diff --git a/src/gpt-crawler/.dockerignore b/src/gpt-crawler/.dockerignore
new file mode 100644
index 0000000..556fbb2
--- /dev/null
+++ b/src/gpt-crawler/.dockerignore
@@ -0,0 +1,13 @@
+# configurations
+.idea
+
+# crawlee and apify storage folders
+apify_storage
+crawlee_storage
+storage
+
+# installed files
+node_modules
+
+# ignore base image 'main.js'
+main.js
\ No newline at end of file
diff --git a/src/gpt-crawler/.github/workflows/build.yml b/src/gpt-crawler/.github/workflows/build.yml
new file mode 100644
index 0000000..b1d9b54
--- /dev/null
+++ b/src/gpt-crawler/.github/workflows/build.yml
@@ -0,0 +1,23 @@
+name: Build workflow
+
+on:
+ pull_request:
+ types: [opened, reopened, synchronize]
+
+jobs:
+ build:
+ name: build
+ runs-on: ubuntu-latest
+ env:
+ CI_JOB_NUMBER: 1
+ steps:
+ - uses: actions/checkout@v2
+ - uses: actions/setup-node@v2
+ with:
+ cache: npm
+ node-version: 18
+ - run: npm i
+ - run: npm run build
+ - uses: preactjs/compressed-size-action@v2
+ with:
+ pattern: ".dist/**/*.{js,ts,json}"
diff --git a/src/gpt-crawler/.github/workflows/release.yml b/src/gpt-crawler/.github/workflows/release.yml
new file mode 100644
index 0000000..fa42132
--- /dev/null
+++ b/src/gpt-crawler/.github/workflows/release.yml
@@ -0,0 +1,23 @@
+name: Release workflow
+
+on:
+ push:
+ branches:
+ - main
+
+jobs:
+ release:
+ name: release
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ - uses: actions/setup-node@v2
+ with:
+ cache: npm
+ node-version: 18
+ - run: npm i
+ - run: npm run build
+ - run: npm run semantic-release
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
+ NPM_TOKEN: ${{ secrets.NPM_TOKEN }}
diff --git a/src/gpt-crawler/.github/workflows/test.yml b/src/gpt-crawler/.github/workflows/test.yml
new file mode 100644
index 0000000..ef57a37
--- /dev/null
+++ b/src/gpt-crawler/.github/workflows/test.yml
@@ -0,0 +1,18 @@
+name: Test workflow
+
+on: [push, pull_request]
+
+jobs:
+ prettier_check:
+ runs-on: ubuntu-latest
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Node.js
+ uses: actions/setup-node@v2
+ with:
+ node-version: "20"
+ - name: Install Dependencies
+ run: npm ci
+ - name: Run prettier
+ run: npm run prettier:check
diff --git a/src/gpt-crawler/.gitignore b/src/gpt-crawler/.gitignore
new file mode 100644
index 0000000..9b56ebd
--- /dev/null
+++ b/src/gpt-crawler/.gitignore
@@ -0,0 +1,23 @@
+# This file tells Git which files shouldn't be added to source control
+
+.idea
+dist
+node_modules
+apify_storage
+crawlee_storage
+storage
+.DS_Store
+
+!package.json
+!package-lock.json
+!tsconfig.json
+
+# any output from the crawler
+*.json
+
+pnpm-lock.yaml
+
+# Python
+__pycache__
+venv/
+.venv/
diff --git a/src/gpt-crawler/.pylintrc b/src/gpt-crawler/.pylintrc
new file mode 100644
index 0000000..97c4883
--- /dev/null
+++ b/src/gpt-crawler/.pylintrc
@@ -0,0 +1,638 @@
+[MAIN]
+
+# Analyse import fallback blocks. This can be used to support both Python 2 and
+# 3 compatible code, which means that the block might have code that exists
+# only in one or another interpreter, leading to false positives when analysed.
+analyse-fallback-blocks=no
+
+# Clear in-memory caches upon conclusion of linting. Useful if running pylint
+# in a server-like mode.
+clear-cache-post-run=no
+
+# Load and enable all available extensions. Use --list-extensions to see a list
+# all available extensions.
+#enable-all-extensions=
+
+# In error mode, messages with a category besides ERROR or FATAL are
+# suppressed, and no reports are done by default. Error mode is compatible with
+# disabling specific errors.
+#errors-only=
+
+# Always return a 0 (non-error) status code, even if lint errors are found.
+# This is primarily useful in continuous integration scripts.
+#exit-zero=
+
+# A comma-separated list of package or module names from where C extensions may
+# be loaded. Extensions are loading into the active Python interpreter and may
+# run arbitrary code.
+extension-pkg-allow-list=
+
+# A comma-separated list of package or module names from where C extensions may
+# be loaded. Extensions are loading into the active Python interpreter and may
+# run arbitrary code. (This is an alternative name to extension-pkg-allow-list
+# for backward compatibility.)
+extension-pkg-whitelist=
+
+# Return non-zero exit code if any of these messages/categories are detected,
+# even if score is above --fail-under value. Syntax same as enable. Messages
+# specified are enabled, while categories only check already-enabled messages.
+fail-on=
+
+# Specify a score threshold under which the program will exit with error.
+fail-under=10
+
+# Interpret the stdin as a python script, whose filename needs to be passed as
+# the module_or_package argument.
+#from-stdin=
+
+# Files or directories to be skipped. They should be base names, not paths.
+ignore=CVS
+
+# Add files or directories matching the regular expressions patterns to the
+# ignore-list. The regex matches against paths and can be in Posix or Windows
+# format. Because '\\' represents the directory delimiter on Windows systems,
+# it can't be used as an escape character.
+ignore-paths=
+
+# Files or directories matching the regular expression patterns are skipped.
+# The regex matches against base names, not paths. The default value ignores
+# Emacs file locks
+ignore-patterns=^\.#
+
+# List of module names for which member attributes should not be checked
+# (useful for modules/projects where namespaces are manipulated during runtime
+# and thus existing member attributes cannot be deduced by static analysis). It
+# supports qualified module names, as well as Unix pattern matching.
+ignored-modules=
+
+# Python code to execute, usually for sys.path manipulation such as
+# pygtk.require().
+#init-hook=
+
+# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
+# number of processors available to use, and will cap the count on Windows to
+# avoid hangs.
+jobs=1
+
+# Control the amount of potential inferred values when inferring a single
+# object. This can help the performance when dealing with large functions or
+# complex, nested conditions.
+limit-inference-results=100
+
+# List of plugins (as comma separated values of python module names) to load,
+# usually to register additional checkers.
+load-plugins=
+
+# Pickle collected data for later comparisons.
+persistent=yes
+
+# Minimum Python version to use for version dependent checks. Will default to
+# the version used to run pylint.
+py-version=3.12
+
+# Discover python modules and packages in the file system subtree.
+recursive=no
+
+# Add paths to the list of the source roots. Supports globbing patterns. The
+# source root is an absolute path or a path relative to the current working
+# directory used to determine a package namespace for modules located under the
+# source root.
+source-roots=
+
+# When enabled, pylint would attempt to guess common misconfiguration and emit
+# user-friendly hints instead of false-positive error messages.
+suggestion-mode=yes
+
+# Allow loading of arbitrary C extensions. Extensions are imported into the
+# active Python interpreter and may run arbitrary code.
+unsafe-load-any-extension=no
+
+# In verbose mode, extra non-checker-related info will be displayed.
+#verbose=
+
+
+[BASIC]
+
+# Naming style matching correct argument names.
+argument-naming-style=snake_case
+
+# Regular expression matching correct argument names. Overrides argument-
+# naming-style. If left empty, argument names will be checked with the set
+# naming style.
+#argument-rgx=
+
+# Naming style matching correct attribute names.
+attr-naming-style=snake_case
+
+# Regular expression matching correct attribute names. Overrides attr-naming-
+# style. If left empty, attribute names will be checked with the set naming
+# style.
+#attr-rgx=
+
+# Bad variable names which should always be refused, separated by a comma.
+bad-names=foo,
+ bar,
+ baz,
+ toto,
+ tutu,
+ tata
+
+# Bad variable names regexes, separated by a comma. If names match any regex,
+# they will always be refused
+bad-names-rgxs=
+
+# Naming style matching correct class attribute names.
+class-attribute-naming-style=any
+
+# Regular expression matching correct class attribute names. Overrides class-
+# attribute-naming-style. If left empty, class attribute names will be checked
+# with the set naming style.
+#class-attribute-rgx=
+
+# Naming style matching correct class constant names.
+class-const-naming-style=UPPER_CASE
+
+# Regular expression matching correct class constant names. Overrides class-
+# const-naming-style. If left empty, class constant names will be checked with
+# the set naming style.
+#class-const-rgx=
+
+# Naming style matching correct class names.
+class-naming-style=PascalCase
+
+# Regular expression matching correct class names. Overrides class-naming-
+# style. If left empty, class names will be checked with the set naming style.
+#class-rgx=
+
+# Naming style matching correct constant names.
+const-naming-style=UPPER_CASE
+
+# Regular expression matching correct constant names. Overrides const-naming-
+# style. If left empty, constant names will be checked with the set naming
+# style.
+#const-rgx=
+
+# Minimum line length for functions/classes that require docstrings, shorter
+# ones are exempt.
+docstring-min-length=-1
+
+# Naming style matching correct function names.
+function-naming-style=snake_case
+
+# Regular expression matching correct function names. Overrides function-
+# naming-style. If left empty, function names will be checked with the set
+# naming style.
+#function-rgx=
+
+# Good variable names which should always be accepted, separated by a comma.
+good-names=i,
+ j,
+ k,
+ ex,
+ Run,
+ _
+
+# Good variable names regexes, separated by a comma. If names match any regex,
+# they will always be accepted
+good-names-rgxs=
+
+# Include a hint for the correct naming format with invalid-name.
+include-naming-hint=no
+
+# Naming style matching correct inline iteration names.
+inlinevar-naming-style=any
+
+# Regular expression matching correct inline iteration names. Overrides
+# inlinevar-naming-style. If left empty, inline iteration names will be checked
+# with the set naming style.
+#inlinevar-rgx=
+
+# Naming style matching correct method names.
+method-naming-style=snake_case
+
+# Regular expression matching correct method names. Overrides method-naming-
+# style. If left empty, method names will be checked with the set naming style.
+#method-rgx=
+
+# Naming style matching correct module names.
+module-naming-style=snake_case
+
+# Regular expression matching correct module names. Overrides module-naming-
+# style. If left empty, module names will be checked with the set naming style.
+#module-rgx=
+
+# Colon-delimited sets of names that determine each other's naming style when
+# the name regexes allow several styles.
+name-group=
+
+# Regular expression which should only match function or class names that do
+# not require a docstring.
+no-docstring-rgx=^_
+
+# List of decorators that produce properties, such as abc.abstractproperty. Add
+# to this list to register other decorators that produce valid properties.
+# These decorators are taken in consideration only for invalid-name.
+property-classes=abc.abstractproperty
+
+# Regular expression matching correct type alias names. If left empty, type
+# alias names will be checked with the set naming style.
+#typealias-rgx=
+
+# Regular expression matching correct type variable names. If left empty, type
+# variable names will be checked with the set naming style.
+#typevar-rgx=
+
+# Naming style matching correct variable names.
+variable-naming-style=snake_case
+
+# Regular expression matching correct variable names. Overrides variable-
+# naming-style. If left empty, variable names will be checked with the set
+# naming style.
+#variable-rgx=
+
+
+[CLASSES]
+
+# Warn about protected attribute access inside special methods
+check-protected-access-in-special-methods=no
+
+# List of method names used to declare (i.e. assign) instance attributes.
+defining-attr-methods=__init__,
+ __new__,
+ setUp,
+ asyncSetUp,
+ __post_init__
+
+# List of member names, which should be excluded from the protected access
+# warning.
+exclude-protected=_asdict,_fields,_replace,_source,_make,os._exit
+
+# List of valid names for the first argument in a class method.
+valid-classmethod-first-arg=cls
+
+# List of valid names for the first argument in a metaclass class method.
+valid-metaclass-classmethod-first-arg=mcs
+
+
+[DESIGN]
+
+# List of regular expressions of class ancestor names to ignore when counting
+# public methods (see R0903)
+exclude-too-few-public-methods=
+
+# List of qualified class names to ignore when counting class parents (see
+# R0901)
+ignored-parents=
+
+# Maximum number of arguments for function / method.
+max-args=5
+
+# Maximum number of attributes for a class (see R0902).
+max-attributes=7
+
+# Maximum number of boolean expressions in an if statement (see R0916).
+max-bool-expr=5
+
+# Maximum number of branch for function / method body.
+max-branches=12
+
+# Maximum number of locals for function / method body.
+max-locals=15
+
+# Maximum number of parents for a class (see R0901).
+max-parents=7
+
+# Maximum number of public methods for a class (see R0904).
+max-public-methods=20
+
+# Maximum number of return / yield for function / method body.
+max-returns=6
+
+# Maximum number of statements in function / method body.
+max-statements=50
+
+# Minimum number of public methods for a class (see R0903).
+min-public-methods=2
+
+
+[EXCEPTIONS]
+
+# Exceptions that will emit a warning when caught.
+overgeneral-exceptions=builtins.BaseException,builtins.Exception
+
+
+[FORMAT]
+
+# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
+expected-line-ending-format=
+
+# Regexp for a line that is allowed to be longer than the limit.
+ignore-long-lines=^\s*(# )??$
+
+# Number of spaces of indent required inside a hanging or continued line.
+indent-after-paren=4
+
+# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
+# tab).
+indent-string=' '
+
+# Maximum number of characters on a single line.
+max-line-length=100
+
+# Maximum number of lines in a module.
+max-module-lines=1000
+
+# Allow the body of a class to be on the same line as the declaration if body
+# contains single statement.
+single-line-class-stmt=no
+
+# Allow the body of an if to be on the same line as the test if there is no
+# else.
+single-line-if-stmt=no
+
+
+[IMPORTS]
+
+# List of modules that can be imported at any level, not just the top level
+# one.
+allow-any-import-level=
+
+# Allow explicit reexports by alias from a package __init__.
+allow-reexport-from-package=no
+
+# Allow wildcard imports from modules that define __all__.
+allow-wildcard-with-all=no
+
+# Deprecated modules which should not be used, separated by a comma.
+deprecated-modules=
+
+# Output a graph (.gv or any supported image format) of external dependencies
+# to the given file (report RP0402 must not be disabled).
+ext-import-graph=
+
+# Output a graph (.gv or any supported image format) of all (i.e. internal and
+# external) dependencies to the given file (report RP0402 must not be
+# disabled).
+import-graph=
+
+# Output a graph (.gv or any supported image format) of internal dependencies
+# to the given file (report RP0402 must not be disabled).
+int-import-graph=
+
+# Force import order to recognize a module as part of the standard
+# compatibility libraries.
+known-standard-library=
+
+# Force import order to recognize a module as part of a third party library.
+known-third-party=enchant
+
+# Couples of modules and preferred modules, separated by a comma.
+preferred-modules=
+
+
+[LOGGING]
+
+# The type of string formatting that logging methods do. `old` means using %
+# formatting, `new` is for `{}` formatting.
+logging-format-style=old
+
+# Logging modules to check that the string format arguments are in logging
+# function parameter format.
+logging-modules=logging
+
+
+[MESSAGES CONTROL]
+
+# Only show warnings with the listed confidence levels. Leave empty to show
+# all. Valid levels: HIGH, CONTROL_FLOW, INFERENCE, INFERENCE_FAILURE,
+# UNDEFINED.
+confidence=HIGH,
+ CONTROL_FLOW,
+ INFERENCE,
+ INFERENCE_FAILURE,
+ UNDEFINED
+
+# Disable the message, report, category or checker with the given id(s). You
+# can either give multiple identifiers separated by comma (,) or put this
+# option multiple times (only on the command line, not in the configuration
+# file where it should appear only once). You can also use "--disable=all" to
+# disable everything first and then re-enable specific checks. For example, if
+# you want to run only the similarities checker, you can use "--disable=all
+# --enable=similarities". If you want to run only the classes checker, but have
+# no Warning level messages displayed, use "--disable=all --enable=classes
+# --disable=W".
+disable=C0330, # Wrong hanging indentation before block (black)
+ C0326, # Bad Whitespace (black)
+ W0718, # Catching too general exception Exception. \
+ # This setting was added intentionally for `conv_html_to_markdown.py`
+ raw-checker-failed,
+ bad-inline-option,
+ locally-disabled,
+ file-ignored,
+ suppressed-message,
+ useless-suppression,
+ deprecated-pragma,
+ use-symbolic-message-instead,
+ use-implicit-booleaness-not-comparison-to-string,
+ use-implicit-booleaness-not-comparison-to-zero
+
+# Enable the message, report, category or checker with the given id(s). You can
+# either give multiple identifier separated by comma (,) or put this option
+# multiple time (only on the command line, not in the configuration file where
+# it should appear only once). See also the "--disable" option for examples.
+enable=
+
+
+[METHOD_ARGS]
+
+# List of qualified names (i.e., library.method) which require a timeout
+# parameter e.g. 'requests.api.get,requests.api.post'
+timeout-methods=requests.api.delete,requests.api.get,requests.api.head,requests.api.options,requests.api.patch,requests.api.post,requests.api.put,requests.api.request
+
+
+[MISCELLANEOUS]
+
+# List of note tags to take in consideration, separated by a comma.
+notes=FIXME,
+ XXX,
+ TODO
+
+# Regular expression of note tags to take in consideration.
+notes-rgx=
+
+
+[REFACTORING]
+
+# Maximum number of nested blocks for function / method body
+max-nested-blocks=5
+
+# Complete name of functions that never returns. When checking for
+# inconsistent-return-statements if a never returning function is called then
+# it will be considered as an explicit return statement and no message will be
+# printed.
+never-returning-functions=sys.exit,argparse.parse_error
+
+
+[REPORTS]
+
+# Python expression which should return a score less than or equal to 10. You
+# have access to the variables 'fatal', 'error', 'warning', 'refactor',
+# 'convention', and 'info' which contain the number of messages in each
+# category, as well as 'statement' which is the total number of statements
+# analyzed. This score is used by the global evaluation report (RP0004).
+evaluation=max(0, 0 if fatal else 10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10))
+
+# Template used to display messages. This is a python new-style format string
+# used to format the message information. See doc for all details.
+msg-template=
+
+# Set the output format. Available formats are: text, parseable, colorized,
+# json2 (improved json format), json (old json format) and msvs (visual
+# studio). You can also give a reporter class, e.g.
+# mypackage.mymodule.MyReporterClass.
+#output-format=
+
+# Tells whether to display a full report or only the messages.
+reports=no
+
+# Activate the evaluation score.
+score=yes
+
+
+[SIMILARITIES]
+
+# Comments are removed from the similarity computation
+ignore-comments=yes
+
+# Docstrings are removed from the similarity computation
+ignore-docstrings=yes
+
+# Imports are removed from the similarity computation
+ignore-imports=yes
+
+# Signatures are removed from the similarity computation
+ignore-signatures=yes
+
+# Minimum lines number of a similarity.
+min-similarity-lines=4
+
+
+[SPELLING]
+
+# Limits count of emitted suggestions for spelling mistakes.
+max-spelling-suggestions=4
+
+# Spelling dictionary name. No available dictionaries : You need to install
+# both the python package and the system dependency for enchant to work.
+spelling-dict=
+
+# List of comma separated words that should be considered directives if they
+# appear at the beginning of a comment and should not be checked.
+spelling-ignore-comment-directives=fmt: on,fmt: off,noqa:,noqa,nosec,isort:skip,mypy:
+
+# List of comma separated words that should not be checked.
+spelling-ignore-words=
+
+# A path to a file that contains the private dictionary; one word per line.
+spelling-private-dict-file=
+
+# Tells whether to store unknown words to the private dictionary (see the
+# --spelling-private-dict-file option) instead of raising a message.
+spelling-store-unknown-words=no
+
+
+[STRING]
+
+# This flag controls whether inconsistent-quotes generates a warning when the
+# character used as a quote delimiter is used inconsistently within a module.
+check-quote-consistency=no
+
+# This flag controls whether the implicit-str-concat should generate a warning
+# on implicit string concatenation in sequences defined over several lines.
+check-str-concat-over-line-jumps=no
+
+
+[TYPECHECK]
+
+# List of decorators that produce context managers, such as
+# contextlib.contextmanager. Add to this list to register other decorators that
+# produce valid context managers.
+contextmanager-decorators=contextlib.contextmanager
+
+# List of members which are set dynamically and missed by pylint inference
+# system, and so shouldn't trigger E1101 when accessed. Python regular
+# expressions are accepted.
+generated-members=
+
+# Tells whether to warn about missing members when the owner of the attribute
+# is inferred to be None.
+ignore-none=yes
+
+# This flag controls whether pylint should warn about no-member and similar
+# checks whenever an opaque object is returned when inferring. The inference
+# can return multiple potential results while evaluating a Python object, but
+# some branches might not be evaluated, which results in partial inference. In
+# that case, it might be useful to still emit no-member and other checks for
+# the rest of the inferred objects.
+ignore-on-opaque-inference=yes
+
+# List of symbolic message names to ignore for Mixin members.
+ignored-checks-for-mixins=no-member,
+ not-async-context-manager,
+ not-context-manager,
+ attribute-defined-outside-init
+
+# List of class names for which member attributes should not be checked (useful
+# for classes with dynamically set attributes). This supports the use of
+# qualified names.
+ignored-classes=optparse.Values,thread._local,_thread._local,argparse.Namespace
+
+# Show a hint with possible names when a member name was not found. The aspect
+# of finding the hint is based on edit distance.
+missing-member-hint=yes
+
+# The minimum edit distance a name should have in order to be considered a
+# similar match for a missing member name.
+missing-member-hint-distance=1
+
+# The total number of similar names that should be taken in consideration when
+# showing a hint for a missing member.
+missing-member-max-choices=1
+
+# Regex pattern to define which classes are considered mixins.
+mixin-class-rgx=.*[Mm]ixin
+
+# List of decorators that change the signature of a decorated function.
+signature-mutators=
+
+
+[VARIABLES]
+
+# List of additional names supposed to be defined in builtins. Remember that
+# you should avoid defining new builtins when possible.
+additional-builtins=
+
+# Tells whether unused global variables should be treated as a violation.
+allow-global-unused-variables=yes
+
+# List of names allowed to shadow builtins
+allowed-redefined-builtins=
+
+# List of strings which can identify a callback function by name. A callback
+# name must start or end with one of those strings.
+callbacks=cb_,
+ _cb
+
+# A regular expression matching the name of dummy variables (i.e. expected to
+# not be used).
+dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
+
+# Argument names that match this expression will be ignored.
+ignored-argument-names=_.*|^ignored_|^unused_
+
+# Tells whether we should check for unused import in __init__ files.
+init-import=no
+
+# List of qualified module names which can have objects that can redefine
+# builtins.
+redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
\ No newline at end of file
diff --git a/src/gpt-crawler/.releaserc b/src/gpt-crawler/.releaserc
new file mode 100644
index 0000000..fd0064d
--- /dev/null
+++ b/src/gpt-crawler/.releaserc
@@ -0,0 +1,12 @@
+{
+ "branches": [
+ "main"
+ ],
+ "plugins": [
+ "@semantic-release/commit-analyzer",
+ "@semantic-release/changelog",
+ "@semantic-release/npm",
+ "@semantic-release/git",
+ "@semantic-release/github"
+ ]
+}
diff --git a/src/gpt-crawler/Dockerfile b/src/gpt-crawler/Dockerfile
new file mode 100644
index 0000000..918e7f4
--- /dev/null
+++ b/src/gpt-crawler/Dockerfile
@@ -0,0 +1,62 @@
+# Specify the base Docker image. You can read more about
+# the available images at https://crawlee.dev/docs/guides/docker-images
+# You can also use any other image from Docker Hub.
+FROM apify/actor-node-playwright-chrome:18 AS builder
+
+# Copy just package.json and package-lock.json
+# to speed up the build using Docker layer cache.
+COPY --chown=myuser package*.json ./
+
+# Install all dependencies. Don't audit to speed up the installation.
+RUN npm install --include=dev --audit=false
+
+# Next, copy the source files using the user set
+# in the base image.
+COPY --chown=myuser . ./
+
+# Install all dependencies and build the project.
+# Don't audit to speed up the installation.
+RUN npm run build
+
+# Create final image
+FROM apify/actor-node-playwright-chrome:18
+
+# Copy only built JS files from builder image
+COPY --from=builder --chown=myuser /home/myuser/dist ./dist
+
+# Copy just package.json and package-lock.json
+# to speed up the build using Docker layer cache.
+COPY --chown=myuser package*.json ./
+
+# Install NPM packages, skip optional and development dependencies to
+# keep the image small. Avoid logging too much and print the dependency
+# tree for debugging
+RUN npm --quiet set progress=false \
+ && npm install --omit=dev --omit=optional \
+ && echo "Installed NPM packages:" \
+ && (npm list --omit=dev --all || true) \
+ && echo "Node.js version:" \
+ && node --version \
+ && echo "NPM version:" \
+ && npm --version
+
+# Install Python and required dependencies for the Python module
+# Switch user to ROOT for installation
+USER root
+RUN apt-get update \
+ && apt-get install -y python3 python3-pip
+USER myuser
+RUN pip3 install -Uq beautifulsoup4 \
+ markdownify transformers torch
+
+# Copy the Python script
+COPY --chown=myuser src/conv_html_to_markdown.py ./
+
+# Next, copy the remaining files and directories with the source code.
+# Since we do this after NPM install, quick build will be really fast
+# for most source file changes.
+COPY --chown=myuser . ./
+
+# Run the image. If you know you won't need headful browsers,
+# you can remove the XVFB start script for a micro perf gain.
+CMD ./start_xvfb_and_run_cmd.sh && npm run start:prod --silent && python3 conv_html_to_markdown.py
diff --git a/src/gpt-crawler/License b/src/gpt-crawler/License
new file mode 100644
index 0000000..5d7a502
--- /dev/null
+++ b/src/gpt-crawler/License
@@ -0,0 +1,15 @@
+ISC License
+
+Copyright (c) 2023 BuilderIO
+
+Permission to use, copy, modify, and/or distribute this software for any purpose
+with or without fee is hereby granted, provided that the above copyright notice
+and this permission notice appear in all copies.
+
+THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH
+REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND
+FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, DIRECT,
+INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS
+OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER
+TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF
+THIS SOFTWARE.
diff --git a/src/gpt-crawler/README.md b/src/gpt-crawler/README.md
new file mode 100644
index 0000000..43bfe4c
--- /dev/null
+++ b/src/gpt-crawler/README.md
@@ -0,0 +1,150 @@
+# GPT Crawler
+
+Crawl a site to generate knowledge files to create your own custom GPT from one or multiple URLs
+
+
+
+- [Example](#example)
+- [Get started](#get-started)
+ - [Running locally](#running-locally)
+ - [Clone the repository](#clone-the-repository)
+ - [Install dependencies](#install-dependencies)
+ - [Configure the crawler](#configure-the-crawler)
+ - [Run your crawler](#run-your-crawler)
+ - [Alternative methods](#alternative-methods)
+ - [Running in a container with Docker](#running-in-a-container-with-docker)
+ - [Running as a CLI](#running-as-a-cli)
+ - [Development](#development)
+ - [Upload your data to OpenAI](#upload-your-data-to-openai)
+ - [Create a custom GPT](#create-a-custom-gpt)
+ - [Create a custom assistant](#create-a-custom-assistant)
+- [Contributing](#contributing)
+
+## Example
+
+[Here is a custom GPT](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) that I quickly made to help answer questions about how to use and integrate [Builder.io](https://www.builder.io) by simply providing the URL to the Builder docs.
+
+This project crawled the docs and generated the file that I uploaded as the basis for the custom GPT.
+
+[Try it out yourself](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) by asking questions about how to integrate Builder.io into a site.
+
+> Note that you may need a paid ChatGPT plan to access this feature
+
+## Get started
+
+### Running locally
+
+#### Clone the repository
+
+Be sure you have Node.js >= 16 installed.
+
+```sh
+git clone https://github.com/builderio/gpt-crawler
+```
+
+#### Install dependencies
+
+```sh
+npm i
+```
+
+#### Configure the crawler
+
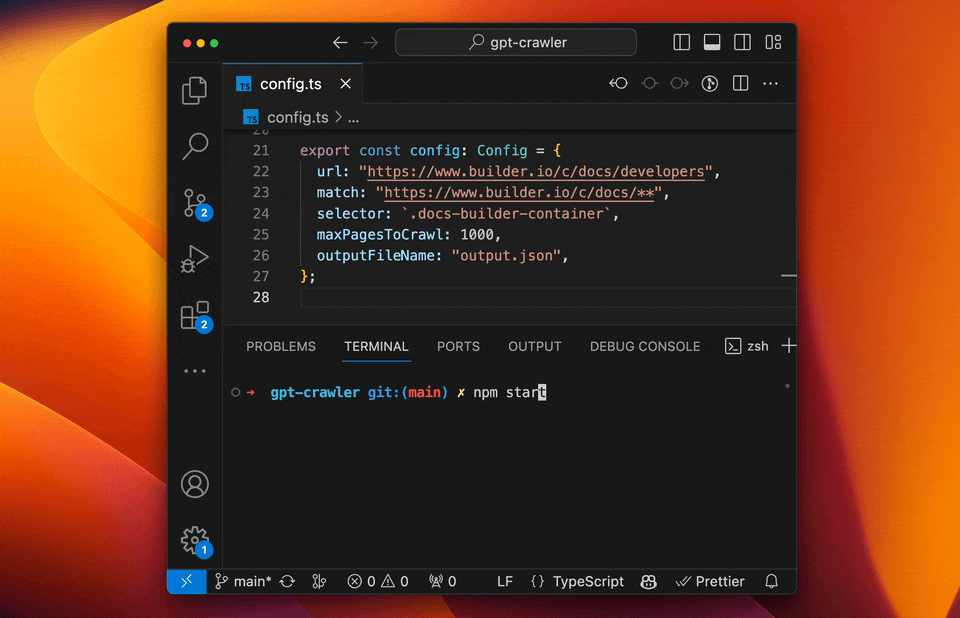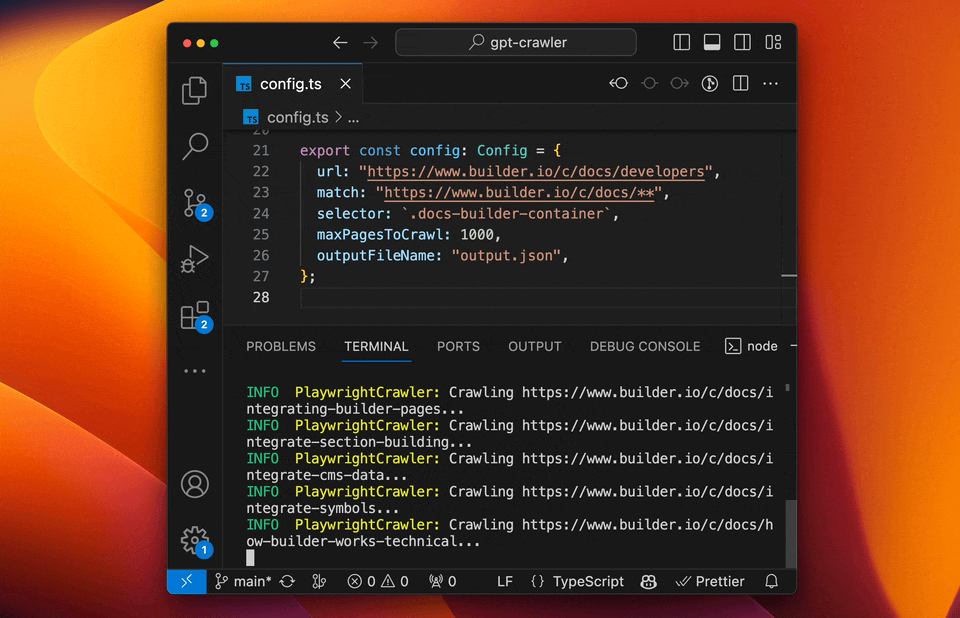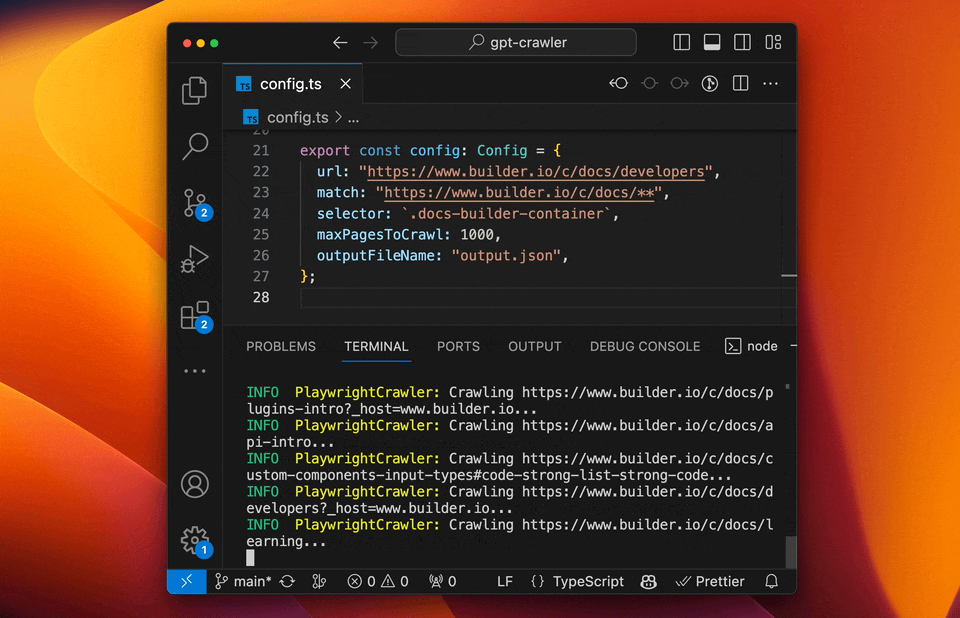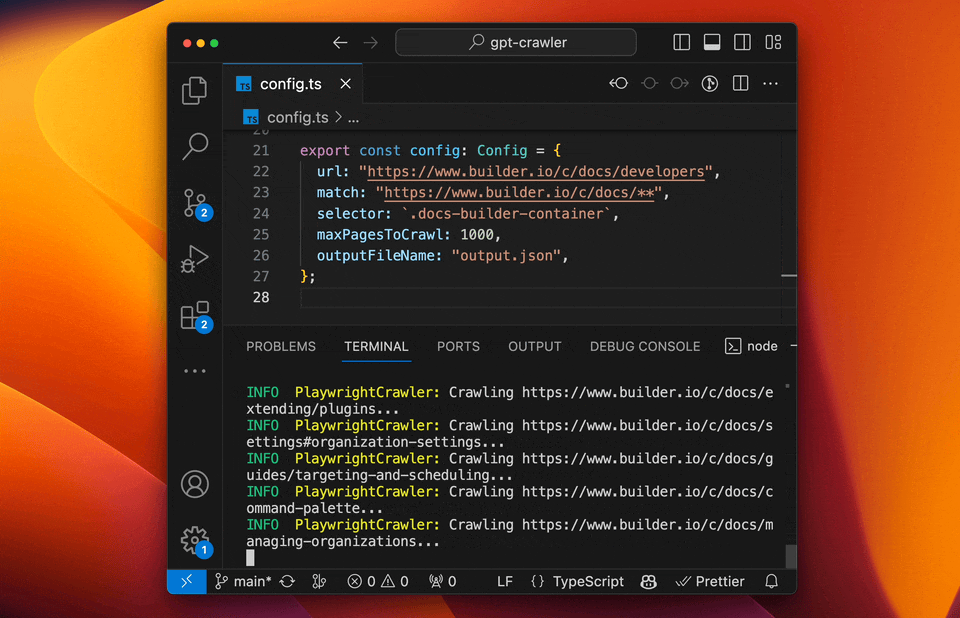
+Open [config.ts](config.ts) and edit the `url` and `selectors` properties to match your needs.
+
+E.g. to crawl the Builder.io docs to make our custom GPT you can use:
+
+```ts
+export const defaultConfig: Config = {
+ url: "https://www.builder.io/c/docs/developers",
+ match: "https://www.builder.io/c/docs/**",
+ selector: `.docs-builder-container`,
+ maxPagesToCrawl: 50,
+ outputFileName: "output.json",
+};
+```
+
+See [config.ts](src/config.ts) for all available options. Here is a sample of the common configu options:
+
+```ts
+type Config = {
+ /** URL to start the crawl, if sitemap is provided then it will be used instead and download all pages in the sitemap */
+ url: string;
+ /** Pattern to match against for links on a page to subsequently crawl */
+ match: string;
+ /** Selector to grab the inner text from */
+ selector: string;
+ /** Don't crawl more than this many pages */
+ maxPagesToCrawl: number;
+ /** File name for the finished data */
+ outputFileName: string;
+ /** Optional resources to exclude
+ *
+ * @example
+ * ['png','jpg','jpeg','gif','svg','css','js','ico','woff','woff2','ttf','eot','otf','mp4','mp3','webm','ogg','wav','flac','aac','zip','tar','gz','rar','7z','exe','dmg','apk','csv','xls','xlsx','doc','docx','pdf','epub','iso','dmg','bin','ppt','pptx','odt','avi','mkv','xml','json','yml','yaml','rss','atom','swf','txt','dart','webp','bmp','tif','psd','ai','indd','eps','ps','zipx','srt','wasm','m4v','m4a','webp','weba','m4b','opus','ogv','ogm','oga','spx','ogx','flv','3gp','3g2','jxr','wdp','jng','hief','avif','apng','avifs','heif','heic','cur','ico','ani','jp2','jpm','jpx','mj2','wmv','wma','aac','tif','tiff','mpg','mpeg','mov','avi','wmv','flv','swf','mkv','m4v','m4p','m4b','m4r','m4a','mp3','wav','wma','ogg','oga','webm','3gp','3g2','flac','spx','amr','mid','midi','mka','dts','ac3','eac3','weba','m3u','m3u8','ts','wpl','pls','vob','ifo','bup','svcd','drc','dsm','dsv','dsa','dss','vivo','ivf','dvd','fli','flc','flic','flic','mng','asf','m2v','asx','ram','ra','rm','rpm','roq','smi','smil','wmf','wmz','wmd','wvx','wmx','movie','wri','ins','isp','acsm','djvu','fb2','xps','oxps','ps','eps','ai','prn','svg','dwg','dxf','ttf','fnt','fon','otf','cab']
+ */
+ resourceExclusions?: string[];
+ /** Optional maximum file size in megabytes to include in the output file */
+ maxFileSize?: number;
+ /** Optional maximum number tokens to include in the output file */
+ maxTokens?: number;
+};
+```
+
+#### Run your crawler
+
+```sh
+npm start
+```
+
+### Alternative methods
+
+#### [Running in a container with Docker](./containerapp/README.md)
+
+To obtain the `output.json` with a containerized execution. Go into the `containerapp` directory. Modify the `config.ts` same as above, the `output.json`file should be generated in the data folder. Note : the `outputFileName` property in the `config.ts` file in containerapp folder is configured to work with the container.
+
+### Upload your data to OpenAI
+
+The crawl will generate a file called `output.json` at the root of this project. Upload that [to OpenAI](https://platform.openai.com/docs/assistants/overview) to create your custom assistant or custom GPT.
+
+#### Create a custom GPT
+
+Use this option for UI access to your generated knowledge that you can easily share with others
+
+> Note: you may need a paid ChatGPT plan to create and use custom GPTs right now
+
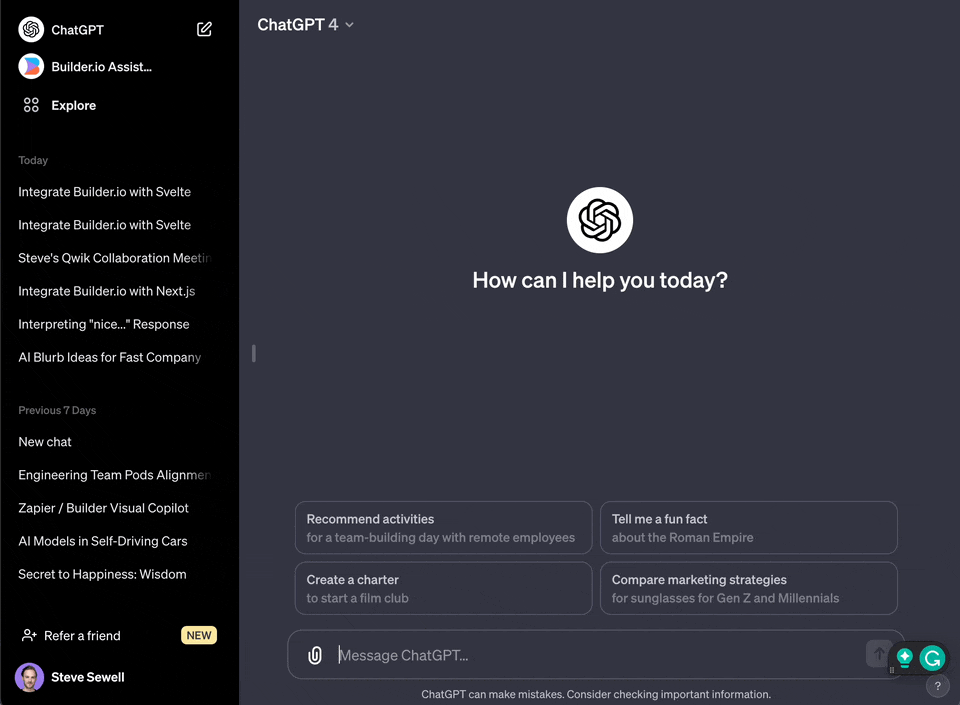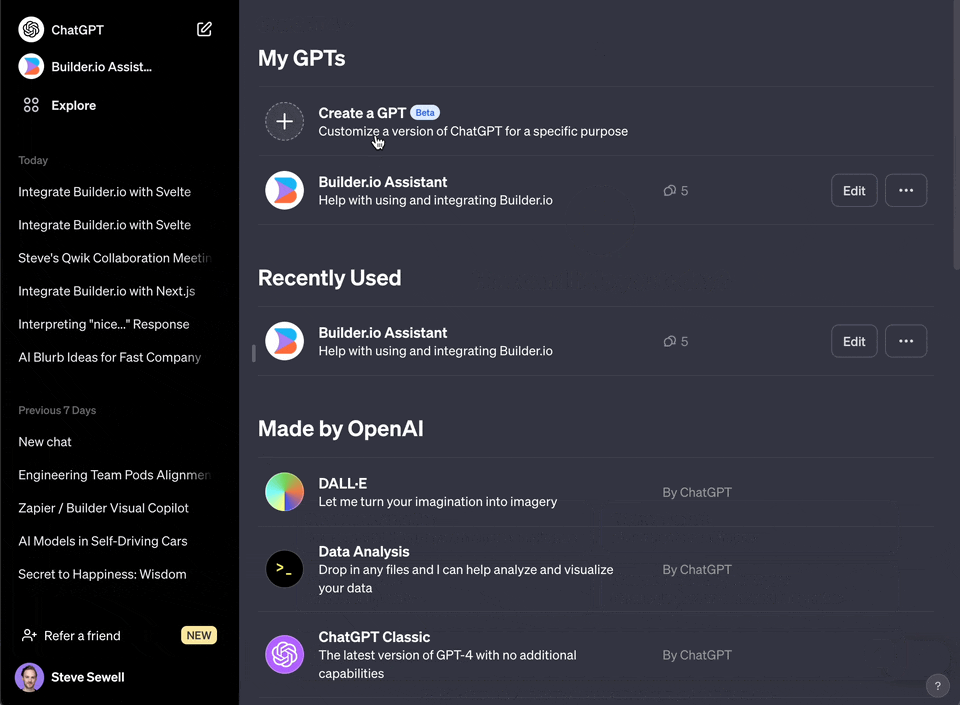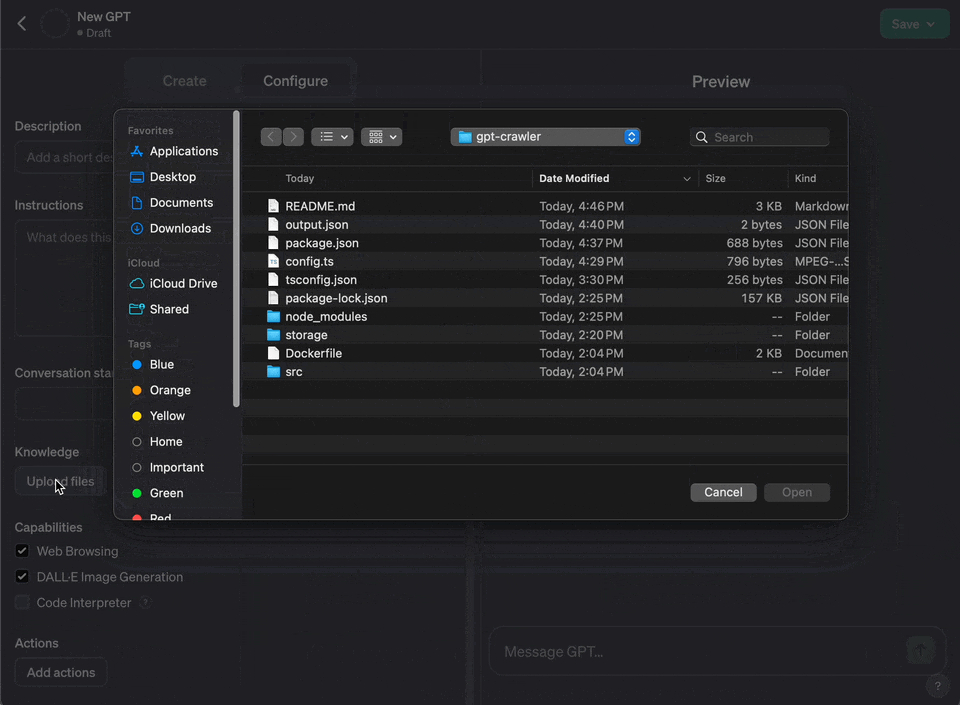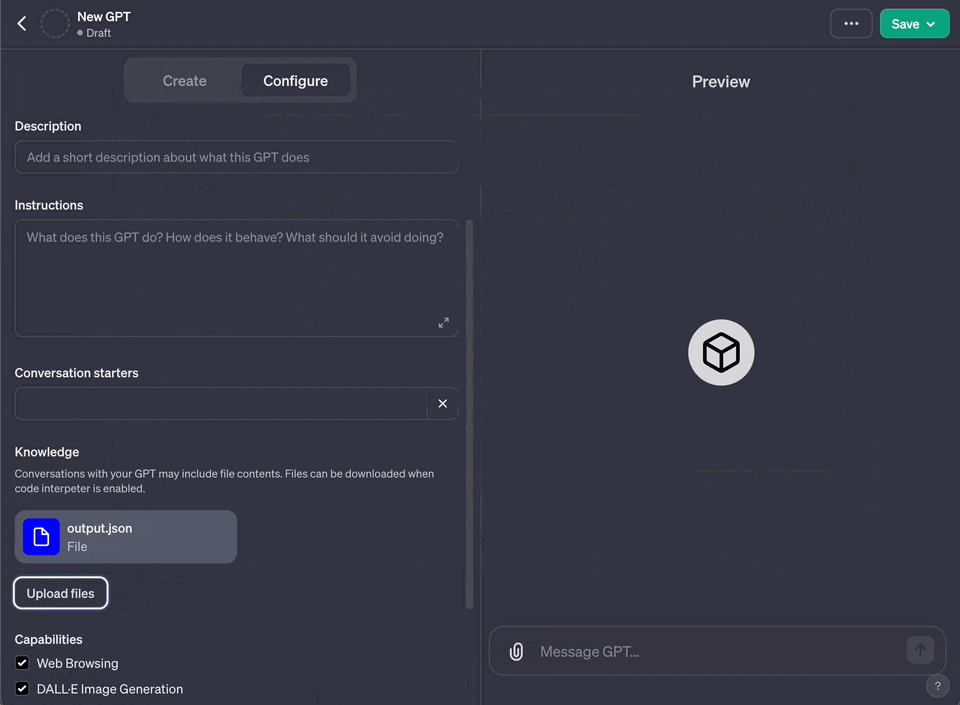
+1. Go to [https://chat.openai.com/](https://chat.openai.com/)
+2. Click your name in the bottom left corner
+3. Choose "My GPTs" in the menu
+4. Choose "Create a GPT"
+5. Choose "Configure"
+6. Under "Knowledge" choose "Upload a file" and upload the file you generated
+7. if you get an error about the file being too large, you can try to split it into multiple files and upload them separately using the option maxFileSize in the config.ts file or also use tokenization to reduce the size of the file with the option maxTokens in the config.ts file
+
+
+
+#### Create a custom assistant
+
+Use this option for API access to your generated knowledge that you can integrate into your product.
+
+1. Go to [https://platform.openai.com/assistants](https://platform.openai.com/assistants)
+2. Click "+ Create"
+3. Choose "upload" and upload the file you generated
+
+
+
+## Contributing
+
+Know how to make this project better? Send a PR!
+
+
+
+
+
 +
+