- Feature Name: hathor_explorer_v1
- Start Date: 2021-04-09
- RFC PR:
- Hathor Issue:
- Author: Giovane Tomaz [email protected]
Version 1 of Hathor Explorer connecting to a exclusive service (instead of connect to the full-node directly) with some new features.
Hathor Explorer currently accesses the full-node directly increasing load, specially with some requests that leads to expensive operations. There are a lot of information that we can cache, store in an simpler way that is easy to retrieve or even request from other running services. Therefore we'll access the full-node only when is strictly necessary, preferably for simple operations.
As the main goal of this upgrade is to provide same Hathor Network data as usual but drastically reducing the overload that some operations can cause on full-node, we are creating a new project called hathor-explorer-service (maybe hathor-explorer-api is a better name?).
At first, this new project will be responsible for:
- Store data that is relevant to the explorer
- Handle WS connections that was handled by the
full-node - Handle Web Requests that was handled by the
full-node - Listen to updates from
full-nodeand store data in its own database - Make requests for other services that are already detached from
full-node - Cache most of these requests tha still need to be made to
full-node
Deploy will be done by Serverless framework (lambdas and API Gateway) and Terraform (all other things)
The following image illustrates how the parts of the services will interact:
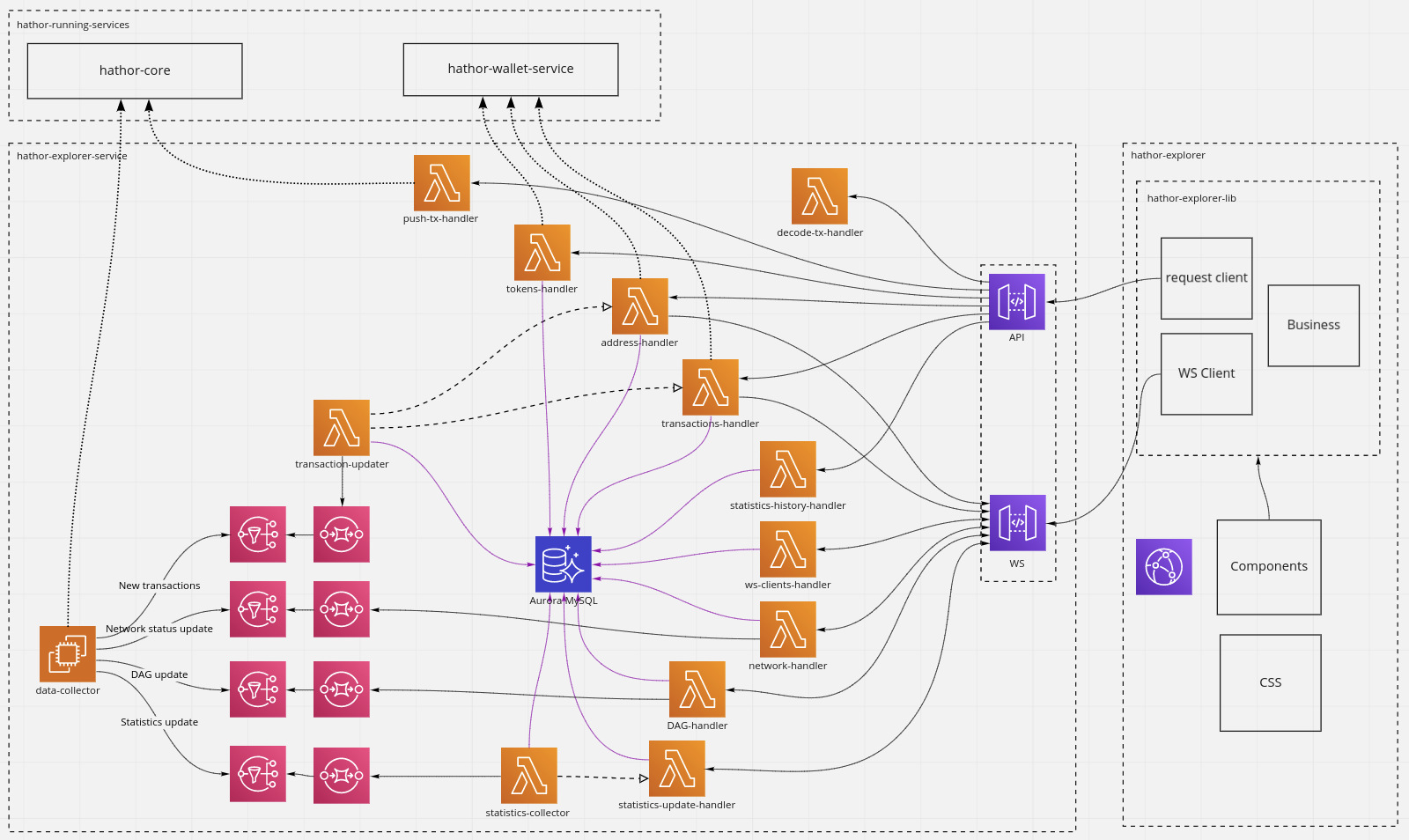
*Note: hathor-running-services is an abstraction for services that are already currently running.
**Note: hathor-explorer-lib might be extracted from hathor-explorer in the future.
Hathor explorer service will be responsible for provide data to be consumed by explorer. Some of this data will be obtained by requesting other services and some will be stored on service own database.
Aurora MySQL will not be deployed by Serverless framework.
As almost any database is fine for our purpose and change it is very easy because all the data is inside the blockchain, we choose Aurora MySQL for convenience because the team is comfortable and the setup is very simple.
Estimated cost: $ 30 Monthly (
db.t3.small)
Decode TX will just decode and return the decoded transaction
Estimated cost: $ 0.50 per million requests.
Push TX will validate the transaction and just make a request to hathor-core, parse response and return the success or error messages.
Estimated cost: $ 0.50 per million requests.
Address handler will return data about a given address. As overall address information is already been stored by hathor-wallet-service and the remaining information will be stored there as well, we can make a request for it.
Requests for this handler will be cached on API gateway.
A new endpoit will have to be made on hathor-wallet-service to deal with public information.
Estimated cost: $ 0.50 per million requests.
Tokens handler will return data about tokens. Tokens list or information about a given token.
Tokens list will be available on hathor-wallet-service and as a token is a transaction, it will be stored there as well.
Requests for this handler will be cached on API gateway.
A new endpoint will have to be made on hathor-wallet-service to retrieve tokens list with pagination.
Estimated cost: $ 0.50 per million requests.
Transactions handler will return data about transactions. Transactions list or specific data about a given transaction.
As this is the main feature on explorer (a list of last transactions is listed on explorer home page) it can easily overload the full-node. To solve this problem, we will store only hash and timestamp of every new transaction on hathor-explorer-service database. This way we can easily list and paginate transactions and access the hathor-wallet-service only to retrieve one single transaction data that is a cheap operation. Requests for this handler will be cached on API gateway.
Estimated cost: $ 0.50 per million requests.
Every new transaction will be pushed to a SNS. A SQS will listen to this SNS and store it. Transaction updater will consume this SQS, store hash and timestamp of each new transaction in the database and trigger other lambdas that will update connected WS clients.
A new feature will be made on hathor-core to push transaction data to SNS. It can be in the same place where this data is pushed to WS.
Estimated cost: $ 0.90 per million transactions.
Statistics history handler will retrieve past statistics data (only hashrate for now) necessary to build a graph that will be updated through WS after.
Estimated cost: $ 0.50 per million requests.
Web Socket Clients handler will handle connections and disconnections from WS on API gateway. When a client connects, the id of the connection will be stored (with a TTL) on the database. This is necessary for other lambdas to send message to API gateway when new updates arrive. When a client disconnects, the connection id will be removed from the database.
Estimated cost: $ 0.50 per million connects/disconnects.
data-collector will listen to DAG updates and send to a SNS. A SQS will be fed from this SNS notifications.
DAG handler will consume this SQS and send a message for every connection stored in the database subscribed to dag topic.
Estimated cost:
$1.50 monthly ($ 0.50 per million update, every second update).
data-collector will listen to statistics updates and send to a SNS. A SQS will be fed from this SNS notifications.
Statistics update handler will consume this SQS and send a message for every connection stored in the database subscribed to statistics topic.
Estimated cost:
$1.50 monthly ($ 0.50 per million update, every second update).
data-collector will listen to network updates and send to a SNS. A SQS will be fed from this SNS notifications.
Network handler will consume this SQS and send a message for every connection stored in the database subscribed to network topic.
Network data will also be improved, showing the overall network instead of a single node point of view.
Estimated cost:
$1.50 monthly ($ 0.50 per million update, every second update).
data-collector will listen to hashrate/statistics updates and send to a SNS. A SQS will listen to this SNS and store it.
Statistics collector updater will consume this SQS and store data in the database.
Statistics collector will also trigger statistics-update-handler to update connected clients.
Estimated cost: $ 0.90 per million transactions.
Data Collector will connect to full-node WebSockets to listen for updates and send messages to SNS topics.
For data which doesn't come from WebSocket, polling will be used.
Estimated cost: $ 14 monthly (
t3.small).
API gateway will handle REST requests and WS connections from the external world. Also will cache requests strategically to prevent services overload.
Estimated cost: $2 monthly (according to AWS example. Variables are quantity of requests, time of connection and data transferred).
As is a good practice use React components as presentation layer only, Hathor Explorer Lib comes as an abstraction for business matters. All requests, WS connections, Entities and business decisions will be made by it and imported by hathor-explorer to be called.
It's a good idea to separate things inside the project first and extract to a different one later. So it will still be part of hathor-explorer for now.
The existing project will not have any big visual modification except by network visualization, token list pagination and the hashrate x time graph that will be "all time" instead of starting only by the time the page is loaded.
Furthermore business logic will be extracted from React components and API calls will be modified, if needed, to fit the new responses from new guide-level-explanation/hathor-explorer-service
Estimated total monthly cost: $ 56.00 with a huge margin of accesses
Some considerations about the service:
As hathor-wallet-service already deal with reorgs, we just need to get transaction data from there.
Cache will be made using API Gateway for endpoints that make sense, with expiration times that makes sense.
Aurora MySQL will have 3 tables with the following columns:
// must be seeded with current transactions
transactions {
hash: varchar
is_block: boolean
timestamp: datetime
}
// must be seeded with current tokens
tokens {
hash: varchar
name: varchar
symbol: varchar
}
statistics {
hashrate: number
peers: number
timestamp: datetime
}
Endpoint: POST /decode_tx
Params:
hash- The transaction hash to be decoded.
Returns: 200 OK | 400 BAD_REQUEST
Transaction {}
(same as described in transactions-handler)
Procedure:
Use hathor-lib transaction classes to decode the Transaction and return.
We can cache these requests using the last n chars of the hash
Endpoint: POST /push_tx
Params:
hash- The transaction hash to be pushed.
Returns: 201 CREATED | 400 BAD_REQUEST
Procedure:
Build a request with received param and make it to hathor-core passing the transaction hash:
GET /v1a/push_tx?hex_tx=hash - Maybe it would be better to change this endpoint to POST instead of GET in hathor-core
Endpoint: GET /address/:address?page=X&sort=[asc|desc]
Params:
address- The address to be retrieved.page- [Optional] Page number of the transactions list.1if none is given.sort- [Optional] Type of sorting of the transactions list.ascif none is given.
Returns: 200 OK | 400 BAD_REQUEST | 404 NOT_FOUND
Address {
hash: string
n_of_tokens: integer
token_name: string
n_of_transactions: integer
total_received: integer
total_spent: integer
final_balance: integer
transactions: {
page: integer
sort: string
items: [
{
id: string
hash: string
timestamp: timestamp // (ISO 8601)
value: integer // positive for received, negative for sent
},
...
]
}
}
Procedure:
Build a request with received params and make it to hathor-wallet-service basically with the same params received.
hathor-wallet-service should return the data in the same structure as described above, as it holds all thos information.
Cache on API GW will use address as key. (10 ~ 20s)
Invoke: hathor-explorer-service-address
Body:
{
"addresses": [
address1,
address2,
...
]
}
Returns: 202 ACCEPTED
Procedure:
Every time transactions-updater processes a new transaction, it will invoke address-handler sending adresses involved on that transaction.
address-handler then will check for connected clients listening to those addresses and trigger an update for each one with the same Address response payload above.
Endpoint: GET /token(/:hash)?page=X&sort=[asc|desc]
Params:
hash- [Optional] The token to be retrieved.page- [Optional] Page number of the list or transactions list.1if none is given.sort- [Optional] Type of sorting of the list or transactions list.ascif none is given.
Returns: 200 OK | 400 BAD_REQUEST | 404 NOT_FOUND
When a hash is given:
Token {
hash: string
name: string
symbol: string
total_supply: integer
can_mint: boolean
can_melt: boolean
n_of_transactions: integer
config_string: string
transactions: {
page: integer
sort: string
items: [
{
hash: string
timestamp: timestamp // (ISO 8601)
},
...
]
}
}
When no hash is given:
TokenList {
page: integer
sort: string
items: [
{
hash: string
name: string
symbol: string
timestamp: timestamp // (ISO 8601)
}
]
}
Procedure:
When no hash provided, a simple query is made to the database to return the stored list.
When a hash is provided, it build a request to the hathor-wallet-service with this hash to return transaction data. This data then is transformed into the structure described above and returned.
Cache on API GW will use hash as key.
Endpoint: GET /transaction(/:hash)?blocks=[1|0]&page=X&sort=[asc|desc]
Params:
hash- [Optional] The token to be retrieved.blocks- [Optional]1to retrieve only blockspage- [Optional] Page number of the list or transactions list.1if none is given.sort- [Optional] Type of sorting of the list or transactions list.ascif none is given.
Returns: 200 OK | 400 BAD_REQUEST | 404 NOT_FOUND
When a hash is given:
Transaction {
hash: string
type: string // transaction or block
time: timestamp
nonce: integer
weight: float
first_block: string
acc_weight: float
confirmation_level: integer
voided: boolean
raw: string
inputs: [
{
output_transaction: string
output_transaction_index: integer
type: string // currency, mint or melt authority
encode_type: string
timelock: timestamp
amount: integer
token: string
address: string
spent_transaction: string
},
...
],
outputs: [
{
type: string // currency, mint or melt authority
encode_type: string
timelock: timestamp
amount: integer
token: string
address: string
spent_transaction: string
},
...
],
tokens: [
{
name: string
symbol: string
transaction: string
},
...
],
parents: [string, ...], // Array of transaction hashes
children: [string, ...], // Array of transaction hashes
twins: [string, ...], , // Array of transaction hashes
voided_by: [string, ...], , // Array of transaction hashes
conflict_with: [string, ...], , // Array of transaction hashes
verification_neighbours: [
{
hash: string
neighbours: [string, ...]
},
...
],
funds_neighbours: [
{
hash: string
neighbours: [string, ...]
}
],
}
When no hash is given:
TransactionList {
page: integer
sort: string
items: [
{
hash: string
timestamp: timestamp // (ISO 8601)
}
]
}
Procedure:
When no hash provided, a simple query is made to the database to return the stored list.
When a hash is provided, it build a request to the hathor-wallet-service with this hash to return transaction data. This data then is transformed into the structure described above and returned.
Cache on API GW will use hash as key.
SNS: hathor-core-transactions
SQS: hathor-explorer-service-transactions
data-collector: Send Transaction to SNS in the following format:
Transaction {
hash: string
is_block: boolean
is_token: boolean
timestamp: timestamp // (ISO 8601)
}
Procedure:
transactions-updater consumes the SQS, storing data into transactions collection for each transaction found.
Then it makes a request to hathor-wallet-service to retrieve transaction information, triggers address-handler with every address contained in the transaction and also triggers transactions-handler with transaction data in order to update clients subscribed to transactions WS topic.
If the transaction is for token creation, the token information is stored into tokens collection.
Endpoint: GET /statistics
Returns: 200 OK | 400 BAD_REQUEST
[
{
timestamp: timestamp
hashrate: integer
},
...
]
Procedure:
statistics-history-handler will retrieve all hashrate history from the database aggregating by a period of time (daily ?) and return.
$connect: $disconnect: $default:
WS Topic: 'dag'
SNS: hathor-core-dag
SQS: hathor-explorer-service-dag
data-collector: Send DAG to SNS in the following format:
DAG {
hash: string
neighbours: [string, ...]
}
Procedure:
dag-handler consumes SQS, checks database for WS connections and send messages for each client connected and subscribed to dag topic.
WS Topic: 'statistics'
Invoke: hathor-explorer-service-statistics-update
Body:
Statistic {}
Returns: 202 ACCEPTED
Procedure: It will be triggered directly by statistics-collector_
statistics-update-handler is triggered by statistics-collector, checks database for WS connections and send messages for each client connected and subscribed to statistics topic.
WS Topic: 'network'
SNS: hathor-core-network
SQS: hathor-explorer-service-network
data-collector: Send Network data to SNS in the following format:
Network {
id: string
uptime: int // in seconds
version: string
latest_timestamp: timestamp // (ISO 8601)
peers: [
{
id: string
uptime: int // in seconds
version: string
address: string
entrypoints: string
state: string
sync_timestamp: timestamp // (ISO 8601)
latest_timestamp: timestamp // (ISO 8601)
},
...
]
timestamp: timestamp // (ISO 8601)
}
Procedure:
network-handler consumes SQS, checks database for WS connections and send messages for each client connected and subscribed to network topic.
SNS: hathor-core-statistics
SQS: hathor-explorer-service-statistics
data-collector: Send Statistics to SNS in the following format:
Statistic {
blocks: int
best_chain_height: int
transactions: int
hashrate: float
peers: int
timestamp: timestamp // (ISO 8601)
}
Procedure:
statistics-collector consumes SQS, saves hashrate into database and triggers statistics-update-handler with received data.
Data collector will get data from full-node by the following ways
WebSocket:
/v1a/ws- Listen to the following events:'dashboard:metrics'- for statistics'network:new_tx_accepted'- for transactions an DAG
Polling:
/v1a/status- Fetch Network information
Every update will be sent to respective SNS.
API Gateway will handle HTTP requests and WS connections. It will also cache requests that leads to hathor-core calls using query params or some header (in POST requests).
[WIP]
- Home
- Home page will keep the same structure and visual. When page loads, two requests will be made to
transactions-handler. One withblocks=1to retrieve blocks and other withblocks=0to retrieve latest non-block transactions. Also, a WS connection subscribing to'transactions'topic for updates.
- Home page will keep the same structure and visual. When page loads, two requests will be made to
- Transactions
- Transactions page will keep the same structure and visual. When page loads, a request will be made to
transactions-handlerwithblocks=0to retrieve latest non-block transactions.
- Transactions page will keep the same structure and visual. When page loads, a request will be made to
- Blocks
- Blocks page will keep the same structure and visual. When page loads, a request will be made to
transactions-handlerwithblocks=1to retrieve latest blocks.
- Blocks page will keep the same structure and visual. When page loads, a request will be made to
- Network
- Network page will keep the same structure and visual except that it will show Network data as a overall instead of a single node point of view. Whe page loads, it connects with WS subscribing to
'network'topic for updates.
- Network page will keep the same structure and visual except that it will show Network data as a overall instead of a single node point of view. Whe page loads, it connects with WS subscribing to
- Statistics
- Statistics page will keep the sabe structure and visual except for the new Hashrate history graph. When page loads, a request will be made to
statistics-history-handlerto retrieve hashrate history and it will connect to WS subscribing to'statistics'topic for updates.
- Statistics page will keep the sabe structure and visual except for the new Hashrate history graph. When page loads, a request will be made to
- Tokens
- Tokens page will keep the same structure and visual just adding pagination to the list. When page loads, a request will be made to
tokens-handlerto retrive latest created Tokens.
- Tokens page will keep the same structure and visual just adding pagination to the list. When page loads, a request will be made to
- Decode TX
- Decode TX page will keep the same structure and visual. Transaction data to decode will be posted to
decode-tx-handler
- Decode TX page will keep the same structure and visual. Transaction data to decode will be posted to
- Push TX
- Push TX page will keep the same structure and visual. Transaction data to be pushed will be posted to
push-tx-handler
- Push TX page will keep the same structure and visual. Transaction data to be pushed will be posted to
- DAG
- DAG page could have a better visual. Maybe use some lib like in this example. When page loads, it connects with WS subscribing to
'dag'topic for updates.
- DAG page could have a better visual. Maybe use some lib like in this example. When page loads, it connects with WS subscribing to
- Address
- Address page will keep the same structure and visual. When page loads, a request will be made to
address-handlerpassingaddressas parameter to load current data and a WS connection subscribing toaddresstopic for updates. When new updates arrive, overall information refreshes and if the list is in the first page, it just updates. If the list is not in the first page, its shows a message saying that new transactions arrived and the user can go to the first page to see it.
- Address page will keep the same structure and visual. When page loads, a request will be made to
- Even though serveless framework works with different providers, this design is pretty bounded to AWS.
- Lambdas are awesome. They're fast, light and cheap. Also it's independent, so we can easily scale a specific function when it grows in demand.
- SNS and SQS ensures data and events integrity between services making it easy to manage and understand who is getting the notifications.
As the goal of V1 is to keep the client side almost the same way, just not overloading the full-node, the prior art is basically itself. For future versions we'll use some other sites as inspiration.
As we have several nodes running we have to deal with several notifications with the same data coming from them. At first i can think in two different solutions for this problem:
- Elect only one node to fire the notifications. It can be the oldest, or follow a list of priorities, for example.
- Deal with duplications at infra/code level. SNS can ignore duplicated messages in FIFO topic if a
MessageDeduplicationIdis passed. However, it has a 5-minute window to consider this ids, so:- We can make nodes send notifications only when syncronized.
- We can deal with duplications on code, using the SNS feature just to drasticaly reduce the duplications
As not every node is connected with all other nodes, we can face scenaries where we miss nodes depending on which node we are retriving Network information. How can we solve this?
NGINX have a good system for throttling. Can we do this with API Gateway?
We already have an API running (that access the full-node). Would this service be a new version of this API? Will we allow anyone to access this service as it is a public API?
[WIP] Still under discussion
- Create Project base structure and Repo
- Create first version of automated tests and deploy
- Setup aurora-mysql
- Design
network-handler - Implement
network-handler - ...
- Implement endpoint for wallet address
- Implement endpoint for list tokens with pagination
- ...
- Design how the updates will be sent to SNS's
- Update libraries (security fixes included)
- Change Pages to fetch/connect to
hathor-explorer-service- Home page
- Transactions page
- Blocks page
- Network page
- Statistics page
- Tokens page
- DAG page
- Decode Tx page
- Push Tx page
- Address page
- ...