ "default": "text",
+ "action": _OutputFormatAction,
+ "callback": lambda x: x,
+ "metavar": "<format>",
+ "short": "f",
+ "group": "Reports",
+ "help": "Set the output format. Available formats are: text, "
+ "parseable, colorized, json2 (improved json format), json "
+ "(old json format) and msvs (visual studio). "
+ "You can also give a reporter class, e.g. mypackage.mymodule."
+ "MyReporterClass.",
+ "kwargs": {"linter": linter},
+ },
+ ),
+ (
+ "reports",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "short": "r",
+ "group": "Reports",
+ "help": "Tells whether to display a full report or only the "
+ "messages.",
+ },
+ ),
+ (
+ "evaluation",
+ {
+ "type": "string",
+ "metavar": "<python_expression>",
+ "group": "Reports",
+ "default": "max(0, 0 if fatal else 10.0 - ((float(5 * error + warning + refactor + "
+ "convention) / statement) * 10))",
+ "help": "Python expression which should return a score less "
+ "than or equal to 10. You have access to the variables 'fatal', "
+ "'error', 'warning', 'refactor', 'convention', and 'info' which "
+ "contain the number of messages in each category, as well as "
+ "'statement' which is the total number of statements "
+ "analyzed. This score is used by the global "
+ "evaluation report (RP0004).",
+ },
+ ),
+ (
+ "score",
+ {
+ "default": True,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "short": "s",
+ "group": "Reports",
+ "help": "Activate the evaluation score.",
+ },
+ ),
+ (
+ "fail-under",
+ {
+ "default": 10,
+ "type": "float",
+ "metavar": "<score>",
+ "help": "Specify a score threshold under which the program will exit with error.",
+ },
+ ),
+ (
+ "fail-on",
+ {
+ "default": "",
+ "type": "csv",
+ "metavar": "<msg ids>",
+ "help": "Return non-zero exit code if any of these messages/categories are detected,"
+ " even if score is above --fail-under value. Syntax same as enable."
+ " Messages specified are enabled, while categories only check already-enabled messages.",
+ },
+ ),
+ (
+ "confidence",
+ {
+ "type": "confidence",
+ "metavar": "<levels>",
+ "default": interfaces.CONFIDENCE_LEVEL_NAMES,
+ "group": "Messages control",
+ "help": "Only show warnings with the listed confidence levels."
+ f" Leave empty to show all. Valid levels: {', '.join(interfaces.CONFIDENCE_LEVEL_NAMES)}.",
+ },
+ ),
+ (
+ "enable",
+ {
+ "action": _EnableAction,
+ "callback": lambda x1, x2, x3, x4: x1,
+ "default": (),
+ "metavar": "<msg ids>",
+ "short": "e",
+ "group": "Messages control",
+ "help": "Enable the message, report, category or checker with the "
+ "given id(s). You can either give multiple identifier "
+ "separated by comma (,) or put this option multiple time "
+ "(only on the command line, not in the configuration file "
+ "where it should appear only once). "
+ 'See also the "--disable" option for examples.',
+ "kwargs": {"linter": linter},
+ },
+ ),
+ (
+ "disable",
+ {
+ "action": _DisableAction,
+ "callback": lambda x1, x2, x3, x4: x1,
+ "metavar": "<msg ids>",
+ "default": (),
+ "short": "d",
+ "group": "Messages control",
+ "help": "Disable the message, report, category or checker "
+ "with the given id(s). You can either give multiple identifiers "
+ "separated by comma (,) or put this option multiple times "
+ "(only on the command line, not in the configuration file "
+ "where it should appear only once). "
+ 'You can also use "--disable=all" to disable everything first '
+ "and then re-enable specific checks. For example, if you want "
+ "to run only the similarities checker, you can use "
+ '"--disable=all --enable=similarities". '
+ "If you want to run only the classes checker, but have no "
+ "Warning level messages displayed, use "
+ '"--disable=all --enable=classes --disable=W".',
+ "kwargs": {"linter": linter},
+ },
+ ),
+ (
+ "msg-template",
+ {
+ "type": "string",
+ "default": "",
+ "metavar": "<template>",
+ "group": "Reports",
+ "help": (
+ "Template used to display messages. "
+ "This is a python new-style format string "
+ "used to format the message information. "
+ "See doc for all details."
+ ),
+ },
+ ),
+ (
+ "jobs",
+ {
+ "type": "int",
+ "metavar": "<n-processes>",
+ "short": "j",
+ "default": 1,
+ "help": "Use multiple processes to speed up Pylint. Specifying 0 will "
+ "auto-detect the number of processors available to use, and will cap "
+ "the count on Windows to avoid hangs.",
+ },
+ ),
+ (
+ "unsafe-load-any-extension",
+ {
+ "type": "yn",
+ "metavar": "<y or n>",
+ "default": False,
+ "hide": True,
+ "help": (
+ "Allow loading of arbitrary C extensions. Extensions"
+ " are imported into the active Python interpreter and"
+ " may run arbitrary code."
+ ),
+ },
+ ),
+ (
+ "limit-inference-results",
+ {
+ "type": "int",
+ "metavar": "<number-of-results>",
+ "default": 100,
+ "help": (
+ "Control the amount of potential inferred values when inferring "
+ "a single object. This can help the performance when dealing with "
+ "large functions or complex, nested conditions."
+ ),
+ },
+ ),
+ (
+ "extension-pkg-allow-list",
+ {
+ "type": "csv",
+ "metavar": "<pkg[,pkg]>",
+ "default": [],
+ "help": (
+ "A comma-separated list of package or module names"
+ " from where C extensions may be loaded. Extensions are"
+ " loading into the active Python interpreter and may run"
+ " arbitrary code."
+ ),
+ },
+ ),
+ (
+ "extension-pkg-whitelist",
+ {
+ "type": "csv",
+ "metavar": "<pkg[,pkg]>",
+ "default": [],
+ "help": (
+ "A comma-separated list of package or module names"
+ " from where C extensions may be loaded. Extensions are"
+ " loading into the active Python interpreter and may run"
+ " arbitrary code. (This is an alternative name to"
+ " extension-pkg-allow-list for backward compatibility.)"
+ ),
+ },
+ ),
+ (
+ "suggestion-mode",
+ {
+ "type": "yn",
+ "metavar": "<y or n>",
+ "default": True,
+ "help": (
+ "When enabled, pylint would attempt to guess common "
+ "misconfiguration and emit user-friendly hints instead "
+ "of false-positive error messages."
+ ),
+ },
+ ),
+ (
+ "exit-zero",
+ {
+ "action": "store_true",
+ "default": False,
+ "metavar": "<flag>",
+ "help": (
+ "Always return a 0 (non-error) status code, even if "
+ "lint errors are found. This is primarily useful in "
+ "continuous integration scripts."
+ ),
+ },
+ ),
+ (
+ "from-stdin",
+ {
+ "action": "store_true",
+ "default": False,
+ "metavar": "<flag>",
+ "help": (
+ "Interpret the stdin as a python script, whose filename "
+ "needs to be passed as the module_or_package argument."
+ ),
+ },
+ ),
+ (
+ "source-roots",
+ {
+ "type": "glob_paths_csv",
+ "metavar": "<path>[,<path>...]",
+ "default": (),
+ "help": "Add paths to the list of the source roots. Supports globbing patterns. "
+ "The source root is an absolute path or a path relative to the current working "
+ "directory used to determine a package namespace for modules located under the "
+ "source root.",
+ },
+ ),
+ (
+ "recursive",
+ {
+ "type": "yn",
+ "metavar": "<yn>",
+ "default": False,
+ "help": "Discover python modules and packages in the file system subtree.",
+ },
+ ),
+ (
+ "py-version",
+ {
+ "default": sys.version_info[:2],
+ "type": "py_version",
+ "metavar": "<py_version>",
+ "help": (
+ "Minimum Python version to use for version dependent checks. "
+ "Will default to the version used to run pylint."
+ ),
+ },
+ ),
+ (
+ "ignored-modules",
+ {
+ "default": (),
+ "type": "csv",
+ "metavar": "<module names>",
+ "help": "List of module names for which member attributes "
+ "should not be checked and will not be imported "
+ "(useful for modules/projects "
+ "where namespaces are manipulated during runtime and "
+ "thus existing member attributes cannot be "
+ "deduced by static analysis). It supports qualified "
+ "module names, as well as Unix pattern matching.",
+ },
+ ),
+ (
+ "analyse-fallback-blocks",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Analyse import fallback blocks. This can be used to "
+ "support both Python 2 and 3 compatible code, which "
+ "means that the block might have code that exists "
+ "only in one or another interpreter, leading to false "
+ "positives when analysed.",
+ },
+ ),
+ (
+ "clear-cache-post-run",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Clear in-memory caches upon conclusion of linting. "
+ "Useful if running pylint in a server-like mode.",
+ },
+ ),
+ (
+ "prefer-stubs",
+ {
+ "default": False,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "Resolve imports to .pyi stubs if available. May "
+ "reduce no-member messages and increase not-an-iterable "
+ "messages.",
+ },
+ ),
+ )
+
+
+def _make_run_options(self: Run) -> Options:
+ """Return the options used in a Run class."""
+ return (
+ (
+ "rcfile",
+ {
+ "action": _DoNothingAction,
+ "kwargs": {},
+ "group": "Commands",
+ "help": "Specify a configuration file to load.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "output",
+ {
+ "action": _DoNothingAction,
+ "kwargs": {},
+ "group": "Commands",
+ "help": "Specify an output file.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "init-hook",
+ {
+ "action": _DoNothingAction,
+ "kwargs": {},
+ "help": "Python code to execute, usually for sys.path "
+ "manipulation such as pygtk.require().",
+ },
+ ),
+ (
+ "help-msg",
+ {
+ "action": _MessageHelpAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "Display a help message for the given message id and "
+ "exit. The value may be a comma separated list of message ids.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "list-msgs",
+ {
+ "action": _ListMessagesAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "Display a list of all pylint's messages divided by whether "
+ "they are emittable with the given interpreter.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "list-msgs-enabled",
+ {
+ "action": _ListMessagesEnabledAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "Display a list of what messages are enabled, "
+ "disabled and non-emittable with the given configuration.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "list-groups",
+ {
+ "action": _ListCheckGroupsAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "List pylint's message groups.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "list-conf-levels",
+ {
+ "action": _ListConfidenceLevelsAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "Generate pylint's confidence levels.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "list-extensions",
+ {
+ "action": _ListExtensionsAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "List available extensions.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "full-documentation",
+ {
+ "action": _FullDocumentationAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "Generate pylint's full documentation.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "generate-rcfile",
+ {
+ "action": _GenerateRCFileAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "Generate a sample configuration file according to "
+ "the current configuration. You can put other options "
+ "before this one to get them in the generated "
+ "configuration.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "generate-toml-config",
+ {
+ "action": _GenerateConfigFileAction,
+ "kwargs": {"Run": self},
+ "group": "Commands",
+ "help": "Generate a sample configuration file according to "
+ "the current configuration. You can put other options "
+ "before this one to get them in the generated "
+ "configuration. The config is in the .toml format.",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "errors-only",
+ {
+ "action": _ErrorsOnlyModeAction,
+ "kwargs": {"Run": self},
+ "short": "E",
+ "help": "In error mode, messages with a category besides "
+ "ERROR or FATAL are suppressed, and no reports are done by default. "
+ "Error mode is compatible with disabling specific errors. ",
+ "hide_from_config_file": True,
+ },
+ ),
+ (
+ "verbose",
+ {
+ "action": _DoNothingAction,
+ "kwargs": {},
+ "short": "v",
+ "help": "In verbose mode, extra non-checker-related info "
+ "will be displayed.",
+ "hide_from_config_file": True,
+ "metavar": "",
+ },
+ ),
+ (
+ "enable-all-extensions",
+ {
+ "action": _DoNothingAction,
+ "kwargs": {},
+ "help": "Load and enable all available extensions. "
+ "Use --list-extensions to see a list all available extensions.",
+ "hide_from_config_file": True,
+ "metavar": "",
+ },
+ ),
+ (
+ "long-help",
+ {
+ "action": _LongHelpAction,
+ "kwargs": {"Run": self},
+ "help": "Show more verbose help.",
+ "group": "Commands",
+ "hide_from_config_file": True,
+ },
+ ),
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/caching.py b/solutions/.venv/Lib/site-packages/pylint/lint/caching.py
new file mode 100644
index 000000000..97c4503d1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/caching.py
@@ -0,0 +1,71 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import pickle
+import sys
+import warnings
+from pathlib import Path
+
+from pylint.constants import PYLINT_HOME
+from pylint.utils import LinterStats
+
+PYLINT_HOME_AS_PATH = Path(PYLINT_HOME)
+
+
+def _get_pdata_path(
+ base_name: Path, recurs: int, pylint_home: Path = PYLINT_HOME_AS_PATH
+) -> Path:
+ # We strip all characters that can't be used in a filename. Also strip '/' and
+ # '\\' because we want to create a single file, not sub-directories.
+ underscored_name = "_".join(
+ str(p.replace(":", "_").replace("/", "_").replace("\\", "_"))
+ for p in base_name.parts
+ )
+ return pylint_home / f"{underscored_name}_{recurs}.stats"
+
+
+def load_results(
+ base: str | Path, pylint_home: str | Path = PYLINT_HOME
+) -> LinterStats | None:
+ base = Path(base)
+ pylint_home = Path(pylint_home)
+ data_file = _get_pdata_path(base, 1, pylint_home)
+
+ if not data_file.exists():
+ return None
+
+ try:
+ with open(data_file, "rb") as stream:
+ data = pickle.load(stream)
+ if not isinstance(data, LinterStats):
+ warnings.warn(
+ "You're using an old pylint cache with invalid data following "
+ f"an upgrade, please delete '{data_file}'.",
+ UserWarning,
+ stacklevel=2,
+ )
+ raise TypeError
+ return data
+ except Exception: # pylint: disable=broad-except
+ # There's an issue with the cache but we just continue as if it isn't there
+ return None
+
+
+def save_results(
+ results: LinterStats, base: str | Path, pylint_home: str | Path = PYLINT_HOME
+) -> None:
+ base = Path(base)
+ pylint_home = Path(pylint_home)
+ try:
+ pylint_home.mkdir(parents=True, exist_ok=True)
+ except OSError: # pragma: no cover
+ print(f"Unable to create directory {pylint_home}", file=sys.stderr)
+ data_file = _get_pdata_path(base, 1)
+ try:
+ with open(data_file, "wb") as stream:
+ pickle.dump(results, stream)
+ except OSError as ex: # pragma: no cover
+ print(f"Unable to create file {data_file}: {ex}", file=sys.stderr)
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/expand_modules.py b/solutions/.venv/Lib/site-packages/pylint/lint/expand_modules.py
new file mode 100644
index 000000000..a7d31dea6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/expand_modules.py
@@ -0,0 +1,171 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import os
+import sys
+from collections.abc import Sequence
+from pathlib import Path
+from re import Pattern
+
+from astroid import modutils
+
+from pylint.typing import ErrorDescriptionDict, ModuleDescriptionDict
+
+
+def _modpath_from_file(filename: str, is_namespace: bool, path: list[str]) -> list[str]:
+ def _is_package_cb(inner_path: str, parts: list[str]) -> bool:
+ return modutils.check_modpath_has_init(inner_path, parts) or is_namespace
+
+ return modutils.modpath_from_file_with_callback( # type: ignore[no-any-return]
+ filename, path=path, is_package_cb=_is_package_cb
+ )
+
+
+def discover_package_path(modulepath: str, source_roots: Sequence[str]) -> str:
+ """Discover package path from one its modules and source roots."""
+ dirname = os.path.realpath(os.path.expanduser(modulepath))
+ if not os.path.isdir(dirname):
+ dirname = os.path.dirname(dirname)
+
+ # Look for a source root that contains the module directory
+ for source_root in source_roots:
+ source_root = os.path.realpath(os.path.expanduser(source_root))
+ if os.path.commonpath([source_root, dirname]) in [dirname, source_root]:
+ return source_root
+
+ # Fall back to legacy discovery by looking for __init__.py upwards as
+ # it's the only way given that source root was not found or was not provided
+ while True:
+ if not os.path.exists(os.path.join(dirname, "__init__.py")):
+ return dirname
+ old_dirname = dirname
+ dirname = os.path.dirname(dirname)
+ if old_dirname == dirname:
+ return os.getcwd()
+
+
+def _is_in_ignore_list_re(element: str, ignore_list_re: list[Pattern[str]]) -> bool:
+ """Determines if the element is matched in a regex ignore-list."""
+ return any(file_pattern.match(element) for file_pattern in ignore_list_re)
+
+
+def _is_ignored_file(
+ element: str,
+ ignore_list: list[str],
+ ignore_list_re: list[Pattern[str]],
+ ignore_list_paths_re: list[Pattern[str]],
+) -> bool:
+ element = os.path.normpath(element)
+ basename = Path(element).absolute().name
+ return (
+ basename in ignore_list
+ or _is_in_ignore_list_re(basename, ignore_list_re)
+ or _is_in_ignore_list_re(element, ignore_list_paths_re)
+ )
+
+
+# pylint: disable = too-many-locals, too-many-statements
+def expand_modules(
+ files_or_modules: Sequence[str],
+ source_roots: Sequence[str],
+ ignore_list: list[str],
+ ignore_list_re: list[Pattern[str]],
+ ignore_list_paths_re: list[Pattern[str]],
+) -> tuple[dict[str, ModuleDescriptionDict], list[ErrorDescriptionDict]]:
+ """Take a list of files/modules/packages and return the list of tuple
+ (file, module name) which have to be actually checked.
+ """
+ result: dict[str, ModuleDescriptionDict] = {}
+ errors: list[ErrorDescriptionDict] = []
+ path = sys.path.copy()
+
+ for something in files_or_modules:
+ basename = os.path.basename(something)
+ if _is_ignored_file(
+ something, ignore_list, ignore_list_re, ignore_list_paths_re
+ ):
+ continue
+ module_package_path = discover_package_path(something, source_roots)
+ additional_search_path = [".", module_package_path, *path]
+ if os.path.exists(something):
+ # this is a file or a directory
+ try:
+ modname = ".".join(
+ modutils.modpath_from_file(something, path=additional_search_path)
+ )
+ except ImportError:
+ modname = os.path.splitext(basename)[0]
+ if os.path.isdir(something):
+ filepath = os.path.join(something, "__init__.py")
+ else:
+ filepath = something
+ else:
+ # suppose it's a module or package
+ modname = something
+ try:
+ filepath = modutils.file_from_modpath(
+ modname.split("."), path=additional_search_path
+ )
+ if filepath is None:
+ continue
+ except ImportError as ex:
+ errors.append({"key": "fatal", "mod": modname, "ex": ex})
+ continue
+ filepath = os.path.normpath(filepath)
+ modparts = (modname or something).split(".")
+ try:
+ spec = modutils.file_info_from_modpath(
+ modparts, path=additional_search_path
+ )
+ except ImportError:
+ # Might not be acceptable, don't crash.
+ is_namespace = not os.path.exists(filepath)
+ is_directory = os.path.isdir(something)
+ else:
+ is_namespace = modutils.is_namespace(spec)
+ is_directory = modutils.is_directory(spec)
+ if not is_namespace:
+ if filepath in result:
+ # Always set arg flag if module explicitly given.
+ result[filepath]["isarg"] = True
+ else:
+ result[filepath] = {
+ "path": filepath,
+ "name": modname,
+ "isarg": True,
+ "basepath": filepath,
+ "basename": modname,
+ }
+ has_init = (
+ not (modname.endswith(".__init__") or modname == "__init__")
+ and os.path.basename(filepath) == "__init__.py"
+ )
+ if has_init or is_namespace or is_directory:
+ for subfilepath in modutils.get_module_files(
+ os.path.dirname(filepath) or ".", ignore_list, list_all=is_namespace
+ ):
+ subfilepath = os.path.normpath(subfilepath)
+ if filepath == subfilepath:
+ continue
+ if _is_in_ignore_list_re(
+ os.path.basename(subfilepath), ignore_list_re
+ ) or _is_in_ignore_list_re(subfilepath, ignore_list_paths_re):
+ continue
+
+ modpath = _modpath_from_file(
+ subfilepath, is_namespace, path=additional_search_path
+ )
+ submodname = ".".join(modpath)
+ # Preserve arg flag if module is also explicitly given.
+ isarg = subfilepath in result and result[subfilepath]["isarg"]
+ result[subfilepath] = {
+ "path": subfilepath,
+ "name": submodname,
+ "isarg": isarg,
+ "basepath": filepath,
+ "basename": modname,
+ }
+ return result, errors
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/message_state_handler.py b/solutions/.venv/Lib/site-packages/pylint/lint/message_state_handler.py
new file mode 100644
index 000000000..5c4498af9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/message_state_handler.py
@@ -0,0 +1,444 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import tokenize
+from collections import defaultdict
+from typing import TYPE_CHECKING, Literal
+
+from pylint import exceptions, interfaces
+from pylint.constants import (
+ MSG_STATE_CONFIDENCE,
+ MSG_STATE_SCOPE_CONFIG,
+ MSG_STATE_SCOPE_MODULE,
+ MSG_TYPES,
+ MSG_TYPES_LONG,
+)
+from pylint.interfaces import HIGH
+from pylint.message import MessageDefinition
+from pylint.typing import ManagedMessage, MessageDefinitionTuple
+from pylint.utils.pragma_parser import (
+ OPTION_PO,
+ InvalidPragmaError,
+ UnRecognizedOptionError,
+ parse_pragma,
+)
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+class _MessageStateHandler:
+ """Class that handles message disabling & enabling and processing of inline
+ pragma's.
+ """
+
+ def __init__(self, linter: PyLinter) -> None:
+ self.linter = linter
+ self.default_enabled_messages: dict[str, MessageDefinitionTuple] = {
+ k: v
+ for k, v in self.linter.msgs.items()
+ if len(v) == 3 or v[3].get("default_enabled", True)
+ }
+ self._msgs_state: dict[str, bool] = {}
+ self._options_methods = {
+ "enable": self.enable,
+ "disable": self.disable,
+ "disable-next": self.disable_next,
+ }
+ self._bw_options_methods = {
+ "disable-msg": self._options_methods["disable"],
+ "enable-msg": self._options_methods["enable"],
+ }
+ self._pragma_lineno: dict[str, int] = {}
+ self._stashed_messages: defaultdict[
+ tuple[str, str], list[tuple[str | None, str]]
+ ] = defaultdict(list)
+ """Some messages in the options (for --enable and --disable) are encountered
+ too early to warn about them.
+
+ i.e. before all option providers have been fully parsed. Thus, this dict stores
+ option_value and msg_id needed to (later) emit the messages keyed on module names.
+ """
+
+ def _set_one_msg_status(
+ self, scope: str, msg: MessageDefinition, line: int | None, enable: bool
+ ) -> None:
+ """Set the status of an individual message."""
+ if scope in {"module", "line"}:
+ assert isinstance(line, int) # should always be int inside module scope
+
+ self.linter.file_state.set_msg_status(msg, line, enable, scope)
+ if not enable and msg.symbol != "locally-disabled":
+ self.linter.add_message(
+ "locally-disabled", line=line, args=(msg.symbol, msg.msgid)
+ )
+ else:
+ msgs = self._msgs_state
+ msgs[msg.msgid] = enable
+
+ def _get_messages_to_set(
+ self, msgid: str, enable: bool, ignore_unknown: bool = False
+ ) -> list[MessageDefinition]:
+ """Do some tests and find the actual messages of which the status should be set."""
+ message_definitions: list[MessageDefinition] = []
+ if msgid == "all":
+ for _msgid in MSG_TYPES:
+ message_definitions.extend(
+ self._get_messages_to_set(_msgid, enable, ignore_unknown)
+ )
+ if not enable:
+ # "all" should not disable pylint's own warnings
+ message_definitions = list(
+ filter(
+ lambda m: m.msgid not in self.default_enabled_messages,
+ message_definitions,
+ )
+ )
+ return message_definitions
+
+ # msgid is a category?
+ category_id = msgid.upper()
+ if category_id not in MSG_TYPES:
+ category_id_formatted = MSG_TYPES_LONG.get(category_id)
+ else:
+ category_id_formatted = category_id
+ if category_id_formatted is not None:
+ for _msgid in self.linter.msgs_store._msgs_by_category[
+ category_id_formatted
+ ]:
+ message_definitions.extend(
+ self._get_messages_to_set(_msgid, enable, ignore_unknown)
+ )
+ return message_definitions
+
+ # msgid is a checker name?
+ if msgid.lower() in self.linter._checkers:
+ for checker in self.linter._checkers[msgid.lower()]:
+ for _msgid in checker.msgs:
+ message_definitions.extend(
+ self._get_messages_to_set(_msgid, enable, ignore_unknown)
+ )
+ return message_definitions
+
+ # msgid is report id?
+ if msgid.lower().startswith("rp"):
+ if enable:
+ self.linter.enable_report(msgid)
+ else:
+ self.linter.disable_report(msgid)
+ return message_definitions
+
+ try:
+ # msgid is a symbolic or numeric msgid.
+ message_definitions = self.linter.msgs_store.get_message_definitions(msgid)
+ except exceptions.UnknownMessageError:
+ if not ignore_unknown:
+ raise
+ return message_definitions
+
+ def _set_msg_status(
+ self,
+ msgid: str,
+ enable: bool,
+ scope: str = "package",
+ line: int | None = None,
+ ignore_unknown: bool = False,
+ ) -> None:
+ """Do some tests and then iterate over message definitions to set state."""
+ assert scope in {"package", "module", "line"}
+
+ message_definitions = self._get_messages_to_set(msgid, enable, ignore_unknown)
+
+ for message_definition in message_definitions:
+ self._set_one_msg_status(scope, message_definition, line, enable)
+
+ # sync configuration object
+ self.linter.config.enable = []
+ self.linter.config.disable = []
+ for msgid_or_symbol, is_enabled in self._msgs_state.items():
+ symbols = [
+ m.symbol
+ for m in self.linter.msgs_store.get_message_definitions(msgid_or_symbol)
+ ]
+ if is_enabled:
+ self.linter.config.enable += symbols
+ else:
+ self.linter.config.disable += symbols
+
+ def _register_by_id_managed_msg(
+ self, msgid_or_symbol: str, line: int | None, is_disabled: bool = True
+ ) -> None:
+ """If the msgid is a numeric one, then register it to inform the user
+ it could furnish instead a symbolic msgid.
+ """
+ if msgid_or_symbol[1:].isdigit():
+ try:
+ symbol = self.linter.msgs_store.message_id_store.get_symbol(
+ msgid=msgid_or_symbol
+ )
+ except exceptions.UnknownMessageError:
+ return
+ managed = ManagedMessage(
+ self.linter.current_name, msgid_or_symbol, symbol, line, is_disabled
+ )
+ self.linter._by_id_managed_msgs.append(managed)
+
+ def disable(
+ self,
+ msgid: str,
+ scope: str = "package",
+ line: int | None = None,
+ ignore_unknown: bool = False,
+ ) -> None:
+ """Disable a message for a scope."""
+ self._set_msg_status(
+ msgid, enable=False, scope=scope, line=line, ignore_unknown=ignore_unknown
+ )
+ self._register_by_id_managed_msg(msgid, line)
+
+ def disable_next(
+ self,
+ msgid: str,
+ _: str = "package",
+ line: int | None = None,
+ ignore_unknown: bool = False,
+ ) -> None:
+ """Disable a message for the next line."""
+ if not line:
+ raise exceptions.NoLineSuppliedError
+ self._set_msg_status(
+ msgid,
+ enable=False,
+ scope="line",
+ line=line + 1,
+ ignore_unknown=ignore_unknown,
+ )
+ self._register_by_id_managed_msg(msgid, line + 1)
+
+ def enable(
+ self,
+ msgid: str,
+ scope: str = "package",
+ line: int | None = None,
+ ignore_unknown: bool = False,
+ ) -> None:
+ """Enable a message for a scope."""
+ self._set_msg_status(
+ msgid, enable=True, scope=scope, line=line, ignore_unknown=ignore_unknown
+ )
+ self._register_by_id_managed_msg(msgid, line, is_disabled=False)
+
+ def disable_noerror_messages(self) -> None:
+ """Disable message categories other than `error` and `fatal`."""
+ for msgcat in self.linter.msgs_store._msgs_by_category:
+ if msgcat in {"E", "F"}:
+ continue
+ self.disable(msgcat)
+
+ def list_messages_enabled(self) -> None:
+ emittable, non_emittable = self.linter.msgs_store.find_emittable_messages()
+ enabled: list[str] = []
+ disabled: list[str] = []
+ for message in emittable:
+ if self.is_message_enabled(message.msgid):
+ enabled.append(f" {message.symbol} ({message.msgid})")
+ else:
+ disabled.append(f" {message.symbol} ({message.msgid})")
+ print("Enabled messages:")
+ for msg in enabled:
+ print(msg)
+ print("\nDisabled messages:")
+ for msg in disabled:
+ print(msg)
+ print("\nNon-emittable messages with current interpreter:")
+ for msg_def in non_emittable:
+ print(f" {msg_def.symbol} ({msg_def.msgid})")
+ print("")
+
+ def _get_message_state_scope(
+ self,
+ msgid: str,
+ line: int | None = None,
+ confidence: interfaces.Confidence | None = None,
+ ) -> Literal[0, 1, 2] | None:
+ """Returns the scope at which a message was enabled/disabled."""
+ if confidence is None:
+ confidence = interfaces.UNDEFINED
+ if confidence.name not in self.linter.config.confidence:
+ return MSG_STATE_CONFIDENCE # type: ignore[return-value] # mypy does not infer Literal correctly
+ try:
+ if line in self.linter.file_state._module_msgs_state[msgid]:
+ return MSG_STATE_SCOPE_MODULE # type: ignore[return-value]
+ except (KeyError, TypeError):
+ return MSG_STATE_SCOPE_CONFIG # type: ignore[return-value]
+ return None
+
+ def _is_one_message_enabled(self, msgid: str, line: int | None) -> bool:
+ """Checks state of a single message for the current file.
+
+ This function can't be cached as it depends on self.file_state which can
+ change.
+ """
+ if line is None:
+ return self._msgs_state.get(msgid, True)
+ try:
+ return self.linter.file_state._module_msgs_state[msgid][line]
+ except KeyError:
+ # Check if the message's line is after the maximum line existing in ast tree.
+ # This line won't appear in the ast tree and won't be referred in
+ # self.file_state._module_msgs_state
+ # This happens for example with a commented line at the end of a module.
+ max_line_number = self.linter.file_state.get_effective_max_line_number()
+ if max_line_number and line > max_line_number:
+ fallback = True
+ lines = self.linter.file_state._raw_module_msgs_state.get(msgid, {})
+
+ # Doesn't consider scopes, as a 'disable' can be in a
+ # different scope than that of the current line.
+ closest_lines = reversed(
+ [
+ (message_line, enable)
+ for message_line, enable in lines.items()
+ if message_line <= line
+ ]
+ )
+ _, fallback_iter = next(closest_lines, (None, None))
+ if fallback_iter is not None:
+ fallback = fallback_iter
+
+ return self._msgs_state.get(msgid, fallback)
+ return self._msgs_state.get(msgid, True)
+
+ def is_message_enabled(
+ self,
+ msg_descr: str,
+ line: int | None = None,
+ confidence: interfaces.Confidence | None = None,
+ ) -> bool:
+ """Is this message enabled for the current file ?
+
+ Optionally, is it enabled for this line and confidence level ?
+
+ The current file is implicit and mandatory. As a result this function
+ can't be cached right now as the line is the line of the currently
+ analysed file (self.file_state), if it changes, then the result for
+ the same msg_descr/line might need to change.
+
+ :param msg_descr: Either the msgid or the symbol for a MessageDefinition
+ :param line: The line of the currently analysed file
+ :param confidence: The confidence of the message
+ """
+ if confidence and confidence.name not in self.linter.config.confidence:
+ return False
+ try:
+ msgids = self.linter.msgs_store.message_id_store.get_active_msgids(
+ msg_descr
+ )
+ except exceptions.UnknownMessageError:
+ # The linter checks for messages that are not registered
+ # due to version mismatch, just treat them as message IDs
+ # for now.
+ msgids = [msg_descr]
+ return any(self._is_one_message_enabled(msgid, line) for msgid in msgids)
+
+ def process_tokens(self, tokens: list[tokenize.TokenInfo]) -> None:
+ """Process tokens from the current module to search for module/block level
+ options.
+
+ See func_block_disable_msg.py test case for expected behaviour.
+ """
+ control_pragmas = {"disable", "disable-next", "enable"}
+ prev_line = None
+ saw_newline = True
+ seen_newline = True
+ for tok_type, content, start, _, _ in tokens:
+ if prev_line and prev_line != start[0]:
+ saw_newline = seen_newline
+ seen_newline = False
+
+ prev_line = start[0]
+ if tok_type in (tokenize.NL, tokenize.NEWLINE):
+ seen_newline = True
+
+ if tok_type != tokenize.COMMENT:
+ continue
+ match = OPTION_PO.search(content)
+ if match is None:
+ continue
+ try: # pylint: disable = too-many-try-statements
+ for pragma_repr in parse_pragma(match.group(2)):
+ if pragma_repr.action in {"disable-all", "skip-file"}:
+ if pragma_repr.action == "disable-all":
+ self.linter.add_message(
+ "deprecated-pragma",
+ line=start[0],
+ args=("disable-all", "skip-file"),
+ )
+ self.linter.add_message("file-ignored", line=start[0])
+ self._ignore_file = True
+ return
+ try:
+ meth = self._options_methods[pragma_repr.action]
+ except KeyError:
+ meth = self._bw_options_methods[pragma_repr.action]
+ # found a "(dis|en)able-msg" pragma deprecated suppression
+ self.linter.add_message(
+ "deprecated-pragma",
+ line=start[0],
+ args=(
+ pragma_repr.action,
+ pragma_repr.action.replace("-msg", ""),
+ ),
+ )
+ for msgid in pragma_repr.messages:
+ # Add the line where a control pragma was encountered.
+ if pragma_repr.action in control_pragmas:
+ self._pragma_lineno[msgid] = start[0]
+
+ if (pragma_repr.action, msgid) == ("disable", "all"):
+ self.linter.add_message(
+ "deprecated-pragma",
+ line=start[0],
+ args=("disable=all", "skip-file"),
+ )
+ self.linter.add_message("file-ignored", line=start[0])
+ self._ignore_file = True
+ return
+ # If we did not see a newline between the previous line and now,
+ # we saw a backslash so treat the two lines as one.
+ l_start = start[0]
+ if not saw_newline:
+ l_start -= 1
+ try:
+ meth(msgid, "module", l_start)
+ except (
+ exceptions.DeletedMessageError,
+ exceptions.MessageBecameExtensionError,
+ ) as e:
+ self.linter.add_message(
+ "useless-option-value",
+ args=(pragma_repr.action, e),
+ line=start[0],
+ confidence=HIGH,
+ )
+ except exceptions.UnknownMessageError:
+ self.linter.add_message(
+ "unknown-option-value",
+ args=(pragma_repr.action, msgid),
+ line=start[0],
+ confidence=HIGH,
+ )
+
+ except UnRecognizedOptionError as err:
+ self.linter.add_message(
+ "unrecognized-inline-option", args=err.token, line=start[0]
+ )
+ continue
+ except InvalidPragmaError as err:
+ self.linter.add_message(
+ "bad-inline-option", args=err.token, line=start[0]
+ )
+ continue
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/parallel.py b/solutions/.venv/Lib/site-packages/pylint/lint/parallel.py
new file mode 100644
index 000000000..af381494c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/parallel.py
@@ -0,0 +1,173 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import functools
+from collections import defaultdict
+from collections.abc import Iterable, Sequence
+from typing import TYPE_CHECKING, Any
+
+import dill
+
+from pylint import reporters
+from pylint.lint.utils import _augment_sys_path
+from pylint.message import Message
+from pylint.typing import FileItem
+from pylint.utils import LinterStats, merge_stats
+
+try:
+ import multiprocessing
+except ImportError:
+ multiprocessing = None # type: ignore[assignment]
+
+try:
+ from concurrent.futures import ProcessPoolExecutor
+except ImportError:
+ ProcessPoolExecutor = None # type: ignore[assignment,misc]
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+# PyLinter object used by worker processes when checking files using parallel mode
+# should only be used by the worker processes
+_worker_linter: PyLinter | None = None
+
+
+def _worker_initialize(
+ linter: bytes, extra_packages_paths: Sequence[str] | None = None
+) -> None:
+ """Function called to initialize a worker for a Process within a concurrent Pool.
+
+ :param linter: A linter-class (PyLinter) instance pickled with dill
+ :param extra_packages_paths: Extra entries to be added to `sys.path`
+ """
+ global _worker_linter # pylint: disable=global-statement
+ _worker_linter = dill.loads(linter)
+ assert _worker_linter
+
+ # On the worker process side the messages are just collected and passed back to
+ # parent process as _worker_check_file function's return value
+ _worker_linter.set_reporter(reporters.CollectingReporter())
+ _worker_linter.open()
+
+ # Re-register dynamic plugins, since the pool does not have access to the
+ # astroid module that existed when the linter was pickled.
+ _worker_linter.load_plugin_modules(_worker_linter._dynamic_plugins, force=True)
+ _worker_linter.load_plugin_configuration()
+
+ if extra_packages_paths:
+ _augment_sys_path(extra_packages_paths)
+
+
+def _worker_check_single_file(
+ file_item: FileItem,
+) -> tuple[
+ int,
+ str,
+ str,
+ str,
+ list[Message],
+ LinterStats,
+ int,
+ defaultdict[str, list[Any]],
+]:
+ if not _worker_linter:
+ raise RuntimeError("Worker linter not yet initialised")
+ _worker_linter.open()
+ _worker_linter.check_single_file_item(file_item)
+ mapreduce_data = defaultdict(list)
+ for checker in _worker_linter.get_checkers():
+ data = checker.get_map_data()
+ if data is not None:
+ mapreduce_data[checker.name].append(data)
+ msgs = _worker_linter.reporter.messages
+ assert isinstance(_worker_linter.reporter, reporters.CollectingReporter)
+ _worker_linter.reporter.reset()
+ return (
+ id(multiprocessing.current_process()),
+ _worker_linter.current_name,
+ file_item.filepath,
+ _worker_linter.file_state.base_name,
+ msgs,
+ _worker_linter.stats,
+ _worker_linter.msg_status,
+ mapreduce_data,
+ )
+
+
+def _merge_mapreduce_data(
+ linter: PyLinter,
+ all_mapreduce_data: defaultdict[int, list[defaultdict[str, list[Any]]]],
+) -> None:
+ """Merges map/reduce data across workers, invoking relevant APIs on checkers."""
+ # First collate the data and prepare it, so we can send it to the checkers for
+ # validation. The intent here is to collect all the mapreduce data for all checker-
+ # runs across processes - that will then be passed to a static method on the
+ # checkers to be reduced and further processed.
+ collated_map_reduce_data: defaultdict[str, list[Any]] = defaultdict(list)
+ for linter_data in all_mapreduce_data.values():
+ for run_data in linter_data:
+ for checker_name, data in run_data.items():
+ collated_map_reduce_data[checker_name].extend(data)
+
+ # Send the data to checkers that support/require consolidated data
+ original_checkers = linter.get_checkers()
+ for checker in original_checkers:
+ if checker.name in collated_map_reduce_data:
+ # Assume that if the check has returned map/reduce data that it has the
+ # reducer function
+ checker.reduce_map_data(linter, collated_map_reduce_data[checker.name])
+
+
+def check_parallel(
+ linter: PyLinter,
+ jobs: int,
+ files: Iterable[FileItem],
+ extra_packages_paths: Sequence[str] | None = None,
+) -> None:
+ """Use the given linter to lint the files with given amount of workers (jobs).
+
+ This splits the work filestream-by-filestream. If you need to do work across
+ multiple files, as in the similarity-checker, then implement the map/reduce functionality.
+ """
+ # The linter is inherited by all the pool's workers, i.e. the linter
+ # is identical to the linter object here. This is required so that
+ # a custom PyLinter object can be used.
+ initializer = functools.partial(
+ _worker_initialize, extra_packages_paths=extra_packages_paths
+ )
+ with ProcessPoolExecutor(
+ max_workers=jobs, initializer=initializer, initargs=(dill.dumps(linter),)
+ ) as executor:
+ linter.open()
+ all_stats = []
+ all_mapreduce_data: defaultdict[int, list[defaultdict[str, list[Any]]]] = (
+ defaultdict(list)
+ )
+
+ # Maps each file to be worked on by a single _worker_check_single_file() call,
+ # collecting any map/reduce data by checker module so that we can 'reduce' it
+ # later.
+ for (
+ worker_idx, # used to merge map/reduce data across workers
+ module,
+ file_path,
+ base_name,
+ messages,
+ stats,
+ msg_status,
+ mapreduce_data,
+ ) in executor.map(_worker_check_single_file, files):
+ linter.file_state.base_name = base_name
+ linter.file_state._is_base_filestate = False
+ linter.set_current_module(module, file_path)
+ for msg in messages:
+ linter.reporter.handle_message(msg)
+ all_stats.append(stats)
+ all_mapreduce_data[worker_idx].append(mapreduce_data)
+ linter.msg_status |= msg_status
+
+ _merge_mapreduce_data(linter, all_mapreduce_data)
+ linter.stats = merge_stats([linter.stats, *all_stats])
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/pylinter.py b/solutions/.venv/Lib/site-packages/pylint/lint/pylinter.py
new file mode 100644
index 000000000..cc4605b96
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/pylinter.py
@@ -0,0 +1,1316 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import argparse
+import collections
+import contextlib
+import functools
+import os
+import sys
+import tokenize
+import traceback
+from collections import defaultdict
+from collections.abc import Callable, Iterable, Iterator, Sequence
+from io import TextIOWrapper
+from pathlib import Path
+from re import Pattern
+from types import ModuleType
+from typing import Any, Protocol
+
+import astroid
+from astroid import nodes
+
+from pylint import checkers, exceptions, interfaces, reporters
+from pylint.checkers.base_checker import BaseChecker
+from pylint.config.arguments_manager import _ArgumentsManager
+from pylint.constants import (
+ MAIN_CHECKER_NAME,
+ MSG_TYPES,
+ MSG_TYPES_STATUS,
+ WarningScope,
+)
+from pylint.interfaces import HIGH
+from pylint.lint.base_options import _make_linter_options
+from pylint.lint.caching import load_results, save_results
+from pylint.lint.expand_modules import (
+ _is_ignored_file,
+ discover_package_path,
+ expand_modules,
+)
+from pylint.lint.message_state_handler import _MessageStateHandler
+from pylint.lint.parallel import check_parallel
+from pylint.lint.report_functions import (
+ report_messages_by_module_stats,
+ report_messages_stats,
+ report_total_messages_stats,
+)
+from pylint.lint.utils import (
+ augmented_sys_path,
+ get_fatal_error_message,
+ prepare_crash_report,
+)
+from pylint.message import Message, MessageDefinition, MessageDefinitionStore
+from pylint.reporters.base_reporter import BaseReporter
+from pylint.reporters.text import TextReporter
+from pylint.reporters.ureports import nodes as report_nodes
+from pylint.typing import (
+ DirectoryNamespaceDict,
+ FileItem,
+ ManagedMessage,
+ MessageDefinitionTuple,
+ MessageLocationTuple,
+ ModuleDescriptionDict,
+ Options,
+)
+from pylint.utils import ASTWalker, FileState, LinterStats, utils
+
+MANAGER = astroid.MANAGER
+
+
+class GetAstProtocol(Protocol):
+ def __call__(
+ self, filepath: str, modname: str, data: str | None = None
+ ) -> nodes.Module: ...
+
+
+def _read_stdin() -> str:
+ # See https://github.com/python/typeshed/pull/5623 for rationale behind assertion
+ assert isinstance(sys.stdin, TextIOWrapper)
+ sys.stdin = TextIOWrapper(sys.stdin.detach(), encoding="utf-8")
+ return sys.stdin.read()
+
+
+def _load_reporter_by_class(reporter_class: str) -> type[BaseReporter]:
+ qname = reporter_class
+ module_part = astroid.modutils.get_module_part(qname)
+ module = astroid.modutils.load_module_from_name(module_part)
+ class_name = qname.split(".")[-1]
+ klass = getattr(module, class_name)
+ assert issubclass(klass, BaseReporter), f"{klass} is not a BaseReporter"
+ return klass # type: ignore[no-any-return]
+
+
+# Python Linter class #########################################################
+
+# pylint: disable-next=consider-using-namedtuple-or-dataclass
+MSGS: dict[str, MessageDefinitionTuple] = {
+ "F0001": (
+ "%s",
+ "fatal",
+ "Used when an error occurred preventing the analysis of a \
+ module (unable to find it for instance).",
+ {"scope": WarningScope.LINE},
+ ),
+ "F0002": (
+ "%s: %s",
+ "astroid-error",
+ "Used when an unexpected error occurred while building the "
+ "Astroid representation. This is usually accompanied by a "
+ "traceback. Please report such errors !",
+ {"scope": WarningScope.LINE},
+ ),
+ "F0010": (
+ "error while code parsing: %s",
+ "parse-error",
+ "Used when an exception occurred while building the Astroid "
+ "representation which could be handled by astroid.",
+ {"scope": WarningScope.LINE},
+ ),
+ "F0011": (
+ "error while parsing the configuration: %s",
+ "config-parse-error",
+ "Used when an exception occurred while parsing a pylint configuration file.",
+ {"scope": WarningScope.LINE},
+ ),
+ "I0001": (
+ "Unable to run raw checkers on built-in module %s",
+ "raw-checker-failed",
+ "Used to inform that a built-in module has not been checked "
+ "using the raw checkers.",
+ {
+ "scope": WarningScope.LINE,
+ "default_enabled": False,
+ },
+ ),
+ "I0010": (
+ "Unable to consider inline option %r",
+ "bad-inline-option",
+ "Used when an inline option is either badly formatted or can't "
+ "be used inside modules.",
+ {
+ "scope": WarningScope.LINE,
+ "default_enabled": False,
+ },
+ ),
+ "I0011": (
+ "Locally disabling %s (%s)",
+ "locally-disabled",
+ "Used when an inline option disables a message or a messages category.",
+ {
+ "scope": WarningScope.LINE,
+ "default_enabled": False,
+ },
+ ),
+ "I0013": (
+ "Ignoring entire file",
+ "file-ignored",
+ "Used to inform that the file will not be checked",
+ {
+ "scope": WarningScope.LINE,
+ "default_enabled": False,
+ },
+ ),
+ "I0020": (
+ "Suppressed %s (from line %d)",
+ "suppressed-message",
+ "A message was triggered on a line, but suppressed explicitly "
+ "by a disable= comment in the file. This message is not "
+ "generated for messages that are ignored due to configuration "
+ "settings.",
+ {
+ "scope": WarningScope.LINE,
+ "default_enabled": False,
+ },
+ ),
+ "I0021": (
+ "Useless suppression of %s",
+ "useless-suppression",
+ "Reported when a message is explicitly disabled for a line or "
+ "a block of code, but never triggered.",
+ {
+ "scope": WarningScope.LINE,
+ "default_enabled": False,
+ },
+ ),
+ "I0022": (
+ 'Pragma "%s" is deprecated, use "%s" instead',
+ "deprecated-pragma",
+ "Some inline pylint options have been renamed or reworked, "
+ "only the most recent form should be used. "
+ "NOTE:skip-all is only available with pylint >= 0.26",
+ {
+ "old_names": [("I0014", "deprecated-disable-all")],
+ "scope": WarningScope.LINE,
+ "default_enabled": False,
+ },
+ ),
+ "E0001": (
+ "%s",
+ "syntax-error",
+ "Used when a syntax error is raised for a module.",
+ {"scope": WarningScope.LINE},
+ ),
+ "E0011": (
+ "Unrecognized file option %r",
+ "unrecognized-inline-option",
+ "Used when an unknown inline option is encountered.",
+ {"scope": WarningScope.LINE},
+ ),
+ "W0012": (
+ "Unknown option value for '%s', expected a valid pylint message and got '%s'",
+ "unknown-option-value",
+ "Used when an unknown value is encountered for an option.",
+ {
+ "scope": WarningScope.LINE,
+ "old_names": [("E0012", "bad-option-value")],
+ },
+ ),
+ "R0022": (
+ "Useless option value for '%s', %s",
+ "useless-option-value",
+ "Used when a value for an option that is now deleted from pylint"
+ " is encountered.",
+ {
+ "scope": WarningScope.LINE,
+ "old_names": [("E0012", "bad-option-value")],
+ },
+ ),
+ "E0013": (
+ "Plugin '%s' is impossible to load, is it installed ? ('%s')",
+ "bad-plugin-value",
+ "Used when a bad value is used in 'load-plugins'.",
+ {"scope": WarningScope.LINE},
+ ),
+ "E0014": (
+ "Out-of-place setting encountered in top level configuration-section '%s' : '%s'",
+ "bad-configuration-section",
+ "Used when we detect a setting in the top level of a toml configuration that"
+ " shouldn't be there.",
+ {"scope": WarningScope.LINE},
+ ),
+ "E0015": (
+ "Unrecognized option found: %s",
+ "unrecognized-option",
+ "Used when we detect an option that we do not recognize.",
+ {"scope": WarningScope.LINE},
+ ),
+}
+
+
+# pylint: disable=too-many-instance-attributes,too-many-public-methods
+class PyLinter(
+ _ArgumentsManager,
+ _MessageStateHandler,
+ reporters.ReportsHandlerMixIn,
+ checkers.BaseChecker,
+):
+ """Lint Python modules using external checkers.
+
+ This is the main checker controlling the other ones and the reports
+ generation. It is itself both a raw checker and an astroid checker in order
+ to:
+ * handle message activation / deactivation at the module level
+ * handle some basic but necessary stats' data (number of classes, methods...)
+
+ IDE plugin developers: you may have to call
+ `astroid.MANAGER.clear_cache()` across runs if you want
+ to ensure the latest code version is actually checked.
+
+ This class needs to support pickling for parallel linting to work. The exception
+ is reporter member; see check_parallel function for more details.
+ """
+
+ name = MAIN_CHECKER_NAME
+ msgs = MSGS
+ # Will be used like this : datetime.now().strftime(crash_file_path)
+ crash_file_path: str = "pylint-crash-%Y-%m-%d-%H-%M-%S.txt"
+
+ option_groups_descs = {
+ "Messages control": "Options controlling analysis messages",
+ "Reports": "Options related to output formatting and reporting",
+ }
+
+ def __init__(
+ self,
+ options: Options = (),
+ reporter: reporters.BaseReporter | reporters.MultiReporter | None = None,
+ option_groups: tuple[tuple[str, str], ...] = (),
+ # TODO: Deprecate passing the pylintrc parameter
+ pylintrc: str | None = None, # pylint: disable=unused-argument
+ ) -> None:
+ _ArgumentsManager.__init__(self, prog="pylint")
+ _MessageStateHandler.__init__(self, self)
+
+ # Some stuff has to be done before initialization of other ancestors...
+ # messages store / checkers / reporter / astroid manager
+
+ # Attributes for reporters
+ self.reporter: reporters.BaseReporter | reporters.MultiReporter
+ if reporter:
+ self.set_reporter(reporter)
+ else:
+ self.set_reporter(TextReporter())
+ self._reporters: dict[str, type[reporters.BaseReporter]] = {}
+ """Dictionary of possible but non-initialized reporters."""
+
+ # Attributes for checkers and plugins
+ self._checkers: defaultdict[str, list[checkers.BaseChecker]] = (
+ collections.defaultdict(list)
+ )
+ """Dictionary of registered and initialized checkers."""
+ self._dynamic_plugins: dict[str, ModuleType | ModuleNotFoundError | bool] = {}
+ """Set of loaded plugin names."""
+
+ # Attributes related to stats
+ self.stats = LinterStats()
+
+ # Attributes related to (command-line) options and their parsing
+ self.options: Options = options + _make_linter_options(self)
+ for opt_group in option_groups:
+ self.option_groups_descs[opt_group[0]] = opt_group[1]
+ self._option_groups: tuple[tuple[str, str], ...] = (
+ *option_groups,
+ ("Messages control", "Options controlling analysis messages"),
+ ("Reports", "Options related to output formatting and reporting"),
+ )
+ self.fail_on_symbols: list[str] = []
+ """List of message symbols on which pylint should fail, set by --fail-on."""
+ self._error_mode = False
+
+ reporters.ReportsHandlerMixIn.__init__(self)
+ checkers.BaseChecker.__init__(self, self)
+ # provided reports
+ self.reports = (
+ ("RP0001", "Messages by category", report_total_messages_stats),
+ (
+ "RP0002",
+ "% errors / warnings by module",
+ report_messages_by_module_stats,
+ ),
+ ("RP0003", "Messages", report_messages_stats),
+ )
+
+ # Attributes related to registering messages and their handling
+ self.msgs_store = MessageDefinitionStore(self.config.py_version)
+ self.msg_status = 0
+ self._by_id_managed_msgs: list[ManagedMessage] = []
+
+ # Attributes related to visiting files
+ self.file_state = FileState("", self.msgs_store, is_base_filestate=True)
+ self.current_name: str = ""
+ self.current_file: str | None = None
+ self._ignore_file = False
+ self._ignore_paths: list[Pattern[str]] = []
+
+ self.register_checker(self)
+
+ def load_default_plugins(self) -> None:
+ checkers.initialize(self)
+ reporters.initialize(self)
+
+ def load_plugin_modules(self, modnames: Iterable[str], force: bool = False) -> None:
+ """Check a list of pylint plugins modules, load and register them.
+
+ If a module cannot be loaded, never try to load it again and instead
+ store the error message for later use in ``load_plugin_configuration``
+ below.
+
+ If `force` is True (useful when multiprocessing), then the plugin is
+ reloaded regardless if an entry exists in self._dynamic_plugins.
+ """
+ for modname in modnames:
+ if modname in self._dynamic_plugins and not force:
+ continue
+ try:
+ module = astroid.modutils.load_module_from_name(modname)
+ module.register(self)
+ self._dynamic_plugins[modname] = module
+ except ModuleNotFoundError as mnf_e:
+ self._dynamic_plugins[modname] = mnf_e
+
+ def load_plugin_configuration(self) -> None:
+ """Call the configuration hook for plugins.
+
+ This walks through the list of plugins, grabs the "load_configuration"
+ hook, if exposed, and calls it to allow plugins to configure specific
+ settings.
+
+ The result of attempting to load the plugin of the given name
+ is stored in the dynamic plugins dictionary in ``load_plugin_modules`` above.
+
+ ..note::
+ This function previously always tried to load modules again, which
+ led to some confusion and silent failure conditions as described
+ in GitHub issue #7264. Making it use the stored result is more efficient, and
+ means that we avoid the ``init-hook`` problems from before.
+ """
+ for modname, module_or_error in self._dynamic_plugins.items():
+ if isinstance(module_or_error, ModuleNotFoundError):
+ self.add_message(
+ "bad-plugin-value", args=(modname, module_or_error), line=0
+ )
+ elif hasattr(module_or_error, "load_configuration"):
+ module_or_error.load_configuration(self)
+
+ # We re-set all the dictionary values to True here to make sure the dict
+ # is pickle-able. This is only a problem in multiprocessing/parallel mode.
+ # (e.g. invoking pylint -j 2)
+ self._dynamic_plugins = {
+ modname: not isinstance(val, ModuleNotFoundError)
+ for modname, val in self._dynamic_plugins.items()
+ }
+
+ def _load_reporters(self, reporter_names: str) -> None:
+ """Load the reporters if they are available on _reporters."""
+ if not self._reporters:
+ return
+ sub_reporters = []
+ output_files = []
+ with contextlib.ExitStack() as stack:
+ for reporter_name in reporter_names.split(","):
+ reporter_name, *reporter_output = reporter_name.split(":", 1)
+
+ reporter = self._load_reporter_by_name(reporter_name)
+ sub_reporters.append(reporter)
+ if reporter_output:
+ output_file = stack.enter_context(
+ open(reporter_output[0], "w", encoding="utf-8")
+ )
+ reporter.out = output_file
+ output_files.append(output_file)
+
+ # Extend the lifetime of all opened output files
+ close_output_files = stack.pop_all().close
+
+ if len(sub_reporters) > 1 or output_files:
+ self.set_reporter(
+ reporters.MultiReporter(
+ sub_reporters,
+ close_output_files,
+ )
+ )
+ else:
+ self.set_reporter(sub_reporters[0])
+
+ def _load_reporter_by_name(self, reporter_name: str) -> reporters.BaseReporter:
+ name = reporter_name.lower()
+ if name in self._reporters:
+ return self._reporters[name]()
+
+ try:
+ reporter_class = _load_reporter_by_class(reporter_name)
+ except (ImportError, AttributeError, AssertionError) as e:
+ raise exceptions.InvalidReporterError(name) from e
+
+ return reporter_class()
+
+ def set_reporter(
+ self, reporter: reporters.BaseReporter | reporters.MultiReporter
+ ) -> None:
+ """Set the reporter used to display messages and reports."""
+ self.reporter = reporter
+ reporter.linter = self
+
+ def register_reporter(self, reporter_class: type[reporters.BaseReporter]) -> None:
+ """Registers a reporter class on the _reporters attribute."""
+ self._reporters[reporter_class.name] = reporter_class
+
+ def report_order(self) -> list[BaseChecker]:
+ reports = sorted(self._reports, key=lambda x: getattr(x, "name", ""))
+ try:
+ # Remove the current reporter and add it
+ # at the end of the list.
+ reports.pop(reports.index(self))
+ except ValueError:
+ pass
+ else:
+ reports.append(self)
+ return reports
+
+ # checkers manipulation methods ############################################
+
+ def register_checker(self, checker: checkers.BaseChecker) -> None:
+ """This method auto registers the checker."""
+ self._checkers[checker.name].append(checker)
+ for r_id, r_title, r_cb in checker.reports:
+ self.register_report(r_id, r_title, r_cb, checker)
+ if hasattr(checker, "msgs"):
+ self.msgs_store.register_messages_from_checker(checker)
+ for message in checker.messages:
+ if not message.default_enabled:
+ self.disable(message.msgid)
+ # Register the checker, but disable all of its messages.
+ if not getattr(checker, "enabled", True):
+ self.disable(checker.name)
+
+ def enable_fail_on_messages(self) -> None:
+ """Enable 'fail on' msgs.
+
+ Convert values in config.fail_on (which might be msg category, msg id,
+ or symbol) to specific msgs, then enable and flag them for later.
+ """
+ fail_on_vals = self.config.fail_on
+ if not fail_on_vals:
+ return
+
+ fail_on_cats = set()
+ fail_on_msgs = set()
+ for val in fail_on_vals:
+ # If value is a category, add category, else add message
+ if val in MSG_TYPES:
+ fail_on_cats.add(val)
+ else:
+ fail_on_msgs.add(val)
+
+ # For every message in every checker, if cat or msg flagged, enable check
+ for all_checkers in self._checkers.values():
+ for checker in all_checkers:
+ for msg in checker.messages:
+ if msg.msgid in fail_on_msgs or msg.symbol in fail_on_msgs:
+ # message id/symbol matched, enable and flag it
+ self.enable(msg.msgid)
+ self.fail_on_symbols.append(msg.symbol)
+ elif msg.msgid[0] in fail_on_cats:
+ # message starts with a category value, flag (but do not enable) it
+ self.fail_on_symbols.append(msg.symbol)
+
+ def any_fail_on_issues(self) -> bool:
+ return any(x in self.fail_on_symbols for x in self.stats.by_msg.keys())
+
+ def disable_reporters(self) -> None:
+ """Disable all reporters."""
+ for _reporters in self._reports.values():
+ for report_id, _, _ in _reporters:
+ self.disable_report(report_id)
+
+ def _parse_error_mode(self) -> None:
+ """Parse the current state of the error mode.
+
+ Error mode: enable only errors; no reports, no persistent.
+ """
+ if not self._error_mode:
+ return
+
+ self.disable_noerror_messages()
+ self.disable("miscellaneous")
+ self.set_option("reports", False)
+ self.set_option("persistent", False)
+ self.set_option("score", False)
+
+ # code checking methods ###################################################
+
+ def get_checkers(self) -> list[BaseChecker]:
+ """Return all available checkers as an ordered list."""
+ return sorted(c for _checkers in self._checkers.values() for c in _checkers)
+
+ def get_checker_names(self) -> list[str]:
+ """Get all the checker names that this linter knows about."""
+ return sorted(
+ {
+ checker.name
+ for checker in self.get_checkers()
+ if checker.name != MAIN_CHECKER_NAME
+ }
+ )
+
+ def prepare_checkers(self) -> list[BaseChecker]:
+ """Return checkers needed for activated messages and reports."""
+ if not self.config.reports:
+ self.disable_reporters()
+ # get needed checkers
+ needed_checkers: list[BaseChecker] = [self]
+ for checker in self.get_checkers()[1:]:
+ messages = {msg for msg in checker.msgs if self.is_message_enabled(msg)}
+ if messages or any(self.report_is_enabled(r[0]) for r in checker.reports):
+ needed_checkers.append(checker)
+ return needed_checkers
+
+ # pylint: disable=unused-argument
+ @staticmethod
+ def should_analyze_file(modname: str, path: str, is_argument: bool = False) -> bool:
+ """Returns whether a module should be checked.
+
+ This implementation returns True for all python source files (.py and .pyi),
+ indicating that all files should be linted.
+
+ Subclasses may override this method to indicate that modules satisfying
+ certain conditions should not be linted.
+
+ :param str modname: The name of the module to be checked.
+ :param str path: The full path to the source code of the module.
+ :param bool is_argument: Whether the file is an argument to pylint or not.
+ Files which respect this property are always
+ checked, since the user requested it explicitly.
+ :returns: True if the module should be checked.
+ """
+ if is_argument:
+ return True
+ return path.endswith((".py", ".pyi"))
+
+ # pylint: enable=unused-argument
+
+ def initialize(self) -> None:
+ """Initialize linter for linting.
+
+ This method is called before any linting is done.
+ """
+ self._ignore_paths = self.config.ignore_paths
+ # initialize msgs_state now that all messages have been registered into
+ # the store
+ for msg in self.msgs_store.messages:
+ if not msg.may_be_emitted(self.config.py_version):
+ self._msgs_state[msg.msgid] = False
+
+ def _discover_files(self, files_or_modules: Sequence[str]) -> Iterator[str]:
+ """Discover python modules and packages in sub-directory.
+
+ Returns iterator of paths to discovered modules and packages.
+ """
+ for something in files_or_modules:
+ if os.path.isdir(something) and not os.path.isfile(
+ os.path.join(something, "__init__.py")
+ ):
+ skip_subtrees: list[str] = []
+ for root, _, files in os.walk(something):
+ if any(root.startswith(s) for s in skip_subtrees):
+ # Skip subtree of already discovered package.
+ continue
+
+ if _is_ignored_file(
+ root,
+ self.config.ignore,
+ self.config.ignore_patterns,
+ self.config.ignore_paths,
+ ):
+ skip_subtrees.append(root)
+ continue
+
+ if "__init__.py" in files:
+ skip_subtrees.append(root)
+ yield root
+ else:
+ yield from (
+ os.path.join(root, file)
+ for file in files
+ if file.endswith((".py", ".pyi"))
+ )
+ else:
+ yield something
+
+ def check(self, files_or_modules: Sequence[str]) -> None:
+ """Main checking entry: check a list of files or modules from their name.
+
+ files_or_modules is either a string or list of strings presenting modules to check.
+ """
+ self.initialize()
+ if self.config.recursive:
+ files_or_modules = tuple(self._discover_files(files_or_modules))
+ if self.config.from_stdin:
+ if len(files_or_modules) != 1:
+ raise exceptions.InvalidArgsError(
+ "Missing filename required for --from-stdin"
+ )
+
+ extra_packages_paths = list(
+ dict.fromkeys(
+ [
+ discover_package_path(file_or_module, self.config.source_roots)
+ for file_or_module in files_or_modules
+ ]
+ ).keys()
+ )
+
+ # TODO: Move the parallel invocation into step 3 of the checking process
+ if not self.config.from_stdin and self.config.jobs > 1:
+ original_sys_path = sys.path[:]
+ check_parallel(
+ self,
+ self.config.jobs,
+ self._iterate_file_descrs(files_or_modules),
+ extra_packages_paths,
+ )
+ sys.path = original_sys_path
+ return
+
+ # 1) Get all FileItems
+ with augmented_sys_path(extra_packages_paths):
+ if self.config.from_stdin:
+ fileitems = self._get_file_descr_from_stdin(files_or_modules[0])
+ data: str | None = _read_stdin()
+ else:
+ fileitems = self._iterate_file_descrs(files_or_modules)
+ data = None
+
+ # The contextmanager also opens all checkers and sets up the PyLinter class
+ with augmented_sys_path(extra_packages_paths):
+ with self._astroid_module_checker() as check_astroid_module:
+ # 2) Get the AST for each FileItem
+ ast_per_fileitem = self._get_asts(fileitems, data)
+
+ # 3) Lint each ast
+ self._lint_files(ast_per_fileitem, check_astroid_module)
+
+ def _get_asts(
+ self, fileitems: Iterator[FileItem], data: str | None
+ ) -> dict[FileItem, nodes.Module | None]:
+ """Get the AST for all given FileItems."""
+ ast_per_fileitem: dict[FileItem, nodes.Module | None] = {}
+
+ for fileitem in fileitems:
+ self.set_current_module(fileitem.name, fileitem.filepath)
+
+ try:
+ ast_per_fileitem[fileitem] = self.get_ast(
+ fileitem.filepath, fileitem.name, data
+ )
+ except astroid.AstroidBuildingError as ex:
+ template_path = prepare_crash_report(
+ ex, fileitem.filepath, self.crash_file_path
+ )
+ msg = get_fatal_error_message(fileitem.filepath, template_path)
+ self.add_message(
+ "astroid-error",
+ args=(fileitem.filepath, msg),
+ confidence=HIGH,
+ )
+
+ return ast_per_fileitem
+
+ def check_single_file_item(self, file: FileItem) -> None:
+ """Check single file item.
+
+ The arguments are the same that are documented in _check_files
+
+ initialize() should be called before calling this method
+ """
+ with self._astroid_module_checker() as check_astroid_module:
+ self._check_file(self.get_ast, check_astroid_module, file)
+
+ def _lint_files(
+ self,
+ ast_mapping: dict[FileItem, nodes.Module | None],
+ check_astroid_module: Callable[[nodes.Module], bool | None],
+ ) -> None:
+ """Lint all AST modules from a mapping.."""
+ for fileitem, module in ast_mapping.items():
+ if module is None:
+ continue
+ try:
+ self._lint_file(fileitem, module, check_astroid_module)
+ except Exception as ex: # pylint: disable=broad-except
+ template_path = prepare_crash_report(
+ ex, fileitem.filepath, self.crash_file_path
+ )
+ msg = get_fatal_error_message(fileitem.filepath, template_path)
+ if isinstance(ex, astroid.AstroidError):
+ self.add_message(
+ "astroid-error", args=(fileitem.filepath, msg), confidence=HIGH
+ )
+ else:
+ self.add_message("fatal", args=msg, confidence=HIGH)
+
+ def _lint_file(
+ self,
+ file: FileItem,
+ module: nodes.Module,
+ check_astroid_module: Callable[[nodes.Module], bool | None],
+ ) -> None:
+ """Lint a file using the passed utility function check_astroid_module).
+
+ :param FileItem file: data about the file
+ :param nodes.Module module: the ast module to lint
+ :param Callable check_astroid_module: callable checking an AST taking the following
+ arguments
+ - ast: AST of the module
+ :raises AstroidError: for any failures stemming from astroid
+ """
+ self.set_current_module(file.name, file.filepath)
+ self._ignore_file = False
+ self.file_state = FileState(file.modpath, self.msgs_store, module)
+ # fix the current file (if the source file was not available or
+ # if it's actually a c extension)
+ self.current_file = module.file
+
+ try:
+ check_astroid_module(module)
+ except Exception as e:
+ raise astroid.AstroidError from e
+
+ # warn about spurious inline messages handling
+ spurious_messages = self.file_state.iter_spurious_suppression_messages(
+ self.msgs_store
+ )
+ for msgid, line, args in spurious_messages:
+ self.add_message(msgid, line, None, args)
+
+ def _check_file(
+ self,
+ get_ast: GetAstProtocol,
+ check_astroid_module: Callable[[nodes.Module], bool | None],
+ file: FileItem,
+ ) -> None:
+ """Check a file using the passed utility functions (get_ast and
+ check_astroid_module).
+
+ :param callable get_ast: callable returning AST from defined file taking the
+ following arguments
+ - filepath: path to the file to check
+ - name: Python module name
+ :param callable check_astroid_module: callable checking an AST taking the following
+ arguments
+ - ast: AST of the module
+ :param FileItem file: data about the file
+ :raises AstroidError: for any failures stemming from astroid
+ """
+ self.set_current_module(file.name, file.filepath)
+ # get the module representation
+ ast_node = get_ast(file.filepath, file.name)
+ if ast_node is None:
+ return
+
+ self._ignore_file = False
+
+ self.file_state = FileState(file.modpath, self.msgs_store, ast_node)
+ # fix the current file (if the source file was not available or
+ # if it's actually a c extension)
+ self.current_file = ast_node.file
+ try:
+ check_astroid_module(ast_node)
+ except Exception as e: # pragma: no cover
+ raise astroid.AstroidError from e
+ # warn about spurious inline messages handling
+ spurious_messages = self.file_state.iter_spurious_suppression_messages(
+ self.msgs_store
+ )
+ for msgid, line, args in spurious_messages:
+ self.add_message(msgid, line, None, args)
+
+ def _get_file_descr_from_stdin(self, filepath: str) -> Iterator[FileItem]:
+ """Return file description (tuple of module name, file path, base name) from
+ given file path.
+
+ This method is used for creating suitable file description for _check_files when the
+ source is standard input.
+ """
+ if _is_ignored_file(
+ filepath,
+ self.config.ignore,
+ self.config.ignore_patterns,
+ self.config.ignore_paths,
+ ):
+ return
+
+ try:
+ # Note that this function does not really perform an
+ # __import__ but may raise an ImportError exception, which
+ # we want to catch here.
+ modname = ".".join(astroid.modutils.modpath_from_file(filepath))
+ except ImportError:
+ modname = os.path.splitext(os.path.basename(filepath))[0]
+
+ yield FileItem(modname, filepath, filepath)
+
+ def _iterate_file_descrs(
+ self, files_or_modules: Sequence[str]
+ ) -> Iterator[FileItem]:
+ """Return generator yielding file descriptions (tuples of module name, file
+ path, base name).
+
+ The returned generator yield one item for each Python module that should be linted.
+ """
+ for descr in self._expand_files(files_or_modules).values():
+ name, filepath, is_arg = descr["name"], descr["path"], descr["isarg"]
+ if self.should_analyze_file(name, filepath, is_argument=is_arg):
+ yield FileItem(name, filepath, descr["basename"])
+
+ def _expand_files(
+ self, files_or_modules: Sequence[str]
+ ) -> dict[str, ModuleDescriptionDict]:
+ """Get modules and errors from a list of modules and handle errors."""
+ result, errors = expand_modules(
+ files_or_modules,
+ self.config.source_roots,
+ self.config.ignore,
+ self.config.ignore_patterns,
+ self._ignore_paths,
+ )
+ for error in errors:
+ message = modname = error["mod"]
+ key = error["key"]
+ self.set_current_module(modname)
+ if key == "fatal":
+ message = str(error["ex"]).replace(os.getcwd() + os.sep, "")
+ self.add_message(key, args=message)
+ return result
+
+ def set_current_module(self, modname: str, filepath: str | None = None) -> None:
+ """Set the name of the currently analyzed module and
+ init statistics for it.
+ """
+ if not modname and filepath is None:
+ return
+ self.reporter.on_set_current_module(modname or "", filepath)
+ self.current_name = modname
+ self.current_file = filepath or modname
+ self.stats.init_single_module(modname or "")
+
+ # If there is an actual filepath we might need to update the config attribute
+ if filepath:
+ namespace = self._get_namespace_for_file(
+ Path(filepath), self._directory_namespaces
+ )
+ if namespace:
+ self.config = namespace or self._base_config
+
+ def _get_namespace_for_file(
+ self, filepath: Path, namespaces: DirectoryNamespaceDict
+ ) -> argparse.Namespace | None:
+ for directory in namespaces:
+ if Path.is_relative_to(filepath, directory):
+ namespace = self._get_namespace_for_file(
+ filepath, namespaces[directory][1]
+ )
+ if namespace is None:
+ return namespaces[directory][0]
+ return None
+
+ @contextlib.contextmanager
+ def _astroid_module_checker(
+ self,
+ ) -> Iterator[Callable[[nodes.Module], bool | None]]:
+ """Context manager for checking ASTs.
+
+ The value in the context is callable accepting AST as its only argument.
+ """
+ walker = ASTWalker(self)
+ _checkers = self.prepare_checkers()
+ tokencheckers = [
+ c for c in _checkers if isinstance(c, checkers.BaseTokenChecker)
+ ]
+ rawcheckers = [
+ c for c in _checkers if isinstance(c, checkers.BaseRawFileChecker)
+ ]
+ for checker in _checkers:
+ checker.open()
+ walker.add_checker(checker)
+
+ yield functools.partial(
+ self.check_astroid_module,
+ walker=walker,
+ tokencheckers=tokencheckers,
+ rawcheckers=rawcheckers,
+ )
+
+ # notify global end
+ self.stats.statement = walker.nbstatements
+ for checker in reversed(_checkers):
+ checker.close()
+
+ def get_ast(
+ self, filepath: str, modname: str, data: str | None = None
+ ) -> nodes.Module | None:
+ """Return an ast(roid) representation of a module or a string.
+
+ :param filepath: path to checked file.
+ :param str modname: The name of the module to be checked.
+ :param str data: optional contents of the checked file.
+ :returns: the AST
+ :rtype: astroid.nodes.Module
+ :raises AstroidBuildingError: Whenever we encounter an unexpected exception
+ """
+ try:
+ if data is None:
+ return MANAGER.ast_from_file(filepath, modname, source=True)
+ return astroid.builder.AstroidBuilder(MANAGER).string_build(
+ data, modname, filepath
+ )
+ except astroid.AstroidSyntaxError as ex:
+ line = getattr(ex.error, "lineno", None)
+ if line is None:
+ line = 0
+ self.add_message(
+ "syntax-error",
+ line=line,
+ col_offset=getattr(ex.error, "offset", None),
+ args=f"Parsing failed: '{ex.error}'",
+ confidence=HIGH,
+ )
+ except astroid.AstroidBuildingError as ex:
+ self.add_message("parse-error", args=ex)
+ except Exception as ex:
+ traceback.print_exc()
+ # We raise BuildingError here as this is essentially an astroid issue
+ # Creating an issue template and adding the 'astroid-error' message is handled
+ # by caller: _check_files
+ raise astroid.AstroidBuildingError(
+ "Building error when trying to create ast representation of module '{modname}'",
+ modname=modname,
+ ) from ex
+ return None
+
+ def check_astroid_module(
+ self,
+ ast_node: nodes.Module,
+ walker: ASTWalker,
+ rawcheckers: list[checkers.BaseRawFileChecker],
+ tokencheckers: list[checkers.BaseTokenChecker],
+ ) -> bool | None:
+ """Check a module from its astroid representation.
+
+ For return value see _check_astroid_module
+ """
+ before_check_statements = walker.nbstatements
+
+ retval = self._check_astroid_module(
+ ast_node, walker, rawcheckers, tokencheckers
+ )
+ self.stats.by_module[self.current_name]["statement"] = (
+ walker.nbstatements - before_check_statements
+ )
+
+ return retval
+
+ def _check_astroid_module(
+ self,
+ node: nodes.Module,
+ walker: ASTWalker,
+ rawcheckers: list[checkers.BaseRawFileChecker],
+ tokencheckers: list[checkers.BaseTokenChecker],
+ ) -> bool | None:
+ """Check given AST node with given walker and checkers.
+
+ :param astroid.nodes.Module node: AST node of the module to check
+ :param pylint.utils.ast_walker.ASTWalker walker: AST walker
+ :param list rawcheckers: List of token checkers to use
+ :param list tokencheckers: List of raw checkers to use
+
+ :returns: True if the module was checked, False if ignored,
+ None if the module contents could not be parsed
+ """
+ try:
+ tokens = utils.tokenize_module(node)
+ except tokenize.TokenError as ex:
+ self.add_message(
+ "syntax-error",
+ line=ex.args[1][0],
+ col_offset=ex.args[1][1],
+ args=ex.args[0],
+ confidence=HIGH,
+ )
+ return None
+
+ if not node.pure_python:
+ self.add_message("raw-checker-failed", args=node.name)
+ else:
+ # assert astroid.file.endswith('.py')
+ # Parse module/block level option pragma's
+ self.process_tokens(tokens)
+ if self._ignore_file:
+ return False
+ # run raw and tokens checkers
+ for raw_checker in rawcheckers:
+ raw_checker.process_module(node)
+ for token_checker in tokencheckers:
+ token_checker.process_tokens(tokens)
+ # generate events to astroid checkers
+ walker.walk(node)
+ return True
+
+ def open(self) -> None:
+ """Initialize counters."""
+ MANAGER.always_load_extensions = self.config.unsafe_load_any_extension
+ MANAGER.max_inferable_values = self.config.limit_inference_results
+ MANAGER.extension_package_whitelist.update(self.config.extension_pkg_allow_list)
+ MANAGER.module_denylist.update(self.config.ignored_modules)
+ MANAGER.prefer_stubs = self.config.prefer_stubs
+ if self.config.extension_pkg_whitelist:
+ MANAGER.extension_package_whitelist.update(
+ self.config.extension_pkg_whitelist
+ )
+ self.stats.reset_message_count()
+
+ def generate_reports(self, verbose: bool = False) -> int | None:
+ """Close the whole package /module, it's time to make reports !
+
+ if persistent run, pickle results for later comparison
+ """
+ # Display whatever messages are left on the reporter.
+ self.reporter.display_messages(report_nodes.Section())
+ if not self.file_state._is_base_filestate:
+ # load previous results if any
+ previous_stats = load_results(self.file_state.base_name)
+ self.reporter.on_close(self.stats, previous_stats)
+ if self.config.reports:
+ sect = self.make_reports(self.stats, previous_stats)
+ else:
+ sect = report_nodes.Section()
+
+ if self.config.reports:
+ self.reporter.display_reports(sect)
+ score_value = self._report_evaluation(verbose)
+ # save results if persistent run
+ if self.config.persistent:
+ save_results(self.stats, self.file_state.base_name)
+ else:
+ self.reporter.on_close(self.stats, LinterStats())
+ score_value = None
+ return score_value
+
+ def _report_evaluation(self, verbose: bool = False) -> int | None:
+ """Make the global evaluation report."""
+ # check with at least a statement (usually 0 when there is a
+ # syntax error preventing pylint from further processing)
+ note = None
+ previous_stats = load_results(self.file_state.base_name)
+ if self.stats.statement == 0:
+ return note
+
+ # get a global note for the code
+ evaluation = self.config.evaluation
+ try:
+ stats_dict = {
+ "fatal": self.stats.fatal,
+ "error": self.stats.error,
+ "warning": self.stats.warning,
+ "refactor": self.stats.refactor,
+ "convention": self.stats.convention,
+ "statement": self.stats.statement,
+ "info": self.stats.info,
+ }
+ note = eval(evaluation, {}, stats_dict) # pylint: disable=eval-used
+ except Exception as ex: # pylint: disable=broad-except
+ msg = f"An exception occurred while rating: {ex}"
+ else:
+ self.stats.global_note = note
+ msg = f"Your code has been rated at {note:.2f}/10"
+ if previous_stats:
+ pnote = previous_stats.global_note
+ if pnote is not None:
+ msg += f" (previous run: {pnote:.2f}/10, {note - pnote:+.2f})"
+
+ if verbose:
+ checked_files_count = self.stats.node_count["module"]
+ unchecked_files_count = self.stats.undocumented["module"]
+ msg += f"\nChecked {checked_files_count} files, skipped {unchecked_files_count} files"
+
+ if self.config.score:
+ sect = report_nodes.EvaluationSection(msg)
+ self.reporter.display_reports(sect)
+ return note
+
+ def _add_one_message(
+ self,
+ message_definition: MessageDefinition,
+ line: int | None,
+ node: nodes.NodeNG | None,
+ args: Any | None,
+ confidence: interfaces.Confidence | None,
+ col_offset: int | None,
+ end_lineno: int | None,
+ end_col_offset: int | None,
+ ) -> None:
+ """After various checks have passed a single Message is
+ passed to the reporter and added to stats.
+ """
+ message_definition.check_message_definition(line, node)
+
+ # Look up "location" data of node if not yet supplied
+ if node:
+ if node.position:
+ if not line:
+ line = node.position.lineno
+ if not col_offset:
+ col_offset = node.position.col_offset
+ if not end_lineno:
+ end_lineno = node.position.end_lineno
+ if not end_col_offset:
+ end_col_offset = node.position.end_col_offset
+ else:
+ if not line:
+ line = node.fromlineno
+ if not col_offset:
+ col_offset = node.col_offset
+ if not end_lineno:
+ end_lineno = node.end_lineno
+ if not end_col_offset:
+ end_col_offset = node.end_col_offset
+
+ # should this message be displayed
+ if not self.is_message_enabled(message_definition.msgid, line, confidence):
+ self.file_state.handle_ignored_message(
+ self._get_message_state_scope(
+ message_definition.msgid, line, confidence
+ ),
+ message_definition.msgid,
+ line,
+ )
+ return
+
+ # update stats
+ msg_cat = MSG_TYPES[message_definition.msgid[0]]
+ self.msg_status |= MSG_TYPES_STATUS[message_definition.msgid[0]]
+ self.stats.increase_single_message_count(msg_cat, 1)
+ self.stats.increase_single_module_message_count(self.current_name, msg_cat, 1)
+ try:
+ self.stats.by_msg[message_definition.symbol] += 1
+ except KeyError:
+ self.stats.by_msg[message_definition.symbol] = 1
+ # Interpolate arguments into message string
+ msg = message_definition.msg
+ if args is not None:
+ msg %= args
+ # get module and object
+ if node is None:
+ module, obj = self.current_name, ""
+ abspath = self.current_file
+ else:
+ module, obj = utils.get_module_and_frameid(node)
+ abspath = node.root().file
+ if abspath is not None:
+ path = abspath.replace(self.reporter.path_strip_prefix, "", 1)
+ else:
+ path = "configuration"
+ # add the message
+ self.reporter.handle_message(
+ Message(
+ message_definition.msgid,
+ message_definition.symbol,
+ MessageLocationTuple(
+ abspath or "",
+ path,
+ module or "",
+ obj,
+ line or 1,
+ col_offset or 0,
+ end_lineno,
+ end_col_offset,
+ ),
+ msg,
+ confidence,
+ )
+ )
+
+ def add_message(
+ self,
+ msgid: str,
+ line: int | None = None,
+ node: nodes.NodeNG | None = None,
+ args: Any | None = None,
+ confidence: interfaces.Confidence | None = None,
+ col_offset: int | None = None,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """Adds a message given by ID or name.
+
+ If provided, the message string is expanded using args.
+
+ AST checkers must provide the node argument (but may optionally
+ provide line if the line number is different), raw and token checkers
+ must provide the line argument.
+ """
+ if confidence is None:
+ confidence = interfaces.UNDEFINED
+ message_definitions = self.msgs_store.get_message_definitions(msgid)
+ for message_definition in message_definitions:
+ self._add_one_message(
+ message_definition,
+ line,
+ node,
+ args,
+ confidence,
+ col_offset,
+ end_lineno,
+ end_col_offset,
+ )
+
+ def add_ignored_message(
+ self,
+ msgid: str,
+ line: int,
+ node: nodes.NodeNG | None = None,
+ confidence: interfaces.Confidence | None = interfaces.UNDEFINED,
+ ) -> None:
+ """Prepares a message to be added to the ignored message storage.
+
+ Some checks return early in special cases and never reach add_message(),
+ even though they would normally issue a message.
+ This creates false positives for useless-suppression.
+ This function avoids this by adding those message to the ignored msgs attribute
+ """
+ message_definitions = self.msgs_store.get_message_definitions(msgid)
+ for message_definition in message_definitions:
+ message_definition.check_message_definition(line, node)
+ self.file_state.handle_ignored_message(
+ self._get_message_state_scope(
+ message_definition.msgid, line, confidence
+ ),
+ message_definition.msgid,
+ line,
+ )
+
+ def _emit_stashed_messages(self) -> None:
+ for keys, values in self._stashed_messages.items():
+ modname, symbol = keys
+ self.linter.set_current_module(modname)
+ for args in values:
+ self.add_message(
+ symbol,
+ args=args,
+ line=0,
+ confidence=HIGH,
+ )
+ self._stashed_messages = collections.defaultdict(list)
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/report_functions.py b/solutions/.venv/Lib/site-packages/pylint/lint/report_functions.py
new file mode 100644
index 000000000..72734e468
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/report_functions.py
@@ -0,0 +1,88 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import collections
+from collections import defaultdict
+from typing import cast
+
+from pylint import checkers, exceptions
+from pylint.reporters.ureports.nodes import Section, Table
+from pylint.typing import MessageTypesFullName
+from pylint.utils import LinterStats
+
+
+def report_total_messages_stats(
+ sect: Section,
+ stats: LinterStats,
+ previous_stats: LinterStats | None,
+) -> None:
+ """Make total errors / warnings report."""
+ lines = ["type", "number", "previous", "difference"]
+ lines += checkers.table_lines_from_stats(stats, previous_stats, "message_types")
+ sect.append(Table(children=lines, cols=4, rheaders=1))
+
+
+def report_messages_stats(
+ sect: Section,
+ stats: LinterStats,
+ _: LinterStats | None,
+) -> None:
+ """Make messages type report."""
+ by_msg_stats = stats.by_msg
+ in_order = sorted(
+ (value, msg_id)
+ for msg_id, value in by_msg_stats.items()
+ if not msg_id.startswith("I")
+ )
+ in_order.reverse()
+ lines = ["message id", "occurrences"]
+ for value, msg_id in in_order:
+ lines += [msg_id, str(value)]
+ sect.append(Table(children=lines, cols=2, rheaders=1))
+
+
+def report_messages_by_module_stats(
+ sect: Section,
+ stats: LinterStats,
+ _: LinterStats | None,
+) -> None:
+ """Make errors / warnings by modules report."""
+ module_stats = stats.by_module
+ if len(module_stats) == 1:
+ # don't print this report when we are analysing a single module
+ raise exceptions.EmptyReportError()
+ by_mod: defaultdict[str, dict[str, int | float]] = collections.defaultdict(dict)
+ for m_type in ("fatal", "error", "warning", "refactor", "convention"):
+ m_type = cast(MessageTypesFullName, m_type)
+ total = stats.get_global_message_count(m_type)
+ for module in module_stats.keys():
+ mod_total = stats.get_module_message_count(module, m_type)
+ percent = 0 if total == 0 else float(mod_total * 100) / total
+ by_mod[module][m_type] = percent
+ sorted_result = []
+ for module, mod_info in by_mod.items():
+ sorted_result.append(
+ (
+ mod_info["error"],
+ mod_info["warning"],
+ mod_info["refactor"],
+ mod_info["convention"],
+ module,
+ )
+ )
+ sorted_result.sort()
+ sorted_result.reverse()
+ lines = ["module", "error", "warning", "refactor", "convention"]
+ for line in sorted_result:
+ # Don't report clean modules.
+ if all(entry == 0 for entry in line[:-1]):
+ continue
+ lines.append(line[-1])
+ for val in line[:-1]:
+ lines.append(f"{val:.2f}")
+ if len(lines) == 5:
+ raise exceptions.EmptyReportError()
+ sect.append(Table(children=lines, cols=5, rheaders=1))
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/run.py b/solutions/.venv/Lib/site-packages/pylint/lint/run.py
new file mode 100644
index 000000000..2bbbb337b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/run.py
@@ -0,0 +1,246 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import os
+import sys
+import warnings
+from collections.abc import Sequence
+from pathlib import Path
+from typing import ClassVar
+
+from pylint import config
+from pylint.checkers.utils import clear_lru_caches
+from pylint.config._pylint_config import (
+ _handle_pylint_config_commands,
+ _register_generate_config_options,
+)
+from pylint.config.config_initialization import _config_initialization
+from pylint.config.exceptions import ArgumentPreprocessingError
+from pylint.config.utils import _preprocess_options
+from pylint.constants import full_version
+from pylint.lint.base_options import _make_run_options
+from pylint.lint.pylinter import MANAGER, PyLinter
+from pylint.reporters.base_reporter import BaseReporter
+
+try:
+ import multiprocessing
+ from multiprocessing import synchronize # noqa pylint: disable=unused-import
+except ImportError:
+ multiprocessing = None # type: ignore[assignment]
+
+try:
+ from concurrent.futures import ProcessPoolExecutor
+except ImportError:
+ ProcessPoolExecutor = None # type: ignore[assignment,misc]
+
+
+def _query_cpu() -> int | None:
+ """Try to determine number of CPUs allotted in a docker container.
+
+ This is based on discussion and copied from suggestions in
+ https://bugs.python.org/issue36054.
+ """
+ cpu_quota, avail_cpu = None, None
+
+ if Path("/sys/fs/cgroup/cpu/cpu.cfs_quota_us").is_file():
+ with open("/sys/fs/cgroup/cpu/cpu.cfs_quota_us", encoding="utf-8") as file:
+ # Not useful for AWS Batch based jobs as result is -1, but works on local linux systems
+ cpu_quota = int(file.read().rstrip())
+
+ if (
+ cpu_quota
+ and cpu_quota != -1
+ and Path("/sys/fs/cgroup/cpu/cpu.cfs_period_us").is_file()
+ ):
+ with open("/sys/fs/cgroup/cpu/cpu.cfs_period_us", encoding="utf-8") as file:
+ cpu_period = int(file.read().rstrip())
+ # Divide quota by period and you should get num of allotted CPU to the container,
+ # rounded down if fractional.
+ avail_cpu = int(cpu_quota / cpu_period)
+ elif Path("/sys/fs/cgroup/cpu/cpu.shares").is_file():
+ with open("/sys/fs/cgroup/cpu/cpu.shares", encoding="utf-8") as file:
+ cpu_shares = int(file.read().rstrip())
+ # For AWS, gives correct value * 1024.
+ avail_cpu = int(cpu_shares / 1024)
+
+ # In K8s Pods also a fraction of a single core could be available
+ # As multiprocessing is not able to run only a "fraction" of process
+ # assume we have 1 CPU available
+ if avail_cpu == 0:
+ avail_cpu = 1
+
+ return avail_cpu
+
+
+def _cpu_count() -> int:
+ """Use sched_affinity if available for virtualized or containerized
+ environments.
+ """
+ cpu_share = _query_cpu()
+ cpu_count = None
+ sched_getaffinity = getattr(os, "sched_getaffinity", None)
+ # pylint: disable=not-callable,using-constant-test,useless-suppression
+ if sched_getaffinity:
+ cpu_count = len(sched_getaffinity(0))
+ elif multiprocessing:
+ cpu_count = multiprocessing.cpu_count()
+ else:
+ cpu_count = 1
+ if sys.platform == "win32":
+ # See also https://github.com/python/cpython/issues/94242
+ cpu_count = min(cpu_count, 56) # pragma: no cover
+ if cpu_share is not None:
+ return min(cpu_share, cpu_count)
+ return cpu_count
+
+
+class Run:
+ """Helper class to use as main for pylint with 'run(*sys.argv[1:])'."""
+
+ LinterClass = PyLinter
+ option_groups = (
+ (
+ "Commands",
+ "Options which are actually commands. Options in this \
+group are mutually exclusive.",
+ ),
+ )
+ _is_pylint_config: ClassVar[bool] = False
+ """Boolean whether or not this is a 'pylint-config' run.
+
+ Used by _PylintConfigRun to make the 'pylint-config' command work.
+ """
+
+ # pylint: disable = too-many-statements, too-many-branches
+ def __init__(
+ self,
+ args: Sequence[str],
+ reporter: BaseReporter | None = None,
+ exit: bool = True, # pylint: disable=redefined-builtin
+ ) -> None:
+ # Immediately exit if user asks for version
+ if "--version" in args:
+ print(full_version)
+ sys.exit(0)
+
+ self._rcfile: str | None = None
+ self._output: str | None = None
+ self._plugins: list[str] = []
+ self.verbose: bool = False
+
+ # Pre-process certain options and remove them from args list
+ try:
+ args = _preprocess_options(self, args)
+ except ArgumentPreprocessingError as ex:
+ print(ex, file=sys.stderr)
+ sys.exit(32)
+
+ # Determine configuration file
+ if self._rcfile is None:
+ default_file = next(config.find_default_config_files(), None)
+ if default_file:
+ self._rcfile = str(default_file)
+
+ self.linter = linter = self.LinterClass(
+ _make_run_options(self),
+ option_groups=self.option_groups,
+ pylintrc=self._rcfile,
+ )
+ # register standard checkers
+ linter.load_default_plugins()
+ # load command line plugins
+ linter.load_plugin_modules(self._plugins)
+
+ # Register the options needed for 'pylint-config'
+ # By not registering them by default they don't show up in the normal usage message
+ if self._is_pylint_config:
+ _register_generate_config_options(linter._arg_parser)
+
+ args = _config_initialization(
+ linter, args, reporter, config_file=self._rcfile, verbose_mode=self.verbose
+ )
+
+ # Handle the 'pylint-config' command
+ if self._is_pylint_config:
+ warnings.warn(
+ "NOTE: The 'pylint-config' command is experimental and usage can change",
+ UserWarning,
+ stacklevel=2,
+ )
+ code = _handle_pylint_config_commands(linter)
+ if exit:
+ sys.exit(code)
+ return
+
+ # Display help if there are no files to lint or only internal checks enabled (`--disable=all`)
+ disable_all_msg_set = set(
+ msg.symbol for msg in linter.msgs_store.messages
+ ) - set(msg[1] for msg in linter.default_enabled_messages.values())
+ if not args or (
+ len(linter.config.enable) == 0
+ and set(linter.config.disable) == disable_all_msg_set
+ ):
+ print("No files to lint: exiting.")
+ sys.exit(32)
+
+ if linter.config.jobs < 0:
+ print(
+ f"Jobs number ({linter.config.jobs}) should be greater than or equal to 0",
+ file=sys.stderr,
+ )
+ sys.exit(32)
+ if linter.config.jobs > 1 or linter.config.jobs == 0:
+ if ProcessPoolExecutor is None:
+ print(
+ "concurrent.futures module is missing, fallback to single process",
+ file=sys.stderr,
+ )
+ linter.set_option("jobs", 1)
+ elif linter.config.jobs == 0:
+ linter.config.jobs = _cpu_count()
+
+ if self._output:
+ try:
+ with open(self._output, "w", encoding="utf-8") as output:
+ linter.reporter.out = output
+ linter.check(args)
+ score_value = linter.generate_reports(verbose=self.verbose)
+ except OSError as ex:
+ print(ex, file=sys.stderr)
+ sys.exit(32)
+ else:
+ linter.check(args)
+ score_value = linter.generate_reports(verbose=self.verbose)
+ if linter.config.clear_cache_post_run:
+ clear_lru_caches()
+ MANAGER.clear_cache()
+
+ if exit:
+ if linter.config.exit_zero:
+ sys.exit(0)
+ elif linter.any_fail_on_issues():
+ # We need to make sure we return a failing exit code in this case.
+ # So we use self.linter.msg_status if that is non-zero, otherwise we just return 1.
+ sys.exit(self.linter.msg_status or 1)
+ elif score_value is not None:
+ if score_value >= linter.config.fail_under:
+ sys.exit(0)
+ else:
+ # We need to make sure we return a failing exit code in this case.
+ # So we use self.linter.msg_status if that is non-zero, otherwise we just return 1.
+ sys.exit(self.linter.msg_status or 1)
+ else:
+ sys.exit(self.linter.msg_status)
+
+
+class _PylintConfigRun(Run):
+ """A private wrapper for the 'pylint-config' command."""
+
+ _is_pylint_config: ClassVar[bool] = True
+ """Boolean whether or not this is a 'pylint-config' run.
+
+ Used by _PylintConfigRun to make the 'pylint-config' command work.
+ """
diff --git a/solutions/.venv/Lib/site-packages/pylint/lint/utils.py b/solutions/.venv/Lib/site-packages/pylint/lint/utils.py
new file mode 100644
index 000000000..c5487a8c6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/lint/utils.py
@@ -0,0 +1,135 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import contextlib
+import platform
+import sys
+import traceback
+from collections.abc import Iterator, Sequence
+from datetime import datetime
+from pathlib import Path
+
+from pylint.constants import PYLINT_HOME, full_version
+
+
+def prepare_crash_report(ex: Exception, filepath: str, crash_file_path: str) -> Path:
+ issue_template_path = (
+ Path(PYLINT_HOME) / datetime.now().strftime(str(crash_file_path))
+ ).resolve()
+ with open(filepath, encoding="utf8") as f:
+ file_content = f.read()
+ template = ""
+ if not issue_template_path.exists():
+ template = """\
+First, please verify that the bug is not already filled:
+https://github.com/pylint-dev/pylint/issues/
+
+Then create a new issue:
+https://github.com/pylint-dev/pylint/issues/new?labels=Crash 💥%2CNeeds triage 📥
+
+
+"""
+ template += f"""
+Issue title:
+Crash ``{ex}`` (if possible, be more specific about what made pylint crash)
+
+### Bug description
+
+When parsing the following ``a.py``:
+
+<!--
+ If sharing the code is not an option, please state so,
+ but providing only the stacktrace would still be helpful.
+ -->
+
+```python
+{file_content}
+```
+
+### Command used
+
+```shell
+pylint a.py
+```
+
+### Pylint output
+
+<details open>
+ <summary>
+ pylint crashed with a ``{ex.__class__.__name__}`` and with the following stacktrace:
+ </summary>
+
+```python
+"""
+ template += traceback.format_exc()
+ template += f"""
+```
+
+
+</details>
+
+### Expected behavior
+
+No crash.
+
+### Pylint version
+
+```shell
+{full_version}
+```
+
+### OS / Environment
+
+{sys.platform} ({platform.system()})
+
+### Additional dependencies
+
+<!--
+Please remove this part if you're not using any of
+your dependencies in the example.
+ -->
+"""
+ try:
+ with open(issue_template_path, "a", encoding="utf8") as f:
+ f.write(template)
+ except Exception as exc: # pylint: disable=broad-except
+ print(
+ f"Can't write the issue template for the crash in {issue_template_path} "
+ f"because of: '{exc}'\nHere's the content anyway:\n{template}.",
+ file=sys.stderr,
+ )
+ return issue_template_path
+
+
+def get_fatal_error_message(filepath: str, issue_template_path: Path) -> str:
+ return (
+ f"Fatal error while checking '{filepath}'. "
+ f"Please open an issue in our bug tracker so we address this. "
+ f"There is a pre-filled template that you can use in '{issue_template_path}'."
+ )
+
+
+def _augment_sys_path(additional_paths: Sequence[str]) -> list[str]:
+ original = list(sys.path)
+ changes = []
+ seen = set()
+ for additional_path in additional_paths:
+ if additional_path not in seen:
+ changes.append(additional_path)
+ seen.add(additional_path)
+
+ sys.path[:] = changes + sys.path
+ return original
+
+
+@contextlib.contextmanager
+def augmented_sys_path(additional_paths: Sequence[str]) -> Iterator[None]:
+ """Augment 'sys.path' by adding non-existent entries from additional_paths."""
+ original = _augment_sys_path(additional_paths)
+ try:
+ yield
+ finally:
+ sys.path[:] = original
diff --git a/solutions/.venv/Lib/site-packages/pylint/message/__init__.py b/solutions/.venv/Lib/site-packages/pylint/message/__init__.py
new file mode 100644
index 000000000..6fa8e44b7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/message/__init__.py
@@ -0,0 +1,17 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""All the classes related to Message handling."""
+
+from pylint.message.message import Message
+from pylint.message.message_definition import MessageDefinition
+from pylint.message.message_definition_store import MessageDefinitionStore
+from pylint.message.message_id_store import MessageIdStore
+
+__all__ = [
+ "Message",
+ "MessageDefinition",
+ "MessageDefinitionStore",
+ "MessageIdStore",
+]
diff --git a/solutions/.venv/Lib/site-packages/pylint/message/_deleted_message_ids.py b/solutions/.venv/Lib/site-packages/pylint/message/_deleted_message_ids.py
new file mode 100644
index 000000000..149a800b7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/message/_deleted_message_ids.py
@@ -0,0 +1,179 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from functools import cache
+from typing import NamedTuple
+
+
+class DeletedMessage(NamedTuple):
+ msgid: str
+ symbol: str
+ old_names: list[tuple[str, str]] = []
+
+
+DELETED_MSGID_PREFIXES: list[int] = []
+
+DELETED_MESSAGES_IDS = {
+ # Everything until the next comment is from the PY3K+ checker
+ "https://github.com/pylint-dev/pylint/pull/4942": [
+ DeletedMessage("W1601", "apply-builtin"),
+ DeletedMessage("E1601", "print-statement"),
+ DeletedMessage("E1602", "parameter-unpacking"),
+ DeletedMessage(
+ "E1603", "unpacking-in-except", [("W0712", "old-unpacking-in-except")]
+ ),
+ DeletedMessage(
+ "E1604", "old-raise-syntax", [("W0121", "old-old-raise-syntax")]
+ ),
+ DeletedMessage("E1605", "backtick", [("W0333", "old-backtick")]),
+ DeletedMessage("E1609", "import-star-module-level"),
+ DeletedMessage("W1601", "apply-builtin"),
+ DeletedMessage("W1602", "basestring-builtin"),
+ DeletedMessage("W1603", "buffer-builtin"),
+ DeletedMessage("W1604", "cmp-builtin"),
+ DeletedMessage("W1605", "coerce-builtin"),
+ DeletedMessage("W1606", "execfile-builtin"),
+ DeletedMessage("W1607", "file-builtin"),
+ DeletedMessage("W1608", "long-builtin"),
+ DeletedMessage("W1609", "raw_input-builtin"),
+ DeletedMessage("W1610", "reduce-builtin"),
+ DeletedMessage("W1611", "standarderror-builtin"),
+ DeletedMessage("W1612", "unicode-builtin"),
+ DeletedMessage("W1613", "xrange-builtin"),
+ DeletedMessage("W1614", "coerce-method"),
+ DeletedMessage("W1615", "delslice-method"),
+ DeletedMessage("W1616", "getslice-method"),
+ DeletedMessage("W1617", "setslice-method"),
+ DeletedMessage("W1618", "no-absolute-import"),
+ DeletedMessage("W1619", "old-division"),
+ DeletedMessage("W1620", "dict-iter-method"),
+ DeletedMessage("W1621", "dict-view-method"),
+ DeletedMessage("W1622", "next-method-called"),
+ DeletedMessage("W1623", "metaclass-assignment"),
+ DeletedMessage(
+ "W1624", "indexing-exception", [("W0713", "old-indexing-exception")]
+ ),
+ DeletedMessage("W1625", "raising-string", [("W0701", "old-raising-string")]),
+ DeletedMessage("W1626", "reload-builtin"),
+ DeletedMessage("W1627", "oct-method"),
+ DeletedMessage("W1628", "hex-method"),
+ DeletedMessage("W1629", "nonzero-method"),
+ DeletedMessage("W1630", "cmp-method"),
+ DeletedMessage("W1632", "input-builtin"),
+ DeletedMessage("W1633", "round-builtin"),
+ DeletedMessage("W1634", "intern-builtin"),
+ DeletedMessage("W1635", "unichr-builtin"),
+ DeletedMessage(
+ "W1636", "map-builtin-not-iterating", [("W1631", "implicit-map-evaluation")]
+ ),
+ DeletedMessage("W1637", "zip-builtin-not-iterating"),
+ DeletedMessage("W1638", "range-builtin-not-iterating"),
+ DeletedMessage("W1639", "filter-builtin-not-iterating"),
+ DeletedMessage("W1640", "using-cmp-argument"),
+ DeletedMessage("W1642", "div-method"),
+ DeletedMessage("W1643", "idiv-method"),
+ DeletedMessage("W1644", "rdiv-method"),
+ DeletedMessage("W1645", "exception-message-attribute"),
+ DeletedMessage("W1646", "invalid-str-codec"),
+ DeletedMessage("W1647", "sys-max-int"),
+ DeletedMessage("W1648", "bad-python3-import"),
+ DeletedMessage("W1649", "deprecated-string-function"),
+ DeletedMessage("W1650", "deprecated-str-translate-call"),
+ DeletedMessage("W1651", "deprecated-itertools-function"),
+ DeletedMessage("W1652", "deprecated-types-field"),
+ DeletedMessage("W1653", "next-method-defined"),
+ DeletedMessage("W1654", "dict-items-not-iterating"),
+ DeletedMessage("W1655", "dict-keys-not-iterating"),
+ DeletedMessage("W1656", "dict-values-not-iterating"),
+ DeletedMessage("W1657", "deprecated-operator-function"),
+ DeletedMessage("W1658", "deprecated-urllib-function"),
+ DeletedMessage("W1659", "xreadlines-attribute"),
+ DeletedMessage("W1660", "deprecated-sys-function"),
+ DeletedMessage("W1661", "exception-escape"),
+ DeletedMessage("W1662", "comprehension-escape"),
+ ],
+ "https://github.com/pylint-dev/pylint/pull/3578": [
+ DeletedMessage("W0312", "mixed-indentation"),
+ ],
+ "https://github.com/pylint-dev/pylint/pull/3577": [
+ DeletedMessage(
+ "C0326",
+ "bad-whitespace",
+ [
+ ("C0323", "no-space-after-operator"),
+ ("C0324", "no-space-after-comma"),
+ ("C0322", "no-space-before-operator"),
+ ],
+ ),
+ ],
+ "https://github.com/pylint-dev/pylint/pull/3571": [
+ DeletedMessage("C0330", "bad-continuation")
+ ],
+ "https://pylint.readthedocs.io/en/latest/whatsnew/1/1.4.html#what-s-new-in-pylint-1-4-3": [
+ DeletedMessage("R0921", "abstract-class-not-used"),
+ DeletedMessage("R0922", "abstract-class-little-used"),
+ DeletedMessage("W0142", "star-args"),
+ ],
+ "https://github.com/pylint-dev/pylint/issues/2409": [
+ DeletedMessage("W0232", "no-init"),
+ ],
+ "https://github.com/pylint-dev/pylint/pull/6421": [
+ DeletedMessage("W0111", "assign-to-new-keyword"),
+ ],
+}
+MOVED_TO_EXTENSIONS = {
+ "https://pylint.readthedocs.io/en/latest/whatsnew/2/2.14/summary.html#removed-checkers": [
+ DeletedMessage("R0201", "no-self-use")
+ ],
+}
+
+
+@cache
+def is_deleted_symbol(symbol: str) -> str | None:
+ """Return the explanation for removal if the message was removed."""
+ for explanation, deleted_messages in DELETED_MESSAGES_IDS.items():
+ for deleted_message in deleted_messages:
+ if symbol == deleted_message.symbol or any(
+ symbol == m[1] for m in deleted_message.old_names
+ ):
+ return explanation
+ return None
+
+
+@cache
+def is_deleted_msgid(msgid: str) -> str | None:
+ """Return the explanation for removal if the message was removed."""
+ for explanation, deleted_messages in DELETED_MESSAGES_IDS.items():
+ for deleted_message in deleted_messages:
+ if msgid == deleted_message.msgid or any(
+ msgid == m[0] for m in deleted_message.old_names
+ ):
+ return explanation
+ return None
+
+
+@cache
+def is_moved_symbol(symbol: str) -> str | None:
+ """Return the explanation for moving if the message was moved to extensions."""
+ for explanation, moved_messages in MOVED_TO_EXTENSIONS.items():
+ for moved_message in moved_messages:
+ if symbol == moved_message.symbol or any(
+ symbol == m[1] for m in moved_message.old_names
+ ):
+ return explanation
+ return None
+
+
+@cache
+def is_moved_msgid(msgid: str) -> str | None:
+ """Return the explanation for moving if the message was moved to extensions."""
+ for explanation, moved_messages in MOVED_TO_EXTENSIONS.items():
+ for moved_message in moved_messages:
+ if msgid == moved_message.msgid or any(
+ msgid == m[0] for m in moved_message.old_names
+ ):
+ return explanation
+ return None
diff --git a/solutions/.venv/Lib/site-packages/pylint/message/message.py b/solutions/.venv/Lib/site-packages/pylint/message/message.py
new file mode 100644
index 000000000..6ee8c5f78
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/message/message.py
@@ -0,0 +1,75 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from dataclasses import asdict, dataclass
+
+from pylint.constants import MSG_TYPES
+from pylint.interfaces import UNDEFINED, Confidence
+from pylint.typing import MessageLocationTuple
+
+
+@dataclass(unsafe_hash=True)
+class Message: # pylint: disable=too-many-instance-attributes
+ """This class represent a message to be issued by the reporters."""
+
+ msg_id: str
+ symbol: str
+ msg: str
+ C: str
+ category: str
+ confidence: Confidence
+ abspath: str
+ path: str
+ module: str
+ obj: str
+ line: int
+ column: int
+ end_line: int | None
+ end_column: int | None
+
+ def __init__(
+ self,
+ msg_id: str,
+ symbol: str,
+ location: MessageLocationTuple,
+ msg: str,
+ confidence: Confidence | None,
+ ) -> None:
+ self.msg_id = msg_id
+ self.symbol = symbol
+ self.msg = msg
+ self.C = msg_id[0]
+ self.category = MSG_TYPES[msg_id[0]]
+ self.confidence = confidence or UNDEFINED
+ self.abspath = location.abspath
+ self.path = location.path
+ self.module = location.module
+ self.obj = location.obj
+ self.line = location.line
+ self.column = location.column
+ self.end_line = location.end_line
+ self.end_column = location.end_column
+
+ def format(self, template: str) -> str:
+ """Format the message according to the given template.
+
+ The template format is the one of the format method :
+ cf. https://docs.python.org/2/library/string.html#formatstrings
+ """
+ return template.format(**asdict(self))
+
+ @property
+ def location(self) -> MessageLocationTuple:
+ return MessageLocationTuple(
+ self.abspath,
+ self.path,
+ self.module,
+ self.obj,
+ self.line,
+ self.column,
+ self.end_line,
+ self.end_column,
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/message/message_definition.py b/solutions/.venv/Lib/site-packages/pylint/message/message_definition.py
new file mode 100644
index 000000000..a318cc83f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/message/message_definition.py
@@ -0,0 +1,131 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import sys
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+from pylint.constants import _SCOPE_EXEMPT, MSG_TYPES, WarningScope
+from pylint.exceptions import InvalidMessageError
+from pylint.utils import normalize_text
+
+if TYPE_CHECKING:
+ from pylint.checkers import BaseChecker
+
+
+class MessageDefinition:
+ # pylint: disable-next=too-many-arguments
+ def __init__(
+ self,
+ checker: BaseChecker,
+ msgid: str,
+ msg: str,
+ description: str,
+ symbol: str,
+ scope: str,
+ minversion: tuple[int, int] | None = None,
+ maxversion: tuple[int, int] | None = None,
+ old_names: list[tuple[str, str]] | None = None,
+ shared: bool = False,
+ default_enabled: bool = True,
+ ) -> None:
+ self.checker_name = checker.name
+ self.check_msgid(msgid)
+ self.msgid = msgid
+ self.symbol = symbol
+ self.msg = msg
+ self.description = description
+ self.scope = scope
+ self.minversion = minversion
+ self.maxversion = maxversion
+ self.shared = shared
+ self.default_enabled = default_enabled
+ self.old_names: list[tuple[str, str]] = []
+ if old_names:
+ for old_msgid, old_symbol in old_names:
+ self.check_msgid(old_msgid)
+ self.old_names.append(
+ (old_msgid, old_symbol),
+ )
+
+ @staticmethod
+ def check_msgid(msgid: str) -> None:
+ if len(msgid) != 5:
+ raise InvalidMessageError(f"Invalid message id {msgid!r}")
+ if msgid[0] not in MSG_TYPES:
+ raise InvalidMessageError(f"Bad message type {msgid[0]} in {msgid!r}")
+
+ def __eq__(self, other: object) -> bool:
+ return (
+ isinstance(other, MessageDefinition)
+ and self.msgid == other.msgid
+ and self.symbol == other.symbol
+ )
+
+ def __repr__(self) -> str:
+ return f"MessageDefinition:{self.symbol} ({self.msgid})"
+
+ def __str__(self) -> str:
+ return f"{self!r}:\n{self.msg} {self.description}"
+
+ def may_be_emitted(self, py_version: tuple[int, ...] | sys._version_info) -> bool:
+ """May the message be emitted using the configured py_version?"""
+ if self.minversion is not None and self.minversion > py_version:
+ return False
+ if self.maxversion is not None and self.maxversion <= py_version:
+ return False
+ return True
+
+ def format_help(self, checkerref: bool = False) -> str:
+ """Return the help string for the given message id."""
+ desc = self.description
+ if checkerref:
+ desc += f" This message belongs to the {self.checker_name} checker."
+ title = self.msg
+ if self.minversion or self.maxversion:
+ restr = []
+ if self.minversion:
+ restr.append(f"< {'.'.join(str(n) for n in self.minversion)}")
+ if self.maxversion:
+ restr.append(f">= {'.'.join(str(n) for n in self.maxversion)}")
+ restriction = " or ".join(restr)
+ if checkerref:
+ desc += f" It can't be emitted when using Python {restriction}."
+ else:
+ desc += (
+ f" This message can't be emitted when using Python {restriction}."
+ )
+ msg_help = normalize_text(" ".join(desc.split()), indent=" ")
+ message_id = f"{self.symbol} ({self.msgid})"
+ if title != "%s":
+ title = title.splitlines()[0]
+ return f":{message_id}: *{title.rstrip(' ')}*\n{msg_help}"
+ return f":{message_id}:\n{msg_help}"
+
+ def check_message_definition(
+ self, line: int | None, node: nodes.NodeNG | None
+ ) -> None:
+ """Check MessageDefinition for possible errors."""
+ if self.msgid[0] not in _SCOPE_EXEMPT:
+ # Fatal messages and reports are special, the node/scope distinction
+ # does not apply to them.
+ if self.scope == WarningScope.LINE:
+ if line is None:
+ raise InvalidMessageError(
+ f"Message {self.msgid} must provide line, got None"
+ )
+ if node is not None:
+ raise InvalidMessageError(
+ f"Message {self.msgid} must only provide line, "
+ f"got line={line}, node={node}"
+ )
+ elif self.scope == WarningScope.NODE:
+ # Node-based warnings may provide an override line.
+ if node is None:
+ raise InvalidMessageError(
+ f"Message {self.msgid} must provide Node, got None"
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/message/message_definition_store.py b/solutions/.venv/Lib/site-packages/pylint/message/message_definition_store.py
new file mode 100644
index 000000000..d56308541
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/message/message_definition_store.py
@@ -0,0 +1,118 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import collections
+import sys
+from collections.abc import Sequence, ValuesView
+from functools import cache
+from typing import TYPE_CHECKING
+
+from pylint.exceptions import UnknownMessageError
+from pylint.message.message_definition import MessageDefinition
+from pylint.message.message_id_store import MessageIdStore
+
+if TYPE_CHECKING:
+ from pylint.checkers import BaseChecker
+
+
+class MessageDefinitionStore:
+ """The messages store knows information about every possible message definition but
+ has no particular state during analysis.
+ """
+
+ def __init__(
+ self, py_version: tuple[int, ...] | sys._version_info = sys.version_info
+ ) -> None:
+ self.message_id_store: MessageIdStore = MessageIdStore()
+ # Primary registry for all active messages definitions.
+ # It contains the 1:1 mapping from msgid to MessageDefinition.
+ # Keys are msgid, values are MessageDefinition
+ self._messages_definitions: dict[str, MessageDefinition] = {}
+ # MessageDefinition kept by category
+ self._msgs_by_category: dict[str, list[str]] = collections.defaultdict(list)
+ self.py_version = py_version
+
+ @property
+ def messages(self) -> ValuesView[MessageDefinition]:
+ """The list of all active messages."""
+ return self._messages_definitions.values()
+
+ def register_messages_from_checker(self, checker: BaseChecker) -> None:
+ """Register all messages definitions from a checker."""
+ checker.check_consistency()
+ for message in checker.messages:
+ self.register_message(message)
+
+ def register_message(self, message: MessageDefinition) -> None:
+ """Register a MessageDefinition with consistency in mind."""
+ self.message_id_store.register_message_definition(
+ message.msgid, message.symbol, message.old_names
+ )
+ self._messages_definitions[message.msgid] = message
+ self._msgs_by_category[message.msgid[0]].append(message.msgid)
+
+ # Since MessageDefinitionStore is only initialized once
+ # and the arguments are relatively small we do not run the
+ # risk of creating a large memory leak.
+ # See discussion in: https://github.com/pylint-dev/pylint/pull/5673
+ @cache # pylint: disable=method-cache-max-size-none # noqa: B019
+ def get_message_definitions(self, msgid_or_symbol: str) -> list[MessageDefinition]:
+ """Returns the Message definition for either a numeric or symbolic id.
+
+ The cache has no limit as its size will likely stay minimal. For each message we store
+ about 1000 characters, so even if we would have 1000 messages the cache would only
+ take up ~= 1 Mb.
+ """
+ return [
+ self._messages_definitions[m]
+ for m in self.message_id_store.get_active_msgids(msgid_or_symbol)
+ ]
+
+ def get_msg_display_string(self, msgid_or_symbol: str) -> str:
+ """Generates a user-consumable representation of a message."""
+ message_definitions = self.get_message_definitions(msgid_or_symbol)
+ if len(message_definitions) == 1:
+ return repr(message_definitions[0].symbol)
+ return repr([md.symbol for md in message_definitions])
+
+ def help_message(self, msgids_or_symbols: Sequence[str]) -> None:
+ """Display help messages for the given message identifiers."""
+ for msgids_or_symbol in msgids_or_symbols:
+ try:
+ for message_definition in self.get_message_definitions(
+ msgids_or_symbol
+ ):
+ print(message_definition.format_help(checkerref=True))
+ print("")
+ except UnknownMessageError as ex:
+ print(ex)
+ print("")
+ continue
+
+ def list_messages(self) -> None:
+ """Output full messages list documentation in ReST format."""
+ emittable, non_emittable = self.find_emittable_messages()
+ print("Emittable messages with current interpreter:")
+ for msg in emittable:
+ print(msg.format_help(checkerref=False))
+ print("\nNon-emittable messages with current interpreter:")
+ for msg in non_emittable:
+ print(msg.format_help(checkerref=False))
+ print("")
+
+ def find_emittable_messages(
+ self,
+ ) -> tuple[list[MessageDefinition], list[MessageDefinition]]:
+ """Finds all emittable and non-emittable messages."""
+ messages = sorted(self._messages_definitions.values(), key=lambda m: m.msgid)
+ emittable = []
+ non_emittable = []
+ for message in messages:
+ if message.may_be_emitted(self.py_version):
+ emittable.append(message)
+ else:
+ non_emittable.append(message)
+ return emittable, non_emittable
diff --git a/solutions/.venv/Lib/site-packages/pylint/message/message_id_store.py b/solutions/.venv/Lib/site-packages/pylint/message/message_id_store.py
new file mode 100644
index 000000000..b07a9c3f7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/message/message_id_store.py
@@ -0,0 +1,162 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import NoReturn
+
+from pylint.exceptions import (
+ DeletedMessageError,
+ InvalidMessageError,
+ MessageBecameExtensionError,
+ UnknownMessageError,
+)
+from pylint.message._deleted_message_ids import (
+ is_deleted_msgid,
+ is_deleted_symbol,
+ is_moved_msgid,
+ is_moved_symbol,
+)
+
+
+class MessageIdStore:
+ """The MessageIdStore store MessageId and make sure that there is a 1-1 relation
+ between msgid and symbol.
+ """
+
+ def __init__(self) -> None:
+ self.__msgid_to_symbol: dict[str, str] = {}
+ self.__symbol_to_msgid: dict[str, str] = {}
+ self.__old_names: dict[str, list[str]] = {}
+ self.__active_msgids: dict[str, list[str]] = {}
+
+ def __len__(self) -> int:
+ return len(self.__msgid_to_symbol)
+
+ def __repr__(self) -> str:
+ result = "MessageIdStore: [\n"
+ for msgid, symbol in self.__msgid_to_symbol.items():
+ result += f" - {msgid} ({symbol})\n"
+ result += "]"
+ return result
+
+ def get_symbol(self, msgid: str) -> str:
+ try:
+ return self.__msgid_to_symbol[msgid.upper()]
+ except KeyError as e:
+ msg = f"'{msgid}' is not stored in the message store."
+ raise UnknownMessageError(msg) from e
+
+ def get_msgid(self, symbol: str) -> str:
+ try:
+ return self.__symbol_to_msgid[symbol]
+ except KeyError as e:
+ msg = f"'{symbol}' is not stored in the message store."
+ raise UnknownMessageError(msg) from e
+
+ def register_message_definition(
+ self, msgid: str, symbol: str, old_names: list[tuple[str, str]]
+ ) -> None:
+ self.check_msgid_and_symbol(msgid, symbol)
+ self.add_msgid_and_symbol(msgid, symbol)
+ for old_msgid, old_symbol in old_names:
+ self.check_msgid_and_symbol(old_msgid, old_symbol)
+ self.add_legacy_msgid_and_symbol(old_msgid, old_symbol, msgid)
+
+ def add_msgid_and_symbol(self, msgid: str, symbol: str) -> None:
+ """Add valid message id.
+
+ There is a little duplication with add_legacy_msgid_and_symbol to avoid a function call,
+ this is called a lot at initialization.
+ """
+ self.__msgid_to_symbol[msgid] = symbol
+ self.__symbol_to_msgid[symbol] = msgid
+
+ def add_legacy_msgid_and_symbol(
+ self, msgid: str, symbol: str, new_msgid: str
+ ) -> None:
+ """Add valid legacy message id.
+
+ There is a little duplication with add_msgid_and_symbol to avoid a function call,
+ this is called a lot at initialization.
+ """
+ self.__msgid_to_symbol[msgid] = symbol
+ self.__symbol_to_msgid[symbol] = msgid
+ existing_old_names = self.__old_names.get(msgid, [])
+ existing_old_names.append(new_msgid)
+ self.__old_names[msgid] = existing_old_names
+
+ def check_msgid_and_symbol(self, msgid: str, symbol: str) -> None:
+ existing_msgid: str | None = self.__symbol_to_msgid.get(symbol)
+ existing_symbol: str | None = self.__msgid_to_symbol.get(msgid)
+ if existing_symbol is None and existing_msgid is None:
+ return # both symbol and msgid are usable
+ if existing_msgid is not None:
+ if existing_msgid != msgid:
+ self._raise_duplicate_msgid(symbol, msgid, existing_msgid)
+ if existing_symbol and existing_symbol != symbol:
+ # See https://github.com/python/mypy/issues/10559
+ self._raise_duplicate_symbol(msgid, symbol, existing_symbol)
+
+ @staticmethod
+ def _raise_duplicate_symbol(msgid: str, symbol: str, other_symbol: str) -> NoReturn:
+ """Raise an error when a symbol is duplicated."""
+ symbols = [symbol, other_symbol]
+ symbols.sort()
+ error_message = f"Message id '{msgid}' cannot have both "
+ error_message += f"'{symbols[0]}' and '{symbols[1]}' as symbolic name."
+ raise InvalidMessageError(error_message)
+
+ @staticmethod
+ def _raise_duplicate_msgid(symbol: str, msgid: str, other_msgid: str) -> NoReturn:
+ """Raise an error when a msgid is duplicated."""
+ msgids = [msgid, other_msgid]
+ msgids.sort()
+ error_message = (
+ f"Message symbol '{symbol}' cannot be used for "
+ f"'{msgids[0]}' and '{msgids[1]}' at the same time."
+ f" If you're creating an 'old_names' use 'old-{symbol}' as the old symbol."
+ )
+ raise InvalidMessageError(error_message)
+
+ def get_active_msgids(self, msgid_or_symbol: str) -> list[str]:
+ """Return msgids but the input can be a symbol.
+
+ self.__active_msgids is used to implement a primitive cache for this function.
+ """
+ try:
+ return self.__active_msgids[msgid_or_symbol]
+ except KeyError:
+ pass
+
+ # If we don't have a cached value yet we compute it
+ msgid: str | None
+ deletion_reason = None
+ moved_reason = None
+ if msgid_or_symbol[1:].isdigit():
+ # Only msgid can have a digit as second letter
+ msgid = msgid_or_symbol.upper()
+ symbol = self.__msgid_to_symbol.get(msgid)
+ if not symbol:
+ deletion_reason = is_deleted_msgid(msgid)
+ if deletion_reason is None:
+ moved_reason = is_moved_msgid(msgid)
+ else:
+ symbol = msgid_or_symbol
+ msgid = self.__symbol_to_msgid.get(msgid_or_symbol)
+ if not msgid:
+ deletion_reason = is_deleted_symbol(symbol)
+ if deletion_reason is None:
+ moved_reason = is_moved_symbol(symbol)
+ if not msgid or not symbol:
+ if deletion_reason is not None:
+ raise DeletedMessageError(msgid_or_symbol, deletion_reason)
+ if moved_reason is not None:
+ raise MessageBecameExtensionError(msgid_or_symbol, moved_reason)
+ error_msg = f"No such message id or symbol '{msgid_or_symbol}'."
+ raise UnknownMessageError(error_msg)
+ ids = self.__old_names.get(msgid, [msgid])
+ # Add to cache
+ self.__active_msgids[msgid_or_symbol] = ids
+ return ids
diff --git a/solutions/.venv/Lib/site-packages/pylint/py.typed b/solutions/.venv/Lib/site-packages/pylint/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/__init__.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/__init__.py
new file mode 100644
index 000000000..175e9cb67
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/__init__.py
@@ -0,0 +1,7 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Pyreverse.extensions."""
+
+__revision__ = "$Id $"
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/diadefslib.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/diadefslib.py
new file mode 100644
index 000000000..59a2f5956
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/diadefslib.py
@@ -0,0 +1,234 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Handle diagram generation options for class diagram or default diagrams."""
+
+from __future__ import annotations
+
+import argparse
+from collections.abc import Generator
+from typing import Any
+
+import astroid
+from astroid import nodes
+from astroid.modutils import is_stdlib_module
+
+from pylint.pyreverse.diagrams import ClassDiagram, PackageDiagram
+from pylint.pyreverse.inspector import Linker, Project
+from pylint.pyreverse.utils import LocalsVisitor
+
+# diagram generators ##########################################################
+
+
+class DiaDefGenerator:
+ """Handle diagram generation options."""
+
+ def __init__(self, linker: Linker, handler: DiadefsHandler) -> None:
+ """Common Diagram Handler initialization."""
+ self.config = handler.config
+ self.module_names: bool = False
+ self._set_default_options()
+ self.linker = linker
+ self.classdiagram: ClassDiagram # defined by subclasses
+
+ def get_title(self, node: nodes.ClassDef) -> str:
+ """Get title for objects."""
+ title = node.name
+ if self.module_names:
+ title = f"{node.root().name}.{title}"
+ return title # type: ignore[no-any-return]
+
+ def _set_option(self, option: bool | None) -> bool:
+ """Activate some options if not explicitly deactivated."""
+ # if we have a class diagram, we want more information by default;
+ # so if the option is None, we return True
+ if option is None:
+ return bool(self.config.classes)
+ return option
+
+ def _set_default_options(self) -> None:
+ """Set different default options with _default dictionary."""
+ self.module_names = self._set_option(self.config.module_names)
+ all_ancestors = self._set_option(self.config.all_ancestors)
+ all_associated = self._set_option(self.config.all_associated)
+ anc_level, association_level = (0, 0)
+ if all_ancestors:
+ anc_level = -1
+ if all_associated:
+ association_level = -1
+ if self.config.show_ancestors is not None:
+ anc_level = self.config.show_ancestors
+ if self.config.show_associated is not None:
+ association_level = self.config.show_associated
+ self.anc_level, self.association_level = anc_level, association_level
+
+ def _get_levels(self) -> tuple[int, int]:
+ """Help function for search levels."""
+ return self.anc_level, self.association_level
+
+ def show_node(self, node: nodes.ClassDef) -> bool:
+ """Determine if node should be shown based on config."""
+ if node.root().name == "builtins":
+ return self.config.show_builtin # type: ignore[no-any-return]
+
+ if is_stdlib_module(node.root().name):
+ return self.config.show_stdlib # type: ignore[no-any-return]
+
+ return True
+
+ def add_class(self, node: nodes.ClassDef) -> None:
+ """Visit one class and add it to diagram."""
+ self.linker.visit(node)
+ self.classdiagram.add_object(self.get_title(node), node)
+
+ def get_ancestors(
+ self, node: nodes.ClassDef, level: int
+ ) -> Generator[nodes.ClassDef]:
+ """Return ancestor nodes of a class node."""
+ if level == 0:
+ return
+ for ancestor in node.ancestors(recurs=False):
+ if not self.show_node(ancestor):
+ continue
+ yield ancestor
+
+ def get_associated(
+ self, klass_node: nodes.ClassDef, level: int
+ ) -> Generator[nodes.ClassDef]:
+ """Return associated nodes of a class node."""
+ if level == 0:
+ return
+ for association_nodes in list(klass_node.instance_attrs_type.values()) + list(
+ klass_node.locals_type.values()
+ ):
+ for node in association_nodes:
+ if isinstance(node, astroid.Instance):
+ node = node._proxied
+ if not (isinstance(node, nodes.ClassDef) and self.show_node(node)):
+ continue
+ yield node
+
+ def extract_classes(
+ self, klass_node: nodes.ClassDef, anc_level: int, association_level: int
+ ) -> None:
+ """Extract recursively classes related to klass_node."""
+ if self.classdiagram.has_node(klass_node) or not self.show_node(klass_node):
+ return
+ self.add_class(klass_node)
+
+ for ancestor in self.get_ancestors(klass_node, anc_level):
+ self.extract_classes(ancestor, anc_level - 1, association_level)
+
+ for node in self.get_associated(klass_node, association_level):
+ self.extract_classes(node, anc_level, association_level - 1)
+
+
+class DefaultDiadefGenerator(LocalsVisitor, DiaDefGenerator):
+ """Generate minimum diagram definition for the project :
+
+ * a package diagram including project's modules
+ * a class diagram including project's classes
+ """
+
+ def __init__(self, linker: Linker, handler: DiadefsHandler) -> None:
+ DiaDefGenerator.__init__(self, linker, handler)
+ LocalsVisitor.__init__(self)
+
+ def visit_project(self, node: Project) -> None:
+ """Visit a pyreverse.utils.Project node.
+
+ create a diagram definition for packages
+ """
+ mode = self.config.mode
+ if len(node.modules) > 1:
+ self.pkgdiagram: PackageDiagram | None = PackageDiagram(
+ f"packages {node.name}", mode
+ )
+ else:
+ self.pkgdiagram = None
+ self.classdiagram = ClassDiagram(f"classes {node.name}", mode)
+
+ def leave_project(self, _: Project) -> Any:
+ """Leave the pyreverse.utils.Project node.
+
+ return the generated diagram definition
+ """
+ if self.pkgdiagram:
+ return self.pkgdiagram, self.classdiagram
+ return (self.classdiagram,)
+
+ def visit_module(self, node: nodes.Module) -> None:
+ """Visit an astroid.Module node.
+
+ add this class to the package diagram definition
+ """
+ if self.pkgdiagram:
+ self.linker.visit(node)
+ self.pkgdiagram.add_object(node.name, node)
+
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ """Visit an astroid.Class node.
+
+ add this class to the class diagram definition
+ """
+ anc_level, association_level = self._get_levels()
+ self.extract_classes(node, anc_level, association_level)
+
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ """Visit astroid.ImportFrom and catch modules for package diagram."""
+ if self.pkgdiagram:
+ self.pkgdiagram.add_from_depend(node, node.modname)
+
+
+class ClassDiadefGenerator(DiaDefGenerator):
+ """Generate a class diagram definition including all classes related to a
+ given class.
+ """
+
+ def class_diagram(self, project: Project, klass: nodes.ClassDef) -> ClassDiagram:
+ """Return a class diagram definition for the class and related classes."""
+ self.classdiagram = ClassDiagram(klass, self.config.mode)
+ if len(project.modules) > 1:
+ module, klass = klass.rsplit(".", 1)
+ module = project.get_module(module)
+ else:
+ module = project.modules[0]
+ klass = klass.split(".")[-1]
+ klass = next(module.ilookup(klass))
+
+ anc_level, association_level = self._get_levels()
+ self.extract_classes(klass, anc_level, association_level)
+ return self.classdiagram
+
+
+# diagram handler #############################################################
+
+
+class DiadefsHandler:
+ """Get diagram definitions from user (i.e. xml files) or generate them."""
+
+ def __init__(self, config: argparse.Namespace) -> None:
+ self.config = config
+
+ def get_diadefs(self, project: Project, linker: Linker) -> list[ClassDiagram]:
+ """Get the diagram's configuration data.
+
+ :param project:The pyreverse project
+ :type project: pyreverse.utils.Project
+ :param linker: The linker
+ :type linker: pyreverse.inspector.Linker(IdGeneratorMixIn, LocalsVisitor)
+
+ :returns: The list of diagram definitions
+ :rtype: list(:class:`pylint.pyreverse.diagrams.ClassDiagram`)
+ """
+ # read and interpret diagram definitions (Diadefs)
+ diagrams = []
+ generator = ClassDiadefGenerator(linker, self)
+ for klass in self.config.classes:
+ diagrams.append(generator.class_diagram(project, klass))
+ if not diagrams:
+ diagrams = DefaultDiadefGenerator(linker, self).visit(project)
+ for diagram in diagrams:
+ diagram.extract_relationships()
+ return diagrams
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/diagrams.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/diagrams.py
new file mode 100644
index 000000000..278102cab
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/diagrams.py
@@ -0,0 +1,331 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Diagram objects."""
+
+from __future__ import annotations
+
+from collections.abc import Iterable
+from typing import Any
+
+import astroid
+from astroid import nodes, util
+
+from pylint.checkers.utils import decorated_with_property, in_type_checking_block
+from pylint.pyreverse.utils import FilterMixIn
+
+
+class Figure:
+ """Base class for counter handling."""
+
+ def __init__(self) -> None:
+ self.fig_id: str = ""
+
+
+class Relationship(Figure):
+ """A relationship from an object in the diagram to another."""
+
+ def __init__(
+ self,
+ from_object: DiagramEntity,
+ to_object: DiagramEntity,
+ relation_type: str,
+ name: str | None = None,
+ ):
+ super().__init__()
+ self.from_object = from_object
+ self.to_object = to_object
+ self.type = relation_type
+ self.name = name
+
+
+class DiagramEntity(Figure):
+ """A diagram object, i.e. a label associated to an astroid node."""
+
+ default_shape = ""
+
+ def __init__(
+ self, title: str = "No name", node: nodes.NodeNG | None = None
+ ) -> None:
+ super().__init__()
+ self.title = title
+ self.node: nodes.NodeNG = node or nodes.NodeNG(
+ lineno=None,
+ col_offset=None,
+ end_lineno=None,
+ end_col_offset=None,
+ parent=None,
+ )
+ self.shape = self.default_shape
+
+
+class PackageEntity(DiagramEntity):
+ """A diagram object representing a package."""
+
+ default_shape = "package"
+
+
+class ClassEntity(DiagramEntity):
+ """A diagram object representing a class."""
+
+ default_shape = "class"
+
+ def __init__(self, title: str, node: nodes.ClassDef) -> None:
+ super().__init__(title=title, node=node)
+ self.attrs: list[str] = []
+ self.methods: list[nodes.FunctionDef] = []
+
+
+class ClassDiagram(Figure, FilterMixIn):
+ """Main class diagram handling."""
+
+ TYPE = "class"
+
+ def __init__(self, title: str, mode: str) -> None:
+ FilterMixIn.__init__(self, mode)
+ Figure.__init__(self)
+ self.title = title
+ # TODO: Specify 'Any' after refactor of `DiagramEntity`
+ self.objects: list[Any] = []
+ self.relationships: dict[str, list[Relationship]] = {}
+ self._nodes: dict[nodes.NodeNG, DiagramEntity] = {}
+
+ def get_relationships(self, role: str) -> Iterable[Relationship]:
+ # sorted to get predictable (hence testable) results
+ return sorted(
+ self.relationships.get(role, ()),
+ key=lambda x: (x.from_object.fig_id, x.to_object.fig_id),
+ )
+
+ def add_relationship(
+ self,
+ from_object: DiagramEntity,
+ to_object: DiagramEntity,
+ relation_type: str,
+ name: str | None = None,
+ ) -> None:
+ """Create a relationship."""
+ rel = Relationship(from_object, to_object, relation_type, name)
+ self.relationships.setdefault(relation_type, []).append(rel)
+
+ def get_relationship(
+ self, from_object: DiagramEntity, relation_type: str
+ ) -> Relationship:
+ """Return a relationship or None."""
+ for rel in self.relationships.get(relation_type, ()):
+ if rel.from_object is from_object:
+ return rel
+ raise KeyError(relation_type)
+
+ def get_attrs(self, node: nodes.ClassDef) -> list[str]:
+ """Return visible attributes, possibly with class name."""
+ attrs = []
+ properties = {
+ local_name: local_node
+ for local_name, local_node in node.items()
+ if isinstance(local_node, nodes.FunctionDef)
+ and decorated_with_property(local_node)
+ }
+ for attr_name, attr_type in list(node.locals_type.items()) + list(
+ node.instance_attrs_type.items()
+ ):
+ if attr_name not in properties:
+ properties[attr_name] = attr_type
+
+ for node_name, associated_nodes in properties.items():
+ if not self.show_attr(node_name):
+ continue
+ names = self.class_names(associated_nodes)
+ if names:
+ node_name = f"{node_name} : {', '.join(names)}"
+ attrs.append(node_name)
+ return sorted(attrs)
+
+ def get_methods(self, node: nodes.ClassDef) -> list[nodes.FunctionDef]:
+ """Return visible methods."""
+ methods = [
+ m
+ for m in node.values()
+ if isinstance(m, nodes.FunctionDef)
+ and not isinstance(m, astroid.objects.Property)
+ and not decorated_with_property(m)
+ and self.show_attr(m.name)
+ ]
+ return sorted(methods, key=lambda n: n.name)
+
+ def add_object(self, title: str, node: nodes.ClassDef) -> None:
+ """Create a diagram object."""
+ assert node not in self._nodes
+ ent = ClassEntity(title, node)
+ self._nodes[node] = ent
+ self.objects.append(ent)
+
+ def class_names(self, nodes_lst: Iterable[nodes.NodeNG]) -> list[str]:
+ """Return class names if needed in diagram."""
+ names = []
+ for node in nodes_lst:
+ if isinstance(node, astroid.Instance):
+ node = node._proxied
+ if (
+ isinstance(
+ node, (nodes.ClassDef, nodes.Name, nodes.Subscript, nodes.BinOp)
+ )
+ and hasattr(node, "name")
+ and not self.has_node(node)
+ ):
+ if node.name not in names:
+ node_name = node.name
+ names.append(node_name)
+ # sorted to get predictable (hence testable) results
+ return sorted(
+ name
+ for name in names
+ if all(name not in other or name == other for other in names)
+ )
+
+ def has_node(self, node: nodes.NodeNG) -> bool:
+ """Return true if the given node is included in the diagram."""
+ return node in self._nodes
+
+ def object_from_node(self, node: nodes.NodeNG) -> DiagramEntity:
+ """Return the diagram object mapped to node."""
+ return self._nodes[node]
+
+ def classes(self) -> list[ClassEntity]:
+ """Return all class nodes in the diagram."""
+ return [o for o in self.objects if isinstance(o, ClassEntity)]
+
+ def classe(self, name: str) -> ClassEntity:
+ """Return a class by its name, raise KeyError if not found."""
+ for klass in self.classes():
+ if klass.node.name == name:
+ return klass
+ raise KeyError(name)
+
+ def extract_relationships(self) -> None:
+ """Extract relationships between nodes in the diagram."""
+ for obj in self.classes():
+ node = obj.node
+ obj.attrs = self.get_attrs(node)
+ obj.methods = self.get_methods(node)
+ obj.shape = "class"
+ # inheritance link
+ for par_node in node.ancestors(recurs=False):
+ try:
+ par_obj = self.object_from_node(par_node)
+ self.add_relationship(obj, par_obj, "specialization")
+ except KeyError:
+ continue
+
+ # associations & aggregations links
+ for name, values in list(node.aggregations_type.items()):
+ for value in values:
+ self.assign_association_relationship(
+ value, obj, name, "aggregation"
+ )
+
+ associations = node.associations_type.copy()
+
+ for name, values in node.locals_type.items():
+ if name not in associations:
+ associations[name] = values
+
+ for name, values in associations.items():
+ for value in values:
+ self.assign_association_relationship(
+ value, obj, name, "association"
+ )
+
+ def assign_association_relationship(
+ self, value: astroid.NodeNG, obj: ClassEntity, name: str, type_relationship: str
+ ) -> None:
+ if isinstance(value, util.UninferableBase):
+ return
+ if isinstance(value, astroid.Instance):
+ value = value._proxied
+ try:
+ associated_obj = self.object_from_node(value)
+ self.add_relationship(associated_obj, obj, type_relationship, name)
+ except KeyError:
+ return
+
+
+class PackageDiagram(ClassDiagram):
+ """Package diagram handling."""
+
+ TYPE = "package"
+
+ def modules(self) -> list[PackageEntity]:
+ """Return all module nodes in the diagram."""
+ return [o for o in self.objects if isinstance(o, PackageEntity)]
+
+ def module(self, name: str) -> PackageEntity:
+ """Return a module by its name, raise KeyError if not found."""
+ for mod in self.modules():
+ if mod.node.name == name:
+ return mod
+ raise KeyError(name)
+
+ def add_object(self, title: str, node: nodes.Module) -> None:
+ """Create a diagram object."""
+ assert node not in self._nodes
+ ent = PackageEntity(title, node)
+ self._nodes[node] = ent
+ self.objects.append(ent)
+
+ def get_module(self, name: str, node: nodes.Module) -> PackageEntity:
+ """Return a module by its name, looking also for relative imports;
+ raise KeyError if not found.
+ """
+ for mod in self.modules():
+ mod_name = mod.node.name
+ if mod_name == name:
+ return mod
+ # search for fullname of relative import modules
+ package = node.root().name
+ if mod_name == f"{package}.{name}":
+ return mod
+ if mod_name == f"{package.rsplit('.', 1)[0]}.{name}":
+ return mod
+ raise KeyError(name)
+
+ def add_from_depend(self, node: nodes.ImportFrom, from_module: str) -> None:
+ """Add dependencies created by from-imports."""
+ mod_name = node.root().name
+ package = self.module(mod_name).node
+
+ if from_module in package.depends:
+ return
+
+ if not in_type_checking_block(node):
+ package.depends.append(from_module)
+ elif from_module not in package.type_depends:
+ package.type_depends.append(from_module)
+
+ def extract_relationships(self) -> None:
+ """Extract relationships between nodes in the diagram."""
+ super().extract_relationships()
+ for class_obj in self.classes():
+ # ownership
+ try:
+ mod = self.object_from_node(class_obj.node.root())
+ self.add_relationship(class_obj, mod, "ownership")
+ except KeyError:
+ continue
+ for package_obj in self.modules():
+ package_obj.shape = "package"
+ # dependencies
+ for dep_name in package_obj.node.depends:
+ try:
+ dep = self.get_module(dep_name, package_obj.node)
+ except KeyError:
+ continue
+ self.add_relationship(package_obj, dep, "depends")
+
+ for dep_name in package_obj.node.type_depends:
+ try:
+ dep = self.get_module(dep_name, package_obj.node)
+ except KeyError: # pragma: no cover
+ continue
+ self.add_relationship(package_obj, dep, "type_depends")
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/dot_printer.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/dot_printer.py
new file mode 100644
index 000000000..4baed6c3c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/dot_printer.py
@@ -0,0 +1,184 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Class to generate files in dot format and image formats supported by Graphviz."""
+
+from __future__ import annotations
+
+import os
+import subprocess
+import tempfile
+from enum import Enum
+from pathlib import Path
+
+from astroid import nodes
+
+from pylint.pyreverse.printer import EdgeType, Layout, NodeProperties, NodeType, Printer
+from pylint.pyreverse.utils import get_annotation_label
+
+
+class HTMLLabels(Enum):
+ LINEBREAK_LEFT = '<br ALIGN="LEFT"/>'
+
+
+ALLOWED_CHARSETS: frozenset[str] = frozenset(("utf-8", "iso-8859-1", "latin1"))
+SHAPES: dict[NodeType, str] = {
+ NodeType.PACKAGE: "box",
+ NodeType.CLASS: "record",
+}
+# pylint: disable-next=consider-using-namedtuple-or-dataclass
+ARROWS: dict[EdgeType, dict[str, str]] = {
+ EdgeType.INHERITS: {"arrowtail": "none", "arrowhead": "empty"},
+ EdgeType.ASSOCIATION: {
+ "fontcolor": "green",
+ "arrowtail": "none",
+ "arrowhead": "diamond",
+ "style": "solid",
+ },
+ EdgeType.AGGREGATION: {
+ "fontcolor": "green",
+ "arrowtail": "none",
+ "arrowhead": "odiamond",
+ "style": "solid",
+ },
+ EdgeType.USES: {"arrowtail": "none", "arrowhead": "open"},
+ EdgeType.TYPE_DEPENDENCY: {
+ "arrowtail": "none",
+ "arrowhead": "open",
+ "style": "dashed",
+ },
+}
+
+
+class DotPrinter(Printer):
+ DEFAULT_COLOR = "black"
+
+ def __init__(
+ self,
+ title: str,
+ layout: Layout | None = None,
+ use_automatic_namespace: bool | None = None,
+ ):
+ layout = layout or Layout.BOTTOM_TO_TOP
+ self.charset = "utf-8"
+ super().__init__(title, layout, use_automatic_namespace)
+
+ def _open_graph(self) -> None:
+ """Emit the header lines."""
+ self.emit(f'digraph "{self.title}" {{')
+ if self.layout:
+ self.emit(f"rankdir={self.layout.value}")
+ if self.charset:
+ assert (
+ self.charset.lower() in ALLOWED_CHARSETS
+ ), f"unsupported charset {self.charset}"
+ self.emit(f'charset="{self.charset}"')
+
+ def emit_node(
+ self,
+ name: str,
+ type_: NodeType,
+ properties: NodeProperties | None = None,
+ ) -> None:
+ """Create a new node.
+
+ Nodes can be classes, packages, participants etc.
+ """
+ if properties is None:
+ properties = NodeProperties(label=name)
+ shape = SHAPES[type_]
+ color = properties.color if properties.color is not None else self.DEFAULT_COLOR
+ style = "filled" if color != self.DEFAULT_COLOR else "solid"
+ label = self._build_label_for_node(properties)
+ label_part = f", label=<{label}>" if label else ""
+ fontcolor_part = (
+ f', fontcolor="{properties.fontcolor}"' if properties.fontcolor else ""
+ )
+ self.emit(
+ f'"{name}" [color="{color}"{fontcolor_part}{label_part}, shape="{shape}", style="{style}"];'
+ )
+
+ def _build_label_for_node(self, properties: NodeProperties) -> str:
+ if not properties.label:
+ return ""
+
+ label: str = properties.label
+ if properties.attrs is None and properties.methods is None:
+ # return a "compact" form which only displays the class name in a box
+ return label
+
+ # Add class attributes
+ attrs: list[str] = properties.attrs or []
+ attrs_string = rf"{HTMLLabels.LINEBREAK_LEFT.value}".join(
+ attr.replace("|", r"\|") for attr in attrs
+ )
+ label = rf"{{{label}|{attrs_string}{HTMLLabels.LINEBREAK_LEFT.value}|"
+
+ # Add class methods
+ methods: list[nodes.FunctionDef] = properties.methods or []
+ for func in methods:
+ args = ", ".join(self._get_method_arguments(func)).replace("|", r"\|")
+ method_name = (
+ f"<I>{func.name}</I>" if func.is_abstract() else f"{func.name}"
+ )
+ label += rf"{method_name}({args})"
+ if func.returns:
+ annotation_label = get_annotation_label(func.returns)
+ label += ": " + self._escape_annotation_label(annotation_label)
+ label += rf"{HTMLLabels.LINEBREAK_LEFT.value}"
+ label += "}"
+ return label
+
+ def _escape_annotation_label(self, annotation_label: str) -> str:
+ # Escape vertical bar characters to make them appear as a literal characters
+ # otherwise it gets treated as field separator of record-based nodes
+ annotation_label = annotation_label.replace("|", r"\|")
+
+ return annotation_label
+
+ def emit_edge(
+ self,
+ from_node: str,
+ to_node: str,
+ type_: EdgeType,
+ label: str | None = None,
+ ) -> None:
+ """Create an edge from one node to another to display relationships."""
+ arrowstyle = ARROWS[type_]
+ attrs = [f'{prop}="{value}"' for prop, value in arrowstyle.items()]
+ if label:
+ attrs.append(f'label="{label}"')
+ self.emit(f'"{from_node}" -> "{to_node}" [{", ".join(sorted(attrs))}];')
+
+ def generate(self, outputfile: str) -> None:
+ self._close_graph()
+ graphviz_extensions = ("dot", "gv")
+ name = self.title
+ if outputfile is None:
+ target = "png"
+ pdot, dot_sourcepath = tempfile.mkstemp(".gv", name)
+ ppng, outputfile = tempfile.mkstemp(".png", name)
+ os.close(pdot)
+ os.close(ppng)
+ else:
+ target = Path(outputfile).suffix.lstrip(".")
+ if not target:
+ target = "png"
+ outputfile = outputfile + "." + target
+ if target not in graphviz_extensions:
+ pdot, dot_sourcepath = tempfile.mkstemp(".gv", name)
+ os.close(pdot)
+ else:
+ dot_sourcepath = outputfile
+ with open(dot_sourcepath, "w", encoding="utf8") as outfile:
+ outfile.writelines(self.lines)
+ if target not in graphviz_extensions:
+ subprocess.run(
+ ["dot", "-T", target, dot_sourcepath, "-o", outputfile], check=True
+ )
+ os.unlink(dot_sourcepath)
+
+ def _close_graph(self) -> None:
+ """Emit the lines needed to properly close the graph."""
+ self.emit("}\n")
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/inspector.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/inspector.py
new file mode 100644
index 000000000..8825363fa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/inspector.py
@@ -0,0 +1,382 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Visitor doing some post-processing on the astroid tree.
+
+Try to resolve definitions (namespace) dictionary, relationship...
+"""
+
+from __future__ import annotations
+
+import collections
+import os
+import traceback
+from abc import ABC, abstractmethod
+from collections.abc import Callable
+from typing import Optional
+
+import astroid
+from astroid import nodes
+
+from pylint import constants
+from pylint.pyreverse import utils
+
+_WrapperFuncT = Callable[
+ [Callable[[str], nodes.Module], str, bool], Optional[nodes.Module]
+]
+
+
+def _astroid_wrapper(
+ func: Callable[[str], nodes.Module],
+ modname: str,
+ verbose: bool = False,
+) -> nodes.Module | None:
+ if verbose:
+ print(f"parsing {modname}...")
+ try:
+ return func(modname)
+ except astroid.exceptions.AstroidBuildingError as exc:
+ print(exc)
+ except Exception: # pylint: disable=broad-except
+ traceback.print_exc()
+ return None
+
+
+class IdGeneratorMixIn:
+ """Mixin adding the ability to generate integer uid."""
+
+ def __init__(self, start_value: int = 0) -> None:
+ self.id_count = start_value
+
+ def init_counter(self, start_value: int = 0) -> None:
+ """Init the id counter."""
+ self.id_count = start_value
+
+ def generate_id(self) -> int:
+ """Generate a new identifier."""
+ self.id_count += 1
+ return self.id_count
+
+
+class Project:
+ """A project handle a set of modules / packages."""
+
+ def __init__(self, name: str = ""):
+ self.name = name
+ self.uid: int | None = None
+ self.path: str = ""
+ self.modules: list[nodes.Module] = []
+ self.locals: dict[str, nodes.Module] = {}
+ self.__getitem__ = self.locals.__getitem__
+ self.__iter__ = self.locals.__iter__
+ self.values = self.locals.values
+ self.keys = self.locals.keys
+ self.items = self.locals.items
+
+ def add_module(self, node: nodes.Module) -> None:
+ self.locals[node.name] = node
+ self.modules.append(node)
+
+ def get_module(self, name: str) -> nodes.Module:
+ return self.locals[name]
+
+ def get_children(self) -> list[nodes.Module]:
+ return self.modules
+
+ def __repr__(self) -> str:
+ return f"<Project {self.name!r} at {id(self)} ({len(self.modules)} modules)>"
+
+
+class Linker(IdGeneratorMixIn, utils.LocalsVisitor):
+ """Walk on the project tree and resolve relationships.
+
+ According to options the following attributes may be
+ added to visited nodes:
+
+ * uid,
+ a unique identifier for the node (on astroid.Project, astroid.Module,
+ astroid.Class and astroid.locals_type). Only if the linker
+ has been instantiated with tag=True parameter (False by default).
+
+ * Function
+ a mapping from locals names to their bounded value, which may be a
+ constant like a string or an integer, or an astroid node
+ (on astroid.Module, astroid.Class and astroid.Function).
+
+ * instance_attrs_type
+ as locals_type but for klass member attributes (only on astroid.Class)
+
+ * associations_type
+ as instance_attrs_type but for association relationships
+
+ * aggregations_type
+ as instance_attrs_type but for aggregations relationships
+ """
+
+ def __init__(self, project: Project, tag: bool = False) -> None:
+ IdGeneratorMixIn.__init__(self)
+ utils.LocalsVisitor.__init__(self)
+ # tag nodes or not
+ self.tag = tag
+ # visited project
+ self.project = project
+ self.associations_handler = AggregationsHandler()
+ self.associations_handler.set_next(OtherAssociationsHandler())
+
+ def visit_project(self, node: Project) -> None:
+ """Visit a pyreverse.utils.Project node.
+
+ * optionally tag the node with a unique id
+ """
+ if self.tag:
+ node.uid = self.generate_id()
+ for module in node.modules:
+ self.visit(module)
+
+ def visit_module(self, node: nodes.Module) -> None:
+ """Visit an astroid.Module node.
+
+ * set the locals_type mapping
+ * set the depends mapping
+ * optionally tag the node with a unique id
+ """
+ if hasattr(node, "locals_type"):
+ return
+ node.locals_type = collections.defaultdict(list)
+ node.depends = []
+ node.type_depends = []
+ if self.tag:
+ node.uid = self.generate_id()
+
+ def visit_classdef(self, node: nodes.ClassDef) -> None:
+ """Visit an astroid.Class node.
+
+ * set the locals_type and instance_attrs_type mappings
+ * optionally tag the node with a unique id
+ """
+ if hasattr(node, "locals_type"):
+ return
+ node.locals_type = collections.defaultdict(list)
+ if self.tag:
+ node.uid = self.generate_id()
+ # resolve ancestors
+ for baseobj in node.ancestors(recurs=False):
+ specializations = getattr(baseobj, "specializations", [])
+ specializations.append(node)
+ baseobj.specializations = specializations
+ # resolve instance attributes
+ node.instance_attrs_type = collections.defaultdict(list)
+ node.aggregations_type = collections.defaultdict(list)
+ node.associations_type = collections.defaultdict(list)
+ for assignattrs in tuple(node.instance_attrs.values()):
+ for assignattr in assignattrs:
+ if not isinstance(assignattr, nodes.Unknown):
+ self.associations_handler.handle(assignattr, node)
+ self.handle_assignattr_type(assignattr, node)
+
+ def visit_functiondef(self, node: nodes.FunctionDef) -> None:
+ """Visit an astroid.Function node.
+
+ * set the locals_type mapping
+ * optionally tag the node with a unique id
+ """
+ if hasattr(node, "locals_type"):
+ return
+ node.locals_type = collections.defaultdict(list)
+ if self.tag:
+ node.uid = self.generate_id()
+
+ def visit_assignname(self, node: nodes.AssignName) -> None:
+ """Visit an astroid.AssignName node.
+
+ handle locals_type
+ """
+ # avoid double parsing done by different Linkers.visit
+ # running over the same project:
+ if hasattr(node, "_handled"):
+ return
+ node._handled = True
+ if node.name in node.frame():
+ frame = node.frame()
+ else:
+ # the name has been defined as 'global' in the frame and belongs
+ # there.
+ frame = node.root()
+ if not hasattr(frame, "locals_type"):
+ # If the frame doesn't have a locals_type yet,
+ # it means it wasn't yet visited. Visit it now
+ # to add what's missing from it.
+ if isinstance(frame, nodes.ClassDef):
+ self.visit_classdef(frame)
+ elif isinstance(frame, nodes.FunctionDef):
+ self.visit_functiondef(frame)
+ else:
+ self.visit_module(frame)
+
+ current = frame.locals_type[node.name]
+ frame.locals_type[node.name] = list(set(current) | utils.infer_node(node))
+
+ @staticmethod
+ def handle_assignattr_type(node: nodes.AssignAttr, parent: nodes.ClassDef) -> None:
+ """Handle an astroid.assignattr node.
+
+ handle instance_attrs_type
+ """
+ current = set(parent.instance_attrs_type[node.attrname])
+ parent.instance_attrs_type[node.attrname] = list(
+ current | utils.infer_node(node)
+ )
+
+ def visit_import(self, node: nodes.Import) -> None:
+ """Visit an astroid.Import node.
+
+ resolve module dependencies
+ """
+ context_file = node.root().file
+ for name in node.names:
+ relative = astroid.modutils.is_relative(name[0], context_file)
+ self._imported_module(node, name[0], relative)
+
+ def visit_importfrom(self, node: nodes.ImportFrom) -> None:
+ """Visit an astroid.ImportFrom node.
+
+ resolve module dependencies
+ """
+ basename = node.modname
+ context_file = node.root().file
+ if context_file is not None:
+ relative = astroid.modutils.is_relative(basename, context_file)
+ else:
+ relative = False
+ for name in node.names:
+ if name[0] == "*":
+ continue
+ # analyze dependencies
+ fullname = f"{basename}.{name[0]}"
+ if fullname.find(".") > -1:
+ try:
+ fullname = astroid.modutils.get_module_part(fullname, context_file)
+ except ImportError:
+ continue
+ if fullname != basename:
+ self._imported_module(node, fullname, relative)
+
+ def compute_module(self, context_name: str, mod_path: str) -> bool:
+ """Should the module be added to dependencies ?"""
+ package_dir = os.path.dirname(self.project.path)
+ if context_name == mod_path:
+ return False
+ # astroid does return a boolean but is not typed correctly yet
+
+ return astroid.modutils.module_in_path(mod_path, (package_dir,)) # type: ignore[no-any-return]
+
+ def _imported_module(
+ self, node: nodes.Import | nodes.ImportFrom, mod_path: str, relative: bool
+ ) -> None:
+ """Notify an imported module, used to analyze dependencies."""
+ module = node.root()
+ context_name = module.name
+ if relative:
+ mod_path = f"{'.'.join(context_name.split('.')[:-1])}.{mod_path}"
+ if self.compute_module(context_name, mod_path):
+ # handle dependencies
+ if not hasattr(module, "depends"):
+ module.depends = []
+ mod_paths = module.depends
+ if mod_path not in mod_paths:
+ mod_paths.append(mod_path)
+
+
+class AssociationHandlerInterface(ABC):
+ @abstractmethod
+ def set_next(
+ self, handler: AssociationHandlerInterface
+ ) -> AssociationHandlerInterface:
+ pass
+
+ @abstractmethod
+ def handle(self, node: nodes.AssignAttr, parent: nodes.ClassDef) -> None:
+ pass
+
+
+class AbstractAssociationHandler(AssociationHandlerInterface):
+ """
+ Chain of Responsibility for handling types of association, useful
+ to expand in the future if we want to add more distinct associations.
+
+ Every link of the chain checks if it's a certain type of association.
+ If no association is found it's set as a generic association in `associations_type`.
+
+ The default chaining behavior is implemented inside the base handler
+ class.
+ """
+
+ _next_handler: AssociationHandlerInterface
+
+ def set_next(
+ self, handler: AssociationHandlerInterface
+ ) -> AssociationHandlerInterface:
+ self._next_handler = handler
+ return handler
+
+ @abstractmethod
+ def handle(self, node: nodes.AssignAttr, parent: nodes.ClassDef) -> None:
+ if self._next_handler:
+ self._next_handler.handle(node, parent)
+
+
+class AggregationsHandler(AbstractAssociationHandler):
+ def handle(self, node: nodes.AssignAttr, parent: nodes.ClassDef) -> None:
+ if isinstance(node.parent, (nodes.AnnAssign, nodes.Assign)) and isinstance(
+ node.parent.value, astroid.node_classes.Name
+ ):
+ current = set(parent.aggregations_type[node.attrname])
+ parent.aggregations_type[node.attrname] = list(
+ current | utils.infer_node(node)
+ )
+ else:
+ super().handle(node, parent)
+
+
+class OtherAssociationsHandler(AbstractAssociationHandler):
+ def handle(self, node: nodes.AssignAttr, parent: nodes.ClassDef) -> None:
+ current = set(parent.associations_type[node.attrname])
+ parent.associations_type[node.attrname] = list(current | utils.infer_node(node))
+
+
+def project_from_files(
+ files: list[str],
+ func_wrapper: _WrapperFuncT = _astroid_wrapper,
+ project_name: str = "no name",
+ black_list: tuple[str, ...] = constants.DEFAULT_IGNORE_LIST,
+ verbose: bool = False,
+) -> Project:
+ """Return a Project from a list of files or modules."""
+ # build the project representation
+ astroid_manager = astroid.MANAGER
+ project = Project(project_name)
+ for something in files:
+ if not os.path.exists(something):
+ fpath = astroid.modutils.file_from_modpath(something.split("."))
+ elif os.path.isdir(something):
+ fpath = os.path.join(something, "__init__.py")
+ else:
+ fpath = something
+ ast = func_wrapper(astroid_manager.ast_from_file, fpath, verbose)
+ if ast is None:
+ continue
+ project.path = project.path or ast.file
+ project.add_module(ast)
+ base_name = ast.name
+ # recurse in package except if __init__ was explicitly given
+ if ast.package and something.find("__init__") == -1:
+ # recurse on others packages / modules if this is a package
+ for fpath in astroid.modutils.get_module_files(
+ os.path.dirname(ast.file), black_list
+ ):
+ ast = func_wrapper(astroid_manager.ast_from_file, fpath, verbose)
+ if ast is None or ast.name == base_name:
+ continue
+ project.add_module(ast)
+ return project
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/main.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/main.py
new file mode 100644
index 000000000..3ba0b6c77
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/main.py
@@ -0,0 +1,322 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Create UML diagrams for classes and modules in <packages>."""
+
+from __future__ import annotations
+
+import sys
+from collections.abc import Sequence
+from typing import NoReturn
+
+from pylint import constants
+from pylint.config.arguments_manager import _ArgumentsManager
+from pylint.config.arguments_provider import _ArgumentsProvider
+from pylint.lint import discover_package_path
+from pylint.lint.utils import augmented_sys_path
+from pylint.pyreverse import writer
+from pylint.pyreverse.diadefslib import DiadefsHandler
+from pylint.pyreverse.inspector import Linker, project_from_files
+from pylint.pyreverse.utils import (
+ check_graphviz_availability,
+ check_if_graphviz_supports_format,
+ insert_default_options,
+)
+from pylint.typing import Options
+
+DIRECTLY_SUPPORTED_FORMATS = (
+ "dot",
+ "puml",
+ "plantuml",
+ "mmd",
+ "html",
+)
+
+DEFAULT_COLOR_PALETTE = (
+ # colorblind scheme taken from https://personal.sron.nl/~pault/
+ "#77AADD", # light blue
+ "#99DDFF", # light cyan
+ "#44BB99", # mint
+ "#BBCC33", # pear
+ "#AAAA00", # olive
+ "#EEDD88", # light yellow
+ "#EE8866", # orange
+ "#FFAABB", # pink
+ "#DDDDDD", # pale grey
+)
+
+OPTIONS: Options = (
+ (
+ "filter-mode",
+ {
+ "short": "f",
+ "default": "PUB_ONLY",
+ "dest": "mode",
+ "type": "string",
+ "action": "store",
+ "metavar": "<mode>",
+ "help": """filter attributes and functions according to
+ <mode>. Correct modes are :
+ 'PUB_ONLY' filter all non public attributes
+ [DEFAULT], equivalent to PRIVATE+SPECIAL_A
+ 'ALL' no filter
+ 'SPECIAL' filter Python special functions
+ except constructor
+ 'OTHER' filter protected and private
+ attributes""",
+ },
+ ),
+ (
+ "class",
+ {
+ "short": "c",
+ "action": "extend",
+ "metavar": "<class>",
+ "type": "csv",
+ "dest": "classes",
+ "default": None,
+ "help": "create a class diagram with all classes related to <class>;\
+ this uses by default the options -ASmy",
+ },
+ ),
+ (
+ "show-ancestors",
+ {
+ "short": "a",
+ "action": "store",
+ "metavar": "<ancestor>",
+ "type": "int",
+ "default": None,
+ "help": "show <ancestor> generations of ancestor classes not in <projects>",
+ },
+ ),
+ (
+ "all-ancestors",
+ {
+ "short": "A",
+ "default": None,
+ "action": "store_true",
+ "help": "show all ancestors off all classes in <projects>",
+ },
+ ),
+ (
+ "show-associated",
+ {
+ "short": "s",
+ "action": "store",
+ "metavar": "<association_level>",
+ "type": "int",
+ "default": None,
+ "help": "show <association_level> levels of associated classes not in <projects>",
+ },
+ ),
+ (
+ "all-associated",
+ {
+ "short": "S",
+ "default": None,
+ "action": "store_true",
+ "help": "show recursively all associated off all associated classes",
+ },
+ ),
+ (
+ "show-builtin",
+ {
+ "short": "b",
+ "action": "store_true",
+ "default": False,
+ "help": "include builtin objects in representation of classes",
+ },
+ ),
+ (
+ "show-stdlib",
+ {
+ "short": "L",
+ "action": "store_true",
+ "default": False,
+ "help": "include standard library objects in representation of classes",
+ },
+ ),
+ (
+ "module-names",
+ {
+ "short": "m",
+ "default": None,
+ "type": "yn",
+ "metavar": "<y or n>",
+ "help": "include module name in representation of classes",
+ },
+ ),
+ (
+ "only-classnames",
+ {
+ "short": "k",
+ "action": "store_true",
+ "default": False,
+ "help": "don't show attributes and methods in the class boxes; this disables -f values",
+ },
+ ),
+ (
+ "no-standalone",
+ {
+ "action": "store_true",
+ "default": False,
+ "help": "only show nodes with connections",
+ },
+ ),
+ (
+ "output",
+ {
+ "short": "o",
+ "dest": "output_format",
+ "action": "store",
+ "default": "dot",
+ "metavar": "<format>",
+ "type": "string",
+ "help": (
+ "create a *.<format> output file if format is available. Available "
+ f"formats are: {', '.join(DIRECTLY_SUPPORTED_FORMATS)}. Any other "
+ f"format will be tried to create by means of the 'dot' command line "
+ f"tool, which requires a graphviz installation."
+ ),
+ },
+ ),
+ (
+ "colorized",
+ {
+ "dest": "colorized",
+ "action": "store_true",
+ "default": False,
+ "help": "Use colored output. Classes/modules of the same package get the same color.",
+ },
+ ),
+ (
+ "max-color-depth",
+ {
+ "dest": "max_color_depth",
+ "action": "store",
+ "default": 2,
+ "metavar": "<depth>",
+ "type": "int",
+ "help": "Use separate colors up to package depth of <depth>",
+ },
+ ),
+ (
+ "color-palette",
+ {
+ "dest": "color_palette",
+ "action": "store",
+ "default": DEFAULT_COLOR_PALETTE,
+ "metavar": "<color1,color2,...>",
+ "type": "csv",
+ "help": "Comma separated list of colors to use",
+ },
+ ),
+ (
+ "ignore",
+ {
+ "type": "csv",
+ "metavar": "<file[,file...]>",
+ "dest": "ignore_list",
+ "default": constants.DEFAULT_IGNORE_LIST,
+ "help": "Files or directories to be skipped. They should be base names, not paths.",
+ },
+ ),
+ (
+ "project",
+ {
+ "default": "",
+ "type": "string",
+ "short": "p",
+ "metavar": "<project name>",
+ "help": "set the project name.",
+ },
+ ),
+ (
+ "output-directory",
+ {
+ "default": "",
+ "type": "path",
+ "short": "d",
+ "action": "store",
+ "metavar": "<output_directory>",
+ "help": "set the output directory path.",
+ },
+ ),
+ (
+ "source-roots",
+ {
+ "type": "glob_paths_csv",
+ "metavar": "<path>[,<path>...]",
+ "default": (),
+ "help": "Add paths to the list of the source roots. Supports globbing patterns. The "
+ "source root is an absolute path or a path relative to the current working directory "
+ "used to determine a package namespace for modules located under the source root.",
+ },
+ ),
+ (
+ "verbose",
+ {
+ "action": "store_true",
+ "default": False,
+ "help": "Makes pyreverse more verbose/talkative. Mostly useful for debugging.",
+ },
+ ),
+)
+
+
+class Run(_ArgumentsManager, _ArgumentsProvider):
+ """Base class providing common behaviour for pyreverse commands."""
+
+ options = OPTIONS
+ name = "pyreverse"
+
+ def __init__(self, args: Sequence[str]) -> NoReturn:
+ # Immediately exit if user asks for version
+ if "--version" in args:
+ print("pyreverse is included in pylint:")
+ print(constants.full_version)
+ sys.exit(0)
+
+ _ArgumentsManager.__init__(self, prog="pyreverse", description=__doc__)
+ _ArgumentsProvider.__init__(self, self)
+
+ # Parse options
+ insert_default_options()
+ args = self._parse_command_line_configuration(args)
+
+ if self.config.output_format not in DIRECTLY_SUPPORTED_FORMATS:
+ check_graphviz_availability()
+ print(
+ f"Format {self.config.output_format} is not supported natively."
+ " Pyreverse will try to generate it using Graphviz..."
+ )
+ check_if_graphviz_supports_format(self.config.output_format)
+
+ sys.exit(self.run(args))
+
+ def run(self, args: list[str]) -> int:
+ """Checking arguments and run project."""
+ if not args:
+ print(self.help())
+ return 1
+ extra_packages_paths = list(
+ {discover_package_path(arg, self.config.source_roots) for arg in args}
+ )
+ with augmented_sys_path(extra_packages_paths):
+ project = project_from_files(
+ args,
+ project_name=self.config.project,
+ black_list=self.config.ignore_list,
+ verbose=self.config.verbose,
+ )
+ linker = Linker(project, tag=True)
+ handler = DiadefsHandler(self.config)
+ diadefs = handler.get_diadefs(project, linker)
+ writer.DiagramWriter(self.config).write(diadefs)
+ return 0
+
+
+if __name__ == "__main__":
+ Run(sys.argv[1:])
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/mermaidjs_printer.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/mermaidjs_printer.py
new file mode 100644
index 000000000..24fa92776
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/mermaidjs_printer.py
@@ -0,0 +1,112 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Class to generate files in mermaidjs format."""
+
+from __future__ import annotations
+
+from pylint.pyreverse.printer import EdgeType, NodeProperties, NodeType, Printer
+from pylint.pyreverse.utils import get_annotation_label
+
+
+class MermaidJSPrinter(Printer):
+ """Printer for MermaidJS diagrams."""
+
+ DEFAULT_COLOR = "black"
+
+ NODES: dict[NodeType, str] = {
+ NodeType.CLASS: "class",
+ NodeType.PACKAGE: "class",
+ }
+ ARROWS: dict[EdgeType, str] = {
+ EdgeType.INHERITS: "--|>",
+ EdgeType.ASSOCIATION: "--*",
+ EdgeType.AGGREGATION: "--o",
+ EdgeType.USES: "-->",
+ EdgeType.TYPE_DEPENDENCY: "..>",
+ }
+
+ def _open_graph(self) -> None:
+ """Emit the header lines."""
+ self.emit("classDiagram")
+ self._inc_indent()
+
+ def emit_node(
+ self,
+ name: str,
+ type_: NodeType,
+ properties: NodeProperties | None = None,
+ ) -> None:
+ """Create a new node.
+
+ Nodes can be classes, packages, participants etc.
+ """
+ # pylint: disable=duplicate-code
+ if properties is None:
+ properties = NodeProperties(label=name)
+ nodetype = self.NODES[type_]
+ body = []
+ if properties.attrs:
+ body.extend(properties.attrs)
+ if properties.methods:
+ for func in properties.methods:
+ args = self._get_method_arguments(func)
+ line = f"{func.name}({', '.join(args)})"
+ line += "*" if func.is_abstract() else ""
+ if func.returns:
+ line += f" {get_annotation_label(func.returns)}"
+ body.append(line)
+ name = name.split(".")[-1]
+ self.emit(f"{nodetype} {name} {{")
+ self._inc_indent()
+ for line in body:
+ self.emit(line)
+ self._dec_indent()
+ self.emit("}")
+
+ def emit_edge(
+ self,
+ from_node: str,
+ to_node: str,
+ type_: EdgeType,
+ label: str | None = None,
+ ) -> None:
+ """Create an edge from one node to another to display relationships."""
+ from_node = from_node.split(".")[-1]
+ to_node = to_node.split(".")[-1]
+ edge = f"{from_node} {self.ARROWS[type_]} {to_node}"
+ if label:
+ edge += f" : {label}"
+ self.emit(edge)
+
+ def _close_graph(self) -> None:
+ """Emit the lines needed to properly close the graph."""
+ self._dec_indent()
+
+
+class HTMLMermaidJSPrinter(MermaidJSPrinter):
+ """Printer for MermaidJS diagrams wrapped in a html boilerplate."""
+
+ HTML_OPEN_BOILERPLATE = """<html>
+ <body>
+ <script src="https://cdn.jsdelivr.net/npm/mermaid/dist/mermaid.min.js"></script>
+ <div class="mermaid">
+ """
+ HTML_CLOSE_BOILERPLATE = """
+ </div>
+ </body>
+</html>
+"""
+ GRAPH_INDENT_LEVEL = 4
+
+ def _open_graph(self) -> None:
+ self.emit(self.HTML_OPEN_BOILERPLATE)
+ for _ in range(self.GRAPH_INDENT_LEVEL):
+ self._inc_indent()
+ super()._open_graph()
+
+ def _close_graph(self) -> None:
+ for _ in range(self.GRAPH_INDENT_LEVEL):
+ self._dec_indent()
+ self.emit(self.HTML_CLOSE_BOILERPLATE)
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/plantuml_printer.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/plantuml_printer.py
new file mode 100644
index 000000000..379d57a4c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/plantuml_printer.py
@@ -0,0 +1,99 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Class to generate files in dot format and image formats supported by Graphviz."""
+
+from __future__ import annotations
+
+from pylint.pyreverse.printer import EdgeType, Layout, NodeProperties, NodeType, Printer
+from pylint.pyreverse.utils import get_annotation_label
+
+
+class PlantUmlPrinter(Printer):
+ """Printer for PlantUML diagrams."""
+
+ DEFAULT_COLOR = "black"
+
+ NODES: dict[NodeType, str] = {
+ NodeType.CLASS: "class",
+ NodeType.PACKAGE: "package",
+ }
+ ARROWS: dict[EdgeType, str] = {
+ EdgeType.INHERITS: "--|>",
+ EdgeType.ASSOCIATION: "--*",
+ EdgeType.AGGREGATION: "--o",
+ EdgeType.USES: "-->",
+ EdgeType.TYPE_DEPENDENCY: "..>",
+ }
+
+ def _open_graph(self) -> None:
+ """Emit the header lines."""
+ self.emit("@startuml " + self.title)
+ if not self.use_automatic_namespace:
+ self.emit("set namespaceSeparator none")
+ if self.layout:
+ if self.layout is Layout.LEFT_TO_RIGHT:
+ self.emit("left to right direction")
+ elif self.layout is Layout.TOP_TO_BOTTOM:
+ self.emit("top to bottom direction")
+ else:
+ raise ValueError(
+ f"Unsupported layout {self.layout}. PlantUmlPrinter only "
+ "supports left to right and top to bottom layout."
+ )
+
+ def emit_node(
+ self,
+ name: str,
+ type_: NodeType,
+ properties: NodeProperties | None = None,
+ ) -> None:
+ """Create a new node.
+
+ Nodes can be classes, packages, participants etc.
+ """
+ if properties is None:
+ properties = NodeProperties(label=name)
+ nodetype = self.NODES[type_]
+ if properties.color and properties.color != self.DEFAULT_COLOR:
+ color = f" #{properties.color.lstrip('#')}"
+ else:
+ color = ""
+ body = []
+ if properties.attrs:
+ body.extend(properties.attrs)
+ if properties.methods:
+ for func in properties.methods:
+ args = self._get_method_arguments(func)
+ line = "{abstract}" if func.is_abstract() else ""
+ line += f"{func.name}({', '.join(args)})"
+ if func.returns:
+ line += " -> " + get_annotation_label(func.returns)
+ body.append(line)
+ label = properties.label if properties.label is not None else name
+ if properties.fontcolor and properties.fontcolor != self.DEFAULT_COLOR:
+ label = f"<color:{properties.fontcolor}>{label}</color>"
+ self.emit(f'{nodetype} "{label}" as {name}{color} {{')
+ self._inc_indent()
+ for line in body:
+ self.emit(line)
+ self._dec_indent()
+ self.emit("}")
+
+ def emit_edge(
+ self,
+ from_node: str,
+ to_node: str,
+ type_: EdgeType,
+ label: str | None = None,
+ ) -> None:
+ """Create an edge from one node to another to display relationships."""
+ edge = f"{from_node} {self.ARROWS[type_]} {to_node}"
+ if label:
+ edge += f" : {label}"
+ self.emit(edge)
+
+ def _close_graph(self) -> None:
+ """Emit the lines needed to properly close the graph."""
+ self.emit("@enduml")
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/printer.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/printer.py
new file mode 100644
index 000000000..caa7917ca
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/printer.py
@@ -0,0 +1,132 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Base class defining the interface for a printer."""
+
+from __future__ import annotations
+
+from abc import ABC, abstractmethod
+from enum import Enum
+from typing import NamedTuple
+
+from astroid import nodes
+
+from pylint.pyreverse.utils import get_annotation_label
+
+
+class NodeType(Enum):
+ CLASS = "class"
+ PACKAGE = "package"
+
+
+class EdgeType(Enum):
+ INHERITS = "inherits"
+ ASSOCIATION = "association"
+ AGGREGATION = "aggregation"
+ USES = "uses"
+ TYPE_DEPENDENCY = "type_dependency"
+
+
+class Layout(Enum):
+ LEFT_TO_RIGHT = "LR"
+ RIGHT_TO_LEFT = "RL"
+ TOP_TO_BOTTOM = "TB"
+ BOTTOM_TO_TOP = "BT"
+
+
+class NodeProperties(NamedTuple):
+ label: str
+ attrs: list[str] | None = None
+ methods: list[nodes.FunctionDef] | None = None
+ color: str | None = None
+ fontcolor: str | None = None
+
+
+class Printer(ABC):
+ """Base class defining the interface for a printer."""
+
+ def __init__(
+ self,
+ title: str,
+ layout: Layout | None = None,
+ use_automatic_namespace: bool | None = None,
+ ) -> None:
+ self.title: str = title
+ self.layout = layout
+ self.use_automatic_namespace = use_automatic_namespace
+ self.lines: list[str] = []
+ self._indent = ""
+ self._open_graph()
+
+ def _inc_indent(self) -> None:
+ """Increment indentation."""
+ self._indent += " "
+
+ def _dec_indent(self) -> None:
+ """Decrement indentation."""
+ self._indent = self._indent[:-2]
+
+ @abstractmethod
+ def _open_graph(self) -> None:
+ """Emit the header lines, i.e. all boilerplate code that defines things like
+ layout etc.
+ """
+
+ def emit(self, line: str, force_newline: bool | None = True) -> None:
+ if force_newline and not line.endswith("\n"):
+ line += "\n"
+ self.lines.append(self._indent + line)
+
+ @abstractmethod
+ def emit_node(
+ self,
+ name: str,
+ type_: NodeType,
+ properties: NodeProperties | None = None,
+ ) -> None:
+ """Create a new node.
+
+ Nodes can be classes, packages, participants etc.
+ """
+
+ @abstractmethod
+ def emit_edge(
+ self,
+ from_node: str,
+ to_node: str,
+ type_: EdgeType,
+ label: str | None = None,
+ ) -> None:
+ """Create an edge from one node to another to display relationships."""
+
+ @staticmethod
+ def _get_method_arguments(method: nodes.FunctionDef) -> list[str]:
+ if method.args.args is None:
+ return []
+
+ first_arg = 0 if method.type in {"function", "staticmethod"} else 1
+ arguments: list[nodes.AssignName] = method.args.args[first_arg:]
+
+ annotations = dict(zip(arguments, method.args.annotations[first_arg:]))
+ for arg in arguments:
+ annotation_label = ""
+ ann = annotations.get(arg)
+ if ann:
+ annotation_label = get_annotation_label(ann)
+ annotations[arg] = annotation_label
+
+ return [
+ f"{arg.name}: {ann}" if ann else f"{arg.name}"
+ for arg, ann in annotations.items()
+ ]
+
+ def generate(self, outputfile: str) -> None:
+ """Generate and save the final outputfile."""
+ self._close_graph()
+ with open(outputfile, "w", encoding="utf-8") as outfile:
+ outfile.writelines(self.lines)
+
+ @abstractmethod
+ def _close_graph(self) -> None:
+ """Emit the lines needed to properly close the graph."""
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/printer_factory.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/printer_factory.py
new file mode 100644
index 000000000..fdbe480ed
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/printer_factory.py
@@ -0,0 +1,22 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from pylint.pyreverse.dot_printer import DotPrinter
+from pylint.pyreverse.mermaidjs_printer import HTMLMermaidJSPrinter, MermaidJSPrinter
+from pylint.pyreverse.plantuml_printer import PlantUmlPrinter
+from pylint.pyreverse.printer import Printer
+
+filetype_to_printer: dict[str, type[Printer]] = {
+ "plantuml": PlantUmlPrinter,
+ "puml": PlantUmlPrinter,
+ "mmd": MermaidJSPrinter,
+ "html": HTMLMermaidJSPrinter,
+ "dot": DotPrinter,
+}
+
+
+def get_printer_for_filetype(filetype: str) -> type[Printer]:
+ return filetype_to_printer.get(filetype, DotPrinter)
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/utils.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/utils.py
new file mode 100644
index 000000000..5ad92d323
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/utils.py
@@ -0,0 +1,271 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Generic classes/functions for pyreverse core/extensions."""
+
+from __future__ import annotations
+
+import os
+import re
+import shutil
+import subprocess
+import sys
+from collections.abc import Callable
+from typing import TYPE_CHECKING, Any, Optional, Union
+
+import astroid
+from astroid import nodes
+from astroid.typing import InferenceResult
+
+if TYPE_CHECKING:
+ from pylint.pyreverse.diagrams import ClassDiagram, PackageDiagram
+
+ _CallbackT = Callable[
+ [nodes.NodeNG],
+ Union[tuple[ClassDiagram], tuple[PackageDiagram, ClassDiagram], None],
+ ]
+ _CallbackTupleT = tuple[Optional[_CallbackT], Optional[_CallbackT]]
+
+
+RCFILE = ".pyreverserc"
+
+
+def get_default_options() -> list[str]:
+ """Read config file and return list of options."""
+ options = []
+ home = os.environ.get("HOME", "")
+ if home:
+ rcfile = os.path.join(home, RCFILE)
+ try:
+ with open(rcfile, encoding="utf-8") as file_handle:
+ options = file_handle.read().split()
+ except OSError:
+ pass # ignore if no config file found
+ return options
+
+
+def insert_default_options() -> None:
+ """Insert default options to sys.argv."""
+ options = get_default_options()
+ options.reverse()
+ for arg in options:
+ sys.argv.insert(1, arg)
+
+
+# astroid utilities ###########################################################
+SPECIAL = re.compile(r"^__([^\W_]_*)+__$")
+PRIVATE = re.compile(r"^__(_*[^\W_])+_?$")
+PROTECTED = re.compile(r"^_\w*$")
+
+
+def get_visibility(name: str) -> str:
+ """Return the visibility from a name: public, protected, private or special."""
+ if SPECIAL.match(name):
+ visibility = "special"
+ elif PRIVATE.match(name):
+ visibility = "private"
+ elif PROTECTED.match(name):
+ visibility = "protected"
+
+ else:
+ visibility = "public"
+ return visibility
+
+
+def is_exception(node: nodes.ClassDef) -> bool:
+ # bw compatibility
+ return node.type == "exception" # type: ignore[no-any-return]
+
+
+# Helpers #####################################################################
+
+_SPECIAL = 2
+_PROTECTED = 4
+_PRIVATE = 8
+MODES = {
+ "ALL": 0,
+ "PUB_ONLY": _SPECIAL + _PROTECTED + _PRIVATE,
+ "SPECIAL": _SPECIAL,
+ "OTHER": _PROTECTED + _PRIVATE,
+}
+VIS_MOD = {
+ "special": _SPECIAL,
+ "protected": _PROTECTED,
+ "private": _PRIVATE,
+ "public": 0,
+}
+
+
+class FilterMixIn:
+ """Filter nodes according to a mode and nodes' visibility."""
+
+ def __init__(self, mode: str) -> None:
+ """Init filter modes."""
+ __mode = 0
+ for nummod in mode.split("+"):
+ try:
+ __mode += MODES[nummod]
+ except KeyError as ex:
+ print(f"Unknown filter mode {ex}", file=sys.stderr)
+ self.__mode = __mode
+
+ def show_attr(self, node: nodes.NodeNG | str) -> bool:
+ """Return true if the node should be treated."""
+ visibility = get_visibility(getattr(node, "name", node))
+ return not self.__mode & VIS_MOD[visibility]
+
+
+class LocalsVisitor:
+ """Visit a project by traversing the locals dictionary.
+
+ * visit_<class name> on entering a node, where class name is the class of
+ the node in lower case
+
+ * leave_<class name> on leaving a node, where class name is the class of
+ the node in lower case
+ """
+
+ def __init__(self) -> None:
+ self._cache: dict[type[nodes.NodeNG], _CallbackTupleT] = {}
+ self._visited: set[nodes.NodeNG] = set()
+
+ def get_callbacks(self, node: nodes.NodeNG) -> _CallbackTupleT:
+ """Get callbacks from handler for the visited node."""
+ klass = node.__class__
+ methods = self._cache.get(klass)
+ if methods is None:
+ kid = klass.__name__.lower()
+ e_method = getattr(
+ self, f"visit_{kid}", getattr(self, "visit_default", None)
+ )
+ l_method = getattr(
+ self, f"leave_{kid}", getattr(self, "leave_default", None)
+ )
+ self._cache[klass] = (e_method, l_method)
+ else:
+ e_method, l_method = methods
+ return e_method, l_method
+
+ def visit(self, node: nodes.NodeNG) -> Any:
+ """Launch the visit starting from the given node."""
+ if node in self._visited:
+ return None
+
+ self._visited.add(node)
+ methods = self.get_callbacks(node)
+ if methods[0] is not None:
+ methods[0](node)
+ if hasattr(node, "locals"): # skip Instance and other proxy
+ for local_node in node.values():
+ self.visit(local_node)
+ if methods[1] is not None:
+ return methods[1](node)
+ return None
+
+
+def get_annotation_label(ann: nodes.Name | nodes.NodeNG) -> str:
+ if isinstance(ann, nodes.Name) and ann.name is not None:
+ return ann.name # type: ignore[no-any-return]
+ if isinstance(ann, nodes.NodeNG):
+ return ann.as_string() # type: ignore[no-any-return]
+ return ""
+
+
+def get_annotation(
+ node: nodes.AssignAttr | nodes.AssignName,
+) -> nodes.Name | nodes.Subscript | None:
+ """Return the annotation for `node`."""
+ ann = None
+ if isinstance(node.parent, nodes.AnnAssign):
+ ann = node.parent.annotation
+ elif isinstance(node, nodes.AssignAttr):
+ init_method = node.parent.parent
+ try:
+ annotations = dict(zip(init_method.locals, init_method.args.annotations))
+ ann = annotations.get(node.parent.value.name)
+ except AttributeError:
+ pass
+ else:
+ return ann
+
+ try:
+ default, *_ = node.infer()
+ except astroid.InferenceError:
+ default = ""
+
+ label = get_annotation_label(ann)
+
+ if (
+ ann
+ and getattr(default, "value", "value") is None
+ and not label.startswith("Optional")
+ and (
+ not isinstance(ann, nodes.BinOp)
+ or not any(
+ isinstance(child, nodes.Const) and child.value is None
+ for child in ann.get_children()
+ )
+ )
+ ):
+ label = rf"Optional[{label}]"
+
+ if label and ann:
+ ann.name = label
+ return ann
+
+
+def infer_node(node: nodes.AssignAttr | nodes.AssignName) -> set[InferenceResult]:
+ """Return a set containing the node annotation if it exists
+ otherwise return a set of the inferred types using the NodeNG.infer method.
+ """
+ ann = get_annotation(node)
+ try:
+ if ann:
+ if isinstance(ann, nodes.Subscript) or (
+ isinstance(ann, nodes.BinOp) and ann.op == "|"
+ ):
+ return {ann}
+ return set(ann.infer())
+ return set(node.infer())
+ except astroid.InferenceError:
+ return {ann} if ann else set()
+
+
+def check_graphviz_availability() -> None:
+ """Check if the ``dot`` command is available on the machine.
+
+ This is needed if image output is desired and ``dot`` is used to convert
+ from *.dot or *.gv into the final output format.
+ """
+ if shutil.which("dot") is None:
+ print("'Graphviz' needs to be installed for your chosen output format.")
+ sys.exit(32)
+
+
+def check_if_graphviz_supports_format(output_format: str) -> None:
+ """Check if the ``dot`` command supports the requested output format.
+
+ This is needed if image output is desired and ``dot`` is used to convert
+ from *.gv into the final output format.
+ """
+ dot_output = subprocess.run(
+ ["dot", "-T?"], capture_output=True, check=False, encoding="utf-8"
+ )
+ match = re.match(
+ pattern=r".*Use one of: (?P<formats>(\S*\s?)+)",
+ string=dot_output.stderr.strip(),
+ )
+ if not match:
+ print(
+ "Unable to determine Graphviz supported output formats. "
+ "Pyreverse will continue, but subsequent error messages "
+ "regarding the output format may come from Graphviz directly."
+ )
+ return
+ supported_formats = match.group("formats")
+ if output_format not in supported_formats.split():
+ print(
+ f"Format {output_format} is not supported by Graphviz. It supports: {supported_formats}"
+ )
+ sys.exit(32)
diff --git a/solutions/.venv/Lib/site-packages/pylint/pyreverse/writer.py b/solutions/.venv/Lib/site-packages/pylint/pyreverse/writer.py
new file mode 100644
index 000000000..093c45959
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/pyreverse/writer.py
@@ -0,0 +1,199 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Utilities for creating diagrams."""
+
+from __future__ import annotations
+
+import argparse
+import itertools
+import os
+from collections import defaultdict
+from collections.abc import Iterable
+
+from astroid import modutils, nodes
+
+from pylint.pyreverse.diagrams import (
+ ClassDiagram,
+ ClassEntity,
+ DiagramEntity,
+ PackageDiagram,
+ PackageEntity,
+)
+from pylint.pyreverse.printer import EdgeType, NodeProperties, NodeType, Printer
+from pylint.pyreverse.printer_factory import get_printer_for_filetype
+from pylint.pyreverse.utils import is_exception
+
+
+class DiagramWriter:
+ """Base class for writing project diagrams."""
+
+ def __init__(self, config: argparse.Namespace) -> None:
+ self.config = config
+ self.printer_class = get_printer_for_filetype(self.config.output_format)
+ self.printer: Printer # defined in set_printer
+ self.file_name = "" # defined in set_printer
+ self.depth = self.config.max_color_depth
+ # default colors are an adaption of the seaborn colorblind palette
+ self.available_colors = itertools.cycle(self.config.color_palette)
+ self.used_colors: dict[str, str] = {}
+
+ def write(self, diadefs: Iterable[ClassDiagram | PackageDiagram]) -> None:
+ """Write files for <project> according to <diadefs>."""
+ for diagram in diadefs:
+ basename = diagram.title.strip().replace("/", "_").replace(" ", "_")
+ file_name = f"{basename}.{self.config.output_format}"
+ if os.path.exists(self.config.output_directory):
+ file_name = os.path.join(self.config.output_directory, file_name)
+ self.set_printer(file_name, basename)
+ if isinstance(diagram, PackageDiagram):
+ self.write_packages(diagram)
+ else:
+ self.write_classes(diagram)
+ self.save()
+
+ def write_packages(self, diagram: PackageDiagram) -> None:
+ """Write a package diagram."""
+ module_info: dict[str, dict[str, int]] = {}
+
+ # sorted to get predictable (hence testable) results
+ for module in sorted(diagram.modules(), key=lambda x: x.title):
+ module.fig_id = module.node.qname()
+
+ if self.config.no_standalone and not any(
+ module in (rel.from_object, rel.to_object)
+ for rel in diagram.get_relationships("depends")
+ ):
+ continue
+
+ self.printer.emit_node(
+ module.fig_id,
+ type_=NodeType.PACKAGE,
+ properties=self.get_package_properties(module),
+ )
+
+ module_info[module.fig_id] = {
+ "imports": 0,
+ "imported": 0,
+ }
+
+ # package dependencies
+ for rel in diagram.get_relationships("depends"):
+ from_id = rel.from_object.fig_id
+ to_id = rel.to_object.fig_id
+
+ self.printer.emit_edge(
+ from_id,
+ to_id,
+ type_=EdgeType.USES,
+ )
+
+ module_info[from_id]["imports"] += 1
+ module_info[to_id]["imported"] += 1
+
+ for rel in diagram.get_relationships("type_depends"):
+ from_id = rel.from_object.fig_id
+ to_id = rel.to_object.fig_id
+
+ self.printer.emit_edge(
+ from_id,
+ to_id,
+ type_=EdgeType.TYPE_DEPENDENCY,
+ )
+
+ module_info[from_id]["imports"] += 1
+ module_info[to_id]["imported"] += 1
+
+ print(
+ f"Analysed {len(module_info)} modules with a total "
+ f"of {sum(mod['imports'] for mod in module_info.values())} imports"
+ )
+
+ def write_classes(self, diagram: ClassDiagram) -> None:
+ """Write a class diagram."""
+ # sorted to get predictable (hence testable) results
+ for obj in sorted(diagram.objects, key=lambda x: x.title):
+ obj.fig_id = obj.node.qname()
+ if self.config.no_standalone and not any(
+ obj in (rel.from_object, rel.to_object)
+ for rel_type in ("specialization", "association", "aggregation")
+ for rel in diagram.get_relationships(rel_type)
+ ):
+ continue
+
+ self.printer.emit_node(
+ obj.fig_id,
+ type_=NodeType.CLASS,
+ properties=self.get_class_properties(obj),
+ )
+ # inheritance links
+ for rel in diagram.get_relationships("specialization"):
+ self.printer.emit_edge(
+ rel.from_object.fig_id,
+ rel.to_object.fig_id,
+ type_=EdgeType.INHERITS,
+ )
+ associations: dict[str, set[str]] = defaultdict(set)
+ # generate associations
+ for rel in diagram.get_relationships("association"):
+ associations[rel.from_object.fig_id].add(rel.to_object.fig_id)
+ self.printer.emit_edge(
+ rel.from_object.fig_id,
+ rel.to_object.fig_id,
+ label=rel.name,
+ type_=EdgeType.ASSOCIATION,
+ )
+ # generate aggregations
+ for rel in diagram.get_relationships("aggregation"):
+ if rel.to_object.fig_id in associations[rel.from_object.fig_id]:
+ continue
+ self.printer.emit_edge(
+ rel.from_object.fig_id,
+ rel.to_object.fig_id,
+ label=rel.name,
+ type_=EdgeType.AGGREGATION,
+ )
+
+ def set_printer(self, file_name: str, basename: str) -> None:
+ """Set printer."""
+ self.printer = self.printer_class(basename)
+ self.file_name = file_name
+
+ def get_package_properties(self, obj: PackageEntity) -> NodeProperties:
+ """Get label and shape for packages."""
+ return NodeProperties(
+ label=obj.title,
+ color=self.get_shape_color(obj) if self.config.colorized else "black",
+ )
+
+ def get_class_properties(self, obj: ClassEntity) -> NodeProperties:
+ """Get label and shape for classes."""
+ properties = NodeProperties(
+ label=obj.title,
+ attrs=obj.attrs if not self.config.only_classnames else None,
+ methods=obj.methods if not self.config.only_classnames else None,
+ fontcolor="red" if is_exception(obj.node) else "black",
+ color=self.get_shape_color(obj) if self.config.colorized else "black",
+ )
+ return properties
+
+ def get_shape_color(self, obj: DiagramEntity) -> str:
+ """Get shape color."""
+ qualified_name = obj.node.qname()
+ if modutils.is_stdlib_module(qualified_name.split(".", maxsplit=1)[0]):
+ return "grey"
+ if isinstance(obj.node, nodes.ClassDef):
+ package = qualified_name.rsplit(".", maxsplit=2)[0]
+ elif obj.node.package:
+ package = qualified_name
+ else:
+ package = qualified_name.rsplit(".", maxsplit=1)[0]
+ base_name = ".".join(package.split(".", self.depth)[: self.depth])
+ if base_name not in self.used_colors:
+ self.used_colors[base_name] = next(self.available_colors)
+ return self.used_colors[base_name]
+
+ def save(self) -> None:
+ """Write to disk."""
+ self.printer.generate(self.file_name)
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/__init__.py b/solutions/.venv/Lib/site-packages/pylint/reporters/__init__.py
new file mode 100644
index 000000000..af8b1a4bf
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/__init__.py
@@ -0,0 +1,34 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Utilities methods and classes for reporters."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from pylint import utils
+from pylint.reporters.base_reporter import BaseReporter
+from pylint.reporters.collecting_reporter import CollectingReporter
+from pylint.reporters.json_reporter import JSON2Reporter, JSONReporter
+from pylint.reporters.multi_reporter import MultiReporter
+from pylint.reporters.reports_handler_mix_in import ReportsHandlerMixIn
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+def initialize(linter: PyLinter) -> None:
+ """Initialize linter with reporters in this package."""
+ utils.register_plugins(linter, __path__[0])
+
+
+__all__ = [
+ "BaseReporter",
+ "ReportsHandlerMixIn",
+ "JSONReporter",
+ "JSON2Reporter",
+ "CollectingReporter",
+ "MultiReporter",
+]
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/base_reporter.py b/solutions/.venv/Lib/site-packages/pylint/reporters/base_reporter.py
new file mode 100644
index 000000000..d370b1910
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/base_reporter.py
@@ -0,0 +1,82 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import os
+import sys
+from typing import TYPE_CHECKING, TextIO
+
+from pylint.message import Message
+from pylint.reporters.ureports.nodes import Text
+from pylint.utils import LinterStats
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+ from pylint.reporters.ureports.nodes import Section
+
+
+class BaseReporter:
+ """Base class for reporters.
+
+ symbols: show short symbolic names for messages.
+ """
+
+ extension = ""
+
+ name = "base"
+ """Name of the reporter."""
+
+ def __init__(self, output: TextIO | None = None) -> None:
+ self.linter: PyLinter
+ self.section = 0
+ self.out: TextIO = output or sys.stdout
+ self.messages: list[Message] = []
+ # Build the path prefix to strip to get relative paths
+ self.path_strip_prefix = os.getcwd() + os.sep
+
+ def handle_message(self, msg: Message) -> None:
+ """Handle a new message triggered on the current file."""
+ self.messages.append(msg)
+
+ def writeln(self, string: str = "") -> None:
+ """Write a line in the output buffer."""
+ print(string, file=self.out)
+
+ def display_reports(self, layout: Section) -> None:
+ """Display results encapsulated in the layout tree."""
+ self.section = 0
+ if layout.report_id:
+ if isinstance(layout.children[0].children[0], Text):
+ layout.children[0].children[0].data += f" ({layout.report_id})"
+ else:
+ raise ValueError(f"Incorrect child for {layout.children[0].children}")
+ self._display(layout)
+
+ def _display(self, layout: Section) -> None:
+ """Display the layout."""
+ raise NotImplementedError()
+
+ def display_messages(self, layout: Section | None) -> None:
+ """Hook for displaying the messages of the reporter.
+
+ This will be called whenever the underlying messages
+ needs to be displayed. For some reporters, it probably
+ doesn't make sense to display messages as soon as they
+ are available, so some mechanism of storing them could be used.
+ This method can be implemented to display them after they've
+ been aggregated.
+ """
+
+ # Event callbacks
+
+ def on_set_current_module(self, module: str, filepath: str | None) -> None:
+ """Hook called when a module starts to be analysed."""
+
+ def on_close(
+ self,
+ stats: LinterStats,
+ previous_stats: LinterStats | None,
+ ) -> None:
+ """Hook called when a module finished analyzing."""
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/collecting_reporter.py b/solutions/.venv/Lib/site-packages/pylint/reporters/collecting_reporter.py
new file mode 100644
index 000000000..943a74d55
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/collecting_reporter.py
@@ -0,0 +1,28 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from pylint.reporters.base_reporter import BaseReporter
+
+if TYPE_CHECKING:
+ from pylint.reporters.ureports.nodes import Section
+
+
+class CollectingReporter(BaseReporter):
+ """Collects messages."""
+
+ name = "collector"
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.messages = []
+
+ def reset(self) -> None:
+ self.messages = []
+
+ def _display(self, layout: Section) -> None:
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/json_reporter.py b/solutions/.venv/Lib/site-packages/pylint/reporters/json_reporter.py
new file mode 100644
index 000000000..7135dfc66
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/json_reporter.py
@@ -0,0 +1,201 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""JSON reporter."""
+
+from __future__ import annotations
+
+import json
+from typing import TYPE_CHECKING, Optional, TypedDict
+
+from pylint.interfaces import CONFIDENCE_MAP, UNDEFINED
+from pylint.message import Message
+from pylint.reporters.base_reporter import BaseReporter
+from pylint.typing import MessageLocationTuple
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+ from pylint.reporters.ureports.nodes import Section
+
+# Since message-id is an invalid name we need to use the alternative syntax
+OldJsonExport = TypedDict(
+ "OldJsonExport",
+ {
+ "type": str,
+ "module": str,
+ "obj": str,
+ "line": int,
+ "column": int,
+ "endLine": Optional[int],
+ "endColumn": Optional[int],
+ "path": str,
+ "symbol": str,
+ "message": str,
+ "message-id": str,
+ },
+)
+
+
+class JSONReporter(BaseReporter):
+ """Report messages and layouts in JSON.
+
+ Consider using JSON2Reporter instead, as it is superior and this reporter
+ is no longer maintained.
+ """
+
+ name = "json"
+ extension = "json"
+
+ def display_messages(self, layout: Section | None) -> None:
+ """Launch layouts display."""
+ json_dumpable = [self.serialize(message) for message in self.messages]
+ print(json.dumps(json_dumpable, indent=4), file=self.out)
+
+ def display_reports(self, layout: Section) -> None:
+ """Don't do anything in this reporter."""
+
+ def _display(self, layout: Section) -> None:
+ """Do nothing."""
+
+ @staticmethod
+ def serialize(message: Message) -> OldJsonExport:
+ return {
+ "type": message.category,
+ "module": message.module,
+ "obj": message.obj,
+ "line": message.line,
+ "column": message.column,
+ "endLine": message.end_line,
+ "endColumn": message.end_column,
+ "path": message.path,
+ "symbol": message.symbol,
+ "message": message.msg or "",
+ "message-id": message.msg_id,
+ }
+
+ @staticmethod
+ def deserialize(message_as_json: OldJsonExport) -> Message:
+ return Message(
+ msg_id=message_as_json["message-id"],
+ symbol=message_as_json["symbol"],
+ msg=message_as_json["message"],
+ location=MessageLocationTuple(
+ abspath=message_as_json["path"],
+ path=message_as_json["path"],
+ module=message_as_json["module"],
+ obj=message_as_json["obj"],
+ line=message_as_json["line"],
+ column=message_as_json["column"],
+ end_line=message_as_json["endLine"],
+ end_column=message_as_json["endColumn"],
+ ),
+ confidence=UNDEFINED,
+ )
+
+
+class JSONMessage(TypedDict):
+ type: str
+ message: str
+ messageId: str
+ symbol: str
+ confidence: str
+ module: str
+ path: str
+ absolutePath: str
+ line: int
+ endLine: int | None
+ column: int
+ endColumn: int | None
+ obj: str
+
+
+class JSON2Reporter(BaseReporter):
+ name = "json2"
+ extension = "json2"
+
+ def display_reports(self, layout: Section) -> None:
+ """Don't do anything in this reporter."""
+
+ def _display(self, layout: Section) -> None:
+ """Do nothing."""
+
+ def display_messages(self, layout: Section | None) -> None:
+ """Launch layouts display."""
+ output = {
+ "messages": [self.serialize(message) for message in self.messages],
+ "statistics": self.serialize_stats(),
+ }
+ print(json.dumps(output, indent=4), file=self.out)
+
+ @staticmethod
+ def serialize(message: Message) -> JSONMessage:
+ return JSONMessage(
+ type=message.category,
+ symbol=message.symbol,
+ message=message.msg or "",
+ messageId=message.msg_id,
+ confidence=message.confidence.name,
+ module=message.module,
+ obj=message.obj,
+ line=message.line,
+ column=message.column,
+ endLine=message.end_line,
+ endColumn=message.end_column,
+ path=message.path,
+ absolutePath=message.abspath,
+ )
+
+ @staticmethod
+ def deserialize(message_as_json: JSONMessage) -> Message:
+ return Message(
+ msg_id=message_as_json["messageId"],
+ symbol=message_as_json["symbol"],
+ msg=message_as_json["message"],
+ location=MessageLocationTuple(
+ abspath=message_as_json["absolutePath"],
+ path=message_as_json["path"],
+ module=message_as_json["module"],
+ obj=message_as_json["obj"],
+ line=message_as_json["line"],
+ column=message_as_json["column"],
+ end_line=message_as_json["endLine"],
+ end_column=message_as_json["endColumn"],
+ ),
+ confidence=CONFIDENCE_MAP[message_as_json["confidence"]],
+ )
+
+ def serialize_stats(self) -> dict[str, str | int | dict[str, int]]:
+ """Serialize the linter stats into something JSON dumpable."""
+ stats = self.linter.stats
+
+ counts_dict = {
+ "fatal": stats.fatal,
+ "error": stats.error,
+ "warning": stats.warning,
+ "refactor": stats.refactor,
+ "convention": stats.convention,
+ "info": stats.info,
+ }
+
+ # Calculate score based on the evaluation option
+ evaluation = self.linter.config.evaluation
+ try:
+ note: int = eval( # pylint: disable=eval-used
+ evaluation, {}, {**counts_dict, "statement": stats.statement or 1}
+ )
+ except Exception as ex: # pylint: disable=broad-except
+ score: str | int = f"An exception occurred while rating: {ex}"
+ else:
+ score = round(note, 2)
+
+ return {
+ "messageTypeCount": counts_dict,
+ "modulesLinted": len(stats.by_module),
+ "score": score,
+ }
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_reporter(JSONReporter)
+ linter.register_reporter(JSON2Reporter)
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/multi_reporter.py b/solutions/.venv/Lib/site-packages/pylint/reporters/multi_reporter.py
new file mode 100644
index 000000000..0c27293b7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/multi_reporter.py
@@ -0,0 +1,111 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import os
+from collections.abc import Callable
+from copy import copy
+from typing import TYPE_CHECKING, TextIO
+
+from pylint.message import Message
+from pylint.reporters.base_reporter import BaseReporter
+from pylint.utils import LinterStats
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+ from pylint.reporters.ureports.nodes import Section
+
+
+class MultiReporter:
+ """Reports messages and layouts in plain text."""
+
+ name = "_internal_multi_reporter"
+ # Note: do not register this reporter with linter.register_reporter as it is
+ # not intended to be used directly like a regular reporter, but is
+ # instead used to implement the
+ # `--output-format=json:somefile.json,colorized`
+ # multiple output formats feature
+
+ extension = ""
+
+ def __init__(
+ self,
+ sub_reporters: list[BaseReporter],
+ close_output_files: Callable[[], None],
+ output: TextIO | None = None,
+ ):
+ self._sub_reporters = sub_reporters
+ self.close_output_files = close_output_files
+ self._path_strip_prefix = os.getcwd() + os.sep
+ self._linter: PyLinter | None = None
+ self.out = output
+ self.messages: list[Message] = []
+
+ @property
+ def out(self) -> TextIO | None:
+ return self.__out
+
+ @out.setter
+ def out(self, output: TextIO | None = None) -> None:
+ """MultiReporter doesn't have its own output.
+
+ This method is only provided for API parity with BaseReporter
+ and should not be called with non-None values for 'output'.
+ """
+ self.__out = None
+ if output is not None:
+ raise NotImplementedError("MultiReporter does not support direct output.")
+
+ def __del__(self) -> None:
+ self.close_output_files()
+
+ @property
+ def path_strip_prefix(self) -> str:
+ return self._path_strip_prefix
+
+ @property
+ def linter(self) -> PyLinter | None:
+ return self._linter
+
+ @linter.setter
+ def linter(self, value: PyLinter) -> None:
+ self._linter = value
+ for rep in self._sub_reporters:
+ rep.linter = value
+
+ def handle_message(self, msg: Message) -> None:
+ """Handle a new message triggered on the current file."""
+ for rep in self._sub_reporters:
+ # We provide a copy so reporters can't modify message for others.
+ rep.handle_message(copy(msg))
+
+ def writeln(self, string: str = "") -> None:
+ """Write a line in the output buffer."""
+ for rep in self._sub_reporters:
+ rep.writeln(string)
+
+ def display_reports(self, layout: Section) -> None:
+ """Display results encapsulated in the layout tree."""
+ for rep in self._sub_reporters:
+ rep.display_reports(layout)
+
+ def display_messages(self, layout: Section | None) -> None:
+ """Hook for displaying the messages of the reporter."""
+ for rep in self._sub_reporters:
+ rep.display_messages(layout)
+
+ def on_set_current_module(self, module: str, filepath: str | None) -> None:
+ """Hook called when a module starts to be analysed."""
+ for rep in self._sub_reporters:
+ rep.on_set_current_module(module, filepath)
+
+ def on_close(
+ self,
+ stats: LinterStats,
+ previous_stats: LinterStats | None,
+ ) -> None:
+ """Hook called when a module finished analyzing."""
+ for rep in self._sub_reporters:
+ rep.on_close(stats, previous_stats)
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/reports_handler_mix_in.py b/solutions/.venv/Lib/site-packages/pylint/reporters/reports_handler_mix_in.py
new file mode 100644
index 000000000..071879ca1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/reports_handler_mix_in.py
@@ -0,0 +1,83 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import collections
+from collections.abc import MutableSequence
+from typing import TYPE_CHECKING
+
+from pylint.exceptions import EmptyReportError
+from pylint.reporters.ureports.nodes import Section
+from pylint.typing import ReportsCallable
+from pylint.utils import LinterStats
+
+if TYPE_CHECKING:
+ from pylint.checkers import BaseChecker
+ from pylint.lint.pylinter import PyLinter
+
+ReportsDict = collections.defaultdict[
+ "BaseChecker", list[tuple[str, str, ReportsCallable]]
+]
+
+
+class ReportsHandlerMixIn:
+ """A mix-in class containing all the reports and stats manipulation
+ related methods for the main lint class.
+ """
+
+ def __init__(self) -> None:
+ self._reports: ReportsDict = collections.defaultdict(list)
+ self._reports_state: dict[str, bool] = {}
+
+ def report_order(self) -> MutableSequence[BaseChecker]:
+ """Return a list of reporters."""
+ return list(self._reports)
+
+ def register_report(
+ self, reportid: str, r_title: str, r_cb: ReportsCallable, checker: BaseChecker
+ ) -> None:
+ """Register a report.
+
+ :param reportid: The unique identifier for the report
+ :param r_title: The report's title
+ :param r_cb: The method to call to make the report
+ :param checker: The checker defining the report
+ """
+ reportid = reportid.upper()
+ self._reports[checker].append((reportid, r_title, r_cb))
+
+ def enable_report(self, reportid: str) -> None:
+ """Enable the report of the given id."""
+ reportid = reportid.upper()
+ self._reports_state[reportid] = True
+
+ def disable_report(self, reportid: str) -> None:
+ """Disable the report of the given id."""
+ reportid = reportid.upper()
+ self._reports_state[reportid] = False
+
+ def report_is_enabled(self, reportid: str) -> bool:
+ """Is the report associated to the given identifier enabled ?"""
+ return self._reports_state.get(reportid, True)
+
+ def make_reports( # type: ignore[misc] # ReportsHandlerMixIn is always mixed with PyLinter
+ self: PyLinter,
+ stats: LinterStats,
+ old_stats: LinterStats | None,
+ ) -> Section:
+ """Render registered reports."""
+ sect = Section("Report", f"{self.stats.statement} statements analysed.")
+ for checker in self.report_order():
+ for reportid, r_title, r_cb in self._reports[checker]:
+ if not self.report_is_enabled(reportid):
+ continue
+ report_sect = Section(r_title)
+ try:
+ r_cb(report_sect, stats, old_stats)
+ except EmptyReportError:
+ continue
+ report_sect.report_id = reportid
+ sect.append(report_sect)
+ return sect
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/text.py b/solutions/.venv/Lib/site-packages/pylint/reporters/text.py
new file mode 100644
index 000000000..894207ad7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/text.py
@@ -0,0 +1,289 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Plain text reporters:.
+
+:text: the default one grouping messages by module
+:colorized: an ANSI colorized text reporter
+"""
+
+from __future__ import annotations
+
+import os
+import re
+import sys
+import warnings
+from dataclasses import asdict, fields
+from typing import TYPE_CHECKING, NamedTuple, TextIO
+
+from pylint.message import Message
+from pylint.reporters import BaseReporter
+from pylint.reporters.ureports.text_writer import TextWriter
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+ from pylint.reporters.ureports.nodes import Section
+
+
+class MessageStyle(NamedTuple):
+ """Styling of a message."""
+
+ color: str | None
+ """The color name (see `ANSI_COLORS` for available values)
+ or the color number when 256 colors are available.
+ """
+ style: tuple[str, ...] = ()
+ """Tuple of style strings (see `ANSI_COLORS` for available values)."""
+
+ def __get_ansi_code(self) -> str:
+ """Return ANSI escape code corresponding to color and style.
+
+ :raise KeyError: if a nonexistent color or style identifier is given
+
+ :return: the built escape code
+ """
+ ansi_code = [ANSI_STYLES[effect] for effect in self.style]
+ if self.color:
+ if self.color.isdigit():
+ ansi_code.extend(["38", "5"])
+ ansi_code.append(self.color)
+ else:
+ ansi_code.append(ANSI_COLORS[self.color])
+ if ansi_code:
+ return ANSI_PREFIX + ";".join(ansi_code) + ANSI_END
+ return ""
+
+ def _colorize_ansi(self, msg: str) -> str:
+ if self.color is None and len(self.style) == 0:
+ # If both color and style are not defined, then leave the text as is.
+ return msg
+ escape_code = self.__get_ansi_code()
+ # If invalid (or unknown) color, don't wrap msg with ANSI codes
+ if escape_code:
+ return f"{escape_code}{msg}{ANSI_RESET}"
+ return msg
+
+
+ColorMappingDict = dict[str, MessageStyle]
+
+TITLE_UNDERLINES = ["", "=", "-", "."]
+
+ANSI_PREFIX = "\033["
+ANSI_END = "m"
+ANSI_RESET = "\033[0m"
+ANSI_STYLES = {
+ "reset": "0",
+ "bold": "1",
+ "italic": "3",
+ "underline": "4",
+ "blink": "5",
+ "inverse": "7",
+ "strike": "9",
+}
+ANSI_COLORS = {
+ "reset": "0",
+ "black": "30",
+ "red": "31",
+ "green": "32",
+ "yellow": "33",
+ "blue": "34",
+ "magenta": "35",
+ "cyan": "36",
+ "white": "37",
+}
+
+MESSAGE_FIELDS = {i.name for i in fields(Message)}
+"""All fields of the Message class."""
+
+
+def colorize_ansi(msg: str, msg_style: MessageStyle) -> str:
+ """Colorize message by wrapping it with ANSI escape codes."""
+ return msg_style._colorize_ansi(msg)
+
+
+def make_header(msg: Message) -> str:
+ return f"************* Module {msg.module}"
+
+
+class TextReporter(BaseReporter):
+ """Reports messages and layouts in plain text."""
+
+ name = "text"
+ extension = "txt"
+ line_format = "{path}:{line}:{column}: {msg_id}: {msg} ({symbol})"
+
+ def __init__(self, output: TextIO | None = None) -> None:
+ super().__init__(output)
+ self._modules: set[str] = set()
+ self._template = self.line_format
+ self._fixed_template = self.line_format
+ """The output format template with any unrecognized arguments removed."""
+
+ def on_set_current_module(self, module: str, filepath: str | None) -> None:
+ """Set the format template to be used and check for unrecognized arguments."""
+ template = str(self.linter.config.msg_template or self._template)
+
+ # Return early if the template is the same as the previous one
+ if template == self._template:
+ return
+
+ # Set template to the currently selected template
+ self._template = template
+
+ # Check to see if all parameters in the template are attributes of the Message
+ arguments = re.findall(r"\{(\w+?)(:.*)?\}", template)
+ for argument in arguments:
+ if argument[0] not in MESSAGE_FIELDS:
+ warnings.warn(
+ f"Don't recognize the argument '{argument[0]}' in the --msg-template. "
+ "Are you sure it is supported on the current version of pylint?",
+ stacklevel=2,
+ )
+ template = re.sub(r"\{" + argument[0] + r"(:.*?)?\}", "", template)
+ self._fixed_template = template
+
+ def write_message(self, msg: Message) -> None:
+ """Convenience method to write a formatted message with class default
+ template.
+ """
+ self_dict = asdict(msg)
+ for key in ("end_line", "end_column"):
+ self_dict[key] = self_dict[key] or ""
+
+ self.writeln(self._fixed_template.format(**self_dict))
+
+ def handle_message(self, msg: Message) -> None:
+ """Manage message of different type and in the context of path."""
+ if msg.module not in self._modules:
+ self.writeln(make_header(msg))
+ self._modules.add(msg.module)
+ self.write_message(msg)
+
+ def _display(self, layout: Section) -> None:
+ """Launch layouts display."""
+ print(file=self.out)
+ TextWriter().format(layout, self.out)
+
+
+class NoHeaderReporter(TextReporter):
+ """Reports messages and layouts in plain text without a module header."""
+
+ name = "no-header"
+
+ def handle_message(self, msg: Message) -> None:
+ """Write message(s) without module header."""
+ if msg.module not in self._modules:
+ self._modules.add(msg.module)
+ self.write_message(msg)
+
+
+class ParseableTextReporter(TextReporter):
+ """A reporter very similar to TextReporter, but display messages in a form
+ recognized by most text editors :
+
+ <filename>:<linenum>:<msg>
+ """
+
+ name = "parseable"
+ line_format = "{path}:{line}: [{msg_id}({symbol}), {obj}] {msg}"
+
+ def __init__(self, output: TextIO | None = None) -> None:
+ warnings.warn(
+ f"{self.name} output format is deprecated. This is equivalent to --msg-template={self.line_format}",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ super().__init__(output)
+
+
+class VSTextReporter(ParseableTextReporter):
+ """Visual studio text reporter."""
+
+ name = "msvs"
+ line_format = "{path}({line}): [{msg_id}({symbol}){obj}] {msg}"
+
+
+class ColorizedTextReporter(TextReporter):
+ """Simple TextReporter that colorizes text output."""
+
+ name = "colorized"
+ COLOR_MAPPING: ColorMappingDict = {
+ "I": MessageStyle("green"),
+ "C": MessageStyle(None, ("bold",)),
+ "R": MessageStyle("magenta", ("bold", "italic")),
+ "W": MessageStyle("magenta"),
+ "E": MessageStyle("red", ("bold",)),
+ "F": MessageStyle("red", ("bold", "underline")),
+ "S": MessageStyle("yellow", ("inverse",)), # S stands for module Separator
+ }
+
+ def __init__(
+ self,
+ output: TextIO | None = None,
+ color_mapping: ColorMappingDict | None = None,
+ ) -> None:
+ super().__init__(output)
+ self.color_mapping = color_mapping or ColorizedTextReporter.COLOR_MAPPING
+ ansi_terms = ["xterm-16color", "xterm-256color"]
+ if os.environ.get("TERM") not in ansi_terms:
+ if sys.platform == "win32":
+ # pylint: disable=import-outside-toplevel
+ import colorama
+
+ self.out = colorama.AnsiToWin32(self.out)
+
+ def _get_decoration(self, msg_id: str) -> MessageStyle:
+ """Returns the message style as defined in self.color_mapping."""
+ return self.color_mapping.get(msg_id[0]) or MessageStyle(None)
+
+ def handle_message(self, msg: Message) -> None:
+ """Manage message of different types, and colorize output
+ using ANSI escape codes.
+ """
+ if msg.module not in self._modules:
+ msg_style = self._get_decoration("S")
+ modsep = colorize_ansi(make_header(msg), msg_style)
+ self.writeln(modsep)
+ self._modules.add(msg.module)
+ msg_style = self._get_decoration(msg.C)
+
+ msg.msg = colorize_ansi(msg.msg, msg_style)
+ msg.symbol = colorize_ansi(msg.symbol, msg_style)
+ msg.category = colorize_ansi(msg.category, msg_style)
+ msg.C = colorize_ansi(msg.C, msg_style)
+ self.write_message(msg)
+
+
+class GithubReporter(TextReporter):
+ """Report messages in GitHub's special format to annotate code in its user
+ interface.
+ """
+
+ name = "github"
+ line_format = "::{category} file={path},line={line},endline={end_line},col={column},title={msg_id}::{msg}"
+ category_map = {
+ "F": "error",
+ "E": "error",
+ "W": "warning",
+ "C": "notice",
+ "R": "notice",
+ "I": "notice",
+ }
+
+ def write_message(self, msg: Message) -> None:
+ self_dict = asdict(msg)
+ for key in ("end_line", "end_column"):
+ self_dict[key] = self_dict[key] or ""
+
+ self_dict["category"] = self.category_map.get(msg.C) or "error"
+ self.writeln(self._fixed_template.format(**self_dict))
+
+
+def register(linter: PyLinter) -> None:
+ linter.register_reporter(TextReporter)
+ linter.register_reporter(NoHeaderReporter)
+ linter.register_reporter(ParseableTextReporter)
+ linter.register_reporter(VSTextReporter)
+ linter.register_reporter(ColorizedTextReporter)
+ linter.register_reporter(GithubReporter)
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/__init__.py b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/__init__.py
new file mode 100644
index 000000000..b87c3c319
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/__init__.py
@@ -0,0 +1,7 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+__all__ = ("BaseWriter",)
+
+from pylint.reporters.ureports.base_writer import BaseWriter
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/base_writer.py b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/base_writer.py
new file mode 100644
index 000000000..9a12123cb
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/base_writer.py
@@ -0,0 +1,107 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Universal report objects and some formatting drivers.
+
+A way to create simple reports using python objects, primarily designed to be
+formatted as text and html.
+"""
+
+from __future__ import annotations
+
+import sys
+from collections.abc import Iterator
+from io import StringIO
+from typing import TYPE_CHECKING, TextIO
+
+if TYPE_CHECKING:
+ from pylint.reporters.ureports.nodes import (
+ BaseLayout,
+ EvaluationSection,
+ Paragraph,
+ Section,
+ Table,
+ )
+
+
+class BaseWriter:
+ """Base class for ureport writers."""
+
+ def format(
+ self,
+ layout: BaseLayout,
+ stream: TextIO = sys.stdout,
+ encoding: str | None = None,
+ ) -> None:
+ """Format and write the given layout into the stream object.
+
+ unicode policy: unicode strings may be found in the layout;
+ try to call 'stream.write' with it, but give it back encoded using
+ the given encoding if it fails
+ """
+ if not encoding:
+ encoding = getattr(stream, "encoding", "UTF-8")
+ self.encoding = encoding or "UTF-8"
+ self.out = stream
+ self.begin_format()
+ layout.accept(self)
+ self.end_format()
+
+ def format_children(self, layout: EvaluationSection | Paragraph | Section) -> None:
+ """Recurse on the layout children and call their accept method
+ (see the Visitor pattern).
+ """
+ for child in getattr(layout, "children", ()):
+ child.accept(self)
+
+ def writeln(self, string: str = "") -> None:
+ """Write a line in the output buffer."""
+ self.write(string + "\n")
+
+ def write(self, string: str) -> None:
+ """Write a string in the output buffer."""
+ self.out.write(string)
+
+ def begin_format(self) -> None:
+ """Begin to format a layout."""
+ self.section = 0
+
+ def end_format(self) -> None:
+ """Finished formatting a layout."""
+
+ def get_table_content(self, table: Table) -> list[list[str]]:
+ """Trick to get table content without actually writing it.
+
+ return an aligned list of lists containing table cells values as string
+ """
+ result: list[list[str]] = [[]]
+ cols = table.cols
+ for cell in self.compute_content(table):
+ if cols == 0:
+ result.append([])
+ cols = table.cols
+ cols -= 1
+ result[-1].append(cell)
+ # fill missing cells
+ result[-1] += [""] * (cols - len(result[-1]))
+ return result
+
+ def compute_content(self, layout: BaseLayout) -> Iterator[str]:
+ """Trick to compute the formatting of children layout before actually
+ writing it.
+
+ return an iterator on strings (one for each child element)
+ """
+ # Patch the underlying output stream with a fresh-generated stream,
+ # which is used to store a temporary representation of a child
+ # node.
+ out = self.out
+ try:
+ for child in layout.children:
+ stream = StringIO()
+ self.out = stream
+ child.accept(self)
+ yield stream.getvalue()
+ finally:
+ self.out = out
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/nodes.py b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/nodes.py
new file mode 100644
index 000000000..c41486512
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/nodes.py
@@ -0,0 +1,190 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Micro reports objects.
+
+A micro report is a tree of layout and content objects.
+"""
+
+from __future__ import annotations
+
+from collections.abc import Callable, Iterable, Iterator
+from typing import Any, TypeVar
+
+from pylint.reporters.ureports.base_writer import BaseWriter
+
+_T = TypeVar("_T")
+_VNodeT = TypeVar("_VNodeT", bound="VNode")
+VisitLeaveFunction = Callable[[_T, Any, Any], None]
+
+
+class VNode:
+ def __init__(self) -> None:
+ self.parent: BaseLayout | None = None
+ self.children: list[VNode] = []
+ self.visitor_name: str = self.__class__.__name__.lower()
+
+ def __iter__(self) -> Iterator[VNode]:
+ return iter(self.children)
+
+ def accept(self: _VNodeT, visitor: BaseWriter, *args: Any, **kwargs: Any) -> None:
+ func: VisitLeaveFunction[_VNodeT] = getattr(
+ visitor, f"visit_{self.visitor_name}"
+ )
+ return func(self, *args, **kwargs)
+
+ def leave(self: _VNodeT, visitor: BaseWriter, *args: Any, **kwargs: Any) -> None:
+ func: VisitLeaveFunction[_VNodeT] = getattr(
+ visitor, f"leave_{self.visitor_name}"
+ )
+ return func(self, *args, **kwargs)
+
+
+class BaseLayout(VNode):
+ """Base container node.
+
+ attributes
+ * children : components in this table (i.e. the table's cells)
+ """
+
+ def __init__(self, children: Iterable[Text | str] = ()) -> None:
+ super().__init__()
+ for child in children:
+ if isinstance(child, VNode):
+ self.append(child)
+ else:
+ self.add_text(child)
+
+ def append(self, child: VNode) -> None:
+ """Add a node to children."""
+ assert child not in self.parents()
+ self.children.append(child)
+ child.parent = self
+
+ def insert(self, index: int, child: VNode) -> None:
+ """Insert a child node."""
+ self.children.insert(index, child)
+ child.parent = self
+
+ def parents(self) -> list[BaseLayout]:
+ """Return the ancestor nodes."""
+ assert self.parent is not self
+ if self.parent is None:
+ return []
+ return [self.parent, *self.parent.parents()]
+
+ def add_text(self, text: str) -> None:
+ """Shortcut to add text data."""
+ self.children.append(Text(text))
+
+
+# non container nodes #########################################################
+
+
+class Text(VNode):
+ """A text portion.
+
+ attributes :
+ * data : the text value as an encoded or unicode string
+ """
+
+ def __init__(self, data: str, escaped: bool = True) -> None:
+ super().__init__()
+ self.escaped = escaped
+ self.data = data
+
+
+class VerbatimText(Text):
+ """A verbatim text, display the raw data.
+
+ attributes :
+ * data : the text value as an encoded or unicode string
+ """
+
+
+# container nodes #############################################################
+
+
+class Section(BaseLayout):
+ """A section.
+
+ attributes :
+ * BaseLayout attributes
+
+ a title may also be given to the constructor, it'll be added
+ as a first element
+ a description may also be given to the constructor, it'll be added
+ as a first paragraph
+ """
+
+ def __init__(
+ self,
+ title: str | None = None,
+ description: str | None = None,
+ children: Iterable[Text | str] = (),
+ ) -> None:
+ super().__init__(children=children)
+ if description:
+ self.insert(0, Paragraph([Text(description)]))
+ if title:
+ self.insert(0, Title(children=(title,)))
+ self.report_id: str = "" # Used in ReportHandlerMixin.make_reports
+
+
+class EvaluationSection(Section):
+ def __init__(self, message: str, children: Iterable[Text | str] = ()) -> None:
+ super().__init__(children=children)
+ title = Paragraph()
+ title.append(Text("-" * len(message)))
+ self.append(title)
+ message_body = Paragraph()
+ message_body.append(Text(message))
+ self.append(message_body)
+
+
+class Title(BaseLayout):
+ """A title.
+
+ attributes :
+ * BaseLayout attributes
+
+ A title must not contain a section nor a paragraph!
+ """
+
+
+class Paragraph(BaseLayout):
+ """A simple text paragraph.
+
+ attributes :
+ * BaseLayout attributes
+
+ A paragraph must not contains a section !
+ """
+
+
+class Table(BaseLayout):
+ """Some tabular data.
+
+ attributes :
+ * BaseLayout attributes
+ * cols : the number of columns of the table (REQUIRED)
+ * rheaders : the first row's elements are table's header
+ * cheaders : the first col's elements are table's header
+ * title : the table's optional title
+ """
+
+ def __init__(
+ self,
+ cols: int,
+ title: str | None = None,
+ rheaders: int = 0,
+ cheaders: int = 0,
+ children: Iterable[Text | str] = (),
+ ) -> None:
+ super().__init__(children=children)
+ assert isinstance(cols, int)
+ self.cols = cols
+ self.title = title
+ self.rheaders = rheaders
+ self.cheaders = cheaders
diff --git a/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/text_writer.py b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/text_writer.py
new file mode 100644
index 000000000..5dd6a5d08
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/reporters/ureports/text_writer.py
@@ -0,0 +1,108 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Text formatting drivers for ureports."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+from pylint.reporters.ureports.base_writer import BaseWriter
+
+if TYPE_CHECKING:
+ from pylint.reporters.ureports.nodes import (
+ EvaluationSection,
+ Paragraph,
+ Section,
+ Table,
+ Text,
+ Title,
+ VerbatimText,
+ )
+
+TITLE_UNDERLINES = ["", "=", "-", "`", ".", "~", "^"]
+BULLETS = ["*", "-"]
+
+
+class TextWriter(BaseWriter):
+ """Format layouts as text
+ (ReStructured inspiration but not totally handled yet).
+ """
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.list_level = 0
+
+ def visit_section(self, layout: Section) -> None:
+ """Display a section as text."""
+ self.section += 1
+ self.writeln()
+ self.format_children(layout)
+ self.section -= 1
+ self.writeln()
+
+ def visit_evaluationsection(self, layout: EvaluationSection) -> None:
+ """Display an evaluation section as a text."""
+ self.section += 1
+ self.format_children(layout)
+ self.section -= 1
+ self.writeln()
+
+ def visit_title(self, layout: Title) -> None:
+ title = "".join(list(self.compute_content(layout)))
+ self.writeln(title)
+ try:
+ self.writeln(TITLE_UNDERLINES[self.section] * len(title))
+ except IndexError:
+ print("FIXME TITLE TOO DEEP. TURNING TITLE INTO TEXT")
+
+ def visit_paragraph(self, layout: Paragraph) -> None:
+ """Enter a paragraph."""
+ self.format_children(layout)
+ self.writeln()
+
+ def visit_table(self, layout: Table) -> None:
+ """Display a table as text."""
+ table_content = self.get_table_content(layout)
+ # get columns width
+ cols_width = [0] * len(table_content[0])
+ for row in table_content:
+ for index, col in enumerate(row):
+ cols_width[index] = max(cols_width[index], len(col))
+ self.default_table(layout, table_content, cols_width)
+ self.writeln()
+
+ def default_table(
+ self, layout: Table, table_content: list[list[str]], cols_width: list[int]
+ ) -> None:
+ """Format a table."""
+ cols_width = [size + 1 for size in cols_width]
+ format_strings = " ".join(["%%-%ss"] * len(cols_width))
+ format_strings %= tuple(cols_width)
+
+ table_linesep = "\n+" + "+".join("-" * w for w in cols_width) + "+\n"
+ headsep = "\n+" + "+".join("=" * w for w in cols_width) + "+\n"
+
+ self.write(table_linesep)
+ split_strings = format_strings.split(" ")
+ for index, line in enumerate(table_content):
+ self.write("|")
+ for line_index, at_index in enumerate(line):
+ self.write(split_strings[line_index] % at_index)
+ self.write("|")
+ if index == 0 and layout.rheaders:
+ self.write(headsep)
+ else:
+ self.write(table_linesep)
+
+ def visit_verbatimtext(self, layout: VerbatimText) -> None:
+ """Display a verbatim layout as text (so difficult ;)."""
+ self.writeln("::\n")
+ for line in layout.data.splitlines():
+ self.writeln(" " + line)
+ self.writeln()
+
+ def visit_text(self, layout: Text) -> None:
+ """Add some text."""
+ self.write(f"{layout.data}")
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/__init__.py b/solutions/.venv/Lib/site-packages/pylint/testutils/__init__.py
new file mode 100644
index 000000000..0ff9b773b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/__init__.py
@@ -0,0 +1,35 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Functional/non regression tests for pylint."""
+
+__all__ = [
+ "_get_tests_info",
+ "_tokenize_str",
+ "CheckerTestCase",
+ "FunctionalTestFile",
+ "linter",
+ "LintModuleTest",
+ "MessageTest",
+ "MinimalTestReporter",
+ "set_config",
+ "GenericTestReporter",
+ "UPDATE_FILE",
+ "UPDATE_OPTION",
+ "UnittestLinter",
+ "create_files",
+]
+
+from pylint.testutils.checker_test_case import CheckerTestCase
+from pylint.testutils.constants import UPDATE_FILE, UPDATE_OPTION
+from pylint.testutils.decorator import set_config
+from pylint.testutils.functional import FunctionalTestFile
+from pylint.testutils.get_test_info import _get_tests_info
+from pylint.testutils.global_test_linter import linter
+from pylint.testutils.lint_module_test import LintModuleTest
+from pylint.testutils.output_line import MessageTest
+from pylint.testutils.reporter_for_tests import GenericTestReporter, MinimalTestReporter
+from pylint.testutils.tokenize_str import _tokenize_str
+from pylint.testutils.unittest_linter import UnittestLinter
+from pylint.testutils.utils import create_files
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/__init__.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/__init__.py
new file mode 100644
index 000000000..2c40f561b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/__init__.py
@@ -0,0 +1,10 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+__all__ = ["PackageToLint", "PRIMER_DIRECTORY_PATH"]
+
+from pylint.testutils._primer.package_to_lint import (
+ PRIMER_DIRECTORY_PATH,
+ PackageToLint,
+)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/package_to_lint.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/package_to_lint.py
new file mode 100644
index 000000000..fb65a90ad
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/package_to_lint.py
@@ -0,0 +1,149 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import logging
+from pathlib import Path
+from typing import Literal
+
+from git import GitCommandError
+from git.cmd import Git
+from git.repo import Repo
+
+PRIMER_DIRECTORY_PATH = Path("tests") / ".pylint_primer_tests"
+
+
+class DirtyPrimerDirectoryException(Exception):
+ """We can't pull if there's local changes."""
+
+ def __init__(self, path: Path | str):
+ super().__init__(
+ rf"""
+
+/!\ Can't pull /!\
+
+In order for the prepare command to be able to pull please cleanup your local repo:
+cd {path}
+git diff
+"""
+ )
+
+
+class PackageToLint:
+ """Represents data about a package to be tested during primer tests."""
+
+ url: str
+ """URL of the repository to clone."""
+
+ branch: str
+ """Branch of the repository to clone."""
+
+ directories: list[str]
+ """Directories within the repository to run pylint over."""
+
+ commit: str | None
+ """Commit hash to pin the repository on."""
+
+ pylint_additional_args: list[str]
+ """Arguments to give to pylint."""
+
+ pylintrc_relpath: str | None
+ """Path relative to project's main directory to the pylintrc if it exists."""
+
+ minimum_python: str | None
+ """Minimum python version supported by the package."""
+
+ def __init__(
+ self,
+ url: str,
+ branch: str,
+ directories: list[str],
+ commit: str | None = None,
+ pylint_additional_args: list[str] | None = None,
+ pylintrc_relpath: str | None = None,
+ minimum_python: str | None = None,
+ ) -> None:
+ self.url = url
+ self.branch = branch
+ self.directories = directories
+ self.commit = commit
+ self.pylint_additional_args = pylint_additional_args or []
+ self.pylintrc_relpath = pylintrc_relpath
+ self.minimum_python = minimum_python
+
+ @property
+ def pylintrc(self) -> Path | Literal[""]:
+ if self.pylintrc_relpath is None:
+ # Fall back to "" to ensure pylint's own pylintrc is not discovered
+ return ""
+ return self.clone_directory / self.pylintrc_relpath
+
+ @property
+ def clone_directory(self) -> Path:
+ """Directory to clone repository into."""
+ clone_name = "/".join(self.url.split("/")[-2:]).replace(".git", "")
+ return PRIMER_DIRECTORY_PATH / clone_name
+
+ @property
+ def paths_to_lint(self) -> list[str]:
+ """The paths we need to lint."""
+ return [str(self.clone_directory / path) for path in self.directories]
+
+ @property
+ def pylint_args(self) -> list[str]:
+ options: list[str] = []
+ # There is an error if rcfile is given but does not exist
+ options += [f"--rcfile={self.pylintrc}"]
+ return self.paths_to_lint + options + self.pylint_additional_args
+
+ def lazy_clone(self) -> str: # pragma: no cover
+ """Concatenates the target directory and clones the file.
+
+ Not expected to be tested as the primer won't work if it doesn't.
+ It's tested in the continuous integration primers, only the coverage
+ is not calculated on everything. If lazy clone breaks for local use
+ we'll probably notice because we'll have a fatal when launching the
+ primer locally.
+ """
+ logging.info("Lazy cloning %s", self.url)
+ if not self.clone_directory.exists():
+ return self._clone_repository()
+ return self._pull_repository()
+
+ def _clone_repository(self) -> str:
+ options: dict[str, str | int] = {
+ "url": self.url,
+ "to_path": str(self.clone_directory),
+ "branch": self.branch,
+ "depth": 1,
+ }
+ logging.info("Directory does not exists, cloning: %s", options)
+ repo = Repo.clone_from(
+ url=self.url, to_path=self.clone_directory, branch=self.branch, depth=1
+ )
+ return str(repo.head.object.hexsha)
+
+ def _pull_repository(self) -> str:
+ remote_sha1_commit = Git().ls_remote(self.url, self.branch).split("\t")[0]
+ local_sha1_commit = Repo(self.clone_directory).head.object.hexsha
+ if remote_sha1_commit != local_sha1_commit:
+ logging.info(
+ "Remote sha is '%s' while local sha is '%s': pulling new commits",
+ remote_sha1_commit,
+ local_sha1_commit,
+ )
+ try:
+ repo = Repo(self.clone_directory)
+ if repo.is_dirty():
+ raise DirtyPrimerDirectoryException(self.clone_directory)
+ origin = repo.remotes.origin
+ origin.pull()
+ except GitCommandError as e:
+ raise SystemError(
+ f"Failed to clone repository for {self.clone_directory}"
+ ) from e
+ else:
+ logging.info("Repository already up to date.")
+ return str(remote_sha1_commit)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer.py
new file mode 100644
index 000000000..5fd83f442
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer.py
@@ -0,0 +1,129 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import argparse
+import json
+import sys
+from pathlib import Path
+
+from pylint.testutils._primer import PackageToLint
+from pylint.testutils._primer.primer_command import PrimerCommand
+from pylint.testutils._primer.primer_compare_command import CompareCommand
+from pylint.testutils._primer.primer_prepare_command import PrepareCommand
+from pylint.testutils._primer.primer_run_command import RunCommand
+
+
+class Primer:
+ """Main class to handle priming of packages."""
+
+ def __init__(self, primer_directory: Path, json_path: Path) -> None:
+ # Preparing arguments
+ self.primer_directory = primer_directory
+ self._argument_parser = argparse.ArgumentParser(prog="Pylint Primer")
+ self._subparsers = self._argument_parser.add_subparsers(
+ dest="command", required=True
+ )
+
+ # All arguments for the prepare parser
+ prepare_parser = self._subparsers.add_parser("prepare")
+ prepare_parser.add_argument(
+ "--clone", help="Clone all packages.", action="store_true", default=False
+ )
+ prepare_parser.add_argument(
+ "--check",
+ help="Check consistencies and commits of all packages.",
+ action="store_true",
+ default=False,
+ )
+ prepare_parser.add_argument(
+ "--make-commit-string",
+ help="Get latest commit string.",
+ action="store_true",
+ default=False,
+ )
+ prepare_parser.add_argument(
+ "--read-commit-string",
+ help="Print latest commit string.",
+ action="store_true",
+ default=False,
+ )
+
+ # All arguments for the run parser
+ run_parser = self._subparsers.add_parser("run")
+ run_parser.add_argument(
+ "--type", choices=["main", "pr"], required=True, help="Type of primer run."
+ )
+ run_parser.add_argument(
+ "--batches",
+ required=False,
+ type=int,
+ help="Number of batches",
+ )
+ run_parser.add_argument(
+ "--batchIdx",
+ required=False,
+ type=int,
+ help="Portion of primer packages to run.",
+ )
+
+ # All arguments for the compare parser
+ compare_parser = self._subparsers.add_parser("compare")
+ compare_parser.add_argument(
+ "--base-file",
+ required=True,
+ help="Location of output file of the base run.",
+ )
+ compare_parser.add_argument(
+ "--new-file",
+ required=True,
+ help="Location of output file of the new run.",
+ )
+ compare_parser.add_argument(
+ "--commit",
+ required=True,
+ help="Commit hash of the PR commit being checked.",
+ )
+ compare_parser.add_argument(
+ "--batches",
+ required=False,
+ type=int,
+ help="Number of batches (filepaths with the placeholder BATCHIDX will be numbered)",
+ )
+
+ # Storing arguments
+ self.config = self._argument_parser.parse_args()
+
+ self.packages = self._get_packages_to_lint_from_json(json_path)
+ """All packages to prime."""
+
+ if self.config.command == "prepare":
+ command_class: type[PrimerCommand] = PrepareCommand
+ elif self.config.command == "run":
+ command_class = RunCommand
+ elif self.config.command == "compare":
+ command_class = CompareCommand
+ # pylint: disable-next=possibly-used-before-assignment
+ self.command = command_class(self.primer_directory, self.packages, self.config)
+
+ def run(self) -> None:
+ self.command.run()
+
+ @staticmethod
+ def _minimum_python_supported(package_data: dict[str, str]) -> bool:
+ min_python_str = package_data.get("minimum_python", None)
+ if not min_python_str:
+ return True
+ min_python_tuple = tuple(int(n) for n in min_python_str.split("."))
+ return min_python_tuple <= sys.version_info[:2]
+
+ @staticmethod
+ def _get_packages_to_lint_from_json(json_path: Path) -> dict[str, PackageToLint]:
+ with open(json_path, encoding="utf8") as f:
+ return {
+ name: PackageToLint(**package_data)
+ for name, package_data in json.load(f).items()
+ if Primer._minimum_python_supported(package_data)
+ }
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_command.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_command.py
new file mode 100644
index 000000000..01c2bed36
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_command.py
@@ -0,0 +1,39 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import abc
+import argparse
+from pathlib import Path
+from typing import TypedDict
+
+from pylint.reporters.json_reporter import OldJsonExport
+from pylint.testutils._primer import PackageToLint
+
+
+class PackageData(TypedDict):
+ commit: str
+ messages: list[OldJsonExport]
+
+
+PackageMessages = dict[str, PackageData]
+
+
+class PrimerCommand:
+ """Generic primer action with required arguments."""
+
+ def __init__(
+ self,
+ primer_directory: Path,
+ packages: dict[str, PackageToLint],
+ config: argparse.Namespace,
+ ) -> None:
+ self.primer_directory = primer_directory
+ self.packages = packages
+ self.config = config
+
+ @abc.abstractmethod
+ def run(self) -> None:
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_compare_command.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_compare_command.py
new file mode 100644
index 000000000..7b245b9e1
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_compare_command.py
@@ -0,0 +1,174 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+from __future__ import annotations
+
+import json
+from pathlib import Path, PurePosixPath
+
+from pylint.reporters.json_reporter import OldJsonExport
+from pylint.testutils._primer.primer_command import (
+ PackageData,
+ PackageMessages,
+ PrimerCommand,
+)
+
+MAX_GITHUB_COMMENT_LENGTH = 65536
+
+
+class CompareCommand(PrimerCommand):
+ def run(self) -> None:
+ if self.config.batches is None:
+ main_data = self._load_json(self.config.base_file)
+ pr_data = self._load_json(self.config.new_file)
+ else:
+ main_data = {}
+ pr_data = {}
+ for idx in range(self.config.batches):
+ main_data.update(
+ self._load_json(
+ self.config.base_file.replace("BATCHIDX", "batch" + str(idx))
+ )
+ )
+ pr_data.update(
+ self._load_json(
+ self.config.new_file.replace("BATCHIDX", "batch" + str(idx))
+ )
+ )
+
+ missing_messages_data, new_messages_data = self._cross_reference(
+ main_data, pr_data
+ )
+ comment = self._create_comment(missing_messages_data, new_messages_data)
+ with open(self.primer_directory / "comment.txt", "w", encoding="utf-8") as f:
+ f.write(comment)
+
+ @staticmethod
+ def _cross_reference(
+ main_data: PackageMessages, pr_data: PackageMessages
+ ) -> tuple[PackageMessages, PackageMessages]:
+ missing_messages_data: PackageMessages = {}
+ for package, data in main_data.items():
+ package_missing_messages: list[OldJsonExport] = []
+ for message in data["messages"]:
+ try:
+ pr_data[package]["messages"].remove(message)
+ except ValueError:
+ package_missing_messages.append(message)
+ missing_messages_data[package] = PackageData(
+ commit=pr_data[package]["commit"], messages=package_missing_messages
+ )
+ return missing_messages_data, pr_data
+
+ @staticmethod
+ def _load_json(file_path: Path | str) -> PackageMessages:
+ with open(file_path, encoding="utf-8") as f:
+ result: PackageMessages = json.load(f)
+ return result
+
+ def _create_comment(
+ self, all_missing_messages: PackageMessages, all_new_messages: PackageMessages
+ ) -> str:
+ comment = ""
+ for package, missing_messages in all_missing_messages.items():
+ if len(comment) >= MAX_GITHUB_COMMENT_LENGTH:
+ break
+ new_messages = all_new_messages[package]
+ if not missing_messages["messages"] and not new_messages["messages"]:
+ continue
+ comment += self._create_comment_for_package(
+ package, new_messages, missing_messages
+ )
+ comment = (
+ f"🤖 **Effect of this PR on checked open source code:** 🤖\n\n{comment}"
+ if comment
+ else (
+ "🤖 According to the primer, this change has **no effect** on the"
+ " checked open source code. 🤖🎉\n\n"
+ )
+ )
+ return self._truncate_comment(comment)
+
+ def _create_comment_for_package(
+ self, package: str, new_messages: PackageData, missing_messages: PackageData
+ ) -> str:
+ comment = f"\n\n**Effect on [{package}]({self.packages[package].url}):**\n"
+ # Create comment for new messages
+ count = 1
+ astroid_errors = 0
+ new_non_astroid_messages = ""
+ if new_messages["messages"]:
+ print("Now emitted:")
+ for message in new_messages["messages"]:
+ filepath = str(
+ PurePosixPath(message["path"]).relative_to(
+ self.packages[package].clone_directory
+ )
+ )
+ # Existing astroid errors may still show up as "new" because the timestamp
+ # in the message is slightly different.
+ if message["symbol"] == "astroid-error":
+ astroid_errors += 1
+ else:
+ new_non_astroid_messages += (
+ f"{count}) {message['symbol']}:\n*{message['message']}*\n"
+ f"{self.packages[package].url}/blob/{new_messages['commit']}/{filepath}#L{message['line']}\n"
+ )
+ print(message)
+ count += 1
+
+ if astroid_errors:
+ comment += (
+ f'{astroid_errors} "astroid error(s)" were found. '
+ "Please open the GitHub Actions log to see what failed or crashed.\n\n"
+ )
+ if new_non_astroid_messages:
+ comment += (
+ "The following messages are now emitted:\n\n<details>\n\n"
+ + new_non_astroid_messages
+ + "\n</details>\n\n"
+ )
+
+ # Create comment for missing messages
+ count = 1
+ if missing_messages["messages"]:
+ comment += "The following messages are no longer emitted:\n\n<details>\n\n"
+ print("No longer emitted:")
+ for message in missing_messages["messages"]:
+ comment += f"{count}) {message['symbol']}:\n*{message['message']}*\n"
+ filepath = str(
+ PurePosixPath(message["path"]).relative_to(
+ self.packages[package].clone_directory
+ )
+ )
+ assert not self.packages[package].url.endswith(
+ ".git"
+ ), "You don't need the .git at the end of the github url."
+ comment += (
+ f"{self.packages[package].url}"
+ f"/blob/{new_messages['commit']}/{filepath}#L{message['line']}\n"
+ )
+ count += 1
+ print(message)
+ if missing_messages:
+ comment += "\n</details>\n\n"
+ return comment
+
+ def _truncate_comment(self, comment: str) -> str:
+ """GitHub allows only a set number of characters in a comment."""
+ hash_information = (
+ f"*This comment was generated for commit {self.config.commit}*"
+ )
+ if len(comment) + len(hash_information) >= MAX_GITHUB_COMMENT_LENGTH:
+ truncation_information = (
+ f"*This comment was truncated because GitHub allows only"
+ f" {MAX_GITHUB_COMMENT_LENGTH} characters in a comment.*"
+ )
+ max_len = (
+ MAX_GITHUB_COMMENT_LENGTH
+ - len(hash_information)
+ - len(truncation_information)
+ )
+ comment = f"{comment[:max_len - 10]}...\n\n{truncation_information}\n\n"
+ comment += hash_information
+ return comment
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_prepare_command.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_prepare_command.py
new file mode 100644
index 000000000..27e216bd5
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_prepare_command.py
@@ -0,0 +1,48 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+from __future__ import annotations
+
+import sys
+
+from git.cmd import Git
+from git.repo import Repo
+
+from pylint.testutils._primer.primer_command import PrimerCommand
+
+
+class PrepareCommand(PrimerCommand):
+ def run(self) -> None:
+ commit_string = ""
+ version_string = ".".join(str(x) for x in sys.version_info[:2])
+ # Shorten the SHA to avoid exceeding GitHub's 512 char ceiling
+ if self.config.clone:
+ for package, data in self.packages.items():
+ local_commit = data.lazy_clone()
+ print(f"Cloned '{package}' at commit '{local_commit}'.")
+ commit_string += local_commit[:8] + "_"
+ elif self.config.check:
+ for package, data in self.packages.items():
+ local_commit = Repo(data.clone_directory).head.object.hexsha
+ print(f"Found '{package}' at commit '{local_commit}'.")
+ commit_string += local_commit[:8] + "_"
+ elif self.config.make_commit_string:
+ for package, data in self.packages.items():
+ remote_sha1_commit = (
+ Git().ls_remote(data.url, data.branch).split("\t")[0][:8]
+ )
+ print(f"'{package}' remote is at commit '{remote_sha1_commit}'.")
+ commit_string += remote_sha1_commit + "_"
+ elif self.config.read_commit_string:
+ with open(
+ self.primer_directory / f"commit_string_{version_string}.txt",
+ encoding="utf-8",
+ ) as f:
+ print(f.read())
+ if commit_string:
+ with open(
+ self.primer_directory / f"commit_string_{version_string}.txt",
+ "w",
+ encoding="utf-8",
+ ) as f:
+ f.write(commit_string)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_run_command.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_run_command.py
new file mode 100644
index 000000000..96a1440e7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_primer/primer_run_command.py
@@ -0,0 +1,109 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import json
+import sys
+import warnings
+from io import StringIO
+
+from git.repo import Repo
+
+from pylint.lint import Run
+from pylint.message import Message
+from pylint.reporters.json_reporter import JSONReporter, OldJsonExport
+from pylint.testutils._primer.package_to_lint import PackageToLint
+from pylint.testutils._primer.primer_command import (
+ PackageData,
+ PackageMessages,
+ PrimerCommand,
+)
+
+GITHUB_CRASH_TEMPLATE_LOCATION = "/home/runner/.cache"
+CRASH_TEMPLATE_INTRO = "There is a pre-filled template"
+
+
+class RunCommand(PrimerCommand):
+ def run(self) -> None:
+ packages: PackageMessages = {}
+ fatal_msgs: list[Message] = []
+ package_data_iter = (
+ self.packages.items()
+ if self.config.batches is None
+ else list(self.packages.items())[
+ self.config.batchIdx :: self.config.batches
+ ]
+ )
+ for package, data in package_data_iter:
+ messages, p_fatal_msgs = self._lint_package(package, data)
+ fatal_msgs += p_fatal_msgs
+ local_commit = Repo(data.clone_directory).head.object.hexsha
+ packages[package] = PackageData(commit=local_commit, messages=messages)
+ path = self.primer_directory / (
+ f"output_{'.'.join(str(i) for i in sys.version_info[:2])}_{self.config.type}"
+ + (f"_batch{self.config.batchIdx}.txt" if self.config.batches else "")
+ )
+ print(f"Writing result in {path}")
+ with open(path, "w", encoding="utf-8") as f:
+ json.dump(packages, f)
+ # Assert that a PR run does not introduce new fatal errors
+ if self.config.type == "pr":
+ plural = "s" if len(fatal_msgs) > 1 else ""
+ assert (
+ not fatal_msgs
+ ), f"We encountered {len(fatal_msgs)} fatal error message{plural} (see log)."
+
+ @staticmethod
+ def _filter_fatal_errors(
+ messages: list[OldJsonExport],
+ ) -> list[Message]:
+ """Separate fatal errors so we can report them independently."""
+ fatal_msgs: list[Message] = []
+ for raw_message in messages:
+ message = JSONReporter.deserialize(raw_message)
+ if message.category == "fatal":
+ if GITHUB_CRASH_TEMPLATE_LOCATION in message.msg:
+ # Remove the crash template location if we're running on GitHub.
+ # We were falsely getting "new" errors when the timestamp changed.
+ message.msg = message.msg.rsplit(CRASH_TEMPLATE_INTRO)[0]
+ fatal_msgs.append(message)
+ return fatal_msgs
+
+ @staticmethod
+ def _print_msgs(msgs: list[Message]) -> str:
+ return "\n".join(f"- {JSONReporter.serialize(m)}" for m in msgs)
+
+ def _lint_package(
+ self, package_name: str, data: PackageToLint
+ ) -> tuple[list[OldJsonExport], list[Message]]:
+ # We want to test all the code we can
+ enables = ["--enable-all-extensions", "--enable=all"]
+ # Duplicate code takes too long and is relatively safe
+ # TODO: Find a way to allow cyclic-import and compare output correctly
+ disables = ["--disable=duplicate-code,cyclic-import"]
+ additional = ["--clear-cache-post-run=y"]
+ arguments = data.pylint_args + enables + disables + additional
+ output = StringIO()
+ reporter = JSONReporter(output)
+ print(f"Running 'pylint {', '.join(arguments)}'")
+ pylint_exit_code = -1
+ try:
+ Run(arguments, reporter=reporter)
+ except SystemExit as e:
+ pylint_exit_code = int(e.code) # type: ignore[arg-type]
+ readable_messages: str = output.getvalue()
+ messages: list[OldJsonExport] = json.loads(readable_messages)
+ fatal_msgs: list[Message] = []
+ if pylint_exit_code % 2 == 0:
+ print(f"Successfully primed {package_name}.")
+ else:
+ fatal_msgs = self._filter_fatal_errors(messages)
+ if fatal_msgs:
+ warnings.warn(
+ f"Encountered fatal errors while priming {package_name} !\n"
+ f"{self._print_msgs(fatal_msgs)}\n\n",
+ stacklevel=2,
+ )
+ return messages, fatal_msgs
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/_run.py b/solutions/.venv/Lib/site-packages/pylint/testutils/_run.py
new file mode 100644
index 000000000..f42cb8d6a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/_run.py
@@ -0,0 +1,41 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Classes and functions used to mimic normal pylint runs.
+
+This module is considered private and can change at any time.
+"""
+
+from __future__ import annotations
+
+from collections.abc import Sequence
+
+from pylint.lint import Run as LintRun
+from pylint.reporters.base_reporter import BaseReporter
+from pylint.testutils.lint_module_test import PYLINTRC
+
+
+def _add_rcfile_default_pylintrc(args: list[str]) -> list[str]:
+ """Add a default pylintrc with the rcfile option in a list of pylint args."""
+ if not any("--rcfile" in arg for arg in args):
+ args.insert(0, f"--rcfile={PYLINTRC}")
+ return args
+
+
+class _Run(LintRun):
+ """Like Run, but we're using an explicitly set empty pylintrc.
+
+ We don't want to use the project's pylintrc during tests, because
+ it means that a change in our config could break tests.
+ But we want to see if the changes to the default break tests.
+ """
+
+ def __init__(
+ self,
+ args: Sequence[str],
+ reporter: BaseReporter | None = None,
+ exit: bool = True, # pylint: disable=redefined-builtin
+ ) -> None:
+ args = _add_rcfile_default_pylintrc(list(args))
+ super().__init__(args, reporter, exit)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/checker_test_case.py b/solutions/.venv/Lib/site-packages/pylint/testutils/checker_test_case.py
new file mode 100644
index 000000000..951f38c0b
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/checker_test_case.py
@@ -0,0 +1,85 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import contextlib
+from collections.abc import Generator, Iterator
+from typing import Any
+
+from astroid import nodes
+
+from pylint.testutils.global_test_linter import linter
+from pylint.testutils.output_line import MessageTest
+from pylint.testutils.unittest_linter import UnittestLinter
+from pylint.utils import ASTWalker
+
+
+class CheckerTestCase:
+ """A base testcase class for unit testing individual checker classes."""
+
+ # TODO: Figure out way to type this as type[BaseChecker] while also
+ # setting self.checker correctly.
+ CHECKER_CLASS: Any
+ CONFIG: dict[str, Any] = {}
+
+ def setup_method(self) -> None:
+ self.linter = UnittestLinter()
+ self.checker = self.CHECKER_CLASS(self.linter)
+ for key, value in self.CONFIG.items():
+ setattr(self.checker.linter.config, key, value)
+ self.checker.open()
+
+ @contextlib.contextmanager
+ def assertNoMessages(self) -> Iterator[None]:
+ """Assert that no messages are added by the given method."""
+ with self.assertAddsMessages():
+ yield
+
+ @contextlib.contextmanager
+ def assertAddsMessages(
+ self, *messages: MessageTest, ignore_position: bool = False
+ ) -> Generator[None]:
+ """Assert that exactly the given method adds the given messages.
+
+ The list of messages must exactly match *all* the messages added by the
+ method. Additionally, we check to see whether the args in each message can
+ actually be substituted into the message string.
+
+ Using the keyword argument `ignore_position`, all checks for position
+ arguments (line, col_offset, ...) will be skipped. This can be used to
+ just test messages for the correct node.
+ """
+ yield
+ got = self.linter.release_messages()
+ no_msg = "No message."
+ expected = "\n".join(repr(m) for m in messages) or no_msg
+ got_str = "\n".join(repr(m) for m in got) or no_msg
+ msg = (
+ "Expected messages did not match actual.\n"
+ f"\nExpected:\n{expected}\n\nGot:\n{got_str}\n"
+ )
+
+ assert len(messages) == len(got), msg
+
+ for expected_msg, gotten_msg in zip(messages, got):
+ assert expected_msg.msg_id == gotten_msg.msg_id, msg
+ assert expected_msg.node == gotten_msg.node, msg
+ assert expected_msg.args == gotten_msg.args, msg
+ assert expected_msg.confidence == gotten_msg.confidence, msg
+
+ if ignore_position:
+ # Do not check for line, col_offset etc...
+ continue
+
+ assert expected_msg.line == gotten_msg.line, msg
+ assert expected_msg.col_offset == gotten_msg.col_offset, msg
+ assert expected_msg.end_line == gotten_msg.end_line, msg
+ assert expected_msg.end_col_offset == gotten_msg.end_col_offset, msg
+
+ def walk(self, node: nodes.NodeNG) -> None:
+ """Recursive walk on the given node."""
+ walker = ASTWalker(linter)
+ walker.add_checker(self.checker)
+ walker.walk(node)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/configuration_test.py b/solutions/.venv/Lib/site-packages/pylint/testutils/configuration_test.py
new file mode 100644
index 000000000..ce2239e5c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/configuration_test.py
@@ -0,0 +1,148 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Utility functions for configuration testing."""
+
+from __future__ import annotations
+
+import copy
+import json
+import logging
+import unittest
+from pathlib import Path
+from typing import Any
+
+from pylint.lint import Run
+
+# We use Any in this typing because the configuration contains real objects and constants
+# that could be a lot of things.
+ConfigurationValue = Any
+PylintConfiguration = dict[str, ConfigurationValue]
+
+
+def get_expected_or_default(
+ tested_configuration_file: str | Path,
+ suffix: str,
+ default: str,
+) -> str:
+ """Return the expected value from the file if it exists, or the given default."""
+ expected = default
+ path = Path(tested_configuration_file)
+ expected_result_path = path.parent / f"{path.stem}.{suffix}"
+ if expected_result_path.exists():
+ with open(expected_result_path, encoding="utf8") as f:
+ expected = f.read()
+ # logging is helpful to realize your file is not taken into
+ # account after a misspelling of the file name. The output of the
+ # program is checked during the test so printing messes with the result.
+ logging.info("%s exists.", expected_result_path)
+ else:
+ logging.info("%s not found, using '%s'.", expected_result_path, default)
+ return expected
+
+
+EXPECTED_CONF_APPEND_KEY = "functional_append"
+EXPECTED_CONF_REMOVE_KEY = "functional_remove"
+
+
+def get_expected_configuration(
+ configuration_path: str, default_configuration: PylintConfiguration
+) -> PylintConfiguration:
+ """Get the expected parsed configuration of a configuration functional test."""
+ result = copy.deepcopy(default_configuration)
+ config_as_json = get_expected_or_default(
+ configuration_path, suffix="result.json", default="{}"
+ )
+ to_override = json.loads(config_as_json)
+ for key, value in to_override.items():
+ if key == EXPECTED_CONF_APPEND_KEY:
+ for fkey, fvalue in value.items():
+ result[fkey] += fvalue
+ elif key == EXPECTED_CONF_REMOVE_KEY:
+ for fkey, fvalue in value.items():
+ new_value = []
+ for old_value in result[fkey]:
+ if old_value not in fvalue:
+ new_value.append(old_value)
+ result[fkey] = new_value
+ else:
+ result[key] = value
+ return result
+
+
+def get_related_files(
+ tested_configuration_file: str | Path, suffix_filter: str
+) -> list[Path]:
+ """Return all the file related to a test conf file ending with a suffix."""
+ conf_path = Path(tested_configuration_file)
+ return [
+ p
+ for p in conf_path.parent.iterdir()
+ if str(p.stem).startswith(conf_path.stem) and str(p).endswith(suffix_filter)
+ ]
+
+
+def get_expected_output(
+ configuration_path: str | Path, user_specific_path: Path
+) -> tuple[int, str]:
+ """Get the expected output of a functional test."""
+ exit_code = 0
+ msg = (
+ "we expect a single file of the form 'filename.32.out' where 'filename' represents "
+ "the name of the configuration file, and '32' the expected error code."
+ )
+ possible_out_files = get_related_files(configuration_path, suffix_filter="out")
+ if len(possible_out_files) > 1:
+ logging.error(
+ "Too much .out files for %s %s.",
+ configuration_path,
+ msg,
+ )
+ return -1, "out file is broken"
+ if not possible_out_files:
+ # logging is helpful to see what the expected exit code is and why.
+ # The output of the program is checked during the test so printing
+ # messes with the result.
+ logging.info(".out file does not exists, so the expected exit code is 0")
+ return 0, ""
+ path = possible_out_files[0]
+ try:
+ exit_code = int(str(path.stem).rsplit(".", maxsplit=1)[-1])
+ except Exception as e: # pylint: disable=broad-except
+ logging.error(
+ "Wrong format for .out file name for %s %s: %s",
+ configuration_path,
+ msg,
+ e,
+ )
+ return -1, "out file is broken"
+
+ output = get_expected_or_default(
+ configuration_path, suffix=f"{exit_code}.out", default=""
+ )
+ logging.info(
+ "Output exists for %s so the expected exit code is %s",
+ configuration_path,
+ exit_code,
+ )
+ return exit_code, output.format(
+ abspath=configuration_path,
+ relpath=Path(configuration_path).relative_to(user_specific_path),
+ )
+
+
+def run_using_a_configuration_file(
+ configuration_path: Path | str, file_to_lint: str = __file__
+) -> Run:
+ """Simulate a run with a configuration without really launching the checks."""
+ configuration_path = str(configuration_path)
+ args = ["--rcfile", configuration_path, file_to_lint]
+ # Do not actually run checks, that could be slow. We don't mock
+ # `PyLinter.check`: it calls `PyLinter.initialize` which is
+ # needed to properly set up messages inclusion/exclusion
+ # in `_msg_states`, used by `is_message_enabled`.
+ check = "pylint.lint.pylinter.check_parallel"
+ with unittest.mock.patch(check):
+ runner = Run(args, exit=False)
+ return runner
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/constants.py b/solutions/.venv/Lib/site-packages/pylint/testutils/constants.py
new file mode 100644
index 000000000..956b44096
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/constants.py
@@ -0,0 +1,29 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+import operator
+import re
+import sys
+from pathlib import Path
+
+SYS_VERS_STR = (
+ "%d%d%d" % sys.version_info[:3] # pylint: disable=consider-using-f-string
+)
+TITLE_UNDERLINES = ["", "=", "-", "."]
+UPDATE_OPTION = "--update-functional-output"
+UPDATE_FILE = Path("pylint-functional-test-update")
+# Common sub-expressions.
+_MESSAGE = {"msg": r"[a-z][a-z\-]+"}
+# Matches a #,
+# - followed by a comparison operator and a Python version (optional),
+# - followed by a line number with a +/- (optional),
+# - followed by a list of bracketed message symbols.
+# Used to extract expected messages from testdata files.
+_EXPECTED_RE = re.compile(
+ r"\s*#\s*(?:(?P<line>[+-]?[0-9]+):)?" # pylint: disable=consider-using-f-string
+ r"(?:(?P<op>[><=]+) *(?P<version>[0-9.]+):)?"
+ r"\s*\[(?P<msgs>{msg}(?:,\s*{msg})*)]".format(**_MESSAGE)
+)
+
+_OPERATORS = {">": operator.gt, "<": operator.lt, ">=": operator.ge, "<=": operator.le}
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/decorator.py b/solutions/.venv/Lib/site-packages/pylint/testutils/decorator.py
new file mode 100644
index 000000000..c20692132
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/decorator.py
@@ -0,0 +1,37 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import functools
+from collections.abc import Callable
+from typing import Any
+
+from pylint.testutils.checker_test_case import CheckerTestCase
+
+
+def set_config(**kwargs: Any) -> Callable[[Callable[..., None]], Callable[..., None]]:
+ """Decorator for setting an option on the linter.
+
+ Passing the args and kwargs back to the test function itself
+ allows this decorator to be used on parameterized test cases.
+ """
+
+ def _wrapper(fun: Callable[..., None]) -> Callable[..., None]:
+ @functools.wraps(fun)
+ def _forward(
+ self: CheckerTestCase, *args: Any, **test_function_kwargs: Any
+ ) -> None:
+ """Set option via argparse."""
+ for key, value in kwargs.items():
+ self.linter.set_option(key, value)
+
+ # Reopen checker in case, it may be interested in configuration change
+ self.checker.open()
+
+ fun(self, *args, **test_function_kwargs)
+
+ return _forward
+
+ return _wrapper
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/functional/__init__.py b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/__init__.py
new file mode 100644
index 000000000..c1c1c5139
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/__init__.py
@@ -0,0 +1,23 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+__all__ = [
+ "FunctionalTestFile",
+ "REASONABLY_DISPLAYABLE_VERTICALLY",
+ "get_functional_test_files_from_directory",
+ "NoFileError",
+ "parse_python_version",
+ "LintModuleOutputUpdate",
+]
+
+from pylint.testutils.functional.find_functional_tests import (
+ REASONABLY_DISPLAYABLE_VERTICALLY,
+ get_functional_test_files_from_directory,
+)
+from pylint.testutils.functional.lint_module_output_update import LintModuleOutputUpdate
+from pylint.testutils.functional.test_file import (
+ FunctionalTestFile,
+ NoFileError,
+ parse_python_version,
+)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/functional/find_functional_tests.py b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/find_functional_tests.py
new file mode 100644
index 000000000..f2e636687
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/find_functional_tests.py
@@ -0,0 +1,139 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import os
+from collections.abc import Iterator
+from pathlib import Path
+
+from pylint.testutils.functional.test_file import FunctionalTestFile
+
+REASONABLY_DISPLAYABLE_VERTICALLY = 49
+"""'Wet finger' number of files that are reasonable to display by an IDE.
+
+'Wet finger' as in 'in my settings there are precisely this many'.
+"""
+
+IGNORED_PARENT_DIRS = {
+ "deprecated_relative_import",
+ "ext",
+ "regression",
+ "regression_02",
+}
+"""Direct parent directories that should be ignored."""
+
+IGNORED_PARENT_PARENT_DIRS = {
+ "docparams",
+ "deprecated_relative_import",
+ "ext",
+}
+"""Parents of direct parent directories that should be ignored."""
+
+
+def get_functional_test_files_from_directory(
+ input_dir: Path | str,
+ max_file_per_directory: int = REASONABLY_DISPLAYABLE_VERTICALLY,
+) -> list[FunctionalTestFile]:
+ """Get all functional tests in the input_dir."""
+ suite = []
+
+ _check_functional_tests_structure(Path(input_dir), max_file_per_directory)
+
+ for dirpath, dirnames, filenames in os.walk(input_dir):
+ if dirpath.endswith("__pycache__"):
+ continue
+ dirnames.sort()
+ filenames.sort()
+ for filename in filenames:
+ if filename != "__init__.py" and filename.endswith(".py"):
+ suite.append(FunctionalTestFile(dirpath, filename))
+ return suite
+
+
+def _check_functional_tests_structure(
+ directory: Path, max_file_per_directory: int
+) -> None:
+ """Check if test directories follow correct file/folder structure.
+
+ Ignore underscored directories or files.
+ """
+ if Path(directory).stem.startswith("_"):
+ return
+
+ files: set[Path] = set()
+ dirs: set[Path] = set()
+
+ def _get_files_from_dir(
+ path: Path, violations: list[tuple[Path, int]]
+ ) -> list[Path]:
+ """Return directories and files from a directory and handles violations."""
+ files_without_leading_underscore = list(
+ p for p in path.iterdir() if not p.stem.startswith("_")
+ )
+ if len(files_without_leading_underscore) > max_file_per_directory:
+ violations.append((path, len(files_without_leading_underscore)))
+ return files_without_leading_underscore
+
+ def walk(path: Path) -> Iterator[Path]:
+ violations: list[tuple[Path, int]] = []
+ violations_msgs: set[str] = set()
+ parent_dir_files = _get_files_from_dir(path, violations)
+ error_msg = (
+ "The following directory contains too many functional tests files:\n"
+ )
+ for _file_or_dir in parent_dir_files:
+ if _file_or_dir.is_dir():
+ _files = _get_files_from_dir(_file_or_dir, violations)
+ yield _file_or_dir.resolve()
+ try:
+ yield from walk(_file_or_dir)
+ except AssertionError as e:
+ violations_msgs.add(str(e).replace(error_msg, ""))
+ else:
+ yield _file_or_dir.resolve()
+ if violations or violations_msgs:
+ _msg = error_msg
+ for offending_file, number in violations:
+ _msg += f"- {offending_file}: {number} when the max is {max_file_per_directory}\n"
+ for error_msg in violations_msgs:
+ _msg += error_msg
+ raise AssertionError(_msg)
+
+ # Collect all sub-directories and files in directory
+ for file_or_dir in walk(directory):
+ if file_or_dir.is_dir():
+ dirs.add(file_or_dir)
+ elif file_or_dir.suffix == ".py":
+ files.add(file_or_dir)
+
+ directory_does_not_exists: list[tuple[Path, Path]] = []
+ misplaced_file: list[Path] = []
+ for file in files:
+ possible_dir = file.parent / file.stem.split("_")[0]
+ if possible_dir.exists():
+ directory_does_not_exists.append((file, possible_dir))
+ # Exclude some directories as they follow a different structure
+ if (
+ not len(file.parent.stem) == 1 # First letter sub-directories
+ and file.parent.stem not in IGNORED_PARENT_DIRS
+ and file.parent.parent.stem not in IGNORED_PARENT_PARENT_DIRS
+ ):
+ if not file.stem.startswith(file.parent.stem):
+ misplaced_file.append(file)
+
+ if directory_does_not_exists or misplaced_file:
+ msg = "The following functional tests are disorganized:\n"
+ for file, possible_dir in directory_does_not_exists:
+ msg += (
+ f"- In '{directory}', '{file.relative_to(directory)}' "
+ f"should go in '{possible_dir.relative_to(directory)}'\n"
+ )
+ for file in misplaced_file:
+ msg += (
+ f"- In '{directory}', {file.relative_to(directory)} should go in a directory"
+ f" that starts with the first letters"
+ f" of '{file.stem}' (not '{file.parent.stem}')\n"
+ )
+ raise AssertionError(msg)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/functional/lint_module_output_update.py b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/lint_module_output_update.py
new file mode 100644
index 000000000..38ed465aa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/lint_module_output_update.py
@@ -0,0 +1,43 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import csv
+import os
+
+from pylint.testutils.lint_module_test import LintModuleTest, MessageCounter
+from pylint.testutils.output_line import OutputLine
+
+
+class LintModuleOutputUpdate(LintModuleTest):
+ """Class to be used if expected output files should be updated instead of
+ checked.
+ """
+
+ class TestDialect(csv.excel):
+ """Dialect used by the csv writer."""
+
+ delimiter = ":"
+ lineterminator = "\n"
+
+ csv.register_dialect("test", TestDialect)
+
+ def _check_output_text(
+ self,
+ _: MessageCounter,
+ expected_output: list[OutputLine],
+ actual_output: list[OutputLine],
+ ) -> None:
+ """Overwrite or remove the expected output file based on actual output."""
+ # Remove the expected file if no output is actually emitted and a file exists
+ if not actual_output:
+ if os.path.exists(self._test_file.expected_output):
+ os.remove(self._test_file.expected_output)
+ return
+ # Write file with expected output
+ with open(self._test_file.expected_output, "w", encoding="utf-8") as f:
+ writer = csv.writer(f, dialect="test")
+ for line in actual_output:
+ writer.writerow(line.to_csv())
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/functional/test_file.py b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/test_file.py
new file mode 100644
index 000000000..37ba3a5fc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/functional/test_file.py
@@ -0,0 +1,112 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import configparser
+from collections.abc import Callable
+from os.path import basename, exists, join
+from typing import TypedDict
+
+
+def parse_python_version(ver_str: str) -> tuple[int, ...]:
+ """Convert python version to a tuple of integers for easy comparison."""
+ return tuple(int(digit) for digit in ver_str.split("."))
+
+
+class NoFileError(Exception):
+ pass
+
+
+class TestFileOptions(TypedDict):
+ min_pyver: tuple[int, ...]
+ max_pyver: tuple[int, ...]
+ min_pyver_end_position: tuple[int, ...]
+ requires: list[str]
+ except_implementations: list[str]
+ exclude_platforms: list[str]
+ exclude_from_minimal_messages_config: bool
+
+
+# mypy need something literal, we can't create this dynamically from TestFileOptions
+POSSIBLE_TEST_OPTIONS = {
+ "min_pyver",
+ "max_pyver",
+ "min_pyver_end_position",
+ "requires",
+ "except_implementations",
+ "exclude_platforms",
+ "exclude_from_minimal_messages_config",
+}
+
+
+class FunctionalTestFile:
+ """A single functional test case file with options."""
+
+ _CONVERTERS: dict[str, Callable[[str], tuple[int, ...] | list[str]]] = {
+ "min_pyver": parse_python_version,
+ "max_pyver": parse_python_version,
+ "min_pyver_end_position": parse_python_version,
+ "requires": lambda s: [i.strip() for i in s.split(",")],
+ "except_implementations": lambda s: [i.strip() for i in s.split(",")],
+ "exclude_platforms": lambda s: [i.strip() for i in s.split(",")],
+ }
+
+ def __init__(self, directory: str, filename: str) -> None:
+ self._directory = directory
+ self.base = filename.replace(".py", "")
+ # TODO:4.0: Deprecate FunctionalTestFile.options and related code
+ # We should just parse these options like a normal configuration file.
+ self.options: TestFileOptions = {
+ "min_pyver": (2, 5),
+ "max_pyver": (4, 0),
+ "min_pyver_end_position": (3, 8),
+ "requires": [],
+ "except_implementations": [],
+ "exclude_platforms": [],
+ "exclude_from_minimal_messages_config": False,
+ }
+ self._parse_options()
+
+ def __repr__(self) -> str:
+ return f"FunctionalTest:{self.base}"
+
+ def _parse_options(self) -> None:
+ cp = configparser.ConfigParser()
+ cp.add_section("testoptions")
+ try:
+ cp.read(self.option_file)
+ except NoFileError:
+ pass
+
+ for name, value in cp.items("testoptions"):
+ conv = self._CONVERTERS.get(name, lambda v: v)
+
+ assert (
+ name in POSSIBLE_TEST_OPTIONS
+ ), f"[testoptions]' can only contains one of {POSSIBLE_TEST_OPTIONS} and had '{name}'"
+ self.options[name] = conv(value) # type: ignore[literal-required]
+
+ @property
+ def option_file(self) -> str:
+ return self._file_type(".rc")
+
+ @property
+ def module(self) -> str:
+ package = basename(self._directory)
+ return ".".join([package, self.base])
+
+ @property
+ def expected_output(self) -> str:
+ return self._file_type(".txt", check_exists=False)
+
+ @property
+ def source(self) -> str:
+ return self._file_type(".py")
+
+ def _file_type(self, ext: str, check_exists: bool = True) -> str:
+ name = join(self._directory, self.base + ext)
+ if not check_exists or exists(name):
+ return name
+ raise NoFileError(f"Cannot find '{name}'.")
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/get_test_info.py b/solutions/.venv/Lib/site-packages/pylint/testutils/get_test_info.py
new file mode 100644
index 000000000..eb2c78cfd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/get_test_info.py
@@ -0,0 +1,50 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from glob import glob
+from os.path import basename, join, splitext
+
+from pylint.testutils.constants import SYS_VERS_STR
+
+
+def _get_tests_info(
+ input_dir: str, msg_dir: str, prefix: str, suffix: str
+) -> list[tuple[str, str]]:
+ """Get python input examples and output messages.
+
+ We use following conventions for input files and messages:
+ for different inputs:
+ test for python >= x.y -> input = <name>_pyxy.py
+ test for python < x.y -> input = <name>_py_xy.py
+ for one input and different messages:
+ message for python >= x.y -> message = <name>_pyxy.txt
+ lower versions -> message with highest num
+ """
+ result = []
+ for fname in glob(join(input_dir, prefix + "*" + suffix)):
+ infile = basename(fname)
+ fbase = splitext(infile)[0]
+ # filter input files :
+ pyrestr = fbase.rsplit("_py", 1)[-1] # like _26 or 26
+ if pyrestr.isdigit(): # '24', '25'...
+ if pyrestr.isdigit() and int(SYS_VERS_STR) < int(pyrestr):
+ continue
+ if pyrestr.startswith("_") and pyrestr[1:].isdigit():
+ # skip test for higher python versions
+ if pyrestr[1:].isdigit() and int(SYS_VERS_STR) >= int(pyrestr[1:]):
+ continue
+ messages = glob(join(msg_dir, fbase + "*.txt"))
+ # the last one will be without ext, i.e. for all or upper versions:
+ if messages:
+ for outfile in sorted(messages, reverse=True):
+ py_rest = outfile.rsplit("_py", 1)[-1][:-4]
+ if py_rest.isdigit() and int(SYS_VERS_STR) >= int(py_rest):
+ break
+ else:
+ # This will provide an error message indicating the missing filename.
+ outfile = join(msg_dir, fbase + ".txt")
+ result.append((infile, outfile))
+ return result
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/global_test_linter.py b/solutions/.venv/Lib/site-packages/pylint/testutils/global_test_linter.py
new file mode 100644
index 000000000..2e0d3d170
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/global_test_linter.py
@@ -0,0 +1,20 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from pylint import checkers
+from pylint.lint import PyLinter
+from pylint.testutils.reporter_for_tests import GenericTestReporter
+
+
+def create_test_linter() -> PyLinter:
+ test_reporter = GenericTestReporter()
+ linter_ = PyLinter()
+ linter_.set_reporter(test_reporter)
+ linter_.config.persistent = 0
+ checkers.initialize(linter_)
+ return linter_
+
+
+# Can't be renamed to a constant (easily), it breaks countless tests
+linter = create_test_linter()
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/lint_module_test.py b/solutions/.venv/Lib/site-packages/pylint/testutils/lint_module_test.py
new file mode 100644
index 000000000..37839c890
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/lint_module_test.py
@@ -0,0 +1,321 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import csv
+import operator
+import platform
+import sys
+from collections import Counter
+from io import StringIO
+from pathlib import Path
+from typing import TextIO
+
+import pytest
+from _pytest.config import Config
+
+from pylint import checkers
+from pylint.config.config_initialization import _config_initialization
+from pylint.lint import PyLinter
+from pylint.message.message import Message
+from pylint.testutils.constants import _EXPECTED_RE, _OPERATORS, UPDATE_OPTION
+
+# need to import from functional.test_file to avoid cyclic import
+from pylint.testutils.functional.test_file import (
+ FunctionalTestFile,
+ NoFileError,
+ parse_python_version,
+)
+from pylint.testutils.output_line import OutputLine
+from pylint.testutils.reporter_for_tests import FunctionalTestReporter
+
+MessageCounter = Counter[tuple[int, str]]
+
+PYLINTRC = Path(__file__).parent / "testing_pylintrc"
+
+
+class LintModuleTest:
+ maxDiff = None
+
+ def __init__(
+ self, test_file: FunctionalTestFile, config: Config | None = None
+ ) -> None:
+ _test_reporter = FunctionalTestReporter()
+ self._linter = PyLinter()
+ self._linter.config.persistent = 0
+ checkers.initialize(self._linter)
+
+ # See if test has its own .rc file, if so we use that one
+ rc_file: Path | str = PYLINTRC
+ try:
+ rc_file = test_file.option_file
+ self._linter.disable("suppressed-message")
+ self._linter.disable("locally-disabled")
+ self._linter.disable("useless-suppression")
+ except NoFileError:
+ pass
+
+ self._test_file = test_file
+ try:
+ args = [test_file.source]
+ except NoFileError:
+ # If we're still raising NoFileError the actual source file doesn't exist
+ args = [""]
+ if config and config.getoption("minimal_messages_config"):
+ with self._open_source_file() as f:
+ messages_to_enable = {msg[1] for msg in self.get_expected_messages(f)}
+ # Always enable fatal errors
+ messages_to_enable.add("astroid-error")
+ messages_to_enable.add("fatal")
+ messages_to_enable.add("syntax-error")
+ args.extend(["--disable=all", f"--enable={','.join(messages_to_enable)}"])
+
+ # Add testoptions
+ self._linter._arg_parser.add_argument(
+ "--min_pyver", type=parse_python_version, default=(2, 5)
+ )
+ self._linter._arg_parser.add_argument(
+ "--max_pyver", type=parse_python_version, default=(4, 0)
+ )
+ self._linter._arg_parser.add_argument(
+ "--min_pyver_end_position", type=parse_python_version, default=(3, 8)
+ )
+ self._linter._arg_parser.add_argument(
+ "--requires", type=lambda s: [i.strip() for i in s.split(",")], default=[]
+ )
+ self._linter._arg_parser.add_argument(
+ "--except_implementations",
+ type=lambda s: [i.strip() for i in s.split(",")],
+ default=[],
+ )
+ self._linter._arg_parser.add_argument(
+ "--exclude_platforms",
+ type=lambda s: [i.strip() for i in s.split(",")],
+ default=[],
+ )
+ self._linter._arg_parser.add_argument(
+ "--exclude_from_minimal_messages_config", default=False
+ )
+
+ _config_initialization(
+ self._linter, args_list=args, config_file=rc_file, reporter=_test_reporter
+ )
+
+ self._check_end_position = (
+ sys.version_info >= self._linter.config.min_pyver_end_position
+ )
+
+ self._config = config
+
+ def setUp(self) -> None:
+ if self._should_be_skipped_due_to_version():
+ pytest.skip(
+ f"Test cannot run with Python {sys.version.split(' ', maxsplit=1)[0]}."
+ )
+ missing = []
+ for requirement in self._linter.config.requires:
+ try:
+ __import__(requirement)
+ except ImportError:
+ missing.append(requirement)
+ if missing:
+ pytest.skip(f"Requires {','.join(missing)} to be present.")
+ except_implementations = self._linter.config.except_implementations
+ if except_implementations:
+ if platform.python_implementation() in except_implementations:
+ msg = "Test cannot run with Python implementation %r"
+ pytest.skip(msg % platform.python_implementation())
+ excluded_platforms = self._linter.config.exclude_platforms
+ if excluded_platforms:
+ if sys.platform.lower() in excluded_platforms:
+ pytest.skip(f"Test cannot run on platform {sys.platform!r}")
+ if (
+ self._config
+ and self._config.getoption("minimal_messages_config")
+ and self._linter.config.exclude_from_minimal_messages_config
+ ):
+ pytest.skip("Test excluded from --minimal-messages-config")
+
+ def runTest(self) -> None:
+ self._runTest()
+
+ def _should_be_skipped_due_to_version(self) -> bool:
+ return ( # type: ignore[no-any-return]
+ sys.version_info < self._linter.config.min_pyver
+ or sys.version_info > self._linter.config.max_pyver
+ )
+
+ def __str__(self) -> str:
+ return f"{self._test_file.base} ({self.__class__.__module__}.{self.__class__.__name__})"
+
+ @staticmethod
+ def get_expected_messages(stream: TextIO) -> MessageCounter:
+ """Parses a file and get expected messages.
+
+ :param stream: File-like input stream.
+ :type stream: enumerable
+ :returns: A dict mapping line,msg-symbol tuples to the count on this line.
+ :rtype: dict
+ """
+ messages: MessageCounter = Counter()
+ for i, line in enumerate(stream):
+ match = _EXPECTED_RE.search(line)
+ if match is None:
+ continue
+ line = match.group("line")
+ if line is None:
+ lineno = i + 1
+ elif line.startswith(("+", "-")):
+ lineno = i + 1 + int(line)
+ else:
+ lineno = int(line)
+
+ version = match.group("version")
+ op = match.group("op")
+ if version:
+ required = parse_python_version(version)
+ if not _OPERATORS[op](sys.version_info, required):
+ continue
+
+ for msg_id in match.group("msgs").split(","):
+ messages[lineno, msg_id.strip()] += 1
+ return messages
+
+ @staticmethod
+ def multiset_difference(
+ expected_entries: MessageCounter,
+ actual_entries: MessageCounter,
+ ) -> tuple[MessageCounter, dict[tuple[int, str], int]]:
+ """Takes two multisets and compares them.
+
+ A multiset is a dict with the cardinality of the key as the value.
+ """
+ missing = expected_entries.copy()
+ missing.subtract(actual_entries)
+ unexpected = {}
+ for key, value in list(missing.items()):
+ if value <= 0:
+ missing.pop(key)
+ if value < 0:
+ unexpected[key] = -value
+ return missing, unexpected
+
+ def _open_expected_file(self) -> TextIO:
+ try:
+ return open(self._test_file.expected_output, encoding="utf-8")
+ except FileNotFoundError:
+ return StringIO("")
+
+ def _open_source_file(self) -> TextIO:
+ if self._test_file.base == "invalid_encoded_data":
+ return open(self._test_file.source, encoding="utf-8")
+ if "latin1" in self._test_file.base:
+ return open(self._test_file.source, encoding="latin1")
+ return open(self._test_file.source, encoding="utf8")
+
+ def _get_expected(self) -> tuple[MessageCounter, list[OutputLine]]:
+ with self._open_source_file() as f:
+ expected_msgs = self.get_expected_messages(f)
+ if not expected_msgs:
+ expected_msgs = Counter()
+ with self._open_expected_file() as f:
+ expected_output_lines = [
+ OutputLine.from_csv(row, self._check_end_position)
+ for row in csv.reader(f, "test")
+ ]
+ return expected_msgs, expected_output_lines
+
+ def _get_actual(self) -> tuple[MessageCounter, list[OutputLine]]:
+ messages: list[Message] = self._linter.reporter.messages
+ messages.sort(key=lambda m: (m.line, m.symbol, m.msg))
+ received_msgs: MessageCounter = Counter()
+ received_output_lines = []
+ for msg in messages:
+ assert (
+ msg.symbol != "fatal"
+ ), f"Pylint analysis failed because of '{msg.msg}'"
+ received_msgs[msg.line, msg.symbol] += 1
+ received_output_lines.append(
+ OutputLine.from_msg(msg, self._check_end_position)
+ )
+ return received_msgs, received_output_lines
+
+ def _runTest(self) -> None:
+ __tracebackhide__ = True # pylint: disable=unused-variable
+ modules_to_check = [self._test_file.source]
+ self._linter.check(modules_to_check)
+ expected_messages, expected_output = self._get_expected()
+ actual_messages, actual_output = self._get_actual()
+ assert (
+ expected_messages == actual_messages
+ ), self.error_msg_for_unequal_messages(
+ actual_messages, expected_messages, actual_output
+ )
+ self._check_output_text(expected_messages, expected_output, actual_output)
+
+ def error_msg_for_unequal_messages(
+ self,
+ actual_messages: MessageCounter,
+ expected_messages: MessageCounter,
+ actual_output: list[OutputLine],
+ ) -> str:
+ msg = [f'Wrong message(s) raised for "{Path(self._test_file.source).name}":']
+ missing, unexpected = self.multiset_difference(
+ expected_messages, actual_messages
+ )
+ if missing:
+ msg.append("\nExpected in testdata:")
+ msg.extend(f" {msg[0]:3}: {msg[1]}" for msg in sorted(missing))
+ if unexpected:
+ msg.append("\nUnexpected in testdata:")
+ msg.extend(f" {msg[0]:3}: {msg[1]}" for msg in sorted(unexpected))
+ error_msg = "\n".join(msg)
+ if self._config and self._config.getoption("verbose") > 0:
+ error_msg += "\n\nActual pylint output for this file:\n"
+ error_msg += "\n".join(str(o) for o in actual_output)
+ return error_msg
+
+ def error_msg_for_unequal_output(
+ self,
+ expected_lines: list[OutputLine],
+ received_lines: list[OutputLine],
+ ) -> str:
+ missing = set(expected_lines) - set(received_lines)
+ unexpected = set(received_lines) - set(expected_lines)
+ error_msg = f'Wrong output for "{Path(self._test_file.expected_output).name}":'
+ sort_by_line_number = operator.attrgetter("lineno")
+ if missing:
+ error_msg += "\n- Missing lines:\n"
+ for line in sorted(missing, key=sort_by_line_number):
+ error_msg += f"{line}\n"
+ if unexpected:
+ error_msg += "\n- Unexpected lines:\n"
+ for line in sorted(unexpected, key=sort_by_line_number):
+ error_msg += f"{line}\n"
+ error_msg += (
+ "\nYou can update the expected output automatically with:\n'"
+ f"python tests/test_functional.py {UPDATE_OPTION} -k "
+ f'"test_functional[{self._test_file.base}]"\'\n\n'
+ "Here's the update text in case you can't:\n"
+ )
+ expected_csv = StringIO()
+ writer = csv.writer(expected_csv, dialect="test")
+ for line in sorted(received_lines, key=sort_by_line_number):
+ writer.writerow(line.to_csv())
+ error_msg += expected_csv.getvalue()
+ return error_msg
+
+ def _check_output_text(
+ self,
+ _: MessageCounter,
+ expected_output: list[OutputLine],
+ actual_output: list[OutputLine],
+ ) -> None:
+ """This is a function because we want to be able to update the text in
+ LintModuleOutputUpdate.
+ """
+ assert expected_output == actual_output, self.error_msg_for_unequal_output(
+ expected_output, actual_output
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/output_line.py b/solutions/.venv/Lib/site-packages/pylint/testutils/output_line.py
new file mode 100644
index 000000000..fbe5b3bbc
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/output_line.py
@@ -0,0 +1,121 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from collections.abc import Sequence
+from typing import Any, NamedTuple, TypeVar
+
+from astroid import nodes
+
+from pylint.interfaces import UNDEFINED, Confidence
+from pylint.message.message import Message
+
+_T = TypeVar("_T")
+
+
+class MessageTest(NamedTuple):
+ msg_id: str
+ line: int | None = None
+ node: nodes.NodeNG | None = None
+ args: Any | None = None
+ confidence: Confidence | None = UNDEFINED
+ col_offset: int | None = None
+ end_line: int | None = None
+ end_col_offset: int | None = None
+ """Used to test messages produced by pylint.
+
+ Class name cannot start with Test as pytest doesn't allow constructors in test classes.
+ """
+
+
+class OutputLine(NamedTuple):
+ symbol: str
+ lineno: int
+ column: int
+ end_lineno: int | None
+ end_column: int | None
+ object: str
+ msg: str
+ confidence: str
+
+ @classmethod
+ def from_msg(cls, msg: Message, check_endline: bool = True) -> OutputLine:
+ """Create an OutputLine from a Pylint Message."""
+ column = cls._get_column(msg.column)
+ end_line = cls._get_end_line_and_end_col(msg.end_line, check_endline)
+ end_column = cls._get_end_line_and_end_col(msg.end_column, check_endline)
+ return cls(
+ msg.symbol,
+ msg.line,
+ column,
+ end_line,
+ end_column,
+ msg.obj or "",
+ msg.msg.replace("\r\n", "\n"),
+ msg.confidence.name,
+ )
+
+ @staticmethod
+ def _get_column(column: str | int) -> int:
+ """Handle column numbers."""
+ return int(column)
+
+ @staticmethod
+ def _get_end_line_and_end_col(value: _T, check_endline: bool) -> _T | None:
+ """Used to make end_line and end_column None as indicated by our version
+ compared to `min_pyver_end_position`.
+ """
+ if not check_endline:
+ return None # pragma: no cover
+ return value
+
+ @classmethod
+ def from_csv(
+ cls, row: Sequence[str] | str, check_endline: bool = True
+ ) -> OutputLine:
+ """Create an OutputLine from a comma separated list (the functional tests
+ expected output .txt files).
+ """
+ if isinstance(row, str):
+ row = row.split(",")
+ try:
+ line = int(row[1])
+ column = cls._get_column(row[2])
+ end_line = cls._value_to_optional_int(
+ cls._get_end_line_and_end_col(row[3], check_endline)
+ )
+ end_column = cls._value_to_optional_int(
+ cls._get_end_line_and_end_col(row[4], check_endline)
+ )
+ # symbol, line, column, end_line, end_column, node, msg, confidences
+ assert len(row) == 8
+ return cls(
+ row[0], line, column, end_line, end_column, row[5], row[6], row[7]
+ )
+ except Exception: # pylint: disable=broad-except
+ # We need this to not fail for the update script to work.
+ return cls("", 0, 0, None, None, "", "", "")
+
+ def to_csv(self) -> tuple[str, str, str, str, str, str, str, str]:
+ """Convert an OutputLine to a tuple of string to be written by a
+ csv-writer.
+ """
+ return (
+ str(self.symbol),
+ str(self.lineno),
+ str(self.column),
+ str(self.end_lineno),
+ str(self.end_column),
+ str(self.object),
+ str(self.msg),
+ str(self.confidence),
+ )
+
+ @staticmethod
+ def _value_to_optional_int(value: str | None) -> int | None:
+ """Checks if a (stringified) value should be None or a Python integer."""
+ if value == "None" or not value:
+ return None
+ return int(value)
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/pyreverse.py b/solutions/.venv/Lib/site-packages/pylint/testutils/pyreverse.py
new file mode 100644
index 000000000..115eda416
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/pyreverse.py
@@ -0,0 +1,126 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import argparse
+import configparser
+import shlex
+from pathlib import Path
+from typing import NamedTuple, TypedDict
+
+from pylint.pyreverse.main import DEFAULT_COLOR_PALETTE
+
+
+# This class could and should be replaced with a simple dataclass when support for Python < 3.7 is dropped.
+# A NamedTuple is not possible as some tests need to modify attributes during the test.
+class PyreverseConfig(
+ argparse.Namespace
+): # pylint: disable=too-many-instance-attributes, too-many-arguments
+ """Holds the configuration options for Pyreverse.
+
+ The default values correspond to the defaults of the options' parser.
+ """
+
+ def __init__(
+ self,
+ *,
+ mode: str = "PUB_ONLY",
+ classes: list[str] | None = None,
+ show_ancestors: int | None = None,
+ all_ancestors: bool | None = None,
+ show_associated: int | None = None,
+ all_associated: bool | None = None,
+ no_standalone: bool = False,
+ show_builtin: bool = False,
+ show_stdlib: bool = False,
+ module_names: bool | None = None,
+ only_classnames: bool = False,
+ output_format: str = "dot",
+ colorized: bool = False,
+ max_color_depth: int = 2,
+ color_palette: tuple[str, ...] = DEFAULT_COLOR_PALETTE,
+ ignore_list: tuple[str, ...] = tuple(),
+ project: str = "",
+ output_directory: str = "",
+ ) -> None:
+ super().__init__()
+ self.mode = mode
+ if classes:
+ self.classes = classes
+ else:
+ self.classes = []
+ self.show_ancestors = show_ancestors
+ self.all_ancestors = all_ancestors
+ self.show_associated = show_associated
+ self.all_associated = all_associated
+ self.no_standalone = no_standalone
+ self.show_builtin = show_builtin
+ self.show_stdlib = show_stdlib
+ self.module_names = module_names
+ self.only_classnames = only_classnames
+ self.output_format = output_format
+ self.colorized = colorized
+ self.max_color_depth = max_color_depth
+ self.color_palette = color_palette
+ self.ignore_list = ignore_list
+ self.project = project
+ self.output_directory = output_directory
+
+
+class TestFileOptions(TypedDict):
+ source_roots: list[str]
+ output_formats: list[str]
+ command_line_args: list[str]
+
+
+class FunctionalPyreverseTestfile(NamedTuple):
+ """Named tuple containing the test file and the expected output."""
+
+ source: Path
+ options: TestFileOptions
+
+
+def get_functional_test_files(
+ root_directory: Path,
+) -> list[FunctionalPyreverseTestfile]:
+ """Get all functional test files from the given directory."""
+ test_files = []
+ for path in root_directory.rglob("*.py"):
+ if path.stem.startswith("_"):
+ continue
+ config_file = path.with_suffix(".rc")
+ if config_file.exists():
+ test_files.append(
+ FunctionalPyreverseTestfile(
+ source=path, options=_read_config(config_file)
+ )
+ )
+ else:
+ test_files.append(
+ FunctionalPyreverseTestfile(
+ source=path,
+ options={
+ "source_roots": [],
+ "output_formats": ["mmd"],
+ "command_line_args": [],
+ },
+ )
+ )
+ return test_files
+
+
+def _read_config(config_file: Path) -> TestFileOptions:
+ config = configparser.ConfigParser()
+ config.read(str(config_file))
+ source_roots = config.get("testoptions", "source_roots", fallback=None)
+ return {
+ "source_roots": source_roots.split(",") if source_roots else [],
+ "output_formats": config.get(
+ "testoptions", "output_formats", fallback="mmd"
+ ).split(","),
+ "command_line_args": shlex.split(
+ config.get("testoptions", "command_line_args", fallback="")
+ ),
+ }
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/reporter_for_tests.py b/solutions/.venv/Lib/site-packages/pylint/testutils/reporter_for_tests.py
new file mode 100644
index 000000000..d3c06eecd
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/reporter_for_tests.py
@@ -0,0 +1,79 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from io import StringIO
+from os import getcwd, sep
+from typing import TYPE_CHECKING
+
+from pylint.message import Message
+from pylint.reporters import BaseReporter
+
+if TYPE_CHECKING:
+ from pylint.reporters.ureports.nodes import Section
+
+
+class GenericTestReporter(BaseReporter):
+ """Reporter storing plain text messages."""
+
+ out: StringIO
+
+ def __init__( # pylint: disable=super-init-not-called # See https://github.com/pylint-dev/pylint/issues/4941
+ self,
+ ) -> None:
+ self.path_strip_prefix: str = getcwd() + sep
+ self.reset()
+
+ def reset(self) -> None:
+ self.out = StringIO()
+ self.messages: list[Message] = []
+
+ def handle_message(self, msg: Message) -> None:
+ """Append messages to the list of messages of the reporter."""
+ self.messages.append(msg)
+
+ def finalize(self) -> str:
+ """Format and print messages in the context of the path."""
+ messages: list[str] = []
+ for msg in self.messages:
+ obj = ""
+ if msg.obj:
+ obj = f":{msg.obj}"
+ messages.append(f"{msg.msg_id[0]}:{msg.line:>3}{obj}: {msg.msg}")
+
+ messages.sort()
+ for message in messages:
+ print(message, file=self.out)
+
+ result = self.out.getvalue()
+ self.reset()
+ return result
+
+ def on_set_current_module(self, module: str, filepath: str | None) -> None:
+ pass
+
+ # pylint: enable=unused-argument
+
+ def display_reports(self, layout: Section) -> None:
+ """Ignore layouts."""
+
+ def _display(self, layout: Section) -> None:
+ pass
+
+
+class MinimalTestReporter(BaseReporter):
+ def on_set_current_module(self, module: str, filepath: str | None) -> None:
+ self.messages = []
+
+ def _display(self, layout: Section) -> None:
+ pass
+
+
+class FunctionalTestReporter(BaseReporter):
+ def display_reports(self, layout: Section) -> None:
+ """Ignore layouts and don't call self._display()."""
+
+ def _display(self, layout: Section) -> None:
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/testing_pylintrc b/solutions/.venv/Lib/site-packages/pylint/testutils/testing_pylintrc
new file mode 100644
index 000000000..9429b858f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/testing_pylintrc
@@ -0,0 +1,13 @@
+# A bare minimum pylintrc used for the functional tests that don't specify
+# their own settings.
+
+[MESSAGES CONTROL]
+
+disable=
+ suppressed-message,
+ locally-disabled,
+ useless-suppression,
+
+enable=
+ deprecated-pragma,
+ use-symbolic-message-instead,
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/tokenize_str.py b/solutions/.venv/Lib/site-packages/pylint/testutils/tokenize_str.py
new file mode 100644
index 000000000..dc9ada72a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/tokenize_str.py
@@ -0,0 +1,13 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import tokenize
+from io import StringIO
+from tokenize import TokenInfo
+
+
+def _tokenize_str(code: str) -> list[TokenInfo]:
+ return list(tokenize.generate_tokens(StringIO(code).readline))
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/unittest_linter.py b/solutions/.venv/Lib/site-packages/pylint/testutils/unittest_linter.py
new file mode 100644
index 000000000..a19afec56
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/unittest_linter.py
@@ -0,0 +1,84 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+# pylint: disable=duplicate-code
+
+from __future__ import annotations
+
+from typing import Any, Literal
+
+from astroid import nodes
+
+from pylint.interfaces import UNDEFINED, Confidence
+from pylint.lint import PyLinter
+from pylint.testutils.output_line import MessageTest
+
+
+class UnittestLinter(PyLinter):
+ """A fake linter class to capture checker messages."""
+
+ def __init__(self) -> None:
+ self._messages: list[MessageTest] = []
+ super().__init__()
+
+ def release_messages(self) -> list[MessageTest]:
+ try:
+ return self._messages
+ finally:
+ self._messages = []
+
+ def add_message(
+ self,
+ msgid: str,
+ line: int | None = None,
+ # TODO: Make node non optional
+ node: nodes.NodeNG | None = None,
+ args: Any = None,
+ confidence: Confidence | None = None,
+ col_offset: int | None = None,
+ end_lineno: int | None = None,
+ end_col_offset: int | None = None,
+ ) -> None:
+ """Add a MessageTest to the _messages attribute of the linter class."""
+ # If confidence is None we set it to UNDEFINED as well in PyLinter
+ if confidence is None:
+ confidence = UNDEFINED
+
+ # Look up "location" data of node if not yet supplied
+ if node:
+ if node.position:
+ if not line:
+ line = node.position.lineno
+ if not col_offset:
+ col_offset = node.position.col_offset
+ if not end_lineno:
+ end_lineno = node.position.end_lineno
+ if not end_col_offset:
+ end_col_offset = node.position.end_col_offset
+ else:
+ if not line:
+ line = node.fromlineno
+ if not col_offset:
+ col_offset = node.col_offset
+ if not end_lineno:
+ end_lineno = node.end_lineno
+ if not end_col_offset:
+ end_col_offset = node.end_col_offset
+
+ self._messages.append(
+ MessageTest(
+ msgid,
+ line,
+ node,
+ args,
+ confidence,
+ col_offset,
+ end_lineno,
+ end_col_offset,
+ )
+ )
+
+ @staticmethod
+ def is_message_enabled(*unused_args: Any, **unused_kwargs: Any) -> Literal[True]:
+ return True
diff --git a/solutions/.venv/Lib/site-packages/pylint/testutils/utils.py b/solutions/.venv/Lib/site-packages/pylint/testutils/utils.py
new file mode 100644
index 000000000..3036d1fd6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/testutils/utils.py
@@ -0,0 +1,107 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import contextlib
+import os
+import sys
+from collections.abc import Generator, Iterator
+from copy import copy
+from pathlib import Path
+from typing import TextIO
+
+
+@contextlib.contextmanager
+def _patch_streams(out: TextIO) -> Iterator[None]:
+ """Patch and subsequently reset a text stream."""
+ sys.stderr = sys.stdout = out
+ try:
+ yield
+ finally:
+ sys.stderr = sys.__stderr__
+ sys.stdout = sys.__stdout__
+
+
+@contextlib.contextmanager
+def _test_sys_path(
+ replacement_sys_path: list[str] | None = None,
+) -> Generator[None]:
+ original_path = sys.path
+ try:
+ if replacement_sys_path is not None:
+ sys.path = copy(replacement_sys_path)
+ yield
+ finally:
+ sys.path = original_path
+
+
+@contextlib.contextmanager
+def _test_cwd(
+ current_working_directory: str | Path | None = None,
+) -> Generator[None]:
+ original_dir = os.getcwd()
+ try:
+ if current_working_directory is not None:
+ os.chdir(current_working_directory)
+ yield
+ finally:
+ os.chdir(original_dir)
+
+
+@contextlib.contextmanager
+def _test_environ_pythonpath(
+ new_pythonpath: str | None = None,
+) -> Generator[None]:
+ original_pythonpath = os.environ.get("PYTHONPATH")
+ if new_pythonpath:
+ os.environ["PYTHONPATH"] = new_pythonpath
+ elif new_pythonpath is None and original_pythonpath is not None:
+ # If new_pythonpath is None, make sure to delete PYTHONPATH if present
+ del os.environ["PYTHONPATH"]
+ try:
+ yield
+ finally:
+ if original_pythonpath is not None:
+ os.environ["PYTHONPATH"] = original_pythonpath
+ elif "PYTHONPATH" in os.environ:
+ del os.environ["PYTHONPATH"]
+
+
+def create_files(paths: list[str], chroot: str = ".") -> None:
+ """Creates directories and files found in <path>.
+
+ :param list paths: list of relative paths to files or directories
+ :param str chroot: the root directory in which paths will be created
+
+ >>> from os.path import isdir, isfile
+ >>> isdir('/tmp/a')
+ False
+ >>> create_files(['a/b/foo.py', 'a/b/c/', 'a/b/c/d/e.py'], '/tmp')
+ >>> isdir('/tmp/a')
+ True
+ >>> isdir('/tmp/a/b/c')
+ True
+ >>> isfile('/tmp/a/b/c/d/e.py')
+ True
+ >>> isfile('/tmp/a/b/foo.py')
+ True
+ """
+ dirs, files = set(), set()
+ for path in paths:
+ path = os.path.join(chroot, path)
+ filename = os.path.basename(path)
+ # path is a directory path
+ if not filename:
+ dirs.add(path)
+ # path is a filename path
+ else:
+ dirs.add(os.path.dirname(path))
+ files.add(path)
+ for dirpath in dirs:
+ if not os.path.isdir(dirpath):
+ os.makedirs(dirpath)
+ for filepath in files:
+ with open(filepath, "w", encoding="utf-8"):
+ pass
diff --git a/solutions/.venv/Lib/site-packages/pylint/typing.py b/solutions/.venv/Lib/site-packages/pylint/typing.py
new file mode 100644
index 000000000..963222871
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/typing.py
@@ -0,0 +1,135 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""A collection of typing utilities."""
+
+from __future__ import annotations
+
+import argparse
+from collections.abc import Iterable
+from pathlib import Path
+from re import Pattern
+from typing import (
+ TYPE_CHECKING,
+ Any,
+ Callable,
+ Literal,
+ NamedTuple,
+ Optional,
+ Protocol,
+ TypedDict,
+ Union,
+)
+
+if TYPE_CHECKING:
+ from pylint.config.callback_actions import _CallbackAction
+ from pylint.pyreverse.inspector import Project
+ from pylint.reporters.ureports.nodes import Section
+ from pylint.utils import LinterStats
+
+
+class FileItem(NamedTuple):
+ """Represents data about a file handled by pylint.
+
+ Each file item has:
+ - name: full name of the module
+ - filepath: path of the file
+ - modname: module name
+ """
+
+ name: str
+ filepath: str
+ modpath: str
+
+
+class ModuleDescriptionDict(TypedDict):
+ """Represents data about a checked module."""
+
+ path: str
+ name: str
+ isarg: bool
+ basepath: str
+ basename: str
+
+
+class ErrorDescriptionDict(TypedDict):
+ """Represents data about errors collected during checking of a module."""
+
+ key: Literal["fatal"]
+ mod: str
+ ex: ImportError | SyntaxError
+
+
+class MessageLocationTuple(NamedTuple):
+ """Tuple with information about the location of a to-be-displayed message."""
+
+ abspath: str
+ path: str
+ module: str
+ obj: str
+ line: int
+ column: int
+ end_line: int | None = None
+ end_column: int | None = None
+
+
+class ManagedMessage(NamedTuple):
+ """Tuple with information about a managed message of the linter."""
+
+ name: str | None
+ msgid: str
+ symbol: str
+ line: int | None
+ is_disabled: bool
+
+
+MessageTypesFullName = Literal[
+ "convention", "error", "fatal", "info", "refactor", "statement", "warning"
+]
+"""All possible message categories."""
+
+
+OptionDict = dict[
+ str,
+ Union[
+ None,
+ str,
+ bool,
+ int,
+ Pattern[str],
+ Iterable[Union[str, int, Pattern[str]]],
+ type["_CallbackAction"],
+ Callable[[Any], Any],
+ Callable[[Any, Any, Any, Any], Any],
+ ],
+]
+Options = tuple[tuple[str, OptionDict], ...]
+
+
+ReportsCallable = Callable[["Section", "LinterStats", Optional["LinterStats"]], None]
+"""Callable to create a report."""
+
+
+class ExtraMessageOptions(TypedDict, total=False):
+ """All allowed keys in the extra options for message definitions."""
+
+ scope: str
+ old_names: list[tuple[str, str]]
+ maxversion: tuple[int, int]
+ minversion: tuple[int, int]
+ shared: bool
+ default_enabled: bool
+
+
+MessageDefinitionTuple = Union[
+ tuple[str, str, str],
+ tuple[str, str, str, ExtraMessageOptions],
+]
+DirectoryNamespaceDict = dict[Path, tuple[argparse.Namespace, "DirectoryNamespaceDict"]]
+
+
+class GetProjectCallable(Protocol):
+ def __call__(
+ self, module: str, name: str | None = "No Name"
+ ) -> Project: ... # pragma: no cover
diff --git a/solutions/.venv/Lib/site-packages/pylint/utils/__init__.py b/solutions/.venv/Lib/site-packages/pylint/utils/__init__.py
new file mode 100644
index 000000000..eecb3cbe3
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/utils/__init__.py
@@ -0,0 +1,53 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Some various utilities and helper classes, most of them used in the
+main pylint class.
+"""
+
+from pylint.utils.ast_walker import ASTWalker
+from pylint.utils.docs import print_full_documentation
+from pylint.utils.file_state import FileState
+from pylint.utils.linterstats import LinterStats, ModuleStats, merge_stats
+from pylint.utils.utils import (
+ HAS_ISORT_5,
+ IsortDriver,
+ _check_csv,
+ _check_regexp_csv,
+ _splitstrip,
+ _unquote,
+ decoding_stream,
+ diff_string,
+ format_section,
+ get_module_and_frameid,
+ get_rst_section,
+ get_rst_title,
+ normalize_text,
+ register_plugins,
+ tokenize_module,
+)
+
+__all__ = [
+ "ASTWalker",
+ "HAS_ISORT_5",
+ "IsortDriver",
+ "_check_csv",
+ "_check_regexp_csv",
+ "_splitstrip",
+ "_unquote",
+ "decoding_stream",
+ "diff_string",
+ "FileState",
+ "format_section",
+ "get_module_and_frameid",
+ "get_rst_section",
+ "get_rst_title",
+ "normalize_text",
+ "register_plugins",
+ "tokenize_module",
+ "merge_stats",
+ "LinterStats",
+ "ModuleStats",
+ "print_full_documentation",
+]
diff --git a/solutions/.venv/Lib/site-packages/pylint/utils/ast_walker.py b/solutions/.venv/Lib/site-packages/pylint/utils/ast_walker.py
new file mode 100644
index 000000000..6cbc7751e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/utils/ast_walker.py
@@ -0,0 +1,102 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import sys
+import traceback
+from collections import defaultdict
+from collections.abc import Callable
+from typing import TYPE_CHECKING
+
+from astroid import nodes
+
+if TYPE_CHECKING:
+ from pylint.checkers.base_checker import BaseChecker
+ from pylint.lint import PyLinter
+
+# Callable parameter type NodeNG not completely correct.
+# Due to contravariance of Callable parameter types,
+# it should be a Union of all NodeNG subclasses.
+# However, since the methods are only retrieved with
+# getattr(checker, member) and thus are inferred as Any,
+# NodeNG will work too.
+AstCallback = Callable[[nodes.NodeNG], None]
+
+
+class ASTWalker:
+ def __init__(self, linter: PyLinter) -> None:
+ # callbacks per node types
+ self.nbstatements = 0
+ self.visit_events: defaultdict[str, list[AstCallback]] = defaultdict(list)
+ self.leave_events: defaultdict[str, list[AstCallback]] = defaultdict(list)
+ self.linter = linter
+ self.exception_msg = False
+
+ def _is_method_enabled(self, method: AstCallback) -> bool:
+ if not hasattr(method, "checks_msgs"):
+ return True
+ return any(self.linter.is_message_enabled(m) for m in method.checks_msgs)
+
+ def add_checker(self, checker: BaseChecker) -> None:
+ """Walk to the checker's dir and collect visit and leave methods."""
+ vcids: set[str] = set()
+ lcids: set[str] = set()
+ visits = self.visit_events
+ leaves = self.leave_events
+ for member in dir(checker):
+ cid = member[6:]
+ if cid == "default":
+ continue
+ if member.startswith("visit_"):
+ v_meth = getattr(checker, member)
+ # don't use visit_methods with no activated message:
+ if self._is_method_enabled(v_meth):
+ visits[cid].append(v_meth)
+ vcids.add(cid)
+ elif member.startswith("leave_"):
+ l_meth = getattr(checker, member)
+ # don't use leave_methods with no activated message:
+ if self._is_method_enabled(l_meth):
+ leaves[cid].append(l_meth)
+ lcids.add(cid)
+ visit_default = getattr(checker, "visit_default", None)
+ if visit_default:
+ for cls in nodes.ALL_NODE_CLASSES:
+ cid = cls.__name__.lower()
+ if cid not in vcids:
+ visits[cid].append(visit_default)
+ # For now, we have no "leave_default" method in Pylint
+
+ def walk(self, astroid: nodes.NodeNG) -> None:
+ """Call visit events of astroid checkers for the given node, recurse on
+ its children, then leave events.
+ """
+ cid = astroid.__class__.__name__.lower()
+
+ visit_events = self.visit_events[cid]
+ leave_events = self.leave_events[cid]
+
+ # pylint: disable = too-many-try-statements
+ try:
+ if astroid.is_statement:
+ self.nbstatements += 1
+ # generate events for this node on each checker
+ for callback in visit_events:
+ callback(astroid)
+ # recurse on children
+ for child in astroid.get_children():
+ self.walk(child)
+ for callback in leave_events:
+ callback(astroid)
+ except Exception:
+ if self.exception_msg is False:
+ file = getattr(astroid.root(), "file", None)
+ print(
+ f"Exception on node {astroid!r} in file '{file}'",
+ file=sys.stderr,
+ )
+ traceback.print_exc()
+ self.exception_msg = True
+ raise
diff --git a/solutions/.venv/Lib/site-packages/pylint/utils/docs.py b/solutions/.venv/Lib/site-packages/pylint/utils/docs.py
new file mode 100644
index 000000000..ba592c4a4
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/utils/docs.py
@@ -0,0 +1,96 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+"""Various helper functions to create the docs of a linter object."""
+
+from __future__ import annotations
+
+import sys
+from typing import TYPE_CHECKING, Any, TextIO
+
+from pylint.constants import MAIN_CHECKER_NAME
+from pylint.utils.utils import get_rst_section, get_rst_title
+
+if TYPE_CHECKING:
+ from pylint.lint.pylinter import PyLinter
+
+
+def _get_checkers_infos(linter: PyLinter) -> dict[str, dict[str, Any]]:
+ """Get info from a checker and handle KeyError."""
+ by_checker: dict[str, dict[str, Any]] = {}
+ for checker in linter.get_checkers():
+ name = checker.name
+ if name != MAIN_CHECKER_NAME:
+ try:
+ by_checker[name]["checker"] = checker
+ by_checker[name]["options"] += checker._options_and_values()
+ by_checker[name]["msgs"].update(checker.msgs)
+ by_checker[name]["reports"] += checker.reports
+ except KeyError:
+ by_checker[name] = {
+ "checker": checker,
+ "options": list(checker._options_and_values()),
+ "msgs": dict(checker.msgs),
+ "reports": list(checker.reports),
+ }
+ return by_checker
+
+
+def _get_global_options_documentation(linter: PyLinter) -> str:
+ """Get documentation for the main checker."""
+ result = get_rst_title("Pylint global options and switches", "-")
+ result += """
+Pylint provides global options and switches.
+
+"""
+ for checker in linter.get_checkers():
+ if checker.name == MAIN_CHECKER_NAME and checker.options:
+ for section, options in checker._options_by_section():
+ if section is None:
+ title = "General options"
+ else:
+ title = f"{section.capitalize()} options"
+ result += get_rst_title(title, "~")
+ assert isinstance(options, list)
+ result += f"{get_rst_section(None, options)}\n"
+ return result
+
+
+def _get_checkers_documentation(linter: PyLinter, show_options: bool = True) -> str:
+ """Get documentation for individual checkers."""
+ if show_options:
+ result = _get_global_options_documentation(linter)
+ else:
+ result = ""
+
+ result += get_rst_title("Pylint checkers' options and switches", "-")
+ result += """\
+
+Pylint checkers can provide three set of features:
+
+* options that control their execution,
+* messages that they can raise,
+* reports that they can generate.
+
+Below is a list of all checkers and their features.
+
+"""
+ by_checker = _get_checkers_infos(linter)
+ for checker_name in sorted(by_checker):
+ information = by_checker[checker_name]
+ checker = information["checker"]
+ del information["checker"]
+ result += checker.get_full_documentation(
+ **information, show_options=show_options
+ )
+ return result
+
+
+def print_full_documentation(
+ linter: PyLinter, stream: TextIO = sys.stdout, show_options: bool = True
+) -> None:
+ """Output a full documentation in ReST format."""
+ print(
+ _get_checkers_documentation(linter, show_options=show_options)[:-3], file=stream
+ )
diff --git a/solutions/.venv/Lib/site-packages/pylint/utils/file_state.py b/solutions/.venv/Lib/site-packages/pylint/utils/file_state.py
new file mode 100644
index 000000000..45217bb7e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/utils/file_state.py
@@ -0,0 +1,254 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import collections
+from collections import defaultdict
+from collections.abc import Iterator
+from typing import TYPE_CHECKING, Literal
+
+from astroid import nodes
+
+from pylint.constants import (
+ INCOMPATIBLE_WITH_USELESS_SUPPRESSION,
+ MSG_STATE_SCOPE_MODULE,
+ WarningScope,
+)
+
+if TYPE_CHECKING:
+ from pylint.message import MessageDefinition, MessageDefinitionStore
+
+
+MessageStateDict = dict[str, dict[int, bool]]
+
+
+class FileState:
+ """Hold internal state specific to the currently analyzed file."""
+
+ def __init__(
+ self,
+ modname: str,
+ msg_store: MessageDefinitionStore,
+ node: nodes.Module | None = None,
+ *,
+ is_base_filestate: bool = False,
+ ) -> None:
+ self.base_name = modname
+ self._module_msgs_state: MessageStateDict = {}
+ self._raw_module_msgs_state: MessageStateDict = {}
+ self._ignored_msgs: defaultdict[tuple[str, int], set[int]] = (
+ collections.defaultdict(set)
+ )
+ self._suppression_mapping: dict[tuple[str, int], int] = {}
+ self._module = node
+ if node:
+ self._effective_max_line_number = node.tolineno
+ else:
+ self._effective_max_line_number = None
+ self._msgs_store = msg_store
+ self._is_base_filestate = is_base_filestate
+ """If this FileState is the base state made during initialization of
+ PyLinter.
+ """
+
+ def _set_state_on_block_lines(
+ self,
+ msgs_store: MessageDefinitionStore,
+ node: nodes.NodeNG,
+ msg: MessageDefinition,
+ msg_state: dict[int, bool],
+ ) -> None:
+ """Recursively walk (depth first) AST to collect block level options
+ line numbers and set the state correctly.
+ """
+ for child in node.get_children():
+ self._set_state_on_block_lines(msgs_store, child, msg, msg_state)
+ # first child line number used to distinguish between disable
+ # which are the first child of scoped node with those defined later.
+ # For instance in the code below:
+ #
+ # 1. def meth8(self):
+ # 2. """test late disabling"""
+ # 3. pylint: disable=not-callable, useless-suppression
+ # 4. print(self.blip)
+ # 5. pylint: disable=no-member, useless-suppression
+ # 6. print(self.bla)
+ #
+ # E1102 should be disabled from line 1 to 6 while E1101 from line 5 to 6
+ #
+ # this is necessary to disable locally messages applying to class /
+ # function using their fromlineno
+ if (
+ isinstance(node, (nodes.Module, nodes.ClassDef, nodes.FunctionDef))
+ and node.body
+ ):
+ firstchildlineno = node.body[0].fromlineno
+ else:
+ firstchildlineno = node.tolineno
+ self._set_message_state_in_block(msg, msg_state, node, firstchildlineno)
+
+ def _set_message_state_in_block(
+ self,
+ msg: MessageDefinition,
+ lines: dict[int, bool],
+ node: nodes.NodeNG,
+ firstchildlineno: int,
+ ) -> None:
+ """Set the state of a message in a block of lines."""
+ first = node.fromlineno
+ last = node.tolineno
+ for lineno, state in list(lines.items()):
+ original_lineno = lineno
+ if first > lineno or last < lineno:
+ continue
+ # Set state for all lines for this block, if the
+ # warning is applied to nodes.
+ if msg.scope == WarningScope.NODE:
+ if lineno > firstchildlineno:
+ state = True
+ first_, last_ = node.block_range(lineno)
+ # pylint: disable=useless-suppression
+ # For block nodes first_ is their definition line. For example, we
+ # set the state of line zero for a module to allow disabling
+ # invalid-name for the module. For example:
+ # 1. # pylint: disable=invalid-name
+ # 2. ...
+ # OR
+ # 1. """Module docstring"""
+ # 2. # pylint: disable=invalid-name
+ # 3. ...
+ #
+ # But if we already visited line 0 we don't need to set its state again
+ # 1. # pylint: disable=invalid-name
+ # 2. # pylint: enable=invalid-name
+ # 3. ...
+ # The state should come from line 1, not from line 2
+ # Therefore, if the 'fromlineno' is already in the states we just start
+ # with the lineno we were originally visiting.
+ # pylint: enable=useless-suppression
+ if (
+ first_ == node.fromlineno
+ and first_ >= firstchildlineno
+ and node.fromlineno in self._module_msgs_state.get(msg.msgid, ())
+ ):
+ first_ = lineno
+
+ else:
+ first_ = lineno
+ last_ = last
+ for line in range(first_, last_ + 1):
+ # Do not override existing entries. This is especially important
+ # when parsing the states for a scoped node where some line-disables
+ # have already been parsed.
+ if (
+ (
+ isinstance(node, nodes.Module)
+ and node.fromlineno <= line < lineno
+ )
+ or (
+ not isinstance(node, nodes.Module)
+ and node.fromlineno < line < lineno
+ )
+ ) and line in self._module_msgs_state.get(msg.msgid, ()):
+ continue
+ if line in lines: # state change in the same block
+ state = lines[line]
+ original_lineno = line
+
+ self._set_message_state_on_line(msg, line, state, original_lineno)
+
+ del lines[lineno]
+
+ def _set_message_state_on_line(
+ self,
+ msg: MessageDefinition,
+ line: int,
+ state: bool,
+ original_lineno: int,
+ ) -> None:
+ """Set the state of a message on a line."""
+ # Update suppression mapping
+ if not state:
+ self._suppression_mapping[(msg.msgid, line)] = original_lineno
+ else:
+ self._suppression_mapping.pop((msg.msgid, line), None)
+
+ # Update message state for respective line
+ try:
+ self._module_msgs_state[msg.msgid][line] = state
+ except KeyError:
+ self._module_msgs_state[msg.msgid] = {line: state}
+
+ def set_msg_status(
+ self,
+ msg: MessageDefinition,
+ line: int,
+ status: bool,
+ scope: str = "package",
+ ) -> None:
+ """Set status (enabled/disable) for a given message at a given line."""
+ assert line > 0
+ if scope != "line":
+ # Expand the status to cover all relevant block lines
+ self._set_state_on_block_lines(
+ self._msgs_store, self._module, msg, {line: status}
+ )
+ else:
+ self._set_message_state_on_line(msg, line, status, line)
+
+ # Store the raw value
+ try:
+ self._raw_module_msgs_state[msg.msgid][line] = status
+ except KeyError:
+ self._raw_module_msgs_state[msg.msgid] = {line: status}
+
+ def handle_ignored_message(
+ self, state_scope: Literal[0, 1, 2] | None, msgid: str, line: int | None
+ ) -> None:
+ """Report an ignored message.
+
+ state_scope is either MSG_STATE_SCOPE_MODULE or MSG_STATE_SCOPE_CONFIG,
+ depending on whether the message was disabled locally in the module,
+ or globally.
+ """
+ if state_scope == MSG_STATE_SCOPE_MODULE:
+ assert isinstance(line, int) # should always be int inside module scope
+
+ try:
+ orig_line = self._suppression_mapping[(msgid, line)]
+ self._ignored_msgs[(msgid, orig_line)].add(line)
+ except KeyError:
+ pass
+
+ def iter_spurious_suppression_messages(
+ self,
+ msgs_store: MessageDefinitionStore,
+ ) -> Iterator[
+ tuple[
+ Literal["useless-suppression", "suppressed-message"],
+ int,
+ tuple[str] | tuple[str, int],
+ ]
+ ]:
+ for warning, lines in self._raw_module_msgs_state.items():
+ for line, enable in lines.items():
+ if (
+ not enable
+ and (warning, line) not in self._ignored_msgs
+ and warning not in INCOMPATIBLE_WITH_USELESS_SUPPRESSION
+ ):
+ yield "useless-suppression", line, (
+ msgs_store.get_msg_display_string(warning),
+ )
+ # don't use iteritems here, _ignored_msgs may be modified by add_message
+ for (warning, from_), ignored_lines in list(self._ignored_msgs.items()):
+ for line in ignored_lines:
+ yield "suppressed-message", line, (
+ msgs_store.get_msg_display_string(warning),
+ from_,
+ )
+
+ def get_effective_max_line_number(self) -> int | None:
+ return self._effective_max_line_number # type: ignore[no-any-return]
diff --git a/solutions/.venv/Lib/site-packages/pylint/utils/linterstats.py b/solutions/.venv/Lib/site-packages/pylint/utils/linterstats.py
new file mode 100644
index 000000000..53afbcfe2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/utils/linterstats.py
@@ -0,0 +1,390 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+from typing import Literal, TypedDict, cast
+
+from pylint.typing import MessageTypesFullName
+
+
+class BadNames(TypedDict):
+ """TypedDict to store counts of node types with bad names."""
+
+ argument: int
+ attr: int
+ klass: int
+ class_attribute: int
+ class_const: int
+ const: int
+ inlinevar: int
+ function: int
+ method: int
+ module: int
+ variable: int
+ typevar: int
+ typealias: int
+
+
+class CodeTypeCount(TypedDict):
+ """TypedDict to store counts of lines of code types."""
+
+ code: int
+ comment: int
+ docstring: int
+ empty: int
+ total: int
+
+
+class DuplicatedLines(TypedDict):
+ """TypedDict to store counts of lines of duplicated code."""
+
+ nb_duplicated_lines: int
+ percent_duplicated_lines: float
+
+
+class NodeCount(TypedDict):
+ """TypedDict to store counts of different types of nodes."""
+
+ function: int
+ klass: int
+ method: int
+ module: int
+
+
+class UndocumentedNodes(TypedDict):
+ """TypedDict to store counts of undocumented node types."""
+
+ function: int
+ klass: int
+ method: int
+ module: int
+
+
+class ModuleStats(TypedDict):
+ """TypedDict to store counts of types of messages and statements."""
+
+ convention: int
+ error: int
+ fatal: int
+ info: int
+ refactor: int
+ statement: int
+ warning: int
+
+
+# pylint: disable-next=too-many-instance-attributes
+class LinterStats:
+ """Class used to linter stats."""
+
+ def __init__(
+ self,
+ bad_names: BadNames | None = None,
+ by_module: dict[str, ModuleStats] | None = None,
+ by_msg: dict[str, int] | None = None,
+ code_type_count: CodeTypeCount | None = None,
+ dependencies: dict[str, set[str]] | None = None,
+ duplicated_lines: DuplicatedLines | None = None,
+ node_count: NodeCount | None = None,
+ undocumented: UndocumentedNodes | None = None,
+ ) -> None:
+ self.bad_names = bad_names or BadNames(
+ argument=0,
+ attr=0,
+ klass=0,
+ class_attribute=0,
+ class_const=0,
+ const=0,
+ inlinevar=0,
+ function=0,
+ method=0,
+ module=0,
+ variable=0,
+ typevar=0,
+ typealias=0,
+ )
+ self.by_module: dict[str, ModuleStats] = by_module or {}
+ self.by_msg: dict[str, int] = by_msg or {}
+ self.code_type_count = code_type_count or CodeTypeCount(
+ code=0, comment=0, docstring=0, empty=0, total=0
+ )
+
+ self.dependencies: dict[str, set[str]] = dependencies or {}
+ self.duplicated_lines = duplicated_lines or DuplicatedLines(
+ nb_duplicated_lines=0, percent_duplicated_lines=0.0
+ )
+ self.node_count = node_count or NodeCount(
+ function=0, klass=0, method=0, module=0
+ )
+ self.undocumented = undocumented or UndocumentedNodes(
+ function=0, klass=0, method=0, module=0
+ )
+
+ self.convention = 0
+ self.error = 0
+ self.fatal = 0
+ self.info = 0
+ self.refactor = 0
+ self.statement = 0
+ self.warning = 0
+
+ self.global_note = 0
+ self.nb_duplicated_lines = 0
+ self.percent_duplicated_lines = 0.0
+
+ def __repr__(self) -> str:
+ return str(self)
+
+ def __str__(self) -> str:
+ return f"""{self.bad_names}
+ {sorted(self.by_module.items())}
+ {sorted(self.by_msg.items())}
+ {self.code_type_count}
+ {sorted(self.dependencies.items())}
+ {self.duplicated_lines}
+ {self.undocumented}
+ {self.convention}
+ {self.error}
+ {self.fatal}
+ {self.info}
+ {self.refactor}
+ {self.statement}
+ {self.warning}
+ {self.global_note}
+ {self.nb_duplicated_lines}
+ {self.percent_duplicated_lines}"""
+
+ def init_single_module(self, module_name: str) -> None:
+ """Use through PyLinter.set_current_module so PyLinter.current_name is
+ consistent.
+ """
+ self.by_module[module_name] = ModuleStats(
+ convention=0, error=0, fatal=0, info=0, refactor=0, statement=0, warning=0
+ )
+
+ def get_bad_names(
+ self,
+ node_name: Literal[
+ "argument",
+ "attr",
+ "class",
+ "class_attribute",
+ "class_const",
+ "const",
+ "inlinevar",
+ "function",
+ "method",
+ "module",
+ "variable",
+ "typevar",
+ "typealias",
+ ],
+ ) -> int:
+ """Get a bad names node count."""
+ if node_name == "class":
+ return self.bad_names.get("klass", 0)
+ return self.bad_names.get(node_name, 0)
+
+ def increase_bad_name(self, node_name: str, increase: int) -> None:
+ """Increase a bad names node count."""
+ if node_name not in {
+ "argument",
+ "attr",
+ "class",
+ "class_attribute",
+ "class_const",
+ "const",
+ "inlinevar",
+ "function",
+ "method",
+ "module",
+ "variable",
+ "typevar",
+ "typealias",
+ }:
+ raise ValueError("Node type not part of the bad_names stat")
+
+ node_name = cast(
+ Literal[
+ "argument",
+ "attr",
+ "class",
+ "class_attribute",
+ "class_const",
+ "const",
+ "inlinevar",
+ "function",
+ "method",
+ "module",
+ "variable",
+ "typevar",
+ "typealias",
+ ],
+ node_name,
+ )
+ if node_name == "class":
+ self.bad_names["klass"] += increase
+ else:
+ self.bad_names[node_name] += increase
+
+ def reset_bad_names(self) -> None:
+ """Resets the bad_names attribute."""
+ self.bad_names = BadNames(
+ argument=0,
+ attr=0,
+ klass=0,
+ class_attribute=0,
+ class_const=0,
+ const=0,
+ inlinevar=0,
+ function=0,
+ method=0,
+ module=0,
+ variable=0,
+ typevar=0,
+ typealias=0,
+ )
+
+ def get_code_count(
+ self, type_name: Literal["code", "comment", "docstring", "empty", "total"]
+ ) -> int:
+ """Get a code type count."""
+ return self.code_type_count.get(type_name, 0)
+
+ def reset_code_count(self) -> None:
+ """Resets the code_type_count attribute."""
+ self.code_type_count = CodeTypeCount(
+ code=0, comment=0, docstring=0, empty=0, total=0
+ )
+
+ def reset_duplicated_lines(self) -> None:
+ """Resets the duplicated_lines attribute."""
+ self.duplicated_lines = DuplicatedLines(
+ nb_duplicated_lines=0, percent_duplicated_lines=0.0
+ )
+
+ def get_node_count(
+ self, node_name: Literal["function", "class", "method", "module"]
+ ) -> int:
+ """Get a node count while handling some extra conditions."""
+ if node_name == "class":
+ return self.node_count.get("klass", 0)
+ return self.node_count.get(node_name, 0)
+
+ def reset_node_count(self) -> None:
+ """Resets the node count attribute."""
+ self.node_count = NodeCount(function=0, klass=0, method=0, module=0)
+
+ def get_undocumented(
+ self, node_name: Literal["function", "class", "method", "module"]
+ ) -> float:
+ """Get a undocumented node count."""
+ if node_name == "class":
+ return self.undocumented["klass"]
+ return self.undocumented[node_name]
+
+ def reset_undocumented(self) -> None:
+ """Resets the undocumented attribute."""
+ self.undocumented = UndocumentedNodes(function=0, klass=0, method=0, module=0)
+
+ def get_global_message_count(self, type_name: str) -> int:
+ """Get a global message count."""
+ return getattr(self, type_name, 0)
+
+ def get_module_message_count(
+ self, modname: str, type_name: MessageTypesFullName
+ ) -> int:
+ """Get a module message count."""
+ return self.by_module[modname].get(type_name, 0)
+
+ def increase_single_message_count(self, type_name: str, increase: int) -> None:
+ """Increase the message type count of an individual message type."""
+ setattr(self, type_name, getattr(self, type_name) + increase)
+
+ def increase_single_module_message_count(
+ self, modname: str, type_name: MessageTypesFullName, increase: int
+ ) -> None:
+ """Increase the message type count of an individual message type of a
+ module.
+ """
+ self.by_module[modname][type_name] += increase
+
+ def reset_message_count(self) -> None:
+ """Resets the message type count of the stats object."""
+ self.convention = 0
+ self.error = 0
+ self.fatal = 0
+ self.info = 0
+ self.refactor = 0
+ self.warning = 0
+
+
+def merge_stats(stats: list[LinterStats]) -> LinterStats:
+ """Used to merge multiple stats objects into a new one when pylint is run in
+ parallel mode.
+ """
+ merged = LinterStats()
+ for stat in stats:
+ merged.bad_names["argument"] += stat.bad_names["argument"]
+ merged.bad_names["attr"] += stat.bad_names["attr"]
+ merged.bad_names["klass"] += stat.bad_names["klass"]
+ merged.bad_names["class_attribute"] += stat.bad_names["class_attribute"]
+ merged.bad_names["class_const"] += stat.bad_names["class_const"]
+ merged.bad_names["const"] += stat.bad_names["const"]
+ merged.bad_names["inlinevar"] += stat.bad_names["inlinevar"]
+ merged.bad_names["function"] += stat.bad_names["function"]
+ merged.bad_names["method"] += stat.bad_names["method"]
+ merged.bad_names["module"] += stat.bad_names["module"]
+ merged.bad_names["variable"] += stat.bad_names["variable"]
+ merged.bad_names["typevar"] += stat.bad_names["typevar"]
+ merged.bad_names["typealias"] += stat.bad_names["typealias"]
+
+ for mod_key, mod_value in stat.by_module.items():
+ merged.by_module[mod_key] = mod_value
+
+ for msg_key, msg_value in stat.by_msg.items():
+ try:
+ merged.by_msg[msg_key] += msg_value
+ except KeyError:
+ merged.by_msg[msg_key] = msg_value
+
+ merged.code_type_count["code"] += stat.code_type_count["code"]
+ merged.code_type_count["comment"] += stat.code_type_count["comment"]
+ merged.code_type_count["docstring"] += stat.code_type_count["docstring"]
+ merged.code_type_count["empty"] += stat.code_type_count["empty"]
+ merged.code_type_count["total"] += stat.code_type_count["total"]
+
+ for dep_key, dep_value in stat.dependencies.items():
+ try:
+ merged.dependencies[dep_key].update(dep_value)
+ except KeyError:
+ merged.dependencies[dep_key] = dep_value
+
+ merged.duplicated_lines["nb_duplicated_lines"] += stat.duplicated_lines[
+ "nb_duplicated_lines"
+ ]
+ merged.duplicated_lines["percent_duplicated_lines"] += stat.duplicated_lines[
+ "percent_duplicated_lines"
+ ]
+
+ merged.node_count["function"] += stat.node_count["function"]
+ merged.node_count["klass"] += stat.node_count["klass"]
+ merged.node_count["method"] += stat.node_count["method"]
+ merged.node_count["module"] += stat.node_count["module"]
+
+ merged.undocumented["function"] += stat.undocumented["function"]
+ merged.undocumented["klass"] += stat.undocumented["klass"]
+ merged.undocumented["method"] += stat.undocumented["method"]
+ merged.undocumented["module"] += stat.undocumented["module"]
+
+ merged.convention += stat.convention
+ merged.error += stat.error
+ merged.fatal += stat.fatal
+ merged.info += stat.info
+ merged.refactor += stat.refactor
+ merged.statement += stat.statement
+ merged.warning += stat.warning
+
+ merged.global_note += stat.global_note
+ return merged
diff --git a/solutions/.venv/Lib/site-packages/pylint/utils/pragma_parser.py b/solutions/.venv/Lib/site-packages/pylint/utils/pragma_parser.py
new file mode 100644
index 000000000..5e066653e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/utils/pragma_parser.py
@@ -0,0 +1,135 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+import re
+from collections.abc import Generator
+from typing import NamedTuple
+
+# Allow stopping after the first semicolon/hash encountered,
+# so that an option can be continued with the reasons
+# why it is active or disabled.
+OPTION_RGX = r"""
+ (?:^\s*\#.*|\s*| # Comment line, or whitespaces,
+ \s*\#.*(?=\#.*?\bpylint:)) # or a beginning of an inline comment
+ # followed by "pylint:" pragma
+ (\# # Beginning of comment
+ .*? # Anything (as little as possible)
+ \bpylint: # pylint word and column
+ \s* # Any number of whitespaces
+ ([^;#\n]+)) # Anything except semicolon or hash or
+ # newline (it is the second matched group)
+ # and end of the first matched group
+ [;#]{0,1} # From 0 to 1 repetition of semicolon or hash
+"""
+OPTION_PO = re.compile(OPTION_RGX, re.VERBOSE)
+
+
+class PragmaRepresenter(NamedTuple):
+ action: str
+ messages: list[str]
+
+
+ATOMIC_KEYWORDS = frozenset(("disable-all", "skip-file"))
+MESSAGE_KEYWORDS = frozenset(
+ ("disable-next", "disable-msg", "enable-msg", "disable", "enable")
+)
+# sorted is necessary because sets are unordered collections and ALL_KEYWORDS
+# string should not vary between executions
+# reverse is necessary in order to have the longest keywords first, so that, for example,
+# 'disable' string should not be matched instead of 'disable-all'
+ALL_KEYWORDS = "|".join(
+ sorted(ATOMIC_KEYWORDS | MESSAGE_KEYWORDS, key=len, reverse=True)
+)
+
+
+TOKEN_SPECIFICATION = [
+ ("KEYWORD", rf"\b({ALL_KEYWORDS:s})\b"),
+ ("MESSAGE_STRING", r"[0-9A-Za-z\-\_]{2,}"), # Identifiers
+ ("ASSIGN", r"="), # Assignment operator
+ ("MESSAGE_NUMBER", r"[CREIWF]{1}\d*"),
+]
+
+TOK_REGEX = "|".join(
+ f"(?P<{token_name:s}>{token_rgx:s})"
+ for token_name, token_rgx in TOKEN_SPECIFICATION
+)
+
+
+def emit_pragma_representer(action: str, messages: list[str]) -> PragmaRepresenter:
+ if not messages and action in MESSAGE_KEYWORDS:
+ raise InvalidPragmaError(
+ "The keyword is not followed by message identifier", action
+ )
+ return PragmaRepresenter(action, messages)
+
+
+class PragmaParserError(Exception):
+ """A class for exceptions thrown by pragma_parser module."""
+
+ def __init__(self, message: str, token: str) -> None:
+ """:args message: explain the reason why the exception has been thrown
+ :args token: token concerned by the exception.
+ """
+ self.message = message
+ self.token = token
+ super().__init__(self.message)
+
+
+class UnRecognizedOptionError(PragmaParserError):
+ """Thrown in case the of a valid but unrecognized option."""
+
+
+class InvalidPragmaError(PragmaParserError):
+ """Thrown in case the pragma is invalid."""
+
+
+def parse_pragma(pylint_pragma: str) -> Generator[PragmaRepresenter]:
+ action: str | None = None
+ messages: list[str] = []
+ assignment_required = False
+ previous_token = ""
+
+ for mo in re.finditer(TOK_REGEX, pylint_pragma):
+ kind = mo.lastgroup
+ value = mo.group()
+
+ if kind == "ASSIGN":
+ if not assignment_required:
+ if action:
+ # A keyword has been found previously but doesn't support assignment
+ raise UnRecognizedOptionError(
+ "The keyword doesn't support assignment", action
+ )
+ if previous_token:
+ # Something found previously but not a known keyword
+ raise UnRecognizedOptionError(
+ "The keyword is unknown", previous_token
+ )
+ # Nothing at all detected before this assignment
+ raise InvalidPragmaError("Missing keyword before assignment", "")
+ assignment_required = False
+ elif assignment_required:
+ raise InvalidPragmaError(
+ "The = sign is missing after the keyword", action or ""
+ )
+ elif kind == "KEYWORD":
+ if action:
+ yield emit_pragma_representer(action, messages)
+ action = value
+ messages = []
+ assignment_required = action in MESSAGE_KEYWORDS
+ elif kind in {"MESSAGE_STRING", "MESSAGE_NUMBER"}:
+ messages.append(value)
+ assignment_required = False
+ else:
+ raise RuntimeError("Token not recognized")
+
+ previous_token = value
+
+ if action:
+ yield emit_pragma_representer(action, messages)
+ else:
+ raise UnRecognizedOptionError("The keyword is unknown", previous_token)
diff --git a/solutions/.venv/Lib/site-packages/pylint/utils/utils.py b/solutions/.venv/Lib/site-packages/pylint/utils/utils.py
new file mode 100644
index 000000000..9316bcb7a
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/pylint/utils/utils.py
@@ -0,0 +1,379 @@
+# Licensed under the GPL: https://www.gnu.org/licenses/old-licenses/gpl-2.0.html
+# For details: https://github.com/pylint-dev/pylint/blob/main/LICENSE
+# Copyright (c) https://github.com/pylint-dev/pylint/blob/main/CONTRIBUTORS.txt
+
+from __future__ import annotations
+
+try:
+ import isort.api
+ import isort.settings
+
+ HAS_ISORT_5 = True
+except ImportError: # isort < 5
+ import isort
+
+ HAS_ISORT_5 = False
+
+import argparse
+import codecs
+import os
+import re
+import sys
+import textwrap
+import tokenize
+import warnings
+from collections import deque
+from collections.abc import Iterable, Sequence
+from io import BufferedReader, BytesIO
+from re import Pattern
+from typing import TYPE_CHECKING, Any, Literal, TextIO, TypeVar, Union
+
+from astroid import Module, modutils, nodes
+
+from pylint.constants import PY_EXTS
+from pylint.typing import OptionDict
+
+if TYPE_CHECKING:
+ from pylint.lint import PyLinter
+
+DEFAULT_LINE_LENGTH = 79
+
+# These are types used to overload get_global_option() and refer to the options type
+GLOBAL_OPTION_BOOL = Literal[
+ "suggestion-mode",
+ "analyse-fallback-blocks",
+ "allow-global-unused-variables",
+ "prefer-stubs",
+]
+GLOBAL_OPTION_INT = Literal["max-line-length", "docstring-min-length"]
+GLOBAL_OPTION_LIST = Literal["ignored-modules"]
+GLOBAL_OPTION_PATTERN = Literal[
+ "no-docstring-rgx",
+ "dummy-variables-rgx",
+ "ignored-argument-names",
+ "mixin-class-rgx",
+]
+GLOBAL_OPTION_PATTERN_LIST = Literal["exclude-too-few-public-methods", "ignore-paths"]
+GLOBAL_OPTION_TUPLE_INT = Literal["py-version"]
+GLOBAL_OPTION_NAMES = Union[
+ GLOBAL_OPTION_BOOL,
+ GLOBAL_OPTION_INT,
+ GLOBAL_OPTION_LIST,
+ GLOBAL_OPTION_PATTERN,
+ GLOBAL_OPTION_PATTERN_LIST,
+ GLOBAL_OPTION_TUPLE_INT,
+]
+T_GlobalOptionReturnTypes = TypeVar(
+ "T_GlobalOptionReturnTypes",
+ bool,
+ int,
+ list[str],
+ Pattern[str],
+ list[Pattern[str]],
+ tuple[int, ...],
+)
+
+
+def normalize_text(
+ text: str, line_len: int = DEFAULT_LINE_LENGTH, indent: str = ""
+) -> str:
+ """Wrap the text on the given line length."""
+ return "\n".join(
+ textwrap.wrap(
+ text, width=line_len, initial_indent=indent, subsequent_indent=indent
+ )
+ )
+
+
+CMPS = ["=", "-", "+"]
+
+
+# py3k has no more cmp builtin
+def cmp(a: float, b: float) -> int:
+ return (a > b) - (a < b)
+
+
+def diff_string(old: float, new: float) -> str:
+ """Given an old and new value, return a string representing the difference."""
+ diff = abs(old - new)
+ diff_str = f"{CMPS[cmp(old, new)]}{diff and f'{diff:.2f}' or ''}"
+ return diff_str
+
+
+def get_module_and_frameid(node: nodes.NodeNG) -> tuple[str, str]:
+ """Return the module name and the frame id in the module."""
+ frame = node.frame()
+ module, obj = "", []
+ while frame:
+ if isinstance(frame, Module):
+ module = frame.name
+ else:
+ obj.append(getattr(frame, "name", "<lambda>"))
+ try:
+ frame = frame.parent.frame()
+ except AttributeError:
+ break
+ obj.reverse()
+ return module, ".".join(obj)
+
+
+def get_rst_title(title: str, character: str) -> str:
+ """Permit to get a title formatted as ReStructuredText test (underlined with a
+ chosen character).
+ """
+ return f"{title}\n{character * len(title)}\n"
+
+
+def get_rst_section(
+ section: str | None,
+ options: list[tuple[str, OptionDict, Any]],
+ doc: str | None = None,
+) -> str:
+ """Format an option's section using as a ReStructuredText formatted output."""
+ result = ""
+ if section:
+ result += get_rst_title(section, "'")
+ if doc:
+ formatted_doc = normalize_text(doc)
+ result += f"{formatted_doc}\n\n"
+ for optname, optdict, value in options:
+ help_opt = optdict.get("help")
+ result += f":{optname}:\n"
+ if help_opt:
+ assert isinstance(help_opt, str)
+ formatted_help = normalize_text(help_opt, indent=" ")
+ result += f"{formatted_help}\n"
+ if value and optname != "py-version":
+ value = str(_format_option_value(optdict, value))
+ result += f"\n Default: ``{value.replace('`` ', '```` ``')}``\n"
+ return result
+
+
+def decoding_stream(
+ stream: BufferedReader | BytesIO,
+ encoding: str,
+ errors: Literal["strict"] = "strict",
+) -> codecs.StreamReader:
+ try:
+ reader_cls = codecs.getreader(encoding or sys.getdefaultencoding())
+ except LookupError:
+ reader_cls = codecs.getreader(sys.getdefaultencoding())
+ return reader_cls(stream, errors)
+
+
+def tokenize_module(node: nodes.Module) -> list[tokenize.TokenInfo]:
+ with node.stream() as stream:
+ readline = stream.readline
+ return list(tokenize.tokenize(readline))
+
+
+def register_plugins(linter: PyLinter, directory: str) -> None:
+ """Load all module and package in the given directory, looking for a
+ 'register' function in each one, used to register pylint checkers.
+ """
+ imported = {}
+ for filename in os.listdir(directory):
+ base, extension = os.path.splitext(filename)
+ if base in imported or base == "__pycache__":
+ continue
+ if (
+ extension in PY_EXTS
+ and base != "__init__"
+ or (
+ not extension
+ and os.path.isdir(os.path.join(directory, base))
+ and not filename.startswith(".")
+ )
+ ):
+ try:
+ module = modutils.load_module_from_file(
+ os.path.join(directory, filename)
+ )
+ except ValueError:
+ # empty module name (usually Emacs auto-save files)
+ continue
+ except ImportError as exc:
+ print(f"Problem importing module {filename}: {exc}", file=sys.stderr)
+ else:
+ if hasattr(module, "register"):
+ module.register(linter)
+ imported[base] = 1
+
+
+def _splitstrip(string: str, sep: str = ",") -> list[str]:
+ r"""Return a list of stripped string by splitting the string given as
+ argument on `sep` (',' by default), empty strings are discarded.
+
+ >>> _splitstrip('a, b, c , 4,,')
+ ['a', 'b', 'c', '4']
+ >>> _splitstrip('a')
+ ['a']
+ >>> _splitstrip('a,\nb,\nc,')
+ ['a', 'b', 'c']
+
+ :type string: str or unicode
+ :param string: a csv line
+
+ :type sep: str or unicode
+ :param sep: field separator, default to the comma (',')
+
+ :rtype: str or unicode
+ :return: the unquoted string (or the input string if it wasn't quoted)
+ """
+ return [word.strip() for word in string.split(sep) if word.strip()]
+
+
+def _unquote(string: str) -> str:
+ """Remove optional quotes (simple or double) from the string.
+
+ :param string: an optionally quoted string
+ :return: the unquoted string (or the input string if it wasn't quoted)
+ """
+ if not string:
+ return string
+ if string[0] in "\"'":
+ string = string[1:]
+ if string[-1] in "\"'":
+ string = string[:-1]
+ return string
+
+
+def _check_csv(value: list[str] | tuple[str] | str) -> Sequence[str]:
+ if isinstance(value, (list, tuple)):
+ return value
+ return _splitstrip(value)
+
+
+def _check_regexp_csv(value: list[str] | tuple[str] | str) -> Iterable[str]:
+ r"""Split a comma-separated list of regexps, taking care to avoid splitting
+ a regex employing a comma as quantifier, as in `\d{1,2}`.
+ """
+ if isinstance(value, (list, tuple)):
+ yield from value
+ else:
+ # None is a sentinel value here
+ regexps: deque[deque[str] | None] = deque([None])
+ open_braces = False
+ for char in value:
+ if char == "{":
+ open_braces = True
+ elif char == "}" and open_braces:
+ open_braces = False
+
+ if char == "," and not open_braces:
+ regexps.append(None)
+ elif regexps[-1] is None:
+ regexps.pop()
+ regexps.append(deque([char]))
+ else:
+ regexps[-1].append(char)
+ yield from ("".join(regexp).strip() for regexp in regexps if regexp is not None)
+
+
+def _comment(string: str) -> str:
+ """Return string as a comment."""
+ lines = [line.strip() for line in string.splitlines()]
+ sep = "\n"
+ return "# " + f"{sep}# ".join(lines)
+
+
+def _format_option_value(optdict: OptionDict, value: Any) -> str:
+ """Return the user input's value from a 'compiled' value.
+
+ TODO: Refactor the code to not use this deprecated function
+ """
+ if optdict.get("type", None) == "py_version":
+ value = ".".join(str(item) for item in value)
+ elif isinstance(value, (list, tuple)):
+ value = ",".join(_format_option_value(optdict, item) for item in value)
+ elif isinstance(value, dict):
+ value = ",".join(f"{k}:{v}" for k, v in value.items())
+ elif hasattr(value, "match"): # optdict.get('type') == 'regexp'
+ # compiled regexp
+ value = value.pattern
+ elif optdict.get("type") == "yn":
+ value = "yes" if value else "no"
+ elif isinstance(value, str) and value.isspace():
+ value = f"'{value}'"
+ return str(value)
+
+
+def format_section(
+ stream: TextIO,
+ section: str,
+ options: list[tuple[str, OptionDict, Any]],
+ doc: str | None = None,
+) -> None:
+ """Format an option's section using the INI format."""
+ warnings.warn(
+ "format_section has been deprecated. It will be removed in pylint 4.0.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ if doc:
+ print(_comment(doc), file=stream)
+ print(f"[{section}]", file=stream)
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=DeprecationWarning)
+ _ini_format(stream, options)
+
+
+def _ini_format(stream: TextIO, options: list[tuple[str, OptionDict, Any]]) -> None:
+ """Format options using the INI format."""
+ warnings.warn(
+ "_ini_format has been deprecated. It will be removed in pylint 4.0.",
+ DeprecationWarning,
+ stacklevel=2,
+ )
+ for optname, optdict, value in options:
+ # Skip deprecated option
+ if "kwargs" in optdict:
+ assert isinstance(optdict["kwargs"], dict)
+ if "new_names" in optdict["kwargs"]:
+ continue
+ value = _format_option_value(optdict, value)
+ help_opt = optdict.get("help")
+ if help_opt:
+ assert isinstance(help_opt, str)
+ help_opt = normalize_text(help_opt, indent="# ")
+ print(file=stream)
+ print(help_opt, file=stream)
+ else:
+ print(file=stream)
+ if value in {"None", "False"}:
+ print(f"#{optname}=", file=stream)
+ else:
+ value = str(value).strip()
+ if re.match(r"^([\w-]+,)+[\w-]+$", str(value)):
+ separator = "\n " + " " * len(optname)
+ value = separator.join(x + "," for x in str(value).split(","))
+ # remove trailing ',' from last element of the list
+ value = value[:-1]
+ print(f"{optname}={value}", file=stream)
+
+
+class IsortDriver:
+ """A wrapper around isort API that changed between versions 4 and 5."""
+
+ def __init__(self, config: argparse.Namespace) -> None:
+ if HAS_ISORT_5:
+ self.isort5_config = isort.settings.Config(
+ # There is no typo here. EXTRA_standard_library is
+ # what most users want. The option has been named
+ # KNOWN_standard_library for ages in pylint, and we
+ # don't want to break compatibility.
+ extra_standard_library=config.known_standard_library,
+ known_third_party=config.known_third_party,
+ )
+ else:
+ # pylint: disable-next=no-member
+ self.isort4_obj = isort.SortImports( # type: ignore[attr-defined]
+ file_contents="",
+ known_standard_library=config.known_standard_library,
+ known_third_party=config.known_third_party,
+ )
+
+ def place_module(self, package: str) -> str:
+ if HAS_ISORT_5:
+ return isort.api.place_module(package, self.isort5_config)
+ return self.isort4_obj.place_module(package) # type: ignore[no-any-return]
diff --git a/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/METADATA b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/METADATA
new file mode 100644
index 000000000..8643f3037
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/METADATA
@@ -0,0 +1,579 @@
+Metadata-Version: 2.4
+Name: ruff
+Version: 0.9.1
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Classifier: Programming Language :: Python :: 3.13
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Rust
+Classifier: Topic :: Software Development :: Libraries :: Python Modules
+Classifier: Topic :: Software Development :: Quality Assurance
+License-File: LICENSE
+Summary: An extremely fast Python linter and code formatter, written in Rust.
+Keywords: automation,flake8,pycodestyle,pyflakes,pylint,clippy
+Home-Page: https://docs.astral.sh/ruff
+Author: Charlie Marsh <charlie.r.marsh@gmail.com>
+Author-email: "Astral Software Inc." <hey@astral.sh>
+License: MIT
+Requires-Python: >=3.7
+Description-Content-Type: text/markdown; charset=UTF-8; variant=GFM
+Project-URL: Repository, https://github.com/astral-sh/ruff
+Project-URL: Documentation, https://docs.astral.sh/ruff/
+Project-URL: Changelog, https://github.com/astral-sh/ruff/blob/main/CHANGELOG.md
+
+<!-- Begin section: Overview -->
+
+# Ruff
+
+[](https://github.com/astral-sh/ruff)
+[](https://pypi.python.org/pypi/ruff)
+[](https://github.com/astral-sh/ruff/blob/main/LICENSE)
+[](https://pypi.python.org/pypi/ruff)
+[](https://github.com/astral-sh/ruff/actions)
+[](https://discord.com/invite/astral-sh)
+
+[**Docs**](https://docs.astral.sh/ruff/) | [**Playground**](https://play.ruff.rs/)
+
+An extremely fast Python linter and code formatter, written in Rust.
+
+<p align="center">
+ <img alt="Shows a bar chart with benchmark results." src="https://user-images.githubusercontent.com/1309177/232603516-4fb4892d-585c-4b20-b810-3db9161831e4.svg">
+</p>
+
+<p align="center">
+ <i>Linting the CPython codebase from scratch.</i>
+</p>
+
+- ⚡️ 10-100x faster than existing linters (like Flake8) and formatters (like Black)
+- 🐍 Installable via `pip`
+- 🛠️ `pyproject.toml` support
+- 🤝 Python 3.13 compatibility
+- ⚖️ Drop-in parity with [Flake8](https://docs.astral.sh/ruff/faq/#how-does-ruffs-linter-compare-to-flake8), isort, and [Black](https://docs.astral.sh/ruff/faq/#how-does-ruffs-formatter-compare-to-black)
+- 📦 Built-in caching, to avoid re-analyzing unchanged files
+- 🔧 Fix support, for automatic error correction (e.g., automatically remove unused imports)
+- 📏 Over [800 built-in rules](https://docs.astral.sh/ruff/rules/), with native re-implementations
+ of popular Flake8 plugins, like flake8-bugbear
+- ⌨️ First-party [editor integrations](https://docs.astral.sh/ruff/integrations/) for
+ [VS Code](https://github.com/astral-sh/ruff-vscode) and [more](https://docs.astral.sh/ruff/editors/setup)
+- 🌎 Monorepo-friendly, with [hierarchical and cascading configuration](https://docs.astral.sh/ruff/configuration/#config-file-discovery)
+
+Ruff aims to be orders of magnitude faster than alternative tools while integrating more
+functionality behind a single, common interface.
+
+Ruff can be used to replace [Flake8](https://pypi.org/project/flake8/) (plus dozens of plugins),
+[Black](https://github.com/psf/black), [isort](https://pypi.org/project/isort/),
+[pydocstyle](https://pypi.org/project/pydocstyle/), [pyupgrade](https://pypi.org/project/pyupgrade/),
+[autoflake](https://pypi.org/project/autoflake/), and more, all while executing tens or hundreds of
+times faster than any individual tool.
+
+Ruff is extremely actively developed and used in major open-source projects like:
+
+- [Apache Airflow](https://github.com/apache/airflow)
+- [Apache Superset](https://github.com/apache/superset)
+- [FastAPI](https://github.com/tiangolo/fastapi)
+- [Hugging Face](https://github.com/huggingface/transformers)
+- [Pandas](https://github.com/pandas-dev/pandas)
+- [SciPy](https://github.com/scipy/scipy)
+
+...and [many more](#whos-using-ruff).
+
+Ruff is backed by [Astral](https://astral.sh). Read the [launch post](https://astral.sh/blog/announcing-astral-the-company-behind-ruff),
+or the original [project announcement](https://notes.crmarsh.com/python-tooling-could-be-much-much-faster).
+
+## Testimonials
+
+[**Sebastián Ramírez**](https://twitter.com/tiangolo/status/1591912354882764802), creator
+of [FastAPI](https://github.com/tiangolo/fastapi):
+
+> Ruff is so fast that sometimes I add an intentional bug in the code just to confirm it's actually
+> running and checking the code.
+
+[**Nick Schrock**](https://twitter.com/schrockn/status/1612615862904827904), founder of [Elementl](https://www.elementl.com/),
+co-creator of [GraphQL](https://graphql.org/):
+
+> Why is Ruff a gamechanger? Primarily because it is nearly 1000x faster. Literally. Not a typo. On
+> our largest module (dagster itself, 250k LOC) pylint takes about 2.5 minutes, parallelized across 4
+> cores on my M1. Running ruff against our _entire_ codebase takes .4 seconds.
+
+[**Bryan Van de Ven**](https://github.com/bokeh/bokeh/pull/12605), co-creator
+of [Bokeh](https://github.com/bokeh/bokeh/), original author
+of [Conda](https://docs.conda.io/en/latest/):
+
+> Ruff is ~150-200x faster than flake8 on my machine, scanning the whole repo takes ~0.2s instead of
+> ~20s. This is an enormous quality of life improvement for local dev. It's fast enough that I added
+> it as an actual commit hook, which is terrific.
+
+[**Timothy Crosley**](https://twitter.com/timothycrosley/status/1606420868514877440),
+creator of [isort](https://github.com/PyCQA/isort):
+
+> Just switched my first project to Ruff. Only one downside so far: it's so fast I couldn't believe
+> it was working till I intentionally introduced some errors.
+
+[**Tim Abbott**](https://github.com/astral-sh/ruff/issues/465#issuecomment-1317400028), lead
+developer of [Zulip](https://github.com/zulip/zulip):
+
+> This is just ridiculously fast... `ruff` is amazing.
+
+<!-- End section: Overview -->
+
+## Table of Contents
+
+For more, see the [documentation](https://docs.astral.sh/ruff/).
+
+1. [Getting Started](#getting-started)
+1. [Configuration](#configuration)
+1. [Rules](#rules)
+1. [Contributing](#contributing)
+1. [Support](#support)
+1. [Acknowledgements](#acknowledgements)
+1. [Who's Using Ruff?](#whos-using-ruff)
+1. [License](#license)
+
+## Getting Started<a id="getting-started"></a>
+
+For more, see the [documentation](https://docs.astral.sh/ruff/).
+
+### Installation
+
+Ruff is available as [`ruff`](https://pypi.org/project/ruff/) on PyPI.
+
+Invoke Ruff directly with [`uvx`](https://docs.astral.sh/uv/):
+
+```shell
+uvx ruff check # Lint all files in the current directory.
+uvx ruff format # Format all files in the current directory.
+```
+
+Or install Ruff with `uv` (recommended), `pip`, or `pipx`:
+
+```shell
+# With uv.
+uv tool install ruff@latest # Install Ruff globally.
+uv add --dev ruff # Or add Ruff to your project.
+
+# With pip.
+pip install ruff
+
+# With pipx.
+pipx install ruff
+```
+
+Starting with version `0.5.0`, Ruff can be installed with our standalone installers:
+
+```shell
+# On macOS and Linux.
+curl -LsSf https://astral.sh/ruff/install.sh | sh
+
+# On Windows.
+powershell -c "irm https://astral.sh/ruff/install.ps1 | iex"
+
+# For a specific version.
+curl -LsSf https://astral.sh/ruff/0.9.1/install.sh | sh
+powershell -c "irm https://astral.sh/ruff/0.9.1/install.ps1 | iex"
+```
+
+You can also install Ruff via [Homebrew](https://formulae.brew.sh/formula/ruff), [Conda](https://anaconda.org/conda-forge/ruff),
+and with [a variety of other package managers](https://docs.astral.sh/ruff/installation/).
+
+### Usage
+
+To run Ruff as a linter, try any of the following:
+
+```shell
+ruff check # Lint all files in the current directory (and any subdirectories).
+ruff check path/to/code/ # Lint all files in `/path/to/code` (and any subdirectories).
+ruff check path/to/code/*.py # Lint all `.py` files in `/path/to/code`.
+ruff check path/to/code/to/file.py # Lint `file.py`.
+ruff check @arguments.txt # Lint using an input file, treating its contents as newline-delimited command-line arguments.
+```
+
+Or, to run Ruff as a formatter:
+
+```shell
+ruff format # Format all files in the current directory (and any subdirectories).
+ruff format path/to/code/ # Format all files in `/path/to/code` (and any subdirectories).
+ruff format path/to/code/*.py # Format all `.py` files in `/path/to/code`.
+ruff format path/to/code/to/file.py # Format `file.py`.
+ruff format @arguments.txt # Format using an input file, treating its contents as newline-delimited command-line arguments.
+```
+
+Ruff can also be used as a [pre-commit](https://pre-commit.com/) hook via [`ruff-pre-commit`](https://github.com/astral-sh/ruff-pre-commit):
+
+```yaml
+- repo: https://github.com/astral-sh/ruff-pre-commit
+ # Ruff version.
+ rev: v0.9.1
+ hooks:
+ # Run the linter.
+ - id: ruff
+ args: [ --fix ]
+ # Run the formatter.
+ - id: ruff-format
+```
+
+Ruff can also be used as a [VS Code extension](https://github.com/astral-sh/ruff-vscode) or with [various other editors](https://docs.astral.sh/ruff/editors/setup).
+
+Ruff can also be used as a [GitHub Action](https://github.com/features/actions) via
+[`ruff-action`](https://github.com/astral-sh/ruff-action):
+
+```yaml
+name: Ruff
+on: [ push, pull_request ]
+jobs:
+ ruff:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ - uses: astral-sh/ruff-action@v3
+```
+
+### Configuration<a id="configuration"></a>
+
+Ruff can be configured through a `pyproject.toml`, `ruff.toml`, or `.ruff.toml` file (see:
+[_Configuration_](https://docs.astral.sh/ruff/configuration/), or [_Settings_](https://docs.astral.sh/ruff/settings/)
+for a complete list of all configuration options).
+
+If left unspecified, Ruff's default configuration is equivalent to the following `ruff.toml` file:
+
+```toml
+# Exclude a variety of commonly ignored directories.
+exclude = [
+ ".bzr",
+ ".direnv",
+ ".eggs",
+ ".git",
+ ".git-rewrite",
+ ".hg",
+ ".ipynb_checkpoints",
+ ".mypy_cache",
+ ".nox",
+ ".pants.d",
+ ".pyenv",
+ ".pytest_cache",
+ ".pytype",
+ ".ruff_cache",
+ ".svn",
+ ".tox",
+ ".venv",
+ ".vscode",
+ "__pypackages__",
+ "_build",
+ "buck-out",
+ "build",
+ "dist",
+ "node_modules",
+ "site-packages",
+ "venv",
+]
+
+# Same as Black.
+line-length = 88
+indent-width = 4
+
+# Assume Python 3.9
+target-version = "py39"
+
+[lint]
+# Enable Pyflakes (`F`) and a subset of the pycodestyle (`E`) codes by default.
+select = ["E4", "E7", "E9", "F"]
+ignore = []
+
+# Allow fix for all enabled rules (when `--fix`) is provided.
+fixable = ["ALL"]
+unfixable = []
+
+# Allow unused variables when underscore-prefixed.
+dummy-variable-rgx = "^(_+|(_+[a-zA-Z0-9_]*[a-zA-Z0-9]+?))$"
+
+[format]
+# Like Black, use double quotes for strings.
+quote-style = "double"
+
+# Like Black, indent with spaces, rather than tabs.
+indent-style = "space"
+
+# Like Black, respect magic trailing commas.
+skip-magic-trailing-comma = false
+
+# Like Black, automatically detect the appropriate line ending.
+line-ending = "auto"
+```
+
+Note that, in a `pyproject.toml`, each section header should be prefixed with `tool.ruff`. For
+example, `[lint]` should be replaced with `[tool.ruff.lint]`.
+
+Some configuration options can be provided via dedicated command-line arguments, such as those
+related to rule enablement and disablement, file discovery, and logging level:
+
+```shell
+ruff check --select F401 --select F403 --quiet
+```
+
+The remaining configuration options can be provided through a catch-all `--config` argument:
+
+```shell
+ruff check --config "lint.per-file-ignores = {'some_file.py' = ['F841']}"
+```
+
+To opt in to the latest lint rules, formatter style changes, interface updates, and more, enable
+[preview mode](https://docs.astral.sh/ruff/rules/) by setting `preview = true` in your configuration
+file or passing `--preview` on the command line. Preview mode enables a collection of unstable
+features that may change prior to stabilization.
+
+See `ruff help` for more on Ruff's top-level commands, or `ruff help check` and `ruff help format`
+for more on the linting and formatting commands, respectively.
+
+## Rules<a id="rules"></a>
+
+<!-- Begin section: Rules -->
+
+**Ruff supports over 800 lint rules**, many of which are inspired by popular tools like Flake8,
+isort, pyupgrade, and others. Regardless of the rule's origin, Ruff re-implements every rule in
+Rust as a first-party feature.
+
+By default, Ruff enables Flake8's `F` rules, along with a subset of the `E` rules, omitting any
+stylistic rules that overlap with the use of a formatter, like `ruff format` or
+[Black](https://github.com/psf/black).
+
+If you're just getting started with Ruff, **the default rule set is a great place to start**: it
+catches a wide variety of common errors (like unused imports) with zero configuration.
+
+<!-- End section: Rules -->
+
+Beyond the defaults, Ruff re-implements some of the most popular Flake8 plugins and related code
+quality tools, including:
+
+- [autoflake](https://pypi.org/project/autoflake/)
+- [eradicate](https://pypi.org/project/eradicate/)
+- [flake8-2020](https://pypi.org/project/flake8-2020/)
+- [flake8-annotations](https://pypi.org/project/flake8-annotations/)
+- [flake8-async](https://pypi.org/project/flake8-async)
+- [flake8-bandit](https://pypi.org/project/flake8-bandit/) ([#1646](https://github.com/astral-sh/ruff/issues/1646))
+- [flake8-blind-except](https://pypi.org/project/flake8-blind-except/)
+- [flake8-boolean-trap](https://pypi.org/project/flake8-boolean-trap/)
+- [flake8-bugbear](https://pypi.org/project/flake8-bugbear/)
+- [flake8-builtins](https://pypi.org/project/flake8-builtins/)
+- [flake8-commas](https://pypi.org/project/flake8-commas/)
+- [flake8-comprehensions](https://pypi.org/project/flake8-comprehensions/)
+- [flake8-copyright](https://pypi.org/project/flake8-copyright/)
+- [flake8-datetimez](https://pypi.org/project/flake8-datetimez/)
+- [flake8-debugger](https://pypi.org/project/flake8-debugger/)
+- [flake8-django](https://pypi.org/project/flake8-django/)
+- [flake8-docstrings](https://pypi.org/project/flake8-docstrings/)
+- [flake8-eradicate](https://pypi.org/project/flake8-eradicate/)
+- [flake8-errmsg](https://pypi.org/project/flake8-errmsg/)
+- [flake8-executable](https://pypi.org/project/flake8-executable/)
+- [flake8-future-annotations](https://pypi.org/project/flake8-future-annotations/)
+- [flake8-gettext](https://pypi.org/project/flake8-gettext/)
+- [flake8-implicit-str-concat](https://pypi.org/project/flake8-implicit-str-concat/)
+- [flake8-import-conventions](https://github.com/joaopalmeiro/flake8-import-conventions)
+- [flake8-logging](https://pypi.org/project/flake8-logging/)
+- [flake8-logging-format](https://pypi.org/project/flake8-logging-format/)
+- [flake8-no-pep420](https://pypi.org/project/flake8-no-pep420)
+- [flake8-pie](https://pypi.org/project/flake8-pie/)
+- [flake8-print](https://pypi.org/project/flake8-print/)
+- [flake8-pyi](https://pypi.org/project/flake8-pyi/)
+- [flake8-pytest-style](https://pypi.org/project/flake8-pytest-style/)
+- [flake8-quotes](https://pypi.org/project/flake8-quotes/)
+- [flake8-raise](https://pypi.org/project/flake8-raise/)
+- [flake8-return](https://pypi.org/project/flake8-return/)
+- [flake8-self](https://pypi.org/project/flake8-self/)
+- [flake8-simplify](https://pypi.org/project/flake8-simplify/)
+- [flake8-slots](https://pypi.org/project/flake8-slots/)
+- [flake8-super](https://pypi.org/project/flake8-super/)
+- [flake8-tidy-imports](https://pypi.org/project/flake8-tidy-imports/)
+- [flake8-todos](https://pypi.org/project/flake8-todos/)
+- [flake8-type-checking](https://pypi.org/project/flake8-type-checking/)
+- [flake8-use-pathlib](https://pypi.org/project/flake8-use-pathlib/)
+- [flynt](https://pypi.org/project/flynt/) ([#2102](https://github.com/astral-sh/ruff/issues/2102))
+- [isort](https://pypi.org/project/isort/)
+- [mccabe](https://pypi.org/project/mccabe/)
+- [pandas-vet](https://pypi.org/project/pandas-vet/)
+- [pep8-naming](https://pypi.org/project/pep8-naming/)
+- [pydocstyle](https://pypi.org/project/pydocstyle/)
+- [pygrep-hooks](https://github.com/pre-commit/pygrep-hooks)
+- [pylint-airflow](https://pypi.org/project/pylint-airflow/)
+- [pyupgrade](https://pypi.org/project/pyupgrade/)
+- [tryceratops](https://pypi.org/project/tryceratops/)
+- [yesqa](https://pypi.org/project/yesqa/)
+
+For a complete enumeration of the supported rules, see [_Rules_](https://docs.astral.sh/ruff/rules/).
+
+## Contributing<a id="contributing"></a>
+
+Contributions are welcome and highly appreciated. To get started, check out the
+[**contributing guidelines**](https://docs.astral.sh/ruff/contributing/).
+
+You can also join us on [**Discord**](https://discord.com/invite/astral-sh).
+
+## Support<a id="support"></a>
+
+Having trouble? Check out the existing issues on [**GitHub**](https://github.com/astral-sh/ruff/issues),
+or feel free to [**open a new one**](https://github.com/astral-sh/ruff/issues/new).
+
+You can also ask for help on [**Discord**](https://discord.com/invite/astral-sh).
+
+## Acknowledgements<a id="acknowledgements"></a>
+
+Ruff's linter draws on both the APIs and implementation details of many other
+tools in the Python ecosystem, especially [Flake8](https://github.com/PyCQA/flake8), [Pyflakes](https://github.com/PyCQA/pyflakes),
+[pycodestyle](https://github.com/PyCQA/pycodestyle), [pydocstyle](https://github.com/PyCQA/pydocstyle),
+[pyupgrade](https://github.com/asottile/pyupgrade), and [isort](https://github.com/PyCQA/isort).
+
+In some cases, Ruff includes a "direct" Rust port of the corresponding tool.
+We're grateful to the maintainers of these tools for their work, and for all
+the value they've provided to the Python community.
+
+Ruff's formatter is built on a fork of Rome's [`rome_formatter`](https://github.com/rome/tools/tree/main/crates/rome_formatter),
+and again draws on both API and implementation details from [Rome](https://github.com/rome/tools),
+[Prettier](https://github.com/prettier/prettier), and [Black](https://github.com/psf/black).
+
+Ruff's import resolver is based on the import resolution algorithm from [Pyright](https://github.com/microsoft/pyright).
+
+Ruff is also influenced by a number of tools outside the Python ecosystem, like
+[Clippy](https://github.com/rust-lang/rust-clippy) and [ESLint](https://github.com/eslint/eslint).
+
+Ruff is the beneficiary of a large number of [contributors](https://github.com/astral-sh/ruff/graphs/contributors).
+
+Ruff is released under the MIT license.
+
+## Who's Using Ruff?<a id="whos-using-ruff"></a>
+
+Ruff is used by a number of major open-source projects and companies, including:
+
+- [Albumentations](https://github.com/albumentations-team/albumentations)
+- Amazon ([AWS SAM](https://github.com/aws/serverless-application-model))
+- Anthropic ([Python SDK](https://github.com/anthropics/anthropic-sdk-python))
+- [Apache Airflow](https://github.com/apache/airflow)
+- AstraZeneca ([Magnus](https://github.com/AstraZeneca/magnus-core))
+- [Babel](https://github.com/python-babel/babel)
+- Benchling ([Refac](https://github.com/benchling/refac))
+- [Bokeh](https://github.com/bokeh/bokeh)
+- CrowdCent ([NumerBlox](https://github.com/crowdcent/numerblox)) <!-- typos: ignore -->
+- [Cryptography (PyCA)](https://github.com/pyca/cryptography)
+- CERN ([Indico](https://getindico.io/))
+- [DVC](https://github.com/iterative/dvc)
+- [Dagger](https://github.com/dagger/dagger)
+- [Dagster](https://github.com/dagster-io/dagster)
+- Databricks ([MLflow](https://github.com/mlflow/mlflow))
+- [Dify](https://github.com/langgenius/dify)
+- [FastAPI](https://github.com/tiangolo/fastapi)
+- [Godot](https://github.com/godotengine/godot)
+- [Gradio](https://github.com/gradio-app/gradio)
+- [Great Expectations](https://github.com/great-expectations/great_expectations)
+- [HTTPX](https://github.com/encode/httpx)
+- [Hatch](https://github.com/pypa/hatch)
+- [Home Assistant](https://github.com/home-assistant/core)
+- Hugging Face ([Transformers](https://github.com/huggingface/transformers),
+ [Datasets](https://github.com/huggingface/datasets),
+ [Diffusers](https://github.com/huggingface/diffusers))
+- IBM ([Qiskit](https://github.com/Qiskit/qiskit))
+- ING Bank ([popmon](https://github.com/ing-bank/popmon), [probatus](https://github.com/ing-bank/probatus))
+- [Ibis](https://github.com/ibis-project/ibis)
+- [ivy](https://github.com/unifyai/ivy)
+- [Jupyter](https://github.com/jupyter-server/jupyter_server)
+- [Kraken Tech](https://kraken.tech/)
+- [LangChain](https://github.com/hwchase17/langchain)
+- [Litestar](https://litestar.dev/)
+- [LlamaIndex](https://github.com/jerryjliu/llama_index)
+- Matrix ([Synapse](https://github.com/matrix-org/synapse))
+- [MegaLinter](https://github.com/oxsecurity/megalinter)
+- Meltano ([Meltano CLI](https://github.com/meltano/meltano), [Singer SDK](https://github.com/meltano/sdk))
+- Microsoft ([Semantic Kernel](https://github.com/microsoft/semantic-kernel),
+ [ONNX Runtime](https://github.com/microsoft/onnxruntime),
+ [LightGBM](https://github.com/microsoft/LightGBM))
+- Modern Treasury ([Python SDK](https://github.com/Modern-Treasury/modern-treasury-python))
+- Mozilla ([Firefox](https://github.com/mozilla/gecko-dev))
+- [Mypy](https://github.com/python/mypy)
+- [Nautobot](https://github.com/nautobot/nautobot)
+- Netflix ([Dispatch](https://github.com/Netflix/dispatch))
+- [Neon](https://github.com/neondatabase/neon)
+- [Nokia](https://nokia.com/)
+- [NoneBot](https://github.com/nonebot/nonebot2)
+- [NumPyro](https://github.com/pyro-ppl/numpyro)
+- [ONNX](https://github.com/onnx/onnx)
+- [OpenBB](https://github.com/OpenBB-finance/OpenBBTerminal)
+- [Open Wine Components](https://github.com/Open-Wine-Components/umu-launcher)
+- [PDM](https://github.com/pdm-project/pdm)
+- [PaddlePaddle](https://github.com/PaddlePaddle/Paddle)
+- [Pandas](https://github.com/pandas-dev/pandas)
+- [Pillow](https://github.com/python-pillow/Pillow)
+- [Poetry](https://github.com/python-poetry/poetry)
+- [Polars](https://github.com/pola-rs/polars)
+- [PostHog](https://github.com/PostHog/posthog)
+- Prefect ([Python SDK](https://github.com/PrefectHQ/prefect), [Marvin](https://github.com/PrefectHQ/marvin))
+- [PyInstaller](https://github.com/pyinstaller/pyinstaller)
+- [PyMC](https://github.com/pymc-devs/pymc/)
+- [PyMC-Marketing](https://github.com/pymc-labs/pymc-marketing)
+- [pytest](https://github.com/pytest-dev/pytest)
+- [PyTorch](https://github.com/pytorch/pytorch)
+- [Pydantic](https://github.com/pydantic/pydantic)
+- [Pylint](https://github.com/PyCQA/pylint)
+- [PyVista](https://github.com/pyvista/pyvista)
+- [Reflex](https://github.com/reflex-dev/reflex)
+- [River](https://github.com/online-ml/river)
+- [Rippling](https://rippling.com)
+- [Robyn](https://github.com/sansyrox/robyn)
+- [Saleor](https://github.com/saleor/saleor)
+- Scale AI ([Launch SDK](https://github.com/scaleapi/launch-python-client))
+- [SciPy](https://github.com/scipy/scipy)
+- Snowflake ([SnowCLI](https://github.com/Snowflake-Labs/snowcli))
+- [Sphinx](https://github.com/sphinx-doc/sphinx)
+- [Stable Baselines3](https://github.com/DLR-RM/stable-baselines3)
+- [Starlette](https://github.com/encode/starlette)
+- [Streamlit](https://github.com/streamlit/streamlit)
+- [The Algorithms](https://github.com/TheAlgorithms/Python)
+- [Vega-Altair](https://github.com/altair-viz/altair)
+- WordPress ([Openverse](https://github.com/WordPress/openverse))
+- [ZenML](https://github.com/zenml-io/zenml)
+- [Zulip](https://github.com/zulip/zulip)
+- [build (PyPA)](https://github.com/pypa/build)
+- [cibuildwheel (PyPA)](https://github.com/pypa/cibuildwheel)
+- [delta-rs](https://github.com/delta-io/delta-rs)
+- [featuretools](https://github.com/alteryx/featuretools)
+- [meson-python](https://github.com/mesonbuild/meson-python)
+- [nox](https://github.com/wntrblm/nox)
+- [pip](https://github.com/pypa/pip)
+
+### Show Your Support
+
+If you're using Ruff, consider adding the Ruff badge to your project's `README.md`:
+
+```md
+[](https://github.com/astral-sh/ruff)
+```
+
+...or `README.rst`:
+
+```rst
+.. image:: https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json
+ :target: https://github.com/astral-sh/ruff
+ :alt: Ruff
+```
+
+...or, as HTML:
+
+```html
+<a href="https://github.com/astral-sh/ruff"><img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json" alt="Ruff" style="max-width:100%;"></a>
+```
+
+## License<a id="license"></a>
+
+This repository is licensed under the [MIT License](https://github.com/astral-sh/ruff/blob/main/LICENSE)
+
+<div align="center">
+ <a target="_blank" href="https://astral.sh" style="background:none">
+ <img src="https://raw.githubusercontent.com/astral-sh/ruff/main/assets/svg/Astral.svg" alt="Made by Astral">
+ </a>
+</div>
+
diff --git a/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/RECORD b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/RECORD
new file mode 100644
index 000000000..fdafa6324
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/RECORD
@@ -0,0 +1,11 @@
+../../Scripts/ruff.exe,sha256=a3BQSlZJpsAGgkATa9C3lfqWWdvupVFd5xYJExHmFaM,27229696
+ruff-0.9.1.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+ruff-0.9.1.dist-info/METADATA,sha256=b090fjc7c_QZiBJnLiV-z7ZPFwiBS0JmEt4tiW7nxwk,26239
+ruff-0.9.1.dist-info/RECORD,,
+ruff-0.9.1.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+ruff-0.9.1.dist-info/WHEEL,sha256=0Ei6eJSnFKalVc4j1oeJi3sd1RljjNRCmAVYi5kThzI,93
+ruff-0.9.1.dist-info/licenses/LICENSE,sha256=MgnAt_tyV8BbFkM3KMHpdLrEAAD-8XG46eifCVYjyVQ,69789
+ruff/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+ruff/__main__.py,sha256=EL9zQrK6OoDEC2ITjWg6VeyDXD3LC5OTzXpY_ooV_WU,2921
+ruff/__pycache__/__init__.cpython-312.pyc,,
+ruff/__pycache__/__main__.cpython-312.pyc,,
diff --git a/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/REQUESTED b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/REQUESTED
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/WHEEL
new file mode 100644
index 000000000..c1bab3b2d
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/WHEEL
@@ -0,0 +1,4 @@
+Wheel-Version: 1.0
+Generator: maturin (1.8.1)
+Root-Is-Purelib: false
+Tag: py3-none-win_amd64
diff --git a/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/licenses/LICENSE b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/licenses/LICENSE
new file mode 100644
index 000000000..f5c3b02be
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/ruff-0.9.1.dist-info/licenses/LICENSE
@@ -0,0 +1,1398 @@
+MIT License
+
+Copyright (c) 2022 Charles Marsh
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
+
+end of terms and conditions
+
+The externally maintained libraries from which parts of the Software is derived
+are:
+
+- flake8-comprehensions, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2017 Adam Johnson
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-no-pep420, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2020 Adam Johnson
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-tidy-imports, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2017 Adam Johnson
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-return, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2019 Afonasev Evgeniy
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-2020, licensed as follows:
+ """
+ Copyright (c) 2019 Anthony Sottile
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- pyupgrade, licensed as follows:
+ """
+ Copyright (c) 2017 Anthony Sottile
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- flake8-blind-except, licensed as follows:
+ """
+ The MIT License (MIT)
+
+ Copyright (c) 2014 Elijah Andrews
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy of
+ this software and associated documentation files (the "Software"), to deal in
+ the Software without restriction, including without limitation the rights to
+ use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
+ the Software, and to permit persons to whom the Software is furnished to do so,
+ subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
+ FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
+ COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
+ IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
+ CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ """
+
+- flake8-gettext, licensed as follows:
+ """
+ BSD Zero Clause License
+
+ Permission to use, copy, modify, and/or distribute this software for any purpose with or without fee is hereby granted.
+
+ THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
+ """
+
+- flake8-implicit-str-concat, licensed as follows:
+ """
+ The MIT License (MIT)
+
+ Copyright (c) 2019 Dylan Turner
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- flake8-debugger, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2016 Joseph Kahn
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-pyi, licensed as follows:
+ """
+ The MIT License (MIT)
+
+ Copyright (c) 2016 Łukasz Langa
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-print, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2016 Joseph Kahn
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-import-conventions, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2021 João Palmeiro
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-simplify, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2020 Martin Thoma
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-slots, licensed as follows:
+ """
+ Copyright (c) 2021 Dominic Davis-Foster
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+ EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+ IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
+ DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
+ OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE
+ OR OTHER DEALINGS IN THE SOFTWARE.
+ """
+
+- flake8-todos, licensed as follows:
+ """
+ Copyright (c) 2019 EclecticIQ. All rights reserved.
+ Copyright (c) 2020 Gram <gram@orsinium.dev>. All rights reserved.
+
+ Redistribution and use in source and binary forms, with or without
+ modification, are permitted provided that the following conditions are met:
+
+ 1. Redistributions of source code must retain the above copyright notice,
+ this list of conditions and the following disclaimer.
+
+ 2. Redistributions in binary form must reproduce the above copyright
+ notice, this list of conditions and the following disclaimer in the
+ documentation and/or other materials provided with the distribution.
+
+ 3. Neither the name of the copyright holder nor the names of its
+ contributors may be used to endorse or promote products derived from this
+ software without specific prior written permission.
+
+ THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+ AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+ IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+ DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+ FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+ DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+ SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+ CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+ OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+ OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+ """
+
+- flake8-unused-arguments, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2019 Nathan Hoad
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- pygrep-hooks, licensed as follows:
+ """
+ Copyright (c) 2018 Anthony Sottile
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- autoflake, licensed as follows:
+ """
+ Copyright (C) 2012-2018 Steven Myint
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy of
+ this software and associated documentation files (the "Software"), to deal in
+ the Software without restriction, including without limitation the rights to
+ use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
+ of the Software, and to permit persons to whom the Software is furnished to do
+ so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- autotyping, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2023 Jelle Zijlstra
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- Flake8, licensed as follows:
+ """
+ == Flake8 License (MIT) ==
+
+ Copyright (C) 2011-2013 Tarek Ziade <tarek@ziade.org>
+ Copyright (C) 2012-2016 Ian Cordasco <graffatcolmingov@gmail.com>
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy of
+ this software and associated documentation files (the "Software"), to deal in
+ the Software without restriction, including without limitation the rights to
+ use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
+ of the Software, and to permit persons to whom the Software is furnished to do
+ so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-bugbear, licensed as follows:
+ """
+ The MIT License (MIT)
+
+ Copyright (c) 2016 Łukasz Langa
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-commas, licensed as follows:
+ """
+ The MIT License (MIT)
+
+ Copyright (c) 2017 Thomas Grainger.
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+
+
+ Portions of this flake8-commas Software may utilize the following
+ copyrighted material, the use of which is hereby acknowledged.
+
+ Original flake8-commas: https://github.com/trevorcreech/flake8-commas/commit/e8563b71b1d5442e102c8734c11cb5202284293d
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- flynt, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2019-2022 Ilya Kamenshchikov
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- isort, licensed as follows:
+ """
+ The MIT License (MIT)
+
+ Copyright (c) 2013 Timothy Edmund Crosley
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- pep8-naming, licensed as follows:
+ """
+ Copyright © 2013 Florent Xicluna <florent.xicluna@gmail.com>
+
+ Licensed under the terms of the Expat License
+
+ Permission is hereby granted, free of charge, to any person
+ obtaining a copy of this software and associated documentation files
+ (the "Software"), to deal in the Software without restriction,
+ including without limitation the rights to use, copy, modify, merge,
+ publish, distribute, sublicense, and/or sell copies of the Software,
+ and to permit persons to whom the Software is furnished to do so,
+ subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be
+ included in all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+ EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+ NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS
+ BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN
+ ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
+ CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- pycodestyle, licensed as follows:
+ """
+ Copyright © 2006-2009 Johann C. Rocholl <johann@rocholl.net>
+ Copyright © 2009-2014 Florent Xicluna <florent.xicluna@gmail.com>
+ Copyright © 2014-2020 Ian Lee <IanLee1521@gmail.com>
+
+ Licensed under the terms of the Expat License
+
+ Permission is hereby granted, free of charge, to any person
+ obtaining a copy of this software and associated documentation files
+ (the "Software"), to deal in the Software without restriction,
+ including without limitation the rights to use, copy, modify, merge,
+ publish, distribute, sublicense, and/or sell copies of the Software,
+ and to permit persons to whom the Software is furnished to do so,
+ subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be
+ included in all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+ EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+ NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS
+ BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN
+ ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
+ CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- pydocstyle, licensed as follows:
+ """
+ Copyright (c) 2012 GreenSteam, <http://greensteam.dk/>
+
+ Copyright (c) 2014-2020 Amir Rachum, <http://amir.rachum.com/>
+
+ Copyright (c) 2020 Sambhav Kothari, <https://github.com/samj1912>
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy of
+ this software and associated documentation files (the "Software"), to deal in
+ the Software without restriction, including without limitation the rights to
+ use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
+ of the Software, and to permit persons to whom the Software is furnished to do
+ so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- Pyflakes, licensed as follows:
+ """
+ Copyright 2005-2011 Divmod, Inc.
+ Copyright 2013-2014 Florent Xicluna
+
+ Permission is hereby granted, free of charge, to any person obtaining
+ a copy of this software and associated documentation files (the
+ "Software"), to deal in the Software without restriction, including
+ without limitation the rights to use, copy, modify, merge, publish,
+ distribute, sublicense, and/or sell copies of the Software, and to
+ permit persons to whom the Software is furnished to do so, subject to
+ the following conditions:
+
+ The above copyright notice and this permission notice shall be
+ included in all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+ EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+ MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+ NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
+ LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+ OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
+ WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
+ """
+
+- flake8-use-pathlib, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2021 Rodolphe Pelloux-Prayer
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- RustPython, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2020 RustPython Team
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-annotations, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2019 - Present S. Co1
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-async, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2022 Cooper Lees
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-type-checking, licensed as follows:
+ """
+ Copyright (c) 2021, Sondre Lillebø Gundersen
+ All rights reserved.
+
+ Redistribution and use in source and binary forms, with or without
+ modification, are permitted provided that the following conditions are met:
+
+ * Redistributions of source code must retain the above copyright notice, this
+ list of conditions and the following disclaimer.
+
+ * Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+ * Neither the name of pytest-{{ cookiecutter.plugin_name }} nor the names of its
+ contributors may be used to endorse or promote products derived from
+ this software without specific prior written permission.
+
+ THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+ AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+ IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+ DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+ FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+ DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+ SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+ CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+ OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+ OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+ """
+
+- flake8-bandit, licensed as follows:
+ """
+ Copyright (c) 2017 Tyler Wince
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- flake8-eradicate, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2018 Nikita Sobolev
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-quotes, licensed as follows:
+ """
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in
+ all copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+ THE SOFTWARE.
+ """
+
+- flake8-logging-format, licensed as follows:
+ """
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "{}"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright {yyyy} {name of copyright owner}
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+ """
+
+- flake8-raise, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2020 Jon Dufresne
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-self, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2023 Korijn van Golen
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-django, licensed under the GPL license.
+
+- perflint, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2022 Anthony Shaw
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-logging, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2023 Adam Johnson
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- flake8-trio, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2022 Zac Hatfield-Dodds
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- Pyright, licensed as follows:
+ """
+ MIT License
+
+ Pyright - A static type checker for the Python language
+ Copyright (c) Microsoft Corporation. All rights reserved.
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE
+ """
+
+- rust-analyzer/text-size, licensed under the MIT license:
+ """
+ Permission is hereby granted, free of charge, to any
+ person obtaining a copy of this software and associated
+ documentation files (the "Software"), to deal in the
+ Software without restriction, including without
+ limitation the rights to use, copy, modify, merge,
+ publish, distribute, sublicense, and/or sell copies of
+ the Software, and to permit persons to whom the Software
+ is furnished to do so, subject to the following
+ conditions:
+
+ The above copyright notice and this permission notice
+ shall be included in all copies or substantial portions
+ of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF
+ ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED
+ TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
+ PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT
+ SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
+ CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+ OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR
+ IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
+ DEALINGS IN THE SOFTWARE.
+ """
+
+- rome/tools, licensed under the MIT license:
+ """
+ MIT License
+
+ Copyright (c) Rome Tools, Inc. and its affiliates.
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
+
+- pydoclint, licensed as follows:
+ """
+ MIT License
+
+ Copyright (c) 2023 jsh9
+
+ Permission is hereby granted, free of charge, to any person obtaining a copy
+ of this software and associated documentation files (the "Software"), to deal
+ in the Software without restriction, including without limitation the rights
+ to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ copies of the Software, and to permit persons to whom the Software is
+ furnished to do so, subject to the following conditions:
+
+ The above copyright notice and this permission notice shall be included in all
+ copies or substantial portions of the Software.
+
+ THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ SOFTWARE.
+ """
diff --git a/solutions/.venv/Lib/site-packages/ruff/__init__.py b/solutions/.venv/Lib/site-packages/ruff/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/ruff/__main__.py b/solutions/.venv/Lib/site-packages/ruff/__main__.py
new file mode 100644
index 000000000..21fa9a20f
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/ruff/__main__.py
@@ -0,0 +1,88 @@
+from __future__ import annotations
+
+import os
+import sys
+import sysconfig
+
+
+def find_ruff_bin() -> str:
+ """Return the ruff binary path."""
+
+ ruff_exe = "ruff" + sysconfig.get_config_var("EXE")
+
+ scripts_path = os.path.join(sysconfig.get_path("scripts"), ruff_exe)
+ if os.path.isfile(scripts_path):
+ return scripts_path
+
+ if sys.version_info >= (3, 10):
+ user_scheme = sysconfig.get_preferred_scheme("user")
+ elif os.name == "nt":
+ user_scheme = "nt_user"
+ elif sys.platform == "darwin" and sys._framework:
+ user_scheme = "osx_framework_user"
+ else:
+ user_scheme = "posix_user"
+
+ user_path = os.path.join(
+ sysconfig.get_path("scripts", scheme=user_scheme), ruff_exe
+ )
+ if os.path.isfile(user_path):
+ return user_path
+
+ # Search in `bin` adjacent to package root (as created by `pip install --target`).
+ pkg_root = os.path.dirname(os.path.dirname(__file__))
+ target_path = os.path.join(pkg_root, "bin", ruff_exe)
+ if os.path.isfile(target_path):
+ return target_path
+
+ # Search for pip-specific build environments.
+ #
+ # Expect to find ruff in <prefix>/pip-build-env-<rand>/overlay/bin/ruff
+ # Expect to find a "normal" folder at <prefix>/pip-build-env-<rand>/normal
+ #
+ # See: https://github.com/pypa/pip/blob/102d8187a1f5a4cd5de7a549fd8a9af34e89a54f/src/pip/_internal/build_env.py#L87
+ paths = os.environ.get("PATH", "").split(os.pathsep)
+ if len(paths) >= 2:
+
+ def get_last_three_path_parts(path: str) -> list[str]:
+ """Return a list of up to the last three parts of a path."""
+ parts = []
+
+ while len(parts) < 3:
+ head, tail = os.path.split(path)
+ if tail or head != path:
+ parts.append(tail)
+ path = head
+ else:
+ parts.append(path)
+ break
+
+ return parts
+
+ maybe_overlay = get_last_three_path_parts(paths[0])
+ maybe_normal = get_last_three_path_parts(paths[1])
+ if (
+ len(maybe_normal) >= 3
+ and maybe_normal[-1].startswith("pip-build-env-")
+ and maybe_normal[-2] == "normal"
+ and len(maybe_overlay) >= 3
+ and maybe_overlay[-1].startswith("pip-build-env-")
+ and maybe_overlay[-2] == "overlay"
+ ):
+ # The overlay must contain the ruff binary.
+ candidate = os.path.join(paths[0], ruff_exe)
+ if os.path.isfile(candidate):
+ return candidate
+
+ raise FileNotFoundError(scripts_path)
+
+
+if __name__ == "__main__":
+ ruff = os.fsdecode(find_ruff_bin())
+ if sys.platform == "win32":
+ import subprocess
+
+ completed_process = subprocess.run([ruff, *sys.argv[1:]])
+ sys.exit(completed_process.returncode)
+ else:
+ os.execvp(ruff, [ruff, *sys.argv[1:]])
diff --git a/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/INSTALLER b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/INSTALLER
new file mode 100644
index 000000000..a1b589e38
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/LICENSE b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/LICENSE
new file mode 100644
index 000000000..44cf2b30e
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/LICENSE
@@ -0,0 +1,20 @@
+Copyright (c) 2018 Sébastien Eustace
+
+Permission is hereby granted, free of charge, to any person obtaining
+a copy of this software and associated documentation files (the
+"Software"), to deal in the Software without restriction, including
+without limitation the rights to use, copy, modify, merge, publish,
+distribute, sublicense, and/or sell copies of the Software, and to
+permit persons to whom the Software is furnished to do so, subject to
+the following conditions:
+
+The above copyright notice and this permission notice shall be
+included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
+LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
+WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/METADATA b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/METADATA
new file mode 100644
index 000000000..3f74211b6
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/METADATA
@@ -0,0 +1,70 @@
+Metadata-Version: 2.1
+Name: tomlkit
+Version: 0.13.2
+Summary: Style preserving TOML library
+Home-page: https://github.com/sdispater/tomlkit
+License: MIT
+Author: Sébastien Eustace
+Author-email: sebastien@eustace.io
+Requires-Python: >=3.8
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Programming Language :: Python :: 3.11
+Classifier: Programming Language :: Python :: 3.12
+Project-URL: Repository, https://github.com/sdispater/tomlkit
+Description-Content-Type: text/markdown
+
+[github_release]: https://img.shields.io/github/release/sdispater/tomlkit.svg?logo=github&logoColor=white
+[pypi_version]: https://img.shields.io/pypi/v/tomlkit.svg?logo=python&logoColor=white
+[python_versions]: https://img.shields.io/pypi/pyversions/tomlkit.svg?logo=python&logoColor=white
+[github_license]: https://img.shields.io/github/license/sdispater/tomlkit.svg?logo=github&logoColor=white
+[github_action]: https://github.com/sdispater/tomlkit/actions/workflows/tests.yml/badge.svg
+
+[![GitHub Release][github_release]](https://github.com/sdispater/tomlkit/releases/)
+[![PyPI Version][pypi_version]](https://pypi.org/project/tomlkit/)
+[![Python Versions][python_versions]](https://pypi.org/project/tomlkit/)
+[![License][github_license]](https://github.com/sdispater/tomlkit/blob/master/LICENSE)
+<br>
+[![Tests][github_action]](https://github.com/sdispater/tomlkit/actions/workflows/tests.yml)
+
+# TOML Kit - Style-preserving TOML library for Python
+
+TOML Kit is a **1.0.0-compliant** [TOML](https://toml.io/) library.
+
+It includes a parser that preserves all comments, indentations, whitespace and internal element ordering,
+and makes them accessible and editable via an intuitive API.
+
+You can also create new TOML documents from scratch using the provided helpers.
+
+Part of the implementation has been adapted, improved and fixed from [Molten](https://github.com/LeopoldArkham/Molten).
+
+## Usage
+
+See the [documentation](https://tomlkit.readthedocs.io/) for more information.
+
+## Installation
+
+If you are using [Poetry](https://poetry.eustace.io),
+add `tomlkit` to your `pyproject.toml` file by using:
+
+```bash
+poetry add tomlkit
+```
+
+If not, you can use `pip`:
+
+```bash
+pip install tomlkit
+```
+
+## Running tests
+
+Please clone the repo with submodules with the following command
+`git clone --recurse-submodules https://github.com/sdispater/tomlkit.git`.
+We need the submodule - `toml-test` for running the tests.
+
+You can run the tests with `poetry run pytest -q tests`
+
diff --git a/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/RECORD b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/RECORD
new file mode 100644
index 000000000..b02213d7c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/RECORD
@@ -0,0 +1,32 @@
+tomlkit-0.13.2.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+tomlkit-0.13.2.dist-info/LICENSE,sha256=8vm0YLpxnaZiat0mTTeC8nWk_3qrZ3vtoIszCRHiOts,1062
+tomlkit-0.13.2.dist-info/METADATA,sha256=O7-SDziwqmggbN-pKWf4rRLVMk5NbC6LeunlqFHITGk,2668
+tomlkit-0.13.2.dist-info/RECORD,,
+tomlkit-0.13.2.dist-info/WHEEL,sha256=sP946D7jFCHeNz5Iq4fL4Lu-PrWrFsgfLXbbkciIZwg,88
+tomlkit/__init__.py,sha256=255jILi1FC2a1kEdynuZoqKosXQjkf7-GN1MUJjCCZk,1282
+tomlkit/__pycache__/__init__.cpython-312.pyc,,
+tomlkit/__pycache__/_compat.cpython-312.pyc,,
+tomlkit/__pycache__/_types.cpython-312.pyc,,
+tomlkit/__pycache__/_utils.cpython-312.pyc,,
+tomlkit/__pycache__/api.cpython-312.pyc,,
+tomlkit/__pycache__/container.cpython-312.pyc,,
+tomlkit/__pycache__/exceptions.cpython-312.pyc,,
+tomlkit/__pycache__/items.cpython-312.pyc,,
+tomlkit/__pycache__/parser.cpython-312.pyc,,
+tomlkit/__pycache__/source.cpython-312.pyc,,
+tomlkit/__pycache__/toml_char.cpython-312.pyc,,
+tomlkit/__pycache__/toml_document.cpython-312.pyc,,
+tomlkit/__pycache__/toml_file.cpython-312.pyc,,
+tomlkit/_compat.py,sha256=gp7P7qNh0yY1dg0wyjiCDbVwFTdUo7p0QwjV4T3Funs,513
+tomlkit/_types.py,sha256=42ht2m-_pJPvQ_uMKMIJf4KL6F9N0NoDa0fymfTeIC4,2619
+tomlkit/_utils.py,sha256=m4OyWq9nw5MGabHhQKTIu1YtUD8SVJyoTImHTN6L7Yc,4089
+tomlkit/api.py,sha256=DsY3yS2rPZN0BdLytZ-hnbAHmaNfT5f8X6B01KrPDso,7763
+tomlkit/container.py,sha256=T8FtBLDL9HXkg1D4z3QOvT_pMIyk17F24qHuaF1XNW4,29470
+tomlkit/exceptions.py,sha256=e-0iKjv-u2ngE6G6XMOxaoBNnKBfPNjDLmaw4YDHpoU,5703
+tomlkit/items.py,sha256=DOB6Sf0y0hZTaUgoMQAmyt6sUbmNMoM-bDBIlliQ2lA,53543
+tomlkit/parser.py,sha256=INQ9Cbmmwq6fHVWZa73jTQXi0XtiLckldT6zKY5Jt4w,37935
+tomlkit/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+tomlkit/source.py,sha256=Nith7mmPmhTf5dMSRc41bY9cuIRR_4CoqOjC-fxzfCo,4835
+tomlkit/toml_char.py,sha256=w3sQZ0dolZ1qjZ2Rxj_svvlpRNNGB_fjfBcYD0gFnDs,1291
+tomlkit/toml_document.py,sha256=OCTkWXd3P58EZT4SD8_ddc1YpkMaqtlS5_stHTBmMOI,110
+tomlkit/toml_file.py,sha256=4gVZvvs_Q1_soWaVxBo80rRzny849boXt2LzdMXQ04I,1599
diff --git a/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/WHEEL b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/WHEEL
new file mode 100644
index 000000000..d73ccaae8
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit-0.13.2.dist-info/WHEEL
@@ -0,0 +1,4 @@
+Wheel-Version: 1.0
+Generator: poetry-core 1.9.0
+Root-Is-Purelib: true
+Tag: py3-none-any
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/__init__.py b/solutions/.venv/Lib/site-packages/tomlkit/__init__.py
new file mode 100644
index 000000000..fbbab82fa
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/__init__.py
@@ -0,0 +1,59 @@
+from tomlkit.api import TOMLDocument
+from tomlkit.api import aot
+from tomlkit.api import array
+from tomlkit.api import boolean
+from tomlkit.api import comment
+from tomlkit.api import date
+from tomlkit.api import datetime
+from tomlkit.api import document
+from tomlkit.api import dump
+from tomlkit.api import dumps
+from tomlkit.api import float_
+from tomlkit.api import inline_table
+from tomlkit.api import integer
+from tomlkit.api import item
+from tomlkit.api import key
+from tomlkit.api import key_value
+from tomlkit.api import load
+from tomlkit.api import loads
+from tomlkit.api import nl
+from tomlkit.api import parse
+from tomlkit.api import register_encoder
+from tomlkit.api import string
+from tomlkit.api import table
+from tomlkit.api import time
+from tomlkit.api import unregister_encoder
+from tomlkit.api import value
+from tomlkit.api import ws
+
+
+__version__ = "0.13.2"
+__all__ = [
+ "aot",
+ "array",
+ "boolean",
+ "comment",
+ "date",
+ "datetime",
+ "document",
+ "dump",
+ "dumps",
+ "float_",
+ "inline_table",
+ "integer",
+ "item",
+ "key",
+ "key_value",
+ "load",
+ "loads",
+ "nl",
+ "parse",
+ "string",
+ "table",
+ "time",
+ "TOMLDocument",
+ "value",
+ "ws",
+ "register_encoder",
+ "unregister_encoder",
+]
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/_compat.py b/solutions/.venv/Lib/site-packages/tomlkit/_compat.py
new file mode 100644
index 000000000..8e76b7fde
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/_compat.py
@@ -0,0 +1,22 @@
+from __future__ import annotations
+
+import contextlib
+import sys
+
+from typing import Any
+
+
+PY38 = sys.version_info >= (3, 8)
+
+
+def decode(string: Any, encodings: list[str] | None = None):
+ if not isinstance(string, bytes):
+ return string
+
+ encodings = encodings or ["utf-8", "latin1", "ascii"]
+
+ for encoding in encodings:
+ with contextlib.suppress(UnicodeEncodeError, UnicodeDecodeError):
+ return string.decode(encoding)
+
+ return string.decode(encodings[0], errors="ignore")
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/_types.py b/solutions/.venv/Lib/site-packages/tomlkit/_types.py
new file mode 100644
index 000000000..501bf4dca
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/_types.py
@@ -0,0 +1,82 @@
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+from typing import Any
+from typing import TypeVar
+
+
+WT = TypeVar("WT", bound="WrapperType")
+
+if TYPE_CHECKING: # pragma: no cover
+ # Define _CustomList and _CustomDict as a workaround for:
+ # https://github.com/python/mypy/issues/11427
+ #
+ # According to this issue, the typeshed contains a "lie"
+ # (it adds MutableSequence to the ancestry of list and MutableMapping to
+ # the ancestry of dict) which completely messes with the type inference for
+ # Table, InlineTable, Array and Container.
+ #
+ # Importing from builtins is preferred over simple assignment, see issues:
+ # https://github.com/python/mypy/issues/8715
+ # https://github.com/python/mypy/issues/10068
+ from builtins import dict as _CustomDict
+ from builtins import float as _CustomFloat
+ from builtins import int as _CustomInt
+ from builtins import list as _CustomList
+ from typing import Callable
+ from typing import Concatenate
+ from typing import ParamSpec
+ from typing import Protocol
+
+ P = ParamSpec("P")
+
+ class WrapperType(Protocol):
+ def _new(self: WT, value: Any) -> WT: ...
+
+else:
+ from collections.abc import MutableMapping
+ from collections.abc import MutableSequence
+ from numbers import Integral
+ from numbers import Real
+
+ class _CustomList(MutableSequence, list):
+ """Adds MutableSequence mixin while pretending to be a builtin list"""
+
+ def __add__(self, other):
+ new_list = self.copy()
+ new_list.extend(other)
+ return new_list
+
+ def __iadd__(self, other):
+ self.extend(other)
+ return self
+
+ class _CustomDict(MutableMapping, dict):
+ """Adds MutableMapping mixin while pretending to be a builtin dict"""
+
+ def __or__(self, other):
+ new_dict = self.copy()
+ new_dict.update(other)
+ return new_dict
+
+ def __ior__(self, other):
+ self.update(other)
+ return self
+
+ class _CustomInt(Integral, int):
+ """Adds Integral mixin while pretending to be a builtin int"""
+
+ class _CustomFloat(Real, float):
+ """Adds Real mixin while pretending to be a builtin float"""
+
+
+def wrap_method(
+ original_method: Callable[Concatenate[WT, P], Any],
+) -> Callable[Concatenate[WT, P], Any]:
+ def wrapper(self: WT, *args: P.args, **kwargs: P.kwargs) -> Any:
+ result = original_method(self, *args, **kwargs)
+ if result is NotImplemented:
+ return result
+ return self._new(result)
+
+ return wrapper
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/_utils.py b/solutions/.venv/Lib/site-packages/tomlkit/_utils.py
new file mode 100644
index 000000000..f87fd7b58
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/_utils.py
@@ -0,0 +1,158 @@
+from __future__ import annotations
+
+import re
+
+from collections.abc import Mapping
+from datetime import date
+from datetime import datetime
+from datetime import time
+from datetime import timedelta
+from datetime import timezone
+from typing import Collection
+
+from tomlkit._compat import decode
+
+
+RFC_3339_LOOSE = re.compile(
+ "^"
+ r"(([0-9]+)-(\d{2})-(\d{2}))?" # Date
+ "("
+ "([Tt ])?" # Separator
+ r"(\d{2}):(\d{2}):(\d{2})(\.([0-9]+))?" # Time
+ r"(([Zz])|([\+|\-]([01][0-9]|2[0-3]):([0-5][0-9])))?" # Timezone
+ ")?"
+ "$"
+)
+
+RFC_3339_DATETIME = re.compile(
+ "^"
+ "([0-9]+)-(0[1-9]|1[012])-(0[1-9]|[12][0-9]|3[01])" # Date
+ "[Tt ]" # Separator
+ r"([01][0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9]|60)(\.([0-9]+))?" # Time
+ r"(([Zz])|([\+|\-]([01][0-9]|2[0-3]):([0-5][0-9])))?" # Timezone
+ "$"
+)
+
+RFC_3339_DATE = re.compile("^([0-9]+)-(0[1-9]|1[012])-(0[1-9]|[12][0-9]|3[01])$")
+
+RFC_3339_TIME = re.compile(
+ r"^([01][0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9]|60)(\.([0-9]+))?$"
+)
+
+_utc = timezone(timedelta(), "UTC")
+
+
+def parse_rfc3339(string: str) -> datetime | date | time:
+ m = RFC_3339_DATETIME.match(string)
+ if m:
+ year = int(m.group(1))
+ month = int(m.group(2))
+ day = int(m.group(3))
+ hour = int(m.group(4))
+ minute = int(m.group(5))
+ second = int(m.group(6))
+ microsecond = 0
+
+ if m.group(7):
+ microsecond = int((f"{m.group(8):<06s}")[:6])
+
+ if m.group(9):
+ # Timezone
+ tz = m.group(9)
+ if tz.upper() == "Z":
+ tzinfo = _utc
+ else:
+ sign = m.group(11)[0]
+ hour_offset, minute_offset = int(m.group(12)), int(m.group(13))
+ offset = timedelta(seconds=hour_offset * 3600 + minute_offset * 60)
+ if sign == "-":
+ offset = -offset
+
+ tzinfo = timezone(offset, f"{sign}{m.group(12)}:{m.group(13)}")
+
+ return datetime(
+ year, month, day, hour, minute, second, microsecond, tzinfo=tzinfo
+ )
+ else:
+ return datetime(year, month, day, hour, minute, second, microsecond)
+
+ m = RFC_3339_DATE.match(string)
+ if m:
+ year = int(m.group(1))
+ month = int(m.group(2))
+ day = int(m.group(3))
+
+ return date(year, month, day)
+
+ m = RFC_3339_TIME.match(string)
+ if m:
+ hour = int(m.group(1))
+ minute = int(m.group(2))
+ second = int(m.group(3))
+ microsecond = 0
+
+ if m.group(4):
+ microsecond = int((f"{m.group(5):<06s}")[:6])
+
+ return time(hour, minute, second, microsecond)
+
+ raise ValueError("Invalid RFC 339 string")
+
+
+# https://toml.io/en/v1.0.0#string
+CONTROL_CHARS = frozenset(chr(c) for c in range(0x20)) | {chr(0x7F)}
+_escaped = {
+ "b": "\b",
+ "t": "\t",
+ "n": "\n",
+ "f": "\f",
+ "r": "\r",
+ '"': '"',
+ "\\": "\\",
+}
+_compact_escapes = {
+ **{v: f"\\{k}" for k, v in _escaped.items()},
+ '"""': '""\\"',
+}
+_basic_escapes = CONTROL_CHARS | {'"', "\\"}
+
+
+def _unicode_escape(seq: str) -> str:
+ return "".join(f"\\u{ord(c):04x}" for c in seq)
+
+
+def escape_string(s: str, escape_sequences: Collection[str] = _basic_escapes) -> str:
+ s = decode(s)
+
+ res = []
+ start = 0
+
+ def flush(inc=1):
+ if start != i:
+ res.append(s[start:i])
+
+ return i + inc
+
+ found_sequences = {seq for seq in escape_sequences if seq in s}
+
+ i = 0
+ while i < len(s):
+ for seq in found_sequences:
+ seq_len = len(seq)
+ if s[i:].startswith(seq):
+ start = flush(seq_len)
+ res.append(_compact_escapes.get(seq) or _unicode_escape(seq))
+ i += seq_len - 1 # fast-forward escape sequence
+ i += 1
+
+ flush()
+
+ return "".join(res)
+
+
+def merge_dicts(d1: dict, d2: dict) -> dict:
+ for k, v in d2.items():
+ if k in d1 and isinstance(d1[k], dict) and isinstance(v, Mapping):
+ merge_dicts(d1[k], v)
+ else:
+ d1[k] = d2[k]
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/api.py b/solutions/.venv/Lib/site-packages/tomlkit/api.py
new file mode 100644
index 000000000..a7f6a61e2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/api.py
@@ -0,0 +1,310 @@
+from __future__ import annotations
+
+import contextlib
+import datetime as _datetime
+
+from collections.abc import Mapping
+from typing import IO
+from typing import Iterable
+from typing import TypeVar
+
+from tomlkit._utils import parse_rfc3339
+from tomlkit.container import Container
+from tomlkit.exceptions import UnexpectedCharError
+from tomlkit.items import CUSTOM_ENCODERS
+from tomlkit.items import AoT
+from tomlkit.items import Array
+from tomlkit.items import Bool
+from tomlkit.items import Comment
+from tomlkit.items import Date
+from tomlkit.items import DateTime
+from tomlkit.items import DottedKey
+from tomlkit.items import Encoder
+from tomlkit.items import Float
+from tomlkit.items import InlineTable
+from tomlkit.items import Integer
+from tomlkit.items import Item as _Item
+from tomlkit.items import Key
+from tomlkit.items import SingleKey
+from tomlkit.items import String
+from tomlkit.items import StringType as _StringType
+from tomlkit.items import Table
+from tomlkit.items import Time
+from tomlkit.items import Trivia
+from tomlkit.items import Whitespace
+from tomlkit.items import item
+from tomlkit.parser import Parser
+from tomlkit.toml_document import TOMLDocument
+
+
+def loads(string: str | bytes) -> TOMLDocument:
+ """
+ Parses a string into a TOMLDocument.
+
+ Alias for parse().
+ """
+ return parse(string)
+
+
+def dumps(data: Mapping, sort_keys: bool = False) -> str:
+ """
+ Dumps a TOMLDocument into a string.
+ """
+ if not isinstance(data, Container) and isinstance(data, Mapping):
+ data = item(dict(data), _sort_keys=sort_keys)
+
+ try:
+ # data should be a `Container` (and therefore implement `as_string`)
+ # for all type safe invocations of this function
+ return data.as_string() # type: ignore[attr-defined]
+ except AttributeError as ex:
+ msg = f"Expecting Mapping or TOML Container, {type(data)} given"
+ raise TypeError(msg) from ex
+
+
+def load(fp: IO[str] | IO[bytes]) -> TOMLDocument:
+ """
+ Load toml document from a file-like object.
+ """
+ return parse(fp.read())
+
+
+def dump(data: Mapping, fp: IO[str], *, sort_keys: bool = False) -> None:
+ """
+ Dump a TOMLDocument into a writable file stream.
+
+ :param data: a dict-like object to dump
+ :param sort_keys: if true, sort the keys in alphabetic order
+
+ :Example:
+
+ >>> with open("output.toml", "w") as fp:
+ ... tomlkit.dump(data, fp)
+ """
+ fp.write(dumps(data, sort_keys=sort_keys))
+
+
+def parse(string: str | bytes) -> TOMLDocument:
+ """
+ Parses a string or bytes into a TOMLDocument.
+ """
+ return Parser(string).parse()
+
+
+def document() -> TOMLDocument:
+ """
+ Returns a new TOMLDocument instance.
+ """
+ return TOMLDocument()
+
+
+# Items
+def integer(raw: str | int) -> Integer:
+ """Create an integer item from a number or string."""
+ return item(int(raw))
+
+
+def float_(raw: str | float) -> Float:
+ """Create an float item from a number or string."""
+ return item(float(raw))
+
+
+def boolean(raw: str) -> Bool:
+ """Turn `true` or `false` into a boolean item."""
+ return item(raw == "true")
+
+
+def string(
+ raw: str,
+ *,
+ literal: bool = False,
+ multiline: bool = False,
+ escape: bool = True,
+) -> String:
+ """Create a string item.
+
+ By default, this function will create *single line basic* strings, but
+ boolean flags (e.g. ``literal=True`` and/or ``multiline=True``)
+ can be used for personalization.
+
+ For more information, please check the spec: `<https://toml.io/en/v1.0.0#string>`__.
+
+ Common escaping rules will be applied for basic strings.
+ This can be controlled by explicitly setting ``escape=False``.
+ Please note that, if you disable escaping, you will have to make sure that
+ the given strings don't contain any forbidden character or sequence.
+ """
+ type_ = _StringType.select(literal, multiline)
+ return String.from_raw(raw, type_, escape)
+
+
+def date(raw: str) -> Date:
+ """Create a TOML date."""
+ value = parse_rfc3339(raw)
+ if not isinstance(value, _datetime.date):
+ raise ValueError("date() only accepts date strings.")
+
+ return item(value)
+
+
+def time(raw: str) -> Time:
+ """Create a TOML time."""
+ value = parse_rfc3339(raw)
+ if not isinstance(value, _datetime.time):
+ raise ValueError("time() only accepts time strings.")
+
+ return item(value)
+
+
+def datetime(raw: str) -> DateTime:
+ """Create a TOML datetime."""
+ value = parse_rfc3339(raw)
+ if not isinstance(value, _datetime.datetime):
+ raise ValueError("datetime() only accepts datetime strings.")
+
+ return item(value)
+
+
+def array(raw: str = "[]") -> Array:
+ """Create an array item for its string representation.
+
+ :Example:
+
+ >>> array("[1, 2, 3]") # Create from a string
+ [1, 2, 3]
+ >>> a = array()
+ >>> a.extend([1, 2, 3]) # Create from a list
+ >>> a
+ [1, 2, 3]
+ """
+ return value(raw)
+
+
+def table(is_super_table: bool | None = None) -> Table:
+ """Create an empty table.
+
+ :param is_super_table: if true, the table is a super table
+
+ :Example:
+
+ >>> doc = document()
+ >>> foo = table(True)
+ >>> bar = table()
+ >>> bar.update({'x': 1})
+ >>> foo.append('bar', bar)
+ >>> doc.append('foo', foo)
+ >>> print(doc.as_string())
+ [foo.bar]
+ x = 1
+ """
+ return Table(Container(), Trivia(), False, is_super_table)
+
+
+def inline_table() -> InlineTable:
+ """Create an inline table.
+
+ :Example:
+
+ >>> table = inline_table()
+ >>> table.update({'x': 1, 'y': 2})
+ >>> print(table.as_string())
+ {x = 1, y = 2}
+ """
+ return InlineTable(Container(), Trivia(), new=True)
+
+
+def aot() -> AoT:
+ """Create an array of table.
+
+ :Example:
+
+ >>> doc = document()
+ >>> aot = aot()
+ >>> aot.append(item({'x': 1}))
+ >>> doc.append('foo', aot)
+ >>> print(doc.as_string())
+ [[foo]]
+ x = 1
+ """
+ return AoT([])
+
+
+def key(k: str | Iterable[str]) -> Key:
+ """Create a key from a string. When a list of string is given,
+ it will create a dotted key.
+
+ :Example:
+
+ >>> doc = document()
+ >>> doc.append(key('foo'), 1)
+ >>> doc.append(key(['bar', 'baz']), 2)
+ >>> print(doc.as_string())
+ foo = 1
+ bar.baz = 2
+ """
+ if isinstance(k, str):
+ return SingleKey(k)
+ return DottedKey([key(_k) for _k in k])
+
+
+def value(raw: str) -> _Item:
+ """Parse a simple value from a string.
+
+ :Example:
+
+ >>> value("1")
+ 1
+ >>> value("true")
+ True
+ >>> value("[1, 2, 3]")
+ [1, 2, 3]
+ """
+ parser = Parser(raw)
+ v = parser._parse_value()
+ if not parser.end():
+ raise parser.parse_error(UnexpectedCharError, char=parser._current)
+ return v
+
+
+def key_value(src: str) -> tuple[Key, _Item]:
+ """Parse a key-value pair from a string.
+
+ :Example:
+
+ >>> key_value("foo = 1")
+ (Key('foo'), 1)
+ """
+ return Parser(src)._parse_key_value()
+
+
+def ws(src: str) -> Whitespace:
+ """Create a whitespace from a string."""
+ return Whitespace(src, fixed=True)
+
+
+def nl() -> Whitespace:
+ """Create a newline item."""
+ return ws("\n")
+
+
+def comment(string: str) -> Comment:
+ """Create a comment item."""
+ return Comment(Trivia(comment_ws=" ", comment="# " + string))
+
+
+E = TypeVar("E", bound=Encoder)
+
+
+def register_encoder(encoder: E) -> E:
+ """Add a custom encoder, which should be a function that will be called
+ if the value can't otherwise be converted. It should takes a single value
+ and return a TOMLKit item or raise a ``TypeError``.
+ """
+ CUSTOM_ENCODERS.append(encoder)
+ return encoder
+
+
+def unregister_encoder(encoder: Encoder) -> None:
+ """Unregister a custom encoder."""
+ with contextlib.suppress(ValueError):
+ CUSTOM_ENCODERS.remove(encoder)
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/container.py b/solutions/.venv/Lib/site-packages/tomlkit/container.py
new file mode 100644
index 000000000..7890880e2
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/container.py
@@ -0,0 +1,894 @@
+from __future__ import annotations
+
+import copy
+
+from typing import Any
+from typing import Iterator
+
+from tomlkit._compat import decode
+from tomlkit._types import _CustomDict
+from tomlkit._utils import merge_dicts
+from tomlkit.exceptions import KeyAlreadyPresent
+from tomlkit.exceptions import NonExistentKey
+from tomlkit.exceptions import TOMLKitError
+from tomlkit.items import AoT
+from tomlkit.items import Comment
+from tomlkit.items import Item
+from tomlkit.items import Key
+from tomlkit.items import Null
+from tomlkit.items import SingleKey
+from tomlkit.items import Table
+from tomlkit.items import Trivia
+from tomlkit.items import Whitespace
+from tomlkit.items import item as _item
+
+
+_NOT_SET = object()
+
+
+class Container(_CustomDict):
+ """
+ A container for items within a TOMLDocument.
+
+ This class implements the `dict` interface with copy/deepcopy protocol.
+ """
+
+ def __init__(self, parsed: bool = False) -> None:
+ self._map: dict[SingleKey, int | tuple[int, ...]] = {}
+ self._body: list[tuple[Key | None, Item]] = []
+ self._parsed = parsed
+ self._table_keys = []
+
+ @property
+ def body(self) -> list[tuple[Key | None, Item]]:
+ return self._body
+
+ def unwrap(self) -> dict[str, Any]:
+ """Returns as pure python object (ppo)"""
+ unwrapped = {}
+ for k, v in self.items():
+ if k is None:
+ continue
+
+ if isinstance(k, Key):
+ k = k.key
+
+ if hasattr(v, "unwrap"):
+ v = v.unwrap()
+
+ if k in unwrapped:
+ merge_dicts(unwrapped[k], v)
+ else:
+ unwrapped[k] = v
+
+ return unwrapped
+
+ @property
+ def value(self) -> dict[str, Any]:
+ """The wrapped dict value"""
+ d = {}
+ for k, v in self._body:
+ if k is None:
+ continue
+
+ k = k.key
+ v = v.value
+
+ if isinstance(v, Container):
+ v = v.value
+
+ if k in d:
+ merge_dicts(d[k], v)
+ else:
+ d[k] = v
+
+ return d
+
+ def parsing(self, parsing: bool) -> None:
+ self._parsed = parsing
+
+ for _, v in self._body:
+ if isinstance(v, Table):
+ v.value.parsing(parsing)
+ elif isinstance(v, AoT):
+ for t in v.body:
+ t.value.parsing(parsing)
+
+ def add(self, key: Key | Item | str, item: Item | None = None) -> Container:
+ """
+ Adds an item to the current Container.
+
+ :Example:
+
+ >>> # add a key-value pair
+ >>> doc.add('key', 'value')
+ >>> # add a comment or whitespace or newline
+ >>> doc.add(comment('# comment'))
+ """
+ if item is None:
+ if not isinstance(key, (Comment, Whitespace)):
+ raise ValueError(
+ "Non comment/whitespace items must have an associated key"
+ )
+
+ key, item = None, key
+
+ return self.append(key, item)
+
+ def _handle_dotted_key(self, key: Key, value: Item) -> None:
+ if isinstance(value, (Table, AoT)):
+ raise TOMLKitError("Can't add a table to a dotted key")
+ name, *mid, last = key
+ name._dotted = True
+ table = current = Table(Container(True), Trivia(), False, is_super_table=True)
+ for _name in mid:
+ _name._dotted = True
+ new_table = Table(Container(True), Trivia(), False, is_super_table=True)
+ current.append(_name, new_table)
+ current = new_table
+
+ last.sep = key.sep
+ current.append(last, value)
+
+ self.append(name, table)
+ return
+
+ def _get_last_index_before_table(self) -> int:
+ last_index = -1
+ for i, (k, v) in enumerate(self._body):
+ if isinstance(v, Null):
+ continue # Null elements are inserted after deletion
+
+ if isinstance(v, Whitespace) and not v.is_fixed():
+ continue
+
+ if isinstance(v, (Table, AoT)) and not k.is_dotted():
+ break
+ last_index = i
+ return last_index + 1
+
+ def _validate_out_of_order_table(self, key: SingleKey | None = None) -> None:
+ if key is None:
+ for k in self._map:
+ assert k is not None
+ self._validate_out_of_order_table(k)
+ return
+ if key not in self._map or not isinstance(self._map[key], tuple):
+ return
+ OutOfOrderTableProxy.validate(self, self._map[key])
+
+ def append(
+ self, key: Key | str | None, item: Item, validate: bool = True
+ ) -> Container:
+ """Similar to :meth:`add` but both key and value must be given."""
+ if not isinstance(key, Key) and key is not None:
+ key = SingleKey(key)
+
+ if not isinstance(item, Item):
+ item = _item(item)
+
+ if key is not None and key.is_multi():
+ self._handle_dotted_key(key, item)
+ return self
+
+ if isinstance(item, (AoT, Table)) and item.name is None:
+ item.name = key.key
+
+ prev = self._previous_item()
+ prev_ws = isinstance(prev, Whitespace) or ends_with_whitespace(prev)
+ if isinstance(item, Table):
+ if not self._parsed:
+ item.invalidate_display_name()
+ if (
+ self._body
+ and not (self._parsed or item.trivia.indent or prev_ws)
+ and not key.is_dotted()
+ ):
+ item.trivia.indent = "\n"
+
+ if isinstance(item, AoT) and self._body and not self._parsed:
+ item.invalidate_display_name()
+ if item and not ("\n" in item[0].trivia.indent or prev_ws):
+ item[0].trivia.indent = "\n" + item[0].trivia.indent
+
+ if key is not None and key in self:
+ current_idx = self._map[key]
+ if isinstance(current_idx, tuple):
+ current_body_element = self._body[current_idx[-1]]
+ else:
+ current_body_element = self._body[current_idx]
+
+ current = current_body_element[1]
+
+ if isinstance(item, Table):
+ if not isinstance(current, (Table, AoT)):
+ raise KeyAlreadyPresent(key)
+
+ if item.is_aot_element():
+ # New AoT element found later on
+ # Adding it to the current AoT
+ if not isinstance(current, AoT):
+ current = AoT([current, item], parsed=self._parsed)
+
+ self._replace(key, key, current)
+ else:
+ current.append(item)
+
+ return self
+ elif current.is_aot():
+ if not item.is_aot_element():
+ # Tried to define a table after an AoT with the same name.
+ raise KeyAlreadyPresent(key)
+
+ current.append(item)
+
+ return self
+ elif current.is_super_table():
+ if item.is_super_table():
+ # We need to merge both super tables
+ if (
+ key.is_dotted()
+ or current_body_element[0].is_dotted()
+ or self._table_keys[-1] != current_body_element[0]
+ ):
+ if key.is_dotted() and not self._parsed:
+ idx = self._get_last_index_before_table()
+ else:
+ idx = len(self._body)
+
+ if idx < len(self._body):
+ self._insert_at(idx, key, item)
+ else:
+ self._raw_append(key, item)
+
+ if validate:
+ self._validate_out_of_order_table(key)
+
+ return self
+
+ # Create a new element to replace the old one
+ current = copy.deepcopy(current)
+ for k, v in item.value.body:
+ current.append(k, v)
+ self._body[
+ (
+ current_idx[-1]
+ if isinstance(current_idx, tuple)
+ else current_idx
+ )
+ ] = (current_body_element[0], current)
+
+ return self
+ elif current_body_element[0].is_dotted():
+ raise TOMLKitError("Redefinition of an existing table")
+ elif not item.is_super_table():
+ raise KeyAlreadyPresent(key)
+ elif isinstance(item, AoT):
+ if not isinstance(current, AoT):
+ # Tried to define an AoT after a table with the same name.
+ raise KeyAlreadyPresent(key)
+
+ for table in item.body:
+ current.append(table)
+
+ return self
+ else:
+ raise KeyAlreadyPresent(key)
+
+ is_table = isinstance(item, (Table, AoT))
+ if (
+ key is not None
+ and self._body
+ and not self._parsed
+ and (not is_table or key.is_dotted())
+ ):
+ # If there is already at least one table in the current container
+ # and the given item is not a table, we need to find the last
+ # item that is not a table and insert after it
+ # If no such item exists, insert at the top of the table
+ last_index = self._get_last_index_before_table()
+
+ if last_index < len(self._body):
+ return self._insert_at(last_index, key, item)
+ else:
+ previous_item = self._body[-1][1]
+ if not (
+ isinstance(previous_item, Whitespace)
+ or ends_with_whitespace(previous_item)
+ or "\n" in previous_item.trivia.trail
+ ):
+ previous_item.trivia.trail += "\n"
+
+ self._raw_append(key, item)
+ return self
+
+ def _raw_append(self, key: Key | None, item: Item) -> None:
+ if key in self._map:
+ current_idx = self._map[key]
+ if not isinstance(current_idx, tuple):
+ current_idx = (current_idx,)
+
+ current = self._body[current_idx[-1]][1]
+ if key is not None and not isinstance(current, Table):
+ raise KeyAlreadyPresent(key)
+
+ self._map[key] = (*current_idx, len(self._body))
+ elif key is not None:
+ self._map[key] = len(self._body)
+
+ self._body.append((key, item))
+ if item.is_table():
+ self._table_keys.append(key)
+
+ if key is not None:
+ dict.__setitem__(self, key.key, item.value)
+
+ def _remove_at(self, idx: int) -> None:
+ key = self._body[idx][0]
+ index = self._map.get(key)
+ if index is None:
+ raise NonExistentKey(key)
+ self._body[idx] = (None, Null())
+
+ if isinstance(index, tuple):
+ index = list(index)
+ index.remove(idx)
+ if len(index) == 1:
+ index = index.pop()
+ else:
+ index = tuple(index)
+ self._map[key] = index
+ else:
+ dict.__delitem__(self, key.key)
+ self._map.pop(key)
+
+ def remove(self, key: Key | str) -> Container:
+ """Remove a key from the container."""
+ if not isinstance(key, Key):
+ key = SingleKey(key)
+
+ idx = self._map.pop(key, None)
+ if idx is None:
+ raise NonExistentKey(key)
+
+ if isinstance(idx, tuple):
+ for i in idx:
+ self._body[i] = (None, Null())
+ else:
+ self._body[idx] = (None, Null())
+
+ dict.__delitem__(self, key.key)
+
+ return self
+
+ def _insert_after(
+ self, key: Key | str, other_key: Key | str, item: Any
+ ) -> Container:
+ if key is None:
+ raise ValueError("Key cannot be null in insert_after()")
+
+ if key not in self:
+ raise NonExistentKey(key)
+
+ if not isinstance(key, Key):
+ key = SingleKey(key)
+
+ if not isinstance(other_key, Key):
+ other_key = SingleKey(other_key)
+
+ item = _item(item)
+
+ idx = self._map[key]
+ # Insert after the max index if there are many.
+ if isinstance(idx, tuple):
+ idx = max(idx)
+ current_item = self._body[idx][1]
+ if "\n" not in current_item.trivia.trail:
+ current_item.trivia.trail += "\n"
+
+ # Increment indices after the current index
+ for k, v in self._map.items():
+ if isinstance(v, tuple):
+ new_indices = []
+ for v_ in v:
+ if v_ > idx:
+ v_ = v_ + 1
+
+ new_indices.append(v_)
+
+ self._map[k] = tuple(new_indices)
+ elif v > idx:
+ self._map[k] = v + 1
+
+ self._map[other_key] = idx + 1
+ self._body.insert(idx + 1, (other_key, item))
+
+ if key is not None:
+ dict.__setitem__(self, other_key.key, item.value)
+
+ return self
+
+ def _insert_at(self, idx: int, key: Key | str, item: Any) -> Container:
+ if idx > len(self._body) - 1:
+ raise ValueError(f"Unable to insert at position {idx}")
+
+ if not isinstance(key, Key):
+ key = SingleKey(key)
+
+ item = _item(item)
+
+ if idx > 0:
+ previous_item = self._body[idx - 1][1]
+ if not (
+ isinstance(previous_item, Whitespace)
+ or ends_with_whitespace(previous_item)
+ or isinstance(item, (AoT, Table))
+ or "\n" in previous_item.trivia.trail
+ ):
+ previous_item.trivia.trail += "\n"
+
+ # Increment indices after the current index
+ for k, v in self._map.items():
+ if isinstance(v, tuple):
+ new_indices = []
+ for v_ in v:
+ if v_ >= idx:
+ v_ = v_ + 1
+
+ new_indices.append(v_)
+
+ self._map[k] = tuple(new_indices)
+ elif v >= idx:
+ self._map[k] = v + 1
+
+ if key in self._map:
+ current_idx = self._map[key]
+ if not isinstance(current_idx, tuple):
+ current_idx = (current_idx,)
+ self._map[key] = (*current_idx, idx)
+ else:
+ self._map[key] = idx
+ self._body.insert(idx, (key, item))
+
+ dict.__setitem__(self, key.key, item.value)
+
+ return self
+
+ def item(self, key: Key | str) -> Item:
+ """Get an item for the given key."""
+ if not isinstance(key, Key):
+ key = SingleKey(key)
+
+ idx = self._map.get(key)
+ if idx is None:
+ raise NonExistentKey(key)
+
+ if isinstance(idx, tuple):
+ # The item we are getting is an out of order table
+ # so we need a proxy to retrieve the proper objects
+ # from the parent container
+ return OutOfOrderTableProxy(self, idx)
+
+ return self._body[idx][1]
+
+ def last_item(self) -> Item | None:
+ """Get the last item."""
+ if self._body:
+ return self._body[-1][1]
+
+ def as_string(self) -> str:
+ """Render as TOML string."""
+ s = ""
+ for k, v in self._body:
+ if k is not None:
+ if isinstance(v, Table):
+ s += self._render_table(k, v)
+ elif isinstance(v, AoT):
+ s += self._render_aot(k, v)
+ else:
+ s += self._render_simple_item(k, v)
+ else:
+ s += self._render_simple_item(k, v)
+
+ return s
+
+ def _render_table(self, key: Key, table: Table, prefix: str | None = None) -> str:
+ cur = ""
+
+ if table.display_name is not None:
+ _key = table.display_name
+ else:
+ _key = key.as_string()
+
+ if prefix is not None:
+ _key = prefix + "." + _key
+
+ if not table.is_super_table() or (
+ any(
+ not isinstance(v, (Table, AoT, Whitespace, Null))
+ for _, v in table.value.body
+ )
+ and not key.is_dotted()
+ ):
+ open_, close = "[", "]"
+ if table.is_aot_element():
+ open_, close = "[[", "]]"
+
+ newline_in_table_trivia = (
+ "\n" if "\n" not in table.trivia.trail and len(table.value) > 0 else ""
+ )
+ cur += (
+ f"{table.trivia.indent}"
+ f"{open_}"
+ f"{decode(_key)}"
+ f"{close}"
+ f"{table.trivia.comment_ws}"
+ f"{decode(table.trivia.comment)}"
+ f"{table.trivia.trail}"
+ f"{newline_in_table_trivia}"
+ )
+ elif table.trivia.indent == "\n":
+ cur += table.trivia.indent
+
+ for k, v in table.value.body:
+ if isinstance(v, Table):
+ if v.is_super_table():
+ if k.is_dotted() and not key.is_dotted():
+ # Dotted key inside table
+ cur += self._render_table(k, v)
+ else:
+ cur += self._render_table(k, v, prefix=_key)
+ else:
+ cur += self._render_table(k, v, prefix=_key)
+ elif isinstance(v, AoT):
+ cur += self._render_aot(k, v, prefix=_key)
+ else:
+ cur += self._render_simple_item(
+ k, v, prefix=_key if key.is_dotted() else None
+ )
+
+ return cur
+
+ def _render_aot(self, key, aot, prefix=None):
+ _key = key.as_string()
+ if prefix is not None:
+ _key = prefix + "." + _key
+
+ cur = ""
+ _key = decode(_key)
+ for table in aot.body:
+ cur += self._render_aot_table(table, prefix=_key)
+
+ return cur
+
+ def _render_aot_table(self, table: Table, prefix: str | None = None) -> str:
+ cur = ""
+ _key = prefix or ""
+ open_, close = "[[", "]]"
+
+ cur += (
+ f"{table.trivia.indent}"
+ f"{open_}"
+ f"{decode(_key)}"
+ f"{close}"
+ f"{table.trivia.comment_ws}"
+ f"{decode(table.trivia.comment)}"
+ f"{table.trivia.trail}"
+ )
+
+ for k, v in table.value.body:
+ if isinstance(v, Table):
+ if v.is_super_table():
+ if k.is_dotted():
+ # Dotted key inside table
+ cur += self._render_table(k, v)
+ else:
+ cur += self._render_table(k, v, prefix=_key)
+ else:
+ cur += self._render_table(k, v, prefix=_key)
+ elif isinstance(v, AoT):
+ cur += self._render_aot(k, v, prefix=_key)
+ else:
+ cur += self._render_simple_item(k, v)
+
+ return cur
+
+ def _render_simple_item(self, key, item, prefix=None):
+ if key is None:
+ return item.as_string()
+
+ _key = key.as_string()
+ if prefix is not None:
+ _key = prefix + "." + _key
+
+ return (
+ f"{item.trivia.indent}"
+ f"{decode(_key)}"
+ f"{key.sep}"
+ f"{decode(item.as_string())}"
+ f"{item.trivia.comment_ws}"
+ f"{decode(item.trivia.comment)}"
+ f"{item.trivia.trail}"
+ )
+
+ def __len__(self) -> int:
+ return dict.__len__(self)
+
+ def __iter__(self) -> Iterator[str]:
+ return iter(dict.keys(self))
+
+ # Dictionary methods
+ def __getitem__(self, key: Key | str) -> Item | Container:
+ item = self.item(key)
+ if isinstance(item, Item) and item.is_boolean():
+ return item.value
+
+ return item
+
+ def __setitem__(self, key: Key | str, value: Any) -> None:
+ if key is not None and key in self:
+ old_key = next(filter(lambda k: k == key, self._map))
+ self._replace(old_key, key, value)
+ else:
+ self.append(key, value)
+
+ def __delitem__(self, key: Key | str) -> None:
+ self.remove(key)
+
+ def setdefault(self, key: Key | str, default: Any) -> Any:
+ super().setdefault(key, default=default)
+ return self[key]
+
+ def _replace(self, key: Key | str, new_key: Key | str, value: Item) -> None:
+ if not isinstance(key, Key):
+ key = SingleKey(key)
+
+ idx = self._map.get(key)
+ if idx is None:
+ raise NonExistentKey(key)
+
+ self._replace_at(idx, new_key, value)
+
+ def _replace_at(
+ self, idx: int | tuple[int], new_key: Key | str, value: Item
+ ) -> None:
+ value = _item(value)
+
+ if isinstance(idx, tuple):
+ for i in idx[1:]:
+ self._body[i] = (None, Null())
+
+ idx = idx[0]
+
+ k, v = self._body[idx]
+ if not isinstance(new_key, Key):
+ if (
+ isinstance(value, (AoT, Table)) != isinstance(v, (AoT, Table))
+ or new_key != k.key
+ ):
+ new_key = SingleKey(new_key)
+ else: # Inherit the sep of the old key
+ new_key = k
+
+ del self._map[k]
+ self._map[new_key] = idx
+ if new_key != k:
+ dict.__delitem__(self, k)
+
+ if isinstance(value, (AoT, Table)) != isinstance(v, (AoT, Table)):
+ # new tables should appear after all non-table values
+ self.remove(k)
+ for i in range(idx, len(self._body)):
+ if isinstance(self._body[i][1], (AoT, Table)):
+ self._insert_at(i, new_key, value)
+ idx = i
+ break
+ else:
+ idx = -1
+ self.append(new_key, value)
+ else:
+ # Copying trivia
+ if not isinstance(value, (Whitespace, AoT)):
+ value.trivia.indent = v.trivia.indent
+ value.trivia.comment_ws = value.trivia.comment_ws or v.trivia.comment_ws
+ value.trivia.comment = value.trivia.comment or v.trivia.comment
+ value.trivia.trail = v.trivia.trail
+ self._body[idx] = (new_key, value)
+
+ if hasattr(value, "invalidate_display_name"):
+ value.invalidate_display_name() # type: ignore[attr-defined]
+
+ if isinstance(value, Table):
+ # Insert a cosmetic new line for tables if:
+ # - it does not have it yet OR is not followed by one
+ # - it is not the last item, or
+ # - The table being replaced has a newline
+ last, _ = self._previous_item_with_index()
+ idx = last if idx < 0 else idx
+ has_ws = ends_with_whitespace(value)
+ replace_has_ws = (
+ isinstance(v, Table)
+ and v.value.body
+ and isinstance(v.value.body[-1][1], Whitespace)
+ )
+ next_ws = idx < last and isinstance(self._body[idx + 1][1], Whitespace)
+ if (idx < last or replace_has_ws) and not (next_ws or has_ws):
+ value.append(None, Whitespace("\n"))
+
+ dict.__setitem__(self, new_key.key, value.value)
+
+ def __str__(self) -> str:
+ return str(self.value)
+
+ def __repr__(self) -> str:
+ return repr(self.value)
+
+ def __eq__(self, other: dict) -> bool:
+ if not isinstance(other, dict):
+ return NotImplemented
+
+ return self.value == other
+
+ def _getstate(self, protocol):
+ return (self._parsed,)
+
+ def __reduce__(self):
+ return self.__reduce_ex__(2)
+
+ def __reduce_ex__(self, protocol):
+ return (
+ self.__class__,
+ self._getstate(protocol),
+ (self._map, self._body, self._parsed, self._table_keys),
+ )
+
+ def __setstate__(self, state):
+ self._map = state[0]
+ self._body = state[1]
+ self._parsed = state[2]
+ self._table_keys = state[3]
+
+ for key, item in self._body:
+ if key is not None:
+ dict.__setitem__(self, key.key, item.value)
+
+ def copy(self) -> Container:
+ return copy.copy(self)
+
+ def __copy__(self) -> Container:
+ c = self.__class__(self._parsed)
+ for k, v in dict.items(self):
+ dict.__setitem__(c, k, v)
+
+ c._body += self.body
+ c._map.update(self._map)
+
+ return c
+
+ def _previous_item_with_index(
+ self, idx: int | None = None, ignore=(Null,)
+ ) -> tuple[int, Item] | None:
+ """Find the immediate previous item before index ``idx``"""
+ if idx is None or idx > len(self._body):
+ idx = len(self._body)
+ for i in range(idx - 1, -1, -1):
+ v = self._body[i][-1]
+ if not isinstance(v, ignore):
+ return i, v
+ return None
+
+ def _previous_item(self, idx: int | None = None, ignore=(Null,)) -> Item | None:
+ """Find the immediate previous item before index ``idx``.
+ If ``idx`` is not given, the last item is returned.
+ """
+ prev = self._previous_item_with_index(idx, ignore)
+ return prev[-1] if prev else None
+
+
+class OutOfOrderTableProxy(_CustomDict):
+ @staticmethod
+ def validate(container: Container, indices: tuple[int, ...]) -> None:
+ """Validate out of order tables in the given container"""
+ # Append all items to a temp container to see if there is any error
+ temp_container = Container(True)
+ for i in indices:
+ _, item = container._body[i]
+
+ if isinstance(item, Table):
+ for k, v in item.value.body:
+ temp_container.append(k, v, validate=False)
+
+ temp_container._validate_out_of_order_table()
+
+ def __init__(self, container: Container, indices: tuple[int, ...]) -> None:
+ self._container = container
+ self._internal_container = Container(True)
+ self._tables = []
+ self._tables_map = {}
+
+ for i in indices:
+ _, item = self._container._body[i]
+
+ if isinstance(item, Table):
+ self._tables.append(item)
+ table_idx = len(self._tables) - 1
+ for k, v in item.value.body:
+ self._internal_container._raw_append(k, v)
+ self._tables_map.setdefault(k, []).append(table_idx)
+ if k is not None:
+ dict.__setitem__(self, k.key, v)
+
+ self._internal_container._validate_out_of_order_table()
+
+ def unwrap(self) -> str:
+ return self._internal_container.unwrap()
+
+ @property
+ def value(self):
+ return self._internal_container.value
+
+ def __getitem__(self, key: Key | str) -> Any:
+ if key not in self._internal_container:
+ raise NonExistentKey(key)
+
+ return self._internal_container[key]
+
+ def __setitem__(self, key: Key | str, item: Any) -> None:
+ if key in self._tables_map:
+ # Overwrite the first table and remove others
+ indices = self._tables_map[key]
+ while len(indices) > 1:
+ table = self._tables[indices.pop()]
+ self._remove_table(table)
+ self._tables[indices[0]][key] = item
+ elif self._tables:
+ table = self._tables[0]
+ table[key] = item
+ else:
+ self._container[key] = item
+
+ self._internal_container[key] = item
+ if key is not None:
+ dict.__setitem__(self, key, item)
+
+ def _remove_table(self, table: Table) -> None:
+ """Remove table from the parent container"""
+ self._tables.remove(table)
+ for idx, item in enumerate(self._container._body):
+ if item[1] is table:
+ self._container._remove_at(idx)
+ break
+
+ def __delitem__(self, key: Key | str) -> None:
+ if key not in self._tables_map:
+ raise NonExistentKey(key)
+
+ for i in reversed(self._tables_map[key]):
+ table = self._tables[i]
+ del table[key]
+ if not table and len(self._tables) > 1:
+ self._remove_table(table)
+
+ del self._tables_map[key]
+ del self._internal_container[key]
+ if key is not None:
+ dict.__delitem__(self, key)
+
+ def __iter__(self) -> Iterator[str]:
+ return iter(dict.keys(self))
+
+ def __len__(self) -> int:
+ return dict.__len__(self)
+
+ def setdefault(self, key: Key | str, default: Any) -> Any:
+ super().setdefault(key, default=default)
+ return self[key]
+
+
+def ends_with_whitespace(it: Any) -> bool:
+ """Returns ``True`` if the given item ``it`` is a ``Table`` or ``AoT`` object
+ ending with a ``Whitespace``.
+ """
+ return (
+ isinstance(it, Table) and isinstance(it.value._previous_item(), Whitespace)
+ ) or (isinstance(it, AoT) and len(it) > 0 and isinstance(it[-1], Whitespace))
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/exceptions.py b/solutions/.venv/Lib/site-packages/tomlkit/exceptions.py
new file mode 100644
index 000000000..8c7e6e749
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/exceptions.py
@@ -0,0 +1,234 @@
+from __future__ import annotations
+
+from typing import Collection
+
+
+class TOMLKitError(Exception):
+ pass
+
+
+class ParseError(ValueError, TOMLKitError):
+ """
+ This error occurs when the parser encounters a syntax error
+ in the TOML being parsed. The error references the line and
+ location within the line where the error was encountered.
+ """
+
+ def __init__(self, line: int, col: int, message: str | None = None) -> None:
+ self._line = line
+ self._col = col
+
+ if message is None:
+ message = "TOML parse error"
+
+ super().__init__(f"{message} at line {self._line} col {self._col}")
+
+ @property
+ def line(self):
+ return self._line
+
+ @property
+ def col(self):
+ return self._col
+
+
+class MixedArrayTypesError(ParseError):
+ """
+ An array was found that had two or more element types.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Mixed types found in array"
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidNumberError(ParseError):
+ """
+ A numeric field was improperly specified.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Invalid number"
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidDateTimeError(ParseError):
+ """
+ A datetime field was improperly specified.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Invalid datetime"
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidDateError(ParseError):
+ """
+ A date field was improperly specified.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Invalid date"
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidTimeError(ParseError):
+ """
+ A date field was improperly specified.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Invalid time"
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidNumberOrDateError(ParseError):
+ """
+ A numeric or date field was improperly specified.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Invalid number or date format"
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidUnicodeValueError(ParseError):
+ """
+ A unicode code was improperly specified.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Invalid unicode value"
+
+ super().__init__(line, col, message=message)
+
+
+class UnexpectedCharError(ParseError):
+ """
+ An unexpected character was found during parsing.
+ """
+
+ def __init__(self, line: int, col: int, char: str) -> None:
+ message = f"Unexpected character: {char!r}"
+
+ super().__init__(line, col, message=message)
+
+
+class EmptyKeyError(ParseError):
+ """
+ An empty key was found during parsing.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Empty key"
+
+ super().__init__(line, col, message=message)
+
+
+class EmptyTableNameError(ParseError):
+ """
+ An empty table name was found during parsing.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Empty table name"
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidCharInStringError(ParseError):
+ """
+ The string being parsed contains an invalid character.
+ """
+
+ def __init__(self, line: int, col: int, char: str) -> None:
+ message = f"Invalid character {char!r} in string"
+
+ super().__init__(line, col, message=message)
+
+
+class UnexpectedEofError(ParseError):
+ """
+ The TOML being parsed ended before the end of a statement.
+ """
+
+ def __init__(self, line: int, col: int) -> None:
+ message = "Unexpected end of file"
+
+ super().__init__(line, col, message=message)
+
+
+class InternalParserError(ParseError):
+ """
+ An error that indicates a bug in the parser.
+ """
+
+ def __init__(self, line: int, col: int, message: str | None = None) -> None:
+ msg = "Internal parser error"
+ if message:
+ msg += f" ({message})"
+
+ super().__init__(line, col, message=msg)
+
+
+class NonExistentKey(KeyError, TOMLKitError):
+ """
+ A non-existent key was used.
+ """
+
+ def __init__(self, key):
+ message = f'Key "{key}" does not exist.'
+
+ super().__init__(message)
+
+
+class KeyAlreadyPresent(TOMLKitError):
+ """
+ An already present key was used.
+ """
+
+ def __init__(self, key):
+ key = getattr(key, "key", key)
+ message = f'Key "{key}" already exists.'
+
+ super().__init__(message)
+
+
+class InvalidControlChar(ParseError):
+ def __init__(self, line: int, col: int, char: int, type: str) -> None:
+ display_code = "\\u00"
+
+ if char < 16:
+ display_code += "0"
+
+ display_code += hex(char)[2:]
+
+ message = (
+ "Control characters (codes less than 0x1f and 0x7f)"
+ f" are not allowed in {type}, "
+ f"use {display_code} instead"
+ )
+
+ super().__init__(line, col, message=message)
+
+
+class InvalidStringError(ValueError, TOMLKitError):
+ def __init__(self, value: str, invalid_sequences: Collection[str], delimiter: str):
+ repr_ = repr(value)[1:-1]
+ super().__init__(
+ f"Invalid string: {delimiter}{repr_}{delimiter}. "
+ f"The character sequences {invalid_sequences} are invalid."
+ )
+
+
+class ConvertError(TypeError, ValueError, TOMLKitError):
+ """Raised when item() fails to convert a value.
+ It should be a TypeError, but due to historical reasons
+ it needs to subclass ValueError as well.
+ """
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/items.py b/solutions/.venv/Lib/site-packages/tomlkit/items.py
new file mode 100644
index 000000000..b46679b36
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/items.py
@@ -0,0 +1,1960 @@
+from __future__ import annotations
+
+import abc
+import copy
+import dataclasses
+import math
+import re
+import string
+import sys
+
+from datetime import date
+from datetime import datetime
+from datetime import time
+from datetime import tzinfo
+from enum import Enum
+from typing import TYPE_CHECKING
+from typing import Any
+from typing import Callable
+from typing import Collection
+from typing import Iterable
+from typing import Iterator
+from typing import Sequence
+from typing import TypeVar
+from typing import cast
+from typing import overload
+
+from tomlkit._compat import PY38
+from tomlkit._compat import decode
+from tomlkit._types import _CustomDict
+from tomlkit._types import _CustomFloat
+from tomlkit._types import _CustomInt
+from tomlkit._types import _CustomList
+from tomlkit._types import wrap_method
+from tomlkit._utils import CONTROL_CHARS
+from tomlkit._utils import escape_string
+from tomlkit.exceptions import ConvertError
+from tomlkit.exceptions import InvalidStringError
+
+
+if TYPE_CHECKING:
+ from tomlkit import container
+
+
+ItemT = TypeVar("ItemT", bound="Item")
+Encoder = Callable[[Any], "Item"]
+CUSTOM_ENCODERS: list[Encoder] = []
+AT = TypeVar("AT", bound="AbstractTable")
+
+
+@overload
+def item(value: bool, _parent: Item | None = ..., _sort_keys: bool = ...) -> Bool: ...
+
+
+@overload
+def item(value: int, _parent: Item | None = ..., _sort_keys: bool = ...) -> Integer: ...
+
+
+@overload
+def item(value: float, _parent: Item | None = ..., _sort_keys: bool = ...) -> Float: ...
+
+
+@overload
+def item(value: str, _parent: Item | None = ..., _sort_keys: bool = ...) -> String: ...
+
+
+@overload
+def item(
+ value: datetime, _parent: Item | None = ..., _sort_keys: bool = ...
+) -> DateTime: ...
+
+
+@overload
+def item(value: date, _parent: Item | None = ..., _sort_keys: bool = ...) -> Date: ...
+
+
+@overload
+def item(value: time, _parent: Item | None = ..., _sort_keys: bool = ...) -> Time: ...
+
+
+@overload
+def item(
+ value: Sequence[dict], _parent: Item | None = ..., _sort_keys: bool = ...
+) -> AoT: ...
+
+
+@overload
+def item(
+ value: Sequence, _parent: Item | None = ..., _sort_keys: bool = ...
+) -> Array: ...
+
+
+@overload
+def item(value: dict, _parent: Array = ..., _sort_keys: bool = ...) -> InlineTable: ...
+
+
+@overload
+def item(value: dict, _parent: Item | None = ..., _sort_keys: bool = ...) -> Table: ...
+
+
+@overload
+def item(value: ItemT, _parent: Item | None = ..., _sort_keys: bool = ...) -> ItemT: ...
+
+
+def item(value: Any, _parent: Item | None = None, _sort_keys: bool = False) -> Item:
+ """Create a TOML item from a Python object.
+
+ :Example:
+
+ >>> item(42)
+ 42
+ >>> item([1, 2, 3])
+ [1, 2, 3]
+ >>> item({'a': 1, 'b': 2})
+ a = 1
+ b = 2
+ """
+
+ from tomlkit.container import Container
+
+ if isinstance(value, Item):
+ return value
+
+ if isinstance(value, bool):
+ return Bool(value, Trivia())
+ elif isinstance(value, int):
+ return Integer(value, Trivia(), str(value))
+ elif isinstance(value, float):
+ return Float(value, Trivia(), str(value))
+ elif isinstance(value, dict):
+ table_constructor = (
+ InlineTable if isinstance(_parent, (Array, InlineTable)) else Table
+ )
+ val = table_constructor(Container(), Trivia(), False)
+ for k, v in sorted(
+ value.items(),
+ key=lambda i: (isinstance(i[1], dict), i[0]) if _sort_keys else 1,
+ ):
+ val[k] = item(v, _parent=val, _sort_keys=_sort_keys)
+
+ return val
+ elif isinstance(value, (list, tuple)):
+ if (
+ value
+ and all(isinstance(v, dict) for v in value)
+ and (_parent is None or isinstance(_parent, Table))
+ ):
+ a = AoT([])
+ table_constructor = Table
+ else:
+ a = Array([], Trivia())
+ table_constructor = InlineTable
+
+ for v in value:
+ if isinstance(v, dict):
+ table = table_constructor(Container(), Trivia(), True)
+
+ for k, _v in sorted(
+ v.items(),
+ key=lambda i: (isinstance(i[1], dict), i[0] if _sort_keys else 1),
+ ):
+ i = item(_v, _parent=table, _sort_keys=_sort_keys)
+ if isinstance(table, InlineTable):
+ i.trivia.trail = ""
+
+ table[k] = i
+
+ v = table
+
+ a.append(v)
+
+ return a
+ elif isinstance(value, str):
+ return String.from_raw(value)
+ elif isinstance(value, datetime):
+ return DateTime(
+ value.year,
+ value.month,
+ value.day,
+ value.hour,
+ value.minute,
+ value.second,
+ value.microsecond,
+ value.tzinfo,
+ Trivia(),
+ value.isoformat().replace("+00:00", "Z"),
+ )
+ elif isinstance(value, date):
+ return Date(value.year, value.month, value.day, Trivia(), value.isoformat())
+ elif isinstance(value, time):
+ return Time(
+ value.hour,
+ value.minute,
+ value.second,
+ value.microsecond,
+ value.tzinfo,
+ Trivia(),
+ value.isoformat(),
+ )
+ else:
+ for encoder in CUSTOM_ENCODERS:
+ try:
+ rv = encoder(value)
+ except ConvertError:
+ pass
+ else:
+ if not isinstance(rv, Item):
+ raise ConvertError(
+ f"Custom encoder is expected to return an instance of Item, got {type(rv)}"
+ )
+ return rv
+
+ raise ConvertError(f"Unable to convert an object of {type(value)} to a TOML item")
+
+
+class StringType(Enum):
+ # Single Line Basic
+ SLB = '"'
+ # Multi Line Basic
+ MLB = '"""'
+ # Single Line Literal
+ SLL = "'"
+ # Multi Line Literal
+ MLL = "'''"
+
+ @classmethod
+ def select(cls, literal=False, multiline=False) -> StringType:
+ return {
+ (False, False): cls.SLB,
+ (False, True): cls.MLB,
+ (True, False): cls.SLL,
+ (True, True): cls.MLL,
+ }[(literal, multiline)]
+
+ @property
+ def escaped_sequences(self) -> Collection[str]:
+ # https://toml.io/en/v1.0.0#string
+ escaped_in_basic = CONTROL_CHARS | {"\\"}
+ allowed_in_multiline = {"\n", "\r"}
+ return {
+ StringType.SLB: escaped_in_basic | {'"'},
+ StringType.MLB: (escaped_in_basic | {'"""'}) - allowed_in_multiline,
+ StringType.SLL: (),
+ StringType.MLL: (),
+ }[self]
+
+ @property
+ def invalid_sequences(self) -> Collection[str]:
+ # https://toml.io/en/v1.0.0#string
+ forbidden_in_literal = CONTROL_CHARS - {"\t"}
+ allowed_in_multiline = {"\n", "\r"}
+ return {
+ StringType.SLB: (),
+ StringType.MLB: (),
+ StringType.SLL: forbidden_in_literal | {"'"},
+ StringType.MLL: (forbidden_in_literal | {"'''"}) - allowed_in_multiline,
+ }[self]
+
+ @property
+ def unit(self) -> str:
+ return self.value[0]
+
+ def is_basic(self) -> bool:
+ return self in {StringType.SLB, StringType.MLB}
+
+ def is_literal(self) -> bool:
+ return self in {StringType.SLL, StringType.MLL}
+
+ def is_singleline(self) -> bool:
+ return self in {StringType.SLB, StringType.SLL}
+
+ def is_multiline(self) -> bool:
+ return self in {StringType.MLB, StringType.MLL}
+
+ def toggle(self) -> StringType:
+ return {
+ StringType.SLB: StringType.MLB,
+ StringType.MLB: StringType.SLB,
+ StringType.SLL: StringType.MLL,
+ StringType.MLL: StringType.SLL,
+ }[self]
+
+
+class BoolType(Enum):
+ TRUE = "true"
+ FALSE = "false"
+
+ def __bool__(self):
+ return {BoolType.TRUE: True, BoolType.FALSE: False}[self]
+
+ def __iter__(self):
+ return iter(self.value)
+
+ def __len__(self):
+ return len(self.value)
+
+
+@dataclasses.dataclass
+class Trivia:
+ """
+ Trivia information (aka metadata).
+ """
+
+ # Whitespace before a value.
+ indent: str = ""
+ # Whitespace after a value, but before a comment.
+ comment_ws: str = ""
+ # Comment, starting with # character, or empty string if no comment.
+ comment: str = ""
+ # Trailing newline.
+ trail: str = "\n"
+
+ def copy(self) -> Trivia:
+ return dataclasses.replace(self)
+
+
+class KeyType(Enum):
+ """
+ The type of a Key.
+
+ Keys can be bare (unquoted), or quoted using basic ("), or literal (')
+ quotes following the same escaping rules as single-line StringType.
+ """
+
+ Bare = ""
+ Basic = '"'
+ Literal = "'"
+
+
+class Key(abc.ABC):
+ """Base class for a key"""
+
+ sep: str
+ _original: str
+ _keys: list[SingleKey]
+ _dotted: bool
+ key: str
+
+ @abc.abstractmethod
+ def __hash__(self) -> int:
+ pass
+
+ @abc.abstractmethod
+ def __eq__(self, __o: object) -> bool:
+ pass
+
+ def is_dotted(self) -> bool:
+ """If the key is followed by other keys"""
+ return self._dotted
+
+ def __iter__(self) -> Iterator[SingleKey]:
+ return iter(self._keys)
+
+ def concat(self, other: Key) -> DottedKey:
+ """Concatenate keys into a dotted key"""
+ keys = self._keys + other._keys
+ return DottedKey(keys, sep=self.sep)
+
+ def is_multi(self) -> bool:
+ """Check if the key contains multiple keys"""
+ return len(self._keys) > 1
+
+ def as_string(self) -> str:
+ """The TOML representation"""
+ return self._original
+
+ def __str__(self) -> str:
+ return self.as_string()
+
+ def __repr__(self) -> str:
+ return f"<Key {self.as_string()}>"
+
+
+class SingleKey(Key):
+ """A single key"""
+
+ def __init__(
+ self,
+ k: str,
+ t: KeyType | None = None,
+ sep: str | None = None,
+ original: str | None = None,
+ ) -> None:
+ if t is None:
+ if not k or any(
+ c not in string.ascii_letters + string.digits + "-" + "_" for c in k
+ ):
+ t = KeyType.Basic
+ else:
+ t = KeyType.Bare
+
+ self.t = t
+ if sep is None:
+ sep = " = "
+
+ self.sep = sep
+ self.key = k
+ if original is None:
+ key_str = escape_string(k) if t == KeyType.Basic else k
+ original = f"{t.value}{key_str}{t.value}"
+
+ self._original = original
+ self._keys = [self]
+ self._dotted = False
+
+ @property
+ def delimiter(self) -> str:
+ """The delimiter: double quote/single quote/none"""
+ return self.t.value
+
+ def is_bare(self) -> bool:
+ """Check if the key is bare"""
+ return self.t == KeyType.Bare
+
+ def __hash__(self) -> int:
+ return hash(self.key)
+
+ def __eq__(self, other: Any) -> bool:
+ if isinstance(other, Key):
+ return isinstance(other, SingleKey) and self.key == other.key
+
+ return self.key == other
+
+
+class DottedKey(Key):
+ def __init__(
+ self,
+ keys: Iterable[SingleKey],
+ sep: str | None = None,
+ original: str | None = None,
+ ) -> None:
+ self._keys = list(keys)
+ if original is None:
+ original = ".".join(k.as_string() for k in self._keys)
+
+ self.sep = " = " if sep is None else sep
+ self._original = original
+ self._dotted = False
+ self.key = ".".join(k.key for k in self._keys)
+
+ def __hash__(self) -> int:
+ return hash(tuple(self._keys))
+
+ def __eq__(self, __o: object) -> bool:
+ return isinstance(__o, DottedKey) and self._keys == __o._keys
+
+
+class Item:
+ """
+ An item within a TOML document.
+ """
+
+ def __init__(self, trivia: Trivia) -> None:
+ self._trivia = trivia
+
+ @property
+ def trivia(self) -> Trivia:
+ """The trivia element associated with this item"""
+ return self._trivia
+
+ @property
+ def discriminant(self) -> int:
+ raise NotImplementedError()
+
+ def as_string(self) -> str:
+ """The TOML representation"""
+ raise NotImplementedError()
+
+ @property
+ def value(self) -> Any:
+ return self
+
+ def unwrap(self) -> Any:
+ """Returns as pure python object (ppo)"""
+ raise NotImplementedError()
+
+ # Helpers
+
+ def comment(self, comment: str) -> Item:
+ """Attach a comment to this item"""
+ if not comment.strip().startswith("#"):
+ comment = "# " + comment
+
+ self._trivia.comment_ws = " "
+ self._trivia.comment = comment
+
+ return self
+
+ def indent(self, indent: int) -> Item:
+ """Indent this item with given number of spaces"""
+ if self._trivia.indent.startswith("\n"):
+ self._trivia.indent = "\n" + " " * indent
+ else:
+ self._trivia.indent = " " * indent
+
+ return self
+
+ def is_boolean(self) -> bool:
+ return isinstance(self, Bool)
+
+ def is_table(self) -> bool:
+ return isinstance(self, Table)
+
+ def is_inline_table(self) -> bool:
+ return isinstance(self, InlineTable)
+
+ def is_aot(self) -> bool:
+ return isinstance(self, AoT)
+
+ def _getstate(self, protocol=3):
+ return (self._trivia,)
+
+ def __reduce__(self):
+ return self.__reduce_ex__(2)
+
+ def __reduce_ex__(self, protocol):
+ return self.__class__, self._getstate(protocol)
+
+
+class Whitespace(Item):
+ """
+ A whitespace literal.
+ """
+
+ def __init__(self, s: str, fixed: bool = False) -> None:
+ self._s = s
+ self._fixed = fixed
+
+ @property
+ def s(self) -> str:
+ return self._s
+
+ @property
+ def value(self) -> str:
+ """The wrapped string of the whitespace"""
+ return self._s
+
+ @property
+ def trivia(self) -> Trivia:
+ raise RuntimeError("Called trivia on a Whitespace variant.")
+
+ @property
+ def discriminant(self) -> int:
+ return 0
+
+ def is_fixed(self) -> bool:
+ """If the whitespace is fixed, it can't be merged or discarded from the output."""
+ return self._fixed
+
+ def as_string(self) -> str:
+ return self._s
+
+ def __repr__(self) -> str:
+ return f"<{self.__class__.__name__} {self._s!r}>"
+
+ def _getstate(self, protocol=3):
+ return self._s, self._fixed
+
+
+class Comment(Item):
+ """
+ A comment literal.
+ """
+
+ @property
+ def discriminant(self) -> int:
+ return 1
+
+ def as_string(self) -> str:
+ return (
+ f"{self._trivia.indent}{decode(self._trivia.comment)}{self._trivia.trail}"
+ )
+
+ def __str__(self) -> str:
+ return f"{self._trivia.indent}{decode(self._trivia.comment)}"
+
+
+class Integer(Item, _CustomInt):
+ """
+ An integer literal.
+ """
+
+ def __new__(cls, value: int, trivia: Trivia, raw: str) -> Integer:
+ return int.__new__(cls, value)
+
+ def __init__(self, value: int, trivia: Trivia, raw: str) -> None:
+ super().__init__(trivia)
+ self._original = value
+ self._raw = raw
+ self._sign = False
+
+ if re.match(r"^[+\-]\d+$", raw):
+ self._sign = True
+
+ def unwrap(self) -> int:
+ return self._original
+
+ __int__ = unwrap
+
+ def __hash__(self) -> int:
+ return hash(self.unwrap())
+
+ @property
+ def discriminant(self) -> int:
+ return 2
+
+ @property
+ def value(self) -> int:
+ """The wrapped integer value"""
+ return self
+
+ def as_string(self) -> str:
+ return self._raw
+
+ def _new(self, result):
+ raw = str(result)
+ if self._sign and result >= 0:
+ raw = f"+{raw}"
+
+ return Integer(result, self._trivia, raw)
+
+ def _getstate(self, protocol=3):
+ return int(self), self._trivia, self._raw
+
+ # int methods
+ __abs__ = wrap_method(int.__abs__)
+ __add__ = wrap_method(int.__add__)
+ __and__ = wrap_method(int.__and__)
+ __ceil__ = wrap_method(int.__ceil__)
+ __eq__ = int.__eq__
+ __floor__ = wrap_method(int.__floor__)
+ __floordiv__ = wrap_method(int.__floordiv__)
+ __invert__ = wrap_method(int.__invert__)
+ __le__ = int.__le__
+ __lshift__ = wrap_method(int.__lshift__)
+ __lt__ = int.__lt__
+ __mod__ = wrap_method(int.__mod__)
+ __mul__ = wrap_method(int.__mul__)
+ __neg__ = wrap_method(int.__neg__)
+ __or__ = wrap_method(int.__or__)
+ __pos__ = wrap_method(int.__pos__)
+ __pow__ = wrap_method(int.__pow__)
+ __radd__ = wrap_method(int.__radd__)
+ __rand__ = wrap_method(int.__rand__)
+ __rfloordiv__ = wrap_method(int.__rfloordiv__)
+ __rlshift__ = wrap_method(int.__rlshift__)
+ __rmod__ = wrap_method(int.__rmod__)
+ __rmul__ = wrap_method(int.__rmul__)
+ __ror__ = wrap_method(int.__ror__)
+ __round__ = wrap_method(int.__round__)
+ __rpow__ = wrap_method(int.__rpow__)
+ __rrshift__ = wrap_method(int.__rrshift__)
+ __rshift__ = wrap_method(int.__rshift__)
+ __rxor__ = wrap_method(int.__rxor__)
+ __trunc__ = wrap_method(int.__trunc__)
+ __xor__ = wrap_method(int.__xor__)
+
+ def __rtruediv__(self, other):
+ result = int.__rtruediv__(self, other)
+ if result is NotImplemented:
+ return result
+ return Float._new(self, result)
+
+ def __truediv__(self, other):
+ result = int.__truediv__(self, other)
+ if result is NotImplemented:
+ return result
+ return Float._new(self, result)
+
+
+class Float(Item, _CustomFloat):
+ """
+ A float literal.
+ """
+
+ def __new__(cls, value: float, trivia: Trivia, raw: str) -> Float:
+ return float.__new__(cls, value)
+
+ def __init__(self, value: float, trivia: Trivia, raw: str) -> None:
+ super().__init__(trivia)
+ self._original = value
+ self._raw = raw
+ self._sign = False
+
+ if re.match(r"^[+\-].+$", raw):
+ self._sign = True
+
+ def unwrap(self) -> float:
+ return self._original
+
+ __float__ = unwrap
+
+ def __hash__(self) -> int:
+ return hash(self.unwrap())
+
+ @property
+ def discriminant(self) -> int:
+ return 3
+
+ @property
+ def value(self) -> float:
+ """The wrapped float value"""
+ return self
+
+ def as_string(self) -> str:
+ return self._raw
+
+ def _new(self, result):
+ raw = str(result)
+
+ if self._sign and result >= 0:
+ raw = f"+{raw}"
+
+ return Float(result, self._trivia, raw)
+
+ def _getstate(self, protocol=3):
+ return float(self), self._trivia, self._raw
+
+ # float methods
+ __abs__ = wrap_method(float.__abs__)
+ __add__ = wrap_method(float.__add__)
+ __eq__ = float.__eq__
+ __floordiv__ = wrap_method(float.__floordiv__)
+ __le__ = float.__le__
+ __lt__ = float.__lt__
+ __mod__ = wrap_method(float.__mod__)
+ __mul__ = wrap_method(float.__mul__)
+ __neg__ = wrap_method(float.__neg__)
+ __pos__ = wrap_method(float.__pos__)
+ __pow__ = wrap_method(float.__pow__)
+ __radd__ = wrap_method(float.__radd__)
+ __rfloordiv__ = wrap_method(float.__rfloordiv__)
+ __rmod__ = wrap_method(float.__rmod__)
+ __rmul__ = wrap_method(float.__rmul__)
+ __round__ = wrap_method(float.__round__)
+ __rpow__ = wrap_method(float.__rpow__)
+ __rtruediv__ = wrap_method(float.__rtruediv__)
+ __truediv__ = wrap_method(float.__truediv__)
+ __trunc__ = float.__trunc__
+
+ if sys.version_info >= (3, 9):
+ __ceil__ = float.__ceil__
+ __floor__ = float.__floor__
+ else:
+ __ceil__ = math.ceil
+ __floor__ = math.floor
+
+
+class Bool(Item):
+ """
+ A boolean literal.
+ """
+
+ def __init__(self, t: int, trivia: Trivia) -> None:
+ super().__init__(trivia)
+
+ self._value = bool(t)
+
+ def unwrap(self) -> bool:
+ return bool(self)
+
+ @property
+ def discriminant(self) -> int:
+ return 4
+
+ @property
+ def value(self) -> bool:
+ """The wrapped boolean value"""
+ return self._value
+
+ def as_string(self) -> str:
+ return str(self._value).lower()
+
+ def _getstate(self, protocol=3):
+ return self._value, self._trivia
+
+ def __bool__(self):
+ return self._value
+
+ __nonzero__ = __bool__
+
+ def __eq__(self, other):
+ if not isinstance(other, bool):
+ return NotImplemented
+
+ return other == self._value
+
+ def __hash__(self):
+ return hash(self._value)
+
+ def __repr__(self):
+ return repr(self._value)
+
+
+class DateTime(Item, datetime):
+ """
+ A datetime literal.
+ """
+
+ def __new__(
+ cls,
+ year: int,
+ month: int,
+ day: int,
+ hour: int,
+ minute: int,
+ second: int,
+ microsecond: int,
+ tzinfo: tzinfo | None,
+ *_: Any,
+ **kwargs: Any,
+ ) -> datetime:
+ return datetime.__new__(
+ cls,
+ year,
+ month,
+ day,
+ hour,
+ minute,
+ second,
+ microsecond,
+ tzinfo=tzinfo,
+ **kwargs,
+ )
+
+ def __init__(
+ self,
+ year: int,
+ month: int,
+ day: int,
+ hour: int,
+ minute: int,
+ second: int,
+ microsecond: int,
+ tzinfo: tzinfo | None,
+ trivia: Trivia | None = None,
+ raw: str | None = None,
+ **kwargs: Any,
+ ) -> None:
+ super().__init__(trivia or Trivia())
+
+ self._raw = raw or self.isoformat()
+
+ def unwrap(self) -> datetime:
+ (
+ year,
+ month,
+ day,
+ hour,
+ minute,
+ second,
+ microsecond,
+ tzinfo,
+ _,
+ _,
+ ) = self._getstate()
+ return datetime(year, month, day, hour, minute, second, microsecond, tzinfo)
+
+ @property
+ def discriminant(self) -> int:
+ return 5
+
+ @property
+ def value(self) -> datetime:
+ return self
+
+ def as_string(self) -> str:
+ return self._raw
+
+ def __add__(self, other):
+ if PY38:
+ result = datetime(
+ self.year,
+ self.month,
+ self.day,
+ self.hour,
+ self.minute,
+ self.second,
+ self.microsecond,
+ self.tzinfo,
+ ).__add__(other)
+ else:
+ result = super().__add__(other)
+
+ return self._new(result)
+
+ def __sub__(self, other):
+ if PY38:
+ result = datetime(
+ self.year,
+ self.month,
+ self.day,
+ self.hour,
+ self.minute,
+ self.second,
+ self.microsecond,
+ self.tzinfo,
+ ).__sub__(other)
+ else:
+ result = super().__sub__(other)
+
+ if isinstance(result, datetime):
+ result = self._new(result)
+
+ return result
+
+ def replace(self, *args: Any, **kwargs: Any) -> datetime:
+ return self._new(super().replace(*args, **kwargs))
+
+ def astimezone(self, tz: tzinfo) -> datetime:
+ result = super().astimezone(tz)
+ if PY38:
+ return result
+ return self._new(result)
+
+ def _new(self, result) -> DateTime:
+ raw = result.isoformat()
+
+ return DateTime(
+ result.year,
+ result.month,
+ result.day,
+ result.hour,
+ result.minute,
+ result.second,
+ result.microsecond,
+ result.tzinfo,
+ self._trivia,
+ raw,
+ )
+
+ def _getstate(self, protocol=3):
+ return (
+ self.year,
+ self.month,
+ self.day,
+ self.hour,
+ self.minute,
+ self.second,
+ self.microsecond,
+ self.tzinfo,
+ self._trivia,
+ self._raw,
+ )
+
+
+class Date(Item, date):
+ """
+ A date literal.
+ """
+
+ def __new__(cls, year: int, month: int, day: int, *_: Any) -> date:
+ return date.__new__(cls, year, month, day)
+
+ def __init__(
+ self,
+ year: int,
+ month: int,
+ day: int,
+ trivia: Trivia | None = None,
+ raw: str = "",
+ ) -> None:
+ super().__init__(trivia or Trivia())
+
+ self._raw = raw
+
+ def unwrap(self) -> date:
+ (year, month, day, _, _) = self._getstate()
+ return date(year, month, day)
+
+ @property
+ def discriminant(self) -> int:
+ return 6
+
+ @property
+ def value(self) -> date:
+ return self
+
+ def as_string(self) -> str:
+ return self._raw
+
+ def __add__(self, other):
+ if PY38:
+ result = date(self.year, self.month, self.day).__add__(other)
+ else:
+ result = super().__add__(other)
+
+ return self._new(result)
+
+ def __sub__(self, other):
+ if PY38:
+ result = date(self.year, self.month, self.day).__sub__(other)
+ else:
+ result = super().__sub__(other)
+
+ if isinstance(result, date):
+ result = self._new(result)
+
+ return result
+
+ def replace(self, *args: Any, **kwargs: Any) -> date:
+ return self._new(super().replace(*args, **kwargs))
+
+ def _new(self, result):
+ raw = result.isoformat()
+
+ return Date(result.year, result.month, result.day, self._trivia, raw)
+
+ def _getstate(self, protocol=3):
+ return (self.year, self.month, self.day, self._trivia, self._raw)
+
+
+class Time(Item, time):
+ """
+ A time literal.
+ """
+
+ def __new__(
+ cls,
+ hour: int,
+ minute: int,
+ second: int,
+ microsecond: int,
+ tzinfo: tzinfo | None,
+ *_: Any,
+ ) -> time:
+ return time.__new__(cls, hour, minute, second, microsecond, tzinfo)
+
+ def __init__(
+ self,
+ hour: int,
+ minute: int,
+ second: int,
+ microsecond: int,
+ tzinfo: tzinfo | None,
+ trivia: Trivia | None = None,
+ raw: str = "",
+ ) -> None:
+ super().__init__(trivia or Trivia())
+
+ self._raw = raw
+
+ def unwrap(self) -> time:
+ (hour, minute, second, microsecond, tzinfo, _, _) = self._getstate()
+ return time(hour, minute, second, microsecond, tzinfo)
+
+ @property
+ def discriminant(self) -> int:
+ return 7
+
+ @property
+ def value(self) -> time:
+ return self
+
+ def as_string(self) -> str:
+ return self._raw
+
+ def replace(self, *args: Any, **kwargs: Any) -> time:
+ return self._new(super().replace(*args, **kwargs))
+
+ def _new(self, result):
+ raw = result.isoformat()
+
+ return Time(
+ result.hour,
+ result.minute,
+ result.second,
+ result.microsecond,
+ result.tzinfo,
+ self._trivia,
+ raw,
+ )
+
+ def _getstate(self, protocol: int = 3) -> tuple:
+ return (
+ self.hour,
+ self.minute,
+ self.second,
+ self.microsecond,
+ self.tzinfo,
+ self._trivia,
+ self._raw,
+ )
+
+
+class _ArrayItemGroup:
+ __slots__ = ("value", "indent", "comma", "comment")
+
+ def __init__(
+ self,
+ value: Item | None = None,
+ indent: Whitespace | None = None,
+ comma: Whitespace | None = None,
+ comment: Comment | None = None,
+ ) -> None:
+ self.value = value
+ self.indent = indent
+ self.comma = comma
+ self.comment = comment
+
+ def __iter__(self) -> Iterator[Item]:
+ return filter(
+ lambda x: x is not None, (self.indent, self.value, self.comma, self.comment)
+ )
+
+ def __repr__(self) -> str:
+ return repr(tuple(self))
+
+ def is_whitespace(self) -> bool:
+ return self.value is None and self.comment is None
+
+ def __bool__(self) -> bool:
+ try:
+ next(iter(self))
+ except StopIteration:
+ return False
+ return True
+
+
+class Array(Item, _CustomList):
+ """
+ An array literal
+ """
+
+ def __init__(
+ self, value: list[Item], trivia: Trivia, multiline: bool = False
+ ) -> None:
+ super().__init__(trivia)
+ list.__init__(
+ self,
+ [v for v in value if not isinstance(v, (Whitespace, Comment, Null))],
+ )
+ self._index_map: dict[int, int] = {}
+ self._value = self._group_values(value)
+ self._multiline = multiline
+ self._reindex()
+
+ def _group_values(self, value: list[Item]) -> list[_ArrayItemGroup]:
+ """Group the values into (indent, value, comma, comment) tuples"""
+ groups = []
+ this_group = _ArrayItemGroup()
+ for item in value:
+ if isinstance(item, Whitespace):
+ if "," not in item.s:
+ groups.append(this_group)
+ this_group = _ArrayItemGroup(indent=item)
+ else:
+ if this_group.value is None:
+ # when comma is met and no value is provided, add a dummy Null
+ this_group.value = Null()
+ this_group.comma = item
+ elif isinstance(item, Comment):
+ if this_group.value is None:
+ this_group.value = Null()
+ this_group.comment = item
+ elif this_group.value is None:
+ this_group.value = item
+ else:
+ groups.append(this_group)
+ this_group = _ArrayItemGroup(value=item)
+ groups.append(this_group)
+ return [group for group in groups if group]
+
+ def unwrap(self) -> list[Any]:
+ unwrapped = []
+ for v in self:
+ if hasattr(v, "unwrap"):
+ unwrapped.append(v.unwrap())
+ else:
+ unwrapped.append(v)
+ return unwrapped
+
+ @property
+ def discriminant(self) -> int:
+ return 8
+
+ @property
+ def value(self) -> list:
+ return self
+
+ def _iter_items(self) -> Iterator[Item]:
+ for v in self._value:
+ yield from v
+
+ def multiline(self, multiline: bool) -> Array:
+ """Change the array to display in multiline or not.
+
+ :Example:
+
+ >>> a = item([1, 2, 3])
+ >>> print(a.as_string())
+ [1, 2, 3]
+ >>> print(a.multiline(True).as_string())
+ [
+ 1,
+ 2,
+ 3,
+ ]
+ """
+ self._multiline = multiline
+
+ return self
+
+ def as_string(self) -> str:
+ if not self._multiline or not self._value:
+ return f'[{"".join(v.as_string() for v in self._iter_items())}]'
+
+ s = "[\n"
+ s += "".join(
+ self.trivia.indent
+ + " " * 4
+ + v.value.as_string()
+ + ("," if not isinstance(v.value, Null) else "")
+ + (v.comment.as_string() if v.comment is not None else "")
+ + "\n"
+ for v in self._value
+ if v.value is not None
+ )
+ s += self.trivia.indent + "]"
+
+ return s
+
+ def _reindex(self) -> None:
+ self._index_map.clear()
+ index = 0
+ for i, v in enumerate(self._value):
+ if v.value is None or isinstance(v.value, Null):
+ continue
+ self._index_map[index] = i
+ index += 1
+
+ def add_line(
+ self,
+ *items: Any,
+ indent: str = " ",
+ comment: str | None = None,
+ add_comma: bool = True,
+ newline: bool = True,
+ ) -> None:
+ """Add multiple items in a line to control the format precisely.
+ When add_comma is True, only accept actual values and
+ ", " will be added between values automatically.
+
+ :Example:
+
+ >>> a = array()
+ >>> a.add_line(1, 2, 3)
+ >>> a.add_line(4, 5, 6)
+ >>> a.add_line(indent="")
+ >>> print(a.as_string())
+ [
+ 1, 2, 3,
+ 4, 5, 6,
+ ]
+ """
+ new_values: list[Item] = []
+ first_indent = f"\n{indent}" if newline else indent
+ if first_indent:
+ new_values.append(Whitespace(first_indent))
+ whitespace = ""
+ data_values = []
+ for i, el in enumerate(items):
+ it = item(el, _parent=self)
+ if isinstance(it, Comment) or add_comma and isinstance(el, Whitespace):
+ raise ValueError(f"item type {type(it)} is not allowed in add_line")
+ if not isinstance(it, Whitespace):
+ if whitespace:
+ new_values.append(Whitespace(whitespace))
+ whitespace = ""
+ new_values.append(it)
+ data_values.append(it.value)
+ if add_comma:
+ new_values.append(Whitespace(","))
+ if i != len(items) - 1:
+ new_values.append(Whitespace(" "))
+ elif "," not in it.s:
+ whitespace += it.s
+ else:
+ new_values.append(it)
+ if whitespace:
+ new_values.append(Whitespace(whitespace))
+ if comment:
+ indent = " " if items else ""
+ new_values.append(
+ Comment(Trivia(indent=indent, comment=f"# {comment}", trail=""))
+ )
+ list.extend(self, data_values)
+ if len(self._value) > 0:
+ last_item = self._value[-1]
+ last_value_item = next(
+ (
+ v
+ for v in self._value[::-1]
+ if v.value is not None and not isinstance(v.value, Null)
+ ),
+ None,
+ )
+ if last_value_item is not None:
+ last_value_item.comma = Whitespace(",")
+ if last_item.is_whitespace():
+ self._value[-1:-1] = self._group_values(new_values)
+ else:
+ self._value.extend(self._group_values(new_values))
+ else:
+ self._value.extend(self._group_values(new_values))
+ self._reindex()
+
+ def clear(self) -> None:
+ """Clear the array."""
+ list.clear(self)
+ self._index_map.clear()
+ self._value.clear()
+
+ def __len__(self) -> int:
+ return list.__len__(self)
+
+ def __getitem__(self, key: int | slice) -> Any:
+ rv = cast(Item, list.__getitem__(self, key))
+ if rv.is_boolean():
+ return bool(rv)
+ return rv
+
+ def __setitem__(self, key: int | slice, value: Any) -> Any:
+ it = item(value, _parent=self)
+ list.__setitem__(self, key, it)
+ if isinstance(key, slice):
+ raise ValueError("slice assignment is not supported")
+ if key < 0:
+ key += len(self)
+ self._value[self._index_map[key]].value = it
+
+ def insert(self, pos: int, value: Any) -> None:
+ it = item(value, _parent=self)
+ length = len(self)
+ if not isinstance(it, (Comment, Whitespace)):
+ list.insert(self, pos, it)
+ if pos < 0:
+ pos += length
+ if pos < 0:
+ pos = 0
+
+ idx = 0 # insert position of the self._value list
+ default_indent = " "
+ if pos < length:
+ try:
+ idx = self._index_map[pos]
+ except KeyError as e:
+ raise IndexError("list index out of range") from e
+ else:
+ idx = len(self._value)
+ if idx >= 1 and self._value[idx - 1].is_whitespace():
+ # The last item is a pure whitespace(\n ), insert before it
+ idx -= 1
+ if (
+ self._value[idx].indent is not None
+ and "\n" in self._value[idx].indent.s
+ ):
+ default_indent = "\n "
+ indent: Item | None = None
+ comma: Item | None = Whitespace(",") if pos < length else None
+ if idx < len(self._value) and not self._value[idx].is_whitespace():
+ # Prefer to copy the indentation from the item after
+ indent = self._value[idx].indent
+ if idx > 0:
+ last_item = self._value[idx - 1]
+ if indent is None:
+ indent = last_item.indent
+ if not isinstance(last_item.value, Null) and "\n" in default_indent:
+ # Copy the comma from the last item if 1) it contains a value and
+ # 2) the array is multiline
+ comma = last_item.comma
+ if last_item.comma is None and not isinstance(last_item.value, Null):
+ # Add comma to the last item to separate it from the following items.
+ last_item.comma = Whitespace(",")
+ if indent is None and (idx > 0 or "\n" in default_indent):
+ # apply default indent if it isn't the first item or the array is multiline.
+ indent = Whitespace(default_indent)
+ new_item = _ArrayItemGroup(value=it, indent=indent, comma=comma)
+ self._value.insert(idx, new_item)
+ self._reindex()
+
+ def __delitem__(self, key: int | slice):
+ length = len(self)
+ list.__delitem__(self, key)
+
+ if isinstance(key, slice):
+ indices_to_remove = list(
+ range(key.start or 0, key.stop or length, key.step or 1)
+ )
+ else:
+ indices_to_remove = [length + key if key < 0 else key]
+ for i in sorted(indices_to_remove, reverse=True):
+ try:
+ idx = self._index_map[i]
+ except KeyError as e:
+ if not isinstance(key, slice):
+ raise IndexError("list index out of range") from e
+ else:
+ del self._value[idx]
+ if (
+ idx == 0
+ and len(self._value) > 0
+ and self._value[idx].indent
+ and "\n" not in self._value[idx].indent.s
+ ):
+ # Remove the indentation of the first item if not newline
+ self._value[idx].indent = None
+ if len(self._value) > 0:
+ v = self._value[-1]
+ if not v.is_whitespace():
+ # remove the comma of the last item
+ v.comma = None
+
+ self._reindex()
+
+ def _getstate(self, protocol=3):
+ return list(self._iter_items()), self._trivia, self._multiline
+
+
+class AbstractTable(Item, _CustomDict):
+ """Common behaviour of both :class:`Table` and :class:`InlineTable`"""
+
+ def __init__(self, value: container.Container, trivia: Trivia):
+ Item.__init__(self, trivia)
+
+ self._value = value
+
+ for k, v in self._value.body:
+ if k is not None:
+ dict.__setitem__(self, k.key, v)
+
+ def unwrap(self) -> dict[str, Any]:
+ unwrapped = {}
+ for k, v in self.items():
+ if isinstance(k, Key):
+ k = k.key
+ if hasattr(v, "unwrap"):
+ v = v.unwrap()
+ unwrapped[k] = v
+
+ return unwrapped
+
+ @property
+ def value(self) -> container.Container:
+ return self._value
+
+ @overload
+ def append(self: AT, key: None, value: Comment | Whitespace) -> AT: ...
+
+ @overload
+ def append(self: AT, key: Key | str, value: Any) -> AT: ...
+
+ def append(self, key, value):
+ raise NotImplementedError
+
+ @overload
+ def add(self: AT, key: Comment | Whitespace) -> AT: ...
+
+ @overload
+ def add(self: AT, key: Key | str, value: Any = ...) -> AT: ...
+
+ def add(self, key, value=None):
+ if value is None:
+ if not isinstance(key, (Comment, Whitespace)):
+ msg = "Non comment/whitespace items must have an associated key"
+ raise ValueError(msg)
+
+ key, value = None, key
+
+ return self.append(key, value)
+
+ def remove(self: AT, key: Key | str) -> AT:
+ self._value.remove(key)
+
+ if isinstance(key, Key):
+ key = key.key
+
+ if key is not None:
+ dict.__delitem__(self, key)
+
+ return self
+
+ def setdefault(self, key: Key | str, default: Any) -> Any:
+ super().setdefault(key, default)
+ return self[key]
+
+ def __str__(self):
+ return str(self.value)
+
+ def copy(self: AT) -> AT:
+ return copy.copy(self)
+
+ def __repr__(self) -> str:
+ return repr(self.value)
+
+ def __iter__(self) -> Iterator[str]:
+ return iter(self._value)
+
+ def __len__(self) -> int:
+ return len(self._value)
+
+ def __delitem__(self, key: Key | str) -> None:
+ self.remove(key)
+
+ def __getitem__(self, key: Key | str) -> Item:
+ return cast(Item, self._value[key])
+
+ def __setitem__(self, key: Key | str, value: Any) -> None:
+ if not isinstance(value, Item):
+ value = item(value, _parent=self)
+
+ is_replace = key in self
+ self._value[key] = value
+
+ if key is not None:
+ dict.__setitem__(self, key, value)
+
+ if is_replace:
+ return
+ m = re.match("(?s)^[^ ]*([ ]+).*$", self._trivia.indent)
+ if not m:
+ return
+
+ indent = m.group(1)
+
+ if not isinstance(value, Whitespace):
+ m = re.match("(?s)^([^ ]*)(.*)$", value.trivia.indent)
+ if not m:
+ value.trivia.indent = indent
+ else:
+ value.trivia.indent = m.group(1) + indent + m.group(2)
+
+
+class Table(AbstractTable):
+ """
+ A table literal.
+ """
+
+ def __init__(
+ self,
+ value: container.Container,
+ trivia: Trivia,
+ is_aot_element: bool,
+ is_super_table: bool | None = None,
+ name: str | None = None,
+ display_name: str | None = None,
+ ) -> None:
+ super().__init__(value, trivia)
+
+ self.name = name
+ self.display_name = display_name
+ self._is_aot_element = is_aot_element
+ self._is_super_table = is_super_table
+
+ @property
+ def discriminant(self) -> int:
+ return 9
+
+ def __copy__(self) -> Table:
+ return type(self)(
+ self._value.copy(),
+ self._trivia.copy(),
+ self._is_aot_element,
+ self._is_super_table,
+ self.name,
+ self.display_name,
+ )
+
+ def append(self, key: Key | str | None, _item: Any) -> Table:
+ """
+ Appends a (key, item) to the table.
+ """
+ if not isinstance(_item, Item):
+ _item = item(_item, _parent=self)
+
+ self._value.append(key, _item)
+
+ if isinstance(key, Key):
+ key = next(iter(key)).key
+ _item = self._value[key]
+
+ if key is not None:
+ dict.__setitem__(self, key, _item)
+
+ m = re.match(r"(?s)^[^ ]*([ ]+).*$", self._trivia.indent)
+ if not m:
+ return self
+
+ indent = m.group(1)
+
+ if not isinstance(_item, Whitespace):
+ m = re.match("(?s)^([^ ]*)(.*)$", _item.trivia.indent)
+ if not m:
+ _item.trivia.indent = indent
+ else:
+ _item.trivia.indent = m.group(1) + indent + m.group(2)
+
+ return self
+
+ def raw_append(self, key: Key | str | None, _item: Any) -> Table:
+ """Similar to :meth:`append` but does not copy indentation."""
+ if not isinstance(_item, Item):
+ _item = item(_item)
+
+ self._value.append(key, _item, validate=False)
+
+ if isinstance(key, Key):
+ key = next(iter(key)).key
+ _item = self._value[key]
+
+ if key is not None:
+ dict.__setitem__(self, key, _item)
+
+ return self
+
+ def is_aot_element(self) -> bool:
+ """True if the table is the direct child of an AOT element."""
+ return self._is_aot_element
+
+ def is_super_table(self) -> bool:
+ """A super table is the intermediate parent of a nested table as in [a.b.c].
+ If true, it won't appear in the TOML representation."""
+ if self._is_super_table is not None:
+ return self._is_super_table
+ if not self:
+ return False
+ # If the table has children and all children are tables, then it is a super table.
+ for k, child in self.items():
+ if not isinstance(k, Key):
+ k = SingleKey(k)
+ index = self.value._map[k]
+ if isinstance(index, tuple):
+ return False
+ real_key = self.value.body[index][0]
+ if (
+ not isinstance(child, (Table, AoT))
+ or real_key is None
+ or real_key.is_dotted()
+ ):
+ return False
+ return True
+
+ def as_string(self) -> str:
+ return self._value.as_string()
+
+ # Helpers
+
+ def indent(self, indent: int) -> Table:
+ """Indent the table with given number of spaces."""
+ super().indent(indent)
+
+ m = re.match("(?s)^[^ ]*([ ]+).*$", self._trivia.indent)
+ if not m:
+ indent_str = ""
+ else:
+ indent_str = m.group(1)
+
+ for _, item in self._value.body:
+ if not isinstance(item, Whitespace):
+ item.trivia.indent = indent_str + item.trivia.indent
+
+ return self
+
+ def invalidate_display_name(self):
+ """Call ``invalidate_display_name`` on the contained tables"""
+ self.display_name = None
+
+ for child in self.values():
+ if hasattr(child, "invalidate_display_name"):
+ child.invalidate_display_name()
+
+ def _getstate(self, protocol: int = 3) -> tuple:
+ return (
+ self._value,
+ self._trivia,
+ self._is_aot_element,
+ self._is_super_table,
+ self.name,
+ self.display_name,
+ )
+
+
+class InlineTable(AbstractTable):
+ """
+ An inline table literal.
+ """
+
+ def __init__(
+ self, value: container.Container, trivia: Trivia, new: bool = False
+ ) -> None:
+ super().__init__(value, trivia)
+
+ self._new = new
+
+ @property
+ def discriminant(self) -> int:
+ return 10
+
+ def append(self, key: Key | str | None, _item: Any) -> InlineTable:
+ """
+ Appends a (key, item) to the table.
+ """
+ if not isinstance(_item, Item):
+ _item = item(_item, _parent=self)
+
+ if not isinstance(_item, (Whitespace, Comment)):
+ if not _item.trivia.indent and len(self._value) > 0 and not self._new:
+ _item.trivia.indent = " "
+ if _item.trivia.comment:
+ _item.trivia.comment = ""
+
+ self._value.append(key, _item)
+
+ if isinstance(key, Key):
+ key = key.key
+
+ if key is not None:
+ dict.__setitem__(self, key, _item)
+
+ return self
+
+ def as_string(self) -> str:
+ buf = "{"
+ last_item_idx = next(
+ (
+ i
+ for i in range(len(self._value.body) - 1, -1, -1)
+ if self._value.body[i][0] is not None
+ ),
+ None,
+ )
+ for i, (k, v) in enumerate(self._value.body):
+ if k is None:
+ if i == len(self._value.body) - 1:
+ if self._new:
+ buf = buf.rstrip(", ")
+ else:
+ buf = buf.rstrip(",")
+
+ buf += v.as_string()
+
+ continue
+
+ v_trivia_trail = v.trivia.trail.replace("\n", "")
+ buf += (
+ f"{v.trivia.indent}"
+ f'{k.as_string() + ("." if k.is_dotted() else "")}'
+ f"{k.sep}"
+ f"{v.as_string()}"
+ f"{v.trivia.comment}"
+ f"{v_trivia_trail}"
+ )
+
+ if last_item_idx is not None and i < last_item_idx:
+ buf += ","
+ if self._new:
+ buf += " "
+
+ buf += "}"
+
+ return buf
+
+ def __setitem__(self, key: Key | str, value: Any) -> None:
+ if hasattr(value, "trivia") and value.trivia.comment:
+ value.trivia.comment = ""
+ super().__setitem__(key, value)
+
+ def __copy__(self) -> InlineTable:
+ return type(self)(self._value.copy(), self._trivia.copy(), self._new)
+
+ def _getstate(self, protocol: int = 3) -> tuple:
+ return (self._value, self._trivia)
+
+
+class String(str, Item):
+ """
+ A string literal.
+ """
+
+ def __new__(cls, t, value, original, trivia):
+ return super().__new__(cls, value)
+
+ def __init__(self, t: StringType, _: str, original: str, trivia: Trivia) -> None:
+ super().__init__(trivia)
+
+ self._t = t
+ self._original = original
+
+ def unwrap(self) -> str:
+ return str(self)
+
+ @property
+ def discriminant(self) -> int:
+ return 11
+
+ @property
+ def value(self) -> str:
+ return self
+
+ def as_string(self) -> str:
+ return f"{self._t.value}{decode(self._original)}{self._t.value}"
+
+ def __add__(self: ItemT, other: str) -> ItemT:
+ if not isinstance(other, str):
+ return NotImplemented
+ result = super().__add__(other)
+ original = self._original + getattr(other, "_original", other)
+
+ return self._new(result, original)
+
+ def _new(self, result: str, original: str) -> String:
+ return String(self._t, result, original, self._trivia)
+
+ def _getstate(self, protocol=3):
+ return self._t, str(self), self._original, self._trivia
+
+ @classmethod
+ def from_raw(cls, value: str, type_=StringType.SLB, escape=True) -> String:
+ value = decode(value)
+
+ invalid = type_.invalid_sequences
+ if any(c in value for c in invalid):
+ raise InvalidStringError(value, invalid, type_.value)
+
+ escaped = type_.escaped_sequences
+ string_value = escape_string(value, escaped) if escape and escaped else value
+
+ return cls(type_, decode(value), string_value, Trivia())
+
+
+class AoT(Item, _CustomList):
+ """
+ An array of table literal
+ """
+
+ def __init__(
+ self, body: list[Table], name: str | None = None, parsed: bool = False
+ ) -> None:
+ self.name = name
+ self._body: list[Table] = []
+ self._parsed = parsed
+
+ super().__init__(Trivia(trail=""))
+
+ for table in body:
+ self.append(table)
+
+ def unwrap(self) -> list[dict[str, Any]]:
+ unwrapped = []
+ for t in self._body:
+ if hasattr(t, "unwrap"):
+ unwrapped.append(t.unwrap())
+ else:
+ unwrapped.append(t)
+ return unwrapped
+
+ @property
+ def body(self) -> list[Table]:
+ return self._body
+
+ @property
+ def discriminant(self) -> int:
+ return 12
+
+ @property
+ def value(self) -> list[dict[Any, Any]]:
+ return [v.value for v in self._body]
+
+ def __len__(self) -> int:
+ return len(self._body)
+
+ @overload
+ def __getitem__(self, key: slice) -> list[Table]: ...
+
+ @overload
+ def __getitem__(self, key: int) -> Table: ...
+
+ def __getitem__(self, key):
+ return self._body[key]
+
+ def __setitem__(self, key: slice | int, value: Any) -> None:
+ raise NotImplementedError
+
+ def __delitem__(self, key: slice | int) -> None:
+ del self._body[key]
+ list.__delitem__(self, key)
+
+ def insert(self, index: int, value: dict) -> None:
+ value = item(value, _parent=self)
+ if not isinstance(value, Table):
+ raise ValueError(f"Unsupported insert value type: {type(value)}")
+ length = len(self)
+ if index < 0:
+ index += length
+ if index < 0:
+ index = 0
+ elif index >= length:
+ index = length
+ m = re.match("(?s)^[^ ]*([ ]+).*$", self._trivia.indent)
+ if m:
+ indent = m.group(1)
+
+ m = re.match("(?s)^([^ ]*)(.*)$", value.trivia.indent)
+ if not m:
+ value.trivia.indent = indent
+ else:
+ value.trivia.indent = m.group(1) + indent + m.group(2)
+ prev_table = self._body[index - 1] if 0 < index and length else None
+ next_table = self._body[index + 1] if index < length - 1 else None
+ if not self._parsed:
+ if prev_table and "\n" not in value.trivia.indent:
+ value.trivia.indent = "\n" + value.trivia.indent
+ if next_table and "\n" not in next_table.trivia.indent:
+ next_table.trivia.indent = "\n" + next_table.trivia.indent
+ self._body.insert(index, value)
+ list.insert(self, index, value)
+
+ def invalidate_display_name(self):
+ """Call ``invalidate_display_name`` on the contained tables"""
+ for child in self:
+ if hasattr(child, "invalidate_display_name"):
+ child.invalidate_display_name()
+
+ def as_string(self) -> str:
+ b = ""
+ for table in self._body:
+ b += table.as_string()
+
+ return b
+
+ def __repr__(self) -> str:
+ return f"<AoT {self.value}>"
+
+ def _getstate(self, protocol=3):
+ return self._body, self.name, self._parsed
+
+
+class Null(Item):
+ """
+ A null item.
+ """
+
+ def __init__(self) -> None:
+ super().__init__(Trivia(trail=""))
+
+ def unwrap(self) -> None:
+ return None
+
+ @property
+ def discriminant(self) -> int:
+ return -1
+
+ @property
+ def value(self) -> None:
+ return None
+
+ def as_string(self) -> str:
+ return ""
+
+ def _getstate(self, protocol=3) -> tuple:
+ return ()
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/parser.py b/solutions/.venv/Lib/site-packages/tomlkit/parser.py
new file mode 100644
index 000000000..b73f277a7
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/parser.py
@@ -0,0 +1,1141 @@
+from __future__ import annotations
+
+import datetime
+import re
+import string
+
+from tomlkit._compat import decode
+from tomlkit._utils import RFC_3339_LOOSE
+from tomlkit._utils import _escaped
+from tomlkit._utils import parse_rfc3339
+from tomlkit.container import Container
+from tomlkit.exceptions import EmptyKeyError
+from tomlkit.exceptions import EmptyTableNameError
+from tomlkit.exceptions import InternalParserError
+from tomlkit.exceptions import InvalidCharInStringError
+from tomlkit.exceptions import InvalidControlChar
+from tomlkit.exceptions import InvalidDateError
+from tomlkit.exceptions import InvalidDateTimeError
+from tomlkit.exceptions import InvalidNumberError
+from tomlkit.exceptions import InvalidTimeError
+from tomlkit.exceptions import InvalidUnicodeValueError
+from tomlkit.exceptions import ParseError
+from tomlkit.exceptions import UnexpectedCharError
+from tomlkit.exceptions import UnexpectedEofError
+from tomlkit.items import AoT
+from tomlkit.items import Array
+from tomlkit.items import Bool
+from tomlkit.items import BoolType
+from tomlkit.items import Comment
+from tomlkit.items import Date
+from tomlkit.items import DateTime
+from tomlkit.items import Float
+from tomlkit.items import InlineTable
+from tomlkit.items import Integer
+from tomlkit.items import Item
+from tomlkit.items import Key
+from tomlkit.items import KeyType
+from tomlkit.items import Null
+from tomlkit.items import SingleKey
+from tomlkit.items import String
+from tomlkit.items import StringType
+from tomlkit.items import Table
+from tomlkit.items import Time
+from tomlkit.items import Trivia
+from tomlkit.items import Whitespace
+from tomlkit.source import Source
+from tomlkit.toml_char import TOMLChar
+from tomlkit.toml_document import TOMLDocument
+
+
+CTRL_I = 0x09 # Tab
+CTRL_J = 0x0A # Line feed
+CTRL_M = 0x0D # Carriage return
+CTRL_CHAR_LIMIT = 0x1F
+CHR_DEL = 0x7F
+
+
+class Parser:
+ """
+ Parser for TOML documents.
+ """
+
+ def __init__(self, string: str | bytes) -> None:
+ # Input to parse
+ self._src = Source(decode(string))
+
+ self._aot_stack: list[Key] = []
+
+ @property
+ def _state(self):
+ return self._src.state
+
+ @property
+ def _idx(self):
+ return self._src.idx
+
+ @property
+ def _current(self):
+ return self._src.current
+
+ @property
+ def _marker(self):
+ return self._src.marker
+
+ def extract(self) -> str:
+ """
+ Extracts the value between marker and index
+ """
+ return self._src.extract()
+
+ def inc(self, exception: type[ParseError] | None = None) -> bool:
+ """
+ Increments the parser if the end of the input has not been reached.
+ Returns whether or not it was able to advance.
+ """
+ return self._src.inc(exception=exception)
+
+ def inc_n(self, n: int, exception: type[ParseError] | None = None) -> bool:
+ """
+ Increments the parser by n characters
+ if the end of the input has not been reached.
+ """
+ return self._src.inc_n(n=n, exception=exception)
+
+ def consume(self, chars, min=0, max=-1):
+ """
+ Consume chars until min/max is satisfied is valid.
+ """
+ return self._src.consume(chars=chars, min=min, max=max)
+
+ def end(self) -> bool:
+ """
+ Returns True if the parser has reached the end of the input.
+ """
+ return self._src.end()
+
+ def mark(self) -> None:
+ """
+ Sets the marker to the index's current position
+ """
+ self._src.mark()
+
+ def parse_error(self, exception=ParseError, *args, **kwargs):
+ """
+ Creates a generic "parse error" at the current position.
+ """
+ return self._src.parse_error(exception, *args, **kwargs)
+
+ def parse(self) -> TOMLDocument:
+ body = TOMLDocument(True)
+
+ # Take all keyvals outside of tables/AoT's.
+ while not self.end():
+ # Break out if a table is found
+ if self._current == "[":
+ break
+
+ # Otherwise, take and append one KV
+ item = self._parse_item()
+ if not item:
+ break
+
+ key, value = item
+ if (key is not None and key.is_multi()) or not self._merge_ws(value, body):
+ # We actually have a table
+ try:
+ body.append(key, value)
+ except Exception as e:
+ raise self.parse_error(ParseError, str(e)) from e
+
+ self.mark()
+
+ while not self.end():
+ key, value = self._parse_table()
+ if isinstance(value, Table) and value.is_aot_element():
+ # This is just the first table in an AoT. Parse the rest of the array
+ # along with it.
+ value = self._parse_aot(value, key)
+
+ try:
+ body.append(key, value)
+ except Exception as e:
+ raise self.parse_error(ParseError, str(e)) from e
+
+ body.parsing(False)
+
+ return body
+
+ def _merge_ws(self, item: Item, container: Container) -> bool:
+ """
+ Merges the given Item with the last one currently in the given Container if
+ both are whitespace items.
+
+ Returns True if the items were merged.
+ """
+ last = container.last_item()
+ if not last:
+ return False
+
+ if not isinstance(item, Whitespace) or not isinstance(last, Whitespace):
+ return False
+
+ start = self._idx - (len(last.s) + len(item.s))
+ container.body[-1] = (
+ container.body[-1][0],
+ Whitespace(self._src[start : self._idx]),
+ )
+
+ return True
+
+ def _is_child(self, parent: Key, child: Key) -> bool:
+ """
+ Returns whether a key is strictly a child of another key.
+ AoT siblings are not considered children of one another.
+ """
+ parent_parts = tuple(parent)
+ child_parts = tuple(child)
+
+ if parent_parts == child_parts:
+ return False
+
+ return parent_parts == child_parts[: len(parent_parts)]
+
+ def _parse_item(self) -> tuple[Key | None, Item] | None:
+ """
+ Attempts to parse the next item and returns it, along with its key
+ if the item is value-like.
+ """
+ self.mark()
+ with self._state as state:
+ while True:
+ c = self._current
+ if c == "\n":
+ # Found a newline; Return all whitespace found up to this point.
+ self.inc()
+
+ return None, Whitespace(self.extract())
+ elif c in " \t\r":
+ # Skip whitespace.
+ if not self.inc():
+ return None, Whitespace(self.extract())
+ elif c == "#":
+ # Found a comment, parse it
+ indent = self.extract()
+ cws, comment, trail = self._parse_comment_trail()
+
+ return None, Comment(Trivia(indent, cws, comment, trail))
+ elif c == "[":
+ # Found a table, delegate to the calling function.
+ return
+ else:
+ # Beginning of a KV pair.
+ # Return to beginning of whitespace so it gets included
+ # as indentation for the KV about to be parsed.
+ state.restore = True
+ break
+
+ return self._parse_key_value(True)
+
+ def _parse_comment_trail(self, parse_trail: bool = True) -> tuple[str, str, str]:
+ """
+ Returns (comment_ws, comment, trail)
+ If there is no comment, comment_ws and comment will
+ simply be empty.
+ """
+ if self.end():
+ return "", "", ""
+
+ comment = ""
+ comment_ws = ""
+ self.mark()
+
+ while True:
+ c = self._current
+
+ if c == "\n":
+ break
+ elif c == "#":
+ comment_ws = self.extract()
+
+ self.mark()
+ self.inc() # Skip #
+
+ # The comment itself
+ while not self.end() and not self._current.is_nl():
+ code = ord(self._current)
+ if code == CHR_DEL or code <= CTRL_CHAR_LIMIT and code != CTRL_I:
+ raise self.parse_error(InvalidControlChar, code, "comments")
+
+ if not self.inc():
+ break
+
+ comment = self.extract()
+ self.mark()
+
+ break
+ elif c in " \t\r":
+ self.inc()
+ else:
+ raise self.parse_error(UnexpectedCharError, c)
+
+ if self.end():
+ break
+
+ trail = ""
+ if parse_trail:
+ while self._current.is_spaces() and self.inc():
+ pass
+
+ if self._current == "\r":
+ self.inc()
+
+ if self._current == "\n":
+ self.inc()
+
+ if self._idx != self._marker or self._current.is_ws():
+ trail = self.extract()
+
+ return comment_ws, comment, trail
+
+ def _parse_key_value(self, parse_comment: bool = False) -> tuple[Key, Item]:
+ # Leading indent
+ self.mark()
+
+ while self._current.is_spaces() and self.inc():
+ pass
+
+ indent = self.extract()
+
+ # Key
+ key = self._parse_key()
+
+ self.mark()
+
+ found_equals = self._current == "="
+ while self._current.is_kv_sep() and self.inc():
+ if self._current == "=":
+ if found_equals:
+ raise self.parse_error(UnexpectedCharError, "=")
+ else:
+ found_equals = True
+ if not found_equals:
+ raise self.parse_error(UnexpectedCharError, self._current)
+
+ if not key.sep:
+ key.sep = self.extract()
+ else:
+ key.sep += self.extract()
+
+ # Value
+ val = self._parse_value()
+ # Comment
+ if parse_comment:
+ cws, comment, trail = self._parse_comment_trail()
+ meta = val.trivia
+ if not meta.comment_ws:
+ meta.comment_ws = cws
+
+ meta.comment = comment
+ meta.trail = trail
+ else:
+ val.trivia.trail = ""
+
+ val.trivia.indent = indent
+
+ return key, val
+
+ def _parse_key(self) -> Key:
+ """
+ Parses a Key at the current position;
+ WS before the key must be exhausted first at the callsite.
+ """
+ self.mark()
+ while self._current.is_spaces() and self.inc():
+ # Skip any leading whitespace
+ pass
+ if self._current in "\"'":
+ return self._parse_quoted_key()
+ else:
+ return self._parse_bare_key()
+
+ def _parse_quoted_key(self) -> Key:
+ """
+ Parses a key enclosed in either single or double quotes.
+ """
+ # Extract the leading whitespace
+ original = self.extract()
+ quote_style = self._current
+ key_type = next((t for t in KeyType if t.value == quote_style), None)
+
+ if key_type is None:
+ raise RuntimeError("Should not have entered _parse_quoted_key()")
+
+ key_str = self._parse_string(
+ StringType.SLB if key_type == KeyType.Basic else StringType.SLL
+ )
+ if key_str._t.is_multiline():
+ raise self.parse_error(UnexpectedCharError, key_str._t.value)
+ original += key_str.as_string()
+ self.mark()
+ while self._current.is_spaces() and self.inc():
+ pass
+ original += self.extract()
+ key = SingleKey(str(key_str), t=key_type, sep="", original=original)
+ if self._current == ".":
+ self.inc()
+ key = key.concat(self._parse_key())
+
+ return key
+
+ def _parse_bare_key(self) -> Key:
+ """
+ Parses a bare key.
+ """
+ while (
+ self._current.is_bare_key_char() or self._current.is_spaces()
+ ) and self.inc():
+ pass
+
+ original = self.extract()
+ key = original.strip()
+ if not key:
+ # Empty key
+ raise self.parse_error(EmptyKeyError)
+
+ if " " in key:
+ # Bare key with spaces in it
+ raise self.parse_error(ParseError, f'Invalid key "{key}"')
+
+ key = SingleKey(key, KeyType.Bare, "", original)
+
+ if self._current == ".":
+ self.inc()
+ key = key.concat(self._parse_key())
+
+ return key
+
+ def _parse_value(self) -> Item:
+ """
+ Attempts to parse a value at the current position.
+ """
+ self.mark()
+ c = self._current
+ trivia = Trivia()
+
+ if c == StringType.SLB.value:
+ return self._parse_basic_string()
+ elif c == StringType.SLL.value:
+ return self._parse_literal_string()
+ elif c == BoolType.TRUE.value[0]:
+ return self._parse_true()
+ elif c == BoolType.FALSE.value[0]:
+ return self._parse_false()
+ elif c == "[":
+ return self._parse_array()
+ elif c == "{":
+ return self._parse_inline_table()
+ elif c in "+-" or self._peek(4) in {
+ "+inf",
+ "-inf",
+ "inf",
+ "+nan",
+ "-nan",
+ "nan",
+ }:
+ # Number
+ while self._current not in " \t\n\r#,]}" and self.inc():
+ pass
+
+ raw = self.extract()
+
+ item = self._parse_number(raw, trivia)
+ if item is not None:
+ return item
+
+ raise self.parse_error(InvalidNumberError)
+ elif c in string.digits:
+ # Integer, Float, Date, Time or DateTime
+ while self._current not in " \t\n\r#,]}" and self.inc():
+ pass
+
+ raw = self.extract()
+
+ m = RFC_3339_LOOSE.match(raw)
+ if m:
+ if m.group(1) and m.group(5):
+ # datetime
+ try:
+ dt = parse_rfc3339(raw)
+ assert isinstance(dt, datetime.datetime)
+ return DateTime(
+ dt.year,
+ dt.month,
+ dt.day,
+ dt.hour,
+ dt.minute,
+ dt.second,
+ dt.microsecond,
+ dt.tzinfo,
+ trivia,
+ raw,
+ )
+ except ValueError:
+ raise self.parse_error(InvalidDateTimeError) from None
+
+ if m.group(1):
+ try:
+ dt = parse_rfc3339(raw)
+ assert isinstance(dt, datetime.date)
+ date = Date(dt.year, dt.month, dt.day, trivia, raw)
+ self.mark()
+ while self._current not in "\t\n\r#,]}" and self.inc():
+ pass
+
+ time_raw = self.extract()
+ time_part = time_raw.rstrip()
+ trivia.comment_ws = time_raw[len(time_part) :]
+ if not time_part:
+ return date
+
+ dt = parse_rfc3339(raw + time_part)
+ assert isinstance(dt, datetime.datetime)
+ return DateTime(
+ dt.year,
+ dt.month,
+ dt.day,
+ dt.hour,
+ dt.minute,
+ dt.second,
+ dt.microsecond,
+ dt.tzinfo,
+ trivia,
+ raw + time_part,
+ )
+ except ValueError:
+ raise self.parse_error(InvalidDateError) from None
+
+ if m.group(5):
+ try:
+ t = parse_rfc3339(raw)
+ assert isinstance(t, datetime.time)
+ return Time(
+ t.hour,
+ t.minute,
+ t.second,
+ t.microsecond,
+ t.tzinfo,
+ trivia,
+ raw,
+ )
+ except ValueError:
+ raise self.parse_error(InvalidTimeError) from None
+
+ item = self._parse_number(raw, trivia)
+ if item is not None:
+ return item
+
+ raise self.parse_error(InvalidNumberError)
+ else:
+ raise self.parse_error(UnexpectedCharError, c)
+
+ def _parse_true(self):
+ return self._parse_bool(BoolType.TRUE)
+
+ def _parse_false(self):
+ return self._parse_bool(BoolType.FALSE)
+
+ def _parse_bool(self, style: BoolType) -> Bool:
+ with self._state:
+ style = BoolType(style)
+
+ # only keep parsing for bool if the characters match the style
+ # try consuming rest of chars in style
+ for c in style:
+ self.consume(c, min=1, max=1)
+
+ return Bool(style, Trivia())
+
+ def _parse_array(self) -> Array:
+ # Consume opening bracket, EOF here is an issue (middle of array)
+ self.inc(exception=UnexpectedEofError)
+
+ elems: list[Item] = []
+ prev_value = None
+ while True:
+ # consume whitespace
+ mark = self._idx
+ self.consume(TOMLChar.SPACES + TOMLChar.NL)
+ indent = self._src[mark : self._idx]
+ newline = set(TOMLChar.NL) & set(indent)
+ if newline:
+ elems.append(Whitespace(indent))
+ continue
+
+ # consume comment
+ if self._current == "#":
+ cws, comment, trail = self._parse_comment_trail(parse_trail=False)
+ elems.append(Comment(Trivia(indent, cws, comment, trail)))
+ continue
+
+ # consume indent
+ if indent:
+ elems.append(Whitespace(indent))
+ continue
+
+ # consume value
+ if not prev_value:
+ try:
+ elems.append(self._parse_value())
+ prev_value = True
+ continue
+ except UnexpectedCharError:
+ pass
+
+ # consume comma
+ if prev_value and self._current == ",":
+ self.inc(exception=UnexpectedEofError)
+ elems.append(Whitespace(","))
+ prev_value = False
+ continue
+
+ # consume closing bracket
+ if self._current == "]":
+ # consume closing bracket, EOF here doesn't matter
+ self.inc()
+ break
+
+ raise self.parse_error(UnexpectedCharError, self._current)
+
+ try:
+ res = Array(elems, Trivia())
+ except ValueError:
+ pass
+ else:
+ return res
+
+ def _parse_inline_table(self) -> InlineTable:
+ # consume opening bracket, EOF here is an issue (middle of array)
+ self.inc(exception=UnexpectedEofError)
+
+ elems = Container(True)
+ trailing_comma = None
+ while True:
+ # consume leading whitespace
+ mark = self._idx
+ self.consume(TOMLChar.SPACES)
+ raw = self._src[mark : self._idx]
+ if raw:
+ elems.add(Whitespace(raw))
+
+ if not trailing_comma:
+ # None: empty inline table
+ # False: previous key-value pair was not followed by a comma
+ if self._current == "}":
+ # consume closing bracket, EOF here doesn't matter
+ self.inc()
+ break
+
+ if (
+ trailing_comma is False
+ or trailing_comma is None
+ and self._current == ","
+ ):
+ # Either the previous key-value pair was not followed by a comma
+ # or the table has an unexpected leading comma.
+ raise self.parse_error(UnexpectedCharError, self._current)
+ else:
+ # True: previous key-value pair was followed by a comma
+ if self._current == "}" or self._current == ",":
+ raise self.parse_error(UnexpectedCharError, self._current)
+
+ key, val = self._parse_key_value(False)
+ elems.add(key, val)
+
+ # consume trailing whitespace
+ mark = self._idx
+ self.consume(TOMLChar.SPACES)
+ raw = self._src[mark : self._idx]
+ if raw:
+ elems.add(Whitespace(raw))
+
+ # consume trailing comma
+ trailing_comma = self._current == ","
+ if trailing_comma:
+ # consume closing bracket, EOF here is an issue (middle of inline table)
+ self.inc(exception=UnexpectedEofError)
+
+ return InlineTable(elems, Trivia())
+
+ def _parse_number(self, raw: str, trivia: Trivia) -> Item | None:
+ # Leading zeros are not allowed
+ sign = ""
+ if raw.startswith(("+", "-")):
+ sign = raw[0]
+ raw = raw[1:]
+
+ if len(raw) > 1 and (
+ raw.startswith("0")
+ and not raw.startswith(("0.", "0o", "0x", "0b", "0e"))
+ or sign
+ and raw.startswith(".")
+ ):
+ return None
+
+ if raw.startswith(("0o", "0x", "0b")) and sign:
+ return None
+
+ digits = "[0-9]"
+ base = 10
+ if raw.startswith("0b"):
+ digits = "[01]"
+ base = 2
+ elif raw.startswith("0o"):
+ digits = "[0-7]"
+ base = 8
+ elif raw.startswith("0x"):
+ digits = "[0-9a-f]"
+ base = 16
+
+ # Underscores should be surrounded by digits
+ clean = re.sub(f"(?i)(?<={digits})_(?={digits})", "", raw).lower()
+
+ if "_" in clean:
+ return None
+
+ if (
+ clean.endswith(".")
+ or not clean.startswith("0x")
+ and clean.split("e", 1)[0].endswith(".")
+ ):
+ return None
+
+ try:
+ return Integer(int(sign + clean, base), trivia, sign + raw)
+ except ValueError:
+ try:
+ return Float(float(sign + clean), trivia, sign + raw)
+ except ValueError:
+ return None
+
+ def _parse_literal_string(self) -> String:
+ with self._state:
+ return self._parse_string(StringType.SLL)
+
+ def _parse_basic_string(self) -> String:
+ with self._state:
+ return self._parse_string(StringType.SLB)
+
+ def _parse_escaped_char(self, multiline):
+ if multiline and self._current.is_ws():
+ # When the last non-whitespace character on a line is
+ # a \, it will be trimmed along with all whitespace
+ # (including newlines) up to the next non-whitespace
+ # character or closing delimiter.
+ # """\
+ # hello \
+ # world"""
+ tmp = ""
+ while self._current.is_ws():
+ tmp += self._current
+ # consume the whitespace, EOF here is an issue
+ # (middle of string)
+ self.inc(exception=UnexpectedEofError)
+ continue
+
+ # the escape followed by whitespace must have a newline
+ # before any other chars
+ if "\n" not in tmp:
+ raise self.parse_error(InvalidCharInStringError, self._current)
+
+ return ""
+
+ if self._current in _escaped:
+ c = _escaped[self._current]
+
+ # consume this char, EOF here is an issue (middle of string)
+ self.inc(exception=UnexpectedEofError)
+
+ return c
+
+ if self._current in {"u", "U"}:
+ # this needs to be a unicode
+ u, ue = self._peek_unicode(self._current == "U")
+ if u is not None:
+ # consume the U char and the unicode value
+ self.inc_n(len(ue) + 1)
+
+ return u
+
+ raise self.parse_error(InvalidUnicodeValueError)
+
+ raise self.parse_error(InvalidCharInStringError, self._current)
+
+ def _parse_string(self, delim: StringType) -> String:
+ # only keep parsing for string if the current character matches the delim
+ if self._current != delim.unit:
+ raise self.parse_error(
+ InternalParserError,
+ f"Invalid character for string type {delim}",
+ )
+
+ # consume the opening/first delim, EOF here is an issue
+ # (middle of string or middle of delim)
+ self.inc(exception=UnexpectedEofError)
+
+ if self._current == delim.unit:
+ # consume the closing/second delim, we do not care if EOF occurs as
+ # that would simply imply an empty single line string
+ if not self.inc() or self._current != delim.unit:
+ # Empty string
+ return String(delim, "", "", Trivia())
+
+ # consume the third delim, EOF here is an issue (middle of string)
+ self.inc(exception=UnexpectedEofError)
+
+ delim = delim.toggle() # convert delim to multi delim
+
+ self.mark() # to extract the original string with whitespace and all
+ value = ""
+
+ # A newline immediately following the opening delimiter will be trimmed.
+ if delim.is_multiline():
+ if self._current == "\n":
+ # consume the newline, EOF here is an issue (middle of string)
+ self.inc(exception=UnexpectedEofError)
+ else:
+ cur = self._current
+ with self._state(restore=True):
+ if self.inc():
+ cur += self._current
+ if cur == "\r\n":
+ self.inc_n(2, exception=UnexpectedEofError)
+
+ escaped = False # whether the previous key was ESCAPE
+ while True:
+ code = ord(self._current)
+ if (
+ delim.is_singleline()
+ and not escaped
+ and (code == CHR_DEL or code <= CTRL_CHAR_LIMIT and code != CTRL_I)
+ ) or (
+ delim.is_multiline()
+ and not escaped
+ and (
+ code == CHR_DEL
+ or code <= CTRL_CHAR_LIMIT
+ and code not in [CTRL_I, CTRL_J, CTRL_M]
+ )
+ ):
+ raise self.parse_error(InvalidControlChar, code, "strings")
+ elif not escaped and self._current == delim.unit:
+ # try to process current as a closing delim
+ original = self.extract()
+
+ close = ""
+ if delim.is_multiline():
+ # Consume the delimiters to see if we are at the end of the string
+ close = ""
+ while self._current == delim.unit:
+ close += self._current
+ self.inc()
+
+ if len(close) < 3:
+ # Not a triple quote, leave in result as-is.
+ # Adding back the characters we already consumed
+ value += close
+ continue
+
+ if len(close) == 3:
+ # We are at the end of the string
+ return String(delim, value, original, Trivia())
+
+ if len(close) >= 6:
+ raise self.parse_error(InvalidCharInStringError, self._current)
+
+ value += close[:-3]
+ original += close[:-3]
+
+ return String(delim, value, original, Trivia())
+ else:
+ # consume the closing delim, we do not care if EOF occurs as
+ # that would simply imply the end of self._src
+ self.inc()
+
+ return String(delim, value, original, Trivia())
+ elif delim.is_basic() and escaped:
+ # attempt to parse the current char as an escaped value, an exception
+ # is raised if this fails
+ value += self._parse_escaped_char(delim.is_multiline())
+
+ # no longer escaped
+ escaped = False
+ elif delim.is_basic() and self._current == "\\":
+ # the next char is being escaped
+ escaped = True
+
+ # consume this char, EOF here is an issue (middle of string)
+ self.inc(exception=UnexpectedEofError)
+ else:
+ # this is either a literal string where we keep everything as is,
+ # or this is not a special escaped char in a basic string
+ value += self._current
+
+ # consume this char, EOF here is an issue (middle of string)
+ self.inc(exception=UnexpectedEofError)
+
+ def _parse_table(
+ self, parent_name: Key | None = None, parent: Table | None = None
+ ) -> tuple[Key, Table | AoT]:
+ """
+ Parses a table element.
+ """
+ if self._current != "[":
+ raise self.parse_error(
+ InternalParserError, "_parse_table() called on non-bracket character."
+ )
+
+ indent = self.extract()
+ self.inc() # Skip opening bracket
+
+ if self.end():
+ raise self.parse_error(UnexpectedEofError)
+
+ is_aot = False
+ if self._current == "[":
+ if not self.inc():
+ raise self.parse_error(UnexpectedEofError)
+
+ is_aot = True
+ try:
+ key = self._parse_key()
+ except EmptyKeyError:
+ raise self.parse_error(EmptyTableNameError) from None
+ if self.end():
+ raise self.parse_error(UnexpectedEofError)
+ elif self._current != "]":
+ raise self.parse_error(UnexpectedCharError, self._current)
+
+ key.sep = ""
+ full_key = key
+ name_parts = tuple(key)
+ if any(" " in part.key.strip() and part.is_bare() for part in name_parts):
+ raise self.parse_error(
+ ParseError, f'Invalid table name "{full_key.as_string()}"'
+ )
+
+ missing_table = False
+ if parent_name:
+ parent_name_parts = tuple(parent_name)
+ else:
+ parent_name_parts = ()
+
+ if len(name_parts) > len(parent_name_parts) + 1:
+ missing_table = True
+
+ name_parts = name_parts[len(parent_name_parts) :]
+
+ values = Container(True)
+
+ self.inc() # Skip closing bracket
+ if is_aot:
+ # TODO: Verify close bracket
+ self.inc()
+
+ cws, comment, trail = self._parse_comment_trail()
+
+ result = Null()
+ table = Table(
+ values,
+ Trivia(indent, cws, comment, trail),
+ is_aot,
+ name=name_parts[0].key if name_parts else key.key,
+ display_name=full_key.as_string(),
+ is_super_table=False,
+ )
+
+ if len(name_parts) > 1:
+ if missing_table:
+ # Missing super table
+ # i.e. a table initialized like this: [foo.bar]
+ # without initializing [foo]
+ #
+ # So we have to create the parent tables
+ table = Table(
+ Container(True),
+ Trivia("", cws, comment, trail),
+ is_aot and name_parts[0] in self._aot_stack,
+ is_super_table=True,
+ name=name_parts[0].key,
+ )
+
+ result = table
+ key = name_parts[0]
+
+ for i, _name in enumerate(name_parts[1:]):
+ child = table.get(
+ _name,
+ Table(
+ Container(True),
+ Trivia(indent, cws, comment, trail),
+ is_aot and i == len(name_parts) - 2,
+ is_super_table=i < len(name_parts) - 2,
+ name=_name.key,
+ display_name=(
+ full_key.as_string() if i == len(name_parts) - 2 else None
+ ),
+ ),
+ )
+
+ if is_aot and i == len(name_parts) - 2:
+ table.raw_append(_name, AoT([child], name=table.name, parsed=True))
+ else:
+ table.raw_append(_name, child)
+
+ table = child
+ values = table.value
+ else:
+ if name_parts:
+ key = name_parts[0]
+
+ while not self.end():
+ item = self._parse_item()
+ if item:
+ _key, item = item
+ if not self._merge_ws(item, values):
+ table.raw_append(_key, item)
+ else:
+ if self._current == "[":
+ _, key_next = self._peek_table()
+
+ if self._is_child(full_key, key_next):
+ key_next, table_next = self._parse_table(full_key, table)
+
+ table.raw_append(key_next, table_next)
+
+ # Picking up any sibling
+ while not self.end():
+ _, key_next = self._peek_table()
+
+ if not self._is_child(full_key, key_next):
+ break
+
+ key_next, table_next = self._parse_table(full_key, table)
+
+ table.raw_append(key_next, table_next)
+
+ break
+ else:
+ raise self.parse_error(
+ InternalParserError,
+ "_parse_item() returned None on a non-bracket character.",
+ )
+ table.value._validate_out_of_order_table()
+ if isinstance(result, Null):
+ result = table
+
+ if is_aot and (not self._aot_stack or full_key != self._aot_stack[-1]):
+ result = self._parse_aot(result, full_key)
+
+ return key, result
+
+ def _peek_table(self) -> tuple[bool, Key]:
+ """
+ Peeks ahead non-intrusively by cloning then restoring the
+ initial state of the parser.
+
+ Returns the name of the table about to be parsed,
+ as well as whether it is part of an AoT.
+ """
+ # we always want to restore after exiting this scope
+ with self._state(save_marker=True, restore=True):
+ if self._current != "[":
+ raise self.parse_error(
+ InternalParserError,
+ "_peek_table() entered on non-bracket character",
+ )
+
+ # AoT
+ self.inc()
+ is_aot = False
+ if self._current == "[":
+ self.inc()
+ is_aot = True
+ try:
+ return is_aot, self._parse_key()
+ except EmptyKeyError:
+ raise self.parse_error(EmptyTableNameError) from None
+
+ def _parse_aot(self, first: Table, name_first: Key) -> AoT:
+ """
+ Parses all siblings of the provided table first and bundles them into
+ an AoT.
+ """
+ payload = [first]
+ self._aot_stack.append(name_first)
+ while not self.end():
+ is_aot_next, name_next = self._peek_table()
+ if is_aot_next and name_next == name_first:
+ _, table = self._parse_table(name_first)
+ payload.append(table)
+ else:
+ break
+
+ self._aot_stack.pop()
+
+ return AoT(payload, parsed=True)
+
+ def _peek(self, n: int) -> str:
+ """
+ Peeks ahead n characters.
+
+ n is the max number of characters that will be peeked.
+ """
+ # we always want to restore after exiting this scope
+ with self._state(restore=True):
+ buf = ""
+ for _ in range(n):
+ if self._current not in " \t\n\r#,]}" + self._src.EOF:
+ buf += self._current
+ self.inc()
+ continue
+
+ break
+ return buf
+
+ def _peek_unicode(self, is_long: bool) -> tuple[str | None, str | None]:
+ """
+ Peeks ahead non-intrusively by cloning then restoring the
+ initial state of the parser.
+
+ Returns the unicode value is it's a valid one else None.
+ """
+ # we always want to restore after exiting this scope
+ with self._state(save_marker=True, restore=True):
+ if self._current not in {"u", "U"}:
+ raise self.parse_error(
+ InternalParserError, "_peek_unicode() entered on non-unicode value"
+ )
+
+ self.inc() # Dropping prefix
+ self.mark()
+
+ if is_long:
+ chars = 8
+ else:
+ chars = 4
+
+ if not self.inc_n(chars):
+ value, extracted = None, None
+ else:
+ extracted = self.extract()
+
+ if extracted[0].lower() == "d" and extracted[1].strip("01234567"):
+ return None, None
+
+ try:
+ value = chr(int(extracted, 16))
+ except (ValueError, OverflowError):
+ value = None
+
+ return value, extracted
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/py.typed b/solutions/.venv/Lib/site-packages/tomlkit/py.typed
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/source.py b/solutions/.venv/Lib/site-packages/tomlkit/source.py
new file mode 100644
index 000000000..8a8b2c3d9
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/source.py
@@ -0,0 +1,180 @@
+from __future__ import annotations
+
+from copy import copy
+from typing import Any
+
+from tomlkit.exceptions import ParseError
+from tomlkit.exceptions import UnexpectedCharError
+from tomlkit.toml_char import TOMLChar
+
+
+class _State:
+ def __init__(
+ self,
+ source: Source,
+ save_marker: bool | None = False,
+ restore: bool | None = False,
+ ) -> None:
+ self._source = source
+ self._save_marker = save_marker
+ self.restore = restore
+
+ def __enter__(self) -> _State:
+ # Entering this context manager - save the state
+ self._chars = copy(self._source._chars)
+ self._idx = self._source._idx
+ self._current = self._source._current
+ self._marker = self._source._marker
+
+ return self
+
+ def __exit__(self, exception_type, exception_val, trace):
+ # Exiting this context manager - restore the prior state
+ if self.restore or exception_type:
+ self._source._chars = self._chars
+ self._source._idx = self._idx
+ self._source._current = self._current
+ if self._save_marker:
+ self._source._marker = self._marker
+
+
+class _StateHandler:
+ """
+ State preserver for the Parser.
+ """
+
+ def __init__(self, source: Source) -> None:
+ self._source = source
+ self._states = []
+
+ def __call__(self, *args, **kwargs):
+ return _State(self._source, *args, **kwargs)
+
+ def __enter__(self) -> _State:
+ state = self()
+ self._states.append(state)
+ return state.__enter__()
+
+ def __exit__(self, exception_type, exception_val, trace):
+ state = self._states.pop()
+ return state.__exit__(exception_type, exception_val, trace)
+
+
+class Source(str):
+ EOF = TOMLChar("\0")
+
+ def __init__(self, _: str) -> None:
+ super().__init__()
+
+ # Collection of TOMLChars
+ self._chars = iter([(i, TOMLChar(c)) for i, c in enumerate(self)])
+
+ self._idx = 0
+ self._marker = 0
+ self._current = TOMLChar("")
+
+ self._state = _StateHandler(self)
+
+ self.inc()
+
+ def reset(self):
+ # initialize both idx and current
+ self.inc()
+
+ # reset marker
+ self.mark()
+
+ @property
+ def state(self) -> _StateHandler:
+ return self._state
+
+ @property
+ def idx(self) -> int:
+ return self._idx
+
+ @property
+ def current(self) -> TOMLChar:
+ return self._current
+
+ @property
+ def marker(self) -> int:
+ return self._marker
+
+ def extract(self) -> str:
+ """
+ Extracts the value between marker and index
+ """
+ return self[self._marker : self._idx]
+
+ def inc(self, exception: type[ParseError] | None = None) -> bool:
+ """
+ Increments the parser if the end of the input has not been reached.
+ Returns whether or not it was able to advance.
+ """
+ try:
+ self._idx, self._current = next(self._chars)
+
+ return True
+ except StopIteration:
+ self._idx = len(self)
+ self._current = self.EOF
+ if exception:
+ raise self.parse_error(exception) from None
+
+ return False
+
+ def inc_n(self, n: int, exception: type[ParseError] | None = None) -> bool:
+ """
+ Increments the parser by n characters
+ if the end of the input has not been reached.
+ """
+ return all(self.inc(exception=exception) for _ in range(n))
+
+ def consume(self, chars, min=0, max=-1):
+ """
+ Consume chars until min/max is satisfied is valid.
+ """
+ while self.current in chars and max != 0:
+ min -= 1
+ max -= 1
+ if not self.inc():
+ break
+
+ # failed to consume minimum number of characters
+ if min > 0:
+ raise self.parse_error(UnexpectedCharError, self.current)
+
+ def end(self) -> bool:
+ """
+ Returns True if the parser has reached the end of the input.
+ """
+ return self._current is self.EOF
+
+ def mark(self) -> None:
+ """
+ Sets the marker to the index's current position
+ """
+ self._marker = self._idx
+
+ def parse_error(
+ self,
+ exception: type[ParseError] = ParseError,
+ *args: Any,
+ **kwargs: Any,
+ ) -> ParseError:
+ """
+ Creates a generic "parse error" at the current position.
+ """
+ line, col = self._to_linecol()
+
+ return exception(line, col, *args, **kwargs)
+
+ def _to_linecol(self) -> tuple[int, int]:
+ cur = 0
+ for i, line in enumerate(self.splitlines()):
+ if cur + len(line) + 1 > self.idx:
+ return (i + 1, self.idx - cur)
+
+ cur += len(line) + 1
+
+ return len(self.splitlines()), 0
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/toml_char.py b/solutions/.venv/Lib/site-packages/tomlkit/toml_char.py
new file mode 100644
index 000000000..b4bb4110c
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/toml_char.py
@@ -0,0 +1,52 @@
+import string
+
+
+class TOMLChar(str):
+ def __init__(self, c):
+ super().__init__()
+
+ if len(self) > 1:
+ raise ValueError("A TOML character must be of length 1")
+
+ BARE = string.ascii_letters + string.digits + "-_"
+ KV = "= \t"
+ NUMBER = string.digits + "+-_.e"
+ SPACES = " \t"
+ NL = "\n\r"
+ WS = SPACES + NL
+
+ def is_bare_key_char(self) -> bool:
+ """
+ Whether the character is a valid bare key name or not.
+ """
+ return self in self.BARE
+
+ def is_kv_sep(self) -> bool:
+ """
+ Whether the character is a valid key/value separator or not.
+ """
+ return self in self.KV
+
+ def is_int_float_char(self) -> bool:
+ """
+ Whether the character if a valid integer or float value character or not.
+ """
+ return self in self.NUMBER
+
+ def is_ws(self) -> bool:
+ """
+ Whether the character is a whitespace character or not.
+ """
+ return self in self.WS
+
+ def is_nl(self) -> bool:
+ """
+ Whether the character is a new line character or not.
+ """
+ return self in self.NL
+
+ def is_spaces(self) -> bool:
+ """
+ Whether the character is a space or not
+ """
+ return self in self.SPACES
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/toml_document.py b/solutions/.venv/Lib/site-packages/tomlkit/toml_document.py
new file mode 100644
index 000000000..71fac2e10
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/toml_document.py
@@ -0,0 +1,7 @@
+from tomlkit.container import Container
+
+
+class TOMLDocument(Container):
+ """
+ A TOML document.
+ """
diff --git a/solutions/.venv/Lib/site-packages/tomlkit/toml_file.py b/solutions/.venv/Lib/site-packages/tomlkit/toml_file.py
new file mode 100644
index 000000000..745913080
--- /dev/null
+++ b/solutions/.venv/Lib/site-packages/tomlkit/toml_file.py
@@ -0,0 +1,58 @@
+import os
+import re
+
+from typing import TYPE_CHECKING
+
+from tomlkit.api import loads
+from tomlkit.toml_document import TOMLDocument
+
+
+if TYPE_CHECKING:
+ from _typeshed import StrPath as _StrPath
+else:
+ from typing import Union
+
+ _StrPath = Union[str, os.PathLike]
+
+
+class TOMLFile:
+ """
+ Represents a TOML file.
+
+ :param path: path to the TOML file
+ """
+
+ def __init__(self, path: _StrPath) -> None:
+ self._path = path
+ self._linesep = os.linesep
+
+ def read(self) -> TOMLDocument:
+ """Read the file content as a :class:`tomlkit.toml_document.TOMLDocument`."""
+ with open(self._path, encoding="utf-8", newline="") as f:
+ content = f.read()
+
+ # check if consistent line endings
+ num_newline = content.count("\n")
+ if num_newline > 0:
+ num_win_eol = content.count("\r\n")
+ if num_win_eol == num_newline:
+ self._linesep = "\r\n"
+ elif num_win_eol == 0:
+ self._linesep = "\n"
+ else:
+ self._linesep = "mixed"
+
+ return loads(content)
+
+ def write(self, data: TOMLDocument) -> None:
+ """Write the TOMLDocument to the file."""
+ content = data.as_string()
+
+ # apply linesep
+ if self._linesep == "\n":
+ content = content.replace("\r\n", "\n")
+ elif self._linesep == "\r\n":
+ content = re.sub(r"(?<!\r)\n", "\r\n", content)
+
+ with open(self._path, "w", encoding="utf-8", newline="") as f:
+ f.write(content)
diff --git a/solutions/.venv/Scripts/Activate.ps1 b/solutions/.venv/Scripts/Activate.ps1
new file mode 100644
index 000000000..e4891d869
--- /dev/null
+++ b/solutions/.venv/Scripts/Activate.ps1
@@ -0,0 +1,502 @@
+<#
+.Synopsis
+Activate a Python virtual environment for the current PowerShell session.
+
+.Description
+Pushes the python executable for a virtual environment to the front of the
+$Env:PATH environment variable and sets the prompt to signify that you are
+in a Python virtual environment. Makes use of the command line switches as
+well as the `pyvenv.cfg` file values present in the virtual environment.
+
+.Parameter VenvDir
+Path to the directory that contains the virtual environment to activate. The
+default value for this is the parent of the directory that the Activate.ps1
+script is located within.
+
+.Parameter Prompt
+The prompt prefix to display when this virtual environment is activated. By
+default, this prompt is the name of the virtual environment folder (VenvDir)
+surrounded by parentheses and followed by a single space (ie. '(.venv) ').
+
+.Example
+Activate.ps1
+Activates the Python virtual environment that contains the Activate.ps1 script.
+
+.Example
+Activate.ps1 -Verbose
+Activates the Python virtual environment that contains the Activate.ps1 script,
+and shows extra information about the activation as it executes.
+
+.Example
+Activate.ps1 -VenvDir C:\Users\MyUser\Common\.venv
+Activates the Python virtual environment located in the specified location.
+
+.Example
+Activate.ps1 -Prompt "MyPython"
+Activates the Python virtual environment that contains the Activate.ps1 script,
+and prefixes the current prompt with the specified string (surrounded in
+parentheses) while the virtual environment is active.
+
+.Notes
+On Windows, it may be required to enable this Activate.ps1 script by setting the
+execution policy for the user. You can do this by issuing the following PowerShell
+command:
+
+PS C:\> Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
+
+For more information on Execution Policies:
+https://go.microsoft.com/fwlink/?LinkID=135170
+
+#>
+Param(
+ [Parameter(Mandatory = $false)]
+ [String]
+ $VenvDir,
+ [Parameter(Mandatory = $false)]
+ [String]
+ $Prompt
+)
+
+<# Function declarations --------------------------------------------------- #>
+
+<#
+.Synopsis
+Remove all shell session elements added by the Activate script, including the
+addition of the virtual environment's Python executable from the beginning of
+the PATH variable.
+
+.Parameter NonDestructive
+If present, do not remove this function from the global namespace for the
+session.
+
+#>
+function global:deactivate ([switch]$NonDestructive) {
+ # Revert to original values
+
+ # The prior prompt:
+ if (Test-Path -Path Function:_OLD_VIRTUAL_PROMPT) {
+ Copy-Item -Path Function:_OLD_VIRTUAL_PROMPT -Destination Function:prompt
+ Remove-Item -Path Function:_OLD_VIRTUAL_PROMPT
+ }
+
+ # The prior PYTHONHOME:
+ if (Test-Path -Path Env:_OLD_VIRTUAL_PYTHONHOME) {
+ Copy-Item -Path Env:_OLD_VIRTUAL_PYTHONHOME -Destination Env:PYTHONHOME
+ Remove-Item -Path Env:_OLD_VIRTUAL_PYTHONHOME
+ }
+
+ # The prior PATH:
+ if (Test-Path -Path Env:_OLD_VIRTUAL_PATH) {
+ Copy-Item -Path Env:_OLD_VIRTUAL_PATH -Destination Env:PATH
+ Remove-Item -Path Env:_OLD_VIRTUAL_PATH
+ }
+
+ # Just remove the VIRTUAL_ENV altogether:
+ if (Test-Path -Path Env:VIRTUAL_ENV) {
+ Remove-Item -Path env:VIRTUAL_ENV
+ }
+
+ # Just remove VIRTUAL_ENV_PROMPT altogether.
+ if (Test-Path -Path Env:VIRTUAL_ENV_PROMPT) {
+ Remove-Item -Path env:VIRTUAL_ENV_PROMPT
+ }
+
+ # Just remove the _PYTHON_VENV_PROMPT_PREFIX altogether:
+ if (Get-Variable -Name "_PYTHON_VENV_PROMPT_PREFIX" -ErrorAction SilentlyContinue) {
+ Remove-Variable -Name _PYTHON_VENV_PROMPT_PREFIX -Scope Global -Force
+ }
+
+ # Leave deactivate function in the global namespace if requested:
+ if (-not $NonDestructive) {
+ Remove-Item -Path function:deactivate
+ }
+}
+
+<#
+.Description
+Get-PyVenvConfig parses the values from the pyvenv.cfg file located in the
+given folder, and returns them in a map.
+
+For each line in the pyvenv.cfg file, if that line can be parsed into exactly
+two strings separated by `=` (with any amount of whitespace surrounding the =)
+then it is considered a `key = value` line. The left hand string is the key,
+the right hand is the value.
+
+If the value starts with a `'` or a `"` then the first and last character is
+stripped from the value before being captured.
+
+.Parameter ConfigDir
+Path to the directory that contains the `pyvenv.cfg` file.
+#>
+function Get-PyVenvConfig(
+ [String]
+ $ConfigDir
+) {
+ Write-Verbose "Given ConfigDir=$ConfigDir, obtain values in pyvenv.cfg"
+
+ # Ensure the file exists, and issue a warning if it doesn't (but still allow the function to continue).
+ $pyvenvConfigPath = Join-Path -Resolve -Path $ConfigDir -ChildPath 'pyvenv.cfg' -ErrorAction Continue
+
+ # An empty map will be returned if no config file is found.
+ $pyvenvConfig = @{ }
+
+ if ($pyvenvConfigPath) {
+
+ Write-Verbose "File exists, parse `key = value` lines"
+ $pyvenvConfigContent = Get-Content -Path $pyvenvConfigPath
+
+ $pyvenvConfigContent | ForEach-Object {
+ $keyval = $PSItem -split "\s*=\s*", 2
+ if ($keyval[0] -and $keyval[1]) {
+ $val = $keyval[1]
+
+ # Remove extraneous quotations around a string value.
+ if ("'""".Contains($val.Substring(0, 1))) {
+ $val = $val.Substring(1, $val.Length - 2)
+ }
+
+ $pyvenvConfig[$keyval[0]] = $val
+ Write-Verbose "Adding Key: '$($keyval[0])'='$val'"
+ }
+ }
+ }
+ return $pyvenvConfig
+}
+
+
+<# Begin Activate script --------------------------------------------------- #>
+
+# Determine the containing directory of this script
+$VenvExecPath = Split-Path -Parent $MyInvocation.MyCommand.Definition
+$VenvExecDir = Get-Item -Path $VenvExecPath
+
+Write-Verbose "Activation script is located in path: '$VenvExecPath'"
+Write-Verbose "VenvExecDir Fullname: '$($VenvExecDir.FullName)"
+Write-Verbose "VenvExecDir Name: '$($VenvExecDir.Name)"
+
+# Set values required in priority: CmdLine, ConfigFile, Default
+# First, get the location of the virtual environment, it might not be
+# VenvExecDir if specified on the command line.
+if ($VenvDir) {
+ Write-Verbose "VenvDir given as parameter, using '$VenvDir' to determine values"
+}
+else {
+ Write-Verbose "VenvDir not given as a parameter, using parent directory name as VenvDir."
+ $VenvDir = $VenvExecDir.Parent.FullName.TrimEnd("\\/")
+ Write-Verbose "VenvDir=$VenvDir"
+}
+
+# Next, read the `pyvenv.cfg` file to determine any required value such
+# as `prompt`.
+$pyvenvCfg = Get-PyVenvConfig -ConfigDir $VenvDir
+
+# Next, set the prompt from the command line, or the config file, or
+# just use the name of the virtual environment folder.
+if ($Prompt) {
+ Write-Verbose "Prompt specified as argument, using '$Prompt'"
+}
+else {
+ Write-Verbose "Prompt not specified as argument to script, checking pyvenv.cfg value"
+ if ($pyvenvCfg -and $pyvenvCfg['prompt']) {
+ Write-Verbose " Setting based on value in pyvenv.cfg='$($pyvenvCfg['prompt'])'"
+ $Prompt = $pyvenvCfg['prompt'];
+ }
+ else {
+ Write-Verbose " Setting prompt based on parent's directory's name. (Is the directory name passed to venv module when creating the virtual environment)"
+ Write-Verbose " Got leaf-name of $VenvDir='$(Split-Path -Path $venvDir -Leaf)'"
+ $Prompt = Split-Path -Path $venvDir -Leaf
+ }
+}
+
+Write-Verbose "Prompt = '$Prompt'"
+Write-Verbose "VenvDir='$VenvDir'"
+
+# Deactivate any currently active virtual environment, but leave the
+# deactivate function in place.
+deactivate -nondestructive
+
+# Now set the environment variable VIRTUAL_ENV, used by many tools to determine
+# that there is an activated venv.
+$env:VIRTUAL_ENV = $VenvDir
+
+if (-not $Env:VIRTUAL_ENV_DISABLE_PROMPT) {
+
+ Write-Verbose "Setting prompt to '$Prompt'"
+
+ # Set the prompt to include the env name
+ # Make sure _OLD_VIRTUAL_PROMPT is global
+ function global:_OLD_VIRTUAL_PROMPT { "" }
+ Copy-Item -Path function:prompt -Destination function:_OLD_VIRTUAL_PROMPT
+ New-Variable -Name _PYTHON_VENV_PROMPT_PREFIX -Description "Python virtual environment prompt prefix" -Scope Global -Option ReadOnly -Visibility Public -Value $Prompt
+
+ function global:prompt {
+ Write-Host -NoNewline -ForegroundColor Green "($_PYTHON_VENV_PROMPT_PREFIX) "
+ _OLD_VIRTUAL_PROMPT
+ }
+ $env:VIRTUAL_ENV_PROMPT = $Prompt
+}
+
+# Clear PYTHONHOME
+if (Test-Path -Path Env:PYTHONHOME) {
+ Copy-Item -Path Env:PYTHONHOME -Destination Env:_OLD_VIRTUAL_PYTHONHOME
+ Remove-Item -Path Env:PYTHONHOME
+}
+
+# Add the venv to the PATH
+Copy-Item -Path Env:PATH -Destination Env:_OLD_VIRTUAL_PATH
+$Env:PATH = "$VenvExecDir$([System.IO.Path]::PathSeparator)$Env:PATH"
+
+# SIG # Begin signature block
+# MIIvJAYJKoZIhvcNAQcCoIIvFTCCLxECAQExDzANBglghkgBZQMEAgEFADB5Bgor
+# BgEEAYI3AgEEoGswaTA0BgorBgEEAYI3AgEeMCYCAwEAAAQQH8w7YFlLCE63JNLG
+# KX7zUQIBAAIBAAIBAAIBAAIBADAxMA0GCWCGSAFlAwQCAQUABCBnL745ElCYk8vk
+# dBtMuQhLeWJ3ZGfzKW4DHCYzAn+QB6CCE8MwggWQMIIDeKADAgECAhAFmxtXno4h
+# MuI5B72nd3VcMA0GCSqGSIb3DQEBDAUAMGIxCzAJBgNVBAYTAlVTMRUwEwYDVQQK
+# EwxEaWdpQ2VydCBJbmMxGTAXBgNVBAsTEHd3dy5kaWdpY2VydC5jb20xITAfBgNV
+# BAMTGERpZ2lDZXJ0IFRydXN0ZWQgUm9vdCBHNDAeFw0xMzA4MDExMjAwMDBaFw0z
+# ODAxMTUxMjAwMDBaMGIxCzAJBgNVBAYTAlVTMRUwEwYDVQQKEwxEaWdpQ2VydCBJ
+# bmMxGTAXBgNVBAsTEHd3dy5kaWdpY2VydC5jb20xITAfBgNVBAMTGERpZ2lDZXJ0
+# IFRydXN0ZWQgUm9vdCBHNDCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIB
+# AL/mkHNo3rvkXUo8MCIwaTPswqclLskhPfKK2FnC4SmnPVirdprNrnsbhA3EMB/z
+# G6Q4FutWxpdtHauyefLKEdLkX9YFPFIPUh/GnhWlfr6fqVcWWVVyr2iTcMKyunWZ
+# anMylNEQRBAu34LzB4TmdDttceItDBvuINXJIB1jKS3O7F5OyJP4IWGbNOsFxl7s
+# Wxq868nPzaw0QF+xembud8hIqGZXV59UWI4MK7dPpzDZVu7Ke13jrclPXuU15zHL
+# 2pNe3I6PgNq2kZhAkHnDeMe2scS1ahg4AxCN2NQ3pC4FfYj1gj4QkXCrVYJBMtfb
+# BHMqbpEBfCFM1LyuGwN1XXhm2ToxRJozQL8I11pJpMLmqaBn3aQnvKFPObURWBf3
+# JFxGj2T3wWmIdph2PVldQnaHiZdpekjw4KISG2aadMreSx7nDmOu5tTvkpI6nj3c
+# AORFJYm2mkQZK37AlLTSYW3rM9nF30sEAMx9HJXDj/chsrIRt7t/8tWMcCxBYKqx
+# YxhElRp2Yn72gLD76GSmM9GJB+G9t+ZDpBi4pncB4Q+UDCEdslQpJYls5Q5SUUd0
+# viastkF13nqsX40/ybzTQRESW+UQUOsxxcpyFiIJ33xMdT9j7CFfxCBRa2+xq4aL
+# T8LWRV+dIPyhHsXAj6KxfgommfXkaS+YHS312amyHeUbAgMBAAGjQjBAMA8GA1Ud
+# EwEB/wQFMAMBAf8wDgYDVR0PAQH/BAQDAgGGMB0GA1UdDgQWBBTs1+OC0nFdZEzf
+# Lmc/57qYrhwPTzANBgkqhkiG9w0BAQwFAAOCAgEAu2HZfalsvhfEkRvDoaIAjeNk
+# aA9Wz3eucPn9mkqZucl4XAwMX+TmFClWCzZJXURj4K2clhhmGyMNPXnpbWvWVPjS
+# PMFDQK4dUPVS/JA7u5iZaWvHwaeoaKQn3J35J64whbn2Z006Po9ZOSJTROvIXQPK
+# 7VB6fWIhCoDIc2bRoAVgX+iltKevqPdtNZx8WorWojiZ83iL9E3SIAveBO6Mm0eB
+# cg3AFDLvMFkuruBx8lbkapdvklBtlo1oepqyNhR6BvIkuQkRUNcIsbiJeoQjYUIp
+# 5aPNoiBB19GcZNnqJqGLFNdMGbJQQXE9P01wI4YMStyB0swylIQNCAmXHE/A7msg
+# dDDS4Dk0EIUhFQEI6FUy3nFJ2SgXUE3mvk3RdazQyvtBuEOlqtPDBURPLDab4vri
+# RbgjU2wGb2dVf0a1TD9uKFp5JtKkqGKX0h7i7UqLvBv9R0oN32dmfrJbQdA75PQ7
+# 9ARj6e/CVABRoIoqyc54zNXqhwQYs86vSYiv85KZtrPmYQ/ShQDnUBrkG5WdGaG5
+# nLGbsQAe79APT0JsyQq87kP6OnGlyE0mpTX9iV28hWIdMtKgK1TtmlfB2/oQzxm3
+# i0objwG2J5VT6LaJbVu8aNQj6ItRolb58KaAoNYes7wPD1N1KarqE3fk3oyBIa0H
+# EEcRrYc9B9F1vM/zZn4wggawMIIEmKADAgECAhAIrUCyYNKcTJ9ezam9k67ZMA0G
+# CSqGSIb3DQEBDAUAMGIxCzAJBgNVBAYTAlVTMRUwEwYDVQQKEwxEaWdpQ2VydCBJ
+# bmMxGTAXBgNVBAsTEHd3dy5kaWdpY2VydC5jb20xITAfBgNVBAMTGERpZ2lDZXJ0
+# IFRydXN0ZWQgUm9vdCBHNDAeFw0yMTA0MjkwMDAwMDBaFw0zNjA0MjgyMzU5NTla
+# MGkxCzAJBgNVBAYTAlVTMRcwFQYDVQQKEw5EaWdpQ2VydCwgSW5jLjFBMD8GA1UE
+# AxM4RGlnaUNlcnQgVHJ1c3RlZCBHNCBDb2RlIFNpZ25pbmcgUlNBNDA5NiBTSEEz
+# ODQgMjAyMSBDQTEwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQDVtC9C
+# 0CiteLdd1TlZG7GIQvUzjOs9gZdwxbvEhSYwn6SOaNhc9es0JAfhS0/TeEP0F9ce
+# 2vnS1WcaUk8OoVf8iJnBkcyBAz5NcCRks43iCH00fUyAVxJrQ5qZ8sU7H/Lvy0da
+# E6ZMswEgJfMQ04uy+wjwiuCdCcBlp/qYgEk1hz1RGeiQIXhFLqGfLOEYwhrMxe6T
+# SXBCMo/7xuoc82VokaJNTIIRSFJo3hC9FFdd6BgTZcV/sk+FLEikVoQ11vkunKoA
+# FdE3/hoGlMJ8yOobMubKwvSnowMOdKWvObarYBLj6Na59zHh3K3kGKDYwSNHR7Oh
+# D26jq22YBoMbt2pnLdK9RBqSEIGPsDsJ18ebMlrC/2pgVItJwZPt4bRc4G/rJvmM
+# 1bL5OBDm6s6R9b7T+2+TYTRcvJNFKIM2KmYoX7BzzosmJQayg9Rc9hUZTO1i4F4z
+# 8ujo7AqnsAMrkbI2eb73rQgedaZlzLvjSFDzd5Ea/ttQokbIYViY9XwCFjyDKK05
+# huzUtw1T0PhH5nUwjewwk3YUpltLXXRhTT8SkXbev1jLchApQfDVxW0mdmgRQRNY
+# mtwmKwH0iU1Z23jPgUo+QEdfyYFQc4UQIyFZYIpkVMHMIRroOBl8ZhzNeDhFMJlP
+# /2NPTLuqDQhTQXxYPUez+rbsjDIJAsxsPAxWEQIDAQABo4IBWTCCAVUwEgYDVR0T
+# AQH/BAgwBgEB/wIBADAdBgNVHQ4EFgQUaDfg67Y7+F8Rhvv+YXsIiGX0TkIwHwYD
+# VR0jBBgwFoAU7NfjgtJxXWRM3y5nP+e6mK4cD08wDgYDVR0PAQH/BAQDAgGGMBMG
+# A1UdJQQMMAoGCCsGAQUFBwMDMHcGCCsGAQUFBwEBBGswaTAkBggrBgEFBQcwAYYY
+# aHR0cDovL29jc3AuZGlnaWNlcnQuY29tMEEGCCsGAQUFBzAChjVodHRwOi8vY2Fj
+# ZXJ0cy5kaWdpY2VydC5jb20vRGlnaUNlcnRUcnVzdGVkUm9vdEc0LmNydDBDBgNV
+# HR8EPDA6MDigNqA0hjJodHRwOi8vY3JsMy5kaWdpY2VydC5jb20vRGlnaUNlcnRU
+# cnVzdGVkUm9vdEc0LmNybDAcBgNVHSAEFTATMAcGBWeBDAEDMAgGBmeBDAEEATAN
+# BgkqhkiG9w0BAQwFAAOCAgEAOiNEPY0Idu6PvDqZ01bgAhql+Eg08yy25nRm95Ry
+# sQDKr2wwJxMSnpBEn0v9nqN8JtU3vDpdSG2V1T9J9Ce7FoFFUP2cvbaF4HZ+N3HL
+# IvdaqpDP9ZNq4+sg0dVQeYiaiorBtr2hSBh+3NiAGhEZGM1hmYFW9snjdufE5Btf
+# Q/g+lP92OT2e1JnPSt0o618moZVYSNUa/tcnP/2Q0XaG3RywYFzzDaju4ImhvTnh
+# OE7abrs2nfvlIVNaw8rpavGiPttDuDPITzgUkpn13c5UbdldAhQfQDN8A+KVssIh
+# dXNSy0bYxDQcoqVLjc1vdjcshT8azibpGL6QB7BDf5WIIIJw8MzK7/0pNVwfiThV
+# 9zeKiwmhywvpMRr/LhlcOXHhvpynCgbWJme3kuZOX956rEnPLqR0kq3bPKSchh/j
+# wVYbKyP/j7XqiHtwa+aguv06P0WmxOgWkVKLQcBIhEuWTatEQOON8BUozu3xGFYH
+# Ki8QxAwIZDwzj64ojDzLj4gLDb879M4ee47vtevLt/B3E+bnKD+sEq6lLyJsQfmC
+# XBVmzGwOysWGw/YmMwwHS6DTBwJqakAwSEs0qFEgu60bhQjiWQ1tygVQK+pKHJ6l
+# /aCnHwZ05/LWUpD9r4VIIflXO7ScA+2GRfS0YW6/aOImYIbqyK+p/pQd52MbOoZW
+# eE4wggd3MIIFX6ADAgECAhAHHxQbizANJfMU6yMM0NHdMA0GCSqGSIb3DQEBCwUA
+# MGkxCzAJBgNVBAYTAlVTMRcwFQYDVQQKEw5EaWdpQ2VydCwgSW5jLjFBMD8GA1UE
+# AxM4RGlnaUNlcnQgVHJ1c3RlZCBHNCBDb2RlIFNpZ25pbmcgUlNBNDA5NiBTSEEz
+# ODQgMjAyMSBDQTEwHhcNMjIwMTE3MDAwMDAwWhcNMjUwMTE1MjM1OTU5WjB8MQsw
+# CQYDVQQGEwJVUzEPMA0GA1UECBMGT3JlZ29uMRIwEAYDVQQHEwlCZWF2ZXJ0b24x
+# IzAhBgNVBAoTGlB5dGhvbiBTb2Z0d2FyZSBGb3VuZGF0aW9uMSMwIQYDVQQDExpQ
+# eXRob24gU29mdHdhcmUgRm91bmRhdGlvbjCCAiIwDQYJKoZIhvcNAQEBBQADggIP
+# ADCCAgoCggIBAKgc0BTT+iKbtK6f2mr9pNMUTcAJxKdsuOiSYgDFfwhjQy89koM7
+# uP+QV/gwx8MzEt3c9tLJvDccVWQ8H7mVsk/K+X+IufBLCgUi0GGAZUegEAeRlSXx
+# xhYScr818ma8EvGIZdiSOhqjYc4KnfgfIS4RLtZSrDFG2tN16yS8skFa3IHyvWdb
+# D9PvZ4iYNAS4pjYDRjT/9uzPZ4Pan+53xZIcDgjiTwOh8VGuppxcia6a7xCyKoOA
+# GjvCyQsj5223v1/Ig7Dp9mGI+nh1E3IwmyTIIuVHyK6Lqu352diDY+iCMpk9Zanm
+# SjmB+GMVs+H/gOiofjjtf6oz0ki3rb7sQ8fTnonIL9dyGTJ0ZFYKeb6BLA66d2GA
+# LwxZhLe5WH4Np9HcyXHACkppsE6ynYjTOd7+jN1PRJahN1oERzTzEiV6nCO1M3U1
+# HbPTGyq52IMFSBM2/07WTJSbOeXjvYR7aUxK9/ZkJiacl2iZI7IWe7JKhHohqKuc
+# eQNyOzxTakLcRkzynvIrk33R9YVqtB4L6wtFxhUjvDnQg16xot2KVPdfyPAWd81w
+# tZADmrUtsZ9qG79x1hBdyOl4vUtVPECuyhCxaw+faVjumapPUnwo8ygflJJ74J+B
+# Yxf6UuD7m8yzsfXWkdv52DjL74TxzuFTLHPyARWCSCAbzn3ZIly+qIqDAgMBAAGj
+# ggIGMIICAjAfBgNVHSMEGDAWgBRoN+Drtjv4XxGG+/5hewiIZfROQjAdBgNVHQ4E
+# FgQUt/1Teh2XDuUj2WW3siYWJgkZHA8wDgYDVR0PAQH/BAQDAgeAMBMGA1UdJQQM
+# MAoGCCsGAQUFBwMDMIG1BgNVHR8Ega0wgaowU6BRoE+GTWh0dHA6Ly9jcmwzLmRp
+# Z2ljZXJ0LmNvbS9EaWdpQ2VydFRydXN0ZWRHNENvZGVTaWduaW5nUlNBNDA5NlNI
+# QTM4NDIwMjFDQTEuY3JsMFOgUaBPhk1odHRwOi8vY3JsNC5kaWdpY2VydC5jb20v
+# RGlnaUNlcnRUcnVzdGVkRzRDb2RlU2lnbmluZ1JTQTQwOTZTSEEzODQyMDIxQ0Ex
+# LmNybDA+BgNVHSAENzA1MDMGBmeBDAEEATApMCcGCCsGAQUFBwIBFhtodHRwOi8v
+# d3d3LmRpZ2ljZXJ0LmNvbS9DUFMwgZQGCCsGAQUFBwEBBIGHMIGEMCQGCCsGAQUF
+# BzABhhhodHRwOi8vb2NzcC5kaWdpY2VydC5jb20wXAYIKwYBBQUHMAKGUGh0dHA6
+# Ly9jYWNlcnRzLmRpZ2ljZXJ0LmNvbS9EaWdpQ2VydFRydXN0ZWRHNENvZGVTaWdu
+# aW5nUlNBNDA5NlNIQTM4NDIwMjFDQTEuY3J0MAwGA1UdEwEB/wQCMAAwDQYJKoZI
+# hvcNAQELBQADggIBABxv4AeV/5ltkELHSC63fXAFYS5tadcWTiNc2rskrNLrfH1N
+# s0vgSZFoQxYBFKI159E8oQQ1SKbTEubZ/B9kmHPhprHya08+VVzxC88pOEvz68nA
+# 82oEM09584aILqYmj8Pj7h/kmZNzuEL7WiwFa/U1hX+XiWfLIJQsAHBla0i7QRF2
+# de8/VSF0XXFa2kBQ6aiTsiLyKPNbaNtbcucaUdn6vVUS5izWOXM95BSkFSKdE45O
+# q3FForNJXjBvSCpwcP36WklaHL+aHu1upIhCTUkzTHMh8b86WmjRUqbrnvdyR2yd
+# I5l1OqcMBjkpPpIV6wcc+KY/RH2xvVuuoHjlUjwq2bHiNoX+W1scCpnA8YTs2d50
+# jDHUgwUo+ciwpffH0Riq132NFmrH3r67VaN3TuBxjI8SIZM58WEDkbeoriDk3hxU
+# 8ZWV7b8AW6oyVBGfM06UgkfMb58h+tJPrFx8VI/WLq1dTqMfZOm5cuclMnUHs2uq
+# rRNtnV8UfidPBL4ZHkTcClQbCoz0UbLhkiDvIS00Dn+BBcxw/TKqVL4Oaz3bkMSs
+# M46LciTeucHY9ExRVt3zy7i149sd+F4QozPqn7FrSVHXmem3r7bjyHTxOgqxRCVa
+# 18Vtx7P/8bYSBeS+WHCKcliFCecspusCDSlnRUjZwyPdP0VHxaZg2unjHY3rMYIa
+# tzCCGrMCAQEwfTBpMQswCQYDVQQGEwJVUzEXMBUGA1UEChMORGlnaUNlcnQsIElu
+# Yy4xQTA/BgNVBAMTOERpZ2lDZXJ0IFRydXN0ZWQgRzQgQ29kZSBTaWduaW5nIFJT
+# QTQwOTYgU0hBMzg0IDIwMjEgQ0ExAhAHHxQbizANJfMU6yMM0NHdMA0GCWCGSAFl
+# AwQCAQUAoIHIMBkGCSqGSIb3DQEJAzEMBgorBgEEAYI3AgEEMBwGCisGAQQBgjcC
+# AQsxDjAMBgorBgEEAYI3AgEVMC8GCSqGSIb3DQEJBDEiBCBnAZ6P7YvTwq0fbF62
+# o7E75R0LxsW5OtyYiFESQckLhjBcBgorBgEEAYI3AgEMMU4wTKBGgEQAQgB1AGkA
+# bAB0ADoAIABSAGUAbABlAGEAcwBlAF8AdgAzAC4AMQAyAC4AMABfADIAMAAyADMA
+# MQAwADAAMgAuADAAMaECgAAwDQYJKoZIhvcNAQEBBQAEggIAk+1ya4KYmJwPdyhn
+# UCoARJ3l7b9UN3AATHE7oO50+piT9AvRbtmqgY0Tper2DQmBe8FRDBu/52l6nBtc
+# 30SBrwPvs3zgvQSfhtjozpOo8bAv23MQaNbMlzW07aVBU+4Vd0v+65FwIkBiCuDk
+# CprYElSno9fsRpktxYJ9lsmdxsgyxdFg6VDzkwwp0wJBT1VVdtBNx3143gVExXE2
+# g+zSfMug1+o3Jj054gmK0BYYvg7T+qHRRjYmVvuXMLXRgY5so6vVHjv6oARFGQ9/
+# dEcY0b04c3jp/lSK+Nd0v3aY1FeguOnxPz32PHNg/ICygyRG+ivLyHkdLIJrGuIo
+# Te6dAgLgCKcooQ9MVNG2F/gw5tVCYrEOAyNwUxgl7zX7fXVlTAgAE2vxawb8NCeQ
+# f3InGRIkocO3hrEFVlCW58WG0utSkUwzknrkpMEscLEIZwO30gBartqyTajYsi4+
+# vSOTW6CQp2+CvwtDpF4ll40sxPmNbDX7KWkD/OhD8zwxvRpKrkgjIpdzlfzen9uV
+# 70E2UV2JHWVvvdqERRILOQPbSERiPPaPwjjtjWa6HwzF386We4USv+mL4AZhmxgP
+# 4ov0+c6qgVdmjUpTA8Q/RoX6WXHyhvflAsfhX/h0sBtqxhdiqoXtIH6bqAZfSpOq
+# 2GN9KZ2WSppZy2nWeULuSvSwjmahghdAMIIXPAYKKwYBBAGCNwMDATGCFywwghco
+# BgkqhkiG9w0BBwKgghcZMIIXFQIBAzEPMA0GCWCGSAFlAwQCAQUAMHgGCyqGSIb3
+# DQEJEAEEoGkEZzBlAgEBBglghkgBhv1sBwEwMTANBglghkgBZQMEAgEFAAQgnmxA
+# vhfTXC1rhKE1Olq0ip2jyhXJM2BAt3lCUFLFnQkCEQC0R5Uki33yd+oDVBKaPX6T
+# GA8yMDIzMTAwMjEzMjMzMlqgghMJMIIGwjCCBKqgAwIBAgIQBUSv85SdCDmmv9s/
+# X+VhFjANBgkqhkiG9w0BAQsFADBjMQswCQYDVQQGEwJVUzEXMBUGA1UEChMORGln
+# aUNlcnQsIEluYy4xOzA5BgNVBAMTMkRpZ2lDZXJ0IFRydXN0ZWQgRzQgUlNBNDA5
+# NiBTSEEyNTYgVGltZVN0YW1waW5nIENBMB4XDTIzMDcxNDAwMDAwMFoXDTM0MTAx
+# MzIzNTk1OVowSDELMAkGA1UEBhMCVVMxFzAVBgNVBAoTDkRpZ2lDZXJ0LCBJbmMu
+# MSAwHgYDVQQDExdEaWdpQ2VydCBUaW1lc3RhbXAgMjAyMzCCAiIwDQYJKoZIhvcN
+# AQEBBQADggIPADCCAgoCggIBAKNTRYcdg45brD5UsyPgz5/X5dLnXaEOCdwvSKOX
+# ejsqnGfcYhVYwamTEafNqrJq3RApih5iY2nTWJw1cb86l+uUUI8cIOrHmjsvlmbj
+# aedp/lvD1isgHMGXlLSlUIHyz8sHpjBoyoNC2vx/CSSUpIIa2mq62DvKXd4ZGIX7
+# ReoNYWyd/nFexAaaPPDFLnkPG2ZS48jWPl/aQ9OE9dDH9kgtXkV1lnX+3RChG4PB
+# uOZSlbVH13gpOWvgeFmX40QrStWVzu8IF+qCZE3/I+PKhu60pCFkcOvV5aDaY7Mu
+# 6QXuqvYk9R28mxyyt1/f8O52fTGZZUdVnUokL6wrl76f5P17cz4y7lI0+9S769Sg
+# LDSb495uZBkHNwGRDxy1Uc2qTGaDiGhiu7xBG3gZbeTZD+BYQfvYsSzhUa+0rRUG
+# FOpiCBPTaR58ZE2dD9/O0V6MqqtQFcmzyrzXxDtoRKOlO0L9c33u3Qr/eTQQfqZc
+# ClhMAD6FaXXHg2TWdc2PEnZWpST618RrIbroHzSYLzrqawGw9/sqhux7UjipmAmh
+# cbJsca8+uG+W1eEQE/5hRwqM/vC2x9XH3mwk8L9CgsqgcT2ckpMEtGlwJw1Pt7U2
+# 0clfCKRwo+wK8REuZODLIivK8SgTIUlRfgZm0zu++uuRONhRB8qUt+JQofM604qD
+# y0B7AgMBAAGjggGLMIIBhzAOBgNVHQ8BAf8EBAMCB4AwDAYDVR0TAQH/BAIwADAW
+# BgNVHSUBAf8EDDAKBggrBgEFBQcDCDAgBgNVHSAEGTAXMAgGBmeBDAEEAjALBglg
+# hkgBhv1sBwEwHwYDVR0jBBgwFoAUuhbZbU2FL3MpdpovdYxqII+eyG8wHQYDVR0O
+# BBYEFKW27xPn783QZKHVVqllMaPe1eNJMFoGA1UdHwRTMFEwT6BNoEuGSWh0dHA6
+# Ly9jcmwzLmRpZ2ljZXJ0LmNvbS9EaWdpQ2VydFRydXN0ZWRHNFJTQTQwOTZTSEEy
+# NTZUaW1lU3RhbXBpbmdDQS5jcmwwgZAGCCsGAQUFBwEBBIGDMIGAMCQGCCsGAQUF
+# BzABhhhodHRwOi8vb2NzcC5kaWdpY2VydC5jb20wWAYIKwYBBQUHMAKGTGh0dHA6
+# Ly9jYWNlcnRzLmRpZ2ljZXJ0LmNvbS9EaWdpQ2VydFRydXN0ZWRHNFJTQTQwOTZT
+# SEEyNTZUaW1lU3RhbXBpbmdDQS5jcnQwDQYJKoZIhvcNAQELBQADggIBAIEa1t6g
+# qbWYF7xwjU+KPGic2CX/yyzkzepdIpLsjCICqbjPgKjZ5+PF7SaCinEvGN1Ott5s
+# 1+FgnCvt7T1IjrhrunxdvcJhN2hJd6PrkKoS1yeF844ektrCQDifXcigLiV4JZ0q
+# BXqEKZi2V3mP2yZWK7Dzp703DNiYdk9WuVLCtp04qYHnbUFcjGnRuSvExnvPnPp4
+# 4pMadqJpddNQ5EQSviANnqlE0PjlSXcIWiHFtM+YlRpUurm8wWkZus8W8oM3NG6w
+# QSbd3lqXTzON1I13fXVFoaVYJmoDRd7ZULVQjK9WvUzF4UbFKNOt50MAcN7MmJ4Z
+# iQPq1JE3701S88lgIcRWR+3aEUuMMsOI5ljitts++V+wQtaP4xeR0arAVeOGv6wn
+# LEHQmjNKqDbUuXKWfpd5OEhfysLcPTLfddY2Z1qJ+Panx+VPNTwAvb6cKmx5Adza
+# ROY63jg7B145WPR8czFVoIARyxQMfq68/qTreWWqaNYiyjvrmoI1VygWy2nyMpqy
+# 0tg6uLFGhmu6F/3Ed2wVbK6rr3M66ElGt9V/zLY4wNjsHPW2obhDLN9OTH0eaHDA
+# dwrUAuBcYLso/zjlUlrWrBciI0707NMX+1Br/wd3H3GXREHJuEbTbDJ8WC9nR2Xl
+# G3O2mflrLAZG70Ee8PBf4NvZrZCARK+AEEGKMIIGrjCCBJagAwIBAgIQBzY3tyRU
+# fNhHrP0oZipeWzANBgkqhkiG9w0BAQsFADBiMQswCQYDVQQGEwJVUzEVMBMGA1UE
+# ChMMRGlnaUNlcnQgSW5jMRkwFwYDVQQLExB3d3cuZGlnaWNlcnQuY29tMSEwHwYD
+# VQQDExhEaWdpQ2VydCBUcnVzdGVkIFJvb3QgRzQwHhcNMjIwMzIzMDAwMDAwWhcN
+# MzcwMzIyMjM1OTU5WjBjMQswCQYDVQQGEwJVUzEXMBUGA1UEChMORGlnaUNlcnQs
+# IEluYy4xOzA5BgNVBAMTMkRpZ2lDZXJ0IFRydXN0ZWQgRzQgUlNBNDA5NiBTSEEy
+# NTYgVGltZVN0YW1waW5nIENBMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKC
+# AgEAxoY1BkmzwT1ySVFVxyUDxPKRN6mXUaHW0oPRnkyibaCwzIP5WvYRoUQVQl+k
+# iPNo+n3znIkLf50fng8zH1ATCyZzlm34V6gCff1DtITaEfFzsbPuK4CEiiIY3+va
+# PcQXf6sZKz5C3GeO6lE98NZW1OcoLevTsbV15x8GZY2UKdPZ7Gnf2ZCHRgB720RB
+# idx8ald68Dd5n12sy+iEZLRS8nZH92GDGd1ftFQLIWhuNyG7QKxfst5Kfc71ORJn
+# 7w6lY2zkpsUdzTYNXNXmG6jBZHRAp8ByxbpOH7G1WE15/tePc5OsLDnipUjW8LAx
+# E6lXKZYnLvWHpo9OdhVVJnCYJn+gGkcgQ+NDY4B7dW4nJZCYOjgRs/b2nuY7W+yB
+# 3iIU2YIqx5K/oN7jPqJz+ucfWmyU8lKVEStYdEAoq3NDzt9KoRxrOMUp88qqlnNC
+# aJ+2RrOdOqPVA+C/8KI8ykLcGEh/FDTP0kyr75s9/g64ZCr6dSgkQe1CvwWcZklS
+# UPRR8zZJTYsg0ixXNXkrqPNFYLwjjVj33GHek/45wPmyMKVM1+mYSlg+0wOI/rOP
+# 015LdhJRk8mMDDtbiiKowSYI+RQQEgN9XyO7ZONj4KbhPvbCdLI/Hgl27KtdRnXi
+# YKNYCQEoAA6EVO7O6V3IXjASvUaetdN2udIOa5kM0jO0zbECAwEAAaOCAV0wggFZ
+# MBIGA1UdEwEB/wQIMAYBAf8CAQAwHQYDVR0OBBYEFLoW2W1NhS9zKXaaL3WMaiCP
+# nshvMB8GA1UdIwQYMBaAFOzX44LScV1kTN8uZz/nupiuHA9PMA4GA1UdDwEB/wQE
+# AwIBhjATBgNVHSUEDDAKBggrBgEFBQcDCDB3BggrBgEFBQcBAQRrMGkwJAYIKwYB
+# BQUHMAGGGGh0dHA6Ly9vY3NwLmRpZ2ljZXJ0LmNvbTBBBggrBgEFBQcwAoY1aHR0
+# cDovL2NhY2VydHMuZGlnaWNlcnQuY29tL0RpZ2lDZXJ0VHJ1c3RlZFJvb3RHNC5j
+# cnQwQwYDVR0fBDwwOjA4oDagNIYyaHR0cDovL2NybDMuZGlnaWNlcnQuY29tL0Rp
+# Z2lDZXJ0VHJ1c3RlZFJvb3RHNC5jcmwwIAYDVR0gBBkwFzAIBgZngQwBBAIwCwYJ
+# YIZIAYb9bAcBMA0GCSqGSIb3DQEBCwUAA4ICAQB9WY7Ak7ZvmKlEIgF+ZtbYIULh
+# sBguEE0TzzBTzr8Y+8dQXeJLKftwig2qKWn8acHPHQfpPmDI2AvlXFvXbYf6hCAl
+# NDFnzbYSlm/EUExiHQwIgqgWvalWzxVzjQEiJc6VaT9Hd/tydBTX/6tPiix6q4XN
+# Q1/tYLaqT5Fmniye4Iqs5f2MvGQmh2ySvZ180HAKfO+ovHVPulr3qRCyXen/KFSJ
+# 8NWKcXZl2szwcqMj+sAngkSumScbqyQeJsG33irr9p6xeZmBo1aGqwpFyd/EjaDn
+# mPv7pp1yr8THwcFqcdnGE4AJxLafzYeHJLtPo0m5d2aR8XKc6UsCUqc3fpNTrDsd
+# CEkPlM05et3/JWOZJyw9P2un8WbDQc1PtkCbISFA0LcTJM3cHXg65J6t5TRxktcm
+# a+Q4c6umAU+9Pzt4rUyt+8SVe+0KXzM5h0F4ejjpnOHdI/0dKNPH+ejxmF/7K9h+
+# 8kaddSweJywm228Vex4Ziza4k9Tm8heZWcpw8De/mADfIBZPJ/tgZxahZrrdVcA6
+# KYawmKAr7ZVBtzrVFZgxtGIJDwq9gdkT/r+k0fNX2bwE+oLeMt8EifAAzV3C+dAj
+# fwAL5HYCJtnwZXZCpimHCUcr5n8apIUP/JiW9lVUKx+A+sDyDivl1vupL0QVSucT
+# Dh3bNzgaoSv27dZ8/DCCBY0wggR1oAMCAQICEA6bGI750C3n79tQ4ghAGFowDQYJ
+# KoZIhvcNAQEMBQAwZTELMAkGA1UEBhMCVVMxFTATBgNVBAoTDERpZ2lDZXJ0IElu
+# YzEZMBcGA1UECxMQd3d3LmRpZ2ljZXJ0LmNvbTEkMCIGA1UEAxMbRGlnaUNlcnQg
+# QXNzdXJlZCBJRCBSb290IENBMB4XDTIyMDgwMTAwMDAwMFoXDTMxMTEwOTIzNTk1
+# OVowYjELMAkGA1UEBhMCVVMxFTATBgNVBAoTDERpZ2lDZXJ0IEluYzEZMBcGA1UE
+# CxMQd3d3LmRpZ2ljZXJ0LmNvbTEhMB8GA1UEAxMYRGlnaUNlcnQgVHJ1c3RlZCBS
+# b290IEc0MIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAv+aQc2jeu+Rd
+# SjwwIjBpM+zCpyUuySE98orYWcLhKac9WKt2ms2uexuEDcQwH/MbpDgW61bGl20d
+# q7J58soR0uRf1gU8Ug9SH8aeFaV+vp+pVxZZVXKvaJNwwrK6dZlqczKU0RBEEC7f
+# gvMHhOZ0O21x4i0MG+4g1ckgHWMpLc7sXk7Ik/ghYZs06wXGXuxbGrzryc/NrDRA
+# X7F6Zu53yEioZldXn1RYjgwrt0+nMNlW7sp7XeOtyU9e5TXnMcvak17cjo+A2raR
+# mECQecN4x7axxLVqGDgDEI3Y1DekLgV9iPWCPhCRcKtVgkEy19sEcypukQF8IUzU
+# vK4bA3VdeGbZOjFEmjNAvwjXWkmkwuapoGfdpCe8oU85tRFYF/ckXEaPZPfBaYh2
+# mHY9WV1CdoeJl2l6SPDgohIbZpp0yt5LHucOY67m1O+SkjqePdwA5EUlibaaRBkr
+# fsCUtNJhbesz2cXfSwQAzH0clcOP9yGyshG3u3/y1YxwLEFgqrFjGESVGnZifvaA
+# sPvoZKYz0YkH4b235kOkGLimdwHhD5QMIR2yVCkliWzlDlJRR3S+Jqy2QXXeeqxf
+# jT/JvNNBERJb5RBQ6zHFynIWIgnffEx1P2PsIV/EIFFrb7GrhotPwtZFX50g/KEe
+# xcCPorF+CiaZ9eRpL5gdLfXZqbId5RsCAwEAAaOCATowggE2MA8GA1UdEwEB/wQF
+# MAMBAf8wHQYDVR0OBBYEFOzX44LScV1kTN8uZz/nupiuHA9PMB8GA1UdIwQYMBaA
+# FEXroq/0ksuCMS1Ri6enIZ3zbcgPMA4GA1UdDwEB/wQEAwIBhjB5BggrBgEFBQcB
+# AQRtMGswJAYIKwYBBQUHMAGGGGh0dHA6Ly9vY3NwLmRpZ2ljZXJ0LmNvbTBDBggr
+# BgEFBQcwAoY3aHR0cDovL2NhY2VydHMuZGlnaWNlcnQuY29tL0RpZ2lDZXJ0QXNz
+# dXJlZElEUm9vdENBLmNydDBFBgNVHR8EPjA8MDqgOKA2hjRodHRwOi8vY3JsMy5k
+# aWdpY2VydC5jb20vRGlnaUNlcnRBc3N1cmVkSURSb290Q0EuY3JsMBEGA1UdIAQK
+# MAgwBgYEVR0gADANBgkqhkiG9w0BAQwFAAOCAQEAcKC/Q1xV5zhfoKN0Gz22Ftf3
+# v1cHvZqsoYcs7IVeqRq7IviHGmlUIu2kiHdtvRoU9BNKei8ttzjv9P+Aufih9/Jy
+# 3iS8UgPITtAq3votVs/59PesMHqai7Je1M/RQ0SbQyHrlnKhSLSZy51PpwYDE3cn
+# RNTnf+hZqPC/Lwum6fI0POz3A8eHqNJMQBk1RmppVLC4oVaO7KTVPeix3P0c2PR3
+# WlxUjG/voVA9/HYJaISfb8rbII01YBwCA8sgsKxYoA5AY8WYIsGyWfVVa88nq2x2
+# zm8jLfR+cWojayL/ErhULSd+2DrZ8LaHlv1b0VysGMNNn3O3AamfV6peKOK5lDGC
+# A3YwggNyAgEBMHcwYzELMAkGA1UEBhMCVVMxFzAVBgNVBAoTDkRpZ2lDZXJ0LCBJ
+# bmMuMTswOQYDVQQDEzJEaWdpQ2VydCBUcnVzdGVkIEc0IFJTQTQwOTYgU0hBMjU2
+# IFRpbWVTdGFtcGluZyBDQQIQBUSv85SdCDmmv9s/X+VhFjANBglghkgBZQMEAgEF
+# AKCB0TAaBgkqhkiG9w0BCQMxDQYLKoZIhvcNAQkQAQQwHAYJKoZIhvcNAQkFMQ8X
+# DTIzMTAwMjEzMjMzMlowKwYLKoZIhvcNAQkQAgwxHDAaMBgwFgQUZvArMsLCyQ+C
+# Xc6qisnGTxmcz0AwLwYJKoZIhvcNAQkEMSIEIBa6X0J/pyxEP0qKmxfT51tQm4Im
+# u/63uybfmuePN1UHMDcGCyqGSIb3DQEJEAIvMSgwJjAkMCIEINL25G3tdCLM0dRA
+# V2hBNm+CitpVmq4zFq9NGprUDHgoMA0GCSqGSIb3DQEBAQUABIICAFRAXwhn3az4
+# r+zhZk2K3gibUwGFM4dHGKh1RD383PsnUii90EaBVzixPIppOs7v0iZOER2tce8u
+# xgQ3IZtjRIuQmCh+9I6zWIH59MssGU6igexTAjc0dIfV66UeFlh2aSWWckxmaTI/
+# jXgpqx2sk4dlqJKrR/d084gyevoCkQNerED/FuwJ6bX8omhIikyHdoo6hbL595tK
+# 4ekxek027svbPFC0WbAxZXLq428C5endJaAQV2RTCk0B1vgPFw5bvznldlQnRqMu
+# vcd1GSoSVN16kw5UKWXEyP0e07yiXEPkFoPBSC/c5o7COjidK2VOlVY/gsorVMEA
+# rx/apEwf1F70vD2caiIsUAhrmPzyslFZfU6o2fKXI/vrBTUvbzb5Vz+IGoXlwTH+
+# loWh4loof+pJjbpJJj26GQwssAl3M/m/3BGamnmf97CJShvPrM0w8WOLkXtn6/M4
+# Y15ywECiRhaQX7NUVzRBl1hGDDD0mFv/OHzMer3C4/8I04whBnfvMxelUb4YhlM6
+# e+F6DzvI91OWTrpjsPKOHE3ds9ra+F1yPkV1RMQMRx/xWd0D274R8W2baHxrYgS3
+# 2LYPSAYFMi3cmF6Df84iIG2d0qj0x3ioXDUUk72YTCUO1Xnz9jkHSCU7Bq2GL9uP
+# z4sEyNDU23dEmfGD672vMRuZ6Ua/ks5J
+# SIG # End signature block
diff --git a/solutions/.venv/Scripts/activate b/solutions/.venv/Scripts/activate
new file mode 100644
index 000000000..41a4590cc
--- /dev/null
+++ b/solutions/.venv/Scripts/activate
@@ -0,0 +1,76 @@
+# This file must be used with "source bin/activate" *from bash*
+# You cannot run it directly
+
+deactivate () {
+ # reset old environment variables
+ if [ -n "${_OLD_VIRTUAL_PATH:-}" ] ; then
+ PATH="${_OLD_VIRTUAL_PATH:-}"
+ export PATH
+ unset _OLD_VIRTUAL_PATH
+ fi
+ if [ -n "${_OLD_VIRTUAL_PYTHONHOME:-}" ] ; then
+ PYTHONHOME="${_OLD_VIRTUAL_PYTHONHOME:-}"
+ export PYTHONHOME
+ unset _OLD_VIRTUAL_PYTHONHOME
+ fi
+
+ # This should detect bash and zsh, which have a hash command that must
+ # be called to get it to forget past commands. Without forgetting
+ # past commands the $PATH changes we made may not be respected
+ if [ -n "${BASH:-}" -o -n "${ZSH_VERSION:-}" ] ; then
+ hash -r 2> /dev/null
+ fi
+
+ if [ -n "${_OLD_VIRTUAL_PS1:-}" ] ; then
+ PS1="${_OLD_VIRTUAL_PS1:-}"
+ export PS1
+ unset _OLD_VIRTUAL_PS1
+ fi
+
+ unset VIRTUAL_ENV
+ unset VIRTUAL_ENV_PROMPT
+ if [ ! "${1:-}" = "nondestructive" ] ; then
+ # Self destruct!
+ unset -f deactivate
+ fi
+}
+
+# unset irrelevant variables
+deactivate nondestructive
+
+# on Windows, a path can contain colons and backslashes and has to be converted:
+if [ "$OSTYPE" = "cygwin" ] || [ "$OSTYPE" = "msys" ] ; then
+ # transform D:\path\to\venv to /d/path/to/venv on MSYS
+ # and to /cygdrive/d/path/to/venv on Cygwin
+ export VIRTUAL_ENV=$(cygpath "C:\Users\Clifford Exael\prime_number\ET6-foundations-group-04\solutions\.venv")
+else
+ # use the path as-is
+ export VIRTUAL_ENV="C:\Users\Clifford Exael\prime_number\ET6-foundations-group-04\solutions\.venv"
+fi
+
+_OLD_VIRTUAL_PATH="$PATH"
+PATH="$VIRTUAL_ENV/Scripts:$PATH"
+export PATH
+
+# unset PYTHONHOME if set
+# this will fail if PYTHONHOME is set to the empty string (which is bad anyway)
+# could use `if (set -u; : $PYTHONHOME) ;` in bash
+if [ -n "${PYTHONHOME:-}" ] ; then
+ _OLD_VIRTUAL_PYTHONHOME="${PYTHONHOME:-}"
+ unset PYTHONHOME
+fi
+
+if [ -z "${VIRTUAL_ENV_DISABLE_PROMPT:-}" ] ; then
+ _OLD_VIRTUAL_PS1="${PS1:-}"
+ PS1="(.venv) ${PS1:-}"
+ export PS1
+ VIRTUAL_ENV_PROMPT="(.venv) "
+ export VIRTUAL_ENV_PROMPT
+fi
+
+# This should detect bash and zsh, which have a hash command that must
+# be called to get it to forget past commands. Without forgetting
+# past commands the $PATH changes we made may not be respected
+if [ -n "${BASH:-}" -o -n "${ZSH_VERSION:-}" ] ; then
+ hash -r 2> /dev/null
+fi
diff --git a/solutions/.venv/Scripts/activate.bat b/solutions/.venv/Scripts/activate.bat
new file mode 100644
index 000000000..f08d5f630
--- /dev/null
+++ b/solutions/.venv/Scripts/activate.bat
@@ -0,0 +1,34 @@
+@echo off
+
+rem This file is UTF-8 encoded, so we need to update the current code page while executing it
+for /f "tokens=2 delims=:." %%a in ('"%SystemRoot%\System32\chcp.com"') do (
+ set _OLD_CODEPAGE=%%a
+)
+if defined _OLD_CODEPAGE (
+ "%SystemRoot%\System32\chcp.com" 65001 > nul
+)
+
+set VIRTUAL_ENV=C:\Users\Clifford Exael\prime_number\ET6-foundations-group-04\solutions\.venv
+
+if not defined PROMPT set PROMPT=$P$G
+
+if defined _OLD_VIRTUAL_PROMPT set PROMPT=%_OLD_VIRTUAL_PROMPT%
+if defined _OLD_VIRTUAL_PYTHONHOME set PYTHONHOME=%_OLD_VIRTUAL_PYTHONHOME%
+
+set _OLD_VIRTUAL_PROMPT=%PROMPT%
+set PROMPT=(.venv) %PROMPT%
+
+if defined PYTHONHOME set _OLD_VIRTUAL_PYTHONHOME=%PYTHONHOME%
+set PYTHONHOME=
+
+if defined _OLD_VIRTUAL_PATH set PATH=%_OLD_VIRTUAL_PATH%
+if not defined _OLD_VIRTUAL_PATH set _OLD_VIRTUAL_PATH=%PATH%
+
+set PATH=%VIRTUAL_ENV%\Scripts;%PATH%
+set VIRTUAL_ENV_PROMPT=(.venv)
+
+:END
+if defined _OLD_CODEPAGE (
+ "%SystemRoot%\System32\chcp.com" %_OLD_CODEPAGE% > nul
+ set _OLD_CODEPAGE=
+)
diff --git a/solutions/.venv/Scripts/deactivate.bat b/solutions/.venv/Scripts/deactivate.bat
new file mode 100644
index 000000000..62a39a758
--- /dev/null
+++ b/solutions/.venv/Scripts/deactivate.bat
@@ -0,0 +1,22 @@
+@echo off
+
+if defined _OLD_VIRTUAL_PROMPT (
+ set "PROMPT=%_OLD_VIRTUAL_PROMPT%"
+)
+set _OLD_VIRTUAL_PROMPT=
+
+if defined _OLD_VIRTUAL_PYTHONHOME (
+ set "PYTHONHOME=%_OLD_VIRTUAL_PYTHONHOME%"
+ set _OLD_VIRTUAL_PYTHONHOME=
+)
+
+if defined _OLD_VIRTUAL_PATH (
+ set "PATH=%_OLD_VIRTUAL_PATH%"
+)
+
+set _OLD_VIRTUAL_PATH=
+
+set VIRTUAL_ENV=
+set VIRTUAL_ENV_PROMPT=
+
+:END
diff --git a/solutions/.venv/Scripts/get_gprof b/solutions/.venv/Scripts/get_gprof
new file mode 100644
index 000000000..fd59029dc
--- /dev/null
+++ b/solutions/.venv/Scripts/get_gprof
@@ -0,0 +1,75 @@
+#!C:\Users\Clifford Exael\prime_number\ET6-foundations-group-04\solutions\.venv\Scripts\python.exe
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+'''
+build profile graph for the given instance
+
+running:
+ $ get_gprof <args> <instance>
+
+executes:
+ gprof2dot -f pstats <args> <type>.prof | dot -Tpng -o <type>.call.png
+
+where:
+ <args> are arguments for gprof2dot, such as "-n 5 -e 5"
+ <instance> is code to create the instance to profile
+ <type> is the class of the instance (i.e. type(instance))
+
+For example:
+ $ get_gprof -n 5 -e 1 "import numpy; numpy.array([1,2])"
+
+will create 'ndarray.call.png' with the profile graph for numpy.array([1,2]),
+where '-n 5' eliminates nodes below 5% threshold, similarly '-e 1' eliminates
+edges below 1% threshold
+'''
+
+if __name__ == "__main__":
+ import sys
+ if len(sys.argv) < 2:
+ print ("Please provide an object instance (e.g. 'import math; math.pi')")
+ sys.exit()
+ # grab args for gprof2dot
+ args = sys.argv[1:-1]
+ args = ' '.join(args)
+ # last arg builds the object
+ obj = sys.argv[-1]
+ obj = obj.split(';')
+ # multi-line prep for generating an instance
+ for line in obj[:-1]:
+ exec(line)
+ # one-line generation of an instance
+ try:
+ obj = eval(obj[-1])
+ except Exception:
+ print ("Error processing object instance")
+ sys.exit()
+
+ # get object 'name'
+ objtype = type(obj)
+ name = getattr(objtype, '__name__', getattr(objtype, '__class__', objtype))
+
+ # profile dumping an object
+ import dill
+ import os
+ import cProfile
+ #name = os.path.splitext(os.path.basename(__file__))[0]
+ cProfile.run("dill.dumps(obj)", filename="%s.prof" % name)
+ msg = "gprof2dot -f pstats %s %s.prof | dot -Tpng -o %s.call.png" % (args, name, name)
+ try:
+ res = os.system(msg)
+ except Exception:
+ print ("Please verify install of 'gprof2dot' to view profile graphs")
+ if res:
+ print ("Please verify install of 'gprof2dot' to view profile graphs")
+
+ # get stats
+ f_prof = "%s.prof" % name
+ import pstats
+ stats = pstats.Stats(f_prof, stream=sys.stdout)
+ stats.strip_dirs().sort_stats('cumtime')
+ stats.print_stats(20) #XXX: save to file instead of print top 20?
+ os.remove(f_prof)
diff --git a/solutions/.venv/Scripts/get_objgraph b/solutions/.venv/Scripts/get_objgraph
new file mode 100644
index 000000000..593438172
--- /dev/null
+++ b/solutions/.venv/Scripts/get_objgraph
@@ -0,0 +1,54 @@
+#!C:\Users\Clifford Exael\prime_number\ET6-foundations-group-04\solutions\.venv\Scripts\python.exe
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+display the reference paths for objects in ``dill.types`` or a .pkl file
+
+Notes:
+ the generated image is useful in showing the pointer references in
+ objects that are or can be pickled. Any object in ``dill.objects``
+ listed in ``dill.load_types(picklable=True, unpicklable=True)`` works.
+
+Examples::
+
+ $ get_objgraph ArrayType
+ Image generated as ArrayType.png
+"""
+
+import dill as pickle
+#pickle.debug.trace(True)
+#import pickle
+
+# get all objects for testing
+from dill import load_types
+load_types(pickleable=True,unpickleable=True)
+from dill import objects
+
+if __name__ == "__main__":
+ import sys
+ if len(sys.argv) != 2:
+ print ("Please provide exactly one file or type name (e.g. 'IntType')")
+ msg = "\n"
+ for objtype in list(objects.keys())[:40]:
+ msg += objtype + ', '
+ print (msg + "...")
+ else:
+ objtype = str(sys.argv[-1])
+ try:
+ obj = objects[objtype]
+ except KeyError:
+ obj = pickle.load(open(objtype,'rb'))
+ import os
+ objtype = os.path.splitext(objtype)[0]
+ try:
+ import objgraph
+ objgraph.show_refs(obj, filename=objtype+'.png')
+ except ImportError:
+ print ("Please install 'objgraph' to view object graphs")
+
+
+# EOF
diff --git a/solutions/.venv/Scripts/isort-identify-imports.exe b/solutions/.venv/Scripts/isort-identify-imports.exe
new file mode 100644
index 000000000..5310057db
Binary files /dev/null and b/solutions/.venv/Scripts/isort-identify-imports.exe differ
diff --git a/solutions/.venv/Scripts/isort.exe b/solutions/.venv/Scripts/isort.exe
new file mode 100644
index 000000000..61bd658c9
Binary files /dev/null and b/solutions/.venv/Scripts/isort.exe differ
diff --git a/solutions/.venv/Scripts/pip.exe b/solutions/.venv/Scripts/pip.exe
new file mode 100644
index 000000000..2c60519ff
Binary files /dev/null and b/solutions/.venv/Scripts/pip.exe differ
diff --git a/solutions/.venv/Scripts/pip3.12.exe b/solutions/.venv/Scripts/pip3.12.exe
new file mode 100644
index 000000000..2c60519ff
Binary files /dev/null and b/solutions/.venv/Scripts/pip3.12.exe differ
diff --git a/solutions/.venv/Scripts/pip3.exe b/solutions/.venv/Scripts/pip3.exe
new file mode 100644
index 000000000..2c60519ff
Binary files /dev/null and b/solutions/.venv/Scripts/pip3.exe differ
diff --git a/solutions/.venv/Scripts/pylint-config.exe b/solutions/.venv/Scripts/pylint-config.exe
new file mode 100644
index 000000000..9222bbc76
Binary files /dev/null and b/solutions/.venv/Scripts/pylint-config.exe differ
diff --git a/solutions/.venv/Scripts/pylint.exe b/solutions/.venv/Scripts/pylint.exe
new file mode 100644
index 000000000..bd895dee0
Binary files /dev/null and b/solutions/.venv/Scripts/pylint.exe differ
diff --git a/solutions/.venv/Scripts/pyreverse.exe b/solutions/.venv/Scripts/pyreverse.exe
new file mode 100644
index 000000000..7c3ba0dbf
Binary files /dev/null and b/solutions/.venv/Scripts/pyreverse.exe differ
diff --git a/solutions/.venv/Scripts/python.exe b/solutions/.venv/Scripts/python.exe
new file mode 100644
index 000000000..71092d086
Binary files /dev/null and b/solutions/.venv/Scripts/python.exe differ
diff --git a/solutions/.venv/Scripts/pythonw.exe b/solutions/.venv/Scripts/pythonw.exe
new file mode 100644
index 000000000..4710dd54c
Binary files /dev/null and b/solutions/.venv/Scripts/pythonw.exe differ
diff --git a/solutions/.venv/Scripts/ruff.exe b/solutions/.venv/Scripts/ruff.exe
new file mode 100644
index 000000000..a8323d279
Binary files /dev/null and b/solutions/.venv/Scripts/ruff.exe differ
diff --git a/solutions/.venv/Scripts/symilar.exe b/solutions/.venv/Scripts/symilar.exe
new file mode 100644
index 000000000..303c5c70b
Binary files /dev/null and b/solutions/.venv/Scripts/symilar.exe differ
diff --git a/solutions/.venv/Scripts/undill b/solutions/.venv/Scripts/undill
new file mode 100644
index 000000000..88b166d33
--- /dev/null
+++ b/solutions/.venv/Scripts/undill
@@ -0,0 +1,22 @@
+#!C:\Users\Clifford Exael\prime_number\ET6-foundations-group-04\solutions\.venv\Scripts\python.exe
+#
+# Author: Mike McKerns (mmckerns @caltech and @uqfoundation)
+# Copyright (c) 2008-2016 California Institute of Technology.
+# Copyright (c) 2016-2024 The Uncertainty Quantification Foundation.
+# License: 3-clause BSD. The full license text is available at:
+# - https://github.com/uqfoundation/dill/blob/master/LICENSE
+"""
+unpickle the contents of a pickled object file
+
+Examples::
+
+ $ undill hello.pkl
+ ['hello', 'world']
+"""
+
+if __name__ == '__main__':
+ import sys
+ import dill
+ for file in sys.argv[1:]:
+ print (dill.load(open(file,'rb')))
+
diff --git a/solutions/.venv/pyvenv.cfg b/solutions/.venv/pyvenv.cfg
new file mode 100644
index 000000000..f57486a4d
--- /dev/null
+++ b/solutions/.venv/pyvenv.cfg
@@ -0,0 +1,5 @@
+home = C:\Python312
+include-system-site-packages = false
+version = 3.12.0
+executable = C:\Python312\python.exe
+command = C:\Python312\python.exe -m venv C:\Users\Clifford Exael\prime_number\ET6-foundations-group-04\solutions\.venv
diff --git a/solutions/challenge_26/README.md b/solutions/challenge_26/README.md
new file mode 100644
index 000000000..e671ec98c
--- /dev/null
+++ b/solutions/challenge_26/README.md
@@ -0,0 +1,35 @@
+# Prime Number Checker
+
+ A prime number is a natural number greater than 1 that has no divisors
+ other than 1 and itself. This function checks if the input number meets
+ the criteria of being a prime number.
+
+ Args:
+ number (int): The number to be checked.
+
+ Returns:
+ str: A string indicating whether the number is prime or not.
+ Returns "is prime" if the number is prime, otherwise "not prime".
+
+ Algorithm:
+ 1. If the number is less than or equal to 1, it is not a prime number.
+ 2. Iterate from 2 to the square root of the number (inclusive).
+ - If the number is divisible by any of these values,
+ it is not a prime number.
+ 3. If no divisors are found, the number is a prime number.
+
+ Example Usage:
+ >>> prime_numbers(9)
+ 'not prime'
+ >>> prime_numbers(7)
+ 'is prime'
+ >>> prime_numbers(1)
+ 'not prime'
+ >>> prime_numbers(13)
+ 'is prime'
+
+ Note:
+ - This function uses a simple algorithm to check for primality by
+ testing divisors up to the square root of the input number for efficiency.
+ - The result is returned as a string, which may be useful for simple
+ display or testing
diff --git a/solutions/challenge_26/__init__.py b/solutions/challenge_26/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/challenge_26/prime_numbers.py b/solutions/challenge_26/prime_numbers.py
new file mode 100644
index 000000000..126f5dd67
--- /dev/null
+++ b/solutions/challenge_26/prime_numbers.py
@@ -0,0 +1,53 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+"""
+Created on Tuesday 31 17:00:00 2024
+
+@author: Cliforde Exael
+"""
+
+
+def prime_numbers(number: int) -> str:
+ """
+ Determines whether a given number is a prime number.
+
+ A prime number is a natural number greater than 1 that has no divisors other than 1 and itself.
+ This function checks if the input number meets the criteria of being a prime number.
+
+ Args:
+ number (int): The number to be checked.
+
+ Returns:
+ str: A string indicating whether the number is prime or not.
+ Returns "is prime" if the number is prime, otherwise "not prime".
+
+ Algorithm:
+ 1. If the number is less than or equal to 1, it is not a prime number.
+ 2. Iterate from 2 to the square root of the number (inclusive).
+ - If the number is divisible by any of these values, it is not a prime number.
+ 3. If no divisors are found, the number is a prime number.
+
+ Example Usage:
+ >>> prime_numbers(9)
+ 'not prime'
+ >>> prime_numbers(7)
+ 'is prime'
+ >>> prime_numbers(1)
+ 'not prime'
+ >>> prime_numbers(13)
+ 'is prime'
+
+ Note:
+ - This function uses a simple algorithm to check for primality by testing divisors
+ up to the square root of the input number for efficiency.
+ - The result is returned as a string, which may be useful for simple display or testing.
+ """
+ if number <= 1:
+ return "not prime"
+ for i in range(2, int(number**0.5) + 1):
+ if number % i == 0:
+ return "not prime"
+ return "is prime"
+
+
+# Example usage
diff --git a/solutions/requirements.txt b/solutions/requirements.txt
new file mode 100644
index 000000000..9a4aec138
--- /dev/null
+++ b/solutions/requirements.txt
@@ -0,0 +1 @@
+ruff==0.9.1
diff --git a/solutions/tests/challenge_26/__init__.py b/solutions/tests/challenge_26/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/solutions/tests/challenge_26/test_prime_numbers.py b/solutions/tests/challenge_26/test_prime_numbers.py
new file mode 100644
index 000000000..44448b6b4
--- /dev/null
+++ b/solutions/tests/challenge_26/test_prime_numbers.py
@@ -0,0 +1,136 @@
+# _*_coding:utf-8_*_
+"""
+Created on Tuesday 31 17:00:00 2024
+
+
+@author: Cliforde Exael
+"""
+
+import unittest
+
+from solutions.challenge_26.prime_numbers import prime_numbers
+
+
+class TestPrimeNumbers(unittest.TestCase):
+ """
+ Unit tests for the prime_numbers function, which checks if a number is a prime number.
+ These tests cover typical cases, boundary cases, and defensive assertions.
+ """
+
+ def test_prime_number(self):
+ """
+ Test that the function correctly identifies a prime number.
+ """
+ number = 7
+ expected = "is prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_non_prime_number(self):
+ """
+ Test that the function correctly identifies a non-prime number.
+ """
+ number = 9
+ expected = "not prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_one_is_not_prime(self):
+ """
+ Test that the function correctly identifies that 1 is not a prime number.
+ """
+ number = 1
+ expected = "not prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_zero_is_not_prime(self):
+ """
+ Test that the function correctly identifies that 0 is not a prime number.
+ """
+ number = 0
+ expected = "not prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_negative_number_is_not_prime(self):
+ """
+ Test that the function correctly identifies that negative numbers are not prime.
+ """
+ number = -5
+ expected = "not prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_large_prime_number(self):
+ """
+ Test that the function correctly identifies a large prime number.
+ """
+ number = 29
+ expected = "is prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_large_non_prime_number(self):
+ """
+ Test that the function correctly identifies a large non-prime number.
+ """
+ number = 100
+ expected = "not prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_smallest_prime_number(self):
+ """
+ Test that the function correctly identifies the smallest prime number (2).
+ """
+ number = 2
+ expected = "is prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_defensive_type_check_string_input(self):
+ """
+ Test that the function raises a TypeError when given a string input.
+ """
+ number = "text"
+ with self.assertRaises(TypeError, msg=f"Expected TypeError for input {number}"):
+ prime_numbers(number)
+
+ def test_boundary_case_next_to_prime(self):
+ """
+ Test that the function correctly identifies a number next to a prime number.
+ """
+ number = 4
+ expected = "not prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )
+
+ def test_boundary_case_very_large_number(self):
+ """
+ Test that the function correctly identifies a very large non-prime number.
+ """
+ number = 10**6
+ expected = "not prime"
+ actual = prime_numbers(number)
+ self.assertEqual(
+ actual, expected, f"Expected {expected} but got {actual} for input {number}"
+ )